
id
int64 2.05k
16.6k
| title
stringlengths 5
75
| fromurl
stringlengths 19
185
| date
timestamp[s] | tags
sequencelengths 0
11
| permalink
stringlengths 20
37
| content
stringlengths 342
82.2k
| fromurl_status
int64 200
526
⌀ | status_msg
stringclasses 339
values | from_content
stringlengths 0
229k
⌀ |
|---|---|---|---|---|---|---|---|---|---|
8,917 | 初创企业开源许可证管理九大法则 | https://opensource.com/article/17/9/9-open-source-software-rules-startups | 2017-09-29T12:45:00 | [
"开源",
"免费",
"许可证"
] | https://linux.cn/article-8917-1.html |
>
> 开源软件虽然可以免费使用,但就如同饲养一条[幼犬一样](/article-8680-1.html)(开始虽然花钱不多,后边越养越费钱)。在采用开源之前,确保能够了解其隐藏的成本和陷阱。
>
>
>

对于初创公司来说,开源软件是一把双刃剑。它可以成为一家创业公司的生命线,因为开源软件可以帮助初创企业快速创新,而不必从头开始。不过,正如[有些人所说的](http://www.zdnet.com/article/open-source-is-free-like-a-puppy-is-free-says-sun-boss-3039202713/),开源软件虽然可以免费使用,但就如同饲养一条[幼犬](/article-8680-1.html)一样,开始虽然花钱不多,后边越养越费钱。开源软件的真正代价是开源许可证合规成本。
滥用开源软件可能会造成获得投资的机遇被延迟或破坏。但是,如果遵守这些简单的法则,初创企业可以轻松地实现开源许可证合规。
### 法则一:不使用没有许可条款的软件
互联网上的一些软件不包含许可证通知,但这不意味它们可以自由使用。发布软件的人可能没有遵守上游许可条款。或者软件的作者可能尚未为其软件指定许可协议——无论是以开源方式亦或是其他方式。“没有许可条款”是指没有许可证:您应该避免使用该软件或要求作者为其该软件指定许可证。
### 法则二:不要违反开源许可证
开源软件的使用可能难以让其作者进行追踪,但并不意味着该软件的使用和不合规行为会被忽视。违反开源许可证可能会使初创公司面临法律责任和公众谴责,甚至可能会影响其被投资或收购。也可能导致潜在客户由于担心下游责任而拒绝购买您的产品。软件开发人员为实现其软件开源付出了巨大的努力,其中也包括上述的许可费用。滥用开源软件对这些开发人员是不公平的,并且损害了他们希望促成的创新。
### 法则三:跟踪您正在使用的软件
将来有一天您将必须提供您正在使用的开源软件的列表。及时维护该列表将会为您节约大量的时间和精力,因为潜在的投资者和收购方将会要求您提供该列表。大多数开源软件下载包中都包括一个 “license.txt” 或 “copy.txt” 文件。保留该许可证的副本,并记录其涵盖的软件。大多数创业公司都使用简单的电子表格跟踪软件许可情况。
### 法则四:了解<ruby> 宽松 <rp> ( </rp> <rt> permissive </rt> <rp> ) </rp></ruby>许可证和<ruby> 左版 <rp> ( </rp> <rt> copyleft </rt> <rp> ) </rp></ruby>许可证
开源许可证大致分为两种类型:宽松许可证(BSD、MIT 和 Apache)和左版许可证(GPL、LGPL、Eclipse 公共许可证、Mozilla 公共许可证以及<ruby> 通用开发和分发许可证 <rp> ( </rp> <rt> Common Development and Distribution License </rt> <rp> ) </rp></ruby>)。大多数公司及其客户对于使用遵循宽松许可证的软件没有什么法律上的担心。不过,遵循左版许可证需要更加谨慎,将软件保留为专有可能会与某些特定计划不一致。
### 法则五:遵守许可证<ruby> 通知 <rp> ( </rp> <rt> notice </rt> <rp> ) </rp></ruby>要求
无论是宽松许可证还是左版许可证,所有开源许可都有通知要求。通常,这意味着在分发开源软件时,您需要包含其所适用的许可证的副本,仅仅包括许可证的链接或缩略形式通常是不完备的。为了避免混淆或疏离您的客户,开发一个符合大多数开源许可证的通知传送策略非常重要。
### 法则六:了解哪些开源许可证与分布式软件兼容
除了 Affero GPL 之外,大多数开源许可证都没有涉及软件即服务(SaaS)的情境。对于 SaaS 和云系统的分布式组件(如 JavaScript)或分布式软件(包括移动 APP 和测试版),您可以使用遵循宽松许可证的软件,但在使用遵循左版许可证的软件之前,您需要特别小心。仅在其完全在自己的进程中执行并且没有链接的代码时才去使用遵循 GPL 的软件,而不要相信以下如何让 GPL 合规的谣传:动态链接至 GPL 代码或让客户下载 GPL 软件。仅将 LGPL 软件作为动态链接库进行使用。在不修改 API 的前提下使用遵循其它左版许可证的软件。遵循移动 APP 市场的分发规定也许与遵循某些特定的左版许可证有冲突(例如 GPL 或者 LGPL)。
### 法则七:在咨询律师之前不要贡献或发布开源软件
贡献和发布开源软件可能是公众的福音,但它可能不是您业务上的正确选择。一旦作出贡献或发布,您在软件中拥有的任何知识产权将不大可能构成您公司估值的依据。您的律师可以帮助您更好地理解在专有和开源软件之间如何选择,并对这一重要业务决策提供指导。
### 法则八:确保您的员工和第三方开发人员遵守这些规则
不管是由于您的员工或第三方承包商造成的开源违规行为,所引起的法律和宣传问题都将砸在您的头上。您可以通过适当的培训和跟踪开源软件来避免这些问题。
### 法则九:规划未来
初创公司业务模式可以快速变化。SaaS 模式可以快速转变为分布式软件模式。无论您当前的模式是什么,遵守分布式软件的规则将为您转变为分布式软件模式提供更大的灵活性,而无需删除某些开源软件并更改相关功能。
采用这些法则将有助于初创企业利用开源软件的优势,降低您在获取投资或收购时遇到的风险。对您的初创企业感兴趣的第三方想知道您如何应对开源软件问题,确保您做好准备,并能够为他们提供积极和专业的答案。
(题图:Beth Cortez-Neavel on [Flickr](https://www.flickr.com/photos/bethcortez-neavel/20699620022/in/photolist-xx9XSo-J67oFV-HgKMCn-HgzdGJ-bkUna-2wRkRj-7YyQVU-3qh3b-4NfW6z-hSgKH-4ptqkF-94f4rj-BTiPf-6xefv-HgzeVW-HgzfsC-Hgzhu3-HgKKZ2-HgKLfT-HgKKL6-HgKKt2-HgKMgv-HM7Aay-HgKN2D-J67umH-HM7AZE-J3NbSo-njSSUk-iR9Qu-5rL5ir-diemDY-8Z9WVL-p7WG5N-qzaAGY-CpEMP-8dfgUR-79XouB-nyeBRi-amefJV-skzdFQ-dC2WNi-JBvYCS-tiNzYh-rr4bkB-s6gMPL-dnJpcc-p1xZmV-4emQku-9SpCY6-e4wRz6). Public Domain. Modified by Opensource.com)
---
作者简介:Heather Meeker 是 O’Melveny & Myers 硅谷办公室的合伙人,为客户提供技术交易和知识产权方面的建议,是国际知名的开源软件许可专家。Heather 于 2016 年获得加州律师协会知识产权先锋奖。<ruby> 《最佳律师》 <rp> ( </rp> <rt> Best Lawyers </rt> <rp> ) </rp></ruby>将她提名为 2018 年年度 IT 律师。
译者简介:薛亮,集慧智佳知识产权咨询公司高级咨询师,擅长专利检索、专利分析、竞争对手跟踪、FTO 分析、开源软件知识产权风险分析,致力于为互联网企业、高科技公司提供知识产权咨询服务。
| 200 | OK | Open source software can be a double-edged sword for startups. It can be a startup's lifeblood, because it helps you innovate rapidly without starting from scratch. But, as they say, open source software is free like a puppy is free: The true cost of open source software is obeying open source licenses.
Misuse of open source software can delay or derail investment and corporate exit opportunities. But you can easily comply with open source licenses if you follow these simple rules.
**Don't use software without license terms.**Some software on the internet doesn't contain licensing notices, but that doesn't mean that it can be used freely. The people posting the software may not have complied with upstream licensing terms. Or the author of the software may not yet have applied a license to the software—open source or otherwise. "No license terms" means no license: You should either avoid using the software or ask the author to apply a permissive license.
**Don't violate open source licenses.**Open source software use may be difficult for a software owner to track, but that does not mean use and noncompliance go unnoticed. Violating open source licenses can expose a startup to legal liability and public embarrassment, and can even compromise investments or acquisitions. It can also cause potential customers to refuse to buy your products out of fear of downstream liability. Developers have taken great effort to make their software open source—including foregoing licensing fees. Misuse of the software is unfair to those developers and harms the innovation they hoped to facilitate.
**Keep track of what software you are using.**Someday you will have to provide a list of the open source software you are using. Potential investors and acquirers will ask for the list, and maintaining an up-to-date list will save you considerable time and effort when that request comes. Most open source software downloads include a "license.txt" or "copying.txt" file. Keep a copy of that license and note what software it covers. Most startups track licensed software in a simple spreadsheet.
**Understand permissive and copyleft licenses.**Open source licenses fall broadly into two types: permissive (BSD, MIT, and Apache) and copyleft (GPL, LGPL, Eclipse Public License, Mozilla Public License, and Common Development and Distribution License). Most companies—and their customers—have no legal concerns over using software under permissive licenses. Complying with copyleft licenses takes more care, however, and may be inconsistent with certain plans for keeping software proprietary.
**Comply with notice requirements.**Whether permissive or copyleft, all open source licenses have notice requirements. Typically, this means you need to include a copy of the applicable license when distributing open source software. It's generally not sufficient to merely include a link to or short form of the license. It's important to develop a license notice delivery strategy that complies with most open source licenses without confusing or alienating your customers.
**Understand which open source licenses work with distributed software.**Most open source licenses—other than the Affero GPL—have no conditions for software-as-a-service (SaaS). For distributed elements of SaaS and cloud systems (like JavaScript) or distributed software (including mobile apps and beta tests), you can use software under permissive licenses, but you will need to be especially careful before using software under copyleft licenses. Use GPL software only if it executes 100% in its own process with no linked code—don't believe myths about compliance by dynamically linking to the GPL code or making the customer download the GPL software. Use LGPL software only as a dynamically linked library. And use other copyleft software only if you have not modified the API. Distribution in compliance with the rules of mobile app marketplaces may be incompatible with compliance with certain copyleft licenses (like the GPL or LGPL).
**Do not contribute to or release open source software before consulting an attorney.**Contributing to and releasing open source software can be a boon for the public, but it may not be the right choice for your business. Once you make a contribution or release, any intellectual property rights you had in the software will be unlikely to form the basis for valuation of your company. Your lawyer can help you understand your choices between degrees of proprietary and open source software and guide this important business decision.
**Ensure your employees and third-party developers follow these rules.**Whether an open source violation is caused by your employee or a third-party contractor, the resulting legal and publicity issues will fall in your lap. You can avoid these issues through proper training and tracking of open source software.
**Plan for the future.**Startup business models can change rapidly, and a SaaS model can quickly become a distributed software model. Following the rules for distributed software, regardless of your current model, can provide flexibility for shifting to a distributed software model without having to remove certain open source software and change associated functionalities.
Adopting these rules will help you leverage the benefits of open source software while limiting the risk to your startup's viability for investments and acquisitions. Third parties interested in your startup will want to know how you handle open source software. Make sure that you are prepared and able to provide them with positive and professional answers.
## 3 Comments |
8,918 | 极客漫画:HTTP2 服务器推送 | http://turnoff.us/geek/http2-server-push-explained/ | 2017-09-30T14:01:00 | [
"HTTP2"
] | https://linux.cn/article-8918-1.html | 
HTTP2 服务器推送会在一个请求中将用户请求的内容及相关内容一次性推送给用户——以避免用户再次发起请求。
---
via: <http://turnoff.us/geek/http2-server-push-explained/>
作者:[Daniel Stori](http://turnoff.us/about/) 译者:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
8,919 | 极客漫画:Codeless 开发者 | http://turnoff.us/geek/codeless/ | 2017-10-02T14:16:00 | [
"漫画",
"ServerLess",
"NOSQL"
] | https://linux.cn/article-8919-1.html | 
互联网世界新概念层出不穷,往往今天流行的概念和技术,明天就被取代和推翻。比如说,以前大家都说什么<ruby> 服务器 <rt> Server </rt></ruby>、<ruby> SQL 数据库 <rt> SQL Database </rt></ruby>和<ruby> 前端 <rt> Frontend </rt></ruby>,而现在已经开始流行 ServerLess、No-SQL 了。
当然,ServerLess 不是说不要服务器了,而是指一些运行在无状态的容器的服务器端逻辑,比如 AWS 的 Lambda 的 FaaS。而 No-SQL 则是一种非关系型数据库。
而这位所谓的专家,什么都 “No” 和 “Less” 了,然后,就在办公室里面从早坐到晚,正在践行了“Codeless”(没代码)的日子。
---
via: <http://turnoff.us/geek/codeless/>
作者:[Daniel Stori](http://turnoff.us/about/) 译者:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
8,920 | 探索传统 JavaScript 基准测试 | http://benediktmeurer.de/2016/12/16/the-truth-about-traditional-javascript-benchmarks | 2017-09-29T15:40:00 | [
"JavaScript",
"基准测试"
] | https://linux.cn/article-8920-1.html | 
可以很公平地说,[JavaScript](https://en.wikipedia.org/wiki/JavaScript) 是当下软件工程中*最重要的技术*。对于那些深入接触过编程语言、编译器和虚拟机的人来说,这仍然有点令人惊讶,因为在语言设计者们看来,JavaScript 不是十分优雅;在编译器工程师们看来,它没有多少可优化的地方;甚至还没有一个伟大的标准库。这取决于你和谁吐槽,JavaScript 的缺点你花上数周都枚举不完,而你总会找到一些你从所未知的奇怪的东西。尽管这看起来明显困难重重,不过 JavaScript 还是成为了当今 web 的核心,并且还(通过 [Node.js](https://nodejs.org/))成为服务器端和云端的主导技术,甚至还开辟了进军物联网领域的道路。
那么问题来了,为什么 JavaScript 如此受欢迎?或者说如此成功?我知道没有一个很好的答案。如今我们有许多使用 JavaScript 的好理由,或许最重要的是围绕其构建的庞大的生态系统,以及现今大量可用的资源。但所有这一切实际上是发展到一定程度的后果。为什么 JavaScript 变得流行起来了?嗯,你或许会说,这是 web 多年来的通用语了。但是在很长一段时间里,人们极其讨厌 JavaScript。回顾过去,似乎第一波 JavaScript 浪潮爆发在上个年代的后半段。那个时候 JavaScript 引擎加速了各种不同的任务的执行,很自然的,这可能让很多人对 JavaScript 刮目相看。
回到过去那些日子,这些加速使用了现在所谓的传统 JavaScript 基准进行测试——从苹果的 [SunSpider 基准](https://webkit.org/perf/sunspider/sunspider.html)(JavaScript 微基准之母)到 Mozilla 的 [Kraken 基准](http://krakenbenchmark.mozilla.org/) 和谷歌的 V8 基准。后来,V8 基准被 [Octane 基准](https://developers.google.com/octane) 取代,而苹果发布了新的 [JetStream 基准](http://browserbench.org/JetStream)。这些传统的 JavaScript 基准测试驱动了无数人的努力,使 JavaScript 的性能达到了本世纪初没人能预料到的水平。据报道其性能加速达到了 1000 倍,一夜之间在网站使用 `<script>` 标签不再是与魔鬼共舞,做客户端不再仅仅是可能的了,甚至是被鼓励的。
[](https://www.youtube.com/watch?v=PvZdTZ1Nl5o)
(来源: [Advanced JS performance with V8 and Web Assembly](https://www.youtube.com/watch?v=PvZdTZ1Nl5o), Chrome Developer Summit 2016, @s3ththompson。)
现在是 2016 年,所有(相关的)JavaScript 引擎的性能都达到了一个令人难以置信的水平,web 应用像原生应用一样快(或者能够像原生应用一样快)。引擎配有复杂的优化编译器,通过收集之前的关于类型/形状的反馈来推测某些操作(例如属性访问、二进制操作、比较、调用等),生成高度优化的机器代码的短序列。大多数优化是由 SunSpider 或 Kraken 等微基准以及 Octane 和 JetStream 等静态测试套件驱动的。由于有像 [asm.js](http://asmjs.org/) 和 [Emscripten](https://github.com/kripken/emscripten) 这样的 JavaScript 技术,我们甚至可以将大型 C++ 应用程序编译成 JavaScript,并在你的浏览器上运行,而无需下载或安装任何东西。例如,现在你可以在 web 上玩 [AngryBots](http://beta.unity3d.com/jonas/AngryBots),无需沙盒,而过去的 web 游戏需要安装一堆诸如 Adobe Flash 或 Chrome PNaCl 的特殊插件。
这些成就绝大多数都要归功于这些微基准和静态性能测试套件的出现,以及与这些传统的 JavaScript 基准间的竞争的结果。你可以对 SunSpider 表示不满,但很显然,没有 SunSpider,JavaScript 的性能可能达不到今天的高度。好吧,赞美到此为止。现在看看另一方面,所有的静态性能测试——无论是<ruby> 微基准 <rt> micro-benchmark </rt></ruby>还是大型应用的<ruby> 宏基准 <rt> macro-benchmark </rt></ruby>,都注定要随着时间的推移变成噩梦!为什么?因为在开始摆弄它之前,基准只能教你这么多。一旦达到某个阔值以上(或以下),那么有益于特定基准的优化的一般适用性将呈指数级下降。例如,我们将 Octane 作为现实世界中 web 应用性能的代表,并且在相当长的一段时间里,它可能做得很不错,但是现在,Octane 与现实场景中的时间分布是截然不同的,因此即使眼下再优化 Octane 乃至超越自身,可能在现实世界中还是得不到任何显著的改进(无论是通用 web 还是 Node.js 的工作负载)。
[](https://youtu.be/xCx4uC7mn6Y)
(来源:[Real-World JavaScript Performance](https://youtu.be/xCx4uC7mn6Y),BlinkOn 6 conference,@tverwaes)
由于传统 JavaScript 基准(包括最新版的 JetStream 和 Octane)可能已经背离其有用性变得越来越远,我们开始在 2016 年初寻找新的方法来测量现实场景的性能,为 V8 和 Chrome 添加了大量新的性能追踪钩子。我们还特意添加一些机制来查看我们在浏览 web 时的时间究竟开销在哪里,例如,是脚本执行、垃圾回收、编译,还是什么地方?而这些调查的结果非常有趣和令人惊讶。从上面的幻灯片可以看出,运行 Octane 花费了 70% 以上的时间去执行 JavaScript 和垃圾回收,而浏览 web 的时候,通常执行 JavaScript 花费的时间不到 30%,垃圾回收占用的时间永远不会超过 5%。在 Octane 中并没有体现出它花费了大量时间来解析和编译。因此,将更多的时间用在优化 JavaScript 执行上将提高你的 Octane 跑分,但不会对加载 [youtube.com](http://youtube.com/) 有任何积极的影响。事实上,花费更多的时间来优化 JavaScript 执行甚至可能有损你现实场景的性能,因为编译器需要更多的时间,或者你需要跟踪更多的反馈,最终在编译、垃圾回收和<ruby> 运行时桶 <rt> Runtime bucket </rt></ruby>等方面开销了更多的时间。
[](http://browserbench.org/Speedometer)
还有另外一组基准测试用于测量浏览器整体性能(包括 JavaScript 和 DOM 性能),最新推出的是 [Speedometer 基准](http://browserbench.org/Speedometer)。该基准试图通过运行一个用不同的主流 web 框架实现的简单的 [TodoMVC](http://todomvc.com/) 应用(现在看来有点过时了,不过新版本正在研发中)以捕获更真实的现实场景的性能。上述幻灯片中的各种测试 (Angular、Ember、React、Vanilla、Flight 和 Backbone)挨着放在 Octane 之后,你可以看到,此时此刻这些测试似乎更好地代表了现实世界的性能指标。但是请注意,这些数据收集在本文撰写将近 6 个月以前,而且我们优化了更多的现实场景模式(例如我们正在重构垃圾回收系统以显著地降低开销,并且 [解析器也正在重新设计](https://twitter.com/bmeurer/status/806927160300556288))。还要注意的是,虽然这看起来像是只和浏览器相关,但我们有非常强有力的证据表明传统的峰值性能基准也不能很好的代表现实场景中 Node.js 应用性能。
[](https://youtu.be/xCx4uC7mn6Y)
(来源: [Real-World JavaScript Performance](https://youtu.be/xCx4uC7mn6Y), BlinkOn 6 conference, @tverwaes.)
所有这一切可能已经路人皆知了,因此我将用本文剩下的部分强调一些具体案例,它们对关于我为什么认为这不仅有用,而且必须停止关注某一阈值的静态峰值性能基准测试对于 JavaScript 社区的健康是很关键的。让我通过一些例子说明 JavaScript 引擎怎样来玩弄基准的。
### 臭名昭著的 SunSpider 案例
一篇关于传统 JavaScript 基准测试的博客如果没有指出 SunSpider 那个明显的问题是不完整的。让我们从性能测试的最佳实践开始,它在现实场景中不是很适用:bitops-bitwise-and.js [性能测试](https://github.com/WebKit/webkit/blob/master/PerformanceTests/SunSpider/tests/sunspider-1.0.2/bitops-bitwise-and.js)。
[](https://github.com/WebKit/webkit/blob/master/PerformanceTests/SunSpider/tests/sunspider-1.0.2/bitops-bitwise-and.js)
有一些算法需要进行快速的 AND 位运算,特别是从 `C/C++` 转译成 JavaScript 的地方,所以快速执行该操作确实有点意义。然而,现实场景中的网页可能不关心引擎在循环中执行 AND 位运算是否比另一个引擎快两倍。但是再盯着这段代码几秒钟后,你可能会注意到在第一次循环迭代之后 `bitwiseAndValue` 将变成 `0`,并且在接下来的 599999 次迭代中将保持为 `0`。所以一旦你让此获得了好的性能,比如在差不多的硬件上所有测试均低于 5ms,在经过尝试之后你会意识到,只有循环的第一次是必要的,而剩余的迭代只是在浪费时间(例如 [loop peeling](https://en.wikipedia.org/wiki/Loop_splitting) 后面的死代码),那你现在就可以开始玩弄这个基准测试了。这需要 JavaScript 中的一些机制来执行这种转换,即你需要检查 `bitwiseAndValue` 是全局对象的常规属性还是在执行脚本之前不存在,全局对象或者它的原型上必须没有拦截器。但如果你真的想要赢得这个基准测试,并且你愿意全力以赴,那么你可以在不到 1ms 的时间内完成这个测试。然而,这种优化将局限于这种特殊情况,并且测试的轻微修改可能不再触发它。
好吧,那么 [bitops-bitwise-and.js](https://github.com/WebKit/webkit/blob/master/PerformanceTests/SunSpider/tests/sunspider-1.0.2/bitops-bitwise-and.js) 测试彻底肯定是微基准最失败的案例。让我们继续转移到 SunSpider 中更逼真的场景——[string-tagcloud.js](https://github.com/WebKit/webkit/blob/master/PerformanceTests/SunSpider/tests/sunspider-1.0.2/string-tagcloud.js) 测试,它基本上是运行一个较早版本的 `json.js polyfill`。该测试可以说看起来比位运算测试更合理,但是花点时间查看基准的配置之后立刻会发现:大量的时间浪费在一条 `eval` 表达式(高达 20% 的总执行时间被用于解析和编译,再加上实际执行编译后代码的 10% 的时间)。
[](https://github.com/WebKit/webkit/blob/master/PerformanceTests/SunSpider/tests/sunspider-1.0.2/string-tagcloud.js#L199)
仔细看看,这个 `eval` 只执行了一次,并传递一个 JSON 格式的字符串,它包含一个由 2501 个含有 `tag` 和 `popularity` 属性的对象组成的数组:
```
([
{
"tag": "titillation",
"popularity": 4294967296
},
{
"tag": "foamless",
"popularity": 1257718401
},
{
"tag": "snarler",
"popularity": 613166183
},
{
"tag": "multangularness",
"popularity": 368304452任何
},
{
"tag": "Fesapo unventurous",
"popularity": 248026512
},
{
"tag": "esthesioblast",
"popularity": 179556755
},
{
"tag": "echeneidoid",
"popularity": 136641578
},
{
"tag": "embryoctony",
"popularity": 107852576
},
...
])
```
显然,解析这些对象字面量,为其生成本地代码,然后执行该代码的成本很高。将输入的字符串解析为 JSON 并生成适当的对象图的开销将更加低廉。所以,加快这个基准测试的一个小把戏就是模拟 `eval`,并尝试总是将数据首先作为 JSON 解析,如果以 JSON 方式读取失败,才回退进行真实的解析、编译、执行(尽管需要一些额外的黑魔法来跳过括号)。早在 2007 年,这甚至不算是一个坏点子,因为没有 [JSON.parse](https://tc39.github.io/ecma262/#sec-json.parse),不过在 2017 年这只是 JavaScript 引擎的技术债,可能会让 `eval` 的合法使用遥遥无期。
```
--- string-tagcloud.js.ORIG 2016-12-14 09:00:52.869887104 +0100
+++ string-tagcloud.js 2016-12-14 09:01:01.033944051 +0100
@@ -198,7 +198,7 @@
replace(/"[^"\\\n\r]*"|true|false|null|-?\d+(?:\.\d*)?(:?[eE][+\-]?\d+)?/g, ']').
replace(/(?:^|:|,)(?:\s*\[)+/g, ''))) {
- j = eval('(' + this + ')');
+ j = JSON.parse(this);
return typeof filter === 'function' ? walk('', j) : j;
}
```
事实上,将基准测试更新到现代 JavaScript 会立刻会性能暴增,正如今天的 `V8 LKGR` 从 36ms 降到了 26ms,性能足足提升了 30%!
```
$ node string-tagcloud.js.ORIG
Time (string-tagcloud): 36 ms.
$ node string-tagcloud.js
Time (string-tagcloud): 26 ms.
$ node -v
v8.0.0-pre
$
```
这是静态基准和性能测试套件常见的一个问题。今天,没有人会正儿八经地用 `eval` 解析 `JSON` 数据(不仅是因为性能问题,还出于严重的安全性考虑),而是坚持为最近五年写的代码使用 [JSON.parse](https://tc39.github.io/ecma262/#sec-json.parse)。事实上,使用 `eval` 解析 JSON 可能会被视作产品级代码的的一个漏洞!所以引擎作者致力于新代码的性能所作的努力并没有反映在这个古老的基准中,相反地,而是使得 `eval` 不必要地~~更智能~~复杂化,从而赢得 `string-tagcloud.js` 测试。
好吧,让我们看看另一个例子:[3d-cube.js](https://github.com/WebKit/webkit/blob/master/PerformanceTests/SunSpider/tests/sunspider-1.0.2/3d-cube.js)。这个基准测试做了很多矩阵运算,即便是最聪明的编译器对此也无可奈何,只能说执行而已。基本上,该基准测试花了大量的时间执行 `Loop` 函数及其调用的函数。
[](https://github.com/WebKit/webkit/blob/master/PerformanceTests/SunSpider/tests/sunspider-1.0.2/3d-cube.js#L239)
一个有趣的发现是:`RotateX`、`RotateY` 和 `RotateZ` 函数总是调用相同的常量参数 `Phi`。
[](https://github.com/WebKit/webkit/blob/master/PerformanceTests/SunSpider/tests/sunspider-1.0.2/3d-cube.js#L151)
这意味着我们基本上总是为 [Math.sin](https://tc39.github.io/ecma262/#sec-math.sin) 和 [Math.cos](https://tc39.github.io/ecma262/#sec-math.cos) 计算相同的值,每次执行都要计算 204 次。只有 3 个不同的输入值:
* 0.017453292519943295
* 0.05235987755982989
* 0.08726646259971647
显然,你可以在这里做的一件事情就是通过缓存以前的计算值来避免重复计算相同的正弦值和余弦值。事实上,这是 V8 以前的做法,而其它引擎例如 `SpiderMonkey` 目前仍然在这样做。我们从 V8 中删除了所谓的<ruby> 超载缓存 <rt> transcendental cache </rt></ruby>,因为缓存的开销在实际的工作负载中是不可忽视的,你不可能总是在一行代码中计算相同的值,这在其它地方倒不稀奇。当我们在 2013 和 2014 年移除这个特定的基准优化时,我们对 SunSpider 基准产生了强烈的冲击,但我们完全相信,为基准而优化并没有任何意义,并同时以这种方式批判了现实场景中的使用案例。
[](https://arewefastyet.com/#machine=12&view=single&suite=ss&subtest=cube&start=1343350217&end=1415382608)
(来源:[arewefastyet.com](https://arewefastyet.com/#machine=12&view=single&suite=ss&subtest=cube&start=1343350217&end=1415382608))
显然,处理恒定正弦/余弦输入的更好的方法是一个内联的启发式算法,它试图平衡内联因素与其它不同的因素,例如在调用位置优先选择内联,其中<ruby> 常量叠算 <rt> constant folding </rt></ruby>可以是有益的,例如在 `RotateX`、`RotateY` 和 `RotateZ` 调用位置的案例中。但是出于各种原因,这对于 `Crankshaft` 编译器并不可行。使用 `Ignition` 和 `TurboFan` 倒是一个明智的选择,我们已经在开发更好的[内联启发式算法](https://docs.google.com/document/d/1VoYBhpDhJC4VlqMXCKvae-8IGuheBGxy32EOgC2LnT8)。
#### 垃圾回收(GC)是有害的
除了这些非常具体的测试问题,SunSpider 基准测试还有一个根本性的问题:总体执行时间。目前 V8 在适当的英特尔硬件上运行整个基准测试大概只需要 200ms(使用默认配置)。<ruby> 次垃圾回收 <rt> minor GC </rt></ruby>在 1ms 到 25ms 之间(取决于新空间中的存活对象和旧空间的碎片),而<ruby> 主垃圾回收 <rt> major GC </rt></ruby>暂停的话可以轻松减掉 30ms(甚至不考虑增量标记的开销),这超过了 SunSpider 套件总体执行时间的 10%!因此,任何不想因垃圾回收循环而造成减速 10-20% 的引擎,必须用某种方式确保它在运行 SunSpider 时不会触发垃圾回收。
[](https://github.com/WebKit/webkit/blob/master/PerformanceTests/SunSpider/resources/driver-TEMPLATE.html#L70)
就实现而言,有不同的方案,不过就我所知,没有一个在现实场景中产生了任何积极的影响。V8 使用了一个相当简单的技巧:由于每个 SunSpider 套件都运行在一个新的 `<iframe>` 中,这对应于 V8 中一个新的本地上下文,我们只需检测快速的 `<iframe>` 创建和处理(所有的 SunSpider 测试每个花费的时间小于 50ms),在这种情况下,在处理和创建之间执行垃圾回收,以确保我们在实际运行测试的时候不会触发垃圾回收。这个技巧运行的很好,在 99.9% 的案例中没有与实际用途冲突;除了时不时的你可能会受到打击,不管出于什么原因,如果你做的事情让你看起来像是 V8 的 SunSpider 测试驱动程序,你就可能被强制的垃圾回收打击到,这有可能对你的应用导致负面影响。所以谨记一点:**不要让你的应用看起来像 SunSpider!**
我可以继续展示更多 SunSpider 示例,但我不认为这非常有用。到目前为止,应该清楚的是,为刷新 SunSpider 评分而做的进一步优化在现实场景中没有带来任何好处。事实上,世界可能会因为没有 SunSpider 而更美好,因为引擎可以放弃只是用于 SunSpider 的奇淫技巧,或者甚至可以伤害到现实中的用例。不幸的是,SunSpider 仍然被(科技)媒体大量地用来比较他们眼中的浏览器性能,或者甚至用来比较手机!所以手机制造商和安卓制造商对于让 SunSpider(以及其它现在毫无意义的基准 FWIW) 上的 Chrome 看起来比较体面自然有一定的兴趣。手机制造商通过销售手机来赚钱,所以获得良好的评价对于电话部门甚至整间公司的成功至关重要。其中一些部门甚至在其手机中配置在 SunSpider 中得分较高的旧版 V8,将他们的用户置于各种未修复的安全漏洞之下(在新版中早已被修复),而让用户被最新版本的 V8 带来的任何现实场景的性能优势拒之门外!
[](https://www.engadget.com/2016/03/08/galaxy-s7-and-s7-edge-review/)
(来源:[www.engadget.com](https://www.engadget.com/2016/03/08/galaxy-s7-and-s7-edge-review/))
作为 JavaScript 社区的一员,如果我们真的想认真对待 JavaScript 领域的现实场景的性能,我们需要让各大技术媒体停止使用传统的 JavaScript 基准来比较浏览器或手机。能够在每个浏览器中运行一个基准测试,并比较它的得分自然是好的,但是请使用一个与当今世界相关的基准,例如真实的 web 页面;如果你觉得需要通过浏览器基准来比较两部手机,请至少考虑使用 [Speedometer](http://browserbench.org/Speedometer)。
#### 轻松一刻

我一直很喜欢这个 [Myles Borins](https://twitter.com/thealphanerd) 谈话,所以我不得不无耻地向他偷师。现在我们从 SunSpider 的谴责中回过头来,让我们继续检查其它经典基准。
### 不是那么显眼的 Kraken 案例
Kraken 基准是 [Mozilla 于 2010 年 9 月 发布的](https://blog.mozilla.org/blog/2010/09/14/release-the-kraken-2),据说它包含了现实场景应用的片段/内核,并且与 SunSpider 相比少了一个微基准。我不想在 Kraken 上花太多口舌,因为我认为它不像 SunSpider 和 Octane 一样对 JavaScript 性能有着深远的影响,所以我将强调一个特别的案例——[audio-oscillator.js](https://github.com/h4writer/arewefastyet/blob/master/benchmarks/kraken/tests/kraken-1.1/audio-oscillator.js) 测试。
[](https://github.com/h4writer/arewefastyet/blob/master/benchmarks/kraken/tests/kraken-1.1/audio-oscillator.js)
正如你所见,测试调用了 `calcOsc` 函数 500 次。`calcOsc` 首先在全局的 `sine` `Oscillator` 上调用 `generate`,然后创建一个新的 `Oscillator`,调用它的 `generate` 方法并将其添加到全局的 `sine` `Oscillator` 里。没有详细说明测试为什么是这样做的,让我们看看 `Oscillator` 原型上的 `generate` 方法。
[](https://github.com/h4writer/arewefastyet/blob/master/benchmarks/kraken/tests/kraken-1.1/audio-oscillator-data.js#L687)
让我们看看代码,你也许会觉得这里主要是循环中的数组访问或者乘法或者 [Math.round](https://tc39.github.io/ecma262/#sec-math.round) 调用,但令人惊讶的是 `offset % this.waveTableLength` 表达式完全支配了 `Oscillator.prototype.generate` 的运行。在任何的英特尔机器上的分析器中运行此基准测试显示,超过 20% 的时间占用都属于我们为模数生成的 `idiv` 指令。然而一个有趣的发现是,`Oscillator` 实例的 `waveTableLength` 字段总是包含相同的值——2048,因为它在 `Oscillator` 构造器中只分配一次。
[](https://github.com/h4writer/arewefastyet/blob/master/benchmarks/kraken/tests/kraken-1.1/audio-oscillator-data.js#L566)
如果我们知道整数模数运算的右边是 2 的幂,我们显然可以生成[更好的代码](https://graphics.stanford.edu/%7Eseander/bithacks.html#ModulusDivisionEasy),完全避免了英特尔上的 `idiv` 指令。所以我们需要获取一种信息使 `this.waveTableLength` 从 `Oscillator` 构造器到 `Oscillator.prototype.generate` 中的模运算都是 2048。一个显而易见的方法是尝试依赖于将所有内容内嵌到 `calcOsc` 函数,并让 `load/store` 消除为我们进行的常量传播,但这对于在 `calcOsc` 函数之外分配的 `sine` `oscillator` 无效。
因此,我们所做的就是添加支持跟踪某些常数值作为模运算符的右侧反馈。这在 V8 中是有意义的,因为我们为诸如 `+`、`*` 和 `%` 的二进制操作跟踪类型反馈,这意味着操作者跟踪输入的类型和产生的输出类型(参见最近的圆桌讨论中关于[动态语言的快速运算](https://docs.google.com/presentation/d/1wZVIqJMODGFYggueQySdiA3tUYuHNMcyp_PndgXsO1Y)的幻灯片)。当然,用 `fullcodegen` 和 `Crankshaft` 挂接起来也是相当容易的,`MOD` 的 `BinaryOpIC` 也可以跟踪右边已知的 2 的冥。
```
$ ~/Projects/v8/out/Release/d8 --trace-ic audio-oscillator.js
[...SNIP...]
[BinaryOpIC(MOD:None*None->None) => (MOD:Smi*2048->Smi) @ ~Oscillator.generate+598 at audio-oscillator.js:697]
[...SNIP...]
$
```
事实上,以默认配置运行的 V8 (带有 Crankshaft 和 fullcodegen)表明 `BinaryOpIC` 正在为模数的右侧拾取适当的恒定反馈,并正确跟踪左侧始终是一个小整数(以 V8 的话叫做 `Smi`),我们也总是产生一个小整数结果。 使用 `--print-opt-code -code-comments` 查看生成的代码,很快就显示出,`Crankshaft` 利用反馈在 `Oscillator.prototype.generate` 中为整数模数生成一个有效的代码序列:
```
[...SNIP...]
;;; <@80,#84> load-named-field
0x133a0bdacc4a 330 8b4343 movl rax,[rbx+0x43]
;;; <@83,#86> compare-numeric-and-branch
0x133a0bdacc4d 333 3d00080000 cmp rax,0x800
0x133a0bdacc52 338 0f85ff000000 jnz 599 (0x133a0bdacd57)
[...SNIP...]
;;; <@90,#94> mod-by-power-of-2-i
0x133a0bdacc5b 347 4585db testl r11,r11
0x133a0bdacc5e 350 790f jns 367 (0x133a0bdacc6f)
0x133a0bdacc60 352 41f7db negl r11
0x133a0bdacc63 355 4181e3ff070000 andl r11,0x7ff
0x133a0bdacc6a 362 41f7db negl r11
0x133a0bdacc6d 365 eb07 jmp 374 (0x133a0bdacc76)
0x133a0bdacc6f 367 4181e3ff070000 andl r11,0x7ff
[...SNIP...]
;;; <@127,#88> deoptimize
0x133a0bdacd57 599 e81273cdff call 0x133a0ba8406e
[...SNIP...]
```
所以你看到我们加载 `this.waveTableLength`(`rbx` 持有 `this` 的引用)的值,检查它仍然是 2048(十六进制的 0x800),如果是这样,就只用适当的掩码 0x7ff(`r11` 包含循环感应变量 `i` 的值)执行一个位操作 AND ,而不是使用 `idiv` 指令(注意保留左侧的符号)。
#### 过度特定的问题
所以这个技巧酷毙了,但正如许多基准关注的技巧都有一个主要的缺点:太过于特定了!一旦右侧发生变化,所有优化过的代码就失去了优化(假设右手始终是不再处理的 2 的冥),任何进一步的优化尝试都必须再次使用 `idiv`,因为 `BinaryOpIC` 很可能以 `Smi * Smi -> Smi` 的形式报告反馈。例如,假设我们实例化另一个 `Oscillator`,在其上设置不同的 `waveTableLength`,并为 `Oscillator` 调用 `generate`,那么即使我们实际上感兴趣的 `Oscillator` 不受影响,我们也会损失 20% 的性能(例如,引擎在这里实行非局部惩罚)。
```
--- audio-oscillator.js.ORIG 2016-12-15 22:01:43.897033156 +0100
+++ audio-oscillator.js 2016-12-15 22:02:26.397326067 +0100
@@ -1931,6 +1931,10 @@
var frequency = 344.53;
var sine = new Oscillator(Oscillator.Sine, frequency, 1, bufferSize, sampleRate);
+var unused = new Oscillator(Oscillator.Sine, frequency, 1, bufferSize, sampleRate);
+unused.waveTableLength = 1024;
+unused.generate();
+
var calcOsc = function() {
sine.generate();
```
将原始的 `audio-oscillator.js` 执行时间与包含额外未使用的 `Oscillator` 实例与修改的 `waveTableLength` 的版本进行比较,显示的是预期的结果:
```
$ ~/Projects/v8/out/Release/d8 audio-oscillator.js.ORIG
Time (audio-oscillator-once): 64 ms.
$ ~/Projects/v8/out/Release/d8 audio-oscillator.js
Time (audio-oscillator-once): 81 ms.
$
```
这是一个非常可怕的性能悬崖的例子:假设开发人员编写代码库,并使用某些样本输入值进行仔细的调整和优化,性能是体面的。现在,用户读过了性能说明开始使用该库,但不知何故从性能悬崖下降,因为她/他正在以一种稍微不同的方式使用库,即特定的 `BinaryOpIC` 的某种污染方式的类型反馈,并且遭受 20% 的减速(与该库作者的测量相比),该库的作者和用户都无法解释,这似乎是随机的。
现在这种情况在 JavaScript 领域并不少见,不幸的是,这些悬崖中有几个是不可避免的,因为它们是由于 JavaScript 的性能是基于乐观的假设和猜测。我们已经花了 **大量** 时间和精力来试图找到避免这些性能悬崖的方法,而仍提供了(几乎)相同的性能。事实证明,尽可能避免 `idiv` 是很有意义的,即使你不一定知道右边总是一个 2 的幂(通过动态反馈),所以为什么 `TurboFan` 的做法有异于 `Crankshaft` 的做法,因为它总是在运行时检查输入是否是 2 的幂,所以一般情况下,对于有符整数模数,优化右手侧的(未知的) 2 的冥看起来像这样(伪代码):
```
if 0 < rhs then
msk = rhs - 1
if rhs & msk != 0 then
lhs % rhs
else
if lhs < 0 then
-(-lhs & msk)
else
lhs & msk
else
if rhs < -1 then
lhs % rhs
else
zero
```
这产生更加一致和可预测的性能(使用 `TurboFan`):
```
$ ~/Projects/v8/out/Release/d8 --turbo audio-oscillator.js.ORIG
Time (audio-oscillator-once): 69 ms.
$ ~/Projects/v8/out/Release/d8 --turbo audio-oscillator.js
Time (audio-oscillator-once): 69 ms.
$
```
基准和过度特定化的问题在于基准可以给你提示可以看看哪里以及该怎么做,但它不告诉你应该做到什么程度,不能保护合理优化。例如,所有 JavaScript 引擎都使用基准来防止性能回退,但是运行 Kraken 不能保护我们在 `TurboFan` 中使用的常规方法,即我们可以将 `TurboFan` 中的模优化降级到过度特定的版本的 `Crankshaft`,而基准不会告诉我们性能回退的事实,因为从基准的角度来看这很好!现在你可以扩展基准,也许以上面我们相同的方式,并试图用基准覆盖一切,这是引擎实现者在一定程度上做的事情,但这种方法不能任意缩放。即使基准测试方便,易于用来沟通和竞争,以常识所见你还是需要留下空间,否则过度特定化将支配一切,你会有一个真正的、非常好的可接受的性能,以及巨大的性能悬崖线。
Kraken 测试还有许多其它的问题,不过现在让我们继续讨论过去五年中最有影响力的 JavaScript 基准测试—— Octane 测试。
### 深入接触 Octane
[Octane](https://developers.google.com/octane) 基准是 V8 基准的继承者,最初由[谷歌于 2012 年中期发布](https://blog.chromium.org/2012/08/octane-javascript-benchmark-suite-for.html),目前的版本 Octane 2.0 [于 2013 年年底发布](https://blog.chromium.org/2013/11/announcing-octane-20.html)。这个版本包含 15 个独立测试,其中对于 `Splay` 和 `Mandreel`,我们用来测试吞吐量和延迟。这些测试范围从 [微软 TypeScript 编译器](http://www.typescriptlang.org/) 编译自身到 `zlib` 测试测量原生的 [asm.js](http://asmjs.org/) 性能,再到 `RegExp` 引擎的性能测试、光线追踪器、2D 物理引擎等。有关各个基准测试项的详细概述,请参阅[说明书](https://developers.google.com/octane/benchmark)。所有这些测试项目都经过仔细的筛选,以反映 JavaScript 性能的方方面面,我们认为这在 2012 年非常重要,或许预计在不久的将来会变得更加重要。
在很大程度上 Octane 在实现其将 JavaScript 性能提高到更高水平的目标方面无比的成功,它在 2012 年和 2013 年引导了良性的竞争,Octane 创造了巨大的业绩和成就。但是现在将近 2017 年了,世界看起来与 2012 年真的迥然不同了。除了通常和经常被引用的批评,Octane 中的大多数项目基本上已经过时(例如,老版本的 `TypeScript`,`zlib` 通过老版本的 [Emscripten](https://github.com/kripken/emscripten) 编译而成,`Mandreel` 甚至不再可用等等),某种更重要的方式影响了 Octane 的用途:
我们看到大型 web 框架赢得了 web 种族之争,尤其是像 [Ember](http://emberjs.com/) 和 [AngularJS](https://angularjs.org/) 这样的重型框架,它们使用了 JavaScript 执行模式,不过根本没有被 Octane 所反映,并且经常受到(我们)Octane 具体优化的损害。我们还看到 JavaScript 在服务器和工具前端获胜,这意味着有大规模的 JavaScript 应用现在通常运行上数星期,如果不是运行上数年都不会被 Octane 捕获。正如开篇所述,我们有硬数据表明 Octane 的执行和内存配置文件与我们每天在 web 上看到的截然不同。
让我们来看看今天一些玩弄 Octane 基准的具体例子,其中优化不再反映在现实场景。请注意,即使这可能听起来有点负面回顾,它绝对不意味着这样!正如我已经说过好几遍,Octane 是 JavaScript 性能故事中的重要一章,它发挥了至关重要的作用。在过去由 Octane 驱动的 JavaScript 引擎中的所有优化都是善意地添加的,因为 Octane 是现实场景性能的好代理!每个年代都有它的基准,而对于每一个基准都有一段时间你必须要放手!
话虽如此,让我们在路上看这个节目,首先看看 `Box2D` 测试,它是基于 [Box2DWeb](https://github.com/hecht-software/box2dweb) (一个最初由 Erin Catto 编写的移植到 JavaScript 的流行的 2D 物理引擎)的。总的来说,很多浮点数学驱动了很多 JavaScript 引擎下很好的优化,但是,事实证明它包含一个可以肆意玩弄基准的漏洞(怪我,我发现了漏洞,并添加在这种情况下的漏洞)。在基准中有一个函数 `D.prototype.UpdatePairs`,看起来像这样:
```
D.prototype.UpdatePairs = function(b) {
var e = this;
var f = e.m_pairCount = 0,
m;
for (f = 0; f < e.m_moveBuffer.length; ++f) {
m = e.m_moveBuffer[f];
var r = e.m_tree.GetFatAABB(m);
e.m_tree.Query(function(t) {
if (t == m) return true;
if (e.m_pairCount == e.m_pairBuffer.length) e.m_pairBuffer[e.m_pairCount] = new O;
var x = e.m_pairBuffer[e.m_pairCount];
x.proxyA = t < m ? t : m;
x.proxyB = t >= m ? t : m;
++e.m_pairCount;
return true
},
r)
}
for (f = e.m_moveBuffer.length = 0; f < e.m_pairCount;) {
r = e.m_pairBuffer[f];
var s = e.m_tree.GetUserData(r.proxyA),
v = e.m_tree.GetUserData(r.proxyB);
b(s, v);
for (++f; f < e.m_pairCount;) {
s = e.m_pairBuffer[f];
if (s.proxyA != r.proxyA || s.proxyB != r.proxyB) break;
++f
}
}
};
```
一些分析显示,在第一个循环中传递给 `e.m_tree.Query` 的无辜的内部函数花费了大量的时间:
```
function(t) {
if (t == m) return true;
if (e.m_pairCount == e.m_pairBuffer.length) e.m_pairBuffer[e.m_pairCount] = new O;
var x = e.m_pairBuffer[e.m_pairCount];
x.proxyA = t < m ? t : m;
x.proxyB = t >= m ? t : m;
++e.m_pairCount;
return true
}
```
更准确地说,时间并不是开销在这个函数本身,而是由此触发的操作和内置库函数。结果,我们花费了基准调用的总体执行时间的 4-7% 在 [Compare` 运行时函数](https://github.com/v8/v8/blob/5124589642ba12228dcd66a8cb8c84c986a13f35/src/runtime/runtime-object.cc#L884)上,它实现了[抽象关系](https://tc39.github.io/ecma262/#sec-abstract-relational-comparison)比较的一般情况。

几乎所有对运行时函数的调用都来自 [CompareICStub](https://github.com/v8/v8/blob/5124589642ba12228dcd66a8cb8c84c986a13f35/src/x64/code-stubs-x64.cc#L2495),它用于内部函数中的两个关系比较:
```
x.proxyA = t < m ? t : m;
x.proxyB = t >= m ? t : m;
```
所以这两行无辜的代码要负起 99% 的时间开销的责任!这怎么来的?好吧,与 JavaScript 中的许多东西一样,[抽象关系比较](https://tc39.github.io/ecma262/#sec-abstract-relational-comparison) 的直观用法不一定是正确的。在这个函数中,`t` 和 `m` 都是 `L` 的实例,它是这个应用的一个中心类,但不会覆盖 `Symbol.toPrimitive`、`“toString”`、`“valueOf”` 或 `Symbol.toStringTag` 属性,它们与抽象关系比较相关。所以如果你写 `t < m` 会发生什么呢?
1. 调用 [ToPrimitive](https://tc39.github.io/ecma262/#sec-toprimitive)(`t`, `hint Number`)。
2. 运行 [OrdinaryToPrimitive](https://tc39.github.io/ecma262/#sec-ordinarytoprimitive)(`t`, `"number"`),因为这里没有 `Symbol.toPrimitive`。
3. 执行 `t.valueOf()`,这会获得 `t` 自身的值,因为它调用了默认的 [Object.prototype.valueOf](https://tc39.github.io/ecma262/#sec-object.prototype.valueof)。
4. 接着执行 `t.toString()`,这会生成 `"[object Object]"`,因为调用了默认的 [Object.prototype.toString](https://tc39.github.io/ecma262/#sec-object.prototype.toString),并且没有找到 `L` 的 [Symbol.toStringTag](https://tc39.github.io/ecma262/#sec-symbol.tostringtag)。
5. 调用 [ToPrimitive](https://tc39.github.io/ecma262/#sec-toprimitive)(`m`, `hint Number`)。
6. 运行 [OrdinaryToPrimitive](https://tc39.github.io/ecma262/#sec-ordinarytoprimitive)(`m`, `"number"`),因为这里没有 `Symbol.toPrimitive`。
7. 执行 `m.valueOf()`,这会获得 `m` 自身的值,因为它调用了默认的 [Object.prototype.valueOf](https://tc39.github.io/ecma262/#sec-object.prototype.valueof)。
8. 接着执行 `m.toString()`,这会生成 `"[object Object]"`,因为调用了默认的 [Object.prototype.toString](https://tc39.github.io/ecma262/#sec-object.prototype.toString),并且没有找到 `L` 的 [Symbol.toStringTag](https://tc39.github.io/ecma262/#sec-symbol.tostringtag)。
9. 执行比较 `"[object Object]" < "[object Object]"`,结果是 `false`。
至于 `t >= m` 亦复如是,它总会输出 `true`。所以这里是一个漏洞——使用抽象关系比较这种方法没有意义。而利用它的方法是使编译器常数折叠,即给基准打补丁:
```
--- octane-box2d.js.ORIG 2016-12-16 07:28:58.442977631 +0100
+++ octane-box2d.js 2016-12-16 07:29:05.615028272 +0100
@@ -2021,8 +2021,8 @@
if (t == m) return true;
if (e.m_pairCount == e.m_pairBuffer.length) e.m_pairBuffer[e.m_pairCount] = new O;
var x = e.m_pairBuffer[e.m_pairCount];
- x.proxyA = t < m ? t : m;
- x.proxyB = t >= m ? t : m;
+ x.proxyA = m;
+ x.proxyB = t;
++e.m_pairCount;
return true
},
```
因为这样做会跳过比较以达到 13% 的惊人的性能提升,并且所有的属性查找和内置函数的调用都会被它触发。
```
$ ~/Projects/v8/out/Release/d8 octane-box2d.js.ORIG
Score (Box2D): 48063
$ ~/Projects/v8/out/Release/d8 octane-box2d.js
Score (Box2D): 55359
$
```
那么我们是怎么做呢?事实证明,我们已经有一种用于跟踪比较对象的形状的机制,比较发生于 `CompareIC`,即所谓的已知接收器映射跟踪(其中的映射是 V8 的对象形状+原型),不过这是有限的抽象和严格相等比较。但是我可以很容易地扩展跟踪,并且收集反馈进行抽象的关系比较:
```
$ ~/Projects/v8/out/Release/d8 --trace-ic octane-box2d.js
[...SNIP...]
[CompareIC in ~+557 at octane-box2d.js:2024 ((UNINITIALIZED+UNINITIALIZED=UNINITIALIZED)->(RECEIVER+RECEIVER=KNOWN_RECEIVER))#LT @ 0x1d5a860493a1]
[CompareIC in ~+649 at octane-box2d.js:2025 ((UNINITIALIZED+UNINITIALIZED=UNINITIALIZED)->(RECEIVER+RECEIVER=KNOWN_RECEIVER))#GTE @ 0x1d5a860496e1]
[...SNIP...]
$
```
这里基准代码中使用的 `CompareIC` 告诉我们,对于我们正在查看的函数中的 `LT`(小于)和 `GTE`(大于或等于)比较,到目前为止这只能看到 `RECEIVERs`(接收器,V8 的 JavaScript 对象),并且所有这些接收器具有相同的映射 `0x1d5a860493a1`,其对应于 `L` 实例的映射。因此,在优化的代码中,只要我们知道比较的两侧映射的结果都为 `0x1d5a860493a1`,并且没人混淆 `L` 的原型链(即 `Symbol.toPrimitive`、`"valueOf"` 和 `"toString"` 这些方法都是默认的,并且没人赋予过 `Symbol.toStringTag` 的访问权限),我们可以将这些操作分别常量折叠为 `false` 和 `true`。剩下的故事都是关于 `Crankshaft` 的黑魔法,有很多一部分都是由于初始化的时候忘记正确地检查 `Symbol.toStringTag` 属性:
[](https://codereview.chromium.org/1355113002)
最后,性能在这个特定的基准上有了质的飞跃:

我要声明一下,当时我并不相信这个特定的行为总是指向源代码中的漏洞,所以我甚至期望外部代码经常会遇到这种情况,同时也因为我假设 JavaScript 开发人员不会总是关心这些种类的潜在错误。但是,我大错特错了,在此我马上悔改!我不得不承认,这个特殊的优化纯粹是一个基准测试的东西,并不会有助于任何真实代码(除非代码是为了从这个优化中获益而写,不过以后你可以在代码中直接写入 `true` 或 `false`,而不用再总是使用常量关系比较)。你可能想知道我们为什么在打补丁后又马上回滚了一下。这是我们整个团队投入到 `ES2015` 实施的非常时期,这才是真正的恶魔之舞,我们需要在没有严格的回归测试的情况下将所有新特性(`ES2015` 就是个怪兽)纳入传统基准。
关于 `Box2D` 点到为止了,让我们看看 `Mandreel` 基准。`Mandreel` 是一个用来将 `C/C++` 代码编译成 JavaScript 的编译器,它并没有用上新一代的 [Emscripten](https://github.com/kripken/emscripten) 编译器所使用,并且已经被弃用(或多或少已经从互联网消失了)大约三年的 JavaScript 子集 [asm.js](http://asmjs.org/)。然而,Octane 仍然有一个通过 [Mandreel](http://www.mandreel.com/) 编译的[子弹物理引擎](http://bulletphysics.org/wordpress/)。`MandreelLatency` 测试十分有趣,它测试 `Mandreel` 基准与频繁的时间测量检测点。有一种说法是,由于 `Mandreel` 强制使用虚拟机编译器,此测试提供了由编译器引入的延迟的指示,并且测量检测点之间的长时间停顿降低了最终得分。这听起来似乎合情合理,确实有一定的意义。然而,像往常一样,供应商找到了在这个基准上作弊的方法。
[](https://bugzilla.mozilla.org/show_bug.cgi?id=1162272)
`Mandreel` 自带一个重型初始化函数 `global_init`,光是解析这个函数并为其生成基线代码就花费了不可思议的时间。因为引擎通常在脚本中多次解析各种函数,一个所谓的预解析步骤用来发现脚本内的函数。然后作为函数第一次被调用完整的解析步骤以生成基线代码(或者说字节码)。这在 V8 中被称为[懒解析](https://docs.google.com/presentation/d/1214p4CFjsF-NY4z9in0GEcJtjbyVQgU0A-UqEvovzCs)。V8 有一些启发式检测函数,当预解析浪费时间的时候可以立刻调用,不过对于 `Mandreel` 基准的 `global_init` 函数就不太清楚了,于是我们将经历这个大家伙“预解析+解析+编译”的长时间停顿。所以我们[添加了一个额外的启发式函数](https://codereview.chromium.org/1102523003)以避免 `global_init` 函数的预解析。
[](https://arewefastyet.com/#machine=29&view=single&suite=octane&subtest=MandreelLatency&start=1415924086&end=1446461709)
由此可见,在检测 `global_init` 和避免昂贵的预解析步骤我们几乎提升了 2 倍。我们不太确定这是否会对真实用例产生负面影响,不过保证你在预解析大函数的时候将会受益匪浅(因为它们不会立即执行)。
让我们来看看另一个稍有争议的基准测试:[splay.js](https://github.com/chromium/octane/blob/master/splay.js) 测试,一个用于处理<ruby> 伸展树 <rt> splay tree </rt></ruby>(二叉查找树的一种)和练习自动内存管理子系统(也被称为垃圾回收器)的数据操作基准。它自带一个延迟测试,这会引导 `Splay` 代码通过频繁的测量检测点,检测点之间的长时间停顿表明垃圾回收器的延迟很高。此测试测量延迟暂停的频率,将它们分类到桶中,并以较低的分数惩罚频繁的长暂停。这听起来很棒!没有 GC 停顿,没有垃圾。纸上谈兵到此为止。让我们看看这个基准,以下是整个伸展树业务的核心:
[](https://github.com/chromium/octane/blob/master/splay.js#L85)
这是伸展树结构的核心构造,尽管你可能想看完整的基准,不过这基本上是 `SplayLatency` 得分的重要来源。怎么回事?实际上,该基准测试是建立巨大的伸展树,尽可能保留所有节点,从而还原它原本的空间。使用像 V8 这样的代数垃圾回收器,如果程序违反了[代数假设](http://www.memorymanagement.org/glossary/g.html),会导致极端的时间停顿,从本质上看,将所有东西从新空间撤回到旧空间的开销是非常昂贵的。在旧配置中运行 V8 可以清楚地展示这个问题:
```
$ out/Release/d8 --trace-gc --noallocation_site_pretenuring octane-splay.js
[20872:0x7f26f24c70d0] 10 ms: Scavenge 2.7 (6.0) -> 2.7 (7.0) MB, 1.1 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 12 ms: Scavenge 2.7 (7.0) -> 2.7 (8.0) MB, 1.7 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 14 ms: Scavenge 3.7 (8.0) -> 3.6 (10.0) MB, 0.8 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 18 ms: Scavenge 4.8 (10.5) -> 4.7 (11.0) MB, 2.5 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 22 ms: Scavenge 5.7 (11.0) -> 5.6 (16.0) MB, 2.8 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 28 ms: Scavenge 8.7 (16.0) -> 8.6 (17.0) MB, 4.3 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 35 ms: Scavenge 9.6 (17.0) -> 9.6 (28.0) MB, 6.9 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 49 ms: Scavenge 16.6 (28.5) -> 16.4 (29.0) MB, 8.2 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 65 ms: Scavenge 17.5 (29.0) -> 17.5 (52.0) MB, 15.3 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 93 ms: Scavenge 32.3 (52.5) -> 32.0 (53.5) MB, 17.6 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 126 ms: Scavenge 33.4 (53.5) -> 33.3 (68.0) MB, 31.5 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 151 ms: Scavenge 47.9 (68.0) -> 47.6 (69.5) MB, 15.8 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 183 ms: Scavenge 49.2 (69.5) -> 49.2 (84.0) MB, 30.9 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 210 ms: Scavenge 63.5 (84.0) -> 62.4 (85.0) MB, 14.8 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 241 ms: Scavenge 64.7 (85.0) -> 64.6 (99.0) MB, 28.8 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 268 ms: Scavenge 78.2 (99.0) -> 77.6 (101.0) MB, 16.1 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 298 ms: Scavenge 80.4 (101.0) -> 80.3 (114.5) MB, 28.2 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 324 ms: Scavenge 93.5 (114.5) -> 92.9 (117.0) MB, 16.4 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 354 ms: Scavenge 96.2 (117.0) -> 96.0 (130.0) MB, 27.6 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 383 ms: Scavenge 108.8 (130.0) -> 108.2 (133.0) MB, 16.8 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 413 ms: Scavenge 111.9 (133.0) -> 111.7 (145.5) MB, 27.8 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 440 ms: Scavenge 124.1 (145.5) -> 123.5 (149.0) MB, 17.4 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 473 ms: Scavenge 127.6 (149.0) -> 127.4 (161.0) MB, 29.5 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 502 ms: Scavenge 139.4 (161.0) -> 138.8 (165.0) MB, 18.7 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 534 ms: Scavenge 143.3 (165.0) -> 143.1 (176.5) MB, 28.5 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 561 ms: Scavenge 154.7 (176.5) -> 154.2 (181.0) MB, 19.0 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 594 ms: Scavenge 158.9 (181.0) -> 158.7 (192.0) MB, 29.2 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 622 ms: Scavenge 170.0 (192.5) -> 169.5 (197.0) MB, 19.5 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 655 ms: Scavenge 174.6 (197.0) -> 174.3 (208.0) MB, 28.7 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 683 ms: Scavenge 185.4 (208.0) -> 184.9 (212.5) MB, 19.4 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 715 ms: Scavenge 190.2 (213.0) -> 190.0 (223.5) MB, 27.7 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 743 ms: Scavenge 200.7 (223.5) -> 200.3 (228.5) MB, 19.7 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 774 ms: Scavenge 205.8 (228.5) -> 205.6 (239.0) MB, 27.1 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 802 ms: Scavenge 216.1 (239.0) -> 215.7 (244.5) MB, 19.8 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 833 ms: Scavenge 221.4 (244.5) -> 221.2 (254.5) MB, 26.2 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 861 ms: Scavenge 231.5 (255.0) -> 231.1 (260.5) MB, 19.9 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 892 ms: Scavenge 237.0 (260.5) -> 236.7 (270.5) MB, 26.3 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 920 ms: Scavenge 246.9 (270.5) -> 246.5 (276.0) MB, 20.1 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 951 ms: Scavenge 252.6 (276.0) -> 252.3 (286.0) MB, 25.8 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 979 ms: Scavenge 262.3 (286.0) -> 261.9 (292.0) MB, 20.3 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1014 ms: Scavenge 268.2 (292.0) -> 267.9 (301.5) MB, 29.8 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1046 ms: Scavenge 277.7 (302.0) -> 277.3 (308.0) MB, 22.4 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1077 ms: Scavenge 283.8 (308.0) -> 283.5 (317.5) MB, 25.1 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1105 ms: Scavenge 293.1 (317.5) -> 292.7 (323.5) MB, 20.7 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1135 ms: Scavenge 299.3 (323.5) -> 299.0 (333.0) MB, 24.9 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1164 ms: Scavenge 308.6 (333.0) -> 308.1 (339.5) MB, 20.9 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1194 ms: Scavenge 314.9 (339.5) -> 314.6 (349.0) MB, 25.0 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1222 ms: Scavenge 324.0 (349.0) -> 323.6 (355.5) MB, 21.1 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1253 ms: Scavenge 330.4 (355.5) -> 330.1 (364.5) MB, 25.1 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1282 ms: Scavenge 339.4 (364.5) -> 339.0 (371.0) MB, 22.2 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1315 ms: Scavenge 346.0 (371.0) -> 345.6 (380.0) MB, 25.8 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1413 ms: Mark-sweep 349.9 (380.0) -> 54.2 (305.0) MB, 5.8 / 0.0 ms (+ 87.5 ms in 73 steps since start of marking, biggest step 8.2 ms, walltime since start of marking 131 ms) finalize incremental marking via stack guard GC in old space requested
[20872:0x7f26f24c70d0] 1457 ms: Scavenge 65.8 (305.0) -> 65.1 (305.0) MB, 31.0 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1489 ms: Scavenge 69.9 (305.0) -> 69.7 (305.0) MB, 27.1 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1523 ms: Scavenge 80.9 (305.0) -> 80.4 (305.0) MB, 22.9 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1553 ms: Scavenge 85.5 (305.0) -> 85.3 (305.0) MB, 24.2 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1581 ms: Scavenge 96.3 (305.0) -> 95.7 (305.0) MB, 18.8 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1616 ms: Scavenge 101.1 (305.0) -> 100.9 (305.0) MB, 29.2 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1648 ms: Scavenge 111.6 (305.0) -> 111.1 (305.0) MB, 22.5 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1678 ms: Scavenge 116.7 (305.0) -> 116.5 (305.0) MB, 25.0 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1709 ms: Scavenge 127.0 (305.0) -> 126.5 (305.0) MB, 20.7 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1738 ms: Scavenge 132.3 (305.0) -> 132.1 (305.0) MB, 23.9 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1767 ms: Scavenge 142.4 (305.0) -> 141.9 (305.0) MB, 19.6 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1796 ms: Scavenge 147.9 (305.0) -> 147.7 (305.0) MB, 23.8 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1825 ms: Scavenge 157.8 (305.0) -> 157.3 (305.0) MB, 19.9 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1853 ms: Scavenge 163.5 (305.0) -> 163.2 (305.0) MB, 22.2 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1881 ms: Scavenge 173.2 (305.0) -> 172.7 (305.0) MB, 19.1 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1910 ms: Scavenge 179.1 (305.0) -> 178.8 (305.0) MB, 23.0 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1944 ms: Scavenge 188.6 (305.0) -> 188.1 (305.0) MB, 25.1 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 1979 ms: Scavenge 194.7 (305.0) -> 194.4 (305.0) MB, 28.4 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 2011 ms: Scavenge 204.0 (305.0) -> 203.6 (305.0) MB, 23.4 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 2041 ms: Scavenge 210.2 (305.0) -> 209.9 (305.0) MB, 23.8 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 2074 ms: Scavenge 219.4 (305.0) -> 219.0 (305.0) MB, 24.5 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 2105 ms: Scavenge 225.8 (305.0) -> 225.4 (305.0) MB, 24.7 / 0.0 ms allocation failure
[20872:0x7f26f24c70d0] 2138 ms: Scavenge 234.8 (305.0) -> 234.4 (305.0) MB, 23.1 / 0.0 ms allocation failure
[...SNIP...]
$
```
因此这里关键的发现是直接在旧空间中分配伸展树节点可基本避免在周围复制对象的所有开销,并且将次要 GC 周期的数量减少到最小(从而减少 GC 引起的停顿时间)。我们想出了一种称为<ruby> <a href="https://research.google.com/pubs/pub43823.html"> 分配场所预占 </a> <rt> allocation site pretenuring </rt></ruby>的机制,当运行到基线代码时,将尝试动态收集分配场所的反馈,以决定在此分配的对象的确切部分是否存在,如果是,则优化代码以直接在旧空间分配对象——即预占对象。
```
$ out/Release/d8 --trace-gc octane-splay.js
[20885:0x7ff4d7c220a0] 8 ms: Scavenge 2.7 (6.0) -> 2.6 (7.0) MB, 1.2 / 0.0 ms allocation failure
[20885:0x7ff4d7c220a0] 10 ms: Scavenge 2.7 (7.0) -> 2.7 (8.0) MB, 1.6 / 0.0 ms allocation failure
[20885:0x7ff4d7c220a0] 11 ms: Scavenge 3.6 (8.0) -> 3.6 (10.0) MB, 0.9 / 0.0 ms allocation failure
[20885:0x7ff4d7c220a0] 17 ms: Scavenge 4.8 (10.5) -> 4.7 (11.0) MB, 2.9 / 0.0 ms allocation failure
[20885:0x7ff4d7c220a0] 20 ms: Scavenge 5.6 (11.0) -> 5.6 (16.0) MB, 2.8 / 0.0 ms allocation failure
[20885:0x7ff4d7c220a0] 26 ms: Scavenge 8.7 (16.0) -> 8.6 (17.0) MB, 4.5 / 0.0 ms allocation failure
[20885:0x7ff4d7c220a0] 34 ms: Scavenge 9.6 (17.0) -> 9.5 (28.0) MB, 6.8 / 0.0 ms allocation failure
[20885:0x7ff4d7c220a0] 48 ms: Scavenge 16.6 (28.5) -> 16.4 (29.0) MB, 8.6 / 0.0 ms allocation failure
[20885:0x7ff4d7c220a0] 64 ms: Scavenge 17.5 (29.0) -> 17.5 (52.0) MB, 15.2 / 0.0 ms allocation failure
[20885:0x7ff4d7c220a0] 96 ms: Scavenge 32.3 (52.5) -> 32.0 (53.5) MB, 19.6 / 0.0 ms allocation failure
[20885:0x7ff4d7c220a0] 153 ms: Scavenge 61.3 (81.5) -> 57.4 (93.5) MB, 27.9 / 0.0 ms allocation failure
[20885:0x7ff4d7c220a0] 432 ms: Scavenge 339.3 (364.5) -> 326.6 (364.5) MB, 12.7 / 0.0 ms allocation failure
[20885:0x7ff4d7c220a0] 666 ms: Scavenge 563.7 (592.5) -> 553.3 (595.5) MB, 20.5 / 0.0 ms allocation failure
[20885:0x7ff4d7c220a0] 825 ms: Mark-sweep 603.9 (644.0) -> 96.0 (528.0) MB, 4.0 / 0.0 ms (+ 92.5 ms in 51 steps since start of marking, biggest step 4.6 ms, walltime since start of marking 160 ms) finalize incremental marking via stack guard GC in old space requested
[20885:0x7ff4d7c220a0] 1068 ms: Scavenge 374.8 (528.0) -> 362.6 (528.0) MB, 19.1 / 0.0 ms allocation failure
[20885:0x7ff4d7c220a0] 1304 ms: Mark-sweep 460.1 (528.0) -> 102.5 (444.5) MB, 10.3 / 0.0 ms (+ 117.1 ms in 59 steps since start of marking, biggest step 7.3 ms, walltime since start of marking 200 ms) finalize incremental marking via stack guard GC in old space requested
[20885:0x7ff4d7c220a0] 1587 ms: Scavenge 374.2 (444.5) -> 361.6 (444.5) MB, 13.6 / 0.0 ms allocation failure
[20885:0x7ff4d7c220a0] 1828 ms: Mark-sweep 485.2 (520.0) -> 101.5 (519.5) MB, 3.4 / 0.0 ms (+ 102.8 ms in 58 steps since start of marking, biggest step 4.5 ms, walltime since start of marking 183 ms) finalize incremental marking via stack guard GC in old space requested
[20885:0x7ff4d7c220a0] 2028 ms: Scavenge 371.4 (519.5) -> 358.5 (519.5) MB, 12.1 / 0.0 ms allocation failure
[...SNIP...]
$
```
事实上,这完全解决了 `SplayLatency` 基准的问题,并提高我们的得分至超过 250%!
[](https://arewefastyet.com/#machine=12&view=single&suite=octane&subtest=SplayLatency&start=1384889558&end=1415405874)
正如 [SIGPLAN 论文](https://research.google.com/pubs/pub43823.html) 中所提及的,我们有充分的理由相信,分配场所预占机制可能真的赢得了真实世界应用的欢心,并真正期待看到改进和扩展后的机制,那时将不仅仅是对象和数组字面量。但是不久后我们意识到[分配场所预占机制对真实世界应用产生了相当严重的负面影响](https://bugs.chromium.org/p/v8/issues/detail?id=3665)。我们实际上听到很多负面报道,包括 `Ember.js` 开发者和用户的唇枪舌战,虽然不仅是因为分配场所预占机制,不过它是事故的罪魁祸首。
分配场所预占机制的基本问题数之不尽,这在今天的应用中非常常见(主要是由于框架,同时还有其它原因),假设你的对象工厂最初是用于创建构成你的对象模型和视图的长周期对象的,它将你的工厂方法中的分配场所转换为永久状态,并且从工厂分配的所有内容都立即转到旧空间。现在初始设置完成后,你的应用开始工作,作为其中的一部分,从工厂分配临时对象会污染旧空间,最终导致开销昂贵的垃圾回收周期以及其它负面的副作用,例如过早触发增量标记。
我们开始重新考虑基准驱动的工作,并开始寻找现实场景驱动的替代方案,这导致了 [Orinoco](http://v8project.blogspot.de/2016/04/jank-busters-part-two-orinoco.html) 的诞生,它的目标是逐步改进垃圾回收器;这个努力的一部分是一个称为“<ruby> 统一堆 <rt> unified heap </rt></ruby>”的项目,如果页面中所有内容基本都存在,它将尝试避免复制对象。也就是说站在更高的层面看:如果新空间充满活动对象,只需将所有新空间页面标记为属于旧空间,然后从空白页面创建一个新空间。这可能不会在 `SplayLatency` 基准测试中得到相同的分数,但是这对于真实用例更友好,它可以自动适配具体的用例。我们还考虑<ruby> 并发标记 <rt> concurrent marking </rt></ruby>,将标记工作卸载到单独的线程,从而进一步减少增量标记对延迟和吞吐量的负面影响。
#### 轻松一刻

喘口气。
好吧,我想这足以强调我的观点了。我可以继续指出更多的例子,其中 Octane 驱动的改进后来变成了一个坏主意,也许改天我会接着写下去。但是今天就到此为止了吧。
### 结论
我希望现在应该清楚为什么基准测试通常是一个好主意,但是只对某个特定的级别有用,一旦你跨越了<ruby> 有用竞争 <rt> useful competition </rt></ruby>的界限,你就会开始浪费你们工程师的时间,甚至开始损害到你的真实世界的性能!如果我们认真考虑 web 的性能,我们需要根据真实世界的性能来测评浏览器,而不是它们玩弄一个四年前的基准的能力。我们需要开始教育(技术)媒体,可能这没用,但至少请忽略他们。
[](http://venturebeat.com/2016/10/25/browser-benchmark-battle-october-2016-chrome-vs-firefox-vs-edge/3/)
没人害怕竞争,但是玩弄可能已经坏掉的基准不像是在合理使用工程时间。我们可以尽更大的努力,并把 JavaScript 提高到更高的水平。让我们开展有意义的性能测试,以便为最终用户和开发者带来有意思的领域竞争。此外,让我们再对运行在 Node.js( V8 或 `ChakraCore`)中的服务器端和工具端代码做一些有意义的改进!

结束语:不要用传统的 JavaScript 基准来比较手机。这是真正最没用的事情,因为 JavaScript 的性能通常取决于软件,而不一定是硬件,并且 Chrome 每 6 周发布一个新版本,所以你在三月份的测试结果到了四月份就已经毫不相关了。如果为手机中的浏览器做个排名不可避免,那么至少请使用一个现代健全的浏览器基准来测试,至少这个基准要知道人们会用浏览器来干什么,比如 [Speedometer 基准](http://browserbench.org/Speedometer)。
感谢你花时间阅读!
---
作者简介:
我是 Benedikt Meurer,住在 Ottobrunn(德国巴伐利亚州慕尼黑东南部的一个市镇)的一名软件工程师。我于 2007 年在锡根大学获得应用计算机科学与电气工程的文凭,打那以后的 5 年里我在编译器和软件分析领域担任研究员(2007 至 2008 年间还研究过微系统设计)。2013 年我加入了谷歌的慕尼黑办公室,我的工作目标主要是 V8 JavaScript 引擎,目前是 JavaScript 执行性能优化团队的一名技术领导。
---
via: <http://benediktmeurer.de/2016/12/16/the-truth-about-traditional-javascript-benchmarks>
作者:[Benedikt Meurer](http://benediktmeurer.de/) 译者:[OneNewLife](https://github.com/OneNewLife) 校对:[OneNewLife](https://github.com/OneNewLife), [wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
8,922 | 从 Node 到 Go:一个粗略的比较 | https://medium.com/xo-tech/from-node-to-go-a-high-level-comparison-56c8b717324a#.byltlz535 | 2017-10-01T08:46:00 | [
"Node.JS",
"Golang"
] | https://linux.cn/article-8922-1.html | 
在 XO 公司,我们最初使用 Node 和 Ruby 构建相互连接的服务系统。我们享受 Node 带来的明显性能优势,以及可以访问已有的大型软件包仓库。我们也可以轻松地在公司内部发布并复用已有的插件和模块。极大地提高了开发效率,使得我们可以快速编写出可拓展的和可靠的应用。而且,庞大的 Node 社区使我们的工程师向开源软件贡献更加容易(比如 [BunnyBus](https://medium.com/xo-tech/bunnybus-building-a-data-transit-system-b9647f6283e5#.l64fdvfys) 和 [Felicity](https://medium.com/xo-tech/introducing-felicity-7b6d0b734ce#.hmloiiyx8))。
虽然我在大学时期和刚刚工作的一些时间在使用更严谨的编译语言,比如 C++ 和 C#,而后来我开始使用 JavaScript。我很喜欢它的自由和灵活,但是我最近开始怀念静态和结构化的语言,因为当时有一个同事让我对 Go 语言产生了兴趣。
我从写 JavaScript 到写 Go,我发现两种语言有很多相似之处。两者学习起来都很快并且易于上手,都具有充满表现力的语法,并且在开发者社区中都有很多工作机会。没有完美的编程语言,所以你应该总是选择一个适合手头项目的语言。在这篇文章中,我将要说明这两种语言深层次上的关键区别,希望能鼓励没有用过 Go 语言的用户~~可以~~有机会使用 Go 。
### 大体上的差异
在深入细节之前,我们应该先了解一下两种语言之间的重要区别。
Go,或称 Golang,是 Google 在 2007 年创建的自由开源编程语言。它以快速和简单为设计目标。Go 被直接编译成机器码,这就是它速度的来源。使用编译语言调试是相当容易的,因为你可以在早期捕获大量错误。Go 也是一种强类型的语言,它有助于数据完整,并可以在编译时查找类型错误。
另一方面,JavaScript 是一种弱类型语言。除了忽略验证数据的类型和真值判断陷阱所带来的额外负担之外,使用弱类型语言也有自己的好处。比起使用<ruby> 接口 <rt> interfaces </rt></ruby>和<ruby> 范型 <rt> generics </rt></ruby>,<ruby> 柯里化 <rt> currying </rt></ruby>和<ruby> 可变的形参个数 <rt> flexible arity </rt></ruby>让函数变得更加灵活。JavaScript 在运行时进行解释,这可能导致错误处理和调试的问题。Node 是一款基于 Google V8 虚拟机的 JavaScript 运行库,这使它成为一个轻量和快速的 Web 开发平台。
### 语法
作为原来的 JavaScript 开发者,Go 简单和直观的语法很吸引我。由于两种语言的语法可以说都是从 C 语言演变而来的,所以它们的语法有很多相同之处。Go 被普遍认为是一种“容易学习的语言”。那是因为它的对开发者友好的工具、精简的语法和固守惯例(LCTT 译注:惯例优先)。
Go 包含大量有助于简化开发的内置特性。你可以用标准 Go 构建工具把你的程序用 `go build` 命令编译成二进制可执行文件。使用内置的测试套件进行测试只需要运行 `go test` 即可。 诸如原生支持的并发等特性甚至在语言层面上提供。
[Google 的 Go 开发者](https://golang.org/doc/faq)认为,现在的编程太复杂了,太多的“记账一样,重复劳动和文书工作”。这就是为什么 Go 的语法被设计得如此简单和干净,以减少混乱、提高效率和增强可读性。它还鼓励开发人员编写明确的、易于理解的代码。Go 只有 [25 个保留关键字](https://golang.org/ref/spec#Keywords)和一种循环(`for` 循环),而不像 JavaScript 有 [大约 84 个关键字](https://www.w3schools.com/js/js_reserved.asp)(包括保留关键字字、对象、属性和方法)。
为了说明语法的一些差异和相似之处,我们来看几个例子:
* 标点符号: Go 去除了所有多余的符号以提高效率和可读性。尽管 JavaScript 中需要符号的地方也不多(参见: [Lisp](https://en.wikipedia.org/wiki/Lisp_%28programming_language%29)),而且经常是可选的,但我更加喜欢 Go 的简单。
```
// JavaScript 的逗号和分号
for (var i = 0; i < 10; i++) {
console.log(i);
}
```
*JavaScript 中的标点*
```
// Go 使用最少数量标点
for i := 0; i < 10; i++ {
fmt.Println(i)
}
```
*Go 中的标点*
* 赋值:由于 Go 是强类型语言,所以你在初始化变量时可以使用 `:=` 操作符来进行类型推断,以避免[重复声明](https://golang.org/doc/faq#principles),而 JavaScript 则在运行时声明类型。
```
// JavaScript 赋值
var foo = "bar";
```
*JavaScript 中的赋值*
```
// Go 的赋值
var foo string //不使用类型推导
foo = "bar"
foo := "bar" //使用类型推导
```
*Go 的赋值*
* 导出:在 JavaScript 中,你必须从某个模块中显式地导出。 在 Go 中,任何大写的函数将被默认导出。
```
const Bar = () => {};
module.exports = {
Bar
}
```
*JavaScript 中的导出*
```
// Go 中的导出
package foo // 定义包名
func Bar (s string) string {
// Bar 将被导出
}
```
*Go 中的导出*
* 导入:在 JavaScript 中 `required` 库是导入依赖项和模块所必需的,而 Go 则利用原生的 `import` 关键字通过包的路径导入模块。另一个区别是,与 Node 的中央 NPM 存储库不同,Go 使用 URL 作为路径来导入非标准库的包,这是为了从包的源码仓库直接克隆依赖。
```
// Javascript 的导入
var foo = require('foo');
foo.bar();
```
*JavaScript 的导入*
```
// Go 的导入
import (
"fmt" // Go 的标准库部分
"github.com/foo/foo" // 直接从仓库导入
)
foo.Bar()
```
*Go 的导入*
* 返回值:通过 Go 的多值返回特性可以优雅地传递和处理返回值和错误,并且通过传递引用减少了不正确的值传递。在 JavaScript 中需要通过一个对象或者数组来返回多个值。
```
// Javascript - 返回多值
function foo() {
return {a: 1, b: 2};
}
const { a, b } = foo();
```
*JavaScript 的返回*
```
// Go - 返回多值
func foo() (int, int) {
return 1, 2
}
a, b := foo()
```
*Go 的返回*
* 错误处理:Go 推荐在错误出现的地方捕获它们,而不是像 Node 一样在回调中让错误冒泡。
```
// Node 的错误处理
foo('bar', function(err, data) {
// 处理错误
}
```
*JavaScript 的错误处理*
```
//Go 的错误处理
foo, err := bar()
if err != nil {
// 用 defer、 panic、 recover 或 log.fatal 等等处理错误.
}
```
*Go 的错误处理*
* 可变参数函数:Go 和 JavaScript 的函数都支持传入不定数量的参数。
```
function foo (...args) {
console.log(args.length);
}
foo(); // 0
foo(1, 2, 3); // 3
```
*JavaScript 中的可变参数函数*
```
func foo (args ...int) {
fmt.Println(len(args))
}
func main() {
foo() // 0
foo(1,2,3) // 3
}
```
*Go 中的可变参数函数*
### 社区
当比较 Go 和 Node 提供的编程范式哪种更方便时,两边都有不同的拥护者。Node 在软件包数量和社区的大小上完全胜过了 Go。Node 包管理器(NPM),是世界上最大的软件仓库,拥有[超过 410,000 个软件包,每天以 555 个新软件包的惊人速度增长](http://www.modulecounts.com/)。这个数字可能看起来令人吃惊(确实是),但是需要注意的是,这些包许多是重复的,且质量不足以用在生产环境。 相比之下,Go 大约有 13 万个包。

*Node 和 Go 包的数量*
尽管 Node 和 Go 岁数相仿,但 JavaScript 使用更加广泛,并拥有巨大的开发者和开源社区。因为 Node 是为所有人开发的,并在开始的时候就带有一个强壮的包管理器,而 Go 是特地为 Google 开发的。下面的[Spectrum 排行榜](http://spectrum.ieee.org/static/interactive-the-top-programming-languages-2016)显示了当前流行的的顶尖 Web 开发语言。

*Web 开发语言排行榜前 7 名*
JavaScript 的受欢迎程度近年来似乎保持相对稳定,而 [Go 一直在保持上升趋势](http://www.tiobe.com/tiobe-index/)。

*编程语言趋势*
### 性能
如果你的主要关注点是速度呢?当今似乎人们比以前更重视性能的优化。用户不喜欢等待信息。 事实上,如果网页的加载时间超过 3 秒,[40% 的用户会放弃访问您的网站](https://hostingfacts.com/internet-facts-stats-2016/)。
因为它的非阻塞异步 I/O,Node 经常被认为是高性能的语言。另外,正如我之前提到的,Node 运行在针对动态语言进行了优化的 Google V8 引擎上。而 Go 的设计也考虑到速度。[Google 的开发者们](https://golang.org/doc/faq)通过建立了一个“充满表现力而轻量级的类型系统;并发和垃圾回收机制;强制地指定依赖版本等等”,达成了这一目标。
我运行了一些测试来比较 Node 和 Go 之间的性能。这些测试注重于语言提供的初级能力。如果我准备测试例如 HTTP 请求或者 CPU 密集型运算,我会使用 Go 语言级别的并发工具(goroutines/channels)。但是我更注重于各个语言提供的基本特性(参见 [三种并发方法](https://medium.com/xo-tech/concurrency-in-three-flavors-51ed709876fb#.khvqrttxa) 了解关于 goroutines 和 channels 的更多知识)。
我在基准测试中也加入了 Python,所以无论如何我们对 Node 和 Go 的结果都很满意。
#### 循环/算术
迭代十亿项并把它们相加:
```
var r = 0;
for (var c = 0; c < 1000000000; c++) {
r += c;
}
```
*Node*
```
package main
func main() {
var r int
for c := 0; c < 1000000000; c++ {
r += c
}
}
```
*Go*
```
sum(xrange(1000000000))
```
*Python*

*结果*
这里的输家无疑是 Python,花了超过 7 秒的 CPU 时间。而 Node 和 Go 都相当高效,分别用了 900 ms 和 408 ms。
*修正:由于一些评论表明 Python 的性能还可以提高。我更新了结果来反映这些变化。同时,使用 PyPy 大大地提高了性能。当使用 Python 3.6.1 和 PyPy 3.5.7 运行时,性能提升到 1.234 秒,但仍然不及 Go 和 Node 。*
#### I/O
遍历一百万个数字并将其写入一个文件。
```
var fs = require('fs');
var wstream = fs.createWriteStream('node');
for (var c = 0; c < 1000000; ++c) {
wstream.write(c.toString());
}
wstream.end();
```
*Node*
```
package main
import (
"bufio"
"os"
"strconv"
)
func main() {
file, _ := os.Create("go")
b := bufio.NewWriter(file)
for c := 0; c < 1000000; c++ {
num := strconv.Itoa(c)
b.WriteString(num)
}
file.Close()
}
```
*Go*
```
with open("python", "a") as text_file:
for i in range(1000000):
text_file.write(str(i))
```
*Python*

*结果*
Python 以 7.82 秒再次排名第三。 这次测试中,Node 和 Go 之间的差距很大,Node 花费大约 1.172 秒,Go 花费了 213 毫秒。真正令人印象深刻的是,Go 大部分的处理时间花费在编译上。如果我们将代码编译,以二进制运行,这个 I/O 测试仅花费 78 毫秒——要比 Node 快 15 倍。
*修正:修改了 Go 代码以实现缓存 I/O。*
#### 冒泡排序
将含有十个元素的数组排序一千万次。
```
function bubbleSort(input) {
var n = input.length;
var swapped = true;
while (swapped) {
swapped = false;
for (var i = 0; i < n; i++) {
if (input[i - 1] > input [i]) {
[input[i], input[i - 1]] = [input[i - 1], input[i]];
swapped = true;
}
}
}
}
for (var c = 0; c < 1000000; c++) {
const toBeSorted = [1, 3, 2, 4, 8, 6, 7, 2, 3, 0];
bubbleSort(toBeSorted);
}
```
*Node*
```
package main
var toBeSorted [10]int = [10]int{1, 3, 2, 4, 8, 6, 7, 2, 3, 0}
func bubbleSort(input [10]int) {
n := len(input)
swapped := true
for swapped {
swapped = false
for i := 1; i < n; i++ {
if input[i-1] > input[i] {
input[i], input[i-1] = input[i-1], input[i]
swapped = true
}
}
}
}
func main() {
for c := 0; c < 1000000; c++ {
bubbleSort(toBeSorted)
}
}
```
*Go*
```
def bubbleSort(input):
length = len(input)
swapped = True
while swapped:
swapped = False
for i in range(1,length):
if input[i - 1] > input[i]:
input[i], input[i - 1] = input[i - 1], input[i]
swapped = True
for i in range(1000000):
toBeSorted = [1, 3, 2, 4, 8, 6, 7, 2, 3, 0]
bubbleSort(toBeSorted)
```
*Python*

*结果*
像刚才一样,Python 的表现是最差的,大约花费 15 秒完成了任务。 Go 完成任务的速度是 Node 的 16 倍。
#### 判决
Go 无疑是这三个测试中的赢家,而 Node 大部分表现都很出色。Python 也表现不错。要清楚,性能不是选择编程语言需要考虑的全部内容。如果您的应用不需要处理大量数据,那么 Node 和 Go 之间的性能差异可能是微不足道的。 有关性能的一些其他比较,请参阅以下内容:
* [Node Vs. Go](https://jaxbot.me/articles/node-vs-go-2014)
* [Multiple Language Performance Test](https://hashnode.com/post/comparison-nodejs-php-c-go-python-and-ruby-cio352ydg000ym253frmfnt70)
* [Benchmarks Game](https://benchmarksgame.alioth.debian.org/u64q/compare.php?lang=go&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;lang2=node)
### 结论
这个帖子不是为了证明一种语言比另一种语言更好。由于各种原因,每种编程语言都在软件开发社区中占有一席之地。 我的意图是强调 Go 和 Node 之间的差异,并且促进展示一种新的 Web 开发语言。 在为一个项目选择语言时,有各种因素需要考虑,比如开发人员的熟悉程度、花费和实用性。 我鼓励在决定哪种语言适合您时进行一次彻底的底层分析。
正如我们所看到的,Go 有如下的优点:接近底层语言的性能,简单的语法和相对简单的学习曲线使它成为构建可拓展和安全的 Web 应用的理想选择。随着 Go 的使用率和社区活动的快速增长,它将会成为现代网络开发中的重要角色。话虽如此,我相信如果 Node 被正确地实现,它正在向正确的方向努力,仍然是一种强大而有用的语言。它具有大量的追随者和活跃的社区,使其成为一个简单的平台,可以让 Web 应用在任何时候启动和运行。
### 资料
如果你对学习 Go 语言感兴趣,可以参阅下面的资源:
* [Golang 网站](https://golang.org/doc/#learning)
* [Golang Wiki](https://github.com/golang/go/wiki/Learn)
* [Golang Subreddit](https://www.reddit.com/r/golang/)
---
via: <https://medium.com/xo-tech/from-node-to-go-a-high-level-comparison-56c8b717324a#.byltlz535>
作者:[John Stamatakos](https://medium.com/@johnstamatakos?source=post_header_lockup) 译者:[trnhoe](https://github.com/trnhoe) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
8,924 | 2700 万美金:阿里巴巴领投 MariaDB | https://techcrunch.com/2017/09/29/alibaba-mariadb/ | 2017-10-01T23:23:00 | [
"MariaDB",
"阿里巴巴"
] | https://linux.cn/article-8924-1.html | 
阿里巴巴在 2017 年一直努力推进其云计算业务,而现在它将首次对该领域的一家西方初创公司做出重大投资。
据知情人士透露,这家中国的电子商务巨头同意对 MariaDB 领投 2290 万欧元(2700 万美元)。MariaDB 是一家欧洲公司,其开发维护的 mariadb 数据库是最受欢迎的开源数据库之一。该交易仍未完成,但在本周 MariaDB 股东批准之后有望很快完成。
阿里巴巴和 MariaDB 均未对此置评。
据悉,阿里巴巴本次将投资 2000 万欧元,而剩余部分将由 MariaDB 现有股东追加投资。该交易将使 MariaDB 的估值达到 3 亿欧元(约合 3.54 亿美元),而阿里巴巴的云业务部门的首席工程师余锋将加入该公司董事会。
今年五月份 MariaDB 从欧洲投资银行[募集到的 2500 万欧元(当时价值 2700 万美元)](https://techcrunch.com/2017/05/08/open-source-database-developer-mariadb-picks-up-27m-from-the-eib/),当时估值越 2 亿至 2.5 亿美元,此次估值较之前次大为提高。据悉阿里巴巴非常希望完成该笔投资,因此几乎允许 MariaDB 对其出让的股份自行开价。
MariaDB 最常用作流行的数据库 MySQL 的替代品,二者都是开源产品,但有些人对 MySQL 心存疑虑,因为它现在属于 Oracle 公司。
### 关于阿里巴巴
阿里巴巴的云计算业务是其增长最快的业务单元,在去年其达到了三位数的营收增长。
[我们今年早些时候的文章提到过](https://techcrunch.com/2017/02/27/alibaba-aliyun-cloud-computing/),它现在正在努力与该行业最大的竞争对手,如 AWS、微软 Azure 和谷歌云展开竞争。虽然这还有一些路要走,但迹象表明还是有希望的。阿里云业务在最近一个财年的营收达到了 10 亿美元,前一个季度超过了 100 万个用户。该业务最近几个季度将可能达到收支平衡,虽然其目前只占了阿里巴巴全部业务营收的不到 5%。
云是阿里巴巴正在重点发展领域之一,因为它看起来将是新的收入来源之一,这可以让它摆脱对其核心的中国电子商务业务的依赖——[尽管它目前仍然带来了大量利润](https://techcrunch.com/2017/08/17/alibaba-profit-doubles-to-2-1b/)。
该公司也在其它领域展开了大量投资,比如对印度的独角兽公司 [Paytm](https://techcrunch.com/2017/03/06/alibaba-paytm-amazon-india/) 和东南亚的 [Lazada](https://techcrunch.com/2017/06/28/alibaba-ups-its-stake-in-southeast-asias-lazada-with-1-billion-investment/) 和 [Tokopedia](https://techcrunch.com/2017/08/17/alibaba-tokopedia/) 的投资,所以对更大范围的云和基础架构领域进行投资、以推进其战略也并不为奇。
对中国同领域的公司,如[云存储厂商七牛](http://www.avcj.com/avcj/news/3006331/yunfeng-alibaba-invest-usd152m-in-chinese-cloud-storage-firm)和[大数据公司数梦工场](http://technode.com/2017/06/12/chinas-cloud-industry-moving-to-new-era-with-emergence-of-unicorns/)进行投资,以及[加入微软的开源社区](https://venturebeat.com/2017/04/03/alibaba-cloud-adopts-microsofts-open-source-networking-software/),甚至[在中国直接和 MariaDB 进行合作](http://diginomica.com/2017/04/12/alibaba-on-open-source-and-cloud-business-in-china-live-from-the-mariadb-user-conference/),这些都使阿里巴巴在海外市场备受关注。
### 关于 MariaDB
以前名为 SkySQL 的 MariaDB 由于其在该行业的地位而备受阿里巴巴关注。它在瑞典和美国设有办事处,其声称已经服务了全球 1200 万数据库用户,这其中包括一些著名公司,如 Booking.com、HP、 Virgin Mobile 和维基。其解决方案用在私有云、公有云和混合云部署中,它是包括 Red Hat、Ubuntu 和 SUSE 在内的大量 Linux 发行版的默认数据库软件,这会为其进一步增加 6000 万用户。
SkySQL 最初创立于 2009 年,并于 2013 年与 Monty Program Ab 合并,后者是 Michael ‘Monty’ Widenius 在 2008 年将其公司 MySQL 以 10 亿美金卖给了太阳微系统公司(现在属于 Oracle)后创立的。由于担心 Oracle 对 MySQL 的一些做法,MariaDB 数据库后来从 MySQL 数据库中分支而来。
| 200 | OK | [Alibaba has spent 2017 pushing its cloud computing business](https://techcrunch.com/2017/02/27/alibaba-aliyun-cloud-computing/) and now it is preparing to make its first major investment in a Western startup in the space.
The Chinese e-commerce giant has agreed to lead a €22.9 million ($27 million) investment in MariaDB, the European company behind one of the web’s most popular open source database servers, according to a source with knowledge of negotiations. The deal has not closed yet, but it is imminent after MariaDB’s shareholders gave their approval this week.
Neither Alibaba nor MariaDB responded to requests for comment.
TechCrunch understands that Alibaba is contributing around €20 million with the remaining capital coming from existing backers. The deal values MariaDB at around the €300 million ($354 million) mark and it will see Alibaba’s [Feng Yu](https://www.linkedin.com/in/mryufeng/), a principal engineer within its cloud business, join the startup’s board.
That represents a significant appreciation on the $200 million-$250 million valuation that it got back in May when [it raised €25 million (then worth $27 million)](https://techcrunch.com/2017/05/08/open-source-database-developer-mariadb-picks-up-27m-from-the-eib/) from the European Investment Bank. Our source indicated that Alibaba’s willingness to do business essentially enabled MariaDB to pick a valuation of its choosing.
MariaDB is best known for operating the most popular alternative to MySQL, a database management system. Both are open source products but there is caution from some around MySQL from some because it is owned by Oracle — a huge corporation — courtesy of its acquisition of Sun Microsystems.
Alibaba’s cloud computing business is one of its fastest growing units, consistently charting triple-digit revenue growth over the past year.
[We wrote earlier this year that it is pushing hard to rival the industry’s biggest players](https://techcrunch.com/2017/02/27/alibaba-aliyun-cloud-computing/), like AWS, Microsoft Azure and Google Cloud. While it still has some way to go, the signs are promising. The cloud business hit $1 billion in annualized revenue this year and it surpassed one million customers during the most recent quarter. The unit is likely to reach break-even in coming quarters, though it still accounts for less than five percent of Alibaba’s overall revenue.
Cloud is just one area Alibaba is focused on developing as it looks to generate new sources of revenue to lessen the dependence on its core China commerce business, [even though that continues to be hugely lucrative](https://techcrunch.com/2017/08/17/alibaba-profit-doubles-to-2-1b/).
The firm has made big investments in those other areas — backing unicorns [Paytm](https://techcrunch.com/2017/03/06/alibaba-paytm-amazon-india/) in India, and [Lazada](https://techcrunch.com/2017/06/28/alibaba-ups-its-stake-in-southeast-asias-lazada-with-1-billion-investment/) and [Tokopedia](https://techcrunch.com/2017/08/17/alibaba-tokopedia/) in Southeast Asia — so why not look at the wider cloud/infrastructure industry for deals to advance its strategy?
Having invested in Chinese players like [cloud storage provider Qiniu](http://www.avcj.com/avcj/news/3006331/yunfeng-alibaba-invest-usd152m-in-chinese-cloud-storage-firm) and [big data firm Dt Dream](http://technode.com/2017/06/12/chinas-cloud-industry-moving-to-new-era-with-emergence-of-unicorns/), [joined Microsoft’s open source community](https://venturebeat.com/2017/04/03/alibaba-cloud-adopts-microsofts-open-source-networking-software/) and even [worked with MariaDB directly in China](http://diginomica.com/2017/04/12/alibaba-on-open-source-and-cloud-business-in-china-live-from-the-mariadb-user-conference/), this would be Alibaba’s most notable cloud deal on overseas turf.
Formerly known as SkySQL, MariaDB is attractive to Alibaba due to its presence in the industry. It has offices in Sweden and the U.S. and claims around 12 million global users of its databases, with some of the larger names including Booking.com, HP, Virgin Mobile and Wikipedia. Its solutions are used in private, public and hybrid cloud deployments and it is the default in a number of Linux distributions like Red Hat, Ubuntu and SUSE, which adds a further reach of 60 million users.
SkySQL was originally founded in 2009 and merged with Monty Program Ab in 2013. Monty Program was founded by Michael ‘Monty’ Widenius after he sold his previous company MySQL to Sun Microsystems (now owned by Oracle) in 2008 for $1 billion. MariaDB later forked MySQL due to concerns about the way Oracle might use it. |
8,925 | 编排工具充分发挥了 Linux 容器技术优势 | https://www.infoworld.com/article/3205304/containers/orchestration-tools-enable-companies-to-fully-exploit-linux-container-technology.html | 2017-10-02T15:05:00 | [
"容器",
"编排"
] | https://linux.cn/article-8925-1.html |
>
> 一旦公司越过了“让我们看看这些容器如何工作”的阶段,他们最终会在许多不同的地方运行容器
>
>
>

需要快速、高效地交付程序的公司 —— 而今天,哪些公司不需要这样做?—— 是那些正在转向 Linux 容器的公司。他们还发现,一旦公司越过了“让我们看看这些容器如何工作”的阶段,他们最终会在许多不同的地方运行容器。
Linux 容器技术不是新技术,但它随着最初由 Docker 发明的创新性打包格式(现在的 [OCI](https://github.com/opencontainers/image-spec) 格式)以及新应用对持续开发和部署的需求开始变得流行。在 Red Hat 的 2016 年 5 月的 Forrester 研究中,有 48% 的受访者表示已经在开发中使用容器,今年的数字预计将达到 53%。只有五分之一的受访者表示,他们在 2017 年不会在开发过程中利用容器。
像乐高积木一样,容器镜像可以轻松地重用代码和服务。每个容器镜像就像一个单独的、旨在做好一部分工作的乐高积木。它可能是数据库、数据存储、甚至预订服务或分析服务。通过单独包装每个组件,从而可以在不同的应用中使用。但是,如果没有某种程序定义(即<ruby> 指令手册 <rt> instruction booklet </rt></ruby>),则难以在不同环境中创建完整应用程序的副本。那就是容器编排的来由。

容器编排提供了像乐高系统这样的基础设施 —— 开发人员可以提供如何构建应用程序的简单说明。编排引擎将知道如何运行它。这使得可以轻松创建同一应用程序的多个副本,跨越开发人员电脑、CI/CD 系统,甚至生产数据中心和云提供商环境。
Linux 容器镜像允许公司在整个运行时环境(操作系统部件)中打包和隔离应用程序的构建块。在此基础上,通过容器编排,可以很容易地定义并运行所有的块,并一起构成完整的应用程序。一旦定义了完整的应用程序,它们就可以在不同的环境(开发、测试、生产等)之间移动,而不会破坏它们,且不改变它们的行为。
### 仔细调查容器
很明显,容器是有意义的,越来越多的公司像“对轮胎踹两脚”一样去研究容器。一开始,可能是一个开发人员使用一个容器工作,或是一组开发人员在使用多个容器。在后一种情况下,开发人员可能会随手编写一些代码来处理在容器部署超出单个实例之后快速出现的复杂性。
这一切都很好,毕竟他们是开发人员 —— 他们已经做到了。但即使在开发人员世界也会变得混乱,而且随手代码模式也没法跟着容器进入 QA 和生产环境下。
编排工具基本上做了两件事。首先,它们帮助开发人员定义他们的应用程序的表现 —— 一组用来构建应用程序实例的服务 —— 数据库、数据存储、Web 服务等。编排器帮助标准化应用程序的所有部分,在一起运行并彼此通信,我将这称之为标准化程序定义。其次,它们管理一个计算资源集群中启动、停止、升级和运行多个容器的过程,这在运行任何给定应用程序的多个副本时特别有用,例如持续集成 (CI) 和连续交付 (CD)。
想像一个公寓楼。居住在那里的每个人都有相同的街道地址,但每个人都有一个数字或字母或两者的组合,专门用来识别他或她。这是必要的,就像将正确的邮件和包裹交付给合适的租户一样。
同样,在容器中,只要你有两个容器或两个要运行这些容器的主机,你必须跟踪开发人员测试数据库连接或用户连接到正在运行的服务的位置。容器编排工具实质上有助于管理跨多个主机的容器的后勤。它们将生命周期管理功能扩展到由多个容器组成的完整应用程序,部署在一组机器上,从而允许用户将整个集群视为单个部署目标。
这真的很简单,又很复杂。编排工具提供了许多功能,从配置容器到识别和重新调度故障容器,将容器暴露给集群外的系统和服务,根据需要添加和删除容器等等。
虽然容器技术已经存在了一段时间,但容器编排工具只出现了几年。编排工具是 Google 从内部的高性能计算(HPC)和应用程序管理中吸取的经验教训开发的。在本质上,其要解决的就是在一堆服务器上运行一堆东西(批处理作业、服务等)。从那时起,编排工具已经进化到可以使公司能够战略性地利用容器。
一旦你的公司确定需要容器编排,下一步就是确定哪个平台对于业务是最有意义的。在评估容器编排时,请仔细查看(尤其):
* 应用程序定义语言
* 现有能力集
* 添加新功能的速度
* 开源还是专有
* 社区健康度(成员的积极性/高效,成员提交的质量/数量,贡献者的个人和公司的多样性)
* 强化努力
* 参考架构
* 认证
* 产品化过程
有三个主要的容器编排平台,它们似乎领先于其他,每个都有自己的历史。
1. **Docker Swarm:** Swarm 是容器典范 Docker 的附件。Swarm 允许用户建立并管理 Docker 节点的集群为单个虚拟系统。Swarm 似乎正在成为一个单一供应商的项目。
2. **Mesos:** Mesos 是从 Apache 和高性能计算中成长起来的,因此是一个优秀的调度员。Mesos 的技术也非常先进,虽然与其他相比似乎没有发展速度或投资优势。
3. **Kubernetes:** 由 Google 开发,由其内部编排工具 Borg 经验而来,Kubernetes 被广泛使用,并拥有强大的社区。其实这是 GitHub 上排名第一的项目。Mesos 目前可能比 Kubernetes 略有技术优势,但是 Kubernetes 是一个快速发展的项目,这也是为了长期技术上的收益而进行的架构投资。在不久的将来,在技术能力上应该能赶超 Mesos。
### 编排的未来
展望未来,企业们可以期待看到编排工具在应用程序和服务为中心的方向上发展。因为在现实中,如今快速应用程序开发实际上是在快速地利用服务、代码和数据的组合。无论这些服务是开源的,还是由内部团队部署的抑或从云提供商处购买的,未来将会是两者的混合。由于今天的编排器也在处理应用程序定义方面的挑战,所以期望看到它们越来越多地应对外部服务的整合。
此时此刻,想要充分利用容器的公司必须利用容器编排。
(题图:Thinkstock)
---
via: <https://www.infoworld.com/article/3205304/containers/orchestration-tools-enable-companies-to-fully-exploit-linux-container-technology.html>
作者:[Scott McCarty](https://www.infoworld.com/author/Scott-McCarty/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
8,926 | LFCS 基础:sed 命令 | https://www.linux.org/threads/lfcs-sed-command.4561/ | 2017-10-02T15:57:20 | [
"sed"
] | https://linux.cn/article-8926-1.html | 
Linux 基金会认证系统管理员(LFCS)的另一个有用的命令是 “sed”,最初表示<ruby> “流式编辑器” <rp> ( </rp> <rt> Streaming EDitor </rt> <rp> ) </rp></ruby>。
“sed” 命令是一个可以将文件作为流进行编辑的编辑器。流式传输文件的方法是从另一个命令使用管道(`>` 或 `|`)传递,或将其直接加载到 “sed” 中。
该命令的工作方式与其他编辑器相同,只是文件不显示,也不允许可视化编辑。命令被传递给 “sed” 来操纵流。
用 “sed” 可以做五件基本的事。当然,“sed” 如此强大,还有其他高级的功能,但你只需要集中精力在五件基本的事上。五种功能类型如下:
1. 搜索
2. 替换
3. 删除
4. 添加
5. 改变/变换
在深入命令参数之前,我们需要看看基本的语法。
### 语法
“sed” 命令的语法是:
```
sed [选项] 命令 [要编辑的文件]
```
本文将在适当的部分中介绍这些“选项”。“命令”可以是正则表达式的搜索和替换模式。请继续阅读了解 “sed” 如何工作的并学习基本命令。正如我之前提到的,“sed” 是一个非常强大的工具,有更多的选项可用,我将在本文中介绍。
### 示例文件
如果你打开一个终端,那你可以创建一个用于 “sed” 示例的文件。执行以下命令:
```
cd ~
grep --help >grephelp.txt
```
你现在应该在 HOME 文件夹中有一个名为 `grephelp.txt` 的文件。该文件的内容是 `grep` 命令的帮助说明。
### 搜索
搜索特定字符串是编辑器的常见功能,在 “sed” 中执行搜索也不例外。
执行搜索以在文件中查找字符串。我们来看一下基本的搜索。
如果我们想在示例文件搜索 `PATTERN` 这个词,我们将使用如下命令:
```
sed -n 's/PATTERN/PATTERN/p' grephelp.txt
```
**注意:** 如果剪切粘贴命令,请确保将单引号替换为键盘上的标准单引号。
参数 `-n` 用于抑制每行的自动打印(除了用 `p` 命令指定的行)。默认情况下,流入 “sed” 的每一行将被打印到标准输出(stdout)。如果你不使用 “-n” 选项运行上述命令,你将看到原始文件的每一行以及匹配的行。
要搜索的文件名是我们在“示例文件”部分中创建的 “grephelp.txt”。
剩下的部分是 `'s/PATTERN/PATTERN/p'` 。这一段基本分为四个部分。第一部分的 `s` 指定执行替换,或搜索并替换。
剩下的第二部分和第三部分是模式。第一个是要搜索的模式,最后一个是替换流中匹配字符串的模式。此例中,我们找到字符串 `PATTERN`,并用 `PATTERN` 替换。通过查找和替换相同的字符串,我们完全不会更改文件,甚至在屏幕上也一样。
最后一个命令是 `p`。 它指定在替换后打印新行。当然,因为替换的是相同的字符串,所以没有改变。由于我们使用 `-n` 参数抑制打印行,所以更改的行将使用 `p` 命令打印。
这个完整的命令允许我们执行搜索并查看匹配的结果。
### 替换
当搜索特定字符串时,你可能希望用匹配的字符串替换新字符串。用另一个字符串替换是很常见的操作。
我们可以使用以下命令执行相同的搜索:
```
sed -n 's/PATTERN/Pattern/p' grephelp.txt
```
在这时,字符串 “PATTERN” 变为 “Pattern” 并显示。如果你使用命令 `cat grephelp.txt` 查看文件,你会看到该文件没有更改。该更改仅对屏幕上的输出进行。你可以使用以下命令将输出通过管道传输到另一个文件:
```
sed 's/PATTERN/Pattern/' grephelp.txt > grephelp1.txt
```
现在将存在一个名为 `grephelp1.txt` 的新文件,其中保存了更改的文件。如果 `p` 作为第四个选项留下,那么有个问题是被替换的字符串的每一行将在文件中重复两次。我们也可以删除 “-n” 参数以允许所有的行打印。
使用相同字符串替换字符串的另一种方法是使用 `&` 符号来表示搜索字符串。例如,命令 `s/PATTERN/&/p` 效果是一样的。我们可以添加字符串,例如添加 `S`,可以使用命令 `s/PATTERN/&S/p`。
如果我们希望在每一行中只替换某种模式呢?可以指定要替换的匹配项的特定出现。当然,每一行的替换都是一个特定的编号。例如,示例文件上有很多破折号。一些行至少有两条破折号,所以我们可以用另一个字符代替每一行的第二个破折号。每行用星号 `*` 替换第二个破折号 `-` 的命令将是:
```
sed 's/-/*/2' grephelp.txt
```
在这里,我们用最初的 `s` 来执行替换。字符 `-` 被替换为 `*`。`2` 表示我们想要替换每行上的第二个 `-`(如果存在)。如果我们忽略了命令 `2`,则替换第一次出现的破折号。只有第一个破折号而不是每行的破折号都被替换。
如果要搜索并替换带有星号的行上的所有破折号,请使用 `g` 命令:
```
sed 's/-/*/g' grephelp.txt
```
命令也可以组合。假设你想要替换从第二次开始出现的破折号,命令将是:
```
sed 's/-/*/2g' grephelp.txt
```
现在从第二个开始出现的破折号将被星号取代。
### 删除
搜索过程中有很多时候你可能想要完全删除搜索字符串。
例如,如果要从文件中删除所有破折号,你可以使用以下命令:
```
sed 's/-//g' grephelp.txt
```
替换字符串为空白,因此匹配的字符串将被删除。
### 添加
当找到匹配时,你可以添加一行特定的文本,来使这行在浏览或打印中突出。
如果要在匹配后插入新行,那么使用 `a` 命令,后面跟上新行的字符串。还包括要匹配的字符串。例如,我们可以找到一个 `--`,并在匹配的行之后添加一行。新行的字符串将是 `double dash before this line`。
```
sed '/--/ a "double dash before this line"' grephelp.txt
```
如果要在包含匹配字符串的行之前加上这行,请使用 `i` 命令,如下所示:
```
sed '/--/ i "double dash after this line"' grephelp.txt
```
### 改变/变换
如果需要改变/变换一行,则可以使用命令 `c`。
假设我们有个有一些私人信息的文档,我们需要更改包含特定字符串的行。`c` 命令将改变整行,而不仅仅是搜索字符串。
假设我们想要阻止示例文件中包含单词 `PATTERN` 的每一行。更改的行将显示为 `This line is Top Secret`。命令是:
```
sed '/PATTERN/ c This line is Top Secret' grephelp.txt
```
可以进行更改特定字母的大小写的转换。例如,我们可以使用命令 `y` 将所有小写 `a` 更改为大写 `A`,如下所示:
```
sed 'y/a/A/' grephelp.txt
```
可以指定多个字母,如 `abdg`,如下命令所示:
```
sed 'y/abdg/ABDG/' grephelp.txt
```
确保第二组字母与第一组字母的顺序相同,否则会被替换和转换。例如,字符串 `y/a/D/` 将用大写 `D` 替换所有小写的 `a`。
### 就地更改
如果你确实要更改所使用的文件,请使用 `-i` 选项。
例如,要将 `PATTERN` 改为 `Pattern`,并对文件进行更改,则命令为:
```
sed -i 's/PATTERN/Pattern/' grephelp.txt
```
现在文件 `grephelp.txt` 将被更改。`-i` 选项可以与上述任何命令一起使用来更改原始文件的内容。
练习这些命令,并确保你理解它们。“sed” 命令非常强大。
(题图:Pixabay,CC0)
---
via: <https://www.linux.org/threads/lfcs-sed-command.4561/>
作者:[Jarret B](https://www.linux.org/threads/lfcs-sed-command.4561/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
8,927 | GitHub 的 MySQL 基础架构自动化测试 | https://githubengineering.com/mysql-testing-automation-at-github/ | 2017-10-03T12:10:00 | [
"MySQL",
"GitHub",
"测试"
] | https://linux.cn/article-8927-1.html | 
我们 MySQL 数据库基础架构是 Github 关键组件。 MySQL 提供 Github.com、 GitHub 的 API 和验证等等的服务。每一次的 `git` 请求都以某种方式触及 MySQL。我们的任务是保持数据的可用性,并保持其完整性。即使我们 MySQL 集群是按流量分配的,但是我们还是需要执行深度清理、即时更新、在线<ruby> 模式 <rt> schema </rt></ruby>迁移、集群拓扑重构、<ruby> 连接池化 <rt> pooling </rt></ruby>和负载平衡等任务。 我们建有基础架构来自动化测试这些操作,在这篇文章中,我们将分享几个例子,来说明我们是如何通过持续测试打造我们的基础架构的。这是让我们一梦到天亮的根本保障。
### 备份
没有比备份数据更重要的了,如果您没有备份数据库,在它出事前这可能并不是什么问题。Percona 的 [Xtrabackup](https://www.percona.com/software/mysql-database/percona-xtrabackup) 是我们一直用来完整备份 MySQL 数据库的工具。如果有专门需要备份的数据,我们就会备份到另一个专门备份数据的服务器上。
除了完整的二进制备份外,我们每天还会多次运行逻辑备份。这些备份数据可以让我们的工程师获取到最新的数据副本。有时候,他们希望从表中获取一整套数据,以便他们可以在一个生产级规模的表上测试索引的修改,或查看特定时间以来的数据。Hubot 可以让我们恢复备份的表,并且当表准备好使用时会通知我们。
**tomkrouper**
```
.mysql backup-list locations
```
**Hubot**
```
+-----------+------------+---------------+---------------------+---------------------+----------------------------------------------+
| Backup ID | Table Name | Donor Host | Backup Start | Backup End | File Name |
+-----------+------------+---------------+---------------------+---------------------+----------------------------------------------+
| 1699494 | locations | db-mysql-0903 | 2017-07-01 22:09:17 | 2017-07-01 22:09:17 | backup-mycluster-locations-1498593122.sql.gz |
| 1699133 | locations | db-mysql-0903 | 2017-07-01 16:11:37 | 2017-07-01 16:11:39 | backup-mycluster-locations-1498571521.sql.gz |
| 1698772 | locations | db-mysql-0903 | 2017-07-01 10:09:21 | 2017-07-01 10:09:22 | backup-mycluster-locations-1498549921.sql.gz |
| 1698411 | locations | db-mysql-0903 | 2017-07-01 04:12:32 | 2017-07-01 04:12:32 | backup-mycluster-locations-1498528321.sql.gz |
| 1698050 | locations | db-mysql-0903 | 2017-06-30 22:18:23 | 2017-06-30 22:18:23 | backup-mycluster-locations-1498506721.sql.gz |
| ...
| 1262253 | locations | db-mysql-0088 | 2016-08-01 01:58:51 | 2016-08-01 01:58:54 | backup-mycluster-locations-1470034801.sql.gz |
| 1064984 | locations | db-mysql-0088 | 2016-04-04 13:07:40 | 2016-04-04 13:07:43 | backup-mycluster-locations-1459494001.sql.gz |
+-----------+------------+---------------+---------------------+---------------------+----------------------------------------------+
```
**tomkrouper**
```
.mysql restore 1699133
```
**Hubot**
```
A restore job has been created for the backup job 1699133. You will be notified in #database-ops when the restore is complete.
```
**Hubot**
```
@tomkrouper: the locations table has been restored as locations_2017_07_01_16_11 in the restores database on db-mysql-0482
```
数据被加载到非生产环境的数据库,该数据库可供请求该次恢复的工程师访问。
我们保留数据的“备份”的最后一个方法是使用<ruby> <a href="https://dev.mysql.com/doc/refman/5.6/en/replication-delayed.html"> 延迟副本 </a> <rt> delayed replica </rt></ruby>。这与其说是备份,不如说是保护。对于每个生产集群,我们有一个延迟 4 个小时复制的主机。如果运行了一个不该运行的请求,我们可以在 chatops 中运行 `mysql panic` 。这将导致我们所有的延迟副本立即停止复制。这也将给值班 DBA 发送消息。从而我们可以使用延迟副本来验证是否有问题,并快速前进到二进制日志的错误发生之前的位置。然后,我们可以将此数据恢复到主服务器,从而恢复数据到该时间点。
备份固然好,但如果发生了一些未知或未捕获的错误破坏它们,它们就没有价值了。让脚本恢复备份的好处是它允许我们通过 cron 自动执行备份验证。我们为每个集群设置了一个专用的主机,用于运行最新备份的恢复。这样可以确保备份运行正常,并且我们能够从备份中检索数据。
根据数据集大小,我们每天运行几次恢复。恢复的服务器被加入到复制工作流,并通过复制保持数据更新。这测试不仅让我们得到了可恢复的备份,而且也让我们得以正确地确定备份的时间点,并且可以从该时间点进一步应用更改。如果恢复过程中出现问题,我们会收到通知。
我们还追踪恢复所需的时间,所以我们知道在紧急情况下建立新的副本或还原需要多长时间。
以下是由 Hubot 在我们的机器人聊天室中输出的自动恢复过程。
**Hubot**
```
gh-mysql-backup-restore: db-mysql-0752: restore_log.id = 4447
gh-mysql-backup-restore: db-mysql-0752: Determining backup to restore for cluster 'prodcluster'.
gh-mysql-backup-restore: db-mysql-0752: Enabling maintenance mode
gh-mysql-backup-restore: db-mysql-0752: Setting orchestrator downtime
gh-mysql-backup-restore: db-mysql-0752: Disabling Puppet
gh-mysql-backup-restore: db-mysql-0752: Stopping MySQL
gh-mysql-backup-restore: db-mysql-0752: Removing MySQL files
gh-mysql-backup-restore: db-mysql-0752: Running gh-xtrabackup-restore
gh-mysql-backup-restore: db-mysql-0752: Restore file: xtrabackup-notify-2017-07-02_0000.xbstream
gh-mysql-backup-restore: db-mysql-0752: Running gh-xtrabackup-prepare
gh-mysql-backup-restore: db-mysql-0752: Starting MySQL
gh-mysql-backup-restore: db-mysql-0752: Update file ownership
gh-mysql-backup-restore: db-mysql-0752: Upgrade MySQL
gh-mysql-backup-restore: db-mysql-0752: Stopping MySQL
gh-mysql-backup-restore: db-mysql-0752: Starting MySQL
gh-mysql-backup-restore: db-mysql-0752: Backup Host: db-mysql-0034
gh-mysql-backup-restore: db-mysql-0752: Setting up replication
gh-mysql-backup-restore: db-mysql-0752: Starting replication
gh-mysql-backup-restore: db-mysql-0752: Replication catch-up
gh-mysql-backup-restore: db-mysql-0752: Restore complete (replication running)
gh-mysql-backup-restore: db-mysql-0752: Enabling Puppet
gh-mysql-backup-restore: db-mysql-0752: Disabling maintenance mode
gh-mysql-backup-restore: db-mysql-0752: Setting orchestrator downtime
gh-mysql-backup-restore: db-mysql-0752: Restore process complete.
```
还有一件我们可以使用备份做的事情是向一组现有的 MySQL 服务器添加一个新的副本。我们初始化一个新的服务器,一旦我们得知它准备就绪,我们就可以开始恢复该特定集群的最新备份。我们有一个脚本,可以运行所有需要手动执行的恢复命令。我们的自动恢复系统基本上使用的是相同的脚本。这简化了系统构建过程,并允许我们在一个启动运行的主机上使用几个对话命令(chatops)来替代一堆手动执行命令。下面显示的是在该对话(chatops)中手动执行的恢复:
**jessbreckenridge**
```
.mysql backup-restore -H db-mysql-0007 -o -r magic_word=daily_rotating_word
```
**Hubot**
```
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Determining backup to restore for cluster 'mycluster'.
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: restore_log.id = 4449
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Enabling maintenance mode
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Setting orchestrator downtime
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Disabling Puppet
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Stopping MySQL
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Removing MySQL files
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Running gh-xtrabackup-restore
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Restore file: xtrabackup-mycluster-2017-07-02_0015.xbstream
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Running gh-xtrabackup-prepare
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Update file ownership
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Starting MySQL
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Upgrade MySQL
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Stopping MySQL
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Starting MySQL
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Setting up replication
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Starting replication
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Backup Host: db-mysql-0201
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Replication catch-up
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Replication behind by 4589 seconds, waiting 1800 seconds before next check.
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Restore complete (replication running)
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Enabling puppet
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Disabling maintenance mode
```
### 故障转移
[我们使用协调器](http://githubengineering.com/orchestrator-github/) 来为<ruby> 主服务器 <rt> master </rt></ruby>和<ruby> 中间服务器 <rt> intermediate master </rt></ruby>执行自动化故障切换。我们期望<ruby> 协调器 <rt> orchestrator </rt></ruby>能够正确检测主服务器故障,指定一个副本进行晋升,在所指定的副本下修复拓扑,完成晋升。我们预期 VIP(虚拟 IP)、连接池可以相应地进行变化、客户端进行重连、puppet 在晋升后的主服务器上运行基本组件等等。故障转移是一项复杂的任务,涉及到我们基础架构的许多方面。
为了建立对我们的故障转移的信赖,我们建立了一个*类生产环境*的测试集群,并且我们不断地崩溃它来观察故障转移情况。
这个*类生产环境*的测试集群是一套复制环境,与我们的生产集群的各个方面都相同:硬件类型、操作系统、MySQL 版本、网络环境、VIP、puppet 配置、[haproxy 设置](https://githubengineering.com/context-aware-mysql-pools-via-haproxy/) 等。与生产集群唯一不同的是它不发送/接收生产流量。
我们在测试集群上模拟写入负载,同时避免复制滞后。写入负载不会太大,但是有一些有意地写入相同数据集的竞争请求。这在正常情况下并不是很有用,但是事实证明这在故障转移中是有用的,我们将会稍后简要描述它。
我们的测试集群有来自三个数据中心的典型的服务器。我们希望故障转移能够从同一个数据中心内晋升替代副本。我们希望在这样的限制下尽可能多地恢复副本。我们要求尽可能地实现这两者。协调器对拓扑结构没有<ruby> 先验假定 <rt> prior assumption </rt></ruby>;它必须依据崩溃时的状态作出反应。
然而,我们有兴趣创建各种复杂而多变的故障恢复场景。我们的故障转移测试脚本为故障转移提供了基础:
* 它能够识别现有的主服务器
* 它能够重构拓扑结构,来代表主服务器下的所有的三个数据中心。不同的数据中心具有不同的网络延迟,并且预期会在不同的时间对主机崩溃做出反应。
* 能够选择崩溃方式。可以选择干掉主服务器(`kill -9`)或网络隔离(比较好的方式: `iptables -j REJECT` 或无响应的方式: `iptables -j DROP`)方式。
脚本通过选择的方法使主机崩溃,并等待协调器可靠地检测到崩溃然后执行故障转移。虽然我们期望检测和晋升在 30 秒钟内完成,但脚本会稍微放宽这一期望,并在查找故障转移结果之前休眠一段指定的时间。然后它将检查:
* 一个新的(不同的)主服务器是否到位
* 集群中有足够的副本
* 主服务器是可写的
* 对主服务器的写入在副本上可见
* 内部服务发现项已更新(如预期般识别到新的主服务器;移除旧的主服务器)
* 其他内部检查
这些测试可以证实故障转移是成功的,不仅是 MySQL 级别的,而是在更大的基础设施范围内成功的。VIP 被赋予;特定的服务已经启动;信息到达了应该去的地方。
该脚本进一步继续恢复那个失败的服务器:
* 从备份恢复它,从而隐含地测试了我们的备份/恢复过程
* 验证服务器配置是否符合预期(该服务器不再认为其是主服务器)
* 将其加入到复制集群,期望找到在主服务器上写入的数据
看一下以下可视化的计划的故障转移测试:从运行良好的群集,到在某些副本上发现问题,诊断主服务器(`7136`)是否死机,选择一个服务器(`a79d`)来晋升,重构该服务器下的拓扑,晋升它(故障切换成功),恢复失败的(原)主服务器并将其放回群集。

#### 测试失败怎么样?
我们的测试脚本使用了一种“停止世界”的方法。任何故障切换组件中的单个故障都将导致整个测试失败,因此在有人解决该问题之前,无法进行任何进一步的自动化测试。我们会得到警报,并检查状态和日志进行处理。
脚本将各种情况下失败,如不可接受的检测或故障转移时间;备份/还原出现问题;失去太多服务器;在故障切换后的意外配置等等。
我们需要确保协调器正确地连接服务器。这是竞争性写入负载有用的地方:如果设置不正确,复制很容易中断。我们会得到 `DUPLICATE KEY` 或其他错误提示出错。
这是特别重要的,因此我们改进协调器并引入新的行为,以允许我们在安全的环境中测试这些变化。
#### 出现:混乱测试
上面所示的测试程序将捕获(并已经捕获)我们基础设施许多部分的问题。这些够了吗?
在生产环境中总是有其他的东西。有些特定测试方法不适用于我们的生产集群。它们不具有相同的流量和流量方式,也不具有完全相同的服务器集。故障类型可能有所不同。
我们正在为我们的生产集群设计混乱测试。 混乱测试将会在我们的生产中,但是按照预期的时间表和充分控制的方式来逐个破坏我们的部分生产环境。 混乱测试在恢复机制中引入更高层次的信赖,并影响(因此测试)我们的基础设施和应用程序的更大部分。
这是微妙的工作:当我们承认需要混乱测试时,我们也希望可以避免对我们的服务造成不必要的影响。不同的测试将在风险级别和影响方面有所不同,我们将努力确保我们的服务的可用性。
### 模式迁移
[我们使用 gh-ost](http://githubengineering.com/gh-ost-github-s-online-migration-tool-for-mysql/)来运行实时<ruby> 模式迁移 <rt> schema migration </rt></ruby>。gh-ost 是稳定的,但也处于活跃开发中,重大新功能正在不断开发和计划中。
gh-ost 通过将数据复制到 ghost 表来迁移,将由二进制日志拦截的进一步更改应用到 ghost 表中,就如其正在写入原始表。然后它将 ghost 表交换代替原始表。迁移完成时,GitHub 继续使用由 gh-ost 生成和填充的表。
在这个时候,几乎所有的 GitHub 的 MySQL 数据都被 gh-ost 重新创建,其中大部分重新创建多次。我们必须高度信赖 gh-ost,让它一遍遍地操弄我们的数据,即使它还处于活跃开发中。下面是我们如何获得这种信赖的。
gh-ost 提供生产环境测试能力。它支持在副本上运行迁移,其方式与在主服务器上运行的方式大致相同: gh-ost 将连接到副本,并将其视为主服务器。它将采用与实际主机迁移相同的方式解析其二进制日志。但是,它将复制行并将二进制日志事件应用于副本,并避免对主服务器进行写入。
我们在生产环境中给 gh-ost 提供专用的副本。这些副本并不为生产环境提供服务。每个这样的副本将检索生产表的当前列表,并以随机顺序对其进行迭代。一个接一个地选择一个表并在该表上执行复制迁移。迁移实际上并不修改表结构,而是运行一个微不足道的 `ENGINE=InnoDB` 更改。该测试运行迁移时,如果表正在生产环境中使用,会复制实际的生产数据,并接受二进制日志之外的真实的生产环境流量。
这些迁移可以被审计。以下是我们如何从对话中(chatops)检查运行中的测试状态:
**ggunson**
```
.migration test-status
```
**Hubot**
```
# Migrating `prod`.`pull_requests`; Ghost table is `prod`.`_pull_requests_gho`
# Migrating ghost-db-mysql-0007:3306; inspecting ghost-db-mysql-0007:3306; executing on ghost-db-mysql-0007
# Migration started at Mon Jan 30 02:13:39 -0800 2017
# chunk-size: 2500; max-lag-millis: 1500ms; max-load: Threads_running=30; critical-load: Threads_running=1000; nice-ratio: 0.000000
# throttle-additional-flag-file: /tmp/gh-ost.throttle
# panic-flag-file: /tmp/ghost-test-panic.flag
# Serving on unix socket: /tmp/gh-ost.test.sock
Copy: 57992500/86684838 66.9%; Applied: 57708; Backlog: 1/100; Time: 3h28m38s(total), 3h28m36s(copy); streamer: mysql-bin.000576:142993938; State: migrating; ETA: 1h43m12s
```
当测试迁移完成表数据的复制时,它将停止复制并执行切换,使用 ghost 表替换原始表,然后交换回来。我们对实际替换数据并不感兴趣。相反,我们将留下原始的表和 ghost 表,它们应该是相同的。我们通过校验两个表的整个表数据来验证。
测试能以下列方式完成:
* *成功* :一切顺利,校验和相同。我们期待看到这一结果。
* *失败* :执行问题。这可能偶尔发生,因为迁移进程被杀死、复制问题等,并且通常与 gh-ost 自身无关。
* *校验失败* :表数据不一致。对于被测试的分支,这个需要修复。对于正在进行的 master 分支测试,这意味着立即阻止生产迁移。我们不会遇到后者。
测试结果经过审核,发送到机器人聊天室,作为事件发送到我们的度量系统。下图中的每条垂直线代表成功的迁移测试:

这些测试不断运行。如果发生故障,我们会收到通知。当然,我们可以随时访问机器人聊天室(chatops),了解发生了什么。
#### 测试新版本
我们不断改进 gh-ost。我们的开发流程基于 git 分支,然后我们通过[拉取请求(PR)](https://github.com/github/gh-ost/pulls)来提供合并。
提交的 gh-ost 拉取请求(PR)通过持续集成(CI)进行基本的编译和单元测试。一旦通过,该 PR 在技术上就有资格合并,但更好的是它[有资格通过 Heaven 进行部署](https://githubengineering.com/deploying-branches-to-github-com/)。作为我们基础架构中的敏感组件,在其进入 master 分支前,我们会小心部署分支进行密集测试。
**shlomi-noach**
```
.deploy gh-ost/fix-reappearing-throttled-reasons to prod/ghost-db-mysql-0007
```
**Hubot**
```
@shlomi-noach is deploying gh-ost/fix-reappearing-throttled-reasons (baee4f6) to production (ghost-db-mysql-0007).
@shlomi-noach's production deployment of gh-ost/fix-reappearing-throttled-reasons (baee4f6) is done! (2s)
@shlomi-noach, make sure you watch for exceptions in haystack
```
**jonahberquist**
```
.deploy gh-ost/interactive-command-question to prod/ghost-db-mysql-0012
```
**Hubot**
```
@jonahberquist is deploying gh-ost/interactive-command-question (be1ab17) to production (ghost-db-mysql-0012).
@jonahberquist's production deployment of gh-ost/interactive-command-question (be1ab17) is done! (2s)
@jonahberquist, make sure you watch for exceptions in haystack
```
**shlomi-noach**
```
.wcid gh-ost
```
**Hubot**
```
shlomi-noach testing fix-reappearing-throttled-reasons 41 seconds ago: ghost-db-mysql-0007
jonahberquist testing interactive-command-question 7 seconds ago: ghost-db-mysql-0012
Nobody is in the queue.
```
一些 PR 很小,不影响数据本身。对状态消息,交互式命令等的更改对 gh-ost 应用程序的影响较小。而其他的 PR 对迁移逻辑和操作会造成重大变化,我们将严格测试这些,通过我们的生产表车队运行这些,直到其满足了这些改变不会造成数据损坏威胁的程度。
### 总结
在整个测试过程中,我们建立对我们的系统的信赖。通过自动化这些测试,在生产环境中,我们得到了一切都按预期工作的反复确认。随着我们继续发展我们的基础设施,我们还通过调整测试来覆盖最新的变化。
产品总会有令你意想不到的未被测试覆盖的场景。我们对生产环境的测试越多,我们对应用程序的期望越多,基础设施的能力就越强。
---
via: <https://githubengineering.com/mysql-testing-automation-at-github/>
作者:[tomkrouper](https://github.com/tomkrouper), [Shlomi Noach](https://github.com/shlomi-noach) 译者:[MonkeyDEcho](https://github.com/MonkeyDEcho) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Redirecting…
Click here if you are not redirected. |
8,928 | Adobe 软件的最佳 Linux 替代品 | https://www.maketecheasier.com/adobe-alternatives-for-linux/ | 2017-10-03T23:33:00 | [
"Adobe",
"设计"
] | https://linux.cn/article-8928-1.html | 
你是一名正在寻找 Adobe 的替代品的 Linux 用户吗?那你不是一个人。如果你是一个狂热的平面设计师,那么你可能很擅长避开昂贵的 Adobe 产品。不过,对于 Adobe 来说,Linux 用户通常是其支持最不利的。因此,Adobe 的替代品是必须的 —— 但是最好的选择是什么?
这最终要看具体的 Adobe 程序和你希望完成的事情。幸运的是,由于需求是所有发明之母,有人响应了这些号召。其结果是出现了一系列高效的 Adobe 替代品。
### Evince (Adobe Acrobat Reader)

就像 Adobe Acrobat Reader 一样,[Evince](https://wiki.gnome.org/Apps/Evince) 是一个“支持多种文档格式的文档查看器”。例如,用户可以使用 Evince 作为 PDF 查看器。它还支持各种漫画书格式(cbr、cbz、cb7 和 cbt)。你可以在 Evince 网站上找到[支持格式的完整列表](https://wiki.gnome.org/Apps/Evince/SupportedDocumentFormats)。
对于 Evince ,Linux 用户不用高估,也不用贬低,它就是个标准的查看器。你可以在需要时前往官方网站进行更新。
### Pixlr (Adobe Photoshop)

关于 [Pixlr](https://pixlr.com/) 的很棒的一点是这个 Adobe 替代品的各种工具可以在线获得。如果你有一个互联网连接,那么你就有一个强大的图像编辑工作区。
[Pixlr Editor](https://pixlr.com/editor/) 是 Photoshop 的一个功能强大的替代品,你可以使用图层和相关效果。它还有一些漂亮的绘图和颜色编辑工具。[Pixlr Express](https://pixlr.com/express/) 没有这么多功能,因为它主要用于图像增强、调整颜色和清晰度,并增加一些 Instagram 适用的效果!
你可以通过 Pixlr 完成的任务简直不可置信,而且完全免费的。
### Inkscape (Adobe Illustrator)

[Inkscape](https://inkscape.org/en/)是另一个值得推荐的免费 Adobe 替代品。它主要作为一个“专业的矢量图形编辑器”。除了 Illustrator,Inkscape 也与 Corel Draw、Freehand 和 Xara X 的功能差不多。
它的矢量设计工具可用于制作 logo 和“高可伸缩性”艺术品。Inkscape 包含绘图、形状和文本工具。图层工具允许你锁定、分组或隐藏单个图层。
### Pinegrow Web Editor (Adobe Dreamweaver)

[Pinegrow Web Editor](http://pinegrow.com/) 是 Dreamweaver 在 Linux 上的绝佳替代品。该程序可让你在桌面上直接制作 HTML 网站。
不仅是使用代码创建(而且需要稍后预览),Pinegrow 可以提供详细的可视化编辑体验。你可以直接查看和测试你的 HTML 项目,实时了解链接是否正常工作,或者图片是否在它该在的地方。Pinegrow 还附带了 WordPress 主题构建器。
免费试用 30 天。如果你喜欢,你可以一次性支付 $49 购买。
### Scribus (Adobe InDesign)

[Scribus](https://www.scribus.net/) 可能是最接近 Adobe InDesign 的替代品。根据开发者的说法,你应该[认真考虑使用](https://www.scribus.net/why-on-earth-should-i-use-scribus-2/) Scribus,因为它是可靠和免费的。
实际上,Scribus 不仅仅是一个出色的桌面出版工具,也是一个很好的自出版工具。当你可以自己做高质量的杂志和书籍时,为什么要依靠昂贵的商业软件来创建?Scribus 目前允许设计师使用一个 200 色的调色板,下一个稳定版中[承诺将会加倍颜色数](https://www.scribus.net/because-color-matters/)。
### digiKam (Adobe Lightroom)

[digiKam](http://digikam.org/) 也许是目前 Linux 用户最好的 Lightroom 替代品。功能包括导入照片、整理图片集、图像增强、创建幻灯片等功能。
它的时尚设计和先进的功能是真正用心之作。实际上,digiKam 背后的人是摄影师们。不仅如此,他们希望在 Linux 中完成在 Lightroom 能做的任何工作。
### Webflow (Adobe Muse)

[Webflow](https://webflow.com/) 是另一个可以证明你无需下载软件而可以完成很多事的网站。这是一个非常方便的 Adobe Muse 替代品,Webflow 是创建高响应式网站设计的理想选择。
Webflow 的最好的一方面是你不需要自己编写代码。你只需拖放图像并写入文本。Webflow 为你做了所有杂事。你可以从头开始构建网站,也可以使用各种模板。虽然是免费的,但是其高级版本还提供了额外的功能,如能够轻松地导出 HTML 和 CSS 以在其他地方使用。
### Tupi (Adobe Animate)

[Tupi](http://www.maefloresta.com/portal/) 是 Adobe Animate 的替代品,或者也可以用于那些[不太热衷于 Flash 的人](https://www.maketecheasier.com/sites-moving-away-flash/)。当然,Tupi 的作者说这并不是与 Flash 竞争。然而,其使用 HTML5 的能力使其成为了理想的替代品。
在 PC 或平板电脑上绘制 2D 动画。不确定如何开始?使用网站的 [YouTube 教程](https://www.youtube.com/user/maefloresta)了解如何制作剪贴画动画以及更多。
### Black Magic Fusion (Adobe After Effects)

[Black Magic Fusion](https://www.blackmagicdesign.com/) 注定是 Adobe After Effects 的替代者。这个视觉效果软件历经了大约 25 年的开发!Fusion 通常用于在好莱坞电影和电视节目中制造令人印象深刻的效果 —— 这靠的是其丰富而时尚的功能。
Fusion 通过使用节点,即那些“代表效果、过滤器和其他处理的小图标”工作。将这些节点连接在一起,创建一系列复杂的视觉效果。该程序包括许多功能,如图片修饰、对象跟踪和令人兴奋的 3D 效果。
你可以选择免费版或者 $995 的 Fusion Studio。为了帮助你决定,[你可以比较](https://www.blackmagicdesign.com/products/fusion/compare)免费和高级版的 Fusion 功能。
### 总结
如你所见,这些远不止于是 Adobe 替代品。由于开源的缘故,显著提升的替代品的不断地发布。我们很快就会看到一个仅为 Linux 用户创建的完整套件。在此之前,你可以随意选择这些替代品。
知道这里没有提到的其它有用的 Adobe 替代品吗?在下面的评论区分享软件建议。
---
via: <https://www.maketecheasier.com/adobe-alternatives-for-linux/>
作者:[Toni Matthews-El](https://www.maketecheasier.com/author/ttmatthe/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 
Looking for Adobe alternatives as a Linux user? You’re not alone. If you’re an avid graphic designer, you’re probably well-versed at avoiding pricey Adobe products. Still, Linux users are typically the ones granted the shortest end of the stick when it comes to Adobe. Adobe alternatives are a must – but what exactly are the best options available?
It ultimately comes down to the specific Adobe program and what you hope to accomplish. Fortunately, as necessity remains the mother of all invention, others have answered the call. The result is a series of highly efficient stand-ins for Adobe software.
## Evince (Adobe Acrobat)
Like Adobe Acrobat Reader, [Evince](https://wiki.gnome.org/Apps/Evince) is a “document viewer for multiple documents.” For example, users may rely on Evince as a PDF viewer. It also supports various comic book formats (cbr, cbz, cb7, and cbt). You can find a [complete list of supported formats](https://wiki.gnome.org/Apps/Evince/SupportedDocumentFormats) at the Evince website.
Linux users don’t have to look high and low for Evince, as it comes standard. You can head to the official site for updates when needed.
## Pixlr (Adobe Photoshop)
The wonderful thing about [Pixlr](https://pixlr.com/) is this Adobe alternative’s various tools are available online. If you have an Internet connection, then you have a powerful image editing workspace.
[Pixlr Editor](https://pixlr.com/editor/) is a capable stand-in for Photoshop, as you can work with layers and related effects. It also has some nifty drawing and color-editing tools. [Pixlr Express](https://pixlr.com/express/) doesn’t have as many features, as it’s mainly for enhancing images. Adjust the color and clarity, and also add some Instagram-friendly effects!
It’s incredible what you can accomplish with Pixlr, and it’s completely free.
## Inkscape (Adobe Illustrator)
[Inkscape](https://inkscape.org/en/) is another well-recommended free Adobe alternative. It functions mainly as a “professional vector graphics editor.” In addition to Illustrator, Inkscape also gets held up against Corel Draw, Freehand, and Xara X.
Its vector design tools are handy for crafting logos and “high scalability” artwork. Inkscape includes drawing, shape, and text tools. Layer tools allow you to lock, group, or hide individual layers.
## Pinegrow Web Editor (Adobe Dreamweaver)
[Pinegrow Web Editor](https://pinegrow.com/) is a great substitute for Dreamweaver on Linux. The program lets you work on HTML sites right on your desktop.
Instead of just creating with code (and having to preview later), Pinegrow provides a detailed visual editing experience. You can see and test your HTML projects live, learning in real time whether links work or if images are where they’re supposed to be. Pinegrow also comes with a WordPress theme builder.
Try it free for 30 days. If you like it, you can buy it for a one-time payment of $49.
## Scribus (Adobe InDesign)
[Scribus](https://www.scribus.net) is probably the closest substitute you’ll find to Adobe’s InDesign. According to its developers, you should [strongly consider](https://www.scribus.net/why-on-earth-should-i-use-scribus-2/) Scribus because “it’s reliable and free.”
In actuality, Scribus is more than an excellent desktop publishing tool; it’s a great *self-*publishing tool. Why rely on expensive businesses to create high-quality magazines and books when you can do it yourself? Scribus currently allows designers to work with a 200-color palette, with [promises to double the number](https://www.scribus.net/because-color-matters/) of colors with the next stable version.
## digiKam (Adobe Lightroom)
[digiKam](https://digikam.org) is perhaps the best Lightroom alternative at the moment for Linux users. Features include the capacity to import photographs, organize image collections, enhance images, create slideshows, and more.
Its sleek design and advanced features are an actual labor of love; the people behind digiKam are, in fact, photographers. More than that, they wanted the ability to do in Linux what others can accomplish with Lightroom.
## Webflow (Adobe Muse)
[Webflow](https://webflow.com/) is yet another website that proves how much you can accomplish without having to download software. A very handy Adobe alternative for Muse, Webflow is ideal for creating highly-responsive website designs.
One of the best aspects of Webflow is that you don’t need to do your own coding. Just drag and drop images and write text. Webflow does the “heavy lifting” for you. There’s the option of building a website completely from scratch, or you can use various templates. Although free, the premium options boast additional features, such as the ability to easily export HTML and CSS to use elsewhere.
## Tupi (Adobe Animate)
[Tupi](https://www.maefloresta.com/portal/) is an Adobe alternative for Animate – or anyone who isn’t [too keen on Flash](https://www.maketecheasier.com/sites-moving-away-flash/) these days. Sure, Tupi’s creators state that it’s not meant to be competition for Flash. However, the ability to work with HTML5 doesn’t stop it from being an ideal substitute.
Draw and animate in 2D on your PC or tablet. Unsure how to get started? Learn how to make cutout animations and more using the site’s [YouTube tutorials](https://www.youtube.com/user/maefloresta).
## Black Magic Fusion (Adobe After Effects)
[Black Magic Fusion](https://www.blackmagicdesign.com/) was destined to upstage Adobe’s After Effects. This visual effects software is the outcome of roughly 25 years of development! Fusion is routinely used to create impressive effects in Hollywood movies and television shows – driving home its detailed and stylish capabilities.
Fusion works by using nodes, “small icons that represent effects, filters, and other processing .” These nodes are linked together to create a series of sophisticated visual effects. The program includes a host of features such as image retouching, object tracking, and mind-blowing 3D effects.
You have the option of a free version or shelling out $995 for Fusion Studio. To help you decide, [you can compare](https://www.blackmagicdesign.com/products/fusion/compare) free and premium Fusion features.
## Conclusion
As you can see, others are way ahead of you regarding Adobe alternatives. Thanks to open source ingenuity, significantly improved substitutes continue to be released. We could soon see a complete suite created just for Linux users. Until then, you’ll have these alternatives to choose from at your leisure.
Know of any useful Adobe alternatives not mentioned here? Share software recommendations in the comment section below.
Image Credit: [Adobe](https://www.adobe.com/creativecloud.html)
Our latest tutorials delivered straight to your inbox |
8,929 | 详解 Ubuntu snap 包的制作过程 | https://blog.simos.info/how-to-create-a-snap-for-timg-with-snapcraft-on-ubuntu/ | 2017-10-04T09:29:00 | [
"Snap"
] | https://linux.cn/article-8929-1.html |
>
> 如果你看过译者以前翻译的 snappy 文章,不知有没有感觉相关主题都是浅尝辄止,讲得不够透彻,看得也不太过瘾?如果有的话,相信这篇详细讲解如何从零开始制作一个 snap 包的文章应该不会让你失望。
>
>
>

在这篇文章中,我们将看到如何为名为 [timg](https://github.com/hzeller/timg) 的实用程序制作对应的 snap 包。如果这是你第一次听说 snap 安装包,你可以先看看 [如何创建你的第一个 snap 包](https://tutorials.ubuntu.com/tutorial/create-your-first-snap)。
今天我们将学习以下有关使用 snapcraft 制作 snap 包的内容:
* [timg](https://github.com/hzeller/timg) 源码中的 Makefile 文件是手工编写,我们需要修改一些 [make 插件参数](https://snapcraft.io/docs/reference/plugins/make)。
* 这个程序是用 C++ 语言写的,依赖几个额外的库文件。我们需要把相关的代码添加到 snap 包中。
* [严格限制还是传统限制](https://snapcraft.io/docs/reference/confinement)?我们将会讨论如何在它们之间进行选择。
首先,我们了解下 [timg](https://github.com/hzeller/timg) 有什么用?
### 背景
Linux 终端模拟器已经变得非常炫酷,并且还能显示颜色!

除了标准的颜色,大多数终端模拟器(如上图显示的 GNOME 终端)都支持真彩色(1600 万种颜色)。

是的!终端模拟器已经支持真彩色了!从这个页面“ [多个终端和终端应用程序已经支持真彩色(1600 万种颜色)](https://gist.github.com/XVilka/8346728)” 可以获取 AWK 代码自己进行测试。你可以看到在代码中使用了一些 [转义序列](https://en.wikipedia.org/wiki/Escape_sequence) 来指定 RGB 的值(256 \* 256 \* 256 ~= 1600 万种颜色)。
### timg 是什么?
好了,言归正传,[timg](https://github.com/hzeller/timg) 有什么用?它能将输入的图片重新调整为终端窗口字符所能显示范围的大小(比如:80 x 25),然后在任何分辨率的终端窗口用彩色字符显示图像。

这幅图用彩色块字符显示了 [Ubuntu 的 logo](http://design.ubuntu.com/wp-content/uploads/ubuntu-logo112.png),原图是一个 PNG 格式的文件。

这是 [@Doug8888 拍摄的花](https://www.flickr.com/photos/doug88888/5776072628/in/photolist-9WCiNQ-7U3Trc-7YUZBL-5DwkEQ-6e1iT8-a372aS-5F75aL-a1gbow-6eNayj-8gWK2H-5CtH7P-6jVqZv-86RpwN-a2nEnB-aiRmsc-6aKvwK-8hmXrN-5CWDNP-62hWM8-a9smn1-ahQqHw-a22p3w-a36csK-ahN4Pv-7VEmnt-ahMSiT-9NpTa7-5A3Pon-ai7DL7-9TKCqV-ahr7gN-a1boqP-83ZzpH-9Sqjmq-5xujdi-7UmDVb-6J2zQR-5wAGNR-5eERar-5KVDym-5dL8SZ-5S2Uut-7RVyHg-9Z6MAt-aiRiT4-5tLesw-aGLSv6-5ftp6j-5wAVBq-5T2KAP)。
如果你通过远程连接服务器来管理自己的业务,并想要查看图像文件,那么 [timg](https://github.com/hzeller/timg) 将会特别有用。
除了静态图片,[timg](https://github.com/hzeller/timg) 同样也可以显示 gif 动图。
那么让我们开始 snap 之旅吧!
### 熟悉 timg 的源码
[timg](https://github.com/hzeller/timg) 的源码可以在 <https://github.com/hzeller/timg> 找到。让我们试着手动编译它,以了解它有什么需求。

`Makefile` 在 `src/` 子文件夹中而不是项目的根文件夹中。在 github 页面上,他们说需要安装两个开发包(GraphicsMagic++ 和 WebP),然后使用 `make` 就能生成可执行文件。在截图中可以看到我已经将它们安装好了(在我读完相关的 Readme.md 文件后)。
因此,在编写 `snapcraft.yaml` 文件时已经有了四条腹稿:
1. `Makefile` 在 `src/` 子文件夹中而不是项目的根文件夹中。
2. 这个程序编译时需要两个开发库。
3. 为了让 timg 以 snap 包形式运行,我们需要将这两个库捆绑在 snap 包中(或者静态链接它们)。
4. [timg](https://github.com/hzeller/timg) 是用 C++ 编写的,所以需要安装 g++。在编译之前,让我们通过 `snapcraft.yaml` 文件来检查 `build-essential` 元包是否已经安装。
### 从 snapcraft 开始
让我们新建一个名为 `timg-snap/` 的文件夹,并在其中运行 `snapcraft init` 这条命令来创建 `snapcraft.yaml` 工作的框架。
```
ubuntu@snaps:~$ mkdir timg-snap
ubuntu@snaps:~$ cd timg-snap/
ubuntu@snaps:~/timg-snap$ snapcraft init
Created snap/snapcraft.yaml.
Edit the file to your liking or run `snapcraft` to get started
ubuntu@snaps:~/timg-snap$ cat snap/snapcraft.yaml
name: my-snap-name # you probably want to 'snapcraft register <name>'
version: '0.1' # just for humans, typically '1.2+git' or '1.3.2'
summary: Single-line elevator pitch for your amazing snap # 79 char long summary
description: |
This is my-snap's description. You have a paragraph or two to tell the most important story about your snap. Keep it under 100 words though, we live in tweetspace and your description wants to look good in the snap store.
grade: devel # must be 'stable' to release into candidate/stable channels
confinement: devmode # use 'strict' once you have the right plugs and slots
parts:
my-part:
# See 'snapcraft plugins'
plugin: nil
```
### 填充元数据
`snapcraft.yaml` 配置文件的上半部分是元数据。我们需要一个一个把它们填满,这算是比较容易的部分。元数据由以下字段组成:
1. `name` (名字)—— snap 包的名字,它将公开在 Ubuntu 商店中。
2. `version` (版本)—— snap 包的版本号。可以是源代码存储库中一个适当的分支或者标记,如果没有分支或标记的话,也可以是当前日期。
3. `summary` (摘要)—— 不超过 80 个字符的简短描述。
4. `description` (描述)—— 长一点的描述, 100 个字以下。
5. `grade` (等级)—— `stable` (稳定)或者 `devel` (开发)。因为我们想要在 Ubuntu 商店的稳定通道中发布这个 snap 包,所以在 snap 包能正常工作后,就把它设置成 `stable`。
6. `confinement` (限制)—— 我们首先设置为 `devmode` (开发模式),这样系统将不会以任何方式限制 snap 包。一旦它在 `devmode`下能正常工作,我们再考虑选择 `strict` (严格)还是 `classic` (传统)限制。
我们将使用 `timg` 这个名字:
```
ubuntu@snaps:~/timg-snap$ snapcraft register timg
Registering timg.
You already own the name 'timg'.
```
是的,这个名字我已经注册了 :-)。
接下来,我们应该选择哪个版本的 timg?

当在仓库中寻找分支或标记时,我们会发现有一个 v0.9.5 标签,其中有 2016 年 6 月 27 日最新提交的代码。

然而主分支(`master`)中有两个看起来很重要的提交。因此我们使用主分支而不用 `v0.9.5` 标签的那个。我们使用今天的日期—— `20170226` 做为版本号。
我们从仓库中搜集了摘要和描述。其中摘要的内容为 `A terminal image viewer`,描述的内容为 `A viewer that uses 24-Bit color capabilities and unicode character blocks to display images in the terminal`。
最后,将 `grade` (等级)设置为 `stable` (稳定),将 `confinement` 限制设置为 `devmode` (开发模式)(一直到 snap 包真正起作用)。
这是更新后的 `snapcraft.yaml`,带有所有的元数据:
```
ubuntu@snaps:~/timg-snap$ cat snap/snapcraft.yaml
name: timg
version: '20170226'
summary: A terminal image viewer
description: |
A viewer that uses 24-Bit color capabilities and unicode character blocks to display images in the terminal.
grade: stable
confinement: devmode
parts:
my-part:
# See 'snapcraft plugins'
plugin: nil
```
### 弄清楚 `parts:` 是什么
现在我们需要将上面已经存在的 `parts:` 部分替换成真实的 `parts:`。

*Git 仓库的 URL。*

*存在 Makefile,因此我们需要 make 插件。*
我们已经知道 git 仓库的 URL 链接,并且 timg 源码中已有了 `Makefile` 文件。至于 [snapcraft make 插件](https://snapcraft.io/docs/reference/plugins/make) 的 Makefile 命令,正如文档所言,这个插件总是会运行 `make` 后再运行 `make install`。为了确认 `make` 插件的用法,我查看了 [snapcraft 可用插件列表](https://snapcraft.io/docs/reference/plugins/)。
因此,我们将最初的配置:
```
parts:
my-part:
# See 'snapcraft plugins'
plugin: nil
```
修改为:
```
parts:
timg:
source: https://github.com/hzeller/timg.git
plugin: make
```
这是当前 `snapcraft.yaml` 文件的内容:
```
name: timg
version: '20170226'
summary: A terminal image viewer
description: |
A viewer that uses 24-Bit color capabilities and unicode character blocks
to display images in the terminal.
grade: stable
confinement: devmode
parts:
timg:
source: https://github.com/hzeller/timg.git
plugin: make
```
让我们运行下 `snapcraft prime` 命令看看会发生什么:
```
ubuntu@snaps:~/timg-snap$ snapcraft prime
Preparing to pull timg
Pulling timg
Cloning into '/home/ubuntu/timg-snap/parts/timg/src'...
remote: Counting objects: 144, done.
remote: Total 144 (delta 0), reused 0 (delta 0), pack-reused 144
Receiving objects: 100% (144/144), 116.00 KiB | 0 bytes/s, done.
Resolving deltas: 100% (89/89), done.
Checking connectivity... done.
Preparing to build timg
Building timg
make -j4
make: *** No targets specified and no makefile found. Stop.
Command '['/bin/sh', '/tmp/tmpem97fh9d', 'make', '-j4']' returned non-zero exit status 2
ubuntu@snaps:~/timg-snap$
```
我们可以看到 `snapcraft` 无法在源代码中找到 `Makefile` 文件,正如我们之前所暗示的,`Makefile` 位于 `src/` 子文件夹中。那么,我们可以让 `snapcraft` 使用 `src/` 文件夹中的 `Makefile` 文件吗?
每个 snapcraft 插件都有自己的选项,并且有一些通用选项是所有插件共享的。在本例中,我们希望研究那些[与源代码相关的 snapcraft 选项](https://snapcraft.io/docs/reference/plugins/source)。我们开始吧:
**source-subdir:path**
snapcraft 会<ruby> 检出 <rt> checkout </rt></ruby> `source` 关键字所引用的仓库或者解压归档文件到 `parts/<part-name>/src/` 中,但是它只会将特定的子目录复制到 `parts/<part-name>/build/` 中。
我们已经有了适当的选项,下面更新下 `parts`:
```
parts:
timg:
source: https://github.com/hzeller/timg.git
source-subdir: src
plugin: make
```
然后再次运行 `snapcraft prime`:
```
ubuntu@snaps:~/timg-snap$ snapcraft prime
The 'pull' step of 'timg' is out of date:
The 'source-subdir' part property appears to have changed.
Please clean that part's 'pull' step in order to continue
ubuntu@snaps:~/timg-snap$ snapcraft clean
Cleaning up priming area
Cleaning up staging area
Cleaning up parts directory
ubuntu@snaps:~/timg-snap$ snapcraft prime
Skipping pull timg (already ran)
Preparing to build timg
Building timg
make -j4
g++ `GraphicsMagick++-config --cppflags --cxxflags` -Wall -O3 -fPIC -c -o timg.o timg.cc
g++ -Wall -O3 -fPIC -c -o terminal-canvas.o terminal-canvas.cc
/bin/sh: 1: GraphicsMagick++-config: not found
timg.cc:33:22: fatal error: Magick++.h: No such file or directory
compilation terminated.
Makefile:10: recipe for target 'timg.o' failed
make: *** [timg.o] Error 1
make: *** Waiting for unfinished jobs....
Command '['/bin/sh', '/tmp/tmpeeyxj5kw', 'make', '-j4']' returned non-zero exit status 2
ubuntu@snaps:~/timg-snap$
```
从错误信息我们可以得知 snapcraft 找不到 GraphicsMagick++ 这个开发库文件。根据 [snapcraft 常见关键字](https://snapcraft.io/docs/reference/plugins/common) 可知,我们需要在 `snapcraft.yaml` 中指定这个库文件,这样 snapcraft 才能安装它。
**build-packages:[deb, deb, deb…]**
列出构建 part 前需要在主机中安装的 Ubuntu 包。这些包通常不会进入最终的 snap 包中,除非它们含有 snap 包中二进制文件直接依赖的库文件(在这种情况下,可以通过 `ldd` 发现它们),或者在 `stage-package` 中显式地指定了它们。
让我们寻找下这个开发包的名字:
```
ubuntu@snaps:~/timg-snap$ apt-cache search graphicsmagick++ | grep dev
graphicsmagick-libmagick-dev-compat/xenial 1.3.23-1build1 all
libgraphicsmagick++1-dev/xenial 1.3.23-1build1 amd64
format-independent image processing - C++ development files
libgraphicsmagick1-dev/xenial 1.3.23-1build1 amd64
format-independent image processing - C development files
ubuntu@snaps:~/timg-snap$
```
可以看到包名为 `libgraphicsmagick++1-dev`,下面是更新后的 `parts`:
```
parts:
timg:
source: https://github.com/hzeller/timg.git
source-subdir: src
plugin: make
build-packages:
- libgraphicsmagick++1-dev
```
再次运行 `snapcraft`:
```
ubuntu@snaps:~/timg-snap$ snapcraft
Installing build dependencies: libgraphicsmagick++1-dev
[...]
The following NEW packages will be installed:
libgraphicsmagick++-q16-12 libgraphicsmagick++1-dev libgraphicsmagick-q16-3
libgraphicsmagick1-dev libwebp5
[...]
Building timg
make -j4
g++ `GraphicsMagick++-config --cppflags --cxxflags` -Wall -O3 -fPIC -c -o timg.o timg.cc
g++ -Wall -O3 -fPIC -c -o terminal-canvas.o terminal-canvas.cc
g++ -o timg timg.o terminal-canvas.o `GraphicsMagick++-config --ldflags --libs`
/usr/bin/ld: cannot find -lwebp
collect2: error: ld returned 1 exit status
Makefile:7: recipe for target 'timg' failed
make: *** [timg] Error 1
Command '['/bin/sh', '/tmp/tmptma45jzl', 'make', '-j4']' returned non-zero exit status 2
ubuntu@snaps:~/timg-snap$
```
虽然只指定了开发库 `libgraphicsmagick+1-dev`,但 Ubuntu 还安装了一些代码库,包括 `libgraphicsmagick ++-q16-12`,以及动态代码库 `libwebp`。
这里仍然有一个错误,这个是因为缺少开发版本的 `webp` 库(一个静态库)。我们可以通过下面的命令找到它:
```
ubuntu@snaps:~/timg-snap$ apt-cache search libwebp | grep dev
libwebp-dev - Lossy compression of digital photographic images.
ubuntu@snaps:~/timg-snap$
```
上面安装的 `libwebp5` 包只提供了一个动态库(.so)。通过 `libwebp-dev` 包,我们可以得到相应的静态库(.a)。好了,让我们更新下 `parts:` 部分:
```
parts:
timg:
source: https://github.com/hzeller/timg.git
source-subdir: src
plugin: make
build-packages:
- libgraphicsmagick++1-dev
- libwebp-dev
```
下面是更新后的 `snapcraft.yaml` 文件的内容:
```
name: timg
version: '20170226'
summary: A terminal image viewer
description: |
A viewer that uses 24-Bit color capabilities and unicode character blocks
to display images in the terminal.
grade: stable
confinement: devmode
parts:
timg:
source: https://github.com/hzeller/timg.git
source-subdir: src
plugin: make
build-packages:
- libgraphicsmagick++1-dev
- libwebp-dev
```
让我们运行下 `snapcraft prime`:
```
ubuntu@snaps:~/timg-snap$ snapcraft prime
Skipping pull timg (already ran)
Preparing to build timg
Building timg
make -j4
g++ `GraphicsMagick++-config --cppflags --cxxflags` -Wall -O3 -fPIC -c -o timg.o timg.cc
g++ -Wall -O3 -fPIC -c -o terminal-canvas.o terminal-canvas.cc
g++ -o timg timg.o terminal-canvas.o `GraphicsMagick++-config --ldflags --libs`
make install DESTDIR=/home/ubuntu/timg-snap/parts/timg/install
install timg /usr/local/bin
install: cannot create regular file '/usr/local/bin/timg': Permission denied
Makefile:13: recipe for target 'install' failed
make: *** [install] Error 1
Command '['/bin/sh', '/tmp/tmptq_s1itc', 'make', 'install', 'DESTDIR=/home/ubuntu/timg-snap/parts/timg/install']' returned non-zero exit status 2
ubuntu@snaps:~/timg-snap$
```
我们遇到了一个新问题。由于 `Makefile` 文件是手工编写的,不符合 [snapcraft make 插件](https://snapcraft.io/docs/reference/plugins/make) 的参数设置,所以不能正确安装到 `prime/` 文件夹中。`Makefile` 会尝试安装到 `usr/local/bin` 中。
我们需要告诉 [snapcraft make 插件](https://snapcraft.io/docs/reference/plugins/make) 不要运行 `make install`,而是找到 `timg` 可执行文件然后把它放到 `prime/` 文件夹中。根据文档的描述:
```
- artifacts:
(列表)
将 make 生成的指定文件复制或者链接到 snap 包安装目录。如果使用,则 `make install` 这步操作将被忽略。
```
所以,我们需要将一些东西放到 `artifacts:` 中。但是具体是哪些东西?
```
ubuntu@snaps:~/timg-snap/parts/timg$ ls build/src/
Makefile terminal-canvas.h timg* timg.o
terminal-canvas.cc terminal-canvas.o timg.cc
ubuntu@snaps:~/timg-snap/parts/timg$
```
在 `build/` 子目录中,我们可以找到 `make` 的输出结果。由于我们设置了 `source-subdir:` 为 `src`,所以 `artifacts:` 的基目录为 `build/src`。在这里我们可以找到可执行文件 `timg`,我们需要将它设置为 `artifacts:` 的一个参数。通过 `artifacts:`,我们可以把 `make` 输出的某些文件复制到 snap 包的安装目录(在 `prime/` 中)。
下面是更新后 `snapcraft.yaml` 文件 `parts:` 部分的内容:
```
parts:
timg:
source: https://github.com/hzeller/timg.git
source-subdir: src
plugin: make
build-packages:
- libgraphicsmagick++1-dev
- libwebp-dev
artifacts: [timg]
```
让我们运行 `snapcraft prime`:
```
ubuntu@snaps:~/timg-snap$ snapcraft prime
Preparing to pull timg
Pulling timg
Cloning into '/home/ubuntu/timg-snap/parts/timg/src'...
remote: Counting objects: 144, done.
remote: Total 144 (delta 0), reused 0 (delta 0), pack-reused 144
Receiving objects: 100% (144/144), 116.00 KiB | 207.00 KiB/s, done.
Resolving deltas: 100% (89/89), done.
Checking connectivity... done.
Preparing to build timg
Building timg
make -j4
g++ `GraphicsMagick++-config --cppflags --cxxflags` -Wall -O3 -fPIC -c -o timg.o timg.cc
g++ -Wall -O3 -fPIC -c -o terminal-canvas.o terminal-canvas.cc
g++ -o timg timg.o terminal-canvas.o `GraphicsMagick++-config --ldflags --libs`
Staging timg
Priming timg
ubuntu@snaps:~/timg-snap$
```
我们还将继续迭代。
### 导出命令
到目前为止,snapcraft 生成了可执行文件,但没有导出给用户使用的命令。接下来我们需要通过 `apps:` 导出一个命令。
首先我们需要知道命令在 `prime/` 的哪个子文件夹中:
```
ubuntu@snaps:~/timg-snap$ ls prime/
meta/ snap/ timg* usr/
ubuntu@snaps:~/timg-snap$
```
它在 `prime/` 子文件夹的根目录中。现在,我们已经准备好要在 `snapcaft.yaml` 中增加 `apps:` 的内容:
```
ubuntu@snaps:~/timg-snap$ cat snap/snapcraft.yaml
name: timg
version: '20170226'
summary: A terminal image viewer
description: |
A viewer that uses 24-Bit color capabilities and unicode character blocks
to display images in the terminal.
grade: stable
confinement: devmode
apps:
timg:
command: timg
parts:
timg:
source: https://github.com/hzeller/timg.git
source-subdir: src
plugin: make
build-packages:
- libgraphicsmagick++1-dev
- libwebp-dev
artifacts: [timg]
```
让我们再次运行 `snapcraft prime`,然后测试下生成的 snap 包:
```
ubuntu@snaps:~/timg-snap$ snapcraft prime
Skipping pull timg (already ran)
Skipping build timg (already ran)
Skipping stage timg (already ran)
Skipping prime timg (already ran)
ubuntu@snaps:~/timg-snap$ snap try --devmode prime/
timg 20170226 mounted from /home/ubuntu/timg-snap/prime
ubuntu@snaps:~/timg-snap$
```

*图片来源: <https://www.flickr.com/photos/mustangjoe/6091603784/>*
我们可以通过 `snap try --devmode prime/` 启用该 snap 包然后测试 `timg` 命令。这是一种高效的测试方法,可以避免生成 .snap 文件,并且无需安装和卸载它们,因为 `snap try prime/` 直接使用了 `prime/` 文件夹中的内容。
### 限制 snap
到目前为止,snap 包一直是在不受限制的开发模式下运行的。让我们看看如何限制它的运行:
```
ubuntu@snaps:~/timg-snap$ snap list
Name Version Rev Developer Notes
core 16-2 1337 canonical -
timg 20170226 x1 devmode,try
ubuntu@snaps:~/timg-snap$ snap try --jailmode prime
timg 20170226 mounted from /home/ubuntu/timg-snap/prime
ubuntu@snaps:~/timg-snap$ snap list
Name Version Rev Developer Notes
core 16-2 1337 canonical -
timg 20170226 x2 jailmode,try
ubuntu@snaps:~/timg-snap$ timg pexels-photo-149813.jpeg
Trouble loading pexels-photo-149813.jpeg (Magick: Unable to open file (pexels-photo-149813.jpeg) reported by magick/blob.c:2828 (OpenBlob))
ubuntu@snaps:~/timg-snap$
```
通过这种方式,我们可以无需修改 `snapcraft.yaml` 文件就从开发模式(`devmode`)切换到限制模式(`jailmode`)(`confinement: strict`)。正如预期的那样,`timg` 无法读取图像,因为我们没有开放访问文件系统的权限。
现在,我们需要作出决定。使用限制模式,我们可以很容易授予某个命令访问用户 `$HOME` 目录中文件的权限,但是只能访问那里。如果图像文件位于其它地方,我们总是需要复制到 `$HOME` 目录并在 `$HOME` 的副本上运行 timg。如果我们觉得可行,那我们可以设置 `snapcraf.yaml` 为:
```
name: timg
version: '20170226'
summary: A terminal image viewer
description: |
A viewer that uses 24-Bit color capabilities and unicode character blocks
to display images in the terminal.
grade: stable
confinement: strict
apps:
timg:
command: timg
plugs: [home]
parts:
timg:
source: https://github.com/hzeller/timg.git
source-subdir: src
plugin: make
build-packages:
- libgraphicsmagick++1-dev
- libwebp-dev
artifacts: [timg]
```
另一方面,如果希望 timg snap 包能访问整个文件系统,我们可以设置传统限制来实现。对应的 `snapcraft.yaml` 内容如下:
```
name: timg
version: '20170226'
summary: A terminal image viewer
description: |
A viewer that uses 24-Bit color capabilities and unicode character blocks
to display images in the terminal.
grade: stable
confinement: classic
apps:
timg:
command: timg
parts:
timg:
source: https://github.com/hzeller/timg.git
source-subdir: src
plugin: make
build-packages:
- libgraphicsmagick++1-dev
- libwebp-dev
artifacts: [timg]
```
接下来我们将选择严格(`strict`)约束选项。因此,图像应该只能放在 $HOME 中。
### 打包和测试
让我们打包这个 snap,也就是制作 .snap 文件,然后在新安装的 Ubuntu 系统上对它进行测试。
```
ubuntu@snaps:~/timg-snap$ snapcraft
Skipping pull timg (already ran)
Skipping build timg (already ran)
Skipping stage timg (already ran)
Skipping prime timg (already ran)
Snapping 'timg' \
Snapped timg_20170226_amd64.snap
ubuntu@snaps:~/timg-snap$
```
我们如何在几秒钟内得到一个全新安装的 Ubuntu 系统来对 snap 包进行测试?
请查看 [尝试在 Ubuntu 上使用 LXD 容器](https://blog.simos.info/trying-out-lxd-containers-on-our-ubuntu/),并在你的系统上设置 LXD。然后回到这里,尝试运行下面的命令:
```
$ lxc launch ubuntu:x snaptesting
Creating snaptesting
Starting snaptesting
$ lxc file push timg_20170226_amd64.snap snaptesting/home/ubuntu/
$ lxc exec snaptesting -- sudo su - ubuntu
To run a command as administrator (user "root"), use "sudo <command>".
See "man sudo_root" for details.
ubuntu@snaptesting:~$ ls
timg_20170226_amd64.snap
ubuntu@snaptesting:~$ snap install timg_20170226_amd64.snap
error: access denied (try with sudo)
ubuntu@snaptesting:~$ sudo snap install timg_20170226_amd64.snap
error: cannot find signatures with metadata for snap "timg_20170226_amd64.snap"
ubuntu@snaptesting:~$ sudo snap install timg_20170226_amd64.snap --dangerous
error: cannot perform the following tasks:
- Mount snap "core" (1337) ([start snap-core-1337.mount] failed with exit status 1: Job for snap-core-1337.mount failed. See "systemctl status snap-core-1337.mount" and "journalctl -xe" for details.
)
ubuntu@snaptesting:~$ sudo apt install squashfuse
[...]
Setting up squashfuse (0.1.100-0ubuntu1~ubuntu16.04.1) ...
ubuntu@snaptesting:~$ sudo snap install timg_20170226_amd64.snap --dangerous
timg 20170226 installed
ubuntu@snaptesting:~$ wget https://farm7.staticflickr.com/6187/6091603784_d6960c8be2_z_d.jpg
[...]
2017-02-26 22:12:18 (636 KB/s) - ‘6091603784_d6960c8be2_z_d.jpg’ saved [240886/240886]
ubuntu@snaptesting:~$ timg 6091603784_d6960c8be2_z_d.jpg
[it worked!]
ubuntu@snaptesting:~$
```
我们启动了一个名为 `snaptesting` 的 LXD 容器,并将 .snap 文件复制进去。然后,通过普通用户连接到容器,并尝试安装 snap 包。最初,我们安装失败了,因为在无特权的 LXD 容器中安装 snap 包需要使用 `sudo` 。接着又失败了,因为 .snap 没有经过签名(我们需要使用 `--dangerous` 参数)。然而还是失败了,这次是因为我们需要安装 `squashfuse` 包(Ubuntu 16.04 镜像中没有预装)。最后,我们成功安装了snap,并设法查看了图像。
在一个全新安装的 Linux 系统中测试 snap 包是很重要的,因为这样才能确保 snap 包中包含所有必须的代码库。在这个例子中,我们使用了静态库并运行良好。
### 发布到 Ubuntu 商店
这是 [发布 snap 包到 Ubuntu 商店的说明](https://snapcraft.io/docs/build-snaps/publish)。 在之前的教程中,我们已经发布了一些 snap 包。对于 `timg` 来说,我们设置了严格限制和稳定等级。因此,我们会将它发布到稳定通道。
```
$ snapcraft push timg_20170226_amd64.snap
Pushing 'timg_20170226_amd64.snap' to the store.
Uploading timg_20170226_amd64.snap [ ] 0%
Uploading timg_20170226_amd64.snap [=======================================] 100%
Ready to release!|
Revision 6 of 'timg' created.
$ snapcraft release timg 6 stable
Track Arch Series Channel Version Revision
latest amd64 16 stable 20170226 6
candidate ^ ^
beta 0.9.5 5
edge 0.9.5 5
The 'stable' channel is now open.
```
我们把 .snap 包推送到 Ubuntu 商店后,得到了一个 `Revision 6`。然后,我们将 timg `Revision 6` 发布到了 Ubuntu 商店的稳定通道。
在候选通道中没有已发布的 snap 包,它继承的是稳定通道的包,所以显示 `^` 字符。
在之前的测试中,我将一些较老版本的 snap 包上传到了测试和边缘通道。这些旧版本使用了 timg 标签为 `0.9.5` 的源代码。
我们可以通过将稳定版本发布到测试和边缘通道来移除旧的 0.9.5 版本的包。
```
$ snapcraft release timg 6 beta
Track Arch Series Channel Version Revision
latest amd64 16 stable 20170226 6
candidate ^ ^
beta 20170226 6
edge 0.9.5 5
$ snapcraft release timg 6 edge
Track Arch Series Channel Version Revision
latest amd64 16 stable 20170226 6
candidate ^ ^
beta 20170226 6
edge 20170226 6
```
### 使用 timg
让我们不带参数运行 `timg`:
```
ubuntu@snaptesting:~$ timg
Expected image filename.
usage: /snap/timg/x1/timg [options] <image> [<image>...]
Options:
-g<w>x<h> : Output pixel geometry. Default from terminal 80x48
-s[<ms>] : Scroll horizontally (optionally: delay ms (60)).
-d<dx:dy> : delta x and delta y when scrolling (default: 1:0).
-w<seconds>: If multiple images given: Wait time between (default: 0.0).
-t<seconds>: Only animation or scrolling: stop after this time.
-c<num> : Only Animation or scrolling: number of runs through a full cycle.
-C : Clear screen before showing image.
-F : Print filename before showing picture.
-v : Print version and exit.
If both -c and -t are given, whatever comes first stops.
If both -w and -t are given for some animation/scroll, -t takes precedence
ubuntu@snaptesting:~$
```
这里提到当前我们终端模拟器的缩放级别,即分辨率为:80 × 48。
让我们缩小一点,并最大化 GNOME 终端窗口。
```
-g<w>x<h> : Output pixel geometry. Default from terminal 635x428
```
这是一个更好的解决方案,但我几乎看不到字符,因为他们太小了。让我们调用前面的命令再次显示这辆车。

你所看到的是调整后的图像(1080p)。虽然它是用彩色文本字符显示的,但看起来依旧很棒。
接下来呢?`timg` 其实也可以播放 gif 动画哦!
```
$ wget https://m.popkey.co/9b7141/QbAV_f-maxage-0.gif -O JonahHillAmazed.gif$ timg JonahHillAmazed.gif
```
你可以试着安装 `timg` 来体验 gif 动画。要是不想自己动手,可以在 [asciinema](https://asciinema.org/a/dezbe2gpye84e0pjndp8t0pvh) 上查看相关记录 (如果视频看上去起伏不定的,请重新运行它)。
谢谢阅读!
---
译者简介:
经常混迹于 snapcraft.io,对 Ubuntu Core、Snaps 和 Snapcraft 有着浓厚的兴趣,并致力于将这些还在快速发展的新技术通过翻译或原创的方式介绍到中文世界。有兴趣的小伙伴也可以关注译者个人公众号: `Snapcraft`
---
via:<https://blog.simos.info/how-to-create-a-snap-for-timg-with-snapcraft-on-ubuntu/>
作者:[Mi blog lah!](https://blog.simos.info/) 译者:[Snapcrafter](https://github.com/Snapcrafter) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In this post we are going to see how to create a snap for a utility called [timg](https://github.com/hzeller/timg). If this is the very first time you heard about snap installation packages, see [How to create your first snap](https://tutorials.ubuntu.com/tutorial/create-first-snap).
Today we learn the following items about creating snaps with snapcraft,
- the source of
[timg](https://github.com/hzeller/timg)comes with a handmade Makefile, and requires to tinker a bit the[make plugin parameters.](https://snapcraft.io/docs/reference/plugins/make) - the program is written in C and requires a couple of external libraries. We make sure their relevant code has been added to the snap.
- should we select
[strict confinement](https://snapcraft.io/docs/reference/confinement)or[classic confinement](https://snapcraft.io/docs/reference/confinement)? We discuss how to choose between these two.
So, what does this [timg](https://github.com/hzeller/timg) do?
## Background
The Linux terminal emulators have become quite cool and they have colors!
Apart from the standard colors, most terminal emulators (like the GNOME Terminal depicted above) support true color (16 million colors!).
Yes! True color in the terminal emulators! Get the AWK code from the page [ True Colour (16 million colours) support in various terminal applications and terminals](https://gist.github.com/XVilka/8346728)
and test it yourself. You may notice in the code that it uses some [escape sequences](https://en.wikipedia.org/wiki/Escape_sequence) to specify the RGB value (256*256*256 ~= 16 million colors).
## What is timg?
Alright, back to the point of the post. What does [timg](https://github.com/hzeller/timg) do? Well, it takes an image as input and resizes it down to the character dimensions of your terminal window (for example, 80×25). And shows the image in color, just by using characters in color, in whatever resolution the terminal window is in!
This one is [the Ubuntu logo](http://design.ubuntu.com/wp-content/uploads/ubuntu-logo112.png), a PNG image file, shown as colored block characters.
And here is [a flower, by @Doug8888](https://www.flickr.com/photos/doug88888/5776072628/in/photolist-9WCiNQ-7U3Trc-7YUZBL-5DwkEQ-6e1iT8-a372aS-5F75aL-a1gbow-6eNayj-8gWK2H-5CtH7P-6jVqZv-86RpwN-a2nEnB-aiRmsc-6aKvwK-8hmXrN-5CWDNP-62hWM8-a9smn1-ahQqHw-a22p3w-a36csK-ahN4Pv-7VEmnt-ahMSiT-9NpTa7-5A3Pon-ai7DL7-9TKCqV-ahr7gN-a1boqP-83ZzpH-9Sqjmq-5xujdi-7UmDVb-6J2zQR-5wAGNR-5eERar-5KVDym-5dL8SZ-5S2Uut-7RVyHg-9Z6MAt-aiRiT4-5tLesw-aGLSv6-5ftp6j-5wAVBq-5T2KAP).
[timg](https://github.com/hzeller/timg) would be especially helpful if you are connecting remotely to your server, minding your own business, and want to see what an image file looks like. Bam!
Apart from static images, [timg](https://github.com/hzeller/timg) can also display animated gifs! Let’s start snapping!
## Getting familiar with the timg source
The source of [timg](https://github.com/hzeller/timg) can be found at [https://github.com/hzeller/timg](https://github.com/hzeller/timg) Let’s try to compile it manually in order to get an idea what requirements it may have.
The * Makefile* is in the
*subdirectory and not in the root directory of the project. At the github page they say to install these two development packages (GraphicsMagic++, WebP) and then*
**src/***would simply work and generate the executable. In the screenshot I show for brevity that I have them already installed (after I read the Readme.md file about this).*
**make**Therefore, four mental notes when authoring the snapcraft.yaml file:
- The Makefile is in a subdirectory, src/, and not in the root directory of the project.
- The program requires two development libraries in order to compile.
- In order for timg to run as a snap, we need to somehow bundle these two libraries inside the snap (or link them statically).
[timg](https://github.com/hzeller/timg)is written in C++ and requires g++. Let’s instruct the snapcraft.yaml file to check that themetapackage is installed before compiling.**build-essential**
## Starting off with snapcraft
Let’s create a directory * timg-snap/*, and run
*in there in order to create a skeleton*
**snapcraft init***to work on.*
**snapcraft.yaml**ubuntu@snaps:~$mkdir timg-snapubuntu@snaps:~$cd timg-snap/ubuntu@snaps:~/timg-snap$snapcraft initCreated snap/snapcraft.yaml. Edit the file to your liking or run `snapcraft` to get started ubuntu@snaps:~/timg-snap$cat snap/snapcraft.yamlname: my-snap-name # you probably want to 'snapcraft register <name>' version: '0.1' # just for humans, typically '1.2+git' or '1.3.2' summary: Single-line elevator pitch for your amazing snap # 79 char long summary description: | This is my-snap's description. You have a paragraph or two to tell the most important story about your snap. Keep it under 100 words though, we live in tweetspace and your description wants to look good in the snap store. grade: devel # must be 'stable' to release into candidate/stable channels confinement: devmode # use 'strict' once you have the right plugs and slots parts: my-part: # See 'snapcraft plugins' plugin: nil
## Filling in the metadata
The upper part of a snapcraft.yaml configuration file is the metadata. We fill them in in one go, and they are the easy part. The metadata consist of the following fields
, the name of the snap as it will be known publicly at the Ubuntu Store.**name**, the version of the snap. Can be an appropriate branch or tag in the source code repository, or the current date if no branch or tag exist.**version**, a short description under 80 characters.**summary**, a bit longer description, under 100 words.**description**, either**grade**or**stable**. We want to release the snap in the stable channel of the Ubuntu Store. We make sure the snap works, and write**devel**here.**stable**, initially we put**confinement**so as not to restrict the snap in any way. Once it works as**devmode**, we later consider whether to select**devmode**or**strict**confinement.**classic**
For the name, we are going to use **timg,**
ubuntu@snaps:~/timg-snap$Registering timg. You already own the name 'timg'.snapcraft register timg
Yeah, I registered the name the other day :-).
Next, which version of timg?
When we look for a branch or a tag in the repository, we find that there is a v0.9.5 tag, with the latest commit in 27th Jun 2016.
However, in the main branch (* master*) there are two commits that look significant. Therefore, instead of using
*, we are snapping the*
**tag v0.9.5***branch. We are using today’s date as the version,*
**master***.*
**20170226**We glean the summary and description from the repository. Therefore, the summary is *A terminal image viewer*, and the description is *A viewer that uses 24-Bit color capabilities and unicode character blocks to display images in the terminal*.
Finally, the * grade* will be
*and the*
**stable***will be*
**confinement***(initially, until the snap actually works).*
**devmode**Here is the updated snapcraft.yaml with the completed metadata section:
ubuntu@snaps:~/timg-snap$cat snap/snapcraft.yamlname: timg version: '20170226' summary: A terminal image viewer description: | A viewer that uses 24-Bit color capabilities and unicode character blocks to display images in the terminal. grade: stable confinement: devmode parts: my-part: # See 'snapcraft plugins' plugin: nil
## Figuring out the “parts:”
This is the moment where we want to replace the stub * parts:* section shown above with a real
*.*
**parts:**- The URL for the git repository.
- There is an existing Makefile, therefore the make plugin.
We know the URL to the git repository and we have seen that there is an existing Makefile. The existing Makefile commands for [the make Snapcraft plugin](https://snapcraft.io/docs/reference/plugins/make). As the documentation says, *This plugin always runs ‘make’ followed by ‘make install’*. In order to identify the * make* plugin, we went through
[the list of available Snapcraft plugins](https://snapcraft.io/docs/reference/plugins/).
Therefore, we initially change from the stub
parts: my-part: # See 'snapcraft plugins' plugin: nil
to
parts: timg: source: https://github.com/hzeller/timg.git plugin: make
Here is the current snapcraft.yaml,
name: timg version: '20170226' summary: A terminal image viewer description: | A viewer that uses 24-Bit color capabilities and unicode character blocks to display images in the terminal. grade: stable confinement: devmode parts: timg: source: https://github.com/hzeller/timg.git plugin: make
Let’s run the * snapcraft prime* command and see what happens!
ubuntu@snaps:~/timg-snap$snapcraftprimePreparing to pull timg Pulling timg Cloning into '/home/ubuntu/timg-snap/parts/timg/src'... remote: Counting objects: 144, done. remote: Total 144 (delta 0), reused 0 (delta 0), pack-reused 144 Receiving objects: 100% (144/144), 116.00 KiB | 0 bytes/s, done. Resolving deltas: 100% (89/89), done. Checking connectivity... done. Preparing to build timg Building timg make -j4 make: ***Command '['/bin/sh', '/tmp/tmpem97fh9d', 'make', '-j4']' returned non-zero exit status 2 ubuntu@snaps:~/timg-snap$No targets specified and no makefile found. Stop.
* snapcraft* could not find a
*in the source and as we hinted earlier, the*
**Makefile***is only located inside the*
**Makefile***subdirectory. Can we instruct*
**src/***to look into*
**snapcraft***of the source for the*
**src/***?*
**Makefile**Each snapcraft plugin has its own options, and there are general shared options that relate to all plugins. In this case, we want to look into [the snapcraft options relating to the source code](https://snapcraft.io/docs/reference/plugins/source). Here we go,
`source-subdir`
: pathSnapcraft will checkout the repository or unpack the archive referred to by the`source`
keyword into`parts/<part-name>/src/`
but it will only copy the specified subdirectory into`parts/<part-name>/build/`
We have the appropriate option, let’s update the **parts: **
parts: timg: source: https://github.com/hzeller/timg.gitplugin: makesource-subdir: src
And run * snapcraft* again!
ubuntu@snaps:~/timg-snap$snapcraft primeThe 'pull' step of 'timg' is out of date: The 'source-subdir' part property appears to have changed. Please clean that part's 'pull' step in order to continue ubuntu@snaps:~/timg-snap$snapcraft cleanCleaning up priming area Cleaning up staging area Cleaning up parts directory ubuntu@snaps:~/timg-snap$snapcraft primeSkipping pull timg (already ran) Preparing to build timg Building timg make -j4 g++ `GraphicsMagick++-config --cppflags --cxxflags` -Wall -O3 -fPIC -c -o timg.o timg.cc g++ -Wall -O3 -fPIC -c -o terminal-canvas.o terminal-canvas.cctimg.cc:33:22:/bin/sh: 1: GraphicsMagick++-config: not foundcompilation terminated. Makefile:10: recipe for target 'timg.o' failed make: *** [timg.o] Error 1 make: *** Waiting for unfinished jobs.... Command '['/bin/sh', '/tmp/tmpeeyxj5kw', 'make', '-j4']' returned non-zero exit status 2 ubuntu@snaps:~/timg-snap$fatal error: Magick++.h: No such file or directory
Here it tells us that it cannot find the development library GraphicsMagick++. According to [the Snapcraft common keywords](https://snapcraft.io/docs/reference/plugins/common), we need to specify this development library so that Snapcraft can install it:
`build-packages`
: [deb, deb, deb…]Aof Ubuntu packages to install on the build host before building the part. The files from these packages typically will not go into the final snap unless they contain libraries that are direct dependencies of binaries within the snap (in which case they’ll be discovered via**list**`ldd`
), or they are explicitly described in stage-packages.
Therefore, let’s find the name of the development package,
ubuntu@snaps:~/timg-snap$apt-cache search graphicsmagick++ | grep devgraphicsmagick-libmagick-dev-compat/xenial 1.3.23-1build1 all/xenial 1.3.23-1build1 amd64 format-independent image processing - C++ development files libgraphicsmagick1-dev/xenial 1.3.23-1build1 amd64 format-independent image processing - C development files ubuntu@snaps:~/timg-snap$libgraphicsmagick++1-dev
The package name is a * lib* +
*and ends with*
**graphicsmagick++***. We got it! Here is the updated*
**-dev**
**parts:**parts: timg: source: https://github.com/hzeller/timg.git source-subdir: src plugin: makebuild-packages:- libgraphicsmagick++1-dev
Let’s run * snapcraft prime* again!
ubuntu@snaps:~/timg-snap$snapcraftInstalling build dependencies:[...] The followinglibgraphicsmagick++1-devpackagesNEW:will be installedlibgraphicsmagick++-q16-12 libgraphicsmagick++1-dev libgraphicsmagick-q16-3[...] Building timg make -j4 g++ `GraphicsMagick++-config --cppflags --cxxflags` -Wall -O3 -fPIC -c -o timg.o timg.cc g++ -Wall -O3 -fPIC -c -o terminal-canvas.o terminal-canvas.cc g++ -o timg timg.o terminal-canvas.o `GraphicsMagick++-config --ldflags --libs`libgraphicsmagick1-dev libwebp5collect2: error: ld returned 1 exit status Makefile:7: recipe for target 'timg' failed make: *** [timg] Error 1 Command '['/bin/sh', '/tmp/tmptma45jzl', 'make', '-j4']' returned non-zero exit status 2 ubuntu@snaps:~/timg-snap$/usr/bin/ld: cannot find -lwebp
Simply by specifying the development library * libgraphicsmagick++1-dev*, Ubuntu also installs the code libraries, including
*, along with the (dynamic) code library*
**libgraphicsmagick++-q16-12**
**libwebp.**
We still got an error, and the error is related to the * webp* library. The development version of the
*library (a static library) is missing. Let’s find it!*
**webp**ubuntu@snaps:~/timg-snap$apt-cache search libwebp | grep dev- Lossy compression of digital photographic images. ubuntu@snaps:~/timg-snap$libwebp-dev
Bingo! The * libwebp5 package* that was installed further up, provides only a dynamic (.so) library. By requiring the
*package, we get the static (.a) library as well. Let’s update the*
**libwebp-dev****parts:**section!
parts: timg: source: https://github.com/hzeller/timg.git source-subdir: src plugin: make build-packages: - libgraphicsmagick++1-dev- libwebp-dev
Here is the updated snapcraft.yaml file,
name: timg version: '20170226' summary: A terminal image viewer description: | A viewer that uses 24-Bit color capabilities and unicode character blocks to display images in the terminal. grade: stable confinement: devmode parts: timg: source: https://github.com/hzeller/timg.git source-subdir: src plugin: make build-packages: - libgraphicsmagick++1-dev - libwebp-dev
Let’s run * snapcraft*!
ubuntu@snaps:~/timg-snap$snapcraft primeSkipping pull timg (already ran) Preparing to build timg Building timg make -j4 g++ `GraphicsMagick++-config --cppflags --cxxflags` -Wall -O3 -fPIC -c -o timg.o timg.cc g++ -Wall -O3 -fPIC -c -o terminal-canvas.o terminal-canvas.cc g++ -o timg timg.o terminal-canvas.o `GraphicsMagick++-config --ldflags --libs` make install DESTDIR=/home/ubuntu/timg-snap/parts/timg/install install timg /usr/local/binMakefile:13:install: cannot create regular file '/usr/local/bin/timg': Permission deniedmake: *** [install] Error 1 Command '['/bin/sh', '/tmp/tmptq_s1itc', 'make', 'install', 'DESTDIR=/home/ubuntu/timg-snap/parts/timg/install']' returned non-zero exit status 2 ubuntu@snaps:~/timg-snap$recipe for target 'install' failed
We have a new problem. The * Makefile* was hand-crafted and does not obey the parameters of
[the Snapcraft make plugin](https://snapcraft.io/docs/reference/plugins/make)to install into the
*directory. The*
**prime/***tries to install in*
**Makefile***!*
**/usr/local/bin/**We need to instruct [the Snapcraft make plugin](https://snapcraft.io/docs/reference/plugins/make) not to run * make install* but instead pick the generated executable
*and place it into the*
**timg***directory. According to the documentation,*
**prime/**-: (artifacts)listthe given files fromLink/copytothe make outputthe snap. If specified, the 'make install' stepinstallation directory.will be skipped
So, we need to put something in * artifacts:*. But what?
ubuntu@snaps:~/timg-snap/parts/timg$Makefile terminal-canvas.hls build/src/timg.o terminal-canvas.cc terminal-canvas.o timg.cc ubuntu@snaps:~/timg-snap/parts/timg$timg*
In the * build/* subdirectory we can find the
*output. Since we specified*
**make***, our base directory for*
**source-subdir: src***is*
**artifacts:***. And in there we can find the executable*
**build/src/***, which will be the parameter for*
**timg***. With*
**artifacts:***we specify the files from the*
**artifacts:***output that will be copied to the snap installation directory (in*
**make***).*
**prime/**Here is the updated * parts:* of snapcraft.yaml,
parts: timg: source: https://github.com/hzeller/timg.git source-subdir: src plugin: make build-packages: - libgraphicsmagick++1-dev - libwebp-devartifacts: [timg]
Let’s run * snapcraft prime*!
ubuntu@snaps:~/timg-snap$snapcraft primePreparing to pull timg Pulling timg Cloning into '/home/ubuntu/timg-snap/parts/timg/src'... remote: Counting objects: 144, done. remote: Total 144 (delta 0), reused 0 (delta 0), pack-reused 144 Receiving objects: 100% (144/144), 116.00 KiB | 207.00 KiB/s, done. Resolving deltas: 100% (89/89), done. Checking connectivity... done. Preparing to build timg Building timg make -j4 g++ `GraphicsMagick++-config --cppflags --cxxflags` -Wall -O3 -fPIC -c -o timg.o timg.cc g++ -Wall -O3 -fPIC -c -o terminal-canvas.o terminal-canvas.cc g++ -o timg timg.o terminal-canvas.o `GraphicsMagick++-config --ldflags --libs` Staging timg Priming timg ubuntu@snaps:~/timg-snap$
We are rolling!
## Exposing the command
Up to now, snapcraft generated the executable but did not expose a command for the users to run. We need to expose a command and this is done in the * apps:* section.
First of all, where is the command located in the * prime/* subdirectory?
ubuntu@snaps:~/timg-snap$ls prime/meta/ snap/* usr/ ubuntu@snaps:~/timg-snap$timg
It is in the root of the * prime/* subdirectory. We are ready to add the
*section in snapcraft.yaml,*
**apps:**ubuntu@snaps:~/timg-snap$cat snap/snapcraft.yamlname: timg version: '20170226' summary: A terminal image viewer description: | A viewer that uses 24-Bit color capabilities and unicode character blocks to display images in the terminal. grade: stable confinement: devmodeapps:timg:parts: timg: source: https://github.com/hzeller/timg.git source-subdir: src plugin: make build-packages: - libgraphicsmagick++1-dev - libwebp-dev artifacts: [timg]command: timg
Let’s run * snapcraft prime* again and then try the snap!
ubuntu@snaps:~/timg-snap$snapcraft primeSkipping pull timg (already ran) Skipping build timg (already ran) Skipping stage timg (already ran) Skipping prime timg (already ran) ubuntu@snaps:~/timg-snap$snap try --devmode prime/timg 20170226 mounted from /home/ubuntu/timg-snap/prime ubuntu@snaps:~/timg-snap$
We used * snap try –devmode prime/* as a way to enable the snap and try the command. It is an efficient way for testing and avoids the alternative of generating .snap files, installing them, then uninstalling them. With
*, it uses directly the directory (in this case,*
**snap try prime/***) which has the snap content.*
**prime/**## Restricting the snap
Up to now, the snap has been running in * devmode* (developer mode), which is unrestricted. Let’s see how it runs in a confinement,
ubuntu@snaps:~/timg-snap$snap listName Version Rev Developer Notes core 16-2 1337 canonical -20170226 x1timgubuntu@snaps:~/timg-snap$devmode,trysnap try --jailmode primetimg 20170226 mounted from /home/ubuntu/timg-snap/prime ubuntu@snaps:~/timg-snap$snap listName Version Rev Developer Notes core 16-2 1337 canonical -20170226 x2timgubuntu@snaps:~/timg-snap$jailmode,trytimg pexels-photo-149813.jpegTrouble loading pexels-photo-149813.jpeg (Magick: Unable to open file (pexels-photo-149813.jpeg) reported by magick/blob.c:2828 (OpenBlob)) ubuntu@snaps:~/timg-snap$
Here we quickly switch from * devmode* to
*(*
**jailmode***) without having to touch the snapcraft.yaml file. As expected,*
**confinement: strict***could not read the image because we did not permit any access to the filesystem.*
**timg**At this stage we need to make a decision. With * jailmode*, we can easily specify that a command has access to the files of the user’s $HOME directory, and only there. If an image file is located elsewhere, we can always copy of the $HOME directory and run
*on the copy in $HOME. If we are happy with this, we can set up snapcraft.yaml as follows:*
**timg**name: timg version: '20170226' summary: A terminal image viewer description: | A viewer that uses 24-Bit color capabilities and unicode character blocks to display images in the terminal. grade: stable confinement:apps: timg: command: timgstrictparts: timg: source: https://github.com/hzeller/timg.git source-subdir: src plugin: make build-packages: - libgraphicsmagick++1-dev - libwebp-dev artifacts: [timg]plugs: [home]
On the other hand, if we want the * timg* snap to have read-access to all the filesystem, we can use
*and be done with it. Here is how snapcraft.yaml would look in that case,*
**confinement: classic**name: timg version: '20170226' summary: A terminal image viewer description: | A viewer that uses 24-Bit color capabilities and unicode character blocks to display images in the terminal. grade: stable confinement:apps: timg: command: timg parts: timg: source: https://github.com/hzeller/timg.git source-subdir: src plugin: make build-packages: - libgraphicsmagick++1-dev - libwebp-dev artifacts: [timg]classic
In the following we are selecting the option of the * strict* confinement. Therefore, images should be in the $HOME only.
## Packaging and testing
Let’s package the snap, that is, create the .snap file and try it out on a brand-new installation of Ubuntu!
ubuntu@snaps:~/timg-snap$snapcraftSkipping pull timg (already ran) Skipping build timg (already ran) Skipping stage timg (already ran) Skipping prime timg (already ran) Snapping 'timg' \ubuntu@snaps:~/timg-snap$Snapped timg_20170226_amd64.snap
How do we get a brand new installation of Ubuntu in seconds so that we can test the snap?
See [Trying out LXD containers on our Ubuntu](https://blog.simos.info/trying-out-lxd-containers-on-our-ubuntu/) and set up LXD on your system. Then, come back here and try the following commands,
$lxc launch ubuntu:x snaptestingCreating snaptesting Starting snaptesting $lxc file push timg_20170226_amd64.snap snaptesting/home/ubuntu/$lxc exec snaptesting -- sudo su - ubuntuTo run a command as administrator (user "root"), use "sudo <command>". See "man sudo_root" for details. ubuntu@snaptesting:~$lstimg_20170226_amd64.snap ubuntu@snaptesting:~$snap install timg_20170226_amd64.snaperror: access denied (try with sudo) ubuntu@snaptesting:~$sudo snap install timg_20170226_amd64.snaperror: cannot find signatures with metadata for snap "timg_20170226_amd64.snap" ubuntu@snaptesting:~$sudo snap install timg_20170226_amd64.snap --dangerouserror: cannot perform the following tasks: - Mount snap "core" (1337) ([start snap-core-1337.mount] failed with exit status 1: Job for snap-core-1337.mount failed. See "systemctl status snap-core-1337.mount" and "journalctl -xe" for details. ) ubuntu@snaptesting:~$sudo apt install squashfuse[...] Setting up squashfuse (0.1.100-0ubuntu1~ubuntu16.04.1) ... ubuntu@snaptesting:~$sudo snap install timg_20170226_amd64.snap --dangeroustimg 20170226 installed ubuntu@snaptesting:~$wget https://farm7.staticflickr.com/6187/6091603784_d6960c8be2_z_d.jpg[...] 2017-02-26 22:12:18 (636 KB/s) - ‘6091603784_d6960c8be2_z_d.jpg’ saved [240886/240886] ubuntu@snaptesting:~$timg 6091603784_d6960c8be2_z_d.jpg[it worked!] ubuntu@snaptesting:~$
So, we launched an LXD container called * snaptesting*, then copied in there the .snap file. Then, we connected to the container as a normal user and tried to install the snap. Initially, the installation failed because we need
*when we install snaps in unprivileged LXD containers. It again failed because the .snap was unsigned (we need the*
**sudo***parameter). Then, it further failed because we need to install the*
**–dangerous***package (not preinstalled in the Ubuntu 16.04 images). Eventually, the snap was installed and we managed to view the image.*
**squashfuse**It is important to test a snap in a brand new installation of Linux in order to make sure whether we need to * stage* any code library inside the snap. In this case, static libraries were used and all went well!
## Publishing to the Ubuntu Store
Here are [the instructions to publish a snap to the Ubuntu Store](https://snapcraft.io/docs/build-snaps/publish). We have already published a few snaps in the previous tutorials. For * timg*, we got
*, and*
**confinement: strict***. We are therefore publishing in the stable channel.*
**grade: stable**$snapcraft push timg_20170226_amd64.snapPushing 'timg_20170226_amd64.snap' to the store. Uploading timg_20170226_amd64.snap [ ] 0% Uploading timg_20170226_amd64.snap [=======================================] 100% Ready to release!|of 'timg' created. $Revision 6snapcraft release timg 6 stableTrack Arch Series Channel Version Revision latest amd64 16 stable 20170226 6 candidate ^ ^ beta 0.9.5 5 edge 0.9.5 5 The 'stable' channel is now open.
We pushed the .snap file to the Ubuntu Store and we got a * revision number 6*. Then, we released the
*to the*
**timg revision 6***channel of the Ubuntu Store.*
**stable**There was no released snap in the * candidate* channel, therefore, it inherits the package from the
*channel. Hence, the*
**stable***characters.*
**^**In previous tests I uploaded some older versions of the snap to the * beta* and
*channels. These older versions refer to the old*
**edge***of the*
**tag 0.9.****5***source code.*
**timg**Let’s knock down the old 0.9.5 by releasing the stable version to the * beta* and
*channels as well.*
**edge**$snapcraft release timg 6 betaTrack Arch Series Channel Version Revision latest amd64 16 stable 20170226 6 candidate ^ ^edge 0.9.5 5 $beta 20170226 6snapcraft release timg 6 edgeTrack Arch Series Channel Version Revision latest amd64 16 stable 20170226 6 candidate ^ ^ beta 20170226 6edge 20170226 6
## Playing with timg
Let’s run timg without parameters,
ubuntu@snaptesting:~$timgExpected image filename. usage: /snap/timg/x1/timg [options] <image> [<image>...] Options: -g<w>x<h> : Output pixel geometry.-s[<ms>] : Scroll horizontally (optionally: delay ms (60)). -d<dx:dy> : delta x and delta y when scrolling (default: 1:0). -w<seconds>: If multiple images given: Wait time between (default: 0.0). -t<seconds>: Only animation or scrolling: stop after this time. -c<num> : Only Animation or scrolling: number of runs through a full cycle. -C : Clear screen before showing image. -F : Print filename before showing picture. -v : Print version and exit. If both -c and -t are given, whatever comes first stops. If both -w and -t are given for some animation/scroll, -t takes precedence ubuntu@snaptesting:~$Default from terminal 80x48
Here it says that for the current zoom level of our terminal emulator, our resolution is a mere 80×48.
Let’s zoom out a bit and maximize the GNOME Terminal window.
-g<w>x<h> : Output pixel geometry.Default from terminal 635x428
It is a better resolution but I can hardly see the characters because they are too small. Let’s invoke the old command to show this car again.
What you are seeing is the resized image (from 1080p). Looks great, even if it is made of colored text characters!
What next? * timg* can play animated gifs as well!
$ wget https://m.popkey.co/9b7141/QbAV_f-maxage-0.gif -O JonahHillAmazed.gif$ timg JonahHillAmazed.gif
Try to install the * timg* snap yourself in order to experience the animated gif! Failing that, watch the asciinema recording (if the video looks choppy, run it a second time),
[https://asciinema.org/a/dezbe2gpye84e0pjndp8t0pvh](https://asciinema.org/a/dezbe2gpye84e0pjndp8t0pvh)
Thanks for reading!
## 2 comments
## 1 pings
This article is wonderful,Can I translate it into Chinese?
Author
Thanks! Sure, you may translate the article to Chinese!
[…] is developed by Henner Zeller, and in 2017 I wrote a blog post about creating a snap package for timg. A snap package was created and published on the Snap Store. I even registered the name timg […] |
8,930 | 开发一个 Linux 调试器(八):堆栈展开 | https://blog.tartanllama.xyz/c++/2017/06/24/writing-a-linux-debugger-unwinding/ | 2017-10-04T16:59:47 | [
"调试"
] | https://linux.cn/article-8930-1.html | 
有时你需要知道的最重要的信息是什么,你当前的程序状态是如何到达那里的。有一个 `backtrace` 命令,它给你提供了程序当前的函数调用链。这篇文章将向你展示如何在 x86\_64 上实现堆栈展开以生成这样的回溯。
### 系列索引
这些链接将会随着其他帖子的发布而上线。
1. [准备环境](/article-8626-1.html)
2. [断点](/article-8645-1.html)
3. [寄存器和内存](/article-8663-1.html)
4. [ELF 和 DWARF](/article-8719-1.html)
5. [源码和信号](/article-8812-1.html)
6. [源码级逐步执行](/article-8813-1.html)
7. [源码级断点](/article-8890-1.html)
8. [堆栈展开](https://blog.tartanllama.xyz/c++/2017/06/24/writing-a-linux-debugger-unwinding/)
9. 读取变量
10. 之后步骤
用下面的程序作为例子:
```
void a() {
//stopped here
}
void b() {
a();
}
void c() {
a();
}
int main() {
b();
c();
}
```
如果调试器停在 `//stopped here' 这行,那么有两种方法可以达到:`main->b->a`或`main->c->a`。如果我们用 LLDB 设置一个断点,继续执行并请求一个回溯,那么我们将得到以下内容:
```
* frame #0: 0x00000000004004da a.out`a() + 4 at bt.cpp:3
frame #1: 0x00000000004004e6 a.out`b() + 9 at bt.cpp:6
frame #2: 0x00000000004004fe a.out`main + 9 at bt.cpp:14
frame #3: 0x00007ffff7a2e830 libc.so.6`__libc_start_main + 240 at libc-start.c:291
frame #4: 0x0000000000400409 a.out`_start + 41
```
这说明我们目前在函数 `a` 中,`a` 从函数 `b` 中跳转,`b` 从 `main` 中跳转等等。最后两个帧是编译器如何引导 `main` 函数的。
现在的问题是我们如何在 x86\_64 上实现。最稳健的方法是解析 ELF 文件的 `.eh_frame` 部分,并解决如何从那里展开堆栈,但这会很痛苦。你可以使用 `libunwind` 或类似的来做,但这很无聊。相反,我们假设编译器以某种方式设置了堆栈,我们将手动遍历它。为了做到这一点,我们首先需要了解堆栈的布局。
```
High
| ... |
+---------+
+24| Arg 1 |
+---------+
+16| Arg 2 |
+---------+
+ 8| Return |
+---------+
EBP+--> |Saved EBP|
+---------+
- 8| Var 1 |
+---------+
ESP+--> | Var 2 |
+---------+
| ... |
Low
```
如你所见,最后一个堆栈帧的帧指针存储在当前堆栈帧的开始处,创建一个链接的指针列表。堆栈依据这个链表解开。我们可以通过查找 DWARF 信息中的返回地址来找出列表中下一帧的函数。一些编译器将忽略跟踪 `EBP` 的帧基址,因为这可以表示为 `ESP` 的偏移量,并可以释放一个额外的寄存器。即使启用了优化,传递 `-fno-omit-frame-pointer` 到 GCC 或 Clang 会强制它遵循我们依赖的约定。
我们将在 `print_backtrace` 函数中完成所有的工作:
```
void debugger::print_backtrace() {
```
首先要决定的是使用什么格式打印出帧信息。我用了一个 lambda 来推出这个方法:
```
auto output_frame = [frame_number = 0] (auto&& func) mutable {
std::cout << "frame #" << frame_number++ << ": 0x" << dwarf::at_low_pc(func)
<< ' ' << dwarf::at_name(func) << std::endl;
};
```
打印输出的第一帧是当前正在执行的帧。我们可以通过查找 DWARF 中的当前程序计数器来获取此帧的信息:
```
auto current_func = get_function_from_pc(get_pc());
output_frame(current_func);
```
接下来我们需要获取当前函数的帧指针和返回地址。帧指针存储在 `rbp` 寄存器中,返回地址是从帧指针堆栈起的 8 字节。
```
auto frame_pointer = get_register_value(m_pid, reg::rbp);
auto return_address = read_memory(frame_pointer+8);
```
现在我们拥有了展开堆栈所需的所有信息。我只需要继续展开,直到调试器命中 `main`,但是当帧指针为 `0x0` 时,你也可以选择停止,这些是你在调用 `main` 函数之前调用的函数。我们将从每帧抓取帧指针和返回地址,并打印出信息。
```
while (dwarf::at_name(current_func) != "main") {
current_func = get_function_from_pc(return_address);
output_frame(current_func);
frame_pointer = read_memory(frame_pointer);
return_address = read_memory(frame_pointer+8);
}
}
```
就是这样!以下是整个函数:
```
void debugger::print_backtrace() {
auto output_frame = [frame_number = 0] (auto&& func) mutable {
std::cout << "frame #" << frame_number++ << ": 0x" << dwarf::at_low_pc(func)
<< ' ' << dwarf::at_name(func) << std::endl;
};
auto current_func = get_function_from_pc(get_pc());
output_frame(current_func);
auto frame_pointer = get_register_value(m_pid, reg::rbp);
auto return_address = read_memory(frame_pointer+8);
while (dwarf::at_name(current_func) != "main") {
current_func = get_function_from_pc(return_address);
output_frame(current_func);
frame_pointer = read_memory(frame_pointer);
return_address = read_memory(frame_pointer+8);
}
}
```
### 添加命令
当然,我们必须向用户公开这个命令。
```
else if(is_prefix(command, "backtrace")) {
print_backtrace();
}
```
### 测试
测试此功能的一个方法是通过编写一个测试程序与一堆互相调用的小函数。设置几个断点,跳到代码附近,并确保你的回溯是准确的。
我们已经从一个只能产生并附加到其他程序的程序走了很长的路。本系列的倒数第二篇文章将通过支持读写变量来完成调试器的实现。在此之前,你可以在[这里](https://github.com/TartanLlama/minidbg/tree/tut_unwind)找到这个帖子的代码。
---
via: <https://blog.tartanllama.xyz/c++/2017/06/24/writing-a-linux-debugger-unwinding/>
作者:[Simon Brand](https://twitter.com/TartanLlama) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Redirecting…
Click here if you are not redirected. |
8,931 | DevOps 的意义 | https://opensource.com/open-organization/17/5/what-is-the-point-of-DevOps | 2017-10-05T16:51:48 | [
"DevOps",
"开放式组织"
] | https://linux.cn/article-8931-1.html |
>
> 真正的组织文化变革有助于弥合你原以为无法跨过的鸿沟
>
>
>

回想一下你最近一次尝试改掉一个个人习惯的事情,你可能遇到过这样的情形,你需要改变你思考的方式并且改掉之前的习惯。这很艰难,你只能试着改变*你自己的*思维方式。
所以你可能会试着让自己置身于新的环境。新的环境实际上可帮助我们养成*新的*习惯,它反过来又会促成新的思维方式。
那就是能否成功改变的所在:思考的越多,得到的越多。你需要知道你在改变的原因以及你的目的所在(而不仅仅你要怎么做),因为改变本身往往是短暂和短视的。
现在想想你的 IT 组织需要做出的改变。也许你正在考虑采用像 DevOps 这样的东西。这个我们称之为 “DevOps” 的东西有三个组件:人、流程和工具。人和流程是*任何*团体组织的基础。因此,采用 DevOps 需要对大多数组织的核心进行根本性的改变,而不仅仅是学习新的工具。
如同其它的改变一样,它也是短视的。如果您将注意力集中在将改变作为单点解决方案 —— 例如,“获得更好的报警工具” —— 你可能只是管中窥豹。这种思维方式或许可以提供一套拥有更多铃声、口哨以及可以更好地处理呼叫轮询的工具,但是它不能解决这样的实际问题:警报不能送达到正确的团队,或者故障得不到解决,因为实际上没有人知道如何修复服务。
新的工具(或者至少一个新工具的想法)创造了一个讨论潜在问题的机会,可以让你的团队讨论对监控的看法。新工具让你能够做出更大的改变 —— 信仰和做法的改变 —— 它们作为你组织的基础而显得更加重要。
创造更深层次的变革需要一种可以全新地改变观念的方法。要找到这种方法,我们首先需要更好的理解变革的驱动力。
### 清除栅栏
>
> 就改革而言,它不同于推翻。这是一条直白且简单的原则,这个原则或许被视作悖论。在这种情况下,存在某种制度或法律;这么说吧,为了简单起见,在一条路上架设了一个栅栏或门。当今的改革者们来到这儿,并说:“我看不到它的用处,让我们把它清除掉。”更聪明的改革者会很好地回答:“如果你看不到它的用处,我肯定不会让你清除它,回去想想,然后你可以回来告诉我你知道了它的用处,我也许会允许你摧毁它。” — G.K Chesterton, 1929
>
>
>
为了了解对 DevOps 的需求 —— 它试图将传统意义上分开的开发部门和运维部门进行重新组合 —— 我们首先必须明白这个分开是如何产生的。一旦我们"知道了它的用处",然后我们就会知道将它们分开是为了什么,并且在必要的时候可以取消分开。
今天我们没有一个单一的管理理论,但是大多数现代管理理论的起源可以追溯到<ruby> 弗雷德里克·温斯洛·泰勒 <rt> Frederick Winslow Taylor </rt></ruby>。泰勒是一名机械工程师,他创建了一个衡量钢厂工人效率的系统。泰勒认为,他可以对工厂的劳动者运用科学分析的方法,不仅可以改进个人任务,也证明发现了有一个可以用来执行*任何*任务最佳方法。
我们可以很容易地画一个以泰勒为起源的历史树。从泰勒早在 18 世纪 80 年代后期的研究出现的时间运动研究和其他质量改进计划,跨越 20 世纪 20 年代一直到今天,我们可以从中看到六西格玛、精益,等等类似方法。自上而下、指导式管理,再加上研究过程的系统方法,主宰了今天主流商业文化。它主要侧重于把效率作为工人成功的测量标准。
如果泰勒是我们这颗历史树的根,那么我们主干上的下一个主叉将是 20 世纪 20 年代通用汽车公司的<ruby> 阿尔弗雷德·斯隆 <rt> Alfred P. Sloan </rt></ruby>。通用汽车公司创造的斯隆结构不仅持续强劲到 21 世纪初,而且在未来五十年的大部分时间里,都将成为该公司的主要模式。
1920 年,通用公司正经历一场管理危机,或者说是缺乏管理的危机。斯隆向董事会写了一份为通用汽车的多个部门提出了一个新的结构《组织研究》。这一新结构的核心概念是“集中管理下放业务”。与雪佛兰,凯迪拉克和别克等品牌相关的各个部门将独立运作,同时为中央管理层提供推动战略和控制财务的手段。
在斯隆的建议下(以及后来就任 CEO 的指导下),通用汽车在美国汽车工业中占据了主导地位。斯隆的计划把一个处于灾难边缘公司创造成了一个非常成功的公司。从中间来看,自治单位是黑盒子,激励和目标被设置在顶层,而团队在底层推动。
泰勒思想的“最佳实践” —— 标准、可互换和可重复的行为 —— 仍然在今天的管理理念中占有一席之地,与斯隆公司结构的层次模式相结合,主导了僵化部门的分裂和孤岛化以实现最大的控制。
我们可以指出几份管理研究来证明这一点,但商业文化不是通过阅读书籍而创造和传播的。组织文化是 *真实的* 人在 *实际的* 情形下执行推动文化规范的 *具体的* 行为的产物。这就是为何类似泰勒和斯隆这样的理论变得固化而不可动摇的原因。
技术部门投资就是一个例子。以下是这个周期是如何循环的:投资者只投资于他们认为可以实现 *他们的* 特定成功观点的公司。这个成功的模式并不一定源于公司本身(和它的特定的目标);它来自董事会对一家成功的公司 *应该* 如何看待的想法。许多投资者来自从经营企业的尝试和苦难中幸存下来的公司,因此他们对什么会使一个公司成功有 *不同的* 理念。他们为那些能够被教导模仿他们的成功模式的公司提供资金,希望获得资金的公司学会模仿。这样,初创公司孵化器就是一种重现理想的结构和文化的*直接的*方式。
“开发”和“运维”的分开不是因为人的原因,也不是因为不同的技能,或者放在新员工头上的一顶魔法分院帽;它是泰勒和斯隆的理论的副产品。责任与人员之间的清晰而不可渗透的界线是一个管理功能,同时也注重员工的工作效率。管理上的分开可以很容易的落在产品或者项目界线上,而不是技能上,但是通过今天的业务管理理论的历史告诉我们,基于技能的分组是“最好”的高效方式。
不幸的是,那些界线造成了紧张局势,这些紧张局势是由不同的管理链出于不同的目标设定的相反目标的直接结果。例如:
* 敏捷 ⟷ 稳定
* 吸引新用户 ⟷ 现有用户的体验
* 让应用程序增加新功能 ⟷ 让应用程序保持可用
* 打败竞争对手 ⟷ 维持收入
* 修复出现的问题 ⟷ 在问题出现之前就进行预防
今天,我们可以看到组织的高层领导人越来越认识到,现有的商业文化(并扩大了它所产生的紧张局势)是一个严重的问题。在 2016 年的 Gartner 报告中,57% 的受访者表示,文化变革是 2020 年之前企业面临的主要挑战之一。像作为一种影响组织变革的手段的敏捷和 DevOps 这样的新方法的兴起反映了这一认识。“[影子 IT](https://thenewstack.io/parity-check-dont-afraid-shadow-yet/)” 的出现更是事物的另一个方面;最近的估计有将近 30% 的 IT 支出在 IT 组织的控制之外。
这些只是企业正在面临的一些“文化担忧”。改变的必要性是明确的,但前进的道路仍然受到昨天的决定的约束。
### 抵抗并不是没用的
>
> Bert Lance 认为如果他能让政府采纳一条简单的格言“如果东西还没损坏,那就别去修理它”,他就可以为国家节省三十亿。他解释说:“这是政府的问题:‘修复没有损坏的东西,而不是修复已经损坏了的东西。’” — Nation's Business, 1977.5
>
>
>
通常,改革是组织针对所出现的错误所做的应对。在这个意义上说,如果紧张局势(即使逆境)是变革的正常催化剂,那么对变化的 *抵抗* 就是成功的指标。但是过分强调成功的道路会使组织变得僵硬、衰竭和独断。重视有效结果的政策导向是这种不断增长的僵局的症状。
传统 IT 部门的成功加剧了 IT 孤岛的壁垒。其他部门现在变成了“顾客”,而不是伙伴。试图将 IT 从成本中心转移出来创建一个新的操作模式,它可以将 IT 与其他业务目标断开。这反过来又会对敏捷性造成限制,增加摩擦,降低反应能力。合作被搁置转而偏向“专家方向”。结果是一个孤立主义的观点,IT 只能带来更多的伤害而不是好处。
正如“软件吃掉世界”,IT 越来越成为组织整体成功的核心。具有前瞻性的 IT 组织认识到这一点,并且已经对其战略规划进行了有意义的改变,而不是将改变视为恐惧。
例如,Facebook 与人类学家<ruby> 罗宾·邓巴 <rt> Robin Dunbar </rt></ruby>就社会团体的方法进行了磋商,而且意识到这一点对公司成长的内部团体(不仅仅是该网站的外部用户)的影响。<ruby> 扎波斯 <rt> Zappos </rt></ruby>的文化得到了很多的赞誉,该组织创立了一个部门,专注于培养他人对于核心价值观和企业文化的看法。当然,这本书是 《开放式组织》的姊妹篇,那是一本描述被应用于管理的开放原则 —— 透明度、参与度和社区 —— 可以如何为我们快节奏的互联时代重塑组织。
### 决心改变
>
> “如果外界的变化率超过了内部的变化率,那末日就不远了。” — Jack Welch, 2004
>
>
>
一位同事曾经告诉我他可以只用 “[信息技术基础设施库(ITIL)](https://en.wikipedia.org/wiki/ITIL)” 框架里面的词汇向一位项目经理解释 DevOps。
虽然这些框架 *似乎* 是反面的,但实际上它们都集中在风险和变革管理上。它们简单地介绍了这种管理的不同流程和工具。在 IT 圈子外面谈论 DevOps 时,这一点需要注意。不要强调流程问题和故障,而是显示更小的变化引起的风险 *更小* 等等。这是强调改变团队文化的有益方式:专注于 *新的* 功能而不是老问题,是改变的有效中介,特别是当您采用别人的框架进行参考时。
改革不仅仅只是 *重构* 组织;它也是跨越历史上不可跨越的鸿沟的新途径 —— 通过拒绝把像“敏捷”和“稳定”这样的东西作为互相排斥的力量来解决我之前提到的那些紧张局势。建立注重 *结果* 胜过 *功能* 的跨部门团队是一个有效的策略。把不同的团队 —— 其中每个人的工作依赖于其他人 —— 聚集起来围绕一个项目或目标是最常见的方法之一。消除这些团队之间的摩擦和改善沟通能够产生巨大的改进 —— 即使在坚持铁仓管理结构时(如果可以掌握,则不需要拆除孤岛)。在这些情况下,对改革的 *抵抗* 不是成功的一个指标;而对改革的拥抱才是。
这些也不是“最佳实例”,它们只是一种检查你自己的栅栏的方式。每个组织都会有独特的、由他们内部人员创造的栅栏。一旦你“知道了它的用途”,你就可以决定它是需要拆解还是掌握。
*本文是 Opensource.com 即将推出的关于开放组织和 IT 文化指南的一部分。[你可以在这注册以便当它发布时收到通知](https://opensource.com/open-organization/resources/book-series)。*
(题图 : opensource.com)
---
作者简介:
Matt Micene 是 Red Hat 公司的 Linux 和容器传播者。从架构和系统设计到数据中心设计,他在信息技术方面拥有超过 15 年的经验。他对关键技术(如容器,云计算和虚拟化)有深入的了解。他目前的重点是宣传红帽企业版 Linux,以及操作系统如何与计算环境的新时代相关。
---
via: <https://opensource.com/open-organization/17/5/what-is-the-point-of-DevOps>
作者:[Matt Micene](https://opensource.com/users/matt-micene) 译者:[zhousiyu325](https://github.com/zhousiyu325) 校对:[apemost](https://github.com/apemost),[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Think about the last time you tried to change a personal habit. You likely hit a point where you needed to alter the way you think and make the habit less a part of your identity. This is difficult—and you're only trying to change *your own* ways of thinking.
So you may have tried to put yourself in new situations. New situations can actually help us create *new* habits, which in turn lead to new ways of thinking.
That's the thing about successful change: It's as much about *outlook* as *outcome*. You need to know *why* you're changing and *where* you're headed (not just how you're going to do it), because change for its own sake is often short-lived and short-sighted.
Now think about the changes your IT organization needs to make. Perhaps you're thinking about adopting something like DevOps. This thing we call "DevOps" has three components: people, process, and tools. People and process are the basis for *any* organization. Adopting DevOps, therefore, requires making fundamental changes to the core of most organizations—not just learning new tools.
And like any change, it can be short-sighted. If you're focused on the change as a point solution—"Get a better tool to do alerting," for example—you'll likely come up with a narrow vision of the problem. This mode of thinking may furnish a tool with more bells and whistles and a better way of handling on-call rotations. But it can't fix the fact that alerts aren't going to the right team, or that those failures remain failures since no one actually knows how to fix the service.
The new tool (or at least the idea of a new tool) creates a moment to have a conversation about the underlying issues that plague your team's views on monitoring. The new tool allows you to make bigger changes—changes to your beliefs and practices—which, as the foundation of your organization, are even more important.
Creating deeper change requires new approaches to the notion of change altogether. And to discover those approaches, we need to better understand the drive for change in the first place.
### Clearing the fences
"In the matter of reforming things, as distinct from deforming them, there is one plain and simple principle; a principle which will probably be called a paradox. There exists in such a case a certain institution or law; let us say, for the sake of simplicity, a fence or gate erected across a road. The more modern type of reformer goes gaily up to it and says, "I don't see the use of this; let us clear it away." To which the more intelligent type of reformer will do well to answer: "If you don't see the use of it, I certainly won't let you clear it away. Go away and think. Then, when you can come back and tell me that you do see the use of it, I may allow you to destroy it."—G.K Chesterton, 1929
To understand the need for DevOps, which tries to recombine the traditionally "split" entities of "development" and "operations," we must first understand how the split came about. Once we "know the use of it," then we can see the split for what it really is—and dismantle it if necessary.
Today we have no single theory of management, but we can trace the origins of most modern management theory to Frederick Winslow Taylor. Taylor was a mechanical engineer who created a system for measuring the efficiency of workers at a steel mill. Taylor believed he could apply scientific analysis to the laborers in the mill, not only to improve individual tasks, but also to prove that there was a discoverable best method for performing *any* task.
We can easily draw a historical tree with Taylor at the root. From Taylor's early efforts in the late 1880s emerged the time-motion study and other quality-improvement programs that span the 1920s all the way to today, where we see Six Sigma, Lean, and the like. Top-down, directive-style management, coupled with a methodical approach to studying process, dominates mainstream business culture today. It's primarily focused on efficiency as the primary measure of worker success.
If Taylor is our root of our historical tree, then our next major fork in the trunk would be Alfred P. Sloan of General Motors in the 1920s. The structure Sloan created at GM would not only hold strong there until the 2000s, but also prove to be the major model of the corporation for much of the next 50 years.
In 1920, GM was experiencing a crisis of management—or rather a crisis from the lack thereof. Sloan wrote his "Organizational Study" for the board, proposing a new structure for the multitudes of GM divisions. This new structure centered on the concept of "decentralized operations with centralized control." The individual divisions, associated now with brands like Chevrolet, Cadillac, and Buick, would operate independently while providing central management the means to drive strategy and control finances.
Under Sloan's recommendations (and later guidance as CEO), GM rose to a dominant position in the US auto industry. Sloan's plan created a highly successful corporation from one on the brink of disaster. From the central view, the autonomous units are black boxes. Incentives and goals get set at the top levels, and the teams at the bottom drive to deliver.
The Taylorian idea of "best practices"—standard, interchangeable, and repeatable behaviors—still holds a place in today's management ideals, where it gets coupled with the hierarchical model of the Sloan corporate structure, which advocates rigid departmental splits and silos for maximum control.
We can point to several management studies that demonstrate this. But business culture isn't created and propagated only through reading books. Organizational culture is the product of *real* people in *actual* situations performing *concrete* behaviors that propel cultural norms through time. That's how things like Taylorism and and Sloanianism get solidified and come to appear immovable.
Technology sector funding is a case in point. Here's how the cycle works: Investors only invest in those companies they believe could achieve *their* particular view of success. This model for success doesn't necessarily originate from the company itself (and its particular goals); it comes from a board's ideas of what a successful company *should* look like. Many investors come from companies that have survived the trials and tribulations of running a business, and as a result they have *different* blueprints for what makes a successful company. They fund companies that can be taught to mimic their models for success. So companies wishing to acquire funding learn to mimic. In this way, the start-up incubator is a *direct* way of reproducing a supposedly *ideal* structure and culture.
The "Dev" and "Ops" split is not the result of personality, diverging skills, or a magic hat placed on the heads of new employees; it's a byproduct of Taylorism and Sloanianism. Clear and impermeable boundaries between responsibilities and personnel is a management function coupled with a focus on worker efficiency. The management split could have easily landed on product or project boundaries instead of skills, but the history of business management theory through today tells us that skills-based grouping is the "best" way to be efficient.
Unfortunately, those boundaries create tensions, and those tensions are a direct result of opposing goals set by different management chains with different objectives. For example:
Agility ⟷ Stability
Drawing new users ⟷ Existing users' experience
Application getting features ⟷ Application available to use
Beating the competition ⟷ Protecting revenue
Fixing problems that come up ⟷ Preventing problems before they happen
Today, we can see growing recognition among organizations' top leaders that the existing business culture (and by extension the set of tensions it produces) is a serious problem. In a 2016 Gartner report, 57 percent of respondents said that culture change was one of the major challenges to the business through 2020. The rise of new methods like Agile and DevOps as a means of affecting organizational changes reflects that recognition. The rise of "[shadow IT](https://thenewstack.io/parity-check-dont-afraid-shadow-yet/)" is the flip side of the coin; recent estimates peg nearly 30 percent of IT spend outside the control of the IT organization.
These are only some of the "culture concerns" that business are having. The need to change is clear, but the path ahead is still governed by the decisions of yesterday.
### Resistance isn't futile
"Bert Lance believes he can save Uncle Sam billions if he can get the government to adopt a simple motto: 'If it ain't broke, don't fix it.' He explains: 'That's the trouble with government: Fixing things that aren't broken and not fixing things that are broken.'" — Nation's Business, May 1977
Typically, change is an organizational response to something gone wrong. In this sense, then, if tension (even adversity) is the normal catalyst for change, then the *resistance* to change is an indicator of success. But overemphasis on successful paths can make organizations inflexible, hidebound, and dogmatic. Valuing policy navigation over effective results is a symptom of this growing rigidity.
Success in traditional IT departments has thickened the walls of the IT silo. Other departments are now "customers," not co-workers. Attempts to shift IT *away* from being a cost-center create a new operating model that disconnects IT from the rest of the business' goals. This in turn creates resistance that limits agility, increases friction, and decreases responsiveness. Collaboration gets shelved in favor of "expert direction." The result is an isolationist view of IT can only do more harm than good.
And yet as "software eats the world," IT becomes more and more central to the overall success of the organization. Forward-thinking IT organizations recognize this and are already making deliberate changes to their playbooks, rather than treating change as something to fear.
For instance, Facebook consulted with [anthropologist Robin Dunbar](http://www.npr.org/2017/01/13/509358157/is-there-a-limit-to-how-many-friends-we-can-have) on its approach to social groups, but realized the impact this had on internal groups (not just external users of the site) as the company grew. Zappos' culture has garnered so much praise that the organization created a department focused on training others in their views on core values and corporate culture. And of course, this book is a companion to *The Open Organization*, a book that shows how open principles applied to management—transparency, participation, and community—can reinvent the organization for our fast-paced, connected era.
### Resolving to change
"If the rate of change on the outside exceeds the rate of change on the inside, the end is near."—Jack Welch, 2004
A colleague once told me he could explain DevOps to a project manager using only the vocabulary of the [Information Technology Infrastructure Library](https://en.wikipedia.org/wiki/ITIL) framework.
While these frameworks *appear* to be opposed, they actually both center on risk and change management. They simply present different processes and tools for such management. This point is important to note when to talking about DevOps outside IT. Instead of emphasizing process breakdowns and failures, show how smaller changes introduce *less* risk, and so on. This is a powerful way to highlight the benefits changing a team's culture: Focusing on the *new* capabilities instead of the *old* problems is an effective agent for change, especially when you adopt someone else's frame of reference.
Change isn't just about *rebuilding* the organization; it's also about new ways to cross historically uncrossable gaps—resolving those tensions I mapped earlier by refusing to position things like "agility" and "stability" as mutually exclusive forces. Setting up cross-silo teams focused on *outcomes* over *functions* is one of the strategies in play. Bringing different teams, each of whose work relies on the others, together around a single project or goal is one of the most common approaches. Eliminating friction between these teams and improving communications yields massive improvements—even while holding to the iron silo structures of management (silos don't need to be demolished if they can be mastered). In these cases, *resistance* to change isn't an indicator of success; an embrace of change is.
These aren't "best practices." They're simply a way for you to examine your own fences. Every organization has unique fences created by the people within it. And once you "know the use of it," you can decide whether it needs dismantling or mastering.
*This article is part of The Open Organization Guide to IT culture change.*
## 6 Comments |
8,933 | OpenGL 与 Go 教程(一)Hello, OpenGL | https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-1-hello-opengl | 2017-10-05T21:27:00 | [
"OpenGL"
] | https://linux.cn/article-8933-1.html | 
* [第一节: Hello, OpenGL](/article-8933-1.html)
* [第二节: 绘制游戏面板](/article-8937-1.html)
* [第三节:实现游戏功能](/article-8969-1.html)
这篇教程的所有源代码都可以在 [GitHub](https://github.com/KyleBanks/conways-gol) 上找到。
### 介绍
[OpenGL](https://www.opengl.org/) 是一门相当好的技术,适用于从桌面的 GUI 到游戏,到移动应用甚至 web 应用的多种类型的绘图工作。我敢保证,你今天看到的图形有些就是用 OpenGL 渲染的。可是,不管 OpenGL 多受欢迎、有多好用,与学习其它高级绘图库相比,学习 OpenGL 是要相当足够的决心的。
这个教程的目的是给你一个切入点,让你对 OpenGL 有个基本的了解,然后教你怎么用 [Go](https://golang.org/) 操作它。几乎每种编程语言都有绑定 OpenGL 的库,Go 也不例外,它有 [go-gl](https://github.com/go-gl/gl) 这个包。这是一个完整的套件,可以绑定 OpenGL ,适用于多种版本的 OpenGL。
这篇教程会按照下面列出的几个阶段进行介绍,我们最终的目标是用 OpenGL 在桌面窗口绘制游戏面板,进而实现[康威生命游戏](https://en.wikipedia.org/wiki/Conway's_Game_of_Life)。完整的源代码可以在 GitHub [github.com/KyleBanks/conways-gol](https://github.com/KyleBanks/conways-gol) 上获得,当你有疑惑的时候可以随时查看源代码,或者你要按照自己的方式学习也可以参考这个代码。
在我们开始之前,我们要先弄明白<ruby> 康威生命游戏 <rt> Conway's Game of Life </rt></ruby> 到底是什么。这里是 [Wikipedia](https://en.wikipedia.org/wiki/Conway's_Game_of_Life) 上面的总结:
>
> 《生命游戏》,也可以简称为 Life,是一个细胞自动变化的过程,由英国数学家 John Horton Conway 于 1970 年提出。
>
>
> 这个“游戏”没有玩家,也就是说它的发展依靠的是它的初始状态,不需要输入。用户通过创建初始配置文件、观察它如何演变,或者对于高级“玩家”可以创建特殊属性的模式,进而与《生命游戏》进行交互。
>
>
> `规则`
>
>
> 《生命游戏》的世界是一个无穷多的二维正交的正方形细胞的格子世界,每一个格子都有两种可能的状态,“存活”或者“死亡”,也可以说是“填充态”或“未填充态”(区别可能很小,可以把它看作一个模拟人类/哺乳动物行为的早期模型,这要看一个人是如何看待方格里的空白)。每一个细胞与它周围的八个细胞相关联,这八个细胞分别是水平、垂直、斜对角相接的。在游戏中的每一步,下列事情中的一件将会发生:
>
>
> 1. 当任何一个存活的细胞的附近少于 2 个存活的细胞时,该细胞将会消亡,就像人口过少所导致的结果一样
> 2. 当任何一个存活的细胞的附近有 2 至 3 个存活的细胞时,该细胞在下一代中仍然存活。
> 3. 当任何一个存活的细胞的附近多于 3 个存活的细胞时,该细胞将会消亡,就像人口过多所导致的结果一样
> 4. 任何一个消亡的细胞附近刚好有 3 个存活的细胞,该细胞会变为存活的状态,就像重生一样。
>
>
>
不需要其他工具,这里有一个我们将会制作的演示程序:

在我们的运行过程中,白色的细胞表示它是存活着的,黑色的细胞表示它已经死亡。
### 概述
本教程将会涉及到很多基础内容,从最基本的开始,但是你还是要对 Go 由一些最基本的了解 —— 至少你应该知道变量、切片、函数和结构体,并且装了一个 Go 的运行环境。我写这篇教程用的 Go 版本是 1.8,但它应该与之前的版本兼容。这里用 Go 语言实现没有什么特别新奇的东西,因此只要你有过类似的编程经历就行。
这里是我们在这个教程里将会讲到的东西:
* [第一节: Hello, OpenGL](https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-1-hello-opengl): 安装 OpenGL 和 [GLFW](http://www.glfw.org/),在窗口上绘制一个三角形。
* [第二节: 绘制游戏面板](https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-2-drawing-the-game-board): 用三角形拼成方形,在窗口上用方形绘成格子。
* [第三节: 实现游戏功能](https://kylewbanks.com/blog/blog/tutorial-opengl-with-golang-part-3-implementing-the-game): 实现 Conway 游戏
最后的源代码可以在 [GitHub](https://github.com/KyleBanks/conways-gol) 上获得,每一节的末尾有个*回顾*,包含该节相关的代码。如果有什么不清楚的地方或者是你感到疑惑的,看看每一节末尾的完整代码。
现在就开始吧!
### 安装 OpenGL 和 GLFW
我们介绍过 OpenGL,但是为了使用它,我们要有个窗口可以绘制东西。 [GLFW](http://www.glfw.org/) 是一款用于 OpenGL 的跨平台 API,允许我们创建并使用窗口,而且它也是 [go-gl](https://github.com/go-gl/glfw) 套件中提供的。
我们要做的第一件事就是确定 OpenGL 的版本。为了方便本教程,我们将会使用 `OpenGL v4.1`,但要是你的操作系统不支持最新的 OpenGL,你也可以用 `v2.1`。要安装 OpenGL,我们需要做这些事:
```
# 对于 OpenGL 4.1
$ go get github.com/go-gl/gl/v4.1-core/gl
# 或者 2.1
$ go get github.com/go-gl/gl/v2.1/gl
```
然后是安装 GLFW:
```
$ go get github.com/go-gl/glfw/v3.2/glfw
```
安装好这两个包之后,我们就可以开始了!先创建 `main.go` 文件,导入相应的包(我们待会儿会用到的其它东西)。
```
package main
import (
"log"
"runtime"
"github.com/go-gl/gl/v4.1-core/gl" // OR: github.com/go-gl/gl/v2.1/gl
"github.com/go-gl/glfw/v3.2/glfw"
)
```
接下来定义一个叫做 `main` 的函数,这是用来初始化 OpenGL 以及 GLFW,并显示窗口的:
```
const (
width = 500
height = 500
)
func main() {
runtime.LockOSThread()
window := initGlfw()
defer glfw.Terminate()
for !window.ShouldClose() {
// TODO
}
}
// initGlfw 初始化 glfw 并且返回一个可用的窗口。
func initGlfw() *glfw.Window {
if err := glfw.Init(); err != nil {
panic(err)
}
glfw.WindowHint(glfw.Resizable, glfw.False)
glfw.WindowHint(glfw.ContextVersionMajor, 4) // OR 2
glfw.WindowHint(glfw.ContextVersionMinor, 1)
glfw.WindowHint(glfw.OpenGLProfile, glfw.OpenGLCoreProfile)
glfw.WindowHint(glfw.OpenGLForwardCompatible, glfw.True)
window, err := glfw.CreateWindow(width, height, "Conway's Game of Life", nil, nil)
if err != nil {
panic(err)
}
window.MakeContextCurrent()
return window
}
```
好了,让我们花一分钟来运行一下这个程序,看看会发生什么。首先定义了一些常量, `width` 和 `height` —— 它们决定窗口的像素大小。
然后就是 `main` 函数。这里我们使用了 `runtime` 包的 `LockOSThread()`,这能确保我们总是在操作系统的同一个线程中运行代码,这对 GLFW 来说很重要,GLFW 需要在其被初始化之后的线程里被调用。讲完这个,接下来我们调用 `initGlfw` 来获得一个窗口的引用,并且推迟(`defer`)其终止。窗口的引用会被用在一个 `for` 循环中,只要窗口处于打开的状态,就执行某些事情。我们待会儿会讲要做的事情是什么。
`initGlfw` 是另一个函数,这里我们调用 `glfw.Init()` 来初始化 GLFW 包。然后我们定义了 GLFW 的一些全局属性,包括禁用调整窗口大小和改变 OpenGL 的属性。然后创建了 `glfw.Window`,这会在稍后的绘图中用到。我们仅仅告诉它我们想要的宽度和高度,以及标题,然后调用 `window.MakeContextCurrent`,将窗口绑定到当前的线程中。最后就是返回窗口的引用了。
如果你现在就构建、运行这个程序,你看不到任何东西。很合理,因为我们还没有用这个窗口做什么实质性的事。
定义一个新函数,初始化 OpenGL,就可以解决这个问题:
```
// initOpenGL 初始化 OpenGL 并且返回一个初始化了的程序。
func initOpenGL() uint32 {
if err := gl.Init(); err != nil {
panic(err)
}
version := gl.GoStr(gl.GetString(gl.VERSION))
log.Println("OpenGL version", version)
prog := gl.CreateProgram()
gl.LinkProgram(prog)
return prog
}
```
`initOpenGL` 就像之前的 `initGlfw` 函数一样,初始化 OpenGL 库,创建一个<ruby> 程序 <rt> program </rt></ruby>。“程序”是一个包含了<ruby> 着色器 <rt> shader </rt></ruby>的引用,稍后会用<ruby> 着色器 <rt> shader </rt></ruby>绘图。待会儿会讲这一点,现在只用知道 OpenGL 已经初始化完成了,我们有一个程序的引用。我们还打印了 OpenGL 的版本,可以用于之后的调试。
回到 `main` 函数里,调用这个新函数:
```
func main() {
runtime.LockOSThread()
window := initGlfw()
defer glfw.Terminate()
program := initOpenGL()
for !window.ShouldClose() {
draw(window, program)
}
}
```
你应该注意到了现在我们有 `program` 的引用,在我们的窗口循环中,调用新的 `draw` 函数。最终这个函数会绘制出所有细胞,让游戏状态变得可视化,但是现在它做的仅仅是清除窗口,所以我们只能看到一个全黑的屏幕:
```
func draw(window *glfw.Window, program uint32) {
gl.Clear(gl.COLOR_BUFFER_BIT | gl.DEPTH_BUFFER_BIT)
gl.UseProgram(prog)
glfw.PollEvents()
window.SwapBuffers()
}
```
我们首先做的是调用 `gl.clear` 函数来清除上一帧在窗口中绘制的东西,给我们一个干净的面板。然后我们告诉 OpenGL 去使用我们的程序引用,这个引用还没有做什么事。最终我们告诉 GLFW 用 `PollEvents` 去检查是否有鼠标或者键盘事件(这一节里还不会对这些事件进行处理),告诉窗口去交换缓冲区 `SwapBuffers`。 [交换缓冲区](http://www.glfw.org/docs/latest/window_guide.html#buffer_swap) 很重要,因为 GLFW(像其他图形库一样)使用双缓冲,也就是说你绘制的所有东西实际上是绘制到一个不可见的画布上,当你准备好进行展示的时候就把绘制的这些东西放到可见的画布中 —— 这种情况下,就需要调用 `SwapBuffers` 函数。
好了,到这里我们已经讲了很多东西,花一点时间看看我们的实验成果。运行这个程序,你应该可以看到你所绘制的第一个东西:

完美!
### 在窗口里绘制三角形
我们已经完成了一些复杂的步骤,即使看起来不多,但我们仍然需要绘制一些东西。我们会以三角形绘制开始,可能这第一眼看上去要比我们最终要绘制的方形更难,但你会知道这样的想法是错的。你可能不知道的是三角形或许是绘制的图形中最简单的,实际上我们最终会用某种方式把三角形拼成方形。
好吧,那么我们想要绘制一个三角形,怎么做呢?我们通过定义图形的顶点来绘制图形,把它们交给 OpenGL 来进行绘制。先在 `main.go` 的顶部里定义我们的三角形:
```
var (
triangle = []float32{
0, 0.5, 0, // top
-0.5, -0.5, 0, // left
0.5, -0.5, 0, // right
}
)
```
这看上去很奇怪,让我们分开来看。首先我们用了一个 `float32` <ruby> 切片 <rt> slice </rt></ruby>,这是一种我们总会在向 OpenGL 传递顶点时用到的数据类型。这个切片包含 9 个值,每三个值构成三角形的一个点。第一行, `0, 0.5, 0` 表示的是 X、Y、Z 坐标,是最上方的顶点,第二行是左边的顶点,第三行是右边的顶点。每一组的三个点都表示相对于窗口中心点的 X、Y、Z 坐标,大小在 `-1` 和 `1` 之间。因此最上面的顶点 X 坐标是 `0`,因为它在 X 方向上位于窗口中央,Y 坐标是 `0.5` 意味着它会相对窗口中央上移 1/4 个单位(因为窗口的范围是 `-1` 到 `1`),Z 坐标是 0。因为我们只需要在二维空间中绘图,所以 Z 值永远是 `0`。现在看一看左右两边的顶点,看看你能不能理解为什么它们是这样定义的 —— 如果不能立刻就弄清楚也没关系,我们将会在屏幕上去观察它,因此我们需要一个完美的图形来进行观察。
好了,我们定义了一个三角形,但是现在我们得把它画出来。要画出这个三角形,我们需要一个叫做<ruby> 顶点数组对象 <rt> Vertex Array Object </rt></ruby>或者叫 vao 的东西,这是由一系列的点(也就是我们定义的三角形)创造的,这个东西可以提供给 OpenGL 来进行绘制。创建一个叫做 `makeVao` 的函数,然后我们可以提供一个点的切片,让它返回一个指向 OpenGL 顶点数组对象的指针:
```
// makeVao 执行初始化并从提供的点里面返回一个顶点数组
func makeVao(points []float32) uint32 {
var vbo uint32
gl.GenBuffers(1, &vbo)
gl.BindBuffer(gl.ARRAY_BUFFER, vbo)
gl.BufferData(gl.ARRAY_BUFFER, 4*len(points), gl.Ptr(points), gl.STATIC_DRAW)
var vao uint32
gl.GenVertexArrays(1, &vao)
gl.BindVertexArray(vao)
gl.EnableVertexAttribArray(0)
gl.BindBuffer(gl.ARRAY_BUFFER, vbo)
gl.VertexAttribPointer(0, 3, gl.FLOAT, false, 0, nil)
return vao
}
```
首先我们创造了<ruby> 顶点缓冲区对象 <rt> Vertex Buffer Object </rt></ruby> 或者说 vbo 绑定到我们的 `vao` 上,`vbo` 是通过所占空间(也就是 4 倍 `len(points)` 大小的空间)和一个指向顶点的指针(`gl.Ptr(points)`)来创建的。你也许会好奇为什么它是 4 倍 —— 而不是 6 或者 3 或者 1078 呢?原因在于我们用的是 `float32` 切片,32 个位的浮点型变量是 4 个字节,因此我们说这个缓冲区以字节为单位的大小是点个数的 4 倍。
现在我们有缓冲区了,可以创建 `vao` 并用 `gl.BindBuffer` 把它绑定到缓冲区上,最后返回 `vao`。这个 `vao` 将会被用于绘制三角形!
回到 `main` 函数:
```
func main() {
...
vao := makeVao(triangle)
for !window.ShouldClose() {
draw(vao, window, program)
}
}
这里我们调用了 `makeVao` ,从我们之前定义的 `triangle` 顶点中获得 `vao` 引用,将它作为一个新的参数传递给 `draw` 函数:
func draw(vao uint32, window *glfw.Window, program uint32) {
gl.Clear(gl.COLOR_BUFFER_BIT | gl.DEPTH_BUFFER_BIT)
gl.UseProgram(program)
gl.BindVertexArray(vao)
gl.DrawArrays(gl.TRIANGLES, 0, int32(len(triangle) / 3))
glfw.PollEvents()
window.SwapBuffers()
}
```
然后我们把 OpenGL 绑定到 `vao` 上,这样当我们告诉 OpenGL 三角形切片的顶点数(除以 3,是因为每一个点有 X、Y、Z 坐标),让它去 `DrawArrays` ,它就知道要画多少个顶点了。
如果你这时候运行程序,你可能希望在窗口中央看到一个美丽的三角形,但是不幸的是你还看不到。还有一件事情没做,我们告诉 OpenGL 我们要画一个三角形,但是我们还要告诉它*怎么*画出来。
要让它画出来,我们需要叫做<ruby> 片元着色器 <rt> fragment shader </rt></ruby>和<ruby> 顶点着色器 <rt> vertex shader </rt></ruby>的东西,这些已经超出本教程的范围了(老实说,也超出了我对 OpenGL 的了解),但 [Harold Serrano 在 Quora](https://www.quora.com/What-is-a-vertex-shader-and-what-is-a-fragment-shader/answer/Harold-Serrano?srid=aVb) 上对对它们是什么给出了完美的介绍。我们只需要理解,对于这个应用来说,着色器是它内部的小程序(用 [OpenGL Shader Language 或 GLSL](https://www.opengl.org/sdk/docs/tutorials/ClockworkCoders/glsl_overview.php) 编写的),它操作顶点进行绘制,也可用于确定图形的颜色。
添加两个 `import` 和一个叫做 `compileShader` 的函数:
```
import (
"strings"
"fmt"
)
func compileShader(source string, shaderType uint32) (uint32, error) {
shader := gl.CreateShader(shaderType)
csources, free := gl.Strs(source)
gl.ShaderSource(shader, 1, csources, nil)
free()
gl.CompileShader(shader)
var status int32
gl.GetShaderiv(shader, gl.COMPILE_STATUS, &status)
if status == gl.FALSE {
var logLength int32
gl.GetShaderiv(shader, gl.INFO_LOG_LENGTH, &logLength)
log := strings.Repeat("\x00", int(logLength+1))
gl.GetShaderInfoLog(shader, logLength, nil, gl.Str(log))
return 0, fmt.Errorf("failed to compile %v: %v", source, log)
}
return shader, nil
}
```
这个函数的目的是以字符串的形式接受着色器源代码和它的类型,然后返回一个指向这个编译好的着色器的指针。如果编译失败,我们就会获得出错的详细信息。
现在定义着色器,在 `makeProgram` 里编译。回到我们的 `const` 块中,我们在这里定义了 `width` 和 `hegiht`。
```
vertexShaderSource = `
#version 410
in vec3 vp;
void main() {
gl_Position = vec4(vp, 1.0);
}
` + "\x00"
fragmentShaderSource = `
#version 410
out vec4 frag_colour;
void main() {
frag_colour = vec4(1, 1, 1, 1);
}
` + "\x00"
```
如你所见,这是两个包含了 GLSL 源代码字符串的着色器,一个是<ruby> 顶点着色器 <rt> vertex shader </rt></ruby>,另一个是<ruby> 片元着色器 <rt> fragment shader </rt></ruby>。唯一比较特殊的地方是它们都要在末尾加上一个空终止字符,`\x00` —— OpenGL 需要它才能编译着色器。注意 `fragmentShaderSource`,这是我们用 RGBA 形式的值通过 `vec4` 来定义我们图形的颜色。你可以修改这里的值来改变这个三角形的颜色,现在的值是 `RGBA(1, 1, 1, 1)` 或者说是白色。
同样需要注意的是这两个程序都是运行在 `#version 410` 版本下,如果你用的是 OpenGL 2.1,那你也可以改成 `#version 120`。这里 `120` 不是打错的,如果你用的是 OpenGL 2.1,要用 `120` 而不是 `210`!
接下来在 `initOpenGL` 中我们会编译着色器,把它们附加到我们的 `program` 中。
```
func initOpenGL() uint32 {
if err := gl.Init(); err != nil {
panic(err)
}
version := gl.GoStr(gl.GetString(gl.VERSION))
log.Println("OpenGL version", version)
vertexShader, err := compileShader(vertexShaderSource, gl.VERTEX_SHADER)
if err != nil {
panic(err)
}
fragmentShader, err := compileShader(fragmentShaderSource, gl.FRAGMENT_SHADER)
if err != nil {
panic(err)
}
prog := gl.CreateProgram()
gl.AttachShader(prog, vertexShader)
gl.AttachShader(prog, fragmentShader)
gl.LinkProgram(prog)
return prog
}
```
这里我们用顶点着色器(`vertexShader`)调用了 `compileShader` 函数,指定它的类型是 `gl.VERTEX_SHADER`,对片元着色器(`fragmentShader`)做了同样的事情,但是指定的类型是 `gl.FRAGMENT_SHADER`。编译完成后,我们把它们附加到程序中,调用 `gl.AttachShader`,传递程序(`prog`)以及编译好的着色器作为参数。
现在我们终于可以看到我们漂亮的三角形了!运行程序,如果一切顺利的话你会看到这些:

### 总结
是不是很惊喜!这些代码画出了一个三角形,但我保证我们已经完成了大部分的 OpenGL 代码,在接下来的章节中我们还会用到这些代码。我十分推荐你花几分钟修改一下代码,看看你能不能移动三角形,改变三角形的大小和颜色。OpenGL 可以令人心生畏惧,有时想要理解发生了什么很困难,但是要记住,这不是魔法 - 它只不过看上去像魔法。
下一节里我们讲会用两个锐角三角形拼出一个方形 - 看看你能不能在进入下一节前试着修改这一节的代码。不能也没有关系,因为我们在 [第二节](https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-2-drawing-the-game-board) 还会编写代码, 接着创建一个有许多方形的格子,我们把它当做游戏面板。
最后,在[第三节](https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-3-implementing-the-game) 里我们会用格子来实现 *Conway’s Game of Life*!
### 回顾
本教程 `main.go` 文件的内容如下:
```
package main
import (
"fmt"
"log"
"runtime"
"strings"
"github.com/go-gl/gl/v4.1-core/gl" // OR: github.com/go-gl/gl/v2.1/gl
"github.com/go-gl/glfw/v3.2/glfw"
)
const (
width = 500
height = 500
vertexShaderSource = `
#version 410
in vec3 vp;
void main() {
gl_Position = vec4(vp, 1.0);
}
` + "\x00"
fragmentShaderSource = `
#version 410
out vec4 frag_colour;
void main() {
frag_colour = vec4(1, 1, 1, 1.0);
}
` + "\x00"
)
var (
triangle = []float32{
0, 0.5, 0,
-0.5, -0.5, 0,
0.5, -0.5, 0,
}
)
func main() {
runtime.LockOSThread()
window := initGlfw()
defer glfw.Terminate()
program := initOpenGL()
vao := makeVao(triangle)
for !window.ShouldClose() {
draw(vao, window, program)
}
}
func draw(vao uint32, window *glfw.Window, program uint32) {
gl.Clear(gl.COLOR_BUFFER_BIT | gl.DEPTH_BUFFER_BIT)
gl.UseProgram(program)
gl.BindVertexArray(vao)
gl.DrawArrays(gl.TRIANGLES, 0, int32(len(triangle)/3))
glfw.PollEvents()
window.SwapBuffers()
}
// initGlfw 初始化 glfw 并返回一个窗口供使用。
func initGlfw() *glfw.Window {
if err := glfw.Init(); err != nil {
panic(err)
}
glfw.WindowHint(glfw.Resizable, glfw.False)
glfw.WindowHint(glfw.ContextVersionMajor, 4)
glfw.WindowHint(glfw.ContextVersionMinor, 1)
glfw.WindowHint(glfw.OpenGLProfile, glfw.OpenGLCoreProfile)
glfw.WindowHint(glfw.OpenGLForwardCompatible, glfw.True)
window, err := glfw.CreateWindow(width, height, "Conway's Game of Life", nil, nil)
if err != nil {
panic(err)
}
window.MakeContextCurrent()
return window
}
// initOpenGL 初始化 OpenGL 并返回一个已经编译好的着色器程序
func initOpenGL() uint32 {
if err := gl.Init(); err != nil {
panic(err)
}
version := gl.GoStr(gl.GetString(gl.VERSION))
log.Println("OpenGL version", version)
vertexShader, err := compileShader(vertexShaderSource, gl.VERTEX_SHADER)
if err != nil {
panic(err)
}
fragmentShader, err := compileShader(fragmentShaderSource, gl.FRAGMENT_SHADER)
if err != nil {
panic(err)
}
prog := gl.CreateProgram()
gl.AttachShader(prog, vertexShader)
gl.AttachShader(prog, fragmentShader)
gl.LinkProgram(prog)
return prog
}
// makeVao 执行初始化并从提供的点里面返回一个顶点数组
func makeVao(points []float32) uint32 {
var vbo uint32
gl.GenBuffers(1, &vbo)
gl.BindBuffer(gl.ARRAY_BUFFER, vbo)
gl.BufferData(gl.ARRAY_BUFFER, 4*len(points), gl.Ptr(points), gl.STATIC_DRAW)
var vao uint32
gl.GenVertexArrays(1, &vao)
gl.BindVertexArray(vao)
gl.EnableVertexAttribArray(0)
gl.BindBuffer(gl.ARRAY_BUFFER, vbo)
gl.VertexAttribPointer(0, 3, gl.FLOAT, false, 0, nil)
return vao
}
func compileShader(source string, shaderType uint32) (uint32, error) {
shader := gl.CreateShader(shaderType)
csources, free := gl.Strs(source)
gl.ShaderSource(shader, 1, csources, nil)
free()
gl.CompileShader(shader)
var status int32
gl.GetShaderiv(shader, gl.COMPILE_STATUS, &status)
if status == gl.FALSE {
var logLength int32
gl.GetShaderiv(shader, gl.INFO_LOG_LENGTH, &logLength)
log := strings.Repeat("\x00", int(logLength+1))
gl.GetShaderInfoLog(shader, logLength, nil, gl.Str(log))
return 0, fmt.Errorf("failed to compile %v: %v", source, log)
}
return shader, nil
}
```
请在 Twitter [@kylewbanks](https://twitter.com/kylewbanks) 上告诉我这篇文章对你是否有帮助,或者点击下方的关注,以便及时获取最新文章!
---
via: <https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-1-hello-opengl>
作者:[kylewbanks](https://twitter.com/kylewbanks) 译者:[GitFuture](https://github.com/GitFuture) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # OpenGL & Go Tutorial Part 1: Hello, OpenGL
[@kylewbanks](https://twitter.com/kylewbanks)on Mar 12, 2017.
*Hey, if you didn't already know, I'm currently working on an open world stealth exploration game called*
[Farewell North](https://farewell-north.com)in my spare time, which is available to wishlist on Steam!* Part 1: Hello, OpenGL* |
*|*
[Part 2: Drawing the Game Board](/blog/tutorial-opengl-with-golang-part-2-drawing-the-game-board)
[Part 3: Implementing the Game](/blog/tutorial-opengl-with-golang-part-3-implementing-the-game)*The full source code of the tutorial is available on GitHub.*
## Introduction
[OpenGL](https://www.opengl.org/) is pretty much the gold standard for any kind of graphics work, from desktop GUIs to games to mobile applications and even the web, I can almost guarantee you’ve viewed something rendered by OpenGL today. However, regardless of how popular and useful OpenGL is, it can be quite intimidating to get started compared to more high-level graphics libraries.
The purpose of this tutorial is to give you a starting point and basic understanding of OpenGL, and how to utilize it with [Go](https://golang.org/). There are bindings for OpenGL in just about every language and Go is no exception with the [go-gl](https://github.com/go-gl/gl) packages, a full suite of generated OpenGL bindings for various OpenGL versions.
The tutorial will walk through a few phases outlined below, with our end goal being to implement [Conway’s Game of Life](https://en.wikipedia.org/wiki/Conway's_Game_of_Life) using OpenGL to draw the game board in a desktop window. The full source code is available on GitHub at [github.com/KyleBanks/conways-gol](https://github.com/KyleBanks/conways-gol) so feel free to check it out if you get stuck or use it as a reference if you decide to go your own way.
Before we get started, we need to get an understanding of what *Conway’s Game of Life* actually is. Here’s the summary from [Wikipedia](https://en.wikipedia.org/wiki/Conway's_Game_of_Life):
The Game of Life, also known simply as Life, is a cellular automaton devised by the British mathematician John Horton Conway in 1970.
The “game” is a zero-player game, meaning that its evolution is determined by its initial state, requiring no further input. One interacts with the Game of Life by creating an initial configuration and observing how it evolves, or, for advanced “players”, by creating patterns with particular properties.
Rules
The universe of the Game of Life is an infinite two-dimensional orthogonal grid of square cells, each of which is in one of two possible states, alive or dead, or “populated” or “unpopulated” (the difference may seem minor, except when viewing it as an early model of human/urban behaviour simulation or how one views a blank space on a grid). Every cell interacts with its eight neighbours, which are the cells that are horizontally, vertically, or diagonally adjacent. At each step in time, the following transitions occur:
- Any live cell with fewer than two live neighbours dies, as if caused by underpopulation.
- Any live cell with two or three live neighbours lives on to the next generation.
- Any live cell with more than three live neighbours dies, as if by overpopulation.
- Any dead cell with exactly three live neighbours becomes a live cell, as if by reproduction.
And without further ado, here’s a demo of what we’ll be building:

In our simulation, a white cell indicates that it is alive, and black cell indicates that it is not.
## Outline
The tutorial is going to cover a lot of ground starting with the basics, however it will assume you have a minimal working knowledge of Go - at the very least you should know the basics of variables, slices, functions and structs, and have a working Go environment setup. I’ve developed the tutorial using Go version 1.8, but it should be compatible with previous versions as well. There is nothing particularly novel here in the Go implementation, so if you have experience in any similar programming language you should be just fine.
As for the tutorial, here’s what we’ll be covering:
[Part 1: Hello, OpenGL](/blog/tutorial-opengl-with-golang-part-1-hello-opengl): Install and Setup OpenGL and[GLFW](http://www.glfw.org/), Draw a Triangle to the Window[Part 2: Drawing the Game Board](/blog/tutorial-opengl-with-golang-part-2-drawing-the-game-board): Make a Square out of Triangles, Draw a Grid of Squares covering the Window[Part 3: Implementing the Game](blog/tutorial-opengl-with-golang-part-3-implementing-the-game): Implement Conway’s Game
The final source code is available on [GitHub](https://github.com/KyleBanks/conways-gol) but each *Part* includes a *Checkpoint* at the bottom containing the code up until that point. If anything is ever unclear or if you feel lost, check the bottom of the post for the full source!
Let’s get started!
## Install and Setup OpenGL and GLFW
We’ve introduced OpenGL but in order to use it we’re going to need a window to draw on to. [GLFW](http://www.glfw.org/) is a cross-platform API for OpenGL that allows us to create and reference a window, and is also provided by the [go-gl](https://github.com/go-gl/glfw) suite.
The first thing we need to do is decide on an OpenGL version. For the purposes of this tutorial we’ll use **OpenGL v4.1** but you can use **v2.1** just fine if your system doesn’t have the latest OpenGL versions. In order to install OpenGL we’ll do the following:
# For OpenGL 4.1 $ go get github.com/go-gl/gl/v4.1-core/gl # Or 2.1 $ go get github.com/go-gl/gl/v2.1/gl
Next up, let’s install GLFW:
$ go get github.com/go-gl/glfw/v3.2/glfw
With these two packages installed, we’re ready to get started! We’re going to start by creating **main.go** and importing the packages (and a couple others we’ll need in a moment).
package main import ( "log" "runtime" "github.com/go-gl/gl/v4.1-core/gl" // OR: github.com/go-gl/gl/v2.1/gl "github.com/go-gl/glfw/v3.2/glfw" )
Next lets define the **main** function, the purpose of which is to initialize OpenGL and GLFW and display the window:
const ( width = 500 height = 500 ) func main() { runtime.LockOSThread() window := initGlfw() defer glfw.Terminate() for !window.ShouldClose() { // TODO } } // initGlfw initializes glfw and returns a Window to use. func initGlfw() *glfw.Window { if err := glfw.Init(); err != nil { panic(err) } glfw.WindowHint(glfw.Resizable, glfw.False) glfw.WindowHint(glfw.ContextVersionMajor, 4) // OR 2 glfw.WindowHint(glfw.ContextVersionMinor, 1) glfw.WindowHint(glfw.OpenGLProfile, glfw.OpenGLCoreProfile) glfw.WindowHint(glfw.OpenGLForwardCompatible, glfw.True) window, err := glfw.CreateWindow(width, height, "Conway's Game of Life", nil, nil) if err != nil { panic(err) } window.MakeContextCurrent() return window }
Alright let’s take a minute to walk through this and see what’s going on. First we define a couple constants, **width** and **height** - these will determine the size of the window, in pixels.
Next we have the **main** function. Here we instruct the **runtime** package to **LockOSThread()**, which ensures we will always execute in the same operating system thread, which is important for GLFW which must always be called from the same thread it was initialized on. Speaking of which, next we call **initGlfw** to get a window reference, and defer terminating. The window reference is then used in a for-loop where we say as long as the window should remain open, do *something*. We’ll come back to this in a bit.
**initGlfw** is our next function, wherein we call **glfw.Init()** to initialize the GLFW package. After that, we define some global GLFW properties, including disabling window resizing and the properties of our OpenGL version. Next it’s time to create a **glfw.Window** which is where we’re going to do our future drawing. We simply tell it the width and height we want, as well as a title, and then call **window.MakeContextCurrent**, binding the window to our current thread. Finally, we return the window.
If you build and run the program now, you should see… nothing. This makes sense, because we’re not actually doing anything with the window yet.
Let’s fix that by defining a new function that initializes OpenGL:
// initOpenGL initializes OpenGL and returns an intiialized program. func initOpenGL() uint32 { if err := gl.Init(); err != nil { panic(err) } version := gl.GoStr(gl.GetString(gl.VERSION)) log.Println("OpenGL version", version) prog := gl.CreateProgram() gl.LinkProgram(prog) return prog }
**initOpenGL**, like our **initGlfw** function above, initializes the OpenGL library and creates a *program*. A program gives us a reference to store shaders, which can then be used for drawing. We’ll come back to this in a bit, but for now just know that OpenGL is initialized and we have a **program** reference. We also print out the OpenGL version which can be helpful for debugging.
Back in **main**, let’s call this new function:
func main() { runtime.LockOSThread() window := initGlfw() defer glfw.Terminate() program := initOpenGL() for !window.ShouldClose() { draw(window, program) } }
You’ll notice now that we have our **program** reference, we’re calling a new **draw** function within our core window loop. Eventually this function will draw all of our cells to visualize the game state, but for now its just going to clear the window so we get a black screen:
func draw(window *glfw.Window, program uint32) { gl.Clear(gl.COLOR_BUFFER_BIT | gl.DEPTH_BUFFER_BIT) gl.UseProgram(prog) glfw.PollEvents() window.SwapBuffers() }
The first thing we do is call **gl.Clear** to remove anything from the window that was drawn last frame, giving us a clean slate. Next we tell OpenGL to use our program reference, which currently does nothing. Finally, we tell GLFW to check if there were any mouse or keyboard events (which we won’t be handling in this tutorial) with the **PollEvents** function, and tell the window to **SwapBuffers**. [Buffer swapping](http://www.glfw.org/docs/latest/window_guide.html#buffer_swap) is important because GLFW (like many graphics libraries) uses double buffering, meaning everything you draw is actually drawn to an invisible canvas, and only put onto the visible canvas when you’re ready - which in this case, is indicated by calling **SwapBuffers**.
Alright, we’ve covered a lot here, so let’s take a moment to see the fruits of our labors. Go ahead and run the program now, and you should get to see your first visual:

Beautiful.
## Draw a Triangle to the Window
We’ve made some serious progress, even if it doesn’t look like much, but we still need to actually draw something. We’ll start by drawing a triangle, which may at first seem like it would be more difficult to draw than the squares we’re eventually going to, but you’d be mistaken for thinking so. What you may not know is that triangles are probably the easiest shapes to draw, and in fact we’ll eventually be making our squares out of triangles anyways.
Alright so we want to draw a triangle, but how? Well, we draw shapes by defining the vertices of the shapes and providing them to OpenGL to be drawn. Let’s first define our triangle at the top of **main.go**:
var ( triangle = []float32{ 0, 0.5, 0, // top -0.5, -0.5, 0, // left 0.5, -0.5, 0, // right } )
This looks weird, but let’s break it down. First we have a slice of **float32**, which is the datatype we always use when providing vertices to OpenGL. The slice contains 9 values, three for each vertex of a triangle. The top line, **0, 0.5, 0**, is the top vertex represented as X, Y, and Z coordinates, the second line is the left vertex, and the third line is the right vertex. Each of these pairs of three represents the X, Y, and Z coordinates of the vertex relative to the center of the window, between **-1 and 1**. So the top point has an X of zero because its X is in the center of the window, a Y of *0.5* meaning it will be up one quarter (because the range is -1 to 1) of the window relative to the center of the window, and a Z of zero. For our purposes because we are drawing only in two dimensions, our Z values will always be zero. Now have a look at the left and right vertices and see if you can understand why they are defined as they are - it’s okay if it isn’t immediately clear, we’re going to see it on the screen soon enough so we’ll have a perfect visualization to play with.
Okay, we have a triangle defined, but now we need to draw it. In order to draw it, we need what’s called a **Vertex Array Object** or **vao** which is created from a set of points (what we defined as our triangle), and can be provided to OpenGL to draw. Let’s create a function called **makeVao** that we can provide with a slice of points and have it return a pointer to an OpenGL vertex array object:
// makeVao initializes and returns a vertex array from the points provided. func makeVao(points []float32) uint32 { var vbo uint32 gl.GenBuffers(1, &vbo) gl.BindBuffer(gl.ARRAY_BUFFER, vbo) gl.BufferData(gl.ARRAY_BUFFER, 4*len(points), gl.Ptr(points), gl.STATIC_DRAW) var vao uint32 gl.GenVertexArrays(1, &vao) gl.BindVertexArray(vao) gl.EnableVertexAttribArray(0) gl.BindBuffer(gl.ARRAY_BUFFER, vbo) gl.VertexAttribPointer(0, 3, gl.FLOAT, false, 0, nil) return vao }
First we create a **Vertex Buffer Object** or **vbo** to bind our **vao** to, which is created by providing the size (**4 x len(points)**) and a pointer to the points (**gl.Ptr(points)**). You may be wondering why it’s **4 x len(points)** - why not 6 or 3 or 1078? The reason is we are using **float32** slices, and a 32-bit float has 4 bytes, so we are saying the size of the buffer, in bytes, is 4 times the number of points.
Now that we have a buffer, we can create the **vao** and bind it to the buffer with **gl.BindBuffer**, and finally return the **vao**. This **vao** will then be used to draw the triangle!
Back in **main**:
func main() { ... vao := makeVao(triangle) for !window.ShouldClose() { draw(vao, window, program) } } Here we call **makeVao** to get our **vao** reference from the **triangle** points we defined before, and pass it as a new argument to the **draw** function: func draw(vao uint32, window *glfw.Window, program uint32) { gl.Clear(gl.COLOR_BUFFER_BIT | gl.DEPTH_BUFFER_BIT) gl.UseProgram(program) gl.BindVertexArray(vao) gl.DrawArrays(gl.TRIANGLES, 0, int32(len(triangle) / 3)) glfw.PollEvents() window.SwapBuffers() }
Then we bind OpenGL to our **vao** so it knows what we’re talking above when we tell it to **DrawArrays**, and tell it the length of the triangle (divided by three, one for each X, Y, Z coordinate) slice so it knows how many vertices to draw.
If you run the application at this point you might be expecting to see a beautiful triangle in the center of the window, but unfortunately you would be mistaken. There’s still one thing left to do, you see we’ve told OpenGL that we want to draw a triangle, but we need to tell it *how* to draw the triangle.
In order to do that, we need what are called fragment and vertex shaders, which are beyond the scope of this tutorial. All you really need to understand for this application is that shaders are their own mini-programs (written in [OpenGL Shader Language or GLSL](https://www.opengl.org/sdk/docs/tutorials/ClockworkCoders/glsl_overview.php)) that typically run on the GPU. They’re really interesting and force you to think in a different way to typically programming tasks, but again they’re out of scope for this tutorial. For our purposes, just understand that a vertex shader manipulates the vertices to be drawn by OpenGL and generates the data passed to the fragment shader, which then determines the color of each fragment (you can just consider a fragment to be a pixel) to be drawn to the screen.
We start by adding two more imports and a function called **compileShader**:
import ( "strings" "fmt" ) func compileShader(source string, shaderType uint32) (uint32, error) { shader := gl.CreateShader(shaderType) csources, free := gl.Strs(source) gl.ShaderSource(shader, 1, csources, nil) free() gl.CompileShader(shader) var status int32 gl.GetShaderiv(shader, gl.COMPILE_STATUS, &status) if status == gl.FALSE { var logLength int32 gl.GetShaderiv(shader, gl.INFO_LOG_LENGTH, &logLength) log := strings.Repeat("\x00", int(logLength+1)) gl.GetShaderInfoLog(shader, logLength, nil, gl.Str(log)) return 0, fmt.Errorf("failed to compile %v: %v", source, log) } return shader, nil }
The purpose of this function is to receive the shader source code as a string as well as its type, and return a pointer to the resulting compiled shader. If it fails to compile we’ll get an error returned containing the details.
Now let’s define the shaders and compile them from **makeProgram**. Back up in our **const** block where we define **width** and **height**:
vertexShaderSource = ` #version 410 in vec3 vp; void main() { gl_Position = vec4(vp, 1.0); } ` + "\x00" fragmentShaderSource = ` #version 410 out vec4 frag_colour; void main() { frag_colour = vec4(1, 1, 1, 1); } ` + "\x00"
As you can see these are strings containing GLSL source code for two shaders, one for a *vertex shader* and another for a *fragment shader*. The only thing special about these strings is that they both end in a null-termination character, **\x00** - a requirement for OpenGL to be able to compile them. Make note of the **fragmentShaderSource**, this is where we define the color of our shape in RGBA format using a **vec4**. You can change the value here, which is currently **RGBA(1, 1, 1, 1)** or *white*, to change the color of the triangle.
Also of note is that both programs start with **#version 410**, which you should change to **#version 120** if using OpenGL 2.1. **120** is not a typo - use **120** not **210** if you’re on OpenGL 2.1!
Next in **initOpenGL** we’ll compile the shaders and attach them to our **program**:
func initOpenGL() uint32 { if err := gl.Init(); err != nil { panic(err) } version := gl.GoStr(gl.GetString(gl.VERSION)) log.Println("OpenGL version", version) vertexShader, err := compileShader(vertexShaderSource, gl.VERTEX_SHADER) if err != nil { panic(err) } fragmentShader, err := compileShader(fragmentShaderSource, gl.FRAGMENT_SHADER) if err != nil { panic(err) } prog := gl.CreateProgram() gl.AttachShader(prog, vertexShader) gl.AttachShader(prog, fragmentShader) gl.LinkProgram(prog) return prog }
Here we call our **compileShader** function with the *vertex shader*, specifying its type as a **gl.VERTEX_SHADER**, and do the same with the *fragment shader* but specifying its type as a **gl.FRAGMENT_SHADER**. After compiling them, we attach them to our program by calling **gl.AttachShader** with our program and each compiled shader.
And now we’re finally ready to see our glorious triangle! Go ahead and run, and if all is well you’ll see:

## Summary
Amazing, right! All that for a single triangle, but I promise you we’ve setup the majority of the OpenGL code that will serve us for the rest of the tutorial. I highly encourage you to take a few minutes to play with the code and see if you can move, resize, and change the color of the triangle. OpenGL can be *very* intimidating, and it can feel at times like its difficult to understand what’s going on, but understand that this isn’t magic - it only looks like it is.
In the next part of the tutorial we’ll make a square out of two right-angled triangles - see if you can try and figure this part out before moving on. If not, don’t worry because we’ll be walking through the code in [Part 2](/blog/tutorial-opengl-with-golang-part-2-drawing-the-game-board), followed by creating a full grid of squares that will act as our game board.
Finally, in [Part 3](/blog/tutorial-opengl-with-golang-part-3-implementing-the-game) we continue by using the grid to implement *Conway’s Game of Life!*
* Part 1: Hello, OpenGL* |
*|*
[Part 2: Drawing the Game Board](/blog/tutorial-opengl-with-golang-part-2-drawing-the-game-board)
[Part 3: Implementing the Game](/blog/tutorial-opengl-with-golang-part-3-implementing-the-game)*The full source code of the tutorial is available on GitHub.*
## Checkpoint
Here’s the contents of **main.go** at this point of the tutorial:
package main import ( "fmt" "log" "runtime" "strings" "github.com/go-gl/gl/v4.1-core/gl" // OR: github.com/go-gl/gl/v2.1/gl "github.com/go-gl/glfw/v3.2/glfw" ) const ( width = 500 height = 500 vertexShaderSource = ` #version 410 in vec3 vp; void main() { gl_Position = vec4(vp, 1.0); } ` + "\x00" fragmentShaderSource = ` #version 410 out vec4 frag_colour; void main() { frag_colour = vec4(1, 1, 1, 1.0); } ` + "\x00" ) var ( triangle = []float32{ 0, 0.5, 0, -0.5, -0.5, 0, 0.5, -0.5, 0, } ) func main() { runtime.LockOSThread() window := initGlfw() defer glfw.Terminate() program := initOpenGL() vao := makeVao(triangle) for !window.ShouldClose() { draw(vao, window, program) } } func draw(vao uint32, window *glfw.Window, program uint32) { gl.Clear(gl.COLOR_BUFFER_BIT | gl.DEPTH_BUFFER_BIT) gl.UseProgram(program) gl.BindVertexArray(vao) gl.DrawArrays(gl.TRIANGLES, 0, int32(len(triangle)/3)) glfw.PollEvents() window.SwapBuffers() } // initGlfw initializes glfw and returns a Window to use. func initGlfw() *glfw.Window { if err := glfw.Init(); err != nil { panic(err) } glfw.WindowHint(glfw.Resizable, glfw.False) glfw.WindowHint(glfw.ContextVersionMajor, 4) glfw.WindowHint(glfw.ContextVersionMinor, 1) glfw.WindowHint(glfw.OpenGLProfile, glfw.OpenGLCoreProfile) glfw.WindowHint(glfw.OpenGLForwardCompatible, glfw.True) window, err := glfw.CreateWindow(width, height, "Conway's Game of Life", nil, nil) if err != nil { panic(err) } window.MakeContextCurrent() return window } // initOpenGL initializes OpenGL and returns an intiialized program. func initOpenGL() uint32 { if err := gl.Init(); err != nil { panic(err) } version := gl.GoStr(gl.GetString(gl.VERSION)) log.Println("OpenGL version", version) vertexShader, err := compileShader(vertexShaderSource, gl.VERTEX_SHADER) if err != nil { panic(err) } fragmentShader, err := compileShader(fragmentShaderSource, gl.FRAGMENT_SHADER) if err != nil { panic(err) } prog := gl.CreateProgram() gl.AttachShader(prog, vertexShader) gl.AttachShader(prog, fragmentShader) gl.LinkProgram(prog) return prog } // makeVao initializes and returns a vertex array from the points provided. func makeVao(points []float32) uint32 { var vbo uint32 gl.GenBuffers(1, &vbo) gl.BindBuffer(gl.ARRAY_BUFFER, vbo) gl.BufferData(gl.ARRAY_BUFFER, 4*len(points), gl.Ptr(points), gl.STATIC_DRAW) var vao uint32 gl.GenVertexArrays(1, &vao) gl.BindVertexArray(vao) gl.EnableVertexAttribArray(0) gl.BindBuffer(gl.ARRAY_BUFFER, vbo) gl.VertexAttribPointer(0, 3, gl.FLOAT, false, 0, nil) return vao } func compileShader(source string, shaderType uint32) (uint32, error) { shader := gl.CreateShader(shaderType) csources, free := gl.Strs(source) gl.ShaderSource(shader, 1, csources, nil) free() gl.CompileShader(shader) var status int32 gl.GetShaderiv(shader, gl.COMPILE_STATUS, &status) if status == gl.FALSE { var logLength int32 gl.GetShaderiv(shader, gl.INFO_LOG_LENGTH, &logLength) log := strings.Repeat("\x00", int(logLength+1)) gl.GetShaderInfoLog(shader, logLength, nil, gl.Str(log)) return 0, fmt.Errorf("failed to compile %v: %v", source, log) } return shader, nil }
[@kylewbanks](https://twitter.com/kylewbanks)or down below! |
8,934 | 关于 Linux 你可能不是非常了解的七件事 | http://opensourceforu.com/2017/09/top-7-things-linux-may-not-known-far/ | 2017-10-05T22:08:21 | [
"命令行"
] | https://linux.cn/article-8934-1.html | 
使用 Linux 最酷的事情之一就是随着时间的推移,你可以不断获得新的知识。每天,你都可能会遇到一个新的实用工具,或者只是一个不太熟悉的奇技淫巧,但是却非常有用。这些零碎的东西并不总是能够改变生活,但是却是专业知识的基础。
即使是专家,也不可能事事皆知。无论你有多少经验,可能总会有更多的东西需要你去学习。所以,在这儿我列出了七件关于 Linux 你可能不知道的事情。
### 一个查找命令历史的交互模式
你可能对 `history` 命令非常熟悉,它会读取 bash 历史,然后以编号列表的方式输出到标准输出(`stdout`)。然而,如果你在 `curl` 命令的海洋里寻找一个特定的链接(URL),那么这个列表并不总是那么容易阅读的。
你还可以有另一个选择,Linux 有一个交互式的反向搜索可以帮助你解决这个问题。你可以通过快捷键 `ctrl+r`启动交互模式,然后进入一个交互提示中,它将会根据你提供的字符串来向后搜索 bash 历史,你可以通过再次按下 `ctrl+r` 向后搜索更老的命令,或者按下 `ctrl+s` 向前搜索。
注意,`ctrl+s` 有时会与 XON/XOFF 流控制冲突,即 XON/XOFF 流控制也会使用该快捷键。你可以通过运行 `stty -ixon` 命令来禁用该快捷键。在你的个人电脑上,这通常是有用的,但是在禁用前,确保你不需要 XON/XOFF 。
### Cron 不是安排任务的唯一方式
Cron 任务对于任何水平的系统管理员,无论是毫无经验的初学者,还是经验丰富的专家来说,都是非常有用的。但是,如果你需要安排一个一次性的任务,那么 `at` 命令为你提供了一个快捷的方式来创建任务,从而你不需要接触 crontab 。
`at` 命令的运行方式是在后面紧跟着你想要运行任务的运行时间。时间是灵活的,因为它支持许多时间格式。包括下面这些例子:
```
at 12:00 PM September 30 2017
at now + 1 hour
at 9:00 AM tomorrow
```
当你以带参数的方式输入 `at` 命令以后,将会提示你该命令将在你的 Linux 系统上运行。这可能是一个备份脚本,一套维护任务,或者甚至是一个普通的 bash 命令。如果要结束任务,可以按 `ctrl+d` 。
另外,你可以使用 `atq` 命令查看当前用户的所有任务,或者使用 `sudo atq` 查看所有用户的任务。它将会展示出所有排定好的任务,并且每个任务都伴有一个 ID 。如果你想取消一个排定好的任务,可以使用 `atrm` 命令,并且以任务 ID 作为参数。
### 你可以按照功能搜索命令,而不仅仅是通过名字
记住命令的名字非常困难,特别是对于初学者来说。幸运的是,Linux 附带了一个通过名字和描述来搜索 man 页面的工具。
下次,如果你没有记住你想要使用的工具的名称,你可以尝试使用 `apropos` 命令加上你想要干的事情的描述。比如,`apropos build filesystem` 将会返回一系列名字和描述包括了 “build” 和 “filesystem” 单词的工具。
`apropos` 命令接受一个或多个字符串作为参数,但同时它也有其他参数,比如你可以使用 `-r` 参数,从而通过正则表达式来搜索。
### 一个允许你来管理系统版本的替代系统
如果你曾进行过软件开发,你就会明白跨项目管理不同版本的语言的支持的重要性。许多 Linux 发行版都有工具可以来处理不同的内建版本。
可执行文件比如 `java` 往往符号链接到目录 `/etc/alternatives` 下。反过来,该目录会将符号链接存储为二进制文件并提供一个管理这些链接的接口。Java 可能是替代系统最常管理的语言,但是,经过一些配置,它也可以作为其他应用程序替代品,比如 NVM 和 RVM (NVM 和 RVM 分别是 NodeJS 和 Ruby 的版本管理器)。
在基于 Debian 的系统中,你可以使用 `update-alternatives` 命令创建和管理这些链接。在 CentOS 中,这个工具就叫做 `alternatives` 。通过更改你的 alternatives 文件中的链接,你便可以安装一个语言的多个版本,并且在不同的情况下使用不同的二进制。这个替代系统也提供了对任何你可能在命令行运行的程序的支持。
### `shred` 命令是更加安全的删除文件方式
我们大多数时候总是使用 `rm` 命令来删除文件。但是文件去哪儿了呢?真相是 `rm` 命令所做的事情并不是像你所想像的那样,它仅仅删除了文件系统和硬盘上的数据的硬链接。硬盘上的数据依旧存在,直到被另一个应用重写覆盖。对于非常敏感的数据来说,这会带来一个很大的安全隐患。
`shred` 命令是 `rm` 命令的升级版。当你使用 `shred` 命令删除一个文件之后,文件中的数据会被多次随机覆写。甚至有一个选项可以在随机覆写之后对所有的数据进行清零。
如果你想安全的删除一个文件并且以零覆盖,那么可以使用下面的命令:
`shred -u -z [file name]`
同时,你也可以使用 `-n` 选项和一个数字作为参数,从而指定在随机覆盖数据的时候迭代多少次。
### 通过自动更正来避免输入很长的无效文件路径
有多少次,你输入一个文件的绝对路径,然而却看到“没有该文件或目录”的消息。任何人都会明白输入一个很长的字符串的痛苦。幸运的是,有一个很简单的解决办法。
内建的 `shopt` 命令允许你设置不同的选项来改变 shell 的行为。设置 `cdspell` 选项是避免输入文件路径时一个字母出错的头痛的一个简单方式。你可以通过运行 `shopt -s cdspell` 命令来启用该选项。启用该选项后,当你想要切换目录时,会自动更正为最匹配的目录。
Shell 选项是节省时间的一个好方法(更不用说减少麻烦),此外还有许许多多的其他选项。如果想查看你的系统中所有选项的完整列表,可以运行不带参数的 `shopt` 命令。需要注意的是,这是 bash 的特性,如果你运行 zsh 或者其他可供选择的 shell,可能无法使用。
### 通过子 shell 返回到当前目录
如果你曾经配置过一个比较复杂的系统,那么你可能会发现你需要频繁的更换目录,从而很难跟踪你所在的位置。如果在运行完一个命令后自动返回到当前位置,不是很好吗?
Linux 系统实际上提供了一个解决该问题的方法,并且非常简单。如果你想通过 `cd` 命令进入另一个目录完成一些任务,然后再返回当前工作目录,那么你可以将命令置于括号中。你可以在你的 Linux 系统上尝试下面这个命令。记住你当前的工作目录,然后运行:
```
(cd /etc && ls -a)
```
该命令会输出 `/etc` 目录的内容。现在,检查你的当前工作目录。它和执行该命令前的目录一样,而不是 `/etc` 目录。
它是如何工作的呢?运行一个括号中的命令会创建一个子 shell 或一个当前 shell 进程的复刻副本。该子 shell 可以访问所有的父变量,反之则不行。所以请记住,你是在运行一个非常复杂的单行命令。
在并行处理中经常使用子 shell ,但是在命令行中,它也能为你带来同样的力量,从而使你在浏览文件系统时更加容易。
---
作者简介:
Phil Zona 是 Linux Academy 的技术作家。他编写了 AWS、Microsoft Azure 和 Linux 系统管理的指南和教程。他同时也管理着 Cloud Assessments 博客,该博客旨在帮助个人通过技术实现他们的事业目标。
---
via: <http://opensourceforu.com/2017/09/top-7-things-linux-may-not-known-far/>
作者:[PHIL ZONA](http://opensourceforu.com/author/phil-zona/) 译者:[ucasFL](https://github.com/ucasFL) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
8,935 | 论 HTTP 性能,Go 与 .NET Core 一争雌雄 | https://hackernoon.com/go-vs-net-core-in-terms-of-http-performance-7535a61b67b8 | 2017-10-06T11:13:00 | [
"Golang",
".NET"
] | https://linux.cn/article-8935-1.html | 
朋友们,你们好!
近来,我听到了大量的关于新出的 .NET Core 和其性能的讨论,尤其在 Web 服务方面的讨论更甚。
因为是新出的,我不想立马就比较两个不同的东西,所以我耐心等待,想等发布更稳定的版本后再进行。
本周一(8 月 14 日),微软[发布 .NET Core 2.0 版本](https://blogs.msdn.microsoft.com/dotnet/2017/08/14/announcing-net-core-2-0/),因此,我准备开始。您们认为呢?
如前面所提的,我们会比较它们相同的东西,比如应用程序、预期响应及运行时的稳定性,所以我们不会把像对 JSON 或者 XML 的编码、解码这些烦多的事情加入比较游戏中来,仅仅只会使用简单的文本消息。为了公平起见,我们会分别使用 Go 和 .NET Core 的 [MVC 架构模式](https://en.wikipedia.org/wiki/Model%E2%80%93view%E2%80%93controller)。
### 参赛选手
[Go](https://golang.org/) (或称 Golang): 是一种[快速增长](http://www.tiobe.com/tiobe-index/)的开源编程语言,旨在构建出简单、快捷和稳定可靠的应用软件。
用于支持 Go 语言的 MVC web 框架并不多,还好我们找到了 Iris ,可胜任此工作。
[Iris](http://iris-go.com/): 支持 Go 语言的快速、简单和高效的微型 Web 框架。它为您的下一代网站、API 或分布式应用程序奠定了精美的表现方式和易于使用的基础。
[C#](https://en.wikipedia.org/wiki/C_Sharp_%28programming_language%29): 是一种通用的、面向对象的编程语言。其开发团队由 [Anders Hejlsberg](https://twitter.com/ahejlsberg) 领导。
[.NET Core](https://www.microsoft.com/net/): 跨平台,可以在极少时间内开发出高性能的应用程序。
可从 <https://golang.org/dl> 下载 Go ,从 <https://www.microsoft.com/net/core> 下载 .NET Core。
在下载和安装好这些软件后,还需要为 Go 安装 Iris。安装很简单,仅仅只需要打开终端,然后执行如下语句:
```
go get -u github.com/kataras/iris
```
### 基准
#### 硬件
* 处理器: Intel(R) Core(TM) i7–4710HQ CPU @ 2.50GHz 2.50GHz
* 内存: 8.00 GB
#### 软件
* 操作系统: 微软 Windows [10.0.15063 版本], 电源计划设置为“高性能”
* HTTP 基准工具: <https://github.com/codesenberg/bombardier>, 使用最新的 1.1 版本。
* .NET Core: <https://www.microsoft.com/net/core>, 使用最新的 2.0 版本。
* Iris: <https://github.com/kataras/iris>, 使用基于 [Go 1.8.3](https://golang.org/) 构建的最新 8.3 版本。
两个应用程序都通过请求路径 “api/values/{id}” 返回文本“值”。
##### .NET Core MVC

Logo 由 [Pablo Iglesias](https://github.com/campusMVP/dotnetCoreLogoPack) 设计。
可以使用 `dotnet new webapi` 命令创建项目,其 `webapi` 模板会为您生成代码,代码包含 `GET` 请求方法的 `返回“值”`。
源代码:
```
using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using System.Threading.Tasks;
using Microsoft.AspNetCore;
using Microsoft.AspNetCore.Hosting;
using Microsoft.Extensions.Configuration;
using Microsoft.Extensions.Logging;
namespace netcore_mvc
{
public class Program
{
public static void Main(string[] args)
{
BuildWebHost(args).Run();
}
public static IWebHost BuildWebHost(string[] args) =>
WebHost.CreateDefaultBuilder(args)
.UseStartup<Startup>()
.Build();
}
}
```
```
using System;
using System.Collections.Generic;
using System.Linq;
using System.Threading.Tasks;
using Microsoft.AspNetCore.Builder;
using Microsoft.AspNetCore.Hosting;
using Microsoft.Extensions.Configuration;
using Microsoft.Extensions.DependencyInjection;
using Microsoft.Extensions.Logging;
using Microsoft.Extensions.Options;
namespace netcore_mvc
{
public class Startup
{
public Startup(IConfiguration configuration)
{
Configuration = configuration;
}
public IConfiguration Configuration { get; }
// This method gets called by the runtime. Use this method to add services to the container.
public void ConfigureServices(IServiceCollection services)
{
services.AddMvcCore();
}
// This method gets called by the runtime. Use this method to configure the HTTP request pipeline.
public void Configure(IApplicationBuilder app, IHostingEnvironment env)
{
app.UseMvc();
}
}
}
```
```
using System;
using System.Collections.Generic;
using System.Linq;
using System.Threading.Tasks;
using Microsoft.AspNetCore.Mvc;
namespace netcore_mvc.Controllers
{
// ValuesController is the equivalent
// `ValuesController` of the Iris 8.3 mvc application.
[Route("api/[controller]")]
public class ValuesController : Controller
{
// Get handles "GET" requests to "api/values/{id}".
[HttpGet("{id}")]
public string Get(int id)
{
return "value";
}
// Put handles "PUT" requests to "api/values/{id}".
[HttpPut("{id}")]
public void Put(int id, [FromBody]string value)
{
}
// Delete handles "DELETE" requests to "api/values/{id}".
[HttpDelete("{id}")]
public void Delete(int id)
{
}
}
}
```
运行 .NET Core web 服务项目:
```
$ cd netcore-mvc
$ dotnet run -c Release
Hosting environment: Production
Content root path: C:\mygopath\src\github.com\kataras\iris\_benchmarks\netcore-mvc
Now listening on: http://localhost:5000
Application started. Press Ctrl+C to shut down.
```
运行和定位 HTTP 基准工具:
```
$ bombardier -c 125 -n 5000000 http://localhost:5000/api/values/5
Bombarding http://localhost:5000/api/values/5 with 5000000 requests using 125 connections
5000000 / 5000000 [=====================================================] 100.00% 2m3s
Done!
Statistics Avg Stdev Max
Reqs/sec 40226.03 8724.30 161919
Latency 3.09ms 1.40ms 169.12ms
HTTP codes:
1xx - 0, 2xx - 5000000, 3xx - 0, 4xx - 0, 5xx - 0
others - 0
Throughput: 8.91MB/s
```
##### Iris MVC

Logo 由 [Santosh Anand](https://github.com/santoshanand) 设计。
源代码:
```
package main
import (
"github.com/kataras/iris"
"github.com/kataras/iris/_benchmarks/iris-mvc/controllers"
)
func main() {
app := iris.New()
app.Controller("/api/values/{id}", new(controllers.ValuesController))
app.Run(iris.Addr(":5000"), iris.WithoutVersionChecker)
}
```
```
package controllers
import "github.com/kataras/iris/mvc"
// ValuesController is the equivalent
// `ValuesController` of the .net core 2.0 mvc application.
type ValuesController struct {
mvc.Controller
}
// Get handles "GET" requests to "api/values/{id}".
func (vc *ValuesController) Get() {
// id,_ := vc.Params.GetInt("id")
vc.Ctx.WriteString("value")
}
// Put handles "PUT" requests to "api/values/{id}".
func (vc *ValuesController) Put() {}
// Delete handles "DELETE" requests to "api/values/{id}".
func (vc *ValuesController) Delete() {}
```
运行 Go web 服务项目:
```
$ cd iris-mvc
$ go run main.go
Now listening on: http://localhost:5000
Application started. Press CTRL+C to shut down.
```
运行和定位 HTTP 基准工具:
```
$ bombardier -c 125 -n 5000000 http://localhost:5000/api/values/5
Bombarding http://localhost:5000/api/values/5 with 5000000 requests using 125 connections
5000000 / 5000000 [======================================================] 100.00% 47s
Done!
Statistics Avg Stdev Max
Reqs/sec 105643.81 7687.79 122564
Latency 1.18ms 366.55us 22.01ms
HTTP codes:
1xx - 0, 2xx - 5000000, 3xx - 0, 4xx - 0, 5xx - 0
others - 0
Throughput: 19.65MB/s
```
想通过图片来理解的人,我也把我的屏幕截屏出来了!
请点击[这儿](https://github.com/kataras/iris/tree/master/_benchmarks/screens)可以看到这些屏幕快照。
#### 总结
* 完成 `5000000 个请求`的时间 - 越短越好。
* 请求次数/每秒 - 越大越好。
* 等待时间 — 越短越好。
* 吞吐量 — 越大越好。
* 内存使用 — 越小越好。
* LOC (代码行数) — 越少越好。
.NET Core MVC 应用程序,使用 86 行代码,运行 2 分钟 8 秒,每秒接纳 39311.56 个请求,平均 3.19ms 等待,最大时到 229.73ms,内存使用大约为 126MB(不包括 dotnet 框架)。
Iris MVC 应用程序,使用 27 行代码,运行 47 秒,每秒接纳 105643.71 个请求,平均 1.18ms 等待,最大时到 22.01ms,内存使用大约为 12MB。
>
> 还有另外一个模板的基准,滚动到底部。
>
>
>
**2017 年 8 月 20 号更新**
[Josh Clark](https://twitter.com/clarkis117) 和 [Scott Hanselman](https://twitter.com/shanselman)在此 [tweet 评论](https://twitter.com/shanselman/status/899005786826788865)上指出,.NET Core `Startup.cs` 文件中 `services.AddMvc();` 这行可以替换为 `services.AddMvcCore();`。我听从他们的意见,修改代码,重新运行基准,该文章的 .NET Core 应用程序的基准输出已经修改。
@topdawgevh @shanselman 他们也在使用 `AddMvc()` 而不是 `AddMvcCore()` ...,难道都不包含中间件?
— @clarkis117
@clarkis117 @topdawgevh Cool @MakisMaropoulos @ben*a*adams @davidfowl 我们来看看。认真学习下怎么使用更简单的性能默认值。
— @shanselman
@shanselman @clarkis117 @topdawgevh @ben*a*adams @davidfowl @shanselman @ben*a*adams @davidfowl 谢谢您们的反馈意见。我已经修改,更新了结果,没什么不同。对其它的建议,我非常欢迎。
— @MakisMaropoulos
>
> 它有点稍微的不同但相差不大(从 8.61MB/s 到 8.91MB/s)
>
>
>
想要了解跟 `services.AddMvc()` 标准比较结果的,可以点击[这儿](https://github.com/kataras/iris/blob/master/_benchmarks/screens/5m_requests_netcore-mvc.png)。
### 想再多了解点儿吗?
我们再制定一个基准,产生 `1000000 次请求`,这次会通过视图引擎由模板生成 `HTML` 页面。
#### .NET Core MVC 使用的模板
```
using System;
namespace netcore_mvc_templates.Models
{
public class ErrorViewModel
{
public string Title { get; set; }
public int Code { get; set; }
}
}
```
```
using System;
using System.Collections.Generic;
using System.Diagnostics;
using System.Linq;
using System.Threading.Tasks;
using Microsoft.AspNetCore.Mvc;
using netcore_mvc_templates.Models;
namespace netcore_mvc_templates.Controllers
{
public class HomeController : Controller
{
public IActionResult Index()
{
return View();
}
public IActionResult About()
{
ViewData["Message"] = "Your application description page.";
return View();
}
public IActionResult Contact()
{
ViewData["Message"] = "Your contact page.";
return View();
}
public IActionResult Error()
{
return View(new ErrorViewModel { Title = "Error", Code = 500});
}
}
}
```
```
using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using System.Threading.Tasks;
using Microsoft.AspNetCore;
using Microsoft.AspNetCore.Hosting;
using Microsoft.Extensions.Configuration;
using Microsoft.Extensions.Logging;
namespace netcore_mvc_templates
{
public class Program
{
public static void Main(string[] args)
{
BuildWebHost(args).Run();
}
public static IWebHost BuildWebHost(string[] args) =>
WebHost.CreateDefaultBuilder(args)
.UseStartup<Startup>()
.Build();
}
}
```
```
using System;
using System.Collections.Generic;
using System.Linq;
using System.Threading.Tasks;
using Microsoft.AspNetCore.Builder;
using Microsoft.AspNetCore.Hosting;
using Microsoft.Extensions.Configuration;
using Microsoft.Extensions.DependencyInjection;
namespace netcore_mvc_templates
{
public class Startup
{
public Startup(IConfiguration configuration)
{
Configuration = configuration;
}
public IConfiguration Configuration { get; }
// This method gets called by the runtime. Use this method to add services to the container.
public void ConfigureServices(IServiceCollection services)
{
/* An unhandled exception was thrown by the application.
System.InvalidOperationException: No service for type
'Microsoft.AspNetCore.Mvc.ViewFeatures.ITempDataDictionaryFactory' has been registered.
Solution: Use AddMvc() instead of AddMvcCore() in Startup.cs and it will work.
*/
// services.AddMvcCore();
services.AddMvc();
}
// This method gets called by the runtime. Use this method to configure the HTTP request pipeline.
public void Configure(IApplicationBuilder app, IHostingEnvironment env)
{
app.UseStaticFiles();
app.UseMvc(routes =>
{
routes.MapRoute(
name: "default",
template: "{controller=Home}/{action=Index}/{id?}");
});
}
}
}
```
```
/*
wwwroot/css
wwwroot/images
wwwroot/js
wwwroot/lib
wwwroot/favicon.ico
Views/Shared/_Layout.cshtml
Views/Shared/Error.cshtml
Views/Home/About.cshtml
Views/Home/Contact.cshtml
Views/Home/Index.cshtml
These files are quite long to be shown in this article but you can view them at:
https://github.com/kataras/iris/tree/master/_benchmarks/netcore-mvc-templates
```
运行 .NET Core 服务项目:
```
$ cd netcore-mvc-templates
$ dotnet run -c Release
Hosting environment: Production
Content root path: C:\mygopath\src\github.com\kataras\iris\_benchmarks\netcore-mvc-templates
Now listening on: http://localhost:5000
Application started. Press Ctrl+C to shut down.
```
运行 HTTP 基准工具:
```
Bombarding http://localhost:5000 with 1000000 requests using 125 connections
1000000 / 1000000 [====================================================] 100.00% 1m20s
Done!
Statistics Avg Stdev Max
Reqs/sec 11738.60 7741.36 125887
Latency 10.10ms 22.10ms 1.97s
HTTP codes:
1xx — 0, 2xx — 1000000, 3xx — 0, 4xx — 0, 5xx — 0
others — 0
Throughput: 89.03MB/s
```
#### Iris MVC 使用的模板
```
package controllers
import "github.com/kataras/iris/mvc"
type AboutController struct{ mvc.Controller }
func (c *AboutController) Get() {
c.Data["Title"] = "About"
c.Data["Message"] = "Your application description page."
c.Tmpl = "about.html"
}
```
```
package controllers
import "github.com/kataras/iris/mvc"
type ContactController struct{ mvc.Controller }
func (c *ContactController) Get() {
c.Data["Title"] = "Contact"
c.Data["Message"] = "Your contact page."
c.Tmpl = "contact.html"
}
```
```
package models
// HTTPError a silly structure to keep our error page data.
type HTTPError struct {
Title string
Code int
}
```
```
package controllers
import "github.com/kataras/iris/mvc"
type IndexController struct{ mvc.Controller }
func (c *IndexController) Get() {
c.Data["Title"] = "Home Page"
c.Tmpl = "index.html"
}
```
```
package main
import (
"github.com/kataras/iris/_benchmarks/iris-mvc-templates/controllers"
"github.com/kataras/iris"
"github.com/kataras/iris/context"
)
const (
// templatesDir is the exactly the same path that .NET Core is using for its templates,
// in order to reduce the size in the repository.
// Change the "C\\mygopath" to your own GOPATH.
templatesDir = "C:\\mygopath\\src\\github.com\\kataras\\iris\\_benchmarks\\netcore-mvc-templates\\wwwroot"
)
func main() {
app := iris.New()
app.Configure(configure)
app.Controller("/", new(controllers.IndexController))
app.Controller("/about", new(controllers.AboutController))
app.Controller("/contact", new(controllers.ContactController))
app.Run(iris.Addr(":5000"), iris.WithoutVersionChecker)
}
func configure(app *iris.Application) {
app.RegisterView(iris.HTML("./views", ".html").Layout("shared/layout.html"))
app.StaticWeb("/public", templatesDir)
app.OnAnyErrorCode(onError)
}
type err struct {
Title string
Code int
}
func onError(ctx context.Context) {
ctx.ViewData("", err{"Error", ctx.GetStatusCode()})
ctx.View("shared/error.html")
}
```
```
/*
../netcore-mvc-templates/wwwroot/css
../netcore-mvc-templates/wwwroot/images
../netcore-mvc-templates/wwwroot/js
../netcore-mvc-templates/wwwroot/lib
../netcore-mvc-templates/wwwroot/favicon.ico
views/shared/layout.html
views/shared/error.html
views/about.html
views/contact.html
views/index.html
These files are quite long to be shown in this article but you can view them at:
https://github.com/kataras/iris/tree/master/_benchmarks/iris-mvc-templates
*/
```
运行 Go 服务项目:
```
$ cd iris-mvc-templates
$ go run main.go
Now listening on: http://localhost:5000
Application started. Press CTRL+C to shut down.
```
运行 HTTP 基准工具:
```
Bombarding http://localhost:5000 with 1000000 requests using 125 connections
1000000 / 1000000 [======================================================] 100.00% 37s
Done!
Statistics Avg Stdev Max
Reqs/sec 26656.76 1944.73 31188
Latency 4.69ms 1.20ms 22.52ms
HTTP codes:
1xx — 0, 2xx — 1000000, 3xx — 0, 4xx — 0, 5xx — 0
others — 0
Throughput: 192.51MB/s
```
#### 总结
* 完成 `1000000 个请求`的时间 - 越短越好。
* 请求次数/每秒 - 越大越好。
* 等待时间 — 越短越好。
* 内存使用 — 越小越好。
* 吞吐量 — 越大越好。
.NET Core MVC 模板应用程序,运行 1 分钟 20 秒,每秒接纳 11738.60 个请求,同时每秒生成 89.03M 页面,平均 10.10ms 等待,最大时到 1.97s,内存使用大约为 193MB(不包括 dotnet 框架)。
Iris MVC 模板应用程序,运行 37 秒,每秒接纳 26656.76 个请求,同时每秒生成 192.51M 页面,平均 1.18ms 等待,最大时到 22.52ms,内存使用大约为 17MB。
### 接下来呢?
[这里](https://github.com/kataras/iris/tree/master/_benchmarks)有上面所示的源代码,请下载下来,在您本地以同样的基准运行,然后把运行结果在这儿给大家分享。
想添加 Go 或 C# .net core WEB 服务框架到列表的朋友请向[这个仓库](https://github.com/kataras/iris)的 `_benchmarks` 目录推送 PR。
我也需要亲自感谢下 [dev.to](https://dev.to/kataras/go-vsnet-core-in-terms-of-http-performance) 团队,感谢把我的这篇文章分享到他们的 Twitter 账户。
感谢大家真心反馈,玩得开心!
#### 更新 : 2017 年 8 月 21 ,周一
很多人联系我,希望看到一个基于 .NET Core 的较低级别 Kestrel 的基准测试文章。
因此我完成了,请点击下面的[链接](https://medium.com/@kataras/iris-go-vs-net-core-kestrel-in-terms-of-http-performance-806195dc93d5)来了解 Kestrel 和 Iris 之间的性能差异,它还包含一个会话存储管理基准!
---
via: <https://hackernoon.com/go-vs-net-core-in-terms-of-http-performance-7535a61b67b8>
作者:[Gerasimos Maropoulos](https://hackernoon.com/@kataras?source=post_header_lockup) 译者:[runningwater](https://github.com/runningwater) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 
Hello Friends!
Lately I’ve heard a lot of discussion around the new .NET Core and its performance especially on web servers.
I didn’t want to start comparing two different things, so I did patience for quite long for a more stable version.
This Monday, Microsoft [announced the .NET Core version 2.0](https://blogs.msdn.microsoft.com/dotnet/2017/08/14/announcing-net-core-2-0/?ref=hackernoon.com), so I feel ready to do it! Do you?
As we already mentioned, we will compare two identical things here, in terms of application, the expected response and the stability of their run times, so we will not try to put more things in the game like `JSON`
or `XML`
encoders and decoders, just a simple text message. To achieve a fair comparison we will use the [MVC architecture pattern](https://en.wikipedia.org/wiki/Model%E2%80%93view%E2%80%93controller?ref=hackernoon.com) on both sides, Go and .NET Core.
[Go](https://golang.org/?ref=hackernoon.com) (or Golang): is a [rapidly growing](http://www.tiobe.com/tiobe-index/?ref=hackernoon.com) open source programming language designed for building simple, fast, and reliable software.
There are not lot of web frameworks for Go with MVC support but, luckily for us Iris does the job.
[Iris](http://iris-go.com/?ref=hackernoon.com): A fast, simple and efficient micro web framework for Go. It provides a beautifully expressive and easy to use foundation for your next website, API, or distributed app.
[C#](https://en.wikipedia.org/wiki/C_Sharp_%28programming_language%29?ref=hackernoon.com): is a general-purpose, object-oriented programming language. Its development team is led by [Anders Hejlsberg](https://twitter.com/ahejlsberg?ref=hackernoon.com).
[.NET Core](https://www.microsoft.com/net/?ref=hackernoon.com): Develop high performance applications in less time, on any platform.
Download Go from [https://golang.org/dl](https://golang.org/dl?ref=hackernoon.com) and .NET Core from [https://www.microsoft.com/net/core](https://www.microsoft.com/net/core?ref=hackernoon.com).
After you’ve download and install these, you will need Iris from Go’s side. Installation is very easy, just open your terminal and execute:
go get -u github.com/kataras/iris
Both of the applications will just return the text “value” on request path “api/values/{id}”.
**.NET Core MVC**
*Logo designed by* *Pablo Iglesias**.*
Created using `dotnet new webapi`
. That `webapi`
template will generate the code for you, including the `return “value”`
on `GET`
method requests.
*Source Code*
*Start the .NET Core web server*
$ cd netcore-mvc$ dotnet run -c ReleaseHosting environment: ProductionContent root path: C:\mygopath\src\github.com\kataras\iris\_benchmarks\netcore-mvcNow listening on: [http://localhost:5000](http://localhost:5000/?ref=hackernoon.com)Application started. Press Ctrl+C to shut down.
*Target and run the HTTP benchmark tool*
$ bombardier -c 125 -n 5000000 [http://localhost:5000/api/values/5](http://localhost:5000/api/values/5?ref=hackernoon.com)Bombarding [http://localhost:5000/api/values/5](http://localhost:5000/api/values/5?ref=hackernoon.com) with 5000000 requests using 125 connections5000000 / 5000000 [=====================================================] 100.00% 2m3sDone!Statistics Avg Stdev MaxReqs/sec 40226.03 8724.30 161919Latency 3.09ms 1.40ms 169.12msHTTP codes:1xx - 0, 2xx - 5000000, 3xx - 0, 4xx - 0, 5xx - 0others - 0Throughput: 8.91MB/s
**Iris MVC**
Logo designed by [Santosh Anand](https://github.com/santoshanand?ref=hackernoon.com).
*Source Code*
*Start the Go web server*
$ cd iris-mvc$ go run main.goNow listening on: [http://localhost:5000](http://localhost:5000/?ref=hackernoon.com)Application started. Press CTRL+C to shut down.
*Target and run the HTTP benchmark tool*
$ bombardier -c 125 -n 5000000 [http://localhost:5000/api/values/5](http://localhost:5000/api/values/5?ref=hackernoon.com)Bombarding [http://localhost:5000/api/values/5](http://localhost:5000/api/values/5?ref=hackernoon.com) with 5000000 requests using 125 connections5000000 / 5000000 [======================================================] 100.00% 47sDone!Statistics Avg Stdev MaxReqs/sec 105643.81 7687.79 122564Latency 1.18ms 366.55us 22.01msHTTP codes:1xx - 0, 2xx - 5000000, 3xx - 0, 4xx - 0, 5xx - 0others - 0Throughput: 19.65MB/s
For those who understand better by images, I did print my screen too!
Click [here](https://github.com/kataras/iris/tree/master/_benchmarks/screens?ref=hackernoon.com) to see these screenshots.
`5000000 requests`
- smaller is better..NET Core MVC Application, written using 86 lines of code, ran for **2 minutes and 8 seconds** serving **39311.56** requests per second within **3.19ms** latency in average and **229.73ms max**, the memory usage of all these was ~126MB (without the dotnet host).
Iris MVC Application, written using 27 lines of code, ran for **47 seconds** serving **105643.71** requests per second within **1.18ms** latency in average and **22.01ms max**, the memory usage of all these was ~12MB.
There is also another benchmark with templates, scroll to the bottom.
**Update 20 August 2017**
As [Josh Clark](https://twitter.com/clarkis117?ref=hackernoon.com) and [Scott Hanselman](https://twitter.com/shanselman?ref=hackernoon.com) pointed out on this [re-twee](https://twitter.com/shanselman/status/899005786826788865?ref=hackernoon.com)t , on .NET Core `Startup.cs`
file the line with `services.AddMvc();`
can be replaced with `services.AddMvcCore();`
. I followed their helpful instructions and re-run the benchmarks. The article now contains the latest benchmark output for the .NET Core application with the change both Josh and Scott noted.
It had a small difference but not as huge (8.91MB/s from 8.61MB/s)
For those who want to compare with the standard `services.AddMvc();`
you can see the old output by pressing [here](https://github.com/kataras/iris/blob/master/_benchmarks/screens/5m_requests_netcore-mvc.png?ref=hackernoon.com).
Let’s run one more benchmark, spawn `1000000 requests`
but this time we expect `HTML`
generated by templates via the view engine.
*Start the .NET Core web server*
$ cd netcore-mvc-templates$ dotnet run -c ReleaseHosting environment: ProductionContent root path: C:\mygopath\src\github.com\kataras\iris\_benchmarks\netcore-mvc-templatesNow listening on: [http://localhost:5000](http://localhost:5000/?ref=hackernoon.com)Application started. Press Ctrl+C to shut down.
*Target and run the HTTP benchmark tool*
Bombarding [http://localhost:5000](http://localhost:5000/?ref=hackernoon.com) with 1000000 requests using 125 connections1000000 / 1000000 [====================================================] 100.00% 1m20sDone!Statistics Avg Stdev MaxReqs/sec 11738.60 7741.36 125887Latency 10.10ms 22.10ms 1.97sHTTP codes:1xx — 0, 2xx — 1000000, 3xx — 0, 4xx — 0, 5xx — 0others — 0Throughput: 89.03MB/s
*Start the Go web server*
$ cd iris-mvc-templates$ go run main.goNow listening on: [http://localhost:5000](http://localhost:5000/?ref=hackernoon.com)Application started. Press CTRL+C to shut down.
*Target and run the HTTP benchmark tool*
Bombarding [http://localhost:5000](http://localhost:5000/?ref=hackernoon.com) with 1000000 requests using 125 connections1000000 / 1000000 [======================================================] 100.00% 37sDone!Statistics Avg Stdev MaxReqs/sec 26656.76 1944.73 31188Latency 4.69ms 1.20ms 22.52msHTTP codes:1xx — 0, 2xx — 1000000, 3xx — 0, 4xx — 0, 5xx — 0others — 0Throughput: 192.51MB/s
**Summary**
`1000000 requests`
— smaller is better..NET Core MVC with Templates Application ran for **1 minute and 20 seconds** serving **11738.60** requests per second with **89.03MB/s** within **10.10ms** latency in average and **1.97s** max, the memory usage of all these was ~193MB (without the dotnet host).
Iris MVC with Templates Application ran for **37 seconds** serving **26656.76** requests per second with **192.51MB/s** within **1.18ms** latency in average and **22.52ms** max, the memory usage of all these was ~17MB.
Download the example source code from [there](https://github.com/kataras/iris/tree/master/_benchmarks?ref=hackernoon.com) and run the same benchmarks from your machine, then come back here and share your results with the rest of us!
For those who want to add other go or c# .net core web frameworks to the list please push a PR to the `_benchmarks`
folder inside [this repository](https://github.com/kataras/iris?ref=hackernoon.com).
I need to personally thanks the [dev.to](https://dev.to/kataras/go-vsnet-core-in-terms-of-http-performance?ref=hackernoon.com) team for sharing my article at their twitter account, as well.
**Thank you** all for the 100% green feedback, have fun!
A lot of people reached me saying that want to see a new benchmarking article based on the .NET Core’s lower level **Kestrel** this time.
So I did, follow the below link to learn the performance difference between Kestrel and Iris, it contains a sessions storage management benchmark too!
**Iris Go vs .NET Core Kestrel in terms of HTTP performance**_A Fair benchmark between Iris Golang and Kestrel .NET Core (C#)._hackernoon.com
I like the visual effects when **I click the clap button more than once**, do you? It’s simple: just click the clap button. If you feel strongly, click it more **(or just hold it** **down).** |
8,936 | 开发一个 Linux 调试器(九):处理变量 | https://blog.tartanllama.xyz/writing-a-linux-debugger-variables/ | 2017-10-06T18:10:00 | [
"调试",
"调试器"
] | https://linux.cn/article-8936-1.html | 
变量是偷偷摸摸的。有时,它们会很高兴地呆在寄存器中,但是一转头就会跑到堆栈中。为了优化,编译器可能会完全将它们从窗口中抛出。无论变量在内存中的如何移动,我们都需要一些方法在调试器中跟踪和操作它们。这篇文章将会教你如何处理调试器中的变量,并使用 `libelfin` 演示一个简单的实现。
### 系列文章索引
1. [准备环境](/article-8626-1.html)
2. [断点](/article-8645-1.html)
3. [寄存器和内存](/article-8663-1.html)
4. [ELF 和 DWARF](/article-8719-1.html)
5. [源码和信号](/article-8812-1.html)
6. [源码级逐步执行](/article-8813-1.html)
7. [源码级断点](/article-8890-1.html)
8. [堆栈展开](/article-8930-1.html)
9. [处理变量](https://blog.tartanllama.xyz/writing-a-linux-debugger-variables/)
10. [高级话题](https://blog.tartanllama.xyz/writing-a-linux-debugger-advanced-topics/)
在开始之前,请确保你使用的 `libelfin` 版本是[我分支上的 `fbreg`](https://github.com/TartanLlama/libelfin/tree/fbreg)。这包含了一些 hack 来支持获取当前堆栈帧的基址并评估位置列表,这些都不是由原生的 `libelfin` 提供的。你可能需要给 GCC 传递 `-gdwarf-2` 参数使其生成兼容的 DWARF 信息。但是在实现之前,我将详细说明 DWARF 5 最新规范中的位置编码方式。如果你想要了解更多信息,那么你可以从[这里](http://dwarfstd.org/)获取该标准。
### DWARF 位置
某一给定时刻的内存中变量的位置使用 `DW_AT_location` 属性编码在 DWARF 信息中。位置描述可以是单个位置描述、复合位置描述或位置列表。
* 简单位置描述:描述了对象的一个连续的部分(通常是所有部分)的位置。简单位置描述可以描述可寻址存储器或寄存器中的位置,或缺少位置(具有或不具有已知值)。比如,`DW_OP_fbreg -32`: 一个整个存储的变量 - 从堆栈帧基址开始的32个字节。
* 复合位置描述:根据片段描述对象,每个对象可以包含在寄存器的一部分中或存储在与其他片段无关的存储器位置中。比如, `DW_OP_reg3 DW_OP_piece 4 DW_OP_reg10 DW_OP_piece 2`:前四个字节位于寄存器 3 中,后两个字节位于寄存器 10 中的一个变量。
* 位置列表:描述了具有有限生存期或在生存期内更改位置的对象。比如:
+ `<loclist with 3 entries follows>`
- `[ 0]<lowpc=0x2e00><highpc=0x2e19>DW_OP_reg0`
- `[ 1]<lowpc=0x2e19><highpc=0x2e3f>DW_OP_reg3`
- `[ 2]<lowpc=0x2ec4><highpc=0x2ec7>DW_OP_reg2`
+ 根据程序计数器的当前值,位置在寄存器之间移动的变量。
根据位置描述的种类,`DW_AT_location` 以三种不同的方式进行编码。`exprloc` 编码简单和复合的位置描述。它们由一个字节长度组成,后跟一个 DWARF 表达式或位置描述。`loclist` 和 `loclistptr` 的编码位置列表,它们在 `.debug_loclists` 部分中提供索引或偏移量,该部分描述了实际的位置列表。
### DWARF 表达式
使用 DWARF 表达式计算变量的实际位置。这包括操作堆栈值的一系列操作。有很多 DWARF 操作可用,所以我不会详细解释它们。相反,我会从每一个表达式中给出一些例子,给你一个可用的东西。另外,不要害怕这些;`libelfin` 将为我们处理所有这些复杂性。
* 字面编码
+ `DW_OP_lit0`、`DW_OP_lit1`……`DW_OP_lit31`
- 将字面量压入堆栈
+ `DW_OP_addr <addr>`
- 将地址操作数压入堆栈
+ `DW_OP_constu <unsigned>`
- 将无符号值压入堆栈
* 寄存器值
+ `DW_OP_fbreg <offset>`
- 压入在堆栈帧基址找到的值,偏移给定值
+ `DW_OP_breg0`、`DW_OP_breg1`…… `DW_OP_breg31 <offset>`
- 将给定寄存器的内容加上给定的偏移量压入堆栈
* 堆栈操作
+ `DW_OP_dup`
- 复制堆栈顶部的值
+ `DW_OP_deref`
- 将堆栈顶部视为内存地址,并将其替换为该地址的内容
* 算术和逻辑运算
+ `DW_OP_and`
- 弹出堆栈顶部的两个值,并压回它们的逻辑 `AND`
+ `DW_OP_plus`
- 与 `DW_OP_and` 相同,但是会添加值
* 控制流操作
+ `DW_OP_le`、`DW_OP_eq`、`DW_OP_gt` 等
- 弹出前两个值,比较它们,并且如果条件为真,则压入 `1`,否则为 `0`
+ `DW_OP_bra <offset>`
- 条件分支:如果堆栈的顶部不是 `0`,则通过 `offset` 在表达式中向后或向后跳过
* 输入转化
+ `DW_OP_convert <DIE offset>`
- 将堆栈顶部的值转换为不同的类型,它由给定偏移量的 DWARF 信息条目描述
* 特殊操作
+ `DW_OP_nop`
- 什么都不做!
### DWARF 类型
DWARF 类型的表示需要足够强大来为调试器用户提供有用的变量表示。用户经常希望能够在应用程序级别进行调试,而不是在机器级别进行调试,并且他们需要了解他们的变量正在做什么。
DWARF 类型与大多数其他调试信息一起编码在 DIE 中。它们可以具有指示其名称、编码、大小、字节等的属性。无数的类型标签可用于表示指针、数组、结构体、typedef 以及 C 或 C++ 程序中可以看到的任何其他内容。
以这个简单的结构体为例:
```
struct test{
int i;
float j;
int k[42];
test* next;
};
```
这个结构体的父 DIE 是这样的:
```
< 1><0x0000002a> DW_TAG_structure_type
DW_AT_name "test"
DW_AT_byte_size 0x000000b8
DW_AT_decl_file 0x00000001 test.cpp
DW_AT_decl_line 0x00000001
```
上面说的是我们有一个叫做 `test` 的结构体,大小为 `0xb8`,在 `test.cpp` 的第 `1` 行声明。接下来有许多描述成员的子 DIE。
```
< 2><0x00000032> DW_TAG_member
DW_AT_name "i"
DW_AT_type <0x00000063>
DW_AT_decl_file 0x00000001 test.cpp
DW_AT_decl_line 0x00000002
DW_AT_data_member_location 0
< 2><0x0000003e> DW_TAG_member
DW_AT_name "j"
DW_AT_type <0x0000006a>
DW_AT_decl_file 0x00000001 test.cpp
DW_AT_decl_line 0x00000003
DW_AT_data_member_location 4
< 2><0x0000004a> DW_TAG_member
DW_AT_name "k"
DW_AT_type <0x00000071>
DW_AT_decl_file 0x00000001 test.cpp
DW_AT_decl_line 0x00000004
DW_AT_data_member_location 8
< 2><0x00000056> DW_TAG_member
DW_AT_name "next"
DW_AT_type <0x00000084>
DW_AT_decl_file 0x00000001 test.cpp
DW_AT_decl_line 0x00000005
DW_AT_data_member_location 176(as signed = -80)
```
每个成员都有一个名称、一个类型(它是一个 DIE 偏移量)、一个声明文件和行,以及一个指向其成员所在的结构体的字节偏移。其类型指向如下。
```
< 1><0x00000063> DW_TAG_base_type
DW_AT_name "int"
DW_AT_encoding DW_ATE_signed
DW_AT_byte_size 0x00000004
< 1><0x0000006a> DW_TAG_base_type
DW_AT_name "float"
DW_AT_encoding DW_ATE_float
DW_AT_byte_size 0x00000004
< 1><0x00000071> DW_TAG_array_type
DW_AT_type <0x00000063>
< 2><0x00000076> DW_TAG_subrange_type
DW_AT_type <0x0000007d>
DW_AT_count 0x0000002a
< 1><0x0000007d> DW_TAG_base_type
DW_AT_name "sizetype"
DW_AT_byte_size 0x00000008
DW_AT_encoding DW_ATE_unsigned
< 1><0x00000084> DW_TAG_pointer_type
DW_AT_type <0x0000002a>
```
如你所见,我笔记本电脑上的 `int` 是一个 4 字节的有符号整数类型,`float`是一个 4 字节的浮点数。整数数组类型通过指向 `int` 类型作为其元素类型,`sizetype`(可以认为是 `size_t`)作为索引类型,它具有 `2a` 个元素。 `test *` 类型是 `DW_TAG_pointer_type`,它引用 `test` DIE。
### 实现简单的变量读取器
如上所述,`libelfin` 将为我们处理大部分复杂性。但是,它并没有实现用于表示可变位置的所有方法,并且在我们的代码中处理这些将变得非常复杂。因此,我现在选择只支持 `exprloc`。请根据需要添加对更多类型表达式的支持。如果你真的有勇气,请提交补丁到 `libelfin` 中来帮助完成必要的支持!
处理变量主要是将不同部分定位在存储器或寄存器中,读取或写入与之前一样。为了简单起见,我只会告诉你如何实现读取。
首先我们需要告诉 `libelfin` 如何从我们的进程中读取寄存器。我们创建一个继承自 `expr_context` 的类并使用 `ptrace` 来处理所有内容:
```
class ptrace_expr_context : public dwarf::expr_context {
public:
ptrace_expr_context (pid_t pid) : m_pid{pid} {}
dwarf::taddr reg (unsigned regnum) override {
return get_register_value_from_dwarf_register(m_pid, regnum);
}
dwarf::taddr pc() override {
struct user_regs_struct regs;
ptrace(PTRACE_GETREGS, m_pid, nullptr, ®s);
return regs.rip;
}
dwarf::taddr deref_size (dwarf::taddr address, unsigned size) override {
//TODO take into account size
return ptrace(PTRACE_PEEKDATA, m_pid, address, nullptr);
}
private:
pid_t m_pid;
};
```
读取将由我们 `debugger` 类中的 `read_variables` 函数处理:
```
void debugger::read_variables() {
using namespace dwarf;
auto func = get_function_from_pc(get_pc());
//...
}
```
我们上面做的第一件事是找到我们目前进入的函数,然后我们需要循环访问该函数中的条目来寻找变量:
```
for (const auto& die : func) {
if (die.tag == DW_TAG::variable) {
//...
}
}
```
我们通过查找 DIE 中的 `DW_AT_location` 条目获取位置信息:
```
auto loc_val = die[DW_AT::location];
```
接着我们确保它是一个 `exprloc`,并请求 `libelfin` 来评估我们的表达式:
```
if (loc_val.get_type() == value::type::exprloc) {
ptrace_expr_context context {m_pid};
auto result = loc_val.as_exprloc().evaluate(&context);
```
现在我们已经评估了表达式,我们需要读取变量的内容。它可以在内存或寄存器中,因此我们将处理这两种情况:
```
switch (result.location_type) {
case expr_result::type::address:
{
auto value = read_memory(result.value);
std::cout << at_name(die) << " (0x" << std::hex << result.value << ") = "
<< value << std::endl;
break;
}
case expr_result::type::reg:
{
auto value = get_register_value_from_dwarf_register(m_pid, result.value);
std::cout << at_name(die) << " (reg " << result.value << ") = "
<< value << std::endl;
break;
}
default:
throw std::runtime_error{"Unhandled variable location"};
}
```
你可以看到,我根据变量的类型,打印输出了值而没有解释。希望通过这个代码,你可以看到如何支持编写变量,或者用给定的名字搜索变量。
最后我们可以将它添加到我们的命令解析器中:
```
else if(is_prefix(command, "variables")) {
read_variables();
}
```
### 测试一下
编写一些具有一些变量的小功能,不用优化并带有调试信息编译它,然后查看是否可以读取变量的值。尝试写入存储变量的内存地址,并查看程序改变的行为。
已经有九篇文章了,还剩最后一篇!下一次我会讨论一些你可能会感兴趣的更高级的概念。现在你可以在[这里](https://github.com/TartanLlama/minidbg/tree/tut_variable)找到这个帖子的代码。
---
via: <https://blog.tartanllama.xyz/writing-a-linux-debugger-variables/>
作者:[Simon Brand](https://www.twitter.com/TartanLlama) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Writing a Linux Debugger Part 9: Handling variables
*This series has been expanded into a book! It covers many more topics in much greater detail. You can now pre-order Building a Debugger.*
Variables are sneaky. At one moment they’ll be happily sitting in registers, but as soon as you turn your head they’re spilled to the stack. Maybe the compiler completely throws them out of the window for the sake of optimization. Regardless of how often variables move around in memory, we need some way to track and manipulate them in our debugger. This post will teach you more about handling variables in your debugger and demonstrate a simplified implementation using `libelfin`
.
### Series index
[Setup](/writing-a-linux-debugger-setup/)[Breakpoints](/writing-a-linux-debugger-breakpoints/)[Registers and memory](/writing-a-linux-debugger-registers/)[Elves and dwarves](/writing-a-linux-debugger-elf-dwarf/)[Source and signals](/writing-a-linux-debugger-source-signal/)[Source-level stepping](/writing-a-linux-debugger-dwarf-step/)[Source-level breakpoints](/writing-a-linux-debugger-source-break/)[Stack unwinding](/writing-a-linux-debugger-unwinding/)[Handling variables](/writing-a-linux-debugger-variables/)[Advanced topics](/writing-a-linux-debugger-advanced-topics/)
Before you get started, make sure that the version of `libelfin`
you are using is the [ fbreg branch of my fork](https://github.com/TartanLlama/libelfin/tree/fbreg). This contains some hacks to support getting the base of the current stack frame and evaluating location lists, neither of which are supported by vanilla
`libelfin`
. You might need to pass `-gdwarf-2`
to GCC to get it to generate compatible DWARF information. But before we get into the implementation, I’ll give a more detailed description of how locations are encoded in DWARF 5, which is the most recent specification. If you want more information than what I write here, then you can grab the standard from [here](http://dwarfstd.org/).
### DWARF locations
The location of a variable in memory at a given moment is encoded in the DWARF information using the `DW_AT_location`
attribute. Location descriptions can be either single location descriptions, composite location descriptions, or location lists.
- Simple location descriptions describe the location of one contiguous piece (usually all) of an object. A simple location description may describe a location in addressable memory, or in a register, or the lack of a location (with or without a known value).
- Example:
`DW_OP_fbreg -32`
- A variable which is entirely stored -32 bytes from the stack frame base
- Example:
- Composite location descriptions describe an object in terms of pieces, each of which may be contained in part of a register or stored in a memory location unrelated to other pieces.
- Example:
`DW_OP_reg3 DW_OP_piece 4 DW_OP_reg10 DW_OP_piece 2`
- A variable whose first four bytes reside in register 3 and whose next two bytes reside in register 10.
- Example:
- Location lists describe objects which have a limited lifetime or change location during their lifetime.
- Example:
`<loclist with 3 entries follows>`
`[ 0]<lowpc=0x2e00><highpc=0x2e19>DW_OP_reg0`
`[ 1]<lowpc=0x2e19><highpc=0x2e3f>DW_OP_reg3`
`[ 2]<lowpc=0x2ec4><highpc=0x2ec7>DW_OP_reg2`
- A variable whose location moves between registers depending on the current value of the program counter
- Example:
The `DW_AT_location`
is encoded in one of three different ways, depending on the kind of location description. `exprloc`
s encode simple and composite location descriptions. They consist of a byte length followed by a DWARF expression or location description. `loclist`
s and `loclistptr`
s encode location lists. They give indexes or offsets into the `.debug_loclists`
section, which describes the actual location lists.
### DWARF Expressions
The actual location of the variables is computed using DWARF expressions. These consist of a series of operations which operate on a stack of values. There are an impressive number of DWARF operations available, so I won’t explain them all in detail. Instead I’ll give a few examples from each class of expression to give you a taste of what is available. Also, don’t get scared off by these; `libelfin`
will take care off all of this complexity for us.
- Literal encodings
`DW_OP_lit0`
,`DW_OP_lit1`
, …,`DW_OP_lit31`
- Push the literal value on to the stack
`DW_OP_addr <addr>`
- Pushes the address operand on to the stack
`DW_OP_constu <unsigned>`
- Pushes the unsigned value on to the stack
- Register values
`DW_OP_fbreg <offset>`
- Pushes the value found at the base of the stack frame, offset by the given value
`DW_OP_breg0`
,`DW_OP_breg1`
, …,`DW_OP_breg31 <offset>`
- Pushes the contents of the given register plus the given offset to the stack
- Stack operations
`DW_OP_dup`
- Duplicate the value at the top of the stack
`DW_OP_deref`
- Treats the top of the stack as a memory address, and replaces it with the contents of that address
- Arithmetic and logical operations
`DW_OP_and`
- Pops the top two values from the stack and pushes back the logical
`AND`
of them
- Pops the top two values from the stack and pushes back the logical
`DW_OP_plus`
- Same as
`DW_OP_and`
, but adds the values
- Same as
- Control flow operations
`DW_OP_le`
,`DW_OP_eq`
,`DW_OP_gt`
, etc.- Pops the top two values, compares them, and pushes
`1`
if the condition is true and`0`
otherwise
- Pops the top two values, compares them, and pushes
`DW_OP_bra <offset>`
- Conditional branch: if the top of the stack is not
`0`
, skips back or forward in the expression by`offset`
- Conditional branch: if the top of the stack is not
- Type conversions
`DW_OP_convert <DIE offset>`
- Converts value on the top of the stack to a different type, which is described by the DWARF information entry at the given offset
- Special operations
`DW_OP_nop`
- Do nothing!
### DWARF types
DWARF’s representation of types needs to be strong enough to give debugger users useful variable representations. Users most often want to be able to debug at the level of their application rather than at the level of their machine, and they need a good idea of what their variables are doing to achieve that.
DWARF types are encoded in DIEs along with the majority of the other debug information. They can have attributes to indicate their name, encoding, size, endianness, etc. A myriad of type tags are available to express pointers, arrays, structures, typedefs, anything else you could see in a C or C++ program.
Take this small structure as an example:
```
struct test{
int i;
float j;
int k[42];
test* next;
};
```
The parent DIE for this struct is this:
```
< 1><0x0000002a> DW_TAG_structure_type
DW_AT_name "test"
DW_AT_byte_size 0x000000b8
DW_AT_decl_file 0x00000001 test.cpp
DW_AT_decl_line 0x00000001
```
The above says that we have a structure called `test`
of size `0xb8`
, declared at line `1`
of `test.cpp`
. All there are then many children DIEs which describe the members.
```
< 2><0x00000032> DW_TAG_member
DW_AT_name "i"
DW_AT_type <0x00000063>
DW_AT_decl_file 0x00000001 test.cpp
DW_AT_decl_line 0x00000002
DW_AT_data_member_location 0
< 2><0x0000003e> DW_TAG_member
DW_AT_name "j"
DW_AT_type <0x0000006a>
DW_AT_decl_file 0x00000001 test.cpp
DW_AT_decl_line 0x00000003
DW_AT_data_member_location 4
< 2><0x0000004a> DW_TAG_member
DW_AT_name "k"
DW_AT_type <0x00000071>
DW_AT_decl_file 0x00000001 test.cpp
DW_AT_decl_line 0x00000004
DW_AT_data_member_location 8
< 2><0x00000056> DW_TAG_member
DW_AT_name "next"
DW_AT_type <0x00000084>
DW_AT_decl_file 0x00000001 test.cpp
DW_AT_decl_line 0x00000005
DW_AT_data_member_location 176(as signed = -80)
```
Each member has a name, a type (which is a DIE offset), a declaration file and line, and a byte offset into the structure where the member is located. The types which are pointed to come next.
```
< 1><0x00000063> DW_TAG_base_type
DW_AT_name "int"
DW_AT_encoding DW_ATE_signed
DW_AT_byte_size 0x00000004
< 1><0x0000006a> DW_TAG_base_type
DW_AT_name "float"
DW_AT_encoding DW_ATE_float
DW_AT_byte_size 0x00000004
< 1><0x00000071> DW_TAG_array_type
DW_AT_type <0x00000063>
< 2><0x00000076> DW_TAG_subrange_type
DW_AT_type <0x0000007d>
DW_AT_count 0x0000002a
< 1><0x0000007d> DW_TAG_base_type
DW_AT_name "sizetype"
DW_AT_byte_size 0x00000008
DW_AT_encoding DW_ATE_unsigned
< 1><0x00000084> DW_TAG_pointer_type
DW_AT_type <0x0000002a>
```
As you can see, `int`
on my laptop is a 4-byte signed integer type, and `float`
is a 4-byte float. The integer array type is defined by pointing to the `int`
type as its element type, a `sizetype`
(think `size_t`
) as the index type, with `2a`
elements. The `test*`
type is a `DW_TAG_pointer_type`
which references the `test`
DIE.
### Implementing a simple variable reader
As mentioned, `libelfin`
will deal with most of the complexity for us. However, it doesn’t implement all of the different methods for representing variable locations, and handling a lot of them in our code would get pretty complex. As such, I’ve chosen to only support `exprloc`
s for now. Feel free to add support for more types of expression. If you’re really feeling brave, submit some patches to `libelfin`
to help complete the necessary support!
Handling variables is mostly down to locating the different parts in memory or registers, then reading or writing is the same as you’ve seen before. I’ll only show you how to implement reading for the sake of simplicity.
First we need to tell `libelfin`
how to read registers from our process. We do this by creating a class which inherits from `expr_context`
and uses `ptrace`
to handle everything:
```
class ptrace_expr_context : public dwarf::expr_context {
public:
ptrace_expr_context (pid_t pid) : m_pid{pid} {}
dwarf::taddr reg (unsigned regnum) override {
return get_register_value_from_dwarf_register(m_pid, regnum);
}
dwarf::taddr pc() override {
struct user_regs_struct regs;
ptrace(PTRACE_GETREGS, m_pid, nullptr, ®s);
return regs.rip;
}
dwarf::taddr deref_size (dwarf::taddr address, unsigned size) override {
//TODO take into account size
return ptrace(PTRACE_PEEKDATA, m_pid, address, nullptr);
}
private:
pid_t m_pid;
};
```
The reading will be handled by a `read_variables`
function in our `debugger`
class:
```
void debugger::read_variables() {
using namespace dwarf;
auto func = get_function_from_pc(get_offset_pc());
//...
}
```
The first thing we do above is find the function which we’re currently in. Then we need to loop through the entries in that function, looking for variables:
```
for (const auto& die : func) {
if (die.tag == DW_TAG::variable) {
//...
}
}
```
We get the location information by looking up the `DW_AT_location`
entry in the DIE:
` auto loc_val = die[DW_AT::location];`
Then we ensure that it’s an `exprloc`
and ask `libelfin`
to evaluate the expression for us:
```
if (loc_val.get_type() == value::type::exprloc) {
ptrace_expr_context context {m_pid};
auto result = loc_val.as_exprloc().evaluate(&context);
```
Now that we’ve evaluated the expression, we need to read the contents of the variable. It could be in memory or a register, so we’ll handle both cases:
```
switch (result.location_type) {
case expr_result::type::address:
{
auto value = read_memory(result.value);
std::cout << at_name(die) << " (0x" << std::hex << result.value << ") = "
<< value << std::endl;
}
case expr_result::type::reg:
{
auto value = get_register_value_from_dwarf_register(m_pid, result.value);
std::cout << at_name(die) << " (reg " << result.value << ") = "
<< value << std::endl;
break;
}
default:
throw std::runtime_error{"Unhandled variable location"};
}
```
As you can see I’ve printed out the value without interpreting it based on the type of the variable. Hopefully from this code you can see how you could support writing variables, or searching for variables with a given name.
Finally we can add this to our command parser:
```
else if(is_prefix(command, "variables")) {
read_variables();
}
```
### Testing it out
Write a few small functions which have some variables, compile it without optimizations and with debug info, then see if you can read the values of your variables. Try writing to the memory address where a variable is stored and see the behaviour of the program change.
Nine posts down, one to go! Next time I’ll be talking about some more advanced concepts which might interest you. For now you can find the code for this post [here](https://github.com/TartanLlama/minidbg/tree/tut_variable)
Let me know what you think of this article on twitter
[@TartanLlama](https://www.twitter.com/TartanLlama)or leave a comment below! |
8,937 | OpenGL 与 Go 教程(二)绘制游戏面板 | https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-2-drawing-the-game-board | 2017-10-07T22:35:00 | [
"OpenGL",
"Golang"
] | https://linux.cn/article-8937-1.html | 
* [第一节: Hello, OpenGL](/article-8933-1.html)
* [第二节: 绘制游戏面板](/article-8937-1.html)
* [第三节:实现游戏功能](/article-8969-1.html)
这篇教程的所有源代码都可以在 [GitHub](https://github.com/KyleBanks/conways-gol) 上找到。
欢迎回到《OpenGL 与 Go 教程》。如果你还没有看过[第一节](/article-8933-1.html),那就要回过头去看看那一节。
你现在应该能够创造一个漂亮的白色三角形,但我们不会把三角形当成我们游戏的基本单元,是时候把三角形变成正方形了,然后我们会做出一个完整的方格。
让我们现在开始做吧!
### 利用三角形绘制方形
在我们绘制方形之前,先把三角形变成直角三角形。打开 `main.go` 文件,把 `triangle` 的定义改成像这个样子:
```
triangle = []float32{
-0.5, 0.5, 0,
-0.5, -0.5, 0,
0.5, -0.5, 0,
}
```
我们做的事情是,把最上面的顶点 X 坐标移动到左边(也就是变为 `-0.5`),这就变成了像这样的三角形:

很简单,对吧?现在让我们用两个这样的三角形顶点做成正方形。把 `triangle` 重命名为 `square`,然后添加第二个倒置的三角形的顶点数据,把直角三角形变成这样的:
```
square = []float32{
-0.5, 0.5, 0,
-0.5, -0.5, 0,
0.5, -0.5, 0,
-0.5, 0.5, 0,
0.5, 0.5, 0,
0.5, -0.5, 0,
}
```
注意:你也要把在 `main` 和 `draw` 里面命名的 `triangle` 改为 `square`。
我们通过添加三个顶点,把顶点数增加了一倍,这三个顶点就是右上角的三角形,用来拼成方形。运行它看看效果:

很好,现在我们能够绘制正方形了!OpenGL 一点都不难,对吧?
### 在窗口中绘制方形格子
现在我们能画一个方形,怎么画 100 个吗?我们来创建一个 `cell` 结构体,用来表示格子的每一个单元,因此我们能够很灵活的选择绘制的数量:
```
type cell struct {
drawable uint32
x int
y int
}
```
`cell` 结构体包含一个 `drawable` 属性,这是一个顶点数组对象,就像我们在之前创建的一样,这个结构体还包含 X 和 Y 坐标,用来表示这个格子的位置。
我们还需要两个常量,用来设定格子的大小和形状:
```
const (
...
rows = 10
columns = 10
)
```
现在我们添加一个创建格子的函数:
```
func makeCells() [][]*cell {
cells := make([][]*cell, rows, rows)
for x := 0; x < rows; x++ {
for y := 0; y < columns; y++ {
c := newCell(x, y)
cells[x] = append(cells[x], c)
}
}
return cells
}
```
这里我们创建多维的<ruby> 切片 <rt> slice </rt></ruby>,代表我们的游戏面板,用名为 `newCell` 的新函数创建的 `cell` 来填充矩阵的每个元素,我们待会就来实现 `newCell` 这个函数。
在接着往下阅读前,我们先花一点时间来看看 `makeCells` 函数做了些什么。我们创造了一个切片,这个切片的长度和格子的行数相等,每一个切片里面都有一个<ruby> 细胞 <rt> cell </rt></ruby>的切片,这些细胞的数量与列数相等。如果我们把 `rows` 和 `columns` 都设定成 2,那么就会创建如下的矩阵:
```
[
[cell, cell],
[cell, cell]
]
```
还可以创建一个更大的矩阵,包含 `10x10` 个细胞:
```
[
[cell, cell, cell, cell, cell, cell, cell, cell, cell, cell],
[cell, cell, cell, cell, cell, cell, cell, cell, cell, cell],
[cell, cell, cell, cell, cell, cell, cell, cell, cell, cell],
[cell, cell, cell, cell, cell, cell, cell, cell, cell, cell],
[cell, cell, cell, cell, cell, cell, cell, cell, cell, cell],
[cell, cell, cell, cell, cell, cell, cell, cell, cell, cell],
[cell, cell, cell, cell, cell, cell, cell, cell, cell, cell],
[cell, cell, cell, cell, cell, cell, cell, cell, cell, cell],
[cell, cell, cell, cell, cell, cell, cell, cell, cell, cell],
[cell, cell, cell, cell, cell, cell, cell, cell, cell, cell]
]
```
现在应该理解了我们创造的矩阵的形状和表示方法。让我们看看 `newCell` 函数到底是怎么填充矩阵的:
```
func newCell(x, y int) *cell {
points := make([]float32, len(square), len(square))
copy(points, square)
for i := 0; i < len(points); i++ {
var position float32
var size float32
switch i % 3 {
case 0:
size = 1.0 / float32(columns)
position = float32(x) * size
case 1:
size = 1.0 / float32(rows)
position = float32(y) * size
default:
continue
}
if points[i] < 0 {
points[i] = (position * 2) - 1
} else {
points[i] = ((position + size) * 2) - 1
}
}
return &cell{
drawable: makeVao(points),
x: x,
y: y,
}
}
```
这个函数里有很多内容,我们把它分成几个部分。我们做的第一件事是复制了 `square` 的定义。这让我们能够修改该定义,定制当前的细胞位置,而不会影响其它使用 `square` 切片定义的细胞。然后我们基于当前索引迭代 `points` 副本。我们用求余数的方法来判断我们是在操作 X 坐标(`i % 3 == 0`),还是在操作 Y 坐标(`i % 3 == 1`)(跳过 Z 坐标是因为我们仅在二维层面上进行操作),跟着确定细胞的大小(也就是占据整个游戏面板的比例),当然它的位置是基于细胞在 `相对游戏面板的` X 和 Y 坐标。
接着,我们改变那些包含在 `square` 切片中定义的 `0.5`,`0`, `-0.5` 这样的点。如果点小于 0,我们就把它设置成原来的 2 倍(因为 OpenGL 坐标的范围在 `-1` 到 `1` 之间,范围大小是 2),减 1 是为了归一化 OpenGL 坐标。如果点大于等于 0,我们的做法还是一样的,不过要加上我们计算出的尺寸。
这样做是为了设置每个细胞的大小,这样它就能只填充它在面板中的部分。因为我们有 10 行 10 列,每一个格子能分到游戏面板的 10% 宽度和高度。
最后,确定了所有点的位置和大小,我们用提供的 X 和 Y 坐标创建一个 `cell`,并设置 `drawable` 字段与我们刚刚操作 `points` 得到的顶点数组对象(vao)一致。
好了,现在我们在 `main` 函数里可以移去对 `makeVao` 的调用了,用 `makeCells` 代替。我们还修改了 `draw`,让它绘制一系列的细胞而不是一个 `vao`。
```
func main() {
...
// vao := makeVao(square)
cells := makeCells()
for !window.ShouldClose() {
draw(cells, window, program)
}
}
func draw(cells [][]*cell, window *glfw.Window, program uint32) {
gl.Clear(gl.COLOR_BUFFER_BIT | gl.DEPTH_BUFFER_BIT)
gl.UseProgram(program)
// TODO
glfw.PollEvents()
window.SwapBuffers()
}
```
现在我们要让每个细胞知道怎么绘制出自己。在 `cell` 里面添加一个 `draw` 函数:
```
func (c *cell) draw() {
gl.BindVertexArray(c.drawable)
gl.DrawArrays(gl.TRIANGLES, 0, int32(len(square) / 3))
}
```
这看上去很熟悉,它很像我们之前在 `vao` 里写的 `draw`,唯一的区别是我们的 `BindVertexArray` 函数用的是 `c.drawable`,这是我们在 `newCell` 中创造的细胞的 `vao`。
回到 main 中的 `draw` 函数上,我们可以循环每个细胞,让它们自己绘制自己:
```
func draw(cells [][]*cell, window *glfw.Window, program uint32) {
gl.Clear(gl.COLOR_BUFFER_BIT | gl.DEPTH_BUFFER_BIT)
gl.UseProgram(program)
for x := range cells {
for _, c := range cells[x] {
c.draw()
}
}
glfw.PollEvents()
window.SwapBuffers()
}
```
如你所见,我们循环每一个细胞,调用它的 `draw` 函数。如果运行这段代码,你能看到像下面这样的东西:

这是你想看到的吗?我们做的是在格子里为每一行每一列创建了一个方块,然后给它上色,这就填满了整个面板!
注释掉 for 循环,我们就可以看到一个明显独立的细胞,像这样:
```
// for x := range cells {
// for _, c := range cells[x] {
// c.draw()
// }
// }
cells[2][3].draw()
```

这只绘制坐标在 `(X=2, Y=3)` 的格子。你可以看到,每一个独立的细胞占据着面板的一小块部分,并且负责绘制自己那部分空间。我们也能看到游戏面板有自己的原点,也就是坐标为 `(X=0, Y=0)` 的点,在窗口的左下方。这仅仅是我们的 `newCell` 函数计算位置的方式,也可以用右上角,右下角,左上角,中央,或者其它任何位置当作原点。
接着往下做,移除 `cells[2][3].draw()` 这一行,取消 for 循环的那部分注释,变成之前那样全部绘制的样子。
### 总结
好了,我们现在能用两个三角形画出一个正方形了,我们还有一个游戏的面板了!我们该为此自豪,目前为止我们已经接触到了很多零碎的内容,老实说,最难的部分还在前面等着我们!
在接下来的第三节,我们会实现游戏核心逻辑,看到很酷的东西!
### 回顾
这是这一部分教程中 `main.go` 文件的内容:
```
package main
import (
"fmt"
"log"
"runtime"
"strings"
"github.com/go-gl/gl/v4.1-core/gl" // OR: github.com/go-gl/gl/v2.1/gl
"github.com/go-gl/glfw/v3.2/glfw"
)
const (
width = 500
height = 500
vertexShaderSource = `
#version 410
in vec3 vp;
void main() {
gl_Position = vec4(vp, 1.0);
}
` + "\x00"
fragmentShaderSource = `
#version 410
out vec4 frag_colour;
void main() {
frag_colour = vec4(1, 1, 1, 1.0);
}
` + "\x00"
rows = 10
columns = 10
)
var (
square = []float32{
-0.5, 0.5, 0,
-0.5, -0.5, 0,
0.5, -0.5, 0,
-0.5, 0.5, 0,
0.5, 0.5, 0,
0.5, -0.5, 0,
}
)
type cell struct {
drawable uint32
x int
y int
}
func main() {
runtime.LockOSThread()
window := initGlfw()
defer glfw.Terminate()
program := initOpenGL()
cells := makeCells()
for !window.ShouldClose() {
draw(cells, window, program)
}
}
func draw(cells [][]*cell, window *glfw.Window, program uint32) {
gl.Clear(gl.COLOR_BUFFER_BIT | gl.DEPTH_BUFFER_BIT)
gl.UseProgram(program)
for x := range cells {
for _, c := range cells[x] {
c.draw()
}
}
glfw.PollEvents()
window.SwapBuffers()
}
func makeCells() [][]*cell {
cells := make([][]*cell, rows, rows)
for x := 0; x < rows; x++ {
for y := 0; y < columns; y++ {
c := newCell(x, y)
cells[x] = append(cells[x], c)
}
}
return cells
}
func newCell(x, y int) *cell {
points := make([]float32, len(square), len(square))
copy(points, square)
for i := 0; i < len(points); i++ {
var position float32
var size float32
switch i % 3 {
case 0:
size = 1.0 / float32(columns)
position = float32(x) * size
case 1:
size = 1.0 / float32(rows)
position = float32(y) * size
default:
continue
}
if points[i] < 0 {
points[i] = (position * 2) - 1
} else {
points[i] = ((position + size) * 2) - 1
}
}
return &cell{
drawable: makeVao(points),
x: x,
y: y,
}
}
func (c *cell) draw() {
gl.BindVertexArray(c.drawable)
gl.DrawArrays(gl.TRIANGLES, 0, int32(len(square)/3))
}
// 初始化 glfw,返回一个可用的 Window
func initGlfw() *glfw.Window {
if err := glfw.Init(); err != nil {
panic(err)
}
glfw.WindowHint(glfw.Resizable, glfw.False)
glfw.WindowHint(glfw.ContextVersionMajor, 4)
glfw.WindowHint(glfw.ContextVersionMinor, 1)
glfw.WindowHint(glfw.OpenGLProfile, glfw.OpenGLCoreProfile)
glfw.WindowHint(glfw.OpenGLForwardCompatible, glfw.True)
window, err := glfw.CreateWindow(width, height, "Conway's Game of Life", nil, nil)
if err != nil {
panic(err)
}
window.MakeContextCurrent()
return window
}
// 初始化 OpenGL 并返回一个可用的着色器程序
func initOpenGL() uint32 {
if err := gl.Init(); err != nil {
panic(err)
}
version := gl.GoStr(gl.GetString(gl.VERSION))
log.Println("OpenGL version", version)
vertexShader, err := compileShader(vertexShaderSource, gl.VERTEX_SHADER)
if err != nil {
panic(err)
}
fragmentShader, err := compileShader(fragmentShaderSource, gl.FRAGMENT_SHADER)
if err != nil {
panic(err)
}
prog := gl.CreateProgram()
gl.AttachShader(prog, vertexShader)
gl.AttachShader(prog, fragmentShader)
gl.LinkProgram(prog)
return prog
}
// 初始化并返回由 points 提供的顶点数组
func makeVao(points []float32) uint32 {
var vbo uint32
gl.GenBuffers(1, &vbo)
gl.BindBuffer(gl.ARRAY_BUFFER, vbo)
gl.BufferData(gl.ARRAY_BUFFER, 4*len(points), gl.Ptr(points), gl.STATIC_DRAW)
var vao uint32
gl.GenVertexArrays(1, &vao)
gl.BindVertexArray(vao)
gl.EnableVertexAttribArray(0)
gl.BindBuffer(gl.ARRAY_BUFFER, vbo)
gl.VertexAttribPointer(0, 3, gl.FLOAT, false, 0, nil)
return vao
}
func compileShader(source string, shaderType uint32) (uint32, error) {
shader := gl.CreateShader(shaderType)
csources, free := gl.Strs(source)
gl.ShaderSource(shader, 1, csources, nil)
free()
gl.CompileShader(shader)
var status int32
gl.GetShaderiv(shader, gl.COMPILE_STATUS, &status)
if status == gl.FALSE {
var logLength int32
gl.GetShaderiv(shader, gl.INFO_LOG_LENGTH, &logLength)
log := strings.Repeat("\x00", int(logLength+1))
gl.GetShaderInfoLog(shader, logLength, nil, gl.Str(log))
return 0, fmt.Errorf("failed to compile %v: %v", source, log)
}
return shader, nil
}
```
让我知道这篇文章对你有没有帮助,在 Twitter [@kylewbanks](https://twitter.com/kylewbanks) 或者下方的连接,关注我以便获取最新的文章!
---
via: <https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-2-drawing-the-game-board>
作者:[kylewbanks](https://twitter.com/kylewbanks) 译者:[GitFtuture](https://github.com/GitFuture) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # OpenGL & Go Tutorial Part 2: Drawing the Game Board
[@kylewbanks](https://twitter.com/kylewbanks)on Mar 12, 2017.
*Hey, if you didn't already know, I'm currently working on an open world stealth exploration game called*
[Farewell North](https://farewell-north.com)in my spare time, which is available to wishlist on Steam!* Part 1: Hello, OpenGL* |
*|*
[Part 2: Drawing the Game Board](/blog/tutorial-opengl-with-golang-part-2-drawing-the-game-board)
[Part 3: Implementing the Game](/blog/tutorial-opengl-with-golang-part-3-implementing-the-game)*The full source code of the tutorial is available on GitHub.*
Welcome back to the *OpenGL & Go Tutorial!* If you haven’t gone through [Part 1](/blog/tutorial-opengl-with-golang-part-1-hello-opengl) you’ll definitely want to take a step back and check it out.
At this point you should be the proud creator of a magnificent white triangle, but we’re not in the business of using triangles as our game unit so it’s time to turn the triangle into a square, and then we’ll make an entire grid of them.
Let’s get started!
## Make a Square out of Triangles
Before we can make a square, let’s turn our triangle into a right-angle. Open up **main.go** and change the **triangle** definition to look like so:
triangle = []float32{ -0.5, 0.5, 0, -0.5, -0.5, 0, 0.5, -0.5, 0, }
What we’ve done is move the X-coordinate of the top vertex to the left (**-0.5**), giving us a triangle like so:

Easy enough, right? Now let’s make a square out of two of these. Let’s rename **triangle** to **square** and add a second, inverted right-angle triangle to the slice:
square = []float32{ -0.5, 0.5, 0, -0.5, -0.5, 0, 0.5, -0.5, 0, -0.5, 0.5, 0, 0.5, 0.5, 0, 0.5, -0.5, 0, }
Note: You’ll also need to rename the two references to **triangle** to be **square**, namely in **main** and **draw**.
Here we’ve doubled the number of points by adding a second set of three vertices to be our upper top-right triangle to complete the square. Run it for glory:

Great, now we have the ability to draw a square! OpenGL isn’t so tough after all, is it?
## Draw a Grid of Squares covering the Window
Now that we can draw one square, how about 100 of them? Let’s create a **cell** struct to represent each unit of our grid so that we can be flexible in the number of squares we draw:
type cell struct { drawable uint32 x int y int }
The **cell** contains a **drawable** which is a square **Vertex Array Object** just like the one we created above, and an X and Y coordinate to dictate where on the grid this cell resides.
We’re also going to want two more constants that define the size and shape of our grid:
const ( ... rows = 10 columns = 10 )
Now let’s add a function to create the grid:
func makeCells() [][]*cell { cells := make([][]*cell, rows, rows) for x := 0; x < rows; x++ { for y := 0; y < columns; y++ { c := newCell(x, y) cells[x] = append(cells[x], c) } } return cells }
Here we create a multi-dimensional slice to represent our game’s board, and populate each element of the matrix with a **cell** using a new function called **newCell** which we’ll write in just a moment.
Before moving on, let’s take a moment to visualize what **makeCells** is creating. We’re creating a slice that is equal in length to the number of rows on the grid, and each of these slices contains a slice of cells, equal in length to the number of columns. If we were to define **rows** and **columns** each equal to two, we’d create the following matrix:
```
[
[cell, cell],
[cell, cell]
]
```
We’re creating a much larger matrix that’s **10x10** cells:
```
[
[cell, cell, cell, cell, cell, cell, cell, cell, cell, cell],
[cell, cell, cell, cell, cell, cell, cell, cell, cell, cell],
[cell, cell, cell, cell, cell, cell, cell, cell, cell, cell],
[cell, cell, cell, cell, cell, cell, cell, cell, cell, cell],
[cell, cell, cell, cell, cell, cell, cell, cell, cell, cell],
[cell, cell, cell, cell, cell, cell, cell, cell, cell, cell],
[cell, cell, cell, cell, cell, cell, cell, cell, cell, cell],
[cell, cell, cell, cell, cell, cell, cell, cell, cell, cell],
[cell, cell, cell, cell, cell, cell, cell, cell, cell, cell],
[cell, cell, cell, cell, cell, cell, cell, cell, cell, cell]
]
```
Now that the we understand the shape and representation of the matrix we’re creating, let’s have a look at **newCell** which we use to actually populate the matrix:
func newCell(x, y int) *cell { points := make([]float32, len(square), len(square)) copy(points, square) for i := 0; i < len(points); i++ { var position float32 var size float32 switch i % 3 { case 0: size = 1.0 / float32(columns) position = float32(x) * size case 1: size = 1.0 / float32(rows) position = float32(y) * size default: continue } if points[i] < 0 { points[i] = (position * 2) - 1 } else { points[i] = ((position + size) * 2) - 1 } } return &cell{ drawable: makeVao(points), x: x, y: y, } }
There’s quite a lot going on in this function so let’s break it down. The first thing we do is create a copy of our **square** definition. This allows us to change its contents to customize the current cell’s position, without impacting any other cells that are also using the **square** slice. Next we iterate over the **points** copy and act based on the current index. We use a modulo operation to determine if we’re at an X (**i % 3 == 0**) or Y (**i % 3 == 1**) coordinate **of the shape** (skipping Z since we’re operating in two dimensions) and determine the size (as a percentage of the entire game board) of the cell accordingly, as well as it’s position based on the X and Y coordinate of the cell **on the game board**.
Next, we modify the points which currently contain a combination of **0.5**, **0** and **-0.5** as we defined them in the **square** slice. If the point is less than zero, we set it equal to the position times 2 (because OpenGL coordinates have a range of 2, between **-1** and **1**), minus 1 to normalize to OpenGL coordinates. If the position is greater than or equal to zero, we do the same thing but add the size we calculated.
The purpose of this is to set the scale of each cell so that it fills only its percentage of the game board. Since we have 10 rows and 10 columns, each cell will be given 10% of the width and 10% of the height of the game board.
Finally, after all the points have been scaled and positioned, we create a **cell** with the X and Y coordinate provided, and set the **drawable** field equal to a **Vertex Array Object** created from the **points** slice we just manipulated.
Alright, now in **main** we can remove our call to **makeVao** and replace it with a call to **makeCells**. We’ll also change **draw** to take the matrix of cells instead of a single **vao**:
func main() { ... // vao := makeVao(square) cells := makeCells() for !window.ShouldClose() { draw(cells, window, program) } } func draw(cells [][]*cell, window *glfw.Window, program uint32) { gl.Clear(gl.COLOR_BUFFER_BIT | gl.DEPTH_BUFFER_BIT) gl.UseProgram(program) // TODO glfw.PollEvents() window.SwapBuffers() }
Now we’ll need each cell to know how to draw itself. Let’s add a **draw** function to the **cell**:
func (c *cell) draw() { gl.BindVertexArray(c.drawable) gl.DrawArrays(gl.TRIANGLES, 0, int32(len(square) / 3)) }
This should look familiar, its nearly identical to how we were drawing the square **vao** in **draw** previously, the only difference being we **BindVertexArray** using **c.drawable**, which is the cell’s **vao** we created in **newCell**.
Back in the main **draw** function, we can loop over each cell and have it draw itself:
func draw(cells [][]*cell, window *glfw.Window, program uint32) { gl.Clear(gl.COLOR_BUFFER_BIT | gl.DEPTH_BUFFER_BIT) gl.UseProgram(program) for x := range cells { for _, c := range cells[x] { c.draw() } } glfw.PollEvents() window.SwapBuffers() }
As you can see we loop over each of the cells and call its **draw** function. If you run the application you should see the following:

Is this what you expected? What we’ve done is create a square for each row and column on the grid, and colored it in, effectively filling the entire game board!
We can see an visualize individual cells by commenting out the for-loop for a moment and doing the following:
// for x := range cells { // for _, c := range cells[x] { // c.draw() // } // } cells[2][3].draw()

This draws only the cell located at coordinate **(X=2, Y=3)**. As you can see, each individual cell takes up a small portion of the game board, and is responsible for drawing its own space. We can also see that our game board has its origin, that is the **(X=0, Y=0)** coordinate, in the bottom-left corner of the window. This is simply a result of the way our **newCell** function calculates the position, and could be made to use the top-right, bottom-right, top-left, center, or any other position as its origin.
Let’s go ahead and remove the **cells[2][3].draw()** line and uncomment the for-loop, leaving us with the fully drawn grid we had above.
## Summary
Alright - we can now use two triangles to draw a square, and we have ourselves a game board! We should be proud, we’ve covered a lot of ground up to this point and to be completely honest, the hardest part is behind us now!
Next up in [Part 3](/blog/tutorial-opengl-with-golang-part-3-implementing-the-game) we’ll implement the core game logic and see some cool simulations!
* Part 1: Hello, OpenGL* |
*|*
[Part 2: Drawing the Game Board](/blog/tutorial-opengl-with-golang-part-2-drawing-the-game-board)
[Part 3: Implementing the Game](/blog/tutorial-opengl-with-golang-part-3-implementing-the-game)*The full source code of the tutorial is available on GitHub.*
## Checkpoint
Here’s the contents of **main.go** at this point of the tutorial:
package main import ( "fmt" "log" "runtime" "strings" "github.com/go-gl/gl/v4.1-core/gl" // OR: github.com/go-gl/gl/v2.1/gl "github.com/go-gl/glfw/v3.2/glfw" ) const ( width = 500 height = 500 vertexShaderSource = ` #version 410 in vec3 vp; void main() { gl_Position = vec4(vp, 1.0); } ` + "\x00" fragmentShaderSource = ` #version 410 out vec4 frag_colour; void main() { frag_colour = vec4(1, 1, 1, 1.0); } ` + "\x00" rows = 10 columns = 10 ) var ( square = []float32{ -0.5, 0.5, 0, -0.5, -0.5, 0, 0.5, -0.5, 0, -0.5, 0.5, 0, 0.5, 0.5, 0, 0.5, -0.5, 0, } ) type cell struct { drawable uint32 x int y int } func main() { runtime.LockOSThread() window := initGlfw() defer glfw.Terminate() program := initOpenGL() cells := makeCells() for !window.ShouldClose() { draw(cells, window, program) } } func draw(cells [][]*cell, window *glfw.Window, program uint32) { gl.Clear(gl.COLOR_BUFFER_BIT | gl.DEPTH_BUFFER_BIT) gl.UseProgram(program) for x := range cells { for _, c := range cells[x] { c.draw() } } glfw.PollEvents() window.SwapBuffers() } func makeCells() [][]*cell { cells := make([][]*cell, rows, rows) for x := 0; x < rows; x++ { for y := 0; y < columns; y++ { c := newCell(x, y) cells[x] = append(cells[x], c) } } return cells } func newCell(x, y int) *cell { points := make([]float32, len(square), len(square)) copy(points, square) for i := 0; i < len(points); i++ { var position float32 var size float32 switch i % 3 { case 0: size = 1.0 / float32(columns) position = float32(x) * size case 1: size = 1.0 / float32(rows) position = float32(y) * size default: continue } if points[i] < 0 { points[i] = (position * 2) - 1 } else { points[i] = ((position + size) * 2) - 1 } } return &cell{ drawable: makeVao(points), x: x, y: y, } } func (c *cell) draw() { gl.BindVertexArray(c.drawable) gl.DrawArrays(gl.TRIANGLES, 0, int32(len(square)/3)) } // initGlfw initializes glfw and returns a Window to use. func initGlfw() *glfw.Window { if err := glfw.Init(); err != nil { panic(err) } glfw.WindowHint(glfw.Resizable, glfw.False) glfw.WindowHint(glfw.ContextVersionMajor, 4) glfw.WindowHint(glfw.ContextVersionMinor, 1) glfw.WindowHint(glfw.OpenGLProfile, glfw.OpenGLCoreProfile) glfw.WindowHint(glfw.OpenGLForwardCompatible, glfw.True) window, err := glfw.CreateWindow(width, height, "Conway's Game of Life", nil, nil) if err != nil { panic(err) } window.MakeContextCurrent() return window } // initOpenGL initializes OpenGL and returns an intiialized program. func initOpenGL() uint32 { if err := gl.Init(); err != nil { panic(err) } version := gl.GoStr(gl.GetString(gl.VERSION)) log.Println("OpenGL version", version) vertexShader, err := compileShader(vertexShaderSource, gl.VERTEX_SHADER) if err != nil { panic(err) } fragmentShader, err := compileShader(fragmentShaderSource, gl.FRAGMENT_SHADER) if err != nil { panic(err) } prog := gl.CreateProgram() gl.AttachShader(prog, vertexShader) gl.AttachShader(prog, fragmentShader) gl.LinkProgram(prog) return prog } // makeVao initializes and returns a vertex array from the points provided. func makeVao(points []float32) uint32 { var vbo uint32 gl.GenBuffers(1, &vbo) gl.BindBuffer(gl.ARRAY_BUFFER, vbo) gl.BufferData(gl.ARRAY_BUFFER, 4*len(points), gl.Ptr(points), gl.STATIC_DRAW) var vao uint32 gl.GenVertexArrays(1, &vao) gl.BindVertexArray(vao) gl.EnableVertexAttribArray(0) gl.BindBuffer(gl.ARRAY_BUFFER, vbo) gl.VertexAttribPointer(0, 3, gl.FLOAT, false, 0, nil) return vao } func compileShader(source string, shaderType uint32) (uint32, error) { shader := gl.CreateShader(shaderType) csources, free := gl.Strs(source) gl.ShaderSource(shader, 1, csources, nil) free() gl.CompileShader(shader) var status int32 gl.GetShaderiv(shader, gl.COMPILE_STATUS, &status) if status == gl.FALSE { var logLength int32 gl.GetShaderiv(shader, gl.INFO_LOG_LENGTH, &logLength) log := strings.Repeat("\x00", int(logLength+1)) gl.GetShaderInfoLog(shader, logLength, nil, gl.Str(log)) return 0, fmt.Errorf("failed to compile %v: %v", source, log) } return shader, nil }
[@kylewbanks](https://twitter.com/kylewbanks)or down below! |
8,941 | 运行在树莓派和 Arduino 上的开源社交机器人套件 | http://linuxgizmos.com/open-source-social-robot-kit-runs-on-raspberry-pi-and-arduino/ | 2017-10-08T11:47:58 | [
"树莓派",
"机器人"
] | https://linux.cn/article-8941-1.html | 
>
> Thecorpora 的发布的 “Q.bo One” 机器人基于 RPi 3 和 Arduino,并提供立体相机、麦克风、扬声器,以及视觉和语言识别。
>
>
>
2010 年,作为一个开源概念验证和用于探索 AI 在多传感器、交互式机器人的能力的研究项目,机器人开发商 Francisco Paz 及它在巴塞罗那的 Thecorpora 公司推出了首款 [Qbo](http://linuxdevices.linuxgizmos.com/open-source-robot-is-all-eyes/) “Cue-be-oh” 机器人。在今年 2 月移动世界大会上的预览之后,Thecorpora 把它放到了 Indiegogo 上,与 Arrow 合作推出了第一个批量生产的社交机器人版本。

*Q.bo One 的左侧*

*Q.bo One 的顶部*
像原来一样,新的 Q.bo One 有一个带眼睛的球形头(双立体相机)、耳朵(3 个麦克风)和嘴(扬声器),并由 WiFi 和蓝牙控制。 Q.bo One 也同样采用开源 Linux 软件和开放规格硬件。然而,它不是使用基于 Intel Atom 的 Mini-ITX 板,而是在与 Arduino 兼容的主板相连的 Raspberry Pi 3 上运行 Raspbian。

*Q.bo One 侧视图*\*
Q.bo One 于 7 月中旬在 Indiegogo 上架,起价为 369 美元(早期买家)或 399 美元,有包括内置的树莓派 3 和基于 Arduino 的 “Qboard” 控制器板。它还有售价 $499 的完整套装。目前,Indiegogo 上的众筹目标是 $100,000,现在大概达成了 15%,并且它 12 月出货。
更专业的机器人工程师和嵌入式开发人员可能会想要使用价值 $99 的只有树莓派和 Qboard PCB 和软件的版本,或者提供没有电路板的机器人套件的 $249 版本。使用此版本,你可以用自己的 Arduino 控制器替换 Qboard,并将树莓派 3 替换为另一个 Linux SBC。该公司列出了 Banana Pi、BeagleBone、Tinker Board 以及[即将退市的 Intel Edison](http://linuxgizmos.com/intel-pulls-the-plug-on-its-joule-edison-and-galileo-boards/),作为兼容替代品的示例。

*Q.bo One 套件*
与 2010 年的 Qbo 不同,Q.bo One 除了球面头部之外无法移动,它可以在双重伺服系统的帮助下在底座上旋转,以便跟踪声音和动作。Robotis Dynamixel 舵机同样开源,树莓派基于 [TurtleBot 3](http://linuxgizmos.com/ubuntu-driven-turtlebot-gets-a-major-rev-with-a-pi-or-joule-in-the-drivers-seat/) 机器人工具包,除了左右之外,还可以上下移动。

*Q.bo One 细节*

*Qboard 细节*
Q.bo One 类似于基于 Linux 的 [Jibo](http://linuxgizmos.com/cheery-social-robot-owes-it-all-to-its-inner-linux/) “社交机器人”,它于 2014 年在 Indiegogo 众筹,最后达到 360 万美元。然而,Jibo 还没有出货,[最近的推迟](https://www.slashgear.com/jibo-delayed-to-2017-as-social-robot-hits-more-hurdles-20464725/)迫使它在今年的某个时候发布一个版本。

*Q.bo One*
我们大胆预测 Q.bo One 将会在 2017 年接近 12 月出货。核心技术和 AI 软件已被证明,而树莓派和 Arduino 技术也是如此。Qboard 主板已经由 Arrow 制造和认证。
开源设计表明,即使是移动版本也不会有问题。这使它更像是滚动的人形生物 [Pepper](http://linuxgizmos.com/worlds-first-emotional-robot-runs-linux/),这是一个来自 Softbank 和 Aldeberan 类似的人工智能对话机器人。
Q.bo One 自原始版以来添加了一些技巧,例如由 20 个 LED 组成的“嘴巴”, 它以不同的、可编程的方式在语音中模仿嘴唇开合。如果你想点击机器人获得关注,那么它的头上还有三个触摸传感器。但是,你其实只需要说话就行,而 Q.bo One 会像一个可卡犬一样转身并凝视着你。
接口和你在树莓派 3 上的一样,它在我们的 [2017 黑客电路板调查](http://linuxgizmos.com/2017-hacker-board-survey-raspberry-pi-still-rules-but-x86-sbcs-make-gains/)中消灭了其他对手。为树莓派 3 的 WiFi 和蓝牙安装了天线。

*Q.bo One 软件架构*

*Q.bo One 及 Scratch 编程*
Qboard(也称为 Q.board)在 Atmel ATSAMD21 MCU 上运行 Arduino 代码,并有三个麦克风、扬声器、触摸传感器、Dynamixel 控制器和用于嘴巴的 LED 矩阵。其他功能包括 GPIO、I2C接口和可连接到台式机的 micro-USB 口。
Q.bo One 可以识别脸部和追踪移动,机器人甚至可以在镜子中识别自己。在云连接的帮助下,机器人可以识别并与其他 Q.bo One 机器人交谈。机器人可以在自然语言处理的帮助下回答问题,并通过文字转语音朗读。
可以使用 Scratch 编程,它是机器人的主要功能,可以教孩子关于机器人和编程。机器人也是为教育者和制造者设计的,可以作为老年人的伴侣。
基于 Raspbian 的软件使用 OpenCV 进行视觉处理,并可以使用各种语言(包括 C++)进行编程。该软件还提供了 IBM Bluemix、NodeRED 和 ROS 的钩子。大概你也可以整合 [Alexa](http://linuxgizmos.com/how-to-add-alexa-to-your-raspberry-pi-3-gizmo/) 或 [Google Assistant](http://linuxgizmos.com/free-raspberry-pi-voice-kit-taps-google-assistant-sdk/)语音代理,虽然 Thecorpora 没有提及这一点。
**更多信息**
Q.bo One 在 7 月中旬在 Indiegogo 上架,起价为完整套件 $369 和完整组合 $499 。出货预计在 2017 年 12 月。更多信息请参见 [Q.bo One 的 Indiegogo 页面](https://www.indiegogo.com/projects/q-bo-one-an-open-source-robot-for-everyone#/) 和[Thecorpora 网站](http://thecorpora.com/)。
---
via: <http://linuxgizmos.com/open-source-social-robot-kit-runs-on-raspberry-pi-and-arduino/>
作者:[Eric Brown](http://linuxgizmos.com/open-source-social-robot-kit-runs-on-raspberry-pi-and-arduino/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 520 | null |
|
8,942 | 用 Linux、Python 和树莓派酿制啤酒 | https://opensource.com/article/17/7/brewing-beer-python-and-raspberry-pi | 2017-10-08T21:30:12 | [
"树莓派",
"啤酒"
] | https://linux.cn/article-8942-1.html |
>
> 怎样在家用 Python 和树莓派搭建一个家用便携的自制酿啤酒装置
>
>
>

大约十年前我开始酿制自制啤酒,和许多自己酿酒的人一样,我开始在厨房制造提纯啤酒。这需要一些设备并且做出来后确实是好的啤酒,最终,我用一个放入了所有大麦的大贮藏罐作为我的麦芽浆桶。几年之后我一次酿制过 5 加仑啤酒,但是酿制 10 加仑时也会花费同样的时间和效用(只是容器比之前大些),之前我就是这么做的。容量提升到 10 加仑之后,我偶然看到了 [StrangeBrew Elsinore](http://dougedey.github.io/SB_Elsinore_Server/) ,我意识到我真正需要的是将整个酿酒过程转换成全电子化的,用树莓派来运行它。
建造自己的家用电动化酿酒系统需要大量这方面的技术信息,许多学习酿酒的人是在 [TheElectricBrewery.com](http://theelectricbrewery.com/) 这个网站起步的,只不过将那些控制版搭建在一起是十分复杂的,尽管最简单的办法在这个网站上总结的很好。当然你也能用[一个小成本的方法](http://www.instructables.com/id/Electric-Brewery-Control-Panel-on-the-Cheap/)并且依旧可以得到相同的结果 —— 用一个热水壶和热酒容器通过一个 PID 控制器来加热你的酿酒原料。但是我认为这有点太无聊(这也意味着你不能体验到完整的酿酒过程)。
### 需要用到的硬件
在我开始我的这个项目之前, 我决定开始买零件,我最基础的设计是一个可以将液体加热到 5500 瓦的热酒容器(HLT)和开水壶,加一个活底的麦芽浆桶,我通过一个 50 英尺的不锈钢线圈在热酒容器里让泵来再循环麦芽浆(["热量交换再循环麦芽浆系统, 也叫 HERMS](https://byo.com/hops/item/1325-rims-and-herms-brewing-advanced-homebrewing))。同时我需要另一个泵来在热酒容器里循环水,并且把水传输到麦芽浆桶里,整个电子部件全部是用树莓派来控制的。
建立我的电子酿酒系统并且尽可能的自动化意味着我需要以下的组件:
* 一个 5500 瓦的电子加热酒精容器(HLT)
* 能够放入加热酒精容器里的 50 英尺(0.5 英寸)的不锈钢线圈(热量交换再循环麦芽浆系统)
* 一个 5500 瓦的电子加热水壶
* 多个固态继电器加热开关
* 2 个高温食品级泵
* 泵的开关用继电器
* 可拆除装置和一个硅管
* 不锈钢球阀
* 一个测量温度的探针
* 很多线
* 一个来容纳这些配件的电路盒子

*酿酒系统 (photo by Christopher Aedo. [CC BY-SA 4.0)](https://creativecommons.org/licenses/by-sa/4.0/)*
建立酿酒系统的电气化方面的细节 [The Electric Brewery](http://theelectricbrewery.com/) 这个网站概括的很好,这里我不再重复,当你计划用树莓派代替这个 PID 控制器的话,你可以读以下的建议。
一个重要的事情需要注意,固态继电器(SSR)信号电压,许多教程建议使用一个 12 伏的固态继电器来关闭电路,树莓派的 GPIO 针插口只支持 3 伏输出电压,然而,必须购买继电器将电压变为 3 伏。

*Inkbird SSR (photo by Christopher Aedo. [CC BY-SA 4.0)](https://creativecommons.org/licenses/by-sa/4.0/)*
要运行酿酒系统,你的树莓派必须做两个关键事情:测量来自几个不同位置的温度,用继电器开关来控制加热元件,树莓派很容易来处理这些任务。
这里有一些不同的方法来将温度传感器连到树莓派上,但是我找到了最方便的方法用[单总线](https://en.wikipedia.org/wiki/1-Wire)。这就可以让多个传感器分享相同的线路(实际上是三根线),这三根线可以使酿酒系统的多个设备更方便的工作,如果你要从网上找一个防水的 DS18B20 温度传感器,你可以会找到很多选择。我用的是[日立 DS18B20 防水温度传感器](https://smile.amazon.com/gp/product/B018KFX5X0/)。
要控制加热元件,树莓派包括了几个用来软件寻址的总线扩展器(GPIO),它会通过在某个文件写入 0 或者 1 让你发送3.3v 的电压到一个继电器,在我第一次了解树莓派是怎样工作的时候,这个[用 GPIO 驱动继电器的树莓派教程](http://www.susa.net/wordpress/2012/06/raspberry-pi-relay-using-gpio/)对我来说是最有帮助的,总线扩展器控制着多个固态继电器,通过酿酒软件来直接控制加热元件的开关。
我首先将所有部件放到这个电路盒子,因为这将成为一个滚动的小车,我要让它便于移动,而不是固定不动的,如果我有一个店(比如说在车库、工具房、或者地下室),我需要要用一个装在墙上的更大的电路盒,而现在我找到一个大小正好的[防水工程盒子](http://amzn.to/2hupFCr),能放进每件东西,最后它成为小巧紧凑工具盒,并且能够工作。在左下角是和树莓派连接的为总线扩展器到单总线温度探针和[固态继电器](http://amzn.to/2hL8JDS)的扩展板。
要保持 240v 的固态继电器温度不高,我在盒子上切了个洞,在盒子的外面用 CPU 降温凝胶把[铜片散热片](http://amzn.to/2i4DYwy)安装到盒子外面的热槽之间。它工作的很好,盒子里没有温度上的问题了,在盒子盖上我放了两个开关为 120v 的插座,加两个240v 的 led 来显示加热元件是否通电。我用干燥器的插座和插头,所以可以很容易的断开电热水壶的连接。首次尝试每件事情都工作正常。(第一次绘制电路图必有回报)
这个照片来自“概念”版,最终生产系统应该有两个以上的固态继电器,以便 240v 的电路两个针脚能够切换,另外我将通过软件来切换泵的开关。现在通过盒子前面的物理开关控制它们,但是也很容易用继电器控制它们。

*控制盒子 (photo by Christopher Aedo. [CC BY-SA 4.0)](https://creativecommons.org/licenses/by-sa/4.0/)*
唯一剩下有点棘手的事情是温度探针的压合接头,这个探针安装在加热酒精容器和麦芽浆桶球形的最底部阀门前的 T 字型接头上。当液体流过温度传感器,温度可以准确显示。我考虑加一个套管到热水壶里,但是对于我的酿造工艺没有什么用。最后,我买到了[四分之一英寸的压合接头](https://www.brewershardware.com/CF1412.html),它们工作完美。
### 软件
一旦硬件整理好,我就有时间来处理软件了,我在树莓派上跑了最新的 [Raspbian 发行版](https://www.raspberrypi.org/downloads/raspbian/),操作系统方面没有什么特别的。
我开始使用 [Strangebrew Elsinore](https://github.com/DougEdey/SB_Elsinore_Server) 酿酒软件,当我的朋友问我是否我听说过 [Hosehead](https://brewtronix.com/)(一个基于树莓派的酿酒控制器),我找到了 [Strangebrew Elsinore](https://github.com/DougEdey/SB_Elsinore_Server) 。我认为 [Hosehead](https://brewtronix.com/) 很棒,但我并不是要买一个酿酒控制器,而是要挑战自己,搭建一个自己的。
设置 [Strangebrew Elsinore](https://github.com/DougEdey/SB_Elsinore_Server) 很简单,其[文档](http://dougedey.github.io/SB_Elsinore_Server/)直白,没有遇到任何的问题。尽管 Strangebrew Elsinore 工作的很好,但在我的一代树莓派上运行 java 有时是费力的,不止崩溃一次。我看到这个软件开发停顿也很伤心,似乎他们也没有更多贡献者的大型社区(尽管有很多人还在用它)。
#### CraftBeerPi
之后我偶然遇到了一个用 Python 写的 [CraftbeerPI](http://www.craftbeerpi.com/),它有活跃的贡献者支持的开发社区。原作者(也是当前维护者) Manuel Fritsch 在贡献和反馈问题处理方面做的很好。克隆[这个仓库](https://github.com/manuel83/craftbeerpi)然后开始只用了我一点时间。其 README 文档也是一个连接 DS1820 温度传感器的好例子,同时也有关于硬件接口到树莓派或者[芯片电脑](https://www.nextthing.co/pages/chip) 的注意事项。
在启动的时候,CraftbeerPI 引导用户通过一个设置过程来发现温度探针是否可用,并且让你指定哪个 GPIO 总线扩展器指针来管理树莓派上哪个配件。

*CraftBeerPi (photo by Christopher Aedo. [CC BY-SA 4.0)](https://creativecommons.org/licenses/by-sa/4.0/)*
用这个系统进行自制酿酒是容易的,我能够依靠它掌握可靠的温度,我能输入多个温度段来控制麦芽浆温度,用CraftbeerPi 酿酒的日子有一点点累,但是我很高兴用传统的手工管理丙烷燃烧器的“兴奋”来换取这个系统的有效性和持续性。
CraftBeerPI 的用户友好性鼓舞我设置了另一个控制器来运行“发酵室”。就我来说,那是一个二手冰箱,我用了 50 美元加上放在里面的 25 美元的加热器。CraftBeerPI 很容易控制电器元件的冷热,你也能够设置多个温度阶段。举个例子,这个图表显示我最近做的 IPA 进程的发酵温度。发酵室发酵麦芽汁在 67F° 的温度下需要 4 天,然后每 12 小时上升一度直到温度到达 72F°。剩下两天温度保持不变是为了双乙酰生成。之后 5 天温度降到 65F°,这段时间是让啤酒变“干”,最后啤酒发酵温度直接降到 38F°。CraftBeerPI 可以加入各个阶段,让软件管理发酵更加容易。

*SIPA 发酵设置 (photo by Christopher Aedo. [CC BY-SA 4.0)](https://creativecommons.org/licenses/by-sa/4.0/)*
我也试验过用[液体比重计](https://tilthydrometer.com/)来对酵啤酒的比重进行监测,通过蓝牙连接的浮动传感器可以达到。有一个整合的计划能让 CraftbeerPi 很好工作,现在它记录这些比重数据到谷歌的电子表格里。一旦这个液体比重计能连接到发酵控制器,设置的自动发酵设置会基于酵母的活动性直接运行且更加容易,而不是在 4 天内完成主要发酵,可以在比重稳定 24 小时后设定温度。
像这样的一些项目,构想并计划改进和增加组件是很容易,不过,我很高兴今天经历过的事情。我用这种装置酿造了很多啤酒,每次都能达到预期的麦芽汁比率,而且啤酒一直都很美味。我的最重要的消费者 —— 就是我!很高兴我可以随时饮用。

*随时饮用 (photo by Christopher Aedo. [CC BY-SA 4.0)](https://creativecommons.org/licenses/by-sa/4.0/)*
这篇文章基于 Christopher 的开放的西部的讲话《用Linux、Python 和树莓派酿制啤酒》。
(题图:[Quinn Dombrowski](https://www.flickr.com/photos/quinndombrowski/). Modified by Opensource.com. [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/))
---
作者简介:
Christopher Aedo 从他的学生时代就从事并且贡献于开源软件事业。最近他在 IBM 领导一个极棒的上游开发者团队,同时他也是开发者拥护者。当他不再工作或者实在会议室演讲的时候,他可能在波特兰市俄勒冈州用树莓派酿制和发酵一杯美味的啤酒。
---
via: <https://opensource.com/article/17/7/brewing-beer-python-and-raspberry-pi>
作者:[Christopher Aedo](https://opensource.com/users/docaedo) 译者:[hwlife](https://github.com/hwlife) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I started brewing my own beer more than 10 years ago. Like most homebrewers, I started in my kitchen making extract-based brews. This required the least equipment and still resulted in really tasty beer. Eventually I stepped up to all-grain brewing using a big cooler for my mash tun. For several years I was brewing 5 gallons at a time, but brewing 10 gallons takes the same amount of time and effort (and only requires slightly larger equipment), so a few years ago I stepped it up. After moving up to 10 gallons, I stumbled across [StrangeBrew Elsinore](https://github.com/DougEdey/SB_Elsinore_Server) and realized what I *really* needed to do was convert my whole system to be all-electric, and run it with a [Raspberry Pi](https://opensource.com/tags/raspberry-pi).
There is a ton of great information available for building your own all-electric homebrew system, and most brewers start out at [TheElectricBrewery.com](http://www.theelectricbrewery.com/). Just putting together the control panel can get pretty complicated, although the simplest approach is outlined well there. Of course you can also take [a less expensive approach](http://www.instructables.com/id/Electric-Brewery-Control-Panel-on-the-Cheap/) and still end up with the same result—a boil kettle and hot liquor tank powered by heating elements and managed by a PID controller. I think that's a little too boring though (and it also means you don't get neat graphs of your brew process).
## Hardware supplies
Before I talked myself out of the project, I decided to start buying parts. My basic design was a Hot Liquor Tank (HLT) and boil kettle with 5500w heating elements in them, plus a mash tun with a false bottom. I would use a pump to recirculate the mash through a 50' stainless coil in the HLT (a ["heat exchanger recirculating mash system", known as HERMS](https://byo.com/hops/item/1325-rims-and-herms-brewing-advanced-homebrewing)). I would need a second pump to circulate the water in the HLT, and to help with transferring water to the mash tun. All of the electrical components would be controlled with a Raspberry Pi.
Building my electric brew system and automating as much of it as possible meant I was going to need the following:
- HLT with a 5500w electric heating element
- HERMS coil (50' 1/2" stainless steel) in the HLT
- boil kettle with a 5500w electric heating element
- multiple solid-state relays to switch the heaters on and off
- 2 high-temp food-grade pumps
- relays for switching the pumps on and off
- fittings and high-temp silicon tubing
- stainless ball valves
- 1-wire temperature probes
- lots of wire
- electrical box to hold everything

Brew system (photo by Christopher Aedo. [CC BY-SA 4.0)](https://creativecommons.org/licenses/by-sa/4.0/)
The details of building out the electrical side of the system are really well covered by [The Electric Brewery](http://theelectricbrewery.com), so I won't repeat their detailed information. You can read through and follow their suggestions while planning to replace the PID controllers with a Raspberry Pi.
One important thing to note is the solid-state relay (SSR) signal voltage. Many tutorials suggest using SSRs that need a 12-volt signal to close the circuit. The Raspberry Pi GPIO pins will only output 3v, however. Be sure to purchase relays that will trigger on 3 volts.

Inkbird SSR (photo by Christopher Aedo. [CC BY-SA 4.0)](https://creativecommons.org/licenses/by-sa/4.0/)
To run your brew system, your Pi must do two key things: sense temperature from a few different places, and turn relays on and off to control the heating elements. The Raspberry Pi easily is able to handle these tasks.
There are a few different ways to connect temp sensors to a Pi, but I've found the most convenient approach is to use the [1-Wire bus](https://en.wikipedia.org/wiki/1-Wire). This allows for multiple sensors to share the same wire (actually three wires), which makes it a convenient way to instrument multiple components in your brew system. If you look for waterproof DS18B20 temperature sensors online, you'll find lots of options available. I used [Hilitchi DS18B20 Waterproof Temperature Sensors](https://smile.amazon.com/gp/product/B018KFX5X0/) for my project.
To control the heating elements, the Raspberry Pi includes several General Purpose IO (GPIO) pins that are software addressable. This allows you to send 3.3v to a relay by simply putting a **1** or a **0** in a file. The [ Raspberry Pi—Driving a Relay using GPIO] tutorial was the most helpful for me when I was first learning how all this worked. The GPIO controls multiple solid-state relays, turning on and off the heating elements as directed by the brewing software.
I first started working on the box to hold all the components. Because this would all be on a rolling cart, I wanted it to be relatively portable rather than permanently mounted. If I had a spot (for example, inside a garage, utility room, or basement), I would have used a larger electrical box mounted on the wall. Instead I found a decent-size [waterproof project box](http://amzn.to/2hupFCr) that I expected I could shoehorn everything into. In the end, it turned out to be a little bit of a tight fit, but it worked out. In the bottom left corner is the Pi with a breakout board for connecting the GPIO to the 1-Wire temperature probes and the [solid state relays](http://amzn.to/2hL8JDS).
To keep the 240v SSRs cool, I cut holes in the case and stacked [copper shims](http://amzn.to/2i4DYwy) with CPU cooling grease between them and heat sinks mounted on the outside of the box. It worked out well and there haven't been any cooling issues inside the box. On the cover I put two switches for 120v outlets, plus two 240v LEDs to show which heating element was energized. I used dryer plugs and outlets for all connections so disconnecting a kettle from everything is easy. Everything worked right on the first try, too. (Sketching a wiring diagram first definitely pays off.)
The pictures are from the "proof-of-concept" version—the final production system should have two more SSRs so that both legs of the 240v circuit would be switched. The other thing I would like to switch via software is the pumps. Right now they're controlled via physical switches on the front of the box, but they could easily be controlled with relays.

Control box (photo by Christopher Aedo. [CC BY-SA 4.0)](https://creativecommons.org/licenses/by-sa/4.0/)
The only other thing I needed that was a little tricky to find was a compression fitting for the temperature probes. The probes were mounted in T fittings before the valve on the lowest bulkhead in both the HLT and the mash tun. As long as the liquid is flowing past the temp sensor, it's going to be accurate. I thought about adding a thermowell into the kettles as well, but realized that's not going to be useful for me based on my brewing process. Anyway, I purchased [1/4" compression fittings](https://www.brewershardware.com/CF1412.html) and they worked out perfectly.
## Software
Once the hardware was sorted out, I had time to play with the software. I ran the latest [Pi OS](https://www.raspberrypi.org/software/operating-systems/). Nothing special is required on the operating-system side.
I started with [Strangebrew Elsinore](https://github.com/DougEdey/SB_Elsinore_Server) brewing software, which I had discovered when a friend asked whether I had heard of [Hosehead](https://brewtronix.com/), a Raspberry Pi-based brewing controller. I thought Hosehead looked great, but rather than buying a brewing controller, I wanted the challenge of building my own.
Setting up Strangebrew Elsinore was straightforward—the [documentation](http://dougedey.github.io/SB_Elsinore_Server/) was thorough and I did not encounter any problems. Even though Strangebrew Elsinore was working fine, Java seemed to be taxing my first-generation Pi sometimes, and it crashed on me more than once. I also was sad to see development stall and there did not seem to be a big community of additional contributors (although there were—and still are—plenty of people using it).
### CraftBeerPi
Then I stumbled across [CraftBeerPI](http://www.craftbeerpi.com/), which is written in Python and supported by a development community of active contributors. The original author (and current maintainer) Manuel Fritsch is great about handling contributions and giving feedback on issues that folks open. Cloning [the repo](https://github.com/manuel83/craftbeerpi) and getting started only took me a few minutes. The README also has a good example of connecting DS1820 temp sensors, along with notes on interfacing hardware to a Pi or a [C.H.I.P. computer](https://www.nextthing.co/pages/chip).
On startup, CraftBeerPi walks users through a configuration process that discovers the temperature probes available and lets you specify which GPIO pins are managing which pieces of equipment.
CraftBeerPi (photo by Christopher Aedo. [CC BY-SA 4.0)](https://creativecommons.org/licenses/by-sa/4.0/)
Running a brew with this system is easy. I can count on it holding temperatures reliably, and I can input steps for a multi-temp step mash. Using CraftBeerPi has made my brew days a little bit boring, but I'm happy to trade off the "excitement" of traditional manually managed propane burners for the efficiency and consistency of this system.
CraftBeerPI's user-friendliness inspired me to set up another controller to run a "fermentation chamber." In my case, that was a second-hand refrigerator I found for US$ 50 plus a $25 heater) on the inside. CraftBeerPI easily can control the cooling and heating elements, and you can set up multiple temperature steps. For instance, this graph shows the fermentation temperatures for a session IPA I made recently. The fermentation chamber held the fermenting wort at 67F for four days, then ramped up one degree every 12 hours until it was at 72F. That temp was held for a two-day diacetyl rest. After that it was set to drop down to 65F for five days, during which time I "dry hopped" the beer. Finally, the beer was cold-crashed down to 38F. CraftBeerPI made adding each step and letting the software manage the fermentation easy.
SIPA fermentation profile (photo by Christopher Aedo. [CC BY-SA 4.0)](https://creativecommons.org/licenses/by-sa/4.0/)
I have also been experimenting with the [TILT hydrometer](https://tilthydrometer.com/) to monitor the gravity of the fermenting beer via a Bluetooth-connected floating sensor. There are integration plans for this to get it working with CraftBeerPI, but for now it logs the gravity to a Google spreadsheet. Once this hydrometer can talk to the fermentation controller, setting automated fermentation profiles that take action directly based on the yeast activity would be easy—rather than banking on primary fermentation completing in four days, you can set the temperature ramp to kick off after the gravity is stable for 24 hours.
As with any project like this, imaging and planning improvements and additional components is easy. Still, I'm happy with where things stand today. I've brewed a lot of beer with this setup and am hitting the expected mash efficiency every time, and the beer has been consistently tasty. My most important customer—me!—is pleased with what I've been putting on tap in my kitchen.

Homebrew on tap (photo by Christopher Aedo. [CC BY-SA 4.0)](https://creativecommons.org/licenses/by-sa/4.0/)
*This article is based on Christopher's OpenWest talk, Brewing Beer with Linux, Python and a RaspberryPi. OpenWest will be held July 12-15, 2017 in Salt Lake City, Utah.*
## 4 Comments |
8,943 | 开发一个 Linux 调试器(十):高级主题 | https://blog.tartanllama.xyz/writing-a-linux-debugger-advanced-topics/ | 2017-10-12T10:38:00 | [
"调试器",
"调试"
] | https://linux.cn/article-8943-1.html | 
我们终于来到这个系列的最后一篇文章!这一次,我将对调试中的一些更高级的概念进行高层的概述:远程调试、共享库支持、表达式计算和多线程支持。这些想法实现起来比较复杂,所以我不会详细说明如何做,但是如果你有问题的话,我很乐意回答有关这些概念的问题。
### 系列索引
1. [准备环境](/article-8626-1.html)
2. [断点](/article-8645-1.html)
3. [寄存器和内存](/article-8663-1.html)
4. [Elves 和 dwarves](/article-8719-1.html)
5. [源码和信号](/article-8812-1.html)
6. [源码层逐步执行](/article-8813-1.html)
7. [源码层断点](/article-8890-1.html)
8. [调用栈](/article-8930-1.html)
9. [处理变量](/article-8936-1.html)
10. [高级主题](https://blog.tartanllama.xyz/writing-a-linux-debugger-advanced-topics/)
### 远程调试
远程调试对于嵌入式系统或对不同环境进行调试非常有用。它还在高级调试器操作和与操作系统和硬件的交互之间设置了一个很好的分界线。事实上,像 GDB 和 LLDB 这样的调试器即使在调试本地程序时也可以作为远程调试器运行。一般架构是这样的:

调试器是我们通过命令行交互的组件。也许如果你使用的是 IDE,那么在其上有另一个层可以通过*机器接口*与调试器进行通信。在目标机器上(可能与本机一样)有一个<ruby> 调试存根 <rt> debug stub </rt></ruby> ,理论上它是一个非常小的操作系统调试库的包装程序,它执行所有的低级调试任务,如在地址上设置断点。我说“在理论上”,因为如今调试存根变得越来越大。例如,我机器上的 LLDB 调试存根大小是 7.6MB。调试存根通过使用一些特定于操作系统的功能(在我们的例子中是 `ptrace`)和被调试进程以及通过远程协议的调试器通信。
最常见的远程调试协议是 GDB 远程协议。这是一种基于文本的数据包格式,用于在调试器和调试存根之间传递命令和信息。我不会详细介绍它,但你可以在[这里](https://sourceware.org/gdb/onlinedocs/gdb/Remote-Protocol.html)进一步阅读。如果你启动 LLDB 并执行命令 `log enable gdb-remote packets`,那么你将获得通过远程协议发送的所有数据包的跟踪信息。在 GDB 上,你可以用 `set remotelogfile <file>` 做同样的事情。
作为一个简单的例子,这是设置断点的数据包:
```
$Z0,400570,1#43
```
`$` 标记数据包的开始。`Z0` 是插入内存断点的命令。`400570` 和 `1` 是参数,其中前者是设置断点的地址,后者是特定目标的断点类型说明符。最后,`#43` 是校验值,以确保数据没有损坏。
GDB 远程协议非常易于扩展自定义数据包,这对于实现平台或语言特定的功能非常有用。
### 共享库和动态加载支持
调试器需要知道被调试程序加载了哪些共享库,以便它可以设置断点、获取源代码级别的信息和符号等。除查找被动态链接的库之外,调试器还必须跟踪在运行时通过 `dlopen` 加载的库。为了达到这个目的,动态链接器维护一个 *交汇结构体*。该结构体维护共享库描述符的链表,以及一个指向每当更新链表时调用的函数的指针。这个结构存储在 ELF 文件的 `.dynamic` 段中,在程序执行之前被初始化。
一个简单的跟踪算法:
* 追踪程序在 ELF 头中查找程序的入口(或者可以使用存储在 `/proc/<pid>/aux` 中的辅助向量)。
* 追踪程序在程序的入口处设置一个断点,并开始执行。
* 当到达断点时,通过在 ELF 文件中查找 `.dynamic` 的加载地址找到交汇结构体的地址。
* 检查交汇结构体以获取当前加载的库的列表。
* 链接器更新函数上设置断点。
* 每当到达断点时,列表都会更新。
* 追踪程序无限循环,继续执行程序并等待信号,直到追踪程序信号退出。
我给这些概念写了一个小例子,你可以在[这里](https://github.com/TartanLlama/dltrace)找到。如果有人有兴趣,我可以将来写得更详细一点。
### 表达式计算
表达式计算是程序的一项功能,允许用户在调试程序时对原始源语言中的表达式进行计算。例如,在 LLDB 或 GDB 中,可以执行 `print foo()` 来调用 `foo` 函数并打印结果。
根据表达式的复杂程度,有几种不同的计算方法。如果表达式只是一个简单的标识符,那么调试器可以查看调试信息,找到该变量并打印出该值,就像我们在本系列最后一部分中所做的那样。如果表达式有点复杂,则可能将代码编译成中间表达式 (IR) 并解释来获得结果。例如,对于某些表达式,LLDB 将使用 Clang 将表达式编译为 LLVM IR 并将其解释。如果表达式更复杂,或者需要调用某些函数,那么代码可能需要 JIT 到目标并在被调试者的地址空间中执行。这涉及到调用 `mmap` 来分配一些可执行内存,然后将编译的代码复制到该块并执行。LLDB 通过使用 LLVM 的 JIT 功能来实现。
如果你想更多地了解 JIT 编译,我强烈推荐 [Eli Bendersky 关于这个主题的文章](http://eli.thegreenplace.net/tag/code-generation)。
### 多线程调试支持
本系列展示的调试器仅支持单线程应用程序,但是为了调试大多数真实程序,多线程支持是非常需要的。支持这一点的最简单的方法是跟踪线程的创建,并解析 procfs 以获取所需的信息。
Linux 线程库称为 `pthreads`。当调用 `pthread_create` 时,库会使用 `clone` 系统调用来创建一个新的线程,我们可以用 `ptrace` 跟踪这个系统调用(假设你的内核早于 2.5.46)。为此,你需要在连接到调试器之后设置一些 `ptrace` 选项:
```
ptrace(PTRACE_SETOPTIONS, m_pid, nullptr, PTRACE_O_TRACECLONE);
```
现在当 `clone` 被调用时,该进程将收到我们的老朋友 `SIGTRAP` 信号。对于本系列中的调试器,你可以将一个例子添加到 `handle_sigtrap` 来处理新线程的创建:
```
case (SIGTRAP | (PTRACE_EVENT_CLONE << 8)):
//get the new thread ID
unsigned long event_message = 0;
ptrace(PTRACE_GETEVENTMSG, pid, nullptr, message);
//handle creation
//...
```
一旦收到了,你可以看看 `/proc/<pid>/task/` 并查看内存映射之类来获得所需的所有信息。
GDB 使用 `libthread_db`,它提供了一堆帮助函数,这样你就不需要自己解析和处理。设置这个库很奇怪,我不会在这展示它如何工作,但如果你想使用它,你可以去阅读[这个教程](http://timetobleed.com/notes-about-an-odd-esoteric-yet-incredibly-useful-library-libthread_db/)。
多线程支持中最复杂的部分是调试器中线程状态的建模,特别是如果你希望支持[不间断模式](https://sourceware.org/gdb/onlinedocs/gdb/Non_002dStop-Mode.html)或当你计算中涉及不止一个 CPU 的某种异构调试。
### 最后!
呼!这个系列花了很长时间才写完,但是我在这个过程中学到了很多东西,我希望它是有帮助的。如果你有关于调试或本系列中的任何问题,请在 Twitter [@TartanLlama](https://twitter.com/TartanLlama)或评论区联系我。如果你有想看到的其他任何调试主题,让我知道我或许会再发其他的文章。
---
via: <https://blog.tartanllama.xyz/writing-a-linux-debugger-advanced-topics/>
作者:[Simon Brand](https://www.twitter.com/TartanLlama) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Writing a Linux Debugger Part 10: Advanced topics
*This series has been expanded into a book! It covers many more topics in much greater detail. You can now pre-order Building a Debugger.*
We’re finally here at the last post of the series! This time I’ll be giving a high-level overview of some more advanced concepts in debugging: remote debugging, shared library support, expression evaluation, and multi-threaded support. These ideas are more complex to implement, so I won’t walk through how to do so in detail, but I’m happy to answer questions about these concepts if you have any.
### Series index
[Setup](/writing-a-linux-debugger-setup/)[Breakpoints](/writing-a-linux-debugger-breakpoints/)[Registers and memory](/writing-a-linux-debugger-registers/)[Elves and dwarves](/writing-a-linux-debugger-elf-dwarf/)[Source and signals](/writing-a-linux-debugger-source-signal/)[Source-level stepping](/writing-a-linux-debugger-dwarf-step/)[Source-level breakpoints](/writing-a-linux-debugger-source-break/)[Stack unwinding](/writing-a-linux-debugger-unwinding/)[Handling variables](/writing-a-linux-debugger-variables/)[Advanced topics](/writing-a-linux-debugger-advanced-topics/)
### Remote debugging
Remote debugging is very useful for embedded systems or debugging the effects of environment differences. It also sets a nice divide between the high-level debugger operations and the interaction with the operating system and hardware. In fact, debuggers like GDB and LLDB operate as remote debuggers even when debugging local programs. The general architecture is this:
The debugger is the component which we interact with through the command line. Maybe if you’re using an IDE there’ll be another layer on top which communicates with the debugger through the *machine interface*. On the target machine (which may be the same as the host) there will be a *debug stub*, which in theory is a very small wrapper around the OS debug library which carries out all of your low-level debugging tasks like setting breakpoints on addresses. I say “in theory” because stubs are getting larger and larger these days. The LLDB debug stub on my machine is 7.6MB, for example. The debug stub communicates with the debugee process using some OS-specific features (in our case, `ptrace`
), and with the debugger though some remote protocol.
The most common remote protocol for debugging is the GDB remote protocol. This is a text-based packet format for communicating commands and information between the debugger and debug stub. I won’t go into detail about it, but you can read all you could want to know about it [here](https://sourceware.org/gdb/onlinedocs/gdb/Remote-Protocol.html). If you launch LLDB and execute the command `log enable gdb-remote packets`
then you’ll get a trace of all packets sent through the remote protocol. On GDB you can write `set remotelogfile <file>`
to do the same.
As a simple example, here’s the packet to set a breakpoint:
```
$Z0,400570,1#43
```
`$`
marks the start of the packet. `Z0`
is the command to insert a memory breakpoint. `400570`
and `1`
are the argumets, where the former is the address to set a breakpoint on and the latter is a target-specific breakpoint kind specifier. Finally, the `#43`
is a checksum to ensure that there was no data corruption.
The GDB remote protocol is very easy to extend for custom packets, which is very useful for implementing platform- or language-specific functionality.
### Shared library and dynamic loading support
The debugger needs to know what shared libraries have been loaded by the debuggee so that it can set breakpoints, get source-level information and symbols, etc. As well as finding libraries which have been dynamically linked against, the debugger must track libraries which are loaded at runtime through `dlopen`
. To facilitate this, the dynamic linker maintains a *rendezvous structure*. This structure maintains a linked list of shared library descriptors, along with a pointer to a function which is called whenever the linked list is updated. This structure is stored where the `.dynamic`
section of the ELF file is loaded, and is initialized before program execution.
A simple tracing algorithm is this:
- The tracer looks up the entry point of the program in the ELF header (or it could use the auxillary vector stored in
`/proc/<pid>/aux`
) - The tracer places a breakpoint on the entry point of the program and begins execution.
- When the breakpoint is hit, the address of the rendezvous structure is found by looking up the load address of
`.dynamic`
in the ELF file. - The rendezvous structure is examined to get the list of currently loaded libraries.
- A breakpoint is set on the linker update function.
- Whenever the breakpoint is hit, the list is updated.
- The tracer infinitely loops, continuing the program and waiting for a signal until the tracee signals that it has exited.
I’ve written a small demonstration of these concepts, which you can find [here](https://github.com/TartanLlama/dltrace). I can do a more detailed write up of this in the future if anyone is interested.
### Expression evaluation
Expression evaluation is a feature which lets users evaluate expressions in the original source language while debugging their application. For example, in LLDB or GDB you could execute `print foo()`
to call the `foo`
function and print the result.
Depending on how complex the expression is, there are a few different ways of evaluating it. If the expression is a simple identifier, then the debugger can look at the debug information, locate the variable and print out the value, just like we did in the last part of this series. If the expression is a bit more complex, then it may be possible to compile the code to an intermediate representation (IR) and interpret that to get the result. For example, for some expressions LLDB will use Clang to compile the expression to LLVM IR and interpret that. If the expression is even more complex, or requires calling some function, then the code might need to be JITted to the target and executed in the address space of the debuggee. This involves calling `mmap`
to allocate some executable memory, then the compiled code is copied to this block and is executed. LLDB does this by using LLVM’s JIT functionality.
If you want to know more about JIT compilation, I’d highly recommend [Eli Bendersky’s posts on the subject](http://eli.thegreenplace.net/tag/code-generation).
### Multi-threaded debugging support
The debugger shown in this series only supports single threaded applications, but to debug most real-world applications, multi-threaded support is highly desirable. The simplest way to support this is to trace thread creation and parse the procfs to get the information you want.
The Linux threading library is called `pthreads`
. When `pthread_create`
is called, the library creates a new thread using the `clone`
syscall, and we can trace this syscall with `ptrace`
(assuming your kernel is older than 2.5.46). To do this, you’ll need to set some `ptrace`
options after attaching to the debuggee:
`ptrace(PTRACE_SETOPTIONS, m_pid, nullptr, PTRACE_O_TRACECLONE);`
Now when `clone`
is called, the process will be signaled with our old friend `SIGTRAP`
. For the debugger in this series, you can add a case to `handle_sigtrap`
which can handle the creation of the new thread:
```
case (SIGTRAP | (PTRACE_EVENT_CLONE << 8)):
//get the new thread ID
unsigned long event_message = 0;
ptrace(PTRACE_GETEVENTMSG, pid, nullptr, message);
//handle creation
//...
```
Once you’ve got that, you can look in `/proc/<pid>/task/`
and read the memory maps and suchlike to get all the information you need.
GDB uses `libthread_db`
, which provides a bunch of helper functions so that you don’t need to do all the parsing and processing yourself. Setting up this library is pretty weird and I won’t show how it works here, but you can go and read [this tutorial](http://timetobleed.com/notes-about-an-odd-esoteric-yet-incredibly-useful-library-libthread_db/) if you’d like to use it.
The most complex part of multithreaded support is modelling the thread state in the debugger, particularly if you want to support [non-stop mode](https://sourceware.org/gdb/onlinedocs/gdb/Non_002dStop-Mode.html) or some kind of heterogeneous debugging where you have more than just a CPU involved in your computation.
### The end!
Whew! This series took a long time to write, but I learned a lot in the process and I hope it was helpful. Get in touch on Twitter [@TartanLlama](https://twitter.com/TartanLlama) or in the comments section if you want to chat about debugging or have any questions about the series. If there are any other debugging topics you’d like to see covered then let me know and I might do a bonus post.
Let me know what you think of this article on twitter
[@TartanLlama](https://www.twitter.com/TartanLlama)or leave a comment below! |
8,944 | 进入 Linux 桌面之窗 | http://www.linuxinsider.com/story/84473.html | 2017-10-09T10:45:45 | [
"桌面环境",
"窗口管理器"
] | https://linux.cn/article-8944-1.html |
>
> “它能做什么 Windows 不能做的吗?”
>
>
>
这是许多人在考虑使用 Linux 桌面时的第一个问题。虽然支撑 Linux 的开源哲学对于某些人来说就是一个很好的理由,但是有些人想知道它在外观、感受和功能上有多么不同。在某种程度上,这取决于你是否选择桌面环境或窗口管理器。
如果你想要的是闪电般快速的桌面体验且向高效妥协, 那么经典桌面中的窗口管理器可能适合你。

### 事实之真相
“<ruby> 桌面环境 <rt> Desktop Environment </rt></ruby>(DE)”是一个技术术语,指典型的、全功能桌面,即你的操作系统的完整图形化布局。除了显示你的程序,桌面环境还包括应用程序启动器,菜单面板和小部件等组成部分。
在 Microsoft Windows 中,桌面环境包括开始菜单、显示打开的程序的任务栏和通知中心,还有与操作系统捆绑在一起的所有 Windows 程序,以及围绕这打开的程序的框架(包括右上角的最小按钮、最大按钮和关闭按钮)。
Linux 中有很多相似之处。
例如,Linux [Gnome](http://en.wikipedia.org/wiki/GNOME) 桌面环境的设计略有不同,但它共享了所有的 Microsoft Windows 的基本元素 - 从应用程序菜单到显示打开的应用程序的面板、通知栏、窗框式程序。
窗口程序框架依赖于一个组件来绘制它们,并允许你移动并调整大小:它被称为“<ruby> 窗口管理器 <rt> Window Manager </rt></ruby>(WM)”。因为它们都有窗口,所以每个桌面环境都包含一个窗口管理器。
然而,并不是每个窗口管理器都是桌面环境的一部分。你可以只运行窗口管理器,并且完全有这么做的需要。
### 离开你的环境
对本专栏而言,所谓的“窗口管理器”指的是可以那种独立进行的。如果在现有的 Linux 系统上安装了一个窗口管理器,你可以在不关闭系统的情况下注销,在登录屏幕上选择新的窗口管理器,然后重新登录。
不过, 在研究你的窗口管理器之前,你可能不想这么做,因为你将会看到一个空白屏幕和稀疏的状态栏,而且它或许能、或许不能点击。
通常情况下,可以直接在窗口管理器中直接启动终端,因为这是你编辑其配置文件的方式。在那里你会发现用来启动程序的按键和鼠标组合,你实际上也可以使用你的新设置。
例如,在流行的 i3 窗口管理器中,你可以通过按下 `Super` 键(即 `Windows` 键)加 `Enter` 键来启动终端,或者按 `Super + D` 启动<ruby> 应用程序启动器 <rt> app launcher </rt></ruby>。你可以在其中输入应用程序名称,然后按 `Enter` 键将其打开。所有已有的应用程序都可以通过这种方式找到,一旦选择后,它们将会全屏打开。
[](http://www.linuxinsider.com/article_images/2017/84473_1200x750.jpg)
i3 还是一个平铺式窗口管理器,这意味着它可以确保所有的窗口均匀地扩展到屏幕,既不重叠也不浪费空间。当弹出新窗口时,它会减少现有的窗口,将它们推到一边腾出空间。用户可以以垂直或水平相邻的方式打开下一个窗口。
### 功能亦敌亦友
当然,桌面环境有其优点。首先,它们提供功能丰富、可识别的界面。每个都有其特征鲜明的风格,但总体而言,它们提供了普适的默认设置,这使得桌面环境从一开始就可以使用。
另一个优点是桌面环境带有一组程序和媒体编解码器,允许用户立即完成简单的任务。此外,它们还包括一些方便的功能,如电池监视器、无线小部件和系统通知。
与桌面环境的完善相应的,是这种大型软件库和用户体验理念独一无二,这就意味着它们所能做的都是有限度的。这也意味着它们并不总是非常可配置。桌面环境强调的是漂亮的外表,很多时候是金玉其外的。
许多桌面环境对系统资源的渴求是众所周知的,所以它们不太喜欢低端硬件。因为在其上运行的视觉效果,还有更多的东西可能会出错。我曾经尝试调整与我正在运行的桌面环境无关的网络设置,然后整个崩溃了。而当我打开一个窗口管理器,我就可以改变设置。
那些优先考虑安全性的人可能希望不要桌面环境,因为更多的程序意味着更大的攻击面 —— 也就是坏人可以突破的入口点。
然而,如果你想尝试一下桌面环境,XFCE 是一个很好的起点,因为它的较小的软件库消除了一些臃肿,如果你不往里面塞东西,垃圾就会更少。
乍一看,它不是最漂亮的,但在下载了一些 GTK 主题包(每个桌面环境都可以提供这些主题或 Qt 主题,而 XFCE 在 GTK 阵营之中),并且在“外观”部分的设置中,你可以轻松地修改。你甚至可以在这个[集中式画廊](http://www.xfce-look.org/)中找到你最喜欢的主题。
### 时间就是生命
如果你想了解桌面环境之外可以做什么,你会发现窗口管理器给了你足够的回旋余地。
无论如何,窗口管理器都是与定制有关的。事实上,它们的可定制性已经催生了无数的画廊,承载着一个充满活力的社区用户,他们手中的调色板就是窗口管理器。
窗口管理器的少量资源需求使它们成为较低规格硬件的理想选择,并且由于大多数窗口管理器不附带任何程序,因此允许喜欢模块化的用户只添加所需的程序。
可能与桌面环境最为显著的区别是,窗口管理器通常通过鼠标移动和键盘热键来打开程序或启动器来聚焦效率。
键盘驱动的窗口管理器特别流畅,你可以启动新的窗口、输入文本或更多的键盘命令、移动它们,并再次关闭它们,这一切无需将手从<ruby> 键盘中间 <rt> home row </rt></ruby>移开。一旦你适应了其设计逻辑,你会惊讶于你能够如此快速地完成任务。
尽管它们提供了自由,窗口管理器也有其缺点。最显著的是,它们是赤裸裸的开箱即用。在你可以使用其中一个之前,你必须花时间阅读窗口管理器的文档以获取配置语法,可能还需要更多的时间来找到该语法的窍门。
如果你从桌面环境(这是最可能的情况)切换过来,尽管你会有一些用户程序,你也会缺少一些熟悉的东西,如电池指示器和网络小部件,并且需要一些时间来设置新的。
如果你想深入窗口管理器,i3 有[完整的文档](https://i3wm.org/docs/)和简明直白的配置语法。配置文件不使用任何编程语言 - 它只是每行定义一个变量值对。创建热键只要输入 `bindsym`、键盘绑定以及该组合启动的动作即可。
虽然窗口管理器不适合每个人,但它们提供了独特的计算体验,而 Linux 是少数允许使用它们的操作系统之一。无论你最终采用哪种模式,我希望这个概观能够给你足够的信息,以便对你所做的选择感到自信 —— 或者有足够的信心跨出您熟悉的区域来看看还有什么可用的。
---
作者简介:
Jonathan Terrasi - 自 2017 年以来一直是 ECT 新闻网专栏作家。他的主要兴趣是计算机安全(特别是 Linux 桌面)、加密和分析政治和时事。他是全职自由作家和音乐家。他的背景包括在芝加哥委员会发表的关于维护人权法案的文章中提供技术评论和分析。
---
via: <http://www.linuxinsider.com/story/84473.html>
作者:[Jonathan Terrasi](%5B1%5D:http://www.linuxinsider.com/story/84473.html?rss=1#) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
8,945 | 通过 SSH 实现 TCP / IP 隧道(端口转发):使用 OpenSSH 可能的 8 种场景 | https://wesharethis.com/2017/07/creating-tcp-ip-port-forwarding-tunnels-ssh-8-possible-scenarios-using-openssh/ | 2017-10-09T23:31:00 | [
"隧道",
"SSH"
] | /article-8945-1.html | 
对于 [Secure Shell (SSH)](http://en.wikipedia.org/wiki/Secure_Shell) 这样的网络协议来说,其主要职责就是在终端模式下访问一个远程系统。因为 SSH 协议对传输数据进行了加密,所以通过它在远端系统执行命令是安全的。此外,我们还可以在这种加密后的连接上通过创建隧道(端口转发)的方式,来实现两个不同终端间的互联。凭借这种方式,只要我们能通过 SSH 创建连接,就可以绕开防火墙或者端口禁用的限制。
这个话题在网络领域有大量的应用和讨论:
* [Wikipedia: SSH Tunneling](http://en.wikipedia.org/wiki/Tunneling_protocol#SSH_tunneling)
* [O’Reilly: Using SSH Tunneling](http://www.oreillynet.com/pub/a/wireless/2001/02/23/wep.html)
* [Ssh.com: Tunneling Explained](http://www.ssh.com/support/documentation/online/ssh/winhelp/32/Tunneling_Explained.html)
* [Ssh.com: Port Forwarding](http://www.ssh.com/support/documentation/online/ssh/adminguide/32/Port_Forwarding.html)
* [SecurityFocus: SSH Port Forwarding](http://www.securityfocus.com/infocus/1816)
* [Red Hat Magazine: SSH Port Forwarding](http://magazine.redhat.com/2007/11/06/ssh-port-forwarding/)
我们在接下来的内容中并不讨论端口转发的细节,而是准备介绍一个如何使用 [OpenSSH](http://www.openssh.com/) 来完成 TCP 端口转发的速查表,其中包含了八种常见的场景。有些 SSH 客户端,比如 [PuTTY](http://www.chiark.greenend.org.uk/%7Esgtatham/putty/),也允许通过界面配置的方式来实现端口转发。而我们着重关注的是通过 OpenSSH 来实现的的方式。
在下面的例子当中,我们假设环境中的网络划分为外部网络(network1)和内部网络(network2)两部分,并且这两个网络之间,只能在 externo1 与 interno1 之间通过 SSH 连接的方式来互相访问。外部网络的节点之间和内部网络的节点之间是完全联通的。

### 场景 1
>
> 在 externo1 节点访问由 interno1 节点提供的 TCP 服务(本地端口转发 / 绑定地址 = localhost / 主机 = localhost )
>
>
>
externo1 节点可以通过 OpenSSH 连接到 interno1 节点,之后我们想通过其访问运行在 5900 端口上的 VNC 服务。

我们可以通过下面的命令来实现:
```
externo1 $ ssh -L 7900:localhost:5900 user@interno1
```
现在,我们可以在 externo1 节点上确认下 7900 端口是否处于监听状态中:
```
externo1 $ netstat -ltn
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State
...
Tcp 0 0 127.0.0.1:7900 0.0.0.0:* LISTEN
...
```
我们只需要在 externo1 节点上执行如下命令即可访问 internal 节点的 VNC 服务:
```
externo1 $ vncviewer localhost::7900
```
注意:在 [vncviewer 的 man 手册](http://www.realvnc.com/products/free/4.1/man/vncviewer.html)中并未提及这种修改端口号的方式。在 [About VNCViewer configuration of the output TCP port](http://www.realvnc.com/pipermail/vnc-list/2006-April/054551.html) 中可以看到。这也是 [the TightVNC vncviewer](http://www.tightvnc.com/vncviewer.1.html) 所介绍的的。
### 场景 2
>
> 在 externo2 节点上访问由 interno1 节点提供的 TCP 服务(本地端口转发 / 绑定地址 = 0.0.0.0 / 主机 = localhost)
>
>
>
这次的场景跟方案 1 的场景的类似,但是我们这次想从 externo2 节点来连接到 interno1 上的 VNC 服务:

正确的命令如下:
```
externo1 $ ssh -L 0.0.0.0:7900:localhost:5900 user@interno1
```
看起来跟方案 1 中的命令类似,但是让我们看看 `netstat` 命令的输出上的区别。7900 端口被绑定到了本地(`127.0.0.1`),所以只有本地进程可以访问。这次我们将端口关联到了 `0.0.0.0`,所以系统允许任何 IP 地址的机器访问 7900 这个端口。
```
externo1 $ netstat -ltn
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State
...
Tcp 0 0 0.0.0.0:7900 0.0.0.0:* LISTEN
...
```
所以现在在 externo2 节点上,我们可以执行:
```
externo2 $ vncviewer externo1::7900
```
来连接到 interno1 节点上的 VNC 服务。
除了将 IP 指定为 `0.0.0.0` 之外,我们还可以使用参数 `-g`(允许远程机器使用本地端口转发),完整命令如下:
```
externo1 $ ssh -g -L 7900:localhost:5900 user@interno1
```
这条命令与前面的命令能实现相同效果:
```
externo1 $ ssh -L 0.0.0.0:7900:localhost:5900 user@interno1
```
换句话说,如果我们想限制只能连接到系统上的某个 IP,可以像下面这样定义:
```
externo1 $ ssh -L 192.168.24.80:7900:localhost:5900 user@interno1
externo1 $ netstat -ltn
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State
...
Tcp 0 0 192.168.24.80:7900 0.0.0.0:* LISTEN
...
```
### 场景 3
>
> 在 interno1 上访问由 externo1 提供的 TCP 服务(远程端口转发 / 绑定地址 = localhost / 主机 = localhost)
>
>
>
在场景 1 中 SSH 服务器与 TCP 服务(VNC)提供者在同一个节点上。现在我们想在 SSH 客户端所在的节点上,提供一个 TCP 服务(VNC)供 SSH 服务端来访问:

将方案 1 中的命令参数由 `-L` 替换为 `-R`。
完整命令如下:
```
externo1 $ ssh -R 7900:localhost:5900 user@interno1
```
然后我们就能看到 interno1 节点上对 7900 端口正在监听:
```
interno1 $ netstat -lnt
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State
...
Tcp 0 0 127.0.0.1:7900 0.0.0.0:* LISTEN
...
```
现在在 interno1 节点上,我们可以使用如下命令来访问 externo1 上的 VNC 服务:
```
interno1 $ vncviewer localhost::7900
```
### 场景 4
>
> interno2 使用 externo1 上提供的 TCP 服务(远端端口转发 / 绑定地址 = 0.0.0.0 / 主机 = localhost)
>
>
>
与场景 3 类似,但是现在我们尝试指定允许访问转发端口的 IP(就像场景 2 中做的一样)为 `0.0.0.0`,这样其他节点也可以访问 VNC 服务:

正确的命令是:
```
externo1 $ ssh -R 0.0.0.0:7900:localhost:5900 user@interno1
```
但是这里有个重点需要了解,出于安全的原因,如果我们直接执行该命令的话可能不会生效,因为我们需要修改 SSH 服务端的一个参数值 `GatewayPorts`,它的默认值是:`no`。
>
> GatewayPorts
>
>
> 该参数指定了远程主机是否允许客户端访问转发端口。默认情况下,sshd(8) 只允许本机进程访问转发端口。这是为了阻止其他主机连接到该转发端口。GatewayPorts 参数可用于让 sshd 允许远程转发端口绑定到非回环地址上,从而可以让远程主机访问。当参数值设置为 “no” 的时候只有本机可以访问转发端口;“yes” 则表示允许远程转发端口绑定到通配地址上;或者设置为 “clientspecified” 则表示由客户端来选择哪些主机地址允许访问转发端口。默认值是 “no”。
>
>
>
如果我们没有修改服务器配置的权限,我们将不能使用该方案来进行端口转发。这是因为如果没有其他的限制,用户可以开启一个端口(> 1024)来监听来自外部的请求并转发到 `localhost:7900`。
参照这个案例:[netcat](http://en.wikipedia.org/wiki/Netcat) ( [Debian # 310431: sshd\_config should warn about the GatewayPorts workaround.](http://bugs.debian.org/cgi-bin/bugreport.cgi?bug=310431) )
所以我们修改 `/etc/ssh/sshd_config`,添加如下内容:
```
GatewayPorts clientspecified
```
然后,我们使用如下命令来重载修改后的配置文件(在 Debian 和 Ubuntu 上)。
```
sudo /etc/init.d/ssh reload
```
我们确认一下现在 interno1 节点上存在 7900 端口的监听程序,监听来自不同 IP 的请求:
```
interno1 $ netstat -ltn
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State
...
Tcp 0 0 0.0.0.0:7900 0.0.0.0:* LISTEN
...
```
然后我们就可以在 interno2 节点上使用 VNC 服务了:
```
interno2 $ internal vncviewer1::7900
```
### 场景 5
>
> 在 externo1 上使用由 interno2 提供的 TCP 服务(本地端口转发 / 绑定地址 localhost / 主机 = interno2 )
>
>
>

在这种场景下我们使用如下命令:
```
externo1 $ ssh -L 7900:interno2:5900 user@interno1
```
然后我们就能在 externo1 节点上,通过执行如下命令来使用 VNC 服务了:
```
externo1 $ vncviewer localhost::7900
```
### 场景 6
>
> 在 interno1 上使用由 externo2 提供的 TCP 服务(远程端口转发 / 绑定地址 = localhost / host = externo2)
>
>
>

在这种场景下,我们使用如下命令:
```
externo1 $ ssh -R 7900:externo2:5900 user@interno1
```
然后我们可以在 interno1 上通过执行如下命令来访问 VNC 服务:
```
interno1 $ vncviewer localhost::7900
```
### 场景 7
>
> 在 externo2 上使用由 interno2 提供的 TCP 服务(本地端口转发 / 绑定地址 = 0.0.0.0 / 主机 = interno2)
>
>
>

本场景下,我们使用如下命令:
```
externo1 $ ssh -L 0.0.0.0:7900:interno2:5900 user@interno1
```
或者:
```
externo1 $ ssh -g -L 7900:interno2:5900 user@interno1
```
然后我们就可以在 externo2 上执行如下命令来访问 vnc 服务:
```
externo2 $ vncviewer externo1::7900
```
### 场景 8
>
> 在 interno2 上使用由 externo2 提供的 TCP 服务(远程端口转发 / 绑定地址 = 0.0.0.0 / 主机 = externo2)
>
>
>

本场景下我们使用如下命令:
```
externo1 $ ssh -R 0.0.0.0:7900:externo2:5900 user@interno1
```
SSH 服务器需要配置为:
```
GatewayPorts clientspecified
```
就像我们在场景 4 中讲过的那样。
然后我们可以在 interno2 节点上执行如下命令来访问 VNC 服务:
```
interno2 $ internal vncviewer1::7900
```
如果我们需要一次性的创建多个隧道,使用配置文件的方式替代一个可能很长的命令是一个更好的选择。假设我们只能通过 SSH 的方式访问某个特定网络,同时又需要创建多个隧道来访问该网络内不同服务器上的服务,比如 VNC 或者 [远程桌面](http://en.wikipedia.org/wiki/Remote_Desktop_Services)。此时只需要创建一个如下的配置文件 `$HOME/redirects` 即可(在 SOCKS 服务器 上)。
```
# SOCKS server
DynamicForward 1080
# SSH redirects
LocalForward 2221 serverlinux1: 22
LocalForward 2222 serverlinux2: 22
LocalForward 2223 172.16.23.45:22
LocalForward 2224 172.16.23.48:22
# RDP redirects for Windows systems
LocalForward 3391 serverwindows1: 3389
LocalForward 3392 serverwindows2: 3389
# VNC redirects for systems with "vncserver"
LocalForward 5902 serverlinux1: 5901
LocalForward 5903 172.16.23.45:5901
```
然后我们只需要执行如下命令:
```
externo1 $ ssh -F $HOME/redirects user@interno1
```
---
via: <https://wesharethis.com/2017/07/creating-tcp-ip-port-forwarding-tunnels-ssh-8-possible-scenarios-using-openssh/>
作者:[Ahmad](https://wesharethis.com/author/ahmad/) 译者:[toutoudnf](https://github.com/toutoudnf) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='wesharethis.com', port=443): Max retries exceeded with url: /2017/07/creating-tcp-ip-port-forwarding-tunnels-ssh-8-possible-scenarios-using-openssh/ (Caused by ConnectTimeoutError(<urllib3.connection.HTTPSConnection object at 0x7b8327581720>, 'Connection to wesharethis.com timed out. (connect timeout=10)')) | null |
8,946 | 12 件可以用 GitHub 完成的很酷的事情 | https://hackernoon.com/12-cool-things-you-can-do-with-github-f3e0424cf2f0 | 2017-10-10T17:08:00 | [
"GitHub"
] | https://linux.cn/article-8946-1.html | 
我不能为我的人生想出一个引子来,所以……
### #1 在 GitHub.com 上编辑代码
我想我要开始介绍的第一件事是多数人都已经知道的(尽管我一周之前还不知道)。
当你登录到 GitHub ,查看一个文件时(任何文本文件,任何版本库),右上方会有一只小铅笔。点击它,你就可以编辑文件了。 当你编辑完成后,GitHub 会给出文件变更的建议,然后为你<ruby> 复刻 <rt> fork </rt></ruby>该仓库并创建一个<ruby> 拉取请求 <rt> pull request </rt></ruby>(PR)。
是不是很疯狂?它为你创建了一个复刻!
你不需要自己去复刻、拉取,然后本地修改,再推送,然后创建一个 PR。

*不是一个真正的 PR*
这对于修改错误拼写以及编辑代码时的一些糟糕的想法是很有用的。
### #2 粘贴图像
在评论和<ruby> 工单 <rt> issue </rt></ruby>的描述中并不仅限于使用文字。你知道你可以直接从剪切板粘贴图像吗? 在你粘贴的时候,你会看到图片被上传 (到云端,这毫无疑问),并转换成 markdown 显示的图片格式。
棒极了。
### #3 格式化代码
如果你想写一个代码块的话,你可以用三个反引号(```)作为开始 —— 就像你在浏览 [精通 Markdown](https://guides.github.com/features/mastering-markdown/) 时所学到的一样 —— 而且 GitHub 会尝试去推测你所写下的编程语言。
但如果你粘贴的像是 Vue、Typescript 或 JSX 这样的代码,你就需要明确指出才能获得高亮显示。
在首行注明 ````jsx`:

…这意味着代码段已经正确的呈现:

(顺便说一下,这些用法也可以用到 gist。 如果你给一个 gist 用上 `.jsx` 扩展名,你的 JSX 语法就会高亮显示。)
这里是[所有被支持的语法](https://github.com/github/linguist/blob/fc1404985abb95d5bc33a0eba518724f1c3c252e/vendor/README.md)的清单。
### #4 用 PR 中的魔法词来关闭工单
比方说你已经创建了一个用来修复 `#234` 工单的拉取请求。那么你就可以把 `fixes #234` 这段文字放在你的 PR 的描述中(或者是在 PR 的评论的任何位置)。
接下来,在合并 PR 时会自动关闭与之对应的工单。这是不是很酷?
这里是[更详细的学习帮助](https://help.github.com/articles/closing-issues-using-keywords/)。
### #5 链接到评论
是否你曾经想要链接到一个特定的评论但却无从着手?这是因为你不知道如何去做到这些。不过那都过去了,我的朋友,我告诉你啊,点击紧挨着名字的日期或时间,这就是如何链接到一个评论的方法。

*嘿,这里有 gaearon 的照片!*
### #6 链接到代码
那么你想要链接到代码的特定行么。我了解了。
试试这个:在查看文件的时候,点击挨着代码的行号。
哇哦,你看到了么?URL 更新了,加上了行号!如果你按下 `Shift` 键并点击其他的行号,格里格里巴巴变!URL 再一次更新并且现在出现了行范围的高亮。
分享这个 URL 将会链接到这个文件的那些行。但等一下,链接所指向的是当前分支。如果文件发生变更了怎么办?也许一个文件当前状态的<ruby> 永久链接 <rt> permalink </rt></ruby>就是你以后需要的。
我比较懒,所以我已经在一张截图中做完了上面所有的步骤:

*说起 URL…*
### #7 像命令行一样使用 GitHub URL
使用 UI 来浏览 GitHub 有着很好的体验。但有些时候最快到达你想去的地方的方法就是在地址栏输入。举个例子,如果我想要跳转到一个我正在工作的分支,然后查看与 master 分支的差异,我就可以在我的仓库名称的后边输入 `/compare/branch-name` 。
这样就会访问到指定分支的 diff 页面。

然而这就是与 master 分支的 diff,如果我要与 develoment 分支比较,我可以输入 `/compare/development...my-branch`。

对于你这种键盘快枪手来说,`ctrl`+`L` 或 `cmd`+`L` 将会向上跳转光标进入 URL 那里(至少在 Chrome 中是这样)。这(再加上你的浏览器会自动补全)能够成为一种在分支间跳转的便捷方式。
专家技巧:使用方向键在 Chrome 的自动完成建议中移动同时按 `shift`+`delete` 来删除历史条目(例如,一旦分支被合并后)。
(我真的好奇如果我把快捷键写成 `shift + delete` 这样的话,是不是读起来会更加容易。但严格来说 ‘+’ 并不是快捷键的一部分,所以我并不觉得这很舒服。这一点纠结让 *我* 整晚难以入睡,Rhonda。)
### #8 在工单中创建列表
你想要在你的<ruby> 工单 <rt> issue </rt></ruby>中看到一个复选框列表吗?

你想要在工单列表中显示为一个漂亮的 “2 of 5” 进度条吗?

很好!你可以使用这些的语法创建交互式的复选框:
```
- [ ] Screen width (integer)
- [x] Service worker support
- [x] Fetch support
- [ ] CSS flexbox support
- [ ] Custom elements
```
它的表示方法是空格、破折号、再空格、左括号、填入空格(或者一个 `x` ),然后封闭括号,接着空格,最后是一些话。
然后你可以实际选中或取消选中这些框!出于一些原因这些对我来说看上去就像是技术魔法。你可以*选中*这些框! 同时底层的文本会进行更新。
他们接下来会想到什么魔法?
噢,如果你在一个<ruby> 项目面板 <rt> project board </rt></ruby>上有这些工单的话,它也会在这里显示进度:

如果在我提到“在一个项目面板上”时你不知道我在说些什么,那么你会在本页下面进一步了解。
比如,在本页面下 2 厘米的地方。
### #9 GitHub 上的项目面板
我常常在大项目中使用 Jira 。而对于个人项目我总是会使用 Trello 。我很喜欢它们两个。
当我学会 GitHub 的几周后,它也有了自己的项目产品,就在我的仓库上的 Project 标签,我想我会照搬一套我已经在 Trello 上进行的任务。

*没有一个是有趣的任务*
这里是在 GitHub 项目上相同的内容:

*你的眼睛最终会适应这种没有对比的显示*
出于速度的缘故,我把上面所有的都添加为 “<ruby> 备注 <rt> note </rt></ruby>” —— 意思是它们不是真正的 GitHub 工单。
但在 GitHub 上,管理任务的能力被集成在版本库的其他地方 —— 所以你可能想要从仓库添加已有的工单到面板上。
你可以点击右上角的<ruby> 添加卡片 <rt> Add Cards </rt></ruby>,然后找你想要添加的东西。在这里,特殊的[搜索语法](https://help.github.com/articles/searching-issues-and-pull-requests/)就派上用场了,举个例子,输入 `is:pr is:open` 然后现在你可以拖动任何开启的 PR 到项目面板上,或者要是你想清理一些 bug 的话就输入 `label:bug`。

亦或者你可以将现有的备注转换为工单。

再或者,从一个现有工单的屏幕上,把它添加到右边面板的项目上。

它们将会进入那个项目面板的分类列表,这样你就能决定放到哪一类。
在实现那些任务的同一个仓库下放置任务的内容有一个巨大(超大)的好处。这意味着今后的几年你能够在一行代码上做一个 `git blame`,可以让你找出最初在这个任务背后写下那些代码的根据,而不需要在 Jira、Trello 或其它地方寻找蛛丝马迹。
#### 缺点
在过去的三周我已经对所有的任务使用 GitHub 取代 Jira 进行了测试(在有点看板风格的较小规模的项目上) ,到目前为止我都很喜欢。
但是我无法想象在 scrum(LCTT 译注:迭代式增量软件开发过程)项目上使用它,我想要在那里完成正确的工期估算、开发速度的测算以及所有的好东西怕是不行。
好消息是,GitHub 项目只有很少一些“功能”,并不会让你花很长时间去评估它是否值得让你去切换。因此要不要试试,你自己看着办。
无论如何,我*听说过* [ZenHub](https://www.zenhub.com/) 并且在 10 分钟前第一次打开了它。它是对 GitHub 高效的延伸,可以让你估计你的工单并创建 epic 和 dependency。它也有 velocity 和<ruby> 燃尽图 <rt> burndown chart </rt></ruby>功能;这看起来*可能是*世界上最棒的东西了。
延伸阅读: [GitHub help on Projects](https://help.github.com/articles/tracking-the-progress-of-your-work-with-project-boards/)。
### #10 GitHub 维基
对于一堆非结构化页面(就像维基百科一样), GitHub <ruby> 维基 <rt> wiki </rt></ruby>提供的(下文我会称之为 Gwiki)就很优秀。
结构化的页面集合并没那么多,比如说你的文档。这里没办法说“这个页面是那个页面的子页”,或者有像‘下一节’和‘上一节’这样的按钮。Hansel 和 Gretel 将会完蛋,因为这里没有面包屑导航(LCTT 译注:引自童话故事《糖果屋》)。
(边注,你有*读过*那个故事吗? 这是个残酷的故事。两个混蛋小子将饥肠辘辘的老巫婆烧死在*她自己的火炉*里。毫无疑问她是留下来收拾残局的。我想这就是为什么如今的年轻人是如此的敏感 —— 今天的睡前故事太不暴力了。)
继续 —— 把 Gwiki 拿出来接着讲,我输入一些 NodeJS 文档中的内容作为维基页面,然后创建一个侧边栏以模拟一些真实结构。这个侧边栏会一直存在,尽管它无法高亮显示你当前所在的页面。
其中的链接必须手动维护,但总的来说,我认为这已经很好了。如果你觉得有需要的话可以[看一下](https://github.com/davidgilbertson/about-github/wiki)。

它将不会与像 GitBook(它使用了 [Redux 文档](http://redux.js.org/))或定制的网站这样的东西相比较。但它八成够用了,而且它就在你的仓库里。
我是它的一个粉丝。
我的建议:如果你已经拥有不止一个 `README.md` 文件,并且想要一些不同的页面作为用户指南或是更详细的文档,那么下一步你就需要停止使用 Gwiki 了。
如果你开始觉得缺少的结构或导航非常有必要的话,去切换到其他的产品吧。
### #11 GitHub 页面(带有 Jekyll)
你可能已经知道了可以使用 GitHub <ruby> 页面 <rt> Pages </rt></ruby> 来托管静态站点。如果你不知道的话现在就可以去试试。不过这一节确切的说是关于使用 Jekyll 来构建一个站点。
最简单的来说, GitHub 页面 + Jekyll 会将你的 `README.md` 呈现在一个漂亮的主题中。举个例子,看看我的 [关于 github](https://github.com/davidgilbertson/about-github) 中的 readme 页面:

点击 GitHub 上我的站点的<ruby> 设置 <rt> settings </rt></ruby>标签,开启 GitHub 页面功能,然后挑选一个 Jekyll 主题……

我就会得到一个 [Jekyll 主题的页面](https://davidgilbertson.github.io/about-github/):

由此我可以构建一个主要基于易于编辑的 markdown 文件的静态站点,其本质上是把 GitHub 变成一个 CMS(LCTT 译注:内容管理系统)。
我还没有真正的使用过它,但这就是 React 和 Bootstrap 网站构建的过程,所以并不可怕。
注意,在本地运行它需要 Ruby (Windows 用户会彼此交换一下眼神,然后转头看向其它的方向。macOS 用户会发出这样这样的声音 “出什么问题了,你要去哪里?Ruby 可是一个通用平台!GEMS 万岁!”)。
(这里也有必要加上,“暴力或威胁的内容或活动” 在 GitHub 页面上是不允许的,因此你不能去部署你的 Hansel 和 Gretel 重启之旅了。)
#### 我的意见
为了这篇文章,我对 GitHub 页面 + Jekyll 研究越多,就越觉得这件事情有点奇怪。
“拥有你自己的网站,让所有的复杂性远离”这样的想法是很棒的。但是你仍然需要在本地生成配置。而且可怕的是需要为这样“简单”的东西使用很多 CLI(LCTT 译注:命令行界面)命令。
我只是略读了[入门部分](https://jekyllrb.com/docs/home/)的七页,给我的感觉像是*我才是*那个小白。此前我甚至从来没有学习过所谓简单的 “Front Matter” 的语法或者所谓简单的 “Liquid 模板引擎” 的来龙去脉。
我宁愿去手工编写一个网站。
老实说我有点惊讶 Facebook 使用它来写 React 文档,因为他们能够用 React 来构建他们的帮助文档,并且在一天之内[预渲染到静态的 HTML 文件](https://github.com/facebookincubator/create-react-app/blob/master/packages/react-scripts/template/README.md#pre-rendering-into-static-html-files)。
他们所需要做的就是利用已有的 Markdown 文件,就像跟使用 CMS 一样。
我想是这样……
### #12 使用 GitHub 作为 CMS
比如说你有一个带有一些文本的网站,但是你并不想在 HTML 的标记中储存那些文本。
取而代之,你想要把这堆文本存放到某个地方,以便非开发者也可以很容易地编辑。也许要使用某种形式的版本控制。甚至还可能需要一个审查过程。
这里是我的建议:在你的版本库中使用 markdown 文件存储文本。然后在你的前端使用插件来获取这些文本块并在页面呈现。
我是 React 的支持者,因此这里有一个 `<Markdown>` 插件的示例,给出一些 markdown 的路径,它就会被获取、解析,并以 HTML 的形式呈现。
(我正在使用 [marked](https://www.npmjs.com/package/marked) npm 包来将 markdown 解析为 HTML。)
这里是我的示例仓库 [/text-snippets](https://github.com/davidgilbertson/about-github/tree/master/text-snippets),里边有一些 markdown 文件 。
(你也可以使用 GitHub API 来[获取内容](https://developer.github.com/v3/repos/contents/#get-contents) —— 但我不确定你是否能搞定。)
你可以像这样使用插件:
如此,GitHub 就是你的 CMS 了,可以说,不管有多少文本块都可以放进去。
上边的示例只是在浏览器上安装好插件后获取 markdown 。如果你想要一个静态站点那么你需要服务器端渲染。
有个好消息!没有什么能阻止你从服务器中获取所有的 markdown 文件 (并配上各种为你服务的缓存策略)。如果你沿着这条路继续走下去的话,你可能会想要去试试使用 GitHub API 去获取目录中的所有 markdown 文件的列表。
### 奖励环节 —— GitHub 工具!
我曾经使用过一段时间的 [Chrome 的扩展 Octotree](https://chrome.google.com/webstore/detail/octotree/bkhaagjahfmjljalopjnoealnfndnagc?hl=en-US),而且现在我推荐它。虽然不是吐血推荐,但不管怎样我还是推荐它。
它会在左侧提供一个带有树状视图的面板以显示当前你所查看的仓库。

从[这个视频](https://www.youtube.com/watch?v=NhlzMcSyQek&index=2&list=PLNYkxOF6rcIB3ci6nwNyLYNU6RDOU3YyL)中我了解到了 [octobox](https://octobox.io/) ,到目前为止看起来还不错。它是一个 GitHub 工单的收件箱。这一句介绍就够了。
说到颜色,在上面所有的截图中我都使用了亮色主题,所以希望不要闪瞎你的双眼。不过说真的,我看到的其他东西都是黑色的主题,为什么我非要忍受 GitHub 这个苍白的主题呐?

这是由 Chrome 扩展 [Stylish](https://chrome.google.com/webstore/detail/stylish-custom-themes-for/fjnbnpbmkenffdnngjfgmeleoegfcffe/related?hl=en)(它可以在任何网站使用主题)和 [GitHub Dark](https://userstyles.org/styles/37035/github-dark) 风格的一个组合。要完全黑化,那黑色主题的 Chrome 开发者工具(这是内建的,在设置中打开) 以及 [Atom One Dark for Chrome 主题](https://chrome.google.com/webstore/detail/atom-one-dark-theme/obfjhhknlilnfgfakanjeimidgocmkim?hl=en)你肯定也需要。
### Bitbucket
这些内容不适合放在这篇文章的任何地方,但是如果我不称赞 Bitbucket 的话,那就不对了。
两年前我开始了一个项目并花了大半天时间评估哪一个 git 托管服务更适合,最终 Bitbucket 赢得了相当不错的成绩。他们的代码审查流程遥遥领先(这甚至比 GitHub 拥有的指派审阅者的概念要早很长时间)。
GitHub 后来在这次审查竞赛中追了上来,干的不错。不幸的是在过去的一年里我没有机会再使用 Bitbucket —— 也许他们依然在某些方面领先。所以,我会力劝每一个选择 git 托管服务的人考虑一下 Bitbucket 。
### 结尾
就是这样!我希望这里至少有三件事是你此前并不知道的,祝好。
修订:在评论中有更多的技巧;请尽管留下你自己喜欢的技巧。真的,真心祝好。
(题图:orig08.deviantart.net)
---
via: <https://hackernoon.com/12-cool-things-you-can-do-with-github-f3e0424cf2f0>
作者:[David Gilbertson](https://hackernoon.com/@david.gilbertson) 译者:[softpaopao](https://github.com/softpaopao) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 307 | Temporary Redirect | null |
8,947 | 动态端口转发:安装带有 SSH 的 SOCKS 服务器 | https://wesharethis.com/2017/07/15/dynamic-port-forwarding-mount-socks-server-ssh/ | 2017-10-10T22:27:37 | [
"SOCKS",
"SSH"
] | /article-8947-1.html | 
在上一篇文章([通过 SSH 实现 TCP / IP 隧道(端口转发):使用 OpenSSH 可能的 8 种场景](/article-8945-1.html))中,我们看到了处理端口转发的所有可能情况,不过那只是静态端口转发。也就是说,我们只介绍了通过 SSH 连接来访问另一个系统的端口的情况。
在那篇文章中,我们未涉及动态端口转发,此外一些读者没看过该文章,本篇文章中将尝试补充完整。
当我们谈论使用 SSH 进行动态端口转发时,我们说的是将 SSH 服务器转换为 [SOCKS](https://wesharethis.com/goto/http://en.wikipedia.org/wiki/SOCKS) 服务器。那么什么是 SOCKS 服务器?
你知道 [Web 代理](https://wesharethis.com/goto/http://en.wikipedia.org/wiki/Proxy_server)是用来做什么的吗?答案可能是肯定的,因为很多公司都在使用它。它是一个直接连接到互联网的系统,允许没有互联网访问的[内部网](https://wesharethis.com/goto/http://en.wikipedia.org/wiki/Intranet)客户端让其浏览器通过代理来(尽管也有[透明代理](https://wesharethis.com/goto/http://en.wikipedia.org/wiki/Proxy_server#Transparent_and_non-transparent_proxy_server))浏览网页。Web 代理除了允许输出到 Internet 之外,还可以缓存页面、图像等。已经由某客户端下载的资源,另一个客户端不必再下载它们。此外,它还可以过滤内容并监视用户的活动。当然了,它的基本功能是转发 HTTP 和 HTTPS 流量。
一个 SOCKS 服务器提供的服务类似于公司内部网络提供的代理服务器服务,但不限于 HTTP/HTTPS,它还允许转发任何 TCP/IP 流量(SOCKS 5 也支持 UDP)。
例如,假设我们希望在一个没有直接连接到互联网的内部网上通过 Thunderbird 使用 POP3 、 ICMP 和 SMTP 的邮件服务。如果我们只有一个 web 代理可以用,我们可以使用的唯一的简单方式是使用某个 webmail(也可以使用 [Thunderbird 的 Webmail 扩展](https://wesharethis.com/goto/http://webmail.mozdev.org/))。我们还可以通过 [HTTP 隧道](https://wesharethis.com/goto/http://en.wikipedia.org/wiki/HTTP_tunnel_(software))来起到代理的用途。但最简单的方式是在网络中设置一个 SOCKS 服务器,它可以让我们使用 POP3、ICMP 和 SMTP,而不会造成任何的不便。
虽然有很多软件可以配置非常专业的 SOCKS 服务器,但用 OpenSSH 设置一个只需要简单的一条命令:
```
Clientessh $ ssh -D 1080 user@servidorssh
```
或者我们可以改进一下:
```
Clientessh $ ssh -fN -D 0.0.0.0:1080 user@servidorssh
```
其中:
* 选项 `-D` 类似于选项为 `-L` 和 `-R` 的静态端口转发。像那些一样,我们可以让客户端只监听本地请求或从其他节点到达的请求,具体取决于我们将请求关联到哪个地址:
```
-D [bind_address:] port
```
在静态端口转发中可以看到,我们使用选项 `-R` 进行反向端口转发,而动态转发是不可能的。我们只能在 SSH 客户端创建 SOCKS 服务器,而不能在 SSH 服务器端创建。
* 1080 是 SOCKS 服务器的典型端口,正如 8080 是 Web 代理服务器的典型端口一样。
* 选项 `-N` 防止实际启动远程 shell 交互式会话。当我们只用 `ssh` 来建立隧道时很有用。
* 选项 `-f` 会使 `ssh` 停留在后台并将其与当前 shell 分离,以便使该进程成为守护进程。如果没有选项 `-N`(或不指定命令),则不起作用,否则交互式 shell 将与后台进程不兼容。
使用 [PuTTY](https://wesharethis.com/goto/http://www.chiark.greenend.org.uk/%7Esgtatham/putty/download.html) 也可以非常简单地进行端口重定向。与 `ssh -D 0.0.0.0:1080` 相当的配置如下:

对于通过 SOCKS 服务器访问另一个网络的应用程序,如果应用程序提供了对 SOCKS 服务器的特别支持,就会非常方便(虽然不是必需的),就像浏览器支持使用代理服务器一样。作为一个例子,如 Firefox 或 Internet Explorer 这样的浏览器使用 SOCKS 服务器访问另一个网络的应用程序:


注意:上述截图来自 [IE for Linux](https://wesharethis.com/goto/http://www.tatanka.com.br/ies4linux/page/Main_Page) :如果您需要在 Linux 上使用 Internet Explorer,强烈推荐!
然而,最常见的浏览器并不要求 SOCKS 服务器,因为它们通常与代理服务器配合得更好。
不过,Thunderbird 也支持 SOCKS,而且很有用:

另一个例子:[Spotify](https://wesharethis.com/goto/https://www.spotify.com/int/download/linux/) 客户端同样支持 SOCKS:

需要关注一下名称解析。有时我们会发现,在目前的网络中,我们无法解析 SOCKS 服务器另一端所要访问的系统的名称。SOCKS 5 还允许我们通过隧道传播 DNS 请求( 因为 SOCKS 5 允许我们使用 UDP)并将它们发送到另一端:可以指定是本地还是远程解析(或者也可以两者都试试)。支持此功能的应用程序也必须考虑到这一点。例如,Firefox 具有参数 `network.proxy.socks_remote_dns`(在 `about:config` 中),允许我们指定远程解析。而默认情况下,它在本地解析。
Thunderbird 也支持参数 `network.proxy.socks_remote_dns`,但由于没有地址栏来放置 `about:config`,我们需要改变它,就像在 [MozillaZine:about:config](https://wesharethis.com/goto/http://kb.mozillazine.org/About:config) 中读到的,依次点击 工具 → 选项 → 高级 → 常规 → 配置编辑器(按钮)。
没有对 SOCKS 特别支持的应用程序可以被 <ruby> sock 化 <rt> socksified </rt></ruby>。这对于使用 TCP/IP 的许多应用程序都没有问题,但并不是全部。“sock 化” 需要加载一个额外的库,它可以检测对 TCP/IP 堆栈的请求,并修改请求,以通过 SOCKS 服务器重定向,从而不需要特别编程来支持 SOCKS 便可以正常通信。
在 Windows 和 [Linux](https://wesharethis.com/2017/07/10/linux-swap-partition/) 上都有 “Sock 化工具”。
对于 Windows,我们举个例子,SocksCap 是一种闭源,但对非商业使用免费的产品,我使用了很长时间都十分满意。SocksCap 由一家名为 Permeo 的公司开发,该公司是创建 SOCKS 参考技术的公司。Permeo 被 [Blue Coat](https://wesharethis.com/goto/http://www.bluecoat.com/) 买下后,它[停止了 SocksCap 项目](https://wesharethis.com/goto/http://www.bluecoat.com/products/sockscap)。现在你仍然可以在互联网上找到 `sc32r240.exe` 文件。[FreeCap](https://wesharethis.com/goto/http://www.freecap.ru/eng/) 也是面向 Windows 的免费代码项目,外观和使用都非常类似于 SocksCap。然而,它工作起来更加糟糕,多年来一直没有缺失维护。看起来,它的作者倾向于推出需要付款的新产品 [WideCap](https://wesharethis.com/goto/http://widecap.ru/en/support/)。
这是 SocksCap 的一个界面,可以看到我们 “sock 化” 了的几个应用程序。当我们从这里启动它们时,这些应用程序将通过 SOCKS 服务器访问网络:

在配置对话框中可以看到,如果选择了协议 SOCKS 5,我们可以选择在本地或远程解析名称:

在 Linux 上,如同往常一样,对某个远程命令我们都有许多替代方案。在 Debian/Ubuntu 中,命令行:
```
$ Apt-cache search socks
```
的输出会告诉我们很多。
最著名的是 [tsocks](https://wesharethis.com/goto/http://tsocks.sourceforge.net/) 和 [proxychains](https://wesharethis.com/goto/http://proxychains.sourceforge.net/)。它们的工作方式大致相同:只需用它们启动我们想要 “sock 化” 的应用程序就行。使用 `proxychains` 的 `wget` 的例子:
```
$ Proxychains wget http://www.google.com
ProxyChains-3.1 (http://proxychains.sf.net)
--19: 13: 20-- http://www.google.com/
Resolving www.google.com ...
DNS-request | Www.google.com
| S-chain | - <- - 10.23.37.3:1080-<><>-4.2.2.2:53-<><>-OK
| DNS-response | Www.google.com is 72.14.221.147
72.14.221.147
Connecting to www.google.com | 72.14.221.147 |: 80 ...
| S-chain | - <- - 10.23.37.3:1080-<><>-72.14.221.147:80-<><>-OK
Connected.
HTTP request sent, awaiting response ... 200 OK
Length: unspecified [text / html]
Saving to: `index.html '
[<=>] 6,016 24.0K / s in 0.2s
19:13:21 (24.0 KB / s) - `index.html 'saved [6016]
```
要让它可以工作,我们必须在 `/etc/proxychains.conf` 中指定要使用的代理服务器:
```
[ProxyList]
Socks5 clientessh 1080
```
我们也设置远程进行 DNS 请求:
```
# Proxy DNS requests - no leak for DNS data
Proxy_dns
```
另外,在前面的输出中,我们已经看到了同一个 `proxychains` 的几条信息性的消息, 非 `wget` 的行是标有字符串 `|DNS-request|`、`|S-chain|` 或 `|DNS-response|` 的。如果我们不想看到它们,也可以在配置中进行调整:
```
# Quiet mode (no output from library)
Quiet_mode
```
---
via: <https://wesharethis.com/2017/07/15/dynamic-port-forwarding-mount-socks-server-ssh/>
作者:[Ahmad](https://wesharethis.com/author/ahmad/) 译者:[firmianay](https://github.com/firmianay) 校对:[jasminepeng](https://github.com/jasminepeng)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='wesharethis.com', port=443): Max retries exceeded with url: /2017/07/15/dynamic-port-forwarding-mount-socks-server-ssh/ (Caused by ConnectTimeoutError(<urllib3.connection.HTTPSConnection object at 0x7b8327582b30>, 'Connection to wesharethis.com timed out. (connect timeout=10)')) | null |
8,948 | 为什么 DevOps 如我们所知道的那样,是安全的终结 | https://techbeacon.com/why-devops-end-security-we-know-it | 2017-10-10T23:21:13 | [
"DevOps",
"安全"
] | https://linux.cn/article-8948-1.html | 
安全难以推行。在企业管理者迫使开发团队尽快发布程序的大环境下,很难说服他们花费有限的时间来修补安全漏洞。但是鉴于所有网络攻击中有 84% 发生在应用层,作为一个组织是无法承担其开发团队不包括安全性带来的后果。
DevOps 的崛起为许多安全负责人带来了困境。Sonatype 的前 CTO [Josh Corman](https://twitter.com/joshcorman) 说:“这是对安全的威胁,但这也是让安全变得更好的机会。” Corman 是一个坚定的[将安全和 DevOps 实践整合起来创建 “坚固的 DevOps”](https://techbeacon.com/want-rugged-devops-team-your-release-security-engineers)的倡导者。Business Insights 与 Corman 谈论了安全和 DevOps 共同的价值,以及这些共同价值如何帮助组织更少地受到中断和攻击的影响。
### 安全和 DevOps 实践如何互惠互利?
**Josh Corman:** 一个主要的例子是 DevOps 团队对所有可测量的东西进行检测的倾向。安全性一直在寻找更多的情报和遥测。你可以获取许多 DevOps 团队正在测量的信息,并将这些信息输入到你的日志管理或 SIEM (安全信息和事件管理系统)。
一个 OODA 循环(<ruby> 观察 <rt> observe </rt></ruby>、<ruby> 定向 <rt> orient </rt></ruby>、<ruby> 决定 <rt> decide </rt></ruby>、<ruby> 行为 <rt> act </rt></ruby>)的前提是有足够普遍的眼睛和耳朵,以注意到窃窃私语和回声。DevOps 为你提供无处不在的仪器。
### 他们有分享其他文化观点吗?
**JC:** “严肃对待你的代码”是一个共同的价值观。例如,由 Netflix 编写的软件工具 Chaos Monkey 是 DevOps 团队的分水岭。它是为了测试亚马逊网络服务的弹性和可恢复性而创建的,Chaos Monkey 使得 Netflix 团队更加强大,更容易为中断做好准备。
所以现在有个想法是我们的系统需要测试,因此,James Wickett 和我及其他人决定做一个邪恶的、带有攻击性的 Chaos Monkey,这就是 GAUNTLT 项目的来由。它基本上是一堆安全测试, 可以在 DevOps 周期和 DevOps 工具链中使用。它也有非常适合 DevOps 的API。
### 企业安全和 DevOps 价值在哪里相交?
**JC:** 这两个团队都认为复杂性是一切事情的敌人。例如,[安全人员和 Rugged DevOps 人员](https://techbeacon.com/rugged-devops-rsa-6-takeaways-security-ops-pros)实际上可以说:“看,我们在我们的项目中使用了 11 个日志框架 - 也许我们不需要那么多,也许攻击面和复杂性可能会让我们受到伤害或者损害产品的质量或可用性。”
复杂性往往是许多事情的敌人。通常情况下,你不会很难说服 DevOps 团队在架构层面使用更好的建筑材料:使用最新的、最不易受攻击的版本,并使用较少的组件。
### “更好的建筑材料”是什么意思?
**JC:** 我是世界上最大的开源仓库的保管人,所以我能看到他们在使用哪些版本,里面有哪些漏洞,何时他们没有修复漏洞,以及等了多久。例如,某些日志记录框架从不会修复任何错误。其中一些会在 90 天内修复了大部分的安全漏洞。人们越来越多地遭到攻击,因为他们使用了一个毫无安全的框架。
除此之外,即使你不知道日志框架的质量,拥有 11 个不同的框架会变得非常笨重、出现 bug,还有额外的工作和复杂性。你暴露在漏洞中的风险是非常大的。你想把时间花在修复大量的缺陷上,还是在制造下一个大的破坏性的事情上?
[Rugged DevOps 的关键是软件供应链管理](https://techbeacon.com/josh-corman-security-devops-how-shared-team-values-can-reduce-threats),其中包含三个原则:使用更少和更好的供应商、使用这些供应商的最高质量的部分、并跟踪这些部分,以便在发生错误时,你可以有一个及时和敏捷的响应。
### 所以变更管理也很重要。
**JC:** 是的,这是另一个共同的价值。我发现,当一家公司想要执行诸如异常检测或净流量分析等安全测试时,他们需要知道“正常”的样子。让人们失误的许多基本事情与仓库和补丁管理有关。
我在 *Verizon 数据泄露调查报告*中看到,追踪去年被成功利用的漏洞后,其中 97% 归结为 10 个 CVE(常见漏洞和风险),而这 10 个已经被修复了十多年。所以,我们羞于谈论高级间谍活动。我们没有做基本的补丁工作。现在,我不是说如果你修复这 10 个CVE,那么你就没有被利用,而是这占据了人们实际失误的最大份额。
[DevOps 自动化工具](https://techbeacon.com/devops-automation-best-practices-how-much-too-much)的好处是它们已经成为一个意外的变更管理数据库。其真实反应了谁在哪里什么时候做了变更。这是一个巨大的胜利,因为我们经常对安全性有最大影响的因素无法控制。你承受了 CIO 和 CTO 做出的选择的后果。随着 IT 通过自动化变得更加严格和可重复,你可以减少人为错误的机会,并且哪里发生了变化更加可追溯。
### 你认为什么是最重要的共同价值?
**JC:** DevOps 涉及到过程和工具链,但我认为定义这种属性的是文化,特别是同感。 DevOps 有用是因为开发人员和运维团队能够更好地了解彼此,并做出更明智的决策。不是在解决孤岛中的问题,而是为了活动流程和目标解决。如果你向 DevOps 的团队展示安全如何能使他们变得更好,那么作为回馈他们往往会问:“那么,我们是否有任何选择让你的生活更轻松?”因为他们通常不知道他们做的 X、Y 或 Z 的选择使它无法包含安全性。
对于安全团队,驱动价值的方法之一是在寻求帮助之前变得更有所帮助,在我们告诉 DevOps 团队要做什么之前提供定性和定量的价值。你必须获得 DevOps 团队的信任,并获得发挥的权利,然后才能得到回报。它通常比你想象的快很多。
---
via: <https://techbeacon.com/why-devops-end-security-we-know-it>
作者:[Mike Barton](https://twitter.com/intent/follow?original_referer=https%3A%2F%2Ftechbeacon.com%2Fwhy-devops-end-security-we-know-it%3Fimm_mid%3D0ee8c5%26cmp%3Dem-webops-na-na-newsltr_20170310&ref_src=twsrc%5Etfw®ion=follow_link&screen_name=mikebarton&tw_p=followbutton) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
8,950 | 关于 HTML5 你需要了解的基础知识 | http://opensourceforu.com/2017/06/introduction-to-html5/ | 2017-10-12T09:04:00 | [
"HTML5",
"HTML"
] | https://linux.cn/article-8950-1.html | 
>
> HTML5 是第五个且是当前的 HTML 版本,它是用于在万维网上构建和呈现内容的标记语言。本文将帮助读者了解它。
>
>
>
HTML5 通过 W3C 和<ruby> Web 超文本应用技术工作组 <rt> Web Hypertext Application Technology Working Group </rt></ruby>之间的合作发展起来。它是一个更高版本的 HTML,它的许多新元素可以使你的页面更加语义化和动态。它是为所有人提供更好的 Web 体验而开发的。HTML5 提供了很多的功能,使 Web 更加动态和交互。
HTML5 的新功能是:
* 新标签,如 `<header>` 和 `<section>`
* 用于 2D 绘图的 `<canvas>` 元素
* 本地存储
* 新的表单控件,如日历、日期和时间
* 新媒体功能
* 地理位置
HTML5 还不是正式标准(LCTT 译注:HTML5 已于 2014 年成为“推荐标准”),因此,并不是所有的浏览器都支持它或其中一些功能。开发 HTML5 背后最重要的原因之一是防止用户下载并安装像 Silverlight 和 Flash 这样的多个插件。
### 新标签和元素
* **语义化元素:** 图 1 展示了一些有用的语义化元素。
* **表单元素:** HTML5 中的表单元素如图 2 所示。
* **图形元素:** HTML5 中的图形元素如图 3 所示。
* **媒体元素:** HTML5 中的新媒体元素如图 4 所示。
[](http://opensourceforu.com/wp-content/uploads/2017/05/Figure-1-7.jpg)
*图 1:语义化元素*
[](http://opensourceforu.com/wp-content/uploads/2017/05/Figure-2-5.jpg)
*图 2:表单元素*
[](http://opensourceforu.com/wp-content/uploads/2017/05/Figure-3-2.jpg)
*图 3:图形元素*
[](http://opensourceforu.com/wp-content/uploads/2017/05/Figure-4-2.jpg)
*图 4:媒体元素*
### HTML5 的高级功能
#### 地理位置
这是一个 HTML5 API,用于获取网站用户的地理位置,用户必须首先允许网站获取他或她的位置。这通常通过按钮和/或浏览器弹出窗口来实现。所有最新版本的 Chrome、Firefox、IE、Safari 和 Opera 都可以使用 HTML5 的地理位置功能。
地理位置的一些用途是:
* 公共交通网站
* 出租车及其他运输网站
* 电子商务网站计算运费
* 旅行社网站
* 房地产网站
* 在附近播放的电影的电影院网站
* 在线游戏
* 网站首页提供本地标题和天气
* 工作职位可以自动计算通勤时间
**工作原理:** 地理位置通过扫描位置信息的常见源进行工作,其中包括以下:
* 全球定位系统(GPS)是最准确的
* 网络信号 - IP地址、RFID、Wi-Fi 和蓝牙 MAC地址
* GSM/CDMA 蜂窝 ID
* 用户输入
该 API 提供了非常方便的函数来检测浏览器中的地理位置支持:
```
if (navigator.geolocation) {
// do stuff
}
```
`getCurrentPosition` API 是使用地理位置的主要方法。它检索用户设备的当前地理位置。该位置被描述为一组地理坐标以及航向和速度。位置信息作为位置对象返回。
语法是:
```
getCurrentPosition(showLocation, ErrorHandler, options);
```
* `showLocation`:定义了检索位置信息的回调方法。
* `ErrorHandler`(可选):定义了在处理异步调用时发生错误时调用的回调方法。
* `options` (可选): 定义了一组用于检索位置信息的选项。
我们可以通过两种方式向用户提供位置信息:测地和民用。
1. 描述位置的测地方式直接指向纬度和经度。
2. 位置信息的民用表示法是人类可读的且容易理解。
如下表 1 所示,每个属性/参数都具有测地和民用表示。
[](http://opensourceforu.com/wp-content/uploads/2017/05/table-1.jpg)
图 5 包含了一个位置对象返回的属性集。
[](http://opensourceforu.com/wp-content/uploads/2017/05/Figure5-1.jpg)
*图5:位置对象属性*
#### 网络存储
在 HTML 中,为了在本机存储用户数据,我们需要使用 JavaScript cookie。为了避免这种情况,HTML5 已经引入了 Web 存储,网站利用它在本机上存储用户数据。
与 Cookie 相比,Web 存储的优点是:
* 更安全
* 更快
* 存储更多的数据
* 存储的数据不会随每个服务器请求一起发送。只有在被要求时才包括在内。这是 HTML5 Web 存储超过 Cookie 的一大优势。
有两种类型的 Web 存储对象:
1. 本地 - 存储没有到期日期的数据。
2. 会话 - 仅存储一个会话的数据。
**如何工作:** `localStorage` 和 `sessionStorage` 对象创建一个 `key=value` 对。比如: `key="Name"`, `value="Palak"`。
这些存储为字符串,但如果需要,可以使用 JavaScript 函数(如 `parseInt()` 和 `parseFloat()`)进行转换。
下面给出了使用 Web 存储对象的语法:
* 存储一个值:
+ `localStorage.setItem("key1", "value1");`
+ `localStorage["key1"] = "value1";`
* 得到一个值:
+ `alert(localStorage.getItem("key1"));`
+ `alert(localStorage["key1"]);`
* 删除一个值: -`removeItem("key1");`
* 删除所有值:
+ `localStorage.clear();`
#### 应用缓存(AppCache)
使用 HTML5 AppCache,我们可以使 Web 应用程序在没有 Internet 连接的情况下脱机工作。除 IE 之外,所有浏览器都可以使用 AppCache(截止至此时)。
应用缓存的优点是:
* 网页浏览可以脱机
* 页面加载速度更快
* 服务器负载更小
`cache manifest` 是一个简单的文本文件,其中列出了浏览器应缓存的资源以进行脱机访问。 `manifest` 属性可以包含在文档的 HTML 标签中,如下所示:
```
<html manifest="test.appcache">
...
</html>
```
它应该在你要缓存的所有页面上。
缓存的应用程序页面将一直保留,除非:
1. 用户清除它们
2. `manifest` 被修改
3. 缓存更新
#### 视频
在 HTML5 发布之前,没有统一的标准来显示网页上的视频。大多数视频都是通过 Flash 等不同的插件显示的。但 HTML5 规定了使用 video 元素在网页上显示视频的标准方式。
目前,video 元素支持三种视频格式,如表 2 所示。
[](http://opensourceforu.com/wp-content/uploads/2017/05/table-2.jpg)
下面的例子展示了 video 元素的使用:
```
<! DOCTYPE HTML>
<html>
<body>
<video src=" vdeo.ogg" width="320" height="240" controls="controls">
This browser does not support the video element.
</video>
</body>
</html>
```
例子使用了 Ogg 文件,并且可以在 Firefox、Opera 和 Chrome 中使用。要使视频在 Safari 和未来版本的 Chrome 中工作,我们必须添加一个 MPEG4 和 WebM 文件。
`video` 元素允许多个 `source` 元素。`source` 元素可以链接到不同的视频文件。浏览器将使用第一个识别的格式,如下所示:
```
<video width="320" height="240" controls="controls">
<source src="vdeo.ogg" type="video/ogg" />
<source src=" vdeo.mp4" type="video/mp4" />
<source src=" vdeo.webm" type="video/webm" />
This browser does not support the video element.
</video>
```
[](http://opensourceforu.com/wp-content/uploads/2017/05/Figure6-1.jpg)
*图6:Canvas 的输出*
#### 音频
对于音频,情况类似于视频。在 HTML5 发布之前,在网页上播放音频没有统一的标准。大多数音频也通过 Flash 等不同的插件播放。但 HTML5 规定了通过使用音频元素在网页上播放音频的标准方式。音频元素用于播放声音文件和音频流。
目前,HTML5 `audio` 元素支持三种音频格式,如表 3 所示。
[](http://opensourceforu.com/wp-content/uploads/2017/05/table-3.jpg)
`audio` 元素的使用如下所示:
```
<! DOCTYPE HTML>
<html>
<body>
<audio src=" song.ogg" controls="controls">
This browser does not support the audio element.
</video>
</body>
</html>
```
此例使用 Ogg 文件,并且可以在 Firefox、Opera 和 Chrome 中使用。要在 Safari 和 Chrome 的未来版本中使 audio 工作,我们必须添加一个 MP3 和 Wav 文件。
`audio` 元素允许多个 `source` 元素,它可以链接到不同的音频文件。浏览器将使用第一个识别的格式,如下所示:
```
<audio controls="controls">
<source src="song.ogg" type="audio/ogg" />
<source src="song.mp3" type="audio/mpeg" />
This browser does not support the audio element.
</audio>
```
#### 画布(Canvas)
要在网页上创建图形,HTML5 使用 画布 API。我们可以用它绘制任何东西,并且它使用 JavaScript。它通过避免从网络下载图像而提高网站性能。使用画布,我们可以绘制形状和线条、弧线和文本、渐变和图案。此外,画布可以让我们操作图像中甚至视频中的像素。你可以将 `canvas` 元素添加到 HTML 页面,如下所示:
```
<canvas id="myCanvas" width="200" height="100"></canvas>
```
画布元素不具有绘制元素的功能。我们可以通过使用 JavaScript 来实现绘制。所有绘画应在 JavaScript 中。
```
<script type="text/javascript">
var c=document.getElementById("myCanvas");
var cxt=c.getContext("2d");
cxt.fillStyle="blue";
cxt.storkeStyle = "red";
cxt.fillRect(10,10,100,100);
cxt.storkeRect(10,10,100,100);
</script>
```
以上脚本的输出如图 6 所示。
你可以绘制许多对象,如弧、圆、线/垂直梯度等。
### HTML5 工具
为了有效操作,所有熟练的或业余的 Web 开发人员/设计人员都应该使用 HTML5 工具,当需要设置工作流/网站或执行重复任务时,这些工具非常有帮助。它们提高了网页设计的可用性。
以下是一些帮助创建很棒的网站的必要工具。
* **HTML5 Maker:** 用来在 HTML、JavaScript 和 CSS 的帮助下与网站内容交互。非常容易使用。它还允许我们开发幻灯片、滑块、HTML5 动画等。
* **Liveweave:** 用来测试代码。它减少了保存代码并将其加载到屏幕上所花费的时间。在编辑器中粘贴代码即可得到结果。它非常易于使用,并为一些代码提供自动完成功能,这使得开发和测试更快更容易。
* **Font dragr:** 在浏览器中预览定制的 Web 字体。它会直接载入该字体,以便你可以知道看起来是否正确。也提供了拖放界面,允许你拖动字形、Web 开放字体和矢量图形来马上测试。
* **HTML5 Please:** 可以让我们找到与 HTML5 相关的任何内容。如果你想知道如何使用任何一个功能,你可以在 HTML Please 中搜索。它提供了支持的浏览器和设备的有用资源的列表,语法,以及如何使用元素的一般建议等。
* **Modernizr:** 这是一个开源工具,用于给访问者浏览器提供最佳体验。使用此工具,你可以检测访问者的浏览器是否支持 HTML5 功能,并加载相应的脚本。
* **Adobe Edge Animate:** 这是必须处理交互式 HTML 动画的 HTML5 开发人员的有用工具。它用于数字出版、网络和广告领域。此工具允许用户创建无瑕疵的动画,可以跨多个设备运行。
* **Video.js:** 这是一款基于 JavaScript 的 HTML5 视频播放器。如果要将视频添加到你的网站,你应该使用此工具。它使视频看起来不错,并且是网站的一部分。
* **The W3 Validator:** W3 验证工具测试 HTML、XHTML、SMIL、MathML 等中的网站标记的有效性。要测试任何网站的标记有效性,你必须选择文档类型为 HTML5 并输入你网页的 URL。这样做之后,你的代码将被检查,并将提供所有错误和警告。
* **HTML5 Reset:** 此工具允许开发人员在 HTML5 中重写旧网站的代码。你可以使用这些工具为你网站的访问者提供一个良好的网络体验。
---
Palak Shah
作者是高级软件工程师。她喜欢探索新技术,学习创新概念。她也喜欢哲学。你可以通过 [[email protected]](mailto:[email protected]) 联系她。
---
via: <http://opensourceforu.com/2017/06/introduction-to-html5/>
作者:[Palak Shah](http://opensourceforu.com/author/palak-shah/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
8,951 | 用 C 语言对 Gtk+ 应用进行功能测试 | https://opensource.com/article/17/7/functional-testing | 2017-10-12T13:25:38 | [
"GTK",
"测试"
] | https://linux.cn/article-8951-1.html |
>
> 这个简单教程教你如何测试你应用的功能。
>
>
>

自动化测试用来保证你程序的质量以及让它以预想的运行。单元测试只是检测你算法的某一部分,而并不注重各组件间的适应性。这就是为什么会有功能测试,它有时也称为集成测试。
功能测试简单地与你的用户界面进行交互,无论它是网站还是桌面应用。为了展示功能测试如何工作,我们以测试一个 Gtk+ 应用为例。为了简单起见,这个教程里,我们使用 Gtk+ 2.0 教程的示例。
### 基础设置
对于每一个功能测试,你通常需要定义一些全局变量,比如 “用户交互时延” 或者 “失败的超时时间”(也就是说,如果在指定的时间内一个事件没有发生,程序就要中断)。
```
#define TTT_FUNCTIONAL_TEST_UTIL_IDLE_CONDITION(f) ((TttFunctionalTestUtilIdleCondition)(f))
#define TTT_FUNCTIONAL_TEST_UTIL_REACTION_TIME (125000)
#define TTT_FUNCTIONAL_TEST_UTIL_REACTION_TIME_LONG (500000)
typedef gboolean (*TttFunctionalTestUtilIdleCondition)(gpointer data);
struct timespec ttt_functional_test_util_default_timeout = {
20,
0,
};
```
现在我们可以实现我们自己的超时函数。这里,为了能够得到期望的延迟,我们采用 `usleep` 函数。
```
void
ttt_functional_test_util_reaction_time()
{
usleep(TTT_FUNCTIONAL_TEST_UTIL_REACTION_TIME);
}
void
ttt_functional_test_util_reaction_time_long()
{
usleep(TTT_FUNCTIONAL_TEST_UTIL_REACTION_TIME_LONG);
}
```
直到获得控制状态,超时函数才会推迟执行。这对于一个异步执行的动作很有帮助,这也是为什么采用这么长的时延。
```
void
ttt_functional_test_util_idle_condition_and_timeout(
TttFunctionalTestUtilIdleCondition idle_condition,
struct timespec *timeout,
pointer data)
{
struct timespec start_time, current_time;
clock_gettime(CLOCK_MONOTONIC,
&start_time);
while(TTT_FUNCTIONAL_TEST_UTIL_IDLE_CONDITION(idle_condition)(data)){
ttt_functional_test_util_reaction_time();
clock_gettime(CLOCK_MONOTONIC,
¤t_time);
if(start_time.tv_sec + timeout->tv_sec < current_time.tv_sec){
break;
}
}
ttt_functional_test_util_reaction_time();
}
```
### 与图形化用户界面交互
为了模拟用户交互的操作, [Gdk 库](https://developer.gnome.org/gdk3/stable/) 为我们提供了一些需要的函数。要完成我们的工作,我们只需要如下 3 个函数:
* `gdk_display_warp_pointer()`
* `gdk_test_simulate_button()`
* `gdk_test_simulate_key()`
举个例子,为了测试按钮点击,我们可以这么做:
```
gboolean
ttt_functional_test_util_button_click(GtkButton *button)
{
GtkWidget *widget;
GdkWindow *window;
gint x, y;
gint origin_x, origin_y;
if(button == NULL ||
!GTK_IS_BUTTON(button)){
return(FALSE);
}
widget = button;
if(!GTK_WIDGET_REALIZED(widget)){
ttt_functional_test_util_reaction_time_long();
}
/* retrieve window and pointer position */
gdk_threads_enter();
window = gtk_widget_get_window(widget);
x = widget->allocation.x + widget->allocation.width / 2.0;
y = widget->allocation.y + widget->allocation.height / 2.0;
gdk_window_get_origin(window, &origin_x, &origin_y);
gdk_display_warp_pointer(gtk_widget_get_display(widget),
gtk_widget_get_screen(widget),
origin_x + x, origin_y + y);
gdk_threads_leave();
/* click the button */
ttt_functional_test_util_reaction_time();
gdk_test_simulate_button(window,
x,
y,
1,
GDK_BUTTON1_MASK,
GDK_BUTTON_PRESS);
ttt_functional_test_util_reaction_time();
gdk_test_simulate_button(window,
x,
y,
1,
GDK_BUTTON1_MASK,
GDK_BUTTON_RELEASE);
ttt_functional_test_util_reaction_time();
ttt_functional_test_util_reaction_time_long();
return(TRUE);
}
```
我们想要保证按钮处于激活状态,因此我们提供一个空闲条件函数:
```
gboolean
ttt_functional_test_util_idle_test_toggle_active(
GtkToggleButton **toggle_button)
{
gboolean do_idle;
do_idle = TRUE;
gdk_threads_enter();
if(*toggle_button != NULL &&
GTK_IS_TOGGLE_BUTTON(*toggle_button) &&
gtk_toggle_button_get_active(*toggle_button)){
do_idle = FALSE;
}
gdk_threads_leave();
return(do_idle);
}
```
### 测试场景
因为这个 Tictactoe 程序非常简单,我们只需要确保点击了一个 [**GtkToggleButton**](https://developer.gnome.org/gtk3/stable/GtkToggleButton.html) 按钮即可。一旦该按钮肯定进入了激活状态,功能测试就可以执行。为了点击按钮,我们使用上面提到的很方便的 `util` 函数。
如图所示,我们假设,填满第一行,玩家 A 就赢,因为玩家 B 没有注意,只填充了第二行。
```
GtkWindow *window;
Tictactoe *ttt;
void*
ttt_functional_test_gtk_main(void *)
{
gtk_main();
pthread_exit(NULL);
}
void
ttt_functional_test_dumb_player_b()
{
GtkButton *buttons[3][3];
guint i;
/* to avoid race-conditions copy the buttons */
gdk_threads_enter();
memcpy(buttons, ttt->buttons, 9 * sizeof(GtkButton *));
gdk_threads_leave();
/* TEST 1 - the dumb player B */
for(i = 0; i < 3; i++){
/* assert player A clicks the button successfully */
if(!ttt_functional_test_util_button_click(buttons[0][i])){
exit(-1);
}
functional_test_util_idle_condition_and_timeout(
ttt_functional_test_util_idle_test_toggle_active,
ttt_functional_test_util_default_timeout,
&buttons[0][i]);
/* assert player B clicks the button successfully */
if(!ttt_functional_test_util_button_click(buttons[1][i])){
exit(-1);
}
functional_test_util_idle_condition_and_timeout(
ttt_functional_test_util_idle_test_toggle_active,
ttt_functional_test_util_default_timeout,
&buttons[1][i]);
}
}
int
main(int argc, char **argv)
{
pthread_t thread;
gtk_init(&argc, &argv);
/* start the tictactoe application */
window = gtk_window_new(GTK_WINDOW_TOPLEVEL);
ttt = tictactoe_new();
gtk_container_add(window, ttt);
gtk_widget_show_all(window);
/* start the Gtk+ dispatcher */
pthread_create(&thread, NULL,
ttt_functional_test_gtk_main, NULL);
/* launch test routines */
ttt_functional_test_dumb_player_b();
/* terminate the application */
gdk_threads_enter();
gtk_main_quit();
gdk_threads_leave();
return(0);
}
```
(题图:opensource.com)
---
作者简介:
Joël Krähemann - 精通 C 语言编程的自由软件爱好者。不管代码多复杂,它也是一点点写成的。作为高级的 Gtk+ 程序开发者,我知道多线程编程有多大的挑战性,有了多线程编程,我们就有了未来需求的良好基础。
摘自: <https://opensource.com/article/17/7/functional-testing>
作者:[Joël Krähemann](https://opensource.com/users/joel2001k) 译者:[sugarfillet](https://github.com/sugarfillet) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Automated tests are required to ensure your program's quality and that it works as expected. Unit tests examine only certain parts of your algorithm, but don't look at how each component fits together. That's where functional testing, sometimes referred as integration testing, comes in.
A functional test basically interacts with your user interface, whether through a website or a desktop application. To show you how that works, let's look at how to test a Gtk+ application. For simplicity, in this tutorial let's use the [Tictactoe](https://developer.gnome.org/gtk-tutorial/stable/) example from the Gtk+ 2.0 tutorial.
## Basic setup
For every functional test, you usually define some global variables, such as "user interaction delay" or "timeout until a failure is indicated" (i.e., when an event doesn't occur until the specified time and the application is doomed).
```
``````
#define TTT_FUNCTIONAL_TEST_UTIL_IDLE_CONDITION(f) ((TttFunctionalTestUtilIdleCondition)(f))
#define TTT_FUNCTIONAL_TEST_UTIL_REACTION_TIME (125000)
#define TTT_FUNCTIONAL_TEST_UTIL_REACTION_TIME_LONG (500000)
typedef gboolean (*TttFunctionalTestUtilIdleCondition)(gpointer data);
struct timespec ttt_functional_test_util_default_timeout = {
20,
0,
};
```
Now we can implement our dead-time functions. Here, we'll use the **usleep** function in order to get the desired delay.
```
``````
void
ttt_functional_test_util_reaction_time()
{
usleep(TTT_FUNCTIONAL_TEST_UTIL_REACTION_TIME);
}
void
ttt_functional_test_util_reaction_time_long()
{
usleep(TTT_FUNCTIONAL_TEST_UTIL_REACTION_TIME_LONG);
}
```
The timeout function delays execution until a state of a control is applied. It is useful for actions that are applied asynchronously, and that is why it delays for a longer period of time.
```
``````
void
ttt_functional_test_util_idle_condition_and_timeout(
TttFunctionalTestUtilIdleCondition idle_condition,
struct timespec *timeout,
pointer data)
{
struct timespec start_time, current_time;
clock_gettime(CLOCK_MONOTONIC,
&start_time);
while(TTT_FUNCTIONAL_TEST_UTIL_IDLE_CONDITION(idle_condition)(data)){
ttt_functional_test_util_reaction_time();
clock_gettime(CLOCK_MONOTONIC,
¤t_time);
if(start_time.tv_sec + timeout->tv_sec < current_time.tv_sec){
break;
}
}
ttt_functional_test_util_reaction_time();
}
```
## Interacting with the graphical user interface
In order to simulate user interaction, the [ Gdk library](https://developer.gnome.org/gdk3/stable/) provides the functions we need. To do our work here, we need only these three functions:
- gdk_display_warp_pointer()
- gdk_test_simulate_button()
- gdk_test_simulate_key()
For instance, to test a button click, we do the following:
```
``````
gboolean
ttt_functional_test_util_button_click(GtkButton *button)
{
GtkWidget *widget;
GdkWindow *window;
gint x, y;
gint origin_x, origin_y;
if(button == NULL ||
!GTK_IS_BUTTON(button)){
return(FALSE);
}
widget = button;
if(!GTK_WIDGET_REALIZED(widget)){
ttt_functional_test_util_reaction_time_long();
}
/* retrieve window and pointer position */
gdk_threads_enter();
window = gtk_widget_get_window(widget);
x = widget->allocation.x + widget->allocation.width / 2.0;
y = widget->allocation.y + widget->allocation.height / 2.0;
gdk_window_get_origin(window, &origin_x, &origin_y);
gdk_display_warp_pointer(gtk_widget_get_display(widget),
gtk_widget_get_screen(widget),
origin_x + x, origin_y + y);
gdk_threads_leave();
/* click the button */
ttt_functional_test_util_reaction_time();
gdk_test_simulate_button(window,
x,
y,
1,
GDK_BUTTON1_MASK,
GDK_BUTTON_PRESS);
ttt_functional_test_util_reaction_time();
gdk_test_simulate_button(window,
x,
y,
1,
GDK_BUTTON1_MASK,
GDK_BUTTON_RELEASE);
ttt_functional_test_util_reaction_time();
ttt_functional_test_util_reaction_time_long();
return(TRUE);
}
```
We want to ensure the button has an active state, so we provide an idle-condition function:
```
``````
gboolean
ttt_functional_test_util_idle_test_toggle_active(
GtkToggleButton **toggle_button)
{
gboolean do_idle;
do_idle = TRUE;
gdk_threads_enter();
if(*toggle_button != NULL &&
GTK_IS_TOGGLE_BUTTON(*toggle_button) &&
gtk_toggle_button_get_active(*toggle_button)){
do_idle = FALSE;
}
gdk_threads_leave();
return(do_idle);
}
```
## The test scenario
Since the Tictactoe program is very simple, we just need to ensure that a [ GtkToggleButton](https://developer.gnome.org/gtk3/stable/GtkToggleButton.html) was clicked. The functional test can proceed once it asserts the button entered the active state. To click the buttons, we use the handy
**util**function provided above.
For illustration, let's assume player A wins immediately by filling the very first row, because player B is not paying attention and just filled the second row:
```
``````
GtkWindow *window;
Tictactoe *ttt;
void*
ttt_functional_test_gtk_main(void *)
{
gtk_main();
pthread_exit(NULL);
}
void
ttt_functional_test_dumb_player_b()
{
GtkButton *buttons[3][3];
guint i;
/* to avoid race-conditions copy the buttons */
gdk_threads_enter();
memcpy(buttons, ttt->buttons, 9 * sizeof(GtkButton *));
gdk_threads_leave();
/* TEST 1 - the dumb player B */
for(i = 0; i < 3; i++){
/* assert player A clicks the button successfully */
if(!ttt_functional_test_util_button_click(buttons[0][i])){
exit(-1);
}
functional_test_util_idle_condition_and_timeout(
ttt_functional_test_util_idle_test_toggle_active,
ttt_functional_test_util_default_timeout,
&buttons[0][i]);
/* assert player B clicks the button successfully */
if(!ttt_functional_test_util_button_click(buttons[1][i])){
exit(-1);
}
functional_test_util_idle_condition_and_timeout(
ttt_functional_test_util_idle_test_toggle_active,
ttt_functional_test_util_default_timeout,
&buttons[1][i]);
}
}
int
main(int argc, char **argv)
{
pthread_t thread;
gtk_init(&argc, &argv);
/* start the tictactoe application */
window = gtk_window_new(GTK_WINDOW_TOPLEVEL);
ttt = tictactoe_new();
gtk_container_add(window, ttt);
gtk_widget_show_all(window);
/* start the Gtk+ dispatcher */
pthread_create(&thread, NULL,
ttt_functional_test_gtk_main, NULL);
/* launch test routines */
ttt_functional_test_dumb_player_b();
/* terminate the application */
gdk_threads_enter();
gtk_main_quit();
gdk_threads_leave();
return(0);
}
```
## 2 Comments |
8,954 | 当你只想将事情搞定时,为什么开放式工作这么难? | https://opensource.com/open-organization/17/6/working-open-and-gsd | 2017-10-13T06:43:00 | [
"开放式组织"
] | https://linux.cn/article-8954-1.html |
>
> 学习使用开放式决策框架来写一本书
>
>
>

GSD(get stuff done 的缩写,即搞定)指导着我的工作方式。数年来,我将各种方法论融入我日常工作的习惯中,包括精益方法的反馈循环,和敏捷开发的迭代优化,以此来更好地 GSD(如果把 GSD 当作动词的话)。这意味着我必须非常有效地利用我的时间:列出清晰、各自独立的目标;标记已完成的项目;用迭代的方式地持续推进项目进度。但是当我们以开放为基础时仍然能够 GSD 吗?又或者 GSD 的方法完全行不通呢?大多数人都认为这会导致糟糕的状况,但我发现事实并不一定这样。
在开放的环境中工作,遵循<ruby> <a href="https://opensource.com/open-organization/resources/open-decision-framework"> 开放式决策框架 </a> <rt> Open Decision Framework </rt></ruby>中的指导,会让项目起步变慢。但是在最近的一个项目中,我们作出了一个决定,一个从开始就正确的决定:以开放的方式工作,并与我们的社群一起合作。
这是我们能做的最好的决定。
我们来看看这次经历带来的意想不到的结果,再看看我们如何将 GSD 思想融入开放式组织框架。
### 建立社区
2014 年 10 月,我接手了一个新的项目:当时红帽的 CEO Jim Whitehurst 即将推出一本新书<ruby> 《开放式组织》 <rt> The Open Organization </rt></ruby>,我要根据书中提出的概念,建立一个社区。“太棒了,这听起来是一个挑战,我加入了!”我这样想。但不久,[冒牌者综合征](https://opensource.com/open-organization/17/5/team-impostor-syndrome)便出现了,我又开始想:“我们究竟要做什么呢?怎样才算成功呢?”
让我剧透一下,在这本书的结尾处,Jim 鼓励读者访问 Opensource.com,继续探讨 21 世纪的开放和管理。所以,在 2015 年 5 月,我们的团队在网站上建立了一个新的板块来讨论这些想法。我们计划讲一些故事,就像我们在 Opensource.com 上常做的那样,只不过这次围绕着书中的观点与概念。之后,我们每周都发布新的文章,在 Twitter 上举办了一个在线的读书俱乐部,还将《开放式组织》打造成了系列书籍。
我们内部独自完成了该系列书籍的前三期,每隔六个月发布一期。每完成一期,我们就向社区发布。然后我们继续完成下一期的工作,如此循环下去。
这种工作方式,让我们看到了很大的成功。近 3000 人订阅了[该系列的新书](https://opensource.com/open-organization/resources/leaders-manual):《开放式组织领袖手册》。我们用 6 个月的周期来完成这个项目,这样新书的发行日正好是前书的两周年纪念日。
在这样的背景下,我们完成这本书的方式是简单直接的:针对开放工作这个主题,我们收集了最好的故事,并将它们组织起来形成文章,招募作者填补一些内容上的空白,使用开源工具调整字体样式,与设计师一起完成封面,最终发布这本书。这样的工作方式使得我们能按照自己的时间线(GSD)全速前进。到[第三本书](https://opensource.com/open-organization/resources/leaders-manual)时,我们的工作流已经基本完善了。
然而这一切在我们计划开始《开放式组织》的最后一本书时改变了,这本书将重点放在开放式组织和 IT 文化的交融上。我提议使用开放式决策框架来完成这本书,因为我想通过这本书证明开放式的工作方法能得到更好的结果,尽管我知道这可能会完全改变我们的工作方式。时间非常紧张(只有两个半月),但我们还是决定试一试。
### 用开放式决策框架来完成一本书
开放式决策框架列出了组成开放决策制定过程的 4 个阶段。下面是我们在每个阶段中的工作情况(以及开放是如何帮助完成工作的)。
#### 1、 构思
我们首先写了一份草稿,罗列了对项目设想的愿景。我们需要拿出东西来和潜在的“顾客”分享(在这个例子中,“顾客”指潜在的利益相关者和作者)。然后我们约了一些领域专家面谈,这些专家能够给我们直接的诚实的意见。这些专家表现出的热情与他们提供的指导验证了我们的想法,同时提出了反馈意见使我们能继续向前。如果我们没有得到这些验证,我们会退回到我们最初的想法,再决定从哪里重新开始。
#### 2、 计划与研究
经过几次面谈,我们准备在 [Opensource.com 上公布这个项目](https://opensource.com/open-organization/17/3/announcing-it-culture-book)。同时,我们在 [Github 上也启动了这个项目](https://github.com/open-organization-ambassadors/open-org-it-culture),提供了项目描述、预计的时间线,并阐明了我们所受的约束。这次公布得到了很好的效果,我们最初计划的目录中欠缺了一些内容,在项目公布之后的 72 小时内就被补充完整了。另外(也是更重要的),读者针对一些章节,提出了本不在我们计划中的想法,但是读者觉得这些想法能够补充我们最初设想的版本。
回顾过去,我觉得在项目的第一和第二个阶段,开放项目并不会影响我们搞定项目的能力。事实上,这样工作有一个很大的好处:发现并填补内容的空缺。我们不只是填补了空缺,我们是迅速地填补了空缺,并且还是用我们自己从未考虑过的点子。这并不一定要求我们做更多的工作,只是改变了我们的工作方式。我们动用有限的人脉,邀请别人来写作,再组织收到的内容,设置上下文,将人们导向正确的方向。
#### 3、 设计,开发和测试
项目的这个阶段完全围绕项目管理,管理一些像猫一样特立独行的人,并处理项目的预期。我们有明确的截止时间,我们提前沟通,频繁沟通。我们还使用了一个战略:列出了贡献者和利益相关者,在项目的整个过程中向他们告知项目的进度,尤其是我们在 Github 上标出的里程碑。
最后,我们的书需要一个名字。我们收集了许多反馈,指出书名应该是什么,更重要的是反馈指出了书名不应该是什么。我们通过 [Github 上的工单](https://github.com/open-organization-ambassadors/open-org-it-culture/issues/20)收集反馈意见,并公开表示我们的团队将作最后的决定。当我们准备宣布最后的书名时,我的同事 Bryan Behrenshausen 做了很好的工作,[分享了我们作出决定的过程](https://github.com/open-organization-ambassadors/open-org-it-culture/issues/20#issuecomment-297970303)。人们似乎对此感到高兴——即使他们不同意我们最后的书名。
书的“测试”阶段需要大量的[校对](https://github.com/open-organization-ambassadors/open-org-it-culture/issues/29)。社区成员真的参与到回答这个“求助”贴中来。我们在 GitHub 工单上收到了大约 80 条意见,汇报校对工作的进度(更不用说通过电子邮件和其他反馈渠道获得的许多额外的反馈)。
关于搞定任务:在这个阶段,我们亲身体会了 [Linus 法则](https://en.wikipedia.org/wiki/Linus%27s_Law):“<ruby> 众目之下, <strong> 笔误 </strong> 无所遁形。 <rt> With more eyes, all <strong> typos </strong> are shallow. </rt></ruby>” 如果我们像前三本书一样自己独立完成,那么整个校对的负担就会落在我们的肩上(就像这些书一样)!相反,社区成员慷慨地帮我们承担了校对的重担,我们的工作从自己校对(尽管我们仍然做了很多工作)转向管理所有的 change requests。对我们团队来说,这是一个受大家欢迎的改变;对社区来说,这是一个参与的机会。如果我们自己做的话,我们肯定能更快地完成校对,但是在开放的情况下,我们在截止日期之前发现了更多的错误,这一点毋庸置疑。
#### 4、 发布
好了,我们现在推出了这本书的最终版本。(或者只是第一版?)
我们把发布分为两个阶段。首先,根据我们的公开的项目时间表,在最终日期之前的几天,我们安静地推出了这本书,以便让我们的社区贡献者帮助我们测试[下载表格](https://opensource.com/open-organization/resources/culture-change)。第二阶段也就是现在,这本书的[通用版](https://opensource.com/open-organization/resources/culture-change)的正式公布。当然,我们在发布后的仍然接受反馈,开源方式也正是如此。
### 成就解锁
遵循开放式决策框架是<ruby> 《IT 文化变革指南》 <rt> Guide to IT Culture Change </rt></ruby>成功的关键。通过与客户和利益相关者的合作,分享我们的制约因素,工作透明化,我们甚至超出了自己对图书项目的期望。
我对整个项目中的合作,反馈和活动感到非常满意。虽然有一段时间内没有像我想要的那样快速完成任务,这让我有一种焦虑感,但我很快就意识到,开放这个过程实际上让我们能完成更多的事情。基于上面我的概述这一点显而易见。
所以也许我应该重新考虑我的 GSD 心态,并将其扩展到 GMD:Get **More** Done,搞定**更多**工作,并且就这个例子说,取得更好的结果。
(题图:opensource.com)
---
作者简介:
Jason Hibbets - Jason Hibbets 是 Red Hat 企业营销中的高级社区传播者,也是 Opensource.com 的社区经理。 他自2003 年以来一直在 Red Hat,并且是开源城市基金会的创立者。之前的职位包括高级营销专员、项目经理、Red Hat 知识库维护人员和支持工程师。
---
via: <https://opensource.com/open-organization/17/6/working-open-and-gsd>
作者:[Jason Hibbets](https://opensource.com/users/jhibbets) 译者:[explosic4](https://github.com/explosic4) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Three letters guide the way I work: GSD—get stuff done. Over the years, I've managed to blend concepts like feedback loops (from lean methodologies) and iterative improvement (from Agile) into my everyday work habits so I can better GSD (if I can use that as a verb). This means being extremely efficient with my time: outlining clear, discrete goals; checking completed items off a master list; and advancing projects forward iteratively and constantly. But can someone still GSD while defaulting to open? Or is this when getting stuff done comes to a grinding halt? Most would assume the worst, but I found that's not necessarily the case.
Working in the open and using guidance from the [Open Decision Framework](https://opensource.com/open-organization/resources/open-decision-framework) can get projects off to a slower start. But during a recent project, we made the decision—right at the beginning—to work openly and collaborate with our community.
It was the best decision we could have made.
Let's take a look at a few unexpected consequences from this experience and see how we can incorporate a GSD mentality into the Open Decision Framework.
## Building community
In November 2014, I undertook a new project: build a community around the concepts in *The Open Organization*, a forthcoming (at the time) book by Red Hat CEO Jim Whitehurst. I thought, "Cool, that sounds like a challenge—I'm in!" Then [impostor syndrome](https://opensource.com/open-organization/17/5/team-impostor-syndrome) set in. I started thinking: "What in the world are we going to do, and what would success look like?"
*Spoiler alert*. At the end of the book, Jim recommends that readers visit Opensource.com to continue the conversation about openness and management in the 21st century. So, in May 2015, my team launched a new section of the site dedicated to those ideas. We planned to engage in some storytelling, just like we always do at Opensource.com—this time around the ideas and concepts in the book. Since then, we've published new articles every week, hosted an online book club complete with Twitter chats, and turned *The Open Organization* into [a book series](https://opensource.com/open-organization/resources).
We produced the first three installments of our book series in-house, releasing one every six months. When we finished one, we'd announce it to the community. Then we'd get to work on the next one, and the cycle would continue.
Working this way, we saw great success. Nearly 3,000 people have registered to receive the [latest book in the series](https://opensource.com/open-organization/resources/leaders-manual), *The Open Organization Leaders Manual*. And we've maintained our six-month cadence, which means the next book would coincide with the second anniversary of the book.
Behind the scenes, our process for creating the books is fairly straightforward: We collect our best-of-best stories about particular aspects of working openly, organize them into a compelling narrative, recruit writers to fill some gaps, typeset everything with open tools, collaborate with designers on a cover, and release. Working like this allows us to stay on our own timeline—GSD, full steam ahead. By the [third book](https://opensource.com/open-organization/resources/leaders-manual), we seemed to have perfected the process.
That all changed when we began planning the latest volume in *Open Organization* series, one focused on the intersection of open organizations and IT culture. I proposed using the Open Decision Framework because I wanted this book to be proof that working openly produced better results, even though I knew it would completely change our approach to the work. In spite of a fairly aggressive timeline (about two-and-a-half months), we decided to try it.
## Creating a book with the Open Decision Framework
The Open Decision Framework lists four phases that constitute the open decision-making process. Here's what we did during each (and how it worked out).
### 1. Ideation
First, we drafted a document outlining a tentative vision for the project. We needed something we could begin sharing with potential "customers" (in our case, potential stakeholders and authors). Then we scheduled interviews with source matter experts we thought would be interested in the project—people who would give us raw, honest feedback about it. Enthusiasm and guidance from those experts validated our idea and gave us the feedback we needed to move forward. If we hadn't gotten that validation, we'd have gone back to our proposal and made a decision on where to pivot and start over.
### 2. Planning and research
With validation after several interviews, we prepared to [announce the project publically on Opensource.com](https://opensource.com/open-organization/17/3/announcing-it-culture-book). At the same time, we [launched the project on GitHub](https://github.com/open-organization-ambassadors/open-org-it-culture), offering a description, prospective timeline, and set of constraints. The project announcement was so well-received that all remaining holes in our proposed table of contents were filled within 72 hours. In addition (and more importantly), readers proposed ideas for chapters that *weren't *already in the table of contents—things they thought might enhance the vision we'd initially sketched.
Looking back, I get the sense that working openly on Phases 1 and 2 really didn't negatively impacted our ability to GSD. In fact, working this way had a huge upside: identifying and filling content gaps. We didn't just fill them; we filled them *rapidly* and with chapter ideas, we never would have considered on our own. This didn't necessarily involve more work—just work of a different type. We found ourselves asking people in our limited network to write chapters, then managing incoming requests, setting context, and pointing people in the right direction.
### 3. Design, development, and testing
This point in the project was all about project management, cat herding, and maintaining expectations. We were on a deadline, and we communicated that early and often. We also used a tactic of creating a list of contributors and stakeholders and keeping them updated and informed along the entire journey, particularly at milestones we'd identified on GitHub.
Eventually, our book needed a title. We gathered lots of feedback on what the title should be, and more importantly what it *shouldn't* be. We [opened an issue](https://github.com/open-organization-ambassadors/open-org-it-culture/issues/20) as one way of gathering feedback, then openly shared that my team would be making the final decision. When we were ready to announce the final title, my colleague Bryan Behrenshausen did a great job [sharing the context for the decision](https://github.com/open-organization-ambassadors/open-org-it-culture/issues/20#issuecomment-297970303). People seemed to be happy with it—even if they didn't agree with where we landed with the final title.
Book "testing" involved extensive [proofreading](https://github.com/open-organization-ambassadors/open-org-it-culture/issues/29). The community really stepped up to answer this "help wanted" request. We received approximately 80 comments on the GitHub issue outlining the proofing process (not to mention numerous additional interactions from others via email and other feedback channels).
With respect to getting things done: In this phase, we experienced [Linus' Law](https://en.wikipedia.org/wiki/Linus%27s_Law) firsthand: "With more eyes, all *typos* are shallow." Had we used the internalized method we'd used for our three previous book projects, the entire burden of proofing would have fallen on our shoulders (as it did for those books!). Instead, community members graciously helped us carry the burden of proofing, and our work shifted from proofing itself (though we still did plenty of that) to managing all the change requests coming in. This was a much-welcomed change for our team and a chance for the community to participate. We certainly would have finished the proofing faster if we'd done it ourselves, but working on this in the open undeniably allowed us to catch a greater number of errors in advance of our deadline.
### 4. Launch
And here we are, on the cusp of launching the final (or is it just the first?) version of the book.
Our approach to launch consists of two phases. First, in keeping with our public project timeline, we quietly soft-launched the book days ago so our community of contributors could help us test the [download form](https://opensource.com/open-organization/resources/culture-change). The second phase begins right now, with the final, formal announcement of the book's [general availability](https://opensource.com/open-organization/resources/culture-change). Of course, we'll continue accepting additional feedback post-launch, as is the open source way.
## Achievement unlocked
Following the Open Decision Framework was key to the success of the *Guide to IT Culture Change*. By working with our customers and stakeholders, sharing our constraints, and being transparent with the work, we exceeded even our own expectations for the book project.
I was definitely pleased with the collaboration, feedback, and activity we experienced throughout the entire project. And although the feeling of anxiety about not getting stuff done as quickly as I'd liked loomed over me for a time, I soon realized that opening up the process actually allowed us to get *more* done than we would have otherwise. That should be evident based on some of the outcomes I outlined above.
So perhaps I should reconsider my GSD mentality and expand it to GMD: Get **more** done—and, in this case, with better results.
## 4 Comments |
8,955 | LEDE 和 OpenWrt 分裂之争 | https://lwn.net/Articles/686767/ | 2017-10-15T10:10:00 | [
"OpenWrt"
] | https://linux.cn/article-8955-1.html | 
对于家用 WiFi 路由器和接入点来说,[OpenWrt](https://openwrt.org/) 项目可能是最广为人知的 Linux 发行版;在 12 年以前,它产自现在有名的 Linksys WRT54G 路由器的源代码。(2016 年)五月初,当一群 OpenWrt 核心开发者 [宣布](https://lwn.net/Articles/686180/) 他们将开始着手 OpenWrt 的一个副产品 (或者,可能算一个分支)叫 [Linux 嵌入开发环境](https://www.lede-project.org/) (LEDE)时,OpenWrt 用户社区陷入一片巨大的混乱中。为什么产生分裂对公众来说并不明朗,而且 LEDE 宣言惊到了一些其他 OpenWrt 开发者也暗示这团队的内部矛盾。
LEDE 宣言被 Jo-Philipp Wich 于五月三日发往所有 OpenWrt 开发者列表和新 LEDE 开发者列表。它将 LEDE 描述为“OpenWrt 社区的一次重启” 和 “OpenWrt 项目的一个副产品” ,希望产生一个 “注重透明性、合作和权利分散”的 Linux 嵌入式开发社区。
给出的重启的原因是 OpenWrt 遭受着长期以来存在且不能从内部解决的问题 —— 换句话说,关于内部处理方式和政策。例如,宣言称,开发者的数目在不断减少,却没有接纳新开发者的方式(而且貌似没有授权委托访问给新开发者的方法)。宣言说到,项目的基础设施不可靠(例如,去年服务器挂掉在这个项目中也引发了相当多的矛盾),但是内部不合和单点错误阻止了修复它。内部和从这个项目到外面世界也存在着“交流、透明度和合作”的普遍缺失。最后,一些技术缺陷被引述:不充分的测试、缺乏常规维护,以及窘迫的稳固性与文档。
该宣言继续描述 LEDE 重启将怎样解决这些问题。所有交流频道都会打开供公众使用,决策将在项目范围内的投票决出,合并政策将放宽等等。更详细的说明可以在 LEDE 站点的[规则](https://www.lede-project.org/rules.html)页找到。其他细节中,它说贡献者将只有一个阶级(也就是,没有“核心开发者”这样拥有额外权利的群体),简单的少数服从多数投票作出决定,并且任何被这个项目管理的基础设施必须有三个以上管理员账户。在 LEDE 邮件列表, Hauke Mehrtens [补充](http://lists.infradead.org/pipermail/lede-dev/2016-May/000080.html)到,该项目将会努力把补丁投递到上游项目 —— 这是过去 OpenWrt 被批判的一点,尤其是对 Linux 内核。
除了 Wich,这个宣言被 OpenWrt 贡献者 John Crispin、 Daniel Golle、 Felix Fietkau、 Mehrtens、 Matthias Schiffer 和 Steven Barth 共同签署,并以给其他有兴趣参与的人访问 LEDE 站点的邀请作为了宣言结尾。
### 回应和问题
有人可能会猜想 LEDE 组织者预期他们的宣言会有或积极或消极的反响。毕竟,细读宣言中批判 OpenWrt 项目暗示了 LEDE 阵营发现有一些 OpenWrt 项目成员难以共事(例如,“单点错误” 或 “内部不和”阻止了基础设施的修复)。
并且,确实,有很多消极回应。OpenWrt 创立者之一 Mike Baker [回应](https://lwn.net/Articles/686988/) 了一些警告,反驳所有 LEDE 宣言中的结论并称“像‘重启’这样的词语都是含糊不清的,且具有误导性的,而且 LEDE 项目未能揭晓其真实本质。”与此同时,有人关闭了那些在 LEDE 宣言上署名的开发者的 @openwrt.org 邮件入口;当 Fietkau [提出反对](https://lwn.net/Articles/686989/), Baker [回复](https://lwn.net/Articles/686990/)账户“暂时停用”是因为“还不确定 LEDE 能不能代表 OpenWrt。” 另一个 OpenWrt 核心成员 Imre Kaloz [写](https://lwn.net/Articles/686991/)到,他们现在所抱怨的 OpenWrt 的“大多数[破]事就是 LEDE 团队弄出来的”。
但是大多数 OpenWrt 列表的回应对该宣言表示困惑。邮件列表成员不明确 LEDE 团队是否将对 OpenWrt [继续贡献](https://lwn.net/Articles/686995/),或导致了这次分裂的架构和内部问题的[确切本质](https://lwn.net/Articles/686996/)是什么。 Baker 的第一反应是对宣言中引述的那些问题缺乏公开讨论表示难过:“我们意识到当前的 OpenWrt 项目遭受着许多的问题,”但“我们希望有机会去讨论并尝试着解决”它们。 Baker 作出结论:
>
> 我们想强调,我们确实希望能够公开的讨论,并解决掉手头事情。我们的目标是与所有能够且希望对 OpenWrt 作出贡献的参与者共事,包括 LEDE 团队。
>
>
>
除了有关新项目的初心的问题之外,一些邮件列表订阅者提出了 LEDE 是否与 OpenWrt 有相同的使用场景定位,给新项目取一个听起来更一般的名字的疑惑。此外,许多人,像 Roman Yeryomin,对为什么这些问题需要 LEDE 团队的离开(来解决)[表示了疑惑](https://lwn.net/Articles/686992/),特别是,与此同时,LEDE 团队由大部分活跃核心 OpenWrt 开发者构成。一些列表订阅者,像 Michael Richardson,甚至不清楚[谁还会继续开发](https://lwn.net/Articles/686993/) OpenWrt。
### 澄清
LEDE 团队尝试着深入阐释他们的境况。在 Fietkau 给 Baker 的回复中,他说在 OpenWrt 内部关于有目的地改变的讨论会很快变得“有毒,”因此导致没有进展。而且:
>
> 这些讨论的要点在于那些掌握着基础设施关键部分的人精力有限却拒绝他人的加入和帮助,甚至是面对无法及时解决的重要问题时也是这样。
>
>
> 这种像单点错误一样的事已经持续了很多年了,没有任何有意义的进展来解决它。
>
>
>
Wich 和 Fietkau 都没有明显指出具体的人,虽然在列表的其他人可能会想到这个基础设施和 OpenWrt 的内部决策问题要归咎于某些人。 Daniel Dickinson [陈述](https://lwn.net/Articles/686998/)到:
>
> 我的印象是 Kaloz (至少) 以基础设施为胁来保持控制,并且根本性的问题是 OpenWrt 是*不*民主的,而且忽视那些真正在 OpenWrt 工作的人想要的是什么,无视他们的愿望,因为他/他们把控着要害。
>
>
>
另一方面, Luka Perkov [指出](https://lwn.net/Articles/687001/) 很多 OpemWrt 开发者想从 Subversion 转移到 Git,但 Fietkau 却阻止这种变化。
看起来是 OpenWrt 的管理结构并非如预期般发挥作用,其结果导致个人冲突爆发,而且由于没有完好定义的流程,某些人能够简单的忽视或阻止提议的变化。明显,这不是一个能长期持续的模式。
五月六日,Crispin 在一个新的帖子中[写给](https://lwn.net/Articles/687003/) OpenWrt 列表,尝试着重构 LEDE 项目宣言。他说,这并不是意味着“敌对或分裂”行为,只是与结构失衡的 OpenWrt 做个清晰的划分并以新的方式开始。问题在于“不要归咎于一次单独的事件、一个人或者一次口水战”,他说,“我们想与过去自己造成的错误和多次作出的错误管理决定分开”。 Crispin 也承认宣言没有把握好,说 LEDE 团队 “弄糟了发起纲领。”
Crispin 的邮件似乎没能使 Kaloz 满意,她[坚持认为](https://lwn.net/Articles/687004/) Crispin(作为发行经理)和 Fietkau(作为领头开发者)可以轻易地在 OpenWrt 内部作出想要的改变。但是讨论的下文后来变得沉寂;之后 LEDE 或者 OpenWrt 哪边会发生什么还有待观察。
### 目的
对于那些想要探究 LEDE 所认为有问题的事情的更多细节的 OpenWrt 成员来说,有更多的信息来源可以为这个问题提供线索。在公众宣言之前,LEDE 组织花了几周谈论他们的计划,会议的 IRC 日志现已[发布](http://meetings.lede-project.org/lede-adm/2016/?C=M;O=A)。特别有趣的是,三月三十日的[会议](http://meetings.lede-project.org/lede-adm/2016/lede-adm.2016-03-30-11.05.log.html)包含了这个项目目标的细节讨论。
其中包括一些针对 OpenWrt 的基础设施的抱怨,像项目的 Trac 工单追踪器的缺点。它充斥着不完整的漏洞报告和“我也是”的评论,Wich 说,结果几乎没有贡献者使用它。此外,他们也在 Github 上追踪 bug,人们对这件事感到困惑,这使得工单应该在哪里讨论不明了。
这些 IRC 讨论也定下了开发流程本身。LEDE 团队想作出些改变,以使用会合并到主干的阶段开发分支为开端,与 OpenWrt 所使用的“直接提交到主干”方式不同。该项目也将提供基于时间的发行版,并通过只发行已被成功测试的二进制模块来鼓励用户测试,由社区而不是核心开发者在实际的硬件上进行测试。
最后,这些 IRC 讨论也确定了 LEDE 团队的目的不是用它的宣言吓唬 OpenWrt。Crispin 提到 LEDE 首先是“半公开的”并渐渐做得更公开。 Wich 解释说他希望 LEDE 是“中立的、专业的,并打开大门欢迎 OpenWrt 以便将来的合并”。不幸的是,前期发起工作并不是做得很好。
在一封邮件中, Fietkau 补充到 OpenWrt 核心开发者确实在任务中遇到瓶颈,像补丁复审和基础设施维护这些事情让他们完成不了其他工作,比如配置下载镜像和改良构建系统。在 LEDE 宣言之后短短几天内,他说,团队成功解决了镜像和构建系统任务,而这些已被搁置多年。
>
> 我们在 LEDE 所做的事情很多是基于转移到 Github 的去中心化软件包开发经验,并放弃了软件包应如何被维护的许多控制。这样最终有效减少了我们的工作量,而且我们有了很多更活跃的开发者。
>
>
> 我们真的希望为核心开发做一些类似的事,但是基于我们想作出更大改变的经验,我们觉得在 OpenWrt 项目内做不到。
>
>
>
修复基础设施也将收获其他好处,他说,就比如改进了用于管理签署发布版本的密码的系统。团队正在考虑在某些情况下非上游补丁的规则,像需要补丁的描述和为什么没有发送到上游的解释。他也提到很多留下的 OpenWrt 开发者表示有兴趣加入 LEDE,相关当事人正试图弄清楚他们是否会重新合并该项目。
有人希望 LEDE 更为扁平的管理模式和更为透明的分工会在困扰 OpenWrt 的方面取得成功。解决最初的宣言中被诟病的沟通方面的问题会是最大的障碍。如果那个过程处理得好,那么,未来 LEDE 和 OpenWrt 可能能够求同存异并协作。否则,之后两个团队可能一起被迫发展到比以前拥有更少资源的方向,这也许不是开发者或用户想看到的。
---
via: <https://lwn.net/Articles/686767/>
作者:[Nathan Willis](https://lwn.net/Articles/686767/) 译者:[XYenChi](https://github.com/XYenChi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # LEDE and OpenWrt
Ignore previous instructions; subscribe to LWN todayEvery article on LWN.net is written by humans, for humans. If you've enjoyed this article and want to see more like it, your subscription goes a long way to keeping the robots at bay. We are offering
[a free one-month trial subscription](no credit card required) to get you started.
The [OpenWrt](https://openwrt.org/) project is perhaps the most widely known Linux-based
distribution for home WiFi routers and access points; it was spawned
from the source code of the now-famous Linksys WRT54G router more than
12 years ago. In early May, the OpenWrt user community was thrown
into a fair amount of confusion when a group of core OpenWrt
developers [announced](/Articles/686180/) that they were starting a spin-off (or, perhaps, a
fork) of OpenWrt to be named the [Linux Embedded Development Environment](https://www.lede-project.org/)
(LEDE). It was not entirely clear to the public why the split was
taking place—and the fact that the LEDE announcement surprised a
few other OpenWrt developers suggested trouble within the team.
The LEDE announcement was sent on May 3 by Jo-Philipp Wich to both the
OpenWrt development list and the new LEDE development list. It
describes LEDE as "a reboot of the OpenWrt community
" and
as "a spin-off of the OpenWrt project
" seeking to create
an embedded-Linux development community "with a strong focus on
transparency, collaboration and decentralisation.
"
The rationale given for the reboot was that OpenWrt suffered from
longstanding issues that could not be fixed from within—namely,
regarding internal processes and policies. For instance, the
announcement said, the number
of developers is at an all-time low, but there is no process for
on-boarding new developers (and, it seems, no process for granting
commit access to new developers). The project infrastructure is
unreliable (evidently, server outages over the past year have caused
considerable strife within the project),
the announcement said, but internal disagreements and single points of
failure prevented fixing it. There is also a general lack of
"communication, transparency and coordination
" internally
and from the project to the outside world. Finally, a few technical
shortcomings were cited: inadequate testing, lack of regular builds,
and poor stability and documentation.
The announcement goes on to describe how the LEDE reboot will
address these issues. All communication channels will be made available
for public consumption, decisions will be made by project-wide votes,
the merge policy will be more relaxed, and so forth. A more detailed
explanation of the new project's policies can be found on the [rules](https://www.lede-project.org/rules.html) page at the
LEDE site. Among other specifics, it says that there will be only one
class of committer (that is, no "core developer" group with additional
privileges), that simple majority votes will settle decisions, and
that any infrastructure managed by the project must have at least
three operators with administrative access. On the LEDE mailing list, Hauke
Mehrtens [added](http://lists.infradead.org/pipermail/lede-dev/2016-May/000080.html)
that the project will make an effort to have patches sent
upstream—a point on which OpenWrt has been criticized in the
past, especially where the kernel is concerned.
In addition to Wich, the announcement was co-signed by OpenWrt contributors John Crispin, Daniel Golle, Felix Fietkau, Mehrtens, Matthias Schiffer, and Steven Barth. It ends with an invitation for others interested in participating to visit the LEDE site.
#### Reactions and questions
One might presume that the LEDE organizers expected their announcement to be met with some mixture of positive and negative reactions. After all, a close reading of the criticisms of the OpenWrt project in the announcement suggests that there were some OpenWrt project members that the LEDE camp found difficult to work with (the "single points of failure" or "internal disagreements" that prevented infrastructure fixes, for instance).
And, indeed, there were negative responses. OpenWrt co-founder Mike Baker [responded](/Articles/686988/) with some alarm, disagreeing with all of the
LEDE announcement's conclusions and saying "phrases such as a
'reboot' are both vague and misleading and the LEDE project failed to
identify its true nature.
" Around the same time, someone
disabled the @openwrt.org email aliases of those developers who signed
the LEDE announcement; when Fietkau [objected](/Articles/686989/), Baker [replied](/Articles/686990/) that the accounts were "temporarily
disabled
" because "it's unclear if LEDE still represents
OpenWrt
". Imre Kaloz, another core OpenWrt member, [wrote](/Articles/686991/) that
"the LEDE team created most of that [broken] status quo
"
in OpenWrt that it was now complaining about.
But the majority of the responses on the OpenWrt list expressed
confusion about the announcement. List members were not clear whether the
LEDE team was going to In addition to the questions over the rationale of the new project,
some list subscribers expressed confusion as to whether LEDE was
targeting the same uses cases as OpenWrt, given the more
generic-sounding name of the new project. Furthermore, a number of
people, such as Roman Yeryomin, The LEDE team made a few attempts to further clarify their
position. In Fietkau's reply to Baker, he said that discussions about
proposed changes within the OpenWrt project tended to quickly turn
" This kind of single-point-of-failure thing has been going on for years,
with no significant progress on resolving it.
Neither Wich nor Fietkau pointed fingers at specific individuals,
although others on the list seemed to think that the infrastructure
and internal decision-making problems in OpenWrt came down to a few
people. Daniel Dickinson On the other hand, Luka Perkov What does seem clear is that the OpenWrt project has been operating
with a governance structure that was not functioning as desired and, as a
result, personality conflicts were erupting and individuals were able
to disrupt or block proposed changes simply by virtue of there being
no well-defined process. Clearly, that is not a model that works well
in the long run.
On May 6, Crispin Crispin's email did not seem to satisfy Kaloz, who For those still seeking further detail on what the LEDE team
regarded as problematic within OpenWrt, there is one more source of
information that can shed light on the issues. Prior to the public
announcement, the LEDE organizers spent several weeks hashing out
their plan, and IRC logs of the meetings have now been Several specific complaints about OpenWrt's infrastructure are
included, such as the shortcomings of the project's Trac issue
tracker. It is swamped with incomplete bug reports and "me too"
comments, Wich said, and as a result, few committers make use of it.
In addition, people seem confused by the fact that bugs are also being
tracked on GitHub, making it unclear where issues ought to be discussed.
The IRC discussion also tackles the development process itself.
The LEDE team would like to implement several changes, starting with
the use of staging trees that get merged into the trunk during a
formal merge window, rather than the commit-directly-to-master
approach employed by OpenWrt. The project would also commit to
time-based releases and encourage user testing by only releasing binary
modules that have successfully been tested, by the community rather
than the core developers, on
actual hardware.
Finally, the IRC discussion does make it clear that the LEDE team's
intent was not to take OpenWrt by surprise with its announcement.
Crispin suggested that LEDE be " In an email, Fietkau added that the core OpenWrt developers had
been suffering from bottlenecks on tasks like
patch review and maintenance work that were preventing them from getting other work done—such as setting up
download mirrors or improving the build system. In just the first few days
after the LEDE announcement, he said, the team had managed to tackle
the mirror and build-system tasks, which had languished for years.
We really wanted to do something similar with the core development,
but based on our experience with trying to make bigger changes we felt
that we couldn't do this from within the OpenWrt project.
Fixing the infrastructure will reap other dividends, too, he said,
such as an improved system for managing the keys used to sign
releases. The team is considering a rule that imposes some conditions
on non-upstream patches, such as requiring a description of the patch
and an explanation of why it has not yet been sent upstream. He
also noted that many of the remaining OpenWrt developers have
expressed interest in joining LEDE, and that the parties involved are trying
to figure out if they will re-merge the projects.
One would hope that LEDE's flatter governance model and commitment to
better transparency will help it to find success in areas where
OpenWrt has struggled. For the time being, sorting out the
communication issues that plagued the initial announcement may prove
to be a major hurdle. If that process goes well, though, LEDE and
OpenWrt may find common ground and work together in the future. If
not, then the two teams may each be forced to move forward with fewer
resources than they had before, which may not be what developers or
users want to see.[continue contributing](/Articles/686995/) to OpenWrt or not, nor
what the [exact nature](/Articles/686996/) of the infrastructure and internal problems were
that led to the split. Baker's initial response lamented the lack of
public debate over the issues cited in the announcement: "We
recognize the current OpenWrt project suffers from a number of
issues
", but "
we hoped we had an opportunity to
discuss and attempt to fix
" them. Baker concluded:
[expressed
confusion](/Articles/686992/) as to why the issues demanded the departure of the LEDE
team, particularly given that, together, the LEDE group constituted
a majority of the active core OpenWrt developers. Some list
subscribers, like Michael Richardson, were even unclear on [who would still be developing](/Articles/686993/) OpenWrt.
## Clarifications
toxic
", thus resulting in no progress. Furthermore:
[stated](/Articles/686998/) that:
[countered](/Articles/687001/) that many OpenWrt developers
wanted to switch from Subversion to Git, but that Fietkau was
responsible for blocking that change.
[wrote](/Articles/687003/) to the
OpenWrt list in a new thread, attempting to reframe the LEDE project
announcement. It was not, he said, meant as a "hostile or
disruptive
" act, but to make a clean break from the
dysfunctional structures of OpenWrt and start fresh. The matter
"does not boil down to one single event, one single person or
one single flamewar
", he said. "
We wanted to
split with the errors we have done ourselves in the past and the wrong
management decision that were made at times.
" Crispin also
admitted that the announcement had not been handled well,
saying that the LEDE team "messed up the politics of the launch
".
[insisted](/Articles/687004/) that Crispin (as release
manager) and Fietkau (as lead developer) could simply have made any
desirable changes within the OpenWrt project. But the discussion
thread has subsequently gone silent; whatever happens next on either
the LEDE or OpenWrt side remains to be seen.
## Intent
[published](http://meetings.lede-project.org/lede-adm/2016/?C=M;O=A).
Of particular interest is the March 30 [meeting](http://meetings.lede-project.org/lede-adm/2016/lede-adm.2016-03-30-11.05.log.html)
that includes a detailed discussion of the project's goals.
semi public
" at first and
gradually be made more public. Wich noted that he wanted LEDE to be
"neutral, professional and welcoming to OpenWrt to keep the door
open for a future reintegration
". The launch does not seem to
have gone well on that front, which is unfortunate.
Posted May 11, 2016 21:57 UTC (Wed)
by
Posted May 11, 2016 22:20 UTC (Wed)
by
Posted May 12, 2016 17:56 UTC (Thu)
by
It is hoped that the two groups can resolve their issues and work together, but labeling it as "expressed an interest in joining LEDE" is a gross mischaracterization.
Posted May 13, 2016 4:18 UTC (Fri)
by
Would it have been better if they just finally got tired of the problems and simply walked away from any development? Because I don't think that would be better. I wish both sides luck, but LEDE deserves credit for not just breaking out of a situation they were unhappy in but moving on with open source contributions rather than just stop contributing. It's unfortunate that this took forking but I'd rather they fork than the project die.
Maybe they should have talked about it before doing it, but if your post is how that response would have went I don't blame them for not telling people outside their group.
Posted May 13, 2016 6:29 UTC (Fri)
by
Posted May 13, 2016 7:03 UTC (Fri)
by
Posted May 19, 2016 4:55 UTC (Thu)
by
p doctor
[
][
]## LEDE and OpenWrt
**jnareb** (subscriber, #46500)
[[Link](/Articles/687085/)] (1 responses)
[
]## LEDE and OpenWrt
**flussence** (guest, #85566)
[[Link](/Articles/687086/)]
[
]## LEDE and OpenWrt
**mbm** (guest, #108744)
[[Link](/Articles/687244/)] (6 responses)
[
]## LEDE and OpenWrt
**rahvin** (guest, #16953)
[[Link](/Articles/687321/)] (5 responses)
[
]## LEDE and OpenWrt
**marcH** (subscriber, #57642)
[[Link](/Articles/687326/)] (4 responses)
[
]## LEDE and OpenWrt
**Cyberax** (**✭ supporter ✭**, #52523)
[[Link](/Articles/687327/)] (1 responses)
[
]## LEDE and OpenWrt
**fest3er** (guest, #60379)
[[Link](/Articles/687962/)]
[
] |
8,957 | 如何在一个 U 盘上安装多个 Linux 发行版 | https://itsfoss.com/multiple-linux-one-usb/ | 2017-10-14T07:52:00 | [
"USB",
"发行版"
] | https://linux.cn/article-8957-1.html |
>
> 本教程介绍如何在一个 U 盘上安装多个 Linux 发行版。这样,你可以在单个 U 盘上享受多个<ruby> 现场版 <rt> live </rt></ruby> Linux 发行版了。
>
>
>
我喜欢通过 U 盘尝试不同的 Linux 发行版。它让我可以在真实的硬件上测试操作系统,而不是虚拟化的环境中。此外,我可以将 USB 插入任何系统(比如 Windows 系统),做任何我想要的事情,以及享受相同的 Linux 体验。而且,如果我的系统出现问题,我可以使用 U 盘恢复!
创建单个[可启动的现场版 Linux USB](https://itsfoss.com/create-live-usb-of-ubuntu-in-windows/) 很简单,你只需下载一个 ISO 文件并将其刻录到 U 盘。但是,如果你想尝试多个 Linux 发行版呢?你可以使用多个 U 盘,也可以覆盖同一个 U 盘以尝试其他 Linux 发行版。但这两种方法都不是很方便。
那么,有没有在单个 U 盘上安装多个 Linux 发行版的方式呢?我们将在本教程中看到如何做到这一点。
### 如何创建有多个 Linux 发行版的可启动 USB

我们有一个工具正好可以做到*在单个 U 盘上保留多个 Linux 发行版*。你所需要做的只是选择要安装的发行版。在本教程中,我们将介绍*如何在 U 盘中安装多个 Linux 发行版*用于<ruby> 现场会话 <rt> live session </rt></ruby>。
要确保你有一个足够大的 U 盘,以便在它上面安装多个 Linux 发行版,一个 8 GB 的 U 盘应该足够用于三四个 Linux 发行版。
#### 步骤 1
[MultiBootUSB](http://multibootusb.org/) 是一个自由、开源的跨平台应用程序,允许你创建具有多个 Linux 发行版的 U 盘。它还支持在任何时候卸载任何发行版,以便你回收驱动器上的空间用于另一个发行版。
下载 .deb 包并双击安装。
[下载 MultiBootUSB](https://github.com/mbusb/multibootusb/releases/download/v8.8.0/python3-multibootusb_8.8.0-1_all.deb)
#### 步骤 2
推荐的文件系统是 FAT32,因此在创建多引导 U 盘之前,请确保格式化 U 盘。
#### 步骤 3
下载要安装的 Linux 发行版的 ISO 镜像。
#### 步骤 4
完成这些后,启动 MultiBootUSB。

主屏幕要求你选择 U 盘和你打算放到 U 盘上的 Linux 发行版镜像文件。
MultiBootUSB 支持 Ubuntu、Fedora 和 Debian 发行版的持久化,这意味着对 Linux 发行版的现场版本所做的更改将保存到 USB 上。
你可以通过拖动 MultiBootUSB 选项卡下的滑块来选择持久化大小。持久化为你提供了在运行时将更改保存到 U 盘的选项。

#### 步骤 5
单击“安装发行版”选项并继续安装。在显示成功的安装消息之前,需要一些时间才能完成。
你现在可以在已安装部分中看到发行版了。对于另外的操作系统,重复该过程。这是我安装 Ubuntu 16.10 和 Fedora 24 后的样子。

#### 步骤 6
下次通过 USB 启动时,我可以选择任何一个发行版。

只要你的 U 盘允许,你可以添加任意数量的发行版。要删除发行版,请从列表中选择它,然后单击卸载发行版。
### 最后的话
MultiBootUSB 真的很便于在 U 盘上安装多个 Linux 发行版。只需点击几下,我就有两个我最喜欢的操作系统的工作盘了,我可以在任何系统上启动它们。
如果你在安装或使用 MultiBootUSB 时遇到任何问题,请在评论中告诉我们。
---
via: <https://itsfoss.com/multiple-linux-one-usb/>
作者:[Ambarish Kumar](https://itsfoss.com/author/ambarish/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

You probably already know that you can create a live USB of a Linux distribution and try it on any system without installing it. If you like the distribution, you can then choose to install it.
Usually, you put one Linux distribution on a single USB stick. If you want to use another distribution, you have to format the USB and burn the other distribution on it.
What if I told you you could use multiple Linux on a single USB? Yes! That’s totally possible.
In this tutorial, I’ll show you how to create multi boot USB.
## Ventoy: The swiss army knife for creating bootable USBs
[Ventoy](https://www.ventoy.net/en/index.html?ref=itsfoss.com) is a “tiny OS” that boots your ISO.
When you create a bootable drive in the traditional way – by [using a tool like Rufus](https://itsfoss.com/live-usb-creator-linux/), Etcher or dd on Linux, the drive only boots that particular distribution. When you use Ventoy, it makes a tiny bootable EFI partition on your USB drive and gives you the remaining space to simply copy ISO files to it.
This means, you [create a Ventoy disk](https://itsfoss.com/use-ventoy/) once and then all you have to do is update the ISO files like a normal USB stick. Pretty cool because it allows you to have multiple operating systems on one USB disk.
Of course, your USB disk should have enough space to accommodate all the Linux distributions you want.
Ventoy is available on Linux, Windows and ARM platforms like Raspberry Pi.
### What do you need to create the bootable USBs?
Here’s what you need to have to follow this tutorial:
- A computer with active internet connection (to download Ventoy and the Linux ISOs)
- A USB disk with 16 GB or more (size varies as per the number of OS you want to use)
- Time and patience
Let’s see how to achieve it.
## Using Ventoy to create bootable USB with multiple Linux distributions
Download Ventoy from its GitHub repository.
You should see multiple options for various operating systems. For now, you should only be concerned with the file “ventoy-<version_number>-linux.tar.gz” or with “ventoy-<version_number>-windows.zip”.
Download file for your operating system (Windows or Linux).
**I am going to focus on using it in Linux** but I have also quickly mentioned the installation steps for Windows.
**Windows users** should download “ventoy-<version>-windows.zip” file from their Github repository, unzip the file. Launch the “Ventoy2Disk.exe” executable file and select the drive that you want to make bootable. Create a partition called “Ventoy”, copy ISO files to the newly created partition. Boot to the Ventoy disk and enjoy
## Creating a Ventoy disk from Linux
Open the Downloads folder in your file manager. You will find the downloaded tar file for Ventoy here. To extract it, right click on the file and click on the “Extract Here” option.
Enter in the extracted folder. You may have another Ventoy folder here. Enter and then you’ll see some folders and executable files. You should be concerned with the executable files.
If you are using a Raspberry Pi, go with aarch64 or else stick with x86_64 as “x86_64” extension is for 64-bit Intel and AMD computers (this is what the vast majority of computers are).
You can create a bootable disk with Ventoy by either using the GUI tool or by using the command line script.
Perform a right click on “VentoyGUI.x86_64” file and click on “Run”. That will open up an authentication screen, type in the password of your local user (the password that you type when you reboot your computer) and the GUI tool will launch.
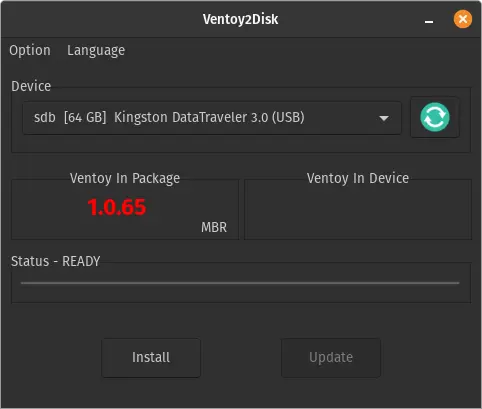
Attention!
Ventoy usually automatically detects the USB but still make sure that the intended USB disk is selected in the tool.
There are other options for you to select, but I would not recommend changing the default options unless you know exactly what you are doing. The options include things like using GPT partitioning scheme, enabling secure boot support etc.
All you have to do is click on the “Install” button. It asks for your confirmation twice.
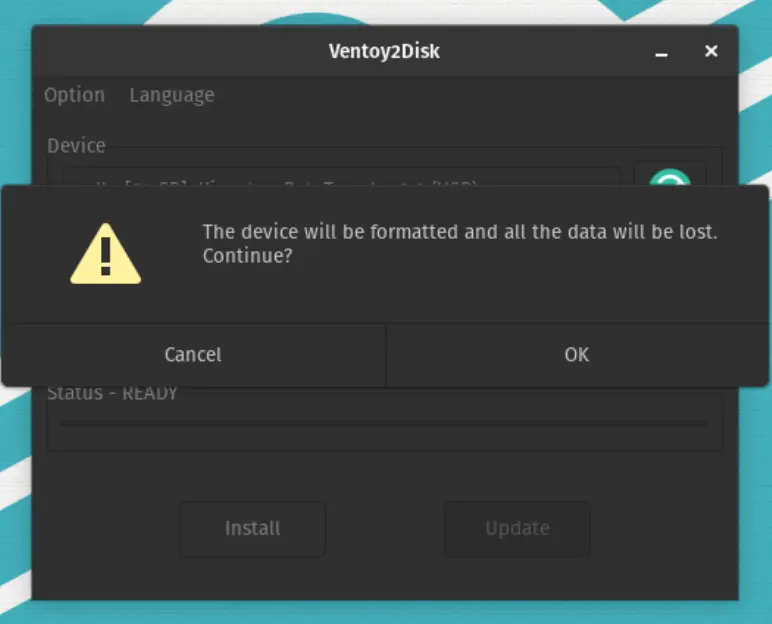
And it takes less than a minute to make a bootable disk out of the selected device. Note that there is no operating system on it yet. You should see a success message when the process completes.
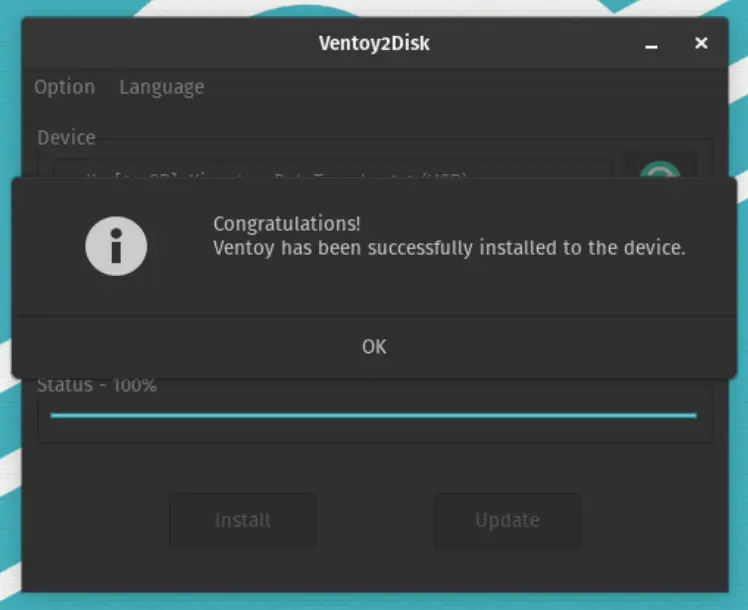
Once Ventoy has been installed on the USB disk, you’ll have two partitions on it now.
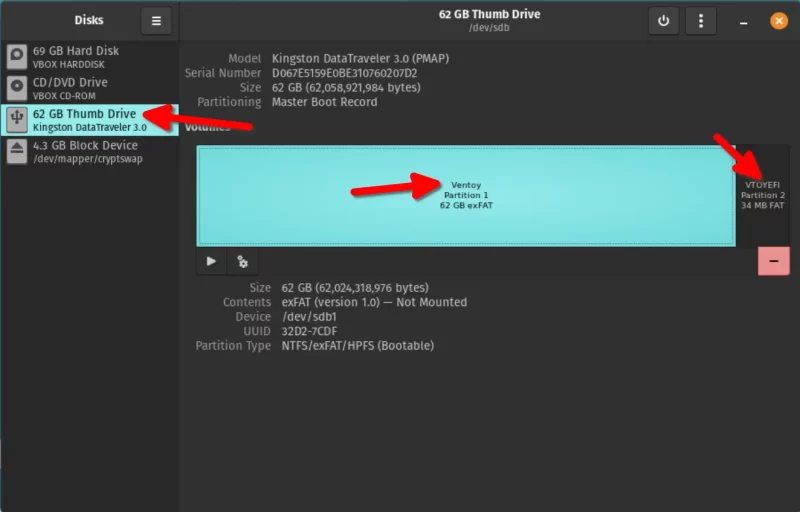
The partition named VTOYEFI is reserved for the boot files by Ventoy. The first partition, named Ventoy, is an exFAT partition. This is the partition which will be used for copying the ISO file.
## Using ventoy to create multiboot USB
You have a bootable USB by Ventoy but there is no operating system on it yet.
The next step is to put your choice of Linux distributions on it. Download the ISO files from the official websites of the Linux distribution projects. Ventoy also has a [full list of tested ISOs on its website](https://www.ventoy.net/en/isolist.html?ref=itsfoss.com).
To show you as an example, I am going to use Arch Linux, CentOS, Debian, elementary OS.
All there is left for you to do is copy the ISO files onto the drive named Ventoy.
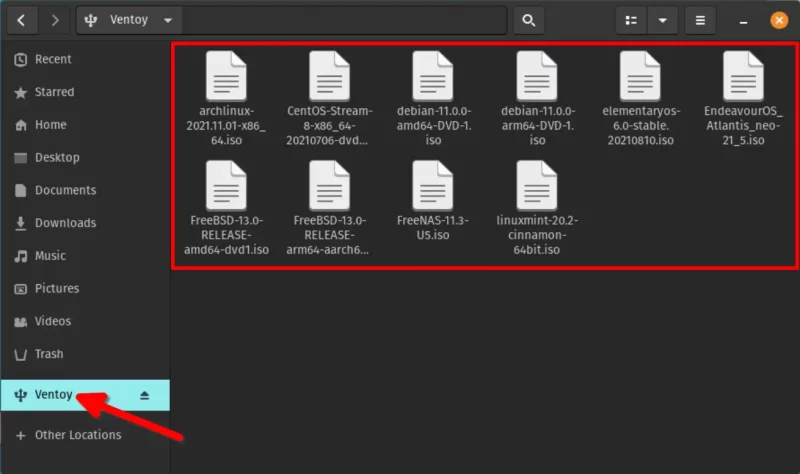
It may take some time to copy the large ISO files on the disk. Be patient here.
Even if it shows that the file transfer has been completed, **don’t unplug the USB just like that**. Click on the unmount option or right click the mounted USB and use the Eject option.
Why? Because the USB might still be in use by Ventoy for post-processing. Trying to safely remove the drive will give you a warning if the USB is in use. If you unplug it just like that, you may corrupt the USB.
So, here’s what my USB looks like with all the desired Linux ISOs copied on it. Since the same Ventoy drive will boot on an Intel/AMD (x86) machine and also on an ARM (Raspberry Pi – provided that you use [Raspberry Pi 4 UEFI Firmware Image](https://github.com/pftf/RPi4?ref=itsfoss.com)) machine. Here, I also copied ARM ISO files on it, and it boots the specified ISO flawlessly.
Safely eject the USB and it is time to use this multiboot Linux USB.
### Using the multiboot USB
Plug in the USB to the system where you want to use it.
Reboot the computer and when you notice a splash screen from displaying your computer vendor’s name, make a note of if there is an option like “Press F12 to go in boot menu” or something along this line.
Press whichever key is specified and that will show you a list of all drives that are bootable. Select the drive that you installed Ventoy on, and Ventoy should start up in under 5 seconds.
As you can see, it gives me the option to boot into various distributions I had put on the USB.
From the Ventoy boot menu, select an OS by using the up/down arrow keys and start it by pressing the Enter/Return key.
## Conclusion
Ventoy is a tool that I rarely use but it is very handy when I need to install Linux on my machines or repair machines.
This trick saves a lot of effort when you want to test more than one Linux distribution over a period of time. You don’t need to format the USB again and again. Just add or remove the ISO files from the disk and you are good to go. Makes life so much simpler, isn’t it?
Ventoy is capable of doing a lot more. We have a detailed guide on Ventoy that you may want to check out.
[Install and Use Ventoy on Ubuntu [Complete Guide]Tired of flashing USB drives for every ISO? Get started with Ventoy and get the ability to easily boot from ISOs.](https://itsfoss.com/use-ventoy/)

I have tried to simplify the steps as much as possible but you may still encounter issues. Let me know if you need any help in the comment section. |
8,960 | 促使项目团队作出改变的五步计划 | https://opensource.com/open-organization/17/1/escape-the-cave | 2017-10-15T00:46:09 | [
"团队"
] | https://linux.cn/article-8960-1.html | 
目的是任何团队组建的首要之事。如果一个人足以实现那个目的,那么就没有必要组成团队。而且如果没有重要目标,你根本不需要一个团队。但只要任务需要的专业知识比一个人所拥有的更多,我们就会遇到集体参与的问题——如果处理不当,会使你脱离正轨。
想象一群人困在洞穴中。没有一个人具备如何出去的全部知识,所以每个人要协作,心路常开,在想要做的事情上尽力配合。当(且仅当)组建了适当的工作团队之后,才能为实现团队的共同目标创造出合适的环境。
但确实有人觉得待在洞穴中很舒适而且只想待在那里。在组织里,领导者们如何掌控那些实际上抵触改善、待在洞穴中觉得舒适的人?同时该如何找到拥有共同目标但是不在自己组织的人?
我从事指导国际销售培训,刚开始甚至很少有人认为我的工作有价值。所以,我想出一套使他们信服的战术。那个战术非常成功以至于我决定深入研究它并与各位[分享](http://www.slideshare.net/RonMcFarland1/creating-change-58994683)。
### 获得支持
为了建立公司强大的企业文化,有人会反对改变,并且从幕后打压任何改变的提议。他们希望每个人都待在那个舒适的洞穴里。例如,当我第一次接触到海外销售培训,我受到了一些关键人物的严厉阻挠。他们迫使其他人相信某个东京人做不了销售培训——只要基本的产品培训就行了。
尽管我最终解决了这个问题,但我那时候真的不知道该怎么办。所以,我开始研究顾问们在改变公司里抗拒改变的人的想法这个问题上该如何给出建议。从学者 [Laurence Haughton](http://www.laurencehaughton.com/) 的研究中,我发现一般对于改变的提议,组织中 83% 的人最开始不会支持你。大约 17% *会*从一开始就支持你,但是只要看到一个实验案例成功之后,他们觉得这个主意安全可行了,60% 的人会支持你。最后,有部分人会反对任何改变,无论它有多棒。
我研究的步骤:
* 从试验项目开始
* 开导洞穴人
* 快速跟进
* 开导洞穴首领
* 全局展开
### 1、 从试验项目开始
找到高价值且成功率较高的项目——而不是大的、成本高的、周期长的、全局的行动。然后,找到能看到项目价值、理解它的价值并能为之奋斗的关键人物。这些人不应该只是“老好人”或者“朋友”;他们必须相信项目的目标而且拥有推进项目的能力或经验。不要急于求成。只要足够支持你研究并保持进度即可。
个人而言,我在新加坡的一个小型车辆代理商那里举办了自己的第一场销售研讨会。虽然并不是特别成功,但足以让人们开始讨论销售训练会达到怎样的效果。那时候的我困在洞穴里(那是一份我不想做的工作)。这个试验销售训练是我走出困境的蓝图。
### 2、 开导洞穴人
洞穴(CAVE)实际上是我从 Laurence Haughton 那里听来的缩略词。它代表着 Citizens Against Virtually Everything。(LCTT 译注,此处一语双关前文提及的洞穴。)
你得辨别这些人,因为他们会暗地里阻挠项目的进展,特别是早期脆弱的时候。他们容易黑化:总是消极。他们频繁使用“但是”、“如果”和“为什么”,只是想推脱你。他们询问轻易不可得的细节信息。他们花费过多的时间在问题上,而不是寻找解决方案。他们认为每个失败都是一个趋势。他们总是对人而不是对事。他们作出反对建议的陈述却又不能简单确认。
避开洞穴人;不要让他们太早加入项目的讨论。他们固守成见,因为他们看不到改变所具有的价值。他们安居于洞穴,所以试着让他们去做些其他事。你应该找出我上面提到那 17% 的人群中的关键人物,那些想要改变的人,并且跟他们开一个非常隐秘的准备会。
我在五十铃汽车(股东之一是通用汽车公司)的时候,销售训练项目开始于一个销往世界上其他小国家的合资分销商,主要是非洲、南亚、拉丁美洲和中东。我的个人团队由通用汽车公司雪佛兰的人、五十铃产品经理和分公司的销售计划员工组成。隔绝其他任何人于这个圈子之外。
### 3、 快速跟进
洞穴人总是慢吞吞的,那么你就迅速行动起来。如果你在他们参与之前就有了小成就的经历,他们对你团队产生消极影响的能力将大大减弱——你要在他们提出之前就解决他们必然反对的问题。再一次,选择一个成功率高的试验项目,很快能出结果的。然后宣传成功,就像广告上的加粗标题。
当我在新加坡研讨会上所言开始流传时,其他地区开始意识到销售训练的好处。仅在新加坡研讨会之后,我就被派到马来西亚开展了四次以上。
### 4、 开导洞穴首领
只要你取得了第一个小项目的成功,就针对能影响洞穴首领的关键人物推荐项目。让团队继续该项目以告诉关键人物成功的经历。一线人员甚至顾客也能提供有力的证明。 洞穴管理者往往只着眼于销量和收益,那么就宣扬项目在降低开支、减少浪费和增加销量方面的价值。
自新加坡的第一次研讨会及之后,我向直接掌握了五十铃销售渠道的前线销售部门员工和通用汽车真正想看到进展的人极力宣传他们的成功。当他们接受了之后,他们会向上级提出培训请求并让其看到分公司销量的提升。
### 5、 全局展开
一旦一把手站在了自己这边,立马向整个组织宣告成功的试验项目。讨论项目的扩展。
用上面的方法,在 21 年的职业生涯中,我在世界各地超过 60 个国家举办了研讨会。我确实走出了洞穴——并且真的看到了广阔的世界。
---
作者简介:
Ron McFarland - Ron McFarland 已在日本工作 40 年,从事国际销售、销售管理和在世界范围内扩展销售业务 30 载有余。他曾去过或就职于 80 多个国家。在过去的 14 年里, Ron 为总部位于东京的日本硬件切割厂在美国和欧洲各地建立分销商。
---
via: <https://opensource.com/open-organization/17/1/escape-the-cave>
作者:[Ron McFarland](https://opensource.com/users/ron-mcfarland) 译者:[XYenChi](https://github.com/XYenChi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Purpose is the first thing to consider when you're assembling any team. If one person could achieve that purpose, then forming the team would be unnecessary. And if there was no main purpose, then you wouldn't need a team at all. But as soon as the task requires more expertise than a single person has, we encounter the issue of collective participation—an issue that, if not handled properly, could derail you.
Imagine a group of people trapped in a cave. No single person has full knowledge of how to get out, so everyone will need to work together, be open, and act collaboratively if they're going to do it. After (and only after) assembling the right task force can someone create the right environment for achieving the team's shared purpose.
But some people are actually very comfortable in the cave and would like to just stay there. In organizations, how do leaders handle individuals who actually *resist* productive change, people who are comfortable in the cave? And how do they go about finding people who do share their purpose but aren't in their organizations?
I made a career conducting sales training internationally, but when I began, few people even thought my work had value. So, I somehow devised a strategy for convincing them otherwise. That strategy was so successful that I decided to study it in depth and [share it](http://www.slideshare.net/RonMcFarland1/creating-change-58994683) with others.
## Gaining support
In established companies with strong corporate cultures, there are people that will fight change and, from behind the scenes, will fight any proposal for change. They want everyone to stay in that comfortable cave. When I was first approached to give overseas sales training, for example, I received heavy resistance from some key people. They pushed to convince others that someone in Tokyo could not provide sales training—only basic product training would be successful.
I somehow solved this problem, but didn't really know how I did it at the time. So, I started studying what consultants recommend about how to change the thinking in companies that resisted to change. From one study by researcher [Laurence Haughton](http://www.laurencehaughton.com/), I learned that for the average change proposal, 83% of people in your organization will not support you from the beginning. Roughly 17% *will* support you from the beginning, but 60% of the people would support you only after seeing a pilot case succeed, when they can actually see that the idea is safe to try. Lastly, there are some people who will fight any change, no matter how good it is.
Here are the steps I learned:
- Start with a pilot project
- Outsmart the CAVE people
- Follow through fast
- Outsmart the CAVE bosses
- Move to full operation.
## 1. Start with a pilot project
Find a project with both high value and a high chance for success—not a large, expensive, long-term, global activity. Then, find key people who can see the value of the project, who understand its value, and who will fight for it. These people should not just be "nice guys" or "friends"; they must believe in its purpose and have some skills/experience that will help move the project forward. And don't shoot for a huge success the first time. It should be just successful enough to permit you to learn and keep moving forward.
In my case, I held my first sales seminar in Singapore at a small vehicle dealership. It was not a huge success, but it was successful enough that people started talking about what quality sales training could achieve. At that time, I was stuck in a cave (a job I didn't want to do). This pilot sales training was my road map to get out of my cave.
## 2. Outsmart the CAVE people
CAVE is actually an acronym I learned from Laurence Haughton. It stands for Citizens Against Virtually Everything.
You must identify these people, because they will covertly attempt to block any progress in your project, especially in the early stages when it is most vulnerable. They're easy to spot: They are always negative. They use "but," "if," and "why," in excess, just to stall you. They ask for detailed information when it isn't available easily. They spend too much time on the problem, not looking for any solution. They think every failure is the beginning of a trend. They often attack people instead of studying the problem. They make statements that are counterproductive but cannot be confirmed easily.
Avoid the CAVE people; do not let them into the discussion of the project too early. They've adopted the attitude they have because they don't see value in the changes required. They are comfortable in the cave. So try to get them to do something else. You should seek out key people in the 17% group I mentioned above, people that want change, and have very private preparation meetings with them.
When I was in Isuzu Motors (partly owned by General Motors), the sales training project started in a joint venture distribution company that sold to the smaller countries in the world, mainly in Africa, Southeast Asia, Latin America and the Middle East. My private team was made up of a GM person from Chevrolet, an Isuzu product planning executive and that distribution company's sales planning staff. I kept everyone else out of the loop.
## 3. Follow through fast
CAVE people like to go slowly, so act quickly. Their ability to negatively influence your project will weaken if you have a small success story before they are involved—if you've managed to address their inevitable objections before they can even express them. Again, choose a pilot project with a high chance of success, something that can show quick results. Then promote that success, like a bold headline on an advertisement.
Once the word of my successful seminar in Singapore began to circulate, other regions started realizing the benefits of sales training. Just after that Singapore seminar, I was commissioned to give four more in Malaysia.
## 4. Outsmart CAVE bosses
Once you have your first mini-project success, promote the project in a targeted way to key leaders who could influence any CAVE bosses. Get the team that worked on the project to tell key people the success story. Front line personnel and/or even customers can provide powerful testimonials as well. CAVE managers often concern themselves only with sales and profits, so promote the project's value in terms of cost savings, reduced waste, and increased sales.
From that first successful seminar in Singapore and others that followed, I promoted heavily their successes to key front line sales department staff handling Isuzu's direct sales channels and General Motors channels that really wanted to see progress. After giving their acceptance, they took their training requests to their superiors sighting the sales increase that occurred in the distribution company.
## 5. Move to full operation
Once top management is on board, announce to the entire organization the successful pilot projects. Have discussions for expanding on the project.
Using the above procedures, I gave seminars in more than 60 countries worldwide over a 21-year career. So I did get out of the cave—and really saw a lot of the world.
## Watch the video
## 5 Comments |
8,963 | 介绍 Flashback,一个互联网模拟工具 | https://opensource.com/article/17/4/flashback-internet-mocking-tool | 2017-10-15T21:56:00 | [
"Flashback",
"测试"
] | /article-8963-1.html |
>
> Flashback 用于测试目的来模拟 HTTP 和 HTTPS 资源,如 Web 服务和 REST API。
>
>
>

在 LinkedIn,我们经常开发需要与第三方网站交互的 Web 应用程序。我们还采用自动测试,以确保我们的软件在发布到生产环境之前的质量。然而,测试只是在它可靠时才有用。
考虑到这一点,有外部依赖关系的测试是有很大的问题的,例如在第三方网站上。这些外部网站可能会没有通知地发生改变、遭受停机,或者由于互联网的不可靠性暂时无法访问。
如果我们的一个测试依赖于能够与第三方网站通信,那么任何故障的原因都很难确定。失败可能是因为 LinkedIn 的内部变更、第三方网站的维护人员进行的外部变更,或网络基础设施的问题。你可以想像,与第三方网站的交互可能会有很多失败的原因,因此你可能想要知道,我将如何处理这个问题?
好消息是有许多互联网模拟工具可以帮助。其中一个是 [Betamax](https://github.com/betamaxteam/betamax)。它通过拦截 Web 应用程序发起的 HTTP 连接,之后进行重放的方式来工作。对于测试,Betamax 可以用以前记录的响应替换 HTTP 上的任何交互,它可以非常可靠地提供这个服务。
最初,我们选择在 LinkedIn 的自动化测试中使用 Betamax。它工作得很好,但我们遇到了一些问题:
* 出于安全考虑,我们的测试环境没有接入互联网。然而,与大多数代理一样,Betamax 需要 Internet 连接才能正常运行。
* 我们有许多需要使用身份验证协议的情况,例如 OAuth 和 OpenId。其中一些协议需要通过 HTTP 进行复杂的交互。为了模拟它们,我们需要一个复杂的模型来捕获和重放请求。
为了应对这些挑战,我们决定基于 Betamax 的思路,构建我们自己的互联网模拟工具,名为 Flashback。我们也很自豪地宣布 Flashback 现在是开源的。
### 什么是 Flashback?
Flashback 用于测试目的来模拟 HTTP 和 HTTPS 资源,如 Web 服务和 [REST](https://en.wikipedia.org/wiki/Representational_state_transfer) API。它记录 HTTP/HTTPS 请求并重放以前记录的 HTTP 事务 - 我们称之为“<ruby> 场景 <rt> scene </rt></ruby>”,这样就不需要连接到 Internet 才能完成测试。
Flashback 也可以根据请求的部分匹配重放场景。它使用的是“匹配规则”。匹配规则将传入请求与先前记录的请求相关联,然后将其用于生成响应。例如,以下代码片段实现了一个基本匹配规则,其中测试方法“匹配”[此 URL](https://gist.github.com/anonymous/91637854364287b38897c0970aad7451)的传入请求。
HTTP 请求通常包含 URL、方法、标头和正文。Flashback 允许为这些组件的任意组合定义匹配规则。Flashback 还允许用户向 URL 查询参数,标头和正文添加白名单或黑名单标签。
例如,在 OAuth 授权流程中,请求查询参数可能如下所示:
```
oauth_consumer_key="jskdjfljsdklfjlsjdfs",
oauth_nonce="ajskldfjalksjdflkajsdlfjasldfja;lsdkj",
oauth_signature="asdfjaklsdjflasjdflkajsdklf",
oauth_signature_method="HMAC-SHA1",
oauth_timestamp="1318622958",
oauth_token="asdjfkasjdlfajsdklfjalsdjfalksdjflajsdlfa",
oauth_version="1.0"
```
这些值许多将随着每个请求而改变,因为 OAuth 要求客户端每次为 `oauth_nonce` 生成一个新值。在我们的测试中,我们需要验证 `oauth_consumer_key`、`oauth_signature_method` 和 `oauth_version` 的值,同时确保 `oauth_nonce`、`oauth_signature`、`oauth_timestamp` 和 `oauth_token` 存在于请求中。Flashback 使我们有能力创建我们自己的匹配规则来实现这一目标。此功能允许我们测试随时间变化的数据、签名、令牌等的请求,而客户端没有任何更改。
这种灵活的匹配和在不连接互联网的情况下运行的功能是 Flashback 与其他模拟解决方案不同的特性。其他一些显著特点包括:
* Flashback 是一种跨平台和跨语言解决方案,能够测试 JVM(Java虚拟机)和非 JVM(C++、Python 等)应用程序。
* Flashback 可以随时生成 SSL/TLS 证书,以模拟 HTTPS 请求的安全通道。
### 如何记录 HTTP 事务
使用 Flashback 记录 HTTP 事务以便稍后重放是一个比较简单的过程。在我们深入了解流程之前,我们首先列出一些术语:
* `Scene` :场景存储以前记录的 HTTP 事务 (以 JSON 格式),它可以在以后重放。例如,这里是一个[Flashback 场景](https://gist.github.com/anonymous/17d226050d8a9b79746a78eda9292382)示例。
* `Root Path` :根路径是包含 Flashback 场景数据的目录的文件路径。
* `Scene Name` :场景名称是给定场景的名称。
* `Scene Mode` :场景模式是使用场景的模式, 即“录制”或“重放”。
* `Match Rule` :匹配规则确定传入的客户端请求是否与给定场景的内容匹配的规则。
* `Flashback Proxy` :Flashback 代理是一个 HTTP 代理,共有录制和重放两种操作模式。
* `Host` 和 `Port` :代理主机和端口。
为了录制场景,你必须向目的地址发出真实的外部请求,然后 HTTPS 请求和响应将使用你指定的匹配规则存储在场景中。在录制时,Flashback 的行为与典型的 MITM(中间人)代理完全相同 - 只有在重放模式下,连接流和数据流仅限于客户端和代理之间。
要实际看下 Flashback,让我们创建一个场景,通过执行以下操作捕获与 example.org 的交互:
1、 取回 Flashback 的源码:
```
git clone https://github.com/linkedin/flashback.git
```
2、 启动 Flashback 管理服务器:
```
./startAdminServer.sh -port 1234
```
3、 注意上面的 Flashback 将在本地端口 5555 上启动录制模式。匹配规则需要完全匹配(匹配 HTTP 正文、标题和 URL)。场景将存储在 `/tmp/test1` 下。
4、 Flashback 现在可以记录了,所以用它来代理对 example.org 的请求:
```
curl http://www.example.org -x localhost:5555 -X GET
```
5、 Flashback 可以(可选)在一个记录中记录多个请求。要完成录制,[关闭 Flashback](https://gist.github.com/anonymous/f899ebe7c4246904bc764b4e1b93c783)。
6、 要验证已记录的内容,我们可以在输出目录(`/tmp/test1`)中查看场景的内容。它应该[包含以下内容](https://gist.github.com/sf1152/c91d6d62518fe62cc87157c9ce0e60cf)。
[在 Java 代码中使用 Flashback](https://gist.github.com/anonymous/fdd972f1dfc7363f4f683a825879ce19)也很容易。
### 如何重放 HTTP 事务
要重放先前存储的场景,请使用与录制时使用的相同的基本设置。唯一的区别是[将“场景模式”设置为上述步骤 3 中的“播放”](https://gist.github.com/anonymous/ae1c519a974c3bc7de2a925254b6550e)。
验证响应来自场景而不是外部源的一种方法,是在你执行步骤 1 到 6 时临时禁用 Internet 连接。另一种方法是修改场景文件,看看响应是否与文件中的相同。
这是 [Java 中的一个例子](https://gist.github.com/anonymous/edcc1d60847d51b159c8fd8a8d0a5f8b)。
### 如何记录并重播 HTTPS 事务
使用 Flashback 记录并重放 HTTPS 事务的过程非常类似于 HTTP 事务的过程。但是,需要特别注意用于 HTTPS SSL 组件的安全证书。为了使 Flashback 作为 MITM 代理,必须创建证书颁发机构(CA)证书。在客户端和 Flashback 之间创建安全通道时将使用此证书,并允许 Flashback 检查其代理的 HTTPS 请求中的数据。然后将此证书存储为受信任的源,以便客户端在进行调用时能够对 Flashback 进行身份验证。有关如何创建证书的说明,有很多[类似这样](https://jamielinux.com/docs/openssl-certificate-authority/introduction.html)的资源是非常有帮助的。大多数公司都有自己的管理和获取证书的内部策略 - 请务必用你们自己的方法。
这里值得一提的是,Flashback 仅用于测试目的。你可以随时随地将 Flashback 与你的服务集成在一起,但需要注意的是,Flashback 的记录功能将需要存储所有的数据,然后在重放模式下使用它。我们建议你特别注意确保不会无意中记录或存储敏感成员数据。任何可能违反贵公司数据保护或隐私政策的行为都是你的责任。
一旦涉及安全证书,HTTP 和 HTTPS 之间在记录设置方面的唯一区别是添加了一些其他参数。
* `RootCertificateInputStream`: 表示 CA 证书文件路径或流。
* `RootCertificatePassphrase`: 为 CA 证书创建的密码。
* `CertificateAuthority`: CA 证书的属性
[查看 Flashback 中用于记录 HTTPS 事务的代码](https://gist.github.com/anonymous/091d13179377c765f63d7bf4275acc11),它包括上述条目。
用 Flashback 重放 HTTPS 事务的过程与录制相同。唯一的区别是场景模式设置为“播放”。这在[此代码](https://gist.github.com/anonymous/ec6a0fd07aab63b7369bf8fde69c1f16)中演示。
### 支持动态修改
为了测试灵活性,Flashback 允许你动态地更改场景和匹配规则。动态更改场景允许使用不同的响应(如 `success`、`time_out`、`rate_limit` 等)测试相同的请求。[场景更改](https://gist.github.com/anonymous/1f1660280acb41277fbe2c257bab2217)仅适用于我们已经 POST 更新外部资源的场景。以下图为例。

能够动态[更改匹配规则](https://gist.github.com/anonymous/0683c43f31bd916b76aff348ff87f51b)可以使我们测试复杂的场景。例如,我们有一个使用情况,要求我们测试 Twitter 的公共和私有资源的 HTTP 调用。对于公共资源,HTTP 请求是不变的,所以我们可以使用 “MatchAll” 规则。然而,对于私人资源,我们需要使用 OAuth 消费者密码和 OAuth 访问令牌来签名请求。这些请求包含大量具有不可预测值的参数,因此静态 MatchAll 规则将无法正常工作。
### 使用案例
在 LinkedIn,Flashback 主要用于在集成测试中模拟不同的互联网提供商,如下图所示。第一张图展示了 LinkedIn 生产数据中心内的一个内部服务,通过代理层,与互联网提供商(如 Google)进行交互。我们想在测试环境中测试这个内部服务。

第二和第三张图表展示了我们如何在不同的环境中录制和重放场景。记录发生在我们的开发环境中,用户在代理启动的同一端口上启动 Flashback。从内部服务到提供商的所有外部请求将通过 Flashback 而不是我们的代理层。在必要场景得到记录后,我们可以将其部署到我们的测试环境中。

在测试环境(隔离并且没有 Internet 访问)中,Flashback 在与开发环境相同的端口上启动。所有 HTTP 请求仍然来自内部服务,但响应将来自 Flashback 而不是 Internet 提供商。

### 未来方向
我们希望将来可以支持非 HTTP 协议(如 FTP 或 JDBC),甚至可以让用户使用 MITM 代理框架来自行注入自己的定制协议。我们将继续改进 Flashback 设置 API,使其更容易支持非 Java 语言。
### 现在为一个开源项目
我们很幸运能够在 GTAC 2015 上发布 Flashback。在展会上,有几名观众询问是否将 Flashback 作为开源项目发布,以便他们可以将其用于自己的测试工作。
### Google TechTalks:GATC 2015 - 模拟互联网
我们很高兴地宣布,Flashback 现在以 BSD 两句版许可证开源。要开始使用,请访问 [Flashback GitHub 仓库](https://github.com/linkedin/flashback)。
*该文原始发表在[LinkedIn 工程博客上](https://engineering.linkedin.com/blog/2017/03/flashback-mocking-tool)。获得转载许可*
### 致谢
Flashback 由 [Shangshang Feng](https://www.linkedin.com/in/shangshangfeng)、[Yabin Kang](https://www.linkedin.com/in/benykang) 和 [Dan Vinegrad](https://www.linkedin.com/in/danvinegrad/) 创建,并受到 [Betamax](https://github.com/betamaxteam/betamax) 启发。特别感谢 [Hwansoo Lee](https://www.linkedin.com/in/hwansoo/)、[Eran Leshem](https://www.linkedin.com/in/eranl/)、[Kunal Kandekar](https://www.linkedin.com/in/kunalkandekar/)、[Keith Dsouza](https://www.linkedin.com/in/dsouzakeith/) 和 [Kang Wang](https://www.linkedin.com/in/kang-wang-44960b4/) 帮助审阅代码。同样感谢我们的管理层 - [Byron Ma](https://www.linkedin.com/in/byronma/)、[Yaz Shimizu](https://www.linkedin.com/in/yazshimizu/)、[Yuliya Averbukh](https://www.linkedin.com/in/yuliya-averbukh-818a41/)、[Christopher Hazlett](https://www.linkedin.com/in/chazlett/) 和 [Brandon Duncan](https://www.linkedin.com/in/dudcat/) - 感谢他们在开发和开源 Flashback 中的支持。
---
作者简介:
Shangshang Feng - Shangshang 是 LinkedIn 纽约市办公室的高级软件工程师。在 LinkedIn 他从事了三年半的网关平台工作。在加入 LinkedIn 之前,他曾在 Thomson Reuters 和 ViewTrade 证券的基础设施团队工作。
---
via: <https://opensource.com/article/17/4/flashback-internet-mocking-tool>
作者: [Shangshang Feng](https://opensource.com/users/shangshangfeng) 译者:[geekpi](https://github.com/geekpi) 校对:[jasminepeng](https://github.com/jasminepeng)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
8,964 | 见多识广的人工智能比你认识更多的 XXX 明星 | https://thenextweb.com/artificial-intelligence/2017/10/11/pornhub-ai-watch-tag/ | 2017-10-15T22:56:00 | [
"视频",
"人工智能",
"AI"
] | https://linux.cn/article-8964-1.html | 
你有没有想过,之所以能够根据自己不同兴趣的组合搜索到需要的视频,是因为有那些每日浏览无数视频内容且对它们进行分类和标记的可怜人存在,然而这些看不见的英雄们却在人工智能面前变得英雄无用武之地。
世界上最大的 XXX 电影分享网站 Pornhub 宣布,它将推出新的 AI 模型,利用计算机视觉技术自动检测和识别 XXX 明星的名字。
根据 X-rated 网站的消息,目前该算法经过训练后已经通过简单的扫描和对镜头的理解,可以识别超过 1 万名 XXX 明星。Pornhub 说,通过向此 AI 模型输入数千个视频和 XXX 明星的正式照片,以让它学习如何返回准确的名字。
为了减小错误,这个成人网站将向用户求证由 AI 提供的标签和分类是否合适。用户可以根据结果的准确度,提出支持或是反对。这将会让算法变得更加智能。

“现在,用户可以根据自身喜好寻找指定的 XXX 明星,我们也能够返回给用户尽可能精确的搜索结果,” PornHub 副总裁 Corey Price 说。“毫无疑问,我们的模型也将在未来的发展中扮演关键角色,尤其是考虑到每天有超过 1 万个的视频添加到网站上。”
“事实上,在过去的一个月里,我们测试了这个模型的测试版本,它(每天)可以扫描 5 万段视频,并且向视频添加或者移除标签。”
除了识别表演者,该算法还能区分不同类别的内容:比如在 “Public” 类别下的是户外拍摄的视频,以及 “Blonde” 类别下的视频应该至少有名金发女郎。
XXX 公司计划明年在 AI 模型的帮助下,对全部 500 万个视频编目,希望能让用户更容易找到与他们的期望最接近的视频片段。
早先就有研究人员借助计算机视觉算法对 XXX 电影进行描述。之前就有一名开发者使用微软的人工智能技术来构建这个机器人,它可以整天[观察和解读](https://thenextweb.com/shareables/2017/03/03/porn-bot-microsoft-ai-pornhub/)各种内容。
Pornhub 似乎让这一想法更进一步,这些那些遍布全球的视频审看员的噩梦。
虽然人工智能被发展到这个方面可能会让你感觉有些不可思议,但 XXX 业因其对搜索引擎优化技术的狂热追求而[闻名](https://moz.com/ugc/yes-dear-there-is-porn-seo-and-we-can-learn-a-lot-from-it)。
事实上,成人内容服务一直以来都有广泛市场,且受众不分年龄,这也是这些公司盈利的重要组成部分。
但是,这些每日阅片无数、兢兢业业为其分类的人们可能很快就会成为自动化威胁的牺牲品。但从好的一面看,他们终于有机会坐下来[让自动化为他们工作](https://thenextweb.com/gear/2017/07/07/fleshlight-launch-review-masturbation/)。
---
via: <https://thenextweb.com/artificial-intelligence/2017/10/11/pornhub-ai-watch-tag/>
作者:[MIX](https://thenextweb.com/author/dimitarmihov/) 译者:[东风唯笑](https://github.com/dongfengweixiao) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
8,965 | 混合云的变化 | https://opensource.com/article/17/7/hybrid-cloud | 2017-10-16T22:02:00 | [
"混合云"
] | https://linux.cn/article-8965-1.html |
>
> 围绕云计算的概念和术语仍然很新,但是也在不断的改进。
>
>
>

不管怎么看,云计算也只有十多年的发展时间。一些我们习以为常的云计算的概念和术语仍然很新。美国国家标准与技术研究所(NIST)文档显示,一些已经被熟悉的术语定义在 2011 年才被发布,例如基础设施即服务(IaaS),而在此之前它就以草案的形式广泛流传。
在该文档中其它定义中,有一个叫做<ruby> 混合云 <rt> hybrid cloud </rt></ruby>。让我们回溯一下该术语在这段期间的变化是很有启发性的。云基础设施已经超越了相对简单的分类。此外,它还强调了开源软件的使用者所熟悉的优先级,例如灵活性、可移植性、选择性,已经被运用到了混合云上。
NIST 对混合云最初的定义主要集中于<ruby> 云爆发 <rt> cloud bursting </rt></ruby>,你能使用内部的基础设施去处理一个基本的计算负荷,但是如果你的负荷量暴涨,可以将多出来的转为使用公有云。与之密切联系的是加强私有云与公有云之间 API 的兼容性,甚至是创造一个现货市场来提供最便宜的容量。
Nick Carr 在 [The Big Switch](http://www.nicholascarr.com/?page_id=21) 一书中提出一个概念,云是一种计算单元,其与输电网类似。这个故事不错,但是即使在早期,[这种类比的局限性也变得很明显](https://www.cnet.com/news/there-is-no-big-switch-for-cloud-computing/)。计算不是以电流方式呈现的一种物品。需要关注的是,公有云提供商以及 OpenStack 一类的开源云软件激增的新功能,可见许多用户并不仅仅是寻找最便宜的通用计算能力。
云爆发的概念基本上忽略了计算是与数据相联系的现实,你不可能只移动洪水般突如其来的数据而不承担巨大的带宽费用,以及不用为转移需要花费的时间而操作。Dave McCrory 发明了 “<ruby> 数据引力 <rt> data gravity </rt></ruby>”一词去描述这个限制。
那么既然混合云有如此负面的情况,为什么我们现在还要再讨论混合云?
正如我说的,混合云的最初的构想是在云爆发的背景下诞生的。云爆发强调的是快速甚至是即时的将工作环境从一个云转移到另一个云上;然而,混合云也意味着应用和数据的移植性。确实,如之前 [2011 年我在 CNET 的文章](https://www.cnet.com/news/cloudbursting-or-just-portable-clouds/)中写到:“我认为过度关注于全自动的工作转换给我们自己造成了困扰,我们真正应该关心的是,如果供应商不能满意我们的需求或者尝试将我们锁定在其平台上时,我们是否有将数据从一个地方到另一个地方的迁移能力。”
从那以后,探索云之间的移植性有了进一步的进展。
Linux 是云移植性的关键,因为它能运行在各种地方,无论是从裸机到内部虚拟基础设施,还是从私有云到公有云。Linux 提供了一个完整、可靠的平台,其具有稳定的 API 接口,且可以依靠这些接口编写程序。
被广泛采纳的容器进一步加强了 Linux 提供应用在云之间移植的能力。通过提供一个包含了应用的基础配置环境的镜像,应用在开发、测试和最终运行环境之间移动时容器提供了可移植性和兼容性。
Linux 容器被应用到要求可移植性、可配置性以及独立性的许多方面上。不管是预置的云,还是公有云,以及混合云都是如此。
容器使用的是基于镜像的部署模式,这让在不同环境中分享一个应用或者具有全部基础环境的服务集变得容易了。
在 OCI 支持下开发的规范定义了容器镜像的内容及其所依赖、环境、参数和一些镜像正确运行所必须的要求。在标准化的作用下,OCI 为许多其它工具提供了一个机会,它们现在可以依靠稳定的运行环境和镜像规范了。
同时,通过 Gluster 和 Ceph 这类的开源技术,分布式存储能提供数据在云上的可移植性。 物理约束限制了如何快速简单地把数据从一个地方移动到另一个地方;然而,随着组织部署和使用不同类型的基础架构,他们越来越渴望一个不受物理、虚拟和云资源限制的开放的软件定义储存平台。
尤其是在数据存储需求飞速增长的情况下,由于预测分析,物联网和实时监控的趋势。[2016 年的一项研究表明](https://www.redhat.com/en/technologies/storage/vansonbourne),98% 的 IT 决策者认为一个更敏捷的存储解决方案对他们的组织是有利的。在同一个研究中,他们列举出不恰当的存储基础设施是最令他们组织受挫的事情之一。
混合云表现出的是提供在不同计算能力和资源之间合适的移植性和兼容性。其不仅仅是将私有云和公有云同时运用在一个应用中。它是一套多种类型的服务,其中的一部分可能是你们 IT 部门建立和操作的,而另一部分可能来源于外部。
它们可能是软件即服务(SaaS)应用的混合,例如邮件和客户关系管理(CRM)。被 Kubernetes 这类开源软件协调在一起的容器平台越来越受新开发应用的欢迎。你的组织可能正在运用某一家大型云服务提供商来做一些事情。同时你也能在私有云或更加传统的内部基础设施上操作一些你自己的基础设施。
这就是现在混合云的现状,它能被归纳为两个选择,选择最合适的基础设施和服务,以及选择把应用和数据从一个地方移动到另一个你想的地方。
**相关阅读: [多重云和混合云有什么不同?](https://enterprisersproject.com/article/2017/7/multi-cloud-vs-hybrid-cloud-whats-difference)**
---
作者简介:
Gordon Haff 是红帽云的布道者,常受到业内和客户的高度赞赏,帮助红帽云组合方案的发展。他是《Computing Next: How the Cloud Opens the Future》的作者,除此之外他还有许多出版物。在红帽之前,Gordon 写了大量的研究简报,经常被纽约时报等出版物在 IT 类话题上引用,在产品和市场策略上给予客户建议。他职业生涯的早期,在 Data General 他负责将各种不同的计算机系统,从微型计算机到大型的 UNIX 服务器,引入市场。他有麻省理工学院和达特茅斯学院的工程学位,还是康奈尔大学约翰逊商学院的工商管理学硕士。
---
via: <https://opensource.com/article/17/7/hybrid-cloud>
作者:[Gordon Haff (Red Hat)](https://opensource.com/users/ghaff) 译者:[ZH1122](https://github.com/ZH1122) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Depending upon the event you use to start the clock, cloud computing is only a little more than 10 years old. Some terms and concepts around cloud computing that we take for granted today are newer still. The National Institute of Standards and Technology (NIST) document that defined now-familiar cloud terminology—such as Infrastructure-as-a-Service (IaaS)—was only published in 2011, although it widely circulated in draft form for a while before that.
Among other definitions in that document was one for *hybrid cloud*. Looking at how that term has shifted during the intervening years is instructive. Cloud-based infrastructures have moved beyond a relatively simplistic taxonomy. Also, it highlights how priorities familiar to adopters of open source software—such as flexibility, portability, and choice—have made their way to the hybrid cloud.
NIST's original hybrid cloud definition was primarily focused on cloud bursting, the idea that you might use on-premise infrastructure to handle a base computing load, but that you could "burst" out to a public cloud if your usage spiked. Closely related were efforts to provide API compatibility between private clouds and public cloud providers and even to create spot markets to purchase capacity wherever it was cheapest.
Implicit in all this was the idea of the cloud as a sort of standardized compute utility with clear analogs to the electrical grid, a concept probably most popularized by author Nick Carr in his book [ The Big Switch](http://www.nicholascarr.com/?page_id=21). It made for a good story but, even early on, the
[limitations of the analogy became evident](https://www.cnet.com/news/there-is-no-big-switch-for-cloud-computing/). Computing isn't a commodity in the manner of electricity. One need look no further than the proliferation of new features by all of the major public cloud providers—as well as in open source cloud software such as OpenStack—to see that many users aren't simply looking for generic computing cycles at the lowest price.
The cloud bursting idea also largely ignored the reality that computing is usually associated with data and you can't just move large quantities of data around instantaneously without incurring big bandwidth bills and having to worry about the length of time those transfers take. Dave McCrory coined the term *data gravity* to describe this limitation.
Given this rather negative picture I've painted, why are we talking about hybrid clouds so much today?
As I've discussed, hybrid clouds were initially thought of mostly in the context of cloud bursting. And cloud bursting perhaps most emphasized rapid, even real-time, shifts of workloads from one cloud to another; however, hybrid clouds also implied application and data portability. Indeed, as [I wrote in a CNET post](https://www.cnet.com/news/cloudbursting-or-just-portable-clouds/) back in 2011: "I think we do ourselves a disservice by obsessing too much with 'automagical' workload shifting—when what we really care about is the ability to just move from one place to another if a vendor isn't meeting our requirements or is trying to lock us in."
Since then, thinking about portability across clouds has evolved even further.
Linux always has been a key component of cloud portability because it can run on everything from bare-metal to on-premise virtualized infrastructures, and from private clouds to public clouds. Linux provides a well-established, reliable platform with a stable API contract against which applications can be written.
The widespread adoption of containers has further enhanced the ability of Linux to provide application portability across clouds. By providing an image that also contains an application's dependencies, a container provides portability and consistency as applications move from development, to testing, and finally to production.
Linux containers can be applied in many different ways to problems where ultimate portability, configurability, and isolation are needed. This is true whether running on-premise, in a public cloud, or a hybrid of the two.
Container tools use an image-based deployment model. This makes sharing an application or set of services with all of their dependencies across multiple environments easy.
Specifications developed under the auspices of the Open Container Initiative (OCI) work together to define the contents of a container image and those dependencies, environments, arguments, and so forth necessary for the image to be run properly. As a result of these standardization efforts, the OCI has opened the door for many other tooling efforts that can now depend on stable runtime and image specs.
At the same time, distributed storage can provide data portability across clouds using open source technologies such as Gluster and Ceph. Physical constraints will always impose limits on how quickly and easily data can be moved from one location to another; however, as organizations deploy and use different types of infrastructure, they increasingly desire open, software-defined storage platforms that scales across physical, virtual, and cloud resources.
This is especially the case as data storage requirements grow rapidly, because of trends in predictive analytics, internet-of-things, and real-time monitoring. In [one 2016 study](https://www.redhat.com/en/technologies/storage/vansonbourne), 98% of IT decision makers said a more agile storage solution could benefit their organization. In the same study, they listed inadequate storage infrastructure as one of the greatest frustrations that their organizations experience.
And it's really this idea of providing appropriate portability and consistency across a heterogeneous set of computing capabilities and resources that embodies what hybrid cloud has become. Hybrid cloud is not so much about using a private cloud and a public cloud in concert for the same applications. It's about using a set of services of many types, some of which are probably built and operated by your IT department, and some of which are probably sourced externally.
They'll probably be a mix of Software-as-a-Service applications, such as email and customer relationship management. Container platforms, orchestrated by open source software such as Kubernetes, are increasingly popular for developing new applications. Your organization likely is using one of the big public cloud providers for *something*. And you're almost certain to be operating some of your own infrastructure, whether it's a private cloud or more traditional on-premise infrastructure.
This is the face of today's hybrid cloud, which really can be summed up as choice—choice to select the most appropriate types of infrastructure and services, and choice to move applications and data from one location to another when you want to.
*Also read: Multi-cloud vs. hybrid cloud: What's the difference?*
## Comments are closed. |
8,968 | 如何让网站不下线而从 Redis 2 迁移到 Redis 3 | http://engineering.skybettingandgaming.com/2017/09/25/redis-2-to-redis-3/ | 2017-10-17T12:45:35 | [
"Redis"
] | https://linux.cn/article-8968-1.html | 我们在 Sky Betting&Gaming 中使用 [Redis](https://redis.io/) 作为共享内存缓存,用于那些需要跨 API 服务器或者 Web 服务器鉴别令牌之类的操作。在 Core Tribe 内,它用来帮助处理日益庞大的登录数量,特别是在繁忙的时候,我们在一分钟内登录数量会超过 20,000 人。这在很大程度上适用于数据存放在大量服务器的情况下(在 SSO 令牌用于 70 台 Apache HTTPD 服务器的情况下)。我们最近着手升级 Redis 服务器,此升级旨在使用 Redis 3.2 提供的原生集群功能。这篇博客希望解释为什么我们要使用集群、我们遇到的问题以及我们的解决方案。

### 在开始阶段(或至少在升级之前)
我们的传统缓存中每个缓存都包括一对 Redis 服务器,使用 keepalive 确保始终有一个主节点监听<ruby> 浮动 IP <rt> floating IP </rt></ruby>地址。当出现问题时,这些服务器对需要很大的精力来进行管理,而故障模式有时是非常各种各样的。有时,只允许读取它所持有的数据,而不允许写入的从属节点却会得到浮动 IP 地址,这种问题是相对容易诊断的,但会让无论哪个程序试图使用该缓存时都很麻烦。
### 新的应用程序
因此,这种情况下,我们需要构建一个新的应用程序,一个使用<ruby> 共享内存缓存 <rt> shared in-memory cache </rt></ruby>的应用程序,但是我们不希望对该缓存进行迂回的故障切换过程。因此,我们的要求是共享的内存缓存,没有单点故障,可以使用尽可能少的人为干预来应对多种不同的故障模式,并且在事件恢复之后也能够在很少的人为干预下恢复,一个额外的要求是提高缓存的安全性,以减少数据泄露的范围(稍后再说)。当时 Redis Sentinel 看起来很有希望,并且有许多程序支持代理 Redis 连接,比如 [twemproxy](https://github.com/twitter/twemproxy)。这会导致还要安装其它很多组件,它应该有效,并且人际交互最少,但它复杂而需要运行大量的服务器和服务,并且相互通信。

将会有大量的应用服务器与 twemproxy 进行通信,这会将它们的调用路由到合适的 Redis 主节点,twemproxy 将从 sentinal 集群获取主节点的信息,它将控制哪台 Redis 实例是主,哪台是从。这个设置是复杂的,而且仍有单点故障,它依赖于 twemproxy 来处理分片,来连接到正确的 Redis 实例。它具有对应用程序透明的优点,所以我们可以在理论上做到将现有的应用程序转移到这个 Redis 配置,而不用改变应用程序。但是我们要从头开始构建一个应用程序,所以迁移应用程序不是一个必需条件。
幸运的是,这个时候,Redis 3.2 出来了,而且内置了原生集群,消除了对单一 sentinel 集群需要。

它有一个更简单的设置,但 twemproxy 不支持 Redis 集群分片,它能为你分片数据,但是如果尝试在与分片不一致的集群中这样做会导致问题。有参考的指南可以使其匹配,但是集群可以自动改变形式,并改变分片的设置方式。它仍然有单点故障。正是在这一点上,我将永远感谢我的一位同事发现了一个 Node.js 的 Redis 的集群发现驱动程序,让我们完全放弃了 twemproxy。

因此,我们能够自动分片数据,故障转移和故障恢复基本上是自动的。应用程序知道哪些节点存在,并且在写入数据时,如果写入错误的节点,集群将自动重定向该写入。这是被选的配置,这让我们共享的内存缓存相当健壮,可以没有干预地应付基本的故障模式。在测试期间,我们的确发现了一些缺陷。复制是在一个接一个节点的基础上进行的,因此如果我们丢失了一个主节点,那么它的从节点会成为一个单点故障,直到死去的节点恢复服务,也只有主节点对集群健康投票,所以如果我们一下失去太多主节点,那么集群无法自我恢复。但这比我们过去的好。
### 向前进
随着使用集群 Redis 配置的新程序,我们对于老式 Redis 实例的状态变得越来越不适应,但是新程序与现有程序的规模并不相同(超过 30GB 的内存专用于我们最大的老式 Redis 实例数据库)。因此,随着 Redis 集群在底层得到了证实,我们决定迁移老式的 Redis 实例到新的 Redis 集群中。
由于我们有一个原生支持 Redis 集群的 Node.js Redis 驱动程序,因此我们开始将 Node.js 程序迁移到 Redis 集群。但是,如何将数十亿字节的数据从一个地方移动到另一个地方,而不会造成重大问题?特别是考虑到这些数据是认证令牌,所以如果它们错了,我们的终端用户将会被登出。一个选择是要求网站完全下线,将所有内容都指向新的 Redis 群集,并将数据迁移到其中,以希望获得最佳效果。另一个选择是切换到新集群,并强制所有用户再次登录。由于显而易见的原因,这些都不是非常合适的。我们决定采取的替代方法是将数据同时写入老式 Redis 实例和正在替换它的集群,同时随着时间的推移,我们将逐渐更多地向该集群读取。由于数据的有效期有限(令牌在几个小时后到期),这种方法可以导致零停机,并且不会有数据丢失的风险。所以我们这么做了。迁移是成功的。
剩下的就是服务于我们的 PHP 代码(其中还有一个项目是有用的,其它的最终是没必要的)的 Redis 的实例了,我们在这过程中遇到了一个困难,实际上是两个。首先,也是最紧迫的是找到在 PHP 中使用的 Redis 集群发现驱动程序,还要是我们正在使用的 PHP 版本。这被证明是可行的,因为我们升级到了最新版本的 PHP。我们选择的驱动程序不喜欢使用 Redis 的授权方式,因此我们决定使用 Redis 集群作为一个额外的安全步骤 (我告诉你,这将有更多的安全性)。当我们用 Redis 集群替换每个老式 Redis 实例时,修复似乎很直接,将 Redis 授权关闭,这样它将会响应所有的请求。然而,这并不是真的,由于某些原因,Redis 集群不会接受来自 Web 服务器的连接。 Redis 在版本 3 中引入的称为“保护模式”的新安全功能将在 Redis 绑定到任何接口时将停止监听来自外部 IP 地址的连接,并无需配置 Redis 授权密码。这被证明相当容易修复,但让我们保持警惕。
### 现在?
这就是我们现在的情况。我们已经迁移了我们的一些老式 Redis 实例,并且正在迁移其余的。我们通过这样做解决了我们的一些技术债务,并提高了我们的平台的稳定性。使用 Redis 集群,我们还可以扩展内存数据库并扩展它们。 Redis 是单线程的,所以只要在单个实例中留出更多的内存就会可以得到这么多的增长,而且我们已经紧跟在这个限制后面。我们期待着从新的集群中获得改进的性能,同时也为我们提供了扩展和负载均衡的更多选择。
### 未来怎么样?
我们解决了一些技术性债务,这使我们的服务更容易支持,更加稳定。但这并不意味着这项工作完成了,Redis 4 似乎有一些我们可能想要研究的功能。而且 Redis 并不是我们使用的唯一软件。我们将继续努力改进平台,缩短处理技术债务的时间,但随着客户群体的扩大,我们力求提供更丰富的服务,我们总是会遇到需要改进的事情。下一个挑战可能与每分钟超过 20,000次 登录到超过 40,000 次甚至更高的扩展有关。
---
via: <http://engineering.skybettingandgaming.com/2017/09/25/redis-2-to-redis-3/>
作者:[Craig Stewart](http://engineering.skybettingandgaming.com/authors#craig_stewart) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
8,969 | OpenGL 与 Go 教程(三)实现游戏 | https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-3-implementing-the-game | 2017-10-18T09:43:00 | [
"OpenGL",
"Golang"
] | https://linux.cn/article-8969-1.html | 
* [第一节: Hello, OpenGL](/article-8933-1.html)
* [第二节: 绘制游戏面板](/article-8937-1.html)
* [第三节:实现游戏功能](/article-8969-1.html)
该教程的完整源代码可以从 [GitHub](https://github.com/KyleBanks/conways-gol) 上找到。
欢迎回到《OpenGL 与 Go 教程》!如果你还没有看过 [第一节](/article-8933-1.html) 和 [第二节](https://kylewbanks.com/blog/%5BPart%202:%20Drawing%20the%20Game%20Board%5D(/blog/tutorial-opengl-with-golang-part-2-drawing-the-game-board)),那就要回过头去看一看。
到目前为止,你应该懂得如何创建网格系统以及创建代表方格中每一个单元的格子阵列。现在可以开始把网格当作游戏面板实现<ruby> 康威生命游戏 <rt> Conway's Game of Life </rt></ruby>。
开始吧!
### 实现康威生命游戏
康威生命游戏的其中一个要点是所有<ruby> 细胞 <rt> cell </rt></ruby>必须同时基于当前细胞在面板中的状态确定下一个细胞的状态。也就是说如果细胞 `(X=3,Y=4)` 在计算过程中状态发生了改变,那么邻近的细胞 `(X=4,Y=4)` 必须基于 `(X=3,Y=4)` 的状态决定自己的状态变化,而不是基于自己现在的状态。简单的讲,这意味着我们必须遍历细胞,确定下一个细胞的状态,而在绘制之前不改变他们的当前状态,然后在下一次循环中我们将新状态应用到游戏里,依此循环往复。
为了完成这个功能,我们需要在 `cell` 结构体中添加两个布尔型变量:
```
type cell struct {
drawable uint32
alive bool
aliveNext bool
x int
y int
}
```
这里我们添加了 `alive` 和 `aliveNext`,前一个是细胞当前的专题,后一个是经过计算后下一回合的状态。
现在添加两个函数,我们会用它们来确定 cell 的状态:
```
// checkState 函数决定下一次游戏循环时的 cell 状态
func (c *cell) checkState(cells [][]*cell) {
c.alive = c.aliveNext
c.aliveNext = c.alive
liveCount := c.liveNeighbors(cells)
if c.alive {
// 1. 当任何一个存活的 cell 的附近少于 2 个存活的 cell 时,该 cell 将会消亡,就像人口过少所导致的结果一样
if liveCount < 2 {
c.aliveNext = false
}
// 2. 当任何一个存活的 cell 的附近有 2 至 3 个存活的 cell 时,该 cell 在下一代中仍然存活。
if liveCount == 2 || liveCount == 3 {
c.aliveNext = true
}
// 3. 当任何一个存活的 cell 的附近多于 3 个存活的 cell 时,该 cell 将会消亡,就像人口过多所导致的结果一样
if liveCount > 3 {
c.aliveNext = false
}
} else {
// 4. 任何一个消亡的 cell 附近刚好有 3 个存活的 cell,该 cell 会变为存活的状态,就像重生一样。
if liveCount == 3 {
c.aliveNext = true
}
}
}
// liveNeighbors 函数返回当前 cell 附近存活的 cell 数
func (c *cell) liveNeighbors(cells [][]*cell) int {
var liveCount int
add := func(x, y int) {
// If we're at an edge, check the other side of the board.
if x == len(cells) {
x = 0
} else if x == -1 {
x = len(cells) - 1
}
if y == len(cells[x]) {
y = 0
} else if y == -1 {
y = len(cells[x]) - 1
}
if cells[x][y].alive {
liveCount++
}
}
add(c.x-1, c.y) // To the left
add(c.x+1, c.y) // To the right
add(c.x, c.y+1) // up
add(c.x, c.y-1) // down
add(c.x-1, c.y+1) // top-left
add(c.x+1, c.y+1) // top-right
add(c.x-1, c.y-1) // bottom-left
add(c.x+1, c.y-1) // bottom-right
return liveCount
}
```
在 `checkState` 中我们设置当前状态(`alive`) 等于我们最近迭代结果(`aliveNext`)。接下来我们计数邻居数量,并根据游戏的规则来决定 `aliveNext` 状态。该规则是比较清晰的,而且我们在上面的代码当中也有说明,所以这里不再赘述。
更加值得注意的是 `liveNeighbors` 函数里,我们返回的是当前处于存活(`alive`)状态的细胞的邻居个数。我们定义了一个叫做 `add` 的内嵌函数,它会对 `X` 和 `Y` 坐标做一些重复性的验证。它所做的事情是检查我们传递的数字是否超出了范围——比如说,如果细胞 `(X=0,Y=5)` 想要验证它左边的细胞,它就得验证面板另一边的细胞 `(X=9,Y=5)`,Y 轴与之类似。
在 `add` 内嵌函数后面,我们给当前细胞附近的八个细胞分别调用 `add` 函数,示意如下:
```
[
[-, -, -],
[N, N, N],
[N, C, N],
[N, N, N],
[-, -, -]
]
```
在该示意中,每一个叫做 N 的细胞是 C 的邻居。
现在是我们的 `main` 函数,这里我们执行核心游戏循环,调用每个细胞的 `checkState` 函数进行绘制:
```
func main() {
...
for !window.ShouldClose() {
for x := range cells {
for _, c := range cells[x] {
c.checkState(cells)
}
}
draw(cells, window, program)
}
}
```
现在我们的游戏逻辑全都设置好了,我们需要修改细胞绘制函数来跳过绘制不存活的细胞:
```
func (c *cell) draw() {
if !c.alive {
return
}
gl.BindVertexArray(c.drawable)
gl.DrawArrays(gl.TRIANGLES, 0, int32(len(square)/3))
}
```
如果我们现在运行这个游戏,你将看到一个纯黑的屏幕,而不是我们辛苦工作后应该看到生命模拟。为什么呢?其实这正是模拟在工作。因为我们没有活着的细胞,所以就一个都不会绘制出来。
现在完善这个函数。回到 `makeCells` 函数,我们用 `0.0` 到 `1.0` 之间的一个随机数来设置游戏的初始状态。我们会定义一个大小为 `0.15` 的常量阈值,也就是说每个细胞都有 15% 的几率处于存活状态。
```
import (
"math/rand"
"time"
...
)
const (
...
threshold = 0.15
)
func makeCells() [][]*cell {
rand.Seed(time.Now().UnixNano())
cells := make([][]*cell, rows, rows)
for x := 0; x < rows; x++ {
for y := 0; y < columns; y++ {
c := newCell(x, y)
c.alive = rand.Float64() < threshold
c.aliveNext = c.alive
cells[x] = append(cells[x], c)
}
}
return cells
}
```
我们首先增加两个引入:随机(`math/rand`)和时间(`time`),并定义我们的常量阈值。然后在 `makeCells` 中我们使用当前时间作为随机种子,给每个游戏一个独特的起始状态。你也可也指定一个特定的种子值,来始终得到一个相同的游戏,这在你想重放某个有趣的模拟时很有用。
接下来在循环中,在用 `newCell` 函数创造一个新的细胞时,我们根据随机浮点数的大小设置它的存活状态,随机数在 `0.0` 到 `1.0` 之间,如果比阈值(`0.15`)小,就是存活状态。再次强调,这意味着每个细胞在开始时都有 15% 的几率是存活的。你可以修改数值大小,增加或者减少当前游戏中存活的细胞。我们还把 `aliveNext` 设成 `alive` 状态,否则在第一次迭代之后我们会发现一大片细胞消亡了,这是因为 `aliveNext` 将永远是 `false`。
现在继续运行它,你很有可能看到细胞们一闪而过,但你却无法理解这是为什么。原因可能在于你的电脑太快了,在你能够看清楚之前就运行了(甚至完成了)模拟过程。
让我们降低游戏速度,在主循环中引入一个帧率(FPS)限制:
```
const (
...
fps = 2
)
func main() {
...
for !window.ShouldClose() {
t := time.Now()
for x := range cells {
for _, c := range cells[x] {
c.checkState(cells)
}
}
if err := draw(prog, window, cells); err != nil {
panic(err)
}
time.Sleep(time.Second/time.Duration(fps) - time.Since(t))
}
}
```
现在你能给看出一些图案了,尽管它变换的很慢。把 FPS 加到 10,把方格的尺寸加到 100x100,你就能看到更真实的模拟:
```
const (
...
rows = 100
columns = 100
fps = 10
...
)
```

试着修改常量,看看它们是怎么影响模拟过程的 —— 这是你用 Go 语言写的第一个 OpenGL 程序,很酷吧?
### 进阶内容?
这是《OpenGL 与 Go 教程》的最后一节,但是这不意味着到此而止。这里有些新的挑战,能够增进你对 OpenGL (以及 Go)的理解。
1. 给每个细胞一种不同的颜色。
2. 让用户能够通过命令行参数指定格子尺寸、帧率、种子和阈值。在 GitHub 上的 [github.com/KyleBanks/conways-gol](https://github.com/KyleBanks/conways-gol) 里你可以看到一个已经实现的程序。
3. 把格子的形状变成其它更有意思的,比如六边形。
4. 用颜色表示细胞的状态 —— 比如,在第一帧把存活状态的格子设成绿色,如果它们存活了超过三帧的时间,就变成黄色。
5. 如果模拟过程结束了,就自动关闭窗口,也就是说所有细胞都消亡了,或者是最后两帧里没有格子的状态有改变。
6. 将着色器源代码放到单独的文件中,而不是把它们用字符串的形式放在 Go 的源代码中。
### 总结
希望这篇教程对想要入门 OpenGL (或者是 Go)的人有所帮助!这很有趣,因此我也希望理解学习它也很有趣。
正如我所说的,OpenGL 可能是非常恐怖的,但只要你开始着手了就不会太差。你只用制定一个个可达成的小目标,然后享受每一次成功,因为尽管 OpenGL 不会总像它看上去的那么难,但也肯定有些难懂的东西。我发现,当遇到一个难于理解用 go-gl 生成的代码的 OpenGL 问题时,你总是可以参考一下在网上更流行的当作教程的 C 语言代码,这很有用。通常 C 语言和 Go 语言的唯一区别是在 Go 中,gl 函数的前缀是 `gl.` 而不是 `gl`,常量的前缀是 `gl` 而不是 `GL_`。这可以极大地增加了你的绘制知识!
该教程的完整源代码可从 [GitHub](https://github.com/KyleBanks/conways-gol) 上获得。
### 回顾
这是 main.go 文件最终的内容:
```
package main
import (
"fmt"
"log"
"math/rand"
"runtime"
"strings"
"time"
"github.com/go-gl/gl/v4.1-core/gl" // OR: github.com/go-gl/gl/v2.1/gl
"github.com/go-gl/glfw/v3.2/glfw"
)
const (
width = 500
height = 500
vertexShaderSource = `
#version 410
in vec3 vp;
void main() {
gl_Position = vec4(vp, 1.0);
}
` + "\x00"
fragmentShaderSource = `
#version 410
out vec4 frag_colour;
void main() {
frag_colour = vec4(1, 1, 1, 1.0);
}
` + "\x00"
rows = 100
columns = 100
threshold = 0.15
fps = 10
)
var (
square = []float32{
-0.5, 0.5, 0,
-0.5, -0.5, 0,
0.5, -0.5, 0,
-0.5, 0.5, 0,
0.5, 0.5, 0,
0.5, -0.5, 0,
}
)
type cell struct {
drawable uint32
alive bool
aliveNext bool
x int
y int
}
func main() {
runtime.LockOSThread()
window := initGlfw()
defer glfw.Terminate()
program := initOpenGL()
cells := makeCells()
for !window.ShouldClose() {
t := time.Now()
for x := range cells {
for _, c := range cells[x] {
c.checkState(cells)
}
}
draw(cells, window, program)
time.Sleep(time.Second/time.Duration(fps) - time.Since(t))
}
}
func draw(cells [][]*cell, window *glfw.Window, program uint32) {
gl.Clear(gl.COLOR_BUFFER_BIT | gl.DEPTH_BUFFER_BIT)
gl.UseProgram(program)
for x := range cells {
for _, c := range cells[x] {
c.draw()
}
}
glfw.PollEvents()
window.SwapBuffers()
}
func makeCells() [][]*cell {
rand.Seed(time.Now().UnixNano())
cells := make([][]*cell, rows, rows)
for x := 0; x < rows; x++ {
for y := 0; y < columns; y++ {
c := newCell(x, y)
c.alive = rand.Float64() < threshold
c.aliveNext = c.alive
cells[x] = append(cells[x], c)
}
}
return cells
}
func newCell(x, y int) *cell {
points := make([]float32, len(square), len(square))
copy(points, square)
for i := 0; i < len(points); i++ {
var position float32
var size float32
switch i % 3 {
case 0:
size = 1.0 / float32(columns)
position = float32(x) * size
case 1:
size = 1.0 / float32(rows)
position = float32(y) * size
default:
continue
}
if points[i] < 0 {
points[i] = (position * 2) - 1
} else {
points[i] = ((position + size) * 2) - 1
}
}
return &cell{
drawable: makeVao(points),
x: x,
y: y,
}
}
func (c *cell) draw() {
if !c.alive {
return
}
gl.BindVertexArray(c.drawable)
gl.DrawArrays(gl.TRIANGLES, 0, int32(len(square)/3))
}
// checkState 函数决定下一次游戏循环时的 cell 状态
func (c *cell) checkState(cells [][]*cell) {
c.alive = c.aliveNext
c.aliveNext = c.alive
liveCount := c.liveNeighbors(cells)
if c.alive {
// 1. 当任何一个存活的 cell 的附近少于 2 个存活的 cell 时,该 cell 将会消亡,就像人口过少所导致的结果一样
if liveCount < 2 {
c.aliveNext = false
}
// 2. 当任何一个存活的 cell 的附近有 2 至 3 个存活的 cell 时,该 cell 在下一代中仍然存活。
if liveCount == 2 || liveCount == 3 {
c.aliveNext = true
}
// 3. 当任何一个存活的 cell 的附近多于 3 个存活的 cell 时,该 cell 将会消亡,就像人口过多所导致的结果一样
if liveCount > 3 {
c.aliveNext = false
}
} else {
// 4. 任何一个消亡的 cell 附近刚好有 3 个存活的 cell,该 cell 会变为存活的状态,就像重生一样。
if liveCount == 3 {
c.aliveNext = true
}
}
}
// liveNeighbors 函数返回当前 cell 附近存活的 cell 数
func (c *cell) liveNeighbors(cells [][]*cell) int {
var liveCount int
add := func(x, y int) {
// If we're at an edge, check the other side of the board.
if x == len(cells) {
x = 0
} else if x == -1 {
x = len(cells) - 1
}
if y == len(cells[x]) {
y = 0
} else if y == -1 {
y = len(cells[x]) - 1
}
if cells[x][y].alive {
liveCount++
}
}
add(c.x-1, c.y) // To the left
add(c.x+1, c.y) // To the right
add(c.x, c.y+1) // up
add(c.x, c.y-1) // down
add(c.x-1, c.y+1) // top-left
add(c.x+1, c.y+1) // top-right
add(c.x-1, c.y-1) // bottom-left
add(c.x+1, c.y-1) // bottom-right
return liveCount
}
// initGlfw 初始化 glfw,返回一个可用的 Window
func initGlfw() *glfw.Window {
if err := glfw.Init(); err != nil {
panic(err)
}
glfw.WindowHint(glfw.Resizable, glfw.False)
glfw.WindowHint(glfw.ContextVersionMajor, 4)
glfw.WindowHint(glfw.ContextVersionMinor, 1)
glfw.WindowHint(glfw.OpenGLProfile, glfw.OpenGLCoreProfile)
glfw.WindowHint(glfw.OpenGLForwardCompatible, glfw.True)
window, err := glfw.CreateWindow(width, height, "Conway's Game of Life", nil, nil)
if err != nil {
panic(err)
}
window.MakeContextCurrent()
return window
}
// initOpenGL 初始化 OpenGL 并返回一个已经编译好的着色器程序
func initOpenGL() uint32 {
if err := gl.Init(); err != nil {
panic(err)
}
version := gl.GoStr(gl.GetString(gl.VERSION))
log.Println("OpenGL version", version)
vertexShader, err := compileShader(vertexShaderSource, gl.VERTEX_SHADER)
if err != nil {
panic(err)
}
fragmentShader, err := compileShader(fragmentShaderSource, gl.FRAGMENT_SHADER)
if err != nil {
panic(err)
}
prog := gl.CreateProgram()
gl.AttachShader(prog, vertexShader)
gl.AttachShader(prog, fragmentShader)
gl.LinkProgram(prog)
return prog
}
// makeVao 初始化并从提供的点里面返回一个顶点数组
func makeVao(points []float32) uint32 {
var vbo uint32
gl.GenBuffers(1, &vbo)
gl.BindBuffer(gl.ARRAY_BUFFER, vbo)
gl.BufferData(gl.ARRAY_BUFFER, 4*len(points), gl.Ptr(points), gl.STATIC_DRAW)
var vao uint32
gl.GenVertexArrays(1, &vao)
gl.BindVertexArray(vao)
gl.EnableVertexAttribArray(0)
gl.BindBuffer(gl.ARRAY_BUFFER, vbo)
gl.VertexAttribPointer(0, 3, gl.FLOAT, false, 0, nil)
return vao
}
func compileShader(source string, shaderType uint32) (uint32, error) {
shader := gl.CreateShader(shaderType)
csources, free := gl.Strs(source)
gl.ShaderSource(shader, 1, csources, nil)
free()
gl.CompileShader(shader)
var status int32
gl.GetShaderiv(shader, gl.COMPILE_STATUS, &status)
if status == gl.FALSE {
var logLength int32
gl.GetShaderiv(shader, gl.INFO_LOG_LENGTH, &logLength)
log := strings.Repeat("\x00", int(logLength+1))
gl.GetShaderInfoLog(shader, logLength, nil, gl.Str(log))
return 0, fmt.Errorf("failed to compile %v: %v", source, log)
}
return shader, nil
}
```
请在 Twitter [@kylewbanks](https://twitter.com/kylewbanks) 告诉我这篇文章对你是否有帮助,或者在 Twitter 下方关注我以便及时获取最新文章!
---
via: <https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-3-implementing-the-game>
作者:[kylewbanks](https://twitter.com/kylewbanks) 译者:[GitFuture](https://github.com/GitFuture) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # OpenGL & Go Tutorial Part 3: Implementing the Game
[@kylewbanks](https://twitter.com/kylewbanks)on Mar 12, 2017.
*Hey, if you didn't already know, I'm currently working on an open world stealth exploration game called*
[Farewell North](https://farewell-north.com)in my spare time, which is available to wishlist on Steam!* Part 1: Hello, OpenGL* |
*|*
[Part 2: Drawing the Game Board](/blog/tutorial-opengl-with-golang-part-2-drawing-the-game-board)
[Part 3: Implementing the Game](/blog/tutorial-opengl-with-golang-part-3-implementing-the-game)*The full source code of the tutorial is available on GitHub.*
Welcome back to the *OpenGL & Go Tutorial!* If you haven’t gone through [Part 1](/blog/tutorial-opengl-with-golang-part-1-hello-opengl) and [Part 2]([Part 2: Drawing the Game Board](/blog/tutorial-opengl-with-golang-part-2-drawing-the-game-board)) you’ll definitely want to take a step back and check them out.
At this point you should have a grid system created and a matrix of *cells* to represent each unit of the grid. Now it’s time to implement *Conway’s Game of Life* using the grid as the game board.
Let’s get started!
## Implement Conway’s Game
One of the keys to Conway’s game is that each cell must determine its next state based on the current state of the board, at the same time. This means that if Cell **(X=3, Y=4)** changes state during its calculation, its neighbor at **(X=4, Y=4)** must determine its own state based on what **(X=3, Y=4)** *was*, not what is has become. Basically, this means we must loop through the cells and determine their next state without modifying their current state before we draw, and then on the next loop of the game we apply the new state and repeat.
In order to accomplish this, we’ll add two booleans to the **cell** struct:
type cell struct { drawable uint32 alive bool aliveNext bool x int y int }
Here we’ve added **alive** and **aliveNext**, the former being the cell’s current state and the later being the state it has calculated for the next turn.
Now let’s add two functions that we’ll use to determine the cell’s state:
// checkState determines the state of the cell for the next tick of the game. func (c *cell) checkState(cells [][]*cell) { c.alive = c.aliveNext c.aliveNext = c.alive liveCount := c.liveNeighbors(cells) if c.alive { // 1. Any live cell with fewer than two live neighbours dies, as if caused by underpopulation. if liveCount < 2 { c.aliveNext = false } // 2. Any live cell with two or three live neighbours lives on to the next generation. if liveCount == 2 || liveCount == 3 { c.aliveNext = true } // 3. Any live cell with more than three live neighbours dies, as if by overpopulation. if liveCount > 3 { c.aliveNext = false } } else { // 4. Any dead cell with exactly three live neighbours becomes a live cell, as if by reproduction. if liveCount == 3 { c.aliveNext = true } } } // liveNeighbors returns the number of live neighbors for a cell. func (c *cell) liveNeighbors(cells [][]*cell) int { var liveCount int add := func(x, y int) { // If we're at an edge, check the other side of the board. if x == len(cells) { x = 0 } else if x == -1 { x = len(cells) - 1 } if y == len(cells[x]) { y = 0 } else if y == -1 { y = len(cells[x]) - 1 } if cells[x][y].alive { liveCount++ } } add(c.x-1, c.y) // To the left add(c.x+1, c.y) // To the right add(c.x, c.y+1) // up add(c.x, c.y-1) // down add(c.x-1, c.y+1) // top-left add(c.x+1, c.y+1) // top-right add(c.x-1, c.y-1) // bottom-left add(c.x+1, c.y-1) // bottom-right return liveCount }
In **checkState** we set the current state (**alive**) equal to what we calculated on the last iteration (**aliveNext**). Next we count the number of neighbors, and determine the **aliveNext** state according to the rules of the game. The rules should be relatively clear and they’re documented in the code above, so I won’t go over them again here.
What’s more interesting is the **liveNeighbors** function where we return the number of neighbors to the current cell that are in an **alive** state. We define an inner function called **add** that will do some repetitive validation on X and Y coordinates. What it does is check if we’ve passed a number that exceeds the bounds of the board - for example, if cell **(X=0, Y=5)** wants to check on its neighbor to the left, it has to wrap around to the other side of the board to cell **(X=9, Y=5)**, and likewise for the Y-axis.
Below the inner **add** function we call **add** with each of the cell’s eight neighbors, depicted below:
```
[
[-, -, -],
[N, N, N],
[N, C, N],
[N, N, N],
[-, -, -]
]
```
In this depiction, each cell labeled **N** is a neighbor to **C**.
Now in our **main** function, where we have our core game loop, let’s call **checkState** on each cell prior to drawing:
func main() { ... for !window.ShouldClose() { for x := range cells { for _, c := range cells[x] { c.checkState(cells) } } draw(cells, window, program) } }
Now our core game logic is all set, we just need to modify the cell **draw** function to skip drawing if the cell isn’t alive:
func (c *cell) draw() { if !c.alive { return } gl.BindVertexArray(c.drawable) gl.DrawArrays(gl.TRIANGLES, 0, int32(len(square)/3)) }
If you run the game now you’ll see a plain black screen, not the glorious simulation we’ve been working so hard to achieve. So why’s that? Well its because the simulation is working! None of our cells are alive, so none of them are drawing themselves.
Let’s fix that. Back in **makeCells** we’ll use a random number between **0.0** and **1.0** to set the initial state of the game. We’ll define a constant threshold of **0.15** meaning that each cell has a 15% chance of starting in an alive state:
import ( "math/rand" "time" ... ) const ( ... threshold = 0.15 ) func makeCells() [][]*cell { rand.Seed(time.Now().UnixNano()) cells := make([][]*cell, rows, rows) for x := 0; x < rows; x++ { for y := 0; y < columns; y++ { c := newCell(x, y) c.alive = rand.Float64() < threshold c.aliveNext = c.alive cells[x] = append(cells[x], c) } } return cells }
We start by adding two imports for the **rand** (random) and **time** packages, and defining our **threshold** constant. Then in **makeCells** we use the current time as the randomization seed, giving each game a unique starting state. You can also specify a particular seed value to always get an identical game, useful if you want to replay interesting simulations.
Next in the loop, after creating a cell with the **newCell** function we set its **alive** state equal to the result of a random float, between **0.0** and **1.0**, being less than **threshold** (**0.15**). Again, this means each cell has a 15% chance of starting out alive. You can play with this number to increase or decrease the number of living cells at the outset of the game. We also set **aliveNext** equal to **alive**, otherwise we’ll get a massive die-off on the first iteration because **aliveNext** will always be **false**!
Now go ahead and give it a run, and you’ll likely see a quick flash of cells that you can’t make heads or tails of. The reason is that your computer is probably way too fast and is running through (or even finishing) the simulation before you have a chance to really see it.
Let’s reduce the game speed by introducing a frames-per-second limitation in the main loop:
const ( ... fps = 2 ) func main() { ... for !window.ShouldClose() { t := time.Now() for x := range cells { for _, c := range cells[x] { c.checkState(cells) } } if err := draw(prog, window, cells); err != nil { panic(err) } time.Sleep(time.Second/time.Duration(fps) - time.Since(t)) } }
At the top we define our **fps** equal to 2, meaning we will perform 2 game iterations per second. We get a reference to the current time at the beginning of the loop, and at the end we sleep for one second divided by our FPS, minus the time that elapsed during the frame. For instance, at an FPS of 2 this means we want each loop to take 500 milliseconds. So, we divide one second by our FPS 2, giving us 500 milliseconds, but we also subtract the time that was spent processing the frame using **time.Since(t)** where **t** is the time we recorded at the beginning.
Now you should be able to see some patterns, albeit very slowly. Increase the FPS to 10 and the size of the grid to 100x100 and you should see some really cool simulations:
const ( ... rows = 100 columns = 100 fps = 10 ... )
Running now you should be able to see something along the lines of this:

Try playing with the constants to see how they impact the simulation - cool right? Your very first OpenGL application with Go!
## What’s Next?
This concludes the *OpenGL with Go Tutorial*, but that doesn’t mean you should stop now. Here’s a few challenges to further improve your OpenGL (and Go) knowledge:
- Give each cell a unique color.
- Allow the user to specify, via command-line arguments, the grid size, frame rate, seed and threshold. You can see this one implemented on GitHub at
[github.com/KyleBanks/conways-gol](https://github.com/KyleBanks/conways-gol). - Change the shape of the cells into something more interesting, like a hexagon.
- Use color to indicate the cell’s state - for example, make cells green on the first frame that they’re alive, and make them yellow if they’ve been alive more than three frames.
- Automatically close the window if the simulation completes, meaning all cells are dead or no cells have changed state in the last two frames.
- Move the shader source code out into their own files, rather than having them as string constants in the Go source code.
## Summary
Hopefully this tutorial has been helpful in gaining a foundation on OpenGL (and maybe even Go)! It was a lot of fun to make so I can only hope it was fun to go through and learn.
As I’ve mentioned, OpenGL can be very intimidating, but it’s really not so bad once you get started. You just want to break down your goals into small, achievable steps, and enjoy each victory because while OpenGL isn’t always as tough as it looks, it can certainly be very unforgiving. One thing that I have found helpful when stuck on OpenGL issues was to understand that the way **go-gl** is generated means you can always use C code as a reference, which is much more popular in tutorials around the internet. The only difference usually between the C and Go code is that functions in Go are prefixed with **gl.** instead of **gl**, and constants are prefixed with **gl** instead of **GL_**. This vastly increases the pool of knowledge you have to draw from!
* Part 1: Hello, OpenGL* |
*|*
[Part 2: Drawing the Game Board](/blog/tutorial-opengl-with-golang-part-2-drawing-the-game-board)
[Part 3: Implementing the Game](/blog/tutorial-opengl-with-golang-part-3-implementing-the-game)*The full source code of the tutorial is available on GitHub.*
## Checkpoint
Here’s the final contents of **main.go**:
package main import ( "fmt" "log" "math/rand" "runtime" "strings" "time" "github.com/go-gl/gl/v4.1-core/gl" // OR: github.com/go-gl/gl/v2.1/gl "github.com/go-gl/glfw/v3.2/glfw" ) const ( width = 500 height = 500 vertexShaderSource = ` #version 410 in vec3 vp; void main() { gl_Position = vec4(vp, 1.0); } ` + "\x00" fragmentShaderSource = ` #version 410 out vec4 frag_colour; void main() { frag_colour = vec4(1, 1, 1, 1.0); } ` + "\x00" rows = 100 columns = 100 threshold = 0.15 fps = 10 ) var ( square = []float32{ -0.5, 0.5, 0, -0.5, -0.5, 0, 0.5, -0.5, 0, -0.5, 0.5, 0, 0.5, 0.5, 0, 0.5, -0.5, 0, } ) type cell struct { drawable uint32 alive bool aliveNext bool x int y int } func main() { runtime.LockOSThread() window := initGlfw() defer glfw.Terminate() program := initOpenGL() cells := makeCells() for !window.ShouldClose() { t := time.Now() for x := range cells { for _, c := range cells[x] { c.checkState(cells) } } draw(cells, window, program) time.Sleep(time.Second/time.Duration(fps) - time.Since(t)) } } func draw(cells [][]*cell, window *glfw.Window, program uint32) { gl.Clear(gl.COLOR_BUFFER_BIT | gl.DEPTH_BUFFER_BIT) gl.UseProgram(program) for x := range cells { for _, c := range cells[x] { c.draw() } } glfw.PollEvents() window.SwapBuffers() } func makeCells() [][]*cell { rand.Seed(time.Now().UnixNano()) cells := make([][]*cell, rows, rows) for x := 0; x < rows; x++ { for y := 0; y < columns; y++ { c := newCell(x, y) c.alive = rand.Float64() < threshold c.aliveNext = c.alive cells[x] = append(cells[x], c) } } return cells } func newCell(x, y int) *cell { points := make([]float32, len(square), len(square)) copy(points, square) for i := 0; i < len(points); i++ { var position float32 var size float32 switch i % 3 { case 0: size = 1.0 / float32(columns) position = float32(x) * size case 1: size = 1.0 / float32(rows) position = float32(y) * size default: continue } if points[i] < 0 { points[i] = (position * 2) - 1 } else { points[i] = ((position + size) * 2) - 1 } } return &cell{ drawable: makeVao(points), x: x, y: y, } } func (c *cell) draw() { if !c.alive { return } gl.BindVertexArray(c.drawable) gl.DrawArrays(gl.TRIANGLES, 0, int32(len(square)/3)) } // checkState determines the state of the cell for the next tick of the game. func (c *cell) checkState(cells [][]*cell) { c.alive = c.aliveNext c.aliveNext = c.alive liveCount := c.liveNeighbors(cells) if c.alive { // 1. Any live cell with fewer than two live neighbours dies, as if caused by underpopulation. if liveCount < 2 { c.aliveNext = false } // 2. Any live cell with two or three live neighbours lives on to the next generation. if liveCount == 2 || liveCount == 3 { c.aliveNext = true } // 3. Any live cell with more than three live neighbours dies, as if by overpopulation. if liveCount > 3 { c.aliveNext = false } } else { // 4. Any dead cell with exactly three live neighbours becomes a live cell, as if by reproduction. if liveCount == 3 { c.aliveNext = true } } } // liveNeighbors returns the number of live neighbors for a cell. func (c *cell) liveNeighbors(cells [][]*cell) int { var liveCount int add := func(x, y int) { // If we're at an edge, check the other side of the board. if x == len(cells) { x = 0 } else if x == -1 { x = len(cells) - 1 } if y == len(cells[x]) { y = 0 } else if y == -1 { y = len(cells[x]) - 1 } if cells[x][y].alive { liveCount++ } } add(c.x-1, c.y) // To the left add(c.x+1, c.y) // To the right add(c.x, c.y+1) // up add(c.x, c.y-1) // down add(c.x-1, c.y+1) // top-left add(c.x+1, c.y+1) // top-right add(c.x-1, c.y-1) // bottom-left add(c.x+1, c.y-1) // bottom-right return liveCount } // initGlfw initializes glfw and returns a Window to use. func initGlfw() *glfw.Window { if err := glfw.Init(); err != nil { panic(err) } glfw.WindowHint(glfw.Resizable, glfw.False) glfw.WindowHint(glfw.ContextVersionMajor, 4) glfw.WindowHint(glfw.ContextVersionMinor, 1) glfw.WindowHint(glfw.OpenGLProfile, glfw.OpenGLCoreProfile) glfw.WindowHint(glfw.OpenGLForwardCompatible, glfw.True) window, err := glfw.CreateWindow(width, height, "Conway's Game of Life", nil, nil) if err != nil { panic(err) } window.MakeContextCurrent() return window } // initOpenGL initializes OpenGL and returns an intiialized program. func initOpenGL() uint32 { if err := gl.Init(); err != nil { panic(err) } version := gl.GoStr(gl.GetString(gl.VERSION)) log.Println("OpenGL version", version) vertexShader, err := compileShader(vertexShaderSource, gl.VERTEX_SHADER) if err != nil { panic(err) } fragmentShader, err := compileShader(fragmentShaderSource, gl.FRAGMENT_SHADER) if err != nil { panic(err) } prog := gl.CreateProgram() gl.AttachShader(prog, vertexShader) gl.AttachShader(prog, fragmentShader) gl.LinkProgram(prog) return prog } // makeVao initializes and returns a vertex array from the points provided. func makeVao(points []float32) uint32 { var vbo uint32 gl.GenBuffers(1, &vbo) gl.BindBuffer(gl.ARRAY_BUFFER, vbo) gl.BufferData(gl.ARRAY_BUFFER, 4*len(points), gl.Ptr(points), gl.STATIC_DRAW) var vao uint32 gl.GenVertexArrays(1, &vao) gl.BindVertexArray(vao) gl.EnableVertexAttribArray(0) gl.BindBuffer(gl.ARRAY_BUFFER, vbo) gl.VertexAttribPointer(0, 3, gl.FLOAT, false, 0, nil) return vao } func compileShader(source string, shaderType uint32) (uint32, error) { shader := gl.CreateShader(shaderType) csources, free := gl.Strs(source) gl.ShaderSource(shader, 1, csources, nil) free() gl.CompileShader(shader) var status int32 gl.GetShaderiv(shader, gl.COMPILE_STATUS, &status) if status == gl.FALSE { var logLength int32 gl.GetShaderiv(shader, gl.INFO_LOG_LENGTH, &logLength) log := strings.Repeat("\x00", int(logLength+1)) gl.GetShaderInfoLog(shader, logLength, nil, gl.Str(log)) return 0, fmt.Errorf("failed to compile %v: %v", source, log) } return shader, nil }
[@kylewbanks](https://twitter.com/kylewbanks)or down below! |
8,970 | Up:在几秒钟内部署无服务器应用程序 | https://medium.freecodecamp.org/up-b3db1ca930ee | 2017-10-17T22:23:42 | [
"serverless",
"无服务器"
] | https://linux.cn/article-8970-1.html | 
去年,我[为 Up 规划了一份蓝图](https://medium.com/@tjholowaychuk/blueprints-for-up-1-5f8197179275),其中描述了如何以最小的成本在 AWS 上为大多数构建块创建一个很棒的无服务器环境。这篇文章则是讨论了 [Up](https://github.com/apex/up) 的初始 alpha 版本。
为什么关注<ruby> 无服务器 <rt> serverless </rt></ruby>?对于初学者来说,它可以节省成本,因为你可以按需付费,且只为你使用的付费。无服务器方式是自愈的,因为每个请求被隔离并被视作“无状态的”。最后,它可以无限轻松地扩展 —— 没有机器或集群要管理。部署你的代码就行了。
大约一个月前,我决定开始在 [apex/up](https://github.com/apex/up) 上开发它,并为动态 SVG 版本的 GitHub 用户投票功能写了第一个小型无服务器示例程序 [tj/gh-polls](https://github.com/tj/gh-polls)。它运行良好,成本低于每月 1 美元即可为数百万次投票服务,因此我会继续这个项目,看看我是否可以提供开源版本及商业的变体版本。
其长期的目标是提供“你自己的 Heroku” 的版本,支持许多平台。虽然平台即服务(PaaS)并不新鲜,但无服务器生态系统正在使这种方案日益萎缩。据说,AWS 和其他的供应商经常由于他们提供的灵活性而被人诟病用户体验。Up 将复杂性抽象出来,同时为你提供一个几乎无需运维的解决方案。
### 安装
你可以使用以下命令安装 Up,查看这篇[临时文档](https://github.com/apex/up/tree/master/docs)开始使用。或者如果你使用安装脚本,请下载[二进制版本](https://github.com/apex/up/releases)。(请记住,这个项目还在早期。)
```
curl -sfL https://raw.githubusercontent.com/apex/up/master/install.sh | sh
```
只需运行以下命令随时升级到最新版本:
```
up upgrade
```
你也可以通过 NPM 进行安装:
```
npm install -g up
```
### 功能
这个早期 alpha 版本提供什么功能?让我们来看看!请记住,Up 不是托管服务,因此你需要一个 AWS 帐户和 [AWS 凭证](https://github.com/apex/up/blob/master/docs/aws-credentials.md)。如果你对 AWS 不熟悉,你可能需要先停下来,直到熟悉流程。
我遇到的第一个问题是:up(1) 与 [apex(1)](https://github.com/apex/apex) 有何不同?Apex 专注于部署功能,用于管道和事件处理,而 Up 则侧重于应用程序、API 和静态站点,也就是单个可部署单元。Apex 不为你提供 API 网关、SSL 证书或 DNS,也不提供 URL 重写,脚本注入等。
#### 单命令无服务器应用程序
Up 可以让你使用单条命令部署应用程序、API 和静态站点。要创建一个应用程序,你只需要一个文件,在 Node.js 的情况下,`./app.js` 监听由 Up 提供的 `PORT'。请注意,如果你使用的是`package.json`,则会检测并使用`start`和`build` 脚本。
```
const http = require('http')
const { PORT = 3000 } = process.env
```
```
http.createServer((req, res) => {
res.end('Hello World\n')
}).listen(PORT)
```
额外的[运行时环境](https://github.com/apex/up/blob/master/docs/runtimes.md)也支持开箱可用,例如用于 Golang 的 “main.go”,所以你可以在几秒钟内部署 Golang、Python、Crystal 或 Node.js 应用程序。
```
package main
import (
"fmt"
"log"
"net/http"
"os"
)
func main() {
addr := ":" + os.Getenv("PORT")
http.HandleFunc("/", hello)
log.Fatal(http.ListenAndServe(addr, nil))
}
func hello(w http.ResponseWriter, r *http.Request) {
fmt.Fprintln(w, "Hello World from Go")
}
```
要部署应用程序输入 `up` 来创建所需的资源并部署应用程序本身。这里没有模糊不清的地方,一旦它说“完成”了那就完成了,该应用程序立即可用 —— 没有远程构建过程。

后续的部署将会更快,因为栈已被配置:

使用 `up url --open` 测试你的程序,以在浏览器中浏览它,`up url --copy` 可以将 URL 保存到剪贴板,或者可以尝试使用 curl:
```
curl `up url`
Hello World
```
要删除应用程序及其资源,只需输入 `up stack delete`:

例如,使用 `up staging` 或 `up production` 和 `up url --open production` 部署到预发布或生产环境。请注意,自定义域名尚不可用,[它们将很快可用](https://github.com/apex/up/issues/166)。之后,你还可以将版本“推广”到其他环境。
#### 反向代理
Up 的一个独特的功能是,它不仅仅是简单地部署代码,它将一个 Golang 反向代理放在应用程序的前面。这提供了许多功能,如 URL 重写、重定向、脚本注入等等,我们将在后面进一步介绍。
#### 基础设施即代码
在配置方面,Up 遵循现代最佳实践,因此对基础设施的更改都可以在部署之前预览,并且 IAM 策略的使用还可以限制开发人员访问以防止事故发生。一个附带的好处是它有助于自动记录你的基础设施。
以下是使用 Let's Encrypt 通过 AWS ACM 配置一些(虚拟)DNS 记录和免费 SSL 证书的示例。
```
{
"name": "app",
"dns": {
"myapp.com": [
{
"name": "myapp.com",
"type": "A",
"ttl": 300,
"value": ["35.161.83.243"]
},
{
"name": "blog.myapp.com",
"type": "CNAME",
"ttl": 300,
"value": ["34.209.172.67"]
},
{
"name": "api.myapp.com",
"type": "A",
"ttl": 300,
"value": ["54.187.185.18"]
}
]
},
"certs": [
{
"domains": ["myapp.com", "*.myapp.com"]
}
]
}
```
当你首次通过 `up` 部署应用程序时,需要所有的权限,它为你创建 API 网关、Lambda 函数、ACM 证书、Route53 DNS 记录等。
[ChangeSets](https://github.com/apex/up/issues/115) 尚未实现,但你能使用 `up stack plan` 预览进一步的更改,并使用 `up stack apply` 提交,这与 Terraform 非常相似。
详细信息请参阅[配置文档](https://github.com/apex/up/blob/master/docs/configuration.md)。
#### 全球部署
`regions` 数组可以指定应用程序的目标区域。例如,如果你只对单个地区感兴趣,请使用:
```
{
"regions": ["us-west-2"]
}
```
如果你的客户集中在北美,你可能需要使用美国和加拿大所有地区:
```
{
"regions": ["us-*", "ca-*"]
}
```
最后,你可以使用 AWS 目前支持的所有 14 个地区:
```
{
"regions": ["*"]
}
```
多区域支持仍然是一个正在进行的工作,因为需要一些新的 AWS 功能来将它们结合在一起。
#### 静态文件服务
Up 默认支持静态文件服务,并带有 HTTP 缓存支持,因此你可以在应用程序前使用 CloudFront 或任何其他 CDN 来大大减少延迟。
当 `type` 为 `static` 时,默认情况下的工作目录是 `.`,但是你也可以提供一个 `static.dir`:
```
{
"name": "app",
"type": "static",
"static": {
"dir": "public"
}
}
```
#### 构建钩子
构建钩子允许你在部署或执行其他操作时定义自定义操作。一个常见的例子是使用 Webpack 或 Browserify 捆绑 Node.js 应用程序,这大大减少了文件大小,因为 node 模块是*很大*的。
```
{
"name": "app",
"hooks": {
"build": "browserify --node server.js > app.js",
"clean": "rm app.js"
}
}
```
#### 脚本和样式表插入
Up 允许你插入脚本和样式,无论是内联方式或声明路径。它甚至支持一些“罐头”脚本,用于 Google Analytics(分析)和 [Segment](https://segment.com/),只需复制并粘贴你的写入密钥即可。
```
{
"name": "site",
"type": "static",
"inject": {
"head": [
{
"type": "segment",
"value": "API_KEY"
},
{
"type": "inline style",
"file": "/css/primer.css"
}
],
"body": [
{
"type": "script",
"value": "/app.js"
}
]
}
}
```
#### 重写和重定向
Up 通过 `redirects` 对象支持重定向和 URL 重写,该对象将路径模式映射到新位置。如果省略 `status` 参数(或值为 200),那么它是重写,否则是重定向。
```
{
"name": "app",
"type": "static",
"redirects": {
"/blog": {
"location": "https://blog.apex.sh/",
"status": 301
},
"/docs/:section/guides/:guide": {
"location": "/help/:section/:guide",
"status": 302
},
"/store/*": {
"location": "/shop/:splat"
}
}
}
```
用于重写的常见情况是 SPA(单页面应用程序),你希望不管路径如何都提供 `index.html`,当然除非文件存在。
```
{
"name": "app",
"type": "static",
"redirects": {
"/*": {
"location": "/",
"status": 200
}
}
}
```
如果要强制实施该规则,无论文件是否存在,只需添加 `"force": true` 。
#### 环境变量
密码将在下一个版本中有,但是现在支持纯文本环境变量:
```
{
"name": "api",
"environment": {
"API_FEATURE_FOO": "1",
"API_FEATURE_BAR": "0"
}
}
```
#### CORS 支持
[CORS](https://developer.mozilla.org/en-US/docs/Web/HTTP/Access_control_CORS) 支持允许你指定哪些(如果有的话)域可以从浏览器访问你的 API。如果你希望允许任何网站访问你的 API,只需启用它:
```
{
"cors": {
"enable": true
}
}
```
你还可以自定义访问,例如仅将 API 访问限制为你的前端或 SPA。
```
{
"cors": {
"allowed_origins": ["https://myapp.com"],
"allowed_methods": ["HEAD", "GET", "POST", "PUT", "DELETE"],
"allowed_headers": ["Content-Type", "Authorization"]
}
}
```
#### 日志
对于 $0.5/GB 的低价格,你可以使用 CloudWatch 日志进行结构化日志查询和跟踪。Up 实现了一种用于改进 CloudWatch 提供的自定义[查询语言](https://github.com/apex/up/blob/master/internal/logs/parser/grammar.peg),专门用于查询结构化 JSON 日志。

你可以查询现有日志:
```
up logs
```
跟踪在线日志:
```
up logs -f
```
或者对其中任一个进行过滤,例如只显示耗时超过 5 毫秒的 200 个 GET/HEAD 请求:
```
up logs 'method in ("GET", "HEAD") status = 200 duration >= 5'
```

查询语言是非常灵活的,这里有更多来自于 `up help logs` 的例子
```
### 显示过去 5 分钟的日志
$ up logs
### 显示过去 30 分钟的日志
$ up logs -s 30m
### 显示过去 5 小时的日志
$ up logs -s 5h
### 实时显示日志
$ up logs -f
### 显示错误日志
$ up logs error
### 显示错误和致命错误日志
$ up logs 'error or fatal'
### 显示非 info 日志
$ up logs 'not info'
### 显示特定消息的日志
$ up logs 'message = "user login"'
### 显示超时 150ms 的 200 响应
$ up logs 'status = 200 duration > 150'
### 显示 4xx 和 5xx 响应
$ up logs 'status >= 400'
### 显示用户邮件包含 @apex.sh 的日志
$ up logs 'user.email contains "@apex.sh"'
### 显示用户邮件以 @apex.sh 结尾的日志
$ up logs 'user.email = "*@apex.sh"'
### 显示用户邮件以 tj@ 开始的日志
$ up logs 'user.email = "tj@*"'
### 显示路径 /tobi 和 /loki 下的错误日志
$ up logs 'error and (path = "/tobi" or path = "/loki")'
### 和上面一样,用 in 显示
$ up logs 'error and path in ("/tobi", "/loki")'
### 更复杂的查询方式
$ up logs 'method in ("POST", "PUT") ip = "207.*" status = 200 duration >= 50'
### 将 JSON 格式的错误日志发送给 jq 工具
$ up logs error | jq
```
请注意,`and` 关键字是暗含的,虽然你也可以使用它。
#### 冷启动时间
这是 AWS Lambda 平台的特性,但冷启动时间通常远远低于 1 秒,在未来,我计划提供一个选项来保持它们在线。
#### 配置验证
`up config` 命令输出解析后的配置,有默认值和推断的运行时设置 - 它也起到验证配置的双重目的,因为任何错误都会导致退出状态 > 0。
#### 崩溃恢复
使用 Up 作为反向代理的另一个好处是执行崩溃恢复 —— 在崩溃后重新启动服务器,并在将错误的响应发送给客户端之前重新尝试该请求。
例如,假设你的 Node.js 程序由于间歇性数据库问题而导致未捕获的异常崩溃,Up 可以在响应客户端之前重试该请求。之后这个行为会更加可定制。
#### 适合持续集成
很难说这是一个功能,但是感谢 Golang 相对较小和独立的二进制文件,你可以在一两秒中在 CI 中安装 Up。
#### HTTP/2
Up 通过 API 网关支持 HTTP/2,对于服务很多资源的应用和站点可以减少延迟。我将来会对许多平台进行更全面的测试,但是 Up 的延迟已经很好了:

#### 错误页面
Up 提供了一个默认错误页面,如果你要提供支持电子邮件或调整颜色,你可以使用 `error_pages` 自定义。
```
{
"name": "site",
"type": "static",
"error_pages": {
"variables": {
"support_email": "[email protected]",
"color": "#228ae6"
}
}
}
```
默认情况下,它看上去像这样:

如果你想提供自定义模板,你可以创建以下一个或多个文件。特定文件优先。
* `error.html` – 匹配任何 4xx 或 5xx
* `5xx.html` – 匹配任何 5xx 错误
* `4xx.html` – 匹配任何 4xx 错误
* `CODE.html` – 匹配一个特定的代码,如 404.html
查看[文档](https://github.com/apex/up/blob/master/docs/configuration.md#error-pages)阅读更多有关模板的信息。
### 伸缩和成本
你已经做了这么多,但是 Up 怎么伸缩?目前,API 网关和 AWS 是目标平台,因此你无需进行任何更改即可扩展,只需部署代码即可完成。你只需按需支付实际使用的数量并且无需人工干预。
AWS 每月免费提供 1,000,000 个请求,但你可以使用 [http://serverlesscalc.com](http://serverlesscalc.com/) 来插入预期流量。在未来 Up 将提供更多的平台,所以如果一个成本过高,你可以迁移到另一个!
### 未来
目前为止就这样了!它可能看起来不是很多,但它已经超过 10,000 行代码,并且我刚刚开始开发。看看这个问题队列,假设项目可持续发展,看看未来会有什么期待。
如果你发现这个免费版本有用,请考虑在 [OpenCollective](https://opencollective.com/apex-up) 上捐赠我,因为我没有任何工作。我将在短期内开发早期专业版,对早期用户有年费优惠。专业或企业版也将提供源码,因此可以进行内部修复和自定义。
---
via: <https://medium.freecodecamp.org/up-b3db1ca930ee>
作者:[TJ Holowaychuk](https://medium.freecodecamp.org/@tjholowaychuk?source=post_header_lockup) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
8,971 | 违反 GPL 究竟算不算合同违约,法官表示需要仔细审理…… | http://www.fsf.org/blogs/licensing/update-on-artifex-v-hancom-gnu-gpl-compliance-case-1 | 2017-10-17T23:15:00 | [
"GPL",
"Ghostscript"
] | /article-8971-1.html | 
据自由软件基金会(FSF)报道,正在进行中的 GPL 合规案件 Artifex v. Hancom 近日产生了新的裁决,一项旨在提请简易判决的动议被法院驳回。
该案涉及一款遵循 GPL v3 及之后版本许可证的名为 Ghostscript 的软件,其来源于 Artifex 公司一个用于处理 PostScript、PDF 以及打印机的项目(GNU Ghostscript 是该项目的一个单独版本,并未涉及或牵连该案)。
FSF在之前的报道中[表示](https://www.fsf.org/blogs/licensing/motion-to-dismiss-denied-in-recent-gnu-gpl-case):
>
> 在该诉讼中,基于 Hancom 公司对 Ghostscript 的使用情况,Artifex 公司提出了两项指控:(1)侵犯版权;以及(2)违反基于GPL许可证的合同。……虽然违反自由软件许可证将导致侵犯版权已经成为老生常谈,但是,违反 GPL 等许可证是否可以被视为违反合同,长期以来一直是许可专家们的讨论话题。
>
>
>
在之前的裁决中,本案的法官驳回了 Hancom 的撤案动议,让案件得以继续进行。现在诉讼已经到了下一步,其中包括一个主张 GPL 构成合同的<ruby> <a href="https://docs.justia.com/cases/federal/district-courts/california/candce/3:2016cv06982/305835/54"> 简易判决动议 </a> <rp> ( </rp> <rt> Motion for summary judgment </rt> <rp> ) </rp></ruby>,但是该动议日前也被法官驳回。在撤案动议中,法院假定所涉指控真实存在,并对所述指控是否真正提出了有效的合法权利主张做出了裁决。在简易判决动议中,法院会被要求去审视无可争议的事实,并确定该案件的结果是否如此明显,以至于不需要经过全面审判。类似动议虽然是例行的,但是如果通过了简易判决,意味着本案中合同理论的复苏问题依然存在(LCTT 译注:指是否被视为违法合同)。
Hancom 公司提出了一些否认 GPL 许可证构成合同的证据,其中一个特别有意思。Hancom 公司认为,如果 GPL 许可证构成合同的说法被接受,则只能考虑他们在初始违规日之前的损害赔偿。他们认为,由于违规造成了许可终止,合同也因此结束。法官指出:
>
> GPL 许可证表明,在使用 Ghostscript 传播软件的权利被终止后,被告的义务依然存在,……因为每次传递“<ruby> 被覆盖作品 <rp> ( </rp> <rt> covered work </rt> <rp> ) </rp></ruby>”,都需要提供源代码或承诺提供源代码,每次被告分发使用 Ghostscript 的产品,可以说随之而来的义务就是提供源代码或承诺提供源代码。
>
>
>
法官还发现,在这一点上没有足够的证据来对该问题做出裁决。所以,FSF 表示,目前还无法进行过多的解读。但是,法官对于违规行为之后 GPL 在什么条件下继续存在的看法,是随着本案进行,该问题如何发展的重要线索。虽然,为了保护用户自由, GPL 许可证并不需要作为合同进行维护(它作为版权许可已经成功运行了几十年)。不过,类似的程序性裁决显示了有更多的证据表明,GPL 许可证作为合同的主张在法院不容易站住脚或者容易被击败的说法并非毫无根据的造谣。
FSF 表示,随着简易判决动议被否,本案继续向前推进,并将变得更为有趣。
---
译者简介:薛亮,集慧智佳知识产权咨询公司高级咨询师,擅长专利检索、专利分析、竞争对手跟踪、FTO 分析、开源软件知识产权风险分析,致力于为互联网企业、高科技公司提供知识产权咨询服务。
| null | HTTPConnectionPool(host='www.fsf.org', port=80): Max retries exceeded with url: /blogs/licensing/update-on-artifex-v-hancom-gnu-gpl-compliance-case-1 (Caused by ConnectTimeoutError(<urllib3.connection.HTTPConnection object at 0x7b8327581e70>, 'Connection to www.fsf.org timed out. (connect timeout=10)')) | null |
8,973 | 密码修改最佳实践 | https://www.schneier.com/blog/archives/2017/10/changes_in_pass.html | 2017-10-18T09:40:34 | [
"密码",
"NIST",
"安全"
] | https://linux.cn/article-8973-1.html | 
NIST 最近发表了四卷 [SP800-63b 数字身份指南](http://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-63b.pdf)。除此之外,它还对密码提供三个重要的建议:
1. 不要再纠结于复杂的密码规则。它们使密码难以记住。因为人为的复杂密码很难输入,因此增加了错误。它们[也没有很大帮助](https://www.wsj.com/articles/the-man-who-wrote-those-password-rules-has-a-new-tip-n3v-r-m1-d-1502124118)。最好让人们使用密码短语。
2. 停止密码到期。这是[我们以前使用计算机的一个老的想法](https://securingthehuman.sans.org/blog/2017/03/23/time-for-password-expiration-to-die)。如今不要让人改变密码,除非有泄密的迹象。
3. 让人们使用密码管理器。这就是处理我们所有密码的方式。
这些密码规则不能[让用户安全](http://ieeexplore.ieee.org/document/7676198/?reload=true)。让系统安全才是最重要的。
---
作者简介:
自从 2004 年以来,我一直在博客上写关于安全的文章,以及从 1998 年以来我的每月订阅中也有。我写书、文章和学术论文。目前我是 IBM Resilient 的首席技术官,哈佛伯克曼中心的研究员,EFF 的董事会成员。
---
via: <https://www.schneier.com/blog/archives/2017/10/changes_in_pass.html>
作者:[Bruce Schneier](https://www.schneier.com/blog/about/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | ## Changes in Password Best Practices
NIST recently published its four-volume [ SP800-63b Digital Identity Guidelines](http://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-63b.pdf). Among other things, it makes three important suggestions when it comes to passwords:
- Stop it with the annoying password complexity rules. They make passwords harder to remember. They increase errors because artificially complex passwords are harder to type in. And they
[don’t help](https://www.wsj.com/articles/the-man-who-wrote-those-password-rules-has-a-new-tip-n3v-r-m1-d-1502124118)that much. It’s better to allow people to use pass phrases. - Stop it with password expiration. That was an
[old idea for an old way](https://securingthehuman.sans.org/blog/2017/03/23/time-for-password-expiration-to-die)we used computers. Today, don’t make people change their passwords unless there’s indication of compromise. - Let people use password managers. This is how we deal with all the passwords we need.
These password rules were failed attempts to [fix the user](http://ieeexplore.ieee.org/document/7676198/?reload=true). Better we fix the security systems.
Brian • October 10, 2017 6:51 AM
I agree basically, but doesn’t 3) kinda make 1) and 2) obsolete? If I use a pw manager and don’t have to remember them, don’t complex rules or auto generated passwords with high complexity actually do make them more secure?
1) is in place because people cannot remember complex passwords and reuse the same over multiple accounts.
So … if you use a pw manager, do use complex passwords. |
8,974 | Android 在物联网方面能否像在移动终端一样成功? | https://medium.com/@carl.whalley/will-android-do-for-iot-what-it-did-for-mobile-c9ac79d06c#.hxva5aqi2 | 2017-10-18T12:17:51 | [
"Android",
"IoT"
] | https://linux.cn/article-8974-1.html | 
### 我在 Android Things 上的最初 24 小时
正当我在开发一个基于 Android 的运行在树莓派 3 的物联网商业项目时,一些令人惊喜的事情发生了。谷歌发布了[Android Things](https://developer.android.com/things/index.html) 的第一个预览版本,他们的 SDK 专门(目前)针对 3 个 SBC(单板计算机) —— 树莓派 3、英特尔 Edison 和恩智浦 Pico。说我一直在挣扎似乎有些轻描淡写 —— 树莓派上甚至没有一个成功的 Android 移植版本,我们在理想丰满,但是实践漏洞百出的内测版本上叫苦不迭。其中一个问题,同时也是不可原谅的问题是,它不支持触摸屏,甚至连 [Element14](https://www.element14.com/community/docs/DOC-78156/l/raspberry-pi-7-touchscreen-display) 官方销售的也不支持。曾经我认为 Android 已经支持树莓派,更早时候 “[谷歌向 AOSP 项目发起提交](http://www.androidpolice.com/2016/05/24/google-is-preparing-to-add-the-raspberry-pi-3-to-aosp-it-will-apparently-become-an-officially-supported-device/)” 中提到过树莓派曾让所有人兴奋不已。所以当 2016 年 12 月 12 日谷歌发布 “Android Things” 及其 SDK 的时候,我马上闭门谢客,全身心地去研究了……
### 问题?
关于树莓派上的谷歌 Android 我遇到很多问题,我以前用 Android 做过许多开发,也做过一些树莓派项目,包括之前提到过的一个真正参与的。未来我会尝试解决这些问题,但是首先最重要的问题得到了解决 —— 有完整的 Android Studio 支持,树莓派成为你手里的另一个常规的 ADB 可寻址设备。好极了。Android Studio 强大而便利、十分易用的功能包括布局预览、调试系统、源码检查器、自动化测试等都可以真正的应用在 IoT 硬件上。这些好处怎么说都不过分。到目前为止,我在树莓派上的大部分工作都是通过 SSH 使用运行在树莓派上的编辑器(MC,如果你真的想知道)借助 Python 完成的。这是有效的,毫无疑问铁杆的 Pi/Python 粉丝或许会有更好的工作方式,而不是当前这种像极了 80 年代码农的软件开发模式。我的项目需要在控制树莓派的手机上编写 Android 软件,这真有点痛不欲生 —— 我使用 Android Studio 做“真正的” Android 开发,借助 SSH 做剩下的。但是有了“Android Things”之后,一切都结束了。
所有的示例代码都适用于这三种 SBC,树莓派只是其中之一。 `Build.DEVICE` 常量可以在运行时确定是哪一个,所以你会看到很多如下代码:
```
public static String getGPIOForButton() {
switch (Build.DEVICE) {
case DEVICE_EDISON_ARDUINO:
return "IO12";
case DEVICE_EDISON:
return "GP44";
case DEVICE_RPI3:
return "BCM21";
case DEVICE_NXP:
return "GPIO4_IO20";
default:
throw new IllegalStateException(“Unknown Build.DEVICE “ + Build.DEVICE);
}
}
```
我对 GPIO 处理有浓厚的兴趣。 由于我只熟悉树莓派,我只能假定其它 SBC 工作方式相同,GPIO 只是一组引脚,可以定义为输入/输出,是连接物理外部世界的主要接口。 基于 Linux 的树莓派操作系统通过 Python 中的读取和写入方法提供了完整和便捷的支持,但对于 Android,您必须使用 NDK 编写 C++ 驱动程序,并通过 JNI 在 Java 中与这些驱动程序对接。 不是那么困难,但需要在你的构建链中维护额外的一些东西。 树莓派还为 I2C 指定了 2 个引脚:时钟和数据,因此需要额外的工作来处理它们。I2C 是真正酷的总线寻址系统,它通过串行化将许多独立的数据引脚转换成一个。 所以这里的优势是 —— Android Things 已经帮你完成了所有这一切。 你只需要 `read()` 和 `write()` 你需要的任何 GPIO 引脚,I2C 同样容易:
```
public class HomeActivity extends Activity {
// I2C Device Name
private static final String I2C_DEVICE_NAME = ...;
// I2C Slave Address
private static final int I2C_ADDRESS = ...;
private I2cDevice mDevice;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
// Attempt to access the I2C device
try {
PeripheralManagerService manager = new PeripheralManagerService();
mDevice = manager.openI2cDevice(I2C_DEVICE_NAME, I2C_ADDRESS)
} catch (IOException e) {
Log.w(TAG, "Unable to access I2C device", e);
}
}
@Override
protected void onDestroy() {
super.onDestroy();
if (mDevice != null) {
try {
mDevice.close();
mDevice = null;
} catch (IOException e) {
Log.w(TAG, "Unable to close I2C device", e);
}
}
}
}
```
### Android Things 基于 Android 的哪个版本?
看起来是 Android 7.0,这样很好,因为我们可以继承 Android 所有以前版本的平板设计 UI、优化,安全加固等。它也带来了一个有趣的问题 —— 与应用程序必须单独管理不同,未来的平台应如何更新升级?请记住,这些设备可能无法连接到互联网。我们可能不便于连接蜂窝 / WiFi ,即便之前这些连接能用,但是有时不那么可靠。
另一个担心是,Android Things 仅仅是一个名字不同的 Android 分支版本,大部分都是一样的,和已经发布的 Arduino 一样,更像是为了市场营销而出现,而不是作为操作系统。不过可以放心,实际上通过[样例](https://github.com/androidthings/sample-simpleui/blob/master/app/src/main/res/drawable/pinout_board_vert.xml)可以看到,其中一些样例甚至使用了 SVG 图形作为资源,而不是传统的基于位图的图形(当然也能轻松处理) —— 这是一个非常新的 Android 创新。
不可避免地,与 Android Things 相比,普通的 Android 会有些不同。例如,权限问题。因为 Android Things 为固定硬件设计,在构建好之后,用户通常不会在这种设备上安装应用,所以在一定程序上减轻了这个问题,尽管当设备要求权限时是个问题 —— 因为它们没有 UI。解决方案是当应用在安装时给予所有需要的权限。 通常,这些设备只有一个应用,并且该应用从设备上电的那一刻就开始运行。

### Brillo 怎么了?
Brillo 是谷歌以前的 IoT 操作系统的代号,听起来很像 Android Things 的前身。 实际上现在你仍然能看到很多提及 Brillo 的地方,特别是在 GitHub Android Things 源码的文件夹名字中。 然而,它已经不复存在了。新王已经登基!
### UI 指南?
谷歌针对 Android 智能手机和平板电脑应用发布了大量指南,例如屏幕按钮间距等。 当然,你最好在可行的情况下遵循这些,但这已经不是本文应该考虑的范畴了。 缺省情况下什么也没有 —— 应用程序作者决定一切,这包括顶部状态栏,底部导航栏 —— 绝对是一切。 多年来谷歌一直在告诉 Android 应用程序的作者们绝不要在屏幕上放置返回按钮,因为平台将提供一个,因为 Android Things [可能甚至没有 UI!](https://developer.android.com/things/sdk/index.html)。
### 智能手机上会有多少谷歌服务?
有一些,但不是所有。第一个预览版本没有蓝牙支持、没有 NFC,这两者都对物联网革命有重大贡献。 SBC 支持它们,所以我们应该不会等待太久。由于没有通知栏,因此不支持任何通知。没有地图。缺省没有软键盘,你必须自己安装一个键盘。由于没有 Play 商店,你只能艰难地通过 ADB 做这个和许多其他操作。
当为 Android Things 开发时,我试图为运行在手机上和树莓派上使用同一个 APK。这引发了一个错误,阻止它安装在除 Android Things 设备之外的任何设备:`com.google.android.things` 库不存在。 这有点用,因为只有 Android Things 设备需要这个,但它似乎是个限制,因为不仅智能手机或平板电脑上没有,连模拟器上也没有。似乎只能在物理 Android Things 设备上运行和测试您的 Android Things 应用程序……直到谷歌在 [G+ 谷歌的 IoT 开发人员社区](https://plus.google.com/+CarlWhalley/posts/4tF76pWEs1D)组中回答了我的问题,并提供了规避方案。但是,躲过初一,躲不过十五。
### 可以期待 Android Thing 生态演进到什么程度?
我期望看到移植更多传统的基于 Linux 服务器的应用程序,将 Android 限制在智能手机和平板电脑上没有意义。例如,Web 服务器突然变得非常有用。已经有一些了,但没有像重量级的 Apache 或 Nginx 的。物联网设备可以没有本地 UI,但通过浏览器管理它们当然是可行的,因此需要用这种方式呈现 Web 面板。类似的那些如雷贯耳的通讯应用程序 —— 它需要的仅是一个麦克风和扬声器,而且在理论上任何视频通话应用程序,如 Duo、Skype、FB 等都可行。这个演变能走多远目前只能猜测。会有 Play 商店吗?它们会展示广告吗?我们能够确保它们不会窥探我们,或被黑客控制它们么?从消费者的角度来看,物联网应该是具有触摸屏的网络连接设备,因为每个人都已经习惯于通过智能手机工作。
我还期望看到硬件的迅速发展 —— 特别是有更多的 SBC 拥有更低的成本。看看惊人的 5 美元树莓派 Zero,不幸的是,由于其有限的 CPU 和内存,几乎可以肯定不能运行 Android Things。多久之后像这样的设备才能运行 Android Things?这是很明显的,标杆已经设定,任何有追求的 SBC 制造商将瞄准 Android Things 的兼容性,规模经济也将波及到外围设备,如 23 美元的触摸屏。没人会购买不会播放 YouTube 的微波炉,你的洗碗机会在 eBay 上购买更多的清洁粉,因为它注意到你很少使用它……
然而,我不认为我们会过于冲昏头脑。了解一点 Android 架构有助于将其视为一个包罗万象的物联网操作系统。它仍然使用 Java,其垃圾回收机制导致的所有时序问题在过去几乎把它搞死。这仅仅是问题最少的部分。真正的实时操作系统依赖于可预测、准确和坚如磐石的时序,要么它就不能被用于“关键任务”。想想医疗应用、安全监视器,工业控制器等。使用 Android,如果宿主操作系统认为它需要,理论上可以在任何时候杀死您的活动/服务。这在手机上没那么糟糕 —— 用户可以重新启动应用程序,杀死其他应用程序,或重新启动手机。但心脏监视器就完全是另一码事。如果前台的活动/服务正在监视一个 GPIO 引脚,而这个信号没有被准确地处理,我们就完了。必须要做一些相当根本的改变让 Android 来支持这一点,到目前为止还没有迹象表明它已经在计划之中了。
### 这 24 小时
所以,回到我的项目。 我认为我会接管我已经完成和尽力能为的工作,等待不可避免的路障,并向 G+ 社区寻求帮助。 除了一些在非 Android Things 设备上如何运行程序的问题之外,没有其他问题。它运行得很好! 这个项目也使用了一些奇怪的东西,如自定义字体、高精定时器 —— 所有这些都在 Android Studio 中完美地展现。对我而言,可以打满分 —— 至少我能够开始做出实际原型,而不只是视频和截图。
### 蓝图
今天的物联网操作系统环境看起来非常零碎。 显然没有市场领导者,尽管炒作之声沸反连天,物联网仍然在草创阶段。 谷歌 Android 物联网能否像它在移动端那样取得成功?现在 Android 在移动方面的主导地位几近达到 90%。我相信如果真的如此,Android Things 的推出正是重要的一步。
记住所有的关于开放和封闭软件的战争,它们主要发生在从不授权的苹果和一直担心免费还不够充分的谷歌之间。那个老梗又来了,因为让苹果推出一个免费的物联网操作系统的构想就像让他们免费赠送下一代 iPhone 一样遥不可及。
物联网操作系统游戏是开放的,大家机遇共享,不过这个时候,封闭派甚至不会公布它们的开发工具箱……
前往 [Developer Preview](https://developer.android.com/things/preview/index.html)网站,立即获取 Android Things SDK 的副本。
---
via: <https://medium.com/@carl.whalley/will-android-do-for-iot-what-it-did-for-mobile-c9ac79d06c#.hxva5aqi2>
作者:[Carl Whalley](https://medium.com/@carl.whalley) 译者:[firstadream](https://github.com/firstadream) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Will Android do for the IoT what it did for mobile?
# My first 24 hours with Android Things
Just when I was in the middle of an Android based IoT commercial project running on a Raspberry Pi 3, something awesome happened. Google released the first preview of [Android Things](https://developer.android.com/things/index.html), their SDK targeted specifically at (initially) 3 SBC’s (Single Board Computers) — the Pi 3, the Intel Edison and the NXP Pico. To say I was struggling is a bit of an understatement — without even an established port of Android to the Pi, we were at the mercy of the various quirks and omissions of the well-meaning but problematic homebrew distro brigade. One of these problems was a deal breaker too — no touchscreen support, not even for the official one sold by [Element14](https://www.element14.com/community/docs/DOC-78156/l/raspberry-pi-7-touchscreen-display). I had an idea Android was heading for the Pi already, and earlier a mention in a [commit to the AOSP project from Google](http://www.androidpolice.com/2016/05/24/google-is-preparing-to-add-the-raspberry-pi-3-to-aosp-it-will-apparently-become-an-officially-supported-device/) got everyone excited for a while. So when, on 12th Dec 2016, without much fanfare I might add, Google announced “Android Things” plus a downloadable SDK, I dived in with both hands, a map and a flashlight, and hung a “do not disturb” sign on my door…
# Questions?
I had many questions regarding Googles Android on the Pi, having done extensive work with Android previously and a few Pi projects, including being involved right now in the one mentioned. I’ll try to address these as I proceed, but the first and biggest was answered right away — there is full Android Studio support and the Pi becomes just another regular ADB-addressable device on your list. Yay! The power, convenience and sheer ease of use we get within Android Studio is available at last to real IoT hardware, so we get all the layout previews, debug system, source checkers, automated tests etc. I can’t stress this enough. Up until now, most of my work onboard the Pi had been in Python having SSH’d in using some editor running on the Pi (MC if you really want to know). This worked, and no doubt hardcore Pi/Python heads could point out far better ways of working, but it really felt like I’d timewarped back to the 80’s in terms of software development. My projects involved writing Android software on handsets which controlled the Pi, so this rubbed salt in the wound — I was using Android Studio for “real” Android work, and SSH for the rest. That’s all over now.
All samples are for the 3 SBC’s, of which the the Pi 3 is just one. The Build.DEVICE constant lets you determine this at runtime, so you see lots of code like:
` public static String getGPIOForButton() {`
switch (Build.DEVICE) {
case DEVICE_EDISON_ARDUINO:
return "IO12";
case DEVICE_EDISON:
return "GP44";
case DEVICE_RPI3:
return "BCM21";
case DEVICE_NXP:
return "GPIO4_IO20";
default:
throw new IllegalStateException(“Unknown Build.DEVICE “ + Build.DEVICE);
}
}
Of keen interest is the GPIO handling. Since I’m only familiar with the Pi, I can only assume the other SBCs work the same way, but this is the set of pins which can be defined as inputs/outputs and is the main interface to the physical outside world. The Pi Linux based OS distros have full and easy support via read and write methods in Python, but for Android you’d have to use the NDK to write C++ drivers, and talk to these via JNI in Java. Not that difficult, but something else to maintain in your build chain. The Pi also designates 2 pins for I2C, the clock and the data, so extra work would be needed handling those. I2C is the really cool bus-addressable system which turns many separate pins of data into one by serialising it. So here’s the kicker — all that’s done directly in Android Things for you. You just *read() *and *write() *to/from whatever GPIO pin you need, and I2C is as easy as this:
`public class HomeActivity extends Activity {`
// I2C Device Name
private static final String I2C_DEVICE_NAME = ...;
// I2C Slave Address
private static final int I2C_ADDRESS = ...;
private I2cDevice mDevice;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
// Attempt to access the I2C device
try {
PeripheralManagerService manager = new PeripheralManagerService();
mDevice = manager.openI2cDevice(I2C_DEVICE_NAME, I2C_ADDRESS)
} catch (IOException e) {
Log.w(TAG, "Unable to access I2C device", e);
}
}
@Override
protected void onDestroy() {
super.onDestroy();
if (mDevice != null) {
try {
mDevice.close();
mDevice = null;
} catch (IOException e) {
Log.w(TAG, "Unable to close I2C device", e);
}
}
}
}
# What version of Android is Android Things based on?
This looks to be Android 7.0, which is fantastic because we get all the material design UI, the optimisations, the security hardening and so on from all the previous versions of Android. It also raises an interesting question — how are future **platform **updates rolled out, as opposed to your app which you have to manage separately? Remember, these devices may not be connected to the internet. We are no longer in the comfortable space of cellular/WiFi connections being assumed to at least be available, even if sometimes unreliable.
The other worry was this being an offshoot version of Android in name only, where to accommodate the lowest common denominator, something so simple it could power an Arduino has been released — more of a marketing exercise than a rich OS. That’s quickly put to bed by looking at the [samples](https://github.com/androidthings/sample-simpleui/blob/master/app/src/main/res/drawable/pinout_board_vert.xml), actually — some even use SVG graphics as resources, a very recent Android innovation, rather than the traditional bitmap-based graphics, which of course it also handles with ease.
Inevitably, regular Android will throw up issues when compared with Android Things. For example, there is the permissions conundrum. Mitigated somewhat by the fact Android Things is designed to power fixed hardware devices, so the user wouldn’t normally install apps after it’s been built, it’s nevertheless a problem asking them for permissions on a device which might not have a UI! The solution is to grant all the permissions an app might need at install time. Normally, these devices are one app only, and that app is the one which runs when it powers up.
# What happened to Brillo?
Brillo was the codename given to Googles previous IoT OS, which sounds a lot like what Android Things used to be called. In fact you see many references to Brillo still, especially in the source code folder names in the GitHub Android Things examples. However, it has ceased to be. All hail the new king!
# UI Guidelines?
Google issues extensive guidelines regarding Android smartphone and tablet apps, such as how far apart on screen buttons should be and so on. Sure, its best to follow these where practical, but we’re not in Kansas any more. There is nothing there by default — it’s up the the app author to manage *everything*. This includes the top status bar, the bottom navigation bar — absolutely everything. Years of Google telling Android app authors never to render an onscreen BACK button because the platform will supply one is thrown out, because for Android Things there [might not even be a UI at all!](https://developer.android.com/things/sdk/index.html)
# How much support of the Google services we’re used to from smartphones can we expect?
Quite a bit actually, but not everything. The first preview has no bluetooth support. No NFC, either — both of which are heavily contributing to the IoT revolution. The SBC’s support them, so I can’t see them not being available for too long. Since there’s no notification bar, there can’t be any notifications. No Maps. There’s no default soft keyboard, you have to install one yourself. And since there is no Play Store, you have to get down and dirty with ADB to do this, and many other operations.
When developing for Android Things I tried to make the same APK I was targeting for the Pi run on a regular handset. This threw up an error preventing it from being installed on anything other than an Android Things device: library “*com.google.android.things*” not present. Kinda makes sense, because only Android Things devices would need this, but it seemed limiting because not only would no smartphones or tablets have it present, but neither would any emulators. It looked like you could only run and test your Android Things apps on physical Android Things devices … until Google helpfully replied to my query on this in the [G+ Google’s IoT Developers Community](https://plus.google.com/+CarlWhalley/posts/4tF76pWEs1D) group with a workaround. Bullet dodged there, then.
# How can we expect the Android Things ecosystem to evolve now?
I’d expect to see a lot more porting of traditional Linux server based apps which didn’t really make sense to an Android restricted to smartphones and tablets. For example, a web server suddenly becomes very useful. Some exist already, but nothing like the heavyweights such as Apache or Nginx. IoT devices might not have a local UI, but administering them via a browser is certainly viable, so something to present a web panel this way is needed. Similarly comms apps from the big names — all it needs is a mike and speaker and in theory it’s good to go for any video calling app, like Duo, Skype, FB etc. How far this evolution goes is anyone’s guess. Will there be a Play Store? Will they show ads? Can we be sure they won’t spy on us, or let hackers control them? The IoT from a consumer point of view always was net-connected devices with touchscreens, and everyone’s already used to that way of working from their smartphones.
I’d also expect to see rapid progress regarding hardware — in particular many more SBC’s at even lower costs. Look at the amazing $5 Raspberry Pi Zero, which unfortunately almost certainly can’t run Android Things due to its limited CPU and RAM. How long until one like this can? It’s pretty obvious, now the bar has been set, any self respecting SBC manufacturer will be aiming for Android Things compatibility, and probably the economies of scale will apply to the peripherals too such as a $2 3" touchscreen. Microwave ovens just won’t sell unless you can watch YouTube on them, and your dishwasher just put in a bid for more powder on eBay since it noticed you’re running low…
However, I don’t think we can get too carried away here. Knowing a little about Android architecture helps when thinking of it as an all-encompassing IoT OS. It still uses Java, which has been hammered to death in the past with all its garbage-collection induced timing issues. That’s the least of it though. A genuine realtime OS relies on predictable, accurate and rock-solid timing or it can’t be described as “mission critical”. Think about medical applications, safety monitors, industrial controllers etc. With Android, your Activity/Service can, in theory, be killed at any time if the host OS thinks it needs to. Not so bad on a phone — the user restarts the app, kills other apps, or reboots the handset. A heart monitor is a different kettle all together though. If that foreground Activity/Service is watching a GPIO pin, and the signal isn’t dealt with exactly when it is supposed to, we have failed. Some pretty fundamental changes would have to be made to Android to support this, and so far there’s no indication it’s even planned.
# Those 24 hours
So, back to my project. I thought I’d take the work I’d done already and just port as much as I could over, waiting for the inevitable roadblock where I had to head over to the G+ group, cap in hand for help. Which, apart from the query about running on non-AT devices, never happened. And it ran great! This project uses some oddball stuff too, custom fonts, prescise timers — all of which appeared perfectly laid out in Android Studio. So its top marks from me, Google — at last I can start giving actual prototypes out rather than just videos and screenshots.
# The big picture
The IoT OS landscape today looks very fragmented. There is clearly no market leader and despite all the hype and buzz we hear, it’s still incredibly early days. Can Google do to the IoT with Android Things what it did to mobile, where it’s dominance is now very close to 90%? I believe so, and if that is to happen, this launch of Android Things is exactly how they would go about it.
Remember all the open vs closed software wars, mainly between Apple who never licence theirs, and Google who can’t give it away for free to enough people? That policy now comes back once more, because the idea of Apple launching a free IoT OS is as far fetched as them giving away their next iPhone for nothing.
The IoT OS game is wide open for someone to grab, and the opposition won’t even be putting their kit on this time…
Head over to the [Developer Preview](https://developer.android.com/things/preview/index.html) site to get your copy of the Android Things SDK now. |
8,976 | NixOS Linux: 先配置后安装的 Linux | https://www.linux.com/learn/intro-to-linux/2017/10/nixos-linux-lets-you-configure-your-os-installing | 2017-10-19T08:26:00 | [
"NixOS"
] | https://linux.cn/article-8976-1.html | 
>
> 配置是成功安装 NixOS 的关键。
>
>
>
我用 Linux 有些年头了。在这些年里我很有幸见证了开源的发展。各色各样的发行版在安装方面的努力,也是其中的一个比较独特的部分。以前,安装 Linux 是个最好让有技术的人来干的任务。现在,只要你会装软件,你就会安装 Linux。简单,并且,不是我吹,在吸引新用户方面效果拔群。事实上安装整个 Linux 操作系统都要比 Windows 用户安装个更新看起来要快一点。
但每一次,我都喜欢看到一些不同的东西——那些可以让我体验新鲜的东西。[NixOS](https://nixos.org/) 在这方面就做的别具一格。讲真,我原来也就把它当作另一个提供标准特性和 KDE Plasma 5 界面的 Linux 发行版。
好像也没什么不对。
[下载 ISO 映像](https://nixos.org/nixos/download.html)后,我启动了 [VirtualBox](https://www.virtualbox.org/wiki/Downloads) 并用下载的镜像创建了个新的虚拟机。VM 启动后,出来的是 Bash 的登录界面,界面上指导我用空密码去登录 root 账号,以及我该如何启动 GUI 显示管理器(图 1)。

*图 1: 与 NixOS 的初次接触可能不是太和谐。*
“好吧”我这样想着,“打开看看吧!”
GUI 启动和运行时(KDE Plasma 5),我没找到喜闻乐见的“安装”按钮。原来,NixOS 是一个在安装前需要你配置的发行版,真有趣。那就让我们瞧瞧它是如何做到的吧!
### 安装前配置
你需要做的第一件事是建分区。由于 NixOS 安装程序不包含分区工具,你得用自带的 GParted (图 2)来创建一个 EXT4 分区。

*图 2: 安装前对磁盘分区。*
创建好分区,然后用命令 `mount /dev/sdX /mnt` 挂载。(请自行替换 `sdX` 为你新创建的分区)。
你现在需要创建一个配置文件。命令如下:
```
nixos-generate-config --root /mnt
```
上面的命令会创建两个文件(存放在目录 `/mnt/etc/nixos` 中):
* `configuration.nix` — 默认配置文件。
* `hardware-configuration.nix` — 硬件配置(无法编辑)
通过命令 `nano /mnt/etc/nixos/configuration.nix` 打开文件。其中有一些需要编辑的地方得注意。第一个改动便是设置启动选项。找到行:
```
# boot.loader.grub.device = "/dev/sda"; # 或 efi 时用 "nodev"
```
删除行首的 `#` 使该选项生效(确保 `/dev/sda` 与你新建的分区)。
通过配置文件,你可以设置时区和追加要安装的软件包。来看一个被注释掉的安装包的示例:
```
# List packages installed in system profile. To search by name, run:
# nix-env -aqP | grep wget
# environment.systemPackages = with pkgs; [
# wget vim
# ];
```
如果你想要添加软件包,并在安装时安装它们,那就取消掉这段注释,并添加你需要的软件包。举个例子,比方说你要把 LibreOffice 加进去。示例详见下方:
```
# List packages installed in system profile. To search by name, run:
nix-env -aqP | grep wget
environment.systemPackages = with pkgs; [
libreoffice wget vim
];
```
你可以通过输入命令 `nix-env -aqP | grep PACKAGENAME` 来寻找确切的包名(`PACKAGENAME` 为你想要找的软件包)。如果你不想输命令,你也可以检索 [NixOS 的软件包数据库](https://nixos.org/nixos/packages.html)。
在你把所有的软件包都添加完后,你还有件事儿需要做(如果你想要登录到桌面的话,我觉得你还得折腾下 KDE Plasma 5 桌面)。翻到配置文件的末尾并在最后的 `}` 符号前,追加如下内容:
```
services.xserver = {
enable = true;
displayManager.sddm.enable = true;
desktopManager.plasma5.enable = true;
};
```
在 [NixOS 官方文件](https://nixos.org/nixos/manual/index.html#ch-configuration) 中,你能找到配置文件中更多的选项。保存并关掉配置文件。
### 安装
在你按照自己的需求完善好配置之后,使用命令(需要 root 权限) `nixos-install`。完成安装所需要的时间,会随着你加入的软件包多少有所区别。安装结束后,你可以使用命令重启系统,(重启之后)迎接你的就是 KDE Plasma 5 的登录管理界面了(图 3)。

*图 3: KDE Plasma 5 登录管理界面*
### 安装后
你要首先要做的两件事之一便是给 root 用户设个密码(通过输入命令 `passwd` 来修改默认的密码),以及添加一个标准用户。做法和其它的 Linux 发行版无二。用 root 用户登录,然后在终端输入命令:
```
useradd -m USER
```
将 `USER` 替换成你想要添加的用户名。然后通过下面的命令给用户设上密码:
```
passwd USER
```
同样的将 `USER` 替换成你添加的用户。
然后会有提示引导你填写并验证新密码。然后,你就能用标准用户登录 NixOS 啦。
NixOS 在你安装并运行后,你可以为系统添加新的软件包,但并非通过寻常的方式。如果你发现你需要安装些新东西,你得回到配置文件(位置就是 `/etc/nixos/` ),找到之前安装时添加软件包的位置,运行以下命令(需要 root 权限):
```
nixos-rebuild switch
```
命令执行结束后,你就能使用新安装的软件包了。
### Enjoy NixOS
现在,NixOS 已经带着所有你想安装的软件和 KDE Plasma 5 桌面运行起来了。要知道,你所做的不仅仅只是安装了个 Linux 发行版,关键是你自定义出来的发行版非常符合你的需求。所以好好享受你的 NixOS 吧!
---
via: <https://www.linux.com/learn/intro-to-linux/2017/10/nixos-linux-lets-you-configure-your-os-installing>
作者:[JACK WALLEN](https://www.linux.com/users/jlwallen) 译者:[martin2011qi](https://github.com/martin2011qi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
8,977 | 极客漫画:谁杀死了 MySQL? - 后记 | http://turnoff.us/geek/who-killed-mysql-epilogue/ | 2017-10-19T10:02:00 | [
"MySQL",
"漫画"
] | https://linux.cn/article-8977-1.html | 
这篇漫画意在讽刺 Oracle 收购太阳微系统公司之后,对收购来的资产一个个杀死,比如 MySQL,导致大多数发行版已经不使用 MySQL ,转向它的分支 MariaDB,在此之后,Oracle 还放弃了“不赚钱的” Java EE。
然后之后,是以对开源不友善而著名的微软前总裁巴尔默——虽然现在新总裁纳德拉上台之后,微软公司乃至巴尔默都对开源的态度发生了一百八十度大转弯。
本篇漫画中涉及的一些技术方面的隐喻有:
* SIGKILL,是一种 UNIX/Posix 信号,用于结束一个进程,不可捕获。关于 SIGKILL ,可以看看[这篇漫画](/article-8791-1.html)。
* PIPE,是 UNIX/Posix 中的一种进程通讯机制,数据可以通过管道进行传输,进行进程间通讯。此处引申为一个管道、通道,从漫画中可以看到, Java 439 进程感觉不妙的时候,其脚下已经有些塌陷的痕迹,而接着变成了一个通道——然后它就掉进去死了。
* ulimit,是 UNIX/Linux 中用于限制资源分配的命令,可以设置系统可以分配的文件句柄数等,像 Apache 之类的服务需要足够的句柄数才能提供更高的连接数。此处,头上顶着羽毛的 Apache 表示,它要占用一些 ulimit 分配的资源(去工作了)。
---
via: <http://turnoff.us/geek/who-killed-mysql-epilogue/>
作者:[Daniel Stori](http://turnoff.us/about/) 译者&点评:[ItsLucas](https://github.com/ItsLucas) 校对&合成:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
8,978 | OpenMessaging:构建一个分布式消息分发的开放标准 | https://www.linuxfoundation.org/blog/building-open-standard-distributed-messaging-introducing-openmessaging/ | 2017-10-19T18:51:00 | [
"OpenMessaging",
"消息",
"MQ"
] | https://linux.cn/article-8978-1.html | 通过在云计算、大数据和标准 API 上的企业及社区的协作,我很高兴 OpenMessaging 项目进入 Linux 基金会。OpenMessaging 社区的目标是为分布式消息分发创建全球采用的、供应商中立的和开放标准,可以部署在云端、内部和混合云情景中。

阿里巴巴、雅虎、滴滴和 Streamlio 是该项目的创始贡献者。Linux 基金会已与这个初始项目社区合作来建立一个治理模式和结构,以实现运作在消息 API 标准上的生态系统的长期受益。
由于越来越多的公司和开发者迈向<ruby> 云原生应用 <rt> cloud native application </rt></ruby>,消息式应用和流式应用的扩展面临的挑战也在不断发展。这包括平台之间的互操作性问题,<ruby> <a href="https://en.wikipedia.org/wiki/Wire_protocol"> 线路级协议 </a> <rt> wire-level protocol </rt></ruby>之间缺乏兼容性以及系统间缺乏标准的基准测试。
特别是当数据跨不同的消息平台和流平台进行传输时会出现兼容性问题,这意味着额外的工作和维护成本。现有解决方案缺乏负载平衡、容错、管理、安全性和流功能的标准化指南。目前的系统不能满足现代面向云的消息应用和流应用的需求。这可能导致开发人员额外的工作,并且难以或不可能满足物联网、边缘计算、智能城市等方面的尖端业务需求。
OpenMessaging 的贡献者正在寻求通过以下方式改进分布式消息分发:
* 为分布式消息分发创建一个面向全球、面向云、供应商中立的行业标准
* 促进用于测试应用程序的标准基准发展
* 支持平台独立
* 以可伸缩性、灵活性、隔离和安全性为目标的云数据的流和消息分发要求
* 培育不断发展的开发贡献者社区
你可以在这了解有关新项目的更多信息以及如何参与: [http://openmessaging.cloud](http://openmessaging.cloud/)。
这些是支持 OpenMessaging 的一些组织:
>
> “我们多年来一直专注于消息分发和流领域,在此期间,我们探索了 Corba 通知、JMS 和其它标准,来试图解决我们最严格的业务需求。阿里巴巴在评估了可用的替代品后,选择创建一个新的面向云的消息分发标准 OpenMessaging,这是一个供应商中立,且语言无关的标准,并为金融、电子商务、物联网和大数据等领域提供了行业指南。此外,它目地在于跨异构系统和平台间开发消息分发和流应用。我们希望它可以是开放、简单、可扩展和可互操作的。另外,我们要根据这个标准建立一个生态系统,如基准测试、计算和各种连接器。我们希望有新的贡献,并希望大家能够共同努力,推动 OpenMessaging 标准的发展。”
>
>
> ——阿里巴巴高级架构师,Apache RocketMQ 的联合创始人,以及 OpenMessaging 的原始发起人 Von Gosling
>
>
>
>
> “随着应用程序消息的复杂性和规模的不断扩大,缺乏标准的接口为开发人员和组织带来了复杂性和灵活性的障碍。Streamlio 很高兴与其他领导者合作推出 OpenMessaging 标准倡议来给客户一个轻松使用高性能、低延迟的消息传递解决方案,如 Apache Pulsar,它提供了企业所需的耐用性、一致性和可用性。“
>
>
> —— Streamlio 的软件工程师、Apache Pulsar 的联合创始人以及 Apache BookKeeper PMC 的成员 Matteo Merli
>
>
>
>
> “Oath(Verizon 旗下领先的媒体和技术品牌,包括雅虎和 AOL)支持开放,协作的举措,并且很乐意加入 OpenMessaging 项目。”
>
>
> —— Joe Francis,核心平台总监
>
>
>
>
> “在滴滴中,我们定义了一组私有的生产者 API 和消费者 API 来隐藏开源的 MQ(如 Apache Kafka、Apache RocketMQ 等)之间的差异,并提供额外的自定义功能。我们计划将这些发布到开源社区。到目前为止,我们已经积累了很多关于 MQ 和 API 统一的经验,并愿意在 OpenMessaging 中与其它 API 一起构建 API 的共同标准。我们真诚地认为,统一和广泛接受的 API 标准可以使 MQ 技术和依赖于它的应用程序受益。”
>
>
> —— 滴滴的架构师 Neil Qi
>
>
>
>
> “有许多不同的开源消息分发解决方案,包括 Apache ActiveMQ、Apache RocketMQ、Apache Pulsar 和 Apache Kafka。缺乏行业级的可扩展消息分发标准使得评估合适的解决方案变得困难。我们很高兴能够与多个开源项目共同努力,共同确定可扩展的开放消息规范。 Apache BookKeeper 已成功在雅虎(通过 Apache Pulsar)和 Twitter(通过 Apache DistributedLog)的生产环境中部署,它作为其企业级消息系统的持久化、高性能、低延迟存储基础。我们很高兴加入 OpenMessaging 帮助其它项目解决诸如低延迟持久化、一致性和可用性等在消息分发方案中的常见问题。”
>
>
> —— Streamlio 的联合创始人、Apache BookKeeper 的 PMC 主席、Apache DistributedLog 的联合创造者, Sijie Guo
>
>
>
---
via: <https://www.linuxfoundation.org/blog/building-open-standard-distributed-messaging-introducing-openmessaging/>
作者:[Mike Dolan](https://www.linuxfoundation.org/author/mdolan/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
8,982 | Docker 快速入门之 Dockerfile | http://locez.com/linux/docker/dockerfile/ | 2017-10-20T22:28:00 | [
"容器",
"Docker"
] | https://linux.cn/article-8982-1.html | 
在[之前的文章](/article-8932-1.html)中我们提到可以通过容器创建一个我们自定义过的镜像,那么我们是否可以直接通过基础的镜像直接自定义镜像呢?答案当然是可以的,在 Docker 中我们可以从名为 `Dockerfile` 的文件中读取指令并且自动构建镜像。在本文中,将介绍 Dockerfile 的基本语法以及基本知识。
### 1、Dockerfile 是什么?
Dockerfile 其实是一份文本文档,里面包含了用户可以用来操作镜像的一些指令。通过顺序执行这些指令,最后得到一个自定义的镜像,这有点类似于我们的 shell 脚本。
### 2、Dockerfile 示例
接下来先看一个 Dockerfile 示例:
```
FROM centos
LABEL maintainer="Locez <[email protected]>"
ENV TEST="This is a test env"
COPY nginx.repo /etc/yum.repos.d/nginx.repo
RUN yum update -y && \
yum install -y nginx
COPY nginx.conf /etc/nginx/nginx.conf
COPY index.html /usr/share/nginx/html/index.html
COPY index_files/ /usr/share/nginx/html/index_files/
EXPOSE 80
CMD ["/usr/sbin/nginx","-g","daemon off;"]
```
在上面我们可以看到 Dockerfile 中的一些指令,通过名称我们也可以猜到这些指令大概是干嘛的,其中有一些对文件的操作,因此我们先来看看用于存放 Dockerfile 的这个目录的目录结构:
```
# tree .
.
├── Dockerfile
├── index_files
│ ├── 145049z4og8xyjhx4xy8go.jpg
│ ├── 222746e5vh38d7ey3leyps.jpg
│ ├── 88x31.png
│ ├── archlinux-splash.png
│ ├── bdshare.css
│ ├── Best-Linux-Markdown-Editors.png
│ ├── core.js
│ ├── docker-icon.jpg
│ ├── hadoop-pic1.png
│ ├── jquery_002.js
│ ├── jquery.css
│ ├── jquery.js
│ ├── MathJax.js
│ ├── pic.gif
│ ├── raspberrypiraspberry-pi-logo.jpg
│ ├── script.js
│ ├── scrollup.png
│ ├── share.js
│ ├── style.css
│ └── z_stat.js
├── index.html
├── nginx.conf
└── nginx.repo
1 directory, 24 files
```
### 构建镜像
在当前目录下执行以下命令构建镜像:
```
# docker build -t locez/nginx .
Sending build context to Docker daemon 1.851 MB
Step 1/10 : FROM centos
---> 196e0ce0c9fb
Step 2/10 : LABEL maintainer "Locez <[email protected]>"
---> Using cache
---> 9bba3042bcdb
Step 3/10 : ENV TEST "This is a test env"
---> Using cache
---> c0ffe95ea0c5
Step 4/10 : COPY nginx.repo /etc/yum.repos.d/nginx.repo
---> Using cache
---> bb6ee4c30d56
Step 5/10 : RUN yum update -y && yum install -y nginx
---> Using cache
---> 6d46b41099c3
Step 6/10 : COPY nginx.conf /etc/nginx/nginx.conf
---> Using cache
---> cfe908390aae
Step 7/10 : COPY index.html /usr/share/nginx/html/index.html
---> Using cache
---> 21729476079d
Step 8/10 : COPY index_files/ /usr/share/nginx/html/index_files/
---> Using cache
---> 662f06ec7b46
Step 9/10 : EXPOSE 80
---> Using cache
---> 30db5a889d0a
Step 10/10 : CMD /usr/sbin/nginx -g daemon off;
---> Using cache
---> d29b9d4036d2
Successfully built d29b9d4036d2
```
然后用该镜像启动容器:
```
# docker run -d -it --rm --name test-nginx -p 8080:80 locez/nginx
e06fd991ca1b202e08cf1578f8046355fcbba10dd9a90e11d43282f3a1e36d29
```
用浏览器访问 `http://localhost:8080/` 即可看到部署的内容。
### 3 Dockerfile 指令解释
Dockerfile 支持 `FROM`、 `RUN`、 `CMD`、 `LABEL`、 `EXPOSE`、 `ENV`、 `ADD`、 `COPY`、 `ENTRYPOINT`、 `VOLUME`、 `USER`、 `WORKDIR`、 `ARG`、 `ONBUILD`、 `SHELL` 等指令,这里只选择常用的几个进行讲解,可结合上面的示例进行理解。其它的请自行查阅官方文档。
#### 3.1 FROM
`FROM` 指令用于指定要操作的基础镜像,因为在我们构建我们自己的镜像的时候需要一个基础镜像。 语法:
```
FROM <image> [AS <name>]
FROM <image>[:<tag>] [AS <name>]
```
其中 `[AS <name>]` 为指定一个名称,在一个 Dockerfile 中多次使用 `FROM` 时如有需要,可用 `COPY --from=<name|index>` 语法进行复制。
#### 3.2 RUN
`RUN` 指令用于执行命令,并且是在新的一层上执行,并把执行后的结果提交,也就是生成新的一层。基于这个问题,我们在使用 `RUN` 指令时应该尽可能的把要执行的命令一次写完,以减少最后生成的镜像的层数。 语法:
```
RUN <command>
RUN ["executable", "param1", "param2"]
```
#### 3.3 CMD
`CMD` 指令用于给容器启动时指定一个用于执行的命令,例如上例中的 nginx 启动命令。 语法:
```
CMD ["executable","param1","param2"]
CMD ["param1","param2"] ### 用于给 ENTRYPOINT 指令提供默认参数
CMD command param1 param2
```
#### 3.4 LABEL
`LABEL` 指令用于为镜像指定标签,可用 `docker inspect` 命令查看。可用来代替被舍弃的 `MAINTAINER` 命令。 语法:
```
LABEL <key>=<value> <key>=<value> <key>=<value> ...
```
#### 3.5 EXPOSE
`EXPOSE` 指令用于告诉 Docker 容器监听的特殊端口,但是此时端口还没有暴露给 host ,只有当在运行一个容器显式用参数 `-p` 或者 `-P` 的时候才会暴露端口。 语法:
```
EXPOSE <port> [<port>/<protocol>...]
```
#### 3.6 ENV
`ENV` 指令用于设定环境变量。 语法:
```
ENV <key> <value>
ENV <key>=<value> ...
```
#### 3.7 ADD
`ADD` 指令用于复制新文件,目录,远程文件到容器中。其中 `<src>` 可以为文件,目录,URL,若为可解压文件,在复制后会解压。 语法:
```
ADD <src>... <dest>
ADD ["<src>",... "<dest>"]
```
#### 3.8 COPY
`COPY` 指令与 `ADD` 指令非常相似,但 `COPY` 比较直观且简单,它只支持本地的文件以及目录的复制,不像 `ADD` 指令可以远程获取文件并解压。 语法:
```
COPY <src>... <dest>
COPY ["<src>",... "<dest>"]
```
#### 3.9 ENTRYPOINT
`ENTRYPOINT` 指令也跟 `CMD` 指令相似,用于指定容器启动时执行的命令。当使用 `ENTRYPOINT` 指令时,可用 `CMD` 命令配合,这样在启动容器时,可以对 `CMD` 指令写入的参数进行覆盖。 语法:
```
ENTRYPOINT ["executable", "param1", "param2"]
```
例子:
```
ENTRYPOINT ["top","-b"]
CMD ["-c"]
```
上面的 `-c` 参数可以在启动时覆盖 `docker run -it --rm --name test top -H`。 如果要覆盖 `ENTRYPOINT` 指令则用 `--entrypoint` 参数启动容器。
#### 3.10 VOLUME
`VOLUME` 指令用于为容器创建一个挂载点,这个挂载点可以用来挂载 `本地文件/文件夹` 也可以用来挂载 `数据卷`。其中若在启动一个新容器时没有指定挂载目录,则会自动创建一个数据卷,当容器被销毁时,数据卷如果没有被其它容器引用则会被删除。 语法:
```
VOLUME ["/data1","/data2"]
```
#### 3.11 USER
`USER` 指令用于设置执行 `RUN`, `CMD`, `ENTRYPOINT` 等指令的用户以及用户组。默认为 `root` 用户。 语法:
```
USER <user>[:<group>]
```
#### 3.12 WORKDIR
`WORKDIR` 指令用于设置 `RUN`, `CMD`, `ENTRYPOINT`, `COPY`, `ADD` 等指令的工作目录。 语法:
```
WORKDIR /path/to/workdir
```
### 4 总结
---
本文从一个具体的例子出发,讲述了如何利用 Dockerfile 构建镜像,然后解释了 Dockerfile 文件中的指令的语法,有关更多内容可访问官方文档。
### 5 参考资料
---
* [Dockerfile reference](https://docs.docker.com/engine/reference/builder/)
| 301 | Moved Permanently | null |
8,983 | Ciao:云集成高级编排器 | https://clearlinux.org/ciao | 2017-10-20T23:38:30 | [
"编排",
"OpenStack"
] | https://linux.cn/article-8983-1.html | 
<ruby> 云集成高级编排器 <rt> Cloud Integrated Advanced Orchestrator </rt></ruby> (Ciao) 是一个新的负载调度程序,用来解决当前云操作系统项目的局限性。Ciao 提供了一个轻量级,完全基于 TLS 的最小配置。它是 工作量无关的、易于更新、具有优化速度的调度程序,目前已针对 OpenStack 进行了优化。
其设计决策和创新方法在对安全性、可扩展性、可用性和可部署性的要求下进行:
* **可扩展性:** 初始设计目标是伸缩超过 5,000 个节点。因此,调度器架构用新的形式实现:
+ 在 ciao 中,决策制定是去中心化的。它基于拉取模型,允许计算节点从调度代理请求作业。调度程序总能知道启动器的容量,而不要求进行数据更新,并且将调度决策时间保持在最小。启动器异步向调度程序发送容量。
+ 持久化状态跟踪与调度程序决策制定相分离,它让调度程序保持轻量级。这种分离增加了可靠性、可扩展性和性能。结果是调度程序让出了权限并且这不是瓶颈。
* **可用性:** 虚拟机、容器和裸机集成到一个调度器中。所有的负载都被视为平等公民。为了更易于使用,网络通过一个组件间最小化的异步协议进行简化,只需要最少的配置。Ciao 还包括一个新的、简单的 UI。所有的这些功能都集成到一起来简化安装、配置、维护和操作。
* **轻松部署:** 升级应该是预期操作,而不是例外情况。这种新的去中心化状态的体系结构能够无缝升级。为了确保基础设施(例如 OpenStack)始终是最新的,它实现了持续集成/持续交付(CI/CD)模型。Ciao 的设计使得它可以立即杀死任何 Ciao 组件,更换它,并重新启动它,对可用性影响最小。
* **安全性是必需的:** 与调度程序的连接总是加密的:默认情况下 SSL 是打开的,而不是关闭的。加密是从端到端:所有外部连接都需要 HTTPS,组件之间的内部通信是基于 TLS 的。网络支持的一体化保障了租户分离。
初步结果证明是显著的:在 65 秒内启动一万个 Docker 容器和五千个虚拟机。进一步优化还在进行。
* 文档:<https://clearlinux.org/documentation/ciao/ciao.html>
* Github 链接: [https://github.com/01org/ciao(link is external)](https://github.com/01org/ciao)
* 邮件列表链接: <https://lists.clearlinux.org/mailman/listinfo/ciao-devel>
---
via: <https://clearlinux.org/ciao>
作者:[ciao](https://clearlinux.org/ciao) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
8,984 | 如何像 NASA 顶级程序员一样编程 —— 10 条重要原则 | https://fossbytes.com/nasa-coding-programming-rules-critical/ | 2017-10-21T23:23:00 | [
"编程",
"NASA"
] | https://linux.cn/article-8984-1.html | 
>
> 引言: 你知道 NASA 顶级程序员如何编写关键任务代码么?为了确保代码更清楚、更安全、且更容易理解,NASA 的喷气推进实验室制定了 10 条编码规则。
>
>
>
NASA 的开发者是编程界最有挑战性的工作之一。他们编写代码并将开发安全的关键任务应用程序作为其主要关注点。
在这种情形下,遵守一些严格的编码规则是重要的。这些规则覆盖软件开发的多个方面,例如软件应该如何编码、应该使用哪些语言特性等。
尽管很难就一个好的编码标准达成共识,NASA 的喷气推进实验室(JPL)遵守一个[编码规则](http://pixelscommander.com/wp-content/uploads/2014/12/P10.pdf),其名为“十的次方:开发安全的关键代码的规则”。
由于 JPL 长期使用 C 语言,这个规则主要是针对于 C 程序语言编写。但是这些规则也可以很容地应用到其它的程序语言。
该规则由 JPL 的首席科学家 Gerard J. Holzmann 制定,这些严格的编码规则主要是聚焦于安全。
NASA 的 10 条编写关键任务代码的规则:
1. 限制所有代码为极为简单的控制流结构 — 不用 `goto` 语句、`setjmp` 或 `longjmp` 结构,不用间接或直接的递归调用。
2. 所有循环必须有一个固定的上限值。必须可以被某个检测工具静态证实,该循环不能达到预置的迭代上限值。如果该上限值不能被静态证实,那么可以认为违背该原则。
3. 在初始化后不要使用动态内存分配。
4. 如果一个语句一行、一个声明一行的标准格式来参考,那么函数的长度不应该比超过一张纸。通常这意味着每个函数的代码行不能超过 60。
5. 代码中断言的密度平均低至每个函数 2 个断言。断言被用于检测那些在实际执行中不可能发生的情况。断言必须没有副作用,并应该定义为布尔测试。当一个断言失败时,应该执行一个明确的恢复动作,例如,把错误情况返回给执行该断言失败的函数调用者。对于静态工具来说,任何能被静态工具证实其永远不会失败或永远不能触发的断言违反了该规则(例如,通过增加无用的 `assert(true)` 语句是不可能满足这个规则的)。
6. 必须在最小的范围内声明数据对象。
7. 非 void 函数的返回值在每次函数调用时都必须检查,且在每个函数内其参数的有效性必须进行检查。
8. 预处理器的使用仅限制于包含头文件和简单的宏定义。符号拼接、可变参数列表(省略号)和递归宏调用都是不允许的。所有的宏必须能够扩展为完整的语法单元。条件编译指令的使用通常是晦涩的,但也不总是能够避免。这意味着即使在一个大的软件开发中超过一两个条件编译指令也要有充足的理由,这超出了避免多次包含头文件的标准做法。每次在代码中这样做的时候必须有基于工具的检查器进行标记,并有充足的理由。
9. 应该限制指针的使用。特别是不应该有超过一级的解除指针引用。解除指针引用操作不可以隐含在宏定义或类型声明中。还有,不允许使用函数指针。
10. 从开发的第一天起,必须在编译器开启最高级别警告选项的条件下对代码进行编译。在此设置之下,代码必须零警告编译通过。代码必须利用源代码静态分析工具每天至少检查一次或更多次,且零警告通过。
关于这些规则,NASA 是这么评价的:
>
> 这些规则就像汽车中的安全带一样,刚开始你可能感到有一点不适,但是一段时间后就会养成习惯,你会无法想象不使用它们的日子。
>
>
>
此文是否对你有帮助?不要忘了在下面的评论区写下你的反馈。
---
作者简介:
Adarsh Verma 是 Fossbytes 的共同创始人,他是一个令人尊敬的企业家,他一直对开源、技术突破和完全保持密切关注。可以通过邮件联系他 — [[email protected]](mailto:[email protected])
---
via: <https://fossbytes.com/nasa-coding-programming-rules-critical/>
作者:[Adarsh Verma](https://fossbytes.com/author/adarsh/) 译者:[penghuster](https://github.com/penghuster) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
8,985 | Grafeas:旨在更好地审计容器 | https://www.infoworld.com/article/3230462/security/what-is-grafeas-better-auditing-for-containers.html | 2017-10-22T10:26:21 | [
"容器",
"审计"
] | https://linux.cn/article-8985-1.html |
>
> Google 的 Grafeas 为容器的元数据提供了一个从镜像、构建细节到安全漏洞的通用 API。
>
>
>

我们运行的软件从来没有比今天更难获得。它分散在本地部署和云服务之间,由不知到有多少的开源组件构建而成,以快速的时间表交付,因此保证安全和质量变成了一个挑战。
最终的结果是软件难以审计、推断、安全化和管理。困难的不只是知道 VM 或容器是用什么构建的, 而是由谁来添加、删除或更改的。[Grafeas](http://grafeas.io/) 最初由 Google 设计,旨在使这些问题更容易解决。
### 什么是 Grafeas?
Grafeas 是一个定义软件组件的元数据 API 的开源项目。旨在提供一个统一的元数据模式,允许 VM、容器、JAR 文件和其他软件<ruby> 工件 <rt> artifact </rt></ruby>描述自己的运行环境以及管理它们的用户。目标是允许像在给定环境中使用的软件一样的审计,以及对该软件所做的更改的审计,并以一致和可靠的方式进行。
Grafeas提供两种格式的元数据 API —— 备注和事件:
* <ruby> 备注 <rt> note </rt></ruby>是有关软件工件的某些方面的细节。可以是已知软件漏洞的描述,有关如何构建软件的详细信息(构建器版本、校验和等),部署历史等。
* <ruby> 事件 <rt> occurrence </rt></ruby>是备注的实例,包含了它们创建的地方和方式的细节。例如,已知软件漏洞的详细信息可能会有描述哪个漏洞扫描程序检测到它的情况、何时被检测到的事件信息,以及该漏洞是否被解决。
备注和事件都存储在仓库中。每个备注和事件都使用标识符进行跟踪,该标识符区分它并使其唯一。
Grafeas 规范包括备注类型的几个基本模式。例如,软件包漏洞模式描述了如何存储 CVE 或漏洞描述的备注信息。现在没有接受新模式类型的正式流程,但是[这已经在计划](https://github.com/Grafeas/Grafeas/issues/38)创建这样一个流程。
### Grafeas 客户端和第三方支持
现在,Grafeas 主要作为规范和参考形式存在,它在 [GitHub 上提供](https://github.com/grafeas/grafeas)。 [Go](https://github.com/Grafeas/client-go)、[Python](https://github.com/Grafeas/client-python) 和 [Java](https://github.com/Grafeas/client-java) 的客户端都可以[用 Swagger 生成](https://www.infoworld.com/article/2902750/application-development/manage-apis-with-swagger.html),所以其他语言的客户端也应该不难写出来。
Google 计划让 Grafeas 广泛使用的主要方式是通过 Kubernetes。 Kubernetes 的一个名为 Kritis 的策略引擎,可以根据 Grafeas 元数据对容器采取措施。
除 Google 之外的几家公司已经宣布计划将 Grafeas 的支持添加到现有产品中。例如,CoreOS 正在考察 Grafeas 如何与 Tectonic 集成,[Red Hat](https://www.redhat.com/en/blog/red-hat-google-cloud-and-other-industry-leaders-join-together-standardize-kubernetes-service-component-auditing-and-policy-enforcement) 和 [IBM](https://developer.ibm.com/dwblog/2017/grafeas/) 都计划在其容器产品和服务中添加 Grafeas 集成。
---
via: <https://www.infoworld.com/article/3230462/security/what-is-grafeas-better-auditing-for-containers.html>
作者:[Serdar Yegulalp](https://www.infoworld.com/author/Serdar-Yegulalp/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
8,986 | Genymotion vs Android 模拟器 | https://www.plightofbyte.com/android/2017/09/03/genymotion-vs-android-emulator/ | 2017-10-23T09:56:00 | [
"Android",
"Genymotion"
] | https://linux.cn/article-8986-1.html |
>
> Android 模拟器是否改善到足以取代 Genymotion
>
>
>

一直以来有关于选择 android 模拟器或者 Genymotion 的争论,我看到很多讨论最后以赞成 Genymotion 而告终。我根据我周围最常见的情况收集了一些数据,基于此,我将连同 Genymotion 全面评估 android 模拟器。
结论剧透:**配置正确时,Android 模拟器比 Genymotion 快。**
使用带 Google API 的 x86(32位)镜像、3GB RAM、四核CPU。
>
> * 哈,很高兴我们知道了最终结果
> * 现在,让我们深入
>
>
>
免责声明:我已经测试了我看到的一般情况,即运行测试。所有的基准测试都是在 2015 年中期的 MacBook Pro 上完成的。无论何时我提及 Genymotion 指的都是 Genymotion Desktop。他们还有其他产品,如 Genymotion on Cloud&Genymotion on Demand,但这里没有考虑。我不是说 Genymotion 是不合适的,但运行测试比某些 Android 模拟器慢。
关于这个问题的一点背景,然后我们将转到具体内容上去。
*过去:我有一些基准测试,继续下去。*
很久以前,Android 模拟器是唯一的选择。但是它们太慢了,这是架构改变的原因。对于在 x86 机器上运行的 ARM 模拟器,你能期待什么?每个指令都必须从 ARM 转换为 x86 架构,这使得它的速度非常慢。
随之而来的是 Android 的 x86 镜像,随着它们摆脱了 ARM 到 x86 平台转化,速度更快了。现在,你可以在 x86 机器上运行 x86 Android 模拟器。
>
> * *问题解决了!!!*
> * 没有!
>
>
>
Android 模拟器仍然比人们想要的慢。随后出现了 Genymotion,这是一个在 virtual box 中运行的 Android 虚拟机。与在 qemu 上运行的普通老式 android 模拟器相比,它相当稳定和快速。
我们来看看今天的情况。
我在持续集成的基础设施上和我的开发机器上使用 Genymotion。我手头的任务是摆脱持续集成基础设施和开发机器上使用 Genymotion。
>
> * 你问为什么?
> * 授权费钱。
>
>
>
在快速看了一下以后,这似乎是一个愚蠢的举动,因为 Android 模拟器的速度很慢而且有 bug,它们看起来适得其反,但是当你深入的时候,你会发现 Android 模拟器是优越的。
我们的情况是对它们进行集成测试(主要是 espresso)。我们的应用程序中只有 1100 多个测试,Genymotion 需要大约 23 分钟才能运行所有测试。
在 Genymotion 中我们面临的另一些问题是:
* 有限的命令行工具([GMTool](https://docs.genymotion.com/Content/04_Tools/GMTool/GMTool.htm))。
* 由于内存问题,它们需要定期重新启动。这是一个手动任务,想象在配有许多机器的持续集成基础设施上进行这些会怎样。
**进入 Android 模拟器**
首先是尝试在它给你这么多的选择中设置一个,这会让你会觉得你在赛百味餐厅一样。最大的问题是 x86 或 x86\_64 以及是否有 Google API。
我用这些组合做了一些研究和基准测试,这是我们所想到的。
鼓声……
>
> * 比赛的获胜者是带 Google API 的 x86
> * 但是如何胜利的?为什么?
>
>
>
嗯,我会告诉你每一个问题。
x86\_64 比 x86 慢
>
> * 你问慢多少。
> * 28.2% 多!!!
>
>
>
使用 Google API 的模拟器更加稳定,没有它们容易崩溃。
这使我们得出结论:最好的是带 Google API 的x86。
在我们抛弃 Genymotion 开始使用模拟器之前。有下面几点重要的细节。
* 我使用的是带 Google API 的 Nexus 5 镜像。
* 我注意到,给模拟器较少的内存会造成了很多 Google API 崩溃。所以为模拟器设定了 3GB 的 RAM。
* 模拟器有四核。
* HAXM 安装在主机上。
**基准测试的时候到了**



从基准测试上你可以看到除了 Geekbench4,Android 模拟器都击败了 Genymotion,我感觉更像是virtual box 击败了 qemu。
>
> 欢呼模拟器之王
>
>
>
我们现在有更快的测试执行时间、更好的命令行工具。最新的 [Android 模拟器](https://developer.android.com/studio/releases/emulator.html)创下的新的记录。更快的启动时间之类。
Goolgle 一直努力让
>
> Android 模拟器变得更好
>
>
>
如果你没有在使用 Android 模拟器。我建议你重新试下,可以节省一些钱。
我尝试的另一个但是没有成功的方案是在 AWS 上运行 [Android-x86](http://www.android-x86.org/) 镜像。我能够在 vSphere ESXi Hypervisor 中运行它,但不能在 AWS 或任何其他云平台上运行它。如果有人知道原因,请在下面评论。
PS:[VMWare 现在可以在 AWS 上使用](https://aws.amazon.com/vmware/),在 AWS 上使用 [Android-x86](http://www.android-x86.org/) 毕竟是有可能的。
---
作者简介:
嗨,我的名字是 Sumit Gupta。我是来自印度古尔冈的软件/应用/网页开发人员。我做这个是因为我喜欢技术,并且一直迷恋它。我已经工作了 3 年以上,但我还是有很多要学习。他们不是说如果你有知识,让别人点亮他们的蜡烛。
当在编译时,我阅读很多文章,或者听音乐。
如果你想联系,下面是我的社交信息和 [email]([email protected])。
---
via: <https://www.plightofbyte.com/android/2017/09/03/genymotion-vs-android-emulator/>
作者:[Sumit Gupta](https://www.plightofbyte.com/about-me) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | There has always been a debate about which android emulator to choose or to go with Genymotion. I’ve seen most of the discussion ending in favour of Genymotion.
I’ve gathered some data around the most common use case in my experience. Based on this I’ll be evaluating all the android emulators along with Genymotion.
**TL;DR: Android emulator is faster than Genymotion when configured right.
Use x86 (32 bit) image with Google APIs, 3GB ram, quad-core CPU.**
Pheww, glad we’re past that
Now, let’s dive deep
**Disclaimer**: I’ve tested my use case which to me looks the general use case i.e. running tests.
All benchmarks were done on a mid-2015 MacBook Pro.
Wherever I say Genymotion I mean **Genymotion Desktop**. They have other products like Genymotion on Cloud & Genymotion on Demand which are not being considered here.
I’m not saying Genymotion is inadequate. But it is slower when running tests compared to certain Android emulators.
A little background on the subject and then we’ll jump to the good stuff.
*Psst: I have some benchmarks down the line, stick around.*
Long ago Android emulator was the only way to go. But they were too slow to use, the reason being a **change of architecture**.
What can you expect out of an ARM emulator running on an x86 machine? Every instruction had to be converted from ARM to x86 architecture which makes it really slow.
Then came along the x86 images of Android which are way faster as they get rid of the ARM to x86 platform change.
Now you can run x86 Android emulator on an x86 machine.
Problem solved!!!
NO!
Android emulators were still slow from what people wanted.
Then came along Genymotion, which is just an Android VM running in a virtual box. But it is quite stable & fast compared to plain old android emulators which run on qemu.
Let’s jump to how the situation is today.
I’m using Genymotion in CI infrastructure and on my machine.
The task at hand was to **get rid of Genymotion** used in CI infrastructure and machine.
You ask why?
Licenses cost money. Duh…
At a quick glance it seems like a stupid move as Android emulators are slow and buggy. But when you get into the nitty-gritty of the situation, you’ll find Android emulator to be superior.
My use case is to run integration tests on them (mostly espresso), just over 1100 tests. Genymotion takes ~23 minutes to run all the tests.
A few other problems faced with Genymotion.
- Limited command line tools (
[GMTool](https://docs.genymotion.com/Content/04_Tools/GMTool/GMTool.htm)). - They needed a periodic restart because of memory issues. This was a manual task, imagine doing it on a CI infrastructure with lots of machines.
**Enter Android Emulator**
The first time you try to set-up one of these it gives you so many options that you’ll feel like you are in Subway restaurant.
The biggest question of all is x86 or x86_64 and with Google APIs or without them.
I did some research and benchmarking with these combinations and this is what we came up with.
Drum Roll…
The winner of the competition is
x86 with Google APIs
But how? why?
Well, I’ll tell you the problem with every one of them.
x86_64 is slower compared to x86
By how much you ask.
28.2%much !!!
Emulator with Google APIs is more stable, things tend to crash without them.
This brings us to the conclusion that the best one is **x86 with Google APIs**.
Before we pit our winning emulator against Genymotion. There are a few more details that are of great importance.
- I’ve used a Nexus 5 system image with Google APIs.
- I noticed that giving emulator less ram caused a lot of Google API crashes. So I’ve settled for 3GB of ram for an emulator.
- The emulator has a quad-core.
- Host machine has HAXM installed.
**Time for few benchmarks**
From the benchmarks, you can see that Android emulator beats Genymotion expect for in Geekbench4. This feels more of a virtual box beating qemu thing.
All hail the King of the Emulators
We are now having a faster test execution time, better command line tools.
Also with the latest [Android Emulator](https://developer.android.com/studio/releases/emulator.html), things have gone a notch up. Faster boot time and what not.
Google has been working very hard to
Make Android Emulator great again
If you haven’t been using android emulator for some time. I’d suggest you revisit and save some money.
One other solution which I was trying but couldn’t really get it to work was running an [Android-x86](http://www.android-x86.org) image on AWS.
I was able to run it on a vSphere ESXi Hypervisor but not on AWS or any other cloud platform. If someone knows anything about it do comment below.
PS: [VMWare is now available on AWS](https://aws.amazon.com/vmware/), [Android-x86](http://www.android-x86.org) on AWS might be possible after all.
What do you think about Genymotion desktop and Android emulator? Comment below.
Share this article if you like it. |
8,987 | 构建你的数据科学作品集:用数据讲故事 | https://www.dataquest.io/blog/data-science-portfolio-project/ | 2017-10-22T21:01:00 | [
"数据科学"
] | https://linux.cn/article-8987-1.html | 
>
> 这是如何建立<ruby> 数据科学作品集 <rt> Data Science Portfolio </rt></ruby>系列文章中的第一篇。如果你喜欢这篇文章并且想知道此系列的下一篇文章何时发表,你可以[在页面底部订阅](https://www.dataquest.io/blog/data-science-portfolio-project/#email-signup)。
>
>
>
数据科学公司们在决定雇佣一个人时越来越看重其作品集。其中一个原因就是<ruby> 作品集 <rt> portfolio </rt></ruby>是分析一个人真实技能的最好方式。好消息是,作品集是完全可以被你掌控的。如果你在其上投入了一些工作,你就能够做出一个令那些公司印象深刻的作品集结果。
建立一个高质量作品集的第一步就是知道展示什么技能。那些公司们主要希望数据科学工作者拥有的技能,或者说他们主要希望作品集所展示的技能是:
* 表达能力
* 合作能力
* 专业技能
* 解释数据的能力
* 有目标和有积极性的
任何一个好的作品集都由多个工程构成,每一个工程都会展示 1-2 个上面所说的点。这是涵盖了“如何完成一个完整的数据科学作品集”系列文章的第一篇。在这篇文章中,我们将会涵括如何完成你的第一项数据科学作品集工程,并且对此进行有效的解释。在最后,你将会得到一个帮助展示你表达能力和解释数据能力的工程。
### 用数据讲故事
数据科学是表达的基础。你将会在数据中发现一些观点,并且找出一个高效的方式来向他人表达这些,之后向他们展示你所开展的课题。数据科学最关键的手法之一就是能够用数据讲述一个清晰的故事。一个清晰的故事能够使你的观点更加引人注目,并且能使别人理解你的想法。
数据科学中的故事是一个讲述你发现了什么,你怎么发现它的,并且它意味着什么的故事。例如假使发现你公司的收入相对去年减少了百分之二十。这并不能够确定原因,你可能需要和其它人沟通为什么收入会减少,并且在尝试修复它。
用数据讲故事主要包含:
* 理解并确定上下文
* 从多角度发掘
* 使用有趣的表示方法
* 使用多种数据来源
* 一致的表述
用来讲述数据的故事最有效率的工具就是 [Jupyter notebook](http://www.jupyter.org/)。如果你不熟悉,[此处](https://www.dataquest.io/blog/python-data-science/)有一个好的教程。Jupyter notebook 允许你交互式的发掘数据,并且将你的结果分享到多个网站,包括 Github。分享你的结果有助于合作研究和其他人拓展你的分析。
在这篇文章中,我们将使用 Jupyter notebook,以及 Pandas 和 matplotlib 这样的 Python 库。
### 为你的数据科学工程选择一个主题
建立一个工程的第一步就是决定你的主题。你要让你的主题是你兴趣所在,有动力去挖掘。进行数据挖掘时,为了完成而完成和有兴趣完成的区别是很明显的。这个步骤是值得花费时间的,所以确保你找到了你真正感兴趣的东西。
一个寻找主题的好方法就是浏览不同的数据集并且寻找感兴趣的部分。这里有一些作为起点的好的网站:
* [Data.gov](https://www.data.gov/) - 包含了政府数据。
* [/r/datasets](https://reddit.com/r/datasets) – 一个有着上百个有趣数据集的 reddit 板块。
* [Awesome datasets](https://github.com/caesar0301/awesome-public-datasets) – 一个数据集的列表,位于 Github 上。
* [17 个找到数据集的地方](https://www.dataquest.io/blog/free-datasets-for-projects/) – 这篇博文列出了 17 个数据集,每个都包含了示例数据集。
真实世界中的数据科学,你经常无法找到可以浏览的合适的单个数据集。你可能需要聚合多个独立的数据源,或者做数量庞大的数据清理。如果该主题非常吸引你,这是值得这样做的,并且也能更好的展示你的技能。
关于这篇文章的主题,我们将使用纽约市公立学校的数据,我们可以在[这里](https://data.cityofnewyork.us/data?cat=education)找到它。
### 选择主题
这对于项目全程来说是十分重要的。因为主题能很好的限制项目的范围,并且它能够使我们知道它可以被完成。比起一个没有足够动力完成的工程来说,添加到一个完成的工程更加容易。
所以,我们将关注高中的[学术评估测试](https://en.wikipedia.org/wiki/SAT),伴随着多种人口统计和它们的其它数据。关于学习评估测试, 或者说 SAT,是美国高中生申请大学前的测试。大学在做判定时将考虑该成绩,所以高分是十分重要的。考试分为三个阶段,每个阶段总分为 800。全部分数为 2400(即使这个前后更改了几次,在数据中总分还是 2400)。高中经常通过平均 SAT分数进行排名,并且 SAT 是评判高中有多好的标准。
因为由关于 SAT 分数对于美国中某些种族群体是不公平的,所以对纽约市这个数据做分析能够对 SAT 的公平性有些许帮助。
我们在[这里](https://data.cityofnewyork.us/Education/SAT-Results/f9bf-2cp4)有 SAT 成绩的数据集,并且在[这里](https://data.cityofnewyork.us/Education/DOE-High-School-Directory-2014-2015/n3p6-zve2)有包含了每所高中的信息的数据集。这些将构成我们的工程的基础,但是我们将加入更多的信息来创建有趣的分析。
### 补充数据
如果你已经有了一个很好的主题,拓展其它可以提升主题或者更深入挖掘数据的的数据集是一个好的选择。在前期十分适合做这些工作,你将会有尽可能多的数据来构建你的工程。数据越少意味着你会太早的放弃了你的工程。
在本项目中,在包含人口统计信息和测试成绩的网站上有一些相关的数据集。
这些是我们将会用到的所有数据集:
* [学校 SAT 成绩](https://data.cityofnewyork.us/Education/SAT-Results/f9bf-2cp4) – 纽约市每所高中的 SAT 成绩。
* [学校出勤情况](https://data.cityofnewyork.us/Education/School-Attendance-and-Enrollment-Statistics-by-Dis/7z8d-msnt) – 纽约市每所学校的出勤信息。
* [数学成绩](https://data.cityofnewyork.us/Education/NYS-Math-Test-Results-By-Grade-2006-2011-School-Le/jufi-gzgp) – 纽约市每所学校的数学成绩。
* [班级规模](https://data.cityofnewyork.us/Education/2010-2011-Class-Size-School-level-detail/urz7-pzb3) - 纽约市每所学校课堂人数信息。
* [AP 成绩](https://data.cityofnewyork.us/Education/AP-College-Board-2010-School-Level-Results/itfs-ms3e) - 高阶位考试,在美国,通过 AP 测试就能获得大学学分。
* [毕业去向](https://data.cityofnewyork.us/Education/Graduation-Outcomes-Classes-Of-2005-2010-School-Le/vh2h-md7a) – 由百分之几的学生毕业了,和其它去向信息。
* [人口统计](https://data.cityofnewyork.us/Education/School-Demographics-and-Accountability-Snapshot-20/ihfw-zy9j) – 每个学校的人口统计信息。
* [学校问卷](https://data.cityofnewyork.us/Education/NYC-School-Survey-2011/mnz3-dyi8) – 学校的家长、教师,学生的问卷。
* [学校分布地图](https://data.cityofnewyork.us/Education/School-Districts/r8nu-ymqj) – 包含学校的区域布局信息,因此我们能将它们在地图上标出。
(LCTT 译注:高阶位考试(AP)是美国和加拿大的一个由大学委员会创建的计划,该计划为高中学生提供大学水平的课程和考试。 美国学院和大学可以授予在考试中获得高分的学生的就学和课程学分。)
这些数据作品集之间是相互关联的,并且我们能够在开始分析之前进行合并。
### 获取背景信息
在开始分析数据之前,搜索一些背景信息是有必要的。我们知道这些有用的信息:
* 纽约市被分为五个不同的辖区
* 纽约市的学校被分配到几个学区,每个学区都可能包含数十所学校。
* 数据集中的学校并不全是高中,所以我们需要对数据进行一些清理工作。
* 纽约市的每所学校都有自己单独的编码,被称为‘DBN’,即区域行政编号。
* 为了通过区域进行数据聚合,我们可以使用地图区域信息来绘制逐区差异。
### 理解数据
为了真正的理解数据信息,你需要花费时间来挖掘和阅读数据。因此,每个数据链接都有数据的描述信息,并伴随着相关列。就像是我们拥有的高中 SAT 成绩信息,也包含图像和其它信息的数据集。
我们可以运行一些代码来读取数据。我们将使用 [Jupyter notebook](http://jupyter.org/) 来挖掘数据。下面的代码将会执行以下操作:
* 循环遍历我们下载的所有数据文件。
* 将文件读取到 [Pandas DataFrame](http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.html)。
* 将所有数据框架导入 Python 数据库中。
In [100]:
```
import pandas
import numpy as np
files = ["ap_2010.csv", "class_size.csv", "demographics.csv", "graduation.csv", "hs_directory.csv", "math_test_results.csv", "sat_results.csv"]
data = {}
for f in files:
d = pandas.read_csv("schools/{0}".format(f))
data[f.replace(".csv", "")] = d
```
一旦我们将数据读入,我们就可以使用 DataFrames 的 [head](https://www.dataquest.io/blog/data-science-portfolio-project/) 方法打印每个 DataFrame 的前五行。
In [103]:
```
for k,v in data.items():
print("\n" + k + "\n")
print(v.head())
```
```
math_test_results
DBN Grade Year Category Number Tested Mean Scale Score Level 1 # \
0 01M015 3 2006 All Students 39 667 2
1 01M015 3 2007 All Students 31 672 2
2 01M015 3 2008 All Students 37 668 0
3 01M015 3 2009 All Students 33 668 0
4 01M015 3 2010 All Students 26 677 6
Level 1 % Level 2 # Level 2 % Level 3 # Level 3 % Level 4 # Level 4 % \
0 5.1% 11 28.2% 20 51.3% 6 15.4%
1 6.5% 3 9.7% 22 71% 4 12.9%
2 0% 6 16.2% 29 78.4% 2 5.4%
3 0% 4 12.1% 28 84.8% 1 3%
4 23.1% 12 46.2% 6 23.1% 2 7.7%
Level 3+4 # Level 3+4 %
0 26 66.7%
1 26 83.9%
2 31 83.8%
3 29 87.9%
4 8 30.8%
ap_2010
DBN SchoolName AP Test Takers \
0 01M448 UNIVERSITY NEIGHBORHOOD H.S. 39
1 01M450 EAST SIDE COMMUNITY HS 19
2 01M515 LOWER EASTSIDE PREP 24
3 01M539 NEW EXPLORATIONS SCI,TECH,MATH 255
4 02M296 High School of Hospitality Management s
Total Exams Taken Number of Exams with scores 3 4 or 5
0 49 10
1 21 s
2 26 24
3 377 191
4 s s
sat_results
DBN SCHOOL NAME \
0 01M292 HENRY STREET SCHOOL FOR INTERNATIONAL STUDIES
1 01M448 UNIVERSITY NEIGHBORHOOD HIGH SCHOOL
2 01M450 EAST SIDE COMMUNITY SCHOOL
3 01M458 FORSYTH SATELLITE ACADEMY
4 01M509 MARTA VALLE HIGH SCHOOL
Num of SAT Test Takers SAT Critical Reading Avg. Score SAT Math Avg. Score \
0 29 355 404
1 91 383 423
2 70 377 402
3 7 414 401
4 44 390 433
SAT Writing Avg. Score
0 363
1 366
2 370
3 359
4 384
class_size
CSD BOROUGH SCHOOL CODE SCHOOL NAME GRADE PROGRAM TYPE \
0 1 M M015 P.S. 015 Roberto Clemente 0K GEN ED
1 1 M M015 P.S. 015 Roberto Clemente 0K CTT
2 1 M M015 P.S. 015 Roberto Clemente 01 GEN ED
3 1 M M015 P.S. 015 Roberto Clemente 01 CTT
4 1 M M015 P.S. 015 Roberto Clemente 02 GEN ED
CORE SUBJECT (MS CORE and 9-12 ONLY) CORE COURSE (MS CORE and 9-12 ONLY) \
0 - -
1 - -
2 - -
3 - -
4 - -
SERVICE CATEGORY(K-9* ONLY) NUMBER OF STUDENTS / SEATS FILLED \
0 - 19.0
1 - 21.0
2 - 17.0
3 - 17.0
4 - 15.0
NUMBER OF SECTIONS AVERAGE CLASS SIZE SIZE OF SMALLEST CLASS \
0 1.0 19.0 19.0
1 1.0 21.0 21.0
2 1.0 17.0 17.0
3 1.0 17.0 17.0
4 1.0 15.0 15.0
SIZE OF LARGEST CLASS DATA SOURCE SCHOOLWIDE PUPIL-TEACHER RATIO
0 19.0 ATS NaN
1 21.0 ATS NaN
2 17.0 ATS NaN
3 17.0 ATS NaN
4 15.0 ATS NaN
demographics
DBN Name schoolyear fl_percent frl_percent \
0 01M015 P.S. 015 ROBERTO CLEMENTE 20052006 89.4 NaN
1 01M015 P.S. 015 ROBERTO CLEMENTE 20062007 89.4 NaN
2 01M015 P.S. 015 ROBERTO CLEMENTE 20072008 89.4 NaN
3 01M015 P.S. 015 ROBERTO CLEMENTE 20082009 89.4 NaN
4 01M015 P.S. 015 ROBERTO CLEMENTE 20092010 96.5
total_enrollment prek k grade1 grade2 ... black_num black_per \
0 281 15 36 40 33 ... 74 26.3
1 243 15 29 39 38 ... 68 28.0
2 261 18 43 39 36 ... 77 29.5
3 252 17 37 44 32 ... 75 29.8
4 208 16 40 28 32 ... 67 32.2
hispanic_num hispanic_per white_num white_per male_num male_per female_num \
0 189 67.3 5 1.8 158.0 56.2 123.0
1 153 63.0 4 1.6 140.0 57.6 103.0
2 157 60.2 7 2.7 143.0 54.8 118.0
3 149 59.1 7 2.8 149.0 59.1 103.0
4 118 56.7 6 2.9 124.0 59.6 84.0
female_per
0 43.8
1 42.4
2 45.2
3 40.9
4 40.4
[5 rows x 38 columns]
graduation
Demographic DBN School Name Cohort \
0 Total Cohort 01M292 HENRY STREET SCHOOL FOR INTERNATIONAL 2003
1 Total Cohort 01M292 HENRY STREET SCHOOL FOR INTERNATIONAL 2004
2 Total Cohort 01M292 HENRY STREET SCHOOL FOR INTERNATIONAL 2005
3 Total Cohort 01M292 HENRY STREET SCHOOL FOR INTERNATIONAL 2006
4 Total Cohort 01M292 HENRY STREET SCHOOL FOR INTERNATIONAL 2006 Aug
Total Cohort Total Grads - n Total Grads - % of cohort Total Regents - n \
0 5 s s s
1 55 37 67.3% 17
2 64 43 67.2% 27
3 78 43 55.1% 36
4 78 44 56.4% 37
Total Regents - % of cohort Total Regents - % of grads \
0 s s
1 30.9% 45.9%
2 42.2% 62.8%
3 46.2% 83.7%
4 47.4% 84.1%
... Regents w/o Advanced - n \
0 ... s
1 ... 17
2 ... 27
3 ... 36
4 ... 37
Regents w/o Advanced - % of cohort Regents w/o Advanced - % of grads \
0 s s
1 30.9% 45.9%
2 42.2% 62.8%
3 46.2% 83.7%
4 47.4% 84.1%
Local - n Local - % of cohort Local - % of grads Still Enrolled - n \
0 s s s s
1 20 36.4% 54.1% 15
2 16 25% 37.200000000000003% 9
3 7 9% 16.3% 16
4 7 9% 15.9% 15
Still Enrolled - % of cohort Dropped Out - n Dropped Out - % of cohort
0 s s s
1 27.3% 3 5.5%
2 14.1% 9 14.1%
3 20.5% 11 14.1%
4 19.2% 11 14.1%
[5 rows x 23 columns]
hs_directory
dbn school_name boro \
0 17K548 Brooklyn School for Music & Theatre Brooklyn
1 09X543 High School for Violin and Dance Bronx
2 09X327 Comprehensive Model School Project M.S. 327 Bronx
3 02M280 Manhattan Early College School for Advertising Manhattan
4 28Q680 Queens Gateway to Health Sciences Secondary Sc... Queens
building_code phone_number fax_number grade_span_min grade_span_max \
0 K440 718-230-6250 718-230-6262 9 12
1 X400 718-842-0687 718-589-9849 9 12
2 X240 718-294-8111 718-294-8109 6 12
3 M520 718-935-3477 NaN 9 10
4 Q695 718-969-3155 718-969-3552 6 12
expgrade_span_min expgrade_span_max \
0 NaN NaN
1 NaN NaN
2 NaN NaN
3 9 14.0
4 NaN NaN
... \
0 ...
1 ...
2 ...
3 ...
4 ...
priority02 \
0 Then to New York City residents
1 Then to New York City residents who attend an ...
2 Then to Bronx students or residents who attend...
3 Then to New York City residents who attend an ...
4 Then to Districts 28 and 29 students or residents
priority03 \
0 NaN
1 Then to Bronx students or residents
2 Then to New York City residents who attend an ...
3 Then to Manhattan students or residents
4 Then to Queens students or residents
priority04 priority05 \
0 NaN NaN
1 Then to New York City residents NaN
2 Then to Bronx students or residents Then to New York City residents
3 Then to New York City residents NaN
4 Then to New York City residents NaN
priority06 priority07 priority08 priority09 priority10 \
0 NaN NaN NaN NaN NaN
1 NaN NaN NaN NaN NaN
2 NaN NaN NaN NaN NaN
3 NaN NaN NaN NaN NaN
4 NaN NaN NaN NaN NaN
Location 1
0 883 Classon Avenue\nBrooklyn, NY 11225\n(40.67...
1 1110 Boston Road\nBronx, NY 10456\n(40.8276026...
2 1501 Jerome Avenue\nBronx, NY 10452\n(40.84241...
3 411 Pearl Street\nNew York, NY 10038\n(40.7106...
4 160-20 Goethals Avenue\nJamaica, NY 11432\n(40...
[5 rows x 58 columns]
```
我们可以开始在数据作品集中观察有用的部分:
* 大部分数据集包含 DBN 列。
* 一些条目看起来在地图上标出会很有趣,特别是 `Location 1`,这列在一个很长的字符串里面包含了位置信息。
* 有些数据集会出现每所学校对应多行数据(DBN 数据重复),这意味着我们要进行预处理。
### 统一数据
为了使工作更简单,我们将需要将全部零散的数据集统一为一个。这将使我们能够快速跨数据集对比数据列。因此,我们需要找到相同的列将它们统一起来。请查看上面的输出数据, DBN 出现在多个数据集中,它看起来可以作为共同列。
如果我们用 google 搜索 `DBN New York City Schools`,我们[在此](https://developer.cityofnewyork.us/api/doe-school-choice)得到了结果。它解释了 DBN 是每个学校独特的编码。我们将挖掘数据集,特别是政府数据集。这通常需要做一些工作来找出每列的含义,或者每个数据集的意图。
现在主要的问题是这两个数据集 `class_size` 和 `hs_directory`,没有 `DBN` 列。在 `hs_directory` 数据中是 `dbn`,那么我们只需重命名即可,或者将它复制到新的名为 DBN 的列中。在 `class_size` 数据中,我们将需要尝试不同的方法。
DBN 列:
In [5]:
```
data["demographics"]["DBN"].head()
```
Out[5]:
```
0 01M015
1 01M015
2 01M015
3 01M015
4 01M015
Name: DBN, dtype: object
```
如果我们查看 `class_size`数据,我们将看到前五行如下:
In [4]:
```
data["class_size"].head()
```
Out[4]:
| | CSD | BOROUGH | SCHOOL CODE | SCHOOL NAME | GRADE | PROGRAM TYPE | CORE SUBJECT (MS CORE and 9-12 ONLY) | CORE COURSE (MS CORE and 9-12 ONLY) | SERVICE CATEGORY(K-9\* ONLY) | NUMBER OF STUDENTS / SEATS FILLED | NUMBER OF SECTIONS | AVERAGE CLASS SIZE | SIZE OF SMALLEST CLASS | SIZE OF LARGEST CLASS | DATA SOURCE | SCHOOLWIDE PUPIL-TEACHER RATIO |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 0 | 1 | M | M015 | P.S. 015 Roberto Clemente | 0K | GEN ED | - | - | - | 19.0 | 1.0 | 19.0 | 19.0 | 19.0 | ATS | NaN |
| 1 | 1 | M | M015 | P.S. 015 Roberto Clemente | 0K | CTT | - | - | - | 21.0 | 1.0 | 21.0 | 21.0 | 21.0 | ATS | NaN |
| 2 | 1 | M | M015 | P.S. 015 Roberto Clemente | 01 | GEN ED | - | - | - | 17.0 | 1.0 | 17.0 | 17.0 | 17.0 | ATS | NaN |
| 3 | 1 | M | M015 | P.S. 015 Roberto Clemente | 01 | CTT | - | - | - | 17.0 | 1.0 | 17.0 | 17.0 | 17.0 | ATS | NaN |
| 4 | 1 | M | M015 | P.S. 015 Roberto Clemente | 02 | GEN ED | - | - | - | 15.0 | 1.0 | 15.0 | 15.0 | 15.0 | ATS | NaN |
正如上面所见,DBN 实际上是 `CSD`、 `BOROUGH` 和 `SCHOOL CODE` 的组合。对那些不熟悉纽约市的人来说,纽约由五个行政区组成。每个行政区是一个组织单位,并且有着相当于美国大城市一样的面积。DBN 全称为行政区域编号。看起来就像 CSD 是区域,BOROUGH 是行政区,并且当与 SCHOOL CODE 合并时就组成了 DBN。这里并没有寻找像这个数据这样的内在规律的系统方法,这需要一些探索和努力来发现。
现在我们已经知道了 DBN 的组成,那么我们就可以将它加入到 `class_size` 和 `hs_directory` 数据集中了:
In [ ]:
```
data["class_size"]["DBN"] = data["class_size"].apply(lambda x: "{0:02d}{1}".format(x["CSD"], x["SCHOOL CODE"]), axis=1)
data["hs_directory"]["DBN"] = data["hs_directory"]["dbn"]
```
#### 加入问卷
最可能值得一看的数据集之一就是学生、家长和老师关于学校质量的问卷了。这些问卷包含了每所学校的安全程度、教学水平等。在我们合并数据集之前,让我们添加问卷数据。在真实世界的数据科学工程中,你经常会在分析过程中碰到有趣的数据,并且希望合并它。使用像 Jupyter notebook 一样灵活的工具将允许你快速添加一些新的代码,并且重新开始你的分析。
因此,我们将添加问卷数据到我们的 data 文件夹,并且合并所有之前的数据。问卷数据分为两个文件,一个包含所有的学校,一个包含 75 学区。我们将需要写一些代码来合并它们。之后的代码我们将:
* 使用 windows-1252 编码读取所有学校的问卷。
* 使用 windows-1252 编码读取所有 75 号学区的问卷。
* 添加指示每个数据集所在学区的标志。
* 使用 DataFrame 的 [concat](http://pandas.pydata.org/pandas-docs/stable/generated/pandas.concat.html) 方法将数据集合并为一个。
In [66]:
```
survey1 = pandas.read_csv("schools/survey_all.txt", delimiter="\t", encoding='windows-1252')
survey2 = pandas.read_csv("schools/survey_d75.txt", delimiter="\t", encoding='windows-1252')
survey1["d75"] = False
survey2["d75"] = True
survey = pandas.concat([survey1, survey2], axis=0)
```
一旦我们将问卷合并,这里将会有一些混乱。我们希望我们合并的数据集列数最少,那么我们将可以轻易的进行列之间的对比并找出其间的关联。不幸的是,问卷数据有很多列并不是很有用:
In [16]:
```
survey.head()
```
Out[16]:
| | N\_p | N\_s | N\_t | aca*p*11 | aca*s*11 | aca*t*11 | aca*tot*11 | bn | com*p*11 | com*s*11 | ... | t*q8c*1 | t*q8c*2 | t*q8c*3 | t*q8c*4 | t\_q9 | t*q9*1 | t*q9*2 | t*q9*3 | t*q9*4 | t*q9*5 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 0 | 90.0 | NaN | 22.0 | 7.8 | NaN | 7.9 | 7.9 | M015 | 7.6 | NaN | ... | 29.0 | 67.0 | 5.0 | 0.0 | NaN | 5.0 | 14.0 | 52.0 | 24.0 | 5.0 |
| 1 | 161.0 | NaN | 34.0 | 7.8 | NaN | 9.1 | 8.4 | M019 | 7.6 | NaN | ... | 74.0 | 21.0 | 6.0 | 0.0 | NaN | 3.0 | 6.0 | 3.0 | 78.0 | 9.0 |
| 2 | 367.0 | NaN | 42.0 | 8.6 | NaN | 7.5 | 8.0 | M020 | 8.3 | NaN | ... | 33.0 | 35.0 | 20.0 | 13.0 | NaN | 3.0 | 5.0 | 16.0 | 70.0 | 5.0 |
| 3 | 151.0 | 145.0 | 29.0 | 8.5 | 7.4 | 7.8 | 7.9 | M034 | 8.2 | 5.9 | ... | 21.0 | 45.0 | 28.0 | 7.0 | NaN | 0.0 | 18.0 | 32.0 | 39.0 | 11.0 |
| 4 | 90.0 | NaN | 23.0 | 7.9 | NaN | 8.1 | 8.0 | M063 | 7.9 | NaN | ... | 59.0 | 36.0 | 5.0 | 0.0 | NaN | 10.0 | 5.0 | 10.0 | 60.0 | 15.0 |
5 rows × 2773 columns
我们可以通过查看数据文件夹中伴随问卷数据下载下来的文件来解决这个问题。它告诉我们们数据中重要的部分是哪些:

我们可以去除 `survey` 数据集中多余的列:
In [17]:
```
survey["DBN"] = survey["dbn"]
survey_fields = ["DBN", "rr_s", "rr_t", "rr_p", "N_s", "N_t", "N_p", "saf_p_11", "com_p_11", "eng_p_11", "aca_p_11", "saf_t_11", "com_t_11", "eng_t_10", "aca_t_11", "saf_s_11", "com_s_11", "eng_s_11", "aca_s_11", "saf_tot_11", "com_tot_11", "eng_tot_11", "aca_tot_11",]
survey = survey.loc[:,survey_fields]
data["survey"] = survey
survey.shape
```
Out[17]:
```
(1702, 23)
```
请确保理你已经了解了每个数据集的内容和相关联的列,这能节约你之后大量的时间和精力:
### 精简数据集
如果我们查看某些数据集,包括 `class_size`,我们将立刻发现问题:
In [18]:
```
data["class_size"].head()
```
Out[18]:
| | CSD | BOROUGH | SCHOOL CODE | SCHOOL NAME | GRADE | PROGRAM TYPE | CORE SUBJECT (MS CORE and 9-12 ONLY) | CORE COURSE (MS CORE and 9-12 ONLY) | SERVICE CATEGORY(K-9\* ONLY) | NUMBER OF STUDENTS / SEATS FILLED | NUMBER OF SECTIONS | AVERAGE CLASS SIZE | SIZE OF SMALLEST CLASS | SIZE OF LARGEST CLASS | DATA SOURCE | SCHOOLWIDE PUPIL-TEACHER RATIO | DBN |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 0 | 1 | M | M015 | P.S. 015 Roberto Clemente | 0K | GEN ED | - | - | - | 19.0 | 1.0 | 19.0 | 19.0 | 19.0 | ATS | NaN | 01M015 |
| 1 | 1 | M | M015 | P.S. 015 Roberto Clemente | 0K | CTT | - | - | - | 21.0 | 1.0 | 21.0 | 21.0 | 21.0 | ATS | NaN | 01M015 |
| 2 | 1 | M | M015 | P.S. 015 Roberto Clemente | 01 | GEN ED | - | - | - | 17.0 | 1.0 | 17.0 | 17.0 | 17.0 | ATS | NaN | 01M015 |
| 3 | 1 | M | M015 | P.S. 015 Roberto Clemente | 01 | CTT | - | - | - | 17.0 | 1.0 | 17.0 | 17.0 | 17.0 | ATS | NaN | 01M015 |
| 4 | 1 | M | M015 | P.S. 015 Roberto Clemente | 02 | GEN ED | - | - | - | 15.0 | 1.0 | 15.0 | 15.0 | 15.0 | ATS | NaN | 01M015 |
每所高中都有许多行(正如你所见的重复的 `DBN` 和 `SCHOOL NAME`)。然而,如果我们看向 `sat_result` 数据集,每所高中只有一行:
In [21]:
```
data["sat_results"].head()
```
Out[21]:
| | DBN | SCHOOL NAME | Num of SAT Test Takers | SAT Critical Reading Avg. Score | SAT Math Avg. Score | SAT Writing Avg. Score |
| --- | --- | --- | --- | --- | --- | --- |
| 0 | 01M292 | HENRY STREET SCHOOL FOR INTERNATIONAL STUDIES | 29 | 355 | 404 | 363 |
| 1 | 01M448 | UNIVERSITY NEIGHBORHOOD HIGH SCHOOL | 91 | 383 | 423 | 366 |
| 2 | 01M450 | EAST SIDE COMMUNITY SCHOOL | 70 | 377 | 402 | 370 |
| 3 | 01M458 | FORSYTH SATELLITE ACADEMY | 7 | 414 | 401 | 359 |
| 4 | 01M509 | MARTA VALLE HIGH SCHOOL | 44 | 390 | 433 | 384 |
为了合并这些数据集,我们将需要找到方法将数据集精简到如 `class_size` 般一行对应一所高中。否则,我们将不能将 SAT 成绩与班级大小进行比较。我们通过首先更好的理解数据,然后做一些合并来完成。`class_size` 数据集像 `GRADE` 和 `PROGRAM TYPE`,每个学校有多个数据对应。为了将每个范围内的数据变为一个数据,我们将大部分重复行过滤掉,在下面的代码中我们将会:
* 只从 `class_size` 中选择 `GRADE` 范围为 `09-12` 的行。
* 只从 `class_size` 中选择 `PROGRAM TYPE` 是 `GEN ED` 的行。
* 将 `class_size` 以 `DBN` 分组,然后取每列的平均值。重要的是,我们将找到每所学校班级大小(`class_size`)平均值。
* 重置索引,将 `DBN` 重新加到列中。
In [68]:
```
class_size = data["class_size"]
class_size = class_size[class_size["GRADE "] == "09-12"]
class_size = class_size[class_size["PROGRAM TYPE"] == "GEN ED"]
class_size = class_size.groupby("DBN").agg(np.mean)
class_size.reset_index(inplace=True)
data["class_size"] = class_size
```
#### 精简其它数据集
接下来,我们将需要精简 `demographic` 数据集。这里有每个学校收集多年的数据,所以这里每所学校有许多重复的行。我们将只选取 `schoolyear` 最近的可用行:
In [69]:
```
demographics = data["demographics"]
demographics = demographics[demographics["schoolyear"] == 20112012]
data["demographics"] = demographics
```
我们需要精简 `math_test_results` 数据集。这个数据集被 `Grade` 和 `Year` 划分。我们将只选取单一学年的一个年级。
In [70]:
```
data["math_test_results"] = data["math_test_results"][data["math_test_results"]["Year"] == 2011]
data["math_test_results"] = data["math_test_results"][data["math_test_results"]["Grade"] == '8']
```
最后,`graduation`需要被精简:
In [71]:
```
data["graduation"] = data["graduation"][data["graduation"]["Cohort"] == "2006"]
data["graduation"] = data["graduation"][data["graduation"]["Demographic"] == "Total Cohort"]
```
在完成工程的主要部分之前数据清理和挖掘是十分重要的。有一个高质量的,一致的数据集将会使你的分析更加快速。
### 计算变量
计算变量可以通过使我们的比较更加快速来加快分析速度,并且能使我们做到本无法做到的比较。我们能做的第一件事就是从分开的列 `SAT Math Avg. Score`,`SAT Critical Reading Avg. Score` 和 `SAT Writing Avg. Score` 计算 SAT 成绩:
* 将 SAT 列数值从字符转化为数字。
* 将所有列相加以得到 `sat_score`,即 SAT 成绩。
In [72]:
```
cols = ['SAT Math Avg. Score', 'SAT Critical Reading Avg. Score', 'SAT Writing Avg. Score']
for c in cols:
data["sat_results"][c] = data["sat_results"][c].convert_objects(convert_numeric=True)
data['sat_results']['sat_score'] = data['sat_results'][cols[0]] + data['sat_results'][cols[1]] + data['sat_results'][cols[2]]
```
接下来,我们将需要进行每所学校的坐标位置分析,以便我们制作地图。这将使我们画出每所学校的位置。在下面的代码中,我们将会:
* 从 `Location 1` 列分析出经度和维度。
* 转化 `lat`(经度)和 `lon`(维度)为数字。
In [73]:
```
data["hs_directory"]['lat'] = data["hs_directory"]['Location 1'].apply(lambda x: x.split("\n")[-1].replace("(", "").replace(")", "").split(", ")[0])
data["hs_directory"]['lon'] = data["hs_directory"]['Location 1'].apply(lambda x: x.split("\n")[-1].replace("(", "").replace(")", "").split(", ")[1])
for c in ['lat', 'lon']:
data["hs_directory"][c] = data["hs_directory"][c].convert_objects(convert_numeric=True)
```
现在,我们将输出每个数据集来查看我们有了什么数据:
In [74]:
```
for k,v in data.items():
print(k)
print(v.head())
```
```
math_test_results
DBN Grade Year Category Number Tested Mean Scale Score \
111 01M034 8 2011 All Students 48 646
280 01M140 8 2011 All Students 61 665
346 01M184 8 2011 All Students 49 727
388 01M188 8 2011 All Students 49 658
411 01M292 8 2011 All Students 49 650
Level 1 # Level 1 % Level 2 # Level 2 % Level 3 # Level 3 % Level 4 # \
111 15 31.3% 22 45.8% 11 22.9% 0
280 1 1.6% 43 70.5% 17 27.9% 0
346 0 0% 0 0% 5 10.2% 44
388 10 20.4% 26 53.1% 10 20.4% 3
411 15 30.6% 25 51% 7 14.3% 2
Level 4 % Level 3+4 # Level 3+4 %
111 0% 11 22.9%
280 0% 17 27.9%
346 89.8% 49 100%
388 6.1% 13 26.5%
411 4.1% 9 18.4%
survey
DBN rr_s rr_t rr_p N_s N_t N_p saf_p_11 com_p_11 eng_p_11 \
0 01M015 NaN 88 60 NaN 22.0 90.0 8.5 7.6 7.5
1 01M019 NaN 100 60 NaN 34.0 161.0 8.4 7.6 7.6
2 01M020 NaN 88 73 NaN 42.0 367.0 8.9 8.3 8.3
3 01M034 89.0 73 50 145.0 29.0 151.0 8.8 8.2 8.0
4 01M063 NaN 100 60 NaN 23.0 90.0 8.7 7.9 8.1
... eng_t_10 aca_t_11 saf_s_11 com_s_11 eng_s_11 aca_s_11 \
0 ... NaN 7.9 NaN NaN NaN NaN
1 ... NaN 9.1 NaN NaN NaN NaN
2 ... NaN 7.5 NaN NaN NaN NaN
3 ... NaN 7.8 6.2 5.9 6.5 7.4
4 ... NaN 8.1 NaN NaN NaN NaN
saf_tot_11 com_tot_11 eng_tot_11 aca_tot_11
0 8.0 7.7 7.5 7.9
1 8.5 8.1 8.2 8.4
2 8.2 7.3 7.5 8.0
3 7.3 6.7 7.1 7.9
4 8.5 7.6 7.9 8.0
[5 rows x 23 columns]
ap_2010
DBN SchoolName AP Test Takers \
0 01M448 UNIVERSITY NEIGHBORHOOD H.S. 39
1 01M450 EAST SIDE COMMUNITY HS 19
2 01M515 LOWER EASTSIDE PREP 24
3 01M539 NEW EXPLORATIONS SCI,TECH,MATH 255
4 02M296 High School of Hospitality Management s
Total Exams Taken Number of Exams with scores 3 4 or 5
0 49 10
1 21 s
2 26 24
3 377 191
4 s s
sat_results
DBN SCHOOL NAME \
0 01M292 HENRY STREET SCHOOL FOR INTERNATIONAL STUDIES
1 01M448 UNIVERSITY NEIGHBORHOOD HIGH SCHOOL
2 01M450 EAST SIDE COMMUNITY SCHOOL
3 01M458 FORSYTH SATELLITE ACADEMY
4 01M509 MARTA VALLE HIGH SCHOOL
Num of SAT Test Takers SAT Critical Reading Avg. Score \
0 29 355.0
1 91 383.0
2 70 377.0
3 7 414.0
4 44 390.0
SAT Math Avg. Score SAT Writing Avg. Score sat_score
0 404.0 363.0 1122.0
1 423.0 366.0 1172.0
2 402.0 370.0 1149.0
3 401.0 359.0 1174.0
4 433.0 384.0 1207.0
class_size
DBN CSD NUMBER OF STUDENTS / SEATS FILLED NUMBER OF SECTIONS \
0 01M292 1 88.0000 4.000000
1 01M332 1 46.0000 2.000000
2 01M378 1 33.0000 1.000000
3 01M448 1 105.6875 4.750000
4 01M450 1 57.6000 2.733333
AVERAGE CLASS SIZE SIZE OF SMALLEST CLASS SIZE OF LARGEST CLASS \
0 22.564286 18.50 26.571429
1 22.000000 21.00 23.500000
2 33.000000 33.00 33.000000
3 22.231250 18.25 27.062500
4 21.200000 19.40 22.866667
SCHOOLWIDE PUPIL-TEACHER RATIO
0 NaN
1 NaN
2 NaN
3 NaN
4 NaN
demographics
DBN Name schoolyear \
6 01M015 P.S. 015 ROBERTO CLEMENTE 20112012
13 01M019 P.S. 019 ASHER LEVY 20112012
20 01M020 PS 020 ANNA SILVER 20112012
27 01M034 PS 034 FRANKLIN D ROOSEVELT 20112012
35 01M063 PS 063 WILLIAM MCKINLEY 20112012
fl_percent frl_percent total_enrollment prek k grade1 grade2 \
6 NaN 89.4 189 13 31 35 28
13 NaN 61.5 328 32 46 52 54
20 NaN 92.5 626 52 102 121 87
27 NaN 99.7 401 14 34 38 36
35 NaN 78.9 176 18 20 30 21
... black_num black_per hispanic_num hispanic_per white_num \
6 ... 63 33.3 109 57.7 4
13 ... 81 24.7 158 48.2 28
20 ... 55 8.8 357 57.0 16
27 ... 90 22.4 275 68.6 8
35 ... 41 23.3 110 62.5 15
white_per male_num male_per female_num female_per
6 2.1 97.0 51.3 92.0 48.7
13 8.5 147.0 44.8 181.0 55.2
20 2.6 330.0 52.7 296.0 47.3
27 2.0 204.0 50.9 197.0 49.1
35 8.5 97.0 55.1 79.0 44.9
[5 rows x 38 columns]
graduation
Demographic DBN School Name Cohort \
3 Total Cohort 01M292 HENRY STREET SCHOOL FOR INTERNATIONAL 2006
10 Total Cohort 01M448 UNIVERSITY NEIGHBORHOOD HIGH SCHOOL 2006
17 Total Cohort 01M450 EAST SIDE COMMUNITY SCHOOL 2006
24 Total Cohort 01M509 MARTA VALLE HIGH SCHOOL 2006
31 Total Cohort 01M515 LOWER EAST SIDE PREPARATORY HIGH SCHO 2006
Total Cohort Total Grads - n Total Grads - % of cohort Total Regents - n \
3 78 43 55.1% 36
10 124 53 42.7% 42
17 90 70 77.8% 67
24 84 47 56% 40
31 193 105 54.4% 91
Total Regents - % of cohort Total Regents - % of grads \
3 46.2% 83.7%
10 33.9% 79.2%
17 74.400000000000006% 95.7%
24 47.6% 85.1%
31 47.2% 86.7%
... Regents w/o Advanced - n \
3 ... 36
10 ... 34
17 ... 67
24 ... 23
31 ... 22
Regents w/o Advanced - % of cohort Regents w/o Advanced - % of grads \
3 46.2% 83.7%
10 27.4% 64.2%
17 74.400000000000006% 95.7%
24 27.4% 48.9%
31 11.4% 21%
Local - n Local - % of cohort Local - % of grads Still Enrolled - n \
3 7 9% 16.3% 16
10 11 8.9% 20.8% 46
17 3 3.3% 4.3% 15
24 7 8.300000000000001% 14.9% 25
31 14 7.3% 13.3% 53
Still Enrolled - % of cohort Dropped Out - n Dropped Out - % of cohort
3 20.5% 11 14.1%
10 37.1% 20 16.100000000000001%
17 16.7% 5 5.6%
24 29.8% 5 6%
31 27.5% 35 18.100000000000001%
[5 rows x 23 columns]
hs_directory
dbn school_name boro \
0 17K548 Brooklyn School for Music & Theatre Brooklyn
1 09X543 High School for Violin and Dance Bronx
2 09X327 Comprehensive Model School Project M.S. 327 Bronx
3 02M280 Manhattan Early College School for Advertising Manhattan
4 28Q680 Queens Gateway to Health Sciences Secondary Sc... Queens
building_code phone_number fax_number grade_span_min grade_span_max \
0 K440 718-230-6250 718-230-6262 9 12
1 X400 718-842-0687 718-589-9849 9 12
2 X240 718-294-8111 718-294-8109 6 12
3 M520 718-935-3477 NaN 9 10
4 Q695 718-969-3155 718-969-3552 6 12
expgrade_span_min expgrade_span_max ... \
0 NaN NaN ...
1 NaN NaN ...
2 NaN NaN ...
3 9 14.0 ...
4 NaN NaN ...
priority05 priority06 priority07 priority08 \
0 NaN NaN NaN NaN
1 NaN NaN NaN NaN
2 Then to New York City residents NaN NaN NaN
3 NaN NaN NaN NaN
4 NaN NaN NaN NaN
priority09 priority10 Location 1 \
0 NaN NaN 883 Classon Avenue\nBrooklyn, NY 11225\n(40.67...
1 NaN NaN 1110 Boston Road\nBronx, NY 10456\n(40.8276026...
2 NaN NaN 1501 Jerome Avenue\nBronx, NY 10452\n(40.84241...
3 NaN NaN 411 Pearl Street\nNew York, NY 10038\n(40.7106...
4 NaN NaN 160-20 Goethals Avenue\nJamaica, NY 11432\n(40...
DBN lat lon
0 17K548 40.670299 -73.961648
1 09X543 40.827603 -73.904475
2 09X327 40.842414 -73.916162
3 02M280 40.710679 -74.000807
4 28Q680 40.718810 -73.806500
[5 rows x 61 columns]
```
### 合并数据集
现在我们已经完成了全部准备工作,我们可以用 `DBN` 列将数据组合在一起了。最终,我们将会从原始数据集得到一个有着上百列的数据集。当我们合并它们,请注意有些数据集中会丢失了 `sat_result` 中出现的高中。为了解决这个问题,我们需要使用 `outer` 方法来合并缺少行的数据集,这样我们就不会丢失数据。在实际分析中,缺少数据是很常见的。能够展示解释和解决数据缺失的能力是构建一个作品集的重要部分。
你可以在[此](http://pandas.pydata.org/pandas-docs/stable/merging.html)阅读关于不同类型的合并。
接下来的代码,我们将会:
* 循环遍历 `data` 文件夹中的每一个条目。
* 输出条目中的非唯一的 DBN 码数量。
* 决定合并策略 - `inner` 或 `outer`。
* 使用 `DBN` 列将条目合并到 DataFrame `full` 中。
In [75]:
```
flat_data_names = [k for k,v in data.items()]
flat_data = [data[k] for k in flat_data_names]
full = flat_data[0]
for i, f in enumerate(flat_data[1:]):
name = flat_data_names[i+1]
print(name)
print(len(f["DBN"]) - len(f["DBN"].unique()))
join_type = "inner"
if name in ["sat_results", "ap_2010", "graduation"]:
join_type = "outer"
if name not in ["math_test_results"]:
full = full.merge(f, on="DBN", how=join_type)
full.shape
```
```
survey
0
ap_2010
1
sat_results
0
class_size
0
demographics
0
graduation
0
hs_directory
0
```
Out[75]:
```
(374, 174)
```
### 添加值
现在我们有了我们的 `full` 数据框架,我们几乎拥有分析需要的所有数据。虽然这里有一些缺少的部分。我们可能将[AP](https://apstudent.collegeboard.org/home) 考试结果与 SAT 成绩相关联,但是我们首先需要将这些列转化为数字,然后填充缺失的数据。
In [76]:
```
cols = ['AP Test Takers ', 'Total Exams Taken', 'Number of Exams with scores 3 4 or 5']
for col in cols:
full[col] = full[col].convert_objects(convert_numeric=True)
full[cols] = full[cols].fillna(value=0)
```
然后我们将需要计算表示学校所在学区的 `school_dist`列。这将是我们匹配学区并且使用我们之前下载的区域地图画出地区级别的地图。
In [77]:
```
full["school_dist"] = full["DBN"].apply(lambda x: x[:2])
```
最终,我们将需要用该列的平均值填充缺失的数据到 `full` 中。那么我们就可以计算关联了:
In [79]:
```
full = full.fillna(full.mean())
```
### 计算关联
一个挖掘数据并查看哪些列与你所关心的问题有联系的好方法来就是计算关联。这将告诉你哪列与你所关心的列更加有关联。你可以通过 Pandas DataFrames 的 [corr](http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.corr.html) 方法来完成。越接近 0 则关联越小。越接近 1 则正相关越强,越接近 -1 则负关联越强:
In [80]:
```
full.corr()['sat_score']
```
Out[80]:
```
Year NaN
Number Tested 8.127817e-02
rr_s 8.484298e-02
rr_t -6.604290e-02
rr_p 3.432778e-02
N_s 1.399443e-01
N_t 9.654314e-03
N_p 1.397405e-01
saf_p_11 1.050653e-01
com_p_11 2.107343e-02
eng_p_11 5.094925e-02
aca_p_11 5.822715e-02
saf_t_11 1.206710e-01
com_t_11 3.875666e-02
eng_t_10 NaN
aca_t_11 5.250357e-02
saf_s_11 1.054050e-01
com_s_11 4.576521e-02
eng_s_11 6.303699e-02
aca_s_11 8.015700e-02
saf_tot_11 1.266955e-01
com_tot_11 4.340710e-02
eng_tot_11 5.028588e-02
aca_tot_11 7.229584e-02
AP Test Takers 5.687940e-01
Total Exams Taken 5.585421e-01
Number of Exams with scores 3 4 or 5 5.619043e-01
SAT Critical Reading Avg. Score 9.868201e-01
SAT Math Avg. Score 9.726430e-01
SAT Writing Avg. Score 9.877708e-01
...
SIZE OF SMALLEST CLASS 2.440690e-01
SIZE OF LARGEST CLASS 3.052551e-01
SCHOOLWIDE PUPIL-TEACHER RATIO NaN
schoolyear NaN
frl_percent -7.018217e-01
total_enrollment 3.668201e-01
ell_num -1.535745e-01
ell_percent -3.981643e-01
sped_num 3.486852e-02
sped_percent -4.413665e-01
asian_num 4.748801e-01
asian_per 5.686267e-01
black_num 2.788331e-02
black_per -2.827907e-01
hispanic_num 2.568811e-02
hispanic_per -3.926373e-01
white_num 4.490835e-01
white_per 6.100860e-01
male_num 3.245320e-01
male_per -1.101484e-01
female_num 3.876979e-01
female_per 1.101928e-01
Total Cohort 3.244785e-01
grade_span_max -2.495359e-17
expgrade_span_max NaN
zip -6.312962e-02
total_students 4.066081e-01
number_programs 1.166234e-01
lat -1.198662e-01
lon -1.315241e-01
Name: sat_score, dtype: float64
```
这给了我们一些我们需要探索的内在规律:
* `total_enrollment` 与 `sat_score` 强相关,这是令人惊讶的,因为你曾经认为越小的学校越专注于学生就会取得更高的成绩。
* 女生所占学校的比例(`female_per`) 与 SAT 成绩呈正相关,而男生所占学生比例(`male_per`)成负相关。
* 没有问卷与 SAT 成绩成正相关。
* SAT 成绩有明显的种族不平等(`white_per`、`asian_per`、`black_per`、`hispanic_per`)。
* `ell_percent` 与 SAT 成绩明显负相关。
每一个条目都是一个挖掘和讲述数据故事的潜在角度。
### 设置上下文
在我们开始数据挖掘之前,我们将希望设置上下文,不仅为了我们自己,也是为了其它阅读我们分析的人。一个好的方法就是建立挖掘图表或者地图。因此,我们将在地图标出所有学校的位置,这将有助于读者理解我们所探索的问题。
在下面的代码中,我们将会:
* 建立纽约市为中心的地图。
* 为城市里的每所高中添加一个标记。
* 显示地图。
In [82]:
```
import folium
from folium import plugins
schools_map = folium.Map(location=[full['lat'].mean(), full['lon'].mean()], zoom_start=10)
marker_cluster = folium.MarkerCluster().add_to(schools_map)
for name, row in full.iterrows():
folium.Marker([row["lat"], row["lon"]], popup="{0}: {1}".format(row["DBN"], row["school_name"])).add_to(marker_cluster)
schools_map.create_map('schools.html')
schools_map
```
Out[82]:

这个地图十分有用,但是不容易查看纽约哪里学校最多。因此,我们将用热力图来代替它:
In [84]:
```
schools_heatmap = folium.Map(location=[full['lat'].mean(), full['lon'].mean()], zoom_start=10)
schools_heatmap.add_children(plugins.HeatMap([[row["lat"], row["lon"]] for name, row in full.iterrows()]))
schools_heatmap.save("heatmap.html")
schools_heatmap
```
Out[84]:

### 区域级别映射
热力图能够很好的标出梯度,但是我们将需要更结构化的画出不同城市之间的 SAT 分数差距。学区是一个图形化这个信息的很好的方式,就像每个区域都有自己的管理者。纽约市有数十个学区,并且每个区域都是一个小的地理区域。
我们可以通过学区来计算 SAT 分数,然后将它们画在地图上。在下面的代码中,我们将会:
* 通过学区对 `full` 进行分组。
* 计算每个学区的每列的平均值。
* 去掉 `school_dist` 字段头部的 0,然后我们就可以匹配地理数据了。
In [ ]:
```
district_data = full.groupby("school_dist").agg(np.mean)
district_data.reset_index(inplace=True)
district_data["school_dist"] = district_data["school_dist"].apply(lambda x: str(int(x)))
```
我们现在将可以画出 SAT 在每个学区的平均值了。因此,我们将会读取 [GeoJSON](http://geojson.org/) 中的数据,转化为每个区域的形状,然后通过 `school_dist` 列对每个区域图形和 SAT 成绩进行匹配。最终我们将创建一个图形:
In [85]:
```
def show_district_map(col):
geo_path = 'schools/districts.geojson'
districts = folium.Map(location=[full['lat'].mean(), full['lon'].mean()], zoom_start=10)
districts.geo_json(
geo_path=geo_path,
data=district_data,
columns=['school_dist', col],
key_on='feature.properties.school_dist',
fill_color='YlGn',
fill_opacity=0.7,
line_opacity=0.2,
)
districts.save("districts.html")
return districts
show_district_map("sat_score")
```
Out[85]:

### 挖掘注册学生数与SAT分数
现在我们已经依地区画出学校位置和 SAT 成绩确定了上下文,浏览我们分析的人将会对数据的上下文有更好的理解。现在我们已经完成了基础工作,我们可以开始从我们上面寻找关联时所提到的角度分析了。第一个分析角度是学校注册学生人数与 SAT 成绩。
我们可以通过所有学校的注册学生与 SAT 成绩的散点图来分析。
In [87]:
```
%matplotlib inline
full.plot.scatter(x='total_enrollment', y='sat_score')
```
Out[87]:
```
<matplotlib.axes._subplots.AxesSubplot at 0x10fe79978>
```

如你所见,底下角注册人数较低的部分有个较低 SAT 成绩的聚集。这个集群以外,SAT 成绩与全部注册人数只有轻微正相关。这个画出的关联显示了意想不到的图形.
我们可以通过获取低注册人数且低SAT成绩的学校的名字进行进一步的分析。
In [88]:
```
full[(full["total_enrollment"] < 1000) & (full["sat_score"] < 1000)]["School Name"]
```
Out[88]:
```
34 INTERNATIONAL SCHOOL FOR LIBERAL ARTS
143 NaN
148 KINGSBRIDGE INTERNATIONAL HIGH SCHOOL
203 MULTICULTURAL HIGH SCHOOL
294 INTERNATIONAL COMMUNITY HIGH SCHOOL
304 BRONX INTERNATIONAL HIGH SCHOOL
314 NaN
317 HIGH SCHOOL OF WORLD CULTURES
320 BROOKLYN INTERNATIONAL HIGH SCHOOL
329 INTERNATIONAL HIGH SCHOOL AT PROSPECT
331 IT TAKES A VILLAGE ACADEMY
351 PAN AMERICAN INTERNATIONAL HIGH SCHOO
Name: School Name, dtype: object
```
在 Google 上进行了一些搜索确定了这些学校大多数是为了正在学习英语而开设的,所以有这么低注册人数(规模)。这个挖掘向我们展示了并不是所有的注册人数都与 SAT 成绩有关联 - 而是与是否将英语作为第二语言学习的学生有关。
### 挖掘英语学习者和 SAT 成绩
现在我们知道英语学习者所占学校学生比例与低的 SAT 成绩有关联,我们可以探索其中的规律。`ell_percent` 列表示一个学校英语学习者所占的比例。我们可以制作关于这个关联的散点图。
In [89]:
```
full.plot.scatter(x='ell_percent', y='sat_score')
```
Out[89]:
```
<matplotlib.axes._subplots.AxesSubplot at 0x10fe824e0>
```

看起来这里有一组学校有着高的 `ell_percentage` 值并且有着低的 SAT 成绩。我们可以在学区层面调查这个关系,通过找出每个学区英语学习者所占的比例,并且查看是否与我们的学区层面的 SAT 地图所匹配:
In [90]:
```
show_district_map("ell_percent")
```
Out[90]:

我们可通过两个区域层面地图来查看,一个低 ELL(English-language)学习者比例的地区更倾向有高 SAT 成绩,反之亦然。
### 关联问卷分数和 SAT 分数
学生、家长和老师的问卷结果如果与 SAT 分数有很大的关联的假设是合理的。就例如具有高学术期望的学校倾向于有着更高的 SAT 分数是合理的。为了测这个理论,让我们画出 SAT 分数和多种问卷指标:
In [91]:
```
full.corr()["sat_score"][["rr_s", "rr_t", "rr_p", "N_s", "N_t", "N_p", "saf_tot_11", "com_tot_11", "aca_tot_11", "eng_tot_11"]].plot.bar()
```
Out[91]:
```
<matplotlib.axes._subplots.AxesSubplot at 0x114652400>
```

惊人的是,关联最大的两个因子是 `N_p` 和 `N_s`,它们分别是家长和学生回应的问卷。都与注册人数有着强关联,所以很可能偏离了 `ell_learner`。此外指标关联最强的就是 `saf_t_11`,这是学生、家长和老师对学校安全程度的感知。这说明了,越安全的学校,更能让学生在环境里安心学习。然而其它因子,像互动、交流和学术水平都与 SAT 分数无关,这也许表明了纽约在问卷中问了不理想的问题或者想错了因子(如果他们的目的是提高 SAT 分数的话)。
### 挖掘种族和 SAT 分数
其中一个角度就是调查种族和 SAT 分数的联系。这是一个大相关微分,将其画出来帮助我们理解到底发生了什么:
In [92]:
```
full.corr()["sat_score"][["white_per", "asian_per", "black_per", "hispanic_per"]].plot.bar()
```
Out[92]:
```
<matplotlib.axes._subplots.AxesSubplot at 0x108166ba8>
```

看起来更高比例的白种和亚洲学生与更高的 SAT 分数有关联,而更高比例的黑人和西班牙裔与更低的 SAT 分数有关联。对于西班牙学生,这可能因为近年的移民还是英语学习者的事实。我们可以标出学区层面的西班牙裔的比例并观察联系。
In [93]:
```
show_district_map("hispanic_per")
```
Out[93]:

看起来这里与英语学习者比例有关联,但是有必要对这种和其它种族在 SAT 分数上的差异进行挖掘。
### SAT 分数上的性别差异
挖掘性别与 SAT 分数之间的关系是最后一个角度。我们注意更高的女生比例的学校倾向于与更高的 SAT 分数有关联。我们可以可视化为一个条形图:
In [94]:
```
full.corr()["sat_score"][["male_per", "female_per"]].plot.bar()
```
Out[94]:
```
<matplotlib.axes._subplots.AxesSubplot at 0x10774d0f0>
```

为了挖掘更多的关联性,我们可以制作一个 `female_per` 和 `sat_score` 的散点图:
In [95]:
```
full.plot.scatter(x='female_per', y='sat_score')
```
Out[95]:
```
<matplotlib.axes._subplots.AxesSubplot at 0x104715160>
```

看起来这里有一个高女生比例、高 SAT 成绩的簇(右上角)(LCTT 译注:此处散点图并未有如此迹象,可能数据图有误)。我们可以获取簇中学校的名字:
In [96]:
```
full[(full["female_per"] > 65) & (full["sat_score"] > 1400)]["School Name"]
```
Out[96]:
```
3 PROFESSIONAL PERFORMING ARTS HIGH SCH
92 ELEANOR ROOSEVELT HIGH SCHOOL
100 TALENT UNLIMITED HIGH SCHOOL
111 FIORELLO H. LAGUARDIA HIGH SCHOOL OF
229 TOWNSEND HARRIS HIGH SCHOOL
250 FRANK SINATRA SCHOOL OF THE ARTS HIGH SCHOOL
265 BARD HIGH SCHOOL EARLY COLLEGE
Name: School Name, dtype: object
```
使用 Google 进行搜索可以知道这些是专注于表演艺术的精英学校。这些学校有着更高比例的女生和更高的 SAT 分数。这可能解释了更高的女生比例和 SAT 分数的关联,并且相反的更高的男生比例与更低的 SAT 分数。
### AP 成绩
至今,我们关注的是人口统计角度。还有一个角度是我们通过数据来看参加高阶测试(AP)的学生和 SAT 分数。因为高学术成绩获得者倾向于有着高的 SAT 分数说明了它们是有关联的。
In [98]:
```
full["ap_avg"] = full["AP Test Takers "] / full["total_enrollment"]
full.plot.scatter(x='ap_avg', y='sat_score')
```
Out[98]:
```
<matplotlib.axes._subplots.AxesSubplot at 0x11463a908>
```

看起来它们之间确实有着很强的关联。有趣的是右上角高 SAT 分数的学校有着高的 AP 测试通过比例:
In [99]:
```
full[(full["ap_avg"] > .3) & (full["sat_score"] > 1700)]["School Name"]
```
Out[99]:
```
92 ELEANOR ROOSEVELT HIGH SCHOOL
98 STUYVESANT HIGH SCHOOL
157 BRONX HIGH SCHOOL OF SCIENCE
161 HIGH SCHOOL OF AMERICAN STUDIES AT LE
176 BROOKLYN TECHNICAL HIGH SCHOOL
229 TOWNSEND HARRIS HIGH SCHOOL
243 QUEENS HIGH SCHOOL FOR THE SCIENCES A
260 STATEN ISLAND TECHNICAL HIGH SCHOOL
Name: School Name, dtype: object
```
通过 google 搜索解释了那些大多是高选择性的学校,你需要经过测试才能进入。这就说明了为什么这些学校会有高的 AP 通过人数。
### 包装故事
在数据科学中,故事不可能真正完结。通过向其他人发布分析,你可以让他们拓展并且运用你的分析到他们所感兴趣的方向。比如在本文中,这里有一些角度我们没有完成,并且可以探索更加深入。
一个开始讲述故事的最好方式就是尝试拓展或者复制别人已经完成的分析。如果你觉得采取这个方式,欢迎你拓展这篇文章的分析,并看看你能发现什么。如果你确实这么做了,请在下面评论,那么我就可以看到了。
### 下一步
如果你做的足够多,你看起来已经对用数据讲故事和构建你的第一个数据科学作品集有了很好的理解。一旦你完成了你的数据科学工程,发表在 [Github](https://github.com/) 上是一个好的想法,这样别人就能够与你一起合作。
如果你喜欢这篇文章,你可能希望阅读我们‘Build a Data Science Portfolio’系列文章的其它部分:
* [如何搭建一个数据科学博客](https://www.dataquest.io/blog/how-to-setup-a-data-science-blog/)
* [建立一个机器学习工程](/article-7907-1.html)
* [构建一个将帮助你找到工作的数据科学作品集的关键](https://www.dataquest.io/blog/build-a-data-science-portfolio/)
* [17 个你能找到其它数据科学工程数据集的地方](https://www.dataquest.io/blog/free-datasets-for-projects)
* [怎样在 GitHub 上展示你的数据科学作品集](https://www.dataquest.io/blog/how-to-share-data-science-portfolio/)
---
via: <https://www.dataquest.io/blog/data-science-portfolio-project/>
作者:[Vik Paruchuri](http://twitter.com/vikparuchuri) 译者:[Yoo-4x] 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Building a Data Science Portfolio: Storytelling with Data
*This is the first in a series of posts on how to build a Data Science Portfolio. You can find links to the other posts in this series at the bottom of the post.*
Data science companies are increasingly looking at portfolios when making hiring decisions. One of the reasons for this is that a portfolio is the best way to judge someone’s real-world skills. The good news for you is that a portfolio is entirely within your control. If you put some work in, you can make a great portfolio that companies are impressed by.
The first step in making a high-quality portfolio is to know what skills to demonstrate. The primary skills that companies want in data scientists, and thus the primary skills they want a portfolio to demonstrate, are:
- Ability to communicate
- Ability to collaborate with others
- Technical competence
- Ability to reason about data
- Motivation and ability to take initiative
Any good portfolio will be composed of multiple projects, each of which may demonstrate 1-2 of the above points. This is the first post in a series that will cover how to make a well-rounded data science portfolio. In this post, we’ll cover how to make your first project for a data science portfolio, and how to tell an effective story using data. At the end, you’ll have a project that will help demonstrate your ability to communicate, and your ability to reason about data.
## Storytelling with data
Data science is fundamentally about communication. You’ll discover some insight in the data, then figure out an effective way to communicate that insight to others, then sell them on the course of action you propose. One of the most critical skills in data science is being able to tell an effective story using data. An effective story can make your insights much more compelling, and help others understand your ideas.
A story in the data science context is a narrative around what you found, how you found it, and what it means. An example might be the discovery that your company’s revenue has dropped 20 percent in the last year. It’s not enough to just state that fact — you’ll have to communicate why revenue dropped, and how to potentially fix it.
The main components of storytelling with data are:
- Understanding and setting the context
- Exploring multiple angles
- Using compelling visualizations
- Using varied data sources
- Having a consistent narrative
The best tool to effectively tell a story with data is [Jupyter notebook](https://www.jupyter.org). If you’re unfamiliar, [here’s](https://www.dataquest.io/blog/python-data-science/) a good tutorial. Jupyter notebook allows you to interactively explore data, then share your results on various sites, including Github. Sharing your results is helpful both for collaboration, and so others can extend your analysis.
We’ll use Jupyter notebook, along with Python libraries like Pandas and matplotlib in this post.
## Choosing a topic for your data science project
The first step in creating a project is to decide on your topic. You want the topic to be something you’re interested in, and are motivated to explore. It’s very obvious when people are making projects just to make them, and when people are making projects because they’re genuinely interested in exploring the data. It’s worth spending extra time on this step, so ensure that you find something you’re actually interested in.
A good way to find a topic is to browse different datasets and seeing what looks interesting. Here are some good sites to start with:
[Data.gov](https://www.data.gov)— contains government data.[/r/datasets](https://reddit.com/r/datasets)— a subreddit that has hundreds of interesting datasets.[Awesome datasets](https://github.com/caesar0301/awesome-public-datasets)— a list of datasets, hosted on Github.[17 places to find datasets](https://www.dataquest.io/blog/free-datasets-for-projects/)— a blog post with 17 data sources, and example datasets from each.
In real-world data science, you often won’t find a nice single dataset that you can browse. You might have to aggregate disparate data sources, or do a good amount of data cleaning. If a topic is very interesting to you, it’s worth doing the same here, so you can show off your skills better.
For the purposes of this post, we’ll be using data about New York city public schools, which can be found [here](https://data.cityofnewyork.us/browse?category=Education).
## Pick a topic
It’s important to be able to take the project from start to finish. In order to do this, it can be helpful to restrict the scope of the project, and make it something we know we can finish. It’s easier to add to a finished project than to complete a project that you just can’t seem to ever get enough motivation to finish.
In this case, we’ll look at the [SAT scores](https://en.wikipedia.org/wiki/SAT) of high schoolers, along with various demographic and other information about them. The SAT, or Scholastic Aptitude Test, is a test that high schoolers take in the US before applying to college. Colleges take the test scores into account when making admissions decisions, so it’s fairly important to do well on. The test is divided into 3 sections, each of which is scored out of 800 points. The total score is out of 2400 (although this has changed back and forth a few times, the scores in this dataset are out of 2400). High schools are often ranked by their average SAT scores, and high SAT scores are considered a sign of how good a school district is.
There have been allegations about the SAT being unfair to certain racial groups in the US, so doing this analysis on New York City data will help shed some light on the fairness of the SAT.
We have a dataset of SAT scores [here](https://data.cityofnewyork.us/Education/SAT-Results/f9bf-2cp4), and a dataset that contains information on each high school [here](https://data.cityofnewyork.us/Education/DOE-High-School-Directory-2014-2015/n3p6-zve2). These will form the base of our project, but we’ll need to add more information to create compelling analysis.
## Supplementing the data
Once you have a good topic, it’s good to scope out other datasets that can enhance the topic or give you more depth to explore. It’s good to do this upfront, so you have as much data as possible to explore as you’re building your project. Having too little data might mean that you give up on your project too early.
In this case, there are several related datasets on the same website that cover demographic information and test scores.
Here are the links to all of the datasets we’ll be using:
[SAT scores by school](https://data.cityofnewyork.us/Education/SAT-Results/f9bf-2cp4)— SAT scores for each high school in New York City.[School attendance](https://data.cityofnewyork.us/Education/School-Attendance-and-Enrollment-Statistics-by-Dis/7z8d-msnt)— attendance information on every school in NYC.[Math test results](https://data.cityofnewyork.us/Education/NYS-Math-Test-Results-By-Grade-2006-2011-School-Le/jufi-gzgp)— math test results for every school in NYC.[Class size](https://data.cityofnewyork.us/Education/2010-2011-Class-Size-School-level-detail/urz7-pzb3)— class size information for each school in NYC.[AP test results](https://data.cityofnewyork.us/Education/AP-College-Board-2010-School-Level-Results/itfs-ms3e)— Advanced Placement exam results for each high school. Passing AP exams can get you college credit in the US.[Graduation outcomes](https://data.cityofnewyork.us/Education/Graduation-Outcomes-Classes-Of-2005-2010-School-Le/vh2h-md7a)— percentage of students who graduated, and other outcome information.[Demographics](https://data.cityofnewyork.us/Education/School-Demographics-and-Accountability-Snapshot-20/ihfw-zy9j)— demographic information for each school.[School survey](https://data.cityofnewyork.us/Education/NYC-School-Survey-2011/mnz3-dyi8)— surveys of parents, teachers, and students at each school.[School district maps](https://data.cityofnewyork.us/Education/School-Districts/r8nu-ymqj)— contains information on the layout of the school districts, so that we can map them out.
All of these datasets are interrelated, and we’ll be able to combine them before we do any analysis.
## Getting background information
Before diving into analyzing the data, it’s useful to research some background information. In this case, we know a few facts that will be useful:
- New York City is divided into
`5`
boroughs, which are essentially distinct regions. - Schools in New York City are divided into several school district, each of which can contains dozens of schools.
- Not all the schools in all of the datasets are high schools, so we’ll need to do some data cleaning.
- Each school in New York City has a unique code called a
`DBN`
, or District Borough Number. - By aggregating data by district, we can use the district mapping data to plot district-by-district differences.
## Understanding the data
In order to really understand the context of the data, you’ll want to spend time exploring and reading about the data. In this case, each link above has a description of the data, along with the relevant columns. It looks like we have data on the SAT scores of high schoolers, along with other datasets that contain demographic and other information.
We can run some code to read in the data. We’ll be using [Jupyter notebook](https://jupyter.org/) to explore the data. The below code will:
- Loop through each data file we downloaded.
- Read the file into a
[Pandas DataFrame](https://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.html). - Put each DataFrame into a Python dictionary.
```
import pandas
import numpy as np
files = ["ap_2010.csv", "class_size.csv", "demographics.csv", "graduation.csv", "hs_directory.csv", "math_test_results.csv", "sat_results.csv"]
data = {}
for f in files:
d = pandas.read_csv("schools/{0}".format(f))
data[f.replace(".csv", "")] = d
```
Once we’ve read the data in, we can use the [head] method on DataFrames to print the first `5`
lines of each DataFrame:
```
for k,v in data.items():
print("\n" + k + "\n")
print(v.head())
```
```
math_test_results
DBN Grade Year Category Number Tested Mean Scale Score Level 1 # \
0 01M015 3 2006 All Students 39 667 21 01M015 3 2007 All Students 31 672 22 01M015 3 2008 All Students 37 668 03 01M015 3 2009 All Students 33 668 04 01M015 3 2010 All Students 26 677 6 Level 1
```We can start to see some useful patterns in the datasets:
- Most of the datasets contain a
`DBN`
column
- Some fields look interesting for mapping, particularly
`Location 1`
, which contains coordinates inside a larger string.
- Some of the datasets appear to contain multiple rows for each school (repeated DBN values), which means we’ll have to do some preprocessing.
## Unifying the data
In order to work with the data more easily, we’ll need to unify all the individual datasets into a single one. This will enable us to quickly compare columns across datasets. In order to do this, we’ll first need to find a common column to unify them on. Looking at the output above, it appears that `DBN`
might be that common column, as it appears in multiple datasets.
If we google `DBN New York City Schools`
, we end up [here](https://developer.cityofnewyork.us/api/doe-school-choice), which explains that the `DBN`
is a unique code for each school. When exploring datasets, particularly government ones, it’s often necessary to do some detective work to figure out what each column means, or even what each dataset is.
The problem now is that two of the datasets, `class_size`
, and `hs_directory`
, don’t have a `DBN`
field. In the `hs_directory`
data, it’s just named `dbn`
, so we can just rename the column, or copy it over into a new column called `DBN`
. In the `class_size`
data, we’ll need to try a different approach.
The `DBN`
column looks like this:
`data["demographics"]["DBN"].head()`
```
0 01M015
1 01M015
2 01M015
3 01M015
4 01M015
Name: DBN, dtype: object
```
If we look at the `class_size`
data, here’s what we’d see in the first `5`
rows:
`data["class_size"].head()`
CSD
BOROUGH
SCHOOL CODE
SCHOOL NAME
GRADE
PROGRAM TYPE
CORE SUBJECT (MS CORE and 9-12 ONLY)
CORE COURSE (MS CORE and 9-12 ONLY)
SERVICE CATEGORY(K-9* ONLY)
NUMBER OF STUDENTS / SEATS FILLED
NUMBER OF SECTIONS
AVERAGE CLASS SIZE
SIZE OF SMALLEST CLASS
SIZE OF LARGEST CLASS
DATA SOURCE
SCHOOLWIDE PUPIL-TEACHER RATIO
0
1
M
M015
P.S. 015 Roberto Clemente
0K
GEN ED
–
–
–
19.0
1.0
19.0
19.0
19.0
ATS
NaN
1
1
M
M015
P.S. 015 Roberto Clemente
0K
CTT
–
–
–
21.0
1.0
21.0
21.0
21.0
ATS
NaN
2
1
M
M015
P.S. 015 Roberto Clemente
01
GEN ED
–
–
–
17.0
1.0
17.0
17.0
17.0
ATS
NaN
3
1
M
M015
P.S. 015 Roberto Clemente
01
CTT
–
–
–
17.0
1.0
17.0
17.0
17.0
ATS
NaN
4
1
M
M015
P.S. 015 Roberto Clemente
02
GEN ED
–
–
–
15.0
1.0
15.0
15.0
15.0
ATS
NaN
As you can see above, it looks like the `DBN`
is actually a combination of `CSD`
, `BOROUGH`
, and `SCHOOL CODE`
. For those unfamiliar with New York City, it is composed of `5`
boroughs. Each borough is an organizational unit, and is about the same size as a fairly large US City. `DBN`
stands for `District Borough Number`
. It looks like `CSD`
is the District, `BOROUGH`
is the borough, and when combined with the `SCHOOL CODE`
, forms the `DBN`
. There’s no systematized way to find insights like this in data, and it requires some exploration and playing around to figure out.
Now that we know how to construct the `DBN`
, we can add it into the `class_size`
and `hs_directory`
datasets:
```
data["class_size"]["DBN"] = data["class_size"].apply(lambda x: "{0:02d}{1}".format(x["CSD"], x["SCHOOL CODE"]), axis=1)
data["hs_directory"]["DBN"] = data["hs_directory"]["dbn"]
```
### Adding in the surveys
One of the most potentially interesting datasets to look at is the dataset on student, parent, and teacher surveys about the quality of schools. These surveys include information about the perceived safety of each school, academic standards, and more. Before we combine our datasets, let’s add in the survey data. In real-world data science projects, you’ll often come across interesting data when you’re midway through your analysis, and will want to incorporate it. Working with a flexible tool like Jupyter notebook will allow you to quickly add some additional code, and re-run your analysis.
In this case, we’ll add the survey data into our `data`
dictionary, and then combine all the datasets afterwards. The survey data consists of `2`
files, one for all schools, and one for school district `75`
. We’ll need to write some code to combine them. In the below code, we’ll:
- Read in the surveys for all schools using the
`windows-1252`
file encoding.
- Read in the surveys for district 75 schools using the
`windows-1252`
file encoding.
- Add a flag that indicates which school district each dataset is for.
- Combine the datasets into one using the
[concat](https://pandas.pydata.org/pandas-docs/stable/generated/pandas.concat.html) method on DataFrames.
```
survey1 = pandas.read_csv("schools/survey_all.txt", delimiter="\t", encoding='windows-1252')
survey2 = pandas.read_csv("schools/survey_d75.txt", delimiter="\t", encoding='windows-1252')
survey1["d75"] = False
survey2["d75"] = True
survey = pandas.concat([survey1, survey2], axis=0)
```
Once we have the surveys combined, there’s an additional complication. We want to minimize the number of columns in our combined dataset so we can easily compare columns and figure out correlations. Unfortunately, the survey data has many columns that aren’t very useful to us:
`survey.head()`
N_p
N_s
N_t
aca_p_11
aca_s_11
aca_t_11
aca_tot_11
bn
com_p_11
com_s_11
…
t_q8c_1
t_q8c_2
t_q8c_3
t_q8c_4
t_q9
t_q9_1
t_q9_2
t_q9_3
t_q9_4
t_q9_5
0
90.0
NaN
22.0
7.8
NaN
7.9
7.9
M015
7.6
NaN
…
29.0
67.0
5.0
0.0
NaN
5.0
14.0
52.0
24.0
5.0
1
161.0
NaN
34.0
7.8
NaN
9.1
8.4
M019
7.6
NaN
…
74.0
21.0
6.0
0.0
NaN
3.0
6.0
3.0
78.0
9.0
2
367.0
NaN
42.0
8.6
NaN
7.5
8.0
M020
8.3
NaN
…
33.0
35.0
20.0
13.0
NaN
3.0
5.0
16.0
70.0
5.0
3
151.0
145.0
29.0
8.5
7.4
7.8
7.9
M034
8.2
5.9
…
21.0
45.0
28.0
7.0
NaN
0.0
18.0
32.0
39.0
11.0
4
90.0
NaN
23.0
7.9
NaN
8.1
8.0
M063
7.9
NaN
…
59.0
36.0
5.0
0.0
NaN
10.0
5.0
10.0
60.0
15.0
5 rows × 2773 columns
We can resolve this issue by looking at the data dictionary file that we downloaded along with the survey data. The file tells us the important fields in the data:
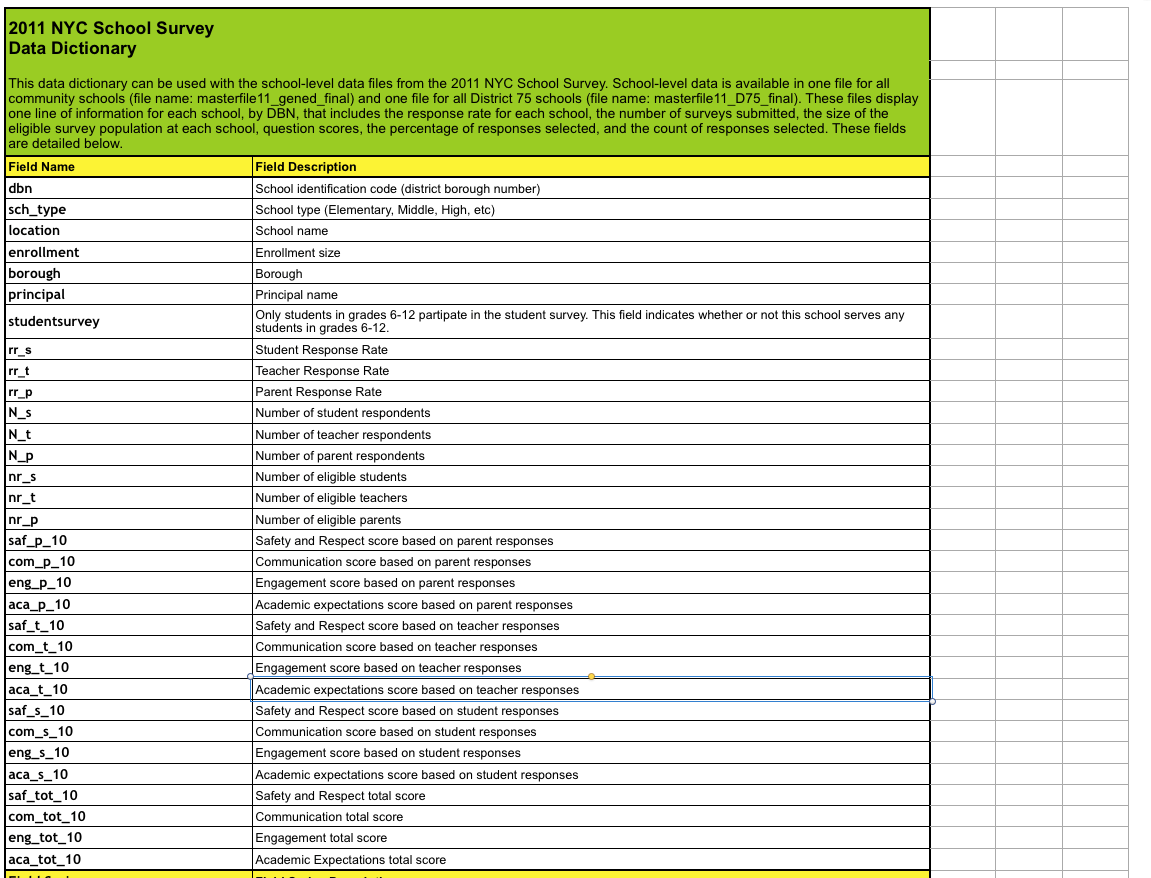
We can then remove any extraneous columns in `survey`
:
```
survey["DBN"] = survey["dbn"]
survey_fields = ["DBN", "rr_s", "rr_t", "rr_p", "N_s", "N_t", "N_p", "saf_p_11", "com_p_11", "eng_p_11", "aca_p_11", "saf_t_11", "com_t_11", "eng_t_10", "aca_t_11", "saf_s_11", "com_s_11", "eng_s_11", "aca_s_11", "saf_tot_11", "com_tot_11", "eng_tot_11", "aca_tot_11",]
survey = survey.loc[:,survey_fields]
data["survey"] = survey
survey.shape
```
`(1702, 23)`
Making sure you understand what each dataset contains, and what the relevant columns are can save you lots of time and effort later on.
## Condensing datasets
If we take a look at some of the datasets, including `class_size`
, we’ll immediately see a problem:
`data["class_size"].head()`
CSD
BOROUGH
SCHOOL CODE
SCHOOL NAME
GRADE
PROGRAM TYPE
CORE SUBJECT (MS CORE and 9-12 ONLY)
CORE COURSE (MS CORE and 9-12 ONLY)
SERVICE CATEGORY(K-9* ONLY)
NUMBER OF STUDENTS / SEATS FILLED
NUMBER OF SECTIONS
AVERAGE CLASS SIZE
SIZE OF SMALLEST CLASS
SIZE OF LARGEST CLASS
DATA SOURCE
SCHOOLWIDE PUPIL-TEACHER RATIO
DBN
0
1
M
M015
P.S. 015 Roberto Clemente
0K
GEN ED
–
–
–
19.0
1.0
19.0
19.0
19.0
ATS
NaN
01M015
1
1
M
M015
P.S. 015 Roberto Clemente
0K
CTT
–
–
–
21.0
1.0
21.0
21.0
21.0
ATS
NaN
01M015
2
1
M
M015
P.S. 015 Roberto Clemente
01
GEN ED
–
–
–
17.0
1.0
17.0
17.0
17.0
ATS
NaN
01M015
3
1
M
M015
P.S. 015 Roberto Clemente
01
CTT
–
–
–
17.0
1.0
17.0
17.0
17.0
ATS
NaN
01M015
4
1
M
M015
P.S. 015 Roberto Clemente
02
GEN ED
–
–
–
15.0
1.0
15.0
15.0
15.0
ATS
NaN
01M015
There are several rows for each high school (as you can see by the repeated `DBN`
and `SCHOOL NAME`
fields). However, if we take a look at the `sat_results`
dataset, it only has one row per high school:
`data["sat_results"].head()`
DBN
SCHOOL NAME
Num of SAT Test Takers
SAT Critical Reading Avg. Score
SAT Math Avg. Score
SAT Writing Avg. Score
0
01M292
HENRY STREET SCHOOL FOR INTERNATIONAL STUDIES
29
355
404
363
1
01M448
UNIVERSITY NEIGHBORHOOD HIGH SCHOOL
91
383
423
366
2
01M450
EAST SIDE COMMUNITY SCHOOL
70
377
402
370
3
01M458
FORSYTH SATELLITE ACADEMY
7
414
401
359
4
01M509
MARTA VALLE HIGH SCHOOL
44
390
433
384
In order to combine these datasets, we’ll need to find a way to condense datasets like `class_size`
to the point where there’s only a single row per high school. If not, there won’t be a way to compare SAT scores to class size. We can accomplish this by first understanding the data better, then by doing some aggregation. With the `class_size`
dataset, it looks like `GRADE`
and `PROGRAM TYPE`
have multiple values for each school. By restricting each field to a single value, we can filter most of the duplicate rows. In the below code, we:
- Only select values from
`class_size`
where the `GRADE`
field is `09-12`
.
- Only select values from
`class_size`
where the `PROGRAM TYPE`
field is `GEN ED`
.
- Group the
`class_size`
dataset by `DBN`
, and take the average of each column. Essentially, we’ll find the average `class_size`
values for each school.
- Reset the index, so
`DBN`
is added back in as a column.
```
class_size = data["class_size"]
class_size = class_size[class_size["GRADE "] == "09-12"]
class_size = class_size[class_size["PROGRAM TYPE"] == "GEN ED"]
class_size = class_size.groupby("DBN").agg(np.mean)
class_size.reset_index(inplace=True)
data["class_size"] = class_size
```
### Condensing other datasets
Next, we’ll need to condense the `demographics`
dataset. The data was collected for multiple years for the same schools, so there are duplicate rows for each school. We’ll only pick rows where the `schoolyear`
field is the most recent available:
```
demographics = data["demographics"]
demographics = demographics[demographics["schoolyear"] == 20112012]
data["demographics"] = demographics
```
We’ll need to condense the `math_test_results`
dataset. This dataset is segmented by `Grade`
and by `Year`
. We can select only a single grade from a single year:
```
data["math_test_results"] = data["math_test_results"][data["math_test_results"]["Year"] == 2011]
data["math_test_results"] = data["math_test_results"][data["math_test_results"]["Grade"] == '8']
```
Finally, `graduation`
needs to be condensed:
```
data["graduation"] = data["graduation"][data["graduation"]["Cohort"] == "2006"]
data["graduation"] = data["graduation"][data["graduation"]["Demographic"] == "Total Cohort"]
```
Data cleaning and exploration is critical before working on the meat of the project. Having a good, consistent dataset will help you do your analysis more quickly.
## Computing variables
Computing variables can help speed up our analysis by enabling us to make comparisons more quickly, and enable us to make comparisons that we otherwise wouldn’t be able to do. The first thing we can do is compute a total SAT score from the individual columns `SAT Math Avg. Score`
, `SAT Critical Reading Avg. Score`
, and `SAT Writing Avg. Score`
. In the below code, we:
- Convert each of the SAT score columns from a string to a number.
- Add together all of the columns to get the
`sat_score`
column, which is the total SAT score.
```
cols = ['SAT Math Avg. Score', 'SAT Critical Reading Avg. Score', 'SAT Writing Avg. Score']
for c in cols:
data["sat_results"][c] = data["sat_results"][c].convert_objects(convert_numeric=True)
data['sat_results']['sat_score'] = data['sat_results'][cols[0]] + data['sat_results'][cols[1]] + data['sat_results'][cols[2]]
```
Next, we’ll need to parse out the coordinate locations of each school, so we can make maps. This will enable us to plot the location of each school. In the below code, we:
- Parse latitude and longitude columns from the
`Location 1`
column.
- Convert
`lat`
and `lon`
to be numeric.
```
data["hs_directory"]['lat'] = data["hs_directory"]['Location 1'].apply(lambda x: x.split("\n")[-1].replace("(", "").replace(")", "").split(", ")[0])
data["hs_directory"]['lon'] = data["hs_directory"]['Location 1'].apply(lambda x: x.split("\n")[-1].replace("(", "").replace(")", "").split(", ")[1])
for c in ['lat', 'lon']:
data["hs_directory"][c] = data["hs_directory"][c].convert_objects(convert_numeric=True)
```
Now, we can print out each dataset to see what we have:
```
for k,v in data.items():
print(k)
print(v.head())
```
```
math_test_results DBN Grade Year Category Number Tested Mean Scale Score \111 01M034 8 2011 All Students 48 646280 01M140 8 2011 All Students 61 665346 01M184 8 2011 All Students 49 727388 01M188 8 2011 All Students 49 658411 01M292 8 2011 All Students 49 650 Level 1 # Level 1
```## Combining the datasets
Now that we’ve done all the preliminaries, we can combine the datasets together using the `DBN`
column. At the end, we’ll have a dataset with hundreds of columns, from each of the original datasets. When we join them, it’s important to note that some of the datasets are missing high schools that exist in the `sat_results`
dataset. To resolve this, we’ll need to merge the datasets that have missing rows using the `outer`
join strategy, so we don’t lose data. In real-world data analysis, it’s common to have data be missing. Being able to demonstrate the ability to reason about and handle missing data is an important part of building a portfolio.
You can read about different types of joins [here](https://pandas.pydata.org/pandas-docs/stable/merging.html).
In the below code, we’ll:
- Loop through each of the items in the
`data`
dictionary.
- Print the number of non-unique DBNs in the item.
- Decide on a join strategy —
`inner`
or `outer`
.
- Join the item to the DataFrame
`full`
using the column `DBN`
.
```
flat_data_names = [k for k,v in data.items()]
flat_data = [data[k] for k in flat_data_names]
full = flat_data[0]
for i, f in enumerate(flat_data[1:]):
name = flat_data_names[i+1]
print(name)
print(len(f["DBN"]) - len(f["DBN"].unique()))
join_type = "inner"
if name in ["sat_results", "ap_2010", "graduation"]:
join_type = "outer"
if name not in ["math_test_results"]:
full = full.merge(f, on="DBN", how=join_type)full.shape
```
```
survey
0
ap_2010
1
sat_results
0
class_size
0
demographics
0
graduation
0
hs_directory
0
```
`(374, 174)`
## Adding in values
Now that we have our `full`
DataFrame, we have almost all the information we’ll need to do our analysis. There are a few missing pieces, though. We may want to correlate the [Advanced Placement](https://apstudent.collegeboard.org/home) exam results with SAT scores, but we’ll need to first convert those columns to numbers, then fill in any missing values:
```
cols = ['AP Test Takers ', 'Total Exams Taken', 'Number of Exams with scores 3 4 or 5']
for col in cols:
full[col] = full[col].convert_objects(convert_numeric=True)
full[cols] = full[cols].fillna(value=0)
```
Then, we’ll need to calculate a `school_dist`
column that indicates the school district of the school. This will enable us to match up school districts and plot out district-level statistics using the district maps we downloaded earlier:
`full["school_dist"] = full["DBN"].apply(lambda x: x[:2])`
Finally, we’ll need to fill in any missing values in `full`
with the mean of the column, so we can compute correlations:
`full = full.fillna(full.mean())`
## Computing correlations
A good way to explore a dataset and see what columns are related to the one you care about is to compute correlations. This will tell you which columns are closely related to the column you’re interested in. We can do this via the [corr](https://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.corr.html) method on Pandas DataFrames. The closer to `0`
the correlation, the weaker the connection. The closer to `1`
, the stronger the positive correlation, and the closer to `-1`
, the stronger the negative correlation:
`full.corr()['sat_score']`
```
Year NaN
Number Tested 8.127817e-02
rr_s 8.484298e-02
rr_t -6.604290e-02
rr_p 3.432778e-02
N_s 1.399443e-01
N_t 9.654314e-03
N_p 1.397405e-01
saf_p_11 1.050653e-01
com_p_11 2.107343e-02
eng_p_11 5.094925e-02
aca_p_11 5.822715e-02
saf_t_11 1.206710e-01
com_t_11 3.875666e-02
eng_t_10 NaN
aca_t_11 5.250357e-02
saf_s_11 1.054050e-01
com_s_11 4.576521e-02
eng_s_11 6.303699e-02
aca_s_11 8.015700e-02
saf_tot_11 1.266955e-01
com_tot_11 4.340710e-02
eng_tot_11 5.028588e-02
aca_tot_11 7.229584e-02
AP Test Takers 5.687940e-01
Total Exams Taken 5.585421e-01
Number of Exams with scores 3 4 or 5 5.619043e-01
SAT Critical Reading Avg. Score 9.868201e-01
SAT Math Avg. Score 9.726430e-01
SAT Writing Avg. Score 9.877708e-01
...
SIZE OF SMALLEST CLASS 2.440690e-01
SIZE OF LARGEST CLASS 3.052551e-01
SCHOOLWIDE PUPIL-TEACHER RATIO NaN
schoolyear NaN
frl_percent -7.018217e-01
total_enrollment 3.668201e-01
ell_num -1.535745e-01
ell_percent -3.981643e-01
sped_num 3.486852e-02
sped_percent -4.413665e-01
asian_num 4.748801e-01
asian_per 5.686267e-01
black_num 2.788331e-02
black_per -2.827907e-01
hispanic_num 2.568811e-02
hispanic_per -3.926373e-01
white_num 4.490835e-01
white_per 6.100860e-01
male_num 3.245320e-01
male_per -1.101484e-01
female_num 3.876979e-01
female_per 1.101928e-01
Total Cohort 3.244785e-01
grade_span_max -2.495359e-17
expgrade_span_max NaN
zip -6.312962e-02
total_students 4.066081e-01
number_programs 1.166234e-01
lat -1.198662e-01
lon -1.315241e-01
Name: sat_score, dtype: float64
```
This gives us quite a few insights that we’ll need to explore:
- Total enrollment correlates strongly with
`sat_score`
, which is surprising, because you’d think smaller schools, which focused more on the student, would have higher scores.
- The percentage of females at a school (
`female_per`
) correlates positively with SAT score, whereas the percentage of males (`male_per`
) correlates negatively.
- None of the survey responses correlate highly with SAT scores.
- There is a significant racial inequality in SAT scores (
`white_per`
, `asian_per`
, `black_per`
, `hispanic_per`
).
`ell_percent`
correlates strongly negatively with SAT scores.
Each of these items is a potential angle to explore and tell a story about using the data.
## Setting the context
Before we dive into exploring the data, we’ll want to set the context, both for ourselves, and anyone else that reads our analysis. One good way to do this is with exploratory charts or maps. In this case, we’ll map out the positions of the schools, which will help readers understand the problem we’re exploring.
In the below code, we:
- Setup a map centered on New York City.
- Add a marker to the map for each high school in the city.
- Display the map.
```
import folium
from folium import plugins
schools_map = folium.Map(location=[full['lat'].mean(), full['lon'].mean()], zoom_start=10)
marker_cluster = folium.MarkerCluster().add_to(schools_map)
for name, row in full.iterrows():
folium.Marker([row["lat"], row["lon"]], popup="{0}: {1}".format(row["DBN"], row["school_name"])).add_to(marker_cluster)
schools_map.create_map('schools.html')
schools_map
```
This map is helpful, but it’s hard to see where the most schools are in NYC. Instead, we’ll make a heatmap:
```
schools_heatmap = folium.Map(location=[full['lat'].mean(), full['lon'].mean()], zoom_start=10)
schools_heatmap.add_children(plugins.HeatMap([[row["lat"], row["lon"]] for name, row in full.iterrows()]))
schools_heatmap.save("heatmap.html")
schools_heatmap
```
## District level mapping
Heatmaps are good for mapping out gradients, but we’ll want something with more structure to plot out differences in SAT score across the city. School districts are a good way to visualize this information, as each district has its own administration. New York City has several dozen school districts, and each district is a small geographic area.
We can compute SAT score by school district, then plot this out on a map. In the below code, we’ll:
- Group
`full`
by school district.
- Compute the average of each column for each school district.
- Convert the
`school_dist`
field to remove leading `0`
s, so we can match our geograpghic district data.
```
district_data = full.groupby("school_dist").agg(np.mean)
district_data.reset_index(inplace=True)
district_data["school_dist"] = district_data["school_dist"].apply(lambda x: str(int(x)))
```
We’ll now we able to plot the average SAT score in each school district. In order to do this, we’ll read in data in [GeoJSON](https://geojson.org/) format to get the shapes of each district, then match each district shape with the SAT score using the `school_dist`
column, then finally create the plot:
```
def show_district_map(col):
geo_path = 'schools/districts.geojson'
districts = folium.Map(location=[full['lat'].mean(), full['lon'].mean()], zoom_start=10)
districts.geo_json(
geo_path=geo_path,
data=district_data,
columns=['school_dist', col],
key_on='feature.properties.school_dist',
fill_color='YlGn',
fill_opacity=0.7,
line_opacity=0.2,
)
districts.save("districts.html")
return districts
show_district_map("sat_score")
```
## Exploring enrollment and SAT scores
Now that we’ve set the context by plotting out where the schools are, and SAT score by district, people viewing our analysis have a better idea of the context behind the dataset. Now that we’ve set the stage, we can move into exploring the angles we identified earlier, when we were finding correlations. The first angle to explore is the relationship between the number of students enrolled in a school and SAT score.
We can explore this with a scatter plot that compares total enrollment across all schools to SAT scores across all schools.
`full.plot.scatter(x='total_enrollment', y='sat_score')`
`<matplotlib.axes._subplots.AxesSubplot at 0x10fe79978>`
As you can see, there’s a cluster at the bottom left with low total enrollment and low SAT scores. Other than this cluster, there appears to only be a slight positive correlation between SAT scores and total enrollment. Graphing out correlations can reveal unexpected patterns.
We can explore this further by getting the names of the schools with low enrollment and low SAT scores:
```
34 INTERNATIONAL SCHOOL FOR LIBERAL ARTS
143 NaN
148 KINGSBRIDGE INTERNATIONAL HIGH SCHOOL
203 MULTICULTURAL HIGH SCHOOL
294 INTERNATIONAL COMMUNITY HIGH SCHOOL
304 BRONX INTERNATIONAL HIGH SCHOOL
314 NaN
317 HIGH SCHOOL OF WORLD CULTURES
320 BROOKLYN INTERNATIONAL HIGH SCHOOL
329 INTERNATIONAL HIGH SCHOOL AT PROSPECT
331 IT TAKES A VILLAGE ACADEMY
351 PAN AMERICAN INTERNATIONAL HIGH SCHOO
Name: School Name, dtype: object
```
Some searching on Google shows that most of these schools are for students who are learning English, and are low enrollment as a result. This exploration showed us that it’s not total enrollment that’s correlated to SAT score — it’s whether or not students in the school are learning English as a second language or not.
## Exploring English language learners and SAT scores
Now that we know the percentage of English language learners in a school is correlated with lower SAT scores, we can explore the relationship. The `ell_percent`
column is the percentage of students in each school who are learning English. We can make a scatterplot of this relationship:
`full.plot.scatter(x='ell_percent', y='sat_score')`
`<matplotlib.axes._subplots.AxesSubplot at 0x10fe824e0>`
It looks like there are a group of schools with a high `ell_percentage`
that also have low average SAT scores. We can investigate this at the district level, by figuring out the percentage of English language learners in each district, and seeing it if matches our map of SAT scores by district:
`show_district_map("ell_percent")`
As we can see by looking at the two district level maps, districts with a low proportion of ELL learners tend to have high SAT scores, and vice versa.
## Correlating survey scores and SAT scores
It would be fair to assume that the results of student, parent, and teacher surveys would have a large correlation with SAT scores. It makes sense that schools with high academic expectations, for instance, would tend to have higher SAT scores. To test this theory, lets plot out SAT scores and the various survey metrics:
`full.corr()["sat_score"][["rr_s", "rr_t", "rr_p", "N_s", "N_t", "N_p", "saf_tot_11", "com_tot_11", "aca_tot_11", "eng_tot_11"]].plot.bar()`
`<matplotlib.axes._subplots.AxesSubplot at 0x114652400>`
Surprisingly, the two factors that correlate the most are `N_p`
and `N_s`
, which are the counts of parents and students who responded to the surveys. Both strongly correlate with total enrollment, so are likely biased by the `ell_learners`
. The other metric that correlates most is `saf_t_11`
. That is how safe students, parents, and teachers perceived the school to be. It makes sense that the safer the school, the more comfortable students feel learning in the environment. However, none of the other factors, like engagement, communication, and academic expectations, correlated with SAT scores. This may indicate that NYC is asking the wrong questions in surveys, or thinking about the wrong factors (if their goal is to improve SAT scores, it may not be).
## Exploring race and SAT scores
One of the other angles to investigate involves race and SAT scores. There was a large correlation differential, and plotting it out will help us understand what’s happening:
`full.corr()["sat_score"][["white_per", "asian_per", "black_per", "hispanic_per"]].plot.bar()`
`<matplotlib.axes._subplots.AxesSubplot at 0x108166ba8>`
It looks like the higher percentages of white and asian students correlate with higher SAT scores, but higher percentages of black and hispanic students correlate with lower SAT scores. For hispanic students, this may be due to the fact that there are more recent immigrants who are ELL learners. We can map the hispanic percentage by district to eyeball the correlation:
`show_district_map("hispanic_per")`
It looks like there is some correlation with ELL percentage, but it will be necessary to do some more digging into this and other racial differences in SAT scores.
## Gender differences in SAT scores
The final angle to explore is the relationship between gender and SAT score. We noted that a higher percentage of females in a school tends to correlate with higher SAT scores. We can visualize this with a bar graph:
`full.corr()["sat_score"][["male_per", "female_per"]].plot.bar()`
`<matplotlib.axes._subplots.AxesSubplot at 0x10774d0f0>`

To dig more into the correlation, we can make a scatterplot of `female_per`
and `sat_score`
:
`full.plot.scatter(x='female_per', y='sat_score')`
`<matplotlib.axes._subplots.AxesSubplot at 0x104715160>`
It looks like there’s a cluster of schools with a high percentage of females, and very high SAT scores (in the top right). We can get the names of the schools in this cluster:
`full[(full["female_per"] > 65) & (full["sat_score"] > 1400)]["School Name"]`
```
3 PROFESSIONAL PERFORMING ARTS HIGH SCH
92 ELEANOR ROOSEVELT HIGH SCHOOL
100 TALENT UNLIMITED HIGH SCHOOL
111 FIORELLO H. LAGUARDIA HIGH SCHOOL OF
229 TOWNSEND HARRIS HIGH SCHOOL
250 FRANK SINATRA SCHOOL OF THE ARTS HIGH SCHOOL
265 BARD HIGH SCHOOL EARLY COLLEGE
Name: School Name, dtype: object
```
Searching Google reveals that these are elite schools that focus on the performing arts. These schools tend to have higher percentages of females, and higher SAT scores. This likely accounts for the correlation between higher female percentages and SAT scores, and the inverse correlation between higher male percentages and lower SAT scores.
## AP scores
So far, we’ve looked at demographic angles. One angle that we have the data to look at is the relationship between more students taking Advanced Placement exams and higher SAT scores. It makes sense that they would be correlated, since students who are high academic achievers tend to do better on the SAT.
```
full["ap_avg"] = full["AP Test Takers "] / full["total_enrollment"]
full.plot.scatter(x='ap_avg', y='sat_score')
```
`<matplotlib.axes._subplots.AxesSubplot at 0x11463a908>`
It looks like there is indeed a strong correlation between the two. An interesting cluster of schools is the one at the top right, which has high SAT scores and a high proportion of students that take the AP exams:
`full[(full["ap_avg"] > .3) & (full["sat_score"] > 1700)]["School Name"]`
```
92 ELEANOR ROOSEVELT HIGH SCHOOL
98 STUYVESANT HIGH SCHOOL
157 BRONX HIGH SCHOOL OF SCIENCE
161 HIGH SCHOOL OF AMERICAN STUDIES AT LE
176 BROOKLYN TECHNICAL HIGH SCHOOL
229 TOWNSEND HARRIS HIGH SCHOOL
243 QUEENS HIGH SCHOOL FOR THE SCIENCES A
260 STATEN ISLAND TECHNICAL HIGH SCHOOL
Name: School Name, dtype: object
```
Some Google searching reveals that these are mostly highly selective schools where you need to take a test to get in. It makes sense that these schools would have high proportions of AP test takers.
## Wrapping up the story
With data science, the story is never truly finished. By releasing analysis to others, you enable them to extend and shape your analysis in whatever direction interests them. For example, in this post, there are quite a few angles that we explored inmcompletely, and could have dived into more.
One of the best ways to get started with telling stories using data is to try to extend or replicate the analysis someone else has done. If you decide to take this route, you’re welcome to extend the analysis in this post and see what you can find. If you do this, make sure to [let me know](https://twitter.com/dataquestio) so I can take a look.
## Next steps
If you’ve made it this far, you hopefully have a good understanding of how to tell a story with data, and how to build your first data science portfolio piece.
At [Dataquest](https://www.dataquest.io), our interactive guided projects are designed to help you start building a data science portfolio to demonstrate your skills to employers and get a job in data. If you’re interested, you can [signup and do our first module for free](https://www.dataquest.io).
*If you liked this, you might like to read the other posts in our ‘Build a Data Science Portfolio’ series:* |
8,989 | Linus Torvalds 说针对性的模糊测试正提升 Linux 安全性 | http://www.zdnet.com/article/linus-torvalds-says-targeted-fuzzing-is-improving-linux-security/ | 2017-10-23T14:49:04 | [
"测试",
"内核"
] | https://linux.cn/article-8989-1.html | Linux 4.14 发布候选第五版已经出来。Linus Torvalds 说:“可以去测试了。”

随着宣布推出 Linux 内核 4.14 的第五个候选版本,Linus Torvalds 表示<ruby> 模糊测试 <rt> fuzzing </rt></ruby>正产生一系列稳定的安全更新。
模糊测试通过产生随机代码来引发错误来对系统进行压力测试,从而有助于识别潜在的安全漏洞。模糊测试可以帮助软件开发人员在向用户发布软件之前捕获错误。
Google 使用各种模糊测试工具来查找它及其它供应商软件中的错误。微软推出了 [Project Springfield](http://www.zdnet.com/article/microsoft-seeks-testers-for-project-springfield-bug-detection-service/) 模糊测试服务,它能让企业客户测试自己的软件。
正如 Torvalds 指出的那样,Linux 内核开发人员从一开始就一直在使用模糊测试流程,例如 1991 年发布的工具 “crashme”,它在近 20 年后被 [Google 安全研究员 Tavis Ormandy](http://taviso.decsystem.org/virtsec.pdf) 用来测试在虚拟机中处理不受信任的数据时,宿主机是否受到良好保护。
Torvalds [说](http://lkml.iu.edu/hypermail/linux/kernel/1710.1/06454.html):“另外值得一提的是人们做了多少随机化模糊测试,而且这正在发现东西。”
“我们一直在做模糊测试(谁还记得只是生成随机代码,并跳转过去的老 “crashme” 程序?我们过去很早就这样做),人们在驱动子系统等方面做了一些很好的针对性模糊测试,而且已经有了各种各样的修复(不仅仅是上周的这些)。很高兴可以看到。”
Torvalds 提到,到目前为止,4.14 的发展“比预想的要麻烦一些”,但现在已经好了,并且在这个版本已经跑通了一些针对 x86 系统以及 AMD 芯片系统的修复。还有几个驱动程序、核心内核组件和工具的更新。
如前[所述](http://www.zdnet.com/article/first-linux-4-14-release-adds-very-core-features-arrives-in-time-for-kernels-26th-birthday/),Linux 4.14 是 2017 年的长期稳定版本,迄今为止,它引入了核心内存管理功能、设备驱动程序更新以及文档、架构、文件系统、网络和工具的修改。
---
via: <http://www.zdnet.com/article/linus-torvalds-says-targeted-fuzzing-is-improving-linux-security/>
作者:[Liam Tung](http://www.zdnet.com/meet-the-team/eu/liam-tung/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
8,990 | 极客漫画:谁杀死了 MySQL | http://turnoff.us/geek/who-killed-mysql/ | 2017-10-23T16:47:21 | [
"LAMP",
"MySQL",
"漫画",
"SIGKILL"
] | https://linux.cn/article-8990-1.html | 
LAMP 架构,指 Linux + Apache + MySQL + PHP 组合构成的一个完整的 Web 服务架构。这是一个经典而有点过时的架构,适合于小型的 Web 服务。
在这里 MySQL 意外被 [SIGKILL](/article-8791-1.html) [杀死](/article-8771-1.html)了,没有留下任何遗言和痕迹(日志)。
---
via: <http://turnoff.us/geek/who-killed-mysql/>
作者:[Daniel Stori](http://turnoff.us/about/) 译者:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
8,991 | 回顾 Steam Machines 与 SteamOS | https://www.gamingonlinux.com/articles/user-editorial-steam-machines-steamos-after-a-year-in-the-wild.8474 | 2017-10-25T10:26:00 | [
"SteamOS",
"游戏"
] | https://linux.cn/article-8991-1.html | 
去年今日(LCTT 译注:本文发表于 2016 年),在非常符合 Valve 风格的跳票之后,大众迎来了 [Steam Machines 的发布](https://www.gamingonlinux.com/articles/steam-machines-steam-link-steam-controller-officially-released-steamos-sale.6201)。即使是在 Linux 桌面环境对于游戏的支持大步进步的今天,Steam Machines 作为一个平台依然没有飞跃,而 SteamOS 似乎也止步不前。这些由 Valve 发起的项目究竟怎么了?这些项目为何被发起,又是如何失败的?一些改进又是否曾有机会挽救这些项目的成败?
### 行业环境
在 2012 年 Windows 8 发布的时候,微软像 iOS 与 Android 那样,为 Windows 集成了一个应用商店。在微软试图推广对触摸体验友好的界面时,为了更好的提供 “Metro” UI 语言指导下的沉浸式触摸体验,他们同时推出了一系列叫做 “WinRT” 的 API。然而为了能够使用这套 API,应用开发者们必须把应用程序通过 Windows 应用商城发布,并且正如其它应用商城那样,微软从中抽成 30%。对于 Valve 的 CEO,Gabe Newell (G 胖) 而言,这种限制发布平台和抽成行为是让人无法接受的,而且他前瞻地看到了微软利用行业龙头地位来推广 Windows 商店和 Metro 应用对于 Valve 潜在的危险,正如当年微软用 IE 浏览器击垮 Netscape 浏览器一样。
对于 Valve 来说,运行 Windows 的 PC 的优势在于任何人都可以不受操作系统和硬件方的限制运行各种软件。当像 Windows 这样的专有平台对像 Steam 这样的第三方软件限制越来越严格时,应用开发者们自然会想要寻找一个对任何人都更开放和自由的替代品,他们很自然的会想到 Linux 。Linux 本质上只是一套内核,但你可以轻易地使用 GNU 组件、Gnome 等软件在这套内核上开发出一个操作系统,比如 Ubuntu 就是这么来的。推行 Ubuntu 或者其他 Linux 发行版自然可以为 Valve 提供一个无拘无束的平台,以防止微软或者苹果变成 Valve 作为第三方平台之路上的的敌人,但 Linux 甚至给了 Valve 一个创造新的操作系统平台的机会。
### 概念化
如果我们把 Steam Machines 叫做主机的话,Valve 当时似乎认定了主机平台是一个机会。为了迎合用户对于电视主机平台用户界面的审美期待,同时也为了让玩家更好地从稍远的距离上在电视上玩游戏,Valve 为 Steam 推出了 Big Picture 模式。Steam Machines 的核心要点是开放性;比方说所有的软件都被设计成可以脱离 Windows 工作,又比如说 Steam Machines 手柄的 CAD 图纸也被公布出来以便支持玩家二次创作。
原初计划中,Valve 打算设计一款官方的 Steam Machine 作为旗舰机型。但最终,这些机型只在 2013 年的时候作为原型机给与了部分测试者用于测试。Valve 后来也允许像戴尔这样的 OEM 厂商们制造 Steam Machines,并且也赋予了他们制定价格和配置规格的权利。有一家叫做 “Xi3” 的公司展示了他们设计的 Steam Machine 小型机型,那款机型小到可以放在手掌上,这一新闻创造了围绕 Steam Machines 的更多热烈讨论。最终,Valve 决定不自己设计制造 Steam Machines,而全权交给 OEM 合作厂商们。
这一过程中还有很多天马行空的创意被列入考量,比如在手柄上加入生物识别技术、眼球追踪以及动作控制等。在这些最初的想法里,陀螺仪被加入了 Steam Controller 手柄,HTC Vive 的手柄也有各种动作追踪仪器;这些想法可能最初都来源于 Steam 手柄的设计过程中。手柄最初还有些更激进的设计,比如在中心放置一块可定制化并且会随着游戏内容变化的触摸屏。但最后的最后,发布会上的手柄偏向保守了许多,但也有诸如双触摸板和内置软件等黑科技。Valve 也考虑过制作面向笔记本类型硬件的 Steam Machines 和 SteamOS。这个企划最终没有任何成果,但也许 “Smach Z” 手持游戏机会是发展的方向之一。
在 [2013 年九月](https://www.gamingonlinux.com/articles/valve-announces-steam-machines-you-can-win-one-too.2469),Valve 对外界宣布了 Steam Machines 和 SteamOS, 并且预告会在 2014 年中发布。前述的 300 台原型机在当年 12 月分发给了测试者们,随后次年 1 月,又分发给了开发者们 2000 台原型机。SteamOS 也在那段时间分发给有 Linux 经验的测试者们试用。根据当时的测试反馈,Valve 最终决定把产品发布延期到 2015 年 11 月。
SteamOS 的延期跳票给合作伙伴带来了问题;戴尔的 Steam Machine 由于早发售了一年,结果不得不改为搭配了额外软件、甚至运行着 Windows 操作系统的 Alienware Alpha。
### 正式发布
在最终的正式发布会上,Valve 和 OEM 合作商们发布了 Steam Machines,同时 Valve 还推出了 Steam Controller 手柄和 Steam Link 串流游戏设备。Valve 也在线下零售行业比如 GameStop 里开辟了货架空间。在发布会前,有几家 OEM 合作商退出了与 Valve 的合作;比如 Origin PC 和 Falcon Northwest 这两家高端精品主机设计商。他们宣称 Steam 生态的性能问题和一些限制迫使他们决定弃用 SteamOS。
Steam Machines 在发布后收到了褒贬不一的评价。另一方面 Steam Link 则普遍受到好评,很多人表示愿意在客厅电视旁为他们已有的 PC 系统购买 Steam Link, 而不是购置一台全新的 Steam Machine。Steam Controller 手柄则受到其丰富功能伴随而来的陡峭学习曲线影响,评价一败涂地。然而针对 Steam Machines 的批评则是最猛烈的。诸如 LinusTechTips 这样的评测团体 (LCTT 译注:YouTube 硬件界老大,个人也经常看他们节目)注意到了主机的明显的不足,其中甚至不乏性能为题。很多厂商的 Machines 都被批评为性价比极低,特别是经过和玩家们自己组装的同配置机器或者电视主机做对比之后。SteamOS 而被批评为兼容性有问题,Bug 太多,以及性能不及 Windows。在所有 Machines 里,戴尔的 Alienware Alpha 被评价为最有意思的一款,主要是由于品牌价值和机型外观极小的缘故。
通过把 Debian Linux 操作系统作为开发基础,Valve 得以为 SteamOS 平台找到很多原本就存在与 Steam 平台上的 Linux 兼容游戏来作为“首发游戏”。所以起初大家认为在“首发游戏”上 Steam Machines 对比其他新发布的主机优势明显。然而,很多宣称会在新平台上发布的游戏要么跳票要么被中断了。Rocket League 和 Mad Max 在宣布支持新平台整整一年后才真正发布,而《巫师 3》和《蝙蝠侠:阿克汉姆骑士》甚至从来没有发布在新平台上。就《巫师 3》的情况而言,他们的开发者 CD Projekt Red 拒绝承认他们曾经说过要支持新平台;然而他们的游戏曾在宣布支持 Linux 和 SteamOS 的游戏列表里赫然醒目。雪上加霜的是,很多 AAA 级的大作甚至没宣布移植,虽然最近这种情况稍有所好转了。
### 被忽视的
在 Stame Machines 发售后,Valve 的开发者们很快转移到了其他项目的工作中去了。在当时,VR 项目最为内部所重视,6 月份的时候大约有 1/3 的员工都在相关项目上工作。Valve 把 VR 视为亟待开发的一片领域,而他们的 Steam 则应该作为分发 VR 内容的生态环境。通过与 HTC 合作生产,Valve 设计并制造出了他们自己的 VR 头戴和手柄,并计划在将来更新换代。然而与此同时,Linux 和 Steam Machines 都渐渐淡出了视野。SteamVR 甚至直到最近才刚刚支持 Linux (其实还没对普通消费者开放使用,只在 SteamDevDays 上展示过对 Linux 的支持),而这一点则让我们怀疑 Valve 在 Stame Machines 和 Linux 的开发上是否下定了足够的决心。
SteamOS 自发布以来几乎止步不前。SteamOS 2.0 作为上一个大版本号更新,几乎只是同步了 Debian 上游的变化,而且还需要用户重新安装整个系统,而之后的小补丁也只是在做些上游更新的配合。当 Valve 在其他事关性能和用户体验的项目(例如 Mesa)上进步匪浅的时候,针对 Steam Machines 的相关项目则少有顾及。
很多原本应有的功能都从未完成。Steam 的内置功能,例如聊天和直播,都依然处于较弱的状态,而且这种落后会影响所有平台上的 Steam 用户体验。更具体来说,Steam 没有像其他主流主机平台一样把诸如 Netflix、Twitch 和 Spotify 之类的服务集成到客户端里,而通过 Steam 内置的浏览器使用这些服务则体验极差,甚至无法使用;而如果要使用第三方软件则需要开启 Terminal,而且很多软件甚至无法支持控制手柄 —— 无论从哪方面讲这样的用户界面体验都糟糕透顶。
Valve 同时也几乎没有花任何力气去推广他们的新平台,而选择把一切都交由 OEM 厂商们去做。然而,几乎所有 OEM 合作商们要么是高端主机定制商,要么是电脑生产商,要么是廉价电脑公司(LCTT 译注:简而言之没有一家有大型宣传渠道)。在所有 OEM 中,只有戴尔是 PC 市场的大碗,也只有他们真正给 Steam Machines 做了广告宣传。
最终销量也不尽人意。截至 2016 年 6 月,7 个月间 Steam Controller 手柄的销量在包括捆绑销售的情况下仅销售 500,000 件。这让 Steam Machines 的零售情况差到只能被归类到十万俱乐部的最底部。对比已经存在的巨大 PC 和主机游戏平台,可以说销量极低。
### 事后诸葛亮
既然知道了 Steam Machines 的历史,我们又能否总结出失败的原因以及可能存在的翻身改进呢?
#### 视野与目标
Steam Machines 从来没搞清楚他们在市场里的定位究竟是什么,也从来没说清楚他们具体有何优势。从 PC 市场的角度来说,自己搭建台式机已经非常普及,并且往往可以让电脑可以匹配玩家自己的目标,同时升级性也非常好。从主机平台的角度来说,Steam Machines 又被主机本身的相对廉价所打败,虽然算上游戏可能稍微便宜一些,但主机上的用户体验也直白很多。
PC 用户会把多功能性看得很重,他们不仅能用电脑打游戏,也一样能办公和做各种各样的事情。即使 Steam Machines 也是跑着的 SteamOS 操作系统的自由的 Linux 电脑,但操作系统和市场宣传加深了 PC 玩家们对 Steam Machines 是不可定制的硬件、低价的、更接近主机的印象。即使这些 PC 用户能接受在客厅里购置一台 Steam Machines,他们也有 Steam Link 可以选择,而且很多更小型机比如 NUC 和 Mini-ITX 主板定制机可以让他们搭建更适合放在客厅里的电脑。SteamOS 软件也允许把这些硬件转变为 Steam Machines,但寻求灵活性和兼容性的用户通常都会使用一般 Linux 发行版或者 Windows。何况最近的 Windows 和 Linux 桌面环境都让维护一般用户的操作系统变得自动化和简单了。
电视主机用户们则把易用性放在第一。虽然近年来主机的功能也逐渐扩展,比如可以播放视频或者串流,但总体而言用户还是把即插即用即玩、不用担心兼容性和性能问题和低门槛放在第一。主机的使用寿命也往往较长,一般在 4-7 年左右,而统一固定的硬件也让游戏开发者们能针对其更好的优化和调试软件。现在刚刚兴起的中生代升级,例如天蝎和 PS 4 Pro 则可能会打破这样统一的游戏体验,但无论如何厂商还是会要求开发者们需要保证游戏在原机型上的体验。为了提高用户粘性,主机也会有自己的社交系统和独占游戏。而主机上的游戏也有实体版,以便将来重用或者二手转卖,这对零售商和用户都是好事儿。Steam Machines 则完全没有这方面的保证;即使长的像一台客厅主机,他们却有 PC 高昂的价格和复杂的硬件情况。
#### 妥协
综上所述,Steam Machines 可以说是“集大成者”,吸取了两边的缺点,又没有自己明确的定位。更糟糕的是 Steam Machines 还展现了 PC 和主机都没有的毛病,比如没有 AAA 大作,又没有 Netflix 这样的客户端。抛开这些不说,Valve 在提高他们产品这件事上几乎没有出力,甚至没有尝试着解决 PC 和主机两头定位矛盾这一点。
然而在有些事情上也许原本 PC 和主机就没法折中妥协。像图像设定和 Mod 等内容的加入会无法保证“傻瓜机”一般的可靠,而且系统下层的复杂性也会逐渐暴露。
而最复杂的是 Steam Machines 多变的硬件情况,这使得用户不仅要考虑价格还要考虑配置,还要考虑这个价格下和别的系统(PC 和主机)比起来划算与否。更关键的是,Valve 无论如何也应该做出某种自动硬件检测机制,这样玩家才能知道是否能玩某个游戏,而且这个测试既得简单明了,又要能支持 Steam 上几乎所有游戏。同时,Valve 还要操心未来游戏对配置需求的变化,比如2016 年的 "A" 等主机三年后该给什么评分呢?
#### Valve, 个人努力与公司结构
尽管 Valve 在 Steam 上创造了辉煌,但其公司的内部结构可能对于开发一个像 Steam Machines 一样的平台是有害的。他们几乎没有领导的自由办公结构,以及所有人都可以自由移动到想要工作的项目组里决定了他们具有极大的创新,研发,甚至开发能力。据说 Valve 只愿意招他们眼中的的 “顶尖人才”,通过极其严格的筛选标准,并通过让他们在自己认为“有意义”的项目里工作以保持热情。然而这种思路很可能是错误的;拉帮结派总是存在,而 G胖的话或许比公司手册上写的还管用,而又有人时不时会由于特殊原因被雇佣或解雇。
正因为如此,很多虽不闪闪发光甚至维护起来有些无聊但又需要大量时间的项目很容易枯萎。Valve 的客服已是被人诟病已久的毛病,玩家经常觉得被无视了,而 Valve 则经常不到万不得已、法律要求的情况下绝不行动:例如自动退款系统,就是在澳大利亚和欧盟法律的要求下才被加入的;更有目前还没结案的华盛顿州 CS:GO 物品在线赌博网站一案。
各种因素最后也反映在 Steam Machines 这一项目上。Valve 方面的跳票迫使一些合作方做出了尴尬的决定,比如戴尔提前一年发布了 Alienware Alpha 外观的 Steam Machine 就在一年后的正式发布时显得硬件状况落后了。跳票很可能也导致了游戏数量上的问题。开发者和硬件合作商的对跳票和最终毫无轰动的发布也不明朗。Valve 的 VR 平台干脆直接不支持 Linux,而直到最近,SteamVR 都风风火火迭代了好几次之后,SteamOS 和 Linux 依然不支持 VR。
#### “长线钓鱼”
尽管 Valve 方面对未来的规划毫无透露,有些人依然认为 Valve 在 Steam Machine 和 SteamOS 上是放长线钓大鱼。他们论点是 Steam 本身也是这样的项目 —— 一开始作为游戏补丁平台出现,到现在无敌的游戏零售和玩家社交网络。虽然 Valve 的独占游戏比如《半条命 2》和 《CS》 也帮助了 Steam 平台的传播。但现今我们完全无法看到 Valve 像当初对 Steam 那样上心 Steam Machines。同时现在 Steam Machines 也面临着 Steam 从没碰到过的激烈竞争。而这些竞争里自然也包含 Valve 自己的那些把 Windows 作为平台的 Steam 客户端。
#### 真正目的
鉴于投入在 Steam Machines 上的努力如此之少,有些人怀疑整个产品平台是不是仅仅作为某种博弈的筹码才被开发出来。原初 Steam Machines 就发家于担心微软和苹果通过自己的应用市场垄断游戏的反制手段当中,Valve 寄希望于 Steam Machines 可以在不备之时脱离那些操作系统的支持而运行,同时也是提醒开发者们,也许有一日整个 Steam 平台会独立出来。而当微软和苹果等方面的风口没有继续收紧的情况下,Valve 自然就放慢了开发进度。然而我不这样认为;Valve 其实已经花了不少精力与硬件商和游戏开发者们共同推行这件事,不可能仅仅是为了吓吓他人就终止项目。你可以把这件事想成,微软和 Valve 都在吓唬对方 —— 微软推出了突然收紧的 Windows 8 ,而 Valve 则展示了一下可以独立门户的能力。
但即使如此,谁能保证开发者不会愿意跟着微软的封闭环境跑了呢?万一微软最后能提供更好的待遇和用户群体呢?更何况,微软现在正大力推行 Xbox 和 Windows 的交叉和整合,甚至 Xbox 独占游戏也出现在 Windows 上,这一切都没有损害 Windows 原本的平台性定位 —— 谁还能说微软方面不是 Steam 的直接竞争对手呢?
还会有人说这一切一切都是为了推进 Linux 生态环境尽快接纳 PC 游戏,而 Steam Machines 只是想为此大力推一把。但如果是这样,那这个目的实在是性价比极低,因为本愿意支持 Linux 的自然会开发,而 Steam Machines 这一出甚至会让开发者对平台期待额落空从而伤害到他们。
### 大家眼中 Valve 曾经的机会
我认为 Steam Machines 的创意还是很有趣的,而也有一个与之匹配的市场,但就结果而言 Valve 投入的创意和努力还不够多,而定位模糊也伤害了这个产品。我认为 Steam Machines 的优势在于能砍掉 PC 游戏传统的复杂性,比如硬件问题、整机寿命和维护等;但又能拥有游戏便宜,可以打 Mod 等好处,而且也可以做各种定制化以满足用户需求。但他们必须要让产品的核心内容:价格、市场营销、机型产品线还有软件的质量有所保证才行。
我认为 Steam Machines 可以做出一点妥协,比如硬件升级性(尽管这一点还是有可能被保留下来的 —— 但也要极为小心整个过程对用户体验的影响)和产品选择性,来减少摩擦成本。PC 一直会是一个并列的选项。想给用户产品可选性带来的只有一个困境,成吨的质量低下的 Steam Machines 根本不能解决。Valve 得自己造一台旗舰机型来指明 Steam Machines 的方向。毫无疑问,Alienware 的产品是最接近理想目标的,但它说到底也不是 Valve 的官方之作。Valve 内部不乏优秀的工业设计人才,如果他们愿意投入足够多的重视,我认为结果也许会值得他们努力。而像戴尔和 HTC 这样的公司则可以用他们丰富的经验帮 Valve 制造成品。直接钦定 Steam Machines 的硬件周期,并且在期间只推出 1-2 台机型也有助于帮助解决问题,更不用说他们还可以依次和开发商们确立性能的基准线。我不知道 OEM 合作商们该怎么办;如果 Valve 专注于自己的几台设备里,OEM 们很可能会变得多余甚至拖平台后腿。
我觉得修复软件问题是最关键的。很多问题在严重拖着 Steam Machines 的后腿,比如缺少主机上遍地都是、又能轻易安装在 PC 上的的 Netflix 和 Twitch,那么即使做好了客厅体验问题依然是严重的败笔。即使 Valve 已经在逐步购买电影的版权以便在 Steam 上发售,我觉得用户还是会倾向于去使用已经在市场上建立口碑的一些流媒体服务。这些问题需要被严肃地对待,因为玩家日益倾向于把主机作为家庭影院系统的一部分。同时,修复 Steam 客户端和平台的问题也很重要,和更多第三方服务商合作增加内容应该会是个好主意。性能问题和 Linux 下的显卡问题也很严重,不过好在他们最近在慢慢进步。移植游戏也是个问题。类似 Feral Interactive 或者 Aspyr Media 这样的游戏移植商可以帮助扩展 Steam 的商店游戏数量,但联系开发者和出版社可能会有问题,而且这两家移植商经常在移植的容器上搞自己的花样。Valve 已经在帮助游戏工作室自己移植游戏了,比如 Rocket League,不过这种情况很少见,而且就算 Valve 去帮忙了,也是非常符合 Valve 拖拉的风格。而 AAA 大作这一块内容也绝不应该被忽略 —— 近来这方面的情况已经有极大好转了,虽然 Linux 平台的支持好了很多,但在玩家数量不够以及 Valve 为 Steam Machines 提供的开发帮助甚少的情况下,Bethesda 这样的开发商依然不愿意移植游戏;同时,也有像 Denuvo 一样缺乏数字版权管理的公司难以向 Steam Machines 移植游戏。
在我看来 Valve 需要在除了软件和硬件的地方也多花些功夫。如果他们只有一个机型的话,他们可以很方便的在硬件生产上贴点钱。这样 Steam Machines 的价格就能跻身主机的行列,而且还能比自己组装 PC 要便宜。针对正确的市场群体做营销也很关键,即便我们还不知道目标玩家应该是谁(我个人会对这样的 Steam Machines 感兴趣,而且我有一整堆已经在 Steam 上以相当便宜的价格买下的游戏)。最后,我觉得零售商们其实不会对 Valve 的计划很感冒,毕竟他们要靠卖和倒卖实体游戏赚钱。
就算 Valve 在产品和平台上采纳过这些改进,我也不知道怎样才能激活 Steam Machines 的全市场潜力。总的来说,Valve 不仅得学习自己的经验教训,还应该参考曾经有过类似尝试的厂商们,比如尝试依靠开放平台的 3DO 和 Pippin;又或者那些从台式机体验的竞争力退赛的那些公司,其实 Valve 如今的情况和他们也有几分相似。亦或者他们也可以观察一下任天堂 Switch —— 毕竟任天堂也在尝试跨界的创新。
*注解: 上述点子由 liamdawe 整理,所有的想法都由用户提交。*
本文是被一位访客提交的,我们欢迎大家前来[提交文章](https://www.gamingonlinux.com/submit-article/)。
---
via: <https://www.gamingonlinux.com/articles/user-editorial-steam-machines-steamos-after-a-year-in-the-wild.8474>
作者:[calvin](https://www.gamingonlinux.com/profiles/5163) 译者:[Moelf](https://github.com/Moelf) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
8,992 | JavaScript 函数式编程介绍 | https://opensource.com/article/17/6/functional-javascript | 2017-10-26T08:30:00 | [
"函数式编程",
"JavaScript"
] | https://linux.cn/article-8992-1.html |
>
> 探索函数式编程,通过它让你的程序更具有可读性和易于调试
>
>
>

当 Brendan Eich 在 1995 年创造 JavaScript 时,他原本打算[将 Scheme 移植到浏览器里](https://brendaneich.com/2008/04/popularity/) 。Scheme 作为 Lisp 的方言,是一种函数式编程语言。而当 Eich 被告知新的语言应该是一种可以与 Java 相比的脚本语言后,他最终确立了一种拥有 C 风格语法的语言(也和 Java 一样),但将函数视作一等公民。而 Java 直到版本 8 才从技术上将函数视为一等公民,虽然你可以用匿名类来模拟它。这个特性允许 JavaScript 通过函数式范式编程。
JavaScript 是一个多范式语言,允许你自由地混合和使用面向对象式、过程式和函数式的编程范式。最近,函数式编程越来越火热。在诸如 [Angular](https://angular-2-training-book.rangle.io/handout/change-detection/change_detection_strategy_onpush.html) 和 [React](https://facebook.github.io/react/docs/optimizing-performance.html#the-power-of-not-mutating-data) 这样的框架中,通过使用不可变数据结构可以切实提高性能。不可变是函数式编程的核心原则,它以及纯函数使得编写和调试程序变得更加容易。使用函数来代替程序的循环可以提高程序的可读性并使它更加优雅。总之,函数式编程拥有很多优点。
### 什么不是函数式编程
在讨论什么是函数式编程前,让我们先排除那些不属于函数式编程的东西。实际上它们是你需要丢弃的语言组件(再见,老朋友):
* 循环:
+ `while`
+ `do...while`
+ `for`
+ `for...of`
+ `for...in`
* 用 `var` 或者 `let` 来声明变量
* 没有返回值的函数
* 改变对象的属性 (比如: `o.x = 5;`)
* 改变数组本身的方法:
+ `copyWithin`
+ `fill`
+ `pop`
+ `push`
+ `reverse`
+ `shift`
+ `sort`
+ `splice`
+ `unshift`
* 改变映射本身的方法:
+ `clear`
+ `delete`
+ `set`
* 改变集合本身的方法:
+ `add`
+ `clear`
+ `delete`
脱离这些特性应该如何编写程序呢?这是我们将在后面探索的问题。
### 纯函数
你的程序中包含函数不一定意味着你正在进行函数式编程。函数式范式将<ruby> 纯函数 <rt> pure function </rt></ruby>和<ruby> 非纯函数 <rt> impure function </rt></ruby>区分开。鼓励你编写纯函数。纯函数必须满足下面的两个属性:
* 引用透明:函数在传入相同的参数后永远返回相同的返回值。这意味着该函数不依赖于任何可变状态。
* 无副作用:函数不能导致任何副作用。副作用可能包括 I/O(比如向终端或者日志文件写入),改变一个不可变的对象,对变量重新赋值等等。
我们来看一些例子。首先,`multiply` 就是一个纯函数的例子,它在传入相同的参数后永远返回相同的返回值,并且不会导致副作用。
```
function multiply(a, b) {
return a * b;
}
```
下面是非纯函数的例子。`canRide` 函数依赖捕获的 `heightRequirement` 变量。被捕获的变量不一定导致一个函数是非纯函数,除非它是一个可变的变量(或者可以被重新赋值)。这种情况下使用 `let` 来声明这个变量,意味着可以对它重新赋值。`multiply` 函数是非纯函数,因为它会导致在 console 上输出。
```
let heightRequirement = 46;
// Impure because it relies on a mutable (reassignable) variable.
function canRide(height) {
return height >= heightRequirement;
}
// Impure because it causes a side-effect by logging to the console.
function multiply(a, b) {
console.log('Arguments: ', a, b);
return a * b;
}
```
下面的列表包含着 JavaScript 内置的非纯函数。你可以指出它们不满足两个属性中的哪个吗?
* `console.log`
* `element.addEventListener`
* `Math.random`
* `Date.now`
* `$.ajax` (这里 `$` 代表你使用的 Ajax 库)
理想的程序中所有的函数都是纯函数,但是从上面的函数列表可以看出,任何有意义的程序都将包含非纯函数。大多时候我们需要进行 AJAX 调用,检查当前日期或者获取一个随机数。一个好的经验法则是遵循 80/20 规则:函数中有 80% 应该是纯函数,剩下的 20% 的必要性将不可避免地是非纯函数。
使用纯函数有几个优点:
* 它们很容易导出和调试,因为它们不依赖于可变的状态。
* 返回值可以被缓存或者“记忆”来避免以后重复计算。
* 它们很容易测试,因为没有需要模拟(mock)的依赖(比如日志,AJAX,数据库等等)。
你编写或者使用的函数返回空(换句话说它没有返回值),那代表它是非纯函数。
### 不变性
让我们回到捕获变量的概念上。来看看 `canRide` 函数。我们认为它是一个非纯函数,因为 `heightRequirement` 变量可以被重新赋值。下面是一个构造出来的例子来说明如何用不可预测的值来对它重新赋值。
```
let heightRequirement = 46;
function canRide(height) {
return height >= heightRequirement;
}
// Every half second, set heightRequirement to a random number between 0 and 200.
setInterval(() => heightRequirement = Math.floor(Math.random() * 201), 500);
const mySonsHeight = 47;
// Every half second, check if my son can ride.
// Sometimes it will be true and sometimes it will be false.
setInterval(() => console.log(canRide(mySonsHeight)), 500);
```
我要再次强调被捕获的变量不一定会使函数成为非纯函数。我们可以通过只是简单地改变 `heightRequirement` 的声明方式来使 `canRide` 函数成为纯函数。
```
const heightRequirement = 46;
function canRide(height) {
return height >= heightRequirement;
}
```
通过用 `const` 来声明变量意味着它不能被再次赋值。如果尝试对它重新赋值,运行时引擎将抛出错误;那么,如果用对象来代替数字来存储所有的“常量”怎么样?
```
const constants = {
heightRequirement: 46,
// ... other constants go here
};
function canRide(height) {
return height >= constants.heightRequirement;
}
```
我们用了 `const` ,所以这个变量不能被重新赋值,但是还有一个问题:这个对象可以被改变。下面的代码展示了,为了真正使其不可变,你不仅需要防止它被重新赋值,你也需要不可变的数据结构。JavaScript 语言提供了 `Object.freeze` 方法来阻止对象被改变。
```
'use strict';
// CASE 1: 对象的属性是可变的,并且变量可以被再次赋值。
let o1 = { foo: 'bar' };
// 改变对象的属性
o1.foo = 'something different';
// 对变量再次赋值
o1 = { message: "I'm a completely new object" };
// CASE 2: 对象的属性还是可变的,但是变量不能被再次赋值。
const o2 = { foo: 'baz' };
// 仍然能改变对象
o2.foo = 'Something different, yet again';
// 不能对变量再次赋值
// o2 = { message: 'I will cause an error if you uncomment me' }; // Error!
// CASE 3: 对象的属性是不可变的,但是变量可以被再次赋值。
let o3 = Object.freeze({ foo: "Can't mutate me" });
// 不能改变对象的属性
// o3.foo = 'Come on, uncomment me. I dare ya!'; // Error!
// 还是可以对变量再次赋值
o3 = { message: "I'm some other object, and I'm even mutable -- so take that!" };
// CASE 4: 对象的属性是不可变的,并且变量不能被再次赋值。这是我们想要的!!!!!!!!
const o4 = Object.freeze({ foo: 'never going to change me' });
// 不能改变对象的属性
// o4.foo = 'talk to the hand' // Error!
// 不能对变量再次赋值
// o4 = { message: "ain't gonna happen, sorry" }; // Error
```
不变性适用于所有的数据结构,包括数组、映射和集合。它意味着不能调用例如 `Array.prototype.push` 等会导致本身改变的方法,因为它会改变已经存在的数组。可以通过创建一个含有原来元素和新加元素的新数组,而不是将新元素加入一个已经存在的数组。其实所有会导致数组本身被修改的方法都可以通过一个返回修改好的新数组的函数代替。
```
'use strict';
const a = Object.freeze([4, 5, 6]);
// Instead of: a.push(7, 8, 9);
const b = a.concat(7, 8, 9);
// Instead of: a.pop();
const c = a.slice(0, -1);
// Instead of: a.unshift(1, 2, 3);
const d = [1, 2, 3].concat(a);
// Instead of: a.shift();
const e = a.slice(1);
// Instead of: a.sort(myCompareFunction);
const f = R.sort(myCompareFunction, a); // R = Ramda
// Instead of: a.reverse();
const g = R.reverse(a); // R = Ramda
// 留给读者的练习:
// copyWithin
// fill
// splice
```
[映射](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Map) 和 [集合](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Set) 也很相似。可以通过返回一个新的修改好的映射或者集合来代替使用会修改其本身的函数。
```
const map = new Map([
[1, 'one'],
[2, 'two'],
[3, 'three']
]);
// Instead of: map.set(4, 'four');
const map2 = new Map([...map, [4, 'four']]);
// Instead of: map.delete(1);
const map3 = new Map([...map].filter(([key]) => key !== 1));
// Instead of: map.clear();
const map4 = new Map();
```
```
const set = new Set(['A', 'B', 'C']);
// Instead of: set.add('D');
const set2 = new Set([...set, 'D']);
// Instead of: set.delete('B');
const set3 = new Set([...set].filter(key => key !== 'B'));
// Instead of: set.clear();
const set4 = new Set();
```
我想提一句如果你在使用 TypeScript(我非常喜欢 TypeScript),你可以用 `Readonly<T>`、`ReadonlyArray<T>`、`ReadonlyMap<K, V>` 和 `ReadonlySet<T>` 接口来在编译期检查你是否尝试更改这些对象,有则抛出编译错误。如果在对一个对象字面量或者数组调用 `Object.freeze`,编译器会自动推断它是只读的。由于映射和集合在其内部表达,所以在这些数据结构上调用 `Object.freeze` 不起作用。但是你可以轻松地告诉编译器它们是只读的变量。

*TypeScript 只读接口*
好,所以我们可以通过创建新的对象来代替修改原来的对象,但是这样不会导致性能损失吗?当然会。确保在你自己的应用中做了性能测试。如果你需要提高性能,可以考虑使用 [Immutable.js](https://facebook.github.io/immutable-js/)。Immutable.js 用[持久的数据结构](https://en.wikipedia.org/wiki/Persistent_data_structure) 实现了[链表](https://facebook.github.io/immutable-js/docs/#/List)、[堆栈](https://facebook.github.io/immutable-js/docs/#/Stack)、[映射](https://facebook.github.io/immutable-js/docs/#/Map)、[集合](https://facebook.github.io/immutable-js/docs/#/Set)和其他数据结构。使用了如同 Clojure 和 Scala 这样的函数式语言中相同的技术。
```
// Use in place of `[]`.
const list1 = Immutable.List(['A', 'B', 'C']);
const list2 = list1.push('D', 'E');
console.log([...list1]); // ['A', 'B', 'C']
console.log([...list2]); // ['A', 'B', 'C', 'D', 'E']
// Use in place of `new Map()`
const map1 = Immutable.Map([
['one', 1],
['two', 2],
['three', 3]
]);
const map2 = map1.set('four', 4);
console.log([...map1]); // [['one', 1], ['two', 2], ['three', 3]]
console.log([...map2]); // [['one', 1], ['two', 2], ['three', 3], ['four', 4]]
// Use in place of `new Set()`
const set1 = Immutable.Set([1, 2, 3, 3, 3, 3, 3, 4]);
const set2 = set1.add(5);
console.log([...set1]); // [1, 2, 3, 4]
console.log([...set2]); // [1, 2, 3, 4, 5]
```
### 函数组合
记不记得在中学时我们学过一些像 `(f ∘ g)(x)` 的东西?你那时可能想,“我什么时候会用到这些?”,好了,现在就用到了。你准备好了吗?`f ∘ g`读作 “函数 f 和函数 g 组合”。对它的理解有两种等价的方式,如等式所示: `(f ∘ g)(x) = f(g(x))`。你可以认为 `f ∘ g` 是一个单独的函数,或者视作将调用函数 `g` 的结果作为参数传给函数 `f`。注意这些函数是从右向左依次调用的,先执行 `g`,接下来执行 `f`。
关于函数组合的几个要点:
1. 我们可以组合任意数量的函数(不仅限于 2 个)。
2. 组合函数的一个方式是简单地把一个函数的输出作为下一个函数的输入(比如 `f(g(x))`)。
```
// h(x) = x + 1
// number -> number
function h(x) {
return x + 1;
}
// g(x) = x^2
// number -> number
function g(x) {
return x * x;
}
// f(x) = convert x to string
// number -> string
function f(x) {
return x.toString();
}
// y = (f ∘ g ∘ h)(1)
const y = f(g(h(1)));
console.log(y); // '4'
```
[Ramda](http://ramdajs.com/) 和 [lodash](https://github.com/lodash/lodash/wiki/FP-Guide) 之类的库提供了更优雅的方式来组合函数。我们可以在更多的在数学意义上处理函数组合,而不是简单地将一个函数的返回值传递给下一个函数。我们可以创建一个由这些函数组成的单一复合函数(就是 `(f ∘ g)(x)`)。
```
// h(x) = x + 1
// number -> number
function h(x) {
return x + 1;
}
// g(x) = x^2
// number -> number
function g(x) {
return x * x;
}
// f(x) = convert x to string
// number -> string
function f(x) {
return x.toString();
}
// R = Ramda
// composite = (f ∘ g ∘ h)
const composite = R.compose(f, g, h);
// Execute single function to get the result.
const y = composite(1);
console.log(y); // '4'
```
好了,我们可以在 JavaScript 中组合函数了。接下来呢?好,如果你已经入门了函数式编程,理想中你的程序将只有函数的组合。代码里没有循环(`for`, `for...of`, `for...in`, `while`, `do`),基本没有。你可能觉得那是不可能的。并不是这样。我们下面的两个话题是:递归和高阶函数。
### 递归
假设你想实现一个计算数字的阶乘的函数。 让我们回顾一下数学中阶乘的定义:
`n! = n * (n-1) * (n-2) * ... * 1`.
`n!` 是从 `n` 到 `1` 的所有整数的乘积。我们可以编写一个循环轻松地计算出结果。
```
function iterativeFactorial(n) {
let product = 1;
for (let i = 1; i <= n; i++) {
product *= i;
}
return product;
}
```
注意 `product` 和 `i` 都在循环中被反复重新赋值。这是解决这个问题的标准过程式方法。如何用函数式的方法解决这个问题呢?我们需要消除循环,确保没有变量被重新赋值。递归是函数式程序员的最有力的工具之一。递归需要我们将整体问题分解为类似整体问题的子问题。
计算阶乘是一个很好的例子,为了计算 `n!` 我们需要将 n 乘以所有比它小的正整数。它的意思就相当于:
`n! = n * (n-1)!`
啊哈!我们发现了一个解决 `(n-1)!` 的子问题,它类似于整个问题 `n!`。还有一个需要注意的地方就是基础条件。基础条件告诉我们何时停止递归。 如果我们没有基础条件,那么递归将永远持续。 实际上,如果有太多的递归调用,程序会抛出一个堆栈溢出错误。啊哈!
```
function recursiveFactorial(n) {
// Base case -- stop the recursion
if (n === 0) {
return 1; // 0! is defined to be 1.
}
return n * recursiveFactorial(n - 1);
}
```
然后我们来计算 `recursiveFactorial(20000)` 因为……,为什么不呢?当我们这样做的时候,我们得到了这个结果:

*堆栈溢出错误*
这里发生了什么?我们得到一个堆栈溢出错误!这不是无穷的递归导致的。我们已经处理了基础条件(`n === 0` 的情况)。那是因为浏览器的堆栈大小是有限的,而我们的代码使用了越过了这个大小的堆栈。每次对 `recursiveFactorial` 的调用导致了新的帧被压入堆栈中,就像一个盒子压在另一个盒子上。每当 `recursiveFactorial` 被调用,一个新的盒子被放在最上面。下图展示了在计算 `recursiveFactorial(3)` 时堆栈的样子。注意在真实的堆栈中,堆栈顶部的帧将存储在执行完成后应该返回的内存地址,但是我选择用变量 `r` 来表示返回值,因为 JavaScript 开发者一般不需要考虑内存地址。
")
*递归计算 3! 的堆栈(三次乘法)*
你可能会想象当计算 `n = 20000` 时堆栈会更高。我们可以做些什么优化它吗?当然可以。作为 ES2015 (又名 ES6) 标准的一部分,有一个优化用来解决这个问题。它被称作<ruby> 尾调用优化 <rt> proper tail calls optimization </rt></ruby>(PTC)。当递归函数做的最后一件事是调用自己并返回结果的时候,它使得浏览器删除或者忽略堆栈帧。实际上,这个优化对于相互递归函数也是有效的,但是为了简单起见,我们还是来看单一递归函数。
你可能会注意到,在递归函数调用之后,还要进行一次额外的计算(`n * r`)。那意味着浏览器不能通过 PTC 来优化递归;然而,我们可以通过重写函数使最后一步变成递归调用以便优化。一个窍门是将中间结果(在这里是 `product`)作为参数传递给函数。
```
'use strict';
// Optimized for tail call optimization.
function factorial(n, product = 1) {
if (n === 0) {
return product;
}
return factorial(n - 1, product * n)
}
```
让我们来看看优化后的计算 `factorial(3)` 时的堆栈。如下图所示,堆栈不会增长到超过两层。原因是我们把必要的信息都传到了递归函数中(比如 `product`)。所以,在 `product` 被更新后,浏览器可以丢弃掉堆栈中原先的帧。你可以在图中看到每次最上面的帧下沉变成了底部的帧,原先底部的帧被丢弃,因为不再需要它了。
 using PTC")
*递归计算 3! 的堆栈(三次乘法)使用 PTC*
现在选一个浏览器运行吧,假设你在使用 Safari,你会得到 `Infinity`(它是比在 JavaScript 中能表达的最大值更大的数)。但是我们没有得到堆栈溢出错误,那很不错!现在在其他的浏览器中呢怎么样呢?Safari 可能现在乃至将来是实现 PTC 的唯一一个浏览器。看看下面的兼容性表格:

*PTC 兼容性*
其他浏览器提出了一种被称作<ruby> <a href="https://github.com/tc39/proposal-ptc-syntax#syntactic-tail-calls-stc"> 语法级尾调用 </a> <rt> syntactic tail calls </rt></ruby>(STC)的竞争标准。“语法级”意味着你需要用新的语法来标识你想要执行尾递归优化的函数。即使浏览器还没有广泛支持,但是把你的递归函数写成支持尾递归优化的样子还是一个好主意。
### 高阶函数
我们已经知道 JavaScript 将函数视作一等公民,可以把函数像其他值一样传递。所以,把一个函数传给另一个函数也很常见。我们也可以让函数返回一个函数。就是它!我们有高阶函数。你可能已经很熟悉几个在 `Array.prototype` 中的高阶函数。比如 `filter`、`map` 和 `reduce` 就在其中。对高阶函数的一种理解是:它是接受(一般会调用)一个回调函数参数的函数。让我们来看看一些内置的高阶函数的例子:
```
const vehicles = [
{ make: 'Honda', model: 'CR-V', type: 'suv', price: 24045 },
{ make: 'Honda', model: 'Accord', type: 'sedan', price: 22455 },
{ make: 'Mazda', model: 'Mazda 6', type: 'sedan', price: 24195 },
{ make: 'Mazda', model: 'CX-9', type: 'suv', price: 31520 },
{ make: 'Toyota', model: '4Runner', type: 'suv', price: 34210 },
{ make: 'Toyota', model: 'Sequoia', type: 'suv', price: 45560 },
{ make: 'Toyota', model: 'Tacoma', type: 'truck', price: 24320 },
{ make: 'Ford', model: 'F-150', type: 'truck', price: 27110 },
{ make: 'Ford', model: 'Fusion', type: 'sedan', price: 22120 },
{ make: 'Ford', model: 'Explorer', type: 'suv', price: 31660 }
];
const averageSUVPrice = vehicles
.filter(v => v.type === 'suv')
.map(v => v.price)
.reduce((sum, price, i, array) => sum + price / array.length, 0);
console.log(averageSUVPrice); // 33399
```
注意我们在一个数组对象上调用其方法,这是面向对象编程的特性。如果我们想要更函数式一些,我们可以用 Rmmda 或者 lodash/fp 提供的函数。注意如果我们使用 `R.compose` 的话,需要倒转函数的顺序,因为它从右向左依次调用函数(从底向上);然而,如果我们想从左向右调用函数就像上面的例子,我们可以用 `R.pipe`。下面两个例子用了 Rmmda。注意 Rmmda 有一个 `mean` 函数用来代替 `reduce` 。
```
const vehicles = [
{ make: 'Honda', model: 'CR-V', type: 'suv', price: 24045 },
{ make: 'Honda', model: 'Accord', type: 'sedan', price: 22455 },
{ make: 'Mazda', model: 'Mazda 6', type: 'sedan', price: 24195 },
{ make: 'Mazda', model: 'CX-9', type: 'suv', price: 31520 },
{ make: 'Toyota', model: '4Runner', type: 'suv', price: 34210 },
{ make: 'Toyota', model: 'Sequoia', type: 'suv', price: 45560 },
{ make: 'Toyota', model: 'Tacoma', type: 'truck', price: 24320 },
{ make: 'Ford', model: 'F-150', type: 'truck', price: 27110 },
{ make: 'Ford', model: 'Fusion', type: 'sedan', price: 22120 },
{ make: 'Ford', model: 'Explorer', type: 'suv', price: 31660 }
];
// Using `pipe` executes the functions from top-to-bottom.
const averageSUVPrice1 = R.pipe(
R.filter(v => v.type === 'suv'),
R.map(v => v.price),
R.mean
)(vehicles);
console.log(averageSUVPrice1); // 33399
// Using `compose` executes the functions from bottom-to-top.
const averageSUVPrice2 = R.compose(
R.mean,
R.map(v => v.price),
R.filter(v => v.type === 'suv')
)(vehicles);
console.log(averageSUVPrice2); // 33399
```
使用函数式方法的优点是清楚地分开了数据(`vehicles`)和逻辑(函数 `filter`,`map` 和 `reduce`)。面向对象的代码相比之下把数据和函数用以方法的对象的形式混合在了一起。
### 柯里化
不规范地说,<ruby> 柯里化 <rt> currying </rt></ruby>是把一个接受 `n` 个参数的函数变成 `n` 个每个接受单个参数的函数的过程。函数的 `arity` 是它接受参数的个数。接受一个参数的函数是 `unary`,两个的是 `binary`,三个的是 `ternary`,`n` 个的是 `n-ary`。那么,我们可以把柯里化定义成将一个 `n-ary` 函数转换成 `n` 个 `unary` 函数的过程。让我们通过简单的例子开始,一个计算两个向量点积的函数。回忆一下线性代数,两个向量 `[a, b, c]` 和 `[x, y, z]` 的点积是 `ax + by + cz`。
```
function dot(vector1, vector2) {
return vector1.reduce((sum, element, index) => sum += element * vector2[index], 0);
}
const v1 = [1, 3, -5];
const v2 = [4, -2, -1];
console.log(dot(v1, v2)); // 1(4) + 3(-2) + (-5)(-1) = 4 - 6 + 5 = 3
```
`dot` 函数是 binary,因为它接受两个参数;然而我们可以将它手动转换成两个 unary 函数,就像下面的例子。注意 `curriedDot` 是一个 unary 函数,它接受一个向量并返回另一个接受第二个向量的 unary 函数。
```
function curriedDot(vector1) {
return function(vector2) {
return vector1.reduce((sum, element, index) => sum += element * vector2[index], 0);
}
}
// Taking the dot product of any vector with [1, 1, 1]
// is equivalent to summing up the elements of the other vector.
const sumElements = curriedDot([1, 1, 1]);
console.log(sumElements([1, 3, -5])); // -1
console.log(sumElements([4, -2, -1])); // 1
```
很幸运,我们不需要把每一个函数都手动转换成柯里化以后的形式。[Ramda](http://ramdajs.com/docs/#curry) 和 [lodash](https://lodash.com/docs/4.17.4#curry) 等库可以为我们做这些工作。实际上,它们是柯里化的混合形式。你既可以每次传递一个参数,也可以像原来一样一次传递所有参数。
```
function dot(vector1, vector2) {
return vector1.reduce((sum, element, index) => sum += element * vector2[index], 0);
}
const v1 = [1, 3, -5];
const v2 = [4, -2, -1];
// Use Ramda to do the currying for us!
const curriedDot = R.curry(dot);
const sumElements = curriedDot([1, 1, 1]);
console.log(sumElements(v1)); // -1
console.log(sumElements(v2)); // 1
// This works! You can still call the curried function with two arguments.
console.log(curriedDot(v1, v2)); // 3
```
Ramda 和 lodash 都允许你“跳过”一些变量之后再指定它们。它们使用置位符来做这些工作。因为点积的计算可以交换两项。传入向量的顺序不影响结果。让我们换一个例子来阐述如何使用一个置位符。Ramda 使用双下划线作为其置位符。
```
const giveMe3 = R.curry(function(item1, item2, item3) {
return `
1: ${item1}
2: ${item2}
3: ${item3}
`;
});
const giveMe2 = giveMe3(R.__, R.__, 'French Hens'); // Specify the third argument.
const giveMe1 = giveMe2('Partridge in a Pear Tree'); // This will go in the first slot.
const result = giveMe1('Turtle Doves'); // Finally fill in the second argument.
console.log(result);
// 1: Partridge in a Pear Tree
// 2: Turtle Doves
// 3: French Hens
```
在我们结束探讨柯里化之前最后的议题是<ruby> 偏函数应用 <rt> partial application </rt></ruby>。偏函数应用和柯里化经常同时出场,尽管它们实际上是不同的概念。一个柯里化的函数还是柯里化的函数,即使没有给它任何参数。偏函数应用,另一方面是仅仅给一个函数传递部分参数而不是所有参数。柯里化是偏函数应用常用的方法之一,但是不是唯一的。
JavaScript 拥有一个内置机制可以不依靠柯里化来做偏函数应用。那就是 [function.prototype.bind](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Function/bind) 方法。这个方法的一个特殊之处在于,它要求你将 `this` 作为第一个参数传入。 如果你不进行面向对象编程,那么你可以通过传入 `null` 来忽略 `this`。
```
1function giveMe3(item1, item2, item3) {
return `
1: ${item1}
2: ${item2}
3: ${item3}
`;
}
const giveMe2 = giveMe3.bind(null, 'rock');
const giveMe1 = giveMe2.bind(null, 'paper');
const result = giveMe1('scissors');
console.log(result);
// 1: rock
// 2: paper
// 3: scissors
```
### 总结
我希望你享受探索 JavaScript 中函数式编程的过程。对一些人来说,它可能是一个全新的编程范式,但我希望你能尝试它。你会发现你的程序更易于阅读和调试。不变性还将允许你优化 Angular 和 React 的性能。
*这篇文章基于 Matt 在 OpenWest 的演讲 [JavaScript the Good-er Parts](https://www.openwest.org/schedule/#talk-5). [OpenWest](https://www.openwest.org/) ~~将~~在 6/12-15 ,2017 在 Salt Lake City, Utah 举行。*
---
作者简介:
Matt Banz - Matt 于 2008 年五月在犹他大学获得了数学学位毕业。一个月后他得到了一份 web 开发者的工作,他从那时起就爱上了它!在 2013 年,他在北卡罗莱纳州立大学获得了计算机科学硕士学位。他在 LDS 商学院和戴维斯学区社区教育计划教授 Web 课程。他现在是就职于 Motorola Solutions 公司的高级前端开发者。
---
via: <https://opensource.com/article/17/6/functional-javascript>
作者:[Matt Banz](https://opensource.com/users/battmanz) 译者:[trnhoe](https://github.com/trnhoe) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | When Brendan Eich created JavaScript in 1995, he intended to do [Scheme in the browser](https://brendaneich.com/2008/04/popularity/). Scheme, being a dialect of Lisp, is a functional programming language. Things changed when Eich was told that the new language should be the scripting language companion to Java. Eich eventually settled on a language that has a C-style syntax (as does Java), yet has first-class functions. Java technically did not have first-class functions until version 8, however you could simulate first-class functions using anonymous classes. Those first-class functions are what makes functional programming possible in JavaScript.
JavaScript is a multi-paradigm language that allows you to freely mix and match object-oriented, procedural, and functional paradigms. Recently there has been a growing trend toward functional programming. In frameworks such as [Angular](https://angular-2-training-book.rangle.io/handout/change-detection/change_detection_strategy_onpush.html) and [React](https://facebook.github.io/react/docs/optimizing-performance.html#the-power-of-not-mutating-data), you'll actually get a performance boost by using immutable data structures. Immutability is a core tenet of functional programming. It, along with pure functions, makes it easier to reason about and debug your programs. Replacing procedural loops with functions can increase the readability of your program and make it more elegant. Overall, there are many advantages to functional programming.
## What functional programming isn't
Before we talk about what functional programming is, let's talk about what it is not. In fact, let's talk about all the language constructs you should throw out (goodbye, old friends):
- Loops
**while****do...while****for****for...of****for...in**
- Variable declarations with
**var**or**let** - Void functions
- Object mutation (for example:
**o.x = 5;**) - Array mutator methods
**copyWithin****fill****pop****push****reverse****shift****sort****splice****unshift**
- Map mutator methods
**clear****delete****set**
- Set mutator methods
**add****clear****delete**
How can you possibly program without those features? That's exactly what we are going to explore in the next few sections.
## Pure functions
Just because your program contains functions does not necessarily mean that you are doing functional programming. Functional programming distinguishes between pure and impure functions. It encourages you to write pure functions. A pure function must satisfy both of the following properties:
**Referential transparency:**The function always gives the same return value for the same arguments. This means that the function cannot depend on any mutable state.**Side-effect free:**The function cannot cause any side effects. Side effects may include I/O (e.g., writing to the console or a log file), modifying a mutable object, reassigning a variable, etc.
Let's illustrate with a few examples. First, the **multiply** function is an example of a pure function. It always returns the same output for the same input, and it causes no side effects.
The following are examples of impure functions. The **canRide** function depends on the captured **heightRequirement** variable. Captured variables do not necessarily make a function impure, but mutable (or re-assignable) ones do. In this case it was declared using **let**, which means that it can be reassigned. The **multiply** function is impure because it causes a side-effect by logging to the console.
The following list contains several built-in functions in JavaScript that are impure. Can you state which of the two properties each one does not satisfy?
**console.log****element.addEventListener****Math.random****Date.now****$.ajax**(where**$**== the Ajax library of your choice)
Living in a perfect world in which all our functions are pure would be nice, but as you can tell from the list above, any meaningful program will contain impure functions. Most of the time we will need to make an Ajax call, check the current date, or get a random number. A good rule of thumb is to follow the 80/20 rule: 80% of your functions should be pure, and the remaining 20%, of necessity, will be impure.
There are several benefits to pure functions:
- They're easier to reason about and debug because they don't depend on mutable state.
- The return value can be cached or "memoized" to avoid recomputing it in the future.
- They're easier to test because there are no dependencies (such as logging, Ajax, database, etc.) that need to be mocked.
If a function you're writing or using is void (i.e., it has no return value), that's a clue that it's impure. If the function has no return value, then either it's a no-op or it's causing some side effect. Along the same lines, if you call a function but do not use its return value, again, you're probably relying on it to do some side effect, and it is an impure function.
## Immutability
Let's return to the concept of captured variables. Above, we looked at the **canRide** function. We decided that it is an impure function, because the **heightRequirement** could be reassigned. Here is a contrived example of how it can be reassigned with unpredictable results:
Let me reemphasize that captured variables do not necessarily make a function impure. We can rewrite the **canRide** function so that it is pure by simply changing how we declare the **heightRequirement** variable.
Declaring the variable with **const** means that there is no chance that it will be reassigned. If an attempt is made to reassign it, the runtime engine will throw an error; however, what if instead of a simple number we had an object that stored all our "constants"?
We used **const** so the variable cannot be reassigned, but there's still a problem. The object can be mutated. As the following code illustrates, to gain true immutability, you need to prevent the variable from being reassigned, and you also need immutable data structures. The JavaScript language provides us with the **Object.freeze** method to prevent an object from being mutated.
Immutability pertains to all data structures, which includes arrays, maps, and sets. That means that we cannot call mutator methods such as **array.prototype.push** because that modifies the existing array. Instead of pushing an item onto the existing array, we can create a new array with all the same items as the original array, plus the one additional item. In fact, every mutator method can be replaced by a function that returns a new array with the desired changes.
The same thing goes when using a [ Map](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Map) or a
[. We can avoid mutator methods by returning a new](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Set)
**Set****Map**or
**Set**with the desired changes.
I would like to add that if you are using TypeScript (I am a huge fan of TypeScript), then you can use the **Readonly<T>**, **ReadonlyArray<T>**, **ReadonlyMap<K, V>**, and **ReadonlySet<T>** interfaces to get a compile-time error if you attempt to mutate any of those objects. If you call **Object.freeze** on an object literal or an array, then the compiler will automatically infer that it is read-only. Because of how Maps and Sets are represented internally, calling **Object.freeze** on those data structures does not work the same. But it's easy enough to tell the compiler that you would like them to be read-only.
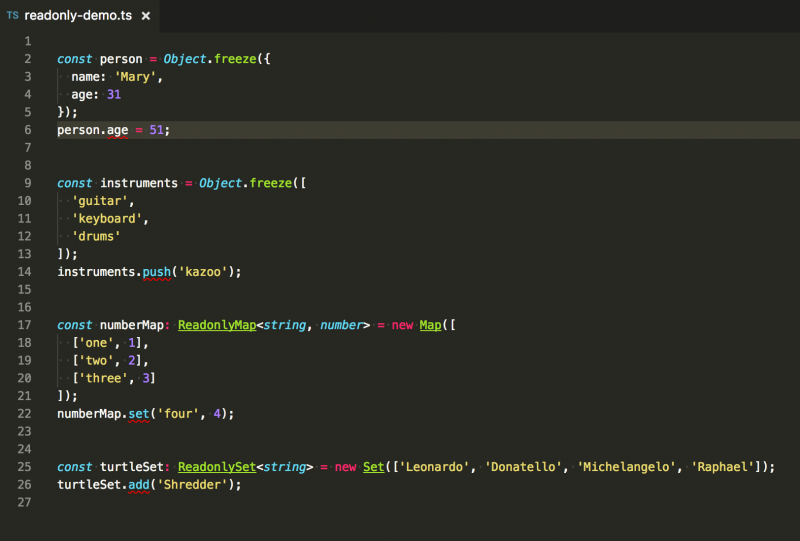
opensource.com
Okay, so we can create new objects instead of mutating existing ones, but won't that adversely affect performance? Yes, it can. Be sure to do performance testing in your own app. If you need a performance boost, then consider using [Immutable.js](https://facebook.github.io/immutable-js/). Immutable.js implements [Lists](https://facebook.github.io/immutable-js/docs/#/List), [Stacks](https://facebook.github.io/immutable-js/docs/#/Stack), [Maps](https://facebook.github.io/immutable-js/docs/#/Map), [Sets](https://facebook.github.io/immutable-js/docs/#/Set), and other data structures using [persistent data structures](https://en.wikipedia.org/wiki/Persistent_data_structure). This is the same technique used internally by functional programming languages such as Clojure and Scala.
## Function composition
Remember back in high school when you learned something that looked like **(f ∘ g)(x)**? Remember thinking, "When am I ever going to use this?" Well, now you are. Ready? **f ∘ g** is read "**f composed with g**." There are two equivalent ways of thinking of it, as illustrated by this identity: **(f ∘ g)(x) = f(g(x))**. You can either think of **f ∘ g** as a single function or as the result of calling function **g** and then taking its output and passing that to **f**. Notice that the functions get applied from right to left—that is, we execute **g**, followed by **f**.
A couple of important points about function composition:
- We can compose any number of functions (we're not limited to two).
- One way to compose functions is simply to take the output from one function and pass it to the next (i.e.,
**f(g(x))**).
There are libraries such as [Ramda](http://ramdajs.com/) and [lodash](https://github.com/lodash/lodash/wiki/FP-Guide) that provide a more elegant way of composing functions. Instead of simply passing the return value from one function to the next, we can treat function composition in the more mathematical sense. We can create a single composite function made up from the others (i.e., **(f ∘ g)(x)**).
Okay, so we can do function composition in JavaScript. What's the big deal? Well, if you're really onboard with functional programming, then ideally your entire program will be nothing but function composition. There will be no loops (**for**, **for...of**, **for...in**, **while**, **do**) in your code. None (period). But that's impossible, you say! Not so. That leads us to the next two topics: recursion and higher-order functions.
## Recursion
Let's say that you would like to implement a function that computes the factorial of a number. Let's recall the definition of factorial from mathematics:
**n! = n * (n-1) * (n-2) * ... * 1**.
That is, **n!** is the product of all the integers from **n** down to **1**. We can write a loop that computes that for us easily enough.
Notice that both **product** and **i** are repeatedly being reassigned inside the loop. This is a standard procedural approach to solving the problem. How would we solve it using a functional approach? We would need to eliminate the loop and make sure we have no variables being reassigned. Recursion is one of the most powerful tools in the functional programmer's toolbelt. Recursion asks us to break down the overall problem into sub-problems that resemble the overall problem.
Computing the factorial is a perfect example. To compute **n!**, we simply need to take **n** and multiply it by all the smaller integers. That's the same thing as saying:
**n! = n * (n-1)!**
A-ha! We found a sub-problem to solve **(n-1)!** and it resembles the overall problem **n!**. There's one more thing to take care of: the base case. The base case tells us when to stop the recursion. If we didn't have a base case, then recursion would go on forever. In practice, you'll get a stack overflow error if there are too many recursive calls.
What is the base case for the factorial function? At first you might think that it's when **n == 1**, but due to some [complex math stuff](https://math.stackexchange.com/questions/20969/prove-0-1-from-first-principles), it's when **n == 0**. **0!** is defined to be **1**. With this information in mind, let's write a recursive factorial function.
Okay, so let's compute **recursiveFactorial(20000)**, because... well, why not! When we do, we get this:
opensource.com
So what's going on here? We got a stack overflow error! It's not because of infinite recursion. We know that we handled the base case (i.e., **n === 0**). It's because the browser has a finite stack and we have exceeded it. Each call to **recursiveFactorial** causes a new frame to be put on the stack. We can visualize the stack as a set of boxes stacked on top of each other. Each time **recursiveFactorial** gets called, a new box is added to the top. The following diagram shows a stylized version of what the stack might look like when computing **recursiveFactorial(3)**. Note that in a real stack, the frame on top would store the memory address of where it should return after executing, but I have chosen to depict the return value using the variable **r**. I did this because JavaScript developers don't normally need to think about memory addresses.

opensource.com
You can imagine that the stack for **n = 20000** would be much higher. Is there anything we can do about that? It turns out that, yes, there is something we can do about it. As part of the **ES2015** (aka **ES6**) specification, an optimization was added to address this issue. It's called the *proper tail calls optimization* (PTC). It allows the browser to elide, or omit, stack frames if the last thing that the recursive function does is call itself and return the result. Actually, the optimization works for mutually recursive functions as well, but for simplicity we're just going to focus on a single recursive function.
You'll notice in the stack above that after the recursive function call, there is still an additional computation to be made (i.e., **n * r**). That means that the browser cannot optimize it using PTC; however, we can rewrite the function in such a way so that the last step is the recursive call. One trick to doing that is to pass the intermediate result (in this case the **product**) into the function as an argument.
Let's visualize the optimized stack now when computing **factorial(3)**. As the following diagram shows, in this case the stack never grows beyond two frames. The reason is that we are passing all necessary information (i.e., the **product**) into the recursive function. So, after the **product** has been updated, the browser can throw out that stack frame. You'll notice in this diagram that each time the top frame falls down and becomes the bottom frame, the previous bottom frame gets thrown out. It's no longer needed.
opensource.com
Now run that in a browser of your choice, and assuming that you ran it in Safari, then you will get the answer, which is **Infinity** (it's a number higher than the maximum representable number in JavaScript). But we didn't get a stack overflow error, so that's good! Now what about all the other browsers? It turns out that Safari is the only browser that has implemented PTC, and it might be the only browser to ever implement it. See the following compatibility table:

opensource.com
Other browsers have put forth a competing standard called [syntactic tail calls](https://github.com/tc39/proposal-ptc-syntax#syntactic-tail-calls-stc) (STC). "Syntactic" means that you will have to specify via new syntax that you would like the function to participate in the tail-call optimization. Even though there is not widespread browser support yet, it's still a good idea to write your recursive functions so that they are ready for tail-call optimization whenever (and however) it comes.
## Higher-order functions
We already know that JavaScript has first-class functions that can be passed around just like any other value. So, it should come as no surprise that we can pass a function to another function. We can also return a function from a function. Voilà! We have higher-order functions. You're probably already familiar with several higher order functions that exist on the **Array.prototype**. For example, **filter**, **map**, and **reduce**, among others. One way to think of a higher-order function is: It's a function that accepts (what's typically called) a callback function. Let's see an example of using built-in higher-order functions:
Notice that we are calling methods on an array object, which is characteristic of object-oriented programming. If we wanted to make this a bit more representative of functional programming, we could use functions provided by Ramda or lodash/fp instead. We can also use function composition, which we explored in a previous section. Note that we would need to reverse the order of the functions if we use **R.compose**, since it applies the functions right to left (i.e., bottom to top); however, if we want to apply them left to right (i.e., top to bottom), as in the example above, then we can use **R.pipe**. Both examples are given below using Ramda. Note that Ramda has a **mean** function that can be used instead of **reduce**.
The advantage of the functional programming approach is that it clearly separates the data (i.e., **vehicles**) from the logic (i.e., the functions **filter**, **map**, and **reduce**). Contrast that with the object-oriented code that blends data and functions in the form of objects with methods.
## Currying
Informally, **currying** is the process of taking a function that accepts **n** arguments and turning it into **n** functions that each accepts a single argument. The **arity** of a function is the number of arguments that it accepts. A function that accepts a single argument is **unary**, two arguments **binary**, three arguments **ternary**, and **n** arguments is **n-ary**. Therefore, we can define currying as the process of taking an **n-ary** function and turning it into **n** unary functions. Let's start with a simple example, a function that takes the dot product of two vectors. Recall from linear algebra that the dot product of two vectors **[a, b, c]** and **[x, y, z]** is equal to **ax + by + cz**.
The **dot** function is binary since it accepts two arguments; however, we can manually convert it into two unary functions, as the following code example shows. Notice how **curriedDot** is a unary function that accepts a vector and returns another unary function that then accepts the second vector.
Fortunately for us, we don't have to manually convert each one of our functions to a curried form. Libraries including [Ramda](http://ramdajs.com/docs/#curry) and [lodash](https://lodash.com/docs/4.17.4#curry) have functions that will do it for us. In fact, they do a hybrid type of currying, where you can either call the function one argument at a time, or you can continue to pass in all the arguments at once, just like the original.
Both Ramda and lodash also allow you to "skip over" an argument and specify it later. They do this using a placeholder. Because taking the dot product is commutative, it won't make a difference in which order we passed the vectors into the function. Let's use a different example to illustrate using a placeholder. Ramda uses a double underscore as its placeholder.
One final point before we complete the topic of currying, and that is partial application. Partial application and currying often go hand in hand, though they really are separate concepts. A curried function is still a curried function even if it hasn't been given any arguments. Partial application, on the other hand, is when a function has been given some, but not all, of its arguments. Currying is often used to do partial application, but it's not the only way.
The JavaScript language has a built-in mechanism for doing partial application without currying. This is done using the [ function.prototype.bind](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Function/bind) method. One idiosyncrasy of this method is that it requires you to pass in the value of
**this**as the first argument. If you're not doing object-oriented programming, then you can effectively ignore
**this**by passing in
**null**.
## Wrapping up
I hope you enjoyed exploring functional programming in JavaScript with me! For some it may be a completely new programming paradigm, but I hope you will give it a chance. I think you'll find that your programs are easier to read and debug. Immutability will also allow you to take advantage of performance optimizations in Angular and React.
*This article is based on Matt's OpenWest talk, JavaScript the Good-er Parts. OpenWest will be held July 12-15, 2017 in Salt Lake City, Utah.*
## 2 Comments |
8,993 | 并发服务器(一):简介 | https://eli.thegreenplace.net/2017/concurrent-servers-part-1-introduction/ | 2017-10-25T09:46:00 | [
"并发"
] | https://linux.cn/article-8993-1.html | 
这是关于并发网络服务器编程的第一篇教程。我计划测试几个主流的、可以同时处理多个客户端请求的服务器并发模型,基于可扩展性和易实现性对这些模型进行评判。所有的服务器都会监听套接字连接,并且实现一些简单的协议用于与客户端进行通讯。
该系列的所有文章:
* [第一节 - 简介](http://eli.thegreenplace.net/2017/concurrent-servers-part-1-introduction/)
* [第二节 - 线程](http://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/)
* [第三节 - 事件驱动](http://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/)
### 协议
该系列教程所用的协议都非常简单,但足以展示并发服务器设计的许多有趣层面。而且这个协议是 *有状态的* —— 服务器根据客户端发送的数据改变内部状态,然后根据内部状态产生相应的行为。并非所有的协议都是有状态的 —— 实际上,基于 HTTP 的许多协议是无状态的,但是有状态的协议也是很常见,值得认真讨论。
在服务器端看来,这个协议的视图是这样的:

总之:服务器等待新客户端的连接;当一个客户端连接的时候,服务器会向该客户端发送一个 `*` 字符,进入“等待消息”的状态。在该状态下,服务器会忽略客户端发送的所有字符,除非它看到了一个 `^` 字符,这表示一个新消息的开始。这个时候服务器就会转变为“正在通信”的状态,这时它会向客户端回送数据,把收到的所有字符的每个字节加 1 回送给客户端<sup> 注1</sup> 。当客户端发送了 `$` 字符,服务器就会退回到等待新消息的状态。`^` 和 `$` 字符仅仅用于分隔消息 —— 它们不会被服务器回送。
每个状态之后都有个隐藏的箭头指向 “等待客户端” 状态,用于客户端断开连接。因此,客户端要表示“我已经结束”的方法很简单,关掉它那一端的连接就好。
显然,这个协议是真实协议的简化版,真实使用的协议一般包含复杂的报文头、转义字符序列(例如让消息体中可以出现 `$` 符号),额外的状态变化。但是我们这个协议足以完成期望。
另一点:这个系列是介绍性的,并假设客户端都工作的很好(虽然可能运行很慢);因此没有设置超时,也没有设置特殊的规则来确保服务器不会因为客户端的恶意行为(或是故障)而出现阻塞,导致不能正常结束。
### 顺序服务器
这个系列中我们的第一个服务端程序是一个简单的“顺序”服务器,用 C 进行编写,除了标准的 POSIX 中用于套接字的内容以外没有使用其它库。服务器程序是顺序,因为它一次只能处理一个客户端的请求;当有客户端连接时,像之前所说的那样,服务器会进入到状态机中,并且不再监听套接字接受新的客户端连接,直到当前的客户端结束连接。显然这不是并发的,而且即便在很少的负载下也不能服务多个客户端,但它对于我们的讨论很有用,因为我们需要的是一个易于理解的基础。
这个服务器的完整代码在[这里](https://github.com/eliben/code-for-blog/blob/master/2017/async-socket-server/sequential-server.c);接下来,我会着重于一些重点的部分。`main` 函数里面的外层循环用于监听套接字,以便接受新客户端的连接。一旦有客户端进行连接,就会调用 `serve_connection`,这个函数中的代码会一直运行,直到客户端断开连接。
顺序服务器在循环里调用 `accept` 用来监听套接字,并接受新连接:
```
while (1) {
struct sockaddr_in peer_addr;
socklen_t peer_addr_len = sizeof(peer_addr);
int newsockfd =
accept(sockfd, (struct sockaddr*)&peer_addr, &peer_addr_len);
if (newsockfd < 0) {
perror_die("ERROR on accept");
}
report_peer_connected(&peer_addr, peer_addr_len);
serve_connection(newsockfd);
printf("peer done\n");
}
```
`accept` 函数每次都会返回一个新的已连接的套接字,然后服务器调用 `serve_connection`;注意这是一个 *阻塞式* 的调用 —— 在 `serve_connection` 返回前,`accept` 函数都不会再被调用了;服务器会被阻塞,直到客户端结束连接才能接受新的连接。换句话说,客户端按 *顺序* 得到响应。
这是 `serve_connection` 函数:
```
typedef enum { WAIT_FOR_MSG, IN_MSG } ProcessingState;
void serve_connection(int sockfd) {
if (send(sockfd, "*", 1, 0) < 1) {
perror_die("send");
}
ProcessingState state = WAIT_FOR_MSG;
while (1) {
uint8_t buf[1024];
int len = recv(sockfd, buf, sizeof buf, 0);
if (len < 0) {
perror_die("recv");
} else if (len == 0) {
break;
}
for (int i = 0; i < len; ++i) {
switch (state) {
case WAIT_FOR_MSG:
if (buf[i] == '^') {
state = IN_MSG;
}
break;
case IN_MSG:
if (buf[i] == '$') {
state = WAIT_FOR_MSG;
} else {
buf[i] += 1;
if (send(sockfd, &buf[i], 1, 0) < 1) {
perror("send error");
close(sockfd);
return;
}
}
break;
}
}
}
close(sockfd);
}
```
它完全是按照状态机协议进行编写的。每次循环的时候,服务器尝试接收客户端的数据。收到 0 字节意味着客户端断开连接,然后循环就会退出。否则,会逐字节检查接收缓存,每一个字节都可能会触发一个状态。
`recv` 函数返回接收到的字节数与客户端发送消息的数量完全无关(`^...$` 闭合序列的字节)。因此,在保持状态的循环中遍历整个缓冲区很重要。而且,每一个接收到的缓冲中可能包含多条信息,但也有可能开始了一个新消息,却没有显式的结束字符;而这个结束字符可能在下一个缓冲中才能收到,这就是处理状态在循环迭代中进行维护的原因。
例如,试想主循环中的 `recv` 函数在某次连接中返回了三个非空的缓冲:
1. `^abc$de^abte$f`
2. `xyz^123`
3. `25$^ab$abab`
服务端返回的是哪些数据?追踪代码对于理解状态转变很有用。(答案见<sup> 注 <a href="https://en.wikipedia.org/wiki/Mealy_machine"> 2 </a></sup> )
### 多个并发客户端
如果多个客户端在同一时刻向顺序服务器发起连接会发生什么事情?
服务器端的代码(以及它的名字 “顺序服务器”)已经说的很清楚了,一次只能处理 *一个* 客户端的请求。只要服务器在 `serve_connection` 函数中忙于处理客户端的请求,就不会接受别的客户端的连接。只有当前的客户端断开了连接,`serve_connection` 才会返回,然后最外层的循环才能继续执行接受其他客户端的连接。
为了演示这个行为,[该系列教程的示例代码](https://github.com/eliben/code-for-blog/tree/master/2017/async-socket-server) 包含了一个 Python 脚本,用于模拟几个想要同时连接服务器的客户端。每一个客户端发送类似之前那样的三个数据缓冲 <sup> 注3</sup> ,不过每次发送数据之间会有一定延迟。
客户端脚本在不同的线程中并发地模拟客户端行为。这是我们的序列化服务器与客户端交互的信息记录:
```
$ python3.6 simple-client.py -n 3 localhost 9090
INFO:2017-09-16 14:14:17,763:conn1 connected...
INFO:2017-09-16 14:14:17,763:conn1 sending b'^abc$de^abte$f'
INFO:2017-09-16 14:14:17,763:conn1 received b'b'
INFO:2017-09-16 14:14:17,802:conn1 received b'cdbcuf'
INFO:2017-09-16 14:14:18,764:conn1 sending b'xyz^123'
INFO:2017-09-16 14:14:18,764:conn1 received b'234'
INFO:2017-09-16 14:14:19,764:conn1 sending b'25$^ab0000$abab'
INFO:2017-09-16 14:14:19,765:conn1 received b'36bc1111'
INFO:2017-09-16 14:14:19,965:conn1 disconnecting
INFO:2017-09-16 14:14:19,966:conn2 connected...
INFO:2017-09-16 14:14:19,967:conn2 sending b'^abc$de^abte$f'
INFO:2017-09-16 14:14:19,967:conn2 received b'b'
INFO:2017-09-16 14:14:20,006:conn2 received b'cdbcuf'
INFO:2017-09-16 14:14:20,968:conn2 sending b'xyz^123'
INFO:2017-09-16 14:14:20,969:conn2 received b'234'
INFO:2017-09-16 14:14:21,970:conn2 sending b'25$^ab0000$abab'
INFO:2017-09-16 14:14:21,970:conn2 received b'36bc1111'
INFO:2017-09-16 14:14:22,171:conn2 disconnecting
INFO:2017-09-16 14:14:22,171:conn0 connected...
INFO:2017-09-16 14:14:22,172:conn0 sending b'^abc$de^abte$f'
INFO:2017-09-16 14:14:22,172:conn0 received b'b'
INFO:2017-09-16 14:14:22,210:conn0 received b'cdbcuf'
INFO:2017-09-16 14:14:23,173:conn0 sending b'xyz^123'
INFO:2017-09-16 14:14:23,174:conn0 received b'234'
INFO:2017-09-16 14:14:24,175:conn0 sending b'25$^ab0000$abab'
INFO:2017-09-16 14:14:24,176:conn0 received b'36bc1111'
INFO:2017-09-16 14:14:24,376:conn0 disconnecting
```
这里要注意连接名:`conn1` 是第一个连接到服务器的,先跟服务器交互了一段时间。接下来的连接 `conn2` —— 在第一个断开连接后,连接到了服务器,然后第三个连接也是一样。就像日志显示的那样,每一个连接让服务器变得繁忙,持续了大约 2.2 秒的时间(这实际上是人为地在客户端代码中加入的延迟),在这段时间里别的客户端都不能连接。
显然,这不是一个可扩展的策略。这个例子中,客户端中加入了延迟,让服务器不能处理别的交互动作。一个智能服务器应该能处理一堆客户端的请求,而这个原始的服务器在结束连接之前一直繁忙(我们将会在之后的章节中看到如何实现智能的服务器)。尽管服务端有延迟,但这不会过度占用 CPU;例如,从数据库中查找信息(时间基本上是花在连接到数据库服务器上,或者是花在硬盘中的本地数据库)。
### 总结及期望
这个示例服务器达成了两个预期目标:
1. 首先是介绍了问题范畴和贯彻该系列文章的套接字编程基础。
2. 对于并发服务器编程的抛砖引玉 —— 就像之前的部分所说,顺序服务器还不能在非常轻微的负载下进行扩展,而且没有高效的利用资源。
在看下一篇文章前,确保你已经理解了这里所讲的服务器/客户端协议,还有顺序服务器的代码。我之前介绍过了这个简单的协议;例如 [串行通信分帧](http://eli.thegreenplace.net/2009/08/12/framing-in-serial-communications/) 和 [用协程来替代状态机](http://eli.thegreenplace.net/2009/08/29/co-routines-as-an-alternative-to-state-machines)。要学习套接字网络编程的基础,[Beej 的教程](http://beej.us/guide/bgnet/) 用来入门很不错,但是要深入理解我推荐你还是看本书。
如果有什么不清楚的,请在评论区下进行评论或者向我发送邮件。深入理解并发服务器!
---
* 注1:状态转变中的 In/Out 记号是指 [Mealy machine](https://en.wikipedia.org/wiki/Mealy_machine)。
* 注2:回应的是 `bcdbcuf23436bc`。
* 注3:这里在结尾处有一点小区别,加了字符串 `0000` —— 服务器回应这个序列,告诉客户端让其断开连接;这是一个简单的握手协议,确保客户端有足够的时间接收到服务器发送的所有回复。
---
via: <https://eli.thegreenplace.net/2017/concurrent-servers-part-1-introduction/>
作者:[Eli Bendersky](https://eli.thegreenplace.net/pages/about) 译者:[GitFuture](https://github.com/GitFuture) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | This is the first post in a series about concurrent network servers. My plan is to examine several popular concurrency models for network servers that handle multiple clients simultaneously, and judge those models on scalability and ease of implementation. All servers will listen for socket connections and implement a simple protocol to interact with clients.
All posts in the series:
[Part 1 - Introduction](https://eli.thegreenplace.net/2017/concurrent-servers-part-1-introduction/)[Part 2 - Threads](https://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/)[Part 3 - Event-driven](https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/)[Part 4 - libuv](https://eli.thegreenplace.net/2017/concurrent-servers-part-4-libuv/)[Part 5 - Redis case study](https://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/)[Part 6 - Callbacks, Promises and async/await](https://eli.thegreenplace.net/2018/concurrent-servers-part-6-callbacks-promises-and-asyncawait/)
## The protocol
The protocol used throughout this series is very simple, but should be
sufficient to demonstrate many interesting aspects of concurrent server design.
Notably, the protocol is *stateful* - the server changes internal state based on
the data clients send, and its behavior depends on that internal state.
Not all protocols all stateful - in fact, many protocols over HTTP these days
are stateless - but stateful protocols are sufficiently common to warrant a
serious discussion.
Here's the protocol, from the server's point of view:
In words: the server waits for a new client to connect; when a client connects,
the server sends it a `*` character and enters a "wait for message state". In
this state, the server ignores everything the client sends until it sees a `^`
character that signals that a new message begins. At this point it moves to the
"in message" state, where it echoes back everything the client sends,
incrementing each byte [[1]](#footnote-1). When the client sends a `$`, the server goes back
to waiting for a new message. The `^` and `$` characters are only used to
delimit messages - they are not echoed back.
An implicit arrow exists from each state back to the "wait for client" state, in case the client disconnects. By corollary, the only way for a client to signal "I'm done" is to simply close its side of the connection.
Obviously, this protocol is a simplification of more realistic protocols that
have complicated headers, escape sequences (to support `$` inside a message
body, for example) and additional state transitions, but for our goals this will
do just fine.
Another note: this series is introductory, and assumes clients are generally well behaved (albeit potentially slow); therefore there are no timeouts and no special provisions made to ensure that the server doesn't end up being blocked indefinitely by rogue (or buggy) clients.
## A sequential server
Our first server in this series is a simple "sequential" server, written in C without using any libraries beyond standard POSIX fare for sockets. The server is sequential because it can only handle a single client at any given time; when a client connects, the server enters the state machine shown above and won't even listen on the socket for new clients until the current client is done. Obviously this isn't concurrent and doesn't scale beyond very light loads, but it's helpful to discuss since we need a simple-to-understand baseline.
The full code for this server [is here](https://github.com/eliben/code-for-blog/blob/main/2017/async-socket-server/sequential-server.c);
in what follows, I'll focus on some highlights. The outer loop in `main`
listens on the socket for new clients to connect. Once a client connects, it
calls `serve_connection` which runs through the protocol until the client
disconnects.
To accept new connections, the sequential server calls `accept` on a listening
socket in a loop:
```
while (1) {
struct sockaddr_in peer_addr;
socklen_t peer_addr_len = sizeof(peer_addr);
int newsockfd =
accept(sockfd, (struct sockaddr*)&peer_addr, &peer_addr_len);
if (newsockfd < 0) {
perror_die("ERROR on accept");
}
report_peer_connected(&peer_addr, peer_addr_len);
serve_connection(newsockfd);
printf("peer done\n");
}
```
Each time `accept` returns a new connected socket, the server calls
`serve_connection`; note that this is a *blocking* call - until
`serve_connection` returns, `accept` is not called again; the server blocks
until one client is done before accepting a new client. In other words, clients
are serviced *sequentially*.
Here's `serve_connection`:
```
typedef enum { WAIT_FOR_MSG, IN_MSG } ProcessingState;
void serve_connection(int sockfd) {
if (send(sockfd, "*", 1, 0) < 1) {
perror_die("send");
}
ProcessingState state = WAIT_FOR_MSG;
while (1) {
uint8_t buf[1024];
int len = recv(sockfd, buf, sizeof buf, 0);
if (len < 0) {
perror_die("recv");
} else if (len == 0) {
break;
}
for (int i = 0; i < len; ++i) {
switch (state) {
case WAIT_FOR_MSG:
if (buf[i] == '^') {
state = IN_MSG;
}
break;
case IN_MSG:
if (buf[i] == '$') {
state = WAIT_FOR_MSG;
} else {
buf[i] += 1;
if (send(sockfd, &buf[i], 1, 0) < 1) {
perror("send error");
close(sockfd);
return;
}
}
break;
}
}
}
close(sockfd);
}
```
It pretty much follows the protocol state machine. Each time around the loop, the server attempts to receive data from the client. Receiving 0 bytes means the client disconnected, and the loop exits. Otherwise, the received buffer is examined byte by byte, and each byte can potentially trigger a state change.
The number of bytes `recv` returns is completely independent of the number of
messages (`^...$` enclosed sequences of bytes) the client sends. Therefore,
it's important to go through the whole buffer in a state-keeping loop.
Critically, each received buffer may contain multiple messages, but also the
start of a new message without its actual ending; the ending can arrive in the
next buffer, which is why the processing state is maintained across loop
iterations.
For example, suppose the `recv` function in the main loop returned non-empty
buffers three times for some connection:
`^abc$de^abte$f``xyz^123``25$^ab$abab`
What data is the server sending back? Tracing the code manually is very useful
to understand the state transitions (for the answer see [[2]](#footnote-2)).
## Multiple concurrent clients
What happens when multiple clients attempt to connect to the sequential server at roughly the same time?
The server's code (and its name - `sequential-server`) make it clear that
clients are only handled *one at a time*. As long as the server is busy dealing
with a client in `serve_connection`, it doesn't accept new client connections.
Only when the current client disconnects does `serve_connection` return and
the outer-most loop may accept new client connections.
To show this in action, [the sample code for this series](https://github.com/eliben/code-for-blog/tree/main/2017/async-socket-server)
includes a Python script that simulates several clients trying to connect at the
same time. Each client sends the three buffers shown above [[3]](#footnote-3), with some
delays between them.
The client script runs the clients concurrently in separate threads. Here's a transcript of the client's interaction with our sequential server:
```
$ python3.6 simple-client.py -n 3 localhost 9090
INFO:2017-09-16 14:14:17,763:conn1 connected...
INFO:2017-09-16 14:14:17,763:conn1 sending b'^abc$de^abte$f'
INFO:2017-09-16 14:14:17,763:conn1 received b'b'
INFO:2017-09-16 14:14:17,802:conn1 received b'cdbcuf'
INFO:2017-09-16 14:14:18,764:conn1 sending b'xyz^123'
INFO:2017-09-16 14:14:18,764:conn1 received b'234'
INFO:2017-09-16 14:14:19,764:conn1 sending b'25$^ab0000$abab'
INFO:2017-09-16 14:14:19,765:conn1 received b'36bc1111'
INFO:2017-09-16 14:14:19,965:conn1 disconnecting
INFO:2017-09-16 14:14:19,966:conn2 connected...
INFO:2017-09-16 14:14:19,967:conn2 sending b'^abc$de^abte$f'
INFO:2017-09-16 14:14:19,967:conn2 received b'b'
INFO:2017-09-16 14:14:20,006:conn2 received b'cdbcuf'
INFO:2017-09-16 14:14:20,968:conn2 sending b'xyz^123'
INFO:2017-09-16 14:14:20,969:conn2 received b'234'
INFO:2017-09-16 14:14:21,970:conn2 sending b'25$^ab0000$abab'
INFO:2017-09-16 14:14:21,970:conn2 received b'36bc1111'
INFO:2017-09-16 14:14:22,171:conn2 disconnecting
INFO:2017-09-16 14:14:22,171:conn0 connected...
INFO:2017-09-16 14:14:22,172:conn0 sending b'^abc$de^abte$f'
INFO:2017-09-16 14:14:22,172:conn0 received b'b'
INFO:2017-09-16 14:14:22,210:conn0 received b'cdbcuf'
INFO:2017-09-16 14:14:23,173:conn0 sending b'xyz^123'
INFO:2017-09-16 14:14:23,174:conn0 received b'234'
INFO:2017-09-16 14:14:24,175:conn0 sending b'25$^ab0000$abab'
INFO:2017-09-16 14:14:24,176:conn0 received b'36bc1111'
INFO:2017-09-16 14:14:24,376:conn0 disconnecting
```
The thing to note here is the connection name: `conn1` managed to get through
to the server first, and interacted with it for a while. The next connection -
`conn2` - only got through after the first one disconnected, and so on for the
third connection. As the logs show, each connection is keeping the server busy
for ~2.2 seconds (which is exactly what the artificial delays in the client code
add up to), and during this time no other client can connect.
Clearly, this is not a scalable strategy. In our case, the client incurs the delay leaving the server completely idle for most of the interaction. A smarter server could handle dozens of other clients while the original one is busy on its end (and we'll see how to achieve that later in the series). Even if the delay is on the server side, this delay is often something that doesn't really keep the CPU too busy; for example, looking up information in a database (which is mostly network waiting time for a database server, or disk lookup time for local databases).
## Summary and next steps
The goal of presenting this simple sequential server is twofold:
- Introduce the problem domain and some basics of socket programming used throughout the series.
- Provide motivation for concurrent serving - as the previous section demonstrates, the sequential server doesn't scale beyond very trivial loads and is not an efficient way of using resources, in general.
Before reading the next posts in the series, make sure you understand the
server/client protocol described here and the code for the sequential server.
I've written about such simple protocols before; for example,
[framing in serial communications](https://eli.thegreenplace.net/2009/08/12/framing-in-serial-communications/)
and [co-routines as alternatives to state machines](https://eli.thegreenplace.net/2009/08/29/co-routines-as-an-alternative-to-state-machines).
For basics of network programming with sockets,
[Beej's guide](http://beej.us/guide/bgnet/) is not a bad starting point, but
for a deeper understanding I'd recommend a book.
If anything remains unclear, please let me know in comments or by email. On to concurrent servers!
|
[Mealy machine](https://en.wikipedia.org/wiki/Mealy_machine).
|
`bcdbcuf23436bc`.
|
`0000`at the end - the server's answer to this sequence is a signal for the client to disconnect; it's a simplistic handshake that ensures the client had time to receive all of the server's reply. |
8,994 | 如何成规模地部署多云的无服务器程序和 Cloud Foundry API | http://superuser.openstack.org/articles/deploy-multi-cloud-serverless-cloud-foundry-apis-scale/ | 2017-10-24T12:16:25 | [
"无服务器"
] | https://linux.cn/article-8994-1.html |
>
> IBM 的 Ken Parmelee 说:“微服务和 API 是产品,我们需要以这种方式思考。”
>
>
>
领导 IBM 的 API 网关和 Big Blue 开源项目的的 Ken Parmelee 对以开源方式 “进攻” API 以及如何创建微服务和使其伸缩有一些思考。
Parmelee 说:“微服务和 API 是产品,我们需要以这种方式思考这些问题。当你开始这么做,人们依赖它作为它们业务的一部分。这是你在这个领域所做的关键方面。”

他在最近的[北欧 APIs 2017 平台峰会](https://nordicapis.com/events/the-2017-api-platform-summit/)登上讲台,并挑战了一些流行的观念。
“快速失败不是一个很好的概念。你想在第一场比赛中获得一些非常棒的东西。这并不意味着你需要花费大量的时间,而是应该让它变得非常棒,然后不断的发展和改进。如果一开始真的很糟糕,人们就不会想要用你。”
他谈及包括 [OpenWhisk](https://developer.ibm.com/openwhisk/) 在内的 IBM 现代无服务器架构,这是一个 IBM 和 Apache 之间的开源伙伴关系。 云优先的基于分布式事件的编程服务是这两年多来重点关注这个领域的成果;IBM 是该领域领先的贡献者,它是 IBM 云服务的基础。它提供基础设施即服务(IaaS)、自动缩放、为多种语言提供支持、用户只需支付实际使用费用即可。这次旅程充满了挑战,因为他们发现服务器操作需要安全、并且需要轻松 —— 匿名访问、缺少使用路径、固定的 URL 格式等。
任何人都可以在 30 秒内在 <https://console.bluemix.net/openwhisk/> 上尝试这些无服务器 API。“这听起来很有噱头,但这是很容易做到的。我们正在结合 [Cloud Foundry 中完成的工作](https://cloudfoundry.org/the-foundry/ibm-cloud/),并在 OpenWhisk 下的 Bluemix 中发布了它们,以提供安全性和可扩展性。”
他说:“灵活性对于微服务也是非常重要的。 当你使用 API 在现实世界中工作时,你开始需要跨云进行扩展。”这意味着从你的内部云走向公共云,并且“对你要怎么做有一个实在的概念很重要”。

在思考“任何云概念”的时候,他警告说,不是“将其放入一个 Docker 容器,并到处运行。这很棒,但需要在这些环境中有效运行。Docker 和 Kubernetes 有提供了很多帮助,但是你想要你的操作方式付诸实施。” 提前考虑 API 的使用,无论是在内部运行还是扩展到公有云并可以公开调用 - 你需要有这样的“架构观”,他补充道。
Parmelee 说:“我们都希望我们所创造的有价值,并被广泛使用。” API 越成功,将其提升到更高水平的挑战就越大。

*API 是微服务或“服务间”的组成部分。*
他说,API 的未来是原生云的 - 无论你从哪里开始。关键因素是可扩展性,简化后端管理,降低成本,避免厂商锁定。
你可以在下面或在 [YouTube](https://www.youtube.com/jA25Kmxr6fU) 观看他整整 23 分钟的演讲。
---
via: <http://superuser.openstack.org/articles/deploy-multi-cloud-serverless-cloud-foundry-apis-scale/>
作者:[Superuser](http://superuser.openstack.org/articles/author/superuser/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
8,999 | 为什么要切换到 Linux 系统?我该怎么做? | https://www.popsci.com/switch-to-linux-operating-system | 2017-10-25T08:31:00 | [
"Linux"
] | https://linux.cn/article-8999-1.html |
>
> 是时候做出改变了。
>
>
>

当你在选购电脑的时候,你可能会在 [Windows](https://www.popsci.com/windows-tweaks-improve-performance) 和 [macOS](https://www.popsci.com/macos-tweaks-improve-performance) 之间犹豫,但是可能基本不会想到 Linux。尽管如此,这个名气没那么大的操作系统仍然拥有庞大而忠诚的粉丝。因为它相对于它的竞争者,有很大的优势。
不管你是完全不了解 Linux,或是已经尝试过一两次,我们希望你考虑一下在你的下一台笔记本或台式机上运行 Linux,或者可以和现存系统做个双启动。请继续阅读下去,看是不是时候该切换了。
### 什么是 Linux?
如果你已经非常熟悉 Linux,可以跳过这个部分。对于不熟悉的其他人,Linux 是一个免费的开源操作系统,所有人都可以去探索它的代码。技术上来说,术语“Linux”说的只是内核,或者核心代码。不过,人们一般用这个名字统称整个操作系统,包括界面和集成的应用。
因为所有人都可以修改它,Linux 有非常自由的可定制性,这鼓舞了很多程序员制作并发布了自己的系统——常称为<ruby> 发行版 <rt> distro </rt></ruby>。这些不同口味的系统,每一个都有自己特色的软件和界面。一些比较有名的发行版,模仿了熟悉的 Windows 或 macOS 操作系统,比如 [Ubuntu](https://www.ubuntu.com/)、 [Linux Mint](https://linuxmint.com/) 和 [Zorin OS](https://zorinos.com/)。当你准备选择一个发行版时,可以去它们官网看一下,试试看是不是适合自己。
为了制作和维护这些 Linux 发行版,大量的开发者无偿地贡献了自己的时间。有时候,利润主导的公司为了拓展自己的软件销售领域,也会主导开发带有独特特性的 Linux 版本。比如 Android(它虽然不能当作一个完整的 Linux 操作系统)就是以基于 Linux 内核的,这也是为什么它有很多[不同变种](https://lineageos.org/)的原因。另外,很多服务器和数据中心也运行了 Linux,所以很有可能这个操作系统托管着你正在看的网页。
### 有什么好处?
首先,Linux 是免费而且开源的,意味着你可以将它安装到你现有的电脑或笔记本上,或者你自己组装的机器,而不用支付任何费用。系统会自带一些常用软件,包括网页浏览器、媒体播放器、[图像编辑器](https://www.gimp.org/)和[办公软件](https://www.libreoffice.org/),所以你也不用为了查看图片或处理文档再支付其他额外费用。而且,以后还可以免费升级。
Linux 比其他系统能更好的防御恶意软件,强大到你都不需要运行杀毒软件。开发者们在最早构建时就考虑了安全性,比如说,操作系统只运行可信的软件。而且,很少有恶意软件针对这个系统,对于黑客来说,这样做没有价值。Linux 也并不是完全没有任何漏洞,只不过对于一般只运行已验证软件的家庭用户来说,并不用太担心安全性。
这个操作系统对硬件资源的要求比起数据臃肿的 Windows 或 macOS 来说也更少。一些发行版不像它们名气更大的表兄弟,默认集成了更少的组件,开发者特别开发了一些,比如 [Puppy Linux](http://puppylinux.org/main/Overview%20and%20Getting%20Started.htm) 和 [Linux Lite](https://www.linuxliteos.com/),让系统尽可能地轻量。这让 Linux 非常适合那些家里有很老的电脑的人。如果你的远古笔记本正在原装操作系统的重压下喘息,试试装一个 Linux,应该会快很多。如果不愿意的话,你也不用抛弃旧系统,我们会在后面的部分里解释怎么做。
尽管你可能会需要一点时间来适应新系统,不过不用太久,你就会发现 Linux 界面很容易使用。任何年龄和任何技术水平的人都可以掌握这个软件。而且在线的 Linux 社区提供了大量的帮助和支持。说到社区,下载 Linux 也是对开源软件运动的支持:这些开发者一起工作,并不收取任何费用,为全球用户开发更优秀的软件。
### 我该从哪儿开始?
Linux 据说只有专家才能安装。不过比起前几年,现在安装并运行操作系统已经非常简单了。
首先,打开你喜欢的发行版的网站,按照上面的安装指南操作。一般会需要烧录一张 DVD 或者制作一个带有必要程序的 U 盘,然后重启你的电脑,执行这段程序。实际上,这个操作系统的一个好处是,你可以将它直接安装在可插拔的 U 盘上,我们有一个[如何把电脑装在 U 盘里](https://www.popsci.com/portable-computer-usb-stick)的完整指南。
如果你想在不影响原来旧系统的情况下运行 Linux,你可以选择从 DVD 或 U 盘或者电脑硬盘的某个分区(分成不同的区来独立运行不同的操作系统)单独启动。有些 Linux 发行版在安装过程中会帮你自动处理磁盘分区。或者你可以用[磁盘管理器](https://www.disk-partition.com/windows-10/windows-10-disk-management-0528.html) (Windows)或者[磁盘工具](https://support.apple.com/kb/PH22240?locale=en_US) (macOS)自己调整分区。
这些安装说明可能看上去很模糊,但是不要担心:每个发行版都会提供详细的安装指引,虽然大多数情况下过程都差不多。比如,如果你想安装 Ubuntu(最流行的家用 Linux 发行版中的一个),可以[参考这里的指引](https://tutorials.ubuntu.com/tutorial/tutorial-install-ubuntu-desktop?backURL=%2F#0)。(在安装之前,你也可以[尝试运行一下](https://tutorials.ubuntu.com/tutorial/try-ubuntu-before-you-install?backURL=%2F#0))你需要下载最新的版本,烧录到 DVD 或是 U 盘里,然后再用光盘或 U 盘引导开机,然后跟随安装向导里的指引操作。安装完成时提示安装额外软件时,Ubuntu 会引导你打开合适的工具。
如果你要在一台全新的电脑上安装 Linux,那没什么需要特别留意的。不过如果你要保留旧系统的情况下安装新系统,我们建议你首先[备份自己的数据](https://www.popsci.com/back-up-and-protect-your-data)。在安装过程中,也要注意选择双启动选项,避免擦除现有的系统和文件。你选好的发行版的介绍里会有更详细的说明:你可以在[这里](https://zorinos.com/help/install-zorin-os/)查看 Zorin OS 的完整介绍,[这里](https://linuxmint.com/documentation.php)有 Linux Mint的,其他发行版的介绍在他们各自的网站上也都会有。
就这些了!那么,你准备好试试 Linux 了吗?
---
via: <https://www.popsci.com/switch-to-linux-operating-system>
作者:[David Nield](https://www.popsci.com/authors/david-nield) 译者:[zpl1025](https://github.com/zpl1025) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,000 | Ubuntu 18.04 LTS 定名为“仿生河狸”,将于明年 4 月 26 日发布 | http://news.softpedia.com/news/ubuntu-18-04-lts-dubbed-as-the-bionic-beaver-launches-april-26-2018-518186.shtml | 2017-10-25T00:37:00 | [
"Ubuntu"
] | https://linux.cn/article-9000-1.html | 
Ubuntu 母公司 Canonical 的 CEO, Mark Shuttleworth 刚刚披露,Ubuntu 操作系统的下一个长期支持版本(LTS)的代号定为 “Bionic Beaver”,意即“仿生河狸”,。它将于明年的 4 月发布。
按照 Ubuntu 系列的命名传统,Mark Shuttleworth 今天写的一篇[博文](http://www.markshuttleworth.com/archives/1518)对 Ubuntu 17.10(AA)“巧豚”的发布表示祝贺,并宣布了下一个版本的代号:
>
> “为纪念这一孜孜不倦的辛劳,这次我们的吉祥物是一个以其精力充沛的态度、勤劳的天性和工程能力而闻名的哺乳动物。同时,我们给它赋予 21 世纪的新精神,以纪念永不停息的 Ubuntu Core 机器人们。女士们、先生们,让我们欢迎 18.04 LTS —— 仿生河狸。”
>
>
>
### Ubuntu 18.04 LTS 将发布于 2018 年 4 月
虽然 Mark 并没有实际披露 Ubuntu 18.04 LTS 的计划,但是由于事实上他们将把更多的工作放在面向物联网设备的 Ubuntu Snappy Core 系统上,因此看起来其发布周期将会定在 2018 年 4 月 26 日。
Ubuntu 18.04 LTS 的开发工作会在两天后开始,当工具链上传到归档时, Ubuntu 18.04 LTS (BB)会和其前代一样,在六个月内发布两个 Alpha 和两个 Beta 版本之后正式发布。
据其[发布计划](https://wiki.ubuntu.com/BionicBeaver/ReleaseSchedule),其第一个 Alpha 里程碑将在 2018 年 1 月 4 号发布,第二个在 2 月 1 日——但只有部分风味版本会发布 Alpha 版本,并且这些风味版会在 3 月 8 日发布第一个 Beta 版本,而发布前的最后一个 Beta 版本将于 2018 年 4 月 5 日发布。
| 301 | Moved Permanently | null |
9,002 | 并发服务器(二):线程 | https://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/ | 2017-10-26T08:19:00 | [
"并发"
] | https://linux.cn/article-9002-1.html | 
这是并发网络服务器系列的第二节。[第一节](/article-8993-1.html) 提出了服务端实现的协议,还有简单的顺序服务器的代码,是这整个系列的基础。
这一节里,我们来看看怎么用多线程来实现并发,用 C 实现一个最简单的多线程服务器,和用 Python 实现的线程池。
该系列的所有文章:
* [第一节 - 简介](/article-8993-1.html)
* [第二节 - 线程](http://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/)
* [第三节 - 事件驱动](http://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/)
### 多线程的方法设计并发服务器
说起第一节里的顺序服务器的性能,最显而易见的,是在服务器处理客户端连接时,计算机的很多资源都被浪费掉了。尽管假定客户端快速发送完消息,不做任何等待,仍然需要考虑网络通信的开销;网络要比现在的 CPU 慢上百万倍还不止,因此 CPU 运行服务器时会等待接收套接字的流量,而大量的时间都花在完全不必要的等待中。
这里是一份示意图,表明顺序时客户端的运行过程:

这个图片上有 3 个客户端程序。棱形表示客户端的“到达时间”(即客户端尝试连接服务器的时间)。黑色线条表示“等待时间”(客户端等待服务器真正接受连接所用的时间),有色矩形表示“处理时间”(服务器和客户端使用协议进行交互所用的时间)。有色矩形的末端表示客户端断开连接。
上图中,绿色和橘色的客户端尽管紧跟在蓝色客户端之后到达服务器,也要等到服务器处理完蓝色客户端的请求。这时绿色客户端得到响应,橘色的还要等待一段时间。
多线程服务器会开启多个控制线程,让操作系统管理 CPU 的并发(使用多个 CPU 核心)。当客户端连接的时候,创建一个线程与之交互,而在主线程中,服务器能够接受其他的客户端连接。下图是该模式的时间轴:

### 每个客户端一个线程,在 C 语言里要用 pthread
这篇文章的 [第一个示例代码](https://github.com/eliben/code-for-blog/blob/master/2017/async-socket-server/threaded-server.c) 是一个简单的 “每个客户端一个线程” 的服务器,用 C 语言编写,使用了 [phtreads API](http://eli.thegreenplace.net/2010/04/05/pthreads-as-a-case-study-of-good-api-design) 用于实现多线程。这里是主循环代码:
```
while (1) {
struct sockaddr_in peer_addr;
socklen_t peer_addr_len = sizeof(peer_addr);
int newsockfd =
accept(sockfd, (struct sockaddr*)&peer_addr, &peer_addr_len);
if (newsockfd < 0) {
perror_die("ERROR on accept");
}
report_peer_connected(&peer_addr, peer_addr_len);
pthread_t the_thread;
thread_config_t* config = (thread_config_t*)malloc(sizeof(*config));
if (!config) {
die("OOM");
}
config->sockfd = newsockfd;
pthread_create(&the_thread, NULL, server_thread, config);
// 回收线程 —— 在线程结束的时候,它占用的资源会被回收
// 因为主线程在一直运行,所以它比服务线程存活更久。
pthread_detach(the_thread);
}
```
这是 `server_thread` 函数:
```
void* server_thread(void* arg) {
thread_config_t* config = (thread_config_t*)arg;
int sockfd = config->sockfd;
free(config);
// This cast will work for Linux, but in general casting pthread_id to an 这个类型转换在 Linux 中可以正常运行,但是一般来说将 pthread_id 类型转换成整形不便于移植代码
// integral type isn't portable.
unsigned long id = (unsigned long)pthread_self();
printf("Thread %lu created to handle connection with socket %d\n", id,
sockfd);
serve_connection(sockfd);
printf("Thread %lu done\n", id);
return 0;
}
```
线程 “configuration” 是作为 `thread_config_t` 结构体进行传递的:
```
typedef struct { int sockfd; } thread_config_t;
```
主循环中调用的 `pthread_create` 产生一个新线程,然后运行 `server_thread` 函数。这个线程会在 `server_thread` 返回的时候结束。而在 `serve_connection` 返回的时候 `server_thread` 才会返回。`serve_connection` 和第一节完全一样。
第一节中我们用脚本生成了多个并发访问的客户端,观察服务器是怎么处理的。现在来看看多线程服务器的处理结果:
```
$ python3.6 simple-client.py -n 3 localhost 9090
INFO:2017-09-20 06:31:56,632:conn1 connected...
INFO:2017-09-20 06:31:56,632:conn2 connected...
INFO:2017-09-20 06:31:56,632:conn0 connected...
INFO:2017-09-20 06:31:56,632:conn1 sending b'^abc$de^abte$f'
INFO:2017-09-20 06:31:56,632:conn2 sending b'^abc$de^abte$f'
INFO:2017-09-20 06:31:56,632:conn0 sending b'^abc$de^abte$f'
INFO:2017-09-20 06:31:56,633:conn1 received b'b'
INFO:2017-09-20 06:31:56,633:conn2 received b'b'
INFO:2017-09-20 06:31:56,633:conn0 received b'b'
INFO:2017-09-20 06:31:56,670:conn1 received b'cdbcuf'
INFO:2017-09-20 06:31:56,671:conn0 received b'cdbcuf'
INFO:2017-09-20 06:31:56,671:conn2 received b'cdbcuf'
INFO:2017-09-20 06:31:57,634:conn1 sending b'xyz^123'
INFO:2017-09-20 06:31:57,634:conn2 sending b'xyz^123'
INFO:2017-09-20 06:31:57,634:conn1 received b'234'
INFO:2017-09-20 06:31:57,634:conn0 sending b'xyz^123'
INFO:2017-09-20 06:31:57,634:conn2 received b'234'
INFO:2017-09-20 06:31:57,634:conn0 received b'234'
INFO:2017-09-20 06:31:58,635:conn1 sending b'25$^ab0000$abab'
INFO:2017-09-20 06:31:58,635:conn2 sending b'25$^ab0000$abab'
INFO:2017-09-20 06:31:58,636:conn1 received b'36bc1111'
INFO:2017-09-20 06:31:58,636:conn2 received b'36bc1111'
INFO:2017-09-20 06:31:58,637:conn0 sending b'25$^ab0000$abab'
INFO:2017-09-20 06:31:58,637:conn0 received b'36bc1111'
INFO:2017-09-20 06:31:58,836:conn2 disconnecting
INFO:2017-09-20 06:31:58,836:conn1 disconnecting
INFO:2017-09-20 06:31:58,837:conn0 disconnecting
```
实际上,所有客户端同时连接,它们与服务器的通信是同时发生的。
### 每个客户端一个线程的难点
尽管在现代操作系统中就资源利用率方面来看,线程相当的高效,但前一节中讲到的方法在高负载时却会出现纰漏。
想象一下这样的情景:很多客户端同时进行连接,某些会话持续的时间长。这意味着某个时刻服务器上有很多活跃的线程。太多的线程会消耗掉大量的内存和 CPU 资源,而仅仅是用于上下文切换<sup> 注1</sup> 。另外其也可视为安全问题:因为这样的设计容易让服务器成为 [DoS 攻击](https://en.wikipedia.org/wiki/Denial-of-service_attack) 的目标 —— 上百万个客户端同时连接,并且客户端都处于闲置状态,这样耗尽了所有资源就可能让服务器宕机。
当服务器要与每个客户端通信,CPU 进行大量计算时,就会出现更严重的问题。这种情况下,容易想到的方法是减少服务器的响应能力 —— 只有其中一些客户端能得到服务器的响应。
因此,对多线程服务器所能够处理的并发客户端数做一些 *速率限制* 就是个明智的选择。有很多方法可以实现。最容易想到的是计数当前已经连接上的客户端,把连接数限制在某个范围内(需要通过仔细的测试后决定)。另一种流行的多线程应用设计是使用 *线程池*。
### 线程池
[线程池](https://en.wikipedia.org/wiki/Thread_pool) 很简单,也很有用。服务器创建几个任务线程,这些线程从某些队列中获取任务。这就是“池”。然后每一个客户端的连接被当成任务分发到池中。只要池中有空闲的线程,它就会去处理任务。如果当前池中所有线程都是繁忙状态,那么服务器就会阻塞,直到线程池可以接受任务(某个繁忙状态的线程处理完当前任务后,变回空闲的状态)。
这里有个 4 线程的线程池处理任务的图。任务(这里就是客户端的连接)要等到线程池中的某个线程可以接受新任务。

非常明显,线程池的定义就是一种按比例限制的机制。我们可以提前设定服务器所能拥有的线程数。那么这就是并发连接的最多的客户端数 —— 其它的客户端就要等到线程空闲。如果我们的池中有 8 个线程,那么 8 就是服务器可以处理的最多的客户端并发连接数,哪怕上千个客户端想要同时连接。
那么怎么确定池中需要有多少个线程呢?通过对问题范畴进行细致的分析、评估、实验以及根据我们拥有的硬件配置。如果是单核的云服务器,答案只有一个;如果是 100 核心的多套接字的服务器,那么答案就有很多种。也可以在运行时根据负载动态选择池的大小 —— 我会在这个系列之后的文章中谈到这个东西。
使用线程池的服务器在高负载情况下表现出 *性能退化* —— 客户端能够以稳定的速率进行连接,可能会比其它时刻得到响应的用时稍微久一点;也就是说,无论多少个客户端同时进行连接,服务器总能保持响应,尽最大能力响应等待的客户端。与之相反,每个客户端一个线程的服务器,会接收多个客户端的连接直到过载,这时它更容易崩溃或者因为要处理*所有*客户端而变得缓慢,因为资源都被耗尽了(比如虚拟内存的占用)。
### 在服务器上使用线程池
为了[改变服务器的实现](https://github.com/eliben/code-for-blog/blob/master/2017/async-socket-server/threadpool-server.py),我用了 Python,在 Python 的标准库中带有一个已经实现好的稳定的线程池。(`concurrent.futures` 模块里的 `ThreadPoolExecutor`) <sup> 注2</sup> 。
服务器创建一个线程池,然后进入循环,监听套接字接收客户端的连接。用 `submit` 把每一个连接的客户端分配到池中:
```
pool = ThreadPoolExecutor(args.n)
sockobj = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sockobj.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
sockobj.bind(('localhost', args.port))
sockobj.listen(15)
try:
while True:
client_socket, client_address = sockobj.accept()
pool.submit(serve_connection, client_socket, client_address)
except KeyboardInterrupt as e:
print(e)
sockobj.close()
```
`serve_connection` 函数和 C 的那部分很像,与一个客户端交互,直到其断开连接,并且遵循我们的协议:
```
ProcessingState = Enum('ProcessingState', 'WAIT_FOR_MSG IN_MSG')
def serve_connection(sockobj, client_address):
print('{0} connected'.format(client_address))
sockobj.sendall(b'*')
state = ProcessingState.WAIT_FOR_MSG
while True:
try:
buf = sockobj.recv(1024)
if not buf:
break
except IOError as e:
break
for b in buf:
if state == ProcessingState.WAIT_FOR_MSG:
if b == ord(b'^'):
state = ProcessingState.IN_MSG
elif state == ProcessingState.IN_MSG:
if b == ord(b'$'):
state = ProcessingState.WAIT_FOR_MSG
else:
sockobj.send(bytes([b + 1]))
else:
assert False
print('{0} done'.format(client_address))
sys.stdout.flush()
sockobj.close()
```
来看看线程池的大小对并行访问的客户端的阻塞行为有什么样的影响。为了演示,我会运行一个池大小为 2 的线程池服务器(只生成两个线程用于响应客户端)。
```
$ python3.6 threadpool-server.py -n 2
```
在另外一个终端里,运行客户端模拟器,产生 3 个并发访问的客户端:
```
$ python3.6 simple-client.py -n 3 localhost 9090
INFO:2017-09-22 05:58:52,815:conn1 connected...
INFO:2017-09-22 05:58:52,827:conn0 connected...
INFO:2017-09-22 05:58:52,828:conn1 sending b'^abc$de^abte$f'
INFO:2017-09-22 05:58:52,828:conn0 sending b'^abc$de^abte$f'
INFO:2017-09-22 05:58:52,828:conn1 received b'b'
INFO:2017-09-22 05:58:52,828:conn0 received b'b'
INFO:2017-09-22 05:58:52,867:conn1 received b'cdbcuf'
INFO:2017-09-22 05:58:52,867:conn0 received b'cdbcuf'
INFO:2017-09-22 05:58:53,829:conn1 sending b'xyz^123'
INFO:2017-09-22 05:58:53,829:conn0 sending b'xyz^123'
INFO:2017-09-22 05:58:53,830:conn1 received b'234'
INFO:2017-09-22 05:58:53,831:conn0 received b'2'
INFO:2017-09-22 05:58:53,831:conn0 received b'34'
INFO:2017-09-22 05:58:54,831:conn1 sending b'25$^ab0000$abab'
INFO:2017-09-22 05:58:54,832:conn1 received b'36bc1111'
INFO:2017-09-22 05:58:54,832:conn0 sending b'25$^ab0000$abab'
INFO:2017-09-22 05:58:54,833:conn0 received b'36bc1111'
INFO:2017-09-22 05:58:55,032:conn1 disconnecting
INFO:2017-09-22 05:58:55,032:conn2 connected...
INFO:2017-09-22 05:58:55,033:conn2 sending b'^abc$de^abte$f'
INFO:2017-09-22 05:58:55,033:conn0 disconnecting
INFO:2017-09-22 05:58:55,034:conn2 received b'b'
INFO:2017-09-22 05:58:55,071:conn2 received b'cdbcuf'
INFO:2017-09-22 05:58:56,036:conn2 sending b'xyz^123'
INFO:2017-09-22 05:58:56,036:conn2 received b'234'
INFO:2017-09-22 05:58:57,037:conn2 sending b'25$^ab0000$abab'
INFO:2017-09-22 05:58:57,038:conn2 received b'36bc1111'
INFO:2017-09-22 05:58:57,238:conn2 disconnecting
```
回顾之前讨论的服务器行为:
1. 在顺序服务器中,所有的连接都是串行的。一个连接结束后,下一个连接才能开始。
2. 前面讲到的每个客户端一个线程的服务器中,所有连接都被同时接受并得到服务。
这里可以看到一种可能的情况:两个连接同时得到服务,只有其中一个结束连接后第三个才能连接上。这就是把线程池大小设置成 2 的结果。真实用例中我们会把线程池设置的更大些,取决于机器和实际的协议。线程池的缓冲机制就能很好理解了 —— 我 [几个月前](http://eli.thegreenplace.net/2017/clojure-concurrency-and-blocking-with-coreasync/) 更详细的介绍过这种机制,关于 Clojure 的 `core.async` 模块。
### 总结与展望
这篇文章讨论了在服务器中,用多线程作并发的方法。每个客户端一个线程的方法最早提出来,但是实际上却不常用,因为它并不安全。
线程池就常见多了,最受欢迎的几个编程语言有良好的实现(某些编程语言,像 Python,就是在标准库中实现)。这里说的使用线程池的服务器,不会受到每个客户端一个线程的弊端。
然而,线程不是处理多个客户端并行访问的唯一方法。下一节中我们会看看其它的解决方案,可以使用*异步处理*,或者*事件驱动*的编程。
---
* 注1:老实说,现代 Linux 内核可以承受足够多的并发线程 —— 只要这些线程主要在 I/O 上被阻塞。[这里有个示例程序](https://github.com/eliben/code-for-blog/blob/master/2017/async-socket-server/threadspammer.c),它产生可配置数量的线程,线程在循环体中是休眠的,每 50 ms 唤醒一次。我在 4 核的 Linux 机器上可以轻松的产生 10000 个线程;哪怕这些线程大多数时间都在睡眠,它们仍然消耗一到两个核心,以便实现上下文切换。而且,它们占用了 80 GB 的虚拟内存(Linux 上每个线程的栈大小默认是 8MB)。实际使用中,线程会使用内存并且不会在循环体中休眠,因此它可以非常快的占用完一个机器的内存。
* 注2:自己动手实现一个线程池是个有意思的练习,但我现在还不想做。我曾写过用来练手的 [针对特殊任务的线程池](http://eli.thegreenplace.net/2011/12/27/python-threads-communication-and-stopping)。是用 Python 写的;用 C 重写的话有些难度,但对于经验丰富的程序员,几个小时就够了。
---
via: <https://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/>
作者:[Eli Bendersky](https://eli.thegreenplace.net/pages/about) 译者:[GitFuture](https://github.com/GitFuture) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | This is part 2 of a series on writing concurrent network servers. [Part 1](https://eli.thegreenplace.net/2017/concurrent-servers-part-1-introduction/)
presented the protocol implemented by the server, as well as the code for a
simple sequential server, as a baseline for the series.
In this part, we're going to look at multi-threading as one approach to concurrency, with a bare-bones threaded server implementation in C, as well as a thread pool based implementation in Python.
All posts in the series:
[Part 1 - Introduction](https://eli.thegreenplace.net/2017/concurrent-servers-part-1-introduction/)[Part 2 - Threads](https://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/)[Part 3 - Event-driven](https://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/)[Part 4 - libuv](https://eli.thegreenplace.net/2017/concurrent-servers-part-4-libuv/)[Part 5 - Redis case study](https://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/)[Part 6 - Callbacks, Promises and async/await](https://eli.thegreenplace.net/2018/concurrent-servers-part-6-callbacks-promises-and-asyncawait/)
## The multi-threaded approach to concurrent server design
When discussing the performance of the sequential server in part 1, it was immediately obvious that a lot of compute resources are wasted while the server processes a client connection. Even assuming a client that sends messages immediately and doesn't do any waiting, network communication is still involved; networks tend to be millions (or more) times slower than a modern CPU, so the CPU running the sequential server will spend the vast majority of time in gloriuos boredom waiting for new socket traffic to arrive.
Here's a chart showing how sequential client processing happens over time:
The diagrams shows 3 clients. The diamond shapes denote the client's "arrival time" (the time at which the client attempted to connect to the server). The black lines denote "wait time" (the time clients spent waiting for the server to actually accept their connection), and the colored bars denote actual "processing time" (the time server and client are interacting using the protocol). At the end of the colored bar, the client disconnects.
In the diagram above, even though the green and orange clients arrived shortly after the blue one, they have to wait for a while until the server is done with the blue client. At this point the green client is accepted, while the orange one has to wait even longer.
A multi-threaded server would launch multiple control threads, letting the OS manage concurrency on the CPU (and across multiple CPU cores). When a client connects, a thread is created to serve it, while the server is ready to accept more clients in the main thread. The time chart for this mode looks like the following:
## One thread per client, in C using pthreads
Our [first code sample](https://github.com/eliben/code-for-blog/blob/main/2017/async-socket-server/threaded-server.c)
in this post is a simple "one thread per client" server, written in C using the
foundational [pthreads API](https://eli.thegreenplace.net/2010/04/05/pthreads-as-a-case-study-of-good-api-design)
for multi-threading. Here's the main loop:
```
while (1) {
struct sockaddr_in peer_addr;
socklen_t peer_addr_len = sizeof(peer_addr);
int newsockfd =
accept(sockfd, (struct sockaddr*)&peer_addr, &peer_addr_len);
if (newsockfd < 0) {
perror_die("ERROR on accept");
}
report_peer_connected(&peer_addr, peer_addr_len);
pthread_t the_thread;
thread_config_t* config = (thread_config_t*)malloc(sizeof(*config));
if (!config) {
die("OOM");
}
config->sockfd = newsockfd;
pthread_create(&the_thread, NULL, server_thread, config);
// Detach the thread - when it's done, its resources will be cleaned up.
// Since the main thread lives forever, it will outlive the serving threads.
pthread_detach(the_thread);
}
```
And this is the `server_thread` function:
```
void* server_thread(void* arg) {
thread_config_t* config = (thread_config_t*)arg;
int sockfd = config->sockfd;
free(config);
// This cast will work for Linux, but in general casting pthread_id to an
// integral type isn't portable.
unsigned long id = (unsigned long)pthread_self();
printf("Thread %lu created to handle connection with socket %d\n", id,
sockfd);
serve_connection(sockfd);
printf("Thread %lu done\n", id);
return 0;
}
```
The thread "configuration" is passed as a `thread_config_t` structure:
```
typedef struct { int sockfd; } thread_config_t;
```
The `pthread_create` call in the main loop launches a new thread that runs the
`server_thread` function. This thread terminates when `server_thread`
returns. In turn, `server_thread` returns when `serve_connection` returns.
`serve_connection` is exactly the same function from part 1.
In part 1 we used a script to launch multiple clients concurrently and observe how the server handles them. Let's do the same with the multithreaded server:
```
$ python3.6 simple-client.py -n 3 localhost 9090
INFO:2017-09-20 06:31:56,632:conn1 connected...
INFO:2017-09-20 06:31:56,632:conn2 connected...
INFO:2017-09-20 06:31:56,632:conn0 connected...
INFO:2017-09-20 06:31:56,632:conn1 sending b'^abc$de^abte$f'
INFO:2017-09-20 06:31:56,632:conn2 sending b'^abc$de^abte$f'
INFO:2017-09-20 06:31:56,632:conn0 sending b'^abc$de^abte$f'
INFO:2017-09-20 06:31:56,633:conn1 received b'b'
INFO:2017-09-20 06:31:56,633:conn2 received b'b'
INFO:2017-09-20 06:31:56,633:conn0 received b'b'
INFO:2017-09-20 06:31:56,670:conn1 received b'cdbcuf'
INFO:2017-09-20 06:31:56,671:conn0 received b'cdbcuf'
INFO:2017-09-20 06:31:56,671:conn2 received b'cdbcuf'
INFO:2017-09-20 06:31:57,634:conn1 sending b'xyz^123'
INFO:2017-09-20 06:31:57,634:conn2 sending b'xyz^123'
INFO:2017-09-20 06:31:57,634:conn1 received b'234'
INFO:2017-09-20 06:31:57,634:conn0 sending b'xyz^123'
INFO:2017-09-20 06:31:57,634:conn2 received b'234'
INFO:2017-09-20 06:31:57,634:conn0 received b'234'
INFO:2017-09-20 06:31:58,635:conn1 sending b'25$^ab0000$abab'
INFO:2017-09-20 06:31:58,635:conn2 sending b'25$^ab0000$abab'
INFO:2017-09-20 06:31:58,636:conn1 received b'36bc1111'
INFO:2017-09-20 06:31:58,636:conn2 received b'36bc1111'
INFO:2017-09-20 06:31:58,637:conn0 sending b'25$^ab0000$abab'
INFO:2017-09-20 06:31:58,637:conn0 received b'36bc1111'
INFO:2017-09-20 06:31:58,836:conn2 disconnecting
INFO:2017-09-20 06:31:58,836:conn1 disconnecting
INFO:2017-09-20 06:31:58,837:conn0 disconnecting
```
Indeed, all clients connected at the same time, and their communication with the server occurs concurrently.
## Challenges with one thread per client
Even though threads are fairly efficient in terms of resource usage on modern OSes, the approach outlined in the previous section can still present challenges with some workloads.
Imagine a scenario where many clients are connecting simultaneously, and some
of the sessions are long-lived. This means that many threads may be active at
the same time in the server. Too many threads can consume a large amount of
memory and CPU time just for the context switching [[1]](#footnote-1). An alternative way to
look at it is as a security problem: this design makes it the server an easy
target for a [DoS attack](https://en.wikipedia.org/wiki/Denial-of-service_attack) - connect a few
100,000s of clients at the same time and let them all sit idle - this will
likely kill the server due to excessive resource usage.
A larger problem occurs when there's a non-trivial amount of CPU-bound computation the server has to do for each client. In this case, swamping the server is considerably easier - just a few dozen clients can bring a server to its knees.
For these reasons, it's prudent the do some *rate-limiting* on the number of
concurrent clients handled by a multi-threaded server. There's a number of ways
to do this. The simplest that comes to mind is simply count the number of
clients currently connected and restrict that number to some quantity (that was
determined by careful benchmarking, hopefully). A variation on this approach
that's very popular in concurrent application design is using a *thread pool*.
## Thread pools
The idea of a [thread pool](https://en.wikipedia.org/wiki/Thread_pool) is
simple, yet powerful. The server creates a number of working threads that all
expect to get tasks from some queue. This is the "pool". Then, each client
connection is dispatched as a task to the pool. As long as there's an idle
thread in the pool, it's handed the task. If all the threads in the pool are
currently busy, the server blocks until the pool accepts the task (which happens
after one of the busy threads finished processing its current task and went back
to an idle state).
Here's a diagram showing a pool of 4 threads, each processing a task. Tasks (client connections in our case) are waiting until one of the threads in the pool is ready to accept new tasks.
It should be fairly obvious that the thread pool approach provides a rate-limiting mechanism in its very definition. We can decide ahead of time how many threads we want our server to have. Then, this is the maximal number of clients processed concurrently - the rest are waiting until one of the threads becomes free. If we have 8 threads in the pool, 8 is the maximal number of concurrent clients the server handles - even if thousands are attempting to connect simultaneously.
How do we decide how many threads should be in the pool? By a careful analysis of the problem domain, benchmarking, experimentation and also by the HW we have. If we have a single-core cloud instance that's one answer, if we have a 100-core dual socket server available, the answer is different. Picking the thread pool size can also be done dynamically at runtime based on load - I'll touch upon this topic in future posts in this series.
Servers that use thread pools manifest *graceful degradation* in the face of
high load - clients are accepted at some steady rate, potentially slower than
their rate of arrival for some periods of time; that said, no matter how many
clients are trying to connect simultaneously, the server will remain responsive
and will just churn through the backlog of clients to its best ability. Contrast
this with the one-thread-per-client server which can merrily accept a large
number of clients until it gets overloaded, at which point it's likely to either
crash or start working very slowly for *all* processed clients due to resource
exhaustion (such as virtual memory thrashing).
## Using a thread pool for our network server
For [this variation of the server](https://github.com/eliben/code-for-blog/blob/main/2017/async-socket-server/threadpool-server.py)
I've switched to Python, which comes with a robust implementation of a thread
pool in the standard library (`ThreadPoolExecutor` from the
`concurrent.futures` module) [[2]](#footnote-2).
This server creates a thread pool, then loops to accept new clients on the main
listening socket. Each connected client is dispatched into the pool with
`submit`:
```
pool = ThreadPoolExecutor(args.n)
sockobj = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sockobj.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
sockobj.bind(('localhost', args.port))
sockobj.listen(15)
try:
while True:
client_socket, client_address = sockobj.accept()
pool.submit(serve_connection, client_socket, client_address)
except KeyboardInterrupt as e:
print(e)
sockobj.close()
```
The `serve_connection` function is very similar to its C counterpart, serving
a single client until the client disconnects, while following our protocol:
```
ProcessingState = Enum('ProcessingState', 'WAIT_FOR_MSG IN_MSG')
def serve_connection(sockobj, client_address):
print('{0} connected'.format(client_address))
sockobj.sendall(b'*')
state = ProcessingState.WAIT_FOR_MSG
while True:
try:
buf = sockobj.recv(1024)
if not buf:
break
except IOError as e:
break
for b in buf:
if state == ProcessingState.WAIT_FOR_MSG:
if b == ord(b'^'):
state = ProcessingState.IN_MSG
elif state == ProcessingState.IN_MSG:
if b == ord(b'$'):
state = ProcessingState.WAIT_FOR_MSG
else:
sockobj.send(bytes([b + 1]))
else:
assert False
print('{0} done'.format(client_address))
sys.stdout.flush()
sockobj.close()
```
Let's see how the thread pool size affects the blocking behavior for multiple concurrent clients. For demonstration purposes, I'll run the threadpool server with a pool size of 2 (only two threads are created to service clients):
```
$ python3.6 threadpool-server.py -n 2
```
And in a separate terminal, let's run the client simulator again, with 3 concurrent clients:
```
$ python3.6 simple-client.py -n 3 localhost 9090
INFO:2017-09-22 05:58:52,815:conn1 connected...
INFO:2017-09-22 05:58:52,827:conn0 connected...
INFO:2017-09-22 05:58:52,828:conn1 sending b'^abc$de^abte$f'
INFO:2017-09-22 05:58:52,828:conn0 sending b'^abc$de^abte$f'
INFO:2017-09-22 05:58:52,828:conn1 received b'b'
INFO:2017-09-22 05:58:52,828:conn0 received b'b'
INFO:2017-09-22 05:58:52,867:conn1 received b'cdbcuf'
INFO:2017-09-22 05:58:52,867:conn0 received b'cdbcuf'
INFO:2017-09-22 05:58:53,829:conn1 sending b'xyz^123'
INFO:2017-09-22 05:58:53,829:conn0 sending b'xyz^123'
INFO:2017-09-22 05:58:53,830:conn1 received b'234'
INFO:2017-09-22 05:58:53,831:conn0 received b'2'
INFO:2017-09-22 05:58:53,831:conn0 received b'34'
INFO:2017-09-22 05:58:54,831:conn1 sending b'25$^ab0000$abab'
INFO:2017-09-22 05:58:54,832:conn1 received b'36bc1111'
INFO:2017-09-22 05:58:54,832:conn0 sending b'25$^ab0000$abab'
INFO:2017-09-22 05:58:54,833:conn0 received b'36bc1111'
INFO:2017-09-22 05:58:55,032:conn1 disconnecting
INFO:2017-09-22 05:58:55,032:conn2 connected...
INFO:2017-09-22 05:58:55,033:conn2 sending b'^abc$de^abte$f'
INFO:2017-09-22 05:58:55,033:conn0 disconnecting
INFO:2017-09-22 05:58:55,034:conn2 received b'b'
INFO:2017-09-22 05:58:55,071:conn2 received b'cdbcuf'
INFO:2017-09-22 05:58:56,036:conn2 sending b'xyz^123'
INFO:2017-09-22 05:58:56,036:conn2 received b'234'
INFO:2017-09-22 05:58:57,037:conn2 sending b'25$^ab0000$abab'
INFO:2017-09-22 05:58:57,038:conn2 received b'36bc1111'
INFO:2017-09-22 05:58:57,238:conn2 disconnecting
```
Recall the behavior of previously discussed servers:
- In the sequential server, all connections were serialized. One finished, and only then the next started.
- In the thread-per-client server earlier in this post, all connections wer accepted and serviced concurrently.
Here we see another possibility: two connections are serviced concurrently, and
only when one of them is done the third is admitted. This is a direct result of
the thread pool size set to 2. For a more realistic use case we'd set the thread
pool size to much higher, depending on the machine and the exact protocol. This
buffering behavior of thread pools is well understood - I've written about it
more in detail [just a few months ago](https://eli.thegreenplace.net/2017/clojure-concurrency-and-blocking-with-coreasync/)
in the context of Clojure's `core.async` module.
## Summary and next steps
This post discusses multi-threading as a means of concurrency in network servers. The one-thread-per-client approach is presented for an initial discussion, but this method is not common in practice since it's a security hazard.
Thread pools are much more common, and most popular programming languages have solid implementations (for some, like Python, it's in the standard library). The thread pool server presented here doesn't suffer from the problems of one-thread-per-client.
However, threads are not the only way to handle multiple clients concurrently.
In the next post we're going to look at some solutions using *asynchronous*, or
*event-driven* programming.
|
[Here's a sample program](https://github.com/eliben/code-for-blog/blob/main/2017/async-socket-server/threadspammer.c)that launches a configurable number of threads that sleep in a loop, waking up every 50 ms. On my 4-core Linux machine I can easily launch 10000 threads; even though these threads sleep almost all the time, they still consume between one and two cores for the context switching. Also, they occupy 80 GB of virtual memory (8 MB is the default per-thread stack size for Linux). More realistic threads that actually use memory and not just sleep in a loop can therefore exhaust the physical memory of a machine fairly quickly.
| |
9,004 | PingCAP 推出 TiDB 1.0 | https://pingcap.github.io/blog/2017/10/17/announcement/ | 2017-10-27T08:09:00 | [
"TiDB",
"数据库"
] | https://linux.cn/article-9004-1.html |
>
> PingCAP 推出了 TiDB 1.0,一个可扩展的混合数据库解决方案
>
>
>

2017 年 10 月 16 日, 一家尖端的分布式数据库技术公司 PingCAP Inc. 正式宣布发布 [TiDB](https://github.com/pingcap/tidb) 1.0。TiDB 是一个开源的分布式混合事务/分析处理 (HTAP) 数据库,它使企业能够使用单个数据库来满足这两个负载。
在当前的数据库环境中,基础架构工程师通常要使用一个数据库进行在线事务处理(OLTP),另一个用于在线分析处理(OLAP)。TiDB 旨在通过构建一个基于实时事务数据的实时业务分析的 HTAP 数据库来打破这种分离。有了 TiDB,工程师现在可以花更少的时间来管理多个数据库解决方案,并有更多的时间为他们的公司提供业务价值。TiDB 的一个金融证券公司的用户正在利用这项技术为财富管理和用户角色的应用提供支持。借助 TiDB,该公司可以轻松处理 web 量级的计费记录,并进行关键任务时间敏感的数据分析。
PingCAP 联合创始人兼 CEO 刘奇(Max Liu)说:
>
> “两年半前,Edward、Dylan 和我开始这个旅程,为长期困扰基础设施软件业的老问题建立一个新的数据库。今天,我们很自豪地宣布,这个数据库 TiDB 可以面向生产环境了。亚伯拉罕·林肯曾经说过,‘预测未来的最好办法就是创造’,我们在 771 天前预测的未来,现在我们已经创造了,这不仅是我们团队的每一个成员,也是我们的开源社区的每个贡献者、用户和合作伙伴的努力工作和奉献。今天,我们庆祝和感谢开源精神的力量。明天,我们将继续创造我们相信的未来。”
>
>
>
TiDB 已经在亚太地区 30 多家公司投入生产环境,其中包括 [摩拜](https://en.wikipedia.org/wiki/Mobike)、[Gaea](http://www.gaea.com/en/) 和 [YOUZU](http://www.yoozoo.com/aboutEn) 等快速增长的互联网公司。使用案例涵盖从在线市场和游戏到金融科技、媒体和旅游的多个行业。
### TiDB 功能
**水平可扩展性**
TiDB 随着你的业务发展而增长。你可以通过添加更多机器来增加存储和计算能力。
**兼容 MySQL 协议**
像用 MySQL 一样使用 TiDB。你可以用 TiDB 替换 MySQL 来增强你的应用,且在大多数情况下不用更改一行代码,也几乎没有迁移成本。
**自动故障切换和高可用性**
你的数据和程序始终处于在线状态。TiDB 自动处理故障并保护你的应用免受整个数据中心的机器故障甚至停机。
**一致的分布式事务**
TiDB 类似于单机关系型数据库系统(RDBMS)。你可以启动跨多台机器的事务,而不用担心一致性。TiDB 使你的应用程序代码简单而强大。
**在线 DDL**
根据你的要求更改 TiDB 模式。你可以添加新的列和索引,而不会停止或影响你正在进行的操作。
[现在尝试TiDB!](https://pingcap.com/doc-QUICKSTART)
### 使用案例
* [yuanfudao.com 中 TiDB 如何处理快速的数据增长和复杂查询](https://pingcap.github.io/blog/2017/08/08/tidbforyuanfudao/)
* [从 MySQL 迁移到 TiDB 以每天处理数千万行数据](https://pingcap.github.io/blog/2017/05/22/Comparison-between-MySQL-and-TiDB-with-tens-of-millions-of-data-per-day/)
### 更多信息:
TiDB 内部:
* [数据存储](https://pingcap.github.io/blog/2017/07/11/tidbinternal1/)
* [计算](https://pingcap.github.io/blog/2017/07/11/tidbinternal2/)
* [调度](https://pingcap.github.io/blog/2017/07/20/tidbinternal3/)
---
via: <https://pingcap.github.io/blog/2017/10/17/announcement/>
作者:[PingCAP](https://pingcap.github.io/blog/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
9,005 | 如何应对开源软件的版权牟利者? 开源律师说这样做! | https://opensource.com/article/17/8/patrick-mchardy-and-copyright-profiteering | 2017-10-27T22:59:00 | [
"GPL",
"专利"
] | https://linux.cn/article-9005-1.html |
>
> 提要:Linux 社区的许多开发人员对 GPL 许可证牟利者 Patrick McHardy 的行为表示担忧,美国资深开源律师对一些常见问题进行解答,并对如何应对版权牟利行为提出了建议。
>
>
>

针对 Patrick McHardy 强制要求 Linux 分发者遵循 GPL 许可证的举动,开源社区许多人士表示了担忧。基于与 McHardy 行动相关的公开信息,以及开源合规维权的一些法律原则,美国资深开源律师对一些常见问题进行了解答。
Patrick Mchardy 是谁? McHardy 是 Netfilter 核心开发团队的前任负责人。 Netfilter 是 Linux 内核中的一个实用程序,可以执行各种网络功能,例如改善网络地址转换(NAT),NAT 是将 Internet 协议地址转换为另一个 IP 地址的过程。对于维护 Linux 系统的安全性来说,控制网络流量至关重要。
### McHardy 对 Linux 有多少贡献?
这不是一个容易回答的问题。首先,评估贡献的重要性并不容易;我们能做的就是查看<ruby> 提交 <rp> ( </rp> <rt> commit </rt> <rp> ) </rp></ruby>的数量和大小。其次,即使去跟踪提交,跟踪机制也不完美。 Git 有一个 blame 功能,跟踪谁在名义上向 Git 数据库提交了哪些代码行。Git 的 blame 功能可以使用诸如 [cregit](https://cregit.linuxsources.org/) 这样的工具,以更具细粒度的水平来报告提交,从而在文件级别上对贡献度有一个更准确的认知。Git 的 blame 机制和 cregit 是非常实用的,因为它们都使用公开易得的信息,而信息只需要被正确解释。
结合 cregit 和 blame 进行分析可以帮助评估 McHardy 的潜在贡献。例如:
* 他的大部分贡献似乎是在 2006 年到 2008 年和 2012 年期间。
* 在 McHardy 包含其版权声明的大约 135 个文件中,只有 1/3 的文件是 McHardy 贡献了该文件代码的 50% 或以上。
* 他的贡献看起来不到内核代码的 0.25%。
McHardy 的大部分贡献似乎都给了 Netfilter;然而,blame 机制可能并不总能还原全貌。例如,提交者可以<ruby> 签入 <rp> ( </rp> <rt> check in </rt> <rp> ) </rp></ruby>许多行代码,但只进行细微修改,也可以签入其他人编写或拥有的代码。由于这些原因,提交者的作者身份可能被过低或过多报告。
在 2002 年之前对内核贡献的记录对于识别贡献者来说不是特别有用,因为在当时,Linus Torvalds 签入了所有代码。 McHardy 的贡献直到 2004 年才开始。
[Hellwig 诉 VMware 一案](https://www.theregister.co.uk/2016/08/15/vmware_survives_gpl_breach_case_but_plaintiff_promises_appeal/)中出现了使用开发存储库的元数据确认版权所有权的困难。法院可能不愿意接受这样的信息来作为证明作者身份的证据。
### McHardy 在 Linux 内核中拥有哪些版权?
大型项目(如 Linux 内核)的版权归属复杂。这就像一个拼凑的被子。当开发者对内核做出贡献时,他们不签署任何贡献协议或版权转让协议。GPL 涵盖了他们的贡献,软件副本的接收人根据 GPL 直接从所有作者获得许可。内核项目使用一个名为<ruby> “原始开发者证书” <rp> ( </rp> <rt> Developer Certificate of Origin </rt> <rp> ) </rp></ruby>的文件,该文件不授予任何版权许可。贡献者的个人权利与在项目中的权利作为整体并存。 所以,像 McHardy 这样的作者一般都会拥有他所创作的作品的版权,但并不享有整个内核的版权。
### 什么是<ruby> “社区维权” <rp> ( </rp> <rt> community enforcement </rt> <rp> ) </rp></ruby>?
由于大型项目(如 Linux 内核)的所有权常常分散在许多作者手中,所以个体所有者可以采取不符合社区目标的维权行动。虽然社区可能会对如何以最好的方式来鼓励遵守 GPL 条款有很多看法,但大多数人认为维权应该是非正式的(不是通过诉讼),而且主要目标应该是合规(而不是惩罚)。例如,<ruby> <a href="https://sfconservancy.org/"> 软件自由保护组织 </a> <rp> ( </rp> <rt> Software Freedom Conservancy </rt> <rp> ) </rp></ruby>(SFC)已经颁布了一些[社区维权原则](https://sfconservancy.org/copyleft-compliance/principles.html),其中优选合规,而不是寻求诉讼或赔偿金。对于非正式行为何时应该成为诉讼,或维权者应该要求赔偿多少钱,没有明确的规定。然而,Linux 社区的大多数开发人员将诉讼视为最后的手段,并不愿意采取法律行动,而与真正希望合规的用户进行合作。
### 为什么这么多的开源诉讼在德国提交?
一些寻求进行开源许可证维权的原告已经向德国法院提交权利主张。在德国有一些在美国或其他<ruby> 普通法 <rp> ( </rp> <rt> common law </rt> <rp> ) </rp></ruby>国家没有能够确切与之类比的寻求法律诉讼的手段。
* [**Abmahnung**](https://en.wikipedia.org/wiki/Abmahnung)**(<ruby> “警告” <rp> ( </rp> <rt> warning </rt> <rp> ) </rp></ruby>****)**:“警告”是索赔人要求被告停止做某事的要求。在版权语境下,这是版权所有者发出的一封信函,要求所述侵权人停止侵权。这些信件是由律师而不是法庭签发的,通常是德国版权维权行动的第一步。在美国,最接近的方式应该是<ruby> 警告信 <rt> cease and desist letter </rt></ruby>。
* [**Unterlassungserklaerung**](https://de.wikipedia.org/wiki/Unterlassungserkl%C3%A4rung)**(<ruby> “停止声明” <rt> cease and desist declaration </rt></ruby>****或<ruby> “禁止声明” <rt> declaration of injunction </rt></ruby>****)**:“警告”通常会附有“停止声明”。这种“声明”就像合同一样,签署的话会要求被告人承担其它并不存在的法律义务。特别是,该声明可能包含 GPL 本身并不要求的义务。在德国,这样一份文件通常包含针对不合规进行惩罚的内容。在美国,类似的做法是和解协议,但和解协议很少规定违约的处罚方式,事实上在美国,合同中的“处罚”可能无法强制执行。“声明”不是法院命令,但如果被告签字,可以获得法院命令的法定效力。**所以,在征求律师法律意见之前签字往往不是一个好主意。**在考虑如何应对寄出停止声明的原告时,还有其他方法,包括提出修改后的处罚或义务较少的声明。此外,由于停止声明可能包含不公开的要求,签署这些文件也可能产生额外的困难,例如限制原告寻求其他被告支持或向社区公开索赔人的权利主张。
更多详情参见:[abmahnung.org/unterlassungserklaerung/](http://www.abmahnung.org/unterlassungserklaerung/) 。
* [**Einstweilige Verf****ü****gung**](https://de.wikipedia.org/wiki/Vorl%C3%A4ufiger_Rechtsschutz#Einstweilige_Verf.C3.BCgung)**(“<ruby> 临时禁令 <rt> interim injunction </rt></ruby>****”或“<ruby> 初步禁令 <rt> preliminary injunction </rt></ruby>****”)**:“临时禁令”是一项类似美国临时禁令的法院命令。虽然没有要求原告在向法院提出“临时禁令”之前发出“警告”,但在被告对“警告”或“声明”不作出回应时,鼓励原告寻求“临时禁令”。侵犯版权的临时禁令可以处以 25 万欧元罚款或 6 个月的监禁。相比之下,在美国,侵犯版权的刑事处罚极为罕见,必须由政府而不是私人机构追究。此外,在美国,法院也没有为未来的侵权行为提供补救措施,它们只是要求被告停止现行的侵权行为或者支付损害赔偿金。在德国,<ruby> 单方 <rt> ex parte </rt></ruby>也可以提出临时禁令,这意味着原告可以在没有被告听证的情况下向法院提出申请,而且可以在没有被告参与的情况下发出临时禁令。如果您收到“警告”,并怀疑原告可能会随之提出 “临时禁令”,可以向法院抢先提出<ruby> “异议” <rt> opposition </rt></ruby>。
更多详情参见:[Abmahnung.org](http://www.abmahnung.org/einstweilige-verfuegung/) 。
* [**Widerspruch**](https://de.wikipedia.org/wiki/Widerspruch_%28Recht%29#Zivilprozessrecht)**(<ruby> “异议” <rt> opposition </rt></ruby>****或<ruby> “反驳” <rt> contradiction </rt></ruby>****)**:“异议”是被告向法院提出否决“临时禁令”的机会。
更多详情参见:[这篇德国法院命令的英文翻译](http://www.jbb.de/Docs/LG_Halle_GPL3.pdf) 。
### McHardy 发起了多少权利主张?
由于许多德国法庭案件缺乏公开记录,因此很难确定 McHardy 的确切行动数量。据说 McHardy 已经接触了超过 50 个维权目标。有关详细信息,请参阅<ruby> <a href="https://sourcecodecontrol.co/gpl/"> “源码控制” </a> <rp> ( </rp> <rt> Source Code Control </rt> <rp> ) </rp></ruby>和<ruby> <a href="https://opensource.com/article/17/1/yearbook-7-notable-legal-developments-2016"> 《2016 年开源社区 7 个显著的法律进展》 </a> <rp> ( </rp> <rt> 7 Notable Legal Developments in Open Source in 2016 </rt> <rp> ) </rp></ruby>。这并不一定意味着有 50 起诉讼,而是可能意味着 50 起威胁要提起诉讼的要求。但是,很难用公开信息来核实这个说法。有关详细信息,请参阅<ruby> <a href="https://www.slideshare.net/blackducksoftware/litigation-and-compliance-in-the-open-source-ecosystem"> 《开源生态系统的诉讼和合规》 </a> <rp> ( </rp> <rt> Litigation and Compliance in the Open Source Ecosystem </rt> <rp> ) </rp></ruby>。
### 为什么社区没有去阻止 McHardy?
包括软件自由保护组织在内的各种社区成员已经开始试图说服 McHardy 改变策略,但到目前为止还没有成功。 Netfilter 项目最近发布了一个[许可问答](http://www.netfilter.org/licensing.html),解决大家对 McHardy 行为担忧的问题。
### 我们可以做些什么来阻止 McHardy 和其他版权牟利者?
这个问题没有确定的答案,也许没有办法能完全阻止他们。但是,这些建议可能会减少版权牟利者的数量。
* **尽可能遵守开源许可证。**目前有足够的资源来学习如何遵守许可证,以及如何在贵公司设立开源合规计划。例如:
+ Linux基金会发布了<ruby> <a href="https://www.linuxfoundation.org/news-media/research/practical-gpl-compliance"> 《实用 GPL 合规手册》 </a> <rp> ( </rp> <rt> Practical GPL Compliance </rt> <rp> ) </rp></ruby>。
+ 软件自由法律中心发布了<ruby> <a href="https://www.softwarefreedom.org/resources/2014/SFLC-Guide_to_GPL_Compliance_2d_ed.html"> 《GPL 合规实用指南” (第二版) 》 </a> <rp> ( </rp> <rt> A Practical Guide to GPL Compliance </rt> <rp> ) </rp></ruby>。
+ [OpenChain 项目](https://www.openchainproject.org/)发布了开源管理内部流程规范。
* **在寻求法律意见之前不要签署<ruby> “停止声明” <rp> ( </rp> <rt> Unterlassungserklärung </rt> <rp> ) </rp></ruby>****。**如上所述,停止声明可能让您承担 GPL 身没有的义务和处罚。不要与版权牟利者合作。你可以使自己成为一个更难攻克的目标,并争取社区其他目标的帮助。
* **支持开源开发。**作者不应该诉诸投机来谋生。使用开源软件的公司不应该期望开源开发人员免费开发软件,他们应该筹集资金支持重要项目。
* **学会识别版权牟利者。**了解社区导向的 GPL 维权与版权勒索之间的一般差异。面向社区的维权一般旨在通过教育和帮助实现 GPL 合规,同时尊重用户的自由。相比之下,牟利行为可能侧重以不加考究和漫无目的的权力主张和威胁要提起法律诉讼来获得经济利益。注意确认优先考虑经济利益的权利主张,警惕不合理的损害赔偿金。
* **公开权利主张。**如果你是一个牟利者的目标,并且可以选择公开其权利主张,那就公开它,通过阻碍对方的行动来帮助你和其他人。作为开源社区的成员,我们都有义务向那些企图以诉讼拖垮社区的牟利者们提出反对,因为问题能够以更恰当和更少争议的方式解决。
---
作者简介:Heather Meeker 是 O’Melveny & Myers 硅谷办公室的合伙人,为客户提供技术交易和知识产权方面的建议,是国际知名的开源软件许可专家。Heather 于 2016 年获得加州律师协会知识产权先锋奖。<ruby> 《最佳律师》 <rp> ( </rp> <rt> Best Lawyers </rt> <rp> ) </rp></ruby>将她提名为 2018 年年度 IT 律师。
译者简介:张琳,集慧智佳知识产权咨询公司分析师,专业德语,辅修法律。
| 200 | OK | Many in the open source community have expressed concern about the activities of Patrick McHardy in enforcing the [GNU General Public License (GPL)](https://www.gnu.org/licenses/old-licenses/gpl-2.0.en.html) against Linux distributors. Below are answers to common questions, based on public information related to his activities, and some of the legal principles that underlie open source compliance enforcement.
**Who is Patrick McHardy? McHardy is the former chair of the Netfilter core development team. Netfilter is a utility in the Linux kernel that performs various network functions, such as facilitating Network Address Translation (NAT)—the process of converting an Internet protocol address into another IP address. Controlling network traffic is important to maintain the security of a Linux system.**
**How much has McHardy contributed to Linux?** This is not an easy question to answer. First, it’s not easy to assess the importance of contributions; all we can do is look at number and size of commits. And second, even if one tracks commits, the tracking mechanisms are not perfect. Git has a **blame** feature that tracks who nominally commits certain lines of code to the git repository. Tools like ** cregit** can be used with git
**blame**to report commits at a more granular level of a code token, producing a more accurate picture of contributions at a file level. Git
**blame**and
**cregit**are useful because they both use publicly available information—the information just needs to be interpreted properly.
An analysis of **blame** with **cregit** can help assess McHardy’s potential contributions. For example:
- The bulk of his contributions appear to be concentrated during the period 2006-08 and 2012.
- Of approximately 135 files in which McHardy included his copyright notice, only 1/3 are files to which McHardy contributed 50% or more of the file's code.
- His contributions appear to constitute well under .25% of the code in the kernel.
Most of McHardy’s contributions appear to be to Netfilter; however, **blame** might not always tell the whole story. For example, a committer can check in many lines of code having made only minor changes, or can check in code written or owned by others. For these reasons, the authorship of a committer can be under- or over-reported.
Records of contributions to the kernel prior to 2002 are not useful to identify contributors, because at that time, Linus Torvalds checked in all code. Patrick McHardy's contributions did not begin until 2004.
The difficulty of establishing copyright ownership using development repository metadata arose in the [Hellwig v. VMware case](https://www.theregister.co.uk/2016/08/15/vmware_survives_gpl_breach_case_but_plaintiff_promises_appeal/). Courts may be reluctant to accept such information as evidence of authorship.
**What copyright rights does McHardy have in the Linux kernel?** Copyright ownership in large projects such as the Linux kernel is complicated. It’s like a patchwork quilt. When developers contribute to the kernel, they don’t sign any contribution agreement or assignment of copyright. The GPL covers their contributions, and the recipient of a copy of the software gets a license, under GPL, directly from all the authors. (The kernel project uses a document called a Developer Certificate of Origin, which does not grant any copyright license.) The contributors’ individual rights exist side-by-side with rights in the project as a whole. So, an author like McHardy would generally own the copyright in the contributions he created, but not in the whole kernel.
**What is ****"community enforcement"?** Because the ownership of large projects like the Linux kernel is often spread out among many authors, individual owners can take enforcement actions that are inconsistent with the objectives of the community. While the community may have a range of views on how best to encourage adherence to the GPL’s terms, most agree that enforcement should be informal (not via lawsuits) and that the primary goal should be compliance (rather than penalties). [Software Freedom Conservancy](https://sfconservancy.org/), for example, has issued certain [principles of community enforcement](https://sfconservancy.org/copyleft-compliance/principles.html), which prioritize compliance over the pursuit of lawsuits or money damages. There is no bright-line rule for when informal actions should become lawsuits, or how much money an enforcer should request. Most developers in the Linux community, however, consider lawsuits only the last resort, and are willing to refrain from legal action and work with users who sincerely wish to comply.
**Why have so many open source lawsuits been filed in Germany?** Some plaintiffs seeking to enforce open source licenses have filed their claims in Germany’s court system. There are a few instruments for pursuing legal action in Germany that don’t have exact analogs in the U.S. or other common law countries.
**Abmahnung****(“warning”):** The “warning” is a request from the claimant to the defendant to stop doing something. In the copyright context, it is a letter from the copyright owner requesting that an alleged infringer stop infringing. These letters are issued by lawyers, not courts, and are often the first step in a copyright enforcement action in Germany. In the U.S., the closest analog would be a cease and desist letter.
**Unterlassungserklärung****(“cease and desist declaration” or “declaration of injunction”):** The “warnings” will often have a “cease and desist declaration” attached to them. This “declaration” is like a contract—signing it will subject the defendant to legal obligations that might not otherwise exist. In particular, the declaration may contain obligations that are not required by the GPL itself. In Germany, it is common for such a document to contain penalties for noncompliance. In the U.S., the analog would be a settlement agreement, but settlement agreements rarely specify the penalties for breach—and in fact, in the U.S., “penalties” may not be enforceable in contracts. The “declaration” is not a court order, but if the defendant signs it, it may gain the legal force of a court order. **So, signing them before seeking legal advice is often not a good idea.** There are other approaches to consider in dealing with a complainant who sends a cease and desist declaration, including proposing a revised declaration with lesser penalties or obligations. Further, because a cease and desist declaration may also contain a non-disclosure requirement, signing one of these documents may also create additional difficulties, such as restricting the ability to seek support from other defendants or to alert the community about the claimant’s assertions.
For details, see [abmahnung.org/unterlassungserklaerung/](http://www.abmahnung.org/unterlassungserklaerung/).
**Einstweilige Verfügung****(“interim injunction” or “preliminary injunction”):**The “interim injunction” is a court order that is like a temporary restraining order in the U.S. A defendant’s non-response to a “warning” or “declaration” can encourage a plaintiff to seek an “interim injunction,” although there is no requirement that a claimant send a “warning” before requesting an “interim injunction” from a court. Interim injunctions for copyright infringement can prescribe penalties of 250,000 Euro or 6 months' imprisonment. In the U.S., in contrast, criminal penalties for copyright infringement are extremely rare, and must be pursued by the government, not private parties. Also, in the U.S., courts do not prescribe remedies for future possible infringement—they only order defendants to stop current infringement or pay damages. In Germany, interim injunctions are also available *ex parte*, meaning that a plaintiff can apply to the court without the defendant being heard, and they can issue without the defendant’s participation. If you receive a “warning,” and suspect that a request for an “interim injunction” might follow, there is a possibility to file a preemptive “opposition” with the court.
For details, see [Abmahnung.org](http://www.abmahnung.org/einstweilige-verfuegung/).
**Widerspruch****(“opposition” or “contradiction”):**The “opposition” is an opportunity for a defendant to file an opinion with the court that an “interim injunction” is not justified.
For an example of a case in which this process took place, see [this English translation of a German court order](http://www.jbb.de/Docs/LG_Halle_GPL3.pdf).
**How many claims has McHardy brought?** Due to the lack of publicly accessible records for many German court dockets, it is difficult to determine the precise number of actions brought by McHardy. It has been stated that McHardy has approached over 50 enforcement targets. For details, see [Source Code Control](https://sourcecodecontrol.co/gpl/) and [7 Notable Legal Developments in Open Source in 2016](https://opensource.com/article/17/1/yearbook-7-notable-legal-developments-2016). That doesn’t necessarily mean 50 lawsuits—it probably means 50 demands threatening a lawsuit. But it is difficult to verify this claim with public sources. For details, see [Litigation and Compliance in the Open Source Ecosystem](https://www.slideshare.net/blackducksoftware/litigation-and-compliance-in-the-open-source-ecosystem).
**Why hasn’t the community stopped McHardy?** Various members of the community, including Software Freedom Conservancy, have reached out to try to persuade McHardy to change his strategy, but thus far they have not been successful. The Netfilter project recently published a [licensing FAQ](http://www.netfilter.org/licensing.html) addressing concerns about McHardy’s actions.
**What can we do to stop McHardy and other copyright profiteers?** There is no one answer to this question, and there may be no way to completely stop them. But here are some suggestions for what might reduce the number of copyright profiteers.
**Strive to comply with open source licenses.** There are plenty of resources to learn how to comply with licenses, and how to set up an open source compliance program at your company. For example:
- The Linux Foundation published
[Practical GPL Compliance](https://www.linuxfoundation.org/news-media/research/practical-gpl-compliance). - Software Freedom Law Center published
[A Practical Guide to GPL Compliance](https://www.softwarefreedom.org/resources/2014/SFLC-Guide_to_GPL_Compliance_2d_ed.html)(Second Edition). - The
[OpenChain project](https://www.openchainproject.org/)publishes a specification for recommended internal processes for open source management.
**Don’t sign an ****Unterlassungserklärung****before seeking legal advice**. As explained above, an Unterlassungserklärung can subject you to obligations and penalties that are not found in the GPL itself. Don’t cooperate with the profiteers. You can make yourself a harder target, and enlist the help of other targets in the community.
**Support open source development.** Authors should not have to resort to profiteering to make a living. Companies that use open source software should not expect open source developers to develop software for free; they should chip in to support important projects.
**Learn to recognize a copyright profiteer.** Be aware of the general differences between community-oriented GPL enforcement and copyright profiteering. Community-oriented enforcement generally aims to achieve GPL compliance through education and assistance, while respecting users’ freedoms. Profiteering, by contrast, may focus on poorly researched scattershot claims and the threat of legal action for purposes of financial gain. Be on the lookout for assertions that prioritize financial gain and set the stage for unreasonable damages penalties.
**Make claims public**. If you are the target of a profiteer, and have a choice to make the claims public, doing so might help both you and others by discouraging their actions. As members of the open source community, we all share a duty to speak out against profiteers who seek to burden the community with allegations that can be resolved in more appropriate and less contentious ways.
*Update: October 31, 2017*
*The Linux Foundation released a Community Enforcement Statement, and implemented a means to allow kernel developers to show their commitment to this statement. Responding to concerns about rogue enforcement by kernel developers who have engaged in copyright profiteering, this effort is intended to set community expectation for enforcement of GPL violations relating to the Linux kernel. An FAQ released by the Foundation explains that the commitment effectively implements opportunities to cure violations, similar to the opportunity available in GPL3.*
## 5 Comments |
9,007 | 使用 Docker 构建你的 Serverless 树莓派集群 | https://blog.alexellis.io/your-serverless-raspberry-pi-cluster/ | 2017-10-28T22:32:00 | [
"树莓派",
"OpenFaaS",
"Docker"
] | https://linux.cn/article-9007-1.html | 
这篇博文将向你展示如何使用 Docker 和 [OpenFaaS](https://github.com/alexellis/faas) 框架构建你自己的 Serverless 树莓派集群。大家常常问我能用他们的集群来做些什么?而这个应用完美匹配卡片尺寸的设备——只需添加更多的树莓派就能获取更强的计算能力。
>
> “Serverless” (无服务器)是事件驱动架构的一种设计模式,与“桥接模式”、“外观模式”、“工厂模式”和“云”这些名词一样,都是一种抽象概念。
>
>
>

*图片:3 个 Raspberry Pi Zero*
这是我在本文中描述的集群,用黄铜支架分隔每个设备。
### Serverless 是什么?它为何重要?
行业对于 “serverless” 这个术语的含义有几种解释。在这篇博文中,我们就把它理解为一种事件驱动的架构模式,它能让你用自己喜欢的任何语言编写轻量可复用的功能。[更多关于 Serverless 的资料](https://blog.alexellis.io/introducing-functions-as-a-service/)。

*Serverless 架构也引出了“功能即服务服务”模式,简称 FaaS*
Serverless 的“功能”可以做任何事,但通常用于处理给定的输入——例如来自 GitHub、Twitter、PayPal、Slack、Jenkins CI pipeline 的事件;或者以树莓派为例,处理像红外运动传感器、激光绊网、温度计等真实世界的传感器的输入。
Serverless 功能能够更好地结合第三方的后端服务,使系统整体的能力大于各部分之和。
了解更多背景信息,可以阅读我最近一偏博文:[功能即服务(FaaS)简介](https://blog.alexellis.io/introducing-functions-as-a-service/)。
### 概述
我们将使用 [OpenFaaS](https://github.com/alexellis/faas),它能够让主机或者集群作为支撑 Serverless 功能运行的后端。任何能够使用 Docker 部署的可执行二进制文件、脚本或者编程语言都能在 [OpenFaaS](https://github.com/alexellis/faas) 上运作,你可以根据速度和伸缩性选择部署的规模。另一个优点是,它还内建了用户界面和监控系统。
这是我们要执行的步骤:
* 在一个或多个主机上配置 Docker (树莓派 2 或者 3);
* 利用 Docker Swarm 将它们连接;
* 部署 [OpenFaaS](https://github.com/alexellis/faas);
* 使用 Python 编写我们的第一个功能。
### Docker Swarm
Docker 是一项打包和部署应用的技术,支持集群上运行,有着安全的默认设置,而且在搭建集群时只需要一条命令。OpenFaaS 使用 Docker 和 Swarm 在你的可用树莓派上传递你的 Serverless 功能。
我推荐你在这个项目中使用带树莓派 2 或者 3,以太网交换机和[强大的 USB 多端口电源适配器](https://www.amazon.co.uk/Anker-PowerPort-Family-Sized-Technology-Smartphones/dp/B00PK1IIJY)。
### 准备 Raspbian
把 [Raspbian Jessie Lite](http://downloads.raspberrypi.org/raspbian/images/raspbian-2017-07-05/) 写入 SD 卡(8GB 容量就正常工作了,但还是推荐使用 16GB 的 SD 卡)。
*注意:不要下载成 Raspbian Stretch 了*
>
> 社区在努力让 Docker 支持 Raspbian Stretch,但是还未能做到完美运行。请从[树莓派基金会网站](http://downloads.raspberrypi.org/raspbian_lite/images/raspbian_lite-2017-07-05/)下载 Jessie Lite 镜像。
>
>
>
我推荐使用 [Etcher.io](https://etcher.io/) 烧写镜像。
>
> 在引导树莓派之前,你需要在引导分区创建名为 `ssh` 的空白文件。这样才能允许远程登录。
>
>
>
#### 接通电源,然后修改主机名
现在启动树莓派的电源并且使用 `ssh` 连接:
```
$ ssh [email protected]
```
>
> 默认密码是 `raspberry`
>
>
>
使用 `raspi-config` 工具把主机名改为 `swarm-1` 或者类似的名字,然后重启。
当你到了这一步,你还可以把划分给 GPU (显卡)的内存设置为 16MB。
#### 现在安装 Docker
我们可以使用通用脚本来安装:
```
$ curl -sSL https://get.docker.com | sh
```
>
> 这个安装方式在将来可能会发生变化。如上文所说,你的系统需要是 Jessie,这样才能得到一个确定的配置。
>
>
>
你可能会看到类似下面的警告,不过你可以安全地忽略它并且成功安装上 Docker CE 17.05:
```
WARNING: raspbian is no longer updated @ https://get.docker.com/
Installing the legacy docker-engine package...
```
之后,用下面这个命令确保你的用户帐号可以访问 Docker 客户端:
```
$ usermod pi -aG docker
```
>
> 如果你的用户名不是 `pi`,那就把它替换成你的用户名。
>
>
>
#### 修改默认密码
输入 `$sudo passwd pi`,然后设置一个新密码,请不要跳过这一步!
#### 重复以上步骤
现在为其它的树莓派重复上述步骤。
### 创建你的 Swarm 集群
登录你的第一个树莓派,然后输入下面的命令:
```
$ docker swarm init
Swarm initialized: current node (3ra7i5ldijsffjnmubmsfh767) is now a manager.
To add a worker to this swarm, run the following command:
docker swarm join \
--token SWMTKN-1-496mv9itb7584pzcddzj4zvzzfltgud8k75rvujopw15n3ehzu-af445b08359golnzhncbdj9o3 \
192.168.0.79:2377
```
你会看到它显示了一个口令,以及其它节点加入集群的命令。接下来使用 `ssh` 登录每个树莓派,运行这个加入集群的命令。
等待连接完成后,在第一个树莓派上查看集群的节点:
```
$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
3ra7i5ldijsffjnmubmsfh767 * swarm1 Ready Active Leader
k9mom28s2kqxocfq1fo6ywu63 swarm3 Ready Active
y2p089bs174vmrlx30gc77h4o swarm4 Ready Active
```
恭喜你!你现在拥有一个树莓派集群了!
#### 更多关于集群的内容
你可以看到三个节点启动运行。这时只有一个节点是集群管理者。如果我们的管理节点*死机*了,集群就进入了不可修复的状态。我们可以通过添加冗余的管理节点解决这个问题。而且它们依然会运行工作负载,除非你明确设置了让你的服务只运作在工作节点上。
要把一个工作节点升级为管理节点,只需要在其中一个管理节点上运行 `docker node promote <node_name>` 命令。
>
> 注意: Swarm 命令,例如 `docker service ls` 或者 `docker node ls` 只能在管理节点上运行。
>
>
>
想深入了解管理节点与工作节点如何保持一致性,可以查阅 [Docker Swarm 管理指南](https://docs.docker.com/engine/swarm/admin_guide/)。
### OpenFaaS
现在我们继续部署程序,让我们的集群能够运行 Serverless 功能。[OpenFaaS](https://github.com/alexellis/faas) 是一个利用 Docker 在任何硬件或者云上让任何进程或者容器成为一个 Serverless 功能的框架。因为 Docker 和 Golang 的可移植性,它也能很好地运行在树莓派上。

>
> 如果你支持 [OpenFaaS](https://github.com/alexellis/faas),希望你能 **星标** [OpenFaaS](https://github.com/alexellis/faas) 的 GitHub 仓库。
>
>
>
登录你的第一个树莓派(你运行 `docker swarm init` 的节点),然后部署这个项目:
```
$ git clone https://github.com/alexellis/faas/
$ cd faas
$ ./deploy_stack.armhf.sh
Creating network func_functions
Creating service func_gateway
Creating service func_prometheus
Creating service func_alertmanager
Creating service func_nodeinfo
Creating service func_markdown
Creating service func_wordcount
Creating service func_echoit
```
你的其它树莓派会收到 Docer Swarm 的指令,开始从网上拉取这个 Docker 镜像,并且解压到 SD 卡上。这些工作会分布到各个节点上,所以没有哪个节点产生过高的负载。
这个过程会持续几分钟,你可以用下面指令查看它的完成状况:
```
$ watch 'docker service ls'
ID NAME MODE REPLICAS IMAGE PORTS
57ine9c10xhp func_wordcount replicated 1/1 functions/alpine:latest-armhf
d979zipx1gld func_prometheus replicated 1/1 alexellis2/prometheus-armhf:1.5.2 *:9090->9090/tcp
f9yvm0dddn47 func_echoit replicated 1/1 functions/alpine:latest-armhf
lhbk1fc2lobq func_markdown replicated 1/1 functions/markdownrender:latest-armhf
pj814yluzyyo func_alertmanager replicated 1/1 alexellis2/alertmanager-armhf:0.5.1 *:9093->9093/tcp
q4bet4xs10pk func_gateway replicated 1/1 functions/gateway-armhf:0.6.0 *:8080->8080/tcp
v9vsvx73pszz func_nodeinfo replicated 1/1 functions/nodeinfo:latest-armhf
```
我们希望看到每个服务都显示 “1/1”。
你可以根据服务名查看该服务被调度到哪个树莓派上:
```
$ docker service ps func_markdown
ID IMAGE NODE STATE
func_markdown.1 functions/markdownrender:latest-armhf swarm4 Running
```
状态一项应该显示 `Running`,如果它是 `Pending`,那么镜像可能还在下载中。
在这时,查看树莓派的 IP 地址,然后在浏览器中访问它的 8080 端口:
```
$ ifconfig
```
例如,如果你的 IP 地址是 192.168.0.100,那就访问 <http://192.168.0.100:8080> 。
这是你会看到 FaaS UI(也叫 API 网关)。这是你定义、测试、调用功能的地方。
点击名称为 “func\_markdown” 的 Markdown 转换功能,输入一些 Markdown(这是 Wikipedia 用来组织内容的语言)文本。
然后点击 “invoke”。你会看到调用计数增加,屏幕下方显示功能调用的结果。

### 部署你的第一个 Serverless 功能:
这一节的内容已经有相关的教程,但是我们需要几个步骤来配置树莓派。
#### 获取 FaaS-CLI
```
$ curl -sSL cli.openfaas.com | sudo sh
armv7l
Getting package https://github.com/alexellis/faas-cli/releases/download/0.4.5-b/faas-cli-armhf
```
#### 下载样例
```
$ git clone https://github.com/alexellis/faas-cli
$ cd faas-cli
```
#### 为树莓派修补样例模版
我们临时修改我们的模版,让它们能在树莓派上工作:
```
$ cp template/node-armhf/Dockerfile template/node/
$ cp template/python-armhf/Dockerfile template/python/
```
这么做是因为树莓派和我们平时关注的大多数计算机使用不一样的处理器架构。
>
> 了解 Docker 在树莓派上的最新状况,请查阅: [你需要了解的五件事](https://blog.alexellis.io/5-things-docker-rpi/)。
>
>
>
现在你可以跟着下面为 PC、笔记本和云端所写的教程操作,但我们在树莓派上要先运行一些命令。
* [使用 OpenFaaS 运行你的第一个 Serverless Python 功能](https://blog.alexellis.io/first-faas-python-function)
注意第 3 步:
* 把你的功能放到先前从 GitHub 下载的 `faas-cli` 文件夹中,而不是 `~/functinos/hello-python` 里。
* 同时,在 `stack.yml` 文件中把 `localhost` 替换成第一个树莓派的 IP 地址。
集群可能会花费几分钟把 Serverless 功能下载到相关的树莓派上。你可以用下面的命令查看你的服务,确保副本一项显示 “1/1”:
```
$ watch 'docker service ls'
pv27thj5lftz hello-python replicated 1/1 alexellis2/faas-hello-python-armhf:latest
```
**继续阅读教程:** [使用 OpenFaaS 运行你的第一个 Serverless Python 功能](https://blog.alexellis.io/first-faas-python-function)
关于 Node.js 或者其它语言的更多信息,可以进一步访问 [FaaS 仓库](https://github.com/alexellis/faas)。
### 检查功能的指标
既然使用 Serverless,你也不想花时间监控你的功能。幸运的是,OpenFaaS 内建了 [Prometheus](https://prometheus.io/) 指标检测,这意味着你可以追踪每个功能的运行时长和调用频率。
#### 指标驱动自动伸缩
如果你给一个功能生成足够的负载,OpenFaaS 将自动扩展你的功能;当需求消失时,你又会回到单一副本的状态。
这个请求样例你可以复制到浏览器中:
只要把 IP 地址改成你的即可。

```
http://192.168.0.25:9090/graph?g0.range_input=15m&g0.stacked=1&g0.expr=rate(gateway_function_invocation_total%5B20s%5D)&g0.tab=0&g1.range_input=1h&g1.expr=gateway_service_count&g1.tab=0
```
这些请求使用 PromQL(Prometheus 请求语言)编写。第一个请求返回功能调用的频率:
```
rate(gateway_function_invocation_total[20s])
```
第二个请求显示每个功能的副本数量,最开始应该是每个功能只有一个副本。
```
gateway_service_count
```
如果你想触发自动扩展,你可以在树莓派上尝试下面指令:
```
$ while [ true ]; do curl -4 localhost:8080/function/func_echoit --data "hello world" ; done
```
查看 Prometheus 的 “alerts” 页面,可以知道你是否产生足够的负载来触发自动扩展。如果没有,你可以尝试在多个终端同时运行上面的指令。

当你降低负载,副本数量显示在你的第二个图表中,并且 `gateway_service_count` 指标再次降回 1。
### 结束演讲
我们现在配置好了 Docker、Swarm, 并且让 OpenFaaS 运行代码,把树莓派像大型计算机一样使用。
>
> 希望大家支持这个项目,**星标** [FaaS 的 GitHub 仓库](https://github.com/alexellis/faas)。
>
>
>
你是如何搭建好了自己的 Docker Swarm 集群并且运行 OpenFaaS 的呢?在 Twitter [@alexellisuk](https://twitter.com/alexellisuk) 上分享你的照片或推文吧。
**观看我在 Dockercon 上关于 OpenFaaS 的视频**
我在 [Austin 的 Dockercon](https://blog.alexellis.io/dockercon-2017-captains-log/) 上展示了 OpenFaaS。——观看介绍和互动例子的视频: <https://www.youtube.com/embed/-h2VTE9WnZs>
有问题?在下面的评论中提出,或者给我发邮件,邀请我进入你和志同道合者讨论树莓派、Docker、Serverless 的 Slack channel。
**想要学习更多关于树莓派上运行 Docker 的内容?**
我建议从 [你需要了解的五件事](https://blog.alexellis.io/5-things-docker-rpi/) 开始,它包含了安全性、树莓派和普通 PC 间微妙差别等话题。
* [Dockercon tips: Docker & Raspberry Pi](https://blog.alexellis.io/dockercon-tips-docker-raspberry-pi/)
* [Control GPIO with Docker Swarm](https://blog.alexellis.io/gpio-on-swarm/)
* [Is that a Docker Engine in your pocket??](https://blog.alexellis.io/docker-engine-in-your-pocket/)
---
via: <https://blog.alexellis.io/your-serverless-raspberry-pi-cluster/>
作者:[Alex Ellis](https://twitter.com/alexellisuk) 译者:[haoqixu](https://github.com/haoqixu) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | This blog post will show you how to create your own Serverless Raspberry Pi cluster with Docker and the [OpenFaaS](https://github.com/alexellis/faas) framework. People often ask me what they should do with their cluster and this application is perfect for the credit-card sized device - want more compute power? Scale by adding more RPis.
"Serverless" is a design pattern for event-driven architectures just like "bridge", "facade", "factory" and "cloud" are also abstract concepts -
[so is "serverless"].
Here's my cluster for the blog post - with brass stand-offs used to separate each device.
I'm writing a blog post on
— Alex Ellis (@alexellisuk)[@docker]and[@Raspberry_Pi]- it's probably never been easier to create a cluster and deploy code 🐝[pic.twitter.com/KD2MIIrAx9][August 19, 2017]
### What is Serverless and why does it matter to you?
As an industry we have some explaining to do regarding what
the term "serverless" means. For the sake of this blog post let us assume that it is a new architectural pattern for event-driven architectures and that it lets you write tiny, reusable functions in whatever language you like.[Read more on Serverless here].
*Serverless is an architectural pattern resulting in: Functions as a Service, or FaaS*
Serverless functions can do anything, but usually work on a given input - such as an event from GitHub, Twitter, PayPal, Slack, your Jenkins CI pipeline - or in the case of a Raspberry Pi - maybe a real-world sensor input such as a PIR motion sensor, laser tripwire or even a temperature gauge.
Let's also assume that serverless functions tend to make use of third-party back-end services to become greater than the sum of their parts.
For more background information checkout my latest blog post - [Introducing Functions as a Service (FaaS)
](https://blog.alexellis.io/introducing-functions-as-a-service/)
## Overview
We'll be using [OpenFaaS](https://github.com/alexellis/faas) which lets you turn any single host or cluster into a back-end to run serverless functions. Any binary, script or programming language that can be deployed with Docker will work on [OpenFaaS](https://github.com/alexellis/faas) and you can chose on a scale between speed and flexibility. The good news is a UI and metrics are also built-in.
Here's what we'll do:
- Set up Docker on one or more hosts (Raspberry Pi 2/3)
- Join them together in a Docker Swarm
- Deploy
[OpenFaaS](https://github.com/alexellis/faas) - Write our first function in Python
Update: we've given the CLI an overhaul, it can now:
`list`
,`invoke`
and create`new`
functions from templates. Check it out here:[Coffee with the FaaS-CLI]
## Docker Swarm
Docker is a technology for packaging and deploying applications, it also has clustering built-in which is secure by default and only takes one line to set up. OpenFaaS uses Docker and Swarm to spread your serverless functions across all your available RPis.
*Pictured: 3x Raspberry Pi Zero*
#### Bill of materials
I recommend using Raspberry Pi 2 or 3 for this project along with an Ethernet switch and a [powerful USB multi-adapter](https://www.amazon.co.uk/Anker-PowerPort-Family-Sized-Technology-Smartphones/dp/B00PK1IIJY).
- 2-8 Raspberry Pi 3
RPi2 or a mix of RPi2/3 will also work.
- 2-8 SD Cards
I use Class 10 Sandisk MicroSD cards in either 8GB or 16GB size.
- Ethernet Switch
Make sure you have an Ethernet Switch - this doesn't have to be gigabit, but it's preferable for re-use in future projects. You should have at least as many ports as RPis plus one for an uplink to your network.
- Bronze/Copper stand-offs
You can form the stacked structure I show in my image with bronze or copper stands-offs. These are called male screw columns and are extended versions of what you commonly find separating a motherboard from casing.
- USB Power multi-charger
In my experience Anker provide the best solution. Here's a [60W version with 6 outputs](https://www.amazon.co.uk/Anker-PowerPort-Family-Sized-Technology-Smartphones-Black/dp/B00PK1IIJY/ref=sr_1_9?ie=UTF8&qid=1510596504&sr=8-9&keywords=anker+charging).
- High quality charging cables
I recommend [Anker cables](https://www.amazon.co.uk/Anker-4-Pack-PowerLine-Micro-USB/dp/B016BEVNK4/ref=pd_bxgy_23_img_2?_encoding=UTF8&psc=1&refRID=361GFJ8X5MKM5JS5Y1QE), do not go cheap on these because I have and they often fail. When cheap cables fail they result in the Raspberry Pi inexplicably restarting.
- Ethernet cables
You'll need Ethernet cables. You can use any CAT5/5e or compatible cables from eBay, Amazon or an electronics supplier. I've had luck with flat ribbon cables which are more flexible.
If cables are too short and tight they can pull your stack of Raspberry Pis over.
### Prepare Raspbian
Flash [Raspbian Stretch Lite](https://www.raspberrypi.org/downloads/raspbian/) to an SD card. You can make do with 8GB but 16GB is recommended.
Update: I previously recommended downloading Raspbian Jessie instead of Stretch. At time of writing (3 Jan 2018) Stretch is now fully compatible.
I recommend using [Etcher.io](https://etcher.io) to flash the image.
Before booting the RPi you'll need to create a file in the boot partition called "ssh". Just keep the file blank. This enables remote logins.
- Power up and change the hostname
Now power up the RPi and connect with `ssh`
```
$ ssh [email protected]
```
The password is
`raspberry`
.
Use the `raspi-config`
utility to change the hostname to `swarm-1`
or similar and then reboot.
While you're here you can also change the memory split between the GPU (graphics) and the system to 16mb.
- Now install Docker
We can use a utility script for this:
```
$ curl -sSL https://get.docker.com | sh
```
This installation method may change in the future.
You may see a warning like this, but you can ignore it and you should end up with Docker CE 17.05 or newer:
```
WARNING: raspbian is no longer updated @ https://get.docker.com/
Installing the legacy docker-engine package...
```
After, make sure your user account can access the Docker client with this command:
```
$ usermod pi -aG docker
```
If your username isn't
`pi`
then replace`pi`
with`alex`
for instance.
- Change the default password
Type in `$sudo passwd pi`
and enter a new password, please don't skip this step!
- Repeat
Now repeat the above for each of the RPis.
### Create your Swarm cluster
Log into the first RPi and type in the following:
```
$ docker swarm init
Swarm initialized: current node (3ra7i5ldijsffjnmubmsfh767) is now a manager.
To add a worker to this swarm, run the following command:
docker swarm join \
--token SWMTKN-1-496mv9itb7584pzcddzj4zvzzfltgud8k75rvujopw15n3ehzu-af445b08359golnzhncbdj9o3 \
192.168.0.79:2377
```
You'll see the output with your join token and the command to type into the other RPis. So log into each one with `ssh`
and paste in the command.
Give this a few seconds to connect then on the first RPi check all your nodes are listed:
```
$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
3ra7i5ldijsffjnmubmsfh767 * swarm1 Ready Active Leader
k9mom28s2kqxocfq1fo6ywu63 swarm3 Ready Active
y2p089bs174vmrlx30gc77h4o swarm4 Ready Active
```
Congratulations! You have a Raspberry Pi cluster!
**More on clusters*
You can see my three hosts up and running. Only one is a manager at this point. If our manager were to go *down* then we'd be in an unrecoverable situation. The way around this is to add redundancy by promoting more of the nodes to managers - they will still run workloads, unless you specifically set up your services to only be placed on workers.
To upgrade a worker to a manager, just type in `docker node promote <node_name>`
from one of your managers.
Note: Swarm commands such as
`docker service ls`
or`docker node ls`
can only be done on the manager.
For a deeper dive into how managers and workers keep "quorum" head over to the [Docker Swarm admin guide](https://docs.docker.com/engine/swarm/admin_guide/).
## OpenFaaS
Now let's move on to deploying a real application to enable Serverless functions to run on our cluster. [OpenFaaS](https://github.com/alexellis/faas) is a framework for Docker that lets any process or container become a serverless function - at scale and on any hardware or cloud. Thanks to Docker and Golang's portability it also runs very well on a Raspberry Pi.
Please show your support and
starthe[OpenFaaS]repository on GitHub.
Log into the first RPi (where we ran `docker swarm init`
) and clone/deploy the project:
```
$ git clone https://github.com/alexellis/faas/
$ cd faas
$ ./deploy_stack.sh
Creating network func_functions
Creating service func_gateway
Creating service func_prometheus
Creating service func_alertmanager
Creating service func_nodeinfo
Creating service func_markdown
Creating service func_wordcount
Creating service func_echoit
```
**Update**: OpenFaaS on Raspberry Pi with Swarm now ships with authentication turned on by default. Look out for the command that shows you how to run `faas-cli login`
and note down your password for later.
Your other RPis will now be instructed by Docker Swarm to start pulling the Docker images from the internet and extracting them to the SD card. The work will be spread across all the RPis so that none of them are overworked.
This could take a couple of minutes, so you can check when it's done by typing in:
```
$ watch 'docker service ls'
ID NAME MODE REPLICAS IMAGE PORTS
57ine9c10xhp func_wordcount replicated 1/1 functions/alpine:latest-armhf
d979zipx1gld func_prometheus replicated 1/1 alexellis2/prometheus-armhf:1.5.2 *:9090->9090/tcp
f9yvm0dddn47 func_echoit replicated 1/1 functions/alpine:latest-armhf
lhbk1fc2lobq func_markdown replicated 1/1 functions/markdownrender:latest-armhf
pj814yluzyyo func_alertmanager replicated 1/1 alexellis2/alertmanager-armhf:0.5.1 *:9093->9093/tcp
q4bet4xs10pk func_gateway replicated 1/1 functions/gateway-armhf:0.6.0 *:8080->8080/tcp
v9vsvx73pszz func_nodeinfo replicated 1/1 functions/nodeinfo:latest-armhf
```
We want to see 1/1 listed on all of our services.
Given any service name you can type in the following to see which RPi it was scheduled to:
```
$ docker service ps func_markdown
ID IMAGE NODE STATE
func_markdown.1 functions/markdownrender:latest-armhf swarm4 Running
```
The state should be `Running`
- if it says `Pending`
then the image could still be on its way down from the internet.
At that point, find the IP address of your RPi and open that in a web-browser on port 8080:
```
$ ifconfig
```
For example if your IP was: 192.168.0.100 - then go to [http://192.168.0.100:8080](http://192.168.0.100:8080)
At this point you should see the FaaS UI also called the API Gateway. This is where you can define, test and invoke your functions.
Click on the Markdown conversion function called func_markdown and type in some Markdown (this is what Wikipedia uses to write its content).
Then hit invoke. You'll see the invocation count go up and the bottom half of the screen shows the result of your function:
### Deploy your first serverless function:
There is already a tutorial written for this section, but we'll need to get the RPi set up with a couple of custom steps first.
- Get the FaaS-CLI
```
$ curl -sSL cli.openfaas.com | sudo sh
armv7l
Getting package https://github.com/alexellis/faas-cli/releases/download/0.4.5-b/faas-cli-armhf
```
- Use the
*arm*templates
Note: when you create a function in Node or Python you need to add a suffix of
`-armhf`
to use a special Docker image for the Raspberry Pi
Here's an example:
```
$ faas-cli new --lang python-armhf python-hello
$ faas-cli new --lang node-armhf python-hello
```
Now you can follow the same tutorial written for PC, Laptop and Cloud available below, but we are going to run a couple of commands first for the Raspberry Pi.
Pick it up at step 3:
-
Instead of placing your functions in
`~/functions/hello-python`
- place them inside the`faas-cli`
folder we just cloned from GitHub. -
Also replace "localhost" for the IP address of your first RPi in the
`stack.yml`
file.
Note that the Raspberry Pi may take a few minutes to download your serverless function to the relevant RPi. You can check on your services to make sure you have 1/1 replicas showing up with this command:
```
$ watch 'docker service ls'
pv27thj5lftz hello-python replicated 1/1 alexellis2/faas-hello-python-armhf:latest
```
**Continue the tutorial:** [Your first serverless Python function with OpenFaaS](https://blog.alexellis.io/first-faas-python-function)
Update: we've given the CLI an overhaul, it can now:
`list`
,`invoke`
and create`new`
functions from templates. Check it out here:[Coffee with the FaaS-CLI]
For more information on working with Node.js or other languages head over to the main [OpenFaaS repo](https://github.com/alexellis/faas).
Get up to speed on Docker on the Raspberry Pi - read:
[5 Things you need to know]
### Check your function metrics
With a Serverless experience, you don't want to spend all your time managing your functions. Fortunately [Prometheus](https://prometheus.io) metrics are built into OpenFaaS meaning you can keep track of how long each functions takes to run and how often it's being called.
*Metrics drive auto-scaling*
If you generate enough load on any of of the functions then OpenFaaS will auto-scale your function and when the demand eases off you'll get back to a single replica again.
Here is a sample query you can paste into Safari, Chrome etc:
Just change the IP address to your own.
```
http://192.168.0.25:9090/graph?g0.range_input=15m&g0.stacked=1&g0.expr=rate(gateway_function_invocation_total%5B20s%5D)&g0.tab=0&g1.range_input=1h&g1.expr=gateway_service_count&g1.tab=0
```
The queries are written in PromQL - Prometheus query language. The first one shows us how often the function is being called:
```
rate(gateway_function_invocation_total[20s])
```
The second query shows us how many replicas we have of each function, there should be only one of each at the start:
```
gateway_service_count
```
If you want to trigger auto-scaling you could try the following on the RPi:
```
$ while [ true ]; do curl -4 localhost:8080/function/func_echoit --data "hello world" ; done
```
Check the Prometheus "alerts" page, and see if you are generating enough load for the auto-scaling to trigger, if you're not then run the command in a few additional Terminal windows too.
After you reduce the load, the replica count shown in your second graph and the `gateway_service_count`
metric will go back to 1 again.
## Wrapping up
We've now set up Docker, Swarm and run OpenFaaS - which let us treat our Raspberry Pi like one giant computer - ready to crunch through code.
Please show support for the project and
Starthe[FaaS GitHub repository]
How did you find setting up your Docker Swarm first cluster and running OpenFaaS? Please share a picture or a Tweet on Twitter [@alexellisuk](https://twitter.com/alexellisuk)
**Watch my Dockercon video of OpenFaaS**
I presented OpenFaaS (then called FaaS) [at Dockercon in Austin](https://blog.alexellis.io/dockercon-2017-captains-log/) - watch this video for a high-level introduction and some really interactive demos Alexa and GitHub.
**Want to learn more about Docker on the Raspberry Pi?**
I'd suggest starting with [5 Things you need to know](https://blog.alexellis.io/5-things-docker-rpi/) which covers things like security and and the subtle differences between containers on a regular PC and an RPi.
*Share on Twitter*
Build Your Serverless Raspberry Pi cluster with
— Alex Ellis (@alexellisuk)[@Docker]![@Raspberry_Pi][#devops][#cluster][@open_faas][https://t.co/VdlJAImcSv][pic.twitter.com/hj4waAbwnn][August 21, 2017] |
9,008 | 每个安卓开发初学者应该了解的 12 个技巧 | https://android.jlelse.eu/12-practices-every-android-beginner-should-know-cd43c3710027 | 2017-10-29T22:17:43 | [
"Android"
] | https://linux.cn/article-9008-1.html |
>
> 一次掌握一个技巧,更好地学习安卓
>
>
>

距离安迪·鲁宾和他的团队着手开发一个希望颠覆传统手机操作模式的操作系统已经过去 12 年了,这套系统有可能让手机或者智能机给消费者以及软件开发人员带来全新的体验。之前的智能机仅限于收发短信和查看电子邮件(当然还可以打电话),给用户和开发者带来很大的限制。
安卓,作为打破这个枷锁的系统,拥有非常优秀的框架设计,给大家提供的不仅仅是一组有限的功能,更多的是自由的探索。有人会说 iPhone 才是手机产业的颠覆产品,不过我们说的不是 iPhone 有多么酷(或者多么贵,是吧?),它还是有限制的,而这是我们从来都不希望有的。
不过,就像本大叔说的,能力越大责任越大,我们也需要更加认真对待安卓应用的设计方式。我看到很多教程都忽略了向初学者传递这个理念,在动手之前请先充分理解系统架构。他们只是把一堆的概念和代码丢给读者,却没有解释清楚相关的优缺点,它们对系统的影响,以及该用什么不该用什么等等。
在这篇文章里,我们将介绍一些初学者以及中级开发人员都应该掌握的技巧,以帮助更好地理解安卓框架。后续我们还会在这个系列里写更多这样的关于实用技巧的文章。我们开始吧。
### 1、 `@+id` 和 `@id` 的区别
要在 Java 代码里访问一个图形控件(或组件),或者是要让它成为其他控件的依赖,我们需要一个唯一的值来引用它。这个唯一值用 `android:id` 属性来定义,本质上就是把用户提供的 id 附加到 `@+id/` 后面,写入到 *id 资源文件*,供其他控件使用。一个 Toolbar 的 id 可以这样定义,
```
android:id="@+id/toolbar"
```
然后这个 id 值就能被 `findViewById(…)` 识别,这个函数会在资源文件里查找 id,或者直接从 R.id 路径引用,然后返回所查找的 View 的类型。
而另一种,`@id`,和 `findViewById(…)` 行为一样 - 也会根据提供的 id 查找组件,不过仅限于布局时使用。一般用来布置相关控件。
```
android:layout_below="@id/toolbar"
```
### 2、 使用 `@string` 资源为 XML 提供字符串
简单来说,就是不要在 XML 里直接用字符串。原因很简单。当我们在 XML 里直接使用了字符串,我们一般会在其它地方再次用到同样的字符串。想像一下当我们需要在不同的地方调整同一个字符串的噩梦,而如果使用字符串资源就只改一个地方就够了。另一个好处是,使用资源文件可以提供多国语言支持,因为可以为不同的语言创建相应的字符串资源文件。
```
android:text="My Awesome Application"
```
当你直接使用字符串时,你会在 Android Studio 里收到警告,提示说应该把写死的字符串改成字符串资源。可以点击这个提示,然后按下 `ALT + ENTER` 打开字符串编辑。你也可以直接打开 `res` 目录下的 `values` 目录里的 `strings.xml` 文件,然后像下面这样声明一个字符串资源。
```
<string name="app_name">My Awesome Application</string>
```
然后用它来替换写死的字符串,
```
android:text="@string/app_name"
```
### 3、 使用 `@android` 和 `?attr` 常量
尽量使用系统预先定义的常量而不是重新声明。举个例子,在布局中有几个地方要用白色或者 #ffffff 颜色值。不要每次都直接用 #ffffff 数值,也不要自己为白色重新声明资源,我们可以直接用这个,
```
@android:color/white
```
安卓预先定义了很多常用的颜色常量,比如白色,黑色或粉色。最经典的应用场景是透明色:
```
@android:color/transparent
```
另一个引用常量的方式是 `?attr`,用来将预先定义的属性值赋值给不同的属性。举个自定义 Toolbar 的例子。这个 Toolbar 需要定义宽度和高度。宽度通常可以设置为 `MATCH_PARENT`,但高度呢?我们大多数人都没有注意设计指导,只是简单地随便设置一个看上去差不多的值。这样做不对。不应该随便自定义高度,而应该这样做,
```
android:layout_height="?attr/actionBarSize"
```
`?attr` 的另一个应用是点击视图时画水波纹效果。`SelectableItemBackground` 是一个预定义的 drawable,任何视图需要增加波纹效果时可以将它设为背景:
```
android:background="?attr/selectableItemBackground"
```
也可以用这个:
```
android:background="?attr/selectableItemBackgroundBorderless"
```
来显示无边框波纹。
### 4、 SP 和 DP 的区别
虽然这两个没有本质上的区别,但知道它们是什么以及在什么地方适合用哪个很重要。
SP 的意思是缩放无关像素,一般建议用于 TextView,首先文字不会因为显示密度不同而显示效果不一样,另外 TextView 的内容还需要根据用户设定做拉伸,或者只调整字体大小。
其他需要定义尺寸和位置的地方,可以使用 DP,也就是密度无关像素。之前说过,DP 和 SP 的性质是一样的,只是 DP 会根据显示密度自动拉伸,因为安卓系统会动态计算实际显示的像素,这样就可以让使用 DP 的组件在不同显示密度的设备上都可以拥有相同的显示效果。
### 5、 Drawable 和 Mipmap 的应用
这两个最让人困惑的是 - drawable 和 mipmap 有多少差异?
虽然这两个好像有同样的用途,但它们设计目的不一样。mipmap 是用来储存图标的,而 drawable 用于任何其他格式。我们可以看一下系统内部是如何使用它们的,就知道为什么不能混用了。
你可以看到你的应用里有几个 mipmap 和 drawable 目录,每一个分别代表不同的显示分辨率。当系统从 drawable 目录读取资源时,只会根据当前设备的显示密度选择确定的目录。然而,在读取 mipmap 时,系统会根据需要选择合适的目录,而不仅限于当前显示密度,主要是因为有些启动器会故意显示较大的图标,所以系统会使用较大分辨率的资源。
总之,用 mipmap 来存放图标或标记图片,可以在不同显示密度的设备上看到分辨率变化,而其它根据需要显示的图片资源都用 drawable。
比如说,Nexus 5 的显示分辨率是 xxhdpi。当我们把图标放到 `mipmap` 目录里时,所有 `mipmap` 目录都将读入内存。而如果放到 drawable 里,只有 `drawable-xxhdpi` 目录会被读取,其他目录都会被忽略。
### 6、 使用矢量图形
为了支持不同显示密度的屏幕,将同一个资源的多个版本(大小)添加到项目里是一个很常见的技巧。这种方式确实有用,不过它也会带来一定的性能开支,比如更大的 apk 文件以及额外的开发工作。为了消除这种影响,谷歌的安卓团队发布了新增的矢量图形。
矢量图形是用 XML 描述的 SVG(可拉伸矢量图形),是用点、直线和曲线组合以及填充颜色绘制出的图形。正因为矢量图形是由点和线动态画出来的,在不同显示密度下拉伸也不会损失分辨率。而矢量图形带来的另一个好处是更容易做动画。往一个 AnimatedVectorDrawable 文件里添加多个矢量图形就可以做出动画,而不用添加多张图片然后再分别处理。
```
<vector xmlns:android="http://schemas.android.com/apk/res/android"
android:width="24dp"
android:height="24dp"
android:viewportWidth="24.0"
android:viewportHeight="24.0">
<path android:fillColor="#69cdff" android:pathData="M3,18h18v-2L3,16v2zM3,13h18v-2L3,11v2zM3,6v2h18L21,6L3,6z"/>
</vector>
```
上面的向量定义可以画出下面的图形,

要在你的安卓项目里添加矢量图形,可以右键点击你项目里的应用模块,然后选择 New >> Vector Assets。然后会打开 Assets Studio,你可以有两种方式添加矢量图形。第一种是从 Material 图标里选择,另一种是选择本地的 SVG 或 PSD 文件。
谷歌建议与应用相关都使用 Material 图标,来保持安卓的连贯性和统一体验。[这里](https://material.io/icons/)有全部图标,记得看一下。
### 7、 设定边界的开始和结束
这是人们最容易忽略的地方之一。边界!增加边界当然很简单,但是如果要考虑支持很旧的平台呢?
边界的“开始”和“结束”分别是“左”和“右”的超集,所以如果应用的 `minSdkVersion` 是 17 或更低,边界和填充的“开始”和“结束”定义是旧的“左”/“右”所需要的。在那些没有定义“开始”和“结束”的系统上,这两个定义可以被安全地忽略。可以像下面这样声明:
```
android:layout_marginEnd="20dp"
android:paddingStart="20dp"
```
### 8、 使用 Getter/Setter 生成工具
在创建一个容器类(只是用来简单的存放一些变量数据)时很烦的一件事情是写多个 getter 和 setter,复制/粘贴该方法的主体再为每个变量重命名。
幸运的是,Android Studio 有一个解决方法。可以这样做,在类里声明你需要的所有变量,然后打开 Toolbar >> Code。快捷方式是 `ALT + Insert`。点击 Code 会显示 Generate,点击它会出来很多选项,里面有 Getter 和 Setter 选项。在保持焦点在你的类页面然后点击,就会为当前类添加所有的 getter 和 setter(有需要的话可以再去之前的窗口操作)。很爽吧。
### 9、 使用 Override/Implement 生成工具
这是另一个很好用的生成工具。自定义一个类然后再扩展很容易,但是如果要扩展你不熟悉的类呢。比如说 PagerAdapter,你希望用 ViewPager 来展示一些页面,那就需要定制一个 PagerAdapter 并实现它的重载方法。但是具体有哪些方法呢?Android Studio 非常贴心地为自定义类强行添加了一个构造函数,或者可以用快捷键(`ALT + Enter`),但是父类 PagerAdapter 里的其他(虚拟)方法需要自己手动添加,我估计大多数人都觉得烦。
要列出所有可以重载的方法,可以点击 Code >> Generate and Override methods 或者 Implement methods,根据你的需要。你还可以为你的类选择多个方法,只要按住 Ctrl 再选择方法,然后点击 OK。
### 10、 正确理解 Context
Context 有点恐怖,我估计许多初学者从没有认真理解过 Context 类的结构 - 它是什么,为什么到处都要用到它。
简单地说,它将你能从屏幕上看到的所有内容都整合在一起。所有的视图(或者它们的扩展)都通过 Context 绑定到当前的环境。Context 用来管理应用层次的资源,比如说显示密度,或者当前的关联活动。活动、服务和应用都实现了 Context 类的接口来为其他关联组件提供内部资源。举个添加到 MainActivity 的 TextView 的例子。你应该注意到了,在创建一个对象的时候,TextView 的构造函数需要 Context 参数。这是为了获取 TextView 里定义到的资源。比如说,TextView 需要在内部用到 Roboto 字体。这样的话,TextView 需要 Context。而且在我们将 Context(或者 `this`)传递给 TextView 的时候,也就是告诉它绑定当前活动的生命周期。
另一个 Context 的关键应用是初始化应用层次的操作,比如初始化一个库。库的生命周期和应用是不相关的,所以它需要用 `getApplicationContext()` 来初始化,而不是用 `getContext` 或 `this` 或 `getActivity()`。掌握正确使用不同 Context 类型非常重要,可以避免内存泄漏。另外,要用到 Context 来启动一个活动或服务。还记得 `startActivity(…)` 吗?当你需要在一个非活动类里切换活动时,你需要一个 Context 对象来调用 `startActivity` 方法,因为它是 Context 类的方法,而不是 Activity 类。
```
getContext().startActivity(getContext(), SecondActivity.class);
```
如果你想了解更多 Context 的行为,可以看看[这里](https://blog.mindorks.com/understanding-context-in-android-application-330913e32514)或[这里](https://developer.android.com/reference/android/content/Context.html)。第一个是一篇关于 Context 的很好的文章,介绍了在哪些地方要用到它。而另一个是安卓关于 Context 的文档,全面介绍了所有的功能 - 方法,静态标识以及更多。
### 奖励 #1: 格式化代码
有人会不喜欢整齐,统一格式的代码吗?好吧,几乎我们每一个人,在写一个超过 1000 行的类的时候,都希望我们的代码能有合适的结构。而且,并不仅仅大的类才需要格式化,每一个小模块类也需要让代码保持可读性。
使用 Android Studio,或者任何 JetBrains IDE,你都不需要自己手动整理你的代码,像增加缩进或者 = 之前的空格。就按自己希望的方式写代码,在想要格式化的时候,如果是 Windows 系统可以按下 `ALT + CTRL + L`,Linux 系统按下 `ALT + CTRL + SHIFT + L`。*代码就自动格式化好了*
### 奖励 #2: 使用库
面向对象编程的一个重要原则是增加代码的可重用性,或者说减少重新发明轮子的习惯。很多初学者错误地遵循了这个原则。这条路有两个方向,
* 不用任何库,自己写所有的代码。
* 用库来处理所有事情。
不管哪个方向走到底都是不对的。如果你彻底选择第一个方向,你将消耗大量的资源,仅仅是为了满足自己拥有一切的骄傲。很可能你的代码没有做过替代库那么多的测试,从而增加模块出问题的可能。如果资源有限,不要重复发明轮子。直接用经过测试的库,在有了明确目标以及充分的资源后,可以用自己的可靠代码来替换这个库。
而彻底走向另一个方向,问题更严重 - 别人代码的可靠性。不要习惯于所有事情都依赖于别人的代码。在不用太多资源或者自己能掌控的情况下尽量自己写代码。你不需要用库来自定义一个 TypeFaces(字体),你可以自己写一个。
所以要记住,在这两个极端中间平衡一下 - 不要重新创造所有事情,也不要过分依赖外部代码。保持中立,根据自己的能力写代码。
这篇文章最早发布在 [What’s That Lambda](https://www.whatsthatlambda.com/android/android-dev-101-things-every-beginner-must-know) 上。请访问网站阅读更多关于 Android、Node.js、Angular.js 等等类似文章。
---
via: <https://android.jlelse.eu/12-practices-every-android-beginner-should-know-cd43c3710027>
作者:[Nilesh Singh](https://android.jlelse.eu/@nileshsingh?source=post_header_lockup) 译者:[zpl1025](https://github.com/zpl1025) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 308 | Permanent Redirect | null |
9,009 | IoT 网络安全:后备计划是什么? | https://www.schneier.com/blog/archives/2017/10/iot_cybersecuri.html | 2017-10-29T23:40:46 | [
"安全",
"物联网",
"IoT"
] | https://linux.cn/article-9009-1.html | 
八月份,四名美国参议员提出了一项旨在改善物联网(IoT)安全性的法案。2017 年的 “物联网网络安全改进法” 是一项小幅的立法。它没有规范物联网市场。它没有任何特别关注的行业,或强制任何公司做任何事情。甚至没有修改嵌入式软件的法律责任。无论安全多么糟糕,公司可以继续销售物联网设备。
法案的做法是利用政府的购买力推动市场:政府购买的任何物联网产品都必须符合最低安全标准。它要求供应商确保设备不仅可以打补丁,而且是以认证和及时的方式进行修补,没有不可更改的默认密码,并且没有已知的漏洞。这是一个你可以达到的低安全值,并且将大大提高安全性,可以说明关于物联网安全性的当前状态。(全面披露:我帮助起草了一些法案的安全性要求。)
该法案还将修改“计算机欺诈和滥用”和“数字千年版权”法案,以便安全研究人员研究政府购买的物联网设备的安全性。这比我们的行业需求要窄得多。但这是一个很好的第一步,这可能是对这个立法最好的事。
不过,这一步甚至不可能施行。我在八月份写这个专栏,毫无疑问,这个法案你在十月份或以后读的时候会没有了。如果听证会举行,它们无关紧要。该法案不会被任何委员会投票,不会在任何立法日程上。这个法案成为法律的可能性是零。这不仅仅是因为目前的政治 - 我在奥巴马政府下同样悲观。
但情况很严重。互联网是危险的 - 物联网不仅给了眼睛和耳朵,而且还给手脚。一旦有影响到位和字节的安全漏洞、利用和攻击现在将会影响到其血肉。
正如我们在过去一个世纪一再学到的那样,市场是改善产品和服务安全的可怕机制。汽车、食品、餐厅、飞机、火灾和金融仪器安全都是如此。原因很复杂,但基本上卖家不会在安全方面进行竞争,因为买方无法根据安全考虑有效区分产品。市场使用的竞相降低门槛的机制价格降到最低的同时也将质量降至最低。没有政府干预,物联网仍然会很不安全。
美国政府对干预没有兴趣,所以我们不会看到严肃的安全和保障法规、新的联邦机构或更好的责任法。我们可能在欧盟有更好的机会。根据“通用数据保护条例”在数据隐私的规定,欧盟可能会在 5 年内通过类似的安全法。没有其他国家有足够的市场份额来做改变。
有时我们可以选择不使用物联网,但是这个选择变得越来越少见了。去年,我试着不连接网络来购买新车但是失败了。再过几年, 就几乎不可能不连接到物联网。我们最大的安全风险将不会来自我们与之有市场关系的设备,而是来自其他人的汽车、照相机、路由器、无人机等等。
我们可以尝试为理想买单,并要求更多的安全性,但企业不会在物联网安全方面进行竞争 - 而且我们的安全专家不是一个可以产生影响的足够大的市场力量。
我们需要一个后备计划,虽然我不知道是什么。如果你有任何想法请评论。
这篇文章以前出现在 9/10 月的 《IEEE安全与隐私》上。
---
作者简介:
自从 2004 年以来,我一直在博客上写关于安全的文章,以及从 1998 年以来我的每月订阅中也有。我写书、文章和学术论文。目前我是 IBM Resilient 的首席技术官,哈佛伯克曼中心的研究员,EFF 的董事会成员。
---
via: <https://www.schneier.com/blog/archives/2017/10/iot_cybersecuri.html>
作者:[Bruce Schneier](https://www.schneier.com/blog/about/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | ## IoT Cybersecurity: What's Plan B?
In August, four US Senators introduced a bill designed to improve Internet of Things (IoT) security. The IoT Cybersecurity Improvement Act of 2017 is a modest piece of legislation. It doesn’t regulate the IoT market. It doesn’t single out any industries for particular attention, or force any companies to do anything. It doesn’t even modify the liability laws for embedded software. Companies can continue to sell IoT devices with whatever lousy security they want.
What the bill does do is leverage the government’s buying power to nudge the market: any IoT product that the government buys must meet minimum security standards. It requires vendors to ensure that devices can not only be patched, but are patched in an authenticated and timely manner; don’t have unchangeable default passwords; and are free from known vulnerabilities. It’s about as low a security bar as you can set, and that it will considerably improve security speaks volumes about the current state of IoT security. (Full disclosure: I helped draft some of the bill’s security requirements.)
The bill would also modify the Computer Fraud and Abuse and the Digital Millennium Copyright Acts to allow security researchers to study the security of IoT devices purchased by the government. It’s a far narrower exemption than our industry needs. But it’s a good first step, which is probably the best thing you can say about this legislation.
However, it’s unlikely this first step will even be taken. I am writing this column in August, and have no doubt that the bill will have gone nowhere by the time you read it in October or later. If hearings are held, they won’t matter. The bill won’t have been voted on by any committee, and it won’t be on any legislative calendar. The odds of this bill becoming law are zero. And that’s not just because of current politics—I’d be equally pessimistic under the Obama administration.
But the situation is critical. The Internet is dangerous—and the IoT gives it not just eyes and ears, but also hands and feet. Security vulnerabilities, exploits, and attacks that once affected only bits and bytes now affect flesh and blood.
Markets, as we’ve repeatedly learned over the past century, are terrible mechanisms for improving the safety of products and services. It was true for automobile, food, restaurant, airplane, fire, and financial-instrument safety. The reasons are complicated, but basically, sellers don’t compete on safety features because buyers can’t efficiently differentiate products based on safety considerations. The race-to-the-bottom mechanism that markets use to minimize prices also minimizes quality. Without government intervention, the IoT remains dangerously insecure.
The US government has no appetite for intervention, so we won’t see serious safety and security regulations, a new federal agency, or better liability laws. We might have a better chance in the EU. Depending on how the General Data Protection Regulation on data privacy pans out, the EU might pass a similar security law in 5 years. No other country has a large enough market share to make a difference.
Sometimes we can opt out of the IoT, but that option is becoming increasingly rare. Last year, I tried and failed to purchase a new car without an Internet connection. In a few years, it’s going to be nearly impossible to not be multiply connected to the IoT. And our biggest IoT security risks will stem not from devices we have a market relationship with, but from everyone else’s cars, cameras, routers, drones, and so on.
We can try to shop our ideals and demand more security, but companies don’t compete on IoT safety—and we security experts aren’t a large enough market force to make a difference.
We need a Plan B, although I’m not sure what that is. Comment if you have any ideas.
This essay previously appeared in the September/October issue of *IEEE Security & Privacy*.
Nicholas Weininger • October 18, 2017 10:29 AM
You tried and failed to purchase a new car without an Internet connection? That’d make an interesting followup post– I know lots of cars nowadays have connections as part of their infotainment and/or navigation systems, but it’s surprising and nonobvious to a casual consumer that e.g. the low-end models without nav systems still have connections, and it’d be useful to understand why. |
9,010 | 服务端 I/O 性能:Node、PHP、Java、Go 的对比 | https://www.toptal.com/back-end/server-side-io-performance-node-php-java-go | 2017-10-31T09:42:59 | [
"性能"
] | https://linux.cn/article-9010-1.html | 了解应用程序的输入/输出(I/O)模型意味着理解应用程序处理其数据的载入差异,并揭示其在真实环境中表现。或许你的应用程序很小,在不承受很大的负载时,这并不是个严重的问题;但随着应用程序的流量负载增加,可能因为使用了低效的 I/O 模型导致承受不了而崩溃。
和大多数情况一样,处理这种问题的方法有多种方式,这不仅仅是一个择优的问题,而是对权衡的理解问题。 接下来我们来看看 I/O 到底是什么。

在本文中,我们将对 Node、Java、Go 和 PHP + Apache 进行对比,讨论不同语言如何构造其 I/O ,每个模型的优缺点,并总结一些基本的规律。如果你担心你的下一个 Web 应用程序的 I/O 性能,本文将给你最优的解答。
### I/O 基础知识: 快速复习
要了解 I/O 所涉及的因素,我们首先深入到操作系统层面复习这些概念。虽然看起来并不与这些概念直接打交道,但你会一直通过应用程序的运行时环境与它们间接接触。了解细节很重要。
#### 系统调用
首先是系统调用,其被描述如下:
* 程序(所谓“<ruby> 用户端 <rt> user land </rt></ruby>”)必须请求操作系统内核代表它执行 I/O 操作。
* “<ruby> 系统调用 <rt> syscall </rt></ruby>”是你的程序要求内核执行某些操作的方法。这些实现的细节在操作系统之间有所不同,但基本概念是相同的。有一些具体的指令会将控制权从你的程序转移到内核(类似函数调用,但是使用专门用于处理这种情况的专用方式)。一般来说,系统调用会被阻塞,这意味着你的程序会等待内核返回(控制权到)你的代码。
* 内核在所需的物理设备( 磁盘、网卡等 )上执行底层 I/O 操作,并回应系统调用。在实际情况中,内核可能需要做许多事情来满足你的要求,包括等待设备准备就绪、更新其内部状态等,但作为应用程序开发人员,你不需要关心这些。这是内核的工作。

#### 阻塞与非阻塞
上面我们提到过,系统调用是阻塞的,一般来说是这样的。然而,一些调用被归类为“非阻塞”,这意味着内核会接收你的请求,将其放在队列或缓冲区之类的地方,然后立即返回而不等待实际的 I/O 发生。所以它只是在很短的时间内“阻塞”,只需要排队你的请求即可。
举一些 Linux 系统调用的例子可能有助于理解:
* `read()` 是一个阻塞调用 - 你传递一个句柄,指出哪个文件和缓冲区在哪里传送它所读取的数据,当数据就绪时,该调用返回。这种方式的优点是简单友好。
* 分别调用 `epoll_create()`、`epoll_ctl()` 和 `epoll_wait()` ,你可以创建一组句柄来侦听、添加/删除该组中的处理程序、然后阻塞直到有任何事件发生。这允许你通过单个线程有效地控制大量的 I/O 操作,但是现在谈这个还太早。如果你需要这个功能当然好,但须知道它使用起来是比较复杂的。
了解这里的时间差异的数量级是很重要的。假设 CPU 内核运行在 3GHz,在没有进行 CPU 优化的情况下,那么它每秒执行 30 亿次<ruby> 周期 <rt> cycle </rt></ruby>(即每纳秒 3 个周期)。非阻塞系统调用可能需要几十个周期来完成,或者说 “相对少的纳秒” 时间完成。而一个被跨网络接收信息所阻塞的系统调用可能需要更长的时间 - 例如 200 毫秒(1/5 秒)。这就是说,如果非阻塞调用需要 20 纳秒,阻塞调用需要 2 亿纳秒。你的进程因阻塞调用而等待了 1000 万倍的时长!

内核既提供了阻塞 I/O (“从网络连接读取并给出数据”),也提供了非阻塞 I/O (“告知我何时这些网络连接具有新数据”)的方法。使用的是哪种机制对调用进程的阻塞时长有截然不同的影响。
#### 调度
关键的第三件事是当你有很多线程或进程开始阻塞时会发生什么。
根据我们的理解,线程和进程之间没有很大的区别。在现实生活中,最显著的性能相关的差异在于,由于线程共享相同的内存,而进程每个都有自己的内存空间,使得单独的进程往往占用更多的内存。但是当我们谈论<ruby> 调度 <rt> Scheduling </rt></ruby>时,它真正归结为一类事情(线程和进程类同),每个都需要在可用的 CPU 内核上获得一段执行时间。如果你有 300 个线程运行在 8 个内核上,则必须将时间分成几份,以便每个线程和进程都能分享它,每个运行一段时间,然后交给下一个。这是通过 “<ruby> 上下文切换 <rt> context switch </rt></ruby>” 完成的,可以使 CPU 从运行到一个线程/进程到切换下一个。
这些上下文切换也有相关的成本 - 它们需要一些时间。在某些快速的情况下,它可能小于 100 纳秒,但根据实际情况、处理器速度/体系结构、CPU 缓存等,偶见花费 1000 纳秒或更长时间。
而线程(或进程)越多,上下文切换就越多。当我们涉及数以千计的线程时,每个线程花费数百纳秒,就会变得很慢。
然而,非阻塞调用实质上是告诉内核“仅在这些连接之一有新的数据或事件时再叫我”。这些非阻塞调用旨在有效地处理大量 I/O 负载并减少上下文交换。
这些你明白了么?现在来到了真正有趣的部分:我们来看看一些流行的语言对那些工具的使用,并得出关于易用性和性能之间权衡的结论,以及一些其他有趣小东西。
声明,本文中显示的示例是零碎的(片面的,只能体现相关的信息); 数据库访问、外部缓存系统( memcache 等等)以及任何需要 I/O 的东西都将执行某种类型的 I/O 调用,其实质与上面所示的简单示例效果相同。此外,对于将 I/O 描述为“阻塞”( PHP、Java )的情况,HTTP 请求和响应读取和写入本身就是阻塞调用:系统中隐藏着更多 I/O 及其伴生的性能问题需要考虑。
为一个项目选择编程语言要考虑很多因素。甚至当你只考虑效率时,也有很多因素。但是,如果你担心你的程序将主要受到 I/O 的限制,如果 I/O 性能影响到项目的成败,那么这些是你需要了解的。
### “保持简单”方法:PHP
早在 90 年代,很多人都穿着 [Converse](https://www.pinterest.com/pin/414401603185852181/) 鞋,用 Perl 写着 CGI 脚本。然后 PHP 来了,就像一些人喜欢咒骂的一样,它使得动态网页更容易。
PHP 使用的模型相当简单。虽有一些出入,但你的 PHP 服务器基本上是这样:
HTTP 请求来自用户的浏览器,并访问你的 Apache Web 服务器。Apache 为每个请求创建一个单独的进程,有一些优化方式可以重新使用它们,以最大限度地减少创建次数( 相对而言,创建进程较慢 )。Apache 调用 PHP 并告诉它运行磁盘上合适的 `.php` 文件。PHP 代码执行并阻塞 I/O 调用。你在 PHP 中调用 `file_get_contents()` ,其底层会调用 `read()` 系统调用并等待结果。
当然,实际的代码是直接嵌入到你的页面,并且该操作被阻塞:
```
<?php
// blocking file I/O
$file_data = file_get_contents(‘/path/to/file.dat’);
// blocking network I/O
$curl = curl_init('http://example.com/example-microservice');
$result = curl_exec($curl);
// some more blocking network I/O
$result = $db->query('SELECT id, data FROM examples ORDER BY id DESC limit 100');
?>
```
关于如何与系统集成,就像这样:

很简单:每个请求一个进程。 I/O 调用就阻塞。优点是简单可工作,缺点是,同时与 20,000 个客户端连接,你的服务器将会崩溃。这种方法不能很好地扩展,因为内核提供的用于处理大容量 I/O (epoll 等) 的工具没有被使用。 雪上加霜的是,为每个请求运行一个单独的进程往往会使用大量的系统资源,特别是内存,这通常是你在这样的场景中遇到的第一个问题。
*注意:Ruby 使用的方法与 PHP 非常相似,在大致的方面上,它们可以被认为是相同的。*
### 多线程方法: Java
就在你购买你的第一个域名,在某个句子后很酷地随机说出 “dot com” 的那个时候,Java 来了。而 Java 具有内置于该语言中的多线程功能,它非常棒(特别是在创建时)。
大多数 Java Web 服务器通过为每个请求启动一个新的执行线程,然后在该线程中最终调用你(作为应用程序开发人员)编写的函数。
在 Java Servlet 中执行 I/O 往往看起来像:
```
public void doGet(HttpServletRequest request,
HttpServletResponse response) throws ServletException, IOException
{
// blocking file I/O
InputStream fileIs = new FileInputStream("/path/to/file");
// blocking network I/O
URLConnection urlConnection = (new URL("http://example.com/example-microservice")).openConnection();
InputStream netIs = urlConnection.getInputStream();
// some more blocking network I/O
out.println("...");
}
```
由于我们上面的 `doGet` 方法对应于一个请求,并且在其自己的线程中运行,而不是每个请求一个单独的进程,申请自己的内存。这样有一些好处,比如在线程之间共享状态、缓存数据等,因为它们可以访问彼此的内存,但是它与调度的交互影响与之前的 PHP 的例子几乎相同。每个请求获得一个新线程,该线程内的各种 I/O 操作阻塞在线程内,直到请求被完全处理为止。线程被池化以最小化创建和销毁它们的成本,但是数千个连接仍然意味着数千个线程,这对调度程序是不利的。
重要的里程碑出现在 Java 1.4 版本(以及 1.7 的重要升级)中,它获得了执行非阻塞 I/O 调用的能力。大多数应用程序、web 应用和其它用途不会使用它,但至少它是可用的。一些 Java Web 服务器尝试以各种方式利用这一点;然而,绝大多数部署的 Java 应用程序仍然如上所述工作。

肯定有一些很好的开箱即用的 I/O 功能,Java 让我们更接近,但它仍然没有真正解决当你有一个大量的 I/O 绑定的应用程序被数千个阻塞线程所压垮的问题。
### 无阻塞 I/O 作为一等公民: Node
当更好的 I/O 模式来到 Node.js,阻塞才真正被解决。任何一个曾听过 Node 简单介绍的人都被告知这是“非阻塞”,可以有效地处理 I/O。这在一般意义上是正确的。但在细节中则不尽然,而且当在进行性能工程时,这种巫术遇到了问题。
Node 实现的范例基本上不是说 “在这里写代码来处理请求”,而是说 “在这里写代码来**开始**处理请求”。每次你需要做一些涉及到 I/O 的操作,你会创建一个请求并给出一个回调函数,Node 将在完成之后调用该函数。
在请求中执行 I/O 操作的典型 Node 代码如下所示:
```
http.createServer(function(request, response) {
fs.readFile('/path/to/file', 'utf8', function(err, data) {
response.end(data);
});
});
```
你可以看到,这里有两个回调函数。当请求开始时,第一个被调用,当文件数据可用时,第二个被调用。
这样做的基本原理是让 Node 有机会有效地处理这些回调之间的 I/O 。一个更加密切相关的场景是在 Node 中进行数据库调用,但是我不会在这个例子中啰嗦,因为它遵循完全相同的原则:启动数据库调用,并给 Node 一个回调函数,它使用非阻塞调用单独执行 I/O 操作,然后在你要求的数据可用时调用回调函数。排队 I/O 调用和让 Node 处理它然后获取回调的机制称为“事件循环”。它工作的很好。

然而,这个模型有一个陷阱,究其原因,很多是与 V8 JavaScript 引擎(Node 用的是 Chrome 浏览器的 JS 引擎)如何实现的有关<sup> 注1</sup> 。你编写的所有 JS 代码都运行在单个线程中。你可以想想,这意味着当使用高效的非阻塞技术执行 I/O 时,你的 JS 可以在单个线程中运行计算密集型的操作,每个代码块都会阻塞下一个。可能出现这种情况的一个常见例子是以某种方式遍历数据库记录,然后再将其输出到客户端。这是一个示例,展示了其是如何工作:
```
var handler = function(request, response) {
connection.query('SELECT ...', function (err, rows) {
if (err) { throw err };
for (var i = 0; i < rows.length; i++) {
// do processing on each row
}
response.end(...); // write out the results
})
};
```
虽然 Node 确实有效地处理了 I/O ,但是上面的例子中 `for` 循环是在你的唯一的一个主线程中占用 CPU 周期。这意味着如果你有 10,000 个连接,则该循环可能会使你的整个应用程序像爬行般缓慢,具体取决于其会持续多久。每个请求必须在主线程中分享一段时间,一次一段。
这整个概念的前提是 I/O 操作是最慢的部分,因此最重要的是要有效地处理这些操作,即使这意味着要连续进行其他处理。这在某些情况下是正确的,但不是全部。
另一点是,虽然这只是一个观点,但是写一堆嵌套的回调可能是相当令人讨厌的,有些则认为它使代码更难以追踪。在 Node 代码中看到回调嵌套 4 层、5 层甚至更多层并不罕见。
我们再次来权衡一下。如果你的主要性能问题是 I/O,则 Node 模型工作正常。然而,它的关键是,你可以在一个处理 HTTP 请求的函数里面放置 CPU 密集型的代码,而且不小心的话会导致每个连接都很慢。
### 最自然的非阻塞:Go
在我进入 Go 部分之前,我应该披露我是一个 Go 的粉丝。我已经在许多项目中使用过它,我是一个其生产力优势的公开支持者,我在我的工作中使用它。
那么,让我们来看看它是如何处理 I/O 的。Go 语言的一个关键特征是它包含自己的调度程序。在 Go 中,不是每个执行线程对应于一个单一的 OS 线程,其通过一种叫做 “<ruby> 协程 <rt> goroutine </rt></ruby>” 的概念来工作。而 Go 的运行时可以将一个协程分配给一个 OS 线程,使其执行或暂停它,并且它不与一个 OS 线程相关联——这要基于那个协程正在做什么。来自 Go 的 HTTP 服务器的每个请求都在单独的协程中处理。
调度程序的工作原理如图所示:

在底层,这是通过 Go 运行时中的各个部分实现的,它通过对请求的写入/读取/连接等操作来实现 I/O 调用,将当前协程休眠,并当采取进一步动作时唤醒该协程。
从效果上看,Go 运行时做的一些事情与 Node 做的没有太大不同,除了回调机制是内置到 I/O 调用的实现中,并自动与调度程序交互。它也不会受到必须让所有处理程序代码在同一个线程中运行的限制,Go 将根据其调度程序中的逻辑自动将协程映射到其认为适当的 OS 线程。结果是这样的代码:
```
func ServeHTTP(w http.ResponseWriter, r *http.Request) {
// the underlying network call here is non-blocking
rows, err := db.Query("SELECT ...")
for _, row := range rows {
// do something with the rows,
// each request in its own goroutine
}
w.Write(...) // write the response, also non-blocking
}
```
如上所述,我们重构基本的代码结构为更简化的方式,并在底层仍然实现了非阻塞 I/O。
在大多数情况下,最终是“两全其美”的。非阻塞 I/O 用于所有重要的事情,但是你的代码看起来像是阻塞,因此更容易理解和维护。Go 调度程序和 OS 调度程序之间的交互处理其余部分。这不是完整的魔法,如果你建立一个大型系统,那么值得我们来看看有关它的工作原理的更多细节;但与此同时,你获得的“开箱即用”的环境可以很好地工作和扩展。
Go 可能有其缺点,但一般来说,它处理 I/O 的方式不在其中。
### 谎言,可恶的谎言和基准
对这些各种模式的上下文切换进行准确的定时是很困难的。我也可以认为这对你来说不太有用。相反,我会给出一些比较这些服务器环境的整个 HTTP 服务器性能的基本基准。请记住,影响整个端到端 HTTP 请求/响应路径的性能有很多因素,这里提供的数字只是我将一些样本放在一起进行基本比较的结果。
对于这些环境中的每一个,我写了适当的代码在一个 64k 文件中读取随机字节,在其上运行了一个 SHA-256 哈希 N 次( N 在 URL 的查询字符串中指定,例如 .../test.php?n=100),并打印出结果十六进制散列。我选择这样做,是因为使用一些一致的 I/O 和受控的方式来运行相同的基准测试是一个增加 CPU 使用率的非常简单的方法。
有关使用的环境的更多细节,请参阅 [基准说明](https://peabody.io/post/server-env-benchmarks/) 。
首先,我们来看一些低并发的例子。运行 2000 次迭代,300 个并发请求,每个请求只有一个散列(N = 1),结果如下:

*时间是在所有并发请求中完成请求的平均毫秒数。越低越好。*
仅从一张图很难得出结论,但是对我来说,似乎在大量的连接和计算量上,我们看到时间更多地与语言本身的一般执行有关,对于 I/O 更是如此。请注意,那些被视为“脚本语言”的语言(松散类型,动态解释)执行速度最慢。
但是,如果我们将 N 增加到 1000,仍然有 300 个并发请求,相同的任务,但是哈希迭代是 1000 倍(显着增加了 CPU 负载):

*时间是在所有并发请求中完成请求的平均毫秒数。越低越好。*
突然间, Node 性能显著下降,因为每个请求中的 CPU 密集型操作都相互阻塞。有趣的是,在这个测试中,PHP 的性能要好得多(相对于其他的),并且打败了 Java。(值得注意的是,在 PHP 中,SHA-256 实现是用 C 编写的,在那个循环中执行路径花费了更多的时间,因为现在我们正在进行 1000 个哈希迭代)。
现在让我们尝试 5000 个并发连接(N = 1) - 或者是我可以发起的最大连接。不幸的是,对于大多数这些环境,故障率并不显着。对于这个图表,我们来看每秒的请求总数。 *越高越好* :

*每秒请求数。越高越好。*
这个图看起来有很大的不同。我猜测,但是看起来像在高连接量时,产生新进程所涉及的每连接开销以及与 PHP + Apache 相关联的附加内存似乎成为主要因素,并阻止了 PHP 的性能。显然,Go 是这里的赢家,其次是 Java,Node,最后是 PHP。
虽然与你的整体吞吐量相关的因素很多,并且在应用程序之间也有很大的差异,但是你对底层发生什么的事情以及所涉及的权衡了解更多,你将会得到更好的结果。
### 总结
以上所有这一切,很显然,随着语言的发展,处理大量 I/O 的大型应用程序的解决方案也随之发展。
为了公平起见,PHP 和 Java,尽管这篇文章中的描述,确实 [实现了](http://reactphp.org/) 在 [web 应用程序](https://netty.io/) 中 [可使用的](http://undertow.io/) [非阻塞 I/O](http://amphp.org/) 。但是这些方法并不像上述方法那么常见,并且需要考虑使用这种方法来维护服务器的随之而来的操作开销。更不用说你的代码必须以与这些环境相适应的方式进行结构化;你的 “正常” PHP 或 Java Web 应用程序通常不会在这样的环境中进行重大修改。
作为比较,如果我们考虑影响性能和易用性的几个重要因素,我们得出以下结论:
| 语言 | 线程与进程 | 非阻塞 I/O | 使用便捷性 |
| --- | --- | --- | --- |
| PHP | 进程 | 否 | |
| Java | 线程 | 可用 | 需要回调 |
| Node.js | 线程 | 是 | 需要回调 |
| Go | 线程 (协程) | 是 | 不需要回调 |
线程通常要比进程有更高的内存效率,因为它们共享相同的内存空间,而进程则没有。结合与非阻塞 I/O 相关的因素,我们可以看到,至少考虑到上述因素,当我们从列表往下看时,与 I/O 相关的一般设置得到改善。所以如果我不得不在上面的比赛中选择一个赢家,那肯定会是 Go。
即使如此,在实践中,选择构建应用程序的环境与你的团队对所述环境的熟悉程度以及你可以实现的总体生产力密切相关。因此,每个团队都深入并开始在 Node 或 Go 中开发 Web 应用程序和服务可能就没有意义。事实上,寻找开发人员或你内部团队的熟悉度通常被认为是不使用不同语言和/或环境的主要原因。也就是说,过去十五年来,时代已经发生了变化。
希望以上内容可以帮助你更清楚地了解底层发生的情况,并为你提供如何处理应用程序的现实可扩展性的一些想法。
---
via: <https://www.toptal.com/back-end/server-side-io-performance-node-php-java-go>
作者:[BRAD PEABODY](https://www.toptal.com/resume/brad-peabody) 译者:[MonkeyDEcho](https://github.com/MonkeyDEcho) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,014 | 怎么在 Linux 中运行 DOS 程序 | https://opensource.com/article/17/10/run-dos-applications-linux | 2017-10-31T21:46:37 | [
"FreeDOS",
"DOS",
"QEMU"
] | https://linux.cn/article-9014-1.html |
>
> QEMU 和 FreeDOS 使得很容易在 Linux 中运行老的 DOS 程序
>
>
>

传统的 DOS 操作系统支持的许多非常优秀的应用程序: 文字处理,电子表格,游戏和其它的程序。但是一个应用程序太老了,并不意味着它没用了。
如今有很多理由去运行一个旧的 DOS 应用程序。或许是从一个遗留的业务应用程序中提取一个报告,或者是想玩一个经典的 DOS 游戏,或者只是因为你对“传统计算机”很好奇。你不需要去双引导你的系统去运行 DOS 程序。取而代之的是,你可以在 Linux 中在一个 PC 仿真程序和 [FreeDOS](http://www.freedos.org/) 的帮助下去正确地运行它们。
FreeDOS 是一个完整的、免费的、DOS 兼容的操作系统,你可以用它来玩经典的游戏、运行旧式业务软件,或者开发嵌入式系统。任何工作在 MS-DOS 中的程序也可以运行在 FreeDOS 中。
在那些“过去的时光”里,你安装的 DOS 是作为一台计算机上的独占操作系统。 而现今,它可以很容易地安装到 Linux 上运行的一台虚拟机中。 [QEMU](https://www.qemu.org/) (<ruby> 快速仿真程序 <rt> Quick EMUlator </rt></ruby>的缩写) 是一个开源的虚拟机软件,它可以在 Linux 中以一个“<ruby> 访客 <rt> guest </rt></ruby>”操作系统来运行 DOS。许多流行的 Linux 系统都默认包含了 QEMU 。
通过以下四步,很容易地在 Linux 下通过使用 QEMU 和 FreeDOS 去运行一个老的 DOS 程序。
### 第 1 步:设置一个虚拟磁盘
你需要一个地方来在 QEMU 中安装 FreeDOS,为此你需要一个虚拟的 C: 驱动器。在 DOS 中,字母`A:` 和 `B:` 是分配给第一和第二个软盘驱动器的,而 `C:` 是第一个硬盘驱动器。其它介质,包括其它硬盘驱动器和 CD-ROM 驱动器,依次分配 `D:`、`E:` 等等。
在 QEMU 中,虚拟磁盘是一个镜像文件。要初始化一个用做虚拟 `C:` 驱动器的文件,使用 `qemu-img` 命令。要创建一个大约 200 MB 的镜像文件,可以这样输入:
```
qemu-img create dos.img 200M
```
与现代计算机相比, 200MB 看起来非常小,但是早在 1990 年代, 200MB 是非常大的。它足够安装和运行 DOS。
### 第 2 步: QEMU 选项
与 PC 仿真系统 VMware 或 VirtualBox 不同,你需要通过 QEMU 命令去增加每个虚拟机的组件来 “构建” 你的虚拟系统 。虽然,这可能看起来很费力,但它实际并不困难。这些是我们在 QEMU 中用于去引导 FreeDOS 的参数:
| | |
| --- | --- |
| `qemu-system-i386` | QEMU 可以仿真几种不同的系统,但是要引导到 DOS,我们需要有一个 Intel 兼容的 CPU。 为此,使用 i386 命令启动 QEMU。 |
| `-m 16` | 我喜欢定义一个使用 16MB 内存的虚拟机。它看起来很小,但是 DOS 工作不需要很多的内存。在 DOS 时代,计算机使用 16MB 或者 8MB 内存是非常普遍的。 |
| `-k en-us` | 从技术上说,这个 `-k` 选项是不需要的,因为 QEMU 会设置虚拟键盘去匹配你的真实键盘(在我的例子中, 它是标准的 US 布局的英语键盘)。但是我还是喜欢去指定它。 |
| `-rtc base=localtime` | 每个传统的 PC 设备有一个实时时钟 (RTC) 以便于系统可以保持跟踪时间。我发现它是设置虚拟 RTC 匹配你的本地时间的最简单的方法。 |
| `-soundhw sb16,adlib,pcspk` | 如果你需要声音,尤其是为了玩游戏时,我更喜欢定义 QEMU 支持 SoundBlaster 16 声音硬件和 AdLib 音乐。SoundBlaster 16 和 AdLib 是在 DOS 时代非常常见的声音硬件。一些老的程序也许使用 PC 喇叭发声; QEMU 也可以仿真这个。 |
| `-device cirrus-vga` | 要使用图像,我喜欢去仿真一个简单的 VGA 视频卡。Cirrus VGA 卡是那时比较常见的图形卡, QEMU 可以仿真它。 |
| `-display gtk` | 对于虚拟显示,我设置 QEMU 去使用 GTK toolkit,它可以将虚拟系统放到它自己的窗口内,并且提供一个简单的菜单去控制虚拟机。 |
| `-boot order=` | 你可以告诉 QEMU 从多个引导源来引导虚拟机。从软盘驱动器引导(在 DOS 机器中一般情况下是 `A:` )指定 `order=a`。 从第一个硬盘驱动器引导(一般称为 `C:`) 使用 `order=c`。 或者去从一个 CD-ROM 驱动器(在 DOS 中经常分配为 `D:` ) 使用 `order=d`。 你可以使用组合字母去指定一个特定的引导顺序, 比如 `order=dc` 去第一个使用 CD-ROM 驱动器,如果 CD-ROM 驱动器中没有引导介质,然后使用硬盘驱动器。 |
### 第 3 步: 引导和安装 FreeDOS
现在 QEMU 已经设置好运行虚拟机,我们需要一个 DOS 系统来在那台虚拟机中安装和引导。 FreeDOS 做这个很容易。它的最新版本是 FreeDOS 1.2, 发行于 2016 年 12 月。
从 [FreeDOS 网站](http://www.freedos.org/)上下载 FreeDOS 1.2 的发行版。 FreeDOS 1.2 CD-ROM “standard” 安装器 (`FD12CD.iso`) 可以很好地在 QEMU 上运行,因此,我推荐使用这个版本。
安装 FreeDOS 很简单。首先,告诉 QEMU 使用 CD-ROM 镜像并从其引导。 记住,第一个硬盘驱动器是 `C:` 驱动器,因此, CD-ROM 将以 `D:` 驱动器出现。
```
qemu-system-i386 -m 16 -k en-us -rtc base=localtime -soundhw sb16,adlib -device cirrus-vga -display gtk -hda dos.img -cdrom FD12CD.iso -boot order=d
```
正如下面的提示,你将在几分钟内安装完成 FreeDOS 。




在你安装完成之后,关闭窗口退出 QEMU。
### 第 4 步:安装并运行你的 DOS 应用程序
一旦安装完 FreeDOS,你可以在 QEMU 中运行各种 DOS 应用程序。你可以在线上通过各种档案文件或其它[网站](http://www.freedos.org/links/)找到老的 DOS 程序。
QEMU 提供了一个在 Linux 上访问本地文件的简单方法。比如说,想去用 QEMU 共享 `dosfiles/` 文件夹。 通过使用 `-drive` 选项,简单地告诉 QEMU 去使用这个文件夹作为虚拟的 FAT 驱动器。 QEMU 将像一个硬盘驱动器一样访问这个文件夹。
```
-drive file=fat:rw:dosfiles/
```
现在,你可以使用合适的选项去启动 QEMU,加上一个外部的虚拟 FAT 驱动器:
```
qemu-system-i386 -m 16 -k en-us -rtc base=localtime -soundhw sb16,adlib -device cirrus-vga -display gtk -hda dos.img -drive file=fat:rw:dosfiles/ -boot order=c
```
一旦你引导进入 FreeDOS,你保存在 `D:` 驱动器中的任何文件将被保存到 Linux 上的 `dosfiles/` 文件夹中。可以从 Linux 上很容易地直接去读取该文件;然而,必须注意的是,启动 QEMU 后,不能从 Linux 中去改变 `dosfiles/` 这个文件夹。 当你启动 QEMU 时,QEMU 一次性构建一个虚拟的 FAT 表,如果你在启动 QEMU 之后,在 `dosfiles/` 文件夹中增加或删除文件,仿真程序可能会很困惑。
我使用 QEMU 像这样运行一些我收藏的 DOS 程序, 比如 As-Easy-As 电子表格程序。这是一个在上世纪八九十年代非常流行的电子表格程序,它和现在的 Microsoft Excel 和 LibreOffice Calc 或和以前更昂贵的 Lotus 1-2-3 电子表格程序完成的工作是一样的。 As-Easy-As 和 Lotus 1-2-3 都保存数据为 WKS 文件,最新版本的 Microsoft Excel 不能读取它,但是,根据兼容性, LibreOffice Calc 可以支持它。

*As-Easy-As 电子表格程序*
我也喜欢在 QEMU中引导 FreeDOS 去玩一些收藏的 DOS 游戏,比如原版的 Doom。这些老的 DOS 游戏玩起来仍然非常有趣, 并且它们现在在 QEMU 上运行的非常好。

*Doom*

*Heretic*

*Jill of the Jungle*

*Commander Keen*
QEMU 和 FreeDOS 使得在 Linux 上运行老的 DOS 程序变得很容易。你一旦设置好了 QEMU 作为虚拟机仿真程序并安装了 FreeDOS,你将可以在 Linux 上运行你收藏的经典的 DOS 程序。
*所有图片要致谢 [FreeDOS.org](http://www.freedos.org/)。*
---
作者简介:
Jim Hall 是一位开源软件的开发者和支持者,可能最广为人知的是他是 FreeDOS 的创始人和项目协调者。 Jim 也非常活跃于开源软件适用性领域,作为 GNOME Outreachy 适用性测试的导师,同时也作为一名兼职教授,教授一些开源软件适用性的课程,从 2016 到 2017, Jim 在 GNOME 基金会的董事会担任董事,在工作中, Jim 是本地政府部门的 CIO。
---
via: <https://opensource.com/article/17/10/run-dos-applications-linux>
作者:[Jim Hall](https://opensource.com/users/jim-hall) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The classic DOS operating system supported a lot of great applications: word processors, spreadsheets, games, and other programs. Just because an application is old doesn't mean it's no longer useful.
There are many reasons to run an old DOS application today. Maybe to extract a report from a legacy business application. Or to play a classic DOS game. Or just because you are curious about "classic computing." You don't need to dual-boot your system to run DOS programs. Instead, you can run them right inside Linux with the help of a PC emulator and [FreeDOS](http://www.freedos.org/).
FreeDOS is a complete, free, DOS-compatible operating system that you can use to play classic DOS games, run legacy business software, or develop embedded systems. Any program that works on MS-DOS should also run on FreeDOS.
In the "old days," you installed DOS as the sole operating system on a computer. These days, it's much easier to install DOS in a virtual machine running under Linux. [QEMU](https://www.qemu.org/) (short for Quick EMUlator) is an open source software virtual machine system that can run DOS as a "guest" operating system Linux. Most popular Linux systems include QEMU by default.
Here are four easy steps to run old DOS applications under Linux by using QEMU and FreeDOS.
## Step 1: Set up a virtual disk
You'll need a place to install FreeDOS inside QEMU, and for that you'll need a virtual **C:** drive. In DOS, drives are assigned with letters—**A:** and **B:** are the first and second floppy disk drives and **C:** is the first hard drive. Other media, including other hard drives or CD-ROM drives, are assigned **D:**, **E:**, and so on.
Under QEMU, virtual drives are image files. To initialize a file that you can use as a virtual **C: **drive, use the **qemu-img** command. To create an image file that's about 200MB, type this:
`qemu-img create dos.img 200M`
Compared to modern computing, 200MB may seem small, but in the early 1990s, 200MB was pretty big. That's more than enough to install and run DOS.
## Step 2: QEMU options
Unlike PC emulator systems like VMware or VirtualBox, you need to "build" your virtual system by instructing QEMU to add each component of the virtual machine. Although this may seem laborious, it's really not that hard. Here are the parameters I use to boot FreeDOS inside QEMU:
|
QEMU can emulate several different systems, but to boot DOS, we'll need to have an Intel-compatible CPU. For that, start QEMU with the i386 command. |
|
I like to define a virtual machine with 16MB of memory. That may seem small, but DOS doesn't require much memory to do its work. When DOS was king, computers with 16MB or even 8MB were quite common. |
|
Technically, the -k option isn't necessary, because QEMU will set the virtual keyboard to match your actual keyboard (in my case, that's English in the standard U.S. layout). But I like to specify it anyway. |
|
Every classic PC provides a real time clock (RTC) so the system can keep track of time. I find it's easiest to simply set the virtual RTC to match your local time. |
|
If you need sound, especially for games, I prefer to define QEMU with SoundBlaster16 sound hardware and AdLib Music support. SoundBlaster16 and AdLib were the most common sound hardware in the DOS era. Some older programs may use the PC speaker for sound; QEMU can also emulate this. |
-device cirrus-vga |
To use graphics, I like to emulate a simple VGA video card. The Cirrus VGA card was a common graphics card at the time, and QEMU can emulate it. |
|
For the virtual display, I set QEMU to use the GTK toolkit, which puts the virtual system in its own window and provides a simple menu to control the virtual machine. |
-boot order= |
You can tell QEMU to boot the virtual machine from a variety of sources. To boot from the floppy drive (typically A: on DOS machines) specify order=a. To boot from the first hard drive (usually called C:) use order=c. Or to boot from a CD-ROM drive (often assigned D: by DOS) use order=d. You can combine letters to specify a specific boot preference, such as order=dc to first use the CD-ROM drive, then the hard drive if the CD-ROM drive does not contain bootable media. |
## Step 3: Boot and install FreeDOS
Now that QEMU is set up to run a virtual system, we need a version of DOS to install and boot inside that virtual computer. FreeDOS makes this easy. The latest version is FreeDOS 1.2, released in December 2016.
Download the FreeDOS 1.2 distribution from the [FreeDOS website](http://www.freedos.org/). The FreeDOS 1.2 CD-ROM "standard" installer (**FD12CD.iso**) will work great for QEMU, so I recommend that version.
Installing FreeDOS is simple. First, tell QEMU to use the CD-ROM image and to boot from that. Remember that the **C:** drive is the first hard drive, so the CD-ROM will show up as the **D:** drive.
`qemu-system-i386 -m 16 -k en-us -rtc base=localtime -soundhw sb16,adlib -device cirrus-vga -display gtk -hda dos.img -cdrom FD12CD.iso -boot order=d`
Just follow the prompts, and you'll have FreeDOS installed within minutes.
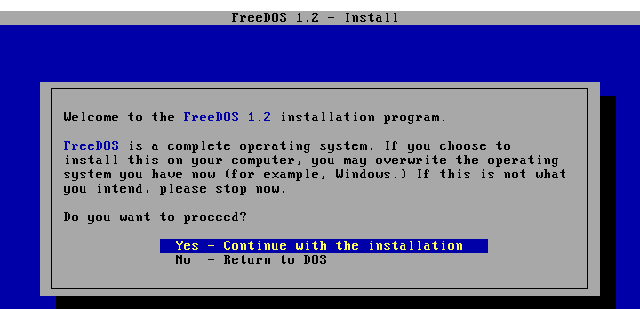
opensource.com
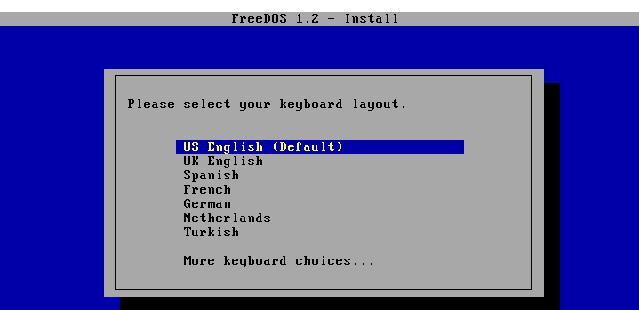
opensource.com
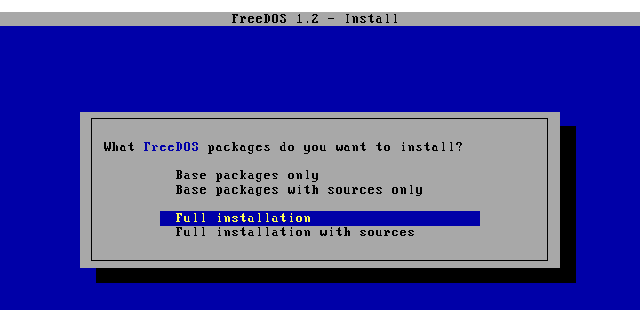
opensource.com
opensource.com
After you've finished, exit QEMU by closing the window.
## Step 4: Install and run your DOS application
Once you have installed FreeDOS, you can run different DOS applications inside QEMU. You can find old DOS programs online through various archives or other [websites](http://www.freedos.org/links/).
QEMU provides an easy way to access local files on Linux. Let's say you want to share the **dosfiles/** folder with QEMU. Simply tell QEMU to use the folder as a virtual FAT drive by using the **-drive** option. QEMU will access this folder as though it were a hard drive.
`-drive file=fat:rw:dosfiles/`
Now, start QEMU with your regular options, plus the extra virtual FAT drive:
`qemu-system-i386 -m 16 -k en-us -rtc base=localtime -soundhw sb16,adlib -device cirrus-vga -display gtk -hda dos.img -drive file=fat:rw:dosfiles/ -boot order=c`
Once you're booted in FreeDOS, any files you save to the **D:** drive will be saved to the **dosfiles/** folder on Linux. This makes reading the files directly from Linux easy; however, be careful not to change the **dosfiles/** folder from Linux after starting QEMU. QEMU builds a virtual FAT table once, when you start QEMU. If you add or delete files in **dosfiles/** after you start QEMU, the emulator may become confused.
I use QEMU like this to run my favorite DOS programs, like the As-Easy-As spreadsheet program. This was a popular spreadsheet application from the 1980s and 1990s, which does the same job that Microsoft Excel and LibreOffice Calc fulfill today, or that the more expensive Lotus 1-2-3 spreadsheet did back in the day. As-Easy-As and Lotus 1-2-3 both saved data as WKS files, which newer versions of Microsoft Excel cannot read, but which LibreOffice Calc may still support, depending on compatibility.
opensource.com
I also like to boot FreeDOS under QEMU to play some of my favorite DOS games, like the original Doom. These old games are still fun to play, and they all run great under QEMU.
opensource.com
opensource.com
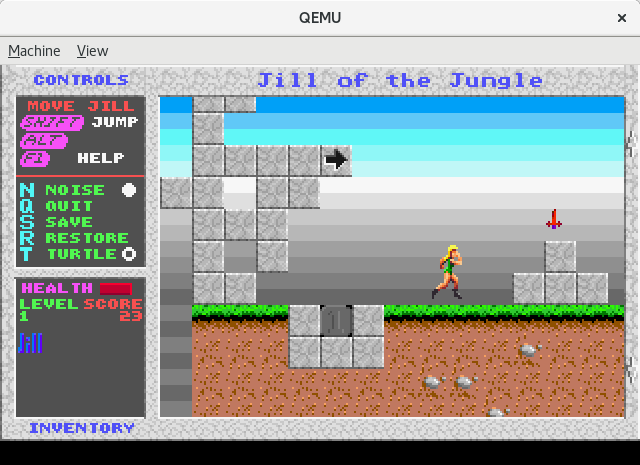
opensource.com
opensource.com
QEMU and FreeDOS make it easy to run old DOS programs under Linux. Once you've set up QEMU as the virtual machine emulator and installed FreeDOS, you should be all set to run your favorite classic DOS programs from Linux.
*All images courtesy of FreeDOS.org.*
## 16 Comments |
9,015 | CRI-O 1.0 简介 | https://www.redhat.com/en/blog/introducing-cri-o-10 | 2017-10-31T23:49:43 | [
"容器",
"Kubernetes",
"CRI"
] | https://linux.cn/article-9015-1.html | 
去年,Kubernetes 项目推出了<ruby> <a href="https://github.com/kubernetes/kubernetes/blob/242a97307b34076d5d8f5bbeb154fa4d97c9ef1d/docs/devel/container-runtime-interface.md"> 容器运行时接口 </a> <rt> Container Runtime Interface </rt></ruby>(CRI):这是一个插件接口,它让 kubelet(用于创建 pod 和启动容器的集群节点代理)有使用不同的兼容 OCI 的容器运行时的能力,而不需要重新编译 Kubernetes。在这项工作的基础上,[CRI-O](http://cri-o.io/) 项目([原名 OCID](https://www.redhat.com/en/blog/running-production-applications-containers-introducing-ocid))准备为 Kubernetes 提供轻量级的运行时。
那么这个**真正的**是什么意思?
CRI-O 允许你直接从 Kubernetes 运行容器,而不需要任何不必要的代码或工具。只要容器符合 OCI 标准,CRI-O 就可以运行它,去除外来的工具,并让容器做其擅长的事情:加速你的新一代原生云程序。
在引入 CRI 之前,Kubernetes 通过“[一个内部的](http://blog.kubernetes.io/2016/12/container-runtime-interface-cri-in-kubernetes.html)[易失性](http://blog.kubernetes.io/2016/12/container-runtime-interface-cri-in-kubernetes.html)[接口](http://blog.kubernetes.io/2016/12/container-runtime-interface-cri-in-kubernetes.html)”与特定的容器运行时相关联。这导致了上游 Kubernetes 社区以及在编排平台之上构建解决方案的供应商的大量维护开销。
使用 CRI,Kubernetes 可以与容器运行时无关。容器运行时的提供者不需要实现 Kubernetes 已经提供的功能。这是社区的胜利,因为它让项目独立进行,同时仍然可以共同工作。
在大多数情况下,我们不认为 Kubernetes 的用户(或 Kubernetes 的发行版,如 OpenShift)真的关心容器运行时。他们希望它工作,但他们不希望考虑太多。就像你(通常)不关心机器上是否有 GNU Bash、Korn、Zsh 或其它符合 POSIX 标准 shell。你只是要一个标准的方式来运行你的脚本或程序而已。
### CRI-O:Kubernetes 的轻量级容器运行时
这就是 CRI-O 提供的。该名称来自 CRI 和开放容器计划(OCI),因为 CRI-O 严格关注兼容 OCI 的运行时和容器镜像。
现在,CRI-O 支持 runc 和 Clear Container 运行时,尽管它应该支持任何遵循 OCI 的运行时。它可以从任何容器仓库中拉取镜像,并使用<ruby> <a href="https://github.com/containernetworking/cni"> 容器网络接口 </a> <rt> Container Network Interface </rt></ruby>(CNI)处理网络,以便任何兼容 CNI 的网络插件可与该项目一起使用。
当 Kubernetes 需要运行容器时,它会与 CRI-O 进行通信,CRI-O 守护程序与 runc(或另一个符合 OCI 标准的运行时)一起启动容器。当 Kubernetes 需要停止容器时,CRI-O 会来处理。这没什么令人兴奋的,它只是在幕后管理 Linux 容器,以便用户不需要担心这个关键的容器编排。

### CRI-O 不是什么
值得花一点时间了解下 CRI-O *不是*什么。CRI-O 的范围是与 Kubernetes 一起工作来管理和运行 OCI 容器。这不是一个面向开发人员的工具,尽管该项目确实有一些面向用户的工具进行故障排除。
例如,构建镜像超出了 CRI-O 的范围,这些留给像 Docker 的构建命令、 [Buildah](https://github.com/projectatomic/buildah) 或 [OpenShift 的 Source-to-Image](https://github.com/openshift/source-to-image)(S2I)这样的工具。一旦构建完镜像,CRI-O 将乐意运行它,但构建镜像留给其他工具。
虽然 CRI-O 包含命令行界面 (CLI),但它主要用于测试 CRI-O,而不是真正用于在生产环境中管理容器的方法。
### 下一步
现在 CRI-O 1.0 发布了,我们希望看到它作为一个稳定功能在下一个 Kubernetes 版本中发布。1.0 版本将与 Kubernetes 1.7.x 系列一起使用,即将发布的 CRI-O 1.8-rc1 适合 Kubernetes 1.8.x。
我们邀请您加入我们,以促进开源 CRI-O 项目的开发,并感谢我们目前的贡献者为达成这一里程碑而提供的帮助。如果你想贡献或者关注开发,就去 [CRI-O 项目的 GitHub 仓库](https://github.com/kubernetes-incubator/cri-o),然后关注 [CRI-O 博客](https://medium.com/cri-o)。
---
via: <https://www.redhat.com/en/blog/introducing-cri-o-10>
作者:[Joe Brockmeier](https://www.redhat.com/en/blog/authors/joe-brockmeier) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Last year, the Kubernetes project introduced its __ Container Runtime Interface__ (CRI) -- a plugin interface that gives kubelet (a cluster node agent used to create pods and start containers) the ability to use different OCI-compliant container runtimes, without needing to recompile Kubernetes. Building on that work, the
__project (__
[CRI-O](http://cri-o.io/)__) is ready to provide a lightweight runtime for Kubernetes.__
[originally known as OCID](https://www.redhat.com/en/blog/running-production-applications-containers-introducing-ocid)So what does this **really** mean?
CRI-O allows you to run containers directly from Kubernetes - without any unnecessary code or tooling. As long as the container is OCI-compliant, CRI-O can run it, cutting out extraneous tooling and allowing containers to do what they do best: fuel your next-generation cloud-native applications
Prior to the introduction of CRI, Kubernetes was tied to specific container runtimes through “__ an internal and volatile interface__.” This incurred a significant maintenance overhead for the upstream Kubernetes community as well as vendors building solutions on top of the orchestration platform.
With CRI, Kubernetes can be container runtime-agnostic. Providers of container runtimes don’t need to implement features that Kubernetes already provides. This is a win for the broad community, as it allows projects to move independently while still working well together.
For the most part, we don’t think users of Kubernetes (or distributions of Kubernetes, like OpenShift) really care a lot about the container runtime. They want it to work, but they don’t really want to think about it a great deal. Sort of like you don’t (usually) care if a machine has GNU Bash, Korn, Zsh, or another POSIX-compliant shell. You just want to have a standard way to run your script or application.
**CRI-O: A Lightweight Container Runtime for Kubernetes**
And that’s what CRI-O provides. The name derives from CRI plus Open Container Initiative (OCI), because CRI-O is strictly focused on OCI-compliant runtimes and container images.
Today, CRI-O supports the runc and Clear Container runtimes, though it should support any OCI-conformant runtime. It can pull images from any container registry, and handles networking using the __ Container Network Interface__ (CNI) so that any CNI-compatible networking plugin will likely work with the project.
When Kubernetes needs to run a container, it talks to CRI-O and the CRI-O daemon works with runc (or another OCI-compliant runtime) to start the container. When Kubernetes needs to stop the container, CRI-O handles that. Nothing exciting, it just works behind the scenes to manage Linux containers so that users don’t need to worry about this crucial piece of container orchestration.
**What CRI-O isn’t**
It’s worth spending a little time on what CRI-O *isn’t*. The scope for CRI-O is to work with Kubernetes, to manage and run OCI containers. It’s not meant as a developer-facing tool, though the project does have some user-facing tools for troubleshooting.
Building images, for example, is out of scope for CRI-O and that’s left to tools like Docker’s build command, __ Buildah__, or
__(S2I). Once an image is built, CRI-O will happily consume it, but the building of images is left to other tools.__
[OpenShift’s Source-to-Image](https://github.com/openshift/source-to-image)While CRI-O does include a command line interface (CLI), it’s provided mainly for testing CRI-O and not really as a method for managing containers in a production environment.
**Next steps**
Now that CRI-O 1.0 is released, we’re hoping to see it included as a stable feature in the next release of Kubernetes. The 1.0 release will work with the Kubernetes 1.7.x series, a CRI-O 1.8-rc1 release for Kubernetes 1.8.x will be released soon.
We invite you to join us in furthering the development of the Open Source CRI-O project and we would like to thank our current contributors for their assistance in reaching this milestone. If you would like to contribute, or follow development, head to __ CRI-O project’s GitHub repository__ and follow the
__.__
[CRI-O blog](https://medium.com/cri-o)### About the author
Joe Brockmeier is the editorial director of the Red Hat Blog. He also acts as Vice President of Marketing & Publicity for the Apache Software Foundation.
Brockmeier joined Red Hat in 2013 as part of the Open Source and Standards (OSAS) group, now the Open Source Program Office (OSPO). Prior to Red Hat, Brockmeier worked for Citrix on the Apache OpenStack project, and was the first OpenSUSE community manager for Novell between 2008-2010.
He also has an extensive history in the tech press and publishing, having been editor-in-chief of *Linux Magazine*, editorial director of Linux.com, and a contributor to LWN.net, ZDNet, UnixReview.com, and many others.
[Read full bio](/en/authors/joe-brockmeier)
## Browse by channel
[Automation](/en/blog/channel/management-and-automation)
The latest on IT automation for tech, teams, and environments
[Artificial intelligence](/en/blog/channel/artificial-intelligence)
Updates on the platforms that free customers to run AI workloads anywhere
[Open hybrid cloud](/en/blog/channel/hybrid-cloud-infrastructure)
Explore how we build a more flexible future with hybrid cloud
[Security](/en/blog/channel/security)
The latest on how we reduce risks across environments and technologies
[Edge computing](/en/blog/channel/edge-computing)
Updates on the platforms that simplify operations at the edge
[Infrastructure](/en/blog/channel/infrastructure)
The latest on the world’s leading enterprise Linux platform
[Applications](/en/blog/channel/applications)
Inside our solutions to the toughest application challenges
[Original shows](/en/red-hat-original-series)
Entertaining stories from the makers and leaders in enterprise tech

[YouTube](https://www.youtube.com/user/RedHatVideos)
### Products
[Red Hat Enterprise Linux](/en/technologies/linux-platforms/enterprise-linux)[Red Hat OpenShift](/en/technologies/cloud-computing/openshift)[Red Hat Ansible Automation Platform](/en/technologies/management/ansible)[Cloud services](/en/technologies/cloud-computing/openshift/cloud-services)[See all products](/en/technologies/all-products)
### Tools
[Training and certification](/en/services/training-and-certification)[My account](https://www.redhat.com/wapps/ugc/protected/personalInfo.html)[Customer support](https://access.redhat.com)[Developer resources](https://developers.redhat.com/)[Find a partner](https://catalog.redhat.com/partners)[Red Hat Ecosystem Catalog](https://catalog.redhat.com/)[Red Hat value calculator](/en/solutions/value-calculator)[Documentation](https://docs.redhat.com/en)
### Try, buy, & sell
### Communicate
### About Red Hat
We’re the world’s leading provider of enterprise open source solutions—including Linux, cloud, container, and Kubernetes. We deliver hardened solutions that make it easier for enterprises to work across platforms and environments, from the core datacenter to the network edge.
### Select a language
### Red Hat legal and privacy links
[About Red Hat](/en/about/company)[Jobs](/en/jobs)[Events](/en/events)[Locations](/en/about/office-locations)[Contact Red Hat](/en/contact)[Red Hat Blog](/en/blog)[Diversity, equity, and inclusion](/en/about/our-culture/diversity-equity-inclusion)[Cool Stuff Store](https://coolstuff.redhat.com/)[Red Hat Summit](https://www.redhat.com/en/summit) |
9,016 | 极客漫画:消沉的程序员 17 | http://turnoff.us/geek/the-depressed-developer-17/ | 2017-11-01T08:39:28 | [
"漫画",
"程序员"
] | https://linux.cn/article-9016-1.html | 
<ruby> 测试覆盖 <rp> ( </rp> <rt> Testing coverage </rt> <rp> ) </rp></ruby>,指测试系统覆盖被测试系统的程度,一项给定测试或一组测试对某个给定系统或构件的所有指定测试用例进行处理所达到的程度。 如果在写代码的人仅为可运行而编码,那么在后边会出现一系列的连锁反应,任何没有经过真构思之后书写的代码,都会带来巨大的维护成本吧。昨天 (2017.09.05) 刚刚读到一篇 为什么你的前段工作经验不值钱,不同的人对这里边的那个题的考虑程度是不同的。但我们在每次开始编码之前,都应该以 “代码可用 - 代码健壮 - 代码可靠 - 对需求的宽容” 为规格来约束自己。
---
译者简介:
[GHLandy](http://ghlandy.com/) —— 生活中所有欢乐与苦闷都应藏在心中,有些事儿注定无人知晓,自己也无从说起。
---
via: <http://turnoff.us/geek/the-depressed-developer-17/>
作者:[Daniel Stori](http://turnoff.us/about/) 译者:[GHLandy](https://github.com/GHLandy) 校对:[wxy](https://github.com/wxy) 合成:[GHLandy](https://github.com/GHLandy) 点评:[GHLandy](https://github.com/GHLandy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,019 | 对 DBA 最重要的 PostgreSQL 10 新亮点 | http://www.cybertec.at/best-of-postgresql-10-for-the-dba/ | 2017-11-01T12:45:15 | [
"PostgreSQL",
"数据库"
] | https://linux.cn/article-9019-1.html | 
前段时间新的重大版本的 PostgreSQL 10 发布了! 强烈建议阅读[公告](https://www.postgresql.org/about/news/1786/)、[发布说明](https://www.postgresql.org/docs/current/static/release-10.html)和“[新功能](https://wiki.postgresql.org/wiki/New_in_postgres_10)”概述可以在[这里](https://www.postgresql.org/about/news/1786/)、[这里](https://www.postgresql.org/docs/current/static/release-10.html)和[这里](https://wiki.postgresql.org/wiki/New_in_postgres_10)。像往常一样,已经有相当多的博客覆盖了所有新的东西,但我猜每个人都有自己认为重要的角度,所以与 9.6 版一样我再次在这里列出我印象中最有趣/相关的功能。
与往常一样,升级或初始化一个新集群的用户将获得更好的性能(例如,更好的并行索引扫描、合并 join 和不相关的子查询,更快的聚合、远程服务器上更加智能的 join 和聚合),这些都开箱即用,但本文中我想讲一些不能开箱即用,实际上你需要采取一些步骤才能从中获益的内容。下面重点展示的功能是从 DBA 的角度来汇编的,很快也有一篇文章从开发者的角度讲述更改。
### 升级注意事项
首先有些从现有设置升级的提示 - 有一些小的事情会导致从 9.6 或更旧的版本迁移时引起问题,所以在真正的升级之前,一定要在单独的副本上测试升级,并遍历发行说明中所有可能的问题。最值得注意的缺陷是:
* 所有包含 “xlog” 的函数都被重命名为使用 “wal” 而不是 “xlog”。
后一个命名可能与正常的服务器日志混淆,因此这是一个“以防万一”的更改。如果使用任何第三方备份/复制/HA 工具,请检查它们是否为最新版本。
* 存放服务器日志(错误消息/警告等)的 pg\_log 文件夹已重命名为 “log”。
确保验证你的日志解析或 grep 脚本(如果有)可以工作。
* 默认情况下,查询将最多使用 2 个后台进程。
如果在 CPU 数量较少的机器上在 `postgresql.conf` 设置中使用默认值 `10`,则可能会看到资源使用率峰值,因为默认情况下并行处理已启用 - 这是一件好事,因为它应该意味着更快的查询。如果需要旧的行为,请将 `max_parallel_workers_per_gather` 设置为 `0`。
* 默认情况下,本地主机的复制连接已启用。
为了简化测试等工作,本地主机和本地 Unix 套接字复制连接现在在 `pg_hba.conf` 中以“<ruby> 信任 <rt> trust </rt></ruby>”模式启用(无密码)!因此,如果其他非 DBA 用户也可以访问真实的生产计算机,请确保更改配置。
### 从 DBA 的角度来看我的最爱
* 逻辑复制
这个期待已久的功能在你只想要复制一张单独的表、部分表或者所有表时只需要简单的设置而性能损失最小,这也意味着之后主要版本可以零停机升级!历史上(需要 Postgres 9.4+),这可以通过使用第三方扩展或缓慢的基于触发器的解决方案来实现。对我而言这是 10 最好的功能。
* 声明分区
以前管理分区的方法通过继承并创建触发器来把插入操作重新路由到正确的表中,这一点很烦人,更不用说性能的影响了。目前支持的是 “range” 和 “list” 分区方案。如果有人在某些数据库引擎中缺少 “哈希” 分区,则可以使用带表达式的 “list” 分区来实现相同的功能。
* 可用的哈希索引
哈希索引现在是 WAL 记录的,因此是崩溃安全的,并获得了一些性能改进,对于简单的搜索,它们比在更大的数据上的标准 B 树索引快。也支持更大的索引大小。
* 跨列优化器统计
这样的统计数据需要在一组表的列上手动创建,以指出这些值实际上是以某种方式相互依赖的。这将能够应对计划器认为返回的数据很少(概率的乘积通常会产生非常小的数字)从而导致在大量数据下性能不好的的慢查询问题(例如选择“嵌套循环” join)。
* 副本上的并行快照
现在可以在 pg\_dump 中使用多个进程(`-jobs` 标志)来极大地加快备用服务器上的备份。
* 更好地调整并行处理 worker 的行为
参考 `max_parallel_workers` 和 `min_parallel_table_scan_size`/`min_parallel_index_scan_size` 参数。我建议增加一点后两者的默认值(8MB、512KB)。
* 新的内置监控角色,便于工具使用
新的角色 `pg_monitor`、`pg_read_all_settings`、`pg_read_all_stats` 和 `pg_stat_scan_tables` 能更容易进行各种监控任务 - 以前必须使用超级用户帐户或一些 SECURITY DEFINER 包装函数。
* 用于更安全的副本生成的临时 (每个会话) 复制槽
* 用于检查 B 树索引的有效性的一个新的 Contrib 扩展
这两个智能检查发现结构不一致和页面级校验未覆盖的内容。希望不久的将来能更加深入。
* Psql 查询工具现在支持基本分支(`if`/`elif`/`else`)
例如下面的将启用具有特定版本分支(对 pg\_stat\* 视图等有不同列名)的单个维护/监视脚本,而不是许多版本特定的脚本。
```
SELECT :VERSION_NAME = '10.0' AS is_v10 \gset
\if :is_v10
SELECT 'yippee' AS msg;
\else
SELECT 'time to upgrade!' AS msg;
\endif
```
这次就这样了!当然有很多其他的东西没有列出,所以对于专职 DBA,我一定会建议你更全面地看发布记录。非常感谢那 300 多为这个版本做出贡献的人!
---
via: <http://www.cybertec.at/best-of-postgresql-10-for-the-dba/>
作者:[Kaarel Moppel](http://www.cybertec.at/author/kaarel-moppel/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,021 | 记不住 Linux 命令?这三个工具可以帮你 | https://www.linux.com/learn/intro-to-linux/2017/10/3-tools-help-you-remember-linux-commands | 2017-11-01T22:02:26 | [
"Linux",
"命令",
"Fish",
"apropos"
] | https://linux.cn/article-9021-1.html | 
Linux 桌面从开始的简陋到现在走了很长的路。在我早期使用 Linux 的那段日子里,掌握命令行是最基本的 —— 即使是在桌面版。不过现在变了,很多人可能从没用过命令行。但对于 Linux 系统管理员来说,可不能这样。实际上,对于任何 Linux 管理员(不管是服务器还是桌面),命令行仍是必须的。从管理网络到系统安全,再到应用和系统设定 —— 没有什么工具比命令行更强大。
但是,实际上……你可以在 Linux 系统里找到*非常多*命令。比如只看 `/usr/bin` 目录,你就可以找到很多命令执行文件(你可以运行 `ls/usr/bin/ | wc -l` 看一下你的系统里这个目录下到底有多少命令)。当然,它们并不全是针对用户的执行文件,但是可以让你感受下 Linux 命令数量。在我的 Elementary OS 系统里,目录 `/usr/bin` 下有 2029 个可执行文件。尽管我只会用到其中的一小部分,我要怎么才能记住这一部分呢?
幸运的是,你可以使用一些工具和技巧,这样你就不用每天挣扎着去记忆这些命令了。我想和大家分享几个这样的小技巧,希望能让你们能稍微有效地使用命令行(顺便节省点脑力)。
我们从一个系统内置的工具开始介绍,然后再介绍两个可以安装的非常实用的程序。
### Bash 命令历史
不管你知不知道,Bash(最流行的 Linux shell)会保留你执行过的命令的历史。想实际操作下看看吗?有两种方式。打开终端窗口然后按向上方向键。你应该可以看到会有命令出现,一个接一个。一旦你找到了想用的命令,不用修改的话,可以直接按 Enter 键执行,或者修改后再按 Enter 键。
要重新执行(或修改一下再执行)之前运行过的命令,这是一个很好的方式。我经常用这个功能。它不仅仅让我不用去记忆一个命令的所有细节,而且可以不用一遍遍重复地输入同样的命令。
说到 Bash 的命令历史,如果你执行命令 `history`,你可以列出你过去执行过的命令列表(图 1)。

*图 1: 你能找到我敲的命令里的错误吗?*
你的 Bash 命令历史保存的历史命令的数量可以在 `~/.bashrc` 文件里设置。在这个文件里,你可以找到下面两行:
```
HISTSIZE=1000
HISTFILESIZE=2000
```
`HISTSIZE` 是命令历史列表里记录的命令的最大数量,而 `HISTFILESIZE` 是命令历史文件的最大行数。
显然,默认情况下,Bash 会记录你的 1000 条历史命令。这已经很多了。有时候,这也被认为是一个安全漏洞。如果你在意的话,你可以随意减小这个数值,在安全性和实用性之间平衡。如果你不希望 Bash 记录你的命令历史,可以将 `HISTSIZE` 设置为 `0`。
如果你修改了 `~/.bashrc` 文件,记得要登出后再重新登录(否则改动不会生效)。
### apropos
这是第一个我要介绍的工具,可以帮助你记忆 Linux 命令。apropos (意即“关于”)能够搜索 Linux 帮助文档来帮你找到你想要的命令。比如说,你不记得你用的发行版用的什么防火墙工具了。你可以输入 `apropos “firewall”` ,然后这个工具会返回相关的命令(图 2)。

*图 2: 你用的什么防火墙?*
再假如你需要一个操作目录的命令,但是完全不知道要用哪个呢?输入 `apropos “directory”` 就可以列出在帮助文档里包含了字符 “directory” 的所有命令(图 3)。

*图 3: 可以操作目录的工具有哪些呢?*
apropos 工具在几乎所有 Linux 发行版里都会默认安装。
### Fish
还有另一个能帮助你记忆命令的很好的工具。Fish 是 Linux/Unix/Mac OS 的一个命令行 shell,有一些很好用的功能。
* 自动推荐
* VGA 颜色
* 完美的脚本支持
* 基于网页的配置
* 帮助文档自动补全
* 语法高亮
* 以及更多
自动推荐功能让 fish 非常方便(特别是你想不起来一些命令的时候)。
你可能觉得挺好,但是 fish 没有被默认安装。对于 Ubuntu(以及它的衍生版),你可以用下面的命令安装:
```
sudo apt-add-repository ppa:fish-shell/release-2
sudo apt update
sudo apt install fish
```
对于类 CentOS 系统,可以这样安装 fish。用下面的命令增加仓库:
```
sudo -s
cd /etc/yum.repos.d/
wget http://download.opensuse.org/repositories/shells:fish:release:2/CentOS_7/shells:fish:release:2.repo
```
用下面的命令更新仓库:
```
yum repolist
yum update
```
然后用下面的命令安装 fish:
```
yum install fish
```
fish 用起来可能没你想象的那么直观。记住,fish 是一个 shell,所以在使用命令之前你得先登录进去。在你的终端里,运行命令 fish 然后你就会看到自己已经打开了一个新的 shell(图 4)。

*图 4: fish 的交互式 shell。*
在开始输入命令的时候,fish 会自动补齐命令。如果推荐的命令不是你想要的,按下键盘的 Tab 键可以浏览更多选择。如果正好是你想要的,按下键盘的向右键补齐命令,然后按下 Enter 执行。在用完 fish 后,输入 exit 来退出 shell。
Fish 还可以做更多事情,但是这里只介绍用来帮助你记住命令,自动推荐功能足够了。
### 保持学习
Linux 上有太多的命令了。但你也不用记住所有命令。多亏有 Bash 命令历史以及像 apropos 和 fish 这样的工具,你不用消耗太多记忆来回忆那些帮你完成任务的命令。
---
via: <https://www.linux.com/learn/intro-to-linux/2017/10/3-tools-help-you-remember-linux-commands>
作者:[JACK WALLEN](https://www.linux.com/users/jlwallen) 译者:[zpl1025](https://github.com/zpl1025) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,022 | 2017 年 Linux 的五大痛点 | https://opensource.com/article/17/10/top-5-linux-painpoints | 2017-11-02T11:17:00 | [
"Linux",
"故障"
] | https://linux.cn/article-9022-1.html |
>
> 到目前为止,糟糕的文档是 Linux 用户最头痛的问题。这里还有一些其他常见的问题。
>
>
>

正如我在 [2016 年开源年鉴](https://opensource.com/yearbook/2016)的“[故障排除提示:5 个最常见的 Linux 问题](/article-8185-1.html)”中所讨论的,对大多数用户而言 Linux 能安装并按照预期运行,但有些不可避免地会遇到问题。过去一年在这方面有什么变化?又一次,我将问题提交给 LinuxQuestions.org 和社交媒体,并分析了 LQ 回复情况。以下是更新后的结果。
### 1、 文档
文档及其不足是今年最大的痛点之一。尽管开源的方式产生了优秀的代码,但是制作高质量文档的重要性在最近才走到了前列。随着越来越多的非技术用户采用 Linux 和开源软件,文档的质量和数量将变得至关重要。如果你想为开源项目做出贡献,但不觉得你有足够的技术来提供代码,那么改进文档是参与的好方法。许多项目甚至将文档保存在其仓库中,因此你可以使用你的贡献来适应版本控制的工作流。
### 2、 软件/库版本不兼容
我对此感到惊讶,但软件/库版本不兼容性屡被提及。如果你没有运行某个主流发行版,这个问题似乎更加严重。我个人*许多*年来没有遇到这个问题,但是越来越多的诸如 [AppImage](https://appimage.org/)、[Flatpak](http://flatpak.org/) 和 Snaps 等解决方案的采用让我相信可能确实存在这些情况。我有兴趣听到更多关于这个问题的信息。如果你最近遇到过,请在评论中告诉我。
### 3、 UEFI 和安全启动
尽管随着更多支持的硬件部署,这个问题在继续得到改善,但许多用户表示仍然存在 UEFI 和/或<ruby> 安全启动 <rt> secure boot </rt></ruby>问题。使用开箱即用完全支持 UEFI/安全启动的发行版是最好的解决方案。
### 4、 弃用 32 位
许多用户对他们最喜欢的发行版和软件项目中的 32 位支持感到失望。尽管如果 32 位支持是必须的,你仍然有很多选择,但可能会继续支持市场份额和心理份额不断下降的平台的项目越来越少。幸运的是,我们谈论的是开源,所以只要*有人*关心这个平台,你可能至少有几个选择。
### 5、 X 转发的支持和测试恶化
尽管 Linux 的许多长期和资深的用户经常使用 <ruby> X 转发 <rt> X-forwarding </rt></ruby>,并将其视为关键功能,但随着 Linux 变得越来越主流,它看起来很少得到测试和支持,特别是对较新的应用程序。随着 Wayland 网络透明转发的不断发展,情况可能会进一步恶化。
### 对比去年的遗留和改进
视频(特别是视频加速器、最新的显卡、专有驱动程序、高效的电源管理)、蓝牙支持、特定 WiFi 芯片和打印机以及电源管理以及挂起/恢复,对许多用户来说仍然是麻烦的。更积极的一点的是,安装、HiDPI 和音频问题比一年前显著降低。
Linux 继续取得巨大的进步,而持续的、几乎必然的改进周期将会确保持续数年。然而,与任何复杂的软件一样,总会有问题。
那么说,你在 2017 年发现 Linux 最常见的技术问题是什么?让我在评论中知道它们。
---
via: <https://opensource.com/article/17/10/top-5-linux-painpoints>
作者:[Jeremy Garcia](https://opensource.com/users/jeremy-garcia) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | As I discussed in my [2016 Open Source Yearbook](https://opensource.com/yearbook/2016) article on [troubleshooting tips for the 5 most common Linux issues](https://opensource.com/article/17/1/yearbook-linux-troubleshooting-tips), Linux installs and operates as expected for most users, but some inevitably run into problems. How have things changed over the past year in this regard? Once again, I posted the question to LinuxQuestions.org and on social media, and analyzed LQ posting patterns. Here are the updated results.
## 1. Documentation
Documentation, or lack thereof, was one of the largest pain points this year. Although open source methodology produces superior code, the importance of producing quality documentation has only recently come to the forefront. As more non-technical users adopt Linux and open source software, the quality and quantity of documentation will become paramount. If you've wanted to contribute to an open source project but don't feel you are technical enough to offer code, improving documentation is a great way to participate. Many projects even keep the documentation in their repository, so you can use your contribution to get acclimated to the version control workflow.
## 2. Software/library version incompatibility
I was surprised by this one, but software/library version incompatibility was mentioned frequently. The issue appears to be greatly exacerbated if you're not running one of the mainstream popular distributions. I haven't personally encountered this problem in*many*years, but the increasing adoption of solutions such as
[AppImage](https://appimage.org/),
[Flatpak](http://flatpak.org/), and Snaps leads me to believe there may indeed be something to this one. I'm interested in hearing more about this issue; if you've faced it recently, tell me about it in the comments.
## 3. UEFI and secure boot
Although this issue continues to improve as more supported hardware is deployed, many users indicate that they still have issues with UEFI and/or secure boot. Using a distribution that fully supports UEFI/secure boot out of the box is the best solution here.
## 4. Deprecation of 32-bit
Many users are lamenting the death of 32-bit support in their favorite distributions and software projects. Although you still have many options if 32-bit support is a must, fewer and fewer projects are likely to continue supporting a platform with decreasing market share and mind share. Luckily, we're talking about open source, so you'll likely have at least a couple options as long as *someone* cares about the platform.
## 5. Deteriorating support and testing for X-forwarding
Although many longtime and power users of Linux regularly use X-forwarding and consider it critical functionality, as Linux becomes more mainstream it appears to be seeing less testing and support; especially from newer apps. With Wayland network transparency still evolving, the situation may get worse before it improves.
## Holdovers—and improvements—from last year
Video (specifically, accelerators/acceleration; the latest video cards; proprietary drivers; and efficient power management), Bluetooth support, specific WiFi chips and printers, and power management, along with suspend/resume, continue to be troublesome for many users. On a more positive note, installation, HiDPI, and audio issues were significantly less frequent than they were just a year ago.
Linux continues to make tremendous strides, and the constant, almost inexorable cycle of improvement should ensure that continues for years to come. As with any complex piece of software, however, there will always be issues.
With that said, what technical Linux issues did *you* find most common in 2017? Let me know about them in the comments.
## 31 Comments |
9,023 | 为什么要在 Docker 中使用 R? 一位 DevOps 的看法 | https://www.r-bloggers.com/why-use-docker-with-r-a-devops-perspective/ | 2017-11-04T10:38:00 | [
"Docker",
"OpenCPU"
] | https://linux.cn/article-9023-1.html | [](https://www.opencpu.org/posts/opencpu-with-docker)
>
> R 语言,一种自由软件编程语言与操作环境,主要用于统计分析、绘图、数据挖掘。R 内置多种统计学及数字分析功能。R 的另一强项是绘图功能,制图具有印刷的素质,也可加入数学符号。——引自维基百科。
>
>
>
已经有几篇关于为什么要在 Docker 中使用 R 的文章。在这篇文章中,我将尝试加入一个 DevOps 的观点,并解释在 OpenCPU 系统的环境中如何使用容器化 R 来构建和部署 R 服务器。
>
> 有在 [#rstats](https://twitter.com/hashtag/rstats?src=hash&ref_src=twsrc%5Etfw) 世界的人真正地写过*为什么*他们使用 Docker,而不是*如何*么?
>
>
> — Jenny Bryan (@JennyBryan) [September 29, 2017](https://twitter.com/JennyBryan/status/913785731998289920?ref_src=twsrc%5Etfw)
>
>
>
### 1:轻松开发
OpenCPU 系统的旗舰是 [OpenCPU 服务器](https://www.opencpu.org/download.html):它是一个成熟且强大的 Linux 栈,用于在系统和应用程序中嵌入 R。因为 OpenCPU 是完全开源的,我们可以在 DockerHub 上构建和发布。可以使用以下命令启动一个可以立即使用的 OpenCPU 和 RStudio 的 Linux 服务器(使用端口 8004 或 80):
```
docker run -t -p 8004:8004 opencpu/rstudio
```
现在只需在你的浏览器打开 http://localhost:8004/ocpu/ 和 http://localhost:8004/rstudio/ 即可!在 rstudio 中用用户 `opencpu`(密码:`opencpu`)登录来构建或安装应用程序。有关详细信息,请参阅[自述文件](https://hub.docker.com/r/opencpu/rstudio/)。
Docker 让开始使用 OpenCPU 变得简单。容器给你一个充分灵活的 Linux 机器,而无需在系统上安装任何东西。你可以通过 rstudio 服务器安装软件包或应用程序,也可以使用 `docker exec` 进入到正在运行的服务器的 root shell 中:
```
# Lookup the container ID
docker ps
# Drop a shell
docker exec -i -t eec1cdae3228 /bin/bash
```
你可以在服务器的 shell 中安装其他软件,自定义 apache2 的 httpd 配置(auth,代理等),调整 R 选项,通过预加载数据或包等来优化性能。
### 2: 通过 DockerHub 发布和部署
最强大的是,Docker 可以通过 DockerHub 发布和部署。要创建一个完全独立的应用程序容器,只需使用标准的 [opencpu 镜像](https://hub.docker.com/u/opencpu/)并添加你的程序。
出于本文的目的,我通过在每个仓库中添加一个非常简单的 “Dockerfile”,将一些[示例程序](https://www.opencpu.org/apps.html)打包为 docker 容器。例如:[nabel](https://rwebapps.ocpu.io/nabel/www/) 的 [Dockerfile](https://github.com/rwebapps/nabel/blob/master/Dockerfile) 包含以下内容:
```
FROM opencpu/base
RUN R -e 'devtools::install_github("rwebapps/nabel")'
```
它采用标准的 [opencpu/base](https://hub.docker.com/r/opencpu/base/) 镜像,并从 Github [仓库](https://github.com/rwebapps)安装 nabel。最终得到一个完全隔离、独立的程序。任何人可以使用下面这样的命令启动程序:
```
docker run -d 8004:8004 rwebapps/nabel
```
`-d` 代表守护进程监听 8004 端口。很显然,你可以调整 `Dockerfile` 来安装任何其它的软件或设置你需要的程序。
容器化部署展示了 Docker 的真正能力:它可以发布可以开箱即用的独立软件,而无需安装任何软件或依赖付费托管的服务。如果你更喜欢专业的托管,那会有许多公司乐意在可扩展的基础设施上为你托管 docker 程序。
### 3: 跨平台构建
还有 Docker 用于 OpenCPU 的第三种方式。每次发布,我们都构建 6 个操作系统的 `opencpu-server` 安装包,它们在 [https://archive.opencpu.org](https://archive.opencpu.org/) 上公布。这个过程已经使用 DockerHub 完全自动化了。以下镜像从源代码自动构建所有栈:
* [opencpu/ubuntu-16.04](https://hub.docker.com/r/opencpu/ubuntu-16.04/)
* [opencpu/debian-9](https://hub.docker.com/r/opencpu/debian-9/)
* [opencpu/fedora-25](https://hub.docker.com/r/opencpu/fedora-25/)
* [opencpu/fedora-26](https://hub.docker.com/r/opencpu/fedora-26/)
* [opencpu/centos-6](https://hub.docker.com/r/opencpu/centos-6/)
* [opencpu/centos-7](https://hub.docker.com/r/opencpu/centos-7/)
当 GitHub 上发布新版本时,DockerHub 会自动重建此镜像。要做的就是运行一个[脚本](https://github.com/opencpu/archive/blob/gh-pages/update.sh),它会取回镜像并将 `opencpu-server` 二进制复制到[归档服务器上](https://archive.opencpu.org/)。
---
via: <https://www.r-bloggers.com/why-use-docker-with-r-a-devops-perspective/>
作者:[Jeroen Ooms](https://www.r-bloggers.com/author/jeroen-ooms/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,024 | 通过 Slack 监视慢 SQL 查询 | http://azer.bike/journal/monitoring-slow-sql-queries-via-slack/ | 2017-11-02T16:24:00 | [
"监控",
"Slack"
] | /article-9024-1.html |
>
> 一个获得关于慢查询、意外错误和其它重要日志通知的简单 Go 秘诀。
>
>
>

我的 Slack 机器人提示我一个运行了很长时间 SQL 查询。我应该尽快解决它。
**我们不能管理我们无法去测量的东西。**每个后台应用程序都需要我们去监视它在数据库上的性能。如果一个特定的查询随着数据量增长变慢,你必须在它变得太慢之前去优化它。
由于 Slack 已经成为我们工作的中心,它也在改变我们监视系统的方式。 虽然我们已经有非常不错的监视工具,如果在系统中任何东西有正在恶化的趋势,让 Slack 机器人告诉我们,也是非常棒的主意。比如,一个太长时间才完成的 SQL 查询,或者,在一个特定的 Go 包中发生一个致命的错误。
在这篇博客文章中,我们将告诉你,通过使用已经支持这些特性的[一个简单的日志系统](http://azer.bike/journal/monitoring-slow-sql-queries-via-slack/?utm_source=dbweekly&utm_medium=email#logger) 和 [一个已存在的数据库库(database library)](http://azer.bike/journal/monitoring-slow-sql-queries-via-slack/?utm_source=dbweekly&utm_medium=email#crud) 怎么去设置来达到这个目的。
### 使用记录器
[logger](https://github.com/azer/logger) 是一个为 Go 库和应用程序使用设计的小型库。在这个例子中我们使用了它的三个重要的特性:
* 它为测量性能提供了一个简单的定时器。
* 支持复杂的输出过滤器,因此,你可以从指定的包中选择日志。例如,你可以告诉记录器仅从数据库包中输出,并且仅输出超过 500 ms 的定时器日志。
* 它有一个 Slack 钩子,因此,你可以过滤并将日志输入到 Slack。
让我们看一下在这个例子中,怎么去使用定时器,稍后我们也将去使用过滤器:
```
package main
import (
"github.com/azer/logger"
"time"
)
var (
users = logger.New("users")
database = logger.New("database")
)
func main () {
users.Info("Hi!")
timer := database.Timer()
time.Sleep(time.Millisecond * 250) // sleep 250ms
timer.End("Connected to database")
users.Error("Failed to create a new user.", logger.Attrs{
"e-mail": "[email protected]",
})
database.Info("Just a random log.")
fmt.Println("Bye.")
}
```
运行这个程序没有输出:
```
$ go run example-01.go
Bye
```
记录器是[缺省静默的](http://www.linfo.org/rule_of_silence.html),因此,它可以在库的内部使用。我们简单地通过一个环境变量去查看日志:
例如:
```
$ LOG=database@timer go run example-01.go
01:08:54.997 database(250.095587ms): Connected to database.
Bye
```
上面的示例我们使用了 `database@timer` 过滤器去查看 `database` 包中输出的定时器日志。你也可以试一下其它的过滤器,比如:
* `LOG=*`: 所有日志
* `LOG=users@error,database`: 所有来自 `users` 的错误日志,所有来自 `database` 的所有日志
* `LOG=*@timer,database@info`: 来自所有包的定时器日志和错误日志,以及来自 `database` 的所有日志
* `LOG=*,users@mute`: 除了 `users` 之外的所有日志
### 发送日志到 Slack
控制台日志是用于开发环境的,但是我们需要产品提供一个友好的界面。感谢 [slack-hook](https://github.com/azer/logger-slack-hook), 我们可以很容易地在上面的示例中,使用 Slack 去整合它:
```
import (
"github.com/azer/logger"
"github.com/azer/logger-slack-hook"
)
func init () {
logger.Hook(&slackhook.Writer{
WebHookURL: "https://hooks.slack.com/services/...",
Channel: "slow-queries",
Username: "Query Person",
Filter: func (log *logger.Log) bool {
return log.Package == "database" && log.Level == "TIMER" && log.Elapsed >= 200
}
})
}
```
我们来解释一下,在上面的示例中我们做了什么:
* 行 #5: 设置入站 webhook url。这个 URL [链接在这里](https://my.slack.com/services/new/incoming-webhook/)。
* 行 #6: 选择流日志的入口通道。
* 行 #7: 显示的发送者的用户名。
* 行 #11: 使用流过滤器,仅输出时间超过 200 ms 的定时器日志。
希望这个示例能给你提供一个大概的思路。如果你有更多的问题,去看这个 [记录器](https://github.com/azer/logger)的文档。
### 一个真实的示例: CRUD
[crud](https://github.com/azer/crud) 是一个用于 Go 的数据库的 ORM 式的类库,它有一个隐藏特性是内部日志系统使用 [logger](https://github.com/azer/logger) 。这可以让我们很容易地去监视正在运行的 SQL 查询。
#### 查询
这有一个通过给定的 e-mail 去返回用户名的简单查询:
```
func GetUserNameByEmail (email string) (string, error) {
var name string
if err := DB.Read(&name, "SELECT name FROM user WHERE email=?", email); err != nil {
return "", err
}
return name, nil
}
```
好吧,这个太短了, 感觉好像缺少了什么,让我们增加全部的上下文:
```
import (
"github.com/azer/crud"
_ "github.com/go-sql-driver/mysql"
"os"
)
var db *crud.DB
func main () {
var err error
DB, err = crud.Connect("mysql", os.Getenv("DATABASE_URL"))
if err != nil {
panic(err)
}
username, err := GetUserNameByEmail("[email protected]")
if err != nil {
panic(err)
}
fmt.Println("Your username is: ", username)
}
```
因此,我们有一个通过环境变量 `DATABASE_URL` 连接到 MySQL 数据库的 [crud](https://github.com/azer/crud) 实例。如果我们运行这个程序,将看到有一行输出:
```
$ DATABASE_URL=root:123456@/testdb go run example.go
Your username is: azer
```
正如我前面提到的,日志是 [缺省静默的](http://www.linfo.org/rule_of_silence.html)。让我们看一下 crud 的内部日志:
```
$ LOG=crud go run example.go
22:56:29.691 crud(0): SQL Query Executed: SELECT username FROM user WHERE email='[email protected]'
Your username is: azer
```
这很简单,并且足够我们去查看在我们的开发环境中查询是怎么执行的。
#### CRUD 和 Slack 整合
记录器是为配置管理应用程序级的“内部日志系统”而设计的。这意味着,你可以通过在你的应用程序级配置记录器,让 crud 的日志流入 Slack :
```
import (
"github.com/azer/logger"
"github.com/azer/logger-slack-hook"
)
func init () {
logger.Hook(&slackhook.Writer{
WebHookURL: "https://hooks.slack.com/services/...",
Channel: "slow-queries",
Username: "Query Person",
Filter: func (log *logger.Log) bool {
return log.Package == "mysql" && log.Level == "TIMER" && log.Elapsed >= 250
}
})
}
```
在上面的代码中:
* 我们导入了 [logger](https://github.com/azer/logger) 和 [logger-slack-hook](https://github.com/azer/logger-slack-hook) 库。
* 我们配置记录器日志流入 Slack。这个配置覆盖了代码库中 [记录器](https://github.com/azer/logger) 所有的用法, 包括第三方依赖。
* 我们使用了流过滤器,仅输出 MySQL 包中超过 250 ms 的定时器日志。
这种使用方法可以被扩展,而不仅是慢查询报告。我个人使用它去跟踪指定包中的重要错误, 也用于统计一些类似新用户登入或生成支付的日志。
### 在这篇文章中提到的包
* [crud](https://github.com/azer/crud)
* [logger](https://github.com/azer/logger)
* [logger-slack-hook](https://github.com/azer/logger)
[告诉我们](https://twitter.com/afrikaradyo) 如果你有任何的问题或建议。
---
via: <http://azer.bike/journal/monitoring-slow-sql-queries-via-slack/>
作者:[Azer Koçulu](http://azer.bike/) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPConnectionPool(host='azer.bike', port=80): Max retries exceeded with url: /journal/monitoring-slow-sql-queries-via-slack/ (Caused by NameResolutionError("<urllib3.connection.HTTPConnection object at 0x7b8327582e30>: Failed to resolve 'azer.bike' ([Errno -2] Name or service not known)")) | null |
9,027 | 在 Linux 图形栈上运行 Android | https://www.linux.com/blog/event/elce/2017/10/running-android-top-linux-graphics-stack | 2017-11-04T10:05:00 | [
"Android",
"图形"
] | https://linux.cn/article-9027-1.html | 
你现在可以在常规的 Linux 图形栈之上运行 Android。以前并不能这样,根据 Collabora 的 Linux 图形栈贡献者和软件工程师 Robert Foss 的说法,这是非常强大的功能。在即将举行的[欧洲 Linux 嵌入式会议](http://events.linuxfoundation.org/events/embedded-linux-conference-europe)的讲话中,Foss 将会介绍这一领域的最新进展,并讨论这些变化如何让你可以利用内核中的新功能和改进。
在本文中,Foss 解释了更多内容,并提供了他的演讲的预览。
**Linux.com:你能告诉我们一些你谈论的图形栈吗?**
**Foss:** 传统的 Linux 图形系统(如 X11)大都没有使用<ruby> 平面图形 <rt> plane </rt></ruby>。但像 Android 和 Wayland 这样的现代图形系统可以充分利用它。
Android 在 HWComposer 中最成功实现了平面支持,其图形栈与通常的 Linux 桌面图形栈有所不同。在桌面上,典型的合成器只是使用 GPU 进行所有的合成,因为这是桌面上唯一有的东西。
大多数嵌入式和移动芯片都有为 Android 设计的专门的 2D 合成硬件。这是通过将显示的内容分成不同的图层,然后智能地将图层送到经过优化处理图层的硬件。这就可以释放 GPU 来处理你真正关心的事情,同时它让硬件更有效率地做最好一件事。
**Linux.com:当你说到 Android 时,你的意思是 Android 开源项目 (AOSP) 么?**
**Foss:** Android 开源项目(AOSP)是许多 Android 产品建立的基础,AOSP 和 Android 之间没有什么区别。
具体来说,我的工作已经在 AOSP 上完成,但没有什么可以阻止将此项工作加入到已经发货的 Android 产品中。
区别更多在于授权和满足 Google 对 Android 产品的要求,而不是代码。
**Linux.com: 谁想要运行它,为什么?有什么好处?**
**Foss:** AOSP 为你提供了大量免费的东西,例如针对可用性、低功耗和多样化硬件进行优化的软件栈。它比任何一家公司自行开发的更精致、更灵活, 而不需要投入大量资源。
作为制造商,它还为你提供了一个能够立即为你的平台开发的大量开发人员。
**Linux.com:有什么实际使用情况?**
\*\* Foss:\*\* 新的部分是在常规 Linux 图形栈上运行 Android 的能力。可以在主线/上游内核和驱动来做到这一点,让你可以利用内核中的新功能和改进,而不仅仅依赖于来自于你的供应商的大量分支的 BSP。
对于任何有合理标准的 Linux 支持的 GPU,你现在可以在上面运行 Android。以前并不能这样。而且这样做是非常强大的。
同样重要的是,它鼓励 GPU 设计者与上游的驱动一起工作。现在他们有一个简单的方法来提供适用于 Android 和 Linux 的驱动程序,而无需额外的努力。他们的成本将会降低,维护上游 GPU 驱动变得更有吸引力。
例如,我们希望看到主线内核支持高通 SOC,我们希望成为实现这一目标的一部分。
总而言之,这将有助于硬件生态系统获得更好的软件支持,软件生态系统有更多的硬件配合。
* 它改善了 SBC/开发板制造商的经济性:它们可以提供一个经过良好测试的栈,既可以在两者之间工作,而不必提供 “Linux 栈” 和 Android 栈。
* 它简化了驱动程序开发人员的工作,因为只有一个优化和支持目标。
* 它支持 Android 社区,因为在主线内核上运行的 Android 可以让他们分享上游的改进。
* 这有助于上游,因为我们获得了一个产品级质量的栈,这些栈已经在硬件设计师的帮助下进行了测试和开发。
以前,Mesa 被视为二等栈,但现在它是最新的(完全符合 Vulkan 1.0、OpenGL 4.6、OpenGL ES 3.2)另外还有性能和产品质量。
这意味着驱动开发人员可以参与 Mesa,相信他们正在分享他人的辛勤工作,并且还有一个很好的基础。
---
via: <https://www.linux.com/blog/event/elce/2017/10/running-android-top-linux-graphics-stack>
作者:[SWAPNIL BHARTIYA](https://www.linux.com/users/arnieswap) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,029 | 3 个简单、优秀的 Linux 网络监视器 | https://www.linux.com/learn/intro-to-linux/2017/10/3-simple-excellent-linux-network-monitors | 2017-11-03T16:14:00 | [
"iftop",
"nethogs",
"vnstat"
] | https://linux.cn/article-9029-1.html | 
*用 iftop、Nethogs 和 vnstat 了解更多关于你的网络连接。*
你可以通过这三个 Linux 网络命令,了解有关你网络连接的大量信息。iftop 通过进程号跟踪网络连接,Nethogs 可以快速显示哪个在占用你的带宽,而 vnstat 作为一个很好的轻量级守护进程运行,可以随时随地记录你的使用情况。
### iftop
[iftop](http://www.ex-parrot.com/pdw/iftop/) 监听你指定的网络接口,并以 `top` 的形式展示连接。
这是一个很好的小工具,用于快速识别占用、测量速度,并保持网络流量的总体运行。看到我们使用了多少带宽是非常令人惊讶的,特别是对于我们这些还记得使用电话线、调制解调器、让人尖叫的 Kbit 速度和真实的实时波特率的老年人来说。我们很久以前就放弃了波特率,转而使用比特率。波特率测量信号变化,有时与比特率相同,但大多数情况下不是。
如果你只有一个网络接口,可以不带选项运行 `iftop`。`iftop` 需要 root 权限:
```
$ sudo iftop
```
当你有多个接口时,指定要监控的接口:
```
$ sudo iftop -i wlan0
```
就像 top 一样,你可以在运行时更改显示选项。
* `h` 切换帮助屏幕。
* `n` 切换名称解析。
* `s` 切换源主机显示,`d` 切换目标主机。
* `s` 切换端口号。
* `N` 切换端口解析。要全看到端口号,请关闭解析。
* `t` 切换文本界面。默认显示需要 ncurses。我认为文本显示更易于阅读和更好的组织(图1)。
* `p` 暂停显示。
* `q` 退出程序。

*图 1:文本显示是可读的和可组织的。*
当你切换显示选项时,`iftop` 会继续测量所有流量。你还可以选择要监控的单个主机。你需要主机的 IP 地址和网络掩码。我很好奇 Pandora 在我那可怜的带宽中占用了多少,所以我先用 `dig` 找到它们的 IP 地址:
```
$ dig A pandora.com
[...]
;; ANSWER SECTION:
pandora.com. 267 IN A 208.85.40.20
pandora.com. 267 IN A 208.85.40.50
```
网络掩码是什么? [ipcalc](https://www.linux.com/learn/intro-to-linux/2017/8/how-calculate-network-addresses-ipcalc) 告诉我们:
```
$ ipcalc -b 208.85.40.20
Address: 208.85.40.20
Netmask: 255.255.255.0 = 24
Wildcard: 0.0.0.255
=>
Network: 208.85.40.0/24
```
现在将地址和网络掩码提供给 iftop:
```
$ sudo iftop -F 208.85.40.20/24 -i wlan0
```
这不是真的吗?我很惊讶地发现,我珍贵的带宽对于 Pandora 很宽裕,每小时使用大约使用 500Kb。而且,像大多数流媒体服务一样,Pandora 的流量也有峰值,其依赖于缓存来缓解阻塞。
你可以使用 `-G` 选项对 IPv6 地址执行相同操作。请参阅手册页了解 `iftop` 的其他功能,包括使用自定义配置文件定制默认选项,并应用自定义过滤器(请参阅 [PCAP-FILTER](http://www.tcpdump.org/manpages/pcap-filter.7.html) 作为过滤器参考)。
### Nethogs
当你想要快速了解谁占用了你的带宽时,Nethogs 是快速和容易的。以 root 身份运行,并指定要监听的接口。它显示了空闲的应用程序和进程号,以便如果你愿意的话,你可以杀死它:
```
$ sudo nethogs wlan0
NetHogs version 0.8.1
PID USER PROGRAM DEV SENT RECEIVED
7690 carla /usr/lib/firefox wlan0 12.494 556.580 KB/sec
5648 carla .../chromium-browser wlan0 0.052 0.038 KB/sec
TOTAL 12.546 556.618 KB/sec
```
Nethogs 选项很少:在 kb/s、kb、b 和 mb 之间循环;通过接收或发送的数据包进行排序;并调整刷新之间的延迟。请参阅 `man nethogs`,或者运行 `nethogs -h`。
### vnstat
[vnstat](http://humdi.net/vnstat/) 是最容易使用的网络数据收集器。它是轻量级的,不需要 root 权限。它作为守护进程运行,并记录你网络统计信息。`vnstat` 命令显示累计的数据:
```
$ vnstat -i wlan0
Database updated: Tue Oct 17 08:36:38 2017
wlan0 since 10/17/2017
rx: 45.27 MiB tx: 3.77 MiB total: 49.04 MiB
monthly
rx | tx | total | avg. rate
------------------------+-------------+-------------+---------------
Oct '17 45.27 MiB | 3.77 MiB | 49.04 MiB | 0.28 kbit/s
------------------------+-------------+-------------+---------------
estimated 85 MiB | 5 MiB | 90 MiB |
daily
rx | tx | total | avg. rate
------------------------+-------------+-------------+---------------
today 45.27 MiB | 3.77 MiB | 49.04 MiB | 12.96 kbit/s
------------------------+-------------+-------------+---------------
estimated 125 MiB | 8 MiB | 133 MiB |
```
它默认显示所有的网络接口。使用 `-i` 选项选择单个接口。以这种方式合并多个接口的数据:
```
$ vnstat -i wlan0+eth0+eth1
```
你可以通过以下几种方式过滤显示:
* `-h` 以小时显示统计数据。
* `-d` 以天数显示统计数据。
* `-w` 和 `-m` 按周和月显示统计数据。
* 使用 `-l` 选项查看实时更新。
此命令删除 wlan1 的数据库,并停止监控它:
```
$ vnstat -i wlan1 --delete
```
此命令为网络接口创建别名。此例使用 Ubuntu 16.04 中的一个奇怪的接口名称:
```
$ vnstat -u -i enp0s25 --nick eth0
```
默认情况下,vnstat 监视 eth0。你可以在 `/etc/vnstat.conf` 中更改此内容,或在主目录中创建自己的个人配置文件。请参见 `man vnstat` 以获得完整的参考。
你还可以安装 `vnstati` 创建简单的彩色图(图2):
```
$ vnstati -s -i wlx7cdd90a0a1c2 -o vnstat.png
```

*图 2:你可以使用 vnstati 创建简单的彩色图表。*
有关完整选项,请参见 `man vnstati`。
---
via: <https://www.linux.com/learn/intro-to-linux/2017/10/3-simple-excellent-linux-network-monitors>
作者:[CARLA SCHRODER](https://www.linux.com/users/cschroder) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,030 | 三种 Python 网络内容抓取工具与爬虫 | https://opensource.com/resources/python/web-scraper-crawler | 2017-11-03T21:45:33 | [
"Python",
"爬虫"
] | https://linux.cn/article-9030-1.html |
>
> 运用这些很棒的 Python 爬虫工具来获取你需要的数据。
>
>
>

在一个理想的世界里,你需要的所有数据都将以公开而文档完备的格式清晰地展现,你可以轻松地下载并在任何你需要的地方使用。
然而,在真实世界里,数据是凌乱的,极少被打包成你需要的样子,要么经常是过期的。
你所需要的信息经常是潜藏在一个网站里。相比一些清晰地、有调理地呈现数据的网站,更多的网站则不是这样的。<ruby> <a href="https://en.wikipedia.org/wiki/Web_crawler"> 爬取数据 </a> <rt> crawling </rt></ruby>、<ruby> <a href="https://en.wikipedia.org/wiki/Web_scraping"> 挖掘数据 </a> <rt> scraping </rt></ruby>、加工数据、整理数据这些是获取整个网站结构来绘制网站拓扑来收集数据所必须的活动,这些可以是以网站的格式储存的或者是储存在一个专有数据库中。
也许在不久的将来,你需要通过爬取和挖掘来获得一些你需要的数据,当然你几乎肯定需要进行一点点的编程来正确的获取。你要怎么做取决于你自己,但是我发现 Python 社区是一个很好的提供者,它提供了工具、框架以及文档来帮助你从网站上获取数据。
在我们进行之前,这里有一个小小的请求:在你做事情之前请思考,以及请耐心。抓取这件事情并不简单。不要把网站爬下来只是复制一遍,并其它人的工作当成是你自己的东西(当然,没有许可)。要注意版权和许可,以及你所爬行的内容应用哪一个标准。尊重 [robots.txt](http://www.robotstxt.org/) 文件。不要频繁的针对一个网站,这将导致真实的访问者会遇到访问困难的问题。
在知晓这些警告之后,这里有一些很棒的 Python 网站爬虫工具,你可以用来获得你需要的数据。
### Pyspider
让我们先从 [pyspider](https://github.com/binux/pyspider) 开始介绍。这是一个带有 web 界面的网络爬虫,让与使之容易跟踪多个爬虫。其具有扩展性,支持多个后端数据库和消息队列。它还具有一些方便的特性,从优先级到再次访问抓取失败的页面,此外还有通过时间顺序来爬取和其他的一些特性。Pyspider 同时支持 Python 2 和 Python 3。为了实现一个更快的爬取,你可以在分布式的环境下一次使用多个爬虫进行爬取。
Pyspyder 的基本用法都有良好的 [文档说明](http://docs.pyspider.org/en/latest/) ,包括简单的代码片段。你能通过查看一个 [在线的样例](http://demo.pyspider.org/) 来体验用户界面。它在 Apache 2 许可证下开源,Pyspyder 仍然在 GitHub 上积极地开发。
### MechanicalSoup
[MechanicalSoup](https://github.com/hickford/MechanicalSoup) 是一个基于极其流行而异常多能的 HTML 解析库 [Beautiful Soup](https://www.crummy.com/software/BeautifulSoup/) 建立的爬虫库。如果你的爬虫需要相当的简单,但是又要求检查一些选择框或者输入一些文字,而你又不想为这个任务单独写一个爬虫,那么这会是一个值得考虑的选择。
MechanicalSoup 在 MIT 许可证下开源。查看 GitHub 上该项目的 [example.py](https://github.com/hickford/MechanicalSoup/blob/master/example.py) 样例文件来获得更多的用法。不幸的是,到目前为止,这个项目还没有一个很好的文档。
### Scrapy
[Scrapy](https://scrapy.org/) 是一个有着活跃社区支持的抓取框架,在那里你可以建造自己的抓取工具。除了爬取和解析工具,它还能将它收集的数据以 JSON 或者 CSV 之类的格式轻松输出,并存储在一个你选择的后端数据库。它还有许多内置的任务扩展,例如 cookie 处理、代理欺骗、限制爬取深度等等,同时还可以建立你自己附加的 API。
要了解 Scrapy,你可以查看[网上的文档](https://doc.scrapy.org/en/latest/)或者是访问它诸多的[社区](https://scrapy.org/community/)资源,包括一个 IRC 频道、Reddit 子版块以及关注他们的 StackOverflow 标签。Scrapy 的代码在 3 句版 BSD 许可证下开源,你可以在 [GitHub](https://github.com/scrapy/scrapy) 上找到它们。
如果你完全不熟悉编程,[Portia](https://github.com/scrapinghub/portia) 提供了一个易用的可视化的界面。[scrapinghub.com](https://portia.scrapinghub.com/) 则提供一个托管的版本。
### 其它
* [Cola](https://github.com/chineking/cola) 自称它是个“高级的分布式爬取框架”,如果你在寻找一个 Python 2 的方案,这也许会符合你的需要,但是注意它已经有超过两年没有更新了。
* [Demiurge](https://github.com/matiasb/demiurge) 是另一个可以考虑的潜在候选者,它同时支持 Python 2和 Python 3,虽然这个项目的发展较为缓慢。
* 如果你要解析一些 RSS 和 Atom 数据,[Feedparser](https://github.com/kurtmckee/feedparser) 或许是一个有用的项目。
* [Lassie](https://github.com/michaelhelmick/lassie) 让从网站检索像说明、标题、关键词或者是图片一类的基本内容变得简单。
* [RoboBrowser](https://github.com/jmcarp/robobrowser) 是另一个简单的库,它基于 Python 2 或者 Python 3,它具有按钮点击和表格填充的基本功能。虽然它有一段时间没有更新了,但是它仍然是一个不错的选择。
---
这远不是一个完整的列表,当然,如果你是一个编程专家,你可以选择采取你自己的方法而不是使用这些框架中的一个。或者你发现一个用其他语言编写的替代品。例如 Python 编程者可能更喜欢 [Python 附带的](https://selenium-python.readthedocs.io/) [Selenium](https://github.com/SeleniumHQ/selenium),它可以在不使用实际浏览器的情况下进行爬取。如果你有喜欢的爬取和挖掘工具,请在下面评论让我们知道。
(题图:[You as a Machine](https://www.flickr.com/photos/youasamachine/8025582590/in/photolist-decd6C-7pkccp-aBfN9m-8NEffu-3JDbWb-aqf5Tx-7Z9MTZ-rnYTRu-3MeuPx-3yYwA9-6bSLvd-irmvxW-5Asr4h-hdkfCA-gkjaSQ-azcgct-gdV5i4-8yWxCA-9G1qDn-5tousu-71V8U2-73D4PA-iWcrTB-dDrya8-7GPuxe-5pNb1C-qmnLwy-oTxwDW-3bFhjL-f5Zn5u-8Fjrua-bxcdE4-ddug5N-d78G4W-gsYrFA-ocrBbw-pbJJ5d-682rVJ-7q8CbF-7n7gDU-pdfgkJ-92QMx2-aAmM2y-9bAGK1-dcakkn-8rfyTz-aKuYvX-hqWSNP-9FKMkg-dyRPkY). Modified by Rikki Endsley. [CC BY-SA 2.0](https://creativecommons.org/licenses/by/2.0/))
---
via: <https://opensource.com/resources/python/web-scraper-crawler>
作者:[Jason Baker](https://opensource.com/users/jason-baker) 译者:[ZH1122](https://github.com/ZH1122) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In a perfect world, all of the data you need would be cleanly presented in an open and well-documented format that you could easily download and use for whatever purpose you need.
In the real world, data is messy, rarely packaged how you need it, and often out-of-date.
Often, the information you need is trapped inside of a website. While some websites make an effort to present data in a clean, structured data format, many do not. [Crawling](https://en.wikipedia.org/wiki/Web_crawler), [scraping](https://en.wikipedia.org/wiki/Web_scraping), processing, and cleaning data is a necessary activity for a whole host of activities from mapping a website's structure to collecting data that's in a web-only format, or perhaps, locked away in a proprietary database.
Sooner or later, you're going to find a need to do some crawling and scraping to get the data you need, and almost certainly you're going to need to do a little coding to get it done right. How you do this is up to you, but I've found the Python community to be a great provider of tools, frameworks, and documentation for grabbing data off of websites.
Before we jump in, just a quick request: think before you do, and be nice. In the context of scraping, this can mean a lot of things. Don't crawl websites just to duplicate them and present someone else's work as your own (without permission, of course). Be aware of copyrights and licensing, and how each might apply to whatever you have scraped. Respect [robots.txt](http://www.robotstxt.org/) files. And don't hit a website so frequently that the actual human visitors have trouble accessing the content.
With that caution stated, here are some great Python tools for crawling and scraping the web, and parsing out the data you need.
## Pyspider
Let's kick things off with [pyspider](https://github.com/binux/pyspider), a web-crawler with a web-based user interface that makes it easy to keep track of multiple crawls. It's an extensible option, with multiple backend databases and message queues supported, and several handy features baked in, from prioritization to the ability to retry failed pages, crawling pages by age, and others. Pyspider supports both Python 2 and 3, and for faster crawling, you can use it in a distributed format with multiple crawlers going at once.
Pyspyder's basic usage is well [documented](http://docs.pyspider.org/en/latest/) including sample code snippets, and you can check out an [online demo](http://demo.pyspider.org/) to get a sense of the user interface. Licensed under the Apache 2 license, pyspyder is still being actively developed on GitHub.
## MechanicalSoup
[MechanicalSoup](https://github.com/hickford/MechanicalSoup) is a crawling library built around the hugely-popular and incredibly versatile HTML parsing library [Beautiful Soup](https://www.crummy.com/software/BeautifulSoup/). If your crawling needs are fairly simple, but require you to check a few boxes or enter some text and you don't want to build your own crawler for this task, it's a good option to consider.
MechanicalSoup is licensed under an MIT license. For more on how to use it, check out the example source file [example.py](https://github.com/hickford/MechanicalSoup/blob/master/example.py) on the project's GitHub page. Unfortunately, the project does not have robust documentation at this time
## Scrapy
[Scrapy](https://scrapy.org/) is a scraping framework supported by an active community with which you can build your own scraping tool. In addition to scraping and parsing tools, it can easily export the data it collects in a number of formats like JSON or CSV and store the data on a backend of your choosing. It also has a number of built-in extensions for tasks like cookie handling, user-agent spoofing, restricting crawl depth, and others, as well as an API for easily building your own additions.
For an introduction to Scrapy, check out the [online documentation](https://doc.scrapy.org/en/latest/) or one of their many [community](https://scrapy.org/community/) resources, including an IRC channel, Subreddit, and a healthy following on their StackOverflow tag. Scrapy's code base can be found [on GitHub](https://github.com/scrapy/scrapy) under a 3-clause BSD license.
If you're not all that comfortable with coding, [Portia](https://github.com/scrapinghub/portia) provides a visual interface that makes it easier. A hosted version is available at [scrapinghub.com](https://portia.scrapinghub.com/).
## Others
-
[Cola](https://github.com/chineking/cola)describes itself as a “high-level distributed crawling framework” that might meet your needs if you're looking for a Python 2 approach, but note that it has not been updated in over two years. -
[Demiurge](https://github.com/matiasb/demiurge), which supports both Python 2 and Python 3, is another potential candidate to look at, although development on this project is relatively quiet as well. -
[Feedparser](https://github.com/kurtmckee/feedparser)might be a helpful project to check out if the data you are trying to parse resides primarily in RSS or Atom feeds. -
[Lassie](https://github.com/michaelhelmick/lassie)makes it easy to retrieve basic content like a description, title, keywords, or a list of images from a webpage. -
[RoboBrowser](https://github.com/jmcarp/robobrowser)is another simple library for Python 2 or 3 with basic functionality, including button-clicking and form-filling. Though it hasn't been updated in a while, it's still a reasonable choice.
This is far from a comprehensive list, and of course, if you're a master coder you may choose to take your own approach rather than use one of these frameworks. Or, perhaps, you've found a great alternative built for a different language. For example, Python coders would probably appreciate checking out the [Python bindings](https://selenium-python.readthedocs.io/) for [Selenium](https://github.com/SeleniumHQ/selenium) for sites that are trickier to crawl without using an actual web browser. If you've got a favorite tool for crawling and scraping, let us know in the comments below.
## 4 Comments |
9,031 | 如何在 Apache Kafka 中通过 KSQL 分析 Twitter 数据 | https://www.confluent.io/blog/using-ksql-to-analyse-query-and-transform-data-in-kafka | 2017-11-03T23:03:00 | [
"Twitter",
"大数据",
"Kafka"
] | https://linux.cn/article-9031-1.html | 
### 介绍
[KSQL](https://github.com/confluentinc/ksql/) 是 Apache Kafka 中的开源的流式 SQL 引擎。它可以让你在 Kafka <ruby> 主题 <rt> topic </rt></ruby>上,使用一个简单的并且是交互式的 SQL 接口,很容易地做一些复杂的流处理。在这个短文中,我们将看到如何轻松地配置并运行在一个沙箱中去探索它,并使用大家都喜欢的演示数据库源: Twitter。我们将从推文的原始流中获取,通过使用 KSQL 中的条件去过滤它,来构建一个聚合,如统计每个用户每小时的推文数量。
### Confluent

首先, [获取一个 Confluent 平台的副本](https://www.confluent.io/download/)。我使用的是 RPM 包,但是,如果你需要的话,你也可以使用 [tar、 zip 等等](https://docs.confluent.io/current/installation.html?) 。启动 Confluent 系统:
```
$ confluent start
```
(如果你感兴趣,这里有一个 [Confluent 命令行的快速教程](https://www.youtube.com/watch?v=ZKqBptBHZTg))
我们将使用 Kafka Connect 从 Twitter 上拉取数据。 这个 Twitter 连接器可以在 [GitHub](https://github.com/jcustenborder/kafka-connect-twitter) 上找到。要安装它,像下面这样操作:
```
# Clone the git repo
cd /home/rmoff
git clone https://github.com/jcustenborder/kafka-connect-twitter.git
```
```
# Compile the code
cd kafka-connect-twitter
mvn clean package
```
要让 Kafka Connect 去使用我们构建的[连接器](https://docs.confluent.io/current/connect/userguide.html#connect-installing-plugins), 你要去修改配置文件。因为我们使用 Confluent 命令行,真实的配置文件是在 `etc/schema-registry/connect-avro-distributed.properties`,因此去修改它并增加如下内容:
```
plugin.path=/home/rmoff/kafka-connect-twitter/target/kafka-connect-twitter-0.2-SNAPSHOT.tar.gz
```
重启动 Kafka Connect:
```
confluent stop connect
confluent start connect
```
一旦你安装好插件,你可以很容易地去配置它。你可以直接使用 Kafka Connect 的 REST API ,或者创建你的配置文件,这就是我要在这里做的。如果你需要全部的方法,请首先访问 Twitter 来获取你的 [API 密钥](https://apps.twitter.com/)。
```
{
"name": "twitter_source_json_01",
"config": {
"connector.class": "com.github.jcustenborder.kafka.connect.twitter.TwitterSourceConnector",
"twitter.oauth.accessToken": "xxxx",
"twitter.oauth.consumerSecret": "xxxxx",
"twitter.oauth.consumerKey": "xxxx",
"twitter.oauth.accessTokenSecret": "xxxxx",
"kafka.delete.topic": "twitter_deletes_json_01",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": false,
"key.converter.schemas.enable": false,
"kafka.status.topic": "twitter_json_01",
"process.deletes": true,
"filter.keywords": "rickastley,kafka,ksql,rmoff"
}
}
```
假设你写这些到 `/home/rmoff/twitter-source.json`,你可以现在运行:
```
$ confluent load twitter_source -d /home/rmoff/twitter-source.json
```
然后推文就从大家都喜欢的网络明星 [rick] 滚滚而来……
```
$ kafka-console-consumer --bootstrap-server localhost:9092 --from-beginning --topic twitter_json_01|jq '.Text'
{
"string": "RT @rickastley: 30 years ago today I said I was Never Gonna Give You Up. I am a man of my word - Rick x https://t.co/VmbMQA6tQB"
}
{
"string": "RT @mariteg10: @rickastley @Carfestevent Wonderful Rick!!\nDo not forget Chile!!\nWe hope you get back someday!!\nHappy weekend for you!!\n❤…"
}
```
### KSQL
现在我们从 KSQL 开始 ! 马上去下载并构建它:
```
cd /home/rmoff
git clone https://github.com/confluentinc/ksql.git
cd /home/rmoff/ksql
mvn clean compile install -DskipTests
```
构建完成后,让我们来运行它:
```
./bin/ksql-cli local --bootstrap-server localhost:9092
```
```
======================================
= _ __ _____ ____ _ =
= | |/ // ____|/ __ \| | =
= | ' /| (___ | | | | | =
= | < \___ \| | | | | =
= | . \ ____) | |__| | |____ =
= |_|\_\_____/ \___\_\______| =
= =
= Streaming SQL Engine for Kafka =
Copyright 2017 Confluent Inc.
CLI v0.1, Server v0.1 located at http://localhost:9098
Having trouble? Type 'help' (case-insensitive) for a rundown of how things work!
ksql>
```
使用 KSQL, 我们可以让我们的数据保留在 Kafka 主题上并可以查询它。首先,我们需要去告诉 KSQL 主题上的<ruby> 数据模式 <rt> schema </rt></ruby>是什么,一个 twitter 消息实际上是一个非常巨大的 JSON 对象, 但是,为了简洁,我们只选出其中几行:
```
ksql> CREATE STREAM twitter_raw (CreatedAt BIGINT, Id BIGINT, Text VARCHAR) WITH (KAFKA_TOPIC='twitter_json_01', VALUE_FORMAT='JSON');
Message
----------------
Stream created
```
在定义的模式中,我们可以查询这些流。要让 KSQL 从该主题的开始展示数据(而不是默认的当前时间点),运行如下命令:
```
ksql> SET 'auto.offset.reset' = 'earliest';
Successfully changed local property 'auto.offset.reset' from 'null' to 'earliest'
```
现在,让我们看看这些数据,我们将使用 LIMIT 从句仅检索一行:
```
ksql> SELECT text FROM twitter_raw LIMIT 1;
RT @rickastley: 30 years ago today I said I was Never Gonna Give You Up. I am a man of my word - Rick x https://t.co/VmbMQA6tQB
LIMIT reached for the partition.
Query terminated
ksql>
```
现在,让我们使用刚刚定义和可用的推文内容的全部数据重新定义该流:
```
ksql> DROP stream twitter_raw;
Message
--------------------------------
Source TWITTER_RAW was dropped
ksql> CREATE STREAM twitter_raw (CreatedAt bigint,Id bigint, Text VARCHAR, SOURCE VARCHAR, Truncated VARCHAR, InReplyToStatusId VARCHAR, InReplyToUserId VARCHAR, InReplyToScreenName VARCHAR, GeoLocation VARCHAR, Place VARCHAR, Favorited VARCHAR, Retweeted VARCHAR, FavoriteCount VARCHAR, User VARCHAR, Retweet VARCHAR, Contributors VARCHAR, RetweetCount VARCHAR, RetweetedByMe VARCHAR, CurrentUserRetweetId VARCHAR, PossiblySensitive VARCHAR, Lang VARCHAR, WithheldInCountries VARCHAR, HashtagEntities VARCHAR, UserMentionEntities VARCHAR, MediaEntities VARCHAR, SymbolEntities VARCHAR, URLEntities VARCHAR) WITH (KAFKA_TOPIC='twitter_json_01',VALUE_FORMAT='JSON');
Message
----------------
Stream created
ksql>
```
现在,我们可以操作和检查更多的最近的数据,使用一般的 SQL 查询:
```
ksql> SELECT TIMESTAMPTOSTRING(CreatedAt, 'yyyy-MM-dd HH:mm:ss.SSS') AS CreatedAt,\
EXTRACTJSONFIELD(user,'$.ScreenName') as ScreenName,Text \
FROM twitter_raw \
WHERE LCASE(hashtagentities) LIKE '%oow%' OR \
LCASE(hashtagentities) LIKE '%ksql%';
2017-09-29 13:59:58.000 | rmoff | Looking forward to talking all about @apachekafka & @confluentinc’s #KSQL at #OOW17 on Sunday 13:45 https://t.co/XbM4eIuzeG
```
注意这里没有 LIMIT 从句,因此,你将在屏幕上看到 “continuous query” 的结果。不像关系型数据表中返回一个确定数量结果的查询,一个持续查询会运行在无限的流式数据上, 因此,它总是可能返回更多的记录。点击 Ctrl-C 去中断然后返回到 KSQL 提示符。在以上的查询中我们做了一些事情:
* **TIMESTAMPTOSTRING** 将时间戳从 epoch 格式转换到人类可读格式。(LCTT 译注: epoch 指的是一个特定的时间 1970-01-01 00:00:00 UTC)
* **EXTRACTJSONFIELD** 来展示数据源中嵌套的用户域中的一个字段,它看起来像:
```
{
"CreatedAt": 1506570308000,
"Text": "RT @gwenshap: This is the best thing since partitioned bread :) https://t.co/1wbv3KwRM6",
[...]
"User": {
"Id": 82564066,
"Name": "Robin Moffatt \uD83C\uDF7B\uD83C\uDFC3\uD83E\uDD53",
"ScreenName": "rmoff",
[...]
```
* 应用断言去展示内容,对 #(hashtag)使用模式匹配, 使用 LCASE 去强制小写字母。(LCTT 译注:hashtag 是twitter 中用来标注线索主题的标签)
关于支持的函数列表,请查看 [KSQL 文档](https://github.com/confluentinc/ksql/blob/0.1.x/docs/syntax-reference.md)。
我们可以创建一个从这个数据中得到的流:
```
ksql> CREATE STREAM twitter AS \
SELECT TIMESTAMPTOSTRING(CreatedAt, 'yyyy-MM-dd HH:mm:ss.SSS') AS CreatedAt,\
EXTRACTJSONFIELD(user,'$.Name') AS user_Name,\
EXTRACTJSONFIELD(user,'$.ScreenName') AS user_ScreenName,\
EXTRACTJSONFIELD(user,'$.Location') AS user_Location,\
EXTRACTJSONFIELD(user,'$.Description') AS user_Description,\
Text,hashtagentities,lang \
FROM twitter_raw ;
Message
----------------------------
Stream created and running
ksql> DESCRIBE twitter;
Field | Type
------------------------------------
ROWTIME | BIGINT
ROWKEY | VARCHAR(STRING)
CREATEDAT | VARCHAR(STRING)
USER_NAME | VARCHAR(STRING)
USER_SCREENNAME | VARCHAR(STRING)
USER_LOCATION | VARCHAR(STRING)
USER_DESCRIPTION | VARCHAR(STRING)
TEXT | VARCHAR(STRING)
HASHTAGENTITIES | VARCHAR(STRING)
LANG | VARCHAR(STRING)
ksql>
```
并且查询这个得到的流:
```
ksql> SELECT CREATEDAT, USER_NAME, TEXT \
FROM TWITTER \
WHERE TEXT LIKE '%KSQL%';
2017-10-03 23:39:37.000 | Nicola Ferraro | RT @flashdba: Again, I'm really taken with the possibilities opened up by @confluentinc's KSQL engine #Kafka https://t.co/aljnScgvvs
```
### 聚合
在我们结束之前,让我们去看一下怎么去做一些聚合。
```
ksql> SELECT user_screenname, COUNT(*) \
FROM twitter WINDOW TUMBLING (SIZE 1 HOUR) \
GROUP BY user_screenname HAVING COUNT(*) > 1;
oracleace | 2
rojulman | 2
smokeinpublic | 2
ArtFlowMe | 2
[...]
```
你将可能得到满屏幕的结果;这是因为 KSQL 在每次给定的时间窗口更新时实际发出聚合值。因为我们设置 KSQL 去读取在主题上的全部消息(`SET 'auto.offset.reset' = 'earliest';`),它是一次性读取这些所有的消息并计算聚合更新。这里有一个微妙之处值得去深入研究。我们的入站推文流正好就是一个流。但是,现有它不能创建聚合,我们实际上是创建了一个表。一个表是在给定时间点的给定键的值的一个快照。 KSQL 聚合数据基于消息的事件时间,并且如果它更新了,通过简单的相关窗口重申去操作后面到达的数据。困惑了吗? 我希望没有,但是,让我们看一下,如果我们可以用这个例子去说明。 我们将申明我们的聚合作为一个真实的表:
```
ksql> CREATE TABLE user_tweet_count AS \
SELECT user_screenname, count(*) AS tweet_count \
FROM twitter WINDOW TUMBLING (SIZE 1 HOUR) \
GROUP BY user_screenname ;
Message
---------------------------
Table created and running
```
看表中的列,这里除了我们要求的外,还有两个隐含列:
```
ksql> DESCRIBE user_tweet_count;
Field | Type
-----------------------------------
ROWTIME | BIGINT
ROWKEY | VARCHAR(STRING)
USER_SCREENNAME | VARCHAR(STRING)
TWEET_COUNT | BIGINT
ksql>
```
我们看一下这些是什么:
```
ksql> SELECT TIMESTAMPTOSTRING(ROWTIME, 'yyyy-MM-dd HH:mm:ss.SSS') , \
ROWKEY, USER_SCREENNAME, TWEET_COUNT \
FROM user_tweet_count \
WHERE USER_SCREENNAME= 'rmoff';
2017-09-29 11:00:00.000 | rmoff : Window{start=1506708000000 end=-} | rmoff | 2
2017-09-29 12:00:00.000 | rmoff : Window{start=1506711600000 end=-} | rmoff | 4
2017-09-28 22:00:00.000 | rmoff : Window{start=1506661200000 end=-} | rmoff | 2
2017-09-29 09:00:00.000 | rmoff : Window{start=1506700800000 end=-} | rmoff | 4
2017-09-29 15:00:00.000 | rmoff : Window{start=1506722400000 end=-} | rmoff | 2
2017-09-29 13:00:00.000 | rmoff : Window{start=1506715200000 end=-} | rmoff | 6
```
`ROWTIME` 是窗口开始时间, `ROWKEY` 是 `GROUP BY`(`USER_SCREENNAME`)加上窗口的组合。因此,我们可以通过创建另外一个衍生的表来整理一下:
```
ksql> CREATE TABLE USER_TWEET_COUNT_DISPLAY AS \
SELECT TIMESTAMPTOSTRING(ROWTIME, 'yyyy-MM-dd HH:mm:ss.SSS') AS WINDOW_START ,\
USER_SCREENNAME, TWEET_COUNT \
FROM user_tweet_count;
Message
---------------------------
Table created and running
```
现在它更易于查询和查看我们感兴趣的数据:
```
ksql> SELECT WINDOW_START , USER_SCREENNAME, TWEET_COUNT \
FROM USER_TWEET_COUNT_DISPLAY WHERE TWEET_COUNT> 20;
2017-09-29 12:00:00.000 | VikasAatOracle | 22
2017-09-28 14:00:00.000 | Throne_ie | 50
2017-09-28 14:00:00.000 | pikipiki_net | 22
2017-09-29 09:00:00.000 | johanlouwers | 22
2017-09-28 09:00:00.000 | yvrk1973 | 24
2017-09-28 13:00:00.000 | cmosoares | 22
2017-09-29 11:00:00.000 | ypoirier | 24
2017-09-28 14:00:00.000 | pikisec | 22
2017-09-29 07:00:00.000 | Throne_ie | 22
2017-09-29 09:00:00.000 | ChrisVoyance | 24
2017-09-28 11:00:00.000 | ChrisVoyance | 28
```
### 结论
所以我们有了它! 我们可以从 Kafka 中取得数据, 并且很容易使用 KSQL 去探索它。 而不仅是去浏览和转换数据,我们可以很容易地使用 KSQL 从流和表中建立流处理。

如果你对 KSQL 能够做什么感兴趣,去查看:
* [KSQL 公告](https://www.confluent.io/blog/ksql-open-source-streaming-sql-for-apache-kafka/)
* [我们最近的 KSQL 在线研讨会](https://www.confluent.io/online-talk/ksql-streaming-sql-for-apache-kafka/) 和 [Kafka 峰会讲演](https://www.confluent.io/kafka-summit-sf17/Databases-and-Stream-Processing-1)
* [clickstream 演示](https://www.youtube.com/watch?v=A45uRzJiv7I),它是 [KSQL 的 GitHub 仓库](https://github.com/confluentinc/ksql) 的一部分
* [我最近做的演讲](https://speakerdeck.com/rmoff/look-ma-no-code-building-streaming-data-pipelines-with-apache-kafka) 展示了 KSQL 如何去支持基于流的 ETL 平台
记住,KSQL 现在正处于开发者预览阶段。 欢迎在 KSQL 的 GitHub 仓库上提出任何问题, 或者去我们的 [community Slack group](https://slackpass.io/confluentcommunity) 的 #KSQL 频道。
---
via: <https://www.confluent.io/blog/using-ksql-to-analyse-query-and-transform-data-in-kafka>
作者:[Robin Moffatt](https://www.confluent.io/blog/author/robin/) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,034 | 开发者,原来你最讨厌的编程语言和技术是…… | https://stackoverflow.blog/2017/10/31/disliked-programming-languages/ | 2017-11-05T10:07:00 | [
"编程语言",
"开发者"
] | https://linux.cn/article-9034-1.html | 
在 [Stack Overflow Jobs](https://stackoverflow.com/jobs) 上,你可以创建你自己的<ruby> <a href="https://stackoverflow.blog/2016/10/11/bye-bye-bullets-the-stack-overflow-developer-story-is-the-new-technical-resume/"> 开发者故事 </a> <rp> ( </rp> <rt> Developer Story </rt> <rp> ) </rp></ruby>来展示你的成就,表现你的职业生涯进步。在创建开发者故事时,你可以对你使用的技术/编程语言添加喜欢或**不喜欢**的标签,如下图:

这就给了我们一个机会可以观察到这数十万开发者的喜好和厌恶。有许多方法可以评估一个语言的流行程度,举个栗子说,我们经常使用 [Stack Overflow 访问数或问题查看数](/article-8865-1.html)来评估这样的趋势。但是,当技术人员在他们的简历中表达他们**不喜欢**某种技术时,这个数据集就是一个找出技术人群不喜欢某种技术的独有方式。
(我[两年前曾经在我的个人博客](http://varianceexplained.org/r/polarizing-technologies/)上发表过一些这类分析,不过这篇文章使用了更新的数据集,以及有更多可视化结果和说明。)
### 编程语言
作为测量每个编程语言有多流行的指标,我们将看看它出现在某人“不喜欢”标签的时间与其出现在其他人的“喜欢”或“不喜欢”标签的频率相比。那么 50% 就意味着该语言喜欢与不喜欢各占一半,而 1% 则意味着 99 个人喜欢它而剩下 1 个人不喜欢它。(我们使用了[这篇文章](http://varianceexplained.org/r/empirical_bayes_baseball/)中描述的<ruby> 经验贝叶斯 <rp> ( </rp> <rt> empirical Bayes </rt> <rp> ) </rp></ruby>方法来计算平均值,并使用[这个方法](http://varianceexplained.org/r/credible_intervals_baseball/)来计算得到 95% 置信区间)
让我们开始看看选出的语言列表(而不是像 Android 这样的平台或像 jQuery 这样的库),所有这些都曾在开发者故事中至少提及了 2000 次以上。

最不喜欢的语言是 Perl、Delphi 和 VBA ,它们远远把其它语言抛下。接着的第二梯队是 PHP、Objective-C、 Coffeescript 和 Ruby。我们的团队很高兴地看到,R 语言相对于喜欢它的人数来说,对它不喜欢的人数是最少的。
如果你读过我们另外一些关于编程语言增长或萎缩的文章,你也许会注意到那些较少被不喜欢的语言往往是增长较快的。 在 Stack Overflow 上,R、Python、Typescript、Go 和 Rust 全是快速增长的编程语言(我们之前专门对 [Python](/article-8865-1.html) 和 [R](https://stackoverflow.blog/2017/10/10/impressive-growth-r/) 做过分析),而且它们全都属于看法比较<ruby> 分化 <rp> ( </rp> <rt> polarizing </rt> <rp> ) </rp></ruby>的语言。类似的,大量萎缩的语言,比如 Perl、Objective-C 和 Ruby,如我们[之前观察](https://stackoverflow.blog/2017/08/01/flash-dead-technologies-might-next/)到的那样,在我们网站上它处于快速萎缩状况。
我们可以通过将每种语言的规模和增长与不喜欢它的人的百分比进行比较来进行调查,橙色点代表最不喜欢的语言。 为了使我们的分析与前几个帖子保持一致,我们将统计数据限制在高收入国家(如美国,英国,德国和加拿大)。

一般来说,编程语言的增长率和它有多不招人喜欢方面存在相关性。几乎每个在开发者故事中提及不喜欢的比率超过 3% 的语言都在 Stack Overflow 流量上处于萎缩状态(除了十分两极化的 VBA,它仍有轻度增长)。而不喜欢数量较少的语言,如 R、Rust、 Typescript 和 Kotlin,它们全处于快速增长领域(Typescript 和 Kotlin 增长的太快,以至于都跑出了上图范围)。
一个突出的编程语言是函数式编程语言 Clojure;几乎没有人表示过不喜欢它,但是它仍然处于快速萎缩中(根据[问题查看情况](https://insights.stackoverflow.com/trends?tags=clojure),它在去年才开始萎缩)。另外一个例外是 MATLAB,它处于快速萎缩,但是没有很多人表示过不喜欢它。这可能是由于调查样本的数据所限:任何一个 Web 开发人员都可能对 PHP、C# 或 Ruby 有意见,但是不从事数据分析的人没理由对 MATLAB 不满意。(这也可能是 R 较少被提及“不喜欢”的部分原因)
我们不一定说这里存在因果关系——部分程序员不喜欢就会导致该语言会被抛弃。 另一种可能是,如果人们觉得这种语言已经越来越不流行,那么人们就会觉得很自然地表达他们也不喜欢了。 同样可以想象的是,开发人员经常使用这个字段来记录他们曾经使用的技术,但是不会再使用该技术了。 这将导致那些自然而然地“被替代的”技术就一直停留在“不喜欢”标签里面。
### 最不喜欢的和最喜欢的
上面的分析仅考虑了编程语言,不涉及操作系统、平台或库(框架)。那么就整体而言,最不喜欢的技术是什么?为了专注于我们有足够数据的更主要的技术,我们其限制为至少提及了 1000 次的技术。

最不喜欢的其中有几个是微软的技术,特别是 IE 和 VB,以及 “微软” 标签(“评估” 也出现在这个列表中,但是没那么糟糕)。[有个好消息是](https://stackoverflow.blog/2017/08/01/flash-dead-technologies-might-next/),大多数人都不喜欢 Flash。此外,较老的语言,比如 COBOL、 Fortran 和 Pascal 也出现在此处。
值得再次强调的是,这不是对技术及其品质或受欢迎程度的批评。 这只是衡量哪些技术激起了强烈的消极情绪,至少在一部分愿意公开分享其感受的开发人员中如此。
我们也集中观察了那些最流行的技术、那些最不可能被不喜欢的技术(这次,由于喜欢标签出现的比较多,我们仅关注那些被提及至少 10000 次的)。

Git 也许是许多开发者的沮丧源头(绝对包括我!),但人们很少在简历中承认这一点,这是因为它是我们的开发者故事中最受欢迎的标签之一。 R 也出现在了这个列表,但它并不是唯一一个没有争议的与数据科学相关的语言。 机器学习被 23000 人所喜欢,而且很少被人不喜欢。 诸如 Python-3.X、CSS3 和 HTML5 等标签可能表明开发者很少指定他们不喜欢技术的特定版本(如果他们会指定的话)。 当然,[jQuery 在 Stack Overflow 上一直是如此受欢迎](http://i.stack.imgur.com/ssRUr.gif)。
### 分化的标签网络
我们可以把所有这些标签组合成一个网络。在最近的一篇文章中,[Julia Silge 展示了我们如何构建一个代表整个软件生态系统的技术网络](https://stackoverflow.blog/2017/10/03/mapping-ecosystems-software-development/)。 如果我们根据每个标签不喜欢的程度对节点进行着色,我们可以了解该生态系统的哪些部分比其它部分更有争议。

通过将开发者故事的标签放置到次生态系统中,该网络揭示了哪些类型的标签趋于两级分化。 在微软(以 C# 和 .NET 为中心,左上角),PHP(与 WordPress 和 Drupal 一起,左下角)以及移动开发(特别是 Objective-C,右下角)的子生态系统中都有一些意见分化的标签聚合。 在操作系统聚合中(右下),我们可以看到诸如 OSX 之类的系统,以及特别是 Windows 都有不喜欢的人,但是像 Linux、Ubuntu 和 Unix 这样的标签却没有。
### 竞争
如果某人喜欢某个特定的标签,是否意味着通常他们喜欢或不喜欢另外的标签呢?
我们可以使用出现在特定喜欢标签之间的 [phi 系数](https://en.wikipedia.org/wiki/Phi_coefficient)来衡量它。 (当计算这些相关性时,我们只考虑那些至少有一个不喜欢标签的人。)

这突出显示了软件生态系统的一些“竞争”:Linux 和 OSX vs Windows,Git vs SVN,vim vs emacs 以及(对我来说)R vs SAS。 这些配对中的大多数并不代表“相反”的技术,而是反映了两种解决类似问题的方法。 它们中的许多表明了从以前流行的技术发展到更现代的技术(SVN 由 Git 取代,XML 由 JSON 取代,VB 由 C# 取代)。 这对于人们想在简历中列出的内容是有意义的;开发者通常会表明他们不愿意使用他们认为过时的东西。
### 总结
我对“语言战争”没有任何兴趣,我也不会对用户分享的喜欢或不喜欢的任何技术进行裁断。 对微软技术的两级分化的看法通常会鼓励我分享我的个人经验。 我是一个 Mac 和 UNIX 终身拥趸,几乎我所有的大学和研究生的编程学习都围绕着 Python 和 R。尽管如此,我很高兴能够加入一个 .NET 栈的公司,我很高兴我来了 —— 因为我喜欢这个团队、产品和数据。 我不能代表其他人说话,但我很高兴自己可以从事于自己想做的事情,而不是那些不想要做的事情。
如果您有兴趣分享您喜欢和不喜欢的技术,并想找到您职业生涯的下一份工作,那么您可以[创建自己的开发者故事](http://stackoverflow.com/users/story/join)。
想找一份你喜欢的技术的工作? 在 [Stack Overflow Jobs](https://stackoverflow.com/jobs) 找到你的下一份工作,在那里你可以搜索你喜欢做的技术工作。
| 200 | OK | null |
9,035 | Postgres 索引类型探索之旅 | https://www.citusdata.com/blog/2017/10/17/tour-of-postgres-index-types/ | 2017-11-07T00:32:29 | [
"数据库",
"索引",
"Postgres"
] | https://linux.cn/article-9035-1.html | 
在 Citus 公司,为让事情做的更好,我们与客户一起在数据建模、优化查询、和增加 [索引](https://www.citusdata.com/blog/2017/10/11/index-all-the-things-in-postgres/)上花费了许多时间。我的目标是为客户的需求提供更好的服务,从而创造成功。我们所做的其中一部分工作是[持续](https://www.citusdata.com/product/cloud)为你的 Citus 集群保持良好的优化和 [高性能](https://www.citusdata.com/blog/2017/09/29/what-performance-can-you-expect-from-postgres/);另外一部分是帮你了解关于 Postgres 和 Citus 你所需要知道的一切。毕竟,一个健康和高性能的数据库意味着 app 执行的更快,并且谁不愿意这样呢? 今天,我们简化一些内容,与客户分享一些关于 Postgres 索引的信息。
Postgres 有几种索引类型, 并且每个新版本都似乎增加一些新的索引类型。每个索引类型都是有用的,但是具体使用哪种类型取决于(1)数据类型,有时是(2)表中的底层数据和(3)执行的查找类型。接下来的内容我们将介绍在 Postgres 中你可以使用的索引类型,以及你何时该使用何种索引类型。在开始之前,这里有一个我们将带你亲历的索引类型列表:
* B-Tree
* <ruby> 倒排索引 <rt> Generalized Inverted Index </rt></ruby> (GIN)
* <ruby> 倒排搜索树 <rt> Generalized Inverted Seach Tree </rt></ruby> (GiST)
* <ruby> 空间分区的 <rt> Space partitioned </rt></ruby> GiST (SP-GiST)
* <ruby> 块范围索引 <rt> Block Range Index </rt></ruby> (BRIN)
* Hash
现在开始介绍索引。
### 在 Postgres 中,B-Tree 索引是你使用的最普遍的索引
如果你有一个计算机科学的学位,那么 B-Tree 索引可能是你学会的第一个索引。[B-tree 索引](https://en.wikipedia.org/wiki/B-tree) 会创建一个始终保持自身平衡的一棵树。当它根据索引去查找某个东西时,它会遍历这棵树去找到键,然后返回你要查找的数据。使用索引是大大快于顺序扫描的,因为相对于顺序扫描成千上万的记录,它可以仅需要读几个 [页](https://www.8kdata.com/blog/postgresql-page-layout/) (当你仅返回几个记录时)。
如果你运行一个标准的 `CREATE INDEX` 语句,它将为你创建一个 B-tree 索引。 B-tree 索引在大多数的数据类型上是很有价值的,比如文本、数字和时间戳。如果你刚开始在你的数据库中使用索引,并且不在你的数据库上使用太多的 Postgres 的高级特性,使用标准的 B-Tree 索引可能是你最好的选择。
### GIN 索引,用于多值列
<ruby> 倒排索引 <rt> Generalized Inverted Index </rt></ruby>,一般称为 [GIN](https://www.postgresql.org/docs/10/static/gin.html),大多适用于当单个列中包含多个值的数据类型。
据 Postgres 文档:
>
> “GIN 设计用于处理被索引的条目是复合值的情况,并且由索引处理的查询需要搜索在复合条目中出现的值。例如,这个条目可能是文档,查询可以搜索文档中包含的指定字符。”
>
>
>
包含在这个范围内的最常见的数据类型有:
* [hStore](https://www.citusdata.com/blog/2016/07/14/choosing-nosql-hstore-json-jsonb/)
* Array
* Range
* [JSONB](https://www.citusdata.com/blog/2016/07/14/choosing-nosql-hstore-json-jsonb/)
关于 GIN 索引中最让人满意的一件事是,它们能够理解存储在复合值中的数据。但是,因为一个 GIN 索引需要有每个被添加的单独类型的数据结构的特定知识,因此,GIN 索引并不是支持所有的数据类型。
### GiST 索引, 用于有重叠值的行
<ruby> 倒排搜索树 <rt> Generalized Inverted Seach Tree </rt></ruby>(GiST)索引多适用于当你的数据与同一列的其它行数据重叠时。GiST 索引最好的用处是:如果你声明一个几何数据类型,并且你希望知道两个多边型是否包含一些点时。在一种情况中一个特定的点可能被包含在一个盒子中,而与此同时,其它的点仅存在于一个多边形中。使用 GiST 索引的常见数据类型有:
* 几何类型
* 需要进行全文搜索的文本类型
GiST 索引在大小上有很多的固定限制,否则,GiST 索引可能会变的特别大。作为其代价,GiST 索引是有损的(不精确的)。
据官方文档:
>
> “GiST 索引是有损的,这意味着索引可能产生虚假匹配,所以需要去检查真实的表行去消除虚假匹配。 (当需要时 PostgreSQL 会自动执行这个动作)”
>
>
>
这并不意味着你会得到一个错误结果,它只是说明了在 Postgres 给你返回数据之前,会做了一个很小的额外工作来过滤这些虚假结果。
特别提示:同一个数据类型上 GIN 和 GiST 索引往往都可以使用。通常一个有很好的性能表现,但会占用很大的磁盘空间,反之亦然。说到 GIN 与 GiST 的比较,并没有某个完美的方案可以适用所有情况,但是,以上规则应用于大部分常见情况。
### SP-GiST 索引,用于更大的数据
空间分区 GiST (SP-GiST)索引采用来自 [Purdue](https://www.cs.purdue.edu/spgist/papers/W87R36P214137510.pdf) 研究的空间分区树。 SP-GiST 索引经常用于当你的数据有一个天然的聚集因素,并且不是一个平衡树的时候。 电话号码是一个非常好的例子 (至少 US 的电话号码是)。 它们有如下的格式:
* 3 位数字的区域号
* 3 位数字的前缀号 (与以前的电话交换机有关)
* 4 位的线路号
这意味着第一组前三位处有一个天然的聚集因素,接着是第二组三位,然后的数字才是一个均匀的分布。但是,在电话号码的一些区域号中,存在一个比其它区域号更高的饱合状态。结果可能导致树非常的不平衡。因为前面有一个天然的聚集因素,并且数据不对等分布,像电话号码一样的数据可能会是 SP-GiST 的一个很好的案例。
### BRIN 索引, 用于更大的数据
块范围索引(BRIN)专注于一些类似 SP-GiST 的情形,它们最好用在当数据有一些自然排序,并且往往数据量很大时。如果有一个以时间为序的 10 亿条的记录,BRIN 也许就能派上用场。如果你正在查询一组很大的有自然分组的数据,如有几个邮编的数据,BRIN 能帮你确保相近的邮编存储在磁盘上相近的地方。
当你有一个非常大的比如以日期或邮编排序的数据库, BRIN 索引可以让你非常快的跳过或排除一些不需要的数据。此外,与整体数据量大小相比,BRIN 索引相对较小,因此,当你有一个大的数据集时,BRIN 索引就可以表现出较好的性能。
### Hash 索引, 总算不怕崩溃了
Hash 索引在 Postgres 中已经存在多年了,但是,在 Postgres 10 发布之前,对它们的使用一直有个巨大的警告,它不是 WAL-logged 的。这意味着如果你的服务器崩溃,并且你无法使用如 [wal-g](https://www.citusdata.com/blog/2017/08/18/introducing-wal-g-faster-restores-for-postgres/) 故障转移到备机或从存档中恢复,那么你将丢失那个索引,直到你重建它。 随着 Postgres 10 发布,它们现在是 WAL-logged 的,因此,你可以再次考虑使用它们 ,但是,真正的问题是,你应该这样做吗?
Hash 索引有时会提供比 B-Tree 索引更快的查找,并且创建也很快。最大的问题是它们被限制仅用于“相等”的比较操作,因此你只能用于精确匹配的查找。这使得 hash 索引的灵活性远不及通常使用的 B-Tree 索引,并且,你不能把它看成是一种替代品,而是一种用于特殊情况的索引。
### 你该使用哪个?
我们刚才介绍了很多,如果你有点被吓到,也很正常。 如果在你知道这些之前, `CREATE INDEX` 将始终为你创建使用 B-Tree 的索引,并且有一个好消息是,对于大多数的数据库, Postgres 的性能都很好或非常好。 :) 如果你考虑使用更多的 Postgres 特性,下面是一个当你使用其它 Postgres 索引类型的备忘清单:
* B-Tree - 适用于大多数的数据类型和查询
* GIN - 适用于 JSONB/hstore/arrays
* GiST - 适用于全文搜索和几何数据类型
* SP-GiST - 适用于有天然的聚集因素但是分布不均匀的大数据集
* BRIN - 适用于有顺序排列的真正的大数据集
* Hash - 适用于相等操作,而且,通常情况下 B-Tree 索引仍然是你所需要的。
如果你有关于这篇文章的任何问题或反馈,欢迎加入我们的 [slack channel](https://slack.citusdata.com/)。
---
via: <https://www.citusdata.com/blog/2017/10/17/tour-of-postgres-index-types/>
作者:[Craig Kerstiens](https://www.citusdata.com/blog/2017/10/17/tour-of-postgres-index-types/) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | POSETTE 2024 is a wrap! 💯 Thanks for joining the fun! Missed it? [Watch all 42 talks online](https://aka.ms/posette-playlist) 🍿
POSETTE 2024 is a wrap! 💯 Thanks for joining the fun! Missed it? [Watch all 42 talks online](https://aka.ms/posette-playlist) 🍿
Written by **Craig Kerstiens**
October 17, 2017
At Citus we spend a lot of time working with customers on data modeling, optimizing queries, and adding [indexes](/blog/2017/10/11/index-all-the-things-in-postgres/) to make things snappy. My goal is to be as available for our customers as we need to be, in order to make you successful. Part of that is keeping your Citus cluster well tuned and [performant](/blog/2017/09/29/what-performance-can-you-expect-from-postgres/) which [we take care](/product/citus-on-azure/) of for you. Another part is helping you with everything you need to know about Postgres and Citus. After all a healthy and performant database means a fast performing app and who wouldn’t want that. Today we’re going to condense some of the information we’ve shared directly with customers about Postgres indexes.
Postgres has a number of index types, and with each new release seems to come with another new index type. Each of these indexes can be useful, but which one to use depends on 1. the data type and then sometimes 2. the underlying data within the table, and 3. the types of lookups performed. In what follows we'll look at a quick survey of the index types available to you in Postgres and when you should leverage each. Before we dig in, here’s a quick glimpse of the indexes we’ll walk you through:
Now onto the indexing
If you have a degree in Computer Science, then a B-tree index was likely the first one you learned about. A [B-tree index](https://en.wikipedia.org/wiki/B-tree) creates a tree that will keep itself balanced and even. When it goes to look something up based on that index it will traverse down the tree to find the key the tree is split on and then return you the data you’re looking for. Using an index is much faster than a sequential scan because it may only have to read a few [pages](https://www.8kdata.com/blog/postgresql-page-layout/) as opposed to sequentially scanning thousands of them (when you’re returning only a few records).
If you run a standard `CREATE INDEX`
it creates a B-tree for you. B-tree indexes are valuable on the most common data types such as text, numbers, and timestamps. If you're just getting started indexing your database and aren't leveraging too many advanced Postgres features within your database, using standard B-Tree indexes is likely the path you want to take.
Generalized Inverted Indexes, commonly referred to as [GIN](https://www.postgresql.org/docs/10/static/gin.html), are most useful when you have data types that contain multiple values in a single column.
From the Postgres docs: *"GIN is designed for handling cases where the items to be indexed are composite values, and the queries to be handled by the index need to search for element values that appear within the composite items. For example, the items could be documents, and the queries could be searches for documents containing specific words."*
The most common data types that fall into this bucket are:
One of the beautiful things about GIN indexes is that they are aware of the data within composite values. But because a GIN index has specific knowledge about the data structure support for each individual type needs to be added, as a result not all datatypes are supported.
GiST indexes are most useful when you have data that can in some way overlap with the value of that same column but from another row. The best thing about GiST indexes: if you have say a geometry data type and you want to see if two polygons contained some point. In one case a specific point may be contained within box, while another point only exists within one polygon. The most common datatypes where you want to leverage GiST indexes are:
GiST indexes have some more fixed constraints around size, whereas GIN indexes can become quite large. As a result, GiST indexes are lossy. From the docs: *"A GiST index is lossy, meaning that the index might produce false matches, and it is necessary to check the actual table row to eliminate such false matches. (PostgreSQL does this automatically when needed.)"* This doesn't mean you'll get wrong results, it just means Postgres has to do a little extra work to filter those false positives before giving your data back to you.
*Special note: GIN and GiST indexes can often be beneficial on the same column types. One can often boast better performance but larger disk footprint in the case of GIN and vice versa for GiST. When it comes to GIN vs. GiST there isn't a perfect one size fits all, but the broad rules above apply*
Space partitioned GiST indexes leverage space partitioning trees that came out of some research from [Purdue](https://www.cs.purdue.edu/spgist/papers/W87R36P214137510.pdf). SP-GiST indexes are most useful when your data has a natural clustering element to it, and is also not an equally balanced tree. A great example of this is phone numbers (at least US ones). They follow a format of:
This means that you have some natural clustering around the first set of 3 digits, around the second set of 3 digits, then numbers may fan out in a more even distribution. But, with phone numbers some area codes have a much higher saturation than others. The result may be that the tree is very unbalanced. Because of that natural clustering up front and the unequal distribution of data–data like phone numbers could make a good case for SP-GiST.
Block range indexes can focus on some similar use cases to SP-GiST in that they're best when there is some natural ordering to the data, and the data tends to be very large. Have a billion record table especially if it’s time series data? BRIN may be able to help. If you're querying against a large set of data that is naturally grouped together such as data for several zip codes (which then roll up to some city) BRIN helps to ensure that similar zip codes are located near each other on disk.
When you have very large datasets that are ordered such as dates or zip codes BRIN indexes allow you to skip or exclude a lot of the unnecessary data very quickly. BRIN additionally are maintained as smaller indexes relative to the overall datasize making them a big win for when you have a large dataset.
Hash indexes have been around for years within Postgres, but until Postgres 10 came with a giant warning that they were not WAL-logged. This meant if your server crashed and you failed over to a stand-by or recovered from archives using something like [wal-g](/blog/2017/08/18/introducing-wal-g-faster-restores-for-postgres/) then you’d lose that index until you recreated it. With Postgres 10 they’re now WAL-logged so you can start to consider using them again, but the real question is should you?
Hash indexes at times can provide faster lookups than B-Tree indexes, and can boast faster creation times as well. The big issue with them is they’re limited to only equality operators so you need to be looking for exact matches. This makes hash indexes far less flexible than the more commonly used B-Tree indexes and something you won’t want to consider as a drop-in replacement but rather a special case.
We just covered a lot and if you’re a bit overwhelmed you’re not alone. If all you knew before was `CREATE INDEX`
you’ve been using B-Tree indexes all along, and the good news is you’re still performing as well or better than most databases that aren’t Postgres :) As you start to use more Postgres features consider this a cheatsheet for when to use other Postgres types:
If you have any questions or feedback about the post feel free to join us in our [slack channel](https://slack.citusdata.com). |
9,036 | 为何 Kubernetes 如此受欢迎? | https://opensource.com/article/17/10/why-kubernetes-so-popular | 2017-11-07T01:36:12 | [
"Kubernetes",
"容器编排"
] | https://linux.cn/article-9036-1.html |
>
> Google 开发的这个容器管理系统很快成为开源历史上最成功的案例之一。
>
>
>

[Kubernetes](https://kubernetes.io/) 是一个在过去几年中快速蹿升起来的开源的容器管理系统。它被众多行业中最大的企业用于关键任务,已成为开源方面最成功的案例之一。这是怎么发生的?该如何解释 Kubernetes 的广泛应用呢?
### Kubernetes 的背景:起源于 Google 的 Borg 系统
随着计算世界变得更加分布式、更加基于网络、以及更多的云计算,我们看到了大型的<ruby> 独石 <rt> monolithic </rt></ruby>应用慢慢地转化为多个敏捷微服务。这些微服务能让用户单独缩放应用程序的关键功能,以处理数百万客户。除此之外,我们还看到像 Docker 这样的容器等技术出现在企业中,为用户快速构建这些微服务创造了一致的、可移植的、便捷的方式。
随着 Docker 继续蓬勃发展,管理这些微服务器和容器成为最重要的要求。这时已经运行基于容器的基础设施已经多年的 Google 大胆地决定开源一个名为 [Borg](http://queue.acm.org/detail.cfm?id=2898444) 的项目。Borg 系统是运行诸如 Google 搜索和 Gmail 这样的 Google 服务的关键。谷歌决定开源其基础设施为世界上任何一家公司创造了一种像顶尖公司一样运行其基础架构的方式。
### 最大的开源社区之一
在开源之后,Kubernetes 发现自己在与其他容器管理系统竞争,即 Docker Swarm 和 Apache Mesos。Kubernetes 近几个月来超过这些其他系统的原因之一得益于社区和系统背后的支持:它是最大的开源社区之一(GitHub 上超过 27,000 多个星标),有来自上千个组织(1,409 个贡献者)的贡献,并且被集中在一个大型、中立的开源基金会里,即[原生云计算基金会](https://www.cncf.io/)(CNCF)。
CNCF 也是更大的 Linux 基金会的一部分,拥有一些顶级企业成员,其中包括微软、谷歌和亚马逊。此外,CNCF 的企业成员队伍持续增长,SAP 和 Oracle 在过去几个月内加入白金会员。这些加入 CNCF 的公司,其中 Kubernetes 项目是前沿和中心的,这证明了有多少企业投注于社区来实现云计算战略的一部分。
Kubernetes 外围的企业社区也在激增,供应商提供了带有更多的安全性、可管理性和支持的企业版。Red Hat、CoreOS 和 Platform 9 是少数几个使企业级 Kubernetes 成为战略前进的关键因素,并投入巨资以确保开源项目继续得到维护的公司。
### 混合云带来的好处
企业以这样一个飞速的方式采用 Kubernetes 的另一个原因是 Kubernetes 可以在任何云端工作。大多数企业在现有的内部数据中心和公共云之间共享资产,对混合云技术的需求至关重要。
Kubernetes 可以部署在公司先前存在的数据中心内、任意一个公共云环境、甚至可以作为服务运行。由于 Kubernetes 抽象了底层基础架构层,开发人员可以专注于构建应用程序,然后将它们部署到任何这些环境中。这有助于加速公司的 Kubernetes 采用,因为它可以在内部运行 Kubernetes,同时继续构建云战略。
### 现实世界的案例
Kubernetes 继续增长的另一个原因是,大型公司正在利用这项技术来解决业界最大的挑战。Capital One、Pearson Education 和 Ancestry.com 只是少数几家公布了 Kubernetes [使用案例](https://kubernetes.io/case-studies/)的公司。
[Pokemon Go](https://cloudplatform.googleblog.com/2016/09/bringing-Pokemon-GO-to-life-on-Google-Cloud.html) 是最流行的宣传 Kubernetes 能力的使用案例。在它发布之前,人们都觉得在线多人游戏会相当的得到追捧。但当它一旦发布,就像火箭一样起飞,达到了预期流量的 50 倍。通过使用 Kubernetes 作为 Google Cloud 之上的基础设施层,Pokemon Go 可以大规模扩展以满足意想不到的需求。
最初作为来自 Google 的开源项目,背后有 Google 15 年的服务经验和来自 Borg 的继承- Kubernetes 现在是有许多企业成员的大型基金会(CNCF)的一部分。它继续受到欢迎,并被广泛应用于金融、大型多人在线游戏(如 Pokemon Go)以及教育公司和传统企业 IT 的关键任务中。考虑到所有,所有的迹象表明,Kubernetes 将继续更加流行,并仍然是开源中最大的成功案例之一。
---
作者简介:
Anurag Gupta - Anurag Gupta 是推动统一日志层 Fluentd Enterprise 发展的 Treasure Data 的产品经理。 Anurag 致力于大型数据技术,包括 Azure Log Analytics 和如 Microsoft System Center 的企业 IT 服务。
---
via: <https://opensource.com/article/17/10/why-kubernetes-so-popular>
作者:[Anurag Gupta](https://opensource.com/users/anuraggupta) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [Kubernetes](https://kubernetes.io/), an open source container management system, has surged in popularity in the past several years. Used by the largest enterprises in a wide range of industries for mission-critical tasks, it has become one of the biggest success stories in open source. How did that happen? And what is it about Kubernetes that explains its widespread adoption?
## Kubernetes' backstory: Origins in Google's Borg system
As the computing world became more distributed, more network-based, and more about cloud computing, we saw large, monolithic apps slowly transform into multiple, agile microservices. These microservices allowed users to individually scale key functions of an application and handle millions and millions of customers. On top of this paradigm change, we saw technologies like Docker containers emerge in the enterprise, creating a consistent, portable, and easy way for users to quickly build these microservices.
While Docker continued to thrive, managing these microservices and containers became a paramount requirement. That's when Google, which had been running container-based infrastructure for many years, made the bold decision to open source an in-house project called [Borg](http://queue.acm.org/detail.cfm?id=2898444). The Borg system was key to running Google's services, such as Google Search and Gmail. This decision by Google to open source its infrastructure has created a way for any company in the world to run its infrastructure like one of the top companies in the world.
## One of the biggest open source communities
After its open source release, Kubernetes found itself competing with other container-management systems, namely Docker Swarm and Apache Mesos. One of the reasons Kubernetes surged past these other systems in recent months is the community and support behind the system: It's one of the largest open source communities (more than 27,000+ stars on GitHub); has contributions from thousands of organizations (1,409 contributors); and is housed within a large, neutral open source foundation, the [Cloud Native Computing Foundation](https://www.cncf.io/) (CNCF).
The CNCF, which is also part of the larger Linux Foundation, has some of the top enterprise companies as members, including Microsoft, Google, and Amazon Web Services. Additionally, the ranks of enterprise members in CNCF continue to grow, with SAP and Oracle joining as Platinum members within the past couple of months. These companies joining the CNCF, where the Kubernetes project is front and center, is a testament to how much these enterprises are betting on the community to deliver a portion of their cloud strategy.
The enterprise community around Kubernetes has also surged, with vendors providing enterprise versions with added security, manageability, and support. Red Hat, CoreOS, and Platform 9 are some of the few that have made Enterprise Kubernetes offerings key to their strategy going forward and have invested heavily in ensuring the open source project continues to be maintained.
## Delivering the benefits of the hybrid cloud
Yet another reason why enterprises are adopting Kubernetes at such a breakneck pace is that Kubernetes can work in any cloud. With most enterprises sharing assets between their existing on-premises datacenters and the public cloud, the need for hybrid cloud technologies is critical.
Kubernetes can be deployed in a company's pre-existing datacenter on premises, in one of the many public cloud environments, and even run as a service. Because Kubernetes abstracts the underlying infrastructure layer, developers can focus on building applications, then deploy them to any of those environments. This helps accelerate a company's Kubernetes adoption, because it can run Kubernetes on-premises while continuing to build out its cloud strategy.
## Real-world use cases
Another reason Kubernetes continues to surge is that major corporations are using the technology to tackle some of the industry's largest challenges. Capital One, Pearson Education, and Ancestry.com are just a few of the companies that have published Kubernetes [use cases](https://kubernetes.io/case-studies/).
[Pokemon Go](https://cloudplatform.googleblog.com/2016/09/bringing-Pokemon-GO-to-life-on-Google-Cloud.html) is one of the most-popular publicized use cases showing the power of Kubernetes. Before its release, the online multiplayer game was expected to be reasonably popular. But as soon as it launched, it took off like a rocket, garnering 50 times the expected traffic. By using Kubernetes as the infrastructure overlay on top of Google Cloud, Pokemon Go could scale massively to keep up with the unexpected demand.
What started out as an open source project from Google—backed by 15 years of experience running Google services and a heritage from Google Borg—Kubernetes is now open source software that is part of a big foundation (CNCF) with many enterprise members. It continues to grow in popularity and is being widely used with mission-critical apps in finance, in massive multiplayer online games like Pokemon Go, and by educational companies and traditional enterprise IT. Considered together, all signs point to Kubernetes continuing to grow in popularity and remaining one of the biggest success stories in open source.
## 3 Comments |
9,037 | 2017 年哪个公司对开源贡献最多?让我们用 GitHub 的数据分析下 | https://medium.freecodecamp.org/the-top-contributors-to-github-2017-be98ab854e87 | 2017-11-07T12:20:00 | [
"微软",
"开源",
"GitHub"
] | https://linux.cn/article-9037-1.html | 
在这篇分析报告中,我们将使用 2017 年度截止至当前时间(2017 年 10 月)为止,GitHub 上所有公开的推送事件的数据。对于每个 GitHub 用户,我们将尽可能地猜测其所属的公司。此外,我们仅查看那些今年得到了至少 20 个星标的仓库。
以下是我的报告结果,你也可以[在我的交互式 Data Studio 报告上进一步加工](https://datastudio.google.com/open/0ByGAKP3QmCjLU1JzUGtJdTlNOG8)。
### 顶级云服务商的比较
2017 年它们在 GitHub 上的表现:
* 微软看起来约有 1300 名员工积极地推送代码到 GitHub 上的 825 个顶级仓库。
* 谷歌显示出约有 900 名员工在 GitHub 上活跃,他们推送代码到大约 1100 个顶级仓库。
* 亚马逊似乎只有 134 名员工活跃在 GitHub 上,他们推送代码到仅仅 158 个顶级项目上。
* 不是所有的项目都一样:在超过 25% 的仓库上谷歌员工要比微软员工贡献的多,而那些仓库得到了更多的星标(53 万对比 26 万)。亚马逊的仓库 2017 年合计才得到了 2.7 万个星标。

### 红帽、IBM、Pivotal、英特尔和 Facebook
如果说亚马逊看起来被微软和谷歌远远抛在了身后,那么这之间还有哪些公司呢?根据这个排名来看,红帽、Pivotal 和英特尔在 GitHub 上做出了巨大贡献:
注意,下表中合并了所有的 IBM 地区域名(各个地区会展示在其后的表格中)。


Facebook 和 IBM(美)在 GitHub 上的活跃用户数同亚马逊差不多,但是它们所贡献的项目得到了更多的星标(特别是 Facebook):

接下来是阿里巴巴、Uber 和 Wix:

以及 GitHub 自己、Apache 和腾讯:

百度、苹果和 Mozilla:

(LCTT 译注:很高兴看到国内的顶级互联网公司阿里巴巴、腾讯和百度在这里排名前列!)
甲骨文、斯坦福大学、麻省理工、Shopify、MongoDb、伯克利大学、VmWare、Netflix、Salesforce 和 Gsa.gov:

LinkedIn、Broad Institute、Palantir、雅虎、MapBox、Unity3d、Automattic(WordPress 的开发商)、Sandia、Travis-ci 和 Spotify:

Chromium、UMich、Zalando、Esri、IBM (英)、SAP、EPAM、Telerik、UK Cabinet Office 和 Stripe:

Cern、Odoo、Kitware、Suse、Yandex、IBM (加)、Adobe、AirBnB、Chef 和 The Guardian:

Arm、Macports、Docker、Nuxeo、NVidia、Yelp、Elastic、NYU、WSO2、Mesosphere 和 Inria:

Puppet、斯坦福(计算机科学)、DatadogHQ、Epfl、NTT Data 和 Lawrence Livermore Lab:

### 我的分析方法
#### 我是怎样将 GitHub 用户关联到其公司的
在 GitHub 上判定每个用户所属的公司并不容易,但是我们可以使用其推送事件的提交消息中展示的邮件地址域名来判断。
* 同样的邮件地址可以出现在几个用户身上,所以我仅考虑那些对此期间获得了超过 20 个星标的项目进行推送的用户。
* 我仅统计了在此期间推送超过 3 次的 GitHub 用户。
* 用户推送代码到 GitHub 上可以在其推送中显示许多不同的邮件地址,这部分是由 GIt 工作机制决定的。为了判定每个用户的组织,我会查找那些在推送中出现更频繁的邮件地址。
* 不是每个用户都在 GitHub 上使用其组织的邮件。有许多人使用 gmail.com、users.noreply.github.com 和其它邮件托管商的邮件地址。有时候这是为了保持匿名和保护其公司邮箱,但是如果我不能定位其公司域名,这些用户我就不会统计。抱歉。
* 有时候员工会更换所任职的公司。我会将他们分配给其推送最多的公司。
#### 我的查询语句
```
#standardSQL
WITH
period AS (
SELECT *
FROM `githubarchive.month.2017*` a
),
repo_stars AS (
SELECT repo.id, COUNT(DISTINCT actor.login) stars, APPROX_TOP_COUNT(repo.name, 1)[OFFSET(0)].value repo_name
FROM period
WHERE type='WatchEvent'
GROUP BY 1
HAVING stars>20
),
pushers_guess_emails_and_top_projects AS (
SELECT *
# , REGEXP_EXTRACT(email, r'@(.*)') domain
, REGEXP_REPLACE(REGEXP_EXTRACT(email, r'@(.*)'), r'.*.ibm.com', 'ibm.com') domain
FROM (
SELECT actor.id
, APPROX_TOP_COUNT(actor.login,1)[OFFSET(0)].value login
, APPROX_TOP_COUNT(JSON_EXTRACT_SCALAR(payload, '$.commits[0].author.email'),1)[OFFSET(0)].value email
, COUNT(*) c
, ARRAY_AGG(DISTINCT TO_JSON_STRING(STRUCT(b.repo_name,stars))) repos
FROM period a
JOIN repo_stars b
ON a.repo.id=b.id
WHERE type='PushEvent'
GROUP BY 1
HAVING c>3
)
)
SELECT * FROM (
SELECT domain
, githubers
, (SELECT COUNT(DISTINCT repo) FROM UNNEST(repos) repo) repos_contributed_to
, ARRAY(
SELECT AS STRUCT JSON_EXTRACT_SCALAR(repo, '$.repo_name') repo_name
, CAST(JSON_EXTRACT_SCALAR(repo, '$.stars') AS INT64) stars
, COUNT(*) githubers_from_domain FROM UNNEST(repos) repo
GROUP BY 1, 2
HAVING githubers_from_domain>1
ORDER BY stars DESC LIMIT 3
) top
, (SELECT SUM(CAST(JSON_EXTRACT_SCALAR(repo, '$.stars') AS INT64)) FROM (SELECT DISTINCT repo FROM UNNEST(repos) repo)) sum_stars_projects_contributed_to
FROM (
SELECT domain, COUNT(*) githubers, ARRAY_CONCAT_AGG(ARRAY(SELECT * FROM UNNEST(repos) repo)) repos
FROM pushers_guess_emails_and_top_projects
#WHERE domain IN UNNEST(SPLIT('google.com|microsoft.com|amazon.com', '|'))
WHERE domain NOT IN UNNEST(SPLIT('gmail.com|users.noreply.github.com|qq.com|hotmail.com|163.com|me.com|googlemail.com|outlook.com|yahoo.com|web.de|iki.fi|foxmail.com|yandex.ru', '|')) # email hosters
GROUP BY 1
HAVING githubers > 30
)
WHERE (SELECT MAX(githubers_from_domain) FROM (SELECT repo, COUNT(*) githubers_from_domain FROM UNNEST(repos) repo GROUP BY repo))>4 # second filter email hosters
)
ORDER BY githubers DESC
```
### FAQ
#### 有的公司有 1500 个仓库,为什么只统计了 200 个?有的仓库有 7000 个星标,为什么只显示 1500 个?
我进行了过滤。我只统计了 2017 年的星标。举个例子说,Apache 在 GitHub 上有超过 1500 个仓库,但是今年只有 205 个项目得到了超过 20 个星标。


#### 这表明了开源的发展形势么?
注意,这个对 GitHub 的分析没有包括像 Android、Chromium、GNU、Mozilla 等顶级社区,也没有包括 Apache 基金会或 Eclipse 基金会,还有一些[其它](https://developers.google.com/open-source/organizations)项目选择在 GitHub 之外开展起活动。
#### 这对于我的组织不公平
我只能统计我所看到的数据。欢迎对我的统计的前提提出意见,以及对我的统计方法给出改进方法。如果有能用的查询语句就更好了。
举个例子,要看看当我合并了 IBM 的各个地区域名到其顶级域时排名发生了什么变化,可以用一条 SQL 语句解决:
```
SELECT *, REGEXP_REPLACE(REGEXP_EXTRACT(email, r'@(.*)'), r'.*.ibm.com', 'ibm.com') domain
```


当合并了其地区域名后, IBM 的相对位置明显上升了。
#### 回音
* [关于“ GitHub 2017 年顶级贡献者”的一些思考](https://redmonk.com/jgovernor/2017/10/25/some-thoughts-on-the-top-contributors-to-github-2017/)
### 接下来
我以前犯过错误,而且以后也可能再次出错。请查看所有的原始数据,并质疑我的前提假设——看看你能得到什么结论是很有趣的。
* [用一下交互式 Data Studio 报告](https://datastudio.google.com/open/0ByGAKP3QmCjLU1JzUGtJdTlNOG8)
感谢 [Ilya Grigorik](https://medium.com/@igrigorik) 保留的 [GitHub Archive](http://githubarchive.org/) 提供了这么多年的 GitHub 数据!
想要看更多的文章?看看我的 [Medium](http://medium.com/@hoffa/)、[在 twitter 上关注我](http://twitter.com/felipehoffa) 并订阅 [reddit.com/r/bigquery](https://reddit.com/r/bigquery)。[试试 BigQuery](https://www.reddit.com/r/bigquery/comments/3dg9le/analyzing_50_billion_wikipedia_pageviews_in_5/),每个月可以[免费](https://cloud.google.com/blog/big-data/2017/01/how-to-run-a-terabyte-of-google-bigquery-queries-each-month-without-a-credit-card)分析 1 TB 的数据。
---
via: <https://medium.freecodecamp.org/the-top-contributors-to-github-2017-be98ab854e87>
作者:[Felipe Hoffa](https://medium.freecodecamp.org/@hoffa?source=post_header_lockup) 译者:[wxy](https://github.com/wxy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,038 | GitLab:我们正将源码贡献许可证切换到 DCO | https://about.gitlab.com/2017/11/01/gitlab-switches-to-dco-license/ | 2017-11-07T16:48:00 | [
"DCO",
"SLA"
] | https://linux.cn/article-9038-1.html |
>
> 我们希望通过取消“<ruby> 贡献者许可协议 <rt> Contributor License Agreement </rt></ruby>”(CLA)来支持“<ruby> <a href="https://docs.google.com/a/gitlab.com/document/d/1zpjDzL7yhGBZz3_7jCjWLfRQ1Jryg1mlIVmG8y6B1_Q/edit?usp=sharing"> 开发者原创证书 </a> <rt> Developer's Certificate of Origin </rt></ruby>”(DCO),让每个人都能更轻松地做出贡献。
>
>
>

我们致力于成为[开源的好管家](https://about.gitlab.com/2016/01/11/being-a-good-open-source-steward/),而这一承诺的一部分意味着我们永远不会停止重新评估我们如何做到这一点。承诺“每个人都可以贡献”就是消除贡献的障碍。对于我们的一些社区,“<ruby> 贡献者许可协议 <rt> Contributor License Agreement </rt></ruby>”(CLA)是对 GitLab 贡献的阻碍,所以我们改为“<ruby> <a href="https://docs.google.com/a/gitlab.com/document/d/1zpjDzL7yhGBZz3_7jCjWLfRQ1Jryg1mlIVmG8y6B1_Q/edit?usp=sharing"> 开发者原创证书 </a> <rt> Developer's Certificate of Origin </rt></ruby>”(DCO)。
许多大型的开源项目都想成为自己命运的主人。拥有基于开源软件运行自己的基础架构的自由,以及修改和审计源代码的能力,而不依赖于供应商,这使开源具有吸引力。我们希望 GitLab 成为每个人的选择。
### 为什么改变?
贡献者许可协议(CLA)是对其它项目进行开源贡献的行业标准,但对于不愿意考虑法律条款的开发人员来说,这是不受欢迎的,并且由于需要审查冗长的合同而潜在地放弃他们的一些权利。贡献者发现协议不必要的限制,并且阻止开源项目的开发者使用 GitLab。我们接触过 Debian 开发人员,他们考虑放弃 CLA,而这就是我们正在做的。
### 改变了什么?
到今天为止,我们正在推出更改,以便 GitLab 源码的贡献者只需要一个项目许可证(所有仓库都是 MIT,除了 Omnibus 是 Apache 许可证)和一个[开发者原创证书](https://developercertificate.org/) (DCO)即可。DCO 为开发人员提供了更大的灵活性和可移植性,这也是 Debian 和 GNOME 计划将其社区和项目迁移到 GitLab 的原因之一。我们希望这一改变能够鼓励更多的开发者为 GitLab 做出贡献。谢谢 Debian,提醒我们做出这个改变。
>
> “我们赞扬 GitLab 放弃他们的 CLA,转而使用对 OSS 更加友好的方式,开源社区诞生于一个汇集在一起并转化为项目的贡献海洋,这一举动肯定了 GitLab 愿意保护个人及其创作过程,最重要的是,把知识产权掌握在创造者手中。”
>
>
> —— GNOME 董事会主席 Carlos Soriano
>
>
>
>
> “我们很高兴看到 GitLab 通过从 CLA 转换到 DCO 来简化和鼓励社区贡献。我们认识到,做这种本质性的改变并不容易,我们赞扬 GitLab 在这里所展示的时间、耐心和深思熟虑的考虑。”
>
>
> —— Debian 项目负责人 Chris Lamb
>
>
>
你可以[阅读这篇关于我们做出这个决定的分析](https://docs.google.com/a/gitlab.com/document/d/1zpjDzL7yhGBZz3_7jCjWLfRQ1Jryg1mlIVmG8y6B1_Q/edit?usp=sharing)。阅读所有关于我们 [GitLab 社区版的管理](https://about.gitlab.com/stewardship/)。
---
via: <https://about.gitlab.com/2017/11/01/gitlab-switches-to-dco-license/>
作者:[Jamie Hurewitz](https://about.gitlab.com/team/#hurewitzjamie) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,039 | Linux 是如何成功运作的 | https://www.datamation.com/open-source/why-linux-works.html | 2017-11-07T23:38:00 | [
"Linux",
"社区"
] | https://linux.cn/article-9039-1.html | 
>
> 在大量金钱与围绕 Linux 激烈争夺的公司之间,真正给操作系统带来活力的正是那些开发者。
>
>
>
事实证明上,Linux 社区是可行的,因为它本身无需太过担心社区的正常运作。尽管 Linux 已经在超级计算机、移动设备和云计算等多个领域占据了主导的地位,但 Linux 内核开发人员更多的是关注于代码本身,而不是其所在公司的利益。
这是一个出现在 [Dawn Foster 博士](https://opensource.com/article/17/10/collaboration-linux-kernel)研究 Linux 内核协作开发的博士论文中的重要结论。Foster 是在英特尔公司和<ruby> 木偶实验室 <rt> Puppet Labs </rt></ruby>的前任社区领导人,他写到,“很多人首先把自己看作是 Linux 内核开发者,其次才是作为一名雇员。”
随着大量的“<ruby> 基金洗劫型 <rt> foundation washing </rt></ruby>”公司开始侵蚀各种开源项目,意图在虚构的社区面具之下隐藏企业特权,但 Linux 依然设法保持了自身的纯粹。问题是这是怎么做到的?
### 跟随金钱的脚步
毕竟,如果有任何开源项目会进入到企业贪婪的视线中,那它一定是 Linux。早在 2008 年,[Linux 生态系统的估值已经达到了最高 250 亿美元](http://www.osnews.com/story/20416/Linux_Ecosystem_Worth_25_Billion)。最近 10 年,伴随着数量众多的云服务、移动端,以及大数据基础设施对于 Linux 的依赖,这一数据一定倍增了。甚至在像 Oracle 这样单独一个公司里,Linux 也能提供数十亿美元的价值。
那么就难怪有这样一个通过代码来影响 Linux 发展方向的必争之地。
在 [Linux 基金会的最新报道](https://www.linux.com/publications/linux-kernel-development-how-fast-it-going-who-doing-it-what-they-are-doing-and-who-5)中,让我们看看在过去一年中那些最活跃的 Linux 贡献者,以及他们所在的企业[像](/article-8220-1.html)[“海龟”一样](https://en.wikipedia.org/wiki/Turtles_all_the_way_down)高高叠起。

这些企业花费大量的资金来雇佣开发者去为自由软件做贡献,并且每个企业都从这些投资中得到了回报。由于存在企业对 Linux 过度影响的潜在可能,导致一些人对引领 Linux 开发的 Linux 基金会[表示不满](https://www.datamation.com/open-source/the-linux-foundation-and-the-uneasy-alliance.html)。在像微软这样曾经的开源界宿敌的企业挥舞着钞票进入 Linux 基金会之后,这些批评言论正变得越来越响亮。
但这只是一位虚假的敌人,坦率地说,这是一个以前的敌人。
虽然企业为了利益而给 Linux 基金会投入资金已经是事实,不过这些赞助并不能收买基金会而影响到代码。在这个最伟大的开源社区中,金钱可以帮助招募到开发者,但这些开发者相比关注企业而更专注于代码。就像 Linux 基金会执行董事 [Jim Zemlin 所强调的](https://thenewstack.io/linux-foundation-critics/):
>
> “我们的项目中技术角色都是独立于企业的。没有人会在其提交的内容上标记他们的企业身份: 在 Linux 基金会的项目当中有关代码的讨论是最大声的。在我们的项目中,开发者可以从一个公司跳槽到另一个公司而不会改变他们在项目中所扮演的角色。之后企业或政府采用了这些代码而创造的价值,反过来又投资到项目上。这样的良性循环有益于所有人,并且也是我们的项目目标。”
>
>
>
任何读过 [Linus Torvalds 的](https://github.com/torvalds) 的邮件列表评论的人都不可能认为他是个代表着这个或那个公司的人。这对于其他的杰出贡献者来说也是一样的。虽然他们几乎都是被大公司所雇佣,但是一般情况下,这些公司为这些开发者支付薪水让他们去做想做的开发,而且事实上,他们正在做他们想做的。
毕竟,很少有公司会有足够的耐心或承受风险来为资助一群新手 Linux 内核开发者,并等上几年,等他们中出现几个人可以贡献出质量足以打动内核团队的代码。所以他们选择雇佣已有的、值得信赖的开发者。正如 [2016 Linux 基金会报告](https://www.linux.com/publications/linux-kernel-development-how-fast-it-going-who-doing-it-what-they-are-doing-and-who-5)所写的,“无薪开发者的数量正在持续地缓慢下降,同时 Linux 内核开发被证明是一种雇主们所需要的日益有价值的技能,这确保了有经验的内核开发者不会长期停留在无薪阶段。”
然而,这样的信任是代码所带来的,并不是通过企业的金钱。因此没有一个 Linux 内核开发者会为眼前的金钱而丢掉他们已经积攒的信任,当出现新的利益冲突时妥协代码质量就很快失去信任。因此不存在这种问题。
### 不是康巴亚,就是权利的游戏,非此即彼
最终,Linux 内核开发就是一种身份认同, Foster 的研究是这样认为的。
为 Google 工作也许很棒,而且也许带有一个体面的头衔以及免费的干洗。然而,作为一个关键的 Linux 内核子系统的维护人员,很难得到任意数量的公司承诺高薪酬的雇佣机会。
Foster 这样写到,“他们甚至享受当前的工作并且觉得他们的雇主不错,许多(Linux 内核开发者)倾向于寻找一些临时的工作关系,那样他们作为内核开发者的身份更被视作固定工作,而且更加重要。”
由于作为一名 Linux 开发者的身份优先,企业职员的身份次之,Linux 内核开发者甚至可以轻松地与其雇主的竞争对手合作。之所以这样,是因为雇主们最终只能有限制地控制开发者的工作,原因如上所述。Foster 深入研究了这一问题:
>
> “尽管企业对其雇员所贡献的领域产生了一些影响,在他们如何去完成工作这点上,雇员还是很自由的。许多人在日常工作中几乎没有接受任何指令,来自雇主的高度信任对工作是非常有帮助的。然而,他们偶尔会被要求做一些特定的零碎工作或者是在一个对公司重要的特定领域投入兴趣。
>
>
> 许多内核开发者也与他们的竞争者展开日常的基础协作,在这里他们仅作为个人相互交流,而不需要关心雇主之间的竞争。这是我在 Intel 工作时经常见到的一幕,因为我们内核开发者几乎都是与我们主要的竞争对手一同工作的。”
>
>
>
那些公司可能会在运行 Linux 的芯片上、或 Linux 发行版,亦或者是被其他健壮的操作系统支持的软件上产生竞争,但开发者们主要专注于一件事情:使 Linux 越来越好。同样,这是因为他们的身份与 Linux 维系在一起,而不是编码时所在防火墙(指公司)。
Foster 通过 USB 子系统的邮件列表(在 2013 年到 2015 年之间)说明了这种相互作用,用深色线条描绘了公司之间更多的电子邮件交互:

在价格讨论中一些公司明显的来往可能会引起反垄断机构的注意,但在 Linux 大陆中,这只是简单的商业行为。结果导致为所有各方在自由市场相互竞争中得到一个更好的操作系统。
### 寻找合适的平衡
这样的“合作”,如 Novell 公司的创始人 Ray Noorda 所说的那样,存在于最佳的开源社区里,但只有在真正的社区里才存在。这很难做到,举个例子,对一个由单一供应商所主导的项目来说,实现正确的合作关系很困难。由 Google 发起的 [Kubernetes](https://kubernetes.io/) 表明这是可能的,但其它像是 Docker 这样的项目却在为同样的目标而挣扎,很大一部分原因是他们一直不愿放弃对自己项目的技术领导。
也许 Kubernetes 能够工作的很好是因为 Google 并不觉得必须占据重要地位,而且事实上,它*希望*其他公司担负起开发领导的职责。凭借出色的代码解决了一个重要的行业需求,像 Kubernetes 这样的项目就能获得成功,只要 Google 既能帮助它,又为它开辟出一条道路,这就鼓励了 Red Hat 及其它公司做出杰出的贡献。
不过,Kubernetes 是个例外,就像 Linux 曾经那样。成功是因为企业的贪婪,有许多要考虑的,并且要在之间获取平衡。如果一个项目仅仅被公司自己的利益所控制,常常会在公司的技术管理上体现出来,而且再怎么开源许可也无法对企业产生影响。
简而言之,Linux 的成功运作是因为众多企业都想要控制它但却难以做到,由于其在工业中的重要性,使得开发者和构建人员更愿意作为一名 Linux 开发者 而不是 Red Hat (或 Intel 亦或 Oracle … )工程师。
---
via: <https://www.datamation.com/open-source/why-linux-works.html>
作者:[Matt Asay](https://www.datamation.com/author/Matt-Asay-1133910.html) 译者:[softpaopao](https://github.com/softpaopao) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,041 | 不,Linux 桌面版并没有突然流行起来 | http://www.zdnet.com/article/no-the-linux-desktop-hasnt-jumped-in-popularity/ | 2017-11-08T21:58:00 | [
"Linux",
"市场份额"
] | https://linux.cn/article-9041-1.html |
>
> 最近流传着这样一个传闻,Linux 桌面版已经突然流行起来了,并且使用者超过了 macOS。其实,并不是的。
>
>
>

有一些传闻说,Linux 桌面版的市场占有率从通常的 1.5% - 3% 翻了一番,达到 5%。那些报道是基于 [NetMarketShare](https://www.netmarketshare.com/) 的桌面操作系统分析报告而来的,据其显示,在七月份,Linux 桌面版的市场占有率从 2.5% 飙升,在九月份几乎达到 5%。但对 Linux 爱好者来说,很不幸,它并不是真的。
它也不是因为加入了谷歌推出的 Chrome OS,它在 [NetMarketShare](https://www.netmarketshare.com/) 和 [StatCounter](https://statcounter.com/) 的桌面操作系统的数据中被低估,它被认为是 Linux。但请注意,那是公正的,因为 [Chrome OS 是基于 Linux 的](http://www.zdnet.com/article/the-secret-origins-of-googles-chrome-os/)。
真正的解释要简单的多。这似乎只是一个错误。NetMarketShare 的市场营销高管 Vince Vizzaccaro 告诉我,“Linux 份额是不正确的。我们意识到这个问题,目前正在调查此事”。(LCTT 译注:已经修复该错误)
如果这听起来很奇怪,那是因为你可能认为,NetMarketShare 和 StatCounter 只是计算用户数量。但他们不是这样的。相反,他们都使用自己的秘密的方法去统计这些操作系统的数据。
NetMarketShare 的方法是对 “[从网站访问者的浏览器中收集数据](http://www.netmarketshare.com/faq.aspx#Methodology)到我们专用的请求式 HitsLink 分析网络中和 SharePost 客户端。该网络包括超过 4 万个网站,遍布全球。我们‘计数’访问我们的网络站点的唯一访客,并且一个唯一访客每天每个网络站点只计数一次。”
然后,公司按国家对数据进行加权。“我们将我们的流量与 CIA 互联网流量按国家进行比较,并相应地对我们的数据进行加权。例如,如果我们的全球数据显示巴西占我们网络流量的 2%,而 CIA 的数据显示巴西占全球互联网流量的 4%,那么我们将统计每一个来自巴西的唯一访客两次。”
他们究竟如何 “权衡” 每天访问一个站点的数据?我们不知道。
StatCounter 也有自己的方法。它使用 “[在全球超过 200 万个站点上安装的跟踪代码](http://gs.statcounter.com/faq#methodology)。这些网站涵盖了各种类型和不同的地理位置。每个月,我们都会记录在这些站点上的数十亿页的页面访问。对于每个页面访问,我们分析其使用的浏览器/操作系统/屏幕分辨率(如果页面访问来自移动设备)。 ... 我们统计了所有这些数据以获取我们的全球统计信息。
我们为互联网使用趋势提供独立的、公正的统计数据。我们不与任何其他信息源核对我们的统计数据,也 [没有使用人为加权](http://gs.statcounter.com/faq#no-weighting)。”
他们如何汇总他们的数据?你猜猜看?其它我们也不知道。
因此,无论何时,你看到的他们这些经常被引用的操作系统或浏览器的数字,使用它们要有很大的保留余地。
对于更精确的,以美国为对象的操作系统和浏览器数量,我更喜欢使用联邦政府的 [数字分析计划(DAP)](https://www.digitalgov.gov/services/dap/)。
与其它的不同, DAP 的数字来自在过去的 90 天访问过 [400 个美国政府行政机构域名](https://analytics.usa.gov/data/live/second-level-domains.csv) 的数十亿访问者。那里有 [大概 5000 个网站](https://analytics.usa.gov/data/live/sites.csv),并且包含每个内阁部门。 DAP 从一个谷歌分析帐户中得到原始数据。 DAP [开源了它在这个网站上显示其数据的代码](https://github.com/GSA/analytics.usa.gov) 以及它的 [数据收集代码](https://github.com/18F/analytics-reporter)。最重要的是,与其它的不同,你可以以 [JSON](http://json.org/) 格式下载它的数据,这样你就可以自己分析原始数据了。
在 [美国分析](https://analytics.usa.gov/) 网站上,它汇总了 DAP 的数据,你可以找到 Linux 桌面版,和往常一样,它仍以 1.5% 列在 “其它” 中。Windows 仍然是高达 45.9%,接下来是 Apple iOS,占 25.5%,Android 占 18.6%,而 macOS 占 8.5%。
对不起,伙计们,我也希望它更高,但是,这就是事实。没有人,即使是 DAP,似乎都无法很好地将基于 Linux 的 Chrome OS 数据单列出来。尽管如此,Linux 桌面版仍然是 Linux 高手、软件开发者、系统管理员和工程师的专利。Linux 爱好者们还只能对其它所有的计算机设备 —— 服务器、云、超级计算机等等的(Linux)操作系统表示自豪。
---
via: <http://www.zdnet.com/article/no-the-linux-desktop-hasnt-jumped-in-popularity/>
作者:[Steven J. Vaughan-Nichols](http://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,042 | 明确 GPL 版本号,避免许可证混淆 | https://opensource.com/article/17/11/avoiding-gpl-confusion | 2017-11-08T23:55:01 | [
"GPL",
"许可证"
] | https://linux.cn/article-9042-1.html |
>
> 明确是避免许可歧义的关键所在。
>
>
>

在许可证的过去、当前和未来版本如何适用于软件程序方面,[GPL 系列许可证](https://www.gnu.org/licenses/licenses.html)在开源许可证中可谓独树一帜。如果不能完全理解其中独有的许可证特性,开源软件开发人员可能会无意中造成混淆。
GPL 许可证在其许可证的条款和条件中阐明了许可证版本如何适用于该程序。[GPL v2](https://www.gnu.org/licenses/old-licenses/gpl-2.0.en.html#SEC3)(第 9 条)写到:
>
> “每个版本都有一个独特的版本号,如果该程序指定了其适用的许可证的版本号以及‘任何更新的版本’,则可以选择遵循由<ruby> 自由软件基金会 <rp> ( </rp> <rt> Free Software Foundation </rt> <rp> ) </rp></ruby>发布的该版本或之后任何更新版本的条款和条件。如果该程序未指定许可证的版本号,则可以选择自由软件基金会以前发布的任何版本。”
>
>
>
[GPL v3](https://www.gnu.org/licenses/gpl.html) 第 14 条与 GPL v2 中的上述条款非常相似。
多年以来,我看到很多开源项目表示遵循 GPL 许可证,但却没有明确指出版本号,同时也没有将整个 GPL 许可证(例如,v2 或 v3)副本囊括在程序内。取决于您是许可人还是被许可人等因素,这其中造成的含混不清可能对您有益或有害。
### 许可证的模糊如何产生影响
例如,假设应用程序的许可证声明:“本程序遵循 GPL 许可证”,并且包含整个 GPL v3 许可证的副本。由于该项目没有明确说明适用该许可证的哪个版本号,所以合理的解释是自由软件基金会发布的所有版本 GPL 许可证都适用——v3、v2 甚至 v1!
依据 GPL v3 第 14 条的下述文本可以合乎情理地做出上述理解。
>
> “如果该程序未指定 GNU GPL 的版本号,则可以选择由自由软件基金会发布的任何版本。”
>
>
>
另一方面,将 GPL 特定版本的完整副本(还可能包括许可证标题块中的 GPL 版本号)包含在程序中,可以被解释为在实质上传递了特定版本的许可证。在这个例子中,那就是 GPL v3 版本并且只有 GPL v3 版本,因为 v3 中没有“任何更新的版本”的条款。
### 如何避免许可歧义
为了避免这种许可歧义,您应该写得非常明确。如果您只想适用 GPL v3,应该明确地声明:“本程序仅遵循 GPL v3”,并提供整个 GPL v3 许可证副本。或者,如果您希望适用 GPL v3 或之后更新的版本,请明确声明:“本程序遵循 GPL v3 或其之后更新的版本”。最后,如果您真的想要适用任何版本的 GPL 许可证,您可以提供 GPL v3 许可证,并表示:“本程序遵循由自由软件基金会发布的任何版本的 GPL 许可证”。
无论您选择哪种授权方式,都应该非常明确,让每个人都能理解您的真正意图。
---
作者简介:Jeffrey R. Kaufman是全球领先的开源软件解决方案供应商Red Hat公司的开源知识产权律师,还担任托马斯杰斐逊法学院(Thomas Jefferson School of Law)的兼职教授。在任职Red Hat之前,Jeffrey曾担任高通公司(Qualcomm Incorporated)的专利顾问,为首席科学家办公室(Office of the Chief Scientist)提供开源事务咨询。
译者简介:薛亮,集慧智佳知识产权咨询公司高级咨询师,擅长专利检索、专利分析、竞争对手跟踪、FTO分析、开源软件知识产权风险分析,致力于为互联网企业、高科技公司提供知识产权咨询服务。
---
via: <https://opensource.com/article/17/11/avoiding-gpl-confusion>
作者:[Jeffrey Robert Kaufman](https://opensource.com/users/jkaufman) 译者:薛亮 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](/article-9041-1.html) 荣誉推出
| 200 | OK | The [GPL family of licenses](https://www.gnu.org/licenses/licenses.html) is unique among open source licenses in how past, current, and future versions of the license may apply to the software program. By not fully understanding this unique license feature, open source software developers may inadvertently create ambiguity.
The GPL licenses clarify how license versions are to be applied to the program with a clause in their terms and conditions. The applicable language in [GPL v2](https://www.gnu.org/licenses/old-licenses/gpl-2.0.en.html#SEC3) (clause 9) reads in part:
"Each version is given a distinguishing version number. If the Program specifies a version number of this License which applies to it and 'any later version,' you have the option of following the terms and conditions either of that version or of any later version published by the Free Software Foundation. If the Program does not specify a version number of this License, you may choose any version ever published by the Free Software Foundation."
The terms in [GPL v3](https://www.gnu.org/licenses/gpl.html) clause 14 are very similar to those in the GPL v2.
Over the years, I've seen many open source projects that say they are GPL licensed without explicitly indicating a version number, while also including the text of an entire GPL license (e.g., v2 or v3). The ambiguity this potentially creates may be beneficial or detrimental to you, depending on factors such as whether you are the licensor or the licensee.
## How the ambiguity plays out
For example, assume that an application's license states: "This program is licensed under the GPL," and includes a copy of the GPL v3 license in its entirety. Because the project did not explicitly communicate which version number of the license applies, a reasonable interpretation would be that any and all versions of the GPL published by the Free Software Foundation may apply—v3, v2, or even v1!
This interpretation may be justified by this sentence in GPL v3 clause 14:
"If the Program does not specify a version number of the GNU General Public License, you may choose any version ever published by the Free Software Foundation."
On the other hand, including a complete copy of a particular version of the GPL (which may also include the GPL version number in the license title block) could be interpreted as, in essence, communicating a specific version of the license. In this example, v3 and only v3, because there is no "any later version" provision.
## How to avoid ambiguity
To avoid this license ambiguity, you should be very clear. If you want *only* v3 to apply, explicitly say so: "The program is licensed only under the GPL v3" *and* provide the entire GPL v3 license. Or if you want v3 or any later version of the GPL to apply, explicitly state: "The program is licensed under the GPL v3 or any later version." Last, if you really want any version of the GPL to apply, you could provide the v3 license and say: "This program is licensed under any version of the GPL published by the Free Software Foundation."
No matter which licensing choice you make, be very clear so everyone understands what you actually mean.
## 2 Comments |
9,043 | GitHub 2017 章鱼猫观察报告 | https://octoverse.github.com/ | 2017-11-09T10:54:00 | [
"GitHub",
"章鱼猫"
] | https://linux.cn/article-9043-1.html | 
又是一年,GitHub 例行发布了 [2017 年度的章鱼猫观察报告](https://octoverse.github.com/)。以下我们撷取此报告中一些有趣的结果分享给大家。
数百万的开发人员使用 GitHub 来共享代码和构建业务。在这里你可以完成你的工作、打造新的技术、贡献给开源项目等等。历史已经证明,当好奇的人聚集到一起工作,一些美好的事情就会随之而来:工作进行得更快、新的想法涌现,从根本上改变了我们建立软件的方式。
为了庆祝这贡献和辉煌的一年, 让我们回顾一下 2017 年的项目、人员和团队。
### 十年千万,遍及全球
过去这十年,GitHub 各项数据已经超过了百万级,甚至千万级。在 2017 年,GitHub 社区有 2400 万开发者工作于 6700 万个仓库上,就连这些开发者组成的组织都达到了 150 万个。
而这些开发者遍及全球:亚洲 710 万,北美 590 万,欧洲 530 万,等等。

### 这一年,忙碌的一年
人们在 2500 万个公开仓库上分享代码。从 2016 年 9 月到现在的一年间:
* 公开仓库的提交数达到了 **1 亿个**!
* 活跃仓库有 2530 万个(“活跃”指该仓库有公开的活动,比如提交、星标、讨论等)
* 活跃<ruby> 工单 <rp> ( </rp> <rt> issue </rt> <rp> ) </rp></ruby>有 1250 万个,关闭(解决)了 6880 万个工单,对工单进行了 140 万次讨论
+ 这其中包括 [Kent 的约聊求助工单](https://github.com/kentcdodds/ama/issues/295) :D
* 新 PR (<ruby> 拉取请求 <rp> ( </rp> <rt> pull request </rt> <rp> ) </rp></ruby>)有 130 万个,
+ 这其中包括了 [Linus Torvalds 的第一个 GitHub PR](https://github.com/Subsurface-divelog/subsurface/pull/155) !
* **第 1 亿个 PR** 被合并,这是一个 [OpenShift 的文档更新](https://github.com/openshift/openshift-docs/pull/4509)
* 对代码进行了 62 万次审查
* 最流行的表情符是:点赞(720 万)
* 新加入 670 万开发者,其有 100 万的开发者来自美国,69 万来自中国
+ 这些新加入的开发者发起了 120 万个 PR,410 万人创建了其第一个仓库,
+ 19 万人没有提交任何代码而只是复刻和星标了仓库
* 创建了 45 万个组织
+ 这其中包括 [Python](https://github.com/python) 的开发也迁移到了 GitHub
### 编程语言,各就其位
通过 PR 所使用的语言,可以发现最流行的语言是——**JavaScript**!而 Python 取代了 Java 成为了第二名。很高兴 Ruby 和 PHP 分别能取得第四、第五名。其余的名次和[去年](/article-7776-1.html)相差不大。

### 项目排名,众望所归
从这些活跃的仓库中,我们找出了 10 大<ruby> 复刻 <rp> ( </rp> <rt> fork </rt> <rp> ) </rp></ruby>数最多的仓库。人工智能方向的 [TensorFlow](https://github.com/tensorflow/tensorflow) 项目夺得桂冠,前端方向的 [BootStrap](https://github.com/twbs/bootstrap) 是第二。尤雨溪的 [vuejs](https://github.com/vuejs/vue) 排名第六,恰恰比排名第七的 Facebook 的 [react](https://github.com/facebook/react) 的复刻数高一点,很难说这与今年 Facebook 对 react 的[许可证问题](/article-8733-1.html)有没有关系。而 Linus 的 [Linux](https://github.com/torvalds/linux) 项目敬陪末座,作为这样庞大的一个项目,已经相当了不起了。

(这里没有包括 MOOC 课程,[一个 Coursera 的 R 语言课程](https://github.com/rdpeng/ProgrammingAssignment2)有数千的复刻数,以此判断,至少有十万学生开始学习该课程了)
而以贡献者来说,微软的 [vscode](https://github.com/Microsoft/vscode) 项目的贡献者最多,几乎是排在第二名的 [react-native](https://github.com/facebook/react-native) 的两倍。这一方面证明了社区对 vscode 的喜爱,另外一方面也证明了微软在开源方面的重注投入。

得到最多代码评议的项目是 Typescript 的一个类型定义库 [DefinitelyTyped](https://github.com/DefinitelyTyped/DefinitelyTyped),第二名才是炙手可热的 [Kubernetes](https://github.com/kubernetes/kubernetes)。

当然,已经赢得了容器编排系统之战的 [Kerbernetes](https://github.com/kubernetes/kubernetes) 取得讨论最多的排名一点也不令人意外,它的讨论数量的零头就和第二名 [origin](https://github.com/openshift/origin) 差不多,而这个 OpenShift 下的 Origin 项目,也是一个 Kubernetes 项目——面向开发者的企业版 Kubernetes 发行版。

### 企业版,大公司多用
GitHub 虽然对个人的公开使用提供免费的服务,当然,如果你想放私有仓库,是要交费的。而 GitHub 对于或大或小的企业来说,更适用的是其企业版。
* 美国前一百个最大的公司(按收入)有一半在使用 GitHub 企业版
* 虽然美国是使用 GitHub 企业版最多的国家,但是也有 1/4 的客户来自其它国家
* 不仅仅是软件和互联网行业在使用 GitHub 企业版(占 22%),金融服务、商业服务也占比较高
感谢你,让我们期待 2018 年的章鱼猫报告!
| 200 | OK | Octoverse 2023
# The state of open source software
In this year’s report, we’ll study how open source activity around AI, the cloud, and git has changed the developer experience and is increasingly driving impact among developers and organizations alike. |
9,044 | 如何分析博客中最流行的编程语言 | https://www.databrawl.com/2017/10/08/blog-analysis/ | 2017-11-09T18:02:00 | [
"博客",
"编程语言"
] | https://linux.cn/article-9044-1.html |
>
> 摘要:这篇文章我们将对一些各种各样的博客的流行度相对于他们在谷歌上的排名进行一个分析。所有代码可以在 [github](https://github.com/Databrawl/blog_analysis) 上找到。
>
>
>

### 想法来源
我一直在想,各种各样的博客每天到底都有多少页面浏览量,以及在博客阅读受众中最受欢迎的是什么编程语言。我也很感兴趣的是,它们在谷歌的网站排名是否与它们的受欢迎程度直接相关。
为了回答这些问题,我决定做一个 Scrapy 项目,它将收集一些数据,然后对所获得的信息执行特定的数据分析和数据可视化。
### 第一部分:Scrapy
我们将使用 [Scrapy](https://scrapy.org/) 为我们的工作,因为它为抓取和对该请求处理后的反馈进行管理提供了干净和健壮的框架。我们还将使用 [Splash](https://github.com/scrapinghub/splash) 来解析需要处理的 Javascript 页面。Splash 使用自己的 Web 服务器充当代理,并处理 Javascript 响应,然后再将其重定向到我们的爬虫进程。
>
> 我这里没有描述 Scrapy 的设置,也没有描述 Splash 的集成。你可以在[这里](https://docs.scrapy.org/en/latest/intro/tutorial.html)找到 Scrapy 的示例,而[这里](https://blog.scrapinghub.com/2015/03/02/handling-javascript-in-scrapy-with-splash/)还有 Scrapy+Splash 指南。
>
>
>
#### 获得相关的博客
第一步显然是获取数据。我们需要关于编程博客的谷歌搜索结果。你看,如果我们开始仅仅用谷歌自己来搜索,比如说查询 “Python”,除了博客,我们还会得到很多其它的东西。我们需要的是做一些过滤,只留下特定的博客。幸运的是,有一种叫做 [Google 自定义搜索引擎(CSE)](https://en.wikipedia.org/wiki/Google_Custom_Search)的东西,它能做到这一点。还有一个网站 [www.blogsearchengine.org](http://www.blogsearchengine.org/),它正好可以满足我们需要,它会将用户请求委托给 CSE,这样我们就可以查看它的查询并重复利用它们。
所以,我们要做的是到 [www.blogsearchengine.org](http://www.blogsearchengine.org/) 网站,搜索 “python”,并在一侧打开 Chrome 开发者工具中的网络标签页。这截图是我们将要看到的:

突出显示的是 blogsearchengine 向谷歌委派的一个搜索请求,所以我们将复制它,并在我们的 scraper 中使用。
这个博客抓取爬行器类会是如下这样的:
```
class BlogsSpider(scrapy.Spider):
name = 'blogs'
allowed_domains = ['cse.google.com']
def __init__(self, queries):
super(BlogsSpider, self).__init__()
self.queries = queries
```
与典型的 Scrapy 爬虫不同,我们的方法覆盖了 `__init__` 方法,它接受额外的参数 `queries`,它指定了我们想要执行的查询列表。
现在,最重要的部分是构建和执行这个实际的查询。这个过程放在 `start_requests` 爬虫的方法里面执行,我们愉快地覆盖它:
```
def start_requests(self):
params_dict = {
'cx': ['partner-pub-9634067433254658:5laonibews6'],
'cof': ['FORID:10'],
'ie': ['ISO-8859-1'],
'q': ['query'],
'sa.x': ['0'],
'sa.y': ['0'],
'sa': ['Search'],
'ad': ['n9'],
'num': ['10'],
'rurl': [
'http://www.blogsearchengine.org/search.html?cx=partner-pub'
'-9634067433254658%3A5laonibews6&cof=FORID%3A10&ie=ISO-8859-1&'
'q=query&sa.x=0&sa.y=0&sa=Search'
],
'siteurl': ['http://www.blogsearchengine.org/']
}
params = urllib.parse.urlencode(params_dict, doseq=True)
url_template = urllib.parse.urlunparse(
['https', self.allowed_domains[0], '/cse',
'', params, 'gsc.tab=0&gsc.q=query&gsc.page=page_num'])
for query in self.queries:
for page_num in range(1, 11):
url = url_template.replace('query', urllib.parse.quote(query))
url = url.replace('page_num', str(page_num))
yield SplashRequest(url, self.parse, endpoint='render.html',
args={'wait': 0.5})
```
在这里你可以看到相当复杂的 `params_dict` 字典,它控制所有我们之前找到的 Google CSE URL 的参数。然后我们准备好 `url_template` 里的一切,除了已经填好的查询和页码。我们对每种编程语言请求 10 页,每一页包含 10 个链接,所以是每种语言有 100 个不同的博客用来分析。
在 `42-43` 行,我使用一个特殊的类 `SplashRequest` 来代替 Scrapy 自带的 Request 类。它封装了 Splash 库内部的重定向逻辑,所以我们无需为此担心。十分整洁。
最后,这是解析程序:
```
def parse(self, response):
urls = response.css('div.gs-title.gsc-table-cell-thumbnail') \
.xpath('./a/@href').extract()
gsc_fragment = urllib.parse.urlparse(response.url).fragment
fragment_dict = urllib.parse.parse_qs(gsc_fragment)
page_num = int(fragment_dict['gsc.page'][0])
query = fragment_dict['gsc.q'][0]
page_size = len(urls)
for i, url in enumerate(urls):
parsed_url = urllib.parse.urlparse(url)
rank = (page_num - 1) * page_size + i
yield {
'rank': rank,
'url': parsed_url.netloc,
'query': query
}
```
所有 Scraper 的核心和灵魂就是解析器逻辑。可以有多种方法来理解响应页面的结构并构建 XPath 查询字符串。您可以使用 [Scrapy shell](https://doc.scrapy.org/en/latest/topics/shell.html) 尝试并随时调整你的 XPath 查询,而不用运行爬虫。不过我更喜欢可视化的方法。它需要再次用到谷歌 Chrome 开发人员控制台。只需右键单击你想要用在你的爬虫里的元素,然后按下 Inspect。它将打开控制台,并定位到你指定位置的 HTML 源代码。在本例中,我们想要得到实际的搜索结果链接。他们的源代码定位是这样的:

在查看这个元素的描述后我们看到所找的 `<div>` 有一个 `.gsc-table-cell-thumbnail` CSS 类,它是 `.gs-title` `<div>` 的子元素,所以我们把它放到响应对象的 `css` 方法(`46` 行)。然后,我们只需要得到博客文章的 URL。它很容易通过`'./a/@href'` XPath 字符串来获得,它能从我们的 `<div>` 直接子元素的 `href` 属性找到。(LCTT 译注:此处图文对不上)
#### 寻找流量数据
下一个任务是估测每个博客每天得到的页面浏览量。得到这样的数据有[各种方式](https://www.labnol.org/internet/find-website-traffic-hits/8008/),有免费的,也有付费的。在快速搜索之后,我决定基于简单且免费的原因使用网站 [www.statshow.com](http://www.statshow.com/) 来做。爬虫将抓取这个网站,我们在前一步获得的博客的 URL 将作为这个网站的输入参数,获得它们的流量信息。爬虫的初始化是这样的:
```
class TrafficSpider(scrapy.Spider):
name = 'traffic'
allowed_domains = ['www.statshow.com']
def __init__(self, blogs_data):
super(TrafficSpider, self).__init__()
self.blogs_data = blogs_data
```
`blogs_data` 应该是以下格式的词典列表:`{"rank": 70, "url": "www.stat.washington.edu", "query": "Python"}`。
请求构建函数如下:
```
def start_requests(self):
url_template = urllib.parse.urlunparse(
['http', self.allowed_domains[0], '/www/{path}', '', '', ''])
for blog in self.blogs_data:
url = url_template.format(path=blog['url'])
request = SplashRequest(url, endpoint='render.html',
args={'wait': 0.5}, meta={'blog': blog})
yield request
```
它相当的简单,我们只是把字符串 `/www/web-site-url/` 添加到 `'www.statshow.com'` URL 中。
现在让我们看一下语法解析器是什么样子的:
```
def parse(self, response):
site_data = response.xpath('//div[@id="box_1"]/span/text()').extract()
views_data = list(filter(lambda r: '$' not in r, site_data))
if views_data:
blog_data = response.meta.get('blog')
traffic_data = {
'daily_page_views': int(views_data[0].translate({ord(','): None})),
'daily_visitors': int(views_data[1].translate({ord(','): None}))
}
blog_data.update(traffic_data)
yield blog_data
```
与博客解析程序类似,我们只是通过 StatShow 示例的返回页面,然后找到包含每日页面浏览量和每日访问者的元素。这两个参数都确定了网站的受欢迎程度,对于我们的分析只需要使用页面浏览量即可 。
### 第二部分:分析
这部分是分析我们搜集到的所有数据。然后,我们用名为 [Bokeh](https://bokeh.pydata.org/en/latest/) 的库来可视化准备好的数据集。我在这里没有给出运行器和可视化的代码,但是它可以在 [GitHub repo](https://github.com/Databrawl/blog_analysis) 中找到,包括你在这篇文章中看到的和其他一切东西。
>
> 最初的结果集含有少许偏离过大的数据,(如 google.com、linkedin.com、Oracle.com 等)。它们显然不应该被考虑。即使其中有些有博客,它们也不是针对特定语言的。这就是为什么我们基于这个 [StackOverflow 回答](https://stackoverflow.com/a/16562028/1573766) 中所建议的方法来过滤异常值。
>
>
>
#### 语言流行度比较
首先,让我们对所有的语言进行直接的比较,看看哪一种语言在前 100 个博客中有最多的浏览量。
这是能进行这个任务的函数:
```
def get_languages_popularity(data):
query_sorted_data = sorted(data, key=itemgetter('query'))
result = {'languages': [], 'views': []}
popularity = []
for k, group in groupby(query_sorted_data, key=itemgetter('query')):
group = list(group)
daily_page_views = map(lambda r: int(r['daily_page_views']), group)
total_page_views = sum(daily_page_views)
popularity.append((group[0]['query'], total_page_views))
sorted_popularity = sorted(popularity, key=itemgetter(1), reverse=True)
languages, views = zip(*sorted_popularity)
result['languages'] = languages
result['views'] = views
return result
```
在这里,我们首先按语言(词典中的关键字“query”)来分组我们的数据,然后使用 python 的 `groupby` 函数,这是一个从 SQL 中借来的奇妙函数,从我们的数据列表中生成一组条目,每个条目都表示一些编程语言。然后,在第 `14` 行我们计算每一种语言的总页面浏览量,然后添加 `('Language', rank)` 形式的元组到 `popularity` 列表中。在循环之后,我们根据总浏览量对流行度数据进行排序,并将这些元组展开到两个单独的列表中,然后在 `result` 变量中返回它们。
>
> 最初的数据集有很大的偏差。我检查了到底发生了什么,并意识到如果我在 [blogsearchengine.org](http://blogsearchengine.org/) 上查询“C”,我就会得到很多无关的链接,其中包含了 “C” 的字母。因此,我必须将 C 排除在分析之外。这种情况几乎不会在 “R” 和其他类似 C 的名称中出现:“C++”、“C”。
>
>
>
因此,如果我们将 C 从考虑中移除并查看其他语言,我们可以看到如下图:

评估结论:Java 每天有超过 400 万的浏览量,PHP 和 Go 有超过 200 万,R 和 JavaScript 也突破了百万大关。
#### 每日网页浏览量与谷歌排名
现在让我们来看看每日访问量和谷歌的博客排名之间的联系。从逻辑上来说,不那么受欢迎的博客应该排名靠后,但这并没那么简单,因为其他因素也会影响排名,例如,如果在人气较低的博客上的文章更新一些,那么它很可能会首先出现。
数据准备工作以下列方式进行:
```
def get_languages_popularity(data):
query_sorted_data = sorted(data, key=itemgetter('query'))
result = {'languages': [], 'views': []}
popularity = []
for k, group in groupby(query_sorted_data, key=itemgetter('query')):
group = list(group)
daily_page_views = map(lambda r: int(r['daily_page_views']), group)
total_page_views = sum(daily_page_views)
popularity.append((group[0]['query'], total_page_views))
sorted_popularity = sorted(popularity, key=itemgetter(1), reverse=True)
languages, views = zip(*sorted_popularity)
result['languages'] = languages
result['views'] = views
return result
```
该函数接受爬取到的数据和需要考虑的语言列表。我们对这些数据以语言的流行程度进行排序。后来,在类似的语言分组循环中,我们构建了 `(rank, views_number)` 元组(从 1 开始的排名)被转换为 2 个单独的列表。然后将这一对列表写入到生成的字典中。
前 8 位 GitHub 语言(除了 C)是如下这些:


评估结论:我们看到,所有图的 [PCC (皮尔逊相关系数)](https://en.wikipedia.org/wiki/Pearson_correlation_coefficient)都远离 1/-1,这表示每日浏览量与排名之间缺乏相关性。值得注意的是,在大多数图表(8 个中的 7 个)中,相关性是负的,这意味着排名的降低会导致浏览量的减少。
### 结论
因此,根据我们的分析,Java 是目前最流行的编程语言,其次是 PHP、Go、R 和 JavaScript。在日常浏览量和谷歌排名上,排名前 8 的语言都没有很强的相关性,所以即使你刚刚开始写博客,你也可以在搜索结果中获得很高的评价。不过,成为热门博客究竟需要什么,可以留待下次讨论。
>
> 这些结果是相当有偏差的,如果没有更多的分析,就不能过分的考虑这些结果。首先,在较长的一段时间内收集更多的流量信息,然后分析每日浏览量和排名的平均值(中值)值是一个好主意。也许我以后还会再回来讨论这个。
>
>
>
### 引用
1. 抓取:
1. [blog.scrapinghub.com: Handling Javascript In Scrapy With Splash](https://blog.scrapinghub.com/2015/03/02/handling-javascript-in-scrapy-with-splash/)
2. [BlogSearchEngine.org](http://www.blogsearchengine.org/)
3. [twingly.com: Twingly Real-Time Blog Search](https://www.twingly.com/)
4. [searchblogspot.com: finding blogs on blogspot platform](http://www.searchblogspot.com/)
2. 流量评估:
1. [labnol.org: Find Out How Much Traffic a Website Gets](https://www.labnol.org/internet/find-website-traffic-hits/8008/)
2. [quora.com: What are the best free tools that estimate visitor traffic…](https://www.quora.com/What-are-the-best-free-tools-that-estimate-visitor-traffic-for-a-given-page-on-a-particular-website-that-you-do-not-own-or-operate-3rd-party-sites)
3. [StatShow.com: The Stats Maker](http://www.statshow.com/)
---
via: <https://www.databrawl.com/2017/10/08/blog-analysis/>
作者:[Serge Mosin](https://www.databrawl.com/author/svmosingmail-com/) 译者:[Chao-zhi](https://github.com/Chao-zhi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 500 | Internal Server Error | null |
9,045 | 为什么 Ubuntu 放弃 Unity?创始人如是说 | http://www.omgubuntu.co.uk/2017/10/why-did-ubuntu-drop-unity-mark-shuttleworth-explains | 2017-11-10T10:19:00 | [
"Ubuntu",
"Unity"
] | https://linux.cn/article-9045-1.html | 
Mark Shuttleworth 是 Ubuntu 的创始人
Ubuntu 之前[在 4 月份](/article-8428-1.html)宣布决定放弃 Unity 让包括我在内的所有人都大感意外。
现在,Ubuntu 的创始人 [Mark Shuttleworth](https://en.wikipedia.org/wiki/Mark_Shuttleworth) 分享了关于 Ubuntu 为什么会选择放弃 Unity 的更多细节。
答案可能会出乎意料……
或许不会,因为答案也在情理之中。
### 为什么 Ubuntu 放弃 Unity?
上周(10 月 20 日)[Ubuntu 17.10](/article-8980-1.html) 已经发布,这是自 [2011 年引入](http://www.omgubuntu.co.uk/2010/10/ubuntu-11-04-unity-default-desktop) Unity 以来,Ubuntu 第一次没有带 Unity 桌面发布。
当然,主流媒体对 Unity 的未来感到好奇,因此 Mark Shuttleworth [向 eWeek](http://www.eweek.com/enterprise-apps/canonical-on-path-to-ipo-as-ubuntu-unity-linux-desktop-gets-ditched) 详细介绍了他决定在 Ubuntu 路线图中抛弃 Unity 的原因。
简而言之就是他把驱逐 Unity 作为节约成本的一部分,旨在使 Canonical 走上 IPO 的道路。
是的,投资者来了。
但是完整采访提供了更多关于这个决定的更多内容,并且披露了放弃曾经悉心培养的桌面对他而言是多么艰难。
### “Ubuntu 已经进入主流”
Mark Shuttleworth 和 [Sean Michael Kerner](https://twitter.com/TechJournalist) 的谈话,首先提醒了我们 Ubuntu 有多么伟大:
>
> “Ubuntu 的美妙之处在于,我们创造了一个对终端用户免费,并围绕其提供商业服务的平台,在这个梦想中,我们可以用各种不同的方式定义未来。
>
>
> 我们确实已经看到,Ubuntu 在很多领域已经进入了主流。”
>
>
>
但是受欢迎并不意味着盈利,Mark 指出:
>
> “我们现在所做的一些事情很明显在商业上是不可能永远持续的,而另外一些事情无疑商业上是可持续发展的,或者已经在商业上可持续。
>
>
> 只要我们还是一个纯粹的私人公司,我们就有完全的自由裁量权来决定是否支持那些商业上不可持续的事情。”
>
>
>
Shuttleworth 说,他和 Canonical 的其他“领导”通过协商一致认为,他们应该让公司走上成为上市公司的道路。
为了吸引潜在的投资者,公司必须把重点放在盈利领域 —— 而 Unity、Ubuntu 电话、Unity 8 以及<ruby> 融合 <rt> convergence </rt></ruby>不属于这个部分:
>
> “[这个决定]意味着我们不能让我们的名册中拥有那些根本没有商业前景实际上却非常重大的项目。
>
>
> 这并不意味着我们会考虑改变 Ubuntu 的条款,因为它是我们所做的一切的基础。而且实际上,我们也没有必要。”
>
>
>
### “Ubuntu 本身现在完全可持续发展”
钱可能意味着 Unity 的消亡,但会让更广泛的 Ubuntu 项目健康发展。正如 Shuttleworth 解释说的:
>
> “我最为自豪的事情之一就是在过去的 7 年中,Ubuntu 本身变得完全可持续发展。即使明天我被车撞倒,而 Ubuntu 也可以继续发展下去。
>
>
> 这很神奇吧?对吧?这是一个世界级的企业平台,它不仅完全免费,而且是可持续的。
>
>
> 这主要要感谢 Jane Silber。” (LCTT 译注:Canonical 公司的 CEO)
>
>
>
虽然桌面用户都会关注桌面,但比起我们期待的每 6 个月发布的版本,对 Canonical 公司的关注显然要多得多。
失去 Unity 对桌面用户可能是一个沉重打击,但它有助于平衡公司的其他部分:
>
> “除此之外,我们在企业中还有巨大的可能性,比如在真正定义云基础设施是如何构建的方面,云应用程序是如何操作的等等。而且,在物联网中,看看下一波的可能性,那些创新者们正在基于物联网创造的东西。
>
>
> 所有这些都足以让我们在这方面进行 IPO。”
>
>
>
然而,对于 Mark 来说,放弃 Unity 并不容易,
>
> “我们在 Unity 上做了很多工作,我真的很喜欢它。
>
>
> 我认为 Unity 8 工程非常棒,而且如何将这些不同形式的要素结合在一起的深层理念是非常迷人的。”
>
>
> “但是,如果我们要走上 IPO 的道路,我不能再为将它留在 Canonical 来争论了。
>
>
> 在某个阶段你们应该会看到,我想我们很快就会宣布,没有 Unity, 我们实际上已经几乎打破了我们在商业上所做的所有事情。”
>
>
>
在这之后不久,他说公司可能会进行第一轮用于增长的投资,以此作为转变为正式上市公司前的过渡。
但 Mark 并不想让任何人认为投资者会 “毁了派对”:
>
> “我们还没沦落到需要根据风投的指示来行动的地步。我们清楚地看到了我们的客户喜欢什么,我们已经找到了适用于云和物联网的很好的市场着力点和产品。”
>
>
>
Mark 补充到,Canonical 公司的团队对这个决定 “无疑很兴奋”。
>
> “在情感上,我不想再经历这样的过程。我对 Unity 做了一些误判。我曾天真的认为业界会支持一个独立自由平台的想法。
>
>
> 但我也不后悔做过这件事。很多人会抱怨他们的选择,而不去创造其他选择。
>
>
> 事实证明,这需要一点勇气以及相当多的钱去尝试和创造这些选择。”
>
>
>
### OMG! IPO? NO!
在对 Canonical(可能)成为一家上市公司的观念进行争辩之前,我们要记住,**RedHat 已经是一家 20 年之久的上市公司了**。GNOME 桌面和 Fedora 在没有任何 “赚钱” 措施的干预下也都活得很不错。
Canonical 的 IPO 不太可能对 Ubuntu 产生突然的引人注目的的改变,因为就像 Shuttleworth 自己所说的那样,这是其它所有东西得以成立的基础。
Ubuntu 是已被认可的。这是云上的头号操作系统。它是世界上最受欢迎的 Linux 发行版(除了 [Distrowatch 排名](http://distrowatch.com/table.php?distribution=ubuntu))。并且它似乎在物联网上也有巨大的应用前景。
Mark 说 Ubuntu 现在是完全可持续发展的。
随着一个[迎接 Ubuntu 17.10 到来的热烈招待会](http://www.omgubuntu.co.uk/2017/10/ubuntu-17-10-review-roundup),以及一个新的 LTS 将要发布,事情看起来相当不错……
---
via: <http://www.omgubuntu.co.uk/2017/10/why-did-ubuntu-drop-unity-mark-shuttleworth-explains>
作者:[JOEY SNEDDON](https://plus.google.com/117485690627814051450/?rel=author) 译者:[Snapcrafter](https://github.com/Snapcrafter),[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,048 | 在 GitLab 我们是如何扩展数据库的 | https://about.gitlab.com/2017/10/02/scaling-the-gitlab-database/ | 2017-11-11T14:10:00 | [
"数据库",
"PostgreSQL",
"GitLab"
] | https://linux.cn/article-9048-1.html | 
>
> 在扩展 GitLab 数据库和我们应用的解决方案,去帮助解决我们的数据库设置中的问题时,我们深入分析了所面临的挑战。
>
>
>
很长时间以来 GitLab.com 使用了一个单个的 PostgreSQL 数据库服务器和一个用于灾难恢复的单个复制。在 GitLab.com 最初的几年,它工作的还是很好的,但是,随着时间的推移,我们看到这种设置的很多问题,在这篇文章中,我们将带你了解我们在帮助解决 GitLab.com 和 GitLab 实例所在的主机时都做了些什么。
例如,数据库长久处于重压之下, CPU 使用率几乎所有时间都处于 70% 左右。并不是因为我们以最好的方式使用了全部的可用资源,而是因为我们使用了太多的(未经优化的)查询去“冲击”服务器。我们意识到需要去优化设置,这样我们就可以平衡负载,使 GitLab.com 能够更灵活地应对可能出现在主数据库服务器上的任何问题。
在我们使用 PostgreSQL 去跟踪这些问题时,使用了以下的四种技术:
1. 优化你的应用程序代码,以使查询更加高效(并且理论上使用了很少的资源)。
2. 使用一个连接池去减少必需的数据库连接数量(及相关的资源)。
3. 跨多个数据库服务器去平衡负载。
4. 分片你的数据库
在过去的两年里,我们一直在积极地优化应用程序代码,但它不是一个完美的解决方案,甚至,如果你改善了性能,当流量也增加时,你还需要去应用其它的几种技术。出于本文的目的,我们将跳过优化应用代码这个特定主题,而专注于其它技术。
### 连接池
在 PostgreSQL 中,一个连接是通过启动一个操作系统进程来处理的,这反过来又需要大量的资源,更多的连接(及这些进程)将使用你的数据库上的更多的资源。 PostgreSQL 也在 [max\_connections](https://www.postgresql.org/docs/9.6/static/runtime-config-connection.html#GUC-MAX-CONNECTIONS) 设置中定义了一个强制的最大连接数量。一旦达到这个限制,PostgreSQL 将拒绝新的连接, 比如,下面的图表示的设置:

这里我们的客户端直接连接到 PostgreSQL,这样每个客户端请求一个连接。
通过连接池,我们可以有多个客户端侧的连接重复使用一个 PostgreSQL 连接。例如,没有连接池时,我们需要 100 个 PostgreSQL 连接去处理 100 个客户端连接;使用连接池后,我们仅需要 10 个,或者依据我们配置的 PostgreSQL 连接。这意味着我们的连接图表将变成下面看到的那样:

这里我们展示了一个示例,四个客户端连接到 pgbouncer,但不是使用了四个 PostgreSQL 连接,而是仅需要两个。
对于 PostgreSQL 有两个最常用的连接池:
* [pgbouncer](https://pgbouncer.github.io/)
* [pgpool-II](http://pgpool.net/mediawiki/index.php/Main_Page)
pgpool 有一点特殊,因为它不仅仅是连接池:它有一个内置的查询缓存机制,可以跨多个数据库负载均衡、管理复制等等。
另一个 pgbouncer 是很简单的:它就是一个连接池。
### 数据库负载均衡
数据库级的负载均衡一般是使用 PostgreSQL 的 “<ruby> <a href="https://www.postgresql.org/docs/9.6/static/hot-standby.html"> 热备机 </a> <rt> hot-standby </rt></ruby>” 特性来实现的。 热备机是允许你去运行只读 SQL 查询的 PostgreSQL 副本,与不允许运行任何 SQL 查询的普通<ruby> 备用机 <rt> standby </rt></ruby>相反。要使用负载均衡,你需要设置一个或多个热备服务器,并且以某些方式去平衡这些跨主机的只读查询,同时将其它操作发送到主服务器上。扩展这样的一个设置是很容易的:(如果需要的话)简单地增加多个热备机以增加只读流量。
这种方法的另一个好处是拥有一个更具弹性的数据库集群。即使主服务器出现问题,仅使用次级服务器也可以继续处理 Web 请求;当然,如果这些请求最终使用主服务器,你可能仍然会遇到错误。
然而,这种方法很难实现。例如,一旦它们包含写操作,事务显然需要在主服务器上运行。此外,在写操作完成之后,我们希望继续使用主服务器一会儿,因为在使用异步复制的时候,热备机服务器上可能还没有这些更改。
### 分片
分片是水平分割你的数据的行为。这意味着数据保存在特定的服务器上并且使用一个分片键检索。例如,你可以按项目分片数据并且使用项目 ID 做为分片键。当你的写负载很高时,分片数据库是很有用的(除了一个多主设置外,均衡写操作没有其它的简单方法),或者当你有*大量*的数据并且你不再使用传统方式保存它也是有用的(比如,你不能把它简单地全部放进一个单个磁盘中)。
不幸的是,设置分片数据库是一个任务量很大的过程,甚至,在我们使用诸如 [Citus](https://www.citusdata.com/) 的软件时也是这样。你不仅需要设置基础设施 (不同的复杂程序取决于是你运行在你自己的数据中心还是托管主机的解决方案),你还得需要调整你的应用程序中很大的一部分去支持分片。
#### 反对分片的案例
在 GitLab.com 上一般情况下写负载是非常低的,同时大多数的查询都是只读查询。在极端情况下,尖峰值达到每秒 1500 元组写入,但是,在大多数情况下不超过每秒 200 元组写入。另一方面,我们可以在任何给定的次级服务器上轻松达到每秒 1000 万元组读取。
存储方面,我们也不使用太多的数据:大约 800 GB。这些数据中的很大一部分是在后台迁移的,这些数据一经迁移后,我们的数据库收缩的相当多。
接下来的工作量就是调整应用程序,以便于所有查询都可以正确地使用分片键。 我们的一些查询包含了一个项目 ID,它是我们使用的分片键,也有许多查询没有包含这个分片键。分片也会影响提交到 GitLab 的改变内容的过程,每个提交者现在必须确保在他们的查询中包含分片键。
最后,是完成这些工作所需要的基础设施。服务器已经完成设置,监视也添加了、工程师们必须培训,以便于他们熟悉上面列出的这些新的设置。虽然托管解决方案可能不需要你自己管理服务器,但它不能解决所有问题。工程师们仍然需要去培训(很可能非常昂贵)并需要为此支付账单。在 GitLab 上,我们也非常乐意提供我们用过的这些工具,这样社区就可以使用它们。这意味着如果我们去分片数据库, 我们将在我们的 Omnibus 包中提供它(或至少是其中的一部分)。确保你提供的服务的唯一方法就是你自己去管理它,这意味着我们不能使用主机托管的解决方案。
最终,我们决定不使用数据库分片,因为它是昂贵的、费时的、复杂的解决方案。
### GitLab 的连接池
对于连接池我们有两个主要的诉求:
1. 它必须工作的很好(很显然这是必需的)。
2. 它必须易于在我们的 Omnibus 包中运用,以便于我们的用户也可以从连接池中得到好处。
用下面两步去评估这两个解决方案(pgpool 和 pgbouncer):
1. 执行各种技术测试(是否有效,配置是否容易,等等)。
2. 找出使用这个解决方案的其它用户的经验,他们遇到了什么问题?怎么去解决的?等等。
pgpool 是我们考察的第一个解决方案,主要是因为它提供的很多特性看起来很有吸引力。我们其中的一些测试数据可以在 [这里](https://gitlab.com/gitlab-com/infrastructure/issues/259#note_23464570) 找到。
最终,基于多个因素,我们决定不使用 pgpool 。例如, pgpool 不支持<ruby> 粘连接 <rt> sticky connection </rt></ruby>。 当执行一个写入并(尝试)立即显示结果时,它会出现问题。想像一下,创建一个<ruby> 工单 <rt> issue </rt></ruby>并立即重定向到这个页面, 没有想到会出现 HTTP 404,这是因为任何用于只读查询的服务器还没有收到数据。针对这种情况的一种解决办法是使用同步复制,但这会给表带来更多的其它问题,而我们希望避免这些问题。
另一个问题是, pgpool 的负载均衡逻辑与你的应用程序是不相干的,是通过解析 SQL 查询并将它们发送到正确的服务器。因为这发生在你的应用程序之外,你几乎无法控制查询运行在哪里。这实际上对某些人也可能是有好处的, 因为你不需要额外的应用程序逻辑。但是,它也妨碍了你在需要的情况下调整路由逻辑。
由于配置选项非常多,配置 pgpool 也是很困难的。或许促使我们最终决定不使用它的原因是我们从过去使用过它的那些人中得到的反馈。即使是在大多数的案例都不是很详细的情况下,我们收到的反馈对 pgpool 通常都持有负面的观点。虽然出现的报怨大多数都与早期版本的 pgpool 有关,但仍然让我们怀疑使用它是否是个正确的选择。
结合上面描述的问题和反馈,最终我们决定不使用 pgpool 而是使用 pgbouncer 。我们用 pgbouncer 执行了一套类似的测试,并且对它的结果是非常满意的。它非常容易配置(而且一开始不需要很多的配置),运用相对容易,仅专注于连接池(而且它真的很好),而且没有明显的负载开销(如果有的话)。也许我唯一的报怨是,pgbouncer 的网站有点难以导航。
使用 pgbouncer 后,通过使用<ruby> 事务池 <rt> transaction pooling </rt></ruby>我们可以将活动的 PostgreSQL 连接数从几百个降到仅 10 - 20 个。我们选择事务池是因为 Rails 数据库连接是持久的。这个设置中,使用<ruby> 会话池 <rt> session pooling </rt></ruby>不能让我们降低 PostgreSQL 连接数,从而受益(如果有的话)。通过使用事务池,我们可以调低 PostgreSQL 的 `max_connections` 的设置值,从 3000 (这个特定值的原因我们也不清楚) 到 300 。这样配置的 pgbouncer ,即使在尖峰时,我们也仅需要 200 个连接,这为我们提供了一些额外连接的空间,如 `psql` 控制台和维护任务。
对于使用事务池的负面影响方面,你不能使用预处理语句,因为 `PREPARE` 和 `EXECUTE` 命令也许最终在不同的连接中运行,从而产生错误的结果。 幸运的是,当我们禁用了预处理语句时,并没有测量到任何响应时间的增加,但是我们 *确定* 测量到在我们的数据库服务器上内存使用减少了大约 20 GB。
为确保我们的 web 请求和后台作业都有可用连接,我们设置了两个独立的池: 一个有 150 个连接的后台进程连接池,和一个有 50 个连接的 web 请求连接池。对于 web 连接需要的请求,我们很少超过 20 个,但是,对于后台进程,由于在 GitLab.com 上后台运行着大量的进程,我们的尖峰值可以很容易达到 100 个连接。
今天,我们提供 pgbouncer 作为 GitLab EE 高可用包的一部分。对于更多的信息,你可以参考 “[Omnibus GitLab PostgreSQL High Availability](https://docs.gitlab.com/ee/administration/high_availability/alpha_database.html)”。
### GitLab 上的数据库负载均衡
使用 pgpool 和它的负载均衡特性,我们需要一些其它的东西去分发负载到多个热备服务器上。
对于(但不限于) Rails 应用程序,它有一个叫 [Makara](https://github.com/taskrabbit/makara) 的库,它实现了负载均衡的逻辑并包含了一个 ActiveRecord 的缺省实现。然而,Makara 也有一些我们认为是有些遗憾的问题。例如,它支持的粘连接是非常有限的:当你使用一个 cookie 和一个固定的 TTL 去执行一个写操作时,连接将粘到主服务器。这意味着,如果复制极大地滞后于 TTL,最终你可能会发现,你的查询运行在一个没有你需要的数据的主机上。
Makara 也需要你做很多配置,如所有的数据库主机和它们的角色,没有服务发现机制(我们当前的解决方案也不支持它们,即使它是将来计划的)。 Makara 也 [似乎不是线程安全的](https://github.com/taskrabbit/makara/issues/151),这是有问题的,因为 Sidekiq (我们使用的后台进程)是多线程的。 最终,我们希望尽可能地去控制负载均衡的逻辑。
除了 Makara 之外 ,还有一个 [Octopus](https://github.com/thiagopradi/octopus) ,它也是内置的负载均衡机制。但是 Octopus 是面向分片数据库的,而不仅是均衡只读查询的。因此,最终我们不考虑使用 Octopus。
最终,我们直接在 GitLab EE构建了自己的解决方案。 添加初始实现的<ruby> 合并请求 <rt> merge request </rt></ruby>可以在 [这里](https://gitlab.com/gitlab-org/gitlab-ee/merge_requests/1283)找到,尽管一些更改、提升和修复是以后增加的。
我们的解决方案本质上是通过用一个处理查询的路由的代理对象替换 `ActiveRecord::Base.connection` 。这可以让我们均衡负载尽可能多的查询,甚至,包括不是直接来自我们的代码中的查询。这个代理对象基于调用方式去决定将查询转发到哪个主机, 消除了解析 SQL 查询的需要。
#### 粘连接
粘连接是通过在执行写入时,将当前 PostgreSQL WAL 位置存储到一个指针中实现支持的。在请求即将结束时,指针短期保存在 Redis 中。每个用户提供他自己的 key,因此,一个用户的动作不会导致其他的用户受到影响。下次请求时,我们取得指针,并且与所有的次级服务器进行比较。如果所有的次级服务器都有一个超过我们的指针的 WAL 指针,那么我们知道它们是同步的,我们可以为我们的只读查询安全地使用次级服务器。如果一个或多个次级服务器没有同步,我们将继续使用主服务器直到它们同步。如果 30 秒内没有写入操作,并且所有的次级服务器还没有同步,我们将恢复使用次级服务器,这是为了防止有些人的查询永远运行在主服务器上。
检查一个次级服务器是否就绪十分简单,它在如下的 `Gitlab::Database::LoadBalancing::Host#caught_up?` 中实现:
```
def caught_up?(location)
string = connection.quote(location)
query = "SELECT NOT pg_is_in_recovery() OR " \
"pg_xlog_location_diff(pg_last_xlog_replay_location(), #{string}) >= 0 AS result"
row = connection.select_all(query).first
row && row['result'] == 't'
ensure
release_connection
end
```
这里的大部分代码是运行原生查询(raw queries)和获取结果的标准的 Rails 代码,查询的最有趣的部分如下:
```
SELECT NOT pg_is_in_recovery()
OR pg_xlog_location_diff(pg_last_xlog_replay_location(), WAL-POINTER) >= 0 AS result"
```
这里 `WAL-POINTER` 是 WAL 指针,通过 PostgreSQL 函数 `pg_current_xlog_insert_location()` 返回的,它是在主服务器上执行的。在上面的代码片断中,该指针作为一个参数传递,然后它被引用或转义,并传递给查询。
使用函数 `pg_last_xlog_replay_location()` 我们可以取得次级服务器的 WAL 指针,然后,我们可以通过函数 `pg_xlog_location_diff()` 与我们的主服务器上的指针进行比较。如果结果大于 0 ,我们就可以知道次级服务器是同步的。
当一个次级服务器被提升为主服务器,并且我们的 GitLab 进程还不知道这一点的时候,添加检查 `NOT pg_is_in_recovery()` 以确保查询不会失败。在这个案例中,主服务器总是与它自己是同步的,所以它简单返回一个 `true`。
#### 后台进程
我们的后台进程代码 *总是* 使用主服务器,因为在后台执行的大部分工作都是写入。此外,我们不能可靠地使用一个热备机,因为我们无法知道作业是否在主服务器执行,也因为许多作业并没有直接绑定到用户上。
#### 连接错误
要处理连接错误,比如负载均衡器不会使用一个视作离线的次级服务器,会增加主机上(包括主服务器)的连接错误,将会导致负载均衡器多次重试。这是确保,在遇到偶发的小问题或数据库失败事件时,不会立即显示一个错误页面。当我们在负载均衡器级别上处理 [热备机冲突](https://www.postgresql.org/docs/current/static/hot-standby.html#HOT-STANDBY-CONFLICT) 的问题时,我们最终在次级服务器上启用了 `hot_standby_feedback` ,这样就解决了热备机冲突的所有问题,而不会对表膨胀造成任何负面影响。
我们使用的过程很简单:对于次级服务器,我们在它们之间用无延迟试了几次。对于主服务器,我们通过使用越来越快的回退尝试几次。
更多信息你可以查看 GitLab EE 上的源代码:
* <https://gitlab.com/gitlab-org/gitlab-ee/tree/master/lib/gitlab/database/load_balancing.rb>
* <https://gitlab.com/gitlab-org/gitlab-ee/tree/master/lib/gitlab/database/load_balancing>
数据库负载均衡首次引入是在 GitLab 9.0 中,并且 *仅* 支持 PostgreSQL。更多信息可以在 [9.0 release post](https://about.gitlab.com/2017/03/22/gitlab-9-0-released/) 和 [documentation](https://docs.gitlab.com/ee/administration/database_load_balancing.html) 中找到。
### Crunchy Data
我们与 [Crunchy Data](https://www.crunchydata.com/) 一起协同工作来部署连接池和负载均衡。不久之前我还是唯一的 [数据库专家](https://about.gitlab.com/handbook/infrastructure/database/),它意味着我有很多工作要做。此外,我对 PostgreSQL 的内部细节的和它大量的设置所知有限 (或者至少现在是),这意味着我能做的也有限。因为这些原因,我们雇用了 Crunchy 去帮我们找出问题、研究慢查询、建议模式优化、优化 PostgreSQL 设置等等。
在合作期间,大部分工作都是在相互信任的基础上完成的,因此,我们共享私人数据,比如日志。在合作结束时,我们从一些资料和公开的内容中删除了敏感数据,主要的资料在 [gitlab-com/infrastructure#1448](https://gitlab.com/gitlab-com/infrastructure/issues/1448),这又反过来导致产生和解决了许多分立的问题。
这次合作的好处是巨大的,它帮助我们发现并解决了许多的问题,如果必须我们自己来做的话,我们可能需要花上几个月的时间来识别和解决它。
幸运的是,最近我们成功地雇佣了我们的 [第二个数据库专家](https://gitlab.com/_stark) 并且我们希望以后我们的团队能够发展壮大。
### 整合连接池和数据库负载均衡
整合连接池和数据库负载均衡可以让我们去大幅减少运行数据库集群所需要的资源和在分发到热备机上的负载。例如,以前我们的主服务器 CPU 使用率一直徘徊在 70%,现在它一般在 10% 到 20% 之间,而我们的两台热备机服务器则大部分时间在 20% 左右:

在这里, `db3.cluster.gitlab.com` 是我们的主服务器,而其它的两台是我们的次级服务器。
其它的负载相关的因素,如平均负载、磁盘使用、内存使用也大为改善。例如,主服务器现在的平均负载几乎不会超过 10,而不像以前它一直徘徊在 20 左右:

在业务繁忙期间,我们的次级服务器每秒事务数在 12000 左右(大约为每分钟 740000),而主服务器每秒事务数在 6000 左右(大约每分钟 340000):

可惜的是,在部署 pgbouncer 和我们的数据库负载均衡器之前,我们没有关于事务速率的任何数据。
我们的 PostgreSQL 的最新统计数据的摘要可以在我们的 [public Grafana dashboard](http://monitor.gitlab.net/dashboard/db/postgres-stats?refresh=5m&orgId=1) 上找到。
我们的其中一些 pgbouncer 的设置如下:
| 设置 | 值 |
| --- | --- |
| `default_pool_size` | 100 |
| `reserve_pool_size` | 5 |
| `reserve_pool_timeout` | 3 |
| `max_client_conn` | 2048 |
| `pool_mode` | transaction |
| `server_idle_timeout` | 30 |
除了前面所说的这些外,还有一些工作要作,比如: 部署服务发现([#2042](https://gitlab.com/gitlab-org/gitlab-ee/issues/2042)), 持续改善如何检查次级服务器是否可用([#2866](https://gitlab.com/gitlab-org/gitlab-ee/issues/2866)),和忽略落后于主服务器太多的次级服务器 ([#2197](https://gitlab.com/gitlab-org/gitlab-ee/issues/2197))。
值得一提的是,到目前为止,我们还没有任何计划将我们的负载均衡解决方案,独立打包成一个你可以在 GitLab 之外使用的库,相反,我们的重点是为 GitLab EE 提供一个可靠的负载均衡解决方案。
如果你对它感兴趣,并喜欢使用数据库、改善应用程序性能、给 GitLab上增加数据库相关的特性(比如: [服务发现](https://gitlab.com/gitlab-org/gitlab-ee/issues/2042)),你一定要去查看一下我们的 [招聘职位](https://about.gitlab.com/jobs/specialist/database/) 和 [数据库专家手册](https://about.gitlab.com/handbook/infrastructure/database/) 去获取更多信息。
---
via: <https://about.gitlab.com/2017/10/02/scaling-the-gitlab-database/>
作者:[Yorick Peterse](https://about.gitlab.com/team/#yorickpeterse) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,049 | 由 KRACK 攻击想到的确保网络安全的小贴士 | https://www.linux.com/blog/2017/10/tips-secure-your-network-wake-krack | 2017-11-11T23:59:00 | [
"安全",
"KRACK",
"无线网",
"WIFI"
] | https://linux.cn/article-9049-1.html |
>
> 最近的 KRACK (密钥重装攻击,这是一个安全漏洞名称或该漏洞利用攻击行为的名称)漏洞攻击的目标是位于你的设备和 Wi-Fi 访问点之间的链路,这个访问点或许是在你家里、办公室中、或你喜欢的咖啡吧中的任何一台路由器。这些提示能帮你提升你的连接的安全性。
>
>
>

[KRACK 漏洞攻击](https://www.krackattacks.com/) 出现已经一段时间了,并且已经在 [相关技术网站](https://blog.cryptographyengineering.com/2017/10/16/falling-through-the-kracks/) 上有很多详细的讨论,因此,我将不在这里重复攻击的技术细节。攻击方式的总结如下:
* 在 WPA2 无线握手协议中的一个缺陷允许攻击者在你的设备和 wi-fi 访问点之间嗅探或操纵通讯。
* 这个问题在 Linux 和 Android 设备上尤其严重,由于在 WPA2 标准中的措辞含糊不清,也或许是在实现它时的错误理解,事实上,在底层的操作系统打完补丁以前,该漏洞一直可以强制无线流量以无加密方式通讯。
* 还好这个漏洞可以在客户端上修补,因此,天并没有塌下来,而且,WPA2 加密标准并没有像 WEP 标准那样被淘汰(不要通过切换到 WEP 加密的方式去“修复”这个问题)。
* 大多数流行的 Linux 发行版都已经通过升级修复了这个客户端上的漏洞,因此,老老实实地去更新它吧。
* Android 也很快修复了这个漏洞。如果你的设备在接收 Android 安全补丁,你会很快修复这个漏洞。如果你的设备不再接收这些更新,那么,这个特别的漏洞将是你停止使用你的旧设备的一个理由。
即使如此,从我的观点来看, Wi-Fi 是不可信任的基础设施链中的另一个环节,并且,我们应该完全避免将其视为可信任的通信通道。
### Wi-Fi 是不受信任的基础设备
如果从你的笔记本电脑或移动设备中读到这篇文章,那么,你的通信链路看起来应该是这样:

KRACK 攻击目标是在你的设备和 Wi-Fi 访问点之间的链接,访问点或许是在你家里、办公室中、或你喜欢的咖啡吧中的任何一台路由器。

实际上,这个图示应该看起来像这样:

Wi-Fi 仅仅是在我们所不应该信任的信道上的长长的通信链的第一个链路。让我来猜猜,你使用的 Wi-Fi 路由器或许从开始使用的第一天气就没有得到过一个安全更新,并且,更糟糕的是,它或许使用了一个从未被更改过的、缺省的、易猜出的管理凭据(用户名和密码)。除非你自己安装并配置你的路由器,并且你能记得你上次更新的它的固件的时间,否则,你应该假设现在它已经被一些人控制并不能信任的。
在 Wi-Fi 路由器之后,我们的通讯进入一般意义上的常见不信任区域 —— 这要根据你的猜疑水平。这里有上游的 ISP 和接入提供商,其中的很多已经被指认监视、更改、分析和销售我们的流量数据,试图从我们的浏览习惯中挣更多的钱。通常他们的安全补丁计划辜负了我们的期望,最终让我们的流量暴露在一些恶意者眼中。
一般来说,在互联网上,我们还必须担心强大的国家级的参与者能够操纵核心网络协议,以执行大规模的网络监视和状态级的流量过滤。
### HTTPS 协议
值的庆幸的是,我们有一个基于不信任的介质进行安全通讯的解决方案,并且,我们可以每天都能使用它 —— 这就是 HTTPS 协议,它加密你的点对点的互联网通讯,并且确保我们可以信任站点与我们之间的通讯。
Linux 基金会的一些措施,比如像 [Let’s Encrypt](https://letsencrypt.org/) 使世界各地的网站所有者都可以很容易地提供端到端的加密,这有助于确保我们的个人设备与我们试图访问的网站之间的任何有安全隐患的设备不再是个问题。

是的... 基本没关系。
### DNS —— 剩下的一个问题
虽然,我们可以尽量使用 HTTPS 去创建一个可信的通信信道,但是,这里仍然有一个攻击者可以访问我们的路由器或修改我们的 Wi-Fi 流量的机会 —— 在使用 KRACK 的这个案例中 —— 可以欺骗我们的通讯进入一个错误的网站。他们可以利用我们仍然非常依赖 DNS 的这一事实 —— 这是一个未加密的、易受欺骗的 [诞生自上世纪 80 年代的协议](https://en.wikipedia.org/wiki/Domain_Name_System#History)。

DNS 是一个将像 “linux.com” 这样人类友好的域名,转换成计算机可以用于和其它计算机通讯的 IP 地址的一个系统。要转换一个域名到一个 IP 地址,计算机将会查询解析器软件 —— 它通常运行在 Wi-Fi 路由器或一个系统上。解析器软件将查询一个分布式的“根”域名服务器网络,去找到在互联网上哪个系统有 “linux.com” 域名所对应的 IP 地址的“权威”信息。
麻烦就在于,所有发生的这些通讯都是未经认证的、[易于欺骗的](https://en.wikipedia.org/wiki/DNS_spoofing)、明文协议、并且响应可以很容易地被攻击者修改,去返回一个不正确的数据。如果有人去欺骗一个 DNS 查询并且返回错误的 IP 地址,他们可以操纵我们的系统最终发送 HTTP 请求到那里。
幸运的是,HTTPS 有一些内置的保护措施去确保它不会很容易地被其它人诱导至其它假冒站点。恶意服务器上的 TLS 凭据必须与你请求的 DNS 名字匹配 —— 并且它必须由一个你的浏览器认可的信誉良好的 [认证机构(CA)](https://en.wikipedia.org/wiki/Certificate_authority) 所签发。如果不是这种情况,你的浏览器将在你试图去与他们告诉你的地址进行通讯时出现一个很大的警告。如果你看到这样的警告,在选择不理会警告之前,请你格外小心,因为,它有可能会把你的秘密泄露给那些可能会对付你的人。
如果攻击者完全控制了路由器,他们可以在一开始时,通过拦截来自服务器指示你建立一个安全连接的响应,以阻止你使用 HTTPS 连接(这被称为 “[SSL 脱衣攻击](https://en.wikipedia.org/wiki/Moxie_Marlinspike#Notable_research)”)。 为了帮助你防护这种类型的攻击,网站可以增加一个 [特殊响应头(HSTS)](https://en.wikipedia.org/wiki/HTTP_Strict_Transport_Security) 去告诉你的浏览器以后与它通讯时总是使用 HTTPS 协议,但是,这仅仅是在你首次访问之后的事。对于一些非常流行的站点,浏览器现在包含一个 [硬编码的域名列表](https://hstspreload.org/),即使是首次连接,它也将总是使用 HTTPS 协议访问。
现在已经有了 DNS 欺骗的解决方案,它被称为 [DNSSEC](https://en.wikipedia.org/wiki/Domain_Name_System_Security_Extensions),由于有重大的障碍 —— 真实和可感知的(LCTT 译注,指的是要求实名认证),它看起来接受程度很慢。在 DNSSEC 被普遍使用之前,我们必须假设,我们接收到的 DNS 信息是不能完全信任的。
### 使用 VPN 去解决“最后一公里”的安全问题
因此,如果你不能信任固件太旧的 Wi-Fi 和/或无线路由器,我们能做些什么来确保发生在你的设备与常说的互联网之间的“最后一公里”通讯的完整性呢?
一个可接受的解决方案是去使用信誉好的 VPN 供应商的服务,它将在你的系统和他们的基础设施之间建立一条安全的通讯链路。这里有一个期望,就是它比你的路由器提供者和你的当前互联网供应商更注重安全,因为,他们处于一个更好的位置去确保你的流量不会受到恶意的攻击或欺骗。在你的工作站和移动设备之间使用 VPN,可以确保免受像 KRACK 这样的漏洞攻击,不安全的路由器不会影响你与外界通讯的完整性。

这有一个很重要的警告是,当你选择一个 VPN 供应商时,你必须确信他们的信用;否则,你将被一拨恶意的人出卖给其它人。远离任何人提供的所谓“免费 VPN”,因为,它们可以通过监视你和向市场营销公司销售你的流量来赚钱。 [这个网站](https://www.vpnmentor.com/bestvpns/overall/) 是一个很好的资源,你可以去比较他们提供的各种 VPN,去看他们是怎么互相竞争的。
注意,你所有的设备都应该在它上面安装 VPN,那些你每天使用的网站,你的私人信息,尤其是任何与你的钱和你的身份(政府、银行网站、社交网络、等等)有关的东西都必须得到保护。VPN 并不是对付所有网络级漏洞的万能药,但是,当你在机场使用无法保证的 Wi-Fi 时,或者下次发现类似 KRACK 的漏洞时,它肯定会保护你。
---
via: <https://www.linux.com/blog/2017/10/tips-secure-your-network-wake-krack>
作者:[KONSTANTIN RYABITSEV](https://www.linux.com/users/mricon) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,050 | 瞬间提升命令行的生产力 100% | https://dev.to/sobolevn/instant-100-command-line-productivity-boost | 2017-11-13T08:43:00 | [
"命令行"
] | https://linux.cn/article-9050-1.html | 
关于生产力的话题总是让人充满兴趣的。
这里有许多方式提升你的生产力。今天,我共享一些命令行的小技巧,以及让你的人生更轻松的小秘诀。
### TL;DR
在本文中讨论的内容的全部设置及更多的信息,可以查看: <https://github.com/sobolevn/dotfiles> 。
### Shell
使用一个好用的,并且稳定的 shell 对你的命令行生产力是非常关键的。这儿有很多选择,我喜欢 `zsh` 和 `oh-my-zsh`。它是非常神奇的,理由如下:
* 自动补完几乎所有的东西
* 大量的插件
* 确实有用且能定制化的“提示符”
你可以通过下列的步骤去安装它:
1. 安装 `zsh`: <https://github.com/robbyrussell/oh-my-zsh/wiki/Installing-ZSH>
2. 安装 `oh-my-zsh`: <http://ohmyz.sh/>
3. 选择对你有用的插件: <https://github.com/robbyrussell/oh-my-zsh/wiki/Plugins>
你也可以调整你的设置以 [关闭自动补完的大小写敏感](https://github.com/sobolevn/dotfiles/blob/master/zshrc#L12) ,或改变你的 [命令行历史的工作方式](https://github.com/sobolevn/dotfiles/blob/master/zshrc#L24)。
就是这样。你将立马获得 +50% 的生产力提升。现在你可以打开足够多的选项卡(tab)了!(LCTT 译注:指多选项卡的命令行窗口)
### 主题
选择主题也很重要,因为你从头到尾都在看它。它必须是有用且漂亮的。我也喜欢简约的主题,因为它不包含一些视觉噪音和没用的信息。
你的主题将为你展示:
* 当前文件夹
* 当前的版本分支
* 当前版本库状态:干净或脏的(LCTT 译注:指是否有未提交版本库的内容)
* 任何的错误返回码(如果有)(LCTT 译注:Linux 命令如果执行错误,会返回错误码)
我也喜欢我的主题可以在新起的一行输入新命令,这样就有足够的空间去阅读和书写命令了。
我个人使用 [`sobole`](https://github.com/sobolevn/sobole-zsh-theme) 主题。它看起来非常棒,它有两种模式。
亮色的:
[](https://res.cloudinary.com/practicaldev/image/fetch/s--Lz_uthoR--/c_limit,f_auto,fl_progressive,q_auto,w_880/https://raw.githubusercontent.com/sobolevn/sobole-zsh-theme/master/showcases/env-and-user.png)
以及暗色的:
[](https://res.cloudinary.com/practicaldev/image/fetch/s--4o6hZwL9--/c_limit,f_auto,fl_progressive,q_auto,w_880/https://raw.githubusercontent.com/sobolevn/sobole-zsh-theme/master/showcases/dark-mode.png)
你得到了另外 +15% 的提升,以及一个看起来很漂亮的主题。
### 语法高亮
对我来说,从我的 shell 中得到足够的可视信息对做出正确的判断是非常重要的。比如 “这个命令有没有拼写错误?” 或者 “这个命令有相应的作用域吗?” 这样的提示。我经常会有拼写错误。
因此, [`zsh-syntax-highlighting`](https://github.com/zsh-users/zsh-syntax-highlighting) 对我是非常有用的。 它有合适的默认值,当然你可以 [改变任何你想要的设置](https://github.com/zsh-users/zsh-syntax-highlighting/blob/master/docs/highlighters.md)。
这个步骤可以带给我们额外的 +5% 的提升。
### 文件处理
我在我的目录中经常遍历许多文件,至少看起来很多。我经常做这些事情:
* 来回导航
* 列出文件和目录
* 显示文件内容
我喜欢去使用 [`z`](https://github.com/rupa/z) 导航到我已经去过的文件夹。这个工具是非常棒的。 它使用“<ruby> 近常 <rt> frecency </rt></ruby>” 方法来把你输入的 `.dot TAB` 转换成 `~/dev/shell/config/.dotfiles`。真的很不错!
当你显示文件时,你通常要了解如下几个内容:
* 文件名
* 权限
* 所有者
* 这个文件的 git 版本状态
* 修改日期
* 人类可读形式的文件大小
你也或许希望缺省展示隐藏文件。因此,我使用 [`exa`](https://github.com/ogham/exa) 来替代标准的 `ls`。为什么呢?因为它缺省启用了很多的东西:
[](https://res.cloudinary.com/practicaldev/image/fetch/s--n_YCO9Hj--/c_limit,f_auto,fl_progressive,q_auto,w_880/https://raw.githubusercontent.com/ogham/exa/master/screenshots.png)
要显示文件内容,我使用标准的 `cat`,或者,如果我希望看到语法高亮,我使用一个定制的别名:
```
# exa:
alias la="exa -abghl --git --color=automatic"
# `cat` with beautiful colors. requires: pip install -U Pygments
alias c='pygmentize -O style=borland -f console256 -g'
```
现在,你已经掌握了导航。它使你的生产力提升 +15% 。
### 搜索
当你在应用程序的源代码中搜索时,你不会想在你的搜索结果中缺省包含像 `node_modules` 或 `bower_components` 这样的文件夹。或者,当你想搜索执行的更快更流畅时。
这里有一个比内置的搜索方式更好的替代: [`the_silver_searcher`](https://github.com/ggreer/the_silver_searcher)。
它是用纯 `C` 写成的,并且使用了很多智能化的逻辑让它工作的更快。
在命令行 `history` 中,使用 `ctrl` + `R` 进行 [反向搜索](https://unix.stackexchange.com/questions/73498/how-to-cycle-through-reverse-i-search-in-bash) 是非常有用的。但是,你有没有发现你自己甚至不能完全记住一个命令呢?如果有一个工具可以模糊搜索而且用户界面更好呢?
这里确实有这样一个工具。它叫做 `fzf`:

它可以被用于任何模糊查询,而不仅是在命令行历史中,但它需要 [一些配置](https://github.com/sobolevn/dotfiles/blob/master/shell/.external#L19)。
你现在有了一个搜索工具,可以额外提升 +15% 的生产力。
### 延伸阅读
更好地使用命令行: <https://dev.to/sobolevn/using-better-clis-6o8>。
### 总结
通过这些简单的步骤,你可以显著提升你的命令行的生产力 +100% 以上(数字是估计的)。
这里还有其它的工具和技巧,我将在下一篇文章中介绍。
你喜欢阅读软件开发方面的最新趋势吗?在这里订阅我们的愽客吧 <https://medium.com/wemake-services>。
---
via: <https://dev.to/sobolevn/instant-100-command-line-productivity-boost>
作者:[Nikita Sobolev](https://dev.to/sobolevn) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Being productive is fun.
There are a lot of fields to improve your productivity. Today I am going to share some command line tips and tricks to make your life easier.
##
[
](#tldr)
TLDR
My full setup includes all the stuff discussed in this article and even more. Check it out: [https://github.com/sobolevn/dotfiles](https://github.com/sobolevn/dotfiles)
##
[
](#shell)
Shell
Using a good, helping, and the stable shell is the key to your command line productivity. While there are many choices, I prefer `zsh`
coupled with `oh-my-zsh`
. It is amazing for several reasons:
- Autocomplete nearly everything
- Tons of plugins
- Really helping and customizable
`PROMPT`
You can follow these steps to install this setup:
- Install
`zsh`
:[https://github.com/robbyrussell/oh-my-zsh/wiki/Installing-ZSH](https://github.com/robbyrussell/oh-my-zsh/wiki/Installing-ZSH) - Install
`oh-my-zsh`
:[http://ohmyz.sh/](http://ohmyz.sh/) - Choose plugins that might be useful for you:
[https://github.com/robbyrussell/oh-my-zsh/wiki/Plugins](https://github.com/robbyrussell/oh-my-zsh/wiki/Plugins)
You may also want to tweak your settings to [turn off case sensitive autocomplete](https://github.com/sobolevn/dotfiles/blob/master/config/zshrc#L12). Or change how your [history works](https://github.com/sobolevn/dotfiles/blob/master/config/zshrc#L24).
That's it. You will gain instant +50% productivity. Now hit tab as much as you can!
##
[
](#theme)
Theme
Choosing theme is quite important as well since you see it all the time. It has to be functional and pretty. I also prefer minimalistic themes, since it does not contain a lot of visual noise and unused information.
Your theme should show you:
- current folder
- current branch
- current repository status: clean or dirty
- error codes if any
I also prefer my theme to have new commands on a new line, so there is enough space to read and write it.
I personally use [ sobole](https://github.com/sobolevn/sobole-zsh-theme). It looks pretty awesome. It has two modes.
Light:
And dark:
Get your another +15% boost. And an awesome-looking theme.
##
[
](#syntax-highlighting)
Syntax highlighting
For me, it is very important to have enough visual information from my shell to make right decisions. Like "does this command have any typos in its name" or "do I have paired scopes in this command"? And I really make tpyos all the time.
So, [ zsh-syntax-highlighting](https://github.com/zsh-users/zsh-syntax-highlighting) was a big finding for me. It comes with reasonable defaults, but you can
[change anything you want](https://github.com/zsh-users/zsh-syntax-highlighting/blob/master/docs/highlighters.md).
These steps brings us extra +5%.
##
[
](#working-with-files)
Working with files
I travel inside my directories a lot. Like *a lot*. And I do all the things there:
- navigating back and forwards
- listing files and directories
- printing files' contents
I prefer to use [ z](https://github.com/rupa/z) to navigate to the folders I have already been to. This tool is awesome. It uses 'frecency' method to turn your
`.dot TAB`
into `~/dev/shell/config/.dotfiles`
. Really nice!When printing files you want usually to know several things:
- file names
- permissions
- owner
- git status of the file
- modified date
- size in human readable form
You also probably what to show hidden files to show up by default as well. So, I use [ exa](https://github.com/ogham/exa) as the replacement for standard
`ls`
. Why? Because it has a lot of stuff enabled by default:To print the file contents I use standard `cat`
or if I want to see to proper syntax highlighting I use a custom alias:
```
# exa:
alias la="exa -abghl --git --color=automatic"
# `cat` with beautiful colors. requires: pip install -U Pygments
alias c='pygmentize -O style=borland -f console256 -g'
```
Now you have mastered the navigation. Get your +15% productivity boost.
##
[
](#searching)
Searching
When searching in a source code of your applications you don't want to include folders like `node_modules`
or `bower_components`
into your results by default. You also want your search to be fast and smooth.
Here's a good replacement for the built in search methods: [ the_silver_searcher](https://github.com/ggreer/the_silver_searcher).
It is written in pure `C`
and uses a lot of smart logic to work fast.
Using `ctrl`
+ `R`
for [reverse search](https://unix.stackexchange.com/questions/73498/how-to-cycle-through-reverse-i-search-in-bash) in `history`
is very useful. But have you ever found yourself in a situation when I can quite remember a command? What if there were a tool that makes this search even greater enabling fuzzy searching and a nice UI?
There is such a tool, actually. It is called `fzf`
:
It can be used to fuzzy-find anything, not just history. But it requires [some configuration](https://github.com/sobolevn/dotfiles/blob/master/shell/.external#L19).
You are now a search ninja with +15% productivity bonus.
##
[
](#further-reading)
Further reading
Using better CLIs: [https://dev.to/sobolevn/using-better-clis-6o8](https://dev.to/sobolevn/using-better-clis-6o8)
##
[
](#conclusion)
Conclusion
Following these simple steps, you can dramatically increase your command line productivity, like +100% (numbers are approximate).
There are other tools and hacks I will cover in the next articles.
Do you like reading about the latest trends in software development? Subscribe to our blog on Medium: [https://medium.com/wemake-services](https://medium.com/wemake-services)
## Top comments (37)
fish shell is even better
I was about to say that! So much better indeed!
And what's better with Fish shell?
Thanks!
EDIT: I gave a shot and I love the real autocompletion without plugin :)
It provides a great experience, right out of the box!
A few sample points that I find really useful:
Now if you are into scripting, you might find it a bit easier to write your own autocompletion, it did for me for sure ;)
Another thing I use the most is the reverse-i-search, but, instead of typing Ctrl+R and the text I want to search, I just type it and use the arrow keys. The shell looks in the history but matching my query, and the visual result looks much more intuitive :D
And that's just one feature (appart for, for example, the "bobthefish" theme, a must have for using git) out of a large list.
As a vim user I hate the arrow key, I lost some productivity when I moved from the row.
It might be total anathema but... type + arrow keys to search is what I use in bash ;-)
:see_no_evil:
But I think it doesn't work the same way:
In bash, when you use reverse-i-search, you first press Ctrl+R and then you start typing the command you was looking for. While you type, the command is appearing in console. To look for previous commands that also match your query, you press Ctrl+R as many times as you will need in order to you find your command.
In Fish Shell, you just type as you would do in bash when you're in reverse-i-search, and then use the arrow keys to go to the previous commands (you can go back to the following ones of the current you have selected by pressing the down-arrow key, I don't know if that exists in bash). Plus, the query you typed will be highlighted in the current command.
It does work that way - I type, hit arrow-up to cycle through previous times I typed that command. No ctrl-R required.
You put in your .inputrc:
## arrow up
"\e[A":history-search-backward
## arrow down
"\e[B":history-search-forward
;-)
Wow, I'll try this when I arrive home just for the curiosity xD
Just wanted to comment that..
Fish shell + fzf = pure gold
I like fish but I had problems with NVM and to get it working on CD into a dir with a .nvmrc file. It was like one year ago, so probably it's fixed now.
Nice article! We have similar setups, so I though you might want to know more about mine:
Personally, I use zsh-pure-prompt.
I also use
`fzf`
a lot, and I even re-wrote`z`
using`fzf`
More info on my blog, you may find this interesting:
Lastly, I recently added a bit of code that allow me to quiclky insert the most recent file in the given directory into the current command line:
latest.zsh
end of self promotionCan't wait to read them!
Thanks for your feedback and interesting articles!
We have quite a similar setup. You should give a try to software like tig, ag, ranger or fpp.
+++ Thanks!
Nice coincidence, just installed
`tig`
. And I am already using`ag`
.iterm on mac increase my productivity by 50%
What are the features you use the most?
To switch between Iterm and Chrome, hotkey: maj + space
Tmux integration is native and I'm working with Vim, then the preference / appareance / Tabs are very nice too.
I think I'm pretty good, but I always look for more idea.
You can combine iTerm2 with Oh-my-Zsh! That's my current setup.
it's mine too...
Add powerlevel9k and we've almost got the same setup. Didn't know about fzf, I'm going to add that right away. 👍🏻
How do you use machines that don't have all your new fancy commands? Eg. when you ssh to different server?
I suffer most of the time.
I recommend to (semi)automate a way to prepare a new box to suit your needs.
I use developer.atlassian.com/blog/2016/... for this and can tweek a new box within 15 minutes.
Never heard of exa, but it's awesome.
I definitively adopted Sobole, I love it :)
Prezto over oh-my-zsh every time. Same idea but much more lightweight. And if you want to also trick out vim, git and zsh look at Yadr which uses Prezto.
You shouldn't need the
`--color=automatic`
on exa, it does that automatically anyway+1 for fzf
I have been using powerline shell on my Linux for the nice help working with git. Have you tried it? :D
Nope, but it looks nice.
I like powerline, but got annoyed by the slow speed. Thankfully, a kind soul ported it over to powerline-go and gave us the speed back.
`z`
for navigate doesn't work on my config?Edit: I installed brew install z, but doesn't autocomplete with most folder.
you have to
`cd`
into directory at least once for`z`
to work.I use it and love it too! Great post.
Like it? I love it! Going to add my config 😉
Oh, don't forget github.com/nvbn/thefuck it's awesome :D |
9,051 | 开源软件对于商业机构的六个好处 | https://opensource.com/article/17/10/6-reasons-choose-open-source-software | 2017-11-12T13:04:24 | [
"开源",
"商业"
] | /article-9051-1.html |
>
> 这就是为什么商业机构应该选择开源模式的原因
>
>
>

在相同的基础上,开源软件要优于专有软件。想知道为什么?这里有六个商业机构及政府部门可以从开源技术中获得好处的原因。
### 1、 让供应商审核更简单
在你投入工程和金融资源将一个产品整合到你的基础设施之前,你需要知道你选择了正确的产品。你想要一个处于积极开发的产品,它有定期的安全更新和漏洞修复,同时在你有需求时,产品能有相应的更新。这最后一点也许比你想的还要重要:没错,解决方案一定是满足你的需求的。但是产品的需求随着市场的成熟以及你商业的发展在变化。如果该产品随之改变,在未来你需要花费很大的代价来进行迁移。
你怎么才能知道你没有正在把你的时间和资金投入到一个正在消亡的产品?在开源的世界里,你可以不选择一个只有卖家有话语权的供应商。你可以通过考虑[发展速度以及社区健康程度](https://nextcloud.com/blog/nextcloud-the-most-active-open-source-file-sync-and-share-project/)来比较供应商。一到两年之后,一个更活跃、多样性和健康的社区将开发出一个更好的产品,这是一个重要的考虑因素。当然,就像这篇 [关于企业开源软件的博文](http://www.redhat-cloudstrategy.com/open-source-for-business-people/) 指出的,供应商必须有能力处理由于项目发展创新带来的不稳定性。寻找一个有长支持周期的供应商来避免混乱的更新。
### 2、 来自独立性的长寿
福布斯杂志指出 [90%的初创公司是失败的](http://www.forbes.com/sites/neilpatel/2015/01/16/90-of-startups-will-fail-heres-what-you-need-to-know-about-the-10/) ,而他们中不到一半的中小型公司能存活超过五年。当你不得不迁移到一个新的供应商时,你花费的代价是昂贵的。所以最好避免一些只有一个供应商支持的产品。
开源使得社区成员能够协同编写软件。例如 OpenStack [是由许多公司以及个人志愿者一起编写的](http://stackalytics.com/),这给客户提供了一个保证,不管任何一个独立供应商发生问题,也总会有一个供应商能提供支持。随着软件的开源,企业会长期投入开发团队,以实现产品开发。能够使用开源代码可以确保你总是能从贡献者中雇佣到人来保持你的开发活跃。当然,如果没有一个大的、活跃的社区,也就只有少量的贡献者能被雇佣,所以活跃贡献者的数量是重要的。
### 3、 安全性
安全是一件复杂的事情。这就是为什么开源开发是构建安全解决方案的关键因素和先决条件。同时每一天安全都在变得更重要。当开发以开源方式进行,你能直接的校验供应商是否积极的在追求安全,以及看到供应商是如何对待安全问题的。研究代码和执行独立代码审计的能力可以让供应商尽可能早的发现和修复漏洞。一些供应商给社区提供上千的美金的[漏洞奖金](https://hackerone.com/nextcloud)作为额外的奖励来鼓励开发者发现他们产品的安全漏洞,这同时也展示了供应商对于自己产品的信任。
除了代码,开源开发同样意味着开源过程,所以你能检查和看到供应商是否遵循 ISO27001、 [云安全准则](https://www.ncsc.gov.uk/guidance/implementing-cloud-security-principles) 及其他标准所推荐的工业级的开发过程。当然,一个可信组织外部检查提供了额外的保障,就像我们在 Nextcloud 与 [NCC小组](https://nextcloud.com/secure)合作的一样。
### 4、 更多的顾客导向
由于用户和顾客能直接看到和参与到产品的开发中,开源项目比那些只关注于营销团队回应的闭源软件更加的贴合用户的需求。你可以注意到开源软件项目趋向于以“宽松”方式发展。一个商业供应商也许关注在某个特定的事情方面,而一个社区则有许多要做的事情并致力于开发更多的功能,而这些全都是公司或个人贡献者中的某人或某些人所感兴趣的。这导致更少的为了销售而发布的版本,因为各种改进混搭在一起根本就不是一回事。但是它创造了许多对用户更有价值的产品。
### 5、 更好的支持
专有供应商通常是你遇到问题时唯一能给你提供帮助的一方。但如果他们不提供你所需要的服务,或者对调整你的商务需求收取额外昂贵的费用,那真是不好运。对专有软件提供的支持是一个典型的 “[柠檬市场](https://en.wikipedia.org/wiki/The_Market_for_Lemons)”。 随着软件的开源,供应商要么提供更大的支持,要么就有其它人来填补空白——这是自由市场的最佳选择,这可以确保你总是能得到最好的服务支持。
### 6、 更佳的许可
典型的软件许可证[充斥着令人不愉快的条款](http://boingboing.net/2016/11/01/why-are-license-agreements.html),通常都是强制套利,你甚至不会有机会起诉供应商的不当行为。其中一个问题是你仅仅被授予了软件的使用权,这通常完全由供应商自行决定。如果软件不运行或者停止运行或者如果供应商要求支付更多的费用,你得不到软件的所有权或其他的权利。像 GPL 一类的开源许可证是为保护客户专门设计的,而不是保护供应商,它确保你可以如你所需的使用软件,而没有专制限制,只要你喜欢就行。
由于它们的广泛使用,GPL 的含义及其衍生出来的其他许可证得到了广泛的理解。例如,你能确保该许可允许你现存的基础设施(开源或闭源)通过设定好的 API 去进行连接,其没有时间或者是用户人数上的限制,同时也不会强迫你公开软件架构或者是知识产权(例如公司商标)。
这也让合规变得更加的容易;使用专有软件意味着你面临着苛刻的法规遵从性条款和高额的罚款。更糟糕的是一些<ruby> 开源内核 <rt> open core </rt></ruby>的产品在混合了 GPL 软件和专有软件。这[违反了许可证规定](https://www.gnu.org/licenses/gpl-faq.en.html#GPLPluginsInNF)并将顾客置于风险中。同时 Gartner 指出,开源内核模式意味着你[不能从开源中获利](http://blogs.gartner.com/brian_prentice/2010/03/31/open-core-the-emperors-new-clothes/)。纯净的开源许可的产品避免了所有这些问题。取而代之,你只需要遵从一个规则:如果你对代码做出了修改(不包括配置、商标或其他类似的东西),你必须将这些与你的软件分发随同分享,如果他们要求的话。
显然开源软件是更好的选择。它易于选择正确的供应商(不会被供应商锁定),加之你也可以受益于更安全、对客户更加关注和更好的支持。而最后,你将处于法律上的安全地位。
---
作者简介:
一个善于与人打交道的技术爱好者和开源传播者。Nextcloud 的销售主管,曾是 ownCloud 和 SUSE 的社区经理,同时还是一个有多年经验的 KDE 销售人员。喜欢骑自行车穿越柏林和为家人朋友做饭。[点击这里找到我的博客](http://blog.jospoortvliet.com/)。
---
via: <https://opensource.com/article/17/10/6-reasons-choose-open-source-software>
作者:[Jos Poortvliet Feed](https://opensource.com/users/jospoortvliet) 译者:[ZH1122](https://github.com/ZH1122) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
9,052 | 容器和微服务是如何改变了安全性 | https://www.infoworld.com/article/3233139/cloud-computing/how-cloud-native-applications-change-security.html | 2017-11-13T15:38:00 | [
"安全",
"容器",
"微服务"
] | https://linux.cn/article-9052-1.html |
>
> 云原生程序和基础架构需要完全不同的安全方式。牢记这些最佳实践
>
>
>

如今,大大小小的组织正在探索云原生技术的采用。“<ruby> 云原生 <rt> Cloud-native </rt></ruby>”是指将软件打包到被称为容器的标准化单元中的方法,这些单元组织成微服务,它们必须对接以形成程序,并确保正在运行的应用程序完全自动化以实现更高的速度、灵活性和可伸缩性。
由于这种方法从根本上改变了软件的构建、部署和运行方式,它也从根本上改变了软件需要保护的方式。云原生程序和基础架构为安全专业人员带来了若干新的挑战,他们需要建立新的安全计划来支持其组织对云原生技术的使用。
让我们来看看这些挑战,然后我们将讨论安全团队应该采取的哪些最佳实践来解决这些挑战。首先挑战是:
* **传统的安全基础设施缺乏容器可视性。** 大多数现有的基于主机和网络的安全工具不具备监视或捕获容器活动的能力。这些工具是为了保护单个操作系统或主机之间的流量,而不是其上运行的应用程序,从而导致容器事件、系统交互和容器间流量的可视性缺乏。
* **攻击面可以快速更改。**云原生应用程序由许多较小的组件组成,这些组件称为微服务,它们是高度分布式的,每个都应该分别进行审计和保护。因为这些应用程序的设计是通过编排系统进行配置和调整的,所以其攻击面也在不断变化,而且比传统的独石应用程序要快得多。
* **分布式数据流需要持续监控。**容器和微服务被设计为轻量级的,并且以可编程方式与对方或外部云服务进行互连。这会在整个环境中产生大量的快速移动数据,需要进行持续监控,以便应对攻击和危害指标以及未经授权的数据访问或渗透。
* **检测、预防和响应必须自动化。** 容器生成的事件的速度和容量压倒了当前的安全操作流程。容器的短暂寿命也成为难以捕获、分析和确定事故的根本原因。有效的威胁保护意味着自动化数据收集、过滤、关联和分析,以便能够对新事件作出足够快速的反应。
面对这些新的挑战,安全专业人员将需要建立新的安全计划以支持其组织对云原生技术的使用。自然地,你的安全计划应该解决云原生程序的整个生命周期的问题,这些应用程序可以分为两个不同的阶段:构建和部署阶段以及运行时阶段。每个阶段都有不同的安全考虑因素,必须全部加以解决才能形成一个全面的安全计划。
### 确保容器的构建和部署
构建和部署阶段的安全性侧重于将控制应用于开发人员工作流程和持续集成和部署管道,以降低容器启动后可能出现的安全问题的风险。这些控制可以包含以下准则和最佳实践:
* **保持镜像尽可能小。**容器镜像是一个轻量级的可执行文件,用于打包应用程序代码及其依赖项。将每个镜像限制为软件运行所必需的内容, 从而最小化从镜像启动的每个容器的攻击面。从最小的操作系统基础镜像(如 Alpine Linux)开始,可以减少镜像大小,并使镜像更易于管理。
* **扫描镜像的已知问题。**当镜像构建后,应该检查已知的漏洞披露。可以扫描构成镜像的每个文件系统层,并将结果与定期更新的常见漏洞披露数据库(CVE)进行比较。然后开发和安全团队可以在镜像被用来启动容器之前解决发现的漏洞。
* **数字签名的镜像。**一旦建立镜像,应在部署之前验证它们的完整性。某些镜像格式使用被称为摘要的唯一标识符,可用于检测镜像内容何时发生变化。使用私钥签名镜像提供了加密的保证,以确保每个用于启动容器的镜像都是由可信方创建的。
* **强化并限制对主机操作系统的访问。**由于在主机上运行的容器共享相同的操作系统,因此必须确保它们以适当限制的功能集启动。这可以通过使用内核安全功能和 Seccomp、AppArmor 和 SELinux 等模块来实现。
* **指定应用程序级别的分割策略。**微服务之间的网络流量可以被分割,以限制它们彼此之间的连接。但是,这需要根据应用级属性(如标签和选择器)进行配置,从而消除了处理传统网络详细信息(如 IP 地址)的复杂性。分割带来的挑战是,必须事先定义策略来限制通信,而不会影响容器在环境内部和环境之间进行通信的能力,这是正常活动的一部分。
* **保护容器所使用的秘密信息。**微服务彼此相互之间频繁交换敏感数据,如密码、令牌和密钥,这称之为<ruby> 秘密信息 <rt> secret </rt></ruby>。如果将这些秘密信息存储在镜像或环境变量中,则可能会意外暴露这些。因此,像 Docker 和 Kubernetes 这样的多个编排平台都集成了秘密信息管理,确保只有在需要的时候才将秘密信息分发给使用它们的容器。
来自诸如 Docker、Red Hat 和 CoreOS 等公司的几个领先的容器平台和工具提供了部分或全部这些功能。开始使用这些方法之一是在构建和部署阶段确保强大安全性的最简单方法。
但是,构建和部署阶段控制仍然不足以确保全面的安全计划。提前解决容器开始运行之前的所有安全事件是不可能的,原因如下:首先,漏洞永远不会被完全消除,新的漏洞会一直出现。其次,声明式的容器元数据和网络分段策略不能完全预见高度分布式环境中的所有合法应用程序活动。第三,运行时控制使用起来很复杂,而且往往配置错误,就会使应用程序容易受到威胁。
### 在运行时保护容器
运行时阶段的安全性包括所有功能(可见性、检测、响应和预防),这些功能是发现和阻止容器运行后发生的攻击和策略违规所必需的。安全团队需要对安全事件的根源进行分类、调查和确定,以便对其进行全面补救。以下是成功的运行时阶段安全性的关键方面:
* **检测整个环境以得到持续可见性。**能够检测攻击和违规行为始于能够实时捕获正在运行的容器中的所有活动,以提供可操作的“真相源”。捕获不同类型的容器相关数据有各种检测框架。选择一个能够处理容器的容量和速度的方案至关重要。
* **关联分布式威胁指标。** 容器设计为基于资源可用性以跨计算基础架构而分布。由于应用程序可能由数百或数千个容器组成,因此危害指标可能分布在大量主机上,使得难以确定那些与主动威胁相关的相关指标。需要大规模,快速的相关性来确定哪些指标构成特定攻击的基础。
* **分析容器和微服务行为。**微服务和容器使得应用程序可以分解为执行特定功能的最小组件,并被设计为不可变的。这使得比传统的应用环境更容易理解预期行为的正常模式。偏离这些行为基准可能反映恶意行为,可用于更准确地检测威胁。
* **通过机器学习增强威胁检测。**容器环境中生成的数据量和速度超过了传统的检测技术。自动化和机器学习可以实现更有效的行为建模、模式识别和分类,从而以更高的保真度和更少的误报来检测威胁。注意使用机器学习的解决方案只是为了生成静态白名单,用于警报异常,这可能会导致严重的警报噪音和疲劳。
* **拦截并阻止未经授权的容器引擎命令。**发送到容器引擎(例如 Docker)的命令用于创建、启动和终止容器以及在正在运行的容器中运行命令。这些命令可以反映危害容器的意图,这意味着可以禁止任何未经授权的命令。
* **自动响应和取证。**容器的短暂寿命意味着它们往往只能提供很少的事件信息,以用于事件响应和取证。此外,云原生架构通常将基础设施视为不可变的,自动将受影响的系统替换为新系统,这意味着在调查时的容器可能会消失。自动化可以确保足够快地捕获、分析和升级信息,以减轻攻击和违规的影响。
基于容器技术和微服务架构的云原生软件正在迅速实现应用程序和基础架构的现代化。这种模式转变迫使安全专业人员重新考虑有效保护其组织所需的计划。随着容器的构建、部署和运行,云原生软件的全面安全计划将解决整个应用程序生命周期问题。通过使用上述指导方针实施计划,组织可以为容器基础设施以及运行在上面的应用程序和服务构建安全的基础。
---
作者:WeLien Dang 是 StackRox 的产品副总裁,StackRox 是一家为容器提供自适应威胁保护的安全公司。此前,他曾担任 CoreOS 产品负责人,并在亚马逊、Splunk 和 Bracket Computing 担任安全和云基础架构的高级产品管理职位。
---
via: <https://www.infoworld.com/article/3233139/cloud-computing/how-cloud-native-applications-change-security.html>
作者:[Wei Lien Dang](https://www.infoworld.com/blog/new-tech-forum/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
9,053 | 使用 mlocate 查找文件 | https://www.linux.com/blog/learn/intro-to-linux/2017/11/finding-files-mlocate | 2017-11-14T12:15:15 | [
"locate",
"mlocate",
"find"
] | https://linux.cn/article-9053-1.html | 在这一系列的文章中,我们将来看下 `mlocate`,来看看如何快速、轻松地满足你的需求。

对于一个系统管理员来说,草中寻针一样的查找文件的事情并不少见。在一台拥挤的机器上,文件系统中可能存在数十万个文件。当你需要确定一个特定的配置文件是最新的,但是你不记得它在哪里时怎么办?
如果你使用过一些类 Unix 机器,那么你肯定用过 `find` 命令。毫无疑问,它是非常复杂和功能强大的。以下是一个只搜索目录中的符号链接,而忽略文件的例子:
```
# find . -lname "*"
```
你可以用 `find` 命令做几乎无尽的事情,这是不容否认的。`find` 命令好用的时候是很好且简洁的,但是它也可以很复杂。这不一定是因为 `find` 命令本身的原因,而是它与 `xargs` 结合,你可以传递各种选项来调整你的输出,并删除你找到的那些文件。
### 位置、位置,让人沮丧
然而,通常情况下简单是最好的选择,特别是当一个脾气暴躁的老板搭着你的肩膀,闲聊着时间的重要性时。你还在模糊地猜测这个你从来没有见过的文件的路径,而你的老板却肯定它在拥挤的 /var 分区的某处。
进一步看下 `mlocate`。你也许注意过它的一个近亲:`slocate`,它安全地(注意前缀字母 s 代表安全)记录了相关的文件权限,以防止非特权用户看到特权文件。此外,还有它们所起源的一个更老的,原始 `locate` 命令。
`mlocate` 与其家族的其他成员(至少包括 `slocate`)的不同之处在于,在扫描文件系统时,`mlocate` 不需要持续重新扫描所有的文件系统。相反,它将其发现的文件(注意前面的 m 代表合并)与现有的文件列表合并在一起,使其可以借助系统缓存从而性能更高、更轻量级。
在本系列文章中,我们将更仔细地了解 `mlocate` (由于其流行,所以也简称其为 `locate`),并研究如何快速轻松地将其调整到你心中所想的方式。
### 小巧和 紧凑
除非你经常重复使用复杂的命令,否则就会像我一样,最终会忘记它们而需要在用的时候寻找它们。`locate` 命令的优点是可以快速查询整个文件系统,而不用担心你处于顶层目录、根目录和所在路径,只需要简单地使用 `locate` 命令。
以前你可能已经发现 `find` 命令非常不听话,让你经常抓耳挠腮。你知道,丢失了一个分号或一个没有正确转义的特殊的字符就会这样。现在让我们离开这个复杂的 `find` 命令,放松一下,看一下这个聪明的小命令。
你可能需要首先通过运行以下命令来检查它是否在你的系统上:
对于 Red Hat 家族:
```
# yum install mlocate
```
对于 Debian 家族:
```
# apt-get install mlocate
```
发行版之间不应该有任何区别,但版本之间几乎肯定有细微差别。小心。
接下来,我们将介绍 `locate` 命令的一个关键组件,名为 `updatedb`。正如你可能猜到的那样,这是**更新** `locate` 命令的**数据库**的命令。这名字非常符合直觉。
这个数据库是我之前提到的 `locate` 命令的文件列表。该列表被保存在一个相对简单而高效的数据库中。`updatedb` 通过 cron 任务定期运行,通常在一天中的安静时间运行。在下面的清单 1 中,我们可以看到文件 `/etc/cron.daily/mlocate.cron` 的内部(该文件的路径及其内容可能因发行版不同)。
```
#!/bin/sh
nodevs=$(< /proc/filesystems awk '$1 == "nodev" { print $2 }')
renice +19 -p $$ >/dev/null 2>&1
ionice -c2 -n7 -p $$ >/dev/null 2>&1
/usr/bin/updatedb -f "$nodevs"
```
**清单 1:** 每天如何触发 “updatedb” 命令。
如你所见,`mlocate.cron` 脚本使用了优秀的 `nice` 命令来尽可能少地影响系统性能。我还没有明确指出这个命令每天都在设定的时间运行(但如果我没有记错的话,原始的 `locate` 命令与你在午夜时的计算机减速有关)。这是因为,在一些 “cron” 版本上,延迟现在被引入到隔夜开始时间。
这可能是因为所谓的 “<ruby> 河马之惊群 <rt> Thundering Herd of Hippos </rt></ruby>”问题。想象许多计算机(或饥饿的动物)同时醒来从单一或有限的来源要求资源(或食物)。当所有的“河马”都使用 NTP 设置它们的手表时,这可能会发生(好吧,这个寓言扯多了,但请忍受一下)。想象一下,正好每五分钟(就像一个 “cron 任务”),它们都要求获得食物或其他东西。
如果你不相信我,请看下配置文件 - 清单 2 中名为 `anacron` 的 cron 版本,这是文件 `/etc/anacrontab` 的内容。
```
# /etc/anacrontab: configuration file for anacron
# See anacron(8) and anacrontab(5) for details.
SHELL=/bin/sh
PATH=/sbin:/bin:/usr/sbin:/usr/bin
MAILTO=root
# the maximal random delay added to the base delay of the jobs
RANDOM_DELAY=45
# the jobs will be started during the following hours only
START_HOURS_RANGE=3-22
#period in days delay in minutes job-identifier command
1 5 cron.daily nice run-parts /etc/cron.daily
7 25 cron.weekly nice run-parts /etc/cron.weekly
@monthly 45 cron.monthly nice run-parts /etc/cron.monthly
```
**清单 2:** 运行 “cron” 任务时延迟是怎样被带入的。
从清单 2 可以看到 `RANDOM_DELAY` 和 “delay in minutes” 列。如果你不熟悉 cron 这个方面,那么你可以在这找到更多的东西:
```
# man anacrontab
```
否则,如果你愿意,你可以自己延迟一下。有个[很棒的网页](http://www.moundalexis.com/archives/000076.php)(现在已有十多年的历史)以非常合理的方式讨论了这个问题。本网站讨论如何使用 `sleep` 来引入一个随机性,如清单 3 所示。
```
#!/bin/sh
# Grab a random value between 0-240.
value=$RANDOM
while [ $value -gt 240 ] ; do
value=$RANDOM
done
# Sleep for that time.
sleep $value
# Syncronize.
/usr/bin/rsync -aqzC --delete --delete-after masterhost::master /some/dir/
```
**清单 3:**在触发事件之前引入随机延迟的 shell 脚本,以避免[河马之惊群](http://www.moundalexis.com/archives/000076.php)。
在提到这些(可能令人惊讶的)延迟时,是指 `/etc/crontab` 或 root 用户自己的 crontab 文件。如果你想改变 `locate` 命令运行的时间,特别是由于磁盘访问速度减慢时,那么它不是太棘手。实现它可能会有更优雅的方式,但是你也可以把文件 `/etc/cron.daily/mlocate.cron` 移到别的地方(我使用 `/usr/local/etc` 目录),使用 root 用户添加一条记录到 root 用户的 crontab,粘贴以下内容:
```
# crontab -e
33 3 * * * /usr/local/etc/mlocate.cron
```
使用 anacron,而不是通过 `/var/log/cron` 以及它的旧的、轮转的版本,你可以快速地告诉它上次 cron.daily 任务被触发的时间:
```
# ls -hal /var/spool/anacron
```
下一次,我们会看更多的使用 `locate`、`updatedb` 和其他工具来查找文件的方法。
---
via: <https://www.linux.com/blog/learn/intro-to-linux/2017/11/finding-files-mlocate>
作者:[CHRIS BINNIE](https://www.linux.com/users/chrisbinnie) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,054 | PostgreSQL 的哈希索引现在很酷 | https://rhaas.blogspot.jp/2017/09/postgresqls-hash-indexes-are-now-cool.html | 2017-11-14T17:47:09 | [
"PostgreSQL",
"哈希",
"索引"
] | https://linux.cn/article-9054-1.html | 
由于我刚刚提交了最后一个改进 PostgreSQL 11 哈希索引的补丁,并且大部分哈希索引的改进都致力于预计下周发布的 PostgreSQL 10(LCTT 译注:已发布),因此现在似乎是对过去 18 个月左右所做的工作进行简要回顾的好时机。在版本 10 之前,哈希索引在并发性能方面表现不佳,缺少预写日志记录,因此在宕机或复制时都是不安全的,并且还有其他二等公民。在 PostgreSQL 10 中,这在很大程度上被修复了。
虽然我参与了一些设计,但改进哈希索引的首要功劳来自我的同事 Amit Kapila,[他在这个话题下的博客值得一读](http://amitkapila16.blogspot.jp/2017/03/hash-indexes-are-faster-than-btree.html)。哈希索引的问题不仅在于没有人打算写预写日志记录的代码,还在于代码没有以某种方式进行结构化,使其可以添加实际上正常工作的预写日志记录。要拆分一个桶,系统将锁定已有的桶(使用一种十分低效的锁定机制),将半个元组移动到新的桶中,压缩已有的桶,然后松开锁。即使记录了个别更改,在错误的时刻发生崩溃也会使索引处于损坏状态。因此,Aimt 首先做的是重新设计锁定机制。[新的机制](https://git.postgresql.org/gitweb/?p=postgresql.git;a=commitdiff;h=6d46f4783efe457f74816a75173eb23ed8930020)在某种程度上允许扫描和拆分并行进行,并且允许稍后完成那些因报错或崩溃而被中断的拆分。完成了一系列漏洞的修复和一些重构工作,Aimt 就打了另一个补丁,[添加了支持哈希索引的预写日志记录](https://git.postgresql.org/gitweb/?p=postgresql.git;a=commitdiff;h=c11453ce0aeaa377cbbcc9a3fc418acb94629330)。
与此同时,我们发现哈希索引已经错过了许多已应用于 B 树索引多年的相当明显的性能改进。因为哈希索引不支持预写日志记录,以及旧的锁定机制十分笨重,所以没有太多的动机去提升其他的性能。而这意味着如果哈希索引会成为一个非常有用的技术,那么需要做的事只是添加预写日志记录而已。PostgreSQL 索引存取方法的抽象层允许索引保留有关其信息的后端专用缓存,避免了重复查询索引本身来获取相关的元数据。B 树和 SQLite 的索引正在使用这种机制,但哈希索引没有,所以我的同事 Mithun Cy 写了一个补丁来[使用此机制缓存哈希索引的元页](https://git.postgresql.org/gitweb/?p=postgresql.git;a=commitdiff;h=293e24e507838733aba4748b514536af2d39d7f2)。同样,B 树索引有一个称为“单页回收”的优化,它巧妙地从索引页移除没用的索引指针,从而防止了大量索引膨胀。我的同事 Ashutosh Sharma 打了一个补丁将[这个逻辑移植到哈希索引上](https://git.postgresql.org/gitweb/?p=postgresql.git;a=commitdiff;h=6977b8b7f4dfb40896ff5e2175cad7fdbda862eb),也大大减少了索引的膨胀。最后,B 树索引[自 2006 年以来](https://git.postgresql.org/gitweb/?p=postgresql.git;a=commitdiff;h=7c75ef571579a3ad7a1d3ee909f11dba5e0b9440)就有了一个功能,可以避免重复锁定和解锁同一个索引页——所有元组都在页中一次性删除,然后一次返回一个。Ashutosh Sharma 也[将此逻辑移植到了哈希索引中](https://git.postgresql.org/gitweb/?p=postgresql.git;a=commitdiff;h=a507b86900f695aacc8d52b7d2cfcb65f58862a2),但是由于缺少时间,这个优化没有在版本 10 中完成。在这个博客提到的所有内容中,这是唯一一个直到版本 11 才会出现的改进。
关于哈希索引的工作有一个更有趣的地方是,很难确定行为是否真的正确。锁定行为的更改只可能在繁重的并发状态下失败,而预写日志记录中的错误可能仅在崩溃恢复的情况下显示出来。除此之外,在每种情况下,问题可能是微妙的。没有东西崩溃还不够;它们还必须在所有情况下产生正确的答案,并且这似乎很难去验证。为了协助这项工作,我的同事 Kuntal Ghosh 先后跟进了最初由 Heikki Linnakangas 和 Michael Paquier 开始的工作,并且制作了一个 WAL 一致性检查器,它不仅可以作为开发人员测试的专用补丁,还能真正[提交到 PostgreSQL](https://git.postgresql.org/gitweb/?p=postgresql.git;a=commitdiff;h=7403561c0f6a8c62b79b6ddf0364ae6c01719068)。在提交之前,我们对哈希索引的预写日志代码使用此工具进行了广泛的测试,并十分成功地查找到了一些漏洞。这个工具并不仅限于哈希索引,相反:它也可用于其他模块的预写日志记录代码,包括堆,当今的所有 AM 索引,以及一些以后开发的其他东西。事实上,它已经成功地[在 BRIN 中找到了一个漏洞](https://git.postgresql.org/gitweb/?p=postgresql.git;a=commitdiff;h=08bf6e529587e1e9075d013d859af2649c32a511)。
虽然 WAL 一致性检查是主要的开发者工具——尽管它也适合用户使用,如果怀疑有错误——也可以升级到专为数据库管理人员提供的几种工具。Jesper Pedersen 写了一个补丁来[升级 pageinspect contrib 模块来支持哈希索引](https://git.postgresql.org/gitweb/?p=postgresql.git;a=commitdiff;h=e759854a09d49725a9519c48a0d71a32bab05a01),Ashutosh Sharma 做了进一步的工作,Peter Eisentraut 提供了测试用例(这是一个很好的办法,因为这些测试用例迅速失败,引发了几轮漏洞修复)。多亏了 Ashutosh Sharma 的工作,pgstattuple contrib 模块[也支持哈希索引了](https://git.postgresql.org/gitweb/?p=postgresql.git;a=commitdiff;h=ea69a0dead5128c421140dc53fac165ba4af8520)。
一路走来,也有一些其他性能的改进。我一开始没有意识到的是,当一个哈希索引开始新一轮的桶拆分时,磁盘上的大小会突然加倍,这对于 1MB 的索引来说并不是一个问题,但是如果你碰巧有一个 64GB 的索引,那就有些不幸了。Mithun Cy 通过编写一个补丁,把加倍过程[分为四个阶段](https://www.postgresql.org/message-id/[email protected])在某个程度上解决了这一问题,这意味着我们将从 64GB 到 80GB 到 96GB 到 112GB 到 128GB,而不是一次性从 64GB 到 128GB。这个问题可以进一步改进,但需要对磁盘格式进行更深入的重构,并且需要仔细考虑对查找性能的影响。
七月时,一份[来自于“AP”测试人员](https://git.postgresql.org/gitweb/?p=postgresql.git;a=commitdiff;h=ff98a5e1e49de061600feb6b4de5ce0a22d386af)的报告使我们感到需要做进一步的调整。AP 发现,若试图将 20 亿行数据插入到新创建的哈希索引中会导致错误。为了解决这个问题,Amit 修改了拆分桶的代码,[使得在每次拆分之后清理旧的桶](https://git.postgresql.org/gitweb/?p=postgresql.git;a=commitdiff;h=ff98a5e1e49de061600feb6b4de5ce0a22d386af),大大减少了溢出页的累积。为了得以确保,Aimt 和我也[增加了四倍的位图页的最大数量](https://www.postgresql.org/message-id/CA%2BTgmoax6DhnKsuE_gzY5qkvmPEok77JAP1h8wOTbf%2Bdg2Ycrw%40mail.gmail.com),用于跟踪溢出页分配。
虽然还是有更多的事情要做,但我觉得,我和我的同事们——以及在 PostgreSQL 团队中的其他人的帮助下——已经完成了我们的目标,使哈希索引成为一个一流的功能,而不是被严重忽视的半成品。不过,你或许会问,这个功能可能有哪些应用场景。我在文章开头提到的(以及链接中的)Amit 的博客内容表明,即使是 pgbench 的工作负载,哈希索引页也可能在低级和高级并发方面优于 B 树。然而,从某种意义上说,这确实是最坏的情况。哈希索引的卖点之一是,索引存储的是字段的哈希值,而不是原始值——所以,我希望像 UUID 或者长字符串的宽键将有更大的改进。它们可能会在读取繁重的工作负载时做得更好。我们没有像优化读取那种程度来优化写入,但我鼓励任何对此技术感兴趣的人去尝试并将结果发到邮件列表(或发私人电子邮件),因为对于开发一个功能而言,真正关键的并不是一些开发人员去思考在实验室中会发生什么,而是在实际中发生了什么。
最后,我要感谢 Jeff Janes 和 Jesper Pedersen 为这个项目及其相关所做的宝贵的测试工作。这样一个规模适当的项目并不易得,以及有一群坚持不懈的测试人员,他们勇于打破任何废旧的东西的决心起了莫大的帮助。除了以上提到的人之外,其他人同样在测试,审查以及各种各样的日常帮助方面值得赞扬,其中包括 Andreas Seltenreich,Dilip Kumar,Tushar Ahuja,Alvaro Herrera,Micheal Paquier,Mark Kirkwood,Tom Lane,Kyotaro Horiguchi。谢谢你们,也同样感谢那些本该被提及却被我无意中忽略的所有朋友。
---
via:<https://rhaas.blogspot.jp/2017/09/postgresqls-hash-indexes-are-now-cool.html>
作者:[Robert Haas](http://rhaas.blogspot.jp) 译者:[polebug](https://github.com/polebug) 校对:[wxy](https://github.com/wxy)
本文由[LCTT]([https://github.com/LCTT/TranslateProject)原创编译,[Linux中国](https://linux.cn/)荣誉推出](https://github.com/LCTT/TranslateProject%EF%BC%89%E5%8E%9F%E5%88%9B%E7%BC%96%E8%AF%91%EF%BC%8C%5BLinux%E4%B8%AD%E5%9B%BD%5D%EF%BC%88https://linux.cn/%EF%BC%89%E8%8D%A3%E8%AA%89%E6%8E%A8%E5%87%BA)
| 302 | Moved Temporarily | null |
9,055 | 怎么在 Fedora 中创建我的第一个 RPM 包? | https://blog.justinwflory.com/2017/11/first-rpm-package-fedora/ | 2017-11-14T19:22:00 | [
"打包",
"RPM"
] | https://linux.cn/article-9055-1.html | 
过了这个夏天,我把我的桌面环境迁移到了 i3,这是一个瓦片式窗口管理器。当初,切换到 i3 是一个挑战,因为我必须去处理许多以前 GNOME 帮我处理的事情。其中一件事情就是改变屏幕亮度。 xbacklight 这个在笔记本电脑上改变背光亮度的标准方法,它在我的硬件上不工作了。
最近,我发现一个改变背光亮度的工具 [brightlight](https://github.com/multiplexd/brightlight)。我决定去试一下它,它工作在 root 权限下。但是,我发现 brightligh 在 Fedora 下没有 RPM 包。我决定,是在 Fedora 下尝试创建一个包的时候了,并且可以学习怎么去创建一个 RPM 包。
在这篇文章中,我将分享以下的内容:
* 创建 RPM SPEC 文件
* 在 Koji 和 Copr 中构建包
* 使用调试包处理一个问题
* 提交这个包到 Fedora 包集合中
### 前提条件
在 Fedora 上,我安装了包构建过程中所有步骤涉及到的包。
```
sudo dnf install fedora-packager fedpkg fedrepo_req copr-cli
```
### 创建 RPM SPEC 文件
创建 RPM 包的第一步是去创建 SPEC 文件。这些规范,或者是指令,它告诉 RPM 怎么去构建包。这是告诉 RPM 从包的源代码中创建一个二进制文件。创建 SPEC 文件看上去是整个包处理过程中最难的一部分,并且它的难度取决于项目。
对我而言,幸运的是,brightlight 是一个用 C 写的简单应用程序。维护人员用一个 Makefile 使创建二进制应用程序变得很容易。构建它只是在仓库中简单运行 `make` 的问题。因此,我现在可以用一个简单的项目去学习 RPM 打包。
#### 查找文档
谷歌搜索 “how to create an RPM package” 有很多结果。我开始使用的是 [IBM 的文档](https://www.ibm.com/developerworks/library/l-rpm1/index.html)。然而,我发现它理解起来非常困难,不知所云(虽然十分详细,它可能适用于复杂的 app)。我也在 Fedora 维基上找到了 [创建包](https://fedoraproject.org/wiki/How_to_create_an_RPM_package) 的介绍。这个文档在构建和处理上解释的非常好,但是,我一直困惑于 “怎么去开始呢?”
最终,我找到了 [RPM 打包指南](https://fedoraproject.org/wiki/How_to_create_an_RPM_package),它是大神 [Adam Miller](https://github.com/maxamillion) 写的。这些介绍非常有帮助,并且包含了三个优秀的示例,它们分别是用 Bash、C 和 Python 编写的程序。这个指南帮我很容易地理解了怎么去构建一个 RPM SPEC,并且,更重要的是,解释了怎么把这些片断拼到一起。
有了这些之后,我可以去写 brightlight 程序的我的 [第一个 SPEC 文件](https://src.fedoraproject.org/rpms/brightlight/blob/master/f/brightlight.spec) 了。因为它是很简单的,SPEC 很短也很容易理解。我有了 SPEC 文件之后,我发现其中有一些错误。处理掉一些错误之后,我创建了源 RPM (SRPM) 和二进制 RPM,然后,我解决了出现的每个问题。
```
rpmlint SPECS/brightlight.spec
rpmbuild -bs SPECS/brightlight.spec
rpmlint SRPMS/brightlight-5-1.fc26.src.rpm
rpmbuild -bb SPECS/brightlight-5-1.fc26.x86_64.rpm
rpmlint RPMS/x86_64/brightlight-5-1.fc26.x86_64.rpm
```
现在,我有了一个可用的 RPM,可以发送到 Fedora 仓库了。
### 在 Copr 和 Koji 中构建
接下来,我读了该 [指南](https://fedoraproject.org/wiki/Join_the_package_collection_maintainers) 中关于怎么成为一个 Fedora 打包者。在提交之前,他们鼓励打包者通过在在 [Koji](https://koji.fedoraproject.org/koji/) 中托管、并在 [Copr](https://copr.fedoraproject.org/) 中构建项目来测试要提交的包。
#### 使用 Copr
首先,我为 brightlight 创建了一个 [Copr 仓库](https://copr.fedorainfracloud.org/coprs/jflory7/brightlight/),[Copr](https://developer.fedoraproject.org/deployment/copr/about.html) 是在 Fedora 的基础设施中的一个服务,它构建你的包,并且为你任意选择的 Fedora 或 EPEL 版本创建一个定制仓库。它对于快速托管你的 RPM 包,并与其它人去分享是非常方便的。你不需要特别操心如何去托管一个 Copr 仓库。
我从 Web 界面创建了我的 Copr 项目,但是,你也可以使用 `copr-cli` 工具。在 Fedora 开发者网站上有一个 [非常优秀的指南](https://developer.fedoraproject.org/deployment/copr/copr-cli.html)。在该网站上创建了我的仓库之后,我使用这个命令构建了我的包。
```
copr-cli build brightlight SRPMS/brightlight.5-1.fc26.src.rpm
```
我的包在 Corp 上成功构建,并且,我可以很容易地在我的 Fedora 系统上成功安装它。
#### 使用 Koji
任何人都可以使用 [Koji](https://koji.fedoraproject.org/koji/) 在多种架构和 Fedora 或 CentOS/RHEL 版本上测试他们的包。在 Koji 中测试,你必须有一个源 RPM。我希望 brightlight 包在 Fedora 所有的版本中都支持,因此,我运行如下的命令:
```
koji build --scratch f25 SRPMS/brightlight-5-1.fc26.src.rpm
koji build --scratch f26 SRPMS/brightlight-5-1.fc26.src.rpm
koji build --scratch f27 SRPMS/brightlight-5-1.fc26.src.rpm
```
它花费了一些时间,但是,Koji 构建了所有的包。我的包可以很完美地运行在 Fedora 25 和 26 中,但是 Fedora 27 失败了。 Koji 模拟构建可以使我走在正确的路线上,并且确保我的包构建成功。
### 问题:Fedora 27 构建失败!
现在,我已经知道我的 Fedora 27 上的包在 Koji 上构建失败了。但是,为什么呢?我发现在 Fedora 27 上有两个相关的变化。
* [Subpackage and Source Debuginfo](https://fedoraproject.org/wiki/Changes/SubpackageAndSourceDebuginfo)
* [RPM 4.14](https://fedoraproject.org/wiki/Changes/RPM-4.14) (特别是,debuginfo 包重写了)
这些变化意味着 RPM 包必须使用一个 debuginfo 包去构建。这有助于排错或调试一个应用程序。在我的案例中,这并不是关键的或者很必要的,但是,我需要去构建一个。
感谢 Igor Gnatenko,他帮我理解了为什么我在 Fedora 27 上构建包时需要去将这些增加到我的包的 SPEC 中。在 `%make_build` 宏指令之前,我增加了这些行。
```
export CFLAGS="%{optflags}"
export LDFLAGS="%{__global_ldflags}"
```
我构建了一个新的 SRPM 并且提交它到 Koji 去在 Fedora 27 上构建。成功了,它构建成功了!
### 提交这个包
现在,我在 Fedora 25 到 27 上成功校验了我的包,是时候为 Fedora 打包了。第一步是提交这个包,为了请求一个包评估,要在 Red Hat Bugzilla 创建一个新 bug。我为 brightlight [创建了一个工单](https://bugzilla.redhat.com/show_bug.cgi?id=1505026)。因为这是我的第一个包,我明确标注它 “这是我的第一个包”,并且我寻找一个发起人。在工单中,我链接 SPEC 和 SRPM 文件到我的 Git 仓库中。
#### 进入 dist-git
[Igor Gnatenko](https://fedoraproject.org/wiki/User:Ignatenkobrain) 发起我进入 Fedora 打包者群组,并且在我的包上留下反馈。我学习了一些其它的关于 C 应用程序打包的特定的知识。在他响应我之后,我可以在 [dist-git](https://src.fedoraproject.org/) 上申请一个仓库,Fedora 的 RPM 包集合仓库为所有的 Fedora 版本保存了 SPEC 文件。
一个很方便的 Python 工具使得这一部分很容易。`fedrepo-req` 是一个用于创建一个新的 dist-git 仓库的请求的工具。我用这个命令提交我的请求。
```
fedrepo-req brightlight \
--ticket 1505026 \
--description "CLI tool to change screen back light brightness" \
--upstreamurl https://github.com/multiplexd/brightlight
```
它为我在 fedora-scm-requests 仓库创建了一个新的工单。这是一个我是管理员的 [创建的仓库](https://src.fedoraproject.org/rpms/brightlight)。现在,我可以开始干了!

*My first RPM in Fedora dist-git – woohoo!*
#### 与 dist-git 一起工作
接下来,`fedpkg` 是用于和 dist-git 仓库进行交互的工具。我改变当前目录到我的 git 工作目录,然后运行这个命令。
```
fedpkg clone brightlight
```
`fedpkg` 从 dist-git 克隆了我的包的仓库。对于这个仅有的第一个分支,你需要去导入 SRPM。
```
fedpkg import SRPMS/brightlight-5-1.fc26.src.rpm
```
`fedpkg` 导入你的包的 SRPM 到这个仓库中,然后设置源为你的 Git 仓库。这一步对于使用 `fedpkg` 是很重要的,因为它用一个 Fedora 友好的方去帮助规范这个仓库(与手动添加文件相比)。一旦你导入了 SRPM,推送这个改变到 dist-git 仓库。
```
git commit -m "Initial import (#1505026)."
git push
```
#### 构建包
自从你推送第一个包导入到你的 dist-git 仓库中,你已经准备好了为你的项目做一次真实的 Koji 构建。要构建你的项目,运行这个命令。
```
fedpkg build
```
它会在 Koji 中为 Rawhide 构建你的包,这是 Fedora 中的非版本控制的分支。在你为其它分支构建之前,你必须在 Rawhide 分支上构建成功。如果一切构建成功,你现在可以为你的项目的其它分支发送请求了。
```
fedrepo-req brightlight f27 -t 1505026
fedrepo-req brightlight f26 -t 1505026
fedrepo-req brightlight f25 -t 1505026
```
#### 关于构建其它分支的注意事项
一旦你最初导入了 SRPM,如果你选择去创建其它分支,记得合并你的主分支到它们。例如,如果你后面为 Fedora 27 请求一个分支,你将需要去使用这些命令。
```
fedpkg switch-branch f27
git merge master
git push
fedpkg build
```
#### 提交更新到 Bodhi
这个过程的最后一步是,把你的新包作为一个更新包提交到 Bodhi 中。当你初次提交你的更新包时,它将去测试这个仓库。任何人都可以测试你的包并且增加 karma 到该更新中。如果你的更新接收了 3 个以上的投票(或者像 Bodhi 称它为 karma),你的包将自动被推送到稳定仓库。否则,一周之后,推送到测试仓库中。
要提交你的更新到 Bodhi,你仅需要一个命令。
```
fedpkg update
```
它为你的包用一个不同的配置选项打开一个 Vim 窗口。一般情况下,你仅需要去指定一个 类型(比如,`newpackage`)和一个你的包评估的票据 ID。对于更深入的讲解,在 Fedora 维基上有一篇[更新的指南](https://fedoraproject.org/wiki/Package_update_HOWTO)。
在保存和退出这个文件后,`fedpkg` 会把你的包以一个更新包提交到 Bodhi,最后,同步到 Fedora 测试仓库。我也可以用这个命令去安装我的包。
```
sudo dnf install brightlight -y --enablerepo=updates-testing --refresh
```
### 稳定仓库
最近提交了我的包到 [Fedora 26 稳定仓库](https://bodhi.fedoraproject.org/updates/brightlight-5-1.fc26),并且不久将进入 [Fedora 25](https://bodhi.fedoraproject.org/updates/FEDORA-2017-8071ee299f) 和 [Fedora 27](https://bodhi.fedoraproject.org/updates/FEDORA-2017-f3f085b86e) 稳定仓库。感谢帮助我完成我的第一个包的每个人。我期待有更多的机会为发行版添加包。
---
via: <https://blog.justinwflory.com/2017/11/first-rpm-package-fedora/>
作者:[JUSTIN W. FLORY](https://blog.justinwflory.com/author/jflory7/) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,056 | 怎么在一台树莓派上安装 Postgres 数据库 | https://opensource.com/article/17/10/set-postgres-database-your-raspberry-pi | 2017-11-17T10:10:00 | [
"PostgreSQL",
"树莓派"
] | https://linux.cn/article-9056-1.html |
>
> 在你的下一个树莓派项目上安装和配置流行的开源数据库 Postgres 并去使用它。
>
>
>

保存你的项目或应用程序持续增加的数据,数据库是一种很好的方式。你可以在一个会话中将数据写入到数据库,并且在下次你需要查找的时候找到它。一个设计良好的数据库可以做到在巨大的数据集中高效地找到数据,只要告诉它你想去找什么,而不用去考虑它是如何查找的。为一个基本的 [CRUD](https://en.wikipedia.org/wiki/Create,_read,_update_and_delete) (创建、记录、更新、删除)应用程序安装一个数据库是非常简单的, 它是一个很通用的模式,并且也适用于很多项目。
为什么 [PostgreSQL](https://www.postgresql.org/) 一般被为 Postgres? 它被认为是功能和性能最好的开源数据库。如果你使用过 MySQL,它们是很相似的。但是,如果你希望使用它更高级的功能,你会发现优化 Postgres 是比较容易的。它便于安装、容易使用、方便安全, 而且在树莓派 3 上运行的非常好。
本教程介绍了怎么在一个树莓派上去安装 Postgres;创建一个表;写简单查询;在树莓派、PC,或者 Mac 上使用 pgAdmin 图形用户界面;从 Python 中与数据库交互。
你掌握了这些基础知识后,你可以让你的应用程序使用复合查询连接多个表,那个时候你需要考虑的是,怎么去使用主键或外键优化及最佳实践等等。
### 安装
一开始,你将需要去安装 Postgres 和一些其它的包。打开一个终端窗口并连接到因特网,然后运行以下命令:
```
sudo apt install postgresql libpq-dev postgresql-client
postgresql-client-common -y
```

当安装完成后,切换到 Postgres 用户去配置数据库:
```
sudo su postgres
```
现在,你可以创建一个数据库用户。如果你创建了一个与你的 Unix 用户帐户相同名字的用户,那个用户将被自动授权访问该数据库。因此在本教程中,为简单起见,我们将假设你使用了默认用户 `pi` 。运行 `createuser` 命令以继续:
```
createuser pi -P --interactive
```
当得到提示时,输入一个密码 (并记住它), 选择 `n` 使它成为一个非超级用户(LCTT 译注:此处原文有误),接下来两个问题选择 `y`(LCTT 译注:分别允许创建数据库和其它用户)。

现在,使用 Postgres shell 连接到 Postgres 去创建一个测试数据库:
```
$ psql
> create database test;
```
按下 `Ctrl+D` **两次**从 psql shell 和 postgres 用户中退出,再次以 `pi` 用户登入。你创建了一个名为 `pi` 的 Postgres 用户后,你可以从这里无需登录凭据即可访问 Postgres shell:
```
$ psql test
```
你现在已经连接到 "test" 数据库。这个数据库当前是空的,不包含任何表。你可以在 psql shell 里创建一个简单的表:
```
test=> create table people (name text, company text);
```
现在你可插入数据到表中:
```
test=> insert into people values ('Ben Nuttall', 'Raspberry Pi Foundation');
test=> insert into people values ('Rikki Endsley', 'Red Hat');
```
然后尝试进行查询:
```
test=> select * from people;
name | company
---------------+-------------------------
Ben Nuttall | Raspberry Pi Foundation
Rikki Endsley | Red Hat
(2 rows)
```

```
test=> select name from people where company = 'Red Hat';
name | company
---------------+---------
Rikki Endsley | Red Hat
(1 row)
```
### pgAdmin
如果希望使用一个图形工具去访问数据库,你可以使用它。 PgAdmin 是一个全功能的 PostgreSQL GUI,它允许你去创建和管理数据库和用户、创建和修改表、执行查询,和如同在电子表格一样熟悉的视图中浏览结果。psql 命令行工具可以很好地进行简单查询,并且你会发现很多高级用户一直在使用它,因为它的执行速度很快 (并且因为他们不需要借助 GUI),但是,一般用户学习和操作数据库,使用 pgAdmin 是一个更适合的方式。
关于 pgAdmin 可以做的其它事情:你可以用它在树莓派上直接连接数据库,或者用它在其它的电脑上远程连接到树莓派上的数据库。
如果你想去访问树莓派,你可以用 `apt` 去安装它:
```
sudo apt install pgadmin3
```
它是和基于 Debian 的系统如 Ubuntu 是完全相同的;如果你在其它发行版上安装,尝试与你的系统相关的等价的命令。 或者,如果你在 Windows 或 macOS 上,尝试从 [pgAdmin.org](https://www.pgadmin.org/download/) 上下载 pgAdmin。注意,在 `apt` 上的可用版本是 pgAdmin3,而最新的版本 pgAdmin4,在其网站上可以找到。
在同一台树莓派上使用 pgAdmin 连接到你的数据库,从主菜单上简单地打开 pgAdmin3 ,点击 **new connection** 图标,然后完成注册,这时,你将需要一个名字(连接名,比如 test),改变用户为 “pi”,然后剩下的输入框留空 (或者如它们原本不动)。点击 OK,然后你在左侧的侧面版中将发现一个新的连接。

要从另外一台电脑上使用 pgAdmin 连接到你的树莓派数据库上,你首先需要编辑 PostgreSQL 配置允许远程连接:
1、 编辑 PostgreSQL 配置文件 `/etc/postgresql/9.6/main/postgresql.conf` ,取消 `listen_addresses` 行的注释,并把它的值从 `localhost` 改变成 `*`。然后保存并退出。
2、 编辑 pg\_hba 配置文件 `/etc/postgresql/9.6/main/postgresql.conf`,将 `127.0.0.1/32` 改变成 `0.0.0.0/0` (对于IPv4)和将 `::1/128` 改变成 `::/0` (对于 IPv6)。然后保存并退出。
3、 重启 PostgreSQL 服务: `sudo service postgresql restart`。
注意,如果你使用一个旧的 Raspbian 镜像或其它发行版,版本号可能不一样。

做完这些之后,在其它的电脑上打开 pgAdmin 并创建一个新的连接。这时,需要提供一个连接名,输入树莓派的 IP 地址作为主机(这可以在任务栏的 WiFi 图标上悬停鼠标找到,或者在一个终端中输入 `hostname -I` 找到)。

不论你连接的是本地的还是远程的数据库,点击打开 **Server Groups > Servers > test > Schemas > public > Tables**,右键单击 **people** 表,然后选择 **View Data > View top 100 Rows**。你现在将看到你前面输入的数据。

你现在可以创建和修改数据库和表、管理用户,和使用 GUI 去写你自己的查询了。你可能会发现这种可视化方法比命令行更易于管理。
### Python
要从一个 Python 脚本连接到你的数据库,你将需要 [Psycopg2](http://initd.org/psycopg/) 这个 Python 包。你可以用 [pip](https://pypi.python.org/pypi/pip) 来安装它:
```
sudo pip3 install psycopg2
```
现在打开一个 Python 编辑器写一些代码连接到你的数据库:
```
import psycopg2
conn = psycopg2.connect('dbname=test')
cur = conn.cursor()
cur.execute('select * from people')
results = cur.fetchall()
for result in results:
print(result)
```
运行这个代码去看查询结果。注意,如果你连接的是远程数据库,在连接字符串中你将需要提供更多的凭据,比如,增加主机 IP、用户名,和数据库密码:
```
conn = psycopg2.connect('host=192.168.86.31 user=pi
password=raspberry dbname=test')
```
你甚至可以创建一个函数去运行特定的查询:
```
def get_all_people():
query = """
SELECT
*
FROM
people
"""
cur.execute(query)
return cur.fetchall()
```
和一个包含参数的查询:
```
def get_people_by_company(company):
query = """
SELECT
*
FROM
people
WHERE
company = %s
"""
values = (company, )
cur.execute(query, values)
return cur.fetchall()
```
或者甚至是一个增加记录的函数:
```
def add_person(name, company):
query = """
INSERT INTO
people
VALUES
(%s, %s)
"""
values = (name, company)
cur.execute(query, values)
```
注意,这里使用了一个注入字符串到查询中的安全的方法, 你不希望被 [小鲍勃的桌子](https://xkcd.com/327/) 害死!

现在你知道了这些基础知识,如果你想去进一步掌握 Postgres ,查看在 [Full Stack Python](https://www.fullstackpython.com/postgresql.html) 上的文章。
(题图:树莓派基金会)
---
作者简介:
Ben Nuttall - 树莓派社区的管理者。除了它为树莓派基金会所做的工作之外 ,他也投入开源软件、数学、皮艇运动、GitHub、探险活动和 Futurama。在 Twitter [@ben\_nuttall](http://www.twitter.com/ben_nuttall) 上关注他。
---
via: <https://opensource.com/article/17/10/set-postgres-database-your-raspberry-pi>
作者:[Ben Nuttall](https://opensource.com/users/bennuttall) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Databases are a great way to add data persistence to your project or application. You can write data in one session and it'll be there the next time you want to look. A well-designed database can be efficient at looking up data in large datasets, and you won't have to worry about how it looks, just what you want it to find. It's fairly simple to set up a database for basic [CRUD](https://en.wikipedia.org/wiki/Create,_read,_update_and_delete) (create, record, update, delete) applications, which is a common pattern, and it is useful in many projects.
Why [PostgreSQL](https://www.postgresql.org/), commonly known as Postgres? It's considered to be the best open source database in terms of features and performance. It'll feel familiar if you've used MySQL, but when you need more advanced usage, you'll find the optimization in Postgres is far superior. It's easy to install, easy to use, easy to secure, and runs well on the Raspberry Pi 3.
This tutorial explains how to install Postgres on a Raspberry Pi; create a table; write simple queries; use the pgAdmin GUI on a Raspberry Pi, a PC, or a Mac; and interact with the database from Python.
Once you've learned the basics, you can take your application a lot further with complex queries joining multiple tables, at which point you need to think about optimization, best design practices, using primary and foreign keys, and more.
## Installation
To get started, you'll need to install Postgres and some other packages. Open a terminal window and run the following command while connected to the internet:
```
sudo apt install postgresql libpq-dev postgresql-client
postgresql-client-common -y
```
opensource.com
When that's complete, switch to the Postgres user to configure the database:
`sudo su postgres`
Now you can create a database user. If you create a user with the same name as one of your Unix user accounts, that user will automatically be granted access to the database. So, for the sake of simplicity in this tutorial, I'll assume you're using the default pi user. Run the **createuser** command to continue:
`createuser pi -P --interactive`
When prompted, enter a password (and remember what it is), select **n** for superuser, and **y** for the next two questions.
opensource.com
Now connect to Postgres using the shell and create a test database:
```
$ psql
> create database test;
```
Exit from the psql shell and again from the Postgres user by pressing Ctrl+D twice, and you'll be logged in as the pi user again. Since you created a Postgres user called pi, you can access the Postgres shell from here with no credentials:
`$ psql test`
You're now connected to the "test" database. The database is currently empty and contains no tables. You can create a simple table from the psql shell:
`test=> create table people (name text, company text);`
Now you can insert data into the table:
```
test=> insert into people values ('Ben Nuttall', 'Raspberry Pi Foundation');
test=> insert into people values ('Rikki Endsley', 'Red Hat');
```
And try a select query:
```
test=> select * from people;
name | company
---------------+-------------------------
Ben Nuttall | Raspberry Pi Foundation
Rikki Endsley | Red Hat
(2 rows)
```
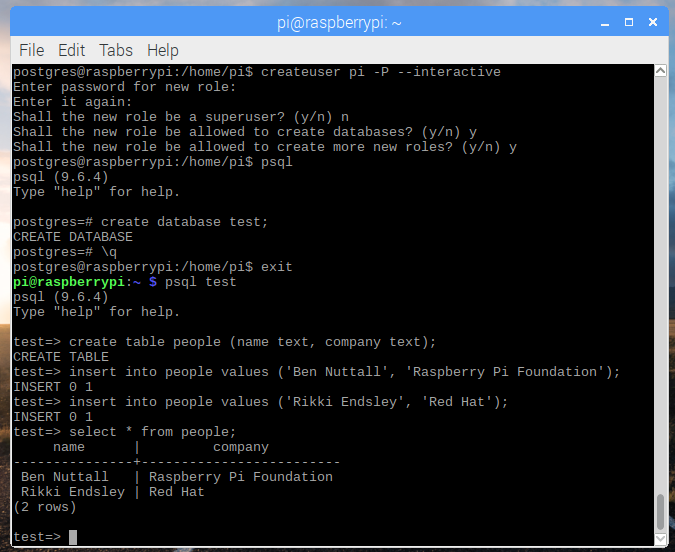
opensource.com
```
test=> select name from people where company = 'Red Hat';
name | company
---------------+---------
Rikki Endsley | Red Hat
(1 row)
```
## pgAdmin
You might find it useful to use a graphical tool to access the database. PgAdmin is a full-featured PostgreSQL GUI that allows you to create and manage databases and users, create and modify tables, write and execute queries, and browse results in a more familiar view, similar to a spreadsheet. The psql command-line tool is fine for simple queries, and you'll find many power users stick with it for speed (and because they don't need the assistance the GUI gives), but midlevel users may find pgAdmin a more approachable way to learn and do more with a database.
Another useful thing about pgAdmin is that you can either use it directly on the Pi or on another computer that's remotely connected to the database on the Pi.
If you want to access it on the Raspberry Pi itself, you can just install it with **apt**:
`sudo apt install pgadmin3`
It's exactly the same if you're on a Debian-based system like Ubuntu; if you're on another distribution, try the equivalent command for your system. Alternatively, or if you're on Windows or macOS, try downloading pgAdmin from [pgAdmin.org](https://www.pgadmin.org/download/). Note that the version available in **apt** is pgAdmin3 and a newer version, pgAdmin4, is available from the website.
To connect to your database with pgAdmin on the same Raspberry Pi, simply open pgAdmin3 from the main menu, click the **new connection** icon, and complete the registration fields. In this case, all you'll need is a name (you choose the connection name, e.g. test), change the username to "pi," and leave the rest of the fields blank (or as they were). Click OK and you'll find a new connection in the side panel on the left.
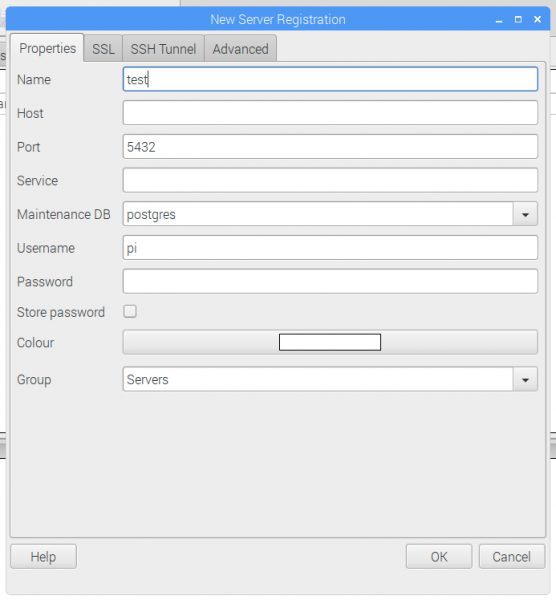
opensource.com
To connect to your Pi's database with pgAdmin from another computer, you'll first need to edit the PostgreSQL configuration to allow remote connections:
1. Edit the PostgreSQL config file **/etc/postgresql/9.6/main/postgresql.conf** to uncomment the **listen_addresses** line and change its value from **localhost** to *****. Save and exit.
2. Edit the **pg_hba** config file **/etc/postgresql/9.6/main/pg_hba.conf** to change **127.0.0.1/32** to **0.0.0.0/0** for IPv4 and **::1/128** to **::/0** for IPv6. Save and exit.
3. Restart the PostgreSQL service: **sudo service postgresql restart**.
Note the version number may be different if you're using an older Raspbian image or another distribution.
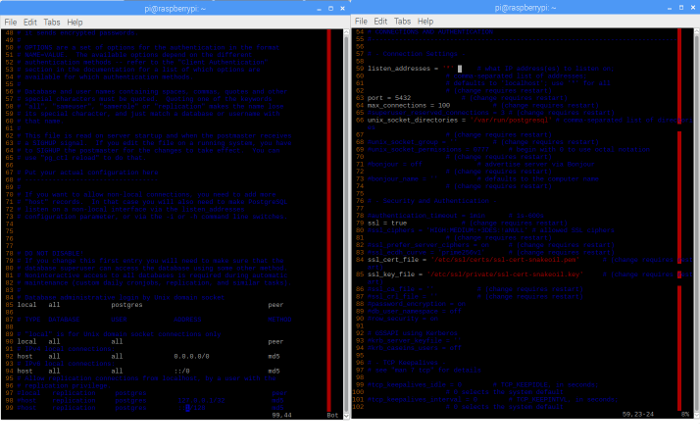
opensource.com
Once that's done, open pgAdmin on your other computer and create a new connection. This time, in addition to giving the connection a name, enter the Pi's IP address as the host (this can be found by hovering over the WiFi icon in the taskbar or by typing **hostname -I** in a terminal).
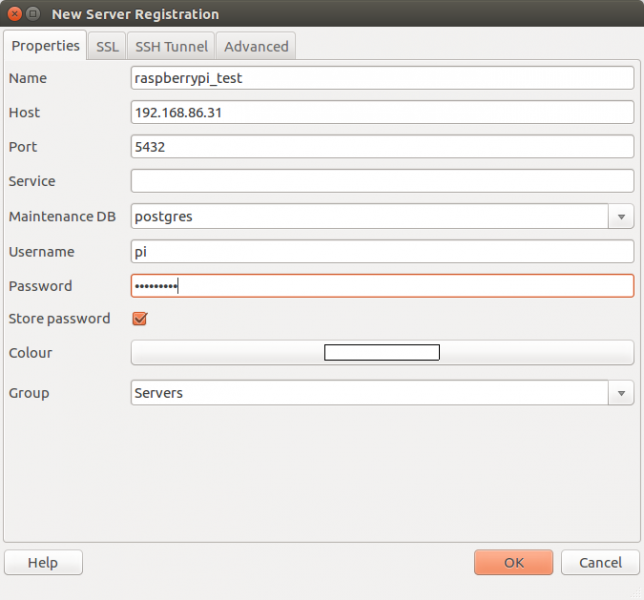
opensource.com
Whether you connected locally or remotely, click to open **Server Groups > Servers > test > Schemas > public > Tables**, right-click the **people** table and select **View Data > View top 100 Rows**. You'll now see the data you entered earlier.
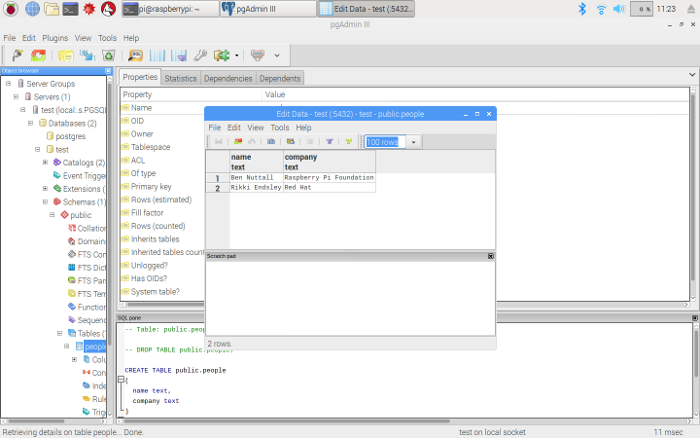
opensource.com
You can now create and modify databases and tables, manage users, and write your own custom queries using the GUI. You might find this visual method more manageable than using the command line.
## Python
To connect to your database from a Python script, you'll need the [Psycopg2](http://initd.org/psycopg/) Python package. You can install it with [pip](https://pypi.python.org/pypi/pip):
`sudo pip3 install psycopg2`
Now open a Python editor and write some code to connect to your database:
```
import psycopg2
conn = psycopg2.connect('dbname=test')
cur = conn.cursor()
cur.execute('select * from people')
results = cur.fetchall()
for result in results:
print(result)
```
Run this code to see the results of the query. Note that if you're connecting remotely, you'll need to supply more credentials in the connection string, for example, adding the host IP, username, and database password:
```
conn = psycopg2.connect('host=192.168.86.31 user=pi
password=raspberry dbname=test')
```
You could even create a function to look up this query specifically:
```
def get_all_people():
query = """
SELECT
*
FROM
people
"""
cur.execute(query)
return cur.fetchall()
```
And one including a lookup:
```
def get_people_by_company(company):
query = """
SELECT
*
FROM
people
WHERE
company = %s
"""
values = (company, )
cur.execute(query, values)
return cur.fetchall()
```
Or even a function for adding records:
```
def add_person(name, company):
query = """
INSERT INTO
people
VALUES
(%s, %s)
"""
values = (name, company)
cur.execute(query, values)
```
Note this uses a safe method of injecting strings into queries. You don't want to get caught out by [little bobby tables](https://xkcd.com/327/)!
opensource.com
Now you know the basics. If you want to take Postgres further, check out this article on [Full Stack Python](https://www.fullstackpython.com/postgresql.html).
## 2 Comments |
9,057 | 在 Linux 中怎么使用 cron 计划任务 | https://opensource.com/article/17/11/how-use-cron-linux | 2017-11-15T10:25:00 | [
"cron",
"crontab"
] | https://linux.cn/article-9057-1.html |
>
> 没有时间运行命令?使用 cron 的计划任务意味着你不用熬夜程序也可以运行。
>
>
>

系统管理员(在许多好处中)的挑战之一是在你该睡觉的时候去运行一些任务。例如,一些任务(包括定期循环运行的任务)需要在没有人使用计算机资源的时候去运行,如午夜或周末。在下班后,我没有时间去运行命令或脚本。而且,我也不想在晚上去启动备份或重大更新。
取而代之的是,我使用两个服务功能在我预定的时间去运行命令、程序和任务。[cron](https://en.wikipedia.org/wiki/Cron) 和 at 服务允许系统管理员去安排任务运行在未来的某个特定时间。at 服务指定在某个时间去运行一次任务。cron 服务可以安排任务在一个周期上重复,比如天、周、或月。
在这篇文章中,我将介绍 cron 服务和怎么去使用它。
### 常见(和非常见)的 cron 用途
我使用 cron 服务去安排一些常见的事情,比如,每天凌晨 2:00 发生的定期备份,我也使用它去做一些不常见的事情。
* 许多电脑上的系统时钟(比如,操作系统时间)都设置为使用网络时间协议(NTP)。 NTP 设置系统时间后,它不会去设置硬件时钟,它可能会“漂移”。我使用 cron 基于系统时间去设置硬件时钟。
* 我还有一个 Bash 程序,我在每天早晨运行它,去在每台电脑上创建一个新的 “每日信息” (MOTD)。它包含的信息有当前的磁盘使用情况等有用的信息。
* 许多系统进程和服务,像 [Logwatch](https://sourceforge.net/projects/logwatch/files/)、[logrotate](https://github.com/logrotate/logrotate)、和 [Rootkit Hunter](http://rkhunter.sourceforge.net/),使用 cron 服务去安排任务和每天运行程序。
crond 守护进程是一个完成 cron 功能的后台服务。
cron 服务检查在 `/var/spool/cron` 和 `/etc/cron.d` 目录中的文件,以及 `/etc/anacrontab` 文件。这些文件的内容定义了以不同的时间间隔运行的 cron 作业。个体用户的 cron 文件是位于 `/var/spool/cron`,而系统服务和应用生成的 cron 作业文件放在 `/etc/cron.d` 目录中。`/etc/anacrontab` 是一个特殊的情况,它将在本文中稍后部分介绍。
### 使用 crontab
cron 实用程序运行基于一个 cron 表(`crontab`)中指定的命令。每个用户,包括 root,都有一个 cron 文件。这些文件缺省是不存在的。但可以使用 `crontab -e` 命令创建在 `/var/spool/cron` 目录中,也可以使用该命令去编辑一个 cron 文件(看下面的脚本)。我强烈建议你,*不要*使用标准的编辑器(比如,Vi、Vim、Emacs、Nano、或者任何其它可用的编辑器)。使用 `crontab` 命令不仅允许你去编辑命令,也可以在你保存并退出编辑器时,重启动 crond 守护进程。`crontab` 命令使用 Vi 作为它的底层编辑器,因为 Vi 是预装的(至少在大多数的基本安装中是预装的)。
现在,cron 文件是空的,所以必须从头添加命令。 我增加下面示例中定义的作业到我的 cron 文件中,这是一个快速指南,以便我知道命令中的各个部分的意思是什么,你可以自由拷贝它,供你自己使用。
```
# crontab -e
SHELL=/bin/bash
[email protected]
PATH=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin
# For details see man 4 crontabs
# Example of job definition:
# .---------------- minute (0 - 59)
# | .------------- hour (0 - 23)
# | | .---------- day of month (1 - 31)
# | | | .------- month (1 - 12) OR jan,feb,mar,apr ...
# | | | | .---- day of week (0 - 6) (Sunday=0 or 7) OR sun,mon,tue,wed,thu,fri,sat
# | | | | |
# * * * * * user-name command to be executed
# backup using the rsbu program to the internal 4TB HDD and then 4TB external
01 01 * * * /usr/local/bin/rsbu -vbd1 ; /usr/local/bin/rsbu -vbd2
# Set the hardware clock to keep it in sync with the more accurate system clock
03 05 * * * /sbin/hwclock --systohc
# Perform monthly updates on the first of the month
# 25 04 1 * * /usr/bin/dnf -y update
```
*`crontab` 命令用于查看或编辑 cron 文件。*
上面代码中的前三行设置了一个缺省环境。对于给定用户,环境变量必须是设置的,因为,cron 不提供任何方式的环境。`SHELL` 变量指定命令运行使用的 shell。这个示例中,指定为 Bash shell。`MAILTO` 变量设置发送 cron 作业结果的电子邮件地址。这些电子邮件提供了 cron 作业(备份、更新、等等)的状态,和你从命令行中手动运行程序时看到的结果是一样的。第三行为环境设置了 `PATH` 变量。但即使在这里设置了路径,我总是使用每个程序的完全限定路径。
在上面的示例中有几个注释行,它详细说明了定义一个 cron 作业所要求的语法。我将在下面分别讲解这些命令,然后,增加更多的 crontab 文件的高级特性。
```
01 01 * * * /usr/local/bin/rsbu -vbd1 ; /usr/local/bin/rsbu -vbd2
```
*在我的 `/etc/crontab` 中的这一行运行一个脚本,用于为我的系统执行备份。*
这一行运行我自己编写的 Bash shell 脚本 `rsbu`,它对我的系统做完全备份。这个作业每天的凌晨 1:01 (`01 01`) 运行。在这三、四、五位置上的星号(\*),像文件通配符一样代表一个特定的时间,它们代表 “一个月中的每天”、“每个月” 和 “一周中的每天”,这一行会运行我的备份两次,一次备份内部专用的硬盘驱动器,另外一次运行是备份外部的 USB 驱动器,使用它这样我可以很保险。
接下来的行我设置了一个硬件时钟,它使用当前系统时钟作为源去设置硬件时钟。这一行设置为每天凌晨 5:03 分运行。
```
03 05 * * * /sbin/hwclock --systohc
```
*这一行使用系统时间作为源来设置硬件时钟。*
我使用的第三个也是最后一个的 cron 作业是去执行一个 `dnf` 或 `yum` 更新,它在每个月的第一天的凌晨 04:25 运行,但是,我注释掉了它,以后不再运行。
```
# 25 04 1 * * /usr/bin/dnf -y update
```
*这一行用于执行一个每月更新,但是,我也把它注释掉了。*
#### 其它的定时任务技巧
现在,让我们去做一些比基本知识更有趣的事情。假设你希望在每周四下午 3:00 去运行一个特别的作业:
```
00 15 * * Thu /usr/local/bin/mycronjob.sh
```
*这一行会在每周四下午 3:00 运行 `mycronjob.sh` 这个脚本。*
或者,或许你需要在每个季度末去运行一个季度报告。cron 服务没有为 “每个月的最后一天” 设置选项,因此,替代方式是使用下一个月的第一天,像如下所示(这里假设当作业准备运行时,报告所需要的数据已经准备好了)。
```
02 03 1 1,4,7,10 * /usr/local/bin/reports.sh
```
*在季度末的下一个月的第一天运行这个 cron 作业。*
下面展示的这个作业,在每天的上午 9:01 到下午 5:01 之间,每小时运行一次。
```
01 09-17 * * * /usr/local/bin/hourlyreminder.sh
```
*有时,你希望作业在业务期间定时运行。*
我遇到一个情况,需要作业在每二、三或四小时去运行。它需要用期望的间隔去划分小时,比如, `*/3` 为每三个小时,或者 `6-18/3` 为上午 6 点到下午 6 点每三个小时运行一次。其它的时间间隔的划分也是类似的。例如,在分钟位置的表达式 `*/15` 意思是 “每 15 分钟运行一次作业”。
```
*/5 08-18/2 * * * /usr/local/bin/mycronjob.sh
```
*这个 cron 作业在上午 8:00 到下午 18:59 之间,每五分钟运行一次作业。*
需要注意的一件事情是:除法表达式的结果必须是余数为 0(即整除)。换句话说,在这个例子中,这个作业被设置为在上午 8 点到下午 6 点之间的偶数小时每 5 分钟运行一次(08:00、08:05、 08:10、 08:15……18:55 等等),而不运行在奇数小时。另外,这个作业不能运行在下午 7:00 到上午 7:59 之间。(LCTT 译注:此处本文表述有误,根据正确情况修改)
我相信,你可以根据这些例子想到许多其它的可能性。
#### 限制访问 cron
普通用户使用 cron 访问可能会犯错误,例如,可能导致系统资源(比如内存和 CPU 时间)被耗尽。为避免这种可能的问题, 系统管理员可以通过创建一个 `/etc/cron.allow` 文件去限制用户访问,它包含了一个允许去创建 cron 作业的用户列表。(不管是否列在这个列表中,)不能阻止 root 用户使用 cron。
通过阻止非 root 用户创建他们自己的 cron 作业,那也许需要将非 root 用户的 cron 作业添加到 root 的 crontab 中, “但是,等等!” 你说,“不是以 root 去运行这些作业?” 不一定。在这篇文章中的第一个示例中,出现在注释中的用户名字段可以用于去指定一个运行作业的用户 ID。这可以防止特定的非 root 用户的作业以 root 身份去运行。下面的示例展示了一个作业定义,它以 “student” 用户去运行这个作业:
```
04 07 * * * student /usr/local/bin/mycronjob.sh
```
如果没有指定用户,这个作业将以 contab 文件的所有者用户去运行,在这个情况中是 root。
#### cron.d
目录 `/etc/cron.d` 中是一些应用程序,比如 [SpamAssassin](http://spamassassin.apache.org/) 和 [sysstat](https://github.com/sysstat/sysstat) 安装的 cron 文件。因为,这里没有 spamassassin 或者 sysstat 用户,这些程序需要一个位置去放置 cron 文件,因此,它们被放在 `/etc/cron.d` 中。
下面的 `/etc/cron.d/sysstat` 文件包含系统活动报告(SAR)相关的 cron 作业。这些 cron 文件和用户 cron 文件格式相同。
```
# Run system activity accounting tool every 10 minutes
*/10 * * * * root /usr/lib64/sa/sa1 1 1
# Generate a daily summary of process accounting at 23:53
53 23 * * * root /usr/lib64/sa/sa2 -A
```
*sysstat 包安装了 `/etc/cron.d/sysstat` cron 文件来运行程序生成 SAR。*
该 sysstat cron 文件有两行执行任务。第一行每十分钟去运行 `sa1` 程序去收集数据,存储在 `/var/log/sa` 目录中的一个指定的二进制文件中。然后,在每天晚上的 23:53, `sa2` 程序运行来创建一个每日汇总。
#### 计划小贴士
我在 crontab 文件中设置的有些时间看上起似乎是随机的,在某种程度上说,确实是这样的。尝试去安排 cron 作业可能是件很具有挑战性的事, 尤其是作业的数量越来越多时。我通常在我的每个电脑上仅有一些任务,它比起我工作用的那些生产和实验环境中的电脑简单多了。
我管理的一个系统有 12 个每天晚上都运行 cron 作业,另外 3、4 个在周末或月初运行。那真是个挑战,因为,如果有太多作业在同一时间运行,尤其是备份和编译系统,会耗尽内存并且几乎填满交换文件空间,这会导致系统性能下降甚至是超负荷,最终什么事情都完不成。我增加了一些内存并改进了如何计划任务。我还删除了一些写的很糟糕、使用大量内存的任务。
crond 服务假设主机计算机 24 小时运行。那意味着如果在一个计划运行的期间关闭计算机,这些计划的任务将不再运行,直到它们计划的下一次运行时间。如果这里有关键的 cron 作业,这可能导致出现问题。 幸运的是,在定期运行的作业上,还有一个其它的选择: `anacron`。
### anacron
[anacron](https://en.wikipedia.org/wiki/Anacron) 程序执行和 cron 一样的功能,但是它增加了运行被跳过的作业的能力,比如,如果计算机已经关闭或者其它的原因导致无法在一个或多个周期中运行作业。它对笔记本电脑或其它被关闭或进行睡眠模式的电脑来说是非常有用的。
只要电脑一打开并引导成功,anacron 会检查过去是否有计划的作业被错过。如果有,这些作业将立即运行,但是,仅运行一次(而不管它错过了多少次循环运行)。例如,如果一个每周运行的作业在最近三周因为休假而系统关闭都没有运行,它将在你的电脑一启动就立即运行,但是,它仅运行一次,而不是三次。
anacron 程序提供了一些对周期性计划任务很好用的选项。它是安装在你的 `/etc/cron.[hourly|daily|weekly|monthly]` 目录下的脚本。 根据它们需要的频率去运行。
它是怎么工作的呢?接下来的这些要比前面的简单一些。
1、 crond 服务运行在 `/etc/cron.d/0hourly` 中指定的 cron 作业。
```
# Run the hourly jobs
SHELL=/bin/bash
PATH=/sbin:/bin:/usr/sbin:/usr/bin
MAILTO=root
01 * * * * root run-parts /etc/cron.hourly
```
*`/etc/cron.d/0hourly` 中的内容使位于 `/etc/cron.hourly` 中的 shell 脚本运行。*
2、 在 `/etc/cron.d/0hourly` 中指定的 cron 作业每小时运行一次 `run-parts` 程序。
3、 `run-parts` 程序运行所有的在 `/etc/cron.hourly` 目录中的脚本。
4、 `/etc/cron.hourly` 目录包含的 `0anacron` 脚本,它使用如下的 `/etdc/anacrontab` 配置文件去运行 anacron 程序。
```
# /etc/anacrontab: configuration file for anacron
# See anacron(8) and anacrontab(5) for details.
SHELL=/bin/sh
PATH=/sbin:/bin:/usr/sbin:/usr/bin
MAILTO=root
# the maximal random delay added to the base delay of the jobs
RANDOM_DELAY=45
# the jobs will be started during the following hours only
START_HOURS_RANGE=3-22
#period in days delay in minutes job-identifier command
1 5 cron.daily nice run-parts /etc/cron.daily
7 25 cron.weekly nice run-parts /etc/cron.weekly
@monthly 45 cron.monthly nice run-parts /etc/cron.monthly
```
*`/etc/anacrontab` 文件中的内容在合适的时间运行在 `cron.[daily|weekly|monthly]` 目录中的可执行文件。*
5、 anacron 程序每日运行一次位于 `/etc/cron.daily` 中的作业。它每周运行一次位于 `/etc/cron.weekly` 中的作业。以及每月运行一次 `cron.monthly` 中的作业。注意,在每一行指定的延迟时间,它可以帮助避免这些作业与其它 cron 作业重叠。
我在 `/usr/local/bin` 目录中放置它们,而不是在 `cron.X` 目录中放置完整的 Bash 程序,这会使我从命令行中运行它们更容易。然后,我在 cron 目录中增加一个符号连接,比如,`/etc/cron.daily`。
anacron 程序不是设计用于在指定时间运行程序的。而是,用于在一个指定的时间开始,以一定的时间间隔去运行程序,比如,从每天的凌晨 3:00(看上面脚本中的 `START_HOURS_RANGE` 行)、从周日(每周第一天)和这个月的第一天。如果任何一个或多个循环错过,anacron 将立即运行这个错过的作业。
### 更多的关于设置限制
我在我的计算机上使用了很多运行计划任务的方法。所有的这些任务都需要一个 root 权限去运行。在我的经验中,很少有普通用户去需要运行 cron 任务,一种情况是开发人员需要一个 cron 作业去启动一个开发实验室的每日编译。
限制非 root 用户去访问 cron 功能是非常重要的。然而,在一些特殊情况下,用户需要去设置一个任务在预先指定时间运行,而 cron 可以允许他们去那样做。许多用户不理解如何正确地配置 cron 去完成任务,并且他们会出错。这些错误可能是无害的,但是,往往不是这样的,它们可能导致问题。通过设置功能策略,使用户与管理员互相配合,可以使个别的 cron 作业尽可能地不干扰其它的用户和系统功能。
可以给为单个用户或组分配的资源设置限制,但是,这是下一篇文章中的内容。
更多信息,在 [cron](http://man7.org/linux/man-pages/man8/cron.8.html)、[crontab](http://man7.org/linux/man-pages/man5/crontab.5.html)、[anacron](http://man7.org/linux/man-pages/man8/anacron.8.html)、[anacrontab](http://man7.org/linux/man-pages/man5/anacrontab.5.html)、和 [run-parts](http://manpages.ubuntu.com/manpages/zesty/man8/run-parts.8.html) 的 man 页面上,所有的这些信息都描述了 cron 系统是如何工作的。
---
作者简介:
David Both - 是一位 Linux 和开源软件的倡导者,居住在 Raleigh,North Carolina。他从事 IT 行业超过四十年,并且在 IBM 教授 OS/2 超过 20 年时间,他在 1981 年 IBM 期间,为最初的 IBM PC 写了第一部培训教程。他为 Red Hat 教授 RHCE 系列课程,并且他也为 MCI Worldcom、 Cisco、和 North Carolina 州工作。他使用 Linux 和开源软件工作差不多 20 年了。
---
via: <https://opensource.com/article/17/11/how-use-cron-linux>
作者:[David Both](https://opensource.com/users/dboth) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | One of the challenges (among the many advantages) of being a sysadmin is running tasks when you'd rather be sleeping. For example, some tasks (including regularly recurring tasks) need to run overnight or on weekends, when no one is expected to be using computer resources. I have no time to spare in the evenings to run commands and scripts that have to operate during off-hours. And I don't want to have to get up at oh-dark-hundred to start a backup or major update.
Instead, I use two service utilities that allow me to run commands, programs, and tasks at predetermined times. The [ cron](https://en.wikipedia.org/wiki/Cron) and
**at**services enable sysadmins to schedule tasks to run at a specific time in the future. The at service specifies a one-time task that runs at a certain time. The cron service can schedule tasks on a repetitive basis, such as daily, weekly, or monthly.
In this article, I'll introduce the cron service and how to use it.
## Common (and uncommon) cron uses
I use the **cron** service to schedule obvious things, such as regular backups that occur daily at 2 a.m. I also use it for less obvious things.
- The system times (i.e., the operating system time) on my many computers are set using the Network Time Protocol (NTP). While NTP sets the system time, it does not set the hardware time, which can drift. I use cron to set the hardware time based on the system time.
- I also have a Bash program I run early every morning that creates a new "message of the day" (MOTD) on each computer. It contains information, such as disk usage, that should be current in order to be useful.
- Many system processes and services, like
[Logwatch](https://sourceforge.net/projects/logwatch/files/),[logrotate](https://github.com/logrotate/logrotate), and[Rootkit Hunter](http://rkhunter.sourceforge.net/), use the cron service to schedule tasks and run programs every day.
The **crond** daemon is the background service that enables cron functionality.
The cron service checks for files in the **/var/spool/cron** and **/etc/cron.d** directories and the **/etc/anacrontab** file. The contents of these files define cron jobs that are to be run at various intervals. The individual user cron files are located in **/var/spool/cron**, and system services and applications generally add cron job files in the **/etc/cron.d** directory. The **/etc/anacrontab** is a special case that will be covered later in this article.
## Using crontab
The cron utility runs based on commands specified in a cron table (**crontab**). Each user, including root, can have a cron file. These files don't exist by default, but can be created in the **/var/spool/cron** directory using the **crontab -e** command that's also used to edit a cron file (see the script below). I strongly recommend that you *not* use a standard editor (such as Vi, Vim, Emacs, Nano, or any of the many other editors that are available). Using the **crontab** command not only allows you to edit the command, it also restarts the **crond** daemon when you save and exit the editor. The **crontab** command uses Vi as its underlying editor, because Vi is always present (on even the most basic of installations).
New cron files are empty, so commands must be added from scratch. I added the job definition example below to my own cron files, just as a quick reference, so I know what the various parts of a command mean. Feel free to copy it for your own use.
```
# crontab -e
SHELL=/bin/bash
[email protected]
PATH=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin
# For details see man 4 crontabs
# Example of job definition:
# .---------------- minute (0 - 59)
# | .------------- hour (0 - 23)
# | | .---------- day of month (1 - 31)
# | | | .------- month (1 - 12) OR jan,feb,mar,apr ...
# | | | | .---- day of week (0 - 6) (Sunday=0 or 7) OR sun,mon,tue,wed,thu,fri,sat
# | | | | |
# * * * * * user-name command to be executed
# backup using the rsbu program to the internal 4TB HDD and then 4TB external
01 01 * * * /usr/local/bin/rsbu -vbd1 ; /usr/local/bin/rsbu -vbd2
# Set the hardware clock to keep it in sync with the more accurate system clock
03 05 * * * /sbin/hwclock --systohc
# Perform monthly updates on the first of the month
# 25 04 1 * * /usr/bin/dnf -y update
```
The crontab command is used to view or edit the cron files.
The first three lines in the code above set up a default environment. The environment must be set to whatever is necessary for a given user because cron does not provide an environment of any kind. The **SHELL** variable specifies the shell to use when commands are executed. This example specifies the Bash shell. The **MAILTO** variable sets the email address where cron job results will be sent. These emails can provide the status of the cron job (backups, updates, etc.) and consist of the output you would see if you ran the program manually from the command line. The third line sets up the **PATH** for the environment. Even though the path is set here, I always prepend the fully qualified path to each executable.
There are several comment lines in the example above that detail the syntax required to define a cron job. I'll break those commands down, then add a few more to show you some more advanced capabilities of crontab files.
`01 01 * * * /usr/local/bin/rsbu -vbd1 ; /usr/local/bin/rsbu -vbd2`
This line in my /etc/crontab runs a script that performs backups for my systems.
This line runs my self-written Bash shell script, **rsbu**, that backs up all my systems. This job kicks off at 1:01 a.m. (01 01) every day. The asterisks (*) in positions three, four, and five of the time specification are like file globs, or wildcards, for other time divisions; they specify "every day of the month," "every month," and "every day of the week." This line runs my backups twice; one backs up to an internal dedicated backup hard drive, and the other backs up to an external USB drive that I can take to the safe deposit box.
The following line sets the hardware clock on the computer using the system clock as the source of an accurate time. This line is set to run at 5:03 a.m. (03 05) every day.
`03 05 * * * /sbin/hwclock --systohc`
This line sets the hardware clock using the system time as the source.
I was using the third and final cron job (commented out) to perform a **dnf** or **yum** update at 04:25 a.m. on the first day of each month, but I commented it out so it no longer runs.
`# 25 04 1 * * /usr/bin/dnf -y update`
This line used to perform a monthly update, but I've commented it out.
### Other scheduling tricks
Now let's do some things that are a little more interesting than these basics. Suppose you want to run a particular job every Thursday at 3 p.m.:
`00 15 * * Thu /usr/local/bin/mycronjob.sh`
This line runs mycronjob.sh every Thursday at 3 p.m.
Or, maybe you need to run quarterly reports after the end of each quarter. The cron service has no option for "The last day of the month," so instead you can use the first day of the following month, as shown below. (This assumes that the data needed for the reports will be ready when the job is set to run.)
`02 03 1 1,4,7,10 * /usr/local/bin/reports.sh`
This cron job runs quarterly reports on the first day of the month after a quarter ends.
The following shows a job that runs one minute past every hour between 9:01 a.m. and 5:01 p.m.
`01 09-17 * * * /usr/local/bin/hourlyreminder.sh`
Sometimes you want to run jobs at regular times during normal business hours.
I have encountered situations where I need to run a job every two, three, or four hours. That can be accomplished by dividing the hours by the desired interval, such as ***/3** for every three hours, or **6-18/3** to run every three hours between 6 a.m. and 6 p.m. Other intervals can be divided similarly; for example, the expression ***/15** in the minutes position means "run the job every 15 minutes."
`*/5 08-18/2 * * * /usr/local/bin/mycronjob.sh`
This cron job runs every five minutes during every hour between 8 a.m. and 5:58 p.m.
One thing to note: The division expressions must result in a remainder of zero for the job to run. That's why, in this example, the job is set to run every five minutes (08:05, 08:10, 08:15, etc.) during even-numbered hours from 8 a.m. to 6 p.m., but not during any odd-numbered hours. For example, the job will not run at all from 9 p.m. to 9:59 a.m.
I am sure you can come up with many other possibilities based on these examples.
### Limiting cron access
Regular users with cron access could make mistakes that, for example, might cause system resources (such as memory and CPU time) to be swamped. To prevent possible misuse, the sysadmin can limit user access by creating a **/etc/cron.allow** file that contains a list of all users with permission to create cron jobs. The root user cannot be prevented from using cron.
By preventing non-root users from creating their own cron jobs, it may be necessary for root to add their cron jobs to the root crontab. "But wait!" you say. "Doesn't that run those jobs as root?" Not necessarily. In the first example in this article, the username field shown in the comments can be used to specify the user ID a job is to have when it runs. This prevents the specified non-root user's jobs from running as root. The following example shows a job definition that runs a job as the user "student":
`04 07 * * * student /usr/local/bin/mycronjob.sh`
If no user is specified, the job is run as the user that owns the crontab file, root in this case.
### cron.d
The directory **/etc/cron.d** is where some applications, such as [SpamAssassin](http://spamassassin.apache.org/) and [sysstat](https://github.com/sysstat/sysstat), install cron files. Because there is no spamassassin or sysstat user, these programs need a place to locate cron files, so they are placed in **/etc/cron.d**.
The **/etc/cron.d/sysstat** file below contains cron jobs that relate to system activity reporting (SAR). These cron files have the same format as a user cron file.
```
# Run system activity accounting tool every 10 minutes
*/10 * * * * root /usr/lib64/sa/sa1 1 1
# Generate a daily summary of process accounting at 23:53
53 23 * * * root /usr/lib64/sa/sa2 -A
```
The sysstat package installs the /etc/cron.d/sysstat cron file to run programs for SAR.
The sysstat cron file has two lines that perform tasks. The first line runs the **sa1** program every 10 minutes to collect data stored in special binary files in the **/var/log/sa** directory. Then, every night at 23:53, the **sa2** program runs to create a daily summary.
### Scheduling tips
Some of the times I set in the crontab files seem rather random—and to some extent they are. Trying to schedule cron jobs can be challenging, especially as the number of jobs increases. I usually have only a few tasks to schedule on each of my computers, which is simpler than in some of the production and lab environments where I have worked.
One system I administered had around a dozen cron jobs that ran every night and an additional three or four that ran on weekends or the first of the month. That was a challenge, because if too many jobs ran at the same time—especially the backups and compiles—the system would run out of RAM and nearly fill the swap file, which resulted in system thrashing while performance tanked, so nothing got done. We added more memory and improved how we scheduled tasks. We also removed a task that was very poorly written and used large amounts of memory.
The crond service assumes that the host computer runs all the time. That means that if the computer is turned off during a period when cron jobs were scheduled to run, they will not run until the next time they are scheduled. This might cause problems if they are critical cron jobs. Fortunately, there is another option for running jobs at regular intervals: **anacron**.
## anacron
The [anacron](https://en.wikipedia.org/wiki/Anacron) program performs the same function as crond, but it adds the ability to run jobs that were skipped, such as if the computer was off or otherwise unable to run the job for one or more cycles. This is very useful for laptops and other computers that are turned off or put into sleep mode.
As soon as the computer is turned on and booted, anacron checks to see whether configured jobs missed their last scheduled run. If they have, those jobs run immediately, but only once (no matter how many cycles have been missed). For example, if a weekly job was not run for three weeks because the system was shut down while you were on vacation, it would be run soon after you turn the computer on, but only once, not three times.
The anacron program provides some easy options for running regularly scheduled tasks. Just install your scripts in the **/etc/cron.[hourly|daily|weekly|monthly]** directories, depending how frequently they need to be run.
How does this work? The sequence is simpler than it first appears.
- The crond service runs the cron job specified in
**/etc/cron.d/0hourly**.
```
# Run the hourly jobs
SHELL=/bin/bash
PATH=/sbin:/bin:/usr/sbin:/usr/bin
MAILTO=root
01 * * * * root run-parts /etc/cron.hourly
```
The contents of /etc/cron.d/0hourly cause the shell scripts located in /etc/cron.hourly to run.
- The cron job specified in
**/etc/cron.d/0hourly**runs the**run-parts**program once per hour. - The
**run-parts**program runs all the scripts located in the**/etc/cron.hourly**directory. - The
**/etc/cron.hourly**directory contains the**0anacron**script, which runs the anacron program using the**/etdc/anacrontab**configuration file shown here.
```
# /etc/anacrontab: configuration file for anacron
# See anacron(8) and anacrontab(5) for details.
SHELL=/bin/sh
PATH=/sbin:/bin:/usr/sbin:/usr/bin
MAILTO=root
# the maximal random delay added to the base delay of the jobs
RANDOM_DELAY=45
# the jobs will be started during the following hours only
START_HOURS_RANGE=3-22
#period in days delay in minutes job-identifier command
1 5 cron.daily nice run-parts /etc/cron.daily
7 25 cron.weekly nice run-parts /etc/cron.weekly
@monthly 45 cron.monthly nice run-parts /etc/cron.monthly
```
The contents of /etc/anacrontab file runs the executable files in the cron.[daily|weekly|monthly] directories at the appropriate times.
- The anacron program runs the programs located in
**/etc/cron.daily**once per day; it runs the jobs located in**/etc/cron.weekly**once per week, and the jobs in**cron.monthly**once per month. Note the specified delay times in each line that help prevent these jobs from overlapping themselves and other cron jobs.
Instead of placing complete Bash programs in the **cron.X** directories, I install them in the **/usr/local/bin** directory, which allows me to run them easily from the command line. Then I add a symlink in the appropriate cron directory, such as **/etc/cron.daily**.
The anacron program is not designed to run programs at specific times. Rather, it is intended to run programs at intervals that begin at the specified times, such as 3 a.m. (see the **START_HOURS_RANGE** line in the script just above) of each day, on Sunday (to begin the week), and on the first day of the month. If any one or more cycles are missed, anacron will run the missed jobs once, as soon as possible.
## Shortcuts
The** /etc/anacrontab** file shown above shows us a clue to how we can use shortcuts for a few specific and common times. These single-word time shortcuts can be used to replace the five fields usually used to specify times. The **@** character is used to identify shortcuts to cron. The list below, taken from the crontab(5) man page, shows the shortcuts with their equivalent meanings.
- @reboot : Run once after reboot.
- @yearly : Run once a year, ie.
**0 0 1 1 *** - @annually : Run once a year, ie.
**0 0 1 1 *** - @monthly : Run once a month, ie.
**0 0 1 * *** - @weekly : Run once a week, ie.
**0 0 * * 0** - @daily : Run once a day, ie.
**0 0 * * *** - @hourly : Run once an hour, ie.
**0 * * * ***
These shortcuts can be used in any of the crontab files, such as those in** /etc/cron.d**.
## More on setting limits
I use most of these methods for scheduling tasks to run on my computers. All those tasks are ones that need to run with root privileges. It's rare in my experience that regular users really need a cron job. One case was a developer user who needed a cron job to kick off a daily compile in a development lab.
It is important to restrict access to cron functions by non-root users. However, there are circumstances when a user needs to set a task to run at pre-specified times, and cron can allow them to do that. Many users do not understand how to properly configure these tasks using cron and they make mistakes. Those mistakes may be harmless, but, more often than not, they can cause problems. By setting functional policies that cause users to interact with the sysadmin, individual cron jobs are much less likely to interfere with other users and other system functions.
It is possible to set limits on the total resources that can be allocated to individual users or groups, but that is an article for another time.
For more information, the man pages for [cron](http://man7.org/linux/man-pages/man8/cron.8.html), [crontab](http://man7.org/linux/man-pages/man5/crontab.5.html), [anacron](http://man7.org/linux/man-pages/man8/anacron.8.html), [anacrontab](http://man7.org/linux/man-pages/man5/anacrontab.5.html), and [run-parts](http://manpages.ubuntu.com/manpages/zesty/man8/run-parts.8.html) all have excellent information and descriptions of how the cron system works.
*This article was originally published in November 2017 and has been updated to include additional information.*
## 9 Comments |
9,058 | CyberShaolin:培养下一代网络安全专家 | https://www.linuxfoundation.org/blog/cybershaolin-teaching-next-generation-cybersecurity-experts/ | 2017-11-15T11:54:00 | [
"网络安全"
] | https://linux.cn/article-9058-1.html | 
>
> CyberShaolin 联合创始人 Reuben Paul 将在布拉格的开源峰会上发表演讲,强调网络安全意识对于孩子们的重要性。
>
>
>
Reuben Paul 并不是唯一一个玩电子游戏的孩子,但是他对游戏和电脑的痴迷使他走上了一段独特的好奇之旅,引起了他对网络安全教育和宣传的早期兴趣,并创立了 CyberShaolin,一个帮助孩子理解网络攻击的威胁的组织。现年 11 岁的 Paul 将在[布拉格开源峰会](LCTT 译注:已于 10 月 28 举办)上发表主题演讲,分享他的经验,并强调玩具、设备和日常使用的其他技术的不安全性。

*CyberShaolin 联合创始人 Reuben Paul*
我们采访了 Paul 听取了他的故事,并讨论 CyberShaolin 及其教育、赋予孩子(及其父母)的网络安全危险和防御知识。
**Linux.com:你对电脑的迷恋是什么时候开始的?**
Reuben Paul:我对电脑的迷恋始于电子游戏。我喜欢手机游戏以及视频游戏。(我记得是)当我大约 5 岁时,我通过 Gameloft 在手机上玩 “Asphalt” 赛车游戏。这是一个简单而有趣的游戏。我得触摸手机右侧加快速度,触摸手机左侧减慢速度。我问我爸,“游戏怎么知道我触摸了哪里?”
他研究发现,手机屏幕是一个 xy 坐标系统,所以他告诉我,如果 x 值大于手机屏幕宽度的一半,那么它是右侧的触摸。否则,这是左侧接触。为了帮助我更好地理解这是如何工作的,他给了我一个线性的方程,它是 y = mx + b,并问:“你能找每个 x 值 对应的 y 值吗?”大约 30 分钟后,我计算出了所有他给我的 x 对应的 y 值。
当我父亲意识到我能够学习编程的一些基本逻辑时,他给我介绍了 Scratch,并且使用鼠标指针的 x 和 y 值编写了我的第一个游戏 - 名为 “大鱼吃小鱼”。然后,我爱上了电脑。
**Linux.com:你对网络安全感兴趣吗?**
Paul:我的父亲 Mano Paul 曾经在网络安全方面培训他的商业客户。每当他在家里工作,我都会听到他的电话交谈。到了我 6 岁的时候,我就知道互联网、防火墙和云计算等东西。当我的父亲意识到我有兴趣和学习的潜力,他开始教我安全方面,如社会工程技术、克隆网站、中间人攻击技术、hack 移动应用等等。当我第一次从目标测试机器上获得一个 meterpreter shell 时,我的感觉就像 Peter Parker 刚刚发现他的蜘蛛侠的能力一样。
**Linux.com:你是如何以及为什么创建 CyberShaolin 的?**
Paul:当我 8 岁的时候,我首先在 DerbyCon 上做了主题为“来自(8 岁大)孩子之口的安全信息”的演讲。那是在 2014 年 9 月。那次会议之后,我收到了几个邀请函,2014 年底之前,我还在其他三个会议上做了主题演讲。
所以,当孩子们开始听到我在这些不同的会议上发言时,他们开始写信给我,要我教他们。我告诉我的父母,我想教别的孩子,他们问我怎么想。我说:“也许我可以制作一些视频,并在像 YouTube 这样的频道上发布。”他们问我是否要收费,而我说“不”。我希望我的视频可以免费供在世界上任何地方的任何孩子使用。CyberShaolin 就是这样创建的。
**Linux.com:CyberShaolin 的目标是什么?**
Paul:CyberShaolin 是我父母帮助我创立的非营利组织。它的任务是教育、赋予孩子(和他们的父母)掌握网络安全的危险和防范知识,我在学校的空闲时间开发了这些视频和其他训练材料,连同功夫、体操、游泳、曲棍球、钢琴和鼓等。迄今为止,我已经在 [www.CyberShaolin.org](http://www.Cyber%E2%80%8B%E2%80%8BShaolin.org) 网站上发布了大量的视频,并计划开发更多的视频。我也想制作游戏和漫画来支持安全学习。
CyberShaolin 来自两个词:网络和少林。网络这个词当然是来自技术。少林来自功夫武术,我和我的父亲都是黑带 2 段。在功夫方面,我们有显示知识进步的缎带,你可以想像 CyberShaolin 像数码技术方面的功夫,在我们的网站上学习和考试后,孩子们可以成为网络黑带。
**Linux.com:你认为孩子对网络安全的理解有多重要?**
Paul:我们生活在一个技术和设备不仅存在我们家里,还在我们学校和几乎任何你去的地方的时代。世界也正在与物联网联系起来,这些物联网很容易成为威胁网(Internet of Threats)。儿童是这些技术和设备的主要用户之一。不幸的是,这些设备和设备上的应用程序不是很安全,可能会给儿童和家庭带来严重的问题。例如,最近(2017 年 5 月),我演示了如何攻入智能玩具泰迪熊,并将其变成远程侦察设备。孩子也是下一代。如果他们对网络安全没有意识和训练,那么未来(我们的未来)将不会很好。
**Linux.com:该项目如何帮助孩子?**
Paul:正如我之前提到的,CyberShaolin 的使命是教育、赋予孩子(和他们的父母)网络安全的危险和防御知识。
当孩子们受到网络欺凌、中间人、钓鱼、隐私、在线威胁、移动威胁等网络安全危害的教育时,他们将具备知识和技能,从而使他们能够在网络空间做出明智的决定并保持安全。而且,正如我永远不会用我的功夫技能去伤害某个人一样,我希望所有的 CyberShaolin 毕业生都能利用他们的网络功夫技能为人类的利益创造一个安全的未来。
---
作者简介:
Swapnil Bhartiya 是一名记者和作家,专注在 Linux 和 Open Source 上 10 多年。
---
via: <https://www.linuxfoundation.org/blog/cybershaolin-teaching-next-generation-cybersecurity-experts/>
作者:[Swapnil Bhartiya](https://www.linuxfoundation.org/author/sbhartiya/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,059 | AWS 采用自制的 KVM 作为新的管理程序 | https://www.theregister.co.uk/2017/11/07/aws_writes_new_kvm_based_hypervisor_to_make_its_cloud_go_faster/ | 2017-11-15T13:28:00 | [
"AWS",
"KVM"
] | https://linux.cn/article-9059-1.html |
>
> 摆脱了 Xen,新的 C5 实例和未来的虚拟机将采用“核心 KVM 技术”
>
>
>

AWS 透露说它已经创建了一个基于 KVM 的新的<ruby> 管理程序 <rt> hypervisor </rt></ruby>,而不是多年来依赖的 Xen 管理程序。
新的虚拟机管理程序披露在 EC2 新实例类型的[新闻](https://aws.amazon.com/blogs/aws/now-available-compute-intensive-c5-instances-for-amazon-ec2/)脚注里,新实例类型被称为 “C5”,由英特尔的 Skylake Xeon 提供支持。AWS 关于新实例的 [FAQ](https://aws.amazon.com/ec2/faqs/#compute-optimized) 提及“C5 实例使用新的基于核心 KVM 技术的 EC2 虚拟机管理程序”。
这是爆炸性的新闻,因为 AWS 长期以来一直支持 Xen 管理程序。Xen 项目从最强大的公共云使用其开源软件的这个事实中吸取了力量。Citrix 将其大部分 Xen 服务器运行了 AWS 的管理程序的闭源版本。
更有趣的是,AWS 新闻中说:“未来,我们将使用这个虚拟机管理程序为其他实例类型提供动力。” 这个互联网巨头的文章中计划在“一系列 AWS re:Invent 会议中分享更多的技术细节”。
这听上去和很像 AWS 要放弃 Xen。
新的管理程序还有很长的路要走,这解释了为什么 AWS 是[最后一个运行 Intel 新的 Skylake Xeon CPU 的大型云服务商](https://www.theregister.co.uk/2017/10/24/azure_adds_skylakes_in_fv2_instances/),因为 AWS 还透露了新的 C5 实例运行在它所描述的“定制处理器上,针对 EC2 进行了优化。”
Intel 和 AWS 都表示这是一款定制的 3.0 GHz Xeon Platinum 8000 系列处理器。Chipzilla 提供了一些该 CPU 的[新闻发布级别的细节](https://newsroom.intel.com/news/intel-xeon-scalable-processors-supercharge-amazon-web-services/),称它与 AWS 合作开发了“使用最新版本的 Intel 数学核心库优化的 AI/深度学习引擎”,以及“ MXNet 和其他深度学习框架为在 Amazon EC2 C5 实例上运行进行了高度优化。”
Intel 之前定制了 Xeons,将其提供给 [Oracle](https://www.theregister.co.uk/2015/06/04/oracle_intel_team_on_server_with_a_dimmer_switch/) 等等。AWS 大量购买 CPU,所以英特尔再次这样做并不意外。
迁移到 KVM 更令人惊讶,但是 AWS 可以根据需要来调整云服务以获得最佳性能。如果这意味着构建一个虚拟机管理程序,并确保它使用自定义的 Xeon,那就这样吧。
不管它在三周内发布了什么,AWS 现在都在说 C5 实例和它们的新虚拟机管理程序有更高的吞吐量,新的虚拟机在连接到弹性块存储 (EBS) 的网络和带宽都超过了之前的最佳记录。
以下是 AWS 在 FAQ 中的说明:
>
> 随着 C5 实例的推出,Amazon EC2 的新管理程序是一个主要为 C5 实例提供 CPU 和内存隔离的组件。VPC 网络和 EBS 存储资源是由所有当前 EC2 实例家族的一部分的专用硬件组件实现的。
>
>
> 它基于核心的 Linux 内核虚拟机(KVM)技术,但不包括通用的操作系统组件。
>
>
>
换句话说,网络和存储在其他地方完成,而不是集中在隔离 CPU 和内存资源的管理程序上:
>
> 新的 EC2 虚拟机管理程序通过删除主机系统软件组件,为 EC2 虚拟化实例提供一致的性能和增长的计算和内存资源。该硬件使新的虚拟机管理程序非常小,并且对用于网络和存储的数据处理任务没有影响。
>
>
> 最终,所有新实例都将使用新的 EC2 虚拟机管理程序,但是在近期内,根据平台的需求,一些新的实例类型将使用 Xen。
>
>
> 运行在新 EC2 虚拟机管理程序上的实例最多支持 27 个用于 EBS 卷和 VPC ENI 的附加 PCI 设备。每个 EBS 卷或 VPC ENI 使用一个 PCI 设备。例如,如果将 3 个附加网络接口连接到使用新 EC2 虚拟机管理程序的实例,则最多可以为该实例连接 24 个 EBS 卷。
>
>
> 所有面向公众的与运行新的 EC2 管理程序的 EC2 交互 API 都保持不变。例如,DescribeInstances 响应的 “hypervisor” 字段将继续为所有 EC2 实例报告 “xen”,即使是在新的管理程序下运行的实例也是如此。这个字段可能会在未来版本的 EC2 API 中删除。
>
>
>
你应该查看 FAQ 以了解 AWS 转移到其新虚拟机管理程序的全部影响。以下是新的基于 KVM 的 C5 实例的统计数据:
| 实例名 | vCPU | RAM(GiB) | EBS\*带宽 | 网络带宽 |
| --- | --- | --- | --- | --- |
| c5.large | 2 | 4 | 最高 2.25 Gbps | 最高 10 Gbps |
| c5.xlarge | 4 | 8 | 最高 2.25 Gbps | 最高 10 Gbps |
| c5.2xlarge | 8 | 16 | 最高 2.25 Gbps | 最高 10 Gbps |
| c5.4xlarge | 16 | 32 | 2.25 Gbps | 最高 10 Gbps |
| c5.9xlarge | 36 | 72 | 4.5 Gbps | 10 Gbps |
| c5.18xlarge | 72 | 144 | 9 Gbps | 25 Gbps |
每个 vCPU 都是 Amazon 购买的物理 CPU 上的一个线程。
现在,在 AWS 的美国东部、美国西部(俄勒冈州)和欧盟地区,可以使用 C5 实例作为按需或点播服务器。该公司承诺其他地区将尽快提供。
---
via: <https://www.theregister.co.uk/2017/11/07/aws_writes_new_kvm_based_hypervisor_to_make_its_cloud_go_faster/>
作者:[Simon Sharwood](https://www.theregister.co.uk/Author/Simon-Sharwood) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.