
id
int64 2.05k
16.6k
| title
stringlengths 5
75
| fromurl
stringlengths 19
185
| date
timestamp[s] | tags
sequencelengths 0
11
| permalink
stringlengths 20
37
| content
stringlengths 342
82.2k
| fromurl_status
int64 200
526
⌀ | status_msg
stringclasses 339
values | from_content
stringlengths 0
229k
⌀ |
|---|---|---|---|---|---|---|---|---|---|
9,706 | 保护你的 Fedora 系统免受这个 DHCP 漏洞 | https://fedoramagazine.org/protect-fedora-system-dhcp-flaw/ | 2018-06-02T06:23:34 | [
"dhcp",
"安全"
] | https://linux.cn/article-9706-1.html | 
前几天在 `dhcp-client` 中发现并披露了一个严重的安全漏洞。此 DHCP 漏洞会对你的系统和数据造成高风险,尤其是在使用不受信任的网络,如非你拥有的 WiFi 接入点时。
动态主机控制协议(DHCP)能让你的系统从其加入的网络中获取配置。你的系统将请求 DHCP 数据,并且通常是由路由器等服务器应答。服务器为你的系统提供必要的数据以进行自我配置。例如,你的系统如何在加入无线网络时正确进行网络配置。
但是,本地网络上的攻击者可能会利用此漏洞。使用在 NetworkManager 下运行的 `dhcp-client` 脚本中的漏洞,攻击者可能能够在系统上以 root 权限运行任意命令。这个 DHCP 漏洞使你的系统和数据处于高风险状态。该漏洞已分配 CVE-2018-1111,并且有 [Bugzilla 来跟踪 bug](https://bugzilla.redhat.com/show_bug.cgi?id=1567974)。
### 防范这个 DHCP 漏洞
新的 dhcp 软件包包含了 Fedora 26、27 和 28 以及 Rawhide 的修复程序。维护人员已将这些更新提交到 updates-testing 仓库。对于大多数用户而言,它们应该在这篇文章的大约一天左右的时间内在稳定仓库出现。所需的软件包是:
* Fedora 26: dhcp-4.3.5-11.fc26
* Fedora 27: dhcp-4.3.6-10.fc27
* Fedora 28: dhcp-4.3.6-20.fc28
* Rawhide: dhcp-4.3.6-21.fc29
#### 更新稳定的 Fedora 系统
要在稳定的 Fedora 版本上立即更新,请[使用 sudo](https://fedoramagazine.org/howto-use-sudo/) 运行此命令。如有必要,请在提示时输入你的密码:
```
sudo dnf --refresh --enablerepo=updates-testing update dhcp-client
```
之后,使用标准稳定仓库进行更新。要从稳定的仓库更新 Fedora 系统,请使用以下命令:
```
sudo dnf --refresh update dhcp-client
```
#### 更新 Rawhide 系统
如果你的系统是 Rawhide,请使用以下命令立即下载和更新软件包:
```
mkdir dhcp && cd dhcp
koji download-build --arch={x86_64,noarch} dhcp-4.3.6-21.fc29
sudo dnf update ./dhcp-*.rpm
```
在每日的 Rawhide compose 后,只需运行 `sudo dnf update` 即可获取更新。
### Fedora Atomic Host
针对 Fedora Atomic Host 的修复程序版本为 28.20180515.1。要获得更新,请运行以下命令:
```
atomic host upgrade -r
```
此命令将重启系统以应用升级。
---
via: <https://fedoramagazine.org/protect-fedora-system-dhcp-flaw/>
作者:[Paul W. Frields](https://fedoramagazine.org/author/pfrields/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | A critical security vulnerability was discovered and disclosed earlier today in *dhcp-client*. This DHCP flaw carries a high risk to your system and data, especially if you use untrusted networks such as a WiFi access point you don’t own. Read more here for how to protect your Fedora system.
Dynamic Host Control Protocol (DHCP) allows your system to get configuration from a network it joins. Your system will make a request for DHCP data, and typically a server such as a router answers. The server provides the necessary data for your system to configure itself. This is how, for instance, your system configures itself properly for networking when it joins a wireless network.
However, an attacker on the local network may be able to exploit this vulnerability. Using a flaw in a dhcp-client script that runs under NetworkManager, the attacker may be able to run arbitrary commands with root privileges on your system. This DHCP flaw puts your system and your data at high risk. The flaw has been assigned CVE-2018-1111 and has a [Bugzilla tracking bug](https://bugzilla.redhat.com/show_bug.cgi?id=1567974).
## Guarding against this DHCP flaw
New *dhcp* packages contain fixes for Fedora 26, 27, and 28, as well as Rawhide. The maintainers have submitted these updates to the *updates-testing* repositories. They should show up in stable repos within a day or so of this post for most users. The desired packages are:
- Fedora 26:
*dhcp-4.3.5-11.fc26* - Fedora 27:
*dhcp-4.3.6-10.fc27* - Fedora 28:
*dhcp-4.3.6-20.fc28* - Rawhide:
*dhcp-4.3.6-21.fc29*
### Updating a stable Fedora system
To update immediately on a stable Fedora release, use this command [with sudo](https://fedoramagazine.org/howto-use-sudo/). Type your password at the prompt, if necessary:
sudo dnf --refresh --enablerepo=updates-testing update dhcp-client
Later, use the standard stable repos to update. To update your Fedora system from the stable repos, use this command:
sudo dnf --refresh update dhcp-client
### Updating a Rawhide system
If your system is on Rawhide, use these commands to download and update the packages immediately:
mkdir dhcp && cd dhcp koji download-build --arch={x86_64,noarch} dhcp-4.3.6-21.fc29 sudo dnf update ./dhcp-*.rpm
After the nightly Rawhide compose, simply run *sudo dnf update* to get the update.
## Fedora Atomic Host
The fixes for Fedora Atomic Host are in ostree version 28.20180515.1. To get the update, run this command:
atomic host upgrade -r
This command reboots your system to apply the upgrade.
Photo by [Markus Spiske](https://unsplash.com/photos/FXFz-sW0uwo?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText) on [Unsplash](https://unsplash.com/search/photos/protect?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText).
## alick
It seems to me we will need to reboot after updating. Can anyone confirm?
## Georg Sauthoff
You have to make sure that any running dhclient process is terminated. Thus, a
is sufficient. The network-manager then automatically restarts the dhclient, after a short timeout.
A reboot is an alternative way to make sure that the update is effective.
## Flo
https://apps.fedoraproject.org/packages/dhcp is confusing. The fixed version has been pushed to
already. However, if right now people add
to their dnf command they actually get an older version that still contains the flaw.
## Paul W. Frields
@Flo: This could happen if your mirror is out of sync. You can try waiting a short while for the sync to catch up, or pull packages from another mirror.
## Jared Busch
Already in
for Fedora 28
## murph
The rawhide instructions didn’t quite work. Got some great help on IRC, they directed me to https://koji.fedoraproject.org/koji/buildinfo?buildID=1081949 where I downloaded the common and libs packages, then got everything to install fine.
A few rough edges when installing brand new patches on Rawhide should be expected, so no problem.
## Costa A.
A “dnf upgrade -y” today was enough to get the updated dhcp-client version.
## Eddie G. O'Connor Jr.
Just wanna say “Thanks” to all the folks who help keep my Fedora systems up and running smoothly. Will be applying this update to my systems just as soon as we get power restored. (High winds knocked down trees which took out the power lines in my neighborhood!) SO by then?…(Fri. evening!) everything should be in place for a smooth update for me!
Fedora? ROCKS!!!
## Eddie G. O'Connor Jr.
Also…..dows anyone know if this will affect CEntOS servers as well? Wondering if I have to pull them offline and perform updates on ’em too?
## Eduard Lucena
Yes, it affects RHEL, CentOS and Fedora.
## Hans
I’d be surprised if your server would use dhcp-client to receive an IP address.
## Michael J Gruber
The rpm package name is dhcp-client, not dhcp.
(dhcp is the source package from which various dhcp related rpm packages are built – including dhcp-client, but not dhcp.)
## Paul W. Frields
@Michael: The dhcp-client package comes from the dhcp source package. It also requires dhcp-common and dhcp-libs. That is why the overall dhcp source package version is used in the article.
## Michael J Gruber
@Paul Yes, that is what I wrote. We are in complete agreement 🙂
It’s just that the natural “rpm -q dhcp” does not work as a check whether you are affected.
## Michael A Hawkins
Some of us are forced to run older versions of Fedora. Any chance this thread could include the offending text from the script and some ways to edit it away or improve it?
## Mike
Is this working for Fedora 25? |
9,707 | 如何在 Ubuntu 18.04 服务器上安装和配置 KVM | https://www.linuxtechi.com/install-configure-kvm-ubuntu-18-04-server/ | 2018-06-03T08:51:00 | [
"虚拟化",
"kvm"
] | https://linux.cn/article-9707-1.html | 
**KVM**(基于内核的虚拟机)是一款为类 Linux 系统提供的开源的全虚拟化解决方案,KVM 使用虚拟化扩展(如 **Intel VT** 或 **AMD-V**)提供虚拟化功能。无论何时我们在任何 Linux 机器上安装 KVM,都会通过加载诸如 `kvm-intel.ko`(基于 Intel 的机器)和 `kvm-amd.ko`(基于 amd 的机器)的内核模块,使其成为<ruby> 管理程序 <rt> hyervisor </rt></ruby>(LCTT 译注:一种监控和管理虚拟机运行的核心软件层)。
KVM 允许我们安装和运行多个虚拟机(Windows 和 Linux)。我们可以通过 `virt-manager` 的图形用户界面或使用 `virt-install` 和 `virsh` 命令在命令行界面来创建和管理基于 KVM 的虚拟机。
在本文中,我们将讨论如何在 Ubuntu 18.04 LTS 服务器上安装和配置 **KVM 管理程序**。我假设你已经在你的服务器上安装了 Ubuntu 18.04 LTS 。接下来登录到您的服务器执行以下步骤。
### 第一步:确认您的硬件是否支持虚拟化
执行 `egrep` 命令以验证您的服务器的硬件是否支持虚拟化,
```
linuxtechi@kvm-ubuntu18-04:~$ egrep -c '(vmx|svm)' /proc/cpuinfo
1
```
如果输出结果大于 0,就意味着您的硬件支持虚拟化。重启,进入 BIOS 设置中启用 VT 技术。
现在使用下面的命令安装 `kvm-ok` 实用程序,该程序用于确定您的服务器是否能够运行硬件加速的 KVM 虚拟机。
```
linuxtechi@kvm-ubuntu18-04:~$ sudo apt install cpu-checker
```
运行 kvm-ok 命令确认输出结果,
```
linuxtechi@kvm-ubuntu18-04:~$ sudo kvm-ok
INFO: /dev/kvm exists
KVM acceleration can be used
```
### 第二步:安装 KVM 及其依赖包
运行下面的 apt 命令安装 KVM 及其依赖项:
```
linuxtechi@kvm-ubuntu18-04:~$ sudo apt update
linuxtechi@kvm-ubuntu18-04:~$ sudo apt install qemu qemu-kvm libvirt-bin bridge-utils virt-manager
```
只要上图相应的软件包安装成功,那么你的本地用户(对于我来说是 `linuxtechi`)将被自动添加到 `libvirtd` 群组。
### 第三步:启动并启用 libvirtd 服务
我们在 Ubuntu 18.04 服务器上安装 qemu 和 libvirtd 软件包之后,它就会自动启动并启用 `libvirtd` 服务,如果 `libvirtd` 服务没有开启,则运行以下命令开启,
```
linuxtechi@kvm-ubuntu18-04:~$ sudo service libvirtd start
linuxtechi@kvm-ubuntu18-04:~$ sudo update-rc.d libvirtd enable
```
现在使用下面的命令确认 libvirtd 服务的状态,
```
linuxtechi@kvm-ubuntu18-04:~$ service libvirtd status
```
输出结果如下所示:

### 第四步:为 KVM 虚拟机配置桥接网络
只有通过桥接网络,KVM 虚拟机才能访问外部的 KVM 管理程序或主机。在Ubuntu 18.04中,网络由 `netplan` 实用程序管理,每当我们新安装一个 Ubuntu 18.04 系统时,会自动创建一个名称为 `/etc/netplan/50-cloud-init.yaml` 文件,其配置了静态 IP 和桥接网络,`netplan` 实用工具将引用这个文件。
截至目前,我已经在此文件配置了静态 IP,文件的具体内容如下:
```
network:
ethernets:
ens33:
addresses: [192.168.0.51/24]
gateway4: 192.168.0.1
nameservers:
addresses: [192.168.0.1]
dhcp4: no
optional: true
version: 2
```
我们在这个文件中添加桥接网络的配置信息,
```
linuxtechi@kvm-ubuntu18-04:~$ sudo vi /etc/netplan/50-cloud-init.yaml
network:
version: 2
ethernets:
ens33:
dhcp4: no
dhcp6: no
bridges:
br0:
interfaces: [ens33]
dhcp4: no
addresses: [192.168.0.51/24]
gateway4: 192.168.0.1
nameservers:
addresses: [192.168.0.1]
```
正如你所看到的,我们已经从接口(`ens33`)中删除了 IP 地址,并将该 IP 添加到 `br0` 中,并且还将接口(`ens33`)添加到 `br0`。使用下面的 `netplan` 命令使更改生效,
```
linuxtechi@kvm-ubuntu18-04:~$ sudo netplan apply
```
如果您想查看 debug 日志请使用以下命令,
```
linuxtechi@kvm-ubuntu18-04:~$ sudo netplan --debug apply
```
现在使用以下方法确认网络桥接状态:
```
linuxtechi@kvm-ubuntu18-04:~$ sudo networkctl status -a
```

```
linuxtechi@kvm-ubuntu18-04:~$ ifconfig
```

### 第五步:创建虚拟机(使用 virt-manager 或 virt-install 命令)
有两种方式创建虚拟机:
* `virt-manager`(图形化工具)
* `virt-install`(命令行工具)
#### 使用 virt-manager 创建虚拟机
通过执行下面的命令启动 `virt-manager`:
```
linuxtechi@kvm-ubuntu18-04:~$ sudo virt-manager
```

创建一个新的虚拟机:

点击“下一步”然后选择 ISO 镜像文件,我使用的是 RHEL 7.3 iso 镜像。

点击“下一步”。
在接下来的几个窗口中,系统会提示要求您为 VM 分配内存,处理器数量和磁盘空间。
并指定虚拟机名字和桥接网络名:

点击“结束”。

接下来只需要按照屏幕指示安装系统。
#### 使用virt-install命令从命令行界面创建虚拟机
使用下面的 `virt-install` 命令从终端创建一个虚拟机,它将在命令行界面中开始安装,并根据您对虚拟机的名字,说明,ISO 文件位置和桥接配置的设置创建虚拟机。
```
linuxtechi@kvm-ubuntu18-04:~$ sudo virt-install -n DB-Server --description "Test VM for Database" --os-type=Linux --os-variant=rhel7 --ram=1096 --vcpus=1 --disk path=/var/lib/libvirt/images/dbserver.img,bus=virtio,size=10 --network bridge:br0 --graphics none --location /home/linuxtechi/rhel-server-7.3-x86_64-dvd.iso --extra-args console=ttyS0
```
本文到此为止,我希望这篇文章能帮助你能够在 Ubuntu 18.04 服务器上成功安装 KVM。 除此之外,KVM 也是 Openstack 默认的管理程序。
阅读更多:“[如何使用 virsh 命令创建,还原和删除 KVM 虚拟机快照](https://www.linuxtechi.com/create-revert-delete-kvm-virtual-machine-snapshot-virsh-command/)”。
---
via: <https://www.linuxtechi.com/install-configure-kvm-ubuntu-18-04-server/>
作者:[Pradeep Kumar](http://www.linuxtechi.com/author/pradeep/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wyxplus](https://github.com/wyxplus) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | **KVM** (Kernel-based Virtual Machine) is an open source full virtualization solution for Linux like systems, KVM provides virtualization functionality using the virtualization extensions like **Intel VT** or** AMD-V**. Whenever we install KVM on any linux box then it turns it into the hyervisor by loading the kernel modules like **kvm-intel.ko**( for intel based machines) and **kvm-amd.ko** ( for amd based machines).
KVM allows us to install and run multiple virtual machines (Windows & Linux). We can create and manage KVM based virtual machines either via **virt-manager** graphical user interface or **virt-install** & **virsh** cli commands.
In this article we will discuss how to install and configure **KVM hypervisor** on Ubuntu 18.04 LTS server. I am assuming you have already installed Ubuntu 18.04 LTS server on your system. Login to your server and perform the following steps.
#### Step:1 Verify Whether your system support hardware virtualization
Execute below egrep command to verify whether your system supports hardware virtualization or not,
linuxtechi@kvm-ubuntu18-04:~$ egrep -c '(vmx|svm)' /proc/cpuinfo 1 linuxtechi@kvm-ubuntu18-04:~$
If the output is greater than 0 then it means your system supports Virtualization else reboot your system, then go to BIOS settings and enable VT technology.
Now Install “**kvm-ok**” utility using below command, it is used to determine if your server is capable of running hardware accelerated KVM virtual machines
linuxtechi@kvm-ubuntu18-04:~$ sudo apt install cpu-checker
Run kvm-ok command and verify the output,
linuxtechi@kvm-ubuntu18-04:~$ sudo kvm-ok INFO: /dev/kvm exists KVM acceleration can be used linuxtechi@kvm-ubuntu18-04:~$
#### Step:2 Install KVM and its required packages
Run the below apt commands to install KVM and its dependencies
linuxtechi@kvm-ubuntu18-04:~$ sudo apt update linuxtechi@kvm-ubuntu18-04:~$ sudo apt install qemu qemu-kvm libvirt-bin bridge-utils virt-manager
Once the above packages are installed successfully, then your local user (In my case linuxtechi) will be added to the group libvirtd automatically.
#### Step:3 Start & enable libvirtd service
Whenever we install qemu & libvirtd packages in Ubuntu 18.04 Server then it will automatically start and enable libvirtd service, In case libvirtd service is not started and enabled then run beneath commands,
linuxtechi@kvm-ubuntu18-04:~$ sudo service libvirtd start linuxtechi@kvm-ubuntu18-04:~$ sudo update-rc.d libvirtd enable
Now verify the status of libvirtd service using below command,
linuxtechi@kvm-ubuntu18-04:~$ service libvirtd status
Output would be something like below:
#### Step:4 Configure Network Bridge for KVM virtual Machines
Network bridge is required to access the KVM based virtual machines outside the KVM hypervisor or host. In Ubuntu 18.04, network is managed by netplan utility, whenever we freshly installed Ubuntu 18.04 server then netplan file is created under **/etc/netplan/.** In most of the hardware and virtualized environment, netplan file name would be “**50-cloud-init.yaml**” or “**01-netcfg.yaml”, **to configure static IP and bridge, netplan utility will refer this file.
As of now I have already configured the static IP via this file and content of this file is below:
network: ethernets: ens33: addresses: [192.168.0.51/24] gateway4: 192.168.0.1 nameservers: addresses: [192.168.0.1] dhcp4: no optional: true version: 2
Let’s add the network bridge definition in this file,
linuxtechi@kvm-ubuntu18-04:~$ sudo vi /etc/netplan/50-cloud-init.yaml
network: version: 2 ethernets: ens33: dhcp4: no dhcp6: no bridges: br0: interfaces: [ens33] dhcp4: no addresses: [192.168.0.51/24] gateway4: 192.168.0.1 nameservers: addresses: [192.168.0.1]
As you can see we have removed the IP address from interface(ens33) and add the same IP to the bridge ‘**br0**‘ and also added interface (ens33) to the bridge br0. Apply these changes using below netplan command,
linuxtechi@kvm-ubuntu18-04:~$ sudo netplan apply linuxtechi@kvm-ubuntu18-04:~$
If you want to see the debug logs then use the below command,
linuxtechi@kvm-ubuntu18-04:~$ sudo netplan --debug apply
Now Verify the bridge status using following methods:
linuxtechi@kvm-ubuntu18-04:~$ sudo networkctl status -a
linuxtechi@kvm-ubuntu18-04:~$ ifconfig
#### Start:5 Creating Virtual machine (virt-manager or virt-install command )
There are two ways to create virtual machine:
- virt-manager (GUI utility)
- virt-install command (cli utility)
**Creating Virtual machine using virt-manager:**
Start the virt-manager by executing the beneath command,
linuxtechi@kvm-ubuntu18-04:~$ sudo virt-manager
Create a new virtual machine
Click on forward and select the ISO file, in my case I am using RHEL 7.3 iso file.
Click on Forward
In the next couple of windows, you will be prompted to specify the RAM, CPU and disk for the VM.
Now Specify the Name of the Virtual Machine and network,
Click on Finish
Now follow the screen instruction and complete the installation,
Read More On : “[ How to Create, Revert and Delete KVM Virtual machine (domain) snapshot with virsh command](https://www.linuxtechi.com/create-revert-delete-kvm-virtual-machine-snapshot-virsh-command/)”
**Creating Virtual machine from CLI using virt-install command,**
Use the below virt-install command to create a VM from terminal, it will start the installation in CLI, replace the name of the VM, description, location of ISO file and network bridge as per your setup.
linuxtechi@kvm-ubuntu18-04:~$ sudo virt-install -n DB-Server --description "Test VM for Database" --os-type=Linux --os-variant=rhel7 --ram=1096 --vcpus=1 --disk path=/var/lib/libvirt/images/dbserver.img,bus=virtio,size=10 --network bridge:br0 --graphics none --location /home/linuxtechi/rhel-server-7.3-x86_64-dvd.iso --extra-args console=ttyS0
That’s conclude the article, I hope this article help you to install KVM on your Ubuntu 18.04 Server. Apart from this, KVM is the default hypervisor for Openstack.
Read More on : **How to Install and Configure KVM on OpenSUSE Leap 15**
AskarTo check virtualization support the command should be …
egrep -c ‘(vmx|svm)’ /proc/cpuinfo
Cristian ArriazaYou are the best thank you very much, better than on the manufacturer’s website 🙂
EricDo I understand correctly from Step 5 that one can be logged into a headless U 18.04 server via ssh and run the graphical virt-manager utility? Even in the absence of a local graphical environment?
If so, how must ssh be configured? Is it just a question of setting X11Forwarding=yes in the respective ssh_config and sshd_config files?
TonyYou’ll also need to install a X server on your host machine (for Windows, I recommend vcxsrv, open source and updated).
EddieDoc states:
whenever we freshly installed Ubuntu 18.04 server then a file with name “/etc/netplan/50-cloud-init.yaml” is created automatically, to configure static IP and bridge, netplan utility will refer this file.
NOT TRUE, this file is missing.
Would be helpful if based on ifconfig output how this file could be created
Pradeep KumarHi Eddie,
In case netplan is not present in your server then i would recommend create a file with name “01-netcfg.yaml” under /etc/netplan directory and copy paste the contents from article to this file.
KamiGreat article, step by step very helpful^_^ Thanks |
9,708 | 使用 Quagga 实现 Linux 动态路由 | https://www.linux.com/learn/intro-to-linux/2018/3/dynamic-linux-routing-quagga | 2018-06-03T10:56:00 | [
"Quagga",
"路由"
] | https://linux.cn/article-9708-1.html |
>
> 学习如何使用 Quagga 套件的路由协议去管理动态路由。
>
>
>

迄今为止,本系列文章中,我们已经在 [Linux 局域网路由新手指南:第 1 部分](/article-9657-1.html) 中学习了复杂的 IPv4 地址,在 [Linux 局域网路由新手指南:第 2 部分](/article-9675-1.html) 中学习了如何去手工创建静态路由。
今天,我们继续使用 [Quagga](https://www.quagga.net/) 去管理动态路由,这是一个安装完后就不用理它的的软件。Quagga 是一个支持 OSPFv2、OSPFv3、RIP v1 和 v2、RIPng、以及 BGP-4 的路由协议套件,并全部由 zebra 守护程序管理。
OSPF 的意思是<ruby> 最短路径优先 <rt> Open Shortest Path First </rt></ruby>。OSPF 是一个内部网关协议(IGP);它可以用在局域网和跨因特网的局域网互联中。在你的网络中的每个 OSPF 路由器都包含整个网络的拓扑,并计算通过网络的最短路径。OSPF 会通过多播的方式自动对外传播它检测到的网络变化。你可以将你的网络分割为区域,以保持路由表的可管理性;每个区域的路由器只需要知道离开它的区域的下一跳接口地址,而不用记录你的网络的整个路由表。
RIP,即路由信息协议,是一个很老的协议,RIP 路由器向网络中周期性多播它的整个路由表,而不是像 OSPF 那样只多播网络的变化。RIP 通过跳数来测量路由,任何超过 15 跳的路由它均视为不可到达。RIP 设置很简单,但是 OSPF 在速度、效率以及弹性方面更佳。
BGP-4 是边界网关协议版本 4。这是用于因特网流量路由的外部网关协议(EGP)。你不会用到 BGP 协议的,除非你是因特网服务提供商。
### 准备使用 OSPF
在我们的小型 KVM 测试实验室中,用两台虚拟机表示两个不同的网络,然后将另一台虚拟机配置为路由器。创建两个网络:net1 是 192.168.110.0/24 ,而 net2 是 192.168.120.0/24。启用 DHCP 是明智的,否则你要分别进入这三个虚拟机,去为它们设置静态地址。Host 1 在 net1 中,Host 2 在 net2 中,而路由器同时与这两个网络连接。设置 Host 1 的网关地址为 192.168.110.126,Host 2 的网关地址为 192.168.120.136。
* Host 1: 192.168.110.125
* Host 2:192.168.120.135
* Router:192.168.110.126 和 192.168.120.136
在路由器上安装 Quagga。在大多数 Linux 中它是 quagga 软件包。在 Debian 上还有一个单独的文档包 quagga-doc。取消 `/etc/sysctl.conf` 配置文件中如下这一行的注释去启用包转发功能:
```
net.ipv4.ip_forward=1
```
然后,运行 `sysctl -p` 命令让变化生效。
### 配置 Quagga
查看你的 Quagga 包中的示例配置文件,比如,`/usr/share/doc/quagga/examples/ospfd.conf.sample`。除非你的 Linux 版本按你的喜好做了创新,否则,一般情况下配置文件应该在 `/etc/quagga` 目录中。大多数 Linux 版本在这个目录下有两个文件,`vtysh.conf` 和 `zebra.conf`。它们提供了守护程序运行所需要的最小配置。除非你的发行版做了一些特殊的配置,否则,zebra 总是首先运行,当你启动 ospfd 的时候,它将自动启动。Debian/Ubuntu 是一个特例,稍后我们将会说到它。
每个路由器守护程序将读取它自己的配置文件,因此,我们必须创建 `/etc/quagga/ospfd.conf`,并输入如下内容:
```
!/etc/quagga/ospfd.conf
hostname router1
log file /var/log/quagga/ospfd.log
router ospf
ospf router-id 192.168.110.15
network 192.168.110.0/0 area 0.0.0.0
network 192.168.120.0/0 area 0.0.0.0
access-list localhost permit 127.0.0.1/32
access-list localhost deny any
line vty
access-class localhost
```
你可以使用感叹号(`!`)或者井号(`#`)去注释掉这些行。我们来快速浏览一下这些选项。
* `hostname` 可以是你希望的任何内容。这里不是一般意义上的 Linux 主机名,但是,当你使用 `vtysh` 或者 `telnet` 登入时,你将看到它们。
* `log file` 是你希望用于保存日志的任意文件。
* `router` 指定路由协议。
* `ospf router-id` 是任意的 32 位数字。使用路由器的一个 IP 地址就是很好的选择。
* `network` 定义你的路由器要通告的网络。
* `access-list` 限制 `vtysh` 登入,它是 Quagga 命令行 shell,它允许本地机器登入,并拒绝任何远程管理。
### Debian/Ubuntu
在你启动守护程序之前,Debian/Ubuntu 相对其它的 Debian 衍生版可能多需要一步到多步。编辑 `/etc/quagga/daemons` ,除了 `zebra=yes` 和 `ospfd=yes` 外,使其它所有的行的值为 `no`。
然后,在 Debian 上运行 `ospfd` 去启动 Quagga:
```
# systemctl start quagga
```
在大多数的其它 Linux 上,包括 Fedora 和 openSUSE,用如下命令启动 `ospfd`:
```
# systemctl start ospfd
```
现在,Host 1 和 Host 2 将可以互相 ping 通对方和路由器。
这里用了许多篇幅去描述非常简单的设置。在现实中,路由器将连接两个交换机,然后为连接到这个交换机上的所有电脑提供一个网关。你也可以在你的路由器上添加更多的网络接口,这样你的路由器就可以为更多的网络提供路由服务,或者也可以直接连接到其它路由器上,或者连接到连接其它路由器的骨干网络上。
你或许不愿意如此麻烦地手工配置网络接口。最简单的方法是使用你的 DHCP 服务器去宣告你的路由器。如果你使用了 Dnsmasq,那么你就有了一个 DHCP 和 DNS 的一体化解决方案。
还有更多的配置选项,比如,加密的密码保护。更多内容请查看 [Quagga 路由套件](https://www.quagga.net/) 的官方文档。
---
via: <https://www.linux.com/learn/intro-to-linux/2018/3/dynamic-linux-routing-quagga>
作者:[CARLA SCHRODER](https://www.linux.com/users/cschroder) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,709 | Audacity 快速指南:快速消除背景噪音 | https://fedoramagazine.org/audacity-quick-tip-quickly-remove-background-noise/ | 2018-06-03T11:01:00 | [
"Audacity",
"噪音"
] | https://linux.cn/article-9709-1.html | 
当在笔记本电脑上录制声音时 —— 比如首次简单地录屏 —— 许多用户通常使用内置麦克风。但是,这些小型麦克风也会捕获很多背景噪音。在这个快速指南中,我们会学习如何使用 Fedora 中的 [Audacity](https://www.audacityteam.org/) 快速移除音频文件中的背景噪音。
### 安装 Audacity
Audacity 是 Fedora 中用于混合、剪切和编辑音频文件的程序。在 Fedora 上它支持各种开箱即用的格式 - 包括 MP3 和 OGG。从软件中心安装 Audacity。

如果你更喜欢终端,请使用以下命令:
```
sudo dnf install audacity
```
### 导入您的音频、样本背景噪音
安装 Audacity 后,打开程序,使用 “File > Import” 菜单项导入你的声音。这个例子使用了一个[来自 freesound.org 添加了噪音的声音](https://freesound.org/people/levinj/sounds/8323/):
* <https://ryanlerch.fedorapeople.org/noise.ogg?_=1>
接下来,采样要滤除的背景噪音。导入音轨后,选择仅包含背景噪音的音轨区域。然后从菜单中选择 “Effect > Noise Reduction”,然后按下 “Get Noise Profile” 按钮。

### 过滤噪音
接下来,选择你要过滤噪音的音轨区域。通过使用鼠标进行选择,或者按 `Ctrl + a` 来选择整个音轨。最后,再次打开 “Effect > Noise Reduction” 对话框,然后单击确定以应用滤镜。

此外,调整设置,直到你的音轨听起来更好。这里是原始文件,接下来是用于比较的降噪音轨(使用默认设置):
* <https://ryanlerch.fedorapeople.org/sidebyside.ogg?_=2>
---
via: <https://fedoramagazine.org/audacity-quick-tip-quickly-remove-background-noise/>
作者:[Ryan Lerch](https://fedoramagazine.org/introducing-flatpak/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | When recording sounds on a laptop — say for a simple first screencast — many users typically use the built-in microphone. However, these small microphones also capture a lot of background noise. In this quick tip, learn how to use [Audacity](https://www.audacityteam.org/) in Fedora to quickly remove the background noise from audio files.
### Installing Audacity
Audacity is an application in Fedora for mixing, cutting, and editing audio files. It supports a wide range of formats out of the box on Fedora — including MP3 and OGG. Install Audacity from the Software application.
If the terminal is more your speed, use the command:
sudo dnf install audacity
### Import your Audio, sample background noise
After installing Audacity, open the application, and import your sound using the **File > Import** menu item. This example uses a [sound bite from freesound.org](https://freesound.org/people/levinj/sounds/8323/) to which noise was added:
Next, take a sample of the background noise to be filtered out. With the tracks imported, select an area of the track that contains only the background noise. Then choose **Effect > Noise Reduction** from the menu, and press the **Get Noise Profile** button.
### Filter the Noise
Next, select the area of the track you want to filter the noise from. Do this either by selecting with the mouse, or **Ctrl + a** to select the entire track. Finally, open the **Effect > Noise Reduction** dialog again, and click OK to apply the filter.
Additionally, play around with the settings until your tracks sound better. Here is the original file again, followed by the noise reduced track for comparison (using the default settings):
## Cătălin George Feștilă
I don’t know very well audacity .
Can be done noise in real time ?
## Jeff Hachtel
I believe any “real time” noise reduction will need to be done by you as you record. This means being in a quiet room with no electronic interference, microphones set up as optimally as possible. Even so, even with good mics, there is usually noise that needs to be reduced using the software.
## Klaatu
Audacity doesn’t really do realtime effects. If you want to run sound through a filter (like a noise gate or a high-pass or low-pass filter or an EQ) then you can do that in applications like Ardour or Qtractor.
Otherwise, Audacity does process noise removal pretty quickly even on an old “slow” computer, so while it’s not realtime processing, it’s still pretty painless.
## Creak
Thanks for this tips, I didn’t know how to do this kind of stuff. Testing on one of my files, it works pretty well!
## JaspEr
You read in minds or what?
I was just looking around for: how the heck do I remove all this noise?
THANKS! |
9,710 | diff 与 patch 的使用 | http://locez.com/linux/diff-and-patch/ | 2018-06-03T11:21:06 | [
"diff",
"patch",
"补丁"
] | https://linux.cn/article-9710-1.html | 
### 摘要
在 Linux 的日常使用中,我们经常需要修改一些配置文件,然而在软件升级以后,经常会面临配置更新后与原配置部分不兼容的问题(当然我们更多的可能是来制作软件升级的补丁)。在这种情况下我们通常有两种选择:
* 对比现有配置,手动在新配置文件中改动
* 利用 `sed`、`awk` 等工具配合改动
* 采用 `diff` 与 `patch` 制作增量补丁的方式改动
本文主要通过一个升级`awesome` 配置的例子,对第三种方法进行介绍和讲解。
### diff 介绍
`diff` 是一个文件比较工具,可以逐行比较两个文件的不同,其中它有三种输出方式,分别是 `normal`, `context` 以及 `unified`。区别如下:
* `normal` 方式为默认输出方式,不需要加任何参数
* `context` 相较于 `normal` 模式的简单输出,`contetx` 模式会输出修改过部分的上下文,默认是前后 **3** 行。使用参数 `-c`
* `unified` 合并上下文模式则为新的上下文输出模式,同样为前后 **3** 行,只不过把上下文合并了显示了。使用参数 `-u`
**注**:本文主要介绍 `unified` 模式
其他常用参数:
* `-r` 递归处理目录
* `-N` 将缺失的文件当作空白文件处理
#### diff 语法与文件格式
```
diff [options] old new
```
先来看一个简单的例子:
```
$ cat test1
linux
linux
linux
linux
```
```
$ cat test2
locez
linux
locez
linux
```
此时输入 `diff -urN test1 test2` 会输出以下信息:
```
--- test1 2018-05-12 18:39:41.508375114 +0800
+++ test2 2018-05-12 18:41:00.124031736 +0800
@@ -1,4 +1,4 @@
+locez
linux
-linux
-linux
+locez
linux
```
先看前面 2 行,这两行为文件的基本信息,`---` 开头为改变前的文件,`+++` 开头为更新后的文件。
```
--- test1 2018-05-12 18:39:41.508375114 +0800
+++ test2 2018-05-12 18:41:00.124031736 +0800
```
第三行为上下文描述块,其中 `-1,4` 为旧文件的 4 行上下文,`+1,4` 为新文件的:
```
@@ -1,4 +1,4 @@
```
而具体到块里面的内容,前面有 `-` 号的则为删除,有 `+` 号为新增,不带符号则未做改变,仅仅是上下文输出。
### patch 介绍
`patch` 是一个可以将 `diff` 生成的**补丁**应用到源文件,生成一个打过补丁版本的文件。语法:
```
patch [oiption] [originalfile [patchfile]]
```
常用参数:
* `-i` 指定补丁文件
* `-pNum` 在 `diff` 生成的补丁中,第一二行是文件信息,其中文件名是可以包含路径的,例如 `--- /tmp/test1 2018-05-12 18:39:41.508375114 +0800` 其中 `-p0` 代表完整的路径 `/tmp/test1`,而 `-p1` 则指 `tmp/test1`,`-pN` 依此类推
* `-E` 删除应用补丁后为空文件的文件
* `-o` 输出到一个文件而不是直接覆盖文件
### 应用
awesome 桌面 3.5 与 4.0 之间的升级是不兼容的,所以在升级完 4.0 以后,awesome 桌面部分功能无法使用,因此需要迁移到新配置,接下来则应用 `diff` 与 `patch` 实现迁移,当然你也可以单纯使用 `diff` 找出不同,然后手动修改新配置。
现在有以下几个文件:
* `rc.lua.3.5` 3.5 版本的默认配置文件,未修改
* `rc.lua.myconfig` 基于 3.5 版本的个人配置文件
* `rc.lua.4.2` 4.2 新默认配置,未修改
思路为利用 `diff` 提取出个人配置与 3.5 默认配置文件的增量补丁,然后把补丁应用在 4.2 的文件上实现迁移。
#### 制作补丁
```
$ diff -urN rc.lua.3.5 rc.lua.myconfig > mypatch.patch
```
#### 应用补丁
```
$ patch rc.lua.4.2 -i mypatch.patch -o rc.lua
patching file rc.lua (read from rc.lua.4.2)
Hunk #1 FAILED at 38.
Hunk #2 FAILED at 55.
Hunk #3 succeeded at 101 with fuzz 1 (offset 5 lines).
Hunk #4 succeeded at 276 with fuzz 2 (offset 29 lines).
2 out of 4 hunks FAILED -- saving rejects to file rc.lua.rej
```
显然应用没有完全成功,其中在 38 行以及 55 行应用失败,并记录在 `rc.lua.rej` 里。
```
$ cat rc.lua.rej
--- rc.lua.3.5 2018-05-12 19:15:54.922286085 +0800
+++ rc.lua.myconfig 2018-05-12 19:13:35.057911463 +0800
@@ -38,10 +38,10 @@
-- {{{ Variable definitions
-- Themes define colours, icons, font and wallpapers.
-beautiful.init("@AWESOME_THEMES_PATH@/default/theme.lua")
+beautiful.init("~/.config/awesome/default/theme.lua")
-- This is used later as the default terminal and editor to run.
-terminal = "xterm"
+terminal = "xfce4-terminal"
editor = os.getenv("EDITOR") or "nano"
editor_cmd = terminal .. " -e " .. editor
@@ -55,18 +55,18 @@
-- Table of layouts to cover with awful.layout.inc, order matters.
local layouts =
{
- awful.layout.suit.floating,
- awful.layout.suit.tile,
- awful.layout.suit.tile.left,
- awful.layout.suit.tile.bottom,
- awful.layout.suit.tile.top,
+-- awful.layout.suit.floating,
+-- awful.layout.suit.tile,
+-- awful.layout.suit.tile.left,
+-- awful.layout.suit.tile.bottom,
+-- awful.layout.suit.tile.top,
awful.layout.suit.fair,
awful.layout.suit.fair.horizontal,
awful.layout.suit.spiral,
awful.layout.suit.spiral.dwindle,
awful.layout.suit.max,
awful.layout.suit.max.fullscreen,
- awful.layout.suit.magnifier
+-- awful.layout.suit.magnifier
}
-- }}}
```
这里是主题,终端,以及常用布局的个人设置。
#### 修正补丁
再次通过对比补丁文件与 4.2 文件,发现 38 行区块是要删除的东西不匹配,而 55 行区块则是上下文与要删除的内容均不匹配,导致不能应用补丁,于是手动修改补丁
```
$ vim mypatch.patch
```
```
--- rc.lua.3.5 2018-05-12 19:15:54.922286085 +0800
+++ rc.lua.myconfig 2018-05-12 19:13:35.057911463 +0800
@@ -38,10 +38,10 @@
-- {{{ Variable definitions
-- Themes define colours, icons, font and wallpapers.
-beautiful.init(gears.filesystem.get_themes_dir() .. "default/theme.lua")
+beautiful.init("~/.config/awesome/default/theme.lua")
-- This is used later as the default terminal and editor to run.
-terminal = "xterm"
+terminal = "xfce4-terminal"
editor = os.getenv("EDITOR") or "nano"
editor_cmd = terminal .. " -e " .. editor
@@ -55,18 +55,18 @@
-- Table of layouts to cover with awful.layout.inc, order matters.
awful.layout.layouts = {
- awful.layout.suit.floating,
- awful.layout.suit.tile,
- awful.layout.suit.tile.left,
- awful.layout.suit.tile.bottom,
- awful.layout.suit.tile.top,
+-- awful.layout.suit.floating,
+-- awful.layout.suit.tile,
+-- awful.layout.suit.tile.left,
+-- awful.layout.suit.tile.bottom,
+-- awful.layout.suit.tile.top,
awful.layout.suit.fair,
awful.layout.suit.fair.horizontal,
awful.layout.suit.spiral,
awful.layout.suit.spiral.dwindle,
awful.layout.suit.max,
awful.layout.suit.max.fullscreen,
- awful.layout.suit.magnifier,
+-- awful.layout.suit.magnifier,
awful.layout.suit.corner.nw,
-- awful.layout.suit.corner.ne,
-- awful.layout.suit.corner.sw,
....
....
```
输出省略显示,有兴趣的读者可以仔细与`rc.lua.rej` 文件对比,看看笔者是怎样改的。
#### 再次应用补丁
```
$ patch rc.lua.4.2 -i mypatch.patch -o rc.lua
patching file rc.lua (read from rc.lua.4.2)
Hunk #1 succeeded at 41 (offset 3 lines).
Hunk #2 succeeded at 57 with fuzz 2 (offset 2 lines).
Hunk #3 succeeded at 101 with fuzz 1 (offset 5 lines).
Hunk #4 succeeded at 276 with fuzz 2 (offset 29 lines).
$ cp rc.lua ~/.config/awesome/rc.lua ### 打完补丁直接使用
```
### 总结
`diff` 与 `patch` 配合使用,能当增量备份,而且还可以将补丁分发给他人使用,而且在日常的软件包打补丁也具有重要的意义,特别是内核补丁或者一些驱动补丁,打补丁遇到错误时候可以尝试自己修改,已满足自身特殊要求,修改的时候一定要抓住 2 个非常重要的要素:
1. 要修改的内容是否匹配?特别是要删除的
2. 上下文是否满足,特别是距离要修改的地方前后一行,以及上下文的行数是否满足,默认是 3 行上下文
| 301 | Moved Permanently | null |
9,711 | 异步决策:帮助远程团队走向成功 | https://opensource.com/article/17/12/asynchronous-decision-making | 2018-06-03T17:12:07 | [
"决策"
] | https://linux.cn/article-9711-1.html |
>
> 更好的沟通和少量的会议并不是白日梦。这里告诉您异步决策是如何实现这一切的。
>
>
>

异步决策能够让地理和文化上分散的软件团队更有效率地做出决策。本文就将讨论一下实现异步决策所需要的一些原则和工具。
同步决策,要求参与者实时地进行互动,而这对那些需要<ruby> <a href="http://www.paulgraham.com/makersschedule.html"> 大块完整时间工作 </a> <rt> Maker's Schedule </rt></ruby>的人来说代价非常大,而且对于远程团队来说这也不现实。我们会发现这种会议最后浪费的时间让人难以置信。
相比之下,异步决策常应用于大型开源项目中(比如我常参与的 Apache 软件基金会 ASF)。它为团队提供了一种尽可能少开会的有效方法。很多开源项目每年只开很少的几次会议(有的甚至完全没开过会),然而开发团队却始终如一地在生产高质量的软件。
怎样才能异步决策呢?
### 所需工具
#### 中心化的异步沟通渠道
异步决策的第一步就是构建一个中心化的异步沟通渠道。你所使用的技术必须能让所有的团队成员都获得同样的信息,并能进行<ruby> 线索讨论 <rt> threaded discussions </rt></ruby>,也就是说你要既能对一个主题进行发散也要能封禁其他主题的讨论。想一想航海专用无线电台,其中广播渠道的作用只是为了引起特定人员的注意,这些人然后再创建一个子渠道来进行详细的讨论。
很多开源项目依旧使用邮件列表作为中心渠道,不过很多新一代的软件开发者可能会觉得这个方法又古老又笨拙。邮件列表需要遵循大量的准则才能有效的管理热门项目,比如你需要进行有意义的引用,每个线索只讨论一个主题,保证 [标题与内容相吻合](https://grep.codeconsult.ch/2017/11/10/large-mailing-lists-survival-guide/)。虽然这么麻烦,但使用得当的话,再加上一个经过索引的归档系统,邮件列表依然在创建中心渠道的工具中占据绝对主导的地位。
公司团队可以从一个更加现代化的协作工具中收益,这类工具更易使用并提供了更加强大的多媒体功能。不管你用的是哪个工具,关键在于要创建一个能让大量的人员有效沟通并异步地讨论各种主题的渠道。要创建一个一致而活跃的社区,使用一个 [繁忙的渠道要好过建立多个渠道](https://grep.codeconsult.ch/2011/12/06/stefanos-mazzocchis-busy-list-pattern/)。
#### 构建共识的机制
第二个工具是一套构建共识的机制,这样你才不会陷入死循环从而确保能做出决策。做决策最理想的情况就是一致同意,而次佳的就是达成共识,也就是 “有决策权的人之间广泛形成了一致的看法”。强求完全一致的赞同或者允许一票否决都会阻碍决策的制定,因此 ASF 中只在非常有限的决策类型中允许否决权。[ASF 投票制度](http://www.apache.org/foundation/voting.html) 为类似 ASF 这样没有大老板的松散组织构建了一个久经考验的,用于达成共识的好方法。当共识无法自然产生时也可以使用该套制度。
#### 案例管理系统
如上所述,我们通常在项目的中心渠道中构建共识。但是在讨论一些复杂的话题时,使用案例管理系统这一第三方的工具很有意义。小组可以使用中心渠道专注于非正式的讨论和头脑风暴上,当讨论要转变成一个决策时将其转到一个更加结构化的案例管理系统中去。
案例管理系统能够更精确地组织决策。小型团队不用做太多决策可以不需要它,但很多团队会发现能有一个相对独立的地方讨论决策的细节并保存相关信息会方便很多。
案例管理系统不一定就是个很复杂的软件; 在 ASF 中我们所使用的只是简单的问题跟踪软件而已,这些基于网页的系统原本是创建来进行软件支持和 bug 管理的。每个案例列在一个单独的网页上,还有一些历史的注释和动作信息。该途径可以很好的追踪决策是怎么制定出来的。比如,某些非紧急的决策或者复杂的决策可能会花很长时间才会制定出来,这时有一个地方能够了解这些决策的历史就很有用了。新来的团队成员也能很快地了解到最近做出了哪些决策,哪些决策还在讨论,每个决策都有那些人参与其中,每个决策的背景是什么。
### 成功的案例
ASF 董事会中的九名董事在每个月的电话会议上只做很少的一些决策,耗时不超过 2 个小时。在准备这些会议之前,大多数的决策都预先通过异步的方式决定好了。这使得我们可以在会议上集中讨论复杂和难以确定的问题,而不是讨论那些已经达成普遍或部分共识的问题上。
软件世界外的一个有趣的案例是 [瑞士联邦委员会的周会](https://www.admin.ch/gov/en/start/federal-council/tasks/decision-making/federal-council-meeting.html),它的运作方式跟 ASF 很类似。团队以异步决策构建共识的方式来准备会议。会议议程由一组不同颜色编码的列表组成,这些颜色标识了那些事项可以很快通过批准,那些事项需要进一步的讨论,哪些事项特别的复杂。这使得只要 7 个人就能每年忙完超过 2500 项决策,共 50 个周会,每个周会只需要几个小时时间。我觉得这个效率已经很高了。
就我的经验来看,异步决策带来的好处完全值得上为此投入的时间和工具。而且它也能让团队成员更快乐,这也是成功的关键因素之一。
---
via: <https://opensource.com/article/17/12/asynchronous-decision-making>
作者:[Bertrand Delacretaz](https://opensource.com) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Asynchronous decision-making* is a strategy that enables geographically and culturally distributed software teams to make decisions more efficiently. In this article, I'll discuss some of the principles and tools that make this approach possible.
*Synchronous decision-making*, in which participants interact with each other in real time, can be expensive for people who work on a [Maker's Schedule](http://www.paulgraham.com/makersschedule.html), and they are often impractical for remote teams. We've all seen how such meetings can devolve into inefficient time wasters that we all dread and avoid.
In contrast, asynchronous decision-making, which is often used in large open source projects—for example, at the Apache Software Foundation (ASF), where I'm most active—provides an efficient way for teams to move forward with minimal meetings. Many open source projects involve only a few meetings each year (and some none at all), yet development teams consistently produce high-quality software.
How does asynchronous decision-making work?
## Required tools
### Central asynchronous communications channel
The first thing you need to enable asynchronous decision-making is a central asynchronous communications channel. The technology you use must enable all team members to get the same information and hold threaded discussions, where you can branch off on a topic while ignoring other topics being discussed on the same channel. Think of marine radio, in which a broadcast channel is used sparingly to get the attention of specific people, who then branch off to a sub-channel to have more detailed discussions.
Many open source projects still use mailing lists as this central channel, although younger software developers might consider this approach old and clunky. Mailing lists require a lot of discipline to efficiently manage the high traffic of a busy project, particularly when it comes to meaningful quoting, sticking to one topic per thread, and making sure [subject lines are relevant](https://grep.codeconsult.ch/2017/11/10/large-mailing-lists-survival-guide/). Still, when used properly and coupled with an indexed archive, mailing lists remain the most ubiquitous tool to create a central channel.
Corporate teams might benefit from more modern collaboration tools, which can be easier to use and provide stronger multimedia features. Regardless of which tools you use, the key is to create a channel in which large groups of people can communicate efficiently and asynchronously on a wide variety of topics. A [busy channel is often preferable to multiple channels](https://grep.codeconsult.ch/2011/12/06/stefanos-mazzocchis-busy-list-pattern/) to create a consistent and engaged community.
### Consensus-building mechanism
The second tool is a mechanism for building consensus so you can avoid deadlocks and ensure that decisions go forward. Unanimity in decision-making is ideal, but *consensus*, defined as "widespread agreement among people who have decision power," is second-best. Requiring unanimity or allowing vetoes in decision-making can block progress, so at the ASF vetoes apply only to a very limited set of decision types. The [ASF's voting rules](http://www.apache.org/foundation/voting.html) constitute a well-established and often-emulated approach to building consensus in loosely coupled teams which, like the ASF, may have no single boss. They can also be used when consensus doesn't emerge naturally.
### Case management system
Building consensus usually happens on the project's central channel, as described above. But for complex topics, it often makes sense to use a third tool: a case management system. Groups can then focus the central channel on informal discussions and brainstorming, then move to a more structured case management system when a discussion evolves into a decision.
The case management system organizes decisions more precisely. Smaller teams with fewer decisions to make could work without one, but many find it convenient to be able to discuss the details of a given decision and keep associated information in a single, relatively isolated place.
A case management system does not require complex software; at the ASF we use simple *issue trackers*, web-based systems originally created for software support and bug management. Each case is handled on a single web page, with a history of comments and actions. This approach works well for keeping track of decisions and the paths that lead to them. Some non-urgent or complex decisions can take a long time to reach closure, for example, and it's useful to have their history in a single place. New team members can also get up to speed quickly by learning which decisions were made most recently, which remain outstanding, who's involved in each one, and the background behind each decision.
## Success stories
The nine members of ASF's board of directors make a few dozen decisions at each monthly phone meeting, which last less than two hours. We carefully prepare for these meetings by making most of our decisions asynchronously in advance. This allows us to focus the meeting on the complex or uncertain issues rather than the ones that already have full or partial consensus.
An interesting example outside of the software world is the [Swiss Federal Council's weekly meeting](https://www.admin.ch/gov/en/start/federal-council/tasks/decision-making/federal-council-meeting.html), which runs in a way similar to ASF. Teams prepare for the meeting by using asynchronous decision-making to build consensus. The meeting agenda consists of a set of color-coded lists that indicate which items can be approved quickly, which need more discussion, and which are expected to be most complex. This allows seven busy people to make more than 2,500 decisions each year, in about 50 weekly sessions of a few hours each. Sounds pretty efficient to me.
In my experience, the benefits of asynchronous decision-making are well worth the investment in time and tools. It also leads to happier team members, which is a key component of success.
## 2 Comments |
9,712 | 最小权限的容器编排 | https://blog.docker.com/2017/10/least-privilege-container-orchestration/ | 2018-06-03T21:57:35 | [
"容器",
"编排",
"Docker",
"Swarm"
] | https://linux.cn/article-9712-1.html | 
Docker 平台和容器已经成为打包、部署、和管理应用程序的标准。为了在一个集群内协调跨节点的容器,必须有一个关键的能力:一个容器编排器。

对于关键的集群化以及计划的任务,编排器是起重大作用的,比如:
* 管理容器计划和资源分配。
* 支持服务发现和无缝的应用程序部署。
* 分配应用程序运行必需的资源。
不幸的是,在这种环境下,编排器的分布式特性和资源的短暂性使得确保编排器的安全是一个极具挑战性的任务。在这篇文章中,我们将讨论容器编排器安全模型中没有考虑到的、但是很重要的这方面的详细情况,以及 Docker 企业版中如何使用内置的编排性能、Swarm 模式,去克服这些问题。
### 诱因和威胁模型
使用 swarm 模式的 Docker 企业版的其中一个主要目标是提供一个内置安全特性的编排器。为达到这个目标,我们部署了第一个在我们心目中认为的以最小权限原则设计的容器编排器。
在计算机科学中,一个分布式系统所要求的最小权限原则是,系统中的每个参与者仅仅能访问它正当目的所需要的信息和资源。不是更多,也不是更少。
>
> “一个进程必须仅仅能去访问它的正当目的所需要的信息和资源”
>
>
>
#### 最小权限原则
在一个 Docker 企业版集群中的每个节点分配的角色:既不是管理者(manager),也不是工人(worker)。这些角色为节点定义了一个很粗粒度的权限级别:分别进行管理和任务执行。尽管如此,不用理会它的角色,通过使用加密的方式,来保证一个节点仅仅有执行它的任务所需要的信息和资源。结果是,确保集群安全变得更容易了,甚至可以防止大多数的有经验的攻击者模式:攻击者控制了底层通讯网络,或者甚至攻陷了集群节点。
### 内核缺省安全
这是一个很老的安全最大化状态:如果它不是缺省的,就没人用它。Docker Swarm 模式将缺省安全这一概念融入了核心,并且使用这一机制去解决编排器生命周期中三个很难并且很重要的部分:
1. 可信引导和节点引入。
2. 节点身份发布和管理。
3. 认证、授权和加密的信息存储和传播。
我们来分别看一下这三个部分:
#### 可信引导和节点引入
确保集群安全的第一步,没有别的,就是严格控制成员和身份。管理员不能依赖它们节点的身份,并且在节点之间强制实行绝对的负载隔离。这意味着,未授权的节点不能允许加入到集群中,并且,已经是集群一部分的节点不能改变身份,突然去伪装成另一个节点。
为解决这种情况,通过 Docker 企业版 Swarm 模式管理的节点,维护了健壮的、不可改变的身份。期望的特性是,通过使用两种关键的构建块去保证加密:
1. 为集群成员使用<ruby> 安全加入令牌 <rt> Secure join token </rt></ruby>。
2. 从一个集中化的认证机构发行的内嵌唯一身份的证书。
##### 加入 Swarm
要加入 Swarm,节点需要一份<ruby> 安全加入令牌 <rt> Secure join token </rt></ruby>的副本。在集群内的每个操作角色的令牌都是独一无二的 —— 现在有两种类型的节点:工人(workers)和管理者(managers)。由于这种区分,拥有一个工人令牌的节点将不允许以管理者角色加入到集群。唯一得到这个特殊令牌的方式是通过 swarm 的管理 API 去向集群管理者请求一个。
令牌是安全的并且是随机生成的,它还有一个使得令牌泄露更容易被检测到的特殊语法:一个可以在你的日志和仓库中很容易监视的特殊前缀。幸运的是,即便发现一个泄露,令牌也可以很容易去更新,并且,推荐你经常去更新它们 —— 特别是,在一段时间中你的集群不进行扩大的情况下。

##### 引导信任
作为它的身份标识创建的一部分,一个新的节点将向任意一个网络管理者请求发布一个新的身份。但是,在我们下面的威胁模型中,所有的通讯可以被一个第三方拦截。这种请求存在的问题是:一个节点怎么知道与它进行对话的对方是合法的管理者?

幸运的是,Docker 有一个内置机制可以避免这种情况。这个加入令牌被主机用于加入 Swarm,包含了一个根 CA 证书的哈希串。所以,主机可以使用单向 TLS,并且使用这个哈希串去验证它加入的 Swarm 是否正确:如果管理者持有的证书没有被正确的 CA 哈希串签名,节点就知道它不可信任。
#### 节点身份发布和管理
在一个 Swarm 中,身份标识是内嵌在每个节点都单独持有的一个 x509 证书中。在一个最小权限原则的表现形式中,证书的私钥被绝对限制在主机的原始位置。尤其是,管理者不能访问除了它自己的私钥以外的任何一个私钥。
##### 身份发布
要接收它们的证书而无需共享它们的私钥,新的主机通过发布一个证书签名请求(CSR)来开始,管理者收到证书签名请求之后,转换成一个证书。这个证书成为这个新的主机的身份标识,使这个节点成为 Swarm 的一个完全合格成员!

当和安全引导机制一起使用时,发行身份标识的这个机制来加入节点是缺省安全的:所有的通讯部分都是经过认证的、授权的,并且非敏感信息从来都不会以明文方式进行交换。
##### 身份标识延期
尽管如此,给一个 Swarm 中安全地加入节点,仅仅是 “故事” 的一部分。为降低证书的泄露或者失窃造成的影响,并且移除管理 CRL 列表的复杂性,Swarm 模式为身份标识使用了较短存活周期的证书。这些证书缺省情况下三个月后将过期,但是,也可以配置为一个小时后即刻过期!

较短的证书过期时间意味着不能手动去处理证书更新,所以,通常会使用一个 PKI 系统。对于 Swarm,所有的证书是以一种不中断的方式进行自动更新的。这个过程很简单:使用一个相互认证的 TLS 连接去证明一个特定身份标识的所有者,一个 Swarm 节点定期生成一个新的公钥/私钥密钥对,并且用相关的 CSR 去签名发送,创建一个维持相同身份标识的完整的新证书。
#### 经过认证、授权、和加密的信息存储和传播。
在一个正常的 Swarm 的操作中,关于任务的信息被发送给去运行的工人(worker)节点。这里不仅仅包含将被一个节点运行的容器的信息;也包含那个容器运行所必需的资源的所有信息,包括敏感的机密信息,比如,私钥、密码和 API 令牌。
##### 传输安全
事实上,参与 Swarm 的每个节点都拥有一个独一无二的 X509 格式的证书,因此,节点之间的通讯安全是没有问题的:节点使用它们各自的证书,与另一个连接方进行相互认证、继承机密、真实性、和 TLS 的完整性。

关于 Swarm 模式的一个有趣的细节是,本质上它是使用了一个推送模式:仅管理者被允许去发送信息到工人们(workers)—— 显著降低了暴露在低权限的工人节点面前的管理者节点的攻击面。
##### 将负载严格隔离进安全区域
管理者节点的其中一个责任是,去决定发送到每个工人(worker)节点的任务是什么。管理者节点使用多种策略去做这个决定;根据每个节点和每个负载的特性,去跨 Swarm 去安排负载。
在使用 Swarm 模式的 Docker 企业版中,管理者节点通过使用附加到每个单个节点标识上的安全标签,去影响这些安排决定。这些标签允许管理者将节点组与不同的安全区域连接到一起,以限制敏感负载暴露,以及使相关机密信息更安全。

##### 安全分发机密
除了加快身份标识发布过程之外,管理者节点还有存储和分发工人节点所需要的任何资源的任务。机密信息像任何其它类型的资源一样处理,并且基于安全的 mTLS 连接,从管理者推送到工人节点。

在主机上,Docker 企业版能确保机密仅提供给它们指定的容器。在同一个主机上的其它容器并不能访问它们。Docker 以一个临时文件系统的方式显露机密给一个容器,确保机密总是保存在内存中,并且从不写入到磁盘。这种方式比其它竞争的替代者更加安全,比如,[在环境变量中存储它们](https://diogomonica.com/2017/03/27/why-you-shouldnt-use-env-variables-for-secret-data/)。一旦这个任务完成,这个机密将永远消失。
##### 存储机密
在管理者主机上的机密总是保持加密的。缺省情况下,加密这些机密的密钥(被称为数据加密密钥,DEK)是以明文的方式存储在硬盘上的。这使得那些对安全性要求较低的人可以轻松地去使用 Docker Swarm 模式。
但是,如果你运行一个生产集群,我们推荐你启用自动锁定模式。当自动锁定模式启用后,一个重新更新过的 DEK 被一个独立的加密密钥的密钥(KEK)所加密。这个密钥从不被存储在集群中;管理者有责任将它存储在一个安全可靠的地方,并且当集群启动的时候可以提供它。这就是所谓的 “解锁” Swarm。
根据 Raft 故障容错一致性算法,Swarm 模式支持多个管理者。在这个场景中,无缝扩展了机密存储的安全性。每个管理者主机除了共享密钥之外,还有一个唯一的磁盘加密密钥。幸运的是,Raft 日志在磁盘上也是加密的,并且,在自动锁定模式下,没有 KEK 同样是不可访问的。
#### 当一个节点被攻陷后发生了什么?

在传统的编排器中,挽回一台被攻陷的主机是一个缓慢而复杂的过程。使用 Swarm 模式,恢复它就像运行一个 Docker 节点的 `rm` 命令一样容易。这是从集群中删除一个受影响的节点,而 Docker 将去处理剩下的事情,即,重新均衡负载,并且确保其它的主机已经知道,而不会去与受影响的节点通讯。
正如我们看到的那样,感谢最小权限的编排器,甚至是,如果攻击者在主机上持续活动,它们将被从剩余的网络上切断。主机的证书 —— 它的身份标识 —— 被列入黑名单,因此,管理者也不能有效访问它。
### 结论
使用 Swarm 模式的 Docker 企业版,在缺省情况下确保了编排器的所有关键区域的安全:
* 加入集群。阻止恶意节点加入到集群。
* 把主机分组为安全区域。阻止攻击者的横向移动。
* 安排任务。任务将仅被委派到允许的节点。
* 分配资源。恶意节点不能 “盗取” 其它的负载或者资源。
* 存储机密。从不明文保存并且从不写入到工人节点的磁盘上。
* 与工人节点的通讯。使用相互认证的 TLS 加密。
因为 Swarm 模式的持续改进,Docker 团队正在努力将最小权限原则进一步推进。我们正在处理的一个任务是:如果一个管理者被攻陷了,怎么去保证剩下的节点的安全?路线图已经有了,其中一些功能已经可以使用,比如,白名单功能,仅允许特定的 Docker 镜像,阻止管理者随意运行负载。这是通过 Docker 可信内容来实现的。
---
via: <https://blog.docker.com/2017/10/least-privilege-container-orchestration/>
作者:[Diogo Mónica](https://blog.docker.com/author/diogo/) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,713 | Go 程序的持续分析 | https://medium.com/google-cloud/continuous-profiling-of-go-programs-96d4416af77b | 2018-06-04T11:00:21 | [
"优化",
"Go"
] | https://linux.cn/article-9713-1.html | 
Google 最有趣的部分之一就是我们规模庞大的持续分析服务。我们可以看到谁在使用 CPU 和内存,我们可以持续地监控我们的生产服务以争用和阻止配置文件,并且我们可以生成分析和报告,并轻松地告诉我们可以进行哪些有重要影响的优化。
我简单研究了 [Stackdriver Profiler](https://cloud.google.com/profiler/),这是我们的新产品,它填补了针对云端用户在云服务范围内分析服务的空白。请注意,你无需在 Google 云平台上运行你的代码即可使用它。实际上,我现在每天都在开发时使用它。它也支持 Java 和 Node.js。
### 在生产中分析
pprof 可安全地用于生产。我们针对 CPU 和堆分配分析的额外会增加 5% 的开销。一个实例中每分钟收集 10 秒。如果你有一个 Kubernetes Pod 的多个副本,我们确保进行分摊收集。例如,如果你拥有一个 pod 的 10 个副本,模式,那么开销将变为 0.5%。这使用户可以一直进行分析。
我们目前支持 Go 程序的 CPU、堆、互斥和线程分析。
### 为什么?
在解释如何在生产中使用分析器之前,先解释为什么你想要在生产中进行分析将有所帮助。一些非常常见的情况是:
* 调试仅在生产中可见的性能问题。
* 了解 CPU 使用率以减少费用。
* 了解争用的累积和优化的地方。
* 了解新版本的影响,例如看到 canary 和产品级之间的区别。
* 通过[关联](https://rakyll.org/profiler-labels/)分析样本以了解延迟的根本原因来丰富你的分布式经验。
### 启用
Stackdriver Profiler 不能与 `net/http/pprof` 处理程序一起使用,并要求你在程序中安装和配置一个一行的代理。
```
go get cloud.google.com/go/profiler
```
在你的主函数中,启动分析器:
```
if err := profiler.Start(profiler.Config{
Service: "indexing-service",
ServiceVersion: "1.0",
ProjectID: "bamboo-project-606", // optional on GCP
}); err != nil {
log.Fatalf("Cannot start the profiler: %v", err)
}
```
当你运行你的程序后,profiler 包将每分钟报告给分析器 10 秒钟。
### 可视化
当分析被报告给后端后,你将在 <https://console.cloud.google.com/profiler> 上看到火焰图。你可以按标签过滤并更改时间范围,也可以按服务名称和版本进行细分。数据将会长达 30 天。

你可以选择其中一个分析,按服务,区域和版本分解。你可以在火焰中移动并通过标签进行过滤。
### 阅读火焰图
[Brendan Gregg](http://www.brendangregg.com/flamegraphs.html) 非常全面地解释了火焰图可视化。Stackdriver Profiler 增加了一点它自己的特点。

我们将查看一个 CPU 分析,但这也适用于其他分析。
1. 最上面的 x 轴表示整个程序。火焰上的每个框表示调用路径上的一帧。框的宽度与执行该函数花费的 CPU 时间成正比。
2. 框从左到右排序,左边是花费最多的调用路径。
3. 来自同一包的帧具有相同的颜色。这里所有运行时功能均以绿色表示。
4. 你可以单击任何框进一步展开执行树。

你可以将鼠标悬停在任何框上查看任何帧的详细信息。
### 过滤
你可以显示、隐藏和高亮符号名称。如果你特别想了解某个特定调用或包的消耗,这些信息非常有用。

1. 选择你的过滤器。你可以组合多个过滤器。在这里,我们将高亮显示 `runtime.memmove`。
2. 火焰将使用过滤器过滤帧并可视化过滤后的框。在这种情况下,它高亮显示所有 `runtime.memmove` 框。
---
via: <https://medium.com/google-cloud/continuous-profiling-of-go-programs-96d4416af77b>
作者:[JBD](https://medium.com/@rakyll?source=post_header_lockup) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Continuous Profiling of Go programs
One of the most interesting parts of Google is our fleet-wide continuous profiling service. We can see who is accountable for CPU and memory usage, we can continuously monitor our production services for contention and blocking profiles, and we can generate analysis and reports and easily can tell what are some highly impactful optimization projects we can work on.
I briefly worked on [Google Cloud Profiler](https://cloud.google.com/profiler/), our new product that is filling the cloud-wide profiling gap for Cloud users. Note that you DON’T need to run your code on Google Cloud Platform in order to use it. Actually, I use it at development time on a daily basis now. It also supports Java and Node.js.
## Profiling in production
pprof is safe to use in production. We target an additional 5% overhead for CPU and heap allocation profiling. The collection is happening for 10 seconds for every minute from a single instance. If you have multiple replicas of a Kubernetes pod, we make sure we do amortized collection. For example, if you have 10 replicas of a pod, the overhead will be 0.5%. This makes it possible for users to keep the profiling always on.
We currently support CPU, heap, mutex and thread profiles for Go programs.
## Why?
Before explaining how you can use the profiler in production, it would be helpful to explain why you would ever want to profile in production. Some very common cases are:
- Debug performance problems only visible in production.
- Understand the CPU usage to reduce billing.
- Understand where the contention cumulates and optimize.
- Understand the impact of new releases, e.g. seeing the difference between canary and production.
- Enrich your distributed traces by
[correlating](https://rakyll.org/profiler-labels/)them with profiling samples to understand the root cause of latency.
## Enabling
Stackdriver Profiler doesn’t work with the *net/http/pprof* handlers and require you to install and configure a one-line agent in your program.
`go get `[cloud.google.com/go/profiler](http://cloud.google.com/go/profiler)
And in your main function, start the profiler:
`if err := profiler.Start(profiler.Config{`
Service: "indexing-service",
ServiceVersion: "1.0",
ProjectID: "bamboo-project-606", // optional on GCP
}); err != nil {
log.Fatalf("Cannot start the profiler: %v", err)
}
Once you start running your program, the profiler package will report the profilers for 10 seconds for every minute.
## Visualization
As soon as profiles are reported to the backend, you will start seeing a flamegraph at [https://console.cloud.google.com/profiler](https://console.cloud.google.com/profiler). You can filter by tags and change the time span, as well as break down by service name and version. The data will be around up to 30 days.
You can choose one of the available profiles; break down by service, zone and version. You can move in the flame and filter by tags.
## Reading the flame
Flame graph visualization is explained by [Brendan Gregg](http://www.brendangregg.com/flamegraphs.html) very comprehensively. Stackdriver Profiler adds a little bit of its own flavor.
We will examine a CPU profile but all also applies to the other profiles.
- The top-most x-axis represents the entire program. Each box on the flame represents a frame on the call path. The width of the box is proportional to the CPU time spent to execute that function.
- Boxes are sorted from left to right, left being the most expensive call path.
- Frames from the same package have the same color. All runtime functions are represented with green in this case.
- You can click on any box to expand the execution tree further.
You can hover on any box to see detailed information for any frame.
## Filtering
You can show, hide and highlight by symbol name. These are extremely useful if you specifically want to understand the cost of a particular call or package.
- Choose your filter. You can combine multiple filters. In this case, we are highlighting runtime.memmove.
- The flame is going to filter the frames with the filter and visualize the filtered boxes. In this case, it is highlighting all runtime.memmove boxes. |
9,714 | 如何使用 Arduino 制作一个绘图仪 | https://opensource.com/article/18/3/diy-plotter-arduino | 2018-06-04T20:11:26 | [
"Arduino",
"绘图仪"
] | https://linux.cn/article-9714-1.html |
>
> 使用开源硬件和软件的 DIY 绘图仪可以自动地绘制、雕刻。
>
>
>

在上学时,科学系的壁橱里藏着一台惠普绘图仪。虽然我在上学的期间可以经常使用它,但我还是想拥有一台属于自己的绘图仪。许多年之后,步进电机已经很容易获得了,我又在从事电子产品和微控制器方面的工作,最近,我看到有人用丙烯酸塑料(acrylic)制作了一个显示器。这件事启发了我,并最终制作了我自己的绘图仪。

*我 DIY 的绘图仪;在这里看它工作的[视频](https://twitter.com/pilhuhn/status/948205323726344193)。*
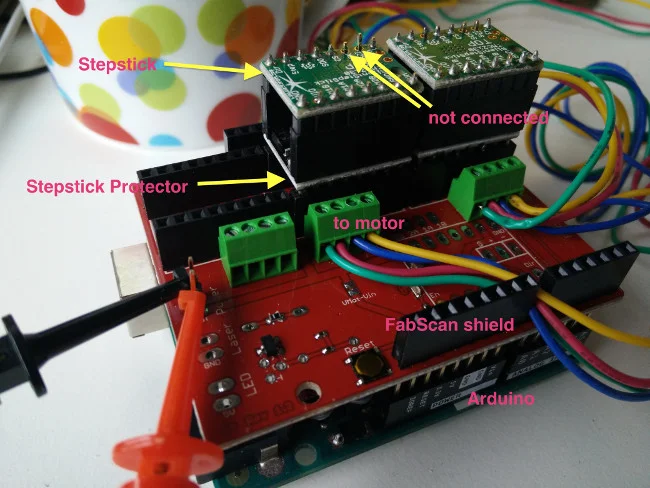
由于我是一个很怀旧的人,我真的很喜欢最初的 [Arduino Uno](https://en.wikipedia.org/wiki/Arduino#Official_boards)。下面是我用到的其它东西的一个清单(仅供参考,其中一些我也不是很满意):
* [FabScan shield](http://www.watterott.com/de/Arduino-FabScan-Shield):承载步进电机驱动器。
* [SilentStepSticks](http://www.watterott.com/de/SilentStepStick-TMC2130):步进电机驱动器,因为 Arduino 自身不能处理步进电机所需的电压和电流。因此我使用了一个 Trinamic TMC2130 芯片,但它是工作在单独模式。这些替换为 Pololu 4988,但是它们运转更安静。
* [SilentStepStick 保护装置](http://www.watterott.com/de/SilentStepStick-Protector):一个防止你的电机驱动器转动过快的二极管(相信我,你肯定会需要它的)。
* 步进电机:我选择的是使用 12 V 电压的 NEMA 17 电机(如,来自 [Watterott](http://www.watterott.com/de/Schrittmotor-incl-Anschlusskabel) 和 [SparkFun](https://www.sparkfun.com/products/9238) 的型号)。
* [直线导杆](https://www.ebay.de/itm/CNC-Set-12x-600mm-Linearfuhrung-Linear-Guide-Rail-Stage-3D-/322917927292?hash=item4b2f68897c)
* 木制的基板
* 木螺丝
* GT2 皮带
* [GT2 同步滑轮](http://www.watterott.com/de/OpenBuilds-GT2-2mm-Aluminium-Timing-Pulley)
这是我作为个人项目而设计的。如果你想找到一个现成的工具套件,你可以从 German Make 杂志上找到 [MaXYposi](https://www.heise.de/make/artikel/MaXYposi-Projektseite-zum-universellen-XY-Portalroboter-von-Make-3676050.html)。
### 硬件安装
正如你所看到的,我刚开始做的太大了。这个绘图仪并不合适放在我的桌子上。但是,没有关系,我只是为了学习它(并且,我也将一些东西进行重新制作,下次我将使用一个更小的横梁)。

*带 X 轴和 Y 轴轨道的绘图仪基板*
皮带安装在轨道的侧面,并且用它将一些辅助轮和电机挂在一起:

*电机上的皮带路由*
我在 Arduino 上堆叠了几个组件。Arduino 在最下面,它之上是 FabScan shield,接着是一个安装在 1 和 2 号电机槽上的 StepStick 保护装置,SilentStepStick 在最上面。注意,SCK 和 SDI 针脚没有连接。

*Arduino 堆叠配置([高清大图](https://www.dropbox.com/s/7bp3bo5g2ujser8/IMG_20180103_110111.jpg?dl=0))*
注意将电机的连接线接到正确的针脚上。如果有疑问,就去查看它的数据表,或者使用欧姆表去找出哪一对线是正确的。
### 软件配置
#### 基础部分
虽然像 [grbl](https://github.com/gnea/grbl) 这样的软件可以解释诸如像装置移动和其它一些动作的 G-codes,并且,我也可以将它刷进 Arduino 中,但是我很好奇,想更好地理解它是如何工作的。(我的 X-Y 绘图仪软件可以在 [GitHub](https://github.com/pilhuhn/xy-plotter) 上找到,不过我不提供任何保修。)
使用 StepStick(或者其它兼容的)驱动器去驱动步进电机,基本上只需要发送一个高电平信号或者低电平信号到各自的针脚即可。或者使用 Arduino 的术语:
```
digitalWrite(stepPin, HIGH);
delayMicroseconds(30);
digitalWrite(stepPin, LOW);
```
在 `stepPin` 的位置上是步进电机的针脚编号:3 是 1 号电机,而 6 是 2 号电机。
在步进电机能够工作之前,它必须先被启用。
```
digitalWrite(enPin, LOW);
```
实际上,StepStick 能够理解针脚的三个状态:
* Low:电机已启用
* High:电机已禁用
* Pin 未连接:电机已启用,但在一段时间后进入节能模式
电机启用后,它的线圈已经有了力量并用来保持位置。这时候几乎不可能用手来转动它的轴。这样可以保证很好的精度,但是也意味着电机和驱动器芯片都“充满着”力量,并且也因此会发热。
最后,也是很重要的,我们需要一个决定绘图仪方向的方法:
```
digitalWrite(dirPin, direction);
```
下面的表列出了功能和针脚:
| 功能 | 1 号电机 | 2 号电机 |
| --- | --- | --- |
| 启用 | 2 | 5 |
| 方向 | 4 | 7 |
| 步进 | 3 | 6 |
在我们使用这些针脚之前,我们需要在代码的 `setup()` 节中设置它的 `OUTPUT` 模式。
```
pinMode(enPin1, OUTPUT);
pinMode(stepPin1, OUTPUT);
pinMode(dirPin1, OUTPUT);
digitalWrite(enPin1, LOW);
```
了解这些知识后,我们可以很容易地让步进电机四处移动:
```
totalRounds = ...
for (int rounds =0 ; rounds < 2*totalRounds; rounds++) {
if (dir==0){ // set direction
digitalWrite(dirPin2, LOW);
} else {
digitalWrite(dirPin2, HIGH);
}
delay(1); // give motors some breathing time
dir = 1-dir; // reverse direction
for (int i=0; i < 6400; i++) {
int t = abs(3200-i) / 200;
digitalWrite(stepPin2, HIGH);
delayMicroseconds(70 + t);
digitalWrite(stepPin2, LOW);
delayMicroseconds(70 + t);
}
}
```
这将使滑块向左和向右移动。这些代码只操纵一个步进电机,但是,对于一个 X-Y 绘图仪,我们要考虑两个轴。
#### 命令解释器
我开始做一个简单的命令解释器去使用规范的路径,比如:
```
"X30|Y30|X-30 Y-30|X-20|Y-20|X20|Y20|X-40|Y-25|X40 Y25
```
用毫米来描述相对移动(1 毫米等于 80 步)。
绘图仪软件实现了一个 *持续模式* ,这可以允许一台 PC 给它提供一个很大的路径(很多的路径)去绘制。(在这个[视频](https://twitter.com/pilhuhn/status/949737734654124032)中展示了如何绘制 Hilbert 曲线)
### 设计一个好用的握笔器
在上面的第一张图中,绘图笔是细绳子绑到 Y 轴上的。这样绘图也不精确,并且也无法在软件中实现提笔和下笔(如示例中的大黑点)。
因此,我设计了一个更好用的、更精确的握笔器,它使用一个伺服器去提笔和下笔。可以在下面的这张图中看到这个新的、改进后的握笔器,上面视频链接中的 Hilbert 曲线就是使用它绘制的。

*图中的特写镜头就是伺服器臂提起笔的图像*
笔是用一个小夹具固定住的(图上展示的是一个大小为 8 的夹具,它一般用于将线缆固定在墙上)。伺服器臂能够提起笔;当伺服器臂放下来的时候,笔就会被放下来。
#### 驱动伺服器
驱动伺服器是非常简单的:只需要提供位置,伺服器就可以完成所有的工作。
```
#include <Servo.h>
// Servo pin
#define servoData PIN_A1
// Positions
#define PEN_UP 10
#define PEN_DOWN 50
Servo penServo;
void setup() {
// Attach to servo and raise pen
penServo.attach(servoData);
penServo.write(PEN_UP);
}
```
我把伺服器接头连接在 FabScan shield 的 4 号电机上,因此,我将用 1 号模拟针脚。
放下笔也很容易:
```
penServo.write(PEN_DOWN);
```
### 进一步扩展
我的进一步扩展的其中一项就是添加一些终止检测器,但是,我也可以不用它们,进而使用 TMC2130 的 StallGuard 模式来代替。这些检测器也可以用于去实现一个 `home` 命令。
以后,我或许还将添加一个真实的 Z 轴,这样它就可以对一个木头进行铣削雕刻,或者钻一个 PCB 板,或者雕刻一块丙烯酸塑料,或者 … (我还想到了用激光)。
这篇文章最初发布在 [Some Things to Remember](http://pilhuhn.blogspot.com/2018/01/homegrown-xy-plotter-with-arduino.html) 博客中并授权重分发。
---
via: <https://opensource.com/article/18/3/diy-plotter-arduino>
作者:[Heiko W.Rupp](https://opensource.com/users/pilhuhn) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Back in school, there was an HP plotter well hidden in a closet in the science department. I got to play with it for a while and always wanted to have one of my own. Fast forward many, many years. Stepper motors are easily available, I am back into doing stuff with electronics and micro-controllers, and I recently saw someone creating displays with engraved acrylic. This triggered me to finally build my own plotter.

opensource.com
As an old-school 5V guy, I really like the original [Arduino Uno](https://en.wikipedia.org/wiki/Arduino#Official_boards). Here's a list of the other components I used (fyi, I am not affiliated with any of these companies):
[FabScan shield](http://www.watterott.com/de/Arduino-FabScan-Shield): Physically hosts the stepper motor drivers.[SilentStepSticks](http://www.watterott.com/de/SilentStepStick-TMC2130): Motor drivers, as the Arduino on its own can't handle the voltage and current that a stepper motor needs. I am using ones with a Trinamic TMC2130 chip, but in standalone mode for now. Those are replacements for the Pololu 4988, but allow for much quieter operation.[SilentStepStick protectors](http://www.watterott.com/de/SilentStepStick-Protector): Diodes that prevent the turning motor from frying your motor drivers (you want them, believe me).- Stepper motors: I selected NEMA 17 motors with 12V (e.g., models from
[Watterott](http://www.watterott.com/de/Schrittmotor-incl-Anschlusskabel)and[SparkFun](https://www.sparkfun.com/products/9238)). [Linear guide rails](https://www.ebay.de/itm/CNC-Set-12x-600mm-Linearfuhrung-Linear-Guide-Rail-Stage-3D-/322917927292?hash=item4b2f68897c)- Wooden base plate
- Wood screws
- GT2 belt
[GT2 timing pulley](http://www.watterott.com/de/OpenBuilds-GT2-2mm-Aluminium-Timing-Pulley)
This is a work in progress that I created as a personal project. If you are looking for a ready-made kit, then check out the [MaXYposi](https://www.heise.de/make/artikel/MaXYposi-Projektseite-zum-universellen-XY-Portalroboter-von-Make-3676050.html) from German *Make* magazine.
## Hardware setup
As you can see here, I started out much too large. This plotter can't comfortably sit on my desk, but it's okay, as I did it for learning purposes (and, as I have to re-do some things, next time I'll use smaller beams).

opensource.com
The belt is mounted on both sides of the rail and then slung around the motor with some helper wheels:

opensource.com
I've stacked several components on top of the Arduino. The Arduino is on the bottom, above that is the FabScan shield, next is a StepStick protector on motor slots 1+2, and the SilentStepStick is on top. Note that the SCK and SDI pins are not connected.
opensource.com
Be careful to correctly attach the wires to the motor. When in doubt, look at the data sheet or an ohmmeter to figure out which wires belong together.
## Software setup
While software like [grbl](https://github.com/gnea/grbl) can interpret so-called G-codes for tool movement and other things, and I could have just flashed it to the Arduino, I am curious and wanted to better understand things. (My X-Y plotter software is available at [GitHub ](https://github.com/pilhuhn/xy-plotter) and comes without any warranty.)
### The basics
To drive a stepper motor with the StepStick (or compatible) driver, you basically need to send a high and then a low signal to the respective pin. Or in Arduino terms:
```
``````
digitalWrite(stepPin, HIGH);
delayMicroseconds(30);
digitalWrite(stepPin, LOW);
```
Where `stepPin`
is the pin number for the stepper: 3 for motor 1 and 6 for motor 2.
Before the stepper does any work, it must be enabled.
```
````digitalWrite(enPin, LOW);`
Actually, the StepStick knows three states for the pin:
- Low: Motor is enabled
- High: Motor is disabled
- Pin not connected: Motor is enabled but goes into an energy-saving mode after a while
When a motor is enabled, its coils are powered and it keeps its position. It is almost impossible to manually turn its axis. This is good for precision purposes, but it also means that both motors and driver chips are "flooded" with power and will warm up.
And last, but not least, we need a way to determine the plotter's direction:
```
````digitalWrite(dirPin, direction);`
The following table lists the functions and the pins
Function | Motor1 | Motor2 |
---|---|---|
Enable | 2 | 5 |
Direction | 4 | 7 |
Step | 3 | 6 |
Before we can use the pins, we need to set them to `OUTPUT`
mode in the `setup()`
section of the code
```
``````
pinMode(enPin1, OUTPUT);
pinMode(stepPin1, OUTPUT);
pinMode(dirPin1, OUTPUT);
digitalWrite(enPin1, LOW);
```
With this knowledge, we can easily get the stepper to move around:
```
``````
totalRounds = ...
for (int rounds =0 ; rounds < 2*totalRounds; rounds++) {
if (dir==0){ // set direction
digitalWrite(dirPin2, LOW);
} else {
digitalWrite(dirPin2, HIGH);
}
delay(1); // give motors some breathing time
dir = 1-dir; // reverse direction
for (int i=0; i < 6400; i++) {
int t = abs(3200-i) / 200;
digitalWrite(stepPin2, HIGH);
delayMicroseconds(70 + t);
digitalWrite(stepPin2, LOW);
delayMicroseconds(70 + t);
}
}
```
This will make the slider move left and right. This code deals with one stepper, but for an X-Y plotter, we have two axes to consider.
### Command interpreter
I started to implement a simple command interpreter to use path specifications, such as:
```
````"X30|Y30|X-30 Y-30|X-20|Y-20|X20|Y20|X-40|Y-25|X40 Y25`
to describe relative movements in millimeters (1mm equals 80 steps).
The plotter software implements a *continuous mode*, which allows a PC to feed large paths (in chunks) to the plotter. (This how I plotted the Hilbert curve in this [video](https://twitter.com/pilhuhn/status/949737734654124032).)
## Building a better pen holder
In the first image above, the pen was tied to the Y-axis with some metal string. This was not precise and also did not enable the software to raise and lower the hand (this explains the big black dots).
I have since created a better, more precise pen holder that uses a servo to raise and lower the pen. This new, improved holder can be seen in this picture and in the Hilbert curve video linked above.

opensource.com
The pen is attached with a little clamp (the one shown is a size 8 clamp typically used to attach cables to walls). The servo arm can raise the pen; when the arm goes down, gravity will lower the pen.
### Driving the servo
Driving the servo is relatively straightforward: Just provide the position and the servo does all the work.
```
``````
#include <Servo.h>
// Servo pin
#define servoData PIN_A1
// Positions
#define PEN_UP 10
#define PEN_DOWN 50
Servo penServo;
void setup() {
// Attach to servo and raise pen
penServo.attach(servoData);
penServo.write(PEN_UP);
}
```
I am using the servo headers on the Motor 4 place of the FabScan shield, so I've used analog pin 1.
Lowering the pen is as easy as:
```
```` penServo.write(PEN_DOWN);`
## Next steps
One of my next steps will be to add some end detectors, but I may skip them and use the StallGuard mode of the TMC2130 instead. Those detectors can also be used to implement a `home`
command.
And perhaps in the future I'll add a real Z-axis that can hold an engraver to do wood milling, or PCB drilling, or acrylic engraving, or ... (a laser comes to mind as well).
*This was originally published on the Some Things to Remember blog and is reprinted with permission.*
## 1 Comment |
9,715 | 如何在 Linux 系统中结束进程或是中止程序 | https://opensource.com/article/18/5/how-kill-process-stop-program-linux | 2018-06-04T22:14:00 | [
"kill",
"killall"
] | https://linux.cn/article-9715-1.html |
>
> 在 Linux 中有几种使用命令行或图形界面终止一个程序的方式。
>
>
>

进程出错的时候,您可能会想要中止或是杀掉这个进程。在本文中,我们将探索在命令行和图形界面中终止进程或是应用程序,这里我们使用 [gedit](https://wiki.gnome.org/Apps/Gedit) 作为样例程序。
### 使用命令行或字符终端界面
#### Ctrl + C
在命令行中调用 `gedit` (如果您没有使用 `gedit &` 命令)程序的一个问题是 shell 会话被阻塞,没法释放命令行提示符。在这种情况下,`Ctrl + C` (`Ctrl` 和 `C` 的组合键) 会很管用。这会终止 `gedit` ,并且所有的工作都将丢失(除非文件已经被保存)。`Ctrl + C` 会给 `gedit` 发送了 `SIGINT` 信号。这是一个默认终止进程的停止信号,它将指示 shell 停止 `gedit` 的运行,并返回到主函数的循环中,您将返回到提示符。
```
$ gedit
^C
```
#### Ctrl + Z
它被称为挂起字符。它会发送 `SIGTSTP` 信号给进程。它也是一个停止信号,但是默认行为不是杀死进程,而是挂起进程。
下面的命令将会停止(杀死/中断) `gedit` 的运行,并返回到 shell 提示符。
```
$ gedit
^Z
[1]+ Stopped gedit
$
```
一旦进程被挂起(以 `gedit` 为例),将不能在 `gedit` 中写入或做任何事情。而在后台,该进程变成了一个作业,可以使用 `jobs` 命令验证。
```
$ jobs
[1]+ Stopped gedit
```
`jobs` 允许您在单个 shell 会话中控制多个进程。您可以终止,恢复作业,或是根据需要将作业移动到前台或是后台。
让我们在后台恢复 `gedit`,释放提示符以运行其它命令。您可以通过 `bg` 命令来做到,后跟作业 ID(注意上面的 `jobs` 命令显示出来的 `[1]`,这就是作业 ID)。
```
$ bg 1
[1]+ gedit &
```
这和直接使用 `gedit &` 启动程序效果差不多:
```
$ gedit &
```
### 使用 kill
`kill` 命令提供信号的精确控制,允许您通过指定信号名或是信号数字为进程发送信号,后跟进程 ID 或是 PID。
我喜欢 `kill` 命令的一点是它也能够根据作业 ID 控制进程。让我们使用 `gedit &` 命令在后台开启 `gedit` 服务。假设通过 `jobs` 命令我得到了一个 `gedit` 的作业 ID,让我们为 `gedit` 发送 `SIGINT` 信号:
```
$ kill -s SIGINT %1
```
作业 ID 需要使用 `%` 前缀,不然 `kill` 会将其视作 PID。
不明确指定信号,`kill` 仍然可以工作。此时,默认会发送能中断进程的 `SIGTERM` 信号。执行 `kill -l` 可以查看信号名列表,使用 `man kill` 命令阅读手册。
### 使用 killall
如果您不想使用特定的工作 ID 或者 PID,`killall` 允许您使用特定的进程名。中断 `gedit` 最简单的 `killall` 使用方式是:
```
$ killall gedit
```
它将终止所有名为 `gedit` 的进程。和 `kill` 相似,默认发送的信号是 `SIGTERM`。使用 `-I` 选项忽略进程名的大小写。
```
$ gedit &
[1] 14852
$ killall -I GEDIT
[1]+ Terminated gedit
```
查看手册学习更多 `killall` 命令选项(如 `-u`)。
### 使用 xkill
您是否遇见过播放器崩溃,比如 [VLC](https://www.videolan.org/vlc/index.html) 灰屏或挂起?现在你可以像上面一样获得进程的 PID 来杀掉它,或者使用 `xkill` 命令终止应用程序。

`xkill` 允许您使用鼠标关闭窗口。仅需在终端执行 `xkill` 命令,它将会改变鼠标光标为一个 **X** 或是一个小骷髅图标。在你想关闭的进程窗口上点击 **x**。小心使用 `xkill`,如手册描述的一致,它很危险。我已经提醒过您了!
参阅手册,了解上述命令更多信息。您还可以接续探索 `pkill` 和 `pgrep` 命令。
---
via: <https://opensource.com/article/18/5/how-kill-process-stop-program-linux>
作者:[Sachin Patil](https://opensource.com/users/psachin) 选题:[lujun9972](https://github.com/lujun9972) 译者:[CYLeft](https://github.com/CYLeft) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | When a process misbehaves, you might sometimes want to terminate or kill it. In this post, we'll explore a few ways to terminate a process or an application from the command line as well as from a graphical interface, using [gedit](https://wiki.gnome.org/Apps/Gedit) as a sample application.
## Using the command line/termination characters
### Ctrl + C
One problem invoking `gedit`
from the command line (if you are not using `gedit &`
) is that it will not free up the prompt, so that shell session is blocked. In such cases, Ctrl+C (the Control key in combination with 'C') comes in handy. That will terminate `gedit`
and all work will be lost (unless the file was saved). Ctrl+C sends the
signal to [SIGINT](http://man7.org/linux/man-pages/man7/signal.7.html)`gedit`
. This is a stop signal whose default action is to terminate the process. It instructs the shell to stop `gedit`
and return to the main loop, and you'll get the prompt back.
```
``````
$ gedit
^C
```
### Ctrl + Z
This is called a *suspend character*. It sends a
signal to process. This is also a stop signal, but the default action is not to kill but to suspend the process.[SIGTSTP](http://man7.org/linux/man-pages/man7/signal.7.html)
It will stop (kill/terminate) `gedit`
and return the shell prompt.
```
``````
$ gedit
^Z
[1]+ Stopped gedit
$
```
Once the process is suspended (in this case, `gedit`
), it is not possible to write or do anything in `gedit`
. In the background, the process becomes a *job*. This can be verified by the `jobs`
command.
```
``````
$ jobs
[1]+ Stopped gedit
```
`jobs`
allows you to control multiple processes within a single shell session. You can stop, resume, and move jobs to the background or foreground as needed.
Let's resume `gedit`
in the background and free up a prompt to run other commands. You can do this using the `bg`
command, followed by job ID (notice `[1]`
from the output of `jobs`
above. `[1]`
is the job ID).
```
``````
$ bg 1
[1]+ gedit &
```
This is similar to starting `gedit`
with `&,`
:
```
```` $ gedit &`
## Using *kill*
`kill`
allows fine control over signals, enabling you to signal a process by specifying either a signal name or a signal number, followed by a process ID, or PID.
What I like about `kill`
is that it can also work with job IDs. Let's start `gedit`
in the background using `gedit &`
. Assuming I have a job ID of `gedit`
from the `jobs`
command, let's send `SIGINT`
to `gedit`
:
```
```` $ kill -s SIGINT %1`
Note that the job ID should be prefixed with `%`
, or `kill`
will consider it a PID.
`kill`
can work without specifying a signal explicitly. In that case, the default action is to send `SIGTERM`
, which will terminate the process. Execute `kill -l`
to list all signal names, and use the `man kill`
command to read the man page.
## Using *killall*
If you don't want to specify a job ID or PID, `killall`
lets you specify a process by name. The simplest way to terminate `gedit`
using `killall`
is:
```
```` $ killall gedit`
This will kill all the processes with the name `gedit`
. Like `kill`
, the default signal is `SIGTERM`
. It has the option to ignore case using `-I`
:
```
``````
$ gedit &
[1] 14852
$ killall -I GEDIT
[1]+ Terminated gedit
```
To learn more about various flags provided by `killall`
(such as `-u`
, which allows you to kill user-owned processes) check the man page (`man killall`
)
## Using *xkill*
Have you ever encountered an issue where a media player, such as [VLC](https://www.videolan.org/vlc/index.html), grayed out or hung? Now you can find the PID and kill the application using one of the commands listed above or use `xkill`
.
`xkill`
allows you to kill a window using a mouse. Simply execute `xkill`
in a terminal, which should change the mouse cursor to an **x** or a tiny skull icon. Click **x** on the window you want to close. Be careful using `xkill`
, though—as its man page explains, it can be dangerous. You have been warned!
Refer to the man page of each command for more information. You can also explore commands like `pkill`
and `pgrep`
.
## 5 Comments |
9,716 | 3 个 Python 模板库比较 | https://opensource.com/resources/python/template-libraries | 2018-06-05T08:38:00 | [
"Python",
"模板"
] | /article-9716-1.html |
>
> 你的下一个 Python 项目需要一个模板引擎来自动生成 HTML 吗?这有几种选择。
>
>
>

在我的日常工作中,我花费大量的时间将各种来源的数据转化为可读的信息。虽然很多时候这只是电子表格或某种类型的图表或其他数据可视化的形式,但也有其他时候,将数据以书面形式呈现是有意义的。
但我的头疼地方就是复制和粘贴。如果你要将数据从源头移动到标准化模板,则不应该复制和粘贴。这很容易出错,说实话,这会浪费你的时间。
因此,对于我定期发送的任何遵循一个共同的模式的信息,我倾向于找到某种方法来自动化至少一部分信息。也许这涉及到在电子表格中创建一些公式,一个快速 shell 脚本或其他解决方案,以便使用从外部源提取的信息自动填充模板。
但最近,我一直在探索 Python 模板来完成从其他数据集创建报告和图表的大部分工作。
Python 模板引擎非常强大。我的简化报告创建的使用案例仅仅触及了它的皮毛。许多开发人员正在利用这些工具来构建完整的 web 应用程序和内容管理系统。但是,你并不需要有一个复杂的 web 应用程序才能使用 Python 模板工具。
### 为什么选择模板?
每个模板工具都不甚相同,你应该阅读文档以了解其确切的用法。但让我们创建一个假设的例子。假设我想创建一个简短的页面,列出我最近编写的所有 Python 主题。就像这样:
```
<html>
<head>
<title>My Python articles</title>
</head>
<body>
<p>These are some of the things I have written about Python:</p>
<ul>
<li>Python GUIs</li>
<li>Python IDEs</li>
<li>Python web scrapers</li>
</ul>
</body>
</html>
```
当它仅仅是这三个项目时,维护它是很简单的。但是当我想添加第四个、第五个或第六十七个时会发生什么?我可以从包含我所有页面列表的 CSV 文件或其他数据文件生成它,而不是手动编码此页面吗?我可以轻松地为我写的每个主题创建重复内容吗?我可以以编程方式更改每个页面上的文本标题吗?这就是模板引擎可以发挥作用的地方。
有许多不同的选择,今天我将与你其中分享三个,顺序不分先后:[Mako](http://www.makotemplates.org/)、 [Jinja2](http://jinja.pocoo.org/) 和 [Genshi](https://genshi.edgewall.org/)。
### Mako
[Mako](http://www.makotemplates.org/) 是以 MIT 许可证发布的 Python 模板工具,专为快速展现而设计的(与 Jinja2 不同)。Reddit 已经使用 Mako 来展现他们的网页,它同时也是 Pyramid 和 Pylons 等 web 框架的默认模板语言。它相当简单且易于使用。你可以使用几行代码来设计模板;支持 Python 2.x 和 3.x,它是一个功能强大且功能丰富的工具,具有[良好的文档](http://docs.makotemplates.org/en/latest/),这一点我认为是必须的。其功能包括过滤器、继承、可调用块和内置缓存系统,这些系统可以被大型或复杂的 web 项目导入。
### Jinja2
Jinja2 是另一个快速且功能全面的选项,可用于 Python 2.x 和 3.x,遵循 BSD 许可证。Jinja2 从功能角度与 Mako 有很多重叠,因此对于新手来说,你在两者之间的选择可能会归结为你喜欢的格式化风格。Jinja2 还将模板编译为字节码,并具有 HTML 转义、沙盒、模板继承和模板沙盒部分的功能。其用户包括 Mozilla、 SourceForge、 NPR、 Instagram 等,并且还具有[强大的文档](http://jinja.pocoo.org/docs/2.10/)。与 Mako 在模板内部使用 Python 逻辑不同的是,Jinja2 使用自己的语法。
### Genshi
[Genshi](https://genshi.edgewall.org/) 是我会提到的第三个选择。它是一个 XML 工具,具有强大的模板组件,所以如果你使用的数据已经是 XML 格式,或者你需要使用网页以外的格式,Genshi 可能成为你的一个很好的解决方案。HTML 基本上是一种 XML(好吧,不是精确的,但这超出了本文的范围,有点卖弄学问了),因此格式化它们非常相似。由于我通常使用的很多数据都是 XML 或其他类型的数据,因此我非常喜欢使用我可以用于多种事物的工具。
发行版目前仅支持 Python 2.x,尽管 Python 3 支持存在于主干中,但我提醒你,它看起来并没有得到有效的开发。Genshi 遵循 BSD 许可证提供。
### 示例
因此,在上面的假设示例中,我不会每次写新主题时都更新 HTML 文件,而是通过编程方式对其进行更新。我可以创建一个模板,如下所示:
```
<html>
<head>
<title>My Python articles</title>
</head>
<body>
<p>These are some of the things I have written about Python:</p>
<ul>
%for topic in topics:
<li>${topic}</li>
%endfor
</ul>
</body>
</html>
```
然后我可以使用我的模板库来迭代每个主题,比如使用 Mako,像这样:
```
from mako.template import Template
mytemplate = Template(filename='template.txt')
print(mytemplate.render(topics=("Python GUIs","Python IDEs","Python web scrapers")))
```
当然,在现实世界的用法中,我不会将这些内容手动地列在变量中,而是将它们从外部数据源(如数据库或 API)中提取出来。
这些不是仅有的 Python 模板引擎。如果你正在开始创建一个将大量使用模板的新项目,那么你考虑的可能不仅仅是这三种选择。在 [Python 维基](https://wiki.python.org/moin/Templating)上查看更全面的列表,以获得更多值得考虑的项目。
---
via: <https://opensource.com/resources/python/template-libraries>
作者:[Jason Baker](https://opensource.com/users/jason-baker) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
9,717 | Linux vs. Unix:有什么不同? | https://opensource.com/article/18/5/differences-between-linux-and-unix | 2018-06-05T22:16:45 | [
"Unix",
"Linux"
] | https://linux.cn/article-9717-1.html |
>
> 深入了解这两个有许多共同的传统和相同的目标的操作系统之间的不同。
>
>
>

如果你是位二、三十岁的软件开发人员,那么你已经成长在一个由 Linux 主导的世界。数十年来,它一直是数据中心的重要参与者,尽管很难找到明确的操作系统市场份额报告,但 Linux 的数据中心操作系统份额可能高达 70%,而 Windows 及其变体几乎涵盖了所有剩余的百分比。使用任何主流公共云服务的开发人员都可以预期目标系统会运行 Linux。近些年来,随着 Android 和基于 Linux 的嵌入式系统在智能手机、电视、汽车和其他设备中的应用,Linux 已经随处可见。
即便如此,大多数软件开发人员,甚至是那些在这场历史悠久的 “Linux 革命”中长大的软件开发人员,也都听过说 Unix。它听起来与 Linux 相似,你可能已经听到人们互换使用这些术语。或者你也许听说过 Linux 被称为“类 Unix ”操作系统。
那么,Unix 是什么?漫画中提到了像巫师一样留着“灰胡子”,坐在发光的绿色屏幕后面,写着 C 代码和 shell 脚本,由老式的、滴灌的咖啡提供动力。但是,Unix 的历史比上世纪 70 年代那些留着胡子的 C 程序员要丰富得多。虽然详细介绍 Unix 历史和 “Unix 与 Linux” 比较的文章比比皆是,但本文将提供高级背景和列出这些互补世界之间的主要区别。
### Unix 的起源
Unix 的历史始于 20 世纪 60 年代后期的 AT&T 贝尔实验室,有一小组程序员希望为 PDP-7 编写一个多任务、多用户操作系统。这个贝尔实验室研究机构的团队中最著名的两名成员是 Ken Thompson 和 Dennis Ritchie。尽管 Unix 的许多概念都是其前身([Multics](https://en.wikipedia.org/wiki/Multics))的衍生物,但 Unix 团队早在 70 年代就决定用 C 语言重写这个小型操作系统,这是将 Unix 与其他操作系统区分开来的原因。当时,操作系统很少,更不要说可移植的操作系统。相反,由于它们的设计和底层语言的本质,操作系统与他们所编写的硬件平台紧密相关。而通过 C 语言重构 Unix、Unix 现在可以移植到许多硬件体系结构中。
除了这种新的可移植性,之所以使得 Unix 迅速扩展到贝尔实验室以外的其他研究和学术机构甚至商业用途,是因为操作系统设计原则的几个关键点吸引了用户和程序员们。首先是 Ken Thompson 的 [Unix 哲学](https://en.wikipedia.org/wiki/Unix_philosophy)成为模块化软件设计和计算的强大模型。Unix 哲学推荐使用小型的、专用的程序组合起来完成复杂的整体任务。由于 Unix 是围绕文件和管道设计的,因此这种“管道”模式的输入和输出程序的组合成一组线性的输入操作,现在仍然流行。事实上,目前的云功能即服务(FaaS)或无服务器计算模型要归功于 Unix 哲学的许多传统。
### 快速增长和竞争
到 70 年代末和 80 年代,Unix 成为了一个操作系统家族的起源,它遍及了研究和学术机构以及日益增长的商业 Unix 操作系统业务领域。Unix 不是开源软件,Unix 源代码可以通过与它的所有者 AT&T 达成协议来获得许可。第一个已知的软件许可证于 1975 年出售给<ruby> 伊利诺伊大学 <rt> University of Illinois </rt></ruby>。
Unix 在学术界迅速发展,在 Ken Thompson 在上世纪 70 年代的学术假期间,伯克利成为一个重要的活动中心。通过在伯克利的各种有关 Unix 的活动,Unix 软件的一种新的交付方式诞生了:<ruby> 伯克利软件发行版 <rt> Berkeley Software Distribution </rt></ruby>(BSD)。最初,BSD 不是 AT&T Unix 的替代品,而是一种添加类似于附加软件和功能。在 1979 年, 2BSD(第二版伯克利软件发行版)出现时,伯克利研究生 Bill Joy 已经添加了现在非常有名的程序,例如 `vi` 和 C shell(`/bin/csh`)。
除了成为 Unix 家族中最受欢迎的分支之一的 BSD 之外,Unix 的商业产品的爆发贯穿了二十世纪八、九十年代,其中包括 HP-UX、IBM 的 AIX、 Sun 的 Solaris、 Sequent 和 Xenix 等。随着分支从根源头发展壮大,“[Unix 战争](https://en.wikipedia.org/wiki/Unix_wars)”开始了,标准化成为社区的新焦点。POSIX 标准诞生于 1988 年,其他标准化后续工作也开始通过 The Open Group 在 90 年代到来。
在此期间,AT&T 和 Sun 发布了 System V Release 4(SVR4),许多商业供应商都采用了这一版本。另外,BSD 系列操作系统多年来一直在增长,最终一些开源的变体在现在熟悉的 [BSD许可证](https://en.wikipedia.org/wiki/BSD_licenses)下发布。这包括 FreeBSD、 OpenBSD 和 NetBSD,每个在 Unix 服务器行业的目标市场略有不同。这些 Unix 变体今天仍然有一些在使用,尽管人们已经看到它们的服务器市场份额缩小到个位数字(或更低)。在当今的所有 Unix 系统中,BSD 可能拥有最大的安装基数。另外,每台 Apple Mac 硬件设备从历史的角度看都可以算做是 BSD ,这是因为 OS X(现在是 macOS)操作系统是 BSD 衍生产品。
虽然 Unix 的全部历史及其学术和商业变体可能需要更多的篇幅,但为了我们文章的重点,让我们来讨论 Linux 的兴起。
### 进入 Linux
今天我们所说的 Linux 操作系统实际上是 90 年代初期的两个努力的结合。Richard Stallman 希望创建一个真正的自由而开放源代码的专有 Unix 系统的替代品。他正在以 GNU 的名义开发实用程序和程序,这是一种递归的说法,意思是“GNU‘s not Unix!”。虽然当时有一个内核项目正在进行,但事实证明这是一件很困难的事情,而且没有内核,自由和开源操作系统的梦想无法实现。而这是 Linus Torvald 的工作 —— 生产出一种可工作和可行的内核,他称之为 Linux -- 它将整个操作系统带入了生活。鉴于 Linus 使用了几个 GNU 工具(例如 GNU 编译器集合,即 [GCC](https://en.wikipedia.org/wiki/GNU_Compiler_Collection)),GNU 工具和 Linux 内核的结合是完美的搭配。
Linux 发行版采用了 GNU 的组件、Linux 内核、MIT 的 X-Windows GUI 以及可以在开源 BSD 许可下使用的其它 BSD 组件。像 Slackware 和 Red Hat 这样的发行版早期的流行给了 20 世纪 90 年代的“普通 PC 用户”一个进入 Linux 操作系统的机会,并且让他们在工作和学术生活中可以使用许多 Unix 系统特有的功能和实用程序。
由于所有 Linux 组件都是自由和开放的源代码,任何人都可以通过一些努力来创建一个 Linux 发行版,所以不久后发行版的总数达到了数百个。今天,[distrowatch.com](https://distrowatch.com/) 列出了 312 种各种形式的独特的 Linux 发行版。当然,许多开发人员通过云提供商或使用流行的免费发行版来使用 Linux,如 Fedora、 Canonical 的 Ubuntu、 Debian、 Arch Linux、 Gentoo 和许多其它变体。随着包括 IBM 在内的许多企业从专有 Unix 迁移到 Linux 上并提供了中间件和软件解决方案,商用 Linux 产品在自由和开源组件之上提供支持变得可行。红帽公司围绕 Red Hat Enterprise Linux(红帽企业版 Linux) 建立了商业支持模式,德国供应商 SUSE 使用 SUSE Linux Enterprise Server(SLES)也提供了这种模式。
### 比较 Unix 和 Linux
到目前为止,我们已经了解了 Unix 的历史以及 Linux 的兴起,以及 GNU/自由软件基金会对 Unix 的自由和开源替代品的支持。让我们来看看这两个操作系统之间的差异,它们有许多共同的传统和许多相同的目标。
从用户体验角度来看,两者差不多!Linux 的很大吸引力在于操作系统在许多硬件体系结构(包括现代 PC)上的可用性以及类似使用 Unix 系统管理员和用户熟悉的工具的能力。
由于 POSIX 的标准和合规性,在 Unix 上编写的软件可以针对 Linux 操作系统进行编译,通常只有少量的移植工作量。在很多情况下,Shell 脚本可以在 Linux 上直接使用。虽然一些工具在 Unix 和 Linux 之间有着略微不同的标志或命令行选项,但许多工具在两者上都是相同的。
一方面要注意的是,macOS 硬件和操作系统作为主要针对 Linux 的开发平台的流行可能归因于类 BSD 的 macOS 操作系统。许多用于 Linux 系统的工具和脚本可以在 macOS 终端内轻松工作。Linux 上的许多开源软件组件都可以通过 [Homebrew](https://brew.sh/) 等工具轻松获得。
Linux 和 Unix 之间的其他差异主要与许可模式有关:开源与专有许可软件。另外,在 Unix 发行版中缺少一个影响软件和硬件供应商的通用内核。对于 Linux,供应商可以为特定的硬件设备创建设备驱动程序,并期望在合理的范围内它可以在大多数发行版上运行。由于 Unix 家族的商业和学术分支,供应商可能必须为 Unix 的变体编写不同的驱动程序,并且需要许可和其他相关的权限才能访问 SDK 或软件的分发模型,以跨越多个二进制设备驱动程序的 Unix 变体。
随着这两个社区在过去十年中的成熟,Linux 的许多优点已经在 Unix 世界中被采用。当开发人员需要来自不属于 Unix 的 GNU 程序的功能时,许多 GNU 实用程序可作为 Unix 系统的附件提供。例如,IBM 的 AIX 为 Linux 应用程序提供了一个 AIX Toolbox,其中包含数百个 GNU 软件包(如 Bash、 GCC、 OpenLDAP 和许多其他软件包),这些软件包可添加到 AIX 安装包中以简化 Linux 和基于 Unix 的 AIX 系统之间的过渡。
专有的 Unix 仍然活着而且还不错,许多主要供应商承诺支持其当前版本,直到 2020 年。不言而喻,Unix 还会在可预见的将来一直出现。此外,Unix 的 BSD 分支是开源的,而 NetBSD、 OpenBSD 和 FreeBSD 都有强大的用户基础和开源社区,它们可能不像 Linux 那样显眼或活跃,但在最近的服务器报告中,在 Web 服务等领域它们远高于专有 Unix 的数量。
Linux 已经显示出其超越 Unix 的显著优势在于其在大量硬件平台和设备上的可用性。<ruby> 树莓派 <rt> Raspberry Pi </rt></ruby>受到业余爱好者的欢迎,它是由 Linux 驱动的,为运行 Linux 的各种物联网设备打开了大门。我们已经提到了 Android 设备,汽车(包括 Automotive Grade Linux)和智能电视,其中 Linux 占有巨大的市场份额。这个星球上的每个云提供商都提供运行 Linux 的虚拟服务器,而且当今许多最受欢迎的原生云架构都是基于 Linux 的,无论你是在谈论容器运行时还是 Kubernetes,或者是许多正在流行的无服务器平台。
其中一个最显著的代表 Linux 的优势是近年来微软的转变。如果你十年前告诉软件开发人员,Windows 操作系统将在 2016 年“运行 Linux”,他们中的大多数人会歇斯底里地大笑。 但是 Windows Linux 子系统(WSL)的存在和普及,以及最近宣布的诸如 Docker 的 Windows 移植版,包括 LCOW(Windows 上的 Linux 容器)支持等功能都证明了 Linux 在整个软件世界中所产生的影响 —— 而且显然还会继续存在。
---
via: <https://opensource.com/article/18/5/differences-between-linux-and-unix>
作者:[Phil Estes](https://opensource.com/users/estesp) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | If you are a software developer in your 20s or 30s, you've grown up in a world dominated by Linux. It has been a significant player in the data center for decades, and while it's hard to find definitive operating system market share reports, Linux's share of data center operating systems could be as high as 70%, with Windows variants carrying nearly all the remaining percentage. Developers using any major public cloud can expect the target system will run Linux. Evidence that Linux is everywhere has grown in recent years when you add in Android and Linux-based embedded systems in smartphones, TVs, automobiles, and many other devices.
Even so, most software developers, even those who have grown up during this venerable "Linux revolution" have at least heard of Unix. It sounds similar to Linux, and you've probably heard people use these terms interchangeably. Or maybe you've heard Linux called a "Unix-like" operating system.
So, what is this Unix? The caricatures speak of wizard-like "graybeards" sitting behind glowing green screens, writing C code and shell scripts, powered by old-fashioned, drip-brewed coffee. But Unix has a much richer history beyond those bearded C programmers from the 1970s. While articles detailing the history of Unix and "Unix vs. Linux" comparisons abound, this article will offer a high-level background and a list of major differences between these complementary worlds.
## Unix's beginnings
The history of Unix begins at AT&T Bell Labs in the late 1960s with a small team of programmers looking to write a multi-tasking, multi-user operating system for the PDP-7. Two of the most notable members of this team at the Bell Labs research facility were Ken Thompson and Dennis Ritchie. While many of Unix's concepts were derivative of its predecessor ([Multics](https://en.wikipedia.org/wiki/Multics)), the Unix team's decision early in the 1970s to rewrite this small operating system in the C language is what separated Unix from all others. At the time, operating systems were rarely, if ever, portable. Instead, by nature of their design and low-level source language, operating systems were tightly linked to the hardware platform for which they had been authored. By refactoring Unix on the C programming language, Unix could now be ported to many hardware architectures.
In addition to this new portability, which allowed Unix to quickly expand beyond Bell Labs to other research, academic, and even commercial uses, several key of the operating system's design tenets were attractive to users and programmers. For one, Ken Thompson's [Unix philosophy](https://en.wikipedia.org/wiki/Unix_philosophy) became a powerful model of modular software design and computing. The Unix philosophy recommended utilizing small, purpose-built programs in combination to do complex overall tasks. Since Unix was designed around files and pipes, this model of "piping" inputs and outputs of programs together into a linear set of operations on the input is still in vogue today. In fact, the current cloud serverless computing model owes much of its heritage to the Unix philosophy.
## Rapid growth and competition
Through the late 1970s and 80s, Unix became the root of a family tree that expanded across research, academia, and a growing commercial Unix operating system business. Unix was not open source software, and the Unix source code was licensable via agreements with its owner, AT&T. The first known software license was sold to the University of Illinois in 1975.
Unix grew quickly in academia, with Berkeley becoming a significant center of activity, given Ken Thompson's sabbatical there in the '70s. With all the activity around Unix at Berkeley, a new delivery of Unix software was born: the Berkeley Software Distribution, or BSD. Initially, BSD was not an alternative to AT&T's Unix, but an add-on with additional software and capabilities. By the time 2BSD (the Second Berkeley Software Distribution) arrived in 1979, Bill Joy, a Berkeley grad student, had added now-famous programs such as `vi`
and the [C shell](https://opensource.com/article/20/8/tcsh) (/bin/csh).
In addition to BSD, which became one of the most popular branches of the Unix family, Unix's commercial offerings exploded through the 1980s and into the '90s with names like HP-UX, IBM's AIX, Sun's Solaris, Sequent, and Xenix. As the branches grew from the original root, the "[Unix wars](https://en.wikipedia.org/wiki/Unix_wars)" began, and standardization became a new focus for the community. The POSIX standard was born in 1988, as well as other standardization follow-ons via The Open Group into the 1990s.
Around this time AT&T and Sun released System V Release 4 (SVR4), which was adopted by many commercial vendors. Separately, the [BSD family](https://opensource.com/article/20/5/furybsd-linux) of operating systems had grown over the years, leading to some open source variations that were released under the now-familiar [BSD license](https://en.wikipedia.org/wiki/BSD_licenses). This included FreeBSD, OpenBSD, and NetBSD, each with a slightly different target market in the Unix server industry. These Unix variants continue to have some usage today, although many have seen their server market share dwindle into the single digits (or lower). BSD may have the largest install base of any modern Unix system today. Also, every Apple Mac hardware unit shipped in recent history can be claimed by BSD, as its OS X (now macOS) operating system is a BSD-derivative.
While the full history of Unix and its academic and commercial variants could take many more pages, for the sake of our article focus, let's move on to the rise of Linux.
## Enter Linux
What we call the Linux operating system today is really the combination of two efforts from the early 1990s. Richard Stallman was looking to create a truly free and open source alternative to the proprietary Unix system. He was working on the utilities and programs under the name GNU, a recursive acronym meaning "GNU's not Unix!" Although there was a kernel project underway, it turned out to be difficult going, and without a kernel, the free and open source operating system dream could not be realized. It was Linus Torvald's work—producing a working and viable kernel that he called Linux—that brought the complete operating system to life. Given that Linus was using several GNU tools (e.g., the GNU Compiler Collection, or [GCC](https://en.wikipedia.org/wiki/GNU_Compiler_Collection)), the marriage of the GNU tools and the Linux kernel was a perfect match.
Linux distributions came to life with the components of GNU, the Linux kernel, MIT's X-Windows GUI, and other BSD components that could be used under the open source BSD license. The early popularity of distributions like Slackware and then Red Hat gave the "common PC user" of the 1990s access to the Linux operating system and, with it, many of the proprietary Unix system capabilities and utilities they used in their work or academic lives.
Because of the free and open source standing of all the Linux components, anyone could create a Linux distribution with a bit of effort, and soon the total number of distros reached into the hundreds. Of course, many developers utilize Linux either via cloud providers or by using popular free distributions like Fedora, Canonical's Ubuntu, Debian, Arch Linux, Gentoo, and many other variants. Commercial Linux offerings, which provide support on top of the free and open source components, became viable as many enterprises, including IBM, migrated from proprietary Unix to offering middleware and software solutions atop Linux. Red Hat built a model of commercial support around Red Hat Enterprise Linux, as did German provider SUSE with SUSE Linux Enterprise Server (SLES).
## Comparing Unix and Linux
So far, we've looked at the history of Unix and the rise of Linux and the GNU/Free Software Foundation underpinnings of a free and open source alternative to Unix. Let's examine the differences between these two operating systems that share much of the same heritage and many of the same goals.
From a user experience perspective, not very much is different! Much of the attraction of Linux was the operating system's availability across many hardware architectures (including the modern PC) and ability to use tools familiar to Unix system administrators and users.
Because of [POSIX](https://opensource.com/article/19/7/what-posix-richard-stallman-explains) standards and compliance, software written on Unix could be compiled for a Linux operating system with a usually limited amount of porting effort. Shell scripts could be used directly on Linux in many cases. While some tools had slightly different flag/command-line options between Unix and Linux, many operated the same on both.
One side note is that the popularity of the macOS hardware and operating system as a platform for development that mainly targets Linux may be attributed to the BSD-like macOS operating system. Many tools and scripts meant for a Linux system work easily within the macOS terminal. Many open source software components available on Linux are easily available through tools like [Homebrew](https://brew.sh/).
The remaining differences between Linux and Unix are mainly related to the licensing model: open source vs. proprietary, licensed software. Also, the lack of a common kernel within Unix distributions has implications for software and hardware vendors. For Linux, a vendor can create a device driver for a specific hardware device and expect that, within reason, it will operate across most distributions. Because of the commercial and academic branches of the Unix tree, a vendor might have to write different drivers for variants of Unix and have licensing and other concerns related to access to an SDK or a distribution model for the software as a binary device driver across many Unix variants.
As both communities have matured over the past decade, many of the advancements in Linux have been adopted in the Unix world. Many GNU utilities were made available as add-ons for Unix systems where developers wanted features from GNU programs that aren't part of Unix. For example, IBM's AIX offered an AIX Toolbox for Linux Applications with hundreds of GNU software packages (like Bash, GCC, OpenLDAP, and many others) that could be added to an AIX installation to ease the transition between Linux and Unix-based AIX systems.
Proprietary Unix is still alive and well and, with many major vendors promising support for their current releases well into the 2020s, it goes without saying that Unix will be around for the foreseeable future. Also, the BSD branch of the Unix tree is open source, and NetBSD, OpenBSD, and FreeBSD all have strong user bases and open source communities that may not be as visible or active as Linux, but are holding their own in recent server share reports, with well above the proprietary Unix numbers in areas like web serving.
Where Linux has shown a significant advantage over proprietary Unix is in its availability across a vast number of hardware platforms and devices. The Raspberry Pi, popular with hobbyists and enthusiasts, is Linux-driven and has opened the door for an entire spectrum of IoT devices running Linux. We've already mentioned Android devices, autos (with Automotive Grade Linux), and smart TVs, where Linux has large market share. Every cloud provider on the planet offers virtual servers running Linux, and many of today's most popular cloud-native stacks are Linux-based, whether you're talking about container runtimes or Kubernetes or many of the serverless platforms that are gaining popularity.
One of the most revealing representations of Linux's ascendancy is Microsoft's transformation in recent years. If you told software developers a decade ago that the Windows operating system would "run Linux" in 2016, most of them would have laughed hysterically. But the existence and popularity of the Windows Subsystem for Linux (WSL), as well as more recently announced capabilities like the Windows port of Docker, including LCOW (Linux containers on Windows) support, are evidence of the impact that Linux has had—and clearly will continue to have—across the software world.
*This article was originally published in May 2018 and has been updated by the editor.*
## 8 Comments |
9,718 | 使用 GNU Parallel 提高 Linux 命令行执行效率 | https://opensource.com/article/18/5/gnu-parallel | 2018-06-07T08:16:00 | [
"并行",
"Parallel"
] | https://linux.cn/article-9718-1.html |
>
> 将您的计算机变成一个多任务的动力室。
>
>
>

你是否有过这种感觉,你的主机运行速度没有预期的那么快?我也曾经有过这种感觉,直到我发现了 GNU Parallel。
GNU Parallel 是一个 shell 工具,可以并行执行任务。它可以解析多种输入,让你可以同时在多份数据上运行脚本或命令。你终于可以使用全部的 CPU 了!
如果你用过 `xargs`,上手 Parallel 几乎没有难度。如果没有用过,这篇教程会告诉你如何使用,同时给出一些其它的用例。
### 安装 GNU Parallel
GNU Parallel 很可能没有预装在你的 Linux 或 BSD 主机上,你可以从软件源中安装。以 Fedora 为例:
```
$ sudo dnf install parallel
```
对于 NetBSD:
```
# pkg_add parallel
```
如果各种方式都不成功,请参考[项目主页](https://www.gnu.org/software/parallel)。
### 从串行到并行
正如其名称所示,Parallel 的强大之处是以并行方式执行任务;而我们中不少人平时仍然以串行方式运行任务。
当你对多个对象执行某个命令时,你实际上创建了一个任务队列。一部分对象可以被命令处理,剩余的对象需要等待,直到命令处理它们。这种方式是低效的。只要数据够多,总会形成任务队列;但与其只使用一个任务队列,为何不使用多个更小规模的任务队列呢?
假设你有一个图片目录,你希望将目录中的图片从 JEEG 格式转换为 PNG 格式。有多种方法可以完成这个任务。可以手动用 GIMP 打开每个图片,输出成新格式,但这基本是最差的选择,费时费力。
上述方法有一个漂亮且简洁的变种,即基于 shell 的方案:
```
$ convert 001.jpeg 001.png
$ convert 002.jpeg 002.png
$ convert 003.jpeg 003.png
... 略 ...
```
对于初学者而言,这是一个不小的转变,而且看起来是个不小的改进。不再需要图像界面和不断的鼠标点击,但仍然是费力的。
进一步改进:
```
$ for i in *jpeg; do convert $i $i.png ; done
```
至少,这一步设置好任务执行,让你节省时间去做更有价值的事情。但问题来了,这仍然是串行操作;一张图片转换完成后,队列中的下一张进行转换,依此类推直到全部完成。
使用 Parallel:
```
$ find . -name "*jpeg" | parallel -I% --max-args 1 convert % %.png
```
这是两条命令的组合:`find` 命令,用于收集需要操作的对象;`parallel` 命令,用于对象排序并确保每个对象按需处理。
* `find . -name "*jpeg"` 查找当前目录下以 `jpeg` 结尾的所有文件。
* `parallel` 调用 GNU Parallel。
* `-I%` 创建了一个占位符 `%`,代表 `find` 传递给 Parallel 的内容。如果不使用占位符,你需要对 `find` 命令的每一个结果手动编写一个命令,而这恰恰是你想要避免的。
* `--max-args 1` 给出 Parallel 从队列获取新对象的速率限制。考虑到 Parallel 运行的命令只需要一个文件输入,这里将速率限制设置为 1。假如你需要执行更复杂的命令,需要两个文件输入(例如 `cat 001.txt 002.txt > new.txt`),你需要将速率限制设置为 2。
* `convert % %.png` 是你希望 Parallel 执行的命令。
组合命令的执行效果如下:`find` 命令收集所有相关的文件信息并传递给 `parallel`,后者(使用当前参数)启动一个任务,(无需等待任务完成)立即获取参数行中的下一个参数(LCTT 译注:管道输出的每一行对应 `parallel` 的一个参数,所有参数构成参数行);只要你的主机没有瘫痪,Parallel 会不断做这样的操作。旧任务完成后,Parallel 会为分配新任务,直到所有数据都处理完成。不使用 Parallel 完成任务大约需要 10 分钟,使用后仅需 3 至 5 分钟。
### 多个输入
只要你熟悉 `find` 和 `xargs` (整体被称为 GNU 查找工具,或 `findutils`),`find` 命令是一个完美的 Parallel 数据提供者。它提供了灵活的接口,大多数 Linux 用户已经很习惯使用,即使对于初学者也很容易学习。
`find` 命令十分直截了当:你向 `find` 提供搜索路径和待查找文件的一部分信息。可以使用通配符完成模糊搜索;在下面的例子中,星号匹配任何字符,故 `find` 定位(文件名)以字符 `searchterm` 结尾的全部文件:
```
$ find /path/to/directory -name "*searchterm"
```
默认情况下,`find` 逐行返回搜索结果,每个结果对应 1 行:
```
$ find ~/graphics -name "*jpg"
/home/seth/graphics/001.jpg
/home/seth/graphics/cat.jpg
/home/seth/graphics/penguin.jpg
/home/seth/graphics/IMG_0135.jpg
```
当使用管道将 `find` 的结果传递给 `parallel` 时,每一行中的文件路径被视为 `parallel` 命令的一个参数。另一方面,如果你需要使用命令处理多个参数,你可以改变队列数据传递给 `parallel` 的方式。
下面先给出一个不那么实际的例子,后续会做一些修改使其更加有意义。如果你安装了 GNU Parallel,你可以跟着这个例子操作。
假设你有 4 个文件,按照每行一个文件的方式列出,具体如下:
```
$ echo ada > ada ; echo lovelace > lovelace
$ echo richard > richard ; echo stallman > stallman
$ ls -1
ada
lovelace
richard
stallman
```
你需要将两个文件合并成第三个文件,后者同时包含前两个文件的内容。这种情况下,Parallel 需要访问两个文件,使用 `-I%` 变量的方式不符合本例的预期。
Parallel 默认情况下读取 1 个队列对象:
```
$ ls -1 | parallel echo
ada
lovelace
richard
stallman
```
现在让 Parallel 每个任务使用 2 个队列对象:
```
$ ls -1 | parallel --max-args=2 echo
ada lovelace
richard stallman
```
现在,我们看到行已经并合并;具体而言,`ls -1` 的两个查询结果会被同时传送给 Parallel。传送给 Parallel 的参数涉及了任务所需的 2 个文件,但目前还只是 1 个有效参数:(对于两个任务分别为)“ada lovelace” 和 “richard stallman”。你真正需要的是每个任务对应 2 个独立的参数。
值得庆幸的是,Parallel 本身提供了上述所需的解析功能。如果你将 `--max-args` 设置为 `2`,那么 `{1}` 和 `{2}` 这两个变量分别代表传入参数的第一和第二部分:
```
$ ls -1 | parallel --max-args=2 cat {1} {2} ">" {1}_{2}.person
```
在上面的命令中,变量 `{1}` 值为 `ada` 或 `richard` (取决于你选取的任务),变量 `{2}` 值为 `lovelace` 或 `stallman`。通过使用重定向符号(放到引号中,防止被 Bash 识别,以便 Parallel 使用),(两个)文件的内容被分别重定向至新文件 `ada_lovelace.person` 和 `richard_stallman.person`。
```
$ ls -1
ada
ada_lovelace.person
lovelace
richard
richard_stallman.person
stallman
$ cat ada_*person
ada lovelace
$ cat ri*person
richard stallman
```
如果你整天处理大量几百 MB 大小的日志文件,那么(上述)并行处理文本的方法对你帮忙很大;否则,上述例子只是个用于上手的示例。
然而,这种处理方法对于很多文本处理之外的操作也有很大帮助。下面是来自电影产业的真实案例,其中需要将一个目录中的视频文件和(对应的)音频文件进行合并。
```
$ ls -1
12_LS_establishing-manor.avi
12_wildsound.flac
14_butler-dialogue-mixed.flac
14_MS_butler.avi
...略...
```
使用同样的方法,使用下面这个简单命令即可并行地合并文件:
```
$ ls -1 | parallel --max-args=2 ffmpeg -i {1} -i {2} -vcodec copy -acodec copy {1}.mkv
```
### 简单粗暴的方式
上述花哨的输入输出处理不一定对所有人的口味。如果你希望更直接一些,可以将一堆命令甩给 Parallel,然后去干些其它事情。
首先,需要创建一个文本文件,每行包含一个命令:
```
$ cat jobs2run
bzip2 oldstuff.tar
oggenc music.flac
opusenc ambiance.wav
convert bigfile.tiff small.jpeg
ffmepg -i foo.avi -v:b 12000k foo.mp4
xsltproc --output build/tmp.fo style/dm.xsl src/tmp.xml
bzip2 archive.tar
```
接着,将文件传递给 Parallel:
```
$ parallel --jobs 6 < jobs2run
```
现在文件中对应的全部任务都在被 Parallel 执行。如果任务数量超过允许的数目(LCTT 译注:应该是 `--jobs` 指定的数目或默认值),Parallel 会创建并维护一个队列,直到任务全部完成。
### 更多内容
GNU Parallel 是个强大而灵活的工具,还有很多很多用例无法在本文中讲述。工具的 man 页面提供很多非常酷的例子可供你参考,包括通过 SSH 远程执行和在 Parallel 命令中使用 Bash 函数等。[YouTube](https://www.youtube.com/watch?v=OpaiGYxkSuQ&list=PL284C9FF2488BC6D1) 上甚至有一个系列,包含大量操作演示,让你可以直接从 GNU Parallel 团队学习。GNU Paralle 的主要维护者还发布了官方使用指导手册,可以从 [Lulu.com](http://www.lulu.com/shop/ole-tange/gnu-parallel-2018/paperback/product-23558902.html) 获取。
GNU Parallel 有可能改变你完成计算的方式;即使没有,也会至少改变你主机花在计算上的时间。马上上手试试吧!
---
via: <https://opensource.com/article/18/5/gnu-parallel>
作者:[Seth Kenlon](https://opensource.com/users/seth) 选题:[lujun9972](https://github.com/lujun9972) 译者:[pinewall](https://github.com/pinewall) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Do you ever get the funny feeling that your computer isn't quite as fast as it should be? I used to feel that way, and then I found GNU Parallel.
GNU Parallel is a shell utility for executing jobs in parallel. It can parse multiple inputs, thereby running your script or command against sets of data at the same time. You can use *all* your CPU at last!
If you've ever used `xargs`
, you already know how to use Parallel. If you don't, then this article teaches you, along with many other use cases.
## Installing GNU Parallel
GNU Parallel may not come pre-installed on your Linux or BSD computer. Install it from your repository or ports collection. For example, on Fedora:
```
$ sudo dnf install parallel
```
Or on NetBSD:
```
# pkg_add parallel
```
If all else fails, refer to the [project homepage](https://www.gnu.org/software/parallel).
## From serial to parallel
As its name suggests, Parallel's strength is that it runs jobs in parallel rather than, as many of us still do, sequentially.
When you run one command against many objects, you're inherently creating a queue. Some number of objects can be processed by the command, and all the other objects just stand around and wait their turn. It's inefficient. Given enough data, there's always going to be a queue, but instead of having just one queue, why not have lots of small queues?
Imagine you have a folder full of images you want to convert from JPEG to PNG. There are many ways to do this. There's the manual way of opening each image in GIMP and exporting it to the new format. That's usually the worst possible way. It's not only time-intensive, it's labor-intensive.
A pretty neat variation on this theme is the shell-based solution:
```
$ convert 001.jpeg 001.png
$ convert 002.jpeg 002.png
$ convert 003.jpeg 003.png
... and so on ...
```
It's a great trick when you first learn it, and at first it's a vast improvement. No need for a GUI and constant clicking. But it's still labor-intensive.
Better still:
```
$ for i in *jpeg; do convert $i $i.png ; done
```
This, at least, sets the job(s) in motion and frees you up to do more productive things. The problem is, it's still a serial process. One image gets converted, and then the next one in the queue steps up for conversion, and so on until the queue has been emptied.
With Parallel:
```
$ find . -name "*jpeg" | parallel -I% --max-args 1 convert % %.png
```
This is a combination of two commands: the `find`
command, which gathers the objects you want to operate on, and the `parallel`
command, which sorts through the objects and makes sure everything gets processed as required.
`find . -name "*jpeg"`
finds all files in the current directory that end in`jpeg`
.`parallel`
invokes GNU Parallel.`-I%`
creates a placeholder, called`%`
, to stand in for whatever`find`
hands over to Parallel. You use this because otherwise you'd have to manually write a new command for each result of`find`
, and that's exactly what you're trying to avoid.`--max-args 1`
limits the rate at which Parallel requests a new object from the queue. Since the command Parallel is running requires only one file, you limit the rate to 1. Were you doing a more complex command that required two files (such as`cat 001.txt 002.txt > new.txt`
), you would limit the rate to 2.`convert % %.png`
is the command you want to run in Parallel.
The result of this command is that `find`
gathers all relevant files and hands them over to `parallel`
, which launches a job and immediately requests the next in line. Parallel continues to do this for as long as it is safe to launch new jobs without crippling your computer. As old jobs are completed, it replaces them with new ones, until all the data provided to it has been processed. What took 10 minutes before might take only 5 or 3 with Parallel.
## Multiple inputs
The `find`
command is an excellent gateway to Parallel as long as you're familiar with `find`
and `xargs`
(collectively called GNU Find Utilities, or `findutils`
). It provides a flexible interface that many Linux users are already comfortable with and is pretty easy to learn if you're a newcomer.
The `find`
command is fairly straightforward: you provide `find`
with a path to a directory you want to search and some portion of the file name you want to search for. Use wildcard characters to cast your net wider; in this example, the asterisk indicates *anything*, so `find`
locates all files that end with the string `searchterm`
:
```
$ find /path/to/directory -name "*searchterm"
```
By default, `find`
returns the results of its search one item at a time, with one item per line:
```
$ find ~/graphics -name "*jpg"
/home/seth/graphics/001.jpg
/home/seth/graphics/cat.jpg
/home/seth/graphics/penguin.jpg
/home/seth/graphics/IMG_0135.jpg
```
When you pipe the results of `find`
to `parallel`
, each item on each line is treated as one argument to the command that `parallel`
is arbitrating. If, on the other hand, you need to process more than one argument in one command, you can split up the way the data in the queue is handed over to `parallel`
.
Here's a simple, unrealistic example, which I'll later turn into something more useful. You can follow along with this example, as long as you have GNU Parallel installed.
Assume you have four files. List them, one per line, to see exactly what you have:
```
$ echo ada > ada ; echo lovelace > lovelace
$ echo richard > richard ; echo stallman > stallman
$ ls -1
ada
lovelace
richard
stallman
```
You want to combine two files into a third that contains the contents of both files. This requires that Parallel has access to two files, so the `-I%`
variable won't work in this case.
Parallel's default behavior is basically invisible:
```
$ ls -1 | parallel echo
ada
lovelace
richard
stallman
```
Now tell Parallel you want to get two objects per job:
```
$ ls -1 | parallel --max-args=2 echo
ada lovelace
richard stallman
```
Now the lines have been combined. Specifically, *two* results from `ls -1`
are passed to Parallel all at once. That's the right number of arguments for this task, but they're effectively one argument right now: "ada lovelace" and "richard stallman." What you actually want is two distinct arguments per job.
Luckily, that technicality is parsed by Parallel itself. If you set `--max-args`
to `2`
, you get two variables, `{1}`
and `{2}`
, representing the first and second parts of the argument:
```
$ ls -1 | parallel --max-args=2 cat {1} {2} ">" {1}_{2}.person
```
In this command, the variable `{1}`
is ada or richard (depending on which job you look at) and `{2}`
is either `lovelace`
or `stallman`
. The contents of the files are redirected with a redirect symbol *in quotes* (the quotes grab the redirect symbol from Bash so Parallel can use it) and placed into new files called `ada_lovelace.person`
and `richard_stallman.person`
.
```
$ ls -1
ada
ada_lovelace.person
lovelace
richard
richard_stallman.person
stallman
$ cat ada_*person
ada lovelace
$ cat ri*person
richard stallman
```
If you spend all day parsing log files that are hundreds of megabytes in size, you might see how parallelized text parsing could be useful to you; otherwise, this is mostly a demonstrative exercise.
However, this kind of processing is invaluable for more than just text parsing. Here's a real-life example from the film world. Consider a directory of video files and audio files that need to be joined together.
```
$ ls -1
12_LS_establishing-manor.avi
12_wildsound.flac
14_butler-dialogue-mixed.flac
14_MS_butler.avi
...and so on...
```
Using the same principles, a simple command can be created so that the files are combined *in parallel*:
```
$ ls -1 | parallel --max-args=2 ffmpeg -i {1} -i {2} -vcodec copy -acodec copy {1}.mkv
```
## Brute. Force.
All this fancy input and output parsing isn't to everyone's taste. If you prefer a more direct approach, you can throw commands at Parallel and walk away.
First, create a text file with one command on each line:
```
$ cat jobs2run
bzip2 oldstuff.tar
oggenc music.flac
opusenc ambiance.wav
convert bigfile.tiff small.jpeg
ffmepg -i foo.avi -v:b 12000k foo.mp4
xsltproc --output build/tmp.fo style/dm.xsl src/tmp.xml
bzip2 archive.tar
```
Then hand the file over to Parallel:
```
$ parallel --jobs 6 < jobs2run
```
And now all jobs in your file are run in Parallel. If more jobs exist than jobs allowed, a queue is formed and maintained by Parallel until all jobs have run.
## Much, much more
GNU Parallel is a powerful and flexible tool, with far more use cases than can fit into this article. Its man page provides examples of really cool things you can do with it, from remote execution over SSH to incorporating Bash functions into your Parallel commands. There's even an extensive demonstration series on [YouTube](https://www.youtube.com/watch?v=OpaiGYxkSuQ&list=PL284C9FF2488BC6D1), so you can learn from the GNU Parallel team directly. The GNU Parallel lead maintainer has also just released the command's official guide, available from [Lulu.com](http://www.lulu.com/shop/ole-tange/gnu-parallel-2018/paperback/product-23558902.html).
GNU Parallel has the power to change the way you compute, and if doesn't do that, it will at the very least change the time your computer spends computing. Try it today!
## 9 Comments |
9,719 | 使用 Buildah 创建小体积的容器 | https://opensource.com/article/18/5/containers-buildah | 2018-06-06T10:40:14 | [
"Buildah",
"协作"
] | https://linux.cn/article-9719-1.html |
>
> 技术问题推动了开源协作的力量。
>
>
>

我最近加入了 Red Hat,在这之前我在另外一家科技公司工作了很多年。在我的上一份工作岗位上,我开发了不少不同类型的软件产品,这些产品是成功的,但都有版权保护。不仅法规限制了我们不能在公司外将软件共享,而且我们在公司内部也基本不进行共享。在那时,我觉得这很有道理:公司花费了时间、精力和预算用于开发软件,理应保护并要求软件涉及的利益。
时间如梭,去年我加入 Red Hat 并培养出一种完全不同的理念。[Buildah 项目](https://github.com/projectatomic/buildah)是我最早加入的项目之一,该项目用于构建 OCI (Open Container Initiative) 标准的镜像,特别擅长让你精简创建好的镜像的体积。那时 Buildah 还处于非常早期的阶段,包含一些瑕疵,不适合用于生产环境。
刚接触项目不久,我做了一些小变更,然后询问公司内部 git 仓库地址,以便提交我做的变更。收到的回答是:没有内部仓库,直接将变更提交到 GitHub 上。这让我感到困惑,将我的变更提交到 GitHub 意味着:任何人都可以查看这部分代码并在他们自己的项目中使用。况且代码还有一些瑕疵,这样做简直有悖常理。但作为一个新人,我只是惊讶地摇了摇头并提交了变更。
一年后,我终于相信了开源软件的力量和价值。我仍为 Buildah 项目工作,我们最近遇到的一个主题很形象地说明了这种力量和价值。这个标题为 [Buildah 镜像体积并不小?](https://github.com/projectatomic/buildah/issues/532) 的工单由 Tim Dudgeon (@tdudgeon) 提出。简而言之,他发现使用 Buildah 创建的镜像比使用 Docker 创建的镜像体积更大,而且 Buildah 镜像中并不包含一些额外应用,但 Docker 镜像中却包含它们。
为了比较,他首先操作如下:
```
$ docker pull centos:7
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
docker.io/centos 7 2d194b392dd1 2 weeks ago 195 MB
```
他发现 Docker 镜像的体积为 195MB。Tim 接着使用 Buildah 创建了一个(基于 scratch 的)最小化镜像,仅仅将 `coreutils` 和 `bash` 软件包加入到镜像中,使用的脚本如下:
```
$ cat ./buildah-base.sh
#!/bin/bash
set -x
# build a minimal image
newcontainer=$(buildah from scratch)
scratchmnt=$(buildah mount $newcontainer)
# install the packages
yum install --installroot $scratchmnt bash coreutils --releasever 7 --setopt install_weak_deps=false -y
yum clean all -y --installroot $scratchmnt --releasever 7
sudo buildah config --cmd /bin/bash $newcontainer
# set some config info
buildah config --label name=centos-base $newcontainer
# commit the image
buildah unmount $newcontainer
buildah commit $newcontainer centos-base
$ sudo ./buildah-base.sh
$ sudo buildah images
IMAGE ID IMAGE NAME CREATED AT SIZE
8379315d3e3e docker.io/library/centos-base:latest Mar 25, 2018 17:08 212.1 MB
```
Tim 想知道为何 Buildah 镜像体积反而大 17MB,毕竟 `python` 和 `yum` 软件包都没有安装到 Buildah 镜像中,而这些软件已经安装到 Docker 镜像中。这个结果并不符合预期,在 Github 的相关主题中引发了广泛的讨论。
不仅 Red Hat 的员工参与了讨论,还有不少公司外人士也加入了讨论,这很有意义。值得一提的是,GitHub 用户 @pixdrift 主导了很多重要的讨论并提出很多发现,他指出在这个 Buildah 镜像中文档和语言包就占据了比 100MB 略多一点的空间。Pixdrift 建议在 yum 安装器中强制指定语言,据此提出如下修改过的 `buildah-bash.sh` 脚本:
```
#!/bin/bash
set -x
# build a minimal image
newcontainer=$(buildah from scratch)
scratchmnt=$(buildah mount $newcontainer)
# install the packages
yum install --installroot $scratchmnt bash coreutils --releasever 7 --setopt=install_weak_deps=false --setopt=tsflags=nodocs --setopt=override_install_langs=en_US.utf8 -y
yum clean all -y --installroot $scratchmnt --releasever 7
sudo buildah config --cmd /bin/bash $newcontainer
# set some config info
buildah config --label name=centos-base $newcontainer
# commit the image
buildah unmount $newcontainer
buildah commit $newcontainer centos-base
```
Tim 运行这个新脚本,得到的镜像体积缩减至 92MB,相比之前的 Buildah 镜像体积减少了 120MB,这比较接近我们的预期;然而,出于工程师的天性,56% 的体积缩减不能让他们满足。讨论继续深入下去,涉及如何移除个人语言包以节省更多空间。如果想了解讨论细节,点击 [Buildah 镜像体积并不小?](https://github.com/projectatomic/buildah/issues/532) 这个链接。说不定你也能给出有帮助的点子,甚至更进一步成为 Buildah 项目的贡献者。这个主题的解决从一个侧面告诉我们,Buildah 软件可以多么快速和容易地创建体积最小化的容器,该容器仅包含你高效运行任务所需的软件。额外的好处是,你无需运行一个守护进程。
这个镜像体积缩减的主题让我意识到开源软件的力量。来自不同公司的大量开发者,在一天多的时间内,以开放讨论的形式进行合作解决问题。虽然解决这个具体问题并没有修改已有代码,但 Red Hat 公司外开发者对 Buildah 做了很多代码贡献,进而帮助项目变得更好。这些贡献也吸引了更多人才关注项目代码;如果像之前那样,代码作为版权保护软件的一部分放置在私有 git 仓库中,不会获得上述好处。我只用了一年的时间就转向拥抱 [开源方式](https://twitter.com/opensourceway),而且可能不会再转回去了。
文章最初发表于 [Project Atomic](http://www.projectatomic.io/blog/2018/04/open-source-what-a-concept/),已获得转载许可。
---
via: <https://opensource.com/article/18/5/containers-buildah>
作者:[Tom Sweeney](https://opensource.com/users/tomsweeneyredhat) 选题:[lujun9972](https://github.com/lujun9972) 译者:[pinewall](https://github.com/pinewall) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I recently joined Red Hat after many years working for another tech company. In my previous job, I developed a number of different software products that were successful but proprietary. Not only were we legally compelled to not share the software outside of the company, we often didn’t even share it within the company. At the time, that made complete sense to me: The company spent time, energy, and budget developing the software, so they should protect and claim the rewards it garnered.
Fast-forward to a year ago, when I joined Red Hat and developed a completely different mindset. One of the first things I jumped into was the [Buildah project](https://github.com/projectatomic/buildah). It facilitates building Open Container Initiative (OCI) images, and it is especially good at allowing you to tailor the size of the image that is created. At that time Buildah was in its very early stages, and there were some warts here and there that weren’t quite production-ready.
Being new to the project, I made a few minor changes, then asked where the company’s internal git repository was so that I could push my changes. The answer: Nothing internal, just push your changes to GitHub. I was baffled—sending my changes out to GitHub would mean anyone could look at that code and use it for their own projects. Plus, the code still had a few warts, so that just seemed so counterintuitive. But being the new guy, I shook my head in wonder and pushed the changes out.
A year later, I’m now convinced of the power and value of open source software. I’m still working on Buildah, and we recently had an issue that illustrates that power and value. The issue, titled [Buildah images not so small?](https://github.com/projectatomic/buildah/issues/532), was raised by Tim Dudgeon (@tdudgeon). To summarize, he noted that images created by Buildah were bigger than those created by Docker, even though the Buildah images didn’t contain the extra "fluff" he saw in the Docker images.
For comparison he first did:
```
``````
$ docker pull centos:7
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
docker.io/centos 7 2d194b392dd1 2 weeks ago 195 MB
```
He noted that the size of the Docker image was 195MB. Tim then created a minimal (scratch) image using Buildah, with only the `coreutils`
and `bash`
packages added to the image, using the following script:
```
``````
$ cat ./buildah-base.sh
#!/bin/bash
set -x
# build a minimal image
newcontainer=$(buildah from scratch)
scratchmnt=$(buildah mount $newcontainer)
# install the packages
yum install --installroot $scratchmnt bash coreutils --releasever 7 --setopt install_weak_deps=false -y
yum clean all -y --installroot $scratchmnt --releasever 7
sudo buildah config --cmd /bin/bash $newcontainer
# set some config info
buildah config --label name=centos-base $newcontainer
# commit the image
buildah unmount $newcontainer
buildah commit $newcontainer centos-base
$ sudo ./buildah-base.sh
$ sudo buildah images
IMAGE ID IMAGE NAME CREATED AT SIZE
8379315d3e3e docker.io/library/centos-base:latest Mar 25, 2018 17:08 212.1 MB
```
Tim wondered why the image was 17MB larger, because `python`
and `yum`
were not installed in the Buildah image, whereas they were installed in the Docker image. This set off quite the discussion in the GitHub issue, as it was not at all an expected result.
What was great about the discussion was that not only were Red Hat folks involved, but several others from outside as well. In particular, a lot of great discussion and investigation was led by GitHub user @pixdrift, who noted that the documentation and locale-archive were chewing up a little more than 100MB of space in the Buildah image. Pixdrift suggested forcing locale in the yum installer and provided this updated `buildah-bash.sh`
script with those changes:
```
``````
#!/bin/bash
set -x
# build a minimal image
newcontainer=$(buildah from scratch)
scratchmnt=$(buildah mount $newcontainer)
# install the packages
yum install --installroot $scratchmnt bash coreutils --releasever 7 --setopt=install_weak_deps=false --setopt=tsflags=nodocs --setopt=override_install_langs=en_US.utf8 -y
yum clean all -y --installroot $scratchmnt --releasever 7
sudo buildah config --cmd /bin/bash $newcontainer
# set some config info
buildah config --label name=centos-base $newcontainer
# commit the image
buildah unmount $newcontainer
buildah commit $newcontainer centos-base
```
When Tim ran this new script, the image size shrank to 92MB, shedding 120MB from the original Buildah image size and getting closer to the expected size; however, engineers being engineers, a size savings of 56% wasn’t enough. The discussion went further, involving how to remove individual locale packages to save even more space. To see more details of the discussion, click the [Buildah images not so small?](https://github.com/projectatomic/buildah/issues/532) link. Who knows—maybe you’ll have a helpful tip, or better yet, become a contributor for Buildah. *On a side note, this solution illustrates how the Buildah software can be used to quickly and easily create a minimally sized container that's loaded only with the software that you need to do your job efficiently. As a bonus, it doesn’t require a daemon to be running.*
This image-sizing issue drove home the power of open source software for me. A number of people from different companies all collaborated to solve a problem through open discussion in a little over a day. Although no code changes were created to address this particular issue, there have been many code contributions to Buildah from contributors outside of Red Hat, and this has helped to make the project even better. These contributions have served to get a wider variety of talented people to look at the code than ever would have if it were a proprietary piece of software stuck in a private git repository. It’s taken only a year to convert me to the [open source way](https://twitter.com/opensourceway), and I don’t think I could ever go back.
*This article was originally posted at Project Atomic. Reposted with permission.*
## Comments are closed. |
9,720 | 5 个理由,开源助你求职成功 | https://opensource.com/article/18/1/5-ways-turn-open-source-new-job | 2018-06-06T11:01:00 | [
"求职"
] | https://linux.cn/article-9720-1.html |
>
> 为开源项目工作可以给你或许从其他地方根本得不到的经验和人脉。
>
>
>

你正在在繁华的技术行业中寻找工作吗?无论你是寻找新挑战的技术团体老手,还是正在寻找第一份工作的毕业生,参加开源项目都是可以让你在众多应聘者中脱颖而出的好方法。以下是从事开源项目工作可以增强你求职竞争力的五个理由。
### 1、 获得项目经验
或许从事开源项目工作能带给你的最明显的好处是提供了项目经验。如果你是一个学生,你可能没有很多实质上的项目可以在你的简历中展示。如果你还在工作,由于保密限制,或者你对正在完成的任务不感兴趣,你不能或者不能很详细的讨论你当前的项目。无论那种情况,找出并参加那些有吸引力的,而且又正好可以展现你的技能的开源项目,无疑对求职有帮助。这些项目不仅在众多简历中引人注目,而且可以是面试环节中完美的谈论主题。
另外,很多开源项目托管在公共仓库(比如 [Github](https://github.com/dbaldwin/DronePan) )上,所以对任何想参与其中的任何人,获取这些项目的源代码都异常简单。同时,你对项目的公开代码贡献,也能很方便的被招聘单位或者潜在雇主找到。开源项目提供了一个可以让你以一种更实际的的方式展现你的技能,而不是仅仅在面试中纸上谈兵。
### 2、 学会提问
开源项目团体的新成员总会有机会去学习大量的新技能。他们肯定会发现该项目独特的的多种交流方式、结构层次、文档格式和其他的方方面面。在刚刚参与到项目中时,你需要问大量的问题,才能找准自己的定位。正如俗语说得好,没有愚蠢的问题。开源社区提倡好奇心,特别是在问题答案不容易找到的时候。
在从事开源项目工作初期,对项目的不熟悉感会驱使个人去提问,去经常提问。这可以帮助参与者学会提问。学会去分辨问什么,怎么问,问谁。学会提问在找工作、[面试](https://www.thebalance.com/why-you-should-ask-questions-in-a-job-interview-1669548),甚至生活中都非常有用。解决问题和寻求帮助的能力在人才市场中都非常重要。
### 3、 获取新的技能与持续学习
大量的软件项目同时使用很多不同的技术。很少有贡献者可以熟悉项目中的所有技术。即使已经在项目中工作了一段时间后,很多人很可能不能对项目中所用的所有技术都熟悉。
虽然一个开源项目中的老手可能会对项目的一些特定的方面不熟悉,但是新手不熟悉的显然更多。这种情况产生了大量的学习机会。在一个人刚开始从事开源工作时,可能只是去提高项目中的一些小功能,甚至很可能是在他熟悉的领域。但是以后的旅程就大不相同了。
从事项目的某一方面的工作可能会把你带进一个不熟悉的领域,可能会驱使你开始新的学习。而从事开源项目的工作,可能会把你带向一个你以前可能从没用过的技术。这会激起新的激情,或者,至少促进你继续学习([这正是雇主渴望具备的能力](https://www.computerworld.com/article/3177442/it-careers/lifelong-learning-is-no-longer-optional.html))。
### 4、增加人脉
开源项目被不同的社区维护和支持。一些人在他们的业余时间进行开源工作,他们都有各自的经历、兴趣和人脉。正如他们所说,“你了解什么人决定你成为什么人”。不通过开源项目,可能你永远不会遇到特定的人。或许你和世界各地的人一起工作,或许你和你的邻里有联系。但是,你不知道谁能帮你找到下一份工作。参加开源项目扩展人脉的可能性将对你寻找下一份(或者第一份)工作极有帮助。
### 5、 建立自信
最后,参与开源项目可能给你新的自信。很多科技企业的新员工会有些[冒充者综合症](https://en.wikipedia.org/wiki/Impostor_syndrome)。由于没有完成重要工作,他们会感到没有归属感,好像自己是冒名顶替的那个人,认为自己配不上他们的新职位。在被雇佣前参加开源项目可以最小化这种问题。
开源项目的工作往往是独立完成的,但是对于项目来说,所有的贡献是一个整体。开源社区具有强大的包容性和合作性,只要你有所贡献,一定会被看到。别的社区成员(特别是更高级的成员)对你肯定无疑也是一种回报。在你进行代码提交时获得的认可可以提高你的自信,打败冒充者综合症。这份自信也会被带到面试,新职位,等等。
这只是从事开源工作的一些好处。如果你知道更多的好处,请在下方评论区留言分享。
### 关于作者
Sophie Polson :一名研究计算机科学的杜克大学的学生。通过杜克大学 2017 秋季课程 “开源世界( Open Source World )”,开始了开源社区的冒险。对探索 [DevOps](https://en.wikipedia.org/wiki/DevOps) 十分有兴趣。在 2018 春季毕业后,将成为一名软件工程师。
---
via: <https://opensource.com/article/18/1/5-ways-turn-open-source-new-job>
作者:[Sophie Polson](https://opensource.com/users/sophiepolson) 译者:[Lontow](https://github.com/lontow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
<sup> <sup> <sup> <sup> <sup> ^ </sup> </sup> </sup> </sup></sup>
| 200 | OK | Are you searching for a job in the bustling tech industry? Whether you're a seasoned member of the tech community looking for a new challenge or a recent graduate looking for your first job, contributing to open source projects can be a great way to boost your attractiveness as a candidate. Below are five ways your work on open source projects may strengthen your job hunt.
## 1. Get project experience
Perhaps the clearest way working on open source projects can assist in your job search is by giving you project experience. If you are a student, you may not have many concrete projects to showcase on your resume. If you are working, perhaps you can't discuss your current projects due to privacy limitations, or maybe you're not working on tasks that interest you. Either way, scouting out appealing open source projects that allow you to showcase your skills may help in your job search. These projects are great eye-catchers on resumes and can be perfect discussion topics in interviews.
In addition, many open source projects are kept in public repositories, such as [GitHub](https://github.com/dbaldwin/DronePan), so accessing the source code is easy for anyone who wants to become involved. Also, it makes your publicly accessible code contributions easy for recruiters and other individuals at potential employers to find. The fact that these projects are open allows you to demonstrate your skills in a more concrete manner than simply discussing them in an interview.
## 2. Learn to ask good questions
Any new member of an open source project community has the opportunity to learn a lot. They must discover avenues of communication; structure and hierarchy; documentation format; and many other aspects unique to the project. To begin participating in and contributing to a project, you need to ask many questions to put yourself in a position for success. As the familiar saying goes, there are no stupid questions. Open source project communities promote inquisivity, especially when answers aren't easy to find.
The unfamiliarity when beginning to work on open source projects teaches individuals to ask questions, and to ask them often. This helps participants develop great skills in identifying what questions to ask, how to ask them, and who to approach. This skill is useful in job searching, [interviewing](https://www.thebalance.com/why-you-should-ask-questions-in-a-job-interview-1669548), and living life in general. Problem-solving skills and reaching out for help when you need it are highly valued in the job market.
## 3. Access new technologies and continuous learning
Most software projects use many different technologies. It is rare for every contributor to be familiar with every piece of technology in a project. Even after working on a project for a while, individuals likely won't be familiar with all the technologies it uses.
While veterans of an open source project may be unfamiliar with certain pieces of the project, newbies will be extremely unfamiliar with many or most. This creates a huge learning opportunity. A person may begin working on an open source project to improve one piece of functionality, most likely in a technical area they are familiar with. But the path from there can take a much different turn.
Working on one aspect of a project might lead you down an unfamiliar road and prompt new learning. Working on an open source project may expose you to new technologies you would never use otherwise. It can also reveal new passions, or at minimum, facilitate continuous learning—which [employers find highly desirable](https://www.computerworld.com/article/3177442/it-careers/lifelong-learning-is-no-longer-optional.html).
## 4. Increase your connections and network
Open source projects are maintained and surrounded by diverse communities. Some individuals working on open source projects do so in their free time, and they all have their own backstories, interests, and connections. As they say, "it's all about who you know." You may never meet certain people except through working an open source project. Maybe you'll work with people around the world, or maybe you'll connect with your next-door neighbor. Regardless, you never know who may help connect you to your next job. The connections and networking possibilities exposed through an open source project may be extremely helpful in finding your next (or first!) job.
## 5. Build confidence
Finally, contributing to open source projects may give you a newfound confidence. Many new employees in the tech industry may feel a sense of [imposter syndrome](https://en.wikipedia.org/wiki/Impostor_syndrome), because without having accomplished significant work, they may feel they don't belong, they are frauds, or they don't deserve to be in their new position. Working on open source projects before you are hired may minimize this issue.
Work on open source projects is often done individually, but it all contributes to the project as a whole. Open source communities are highly inclusive and cooperative, and your contributions will be noticed. It is always rewarding to be validated by other community members (especially more senior members). The recognition you may gain from code commits to an open source project could improve your confidence and counter imposter syndrome. This confidence can then carry over to interviews, new positions, and beyond.
These are only a handful of the benefits you may see from working on open source projects. If you know of other advantages, please share them in the comments below.
## 1 Comment |
9,721 | IT 自动化:如何去实现 | https://enterprisersproject.com/article/2018/1/how-make-case-it-automation | 2018-06-06T19:08:45 | [
"自动化"
] | https://linux.cn/article-9721-1.html |
>
> 想要你的整个团队都登上 IT 自动化之旅吗? IT 执行者们分享了他们的战略。
>
>
>

在任何重要的项目或主动变更刚开始的时候,IT 的管理者在前进的道路上面临着普遍的抉择。
第一条路径看上去是提供了一个从 A 到 B 的最短路径:简单的把项目强制分配给每个人去执行,本质来说就是你要么按照要求去做要么就不要做了。
第二条路径可能看上去会不是很直接,因为要通过这条路径你需要花时间去解释项目背后的策略以及原因。你会沿着这条路线设置停靠站点而不是从起点到终点的马拉松:“这就是我们正在做的 —— 和为什么我们这么做。”
猜想一下哪条路径会赢得更好的结果?
如果你选的是路径 2,你肯定是以前都经历过这两条路径——而且经历了第一次的结局。让人们参与到重大变革中总会是最明智的选择。
IT 领导者也知道重大的变革总会带来严重的恐慌、怀疑,和其他的挑战。IT 自动化确实是很正确的改变。这个术语对某些人来说是很可怕的,而且容易被曲解。帮助人们理解你的公司需要 IT 自动化的必要性的原因以及如何去实现是达到你的目标和策略的重要步骤。
[**阅读我们的相关文章,**[**IT自动化最佳实践:持久成功的7个关键点**](https://enterprisersproject.com/article/2018/1/it-automation-best-practices-7-keys-long-term-success?sc_cid=70160000000h0aXAAQ)。]
考虑到这一点,我们咨询了许多 IT 管理者关于如何在你的组织中实现 IT 自动化。
### 1、向人们展示它的优点
我们要面对的一点事实是:自我利益和自我保护是本能。利用人们的这种本能是一个吸引他们的好方法:向他们展示自动化策略将如何让他们和他们的工作获益。自动化将会是软件管道中的一个特定过程意味着将会减少在半夜呼叫团队同事来解决故障?它将能让一些人丢弃技术含量低的技能,用更有策略、高效的有序工作代替手工作业,这将会帮助他们的职业生涯更进一步?
“向他们传达他们能得到什么好处,自动化将会如何让他们的客户和公司受益,”来自 ADP 全球首席技术官 vipual Nagrath 的建议。“将现在的状态和未来光明的未来进行对比,展现公司将会变得如何稳定,敏捷,高效和安全。”
这样的方法同样适用于 IT 领域之外的其他领域;只要在向非技术领域的股东们解读利益的时候解释清楚一些术语即可,Nagrath 说道。
设置好前后的情景是一个不错的帮助人们理解的更透彻的故事机。
“你要描述一幅人们能够联想到的当前状态的画面,” Nagrath 说。“描述现在是什么工作,但也要重点强调是什么导致团队的工作效率不够敏捷。”然后再阐释自动化过程将如何提高现在的状态。
### 2、将自动化和特定的商业目标绑定在一起
一个强有力的案列的一部分要确保人们理解你不只是在追逐潮流趋势。如果只是为了自动化而自动化,人们会很快察觉到进而会更加抵制的——也许在 IT 界更是如此。
“自动化需要商业需求的驱动,例如收入和运营开销,” Cyxtera的副总裁和首席信息安全官 David Emerson 说道。“没有自动化的努力是自我辩护的,而且任何技术专长都不应该被当做一种手段,除非它是公司的一项核心能力。”
像 Nagrath 一样,Emerson 建议将达到自动化的商业目标和奖励措施挂钩,用迭代式的循序渐进的方式推进这些目标和相关的激励措施。
### 3、 将自动化计划分解为可管理的条目
即使你的自动化策略字面上是“一切都自动化”,对大多数组织来说那也是很艰难的,而且可能是没有灵活性的。你需要制定一个强有力的方案,将自动化目标分解为可管理的目标计划。而且这将能够创造很大的灵活性来适应之后漫长的道路。
“当制定一个自动化方案的时候,我建议详细的阐明推进自动化进程的奖励措施,而且允许迭代朝着目标前进来介绍和证明利益处于一个低风险水平,”Emerson 说道。
GA Connector 的创始人 Sergey Zuev 分享了一个为什么自动化如此重要的快节奏体验的报告——它将怎样为你的策略建立一个强壮持久的论点。Zuevz 应该知道:他的公司的自动化工具将公司的客户关系应用数据导入谷歌分析。但实际上是公司的内部经验使顾客培训进程自动化从而出现了一个闪耀的时刻。
“起初, 我们曾尝试去建立整个培训机制,结果这个项目搁浅了好几个月,”Zuev 说道。“认识到这将无法继续下去之后,我们决定挑选其中的一个能够有巨大的时效的领域,而且立即启动。结果我们只用了一周就实现了其中的电子邮件序列的目标,而且我们已经从被亵渎的体力劳动中获益。”
### 4、 出售主要部分也有好处
循序渐进的方法并不会阻碍构建一个宏伟的蓝图。就像以个人或者团队的水平来制定方案是一个好主意,帮助人们理解全公司的利益也是一个不错的主意。
“如果我们能够加速达到商业需求所需的时间,那么一切质疑将会平息。”
AHEAD 的首席技术官 Eric Kaplan 赞同通过小范围的胜利来展示自动化的价值是一个赢得人心的聪明策略。但是那些所谓的“小的”的价值揭示能够帮助你提高人们的整体形象。Kaplan 指出个人和组织间的价值是每个人都可以容易联系到的领域。
“最能展现的地方就是你能够节约多少时间,”Kaaplan 说。“如果我们能够加速达到商业需求所需的时间,那么一切质疑将会消失。”
时间和可伸缩性是业务和 IT 同事的强大优势,都复制业务的增长,可以把握。
“自动化的结果是灵活伸缩的——每个人只需较少的努力就能保持和改善你的 IT 环境”,红帽的全球服务副总裁 John Allessio 最近提到。“如果增加人力是提升你的商业的唯一途径,那么灵活伸缩就是白日梦。自动化减少了你的人力需求而且提供了 IT 演进所需的灵活性和韧性。”(详细内容请参考他的文章,[DevOps 团队对 CIO 的真正需求是什么。])
### 5、 推广你的成果。
在你自动化策略的开始时,你可能是在目标和要达到目标的预期利益上制定方案。但随着你的自动化策略的不断演进,没有什么能够比现实中的实际结果令人信服。
“眼见为实,”ADP 的首席技术官 Nagrath 说。“没有什么比追踪记录能够平息质疑。”
那意味着,不仅仅要达到你的目标,还要准时的完成——这是迭代的循序渐进的方法论的另一个不错的解释。
而量化的结果如比利润的提高或者成本的节省可以大声宣扬出来,Nagrath 建议他的 IT 领导者同行在讲述你们的自动化故事的时候不要仅仅止步于此。
为自动化提供案例也是一个定性的讨论,通过它我们能够促进问题的预防,归总商业的连续性,减伤失败或错误,而且能够在他们处理更有价值的任务时承担更多的责任。
---
via: <https://enterprisersproject.com/article/2018/1/how-make-case-it-automation>
作者:[Kevin Casey](https://enterprisersproject.com/user/kevin-casey) 译者:[FelixYFZ](https://github.com/FelixYFZ) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | At the start of any significant project or change initiative, IT leaders face a proverbial fork in the road.
Path #1 might seem to offer the shortest route from A to B: Simply force-feed the project to everyone by executive mandate, essentially saying, *“You’re going to do this – or else.”*
Path #2 might appear less direct, because on this journey you take the time to explain the strategy and the reasons behind it. In fact, you’re going to be making pit stops along this route, rather than marathoning from start to finish: *“Here’s what we’re doing – and why we’re doing it.”*
Guess which path bears better results?
If you said #2, you’ve traveled both paths before – and experienced the results first-hand. Getting people on board with major changes beforehand is almost always the smarter choice.
IT leaders know as well as anyone that with significant change often comes [significant fear](https://enterprisersproject.com/article/2017/10/how-beat-fear-and-loathing-it-change), skepticism, and other challenges. It may be especially true with IT automation. The term alone sounds scary to some people, and it is often tied to misconceptions. Helping people understand the what, why, and how of your company’s automation strategy is a necessary step to achieving your goals associated with that strategy.
[ **Read our related article, **[ IT automation best practices: 7 keys to long-term success](https://enterprisersproject.com/article/2018/1/it-automation-best-practices-7-keys-long-term-success?sc_cid=70160000000h0aXAAQ). ]
With that in mind, we asked a variety of IT leaders for their advice on making the case for automation in your organization:
**1. Show people what’s in it for them**
Let’s face it: Self-interest and self-preservation are natural instincts. Tapping into that human tendency is a good way to get people on board: Show people how your automation strategy will benefit them and their jobs. Will automating a particular process in the software pipeline mean fewer middle-of-the-night calls for team members? Will it enable some people to dump low-skill, manual tasks in favor of more strategic, higher-order work – the sort that helps them take the next step in their career?
“Convey what’s in it for them, and how it will benefit clients and the whole company,” advises Vipul Nagrath, global CIO at [ADP](https://www.adp.com/). “Compare the current state to a brighter future state, where the company enjoys greater stability, agility, efficiency, and security.”
The same approach holds true when making the case outside of IT; just lighten up on the jargon when explaining the benefits to non-technical stakeholders, Nagrath says.
Setting up a before-and-after picture is a good storytelling device for helping people see the upside.
“You want to paint a picture of the current state that people can relate to,” Nagrath says. “Present what’s working, but also highlight what’s causing teams to be less than agile.” Then explain how automating certain processes will improve that current state.
**2. Connect automation to specific business goals**
Part of making a strong case entails making sure people understand that you’re not just trend-chasing. If you’re automating simply for the sake of automating, people will sniff that out and become more resistant – perhaps especially within IT.
“The case for automation needs to be driven by a business demand signal, such as revenue or operating expense,” says David Emerson, VP and deputy CISO at [Cyxtera](https://www.cyxtera.com/). “No automation endeavor is self-justifying, and no technical feat, generally, should be a means unto itself, unless it’s a core competency of the company.”
Like Nagrath, Emerson recommends promoting the incentives associated with achieving the business goals of automation, and working toward these goals (and corresponding incentives) in an iterative, step-by-step fashion.
**3. Break the automation plan into manageable pieces**
Even if your automation strategy is literally “automate everything,” that’s a tough sell (and probably unrealistic) for most organizations. You’ll make a stronger case with a plan that approaches automation manageable piece by manageable piece, and that enables greater flexibility to adapt along the way.
“When making a case for automation, I recommend clearly illustrating the incentive to move to an automated process, and allowing iteration toward that goal to introduce and prove the benefits at lower risk,” Emerson says.
Sergey Zuev, founder at [GA Connector](http://gaconnector.com/), shares an in-the-trenches account of why automating incrementally is crucial – and how it will help you build a stronger, longer-lasting argument for your strategy. Zuev should know: His company’s tool automates the import of data from CRM applications into Google Analytics. But it was actually the company’s internal experience automating its own customer onboarding process that led to a lightbulb moment.
“At first, we tried to build the whole onboarding funnel at once, and as a result, the project dragged [on] for months,” Zuev says. “After realizing that it [was] going nowhere, we decided to select small chunks that would have the biggest immediate effect, and start with that. As a result, we managed to implement one of the email sequences in just a week, and are already reaping the benefits of the desecrated manual effort.”
**4. Sell the big-picture benefits too**
A step-by-step approach does not preclude painting a bigger picture. Just as it’s a good idea to make the case at the individual or team level, it’s also a good idea for help people understand the company-wide benefits.
Eric Kaplan, CTO at [AHEAD](https://www.thinkahead.com/), agrees that using small wins to show automation’s value is a smart strategy for winning people over. But the value those so-called “small” wins reveal can actually help you sharpen the big picture for people. Kaplan points to the value of individual and organizational time as an area everyone can connect with easily.
“The best place to do this is where you can show savings in terms of time,” Kaplan says. “If we can accelerate the time it takes for the business to get what it needs, it will silence the skeptics.”
Time and scalability are powerful benefits business and IT colleagues, both charged with growing the business, can grasp.
“The result of automation is scalability – less effort per person to maintain and grow your IT environment, as [Red Hat](https://www.redhat.com/en?intcmp=701f2000000tjyaAAA) VP, Global Services John Allessio recently [noted](https://enterprisersproject.com/article/2017/12/what-devops-teams-really-need-cio). “If adding manpower is the only way to grow your business, then scalability is a pipe dream. Automation reduces your manpower requirements and provides the flexibility required for continued IT evolution.” (See his full article, [What DevOps teams really need from a CIO](https://enterprisersproject.com/article/2017/12/what-devops-teams-really-need-cio).)
**5. Promote the heck out of your results**
At the outset of your automation strategy, you’ll likely be making the case based on goals and the *anticipated* benefits of achieving those goals. But as your automation strategy evolves, there’s no case quite as convincing as one grounded in real-world results.
“Seeing is believing,” says Nagrath, ADP’s CIO. “Nothing quiets skeptics like a track record of delivery.”
That means, of course, not only achieving your goals, but also doing so on time – another good reason for the iterative, step-by-step approach.
While quantitative results such as percentage improvements or cost savings can speak loudly, Nagrath advises his fellow IT leaders not to stop there when telling your automation story.
“Making a case for automation is also a qualitative discussion, where we can promote the issues prevented, overall business continuity, reductions in failures/errors, and associates taking on [greater] responsibility as they tackle more value-added tasks.”
**Want more wisdom like this, IT leaders? Sign up for our weekly email newsletter.** |
9,722 | 最好的 Linux 工具献给老师和学生们 | https://www.linux.com/news/best-linux-tools-teachers-and-students | 2018-06-08T08:02:00 | [
"教育",
"教学"
] | https://linux.cn/article-9722-1.html | 
Linux 是一个适合每个人的平台。如果你有一份合适的工作,Linux 已经可以满足或超过它的需求,其中一个工作是教育。如果你是一名教师或一名学生,Linux 已经准备好帮助你在几乎任何级别的教育系统领域中畅游。从辅助学习、写作论文、管理课程,到管理整个机构,Linux 已经全部涵盖了。
如果你不确定,请让我介绍一下 Linux 准备好的一些工具。其中一些工具几乎没有学习曲线,而另一些工具则需要一个全面的系统管理员来安装、设置和管理。我们将从简单开始,然后到复杂。
### 学习辅助工具
每个人的学习方式都有所不同,每个班级都需要不同的学习类型和水平。幸运的是,Linux 有很多学习辅助工具。让我们来看几个例子:
闪卡 —— [KWordQuiz](https://edu.kde.org/kwordquiz/)(图 1)是适用于 Linux 平台的许多闪卡应用程序之一。KWordQuiz 使用 kvtml 文件格式,你可以下载大量预制的、人们贡献的文件。 KWordQuiz 是 KDE 桌面环境的一部分,但可以安装在其他桌面上(KDE 依赖文件将与闪卡应用程序一起安装)。

### 语言工具
由于全球化进程,外语已成为教育的重要组成部分。你会发现很多语言工具,包括 [Kiten](https://edu.kde.org/kiten/)(图 2)—— KDE 桌面的日语汉字浏览器。

如果日文不是你的母语,你可以试试 [Jargon Informatique](http://jargon.asher256.com/index.php)。这本词典完全是法文的,所以如果你对这门语言还不熟悉,你可能要需要 [Google 翻译](https://translate.google.com/)的帮助才能坚持下去。
### Writing Aids / Note Taking
Linux 拥有你需要的所有东西比如记录一个主题,撰写那些学期论文。让我们从记笔记开始。如果你熟悉 Microsoft OneNote,你一定会喜欢 [BasKet Note Pads](http://basket.kde.org/)。有了这个应用程序,你可以为主题创建<ruby> 笔记本 <rt> basket </rt></ruby>,并添加任何东西——注释、链接、图像、交叉引用(到其他笔记本─图 3)、应用程序启动器、从文件加载等等。

你可以创建任意形式的笔记本,可以移动元素来满足你的需求。如果你更喜欢有序的感觉,那么创建一个表状的 basket 来保留那些封装的笔记。
当然,所有 Linux 写作辅助工具都是由 [LibreOffice](http://www.libreoffice.com) 发展而来。LibreOffice 是大多数 Linux 发行版默认的办公套件,它能打开文本文档、电子表格、演示文稿、数据库、公式和绘图。
在教育环境中使用 LibreOffice 的一个警告是,你很可能不得不将文档以 MS Office 格式保存。
### 为教育而生的发行版
所有这些都是关于 Linux 面向学生的应用程序,你可以看看专门为教育而开发的一个发行版。最好的是 [Edubuntu](http://www.edubuntu.org/)。这种平易的 Linux 发行版旨在让 Linux 进入学校、家庭和社区。Edubuntu 使用默认的 Ubuntu 桌面(Unity shell)并添加以下软件:
* KDE 教育套件
* GCompris
* Celestia
* Tux4Kids
* Epoptes
* LTSP
* GBrainy
* 等等
Edubuntu 并不是唯一的发行版。如果你想测试其他特定于教育的 Linux 发行版,以下是简短列表:
* Debian-Edu
* Fedora Education Spin
* Guadalinux-Edu
* OpenSuse-Edu
* Qimo
* Uberstudent
### 课堂/机构管理
这是 Linux 平台真正闪耀的地方。有许多专门用于管理的工具。我们先来看看教室特有的工具。
[iTalc](http://italc.sourceforge.net/) 是一个强大的课堂教学环境。借助此工具,教师可以查看和控制学生桌面(支持 Linux 和 Windows)。iTalc 系统允许教师查看学生桌面上发生了什么,控制他们的桌面,锁定他们的桌面,对桌面演示,打开或关闭桌面,向学生桌面发送文本消息等等。
[aTutor](http://www.atutor.ca/)(图 4)是一个开源的学习管理系统(LMS),专注于开发在线课程和电子学习内容。一个老师真正发挥的就是创建和管理在线考试和测验。当然,aTutor 不限于测试的目的,有了这个强大的软件,学生和老师可以享受:
* 社交网络
* 配置文件
* 消息
* 自适应导航
* 工作组
* 文件存储
* 小组博客
* 以及更多。

课程资料易于创建和部署(你甚至可以将考试/测验分配给特定的学习小组)。
[Moodle](https://moodle.org/) 是目前使用最广泛的教育管理软件之一。通过 Moodle,你可以管理、教授、学习甚至参与孩子的教育。这个强大的软件为教师和学生、考试、日历、论坛、文件管理、课程管理(图 5)、通知、进度跟踪、大量注册、批量课程创建、考勤等提供协作工具。

[OpenSIS](http://www.opensis.com/) 意即开源学生信息系统,在管理你的教育机构方面做得很好。有一个免费的社区版,但即使使用付费版本,你也可以期待将学区的拥有成本降低高达 75%(与专有解决方案相比)。
OpenSIS 包括以下特点或模块:
* 出席情况(图 6)
* 联系信息
* 学生人口统计
* 成绩簿
* 计划
* 健康记录
* 报告卡

OpenSIS 有四个版本,在[这里](http://www.opensis.com/compare_edition.php)查看它们的功能比较。
[vufind](http://vufind-org.github.io/vufind/) 是一个优秀的图书馆管理系统,允许学生和教师轻松浏览图书馆资源,例如:
* 目录记录
* 本地缓存期刊
* 数字图书馆项目
* 机构知识库
* 机构书目
* 其他图书馆集合和资源
Vufind 系统允许用户登录,通过认证的用户可以节省资源以便快速回忆,并享受“更像这样”的结果。
这份列表仅仅触及了 Linux 在教育领域可用性的一点皮毛。而且,正如你所期望的那样,每个工具都是高度可定制且开放源代码的 —— 所以如果软件不能精确地满足你的需求,那么你可以自由(在大多数情况下)修改源代码并进行更改。
Linux 与教育齐头并进。无论你是老师,学生还是管理员,你都会找到大量工具来帮助教育机构开放,灵活和强大。
---
via: <https://www.linux.com/news/best-linux-tools-teachers-and-students>
作者:[Jack Wallen](https://www.linux.com/users/jlwallen) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,723 | Pidgin:Skype for Business 的开源替代品 | https://opensource.com/article/18/4/pidgin-open-source-replacement-skype-business | 2018-06-06T21:46:54 | [
"Office",
"Pidgin",
"Skype"
] | https://linux.cn/article-9723-1.html |
>
> 用可以和 Office 365 协同工作的开源软件换下你的专有化的沟通软件。
>
>
>

技术正处在一个有趣的十字路口,Linux 统治服务器领域,但微软统治企业桌面。 Office 365、Skype for Business、Microsoft Teams、OneDrive、Outlook ......等等,这些是支配企业工作空间的是微软软件和服务。
如果你可以使用自由和开源程序替换该专有软件,并使其与你别无选择,但只能使用的 Office 365 的后端一起工作?是的,因为这正是我们要用 Pidgin 做的,它是 Skype 的开源替代品。
### 安装 Pidgin 和 SIPE
微软的 Office Communicator 变成了 Microsoft Lync,它成为我们今天所知的 Skype for Business。现在有针对 Linux 的[付费软件](https://tel.red/linux.php)提供了与 Skype for Business 相同的功能,但 [Pidgin](https://pidgin.im/) 是 GNU GPL 授权的、完全自由开源的选择。
Pidgin 可以在几乎每个 Linux 发行版的仓库中找到,因此,使用它不应该是一个问题。唯一不能在 Pidgin 中使用的 Skype 功能是屏幕共享,并且文件共享可能会失败,但有办法解决这个问题。
你还需要一个 [SIPE](http://sipe.sourceforge.net/) 插件,因为它是使 Pidgin 成为 Skype for Business 替代品的秘密武器的一部分。请注意,`sipe` 库在不同的发行版中有不同的名称。例如,库在 System76 的 Pop\_OS! 中是 `pidgin-sipe`,而在 Solus 3 仓库中是 `sipe`。
满足了先决条件,你可以开始配置 Pidgin。
### 配置 Pidgin
首次启动 Pidgin 时,点击 “Add” 添加一个新帐户。在基本选项卡(如下截图所示)中,选择 “Protocol” 下拉菜单中的 “Office Communicator”,然后在 “Username” 字段中输入你的“公司电子邮件地址”。

接下来,点击高级选项卡。在 “Server[:Port]” 字段中输入 “sipdir.online.lync.com:443”,在 “User Agent” 中输入 “UCCAPI/16.0.6965.5308 OC/16.0.6965.2117”。
你的高级选项卡现在应该如下所示:

你不需要对“Proxy”选项卡或“Voice and Video”选项卡进行任何更改。只要确定,请确保 “Proxy type” 设置为 “Use Global Proxy Settings”,并且在“Voice and Video”选项卡中,“Use silence suppression” 复选框为**取消选中**。


完成这些配置后,点击 “Add”,系统会提示你输入电子邮件帐户的密码。
### 添加联系人
要将联系人添加到好友列表,请点击**好友窗口**中的 “Manage Accounts”。将鼠标悬停在你的帐户上,然后选择 “Contact Search” 查找你的同事。如果您在使用姓氏和名字进行搜索时遇到任何问题,请尝试使用你同事的完整电子邮件地址进行搜索,你就会找到正确的人。
你现在已经开始使用 Skype for Business 替代产品,该产品可为你提供 98% 的功能,从你的桌面上消除专有软件。
---
via: <https://opensource.com/article/18/4/pidgin-open-source-replacement-skype-business>
作者:[Ray Shimko](https://opensource.com/users/shickmo) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Technology is at an interesting crossroads, where Linux rules the server landscape but Microsoft rules the enterprise desktop. Office 365, Skype for Business, Microsoft Teams, OneDrive, Outlook... the list goes on of Microsoft software and services that dominate the enterprise workspace.
What if you could replace that proprietary software with free and open source applications *and* make them work with an Office 365 backend you have no choice but to use? Buckle up, because that is exactly what we are going to do with Pidgin, an open source replacement for Skype.
## Installing Pidgin and SIPE
Microsoft's Office Communicator became Microsoft Lync which became what we know today as Skype for Business. There are [pay software options](https://tel.red/linux.php) for Linux that provide feature parity with Skype for Business, but [Pidgin](https://pidgin.im/) is a fully free and open source option licensed under the GNU GPL.
Pidgin can be found in just about every Linux distro's repository, so getting your hands on it should not be a problem. The only Skype feature that won't work with Pidgin is screen sharing, and file sharing can be a bit hit or miss—but there are ways to work around it.
You also need a [SIPE](http://sipe.sourceforge.net/) plugin, as it's part of the secret sauce to make Pidgin work as a Skype for Business replacement. Please note that the `sipe`
library has different names in different distros. For example, the library's name on System76's Pop_OS! is `pidgin-sipe`
while in the Solus 3 repo it is simply `sipe`
.
With the prerequisites out of the way, you can begin configuring Pidgin.
## Configuring Pidgin
When firing up Pidgin for the first time, click on **Add** to add a new account. In the Basic tab (shown in the screenshot below), select** Office Communicator** in the **Protocol** drop-down, then type your **business email address** in the **Username** field.
opensource.com
Next, click on the Advanced tab. In the **Server[****:Port****]** field enter **sipdir.online.lync.com:443** and in **User Agent** enter **UCCAPI/16.0.6965.5308 OC/16.0.6965.2117**.
Your Advanced tab should now look like this:
opensource.com
You shouldn't need to make any changes to the Proxy tab or the Voice and Video tab. Just to be certain, make sure **Proxy type** is set to **Use Global Proxy Settings** and in the Voice and Video tab, the **Use silence suppression** checkbox is **unchecked**.
opensource.com
opensource.com
After you've completed those configurations, click **Add,** and you'll be prompted for your email account's password.
## Adding contacts
To add contacts to your buddy list, click on **Manage Accounts** in the **Buddy Window**. Hover over your account and select **Contact Search** to look up your colleagues. If you run into any problems when searching by first and last name, try searching with your colleague's full email address, and you should always get the right person.
You are now up and running with a Skype for Business replacement that gives you about 98% of the functionality you need to banish the proprietary option from your desktop.
*Ray Shimko will be speaking about Linux in a Microsoft World at LinuxFest NW April 28-29. See program highlights or register to attend.*
## 7 Comments |
9,724 | Git 分支操作介绍 | https://opensource.com/article/18/5/git-branching | 2018-06-07T23:22:50 | [
"Git"
] | https://linux.cn/article-9724-1.html |
>
> 在这个 Git 入门系列的第三篇中,我们来学习一下如何添加和删除 Git 分支。
>
>
>

在本系列的前两篇文章中,我们[开始使用 Git](/article-9319-1.html),学会如何[克隆项目,修改、增加和删除内容](/article-9517-1.html)。在这第三篇文章中,我将介绍 Git 分支,为何以及如何使用分支。

不妨用树来描绘 Git 仓库。图中的树有很多分支,或长或短,或从树干延伸或从其它分支延伸。在这里,我们用树干比作仓库的 master 分支,其中 `master` 代指 ”master 分支”,是 Git 仓库的中心分支或第一个分支。为简单起见,我们假设 `master` 是树干,其它分支都是从该分支分出的。
### 为何在 Git 仓库中使用分支
使用分支的主要理由为:
* 如果你希望为项目增加新特性,但很可能会影响当前可正常工作的代码。对于该项目的活跃用户而言,这是很糟糕的事情。与其将特性加入到其它人正在使用的 `master` 分支,更好的方法是在仓库的其它分支中变更代码,下面会给出具体的工作方式。
* 更重要的是,[Git 其设计](https://en.wikipedia.org/wiki/Git)用于协作。如果所有人都在你代码仓库的 `master` 分支上操作,会引发很多混乱。对编程语言或项目的知识和阅历因人而异;有些人可能会编写有错误或缺陷的代码,也可能会编写你觉得不适合该项目的代码。使用分支可以让你核验他人的贡献并选择适合的加入到项目中。(这里假设你是代码库唯一的所有者,希望对增加到项目中的代码有完全的控制。在真实的项目中,代码库有多个具有合并代码权限的所有者)
### 创建分支
让我们回顾[本系列上一篇文章](/article-9517-1.html),看一下在我们的 Demo 目录中分支是怎样的。如果你没有完成上述操作,请按照文章中的指示从 GitHub 克隆代码并进入 Demo 目录。运行如下命令:
```
pwd
git branch
ls -la
```
`pwd` 命令(是当前工作目录的英文缩写)返回当前你所处的目录(以便确认你在 `Demo` 目录中),`git branch` 列出该项目在你主机上的全部分支,`ls -la` 列出当前目录下的所有文件。你的终端输出类似于:

在 `master` 分支中,只有一个文件 `README.md`。(Git 会友好地忽略掉其它目录和文件。)
接下来,运行如下命令:
```
git status
git checkout -b myBranch
git status
```
第一条命令 `git status` 告知你当前位于 `branch master`,(就像在终端中看到的那样)它与 `origin/master` 处于同步状态,这意味着 master 分支的本地副本中的全部文件也出现在 GitHub 中。两份副本没有差异,所有的提交也是一致的。
下一条命令 `git checkout -b myBranch` 中的 `-b` 告知 Git 创建一个名为 `myBranch` 的新分支,然后 `checkout` 命令将我们切换到新创建的分支。运行第三条命令 `git status` 确保你已经位于刚创建的分支下。
如你所见,`git status` 告知你当前处于 `myBranch` 分支,没有变更需要提交。这是因为我们既没有增加新文件,也没有修改已有文件。

如果希望以可视化的方式查看分支,可以运行 `gitk` 命令。如果遇到报错 `bash: gitk: command not found...`,请先安装 `gitk` 软件包(找到你操作系统对应的安装文档,以获得安装方式)。
(LCTT 译注:需要在有 X 服务器的终端运行 `gitk`,否则会报错)
下图展示了我们在 Demo 项目中的所作所为:你最后一次提交(的对应信息)是 `Delete file.txt`,在此之前有三次提交。当前的提交用黄点标注,之前的提交用蓝点标注,黄点和 `Delete file.txt` 之间的三个方块展示每个分支所在的位置(或者说每个分支中的最后一次提交的位置)。由于 `myBranch` 刚创建,提交状态与 `master` 分支及其对应的记为 `remotes/origin/master` 的远程 `master` 分支保持一致。(非常感谢来自 Red Hat 的 [Peter Savage](https://opensource.com/users/psav) 让我知道 `gitk` 这个工具)

下面让我们在 `myBranch` 分支下创建一个新文件并观察终端输出。运行如下命令:
```
echo "Creating a newFile on myBranch" > newFile
cat newFile
git status
```
第一条命令中的 `echo` 创建了名为 `newFile` 的文件,接着 `cat newFile` 打印出文件内容,最后 `git status` 告知你我们 `myBranch` 分支的当前状态。在下面的终端输出中,Git 告知 `myBranch` 分支下有一个名为 `newFile` 的文件当前处于 `untracked` 状态。这表明我们没有让 Git 追踪发生在文件 `newFile` 上的变更。

下一步是增加文件,提交变更并将 `newFile` 文件推送至 `myBranch` 分支(请回顾本系列上一篇文章获得更多细节)。
```
git add newFile
git commit -m "Adding newFile to myBranch"
git push origin myBranch
```
在上述命令中,`push` 命令使用的分支参数为 `myBranch` 而不是 `master`。Git 添加 `newFile` 并将变更推送到你 GitHub 账号下的 Demo 仓库中,告知你在 GitHub 上创建了一个与你本地副本分支 `myBranch` 一样的新分支。终端输出截图给出了运行命令的细节及命令输出。

当你访问 GitHub 时,在分支选择的下拉列表中可以发现两个可供选择的分支。

点击 `myBranch` 切换到 `myBranch` 分支,你可以看到在此分支上新增的文件。

截至目前,我们有两个分支:一个是 `master` 分支,只有一个 `README.md` 文件;另一个是 `myBranch` 分支,有两个文件。
你已经知道如何创建分支了,下面我们再创建一个分支。输入如下命令:
```
git checkout master
git checkout -b myBranch2
touch newFile2
git add newFile2
git commit -m "Adding newFile2 to myBranch2"
git push origin myBranch2
```
我不再给出终端输出,需要你自己尝试,但你可以在 [GitHub 代码库](https://github.com/kedark3/Demo/tree/myBranch2) 中验证你的结果。
### 删除分支
由于我们增加了两个分支,下面删除其中的一个(`myBranch`),包括两步:
1. **删除本地分支** 你不能删除正在操作的分支,故切换到 `master` 分支 (或其它你希望保留的分支),命令及终端输出如下:

`git branch` 可以列出可用的分支,使用 `checkout` 切换到 `master` 分支,然后使用 `git branch -D myBranch` 删除该分支。再次运行 `git branch` 检查是否只剩下两个分支(而不是三个)。
2. **删除 GitHub 上的分支** 使用如下命令删除 `myBranch` 的远程分支:
```
git push origin :myBranch
```

上面 `push` 命令中分支名称前面的冒号(`:`)告知 GitHub 删除分支。另一种写法为:
```
git push -d origin myBranch
```
其中 `-d` (也可以用 `--delete`) 也用于告知 GitHub 删除你的分支。
我们学习了 Git 分支的使用,在本系列的下一篇文章中,我们将介绍如何执行 `fetch` 和 `rebase` 操作,对于多人同时的贡献的项目而言,这是很必须学会的。
---
via: <https://opensource.com/article/18/5/git-branching>
作者:[Kedar Vijay Kulkarni](https://opensource.com/users/kkulkarn) 选题:[lujun9972](https://github.com/lujun9972) 译者:[pinewall](https://github.com/pinewall) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In my two previous articles in this series, we [started using Git](https://opensource.com/article/18/1/step-step-guide-git) and learned how to [clone, modify, add, and delete](https://opensource.com/article/18/2/how-clone-modify-add-delete-git-files) Git files. In this third installment, we'll explore Git branching and why and how it is used.
Picture this tree as a Git repository. It has a lot of branches, long and short, stemming from the trunk and stemming from other branches. Let's say the tree's trunk represents a master branch of our repo. I will use `master`
in this article as an alias for "master branch"—i.e., the central or first branch of a repo. To simplify things, let's assume that the `master`
is a tree trunk and the other branches start from it.
## Why we need branches in a Git repo
The main reasons for having branches are:
- If you are creating a new feature for your project, there's a reasonable chance that adding it could break your working code. This would be very bad for active users of your project. It's better to start with a prototype, which you would want to design roughly in a different branch and see how it works, before you decide whether to add the feature to the repo's
`master`
for others to use. - Another, probably more important, reason is
[Git was made](https://en.wikipedia.org/wiki/Git)for collaboration. If everyone starts programming on top of your repo's`master`
branch, it will cause a lot of confusion. Everyone has different knowledge and experience (in the programming language and/or the project); some people may write faulty/buggy code or simply the kind of code/feature you may not want in your project. Using branches allows you to verify contributions and select which to add to the project. (This assumes you are the only owner of the repo and want full control of what code is added to it. In real-life projects, there are multiple owners with the rights to merge code in a repo.)
## Adding a branch
Let's go back to the [previous article in this series](https://opensource.com/article/18/2/how-clone-modify-add-delete-git-files) and see what branching in our *Demo* directory looks like. If you haven't yet done so, follow the instructions in that article to clone the repo from GitHub and navigate to *Demo*. Run the following commands:
```
pwd
git branch
ls -la
```
The `pwd`
command (which stands for present working directory) reports which directory you're in (so you can check that you're in *Demo*), `git branch`
lists all the branches on your computer in the *Demo* repository, and `ls -la`
lists all the files in the PWD. Now your terminal will look like this:
There's only one file, `README.md`
, on the branch master. (Kindly ignore the other directories and files listed.)
Next, run the following commands:
```
git status
git checkout -b myBranch
git status
```
The first command, `git status`
reports you are currently on `branch master`
, and (as you can see in the terminal screenshot below) it is up to date with `origin/master`
, which means all the files you have on your local copy of the branch master are also present on GitHub. There is no difference between the two copies. All commits are identical on both the copies as well.
The next command, `git checkout -b myBranch`
, `-b`
tells Git to create a new branch and name it `myBranch`
, and `checkout`
switches us to the newly created branch. Enter the third line, `git status`
, to verify you are on the new branch you just created.
As you can see below, `git status`
reports you are on branch `myBranch`
and there is nothing to commit. This is because there is neither a new file nor any modification in existing files.
If you want to see a visual representation of branches, run the command `gitk`
. If the computer complains `bash: gitk: command not found…`
, then install `gitk`
. (See documentation for your operating system for the install instructions.)
The image below reports what we've done in *Demo*: Your last commit was `Delete file.txt`
and there were three commits before that. The current commit is noted with a yellow dot, previous commits with blue dots, and the three boxes between the yellow dot and `Delete file.txt`
tell you where each branch is (i.e., what is the last commit on each branch). Since you just created `myBranch`
, it is on the same commit as `master`
and the remote counterpart of `master`
, namely `remotes/origin/master`
. (A big thanks to [Peter Savage](https://opensource.com/users/psav) from Red Hat who made me aware of `gitk`
.)
Now let's create a new file on our branch `myBranch`
and let's observe terminal output. ** **Run the following commands:
```
echo "Creating a newFile on myBranch" > newFile
cat newFile
git status
```
The first command, `echo`
, creates a file named `newFile`
, and `cat newFile`
shows what is written in it. `git status`
tells you the current status of our branch `myBranch`
. In the terminal screenshot below, Git reports there is a file called `newFile`
on `myBranch`
and `newFile`
is currently `untracked`
. That means Git has not been told to track any changes that happen to `newFile`
.
The next step is to add, commit, and push `newFile`
to `myBranch`
(go back to the last article in this series for more details).
```
git add newFile
git commit -m "Adding newFile to myBranch"
git push origin myBranch
```
In these commands, the branch in the `push`
command is `myBranch`
instead of `master`
. Git is taking `newFile`
, pushing it to your *Demo* repository in GitHub, and telling you it's created a new branch on GitHub that is identical to your local copy of `myBranch`
. The terminal screenshot below details the run of commands and its output.
If you go to GitHub, you can see there are two branches to pick from in the branch drop-down.
Switch to `myBranch`
by clicking on it, and you can see the file you added on that branch.
Now there are two different branches; one, `master`
, has a single file, `README.md`
, and the other, `myBranch`
, has two files.
Now that you know how to create a branch, let's create another branch. Enter the following commands:
```
git checkout master
git checkout -b myBranch2
touch newFile2
git add newFile2
git commit -m "Adding newFile2 to myBranch2"
git push origin myBranch2
```
I won't show this terminal output as I want you to try it yourself, but you are more than welcome to check out the [repository on GitHub](https://github.com/kedark3/Demo/tree/myBranch2).
## Deleting a branch
Since we've added two branches, let's delete one of them (`myBranch`
) using a two-step process.
**1. Delete the local copy of your branch:** Since you can't delete a branch you're on, switch to the `master`
branch (or another one you plan to keep) by running the commands shown in the terminal image below:
`git branch`
lists the available branches; `checkout`
changes to the `master`
branch and `git branch -D myBranch`
removes that branch. Run `git branch`
again to verify there are now only two branches (instead of three).
**2. Delete the branch from GitHub:** Delete the remote copy of `myBranch`
by running the following command:
`git push origin :myBranch`
The colon (`:`
) before the branch name in the `push`
command tells GitHub to delete the branch. Another option is:
`git push -d origin myBranch`
as `-d`
(or `--delete`
) also tells GitHub to remove your branch.
Now that we've learned about using Git branches, in the next article in this series we'll look at how to fetch and rebase branch operations. These are essential things to know when you are working on a project with multiple contributors.
## 2 Comments |
9,725 | GDPR 将如何影响开源社区? | https://opensource.com/article/18/4/gdpr-impact | 2018-06-07T23:52:49 | [
"GDPR"
] | https://linux.cn/article-9725-1.html |
>
> 许多组织正在争先恐后地了解隐私法的变化如何影响他们的工作。
>
>
>

2018 年 5 月 25 日,[<ruby> 通用数据保护条例 <rt> General Data Protection Regulation, GDPR </rt></ruby>](https://www.eugdpr.org/eugdpr.org.html) 开始生效。欧盟出台的该条例将在全球范围内对企业如何保护个人数据产生重大影响。影响也会波及到开源项目以及开源社区。
### GDPR 概述
GDPR 于 2016 年 4 月 14 日在欧盟议会通过,从 2018 年 5 月 25 日起开始生效。GDPR 用于替代 95/46/EC 号<ruby> 数据保护指令 <rt> Data Protection Directive </rt></ruby>,该指令被设计用于“协调欧洲各国数据隐私法,保护和授权全体欧盟公民的数据隐私,改变欧洲范围内企业处理数据隐私的方式”。
GDPR 目标是在当前日益数据驱动的世界中保护欧盟公民的个人数据。
### 它对谁生效
GDPR 带来的最大改变之一是影响范围的扩大。不管企业本身是否位于欧盟,只要涉及欧盟公民个人数据的处理,GDPR 就会对其生效。
大部分提及 GDPR 的网上文章关注销售商品或服务的公司,但关注影响范围时,我们也不要忘记开源项目。有几种不同的类型,包括运营开源社区的(营利性)软件公司和非营利性组织(例如,开源软件项目及其社区)。对于面向全球的社区,几乎总是会有欧盟居民加入其中。
如果一个面向全球的社区有对应的在线平台,包括网站、论坛和问题跟踪系统等,那么很可能会涉及欧盟居民的个人数据处理,包括姓名、邮箱地址甚至更多。这些处理行为都需要遵循 GDPR。
### GDPR 带来的改变及其影响
相比被替代的指令,GDPR 带来了[很多改变](https://www.eugdpr.org/key-changes.html),强化了对欧盟居民数据和隐私的保护。正如前文所说,一些改变给社区带来了直接的影响。我们来看看若干改变。
#### 授权
我们假设社区为成员提供论坛,网站中包含若干个用于注册的表单。要遵循 GDPR,你不能再使用冗长、无法辨识的隐私策略和条件条款。无论是每种特殊用途,在论坛注册或使用网站表单注册,你都需要获取明确的授权。授权必须是无条件的、具体的、通知性的以及无歧义的。
以表单为例,你需要提供一个复选框,处于未选中状态并给出个人数据用途的明确说明,一般是当前使用的隐私策略和条件条款附录的超链接。
#### 访问权
GDPR 赋予欧盟公民更多的权利。其中一项权利是向企业查询个人数据包括哪些,保存在哪里;如果<ruby> 数据相关人 <rt> data subject </rt></ruby>(例如欧盟公民)提出获取相应数据副本的需求,企业还应免费提供数字形式的数据。
#### 遗忘权
欧盟居民还从 GDPR 获得了“遗忘权”,即数据擦除。该权利是指,在一定限制条件下,企业必须删除个人数据,甚至可能停止其自身或第三方机构后续处理申请人的数据。
上述三种改变要求你的平台软件也要遵循 GDPR 的某些方面。需要提供特定的功能,例如获取并保存授权,提取数据并向数据相关人提供数字形式的副本,以及删除数据相关人对应的数据等。
#### 泄露通知
在 GDPR 看来,不经数据相关人授权情况下使用或偷取个人数据都被视为<ruby> 数据泄露 <rt> data breach </rt></ruby>。一旦发现,你应该在 72 小时内通知社区成员,除非这些个人数据不太可能给<ruby> 自然人 <rt> natural persons </rt></ruby>的权利与自由带来风险。GDPR 强制要求执行泄露通知。
#### 披露记录
企业负责提供一份记录,用于详细披露个人数据处理的过程和目的等。该记录用于证明企业遵从 GDPR 要求,维护了一份个人数据处理行为的记录;同时该记录也用于审计。
#### 罚款
不遵循 GDPR 的企业最高可面临全球年收入总额 4% 或 2000 万欧元 (取两者较大值)的罚款。根据 GDPR,“最高处罚针对严重的侵权行为,包括未经用户充分授权的情况下处理数据,以及违反设计理念中核心隐私部分”。
### 补充说明
本文不应用于法律建议或 GDPR 合规的指导书。我提到了可能对开源社区有影响的条约部分,希望引起大家对 GDPR 及其影响的关注。当然,条约包含了更多你需要了解和可能需要遵循的条款。
你自己也可能认识到,当运营一个面向全球的社区时,需要行动起来使其遵循 GDPR。如果在社区中,你已经遵循包括 ISO 27001,NIST 和 PCI DSS 在内的健壮安全标准,你已经先人一步。
可以从如下网站/资源中获取更多关于 GDPR 的信息:
* [GDPR 官网](https://www.eugdpr.org/eugdpr.org.html) (欧盟提供)
* [官方条约 (欧盟) 2016/679](http://eur-lex.europa.eu/legal-content/EN/TXT/?qid=1520531479111&uri=CELEX:32016R0679) (GDPR,包含翻译)
* [GDPR 是什么? 领导人需要知道的 8 件事](https://enterprisersproject.com/article/2018/4/what-gdpr-8-things-leaders-should-know) (企业人项目)
* [如何规避 GDPR 合规审计:最佳实践](https://enterprisersproject.com/article/2017/9/avoiding-gdpr-compliance-audit-best-practices) (企业人项目)
### 关于作者
Robin Muilwijk 是一名互联网和电子政务顾问,在 Red Hat 旗下在线发布平台 Opensource.com 担任社区版主,在 Open Organization 担任大使。此外,Robin 还是 eZ 社区董事会成员,[eZ 系统](http://ez.no) 社区的管理员。Robin 活跃在社交媒体中,促进和支持商业和生活领域的开源项目。可以在 Twitter 上关注 [Robin Muilwijk](https://opensource.com/users/robinmuilwijk) 以获取更多关于他的信息。[更多关于我的信息](https://opensource.com/users/robinmuilwijk)
---
via: <https://opensource.com/article/18/4/gdpr-impact>
作者: [Robin Muilwijk](https://opensource.com/users/robinmuilwijk) 选题者: [lujun9972](https://github.com/lujun9972) 译者: [pinewall](https://github.com/pinewall) 校对: [wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | On May 25, 2018 the [General Data Protection Regulation](https://www.eugdpr.org/eugdpr.org.html) will go into effect. This new regulation by the European Union will impact how organizations need to protect personal data on a global scale. This could include open source projects, including communities.
## GDPR details
The General Data Protection Regulation (GDPR) was approved by the EU Parliament on April 14, 2016, and will be enforced beginning May 25, 2018. The GDPR replaces the Data Protection Directive 95/46/EC that was designed "to harmonize data privacy laws across Europe, to protect and empower all EU citizens data privacy and to reshape the way organizations across the region approach data privacy."
The aim of the GDPR is to protect the personal data of individuals in the EU in an increasingly data-driven world.
## To whom does it apply
One of the biggest changes that comes with the GDPR is an increased territorial scope. The GDPR applies to all organizations processing the personal data of data subjects residing in the European Union, irrelevant to its location.
While most of the online articles covering the GDPR mention companies selling goods or services, we can also look at this territorial scope with open source projects in mind. There are a few variations, such as a software company (profit) running a community, and a non-profit organization, i.e. an open source software project and its community. Once these communities are run on a global scale, it is most likely that EU-based persons are taking part in this community.
When such a global community has an online presence, using platforms such as a website, forum, issue tracker etcetera, it is very likely that they are processing personal data of these EU persons, such as their names, e-mail addresses and possibly even more. These activities will trigger a need to comply with the GDPR.
## GDPR changes and its impact
The GDPR brings [many changes](https://www.eugdpr.org/key-changes.html), strengthening data protection and privacy of EU persons, compared to the previous Directive. Some of these changes have a direct impact on a community as described earlier. Let's look at some of these changes.
### Consent
Let's assume that the community in question uses a forum for its members, and also has one or more forms on their website for registration purposes. With the GDPR you will no longer be able to use one lengthy and illegible privacy policy and terms of conditions. For each of those specific purposes, registering on the forum, and on one of those forms, you will need to obtain explicit consent. This consent must be “freely given, specific, informed, and unambiguous.”
In case of such a form, you could have a checkbox, which should not be pre-checked, with clear text indicating for which purposes the personal data is used, preferably linking to an ‘addendum’ of your existing privacy policy and terms of use.
### Right to access
EU persons get expanded rights by the GDPR. One of them is the right to ask an organization if, where and which personal data is processed. Upon request, they should also be provided with a copy of this data, free of charge, and in an electronic format if this data subject (e.g. EU citizen) asks for it.
### Right to be forgotten
Another right EU citizens get through the GDPR is the "right to be forgotten," also known as data erasure. This means that subject to certain limitation, the organization will have to erase his/her data, and possibly even stop any further processing, including by the organization’s third parties.
The above three changes imply that your platform(s) software will need to comply with certain aspects of the GDPR as well. It will need to have specific features such as obtaining and storing consent, extracting data and providing a copy in electronic format to a data subject, and finally the means to erase specific data about a data subject.
### Breach notification
Under the GDPR, a data breach occurs whenever personal data is taken or stolen without the authorization of the data subject. Once discovered, you should notify your affected community members within 72 hours unless the personal data breach is unlikely to result in a risk to the rights and freedoms of natural persons. This breach notification is mandatory under the GDPR.
### Register
As an organization, you will become responsible for keeping a register which will include detailed descriptions of all procedures, purposes etc for which you process personal data. This register will act as proof of the organization's compliance with the GDPR’s requirement to maintain a record of personal data processing activities, and will be used for audit purposes.
### Fines
Organizations that do not comply with the GDPR risk fines up to 4% of annual global turnover or €20 million (whichever is greater). According to the GDPR, "this is the maximum fine that can be imposed for the most serious infringements e.g.not having sufficient customer consent to process data or violating the core of Privacy by Design concepts."
## Final words
My article should not be used as legal advice or a definite guide to GDPR compliance. I have covered some of the parts of the regulation that could be of impact to an open source community, raising awareness about the GDPR and its impact. Obviously, the regulation contains much more which you will need to know about and possibly comply with.
As you can probably conclude yourself, you will have to take steps when you are running a global community, to comply with the GDPR. If you already apply robust security standards in your community, such as ISO 27001, NIST or PCI DSS, you should have a head start.
You can find more information about the GDPR at the following sites/resources:
-
[GDPR Portal](https://www.eugdpr.org/eugdpr.org.html)(by the EU) -
[Official Regulation (EU) 2016/679](http://eur-lex.europa.eu/legal-content/EN/TXT/?qid=1520531479111&uri=CELEX:32016R0679)(GDPR, including translations) -
[What is GDPR? 8 things leaders should know](https://enterprisersproject.com/article/2018/4/what-gdpr-8-things-leaders-should-know)(The Enterprisers Project) -
[How to avoid a GDPR compliance audit: Best practices](https://enterprisersproject.com/article/2017/9/avoiding-gdpr-compliance-audit-best-practices)(The Enterprisers Project)
## Comments are closed. |
9,726 | 一些常见的并发编程错误 | https://go101.org/article/concurrent-common-mistakes.html | 2018-06-08T00:52:05 | [
"Go",
"并发",
"协程"
] | https://linux.cn/article-9726-1.html | 
Go 是一个内置支持并发编程的语言。借助使用 `go` 关键字去创建<ruby> 协程 <rt> goroutine </rt></ruby>(轻量级线程)和在 Go 中提供的 [使用](https://go101.org/article/channel-use-cases.html) [信道](https://go101.org/article/channel.html) 和 [其它的并发](https://go101.org/article/concurrent-atomic-operation.html) [同步方法](https://go101.org/article/concurrent-synchronization-more.html),使得并发编程变得很容易、很灵活和很有趣。
另一方面,Go 并不会阻止一些因 Go 程序员粗心大意或者缺乏经验而造成的并发编程错误。在本文的下面部分将展示一些在 Go 编程中常见的并发编程错误,以帮助 Go 程序员们避免再犯类似的错误。
### 需要同步的时候没有同步
代码行或许 [不是按出现的顺序运行的](https://go101.org/article/memory-model.html)。
在下面的程序中有两个错误。
* 第一,在 `main` 协程中读取 `b` 和在新的 协程 中写入 `b` 可能导致数据争用。
* 第二,条件 `b == true` 并不能保证在 `main` 协程 中的 `a != nil`。在新的协程中编译器和 CPU 可能会通过 [重排序指令](https://go101.org/article/memory-model.html) 进行优化,因此,在运行时 `b` 赋值可能发生在 `a` 赋值之前,在 `main` 协程 中当 `a` 被修改后,它将会让部分 `a` 一直保持为 `nil`。
```
package main
import (
"time"
"runtime"
)
func main() {
var a []int // nil
var b bool // false
// a new goroutine
go func () {
a = make([]int, 3)
b = true // write b
}()
for !b { // read b
time.Sleep(time.Second)
runtime.Gosched()
}
a[0], a[1], a[2] = 0, 1, 2 // might panic
}
```
上面的程序或者在一台计算机上运行的很好,但是在另一台上可能会引发异常。或者它可能运行了 *N* 次都很好,但是可能在第 *(N+1)* 次引发了异常。
我们将使用 `sync` 标准包中提供的信道或者同步方法去确保内存中的顺序。例如,
```
package main
func main() {
var a []int = nil
c := make(chan struct{})
// a new goroutine
go func () {
a = make([]int, 3)
c <- struct{}{}
}()
<-c
a[0], a[1], a[2] = 0, 1, 2
}
```
### 使用 `time.Sleep` 调用去做同步
我们先来看一个简单的例子。
```
package main
import (
"fmt"
"time"
)
func main() {
var x = 123
go func() {
x = 789 // write x
}()
time.Sleep(time.Second)
fmt.Println(x) // read x
}
```
我们预期程序将打印出 `789`。如果我们运行它,通常情况下,它确定打印的是 `789`。但是,这个程序使用的同步方式好吗?No!原因是 Go 运行时并不保证 `x` 的写入一定会发生在 `x` 的读取之前。在某些条件下,比如在同一个操作系统上,大部分 CPU 资源被其它运行的程序所占用的情况下,写入 `x` 可能就会发生在读取 `x` 之后。这就是为什么我们在正式的项目中,从来不使用 `time.Sleep` 调用去实现同步的原因。
我们来看一下另外一个示例。
```
package main
import (
"fmt"
"time"
)
var x = 0
func main() {
var num = 123
var p = &num
c := make(chan int)
go func() {
c <- *p + x
}()
time.Sleep(time.Second)
num = 789
fmt.Println(<-c)
}
```
你认为程序的预期输出是什么?`123` 还是 `789`?事实上它的输出与编译器有关。对于标准的 Go 编译器 1.10 来说,这个程序很有可能输出是 `123`。但是在理论上,它可能输出的是 `789`,或者其它的随机数。
现在,我们来改变 `c <- *p + x` 为 `c <- *p`,然后再次运行这个程序。你将会发现输出变成了 `789` (使用标准的 Go 编译器 1.10)。这再次说明它的输出是与编译器相关的。
是的,在上面的程序中存在数据争用。表达式 `*p` 可能会被先计算、后计算、或者在处理赋值语句 `num = 789` 时计算。`time.Sleep` 调用并不能保证 `*p` 发生在赋值语句处理之前进行。
对于这个特定的示例,我们将在新的协程创建之前,将值保存到一个临时值中,然后在新的协程中使用临时值去消除数据争用。
```
...
tmp := *p + x
go func() {
c <- tmp
}()
...
```
### 使协程挂起
挂起协程是指让协程一直处于阻塞状态。导致协程被挂起的原因很多。比如,
* 一个协程尝试从一个 nil 信道中或者从一个没有其它协程给它发送值的信道中检索数据。
* 一个协程尝试去发送一个值到 nil 信道,或者发送到一个没有其它的协程接收值的信道中。
* 一个协程被它自己死锁。
* 一组协程彼此死锁。
* 当运行一个没有 `default` 分支的 `select` 代码块时,一个协程被阻塞,以及在 `select` 代码块中 `case` 关键字后的所有信道操作保持阻塞状态。
除了有时我们为了避免程序退出,特意让一个程序中的 `main` 协程保持挂起之外,大多数其它的协程挂起都是意外情况。Go 运行时很难判断一个协程到底是处于挂起状态还是临时阻塞。因此,Go 运行时并不会去释放一个挂起的协程所占用的资源。
在 [谁先响应谁获胜](https://go101.org/article/channel-use-cases.html#first-response-wins) 的信道使用案例中,如果使用的 future 信道容量不够大,当尝试向 Future 信道发送结果时,一些响应较慢的信道将被挂起。比如,如果调用下面的函数,将有 4 个协程处于永远阻塞状态。
```
func request() int {
c := make(chan int)
for i := 0; i < 5; i++ {
i := i
go func() {
c <- i // 4 goroutines will hang here.
}()
}
return <-c
}
```
为避免这 4 个协程一直处于挂起状态, `c` 信道的容量必须至少是 `4`。
在 [实现谁先响应谁获胜的第二种方法](https://go101.org/article/channel-use-cases.html#first-response-wins-2) 的信道使用案例中,如果将 future 信道用做非缓冲信道,那么有可能这个信息将永远也不会有响应而挂起。例如,如果在一个协程中调用下面的函数,协程可能会挂起。原因是,如果接收操作 `<-c` 准备就绪之前,五个发送操作全部尝试发送,那么所有的尝试发送的操作将全部失败,因此那个调用者协程将永远也不会接收到值。
```
func request() int {
c := make(chan int)
for i := 0; i < 5; i++ {
i := i
go func() {
select {
case c <- i:
default:
}
}()
}
return <-c
}
```
将信道 `c` 变成缓冲信道将保证五个发送操作中的至少一个操作会发送成功,这样,上面函数中的那个调用者协程将不会被挂起。
### 在 `sync` 标准包中拷贝类型值
在实践中,`sync` 标准包中的类型值不会被拷贝。我们应该只拷贝这个值的指针。
下面是一个错误的并发编程示例。在这个示例中,当调用 `Counter.Value` 方法时,将拷贝一个 `Counter` 接收值。作为接收值的一个字段,`Counter` 接收值的各个 `Mutex` 字段也会被拷贝。拷贝不是同步发生的,因此,拷贝的 `Mutex` 值可能会出错。即便是没有错误,拷贝的 `Counter` 接收值的访问保护也是没有意义的。
```
import "sync"
type Counter struct {
sync.Mutex
n int64
}
// This method is okay.
func (c *Counter) Increase(d int64) (r int64) {
c.Lock()
c.n += d
r = c.n
c.Unlock()
return
}
// The method is bad. When it is called, a Counter
// receiver value will be copied.
func (c Counter) Value() (r int64) {
c.Lock()
r = c.n
c.Unlock()
return
}
```
我们只需要改变 `Value` 接收类型方法为指针类型 `*Counter`,就可以避免拷贝 `Mutex` 值。
在官方的 Go SDK 中提供的 `go vet` 命令将会报告潜在的错误值拷贝。
### 在错误的地方调用 `sync.WaitGroup` 的方法
每个 `sync.WaitGroup` 值维护一个内部计数器,这个计数器的初始值为 0。如果一个 `WaitGroup` 计数器的值是 0,调用 `WaitGroup` 值的 `Wait` 方法就不会被阻塞,否则,在计数器值为 0 之前,这个调用会一直被阻塞。
为了让 `WaitGroup` 值的使用有意义,当一个 `WaitGroup` 计数器值为 0 时,必须在相应的 `WaitGroup` 值的 `Wait` 方法调用之前,去调用 `WaitGroup` 值的 `Add` 方法。
例如,下面的程序中,在不正确位置调用了 `Add` 方法,这将使最后打印出的数字不总是 `100`。事实上,这个程序最后打印的数字可能是在 `[0, 100)` 范围内的一个随意数字。原因就是 `Add` 方法的调用并不保证一定会发生在 `Wait` 方法调用之前。
```
package main
import (
"fmt"
"sync"
"sync/atomic"
)
func main() {
var wg sync.WaitGroup
var x int32 = 0
for i := 0; i < 100; i++ {
go func() {
wg.Add(1)
atomic.AddInt32(&x, 1)
wg.Done()
}()
}
fmt.Println("To wait ...")
wg.Wait()
fmt.Println(atomic.LoadInt32(&x))
}
```
为让程序的表现符合预期,在 `for` 循环中,我们将把 `Add` 方法的调用移动到创建的新协程的范围之外,修改后的代码如下。
```
...
for i := 0; i < 100; i++ {
wg.Add(1)
go func() {
atomic.AddInt32(&x, 1)
wg.Done()
}()
}
...
```
### 不正确使用 futures 信道
在 [信道使用案例](https://go101.org/article/channel-use-cases.html) 的文章中,我们知道一些函数将返回 [futures 信道](https://go101.org/article/channel-use-cases.html#future-promise)。假设 `fa` 和 `fb` 就是这样的两个函数,那么下面的调用就使用了不正确的 future 参数。
```
doSomethingWithFutureArguments(<-fa(), <-fb())
```
在上面的代码行中,两个信道接收操作是顺序进行的,而不是并发的。我们做如下修改使它变成并发操作。
```
ca, cb := fa(), fb()
doSomethingWithFutureArguments(<-c1, <-c2)
```
### 没有等协程的最后的活动的发送结束就关闭信道
Go 程序员经常犯的一个错误是,还有一些其它的协程可能会发送值到以前的信道时,这个信道就已经被关闭了。当这样的发送(发送到一个已经关闭的信道)真实发生时,将引发一个异常。
这种错误在一些以往的著名 Go 项目中也有发生,比如在 Kubernetes 项目中的 [这个 bug](https://github.com/kubernetes/kubernetes/pull/45291/files?diff=split) 和 [这个 bug](https://github.com/kubernetes/kubernetes/pull/39479/files?diff=split)。
如何安全和优雅地关闭信道,请阅读 [这篇文章](https://go101.org/article/channel-closing.html)。
### 在值上做 64 位原子操作时没有保证值地址 64 位对齐
到目前为止(Go 1.10),在标准的 Go 编译器中,在一个 64 位原子操作中涉及到的值的地址要求必须是 64 位对齐的。如果没有对齐则导致当前的协程异常。对于标准的 Go 编译器来说,这种失败仅发生在 32 位的架构上。请阅读 [内存布局](https://go101.org/article/memory-layout.html) 去了解如何在一个 32 位操作系统上保证 64 位对齐。
### 没有注意到大量的资源被 `time.After` 函数调用占用
在 `time` 标准包中的 `After` 函数返回 [一个延迟通知的信道](https://go101.org/article/channel-use-cases.html#timer)。这个函数在某些情况下用起来很便捷,但是,每次调用它将创建一个 `time.Timer` 类型的新值。这个新创建的 `Timer` 值在通过传递参数到 `After` 函数指定期间保持激活状态,如果在这个期间过多的调用了该函数,可能会有太多的 `Timer` 值保持激活,这将占用大量的内存和计算资源。
例如,如果调用了下列的 `longRunning` 函数,将在一分钟内产生大量的消息,然后在某些周期内将有大量的 `Timer` 值保持激活,即便是大量的这些 `Timer` 值已经没用了也是如此。
```
import (
"fmt"
"time"
)
// The function will return if a message arrival interval
// is larger than one minute.
func longRunning(messages <-chan string) {
for {
select {
case <-time.After(time.Minute):
return
case msg := <-messages:
fmt.Println(msg)
}
}
}
```
为避免在上述代码中创建过多的 `Timer` 值,我们将使用一个单一的 `Timer` 值去完成同样的任务。
```
func longRunning(messages <-chan string) {
timer := time.NewTimer(time.Minute)
defer timer.Stop()
for {
select {
case <-timer.C:
return
case msg := <-messages:
fmt.Println(msg)
if !timer.Stop() {
<-timer.C
}
}
// The above "if" block can also be put here.
timer.Reset(time.Minute)
}
}
```
### 不正确地使用 `time.Timer` 值
在最后,我们将展示一个符合语言使用习惯的 `time.Timer` 值的使用示例。需要注意的一个细节是,那个 `Reset` 方法总是在停止或者 `time.Timer` 值释放时被使用。
在 `select` 块的第一个 `case` 分支的结束部分,`time.Timer` 值被释放,因此,我们不需要去停止它。但是必须在第二个分支中停止定时器。如果在第二个分支中 `if` 代码块缺失,它可能至少在 `Reset` 方法调用时,会(通过 Go 运行时)发送到 `timer.C` 信道,并且那个 `longRunning` 函数可能会早于预期返回,对于 `Reset` 方法来说,它可能仅仅是重置内部定时器为 0,它将不会清理(耗尽)那个发送到 `timer.C` 信道的值。
例如,下面的程序很有可能在一秒内而不是十秒时退出。并且更重要的是,这个程序并不是 DRF 的(LCTT 译注:data race free,多线程程序的一种同步程度)。
```
package main
import (
"fmt"
"time"
)
func main() {
start := time.Now()
timer := time.NewTimer(time.Second/2)
select {
case <-timer.C:
default:
time.Sleep(time.Second) // go here
}
timer.Reset(time.Second * 10)
<-timer.C
fmt.Println(time.Since(start)) // 1.000188181s
}
```
当 `time.Timer` 的值不再被其它任何一个东西使用时,它的值可能被停留在一种非停止状态,但是,建议在结束时停止它。
在多个协程中如果不按建议使用 `time.Timer` 值并发,可能会有 bug 隐患。
我们不应该依赖一个 `Reset` 方法调用的返回值。`Reset` 方法返回值的存在仅仅是为了兼容性目的。
---
via: <https://go101.org/article/concurrent-common-mistakes.html>
作者:<go101.org> 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Go is a language supporting built-in concurrent programming.
By using the `go`
keyword to create goroutines (light weight threads)
and by [using](channel-use-cases.html)
[channels](channel.html) and
[other concurrency](concurrent-atomic-operation.html)
[synchronization techniques](concurrent-synchronization-more.html)
provided in Go, concurrent programming becomes easy, flexible and enjoyable.
On the other hand, Go doesn't prevent Go programmers from making some concurrent programming mistakes which are caused by either carelessness or lacking of experience. The remaining of the current article will show some common mistakes in Go concurrent programming, to help Go programmers avoid making such mistakes.
Code lines might be [not executed by their appearance order](memory-model.html).
`b`
in the main goroutine and the write
of `b`
in the new goroutine might cause data races.
`b == true`
can't ensure
that `a != nil`
in the main goroutine.
Compilers and CPUs may make optimizations by
`b`
may happen
before the assignment of `a`
at run time,
which makes that slice `a`
is still `nil`
when the elements of `a`
are modified in the main goroutine.
```
package main
import (
"time"
"runtime"
)
func main() {
var a []int // nil
var b bool // false
// a new goroutine
go func () {
a = make([]int, 3)
b = true // write b
}()
for !b { // read b
time.Sleep(time.Second)
runtime.Gosched()
}
a[0], a[1], a[2] = 0, 1, 2 // might panic
}
```
The above program may run well on one computer, but may panic on another one, or it runs well when it is compiled by one compiler, but panics when another compiler is used.
We should use channels or the synchronization techniques provided in the`sync`
standard package to ensure the memory orders.
For example,
```
package main
func main() {
var a []int = nil
c := make(chan struct{})
go func () {
a = make([]int, 3)
c <- struct{}{}
}()
<-c
// The next line will not panic for sure.
a[0], a[1], a[2] = 0, 1, 2
}
```
`time.Sleep`
Calls to Do Synchronizations```
package main
import (
"fmt"
"time"
)
func main() {
var x = 123
go func() {
x = 789 // write x
}()
time.Sleep(time.Second)
fmt.Println(x) // read x
}
```
We expect this program to print `789`
.
In fact, it really prints `789`
, almost always, in running.
But is it a program with good synchronization?
No! The reason is Go runtime doesn't guarantee the write of `x`
happens before the read of `x`
for sure.
Under certain conditions, such as most CPU resources are consumed by
some other computation-intensive programs running on the same OS,
the write of `x`
might happen after the read of `x`
.
This is why we should never use `time.Sleep`
calls to do
synchronizations in formal projects.
```
package main
import (
"fmt"
"time"
)
func main() {
var n = 123
c := make(chan int)
go func() {
c <- n + 0
}()
time.Sleep(time.Second)
n = 789
fmt.Println(<-c)
}
```
What do you expect the program will output? `123`
, or `789`
?
In fact, the output is compiler dependent.
For the standard Go compiler 1.22.n,
it is very possible the program will output `123`
.
But in theory, it might also output `789`
.
Now, let's change `c <- n + 0`
to `c <- n`
and run the program again, you will find the output becomes to `789`
(for the standard Go compiler 1.22.n).
Again, the output is compiler dependent.
Yes, there are data races in the above program.
The expression `n`
might be evaluated before, after, or when
the assignment statement `n = 789`
is processed.
The `time.Sleep`
call can't guarantee the evaluation of
`n`
happens before the assignment is processed.
```
...
tmp := n
go func() {
c <- tmp
}()
...
```
`select`
code block
without `default`
branch, and all the channel operations
following the `case`
keywords in the `select`
code block keep blocking for ever.
Except sometimes we deliberately let the main goroutine in a program hanging to avoid the program exiting, most other hanging goroutine cases are unexpected. It is hard for Go runtime to judge whether or not a goroutine in blocking state is hanging or stays in blocking state temporarily, so Go runtime will never release the resources consumed by a hanging goroutine.
In the```
func request() int {
c := make(chan int)
for i := 0; i < 5; i++ {
i := i
go func() {
c <- i // 4 goroutines will hang here.
}()
}
return <-c
}
```
To avoid the four goroutines hanging, the capacity of channel `c`
must be at least `4`
.
```
func request() int {
c := make(chan int)
for i := 0; i < 5; i++ {
i := i
go func() {
select {
case c <- i:
default:
}
}()
}
return <-c // might hang here
}
```
The reason why the receiver goroutine might hang is that if the five try-send operations
all happen before the receive operation `<-c`
is ready,
then all the five try-send operations will fail to send values
so that the caller goroutine will never receive a value.
Changing the channel `c`
as a buffered channel will guarantee
at least one of the five try-send operations succeed so that the caller
goroutine will never hang in the above function.
`sync`
Standard Package
In practice, values of the types (except the `Locker`
interface values)
in the `sync`
standard package should never be copied.
We should only copy pointers of such values.
`Counter.Value`
method is called,
a `Counter`
receiver value will be copied.
As a field of the receiver value, the respective `Mutex`
field
of the `Counter`
receiver value will also be copied.
The copy is not synchronized, so the copied `Mutex`
value might be corrupted.
Even if it is not corrupted, what it protects is the use of
the copied field `n`
, which is meaningless generally.
```
import "sync"
type Counter struct {
sync.Mutex
n int64
}
// This method is okay.
func (c *Counter) Increase(d int64) (r int64) {
c.Lock()
c.n += d
r = c.n
c.Unlock()
return
}
// The method is bad. When it is called,
// the Counter receiver value will be copied.
func (c Counter) Value() (r int64) {
c.Lock()
r = c.n
c.Unlock()
return
}
```
We should change the receiver type of the `Value`
method to
the pointer type `*Counter`
to avoid copying `sync.Mutex`
values.
The `go vet`
command provided in Go Toolchain will report
potential bad value copies.
`sync.WaitGroup.Add`
Method at Wrong Places
Each `sync.WaitGroup`
value maintains a counter internally,
The initial value of the counter is zero.
If the counter of a `WaitGroup`
value is zero,
a call to the `Wait`
method of the `WaitGroup`
value
will not block, otherwise, the call blocks until the counter value becomes zero.
To make the uses of `WaitGroup`
value meaningful,
when the counter of a `WaitGroup`
value is zero,
the next call to the `Add`
method of the `WaitGroup`
value
must happen before the next call to the `Wait`
method of
the `WaitGroup`
value.
`Add`
method
is called at an improper place, which makes that the final printed number
is not always `100`
. In fact, the final printed number of
the program may be an arbitrary number in the range `[0, 100)`
.
The reason is none of the `Add`
method calls are guaranteed to
happen before the `Wait`
method call, which causes none of
the `Done`
method calls are guaranteed to
happen before the `Wait`
method call returns.
```
package main
import (
"fmt"
"sync"
"sync/atomic"
)
func main() {
var wg sync.WaitGroup
var x int32 = 0
for i := 0; i < 100; i++ {
go func() {
wg.Add(1)
atomic.AddInt32(&x, 1)
wg.Done()
}()
}
fmt.Println("Wait ...")
wg.Wait()
fmt.Println(atomic.LoadInt32(&x))
}
```
To make the program behave as expected, we should move the
`Add`
method calls out of the new goroutines created in the `for`
loop,
as the following code shown.
```
...
for i := 0; i < 100; i++ {
wg.Add(1)
go func() {
atomic.AddInt32(&x, 1)
wg.Done()
}()
}
...
```
`fa`
and `fb`
are two such functions,
then the following call uses future arguments improperly.
```
doSomethingWithFutureArguments(<-fa(), <-fb())
```
In the above code line, the generations of the two arguments are processed sequentially, instead of concurrently.
We should modify it as the following to process them concurrently.```
ca, cb := fa(), fb()
doSomethingWithFutureArguments(<-ca, <-cb)
```
A common mistake made by Go programmers is closing a channel when there are still some other goroutines will potentially send values to the channel later. When such a potential send (to the closed channel) really happens, a panic might occur.
This mistake was ever made in some famous Go projects, such as
[this bug](https://github.com/kubernetes/kubernetes/pull/45291/files?diff=split)
and
[this bug](https://github.com/kubernetes/kubernetes/pull/39479/files?diff=split)
in the kubernetes project.
Please read [this article](channel-closing.html) for explanations
on how to safely and gracefully close channels.
The address of the value involved in a non-method 64-bit atomic operation is required to be 8-byte aligned.
Failure to do so may make the current goroutine panic.
For the standard Go compiler, such failure can only
[happen on 32-bit architectures](https://golang.org/pkg/sync/atomic/#pkg-note-BUG).
Since Go 1.19, we can use 64-bit method atomic operations to avoid the drawback.
Please read [memory layouts](memory-layout.html) to get how to
guarantee the addresses of 64-bit word 8-byte aligned on 32-bit OSes.
`time.After`
Function
The `After`
function in the `time`
standard package
returns [a channel for delay notification](channel-use-cases.html#timer).
The function is convenient, however each of its calls will
create a new value of the `time.Timer`
type.
Before Go 1.23, the new created `Timer`
value will keep alive within the duration
specified by the passed argument to the `After`
function.
If the function is called many times in a certain period,
there will be many alive `Timer`
values accumulated
so that much memory and computation is consumed.
`longRunning`
function is called
and there are millions of messages coming in one minute, then there will
be millions of `Timer`
values alive in a certain small period (several seconds),
even if most of these `Timer`
values have already become useless.
```
import (
"fmt"
"time"
)
// The function will return if a message
// arrival interval is larger than one minute.
func longRunning(messages <-chan string) {
for {
select {
case <-time.After(time.Minute):
return
case msg := <-messages:
fmt.Println(msg)
}
}
}
```
Note: since Go 1.23, this problem has gone.
Because, since Go 1.23, a `Timer`
value can be collected without expiring or being stopped.
`Timer`
values being created in the above code,
we should use (and reuse) a single `Timer`
value to do the same job.
```
func longRunning(messages <-chan string) {
timer := time.NewTimer(time.Minute)
defer timer.Stop()
for {
select {
case <-timer.C: // expires (timeout)
return
case msg := <-messages:
fmt.Println(msg)
// This "if" block is important.
if !timer.Stop() {
<-timer.C
}
}
// Reset to reuse.
timer.Reset(time.Minute)
}
}
```
Note, the `if`
code block is used to discard/drain the potential timer notification
which is sent in the small period when executing the second branch code block
(since Go 1.23, this has become needless).
`Timer.Reset`
method will aoutomatically discard/drain the potential stale timer notification.
So the above code can be simplified as
```
func longRunning(messages <-chan string) {
timer := time.NewTimer(time.Minute)
// defer timer.Stop() // become needless since Go 1.23
for {
select {
case <-timer.C:
return
case msg := <-messages:
fmt.Println(msg)
}
timer.Reset(time.Minute)
}
}
```
`time.Timer`
Values Incorrectly*
(Note: the problems described in the current section only existed before Go 1.23.
Since Go 1.23, they have gone.)
*
`time.Timer`
values has been shown in the last section.
Some explanations:
`Stop`
method of a `*Timer`
value returns `false`
if the corresponding `Timer`
value has already expired or been stopped.
If we know the `Timer`
value has not been stopped yet, and
the `Stop`
method returns `false`
,
then the `Timer`
value must have already expired.
`Timer`
value is stopped, its `C`
channel field
can only contain most one timeout notification.
`Timer`
value after the `Timer`
value is stopped
and before resetting and reusing the `Timer`
value.
This is the meaningfulness of the `if`
code block in the example in the last section.
The `Reset`
method of a `*Timer`
value must be called
when the corresponding `Timer`
value has already expired or been stopped, otherwise,
a data race may occur between the `Reset`
call and
a possible notification send to the `C`
channel field of the `Timer`
value
(before Go 1.23).
If the first `case`
branch of the `select`
block is selected,
it means the `Timer`
value has already expired, so we don't need to stop it,
for the sent notification has already been taken out.
However, we must stop the timer in the second branch to check whether or not a timeout notification exists.
If it does exist, we should drain it before reusing the timer,
otherwise, the notification will be fired immediately in the next loop step.
```
package main
import (
"fmt"
"time"
)
func main() {
start := time.Now()
timer := time.NewTimer(time.Second/2)
select {
case <-timer.C:
default:
// Most likely go here.
time.Sleep(time.Second)
}
// Potential data race in the next line.
timer.Reset(time.Second * 10)
<-timer.C
fmt.Println(time.Since(start)) // about 1s
}
```
A `time.Timer`
value can be leaved in non-stopping status
when it is not used any more, but it is recommended to stop it in the end.
It is bug prone and not recommended to use a `time.Timer`
value
concurrently among multiple goroutines.
We should not rely on the return value of a `Reset`
method call.
The return result of the `Reset`
method exists
just for compatibility purpose.
The ** Go 101** project is hosted on
If you would like to learn some Go details and facts every serveral days,
please follow Go 101's official Twitter account [@zigo_101](https://twitter.com/zigo_101).
`reflect`
standard package.`sync`
standard package.`sync/atomic`
standard package. |
9,727 | 基于 FUSE 的 Bittorrent 文件系统 | https://www.ostechnix.com/btfs-a-bittorrent-filesystem-based-on-fuse/ | 2018-06-08T13:36:00 | [
"BTFS",
"Bittorrent"
] | https://linux.cn/article-9727-1.html | 
Bittorrent 已经存在了很长时间,它可以从互联网上共享和下载数据。市场上有大量的 GUI 和 CLI 的 Bittorrent 客户端。有时,你不能坐下来等待你的下载完成。你可能想要立即观看内容。这就是 **BTFS** 这个不起眼的文件系统派上用场的地方。使用 BTFS,你可以将种子文件或磁力链接挂载为目录,然后在文件树中作为只读目录。这些文件的内容将在程序读取时按需下载。由于 BTFS 在 FUSE 之上运行,因此不需要干预 Linux 内核。
### 安装 BTFS
BTFS 存在于大多数 Linux 发行版的默认仓库中。
在 Arch Linux 及其变体上,运行以下命令来安装 BTFS。
```
$ sudo pacman -S btfs
```
在Debian、Ubuntu、Linux Mint 上:
```
$ sudo apt-get install btfs
```
在 Gentoo 上:
```
# emerge -av btfs
```
BTFS 也可以使用 [Linuxbrew](https://www.ostechnix.com/linuxbrew-common-package-manager-linux-mac-os-x/) 包管理器进行安装。
```
$ brew install btfs
```
### 用法
BTFS 的使用非常简单。你所要做的就是找到 .torrent 文件或磁力链接,并将其挂载到一个目录中。种子文件或磁力链接的内容将被挂载到你选择的目录内。当一个程序试图访问该文件进行读取时,实际的数据将按需下载。此外,像 `ls` 、`cat` 和 `cp` 这样的工具能按照预期的方式来操作种子。像 `vlc` 和 `mplayer` 这样的程序也可以不加修改地工作。玩家甚至不知道实际内容并非物理存在于本地磁盘中,而是根据需要从 peer 中收集。
创建一个目录来挂载 torrent/magnet 链接:
```
$ mkdir mnt
```
挂载 torrent/magnet 链接:
```
$ btfs video.torrent mnt
```

cd 到目录:
```
$ cd mnt
```
然后,开始观看!
```
$ vlc <path-to-video.mp4>
```
给 BTFS 一些时间来找到并获取网站 tracker。一旦加载了真实数据,BTFS 将不再需要 tracker。

要卸载 BTFS 文件系统,只需运行以下命令:
```
$ fusermount -u mnt
```
现在,挂载目录中的内容将消失。要再次访问内容,你需要按照上面的描述挂载 torrent。
BTFS 会将你的 VLC 或 Mplayer 变成爆米花时间。挂载你最喜爱的电视节目或电影的种子文件或磁力链接,然后开始观看,无需下载整个种子内容或等待下载完成。种子或磁力链接的内容将在程序访问时按需下载。
就是这些了。希望这些有用。还会有更好的东西。敬请关注!
干杯!
---
via: <https://www.ostechnix.com/btfs-a-bittorrent-filesystem-based-on-fuse/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,728 | 解决构建全球社区带来的挑战 | https://opensource.com/article/17/12/working-worldwide-communities | 2018-06-08T15:54:00 | [
"开源社区"
] | /article-9728-1.html |
>
> 全球开源社区通常面临着语音壁垒、文化差异以及其它的挑战。如何去解决它们呢?
>
>
>

今天的开源组织参与人员来自于全世界。你能预见到组建在线社区可能遇到哪些困难吗?有没有什么办法能够克服这些困难呢?
为开源社区贡献力量的人共同合作推动软件的开发和发展。在过去,人们是面对面或者通过邮件和电话来交流的。今天,科技孕育出了在线交流——人们只需要进入一个聊天室或消息渠道就能一起工作了。比如,你可以早上跟摩洛哥的人一起工作,到了晚上又跟夏威夷的人一起工作。
### 全球社区的三个挑战
任何一个团队合作过的人都知道意见分歧是很难被克服的。对于在线社区来说,语言障碍、不同的时区,以及文化差异也带来了新的挑战。
#### 语言障碍
英语是开源社区中的主流语言,因此英语不好的人会很难看懂文档和修改意见。为了克服这个问题,吸引其他地区的社区成员,你需要邀请双语者参与到社区中来。问问周围的人——你会发现意想不到的精通其他语言的人。社区的双语成员可以帮助别人跨越语言障碍,并且可以通过翻译软件和文档来扩大项目的受众范围。
人们使用的编程语言也不一样。你可能喜欢用 Bash 而其他人则可能更喜欢 Python、Ruby、C 等其他语言。这意味着,人们可能由于编程语言的原因而难以为你的代码库做贡献。项目负责人为项目选择一门被软件社区广泛认可的语言至关重要。如果你选择了一门偏门的语言,则很少人能够参与其中。
#### 不同的时区
时区为开源社区带来了另一个挑战。比如,若你在芝加哥,想与一个在伦敦的成员安排一次视频会议,你需要调整 8 小时的时差。根据合作者的地理位置,你可能要在深夜或者清晨工作。
肉身转移,可以让你的团队在同一个时区工作可以帮助克服这个挑战,但这种方法只有极少数社区才能够负担的起。我们还可以定期举行虚拟会议讨论项目,建立一个固定的时间和地点以供所有人来讨论未决的事项,即将发布的版本等其他主题。
不同的时区也可以成为你的优势,因为团队成员可以全天候的工作。若你拥有一个类似 IRC 这样的实时交流平台,用户可以在任意时间都能找到人来回答问题。
#### 文化差异
文化差异是开源组织面临的最大挑战。世界各地的人都有不同的思考方式、计划以及解决问题的方法。政治环境也会影响工作环境并影响决策。
作为项目负责人,你应该努力构建一种能包容不同看法的环境。文化差异可以鼓励社区沟通。建设性的讨论总是对项目有益,因为它可以帮助社区成员从不同角度看待问题。不同意见也有助于解决问题。
要成功开源,团队必须学会拥抱差异。这不简单,但多样性最终会使社区收益。
### 加强在线沟通的其他方法
* **本地化:** 在线社区成员可能会发现位于附近的贡献者——去见个面并组织一个本地社区。只需要两个人就能组建一个社区了。可以邀请其他当地用户或雇员参与其中;他们甚至还能为以后的聚会提供场所呢。
* **组织活动:** 组织活动是构建本地社区的好方法,而且费用也不高。你可以在当地的咖啡屋或者啤酒厂聚会,庆祝最新版本的发布或者某个核心功能的实现。组织的活动越多,人们参与的热情就越高(即使只是因为单纯的好奇心)。最终,可能会找到一家公司为你提供聚会的场地,或者为你提供赞助。
* **保持联系:** 每次活动后,联系本地社区成员。收起电子邮箱地址或者其他联系方式并邀请他们参与到你的交流平台中。邀请他们为其他社区做贡献。你很可能会发现很多当地的人才,运气好的话,甚至可能发现新的核心开发人员!
* **分享经验:** 本地社区是一种非常有价值的资源,对你,对其他社区来说都是。与可能受益的人分享你的发现和经验。如果你不清楚(LCTT 译注:这里原文是说 sure,但是根据上下文,这里应该是 not sure)如何策划一场活动或会议,可以咨询其他人的意见。也许能找到一些有经验的人帮你走到正轨。
* **关注文化差异:** 记住,文化规范因地点和人而异,因此在清晨安排某项活动可能适用于一个地方的人,但是不合适另一个地方的人。当然,你可以(也应该)利用其他社区的参考资料来更好地理解这种差异性,但有时你也需要通过试错的方式来学习。不要忘了分享你所学到的东西,让别人也从中获益。
* **检查个人观点:** 避免在工作场合提出带有很强主观色彩的观点(尤其是与政治相关的观点)。这会抑制开放式的沟通和问题的解决。相反,应该专注于鼓励与团队成员展开建设性讨论。如果你发现陷入了激烈的争论中,那么后退一步,冷静一下,然后再从更加积极的角度出发重新进行讨论。讨论必须是有建设性的,从多个角度讨论问题对社区有益。永远不要把自己的主观观念放在社区的总体利益之前。
* **尝试异步沟通:** 这些天,实时通讯平台已经引起了大家的关注,但除此之外还别忘了电子邮件。如果没有在网络平台上找到人的话,可以给他们发送一封电子邮件。有可能你很快就能得到回复。考虑使用那些专注于异步沟通的平台,比如 [Twist](https://twistapp.com),也不要忘了查看并更新论坛和维基。
* **使用不同的解决方案:** 并不存在一个单一的完美的解决方法,学习最有效的方法还是通过经验来学习。从反复试验中你可以学到很多东西。不要害怕失败;你会从失败中学到很多东西从而不停地进步。
### 社区需要营养
将社区想象成是一颗植物的幼苗。你需要每天给它浇水,提供阳光和氧气。社区也是一样:倾听贡献者的声音,记住你在与活生生的人进行互动,他们需要以合适的方式进行持续的交流。如果社区缺少了人情味,人们会停止对它的贡献。
最后,请记住,每个社区都是不同的,没有一种单一的解决方法能够适用于所有社区。坚持不断地从社区中学习并适应这个社区。
---
via: <https://opensource.com/article/17/12/working-worldwide-communities>
作者:[José Antonio Rey](https://opensource.com/users/jose) 译者:[lujun9972](https://github.com/lujun9972) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
9,729 | 面向数据科学的 Anaconda Python 入门 | https://opensource.com/article/18/4/getting-started-anaconda-python | 2018-06-08T22:19:37 | [
"Anaconda",
"数据科学"
] | https://linux.cn/article-9729-1.html |
>
> Anaconda 是一个完备的、开源的数据科学软件包,拥有超过 600 万社区用户。
>
>
>

像很多人一样,我一直努力加入到快速发展的数据科学领域。我上过 Udemy 的 [R](https://www.r-project.org/) 及 [Python](https://www.python.org/) 语言编程课,那时我分别下载并安装了应用程序。当我试图解决各种依赖关系,安装类似 [Numpy](http://www.numpy.org/) 和 [Matplotlib](https://matplotlib.org/) 这样的数据科学扩展包时,我了解了 [Anaconda Python 发行版](https://www.anaconda.com/distribution/)。
Anaconda 是一个完备的、[开源](https://docs.anaconda.com/anaconda/eula)的数据科学包,拥有超过 600 万社区用户。[下载](https://www.anaconda.com/download/#linux)和安装 Anaconda 都很容易,支持的操作系统包括 Linux, MacOS 及 Windows。
我感谢 Anaconda 降低了初学者的学习门槛。发行版自带 1000 多个数据科学包以及 [Conda](https://conda.io/) 包和虚拟环境管理器,让你无需单独学习每个库的安装方法。就像 Anaconda 官网上提到的,“Anaconda 库中的 Python 和 R 语言的 conda 包是我们在安全环境中修订并编译得到的优化二进制程序,可以在你系统上工作”。
我推荐使用 [Anaconda Navigator](https://docs.anaconda.com/anaconda/navigator/),它是一个桌面 GUI 系统,包含了发行版自带的全部应用的链接,包括 [RStudio](https://www.rstudio.com/)、 [iPython](https://ipython.org/)、 [Jupyter Notebook](http://jupyter.org/)、 [JupyterLab](https://blog.jupyter.org/jupyterlab-is-ready-for-users-5a6f039b8906)、 [Spyder](https://spyder-ide.github.io/)、 [Glue](http://glueviz.org/) 和 [Orange](https://orange.biolab.si/)。默认环境采用 Python 3.6,但你可以轻松安装 Python 3.5、 Python 2.7 或 R。[文档](https://orange.biolab.si/)十分详尽,而且用户社区极好,可以提供额外的支持。
### 安装 Anaconda
为在我的 Linux 笔记本(I3 CPU,4GB 内存)上安装 Anaconda,我下载了 Anaconda 5.1 Linux 版安装器并运行 `md5sum` 进行文件校验:
```
$ md5sum Anaconda3-5.1.0-Linux-x86_64.sh
```
接着按照[安装文档](https://docs.anaconda.com/anaconda/install/linux)的说明,无论是否在 Bash shell 环境下,执行如下 shell 命令:
```
$ bash Anaconda3-5.1.0-Linux-x86_64.sh
```
我完全按照安装指南操作,运行这个精心编写的脚本,大约花费 5 分钟可以完成安装。安装过程中会提示:“是否希望安装器将 Anaconda 的安装路径加入到你的 `/home/<user>/.bashrc`?”我选择允许并重启了 shell,这会让 `.bashrc` 中的环境变量生效。
安装完成后,我启动了 Anaconda Navigator,具体操作是在 shell 中执行如下命令:
```
$ anaconda-navigator
```
Anaconda Navigator 每次启动时会检查是否有可更新的软件包,如果有,会提醒你进行更新。

按照提醒进行更新即可,无需使用命令行。Anaconda 初次启动会有些慢,如果涉及更新会额外花费几分钟。
当然,你也可以通过执行如下命令手动更新:
```
$ conda update anaconda-navigator
```
### 浏览和安装应用
Navigator 启动后,可以很容易地浏览 Anaconda 发行版包含的应用。按照文档所述,64 位 Python 3.6 版本的 Anaconda [支持 499 个软件包](https://docs.anaconda.com/anaconda/packages/py3.6_linux-64)。我浏览的第一个应用是 [Jupyter QtConsole](http://qtconsole.readthedocs.io/en/stable/),这个简单易用的 GUI 支持内联数据 (inline figures) 和语法高亮。

发行版中包含 Jupyter Notebook,故无需另外安装(不像我用的其它 Python 环境那样)。

我习惯使用的 RStudio 并没有默认安装,但安装它也仅需点击一下鼠标。其它应用的启动或安装也仅需点击一下鼠标,包括 JupyterLab、 Orange、 Glue 和 Spyder 等。

Anaconda 发行版的一个强大功能是创建多套环境。假如我需要创建一套与默认 Python 3.6 不同的 Python 2.7 的环境,可以在 shell 中执行如下命令:
```
$ conda create -n py27 python=2.7 anaconda
```
Conda 负责整个安装流程,如需启动它,仅需在 shell 中执行如下命令:
```
$ anaconda-navigator
```
在 Anaconda GUI 的 “Applications on” 下拉菜单中选取 **py27** 即可。

### 更多内容
如果你想了解更多关于 Anaconda 的信息,可供参考的资源十分丰富。不妨从检索 [Anaconda 社区](https://www.anaconda.com/community/)及对应的[邮件列表](https://groups.google.com/a/continuum.io/forum/#!forum/anaconda)开始。
你是否在使用 Anaconda 发行版及 Navigator 呢?欢迎在评论中留下你的使用感想。
---
via: <https://opensource.com/article/18/4/getting-started-anaconda-python>
作者:[Don Watkins](https://opensource.com/users/don-watkins) 选题:[lujun9972](https://github.com/lujun9972) 译者:[pinewall](https://github.com/pinewall) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Like many others, I've been trying to get involved in the rapidly expanding field of data science. When I took Udemy courses on the [R](https://www.r-project.org/) and [Python](https://www.python.org/) programming languages, I downloaded and installed the applications independently. As I was trying to work through the challenges of installing data science packages like [NumPy](http://www.numpy.org/) and [Matplotlib](https://matplotlib.org/) and solving the various dependencies, I learned about the [Anaconda Python distribution](https://www.anaconda.com/distribution/).
Anaconda is a complete, [open source](https://docs.anaconda.com/anaconda/eula) data science package with a community of over 6 million users. It is easy to [download](https://www.anaconda.com/download/#linux) and install, and it is supported on Linux, MacOS, and Windows.
I appreciate that Anaconda eases the frustration of getting started for new users. The distribution comes with more than 1,000 data packages as well as the [Conda](https://conda.io/) package and virtual environment manager, so it eliminates the need to learn to install each library independently. As Anaconda's website says, "The Python and R conda packages in the Anaconda Repository are curated and compiled in our secure environment so you get optimized binaries that 'just work' on your system."
I recommend using [Anaconda Navigator](https://docs.anaconda.com/anaconda/navigator/), a desktop graphical user interface (GUI) system that includes links to all the applications included with the distribution including [RStudio](https://www.rstudio.com/), [iPython](https://ipython.org/), [Jupyter Notebook](http://jupyter.org/), [JupyterLab](https://blog.jupyter.org/jupyterlab-is-ready-for-users-5a6f039b8906), [Spyder](https://spyder-ide.github.io/), [Glue](http://glueviz.org/), and [Orange](https://orange.biolab.si/). The default environment is Python 3.6, but you can also easily install Python 3.5, Python 2.7, or R. The [documentation](https://docs.anaconda.com/anaconda/navigator/) is incredibly detailed and there is an excellent community of users for additional support.
## Installing Anaconda
To install Anaconda on my Linux laptop (an I3 with 4GB of RAM), I downloaded the Anaconda 5.1 Linux installer and ran `md5sum`
to verify the file:
```
````$ md5sum Anaconda3-5.1.0-Linux-x86_64.sh`
Then I followed the directions in the [documentation](https://docs.anaconda.com/anaconda/install/linux), which instructed me to issue the following Bash command whether I was in the Bash shell or not:
```
````$ bash Anaconda3-5.1.0-Linux-x86_64.sh`
I followed the installation directions exactly, and the well-scripted install took about five minutes to complete. When the installation prompted: "Do you wish the installer to prepend the Anaconda install location to PATH in your `/home/<user>/.bashrc`
?" I allowed it and restarted the shell, which I found was necessary for the `.bashrc`
environment to work correctly.
After completing the install, I launched Anaconda Navigator by entering the following at the command prompt in the shell:
```
````$ anaconda-navigator`
Every time Anaconda Navigator launches, it checks to see if new software is available and prompts you to update if necessary.
opensource.com
Anaconda updated successfully without needing to return to the command line. Anaconda's initial launch was a little slow; that plus the update meant it took a few additional minutes to get started.
You can also update manually by entering the following:
```
````$ conda update anaconda-navigator`
## Exploring and installing applications
Once Navigator launched, I was free to explore the range of applications included with Anaconda Distribution. According to the documentation, the 64-bit Python 3.6 version of Anaconda [supports 499 packages](https://docs.anaconda.com/anaconda/packages/py3.6_linux-64). The first application I explored was [Jupyter QtConsole](http://qtconsole.readthedocs.io/en/stable/). The easy-to-use GUI supports inline figures and syntax highlighting.
opensource.com
Jupyter Notebook is included with the distribution, so (unlike other Python environments I have used) there is no need for a separate install.
opensource.com
I was already familiar with RStudio. It's not installed by default, but it's easy to add with the click of a mouse. Other applications, including JupyterLab, Orange, Glue, and Spyder, can be launched or installed with just a mouse click.

opensource.com
One of the Anaconda distribution's strengths is the ability to create multiple environments. For example, if I wanted to create a Python 2.7 environment instead of the default Python 3.6, I would enter the following in the shell:
```
````$ conda create -n py27 python=2.7 anaconda`
Conda takes care of the entire install; to launch it, just open the shell and enter:
```
````$ anaconda-navigator`
Select the **py27** environment from the "Applications on" drop-down in the Anaconda GUI.

opensource.com
## Learn more
There's a wealth of information available about Anaconda if you'd like to know more. You can start by searching the [Anaconda Community](https://www.anaconda.com/community/) and its [mailing list](https://groups.google.com/a/continuum.io/forum/#!forum/anaconda).
Are you using Anaconda Distribution and Navigator? Let us know your impressions in the comments.
## Comments are closed. |
9,730 | 如何在 Arch Linux 中降级软件包 | https://www.ostechnix.com/downgrade-package-arch-linux/ | 2018-06-08T22:27:31 | [
"Arch"
] | https://linux.cn/article-9730-1.html | 
正如你了解的,Arch Linux 是一个滚动版本和 DIY(自己动手)发行版。因此,在经常更新时必须小心,特别是从 AUR 等第三方存储库安装或更新软件包。如果你不知道自己在做什么,那么最终很可能会破坏系统。你有责任使 Arch Linux 更加稳定。但是,我们都会犯错误,要时刻小心是很难的。有时候,你想更新到最新的版本,但你可能会被破损的包卡住。不要惊慌!在这种情况下,你可以简单地回滚到旧的稳定包。这个简短的教程描述了如何在 Arch Linux 中以及它的变体,如 Antergos,Manjaro Linux 中降级一个包,
### 在 Arch Linux 中降级一个包
在 Arch Linux 中,有一个名为 “downgrade” 的实用程序,可帮助你将安装的软件包降级为任何可用的旧版本。此实用程序将检查你的本地缓存和远程服务器(Arch Linux 仓库)以查找所需软件包的旧版本。你可以从该列表中选择任何一个旧的稳定的软件包并进行安装。
该软件包在官方仓库中不可用,你需要添加非官方的 **archlinuxfr** 仓库。
为此,请编辑 `/etc/pacman.conf` 文件:
```
$ sudo nano /etc/pacman.conf
```
添加以下行:
```
[archlinuxfr]
SigLevel = Never
Server = http://repo.archlinux.fr/$arch
```
保存并关闭文件。
使用以下命令来更新仓库:
```
$ sudo pacman -Sy
```
然后在终端中使用以下命令安装 “Downgrade” 实用程序:
```
$ sudo pacman -S downgrade
```
示例输出:
```
resolving dependencies...
looking for conflicting packages...
Packages (1) downgrade-5.2.3-1
Total Download Size: 0.01 MiB
Total Installed Size: 0.10 MiB
:: Proceed with installation? [Y/n]
```
“downgrade” 命令的典型用法是:
```
$ sudo downgrade [PACKAGE, ...] [-- [PACMAN OPTIONS]]
```
让我们假设你想要将 opera web 浏览器 降级到任何可用的旧版本。
为此,运行:
```
$ sudo downgrade opera
```
此命令将从本地缓存和远程镜像列出所有可用的 opera 包(新旧两种版本)。
示例输出:
```
Available packages:
1) opera-37.0.2178.43-1-x86_64.pkg.tar.xz (local)
2) opera-37.0.2178.43-1-x86_64.pkg.tar.xz (remote)
3) opera-37.0.2178.32-1-x86_64.pkg.tar.xz (remote)
4) opera-36.0.2130.65-2-x86_64.pkg.tar.xz (remote)
5) opera-36.0.2130.65-1-x86_64.pkg.tar.xz (remote)
6) opera-36.0.2130.46-2-x86_64.pkg.tar.xz (remote)
7) opera-36.0.2130.46-1-x86_64.pkg.tar.xz (remote)
8) opera-36.0.2130.32-2-x86_64.pkg.tar.xz (remote)
9) opera-36.0.2130.32-1-x86_64.pkg.tar.xz (remote)
10) opera-35.0.2066.92-1-x86_64.pkg.tar.xz (remote)
11) opera-35.0.2066.82-1-x86_64.pkg.tar.xz (remote)
12) opera-35.0.2066.68-1-x86_64.pkg.tar.xz (remote)
13) opera-35.0.2066.37-2-x86_64.pkg.tar.xz (remote)
14) opera-34.0.2036.50-1-x86_64.pkg.tar.xz (remote)
15) opera-34.0.2036.47-1-x86_64.pkg.tar.xz (remote)
16) opera-34.0.2036.25-1-x86_64.pkg.tar.xz (remote)
17) opera-33.0.1990.115-2-x86_64.pkg.tar.xz (remote)
18) opera-33.0.1990.115-1-x86_64.pkg.tar.xz (remote)
19) opera-33.0.1990.58-1-x86_64.pkg.tar.xz (remote)
20) opera-32.0.1948.69-1-x86_64.pkg.tar.xz (remote)
21) opera-32.0.1948.25-1-x86_64.pkg.tar.xz (remote)
22) opera-31.0.1889.174-1-x86_64.pkg.tar.xz (remote)
23) opera-31.0.1889.99-1-x86_64.pkg.tar.xz (remote)
24) opera-30.0.1835.125-1-x86_64.pkg.tar.xz (remote)
25) opera-30.0.1835.88-1-x86_64.pkg.tar.xz (remote)
26) opera-30.0.1835.59-1-x86_64.pkg.tar.xz (remote)
27) opera-30.0.1835.52-1-x86_64.pkg.tar.xz (remote)
28) opera-29.0.1795.60-1-x86_64.pkg.tar.xz (remote)
29) opera-29.0.1795.47-1-x86_64.pkg.tar.xz (remote)
30) opera-28.0.1750.51-1-x86_64.pkg.tar.xz (remote)
31) opera-28.0.1750.48-1-x86_64.pkg.tar.xz (remote)
32) opera-28.0.1750.40-1-x86_64.pkg.tar.xz (remote)
33) opera-27.0.1689.76-1-x86_64.pkg.tar.xz (remote)
34) opera-27.0.1689.69-1-x86_64.pkg.tar.xz (remote)
35) opera-27.0.1689.66-1-x86_64.pkg.tar.xz (remote)
36) opera-27.0.1689.54-2-x86_64.pkg.tar.xz (remote)
37) opera-27.0.1689.54-1-x86_64.pkg.tar.xz (remote)
38) opera-26.0.1656.60-1-x86_64.pkg.tar.xz (remote)
39) opera-26.0.1656.32-1-x86_64.pkg.tar.xz (remote)
40) opera-12.16.1860-2-x86_64.pkg.tar.xz (remote)
41) opera-12.16.1860-1-x86_64.pkg.tar.xz (remote)
select a package by number:
```
只需输入你选择的包号码,然后按回车即可安装。
就这样。当前安装的软件包将被降级为旧版本。
另外阅读:[在 Arch Linux 中如何将所有软件包降级到特定日期](https://www.ostechnix.com/downgrade-packages-specific-date-arch-linux/)
### 那么,如何避免已损坏的软件包并使 Arch Linux 更加稳定?
在更新 Arch Linux 之前查看 [Arch Linux 新闻](https://www.archlinux.org/news/)和[论坛](https://bbs.archlinux.org/),看看是否有任何已报告的问题。过去几周我一直在使用 Arch Linux 作为我的主要操作系统,以下是我在这段时间内发现的一些简单提示,以避免在 Arch Linux 中安装不稳定的软件包。
1. 避免部分升级。这意味着永远不要运行 `pacman -Sy <软件包名称>`。此命令将在安装软件包时部分升级你的系统。相反,优先使用 `pacman -Syu` 来更新系统,然后使用 `package -S <软件包名称>` 安装软件包。
2. 避免使用 `pacman -Syu -force` 命令。`-force` 标志将忽略程序包和文件冲突,并且可能会以破损的程序包或损坏的系统结束。
3. 不要跳过依赖性检查。这意味着不要使用 `pacman -Rdd <软件包名称>`。此命令将在删除软件包时避免依赖性检查。如果你运行这个命令,另一个重要的包所需的关键依赖也可以被删除。最终,它会损坏你的 Arch Linux。
4. 定期备份重要数据和配置文件以避免数据丢失总是一个好习惯。
5. 安装第三方软件包和 AUR 等非官方软件包时要小心。不要安装那些正在经历重大发展的软件包。
有关更多详细信息,请查看 [Arch Linux 维护指南](https://wiki.archlinux.org/index.php/System_maintenance)。
我不是 Arch Linux 专家,我仍然在学习如何使它更稳定。如果你有任何技巧让 Arch Linux 保持稳定和安全,请在下面的评论部分保持稳定和安全告诉我,我将洗耳恭听。
希望这可以有帮助。目前为止这就是全部了。我很快会再次在这里与另一篇有趣的文章。在此之前,请继续关注。
干杯!
---
via: <https://www.ostechnix.com/downgrade-package-arch-linux/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,731 | 探秘“栈”之旅(II):结语、金丝雀和缓冲区溢出 | https://manybutfinite.com/post/epilogues-canaries-buffer-overflows/ | 2018-06-09T23:26:39 | [
"序言",
"结语"
] | https://linux.cn/article-9731-1.html | 
上一周我们讲解了 [栈是如何工作的](/article-9645-1.html) 以及在函数的<ruby> 序言 <rt> prologue </rt></ruby>上栈帧是如何被构建的。今天,我们来看一下它的相反的过程,在函数<ruby> 结语 <rt> epilogue </rt></ruby>中栈帧是如何被销毁的。重新回到我们的 `add.c` 上:
```
int add(int a, int b)
{
int result = a + b;
return result;
}
int main(int argc)
{
int answer;
answer = add(40, 2);
}
```
*简单的一个做加法的程序 - add.c*
在运行到第 4 行时,在把 `a + b` 值赋给 `result` 后,这时发生了什么:

第一个指令是有些多余而且有点傻的,因为我们知道 `eax` 已经等于 `result` 了,但这就是关闭优化时得到的结果。`leave` 指令接着运行,这一小段做了两个任务:重置 `esp` 并将它指向到当前栈帧开始的地方,另一个是恢复在 `ebp` 中保存的值。这两个操作在逻辑上是独立的,因此,在图中将它们分开来说,但是,如果你使用一个调试器去跟踪,你就会发现它们都是自动发生的。
在 `leave` 运行后,恢复了前一个栈帧。`add` 调用唯一留下的东西就是在栈顶部的返回地址。它包含了运行完 `add` 之后在 `main` 中必须运行的指令的地址。`ret` 指令用来处理它:它弹出返回地址到 `eip` 寄存器(LCTT 译注:32 位的指令寄存器),这个寄存器指向下一个要执行的指令。现在程序将返回到 `main` ,主要部分如下:

`main` 从 `add` 中拷贝返回值到本地变量 `answer`,然后,运行它自己的<ruby> 结语 <rt> epilogue </rt></ruby>,这一点和其它的函数是一样的。在 `main` 中唯一的怪异之处是,保存在 `ebp` 中的是 `null` 值,因为它是我们的代码中的第一个栈帧。最后一步执行的是,返回到 C 运行时库(`libc`),它将退回到操作系统中。这里为需要的人提供了一个 [完整的返回顺序](https://manybutfinite.com/img/stack/returnSequence.png) 的图。
现在,你已经理解了栈是如何运作的,所以我们现在可以来看一下,一直以来最臭名昭著的黑客行为:利用缓冲区溢出。这是一个有漏洞的程序:
```
void doRead()
{
char buffer[28];
gets(buffer);
}
int main(int argc)
{
doRead();
}
```
*有漏洞的程序 - buffer.c*
上面的代码中使用了 [gets](http://linux.die.net/man/3/gets) 从标准输入中去读取内容。`gets` 持续读取直到一个新行或者文件结束。下图是读取一个字符串之后栈的示意图:

在这里存在的问题是,`gets` 并不知道缓冲区(`buffer`)大小:它毫无查觉地持续读取输入内容,并将读取的内容填入到缓冲区那边的栈,清除保存在 `ebp` 中的值、返回地址,下面的其它内容也是如此。对于利用这种行为,攻击者制作一个精密的载荷并将它“喂”给程序。在这个时候,栈应该是下图所示的样子,然后去调用 `gets`:

基本的思路是提供一个恶意的汇编代码去运行,通过覆写栈上的返回地址指向到那个代码。这有点像病毒侵入一个细胞,颠覆它,然后引入一些 RNA 去达到它的目的。
和病毒一样,挖掘者的载荷有许多特别的功能。它以几个 `nop` 指令开始,以提升成功利用的可能性。这是因为返回的地址是一个绝对的地址,需要猜测,而攻击者并不知道保存它的代码的栈的准确位置。但是,只要它们进入一个 `nop`,这个漏洞利用就成功了:处理器将运行 `nop` 指令,直到命中它希望去运行的指令。
`exec /bin/sh` 表示运行一个 shell 的原始汇编指令(假设漏洞是在一个网络程序中,因此,这个漏洞可能提供一个访问系统的 shell)。将一个命令或用户输入以原始汇编指令的方式嵌入到一个程序中的思路是很可怕的,但是,那只是让安全研究如此有趣且“脑洞大开”的一部分而已。对于防范这个怪异的 `get`,给你提供一个思路,有时候,在有漏洞的程序上,让它的输入转换为小写或者大写,将迫使攻击者写的汇编指令的完整字节不属于小写或者大写的 ascii 字母的范围内。
最后,攻击者重复猜测几次返回地址,这将再次提升他们的胜算。以 4 字节为界进行多次重复,它们就会更好地覆写栈上的原始返回地址。
幸亏,现代操作系统有了 [防止缓冲区溢出](http://paulmakowski.wordpress.com/2011/01/25/smashing-the-stack-in-2011/) 的一系列保护措施,包括不可执行的栈和<ruby> 栈内金丝雀 <rt> stack canary </rt></ruby>。这个 “<ruby> 金丝雀 <rt> canary </rt></ruby>” 名字来自 <ruby> <a href="http://en.wiktionary.org/wiki/canary_in_a_coal_mine"> 煤矿中的金丝雀 </a> <rt> canary in a coal mine </rt></ruby> 中的表述(LCTT 译注:指在过去煤矿工人下井时会带一只金丝雀,因为金丝雀对煤矿中的瓦斯气体非常敏感,如果进入煤矿后,金丝雀死亡,说明瓦斯超标,矿工会立即撤出煤矿。金丝雀做为煤矿中瓦斯预警器来使用),这是对计算机科学词汇的补充,用 Steve McConnell 的话解释如下:
>
> 计算机科学拥有比其它任何领域都丰富多彩的语言,在其它的领域中你进入一个无菌室,小心地将温度控制在 68°F,然后,能找到病毒、特洛伊木马、蠕虫、臭虫(bug)、炸弹(逻辑炸弹)、崩溃、爆发(口水战)、扭曲的变性者(双绞线转换头),以及致命错误吗?
>
>
> —— Steve McConnell 《代码大全 2》
>
>
>
不管怎么说,这里所谓的“栈金丝雀”应该看起来是这个样子的:

金丝雀是通过汇编来实现的。例如,由于 GCC 的 [栈保护器](http://gcc.gnu.org/onlinedocs/gcc-4.2.3/gcc/Optimize-Options.html) 选项的原因使金丝雀能被用于任何可能有漏洞的函数上。函数序言加载一个魔法值到金丝雀的位置,并且在函数结语时确保这个值完好无损。如果这个值发生了变化,那就表示发生了一个缓冲区溢出(或者 bug),这时,程序通过 [`__stack_chk_fail`](http://refspecs.linux-foundation.org/LSB_4.0.0/LSB-Core-generic/LSB-Core-generic/libc---stack-chk-fail-1.html) 被终止运行。由于金丝雀处于栈的关键位置上,它使得栈缓冲区溢出的漏洞挖掘变得非常困难。
深入栈的探秘之旅结束了。我并不想过于深入。下一周我将深入递归、尾调用以及其它相关内容。或许要用到谷歌的 V8 引擎。作为函数的序言和结语的讨论的结束,我引述了美国国家档案馆纪念雕像上的一句名言:(<ruby> 凡是过去 皆为序章 <rt> what is past is prologue </rt></ruby>)。

---
via:<https://manybutfinite.com/post/epilogues-canaries-buffer-overflows/>
作者:[Gustavo Duarte](http://duartes.org/gustavo/blog/about/) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Last week we looked at [how the stack works](/post/journey-to-the-stack) and how stack frames are
built during function *prologues*. Now it’s time to look at the inverse process
as stack frames are destroyed in function *epilogues*. Let’s bring back our
friend `add.c`
:
1 | int add(int a, int b) |
We’re executing line 4, right after the assignment of `a + b`
into `result`
. This is
what happens:
The first instruction is redundant and a little silly because we know `eax`
is
already equal to `result`
, but this is what you get with optimization turned
off. The `leave`
instruction then runs, doing two tasks for the price of one: it
resets `esp`
to point to the start of the current stack frame, and then restores
the saved ebp value. These two operations are logically distinct and thus are
broken up in the diagram, but they happen atomically if you’re tracing with
a debugger.
After `leave`
runs the previous stack frame is restored. The only vestige of the
call to `add`
is the return address on top of the stack. It contains the address
of the instruction in `main`
that must run after `add`
is done. The `ret`
instruction takes care of it: it pops the return address into the `eip`
register, which points to the next instruction to be executed. The program has
now returned to main, which resumes:
`main`
copies the return value from `add`
into local variable `answer`
and then
runs its own epilogue, which is identical to any other. Again the only
peculiarity in `main`
is that the saved ebp is null, since it is the first stack
frame in our code. In the last step, execution has been returned to the
C runtime (`libc`
), which will exit to the operating system. Here’s a diagram
with the [full return sequence](/img/stack/returnSequence.png) for those
who need it.
You now have an excellent grasp of how the stack operates, so let’s have some fun and look at one of the most infamous hacks of all time: exploiting the stack buffer overflow. Here is a vulnerable program:
1 | void doRead() |
The code above uses [gets](http://linux.die.net/man/3/gets) to read from
standard input. `gets`
keeps reading until it encounters a newline or end of
file. Here’s what the stack looks like after a string has been read:

The problem here is that `gets`
is unaware of `buffer`
's size: it will blithely
keep reading input and stuffing data into the stack beyond `buffer`
,
obliterating the saved ebp value, return address, and whatever else is below.
To exploit this behavior, attackers craft a precise payload and feed it into the
program. This is what the stack looks like during an attack, after the call to
`gets`
:

The basic idea is to provide malicious assembly code to be executed *and*
overwrite the return address on the stack to point to that code. It is a bit
like a virus invading a cell, subverting it, and introducing some RNA to further
its goals.
And like a virus, the exploit’s payload has many notable features. It starts
with several `nop`
instructions to increase the odds of successful exploitation.
This is because the return address is absolute and must be guessed, since
attackers don’t know exactly where in the stack their code will be stored. But
as long as they land on a `nop`
, the exploit works: the processor will execute
the nops until it hits the instructions that do work.
The `exec /bin/sh`
symbolizes raw assembly instructions that execute a shell
(imagine for example that the vulnerability is in a networked program, so the
exploit might provide shell access to the system). The idea of feeding raw
assembly to a program expecting a command or user input is shocking at first,
but that’s part of what makes security research so fun and mind-expanding. To
give you an idea of how weird things get, sometimes the vulnerable program calls
`tolower`
or `toupper`
on its inputs, forcing attackers to write assembly
instructions whose bytes do not fall into the range of upper- or lower-case
ascii letters.
Finally, attackers repeat the guessed return address several times, again to tip the odds ever in their favor. By starting on a 4-byte boundary and providing multiple repeats, they are more likely to overwrite the original return address on the stack.
Thankfully, modern operating systems have a host of
[protections against buffer overflows](http://paulmakowski.wordpress.com/2011/01/25/smashing-the-stack-in-2011/), including non-executable stacks and *stack canaries*. The “canary” name comes from the [canary in a coal mine](http://en.wiktionary.org/wiki/canary_in_a_coal_mine) expression, an addition to computer science’s rich vocabulary. In the words of Steve McConnell:
Computer science has some of the most colorful language of any field. In what other field can you walk into a sterile room, carefully controlled at 68°F, and find viruses, Trojan horses, worms, bugs, bombs, crashes, flames, twisted sex changers, and fatal errors?
At any rate, here’s what a stack canary looks like:

Canaries are implemented by the compiler. For example, GCC’s
[stack-protector](http://gcc.gnu.org/onlinedocs/gcc-4.2.3/gcc/Optimize-Options.html)
option causes canaries to be used in any function that is potentially
vulnerable. The function prologue loads a magic value into the canary location,
and the epilogue makes sure the value is intact. If it’s not, a buffer overflow
(or bug) likely happened and the program is aborted via
[__stack_chk_fail](http://refspecs.linux-foundation.org/LSB_4.0.0/LSB-Core-generic/LSB-Core-generic/libc---stack-chk-fail-1.html).
Due to their strategic location on the stack, canaries make the exploitation of
stack buffer overflows much harder.
This finishes our journey within the depths of the stack. We don’t want to delve too greedily and too deep. Next week we’ll go up a notch in abstraction to take a good look at recursion, tail calls and other tidbits, probably using Google’s V8. To end this epilogue and prologue talk, I’ll close with a cherished quote inscribed on a monument in the American National Archives:

## Comments |
9,732 | 在 Fedora 系统上设置 zsh | https://fedoramagazine.org/set-zsh-fedora-system/ | 2018-06-09T23:40:43 | [
"zsh",
"shell"
] | https://linux.cn/article-9732-1.html | 
对于一些人来说,终端可能会很吓人。但终端不仅仅是一个输入的黑屏。它通常运行一个 shell(外壳),如此称呼的原因是它围绕着内核。shell 是一个基于文本的界面,可让你在系统上运行命令。它有时也被称为<ruby> 命令行解释器 <rt> command line interpreter </rt></ruby>(CLI)。与大多数 Linux 发行版一样,Fedora 带有 bash 作为默认 shell。但是,它不是唯一可用的 shell,你可以安装其他的 shell。本文重点介绍 Z Shell (即 zsh)。
Bash 是对 UNIX 中提供的旧式 Bourne shell(sh)的重写(LCTT 译注:Bourne Again SHell)。zsh 视图通过更好的交互以比 bash 更友善。它的一些有用功能是:
* 可编程的命令行补全 \* 在运行的 shell 会话之间共享命令历史 \* 拼写纠正 \* 可加载模块 \* 交互式选择文件和文件夹
zsh 在 Fedora 仓库中存在。要安装,请运行以下命令:
```
$ sudo dnf install zsh
```
### 使用 zsh
要开始使用它,只需输入 `zsh`,新的 shell 在第一次运行时显示向导。该向导可帮助你配置初始功能,如历史记录行为和自动补全。或者你可以选择保持 [rc 文件](https://en.wikipedia.org/wiki/Configuration_file) 为空:

如果输入 `1`,则启动配置向导。其他选项立即启动 shell。
请注意,用户提示符是 `%` 而不是与 bash 的 `$`。这里的一个重要功能是自动补全功能,它允许你使用 `Tab` 键在文件和目录之间移动,非常类似于菜单:

另一个有趣的功能是拼写纠正,这有助于在混合大小写的情况下输入文件名:

使用 zsh 成为你的默认 shell
-------------------
zsh 提供了很多插件,如 zsh-syntax-highlighting 和著名的 “Oh my zsh”([在此查看其页面](http://ohmyz.sh/))。也许你希望将其设为默认 shell,以便在你在开始会话或打开终端时运行。为此,请使用 `chsh`(“更改 shell”)命令:
```
$ chsh -s $(which zsh)
```
这个命令告诉你的系统你要设置(`-s`)默认 shell 为该 shell 的正确位置(`which zsh`)。
图片来自 [Flickr](https://www.flickr.com/photos/katerha/34714051013/) 由 [Kate Ter Haar](https://www.flickr.com/photos/katerha/) 提供(CC BY-SA)。
---
via: <https://fedoramagazine.org/set-zsh-fedora-system/>
作者:[Eduard Lucena](https://fedoramagazine.org/author/x3mboy/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | For some people, the terminal can be scary. But a terminal is more than just a black screen to type in. It usually runs a *shell*, so called because it wraps around the kernel. The shell is a text-based interface that lets you run commands on the system. It’s also sometimes called a command line interpreter or *CLI*. Fedora, like most Linux distributions, comes with *bash* as the default shell. However, it isn’t the only shell available; several other shells can be installed. This article focuses on the Z Shell, or *zsh*.
Bash is a rewrite of the old Bourne shell (*sh*) that shipped in UNIX. Zsh is intended to be friendlier than bash, through better interaction. Some of its useful features are:
- Programmable command line completion
- Shared command history between running shell sessions
- Spelling correction
- Loadable modules
- Interactive selection of files and folders
Zsh is available in the Fedora repositories. To install, run this command:
$ sudo dnf install zsh
### Using zsh
To start using it, just type *zsh* and the new shell prompts you with a first run wizard. This wizard helps you configure initial features, like history behavior and auto-completion. Or you can opt to keep the [rc file](https://en.wikipedia.org/wiki/Configuration_file) empty:
First-run wizard
If you type 1 the configuration wizard starts. The other options launch the shell immediately.
Note that the user prompt is **%** and not **$** as with bash. A significant feature here is the auto-completion that allows you to move among files and directories with the *Tab* key, much like a menu:
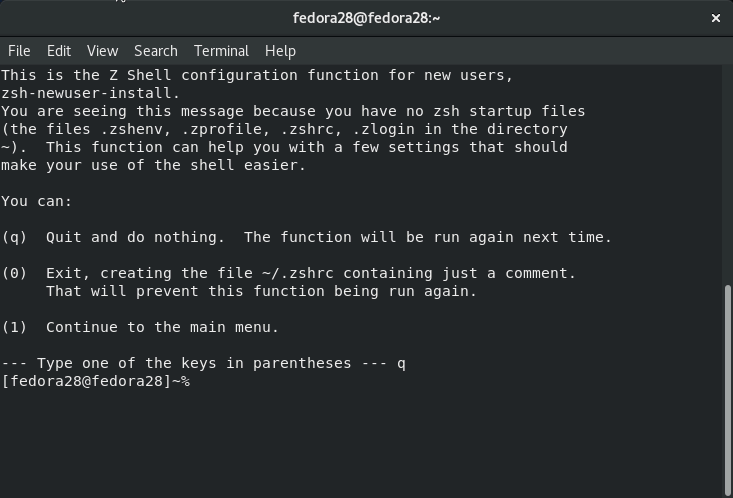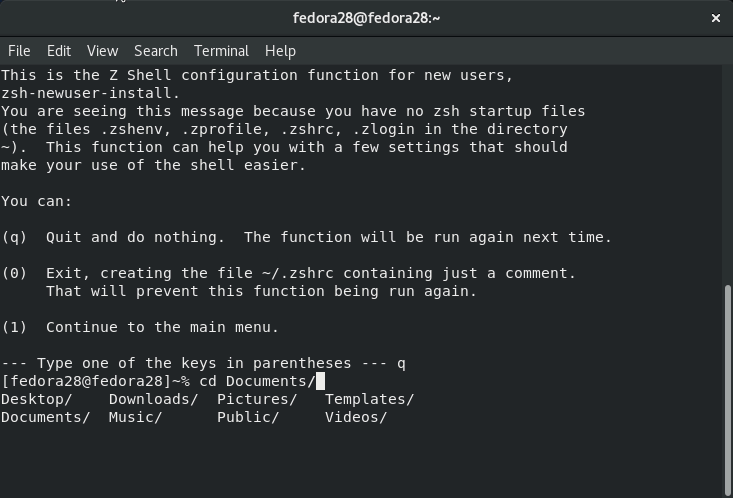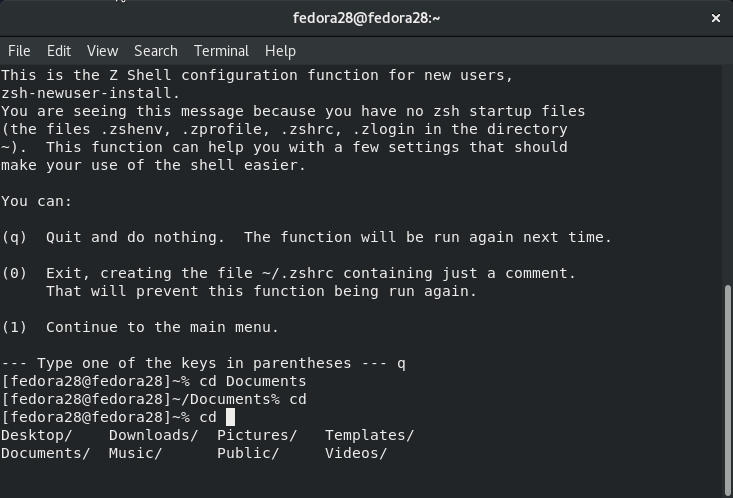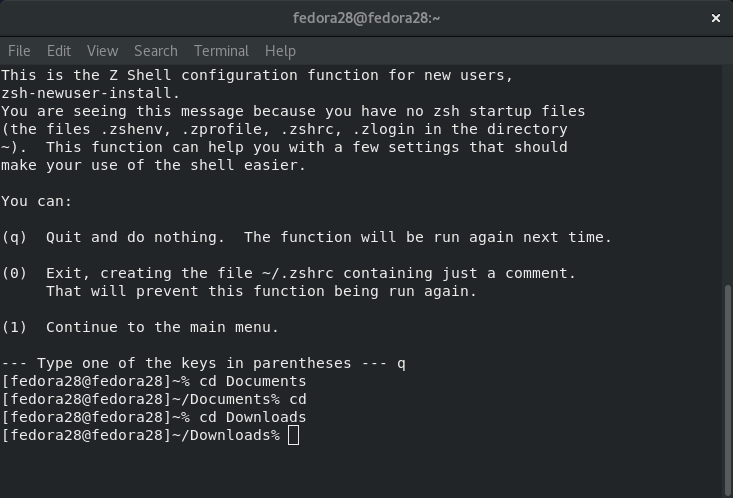
Using the auto-completion feature with the *cd* command
Another interesting feature is spelling correction, which helps when writing filenames with mixed cases:
Auto completion performing spelling correction
## Making zsh your default shell
Zsh offers a lot of plugins, like zsh-syntax-highlighting, and the famous “Oh my zsh” ([check out its page here](http://ohmyz.sh/)). You might want to make it the default, so it runs whenever you start a session or open a terminal. To do this, use the *chsh* (“change shell”) command:
$ chsh -s $(which zsh)
This command tells your system that you want to set (*-s*) your default shell to the correct location of the shell (*which zsh*).
Photo by [Kate Ter Haar](https://www.flickr.com/photos/katerha/) from [Flickr](https://www.flickr.com/photos/katerha/34714051013/) (CC BY-SA).
## Creak
It’s when I discovered Oh-My-Zsh that I definitely changed from bash to zsh, and never looked back 😉
## Isaac
Using with “antigen” is very useful!
## Ivan Augusto
Really good tip, ZSH is much powerful! 😀
A full guide to have a really, really powerful terminal using it: https://medium.com/@ivanaugustobd/seu-terminal-pode-ser-muito-muito-mais-produtivo-3159c8ef77b2 (it’s in Brazilian Portuguese, but can be easily translated using your favorite tool)
## Dirk
I use ZHS with antigen and various activated plug-ins on Fedora for years now. And I don’t want to miss it.
## Leslie Satenstein
Whats wrong with bash?
## Creak
Bash is very good, but quite limited in its features. I thought bash was largely enough for me (I’m not a hardcore shell user), but I tried zsh, just to see what it is.
What really changed my mind about zsh is when I configured it with Oh-My-Zsh (or Antigen, which is an attempt to make Oh-My-Zsh modular). Some day-to-day features are so useful, I just get frustrated when I go back to bash 😀
## Brian Vaughan
Nothing. ZSH just has some syntactic sugar some may like. I played with it for a while, and used Oh-My-Zsh, which has some cute tricks for the command line.
But, I’d never consider installing Oh-My-Zsh on a production system. And, I never got around to learning how to use ZSH’s unique features for scripting; it occurred to me that it didn’t make a lot of sense to do so. BASH is ubiquitous, and if BASH isn’t adequate to a task, I’d rather use Perl or Python, which are nearly as ubiquitous.
## Sudhir
What happens when you run bash or the usual commands on Zsh? I suppose ~/.bashrc, scripts, etc. continues to work as usual.
## Eduard Lucena
If you run bash, you just goes to bash through the normal process that include reading .bashrc .bash_profile and all other files needed to run bash. The commands just call programs, so yes, they work as usual: ls, cd, mv, cp, ln and everything works as usual, regular expression matching is a little different, the work with wildcards is also a little different, and the scripting is totally different. The scripts made for bash including th shabang works as usual.
## Brian Vaughan
Zsh, like Bash, is POSIX-compliant; the command line functions basically the same way, scripts that stick to POSIX features only should work with either shell, and a lot of Bash’s special features are also present in Zsh.
Normally, a shell script starts with a shebang, as in “#!/bin/bash” or “#!/bin/zsh”, which specifies the script interpreter. So a properly written script would run correctly, regardless of which shell the user is using at the command line.
You can launch an instance of Bash from within an instance of Zsh, or vice versa, just as you can launch a new instance of Bash from within an instance of Bash.
~/.bashrc, and the other related dotfiles that begin with “.bash”, are specific to Bash. Zsh uses ~/.zshrc . There are other dotfiles that are independent of a particular shell, e.g., .profile.
## Creak
Zsh is more for your day-to-day use of the command line. It brings useful features that bash simply doesn’t have (e.g. the exceptional completion system).
But if you’re writing a script for general purpose, always use a shebang to sh (i.e. #!/bin/sh) at the top of your script. Doing so, you’re scripts will run in a strong, cross-compatible shell environment.
## bladekp
Here you can find some nice startup confings for your ZSH: https://bitbucket.org/Vifon/zsh-config |
9,733 | 4 种基于 Markdown 的幻灯片生成器 | https://opensource.com/article/18/5/markdown-slide-generators | 2018-06-09T23:49:51 | [
"markdown",
"演示",
"幻灯片"
] | https://linux.cn/article-9733-1.html |
>
> 这些简单的幻灯片创建工具可以无缝地使用 Markdown,可以让你的演示添加魅力。
>
>
>

假设你需要做一个<ruby> 演示 <rt> presentation </rt></ruby>。在准备的过程中,你想到“我需要写几张幻灯片”。
你可能倾向于简洁的[纯文本](https://plaintextproject.online/),认为 LibreOffice Writer 这样的软件对你要做的事情而言像是杀鸡用牛刀。或者你只是遵从你内心深处的极客意识。
将 [Markdown](https://en.wikipedia.org/wiki/Markdown) 格式的文件转换为优雅的演示幻灯片并不困难。下面介绍可以完成这项工作的四种工具。
### Landslide
在这些工具中,[Landslide](https://github.com/adamzap/landslide) 具有更高的灵活性。它是一个命令行工具,可以将 Markdown、[reStructuredText](https://en.wikipedia.org/wiki/ReStructuredText) 或 [Textile](https://en.wikipedia.org/wiki/Textile_(markup_language)) 格式的文件转换为基于 [Google HTML5 幻灯片模板](https://github.com/skaegi/html5slides)的 HTML 文件。
你要做的不过是编写 Markdown 格式的幻灯片源文件,打开一个终端窗口并运行 `landslide` 命令即可,其中命令参数为 Markdown 文件的文件名。Landslide 会生成 `presentation.html`,可以在任何 Web 浏览器中打开。简单吧?
但不要被简易的操作误导你。Landslide 提供了不少有用的特性,例如增加注记以及为幻灯片增加配置文件。为何要使用这些特性呢?按照 Landslide 开发者的说法,这样可以汇聚不同演示中的源文件目录并重用。

*在 Landslide 演示中查看演示者注记*
### Marp
[Marp](https://yhatt.github.io/marp/) 仍处于开发中,但值得期待。它是 “Markdown Presentation Writer” 的简写。Marp 是一个基于 [Electron](https://en.wikipedia.org/wiki/Electron_(software_framework)) 的工具,让你在一个简单的双栏编辑器中编写幻灯片:在左栏编写 Markdown,在右栏中预览效果。
Marp 支持 [GitHub 风格 Markdown](https://guides.github.com/features/mastering-markdown/)。如果你需要一个使用 GitHub 风格 Markdown 编写幻灯片的快速教程,可以参考 [示例项目](https://raw.githubusercontent.com/yhatt/marp/master/example.md)。GitHub 风格 Markdown 比基础 Markdown 更加灵活。
Marp 只自带两个基础主题,但你可以为幻灯片增加背景图片、调整图片大小以及增加数学表达式。不足之处,目前只支持 PDF 格式导出。老实说,我很好奇为何不一开始就提供 HTML 格式导出。

*使用 Marp 编辑简单的幻灯片*
### Pandoc
你可能已经知道 [pandoc](https://pandoc.org/) 是一种支持多种<ruby> 标记语言 <rt> markup languages </rt></ruby>相互转换的神奇工具。但你可能不知道,pandoc 可以将 Markdown 格式文件转换为 [Slidy](https://www.w3.org/Talks/Tools/Slidy2/Overview.html#(1))、[Slideous](http://goessner.net/articles/slideous/)、[DZSlides](http://paulrouget.com/dzslides/) 和 [Reveal.js](https://revealjs.com/#/) 等演示框架支持的优雅 HTML 幻灯片。如果你使用 [LaTeX](https://www.latex-project.org/),可以使用 [Beamer 软件包](https://en.wikipedia.org/wiki/Beamer_(LaTeX))输出 PDF 格式的幻灯片。
你需要在幻灯片中[使用特定格式](https://pandoc.org/MANUAL.html#producing-slide-shows-with-pandoc),但可以通过[变量](https://pandoc.org/MANUAL.html#variables-for-slides)控制其效果。你也可以更改幻灯片的外观与风格,增加幻灯片之间的暂停,添加演示者注记等。
当然,你需要在你的主机上安装你喜欢的演示框架,因为 Pandoc 只生成原始幻灯片文件。

*查看使用 Pandoc 和 DZSlides 创建的幻灯片*
### Hacker Slides
[Hacker Slides](https://github.com/jacksingleton/hacker-slides) 是一个 [Sandstorm](https://sandstorm.io/) 和 [Sandstorm Oasis](https://oasis.sandstorm.io/) 平台上的应用,基于 Markdown 和 [Reveal.js](https://revealjs.com/#/) 幻灯片框架。生成的幻灯片可以比较朴素,也可以很炫。
在浏览器的两栏界面中编写幻灯片,左栏输入 Markdown 文本,右栏渲染效果。当你制作完成后,可以在 Sandstorm 中演示,也可以生成分享链接让其它人演示。
你可能会说,你不使用 Sandstorm 或 Sandstorm Oasis 怎么办?不要担心,Hacker Slides 提供了可以在桌面或服务器上运行的[版本](https://github.com/msoedov/hacker-slides)。

*在 Hacker Slides 中编辑幻灯片*
### 两点特别补充
如果你使用 [Jupyter <ruby> 笔记本 <rt> Notebooks </rt></ruby>](http://jupyter.org/) (参考社区版主 Don Watkins 的[文章](/article-9664-1.html))发布数据或指令文本,你可以使用 [Jupyter2slides](https://github.com/datitran/jupyter2slides)。该工具基于 Reveal.js,可以将笔记本转换为一系列精美的 HTML 幻灯片。
如果你倾向于托管应用,试试 [GitPitch](https://gitpitch.com/),支持 GitHub、GitLab 和 Bitbucket。只需在将幻灯片源文件推送到支持的代码仓库中,在 GitPitch 中指向该仓库,这样你就可以在 GitPitch 网站上看到你的幻灯片了。
你有最喜欢的基于 Markdown 的幻灯片生成器吗?留下评论分享吧。
---
via: <https://opensource.com/article/18/5/markdown-slide-generators>
作者:[Scott Nesbitt](https://opensource.com/users/scottnesbitt) 选题:[lujun9972](https://github.com/lujun9972) 译者:[pinewall](https://github.com/pinewall) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Imagine you've been tapped to give a presentation. As you're preparing your talk, you think, "I should whip up a few slides."
Maybe you prefer the simplicity of [plain text](https://plaintextproject.online/), or maybe you think software like LibreOffice Writer is overkill for what you need to do. Or perhaps you just want to embrace your inner geek.
It's easy to turn files formatted with [Markdown](https://en.wikipedia.org/wiki/Markdown) into attractive presentation slides. Here are four tools that can do help you do the job.
## Landslide
One of the more flexible applications on this list, [Landslide](https://github.com/adamzap/landslide) is a command-line application that takes files formatted with Markdown, [reStructuredText](https://en.wikipedia.org/wiki/ReStructuredText), or [Textile](https://en.wikipedia.org/wiki/Textile_(markup_language)) and converts them into an HTML file based on [Google’s HTML5 slides template](https://github.com/skaegi/html5slides).
All you need to do is write up your slides with Markdown, crack open a terminal window, and run the command `landslide`
followed by the name of the file. Landslide will spit out *presentation.html*, which you can open in any web browser. Simple, isn’t it?
Don't let that simplicity fool you. Landslide offers more than a few useful features, such as the ability to add notes and create configuration files for your slides. Why would you want to do that? According to Landslide's developer, it helps with aggregating and reusing source directories across presentations.
Viewing presenter notes in a Landslide presentation
## Marp
[Marp](https://yhatt.github.io/marp/) is a work in progress, but it shows promise. Short for "Markdown Presentation Writer," Marp is an [Electron](https://en.wikipedia.org/wiki/Electron_(software_framework)) app in which you craft slides using a simple two-pane editor: Write in Markdown in the left pane and you get a preview in the right pane.
Marp supports [GitHub Flavored Markdown](https://guides.github.com/features/mastering-markdown/). If you need a quick tutorial on using GitHub Flavored Markdown to write slides, check out the [sample presentation](https://raw.githubusercontent.com/yhatt/marp/master/example.md). It's a bit more flexible than baseline Markdown.
While Marp comes with only two very basic themes, you can add background images to your slides, resize them, and include math. On the down side, it currently lets you export your slides only as PDF files. To be honest, I wonder why HTML export wasn’t a feature from day one.
Editing some simple slides in Marp
## Pandoc
You probably know [pandoc](https://pandoc.org/) as a magic wand for converting between various markup languages. What you might not know is that pandoc can take a file formatted with Markdown and create attractive HTML slides that work with the [Slidy](https://www.w3.org/Talks/Tools/Slidy2/Overview.html#(1)), [Slideous](http://goessner.net/articles/slideous/), [DZSlides](http://paulrouget.com/dzslides/), [S5](https://meyerweb.com/eric/tools/s5/), and [Reveal.js](https://revealjs.com/#/) presentation frameworks. If you prefer [LaTeX](https://www.latex-project.org/), you can also output PDF slides using the [Beamer package](https://en.wikipedia.org/wiki/Beamer_(LaTeX)).
You'll need to [use specific formatting](https://pandoc.org/MANUAL.html#producing-slide-shows-with-pandoc) for your slides, but you can add some [variables](https://pandoc.org/MANUAL.html#variables-for-slides) to control how they behave. You can also change the look and feel of your slides, add pauses between slides, and include speaker notes.
Of course, you must have the supporting files for your preferred presentation framework installed on your computer. Pandoc spits out only the raw slide file.
Viewing slides created with Pandoc and DZSlides
## Hacker Slides
[Hacker Slides](https://github.com/jacksingleton/hacker-slides) is an application for [Sandstorm](https://sandstorm.io/) and [Sandstorm Oasis](https://oasis.sandstorm.io/) that mates Markdown and the [Reveal.js](https://revealjs.com/#/) slide framework. The slides are simple, but they can be visually striking.
Craft your slide deck in a two-pane editor in your browser—type in Markdown on the left and see it rendered on the right. When you're ready to present, you can do it from within Sandstorm or get a link that you can share with others to present remotely.
What’s that—you say that you don’t use Sandstorm or Sandstorm Oasis? No worries.There's a [version of Hacker Slides](https://github.com/msoedov/hacker-slides) that you can run on your desktop or server.
Editing slides in Hacker Slides
## Two honorable mentions
If you use [Jupyter Notebooks](http://jupyter.org/) (see community moderator Don Watkins' [article](https://opensource.com/article/18/3/getting-started-jupyter-notebooks)) to publish data or instructional texts, then [Jupyter2slides](https://github.com/datitran/jupyter2slides) is for you. It works with Reveal.js to convert a notebook into a nice set of HTML slides.
If you prefer your applications hosted, test-drive [GitPitch](https://gitpitch.com/). It works with GitHub, GitLab, and Bitbucket. Just push the source files for your slides to a repository on one of those services, point GitPitch to that repository, and your slides are ready to view at the GitPitch site.
Do you have a favorite Markdown-powered slide generator? Share it by leaving a comment.
## 4 Comments |
9,734 | 面向 Linux 和开源爱好者的书单 | https://opensource.com/article/18/5/list-books-Linux-open-source | 2018-06-11T08:55:40 | [
"书籍"
] | https://linux.cn/article-9734-1.html |
>
> 看看我们现在在读什么?
>
>
>

最近我在作者社区征集分享大家正在读的书。大家生活阅历和工作岗位各不相同,共同点是每天都与 Linux 和开源打交道。
享受这份不可思议的书单吧,其中大部分是免费的,可以下载。
在书单中,你可能发现一直想读的书、完全陌生的书以及像老朋友一样的已经读过的书。
我们期待你给出对书单的看法,可以在分享在下方的评论区,也可以通过 #Linuxbooks 和 #opensourcebooks 主题词分享在 Twitter 上。
### 加入你书单的 17 本书
**文末,还附赠了一篇科幻小说作品。**
#### [*FreeDOS 的 23 年岁月*](http://www.freedos.org/ebook/),作者 Jim Hall
从去年起,[FreeDOS](https://opensource.com/article/18/5/node/44116) 项目已经 23 岁了。虽然在 23 年中并没有什么特殊事件,但该项目决定庆祝这个里程碑,形式为分享不同人群使用 FreeDOS 或对 FreeDOS 做出贡献的故事。这本以 CC BY 协议开源的书籍收录了一系列短文,描绘了 FreeDOS 从 1994 开始的历程,以及人们现在如何使用 FreeDOS。([Jim Hall](https://opensource.com/users/jim-hall) 推荐并评论)
#### [*JavaScript 编程精解*](https://eloquentjavascript.net/),作者 Marijn Haverbeke
这本书基于无处不在的编程语言 [Javascript](https://opensource.com/article/18/5/node/32826),教你编写制作精美的程序。你可以学习语言的基本知识和高级特性,学习如何编写可在浏览器或 Node.js 环境中运行的程序。本书包含 5 个有趣的项目,例如制作游戏平台,甚至编写你自己的编程语言,在这过程中你会更加深入理解真实的编程。([Rahul Thakoor](https://opensource.com/users/rahul27) 推荐并评论)
#### [*使用开源打造未来*](https://pragprog.com/book/vbopens/forge-your-future-with-open-source),作者 VM (Vicky) Brasseur
如果你希望在开源领域做出贡献但无从下手,这本书会教会你。内容包括如何确定要加入的项目,以及如何做出你的首次贡献。([Ben Cotton](https://opensource.com/users/bcotton) 推荐并评论)
#### [*Git 团队协作*](http://gitforteams.com/),作者 Emma Jane Hogbin Westby
Git 是一款版本管理系统,被个人和团队广泛使用;但其强大的功能也意味着复杂性。这本书指导你如何在团队环境中有效地使用 [Git](https://opensource.com/article/18/5/node/43741)。想了解更多信息,请参考我们的[深入点评](https://opensource.com/business/15/11/git-for-teams-review)。([Ben Cotton](https://opensource.com/users/bcotton) 推荐并评论)
#### [*谈判力*](http://www.williamury.com/books/getting-to-yes/),作者 Fisher, Ury 及 Patton
<ruby> 哈佛谈判项目 <rt> The Harvard Negotiation Project </rt></ruby>成立于 20 世纪七十年代,是一个经济学家、心理学家、社会学家和政治学者共同参与的学术项目,目标是建立一个让谈判各方都受益更多的谈判框架。他们的框架和技巧已经在各类场景发挥作用,其中包括 1978 年埃及与以色列之间的签订的<ruby> 戴维营协议 <rt> Camp David Accords </rt></ruby>。
<ruby> 原则式谈判 <rt> Principled Negotiation </rt></ruby> 包括理解谈判参与者的真实需求,以及基于该信息达成各方都可接受的条款。同样的技巧可以在处理人与人之间的纠纷、关于车辆与房屋的谈判以及与保险公司的商讨时发挥作用。
这与开源软件开发有什么联系呢?在某种意义上,开源领域中的一切都是谈判。提交漏洞报告就是指出某些代码工作不正常,让某些人放下手头工作并优先处理该漏洞。邮件列表中对完成某些工作的正确方式的激烈讨论或对功能请求的评论,都是一种关于项目范畴和目标的谈判,通常是在信息不充足情况下进行的。
将上述对话视为一种探索,试图理解为何其它人提出来某些需求,让其明白你为何持有另外的观点,可以让你在开源项目中显著地改善人际关系和提高工作效率。([Dave Neary](https://opensource.com/users/dneary) 推荐并评论)
#### [*只是为了好玩:Linux 之父 Linus Torvalds 自传*](http://a.co/749s27n),作者 Linus Torvalds 等
Linux 是一款令人惊奇的、强力的操作系统,引发了关于透明和开放的运动。驱动 Linux 的开源思潮对传统商业和资本增值模型造成冲击。在本书中,你会了解到 Linus 本人及 [Linux](https://opensource.com/article/18/5/node/19796) 操作系统的过人之处。洞悉那些改变 Linus 命运的经历,这些经历让他从一个喜欢折腾他祖父钟表的怪人,转变成编写全球主流操作系统 Linux 的大师。([Don Watkins](https://opensource.com/users/don-watkins) 推荐并评论)
#### [*1 个月速成 Linux*](https://manning.com/ovadia),作者 Steven Ovadia
这本书用于教会非技术领域的用户如何使用桌面版 [Linux](https://opensource.com/article/18/5/node/42626),读者每天花费一小时即可。这本书覆盖面比较很广,包括选择桌面环境、安装软件以及如何使用 Git。阅读完这本书,你可以完全使用 Linux 替换掉其它操作系统。([Steven Ovadia](https://opensource.com/users/stevenov) 推荐并评论)
#### [*Linux 实战*](https://www.manning.com/books/linux-in-action?a_aid=bootstrap-it&a_bid=4ca15fc9),作者 David Clinton
这本身介绍了不少 Linux 管理工具的干货,适用于想提升技术水平的人群,包括 IT 专家、开发者、[DevOps](https://opensource.com/article/18/5/node/44696) 专家等。本书不是割裂地介绍各种技术,而是按照真实项目组织内容,例如异地备份自动化、Web 服务器安全加密以及搭建可以安全连接公司资源的 VPN 等。更多内容可以参考作者的[另一本书](https://bootstrap-it.com/index.php/books/)。([David Clinton](https://opensource.com/users/dbclinton) 推荐并评论)
#### [*创客丛书: 为创客准备的 Linux*](https://www.makershed.com/products/make-linux-for-makers),作者 Aaron Newcomb
对于想通过 [树莓派](https://opensource.com/article/18/5/node/35731) 创造和创新的人来说,这本书是必读的。这本书将领你入门,让你玩转你的树莓派,同时帮你理解 Raspbian Linux 操作系统(与传统 Linux )的细微差别。书中文字巧妙又浅显,可以让任何阅读本书的创客解锁树莓派的潜力。文字简洁,编写精良,包含大量极好的阐述和实战案例。(Jason Hibbets 推荐,[Don Watkins](https://opensource.com/users/don-watkins) 评论)
#### [*人性管理:一个软件工程经理刺激诙谐的经历*](https://www.amazon.com/Managing-Humans-Humorous-Software-Engineering/dp/1484221575/ref=dp_ob_title_bk) by Michael Lopp
Michael Lopp 是热门博客 [Rands 在休息](http://randsinrepose.com/)的作者,他的笔名 Rands 更为人熟知。这本书是在博客帖子的基础上修订集结而成,内容为软件开发团队的管理。Rands 的工作哲学为“软件开发中最复杂的部分是人际交往”,这是我对于本书和博客内容最欣赏的一点。本书涵盖一系列主题,包括分析一个团队,理解每个团队成员的个性以及设计如何让每个人都各尽所能。
这些主题适用面很广,作为一个开源社区管理者,我一直和这些事情打交道。如何得知某个成员已经精疲力尽?如何组织一个好的会议?如何在项目和团队扩大时形成项目和团队文化?如何判断流程是适度的?在开发之外,这类问题一直涌现出来;Rands 的不羁、诙谐的看法让人受教的同时给人感到快乐。([Dave Neary](https://opensource.com/users/dneary) 推荐并评论)
#### [*开源:来自开源革命的呐喊*](https://www.oreilly.com/openbook/opensources/book/index.html) (O'Reilly, 1999)
对于开源狂热者而言,这本书是必读的。Linus Torvalds、Eric S. Raymond、Richard Stallman、Michael Tiemann、 Tim O'Reilly 等开源运动中的领军人物分享他们对发展迅猛的[开源软件](https://opensource.com/article/18/5/node/42001)运动的看法。([Jim Hall](https://opensource.com/users/jim-hall) 推荐,Jen Wike Huger 评论)
#### [*创作开源软件:如何运营一个成功的自由软件项目*](https://producingoss.com/),作者 Karl Fogel
这本书面向人群包括,期望建立或已经正在建立开源社区,或更好的理解成功开源项目社区的开发趋势。Karl Fogel 分析研究了成功开源项目的特点,以及它们如何围绕项目发展成社区。对于如何围绕项目发展社区,这本书为社区管理者(或致力于成为社区管理者的人)提供了建设性的建议。鲜有书籍可以(像本书这样)深入观察开源社区的发展并给出大量成功点子,但你仍需要结合你的项目和社区因地制宜的行动。([Justin Flory](https://opensource.com/users/justinflory) 推荐并评论)
#### [*机器人编程*](http://engineering.nyu.edu/gk12/amps-cbri/pdf/RobotC%20FTC%20Books/notesRobotC.pdf),作者 Albert W. Schueller
这本书介绍乐高头脑风暴 NXT 编程的基础。并不需要读者编写复杂的程序,而是通过编程让设备可以感知并与真实世界进行交互。通过完成传感器、电机实验,以及编程制作音乐,你可以了解软硬件如何协调工作。([Rahul Thakoor](https://opensource.com/users/rahul27) 推荐并评论)
#### [*AWK 编程语言*](https://archive.org/details/pdfy-MgN0H1joIoDVoIC7),作者 Alfred V. Aho, Brian W. Kernighan 和 Peter J. Weinberger
这本书的作者就是 awk 语言的发明者,本书风格类似于 20 世纪 70 至 90 年代贝尔实验室 Unix 小组出版的类 Unix 工具书籍,使用简明、紧凑的文字介绍了 awk 的原理和目标。书中包含不少示例,从简单的开始,后面会结合描述详尽的问题或前沿案例,示例也变得复杂。本书刚出版时,典型的读者需求如下:处理和转换文本或数据文件,以及便捷地创建查询表、使用正则表达式、根据输入调整结构、对数值执行数学变换并便捷设置输出格式等。
上述需求依然存在,现在这本书也可以给人们提供一个回顾那个只能使用终端交互的年代的机会。在那时,通过“模块化”可以使用多个单一用途的程序编写 shell 脚本,用于管道处理数据,最终计算机给出人们预期的结果。在今天,awk 被视为运维工具,在处理配置文件和日志文件方面效果不错,这本书也介绍了一些这方面的内容。([Jim Hall](https://opensource.com/users/jim-hall) 推荐,[Chris Hermansen](https://opensource.com/users/clhermansen) 评论)
#### [*像计算机科学家一样思考 Python*](http://greenteapress.com/thinkpython2/thinkpython2.pdf),作者 Allen Downey
这本书是作者系列图书中的一本,介绍 Python 编程语言,系列中还有其它编程语言,包括 Java 和 [Perl](https://opensource.com/article/18/5/node/35141) 等。介绍完基础的编程语法后,本书进入主题环节,着重介绍问题解决者如何构建解决方案。本书概念层次清晰,对编程初学者是很好的入门读物;对于希望在课堂等地方提高编程技能的新手,本书也适用;本书的若干章节配有例子和习题,可供测试已学的技能。([Steve Morris](https://opensource.com/users/smorris12) 介绍并评论)
#### [*认识开源和自由软件协议*](http://shop.oreilly.com/product/9780596005818.do) (O'Reilly, 2004)
“这本书填补了开源理念与法律基础上的真实意义之间的空白。如果你对开源和自由软件协议感兴趣,那么本书可以帮忙加深理解。如果你是一名开源/自由软件开发者,这本书显然是必须的。“([Jim Hall](https://opensource.com/users/jim-hall) 推荐,评论来自 [Amazon](https://www.amazon.com/Understanding-Open-Source-Software-Licensing/dp/0596005814))
#### [*Unix 文本处理*](http://www.oreilly.com/openbook/utp/),作者 Dale Dougherty 及 Tim O'Reilly
本书写于 1987 年,用于介绍 Unix 系统及作家如何使用 Unix 工具帮助其工作。对于希望学习包括 vi 编辑器、awk、shell 脚本在内的 Unix shell 基础及 nroff/troff 排版系统的初学者而言,本书仍然是有用的资源。原版已绝版,但 O'Reilly 将本书制作为电子书,可在其网站上免费获得。([Jim Hall](https://opensource.com/users/jim-hall) 推荐并评论)
### 福利:科幻小说
#### [*11 号太空站*](http://www.emilymandel.com/stationeleven.html),作者 Emily St. John Mandel
故事时间设定为不远的未来,地球人口随着神秘而致命的流感爆发而锐减,故事发生在 20 年后。主人公 Kirsten Raymonde 是一名年轻女性,坚信“仅仅活着是不够的”,为此她在后世界末日时代带着一个游牧剧团在五大湖区域附近勇敢地旅行。这是个精彩的故事,很值得一读。
这本书让我震惊的是我们与技术之间实际上那么脆弱的关系。Douglas Adams 的 《Mostly Harmless》 书中有一句话很经典:“仅靠双手,他无法制造一个面包机。但他可以制作三明治,就是这样”。在 Kristin Raymonde 的世界中,每个人仅能靠自己的双手。这里没有电,因为电力网络无法运作;没有汽车,因为炼油厂无法运作。
书中有一个有趣的桥段,一个发明家使用自行车组装了一台发电机,试图启动一台笔记本电脑,尝试查看是否还存在互联网。我们看到旧世界留存的、无用的东西堆成的文明博物馆,内容包括护照、移动电话、信用卡和高跟鞋等。
世界上的全部技术都变得无用。([Dave Neary](https://opensource.com/users/dneary) 推荐并评论)
---
via: <https://opensource.com/article/18/5/list-books-Linux-open-source>
作者:[Jen Wike Huger](https://opensource.com/users/remyd) 选题:[lujun9972](https://github.com/lujun9972) 译者:[pinewall](https://github.com/pinewall) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I recently asked our writer community to share with us what they're reading. These folks come from all different walks of life and roles in tech. What they have in common is that they are living and breathing Linux and open source every day.
Drink in this fantastic list. Many of them are free and available to download.
You may see books you've been meaning to get around to, books that are completely new to you, and some that feel like old friends.
We'd love to hear what you think of this list. Share with us in the comments below or on [Twitter](https://twitter.com/opensourceway) with #Linuxbooks #opensourcebooks.
## 17 books to add to your reading list
**Plus, a bonus fiction read.**
by Jim Hall
[23 Years of FreeDOS](http://www.freedos.org/ebook/)
Last year, the [FreeDOS](https://opensource.com/node/44116) Project turned 23 years old. While there's nothing special about 23 years, the project decided to celebrate that milestone by sharing stories about how different people use or contribute to FreeDOS. The free, CC BY eBook is a collection of essays that describe the history of FreeDOS since 1994, and how people use FreeDOS today. (Recommendation and review by [Jim Hall](https://opensource.com/users/jim-hall))
* Eloquent JavaScript* by Marijn Haverbeke
This book teaches you how to write beautifully crafted programs using one of the most ubiquitous programming languages: [Javascript](https://opensource.com/node/32826). Learn the basics and advanced concepts of the language, and how to write programs that run in the browser or Node.js environment. The book also includes five fun projects so you can dive into actual programming while making a platform game or even writing your own programming language. (Recommendation and review by [Rahul Thakoor](https://opensource.com/users/rahul27))
[ Forge Your Future with Open Source](https://pragprog.com/book/vbopens/forge-your-future-with-open-source) by VM (Vicky) Brasseur
If you're looking to contribute to open source, but you don't know how to start, this is the book for you. It covers how to find a project to join and how to make your first contributions. (Recommendation and review by [Ben Cotton](https://opensource.com/users/bcotton))
[ Git for Teams](http://gitforteams.com/) by Emma Jane Hogbin Westby
Git is a widely-used version control system for individuals and teams alike, but its power means it can be complex. This book provides guidance on how to effectively use [git](https://opensource.com/node/43741) in a team environment. For more, read our [in-depth review](https://opensource.com/business/15/11/git-for-teams-review). (Recommendation and review by [Ben Cotton](https://opensource.com/users/bcotton))
[ Getting to Yes](http://www.williamury.com/books/getting-to-yes/) by Fisher, Ury, and Patton
The Harvard Negotiation Project, formed in the 1970s, was an academic effort involving economists, psychologists, sociologists, and political scientists to create a framework for negotiations which allows better outcomes for all involved. Their framework and techniques have been used in a diverse set of circumstances, including the Camp David Accords between Egypt and Israel in 1978.
Principled Negotiation involves understanding the real interests of the participants in a negotiation and using this knowledge to generate options acceptable to all. The same techniques can be used to resolve interpersonal issues, negotiations over cars and houses, discussions with insurance companies, and so on.
What does this have to do with open source software development? Everything in open source is a negotiation, in some sense. Submitting a bug report is outlining a position—that something does not work correctly—and requesting that someone reprioritize their work to fix it. A heated discussion on a mailing list over the right way to do something or a comment on a feature request is a negotiation, often with imperfect knowledge, about the scope and goals of the project.
Reframing these conversations as explorations, trying to understand why the other person is asking for something, and being transparent about the reasons why you believe another viewpoint to apply, can dramatically change your relationships and effectiveness working in an open source project. (Recommendation and review by [Dave Neary](https://opensource.com/users/dneary))
[ Just for Fun: The Story of an Accidental Revolutionary](http://a.co/749s27n) by Linus Torvalds et al.
Linux is an amazing and powerful operating system that spawned a movement to transparency and openness. And, the open source ethos that drives it flies in the face of traditional models of business and capital appreciation. In this book, learn about the genius of Linus the man and [Linux](https://opensource.com/node/19796) the operating system. Get insight into the experiences that shaped Linus's life and fueled his transformation from a nerdy young man who enjoyed toying with his grandfather's clock to the master programmer of the world's predominant operating system. (Recommendation and review by [Don Watkins](https://opensource.com/users/don-watkins))
by Steven Ovadia
*Linux in a Month of Lunches*
This book is designed to teach non-technical users how to use desktop [Linux](https://opensource.com/node/42626) in about an hour a day. The book covers everything from choosing a desktop environment to installing software, to using Git. At the end of the month, readers can use Linux fulltime, replacing their other operating systems. (Recommendation and review by [Steven Ovadia](https://opensource.com/users/stevenov))
* Linux in Action* by David Clinton
This book introduces serious Linux administration tools for anyone interested in getting more out of their tech, including IT professionals, developers, [DevOps](https://opensource.com/node/44696) specialists, and more. Rather than teaching skills in isolation, the book is organized around practical projects like automating off-site data backups, securing a web server, and creating a VPN to safely connect an organization's resources. [Read more](https://bootstrap-it.com/index.php/books/) by this author. (Recommendation and review by [David Clinton](https://opensource.com/users/dbclinton))
by Aaron Newcomb
*Make: Linux for Makers*
This book is a must-read for anyone wanting to create and innovate with the [Raspberry Pi](https://opensource.com/node/35731). This book will have you up and operating your Raspberry Pi while at the same time understanding the nuances of it Raspbian Linux operating system. This is a masterful basic text that will help any maker unlock the potential of the Raspberry Pi. It’s concise and well written with a lot of fantastic illustrations and practical examples. (Recommendation by Jason Hibbets | Review by [Don Watkins](https://opensource.com/users/don-watkins))
[ Managing Humans: Biting and Humorous Tales of a Software Engineering Manager](https://www.amazon.com/Managing-Humans-Humorous-Software-Engineering/dp/1484221575/ref=dp_ob_title_bk) by Michael Lopp
Michael Lopp is better known by the nom de plume Rands, author of the popular blog [ Rands in Repose](http://randsinrepose.com/). This book is an edited, curated collection of blog posts, all related to the management of software development teams. What I love about the book and the blog, is that Rands starts from the fundamental principle that the most complex part of software development is human interactions. The book covers a range of topics about reading a group, understanding the personalities that make it up, and figuring out how to get the best out of everyone.
These things are universal, and as an open source community manager, I come across them all the time. How do you know if someone might be burning out? How do you run a good meeting? How do you evolve the culture of a project and team as it grows? How much process is the right amount? Regardless of the activity, questions like these arise all the time, and Rands's irreverent, humorous take is educational and entertaining. (Recommendation and review by [Dave Neary](https://opensource.com/users/dneary))
* Open Sources: Voices from the Open Source Revolution* (O'Reilly, 1999)
This book is a must-read for all open source enthusiasts. Linus Torvalds, Eric S. Raymond, Richard Stallman, Michael Tiemann, Tim O'Reilly, and other important figures in the open source movement share their thoughts on the forward momentum of [open source software](https://opensource.com/node/42001). (Recommendation by [Jim Hall](https://opensource.com/users/jim-hall) | Review by Jen Wike Huger)
* Producing Open Source Software: How to Run a Successful Free Software Project* by Karl Fogel
This book is for anyone who wants to build an open source community, is already building one, or wants to better understand trends in successful open source project community development. Karl Fogel analyzes and studies traits and characteristics of successful open source projects and how they have developed a community around the project. The book offers helpful advice to community managers (or want-to-be community managers) on how to navigate community development around a project. This is a rare book that takes a deeper look into open source community development and offers plenty of ingredients for success, but you have to take it and create the recipe for your project or community. (Recommendation and review by [Justin Flory](https://opensource.com/users/justinflory))
by Albert W. Schueller
*Programming with Robots*
This book introduces the basics of programming using the Lego Mindstorms NXT. Instead of writing abstract programs, learn how to program devices that can sense and interface with the physical world. Learn how software and hardware interact with each other while experimenting with sensors, motors or making music using code. (Recommendation and review by [Rahul Thakoor](https://opensource.com/users/rahul27))
by Alfred V. Aho, Brian W. Kernighan, and Peter J. Weinberger
*The AWK programming language*
This book, written by the creators of awk, follows a pattern similar to other books about *nix tools written by the original Bell Labs Unix team and published in the 1970s-1990s, explaining the rationale and intended use of awk in clear and compact prose, liberally sprinkled with examples that start simply and are further elaborated by the need to deal with more fully-detailed problems and edge cases. When published, the typical reader of this book would have been someone who had files of textual or numeric data that needed to be processed and transformed, and who wanted to be able to easily create lookup tables, apply regular expressions, react to structure changes within the input, apply mathematical transformations to numbers and easily format the output.
While that characterization still applies, today the book can also provide a window back into the time when the only user interface available was a terminal, when "modularity" created the ability to string together numerous single-purpose utility programs in shell scripts to create data transformation pipelines that crunched the data and produced the reports that everyone expected of computers. Today, awk should be a part of the operations toolbox, providing a fine ability to further process configuration and log files, and this book still provides a great introduction to that process. (Recommendation by [Jim Hall](https://opensource.com/users/jim-hall) | Review by [Chris Hermansen](https://opensource.com/users/clhermansen))
by Allen Downey
*Think Python: Think Like a Computer Scientist*
This book about [Python](https://opensource.com/node/40481) is part of [a series](http://greenteapress.com/wp/) that covers other languages as well, like Java, [Perl](https://opensource.com/node/35141), etc. It moves past simple language syntax downloads and approaches the topic through the lens of how a problem solver would build a solution. It's both a great introductory guide to programming through a layering of concepts, but it can serve the dabbler who is looking to develop skills in an area such as classes or inheritance with chapters that have examples and exercises to then apply the skills taught. (Recommendation and review by [Steve Morris](https://opensource.com/users/smorris12))
* Understanding Open Source and Free Software Licensing* (O'Reilly, 2004)
"This book bridges the gap between the open source vision and the practical implications of its legal underpinnings. If open source and free software licenses interest you, this book will help you understand them. If you're an open source/free software developer, this book is an absolute necessity." (Recommendation by [Jim Hall](https://opensource.com/users/jim-hall) | review from [Amazon](https://www.amazon.com/Understanding-Open-Source-Software-Licensing/dp/0596005814))
by Dale Dougherty and Tim O'Reilly
[Unix Text Processing](http://www.oreilly.com/openbook/utp/)
This book was written in 1987 as an introduction to Unix systems and how writers could use Unix tools to do work. It's still a useful resource for beginners to learn the basics of the Unix shell, the vi editor, awk and shell scripts, and the nroff and troff typesetting system. The original edition is out of print, but O'Reilly has made the book available for free via their website. (Recommendation and review by [Jim Hall](https://opensource.com/users/jim-hall))
## Bonus: Fiction book
* Station Eleven* by Emily St. John Mandel
This story is set in a near future, twenty years after the earth's population has been decimated by a mysterious and deadly flu. We follow Kirsten Raymonde, a young woman who is traveling near the Great Lakes with a nomadic theatre group because "Survival is insufficient," as she makes her way through the post-apocalyptic world. It's a wonderful story, well worth reading.
What struck me about the book is how tenuous our relationship with technology actually is. In the Douglas Adams book "Mostly Harmless", there is a great line: "Left to his own devices he couldn't build a toaster. He could just about make a sandwich and that was it." This is the world of Kristin Raymonde. Everyone has been left to their own devices: There is no electricity because no one can work the power grid. No cars, no oil refineries.
There is a fascinating passage where one inventor has rigged up a generator with a bicycle and is trying to turn on a laptop, trying to see if there is still an internet. We discover the Museum of Civilization, stocked with objects which have no use, which has been left over from the old world: passports, mobile phones, credit cards, stilettoes.
All of the world's technology becomes useless. (Recommendation and review by [Dave Neary](https://opensource.com/users/dneary))
## 5 Comments |
9,735 | Ohcount:源代码行计数器和分析器 | https://www.ostechnix.com/ohcount-the-source-code-line-counter-and-analyzer/ | 2018-06-11T11:33:02 | [
"代码"
] | https://linux.cn/article-9735-1.html | 
**Ohcount** 是一个简单的命令行工具,可用于分析源代码并打印代码的总行数。它不仅仅是代码行计数器,还可以在含有大量代码的目录中检测流行的开源许可证,例如 GPL。此外,Ohcount 还可以检测针对特定编程 API(例如 KDE 或 Win32)的代码。在编写本指南时,Ohcount 目前支持 70 多种流行的编程语言。它用 **C** 语言编写,最初由 **Ohloh** 开发,用于在 [www.openhub.net](http://www.openhub.net) 中生成报告。
在这篇简短的教程中,我们将介绍如何安装和使用 Ohcount 来分析 Debian、Ubuntu 及其变体(如 Linux Mint)中的源代码文件。
### Ohcount – 代码行计数器
#### 安装
Ohcount 存在于 Debian 和 Ubuntu 及其派生版的默认仓库中,因此你可以使用 APT 软件包管理器来安装它,如下所示。
```
$ sudo apt-get install ohcount
```
#### 用法
Ohcount 的使用非常简单。
你所要做的就是进入你想要分析代码的目录并执行程序。
举例来说,我将分析 [coursera-dl](https://www.ostechnix.com/coursera-dl-a-script-to-download-coursera-videos/) 程序的源代码。
```
$ cd coursera-dl-master/
$ ohcount
```
以下是 Coursera-dl 的行数摘要:

如你所见,Coursera-dl 的源代码总共包含 141 个文件。第一列说明源码含有的编程语言的名称。第二列显示每种编程语言的文件数量。第三列显示每种编程语言的总行数。第四行和第五行显示代码中由多少行注释及其百分比。第六列显示空行的数量。最后一列和第七列显示每种语言的全部代码行数以及 coursera-dl 的总行数。
或者,直接使用下面的完整路径。
```
$ ohcount coursera-dl-master/
```
路径可以是任何数量的单个文件或目录。目录将被递归探测。如果没有给出路径,则使用当前目录。
如果你不想每次都输入完整目录路径,只需 cd 进入它,然后使用 ohcount 来分析该目录中的代码。
要计算每个文件的代码行数,请使用 `-i` 标志。
```
$ ohcount -i
```
示例输出:

当您使用 `-a` 标志时,ohcount 还可以显示带标注的源码。
```
$ ohcount -a
```

如你所见,显示了目录中所有源代码的内容。每行都以制表符分隔的语言名称和语义分类(代码、注释或空白)为前缀。
有时候,你只是想知道源码中使用的许可证。为此,请使用 `-l` 标志。
```
$ ohcount -l
lgpl3, coursera_dl.py
gpl coursera_dl.py
```
另一个可用选项是 `-re`,用于将原始实体信息打印到屏幕(主要用于调试)。
```
$ ohcount -re
```
要递归地查找给定路径内的所有源码文件,请使用 `-d` 标志。
```
$ ohcount -d
```
上述命令将显示当前工作目录中的所有源码文件,每个文件名将以制表符分隔的语言名称为前缀。
要了解更多详细信息和支持的选项,请运行:
```
$ ohcount --help
```
对于想要分析自己或其他开发人员开发的代码,并检查代码的行数,用于编写这些代码的语言以及代码的许可证详细信息等,ohcount 非常有用。
就是这些了。希望对你有用。会有更好的东西。敬请关注!
干杯!
---
via: <https://www.ostechnix.com/ohcount-the-source-code-line-counter-and-analyzer/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,736 | 在 Linux 中使用 Stratis 配置本地存储 | https://opensource.com/article/18/4/stratis-easy-use-local-storage-management-linux | 2018-06-11T11:54:24 | [
"Stratis",
"存储"
] | https://linux.cn/article-9736-1.html |
>
> 关注于易用性,Stratis 为桌面用户提供了一套强力的高级存储功能。
>
>
>

对桌面 Linux 用户而言,极少或仅在安装系统时配置本地存储。Linux 存储技术进展比较慢,以至于 20 年前的很多存储工具仍在今天广泛使用。但从那之后,存储技术已经提升了不少,我们为何不享受新特性带来的好处呢?
本文介绍 Startis,这是一个新项目,试图让所有 Linux 用户从存储技术进步中受益,适用场景可以是仅有一块 SSD 的单台笔记本,也可以是包含上百块硬盘的存储阵列。Linux 支持新特性,但由于缺乏易于使用的解决方案,使其没有被广泛采用。Stratis 的目标就是让 Linux 的高级存储特性更加可用。
### 简单可靠地使用高级存储特性
Stratis 希望让如下三件事变得更加容易:存储初始化配置;后续变更;使用高级存储特性,包括<ruby> 快照 <rt> snapshots </rt></ruby>、<ruby> 精简配置 <rt> thin provisioning </rt></ruby>,甚至<ruby> 分层 <rt> tiering </rt></ruby>。
### Stratis:一个卷管理文件系统
Stratis 是一个<ruby> 卷管理文件系统 <rt> volume-managing filesystem </rt></ruby>(VMF),类似于 [ZFS](https://en.wikipedia.org/wiki/ZFS) 和 [Btrfs](https://en.wikipedia.org/wiki/Btrfs)。它使用了存储“池”的核心思想,该思想被各种 VMF 和 形如 [LVM](https://en.wikipedia.org/wiki/Logical_Volume_Manager_(Linux)) 的独立卷管理器采用。使用一个或多个硬盘(或分区)创建存储池,然后在存储池中创建<ruby> 卷 <rt> volume </rt></ruby>。与使用 [fdisk](https://en.wikipedia.org/wiki/Fdisk) 或 [GParted](https://gparted.org/) 执行的传统硬盘分区不同,存储池中的卷分布无需用户指定。
VMF 更进一步与文件系统层结合起来。用户无需在卷上部署选取的文件系统,因为文件系统和卷已经被合并在一起,成为一个概念上的文件树(ZFS 称之为<ruby> 数据集 <rt> dataset </rt></ruby>,Brtfs 称之为<ruby> 子卷 <rt> subvolume </rt></ruby>,Stratis 称之为文件系统),文件数据位于存储池中,但文件大小仅受存储池整体容量限制。
换一个角度来看:正如文件系统对其中单个文件的真实存储块的实际位置做了一层<ruby> 抽象 <rt> abstract </rt></ruby>,而 VMF 对存储池中单个文件系统的真实存储块的实际位置做了一层抽象。
基于存储池,我们可以启用其它有用的特性。特性中的一部分理所当然地来自典型的 VMF <ruby> 实现 <rt> implementation </rt></ruby>,例如文件系统快照,毕竟存储池中的多个文件系统可以共享<ruby> 物理数据块 <rt> physical data block </rt></ruby>;<ruby> 冗余 <rt> redundancy </rt></ruby>,分层,<ruby> 完整性 <rt> integrity </rt></ruby>等其它特性也很符合逻辑,因为存储池是操作系统中管理所有文件系统上述特性的重要场所。
上述结果表明,相比独立的卷管理器和文件系统层,VMF 的搭建和管理更简单,启用高级存储特性也更容易。
### Stratis 与 ZFS 和 Btrfs 有哪些不同?
作为新项目,Stratis 可以从已有项目中吸取经验,我们将在[第二部分](https://opensource.com/article/18/4/stratis-lessons-learned)深入介绍 Stratis 采用了 ZFS、Brtfs 和 LVM 的哪些设计。总结一下,Stratis 与其不同之处来自于对功能特性支持的观察,来自于个人使用及计算机自动化运行方式的改变,以及来自于底层硬件的改变。
首先,Stratis 强调易用性和安全性。对个人用户而言,这很重要,毕竟他们与 Stratis 交互的时间间隔可能很长。如果交互不那么友好,尤其是有丢数据的可能性,大部分人宁愿放弃使用新特性,继续使用功能比较基础的文件系统。
第二,当前 API 和 <ruby> DevOps 式 <rt> Devops-style </rt></ruby>自动化的重要性远高于早些年。Stratis 提供了支持自动化的一流 API,这样人们可以直接通过自动化工具使用 Stratis。
第三,SSD 的容量和市场份额都已经显著提升。早期的文件系统中很多代码用于优化机械介质访问速度慢的问题,但对于基于闪存的介质,这些优化变得不那么重要。即使当存储池过大而不适合使用 SSD 的情况,仍可以考虑使用 SSD 充当<ruby> 缓存层 <rt> caching tier </rt></ruby>,可以提供不错的性能提升。考虑到 SSD 的优良性能,Stratis 主要聚焦存储池设计方面的<ruby> 灵活性 <rt> flexibility </rt></ruby>和<ruby> 可靠性 <rt> reliability </rt></ruby>。
最后,与 ZFS 和 Btrfs 相比,Stratis 具有明显不一样的<ruby> 实现模型 <rt> implementation model </rt></ruby>(我会在[第二部分](https://opensource.com/article/18/4/stratis-lessons-learned)进一步分析)。这意味着对 Stratis 而言,虽然一些功能较难实现,但一些功能较容易实现。这也加快了 Stratis 的开发进度。
### 了解更多
如果希望更多了解 Stratis,可以查看本系列的[第二部分](https://opensource.com/article/18/4/stratis-lessons-learned)。你还可以在 [Stratis 官网](https://stratis-storage.github.io/) 找到详细的[设计文档](https://stratis-storage.github.io/StratisSoftwareDesign.pdf)。
### 如何参与
如果希望参与开发、测试 Stratis 或给出反馈,请订阅我们的[邮件列表](https://lists.fedoraproject.org/admin/lists/stratis-devel.lists.fedorahosted.org/)。
[GitHub](https://github.com/stratis-storage/) 上的开发项目包括 [守护进程](https://github.com/stratis-storage/stratisd) (使用 [Rust](https://www.rust-lang.org/) 开发)和 [命令行工具](https://github.com/stratis-storage/stratis-cli) (使用 [Python](https://www.python.org/) 开发)两部分。
可以在 [Freenode](https://freenode.net/) IRC 网络的 #stratis-storage 频道加入我们。
Andy Grover 将在今年的 LinuxFest Northwest 会议上演讲。查看[会议安排](https://www.linuxfestnorthwest.org/conferences/lfnw18) 或 [注册参会](https://www.linuxfestnorthwest.org/conferences/lfnw18/register/new)。
---
via: <https://opensource.com/article/18/4/stratis-easy-use-local-storage-management-linux>
作者:[Andy Grover](https://opensource.com/users/agrover) 选题:[lujun9972](https://github.com/lujun9972) 译者:[pinewall](https://github.com/pinewall) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Configuring local storage is something desktop Linux users do very infrequently—maybe only once, during installation. Linux storage tech moves slowly, and many storage tools used 20 years ago are still used regularly today. But some things *have* improved since then. Why aren't people taking advantage of these new capabilities?
This article is about Stratis, a new project that aims to bring storage advances to all Linux users, from the simple laptop single SSD to a hundred-disk array. Linux has the capabilities, but its lack of an easy-to-use solution has hindered widespread adoption. Stratis's goal is to make Linux's advanced storage features accessible.
## Simple, reliable access to advanced storage features
Stratis aims to make three things easier: initial configuration of storage; making later changes; and using advanced storage features like snapshots, thin provisioning, and even tiering.
## Stratis: a volume-managing filesystem
Stratis is a volume-managing filesystem (VMF) like [ZFS](https://en.wikipedia.org/wiki/ZFS) and [Btrfs](https://en.wikipedia.org/wiki/Btrfs). It starts with the central idea of a storage "pool," an idea common to VMFs and also standalone volume managers such as [LVM](https://en.wikipedia.org/wiki/Logical_Volume_Manager_(Linux)). This pool is created from one or more local disks (or partitions), and volumes are created from the pool. Their exact layout is not specified by the user, unlike traditional disk partitioning using [fdisk](https://en.wikipedia.org/wiki/Fdisk) or [GParted](https://gparted.org/).
VMFs take it a step further and integrate the filesystem layer. The user no longer picks a filesystem to put on the volume. The filesystem and volume are merged into a single thing—a conceptual tree of files (which ZFS calls a *dataset*, Btrfs a *subvolume*, and Stratis a *filesystem*) whose data resides in the pool but that has no size limit except for the pool's total size.
Another way of looking at this: Just as a filesystem abstracts the actual location of storage blocks that make up a single file within the filesystem, a VMF abstracts the actual storage blocks of a filesystem within the pool.
The pool enables other useful features. Some of these, like filesystem snapshots, occur naturally from the typical implementation of a VMF, where multiple filesystems can share physical data blocks within the pool. Others, like redundancy, tiering, and integrity, make sense because the pool is a central place to manage these features for all the filesystems on the system.
The result is that a VMF is simpler to set up and manage and easier to enable for advanced storage features than independent volume manager and filesystem layers.
## What makes Stratis different from ZFS or Btrfs?
Stratis is a new project, which gives it the benefit of learning from previous projects. What Stratis learned from ZFS, Btrfs, and LVM will be covered in depth in [Part 2](https://opensource.com/article/18/4/stratis-lessons-learned), but to summarize, the differences in Stratis come from seeing what worked and what didn't work for others, from changes in how people use and automate computers, and changes in the underlying hardware.
First, Stratis focuses on being easy and safe to use. This is important for the individual user, who may go for long stretches of time between interactions with Stratis. If these interactions are unfriendly, especially if there's a possibility of losing data, most people will stick with the basics instead of using new features.
Second, APIs and DevOps-style automation are much more important today than they were even a few years ago. Stratis supports automation by providing a first-class API, so people and software tools alike can use Stratis directly.
Third, SSDs have greatly expanded in capacity as well as market share. Earlier filesystems went to great lengths to optimize for rotational media's slow access times, but flash-based media makes these efforts less important. Even if a pool's data is too big to use SSDs economically for the entire pool, an SSD caching tier is still an option and can give excellent results. Assuming good performance because of SSDs lets Stratis focus its pool design on flexibility and reliability.
Finally, Stratis has a very different implementation model from ZFS and Btrfs (I'll this discuss further in [Part 2](https://opensource.com/article/18/4/stratis-lessons-learned)). This means some things are easier for Stratis, while other things are harder. It also increases Stratis's pace of development.
## Learn more
To learn more about Stratis, check out [Part 2](https://opensource.com/article/18/4/stratis-lessons-learned) of this series. You'll also find a detailed [design document](https://stratis-storage.github.io/StratisSoftwareDesign.pdf) on the [Stratis website](https://stratis-storage.github.io/).
## Get involved
To develop, test, or offer feedback on Stratis, subscribe to our [mailing list](https://lists.fedoraproject.org/admin/lists/stratis-devel.lists.fedorahosted.org/).
Development is on [GitHub](https://github.com/stratis-storage/) for both the [daemon](https://github.com/stratis-storage/stratisd) (written in [Rust](https://www.rust-lang.org/)) and the [command-line tool](https://github.com/stratis-storage/stratis-cli) (written in [Python](https://www.python.org/)).
Join us on the [Freenode](https://freenode.net/) IRC network on channel #stratis-storage.
*Andy Grover will be speaking at LinuxFest Northwest this year. See program highlights or register to attend.*
## 1 Comment |
9,737 | 如何在 RHEL 中使用订阅管理器启用软件仓库 | https://kerneltalks.com/howto/how-to-enable-repository-using-subscription-manager-in-rhel/ | 2018-06-12T10:21:12 | [
"RedHat",
"RHEL",
"订阅"
] | https://linux.cn/article-9737-1.html |
>
> 了解如何在 RHEL 中使用订阅管理器来启用软件仓库。 这篇文章还包括了将系统注册到 Red Hat 的步骤、添加订阅和发生错误时的解决方案。
>
>
>

在本文中,我们将逐步介绍如何在刚安装的 RHEL 服务器中启用 Red Hat 软件仓库。
可以利用 `subscription-manager` 命令启用软件仓库,如下所示:
```
root@kerneltalks # subscription-manager repos --enable rhel-6-server-rhv-4-agent-beta-debug-rpms
Error: 'rhel-6-server-rhv-4-agent-beta-debug-rpms' does not match a valid repository ID. Use "subscription-manager repos --list" to see valid repositories.
```
当您的订阅没有配置好时,您会看到上述错误。让我们一步一步地通过 `subscription-manager` 来启用软件仓库。
### 步骤 1:使用 Red Hat 注册您的系统
这里假设您已经安装了新系统并且尚未在 Red Hat 上注册。如果您已经注册了该系统,那么您可以忽略此步骤。
您可以使用下面的命令来检查您的系统是否已在 Red Hat 注册了该订阅:
```
# subscription-manager version
server type: This system is currently not registered.
subscription management server: Unknown
subscription management rules: Unknown
subscription-manager: 1.18.10-1.el6
python-rhsm: 1.18.6-1.el6
```
在这里输出的第一行中,您可以看到该系统未注册。那么,让我们开始注册系统。您需要在 `subscription-manager` 命令中使用 `register` 选项。在这一步需要使用您的 Red Hat 帐户凭证。
```
root@kerneltalks # subscription-manager register
Registering to: subscription.rhsm.redhat.com:443/subscription
Username: [email protected]
Password:
Network error, unable to connect to server. Please see /var/log/rhsm/rhsm.log for more information.
```
如果您遇到上述错误,那么表明您的服务器无法连接到 RedHat。检查您的网络连接,或者您能[解决网站名称解析的问题](https://kerneltalks.com/howto/how-to-configure-nameserver-in-linux/)。有时候,即使你能够 ping 通订阅服务器,你也会看到这个错误。这可能是因为您的环境中有代理服务器。在这种情况下,您需要将其详细信息添加到文件 `/etc/rhsm/rhsm.conf` 中。以下详细的代理信息应根据你的环境填充:
```
# an http proxy server to use
proxy_hostname =
# port for http proxy server
proxy_port =
# user name for authenticating to an http proxy, if needed
proxy_user =
# password for basic http proxy auth, if needed
proxy_password =
```
一旦你完成了这些,通过使用下面的命令重新检查 `subscription-manager` 是否获得了新的代理信息:
```
root@kerneltalks # subscription-manager config
[server]
hostname = [subscription.rhsm.redhat.com]
insecure = [0]
port = [443]
prefix = [/subscription]
proxy_hostname = [kerneltalksproxy.abc.com]
proxy_password = [asdf]
proxy_port = [3456]
proxy_user = [user2]
server_timeout = [180]
ssl_verify_depth = [3]
[rhsm]
baseurl = [https://cdn.redhat.com]
ca_cert_dir = [/etc/rhsm/ca/]
consumercertdir = [/etc/pki/consumer]
entitlementcertdir = [/etc/pki/entitlement]
full_refresh_on_yum = [0]
manage_repos = [1]
pluginconfdir = [/etc/rhsm/pluginconf.d]
plugindir = [/usr/share/rhsm-plugins]
productcertdir = [/etc/pki/product]
repo_ca_cert = /etc/rhsm/ca/redhat-uep.pem
report_package_profile = [1]
[rhsmcertd]
autoattachinterval = [1440]
certcheckinterval = [240]
[logging]
default_log_level = [INFO]
[] - Default value in use
```
现在,请尝试重新注册您的系统。
```
root@kerneltalks # subscription-manager register
Registering to: subscription.rhsm.redhat.com:443/subscription
Username: [email protected]
Password:
You must first accept Red Hat's Terms and conditions. Please visit https://www.redhat.com/wapps/tnc/termsack?event[]=signIn . You may have to log out of and back into the Customer Portal in order to see the terms.
```
如果您是第一次将服务器添加到 Red Hat 帐户,您将看到上述错误。转到该 [URL](https://www.redhat.com/wapps/tnc/termsack?event%5B%5D=signIn)并接受条款。回到终端,然后再试一次。
```
oot@kerneltalks # subscription-manager register
Registering to: subscription.rhsm.redhat.com:443/subscription
Username: [email protected]
Password:
The system has been registered with ID: xxxxb2-xxxx-xxxx-xxxx-xx8e199xxx
```
Bingo!系统现在已在 Red Hat 上注册。你可以再次用 `version` 选项来验证它。
```
#subscription-managerversionservertype:RedHatSubscriptionManagementsubscriptionmanagementserver:2.0.43-1subscriptionmanagementrules:5.26subscription-manager:1.18.10-1.el6python-rhsm:1.18.6-1.el6" decode="true" ]root@kerneltalks # subscription-manager version
server type: Red Hat Subscription Management
subscription management server: 2.0.43-1
subscription management rules: 5.26
subscription-manager: 1.18.10-1.el6
python-rhsm: 1.18.6-1.el6
```
### 步骤 2:将订阅添加到您的服务器
首先尝试列出软件仓库。您将无法列出任何内容,因为我们尚未在我们的服务器中添加任何订阅。
```
root@kerneltalks # subscription-manager repos --list
This system has no repositories available through subscriptions.
```
正如您所看到 `subscription-manager` 找不到任何软件仓库,您需要将订阅添加到您的服务器上。一旦订阅被添加,`subscription-manager` 将能够列出下列的软件仓库。
要添加订阅,请先使用以下命令检查服务器的所有可用订阅:
```
root@kerneltalks # subscription-manager list --available
+-------------------------------------------+
Available Subscriptions
+-------------------------------------------+
Subscription Name: Red Hat Enterprise Linux for Virtual Datacenters, Standard
Provides: Red Hat Beta
Red Hat Software Collections (for RHEL Server)
Red Hat Enterprise Linux Atomic Host Beta
Oracle Java (for RHEL Server)
Red Hat Enterprise Linux Server
dotNET on RHEL (for RHEL Server)
Red Hat Enterprise Linux Atomic Host
Red Hat Software Collections Beta (for RHEL Server)
Red Hat Developer Tools Beta (for RHEL Server)
Red Hat Developer Toolset (for RHEL Server)
Red Hat Developer Tools (for RHEL Server)
SKU: RH00050
Contract: xxxxxxxx
Pool ID: 8a85f98c6011059f0160110a2ae6000f
Provides Management: Yes
Available: Unlimited
Suggested: 0
Service Level: Standard
Service Type: L1-L3
Subscription Type: Stackable (Temporary)
Ends: 12/01/2018
System Type: Virtual
```
您将获得可用于您的服务器的此类订阅的软件仓库列表。您需要阅读它提供的内容并记下对您有用或需要的订阅的 `Pool ID`。
现在,使用 pool ID 将订阅添加到您的服务器。
```
# subscription-manager attach --pool=8a85f98c6011059f0160110a2ae6000f
Successfully attached a subscription for: Red Hat Enterprise Linux for Virtual Datacenters, Standard
```
如果您不确定选择哪一个,则可以使用下面的命令自动地添加最适合您的服务器的订阅:
```
root@kerneltalks # subscription-manager attach --auto
Installed Product Current Status:
Product Name: Red Hat Enterprise Linux Server
Status: Subscribed
```
接下来是最后一步启用软件仓库。
### 步骤 3:启用软件仓库
现在您将能够启用软件仓库,该软件仓库在您的附加订阅下可用。
```
root@kerneltalks # subscription-manager repos --enable rhel-6-server-rhv-4-agent-beta-debug-rpms
Repository 'rhel-6-server-rhv-4-agent-beta-debug-rpms' is enabled for this system.
```
到这里,您已经完成了。您可以[用 yum 命令列出软件仓库](https://kerneltalks.com/howto/how-to-list-yum-repositories-in-rhel-centos/)并确认。
---
via: <https://kerneltalks.com/howto/how-to-enable-repository-using-subscription-manager-in-rhel/>
作者:[kerneltalks](https://kerneltalks.com) 译者:[S9mtAt](https://github.com/S9mtAt) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Learn how to enable repository using subscription-manager in RHEL. The article also includes steps to register system with Red Hat, attach subscription and errors along with resolutions.*

In this article, we will walk you through step by step process to enable Red Hat repository in RHEL fresh installed server.
The repository can be enabled using `subscription-manager`
command like below –
```
root@kerneltalks # subscription-manager repos --enable rhel-6-server-rhv-4-agent-beta-debug-rpms
Error: 'rhel-6-server-rhv-4-agent-beta-debug-rpms' does not match a valid repository ID. Use "subscription-manager repos --list" to see valid repositories.
```
You will see the above error when your subscription is not in place. Let’s go through step by step procedure to enable repositories via `subscription-manager`
### Step 1 : Register your system with Red Hat
We are considering you have a freshly installed system and it’s not yet registered with Red Hat. If you have a registered system already then you can ignore this step.
You can check if your system is registered with Red Hat for the subscription using below command –
```
# subscription-manager version
server type: This system is currently not registered.
subscription management server: Unknown
subscription management rules: Unknown
subscription-manager: 1.18.10-1.el6
python-rhsm: 1.18.6-1.el6
```
Here, in the first line of output, you can see the system is not registered. So, let’s start with the registering system. You need to use the `subscription-manager`
command with `register`
switch. You need to use your Red Hat account credentials here.
```
root@kerneltalks # subscription-manager register
Registering to: subscription.rhsm.redhat.com:443/subscription
Username: [email protected]
Password:
Network error, unable to connect to server. Please see /var/log/rhsm/rhsm.log for more information.
```
If you are getting above error then your server is not able to reach RedHat. Check internet connection & if you are able to [resolve site name](https://kerneltalks.com/howto/how-to-configure-nameserver-in-linux/)s. Sometimes even if you are able to ping the subscription server, you will see this error. This might be because you have the proxy server in your environment. In such a case, you need to add its details in file `/etc/rhsm/rhsm.conf`
. Below proxy details should be populated :
```
# an http proxy server to use
proxy_hostname =
# port for http proxy server
proxy_port =
# user name for authenticating to an http proxy, if needed
proxy_user =
# password for basic http proxy auth, if needed
proxy_password =
```
Once you are done, recheck if `subscription-manager`
taken up new proxy details by using below command –
```
root@kerneltalks # subscription-manager config
[server]
hostname = [subscription.rhsm.redhat.com]
insecure = [0]
port = [443]
prefix = [/subscription]
proxy_hostname = [kerneltalksproxy.abc.com]
proxy_password = [asdf]
proxy_port = [3456]
proxy_user = [user2]
server_timeout = [180]
ssl_verify_depth = [3]
[rhsm]
baseurl = [https://cdn.redhat.com]
ca_cert_dir = [/etc/rhsm/ca/]
consumercertdir = [/etc/pki/consumer]
entitlementcertdir = [/etc/pki/entitlement]
full_refresh_on_yum = [0]
manage_repos = [1]
pluginconfdir = [/etc/rhsm/pluginconf.d]
plugindir = [/usr/share/rhsm-plugins]
productcertdir = [/etc/pki/product]
repo_ca_cert = /etc/rhsm/ca/redhat-uep.pem
report_package_profile = [1]
[rhsmcertd]
autoattachinterval = [1440]
certcheckinterval = [240]
[logging]
default_log_level = [INFO]
[] - Default value in use
```
Now, try registering your system again.
```
root@kerneltalks # subscription-manager register
Registering to: subscription.rhsm.redhat.com:443/subscription
Username: [email protected]
Password:
You must first accept Red Hat's Terms and conditions. Please visit https://www.redhat.com/wapps/tnc/termsack?event[]=signIn . You may have to log out of and back into the Customer Portal in order to see the terms.
```
You will see the above error if you are adding the server to your Red Hat account for the first time. Go to the [URL ](https://www.redhat.com/wapps/tnc/termsack?event[]=signIn)and accept the terms. Come back to the terminal and try again.
```
root@kerneltalks # subscription-manager register
Registering to: subscription.rhsm.redhat.com:443/subscription
Username: [email protected]
Password:
The system has been registered with ID: xxxxb2-xxxx-xxxx-xxxx-xx8e199xxx
```
Bingo! The system is registered with Red Hat now. You can again verify it with `version`
switch.
```
root@kerneltalks # subscription-manager version
server type: Red Hat Subscription Management
subscription management server: 2.0.43-1
subscription management rules: 5.26
subscription-manager: 1.18.10-1.el6
python-rhsm: 1.18.6-1.el6
```
### Step 2: Attach subscription to your server
First, try to list repositories. You won’t be able to list any since we haven’t attached any subscription to our server yet.
```
root@kerneltalks # subscription-manager repos --list
This system has no repositories available through subscriptions.
```
As you can see `subscription-manager`
couldn’t found any repositories, you need to attach subscriptions to your server. Once the subscription is attached, `subscription-manager`
will be able to list repositories under it.
To attach subscription, check all available subscriptions for your server with below command –
```
root@kerneltalks # subscription-manager list --available
+-------------------------------------------+
Available Subscriptions
+-------------------------------------------+
Subscription Name: Red Hat Enterprise Linux for Virtual Datacenters, Standard
Provides: Red Hat Beta
Red Hat Software Collections (for RHEL Server)
Red Hat Enterprise Linux Atomic Host Beta
Oracle Java (for RHEL Server)
Red Hat Enterprise Linux Server
dotNET on RHEL (for RHEL Server)
Red Hat Enterprise Linux Atomic Host
Red Hat Software Collections Beta (for RHEL Server)
Red Hat Developer Tools Beta (for RHEL Server)
Red Hat Developer Toolset (for RHEL Server)
Red Hat Developer Tools (for RHEL Server)
SKU: RH00050
Contract: xxxxxxxx
Pool ID: 8a85f98c6011059f0160110a2ae6000f
Provides Management: Yes
Available: Unlimited
Suggested: 0
Service Level: Standard
Service Type: L1-L3
Subscription Type: Stackable (Temporary)
Ends: 12/01/2018
System Type: Virtual
```
You will get the list of such subscriptions available for your server. You need to read through what it provides and note down `Pool ID`
of subscriptions that are useful/required for you.
Now, attach subscriptions to your server by using pool ID.
```
root@kerneltalks # subscription-manager attach --pool=8a85f98c6011059f0160110a2ae6000f
Successfully attached a subscription for: Red Hat Enterprise Linux for Virtual Datacenters, Standard
```
If you are not sure which one to pick, you can simply attach subscriptions automatically which are best suited for your server with below command –
```
root@kerneltalks # subscription-manager attach --auto
Installed Product Current Status:
Product Name: Red Hat Enterprise Linux Server
Status: Subscribed
```
Move on to the final step to enable repository.
### Step 3: Enable repository
Now you will enable repository which is available under your attached subscription.
```
root@kerneltalks # subscription-manager repos --enable rhel-6-server-rhv-4-agent-beta-debug-rpms
Repository 'rhel-6-server-rhv-4-agent-beta-debug-rpms' is enabled for this system.
```
That’s it. You are done. You can [list repositories with yum command](https://kerneltalks.com/howto/how-to-list-yum-repositories-in-rhel-centos/) and confirm.
you are fantastic, straight to the point. IT worked perfectly
Do you need a paid redhat subscription for this?
Excellent, thanks for the contribution.
Do you need a paid redhat subscription for this?
Excellent, I followed your exact steps and was successful.
Thank you for your contribution! 🙂
Agent for Linux has been tested on Ubuntu 18.04, 19.10, Debian 10 and Linux Mint 19.3.
Other distributions might require further dependencies. Alternately, extra superior customers
with specific server needs should consider Debian. Who ought to use this:
ClearOS is a devoted Linux server operating.
In the same manner, use ‘cls’ for the primary argument for the class technique.
Documenting every technique with proper specification of parameters,
return sort, and data types. All managed disks running Cloud PCs are encrypted, all
stored knowledge is encrypted at rest, and all network traffic
to and from your Cloud PCs is also encrypted. Use tuples when data
is non-changeable, dictionaries when you want to map
things, and lists in case your data can change later on. This will not assist that a lot on a
pre-compiled Arch Linux kernel, since a decided attacker might simply download the kernel
bundle and get the symbols manually from there, but if you are compiling your personal kernel, this may
also help mitigating native root exploits. In this text we are going to learn about a few of the benefits of using
Amazon Web Services (AWS) and easy methods to dynamically create virtual machines (EC2) that will help with these limitations in minutes.
One among the nice advantages of using EC2 is the
financial savings in administrative value, planning and funding in further-hardware that is
not necessary, which turns corporations large costs
into much smaller one.
im getting problem after this command “subscription-manager list –available”
saying “No available subscription pools to list” |
9,738 | PacVim:一个学习 vim 命令的命令行游戏 | https://www.ostechnix.com/pacvim-a-cli-game-to-learn-vim-commands/ | 2018-06-12T10:42:00 | [
"PacVim",
"Vim"
] | https://linux.cn/article-9738-1.html | 
你好,Vim用户!今天,我偶然发现了一个很酷的程序来提高 Vim 的使用技巧。Vim 是编写和编辑代码的绝佳编辑器。然而,你们中的一些人(包括我)仍在陡峭的学习曲线中挣扎。再也不用了!来看看 **PacVim**,一款可帮助你学习 Vim 命令的命令行游戏。PacVim 的灵感来源于经典游戏 [PacMan](https://en.wikipedia.org/wiki/Pac-Man),它以一种好玩有趣的方式为你提供了大量的 Vim 命令练习。简而言之,PacVim 是一种深入了解 vim 命令的有趣而自由的方式。请不要将 PacMan 与 [pacman](https://www.ostechnix.com/getting-started-pacman/) (arch Linux 包管理器)混淆。 PacMan 是 20 世纪 80 年代发布的经典流行街机游戏。
在本简要指南中,我们将看到如何在 Linux 中安装和使用 PacVim。
### 安装 PacVim
首先按如下链接安装 **Ncurses** 库和**开发工具**。
* [如何在 Linux 中安装 Ncurses 库](https://www.ostechnix.com/how-to-install-ncurses-library-in-linux/)
* [如何在 Linux 中安装开发工具](https://www.ostechnix.com/install-development-tools-linux/)
请注意,如果没有 gcc 4.8.X 或更高版本,这款游戏可能无法正确编译和安装。我在 Ubuntu 18.04 LTS 上测试了 PacVim,并且完美运行。
安装 Ncurses 和 gcc 后,运行以下命令来安装 PacVim。
```
$ git clone https://github.com/jmoon018/PacVim.git
$ cd PacVim
$ sudo make install
```
### 使用 PacVim 学习 Vim 命令
#### 启动 PacVim 游戏
要玩这个游戏,只需运行:
```
$ pacvim [LEVEL_NUMER] [MODE]
```
例如,以下命令以普通模式启动游戏第 5 关。
```
$ pacvim 5 n
```
这里,`5` 表示等级,`n`表示模式。有两种模式:
* `n` – 普通模式。
* `h` – 困难模式。
默认模式是 `h`,这很难:
要从头开始(`0` 级),请运行:
```
$ pacvim
```
以下是我 Ubuntu 18.04 LTS 的示例输出。

要开始游戏,只需按下回车。

现在开始游戏。阅读下一节了解如何玩。
要退出,请按下 `ESC` 或 `q`。
以下命令以困难模式启动游戏第 `5` 关。
```
$ pacvim 5 h
```
或者,
```
$ pacvim 5
```
#### 如何玩 PacVim?
PacVim 的使用与 PacMan 非常相似。
你必须跑过屏幕上所有的字符,同时避免鬼魂(红色字符)。
PacVim有两个特殊的障碍:
1. 你不能移动到墙壁中(黄色)。你必须使用 vim 动作来跳过它们。
2. 如果你踩到波浪字符(青色的 `~`),你就输了!
你有三条生命。每次打赢 0、3、6、9 关时你都会获得新生命。总共有 10 关,从 0 到 9,打赢第 9 关后,游戏重置为第 0 关,但是鬼魂速度变快。
**获胜条件**
使用 vim 命令将光标移动到字母上并高亮显示它们。所有字母都高亮显示后,你就会获胜并进入下一关。
**失败条件**
如果你碰到鬼魂(用**红色 G** 表示)或者**波浪字符**,你就会失去一条命。如果命小于 0 条,你将会输掉整个游戏。
这是实现的命令列表:
| 键 | 作用 |
| --- | --- |
| q | 退出游戏 |
| h | 向左移动 |
| j | 向下移动 |
| k | 向上移动 |
| l | 向右移动 |
| w | 向前移动到下一个 word 开始 |
| W | 向前移动到下一个 WORD 开始 |
| e | 向前移动到下一个 word 结束 |
| E | 向前移动到下一个 WORD 结束 |
| b | 向后移动到下一个 word 开始 |
| B | 向后移动到下一个 WORD 开始 |
| $ | 移动到行的末尾 |
| 0 | 移动到行的开始 |
| gg/1G | 移动到第一行的开始 |
| 数字加 G | 移动到由数字给出的行的开始 |
| G | 移到最后一行的开头 |
| ^ | 移到当前行的第一个 word |
| & | 1337 cheatz(打赢当前关) |
玩过几关之后,你可能会注意到 vim 的使用有改善。一段时间后继续玩这个游戏,直到你掌握 Vim 的使用。
**建议阅读:**
今天就是这些。希望这篇文章有用。PacVim 好玩又有趣并且让你有事做。同时,你应该能够彻底学习足够的 Vim 命令。试试看,你不会感到失望。
还有更多的好东西。敬请关注!
干杯!
---
via: <https://www.ostechnix.com/pacvim-a-cli-game-to-learn-vim-commands/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,739 | 使用 ARA 分析 Ansible 运行 | https://opensource.com/article/18/5/analyzing-ansible-runs-using-ara | 2018-06-12T11:00:00 | [
"Ansible"
] | https://linux.cn/article-9739-1.html |
>
> Ansible 运行分析工具(ARA)与 Ansible 无缝集成,可以简单便捷的找到你所需数据的方法。
>
>
>

[Ansible](https://www.ansible.com/) 是一个多功能平台,它已经成为管理服务器和服务器配置的流行平台。如今,Ansible 大量用于通过持续集成 (CI) 进行部署和测试。
在自动化持续集成的世界中,每天都有数百个甚至数千个作业运行测试、构建、编译、部署等等,这并不罕见。
### Ansible 运行分析 (ARA) 工具
Ansible 运行生成大量控制台数据,在 CI 的环境下跟上大量的 Ansible 输出是具有挑战性的。Ansible Run Analysis(ARA) 工具使此详细输出可读并且使作业状态和调试信息更有代表性。ARA 组织了记录的<ruby> 剧本 <rt> playbook </rt></ruby>数据,以便你尽可能快速和容易地搜索并找到你感兴趣的内容。
请注意,ARA 不会运行你的<ruby> 剧本 <rt> playbook </rt></ruby>。相反,无论在哪它都它作为回调插件与 Ansible 集成。回调插件可以在响应事件时向 Ansible 添加新行为。它可以根据 Ansible 事件执行自定义操作,例如在主机开始执行或任务完成时执行。
与 [AWX](https://www.ansible.com/products/awx-project) 和 [Tower](https://www.ansible.com/products/tower) 相比,它们是控制整个工作流程的工具,具有仓库管理、<ruby> 剧本 <rt> playbook </rt></ruby>执行、编辑功能等功能,ARA 的范围相对较窄:记录数据并提供直观的界面。这是一个相对简单的程序,易于安装和配置。
#### 安装
在系统上安装 ARA 有两种方法:
* 使用托管在 [GitHub 帐户](https://github.com/AjinkyaBapat/Ansible-Run-Analyser) 上的 Ansible 角色。克隆仓库并:
```
ansible-playbook Playbook.yml
```
如果剧本执行成功,你将看到:
```
TASK [ara : Display ara UI URL] ************************
ok: [localhost] => {}
"msg": "Access playbook records at http://YOUR_IP:9191"
```
注意:它从 Ansible 收集的 `ansible_default_ipv4` fact 中选择 IP 地址。如果没有收集这些 fact,请用 `roles/ara/tasks/` 文件夹中 `main.yml` 文件中的 IP 替换它。
* ARA 是一个在 [GitHub](https://github.com/dmsimard/ara) 上以 Apache v2 许可证授权的开源项目。安装说明在快速入门章节。[文档](http://ara.readthedocs.io/en/latest/)和 [FAQ](http://ara.readthedocs.io/en/latest/faq.html) 可在 [readthedocs.io](http://ara.readthedocs.io/en/latest/) 上找到。
#### ARA 能做些什么?
下图显示了从浏览器启动 ARA 登录页面:

*ARA 登录页面*
它提供了每个主机或每个 playbook 的任务结果摘要:

*ARA 显示任务摘要*
它允许你通过剧本,play,主机、任务或状态来过滤任务结果:

*通过主机过滤剧本运行*
借助 ARA,你可以在摘要视图中轻松查看你感兴趣的结果,无论是特定的主机还是特定的任务:

*每项任务的详细摘要*
ARA 支持在同一数据库中记录和查看多个运行。

*显示收集的 fact*
#### 总结
ARA 是一个已经帮助我从 Ansible 运行日志和输出中了解更多的有用资源。我强烈推荐给所有的 Ansible 使用者。
请随意分享,并请在评论中告诉我你使用 ARA 的经历。
[参见我们的相关文章,[成功使用 Ansible 的秘诀](/article/18/2/tips-success-when-getting-started-ansible)]。
---
via: <https://opensource.com/article/18/5/analyzing-ansible-runs-using-ara>
作者:[Ajinkya Bapat](https://opensource.com/users/iamajinkya) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [Ansible](https://www.ansible.com/) is a versatile platform that has become popular for managing servers and server configurations. Today, Ansible is used heavily to deploy and test through continuous integration (CI).
In the world of automated continuous integration, it’s not uncommon to have hundreds, if not thousands, of jobs running every day for testing, building, compiling, deploying, and more.
## The Ansible Run Analysis (ARA) tool
Ansible runs generate a large amount of console data, and keeping up with high volumes of Ansible output in the context of CI is challenging. The Ansible Run Analysis (ARA) tool makes this verbose output readable and more representative of the job status and debug information. ARA organizes recorded playbook data so you can search and find what you’re interested in as quickly and as easily as possible.
Note that ARA doesn't run your playbooks for you; rather, it integrates with Ansible as a callback plugin wherever it is. A callback plugin enables adding new behaviors to Ansible when responding to events. It can perform custom actions in response to Ansible events such as a play starting or a task completing on a host.
Compared to [AWX](https://www.ansible.com/products/awx-project) and [Tower](https://www.ansible.com/products/tower), which are tools that control the entire workflow, with features like inventory management, playbook execution, editing features, and more, the scope of ARA is comparatively narrow: It records data and provides an intuitive interface. It is a relatively simple application that is easy to install and configure.
### Installation
There are two ways to install ARA on your system:
- Using the Ansible role hosted on your
[GitHub account](https://github.com/AjinkyaBapat/Ansible-Run-Analyser). Clone the repo and do:
```
````ansible-playbook Playbook.yml`
If the playbook run is successful, you will get:
```
``````
TASK [ara : Display ara UI URL] ************************
ok: [localhost] => {}
"msg": "Access playbook records at http://YOUR_IP:9191"
```
Note: It picks the IP address from `ansible_default_ipv4`
fact gathered by Ansible. If there is no such fact gathered, replace it with your IP in `main.yml`
file in the `roles/ara/tasks/`
folder.
- ARA is an open source project available on
[GitHub](https://github.com/dmsimard/ara)under the Apache v2 license. Installation instructions are in the Quickstart chapter. The[documentation](http://ara.readthedocs.io/en/latest/)and[FAQs](http://ara.readthedocs.io/en/latest/faq.html)are available on[readthedocs.io](http://ara.readthedocs.io/en/latest/).
### What can ARA do?
The image below shows the ARA landing page launched from the browser:

It provides summaries of task results per host or per playbook:
It allows you to filter task results by playbook, play, host, task, or status:
With ARA, you can easily drill down from the summary view to find the results you’re interested in, whether it’s a particular host or a specific task:
ARA supports recording and viewing multiple runs in the same database.
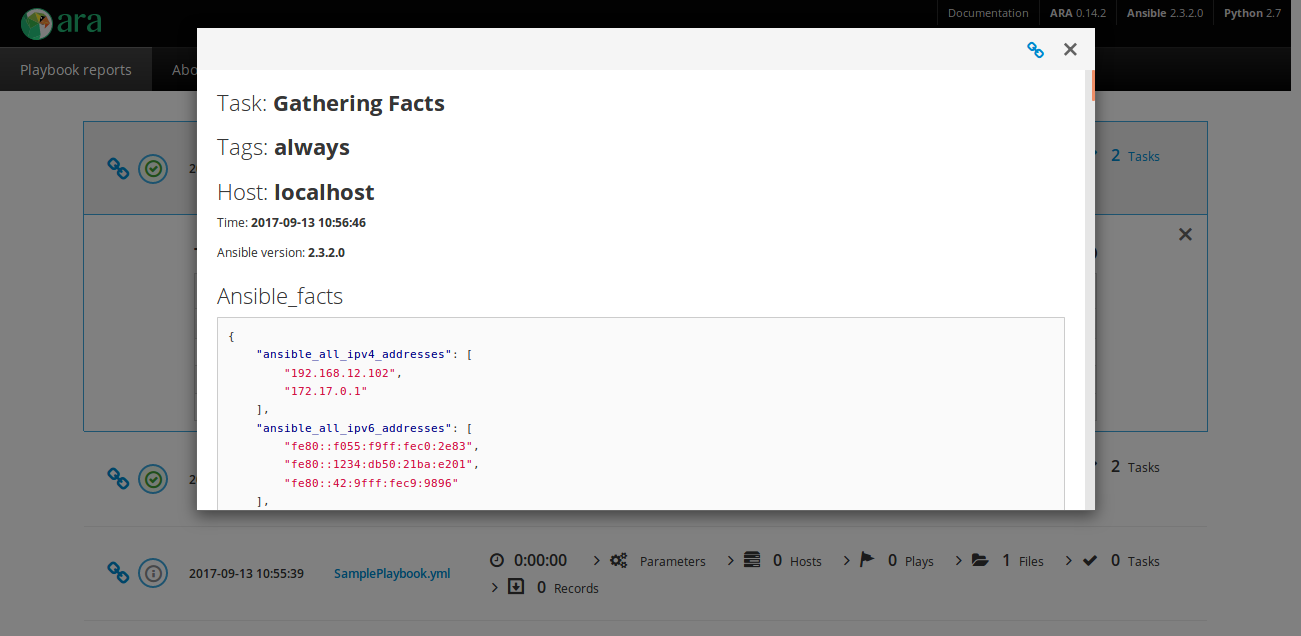
### Wrapping up
ARA is a useful resource that has helped me get more out of Ansible run logs and outputs. I highly recommend it to all Ansible ninjas out there.
Feel free to share this, and please let me know about your experience using ARA in the comments.
**[See our related story, Tips for success when getting started with Ansible.]**
## Comments are closed. |
9,740 | Caffeinated 6.828:实验 1:PC 的引导过程 | https://sipb.mit.edu/iap/6.828/lab/lab1/ | 2018-06-12T18:08:00 | [
"内核",
"引导"
] | https://linux.cn/article-9740-1.html | 
### 简介
这个实验分为三个部分。第一部分主要是为了熟悉使用 x86 汇编语言、QEMU x86 仿真器、以及 PC 的加电引导过程。第二部分查看我们的 6.828 内核的引导加载器,它位于 `lab` 树的 `boot` 目录中。第三部分深入到我们的名为 JOS 的 6.828 内核模型内部,它在 `kernel` 目录中。
#### 软件安装
本课程中你需要的文件和接下来的实验任务所需要的文件都是通过使用 [Git](http://www.git-scm.com/) 版本控制系统来分发的。学习更多关于 Git 的知识,请查看 [Git 用户手册](http://www.kernel.org/pub/software/scm/git/docs/user-manual.html),或者,如果你熟悉其它的版本控制系统,这个 [面向 CS 的 Git 概述](http://eagain.net/articles/git-for-computer-scientists/) 可能对你有帮助。
本课程在 Git 仓库中的地址是 <https://exokernel.scripts.mit.edu/joslab.git> 。在你的 Athena 帐户中安装文件,你需要运行如下的命令去克隆课程仓库。你也可以使用 `ssh -X athena.dialup.mit.edu` 去登入到一个公共的 Athena 主机。
```
athena% mkdir ~/6.828
athena% cd ~/6.828
athena% add git
athena% git clone https://exokernel.scripts.mit.edu/joslab.git lab
Cloning into lab...
athena% cd lab
athena%
```
Git 可以帮你跟踪代码中的变化。比如,如果你完成了一个练习,想在你的进度中打一个检查点,你可以运行如下的命令去提交你的变更:
```
athena% git commit -am 'my solution for lab1 exercise 9'
Created commit 60d2135: my solution for lab1 exercise 9
1 files changed, 1 insertions(+), 0 deletions(-)
athena%
```
你可以使用 `git diff` 命令跟踪你的变更。运行 `git diff` 将显示你的代码自最后一次提交之后的变更,而 `git diff origin/lab1` 将显示这个实验相对于初始代码的变更。在这里,`origin/lab1` 是为了完成这个作业,从我们的服务器上下载的初始代码在 Git 分支上的名字。
在 Athena 上,我们为你配置了合适的编译器和模拟器。如果你要去使用它们,请运行 `add exokernel` 命令。 每次登入 Athena 主机你都必须要运行这个命令(或者你可以将它添加到你的 `~/.environment` 文件中)。如果你在编译或者运行 `qemu` 时出现晦涩难懂的错误,可以双击 "check" 将它添加到你的课程收藏夹中。
如果你使用的是非 Athena 机器,你需要安装 `qemu` 和 `gcc`,它们在 [工具页面](https://sipb.mit.edu/iap/6.828/tools) 目录中。为了以后的实验需要,我们做了一些 `qemu` 调试方面的变更和补丁,因此,你必须构建你自己的工具。如果你的机器使用原生的 ELF 工具链(比如,Linux 和大多数 BSD,但不包括 OS X),你可以简单地从你的包管理器中安装 `gcc`。除此之外,都应该按工具页面的指导去做。
#### 动手过程
我们为了你便于做实验,为你使用了不同的 Git 仓库。做实验用的仓库位于一个 SSH 服务器后面。你可以拥有你自己的实验仓库,其他的任何同学都不可访问你的这个仓库。为了通过 SSH 服务器的认证,你必须有一对 RSA 密钥,并让服务器知道你的公钥。
实验代码同时还带有一个脚本,它可以帮你设置如何访问你的实验仓库。在运行这个脚本之前,你必须在我们的 [submission web 界面](https://exokernel.scripts.mit.edu/submit/) 上有一个帐户。在登陆页面上,输入你的 Athena 用户名,然后点击 “Mail me my password”。在你的邮箱中将马上接收到一封包含有你的 `6.828` 课程密码的邮件。注意,每次你点击这个按钮的时候,系统将随机给你分配一个新密码。
现在,你已经有了你的 `6.828` 密码,在 `lab` 目录下,运行如下的命令去配置实践仓库:
```
athena% make handin-prep
Using public key from ~/.ssh/id_rsa:
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQD0lnnkoHSi4JDFA ...
Continue? [Y/n] Y
Login to 6.828 submission website.
If you do not have an account yet, sign up at https://exokernel.scripts.mit.edu/submit/
before continuing.
Username: <your Athena username>
Password: <your 6.828 password>
Your public key has been successfully updated.
Setting up hand-in Git repository...
Adding remote repository ssh://[email protected]/joslab.git as 'handin'.
Done! Use 'make handin' to submit your lab code.
athena%
```
如果你没有 RSA 密钥对,这个脚本可能会询问你是否生成一个新的密钥对:
```
athena% make handin-prep
SSH key file ~/.ssh/id_rsa does not exists, generate one? [Y/n] Y
Generating public/private rsa key pair.
Your identification has been saved in ~/.ssh/id_rsa.
Your public key has been saved in ~/.ssh/id_rsa.pub.
The key fingerprint is:
xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx
The keyʼs randomart image is:
+--[ RSA 2048]----+
| ........ |
| ........ |
+-----------------+
Using public key from ~/.ssh/id_rsa:
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQD0lnnkoHSi4JDFA ...
Continue? [Y/n] Y
.....
athena%
```
当你开始动手做实验时,在 `lab` 目录下,输入 `make handin` 去使用 git 做第一次提交。后面将运行 `git push handin HEAD`,它将推送当前分支到远程 `handin` 仓库的同名分支上。
```
athena% git commit -am "ready to submit my lab"
[lab1 c2e3c8b] ready to submit my lab
2 files changed, 18 insertions(+), 2 deletions(-)
athena% make handin
Handin to remote repository using 'git push handin HEAD' ...
Counting objects: 59, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (55/55), done.
Writing objects: 100% (59/59), 49.75 KiB, done.
Total 59 (delta 3), reused 0 (delta 0)
To ssh://[email protected]/joslab.git
* [new branch] HEAD -> lab1
athena%
```
如果在你的实验仓库上产生变化,你将收到一封电子邮件,让你去确认这个提交。以后,你可能会多次去运行 `run make handin`(或者 `git push handin`)。对于一个指定实验的最后提交时间是由相应分支的最新推送(最后一个推送)的时间决定的。
在这个案例中,`make handin` 运行可能并不正确,你可以使用 Git 命令去尝试修复这个问题。或者,你可以去运行 `make tarball`。它将为你生成一个 tar 文件,这个文件可以通过我们的 [web 界面](https://exokernel.scripts.mit.edu/submit/) 来上传。`make handin` 提供了很多特殊说明。
对于实验 1,你不需要去回答下列的任何一个问题。(尽管你不用自己回答,但是它们对下面的实验有帮助)
我们将使用一个评级程序来分级你的解决方案。你可以使用这个评级程序去测试你的解决方案的分级情况。
### 第一部分:PC 引导
第一个练习的目的是向你介绍 x86 汇编语言和 PC 引导过程,你可以使用 QEMU 和 QEMU/GDB 调试开始你的练习。这部分的实验你不需要写任何代码,但是,通过这个实验,你将对 PC 引导过程有了你自己的理解,并且为回答后面的问题做好准备。
#### 从使用 x86 汇编语言开始
如果你对 x86 汇编语言的使用还不熟悉,通过这个课程,你将很快熟悉它!如果你想学习它,[PC 汇编语言](https://sipb.mit.edu/iap/6.828/readings/pcasm-book.pdf) 这本书是一个很好的开端。希望这本书中有你所需要的一切内容。
警告:很不幸,这本书中的示例是为 NASM 汇编语言写的,而我们使用的是 GNU 汇编语言。NASM 使用所谓的 Intel 语法,而 GNU 使用 AT&T 语法。虽然在语义上是等价的,但是根据你使用的语法不同,至少从表面上看,汇编文件的差别还是挺大的。幸运的是,这两种语法的转换很简单,在 [Brennan's Guide to Inline Assembly](http://www.delorie.com/djgpp/doc/brennan/brennan_att_inline_djgpp.html) 有详细的介绍。
>
> **练习 1**
>
>
> 熟悉在 [6.828 参考页面](https://sipb.mit.edu/iap/6.828/reference) 上列出的你想去使用的可用汇编语言。你不需要现在就去阅读它们,但是在你阅读和写 x86 汇编程序的时候,你可以去参考相关的内容。
>
>
>
我并不推荐你阅读 [Brennan's Guide to Inline Assembly](http://www.delorie.com/djgpp/doc/brennan/brennan_att_inline_djgpp.html) 上的 “语法” 章节。虽然它对 AT&T 汇编语法描述的很好(并且非常详细),而且我们在 JOS 中使用的 GNU 汇编就是它。
对于 x86 汇编语言程序最终还是需要参考 Intel 的指令集架构,你可以在 [6.828 参考页面](https://sipb.mit.edu/iap/6.828/reference) 上找到它,它有两个版本:一个是 HTML 版的,是老的 [80386 程序员参考手册](https://sipb.mit.edu/iap/6.828/readings/i386/toc.htm),它比起最新的手册更简短,更易于查找,但是,它包含了我们的 6.828 上所使用的 x86 处理器的所有特性;而更全面的、更新的、更好的是,来自 Intel 的 [IA-32 Intel 架构软件开发者手册](http://www.intel.com/content/www/us/en/processors/architectures-software-developer-manuals.html),它涵盖了我们在课程中所需要的、(并且可能有些是你不感兴趣的)大多数处理器的全部特性。另一个差不多的(并且经常是很友好的)一套手册是 [来自 AMD](http://developer.amd.com/documentation/guides/Pages/default.aspx#manuals) 的。当你为了一个特定的处理器特性或者指令,去查找最终的解释时,保存的最新的 Intel/AMD 架构手册或者它们的参考就很有用了。
#### 仿真 x86
与在一台真实的、物理的、个人电脑上引导一个操作系统不同,我们使用程序去如实地仿真一台完整的 PC:你在仿真器中写的代码,也能够引导一台真实的 PC。使用仿真器可以简化调试工作;比如,你可以在仿真器中设置断点,而这在真实的机器中是做不到的。
在 6.828 中,我们将使用 [QEMU 仿真器](http://www.qemu.org/),它是一个现代化的并且速度非常快的仿真器。虽然 QEMU 内置的监视功能提供了有限的调试支持,但是,QEMU 也可以做为 [GNU 调试器](http://www.gnu.org/software/gdb/) (GDB) 的远程调试目标,我们在这个实验中将使用它来一步一步完成引导过程。
在开始之前,按照前面 “软件安装“ 中在 Athena 主机上描述的步骤,提取实验 1 的文件到你自己的目录中,然后,在 `lab` 目录中输入 `make`(如果是 BSD 的系统,是输入 `gmake` )来构建最小的 6.828 引导加载器和用于启动的内核。(把在这里我们运行的这些代码称为 ”内核“ 有点夸大,但是,通过这个学期的课程,我们将把这些代码充实起来,成为真正的 ”内核“)
```
athena% cd lab
athena% make
+ as kern/entry.S
+ cc kern/init.c
+ cc kern/console.c
+ cc kern/monitor.c
+ cc kern/printf.c
+ cc lib/printfmt.c
+ cc lib/readline.c
+ cc lib/string.c
+ ld obj/kern/kernel
+ as boot/boot.S
+ cc -Os boot/main.c
+ ld boot/boot
boot block is 414 bytes (max 510)
+ mk obj/kern/kernel.img
```
(如果你看到有类似 ”undefined reference to `\_\_udivdi3'” 这样的错误,可能是因为你的电脑上没有 32 位的 “gcc multilib”。如果你运行在 Debian 或者 Ubuntu,你可以尝试去安装 “gcc-multilib” 包。)
现在,你可以去运行 QEMU 了,并将上面创建的 `obj/kern/kernel.img` 文件提供给它,以作为仿真 PC 的 “虚拟硬盘”,这个虚拟硬盘中包含了我们的引导加载器(`obj/boot/boot`) 和我们的内核(`obj/kernel`)。
```
athena% make qemu
```
运行 QEMU 时需要使用选项去设置硬盘,以及指示串行端口输出到终端。在 QEMU 窗口中将出现一些文本内容:
```
Booting from Hard Disk...
6828 decimal is XXX octal!
entering test_backtrace 5
entering test_backtrace 4
entering test_backtrace 3
entering test_backtrace 2
entering test_backtrace 1
entering test_backtrace 0
leaving test_backtrace 0
leaving test_backtrace 1
leaving test_backtrace 2
leaving test_backtrace 3
leaving test_backtrace 4
leaving test_backtrace 5
Welcome to the JOS kernel monitor!
Type 'help' for a list of commands.
K>
```
在 `Booting from Hard Disk...` 之后的内容,就是由我们的基本 JOS 内核输出的:`K>` 是包含在我们的内核中的小型监听器或者交互式控制程序的提示符。内核输出的这些行也会出现在你运行 QEMU 的普通 shell 窗口中。这是因为测试和实验分级的原因,我们配置了 JOS 的内核,使它将控制台输出不仅写入到虚拟的 VGA 显示器(就是 QEMU 窗口),也写入到仿真 PC 的虚拟串口上,QEMU 会将虚拟串口上的信息转发到它的标准输出上。同样,JOS 内核也将接收来自键盘和串口的输入,因此,你既可以从 VGA 显示窗口中输入命令,也可以从运行 QEMU 的终端窗口中输入命令。或者,你可以通过运行 `make qemu-nox` 来取消虚拟 VGA 的输出,只使用串行控制台来输出。如果你是通过 SSH 拨号连接到 Athena 主机,这样可能更方便。
在这里有两个可以用来监视内核的命令,它们是 `help` 和 `kerninfo`。
```
K> help
help - display this list of commands
kerninfo - display information about the kernel
K> kerninfo
Special kernel symbols:
entry f010000c (virt) 0010000c (phys)
etext f0101a75 (virt) 00101a75 (phys)
edata f0112300 (virt) 00112300 (phys)
end f0112960 (virt) 00112960 (phys)
Kernel executable memory footprint: 75KB
K>
```
`help` 命令的用途很明确,我们将简短地讨论一下 `kerninfo` 命令输出的内容。虽然它很简单,但是,需要重点注意的是,这个内核监视器是 “直接” 运行在仿真 PC 的 “原始(虚拟)硬件” 上的。这意味着你可以去拷贝 `obj/kern/kernel.img` 的内容到一个真实硬盘的前几个扇区,然后将那个硬盘插入到一个真实的 PC 中,打开这个 PC 的电源,你将在一台真实的 PC 屏幕上看到和上面在 QEMU 窗口完全一样的内容。(我们并不推荐你在一台真实机器上这样做,因为拷贝 `kernel.img` 到硬盘的前几个扇区将覆盖掉那个硬盘上原来的主引导记录,这将导致这个硬盘上以前的内容丢失!)
#### PC 的物理地址空间
我们现在将更深入去了解 “关于 PC 是如何启动” 的更多细节。一台 PC 的物理地址空间是硬编码为如下的布局:
```
+------------------+ <- 0xFFFFFFFF (4GB)
| 32-bit |
| memory mapped |
| devices |
| |
/\/\/\/\/\/\/\/\/\/\
/\/\/\/\/\/\/\/\/\/\
| |
| Unused |
| |
+------------------+ <- depends on amount of RAM
| |
| |
| Extended Memory |
| |
| |
+------------------+ <- 0x00100000 (1MB)
| BIOS ROM |
+------------------+ <- 0x000F0000 (960KB)
| 16-bit devices, |
| expansion ROMs |
+------------------+ <- 0x000C0000 (768KB)
| VGA Display |
+------------------+ <- 0x000A0000 (640KB)
| |
| Low Memory |
| |
+------------------+ <- 0x00000000
```
首先,这台 PC 是基于 16 位的 Intel 8088 处理器,它仅能处理 1 MB 的物理地址。所以,早期 PC 的物理地址空间开始于 `0x00000000`,结束于 `0x000FFFFF` 而不是 `0xFFFFFFFF`。被标记为 “低位内存” 的区域是早期 PC 唯一可以使用的随机访问内存(RAM);事实上,更早期的 PC 仅可以配置 16KB、32KB、或者 64KB 的内存!
从 `0x000A0000` 到 `0x000FFFFF` 的 384 KB 的区域是为特定硬件保留的区域,比如,视频显示缓冲和保存在非易失存储中的固件。这个保留区域中最重要的部分是基本输入/输出系统(BIOS),它位于从 `0x000F0000` 到 `0x000FFFFF` 之间的 64KB 大小的区域。在早期的 PC 中,BIOS 在真正的只读存储(ROM)中,但是,现在的 PC 的 BIOS 都保存在可更新的 FLASH 存储中。BIOS 负责执行基本系统初始化工作,比如,激活视频卡和检查已安装的内存数量。这个初始化工作完成之后,BIOS 从相关位置加载操作系统,比如从软盘、硬盘、CD-ROM、或者网络,然后将机器的控制权传递给操作系统。
当 Intel 最终在 80286 和 80386 处理器上 “打破了 1MB 限制” 之后,这两个处理器各自支持 16MB 和 4GB 物理地址空间,尽管如此,为了确保向下兼容现存软件,PC 架构还是保留着 1 MB 以内物理地址空间的原始布局。因此,现代 PC 的物理内存,在 `0x000A0000` 和 `0x00100000` 之间有一个 “黑洞区域”,将内存分割为 “低位” 或者 “传统内存” 区域(前 640 KB)和 “扩展内存”(其它的部分)。除此之外,在 PC 的 32 位物理地址空间顶部之上的一些空间,在全部的物理内存上面,现在一般都由 BIOS 保留给 32 位的 PCI 设备使用。
最新的 x86 处理器可以支持超过 4GB 的物理地址空间,因此,RAM 可以进一步扩展到 `0xFFFFFFFF` 之上。在这种情况下,BIOS 必须在 32 位可寻址空间顶部之上的系统 RAM 上,设置第二个 “黑洞区域”,以便于为这些 32 位的设备映射留下空间。因为 JOS 设计的限制,它仅可以使用 PC 物理内存的前 256 MB,因此,我们将假设所有的 PC “仅仅” 拥有 32 位物理地址空间。但是处理复杂的物理地址空间和其它部分的硬件系统,将涉及到许多年前操作系统开发所遇到的实际挑战之一。
#### ROM BIOS
在实验的这一部分中,你将使用 QEMU 的调试功能去研究 IA-32 相关的计算机是如何引导的。
打开两个终端窗口,在其中一个中,输入 `make qemu-gdb`(或者 `make qemu-nox-gdb`),这将启动 QEMU,但是处理器在运行第一个指令之前将停止 QEMU,以等待来自 GDB 的调试连接。在第二个终端窗口中,从相同的目录中运行 `make`,以及运行 `make gdb`。你将看到如下的输出。
```
athena% make gdb
GNU gdb (GDB) 6.8-debian
Copyright (C) 2008 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "i486-linux-gnu".
+ target remote localhost:1234
The target architecture is assumed to be i8086
[f000:fff0] 0xffff0: ljmp $0xf000,$0xe05b
0x0000fff0 in ?? ()
+ symbol-file obj/kern/kernel
(gdb)
```
`make gdb` 的运行目标是一个称为 `.gdbrc` 的脚本,它设置了 GDB 在早期引导期间调试所用到的 16 位代码,并且将它指向到正在监听的 QEMU 上。
下列行:
```
[f000:fff0] 0xffff0: ljmp $0xf000,$0xe05b
```
是 GDB 运行的第一个指令的反汇编。这个输出包含如下的信息:
* IBM PC 从物理地址 `0x000ffff0` 开始运行,这个地址位于为 ROM BIOS 保留的 64 KB 区域的顶部。
* PC 使用 `CS = 0xf000` 和 `IP = 0xfff0` 开始运行。
* 运行的第一个指令是一个 `jmp` 指令,它跳转段地址 `CS = 0xf000` 和 `IP = 0xe05b`。
为什么 QEMU 是这样开始的呢?这是因为 Intel 设计的 8088 处理器是这样做的,这个处理器是 IBM 最早用在他们的 PC 上的处理器。因为在一台 PC 中,BIOS 是硬编码在物理地址范围 `0x000f0000-0x000fffff` 中的,这样的设计确保了在机器接通电源或者任何系统重启之后,BIOS 总是能够首先控制机器 —— 这是至关重要的,因为机器接通电源之后,在机器的内存中没有处理器可以运行的任何软件。QEMU 仿真器有它自己的 BIOS,它的位置在处理器的模拟地址空间中。在处理器复位之后,(模拟的)处理器进入了实模式,然后设置 `CS` 为 `0xf000` 、`IP` 为 `0xfff0`,所以,运行开始于那个(`CS:IP`)段地址。那么,段地址 `0xf000:fff0` 是如何转到物理地址的呢?
在回答这个问题之前,我们需要了解有关实模式地址的知识。在实模式(PC 启动之后就处于实模式)中,物理地址是根据这个公式去转换的:物理地址 = 16 \* 段地址 + 偏移。因此,当 PC 设置 `CS` 为 `0xf000` 、`IP` 为 `0xfff0` 之后,物理地址指向到:
```
16 * 0xf000 + 0xfff0 # in hex multiplication by 16 is
= 0xf0000 + 0xfff0 # easy--just append a 0.
= 0xffff0
```
`0xffff0` 是 BIOS (`0x100000`) 结束之前的 16 字节。因此,BIOS 所做的第一件事情是向后 `jmp` 到 BIOS 中的早期位置就一点也不奇怪了;毕竟只有 16 字节,还能指望它做些什么呢?
>
> **练习 2**
>
>
> 使用 GDB 的 `si`(步进指令)指令去跟踪进入到 ROM BIOS 的更多指令,然后尝试猜测它可能会做什么。你可能需要去查看 [Phil Storrs I/O 端口描述](http://web.archive.org/web/20040404164813/members.iweb.net.au/%7Epstorr/pcbook/book2/book2.htm),以及在 [6.828 参考资料页面](https://sipb.mit.edu/iap/6.828/reference) 上的其它资料。不需要了解所有的细节 —— 只要搞明白 BIOS 首先要做什么就可以了。
>
>
>
当 BIOS 运行后,它将设置一个中断描述符表和初始化各种设备,比如, VGA 显示。在这时,你在 QEMU 窗口中将出现 `Starting SeaBIOS` 的信息。
在初始化 PCI 产品线和 BIOS 知道的所有重要设备之后,它将搜索可引导设备,比如,一个软盘、硬盘、或者 CD-ROM。最后,当它找到可引导磁盘之后,BIOS 从可引导硬盘上读取引导加载器,然后将控制权交给它。
### 第二部分:引导加载器
在 PC 的软盘和硬盘中,将它们分割成 512 字节大小的区域,每个区域称为一个扇区。一个扇区就是磁盘的最小转存单元:每个读或写操作都必须是一个或多个扇区大小,并且按扇区边界进行对齐。如果磁盘是可引导盘,第一个扇区则为引导扇区,因为,第一个扇区中驻留有引导加载器的代码。当 BIOS 找到一个可引导软盘或者硬盘时,它将 512 字节的引导扇区加载进物理地址为 `0x7c00` 到 `0x7dff` 的内存中,然后使用一个 `jmp` 指令设置 `CS:IP` 为 `0000:7c00`,并传递控制权到引导加载器。与 BIOS 加载地址一样,这些地址是任意的 —— 但是它们对于 PC 来说是固定的,并且是标准化的。
后来,随着 PC 的技术进步,它们可以从 CD-ROM 中引导,因此,PC 架构师趁机对引导过程进行轻微的调整。最后的结果使现代的 BIOS 从 CD-ROM 中引导的过程更复杂(并且功能更强大)。CD-ROM 使用 2048 字节大小的扇区,而不是 512 字节的扇区,并且,BIOS 在传递控制权之前,可以从磁盘上加载更大的(不止是一个扇区)引导镜像到内存中。更多内容,请查看 [“El Torito” 可引导 CD-ROM 格式规范](https://sipb.mit.edu/iap/6.828/readings/boot-cdrom.pdf)。
不过对于 6.828,我们将使用传统的硬盘引导机制,意味着我们的引导加载器必须小于 512 字节。引导加载器是由一个汇编源文件 `boot/boot.S` 和一个 C 源文件 `boot/main.c` 构成,仔细研究这些源文件可以让你彻底理解引导加载器都做了些什么。引导加载器必须要做两件主要的事情:
1. 第一、引导加载器将处理器从实模式切换到 32 位保护模式,因为只有在 32 位保护模式中,软件才能够访问处理器中 1 MB 以上的物理地址空间。关于保护模式将在 [PC 汇编语言](https://sipb.mit.edu/iap/6.828/readings/pcasm-book.pdf) 的 1.2.7 和 1.2.8 节中详细描述,更详细的内容请参阅 Intel 架构手册。在这里,你只要理解在保护模式中段地址(段基地址:偏移量)与物理地址转换的差别就可以了,并且转换后的偏移是 32 位而不是 16 位。
2. 第二、引导加载器通过 x86 的专用 I/O 指令直接访问 IDE 磁盘设备寄存器,从硬盘中读取内核。如果你想去更好地了解在这里说的专用 I/O 指令,请查看 [6.828 参考页面](https://sipb.mit.edu/iap/6.828/reference) 上的 “IDE 硬盘控制器” 章节。你不用学习太多的专用设备编程方面的内容:在实践中,写设备驱动程序是操作系统开发中的非常重要的部分,但是,从概念或者架构的角度看,它也是最让人乏味的部分。
理解了引导加载器源代码之后,我们来看一下 `obj/boot/boot.asm` 文件。这个文件是在引导加载器编译过程中,由我们的 GNUmakefile 创建的引导加载器的反汇编文件。这个反汇编文件让我们可以更容易地看到引导加载器代码所处的物理内存位置,并且也可以更容易地跟踪在 GDB 中步进的引导加载器发生了什么事情。同样的,`obj/kern/kernel.asm` 文件中包含了 JOS 内核的一个反汇编,它也经常被用于内核调试。
你可以使用 `b` 命令在 GDB 中设置中断点地址。比如,`b *0x7c00` 命令在地址 `0x7C00` 处设置了一个断点。当处于一个断点中时,你可以使用 `c` 和 `si` 命令去继续运行:`c` 命令让 QEMU 继续运行,直到下一个断点为止(或者是你在 GDB 中按下了 Ctrl - C),而 `si N` 命令是每次步进 `N` 个指令。
要检查内存中的指令(除了要立即运行的下一个指令之外,因为它是由 GDB 自动输出的),你可以使用 `x/i` 命令。这个命令的语法是 `x/Ni ADDR`,其中 `N` 是连接的指令个数,`ADDR` 是开始反汇编的内存地址。
>
> **练习 3**
>
>
> 查看 [实验工具指南](https://sipb.mit.edu/iap/6.828/labguide),特别是 GDB 命令的相关章节。即便你熟悉使用 GDB 也要好好看一看,GDB 的一些命令比较难理解,但是它对操作系统的工作很有帮助。
>
>
>
在地址 0x7c00 处设置断点,它是加载后的引导扇区的位置。继续运行,直到那个断点。在 `boot/boot.S` 中跟踪代码,使用源代码和反汇编文件 `obj/boot/boot.asm` 去保持跟踪。你也可以使用 GDB 中的 `x/i` 命令去反汇编引导加载器接下来的指令,比较引导加载器源代码与在 `obj/boot/boot.asm` 和 GDB 中的反汇编文件。
在 `boot/main.c` 文件中跟踪进入 `bootmain()` ,然后进入 `readsect()`。识别 `readsect()` 中相关的每一个语句的准确汇编指令。跟踪 `readsect()` 中剩余的指令,然后返回到 `bootmain()` 中,识别 `for` 循环的开始和结束位置,这个循环从磁盘上读取内核的剩余扇区。找出循环结束后运行了什么代码,在这里设置一个断点,然后继续。接下来再走完引导加载器的剩余工作。
完成之后,就能够回答下列的问题了:
* 处理器开始运行 32 代码时指向到什么地方?从 16 位模式切换到 32 位模式的真实原因是什么?
* 引导加载器执行的最后一个指令是什么,内核加载之后的第一个指令是什么?
* 内核的第一个指令在哪里?
* 为从硬盘上获取完整的内核,引导加载器如何决定有多少扇区必须被读入?在哪里能找到这些信息?
#### 加载内核
我们现在来进一步查看引导加载器在 `boot/main.c` 中的 C 语言部分的详细细节。在继续之前,我们先停下来回顾一下 C 语言编程的基础知识。
>
> **练习 4**
>
>
> 下载 [pointers.c](https://sipb.mit.edu/iap/6.828/files/pointers.c) 的源代码,运行它,然后确保你理解了输出值的来源的所有内容。尤其是,确保你理解了第 1 行和第 6 行的指针地址的来源、第 2 行到第 4 行的值是如何得到的、以及为什么第 5 行指向的值表面上看像是错误的。
>
>
> 如果你对指针的使用不熟悉,Brian Kernighan 和 Dennis Ritchie(就是大家知道的 “K&R”)写的《C Programming Language》是一个非常好的参考书。同学们可以去买这本书(这里是 [Amazon 购买链接](http://www.amazon.com/C-Programming-Language-2nd/dp/0131103628/sr=8-1/qid=1157812738/ref=pd_bbs_1/104-1502762-1803102?ie=UTF8&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;s=books)),或者在 [MIT 的图书馆的 7 个副本](http://library.mit.edu/F/AI9Y4SJ2L5ELEE2TAQUAAR44XV5RTTQHE47P9MKP5GQDLR9A8X-10422?func=item-global&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;doc_library=MIT01&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;doc_number=000355242&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;year=&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;volume=&amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;amp;sub_library=) 中找到其中一个。在 [SIPB Office](http://sipb.mit.edu/) 也有三个副本可以细读。
>
>
> 在课程阅读中,[Ted Jensen 写的教程](https://sipb.mit.edu/iap/6.828/readings/pointers.pdf) 可以使用,它大量引用了 K&R 的内容。
>
>
> 警告:除非你特别精通 C 语言,否则不要跳过这个阅读练习。如果你没有真正理解了 C 语言中的指针,在接下来的实验中你将非常痛苦,最终你将很难理解它们。相信我们;你将不会遇到什么是 ”最困难的方式“。
>
>
>
要了解 `boot/main.c`,你需要了解一个 ELF 二进制格式的内容。当你编译和链接一个 C 程序时,比如,JOS 内核,编译器将每个 C 源文件('`.c`')转换为一个包含预期硬件平台的汇编指令编码的二进制格式的对象文件('`.o`'),然后链接器将所有编译过的对象文件组合成一个单个的二进制镜像,比如,`obj/kern/kernel`,在本案例中,它就是 ELF 格式的二进制文件,它表示是一个 ”可运行和可链接格式“。
关于这个格式的全部信息可以在 [我们的参考页面](https://sipb.mit.edu/iap/6.828/reference) 上的 [ELF 规范](https://sipb.mit.edu/iap/6.828/readings/elf.pdf) 中找到,但是,你并不需要深入地研究这个格式 的细节。虽然完整的格式是非常强大和复杂的,但是,大多数复杂的部分是为了支持共享库的动态加载,在我们的课程中,并不需要做这些。
鉴于 6.828 的目的,你可以认为一个 ELF 可运行文件是一个用于加载信息的头文件,接下来的几个程序节,根据加载到内存中的特定地址的不同,每个都是连续的代码块或数据块。引导加载器并不修改代码或者数据;它加载它们到内存,然后开始运行它。
一个 ELF 二进制文件使用一个固定长度的 ELF 头开始,紧接着是一个可变长度的程序头,列出了每个加载的程序节。C 语言在 `inc/elf.h` 中定义了这些 ELF 头。在程序节中我们感兴趣的部分有:
* `.text`:程序的可运行指令。
* `.rodata`:只读数据,比如,由 C 编译器生成的 ASCII 字符串常量。(然而我们并不需要操心设置硬件去禁止写入它)
* `.data`:保持在程序的初始化数据中的数据节,比如,初始化声明所需要的全局变量,比如,像 `int x = 5;`。
当链接器计算程序的内存布局的时候,它为未初始化的全局变量保留一些空间,比如,`int x;`,在内存中的被称为 `.bss` 的节后面会马上跟着一个 `.data`。C 规定 "未初始化的" 全局变量以一个 0 值开始。因此,在 ELF 二进制中 `.bss` 中并不存储内容;而是,链接器只记录地址和`.bss` 节的大小。加载器或者程序自身必须在 `.bss` 节中写入 0。
通过输入如下的命令来检查在内核中可运行的所有节的名字、大小、以及链接地址的列表:
```
athena% i386-jos-elf-objdump -h obj/kern/kernel
```
如果在你的计算机上默认使用的是一个 ELF 工具链,比如像大多数现代的 Linux 和 BSD,你可以使用 `objdump` 来代替 `i386-jos-elf-objdump`。
你将看到更多的节,而不仅是上面列出的那几个,但是,其它的那些节对于我们的实验目标来说并不重要。其它的那些节中大多数都是为了保留调试信息,它们一般包含在程序的可执行文件中,但是,这些节并不会被程序加载器加载到内存中。
我们需要特别注意 `.text` 节中的 VMA(或者链接地址)和 LMA(或者加载地址)。一个节的加载地址是那个节加载到内存中的地址。在 ELF 对象中,它保存在 `ph->p_pa` 域(在本案例中,它实际上是物理地址,不过 ELF 规范在这个域的意义方面规定的很模糊)。
一个节的链接地址是这个节打算在内存中运行时的地址。链接器在二进制代码中以变量的方式去编码这个链接地址,比如,当代码需要全局变量的地址时,如果二进制代码从一个未链接的地址去运行,结果将是无法运行。(它一般是去生成一个不包含任何一个绝对地址的、与位置无关的代码。现在的共享库大量使用的就是这种方法,但这是以性能和复杂性为代价的,所以,我们在 6.828 中不使用这种方法。)
一般情况下,链接和加载地址是一样的。比如,通过如下的命令去查看引导加载器的 `.text` 节:
```
athena% i386-jos-elf-objdump -h obj/boot/boot.out
```
BIOS 加载引导扇区到内存中的 0x7c00 地址,因此,这就是引导扇区的加载地址。这也是引导扇区的运行地址,因此,它也是链接地址。我们在`boot/Makefrag` 中通过传递 `-Ttext 0x7C00` 给链接器来设置链接地址,因此,链接器将在生成的代码中产生正确的内存地址。
>
> **练习 5**
>
>
> 如果你得到一个错误的引导加载器链接地址,通过再次跟踪引导加载器的前几个指令,你将会发现第一个指令会 “中断” 或者出错。然后在 `boot/Makefrag` 修改链接地址来修复错误,运行 `make clean`,使用 `make` 重新编译,然后再次跟踪引导加载器去查看会发生什么事情。不要忘了改回正确的链接地址,然后再次 `make clean`!
>
>
>
我们继续来看内核的加载和链接地址。与引导加载器不同,这里有两个不同的地址:内核告诉引导加载器加载它到内存的低位地址(小于 1 MB 的地址),但是它期望在一个高位地址来运行。我们将在下一节中深入研究它是如何实现的。
除了节的信息之外,在 ELF 头中还有一个对我们很重要的域,它叫做 `e_entry`。这个域保留着程序入口的链接地址:程序的 `.text` 节中的内存地址就是将要被执行的程序的地址。你可以用如下的命令来查看程序入口链接地址:
```
athena% i386-jos-elf-objdump -f obj/kern/kernel
```
你现在应该能够理解在 `boot/main.c` 中的最小的 ELF 加载器了。它从硬盘中读取内核的每个节,并将它们节的加载地址读入到内存中,然后跳转到内核的入口点。
>
> **练习 6**
>
>
> 我们可以使用 GDB 的 `x` 命令去检查内存。[GDB 手册](http://sourceware.org/gdb/current/onlinedocs/gdb_9.html#SEC63) 上讲的非常详细,但是现在,我们知道命令 `x/Nx ADDR` 是输出地址 `ADDR` 上 `N` 个<ruby> 词 <rt> word </rt></ruby>就够了。(注意在命令中所有的 `x` 都是小写。)警告:<ruby> 词 <rt> word </rt></ruby>的多少并没有一个普遍的标准。在 GNU 汇编中,一个<ruby> 词 <rt> word </rt></ruby>是两个字节(在 xorw 中的 'w',它在这个词中就是 2 个字节)。
>
>
>
重置机器(退出 QEMU/GDB 然后再次启动它们)。检查内存中在 `0x00100000` 地址上的 8 个词,输出 BIOS 上的引导加载器入口,然后再次找出引导载器上的内核的入口。为什么它们不一样?在第二个断点上有什么内容?(你并不用真的在 QEMU 上去回答这个问题,只需要思考就可以。)
### 第三部分:内核
我们现在开始去更详细地研究最小的 JOS 内核。(最后你还将写一些代码!)就像引导加载器一样,内核也是从一些汇编语言代码设置一些东西开始的,以便于 C 语言代码可以正确运行。
#### 使用虚拟内存去解决位置依赖问题
前面在你检查引导加载器的链接和加载地址时,它们是完全一样的,但是内核的链接地址(可以通过 `objdump` 来输出)和它的加载地址之间差别很大。可以回到前面去看一下,以确保你明白我们所讨论的内容。(链接内核比引导加载器更复杂,因此,链接和加载地址都在 `kern/kernel.ld` 的顶部。)
操作系统内核经常链接和运行在高位的虚拟地址,比如,`0xf0100000`,为的是给让用户程序去使用处理器的虚拟地址空间的低位部分。至于为什么要这么安排,在下一个实验中我们将会知道。
许多机器在 `0xf0100000` 处并没有物理地址,因此,我们不能指望在那个位置可以存储内核。相反,我们使用处理器的内存管理硬件去映射虚拟地址 `0xf0100000`(内核代码打算运行的链接地址)到物理地址 `0x00100000`(引导加载器将内核加载到内存的物理地址的位置)。通过这种方法,虽然内核的虚拟地址是高位的,离用户程序的地址空间足够远,它将被加载到 PC 的物理内存的 1MB 的位置,只处于 BIOS ROM 之上。这种方法要求 PC 至少要多于 1 MB 的物理内存(以便于物理地址 `0x00100000` 可以工作),这在上世纪九十年代以后生产的PC 上应该是没有问题的。
实际上,在下一个实验中,我们将映射整个 256 MB 的 PC 的物理地址空间,从物理地址 `0x00000000` 到 `0x0fffffff`,映射到虚拟地址 `0xf0000000` 到 `0xffffffff`。你现在就应该明白了为什么 JOS 只能使用物理内存的前 256 MB 的原因了。
现在,我们只映射前 4 MB 的物理内存,它足够我们的内核启动并运行。我们通过在 `kern/entrypgdir.c` 中手工写入静态初始化的页面目录和页面表就可以实现。现在,你不需要理解它们是如何工作的详细细节,只需要达到目的就行了。将上面的 `kern/entry.S` 文件中设置 `CR0_PG` 标志,内存引用就被视为物理地址(严格来说,它们是线性地址,但是,在 `boot/boot.S` 中设置了一个从线性地址到物理地址的映射标识,我们绝对不能改变它)。一旦 `CR0_PG` 被设置,内存引用的就是虚拟地址,这个虚拟地址是通过虚拟地址硬件将物理地址转换得到的。`entry_pgdir` 将把从 `0x00000000` 到 `0x00400000` 的物理地址范围转换在 `0xf0000000` 到 `0xf0400000` 的范围内的虚拟地址。任何不在这两个范围之一中的地址都将导致硬件异常,因为,我们还没有设置中断去处理这种情况,这种异常将导致 QEMU 去转储机器状态然后退出。(或者如果你没有在 QEMU 中应用 6.828 专用补丁,将导致 QEMU 无限重启。)
>
> **练习 7**
>
>
> 使用 QEMU 和 GDB 去跟踪进入到 JOS 内核,然后停止在 `movl %eax, %cr0` 指令处。检查 `0x00100000` 和 `0xf0100000` 处的内存。现在使用GDB 的 `stepi` 命令去单步执行那个指令。再次检查 `0x00100000` 和 `0xf0100000` 处的内存。确保你能理解这时发生的事情。
>
>
>
新映射建立之后的第一个指令是什么?如果没有映射到位,它将不能正常工作。在 `kern/entry.S` 中注释掉 `movl %eax, %cr0`。然后跟踪它,看看你的猜测是否正确。
#### 格式化控制台的输出
大多数人认为像 `printf()` 这样的函数是天生就有的,有时甚至认为这是 C 语言的 “原语”。但是在操作系统的内核中,我们需要自己去实现所有的 I/O。
通过阅读 `kern/printf.c`、`lib/printfmt.c`、以及 `kern/console.c`,确保你理解了它们之间的关系。在后面的实验中,你将会明白为什么 `printfmt.c` 是位于单独的 `lib` 目录中。
>
> **练习 8**
>
>
> 我们将省略掉一小部分代码片断 —— 这部分代码片断是使用 ”%o" 模式输出八进制数字所需要的。找到它并填充到这个代码片断中。
>
>
> 然后你就能够回答下列的问题:
>
>
> 1. 解释 `printf.c` 和 `console.c` 之间的接口。尤其是,`console.c` 出口的函数是什么?这个函数是如何被 `printf.c` 使用的?
> 2. 在 `console.c` 中解释下列的代码:
>
>
>
> ```
> if (crt_pos >= CRT_SIZE) {
> int i;
> memcpy(crt_buf, crt_buf + CRT_COLS, (CRT_SIZE - CRT_COLS) * sizeof(uint16_t));
> for (i = CRT_SIZE - CRT_COLS; i < CRT_SIZE; i++)
> crt_buf[i] = 0x0700 | ' ';
> crt_pos -= CRT_COLS;
> }
>
> ```
> 3. 下列的问题你可能需要参考第一节课中的笔记。这些笔记涵盖了 GCC 在 x86 上的调用规则。
>
>
> 一步一步跟踪下列代码的运行:
>
>
>
> ```
> int x = 1, y = 3, z = 4;
> cprintf("x %d, y %x, z %d\n", x, y, z);
>
> ```
>
> 1. 在调用 `cprintf()` 时,`fmt` 做了些什么?`ap` 做了些什么?
> 2. (按运行顺序)列出 `cons_putc`、`va_arg`、以及 `vcprintf` 的调用列表。对于 `cons_putc`,同时列出它的参数。对于`va_arg`,列出调用之前和之后的 `ap` 内容?对于 `vcprintf`,列出它的两个参数值。
> 4. 运行下列代码:
>
>
>
> ```
> unsigned int i = 0x00646c72;
> cprintf("H%x Wo%s", 57616, &i);
>
> ```
>
> 输出是什么?解释如何在前面的练习中一步一步实现这个输出。这是一个 [ASCII 表](http://web.cs.mun.ca/%7Emichael/c/ascii-table.html),它是一个字节到字符串的映射表。
>
>
> 这个输出取决于 x86 是小端法这一事实。如果这个 x86 采用大端法格式,你怎么去设置 `i`,以产生相同的输出?你需要将 `57616` 改变为一个不同值吗?
>
>
> [这是小端法和大端法的描述](http://www.webopedia.com/TERM/b/big_endian.html) 和 [一个更古怪的描述](http://www.networksorcery.com/enp/ien/ien137.txt)。
> 5. 在下列代码中,`y=` 会输出什么?(注意:这个问题没有确切值)为什么会发生这种情况? `cprintf("x=%d y=%d", 3);`
> 6. 假设修改了 GCC 的调用规则,以便于按声明的次序在栈上推送参数,这样最后的参数就是最后一个推送进去的。那你如何去改变 `cprintf` 或者它的接口,以便它仍然可以传递数量可变的参数?
>
>
>
#### 栈
在本实验的最后一个练习中,我们将理详细地解释在 x86 中 C 语言是如何使用栈的,以及在这个过程中,我们将写一个新的内核监视函数,这个函数将输出栈的回溯信息:一个保存了指令指针(IP)值的列表,这个列表中有嵌套的 `call` 指令运行在当前运行点的指针值。
>
> **练习 9**
>
>
> 搞清楚内核在什么地方初始化栈,以及栈在内存中的准确位置。内核如何为栈保留空间?以及这个保留区域的 “结束” 位置是指向初始化结束后的指针吗?
>
>
>
x86 栈指针(`esp` 寄存器)指向当前使用的栈的最低位置。在这个区域中那个位置以下的所有部分都是空闲的。给一个栈推送一个值涉及下移栈指针和栈指针指向的位置中写入值。从栈中弹出一个值涉及到从栈指针指向的位置读取值和上移栈指针。在 32 位模式中,栈中仅能保存 32 位值,并且 `esp` 通常分为四部分。各种 x86 指令,比如,`call`,是 “硬编码” 去使用栈指针寄存器的。
相比之下,`ebp`(基指针)寄存器,按软件惯例主要是由栈关联的。在进入一个 C 函数时,函数的前序代码在函数运行期间,通常会通过推送它到栈中来保存前一个函数的基指针,然后拷贝当前的 `esp` 值到 `ebp` 中。如果一个程序中的所有函数都遵守这个规则,那么,在程序运行过程中的任何一个给定时间点,通过在 `ebp` 中保存的指针链和精确确定的函数嵌套调用顺序是如何到达程序中的这个特定的点,就可以通过栈来跟踪回溯。这种跟踪回溯的函数在实践中非常有用,比如,由于给某个函数传递了一个错误的参数,导致一个 `assert` 失败或者 `panic`,但是,你并不能确定是谁传递了错误的参数。栈的回溯跟踪可以让你找到这个惹麻烦的函数。
>
> **练习 10**
>
>
> 要熟悉 x86 上的 C 调用规则,可以在 `obj/kern/kernel.asm` 文件中找到函数 `test_backtrace` 的地址,设置一个断点,然后检查在内核启动后,每次调用它时发生了什么。每个递归嵌套的 `test_backtrace` 函数在栈上推送了多少个词(word),这些词(word)是什么?
>
>
>
上面的练习可以给你提供关于实现栈跟踪回溯函数的一些信息,为实现这个函数,你应该去调用 `mon_backtrace()`。在 `kern/monitor.c` 中已经给你提供了这个函数的一个原型。你完全可以在 C 中去使用它,但是,你可能需要在 `inc/x86.h` 中使用到 `read_ebp()` 函数。你应该在这个新函数中实现一个到内核监视命令的钩子,以便于用户可以与它交互。
这个跟踪回溯函数将以下面的格式显示一个函数调用列表:
```
Stack backtrace:
ebp f0109e58 eip f0100a62 args 00000001 f0109e80 f0109e98 f0100ed2 00000031
ebp f0109ed8 eip f01000d6 args 00000000 00000000 f0100058 f0109f28 00000061
...
```
输出的第一行列出了当前运行的函数,名字为 `mon_backtrace`,就是它自己,第二行列出了被 `mon_backtrace` 调用的函数,第三行列出了另一个被调用的函数,依次类推。你可以输出所有未完成的栈帧。通过研究 `kern/entry.S`,你可以发现,有一个很容易的方法告诉你何时停止。
在每一行中,`ebp` 表示了那个函数进入栈的基指针:即,栈指针的位置,它就是函数进入之后,函数的前序代码设置的基指针。`eip` 值列出的是函数的返回指令指针:当函数返回时,指令地址将控制返回。返回指令指针一般指向 `call` 指令之后的指令(想一想为什么?)。在 `args` 之后列出的五个十六进制值是在问题中传递给函数的前五个参数。当然,如果函数调用时传递的参数少于五个,那么,在这里就不会列出全部五个值了。(为什么跟踪回溯代码不能检测到调用时实际上传递了多少个参数?如何去修复这个 “缺陷”?)
下面是在阅读 K&R 的书中的第 5 章中的一些关键点,为了接下来的练习和将来的实验,你应该记住它们。
* 如果 `int *p = (int*)100`,那么 `(int)p + 1` 和 `(int)(p + 1)` 是不同的数字:前一个是 `101`,但是第二个是 `104`。当在一个指针上加一个整数时,就像第二种情况,这个整数将隐式地与指针所指向的对象相乘。
* `p[i]` 的定义与 `*(p+i)` 定义是相同的,都反映了在内存中由 `p` 指向的第 `i` 个对象。当对象大于一个字节时,上面的加法规则可以使这个定义正常工作。
* `&p[i]` 与 `(p+i)` 是相同的,获取在内存中由 p 指向的第 `i` 个对象的地址。
虽然大多数 C 程序不需要在指针和整数之间转换,但是操作系统经常做这种转换。不论何时,当你看到一个涉及内存地址的加法时,你要问你自己,你到底是要做一个整数加法还是一个指针加法,以确保做完加法后的值是正确的,而不是相乘后的结果。
>
> **练 11**
>
>
> 实现一个像上面详细描述的那样的跟踪回溯函数。一定使用与示例中相同的输出格式,否则,将会引发评级脚本的识别混乱。在你认为你做的很好的时候,运行 `make grade` 这个评级脚本去查看它的输出是否是我们的脚本所期望的结果,如果不是去修改它。你提交了你的实验 1 代码后,我们非常欢迎你将你的跟踪回溯函数的输出格式修改成任何一种你喜欢的格式。
>
>
>
在这时,你的跟踪回溯函数将能够给你提供导致 `mon_backtrace()` 被运行的,在栈上调用它的函数的地址。但是,在实践中,你经常希望能够知道这个地址相关的函数名字。比如,你可能希望知道是哪个有 Bug 的函数导致了你的内核崩溃。
为帮助你实现这个功能,我们提供了 `debuginfo_eip()` 函数,它在符号表中查找 `eip`,然后返回那个地址的调试信息。这个函数定义在 `kern/kdebug.c` 文件中。
>
> **练习 12**
>
>
> 修改你的栈跟踪回溯函数,对于每个 `eip`,显示相关的函数名字、源文件名、以及那个 `eip` 的行号。
>
>
>
在 `debuginfo_eip` 中,`__STAB_*` 来自哪里?这个问题的答案很长;为帮助你找到答案,下面是你需要做的一些事情:
* 在 `kern/kernel.ld` 文件中查找 `__STAB_*`
* 运行 `i386-jos-elf-objdump -h obj/kern/kernel`
* 运行 `i386-jos-elf-objdump -G obj/kern/kernel`
* 运行 `i386-jos-elf-gcc -pipe -nostdinc -O2 -fno-builtin -I. -MD -Wall -Wno-format -DJOS_KERNEL -gstabs -c -S kern/init.c, and look at init.s`。
* 如果引导加载器在加载二进制内核时,将符号表作为内核的一部分加载进内存中,那么,去查看它。
通过在 `stab_binsearch` 中插入调用,可以完成在 `debuginfo_eip` 中通过地址找到行号的功能。
在内核监视中添加一个 `backtrace` 命令,扩展你实现的 `mon_backtrace` 的功能,通过调用 `debuginfo_eip`,然后以下面的格式来输出每个栈帧行:
```
K> backtrace
Stack backtrace:
ebp f010ff78 eip f01008ae args 00000001 f010ff8c 00000000 f0110580 00000000
kern/monitor.c:143: monitor+106
ebp f010ffd8 eip f0100193 args 00000000 00001aac 00000660 00000000 00000000
kern/init.c:49: i386_init+59
ebp f010fff8 eip f010003d args 00000000 00000000 0000ffff 10cf9a00 0000ffff
kern/entry.S:70: <unknown>+0
K>
```
每行都给出了文件名和在那个文件中栈帧的 `eip` 所在的行,紧接着是函数的名字和那个函数的第一个指令到 `eip` 的偏移量(比如,`monitor+106` 意味着返回 `eip` 是从 `monitor` 开始之后的 106 个字节)。
为防止评级脚本引起混乱,应该将文件和函数名输出在单独的行上。
提示:`printf` 格式的字符串提供一个易用(尽管有些难理解)的方式去输出<ruby> 非空终止 <rt> non-null-terminated </rt></ruby>字符串,就像在 STABS 表中的这些一样。`printf("%.*s", length, string)` 输出 `string` 中的最多 `length` 个字符。查阅 `printf` 的 man 页面去搞清楚为什么这样工作。
你可以从 `backtrace` 中找到那些没有的功能。比如,你或者可能看到一个到 `monitor()` 的调用,但是没有到 `runcmd()` 中。这是因为编译器的行内(in-lines)函数调用。其它的优化可能导致你看到一些意外的行号。如果你从 `GNUMakefile` 删除 `-O2` 参数,`backtraces` 可能会更有意义(但是你的内核将运行的更慢)。
**到此为止, 在 `lab` 目录中的实验全部完成**,使用 `git commit` 提交你的改变,然后输入 `make handin` 去提交你的代码。
---
via: <https://sipb.mit.edu/iap/6.828/lab/lab1/>
作者:[mit](https://sipb.mit.edu) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | This lab is split into three parts. The first part concentrates on
getting familiarized with x86 assembly language, the QEMU x86 emulator,
and the PC's power-on bootstrap procedure. The second part examines the
boot loader for our 6.828 kernel, which resides in the `boot`
directory
of the `lab`
tree. Finally, the third part delves into the initial
template for our 6.828 kernel itself, named JOS, which resides in the
`kernel`
directory.
The files you will need for this and subsequent lab assignments in this
course are distributed using the [Git](http://www.git-scm.com/) version
control system. To learn more about Git, take a look at the [Git user's
manual](http://www.kernel.org/pub/software/scm/git/docs/user-manual.html),
or, if you are already familiar with other version control systems, you
may find this [CS-oriented overview of
Git](http://eagain.net/articles/git-for-computer-scientists/) useful.
The URL for the course Git repository is
`https://exokernel.scripts.mit.edu/joslab.git`
.
To install the files in your Athena account, you need to *clone* the
course repository, by running the commands below.
You can log into a public Athena host with
`ssh -X athena.dialup.mit.edu`
.
```
athena% mkdir ~/6.828
athena% cd ~/6.828
athena% add git
athena% git clone https://exokernel.scripts.mit.edu/joslab.git lab
Cloning into lab...
athena% cd lab
athena%
```
Git allows you to keep track of the changes you make to the code. For
example, if you are finished with one of the exercises, and want to
checkpoint your progress, you can *commit* your changes by running:
```
athena% git commit -am 'my solution for lab1 exercise 9'
Created commit 60d2135: my solution for lab1 exercise 9
1 files changed, 1 insertions(+), 0 deletions(-)
athena%
```
You can keep track of your changes by using the `git diff`
command.
Running `git diff`
will display the changes to your code since your last
commit, and `git diff origin/lab1`
will display the changes relative to
the initial code supplied for this lab. Here, `origin/lab1`
is the name
of the git branch with the initial code you downloaded from our server
for this assignment.
We have set up the appropriate compilers and simulators for you on
Athena. To use them, run `add exokernel`
. You must run this command every
time you log in (or add it to your `~/.environment`
file). If you get
obscure errors while compiling or running `qemu`
, double check that you
added the course locker.
If you are working on a non-Athena machine, you'll need to install
`qemu`
and possibly `gcc`
following the directions on the [tools
page](../../tools). We've made several useful debugging changes to
`qemu`
and some of the later labs depend on these patches, so you must
build your own. If your machine uses a native ELF toolchain (such as
Linux and most BSD's, but notably *not* OS X), you can simply install
`gcc`
from your package manager. Otherwise, follow the directions on the
tools page.
We use different Git repositories for you to hand in your lab. The hand-in repositories reside behind an SSH server. You will get your own hand-in repository, which is inaccessible by any other students. To authenticate yourself with the SSH server, you should have an RSA key pair, and let the server know your public key.
The lab code comes with a script that helps you to set up access to your
hand-in repository. Before running the script, you must have an account
at our [submission web interface](https://exokernel.scripts.mit.edu/submit/). On the login page,
type in your Athena user name and click on "Mail me my password". You
will receive your `6.828`
password in your mailbox shortly. Note that
every time you click the button, the system will assign you a new random
password.
Now that you have your `6.828`
password, in the `lab`
directory, set up
the hand-in repository by running:
```
athena% make handin-prep
Using public key from ~/.ssh/id_rsa:
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQD0lnnkoHSi4JDFA ...
Continue? [Y/n] Y
Login to 6.828 submission website.
If you do not have an account yet, sign up at https://exokernel.scripts.mit.edu/submit/
before continuing.
Username: <your Athena username>
Password: <your 6.828 password>
Your public key has been successfully updated.
Setting up hand-in Git repository...
Adding remote repository ssh://[email protected]/joslab.git as 'handin'.
Done! Use 'make handin' to submit your lab code.
athena%
```
The script may also ask you to generate a new key pair if you did not have one:
```
athena% make handin-prep
SSH key file ~/.ssh/id_rsa does not exists, generate one? [Y/n] Y
Generating public/private rsa key pair.
Your identification has been saved in ~/.ssh/id_rsa.
Your public key has been saved in ~/.ssh/id_rsa.pub.
The key fingerprint is:
xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx
The keyʼs randomart image is:
+--[ RSA 2048]----+
| ........ |
| ........ |
+-----------------+
Using public key from ~/.ssh/id_rsa:
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQD0lnnkoHSi4JDFA ...
Continue? [Y/n] Y
.....
athena%
```
When you are ready to hand in your lab, first commit your changes with
git commit, and then type make handin in the `lab`
directory. The latter
will run git push handin HEAD, which pushes the current branch to the
same name on the remote `handin`
repository.
```
athena% git commit -am "ready to submit my lab"
[lab1 c2e3c8b] ready to submit my lab
2 files changed, 18 insertions(+), 2 deletions(-)
athena% make handin
Handin to remote repository using 'git push handin HEAD' ...
Counting objects: 59, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (55/55), done.
Writing objects: 100% (59/59), 49.75 KiB, done.
Total 59 (delta 3), reused 0 (delta 0)
To ssh://[email protected]/joslab.git
* [new branch] HEAD -> lab1
athena%
```
If you have made changes to your hand-in repository, an email receipt will be sent to you to confirm the submission. You can run make handin (or git push handin) as many times as you want. The late hours of your submission for a specific lab is based on the latest hand-in (push) time of the corresponding branch.
In the case that make handin does not work properly, try fixing the
problem with Git commands. Or you can run make tarball. This will make a
tar file for you, which you can then upload via our [web
interface](https://exokernel.scripts.mit.edu/submit/). `make handin`
provides more specific
directions.
For Lab 1, you do not need to turn in answers to any of the questions below. (Do answer them for yourself though! They will help with the rest of the lab.)
We will be grading your solutions with a grading program. You can run make grade to test your solutions with the grading program.
The purpose of the first exercise is to introduce you to x86 assembly language and the PC bootstrap process, and to get you started with QEMU and QEMU/GDB debugging. You will not have to write any code for this part of the lab, but you should go through it anyway for your own understanding and be prepared to answer the questions posed below.
If you are not already familiar with x86 assembly language, you will
quickly become familiar with it during this course! The [PC Assembly
Language Book](../../readings/pcasm-book.pdf) is an excellent place to
start. Hopefully, the book contains mixture of new and old material for
you.
*Warning:* Unfortunately the examples in the book are written for the
NASM assembler, whereas we will be using the GNU assembler. NASM uses
the so-called *Intel* syntax while GNU uses the *AT&T* syntax. While
semantically equivalent, an assembly file will differ quite a lot, at
least superficially, depending on which syntax is used. Luckily the
conversion between the two is pretty simple, and is covered in
[Brennan's Guide to Inline
Assembly](http://www.delorie.com/djgpp/doc/brennan/brennan_att_inline_djgpp.html).
Exercise 1Familiarize yourself with the assembly language materials available on
[the 6.828 reference page]. You don't have to read them now, but you'll almost certainly want to refer to some of this material when reading and writing x86 assembly.
We do recommend reading the section "The Syntax" in [Brennan's Guide to
Inline
Assembly](http://www.delorie.com/djgpp/doc/brennan/brennan_att_inline_djgpp.html).
It gives a good (and quite brief) description of the AT&T assembly
syntax we'll be using with the GNU assembler in JOS.
Certainly the definitive reference for x86 assembly language programming
is Intel's instruction set architecture reference, which you can find on
[the 6.828 reference page](../../reference) in two flavors: an HTML
edition of the old [80386 Programmer's Reference
Manual](../../readings/i386/toc.htm), which is much shorter and easier
to navigate than more recent manuals but describes all of the x86
processor features that we will make use of in 6.828; and the full,
latest and greatest [IA-32 Intel Architecture Software Developer's
Manuals](http://www.intel.com/content/www/us/en/processors/architectures-software-developer-manuals.html)
from Intel, covering all the features of the most recent processors that
we won't need in class but you may be interested in learning about. An
equivalent (and often friendlier) set of manuals is [available from
AMD](http://developer.amd.com/documentation/guides/Pages/default.aspx#manuals).
Save the Intel/AMD architecture manuals for later or use them for
reference when you want to look up the definitive explanation of a
particular processor feature or instruction.
Instead of developing the operating system on a real, physical personal computer (PC), we use a program that faithfully emulates a complete PC: the code you write for the emulator will boot on a real PC too. Using an emulator simplifies debugging; you can, for example, set break points inside of the emulated x86, which is difficult to do with the silicon version of an x86.
In 6.828 we will use the [QEMU Emulator](http://www.qemu.org/), a modern
and relatively fast emulator. While QEMU's built-in monitor provides
only limited debugging support, QEMU can act as a remote debugging
target for the [GNU debugger](http://www.gnu.org/software/gdb/) (GDB),
which we'll use in this lab to step through the early boot process.
To get started, extract the Lab 1 files into your own directory on
Athena as described above in "Software Setup", then type make (or gmake
on BSD systems) in the `lab`
directory to build the minimal 6.828 boot
loader and kernel you will start with. (It's a little generous to call
the code we're running here a "kernel," but we'll flesh it out
throughout the semester.)
```
athena% cd lab
athena% make
+ as kern/entry.S
+ cc kern/init.c
+ cc kern/console.c
+ cc kern/monitor.c
+ cc kern/printf.c
+ cc lib/printfmt.c
+ cc lib/readline.c
+ cc lib/string.c
+ ld obj/kern/kernel
+ as boot/boot.S
+ cc -Os boot/main.c
+ ld boot/boot
boot block is 414 bytes (max 510)
+ mk obj/kern/kernel.img
```
(If you get errors like "undefined reference to `__udivdi3'", you probably don't have the 32-bit gcc multilib. If you're running Debian or Ubuntu, try installing the gcc-multilib package.)
Now you're ready to run QEMU, supplying the file `obj/kern/kernel.img`
,
created above, as the contents of the emulated PC's "virtual hard disk."
This hard disk image contains both our boot loader (`obj/boot/boot`
) and
our kernel (`obj/kernel`
).
```
athena% make qemu
```
This executes QEMU with the options required to set the hard disk and direct serial port output to the terminal. Some text should appear in the QEMU window:
```
Booting from Hard Disk...
6828 decimal is XXX octal!
entering test_backtrace 5
entering test_backtrace 4
entering test_backtrace 3
entering test_backtrace 2
entering test_backtrace 1
entering test_backtrace 0
leaving test_backtrace 0
leaving test_backtrace 1
leaving test_backtrace 2
leaving test_backtrace 3
leaving test_backtrace 4
leaving test_backtrace 5
Welcome to the JOS kernel monitor!
Type 'help' for a list of commands.
K>
```
Everything after '`Booting from Hard Disk...`
' was printed by our
skeletal JOS kernel; the `K>`
is the prompt printed by the small
*monitor*, or interactive control program, that we've included in the
kernel. These lines printed by the kernel will also appear in the
regular shell window from which you ran QEMU. This is because for
testing and lab grading purposes we have set up the JOS kernel to write
its console output not only to the virtual VGA display (as seen in the
QEMU window), but also to the simulated PC's virtual serial port, which
QEMU in turn outputs to its own standard output. Likewise, the JOS
kernel will take input from both the keyboard and the serial port, so
you can give it commands in either the VGA display window or the
terminal running QEMU. Alternatively, you can use the serial console
without the virtual VGA by running make qemu-nox. This may be convenient
if you are SSH'd into an Athena dialup.
There are only two commands you can give to the kernel monitor, `help`
and `kerninfo`
.
```
K> help
help - display this list of commands
kerninfo - display information about the kernel
K> kerninfo
Special kernel symbols:
entry f010000c (virt) 0010000c (phys)
etext f0101a75 (virt) 00101a75 (phys)
edata f0112300 (virt) 00112300 (phys)
end f0112960 (virt) 00112960 (phys)
Kernel executable memory footprint: 75KB
K>
```
The `help`
command is obvious, and we will shortly discuss the meaning
of what the `kerninfo`
command prints. Although simple, it's important
to note that this kernel monitor is running "directly" on the "raw
(virtual) hardware" of the simulated PC. This means that you should be
able to copy the contents of `obj/kern/kernel.img`
onto the first few
sectors of a *real* hard disk, insert that hard disk into a real PC,
turn it on, and see exactly the same thing on the PC's real screen as
you did above in the QEMU window. (We don't recommend you do this on a
real machine with useful information on its hard disk, though, because
copying `kernel.img`
onto the beginning of its hard disk will trash the
master boot record and the beginning of the first partition, effectively
causing everything previously on the hard disk to be lost!)
We will now dive into a bit more detail about how a PC starts up. A PC's physical address space is hard-wired to have the following general layout:
```
+------------------+ <- 0xFFFFFFFF (4GB)
| 32-bit |
| memory mapped |
| devices |
| |
/\/\/\/\/\/\/\/\/\/\
/\/\/\/\/\/\/\/\/\/\
| |
| Unused |
| |
+------------------+ <- depends on amount of RAM
| |
| |
| Extended Memory |
| |
| |
+------------------+ <- 0x00100000 (1MB)
| BIOS ROM |
+------------------+ <- 0x000F0000 (960KB)
| 16-bit devices, |
| expansion ROMs |
+------------------+ <- 0x000C0000 (768KB)
| VGA Display |
+------------------+ <- 0x000A0000 (640KB)
| |
| Low Memory |
| |
+------------------+ <- 0x00000000
```
The first PCs, which were based on the 16-bit Intel 8088 processor, were
only capable of addressing 1MB of physical memory. The physical address
space of an early PC would therefore start at `0x00000000`
but end at
`0x000FFFFF`
instead of `0xFFFFFFFF`
. The 640KB area marked "Low Memory" was
the *only* random-access memory (RAM) that an early PC could use; in
fact the very earliest PCs only could be configured with 16KB, 32KB, or
64KB of RAM!
The 384KB area from `0x000A0000`
through `0x000FFFFF`
was reserved by the
hardware for special uses such as video display buffers and firmware
held in non-volatile memory. The most important part of this reserved
area is the Basic Input/Output System (BIOS), which occupies the 64KB
region from `0x000F0000`
through `0x000FFFFF`
. In early PCs the BIOS was
held in true read-only memory (ROM), but current PCs store the BIOS in
updateable flash memory. The BIOS is responsible for performing basic
system initialization such as activating the video card and checking the
amount of memory installed. After performing this initialization, the
BIOS loads the operating system from some appropriate location such as
floppy disk, hard disk, CD-ROM, or the network, and passes control of
the machine to the operating system.
When Intel finally "broke the one megabyte barrier" with the 80286 and
80386 processors, which supported 16MB and 4GB physical address spaces
respectively, the PC architects nevertheless preserved the original
layout for the low 1MB of physical address space in order to ensure
backward compatibility with existing software. Modern PCs therefore have
a "hole" in physical memory from `0x000A0000`
to `0x00100000`
, dividing RAM
into "low" or "conventional memory" (the first 640KB) and "extended
memory" (everything else). In addition, some space at the very top of
the PC's 32-bit physical address space, above all physical RAM, is now
commonly reserved by the BIOS for use by 32-bit PCI devices.
Recent x86 processors can support *more* than 4GB of physical RAM, so
RAM can extend further above `0xFFFFFFFF`
. In this case the BIOS must
arrange to leave a *second* hole in the system's RAM at the top of the
32-bit addressable region, to leave room for these 32-bit devices to be
mapped. Because of design limitations JOS will use only the first 256MB
of a PC's physical memory anyway, so for now we will pretend that all
PCs have "only" a 32-bit physical address space. But dealing with
complicated physical address spaces and other aspects of hardware
organization that evolved over many years is one of the important
practical challenges of OS development.
In this portion of the lab, you'll use QEMU's debugging facilities to investigate how an IA-32 compatible computer boots.
Open two terminal windows. In one, enter `make qemu-gdb`
(or ```
make
qemu-nox-gdb
```
). This starts up QEMU, but QEMU stops just before the
processor executes the first instruction and waits for a debugging
connection from GDB. In the second terminal, from the same directory you
ran `make`
, run `make gdb`
. You should see something like this,
```
athena% make gdb
GNU gdb (GDB) 6.8-debian
Copyright (C) 2008 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "i486-linux-gnu".
+ target remote localhost:1234
The target architecture is assumed to be i8086
[f000:fff0] 0xffff0: ljmp $0xf000,$0xe05b
0x0000fff0 in ?? ()
+ symbol-file obj/kern/kernel
(gdb)
```
The `make gdb`
target runs a script called `.gdbrc`
, which sets up GDB
to debug the 16-bit code used during early boot and directs it to attach
to the listening QEMU.
The following line:
```
[f000:fff0] 0xffff0: ljmp $0xf000,$0xe05b
```
is GDB's disassembly of the first instruction to be executed. From this output you can conclude a few things:
`0x000ffff0`
, which is
at the very top of the 64KB area reserved for the ROM BIOS.`CS = 0xf000`
and `IP = 0xfff0`
.`jmp`
instruction, which
jumps to the segmented address `CS = 0xf000`
and `IP = 0xe05b`
.Why does QEMU start like this? This is how Intel designed the 8088
processor, which IBM used in their original PC. Because the BIOS in a PC
is "hard-wired" to the physical address range `0x000f0000-0x000fffff`
,
this design ensures that the BIOS always gets control of the machine
first after power-up or any system restart - which is crucial because on
power-up there *is* no other software anywhere in the machine's RAM that
the processor could execute. The QEMU emulator comes with its own BIOS,
which it places at this location in the processor's simulated physical
address space. On processor reset, the (simulated) processor enters real
mode and sets CS to `0xf000`
and the IP to `0xfff0`
, so that execution
begins at that (CS:IP) segment address. How does the segmented address
0xf000:fff0 turn into a physical address?
To answer that we need to know a bit about real mode addressing. In real
mode (the mode that PC starts off in), address translation works
according to the formula: *physical address* = 16 * *segment* +
*offset*. So, when the PC sets CS to `0xf000`
and IP to `0xfff0`
, the
physical address referenced is:
```
16 * 0xf000 + 0xfff0 # in hex multiplication by 16 is
= 0xf0000 + 0xfff0 # easy--just append a 0.
= 0xffff0
```
`0xffff0`
is 16 bytes before the end of the BIOS (`0x100000`
). Therefore
we shouldn't be surprised that the first thing that the BIOS does is
`jmp`
backwards to an earlier location in the BIOS; after all how much
could it accomplish in just 16 bytes?
Exercise 2Use GDB's
`si`
(Step Instruction) command to trace into the ROM BIOS for a few more instructions, and try to guess what it might be doing. You might want to look at[Phil Storrs I/O Ports Description], as well as other materials on the[6.828 reference materials page]. No need to figure out all the details - just the general idea of what the BIOS is doing first.
When the BIOS runs, it sets up an interrupt descriptor table and
initializes various devices such as the VGA display. This is where the
"`Starting SeaBIOS`
" message you see in the QEMU window comes from.
After initializing the PCI bus and all the important devices the BIOS
knows about, it searches for a bootable device such as a floppy, hard
drive, or CD-ROM. Eventually, when it finds a bootable disk, the BIOS
reads the *boot loader* from the disk and transfers control to it.
Floppy and hard disks for PCs are divided into 512 byte regions called
*sectors*. A sector is the disk's minimum transfer granularity: each
read or write operation must be one or more sectors in size and aligned
on a sector boundary. If the disk is bootable, the first sector is
called the *boot sector*, since this is where the boot loader code
resides. When the BIOS finds a bootable floppy or hard disk, it loads
the 512-byte boot sector into memory at physical addresses 0x7c00
through `0x7dff`
, and then uses a `jmp`
instruction to set the CS:IP to
`0000:7c00`
, passing control to the boot loader. Like the BIOS load
address, these addresses are fairly arbitrary - but they are fixed and
standardized for PCs.
The ability to boot from a CD-ROM came much later during the evolution
of the PC, and as a result the PC architects took the opportunity to
rethink the boot process slightly. As a result, the way a modern BIOS
boots from a CD-ROM is a bit more complicated (and more powerful).
CD-ROMs use a sector size of 2048 bytes instead of 512, and the BIOS can
load a much larger boot image from the disk into memory (not just one
sector) before transferring control to it. For more information, see the
["El Torito" Bootable CD-ROM Format
Specification](../../readings/boot-cdrom.pdf).
For 6.828, however, we will use the conventional hard drive boot
mechanism, which means that our boot loader must fit into a measly 512
bytes. The boot loader consists of one assembly language source file,
`boot/boot.S`
, and one C source file, `boot/main.c`
Look through these
source files carefully and make sure you understand what's going on. The
boot loader must perform two main functions:
After you understand the boot loader source code, look at the file
`obj/boot/boot.asm`
. This file is a disassembly of the boot loader that
our GNUmakefile creates *after* compiling the boot loader. This
disassembly file makes it easy to see exactly where in physical memory
all of the boot loader's code resides, and makes it easier to track
what's happening while stepping through the boot loader in GDB.
Likewise, `obj/kern/kernel.asm`
contains a disassembly of the JOS
kernel, which can often be useful for debugging.
You can set address breakpoints in GDB with the `b`
command. For
example, `b *0x7c00`
sets a breakpoint at address `0x7C00`
. Once at a
breakpoint, you can continue execution using the `c`
and `si`
commands: `c`
causes QEMU to continue execution until the next breakpoint (or until
you press Ctrl-C in GDB), and `si N`
steps through the instructions
`N`
at a time.
To examine instructions in memory (besides the immediate next one to be
executed, which GDB prints automatically), you use the `x/i`
command. This
command has the syntax `x/Ni ADDR`
, where `N`
is the number of
consecutive instructions to disassemble and `ADDR`
is the memory address
at which to start disassembling.
Exercise 3Take a look at the
[lab tools guide], especially the section on GDB commands. Even if you're familiar with GDB, this includes some esoteric GDB commands that are useful for OS work.
Set a breakpoint at address 0x7c00, which is where the boot sector will
be loaded. Continue execution until that breakpoint. Trace through the
code in `boot/boot.S`
, using the source code and the disassembly file
`obj/boot/boot.asm`
to keep track of where you are. Also use the `x/i`
command in GDB to disassemble sequences of instructions in the boot
loader, and compare the original boot loader source code with both the
disassembly in `obj/boot/boot.asm`
and GDB.
Trace into `bootmain()`
in `boot/main.c`
, and then into `readsect()`
.
Identify the exact assembly instructions that correspond to each of the
statements in `readsect()`
. Trace through the rest of `readsect()`
and
back out into `bootmain()`
, and identify the begin and end of the `for`
loop that reads the remaining sectors of the kernel from the disk. Find
out what code will run when the loop is finished, set a breakpoint
there, and continue to that breakpoint. Then step through the remainder
of the boot loader.
Be able to answer the following questions:
We will now look in further detail at the C language portion of the boot
loader, in `boot/main.c`
. But before doing so, this is a good time to
stop and review some of the basics of C programming.
Exercise 4Download the code for
[pointers.c], run it, and make sure you understand where all of the printed values come from. In particular, make sure you understand where the pointer addresses in lines 1 and 6 come from, how all the values in lines 2 through 4 get there, and why the values printed in line 5 are seemingly corrupted.If you're not familiar with pointers,
The C Programming Languageby Brian Kernighan and Dennis Ritchie (known as 'K&R') is a good reference. Students can purchase this book (here is an[Amazon Link]) or find one of[MIT's 7 copies]. 3 copies are also available for perusal in the[SIPB Office].
[A tutorial by Ted Jensen]that cites K&R heavily is available in the course readings.
Warning:Unless you are already thoroughly versed in C, do not skip or even skim this reading exercise. If you do not really understand pointers in C, you will suffer untold pain and misery in subsequent labs, and then eventually come to understand them the hard way. Trust us; you don't want to find out what "the hard way" is.
To make sense out of `boot/main.c`
you'll need to know what an ELF
binary is. When you compile and link a C program such as the JOS kernel,
the compiler transforms each C source ('`.c`
') file into an *object*
('`.o`
') file containing assembly language instructions encoded in the
binary format expected by the hardware. The linker then combines all of
the compiled object files into a single *binary image* such as
`obj/kern/kernel`
, which in this case is a binary in the ELF format,
which stands for "Executable and Linkable Format".
Full information about this format is available in [the ELF
specification](../../readings/elf.pdf) on [our reference
page](../../reference), but you will not need to delve very deeply
into the details of this format in this class. Although as a whole the
format is quite powerful and complex, most of the complex parts are for
supporting dynamic loading of shared libraries, which we will not do in
this class.
For purposes of 6.828, you can consider an ELF executable to be a header
with loading information, followed by several *program sections*, each
of which is a contiguous chunk of code or data intended to be loaded
into memory at a specified address. The boot loader does not modify the
code or data; it loads it into memory and starts executing it.
An ELF binary starts with a fixed-length *ELF header*, followed by a
variable-length *program header* listing each of the program sections to
be loaded. The C definitions for these ELF headers are in `inc/elf.h`
.
The program sections we're interested in are:
`.text`
: The program's executable instructions.`.rodata`
: Read-only data, such as ASCII string constants produced
by the C compiler. (We will not bother setting up the hardware to
prohibit writing, however.)`.data`
: The data section holds the program's initialized data, such
as global variables declared with initializers like `int x = 5;`
.When the linker computes the memory layout of a program, it reserves
space for *uninitialized* global variables, such as `int x;`
, in a
section called `.bss`
that immediately follows `.data`
in memory. C
requires that "uninitialized" global variables start with a value of
zero. Thus there is no need to store contents for `.bss`
in the ELF
binary; instead, the linker records just the address and size of the
`.bss`
section. The loader or the program itself must arrange to zero
the `.bss`
section.
Examine the full list of the names, sizes, and link addresses of all the sections in the kernel executable by typing:
```
athena% i386-jos-elf-objdump -h obj/kern/kernel
```
You can substitute `objdump`
for `i386-jos-elf-objdump`
if your computer
uses an ELF toolchain by default like most modern Linuxen and BSDs.
You will see many more sections than the ones we listed above, but the others are not important for our purposes. Most of the others are to hold debugging information, which is typically included in the program's executable file but not loaded into memory by the program loader.
Take particular note of the "VMA" (or *link address*) and the "LMA" (or
*load address*) of the `.text`
section. The load address of a section is
the memory address at which that section should be loaded into memory.
In the ELF object, this is stored in the `ph->p_pa`
field (in this case,
it really is a physical address, though the ELF specification is vague
on the actual meaning of this field).
The link address of a section is the memory address from which the
section expects to execute. The linker encodes the link address in the
binary in various ways, such as when the code needs the address of a
global variable, with the result that a binary usually won't work if it
is executing from an address that it is not linked for. (It is possible
to generate *position-independent* code that does not contain any such
absolute addresses. This is used extensively by modern shared libraries,
but it has performance and complexity costs, so we won't be using it in
6.828.)
Typically, the link and load addresses are the same. For example, look
at the `.text`
section of the boot loader:
```
athena% i386-jos-elf-objdump -h obj/boot/boot.out
```
The BIOS loads the boot sector into memory starting at address 0x7c00,
so this is the boot sector's load address. This is also where the boot
sector executes from, so this is also its link address. We set the link
address by passing `-Ttext 0x7C00`
to the linker in `boot/Makefrag`
, so
the linker will produce the correct memory addresses in the generated
code.
Exercise 5Trace through the first few instructions of the boot loader again and identify the first instruction that would "break" or otherwise do the wrong thing if you were to get the boot loader's link address wrong. Then change the link address in
`boot/Makefrag`
to something wrong, run make clean, recompile the lab with make, and trace into the boot loader again to see what happens. Don't forget to change the link address back and make clean again afterward!
Look back at the load and link addresses for the kernel. Unlike the boot loader, these two addresses aren't the same: the kernel is telling the boot loader to load it into memory at a low address (1 megabyte), but it expects to execute from a high address. We'll dig in to how we make this work in the next section.
Besides the section information, there is one more field in the ELF
header that is important to us, named `e_entry`
. This field holds the
link address of the *entry point* in the program: the memory address in
the program's text section at which the program should begin executing.
You can see the entry point:
```
athena% i386-jos-elf-objdump -f obj/kern/kernel
```
You should now be able to understand the minimal ELF loader in
`boot/main.c`
. It reads each section of the kernel from disk into memory
at the section's load address and then jumps to the kernel's entry
point.
Exercise 6We can examine memory using GDB's x command. The
[GDB manual]has full details, but for now, it is enough to know that the command`x/Nx ADDR`
prints`N`
words of memory at`ADDR`
. (Note that both`x`
s in the command are lowercase.)Warning: The size of a word is not a universal standard. In GNU assembly, a word is two bytes (the 'w' in xorw, which stands for word, means 2 bytes).
Reset the machine (exit QEMU/GDB and start them again). Examine the 8
words of memory at `0x00100000`
at the point the BIOS enters the boot
loader, and then again at the point the boot loader enters the kernel.
Why are they different? What is there at the second breakpoint? (You do
not really need to use QEMU to answer this question. Just think.)
We will now start to examine the minimal JOS kernel in a bit more detail. (And you will finally get to write some code!). Like the boot loader, the kernel begins with some assembly language code that sets things up so that C language code can execute properly.
When you inspected the boot loader's link and load addresses above, they
matched perfectly, but there was a (rather large) disparity between the
*kernel's* link address (as printed by objdump) and its load address. Go
back and check both and make sure you can see what we're talking about.
(Linking the kernel is more complicated than the boot loader, so the
link and load addresses are at the top of `kern/kernel.ld`
.)
Operating system kernels often like to be linked and run at very high
*virtual address*, such as `0xf0100000`
, in order to leave the lower part
of the processor's virtual address space for user programs to use. The
reason for this arrangement will become clearer in the next lab.
Many machines don't have any physical memory at address `0xf0100000`
, so
we can't count on being able to store the kernel there. Instead, we will
use the processor's memory management hardware to map virtual address
`0xf0100000`
(the link address at which the kernel code *expects* to run)
to physical address `0x00100000`
(where the boot loader loaded the kernel
into physical memory). This way, although the kernel's virtual address
is high enough to leave plenty of address space for user processes, it
will be loaded in physical memory at the 1MB point in the PC's RAM, just
above the BIOS ROM. This approach requires that the PC have at least a
few megabytes of physical memory (so that physical address `0x00100000`
works), but this is likely to be true of any PC built after about 1990.
In fact, in the next lab, we will map the *entire* bottom 256MB of the
PC's physical address space, from physical addresses `0x00000000`
through
`0x0fffffff`
, to virtual addresses `0xf0000000`
through `0xffffffff`
respectively. You should now see why JOS can only use the first 256MB of
physical memory.
For now, we'll just map the first 4MB of physical memory, which will be
enough to get us up and running. We do this using the hand-written,
statically-initialized page directory and page table in
`kern/entrypgdir.c`
. For now, you don't have to understand the details
of how this works, just the effect that it accomplishes. Up until
`kern/entry.S`
sets the `CR0_PG`
flag, memory references are treated as
physical addresses (strictly speaking, they're linear addresses, but
boot/boot.S set up an identity mapping from linear addresses to physical
addresses and we're never going to change that). Once `CR0_PG`
is set,
memory references are virtual addresses that get translated by the
virtual memory hardware to physical addresses. `entry_pgdir`
translates
virtual addresses in the range `0xf0000000`
through `0xf0400000`
to physical
addresses `0x00000000`
through `0x00400000`
, as well as virtual addresses
`0x00000000`
through `0x00400000`
to physical addresses `0x00000000`
through
`0x00400000`
. Any virtual address that is not in one of these two ranges
will cause a hardware exception which, since we haven't set up interrupt
handling yet, will cause QEMU to dump the machine state and exit (or
endlessly reboot if you aren't using the 6.828-patched version of QEMU).
Exercise 7Use QEMU and GDB to trace into the JOS kernel and stop at the
`movl %eax, %cr0`
. Examine memory at`0x00100000`
and at`0xf0100000`
. Now, single step over that instruction using the`stepi`
GDB command. Again, examine memory at`0x00100000`
and at`0xf0100000`
. Make sure you understand what just happened.
What is the first instruction *after* the new mapping is established
that would fail to work properly if the mapping weren't in place?
Comment out the `movl %eax, %cr0`
in `kern/entry.S`
, trace into it, and
see if you were right.
Most people take functions like `printf()`
for granted, sometimes even
thinking of them as "primitives" of the C language. But in an OS kernel,
we have to implement all I/O ourselves.
Read through `kern/printf.c`
, `lib/printfmt.c`
, and `kern/console.c`
,
and make sure you understand their relationship. It will become clear in
later labs why `printfmt.c`
is located in the separate `lib`
directory.
Exercise 8We have omitted a small fragment of code - the code necessary to print octal numbers using patterns of the form "%o". Find and fill in this code fragment.
Be able to answer the following questions:
- Explain the interface between
`printf.c`
and`console.c`
. Specifically, what function does`console.c`
export? How is this function used by`printf.c`
?Explain the following from
`console.c`
:`if (crt_pos >= CRT_SIZE) { int i; memcpy(crt_buf, crt_buf + CRT_COLS, (CRT_SIZE - CRT_COLS) * sizeof(uint16_t)); for (i = CRT_SIZE - CRT_COLS; i < CRT_SIZE; i++) crt_buf[i] = 0x0700 | ' '; crt_pos -= CRT_COLS; }`
For the following questions you might wish to consult the notes for Lecture 1. These notes cover GCC's calling convention on the x86.
Trace the execution of the following code step-by-step:
`int x = 1, y = 3, z = 4; cprintf("x %d, y %x, z %d\n", x, y, z);`
- In the call to
`cprintf()`
, to what does`fmt`
point? To what does`ap`
point?- List (in order of execution) each call to
`cons_putc`
,`va_arg`
, and`vcprintf`
. For`cons_putc`
, list its argument as well. For`va_arg`
, list what`ap`
points to before and after the call. For`vcprintf`
list the values of its two arguments.Run the following code.
`unsigned int i = 0x00646c72; cprintf("H%x Wo%s", 57616, &i);`
What is the output? Explain how this output is arrived at in the step-by-step manner of the previous exercise.
[Here's an ASCII table]that maps bytes to characters.The output depends on that fact that the x86 is little-endian. If the x86 were instead big-endian what would you set
`i`
to in order to yield the same output? Would you need to change`57616`
to a different value?
[Here's a description of little- and big-endian]and[a more whimsical description].In the following code, what is going to be printed after
`y=`
? (note: the answer is not a specific value.) Why does this happen?`cprintf("x=%d y=%d", 3);`
Let's say that GCC changed its calling convention so that it pushed arguments on the stack in declaration order, so that the last argument is pushed last. How would you have to change
`cprintf`
or its interface so that it would still be possible to pass it a variable number of arguments?
In the final exercise of this lab, we will explore in more detail the
way the C language uses the stack on the x86, and in the process write a
useful new kernel monitor function that prints a *backtrace* of the
stack: a list of the saved Instruction Pointer (IP) values from the
nested `call`
instructions that led to the current point of execution.
Exercise 9Determine where the kernel initializes its stack, and exactly where in memory its stack is located. How does the kernel reserve space for its stack? And at which "end" of this reserved area is the stack pointer initialized to point to?
The x86 stack pointer (`esp`
register) points to the lowest location on
the stack that is currently in use. Everything *below* that location in
the region reserved for the stack is free. Pushing a value onto the
stack involves decreasing the stack pointer and then writing the value
to the place the stack pointer points to. Popping a value from the stack
involves reading the value the stack pointer points to and then
increasing the stack pointer. In 32-bit mode, the stack can only hold
32-bit values, and esp is always divisible by four. Various x86
instructions, such as `call`
, are "hard-wired" to use the stack pointer
register.
The `ebp`
(base pointer) register, in contrast, is associated with the
stack primarily by software convention. On entry to a C function, the
function's *prologue* code normally saves the previous function's base
pointer by pushing it onto the stack, and then copies the current `esp`
value into `ebp`
for the duration of the function. If all the functions
in a program obey this convention, then at any given point during the
program's execution, it is possible to trace back through the stack by
following the chain of saved `ebp`
pointers and determining exactly what
nested sequence of function calls caused this particular point in the
program to be reached. This capability can be particularly useful, for
example, when a particular function causes an `assert`
failure or
`panic`
because bad arguments were passed to it, but you aren't sure
*who* passed the bad arguments. A stack backtrace lets you find the
offending function.
Exercise 10To become familiar with the C calling conventions on the x86, find the address of the
`test_backtrace`
function in`obj/kern/kernel.asm`
, set a breakpoint there, and examine what happens each time it gets called after the kernel starts. How many 32-bit words does each recursive nesting level of`test_backtrace`
push on the stack, and what are those words?
The above exercise should give you the information you need to implement
a stack backtrace function, which you should call `mon_backtrace()`
. A
prototype for this function is already waiting for you in
`kern/monitor.c`
. You can do it entirely in C, but you may find the
`read_ebp()`
function in `inc/x86.h`
useful. You'll also have to hook
this new function into the kernel monitor's command list so that it can
be invoked interactively by the user.
The backtrace function should display a listing of function call frames in the following format:
```
Stack backtrace:
ebp f0109e58 eip f0100a62 args 00000001 f0109e80 f0109e98 f0100ed2 00000031
ebp f0109ed8 eip f01000d6 args 00000000 00000000 f0100058 f0109f28 00000061
...
```
The first line printed reflects the *currently executing* function,
namely `mon_backtrace`
itself, the second line reflects the function
that called `mon_backtrace`
, the third line reflects the function that
called that one, and so on. You should print *all* the outstanding stack
frames. By studying `kern/entry.S`
you'll find that there is an easy way
to tell when to stop.
Within each line, the `ebp`
value indicates the base pointer into the
stack used by that function: i.e., the position of the stack pointer
just after the function was entered and the function prologue code set
up the base pointer. The listed `eip`
value is the function's *return
instruction pointer*: the instruction address to which control will
return when the function returns. The return instruction pointer
typically points to the instruction after the `call`
instruction (why?).
Finally, the five hex values listed after `args`
are the first five
arguments to the function in question, which would have been pushed on
the stack just before the function was called. If the function was
called with fewer than five arguments, of course, then not all five of
these values will be useful. (Why can't the backtrace code detect how
many arguments there actually are? How could this limitation be fixed?)
Here are a few specific points you read about in K&R Chapter 5 that are worth remembering for the following exercise and for future labs.
`int *p = (int*)100`
, then `(int)p + 1`
and `(int)(p + 1)`
are
different numbers: the first is `101`
but the second is `104`
. When
adding an integer to a pointer, as in the second case, the integer
is implicitly multiplied by the size of the object the pointer
points to.`p[i]`
is defined to be the same as `*(p+i)`
, referring to the i'th
object in the memory pointed to by p. The above rule for addition
helps this definition work when the objects are larger than one
byte.`&p[i]`
is the same as `(p+i)`
, yielding the address of the i'th
object in the memory pointed to by p.Although most C programs never need to cast between pointers and integers, operating systems frequently do. Whenever you see an addition involving a memory address, ask yourself whether it is an integer addition or pointer addition and make sure the value being added is appropriately multiplied or not.
Exercise 11Implement the backtrace function as specified above. Use the same format as in the example, since otherwise the grading script will be confused. When you think you have it working right, run make grade to see if its output conforms to what our grading script expects, and fix it if it doesn't.
Afteryou have handed in your Lab 1 code, you are welcome to change the output format of the backtrace function any way you like.
At this point, your backtrace function should give you the addresses of
the function callers on the stack that lead to `mon_backtrace()`
being
executed. However, in practice you often want to know the function names
corresponding to those addresses. For instance, you may want to know
which functions could contain a bug that's causing your kernel to crash.
To help you implement this functionality, we have provided the function
`debuginfo_eip()`
, which looks up `eip`
in the symbol table and returns
the debugging information for that address. This function is defined in
`kern/kdebug.c`
.
Exercise 12Modify your stack backtrace function to display, for each
`eip`
, the function name, source file name, and line number corresponding to that`eip`
.
In `debuginfo_eip`
, where do `__STAB_*`
come from? This question has a
long answer; to help you to discover the answer, here are some things
you might want to do:
`kern/kernel.ld`
for `__STAB_*`
Complete the implementation of `debuginfo_eip`
by inserting the call to
`stab_binsearch`
to find the line number for an address.
Add a `backtrace`
command to the kernel monitor, and extend your
implementation of `mon_backtrace`
to call `debuginfo_eip`
and print a
line for each stack frame of the form:
```
K> backtrace
Stack backtrace:
ebp f010ff78 eip f01008ae args 00000001 f010ff8c 00000000 f0110580 00000000
kern/monitor.c:143: monitor+106
ebp f010ffd8 eip f0100193 args 00000000 00001aac 00000660 00000000 00000000
kern/init.c:49: i386_init+59
ebp f010fff8 eip f010003d args 00000000 00000000 0000ffff 10cf9a00 0000ffff
kern/entry.S:70: <unknown>+0
K>
```
Each line gives the file name and line within that file of the stack
frame's `eip`
, followed by the name of the function and the offset of
the `eip`
from the first instruction of the function (e.g.,
`monitor+106`
means the return `eip`
is 106 bytes past the beginning of
`monitor`
).
Be sure to print the file and function names on a separate line, to avoid confusing the grading script.
Tip: printf format strings provide an easy, albeit obscure, way to print
non-null-terminated strings like those in STABS tables.
`printf("%.*s", length, string)`
prints at most `length`
characters of
`string`
. Take a look at the printf man page to find out why this works.
You may find that some functions are missing from the backtrace. For
example, you will probably see a call to `monitor()`
but not to
`runcmd()`
. This is because the compiler in-lines some function calls.
Other optimizations may cause you to see unexpected line numbers. If you
get rid of the `-O2`
from `GNUMakefile`
, the backtraces may make more
sense (but your kernel will run more slowly).
**This completes the lab.** In the `lab`
directory, commit your changes
with `git commit`
and type `make handin`
to submit your code. |
9,741 | 完全指南:在容器中运行 Jenkins 构建 | https://opensource.com/article/18/4/running-jenkins-builds-containers | 2018-06-13T11:15:05 | [
"Jenkins",
"Maven",
"CI",
"CD"
] | https://linux.cn/article-9741-1.html |
>
> 容器应用程序平台能够动态地启动具有资源限制的独立容器,从而改变了运行 CI/CD 任务的方式。
>
>
>

现今,由于 [Docker](https://opensource.com/resources/what-docker) 和 [Kubernetes](https://opensource.com/resources/what-is-kubernetes)(K8S)提供了可扩展、可管理的应用平台,将应用运行在容器中的实践已经被企业广泛接受。近些年势头很猛的[微服务架构](https://martinfowler.com/articles/microservices.html)也很适合用容器实现。
容器应用平台可以动态启动指定资源配额、互相隔离的容器,这是其最主要的优势之一。让我们看看这会对我们运行<ruby> 持续集成/持续部署 <rt> continuous integration/continuous development </rt></ruby>(CI/CD)任务的方式产生怎样的改变。
构建并打包应用需要一定的环境,要求能够下载源代码、使用相关依赖及已经安装构建工具。作为构建的一部分,运行单元及组件测试可能会用到本地端口或需要运行第三方应用(如数据库及消息中间件等)。另外,我们一般定制化多台构建服务器,每台执行一种指定类型的构建任务。为方便测试,我们维护一些实例专门用于运行第三方应用(或者试图在构建服务器上启动这些第三方应用),避免并行运行构建任务导致结果互相干扰。为 CI/CD 环境定制化构建服务器是一项繁琐的工作,而且随着开发团队使用的开发平台或其版本变更,会需要大量的构建服务器用于不同的任务。
一旦我们有了容器管理平台(自建或在云端),将资源密集型的 CI/CD 任务在动态生成的容器中执行是比较合理的。在这种方案中,每个构建任务运行在独立启动并配置的构建环境中。构建过程中,构建任务的测试环节可以任意使用隔离环境中的可用资源;此外,我们也可以在辅助容器中启动一个第三方应用,只在构建任务生命周期中为测试提供服务。
听上去不错,让我们在现实环境中实践一下。
注:本文基于现实中已有的解决方案,即一个在 [Red Hat OpenShift](https://www.openshift.com/) v3.7 集群上运行的项目。OpenShift 是企业级的 Kubernetes 版本,故这些实践也适用于 K8S 集群。如果愿意尝试,可以下载 [Red Hat CDK](https://developers.redhat.com/products/cdk/overview/),运行 `jenkins-ephemeral` 或 `jenkins-persistent` [模板](https://github.com/openshift/origin/tree/master/examples/jenkins)在 OpenShift 上创建定制化好的 Jenkins 管理节点。
### 解决方案概述
在 OpenShift 容器中执行 CI/CD 任务(构建和测试等) 的方案基于[分布式 Jenkins 构建](https://wiki.jenkins.io/display/JENKINS/Distributed+builds),具体如下:
* 我们需要一个 Jenkins 主节点;可以运行在集群中,也可以是外部提供
* 支持 Jenkins 特性和插件,以便已有项目仍可使用
* 可以用 Jenkins GUI 配置、运行任务或查看任务输出
* 如果你愿意编码,也可以使用 [Jenkins Pipeline](https://jenkins.io/doc/book/pipeline/)
从技术角度来看,运行任务的动态容器是 Jenkins 代理节点。当构建启动时,首先是一个新节点启动,通过 Jenkins 主节点的 JNLP(5000 端口) 告知就绪状态。在代理节点启动并提取构建任务之前,构建任务处于排队状态。就像通常 Jenkins 代理服务器那样,构建输出会送达主节点;不同的是,构建完成后代理节点容器会自动关闭。

不同类型的构建任务(例如 Java、 NodeJS、 Python等)对应不同的代理节点。这并不新奇,之前也是使用标签来限制哪些代理节点可以运行指定的构建任务。启动用于构建任务的 Jenkins 代理节点容器需要配置参数,具体如下:
* 用于启动容器的 Docker 镜像
* 资源限制
* 环境变量
* 挂载的卷
这里用到的关键组件是 [Jenkins Kubernetes 插件](https://github.com/jenkinsci/kubernetes-plugin)。该插件(通过使用一个服务账号) 与 K8S 集群交互,可以启动和关闭代理节点。在插件的配置管理中,多种代理节点类型表现为多种 Kubernetes pod 模板,它们通过项目标签对应。
这些[代理节点镜像](https://access.redhat.com/containers/#/search/jenkins%2520slave)以开箱即用的方式提供(也有 [CentOS7](https://hub.docker.com/search/?isAutomated=0&isOfficial=0&page=1&pullCount=0&q=openshift+jenkins+slave+&starCount=0) 系统的版本):
* [jenkins-slave-base-rhel7](https://github.com/openshift/jenkins/tree/master/slave-base):基础镜像,启动与 Jenkins 主节点连接的代理节点;其中 Java 堆大小根据容器内容设置
* [jenkins-slave-maven-rhel7](https://github.com/openshift/jenkins/tree/master/slave-maven):用于 Maven 和 Gradle 构建的镜像(从基础镜像扩展)
* [jenkins-slave-nodejs-rhel7](https://github.com/openshift/jenkins/tree/master/slave-nodejs):包含 NodeJS4 工具的镜像(从基础镜像扩展)
注意:本解决方案与 OpenShift 中的 [Source-to-Image(S2I)](https://docs.openshift.com/container-platform/3.7/architecture/core_concepts/builds_and_image_streams.html#source-build) 构建无关,虽然后者也可以用于某些特定的 CI/CD 任务。
### 入门学习资料
有很多不错的博客和文档介绍了如何在 OpenShift 上执行 Jenkins 构建。不妨从下面这些开始:
* [OpenShift Jenkins](https://docs.openshift.com/container-platform/3.7/using_images/other_images/jenkins.html) 镜像文档及 [源代码](https://github.com/openshift/jenkins)
* 网络播客:[基于 OpenShift 的 CI/CD](https://blog.openshift.com/cicd-with-openshift/)
* [外部 Jenkins 集成](http://v1.uncontained.io/playbooks/continuous_delivery/external-jenkins-integration.html) 剧本
阅读这些博客和文档有助于完整的理解本解决方案。在本文中,我们主要关注具体实践中遇到的各类问题。
### 构建我的应用
作为[示例项目](https://github.com/bszeti/camel-springboot/tree/master/camel-rest-complex),我们选取了包含如下构建步骤的 Java 项目:
* **代码源:** 从一个 Git 代码库中获取项目代码
* **使用 Maven 编译:** 依赖可从内部仓库获取,(不妨使用 Apache Nexus) 镜像自外部 Maven 仓库
* **发布成品:** 将编译好的 JAR 上传至内部仓库
在 CI/CD 过程中,我们需要与 Git 和 Nexus 交互,故 Jenkins 任务需要能够访问这些系统。这要求参数配置和已存储凭证可以在下列位置进行管理:
* **在 Jenkins 中:** 我们可以在 Jenkins 中添加凭证,通过 Git 插件能够对项目添加和使用文件(使用容器不会改变操作)
* **在 OpenShift 中:** 使用 ConfigMap 和 Secret 对象,以文件或环境变量的形式附加到 Jenkins 代理容器中
* **在高度定制化的 Docker 容器中:** 镜像是定制化的,已包含完成特定类型构建的全部特性;从一个代理镜像进行扩展即可得到。
你可以按自己的喜好选择一种实现方式,甚至你最终可能混用多种实现方式。下面我们采用第二种实现方式,即首选在 OpenShift 中管理参数配置。使用 Kubernetes 插件配置来定制化 Maven 代理容器,包括设置环境变量和映射文件等。
注意:对于 Kubernetes 插件 v1.0 版,由于 [bug](https://issues.jenkins-ci.org/browse/JENKINS-47112),在 UI 界面增加环境变量并不生效。可以升级插件,或(作为变通方案) 直接修改 `config.xml` 文件并重启 Jenkins。
### 从 Git 获取源代码
从公共 Git 仓库获取源代码很容易。但对于私有 Git 仓库,不仅需要认证操作,客户端还需要信任服务器以便建立安全连接。一般而言,通过两种协议获取源代码:
* HTTPS:验证通过用户名/密码完成。Git 服务器的 SSL 证书必须被代理节点信任,这仅在证书被自建 CA 签名时才需要特别注意。
```
git clone https://git.mycompany.com:443/myapplication.git
```
* SSH:验证通过私钥完成。如果服务器的公钥指纹出现在 `known_hosts` 文件中,那么该服务器是被信任的。
```
git clone ssh://[email protected]:22/myapplication.git
```
对于手动操作,使用用户名/密码通过 HTTP 方式下载源代码是可行的;但对于自动构建而言,SSH 是更佳的选择。
#### 通过 SSH 方式使用 Git
要通过 SSH 方式下载源代码,我们需要保证代理容器与 Git 的 SSH 端口之间可以建立 SSH 连接。首先,我们需要创建一个私钥-公钥对。使用如下命令生成:
```
ssh keygen -t rsa -b 2048 -f my-git-ssh -N ''
```
命令生成的私钥位于 `my-git-ssh` 文件中(口令为空),对应的公钥位于 `my-git-ssh.pub` 文件中。将公钥添加至 Git 服务器的对应用户下(推荐使用“服务账号”);网页界面一般支持公钥上传。为建立 SSH 连接,我们还需要在代理容器上配置两个文件:
* 私钥文件位于 `~/.ssh/id_rsa`
* 服务器的公钥位于 `~/.ssh/known_hosts`。要实现这一点,运行 `ssh git.mycompany.com` 并接受服务器指纹,系统会在 `~/.ssh/known_hosts` 文件中增加一行。这样需求得到了满足。
将 `id_rsa` 对应的私钥和 `known_hosts` 对应的公钥保存到一个 OpenShift 的 secret(或 ConfigMap) 对象中。
```
apiVersion: v1
kind: Secret
metadata:
name: mygit-ssh
stringData:
id_rsa: |-
-----BEGIN RSA PRIVATE KEY-----
...
-----END RSA PRIVATE KEY-----
known_hosts: |-
git.mycompany.com ecdsa-sha2-nistp256 AAA...
```
在 Kubernetes 插件中将 secret 对象配置为卷,挂载到 `/home/jenkins/.ssh/`,供 Maven pod 使用。secret 中的每个对象对应挂载目录的一个文件,文件名与 key 名称相符。我们可以使用 UI(管理 Jenkins / 配置 / 云 / Kubernetes),也可以直接编辑 Jenkins 配置文件 `/var/lib/jenkins/config.xml`:
```
<org.csanchez.jenkins.plugins.kubernetes.PodTemplate>
<name>maven</name>
...
<volumes>
<org.csanchez.jenkins.plugins.kubernetes.volumes.SecretVolume>
<mountPath>/home/jenkins/.ssh</mountPath>
<secretName>mygit-ssh</secretName>
</org.csanchez.jenkins.plugins.kubernetes.volumes.SecretVolume>
</volumes>
```
此时,在代理节点上运行的任务应该可以通过 SSH 方式从 Git 代码库获取源代码。
注:我们也可以在 `~/.ssh/config` 文件中自定义 SSH 连接。例如,如果你不想处理 `known_hosts` 或私钥位于其它挂载目录中:
```
Host git.mycompany.com
StrictHostKeyChecking no
IdentityFile /home/jenkins/.config/git-secret/ssh-privatekey
```
#### 通过 HTTP 方式使用 Git
如果你选择使用 HTTP 方式下载,在指定的 [Git-credential-store](https://git-scm.com/docs/git-credential-store/1.8.2) 文件中添加用户名/密码:
* 例如,在一个 OpenShift secret 对象中增加 `/home/jenkins/.config/git-secret/credentials` 文件对应,其中每个站点对应文件中的一行:
```
https://username:[email protected]
https://user:[email protected]
```
* 在 [git-config](https://git-scm.com/docs/git-config/1.8.2) 配置中启用该文件,其中配置文件默认路径为 `/home/jenkins/.config/git/config`:
```
[credential]
helper = store --file=/home/jenkins/.config/git-secret/credentials
```
如果 Git 服务使用了自有 CA 签名的证书,为代理容器设置环境变量 `GIT_SSL_NO_VERIFY=true` 是最便捷的方式。更恰当的解决方案包括如下两步:
* 利用 ConfigMap 将自有 CA 的公钥映射到一个路径下的文件中,例如 `/usr/ca/myTrustedCA.pem`)。
* 通过环境变量 `GIT_SSL_CAINFO=/usr/ca/myTrustedCA.pem` 或上面提到的 `git-config` 文件的方式,将证书路径告知 Git。
```
[http "https://git.mycompany.com"]
sslCAInfo = /usr/ca/myTrustedCA.pem
```
注:在 OpenShift v3.7 及早期版本中,ConfigMap 及 secret 的挂载点之间[不能相互覆盖](https://bugzilla.redhat.com/show_bug.cgi?id=1430322),故我们不能同时映射 `/home/jenkins` 和 `/home/jenkins/dir`。因此,上面的代码中并没有使用常见的文件路径。预计 OpenShift v3.9 版本会修复这个问题。
### Maven
要完成 Maven 构建,一般需要完成如下两步:
* 建立一个社区 Maven 库(例如 Apache Nexus),充当外部库的代理。将其当作镜像使用。
* 这个内部库可能提供 HTTPS 服务,其中使用自建 CA 签名的证书。
对于容器中运行构建的实践而言,使用内部 Maven 库是非常关键的,因为容器启动后并没有本地库或缓存,这导致每次构建时 Maven 都下载全部的 Jar 文件。在本地网络使用内部代理库下载明显快于从因特网下载。
[Maven Jenkins 代理](https://github.com/openshift/jenkins/tree/master/slave-maven)镜像允许配置环境变量,指定代理的 URL。在 Kubernetes 插件的容器模板中设置如下:
```
MAVEN_MIRROR_URL=https://nexus.mycompany.com/repository/maven-public
```
构建好的成品(JAR) 也应该保存到库中,可以是上面提到的用于提供依赖的镜像库,也可以是其它库。Maven 完成 `deploy` 操作需要在 `pom.xml` 的[分发管理](https://maven.apache.org/pom.html#Distribution_Management) 下配置库 URL,这与代理镜像无关。
```
<project ...>
<distributionManagement>
<snapshotRepository>
<id>mynexus</id>
<url>https://nexus.mycompany.com/repository/maven-snapshots/</url>
</snapshotRepository>
<repository>
<id>mynexus</id>
<url>https://nexus.mycompany.com/repository/maven-releases/</url>
</repository>
</distributionManagement>
```
上传成品可能涉及认证。在这种情况下,在 `settings.xml` 中配置的用户名/密码要与 `pom.xml` 文件中的对应的服务器 `id` 下的设置匹配。我们可以使用 OpenShift secret 将包含 URL、用户名和密码的完整 `settings.xml` 映射到 Maven Jenkins 代理容器中。另外,也可以使用环境变量。具体如下:
* 利用 secret 为容器添加环境变量:
```
MAVEN_SERVER_USERNAME=admin
MAVEN_SERVER_PASSWORD=admin123
```
* 利用 config map 将 `settings.xml` 挂载至 `/home/jenkins/.m2/settings.xml`:
```
<settings ...>
<mirrors>
<mirror>
<mirrorOf>external:*</mirrorOf>
<url>${env.MAVEN_MIRROR_URL}</url>
<id>mirror</id>
</mirror>
</mirrors>
<servers>
<server>
<id>mynexus</id>
<username>${env.MAVEN_SERVER_USERNAME}</username>
<password>${env.MAVEN_SERVER_PASSWORD}</password>
</server>
</servers>
</settings>
```
禁用交互模式(即,使用批处理模式) 可以忽略下载日志,一种方式是在 Maven 命令中增加 `-B` 参数,另一种方式是在 `settings.xml` 配置文件中增加 `<interactiveMode>false</interactiveMode>` 配置。
如果 Maven 库的 HTTPS 服务使用自建 CA 签名的证书,我们需要使用 [keytool](https://docs.oracle.com/javase/8/docs/technotes/tools/unix/keytool.html) 工具创建一个将 CA 公钥添加至信任列表的 Java KeyStore。在 OpenShift 中使用 ConfigMap 将这个 Keystore 上传。使用 `oc` 命令基于文件创建一个 ConfigMap:
```
oc create configmap maven-settings --from-file=settings.xml=settings.xml --from-
file=myTruststore.jks=myTruststore.jks
```
将这个 ConfigMap 挂载至 Jenkins 代理容器。在本例中我们使用 `/home/jenkins/.m2` 目录,但这仅仅是因为配置文件 `settings.xml` 也对应这个 ConfigMap。KeyStore 可以放置在任意路径下。
接着在容器环境变量 `MAVEN_OPTS` 中设置 Java 参数,以便让 Maven 对应的 Java 进程使用该文件:
```
MAVEN_OPTS=
-Djavax.net.ssl.trustStore=/home/jenkins/.m2/myTruststore.jks
-Djavax.net.ssl.trustStorePassword=changeit
```
### 内存使用量
这可能是最重要的一部分设置,如果没有正确的设置最大内存,我们会遇到间歇性构建失败,虽然每个组件都似乎工作正常。
如果没有在 Java 命令行中设置堆大小,在容器中运行 Java 可能导致高内存使用量的报错。JVM [可以利用全部的宿主机内存](https://developers.redhat.com/blog/2017/03/14/java-inside-docker/),而不是使用容器内存现在并相应设置[默认的堆大小](https://docs.oracle.com/javase/8/docs/technotes/guides/vm/gctuning/parallel.html#default_heap_size)。这通常会超过容器的内存资源总额,故当 Java 进程为堆分配过多内存时,OpenShift 会直接杀掉容器。
虽然 `jenkins-slave-base` 镜像包含一个内建[脚本设置堆最大为](https://github.com/openshift/jenkins/blob/master/slave-base/contrib/bin/run-jnlp-client)容器内存的一半(可以通过环境变量 `CONTAINER_HEAP_PERCENT=0.50` 修改),但这只适用于 Jenkins 代理节点中的 Java 进程。在 Maven 构建中,还有其它重要的 Java 进程运行:
* `mvn` 命令本身就是一个 Java 工具。
* [Maven Surefire 插件](http://maven.apache.org/surefire/maven-surefire-plugin/examples/fork-options-and-parallel-execution.html) 默认派生一个 JVM 用于运行单元测试。
总结一下,容器中同时运行着三个重要的 Java 进程,预估内存使用量以避免 pod 被误杀是很重要的。每个进程都有不同的方式设置 JVM 参数:
* 我们在上面提到了 Jenkins 代理容器堆最大值的计算方法,但我们显然不应该让代理容器使用如此大的堆,毕竟还有两个 JVM 需要使用内存。对于 Jenkins 代理容器,可以设置 `JAVA_OPTS`。
* `mvn` 工具被 Jenkins 任务调用。设置 `MAVEN_OPTS` 可以用于自定义这类 Java 进程。
* Maven `surefire` 插件滋生的用于单元测试的 JVM 可以通过 Maven [argLine](http://maven.apache.org/surefire/maven-surefire-plugin/test-mojo.html#argLine) 属性自定义。可以在 `pom.xml` 或 `settings.xml` 的某个配置文件中设置,也可以直接在 `maven` 命令参数 `MAVEN_OPS` 中增加 `-DargLine=…`。
下面例子给出 Maven 代理容器环境变量设置方法:
```
JAVA_OPTS=-Xms64m -Xmx64m
MAVEN_OPTS=-Xms128m -Xmx128m -DargLine=${env.SUREFIRE_OPTS}
SUREFIRE_OPTS=-Xms256m -Xmx256m
```
我们的测试环境是具有 1024Mi 内存限额的代理容器,使用上述参数可以正常构建一个 SpringBoot 应用并进行单元测试。测试环境使用的资源相对较小,对于复杂的 Maven 项目和对应的单元测试,我们需要更大的堆大小及更大的容器内存限额。
注:Java8 进程的实际内存使用量包括“堆大小 + 元数据 + 堆外内存”,因此内存使用量会明显高于设置的最大堆大小。在我们上面的测试环境中,三个 Java 进程使用了超过 900Mi 的内存。可以在容器内查看进程的 RSS 内存使用情况,命令如下:`ps -e -o pid,user,rss,comm,args`。
Jenkins 代理镜像同时安装了 JDK 64 位和 32 位版本。对于 `mvn` 和 `surefire`,默认使用 64 位版本 JVM。为减低内存使用量,只要 `-Xmx` 不超过 1.5 GB,强制使用 32 位 JVM 都是有意义的。
```
JAVA_HOME=/usr/lib/jvm/Java-1.8.0-openjdk-1.8.0.161–0.b14.el7_4.i386
```
注意到我们可以在 `JAVA_TOOL_OPTIONS` 环境变量中设置 Java 参数,每个 JVM 启动时都会读取该参数。`JAVA_OPTS` 和 `MAVEN_OPTS` 中的参数会覆盖 `JAVA_TOOL_OPTIONS` 中的对应值,故我们可以不使用 `argLine`,实现对 Java 进程同样的堆配置:
```
JAVA_OPTS=-Xms64m -Xmx64m
MAVEN_OPTS=-Xms128m -Xmx128m
JAVA_TOOL_OPTIONS=-Xms256m -Xmx256m
```
但缺点是每个 JVM 的日志中都会显示 `Picked up JAVA_TOOL_OPTIONS:`,这可能让人感到迷惑。
### Jenkins 流水线
完成上述配置,我们应该已经可以完成一次成功的构建。我们可以获取源代码,下载依赖,运行单元测试并将成品上传到我们的库中。我们可以通过创建一个 Jenkins 流水线项目来完成上述操作。
```
pipeline {
/* Which container to bring up for the build. Pick one of the templates configured in Kubernetes plugin. */
agent {
label 'maven'
}
stages {
stage('Pull Source') {
steps {
git url: 'ssh://[email protected]:22/myapplication.git', branch: 'master'
}
}
stage('Unit Tests') {
steps {
sh 'mvn test'
}
}
stage('Deploy to Nexus') {
steps {
sh 'mvn deploy -DskipTests'
}
}
}
}
```
当然,对应真实项目,CI/CD 流水线不仅仅完成 Maven 构建,还可以部署到开发环境,运行集成测试,提升至更接近于生产的环境等。上面给出的学习资料中有执行这些操作的案例。
### 多容器
一个 pod 可以运行多个容器,每个容器有单独的资源限制。这些容器共享网络接口,故我们可以从 `localhost` 访问已启动的服务,但我们需要考虑端口冲突的问题。在一个 Kubernetes pod 模板中,每个容器的环境变量是单独设置的,但挂载的卷是统一的。
当一个外部服务需要单元测试且嵌入式方案无法工作(例如,数据库、消息中间件等) 时,可以启动多个容器。在这种情况下,第二个容器会随着 Jenkins 代理容器启停。
查看 Jenkins `config.xml` 片段,其中我们启动了一个辅助的 `httpbin` 服务用于 Maven 构建:
```
<org.csanchez.jenkins.plugins.kubernetes.PodTemplate>
<name>maven</name>
<volumes>
...
</volumes>
<containers>
<org.csanchez.jenkins.plugins.kubernetes.ContainerTemplate>
<name>jnlp</name>
<image>registry.access.redhat.com/openshift3/jenkins-slave-maven-rhel7:v3.7</image>
<resourceLimitCpu>500m</resourceLimitCpu>
<resourceLimitMemory>1024Mi</resourceLimitMemory>
<envVars>
...
</envVars>
...
</org.csanchez.jenkins.plugins.kubernetes.ContainerTemplate>
<org.csanchez.jenkins.plugins.kubernetes.ContainerTemplate>
<name>httpbin</name>
<image>citizenstig/httpbin</image>
<resourceLimitCpu></resourceLimitCpu>
<resourceLimitMemory>256Mi</resourceLimitMemory>
<envVars/>
...
</org.csanchez.jenkins.plugins.kubernetes.ContainerTemplate>
</containers>
<envVars/>
</org.csanchez.jenkins.plugins.kubernetes.PodTemplate>
```
### 总结
作为总结,我们查看上面已描述配置的 Jenkins `config.xml` 对应创建的 OpenShift 资源以及 Kubernetes 插件的配置。
```
apiVersion: v1
kind: List
metadata: {}
items:
- apiVersion: v1
kind: ConfigMap
metadata:
name: git-config
data:
config: |
[credential]
helper = store --file=/home/jenkins/.config/git-secret/credentials
[http "http://git.mycompany.com"]
sslCAInfo = /home/jenkins/.config/git/myTrustedCA.pem
myTrustedCA.pem: |-
-----BEGIN CERTIFICATE-----
MIIDVzCCAj+gAwIBAgIJAN0sC...
-----END CERTIFICATE-----
- apiVersion: v1
kind: Secret
metadata:
name: git-secret
stringData:
ssh-privatekey: |-
-----BEGIN RSA PRIVATE KEY-----
...
-----END RSA PRIVATE KEY-----
credentials: |-
https://username:[email protected]
https://user:[email protected]
- apiVersion: v1
kind: ConfigMap
metadata:
name: git-ssh
data:
config: |-
Host git.mycompany.com
StrictHostKeyChecking yes
IdentityFile /home/jenkins/.config/git-secret/ssh-privatekey
known_hosts: '[git.mycompany.com]:22 ecdsa-sha2-nistp256 AAAdn7...'
- apiVersion: v1
kind: Secret
metadata:
name: maven-secret
stringData:
username: admin
password: admin123
```
基于文件创建另一个 ConfigMap:
```
oc create configmap maven-settings --from-file=settings.xml=settings.xml
--from-file=myTruststore.jks=myTruststore.jks
```
Kubernetes 插件配置如下:
```
<?xml version='1.0' encoding='UTF-8'?>
<hudson>
...
<clouds>
<org.csanchez.jenkins.plugins.kubernetes.KubernetesCloud plugin="[email protected]">
<name>openshift</name>
<defaultsProviderTemplate></defaultsProviderTemplate>
<templates>
<org.csanchez.jenkins.plugins.kubernetes.PodTemplate>
<inheritFrom></inheritFrom>
<name>maven</name>
<namespace></namespace>
<privileged>false</privileged>
<alwaysPullImage>false</alwaysPullImage>
<instanceCap>2147483647</instanceCap>
<slaveConnectTimeout>100</slaveConnectTimeout>
<idleMinutes>0</idleMinutes>
<label>maven</label>
<serviceAccount>jenkins37</serviceAccount>
<nodeSelector></nodeSelector>
<nodeUsageMode>NORMAL</nodeUsageMode>
<customWorkspaceVolumeEnabled>false</customWorkspaceVolumeEnabled>
<workspaceVolume class="org.csanchez.jenkins.plugins.kubernetes.volumes.workspace.EmptyDirWorkspaceVolume">
<memory>false</memory>
</workspaceVolume>
<volumes>
<org.csanchez.jenkins.plugins.kubernetes.volumes.SecretVolume>
<mountPath>/home/jenkins/.config/git-secret</mountPath>
<secretName>git-secret</secretName>
</org.csanchez.jenkins.plugins.kubernetes.volumes.SecretVolume>
<org.csanchez.jenkins.plugins.kubernetes.volumes.ConfigMapVolume>
<mountPath>/home/jenkins/.ssh</mountPath>
<configMapName>git-ssh</configMapName>
</org.csanchez.jenkins.plugins.kubernetes.volumes.ConfigMapVolume>
<org.csanchez.jenkins.plugins.kubernetes.volumes.ConfigMapVolume>
<mountPath>/home/jenkins/.config/git</mountPath>
<configMapName>git-config</configMapName>
</org.csanchez.jenkins.plugins.kubernetes.volumes.ConfigMapVolume>
<org.csanchez.jenkins.plugins.kubernetes.volumes.ConfigMapVolume>
<mountPath>/home/jenkins/.m2</mountPath>
<configMapName>maven-settings</configMapName>
</org.csanchez.jenkins.plugins.kubernetes.volumes.ConfigMapVolume>
</volumes>
<containers>
<org.csanchez.jenkins.plugins.kubernetes.ContainerTemplate>
<name>jnlp</name>
<image>registry.access.redhat.com/openshift3/jenkins-slave-maven-rhel7:v3.7</image>
<privileged>false</privileged>
<alwaysPullImage>false</alwaysPullImage>
<workingDir>/tmp</workingDir>
<command></command>
<args>${computer.jnlpmac} ${computer.name}</args>
<ttyEnabled>false</ttyEnabled>
<resourceRequestCpu>500m</resourceRequestCpu>
<resourceRequestMemory>1024Mi</resourceRequestMemory>
<resourceLimitCpu>500m</resourceLimitCpu>
<resourceLimitMemory>1024Mi</resourceLimitMemory>
<envVars>
<org.csanchez.jenkins.plugins.kubernetes.ContainerEnvVar>
<key>JAVA_HOME</key>
<value>/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.161-0.b14.el7_4.i386</value>
</org.csanchez.jenkins.plugins.kubernetes.ContainerEnvVar>
<org.csanchez.jenkins.plugins.kubernetes.ContainerEnvVar>
<key>JAVA_OPTS</key>
<value>-Xms64m -Xmx64m</value>
</org.csanchez.jenkins.plugins.kubernetes.ContainerEnvVar>
<org.csanchez.jenkins.plugins.kubernetes.ContainerEnvVar>
<key>MAVEN_OPTS</key>
<value>-Xms128m -Xmx128m -DargLine=${env.SUREFIRE_OPTS} -Djavax.net.ssl.trustStore=/home/jenkins/.m2/myTruststore.jks -Djavax.net.ssl.trustStorePassword=changeit</value>
</org.csanchez.jenkins.plugins.kubernetes.ContainerEnvVar>
<org.csanchez.jenkins.plugins.kubernetes.ContainerEnvVar>
<key>SUREFIRE_OPTS</key>
<value>-Xms256m -Xmx256m</value>
</org.csanchez.jenkins.plugins.kubernetes.ContainerEnvVar>
<org.csanchez.jenkins.plugins.kubernetes.ContainerEnvVar>
<key>MAVEN_MIRROR_URL</key>
<value>https://nexus.mycompany.com/repository/maven-public</value>
</org.csanchez.jenkins.plugins.kubernetes.ContainerEnvVar>
<org.csanchez.jenkins.plugins.kubernetes.model.SecretEnvVar>
<key>MAVEN_SERVER_USERNAME</key>
<secretName>maven-secret</secretName>
<secretKey>username</secretKey>
</org.csanchez.jenkins.plugins.kubernetes.model.SecretEnvVar>
<org.csanchez.jenkins.plugins.kubernetes.model.SecretEnvVar>
<key>MAVEN_SERVER_PASSWORD</key>
<secretName>maven-secret</secretName>
<secretKey>password</secretKey>
</org.csanchez.jenkins.plugins.kubernetes.model.SecretEnvVar>
</envVars>
<ports/>
<livenessProbe>
<execArgs></execArgs>
<timeoutSeconds>0</timeoutSeconds>
<initialDelaySeconds>0</initialDelaySeconds>
<failureThreshold>0</failureThreshold>
<periodSeconds>0</periodSeconds>
<successThreshold>0</successThreshold>
</livenessProbe>
</org.csanchez.jenkins.plugins.kubernetes.ContainerTemplate>
<org.csanchez.jenkins.plugins.kubernetes.ContainerTemplate>
<name>httpbin</name>
<image>citizenstig/httpbin</image>
<privileged>false</privileged>
<alwaysPullImage>false</alwaysPullImage>
<workingDir></workingDir>
<command>/run.sh</command>
<args></args>
<ttyEnabled>false</ttyEnabled>
<resourceRequestCpu></resourceRequestCpu>
<resourceRequestMemory>256Mi</resourceRequestMemory>
<resourceLimitCpu></resourceLimitCpu>
<resourceLimitMemory>256Mi</resourceLimitMemory>
<envVars/>
<ports/>
<livenessProbe>
<execArgs></execArgs>
<timeoutSeconds>0</timeoutSeconds>
<initialDelaySeconds>0</initialDelaySeconds>
<failureThreshold>0</failureThreshold>
<periodSeconds>0</periodSeconds>
<successThreshold>0</successThreshold>
</livenessProbe>
</org.csanchez.jenkins.plugins.kubernetes.ContainerTemplate>
</containers>
<envVars/>
<annotations/>
<imagePullSecrets/>
</org.csanchez.jenkins.plugins.kubernetes.PodTemplate>
</templates>
<serverUrl>https://172.30.0.1:443</serverUrl>
<serverCertificate>-----BEGIN CERTIFICATE-----
MIIC6jCC...
-----END CERTIFICATE-----</serverCertificate>
<skipTlsVerify>false</skipTlsVerify>
<namespace>first</namespace>
<jenkinsUrl>http://jenkins.cicd.svc:80</jenkinsUrl>
<jenkinsTunnel>jenkins-jnlp.cicd.svc:50000</jenkinsTunnel>
<credentialsId>1a12dfa4-7fc5-47a7-aa17-cc56572a41c7</credentialsId>
<containerCap>10</containerCap>
<retentionTimeout>5</retentionTimeout>
<connectTimeout>0</connectTimeout>
<readTimeout>0</readTimeout>
<maxRequestsPerHost>32</maxRequestsPerHost>
</org.csanchez.jenkins.plugins.kubernetes.KubernetesCloud>
</clouds>
</hudson>
```
尝试愉快的构建吧!
原文发表于 [ITNext](https://itnext.io/running-jenkins-builds-in-containers-458e90ff2a7b),已获得翻版授权。
---
via: <https://opensource.com/article/18/4/running-jenkins-builds-containers>
作者:[Balazs Szeti](https://opensource.com/users/bszeti) 选题:[lujun9972](https://github.com/lujun9972) 译者:[pinewall](https://github.com/pinewall) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Running applications in containers has become a well-accepted practice in the enterprise sector, as [Docker](https://opensource.com/resources/what-docker) with [Kubernetes](https://opensource.com/resources/what-is-kubernetes) (K8s) now provides a scalable, manageable application platform. The container-based approach also suits the [microservices architecture](https://martinfowler.com/articles/microservices.html) that's gained significant momentum in the past few years.
One of the most important advantages of a container application platform is the ability to dynamically bring up isolated containers with resource limits. Let's check out how this can change the way we run our continuous integration/continuous development (CI/CD) tasks.
Building and packaging an application requires an environment that can download the source code, access dependencies, and have the build tools installed. Running unit and component tests as part of the build may use local ports or require third-party applications (e.g., databases, message brokers, etc.) to be running. In the end, we usually have multiple, pre-configured build servers with each running a certain type of job. For tests, we maintain dedicated instances of third-party apps (or try to run them embedded) and avoid running jobs in parallel that could mess up each other's outcome. The pre-configuration for such a CI/CD environment can be a hassle, and the required number of servers for different jobs can significantly change over time as teams shift between versions and development platforms.
Once we have access to a container platform (onsite or in the cloud), it makes sense to move the resource-intensive CI/CD task executions into dynamically created containers. In this scenario, build environments can be independently started and configured for each job execution. Tests during the build have free reign to use available resources in this isolated box, while we can also bring up a third-party application in a side container that exists only for this job's lifecycle.
It sounds nice… Let's see how it works in real life.
*Note: This article is based on a real-world solution for a project running on a Red Hat OpenShift v3.7 cluster. OpenShift is the enterprise-ready version of Kubernetes, so these practices work on a K8s cluster as well. To try, download the Red Hat CDK and run *
*the*
`jenkins-ephemeral`
*or*
`jenkins-persistent`
[templates](https://github.com/openshift/origin/tree/master/examples/jenkins)that create preconfigured Jenkins masters on OpenShift.
## Solution overview
The solution to executing CI/CD tasks (builds, tests, etc.) in containers on OpenShift is based on [Jenkins distributed builds](https://wiki.jenkins.io/display/JENKINS/Distributed+builds), which means:
- We need a Jenkins master; it may run inside the cluster but also works with an external master
- Jenkins features/plugins are available as usual, so existing projects can be used
- The Jenkins GUI is available to configure, run, and browse job output
- if you prefer code,
[Jenkins Pipeline](https://jenkins.io/doc/book/pipeline/)is also available
From a technical point of view, the dynamic containers to run jobs are Jenkins agent nodes. When a build kicks off, first a new node starts and "reports for duty" to the Jenkins master via JNLP (port 5000). The build is queued until the agent node comes up and picks up the build. The build output is sent back to the master—just like with regular Jenkins agent servers—but the agent container is shut down once the build is done.
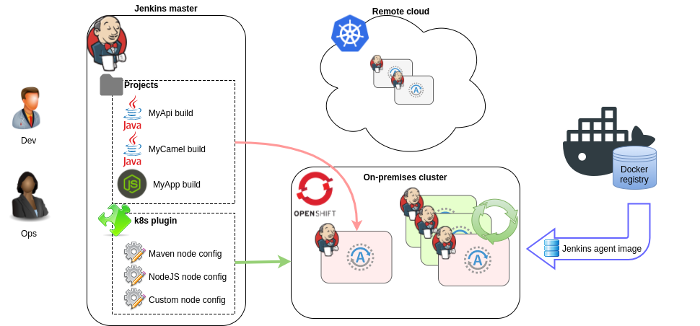
opensource.com
Different kinds of builds (e.g., Java, NodeJS, Python, etc.) need different agent nodes. This is nothing new—labels could previously be used to restrict which agent nodes should run a build. To define the config for these Jenkins agent containers started for each job, we will need to set the following:
- The Docker image to boot up
- Resource limits
- Environment variables
- Volumes mounted
The core component here is the [Jenkins Kubernetes plugin](https://github.com/jenkinsci/kubernetes-plugin). This plugin interacts with the K8s cluster (by using a ServiceAccount) and starts/stops the agent nodes. Multiple agent types can be defined as *Kubernetes pod templates* under the plugin's configuration (refer to them by label in projects).
These [agent images](https://access.redhat.com/containers/#/search/jenkins%2520slave) are provided out of the box (also on [CentOS7](https://hub.docker.com/search/?isAutomated=0&isOfficial=0&page=1&pullCount=0&q=openshift+jenkins+slave+&starCount=0)):
[jenkins-slave-base-rhel7](https://github.com/openshift/jenkins/tree/master/slave-base): Base image starting the agent that connects to Jenkins master; the Java heap is set according to container memory[jenkins-slave-maven-rhel7](https://github.com/openshift/jenkins/tree/master/slave-maven): Image for Maven and Gradle builds (extends base)[jenkins-slave-nodejs-rhel7](https://github.com/openshift/jenkins/tree/master/slave-nodejs): Image with NodeJS4 tools (extends base)
*Note: This solution is not related to OpenShift's Source-to-Image (S2I) build, which can also be used for certain CI/CD tasks.*
## Background learning material
There are several good blogs and documentation about Jenkins builds on OpenShift. The following are good to start with:
[OpenShift Jenkins](https://docs.openshift.com/container-platform/3.7/using_images/other_images/jenkins.html)image documentation and[source](https://github.com/openshift/jenkins)[CI/CD with OpenShift](https://blog.openshift.com/cicd-with-openshift/)webcast[External Jenkins Integration](http://v1.uncontained.io/playbooks/continuous_delivery/external-jenkins-integration.html)playbook
Take a look at them to understand the overall solution. In this article, we'll look at the different issues that come up while applying those practices.
## Build my application
For our [example](https://github.com/bszeti/camel-springboot/tree/master/camel-rest-complex), let's assume a Java project with the following build steps:
**Source:**Pull project source from a Git repository**Build with Maven:**Dependencies come from an internal repository (let's use Apache Nexus) mirroring external Maven repos**Deploy artifact:**The built JAR is uploaded to the repository
During the CI/CD process, we need to interact with Git and Nexus, so the Jenkins jobs have be able to access those systems. This requires configuration and stored credentials that can be managed at different places:
**In Jenkins:**We can add credentials to Jenkins that the Git plugin can use and add files to the project (using containers doesn't change anything).**In OpenShift:**Use ConfigMap and secret objects that are added to the Jenkins agent containers as files or environment variables.**In a fully customized Docker image:**These are pre-configured with everything to run a type of job; just extend one of the agent images.
Which approach you use is a question of taste, and your final solution may be a mix. Below we'll look at the second option, where the configuration is managed primarily in OpenShift. Customize the Maven agent container via the Kubernetes plugin configuration by setting environment variables and mounting files.
*Note: Adding environment variables through the UI doesn't work with Kubernetes plugin v1.0 due to a bug. Either update the plugin or (as a workaround) *
*edit*
`config.xml`
*directly*
*and restart Jenkins.*
## Pull source from Git
Pulling a public Git is trivial. For a private Git repo, authentication is required and the client also needs to trust the server for a secure connection. A Git pull can typically be done via two protocols:
- HTTPS: Authentication is with username/password. The server's SSL certificate must be trusted by the job, which is only tricky if it's signed by a custom CA.
```
````git clone https://git.mycompany.com:443/myapplication.git`
- SSH: Authentication is with a private key. The server is trusted when its public key's fingerprint is found in the
`known_hosts`
file.
```
````git clone ssh://[email protected]:22/myapplication.git`
Downloading the source through HTTP with username/password is OK when it's done manually; for automated builds, SSH is better.
### Git with SSH
For a SSH download, we need to ensure that the SSH connection works between the agent container and the Git's SSH port. First, we need a private-public key pair. To generate one, run:
```
````ssh keygen -t rsa -b 2048 -f my-git-ssh -N ''`
It generates a private key in `my-git-ssh`
(empty passphrase) and the matching public key in `my-git-ssh.pub`
. Add the public key to the user on the Git server (preferably a ServiceAccount); web UIs usually support upload. To make the SSH connection work, we need two files on the agent container:
- The private key at
`~/.ssh/id_rsa`
- The server's public key in
`~/.ssh/known_hosts`
. To get this, try`ssh git.mycompany.com`
and accept the fingerprint; this will create a new line in the`known_hosts`
file. Use that.
Store the private key as `id_rsa`
and server's public key as `known_hosts`
in an OpenShift secret (or config map).
```
``````
apiVersion: v1
kind: Secret
metadata:
name: mygit-ssh
stringData:
id_rsa: |-
-----BEGIN RSA PRIVATE KEY-----
...
-----END RSA PRIVATE KEY-----
known_hosts: |-
git.mycompany.com ecdsa-sha2-nistp256 AAA...
```
Then configure this as a volume in the Kubernetes plugin for the Maven pod at mount point `/home/jenkins/.ssh/`
. Each item in the secret will be a file matching the key name under the mount directory. We can use the UI (`Manage Jenkins / Configure / Cloud / Kubernetes`
), or edit Jenkins config `/var/lib/jenkins/config.xml`
:
```
``````
<org.csanchez.jenkins.plugins.kubernetes.PodTemplate>
<name>maven</name>
...
<volumes>
<org.csanchez.jenkins.plugins.kubernetes.volumes.SecretVolume>
<mountPath>/home/jenkins/.ssh</mountPath>
<secretName>mygit-ssh</secretName>
</org.csanchez.jenkins.plugins.kubernetes.volumes.SecretVolume>
</volumes>
```
Pulling a Git source through SSH should work in the jobs running on this agent now.
*Note: It's also possible to customize the SSH connection **in *`~/.ssh/config`
*,** for example, if we don't want to bother with known_hosts or the private key is mounted to a different location:*
```
``````
Host git.mycompany.com
StrictHostKeyChecking no
IdentityFile /home/jenkins/.config/git-secret/ssh-privatekey
```
### Git with HTTP
If you prefer an HTTP download, add the username/password to a [Git-credential-store](https://git-scm.com/docs/git-credential-store/1.8.2) file somewhere:
- E.g.
`/home/jenkins/.config/git-secret/credentials`
from an OpenShift secret, one site per line:
```
``````
https://username:[email protected]
https://user:[email protected]
```
- Enable it in
[git-config](https://git-scm.com/docs/git-config/1.8.2)expected at`/home/jenkins/.config/git/config`
:
```
``````
[credential]
helper = store --file=/home/jenkins/.config/git-secret/credentials
```
If the Git service has a certificate signed by a custom certificate authority (CA), the quickest hack is to set the `GIT_SSL_NO_VERIFY=true`
environment variable (EnvVar) for the agent. The proper solution needs two things:
- Add the custom CA's public certificate to the agent container from a config map to a path (e.g.
`/usr/ca/myTrustedCA.pem`
). - Tell Git the path to this cert in an EnvVar
`GIT_SSL_CAINFO=/usr/ca/myTrustedCA.pem`
or in the`git-config`
file mentioned above:
```
``````
[http "https://git.mycompany.com"]
sslCAInfo = /usr/ca/myTrustedCA.pem
```
*Note: In OpenShift v3.7 (and earlier), the config map and secret mount points must not overlap, so we can't map *
*to*
`/home/jenkins`
*and*
`/home/jenkins/dir`
*at*
*the same time. This is why we didn't use the well-known file locations above. A fix is expected in OpenShift v3.9.*
## Maven
To make a Maven build work, there are usually two things to do:
- A corporate Maven repository (e.g., Apache Nexus) should be set up to act as a proxy for external repos. Use this as a mirror.
- This internal repository may have an HTTPS endpoint with a certificate signed by a custom CA.
Having an internal Maven repository is practically essential if builds run in containers because they start with an empty local repository (cache), so Maven downloads all the JARs every time. Downloading from an internal proxy repo on the local network is obviously quicker than downloading from the Internet.
The [Maven Jenkins agent](https://github.com/openshift/jenkins/tree/master/slave-maven) image supports an environment variable that can be used to set the URL for this proxy. Set the following in the Kubernetes plugin container template:
```
````MAVEN_MIRROR_URL=https://nexus.mycompany.com/repository/maven-public`
The build artifacts (JARs) should also be archived in a repository, which may or may not be the same as the one acting as a mirror for dependencies above. Maven `deploy`
requires the repo URL in the `pom.xml`
under [Distribution management](https://maven.apache.org/pom.html#Distribution_Management) (this has nothing to do with the agent image):
```
``````
<project ...>
<distributionManagement>
<snapshotRepository>
<id>mynexus</id>
<url>https://nexus.mycompany.com/repository/maven-snapshots/</url>
</snapshotRepository>
<repository>
<id>mynexus</id>
<url>https://nexus.mycompany.com/repository/maven-releases/</url>
</repository>
</distributionManagement>
```
Uploading the artifact may require authentication. In this case, username/password must be set in the `settings.xml`
under the server ID matching the one in `pom.xml`
. We need to mount a whole `settings.xml`
with the URL, username, and password on the Maven Jenkins agent container from an OpenShift secret. We can also use environment variables as below:
- Add environment variables from a secret to the container:
```
``````
MAVEN_SERVER_USERNAME=admin
MAVEN_SERVER_PASSWORD=admin123
```
- Mount
`settings.xml`
from a config map to`/home/jenkins/.m2/settings.xml`
:
```
``````
<settings ...>
<mirrors>
<mirror>
<mirrorOf>external:*</mirrorOf>
<url>${env.MAVEN_MIRROR_URL}</url>
<id>mirror</id>
</mirror>
</mirrors>
<servers>
<server>
<id>mynexus</id>
<username>${env.MAVEN_SERVER_USERNAME}</username>
<password>${env.MAVEN_SERVER_PASSWORD}</password>
</server>
</servers>
</settings>
```
Disable interactive mode (use batch mode) to skip the download log by using `-B`
for Maven commands or by adding `<interactiveMode>false</interactiveMode>`
to `settings.xml`
.
If the Maven repository's HTTPS endpoint uses a certificate signed by a custom CA, we need to create a Java KeyStore using the [keytool](https://docs.oracle.com/javase/8/docs/technotes/tools/unix/keytool.html) containing the CA certificate as trusted. This KeyStore should be uploaded as a config map in OpenShift. Use the `oc`
command to create a config map from files:
```
``````
oc create configmap maven-settings --from-file=settings.xml=settings.xml --from-
file=myTruststore.jks=myTruststore.jks
```
Mount the config map somewhere on the Jenkins agent. In this example we use `/home/jenkins/.m2`
, but only because we have `settings.xml`
in the same config map. The KeyStore can go under any path.
Then make the Maven Java process use this file as a trust store by setting Java parameters in the `MAVEN_OPTS`
environment variable for the container:
```
``````
MAVEN_OPTS=
-Djavax.net.ssl.trustStore=/home/jenkins/.m2/myTruststore.jks
-Djavax.net.ssl.trustStorePassword=changeit
```
## Memory usage
This is probably the most important part—if we don't set max memory correctly, we'll run into intermittent build failures after everything seems to work.
Running Java in a container can cause high memory usage errors if we don't set the heap in the Java command line. The JVM [sees the total memory of the host machine](https://developers.redhat.com/blog/2017/03/14/java-inside-docker/) instead of the container's memory limit and sets the [default max heap](https://docs.oracle.com/javase/8/docs/technotes/guides/vm/gctuning/parallel.html#default_heap_size) accordingly. This is typically much more than the container's memory limit, and OpenShift simply kills the container when a Java process allocates more memory for the heap.
Although the `jenkins`
`-slave-base`
image has a built-in [script to set max heap ](https://github.com/openshift/jenkins/blob/master/slave-base/contrib/bin/run-jnlp-client)to half the container memory (this can be modified via EnvVar `CONTAINER_HEAP_PERCENT=0.50`
), it only applies to the Jenkins agent Java process. In a Maven build, we have important additional Java processes running:
- The
`mvn`
command itself is a Java tool. - The
[Maven Surefire-plugin](http://maven.apache.org/surefire/maven-surefire-plugin/examples/fork-options-and-parallel-execution.html)executes the unit tests in a forked JVM by default.
At the end of the day, we'll have three Java processes running at the same time in the container, and it's important to estimate their memory usage to avoid unexpectedly killed pods. Each process has a different way to set JVM options:
- Jenkins agent heap is calculated as mentioned above, but we definitely shouldn't let the agent have such a big heap. Memory is needed for the other two JVMs. Setting
`JAVA_OPTS`
works for the Jenkins agent. - The
`mvn`
tool is called by the Jenkins job. Set`MAVEN_OPTS`
to customize this Java process. - The JVM spawned by the Maven
`surefire`
plugin for the unit tests can be customized by the[argLine](http://maven.apache.org/surefire/maven-surefire-plugin/test-mojo.html#argLine)Maven property. It can be set in the`pom.xml`
, in a profile in`settings.xml`
or simply by adding`-DargLine=… to mvn`
command in`MAVEN_OPTS`
.
Here is an example of how to set these environment variables for the Maven agent container:
```
``````
JAVA_OPTS=-Xms64m -Xmx64m
MAVEN_OPTS=-Xms128m -Xmx128m -DargLine=${env.SUREFIRE_OPTS}
SUREFIRE_OPTS=-Xms256m -Xmx256m
```
These numbers worked in our tests with 1024Mi agent container memory limit building and running unit tests for a SpringBoot app. These are relatively low numbers and a bigger heap size; a higher limit may be needed for complex Maven projects and unit tests.
*Note: The actual memory usage of a Java8 process is something **like *`HeapSize + MetaSpace + OffHeapMemory`
*,** and this can be significantly more than the max heap size set. With the settings above, the three Java processes took more than 900Mi memory in our case. See RSS memory for processes within the container: ps -e -o pid,user,rss,comm,args*
The Jenkins agent images have both JDK 64 bit and 32 bit installed. For `mvn`
and `surefire`
, the 64-bit JVM is used by default. To lower memory usage, it makes sense to force 32-bit JVM as long as `-Xmx`
is less than 1.5 GB:
```
````JAVA_HOME=/usr/lib/jvm/Java-1.8.0-openjdk-1.8.0.161–0.b14.el7_4.i386`
*Note that it's also possible to set Java arguments in the JAVA_TOOL_OPTIONS EnvVar, which is picked up by any JVM started. The parameters in JAVA_OPTS and MAVEN_OPTS overwrite the ones in JAVA_TOOL_OPTIONS, so we can achieve the same heap configuration for our Java processes as above without using argLine:*
```
``````
JAVA_OPTS=-Xms64m -Xmx64m
MAVEN_OPTS=-Xms128m -Xmx128m
JAVA_TOOL_OPTIONS=-Xms256m -Xmx256m
```
*It's still a bit confusing, as all JVMs log Picked up JAVA_TOOL_OPTIONS:*
## Jenkins Pipeline
Following the settings above, we should have everything prepared to run a successful build. We can pull the code, download the dependencies, run the unit tests, and upload the artifact to our repository. Let's create a Jenkins Pipeline project that does this:
```
``````
pipeline {
/* Which container to bring up for the build. Pick one of the templates configured in Kubernetes plugin. */
agent {
label 'maven'
}
stages {
stage('Pull Source') {
steps {
git url: 'ssh://[email protected]:22/myapplication.git', branch: 'master'
}
}
stage('Unit Tests') {
steps {
sh 'mvn test'
}
}
stage('Deploy to Nexus') {
steps {
sh 'mvn deploy -DskipTests'
}
}
}
}
```
For a real project, of course, the CI/CD pipeline should do more than just the Maven build; it could deploy to a development environment, run integration tests, promote to higher environments, etc. The learning articles linked above show examples of how to do those things.
## Multiple containers
One pod can be running multiple containers with each having their own resource limits. They share the same network interface, so we can reach started services on `localhost`
, but we need to think about port collisions. Environment variables are set separately, but the volumes mounted are the same for all containers configured in one Kubernetes pod template.
Bringing up multiple containers is useful when an external service is required for unit tests and an embedded solution doesn't work (e.g., database, message broker, etc.). In this case, this second container also starts and stops with the Jenkins agent.
See the Jenkins `config.xml`
snippet where we start an `httpbin`
service on the side for our Maven build:
```
``````
<org.csanchez.jenkins.plugins.kubernetes.PodTemplate>
<name>maven</name>
<volumes>
...
</volumes>
<containers>
<org.csanchez.jenkins.plugins.kubernetes.ContainerTemplate>
<name>jnlp</name>
<image>registry.access.redhat.com/openshift3/jenkins-slave-maven-rhel7:v3.7</image>
<resourceLimitCpu>500m</resourceLimitCpu>
<resourceLimitMemory>1024Mi</resourceLimitMemory>
<envVars>
...
</envVars>
...
</org.csanchez.jenkins.plugins.kubernetes.ContainerTemplate>
<org.csanchez.jenkins.plugins.kubernetes.ContainerTemplate>
<name>httpbin</name>
<image>citizenstig/httpbin</image>
<resourceLimitCpu></resourceLimitCpu>
<resourceLimitMemory>256Mi</resourceLimitMemory>
<envVars/>
...
</org.csanchez.jenkins.plugins.kubernetes.ContainerTemplate>
</containers>
<envVars/>
</org.csanchez.jenkins.plugins.kubernetes.PodTemplate>
```
## Summary
For a summary, see the created OpenShift resources and the Kubernetes plugin configuration from Jenkins `config.xml`
with the configuration described above.
```
``````
apiVersion: v1
kind: List
metadata: {}
items:
- apiVersion: v1
kind: ConfigMap
metadata:
name: git-config
data:
config: |
[credential]
helper = store --file=/home/jenkins/.config/git-secret/credentials
[http "http://git.mycompany.com"]
sslCAInfo = /home/jenkins/.config/git/myTrustedCA.pem
myTrustedCA.pem: |-
-----BEGIN CERTIFICATE-----
MIIDVzCCAj+gAwIBAgIJAN0sC...
-----END CERTIFICATE-----
- apiVersion: v1
kind: Secret
metadata:
name: git-secret
stringData:
ssh-privatekey: |-
-----BEGIN RSA PRIVATE KEY-----
...
-----END RSA PRIVATE KEY-----
credentials: |-
https://username:[email protected]
https://user:[email protected]
- apiVersion: v1
kind: ConfigMap
metadata:
name: git-ssh
data:
config: |-
Host git.mycompany.com
StrictHostKeyChecking yes
IdentityFile /home/jenkins/.config/git-secret/ssh-privatekey
known_hosts: '[git.mycompany.com]:22 ecdsa-sha2-nistp256 AAAdn7...'
- apiVersion: v1
kind: Secret
metadata:
name: maven-secret
stringData:
username: admin
password: admin123
```
One additional config map was created from files:
```
``````
oc create configmap maven-settings --from-file=settings.xml=settings.xml
--from-file=myTruststore.jks=myTruststore.jks
```
Kubernetes plugin configuration:
```
``````
<?xml version='1.0' encoding='UTF-8'?>
<hudson>
...
<clouds>
<org.csanchez.jenkins.plugins.kubernetes.KubernetesCloud plugin="[email protected]">
<name>openshift</name>
<defaultsProviderTemplate></defaultsProviderTemplate>
<templates>
<org.csanchez.jenkins.plugins.kubernetes.PodTemplate>
<inheritFrom></inheritFrom>
<name>maven</name>
<namespace></namespace>
<privileged>false</privileged>
<alwaysPullImage>false</alwaysPullImage>
<instanceCap>2147483647</instanceCap>
<slaveConnectTimeout>100</slaveConnectTimeout>
<idleMinutes>0</idleMinutes>
<label>maven</label>
<serviceAccount>jenkins37</serviceAccount>
<nodeSelector></nodeSelector>
<nodeUsageMode>NORMAL</nodeUsageMode>
<customWorkspaceVolumeEnabled>false</customWorkspaceVolumeEnabled>
<workspaceVolume class="org.csanchez.jenkins.plugins.kubernetes.volumes.workspace.EmptyDirWorkspaceVolume">
<memory>false</memory>
</workspaceVolume>
<volumes>
<org.csanchez.jenkins.plugins.kubernetes.volumes.SecretVolume>
<mountPath>/home/jenkins/.config/git-secret</mountPath>
<secretName>git-secret</secretName>
</org.csanchez.jenkins.plugins.kubernetes.volumes.SecretVolume>
<org.csanchez.jenkins.plugins.kubernetes.volumes.ConfigMapVolume>
<mountPath>/home/jenkins/.ssh</mountPath>
<configMapName>git-ssh</configMapName>
</org.csanchez.jenkins.plugins.kubernetes.volumes.ConfigMapVolume>
<org.csanchez.jenkins.plugins.kubernetes.volumes.ConfigMapVolume>
<mountPath>/home/jenkins/.config/git</mountPath>
<configMapName>git-config</configMapName>
</org.csanchez.jenkins.plugins.kubernetes.volumes.ConfigMapVolume>
<org.csanchez.jenkins.plugins.kubernetes.volumes.ConfigMapVolume>
<mountPath>/home/jenkins/.m2</mountPath>
<configMapName>maven-settings</configMapName>
</org.csanchez.jenkins.plugins.kubernetes.volumes.ConfigMapVolume>
</volumes>
<containers>
<org.csanchez.jenkins.plugins.kubernetes.ContainerTemplate>
<name>jnlp</name>
<image>registry.access.redhat.com/openshift3/jenkins-slave-maven-rhel7:v3.7</image>
<privileged>false</privileged>
<alwaysPullImage>false</alwaysPullImage>
<workingDir>/tmp</workingDir>
<command></command>
<args>${computer.jnlpmac} ${computer.name}</args>
<ttyEnabled>false</ttyEnabled>
<resourceRequestCpu>500m</resourceRequestCpu>
<resourceRequestMemory>1024Mi</resourceRequestMemory>
<resourceLimitCpu>500m</resourceLimitCpu>
<resourceLimitMemory>1024Mi</resourceLimitMemory>
<envVars>
<org.csanchez.jenkins.plugins.kubernetes.ContainerEnvVar>
<key>JAVA_HOME</key>
<value>/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.161-0.b14.el7_4.i386</value>
</org.csanchez.jenkins.plugins.kubernetes.ContainerEnvVar>
<org.csanchez.jenkins.plugins.kubernetes.ContainerEnvVar>
<key>JAVA_OPTS</key>
<value>-Xms64m -Xmx64m</value>
</org.csanchez.jenkins.plugins.kubernetes.ContainerEnvVar>
<org.csanchez.jenkins.plugins.kubernetes.ContainerEnvVar>
<key>MAVEN_OPTS</key>
<value>-Xms128m -Xmx128m -DargLine=${env.SUREFIRE_OPTS} -Djavax.net.ssl.trustStore=/home/jenkins/.m2/myTruststore.jks -Djavax.net.ssl.trustStorePassword=changeit</value>
</org.csanchez.jenkins.plugins.kubernetes.ContainerEnvVar>
<org.csanchez.jenkins.plugins.kubernetes.ContainerEnvVar>
<key>SUREFIRE_OPTS</key>
<value>-Xms256m -Xmx256m</value>
</org.csanchez.jenkins.plugins.kubernetes.ContainerEnvVar>
<org.csanchez.jenkins.plugins.kubernetes.ContainerEnvVar>
<key>MAVEN_MIRROR_URL</key>
<value>https://nexus.mycompany.com/repository/maven-public</value>
</org.csanchez.jenkins.plugins.kubernetes.ContainerEnvVar>
<org.csanchez.jenkins.plugins.kubernetes.model.SecretEnvVar>
<key>MAVEN_SERVER_USERNAME</key>
<secretName>maven-secret</secretName>
<secretKey>username</secretKey>
</org.csanchez.jenkins.plugins.kubernetes.model.SecretEnvVar>
<org.csanchez.jenkins.plugins.kubernetes.model.SecretEnvVar>
<key>MAVEN_SERVER_PASSWORD</key>
<secretName>maven-secret</secretName>
<secretKey>password</secretKey>
</org.csanchez.jenkins.plugins.kubernetes.model.SecretEnvVar>
</envVars>
<ports/>
<livenessProbe>
<execArgs></execArgs>
<timeoutSeconds>0</timeoutSeconds>
<initialDelaySeconds>0</initialDelaySeconds>
<failureThreshold>0</failureThreshold>
<periodSeconds>0</periodSeconds>
<successThreshold>0</successThreshold>
</livenessProbe>
</org.csanchez.jenkins.plugins.kubernetes.ContainerTemplate>
<org.csanchez.jenkins.plugins.kubernetes.ContainerTemplate>
<name>httpbin</name>
<image>citizenstig/httpbin</image>
<privileged>false</privileged>
<alwaysPullImage>false</alwaysPullImage>
<workingDir></workingDir>
<command>/run.sh</command>
<args></args>
<ttyEnabled>false</ttyEnabled>
<resourceRequestCpu></resourceRequestCpu>
<resourceRequestMemory>256Mi</resourceRequestMemory>
<resourceLimitCpu></resourceLimitCpu>
<resourceLimitMemory>256Mi</resourceLimitMemory>
<envVars/>
<ports/>
<livenessProbe>
<execArgs></execArgs>
<timeoutSeconds>0</timeoutSeconds>
<initialDelaySeconds>0</initialDelaySeconds>
<failureThreshold>0</failureThreshold>
<periodSeconds>0</periodSeconds>
<successThreshold>0</successThreshold>
</livenessProbe>
</org.csanchez.jenkins.plugins.kubernetes.ContainerTemplate>
</containers>
<envVars/>
<annotations/>
<imagePullSecrets/>
</org.csanchez.jenkins.plugins.kubernetes.PodTemplate>
</templates>
<serverUrl>https://172.30.0.1:443</serverUrl>
<serverCertificate>-----BEGIN CERTIFICATE-----
MIIC6jCC...
-----END CERTIFICATE-----</serverCertificate>
<skipTlsVerify>false</skipTlsVerify>
<namespace>first</namespace>
<jenkinsUrl>http://jenkins.cicd.svc:80</jenkinsUrl>
<jenkinsTunnel>jenkins-jnlp.cicd.svc:50000</jenkinsTunnel>
<credentialsId>1a12dfa4-7fc5-47a7-aa17-cc56572a41c7</credentialsId>
<containerCap>10</containerCap>
<retentionTimeout>5</retentionTimeout>
<connectTimeout>0</connectTimeout>
<readTimeout>0</readTimeout>
<maxRequestsPerHost>32</maxRequestsPerHost>
</org.csanchez.jenkins.plugins.kubernetes.KubernetesCloud>
</clouds>
</hudson>
```
Happy builds!
*This was originally published on ITNext and is reprinted with permission.*
## Comments are closed. |
9,742 | 程序员最佳网站 | http://www.theitstuff.com/best-websites-programmers | 2018-06-13T11:34:00 | [
"网站"
] | https://linux.cn/article-9742-1.html | 
作为程序员,你经常会发现自己是某些网站的永久访问者。它们可以是教程、参考或论坛。因此,在这篇文章中,让我们看看给程序员的最佳网站。
### W3Schools
[W3Schools](https://www.w3schools.com/) 是为初学者和有经验的 Web 开发人员学习各种编程语言的最佳网站之一。你可以学习 HTML5、CSS3、PHP、 JavaScript、ASP 等。
更重要的是,该网站为网页开发人员提供了大量资源和参考资料。
[](http://www.theitstuff.com/wp-content/uploads/2017/12/w3schools-logo.png)
你可以快速浏览各种关键字及其功能。该网站非常具有互动性,它允许你在网站本身的嵌入式编辑器中尝试和练习代码。该网站是你作为网页开发人员少数需要经常访问的网站之一。
(LCTT 译注:有一个国内网站 [www.w3school.com.cn](http://www.w3school.com.cn) 提供类似的中文内容,但二者似无关系。)
### GeeksforGeeks
[GeeksforGeeks](http://www.geeksforgeeks.org/) 是一个主要专注于计算机科学的网站。它有大量的算法,解决方案和编程问题。
[](http://www.theitstuff.com/wp-content/uploads/2017/12/geeksforgeeks-programming-support.png)
该网站也有很多面试中经常问到的问题。由于该网站更多地涉及计算机科学,因此你可以找到很多编程问题在大多数著名语言下的解决方案。
### TutorialsPoint
一个学习任何东西的地方。[TutorialsPoint](https://www.tutorialspoint.com/) 有一些又好又简单的教程,它可以教你任何编程语言。我真的很喜欢这个网站,它不仅限于通用编程语言。

你可以在这里上找到几乎所有语言框架的教程。
### StackOverflow
你可能已经知道 [StackOverflow](https://stackoverflow.com/) 是遇到程序员的地方。你在代码中遇到问题,只要在 StackOverflow 问一个问题,来自互联网的程序员将会在那里帮助你。
[](http://www.theitstuff.com/wp-content/uploads/2017/12/stackoverflow-linux-programming-website.png)
关于 StackOverflow 最好的是几乎所有的问题都得到了答案。你可能会从其他程序员的几个不同观点获得答案。
### HackerRank
[HackerRank](https://www.hackerrank.com/) 是一个你可以参与各种编码竞赛并检测你的竞争能力的网站。
[](http://www.theitstuff.com/wp-content/uploads/2017/12/hackerrank-programming-forums.png)
这里有以各种编程语言举办的各种比赛,赢得比赛将增加你的分数。这个分数可以让你处于最高级别,并增加你获得一些软件公司注意的机会。
### Codebeautify
由于我们是程序员,所以美不是我们所关心的。很多时候,我们的代码很难被其他人阅读。[Codebeautify](https://codebeautify.org/) 可以使你的代码易于阅读。

该网站有大多数可以美化的语言。另外,如果你想让你的代码不能被某人读取,你也可以这样做。
这些是我选择的一些最好的程序员网站。如果你有经常访问的我没有提及的网站,请在下面的评论区让我知道。
---
via: <http://www.theitstuff.com/best-websites-programmers>
作者:[Rishabh Kandari](http://www.theitstuff.com/author/reevkandari) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 520 | null |
|
9,743 | Stratis 从 ZFS、Btrfs 和 LVM 学到哪些 | https://opensource.com/article/18/4/stratis-lessons-learned | 2018-06-13T22:59:00 | [
"存储",
"Stratis"
] | /article-9743-1.html |
>
> 深入了解这个强大而不繁琐的 Linux 存储管理系统。
>
>
>

在本系列[第一部分](/article-9736-1.html)中提到,Stratis 是一个<ruby> 卷管理文件系统 <rt> volume-managing filesystem </rt></ruby>(VMF),功能特性类似于 [ZFS](https://en.wikipedia.org/wiki/ZFS) 和 [Btrfs](https://en.wikipedia.org/wiki/Btrfs)。在设计 Stratis 过程中,我们研究了已有解决方案开发者做出的取舍。
### 为何不使用已有解决方案
理由千差万别。先说说 [ZFS](https://en.wikipedia.org/wiki/ZFS),它最初由 Sun Microsystems 为 Solaris (目前为 Oracle 所有)开发,后移植到 Linux。但 [CDDL](https://en.wikipedia.org/wiki/Common_Development_and_Distribution_License) 协议授权的代码无法合并到 [GPL](https://en.wikipedia.org/wiki/GNU_General_Public_License) 协议授权的 Linux 源码树中。CDDL 与 GPLv2 是否真的不兼容有待讨论,但这种不确定性足以打消企业级 Linux 供应商采用并支持 ZFS 的积极性。
[Btrfs](https://en.wikipedia.org/wiki/Btrfs) 发展也很好,没有授权问题。它已经多年被很多用户列为“最佳文件系统”,但在稳定性和功能特性方面仍有待提高。
我们希望打破现状,解决已有方案的种种问题,这种渴望促成了 Stratis。
### Stratis 如何与众不同
ZFS 和 Btrfs 让我们知道一件事情,即编写一个内核支持的 VMF 文件系统需要花费极大的时间和精力,才能消除漏洞、增强稳定性。涉及核心数据时,提供正确性保证是必要的。如果 Stratis 也采用这种方案并从零开始的话,开发工作也需要十数年,这是无法接受的。
相反地,Stratis 采用 Linux 内核的其它一些已有特性:[device mapper](https://en.wikipedia.org/wiki/Device_mapper) 子系统以及久经考验的高性能文件系统 [XFS](https://en.wikipedia.org/wiki/XFS),其中前者被 LVM 用于提供 RAID、精简配置和其它块设备特性而广为人知。Stratis 将已有技术作为(技术架构中的)层来创建存储池,目标是通过集成为用户提供一个看似无缝的整体。
### Stratis 从 ZFS 学到哪些
对很多用户而言,ZFS 影响了他们对下一代文件系统的预期。通过查看人们在互联网上关于 ZFS 的讨论,我们设定了 Stratis 的最初开发目标。ZFS 的设计思路也潜在地为我们指明应该避免哪些东西。例如,当挂载一个在其它主机上创建的存储池时,ZFS 需要一个“<ruby> 导入 <rt> import </rt></ruby>”步骤。这样做出于某些原因,但每一种原因都似乎是 Stratis 需要解决的问题,无论是否采用同样的实现方式。
对于增加新硬盘或将已有硬盘替换为更大容量的硬盘,ZFS 有一些限制,尤其是存储池做了冗余配置的时候,这一点让我们不太满意。当然,这么设计也是有其原因的,但我们更愿意将其视为可以改进的空间。
最后,一旦掌握了 ZFS 的命令行工具,用户体验很好。我们希望让 Stratis 的命令行工具能够保持这种体验;同时,我们也很喜欢 ZFS 命令行工具的发展趋势,包括使用<ruby> 位置参数 <rt> positional parameters </rt></ruby>和控制每个命令需要的键盘输入量。
(LCTT 译注:位置参数来自脚本,$n 代表第 n 个参数)
### Stratis 从 Btrfs 学到哪些
Btrfs 让我们满意的一点是,有单一的包含位置子命令的命令行工具。Btrfs 也将冗余(选择对应的 Btrfs profiles)视为存储池的特性之一。而且和 ZFS 相比实现方式更好理解,也允许增加甚至移除硬盘。
(LCTT 译注:Btrfs profiles 包括 single/DUP 和 各种 RAID 等类型)
最后,通过了解 ZFS 和 Btrfs 共有的特性,例如快照的实现、对发送/接收的支持,让我们更好的抉择 Stratis 应该包括的特性。
### Stratis 从 LVM 学到哪些
在 Stratis 设计阶段早期,我们仔细研究了 LVM。LVM 目前是 Linux device mapper (DM) 最主要的使用者;事实上,DM 就是由 LVM 的核心开发团队维护的。我们研究了将 LVM 真的作为 Stratis 其中一层的可能性,也使用 DM 做了实验,其中 Stratis 可以作为<ruby> 对等角色 <rt> peer </rt></ruby>直接与 LVM 打交道。我们参考了 LVM 的<ruby> 磁盘元数据格式 <rt> on-disk metadata format </rt></ruby>(也结合 ZFS 和 XFS 的相应格式),获取灵感并定义了 Stratis 的磁盘元数据格式。
在提到的项目中,LVM 与 Stratis 内在地有最多的共性,毕竟它们都使用 DM。不过从使用的角度来看,LVM 内在工作更加透明,为专业用户提供相当多的控制和选项,使其可以精确配置<ruby> 卷组 <rt> volume group </rt></ruby>(存储池)的<ruby> 布局 <rt> layout </rt></ruby>;但 Stratis 不采用这种方式。
### 多种多样的解决方案
基于自由和开源软件工作的明显好处在于,没有什么组件是不可替代的。包括内核在内的每个组成部分都是开源的,可以查看修改源代码,如果当前的软件不能满足用户需求可以用其它软件替换。新项目产生不一定意味着旧项目的终结,只要都有足够的(社区)支持,两者可以并行存在。
对于寻找一个不存在争议、简单易用、强大的本地存储管理解决方案的人而言,Stratis 是更好满足其需求的一种尝试。这意味着一种设计思路所做的抉择不一定对所有用户适用。考虑到用户的其它需求,另一种设计思路可能需要艰难的做出抉择。所有用户可以选择最适合其的工作的工具并从这种自由选择中受益。
---
via: <https://opensource.com/article/18/4/stratis-lessons-learned>
作者:[Andy Grover](https://opensource.com/users/agrover) 选题:[lujun9972](https://github.com/lujun9972) 译者:[pinewall](https://github.com/pinewall) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
9,744 | 使用机器学习来进行卡通上色 | https://opensource.com/article/18/4/dragonpaint-bootstrapping | 2018-06-14T11:17:29 | [
"机器学习"
] | https://linux.cn/article-9744-1.html |
>
> 我们可以自动应用简单的配色方案,而无需手绘几百个训练数据示例吗?
>
>
>

监督式机器学习的一个大问题是需要大量的归类数据,特别是如果你没有这些数据时——即使这是一个充斥着大数据的世界,我们大多数人依然没有大数据——这就真的是一个大问题了。
尽管少数公司可以访问某些类型的大量归类数据,但对于大多数的组织和应用来说,创造足够的正确类型的归类数据,花费还是太高了,以至于近乎不可能。在某些时候,这个领域还是一个没有太多数据的领域(比如说,当我们诊断一种稀有的疾病,或者判断一个数据是否匹配我们已知的那一点点样本时)。其他时候,通过 Amazon Turkers 或者暑假工这些人工方式来给我们需要的数据做分类,这样做的花费太高了。对于一部电影长度的视频,因为要对每一帧做分类,所以成本上涨得很快,即使是一帧一美分。
### 大数据需求的一个大问题
我们团队目前打算解决一个问题是:我们能不能在没有手绘的数百或者数千训练数据的情况下,训练出一个模型,来自动化地为黑白像素图片提供简单的配色方案。
在这个实验中(我们称这个实验为龙画),面对深度学习庞大的对分类数据的需求,我们使用以下这种方法:
* 对小数据集的快速增长使用基于规则的的策略。
* 借用 tensorflow 图像转换的模型,Pix2Pix 框架,从而在训练数据非常有限的情况下实现自动化卡通渲染。
我曾见过 Pix2Pix 框架,在一篇论文(由 Isola 等人撰写的“Image-to-Image Translation with Conditional Adversarial Networks”)中描述的机器学习图像转换模型,假设 A 是风景图 B 的灰度版,在对 AB 对进行训练后,再给风景图片进行上色。我的问题和这是类似的,唯一的问题就是训练数据。
我需要的训练数据非常有限,因为我不想为了训练这个模型,一辈子画画和上色来为它提供彩色图片,深度学习模型需要成千上万(或者成百上千)的训练数据。
基于 Pix2Pix 的案例,我们需要至少 400 到 1000 个黑白、彩色成对的数据。你问我愿意画多少?可能就只有 30 个。我画了一小部分卡通花和卡通龙,然后去确认我是否可以把他们放进数据集中。
### 80% 的解决方案:按组件上色

*按组件规则对黑白像素进行上色*
当面对训练数据的短缺时,要问的第一个问题就是,是否有一个好的非机器学习的方法来解决我们的问题,如果没有一个完整的解决方案,那是否有一个部分的解决方案,这个部分解决方案对我们是否有好处?我们真的需要机器学习的方法来为花和龙上色吗?或者我们能为上色指定几何规则吗?

*如何按组件进行上色*
现在有一种非机器学习的方法来解决我的问题。我可以告诉一个孩子,我想怎么给我的画上色:把花的中心画成橙色,把花瓣画成黄色,把龙的身体画成橙色,把龙的尖刺画成黄色。
开始的时候,这似乎没有什么帮助,因为我们的电脑不知道什么是中心,什么是花瓣,什么是身体,什么是尖刺。但事实证明,我们可以依据连接组件来定义花和龙的部分,然后得到一个几何解决方案为我们 80% 的画来上色,虽然 80% 还不够,我们可以使用战略性违规转换、参数和机器学习来引导基于部分规则的解决方案达到 100%。
连接的组件使用的是 Windows 画图(或者类似的应用)上的色,例如,当我们对一个二进制黑白图像上色时,如果你单击一个白色像素,这个白色像素会在不穿过黑色的情况下变成一种新的颜色。在一个规则相同的卡通龙或者花的素描中,最大的白色组件就是背景,下一个最大的组件就是身体(加上手臂和腿)或者花的中心,其余的部分就是尖刺和花瓣,除了龙眼睛,它可以通过和背景的距离来做区分。
### 使用战略规则和 Pix2Pix 来达到 100%
我的一部分素描不符合规则,一条粗心画下的线可能会留下一个缺口,一条后肢可能会上成尖刺的颜色,一个小的,居中的雏菊会交换花瓣和中心的上色规则。

对于那 20% 我们不能用几何规则进行上色的部分,我们需要其他的方法来对它进行处理,我们转向 Pix2Pix 模型,它至少需要 400 到 1000 个素描/彩色对作为数据集(在 Pix2Pix 论文里的最小的数据集),里面包括违反规则的例子。
所以,对于每个违反规则的例子,我们最后都会通过手工的方式进行上色(比如后肢)或者选取一些符合规则的素描 / 彩色对来打破规则。我们在 A 中删除一些线,或者我们多转换一些,居中的花朵 A 和 B 使用相同的函数 (f) 来创造新的一对,f(A) 和 f(B),一个小而居中的花朵,这可以加入到数据集。
### 使用高斯滤波器和同胚增大到最大
在计算机视觉中使用几何转换增强数据集是很常见的做法。例如循环,平移,和缩放。
但是如果我们需要把向日葵转换为雏菊或者把龙的鼻子变成球型和尖刺型呢?
或者如果说我们只需要大量增加数据量而不管过拟合?那我们需要比我们一开始使用的数据集大 10 到 30 倍的数据集。

*向日葵通过 r -> r 立方体方式变成一个雏菊*

*高斯滤波器增强*
单位盘的某些同胚可以形成很好的雏菊(比如 r -> r 立方体,高斯滤波器可以改变龙的鼻子。这两者对于数据集的快速增长是非常有用的,并且产生的大量数据都是我们需要的。但是他们也会开始用一种不能仿射转换的方式来改变画的风格。
之前我们考虑的是如何自动化地设计一个简单的上色方案,上述内容激发了一个在这之外的问题:什么东西定义了艺术家的风格,不管是外部的观察者还是艺术家自己?他们什么时候确定了自己的的绘画风格呢?他们不可能没有自己画画的算法?工具、助手和合作者之间的区别是什么?
### 我们可以走多远?
我们画画的投入可以有多低?保持在一个主题之内并且风格可以辨认出为某个艺术家的作品,在这个范围内我们可以创造出多少的变化和复杂性?我们需要做什么才能完成一个有无限的长颈鹿、龙、花的游行画卷?如果我们有了这样一幅,我们可以用它来做什么?
这些都是我们会继续在后面的工作中进行探索的问题。
但是现在,规则、增强和 Pix2Pix 模型起作用了。我们可以很好地为花上色了,给龙上色也不错。

*结果:通过花这方面的模型训练来给花上色。*

*结果:龙的模型训练的训练结果。*
想了解更多,参与 Gretchen Greene's talk, DragonPaint – bootstrapping small data to color cartoons, 在 PyCon Cleveland 2018.
---
via: <https://opensource.com/article/18/4/dragonpaint-bootstrapping>
作者:[K. Gretchen Greene](https://opensource.com/users/kggreene) 选题:[lujun9972](https://github.com/lujun9972) 译者:[hopefully2333](https://github.com/hopefully2333) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | A big problem with supervised machine learning is the need for huge amounts of labeled data. It's a big problem especially if you don't have the labeled data—and even in a world awash with big data, most of us don't.
Although a few companies have access to enormous quantities of certain kinds of labeled data, for most organizations and many applications, creating sufficient quantities of the right kind of labeled data is cost prohibitive or impossible. Sometimes the domain is one in which there just isn't much data (for example, when diagnosing a rare disease or determining whether a signature matches a few known exemplars). Other times the volume of data needed multiplied by the cost of human labeling by [Amazon Turkers](https://www.mturk.com/) or summer interns is just too high. Paying to label every frame of a movie-length video adds up fast, even at a penny a frame.
## The big problem of big data requirements
The specific problem our group set out to solve was: Can we train a model to automate applying a simple color scheme to a black and white character without hand-drawing hundreds or thousands of examples as training data?
In this experiment (which we called DragonPaint), we confronted the problem of deep learning's enormous labeled-data requirements using:
- A rule-based strategy for extreme augmentation of small datasets
- A borrowed TensorFlow image-to-image translation model, Pix2Pix, to automate cartoon coloring with very limited training data
I had seen [Pix2Pix](https://phillipi.github.io/pix2pix/), a machine learning image-to-image translation model described in a paper ("Image-to-Image Translation with Conditional Adversarial Networks," by Isola, et al.), that colorizes landscapes after training on AB pairs where A is the grayscale version of landscape B. My problem seemed similar. The only problem was training data.
I needed the training data to be very limited because I didn't want to draw and color a lifetime supply of cartoon characters just to train the model. The tens of thousands (or hundreds of thousands) of examples often required by deep-learning models were out of the question.
Based on Pix2Pix's examples, we would need at least 400 to 1,000 sketch/colored pairs. How many was I willing to draw? Maybe 30. I drew a few dozen cartoon flowers and dragons and asked whether I could somehow turn this into a training set.
## The 80% solution: color by component

opensource.com
When faced with a shortage of training data, the first question to ask is whether there is a good non-machine-learning based approach to our problem. If there's not a complete solution, is there a partial solution, and would a partial solution do us any good? Do we even need machine learning to color flowers and dragons? Or can we specify geometric rules for coloring?

opensource.com
There *is* a non-machine-learning approach to solving my problem. I could tell a kid how I want my drawings colored: Make the flower's center orange and the petals yellow. Make the dragon's body orange and the spikes yellow.
At first, that doesn't seem helpful because our computer doesn't know what a center or a petal or a body or a spike is. But it turns out we can define the flower or dragon parts in terms of connected components and get a geometric solution for coloring about 80% of our drawings. Although 80% isn't enough, we can bootstrap from that partial-rule-based solution to 100% using strategic rule-breaking transformations, augmentations, and machine learning.
Connected components are what is colored when you use Windows Paint (or a similar application). For example, when coloring a binary black and white image, if you click on a white pixel, the white pixels that are be reached without crossing over black are colored the new color. In a "rule-conforming" cartoon dragon or flower sketch, the biggest white component is the background. The next biggest is the body (plus the arms and legs) or the flower's center. The rest are spikes or petals, except for the dragon's eye, which can be distinguished by its distance from the background.
## Using strategic rule breaking and Pix2Pix to get to 100%
Some of my sketches aren't rule-conforming. A sloppily drawn line might leave a gap. A back limb will get colored like a spike. A small, centered daisy will switch a petal and the center's coloring rules.

opensource.com
For the 20% we couldn't color with the geometric rules, we needed something else. We turned to Pix2Pix, which requires a minimum training set of 400 to 1,000 sketch/colored pairs (i.e., the smallest training sets in the [Pix2Pix paper](https://arxiv.org/abs/1611.07004)) including rule-breaking pairs.
So, for each rule-breaking example, we finished the coloring by hand (e.g., back limbs) or took a few rule-abiding sketch/colored pairs and broke the rule. We erased a bit of a line in A or we transformed a fat, centered flower pair A and B with the same function (*f*) to create a new pair *f*(A) and *f*(B)—a small, centered flower. That got us to a training set.
## Extreme augmentations with gaussian filters and homeomorphisms
It's common in computer vision to augment an image training set with geometric transformations, such as rotation, translation, and zoom.
But what if we need to turn sunflowers into daisies or make a dragon's nose bulbous or pointy?
Or what if we just need an enormous increase in data volume without overfitting? Here we need a dataset 10 to 30 times larger than what we started with.
opensource.com
opensource.com
Certain homeomorphisms of the unit disk make good daisies (e.g., *r -> r cubed*) and Gaussian filters change a dragon's nose. Both were extremely useful for creating augmentations for our dataset and produced the augmentation volume we needed, but they also started to change the style of the drawings in ways that an [affine transformation](https://en.wikipedia.org/wiki/Affine_transformation) could not.
This inspired questions beyond how to automate a simple coloring scheme: What defines an artist's style, either to an outside viewer or the artist? When does an artist adopt as their own a drawing they could not have made without the algorithm? When does the subject matter become unrecognizable? What's the difference between a tool, an assistant, and a collaborator?
## How far can we go?
How little can we draw for input and how much variation and complexity can we create while staying within a subject and style recognizable as the artist's? What would we need to do to make an infinite parade of giraffes or dragons or flowers? And if we had one, what could we do with it?
Those are questions we'll continue to explore in future work.
But for now, the rules, augmentations, and Pix2Pix model worked. We can color flowers really well, and the dragons aren't bad.

opensource.com

opensource.com
To learn more, attend Gretchen Greene's talk, [DragonPaint – bootstrapping small data to color cartoons](https://us.pycon.org/2018/schedule/presentation/113/), at [PyCon Cleveland 2018](https://us.pycon.org/2018/).
## 1 Comment |
9,745 | 大学生对开源的反思 | https://opensource.com/article/18/3/college-getting-started | 2018-06-14T12:02:36 | [
"开源"
] | https://linux.cn/article-9745-1.html |
>
> 开源工具的威力和开源运动的重要性。
>
>
>

我刚刚完成大学二年级的第一学期,我正在思考我在课堂上学到的东西。有一节课特别引起了我的注意:“[开源世界的基础](https://ssri.duke.edu/news/new-course-explores-open-source-principles)”,它由杜克大学的 Bryan Behrenshausen 博士讲授。我在最后一刻参加了课程,因为它看起来很有趣,诚实地来说,因为它符合我的日程安排。
第一天,Behrenshausen 博士问我们学生是否知道或使用过任何开源程序。直到那一天,我几乎没有听过[术语“开源”](https://opensource.com/node/42001),当然也不知道任何属于该类别的产品。然而,随着学期的继续,对我而言,如果没有开源,我对事业抱负的激情就不会存在。
### Audacity 和 GIMP
我对技术的兴趣始于 12 岁。我负责为我的舞蹈团队裁剪音乐,我在网上搜索了几个小时,直到找到开源音频编辑器 Audacity。Audacity 为我敞开了大门。我不再局限于重复的 8 音节。我开始接受其他想要独特演绎他们最喜爱歌曲的人的请求。
几周后,我偶然在互联网上看到了一只有着 Pop-Tart 躯干并且后面拖着彩虹在太空飞行的猫。我搜索了“如何制作动态图像”,并发现了一个开源的图形编辑器 [GIMP](https://www.gimp.org/),并用它为我兄弟做了一张“辛普森一家”的 GIF 作为生日礼物。
我萌芽的兴趣成长为完全的痴迷:在我笨重的、落后的笔记本上制作艺术品。由于我没有很好的炭笔,油彩或水彩,所以我用[图形设计](https://opensource.com/node/30251)作为创意的表达。我花了几个小时在计算机实验室上 [W3Schools](https://www.w3schools.com/) 学习 HTML 和 CSS 的基础知识,以便我可以用我幼稚的 GIF 填充在线作品集。几个月后,我在 [WordPress](https://opensource.com/node/31441) 发布了我的第一个网站。
### 为什么开源
开源让我们不仅可以实现我们的目标,还可以发现驱动这些目标的兴趣。
快进近十年。虽然有些仍然保持一致,但许多事情已经发生了变化:我仍然在制作图形(主要是传单),为舞蹈团编辑音乐,以及设计网站(我希望更时尚、更有效)。我使用的产品经历了无数版本升级。但最戏剧性的变化是我对开源资源的态度。
考虑到开源产品在我的生活中的意义,使我珍视开放运动和它的使命。开源项目提醒我,科技领域有些倡议可以促进社会的良好和自我学习,而不会被那些具有社会经济优势的人排斥。我中学时的自己,像无数其他人一样,无法购买 Adobe Creative Suite、GarageBand 或 Squarespace。开源平台使我们不仅能够实现我们的目标,而且还能通过扩大我们接触来发现推动这些目标的兴趣。
我的建议?一时心血来潮报名上课。它可能会改变你对世界的看法。
---
via: <https://opensource.com/article/18/3/college-getting-started>
作者:[Christine Hwang](https://opensource.com/users/christinehwang) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I just completed the first semester of my second year in college, and I'm reflecting on what I learned in my classes. One class, in particular, stood out to me: "[Foundations of an Open Source World](https://ssri.duke.edu/news/new-course-explores-open-source-principles)," taught by Dr. Bryan Behrenshausen at Duke University. I enrolled in the class at the last minute because it seemed interesting and, if I’m being honest because it fit my schedule.
On the first day, Dr. Behrenshausen asked if we students knew or had used any open source programs. Until that day I had hardly heard [the term “open source”](https://opensource.com/node/42001) and certainly wasn't cognizant of any products that fell into that category. As the semester went on, however, it dawned on me that the passion I have towards my career aspirations would not exist without open source.
## Audacity and GIMP
My interest in technology started at age 12. Charged with the task of cutting music for my dance team, I searched the web for hours until I found Audacity, an open source audio editor. Audacity opened doors for me; no longer was I confined to repetitive eight-counts of the same beat. I started receiving requests left and right from others who wanted unique renditions of their favorite songs.
Weeks later, I stumbled upon a GIF on the internet of a cat with a Pop-Tart torso and a rainbow trail flying through space. I searched “how to make moving images” and discovered [GIMP](https://www.gimp.org/), an open source graphics editor, and used it to create a GIF of "The Simpsons" for my brother’s birthday present.
My budding interest grew into a full-time obsession: creating artwork on my clunky, laggy laptop. Since I didn’t have much luck with charcoal, paint, or watercolors, I used [graphic design](https://opensource.com/node/30251) as an outlet for creative expression. I spent hours in the computer lab learning the basics of HTML and CSS on [W3Schools](https://www.w3schools.com/) so that I could fill an online portfolio with my childish GIFs. A few months later, I published my first website on [WordPress](https://opensource.com/node/31441).
## Why open source
Fast-forward nearly a decade. Many things have changed, although some have stayed consistent: I still make graphics (mostly flyers), edit music for a dance group, and design websites (sleeker, more effective ones, I hope). The products I used have gone through countless version upgrades. But the most dramatic change is my approach to open source resources.
Considering the significance of open source products in my life has made me cherish the open movement and its mission. Open source projects remind me that there are initiatives in tech that promote social good and self-learning without being exclusive to those who are socioeconomically advantaged. My middle-school self, like countless others, couldn’t afford to purchase the Adobe Creative Suite, GarageBand, or Squarespace. Open source platforms allow us to not only achieve our goals but to discover interests that drive those goals by broadening our access networks.
My advice? Enroll in a class on a whim. It just might change the way you view the world.
## 2 Comments |
9,746 | 尾调用、优化和 ES6 | https://manybutfinite.com/post/tail-calls-optimization-es6/ | 2018-06-14T12:50:16 | [
"尾调用",
"堆栈"
] | https://linux.cn/article-9746-1.html | 
在探秘“栈”的倒数第二篇文章中,我们提到了<ruby> 尾调用 <rt> tail call </rt></ruby>、编译优化、以及新发布的 JavaScript 上<ruby> 合理尾调用 <rt> proper tail call </rt></ruby>。
当一个函数 F 调用另一个函数作为它的结束动作时,就发生了一个**尾调用**。在那个时间点,函数 F 绝对不会有多余的工作:函数 F 将“球”传给被它调用的任意函数之后,它自己就“消失”了。这就是关键点,因为它打开了尾调用优化的“可能之门”:我们可以简单地重用函数 F 的栈帧,而不是为函数调用 [创建一个新的栈帧](https://manybutfinite.com/post/journey-to-the-stack),因此节省了栈空间并且避免了新建一个栈帧所需要的工作量。下面是一个用 C 写的简单示例,然后使用 [mild 优化](https://github.com/gduarte/blog/blob/master/code/x86-stack/asm-tco.sh) 来编译它的结果:
```
int add5(int a)
{
return a + 5;
}
int add10(int a)
{
int b = add5(a); // not tail
return add5(b); // tail
}
int add5AndTriple(int a){
int b = add5(a); // not tail
return 3 * add5(a); // not tail, doing work after the call
}
int finicky(int a){
if (a > 10){
return add5AndTriple(a); // tail
}
if (a > 5){
int b = add5(a); // not tail
return finicky(b); // tail
}
return add10(a); // tail
}
```
*简单的尾调用 [下载](https://manybutfinite.com/code/x86-stack/tail.c)*
在编译器的输出中,在预期会有一个 [调用](https://github.com/gduarte/blog/blob/master/code/x86-stack/tail.s#L37-L39) 的地方,你可以看到一个 [跳转](https://github.com/gduarte/blog/blob/master/code/x86-stack/tail-tco.s#L27) 指令,一般情况下你可以发现尾调用优化(以下简称 TCO)。在运行时中,TCO 将会引起调用栈的减少。
一个通常认为的错误观念是,尾调用必须要 [递归](https://manybutfinite.com/post/recursion/)。实际上并不是这样的:一个尾调用可以被递归,比如在上面的 `finicky()` 中,但是,并不是必须要使用递归的。在调用点只要函数 F 完成它的调用,我们将得到一个单独的尾调用。是否能够进行优化这是一个另外的问题,它取决于你的编程环境。
“是的,它总是可以!”,这是我们所希望的最佳答案,它是著名的 Scheme 中的方式,就像是在 [SICP](https://mitpress.mit.edu/sites/default/files/sicp/full-text/book/book-Z-H-11.html)上所讨论的那样(顺便说一声,如果你的程序不像“一个魔法师使用你的咒语召唤你的电脑精灵”那般有效,建议你读一下这本书)。它也是 [Lua](http://www.lua.org/pil/6.3.html) 的方式。而更重要的是,它是下一个版本的 JavaScript —— ES6 的方式,这个规范清晰地定义了[尾的位置](https://people.mozilla.org/%7Ejorendorff/es6-draft.html#sec-tail-position-calls),并且明确了优化所需要的几个条件,比如,[严格模式](https://people.mozilla.org/%7Ejorendorff/es6-draft.html#sec-strict-mode-code)。当一个编程语言保证可用 TCO 时,它将支持<ruby> 合理尾调用 <rt> proper tail call </rt></ruby>。
现在,我们中的一些人不能抛开那些 C 的习惯,心脏出血,等等,而答案是一个更复杂的“有时候”,它将我们带进了编译优化的领域。我们看一下上面的那个 [简单示例](https://github.com/gduarte/blog/blob/master/code/x86-stack/tail.c);把我们 [上篇文章](/article-9609-1.html) 的阶乘程序重新拿出来:
```
#include <stdio.h>
int factorial(int n)
{
int previous = 0xdeadbeef;
if (n == 0 || n == 1) {
return 1;
}
previous = factorial(n-1);
return n * previous;
}
int main(int argc)
{
int answer = factorial(5);
printf("%d\n", answer);
}
```
*递归阶乘 [下载](https://manybutfinite.com/code/x86-stack/factorial.c)*
像第 11 行那样的,是尾调用吗?答案是:“不是”,因为它被后面的 `n` 相乘了。但是,如果你不去优化它,GCC 使用 [O2 优化](https://gcc.gnu.org/onlinedocs/gcc/Optimize-Options.html) 的 [结果](https://github.com/gduarte/blog/blob/master/code/x86-stack/factorial-o2.s) 会让你震惊:它不仅将阶乘转换为一个 [无递归循环](https://github.com/gduarte/blog/blob/master/code/x86-stack/factorial-o2.s#L16-L19),而且 `factorial(5)` 调用被整个消除了,而以一个 120 (`5! == 120`) 的 [编译时常数](https://github.com/gduarte/blog/blob/master/code/x86-stack/factorial-o2.s#L38)来替换。这就是调试优化代码有时会很难的原因。好的方面是,如果你调用这个函数,它将使用一个单个的栈帧,而不会去考虑 n 的初始值。编译算法是非常有趣的,如果你对它感兴趣,我建议你去阅读 [构建一个优化编译器](http://www.amazon.com/Building-Optimizing-Compiler-Bob-Morgan-ebook/dp/B008COCE9G/) 和 [ACDI](http://www.amazon.com/Advanced-Compiler-Design-Implementation-Muchnick-ebook/dp/B003VM7GGK/)。
但是,这里**没有**做尾调用优化时到底发生了什么?通过分析函数的功能和无需优化的递归发现,GCC 比我们更聪明,因为一开始就没有使用尾调用。由于过于简单以及很确定的操作,这个任务变得很简单。我们给它增加一些可以引起混乱的东西(比如,`getpid()`),我们给 GCC 增加难度:
```
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int pidFactorial(int n)
{
if (1 == n) {
return getpid(); // tail
}
return n * pidFactorial(n-1) * getpid(); // not tail
}
int main(int argc)
{
int answer = pidFactorial(5);
printf("%d\n", answer);
}
```
*递归 PID 阶乘 [下载](https://manybutfinite.com/code/x86-stack/pidFactorial.c)*
优化它,unix 精灵!现在,我们有了一个常规的 [递归调用](https://github.com/gduarte/blog/blob/master/code/x86-stack/pidFactorial-o2.s#L20) 并且这个函数分配 O(n) 栈帧来完成工作。GCC 在递归的基础上仍然 [为 getpid 使用了 TCO](https://github.com/gduarte/blog/blob/master/code/x86-stack/pidFactorial-o2.s#L43)。如果我们现在希望让这个函数尾调用递归,我需要稍微变一下:
```
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int tailPidFactorial(int n, int acc)
{
if (1 == n) {
return acc * getpid(); // not tail
}
acc = (acc * getpid() * n);
return tailPidFactorial(n-1, acc); // tail
}
int main(int argc)
{
int answer = tailPidFactorial(5, 1);
printf("%d\n", answer);
}
```
*tailPidFactorial.c [下载](https://manybutfinite.com/code/x86-stack/tailPidFactorial.c)*
现在,结果的累加是 [一个循环](https://github.com/gduarte/blog/blob/master/code/x86-stack/tailPidFactorial-o2.s#L22-L27),并且我们获得了真实的 TCO。但是,在你庆祝之前,我们能说一下关于在 C 中的一般情形吗?不幸的是,虽然优秀的 C 编译器在大多数情况下都可以实现 TCO,但是,在一些情况下它们仍然做不到。例如,正如我们在 [函数序言](https://manybutfinite.com/post/epilogues-canaries-buffer-overflows/) 中所看到的那样,函数调用者在使用一个标准的 C 调用规则调用一个函数之后,它要负责去清理栈。因此,如果函数 F 带了两个参数,它只能使 TCO 调用的函数使用两个或者更少的参数。这是 TCO 的众多限制之一。Mark Probst 写了一篇非常好的论文,他们讨论了 [在 C 中的合理尾递归](http://www.complang.tuwien.ac.at/schani/diplarb.ps),在这篇论文中他们讨论了这些属于 C 栈行为的问题。他也演示一些 [疯狂的、很酷的欺骗方法](http://www.complang.tuwien.ac.at/schani/jugglevids/index.html)。
“有时候” 对于任何一种关系来说都是不坚定的,因此,在 C 中你不能依赖 TCO。它是一个在某些地方可以或者某些地方不可以的离散型优化,而不是像合理尾调用一样的编程语言的特性,虽然在实践中可以使用编译器来优化绝大部分的情形。但是,如果你想必须要实现 TCO,比如将 Scheme <ruby> 转译 <rt> transpilation </rt></ruby>成 C,你将会 [很痛苦](http://en.wikipedia.org/wiki/Tail_call#Through_trampolining)。
因为 JavaScript 现在是非常流行的转译对象,合理尾调用比以往更重要。因此,对 ES6 及其提供的许多其它的重大改进的赞誉并不为过。它就像 JS 程序员的圣诞节一样。
这就是尾调用和编译优化的简短结论。感谢你的阅读,下次再见!
---
via:<https://manybutfinite.com/post/tail-calls-optimization-es6/>
作者:[Gustavo Duarte](http://duartes.org/gustavo/blog/about/) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In this penultimate post about the stack, we take a quick look at **tail
calls**, compiler optimizations, and the *proper tail calls* landing in the
newest version of JavaScript.
A **tail call** happens when a function `F`
makes a function call as its final
action. At that point `F`
will do absolutely no more work: it passes the ball to
whatever function is being called and vanishes from the game. This is notable
because it opens up the possibility of **tail call optimization**: instead of
[creating a new stack frame](/post/journey-to-the-stack) for the function call, we can simply *reuse*
`F`
's stack frame, thereby saving stack space and avoiding the work involved in
setting up a new frame. Here are some examples in C and their results compiled
with [mild optimization](https://github.com/gduarte/blog/blob/master/code/x86-stack/asm-tco.sh):
[view raw](/code/x86-stack/tail.c)
1 | int add5(int a) |
You can normally spot tail call optimization (hereafter, TCO) in compiler output
by seeing a [jump](https://github.com/gduarte/blog/blob/master/code/x86-stack/tail-tco.s#L27) instruction where a [call](https://github.com/gduarte/blog/blob/master/code/x86-stack/tail.s#L37-L39) would have been
expected. At runtime TCO leads to a reduced call stack.
A common misconception is that tail calls are necessarily
[recursive](/post/recursion/). That’s not the case: a tail call *may* be recursive,
such as in `finicky()`
above, but it need not be. As long as caller `F`
is
completely done at the call site, we’ve got ourselves a tail call. *Whether it
can be optimized* is a different question whose answer depends on your
programming environment.
“Yes, it can, always!” is the best answer we can hope for, which is famously the
case for Scheme, as discussed in [SICP](http://mitpress.mit.edu/sicp/full-text/book/book-Z-H-11.html) (by the way, if when you program
you don’t feel like “a Sorcerer conjuring the spirits of the computer with your
spells,” I urge you to read that book). It’s also the case for [Lua](http://www.lua.org/pil/6.3.html). And
most importantly, it is the case for the next version of JavaScript, ES6, whose
spec does a good job defining [tail position](https://people.mozilla.org/~jorendorff/es6-draft.html#sec-tail-position-calls) and clarifying the few
conditions required for optimization, such as [strict mode](https://people.mozilla.org/~jorendorff/es6-draft.html#sec-strict-mode-code). When
a language guarantees TCO, it supports *proper tail calls*.
Now some of us can’t kick that C habit, heart bleed and all, and the answer
there is a more complicated “sometimes” that takes us into compiler optimization
territory. We’ve seen the [simple examples](https://github.com/gduarte/blog/blob/master/code/x86-stack/tail.c) above; now let’s resurrect
our factorial from [last post](/post/recursion/):
[view raw](/code/x86-stack/factorial.c)
1 |
|
So, is line 11 a tail call? It’s not, because of the multiplication by `n`
afterwards. But if you’re not used to optimizations, gcc’s
[result](https://github.com/gduarte/blog/blob/master/code/x86-stack/factorial-o2.s) with [O2 optimization](https://gcc.gnu.org/onlinedocs/gcc/Optimize-Options.html) might shock you: not only it
transforms `factorial`
into a [recursion-free loop](https://github.com/gduarte/blog/blob/master/code/x86-stack/factorial-o2.s#L16-L19), but the
`factorial(5)`
call is eliminated entirely and replaced by a
[compile-time constant](https://github.com/gduarte/blog/blob/master/code/x86-stack/factorial-o2.s#L38) of 120 (5! == 120). This is why debugging optimized
code can be hard sometimes. On the plus side, if you call this function it will
use a single stack frame regardless of n’s initial value. Compiler algorithms
are pretty fun, and if you’re interested I suggest you check out
[Building an Optimizing Compiler](http://www.amazon.com/Building-Optimizing-Compiler-Bob-Morgan-ebook/dp/B008COCE9G/) and [ACDI](http://www.amazon.com/Advanced-Compiler-Design-Implementation-Muchnick-ebook/dp/B003VM7GGK/).
However, what happened here was **not** tail call optimization, since there was
*no tail call to begin with*. gcc outsmarted us by analyzing what the function
does and optimizing away the needless recursion. The task was made easier by
the simple, deterministic nature of the operations being done. By adding a dash
of chaos (*e.g.*, `getpid()`
) we can throw gcc off:
[view raw](/code/x86-stack/pidFactorial.c)
1 |
|
Optimize *that*, unix fairies! So now we have a regular
[recursive call](https://github.com/gduarte/blog/blob/master/code/x86-stack/pidFactorial-o2.s#L20) and this function allocates O(n) stack
frames to do its work. Heroically, gcc still does [TCO for getpid](https://github.com/gduarte/blog/blob/master/code/x86-stack/pidFactorial-o2.s#L43)
in the recursion base case. If we now wished to make this function tail recursive,
we’d need a slight change:
[view raw](/code/x86-stack/tailPidFactorial.c)
1 |
|
The accumulation of the result is now [a loop](https://github.com/gduarte/blog/blob/master/code/x86-stack/tailPidFactorial-o2.s#L22-L27) and we’ve
achieved true TCO. But before you go out partying, what can we say about the
general case in C? Sadly, while good C compilers do TCO in a number of cases,
there are many situations where they cannot do it. For example, as we saw in our
[function epilogues](/post/epilogues-canaries-buffer-overflows/), the *caller* is responsible for cleaning up the
stack after a function call using the standard C calling convention. So if
function `F`
takes two arguments, it can only make TCO calls to functions taking
two or fewer arguments. This is one among many restrictions. Mark Probst wrote
an excellent thesis discussing [Proper Tail Recursion in C](http://www.complang.tuwien.ac.at/schani/diplarb.ps) where he
discusses these issues along with C stack behavior. He also does
[insanely cool juggling](http://www.complang.tuwien.ac.at/schani/jugglevids/index.html).
“Sometimes” is a rocky foundation for any relationship, so you can’t rely on TCO
in C. It’s a discrete optimization that may or may not take place, rather than
a language *feature* like proper tail calls, though in practice the compiler
will optimize the vast majority of cases. But if you *must have it*, say for
transpiling Scheme into C, you will [suffer](http://en.wikipedia.org/wiki/Tail_call#Through_trampolining).
Since JavaScript is now the most popular transpilation target, proper tail calls become even more important there. So kudos to ES6 for delivering it along with many other significant improvements. It’s like Christmas for JS programmers.
This concludes our brief tour of tail calls and compiler optimization. Thanks for reading and see you next time.
## Comments |
9,747 | 底层 Linux 容器运行时之发展史 | https://opensource.com/article/18/1/history-low-level-container-runtimes | 2018-06-14T22:51:00 | [
"容器",
"Docker"
] | https://linux.cn/article-9747-1.html |
>
> “容器运行时”是一个被过度使用的名词。
>
>
>

在 Red Hat,我们乐意这么说,“容器即 Linux,Linux 即容器”。下面解释一下这种说法。传统的容器是操作系统中的进程,通常具有如下 3 个特性:
1. 资源限制
当你在系统中运行多个容器时,你肯定不希望某个容器独占系统资源,所以我们需要使用资源约束来控制 CPU、内存和网络带宽等资源。Linux 内核提供了 cgroup 特性,可以通过配置控制容器进程的资源使用。
2. 安全性配置
一般而言,你不希望你的容器可以攻击其它容器或甚至攻击宿主机系统。我们使用了 Linux 内核的若干特性建立安全隔离,相关特性包括 SELinux、seccomp 和 capabilities。
(LCTT 译注:从 2.2 版本内核开始,Linux 将特权从超级用户中分离,产生了一系列可以单独启用或关闭的 capabilities)
3. 虚拟隔离
容器外的任何进程对于容器而言都应该不可见。容器应该使用独立的网络。不同的容器对应的进程应该都可以绑定 80 端口。每个容器的<ruby> 内核映像 <rt> image </rt></ruby>、<ruby> 根文件系统 <rt> rootfs </rt></ruby>(rootfs)都应该相互独立。在 Linux 中,我们使用内核的<ruby> 名字空间 <rt> namespace </rt></ruby>特性提供<ruby> 虚拟隔离 <rt> virtual separation </rt></ruby>。
那么,具有安全性配置并且在 cgroup 和名字空间下运行的进程都可以称为容器。查看一下 Red Hat Enterprise Linux 7 操作系统中的 PID 1 的进程 systemd,你会发现 systemd 运行在一个 cgroup 下。
```
# tail -1 /proc/1/cgroup
1:name=systemd:/
```
`ps` 命令让我们看到 systemd 进程具有 SELinux 标签:
```
# ps -eZ | grep systemd
system_u:system_r:init_t:s0 1 ? 00:00:48 systemd
```
以及 capabilities:
```
# grep Cap /proc/1/status
...
CapEff: 0000001fffffffff
CapBnd: 0000001fffffffff
CapBnd: 0000003fffffffff
```
最后,查看 `/proc/1/ns` 子目录,你会发现 systemd 运行所在的名字空间。
```
ls -l /proc/1/ns
lrwxrwxrwx. 1 root root 0 Jan 11 11:46 mnt -> mnt:[4026531840]
lrwxrwxrwx. 1 root root 0 Jan 11 11:46 net -> net:[4026532009]
lrwxrwxrwx. 1 root root 0 Jan 11 11:46 pid -> pid:[4026531836]
...
```
如果 PID 1 进程(实际上每个系统进程)具有资源约束、安全性配置和名字空间,那么我可以说系统上的每一个进程都运行在容器中。
容器运行时工具也不过是修改了资源约束、安全性配置和名字空间,然后 Linux 内核运行起进程。容器启动后,容器运行时可以在容器内监控 PID 1 进程,也可以监控容器的标准输入/输出,从而进行容器进程的生命周期管理。
### 容器运行时
你可能自言自语道,“哦,systemd 看起来很像一个容器运行时”。经过若干次关于“为何容器运行时不使用 `systemd-nspawn` 工具来启动容器”的邮件讨论后,我认为值得讨论一下容器运行时及其发展史。
[Docker](https://github.com/docker) 通常被称为容器运行时,但“<ruby> 容器运行时 <rt> container runtime </rt></ruby>”是一个被过度使用的词语。当用户提到“容器运行时”,他们其实提到的是为开发人员提供便利的<ruby> 上层 <rt> high-level </rt></ruby>工具,包括 Docker,[CRI-O](https://github.com/kubernetes-incubator/cri-o) 和 [RKT](https://github.com/rkt/rkt)。这些工具都是基于 API 的,涉及操作包括从容器仓库拉取容器镜像、配置存储和启动容器等。启动容器通常涉及一个特殊工具,用于配置内核如何运行容器,这类工具也被称为“容器运行时”,下文中我将称其为“底层容器运行时”以作区分。像 Docker、CRI-O 这样的守护进程及形如 [Podman](https://github.com/projectatomic/libpod/tree/master/cmd/podman)、[Buildah](https://github.com/projectatomic/buildah) 的命令行工具,似乎更应该被称为“容器管理器”。
早期版本的 Docker 使用 `lxc` 工具集启动容器,该工具出现在 `systemd-nspawn` 之前。Red Hat 最初试图将 [libvirt](https://libvirt.org/) (`libvirt-lxc`)集成到 Docker 中替代 `lxc` 工具,因为 RHEL 并不支持 `lxc`。`libvirt-lxc` 也没有使用 `systemd-nspawn`,在那时 systemd 团队仅将 `systemd-nspawn` 视为测试工具,不适用于生产环境。
与此同时,包括我的 Red Hat 团队部分成员在内的<ruby> 上游 <rt> upstream </rt></ruby> Docker 开发者,认为应该采用 golang 原生的方式启动容器,而不是调用外部应用。他们的工作促成了 libcontainer 这个 golang 原生库,用于启动容器。Red Hat 工程师更看好该库的发展前景,放弃了 `libvirt-lxc`。
后来成立 <ruby> <a href="https://www.opencontainers.org/"> 开放容器组织 </a> <rt> Open Container Initiative </rt></ruby>(OCI)的部分原因就是人们希望用其它方式启动容器。传统的基于名字空间隔离的容器已经家喻户晓,但人们也有<ruby> 虚拟机级别隔离 <rt> virtual machine-level isolation </rt></ruby>的需求。Intel 和 [Hyper.sh](https://www.hyper.sh/) 正致力于开发基于 KVM 隔离的容器,Microsoft 致力于开发基于 Windows 的容器。OCI 希望有一份定义容器的标准规范,因而产生了 [OCI <ruby> 运行时规范 <rt> Runtime Specification </rt></ruby>](https://github.com/opencontainers/runtime-spec)。
OCI 运行时规范定义了一个 JSON 文件格式,用于描述要运行的二进制,如何容器化以及容器根文件系统的位置。一些工具用于生成符合标准规范的 JSON 文件,另外的工具用于解析 JSON 文件并在该根文件系统(rootfs)上运行容器。Docker 的部分代码被抽取出来构成了 libcontainer 项目,该项目被贡献给 OCI。上游 Docker 工程师及我们自己的工程师创建了一个新的前端工具,用于解析符合 OCI 运行时规范的 JSON 文件,然后与 libcontainer 交互以便启动容器。这个前端工具就是 [runc](https://github.com/opencontainers/runc),也被贡献给 OCI。虽然 `runc` 可以解析 OCI JSON 文件,但用户需要自行生成这些文件。此后,`runc` 也成为了最流行的底层容器运行时,基本所有的容器管理工具都支持 `runc`,包括 CRI-O、Docker、Buildah、Podman 和 [Cloud Foundry Garden](https://github.com/cloudfoundry/garden) 等。此后,其它工具的实现也参照 OCI 运行时规范,以便可以运行 OCI 兼容的容器。
[Clear Containers](https://clearlinux.org/containers) 和 Hyper.sh 的 `runV` 工具都是参照 OCI 运行时规范运行基于 KVM 的容器,二者将其各自工作合并到一个名为 [Kata](https://clearlinux.org/containers) 的新项目中。在去年,Oracle 创建了一个示例版本的 OCI 运行时工具,名为 [RailCar](https://github.com/oracle/railcar),使用 Rust 语言编写。但该 GitHub 项目已经两个月没有更新了,故无法判断是否仍在开发。几年前,Vincent Batts 试图创建一个名为 [nspawn-oci](https://github.com/vbatts/nspawn-oci) 的工具,用于解析 OCI 运行时规范文件并启动 `systemd-nspawn`;但似乎没有引起大家的注意,而且也不是原生的实现。
如果有开发者希望实现一个原生的 `systemd-nspawn --oci OCI-SPEC.json` 并让 systemd 团队认可和提供支持,那么CRI-O、Docker 和 Podman 等容器管理工具将可以像使用 `runc` 和 Clear Container/runV ([Kata](https://github.com/kata-containers)) 那样使用这个新的底层运行时。(目前我的团队没有人参与这方面的工作。)
总结如下,在 3-4 年前,上游开发者打算编写一个底层的 golang 工具用于启动容器,最终这个工具就是 `runc`。那时开发者有一个使用 C 编写的 `lxc` 工具,在 `runc` 开发后,他们很快转向 `runc`。我很确信,当决定构建 libcontainer 时,他们对 `systemd-nspawn` 或其它非原生(即不使用 golang)的运行 namespaces 隔离的容器的方式都不感兴趣。
---
via: <https://opensource.com/article/18/1/history-low-level-container-runtimes>
作者:[Daniel Walsh](https://opensource.com/users/rhatdan) 译者:[pinewall](https://github.com/pinewall) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | At Red Hat we like to say, "Containers are Linux—Linux is Containers." Here is what this means. Traditional containers are processes on a system that usually have the following three characteristics:
### 1. Resource constraints
When you run lots of containers on a system, you do not want to have any container monopolize the operating system, so we use resource constraints to control things like CPU, memory, network bandwidth, etc. The Linux kernel provides the cgroups feature, which can be configured to control the container process resources.
### 2. Security constraints
Usually, you do not want your containers being able to attack each other or attack the host system. We take advantage of several features of the Linux kernel to set up security separation, such as SELinux, seccomp, capabilities, etc.
### 3. Virtual separation
Container processes should not have a view of any processes outside the container. They should be on their own network. Container processes need to be able to bind to port 80 in different containers. Each container needs a different view of its image, needs its own root filesystem (rootfs). In Linux we use kernel namespaces to provide virtual separation.
Therefore, a process that runs in a cgroup, has security settings, and runs in namespaces can be called a container. Looking at PID 1, systemd, on a Red Hat Enterprise Linux 7 system, you see that systemd runs in a cgroup.
```
``````
# tail -1 /proc/1/cgroup
1:name=systemd:/
```
The `ps`
command shows you that the system process has an SELinux label ...
```
``````
# ps -eZ | grep systemd
system_u:system_r:init_t:s0 1 ? 00:00:48 systemd
```
and capabilities.
```
``````
# grep Cap /proc/1/status
...
CapEff: 0000001fffffffff
CapBnd: 0000001fffffffff
CapBnd: 0000003fffffffff
```
Finally, if you look at the `/proc/1/ns`
subdir, you will see the namespace that systemd runs in.
```
``````
ls -l /proc/1/ns
lrwxrwxrwx. 1 root root 0 Jan 11 11:46 mnt -> mnt:[4026531840]
lrwxrwxrwx. 1 root root 0 Jan 11 11:46 net -> net:[4026532009]
lrwxrwxrwx. 1 root root 0 Jan 11 11:46 pid -> pid:[4026531836]
...
```
If PID 1 (and really every other process on the system) has resource constraints, security settings, and namespaces, I argue that every process on the system is in a container.
Container runtime tools just modify these resource constraints, security settings, and namespaces. Then the Linux kernel executes the processes. After the container is launched, the container runtime can monitor PID 1 inside the container or the container's `stdin`
/`stdout`
—the container runtime manages the lifecycles of these processes.
## Container runtimes
You might say to yourself, well systemd sounds pretty similar to a container runtime. Well, after having several email discussions about why container runtimes do not use `systemd-nspawn`
as a tool for launching containers, I decided it would be worth discussing container runtimes and giving some historical context.
[Docker](https://github.com/docker) is often called a container runtime, but "container runtime" is an overloaded term. When folks talk about a "container runtime," they're really talking about higher-level tools like Docker, [ CRI-O](https://github.com/kubernetes-incubator/cri-o), and [ RKT](https://github.com/rkt/rkt) that come with developer functionality. They are API driven. They include concepts like pulling the container image from the container registry, setting up the storage, and finally launching the container. Launching the container often involves running a specialized tool that configures the kernel to run the container, and these are also referred to as "container runtimes." I will refer to them as "low-level container runtimes." Daemons like Docker and CRI-O, as well as command-line tools like [ Podman](https://github.com/projectatomic/libpod/tree/master/cmd/podman) and [ Buildah](https://github.com/projectatomic/buildah), should probably be called "container managers" instead.
When Docker was originally written, it launched containers using the `lxc`
toolset, which predates `systemd-nspawn`
. Red Hat's original work with Docker was to try to integrate
([ libvirt](https://libvirt.org/)`libvirt-lxc`
) into Docker as an alternative to the `lxc`
tools, which were not supported in RHEL. `libvirt-lxc`
also did not use `systemd-nspawn`
. At that time, the systemd team was saying that `systemd-nspawn`
was only a tool for testing, not for production.
At the same time, the upstream Docker developers, including some members of my Red Hat team, decided they wanted a golang-native way to launch containers, rather than launching a separate application. Work began on libcontainer, as a native golang library for launching containers. Red Hat engineering decided that this was the best path forward and dropped `libvirt-lxc`
.
Later, the [Open Container Initiative](https://www.opencontainers.org/) (OCI) was formed, party because people wanted to be able to launch containers in additional ways. Traditional namespace-separated containers were popular, but people also had the desire for virtual machine-level isolation. Intel and [Hyper.sh](https://www.hyper.sh/) were working on KVM-separated containers, and Microsoft was working on Windows-based containers. The OCI wanted a standard specification defining what a container is, so the [ OCI Runtime Specification](https://github.com/opencontainers/runtime-spec) was born.
The OCI Runtime Specification defines a JSON file format that describes what binary should be run, how it should be contained, and the location of the rootfs of the container. Tools can generate this JSON file. Then other tools can read this JSON file and execute a container on the rootfs. The libcontainer parts of Docker were broken out and donated to the OCI. The upstream Docker engineers and our engineers helped create a new frontend tool to read the OCI Runtime Specification JSON file and interact with libcontainer to run the container. This tool, called
, was also donated to the OCI. While [ runc](https://github.com/opencontainers/runc)`runc`
can read the OCI JSON file, users are left to generate it themselves. `runc`
has since become the most popular low-level container runtime. Almost all container-management tools support `runc`
, including CRI-O, Docker, Buildah, Podman, and [ Cloud Foundry Garden](https://github.com/cloudfoundry/garden). Since then, other tools have also implemented the OCI Runtime Spec to execute OCI-compliant containers.
Both [Clear Containers](https://clearlinux.org/containers) and Hyper.sh's `runV`
tools were created to use the OCI Runtime Specification to execute KVM-based containers, and they are combining their efforts in a new project called [ Kata](https://clearlinux.org/containers). Last year, Oracle created a demonstration version of an OCI runtime tool called [RailCar](https://github.com/oracle/railcar), written in Rust. It's been two months since the GitHub project has been updated, so it's unclear if it is still in development. A couple of years ago, Vincent Batts worked on adding a tool,
, that interpreted an OCI Runtime Specification file and launched [ nspawn-oci](https://github.com/vbatts/nspawn-oci)`systemd-nspawn`
, but no one really picked up on it, and it was not a native implementation.
If someone wants to implement a native `systemd-nspawn --oci OCI-SPEC.json`
and get it accepted by the systemd team for support, then CRI-O, Docker, and eventually Podman would be able to use it in addition to `runc `
and Clear Container/runV ([Kata](https://github.com/kata-containers)). (No one on my team is working on this.)
The bottom line is, back three or four years, the upstream developers wanted to write a low-level golang tool for launching containers, and this tool ended up becoming `runc`
. Those developers at the time had a C-based tool for doing this called `lxc`
and moved away from it. I am pretty sure that at the time they made the decision to build libcontainer, they would not have been interested in `systemd-nspawn`
or any other non-native (golang) way of running "namespace" separated containers.
## Comments are closed. |
9,748 | 无密码验证:服务器 | https://nicolasparada.netlify.com/posts/passwordless-auth-server/ | 2018-06-15T00:01:00 | [
"密码",
"登录"
] | https://linux.cn/article-9748-1.html | 
无密码验证可以让你只输入一个 email 而无需输入密码即可登入系统。这是一种比传统的电子邮件/密码验证方式登入更安全的方法。
下面我将为你展示,如何在 [Go](https://golang.org/) 中实现一个 HTTP API 去提供这种服务。
### 流程
* 用户输入他的电子邮件地址。
* 服务器创建一个临时的一次性使用的代码(就像一个临时密码一样)关联到用户,然后给用户邮箱中发送一个“魔法链接”。
* 用户点击魔法链接。
* 服务器提取魔法链接中的代码,获取关联的用户,并且使用一个新的 JWT 重定向到客户端。
* 在每次有新请求时,客户端使用 JWT 去验证用户。
### 必需条件
* 数据库:我们为这个服务使用了一个叫 [CockroachDB](https://www.cockroachlabs.com/) 的 SQL 数据库。它非常像 postgres,但它是用 Go 写的。
* SMTP 服务器:我们将使用一个第三方的邮件服务器去发送邮件。开发的时我们使用 [mailtrap](https://mailtrap.io/)。Mailtrap 发送所有的邮件到它的收件箱,因此,你在测试时不需要创建多个假邮件帐户。
从 [Go 的主页](https://golang.org/dl/) 上安装它,然后使用 `go version`(1.10.1 atm)命令去检查它能否正常工作。
从 [CockroachDB 的主页](https://www.cockroachlabs.com/docs/stable/install-cockroachdb.html) 上下载它,展开它并添加到你的 `PATH` 变量中。使用 `cockroach version`(2.0 atm)命令检查它能否正常工作。
### 数据库模式
现在,我们在 `GOPATH` 目录下为这个项目创建一个目录,然后使用 `cockroach start` 启动一个新的 CockroachDB 节点:
```
cockroach start --insecure --host 127.0.0.1
```
它会输出一些内容,找到 SQL 地址行,它将显示像 `postgresql://[email protected]:26257?sslmode=disable` 这样的内容。稍后我们将使用它去连接到数据库。
使用如下的内容去创建一个 `schema.sql` 文件。
```
DROP DATABASE IF EXISTS passwordless_demo CASCADE;
CREATE DATABASE IF NOT EXISTS passwordless_demo;
SET DATABASE = passwordless_demo;
CREATE TABLE IF NOT EXISTS users (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
email STRING UNIQUE,
username STRING UNIQUE
);
CREATE TABLE IF NOT EXISTS verification_codes (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
user_id UUID NOT NULL REFERENCES users ON DELETE CASCADE,
created_at TIMESTAMPTZ NOT NULL DEFAULT now()
);
INSERT INTO users (email, username) VALUES
('[email protected]', 'john_doe');
```
这个脚本创建了一个名为 `passwordless_demo` 的数据库、两个名为 `users` 和 `verification_codes` 的表,以及为了稍后测试而插入的一些假用户。每个验证代码都与用户关联并保存创建时间,以用于去检查验证代码是否过期。
在另外的终端中使用 `cockroach sql` 命令去运行这个脚本:
```
cat schema.sql | cockroach sql --insecure
```
### 环境配置
需要配置两个环境变量:`SMTP_USERNAME` 和 `SMTP_PASSWORD`,你可以从你的 mailtrap 帐户中获得它们。将在我们的程序中用到它们。
### Go 依赖
我们需要下列的 Go 包:
* [github.com/lib/pq](https://github.com/lib/pq):它是 CockroachDB 使用的 postgres 驱动
* [github.com/matryer/way](https://github.com/matryer/way): 路由器
* [github.com/dgrijalva/jwt-go](https://github.com/dgrijalva/jwt-go): JWT 实现
```
go get -u github.com/lib/pq
go get -u github.com/matryer/way
go get -u github.com/dgrijalva/jwt-go
```
### 代码
#### 初始化函数
创建 `main.go` 并且通过 `init` 函数里的环境变量中取得一些配置来启动。
```
var config struct {
port int
appURL *url.URL
databaseURL string
jwtKey []byte
smtpAddr string
smtpAuth smtp.Auth
}
func init() {
config.port, _ = strconv.Atoi(env("PORT", "80"))
config.appURL, _ = url.Parse(env("APP_URL", "http://localhost:"+strconv.Itoa(config.port)+"/"))
config.databaseURL = env("DATABASE_URL", "postgresql://[email protected]:26257/passwordless_demo?sslmode=disable")
config.jwtKey = []byte(env("JWT_KEY", "super-duper-secret-key"))
smtpHost := env("SMTP_HOST", "smtp.mailtrap.io")
config.smtpAddr = net.JoinHostPort(smtpHost, env("SMTP_PORT", "25"))
smtpUsername, ok := os.LookupEnv("SMTP_USERNAME")
if !ok {
log.Fatalln("could not find SMTP_USERNAME on environment variables")
}
smtpPassword, ok := os.LookupEnv("SMTP_PASSWORD")
if !ok {
log.Fatalln("could not find SMTP_PASSWORD on environment variables")
}
config.smtpAuth = smtp.PlainAuth("", smtpUsername, smtpPassword, smtpHost)
}
func env(key, fallbackValue string) string {
v, ok := os.LookupEnv(key)
if !ok {
return fallbackValue
}
return v
}
```
* `appURL` 将去构建我们的 “魔法链接”。
* `port` 将要启动的 HTTP 服务器。
* `databaseURL` 是 CockroachDB 地址,我添加 `/passwordless_demo` 前面的数据库地址去表示数据库名字。
* `jwtKey` 用于签名 JWT。
* `smtpAddr` 是 `SMTP_HOST` + `SMTP_PORT` 的联合;我们将使用它去发送邮件。
* `smtpUsername` 和 `smtpPassword` 是两个必需的变量。
* `smtpAuth` 也是用于发送邮件。
`env` 函数允许我们去获得环境变量,不存在时返回一个回退值。
#### 主函数
```
var db *sql.DB
func main() {
var err error
if db, err = sql.Open("postgres", config.databaseURL); err != nil {
log.Fatalf("could not open database connection: %v\n", err)
}
defer db.Close()
if err = db.Ping(); err != nil {
log.Fatalf("could not ping to database: %v\n", err)
}
router := way.NewRouter()
router.HandleFunc("POST", "/api/users", jsonRequired(createUser))
router.HandleFunc("POST", "/api/passwordless/start", jsonRequired(passwordlessStart))
router.HandleFunc("GET", "/api/passwordless/verify_redirect", passwordlessVerifyRedirect)
router.Handle("GET", "/api/auth_user", authRequired(getAuthUser))
addr := fmt.Sprintf(":%d", config.port)
log.Printf("starting server at %s \n", config.appURL)
log.Fatalf("could not start server: %v\n", http.ListenAndServe(addr, router))
}
```
首先,打开数据库连接。记得要加载驱动。
```
import (
_ "github.com/lib/pq"
)
```
然后,我们创建路由器并定义一些端点。对于无密码流程来说,我们使用两个端点:`/api/passwordless/start` 发送魔法链接,和 `/api/passwordless/verify_redirect` 用 JWT 响应。
最后,我们启动服务器。
你可以创建空处理程序和中间件去测试服务器启动。
```
func createUser(w http.ResponseWriter, r *http.Request) {
http.Error(w, http.StatusText(http.StatusNotImplemented), http.StatusNotImplemented)
}
func passwordlessStart(w http.ResponseWriter, r *http.Request) {
http.Error(w, http.StatusText(http.StatusNotImplemented), http.StatusNotImplemented)
}
func passwordlessVerifyRedirect(w http.ResponseWriter, r *http.Request) {
http.Error(w, http.StatusText(http.StatusNotImplemented), http.StatusNotImplemented)
}
func getAuthUser(w http.ResponseWriter, r *http.Request) {
http.Error(w, http.StatusText(http.StatusNotImplemented), http.StatusNotImplemented)
}
func jsonRequired(next http.HandlerFunc) http.HandlerFunc {
return func(w http.ResponseWriter, r *http.Request) {
next(w, r)
}
}
func authRequired(next http.HandlerFunc) http.HandlerFunc {
return func(w http.ResponseWriter, r *http.Request) {
next(w, r)
}
}
```
接下来:
```
go build
./passwordless-demo
```
我们在目录中有了一个 “passwordless-demo”,但是你的目录中可能与示例不一样,`go build` 将创建一个同名的可执行文件。如果你没有关闭前面的 cockroach 节点,并且你正确配置了 `SMTP_USERNAME` 和 `SMTP_PASSWORD` 变量,你将看到命令 `starting server at http://localhost/` 没有错误输出。
#### 请求 JSON 的中间件
端点需要从请求体中解码 JSON,因此要确保请求是 `application/json` 类型。因为它是一个通用的东西,我将它解耦到中间件。
```
func jsonRequired(next http.HandlerFunc) http.HandlerFunc {
return func(w http.ResponseWriter, r *http.Request) {
ct := r.Header.Get("Content-Type")
isJSON := strings.HasPrefix(ct, "application/json")
if !isJSON {
respondJSON(w, "JSON body required", http.StatusUnsupportedMediaType)
return
}
next(w, r)
}
}
```
实现很容易。首先它从请求头中获得内容的类型,然后检查它是否是以 “application/json” 开始,如果不是则以 `415 Unsupported Media Type` 提前返回。
#### 响应 JSON 的函数
以 JSON 响应是非常通用的做法,因此我把它提取到函数中。
```
func respondJSON(w http.ResponseWriter, payload interface{}, code int) {
switch value := payload.(type) {
case string:
payload = map[string]string{"message": value}
case int:
payload = map[string]int{"value": value}
case bool:
payload = map[string]bool{"result": value}
}
b, err := json.Marshal(payload)
if err != nil {
respondInternalError(w, fmt.Errorf("could not marshal response payload: %v", err))
return
}
w.Header().Set("Content-Type", "application/json; charset=utf-8")
w.WriteHeader(code)
w.Write(b)
}
```
首先,对原始类型做一个类型判断,并将它们封装到一个 `map`。然后将它们编组到 JSON,设置响应内容类型和状态码,并写 JSON。如果 JSON 编组失败,则响应一个内部错误。
#### 响应内部错误的函数
`respondInternalError` 是一个响应 `500 Internal Server Error` 的函数,但是也同时将错误输出到控制台。
```
func respondInternalError(w http.ResponseWriter, err error) {
log.Println(err)
respondJSON(w,
http.StatusText(http.StatusInternalServerError),
http.StatusInternalServerError)
}
```
#### 创建用户的处理程序
下面开始编写 `createUser` 处理程序,因为它非常容易并且是 REST 式的。
```
type User struct {
ID string `json:"id"`
Email string `json:"email"`
Username string `json:"username"`
}
```
`User` 类型和 `users` 表相似。
```
var (
rxEmail = regexp.MustCompile("^[^\\s@]+@[^\\s@]+\\.[^\\s@]+$")
rxUsername = regexp.MustCompile("^[a-zA-Z][\\w|-]{1,17}$")
)
```
这些正则表达式是分别用于去验证电子邮件和用户名的。这些都很简单,可以根据你的需要随意去适配。
现在,在 `createUser` 函数内部,我们将开始解码请求体。
```
var user User
if err := json.NewDecoder(r.Body).Decode(&user); err != nil {
respondJSON(w, err.Error(), http.StatusBadRequest)
return
}
defer r.Body.Close()
```
我们将使用请求体去创建一个 JSON 解码器来解码出一个用户指针。如果发生错误则返回一个 `400 Bad Request`。不要忘记关闭请求体读取器。
```
errs := make(map[string]string)
if user.Email == "" {
errs["email"] = "Email required"
} else if !rxEmail.MatchString(user.Email) {
errs["email"] = "Invalid email"
}
if user.Username == "" {
errs["username"] = "Username required"
} else if !rxUsername.MatchString(user.Username) {
errs["username"] = "Invalid username"
}
if len(errs) != 0 {
respondJSON(w, errs, http.StatusUnprocessableEntity)
return
}
```
这是我如何做验证;一个简单的 `map` 并检查如果 `len(errs) != 0`,则使用 `422 Unprocessable Entity` 去返回。
```
err := db.QueryRowContext(r.Context(), `
INSERT INTO users (email, username) VALUES ($1, $2)
RETURNING id
`, user.Email, user.Username).Scan(&user.ID)
if errPq, ok := err.(*pq.Error); ok && errPq.Code.Name() == "unique_violation" {
if strings.Contains(errPq.Error(), "email") {
errs["email"] = "Email taken"
} else {
errs["username"] = "Username taken"
}
respondJSON(w, errs, http.StatusForbidden)
return
} else if err != nil {
respondInternalError(w, fmt.Errorf("could not insert user: %v", err))
return
}
```
这个 SQL 查询使用一个给定的 email 和用户名去插入一个新用户,并返回自动生成的 id,每个 `$` 将被接下来传递给 `QueryRowContext` 的参数替换掉。
因为 `users` 表在 `email` 和 `username` 字段上有唯一性约束,因此我将检查 “unique\_violation” 错误并返回 `403 Forbidden` 或者返回一个内部错误。
```
respondJSON(w, user, http.StatusCreated)
```
最后使用创建的用户去响应。
#### 无密码验证开始部分的处理程序
```
type PasswordlessStartRequest struct {
Email string `json:"email"`
RedirectURI string `json:"redirectUri"`
}
```
这个结构体含有 `passwordlessStart` 的请求体:希望去登入的用户 email、来自客户端的重定向 URI(这个应用中将使用我们的 API)如:`https://frontend.app/callback`。
```
var magicLinkTmpl = template.Must(template.ParseFiles("templates/magic-link.html"))
```
我们将使用 golang 模板引擎去构建邮件,因此需要你在 `templates` 目录中,用如下的内容创建一个 `magic-link.html` 文件:
```
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Magic Link</title>
</head>
<body>
Click <a href="{{ .MagicLink }}" target="_blank">here</a> to login.
<br>
<em>This link expires in 15 minutes and can only be used once.</em>
</body>
</html>
```
这个模板是给用户发送魔法链接邮件用的。你可以根据你的需要去随意调整它。
现在, 进入 `passwordlessStart` 函数内部:
```
var input PasswordlessStartRequest
if err := json.NewDecoder(r.Body).Decode(&input); err != nil {
respondJSON(w, err.Error(), http.StatusBadRequest)
return
}
defer r.Body.Close()
```
首先,我们像前面一样解码请求体。
```
errs := make(map[string]string)
if input.Email == "" {
errs["email"] = "Email required"
} else if !rxEmail.MatchString(input.Email) {
errs["email"] = "Invalid email"
}
if input.RedirectURI == "" {
errs["redirectUri"] = "Redirect URI required"
} else if u, err := url.Parse(input.RedirectURI); err != nil || !u.IsAbs() {
errs["redirectUri"] = "Invalid redirect URI"
}
if len(errs) != 0 {
respondJSON(w, errs, http.StatusUnprocessableEntity)
return
}
```
我们使用 golang 的 URL 解析器去验证重定向 URI,检查那个 URI 是否为绝对地址。
```
var verificationCode string
err := db.QueryRowContext(r.Context(), `
INSERT INTO verification_codes (user_id) VALUES
((SELECT id FROM users WHERE email = $1))
RETURNING id
`, input.Email).Scan(&verificationCode)
if errPq, ok := err.(*pq.Error); ok && errPq.Code.Name() == "not_null_violation" {
respondJSON(w, "No user found with that email", http.StatusNotFound)
return
} else if err != nil {
respondInternalError(w, fmt.Errorf("could not insert verification code: %v", err))
return
}
```
这个 SQL 查询将插入一个验证代码,这个代码通过给定的 email 关联到用户,并且返回一个自动生成的 id。因为有可能会出现用户不存在的情况,那样的话子查询可能解析为 `NULL`,这将导致在 `user_id` 字段上因违反 `NOT NULL` 约束而导致失败,因此需要对这种情况进行检查,如果用户不存在,则返回 `404 Not Found` 或者一个内部错误。
```
q := make(url.Values)
q.Set("verification_code", verificationCode)
q.Set("redirect_uri", input.RedirectURI)
magicLink := *config.appURL
magicLink.Path = "/api/passwordless/verify_redirect"
magicLink.RawQuery = q.Encode()
```
现在,构建魔法链接并设置查询字符串中的 `verification_code` 和 `redirect_uri` 的值。如:`http://localhost/api/passwordless/verify_redirect?verification_code=some_code&redirect_uri=https://frontend.app/callback`。
```
var body bytes.Buffer
data := map[string]string{"MagicLink": magicLink.String()}
if err := magicLinkTmpl.Execute(&body, data); err != nil {
respondInternalError(w, fmt.Errorf("could not execute magic link template: %v", err))
return
}
```
我们将得到的魔法链接模板的内容保存到缓冲区中。如果发生错误则返回一个内部错误。
```
to := mail.Address{Address: input.Email}
if err := sendMail(to, "Magic Link", body.String()); err != nil {
respondInternalError(w, fmt.Errorf("could not mail magic link: %v", err))
return
}
```
现在来写给用户发邮件的 `sendMail` 函数。如果发生错误则返回一个内部错误。
```
w.WriteHeader(http.StatusNoContent)
```
最后,设置响应状态码为 `204 No Content`。对于成功的状态码,客户端不需要很多数据。
#### 发送邮件函数
```
func sendMail(to mail.Address, subject, body string) error {
from := mail.Address{
Name: "Passwordless Demo",
Address: "noreply@" + config.appURL.Host,
}
headers := map[string]string{
"From": from.String(),
"To": to.String(),
"Subject": subject,
"Content-Type": `text/html; charset="utf-8"`,
}
msg := ""
for k, v := range headers {
msg += fmt.Sprintf("%s: %s\r\n", k, v)
}
msg += "\r\n"
msg += body
return smtp.SendMail(
config.smtpAddr,
config.smtpAuth,
from.Address,
[]string{to.Address},
[]byte(msg))
}
```
这个函数创建一个基本的 HTML 邮件结构体并使用 SMTP 服务器去发送它。邮件的内容你可以随意定制,我喜欢使用比较简单的内容。
#### 无密码验证重定向的处理程序
```
var rxUUID = regexp.MustCompile("^[0-9a-f]{8}-[0-9a-f]{4}-4[0-9a-f]{3}-[89ab][0-9a-f]{3}-[0-9a-f]{12}$")
```
首先,这个正则表达式去验证一个 UUID(即验证代码)。
现在进入 `passwordlessVerifyRedirect` 函数内部:
```
q := r.URL.Query()
verificationCode := q.Get("verification_code")
redirectURI := q.Get("redirect_uri")
```
`/api/passwordless/verify_redirect` 是一个 `GET` 端点,以便于我们从查询字符串中读取数据。
```
errs := make(map[string]string)
if verificationCode == "" {
errs["verification_code"] = "Verification code required"
} else if !rxUUID.MatchString(verificationCode) {
errs["verification_code"] = "Invalid verification code"
}
var callback *url.URL
var err error
if redirectURI == "" {
errs["redirect_uri"] = "Redirect URI required"
} else if callback, err = url.Parse(redirectURI); err != nil || !callback.IsAbs() {
errs["redirect_uri"] = "Invalid redirect URI"
}
if len(errs) != 0 {
respondJSON(w, errs, http.StatusUnprocessableEntity)
return
}
```
类似的验证,我们保存解析后的重定向 URI 到一个 `callback` 变量中。
```
var userID string
if err := db.QueryRowContext(r.Context(), `
DELETE FROM verification_codes
WHERE id = $1
AND created_at >= now() - INTERVAL '15m'
RETURNING user_id
`, verificationCode).Scan(&userID); err == sql.ErrNoRows {
respondJSON(w, "Link expired or already used", http.StatusBadRequest)
return
} else if err != nil {
respondInternalError(w, fmt.Errorf("could not delete verification code: %v", err))
return
}
```
这个 SQL 查询通过给定的 id 去删除相应的验证代码,并且确保它创建之后时间不超过 15 分钟,它也返回关联的 `user_id`。如果没有检索到内容,意味着代码不存在或者已过期,我们返回一个响应信息,否则就返回一个内部错误。
```
expiresAt := time.Now().Add(time.Hour * 24 * 60)
tokenString, err := jwt.NewWithClaims(jwt.SigningMethodHS256, jwt.StandardClaims{
Subject: userID,
ExpiresAt: expiresAt.Unix(),
}).SignedString(config.jwtKey)
if err != nil {
respondInternalError(w, fmt.Errorf("could not create JWT: %v", err))
return
}
```
这些是如何去创建 JWT。我们为 JWT 设置一个 60 天的过期值,你也可以设置更短的时间(大约 2 周),并添加一个新端点去刷新令牌,但是不要搞的过于复杂。
```
expiresAtB, err := expiresAt.MarshalText()
if err != nil {
respondInternalError(w, fmt.Errorf("could not marshal expiration date: %v", err))
return
}
f := make(url.Values)
f.Set("jwt", tokenString)
f.Set("expires_at", string(expiresAtB))
callback.Fragment = f.Encode()
```
我们去规划重定向;你可使用查询字符串去添加 JWT,但是更常见的是使用一个哈希片段。如:`https://frontend.app/callback#jwt=token_here&expires_at=some_date`.
过期日期可以从 JWT 中提取出来,但是这样做的话,就需要在客户端上实现一个 JWT 库来解码它,因此为了简化,我将它加到这里。
```
http.Redirect(w, r, callback.String(), http.StatusFound)
```
最后我们使用一个 `302 Found` 重定向。
---
无密码的流程已经完成。现在需要去写 `getAuthUser` 端点的代码了,它用于获取当前验证用户的信息。你应该还记得,这个端点使用了 `guard` 中间件。
#### 使用 Auth 中间件
在编写 `guard` 中间件之前,我将编写一个不需要验证的分支。目的是,如果没有传递 JWT,它将不去验证用户。
```
type ContextKey struct {
Name string
}
var keyAuthUserID = ContextKey{"auth_user_id"}
func withAuth(next http.HandlerFunc) http.HandlerFunc {
return func(w http.ResponseWriter, r *http.Request) {
a := r.Header.Get("Authorization")
hasToken := strings.HasPrefix(a, "Bearer ")
if !hasToken {
next(w, r)
return
}
tokenString := a[7:]
p := jwt.Parser{ValidMethods: []string{jwt.SigningMethodHS256.Name}}
token, err := p.ParseWithClaims(
tokenString,
&jwt.StandardClaims{},
func (*jwt.Token) (interface{}, error) { return config.jwtKey, nil },
)
if err != nil {
respondJSON(w, http.StatusText(http.StatusUnauthorized), http.StatusUnauthorized)
return
}
claims, ok := token.Claims.(*jwt.StandardClaims)
if !ok || !token.Valid {
respondJSON(w, http.StatusText(http.StatusUnauthorized), http.StatusUnauthorized)
return
}
ctx := r.Context()
ctx = context.WithValue(ctx, keyAuthUserID, claims.Subject)
next(w, r.WithContext(ctx))
}
}
```
JWT 将在每次请求时以 `Bearer <token_here>` 格式包含在 `Authorization` 头中。因此,如果没有提供令牌,我们将直接通过,进入接下来的中间件。
我们创建一个解析器来解析令牌。如果解析失败则返回 `401 Unauthorized`。
然后我们从 JWT 中提取出要求的内容,并添加 `Subject`(就是用户 ID)到需要的地方。
#### Guard 中间件
```
func guard(next http.HandlerFunc) http.HandlerFunc {
return withAuth(func(w http.ResponseWriter, r *http.Request) {
_, ok := r.Context().Value(keyAuthUserID).(string)
if !ok {
respondJSON(w, http.StatusText(http.StatusUnauthorized), http.StatusUnauthorized)
return
}
next(w, r)
})
}
```
现在,`guard` 将使用 `withAuth` 并从请求内容中提取出验证用户的 ID。如果提取失败,它将返回 `401 Unauthorized`,提取成功则继续下一步。
#### 获取 Auth 用户
在 `getAuthUser` 处理程序内部:
```
ctx := r.Context()
authUserID := ctx.Value(keyAuthUserID).(string)
user, err := fetchUser(ctx, authUserID)
if err == sql.ErrNoRows {
respondJSON(w, http.StatusText(http.StatusTeapot), http.StatusTeapot)
return
} else if err != nil {
respondInternalError(w, fmt.Errorf("could not query auth user: %v", err))
return
}
respondJSON(w, user, http.StatusOK)
```
首先,我们从请求内容中提取验证用户的 ID,我们使用这个 ID 去获取用户。如果没有获取到内容,则发送一个 `418 I'm a teapot`,或者一个内部错误。最后,我们将用这个用户去响应。
#### 获取 User 函数
下面你看到的是 `fetchUser` 函数。
```
func fetchUser(ctx context.Context, id string) (User, error) {
user := User{ID: id}
err := db.QueryRowContext(ctx, `
SELECT email, username FROM users WHERE id = $1
`, id).Scan(&user.Email, &user.Username)
return user, err
}
```
我将它解耦是因为通过 ID 来获取用户是个常做的事。
---
以上就是全部的代码。你可以自己去构建它和测试它。[这里](https://go-passwordless-demo.herokuapp.com/) 还有一个 demo 你可以试用一下。
如果你在 mailtrap 上点击之后出现有关 `脚本运行被拦截,因为文档的框架是沙箱化的,并且没有设置 'allow-scripts' 权限` 的问题,你可以尝试右键点击 “在新标签中打开链接“。这样做是安全的,因为邮件内容是 [沙箱化的](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/iframe#attr-sandbox)。我在 `localhost` 上有时也会出现这个问题,但是我认为你一旦以 `https://` 方式部署到服务器上应该不会出现这个问题了。
如果有任何问题,请在我的 [GitHub repo](https://github.com/nicolasparada/go-passwordless-demo) 留言或者提交 PRs
以后,我为这个 API 写了一个客户端作为这篇文章的[第二部分](https://nicolasparada.netlify.com/posts/passwordless-auth-client/)。
---
via: <https://nicolasparada.netlify.com/posts/passwordless-auth-server/>
作者:[Nicolás Parada](https://nicolasparada.netlify.com/) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
9,750 | 如何装载/卸载 Linux 内核模块 | https://opensource.com/article/18/5/how-load-or-unload-linux-kernel-module | 2018-06-16T11:20:38 | [
"模块",
"内核"
] | https://linux.cn/article-9750-1.html |
>
> 找到并装载内核模块以解决外设问题。
>
>
>

本文来自 Manning 出版的 [Linux in Action](https://www.manning.com/books/linux-in-action?a_aid=bootstrap-it&a_bid=4ca15fc9&chan=opensource) 的第 15 章。
Linux 使用内核模块管理硬件外设。 我们来看看它是如何工作的。
运行中的 Linux 内核是您不希望被破坏的东西之一。毕竟,内核是驱动计算机所做的一切工作的软件。考虑到在一个运行的系统上必须同时管理诸多细节,最好能让内核尽可能的减少分心,专心的完成它的工作。但是,如果对计算环境进行任何微小的更改都需要重启整个系统,那么插入一个新的网络摄像头或打印机就可能会严重影响您的工作流程。每次添加设备时都必须重新启动,以使系统识别它,这效率很低。
为了在稳定性和可用性之间达成有效的平衡,Linux 将内核隔离,但是允许您通过可加载内核模块 (LKM) 实时添加特定的功能。如下图所示,您可以将模块视为软件的一部分,它告诉内核在哪里找到一个设备以及如何使用它。反过来,内核使设备对用户和进程可用,并监视其操作。

*内核模块充当设备和 Linux 内核之间的转换器。*
虽然你可以自己编写模块来完全按照你喜欢的方式来支持一个设备,但是为什么要这样做呢?Linux 模块库已经非常强大,通常不需要自己去实现一个模块。 而绝大多数时候,Linux 会自动加载新设备的模块,而您甚至不知道它。
不过,有时候,出于某种原因,它本身并不会自动进行。(你肯定不想让那个招聘经理不耐烦地一直等待你的笑脸加入视频面试。)为了帮助你解决问题,你需要更多地了解内核模块,特别是,如何找到运行你的外设的实际模块,然后如何手动激活它。
### 查找内核模块
按照公认的约定,内核模块是位于 `/lib/modules/` 目录下的具有 .ko(内核对象)扩展名的文件。 然而,在你找到这些文件之前,你还需要选择一下。因为在引导时你需要从版本列表中选择其一加载,所以支持您选择的特定软件(包括内核模块)必须存在某处。 那么,`/lib/modules/` 就是其中之一。 你会发现目录里充满了每个可用的 Linux 内核版本的模块; 例如:
```
$ ls /lib/modules
4.4.0-101-generic
4.4.0-103-generic
4.4.0-104-generic
```
在我的电脑上,运行的内核是版本号最高的版本(4.4.0-104-generic),但不能保证这对你来说是一样的(内核经常更新)。 如果您将要在一个运行的系统上使用模块完成一些工作的话,你需要确保您找到正确的目录树。
好消息:有一个可靠的窍门。相对于通过名称来识别目录,并希望能够找到正确的目录,你可以使用始终指向使用的内核名称的系统变量。 您可以使用 `uname -r`( `-r` 从系统信息中指定通常显示的内核版本号)来调用该变量:
```
$ uname -r
4.4.0-104-generic
```
通过这些信息,您可以使用称为命令替换的过程将 `uname` 并入您的文件系统引用中。 例如,要导航到正确的目录,您需要将其添加到 `/lib/modules` 。 要告诉 Linux “uname” 不是一个文件系统中的位置,请将 `uname` 部分用反引号括起来,如下所示:
```
$ ls /lib/modules/`uname -r`
build modules.alias modules.dep modules.softdep
initrd modules.alias.bin modules.dep.bin modules.symbols
kernel modules.builtin modules.devname modules.symbols.bin
misc modules.builtin.bin modules.order vdso
```
你可以在 `kernel/` 目录下的子目录中找到大部分模块。 花几分钟时间浏览这些目录,了解事物的排列方式和可用内容。 这些文件名通常会让你知道它们是什么。
```
$ ls /lib/modules/`uname -r`/kernel
arch crypto drivers fs kernel lib mm
net sound ubuntu virt zfs
```
这是查找内核模块的一种方法;实际上,这是一种快速的方式。 但这不是唯一的方法。 如果你想获得完整的集合,你可以使用 `lsmod` 列出所有当前加载的模块以及一些基本信息。 这个截断输出的第一列(在这里列出的太多了)是模块名称,后面是文件大小和数量,然后是每个模块的名称:
```
$ lsmod
[...]
vboxdrv 454656 3 vboxnetadp,vboxnetflt,vboxpci
rt2x00usb 24576 1 rt2800usb
rt2800lib 94208 1 rt2800usb
[...]
```
到底有多少?好吧,我们再运行一次 `lsmod` ,但是这一次将输出管道输送到 `wc -l` 看一下一共多少行:
```
$ lsmod | wc -l
113
```
这是已加载的模块。 总共有多少个? 运行 `modprobe -c` 并计算这些行将给我们这个数字:
```
$ modprobe -c | wc -l
33350
```
有 33,350 个可用模块!? 看起来好像有人多年来一直在努力为我们提供软件来驱动我们的物理设备。
注意:在某些系统中,您可能会遇到自定义的模块,这些模块要么在 `/etc/modules` 文件中使用独特的条目进行引用,要么在 `/etc/modules-load.d/` 下的配置文件中。这些模块很可能是本地开发项目的产物,可能涉及前沿实验。不管怎样,知道你看到的是什么总是好的。
这就是如何找到模块的方法。 如果出于某种原因,它不会自行加载,您的下一个工作就是弄清楚如何手动加载未激活的模块。
### 手动加载内核模块
在加载内核模块之前,逻辑上您必须确认它存在。在这之前,你需要知道它叫什么。要做到这一点,有时需要兼有魔法和运气以及在线文档作者的辛勤工作的帮助。
我将通过描述一段时间前遇到的问题来说明这个过程。在一个晴朗的日子里,出于某种原因,笔记本电脑上的 WiFi 接口停止工作了。就这样。也许是软件升级把它搞砸了。谁知道呢?我运行了 `lshw -c network` ,得到了这个非常奇怪的信息:
```
network UNCLAIMED
AR9485 Wireless Network Adapter
```
Linux 识别到了接口(Atheros AR9485),但将其列为未声明。 那么,正如他们所说的那样,“当情况变得严峻时,就会在互联网上进行艰难的搜索。” 我搜索了一下 atheros ar9 linux 模块,在浏览了一页又一页五年前甚至是十年前的页面后,它们建议我自己写个模块或者放弃吧,然后我终于发现(最起码 Ubuntu 16.04)有一个可以工作的模块。 它的名字是 ath9k 。
是的! 这场战斗胜券在握!向内核添加模块比听起来容易得多。 要仔细检查它是否可用,可以针对模块的目录树运行 `find`,指定 `-type f` 来告诉 Linux 您正在查找文件,然后将字符串 `ath9k` 和星号一起添加以包含所有以你的字符串打头的文件:
```
$ find /lib/modules/$(uname -r) -type f -name ath9k*
/lib/modules/4.4.0-97-generic/kernel/drivers/net/wireless/ath/ath9k/ath9k_common.ko
/lib/modules/4.4.0-97-generic/kernel/drivers/net/wireless/ath/ath9k/ath9k.ko
/lib/modules/4.4.0-97-generic/kernel/drivers/net/wireless/ath/ath9k/ath9k_htc.ko
/lib/modules/4.4.0-97-generic/kernel/drivers/net/wireless/ath/ath9k/ath9k_hw.ko
```
再一步,加载模块:
```
# modprobe ath9k
```
就是这样。无启动,没烦恼。
这里还有一个示例,向您展示如何使用已经崩溃的运行模块。曾经有一段时间,我使用罗技网络摄像头和一个特定的软件会使摄像头在下次系统启动前无法被任何其他程序访问。有时我需要在不同的应用程序中打开相机,但没有时间关机重新启动。(我运行了很多应用程序,在引导之后将它们全部准备好需要一些时间。)
由于这个模块可能是运行的,所以使用 `lsmod` 来搜索 video 这个词应该给我一个关于相关模块名称的提示。 实际上,它比提示更好:用 video 这个词描述的唯一模块是 uvcvideo(如下所示):
```
$ lsmod | grep video
uvcvideo 90112 0
videobuf2_vmalloc 16384 1 uvcvideo
videobuf2_v4l2 28672 1 uvcvideo
videobuf2_core 36864 2 uvcvideo,videobuf2_v4l2
videodev 176128 4 uvcvideo,v4l2_common,videobuf2_core,videobuf2_v4l2
media 24576 2 uvcvideo,videodev
```
有可能是我自己的操作导致了崩溃,我想我可以挖掘更深一点,看看我能否以正确的方式解决问题。但结果你知道的;有时你不关心理论,只想让设备工作。 所以我用 `rmmod` 杀死了 `uvcvideo` 模块,然后用 `modprobe` 重新启动它,一切都好:
```
# rmmod uvcvideo
# modprobe uvcvideo
```
再一次:不重新启动。没有其他的后续影响。
---
via: <https://opensource.com/article/18/5/how-load-or-unload-linux-kernel-module>
作者:[David Clinton](https://opensource.com/users/dbclinton) 选题:[lujun9972](https://github.com/lujun9972) 译者:[amwps290](https://github.com/amwps290) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *This article is excerpted from chapter 15 of Linux in Action, published by Manning.*
Linux manages hardware peripherals using kernel modules. Here's how that works.
A running Linux kernel is one of those things you don't want to upset. After all, the kernel is the software that drives everything your computer does. Considering how many details have to be simultaneously managed on a live system, it's better to leave the kernel to do its job with as few distractions as possible. But if it's impossible to make even small changes to the compute environment without rebooting the whole system, then plugging in a new webcam or printer could cause a painful disruption to your workflow. Having to reboot each time you add a device to get the system to recognize it is hardly efficient.
To create an effective balance between the opposing virtues of stability and usability, Linux isolates the kernel, but lets you add specific functionality on the fly through loadable kernel modules (LKMs). As shown in the figure below, you can think of a module as a piece of software that tells the kernel where to find a device and what to do with it. In turn, the kernel makes the device available to users and processes and oversees its operation.
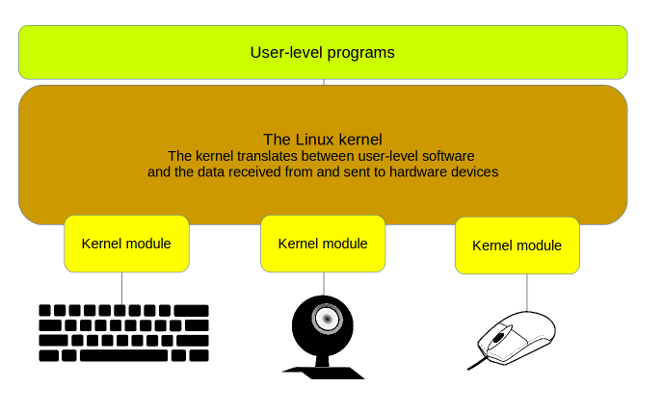
Kernel modules act as translators between devices and the Linux kernel.
There's nothing stopping you from writing your own module to support a device exactly the way you'd like it, but why bother? The Linux module library is already so robust that there's usually no need to roll your own. And the vast majority of the time, Linux will automatically load a new device's module without you even knowing it.
Still, there are times when, for some reason, it doesn't happen by itself. (You don't want to leave that hiring manager impatiently waiting for your smiling face to join the video conference job interview for too long.) To help things along, you'll want to understand a bit more about kernel modules and, in particular, how to find the actual module that will run your peripheral and then how to manually activate it.
## Finding kernel modules
By accepted convention, modules are files with a .ko (kernel object) extension that live beneath the `/lib/modules/`
directory. Before you navigate all the way down to those files, however, you'll probably have to make a choice. Because you're given the option at boot time of loading one from a list of releases, the specific software needed to support your choice (including the kernel modules) has to exist somewhere. Well, `/lib/modules`
/ is one of those somewheres. And that's where you'll find directories filled with the modules for each available Linux kernel release; for example:
```
$ ls /lib/modules
4.4.0-101-generic
4.4.0-103-generic
4.4.0-104-generic
```
In my case, the active kernel is the version with the highest release number (4.4.0-104-generic), but there's no guarantee that that'll be the same for you (kernels are frequently updated). If you're going to be doing some work with modules that you'd like to use on a live system, you need to be sure you've got the right directory tree.
Good news: there's a reliable trick. Rather than identifying the directory by name and hoping you'll get the right one, use the system variable that always points to the name of the active kernel. You can invoke that variable using `uname -r`
(the `-r`
specifies the kernel release number from within the system information that would normally be displayed):
```
$ uname -r
4.4.0-104-generic
```
With that information, you can incorporate `uname`
into your filesystem references using a process known as *command substitution*. To navigate to the right directory, for instance, you'd add it to `/lib/modules`
. To tell Linux that "uname" isn't a filesystem location, enclose the `uname`
part in backticks, like this:
```
$ ls /lib/modules/`uname -r`
build modules.alias modules.dep modules.softdep
initrd modules.alias.bin modules.dep.bin modules.symbols
kernel modules.builtin modules.devname modules.symbols.bin
misc modules.builtin.bin modules.order vdso
```
You'll find most of the modules organized within their subdirectories beneath the `kernel/`
directory. Take a few minutes to browse through those directories to get an idea of how things are arranged and what's available. The filenames usually give you a good idea of what you're looking at.
```
$ ls /lib/modules/`uname -r`/kernel
arch crypto drivers fs kernel lib mm
net sound ubuntu virt zfs
```
That's one way to locate kernel modules; actually, it's the quick and dirty way to go about it. But it's not the only way. If you want to get the complete set, you can list all currently loaded modules, along with some basic information, by using `lsmod`
. The first column of this truncated output (there would be far too many to list here) is the module name, followed by the file size and number, and then the names of other modules on which each is dependent:
```
$ lsmod
[...]
vboxdrv 454656 3 vboxnetadp,vboxnetflt,vboxpci
rt2x00usb 24576 1 rt2800usb
rt2800lib 94208 1 rt2800usb
[...]
```
How many are far too many? Well, let's run `lsmod`
once again, but this time piping the output to `wc -l`
to get a count of the lines:
```
$ lsmod | wc -l
113
```
Those are the loaded modules. How many are available in total? Running `modprobe -c`
and counting the lines will give us that number:
```
$ modprobe -c | wc -l
33350
```
There are 33,350 available modules!?! It looks like someone's been working hard over the years to provide us with the software to run our physical devices.
Note: On some systems, you might encounter customized modules that are referenced either with their unique entries in the `/etc/modules`
file or as a configuration file saved to `/etc/modules-load.d/`
. The odds are that such modules are the product of local development projects, perhaps involving cutting-edge experiments. Either way, it's good to have some idea of what it is you're looking at.
That's how you find modules. Your next job is to figure out how to manually load an inactive module if, for some reason, it didn't happen on its own.
## Manually loading kernel modules
Before you can load a kernel module, logic dictates that you'll have to confirm it exists. And before you can do that, you'll need to know what it's called. Getting that part sometimes requires equal parts magic and luck and some help from of the hard work of online documentation authors.
I'll illustrate the process by describing a problem I ran into some time back. One fine day, for a reason that still escapes me, the WiFi interface on a laptop stopped working. Just like that. Perhaps a software update knocked it out. Who knows? I ran `lshw -c network`
and was treated to this very strange information:
```
network UNCLAIMED
AR9485 Wireless Network Adapter
```
Linux recognized the interface (the Atheros AR9485) but listed it as unclaimed. Well, as they say, "When the going gets tough, the tough search the internet." I ran a search for *atheros ar9 linux module* and, after sifting through pages and pages of five- and even 10-year-old results advising me to either write my own module or just give up, I finally discovered that (with Ubuntu 16.04, at least) a working module existed. Its name is ath9k.
Yes! The battle's as good as won! Adding a module to the kernel is a lot easier than it sounds. To double check that it's available, you can run `find`
against the module's directory tree, specify `-type f`
to tell Linux you're looking for a file, and then add the string `ath9k`
along with a glob asterisk to include all filenames that start with your string:
```
$ find /lib/modules/$(uname -r) -type f -name ath9k*
/lib/modules/4.4.0-97-generic/kernel/drivers/net/wireless/ath/ath9k/ath9k_common.ko
/lib/modules/4.4.0-97-generic/kernel/drivers/net/wireless/ath/ath9k/ath9k.ko
/lib/modules/4.4.0-97-generic/kernel/drivers/net/wireless/ath/ath9k/ath9k_htc.ko
/lib/modules/4.4.0-97-generic/kernel/drivers/net/wireless/ath/ath9k/ath9k_hw.ko
```
Just one more step, load the module:
`# modprobe ath9k`
That's it. No reboots. No fuss.
Here's one more example to show you how to work with active modules that have become corrupted. There was a time when using my Logitech webcam with a particular piece of software would make the camera inaccessible to any other programs until the next system boot. Sometimes I needed to open the camera in a different application but didn't have the time to shut down and start up again. (I run a lot of applications, and getting them all in place after booting takes some time.)
Because this module is presumably active, using `lsmod`
to search for the word *video* should give me a hint about the name of the relevant module. In fact, it's better than a hint: The only module described with the word *video* is *uvcvideo* (as you can see in the following):
```
$ lsmod | grep video
uvcvideo 90112 0
videobuf2_vmalloc 16384 1 uvcvideo
videobuf2_v4l2 28672 1 uvcvideo
videobuf2_core 36864 2 uvcvideo,videobuf2_v4l2
videodev 176128 4 uvcvideo,v4l2_common,videobuf2_core,videobuf2_v4l2
media 24576 2 uvcvideo,videodev
```
There was probably something I could have controlled for that was causing the crash, and I guess I could have dug a bit deeper to see if I could fix things the right way. But you know how it is; sometimes you don't care about the theory and just want your device working. So I used `rmmod`
to kill the uvcvideo module and `modprobe`
to start it up again all nice and fresh:
```
# rmmod uvcvideo
# modprobe uvcvideo
```
Again: no reboots. No stubborn blood stains.
## Comments are closed. |
9,751 | Vim-plug:极简 Vim 插件管理器 | https://www.ostechnix.com/vim-plug-a-minimalist-vim-plugin-manager/ | 2018-06-16T11:44:32 | [
"Vim",
"插件"
] | https://linux.cn/article-9751-1.html | 
当没有插件管理器时,Vim 用户必须手动下载 tarball 包形式的插件,并将它们解压到 `~/.vim` 目录中。在少量插件的时候可以。但当他们安装更多的插件时,就会变得一团糟。所有插件文件分散在单个目录中,用户无法找到哪个文件属于哪个插件。此外,他们无法找到他们应该删除哪个文件来卸载插件。这时 Vim 插件管理器就可以派上用场。插件管理器将安装插件的文件保存在单独的目录中,因此管理所有插件变得非常容易。我们几个月前已经写了关于 [Vundle](/article-9416-1.html) 的文章。今天,我们将看到又一个名为 “Vim-plug” 的 Vim 插件管理器。
Vim-plug 是一个自由、开源、速度非常快的、极简的 vim 插件管理器。它可以并行地安装或更新插件。你还可以回滚更新。它创建<ruby> 浅层克隆 <rt> shallow clone </rt></ruby>最小化磁盘空间使用和下载时间。它支持按需加载插件以加快启动时间。其他值得注意的特性是支持分支/标签/提交、post-update 钩子、支持外部管理的插件等。
### 安装
安装和使用起来非常容易。你只需打开终端并运行以下命令:
```
$ curl -fLo ~/.vim/autoload/plug.vim --create-dirs https://raw.githubusercontent.com/junegunn/vim-plug/master/plug.vim
```
Neovim 用户可以使用以下命令安装 Vim-plug:
```
$ curl -fLo ~/.config/nvim/autoload/plug.vim --create-dirs https://raw.githubusercontent.com/junegunn/vim-plug/master/plug.vim
```
### 用法
#### 安装插件
要安装插件,你必须如下所示首先在 Vim 配置文件中声明它们。一般 Vim 的配置文件是 `~/.vimrc`,Neovim 的配置文件是 `~/.config/nvim/init.vim`。请记住,当你在配置文件中声明插件时,列表应该以 `call plug#begin(PLUGIN_DIRECTORY)` 开始,并以 `plug#end()` 结束。
例如,我们安装 “lightline.vim” 插件。为此,请在 `~/.vimrc` 的顶部添加以下行。
```
call plug#begin('~/.vim/plugged')
Plug 'itchyny/lightline.vim'
call plug#end()
```
在 vim 配置文件中添加上面的行后,通过输入以下命令重新加载:
```
:source ~/.vimrc
```
或者,只需重新加载 Vim 编辑器。
现在,打开 vim 编辑器:
```
$ vim
```
使用以下命令检查状态:
```
:PlugStatus
```
然后输入下面的命令,然后按回车键安装之前在配置文件中声明的插件。
```
:PlugInstall
```
#### 更新插件
要更新插件,请运行:
```
:PlugUpdate
```
更新插件后,按下 `d` 查看更改。或者,你可以之后输入 `:PlugDiff`。
#### 审查插件
有时,更新的插件可能有新的 bug 或无法正常工作。要解决这个问题,你可以简单地回滚有问题的插件。输入 `:PlugDiff` 命令,然后按回车键查看上次 `:PlugUpdate`的更改,并在每个段落上按 `X` 将每个插件回滚到更新前的前一个状态。
#### 删除插件
删除一个插件删除或注释掉你以前在你的 vim 配置文件中添加的 `plug` 命令。然后,运行 `:source ~/.vimrc` 或重启 Vim 编辑器。最后,运行以下命令卸载插件:
```
:PlugClean
```
该命令将删除 vim 配置文件中所有未声明的插件。
#### 升级 Vim-plug
要升级vim-plug本身,请输入:
```
:PlugUpgrade
```
如你所见,使用 Vim-plug 管理插件并不难。它简化了插件管理。现在去找出你最喜欢的插件并使用 Vim-plug 来安装它们。
就是这些了。我将很快在这里发布另一个有趣的话题。在此之前,请继续关注我们。
干杯!
---
via: <https://www.ostechnix.com/vim-plug-a-minimalist-vim-plugin-manager/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,752 | 机器人学影响 CIO 角色的 3 种方式 | https://enterprisersproject.com/article/2017/11/3-ways-robotics-affects-cio-role | 2018-06-16T12:08:41 | [
"CIO"
] | https://linux.cn/article-9752-1.html |
>
> 机器人流程自动化如何影响 CIO ?考虑这些可能。
>
>
>

随着 2017 的结束,许多 CIO 们的 2018 年目标也将确定。或许你们将参与到机器人流程自动化(RPA)中。多年以来,RPA 对许多公司来说只是一个可望不可及的概念。但是随着组织被迫变得越来越敏捷高效,RPA 所具有的潜在优势开始受到重视。
根据 Redwood Sofeware 和 Sapio Research 的最新 [研究报告](https://www.redwood.com/press-releases/it-decision-makers-speak-59-of-business-processes-could-be-automated-by-2022/),IT 决策者们相信,未来 5 年有 59% 的业务可以被自动化处理,从而产生新的速度和效率,并且消减相应的重复性的人工工作量的岗位。但是,目前在相应岗位上没有实施 RPA 的公司中,有 20% 的公司员工超过 1000 人。
对于 CIO 们来说,RPA 会潜在影响你在业务中的角色和你的团队。随着 RPA 的地位在 2018 年中越来越重要,CIO 们和其它 IT 决策者的角色也能会受到如下三种方式的改变:
### 成为战略性变革代理人的机会增加
随着压力的增长,用最少的时间做更多的事,内部流程越来越重要。在每个企业中,员工们每天做着既重要又枯燥的一些任务。这些任务可能是枯燥且重复性的任务,但是要求他们必须快速完成且不能出错。
**[有关你的自动化策略的 ROI 建议,查看我们相关的文章,[如何在自动化方面提升 ROI:4 个小提示](https://enterprisersproject.com/article/2017/11/how-improve-roi-automation-4-tips?sc_cid=70160000000h0aXAAQ)。]**
在财务中从后台的一些操作到采购、供应链、账务、客户服务、以及人力资源,在一个组织中几乎所有的岗位都有一些枯燥的任务。这就为 CIO 们提供了一个机会,将 IT 与业务联合起来,成为使用 RPA 进行战略变革的先锋。
除了过去的屏幕抓取技术,机器人现在已经实现可定制化,即插即用的解决方案可以根据企业的需要进行设计。使用这种以流程为中心的方法,企业不仅可以将以前由人来完成的任务进行自动化,也可以将应用程序和系统特定任务自动化,比如 ERP 和企业其它应用程序。
为端到端的流程实施更高级别的自动化将是 CIO 们的价值所在。CIO 们将会站在这种机遇的最前沿。
### 重新关注人和培训
技术的变动将让员工更加恐慌,尤其是当这些自动化的变动涉及到他们每日职责的相当大的部分。CIO 们应该清楚地告诉他们,RPA 将如何让他们的角色和责任变得更好,以及用数据说明的、最终将影响到他们底线的战略决策。
当实施 RPA 时,清晰明确地表达出“人对组织的成功来说是很重要的”信息是很关键的,并且,这种成功需要使技术和人的技能实现适当的平衡。
CIO 们也应该分析工作流并实施更好的流程,这种流程能够超越以前由终端用户完成的特定任务。通过端到端的流程自动化,CIO 们可以让员工表现更加出色。
因为在整个自动化的过程中,提升和培训员工技术是很重要的,CIO 们必须与企业高管们一起去决定,帮助员工自信地应对变化的培训项目。
### 需要长远的规划
为确保机器人流程自动化的成功,甲方必须有一个长期的方法。这将要求一个弹性的解决方案,它将对整个业务模型有好处,包括消费者。比如,当年亚马逊为他的 Prime 消费者推广快速投递服务时,他们不仅在他们的仓库中重新调整了订单交付流程,他们也自动化了他们的在线客户体验,让它们变得更简化、更快速,并且让消费者比以前更容易下订单。
在即将到来的一年里,CIO 们可以用同样的方法来应用技术,构建整体的解决方案来改变组织的动作方式。裁员只会让最终效益产生很大影响,但是流程自动化将使 CIO 们能够通过优化和授权来考虑更大的问题。这种方法让 CIO 们去为他们自己和 RPA 构建长期的信誉。这反过来将强化 CIO 们作为探路者的角色,并为整个组织的成功作出贡献。
对于 CIO 们来说,采用一个长期的、策略性的方法让 RPA 成功,需要时间和艰苦的努力。尽管如此,那些致力于创建一种人力和技术平衡战略的 CIO 们,将会在现在和将来实现更大的价值。
---
via: <https://enterprisersproject.com/article/2017/11/3-ways-robotics-affects-cio-role>
作者:[Dennis Walsh](https://enterprisersproject.com/user/dennis-walsh) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | As 2017 comes to a close, many CIOs are solidifying their goals for 2018. Perhaps yours involve robotic process automation (RPA.) For years, RPA has been a distant concept for many companies. But as organizations are forced to become ever more nimble and efficient, the potential benefits of RPA bear examining.
According to a recent[ survey](https://www.redwood.com/press-releases/it-decision-makers-speak-59-of-business-processes-could-be-automated-by-2022/) by Redwood Software and Sapio Research, IT decision makers believe that 59 percent of business processes can be automated in the next five years, creating new speed and efficiency while relieving their human counterparts of repetitive manual workloads. However, 20 percent of companies with more than 1000 employees currently have no RPA strategy in place.
For CIOs, RPA has implications for your role in the business and for your team. Here are three ways that the role of the CIO and other IT decision makers can change as RPA gains prominence in 2018:
## Added opportunity to be strategic change agents
As the pressure grows to do more with less, internal processes matter greatly. In every enterprise, employees across departments are performing critical – yet mundane – tasks every single day. These tasks may be boring and repetitive, but they must be performed quickly, and often with no room for error.
**[ For advice on maximizing your automation strategy's ROI, see our related article, How to improve ROI on automation: 4 tips. ]**
From back-office operations in finance to procurement, supply chain, accounting, customer service, and human resources, nearly every position within an organization is plagued with at least some monotonous tasks. For CIOs, this opens up an opportunity to unite the business with IT and spearhead strategic change with RPA.
Having evolved far beyond screen-scraping technology of the past, robots are now customizable, plug-and-play solutions that can be built to an organization’s specific needs. With such a process-centric approach, companies can automate not only tasks previously executed by humans, but also application and system-specific tasks, such as ERP and other enterprise applications.
Enabling a greater level of automation for end-to-end processes is where the value lies. CIOs will be on the front line of this opportunity.
## Renewed focus on people and training
Technology shifts can be unnerving to employees, especially when these changes involve automating substantial portions of their daily duties. The CIO should articulate how RPA will change roles and responsibilities for the better, and fuel data-driven, strategic decisions that will ultimately impact the bottom line.
When implementing RPA, it’s important to convey that humans will always be critical to the success of the organization, and that success requires the right balance of technology and human skills.
CIOs should also analyze workflow and implement better processes that go beyond mimicking end-user specific tasks. Through end-to-end process automation, CIOs can enable employees to shine.
Because it will be important to upskill and retrain employees throughout the automation process, CIOs must be prepared to collaborate with the C-suite to determine training programs that help employees navigate the change with confidence.
## Demand for long-term thinking
To succeed with robotic process automation, brands must take a long-term approach. This will require a scalable solution, which in turn will benefit the entire business model, including customers. When Amazon introduced faster delivery options for Prime customers, for example, it didn’t just retool the entire order fulfillment process in its warehouses; it automated its online customer experience to make it simpler, faster, and easier than ever for consumers to place orders.
In the coming year, CIOs can approach technology in the same way, architecting holistic solutions to change the way an organization operates. Reducing headcount will net only so much in bottom-line results, but process automation allows CIOs to think bigger through optimization and empowerment. This approach gives CIOs the opportunity to build credibility for the long haul, for themselves and for RPA. This in turn will enhance the CIO’s role as a navigator and contributor to the organization's overall success.
For CIOs, taking a long-term, strategic approach to RPA success takes time and hard work. Nevertheless, CIOs who commit the time to create a strategy that balances manpower and technology will deliver value now and in the future.
## Comments
Good pointers for CIOs to take note of with regards to Robotic Process Automation (RPA).. |
9,753 | 如何在 Linux 中不安装软件测试一个软件包 | https://www.ostechnix.com/how-to-test-a-package-without-installing-it-in-linux/ | 2018-06-16T22:57:00 | [
"安装",
"软件包"
] | https://linux.cn/article-9753-1.html | 
出于某种原因,你可能需要在将软件包安装到你的 Linux 系统之前对其进行测试。如果是这样,你很幸运!今天,我将向你展示如何在 Linux 中使用 **Nix** 包管理器来实现。Nix 包管理器的一个显著特性是它允许用户测试软件包而无需先安装它们。当你想要临时使用特定的程序时,这会很有帮助。
### 测试一个软件包而不在 Linux 中安装它
确保你先安装了 Nix 包管理器。如果尚未安装,请参阅以下指南。
例如,假设你想测试你的 C++ 代码。你不必安装 GCC。只需运行以下命令:
```
$ nix-shell -p gcc
```
该命令会构建或下载 gcc 软件包及其依赖项,然后将其放入一个存在 `gcc` 命令的 Bash shell 中,所有这些都不会影响正常环境。
```
LANGUAGE = (unset),
LC_ALL = (unset),
LANG = "en_US.UTF-8"
are supported and installed on your system.
perl: warning: Falling back to the standard locale ("C").
download-using-manifests.pl: perl: warning: Setting locale failed.
download-using-manifests.pl: perl: warning: Please check that your locale settings:
download-using-manifests.pl: LANGUAGE = (unset),
download-using-manifests.pl: LC_ALL = (unset),
download-using-manifests.pl: LANG = "en_US.UTF-8"
download-using-manifests.pl: are supported and installed on your system.
download-using-manifests.pl: perl: warning: Falling back to the standard locale ("C").
download-from-binary-cache.pl: perl: warning: Setting locale failed.
download-from-binary-cache.pl: perl: warning: Please check that your locale settings:
download-from-binary-cache.pl: LANGUAGE = (unset),
download-from-binary-cache.pl: LC_ALL = (unset),
download-from-binary-cache.pl: LANG = "en_US.UTF-8"
[...]
fetching path ‘/nix/store/6mk1s81va81dl4jfbhww86cwkl4gyf4j-stdenv’...
perl: warning: Setting locale failed.
perl: warning: Please check that your locale settings:
LANGUAGE = (unset),
LC_ALL = (unset),
LANG = "en_US.UTF-8"
are supported and installed on your system.
perl: warning: Falling back to the standard locale ("C").
*** Downloading ‘https://cache.nixos.org/nar/0aznfg1g17a8jdzvnp3pqszs9rq2wiwf2rcgczyg5b3k6d0iricl.nar.xz’ to ‘/nix/store/6mk1s81va81dl4jfbhww86cwkl4gyf4j-stdenv’...
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 8324 100 8324 0 0 6353 0 0:00:01 0:00:01 --:--:-- 6373
[nix-shell:~]$
```
检查GCC版本:
```
[nix-shell:~]$ gcc -v
Using built-in specs.
COLLECT_GCC=/nix/store/dyj2k6ch35r1ips4vr97md2i0yvl4r5c-gcc-5.4.0/bin/gcc
COLLECT_LTO_WRAPPER=/nix/store/dyj2k6ch35r1ips4vr97md2i0yvl4r5c-gcc-5.4.0/libexec/gcc/x86_64-unknown-linux-gnu/5.4.0/lto-wrapper
Target: x86_64-unknown-linux-gnu
Configured with:
Thread model: posix
gcc version 5.4.0 (GCC)
```
现在,继续并测试代码。完成后,输入 `exit` 返回到控制台。
```
[nix-shell:~]$ exit
exit
```
一旦你从 nix-shell 中退出,你就不能使用 GCC。
这是另一个例子。
```
$ nix-shell -p hello
```
这会构建或下载 GNU Hello 和它的依赖关系,然后将其放入 `hello` 命令所在的 Bash shell 中,所有这些都不会影响你的正常环境:
```
[nix-shell:~]$ hello
Hello, world!
```
输入 `exit` 返回到控制台。
```
[nix-shell:~]$ exit
```
现在测试你的 `hello` 程序是否可用。
```
$ hello
hello: command not found
```
有关 Nix 包管理器的更多详细信息,请参阅以下指南。
希望本篇对你有帮助!还会有更好的东西。敬请关注!!
干杯!
---
via: <https://www.ostechnix.com/how-to-test-a-package-without-installing-it-in-linux/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,754 | 使用 OpenCV 进行高动态范围(HDR)成像 | http://www.learnopencv.com/high-dynamic-range-hdr-imaging-using-opencv-cpp-python/ | 2018-06-16T23:52:00 | [
"图像",
"OpenCV",
"HDR"
] | https://linux.cn/article-9754-1.html | 
在本教程中,我们将学习如何使用由不同曝光设置拍摄的多张图像创建<ruby> 高动态范围 <rt> High Dynamic Range </rt></ruby>(HDR)图像。 我们将以 C++ 和 Python 两种形式分享代码。
### 什么是高动态范围成像?
大多数数码相机和显示器都是按照 24 位矩阵捕获或者显示彩色图像。 每个颜色通道有 8 位,因此每个通道的像素值在 0-255 范围内。 换句话说,普通的相机或者显示器的动态范围是有限的。
但是,我们周围世界动态范围极大。 在车库内关灯就会变黑,直接看着太阳就会变得非常亮。 即使不考虑这些极端,在日常情况下,8 位的通道勉强可以捕捉到现场场景。 因此,相机会尝试去评估光照并且自动设置曝光,这样图像的最关注区域就会有良好的动态范围,并且太暗和太亮的部分会被相应截取为 0 和 255。
在下图中,左侧的图像是正常曝光的图像。 请注意,由于相机决定使用拍摄主体(我的儿子)的设置,所以背景中的天空已经完全流失了,但是明亮的天空也因此被刷掉了。 右侧的图像是由 iPhone 生成的HDR图像。
[](http://www.learnopencv.com/wp-content/uploads/2017/09/high-dynamic-range-hdr.jpg)
iPhone 是如何拍摄 HDR 图像的呢? 它实际上采用三种不同的曝光度拍摄了 3 张图像,3 张图像拍摄非常迅速,在 3 张图像之间几乎没有产生位移。然后组合三幅图像来产生 HDR 图像。 我们将在下一节看到一些细节。
>
> 将在不同曝光设置下获取的相同场景的不同图像组合的过程称为高动态范围(HDR)成像。
>
>
>
### 高动态范围(HDR)成像是如何工作的?
在本节中,我们来看下使用 OpenCV 创建 HDR 图像的步骤。
>
> 要想轻松学习本教程,请点击[此处](http://www.learnopencv.com/wp-content/uploads/2017/10/hdr.zip)[下载](http://www.learnopencv.com/wp-content/uploads/2017/10/hdr.zip) C++ 和 Python 代码还有图像。 如果您有兴趣了解更多关于人工智能,计算机视觉和机器学习的信息,请[订阅](https://bigvisionllc.leadpages.net/leadbox/143948b73f72a2%3A173c9390c346dc/5649050225344512/)我们的电子杂志。
>
>
>
### 第 1 步:捕获不同曝光度的多张图像
当我们使用相机拍照时,每个通道只有 8 位来表示场景的动态范围(亮度范围)。 但是,通过改变快门速度,我们可以在不同的曝光条件下拍摄多个场景图像。 大多数单反相机(SLR)有一个功能称为<ruby> 自动包围式曝光 <rt> Auto Exposure Bracketing </rt></ruby>(AEB),只需按一下按钮,我们就可以在不同的曝光下拍摄多张照片。 如果你正在使用 iPhone,你可以使用这个[自动包围式 HDR 应用程序](https://itunes.apple.com/us/app/autobracket-hdr/id923626339?mt=8&amp;ign-mpt=uo%3D8),如果你是一个 Android 用户,你可以尝试一个[更好的相机应用程序](https://play.google.com/store/apps/details?id=com.almalence.opencam&amp;hl=en)。
场景没有变化时,在相机上使用自动包围式曝光或在手机上使用自动包围式应用程序,我们可以一张接一张地快速拍摄多张照片。 当我们在 iPhone 中使用 HDR 模式时,会拍摄三张照片。
1. 曝光不足的图像:该图像比正确曝光的图像更暗。 目标是捕捉非常明亮的图像部分。
2. 正确曝光的图像:这是相机将根据其估计的照明拍摄的常规图像。
3. 曝光过度的图像:该图像比正确曝光的图像更亮。 目标是拍摄非常黑暗的图像部分。
但是,如果场景的动态范围很大,我们可以拍摄三张以上的图片来合成 HDR 图像。 在本教程中,我们将使用曝光时间为1/30 秒,0.25 秒,2.5 秒和 15 秒的 4 张图像。 缩略图如下所示。
[](http://www.learnopencv.com/wp-content/uploads/2017/10/hdr-image-sequence.jpg)
单反相机或手机的曝光时间和其他设置的信息通常存储在 JPEG 文件的 EXIF 元数据中。 查看此[链接](https://www.howtogeek.com/289712/how-to-see-an-images-exif-data-in-windows-and-macos)可在 Windows 和 Mac 中查看存储在 JPEG 文件中的 EXIF 元数据。 或者,您可以使用我最喜欢的名为 [EXIFTOOL](https://www.sno.phy.queensu.ca/%7Ephil/exiftool) 的查看 EXIF 的命令行工具。
我们先从读取分配到不同曝光时间的图像开始。
**C++**
```
void readImagesAndTimes(vector<Mat> &images, vector<float> ×)
{
int numImages = 4;
// 曝光时间列表
static const float timesArray[] = {1/30.0f,0.25,2.5,15.0};
times.assign(timesArray, timesArray + numImages);
// 图像文件名称列表
static const char* filenames[] = {"img_0.033.jpg", "img_0.25.jpg", "img_2.5.jpg", "img_15.jpg"};
for(int i=0; i < numImages; i++)
{
Mat im = imread(filenames[i]);
images.push_back(im);
}
}
```
**Python**
```
def readImagesAndTimes():
# 曝光时间列表
times = np.array([ 1/30.0, 0.25, 2.5, 15.0 ], dtype=np.float32)
# 图像文件名称列表
filenames = ["img_0.033.jpg", "img_0.25.jpg", "img_2.5.jpg", "img_15.jpg"]
images = []
for filename in filenames:
im = cv2.imread(filename)
images.append(im)
return images, times
```
### 第 2 步:对齐图像
合成 HDR 图像时使用的图像如果未对齐可能会导致严重的伪影。 在下图中,左侧的图像是使用未对齐的图像组成的 HDR 图像,右侧的图像是使用对齐的图像的图像。 通过放大图像的一部分(使用红色圆圈显示的)我们会在左侧图像中看到严重的鬼影。
[](http://www.learnopencv.com/wp-content/uploads/2017/10/aligned-unaligned-hdr-comparison.jpg)
在拍摄照片制作 HDR 图像时,专业摄影师自然是将相机安装在三脚架上。 他们还使用称为[镜像锁定](https://www.slrlounge.com/workshop/using-mirror-up-mode-mirror-lockup)功能来减少额外的振动。 即使如此,图像可能仍然没有完美对齐,因为没有办法保证无振动的环境。 使用手持相机或手机拍摄图像时,对齐问题会变得更糟。
幸运的是,OpenCV 提供了一种简单的方法,使用 `AlignMTB` 对齐这些图像。 该算法将所有图像转换为<ruby> 中值阈值位图 <rt> median threshold bitmaps </rt></ruby>(MTB)。 图像的 MTB 生成方式为将比中值亮度的更亮的分配为 1,其余为 0。 MTB 不随曝光时间的改变而改变。 因此不需要我们指定曝光时间就可以对齐 MTB。
基于 MTB 的对齐方式的代码如下。
**C++**
```
// 对齐输入图像
Ptr<AlignMTB> alignMTB = createAlignMTB();
alignMTB->process(images, images);
```
**Python**
```
# 对齐输入图像
alignMTB = cv2.createAlignMTB()
alignMTB.process(images, images)
```
### 第 3 步:提取相机响应函数
典型相机的响应与场景亮度不成线性关系。 那是什么意思呢? 假设有两个物体由同一个相机拍摄,在现实世界中其中一个物体是另一个物体亮度的两倍。 当您测量照片中两个物体的像素亮度时,较亮物体的像素值将不会是较暗物体的两倍。 在不估计<ruby> 相机响应函数 <rt> Camera Response Function </rt></ruby>(CRF)的情况下,我们将无法将图像合并到一个HDR图像中。
将多个曝光图像合并为 HDR 图像意味着什么?
只考虑图像的某个位置 `(x,y)` 一个像素。 如果 CRF 是线性的,则像素值将直接与曝光时间成比例,除非像素在特定图像中太暗(即接近 0)或太亮(即接近 255)。 我们可以过滤出这些不好的像素(太暗或太亮),并且将像素值除以曝光时间来估计像素的亮度,然后在像素不差的(太暗或太亮)所有图像上对亮度值取平均。我们可以对所有像素进行这样的处理,并通过对“好”像素进行平均来获得所有像素的单张图像。
但是 CRF 不是线性的, 我们需要评估 CRF 把图像强度变成线性,然后才能合并或者平均它们。
好消息是,如果我们知道每个图像的曝光时间,则可以从图像估计 CRF。 与计算机视觉中的许多问题一样,找到 CRF 的问题本质是一个最优解问题,其目标是使由数据项和平滑项组成的目标函数最小化。 这些问题通常会降维到线性最小二乘问题,这些问题可以使用<ruby> 奇异值分解 <rt> Singular Value Decomposition </rt></ruby>(SVD)来解决,奇异值分解是所有线性代数包的一部分。 CRF 提取算法的细节在[从照片提取高动态范围辐射图](http://www.pauldebevec.com/Research/HDR/debevec-siggraph97.pdf)这篇论文中可以找到。
使用 OpenCV 的 `CalibrateDebevec` 或者 `CalibrateRobertson` 就可以用 2 行代码找到 CRF。本篇教程中我们使用 `CalibrateDebevec`
**C++**
```
// 获取图像响应函数 (CRF)
Mat responseDebevec;
Ptr<CalibrateDebevec> calibrateDebevec = createCalibrateDebevec();
calibrateDebevec->process(images, responseDebevec, times);
```
**Python**
```
# 获取图像响应函数 (CRF)
calibrateDebevec = cv2.createCalibrateDebevec()
responseDebevec = calibrateDebevec.process(images, times)
```
下图显示了使用红绿蓝通道的图像提取的 CRF。
[](http://www.learnopencv.com/wp-content/uploads/2017/10/camera-response-function.jpg)
### 第 4 步:合并图像
一旦 CRF 评估结束,我们可以使用 `MergeDebevec` 将曝光图像合并成一个HDR图像。 C++ 和 Python 代码如下所示。
**C++**
```
// 将图像合并为HDR线性图像
Mat hdrDebevec;
Ptr<MergeDebevec> mergeDebevec = createMergeDebevec();
mergeDebevec->process(images, hdrDebevec, times, responseDebevec);
// 保存图像
imwrite("hdrDebevec.hdr", hdrDebevec);
```
**Python**
```
# 将图像合并为HDR线性图像
mergeDebevec = cv2.createMergeDebevec()
hdrDebevec = mergeDebevec.process(images, times, responseDebevec)
# 保存图像
cv2.imwrite("hdrDebevec.hdr", hdrDebevec)
```
上面保存的 HDR 图像可以在 Photoshop 中加载并进行色调映射。示例图像如下所示。
[](http://www.learnopencv.com/wp-content/uploads/2017/10/hdr-Photoshop-Tonemapping.jpg)
*HDR Photoshop 色调映射*
### 第 5 步:色调映射
现在我们已经将我们的曝光图像合并到一个 HDR 图像中。 你能猜出这个图像的最小和最大像素值吗? 对于黑色条件,最小值显然为 0。 理论最大值是什么? 无限大! 在实践中,不同情况下的最大值是不同的。 如果场景包含非常明亮的光源,那么最大值就会非常大。
尽管我们已经使用多个图像恢复了相对亮度信息,但是我们现在又面临了新的挑战:将这些信息保存为 24 位图像用于显示。
>
> 将高动态范围(HDR)图像转换为 8 位单通道图像的过程称为色调映射。这个过程的同时还需要保留尽可能多的细节。
>
>
>
有几种色调映射算法。 OpenCV 实现了其中的四个。 要记住的是没有一个绝对正确的方法来做色调映射。 通常,我们希望在色调映射图像中看到比任何一个曝光图像更多的细节。 有时色调映射的目标是产生逼真的图像,而且往往是产生超现实图像的目标。 在 OpenCV 中实现的算法倾向于产生现实的并不那么生动的结果。
我们来看看各种选项。 以下列出了不同色调映射算法的一些常见参数。
1. <ruby> 伽马 <rt> gamma </rt></ruby>:该参数通过应用伽马校正来压缩动态范围。 当伽马等于 1 时,不应用修正。 小于 1 的伽玛会使图像变暗,而大于 1 的伽马会使图像变亮。
2. <ruby> 饱和度 <rt> saturation </rt></ruby>:该参数用于增加或减少饱和度。 饱和度高时,色彩更丰富,更浓。 饱和度值接近零,使颜色逐渐消失为灰度。
3. <ruby> 对比度 <rt> contrast </rt></ruby>:控制输出图像的对比度(即 `log(maxPixelValue/minPixelValue)`)。
让我们来探索 OpenCV 中可用的四种色调映射算法。
#### Drago 色调映射
Drago 色调映射的参数如下所示:
```
createTonemapDrago
(
float gamma = 1.0f,
float saturation = 1.0f,
float bias = 0.85f
)
```
这里,`bias` 是 `[0, 1]` 范围内偏差函数的值。 从 0.7 到 0.9 的值通常效果较好。 默认值是 0.85。 有关更多技术细节,请参阅这篇[论文](http://resources.mpi-inf.mpg.de/tmo/logmap/logmap.pdf)。
C++ 和 Python 代码如下所示。 参数是通过反复试验获得的。 最后的结果乘以 3 只是因为它给出了最令人满意的结果。
**C++**
```
// 使用Drago色调映射算法获得24位彩色图像
Mat ldrDrago;
Ptr<TonemapDrago> tonemapDrago = createTonemapDrago(1.0, 0.7);
tonemapDrago->process(hdrDebevec, ldrDrago);
ldrDrago = 3 * ldrDrago;
imwrite("ldr-Drago.jpg", ldrDrago * 255);
```
**Python**
```
# 使用Drago色调映射算法获得24位彩色图像
tonemapDrago = cv2.createTonemapDrago(1.0, 0.7)
ldrDrago = tonemapDrago.process(hdrDebevec)
ldrDrago = 3 * ldrDrago
cv2.imwrite("ldr-Drago.jpg", ldrDrago * 255)
```
结果如下:
[](http://www.learnopencv.com/wp-content/uploads/2017/10/hdr-Drago.jpg)
*使用Drago算法的HDR色调映射*
#### Durand 色调映射
Durand 色调映射的参数如下所示:
```
createTonemapDurand
(
float gamma = 1.0f,
float contrast = 4.0f,
float saturation = 1.0f,
float sigma_space = 2.0f,
float sigma_color = 2.0f
);
```
该算法基于将图像分解为基础层和细节层。 使用称为双边滤波器的边缘保留滤波器来获得基本层。 `sigma_space` 和`sigma_color` 是双边滤波器的参数,分别控制空间域和彩色域中的平滑量。
有关更多详细信息,请查看这篇[论文](https://people.csail.mit.edu/fredo/PUBLI/Siggraph2002/DurandBilateral.pdf)。
**C++**
```
// 使用Durand色调映射算法获得24位彩色图像
Mat ldrDurand;
Ptr<TonemapDurand> tonemapDurand = createTonemapDurand(1.5,4,1.0,1,1);
tonemapDurand->process(hdrDebevec, ldrDurand);
ldrDurand = 3 * ldrDurand;
imwrite("ldr-Durand.jpg", ldrDurand * 255);
```
**Python**
```
# 使用Durand色调映射算法获得24位彩色图像
tonemapDurand = cv2.createTonemapDurand(1.5,4,1.0,1,1)
ldrDurand = tonemapDurand.process(hdrDebevec)
ldrDurand = 3 * ldrDurand
cv2.imwrite("ldr-Durand.jpg", ldrDurand * 255)
```
结果如下:
[](http://www.learnopencv.com/wp-content/uploads/2017/10/hdr-Durand.jpg)
*使用Durand算法的HDR色调映射*
#### Reinhard 色调映射
```
createTonemapReinhard
(
float gamma = 1.0f,
float intensity = 0.0f,
float light_adapt = 1.0f,
float color_adapt = 0.0f
)
```
`intensity` 参数应在 `[-8, 8]` 范围内。 更高的亮度值会产生更明亮的结果。 `light_adapt` 控制灯光,范围为 `[0, 1]`。 值 1 表示仅基于像素值的自适应,而值 0 表示全局自适应。 中间值可以用于两者的加权组合。 参数 `color_adapt` 控制色彩,范围为 `[0, 1]`。 如果值被设置为 1,则通道被独立处理,如果该值被设置为 0,则每个通道的适应级别相同。中间值可以用于两者的加权组合。
有关更多详细信息,请查看这篇[论文](http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.106.8100&amp;rep=rep1&amp;type=pdf)。
**C++**
```
// 使用Reinhard色调映射算法获得24位彩色图像
Mat ldrReinhard;
Ptr<TonemapReinhard> tonemapReinhard = createTonemapReinhard(1.5, 0,0,0);
tonemapReinhard->process(hdrDebevec, ldrReinhard);
imwrite("ldr-Reinhard.jpg", ldrReinhard * 255);
```
**Python**
```
# 使用Reinhard色调映射算法获得24位彩色图像
tonemapReinhard = cv2.createTonemapReinhard(1.5, 0,0,0)
ldrReinhard = tonemapReinhard.process(hdrDebevec)
cv2.imwrite("ldr-Reinhard.jpg", ldrReinhard * 255)
```
结果如下:
[](http://www.learnopencv.com/wp-content/uploads/2017/10/hdr-Reinhard.jpg)
*使用Reinhard算法的HDR色调映射*
#### Mantiuk 色调映射
```
createTonemapMantiuk
(
float gamma = 1.0f,
float scale = 0.7f,
float saturation = 1.0f
)
```
参数 `scale` 是对比度比例因子。 从 0.7 到 0.9 的值通常效果较好
有关更多详细信息,请查看这篇[论文](http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.60.4077&amp;rep=rep1&amp;type=pdf)。
**C++**
```
// 使用Mantiuk色调映射算法获得24位彩色图像
Mat ldrMantiuk;
Ptr<TonemapMantiuk> tonemapMantiuk = createTonemapMantiuk(2.2,0.85, 1.2);
tonemapMantiuk->process(hdrDebevec, ldrMantiuk);
ldrMantiuk = 3 * ldrMantiuk;
imwrite("ldr-Mantiuk.jpg", ldrMantiuk * 255);
```
**Python**
```
# 使用Mantiuk色调映射算法获得24位彩色图像
tonemapMantiuk = cv2.createTonemapMantiuk(2.2,0.85, 1.2)
ldrMantiuk = tonemapMantiuk.process(hdrDebevec)
ldrMantiuk = 3 * ldrMantiuk
cv2.imwrite("ldr-Mantiuk.jpg", ldrMantiuk * 255)
```
结果如下:
[](http://www.learnopencv.com/wp-content/uploads/2017/10/hdr-Mantiuk.jpg)
*使用Mantiuk算法的HDR色调映射*
### 订阅然后下载代码
如果你喜欢这篇文章,并希望下载本文中使用的代码(C++ 和 Python)和示例图片,请[订阅](https://bigvisionllc.leadpages.net/leadbox/143948b73f72a2%3A173c9390c346dc/5649050225344512/)我们的电子杂志。 您还将获得免费的[计算机视觉资源](https://bigvisionllc.leadpages.net/leadbox/143948b73f72a2%3A173c9390c346dc/5649050225344512/)指南。 在我们的电子杂志中,我们分享了用 C++ 还有 Python 编写的 OpenCV 教程和例子,以及计算机视觉和机器学习的算法和新闻。
[点此订阅](https://bigvisionllc.leadpages.net/leadbox/143948b73f72a2%3A173c9390c346dc/5649050225344512/)
图片致谢
本文中使用的四个曝光图像获得 [CC BY-SA 3.0](https://creativecommons.org/licenses/by-sa/3.0/) 许可,并从[维基百科的 HDR 页面](https://en.wikipedia.org/wiki/High-dynamic-range_imaging)下载。 图像由 Kevin McCoy拍摄。
---
作者简介:
我是一位热爱计算机视觉和机器学习的企业家,拥有十多年的实践经验(还有博士学位)。
2007 年,在完成博士学位之后,我和我的顾问 David Kriegman 博士还有 Kevin Barnes 共同创办了 TAAZ 公司。 我们的计算机视觉和机器学习算法的可扩展性和鲁棒性已经经过了试用了我们产品的超过 1 亿的用户的严格测试。
---
via: <http://www.learnopencv.com/high-dynamic-range-hdr-imaging-using-opencv-cpp-python/>
作者:[SATYA MALLICK](http://www.learnopencv.com/about/) 译者:[Flowsnow](https://github.com/Flowsnow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,755 | 使用 Stratis 从命令行管理 Linux 存储 | https://opensource.com/article/18/5/stratis-storage-linux-command-line | 2018-06-17T00:09:00 | [
"存储",
"Stratis"
] | /article-9755-1.html |
>
> 通过从命令行运行它,得到这个易于使用的 Linux 存储工具的主要用途。
>
>
>

正如本系列的[第一部分](/article-9736-1.html)和[第二部分](/article-9743-1.html)中所讨论的,Stratis 是一个具有与 [ZFS](https://en.wikipedia.org/wiki/ZFS) 和 [Btrfs](https://en.wikipedia.org/wiki/Btrfs) 相似功能的卷管理文件系统。在本文中,我们将介绍如何在命令行上使用 Stratis。
### 安装 Stratis
对于非开发人员,现在尝试 Stratis 最简单的方法是在 [Fedora 28](https://fedoraproject.org/wiki/Releases/28/Schedule) 中。
你可以用以下命令安装 Stratis 守护进程和 Stratis 命令行工具:
```
# dnf install stratis-cli stratisd
```
### 创建一个池
Stratis 有三个概念:blockdevs、池和文件系统。 Blockdevs 是组成池的块设备,例如磁盘或磁盘分区。一旦创建池,就可以从中创建文件系统。
假设你的系统上有一个名为 `vdg` 的块设备,它目前没有被使用或挂载,你可以在它上面创建一个 Stratis 池:
```
# stratis pool create mypool /dev/vdg
```
这假设 `vdg` 是完全清零并且是空的。如果它没有被使用,但有旧数据,则可能需要使用 `pool create` 的 `-force` 选项。如果正在使用,请勿将它用于 Stratis。
如果你想从多个块设备创建一个池,只需在 `pool create` 命令行中列出它们。你也可以稍后使用 `blockdev add-data` 命令添加更多的 blockdevs。请注意,Stratis 要求 blockdevs 的大小至少为 1 GiB。
### 创建文件系统
在你创建了一个名为 `mypool` 的池后,你可以从它创建文件系统:
```
# stratis fs create mypool myfs1
```
从 `mypool` 池创建一个名为 `myfs1` 的文件系统后,可以使用 Stratis 在 `/dev/stratis` 中创建的条目来挂载并使用它:
```
# mkdir myfs1
# mount /dev/stratis/mypool/myfs1 myfs1
```
文件系统现在已被挂载在 `myfs1` 上并准备可以使用。
### 快照
除了创建空文件系统之外,你还可以创建一个文件系统作为现有文件系统的快照:
```
# stratis fs snapshot mypool myfs1 myfs1-experiment
```
这样做后,你可以挂载新的 `myfs1-experiment`,它将初始包含与 `myfs1` 相同的文件内容,但它可能随着文件系统的修改而改变。无论你对 `myfs1-experiment` 所做的任何更改都不会反映到 `myfs1` 中,除非你卸载了 `myfs1` 并将其销毁:
```
# umount myfs1
# stratis fs destroy mypool myfs1
```
然后进行快照以重新创建并重新挂载它:
```
# stratis fs snapshot mypool myfs1-experiment myfs1
# mount /dev/stratis/mypool/myfs1 myfs1
```
### 获取信息
Stratis 可以列出系统中的池:
```
# stratis pool list
```
随着文件系统写入更多数据,你将看到 “Total Physical Used” 值的增加。当这个值接近 “Total Physical Size” 时要小心。我们仍在努力处理这个问题。
列出池中的文件系统:
```
# stratis fs list mypool
```
列出组成池的 blockdevs:
```
# stratis blockdev list mypool
```
目前只提供这些最少的信息,但它们将在未来提供更多信息。
### 摧毁池
当你了解了 Stratis 可以做什么后,要摧毁池,首先确保从它创建的所有文件系统都被卸载并销毁,然后使用 `pool destroy` 命令:
```
# umount myfs1
# umount myfs1-experiment (if you created it)
# stratis fs destroy mypool myfs1
# stratis fs destroy mypool myfs1-experiment
# stratis pool destroy mypool
```
`stratis pool list` 现在应该显示没有池。
就是这些!有关更多信息,请参阅手册页:“man stratis”。
---
via: <https://opensource.com/article/18/5/stratis-storage-linux-command-line>
作者:[Andy Grover](https://opensource.com/users/agrover) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
9,756 | 什么是 Linux 服务器,你的业务为什么需要它? | https://opensource.com/article/18/5/what-linux-server | 2018-06-17T18:57:11 | [
"服务器"
] | https://linux.cn/article-9756-1.html |
>
> 想寻找一个稳定、安全的基础来为您的企业应用程序的未来提供动力?Linux 服务器可能是答案。
>
>
>

IT 组织力求通过提高生产力和提供更快速的服务来提供商业价值,同时保持足够的灵活性,将云、容器和配置自动化等创新融入其中。现代的工作任务,无论是裸机、虚拟机、容器,还是私有云或公共云,都需要是可移植且可扩展的。支持所有的这些需要一个现代且安全的平台。
通往创新最直接的途径并不总是一条直线。随着私有云和公共云、多种体系架构和虚拟化的日益普及,当今的数据中心就像一个球一样,基础设施的选择各不相同,从而带来了维度和深度。就像飞行员依赖空中交通管制员提供持续更新一样,数字化转型之旅应该由像 Linux 这样可信赖的操作系统来指引,以提供持续更新的技术,以及对云、容器和配置自动化等创新的最有效和安全的访问。
Linux 是一个家族,它围绕 Linux 内核构建的自由、开源软件操作系统。最初开发的是基于 Intel x86 架构的个人电脑,此后比起任何其他操作系统,Linux 被移植到更多的平台上。得益于基于 Linux 内核的 Android 操作系统在智能手机上的主导地位,Linux 拥有所有通用操作系统中最大的安装基数。Linux 也是服务器和大型计算机等“大型机”系统的主要操作系统,也是 [TOP500](https://en.wikipedia.org/wiki/TOP500) 超级计算机上唯一使用的操作系统。
为了利用这一功能,许多企业公司已经采用具有高性能的 Linux 开源操作系统的服务器。这些旨在处理最苛刻的业务应用程序要求,如网络和系统管理、数据库管理和 Web 服务。出于其稳定性、安全性和灵活性,通常选择 Linux 服务器而不是其他服务器操作系统。位居前列的 Linux 服务器操作系统包括 [Debian](https://www.debian.org/)、 [Ubuntu Server](https://www.ubuntu.com/download/server)、 [CentOS](https://www.centos.org/)、[Slackware](http://www.slackware.com/) 和 [Gentoo](https://www.gentoo.org/)。
在企业级工作任务中,你应该考虑企业级 Linux 服务器上的哪些功能和优势?首先,通过对 Linux 和 Windows 管理员都熟悉的界面,内置的安全控制和可管理的扩展使你可以专注于业务增长,而不是对安全漏洞和昂贵的管理配置错误担心。你选择的 Linux 服务器应提供安全技术和认证,并保持增强以抵御入侵,保护你的数据,而且满足一个开放源代码项目或特定系统供应商的合规性。它应该:
* 使用集中式身份管理和[安全增强型 Linux](https://en.wikipedia.org/wiki/Security-Enhanced_Linux)(SELinux)、强制访问控制(MAC)等集成控制功能来**安全地交付资源**,这是[通用标准认证](https://en.wikipedia.org/wiki/Common_Criteria) 和 [FIPS 140-2 认证](https://en.wikipedia.org/wiki/FIPS_140-2),并且第一个 Linux 容器框架支持也是通用标准认证。
* **自动执行法规遵从和安全配置修复** 应贯穿于你的系统和容器。通过像 OpenSCAP 的映像扫描,它应该可以检查、补救漏洞和配置安全基准,包括针对 [PCI-DSS](https://www.pcisecuritystandards.org/pci_security/)、 [DISA STIG](https://iase.disa.mil/stigs/Pages/index.aspx) 等的[国家清单程序](https://www.nist.gov/programs-projects/national-checklist-program)内容。另外,它应该在整个混合环境中集中和扩展配置修复。
* **持续接收漏洞安全更新**,从上游社区或特定的系统供应商,如有可能,可在下一工作日补救并提供所有关键问题,以最大限度地降低业务影响。
作为混合数据中心的基础,Linux 服务器应提供平台可管理性和与传统管理和自动化基础设施的灵活集成。与非付费的 Linux 基础设施相比,这将节省 IT 员工的时间并减少意外停机的情况。它应该:
* 通过内置功能 **加速整个数据中心的映像构建、部署和补丁管理**,并丰富系统生命周期管理,配置和增强的修补等等。
* 通过一个 **简单易用的 web 界面管理单个系统**,包括存储、网络、容器、服务等等。
* 通过使用 [Ansible](https://www.ansible.com/)、 [Chef](https://www.chef.io/chef/)、 [Salt](https://saltstack.com/salt-open-source/)、 [Puppet](https://puppet.com/) 等原生配置管理工具,可以跨多个异构环境实现 **自动化一致性和合规性**,并通过系统角色减少脚本返工。
* 通过就地升级 **简化平台更新**,消除机器迁移和应用程序重建的麻烦。
* 通过使用预测分析工具自动识别和修复异常情况及其根本原因,在技术问题影响业务运营之前 **解决技术问题**。
Linux 服务器正在在全球范围内推动创新。作为一个企业工作任务的平台,Linux 服务器应该为运行当下和未来业务的应用程序提供稳定,安全和性能驱动的基础。
---
via: <https://opensource.com/article/18/5/what-linux-server>
作者:[Daniel Oh](https://opensource.com/users/daniel-oh) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | IT organizations strive to deliver business value by increasing productivity and delivering services faster while remaining flexible enough to incorporate innovations like cloud, containers, and configuration automation. Modern workloads, whether they run on bare metal, virtual machines, containers, or private or public clouds, are expected to be portable and scalable. Supporting all this requires a modern, secure platform.
The most direct route to innovation is not always a straight line. With the growing adoption of private and public clouds, multiple architectures, and virtualization, today’s data center is like a globe, with varying infrastructure choices bringing it dimension and depth. And just as a pilot depends on air traffic controllers to provide continuous updates, your digital transformation journey should be guided by a trusted operating system like Linux to provide continuously updated technology and the most efficient and secure access to innovations like cloud, containers, and configuration automation.
Linux is a family of free, open source software operating systems built around the Linux kernel. Originally developed for personal computers based on the Intel x86 architecture, Linux has since been ported to more platforms than any other operating system. Thanks to the dominance of the Linux kernel-based Android OS on smartphones, Linux has the largest installed base of all general-purpose operating systems. Linux is also the leading operating system on servers and "big iron" systems such as mainframe computers, and it is the only OS used on [TOP500](https://en.wikipedia.org/wiki/TOP500) supercomputers.
To tap this functionality, many enterprise companies have adopted servers with a high-powered variant of the Linux open source operating system. These are designed to handle the most demanding business application requirements, such as network and system administration, database management, and web services. Linux servers are often chosen over other server operating systems for their stability, security, and flexibility. Leading Linux server operating systems include [CentOS](https://www.centos.org/), [Debian](https://www.debian.org/), [Ubuntu Server](https://www.ubuntu.com/download/server), [Slackware](http://www.slackware.com/), and [Gentoo](https://www.gentoo.org/).
What features and benefits on an enterprise-grade Linux server should you consider for an enterprise workload? First, built-in security controls and scale-out manageability through interfaces that are familiar to both Linux and Windows administrators will enable you to focus on business growth instead of reacting to security vulnerabilities and costly management configuration mistakes. The Linux server you choose should provide security technologies and certifications and maintain enhancements to combat intrusions, protect your data, and meet regulatory compliance for an open source project or a specific OS vendor. It should:
**Deliver resources with security**using integrated control features such as centralized identity management and[Security-Enhanced Linux](https://en.wikipedia.org/wiki/Security-Enhanced_Linux)(SELinux), mandatory access controls (MAC) on a foundation that is[Common Criteria-](https://en.wikipedia.org/wiki/Common_Criteria)and[FIPS 140-2-certified](https://en.wikipedia.org/wiki/FIPS_140-2), as well as the first Linux container framework support to be Common Criteria-certified.**Automate regulatory compliance and security configuration remediation**across your system and within containers with image scanning like[OpenSCAP](https://www.open-scap.org/)that checks, remediates against vulnerabilities and configuration security baselines, including against[National Checklist Program](https://www.nist.gov/programs-projects/national-checklist-program)content for[PCI-DSS](https://www.pcisecuritystandards.org/pci_security/),[DISA STIG](https://iase.disa.mil/stigs/Pages/index.aspx), and more. Additionally, it should centralize and scale out configuration remediation across your entire hybrid environment.**Receive continuous vulnerability security updates**from the upstream community itself or a specific OS vendor, which remedies and delivers all critical issues by next business day, if possible, to minimize business impact.
As the foundation of your hybrid data center, the Linux server should provide platform manageability and flexible integration with legacy management and automation infrastructure. This will save IT staff time and reduce unplanned downtime compared to a non-paid Linux infrastructure. It should:
**Speed image building, deployment, and patch management**across the data center with built-in capabilities and enrich system life-cycle management, provisioning, and enhanced patching, and more.**Manage individual systems from an easy-to-use web interface**that includes storage, networking, containers, services, and more.**Automate consistency and compliance**across heterogeneous multiple environments and reduce scripting rework with system roles using native configuration management tools like[Ansible](https://www.ansible.com/),[Chef](https://www.chef.io/chef/),[Salt](https://saltstack.com/salt-open-source/),[Puppet](https://puppet.com/), and more.**Simplify platform updates**with in-place upgrades that eliminate the hassle of machine migrations and application rebuilds.**Resolve technical issues**before they impact business operations by using predictive analytics tools to automate identification and remediation of anomalies and their root causes.
Linux servers are powering innovation around the globe. As the platform for enterprise workloads, a Linux server should provide a stable, secure, and performance-driven foundation for the applications that run the business of today and tomorrow.
## Comments are closed. |
9,759 | 闭包、对象,以及堆“族” | https://manybutfinite.com/post/closures-objects-heap/ | 2018-06-18T11:05:00 | [
"闭包"
] | https://linux.cn/article-9759-1.html | 
在上篇文章中我们提到了闭包、对象、以及栈外的其它东西。我们学习的大部分内容都是与特定编程语言无关的元素,但是,我主要还是专注于 JavaScript,以及一些 C。让我们以一个简单的 C 程序开始,它的功能是读取一首歌曲和乐队名字,然后将它们输出给用户:
```
#include <stdio.h>
#include <string.h>
char *read()
{
char data[64];
fgets(data, 64, stdin);
return data;
}
int main(int argc, char *argv[])
{
char *song, *band;
puts("Enter song, then band:");
song = read();
band = read();
printf("\n%sby %s", song, band);
return 0;
}
```
*stackFolly.c [下载](https://manybutfinite.com/code/x86-stack/stackFolly.c)*
如果你运行这个程序,你会得到什么?(=> 表示程序输出):
```
./stackFolly
=> Enter song, then band:
The Past is a Grotesque Animal
of Montreal
=> ?ǿontreal
=> by ?ǿontreal
```
(曾经的 C 新手说)发生了错误?
事实证明,函数的栈变量的内容仅在栈帧活动期间才是可用的,也就是说,仅在函数返回之前。在上面的返回中,被栈帧使用过的内存 [被认为是可用的](https://manybutfinite.com/post/epilogues-canaries-buffer-overflows/),并且在下一个函数调用中可以被覆写。
下面的图展示了这种情况下究竟发生了什么。这个图现在有一个图片映射(LCTT 译注:译文中无法包含此映射,上下两个矩形区域分别链接至输出的 [#47](https://github.com/gduarte/blog/blob/master/code/x86-stack/stackFolly-gdb-output.txt#L47) 行和 [#70](https://github.com/gduarte/blog/blob/master/code/x86-stack/stackFolly-gdb-output.txt#L70) 行),因此,你可以点击一个数据片断去看一下相关的 GDB 输出(GDB 命令在 [这里](https://github.com/gduarte/blog/blob/master/code/x86-stack/stackFolly-gdb-commands.txt))。只要 `read()` 读取了歌曲的名字,栈将是这个样子:

在这个时候,这个 `song` 变量立即指向到歌曲的名字。不幸的是,存储字符串的内存位置准备被下次调用的任意函数的栈帧重用。在这种情况下,`read()` 再次被调用,而且使用的是同一个位置的栈帧,因此,结果变成下图的样子(LCTT 译注:上下两个矩形映射分别链接至 [#76](https://github.com/gduarte/blog/blob/master/code/x86-stack/stackFolly-gdb-output.txt#L76) 行和 [#79](https://github.com/gduarte/blog/blob/master/code/x86-stack/stackFolly-gdb-output.txt#L79) 行):

乐队名字被读入到相同的内存位置,并且覆盖了前面存储的歌曲名字。`band` 和 `song` 最终都准确指向到相同点。最后,我们甚至都不能得到 “of Montreal”(LCTT 译注:一个欧美乐队的名字) 的正确输出。你能猜到是为什么吗?
因此,即使栈很有用,但也有很重要的限制。它不能被一个函数用于去存储比该函数的运行周期还要长的数据。你必须将它交给 [堆](https://github.com/gduarte/blog/blob/master/code/x86-stack/readIntoHeap.c),然后与热点缓存、明确的瞬时操作、以及频繁计算的偏移等内容道别。有利的一面是,它是[工作](https://github.com/gduarte/blog/blob/master/code/x86-stack/readIntoHeap-gdb-output.txt#L47) 的:

这个代价是你必须记得去 `free()` 内存,或者由一个垃圾回收机制花费一些性能来随机回收,垃圾回收将去找到未使用的堆对象,然后去回收它们。那就是栈和堆之间在本质上的权衡:性能 vs. 灵活性。
大多数编程语言的虚拟机都有一个中间层用来做一个 C 程序员该做的一些事情。栈被用于**值类型**,比如,整数、浮点数、以及布尔型。这些都按特定值(像上面的 `argc` )的字节顺序被直接保存在本地变量和对象字段中。相比之下,堆被用于**引用类型**,比如,字符串和 [对象](https://code.google.com/p/v8/source/browse/trunk/src/objects.h#37)。 变量和字段包含一个引用到这个对象的内存地址,像上面的 `song` 和 `band`。
参考这个 JavaScript 函数:
```
function fn()
{
var a = 10;
var b = { name: 'foo', n: 10 };
}
```
它可能的结果如下(LCTT 译注:图片内“object”、“string”和“a”的映射分别链接至 [#1671](https://code.google.com/p/v8/source/browse/trunk/src/objects.h#1671) 行、 [#8656](https://code.google.com/p/v8/source/browse/trunk/src/objects.h#8656) 行和 [#1264](https://code.google.com/p/v8/source/browse/trunk/src/objects.h#1264) 行):

我之所以说“可能”的原因是,特定的行为高度依赖于实现。这篇文章使用的许多流程图形是以一个 V8 为中心的方法,这些图形都链接到相关的源代码。在 V8 中,仅 [小整数](https://code.google.com/p/v8/source/browse/trunk/src/objects.h#1264) 是 [以值的方式保存](https://code.google.com/p/v8/source/browse/trunk/src/objects.h#148)。因此,从现在开始,我将在对象中直接以字符串去展示,以避免引起混乱,但是,请记住,正如上图所示的那样,它们在堆中是分开保存的。
现在,我们来看一下闭包,它其实很简单,但是由于我们将它宣传的过于夸张,以致于有点神化了。先看一个简单的 JS 函数:
```
function add(a, b)
{
var c = a + b;
return c;
}
```
这个函数定义了一个<ruby> 词法域 <rt> lexical scope </rt></ruby>,它是一个快乐的小王国,在这里它的名字 `a`、`b`、`c` 是有明确意义的。它有两个参数和由函数声明的一个本地变量。程序也可以在别的地方使用相同的名字,但是在 `add` 内部它们所引用的内容是明确的。尽管词法域是一个很好的术语,它符合我们直观上的理解:毕竟,我们从字面意义上看,我们可以像词法分析器一样,把它看作在源代码中的一个文本块。
在看到栈帧的操作之后,很容易想像出这个名称的具体实现。在 `add` 内部,这些名字引用到函数的每个运行实例中私有的栈的位置。这种情况在一个虚拟机中经常发生。
现在,我们来嵌套两个词法域:
```
function makeGreeter()
{
return function hi(name){
console.log('hi, ' + name);
}
}
var hi = makeGreeter();
hi('dear reader'); // prints "hi, dear reader"
```
那样更有趣。函数 `hi` 在函数 `makeGreeter` 运行的时候被构建在它内部。它有它自己的词法域,`name` 在这个地方是一个栈上的参数,但是,它似乎也可以访问父级的词法域,它可以那样做。我们来看一下那样做的好处:
```
function makeGreeter(greeting)
{
return function greet(name){
console.log(greeting + ', ' + name);
}
}
var heya = makeGreeter('HEYA');
heya('dear reader'); // prints "HEYA, dear reader"
```
虽然有点不习惯,但是很酷。即便这样违背了我们的直觉:`greeting` 确实看起来像一个栈变量,这种类型应该在 `makeGreeter()` 返回后消失。可是因为 `greet()` 一直保持工作,出现了一些奇怪的事情。进入闭包(LCTT 译注:“Context” 和 “JSFunction” 映射分别链接至 [#188](https://code.google.com/p/v8/source/browse/trunk/src/contexts.h#188) 行和 [#7245](https://code.google.com/p/v8/source/browse/trunk/src/objects.h#7245) 行):

虚拟机分配一个对象去保存被里面的 `greet()` 使用的父级变量。它就好像是 `makeGreeter` 的词法作用域在那个时刻被<ruby> 关闭 <rt> closed over </rt></ruby>了,一旦需要时被具体化到一个堆对象(在这个案例中,是指返回的函数的生命周期)。因此叫做<ruby> 闭包 <rt> closure </rt></ruby>,当你这样去想它的时候,它的名字就有意义了。如果使用(或者捕获)了更多的父级变量,对象内容将有更多的属性,每个捕获的变量有一个。当然,发送到 `greet()` 的代码知道从对象内容中去读取问候语,而不是从栈上。
这是完整的示例:
```
function makeGreeter(greetings)
{
var count = 0;
var greeter = {};
for (var i = 0; i < greetings.length; i++) {
var greeting = greetings[i];
greeter[greeting] = function(name){
count++;
console.log(greeting + ', ' + name);
}
}
greeter.count = function(){return count;}
return greeter;
}
var greeter = makeGreeter(["hi", "hello","howdy"])
greeter.hi('poppet');//prints "howdy, poppet"
greeter.hello('darling');// prints "howdy, darling"
greeter.count(); // returns 2
```
是的,`count()` 在工作,但是我们的 `greeter` 是在 `howdy` 中的栈上。你能告诉我为什么吗?我们使用 `count` 是一条线索:尽管词法域进入一个堆对象中被关闭,但是变量(或者对象属性)带的值仍然可能被改变。下图是我们拥有的内容(LCTT 译注:映射从左到右“Object”、“JSFunction”和“Context”分别链接至 [#1671](https://code.google.com/p/v8/source/browse/trunk/src/objects.h#1671) 行、[#7245](https://code.google.com/p/v8/source/browse/trunk/src/objects.h#7245) 行和 [#188](https://code.google.com/p/v8/source/browse/trunk/src/contexts.h#188) 行):

这是一个被所有函数共享的公共内容。那就是为什么 `count` 工作的原因。但是,`greeting` 也是被共享的,并且它被设置为迭代结束后的最后一个值,在这个案例中是 “howdy”。这是一个很常见的一般错误,避免它的简单方法是,引用一个函数调用,以闭包变量作为一个参数。在 CoffeeScript 中, [do](http://coffeescript.org/#loops) 命令提供了一个实现这种目的的简单方式。下面是对我们的 `greeter` 的一个简单的解决方案:
```
function makeGreeter(greetings)
{
var count = 0;
var greeter = {};
greetings.forEach(function(greeting){
greeter[greeting] = function(name){
count++;
console.log(greeting + ', ' + name);
}
});
greeter.count = function(){return count;}
return greeter;
}
var greeter = makeGreeter(["hi", "hello", "howdy"])
greeter.hi('poppet'); // prints "hi, poppet"
greeter.hello('darling'); // prints "hello, darling"
greeter.count(); // returns 2
```
它现在是工作的,并且结果将变成下图所示(LCTT 译注:映射从左到右“Object”、“JSFunction”和“Context”分别链接至 [#1671](https://code.google.com/p/v8/source/browse/trunk/src/objects.h#1671) 行、[#7245](https://code.google.com/p/v8/source/browse/trunk/src/objects.h#7245) 行和 [#188](https://code.google.com/p/v8/source/browse/trunk/src/contexts.h#188) 行):

这里有许多箭头!在这里我们感兴趣的特性是:在我们的代码中,我们闭包了两个嵌套的词法内容,并且完全可以确保我们得到了两个链接到堆上的对象内容。你可以嵌套并且闭包任何词法内容,像“俄罗斯套娃”似的,并且最终从本质上说你使用的是所有那些 Context 对象的一个链表。
当然,就像受信鸽携带信息启发实现了 TCP 一样,去实现这些编程语言的特性也有很多种方法。例如,ES6 规范定义了 [词法环境](http://people.mozilla.org/%7Ejorendorff/es6-draft.html#sec-lexical-environments) 作为 [环境记录](http://people.mozilla.org/%7Ejorendorff/es6-draft.html#sec-environment-records)( 大致相当于在一个块内的本地标识)的组成部分,加上一个链接到外部环境的记录,这样就允许我们看到的嵌套。逻辑规则是由规范(一个希望)所确定的,但是其实现取决于将它们变成比特和字节的转换。
你也可以检查具体案例中由 V8 产生的汇编代码。[Vyacheslav Egorov](http://mrale.ph) 有一篇很好的文章,它使用 V8 的 [闭包内部构件](http://mrale.ph/blog/2012/09/23/grokking-v8-closures-for-fun.html) 详细解释了这一过程。我刚开始学习 V8,因此,欢迎指教。如果你熟悉 C#,检查闭包产生的中间代码将会很受启发 —— 你将看到显式定义的 V8 内容和实例化的模拟。
闭包是个强大的“家伙”。它在被一组函数共享期间,提供了一个简单的方式去隐藏来自调用者的信息。我喜欢它们真正地隐藏你的数据:不像对象字段,调用者并不能访问或者甚至是看到闭包变量。保持接口清晰而安全。
但是,它们并不是“银弹”(LCTT 译注:意指极为有效的解决方案,或者寄予厚望的新技术)。有时候一个对象的拥护者和一个闭包的狂热者会无休止地争论它们的优点。就像大多数的技术讨论一样,他们通常更关注的是自尊而不是真正的权衡。不管怎样,Anton van Straaten 的这篇 [史诗级的公案](http://people.csail.mit.edu/gregs/ll1-discuss-archive-html/msg03277.html) 解决了这个问题:
>
> 德高望重的老师 Qc Na 和它的学生 Anton 一起散步。Anton 希望将老师引入到一个讨论中,Anton 说:“老师,我听说对象是一个非常好的东西,是这样的吗?Qc Na 同情地看了一眼,责备它的学生说:“可怜的孩子 —— 对象不过是穷人的闭包而已。” Anton 待它的老师走了之后,回到他的房间,专心学习闭包。他认真地阅读了完整的 “Lambda:The Ultimate…" 系列文章和它的相关资料,并使用一个基于闭包的对象系统实现了一个小的架构解释器。他学到了很多的东西,并期待告诉老师他的进步。在又一次和 Qc Na 散步时,Anton 尝试给老师留下一个好的印象,说“老师,我仔细研究了这个问题,并且,现在理解了对象真的是穷人的闭包。”Qc Na 用它的手杖打了一下 Anton 说:“你什么时候才能明白?闭包是穷人的对象。”在那个时候,Anton 顿悟了。Anton van Straaten 说:“原来架构这么酷啊?”
>
>
>
探秘“栈”系列文章到此结束了。后面我将计划去写一些其它的编程语言实现的主题,像对象绑定和虚表。但是,内核调用是很强大的,因此,明天将发布一篇操作系统的文章。我邀请你 [订阅](https://manybutfinite.com/feed.xml) 并 [关注我](http://twitter.com/manybutfinite)。
---
via:<https://manybutfinite.com/post/closures-objects-heap/>
作者:[Gustavo Duarte](http://duartes.org/gustavo/blog/about/) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The last post in this series looks at closures, objects, and other creatures roaming beyond the stack. Much of what we’ll see is language neutral, but I’ll focus on JavaScript with a dash of C. Let’s start with a simple C program that reads a song and a band name and outputs them back to the user:
[view raw](/code/x86-stack/stackFolly.c)
1 |
|
If you run this gem, here’s what you get (=> denotes program output):
1 | ./stackFolly |
Ayeee! Where did things go so wrong? (Said every C beginner, ever.)
It turns out that the contents of a function’s stack variables are **only valid
while the stack frame is active**, that is, until the function returns. Upon
return, the memory used by the stack frame is [deemed free](/post/epilogues-canaries-buffer-overflows/) and
liable to be overwritten in the next function call.
Below is *exactly* what happens in this case. The diagrams now have image maps,
so you can click on a piece of data to see the relevant gdb output (gdb commands
are [here](https://github.com/gduarte/blog/blob/master/code/x86-stack/stackFolly-gdb-commands.txt)). As soon as `read()`
is done with the song
name, the stack is thus:
At this point, the `song`
variable actually points to the song name. Sadly, the
memory storing that string is *ready to be reused* by the stack frame of
whatever function is called next. In this case, `read()`
is called again, with
the same stack frame layout, so the result is this:
The band name is read into the same memory location and overwrites the
previously stored song name. `band`
and `song`
end up pointing to the exact
same spot. Finally, we didn’t even get “of Montreal” output correctly. Can you
guess why?
And so it happens that the stack, for all its usefulness, has this serious
limitation. It cannot be used by a function to store data that needs to outlive
the function’s execution. You must resort to the [heap](https://github.com/gduarte/blog/blob/master/code/x86-stack/readIntoHeap.c) and say
goodbye to the hot caches, deterministic instantaneous operations, and easily
computed offsets. On the plus side, it [works](https://github.com/gduarte/blog/blob/master/code/x86-stack/readIntoHeap-gdb-output.txt#L47):

The price is you must now remember to `free()`
memory or take a performance hit
on a garbage collector, which finds unused heap objects and frees them. That’s
the fundamental tradeoff between stack and heap: performance vs. flexibility.
Most languages’ virtual machines take a middle road that mirrors what
C programmers do. The stack is used for **value types**, things like integers,
floats and booleans. These are stored *directly* in local variables and object
fields as a sequence of bytes specifying a *value* (like `argc`
above). In
contrast, heap inhabitants are **reference types** such as strings and
[objects](https://code.google.com/p/v8/source/browse/trunk/src/objects.h#37). Variables and fields contain a memory address that
*references* these objects, like `song`
and `band`
above.
Consider this JavaScript function:
1 | function fn() |
This might produce the following:
I say “might” because specific behaviors depend heavily on implementation. This
post takes a V8-centric approach with many diagram shapes linking to relevant
source code. In V8, only [small integers](https://code.google.com/p/v8/source/browse/trunk/src/objects.h#1264) are
[stored as values](https://code.google.com/p/v8/source/browse/trunk/src/objects.h#148). Also,
from now on I’ll show strings directly in objects to reduce visual noise, but
keep in mind they exist separately in the heap, as shown above.
Now let’s take a look at closures, which are simple but get weirdly hyped up and mythologized. Take a trivial JS function:
1 | function add(a, b) |
This function defines a **lexical scope**, a happy little kingdom where the
names `a`
, `b`
, and `c`
have precise meanings. They are the two parameters and
one local variable declared by the function. The program might use those same
names elsewhere, but within `add`
*that’s what they refer to*. And while
lexical scope is a fancy term, it aligns well with our intuitive understanding:
after all, we can quite literally **see** the bloody thing, much as a lexer
does, as a textual block in the program’s source.
Having seen stack frames in action, it’s easy to imagine an implementation for
this name specificity. Within `add`
, these names refer to stack locations
private to *each running instance* of the function. That’s in fact how it
often plays out in a VM.
So let’s nest two lexical scopes:
1 | function makeGreeter() |
That’s more interesting. Function `hi`
is built at runtime within `makeGreeter`
.
It has its own lexical scope, where `name`
is an argument on the stack, but
*visually* it sure looks like it can access its parent’s lexical scope as well,
which it can. Let’s take advantage of that:
1 | function makeGreeter(greeting) |
A little strange, but pretty cool. There’s something about it though that
violates our intuition: `greeting`
sure looks like a stack variable, the kind
that should be dead after `makeGreeter()`
returns. And yet, since `greet()`
keeps working, *something funny* is going on. Enter the closure:
The VM allocated an object to store the parent variable used by the inner
`greet()`
. It’s as if `makeGreeter`
's lexical scope had been **closed over** at
that moment, crystallized into a heap object for as long as needed (in this case,
the lifetime of the returned function). Hence the name **closure**, which makes
a lot of sense when you see it that way. If more parent variables had been used
(or *captured*), the `Context`
object would have more properties, one per
captured variable. Naturally, the code emitted for `greet()`
knows to read
`greeting`
from the Context object, rather than expect it on the stack.
Here’s a fuller example:
1 | function makeGreeter(greetings) |
Well… `count()`
works, but our greeter is stuck in *howdy*. Can you tell why?
What we’re doing with `count`
is a clue: even though the lexical scope is closed
over into a heap object, the *values* taken by the variables (or object
properties) can still be changed. Here’s what we have:

There is one common context shared by all functions. That’s why `count`
works.
But the greeting is also being shared, and it was set to the last value iterated
over, “howdy” in this case. That’s a pretty common error, and the easiest way to
avoid it is to introduce a function call to take the closed-over variable as an
argument. In CoffeeScript, the [do](http://coffeescript.org/#loops) command provides an easy way to
do so. Here’s a simple solution for our greeter:
1 | function makeGreeter(greetings) |
It now works, and the result becomes:
That’s a lot of arrows! But here’s the interesting feature: in our code, we closed over two nested lexical contexts, and sure enough we get two linked Context objects in the heap. You could nest and close over many lexical contexts, Russian-doll style, and you end up with essentially a linked list of all these Context objects.
Of course, just as you can implement TCP over carrier pigeons, there are many
ways to implement these language features. For example, the ES6 spec defines
[lexical environments](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-lexical-environments) as consisting of an [environment record](http://people.mozilla.org/~jorendorff/es6-draft.html#sec-environment-records) (roughly, the
local identifiers within a block) plus a link to an outer environment record,
allowing the nesting we have seen. The *logical rules* are nailed by the spec
(one hopes), but it’s up to the implementation to translate them into bits and
bytes.
You can also inspect the assembly code produced by V8 for specific cases.
[Vyacheslav Egorov](http://mrale.ph) has great posts and explains this process along with
V8 [closure internals](http://mrale.ph/blog/2012/09/23/grokking-v8-closures-for-fun.html) in detail. I’ve only started studying V8, so
pointers and corrections are welcome. If you know C#, inspecting the IL code
emitted for closures is enlightening - you will see the analog of V8 Contexts
explicitly defined and instantiated.
Closures are powerful beasts. They provide a succinct way to hide information
from a caller while sharing it among a set of functions. I love that they
**truly hide** your data: unlike object fields, callers cannot access or even
*see* closed-over variables. Keeps the interface cleaner and safer.
But they’re no silver bullet. Sometimes an object nut and a closure fanatic will
argue endlessly about their relative merits. Like most tech discussions, it’s
often more about ego than real tradeoffs. At any rate, this [epic koan](http://people.csail.mit.edu/gregs/ll1-discuss-archive-html/msg03277.html) by
Anton van Straaten settles the issue:
The venerable master Qc Na was walking with his student, Anton. Hoping to prompt the master into a discussion, Anton said “Master, I have heard that objects are a very good thing - is this true?” Qc Na looked pityingly at his student and replied, “Foolish pupil - objects are merely a poor man’s closures.”
Chastised, Anton took his leave from his master and returned to his cell, intent on studying closures. He carefully read the entire “Lambda: The Ultimate…” series of papers and its cousins, and implemented a small Scheme interpreter with a closure-based object system. He learned much, and looked forward to informing his master of his progress.
On his next walk with Qc Na, Anton attempted to impress his master by saying “Master, I have diligently studied the matter, and now understand that objects are truly a poor man’s closures.” Qc Na responded by hitting Anton with his stick, saying “When will you learn? Closures are a poor man’s object.” At that moment, Anton became enlightened.
And that closes our stack series. In the future I plan to cover other language
implementation topics like object binding and vtables. But the call of the
kernel is strong, so there’s an OS post coming out tomorrow. I invite you to
[subscribe](https://manybutfinite.com/feed.xml) and [follow me](http://twitter.com/manybutfinite).
## Comments |
9,760 | 我正在运行的 Linux 是什么版本? | https://opensource.com/article/18/6/linux-version | 2018-06-18T22:35:18 | [
"Linux",
"版本",
"发行版"
] | https://linux.cn/article-9760-1.html |
>
> 掌握这些快捷命令以找出你正在运行的 Linux 系统的内核版本和发行版。
>
>
>

“什么版本的 Linux ?”这个问题可能意味着两个不同的东西。严格地说,Linux 是内核,所以问题可以特指内核的版本号,或者 “Linux” 可以更通俗地用来指整个发行版,就像在 Fedora Linux 或 Ubuntu Linux 中一样。
两者都很重要,你可能需要知道其中一个或全部答案来修复系统中的问题。例如,了解已安装的内核版本可能有助于诊断带有专有驱动程序的问题,并且确定正在运行的发行版将帮助你快速确定是否应该使用 `apt`、 `dnf`、 `yum` 或其他命令来安装软件包。
以下内容将帮助你了解 Linux 内核的版本和/或系统上正在运行的 Linux 发行版是什么。
### 如何找到 Linux 内核版本
要找出哪个 Linux 内核版本正在运行,运行以下命令:
```
uname -srm
```
或者,可以使用更长,更具描述性的各种标志的版本来运行该命令:
```
uname --kernel-name --kernel-release --machine
```
无论哪种方式,输出都应该类似于以下内容:
```
Linux 4.16.10-300.fc28.x86_64 x86_64
```
这为你提供了(按顺序):内核名称、内核版本以及运行内核的硬件类型。在上面的情况下,内核是 Linux ,版本 4.16.10-300.fc28.x86*64 ,运行于 x86*64 系统。
有关 `uname` 命令的更多信息可以通过运行 `man uname` 找到。
### 如何找出 Linux 发行版
有几种方法可以确定系统上运行的是哪个发行版,但最快的方法是检查 `/etc/os-release` 文件的内容。此文件提供有关发行版的信息,包括但不限于发行版名称及其版本号。某些发行版的 `os-release` 文件包含比其他发行版更多的细节,但任何包含 `os-release` 文件的发行版都应该提供发行版的名称和版本。
要查看 `os-release` 文件的内容,运行以下命令:
```
cat /etc/os-release
```
在 Fedora 28 中,输出如下所示:
```
NAME=Fedora
VERSION="28 (Workstation Edition)"
ID=fedora
VERSION_ID=28
PLATFORM_ID="platform:f28"
PRETTY_NAME="Fedora 28 (Workstation Edition)"
ANSI_COLOR="0;34"
CPE_NAME="cpe:/o:fedoraproject:fedora:28"
HOME_URL="https://fedoraproject.org/"
SUPPORT_URL="https://fedoraproject.org/wiki/Communicating_and_getting_help"
BUG_REPORT_URL="https://bugzilla.redhat.com/"
REDHAT_BUGZILLA_PRODUCT="Fedora"
REDHAT_BUGZILLA_PRODUCT_VERSION=28
REDHAT_SUPPORT_PRODUCT="Fedora"
REDHAT_SUPPORT_PRODUCT_VERSION=28
PRIVACY_POLICY_URL="https://fedoraproject.org/wiki/Legal:PrivacyPolicy"
VARIANT="Workstation Edition"
VARIANT_ID=workstation
```
如上面那个例子展示的那样,Fedora 的 `os-release` 文件提供了发行版的名称和版本,但它也标识这个安装的变体(“Workstation Edition”)。如果我们在 Fedora 28 服务器版本上运行相同的命令,`os-release` 文件的内容会反映在 `VARIANT` 和 `VARIANT_ID` 行中。
有时候知道一个发行版是否与另一个发行版相似非常有用,因此 `os-release` 文件可以包含一个 `ID_LIKE` 行,用于标识正在运行的是基于什么的发行版或类似的发行版。例如,Red Hat Linux 企业版的 `os-release` 文件包含 `ID_LIKE` 行,声明 RHEL 与 Fedora 类似;CentOS 的 `os-release` 文件声明 CentOS 与 RHEL 和 Fedora 类似。如果你正在使用基于另一个发行版的发行版并需要查找解决问题的说明,那么 `ID_LIKE` 行非常有用。
CentOS 的 `os-release` 文件清楚地表明它就像 RHEL 一样,所以在各种论坛中关于 RHEL 的文档,问题和答案应该(大多数情况下)适用于 CentOS。CentOS 被设计成一个 RHEL 近亲,因此在某些字段它更兼容其 `ID_LIKE` 系统的字段。如果你找不到正在运行的发行版的信息,检查有关 “类似” 发行版的答案总是一个好主意。
有关 `os-release` 文件的更多信息可以通过运行 `man os-release` 命令来查找。
---
via: <https://opensource.com/article/18/6/linux-version>
作者:[Joshua Allen Holm](https://opensource.com/users/holmja) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The question "what version of Linux" can mean two different things. Strictly speaking, Linux is the kernel, so the question can refer specifically to the kernel's version number, or "Linux" can be used more colloquially to refer to the entire distribution, as in Fedora Linux or Ubuntu Linux.
Both are important, and you may need to know one or both answers to fix a problem with a system. For example, knowing the installed kernel version might help diagnose an issue with proprietary drivers, and identifying what distribution is running will help you quickly figure out if you should be using `apt`
, `dnf`
, `yum`
, or some other command to install packages.
The following will help you find out what version of the Linux kernel and/or what Linux distribution is running on a system.
## How to find the Linux kernel version
To find out what version of the Linux kernel is running, run the following command:
`uname -srm`
Alternatively, the command can be run by using the longer, more descriptive, versions of the various flags:
`uname --kernel-name --kernel-release --machine`
Either way, the output should look similar to the following:
`Linux 4.16.10-300.fc28.x86_64 x86_64`
This gives you (in order): the kernel name, the version of the kernel, and the type of hardware the kernel is running on. In this case, the kernel is Linux version 4.16.10-300.fc28.x86_64 running on an x86_64 system.
More information about the `uname`
command can be found by running `man uname`
.
## How to find the Linux distribution
There are several ways to figure out what distribution is running on a system, but the quickest way is the check the contents of the `/etc/os-release`
file. This file provides information about a distribution including, but not limited to, the name of the distribution and its version number. The os-release file in some distributions contains more details than in others, but any distribution that includes an os-release file should provide a distribution's name and version.
To view the contents of the os-release file, run the following command:
`cat /etc/os-release`
On Fedora 28, the output looks like this:
```
NAME=Fedora
VERSION="28 (Workstation Edition)"
ID=fedora
VERSION_ID=28
PLATFORM_ID="platform:f28"
PRETTY_NAME="Fedora 28 (Workstation Edition)"
ANSI_COLOR="0;34"
CPE_NAME="cpe:/o:fedoraproject:fedora:28"
HOME_URL="https://fedoraproject.org/"
SUPPORT_URL="https://fedoraproject.org/wiki/Communicating_and_getting_help"
BUG_REPORT_URL="https://bugzilla.redhat.com/"
REDHAT_BUGZILLA_PRODUCT="Fedora"
REDHAT_BUGZILLA_PRODUCT_VERSION=28
REDHAT_SUPPORT_PRODUCT="Fedora"
REDHAT_SUPPORT_PRODUCT_VERSION=28
PRIVACY_POLICY_URL="https://fedoraproject.org/wiki/Legal:PrivacyPolicy"
VARIANT="Workstation Edition"
VARIANT_ID=workstation
```
As the example above shows, Fedora's os-release file provides the name of the distribution and the version, but it also identifies the installed variant (the "Workstation Edition"). If we ran the same command on Fedora 28 Server Edition, the contents of the os-release file would reflect that on the `VARIANT`
and `VARIANT_ID`
lines.
Sometimes it is useful to know if a distribution is like another, so the os-release file can contain an `ID_LIKE`
line that identifies distributions the running distribution is based on or is similar to. For example, Red Hat Enterprise Linux's os-release file includes an `ID_LIKE`
line stating that RHEL is like Fedora, and CentOS's os-release file states that CentOS is like RHEL and Fedora. The `ID_LIKE`
line is very helpful if you are working with a distribution that is based on another distribution and need to find instructions to solve a problem.
CentOS's os-release file makes it clear that it is like RHEL, so documentation and questions and answers in various forums about RHEL should (in most cases) apply to CentOS. CentOS is designed to be a near clone of RHEL, so it is more compatible with its `LIKE`
than some entries that might be found in the `ID_LIKE`
field, but checking for answers about a "like" distribution is always a good idea if you cannot find the information you are seeking for the running distribution.
More information about the os-release file can be found by running `man os-release`
.
## Screenfetch and neofetch
The `uname`
and `/etc/os-release`
commands are the most common methods for getting the version of Linux you're running and are available by default on any Linux system you run. There are, however, additional tools that can provide you a report about your system.
The [screenfetch and neofetch](https://opensource.com/article/20/1/screenfetch-neofetch) commands give a verbose overview of your system, with details about your kernel, architecture, available RAM, CPU speed and core count, desktop version, and so on.
## Hostnamectl
The `hostnamectl`
command is available on most modern Linux distributions. If it's not already installed, you can install it from your software repository. Despite its humble name, it provides far more than just your hostname;
```
$ hostnamectl
Static hostname: yorktown.local
Icon name: computer-laptop
Chassis: laptop
Machine ID: 442fd448a2764239b6c0b81fe9099582
Boot ID: a23e2566b1db42ffe57089c71007ef33
Operating System: CentOS Stream 8
CPE OS Name: cpe:/o:centos:centos:8
Kernel: Linux 4.18.0-301.1.el8.x86_64
Architecture: x86-64
```
## Desktop utilities
Some desktop environments offer similar system reporting tools. For instance, the [KDE Plasma desktop](https://opensource.com/article/19/12/linux-kde-plasma) provides KInfoCenter, which can tell you everything from your kernel and architecture to your available network interface cards, IP address, and much more.
## Know your OS
Regardless of what tool you decide to make your default, getting the version and features of your OS is a seemingly simple but important skill. Remember these tips so the next time you need to see what you're running, you'll know several places you can find out.
*This article originally published in 2018 and has been updated by the editor with additional information. *
## 5 Comments |
9,761 | Oracle Linux 系统如何去注册使用坚不可摧 Linux 网络(ULN) | https://www.2daygeek.com/how-to-register-the-oracle-linux-system-with-the-unbreakable-linux-network-uln/ | 2018-06-18T23:03:00 | [
"Oracle",
"ULN"
] | https://linux.cn/article-9761-1.html | 
大多数人都知道 RHEL 的订阅 ,但是知道 Oracle 订阅及细节的人却很少。
甚至我也不知道关于它的信息,我是最近才了解了有关它的信息,想将这些内容共享给其他人。因此写了这篇文章,它将指导你去注册 Oracle Linux 系统去使用坚不可摧 Linux 网络(ULN) 。
这将允许你去注册系统以尽快获得软件更新和其它的补丁。
### 什么是坚不可摧 Linux 网络
ULN 代表<ruby> 坚不可摧 Linux 网络 <rt> Unbreakable Linux Network </rt></ruby>,它是由 Oracle 所拥有的。如果你去 Oracle OS 支持中去激活这个订阅,你就可以注册你的系统去使用坚不可摧 Linux 网络(ULN)。
ULN 为 Oracle Linux 和 Oracle VM 提供软件补丁、更新、以及修复,这些信息同时提供在 yum、Ksplice、并提供支持策略。你也可以通过它来下载原始发行版中没有包含的有用的安装包。
ULN 的告警提示工具会周期性地使用 ULN 进行检查,当有更新的时候它给你发送警报信息。
如果你想在 yum 上使用 ULN 仓库去管理你的系统,需要确保你的系统已经注册到 ULN 上,并且订阅了一个或多个 ULN 频道。当你注册一个系统使用 ULN,它将基于你的系统架构和操作系统去自动选择频道中最新的版本。
### 如何注册为一个 ULN 用户
要注册为一个 ULN 用户,需要你有一个 Oracle Linux 支持或者 Oracle VM 支持的有效客户支持代码(CSI)。
请按以下步骤去注册为一个 ULN 用户。
请访问 [linux.oracle.com](https://linux.oracle.com/register):

如果你已经有一个 SSO 帐户,请点击 “Sign On”。

如果你没有帐户,点击 “Create New Single Signon Account” 然后按屏幕上的要求去创建一个帐户。

验证你的电子邮件地址以完成帐户设置。
使用你的 SSO 帐户的用户名和密码去登入。在 “Create New ULN User” 页面上,输入你的 CSI 然后点击 “Create New User”。

**注意:**
* 如果当前没有分配管理员去管理 CSI,将会提示你去点击确认让你成为 CSI 管理员。
* 如果你的用户名已经在系统上存在,你将被提示通过点击坚不可摧 Linux 网络的链接去操作 ULN。
### 如何注册 Oracle Linux 6/7 系统使用 ULN
只需要运行下列的命令,并按随后的指令提示去注册系统。
```
# uln_register
```
确保你的系统有一个激活的因特网连接。同时准备好你的 Oracle 单点登录帐户(SSO)的用户名和密码,然后点击 `Next`。
```
Copyright ▪© 2006--2010 Red Hat, Inc. All rights reserved.
▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪¤ Setting up software updates ▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪
▪ This assistant will guide you through connecting your system to Unbreakable Linux Network (ULN) to receive software updates, ▪
▪ including security updates, to keep your system supported and compliant. You will need the following at this time: ▪
▪ ▪
▪ * A network connection ▪
▪ * Your Oracle Single Sign-On Login & password ▪
▪ ▪
▪ ▪
▪ ▪
▪ ▪
▪ ▪
▪ ▪
▪ ▪
▪ ▪
▪ ▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪ ▪▪▪▪▪▪▪▪ ▪▪▪▪▪▪▪▪▪▪ ▪
▪ ▪ Why Should I Connect to ULN? ... ▪ ▪ Next ▪ ▪ Cancel ▪ ▪
▪ ▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪ ▪▪▪▪▪▪▪▪ ▪▪▪▪▪▪▪▪▪▪ ▪
▪ ▪
▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪
```
输入你的 ULN 登录信息,然后点击 `Next`。
```
Copyright ▪© 2006--2010 Red Hat, Inc. All rights reserved.
▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪¤ Setting up software updates ▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪
▪ ▪
▪ Please enter your login information for Unbreakable Linux Network (http://linux.oracle.com/): ▪
▪ ▪
▪ ▪
▪ Oracle Single Sign-On Login: [email protected]_ ▪
▪ Password: **********__________ ▪
▪ CSI: 12345678____________ ▪
▪ Tip: Forgot your login or password? Visit: http://www.oracle.com/corporate/contact/getaccthelp.html ▪
▪ ▪
▪ ▪▪▪▪▪▪▪▪ ▪▪▪▪▪▪▪▪ ▪▪▪▪▪▪▪▪▪▪ ▪
▪ ▪ Next ▪ ▪ Back ▪ ▪ Cancel ▪ ▪
▪ ▪▪▪▪▪▪▪▪ ▪▪▪▪▪▪▪▪ ▪▪▪▪▪▪▪▪▪▪ ▪
▪ ▪
▪ ▪
▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪
```
注册一个系统概要 – 硬件信息,然后点击 `Next`。
```
Copyright ▪© 2006--2010 Red Hat, Inc. All rights reserved.
▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪¤ Register a System Profile - Hardware ▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪
▪ ▪
▪ A Profile Name is a descriptive name that you choose to identify this ▪
▪ System Profile on the Unbreakable Linux Network web pages. Optionally, ▪
▪ include a computer serial or identification number. ▪
▪ Profile name: 2g-oracle-sys___________________________ ▪
▪ ▪
▪ [*] Include the following information about hardware and network: ▪
▪ Press to deselect the option. ▪
▪ ▪
▪ Version: 6 CPU model: Intel(R) Xeon(R) CPU E5-5650 0 @ 2.00GHz ▪
▪ Hostname: 2g-oracle-sys ▪
▪ CPU speed: 1199 MHz IP Address: 192.168.1.101 Memory: ▪
▪ ▪
▪ Additional hardware information including PCI devices, disk sizes and mount points will be included in the profile. ▪
▪ ▪
▪ ▪▪▪▪▪▪▪▪ ▪▪▪▪▪▪▪▪ ▪▪▪▪▪▪▪▪▪▪ ▪
▪ ▪ Next ▪ ▪ Back ▪ ▪ Cancel ▪ ▪
▪ ▪▪▪▪▪▪▪▪ ▪▪▪▪▪▪▪▪ ▪▪▪▪▪▪▪▪▪▪ ▪
▪ ▪
▪ ▪
▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪
```
注册一个系统概要 – 包配置,然后点击 `Next`。
```
Copyright ▪© 2006--2010 Red Hat, Inc. All rights reserved.
▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪¤ Register a System Profile - Packages ▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪
▪ ▪
▪ RPM information is important to determine what updated software packages are relevant to this system. ▪
▪ ▪
▪ [*] Include RPM packages installed on this system in my System Profile ▪
▪ ▪
▪ You may deselect individual packages by unchecking them below. ▪
▪ [*] ConsoleKit-0.4.1-6.el6 ▪ ▪
▪ [*] ConsoleKit-libs-0.4.1-6.el6 ▪ ▪
▪ [*] ConsoleKit-x11-0.4.1-6.el6 ▪ ▪
▪ [*] DeviceKit-power-014-3.el6 ▪ ▪
▪ [*] GConf2-2.28.0-7.el6 ▪ ▪
▪ [*] GConf2-2.28.0-7.el6 ▪ ▪
▪ [*] GConf2-devel-2.28.0-7.el6 ▪ ▪
▪ [*] GConf2-gtk-2.28.0-7.el6 ▪ ▪
▪ [*] MAKEDEV-3.24-6.el6 ▪ ▪
▪ [*] MySQL-python-1.2.3-0.3.c1.1.el6 ▪ ▪
▪ [*] NessusAgent-7.0.3-es6 ▪ ▪
▪ [*] ORBit2-2.14.17-6.el6_8 ▪ ▪
▪ [*] ORBit2-2.14.17-6.el6_8 ▪ ▪
▪ [*] ORBit2-devel-2.14.17-6.el6_8 ▪ ▪
▪ [*] PackageKit-0.5.8-26.0.1.el6 ▪ ▪
▪ [*] PackageKit-device-rebind-0.5.8-26.0.1.el6 ▪ ▪
▪ [*] PackageKit-glib-0.5.8-26.0.1.el6 ▪ ▪
▪ ▪
▪ ▪▪▪▪▪▪▪▪ ▪▪▪▪▪▪▪▪ ▪▪▪▪▪▪▪▪▪▪ ▪
▪ ▪ Next ▪ ▪ Back ▪ ▪ Cancel ▪ ▪
▪ ▪▪▪▪▪▪▪▪ ▪▪▪▪▪▪▪▪ ▪▪▪▪▪▪▪▪▪▪ ▪
▪ ▪
▪ ▪
▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪
```
按下 “Next” 去发送系统概要到 ULN。
```
Copyright ▪© 2006--2010 Red Hat, Inc. All rights reserved.
▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪¤ Send Profile Information to Unbreakable Linux Network ▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪
▪ ▪
▪ We are finished collecting information for the System Profile. ▪
▪ ▪
▪ Press "Next" to send this System Profile to Unbreakable Linux Network. Click "Cancel" and no information will be sent. You ▪
▪ can run the registration program later by typing `uln_register` at the command line. ▪
▪ ▪
▪ ▪▪▪▪▪▪▪▪ ▪▪▪▪▪▪▪▪ ▪▪▪▪▪▪▪▪▪▪ ▪
▪ ▪ Next ▪ ▪ Back ▪ ▪ Cancel ▪ ▪
▪ ▪▪▪▪▪▪▪▪ ▪▪▪▪▪▪▪▪ ▪▪▪▪▪▪▪▪▪▪ ▪
▪ ▪
▪ ▪
▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪
```
发送概要到 ULN 是如下的一个过程。
```
Copyright ▪© 2006--2010 Red Hat, Inc. All rights reserved.
▪▪¤ Sending Profile to Unbreakable Linux Network ▪
▪ ▪
▪ 75% ▪
▪ ▪
▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪
```
ULN 注册做完后,重新回顾系统订阅的详细情况。如果一切正确,然后点击 `ok`。
```
Copyright ▪© 2006--2010 Red Hat, Inc. All rights reserved.
▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪¤ Review system subscription details ▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪
▪ ▪
▪ ▪
▪ Note: yum-rhn-plugin has been enabled. ▪
▪ ▪
▪ Please review the subscription details below: ▪
▪ ▪
▪ Software channel subscriptions: ▪
▪ This system will receive updates from the following Unbreakable Linux Network software channels: ▪
▪ Oracle Linux 6 Latest (x86_64) ▪
▪ Unbreakable Enterprise Kernel Release 4 for Oracle Linux 6 (x86_64) ▪
▪ ▪
▪ Warning: If an installed product on this system is not listed above, you will not receive updates or support for that product. If ▪
▪ you would like to receive updates for that product, please visit http://linux.oracle.com/ and subscribe this system to the ▪
▪ appropriate software channels to get updates for that product. ▪
▪ ▪
▪ ▪
▪ ▪
▪ ▪
▪ ▪
▪ ▪
▪ ▪
▪ ▪▪▪▪▪▪ ▪
▪ ▪ OK ▪ ▪
▪ ▪▪▪▪▪▪ ▪
▪ ▪
▪ ▪
▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪
```
最后点击 `Finish` 完成注册。
```
Copyright ▪© 2006--2010 Red Hat, Inc. All rights reserved.
▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪¤ Finish setting up software updates ▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪
▪ ▪
▪ You may now run 'yum update' from this system's command line to get the latest software updates from Unbreakable Linux Network. ▪
▪ You will need to run this periodically to get the latest updates. ▪
▪ ▪
▪ ▪▪▪▪▪▪▪▪▪▪ ▪
▪ ▪ Finish ▪ ▪
▪ ▪▪▪▪▪▪▪▪▪▪ ▪
▪ ▪
▪ ▪
▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪▪
```
ULN 注册已经成功,为了从 ULN 中得到仓库,运行如下的命令。
```
# yum repolist
Loaded plugins: aliases, changelog, presto, refresh-packagekit, rhnplugin, security, tmprepo, ulninfo, verify, versionlock
This system is receiving updates from ULN.
ol6_x86_64_UEKR3_latest | 1.2 kB 00:00
ol6_x86_64_UEKR3_latest/primary | 35 MB 00:14
ol6_x86_64_UEKR3_latest 874/874
repo id repo name status
ol6_x86_64_UEKR3_latest Unbreakable Enterprise Kernel Release 3 for Oracle Linux 6 (x86_64) - Latest 874
ol6_x86_64_latest Oracle Linux 6 Latest (x86_64) 40,092
repolist: 40,966
```
另外,你也可以在 ULN 网站上查看到相同的信息。转到 `System` 标签页去查看已注册的系统列表。

去查看已经启用的仓库列表。转到 `System` 标签页,然后点击相应的系统。另外,你也能够看到系统勘误及可用更新。

去管理订阅的频道。转到 `System` 标签页,然后点击有关的 `system name`,最后点击 `Manage Subscriptions`。

---
via: <https://www.2daygeek.com/how-to-register-the-oracle-linux-system-with-the-unbreakable-linux-network-uln/>
作者:[Vinoth Kumar](https://www.2daygeek.com/author/vinoth/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
9,763 | 献给写作者的 Linux 工具 | https://opensource.com/article/18/3/top-Linux-tools-for-writers | 2018-06-20T11:01:43 | [
"写作"
] | https://linux.cn/article-9763-1.html |
>
> 这些易用的开源应用可以帮助你打磨你的写作技巧、使研究更高效、更具有条理。
>
>
>

如果你已经阅读过[我关于如何切换到 Linux 的文章](https://opensource.com/article/18/2/my-linux-story-Antergos),那么你就知道我是一个超级用户。另外,我不是任何方面的“专家”,目前仍然如此。但是在过去几年里我学到了很多有用的东西,我想将这些技巧传给其他新的 Linux 用户。
今天,我将讨论我写作时使用的工具,基于三个标准来选择:
1. 当我提交作品或文章时,我的主要写作工具必须与任何发布者兼容。
2. 该软件使用起来必须简单快捷。
3. 免费(自由)是很棒的。
有一些很棒的一体化免费解决方案,比如:
1. [bibisco](http://www.bibisco.com/)
2. [Manuskript](http://www.theologeek.ch/manuskript/)
3. [oStorybook](http://ostorybook.tuxfamily.org/index.php?lng=en)
但是,当我试图寻找信息时,我往往会迷失方向并失去思路,所以我选择了适合我需求的多个应用程序。另外,我不想依赖互联网,以免服务下线。我把这些程序放在显示器桌面上,以便我一下全看到它们。
请考虑以下工具建议 : 每个人的工作方式都不相同,并且你可能会发现一些更适合你工作方式的其他应用程序。以下这些工具是目前的写作工具:
### 文字处理器
[LibreOffice 6.0.1](https://www.libreoffice.org/)。直到最近,我使用了 [WPS](http://wps-community.org/),但由于字体渲染问题(Times New Roman 总是以粗体显示)而否定了它。LibreOffice 的最新版本非常适应 Microsoft Office,而且事实上它是开源的,这对我来说很重要。
### 词库
[Artha](https://sourceforge.net/projects/artha/) 可以给出同义词、反义词、派生词等等。它外观整洁、速度快。例如,输入 “fast” 这个词,你会得到字典定义以及上面列出的其他选项。Artha 是送给开源社区的一个巨大的礼物,人们应该试试它,因为它似乎是一个冷僻的小程序。如果你使用 Linux,请立即安装此应用程序,你不会后悔的。
### 记笔记
[Zim](http://zim-wiki.org/) 标榜自己是一个桌面维基,但它也是你所能找到的最简单的多层级笔记应用程序。还有其它更漂亮的笔记程序,但 Zim 正是那种我需要管理角色、地点、情节和次要情节的程序。
### 投稿跟踪
我曾经使用过一款名为 [FileMaker Pro](http://www.filemaker.com/) 的专有软件,它惯坏了我。有很多数据库应用程序,但在我看来,最容易使用的某过于 [Glom](https://www.glom.org/) 了。它以图形方式满足我的需求,让我以表单形式输入信息而不是表格。在 Glom 中,你可以创建你需要的表单,这样你就可以立即看到相关信息(对于我来说,通过电子表格来查找信息就像将我的眼球拖到玻璃碎片上)。尽管 Glom 不再处于开发阶段,但它仍然是很棒的。
### 搜索
我已经开始使用 [StartPage.com](https://www.startpage.com/) 作为我的默认搜索引擎。当然,当你写作时,[Google](https://www.google.com/) 可以成为你最好的朋友之一。但我不喜欢每次我想了解特定人物、地点或事物时,Google 都会跟踪我。所以我使用 StartPage.com 来代替。它速度很快,并且不会跟踪你的搜索。我也使用 [DuckDuckGo.com](https://duckduckgo.com/) 作为 Google 的替代品。
### 其他的工具
[Chromium 浏览器](https://www.chromium.org/) 是 [Google Chrome](https://www.google.com/chrome/) 的开源版本,带有隐私插件。
尽管来自 [Mozilla](https://www.mozilla.org/en-US/) 的 [Thunderbird](https://www.mozilla.org/en-US/thunderbird/) 是一个很棒的程序,但我发现 [Geary](https://wiki.gnome.org/Apps/Geary) 是一个更快更轻的电子邮件应用程序。有关开源电子邮件应用程序的更多信息,请阅读 [Jason Baker](https://opensource.com/users/jason-baker) 的优秀文章:[6 个开源的桌面电子邮件客户端](https://opensource.com/business/18/1/desktop-email-clients)。
正如你可能已经注意到,我对应用程序的喜爱趋向于将最好的 Windows、MacOS 都能运行,以及此处提到的开源 Linux 替代品融合在一起。我希望这些建议能帮助你发现有用的新方法来撰写并跟踪你的写作(谢谢你,Artha!)。
写作愉快!
---
via: <https://opensource.com/article/18/3/top-Linux-tools-for-writers>
作者:[Adam Worth](https://opensource.com/users/adamworth) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | If you've read [my article about how I switched to Linux](https://opensource.com/article/18/2/my-linux-story-Antergos), then you know that I’m a superuser. I also stated that I’m not an “expert” on anything. That’s still fair to say. But I have learned many helpful things over the last several years, and I'd like to pass these tips along to other new Linux users.
Today, I’m going to discuss the tools I use when I write. I based my choices on three criteria:
- My main writing tool must be compatible for any publisher when I submit stories or articles.
- The software must be quick and simple to use.
- Free is good.
There are some wonderful all-in-one free solutions, such as:
However, I tend to get lost and lose my train of thought when I'm trying to find information, so I opted to go with multiple applications that suit my needs. Also, I don’t want to be reliant on the internet in case service goes down. I set these programs up on my monitor so I can see them all at once.
Consider the following tools suggestions—everyone works differently, and you might find some other app that better fits the way you work. These tools are current to this writing:
## Word processor
[LibreOffice 6.0.1](https://www.libreoffice.org/). Until recently, I used [WPS](http://wps-community.org/), but font-rendering problems (Times New Roman was always in bold format) nixed it. The newest version of LibreOffice adapts to Microsoft Office very nicely, and the fact that it's open source ticks the box for me.
## Thesaurus
[Artha](https://sourceforge.net/projects/artha/) gives you synonyms, antonyms, derivatives, and more. It’s clean-looking and *fast.* Type the word "fast," for example, and you'll get the dictionary definition as well as the other options listed above. Artha is a huge gift to the open source community, and more people should try it as it seems to be one of those obscure little programs. If you’re using Linux, install this application now. You won’t regret it.
## Note-taking
[Zim](http://zim-wiki.org/) touts itself as a desktop wiki, but it’s also the easiest multi-level note-taking app you’ll find anywhere. There are other, prettier note-taking programs available, but Zim is exactly what I need to manage my characters, locations, plots, and sub-plots.
## Submission tracking
I once used a proprietary piece of software called [FileMaker Pro](http://www.filemaker.com/), and it spoiled me. There are plenty of database applications out there, but in my opinion the easiest one to use is [Glom](https://www.glom.org/). It suits my needs graphically, letting me enter information in a form rather than a table. In Glom, you create the form you need so you can see relevant information instantly (for me, digging through a spreadsheet table to find information is like dragging my eyeballs over shards of glass). Although Glom no longer appears to be in development, it remains relevant.
## Research
I’ve begun using [StartPage.com](https://www.startpage.com/) as my default search engine. Sure, [Google](https://www.google.com/) can be one of your best friends when you're writing. But I don't like how Google tracks me every time I want to learn about a specific person/place/thing. So I use StartPage.com instead; it's fast and does not track your searches. I also use [DuckDuckGo.com](https://duckduckgo.com/) as an alternative to Google.
## Other tools
[Chromium Browser](https://www.chromium.org/) is an open source version of [Google Chrome](https://www.google.com/chrome/), with privacy plugins.
Though [Thunderbird](https://www.mozilla.org/en-US/thunderbird/), from [Mozilla](https://www.mozilla.org/en-US/), is a great program, I find [Geary](https://wiki.gnome.org/Apps/Geary) a much quicker and lighter email app. For more on open source email apps, read [Jason Baker](https://opensource.com/users/jason-baker)'s excellent article, [Top 6 open source desktop email clients](https://opensource.com/business/18/1/desktop-email-clients).
As you might have noticed, my taste in apps tends to merge the best of Windows, MacOS, and the open source Linux alternatives mentioned here. I hope these suggestions help you discover helpful new ways to compose (thank you, Artha!) and track your written works.
Happy writing!
## 19 Comments |
9,764 | 如何在 Linux 中禁用内置摄像头 | https://www.ostechnix.com/how-to-disable-built-in-webcam-in-ubuntu/ | 2018-06-20T11:07:00 | [
"摄像头"
] | https://linux.cn/article-9764-1.html | 
今天,我们将看到如何禁用未使用的内置网络摄像头或外置摄像头,以及如何在 Linux 中需要时启用它。禁用网络摄像头可以在很多方面为你提供帮助。你可以防止恶意软件控制你的集成摄像头,并监视你和你的家庭。我们已经阅读过无数的故事,一些黑客可以在你不知情的情况下使用你的摄像头监视你。通过黑客攻击你的网络摄像头,用户可以在线共享你的私人照片和视频。可能有很多原因。如果你想知道如何禁用笔记本电脑或台式机中的网络摄像头,那么你很幸运。这个简短的教程将告诉你如何做。请继续阅读。
我在 Arch Linux 和 Ubuntu 上测试了这个指南。它的工作原理如下所述。我希望这也可以用在其他 Linux 发行版上。
### 在 Linux 中禁用内置摄像头
首先,使用如下命令找到网络摄像头驱动:
```
$ sudo lsmod | grep uvcvideo
```
示例输出:
```
uvcvideo 114688 1
videobuf2_vmalloc 16384 1 uvcvideo
videobuf2_v4l2 28672 1 uvcvideo
videobuf2_common 53248 2 uvcvideo,videobuf2_v4l2
videodev 208896 4 uvcvideo,videobuf2_common,videobuf2_v4l2
media 45056 2 uvcvideo,videodev
usbcore 286720 9 uvcvideo,usbhid,usb_storage,ehci_hcd,ath3k,btusb,uas,ums_realtek,ehci_pci
```
这里,**uvcvideo** 是我的网络摄像头驱动。
现在,让我们禁用网络摄像头。
为此,请编辑以下文件(如果文件不存在,只需创建它):
```
$ sudo nano /etc/modprobe.d/blacklist.conf
```
添加以下行:
```
##Disable webcam.
blacklist uvcvideo
```
`##Disable webcam` 这行不是必需的。为了便于理解,我添加了它。
保存并退出文件。重启系统以使更改生效。
要验证网络摄像头是否真的被禁用,请打开任何即时通讯程序或网络摄像头软件,如 Cheese 或 Guvcview。你会看到如下的空白屏幕。
Cheese 输出:

Guvcview 输出:

看见了么?网络摄像头被禁用而无法使用。
要启用它,请编辑:
```
$ sudo nano /etc/modprobe.d/blacklist.conf
```
注释掉你之前添加的行。
```
##Disable webcam.
#blacklist uvcvideo
```
保存并关闭文件。然后,重启计算机以启用网络摄像头。
这样够了吗?不。为什么?如果有人可以远程访问你的系统,他们可以轻松启用网络摄像头。所以,在不使用时用胶带覆盖它或者拔掉相机或者在 BIOS 中禁用它是一个不错的主意。此方法不仅用于禁用内置摄像头,还用于外部网络摄像头。
就是这些了。希望对你有用。还有更好的东西。敬请关注!
干杯!
---
via: <https://www.ostechnix.com/how-to-disable-built-in-webcam-in-ubuntu/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,765 | 为什么 Linux 比 Windows 和 macOS 更安全? | https://www.computerworld.com/article/3252823/linux/why-linux-is-better-than-windows-or-macos-for-security.html | 2018-06-21T01:03:00 | [
"操作系统",
"安全"
] | https://linux.cn/article-9765-1.html |
>
> 多年前做出的操作系统选型终将影响到如今的企业安全。在三大主流操作系统当中,有一个能被称作最安全的。
>
>
>

企业投入了大量时间、精力和金钱来保障系统的安全性。最强的安全意识可能就是有一个安全运行中心(SOC),肯定用上了防火墙以及反病毒软件,或许还花费了大量时间去监控他们的网络,以寻找可能表明违规的异常信号,用那些 IDS、SIEM 和 NGFW 之类的东西,他们部署了一个名副其实的防御阵列。
然而又有多少人想过数字化操作的基础之一——部署在员工的个人电脑上的操作系统呢?当选择桌面操作系统时,安全性是一个考虑的因素吗?
这就产生了一个 IT 人士都应该能回答的问题:一般部署哪种操作系统最安全呢?
我们问了一些专家他们对于以下三种选择的看法:Windows,最复杂的平台也是最受欢迎的桌面操作系统;macOS X,基于 FreeBSD 的 Unix 操作系统,驱动着苹果的 Macintosh 系统运行;还有 Linux,这里我们指的是所有的 Linux 发行版以及与基于 Unix 的操作系统相关的系统。
### 怎么会这样
企业可能没有评估他们部署给工作人员的操作系统的安全性的一个原因是,他们多年前就已经做出了选择。退一步讲,所有操作系统都还算安全,因为侵入它们、窃取数据或安装恶意软件的牟利方式还处于起步阶段。而且一旦选择了操作系统,就很难再改变。很少有 IT 组织想要面对将全球分散的员工队伍转移到全新的操作系统上的痛苦。唉,他们已经受够了把用户搬到一个现有的操作系统的新版本时的负面反响。
还有,重新考虑操作系统是高明的吗?这三款领先的桌面操作系统在安全方面的差异是否足以值得我们去做出改变呢?
当然商业系统面临的威胁近几年已经改变了。攻击变得成熟多了。曾经支配了公众想象力的单枪匹马的青少年黑客已经被组织良好的犯罪分子网络以及具有庞大计算资源的政府资助组织的网络所取代。
像你们许多人一样,我有过很多那时的亲身经历:我曾经在许多 Windows 电脑上被恶意软件和病毒感染,我甚至被宏病毒感染了 Mac 上的文件。最近,一个广泛传播的自动黑客攻击绕开了网站的保护程序并用恶意软件感染了它。这种恶意软件的影响一开始是隐形的,甚至有些东西你没注意,直到恶意软件最终深深地植入系统以至于它的性能开始变差。一件有关病毒蔓延的震惊之事是不法之徒从来没有特定针对过我;当今世界,用僵尸网络攻击 100,000 台电脑容易得就像一次攻击几台电脑一样。
### 操作系统真的很重要吗?
给你的用户部署的哪个操作系统确实对你的安全态势产生了影响,但那并不是一个可靠的安全措施。首先,现在的攻击很可能会发生,因为攻击者探测的是你的用户,而不是你的系统。一项对参加了 DEFCON 会议的黑客的[调查](https://www.esecurityplanet.com/hackers/fully-84-percent-of-hackers-leverage-social-engineering-in-attacks.html)表明,“84% 的人使用社交工程作为攻击策略的一部分。”部署安全的操作系统只是一个重要的起点,但如果没有用户培训、强大的防火墙和持续的警惕性,即使是最安全的网络也会受到入侵。当然,用户下载的软件、扩展程序、实用程序、插件和其他看起来还好的软件总是有风险的,成为了恶意软件出现在系统上的一种途径。
无论你选择哪种平台,保持你系统安全最好的方法之一就是确保立即应用了软件更新。一旦补丁正式发布,黑客就可以对其进行反向工程并找到一种新的漏洞,以便在下一波攻击中使用。
而且别忘了最基本的操作。别用 root 权限,别授权访客连接到网络中的老服务器上。教您的用户如何挑选一个真正的好密码并且使用例如 [1Password](http://www.1password.com) 这样的工具,以便在每个他们使用的帐户和网站上拥有不同的密码
因为底线是您对系统做出的每一个决定都会影响您的安全性,即使您的用户工作使用的操作系统也是如此。
### Windows,流行之选
若你是一个安全管理人员,很可能文章中提出的问题就会变成这样:是否我们远离微软的 Windows 会更安全呢?说 Windows 主导企业市场都是低估事实了。[NetMarketShare](https://www.netmarketshare.com/operating-system-market-share.aspx?options=%7B%22filter%22%3A%7B%22%24and%22%3A%5B%7B%22deviceType%22%3A%7B%22%24in%22%3A%5B%22Desktop%2Flaptop%22%5D%7D%7D%5D%7D%2C%22dateLabel%22%3A%22Trend%22%2C%22attributes%22%3A%22share%22%2C%22group%22%3A%22platform%22%2C%22sort%22%3A%7B%22share%22%3A-1%7D%2C%22id%22%3A%22platformsDesktop%22%2C%22dateInterval%22%3A%22Monthly%22%2C%22dateStart%22%3A%222017-02%22%2C%22dateEnd%22%3A%222018-01%22%2C%22segments%22%3A%22-1000%22%7D) 估计互联网上 88% 的电脑令人震惊地运行着 Windows 的某个版本。
如果你的系统在这 88% 之中,你可能知道微软会继续加强 Windows 系统的安全性。这些改进被不断重写,或者重新改写了其代码库,增加了它的反病毒软件系统,改进了防火墙以及实现了沙箱架构,这样在沙箱里的程序就不能访问系统的内存空间或者其他应用程序。
但可能 Windows 的流行本身就是个问题,操作系统的安全性可能很大程度上依赖于装机用户量的规模。对于恶意软件作者来说,Windows 提供了大的施展平台。专注其中可以让他们的努力发挥最大作用。
就像 Troy Wilkinson,Axiom Cyber Solutions 的 CEO 解释的那样,“Windows 总是因为很多原因而导致安全性保障来的最晚,主要是因为消费者的采用率。由于市场上大量基于 Windows 的个人电脑,黑客历来最有针对性地将这些系统作为目标。”
可以肯定地说,从梅丽莎病毒到 WannaCry 或者更强的,许多世界上已知的恶意软件早已对准了 Windows 系统.
### macOS X 以及通过隐匿实现的安全
如果最流行的操作系统总是成为大目标,那么用一个不流行的操作系统能确保安全吗?这个主意是老法新用——而且是完全不可信的概念——“通过隐匿实现的安全”,这秉承了“让软件内部运作保持专有,从而不为人知是抵御攻击的最好方法”的理念。
Wilkinson 坦言,macOS X “比 Windows 更安全”,但他马上补充说,“macOS 曾被认为是一个安全漏洞很小的完全安全的操作系统,但近年来,我们看到黑客制造了攻击苹果系统的额外漏洞。”
换句话说,攻击者会扩大活动范围而不会无视 Mac 领域。
Comparitech 的安全研究员 Lee Muson 说,在选择更安全的操作系统时,“macOS 很可能是被选中的目标”,但他提醒说,这一想法并不令人费解。它的优势在于“它仍然受益于通过隐匿实现的安全感和微软提供的操作系统是个更大的攻击目标。”
Wolf Solutions 公司的 Joe Moore 给予了苹果更多的信任,称“现成的 macOS X 在安全方面有着良好的记录,部分原因是它不像 Windows 那么广泛,而且部分原因是苹果公司在安全问题上干的不错。”
### 最终胜者是 ……
你可能一开始就知道它:专家们的明确共识是 Linux 是最安全的操作系统。然而,尽管它是服务器的首选操作系统,而将其部署在桌面上的企业很少。
如果你确定 Linux 是要选择的系统,你仍然需要决定选择哪种 Linux 系统,并且事情会变得更加复杂。 用户需要一个看起来很熟悉的用户界面,而你需要最安全的操作系统。
像 Moore 解释的那样,“Linux 有可能是最安全的,但要求用户是资深用户。”所以,它不是针对所有人的。
将安全性作为主要功能的 Linux 发行版包括 [Parrot Linux](https://www.parrotsec.org/),这是一个基于 Debian 的发行版,Moore 说,它提供了许多与安全相关开箱即用的工具。
当然,一个重要的区别是 Linux 是开源的。Simplex Solutions 的 CISO Igor Bidenko 说,编码人员可以阅读和审查彼此工作的现实看起来像是一场安全噩梦,但这确实是让 Linux 如此安全的重要原因。 “Linux 是最安全的操作系统,因为它的源代码是开放的。任何人都可以查看它,并确保没有错误或后门。”
Wilkinson 阐述说:“Linux 和基于 Unix 的操作系统具有较少的在信息安全领域已知的、可利用的安全缺陷。技术社区对 Linux 代码进行了审查,该代码有助于提高安全性:通过进行这么多的监督,易受攻击之处、漏洞和威胁就会减少。”
这是一个微妙而违反直觉的解释,但是通过让数十人(有时甚至数百人)通读操作系统中的每一行代码,代码实际上更加健壮,并且发布漏洞错误的机会减少了。这与 《PC World》 为何出来说 Linux 更安全有很大关系。正如 Katherine Noyes [解释](https://www.pcworld.com/article/202452/why_linux_is_more_secure_than_windows.html)的那样,“微软可能吹捧它的大型的付费开发者团队,但团队不太可能与基于全球的 Linux 用户开发者进行比较。 安全只能通过所有额外的关注获益。”
另一个被 《PC World》举例的原因是 Linux 更好的用户特权模式:Noye 的文章讲到,Windows 用户“一般被默认授予管理员权限,那意味着他们几乎可以访问系统中的一切”。Linux,反而很好地限制了“root”权限。
Noyes 还指出,Linux 环境下的多样性可能比典型的 Windows 单一文化更好地对抗攻击:Linux 有很多不同的发行版。其中一些以其特别的安全关注点而差异化。Comparitech 的安全研究员 Lee Muson 为 Linux 发行版提供了这样的建议:“[Qubes OS](https://www.qubes-os.org/) 对于 Linux 来说是一个很好的出发点,现在你可以发现,[爱德华·斯诺登的认可](https://twitter.com/snowden/status/781493632293605376?lang=en)极大地超过了其谦逊的宣传。”其他安全性专家指出了专门的安全 Linux 发行版,如 [Tails Linux](https://tails.boum.org/about/index.en.html),它旨在直接从 USB 闪存驱动器或类似的外部设备安全地匿名运行。
### 构建安全趋势
惯性是一股强大的力量。虽然人们有明确的共识,认为 Linux 是桌面系统的最安全选择,但并没有出现对 Windows 和 Mac 机器压倒性的倾向。尽管如此,Linux 采用率的小幅增长却可能会产生对所有人都更加安全的计算,因为市场份额的丧失是确定能获得微软和苹果公司关注的一个方式。换句话说,如果有足够的用户在桌面上切换到 Linux,Windows 和 Mac PC 很可能成为更安全的平台。
---
via: <https://www.computerworld.com/article/3252823/linux/why-linux-is-better-than-windows-or-macos-for-security.html>
作者:[Dave Taylor](https://www.computerworld.com/author/Dave-Taylor/) 译者:[fuzheng1998](https://github.com/fuzheng1998) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
9,766 | 如何使用树莓派制作一个数字针孔摄像头 | https://opensource.com/article/18/3/how-build-digital-pinhole-camera-raspberry-pi | 2018-06-21T09:50:09 | [
"树莓派",
"相机"
] | https://linux.cn/article-9766-1.html |
>
> 学习如何使用一个树莓派 Zero、高清网络摄像头和一个空的粉盒来搭建一个简单的相机。
>
>
>

在 2015 年底的时候,树莓派基金会发布了一个让大家很惊艳的非常小的 [树莓派 Zero](https://www.raspberrypi.org/products/raspberry-pi-zero/)。更夸张的是,他们随 MagPi 杂志一起 [免费赠送](https://opensource.com/users/node/24776)。我看到这个消息后立即冲出去到处找报刊亭,直到我在这一地区的某处找到最后两份。实际上我还没有想好如何去使用它们,但是我知道,因为它们非常小,所以,它们可以做很多全尺寸树莓派没法做的一些项目。

*从 MagPi 杂志上获得的树莓派 Zero。CC BY-SA.4.0。*
因为我对天文摄影非常感兴趣,我以前还改造过一台微软出的 LifeCam Cinema 高清网络摄像头,拆掉了它的外壳、镜头、以及红外滤镜,露出了它的 [CCD 芯片](https://en.wikipedia.org/wiki/Charge-coupled_device)。我把它定制为我的 Celestron 天文望远镜的目镜。用它我捕获到了令人难以置信的木星照片、月球上的陨石坑、以及太阳黑子的特写镜头(使用了适当的 Baader 安全保护膜)。
在那之前,我甚至还在我的使用胶片的 SLR 摄像机上,通过在镜头盖(这个盖子就是在摄像机上没有安装镜头时,用来保护摄像机的内部元件的那个盖子)上钻一个小孔来变成一个 [针孔摄像机](https://en.wikipedia.org/wiki/Pinhole_camera),将这个钻了小孔的盖子,盖到一个汽水罐上切下来的小圆盘上,以提供一个针孔。碰巧有一天,这个放在我的桌子上的针孔镜头盖被改成了用于天文摄像的网络摄像头。我很好奇这个网络摄像头是否有从针孔盖子后面捕获低照度图像的能力。我花了一些时间使用 [GNOME Cheese](https://help.gnome.org/users/cheese/stable/) 应用程序,去验证这个针孔摄像头确实是个可行的创意。
自从有了这个想法,我就有了树莓派 Zero 的一个用法!针孔摄像机一般都非常小,除了曝光时间和胶片的 ISO 速率外,一般都不提供其它的控制选项。数字摄像机就不一样了,它至少有 20 多个按钮和成百上千的设置菜单。我的数字针孔摄像头的目标是真实反映天文摄像的传统风格,设计一个没有控制选项的极简设备,甚至连曝光时间控制也没有。
用树莓派 Zero、高清网络镜头和空的粉盒设计的数字针孔摄像头,是我设计的 [一系列](https://pinholemiscellany.berrange.com/) 针孔摄像头的 [第一个项目](https://pinholemiscellany.berrange.com/motivation/m-arcturus/)。现在,我们开始来制作它。
### 硬件
因为我手头已经有了一个树莓派 Zero,为完成这个项目我还需要一个网络摄像头。这个树莓派 Zero 在英国的零售价是 4 英磅,这个项目其它部件的价格,我希望也差不多是这样的价格水平。花费 30 英磅买来的摄像头安装在一个 4 英磅的计算机主板上,让我感觉有些不平衡。显而易见的答案是前往一个知名的拍卖网站上,去找到一些二手的网络摄像头。不久之后,我仅花费了 1 英磅再加一些运费,获得了一个普通的高清摄像头。之后,在 Fedora 上做了一些测试操作,以确保它是可用正常使用的,我拆掉了它的外壳,以检查它的电子元件的大小是否适合我的项目。

*Hercules DualPix 高清网络摄像头,它将被解剖以提取它的电路板和 CCD 图像传感器。CC BY-SA 4.0.*
接下来,我需要一个安放摄像头的外壳。树莓派 Zero 电路板大小仅仅为 65mm x 30mm x 5mm。虽然网络摄像头的 CCD 芯片周围有一个用来安装镜头的塑料支架,但是,实际上它的电路板尺寸更小。我在家里找了一圈,希望能够找到一个适合盛放这两个极小的电路板的容器。最后,我发现我妻子的粉盒足够去安放树莓派的电路板。稍微做一些小调整,似乎也可以将网络摄像头的电路板放进去。

*变成我的针孔摄像头外壳的粉盒。CC BY-SA 4.0.*
我拆掉了网络摄像头外壳上的一些螺丝,取出了它的内部元件。网络摄像头外壳的大小反映了它的电路板的大小或 CCD 的位置。我很幸运,这个网络摄像头很小而且它的电路板的布局也很方便。因为我要做一个针孔摄像头,我需要取掉镜头,露出 CCD 芯片。
它的塑料外壳大约有 1 厘米高,它太高了没有办法放进粉盒里。我拆掉了电路板后面的螺丝,将它完全拆开,我认为将它放在盒子里有助于阻挡从缝隙中来的光线,因此,我用一把工艺刀将它修改成 4 毫米高,然后将它重新安装。我折弯了 LED 的支脚以降低它的高度。最后,我切掉了安装麦克风的塑料管,因为我不想采集声音。

*取下镜头以后,就可以看到裸露的 CCD 芯片了。圆柱形的塑料柱将镜头固定在合适的位置上,并阻挡 LED 光进入镜头破坏图像。CC BY-SA 4.0*
网络摄像头有一个很长的带全尺寸插头的 USB 线缆,而树莓派 Zero 使用的是一个 Micro-USB 插座,因此,我需要一个 USB 转 Micro-USB 的适配器。但是,使用适配器插入,这个树莓派将放不进这个粉盒中,更不用说还有将近一米长的 USB 线缆。因此,我用刀将 Micro-USB 适配器削开,切掉了它的 USB 插座并去掉这些塑料,露出连接到 Micro-USB 插头上的金属材料。同时也把网络摄像头的 USB 电缆切到大约 6 厘米长,并剥掉裹在它外面的锡纸,露出它的四根电线。我把它们直接焊接到 Micro-USB 插头上。现在网络摄像头可以插入到树莓派 Zero 上了,并且电线也可以放到粉盒中了。

*网络摄像头使用的 Micro-USB 插头已经剥掉了线,并直接焊接到触点上。这个插头现在插入到树莓派 Zero 后大约仅高出树莓派 1 厘米。CC BY-SA 4.0*
最初,我认为到此为止,已经全部完成了电子设计部分,但是在测试之后,我意识到,如果摄像头没有捕获图像或者甚至没有加电我都不知道。我决定使用树莓派的 GPIO 针脚去驱动 LED 指示灯。一个黄色的 LED 表示网络摄像头控制软件已经运行,而一个绿色的 LED 表示网络摄像头正在捕获图像。我在 BCM 的 17 号和 18 号针脚上各自串接一个 300 欧姆的电阻,并将它们各自连接到 LED 的正极上,然后将 LED 的负极连接到一起并接入到公共地针脚上。

*LED 使用一个 300 欧姆的电阻连接到 GPIO 的 BCM 17 号和 BCM 18 号针脚上,负极连接到公共地针脚。CC BY-SA 4.0.*
接下来,该去修改粉盒了。首先,我去掉了卡在粉盒上的托盘以腾出更多的空间,并且用刀将连接处切开。我打算在一个便携式充电宝上运行树莓派 Zero,充电宝肯定是放不到这个盒子里面,因此,我挖了一个孔,这样就可以引出 USB 连接头。LED 的光需要能够从盒子外面看得见,因此,我在盖子上钻了两个 3 毫米的小孔。
然后,我使用一个 6 毫米的钻头在盖子的底部中间处钻了一个孔,并找了一个薄片盖在它上面,然后用针在它的中央扎了一个小孔。一定要确保针尖很细,因为如果插入整个针会使孔太大。我使用干/湿砂纸去打磨这个针孔,以让它更光滑,然后从另一面再次打孔,再强调一次仅使用针尖。使用针孔摄像头的目的是为了得到一个规则的、没有畸形或凸起的圆孔,并且勉强让光通过。孔越小,图像越锐利。

*带针孔的盒子底部。CC BY-SA 4.0*
剩下的工作就是将这些已经改造完成的设备封装起来。首先我使用蓝色腻子将摄像头的电路板固定在盒子中合适的位置,这样针孔就直接处于 CCD 之上了。使用蓝色腻子的好处是,如果我需要清理污渍(或者如果放错了位置)时,就可以很容易地重新安装 CCD 了。将树莓派 Zero 直接放在摄像头电路板上面。为防止这两个电路板之间可能出现的短路情况,我在树莓派的背面贴了几层防静电胶带。
[树莓派 Zero](https://opensource.com/users/node/34916) 非常适合放到这个粉盒中,并且不需要任何固定,而从小孔中穿出去连接充电宝的 USB 电缆需要将它粘住固定。最后,我将 LED 塞进了前面在盒子上钻的孔中,并用胶水将它们固定住。我在 LED 的针脚之中放了一些防静电胶带,以防止盒子盖上时,它与树莓派电路板接触而发生短路。

*树莓派 Zero 塞入到这个盒子中后,周围的空隙不到 1mm。从盒子中引出的连接到网络摄像头上的 Micro-USB 插头,接下来需要将它连接到充电宝上。CC BY-SA 4.0*
### 软件
当然,计算机硬件离开控制它的软件是不能使用的。树莓派 Zero 同样可以运行全尺寸树莓派能够运行的软件,但是,因为树莓派 Zero 的 CPU 速度比较慢,让它去引导传统的 [Raspbian OS](https://www.raspberrypi.org/downloads/raspbian/) 镜像非常耗时。打开摄像头都要花费差不多一分钟的时间,这样的速度在现实中是没有什么用处的。而且,一个完整的树莓派操作系统对我的这个摄像头项目来说也没有必要。甚至是,我禁用了引导时启动的所有可禁用的服务,启动仍然需要很长的时间。因此,我决定仅使用需要的软件,我将用一个 [U-Boot](https://www.denx.de/wiki/U-Boot) 引导加载器和 Linux 内核。自定义 `init` 二进制文件从 microSD 卡上加载 root 文件系统、读入驱动网络摄像头所需要的内核模块,并将它放在 `/dev` 目录下,然后运行二进制的应用程序。
这个二进制的应用程序是另一个定制的 C 程序,它做的核心工作就是管理摄像头。首先,它等待内核驱动程序去初始化网络摄像头、打开它、以及通过低级的 `v4l ioctl` 调用去初始化它。GPIO 针配置用来通过 `/dev/mem` 寄存器去驱动 LED。
初始化完成之后,摄像头进入一个循环。每个图像捕获循环是摄像头使用缺省配置,以 JPEG 格式捕获一个单一的图像帧、保存这个图像帧到 SD 卡、然后休眠三秒。这个循环持续运行直到断电为止。这已经很完美地实现了我的最初目标,那就是用一个传统的模拟的针孔摄像头设计一个简单的数字摄像头。
定制的用户空间 [代码](https://gitlab.com/berrange/pinholemiscellany/) 在遵守 [GPLv3](https://www.gnu.org/licenses/gpl-3.0.en.html) 或者更新版许可下自由使用。树莓派 Zero 需要 ARMv6 的二进制文件,因此,我使用了 [QEMU ARM](https://wiki.qemu.org/Documentation/Platforms/ARM) 模拟器在一台 x86\_64 主机上进行编译,它使用了 [Pignus](https://pignus.computer/) 发行版(一个针对 ARMv6 移植/重构建的 Fedora 23 版本)下的工具链,在 `chroot` 环境下进行编译。所有的二进制文件都静态链接了 [glibc](https://www.gnu.org/software/libc/),因此,它们都是自包含的。我构建了一个定制的 RAMDisk 去包含这些二进制文件和所需的内核模块,并将它拷贝到 SD 卡,这样引导加载器就可以找到它们了。

*最终完成的摄像机完全隐藏在这个粉盒中了。唯一露在外面的东西就是 USB 电缆。CC BY-SA 4.0*
### 照像
软件和硬件已经完成了,是该去验证一下它能做什么了。每个人都熟悉用现代的数字摄像头拍摄的高质量图像,不论它是用专业的 DSLRs 还是移动电话拍的。但是,这个高清的 1280x1024 分辨率的网络摄像头(差不多是一百万像素),在这里可能会让你失望。这个 CCD 从一个光通量极小的针孔中努力捕获图像。网络摄像头自动提升增益和曝光时间来进行补偿,最后的结果是一幅噪点很高的图像。图像的动态范围也非常窄,从一个非常拥挤的柱状图就可以看出来,这可以通过后期处理来拉长它,以得到更真实的亮部和暗部。
在户外阳光充足时捕获的图像达到了最佳效果,因此在室内获得的图像大多数都是不可用的图像。它的 CCD 直径仅有大约 1cm,并且是从一个几毫米的针孔中来捕获图像的,它的视界相当窄。比如,在自拍时,手臂拿着相机尽可能伸长,所获得的图像也就是充满整个画面的人头。最后,图像都是失焦的,所有的针孔摄像机都是这样的。

*在伦敦,大街上的屋顶。CC BY-SA 4.0*

*范堡罗机场的老航站楼。CC BY-SA 4.0*
最初,我只是想使用摄像头去捕获一些静态图像。后面,我降低了循环的延迟时间,从三秒改为一秒,然后用它捕获一段时间内的一系列图像。我使用 [GStreamer](https://gstreamer.freedesktop.org/modules/gst-ffmpeg.html) 将这些图像做成了延时视频。
以下是我创建视频的过程:
*视频是我在某天下班之后,从银行沿着泰晤式河到滑铁卢的画面。以每分钟 40 帧捕获的 1200 帧图像被我制作成了每秒 20 帧的动画。*
---
via: <https://opensource.com/article/18/3/how-build-digital-pinhole-camera-raspberry-pi>
作者:[Daniel Berrange](https://opensource.com/users/berrange) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | At the tail end of 2015, the Raspberry Pi Foundation surprised the world by releasing the diminutive [Raspberry Pi Zero](https://www.raspberrypi.org/products/raspberry-pi-zero/). What's more, they [gave it away for free](https://opensource.com/node/24776) on the cover of the *MagPi* magazine. I immediately rushed out and trawled around several newsagents until I found the last two copies in the area. I wasn't sure what I would use them for, but I knew their small size would allow me to do interesting projects that a full-sized Pi could not satisfy.

opensource.com
Because of my interest in astrophotography, I had previously modified a Microsoft LifeCam Cinema HD webcam, stripping its case, lens, and infrared cut filter to expose the bare [CCD chip](https://en.wikipedia.org/wiki/Charge-coupled_device). I used it with a custom-built case in place of an eyepiece in my Celestron telescope for astrophotography. It has captured incredible views of Jupiter, close-ups of craters on the Moon, and sunspots on the Sun (with suitable Baader safety film protection).
Even before that, I had turned my film SLR camera into a [pinhole camera](https://en.wikipedia.org/wiki/Pinhole_camera) by drilling a hole in a body cap (the cap that protects a camera's internal workings when it doesn't have a lens attached) and covering it in a thin disc cut from a soda can, pierced with a needle to provide a pinhole. Quite by chance, one day this pinhole body cap was sitting on my desk next to the modified astrophotography webcam. I wondered whether the webcam had good enough low-light performance to capture an image from behind the pinhole body cap. It only took a minute with the [GNOME Cheese](https://help.gnome.org/users/cheese/stable/) application to verify that a pinhole webcam was indeed a viable idea.
From this seed of an idea, I had a way to use one of my Raspberry Pi Zeros! The pinhole cameras that people build are typically minimalistic, offering no controls other than the exposure duration and film's ISO rating. Digital cameras, by contrast, have 20 or more buttons and hundreds more settings buried in menus. My goal for the digital pinhole webcam was to stay true to pinhole photography traditions and build a minimalist device with no controls at all, not even exposure time.
The digital pinhole camera, created from a Raspberry Pi Zero, HD webcam, and empty powder compact, was the [first project](https://pinholemiscellany.berrange.com/motivation/m-arcturus/) in an [ongoing series](https://pinholemiscellany.berrange.com/) of pinhole cameras I built. Here's how I made it.
## Hardware
Since I already had the Raspberry Pi Zero in hand, I needed a webcam for this project. Given that the Pi Zero retails for £4 in the UK, I wanted other parts of the project to be priced similarly. Spending £30 on a camera to use with a £4 computer board just feels unbalanced. The obvious answer was to head over to a well-known internet auction site and bid on some secondhand webcams. Soon, I'd acquired a generic HD resolution webcam for a mere £1 plus shipping. After a quick test to ensure it operated correctly with Fedora, I went about stripping the case to examine the size of the electronics.

opensource.com
Next, I needed a case to house the camera. The Raspberry Pi Zero circuit board is a mere 65mm x 30mm x 5mm. The webcam's circuit board is even smaller, although it has a plastic mounting around the CCD chip to hold the lens in place. I looked around the house for a container that would fit the two tiny circuit boards. I discovered that my wife's powder compact was just wide enough to fit the Pi Zero circuit board. With a little fiddling, it looked as though I could squeeze the webcam board inside, too.

opensource.com
I set out to strip the case off of the webcam by removing a handful of tiny screws to get at the innards. The size of a webcam's case gives little clue about the size of the circuit board inside or where the CCD is positioned. I was lucky that this webcam was small with a convenient layout. Since I was making a pinhole camera, I had to remove the lens to expose the bare CCD chip.
The plastic mounting was about 1cm high, which would be too tall to fit inside the powder compact. I could remove it entirely with a couple more screws on the rear of the circuit board, but I thought it would be useful to keep it to block light coming from gaps in the case, so I trimmed it down to 4mm high using a craft knife, then reattached it. I bent the legs on the LED to reduce its height. Finally, I chopped off a second plastic tube mounted over the microphone that funneled the sound, since I didn't intend to capture audio.

opensource.com
The webcam had a long USB cable with a full-size plug, while the Raspberry Pi Zero uses a Micro-USB socket, so I needed a USB-to-Micro-USB adapter. But, with the adapter plugged in, the Pi wouldn't fit inside the powder compact, nor would the 1m of USB cable. So I took a sharp knife to the Micro-USB adapter, cutting off its USB socket entirely and stripping plastic to reveal the metal tracks leading to the Micro-USB plug. I also cut the webcam's USB cable down to about 6cm and removed its outer sheaf and foil wrap to expose the four individual cable strands. I soldered them directly to the tracks on the Micro-USB plug. Now the webcam could be plugged into the Pi Zero, and the pair would still fit inside the powder compact case.

opensource.com
Originally I thought this would be the end of my electrical design, but after testing, I realized I couldn't tell if the camera was capturing images or even powered on. I decided to use the Pi's GPIO pins to drive indicator LEDs. A yellow LED illuminates when the camera control software is running, and a green LED illuminates when the webcam is capturing an image. I connected BCM pins 17 and 18 to the positive leg of the LEDs via 300ohm current-limiting resistors, then connected both negative legs to a common ground pin.
opensource.com
Next, it was time to modify the powder compact. First, I removed the inner tray that holds the powder to free up space inside the case by cutting it off with a knife at its hinge. I was planning to run the Pi Zero on a portable USB power-bank battery, which wouldn't fit inside the case, so I cut a hole in the side of the case for the USB cable connector. The LEDs needed to be visible outside the case, so I used a 3mm drill bit to make two holes in the lid.
Then I used a 6mm drill bit to make a hole in the center of the bottom of the case, which I covered with a thin piece of metal and used a sewing needle to pierce a pinhole in its center. I made sure that only the very tip of the needle poked through, as inserting the entire needle would make the hole far too large. I used fine wet/dry sandpaper to smooth out the pinhole, then re-pierced it from the other side, again using only the tip of the needle. The goal with a pinhole camera is to get a clean, round hole with no deformations or ridges and that just barely lets light through. The smaller the hole, the sharper the images.

opensource.com
All that remained was assembling the finished device. First I fixed the webcam circuit board in the case, using blue putty to hold it in position so the CCD was directly over the pinhole. Using putty allows me to easily reposition the CCD when I need to clean dust spots (and as insurance in case I put it in the wrong place). I placed the Raspberry Pi Zero board directly on top of the webcam board. To protect against electrical short circuits between the two boards, I covered the back of the Pi in several layers of electrical tape.
The [Raspberry Pi Zero](https://opensource.com/node/34916) was such a perfect fit for the powder compact that it didn't need anything else to hold it in position, besides the USB cable for the battery that sticks out through the hole in the case. Finally, I poked the LEDs through the previously drilled holes and glued them into place. I added more electrical tape on the legs of the LEDs to prevent short circuits against the Pi Zero board when the lid is closed.

opensource.com
## Software
Computer hardware is useless without software to control it, of course. The Raspberry Pi Zero can run the same software as a full-sized Pi, but booting up a traditional [Raspbian OS](https://www.raspberrypi.org/downloads/raspbian/) image is a very time-consuming process due to the Zero's slow CPU speed. A camera that takes more than a minute to turn on is a camera that will not get much real-world use. Furthermore, almost nothing that a full Raspbian OS runs is useful to this camera. Even if I disable all the redundant services launched at boot, it still takes unreasonably long to boot. I decided the only stock software I would use is a [U-Boot](https://www.denx.de/wiki/U-Boot) bootloader and the Linux kernel. A custom written `init`
binary mounts the root filesystem from the microSD card, loads the kernel modules needed to drive the webcam, populates `/dev`
, and runs the application binary.
The application binary is another custom C program that does the core job of controlling the camera. First, it waits for the kernel driver to initialize the webcam, opens it, and initializes it via low-level `v4l ioctl`
calls. The GPIO pins are configured to drive the LEDs by poking registers via `/dev/mem`
.
With initialization out of the way, the camera goes into a loop. Each iteration captures a single frame from the webcam in JPEG format using default exposure settings, saves the image straight to the SD card, then sleeps for three seconds. This loop runs forever until the battery is unplugged. This nicely achieves the original goal, which was to create a digital camera with the simplicity on par with a typical analog pinhole camera.
[The code](https://gitlab.com/berrange/pinholemiscellany/) for this custom userspace is made available under [GPLv3](https://www.gnu.org/licenses/gpl-3.0.en.html) or any later version. The Raspberry Pi Zero requires an ARMv6 binary, so I built it from an x86_64 host using the [QEMU ARM](https://wiki.qemu.org/Documentation/Platforms/ARM) emulator to run compilers from a `chroot`
populated with the toolchain for the [Pignus](https://pignus.computer/) distro (a Fedora 23 port/rebuild for ARMv6). Both binaries were statically linked with [glibc](https://www.gnu.org/software/libc/), so they are self-contained. I built a custom RAMDisk containing the binaries and a few required kernel modules and copied it to the SD card, where the bootloader can find them.

opensource.com
## Taking photos
With both the hardware and software complete, it was time to see what the camera was capable of. Everyone is familiar with the excellent quality of images produced by modern digital cameras, whether professional DSLRs or mobile phones. It is important to reset expectations here to a more realistic level. The HD webcam captures 1280x1024 resolution (~1 megapixel). The CCD struggles to capture an image from the tiny amount of light allowed through the pinhole. The webcam automatically increases gain and exposure time to compensate, which results in very noisy images. The images also suffer from a very narrow dynamic range, as evidenced by a squashed histogram, which has to be stretched in post-processing to get true blacks and whites.
The best results are achieved by capturing images outside in daylight, as most interiors have insufficient illumination to register any kind of usable image. The CCD is only about 1cm in diameter, and it's just a few millimeters away from the pinhole, which creates a relatively narrow field of view. For example, in a selfie taken by holding the camera at arm's length, the person's head fills the entire frame. Finally, the images are in very soft focus, which is a defining characteristic of all pinhole cameras.

opensource.com

opensource.com
Initially, I just used the camera to capture small numbers of still images. I later reduced the loop delay from three seconds to one second and used the camera used to capture sequences of images over many minutes. I rendered the images into time-lapse videos using [GStreamer.](https://gstreamer.freedesktop.org/modules/gst-ffmpeg.html)
Here's a video I created with this process:
Video of the walk from Bank to Waterloo along the Thames to unwind after a day's work. 1200 frames captured at 40 frames per minute animated at 20 frames per second.
## Comments are closed. |
9,767 | Linux 中一种友好的 find 替代工具 | https://opensource.com/article/18/6/friendly-alternative-find | 2018-06-21T10:06:29 | [
"fd",
"find",
"查找"
] | /article-9767-1.html |
>
> fd 命令提供了一种简单直白的搜索 Linux 文件系统的方式。
>
>
>

[fd](https://github.com/sharkdp/fd) 是一个超快的,基于 [Rust](https://www.rust-lang.org/en-US/) 的 Unix/Linux `find` 命令的替代品。它不提供所有 `find` 的强大功能。但是,它确实提供了足够的功能来覆盖你可能遇到的 80% 的情况。诸如良好的规划和方便的语法、彩色输出、智能大小写、正则表达式以及并行命令执行等特性使 `fd` 成为一个非常有能力的后继者。
### 安装
进入 [fd](https://github.com/sharkdp/fd) GitHub 页面,查看安装部分。它涵盖了如何在[macOS](https://en.wikipedia.org/wiki/MacOS)、 [Debian/Ubuntu](https://www.ubuntu.com/community/debian) [Red Hat](https://www.redhat.com/en) 和 [Arch Linux](https://www.archlinux.org/) 上安装程序。安装完成后,你可以通过运行帮助来获得所有可用命令行选项的完整概述,通过 `fd -h` 获取简明帮助,或者通过 `fd --help` 获取更详细的帮助。
### 简单搜索
`fd` 旨在帮助你轻松找到文件系统中的文件和文件夹。你可以用 `fd` 带上一个参数执行最简单的搜索,该参数就是你要搜索的任何东西。例如,假设你想要找一个 Markdown 文档,其中包含单词 `services` 作为文件名的一部分:
```
$ fd services
downloads/services.md
```
如果仅带一个参数调用,那么 `fd` 递归地搜索当前目录以查找与莫的参数匹配的任何文件和/或目录。使用内置的 `find` 命令的等效搜索如下所示:
```
$ find . -name 'services'
downloads/services.md
```
如你所见,`fd` 要简单得多,并需要更少的输入。在我心中用更少的输入做更多的事情总是对的。
### 文件和文件夹
您可以使用 `-t` 参数将搜索范围限制为文件或目录,后面跟着代表你要搜索的内容的字母。例如,要查找当前目录中文件名中包含 `services` 的所有文件,可以使用:
```
$ fd -tf services
downloads/services.md
```
以及,找到当前目录中文件名中包含 `services` 的所有目录:
```
$ fd -td services
applications/services
library/services
```
如何在当前文件夹中列出所有带 `.md` 扩展名的文档?
```
$ fd .md
administration/administration.md
development/elixir/elixir_install.md
readme.md
sidebar.md
linux.md
```
从输出中可以看到,`fd` 不仅可以找到并列出当前文件夹中的文件,还可以在子文件夹中找到文件。很简单。
你甚至可以使用 `-H` 参数来搜索隐藏文件:
```
fd -H sessions .
.bash_sessions
```
### 指定目录
如果你想搜索一个特定的目录,这个目录的名字可以作为第二个参数传给 `fd`:
```
$ fd passwd /etc
/etc/default/passwd
/etc/pam.d/passwd
/etc/passwd
```
在这个例子中,我们告诉 `fd` 我们要在 `etc` 目录中搜索 `passwd` 这个单词的所有实例。
### 全局搜索
如果你知道文件名的一部分,但不知道文件夹怎么办?假设你下载了一本关于 Linux 网络管理的书,但你不知道它的保存位置。没有问题:
```
fd Administration /
/Users/pmullins/Documents/Books/Linux/Mastering Linux Network Administration.epub
```
### 总结
`fd` 是 `find` 命令的极好的替代品,我相信你会和我一样发现它很有用。要了解该命令的更多信息,只需浏览手册页。
---
via: <https://opensource.com/article/18/6/friendly-alternative-find>
作者:[Patrick H. Mullins](https://opensource.com/users/pmullins) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
9,768 | 8 个基本的 Docker 容器管理命令 | https://kerneltalks.com/virtualization/8-basic-docker-container-management-commands/ | 2018-06-21T18:53:54 | [
"容器",
"Docker"
] | https://linux.cn/article-9768-1.html |
>
> 利用这 8 个命令可以学习 Docker 容器的基本管理方式。这是一个为 Docker 初学者准备的,带有示范命令输出的指南。
>
>
>

在这篇文章中,我们将带你学习 8 个基本的 Docker 容器命令,它们操控着 Docker 容器的基本活动,例如 <ruby> 运行 <rt> run </rt></ruby>、 <ruby> 列举 <rt> list </rt></ruby>、 <ruby> 停止 <rt> stop </rt></ruby>、 查看<ruby> 历史纪录 <rt> logs </rt></ruby>、 <ruby> 删除 <rt> delete </rt></ruby> 等等。如果你对 Docker 的概念很陌生,推荐你看看我们的 [介绍指南](https://kerneltalks.com/virtualization/what-is-docker-introduction-guide-to-docker/),来了解 Docker 的基本内容以及 [如何](https://kerneltalks.com/virtualization/how-to-install-docker-in-linux/) 在 Linux 上安装 Docker。 现在让我们赶快进入要了解的命令:
### 如何运行 Docker 容器?
众所周知,Docker 容器只是一个运行于<ruby> 宿主操作系统 <rt> host OS </rt></ruby>上的应用进程,所以你需要一个镜像来运行它。Docker 镜像以进程的方式运行时就叫做 Docker 容器。你可以加载本地 Docker 镜像,也可以从 Docker Hub 上下载。Docker Hub 是一个提供公有和私有镜像来进行<ruby> 拉取 <rt> pull </rt></ruby>操作的集中仓库。官方的 Docker Hub 位于 [hub.docker.com](https://hub.docker.com/)。 当你指示 Docker 引擎运行容器时,它会首先搜索本地镜像,如果没有找到,它会从 Docker Hub 上拉取相应的镜像。
让我们运行一个 Apache web 服务器的 Docker 镜像,比如 httpd 进程。你需要运行 `docker container run` 命令。旧的命令为 `docker run`, 但后来 Docker 添加了子命令部分,所以新版本支持下列命令:
```
root@kerneltalks # docker container run -d -p 80:80 httpd
Unable to find image 'httpd:latest' locally
latest: Pulling from library/httpd
3d77ce4481b1: Pull complete
73674f4d9403: Pull complete
d266646f40bd: Pull complete
ce7b0dda0c9f: Pull complete
01729050d692: Pull complete
014246127c67: Pull complete
7cd2e04cf570: Pull complete
Digest: sha256:f4610c3a1a7da35072870625733fd0384515f7e912c6223d4a48c6eb749a8617
Status: Downloaded newer image for httpd:latest
c46f2e9e4690f5c28ee7ad508559ceee0160ac3e2b1688a61561ce9f7d99d682
```
Docker 的 `run` 命令将镜像名作为强制参数,另外还有很多可选参数。常用的参数有:
* `-d`:从当前 shell 脱离容器
* `-p X:Y`:绑定容器的端口 Y 到宿主机的端口 X
* `--name`:命名你的容器。如果未指定,它将被赋予随机生成的名字
* `-e`:当启动容器时传递环境编辑及其值
通过以上输出你可以看到,我们将 `httpd` 作为镜像名来运行容器。接着,本地镜像没有找到,Docker 引擎从 Docker Hub 拉取了它。注意,它下载了镜像 `httpd:latest`, 其中 `:` 后面跟着版本号。如果你需要运行特定版本的容器,你可以在镜像名后面注明版本名。如果不提供版本名,Docker 引擎会自动拉取最新的版本。
输出的最后一行显示了你新运行的 httpd 容器的唯一 ID。
### 如何列出所有运行中的 Docker 容器?
现在,你的容器已经运行起来了,你可能想要确认这一点,或者你想要列出你的机器上运行的所有容器。你可以使用 `docker container ls` 命令。在旧的 Docker 版本中,对应的命令为 `docker ps`。
```
root@kerneltalks # docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
c46f2e9e4690 httpd "httpd-foreground" 11 minutes ago Up 11 minutes 0.0.0.0:80->80/tcp cranky_cori
```
列出的结果是按列显示的。每一列的值分别为:
1. Container ID :一开始的几个字符对应你的容器的唯一 ID
2. Image :你运行容器的镜像名
3. Command :容器启动后运行的命令
4. Created :创建时间
5. Status :容器当前状态
6. Ports :与宿主端口相连接的端口信息
7. Names :容器名(如果你没有命名你的容器,那么会随机创建)
### 如何查看 Docker 容器的历史纪录?
在第一步我们使用了 `-d` 参数来将容器,在它一开始运行的时候,就从当前的 shell 中脱离出来。在这种情况下,我们不知道容器里面发生了什么。所以为了查看容器的历史纪录,Docker 提供了 `logs` 命令。它采用容器名称或 ID 作为参数。
```
root@kerneltalks # docker container logs cranky_cori
AH00558: httpd: Could not reliably determine the server's fully qualified domain name, using 172.17.0.2. Set the 'ServerName' directive globally to suppress this message
AH00558: httpd: Could not reliably determine the server's fully qualified domain name, using 172.17.0.2. Set the 'ServerName' directive globally to suppress this message
[Thu May 31 18:35:07.301158 2018] [mpm_event:notice] [pid 1:tid 139734285989760] AH00489: Apache/2.4.33 (Unix) configured -- resuming normal operations
[Thu May 31 18:35:07.305153 2018] [core:notice] [pid 1:tid 139734285989760] AH00094: Command line: 'httpd -D FOREGROUND'
```
这里我使用了容器名称作为参数。你可以看到在我们的 httpd 容器中与 Apache 相关的历史纪录。
### 如何确定 Docker 容器的进程?
容器是一个使用宿主资源来运行的进程。这样,你可以在宿主系统的进程表中定位容器的进程。让我们在宿主系统上确定容器进程。
Docker 使用著名的 `top` 命令作为子命令的名称,来查看容器产生的进程。它采用容器的名称或 ID 作为参数。在旧版本的 Docker 中,只可运行 `docker top` 命令。在新版本中,`docker top` 和 `docker container top` 命令都可以生效。
```
root@kerneltalks # docker container top cranky_cori
UID PID PPID C STIME TTY TIME CMD
root 15702 15690 0 18:35 ? 00:00:00 httpd -DFOREGROUND
bin 15729 15702 0 18:35 ? 00:00:00 httpd -DFOREGROUND
bin 15730 15702 0 18:35 ? 00:00:00 httpd -DFOREGROUND
bin 15731 15702 0 18:35 ? 00:00:00 httpd -DFOREGROUND
root@kerneltalks # ps -ef |grep -i 15702
root 15702 15690 0 18:35 ? 00:00:00 httpd -DFOREGROUND
bin 15729 15702 0 18:35 ? 00:00:00 httpd -DFOREGROUND
bin 15730 15702 0 18:35 ? 00:00:00 httpd -DFOREGROUND
bin 15731 15702 0 18:35 ? 00:00:00 httpd -DFOREGROUND
root 15993 15957 0 18:59 pts/0 00:00:00 grep --color=auto -i 15702
```
在第一个输出中,列出了容器产生的进程的列表。它包含了所有细节,包括<ruby> 用户号 <rt> uid </rt></ruby>、<ruby> 进程号 <rt> pid </rt></ruby>,<ruby> 父进程号 <rt> ppid </rt></ruby>、开始时间、命令,等等。这里所有的进程号你都可以在宿主的进程表里搜索到。这就是我们在第二个命令里做得。这证明了容器确实是宿主系统中的进程。
### 如何停止 Docker 容器?
只需要 `stop` 命令!同样,它采用容器名称或 ID 作为参数。
```
root@kerneltalks # docker container stop cranky_cori
cranky_cori
```
### 如何列出停止的或不活动的 Docker 容器?
现在我们停止了我们的容器,这时如果我们使用 `ls` 命令,它将不会出现在列表中。
```
root@kerneltalks # docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
```
所以,在这种情况下,如果想要查看停止的或不活动的容器,你需要在 `ls` 命令里同时使用 `-a` 参数。
```
root@kerneltalks # docker container ls -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
c46f2e9e4690 httpd "httpd-foreground" 33 minutes ago Exited (0) 2 minutes ago cranky_cori
```
有了 `-a` 参数,现在我们可以查看已停止的容器。注意这些容器的状态被标注为 <ruby> 已退出 <rt> exited </rt></ruby>。既然容器只是一个进程,那么用“退出”比“停止”更合适!
### 如何(重新)启动 Docker 容器?
现在,我们来启动这个已停止的容器。这和运行一个容器有所区别。当你运行一个容器时,你将启动一个全新的容器。当你启动一个容器时,你将开始一个已经停止并保存了当时运行状态的容器。它将以停止时的状态重新开始运行。
```
root@kerneltalks # docker container start c46f2e9e4690
c46f2e9e4690
root@kerneltalks # docker container ls -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
c46f2e9e4690 httpd "httpd-foreground" 35 minutes ago Up 8 seconds 0.0.0.0:80->80/tcp cranky_cori
```
### 如何移除 Docker 容器?
我们使用 `rm` 命令来移除容器。你不可以移除运行中的容器。移除之前需要先停止容器。你可以使用 `-f` 参数搭配 `rm` 命令来强制移除容器,但并不推荐这么做。
```
root@kerneltalks # docker container rm cranky_cori
cranky_cori
root@kerneltalks # docker container ls -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
```
你看,一旦移除了容器,即使再使用 `ls -a` 命令也查看不到容器了。
---
via: <https://kerneltalks.com/virtualization/8-basic-docker-container-management-commands/>
作者:[Shrikant Lavhate](https://kerneltalks.com) 选题:[lujun9972](https://github.com/lujun9972) 译者:[lonaparte](https://github.com/lonaparte) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Learn basic Docker container management with the help of these 8 commands. A useful guide for Docker beginners which includes sample command outputs.*

In this article we will walk you through 6 basic Docker container commands which are useful in performing basic activities on Docker containers like run, list, stop, view logs, delete, etc. If you are new to the Docker concept then do check our [introduction guide](https://kerneltalks.com/virtualization/what-is-docker-introduction-guide-to-docker/) to know what is Docker & [how-to guide](https://kerneltalks.com/virtualization/how-to-install-docker-in-linux/) to install Docker in Linux. Without further delay lets directly jump into commands.
### How to run Docker container?
As you know, the Docker container is just an application process running on the host OS. For Docker container, you need a image to run from. Docker image when runs as process called a Docker container. You can have Docker image available locally or you have to download it from Docker hub. Docker hub is a centralized repository that has public and private images stored to pull from. Docker’s official hub is at [hub.docker.com](https://hub.docker.com/). So whenever you instruct the Docker engine to run a container, it looks for image locally, and if not found it pulls it from Docker hub.
Read all docker or containerization related
[articles here]from KernelTalk’s archives.
Let’s run a Docker container for Apache web-server i.e httpd process. You need to run the command `docker container run`
. The old command was just `docker run`
but lately, Docker added sub-command section so new versions support below command –
```
root@kerneltalks # docker container run -d -p 80:80 httpd
Unable to find image 'httpd:latest' locally
latest: Pulling from library/httpd
3d77ce4481b1: Pull complete
73674f4d9403: Pull complete
d266646f40bd: Pull complete
ce7b0dda0c9f: Pull complete
01729050d692: Pull complete
014246127c67: Pull complete
7cd2e04cf570: Pull complete
Digest: sha256:f4610c3a1a7da35072870625733fd0384515f7e912c6223d4a48c6eb749a8617
Status: Downloaded newer image for httpd:latest
c46f2e9e4690f5c28ee7ad508559ceee0160ac3e2b1688a61561ce9f7d99d682
```
Docker `run`
command takes image name as a mandatory argument along with many other optional ones. Commonly used arguments are –
`-d`
: Detach container from the current shell`-p X:Y`
: Bind container port Y with host’s port X`--name`
: Name your container. If not used, it will be assigned randomly generated name`-e`
: Pass environmental variables and their values while starting a container
In the above output you can see, we supply `httpd`
as an image name to run a container from. Since the image was not locally found, the Docker engine pulled it from Docker Hub. Now, observe it downloaded image **httpd:latest **where: is followed by version. That’s the naming convention of Docker container image. If you want a specific version container to run from then you can provide a version name along with image name. If not supplied, the Docker engine will always pull the latest one.
The very last line of output shown a unique container ID of your newly running httpd container.
### How to list all running Docker containers?
Now, your container is running, you may want to check it or you want to list all running containers on your machine. You can list all running containers using `docker container ls`
command. In the old Docker version, `docker ps`
does this task for you.
```
root@kerneltalks # docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
c46f2e9e4690 httpd "httpd-foreground" 11 minutes ago Up 11 minutes 0.0.0.0:80->80/tcp cranky_cori
```
Listing output is presented in column-wise format. Where column-wise values are –
- Container ID: First few digits of the unique container ID
- Image: Name of the image used to run the container
- Command: Command ran by container after it ran
- Created: Time created
- Status: Current status of the container
- Ports: Port binding details with host’s ports
- Names: Name of the container (since we haven’t named our container you can see randomly generated name assigned to our container)
### How to view logs of Docker container?
Since during the first step we used -d switch to detach container from the current shell once it ran its running in the background. In this case, we are clueless about what’s happening inside the container. So to view logs of the container, Docker provided `logs`
command. It takes a container name or ID as an argument.
```
root@kerneltalks # docker container logs cranky_cori
AH00558: httpd: Could not reliably determine the server's fully qualified domain name, using 172.17.0.2. Set the 'ServerName' directive globally to suppress this message
AH00558: httpd: Could not reliably determine the server's fully qualified domain name, using 172.17.0.2. Set the 'ServerName' directive globally to suppress this message
[Thu May 31 18:35:07.301158 2018] [mpm_event:notice] [pid 1:tid 139734285989760] AH00489: Apache/2.4.33 (Unix) configured -- resuming normal operations
[Thu May 31 18:35:07.305153 2018] [core:notice] [pid 1:tid 139734285989760] AH00094: Command line: 'httpd -D FOREGROUND'
```
I used the container name in my command as an argument. You can see the Apache related log within our httpd container.
### How to identify Docker container process?
The container is a process that uses host resources to run. If it’s true, then you will be able to locate the container process on the host’s process table. Let’s see how to check the container process on the host.
Docker used famous `top`
command as its sub-commands name to view processes spawned by the container. It takes the container name/ID as an argument. In the old Docker version, only `docker top`
command works. In newer versions, `docker top`
and `docker container top`
both works.
```
root@kerneltalks # docker container top cranky_cori
UID PID PPID C STIME TTY TIME CMD
root 15702 15690 0 18:35 ? 00:00:00 httpd -DFOREGROUND
bin 15729 15702 0 18:35 ? 00:00:00 httpd -DFOREGROUND
bin 15730 15702 0 18:35 ? 00:00:00 httpd -DFOREGROUND
bin 15731 15702 0 18:35 ? 00:00:00 httpd -DFOREGROUND
root@kerneltalks # ps -ef |grep -i 15702
root 15702 15690 0 18:35 ? 00:00:00 httpd -DFOREGROUND
bin 15729 15702 0 18:35 ? 00:00:00 httpd -DFOREGROUND
bin 15730 15702 0 18:35 ? 00:00:00 httpd -DFOREGROUND
bin 15731 15702 0 18:35 ? 00:00:00 httpd -DFOREGROUND
root 15993 15957 0 18:59 pts/0 00:00:00 grep --color=auto -i 15702
```
In the first output, the list of processes spawned by that container. It has all details like use, PID, PPID, start time, command, etc. All those PID you can search in your host’s process table and you can find them there. That’s what we did in the second command. So, this proves containers are indeed just processes on Host’s OS.
### How to stop Docker container?
It’s simple `stop`
command! Again it takes container name /ID as an argument.
```
root@kerneltalks # docker container stop cranky_cori
cranky_cori
```
### How to list stopped or not running Docker containers?
Now we stopped our container if we try to list container using `ls`
command, we won’t be able to see it.
```
root@kerneltalks # docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
```
So, in this case, to view stopped or nonrunning container you need to use `-a`
switch along with `ls`
command.
```
root@kerneltalks # docker container ls -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
c46f2e9e4690 httpd "httpd-foreground" 33 minutes ago Exited (0) 2 minutes ago cranky_cori
```
With `-a`
switch we can see stopped container now. The notice status of this container is mentioned ‘Exited’. Since the container is just a process its termed as ‘exited’ rather than stopped!
### How to start Docker container?
Now, we will start this stopped container. There is a difference between running and starting a container. When you run a container, you are starting a command in a fresh container. When you start a container, you are starting an old stopped container which has an old state saved in it. It will start it from that state forward.
```
root@kerneltalks # docker container start c46f2e9e4690
c46f2e9e4690
root@kerneltalks # docker container ls -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
c46f2e9e4690 httpd "httpd-foreground" 35 minutes ago Up 8 seconds 0.0.0.0:80->80/tcp cranky_cori
```
### How to remove Docker container?
To remove the container from your Docker engine use `rm`
command. You can not remove the running containers. You have to first stop the container and then remove it. You can remove it forcefully using `-f`
switch with `rm`
command but that’s not recommended.
```
root@kerneltalks # docker container rm cranky_cori
cranky_cori
root@kerneltalks # docker container ls -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
```
You can see once we remove container, its not visible in `ls -a`
listing too.
How do I login any running container?
Hi Dipanjan,
You can but your container should have shell capability.
Here is detailed article.
https://kerneltalks.com/howto/how-to-execute-command-inside-docker-container/
Thanks. |
9,769 | 将 DEB 软件包转换成 Arch Linux 软件包 | https://www.ostechnix.com/convert-deb-packages-arch-linux-packages/ | 2018-06-21T19:03:05 | [
"AUR",
"Arch"
] | https://linux.cn/article-9769-1.html | 
我们已经学会了如何[为多个平台构建包](https://www.ostechnix.com/build-linux-packages-multiple-platforms-easily/),以及如何从[源代码构建包](https://www.ostechnix.com/build-packages-source-using-checkinstall/)。 今天,我们将学习如何将 DEB 包转换为 Arch Linux 包。 您可能会问,AUR 是这个星球上的大型软件存储库,几乎所有的软件都可以在其中使用。 为什么我需要将 DEB 软件包转换为 Arch Linux 软件包? 这的确没错! 但是,由于某些软件包无法编译(封闭源代码软件包),或者由于各种原因(如编译时出错或文件不可用)而无法从 AUR 生成。 或者,开发人员懒得在 AUR 中构建一个包,或者他/她不想创建 AUR 包。 在这种情况下,我们可以使用这种快速但有点粗糙的方法将 DEB 包转换成 Arch Linux 包。
### Debtap - 将 DEB 包转换成 Arch Linux 包
为此,我们将使用名为 “Debtap” 的实用程序。 它代表了 **DEB** **T** o **A** rch (Linux) **P** ackage。 Debtap 在 AUR 中可以使用,因此您可以使用 AUR 辅助工具(如 [Pacaur](https://www.ostechnix.com/install-pacaur-arch-linux/)、[Packer](https://www.ostechnix.com/install-packer-arch-linux-2/) 或 [Yaourt](https://www.ostechnix.com/install-yaourt-arch-linux/) )来安装它。
使用 pacaur 安装 debtap 运行:
```
pacaur -S debtap
```
使用 Packer 安装:
```
packer -S debtap
```
使用 Yaourt 安装:
```
yaourt -S debtap
```
同时,你的 Arch 系统也应该已经安装好了 `bash`, `binutils` ,`pkgfile` 和 `fakeroot` 包。
在安装 Debtap 和所有上述依赖关系之后,运行以下命令来创建/更新 pkgfile 和 debtap 数据库。
```
sudo debtap -u
```
示例输出是:
```
==> Synchronizing pkgfile database...
:: Updating 6 repos...
download complete: archlinuxfr [ 151.7 KiB 67.5K/s 5 remaining]
download complete: multilib [ 319.5 KiB 36.2K/s 4 remaining]
download complete: core [ 707.7 KiB 49.5K/s 3 remaining]
download complete: testing [ 1716.3 KiB 58.2K/s 2 remaining]
download complete: extra [ 7.4 MiB 109K/s 1 remaining]
download complete: community [ 16.9 MiB 131K/s 0 remaining]
:: download complete in 131.47s < 27.1 MiB 211K/s 6 files >
:: waiting for 1 process to finish repacking repos...
==> Synchronizing debtap database...
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 34.1M 100 34.1M 0 0 206k 0 0:02:49 0:02:49 --:--:-- 180k
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 814k 100 814k 0 0 101k 0 0:00:08 0:00:08 --:--:-- 113k
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 120k 100 120k 0 0 61575 0 0:00:02 0:00:02 --:--:-- 52381
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 35.4M 100 35.4M 0 0 175k 0 0:03:27 0:03:27 --:--:-- 257k
==> Downloading latest virtual packages list...
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 149 0 149 0 0 49 0 --:--:-- 0:00:03 --:--:-- 44
100 11890 0 11890 0 0 2378 0 --:--:-- 0:00:05 --:--:-- 8456
==> Downloading latest AUR packages list...
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 264k 0 264k 0 0 30128 0 --:--:-- 0:00:09 --:--:-- 74410
==> Generating base group packages list...
==> All steps successfully completed!
```
你至少需要运行上述命令一次。
现在是时候开始转换包了。
比如说要使用 debtap 转换包 Quadrapassel,你可以这样做:
```
debtap quadrapassel_3.22.0-1.1_arm64.deb
```
上述的命令会将 DEB 包文件转换为 Arch Linux 包。你需要输入包的维护者和许可证,输入他们,然后按下回车键就可以开始转换了。
包转换的过程可能依赖于你的 CPU 的速度从几秒到几分钟不等。喝一杯咖啡等一等。
示例输出:
```
==> Extracting package data...
==> Fixing possible directories structure differencies...
==> Generating .PKGINFO file...
:: Enter Packager name:
quadrapassel
:: Enter package license (you can enter multiple licenses comma separated):
GPL
*** Creation of .PKGINFO file in progress. It may take a few minutes, please wait...
Warning: These dependencies (depend = fields) could not be translated into Arch Linux packages names:
gsettings-backend
==> Checking and generating .INSTALL file (if necessary)...
:: If you want to edit .PKGINFO and .INSTALL files (in this order), press (1) For vi (2) For nano (3) For default editor (4) For a custom editor or any other key to continue:
==> Generating .MTREE file...
==> Creating final package...
==> Package successfully created!
==> Removing leftover files...
```
**注**:Quadrapassel 在 Arch Linux 官方的软件库中早已可用,我只是用它来说明一下。
如果在包转化的过程中,你不想回答任何问题,使用 `-q` 略过除了编辑元数据之外的所有问题。
```
debtap -q quadrapassel_3.22.0-1.1_arm64.deb
```
为了略过所有的问题(不推荐),使用 `-Q`。
```
debtap -Q quadrapassel_3.22.0-1.1_arm64.deb
```
转换完成后,您可以使用 `pacman` 在 Arch 系统中安装新转换的软件包,如下所示。
```
sudo pacman -U <package-name>
```
显示帮助文档,使用 `-h`:
```
$ debtap -h
Syntax: debtap [options] package_filename
Options:
-h --h -help --help Prints this help message
-u --u -update --update Update debtap database
-q --q -quiet --quiet Bypass all questions, except for editing metadata file(s)
-Q --Q -Quiet --Quiet Bypass all questions (not recommended)
-s --s -pseudo --pseudo Create a pseudo-64-bit package from a 32-bit .deb package
-w --w -wipeout --wipeout Wipeout versions from all dependencies, conflicts etc.
-p --p -pkgbuild --pkgbuild Additionally generate a PKGBUILD file
-P --P -Pkgbuild --Pkgbuild Generate a PKGBUILD file only
```
这就是现在要讲的。希望这个工具有所帮助。如果你发现我们的指南有用,请花一点时间在你的社交、专业网络分享并支持我们!
更多的好东西来了。请继续关注!
干杯!
---
via: <https://www.ostechnix.com/convert-deb-packages-arch-linux-packages/>
作者:[SK](https://www.ostechnix.com/author/sk/) 译者:[amwps290](https://github.com/amwps290) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,770 | 怎么去转换任何系统调用为一个事件:对 eBPF 内核探针的介绍 | https://blog.yadutaf.fr/2016/03/30/turn-any-syscall-into-event-introducing-ebpf-kernel-probes/ | 2018-06-22T14:43:21 | [
"eBPF",
"内核"
] | https://linux.cn/article-9770-1.html | 
长文预警:在最新的 Linux 内核(>=4.4)中使用 eBPF,你可以将任何内核函数调用转换为一个带有任意数据的用户空间事件。这通过 bcc 来做很容易。这个探针是用 C 语言写的,而数据是由 Python 来处理的。
如果你对 eBPF 或者 Linux 跟踪不熟悉,那你应该好好阅读一下整篇文章。本文尝试逐步去解决我在使用 bcc/eBPF 时遇到的困难,以为您节省我在搜索和挖掘上花费的时间。
### 在 Linux 的世界中关于推送与轮询的一个看法
当我开始在容器上工作的时候,我想知道我们怎么基于一个真实的系统状态去动态更新一个负载均衡器的配置。一个通用的策略是这样做的,无论什么时候只要一个容器启动,容器编排器触发一个负载均衡配置更新动作,负载均衡器去轮询每个容器,直到它的健康状态检查结束。它也许只是简单进行 “SYN” 测试。
虽然这种配置方式可以有效工作,但是它的缺点是你的负载均衡器为了让一些系统变得可用需要等待,而不是 … 让负载去均衡。
可以做的更好吗?
当你希望在一个系统中让一个程序对一些变化做出反应,这里有两种可能的策略。程序可以去 *轮询* 系统去检测变化,或者,如果系统支持,系统可以 *推送* 事件并且让程序对它作出反应。你希望去使用推送还是轮询取决于上下文环境。一个好的经验法则是,基于处理时间的考虑,如果事件发生的频率较低时使用推送,而当事件发生的较快或者让系统变得不可用时切换为轮询。例如,一般情况下,网络驱动程序将等待来自网卡的事件,但是,像 dpdk 这样的框架对事件将主动轮询网卡,以达到高吞吐低延迟的目的。
理想状态下,我们将有一些内核接口告诉我们:
>
> * “容器管理器,你好,我刚才为容器 *servestaticfiles* 的 Nginx-ware 创建了一个套接字,或许你应该去更新你的状态?
> * “好的,操作系统,感谢你告诉我这个事件”
>
>
>
虽然 Linux 有大量的接口去处理事件,对于文件事件高达 3 个,但是没有专门的接口去得到套接字事件提示。你可以得到路由表事件、邻接表事件、连接跟踪事件、接口变化事件。唯独没有套接字事件。或者,也许它深深地隐藏在一个 Netlink 接口中。
理想情况下,我们需要一个做这件事的通用方法,怎么办呢?
### 内核跟踪和 eBPF,一些它们的历史
直到最近,内核跟踪的唯一方式是对内核上打补丁或者借助于 SystemTap。[SytemTap](https://en.wikipedia.org/wiki/SystemTap) 是一个 Linux 系统跟踪器。简单地说,它提供了一个 DSL,编译进内核模块,然后被内核加载运行。除了一些因安全原因禁用动态模块加载的生产系统之外,包括在那个时候我开发的那一个。另外的方式是为内核打一个补丁程序以触发一些事件,可能是基于 netlink。但是这很不方便。深入内核所带来的缺点包括 “有趣的” 新 “特性” ,并增加了维护负担。
从 Linux 3.15 开始给我们带来了希望,它支持将任何可跟踪内核函数可安全转换为用户空间事件。在一般的计算机科学中,“安全” 是指 “某些虚拟机”。在此也不例外。自从 Linux 2.1.75 在 1997 年正式发行以来,Linux 已经有这个多好年了。但是,它被称为伯克利包过滤器,或简称 BPF。正如它的名字所表达的那样,它最初是为 BSD 防火墙开发的。它仅有两个寄存器,并且它仅允许向前跳转,这意味着你不能使用它写一个循环(好吧,如果你知道最大迭代次数并且去手工实现它,你也可以实现循环)。这一点保证了程序总会终止,而不会使系统处于挂起的状态。还不知道它有什么用?你用过 iptables 的话,其作用就是 [CloudFlare 的 DDos 防护的基础](https://blog.cloudflare.com/bpf-the-forgotten-bytecode/)。
好的,因此,随着 Linux 3.15,[BPF 被扩展](https://blog.yadutaf.fr/2016/03/30/turn-any-syscall-into-event-introducing-ebpf-kernel-probes/TODO) 成为了 eBPF。对于 “扩展的” BPF。它从两个 32 位寄存器升级到 10 个 64 位寄存器,并且增加了它们之间向后跳转的特性。然后它 [在 Linux 3.18 中被进一步扩展](https://lwn.net/Articles/604043/),并将被移出网络子系统中,并且增加了像映射(map)这样的工具。为保证安全,它 [引进了一个检查器](http://lxr.free-electrons.com/source/kernel/bpf/verifier.c#L21),它验证所有的内存访问和可能的代码路径。如果检查器不能保证代码会终止在固定的边界内,它一开始就要拒绝程序的插入。
关于它的更多历史,可以看 [Oracle 的关于 eBPF 的一个很棒的演讲](http://events.linuxfoundation.org/sites/events/files/slides/tracing-linux-ezannoni-linuxcon-ja-2015_0.pdf)。
让我们开始吧!
### 来自 inet\_listen 的问候
因为写一个汇编程序并不是件十分容易的任务,甚至对于很优秀的我们来说,我将使用 [bcc](https://github.com/iovisor/bcc)。bcc 是一个基于 LLVM 的工具集,并且用 Python 抽象了底层机制。探针是用 C 写的,并且返回的结果可以被 Python 利用,可以很容易地写一些不算简单的应用程序。
首先安装 bcc。对于一些示例,你可能会需要使用一个最新的内核版本(>= 4.4)。如果你想亲自去尝试一下这些示例,我强烈推荐你安装一台虚拟机, *而不是* 一个 Docker 容器。你不能在一个容器中改变内核。作为一个非常新的很活跃的项目,其安装教程高度依赖于平台/版本。你可以在 <https://github.com/iovisor/bcc/blob/master/INSTALL.md> 上找到最新的教程。
现在,我希望不管在什么时候,只要有任何程序开始监听 TCP 套接字,我将得到一个事件。当我在一个 `AF_INET` + `SOCK_STREAM` 套接字上调用一个 `listen()` 系统调用时,其底层的内核函数是 [`inet_listen`](http://lxr.free-electrons.com/source/net/ipv4/af_inet.c#L194)。我将从钩在一个“Hello World” `kprobe` 的入口上开始。
```
from bcc import BPF
# Hello BPF Program
bpf_text = """
#include <net/inet_sock.h>
#include <bcc/proto.h>
// 1. Attach kprobe to "inet_listen"
int kprobe__inet_listen(struct pt_regs *ctx, struct socket *sock, int backlog)
{
bpf_trace_printk("Hello World!\\n");
return 0;
};
"""
# 2. Build and Inject program
b = BPF(text=bpf_text)
# 3. Print debug output
while True:
print b.trace_readline()
```
这个程序做了三件事件:
1. 它通过命名惯例来附加到一个内核探针上。如果函数被调用,比如说 `my_probe` 函数,它会使用 `b.attach_kprobe("inet_listen", "my_probe")` 显式附加。
2. 它使用 LLVM 新的 BPF 后端来构建程序。使用(新的) `bpf()` 系统调用去注入结果字节码,并且按匹配的命名惯例自动附加探针。
3. 从内核管道读取原生输出。
注意:eBPF 的后端 LLVM 还很新。如果你认为你遇到了一个 bug,你也许应该去升级。
注意到 `bpf_trace_printk` 调用了吗?这是一个内核的 `printk()` 精简版的调试函数。使用时,它产生跟踪信息到一个专门的内核管道 `/sys/kernel/debug/tracing/trace_pipe` 。就像名字所暗示的那样,这是一个管道。如果多个读取者在读取它,仅有一个将得到一个给定的行。对生产系统来说,这样是不合适的。
幸运的是,Linux 3.19 引入了对消息传递的映射,以及 Linux 4.4 带来了对任意 perf 事件的支持。在这篇文章的后面部分,我将演示基于 perf 事件的方式。
```
# From a first console
ubuntu@bcc:~/dev/listen-evts$ sudo /python tcv4listen.py
nc-4940 [000] d... 22666.991714: : Hello World!
# From a second console
ubuntu@bcc:~$ nc -l 0 4242
^C
```
搞定!
### 抓取 backlog
现在,让我们输出一些很容易访问到的数据,比如说 “backlog”。backlog 是正在建立 TCP 连接的、即将被 `accept()` 的连接的数量。
只要稍微调整一下 `bpf_trace_printk`:
```
bpf_trace_printk("Listening with with up to %d pending connections!\\n", backlog);
```
如果你用这个 “革命性” 的改善重新运行这个示例,你将看到如下的内容:
```
(bcc)ubuntu@bcc:~/dev/listen-evts$ sudo python tcv4listen.py
nc-5020 [000] d... 25497.154070: : Listening with with up to 1 pending connections!
```
`nc` 是个单连接程序,因此,其 backlog 是 1。而 Nginx 或者 Redis 上的 backlog 将在这里输出 128 。但是,那是另外一件事。
简单吧?现在让我们获取它的端口。
### 抓取端口和 IP
正在研究的 `inet_listen` 来源于内核,我们知道它需要从 `socket` 对象中取得 `inet_sock`。只需要从源头拷贝,然后插入到跟踪器的开始处:
```
// cast types. Intermediate cast not needed, kept for readability
struct sock *sk = sock->sk;
struct inet_sock *inet = inet_sk(sk);
```
端口现在可以按网络字节顺序(就是“从小到大、大端”的顺序)从 `inet->inet_sport` 访问到。很容易吧!因此,我们只需要把 `bpf_trace_printk` 替换为:
```
bpf_trace_printk("Listening on port %d!\\n", inet->inet_sport);
```
然后运行:
```
ubuntu@bcc:~/dev/listen-evts$ sudo /python tcv4listen.py
...
R1 invalid mem access 'inv'
...
Exception: Failed to load BPF program kprobe__inet_listen
```
抛出的异常并没有那么简单,Bcc 现在提升了 *许多*。直到写这篇文章的时候,有几个问题已经被处理了,但是并没有全部处理完。这个错误意味着内核检查器可以证实程序中的内存访问是正确的。看这个显式的类型转换。我们需要一点帮助,以使访问更加明确。我们将使用 `bpf_probe_read` 可信任的函数去读取一个任意内存位置,同时确保所有必要的检查都是用类似这样方法完成的:
```
// Explicit initialization. The "=0" part is needed to "give life" to the variable on the stack
u16 lport = 0;
// Explicit arbitrary memory access. Read it:
// Read into 'lport', 'sizeof(lport)' bytes from 'inet->inet_sport' memory location
bpf_probe_read(&lport, sizeof(lport), &(inet->inet_sport));
```
读取 IPv4 边界地址和它基本上是相同的,使用 `inet->inet_rcv_saddr` 。如果我把这些一起放上去,我们将得到 backlog、端口和边界 IP:
```
from bcc import BPF
# BPF Program
bpf_text = """
#include <net/sock.h>
#include <net/inet_sock.h>
#include <bcc/proto.h>
// Send an event for each IPv4 listen with PID, bound address and port
int kprobe__inet_listen(struct pt_regs *ctx, struct socket *sock, int backlog)
{
// Cast types. Intermediate cast not needed, kept for readability
struct sock *sk = sock->sk;
struct inet_sock *inet = inet_sk(sk);
// Working values. You *need* to initialize them to give them "life" on the stack and use them afterward
u32 laddr = 0;
u16 lport = 0;
// Pull in details. As 'inet_sk' is internally a type cast, we need to use 'bpf_probe_read'
// read: load into 'laddr' 'sizeof(laddr)' bytes from address 'inet->inet_rcv_saddr'
bpf_probe_read(&laddr, sizeof(laddr), &(inet->inet_rcv_saddr));
bpf_probe_read(&lport, sizeof(lport), &(inet->inet_sport));
// Push event
bpf_trace_printk("Listening on %x %d with %d pending connections\\n", ntohl(laddr), ntohs(lport), backlog);
return 0;
};
"""
# Build and Inject BPF
b = BPF(text=bpf_text)
# Print debug output
while True:
print b.trace_readline()
```
测试运行输出的内容像下面这样:
```
(bcc)ubuntu@bcc:~/dev/listen-evts$ sudo python tcv4listen.py
nc-5024 [000] d... 25821.166286: : Listening on 7f000001 4242 with 1 pending connections
```
这证明你的监听是在本地主机上的。因为没有处理为友好的输出,这里的地址以 16 进制的方式显示,但是这是没错的,并且它很酷。
注意:你可能想知道为什么 `ntohs` 和 `ntohl` 可以从 BPF 中被调用,即便它们并不可信。这是因为它们是宏,并且是从 “.h” 文件中来的内联函数,并且,在写这篇文章的时候一个小的 bug 已经 [修复了](https://github.com/iovisor/bcc/pull/453)。
全部达成了,还剩下一些:我们希望获取相关的容器。在一个网络环境中,那意味着我们希望取得网络的命名空间。网络命名空间是一个容器的构建块,它允许它们拥有独立的网络。
### 抓取网络命名空间:被迫引入的 perf 事件
在用户空间中,网络命名空间可以通过检查 `/proc/PID/ns/net` 的目标来确定,它将看起来像 `net:[4026531957]` 这样。方括号中的数字是网络空间的 inode 编号。这就是说,我们可以通过 `/proc` 来取得,但是这并不是好的方式,我们或许可以临时处理时用一下。我们可以从内核中直接抓取 inode 编号。幸运的是,那样做很容易:
```
// Create an populate the variable
u32 netns = 0;
// Read the netns inode number, like /proc does
netns = sk->__sk_common.skc_net.net->ns.inum;
```
很容易!而且它做到了。
但是,如果你看到这里,你可能猜到那里有一些错误。它在:
```
bpf_trace_printk("Listening on %x %d with %d pending connections in container %d\\n", ntohl(laddr), ntohs(lport), backlog, netns);
```
如果你尝试去运行它,你将看到一些令人难解的错误信息:
```
(bcc)ubuntu@bcc:~/dev/listen-evts$ sudo python tcv4listen.py
error: in function kprobe__inet_listen i32 (%struct.pt_regs*, %struct.socket*, i32)
too many args to 0x1ba9108: i64 = Constant<6>
```
clang 想尝试去告诉你的是 “嗨,哥们,`bpf_trace_printk` 只能带四个参数,你刚才给它传递了 5 个”。在这里我不打算继续追究细节了,但是,那是 BPF 的一个限制。如果你想继续去深入研究,[这里是一个很好的起点](http://lxr.free-electrons.com/source/kernel/trace/bpf_trace.c#L86)。
去修复它的唯一方式是 … 停止调试并且准备投入使用。因此,让我们开始吧(确保运行在内核版本为 4.4 的 Linux 系统上)。我将使用 perf 事件,它支持传递任意大小的结构体到用户空间。另外,只有我们的读者可以获得它,因此,多个没有关系的 eBPF 程序可以并发产生数据而不会出现问题。
去使用它吧,我们需要:
1. 定义一个结构体
2. 声明事件
3. 推送事件
4. 在 Python 端重新声明事件(这一步以后将不再需要)
5. 处理和格式化事件
这看起来似乎很多,其它并不多,看下面示例:
```
// At the begining of the C program, declare our event
struct listen_evt_t {
u64 laddr;
u64 lport;
u64 netns;
u64 backlog;
};
BPF_PERF_OUTPUT(listen_evt);
// In kprobe__inet_listen, replace the printk with
struct listen_evt_t evt = {
.laddr = ntohl(laddr),
.lport = ntohs(lport),
.netns = netns,
.backlog = backlog,
};
listen_evt.perf_submit(ctx, &evt, sizeof(evt));
```
Python 端将需要一点更多的工作:
```
# We need ctypes to parse the event structure
import ctypes
# Declare data format
class ListenEvt(ctypes.Structure):
_fields_ = [
("laddr", ctypes.c_ulonglong),
("lport", ctypes.c_ulonglong),
("netns", ctypes.c_ulonglong),
("backlog", ctypes.c_ulonglong),
]
# Declare event printer
def print_event(cpu, data, size):
event = ctypes.cast(data, ctypes.POINTER(ListenEvt)).contents
print("Listening on %x %d with %d pending connections in container %d" % (
event.laddr,
event.lport,
event.backlog,
event.netns,
))
# Replace the event loop
b["listen_evt"].open_perf_buffer(print_event)
while True:
b.kprobe_poll()
```
来试一下吧。在这个示例中,我有一个 redis 运行在一个 Docker 容器中,并且 `nc` 运行在主机上:
```
(bcc)ubuntu@bcc:~/dev/listen-evts$ sudo python tcv4listen.py
Listening on 0 6379 with 128 pending connections in container 4026532165
Listening on 0 6379 with 128 pending connections in container 4026532165
Listening on 7f000001 6588 with 1 pending connections in container 4026531957
```
### 结束语
现在,所有事情都可以在内核中使用 eBPF 将任何函数的调用设置为触发事件,并且你看到了我在学习 eBPF 时所遇到的大多数的问题。如果你希望去看这个工具的完整版本,像 IPv6 支持这样的一些技巧,看一看 <https://github.com/iovisor/bcc/blob/master/tools/solisten.py>。它现在是一个官方的工具,感谢 bcc 团队的支持。
更进一步地去学习,你可能需要去关注 Brendan Gregg 的博客,尤其是 [关于 eBPF 映射和统计的文章](http://www.brendangregg.com/blog/2015-05-15/ebpf-one-small-step.html)。他是这个项目的主要贡献人之一。
---
via: <https://blog.yadutaf.fr/2016/03/30/turn-any-syscall-into-event-introducing-ebpf-kernel-probes/>
作者:[Jean-Tiare Le Bigot](https://blog.yadutaf.fr/about) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | TL;DR: Using eBPF in recent (>=4.4) Linux kernel, you can turn any kernel function call into a user land event with arbitrary data. This is made easy by bcc. The probe is written in C while the data is handled by python.
If you are not familiar with eBPF or linux tracing, you really should read the full post. It tries to progressively go through the pitfalls I stumbled unpon while playing around with bcc / eBPF while saving you a lot of the time I spent searching and digging.
### A note on push vs pull in a Linux world
When I started to work on containers, I was wondering how we could update a load balancer configuration dynamically based on actual system state. A common strategy, which works, it to let the container orchestrator trigger a load balancer configuration update whenever it starts a container and then let the load balancer poll the container until some health check passes. It may be a simple “SYN” test.
While this configuration works, it has the downside of making your load balancer waiting for some system to be available while it should be… load balancing.
Can we do better?
When you want a program to react to some change in a system there are 2 possible strategies. The program may *poll* the system to detect changes or, if the system supports it, the system may *push* events and let the program react to them. Wether you want to use push or poll depends on the context. A good rule of the thumb is to use push events when the event rate is low with respect to the processing time and switch to polling when the events are coming fast or the system may become unusable. For example, typical network driver will wait for events from the network card while frameworks like dpdk will actively poll the card for events to achieve the highest throughput and lowest latency.
In an ideal world, we’d have some kernel interface telling us:
- “Hey Mr. ContainerManager, I’ve just created a socket for the Nginx-ware of container
servestaticfiles, maybe you want to update your state?”- “Sure Mr. OS, Thanks for letting me know”
While Linux has a wide range of interfaces to deal with events, up to 3 for file events, there is no dedicated interface to get socket event notifications. You can get routing table events, neighbor table events, conntrack events, interface change events. Just, not socket events. Or maybe there is, deep hidden in a Netlink interface.
Ideally, we’d need a generic way to do it. How?
### Kernel tracing and eBPF, a bit of history
Until recently the only way was to patch the kernel or resort on SystemTap. [SytemTap](https://en.wikipedia.org/wiki/SystemTap) is a tracing Linux system. In a nutshell, it provides a DSL which is then compiled into a kernel module which is then live-loaded into the running kernel. Except that some production system disable dynamic module loading for security reasons. Including the one I was working on at that time. The other way would be to patch the kernel to trigger some events, probably based on netlink. This is not really convenient. Kernel hacking come with downsides including “interesting” new “features” and increased maintenance burden.
Hopefully, starting with Linux 3.15 the ground was laid to safely transform any traceable kernel function into userland events. “Safely” is common computer science expression referring to “some virtual machine”. This case is no exception. Linux has had one for years. Since Linux 2.1.75 released in 1997 actually. It’s called Berkeley Packet Filter of BPF for short. As its name suggests, it was originally developed for the BSD firewalls. It had only 2 registers and only allowed forward jumps meaning that you could not write loops with it (Well, you can, if you know the maximum iterations and you manually unroll them). The point was to guarantee the program would always terminate and hence never hang the system. Still not sure if it has any use while you have iptables? It serves as the [foundation of CloudFlare’s AntiDDos protection](https://blog.cloudflare.com/bpf-the-forgotten-bytecode/).
OK, so, with Linux the 3.15, [BPF was extended](TODO) turning it into eBPF. For “extended” BPF. It upgrades from 2 32 bits registers to 10 64 bits 64 registers and adds backward jumping among others. It has then been [further extended in Linux 3.18](https://lwn.net/Articles/604043/) moving it out of the networking subsystem, and adding tools like maps. To preserve the safety guarantees, it [introduces a checker](http://lxr.free-electrons.com/source/kernel/bpf/verifier.c#L21) which validates all memory accesses and possible code path. If the checker can’t guarantee the code will terminate within fixed boundaries, it will deny the initial insertion of the program.
For more history, there is [an excellent Oracle presentation on eBPF](http://events.linuxfoundation.org/sites/events/files/slides/tracing-linux-ezannoni-linuxcon-ja-2015_0.pdf).
Let’s get started.
### Hello from from `inet_listen`
As writing assembly is not the most convenient task, even for the best of us, we’ll use [bcc](https://github.com/iovisor/bcc). bcc is a collection of tools based on LLVM and Python abstracting the underlying machinery. Probes are written in C and the results can be exploited from python allowing to easily write non trivial applications.
Start by install bcc. For some of these examples, you may require a recent (read >= 4.4) version of the kernel. If you are willing to actually try these examples, I highly recommend that you setup a VM. *NOT* a docker container. You can’t change the kernel in a container. As this is a young and dynamic projects, install instructions are highly platform/version dependant. You can find up to date instructions on [https://github.com/iovisor/bcc/blob/master/INSTALL.md](https://github.com/iovisor/bcc/blob/master/INSTALL.md)
So, we want to get an event whenever a program starts to listen on TCP socket. When calling the `listen()`
syscall on a `AF_INET`
+ `SOCK_STREAM`
socket, the underlying kernel function is [ inet_listen](http://lxr.free-electrons.com/source/net/ipv4/af_inet.c#L194). We’ll start by hooking a “Hello World”
`kprobe`
on it’s entrypoint.```
from bcc import BPF
# Hello BPF Program
bpf_text = """
#include <net/inet_sock.h>
#include <bcc/proto.h>
// 1. Attach kprobe to "inet_listen"
int kprobe__inet_listen(struct pt_regs *ctx, struct socket *sock, int backlog)
{
bpf_trace_printk("Hello World!\\n");
return 0;
};
"""
# 2. Build and Inject program
b = BPF(text=bpf_text)
# 3. Print debug output
while True:
print b.trace_readline()
```
This program does 3 things:
- It attaches a kernel probe to “inet_listen” using a naming convention. If the function was called, say, “my_probe”, it could be explicitly attached with
`b.attach_kprobe("inet_listen", "my_probe"`
. - It builds the program using LLVM new BPF backend, inject the resulting bytecode using the (new)
`bpf()`
syscall and automatically attaches the probes matching the naming convention. - It reads the raw output from the kernel pipe.
Note: eBPF backend of LLVM is still young. If you think you’ve hit a bug, you may want to upgrade.
Noticed the `bpf_trace_printk`
call? This is a stripped down version of the kernel’s `printk()`
debug function. When used, it produces tracing informations to a special kernel pipe in `/sys/kernel/debug/tracing/trace_pipe`
. As the name implies, this is a pipe. If multiple readers are consuming it, only 1 will get a given line. This makes it unsuitable for production.
Fortunately, Linux 3.19 introduced maps for message passing and Linux 4.4 brings arbitrary perf events support. I’ll demo the perf event based approach later in this post.
```
# From a first console
ubuntu@bcc:~/dev/listen-evts$ sudo /python tcv4listen.py
nc-4940 [000] d... 22666.991714: : Hello World!
# From a second console
ubuntu@bcc:~$ nc -l 0 4242
^C
```
Yay!
### Grab the backlog
Now, let’s print some easily accessible data. Say the “backlog”. The backlog is the number of pending established TCP connections, pending to be `accept()`
ed.
Just tweak a bit the `bpf_trace_printk`
:
```
bpf_trace_printk("Listening with with up to %d pending connections!\\n", backlog);
```
If you re-run the example with this world-changing improvement, you should see something like:
```
(bcc)ubuntu@bcc:~/dev/listen-evts$ sudo python tcv4listen.py
nc-5020 [000] d... 25497.154070: : Listening with with up to 1 pending connections!
```
`nc`
is a single connection program, hence the backlog of 1. Nginx or Redis would output 128 here. But that’s another story.
Easy hue? Now let’s get the port.
### Grab the port and IP
Studying `inet_listen`
source from the kernel, we know that we need to get the `inet_sock`
from the `socket`
object. Just copy from the sources, and insert at the beginning of the tracer:
```
// cast types. Intermediate cast not needed, kept for readability
struct sock *sk = sock->sk;
struct inet_sock *inet = inet_sk(sk);
```
The port can now be accessed from `inet->inet_sport`
in network byte order (aka: Big Endian). Easy! So, we could just replace the `bpf_trace_printk`
with:
```
bpf_trace_printk("Listening on port %d!\\n", inet->inet_sport);
```
Then run:
```
ubuntu@bcc:~/dev/listen-evts$ sudo /python tcv4listen.py
...
R1 invalid mem access 'inv'
...
Exception: Failed to load BPF program kprobe__inet_listen
```
Except that it’s not (yet) so simple. Bcc is improving a *lot* currently. While writing this post, a couple of pitfalls had already been addressed. But not yet all. This Error means the in-kernel checker could prove the memory accesses in program are correct. See the explicit cast. We need to help is a little by making the accesses more explicit. We’ll use `bpf_probe_read`
trusted function to read an arbitrary memory location while guaranteeing all necessary checks are done with something like:
```
// Explicit initialization. The "=0" part is needed to "give life" to the variable on the stack
u16 lport = 0;
// Explicit arbitrary memory access. Read it:
// Read into 'lport', 'sizeof(lport)' bytes from 'inet->inet_sport' memory location
bpf_probe_read(&lport, sizeof(lport), &(inet->inet_sport));
```
Reading the bound address for IPv4 is basically the same, using `inet->inet_rcv_saddr`
. If we put is all together, we should get the backlog, the port and the bound IP:
```
from bcc import BPF
# BPF Program
bpf_text = """
#include <net/sock.h>
#include <net/inet_sock.h>
#include <bcc/proto.h>
// Send an event for each IPv4 listen with PID, bound address and port
int kprobe__inet_listen(struct pt_regs *ctx, struct socket *sock, int backlog)
{
// Cast types. Intermediate cast not needed, kept for readability
struct sock *sk = sock->sk;
struct inet_sock *inet = inet_sk(sk);
// Working values. You *need* to initialize them to give them "life" on the stack and use them afterward
u32 laddr = 0;
u16 lport = 0;
// Pull in details. As 'inet_sk' is internally a type cast, we need to use 'bpf_probe_read'
// read: load into 'laddr' 'sizeof(laddr)' bytes from address 'inet->inet_rcv_saddr'
bpf_probe_read(&laddr, sizeof(laddr), &(inet->inet_rcv_saddr));
bpf_probe_read(&lport, sizeof(lport), &(inet->inet_sport));
// Push event
bpf_trace_printk("Listening on %x %d with %d pending connections\\n", ntohl(laddr), ntohs(lport), backlog);
return 0;
};
"""
# Build and Inject BPF
b = BPF(text=bpf_text)
# Print debug output
while True:
print b.trace_readline()
```
A test run should output something like:
```
(bcc)ubuntu@bcc:~/dev/listen-evts$ sudo python tcv4listen.py
nc-5024 [000] d... 25821.166286: : Listening on 7f000001 4242 with 1 pending connections
```
Provided that you listen on localhost. The address is displayed as hex here to avoid dealing with the IP pretty printing but that’s all wired. And that’s cool.
Note: you may wonder why `ntohs`
and `ntohl`
can be called from BPF while they are not trusted. This is because they are macros and inline functions from “.h” files and a small bug was [fixed](https://github.com/iovisor/bcc/pull/453) while writing this post.
All done, one more piece: We want to get the related container. In the context of networking, that’s means we want the network namespace. The network namespace being the building block of containers allowing them to have isolated networks.
### Grab the network namespace: a forced introduction to perf events
On the userland, the network namespace can be determined by checking the target of `/proc/PID/ns/net`
. It should look like `net:[4026531957]`
. The number between brackets is the inode number of the network namespace. This said, we could grab it by scrapping ‘/proc’ but this is racy, we may be dealing with short-lived processes. And races are never good. We’ll grab the inode number directly from the kernel. Fortunately, that’s an easy one:
```
// Create an populate the variable
u32 netns = 0;
// Read the netns inode number, like /proc does
netns = sk->__sk_common.skc_net.net->ns.inum;
```
Easy. And it works.
But if you’ve read so far, you may guess there is something wrong somewhere. And there is:
```
bpf_trace_printk("Listening on %x %d with %d pending connections in container %d\\n", ntohl(laddr), ntohs(lport), backlog, netns);
```
If you try to run it, you’ll get some cryptic error message:
```
(bcc)ubuntu@bcc:~/dev/listen-evts$ sudo python tcv4listen.py
error: in function kprobe__inet_listen i32 (%struct.pt_regs*, %struct.socket*, i32)
too many args to 0x1ba9108: i64 = Constant<6>
```
What clang is trying to tell you is “Hey pal, `bpf_trace_printk`
can only take 4 arguments, you’ve just used 5.”. I won’t dive into the details here, but that’s a BPF limitation. If you want to dig it, [here is a good starting point](http://lxr.free-electrons.com/source/kernel/trace/bpf_trace.c#L86).
The only way to fix it is to… stop debugging and make it production ready. So let’s get started (and make sure run at least Linux 4.4). We’ll use perf events which supports passing arbitrary sized structures to userland. Additionally, only our reader will get it so that multiple unrelated eBPF programs can produce data concurrently without issues.
To use it, we need to:
- define a structure
- declare the event
- push the event
- re-declare the event on Python’s side (This step should go away in the future)
- consume and format the event
This may seem like a lot, but it ain’t. See:
```
// At the begining of the C program, declare our event
struct listen_evt_t {
u64 laddr;
u64 lport;
u64 netns;
u64 backlog;
};
BPF_PERF_OUTPUT(listen_evt);
// In kprobe__inet_listen, replace the printk with
struct listen_evt_t evt = {
.laddr = ntohl(laddr),
.lport = ntohs(lport),
.netns = netns,
.backlog = backlog,
};
listen_evt.perf_submit(ctx, &evt, sizeof(evt));
```
Python side will require a little more work, though:
```
# We need ctypes to parse the event structure
import ctypes
# Declare data format
class ListenEvt(ctypes.Structure):
_fields_ = [
("laddr", ctypes.c_ulonglong),
("lport", ctypes.c_ulonglong),
("netns", ctypes.c_ulonglong),
("backlog", ctypes.c_ulonglong),
]
# Declare event printer
def print_event(cpu, data, size):
event = ctypes.cast(data, ctypes.POINTER(ListenEvt)).contents
print("Listening on %x %d with %d pending connections in container %d" % (
event.laddr,
event.lport,
event.backlog,
event.netns,
))
# Replace the event loop
b["listen_evt"].open_perf_buffer(print_event)
while True:
b.kprobe_poll()
```
Give it a try. In this example, I have a redis running in a docker container and nc on the host:
```
(bcc)ubuntu@bcc:~/dev/listen-evts$ sudo python tcv4listen.py
Listening on 0 6379 with 128 pending connections in container 4026532165
Listening on 0 6379 with 128 pending connections in container 4026532165
Listening on 7f000001 6588 with 1 pending connections in container 4026531957
```
### Last word
Absolutely everything is now setup to use trigger events from arbitrary function calls in the kernel using eBPF, and you should have seen most of the common pitfalls I hit while learning eBPF. If you want to see the full version of this tool, along with some more tricks like IPv6 support, have a look at [https://github.com/iovisor/bcc/blob/master/tools/solisten.py](https://github.com/iovisor/bcc/blob/master/tools/solisten.py). It’s now an official tool, thanks to the support of the bcc team.
To go further, you may want to checkout Brendan Gregg’s blog, in particular [the post about eBPF maps and statistics](http://www.brendangregg.com/blog/2015-05-15/ebpf-one-small-step.html). He his one of the project’s main contributor. |
9,771 | 如何在 Linux 中使用 parted 对磁盘分区 | https://opensource.com/article/18/6/how-partition-disk-linux | 2018-06-22T23:38:51 | [
"分区",
"parted"
] | https://linux.cn/article-9771-1.html |
>
> 学习如何在 Linux 中使用 parted 命令来对存储设备分区。
>
>
>

在 Linux 中创建和删除分区是一种常见的操作,因为存储设备(如硬盘驱动器和 USB 驱动器)在使用之前必须以某种方式进行结构化。在大多数情况下,大型存储设备被分为称为<ruby> 分区 <rt> partition </rt></ruby>的独立部分。分区操作允许您将硬盘分割成独立的部分,每个部分都像是一个硬盘驱动器一样。如果您运行多个操作系统,那么分区是非常有用的。
在 Linux 中有许多强大的工具可以创建、删除和操作磁盘分区。在本文中,我将解释如何使用 `parted` 命令,这对于大型磁盘设备和许多磁盘分区尤其有用。`parted` 与更常见的 `fdisk` 和 `cfdisk` 命令之间的区别包括:
* **GPT 格式:**`parted` 命令可以创建全局惟一的标识符分区表 [GPT](https://en.wikipedia.org/wiki/GUID_Partition_Table),而 `fdisk` 和 `cfdisk` 则仅限于 DOS 分区表。
* **更大的磁盘:** DOS 分区表可以格式化最多 2TB 的磁盘空间,尽管在某些情况下最多可以达到 16TB。然而,一个 GPT 分区表可以处理最多 8ZiB 的空间。
* **更多的分区:** 使用主分区和扩展分区,DOS 分区表只允许 16 个分区。在 GPT 中,默认情况下您可以得到 128 个分区,并且可以选择更多的分区。
* **可靠性:** 在 DOS 分区表中,只保存了一份分区表备份,在 GPT 中保留了两份分区表的备份(在磁盘的起始和结束部分),同时 GPT 还使用了 [CRC](https://en.wikipedia.org/wiki/Cyclic_redundancy_check) 校验和来检查分区表的完整性,在 DOS 分区中并没有实现。
由于现在的磁盘更大,需要更灵活地使用它们,建议使用 `parted` 来处理磁盘分区。大多数时候,磁盘分区表是作为操作系统安装过程的一部分创建的。在向现有系统添加存储设备时,直接使用 `parted` 命令非常有用。
### 尝试一下 parted
下面解释了使用 `parted` 命令对存储设备进行分区的过程。为了尝试这些步骤,我强烈建议使用一块全新的存储设备或一种您不介意将其内容删除的设备。
#### 1、列出分区
使用 `parted -l` 来标识你要进行分区的设备。一般来说,第一个硬盘 (`/dev/sda` 或 `/dev/vda` )保存着操作系统, 因此要寻找另一个磁盘,以找到你想要分区的磁盘 (例如,`/dev/sdb`、`/dev/sdc`、 `/dev/vdb`、`/dev/vdc` 等)。
```
$ sudo parted -l
[sudo] password for daniel:
Model: ATA RevuAhn_850X1TU5 (scsi)
Disk /dev/vdc: 512GB
Sector size (logical/physical): 512B/512B
Partition Table: msdos
Disk Flags:
Number Start End Size Type File system Flags
1 1049kB 525MB 524MB primary ext4 boot
2 525MB 512GB 512GB primary lvm
```
#### 2、打开存储设备
使用 `parted` 选中您要分区的设备。在这里例子中,是虚拟系统上的第三个磁盘(`/dev/vdc`)。指明你要使用哪一个设备非常重要。 如果你仅仅输入了 `parted` 命令而没有指定设备名字, 它会**随机**选择一个设备进行操作。
```
$ sudo parted /dev/vdc
GNU Parted 3.2
Using /dev/vdc
Welcome to GNU Parted! Type 'help' to view a list of commands.
(parted)
```
#### 3、 设定分区表
设置分区表为 GPT ,然后输入 `Yes` 开始执行。
```
(parted) mklabel gpt
Warning: the existing disk label on /dev/vdc will be destroyed
and all data on this disk will be lost. Do you want to continue?
Yes/No? Yes
```
`mklabel` 和 `mktable` 命令用于相同的目的(在存储设备上创建分区表)。支持的分区表有:aix、amiga、bsd、dvh、gpt、mac、ms-dos、pc98、sun 和 loop。记住 `mklabel` 不会创建一个分区,而是创建一个分区表。
#### 4、 检查分区表
查看存储设备信息:
```
(parted) print
Model: Virtio Block Device (virtblk)
Disk /dev/vdc: 1396MB
Sector size (logical/physical): 512B/512B
Partition Table: gpt
Disk Flags:
Number Start End Size File system Name Flags
```
#### 5、 获取帮助
为了知道如何去创建一个新分区,输入: `(parted) help mkpart` 。
```
(parted) help mkpart
mkpart PART-TYPE [FS-TYPE] START END make a partition
PART-TYPE is one of: primary, logical, extended
FS-TYPE is one of: btrfs, nilfs2, ext4, ext3, ext2, fat32, fat16, hfsx, hfs+, hfs, jfs, swsusp,
linux-swap(v1), linux-swap(v0), ntfs, reiserfs, hp-ufs, sun-ufs, xfs, apfs2, apfs1, asfs, amufs5,
amufs4, amufs3, amufs2, amufs1, amufs0, amufs, affs7, affs6, affs5, affs4, affs3, affs2, affs1,
affs0, linux-swap, linux-swap(new), linux-swap(old)
START and END are disk locations, such as 4GB or 10%. Negative values count from the end of the
disk. For example, -1s specifies exactly the last sector.
'mkpart' makes a partition without creating a new file system on the partition. FS-TYPE may be
specified to set an appropriate partition ID.
```
#### 6、 创建分区
为了创建一个新分区(在这个例子中,分区 0 有 1396MB),输入下面的命令:
```
(parted) mkpart primary 0 1396MB
Warning: The resulting partition is not properly aligned for best performance
Ignore/Cancel? I
(parted) print
Model: Virtio Block Device (virtblk)
Disk /dev/vdc: 1396MB
Sector size (logical/physical): 512B/512B
Partition Table: gpt
Disk Flags:
Number Start End Size File system Name Flags
1 17.4kB 1396MB 1396MB primary
```
文件系统类型(`fstype`)并不是在 `/dev/vdc1`上创建 ext4 文件系统。 DOS 分区表的分区类型是<ruby> 主分区 <rt> primary </rt></ruby>、<ruby> 逻辑分区 <rt> logical </rt></ruby>和<ruby> 扩展分区 <rt> extended </rt></ruby>。 在 GPT 分区表中,分区类型用作分区名称。 在 GPT 下必须提供分区名称;在上例中,`primary` 是分区名称,而不是分区类型。
#### 7、 保存退出
当你退出 `parted` 时,修改会自动保存。退出请输入如下命令:
```
(parted) quit
Information: You may need to update /etc/fstab.
$
```
### 谨记
当您添加新的存储设备时,请确保在开始更改其分区表之前确定正确的磁盘。如果您错误地更改了包含计算机操作系统的磁盘分区,会使您的系统无法启动。
---
via: <https://opensource.com/article/18/6/how-partition-disk-linux>
作者:[Daniel Oh](https://opensource.com/users/daniel-oh) 选题:[lujun9972](https://github.com/lujun9972) 译者:[amwps290](https://github.com/amwps290) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Creating and deleting partitions in Linux is a regular practice because storage devices (such as hard drives and USB drives) must be structured in some way before they can be used. In most cases, large storage devices are divided into separate sections called *partitions*. Partitioning also allows you to divide your hard drive into isolated sections, where each section behaves as its own hard drive. Partitioning is particularly useful if you run multiple operating systems.
There are lots of powerful tools for creating, removing, and otherwise manipulating disk partitions in Linux. In this article, I'll explain how to use the `parted`
command, which is particularly useful with large disk devices and many disk partitions. Differences between `parted`
and the more common `fdisk`
and `cfdisk`
commands include:
**GPT format:**The`parted`
command can create a Globally Unique Identifiers Partition Table[GPT](https://en.wikipedia.org/wiki/GUID_Partition_Table)), while`fdisk`
and`cfdisk`
are limited to DOS partition tables.**Larger disks:**A DOS partition table can format up to 2TB of disk space, although up to 16TB is possible in some cases. However, a GPT partition table can address up to 8ZiB of space.**More partitions:**Using primary and extended partitions, DOS partition tables allow only 16 partitions. With GPT, you get up to 128 partitions by default and can choose to have many more.**Reliability:**Only one copy of the partition table is stored in a DOS partition. GPT keeps two copies of the partition table (at the beginning and the end of the disk). The GPT also uses a[CRC](https://en.wikipedia.org/wiki/Cyclic_redundancy_check)checksum to check the partition table integrity, which is not done with DOS partitions.
With today's larger disks and the need for more flexibility in working with them, using `parted`
to work with disk partitions is recommended. Most of the time, disk partition tables are created as part of the operating system installation process. Direct use of the `parted`
command is most useful when adding a storage device to an existing system.
## Give 'parted' a try
The following explains the process of partitioning a storage device with the `parted`
command. To try these steps, I strongly recommend using a brand new storage device or one where you don't mind wiping out the contents.
**1. List the partitions:** Use `parted -l`
to identify the storage device you want to partition. Typically, the first hard disk (`/dev/sda`
or `/dev/vda`
) will contain the operating system, so look for another disk to find the one you want (e.g., `/dev/sdb`
, `/dev/sdc`
, `/dev/vdb`
, `/dev/vdc`
, etc.).
```
$ sudo parted -l
[sudo] password for daniel:
Model: ATA RevuAhn_850X1TU5 (scsi)
Disk /dev/vdc: 512GB
Sector size (logical/physical): 512B/512B
Partition Table: msdos
Disk Flags:
Number Start End Size Type File system Flags
1 1049kB 525MB 524MB primary ext4 boot
2 525MB 512GB 512GB primary lvm
```
**2. Open the storage device:** Use `parted`
to begin working with the selected storage device. In this example, the device is the third disk on a virtual system (`/dev/vdc`
). It is important to indicate the specific device you want to use. If you just type `parted`
with no device name, it will randomly select a storage device to modify.
```
$ sudo parted /dev/vdc
GNU Parted 3.2
Using /dev/vdc
Welcome to GNU Parted! Type 'help' to view a list of commands.
(parted)
```
**3. Set the partition table:** Set the partition table type to GPT, then type "Yes" to accept it.
```
(parted) mklabel gpt
Warning: the existing disk label on /dev/vdc will be destroyed
and all data on this disk will be lost. Do you want to continue?
Yes/No? Yes
```
The `mklabel`
and `mktable`
commands are used for the same purpose (making a partition table on a storage device). The supported partition tables are: aix, amiga, bsd, dvh, gpt, mac, ms-dos, pc98, sun, and loop. Remember `mklabel`
will not make a partition, rather it will make a partition table.
**4. Review the partition table:** Show information about the storage device.
```
(parted) print
Model: Virtio Block Device (virtblk)
Disk /dev/vdc: 1396MB
Sector size (logical/physical): 512B/512B
Partition Table: gpt
Disk Flags:
Number Start End Size File system Name Flags
```
**5. Get help:** To find out how to make a new partition, type: `(parted) help mkpart`
.
```
(parted) help mkpart
mkpart PART-TYPE [FS-TYPE] START END make a partition
PART-TYPE is one of: primary, logical, extended
FS-TYPE is one of: btrfs, nilfs2, ext4, ext3, ext2, fat32, fat16, hfsx, hfs+, hfs, jfs, swsusp,
linux-swap(v1), linux-swap(v0), ntfs, reiserfs, hp-ufs, sun-ufs, xfs, apfs2, apfs1, asfs, amufs5,
amufs4, amufs3, amufs2, amufs1, amufs0, amufs, affs7, affs6, affs5, affs4, affs3, affs2, affs1,
affs0, linux-swap, linux-swap(new), linux-swap(old)
START and END are disk locations, such as 4GB or 10%. Negative values count from the end of the
disk. For example, -1s specifies exactly the last sector.
'mkpart' makes a partition without creating a new file system on the partition. FS-TYPE may be
specified to set an appropriate partition ID.
```
**6. Make a partition:** To make a new partition (in this example, 1,396MB on partition 0), type the following:
```
(parted) mkpart primary 0 1396MB
Warning: The resulting partition is not properly aligned for best performance
Ignore/Cancel? I
(parted) print
Model: Virtio Block Device (virtblk)
Disk /dev/vdc: 1396MB
Sector size (logical/physical): 512B/512B
Partition Table: gpt
Disk Flags:
Number Start End Size File system Name Flags
1 17.4kB 1396MB 1396MB primary
```
Filesystem type (fstype) will not create an ext4 filesystem on `/dev/vdc1`
. A DOS partition table's partition types are *primary*, *logical*, and *extended*. In a GPT partition table, the partition type is used as the partition name. Providing a partition name under GPT is a must; in the above example, *primary* is the name, not the partition type.
**7. Save and quit:** Changes are automatically saved when you quit `parted`
. To quit, type the following:
```
(parted) quit
Information: You may need to update /etc/fstab.
$
```
## Words to the wise
Make sure to identify the correct disk before you begin changing its partition table when you add a new storage device. If you mistakenly change the disk partition that contains your computer's operating system, you could make your system unbootable.
## Comments are closed. |
9,772 | 在 Linux 上复制和重命名文件 | https://www.networkworld.com/article/3276349/linux/copying-and-renaming-files-on-linux.html | 2018-06-23T00:06:57 | [
"cp",
"mv"
] | https://linux.cn/article-9772-1.html |
>
> cp 和 mv 之外,在 Linux 上有更多的复制和重命名文件的命令。试试这些命令或许会惊艳到你,并能节省一些时间。
>
>
>

Linux 用户数十年来一直在使用简单的 `cp` 和 `mv` 命令来复制和重命名文件。这些命令是我们大多数人首先学到的,每天可能有数百万人在使用它们。但是还有其他技术、方便的方法和另外的命令,这些提供了一些独特的选项。
首先,我们来思考为什么你想要复制一个文件。你可能需要在另一个位置使用同一个文件,或者因为你要编辑该文件而需要一个副本,并且希望确保备有便利的备份以防万一需要恢复原始文件。这样做的显而易见的方式是使用像 `cp myfile myfile-orig` 这样的命令。
但是,如果你想复制大量的文件,那么这个策略可能就会变得很老。更好的选择是:
* 在开始编辑之前,使用 `tar` 创建所有要备份的文件的存档。
* 使用 `for` 循环来使备份副本更容易。
使用 `tar` 的方式很简单。对于当前目录中的所有文件,你可以使用如下命令:
```
$ tar cf myfiles.tar *
```
对于一组可以用模式标识的文件,可以使用如下命令:
```
$ tar cf myfiles.tar *.txt
```
在每种情况下,最终都会生成一个 `myfiles.tar` 文件,其中包含目录中的所有文件或扩展名为 .txt 的所有文件。
一个简单的循环将允许你使用修改后的名称来制作备份副本:
```
$ for file in *
> do
> cp $file $file-orig
> done
```
当你备份单个文件并且该文件恰好有一个长名称时,可以依靠使用 `tab` 来补全文件名(在输入足够的字母以便唯一标识该文件后点击 `Tab` 键)并使用像这样的语法将 `-orig` 附加到副本的名字后。
```
$ cp file-with-a-very-long-name{,-orig}
```
然后你有一个 `file-with-a-very-long-name` 和一个 `file-with-a-very-long-name-orig`。
### 在 Linux 上重命名文件
重命名文件的传统方法是使用 `mv` 命令。该命令将文件移动到不同的目录,或原地更改其名称,或者同时执行这两个操作。
```
$ mv myfile /tmp
$ mv myfile notmyfile
$ mv myfile /tmp/notmyfile
```
但我们也有 `rename` 命令来做重命名。使用 `rename` 命令的窍门是习惯它的语法,但是如果你了解一些 Perl,你可能发现它并不棘手。
有个非常有用的例子。假设你想重新命名一个目录中的文件,将所有的大写字母替换为小写字母。一般来说,你在 Unix 或 Linux 系统上找不到大量大写字母的文件,但你可以有。这里有一个简单的方法来重命名它们,而不必为它们中的每一个使用 `mv` 命令。 `/A-Z/a-z/` 告诉 `rename` 命令将范围 `A-Z` 中的任何字母更改为 `a-z` 中的相应字母。
```
$ ls
Agenda Group.JPG MyFile
$ rename 'y/A-Z/a-z/' *
$ ls
agenda group.jpg myfile
```
你也可以使用 `rename` 来删除文件扩展名。也许你厌倦了看到带有 .txt 扩展名的文本文件。简单删除这些扩展名 —— 用一个命令。
```
$ ls
agenda.txt notes.txt weekly.txt
$ rename 's/.txt//' *
$ ls
agenda notes weekly
```
现在让我们想象一下,你改变了心意,并希望把这些扩展名改回来。没问题。只需修改命令。窍门是理解第一个斜杠前的 `s` 意味着“替代”。前两个斜线之间的内容是我们想要改变的东西,第二个斜线和第三个斜线之间是改变后的东西。所以,`$` 表示文件名的结尾,我们将它改为 `.txt`。
```
$ ls
agenda notes weekly
$ rename 's/$/.txt/' *
$ ls
agenda.txt notes.txt weekly.txt
```
你也可以更改文件名的其他部分。牢记 `s/旧内容/新内容/` 规则。
```
$ ls
draft-minutes-2018-03 draft-minutes-2018-04 draft-minutes-2018-05
$ rename 's/draft/approved/' *minutes*
$ ls
approved-minutes-2018-03 approved-minutes-2018-04 approved-minutes-2018-05
```
在上面的例子中注意到,当我们在 `s/old/new/` 中使用 `s` 时,我们用另一个名称替换名称的一部分。当我们使用 `y` 时,我们就是直译(将字符从一个范围替换为另一个范围)。
### 总结
现在有很多复制和重命名文件的方法。我希望其中的一些会让你在使用命令行时更愉快。
---
via: <https://www.networkworld.com/article/3276349/linux/copying-and-renaming-files-on-linux.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
9,773 | 怎样在桌面上安装 Docker CE? | https://www.linux.com/blog/learn/intro-to-linux/how-install-docker-ce-your-desktop | 2018-06-23T21:50:00 | [
"Docker"
] | https://linux.cn/article-9773-1.html |
>
> 按照这些简单的步骤在你的 Linux、Mac 或 Windows 桌面上安装 Docker CE。
>
>
>

[在上一篇文章中](/article-9799-1.html),我们学习了容器世界的一些基本术语。当我们运行命令并在后续文章中使用其中一些术语时,这些背景信息将会派上用场,包括这篇文章。本文将介绍在桌面 Linux、 macOS 和 Windows 上安装 Docker,它适用于想要开始使用 Docker 容器的初学者。唯一的先决条件是你对命令行界面满意。
### 为什么我在本地机器上需要 Docker CE?
作为一个新用户,你很可能想知道为什么你在本地系统上需要容器。难道它们不是作为微服务在云和服务器中运行吗?尽管容器长期以来一直是 Linux 世界的一部分,但 Docker 才真正使容器的工具和技术步入使用。
Docker 容器最大的优点是可以使用本地机器进行开发和测试。你在本地系统上创建的容器映像可以在“任何位置”运行。开发人员和操作人员之间不再会为应用程序在开发系统上运行良好但生产环境中出现问题而产生纷争。
而这个关键是,要创建容器化的应用程序,你必须能够在本地系统上运行和创建容器。
你可以使用以下三个平台中的任何一个 —— 桌面 Linux、 Windows 或 macOS 作为容器的开发平台。一旦 Docker 在这些系统上成功运行,你将可以在不同的平台上使用相同的命令。因此,接下来你运行的操作系统无关紧要。
这就是 Docker 之美。
### 让我们开始吧
现在有两个版本的 Docker:Docker 企业版(EE)和 Docker 社区版(CE)。我们将使用 Docker 社区版,这是一个免费的 Docker 版本,面向想要开始使用 Docker 的开发人员和爱好者。
Docker CE 有两个版本:stable 和 edge。顾名思义,stable(稳定)版本会为你提供经过充分测试的季度更新,而 edge 版本每个月都会提供新的更新。经过进一步的测试之后,这些边缘特征将被添加到稳定版本中。我建议新用户使用 stable 版本。
Docker CE 支持 macOS、 Windows 10、 Ubuntu 14.04/16.04/17.04/17.10、 Debian 7.7/8/9/10、 Fedora 25/26/27 和 CentOS。虽然你可以下载 Docker CE 二进制文件并安装到桌面 Linux 上,但我建议添加仓库源以便继续获得修补程序和更新。
### 在桌面 Linux 上安装 Docker CE
你不需要一个完整的桌面 Linux 来运行 Docker,你也可以将它安装在最小的 Linux 服务器上,即你可以在一个虚拟机中运行。在本教程中,我将在我的主系统的 Fedora 27 和 Ubuntu 17.04 上运行它。
### 在 Ubuntu 上安装
首先,运行系统更新,以便你的 Ubuntu 软件包完全更新:
```
$ sudo apt-get update
```
现在运行系统升级:
```
$ sudo apt-get dist-upgrade
```
然后安装 Docker PGP 密钥:
```
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"
```
```
Update the repository info again:
$ sudo apt-get update
```
现在安装 Docker CE:
```
$ sudo apt-get install docker-ce
```
一旦安装完成,Docker CE 就会在基于 Ubuntu 的系统上自动运行,让我们来检查它是否在运行:
```
$ sudo systemctl status docker
```
你应该得到以下输出:
```
docker.service - Docker Application Container Engine
Loaded: loaded (/lib/systemd/system/docker.service; enabled; vendor preset: enabled)
Active: active (running) since Thu 2017-12-28 15:06:35 EST; 19min ago
Docs: https://docs.docker.com
Main PID: 30539 (dockerd)
```
由于 Docker 安装在你的系统上,你现在可以使用 Docker CLI(命令行界面)运行 Docker 命令。像往常一样,我们运行 ‘Hello World’ 命令:
```
$ sudo docker run hello-world
```

恭喜!在你的 Ubuntu 系统上正在运行着 Docker。
### 在 Fedora 上安装 Docker CE
Fedora 27 上的情况有些不同。在 Fedora 上,你首先需要安装 `def-plugins-core` 包,这将允许你从 CLI 管理你的 DNF 包。
```
$ sudo dnf -y install dnf-plugins-core
```
现在在你的系统上安装 Docker 仓库:
```
$ sudo dnf config-manager \
--add-repo \
https://download.docker.com/linux/fedora/docker-ce.repo
It’s time to install Docker CE:
```
```
$ sudo dnf install docker-ce
```
与 Ubuntu 不同,Docker 不会在 Fedora 上自动启动。那么让我们启动它:
```
$ sudo systemctl start docker
```
你必须在每次重新启动后手动启动 Docker,因此让我们将其配置为在重新启动后自动启动。`$ systemctl enable docker` 就行。现在该运行 Hello World 命令了:
```
$ sudo docker run hello-world
```
恭喜,在你的 Fedora 27 系统上正在运行着 Docker。
### 解除 root
你可能已经注意到你必须使用 `sudo` 来运行 `docker` 命令。这是因为 Docker 守护进程与 UNIX 套接字绑定,而不是 TCP 端口,套接字由 root 用户拥有。所以,你需要 `sudo` 权限才能运行 `docker` 命令。你可以将系统用户添加到 docker 组,这样它就不需要 `sudo` 了:
```
$ sudo groupadd docker
```
在大多数情况下,在安装 Docker CE 时会自动创建 Docker 用户组,因此你只需将用户添加到该组中即可:
```
$ sudo usermod -aG docker $USER
```
为了测试该组是否已经成功添加,根据用户名运行 `groups` 命令:
```
$ groups swapnil
```
(这里,`swapnil` 是用户名。)
这是在我系统上的输出:
```
swapnil : swapnil adm cdrom sudo dip plugdev lpadmin sambashare docker
```
你可以看到该用户也属于 docker 组。注销系统,这样组就会生效。一旦你再次登录,在不使用 `sudo` 的情况下试试 Hello World 命令:
```
$ docker run hello-world
```
你可以通过运行以下命令来查看关于 Docker 的安装版本以及更多系统信息:
```
$ docker info
```
### 在 macOS 和 Windows 上安装 Docker CE
你可以在 macOS 和 Windows 上很轻松地安装 Docker CE(和 EE)。下载官方为 macOS 提供的 Docker 安装包,在 macOS 上安装应用程序的方式是只需将它们拖到 Applications 目录即可。一旦文件被复制,从 spotlight(LCTT 译注:mac 下的搜索功能)下打开 Docker 开始安装。一旦安装,Docker 将自动启动,你可以在 macOS 的顶部看到它。

macOS 是类 UNIX 系统,所以你可以简单地打开终端应用程序,并开始使用 Docker 命令。测试 hello world 应用:
```
$ docker run hello-world
```
恭喜,你已经在你的 macOS 上运行了 Docker。
### 在 Windows 10 上安装 Docker
你需要最新版本的 Windows 10 Pro 或 Server 才能在它上面安装或运行 Docker。如果你没有完全更新,Windows 将不会安装 Docker。我在 Windows 10 系统上遇到了错误,必须运行系统更新。我的版本还很落后,我出现了[这个][14] bug。所以,如果你无法在 Windows 上安装 Docker,只要知道并不是只有你一个。仔细检查该 bug 以找到解决方案。
一旦你在 Windows 上安装 Docker 后,你可以通过 WSL 使用 bash shell,或者使用 PowerShell 来运行 Docker 命令。让我们在 PowerShell 中测试 “Hello World” 命令:
```
PS C:\Users\swapnil> docker run hello-world
```
恭喜,你已经在 Windows 上运行了 Docker。
在下一篇文章中,我们将讨论如何从 DockerHub 中拉取镜像并在我们的系统上运行容器。我们还会讨论推送我们自己的容器到 Docker Hub。
---
via: <https://www.linux.com/blog/learn/intro-to-linux/how-install-docker-ce-your-desktop>
作者:[SWAPNIL BHARTIYA](https://www.linux.com/users/arnieswap) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,774 | DevOps 如何帮助你将很酷的应用交付给用户 | https://opensource.com/article/18/2/devops-delivers-cool-apps-users | 2018-06-23T22:43:00 | [
"DevOps"
] | /article-9774-1.html |
>
> 想要在今天的快节奏的商业环境中获得成功?要么选择 DevOps,要么死亡。
>
>
>

在很久之前,遥远的银河系中,在 DevOps 成为主流实践之前,软件开发的过程是极其缓慢、单调和按部就班的。当一个应用准备要部署的时候,就已经为下一个主要版本迭代积累了一长串的变更和修复。每次为新版本迭代所花费的准备时间都需要花费数个月的时间去回顾和贯穿整个开发周期。请记住这个过程将会在交付更新给用户的过程中不断的 重复。
今天一切都是瞬间和实时完成的,这个概念似乎很原始。这场移动革命已经极大的改变了我们和软件之间的交互。那些早期采用 DevOps 的公司已经彻底改变了对软件开发和部署的期望。
让我们看看 Facebook:这个移动应用每两周更新和刷新一次,像钟表一样。这就是新的标准,因为现在的用户期望软件持续的被修复和更新。任何一家要花费一个月或者更多的时间来部署新的功能或者修复 bug 的公司将会逐渐走向没落。如果你不能交付用户所期待的,他们将会去寻找那些能够满足他们需求的。
Facebook,以及一些工业巨头如亚马逊、Netfix、谷歌以及其他公司,都已经强制要求企业变得更快速、更有效的来满足今天的顾客们的需求。
### 为什么是 DevOps?
敏捷和 DevOps 对于移动应用开发领域是相当重要的,因为开发周期正变得如闪电般的快。现在是一个密集、快节奏的环境,公司必须加紧步伐赶超,思考的更深入,运用策略来去完成,从而生存下去。在应用商店中,排名前十的应用平均能够保持的时间只有一个月左右。
为了说明老式的瀑布方法,回想一下你第一次学习驾驶。起先,你专注于每个独立的层面,使用一套方法论的过程:你上车;系上安全带;调整座椅、镜子,控制方向盘;发动汽车,将你的手放在 10 点和 2 点钟的方向,等等。完成一个换车道一样简单的任务需要付出艰苦的努力,以一个特定的顺序执行多个步骤。
DevOps,正好相反,是在你有了几年的经验之后如何去驾驶的。一切都是靠直觉同时发生的,你可以不用过多的思考就很平滑的从 A 点移动到 B 点。
移动 app 的世界对越老式的 app 开发环境来说太快节奏了。DevOps 被设计用来快速交付有效、稳定的 app,而不需要增加资源。然而你不能像购买一件普通的商品或者服务一样去购买 DevOps。DevOps 是用来指导改变团队如何一起工作的文化和活动的。
不是只有像亚马逊和 Facebook 这样的大公司才拥抱 DevOps 文化;小的移动应用公司也在很好的使用。“缩短迭代周期,同时保持生产事故处于一个较低水平,以及满足顾客追求的整体故障成本。”来自移动产品代理 [Reinvently](https://reinvently.com/)的工程部的负责人,Oleg Reshetnyak 说道。
### DevOps: 不是如果,而是什么时候
在今天的快节奏的商业环境中,选在了 DevOps 就像是选择了呼吸:要么去[做要么就死亡](https://squadex.com/insights/devops-or-die/)。
根据[美国小企业管理局](https://www.sba.gov/)的报道,现在只有 16% 的公司能够持续一代人的时间。不采用 DevOps 的移动应用公司将冒着逐渐走向灭绝的风险。而且,同样的研究表明采用 DevOps 的公司组织可能能够获得两倍的盈利能力、生产目标以及市场份额。
更快速、更安全的革新需要做到三点:云、自动化和 DevOps。根据你对 DevOps 的定义的不同,这三个要点之间的界限是不清晰的。然而,有一点是确定的:DevOps 围绕着更快、更少风险地交付高质量的软件的共同目标将组织内的每个人都统一起来。
---
via: <https://opensource.com/article/18/2/devops-delivers-cool-apps-users>
作者:[Stanislav Ivaschenko](https://opensource.com/users/ilyadudkin) 译者:[FelixYFZ](https://github.com/FelixYFZ) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
9,775 | 不像 MySQL 的 MySQL:MySQL 文档存储介绍 | https://opensource.com/article/18/6/mysql-document-store | 2018-06-24T09:19:00 | [
"MySQL",
"JSON"
] | https://linux.cn/article-9775-1.html |
>
> MySQL 文档存储 可以跳过底层数据结构创建、数据规范化和其它使用传统数据库时需要做的工作,直接存储数据。
>
>
>

MySQL 可以提供 NoSQL JSON <ruby> 文档存储 <rt> Document Store </rt></ruby>了,这样开发者保存数据前无需<ruby> 规范化 <rt> normalize </rt></ruby>数据、创建数据库,也无需在开发之前就制定好数据样式。从 MySQL 5.7 版本和 MySQL 8.0 版本开始,开发者可以在表的一列中存储 JSON 文档。由于引入 X DevAPI,你可以从你的代码中移除令人不爽的结构化查询字符串,改为使用支持现代编程设计的 API 调用。
系统学习过结构化查询语言(SQL)、<ruby> 关系理论 <rt> relational theory </rt></ruby>、<ruby> 集合 <rt> set </rt></ruby>和其它关系数据库底层理论的开发者并不多,但他们需要一个安全可靠的数据存储。如果数据库管理人员不足,事情很快就会变得一团糟,
[MySQL 文档存储](https://www.mysql.com/products/enterprise/document_store.html) 允许开发者跳过底层数据结构创建、数据规范化和其它使用传统数据库时需要做的工作,直接存储数据。只需创建一个 JSON <ruby> 文档集合 <rt> document collection </rt></ruby>,接着就可以使用了。
### JSON 数据类型
所有这一切都基于多年前 MySQL 5.7 引入的 JSON 数据类型。它允许在表的一行中提供大约 1GB 大小的列。数据必须是有效的 JSON,否则服务器会报错;但开发者可以自由使用这些空间。
### X DevAPI
旧的 MySQL 协议已经历经差不多四分之一个世纪,已经显现出疲态,因此新的协议被开发出来,协议名为 [X DevAPI](https://dev.mysql.com/doc/x-devapi-userguide/en/)。协议引入高级会话概念,允许代码从单台服务器扩展到多台,使用符合<ruby> 通用主机编程语言样式 <rt> common host-language programming patterns </rt></ruby>的非阻塞异步 I/O。需要关注的是如何遵循现代实践和编码风格,同时使用 CRUD (Create、 Read、 Update、 Delete)样式。换句话说,你不再需要在你精美、纯洁的代码中嵌入丑陋的 SQL 语句字符串。
一个新的 shell 支持这种新协议,即所谓的 [MySQL Shell](https://dev.mysql.com/downloads/shell/)。该 shell 可用于设置<ruby> 高可用集群 <rt> high-availability cluster </rt></ruby>、检查服务器<ruby> 升级就绪状态 <rt> upgrade readiness </rt></ruby>以及与 MySQL 服务器交互。支持的交互方式有以下三种:JavaScript,Python 和 SQL。
### 代码示例
下面的代码示例基于 JavaScript 方式使用 MySQL Shell,可以从 `JS>` 提示符看出。
下面,我们将使用用户 `dstokes` 、密码 `password` 登录本地系统上的 `demo` 库。`db` 是一个指针,指向 `demo` 库。
```
$ mysqlsh dstokes:password@localhost/demo
JS> db.createCollection("example")
JS> db.example.add(
{
Name: "Dave",
State: "Texas",
foo : "bar"
}
)
JS>
```
在上面的示例中,我们登录服务器,连接到 `demo` 库,创建了一个名为 `example` 的集合,最后插入一条记录;整个过程无需创建表,也无需使用 SQL。只要你能想象的到,你可以使用甚至滥用这些数据。这不是一种代码对象与关系语句之间的映射器,因为并没有将代码映射为 SQL;新协议直接与服务器层打交道。
### Node.js 支持
新 shell 看起来挺不错,你可以用其完成很多工作;但你可能更希望使用你选用的编程语言。下面的例子使用 `world_x` 示例数据库,搜索 `_id` 字段匹配 `CAN.` 的记录。我们指定数据库中的特定集合,使用特定参数调用 `find` 命令。同样地,操作也不涉及 SQL。
```
var mysqlx = require('@mysql/xdevapi');
mysqlx.getSession({ //Auth to server
host: 'localhost',
port: '33060',
dbUser: 'root',
dbPassword: 'password'
}).then(function (session) { // use world_x.country.info
var schema = session.getSchema('world_x');
var collection = schema.getCollection('countryinfo');
collection // Get row for 'CAN'
.find("$._id == 'CAN'")
.limit(1)
.execute(doc => console.log(doc))
.then(() => console.log("\n\nAll done"));
session.close();
})
```
下面例子使用 PHP,搜索 `_id` 字段匹配 `USA` 的记录:
```
<?PHP
// Connection parameters
$user = 'root';
$passwd = 'S3cret#';
$host = 'localhost';
$port = '33060';
$connection_uri = 'mysqlx://'.$user.':'.$passwd.'@'.$host.':'.$port;
echo $connection_uri . "\n";
// Connect as a Node Session
$nodeSession = mysql_xdevapi\getNodeSession($connection_uri);
// "USE world_x" schema
$schema = $nodeSession->getSchema("world_x");
// Specify collection to use
$collection = $schema->getCollection("countryinfo");
// SELECT * FROM world_x WHERE _id = "USA"
$result = $collection->find('_id = "USA"')->execute();
// Fetch/Display data
$data = $result->fetchAll();
var_dump($data);
?>
```
可以看出,在上面两个使用不同编程语言的例子中,`find` 操作符的用法基本一致。这种一致性对跨语言编程的开发者有很大帮助,对试图降低新语言学习成本的开发者也不无裨益。
支持的语言还包括 C、Java、Python 和 JavaScript 等,未来还会有更多支持的语言。
### 从两种方式受益
我会告诉你使用 NoSQL 方式录入的数据也可以用 SQL 方式使用?换句话说,我会告诉你新引入的 NoSQL 方式可以访问旧式关系型表中的数据?现在使用 MySQL 服务器有多种方式,作为 SQL 服务器,作为 NoSQL 服务器或者同时作为两者。
---
via: <https://opensource.com/article/18/6/mysql-document-store>
作者:[Dave Stokes](https://opensource.com/users/davidmstokes) 选题:[lujun9972](https://github.com/lujun9972) 译者:[pinewall](https://github.com/pinewall) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | MySQL can act as a NoSQL JSON Document Store so programmers can save data without having to normalize data, set up schemas, or even have a clue what their data looks like before starting to code. Since MySQL version 5.7 and in MySQL 8.0, developers can store JSON documents in a column of a table. By adding the new X DevAPI, you can stop embedding nasty strings of structured query language in your code and replace them with API calls that support modern programming design.
Very few developers have any formal training in structured query language (SQL), relational theory, sets, or other foundations of relational databases. But they need a secure, reliable data store. Add in a dearth of available database administrators, and things can get very messy quickly.
The [MySQL Document Store](https://www.mysql.com/products/enterprise/document_store.html) allows programmers to store data without having to create an underlying schema, normalize data, or any of the other tasks normally required to use a database. A JSON document collection is created and can then be used.
## JSON data type
This is all based on the JSON data type introduced a few years ago in MySQL 5.7. This provides a roughly 1GB column in a row of a table. The data has to be valid JSON or the server will return an error, but developers are free to use that space as they want.
## X DevAPI
The old MySQL protocol is showing its age after almost a quarter-century, so a new protocol was developed called [X DevAPI](https://dev.mysql.com/doc/x-devapi-userguide/en/). It includes a new high-level session concept that allows code to scale from one server to many with non-blocking, asynchronous I/O that follows common host-language programming patterns. The focus is put on using CRUD (create, replace, update, delete) patterns while following modern practices and coding styles. Or, to put it another way, you no longer have to embed ugly strings of SQL statements in your beautiful, pristine code.
A new shell, creatively called the [MySQL Shell](https://dev.mysql.com/downloads/shell/), supports this new protocol. It can be used to set up high-availability clusters, check servers for upgrade readiness, and interact with MySQL servers. This interaction can be done in three modes: JavaScript, Python, and SQL.
## Coding examples
The coding examples that follow are in the JavaScript mode of the MySQL Shell; it has a `JS>`
prompt.
Here, we will log in as `dstokes`
with the password `password`
to the local system and a schema named `demo`
. There is a pointer to the schema demo that is named `db`
.
```
$ mysqlsh dstokes:password@localhost/demo
JS> db.createCollection("example")
JS> db.example.add(
{
Name: "Dave",
State: "Texas",
foo : "bar"
}
)
JS>
```
Above we logged into the server, connected to the `demo`
schema, created a collection named `example`
, and added a record, all without creating a table definition or using SQL. We can use or abuse this data as our whims desire. This is not an object-relational mapper, as there is no mapping the code to the SQL because the new protocol “speaks” at the server layer.
## Node.js supported
The new shell is pretty sweet; you can do a lot with it, but you will probably want to use your programming language of choice. The following example uses the `world_x`
demo database to search for a record with the `_id`
field matching "CAN." We point to the desired collection in the schema and issue a `find`
command with the desired parameters. Again, there’s no SQL involved.
```
var mysqlx = require('@mysql/xdevapi');
mysqlx.getSession({ //Auth to server
host: 'localhost',
port: '33060',
dbUser: 'root',
dbPassword: 'password'
}).then(function (session) { // use world_x.country.info
var schema = session.getSchema('world_x');
var collection = schema.getCollection('countryinfo');
collection // Get row for 'CAN'
.find("$._id == 'CAN'")
.limit(1)
.execute(doc => console.log(doc))
.then(() => console.log("\n\nAll done"));
session.close();
})
```
Here is another example in PHP that looks for "USA":
```
#!/usr/bin/php
<?PHP
// Connection parameters
$user = 'root';
$passwd = 'S3cret#';
$host = 'localhost';
$port = '33060';
$connection_uri = 'mysqlx://'.$user.':'.$passwd.'@'.$host.':'.$port;
echo $connection_uri . "\n";
// Connect as a Node Session
$nodeSession = mysql_xdevapi\getNodeSession($connection_uri);
// "USE world_x" schema
$schema = $nodeSession->getSchema("world_x");
// Specify collection to use
$collection = $schema->getCollection("countryinfo");
// SELECT * FROM world_x WHERE _id = "USA"
$result = $collection->find('_id = "USA"')->execute();
// Fetch/Display data
$data = $result->fetchAll();
var_dump($data);
?>
```
Note that the `find`
operator used in both examples looks pretty much the same between the two different languages. This consistency should help developers who hop between programming languages or those looking to reduce the learning curve with a new language.
Other supported languages include C, Java, Python, and JavaScript, and more are planned.
## Best of both worlds
Did I mention that the data entered in this NoSQL fashion is also available from the SQL side of MySQL? Or that the new NoSQL method can access relational data in old-fashioned relational tables? You now have the option to use your MySQL server as a SQL server, a NoSQL server, or both.
*Dave Stokes will present "MySQL Without the SQL—Oh My!" at Southeast LinuxFest, June 8-10, in Charlotte, N.C.*
## 2 Comments |
9,776 | 如何在命令行中整理数据 | https://opensource.com/article/18/5/command-line-data-auditing | 2018-06-24T21:34:47 | [
"命令行",
"审计",
"数据库"
] | /article-9776-1.html |
>
> 命令行审计不会影响数据库,因为它使用从数据库中释放的数据。
>
>
>

我兼职做数据审计。把我想象成一个校对者,校对的是数据表格而不是一页一页的文章。这些表是从关系数据库导出的,并且规模相当小:100,000 到 1,000,000条记录,50 到 200 个字段。
我从来没有见过没有错误的数据表。如你所能想到的,这种混乱并不局限于重复记录、拼写和格式错误以及放置在错误字段中的数据项。我还发现:
* 损坏的记录分布在几行上,因为数据项具有内嵌的换行符
* 在同一记录中一个字段中的数据项与另一个字段中的数据项不一致
* 使用截断数据项的记录,通常是因为非常长的字符串被硬塞到具有 50 或 100 字符限制的字段中
* 字符编码失败产生称为[乱码](https://en.wikipedia.org/wiki/Mojibake)的垃圾
* 不可见的[控制字符](https://en.wikipedia.org/wiki/Control_character),其中一些会导致数据处理错误
* 由上一个程序插入的[替换字符](https://en.wikipedia.org/wiki/Specials_(Unicode_block)#Replacement_character)和神秘的问号,这是由于不知道数据的编码是什么
解决这些问题并不困难,但找到它们存在非技术障碍。首先,每个人都不愿处理数据错误。在我看到表格之前,数据所有者或管理人员可能已经经历了<ruby> 数据悲伤 <rt> Data Grief </rt></ruby>的所有五个阶段:
1. 我们的数据没有错误。
2. 好吧,也许有一些错误,但它们并不重要。
3. 好的,有很多错误;我们会让我们的内部人员处理它们。
4. 我们已经开始修复一些错误,但这很耗时间;我们将在迁移到新的数据库软件时执行此操作。
5. 移至新数据库时,我们没有时间整理数据; 我们需要一些帮助。
第二个阻碍进展的是相信数据整理需要专用的应用程序——要么是昂贵的专有程序,要么是优秀的开源程序 [OpenRefine](http://openrefine.org/) 。为了解决专用应用程序无法解决的问题,数据管理人员可能会向程序员寻求帮助,比如擅长 [Python](https://www.python.org/) 或 [R](https://www.r-project.org/about.html) 的人。
但是数据审计和整理通常不需要专用的应用程序。纯文本数据表已经存在了几十年,文本处理工具也是如此。打开 Bash shell,您将拥有一个工具箱,其中装载了强大的文本处理器,如 `grep`、`cut`、`paste`、`sort`、`uniq`、`tr` 和 `awk`。它们快速、可靠、易于使用。
我在命令行上执行所有的数据审计工作,并且在 “[cookbook](https://www.polydesmida.info/cookbook/index.html)” 网站上发布了许多数据审计技巧。我经常将操作存储为函数和 shell 脚本(参见下面的示例)。
是的,命令行方法要求将要审计的数据从数据库中导出。而且,审计结果需要稍后在数据库中进行编辑,或者(数据库允许)将整理的数据项导入其中,以替换杂乱的数据项。
但其优势是显著的。awk 将在普通的台式机或笔记本电脑上以几秒钟的时间处理数百万条记录。不复杂的正则表达式将找到您可以想象的所有数据错误。所有这些都将安全地发生在数据库结构之外:命令行审计不会影响数据库,因为它使用从数据库中释放的数据。
受过 Unix 培训的读者此时会沾沾自喜。他们还记得许多年前用这些方法操纵命令行上的数据。从那时起,计算机的处理能力和 RAM 得到了显著提高,标准命令行工具的效率大大提高。数据审计从来没有这么快、这么容易过。现在微软的 Windows 10 可以运行 Bash 和 GNU/Linux 程序了,Windows 用户也可以用 Unix 和 Linux 的座右铭来处理混乱的数据:保持冷静,打开一个终端。

### 例子
假设我想在一个大的表中的特定字段中找到最长的数据项。 这不是一个真正的数据审计任务,但它会显示 shell 工具的工作方式。 为了演示目的,我将使用制表符分隔的表 `full0` ,它有 1,122,023 条记录(加上一个标题行)和 49 个字段,我会查看 36 号字段。(我得到字段编号的函数在我的[网站](https://www.polydesmida.info/cookbook/functions.html#fields)上有解释)
首先,使用 `tail` 命令从表 `full0` 移除标题行,结果管道至 `cut` 命令,截取第 36 个字段,接下来,管道至 `awk` ,这里有一个初始化为 0 的变量 `big` ,然后 `awk` 开始检测第一行数据项的长度,如果长度大于 0 ,`awk` 将会设置 `big` 变量为新的长度,同时存储行数到变量 `line` 中。整个数据项存储在变量 `text` 中。然后 `awk` 开始轮流处理剩余的 1,122,022 记录项。同时,如果发现更长的数据项时,更新 3 个变量。最后,它打印出行号、数据项的长度,以及最长数据项的内容。(在下面的代码中,为了清晰起见,将代码分为几行)
```
tail -n +2 full0 \
> | cut -f36 \
> | awk 'BEGIN {big=0} length($0)>big \
> {big=length($0);line=NR;text=$0} \
> END {print "\nline: "line"\nlength: "big"\ntext: "text}'
```
大约花了多长时间?我的电脑大约用了 4 秒钟(core i5,8GB RAM);

现在我可以将这个长长的命令封装成一个 shell 函数,`longest`,它把第一个参数认为是文件名,第二个参数认为是字段号:

现在,我可以以函数的方式重新运行这个命令,在另一个文件中的另一个字段中找最长的数据项,而不需要去记忆这个命令是如何写的:

最后调整一下,我还可以输出我要查询字段的名称,我只需要使用 `head` 命令抽取表格第一行的标题行,然后将结果管道至 `tr` 命令,将制表位转换为换行,然后将结果管道至 `tail` 和 `head` 命令,打印出第二个参数在列表中名称,第二个参数就是字段号。字段的名字就存储到变量 `field` 中,然后将它传向 `awk` ,通过变量 `fld` 打印出来。(LCTT 译注:按照下面的代码,编号的方式应该是从右向左)
```
longest() { field=$(head -n 1 "$1" | tr '\t' '\n' | tail -n +"$2" | head -n 1); \
tail -n +2 "$1" \
| cut -f"$2" | \
awk -v fld="$field" 'BEGIN {big=0} length($0)>big \
{big=length($0);line=NR;text=$0}
END {print "\nfield: "fld"\nline: "line"\nlength: "big"\ntext: "text}'; }
```

注意,如果我在多个不同的字段中查找最长的数据项,我所要做的就是按向上箭头来获得最后一个最长的命令,然后删除字段号并输入一个新的。
---
via: <https://opensource.com/article/18/5/command-line-data-auditing>
作者:[Bob Mesibov](https://opensource.com/users/bobmesibov) 选题:[lujun9972](https://github.com/lujun9972) 译者:[amwps290](https://github.com/amwps290) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
9,777 | 在 Linux 上用 DNS 实现简单的负载均衡 | https://www.linux.com/learn/intro-to-linux/2018/3/simple-load-balancing-dns-linux | 2018-06-24T23:06:28 | [
"DNS",
"负载均衡",
"轮询"
] | https://linux.cn/article-9777-1.html |
>
> DNS 轮询将多个服务器映射到同一个主机名,并没有为这里展示的魔法做更多的工作。
>
>
>

如果你的后端服务器是由多台服务器构成的,比如集群化或者镜像的 Web 或者文件服务器,通过负载均衡器提供了单一的入口点。业务繁忙的大型电商在高端负载均衡器上花费了大量的资金,用它来执行各种各样的任务:代理、缓存、状况检查、SSL 处理、可配置的优先级、流量整形等很多任务。
但是你并不需要做那么多工作的负载均衡器。你需要的是一个跨服务器分发负载的简单方法,它能够提供故障切换,并且不太在意它是否高效和完美。DNS 轮询和使用轮询的子域委派是实现这个目标的两种简单方法。
DNS 轮询是将多台服务器映射到同一个主机名上,当用户访问 `foo.example.com` 时多台服务器都可用于处理它们的请求,使用的就是这种方式。
当你有多个子域或者你的服务器在地理上比较分散时,使用轮询的子域委派就比较有用。你有一个主域名服务器,而子域有它们自己的域名服务器。你的主域名服务器将所有的到子域的请求指向到它们自己的域名服务器上。这将提升响应时间,因为 DNS 协议会自动查找最快的链路。
### DNS 轮询
轮询和<ruby> 旅鸫鸟 <rt> robins </rt></ruby>没有任何关系,据我相熟的图书管理员说,它最初是一个法语短语,*ruban rond*、或者 *round ribbon*。很久以前,法国政府官员以不分级的圆形、波浪线、或者直线形状来在请愿书上签字,以盖住原来的发起人。
DNS 轮询也是不分级的,简单配置一个服务器列表,然后将请求转到每个服务器上。它并不做真正的负载均衡,因为它根本就不测量负载,也没有状况检查,因此如果一个服务器宕机,请求仍然会发送到那个宕机的服务器上。它的优点就是简单。如果你有一个小的文件或者 Web 服务器集群,想通过一个简单的方法在它们之间分散负载,那么 DNS 轮询很适合你。
你所做的全部配置就是创建多条 A 或者 AAAA 记录,映射多台服务器到单个的主机名。这个 BIND 示例同时使用了 IPv4 和 IPv6 私有地址类:
```
fileserv.example.com. IN A 172.16.10.10
fileserv.example.com. IN A 172.16.10.11
fileserv.example.com. IN A 172.16.10.12
fileserv.example.com. IN AAAA fd02:faea:f561:8fa0:1::10
fileserv.example.com. IN AAAA fd02:faea:f561:8fa0:1::11
fileserv.example.com. IN AAAA fd02:faea:f561:8fa0:1::12
```
Dnsmasq 在 `/etc/hosts` 文件中保存 A 和 AAAA 记录:
```
172.16.1.10 fileserv fileserv.example.com
172.16.1.11 fileserv fileserv.example.com
172.16.1.12 fileserv fileserv.example.com
fd02:faea:f561:8fa0:1::10 fileserv fileserv.example.com
fd02:faea:f561:8fa0:1::11 fileserv fileserv.example.com
fd02:faea:f561:8fa0:1::12 fileserv fileserv.example.com
```
请注意这些示例都是很简化的,解析完全合格域名有多种方法,因此,关于如何配置 DNS 请自行学习。
使用 `dig` 命令去检查你的配置能否按预期工作。将 `ns.example.com` 替换为你的域名服务器:
```
$ dig @ns.example.com fileserv A fileserv AAA
```
它将同时显示出 IPv4 和 IPv6 的轮询记录。
### 子域委派和轮询
子域委派结合轮询要做的配置会更多,但是这样有一些好处。当你有多个子域或者地理位置比较分散的服务器时,就应该去使用它。它的响应时间更快,并且宕机的服务器不会去响应,因此客户端不会因为等待回复而被挂住。一个短的 TTL,比如 60 秒,就能帮你做到。
这种方法需要多台域名服务器。在最简化的场景中,你需要一台主域名服务器和两个子域,每个子域都有它们自己的域名服务器。在子域服务器上配置你的轮询记录,然后在你的主域名服务器上配置委派。
在主域名服务器上的 BIND 中,你至少需要两个额外的配置,一个区声明以及在区数据文件中的 A/AAAA 记录。主域名服务器中的委派应该像如下的内容:
```
ns1.sub.example.com. IN A 172.16.1.20
ns1.sub.example.com. IN AAAA fd02:faea:f561:8fa0:1::20
ns2.sub.example.com. IN A 172.16.1.21
ns2.sub.example.com. IN AAA fd02:faea:f561:8fa0:1::21
sub.example.com. IN NS ns1.sub.example.com.
sub.example.com. IN NS ns2.sub.example.com.
```
接下来的每台子域服务器上有它们自己的区文件。在这里它的关键点是每个服务器去返回它**自己的** IP 地址。在 `named.conf` 中的区声明,所有的服务上都是一样的:
```
zone "sub.example.com" {
type master;
file "db.sub.example.com";
};
```
然后数据文件也是相同的,除了那个 A/AAAA 记录使用的是各个服务器自己的 IP 地址。SOA 记录都指向到主域名服务器:
```
; first subdomain name server
$ORIGIN sub.example.com.
$TTL 60
sub.example.com IN SOA ns1.example.com. admin.example.com. (
2018123456 ; serial
3H ; refresh
15 ; retry
3600000 ; expire
)
sub.example.com. IN NS ns1.sub.example.com.
sub.example.com. IN A 172.16.1.20
ns1.sub.example.com. IN AAAA fd02:faea:f561:8fa0:1::20
; second subdomain name server
$ORIGIN sub.example.com.
$TTL 60
sub.example.com IN SOA ns1.example.com. admin.example.com. (
2018234567 ; serial
3H ; refresh
15 ; retry
3600000 ; expire
)
sub.example.com. IN NS ns1.sub.example.com.
sub.example.com. IN A 172.16.1.21
ns2.sub.example.com. IN AAAA fd02:faea:f561:8fa0:1::21
```
接下来生成子域服务器上的轮询记录,方法和前面一样。现在你已经有了多个域名服务器来处理到你的子域的请求。再说一次,BIND 是很复杂的,做同一件事情它有多种方法,因此,给你留的家庭作业是找出适合你使用的最佳配置方法。
在 Dnsmasq 中做子域委派很容易。在你的主域名服务器上的 `dnsmasq.conf` 文件中添加如下的行,去指向到子域的域名服务器:
```
server=/sub.example.com/172.16.1.20
server=/sub.example.com/172.16.1.21
server=/sub.example.com/fd02:faea:f561:8fa0:1::20
server=/sub.example.com/fd02:faea:f561:8fa0:1::21
```
然后在子域的域名服务器上的 `/etc/hosts` 中配置轮询。
获取配置方法的详细内容和帮助,请参考这些资源:
* [Dnsmasq](http://www.thekelleys.org.uk/dnsmasq/doc.html)
* [DNS and BIND, 5th Edition](http://shop.oreilly.com/product/9780596100575.do)
通过来自 Linux 基金会和 edX 的免费课程 ["Linux 入门"](https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux) 学习更多 Linux 的知识。
---
via: <https://www.linux.com/learn/intro-to-linux/2018/3/simple-load-balancing-dns-linux>
作者:[CARLA SCHRODER](https://www.linux.com/users/cschroder) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,780 | 如何在 Linux 中使用 history 命令 | https://opensource.com/article/18/6/history-command | 2018-06-26T08:24:46 | [
"历史",
"history"
] | https://linux.cn/article-9780-1.html |
>
> 用强大的 history 命令使你的命令行提示符更有效率。
>
>
>

随着我在终端中花费越来越多的时间,我感觉就像在不断地寻找新的命令,以使我的日常任务更加高效。GNU 的 `history` 命令是一个真正改变我日常工作的命令。
GNU `history` 命令保存了从该终端会话运行的所有其他命令的列表,然后允许你重放或者重用这些命令,而不用重新输入它们。如果你是一个老玩家,你知道 `history` 的力量,但对于我们这些半吊子或新手系统管理员来说, `history` 是一个立竿见影的生产力增益。
### 历史 101
要查看命令历史,请在 Linux 中打开终端程序,然后输入:
```
$ history
```
这是我得到的响应:
```
1 clear
2 ls -al
3 sudo dnf update -y
4 history
```
`history` 命令显示自开始会话后输入的命令列表。 `history` 有趣的地方是你可以使用以下命令重放任意一个命令:
```
$ !3
```
提示符中的 `!3` 告诉 shell 重新运行历史列表中第 3 个命令。我还可以输入以下命令来使用:
```
linuser@my_linux_box: !sudo dnf
```
`history` 将搜索与你提供的模式相匹配的最后一个命令,并运行它。
### 搜索历史
你还可以输入 `!!` 重新运行命令历史中的最后一条命令。而且,通过与`grep` 配对,你可以搜索与文本模式相匹配的命令,或者通过与 `tail` 一起使用,你可以找到你最后几条执行的命令。例如:
```
$ history | grep dnf
3 sudo dnf update -y
5 history | grep dnf
$ history | tail -n 3
4 history
5 history | grep dnf
6 history | tail -n 3
```
另一种实现这个功能的方法是输入 `Ctrl-R` 来调用你的命令历史记录的递归搜索。输入后,提示变为:
```
(reverse-i-search)`':
```
现在你可以开始输入一个命令,并且会显示匹配的命令,按回车键执行。
### 更改已执行的命令
`history` 还允许你使用不同的语法重新运行命令。例如,如果我想改变我以前的命令 `history | grep dnf` 成 `history | grep ssh`,我可以在提示符下执行以下命令:
```
$ ^dnf^ssh^
```
`history` 将重新运行该命令,但用 `ssh` 替换 `dnf`,并执行它。
### 删除历史
有时你想要删除一些或全部的历史记录。如果要删除特定命令,请输入 `history -d <行号>`。要清空历史记录,请执行 `history -c`。
历史文件存储在一个你可以修改的文件中。bash shell 用户可以在他们的家目录下找到 `.bash_history`。
### 下一步
你可以使用 `history` 做许多其他事情:
* 将历史缓冲区设置为一定数量
* 记录历史中每行的日期和时间
* 防止某些命令被记录在历史记录中
有关 `history` 命令的更多信息和其他有趣的事情,请参考 [GNU Bash 手册](https://www.gnu.org/software/bash/manual/)。
---
via: <https://opensource.com/article/18/6/history-command>
作者:[Steve Morris](https://opensource.com/users/smorris12) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | As I spend more and more time in terminal sessions, it feels like I'm continually finding new commands that make my daily tasks more efficient. The GNU `history`
command is one that really changed my work day.
The GNU `history`
command keeps a list of all the other commands that have been run from that terminal session, then allows you to replay or reuse those commands instead of retyping them. If you are an experienced terminal user, you know about the power of `history`
, but for us dabblers or new sysadmin folks, `history`
is an immediate productivity gain.
First of all, the `history`
command isn't actually a command. You can see this for yourself by looking for the command on your system:
```
$ which history
which: no history in (/usr/local/bin:/usr/bin:/bin:/usr/games:/usr/local/sbin)
```
Your computer can't find the `history`
command because it's a built-in keyword of your shell. Because it's written into the shell you're using, there can be some variation in how history behaves depending on whether you're using [Bash](https://opensource.com/article/20/4/bash-sysadmins-ebook), tcsh, [Zsh](https://opensource.com/article/19/9/getting-started-zsh), dash, [fish](https://opensource.com/article/20/3/fish-shell), ksh, and so on. This article is based upon the Bash implementation of history, so some functions may not work in other shells. However, most of the basic functions are the same.
## History 101
To see `history`
in action, open a terminal program on your Linux installation and type:
`$ history`
Here's the response I got:
```
1 clear
2 ls -al
3 sudo dnf update -y
4 history
```
The `history`
command shows a list of the commands entered since you started the session. The joy of `history`
is that now you can replay any of them by using a command such as:
`$ !3`
The `!3`
command at the prompt tells the shell to rerun the command on line 3 of the history list. I could also access that command by entering:
`$ !sudo dnf`
This prompts `history`
to search for the last command that matches the pattern you provided (in this case, that pattern is **dnf**) and run it.
## Searching history
You can also use `history`
to rerun the last command you entered by typing `!!`
. By pairing it with `grep`
, you can search for commands that match a text pattern or, by using it with `tail`
, you can find the last few commands you executed. For example:
```
$ history | grep dnf
3 sudo dnf update -y
5 history | grep dnf
$ history | tail -n 3
4 history
5 history | grep dnf
6 history | tail -n 3
```
Another way to get to this search functionality is by typing `Ctrl-R`
to invoke a recursive search of your command history. After typing this, the prompt changes to:
`(reverse-i-search)`':`
Now you can start typing a command, and matching commands will be displayed for you to execute by pressing **Return** or **Enter**.
## Changing an executed command
You can also use `history`
to rerun a command with different syntax. You can revise history with `history`
. For example, if I want to change my previous command `history | grep dnf`
to `history | grep ssh`
, I can execute the following at the prompt:
`$ ^dnf^ssh^`
The command is rerun, but with `dnf`
replaced by `ssh`
. In other words, this command is run:
`$ history | grep ssh`
## Removing history
There may come a time that you want to remove some or all the commands in your history file. If you want to delete a particular command, enter `history -d <line number>`
. To clear the entire contents of the history file, execute `history -c`
.
The history file is stored in a file that you can modify, as well. Bash shell users find it in their home directory as `.bash_history`
.
## Next steps
There are a number of other things that you can do with `history`
:
- Set the size of your history buffer to a certain number of commands
- Record the date and time for each line in history
- Prevent certain commands from being recorded in history
For more information about the `history`
command and other interesting things you can do with it, take a look at Seth Kenlon's articles about [parsing history](https://www.redhat.com/sysadmin/parsing-bash-history), [history search modifiers](https://www.redhat.com/sysadmin/modifiers-bash-history), and the [GNU Bash Manual](https://www.gnu.org/software/bash/manual/).
*This article was originally published in June 2018 and has been updated with additional information by the editor. *
## 4 Comments |
9,781 | 如何在 Linux 和 Windows 之间共享文件? | https://www.networkworld.com/article/3269189/linux/sharing-files-between-linux-and-windows.html | 2018-06-26T08:38:42 | [
"Windows",
"共享"
] | https://linux.cn/article-9781-1.html |
>
> 用一些来自 Linux 社区的工具,在 Linux 和 Windows 之间共享文件是超容易的。让我们看看可以做这件事的两种不同方法。
>
>
>

现代很多人都在混合网络上工作,Linux 和 Windows 系统都扮演着重要的结束。在两者之间共享文件有时是非常关键的,并且使用正确的工具非常容易。只需很少的功夫,你就可以将文件从 Windows 复制到 Linux 或从 Linux 到 Windows。在这篇文章中,我们将讨论配置 Linux 和 Windows 系统所需的东西,以允许你轻松地将文件从一个操作系统转移到另一个。
### 在 Linux 和 Windows 之间复制文件
在 Windows 和 Linux 之间移动文件的第一步是下载并安装诸如 PuTTY 的 `pscp` 之类的工具。你可以从 [putty.org](https://www.putty.org) 获得它(LCTT 译注:切记从官方网站下载,并最好对比其 md5/sha1 指纹),并轻松将其设置在 Windows 系统上。PuTTY 带有一个终端仿真器(`putty`)以及像 `pscp` 这样的工具,用于在 Linux 和 Windows 系统之间安全地复制文件。当你进入 PuTTY 站点时,你可以选择安装所有工具,或选择安装你想要的工具,也可以选择单个 .exe 文件。
你还需要在你的 Linux 系统上设置并运行 ssh 服务器。这允许它支持客户端(Windows 端)连接请求。如果你还没有安装 ssh 服务器,那么以下步骤可以在 Debian 系统上运行(包括 Ubuntu 等):
```
sudo apt update
sudo apt install ssh-server
sudo service ssh start
```
对于 Red Hat 及其相关的 Linux 系统,使用类似的命令:
```
sudo yum install openssh-server
sudo systemctl start sshd
```
注意,如果你正在运行防火墙(例如 ufw),则可能需要打开 22 端口以允许连接。
使用 `pscp` 命令,你可以将文件从 Windows 移到 Linux,反之亦然。它的 “copy from to” 命令的语法非常简单。
#### 从 Windows 到 Linux
在下面显示的命令中,我们将 Windows 系统上用户账户中的文件复制到 Linux 系统下的 /tmp 目录。
```
C:\Program Files\PuTTY>pscp \Users\shs\copy_me.txt [email protected]:/tmp
[email protected]'s password:
copy_me.txt | 0 kB | 0.1 kB/s | ETA: 00:00:00 | 100%
```
#### 从 Linux 到 Windows
将文件从 Linux 转移到 Windows 也同样简单。只要颠倒参数即可。
```
C:\Program Files\PuTTY>pscp [email protected]:/tmp/copy_me.txt \Users\shs
[email protected]'s password:
copy_me.txt | 0 kB | 0.1 kB/s | ETA: 00:00:00 | 100%
```
如果 1) `pscp` 位于 Windows 搜索路径中,并且 2) 你的 Linux 系统在 Windows 的 hosts 文件中,则该过程可以变得更加顺畅和轻松。
#### Windows 搜索路径
如果你使用 PuTTY 安装程序安装 PuTTY 工具,你可能会发现 `C:\Program files\PuTTY` 位于 Windows 搜索路径中。你可以通过在 Windows 命令提示符下键入 `echo %path%` 来检查是否属于这种情况(在搜索栏中键入 `cmd` 来打开命令提示符)。如果是这样,你不需要关心文件系统中相对于 `pscp` 可执行文件的位置。进入到包含你想要移动文件的文件夹可能会更容易。
```
C:\Users\shs>pscp copy_me.txt [email protected]:/tmp
[email protected]'s password:
copy_me.txt | 0 kB | 0.1 kB/s | ETA: 00:00:00 | 100%
```
#### 更新你的 Windows 的 hosts 文件
这是另一个小修补。使用管理员权限,你可以将 Linux 系统添加到 Windows 的 hosts 文件中(`C:\Windows\System32\drivers\etc\hosts`),然后使用其主机名代替其 IP 地址。请记住,如果你的 Linux 系统的 IP 地址是动态分配的,那么它不会一直发挥作用。
```
C:\Users\shs>pscp copy_me.txt shs@stinkbug:/tmp
[email protected]'s password:
hosts | 0 kB | 0.8 kB/s | ETA: 00:00:00 | 100%
```
请注意,Windows 的 hosts 文件与 Linux 系统上的 `/etc/hosts` 文件格式相同 -- IP 地址、空格、主机名。注释以 `#` 符号来表示的。
```
# Linux systems
192.168.0.18 stinkbug
```
#### 讨厌的行结尾符
请记住,Windows 上文本文件中的行以回车符和换行符结束。`pscp` 工具不会删除回车符,以使文件看起来像 Linux 文本文件。相反,它只是完整地复制文件。你可以考虑安装 `tofrodos` 包,这使你能够在 Linux 系统上使用 `fromdos` 和 `todos` 命令来调整在平台之间移动的文件。
### 在 Windows 和 Linux 之间共享文件夹
共享文件夹是完全不同的操作。你最终将 Windows 文件夹挂载到你的 Linux 系统或将 Linux 文件夹挂载到 Windows 文件夹中,以便两个系统可以使用同一组文件,而不是将文件从一个系统复制到另一个系统。最好的工具之一就是 Samba,它模拟 Windows 协议并在 Linux 系统上运行。
一旦安装了 Samba,你将能够将 Linux 文件夹挂载到 Windows 上或将 Windows 文件夹挂载到 Linux 上。当然,这与本文前面描述的复制文件有很大的不同。相反,这两个系统中的每一个都可以同时访问相同的文件。
关于选择在 Linux 和 Windows 系统之间共享文件的正确工具的更多提示可以在[这里](https://www.infoworld.com/article/2617683/linux/linux-moving-files-between-unix-and-windows-systems.html)找到。
---
via: <https://www.networkworld.com/article/3269189/linux/sharing-files-between-linux-and-windows.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
9,782 | 如何在 Ubuntu Linux 上挂载和使用 exFAT 驱动器 | https://itsfoss.com/mount-exfat/ | 2018-06-26T17:23:20 | [
"exFAT"
] | https://linux.cn/article-9782-1.html |
>
> 简介:本教程将向你展示如何在 Ubuntu 和其他基于 Ubuntu 的 Linux 发行版上启用 exFAT 文件系统支持。用此种方法在系统上挂载 exFAT 驱动器时,你将不会看到错误消息。
>
>
>
### 在 Ubuntu 上挂载 exFAT 磁盘时出现问题
有一天,我试图使用以 exFAT 格式化 的 U 盘,其中包含约为 10GB 大小的文件。只要我插入 U 盘,我的 Ubuntu 16.04 就会抛出一个错误说**无法挂载未知的文件系统类型 ‘exfat’**。

确切的错误信息是这样的:
```
Error mounting /dev/sdb1 at /media/abhishek/SHADI DATA: Command-line `mount -t "exfat" -o "uhelper=udisks2,nodev,nosuid,uid=1001,gid=1001,iocharset=utf8,namecase=0,errors=remount-ro,umask=0077" "/dev/sdb1" "/media/abhishek/SHADI DATA"` exited with non-zero exit status 32: mount: unknown filesystem type 'exfat'
```
### exFAT 挂载错误的原因
微软最喜欢的 [FAT 文件系统](http://www.ntfs.com/fat-systems.htm)仅限于最大 4GB 的文件。你不能将大于 4GB 的文件传输到 FAT 驱动器。为了克服 FAT 文件系统的限制,微软在 2006 年推出了 [exFAT](https://en.wikipedia.org/wiki/ExFAT) 文件系统。
由于大多数微软相关的东西都是专有的,exFAT 文件格式也不例外。Ubuntu 和许多其他 Linux 发行版默认不提供专有的 exFAT 文件支持。这就是你看到 exFAT 文件出现挂载错误的原因。
### 如何在 Ubuntu Linux 上挂载 exFAT 驱动器

解决这个问题很简单。你只需启用 exFAT 支持即可。
我将展示在 Ubuntu 中的命令,但这应该适用于其他基于 Ubuntu 的发行版,例如 [Linux Mint](https://linuxmint.com/)、elementary OS 等。
打开终端(Ubuntu 中 `Ctrl+Alt+T` 快捷键)并使用以下命令:
```
sudo apt install exfat-fuse exfat-utils
```
安装完这些软件包后,进入文件管理器并再次点击 U 盘来挂载它。无需重新插入 USB。它应该能直接挂载。
#### 这对你有帮助么
我希望这个提示可以帮助你修复 Linux 发行版的 exFAT 的挂载错误。如果你有任何其他问题、建议或感谢,请在评论中留言。
---
via: <https://itsfoss.com/mount-exfat/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

The other day, I tried to use an external USB key formatted in exFAT format that contained a file of around 10 GB in size. As soon as I plugged the USB key, my Ubuntu 16.04 throw an error complaining that it **cannot mount unknown filesystem type ‘exfat’**.

The exact error message was this:
**Error mounting /dev/sdb1 at /media/abhishek/SHADI DATA: Command-line `mount -t “exfat” -o “uhelper=udisks2,nodev,nosuid,uid=1001,gid=1001,iocharset=utf8,namecase=0,errors=remount-ro,umask=0077” “/dev/sdb1” “/media/abhishek/SHADI DATA”‘ exited with non-zero exit status 32: mount: unknown filesystem type ‘exfat’**
## The reason behind this exFAT mount error
Microsoft’s favorite [FAT file system](http://www.ntfs.com/fat-systems.htm?ref=itsfoss.com) is limited to files up to 4GB in size. You cannot transfer a file bigger than 4 GB in size to a FAT drive. To overcome the limitations of the FAT filesystem, Microsoft introduced [exFAT](https://en.wikipedia.org/wiki/ExFAT?ref=itsfoss.com) file system in 2006.
As most of the Microsoft related stuff are proprietary, exFAT file format was no exception to that. Microsoft has been open sourcing few of its technologies and exFAT is one of them. The newly open sources exFAT file system will be supported in the upcoming [Linux Kernel 5.4 release](https://itsfoss.com/linux-kernel-5-4/). You may [check your Linux kernel version](https://itsfoss.com/find-which-kernel-version-is-running-in-ubuntu/) to make things sure.
But for Linux Kernel 5.3 and lower versions, it remains a proprietary software. Ubuntu and many other Linux distributions don’t provide the proprietary exFAT file support by default. This is the reason why you see the mount error with exFAT files.
## How to mount exFAT drive on Ubuntu Linux
The solution to this problem is simple. All you need to do is to enable exFAT support.
I am going to show the commands for Ubuntu but this should be applicable to other Ubuntu-based distributions such as [Linux Mint](https://linuxmint.com/?ref=itsfoss.com), elementary OS etc.
Open a terminal (Ctrl+Alt+T shortcut in Ubuntu) and use the following command to [enable the universe repository](https://itsfoss.com/ubuntu-repositories/) because this repo contains your packages. Chances are that you already have the Universe repository enabled but there is no harm in double-checking.
`sudo add-apt-repository universe`
Update the repository information:
`sudo apt update`
[Check your Ubuntu version](https://itsfoss.com/how-to-know-ubuntu-unity-version/). For Ubuntu 22.04, you just the `exfat-fuse`
package.
`sudo apt install exfat-fuse`
But for Ubuntu 22.04, you'll also need the `exfat-utils`
package.
`sudo apt install exfat-fuse exfat-utils`
Once you have installed these packages, go to the file manager and click on the USB disk again to mount it. There is no need to replug the USB. It should be mounted straight away.
If you prefer videos, I made a quick video showing the steps in action.
## Did it help you?
I hope this quick tip helped you to fix the exFAT mount error for your Linux distribution. If you have any further questions, suggestions or a simple thanks, please use the comment box below. |
9,784 | 学习用 Thonny 写代码: 一个面向初学者的Python IDE | https://fedoramagazine.org/learn-code-thonny-python-ide-beginners/ | 2018-06-27T09:33:37 | [
"Thonny",
"Python"
] | https://linux.cn/article-9784-1.html | 
学习编程很难。即使当你最终怎么正确使用你的冒号和括号,但仍然有很大的可能你的程序不会如果所想的工作。 通常,这意味着你忽略了某些东西或者误解了语言结构,你需要在代码中找到你的期望与现实存在分歧的地方。
程序员通常使用被叫做<ruby> 调试器 <rt> debugger </rt></ruby>的工具来处理这种情况,它允许一步一步地运行他们的程序。不幸的是,大多数调试器都针对专业用途进行了优化,并假设用户已经很好地了解了语言结构的语义(例如:函数调用)。
Thonny 是一个适合初学者的 Python IDE,由爱沙尼亚的 [Tartu 大学](https://www.ut.ee/en) 开发,它采用了不同的方法,因为它的调试器是专为学习和教学编程而设计的。
虽然 Thonny 适用于像小白一样的初学者,但这篇文章面向那些至少具有 Python 或其他命令式语言经验的读者。
### 开始
从第 Fedora 27 开始,Thonny 就被包含在 Fedora 软件库中。 使用 `sudo dnf install thonny` 或者你选择的图形工具(比如“<ruby> 软件 <rt> Software </rt></ruby>”)安装它。
当第一次启动 Thonny 时,它会做一些准备工作,然后呈现一个空白的编辑器和 Python shell 。将下列程序文本复制到编辑器中,并将其保存到文件中(`Ctrl+S`)。
```
n = 1
while n < 5:
print(n * "*")
n = n + 1
```
我们首先运行该程序。 为此请按键盘上的 `F5` 键。 你应该看到一个由星号组成的三角形出现在 shell 窗格中。

Python 分析了你的代码并理解了你想打印一个三角形了吗?让我们看看!
首先从“<ruby> 查看 <rt> View </rt></ruby>”菜单中选择“<ruby> 变量 <rt> Variables </rt></ruby>”。这将打开一张表格,向我们展示 Python 是如何管理程序的变量的。现在通过按 `Ctrl + F5`(在 XFCE 中是 `Ctrl + Shift + F5`)以调试模式运行程序。在这种模式下,Thonny 使 Python 在每一步所需的步骤之前暂停。你应该看到程序的第一行被一个框包围。我们将这称为焦点,它表明 Python 将接下来要执行的部分代码。

你在焦点框中看到的一段代码段被称为赋值语句。 对于这种声明,Python 应该计算右边的表达式,并将值存储在左边显示的名称下。按 `F7` 进行下一步。你将看到 Python 将重点放在语句的正确部分。在这个例子中,表达式实际上很简单,但是为了通用性,Thonny 提供了表达式计算框,它允许将表达式转换为值。再次按 `F7` 将文字 `1` 转换为值 `1`。现在 Python 已经准备好执行实际的赋值—再次按 `F7`,你应该会看到变量 `n` 的值为 `1` 的变量出现在变量表中。

继续按 `F7` 并观察 Python 如何以非常小的步骤前进。它看起来像是理解你的代码的目的或者更像是一个愚蠢的遵循简单规则的机器?
### 函数调用
<ruby> 函数调用 <rt> Function Call </rt></ruby>是一种编程概念,它常常给初学者带来很大的困惑。从表面上看,没有什么复杂的事情——给代码命名,然后在代码中的其他地方引用它(调用它)。传统的调试器告诉我们,当你进入调用时,焦点跳转到函数定义中(然后稍后神奇地返回到原来的位置)。这是整件事吗?这需要我们关心吗?
结果证明,“跳转模型” 只对最简单的函数是足够的。理解参数传递、局部变量、返回和递归都得理解堆栈框架的概念。幸运的是,Thonny 可以直观地解释这个概念,而无需在厚厚的掩盖下搜索重要的细节。
将以下递归程序复制到 Thonny 并以调试模式(`Ctrl+F5` 或 `Ctrl+Shift+F5`)运行。
```
def factorial(n):
if n == 0:
return 1
else:
return factorial(n-1) * n
print(factorial(4))
```
重复按 `F7`,直到你在对话框中看到表达式 `factorial(4)`。 当你进行下一步时,你会看到 Thonny 打开一个包含了函数代码、另一个变量表和另一个焦点框的新窗口(移动窗口以查看旧的焦点框仍然存在)。

此窗口表示堆栈帧,即用于解析函数调用的工作区。几个放在彼此顶部的这样的窗口称为<ruby> 调用堆栈 <rt> call stack </rt></ruby>。注意调用位置的参数 `4` 与 “局部变量” 表中的输入 `n` 之间的关系。继续按 `F7` 步进, 观察在每次调用时如何创建新窗口并在函数代码完成时被销毁,以及如何用返回值替换了调用位置。
### 值与参考
现在,让我们在 Python shell 中进行一个实验。首先输入下面屏幕截图中显示的语句:

正如你所看到的, 我们追加到列表 `b`, 但列表 `a` 也得到了更新。你可能知道为什么会发生这种情况, 但是对初学者来说,什么才是最好的解释呢?
当教我的学生列表时,我告诉他们我一直欺骗了他们关于 Python 内存模型。实际上,它并不像变量表所显示的那样简单。我告诉他们重新启动解释器(工具栏上的红色按钮),从“<ruby> 查看 <rt> View </rt></ruby>”菜单中选择“<ruby> 堆 <rt> Heap </rt></ruby>”,然后再次进行相同的实验。如果这样做,你就会发现变量表不再包含值——它们实际上位于另一个名为“<ruby> 堆 <rt> Heap </rt></ruby>”的表中。变量表的作用实际上是将变量名映射到地址(或称 ID),地址又指向了<ruby> 堆 <rt> Heap </rt></ruby>表中的行。由于赋值仅更改变量表,因此语句 `b = a` 只复制对列表的引用,而不是列表本身。这解释了为什么我们通过这两个变量看到了变化。

(为什么我要在教列表的主题之前推迟说出内存模型的事实?Python 存储的列表是否有所不同?请继续使用 Thonny 的堆模式来找出结果!在评论中告诉我你认为怎么样!)
如果要更深入地了解参考系统, 请将以下程序通过打开堆表复制到 Thonny 并进行小步调试(`F7`) 中。
```
def do_something(lst, x):
lst.append(x)
a = [1,2,3]
n = 4
do_something(a, n)
print(a)
```
即使“堆模式”向我们显示真实的图片,但它使用起来也相当不方便。 因此,我建议你现在切换回普通模式(取消选择“<ruby> 查看 <rt> View </rt></ruby>”菜单中的“<ruby> 堆 <rt> Heap </rt></ruby>”),但请记住,真实模型包含变量、参考和值。
### 结语
我在这篇文章中提及到的特性是创建 Thonny 的主要原因。很容易对函数调用和引用形成错误的理解,但传统的调试器并不能真正帮助减少混淆。
除了这些显著的特性,Thonny 还提供了其他几个初学者友好的工具。 请查看 [Thonny的主页](http://thonny.org) 以了解更多信息!
---
via: <https://fedoramagazine.org/learn-code-thonny-python-ide-beginners/>
作者:[Aivar Annamaa](https://fedoramagazine.org/) 译者:[Auk7F7](https://github.com/Auk7F7) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Learning to program is hard. Even when you finally get your colons and parentheses right, there is still a big chance that the program doesn’t do what you intended. Commonly, this means you overlooked something or misunderstood a language construct, and you need to locate the place in the code where your expectations and reality diverge.
Programmers usually tackle this situation with a tool called a *debugger*, which allows running their program step-by-step. Unfortunately, most debuggers are optimized for professional usage and assume the user already knows the semantics of language constructs (e.g. function call) very well.
Thonny is a beginner-friendly Python IDE, developed in [University of Tartu](https://www.ut.ee/en), Estonia, which takes a different approach as its debugger is designed specifically for learning and teaching programming.
Although Thonny is suitable for even total beginners, this post is meant for readers who have at least some experience with Python or another imperative language.
# Getting started
Thonny is included in Fedora repositories since version 27. Install it with *sudo dnf install thonny* or with a graphical tool of your choice (such as *Software*).
When first launching Thonny, it does some preparations and then presents an empty editor and the Python shell. Copy following program text into the editor and save it into a file (Ctrl+S).
n = 1 while n < 5: print(n * "*") n = n + 1
Let’s first run the program in one go. For this press *F5* on the keyboard. You should see a triangle made of periods appear in the shell pane.
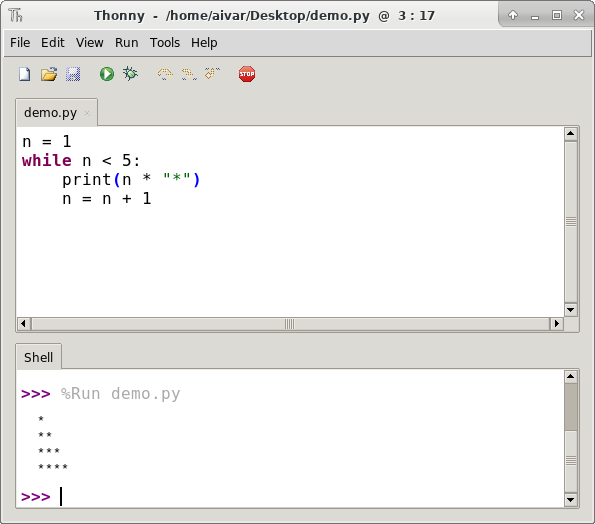
A simple program in Thonny
Did Python just analyze your code and understand that you wanted to print a triangle? Let’s find out!
Start by selecting “Variables” from the “View” menu. This opens a table which will show us how Python manages program’s variables. Now run the program in *debug mode* by pressing *Ctrl+F5* (or *Ctrl+Shift+F5* in XFCE). In this mode Thonny makes Python pause before each step it takes. You should see the first line of the program getting surrounded with a box. We’ll call this *the focus* and it indicates the part of the code Python is going to execute next.
Thonny debugger focus
The piece of code you see in the focus box is called assignment statement. For this kind of statement, Python is supposed to evaluate the expression on the right and store the value under the name shown on the left. Press *F7* to take the next step. You will see that Python focused on the right part of the statement. In this case the expression is really simple, but for generality Thonny presents the expression evaluation box, which allows turning expressions into values. Press *F7* again to turn the *literal* 1 into *value* 1. Now Python is ready to do the actual assignment — press *F7* again and you should see the variable *n* with value 1 appear in the variables table.
Thonny with variables table
Continue pressing F7 and observe how Python moves forward with really small steps. Does it look like something which understands the purpose of your code or more like a dumb machine following simple rules?
# Function calls
Function call is a programming concept which often causes great deal of confusion to beginners. On the surface there is nothing complicated — you give name to a code and refer to it (call it) somewhere else in the code. Traditional debuggers show us that when you step into the call, the focus jumps into the function definition (and later magically back to the original location). Is it the whole story? Do we need to care?
Turns out the “jump model” is sufficient only with the simplest functions. Understanding parameter passing, local variables, returning and recursion all benefit from the notion of *stack frame*. Luckily, Thonny can explain this concept intuitively without sweeping important details under the carpet.
Copy following recursive program into Thonny and run it in debug mode (*Ctrl+F5* or *Ctrl+Shift+F5*).
deffactorial(n):ifn == 0: return 1else: return factorial(n-1) * n print(factorial(4))
Press *F7* repeatedly until you see the expression *factorial(4)* in the focus box. When you take the next step, you see that Thonny opens a new window containing function code, another variables table and another focus box (move the window to see that the old focus box is still there).
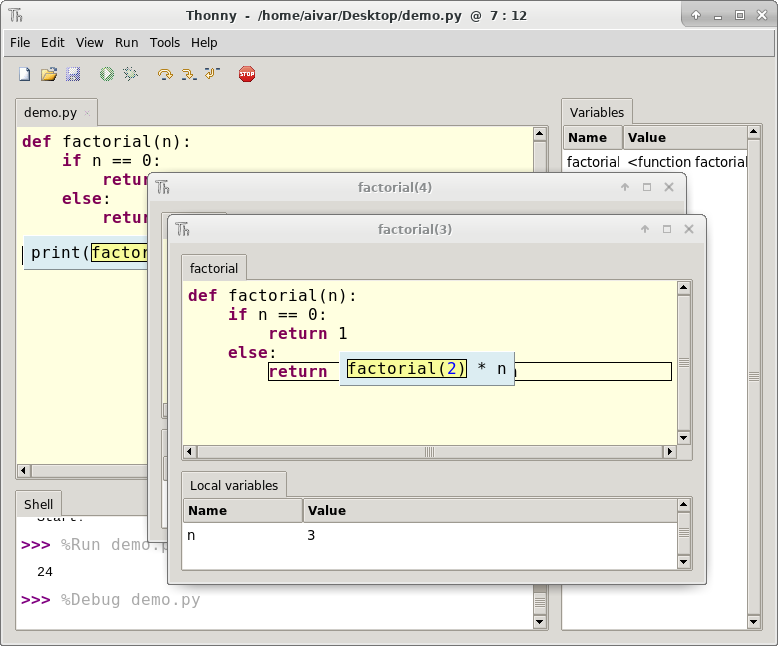
Thonny stepping through a recursive function
This window represents a stack frame, the working area for resolving a function call. Several such windows on top of each other is called *the call stack*. Notice the relationship between argument *4* on the call site and entry *n* in the local variables table. Continue stepping with *F7* and observe how new windows get created on each call and destroyed when the function code completes and how the call site gets replaced by the return value.
# Values vs. references
Now let’s make an experiment inside the Python shell. Start by typing in the statements shown in the screenshot below:
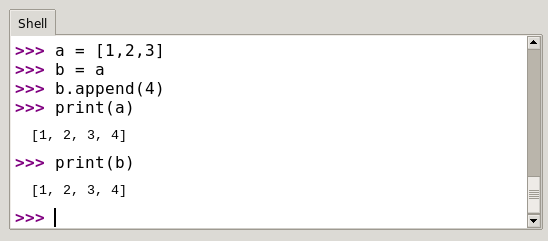
Thonny shell showing list mutation
As you see, we appended to list *b*, but list *a* also got updated. You may know why this happened, but what’s the best way to explain it to a beginner?
When teaching lists to my students I tell them that I have been lying about Python memory model. It is actually not as simple as the variables table suggests. I tell them to restart the interpreter (the red button on the toolbar), select “Heap” from the “View” menu and make the same experiment again. If you do this, then you see that variables table doesn’t contain the values anymore — they actually live in another table called “Heap”. The role of the variables table is actually to map the variable names to addresses (or ID-s) which refer to the rows in the heap table. As assignment changes only the variables table, the statement *b = a* only copied the reference to the list, not the list itself. This explained why we see the change via both variables.
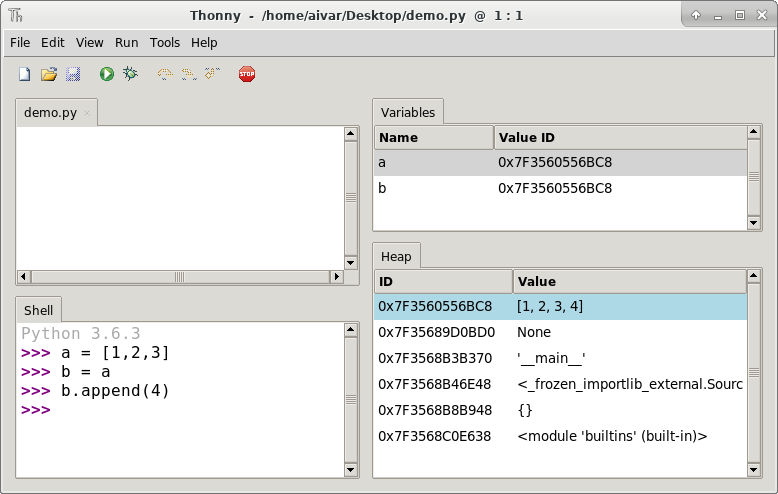
Thonny in heap mode
(Why do I postpone telling the truth about the memory model until the topic of lists? Does Python store lists differently compared to floats or strings? Go ahead and use Thonny’s heap mode to find this out! Tell me in the comments what do you think!)
If you want to understand the references system deeper, copy following program to Thonny and small-step (*F7*) through it with the heap table open.
defdo_something(lst, x): lst.append(x) a = [1,2,3] n = 4 do_something(a, n) print(a)
Even if the “heap mode” shows us authentic picture, it is rather inconvenient to use. For this reason, I recommend you now switch back to normal mode (unselect “Heap” in the View menu) but remember that the real model includes variables, references and values.
# Conclusion
The features I touched in this post were the main reason for creating Thonny. It’s easy to form misconceptions about both function calls and references but traditional debuggers don’t really help in reducing the confusion.
Besides these distinguishing features, Thonny offers several other beginner friendly tools. Please look around at [Thonny’s homepage](http://thonny.org) to learn more!
## Dane
I’m no python expert, but when I started playing around with it Thonny made it a lot easier. Seems to be one of the IDE’s most people recommend when learning the language.
## Nice
Ruby is more clear and nice
n = 1
while n<5
puts “*” * n
n += 1
end
or better
5.times {|t| puts “*” * t}
## Nick
@nice
You should do a bit more reading on python before you make such calls.
Ruby is not clearer or nicer.
Here is that same loop in python:
for i in range(1,5):
print(“*” * i)
Also, the last example is very unclear.
Being able to write something shorter, or on one line, is not always an advantage.
I will admit that it’s probably because I find that to be a strange notation of lambda expressions.
## Rene Reichenbach
It is usually not helpful to respond with “use another language” to an article that describes use of an IDE. It obviously assumes that someone already decided for Python to learn.
Article and tool are nice i think.
If you do not like Python as I do not really like it you still should not just “offend” others. Its important to not be toxic in the community.
## Cornel Panceac
Easy intro to debugging, stack frames, heap and python. Thank you!
## gokhan s.
thonny install step;
fedora 21-to 26 > bash <(curl -s http://thonny.org/installer-for-linux)
fedora 27> dnf install thonny
thats all 🙂
## Dani Konoplya
Great idea! I think it will very help for people are learn algorithms and different coding interview questions are using recursion. Frequently we have hear not think too much about how is recursion working because it is too complex . However with your tool it is possible to understand exactly what is going inside. This is even change variable to their value , amazing, you even don’t need to use watches . Everything is straight in front of your eyes.
## Yushi
Great idea! I think it will very help for people are learn algorithms and different coding interview questions are using recursion. Frequently we have hear not think too much about how is recursion working because it is too complex . However with your tool it is possible to understand exactly what is going inside. This is even change variable to their value , amazing, you even don’t need to use watches . Everything is straight in front of your eyes. |
9,785 | 值得考虑的 9 个开源 ERP 系统 | https://opensource.com/tools/enterprise-resource-planning | 2018-06-27T16:13:49 | [
"ERP"
] | https://linux.cn/article-9785-1.html |
>
> 有一些使用灵活、功能丰富而物有所值的开源 ERP 系统,这里有 9 个值得你看看。
>
>
>

拥有一定数量员工的企业就需要大量的协调工作,包括制定价格、计划生产、会计和财务、管理支出、管理存货等等。把一套截然不同的工具拼接到一起去处理这些工作,是一种粗制滥造和无价值的做法。
那种方法没有任何弹性。并且那样在各种各样的自组织系统之间高效移动数据是非常困难的。同样,它也很难维护。
因此,大多数成长型企业都转而使用一个 [企业资源计划](http://en.wikipedia.org/wiki/Enterprise_resource_planning) (ERP)系统。
在这个行业中的大咖有 Oracle、SAP、以及 Microsoft Dynamics。它们都提供了一个综合的系统,但同时也很昂贵。如果你的企业支付不起如此昂贵的大系统,或者你仅需要一个简单的系统,怎么办呢?你可以使用开源的产品来作为替代。
### 一个 ERP 系统中有什么东西
显然,你希望有一个满足你需要的系统。基于那些需要,更多的功能并不意味着就更好。但是,你的需要会根据你的业务的增长而变化的,因此,你希望能够找到一个 ERP 系统,它能够根据你新的需要而扩展它。那就意味着系统有额外的模块或者支持插件和附加功能。
大多数的开源 ERP 系统都是 web 应用程序。你可以下载并将它们安装到你的服务器上。但是,如果你不希望(或者没有相应技能或者人员)自己去维护系统,那么应该确保它们的应用程序提供托管版本。
最后,你还应该确保应用程序有良好的文档和支持 —— 要么是付费支持或者有一个活跃的用户社区。
有很多弹性很好的、功能丰富的、很划算的开源 ERP 系统。如果你正打算购买这样的系统,这里有我们挑选出来的 9 个。
### ADempiere
像大多数其它开源 ERP 解决方案,[ADempiere](http://www.adempiere.net/welcome) 的目标客户是中小企业。它已经存在一段时间了 — 这个项目出现于 2006,它是 Compiere ERP 软件的一个分支。
它的意大利语名字的意思是“实现”或者“满足”,它“涉及多个方面”的 ERP 特性,旨在帮企业去满足各种需求。它在 ERP 中增加了供应链管理(SCM)和客户关系管理(CRM)功能,能够让该 ERP 套件在一个软件中去管理销售、采购、库存以及帐务处理。它的最新版本是 v.3.9.0,更新了用户界面、POS、人力资源、工资以及其它的特性。
因为是一个跨平台的、基于 Java 的云解决方案,ADempiere 可以运行在Linux、Unix、Windows、MacOS、智能手机、平板电脑上。它使用 [GPLv2](http://wiki.adempiere.net/License) 授权。如果你想了解更多信息,这里有一个用于测试的 [demo](http://www.adempiere.net/web/guest/demo),或者也可以在 GitHub 上查看它的 [源代码](https://github.com/adempiere/adempiere)。
### Apache OFBiz
[Apache OFBiz](http://ofbiz.apache.org/) 的业务相关的套件是构建在通用的架构上的,它允许企业根据自己的需要去定制 ERP。因此,它是有内部开发资源的大中型企业的最佳套件,可以去修改和集成它到它们现有的 IT 和业务流程。
OFBiz 是一个成熟的开源 ERP 系统;它的网站上说它是一个有十年历史的顶级 Apache 项目。可用的 [模块](https://ofbiz.apache.org/business-users.html#UsrModules) 有会计、生产制造、人力资源、存货管理、目录管理、客户关系管理,以及电子商务。你可以在它的 [demo 页面](http://ofbiz.apache.org/ofbiz-demos.html) 上试用电子商务的网上商店以及后端的 ERP 应用程序。
Apache OFBiz 的源代码能够在它的 [项目仓库](http://ofbiz.apache.org/source-repositories.html) 中找到。它是用 Java 写的,它在 [Apache 2.0 license](http://www.apache.org/licenses/LICENSE-2.0) 下可用。
### Dolibarr
[Dolibarr](http://www.dolibarr.org/) 提供了中小型企业端到端的业务管理,从发票跟踪、合同、存货、订单,以及支付,到文档管理和电子化 POS 系统支持。它的全部功能封装在一个清晰的界面中。
如果你担心不会使用 Dolibarr,[这里有一些关于它的文档](http://wiki.dolibarr.org/index.php/What_Dolibarr_can%27t_do)。
另外,还有一个 [在线演示](http://www.dolibarr.org/onlinedemo),Dolibarr 也有一个 [插件商店](http://www.dolistore.com/),你可以在那是购买一些软件来扩展它的功能。你可以在 GitHub 上查看它的 [源代码](https://github.com/Dolibarr/dolibarr);它在 [GPLv3](https://github.com/Dolibarr/dolibarr/blob/develop/COPYING) 或者任何它的最新版本许可下面使用。
### ERPNext
[ERPNext](https://erpnext.com/) 是这类开源项目中的其中一个;实际上它最初在 2014 年就被 [Opensource.com 推荐了](https://opensource.com/business/14/11/building-open-source-erp)。它被设计用于打破一个陈旧而昂贵的专用 ERP 系统的垄断局面。
ERPNext 适合于中小型企业。它包含的模块有会计、存货管理、销售、采购、以及项目管理。ERPNext 是表单驱动的应用程序 — 你可以在一组字段中填入信息,然后让应用程序去完成剩余部分。整个套件非常易用。
如果你感兴趣,在你考虑参与之前,你可以请求获取一个 [demo](https://frappe.erpnext.com/request-a-demo),去 [下载它](https://erpnext.com/download) 或者在托管服务上 [购买一个订阅](https://erpnext.com/pricing)。
### Metasfresh
[Metasfresh](http://metasfresh.com/en/) 的名字表示它承诺软件的代码始终保持“新鲜”。它自 2015 年以来每周发行一个更新版本,那时,它的代码是由创始人从 ADempiere 项目中分叉的。与 ADempiere 一样,它是一个基于 Java 的开源 ERP,目标客户是中小型企业。
虽然,相比在这里介绍的其它软件来说,它是一个很 “年青的” 项目,但是它早早就引起了一起人的注意,获得很多积极的评价,比如,被提名为“最佳开源”的 IT 创新奖入围者。
Metasfresh 在自托管系统上或者在云上单用户使用时是免费的,或者可以按月交纳订阅费用。它的 [源代码](https://github.com/metasfresh/metasfresh) 在 GitHub 上,可以在遵守 [GPLv2](https://github.com/metasfresh/metasfresh/blob/master/LICENSE.md) 许可的情况下使用,它的云版本是以 GPLv3 方式授权使用。
### Odoo
[Odoo](https://www.odoo.com/) 是一个应用程序集成解决方案,它包含的模块有项目管理、帐单、存货管理、生产制造、以及采购。这些模块之间可以相互通讯,实现高效平滑地信息交换。
虽然 ERP 可能很复杂,但是,Odoo 通过简单的,甚至是简洁的界面使它变得很友好。这个界面让人联想到谷歌云盘,它只让你需要的功能可见。在你决定签定采购合同之前,你可以 [得到一个 Odoo 去试用](https://www.odoo.com/page/start)。
Odoo 是基于 web 的工具。按单个模块来订阅的话,每个模块每月需要支付 20 美元。你也可以 [下载它](https://www.odoo.com/page/download),或者可以从 GitHub 上获得 [源代码](https://github.com/odoo),它以 [LGPLv3](https://github.com/odoo/odoo/blob/11.0/LICENSE) 方式授权。
### Opentaps
[Opentaps](http://www.opentaps.org/) 是专为大型业务设计的几个开源 ERP 解决方案之一,它的功能强大而灵活。这并不奇怪,因为它是在 Apache OFBiz 基础之上构建的。
你可以得到你所希望的模块组合,来帮你管理存货、生产制造、财务,以及采购。它也有分析功能,帮你去分析业务的各个方面。你可以借助这些信息让未来的计划做的更好。Opentaps 也包含一个强大的报表功能。
在它的基础之上,你还可以 [购买一些插件和附加模块](http://shop.opentaps.org/) 去增强 Opentaps 的功能。包括与 Amazon Marketplace Services 和 FedEx 的集成等。在你 [下载 Opentaps](http://www.opentaps.org/products/download) 之前,你可以到 [在线 demo](http://www.opentaps.org/products/online-demo) 上试用一下。它遵守 [GPLv3](https://www.gnu.org/licenses/agpl-3.0.html) 许可。
### WebERP
[WebERP](http://www.weberp.org/) 是一个如它的名字所表示的那样:一个通过 Web 浏览器来使用的 ERP 系统。另外还需要的其它软件只有一个,那就是查看报告所使用的 PDF 阅读器。
具体来说,它是一个面向批发、分销、生产制造业务的账务和业务管理解决方案。它也可以与 [第三方的业务软件](http://www.weberp.org/Links.html) 集成,包括多地点零售管理的销售点系统、电子商务模块、以及构建业务知识库的 wiki 软件。它是用 PHP 写的,并且它致力于成为低资源占用、高效、快速、以及平台无关的、普通商业用户易于使用的 ERP 系统。
WebERP 正在积极地进行开发,并且它有一个活跃的 [论坛](http://www.weberp.org/forum/),在那里你可以咨询问题或者学习关于如何使用这个应用程序的相关知识。你也可以试用一个 [demo](http://www.weberp.org/weberp/),或者在 GitHub 上下载它的 [源代码](https://github.com/webERP-team/webERP)(遵守 [GPLv2](https://github.com/webERP-team/webERP#legal) 许可)
### xTuple PostBooks
如果你的生产制造、分销、电子商务业务已经从小规模业务成长起来了,并且正在寻找一个适合你的成长型企业的 ERP 系统,那么,你可以去了解一下 [xTuple PostBooks](https://xtuple.com/)。它是围绕核心 ERP 功能、帐务、以及可以添加存货、分销、采购、以及供应商报告等 CRM 功能构建的全面解决方案的系统。
xTuple 在通用公共属性许可证([CPAL](https://xtuple.com/products/license-options#cpal))下使用,并且这个项目欢迎开发者去分叉它,然后为基于存货的生产制造型企业开发其它的业务软件。它的基于 web 的核心是用 JavaScript 写的,它的 [源代码](http://xtuple.github.io/) 可以在 GitHub 上找到。你可以去在 xTuple 的网站上注册一个免费的 [demo](https://xtuple.com/free-demo) 去了解它。
还有许多其它的开源 ERP 可供你选择 — 另外你可以去了解的还有 [Tryton](http://www.tryton.org/),它是用 Python 写的,并且使用的是 PostgreSQL 数据库引擎,或者基于 Java 的 [Axelor](https://www.axelor.com/),它的好处是用户可以使用拖放界面来创建或者修改业务应用。如果还有在这里没有列出的你喜欢的开源 ERP 解决方案,请在下面的评论区共享出来。你也可以去查看我们的 [供应链管理工具](https://opensource.com/tools/supply-chain-management) 榜单。
这篇文章是 [以前版本](https://opensource.com/article/16/3/top-4-open-source-erp-systems) 的一个更新版,它是由 Opensource.com 的主席 [Scott Nesbitt](https://opensource.com/users/scottnesbitt) 所写。
---
via: <https://opensource.com/tools/enterprise-resource-planning>
作者:[Opensource.com](https://opensource.com) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Businesses with more than a handful of employees have a lot to balance including pricing, product planning, accounting and finance, managing payroll, dealing with inventory, and more. Stitching together a set of disparate tools to handle those jobs is a quick, cheap, and dirty way to get things done.
That approach isn't scalable. It's difficult to efficiently move data between the various pieces of such an ad-hoc system. As well, it can be difficult to maintain.
Instead, most growing businesses turn to an [enterprise resource planning](http://en.wikipedia.org/wiki/Enterprise_resource_planning) (ERP) system.
The big guns in that space are Oracle, SAP, and Microsoft Dynamics. Their offerings are comprehensive, but also expensive. What happens if your business can't afford one of those big implementations or if your needs are simple? You turn to the open source alternatives.
## What to look for in an ERP system
Obviously, you want a system that suits your needs. Depending on those needs, *more features* doesn't always mean *better*. However, your needs might change as your business grows, so you'll want to find an ERP system that can expand to meet your new needs. That could mean the system has additional modules or just supports plugins and add-ons.
Most open source ERP systems are web applications. You can download and install them on your server. But if you don't want (or don't have the skills or staff) to maintain a system yourself, then make sure there's a hosted version of the application available.
Finally, you'll want to make sure the application has good documentation and good support—either in the form of paid support or an active user community.
There are a number of flexible, feature-rich, and cost-effective open source ERP systems out there. Here are nine to check out if you're in the market for such a system.
## ADempiere
Like most other open source ERP solutions, [ADempiere](http://www.adempiere.net/welcome) is targeted at small and midsized businesses. It's been around awhile—the project was formed in 2006 as a fork from the Compiere ERP software.
Its Italian name means to achieve or satisfy, and its "multidimensional" ERP features aim to help businesses satisfy a wide range of needs. It adds supply chain management (SCM) and customer relationship management (CRM) features to its ERP suite to help manage sales, purchasing, inventory, and accounting processes in one piece of software. Its latest release, v.3.9.0, updated its user interface, point-of-sale, HR, payroll, and other features.
As a multiplatform, Java-based cloud solution, ADempiere is accessible on Linux, Unix, Windows, MacOS, smartphones, and tablets. It is licensed under [GPLv2](http://wiki.adempiere.net/License). If you'd like to learn more, take its [demo](http://www.adempiere.net/web/guest/demo) for a test run or access its [source code](https://github.com/adempiere/adempiere) on GitHub.
## Apache OFBiz
[Apache OFBiz](http://ofbiz.apache.org/)'s suite of related business tools is built on a common architecture that enables organizations to customize the ERP to their needs. As a result, it's best suited for midsize or large enterprises that have the internal development resources to adapt and integrate it within their existing IT and business processes.
OFBiz is a mature open source ERP system; its website says it's been a top-level Apache project for a decade. [Modules](https://ofbiz.apache.org/business-users.html#UsrModules) are available for accounting, manufacturing, HR, inventory management, catalog management, CRM, and e-commerce. You can also try out its e-commerce web store and backend ERP applications on its [demo page](http://ofbiz.apache.org/ofbiz-demos.html).
Apache OFBiz's source code can be found in the [project's repository](http://ofbiz.apache.org/source-repositories.html). It is written in Java and licensed under an [Apache 2.0 license](http://www.apache.org/licenses/LICENSE-2.0).
## Dolibarr
[Dolibarr](http://www.dolibarr.org/) offers end-to-end management for small and midsize businesses—from keeping track of invoices, contracts, inventory, orders, and payments to managing documents and supporting electronic point-of-sale system. It's all wrapped in a fairly clean interface.
If you're wondering what Dolibarr *can't* do, [here's some documentation about that](http://wiki.dolibarr.org/index.php/What_Dolibarr_can%27t_do).
In addition to an [online demo](http://www.dolibarr.org/onlinedemo), Dolibarr also has an [add-ons store](http://www.dolistore.com/) where you can buy software that extends its features. You can check out its [source code](https://github.com/Dolibarr/dolibarr) on GitHub; it's licensed under [GPLv3](https://github.com/Dolibarr/dolibarr/blob/develop/COPYING) or any later version.
## ERPNext
[ERPNext](https://erpnext.com/) is one of those classic open source projects; in fact, it was [featured on Opensource.com](https://opensource.com/business/14/11/building-open-source-erp) way back in 2014. It was designed to scratch a particular itch, in this case replacing a creaky and expensive proprietary ERP implementation.
ERPNext was built for small and midsized businesses. It includes modules for accounting, managing inventory, sales, purchase, and project management. The applications that make up ERPNext are form-driven—you fill information in a set of fields and let the application do the rest. The whole suite is easy to use.
If you're interested, you can request a [demo](https://frappe.erpnext.com/request-a-demo) before taking the plunge and [downloading it](https://erpnext.com/download) or [buying a subscription](https://erpnext.com/pricing) to the hosted service.
## Metasfresh
[Metasfresh](http://metasfresh.com/en/)'s name reflects its commitment to keeping its code "fresh." It's released weekly updates since late 2015, when its founders forked the code from the ADempiere project. Like ADempiere, it's an open source ERP based on Java targeted at the small and midsize business market.
While it's a younger project than most of the other software described here, it's attracted some early, positive attention, such as being named a finalist for the Initiative Mittelstand "best of open source" IT innovation award.
Metasfresh is free when self-hosted or for one user via the cloud, or on a monthly subscription fee basis as a cloud-hosted solution for 1-100 users. Its [source code](https://github.com/metasfresh/metasfresh) is available under the [GPLv2](https://github.com/metasfresh/metasfresh/blob/master/LICENSE.md) license at GitHub and its cloud version is licensed under GPLv3.
## Odoo
[Odoo](https://www.odoo.com/) is an integrated suite of applications that includes modules for project management, billing, accounting, inventory management, manufacturing, and purchasing. Those modules can communicate with each other to efficiently and seamlessly exchange information.
While ERP can be complex, Odoo makes it friendlier with a simple, almost spartan interface. The interface is reminiscent of Google Drive, with just the functions you need visible. You can [give Odoo a try](https://www.odoo.com/page/start) before you decide to sign up.
Odoo is a web-based tool. Subscriptions to individual modules will set you back $20 (USD) a month for each one. You can also [download it](https://www.odoo.com/page/download) or grab the [source code](https://github.com/odoo) from GitHub. It's licensed under [LGPLv3](https://github.com/odoo/odoo/blob/11.0/LICENSE).
## Tryton
[Tryton](https://www.tryton.org/)'s based on a EPR system called TinyERP and has been around since 2008. Over its lifetime, Tryton has grown both in popularity and flexibility.
Tryton is aimed at businesses of all sizes, and has a range of modules. Those include accounting, sales, invoicing, project management, shipping, analytics, and inventory management. Tryton's not all or not, though. The system is modular, so you can install only the modules your business needs. While the system is web based, there are desktop clients for Windows and MacOS.
The [online demo](https://demo.tryton.org/) will give you an idea of what Tryton can do. When you're ready, you can install it using a [Docker image](https://hub.docker.com/r/tryton/tryton/), download the [source code](https://downloads-cdn.tryton.org/5.4/) or get the code from the project's [Mercurial repository](https://hg.tryton.org/). The source code, in case you're wondering, is licensed under GPLv3 or later.
## Axelor ERP
Boasting over 20 components, [Axelor ERP](https://www.axelor.com/erp/) is a complete ERP system — one that covers purchasing and invoicing, sales and accounting, stock and cash management, and more. All of that comes wrapped in a clean and easy-to-use interface.
And it's that interface that sets Axelor apart from many of its competitors. All of Alexor's components are grouped in the pane on the left side of its window. Everything you need to do is a couple of clicks away. If, say, you need to refund a customer click **Invoicing** and then click **Cust. Refunds**. Everything you need is at the beck and call of your mouse cursor.
Install Axelor using a [Docker image](https://hub.docker.com/r/axelor/aio-erp) or grab the source code [from GitHub](https://github.com/axelor), which is published under an [AGPLv3](https://www.axelor.com/licence/) license. Before you install Axelor, consider [taking it for a spin](https://demo.axelor.com/open-suite-fr/login.jsp) to get a feel for the system.
## xTuple PostBooks
If your manufacturing, distribution, or e-commerce business has outgrown its small business roots and is looking for an ERP to grow with you, you may want to check out [xTuple PostBooks](https://xtuple.com/). It's a comprehensive solution built around its core ERP, accounting, and CRM features that adds inventory, distribution, purchasing, and vendor reporting capabilities.
xTuple is available under the Common Public Attribution License ([CPAL](https://xtuple.com/products/license-options#cpal)), and the project welcomes developers to fork it to create other business software for inventory-based manufacturers. Its web app core is written in JavaScript, and its [source code](http://xtuple.github.io/) can be found on GitHub. To see if it's right for you, register for a free [demo](https://xtuple.com/free-demo) on xTuple's website.
There are many other open source ERP options you can choose from—others you might want to check out include [Tryton](http://www.tryton.org/), which is written in Python and uses the PostgreSQL database engine, or the Java-based [Axelor](https://www.axelor.com/), which touts users' ability to create or modify business apps with a drag-and-drop interface. And, if your favorite open source ERP solution isn't on the list, please share it with us in the comments. You might also check out our list of top [supply chain management tools](https://opensource.com/tools/supply-chain-management).
*This article is updated from a previous version authored by Opensource.com moderator *
[Scott Nesbitt](https://opensource.com/users/scottnesbitt).*This article was originally published in 2018 and has been updated with new information*
## 8 Comments |
9,786 | 对可互换通证(ERC-20 系列)的通证 ERC 的比较 | http://blockchainers.org/index.php/2018/02/08/token-erc-comparison-for-fungible-tokens/ | 2018-06-28T10:33:39 | [
"ERC-20",
"以太坊"
] | https://linux.cn/article-9786-1.html |
>
> “对于标准来说,最好的事情莫过于大量的人都去选择使用它。“
>
>
> —— [*Andrew S. Tanenbaum*](https://www.goodreads.com/quotes/589703-the-good-thing-about-standards-is-that-there-are-so)
>
>
>

### 通证标准的现状
在以太坊平台上,通证标准的现状出奇的简单:ERC-20 <ruby> 通证 <rt> token </rt></ruby>标准是通证接口中唯一被采用( [EIP-20](https://github.com/ethereum/EIPs/blob/master/EIPS/eip-20.md))和接受的通证标准。
它在 2015 年被提出,最终接受是在 2017 年末。
在此期间,提出了许多解决 ERC-20 缺点的<ruby> 以太坊意见征集 <rt> Ethereum Requests for Comments </rt></ruby>(ERC),其中的一部分是因为以太坊平台自身变更所导致的,比如,由 [EIP-150](https://github.com/ethereum/EIPs/blob/master/EIPS/eip-150.md) 修复的<ruby> 重入 <rt> re-entrancy </rt></ruby> bug。其它 ERC 提出的对 ERC-20 通证模型的强化。这些强化是通过收集大量的以太坊区块链和 ERC-20 通证标准的使用经验所确定的。ERC-20 通证接口的实际应用产生了新的要求和需要,比如像权限和操作方面的非功能性需求。
这篇文章将浅显但完整地对以太坊平台上提出的所有通证(类)的标准进行简单概述。我将尽可能客观地去做比较,但不可避免地仍有一些不客观的地方。
### 通证标准之母:ERC-20
有成打的 [非常好的](https://medium.com/@jgm.orinoco/understanding-erc-20-token-contracts-a809a7310aa5) 关于 ERC-20 的详细描述,在这里就不一一列出了。只对在文章中提到的相关核心概念做个比较。
#### 提取模式
用户不太好理解 ERC-20 接口,尤其是从一个<ruby> 外部所有者帐户 <rt> externally owned account </rt></ruby>(EOA)*转账* 通证的模式,即一个终端用户(“Alice”)到一个智能合约的转账,很难正确理解 `approve`/`transferFrom` 模式。

从软件工程师的角度看,这个提取模式非常类似于 <ruby> <a href="http://matthewtmead.com/blog/hollywood-principle-dont-call-us-well-call-you-4/"> 好莱坞原则 </a> <rt> Hollywood Principle </rt></ruby> (“不要给我们打电话,我们会给你打电话的!”)。那个调用链的想法正好相反:在 ERC-20 通证转账中,通证不能调用合约,但是合约可以调用通证上的 `transferFrom`。
虽然好莱坞原则经常用于去实现<ruby> 关注点分离 <rt> Separation-of-Concerns </rt></ruby>(SoC),但在以太坊中它是一个安全模式,目的是为了防止通证合约去调用外部合约上的未知的函数。这种行为是非常有必要的,因为会出现 <ruby> <a href="https://consensys.github.io/smart-contract-best-practices/known_attacks/"> 调用深度攻击 </a> <rt> Call Depth Attack </rt></ruby>,直到 [EIP-150](https://github.com/ethereum/EIPs/blob/master/EIPS/eip-150.md) 被启用才解决。在这个硬分叉之后,这个重入 bug 将不再可能出现了,并且提取模式也不能提供任何比直接通证调用更好的安全性。
但是,为什么现在它成了一个问题呢?可能是由于某些原因,它的用法设计有些欠佳,但是我们可以通过前端的 DApp 来修复这个问题,对吗?
因此,我们来看一看,如果一个用户使用 `transfer` 去发送一些通证到智能合约会发生什么事情。Alice 对通证合约的合约地址进行转账,
**….啊啊啊,它不见了!**
是的,通证没有了。很有可能,没有任何人再能拿回通证了。但是像 Alice 的这种做法并不鲜见,正如 ERC-223 的发明者 Dexaran 所发现的,大约有 $400.000 的通证(由于 ETH 波动很大,我们只能说很多)是由于用户意外发送到智能合约中,并因此而丢失。
即便合约开发者是一个非常友好和无私的用户,他也不能创建一个合约以便将它收到的通证返还给你。因为合约并不会提示这类转账,并且事件仅在通证合约上发出。
从软件工程师的角度来看,那就是 ERC-20 的重大缺点。如果发生一个事件(为简单起见,我们现在假设以太坊交易是真实事件),对参与的当事人应该有一个提示。但是,这个事件是在通证的智能合约中触发的,合约接收方是无法知道它的。
目前,还不能做到防止用户向智能合约发送通证,并且在 ERC-20 通证合约上使用这种不直观的转账将导致这些发送的通证永远丢失。
### 帝国反击战:ERC-223
第一个尝试去修复 ERC-20 的问题的提案是 [Dexaran](https://github.com/Dexaran) 提出来的。这个提议通过将 EOA 和智能合约账户做不同的处理的方式来解决这个问题。
强制的策略是去反转调用链(并且使用 [EIP-150](https://github.com/ethereum/EIPs/blob/master/EIPS/eip-150.md) 解决它现在能做到了),并且在正在接收的智能合约上使用一个预定义的回调(`tokenFallback`)。如果回调没有实现,转账将失败(将消耗掉发送方的燃料,这是 ERC-223 最常被批评的一个地方)。

**好处:**
* 创建一个新接口,有意使用这个废弃的函数来不遵守 ERC-20
* 允许合约开发者去处理收到的通证(即:接受/拒绝)并因此遵守事件模式
* 用一个交易来代替两个交易(`transfer` vs. `approve`/`transferFrom`)并且节省了燃料和区域链的存储空间
**坏处:**
* 如果 `tokenFallback` 不存在,那么合约的 `fallback` 功能将运行,这可能会产生意料之外的副作用
* 假如合约使用通证转账功能的话,比如,发送通证到一个特定的像多签名钱包一样的账户,这将使 ERC-223 通证失败,它将不能转移(即它们会丢失)。
### 程序员修练之道:ERC-677
[ERC-667:transferAndCall 通证标准](https://github.com/ethereum/EIPs/issues/677) 尝试将 ERC-20 和 ERC-223 结合起来。这个创意是在 ERC-20 中引入一个 `transferAndCall` 函数,并保持标准不变。ERC-223 有意不完全向后兼容,由于不再需要 `approve`/`allowance` 模式,并因此将它删除。
ERC-667 的主要目标是向后兼容,为新合约向外部合约转账提供一个安全的方法。

**好处:**
* 容易适用新的通证
* 兼容 ERC-20
* 为 ERC-20 设计的适配器用于安全使用 ERC-20
**坏处:**
* 不是真正的新方法。只是一个 ERC-20 和 ERC-223 的折衷
* 目前实现 [尚未完成](https://github.com/ethereum/EIPs/issues/677#issuecomment-353871138)
### 重逢:ERC-777
[ERC-777:一个先进的新通证标准](https://github.com/ethereum/EIPs/issues/777),引入它是为了建立一个演进的通证标准,它是吸取了像带值的 `approve()` 以及上面提到的将通证发送到合约这样的错误观念的教训之后得来的演进后标准。
另外,ERC-777 使用了新标准 [ERC-820:使用一个注册合约的伪内省](https://github.com/ethereum/EIPs/issues/820),它允许为合约注册元数据以提供一个简单的内省类型。并考虑到了向后兼容和其它的功能扩展,这些取决于由一个 EIP-820 查找到的地址返回的 `ITokenRecipient`,和由目标合约实现的函数。
ERC-777 增加了许多使用 ERC-20 通证的经验,比如,白名单操作者、提供带 `send(…)` 的以太兼容的接口,为了向后兼容而使用 ERC-820 去覆盖和调整功能。

**好处:**
* 从 ERC-20 的使用经验上得来的、经过深思熟虑的、进化的通证接口
* 为内省要求 ERC-820 使用新标准,接受了增加的功能
* 白名单操作者非常有用,而且比 `approve`/`allowance` 更有必要,它经常是无限的
**坏处:**
* 刚刚才开始,复杂的依赖合约调用的结构
* 依赖导致出现安全问题的可能性增加:第一个安全问题并不是在 ERC-777 中 [确认(并解决的)](https://github.com/ethereum/EIPs/issues/820#issuecomment-362049573),而是在最新的 ERC-820 中
### (纯主观的)结论(轻喷)
目前为止,如果你想遵循 “行业标准”,你只能选择 ERC-20。它获得了最广泛的理解与支持。但是,它还是有缺陷的,最大的一个缺陷是因为非专业用户设计和规范问题导致的用户真实地损失金钱的问题。ERC-223 是非常好的,并且在理论上找到了 ERC-20 中这个问题的答案了,它应该被考虑为 ERC-20 的一个很好的替代标准。在一个新通证中实现这两个接口并不复杂,并且可以降低燃料的使用。
ERC-677 是事件和金钱丢失问题的一个务实的解决方案,但是它并没能提供足够多的新方法,以促使它成为一个标准。但是它可能是 ERC-20 2.0 的一个很好的候选者。
ERC-777 是一个更先进的通证标准,它应该成为 ERC-20 的合法继任者,它提供了以太坊平台所需要的非常好的成熟概念,像白名单操作者,并允许以优雅的方式进行扩展。由于它的复杂性和对其它新标准的依赖,在主链上出现第一个 ERC-777 标准的通证还需要些时日。
### 链接
1. 在 ERC-20 中使用 approve/transferFrom 模式的安全问题: <https://drive.google.com/file/d/0ByMtMw2hul0EN3NCaVFHSFdxRzA/view>
2. ERC-20 中的无事件操作:<https://docs.google.com/document/d/1Feh5sP6oQL1-1NHi-X1dbgT3ch2WdhbXRevDN681Jv4>
3. ERC-20 的故障及历史:<https://github.com/ethereum/EIPs/issues/223#issuecomment-317979258>
4. ERC-20/223 的不同之处:<https://ethereum.stackexchange.com/questions/17054/erc20-vs-erc223-list-of-differences>
---
via: <http://blockchainers.org/index.php/2018/02/08/token-erc-comparison-for-fungible-tokens/>
作者:[Alexander Culum](http://blockchainers.org/index.php/author/alex/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | “The good thing about standards is that there are so many to choose from.” *Andrew S. Tanenbaum*
# Current State of Token Standards
The current state of Token standards on the Ethereum platform is surprisingly simple: ERC-20 Token Standard is the only accepted and adopted (as [EIP-20](https://github.com/ethereum/EIPs/blob/master/EIPS/eip-20.md)) standard for a Token interface.
Proposed in 2015, it has finally been accepted at the end of 2017.
In the meantime, many Ethereum Requests for Comments (ERC) have been proposed which address shortcomings of the ERC-20, which partly were caused by changes in the Ethereum platform itself, eg. the fix for the re-entrancy bug with [EIP-150](https://github.com/ethereum/EIPs/blob/master/EIPS/eip-150.md). Other ERC propose enhancements to the ERC-20 Token model. These enhancements were identified by experiences gathered due to the broad adoption of the Ethereum blockchain and the ERC-20 Token standard. The actual usage of the ERC-20 Token interface resulted in new demands and requirements to address non-functional requirements like permissioning and operations.
This blogpost should give a superficial, but complete, overview of all proposals for Token(-like) standards on the Ethereum platform. This comparison tries to be objective but most certainly will fail in doing so.
# The Mother of all Token Standards: ERC-20
There are dozens of [very good](https://medium.com/@jgm.orinoco/understanding-erc-20-token-contracts-a809a7310aa5) and detailed description of the ERC-20, which will not be repeated here. Just the core concepts relevant for comparing the proposals are mentioned in this post.
## The Withdraw Pattern
Users trying to understand the ERC-20 interface and especially the usage pattern for *transfer*ing Tokens *from* one externally owned account (EOA), ie. an end-user (“Alice”), to a smart contract, have a hard time getting the approve/transferFrom pattern right.
From a software engineering perspective, this withdraw pattern is very similar to the [Hollywood principle](http://matthewtmead.com/blog/hollywood-principle-dont-call-us-well-call-you-4/) (“Don’t call us, we’ll call you!”). The idea is that the call chain is reversed: during the ERC-20 Token transfer, the Token doesn’t call the contract, but the contract does the call transferFrom on the Token.
While the Hollywood Principle is often used to implement Separation-of-Concerns (SoC), in Ethereum it is a security pattern to avoid having the Token contract to call an unknown function on an external contract. This behaviour was necessary due to the [Call Depth Attack](https://consensys.github.io/smart-contract-best-practices/known_attacks/) until [EIP-150](https://github.com/ethereum/EIPs/blob/master/EIPS/eip-150.md) was activated. After this hard fork, the re-entrancy bug was not possible anymore and the withdraw pattern did not provide any more security than calling the Token directly.
But why should it be a problem now, the usage might be somehow clumsy, but we can fix this in the DApp frontend, right?
So, let’s see what happens if a user used transfer to send Tokens to a smart contract. Alice calls transfer on the Token contract with the contract address
**….aaaaand it’s gone!**
That’s right, the Tokens are gone. Most likely, nobody will ever get the Tokens back. But Alice is not alone, as Dexaran, inventor of ERC-223, found out, about $400.000 in tokens (let’s just say *a lot* due to the high volatility of ETH) are irretrievably lost for all of us due to users accidentally sending Tokens to smart contracts.
Even if the contract developer was extremely user friendly and altruistic, he couldn’t create the contract so that it could react to getting Tokens transferred to it and eg. return them, as the contract will never be notified of this transfer and the event is only emitted on the Token contract.
From a software engineering perspective that’s a severe shortcoming of ERC-20. If an event occurs (and for the sake of simplicity, we are now assuming Ethereum transactions are actually events), there should be a notification to the parties involved. However, there is an event, but it’s triggered in the Token smart contract which the receiving contract cannot know.
Currently, it’s not possible to prevent users sending Tokens to smart contracts and losing them forever using the unintuitive transfer on the ERC-20 Token contract.
# The Empire Strikes Back: ERC-223
The first attempt at fixing the problems of ERC-20 was proposed by [Dexaran](https://github.com/Dexaran). The main issue solved by this proposal is the different handling of EOA and smart contract accounts.
The compelling strategy is to reverse the calling chain (and with [EIP-150](https://github.com/ethereum/EIPs/blob/master/EIPS/eip-150.md) solved this is now possible) and use a pre-defined callback (tokenFallback) on the receiving smart contract. If this callback is not implemented, the transfer will fail (costing all gas for the sender, a common criticism for ERC-223).
#### Pros:
- Establishes a new interface, intentionally being not compliant to ERC-20 with respect to the deprecated functions
- Allows contract developers to handle incoming tokens (eg. accept/reject) since event pattern is followed
- Uses one transaction instead of two (transfer vs. approve/transferFrom) and thus saves gas and Blockchain storage
#### Cons:
- If tokenFallback doesn’t exist then the contract fallback function is executed, this might have unintended side-effects
- If contracts assume that transfer works with Tokens, eg. for sending Tokens to specific contracts like multi-sig wallets, this would fail with ERC-223 Tokens, making it impossible to move them (ie. they are lost)
# The Pragmatic Programmer: ERC-677
The [ERC-667 transferAndCall Token Standard](https://github.com/ethereum/EIPs/issues/677) tries to marriage the ERC-20 and ERC-223. The idea is to introduce a transferAndCall function to the ERC-20, but keep the standard as is. ERC-223 intentionally is not completely backwards compatible, since the approve/allowance pattern is not needed anymore and was therefore removed.
The main goal of ERC-667 is backward compatibility, providing a safe way for new contracts to transfer tokens to external contracts.
#### Pros:
- Easy to adapt for new Tokens
- Compatible to ERC-20
- Adapter for ERC-20 to use ERC-20 safely
#### Cons:
- No real innovations. A compromise of ERC-20 and ERC-223
- Current implementation
[is not finished](https://github.com/ethereum/EIPs/issues/677#issuecomment-353871138)
# The Reunion: ERC-777
[ERC-777 A New Advanced Token Standard](https://github.com/ethereum/EIPs/issues/777) was introduced to establish an evolved Token standard which learned from misconceptions like approve() with a value and the aforementioned send-tokens-to-contract-issue.
Additionally, the ERC-777 uses the new standard [ERC-820: Pseudo-introspection using a registry contract](https://github.com/ethereum/EIPs/issues/820) which allows for registering meta-data for contracts to provide a simple type of introspection. This allows for backwards compatibility and other functionality extensions, depending on the ITokenRecipient returned by a EIP-820 lookup on the to address, and the functions implemented by the target contract.
ERC-777 adds a lot of learnings from using ERC-20 Tokens, eg. white-listed operators, providing Ether-compliant interfaces with send(…), using the ERC-820 to override and adapt functionality for backwards compatibility.
#### Pros:
- Well thought and evolved interface for tokens, learnings from ERC-20 usage
- Uses the new standard request ERC-820 for introspection, allowing for added functionality
- White-listed operators are very useful and are more necessary than approve/allowance, which was often left infinite
#### Cons:
- Is just starting, complex construction with dependent contract calls
- Dependencies raise the probability of security issues: first security issues have been
[identified (and solved)](https://github.com/ethereum/EIPs/issues/820#issuecomment-362049573)not in the ERC-777, but in the even newer ERC-820
# (Pure Subjective) Conclusion
For now, if you want to go with the “industry standard” you have to choose ERC-20. It is widely supported and well understood. However, it has its flaws, the biggest one being the risk of non-professional users actually losing money due to design and specification issues. ERC-223 is a very good and theoretically founded answer for the issues in ERC-20 and should be considered a good alternative standard. Implementing both interfaces in a new token is not complicated and allows for reduced gas usage.
A pragmatic solution to the event and money loss problem is ERC-677, however it doesn’t offer enough innovation to establish itself as a standard. It could however be a good candidate for an ERC-20 2.0.
ERC-777 is an advanced token standard which should be the legitimate successor to ERC-20, it offers great concepts which are needed on the matured Ethereum platform, like white-listed operators, and allows for extension in an elegant way. Due to its complexity and dependency on other new standards, it will take time till the first ERC-777 tokens will be on the Mainnet.
## Links
[1] Security Issues with approve/transferFrom-Pattern in ERC-20: [https://drive.google.com/file/d/0ByMtMw2hul0EN3NCaVFHSFdxRzA/view](https://drive.google.com/file/d/0ByMtMw2hul0EN3NCaVFHSFdxRzA/view)
[2] No Event Handling in ERC-20: [https://docs.google.com/document/d/1Feh5sP6oQL1-1NHi-X1dbgT3ch2WdhbXRevDN681Jv4](https://docs.google.com/document/d/1Feh5sP6oQL1-1NHi-X1dbgT3ch2WdhbXRevDN681Jv4)
[3] Statement for ERC-20 failures and history: [https://github.com/ethereum/EIPs/issues/223#issuecomment-317979258](https://github.com/ethereum/EIPs/issues/223#issuecomment-317979258)
[4] List of differences ERC-20/223: [https://ethereum.stackexchange.com/questions/17054/erc20-vs-erc223-list-of-differences](https://ethereum.stackexchange.com/questions/17054/erc20-vs-erc223-list-of-differences) |
9,787 | 让孩子爱上计算机和编程的 15 本书 | https://opensource.com/article/18/5/books-kids-linux-open-source | 2018-06-28T11:15:45 | [
"孩子",
"书籍"
] | https://linux.cn/article-9787-1.html |
>
> 以及,还有三本是给宝宝的。
>
>
>

在工作之余,我听说不少技术专家透露出让他们自己的孩子学习更多关于 [Linux](https://opensource.com/resources/linux) 和 [开源](https://opensource.com/article/18/3/what-open-source-programming)知识的意愿,他们中有的来自高管层,有的来自普通岗位。其中一些似乎时间比较充裕,伴随其孩子一步一步成长。另一些人可能没有充足的时间让他们的孩子看到为何 Linux 和 开源如此之酷。也许他们能抽出时间,但这不一定。在这个大世界中,有太多有趣、有价值的事物。
不论是哪种方式,如果你的或你认识的孩子愿意学习使用编程和硬件,实现游戏或机器人之类东西,那么这份书单很适合你。
### 面向儿童 Linux 和 开源爱好者的 15 本书
**《[零基础学 Raspberry Pi](https://www.amazon.com/Adventures-Raspberry-Carrie-Anne-Philbin/dp/1119046025)》,作者 Carrie Anne Philbin**
在对编程感兴趣的儿童和成人中,体积小小的、仅信用卡一般大的树莓派引起了强烈的反响。你台式机能做的事情它都能做,具备一定的基础编程技能后,你可以让它做更多的事情。本书操作简明、项目风趣、技能扎实,是一本儿童可用的终极编程指南。([Joshua Allen Holm](https://opensource.com/users/holmja) 推荐,评论节选于本书的内容提要)
**《[Python 编程快速上手:让繁琐工作自动化](https://automatetheboringstuff.com/)》,作者 Al Sweigart**
这是一本经典的编程入门书,行文足够清晰,11 岁及以上的编程爱好者都可以读懂本书并从中受益。读者很快就会投入到真实且实用的任务中,在此过程中顺便掌握了优秀的编程实践。最好的一点是,如果你愿意,你可以在互联网上阅读本书。([DB Clinton](https://opensource.com/users/dbclinton) 推荐并评论)
**《[Scratch 游戏编程](https://www.goodreads.com/book/show/25733628-coding-games-in-scratch)》,作者 Jon Woodcock**
本书适用于 8-12 岁没有或仅有有限编程经验的儿童。作为一本直观的可视化入门书,它使用有趣的图形和易于理解的操作,教导年轻的读者如何使用 Scratch 这款流行的自由编程语言构建他们自己的编程项目。([Joshua Allen Holm](https://opensource.com/users/holmja) 推荐,评论节选于本书的内容提要)
**《[用 Python 巧学数学](https://nostarch.com/doingmathwithpython)》,作者 Amit Saha**
无论你是一名学生还是教师,只要你对使用 Python 学习数学感兴趣,不妨读读本书。在逻辑上,本书带领读者一步一步地从基础到更为复杂的操作,从最开始简单的 Python shell 数字运算,到使用类似 matplotlib 这样的 Python 库实现数据可视化,读者可以很容易跟上作者的思路。本书充分调动你的好奇心,感叹 Python 与 数学结合的威力。([Don Watkins](https://opensource.com/users/don-watkins) 推荐并评论)
**《[编程女生:学习编程,改变世界](https://www.amazon.com/Girls-Who-Code-Learn-Change/dp/042528753X)》,作者 Reshma Saujani**
作者是 Girls Who Code 运动的发起人,该运动得到 Sheryl Sandberg、 Malala Yousafzai 和 John Legend 支持。本书一部分是编程介绍,一部分女生赋能,这两部分都写得很有趣。本书包括动态艺术作品、零基础的编程原理讲解以及在 Pixar 和 NASA 等公司工作的女生的真实故事。这本书形象生动,向读者展示了计算机科学在我们生活中发挥的巨大作用以及其中的趣味。([Joshua Allen Holm](https://opensource.com/users/holmja) 推荐,评论节选于本书的内容提要)
**《[Python 游戏编程快速上手](http://inventwithpython.com/invent4thed/)》,作者 Al Sweigart**
本书将让你学会如何使用流行的 Python 编程语言编写计算机游戏,不要求具有编程经验!入门阶段编写<ruby> 刽子手 <rt> Hangman </rt></ruby>,猜数字,<ruby> 井字游戏 <rt> Tic-Tac-Toe </rt></ruby>这样的经典游戏,后续更进一步编写高级一些的游戏,例如文字版寻宝游戏,以及带音效和动画的<ruby> 碰撞与闪避 <rt> collision-dodgoing </rt></ruby>游戏。([Joshua Allen Holm](https://opensource.com/users/holmja) 推荐,评论节选于本书的内容提要)
**《[Lauren Ipsum:关于计算机科学和一些不可思议事物的故事](https://www.amazon.com/gp/product/1593275749/ref=as_li_tl?ie=UTF8&tag=projemun-20&camp=1789&creative=9325&linkCode=as2&creativeASIN=1593275749&linkId=e05e1f12176c4959cc1aa1a050908c4a)》,作者 Carlos Bueno**
本书采用爱丽丝梦游仙境的风格,女主角 Lauren Ipsum 来到一个稍微具有魔幻色彩的世界。世界的自然法则是逻辑学和计算机科学,世界谜题只能通过学习计算机编程原理并编写代码完成。书中没有提及计算机,但其作为世界的核心存在。([DB Clinton](https://opensource.com/users/dbclinton) 推荐并评论)
**《[Java 轻松学](https://nostarch.com/learnjava)》,作者 Bryson Payne**
Java 是全世界最流行的编程语言,但众所周知上手比较难。本书让 Java 学习不再困难,通过若干实操项目,让你马上学会构建真实可运行的应用。([Joshua Allen Holm](https://opensource.com/users/holmja) 推荐,评论节选于本书的内容提要)
**《[终身幼儿园](http://lifelongkindergarten.net/)》,作者 Mitchell Resnick**
幼儿园正变得越来越像学校。在本书中,学习专家 Mitchel Resnick 提出相反的看法:学校(甚至人的一生)应该更像幼儿园。要适应当今快速变化的世界,各个年龄段的人们都必须学会开创性思维和行动;想要达到这个目标,最好的方式就是更加专注于想象、创造、玩耍、分享和反馈,就像孩子在传统幼儿园中那样。基于在 MIT <ruby> 媒体实验室 <rt> Media Lab </rt></ruby> 30 多年的经历, Resnick 讨论了新的技术和策略,可以让年轻人拥有开创性的学习体验。([Don Watkins](https://opensource.com/users/don-watkins) 推荐,评论来自 Amazon 书评)
**《[趣学 Python:教孩子学编程](https://nostarch.com/pythonforkids)》,作者 Jason Briggs**
在本书中,Jason Briggs 将 Python 编程教学艺术提升到新的高度。我们可以很容易地将本书用作入门书,适用群体可以是教师/学生,也可以是父母/儿童。通过一步步引导的方式介绍复杂概念,让编程新手也可以成功完成,进一步激发学习欲望。本书是一本极为易读、寓教于乐但又强大的 Python 编程入门书。读者将学习基础数据结构,包括<ruby> 元组 <rt> turple </rt></ruby>、<ruby> 列表 <rt> list </rt></ruby>和<ruby> 映射 <rt> map </rt></ruby>等,学习如何创建函数、重用代码或者使用包括循环和条件语句在内的控制结构。孩子们还将学习如何创建游戏和动画,体验 Tkinter 的强大并创建高级图形。([Don Watkins](https://opensource.com/users/don-watkins) 推荐并评论)
**《[Scratch 编程园地](https://nostarch.com/scratchplayground)》,作者 Al Sweigart**
Scratch 编程一般被视为一种寓教于乐的教年轻人编程的方式。在本书中,Al Sweigart 告诉我们 Scratch 是一种超出绝大多数人想象的强大编程语言。独特的风格,大师级的编写和呈现。Al 让孩子通过创造复杂图形和动画,短时间内认识到 Scratch 的强大之处。([Don Watkins](https://opensource.com/users/don-watkins) 推荐并评论)
**《[秘密编程者](http://www.secret-coders.com/)》,作者 Gene Luen Yang,插图作者 Mike Holmes**
Gene Luen Yang 是漫画小说超级巨星,也是一所高中的计算机编程教师。他推出了一个非常有趣的系列作品,将逻辑谜题、基础编程指令与引入入胜的解谜情节结合起来。故事发生在 Stately Academy 这所学校,其中充满有待解开的谜团。([Joshua Allen Holm](https://opensource.com/users/holmja) 推荐,评论节选于本书的内容提要)
**《[想成为编程者吗?编程、视频游戏制作、机器人等职业终极指南!](https://www.amazon.com/So-You-Want-Coder-Programming/dp/1582705798?tag=ad-backfill-amzn-no-or-one-good-20)》,作者 Jane Bedell**
酷爱编程?这本书易于理解,描绘了以编程为生的完整图景,激发你的热情,磨练你的专业技能。([Joshua Allen Holm](https://opensource.com/users/holmja) 推荐,评论节选于本书的内容提要)
**《[教孩子编程](https://opensource.com/education/15/9/review-bryson-payne-teach-your-kids-code)》,作者 Bryson Payne**
你是否在寻找一种寓教于乐的方式教你的孩子 Python 编程呢?Bryson Payne 已经写了这本大师级的书。本书通过乌龟图形打比方,引导你编写一些简单程序,为高级 Python 编程打下基础。如果你打算教年轻人编程,这本书不容错过。([Don Watkins](https://opensource.com/users/don-watkins) 推荐并评论)
**《[图解 Kubernetes(儿童版)](https://deis.com/blog/2016/kubernetes-illustrated-guide/)》,作者 Matt Butcher, 插画作者 Bailey Beougher**
介绍了 Phippy 这个勇敢的 PHP 小应用及其 Kubernetes 之旅。([Chris Short](https://opensource.com/users/chrisshort) 推荐,评论来自 [Matt Butcher 的博客](https://deis.com/blog/2016/kubernetes-illustrated-guide/))
### 给宝宝的福利书
**《[宝宝的 CSS](https://www.amazon.com/CSS-Babies-Code-Sterling-Childrens/dp/1454921560/)》、《[宝宝的 Javascript](https://www.amazon.com/Javascript-Babies-Code-Sterling-Childrens/dp/1454921579/)》、《[宝宝的 HTML](https://www.amazon.com/HTML-Babies-Code-Sterling-Childrens/dp/1454921552)》,作者 Sterling Children's**
这本概念书让宝宝熟悉图形和颜色的种类,这些是互联网编程语言的基石。这本漂亮的书用富有色彩的方式介绍了编程和互联网,对于技术人士的家庭而言,本书是一份绝佳的礼物。([Chris Short](https://opensource.com/users/chrisshort) 推荐,评论来自 Amazon 书评)
你是否有想要分享的适合宝宝或儿童的书呢?请在评论区留言告诉我们。
---
via: <https://opensource.com/article/18/5/books-kids-linux-open-source>
作者:[Jen Wike Huger](https://opensource.com/users/remyd) 选题:[lujun9972](https://github.com/lujun9972) 译者:[pinewall](https://github.com/pinewall) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | In my job I've heard professionals in tech, from C-level executives to everyone in between, say they want their own kids to learn more about [Linux](https://opensource.com/resources/linux) and [open source](https://opensource.com/article/18/3/what-open-source-programming). Some of them seem to have an easy time with their kids following closely in their footsteps. And some have a tough time getting their kids to see what makes Linux and open source so cool. Maybe their time will come, maybe it won't. There's a lot of interesting, valuable stuff out there in this big world.
Either way, if you have a kid or know a kid that may be interested in learning more about making something with code or hardware, from games to robots, this list is for you.
## 15 books for kids with a focus on Linux and open source
* Adventures in Raspberry Pi* by Carrie Anne Philbin
The tiny, credit-card sized Raspberry Pi has become a huge hit among kids—and adults—interested in programming. It does everything your desktop can do, but with a few basic programming skills you can make it do so much more. With simple instructions, fun projects, and solid skills, *Adventures in Raspberry Pi* is the ultimate kids' programming guide! (Recommendation by [Joshua Allen Holm](https://opensource.com/users/holmja) | Review is an excerpt from the book's abstract)
[Automate the Boring Stuff with Python](https://automatetheboringstuff.com/)* *by Al Sweigart
This is a classic introduction to programming that's written clearly enough for a motivated 11-year-old to understand and enjoy. Readers will quickly find themselves working on practical and useful tasks while picking up good coding practices almost by accident. The best part: If you like, you can read the whole book online. (Recommendation and review by [DB Clinton](https://opensource.com/users/dbclinton))
* Coding Games in Scratch* by Jon Woodcock
Written for children ages 8-12 with little to no coding experience, this straightforward visual guide uses fun graphics and easy-to-follow instructions to show young learners how to build their own computer projects using Scratch, a popular free programming language. (Recommendation by [Joshua Allen Holm](https://opensource.com/users/holmja) | Review is an excerpt from the book's abstract)
* Doing Math with Python* by Amit Saha
Whether you're a student or a teacher who's curious about how you can use Python for mathematics, this book is for you. Beginning with simple mathematical operations in the Python shell to the visualization of data using Python libraries like matplotlib, this books logically takes the reader step by easily followed step from the basics to more complex operations. This book will invite your curiosity about the power of Python with mathematics. (Recommendation and review by [Don Watkins](https://opensource.com/users/don-watkins))
* Girls Who Code: Learn to Code and Change the World* by Reshma Saujani
From the leader of the movement championed by Sheryl Sandberg, Malala Yousafzai, and John Legend, this book is part how-to, part girl-empowerment, and all fun. Bursting with dynamic artwork, down-to-earth explanations of coding principles, and real-life stories of girls and women working at places like Pixar and NASA, this graphically animated book shows what a huge role computer science plays in our lives and how much fun it can be. (Recommendation by [Joshua Allen Holm](https://opensource.com/users/holmja) | Review is an excerpt from the book's abstract)
* Invent Your Own Computer Games with Python* by Al Sweigart
This book will teach you how to make computer games using the popular Python programming language—even if you’ve never programmed before! Begin by building classic games like Hangman, Guess the Number, and Tic-Tac-Toe, and then work your way up to more advanced games, like a text-based treasure hunting game and an animated collision-dodging game with sound effects. (Recommendation by [Joshua Allen Holm](https://opensource.com/users/holmja) | Review is an excerpt from the book's abstract)
* Lauren Ipsum: A Story About Computer Science and Other Improbable Things* by Carlos Bueno
Written in the spirit of *Alice in Wonderland*, *Lauren Ipsum* takes its heroine through a slightly magical world whose natural laws are the laws of logic and computer science and whose puzzles can be solved only through learning and applying the principles of computer code. Computers are never mentioned, but they're at the center of it all. (Recommendation and review by [DB Clinton](https://opensource.com/users/dbclinton))
* Learn Java the Easy Way: A Hands-On Introduction to Programming* by Bryson Payne
Java is the world's most popular programming language, but it’s known for having a steep learning curve. This book takes the chore out of learning Java with hands-on projects that will get you building real, functioning apps right away. (Recommendation by [Joshua Allen Holm](https://opensource.com/users/holmja) | Review is an excerpt from the book's abstract)
* Lifelong Kindergarten* by Mitchell Resnick
Kindergarten is becoming more like the rest of school. In this book, learning expert Mitchel Resnick argues for exactly the opposite: The rest of school (even the rest of life) should be more like kindergarten. To thrive in today's fast-changing world, people of all ages must learn to think and act creatively―and the best way to do that is by focusing more on imagining, creating, playing, sharing, and reflecting, just as children do in traditional kindergartens. Drawing on experiences from more than 30 years at MIT's Media Lab, Resnick discusses new technologies and strategies for engaging young people in creative learning experiences. (Recommendation by [Don Watkins](https://opensource.com/users/don-watkins) | Review from Amazon)
* Python for Kids* by Jason Briggs
Jason Briggs has taken the art of teaching Python programming to a new level in this book that can easily be an introductory text for teachers and students as well as parents and kids. Complex concepts are presented with step-by-step directions that will have even neophyte programmers experiencing the success that invites you to learn more. This book is an extremely readable, playful, yet powerful introduction to Python programming. You will learn fundamental data structures like tuples, lists, and maps. The reader is shown how to create functions, reuse code, and use control structures like loops and conditional statements. Kids will learn how to create games and animations, and they will experience the power of Tkinter to create advanced graphics. (Recommendation and review by [Don Watkins](https://opensource.com/users/don-watkins))
* Scratch Programming Playground* by Al Sweigart
Scratch programming is often seen as a playful way to introduce young people to programming. In this book, Al Sweigart demonstrates that Scratch is in fact a much more powerful programming language than most people realize. Masterfully written and presented in his own unique style, Al will have kids exploring the power of Scratch to create complex graphics and animation in no time. (Recommendation and review by [Don Watkins](https://opensource.com/users/don-watkins))
* Secret Coders* by Mike Holmes
From graphic novel superstar (and high school computer programming teacher) Gene Luen Yang comes a wildly entertaining new series that combines logic puzzles and basic programming instruction with a page-turning mystery plot. Stately Academy is the setting, a school that is crawling with mysteries to be solved! (Recommendation by [Joshua Allen Holm](https://opensource.com/users/holmja) | Review is an excerpt from the book's abstract)
* So, You Want to Be a Coder?: The Ultimate Guide to a Career in Programming, Video Game Creation, Robotics, and More!* by Jane Bedell
Love coding? Make your passion your profession with this comprehensive guide that reveals a whole host of careers working with code. (Recommendation by [Joshua Allen Holm](https://opensource.com/users/holmja) | Review is an excerpt from the book's abstract)
* Teach Your Kids to Code* by Bryson Payne
Are you looking for a playful way to introduce children to programming with Python? Bryson Payne has written a masterful book that uses the metaphor of turtle graphics in Python. This book will have you creating simple programs that are the basis for advanced Python programming. This book is a must-read for anyone who wants to teach young people to program. (Recommendation and review by [Don Watkins](https://opensource.com/users/don-watkins))
* The Children's Illustrated Guide to Kubernetes* by Matt Butcher, illustrated by Bailey Beougher
Introducing Phippy, an intrepid little PHP app, and her journey to Kubernetes. (Recommendation by [Chris Short](https://opensource.com/users/chrisshort) | Review from [Matt Butcher's blog post](https://deis.com/blog/2016/kubernetes-illustrated-guide/).)
## Bonus books for babies
* CSS for Babies*,
*, and*
[Javascript for Babies](https://www.amazon.com/Javascript-Babies-Code-Sterling-Childrens/dp/1454921579/)*by Sterling Children's*
[HTML for Babies](https://www.amazon.com/HTML-Babies-Code-Sterling-Childrens/dp/1454921552)These concept books familiarize young ones with the kind of shapes and colors that make up web-based programming languages. This beautiful book is a colorful introduction to coding and the web, and it's the perfect gift for any technologically minded family. (Recommendation by [Chris Short](https://opensource.com/users/chrisshort) | Review from Amazon)
*Have other books for babies or kids to share? Let us know in the comments.*
## 4 Comments |
9,788 | 在 GitHub 上对编程语言与软件质量的一个大规模研究 | https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007 | 2018-06-28T18:01:00 | [
"编程语言",
"GitHub",
"软件质量"
] | https://linux.cn/article-9788-1.html | 
编程语言对软件质量的影响是什么?这个问题在很长一段时间内成为一个引起了大量辩论的主题。在这项研究中,我们从 GitHub 上收集了大量的数据(728 个项目,6300 万行源代码,29000 位作者,150 万个提交,17 种编程语言),尝试在这个问题上提供一些实证。这个还算比较大的样本数量允许我们去使用一个混合的方法,结合多种可视化的回归模型和文本分析,去研究语言特性的影响,比如,在软件质量上,静态与动态类型和允许混淆与不允许混淆的类型。通过从不同的方法作三角测量研究(LCTT 译注:一种测量研究的方法),并且去控制引起混淆的因素,比如,团队大小、项目大小和项目历史,我们的报告显示,语言设计确实(对很多方面)有很大的影响,但是,在软件质量方面,语言的影响是非常有限的。最明显的似乎是,不允许混淆的类型比允许混淆的类型要稍微好一些,并且,在函数式语言中,静态类型也比动态类型好一些。值得注意的是,这些由语言设计所引起的轻微影响,绝大多数是由过程因素所主导的,比如,项目大小、团队大小和提交数量。但是,我们需要提示读者,即便是这些不起眼的轻微影响,也是由其它的无形的过程因素所造成的,例如,对某些函数类型、以及不允许类型混淆的静态语言的偏爱。
### 1 序言
在给定的编程语言是否是“适合这个工作的正确工具”的讨论期间,紧接着又发生了多种辩论。虽然一些辩论出现了带有宗教般狂热的色彩,但是大部分人都一致认为,编程语言的选择能够对编码过程和由此生成的结果都有影响。
主张强静态类型的人,倾向于认为静态方法能够在早期捕获到缺陷;他们认为,一点点的预防胜过大量的矫正。动态类型拥护者主张,保守的静态类型检查无论怎样都是非常浪费开发者资源的,并且,最好是依赖强动态类型检查来捕获错误类型。然而,这些辩论,大多数都是“纸上谈兵”,只靠“传说中”的证据去支持。
这些“传说”也许并不是没有道理的;考虑到影响软件工程结果的大量其它因素,获取这种经验性的证据支持是一项极具挑战性的任务,比如,代码质量、语言特征,以及应用领域。比如软件质量,考虑到它有大量的众所周知的影响因素,比如,代码数量, <sup> <a href="https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R6"> 6 </a></sup> 团队大小, <sup> <a href="https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R2"> 2 </a></sup> 和年龄/熟练程度。 <sup> <a href="https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R9"> 9 </a></sup>
受控实验是检验语言选择在面对如此令人气馁的混淆影响时的一种方法,然而,由于成本的原因,这种研究通常会引入一种它们自己的混淆,也就是说,限制了范围。在这种研究中,完整的任务是必须要受限制的,并且不能去模拟 *真实的世界* 中的开发。这里有几个最近的这种大学本科生使用的研究,或者,通过一个实验因素去比较静态或动态类型的语言。<sup> <a href="https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R7"> 7 </a> , <a href="https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R12"> 12 </a> , <a href="https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R15"> 15 </a></sup>
幸运的是,现在我们可以基于大量的真实世界中的软件项目去研究这些问题。GitHub 包含了多种语言的大量的项目,并且在大小、年龄、和开发者数量上有很大的差别。每个项目的仓库都提供一个详细的记录,包含贡献历史、项目大小、作者身份以及缺陷修复。然后,我们使用多种工具去研究语言特性对缺陷发生的影响。对我们的研究方法的最佳描述应该是“混合方法”,或者是三角测量法; <sup> <a href="https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R5"> 5 </a></sup> 我们使用文本分析、聚簇和可视化去证实和支持量化回归研究的结果。这个以经验为根据的方法,帮助我们去了解编程语言对软件质量的具体影响,因为,他们是被开发者非正式使用的。
### 2 方法
我们的方法是软件工程中典型的大范围观察研究法。我们首先大量的使用自动化方法,从几种数据源采集数据。然后使用预构建的统计分析模型对数据进行过滤和清洗。过滤器的选择是由一系列的因素共同驱动的,这些因素包括我们研究的问题的本质、数据质量和认为最适合这项统计分析研究的数据。尤其是,GitHub 包含了由大量的编程语言所写的非常多的项目。对于这项研究,我们花费大量的精力专注于收集那些用大多数的主流编程语言写的流行项目的数据。我们选择合适的方法来评估计数数据上的影响因素。
#### 2.1 数据收集
我们选择了 GitHub 上的排名前 19 的编程语言。剔除了 CSS、Shell 脚本、和 Vim 脚本,因为它们不是通用的编程语言。我们包含了 Typescript,它是 JavaScript 的超集。然后,对每个被研究的编程语言,我们检索出以它为主要编程语言的前 50 个项目。我们总共分析了 17 种不同的语言,共计 850 个项目。
我们的编程语言和项目的数据是从 *GitHub Archive* 中提取的,这是一个记录所有活跃的公共 GitHub 项目的数据库。它记录了 18 种不同的 GitHub 事件,包括新提交、fork 事件、PR(拉取请求)、开发者信息和以每小时为基础的所有开源 GitHub 项目的问题跟踪。打包后的数据上传到 Google BigQuery 提供的交互式数据分析接口上。
**识别编程语言排名榜单**
我们基于它们的主要编程语言分类合计项目。然后,我们选择大多数的项目进行进一步分析,如 [表 1](http://deliveryimages.acm.org/10.1145/3130000/3126905/t1.jpg) 所示。一个项目可能使用多种编程语言;将它确定成单一的编程语言是很困难的。Github Archive 保存的信息是从 GitHub Linguist 上采集的,它使用项目仓库中源文件的扩展名来确定项目的发布语言是什么。源文件中使用数量最多的编程语言被确定为这个项目的 *主要编程语言*。
[](http://deliveryimages.acm.org/10.1145/3130000/3126905/t1.jpg)
*表 1 每个编程语言排名前三的项目*
**检索流行的项目**
对于每个选定的编程语言,我们先根据项目所使用的主要编程语言来选出项目,然后根据每个项目的相关 *星* 的数量排出项目的流行度。 *星* 的数量表示了有多少人主动表达对这个项目感兴趣,并且它是流行度的一个合适的代表指标。因此,在 C 语言中排名前三的项目是 linux、git、php-src;而对于 C++,它们则是 node-webkit、phantomjs、mongo ;对于 Java,它们则是 storm、elasticsearch、ActionBarSherlock 。每个编程语言,我们各选了 50 个项目。
为确保每个项目有足够长的开发历史,我们剔除了少于 28 个提交的项目(28 是候选项目的第一个四分位值数)。这样我们还剩下 728 个项目。[表 1](http://deliveryimages.acm.org/10.1145/3130000/3126905/t1.jpg) 展示了每个编程语言的前三个项目。
**检索项目演进历史**
对于 728 个项目中的每一个项目,我们下载了它们的非合并提交、提交记录、作者数据、作者使用 *git* 的名字。我们从每个文件的添加和删除的行数中计算代码改动和每个提交的修改文件数量。我们以每个提交中修改的文件的扩展名所代表的编程语言,来检索出所使用的编程语言(一个提交可能有多个编程语言标签)。对于每个提交,我们通过它的提交日期减去这个项目的第一个提交的日期,来计算它的 *提交年龄* 。我们也计算其它的项目相关的统计数据,包括项目的最大提交年龄和开发者总数,用于我们的回归分析模型的控制变量,它在第三节中会讨论到。我们通过在提交记录中搜索与错误相关的关键字,比如,`error`、`bug`、`fix`、`issue`、`mistake`、`incorrect`、`fault`、`defect`、`flaw`,来识别 bug 修复提交。这一点与以前的研究类似。<sup> <a href="https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R18"> 18 </a></sup>
[表 2](http://deliveryimages.acm.org/10.1145/3130000/3126905/t2.jpg) 汇总了我们的数据集。因为一个项目可能使用多个编程语言,表的第二列展示了使用某种编程语言的项目的总数量。我们进一步排除了项目中该编程语言少于 20 个提交的那些编程语言。因为 20 是每个编程语言的每个项目的提交总数的第一个四分位值。例如,我们在 C 语言中共找到 220 项目的提交数量多于 20 个。这确保了每个“编程语言 – 项目”对有足够的活跃度。
[](http://deliveryimages.acm.org/10.1145/3130000/3126905/t2.jpg)
*表 2 研究主题*
总而言之,我们研究了最近 18 年以来,用了 17 种编程语言开发的,总共 728 个项目。总共包括了 29,000 个不同的开发者,157 万个提交,和 564,625 个 bug 修复提交。
#### 2.2 语言分类
我们基于影响语言质量的几种编程语言特性定义了语言类别,<sup> <a href="https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R7"> 7 </a> , <a href="https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R8"> 8 </a> , <a href="https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R12"> 12 </a></sup> ,如 [表 3](http://deliveryimages.acm.org/10.1145/3130000/3126905/t3.jpg) 所示。
<ruby> 编程范式 <rt> Programming Paradigm </rt></ruby> 表示项目是以命令方式、脚本方式、还是函数语言所写的。在本文的下面部分,我们分别使用 <ruby> 命令 <rt> procedural </rt></ruby> 和 <ruby> 脚本 <rt> scripting </rt></ruby> 这两个术语去代表命令方式和脚本方式。
[](http://deliveryimages.acm.org/10.1145/3130000/3126905/t3.jpg)
*表 3. 语言分类的不同类型*
<ruby> 类型检查 <rt> Type Checking </rt></ruby> 代表静态或者动态类型。在静态类型语言中,在编译时进行类型检查,并且变量名是绑定到一个值和一个类型的。另外,(包含变量的)表达式是根据运行时,它们可能产生的值所符合的类型来分类的。在动态类型语言中,类型检查发生在运行时。因此,在动态类型语言中,它可能出现在同一个程序中,一个变量名可能会绑定到不同类型的对象上的情形。
<ruby> 隐式类型转换 <rt> Implicit Type Conversion </rt></ruby> 允许一个类型为 T1 的操作数,作为另一个不同的类型 T2 来访问,而无需进行显式的类型转换。这样的隐式类型转换在一些情况下可能会带来类型混淆,尤其是当它表示一个明确的 T1 类型的操作数时,把它再作为另一个不同的 T2 类型的情况下。因为,并不是所有的隐式类型转换都会立即出现问题,通过我们识别出的允许进行隐式类型转换的所有编程语言中,可能发生隐式类型转换混淆的例子来展示我们的定义。例如,在像 Perl、 JavaScript、CoffeeScript 这样的编程语言中,一个字符和一个数字相加是允许的(比如,`"5" + 2` 结果是 `"52"`)。但是在 Php 中,相同的操作,结果是 `7`。像这种操作在一些编程语言中是不允许的,比如 Java 和 Python,因为,它们不允许隐式转换。在强数据类型的 C 和 C++ 中,这种操作的结果是不可预料的,例如,`int x; float y; y=3.5; x=y`;是合法的 C 代码,并且对于 `x` 和 `y` 其结果是不同的值,具体是哪一个值,取决于含义,这可能在后面会产生问题。<sup> <a href="https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#FNA"> a </a></sup> 在 `Objective-C` 中,数据类型 *id* 是一个通用对象指针,它可以被用于任何数据类型的对象,而不管分类是什么。<sup> <a href="https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#FNB"> b </a> 像这种通用数据类型提供了很好的灵活性,它可能导致隐式的类型转换,并且也会出现不可预料的结果。 <sup> <a href="https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#FNC"> c </a> </sup></sup> 因此,我们根据它的编译器是否 *允许* 或者 *不允许* 如上所述的隐式类型转换,对编程语言进行分类;而不允许隐式类型转换的编程语言,会显式检测类型混淆,并报告类型不匹配的错误。
不允许隐式类型转换的编程语言,使用一个类型判断算法,比如,Hindley <sup> <a href="https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R10"> 10 </a></sup> 和 Milner,<sup> <a href="https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R17"> 17 </a></sup> 或者,在运行时上使用一个动态类型检查器,可以在一个编译器(比如,使用 Java)中判断静态类型的结果。相比之下,一个类型混淆可能会悄无声息地发生,因为,它可能因为没有检测到,也可能是没有报告出来。无论是哪种方式,允许隐式类型转换在提供了灵活性的同时,最终也可能会出现很难确定原因的错误。为了简单起见,我们将用 <ruby> 隐含 <rt> implicit </rt></ruby> 代表允许隐式类型转换的编程语言,而不允许隐式类型转换的语言,我们用 <ruby> 明确 <rt> explicit </rt></ruby> 代表。
<ruby> 内存分类 <rt> Memory Class </rt></ruby> 表示是否要求开发者去管理内存。尽管 Objective-C 遵循了一个混合模式,我们仍将它放在非管理的分类中来对待,因为,我们在它的代码库中观察到很多的内存错误,在第 3 节的 RQ4 中会讨论到。
请注意,我们之所以使用这种方式对编程语言来分类和研究,是因为,这种方式在一个“真实的世界”中被大量的开发人员非正式使用。例如,TypeScript 被有意地分到静态编程语言的分类中,它不允许隐式类型转换。然而,在实践中,我们注意到,开发者经常(有 50% 的变量,并且跨 TypeScript —— 在我们的数据集中使用的项目)使用 `any` 类型,这是一个笼统的联合类型,并且,因此在实践中,TypeScript 允许动态地、隐式类型转换。为减少混淆,我们从我们的编程语言分类和相关的模型中排除了 TypeScript(查看 [表 3](http://deliveryimages.acm.org/10.1145/3130000/3126905/t3.jpg) 和 [7](http://deliveryimages.acm.org/10.1145/3130000/3126905/t7.jpg))。
#### 2.3 识别项目领域
我们基于编程语言的特性和功能,使用一个自动加手动的混合技术,将研究的项目分类到不同的领域。在 GitHub 上,项目使用 `project descriptions` 和 `README` 文件来描述它们的特性。我们使用一种文档主题生成模型(Latent Dirichlet Allocation,缩写为:LDA) <sup> <a href="https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R3"> 3 </a></sup> 去分析这些文本。提供一组文档给它,LDA 将生成不同的关键字,然后来识别可能的主题。对于每个文档,LDA 也估算每个主题分配的文档的概率。
我们检测到 30 个不同的领域(换句话说,就是主题),并且评估了每个项目从属于每个领域的概率。因为,这些自动检测的领域包含了几个具体项目的关键字,例如,facebook,很难去界定它的底层的常用功能。为了给每个领域分配一个有意义的名字,我们手动检查了 30 个与项目名字无关的用于识别领域的领域识别关键字。我们手动重命名了所有的 30 个自动检测的领域,并且找出了以下六个领域的大多数的项目:应用程序、数据库、代码分析、中间件、库,和框架。我们也找出了不符合以上任何一个领域的一些项目,因此,我们把这个领域笼统地标记为 *其它* 。随后,我们研究组的另一名成员检查和确认了这种项目领域分类的方式。[表 4](http://deliveryimages.acm.org/10.1145/3130000/3126905/t4.jpg) 汇总了这个过程识别到的领域结果。
[](http://deliveryimages.acm.org/10.1145/3130000/3126905/t4.jpg)
*表 4 领域特征*
#### 2.4 bug 分类
尽管修复软件 bug 时,开发者经常会在提交日志中留下关于这个 bug 的原始的重要信息;例如,为什么会产生 bug,以及怎么去修复 bug。我们利用很多信息去分类 bug,与 Tan 的 *et al* 类似。 <sup> <a href="https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R13"> 13 </a> , <a href="https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R24"> 24 </a></sup>
首先,我们基于 bug 的 <ruby> 原因 <rt> Cause </rt></ruby> 和 <ruby> 影响 <rt> Impact </rt></ruby> 进行分类。\_ 原因 \_ 进一步分解为不相关的错误子类:算法方面的、并发方面的、内存方面的、普通编程错误,和未知的。bug 的 *影响* 也分成四个不相关的子类:安全、性能、失败、和其它的未知类。因此,每个 bug 修复提交也包含原因和影响的类型。[表 5](http://deliveryimages.acm.org/10.1145/3130000/3126905/t5.jpg) 展示了描述的每个 bug 分类。这个类别分别在两个阶段中被执行:
[](http://deliveryimages.acm.org/10.1145/3130000/3126905/t5.jpg)
*表 5 bug 分类和在整个数据集中的描述*
**(1) 关键字搜索** 我们随机选择了 10% 的 bug 修复信息,并且使用一个基于关键字的搜索技术去对它们进行自动化分类,作为可能的 bug 类型。我们对这两种类型(原因和影响)分别使用这个注释。我们选择了一个限定的关键字和习惯用语集,如 [表 5](http://deliveryimages.acm.org/10.1145/3130000/3126905/t5.jpg) 所展示的。像这种限定的关键字和习惯用语集可以帮我们降低误报。
**(2) 监督分类** 我们使用前面步骤中的有注释的 bug 修复日志作为训练数据,为监督学习分类技术,通过测试数据来矫正,去对剩余的 bug 修复信息进行分类。我们首先转换每个 bug 修复信息为一个词袋(LCTT 译注:bag-of-words,一种信息检索模型)。然后,删除在所有的 bug 修复信息中仅出现过一次的词。这样减少了具体项目的关键字。我们也使用标准的自然语言处理技术来解决这个问题。最终,我们使用支持向量机(LCTT 译注:Support Vector Machine,缩写为 SVM,在机器学习领域中,一种有监督的学习算法)去对测试数据进行分类。
为精确评估 bug 分类器,我们手动注释了 180 个随机选择的 bug 修复,平均分布在所有的分类中。然后,我们比较手动注释的数据集在自动分类器中的结果。最终处理后的,表现出的精确度是可接受的,性能方面的精确度最低,是 70%,并发错误方面的精确度最高,是 100%,平均是 84%。再次运行,精确度从低到高是 69% 到 91%,平均精确度还是 84%。
我们的 bug 分类的结果展示在 [表 5](http://deliveryimages.acm.org/10.1145/3130000/3126905/t5.jpg) 中。大多数缺陷的原因都与普通编程错误相关。这个结果并不意外,因为,在这个分类中涉及了大量的编程错误,比如,类型错误、输入错误、编写错误、等等。我们的技术并不能将在任何(原因或影响)分类中占比为 1.4% 的 bug 修复信息再次进行分类;我们将它归类为未知。
#### 2.5 统计方法
我们使用回归模型对软件项目相关的其它因素中的有缺陷的提交数量进行了建模。所有的模型使用<ruby> 负二项回归 <rt> negative binomial regression </rt></ruby>(缩写为 NBR)(LCTT 译注:一种回归分析模型) 去对项目属性计数进行建模,比如,提交数量。NBR 是一个广义的线性模型,用于对非负整数进行响应建模。<sup> <a href="https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R4"> 4 </a></sup>
在我们的模型中,我们对每个项目的编程语言,控制几个可能影响最终结果的因素。因此,在我们的回归分析中,每个(语言/项目)对是一个行,并且可以视为来自流行的开源项目中的样本。我们依据变量计数进行对象转换,以使变量保持稳定,并且提升了模型的适用度。<sup> <a href="https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R4"> 4 </a></sup> 我们通过使用 AIC 和 Vuong 对非嵌套模型的测试比较来验证它们。
去检查那些过度的多重共线性(LCTT 译注:多重共线性是指,在线性回归模型中解释变量之间由于存在精确相关关系或高度相关关系而使模型估计失真或难以估计准确。)并不是一个问题,我们在所有的模型中使用一个保守的最大值 5,去计算每个依赖的变量的膨胀因子的方差。<sup> <a href="https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R4"> 4 </a></sup> 我们通过对每个模型的残差和杠杆图进行视觉检查来移除高杠杆点,找出库克距离(LCTT 译注:一个统计学术语,用于诊断回归分析中是否存在异常数据)的分离值和最大值。
我们利用 *效果* ,或者 *差异* ,编码到我们的研究中,以提高编程语言回归系数的表现。<sup> <a href="https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R4"> 4 </a></sup> 加权的效果代码允许我们将每种编程语言与所有编程语言的效果进行比较,同时弥补了跨项目使用编程语言的不均匀性。<sup> <a href="https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R23"> 23 </a></sup> 去测试两种变量因素之间的联系,我们使用一个独立的卡方检验(LCTT 译注:Chi-square,一种统计学上的假设检验方法)测试。<sup> <a href="https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R14"> 14 </a></sup> 在证实一个依赖之后,我们使用 Cramer 的 V,它是与一个 `r × c` 等价的正常数据的 `phi(φ)` 系数,去建立一个效果数据。
### 3 结果
我们从简单明了的问题开始,它非常直接地解决了人们坚信的一些核心问题,即:
#### 问题 1:一些编程语言相比其它语言来说更易于出现缺陷吗?
我们使用了回归分析模型,去比较每个编程语言对所有编程语言缺陷数量平均值的影响,以及对缺陷修复提交的影响(查看 [表 6](http://deliveryimages.acm.org/10.1145/3130000/3126905/t6.jpg))。
[](http://deliveryimages.acm.org/10.1145/3130000/3126905/t6.jpg)
*表 6. 一些语言的缺陷要少于其它语言*
我们包括了一些变量,作为对明确影响反应的控制因子。项目<ruby> 年龄 <rt> age </rt></ruby>也包括在内,因为,越老的项目生成的缺陷修复数量越大。<ruby> 提交 <rt> commits </rt></ruby>数量也会对项目反应有轻微的影响。另外,从事该项目的<ruby> 开发人员 <rt> dev </rt></ruby>的数量和项目的原始<ruby> 大小 <rt> size </rt></ruby>,都会随着项目的活跃而增长。
上述模型中估算系数的大小和符号(LCTT 译注:指 “+”或者“-”)与结果的预测因子有关。初始的四种变量是控制变量,并且,我们对这些变量对最终结果的影响不感兴趣,只是说它们都是积极的和有意义的。语言变量是指示变量,是每个项目的变化因子,该因子将每种编程语言与所有项目的编程语言的加权平均值进行比较。编程语言系数可以大体上分为三类。第一类是,那些在统计学上无关紧要的系数,并且在建模过程中这些系数不能从 0 中区分出来。这些编程语言的表现与平均值相似,或者它们也可能有更大的方差。剩余的系数是非常明显的,要么是正的,要么是负的。对于那些正的系数,我们猜测可能与这个编程语言有大量的缺陷修复相关。这些语言包括 C、C++、Objective-C、Php,以及 Python。所有的有一个负的系数的编程语言,比如 Clojure、Haskell、Ruby,和 Scala,暗示这些语言的缺陷修复提交可能小于平均值。
应该注意的是,虽然,从统计学的角度观察到编程语言与缺陷之间有明显的联系,但是,大家不要过高估计编程语言对于缺陷的影响,因为,这种影响效应是非常小的。异常分析的结果显示,这种影响小于总异常的 1%。
[](http://deliveryimages.acm.org/10.1145/3130000/3126905/ut1.jpg)
我们可以这样去理解模型的系数,它代表一个预测因子在所有其它预测因子保持不变的情况下,这个预测因子一个<ruby> 单位 <rt> unit </rt></ruby>的变化,所反应出的预期的响应的对数变化;换句话说,对于一个系数 β<sub> i</sub> ,在 β<sub> i</sub> 中一个单位的变化,产生一个预期的 e<sup> β <sub> i </sub></sup> 响应的变化。对于可变因子,这个预期的变化是与所有编程语言的平均值进行比较。因此,如果对于一定数量的提交,用一个处于平均值的编程语言开发的特定项目有四个缺陷提交,那么,如果选择使用 C++ 来开发,意味着我们预计应该有一个额外的(LCTT 译注:相对于平均值 4,多 1 个)缺陷提交,因为 e<sup> 0.18</sup> × 4 = 4.79。对于相同的项目,如果选择使用 Haskell 来开发,意味着我们预计应该少一个(LCTT 译注:同上,相对于平均值 4)缺陷提交。因为, e<sup> −0.26</sup> × 4 = 3.08。预测的精确度取决于剩余的其它因子都保持不变,除了那些微不足道的项目之外,所有的这些都是一个极具挑战性的命题。所有观察性研究都面临类似的局限性;我们将在第 5 节中详细解决这些事情。
**结论 1:一些编程语言相比其它编程语言有更高的缺陷相关度,不过,影响非常小。**
在这篇文章的剩余部分,我们会在基本结论的基础上详细阐述,通过考虑不同种类的应用程序、缺陷、和编程语言,可以进一步深入了解编程语言和缺陷倾向之间的关系。
软件 bug 通常落进两种宽泛的分类中:
1. *特定领域的 bug* :特定于项目功能,并且不依赖于底层编程语言。
2. *普通 bug* :大多数的普通 bug 是天生的,并且与项目功能无关,比如,输入错误,并发错误、等等。
因此,在一个项目中,应用程序领域和编程语言相互作用可能会影响缺陷的数量,这一结论被认为是合理的。因为一些编程语言被认为在一些任务上相比其它语言表现更突出,例如,C 对于低级别的(底层)工作,或者,Java 对于用户应用程序,对于编程语言的一个不合适的选择,可能会带来更多的缺陷。为研究这种情况,我们将理想化地忽略领域特定的 bug,因为,普通 bug 更依赖于编程语言的特性。但是,因为一个领域特定的 bug 也可能出现在一个普通的编程错误中,这两者是很难区分的。一个可能的变通办法是在控制领域的同时去研究编程语言。从统计的角度来看,虽然,使用 17 种编程语言跨 7 个领域,在给定的样本数量中,理解大量的术语将是一个极大的挑战。
鉴于这种情况,我们首先考虑在一个项目中测试领域和编程语言使用之间的依赖关系,独立使用一个<ruby> 卡方检验 <rt> Chi-square </rt></ruby>测试。在 119 个单元中,是 46 个,也就是说是 39%,它在我们设定的保守值 5 以上,它太高了。这个数字不能超过 20%,应该低于 5。<sup> <a href="https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R14"> 14 </a></sup> 我们在这里包含了完整有值; <sup> <a href="https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#FND"> d </a></sup> 但是,通过 Cramer 的 V 测试的值是 0.191,是低相关度的,表明任何编程语言和领域之间的相关度是非常小的,并且,在回归模型中包含领域并不会产生有意义的结果。
去解决这种情况的一个选择是,去移除编程语言,或者混合领域,但是,我们现有的数据没有进行完全挑选。或者,我们混合编程语言;这个选择导致一个相关但略有不同的问题。
#### 问题 2: 哪些编程语言特性与缺陷相关?
我们按编程语言类别聚合它们,而不是考虑单独的编程语言,正如在第 2.2 节所描述的那样,然后去分析与缺陷的关系。总体上说,这些属性中的每一个都将编程语言按照在上下文中经常讨论的错误、用户辩论驱动、或者按以前工作主题来划分的。因此,单独的属性是高度相关的,我们创建了六个模型因子,将所有的单独因子综合到我们的研究中。然后,我们对六个不同的因子对缺陷数量的影响进行建模,同时控制我们在 *问题 1* 节中使用的模型中的相同的基本协变量(LCTT 译注:协变量是指在实验中不能被人为操纵的独立变量)。
关于使用的编程语言(在前面的 [表 6](http://deliveryimages.acm.org/10.1145/3130000/3126905/t6.jpg)中),我们使用跨所有语言类的平均反应来比较编程语言 *类* 。这个模型在 [表 7](http://deliveryimages.acm.org/10.1145/3130000/3126905/t7.jpg) 中表达了出来。很明显,`Script-Dynamic-Explicit-Managed` 类有最小的量级系数。这个系数是微不足道的,换句话说,对这个系数的 <ruby> Z 校验 <rt> z-test </rt></ruby>(LCTT 译注:统计学上的一种平均值差异校验的方法) 并不能把它从 0 中区分出来。鉴于标准错误的量级,我们可以假设,在这个类别中的编程语言的行为是非常接近于所有编程语言行为的平均值。我们可以通过使用 `Proc-Static-Implicit-Unmanaged` 作为基本级并用于处理,或者使用基本级来虚假编码比较每个语言类,来证明这一点。在这种情况下,`Script-Dynamic-Explicit-Managed` 是明显不同于 *p* = 0.00044 的。注意,虽然我们在这是选择了不同的编码方法,影响了系数和 Z 值,这个方法和所有其它的方面都是一样的。当我们改变了编码,我们调整系数去反应我们希望生成的对比。<sup> <a href="https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R4"> 4 </a></sup> 将其它类的编程语言与总体平均数进行比较,`Proc-Static-Implicit-Unmanaged` 类编程语言更容易引起缺陷。这意味着与其它过程类编程语言相比,隐式类型转换或者管理内存会导致更多的缺陷倾向。
[](http://deliveryimages.acm.org/10.1145/3130000/3126905/t7.jpg)
*表 7. 函数式语言与缺陷的关联度和其它类语言相比要低,而过程类语言则大于或接近于平均值。*
在脚本类编程语言中,我们观察到类似于允许与不允许隐式类型转换的编程语言之间的关系,它们提供的一些证据表明,隐式类型转换(与显式类型转换相比)才是导致这种差异的原因,而不是内存管理。鉴于各种因素之间的相关性,我们并不能得出这个结论。但是,当它们与平均值进行比较时,作为一个组,那些不允许隐式类型转换的编程语言出现错误的倾向更低一些,而那些出现错误倾向更高的编程语言,出现错误的机率则相对更高。在函数式编程语言中静态和动态类型之间的差异也很明显。
函数式语言作为一个组展示了与平均值的很明显的差异。静态类型语言的系数要小很多,但是函数式语言类都有同样的标准错误。函数式静态编程语言出现错误的倾向要小于函数式动态编程语言,这是一个强有力的证据,尽管如此,Z 校验仅仅是检验系数是否能从 0 中区分出来。为了强化这个推论,我们使用处理编码,重新编码了上面的模型,并且观察到,`Functional-Static-Explicit-Managed` 编程语言类的错误倾向是明显小于 `Functional-Dynamic-Explicit-Managed` 编程语言类的 *p* = 0.034。
[](http://deliveryimages.acm.org/10.1145/3130000/3126905/ut2.jpg)
与编程语言和缺陷一样,编程语言类与缺陷之间关系的影响是非常小的。解释类编程语言的这种差异也是相似的,虽然很小,解释类编程语言的这种差异小于 1%。
我们现在重新回到应用领域这个问题。应用领域是否与语言类相互影响?怎么选择?例如,一个函数化编程语言,对特定的领域有一定的优势?与上面一样,对于这些因素和项目领域之间的关系做一个卡方检验,它的值是 99.05, *df* = 30, *p* = 2.622e–09,我们拒绝无意义假设,Cramer 的 V 产生的值是 0.133,表示一个弱关联。因此,虽然领域和编程语言之间有一些关联,但在这里应用领域和编程语言类之间仅仅是一个非常弱的关联。
**结论 2:在编程语言类与缺陷之间有一个很小但是很明显的关系。函数式语言与过程式或者脚本式语言相比,缺陷要少。**
这个结论有些不太令人满意的地方,因为,我们并没有一个强有力的证据去证明,在一个项目中编程语言或者语言类和应用领域之间的关联性。一个替代方法是,基于全部的编程语言和应用领域,忽略项目和缺陷总数,而去查看相同的数据。因为,这样不再产生不相关的样本,我们没有从统计学的角度去尝试分析它,而是使用一个描述式的、基于可视化的方法。
我们定义了 <ruby> 缺陷倾向 <rt> Defect Proneness </rt></ruby> 作为 bug 修复提交与每语言每领域总提交的比率。[图 1](http://deliveryimages.acm.org/10.1145/3130000/3126905/f1.jpg) 使用了一个热力图展示了应用领域与编程语言之间的相互作用,从亮到暗表示缺陷倾向在增加。我们研究了哪些编程语言因素影响了跨多种语言写的项目的缺陷修复提交。它引出了下面的研究问题:
[](http://deliveryimages.acm.org/10.1145/3130000/3126905/f1.jpg)
*图 1. 编程语言的缺陷倾向与应用领域之间的相互作用。对于一个给定的领域(列底部),热力图中的每个格子表示了一个编程语言的缺陷倾向(行头部)。“整体”列表示一个编程语言基于所有领域的缺陷倾向。用白色十字线标记的格子代表一个 null 值,换句话说,就是在那个格子里没有符合的提交。*
#### 问题 3: 编程语言的错误倾向是否取决于应用领域?
为了回答这个问题,我们首先在我们的回归模型中,以高杠杆点过滤掉认为是异常的项目,这种方法在这里是必要的,尽管这是一个非统计学的方法,一些关系可能影响可视化。例如,我们找到一个简单的项目,Google 的 v8,一个 JavaScript 项目,负责中间件中的所有错误。这对我们来说是一个惊喜,因为 JavaScript 通常不用于中间件。这个模式一直在其它应用领域中不停地重复着,因此,我们过滤出的项目的缺陷度都低于 10% 和高于 90%。这个结果在 [图 1](http://deliveryimages.acm.org/10.1145/3130000/3126905/f1.jpg) 中。
我们看到在这个热力图中仅有一个很小的差异,正如在问题 1 节中看到的那样,这个结果仅表示编程语言固有的错误倾向。为验证这个推论,我们测量了编程语言对每个应用领域和对全部应用领域的缺陷倾向。对于除了数据库以外的全部领域,关联性都是正向的,并且 p 值是有意义的(<0.01)。因此,关于缺陷倾向,在每个领域的语言排序与全部领域的语言排序是基本相同的。
[](http://deliveryimages.acm.org/10.1145/3130000/3126905/ut3.jpg)
**结论 3: 应用领域和编程语言缺陷倾向之间总体上没有联系。**
我们证明了不同的语言产生了大量的缺陷,并且,这个关系不仅与特定的语言相关,也适用于一般的语言类;然而,我们发现,项目类型并不能在一定程度上协调这种关系。现在,我们转变我们的注意力到反应分类上,我想去了解,编程语言与特定种类的缺陷之间有什么联系,以及这种关系怎么与我们观察到的更普通的关系去比较。我们将缺陷分为不同的类别,如 [表 5](http://deliveryimages.acm.org/10.1145/3130000/3126905/t5.jpg) 所描述的那样,然后提出以下的问题:
#### 问题 4:编程语言与 bug 分类之间有什么关系?
我们使用了一个类似于问题 3 中所用的方法,去了解编程语言与 bug 分类之间的关系。首先,我们研究了 bug 分类和编程语言类之间的关系。一个热力图([图 2](http://deliveryimages.acm.org/10.1145/3130000/3126905/f2.jpg))展示了在编程语言类和 bug 类型之上的总缺陷数。去理解 bug 分类和语言之间的相互作用,我们对每个类别使用一个 NBR 回归模型。对于每个模型,我们使用了与问题 1 中相同的控制因素,以及使用加权效应编码后的语言,去预测缺陷修复提交。
[](http://deliveryimages.acm.org/10.1145/3130000/3126905/f2.jpg)
*图 2. bug 类别与编程语言类之间的关系。每个格子表示每语言类(行头部)每 bug 类别(列底部)的 bug 修复提交占全部 bug 修复提交的百分比。这个值是按列规范化的。*
结果和编程语言的方差分析值展示在 [表 8](http://deliveryimages.acm.org/10.1145/3130000/3126905/t8.jpg) 中。每个模型的整体异常是非常小的,并且对于特定的缺陷类型,通过语言所展示的比例在大多数类别中的量级是类似的。我们解释这种关系为,编程语言对于特定的 bug 类别的影响要大于总体的影响。尽管我们结论概括了全部的类别,但是,在接下来的一节中,我们对 [表 5](http://deliveryimages.acm.org/10.1145/3130000/3126905/t5.jpg) 中反应出来的 bug 数较多的 bug 类别做进一步研究。
[](http://deliveryimages.acm.org/10.1145/3130000/3126905/t8.jpg)
*表 8. 虽然编程语言对缺陷的影响因缺陷类别而不同,但是,编程语言对特定的类别的影响要大于一般的类别。*
**编程错误** 普通的编程错误占所有 bug 修复提交的 88.53% 左右,并且在所有的编程语言类中都有。因此,回归分析给出了一个与问题 1 中类似的结论(查看 [表 6](http://deliveryimages.acm.org/10.1145/3130000/3126905/t6.jpg))。所有的编程语言都会导致这种编程错误,比如,处理错误、定义错误、输入错误、等等。
**内存错误** 内存错误占所有 bug 修复提交的 5.44%。热力图 [图 2](http://deliveryimages.acm.org/10.1145/3130000/3126905/f2.jpg) 证明了在 `Proc-Static-Implicit-Unmanaged` 类和内存错误之间存在着非常紧密的联系。非管理内存的编程语言出现内存 bug,这是预料之中的。[表 8](http://deliveryimages.acm.org/10.1145/3130000/3126905/t8.jpg) 也证明了这一点,例如,C、C++、和 Objective-C 引发了很多的内存错误。在管理内存的语言中 Java 引发了更多的内存错误,尽管它少于非管理内存的编程语言。虽然 Java 自己做内存回收,但是,它出现内存泄露一点也不奇怪,因为对象引用经常阻止内存回收。<sup> <a href="https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R11"> 11 </a></sup> 在我们的数据中,Java 的所有内存错误中,28.89% 是内存泄漏造成的。就数量而言,编程语言中内存缺陷相比其它类别的 *原因* 造成的影响要大很多。
**并发错误** 在总的 bug 修复提交中,并发错误相关的修复提交占 1.99%。热力图显示,`Proc-Static-Implicit-Unmanaged` 是主要的错误类型。在这种错误中,C 和 C++ 分别占 19.15% 和 7.89%,并且它们分布在各个项目中。
[](http://deliveryimages.acm.org/10.1145/3130000/3126905/ut4.jpg)
属于 `Static-Strong-Managed` 语言类的编程语言都被证实处于热力图中的暗区中,普通的静态语言相比其它语言产生更多的并发错误。在动态语言中,仅仅有 Erlang 有更多的并发错误倾向,或许与使用这种语言开发的并发应用程序非常多有关系。同样地,在 [表 8](http://deliveryimages.acm.org/10.1145/3130000/3126905/t8.jpg) 中的负的系数表明,用诸如 Ruby 和 `Php 这样的动态编程语言写的项目,并发错误要少一些。请注意,某些语言,如 JavaScript、CoffeeScript 和 TypeScript 是不支持并发的,在传统的惯例中,虽然 Php 具有有限的并发支持(取决于它的实现)。这些语言在我们的数据中引入了虚假的 0,因此,在 [表 8](http://deliveryimages.acm.org/10.1145/3130000/3126905/t8.jpg) 中这些语言的并发模型的系数,不能像其它的语言那样去解释。因为存在这些虚假的 0,所以在这个模型中所有语言的平均数非常小,它可能影响系数的大小,因此,她们给 w.r.t. 一个平均数,但是,这并不影响他们之间的相对关系,因为我们只关注它们的相对关系。
基于 bug 修复消息中高频词的文本分析表明,大多数的并发错误发生在一个条件争用、死锁、或者不正确的同步上,正如上面表中所示。遍历所有语言,条件争用是并发错误出现最多的原因,例如,在 Go 中占 92%。在 Go 中条件争用错误的改进,或许是因为使用了一个争用检测工具帮助开发者去定位争用。同步错误主要与消息传递接口(MPI)或者共享内存操作(SHM)相关。Erlang 和 Go 对线程间通讯使用 MPI <sup> <a href="https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#FNE"> e </a></sup> ,这就是为什么这两种语言没有发生任何 SHM 相关的错误的原因,比如共享锁、互斥锁等等。相比之下,为线程间通讯使用早期的 SHM 技术的语言写的项目,就可能存在锁相关的错误。
**安全和其它冲突错误** 在所有的 bug 修复提交中,与<ruby> 冲突 <rt> Impact </rt></ruby>错误相关的提交占了 7.33% 左右。其中,Erlang、C++、Python 与安全相关的错误要高于平均值([表 8](http://deliveryimages.acm.org/10.1145/3130000/3126905/t8.jpg))。Clojure 项目相关的安全错误较少([图 2](http://deliveryimages.acm.org/10.1145/3130000/3126905/f2.jpg))。从热力图上我们也可以看出来,静态语言一般更易于发生失败和性能错误,紧随其后的是 `Functional-Dynamic-Explicit-Managed` 语言,比如 Erlang。对异常结果的分析表明,编程语言与冲突失败密切相关。虽然安全错误在这个类别中是弱相关的,与残差相比,解释类语言的差异仍然比较大。
**结论 4: 缺陷类型与编程语言强相关;一些缺陷类型比如内存错误和并发错误也取决于早期的语言(所使用的技术)。对于特定类别,编程语言所引起的错误比整体更多。**
### 4. 相关工作
在编程语言比较之前做的工作分为以下三类:
#### (1) 受控实验
对于一个给定的任务,开发者使用不同的语言进行编程时受到监视。研究然后比较结果,比如,开发成果和代码质量。Hanenberg <sup> <a href="https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R7"> 7 </a></sup> 通过开发一个解析程序,对 48 位程序员监视了 27 小时,去比较了静态与动态类型。他发现这两者在代码质量方面没有显著的差异,但是,基于动态类型的语言花费了更短的开发时间。他们的研究是在一个实验室中,使用本科学生,设置了定制的语言和 IDE 来进行的。我们的研究正好相反,是一个实际的流行软件应用的研究。虽然我们只能够通过使用回归模型间接(和 *事后* )控制混杂因素,我们的优势是样本数量大,并且更真实、使用更广泛的软件。我们发现在相同的条件下,静态化类型的语言比动态化类型的语言更少出现错误倾向,并且不允许隐式类型转换的语言要好于允许隐式类型转换的语言,其对结果的影响是非常小的。这是合理的,因为样本量非常大,所以这种非常小的影响在这个研究中可以看得到。
Harrison et al. <sup> <a href="https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R8"> 8 </a></sup> 比较了 C++ 与 SML,一个是过程化编程语言,一个是函数化编程语言,在总的错误数量上没有找到显著的差异,不过 SML 相比 C++ 有更高的缺陷密集度。SML 在我们的数据中并没有体现出来,不过,认为函数式编程语言相比过程化编程语言更少出现缺陷。另一个重点工作是比较跨不同语言的开发工作。<sup> <a href="https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R12"> 12 </a> , <a href="https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R20"> 20 </a></sup> 不过,他们并不分析编程语言的缺陷倾向。
#### (2) 调查
Meyerovich 和 Rabkin <sup> <a href="https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R16"> 16 </a></sup> 调查了开发者对编程语言的观点,去研究为什么一些编程语言比其它的语言更流行。他们的报告指出,非编程语言的因素影响非常大:先前的编程语言技能、可用的开源工具、以及现有的老式系统。我们的研究也证明,可利用的外部工具也影响软件质量;例如,在 Go 中的并发 bug(请查看问题 4 节内容)。
#### (3) 对软件仓库的挖掘
Bhattacharya 和 Neamtiu <sup> <a href="https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R1"> 1 </a></sup> 研究了用 C 和 C++ 开发的四个项目,并且发现在 C++ 中开发的组件一般比在 C 中开发的组件更可靠。我们发现 C 和 C++ 的错误倾向要高于全部编程语言的平均值。但是,对于某些 bug 类型,像并发错误,C 的缺陷倾向要高于 C++(请查看第 3 节中的问题 4)。
### 5. 有效的风险
我们认为,我们的报告的结论几乎没有风险。首先,在识别 bug 修复提交方面,我们依赖的关键字是开发者经常用于表示 bug 修复的关键字。我们的选择是经过认真考虑的。在一个持续的开发过程中,我们去捕获那些开发者一直面对的问题,而不是他们报告的 bug。不过,这种选择存在过高估计的风险。我们对领域分类是为了去解释缺陷的倾向,而且,我们研究组中另外的成员验证过分类。此外,我们花费精力去对 bug 修复提交进行分类,也可能有被最初选择的关键字所污染的风险。每个项目在提交日志的描述上也不相同。为了缓解这些风险,我们像 2.4 节中描述的那样,利用手工注释评估了我们的类别。
我们判断文件所属的编程语言是基于文件的扩展名。如果使用不同的编程语言写的文件使用了我们研究的通用的编程语言文件的扩展名,这种情况下也容易出现错误倾向。为减少这种错误,我们使用一个随机样本文件集手工验证了我们的语言分类。
根据我们的数据集所显示的情形,2.2 节中的解释类编程语言,我们依据编程语言属性的主要用途作了一些假设。例如,我们将 Objective-C 分到非管理内存类型中,而不是混合类型。同样,我们将 Scala 注释为函数式编程语言,将 C# 作为过程化的编程语言,虽然,它们在设计的选择上两者都支持。 <sup> <a href="https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R19"> 19 </a> , <a href="https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R21"> 21 </a></sup> 在这项研究工作中,我们没有从过程化编程语言中分离出面向对象的编程语言(OOP),因为,它们没有清晰的区别,主要差异在于编程类型。我们将 C++ 分到允许隐式类型转换的类别中是因为,某些类型的内存区域可以通过使用指针操作被进行不同的处理, <sup> <a href="https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007#R22"> 22 </a></sup> 并且我们注意到大多数 C++ 编译器可以在编译时检测类型错误。
最后,我们将缺陷修复提交关联到编程语言属性上,它们可以反应出报告的风格或者其它开发者的属性。可用的外部工具或者<ruby> 库 <rt> library </rt></ruby>也可以影响一个相关的编程语言的 bug 数量。
### 6. 总结
我们对编程语言和使用进行了大规模的研究,因为它涉及到软件质量。我们使用的 Github 上的数据,具有很高的复杂性和多个维度上的差异的特性。我们的样本数量允许我们对编程语言效果以及在控制一些混杂因素的情况下,对编程语言、应用领域和缺陷类型之间的相互作用,进行一个混合方法的研究。研究数据显示,函数式语言是好于过程化语言的;不允许隐式类型转换的语言是好于允许隐式类型转换的语言的;静态类型的语言是好于动态类型的语言的;管理内存的语言是好于非管理的语言的。进一步讲,编程语言的缺陷倾向与软件应用领域并没有关联。另外,每个编程语言更多是与特定的 bug 类别有关联,而不是与全部 bug。
另一方面,即便是很大规模的数据集,它们被多种方法同时进行分割后,也变得很小且不全面。因此,随着依赖的变量越来越多,很难去回答某个变量所产生的影响有多大这种问题,尤其是在变量之间相互作用的情况下。因此,我们无法去量化编程语言在使用中的特定的效果。其它的方法,比如调查,可能对此有帮助。我们将在以后的工作中来解决这些挑战。
### 致谢
这个材料是在美国国家科学基金会(NSF)以及美国空军科学研究办公室(AFOSR)的授权和支持下完成的。授权号 1445079, 1247280, 1414172,1446683,FA955-11-1-0246。
### 参考资料
1. Bhattacharya, P., Neamtiu, I. Assessing programming language impact on development and maintenance: A study on C and C++. In *Proceedings of the 33rd International Conference on Software Engineering, ICSE'11* (New York, NY USA, 2011). ACM, 171–180.
2. Bird, C., Nagappan, N., Murphy, B., Gall, H., Devanbu, P. Don't touch my code! Examining the effects of ownership on software quality. In *Proceedings of the 19th ACM SIGSOFT Symposium and the 13th European Conference on Foundations of Software Engineering* (2011). ACM, 4–14.
3. Blei, D.M. Probabilistic topic models. *Commun. ACM 55* , 4 (2012), 77–84.
4. Cohen, J. *Applied Multiple Regression/Correlation Analysis for the Behavioral Sciences.* Lawrence Erlbaum, 2003.
5. Easterbrook, S., Singer, J., Storey, M.-A., Damian, D. Selecting empirical methods for software engineering research. In *Guide to Advanced Empirical Software Engineering* (2008). Springer, 285–311.
6. El Emam, K., Benlarbi, S., Goel, N., Rai, S.N. The confounding effect of class size on the validity of object-oriented metrics. *IEEE Trans. Softw. Eng. 27* , 7 (2001), 630–650.
7. Hanenberg, S. An experiment about static and dynamic type systems: Doubts about the positive impact of static type systems on development time. In *Proceedings of the ACM International Conference on Object Oriented Programming Systems Languages and Applications, OOPSLA'10* (New York, NY, USA, 2010). ACM, 22–35.
8. Harrison, R., Smaraweera, L., Dobie, M., Lewis, P. Comparing programming paradigms: An evaluation of functional and object-oriented programs. *Softw. Eng. J. 11* , 4 (1996), 247–254.
9. Harter, D.E., Krishnan, M.S., Slaughter, S.A. Effects of process maturity on quality, cycle time, and effort in software product development. *Manage. Sci. 46* 4 (2000), 451–466.
10. Hindley, R. The principal type-scheme of an object in combinatory logic. *Trans. Am. Math. Soc.* (1969), 29–60.
11. Jump, M., McKinley, K.S. Cork: Dynamic memory leak detection for garbage-collected languages. In *ACM SIGPLAN Notices* , Volume 42 (2007). ACM, 31–38.
12. Kleinschmager, S., Hanenberg, S., Robbes, R., Tanter, É., Stefik, A. Do static type systems improve the maintainability of software systems? An empirical study. In *2012 IEEE 20th International Conference on Program Comprehension (ICPC)* (2012). IEEE, 153–162.
13. Li, Z., Tan, L., Wang, X., Lu, S., Zhou, Y., Zhai, C. Have things changed now? An empirical study of bug characteristics in modern open source software. In *ASID'06: Proceedings of the 1st Workshop on Architectural and System Support for Improving Software Dependability* (October 2006).
14. Marques De Sá, J.P. *Applied Statistics Using SPSS, Statistica and Matlab* , 2003.
15. Mayer, C., Hanenberg, S., Robbes, R., Tanter, É., Stefik, A. An empirical study of the influence of static type systems on the usability of undocumented software. In *ACM SIGPLAN Notices* , Volume 47 (2012). ACM, 683–702.
16. Meyerovich, L.A., Rabkin, A.S. Empirical analysis of programming language adoption. In *Proceedings of the 2013 ACM SIGPLAN International Conference on Object Oriented Programming Systems Languages & Applications* (2013). ACM, 1–18.
17. Milner, R. A theory of type polymorphism in programming. *J. Comput. Syst. Sci. 17* , 3 (1978), 348–375.
18. Mockus, A., Votta, L.G. Identifying reasons for software changes using historic databases. In *ICSM'00. Proceedings of the International Conference on Software Maintenance* (2000). IEEE Computer Society, 120.
19. Odersky, M., Spoon, L., Venners, B. *Programming in Scala.* Artima Inc, 2008.
20. Pankratius, V., Schmidt, F., Garretón, G. Combining functional and imperative programming for multicore software: An empirical study evaluating scala and java. In *Proceedings of the 2012 International Conference on Software Engineering* (2012). IEEE Press, 123–133.
21. Petricek, T., Skeet, J. *Real World Functional Programming: With Examples in F# and C#.* Manning Publications Co., 2009.
22. Pierce, B.C. *Types and Programming Languages.* MIT Press, 2002.
23. Posnett, D., Bird, C., Dévanbu, P. An empirical study on the influence of pattern roles on change-proneness. *Emp. Softw. Eng. 16* , 3 (2011), 396–423.
24. Tan, L., Liu, C., Li, Z., Wang, X., Zhou, Y., Zhai, C. Bug characteristics in open source software. *Emp. Softw. Eng.* (2013).
### 作者
**Baishakhi Ray** ([[email protected]](mailto:[email protected])), Department of Computer Science, University of Virginia, Charlottesville, VA.
**Daryl Posnett** ([[email protected]](mailto:[email protected])), Department of Computer Science, University of California, Davis, CA.
**Premkumar Devanbu** ([[email protected]](mailto:[email protected])), Department of Computer Science, University of California, Davis, CA.
**Vladimir Filkov** ([[email protected]](mailto:[email protected])), Department of Computer Science, University of California, Davis, CA.
### 脚注
* a. Wikipedia's article on type conversion, <https://en.wikipedia.org/wiki/Type_conversion>, has more examples of unintended behavior in C.
* b. This Apple developer article describes the usage of "id" <http://tinyurl.com/jkl7cby>.
* c. Some examples can be found here <http://dobegin.com/objc-id-type/> and here <http://tinyurl.com/hxv8kvg>.
* d. Chi-squared value of 243.6 with 96 df. and p = 8.394e–15
* e. MPI does not require locking of shared resources.
---
via: <https://cacm.acm.org/magazines/2017/10/221326-a-large-scale-study-of-programming-languages-and-code-quality-in-github/fulltext?imm_mid=0f7103&cmp=em-prog-na-na-newsltr_20171007>
作者:[Baishakhi Ray](http://delivery.acm.org/10.1145/3130000/3126905/mailto:[email protected]), [Daryl Posnett](http://delivery.acm.org/10.1145/3130000/3126905/mailto:[email protected]), [Premkumar Devanbu](http://delivery.acm.org/10.1145/3130000/3126905/mailto:[email protected]), [Vladimir Filkov](http://delivery.acm.org/10.1145/3130000/3126905/mailto:[email protected]) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,789 | 10 条加速 Ubuntu Linux 的杀手级技巧 | https://itsfoss.com/speed-up-ubuntu-1310/ | 2018-06-29T08:45:00 | [
"Ubuntu",
"优化"
] | https://linux.cn/article-9789-1.html |
>
> 一些实际的**加速 Ubuntu Linux 的技巧**。 这里的技巧对于大多数版本的 Ubuntu 是有效的,也可以应用于 Linux Mint 以及其他的基于 Ubuntu 的发行版。
>
>
>
也许你经历过使用 Ubuntu 一段时间后系统开始运行缓慢的情况。 在这篇文章里,我们将看到几项调整以及**使 Ubuntu 运行更快的窍门**。
在我们了解如何提升 Ubuntu 的总体系统表现之前,首先让我们思考为什么系统逐渐变慢。这个问题可能有很多原因。也许你有一台只有基础配置的简陋的电脑;也许你安装了一些在启动时即耗尽资源的应用。事实上原因无穷无尽。
这里我列出一些能够帮助你稍微加速 Ubuntu 的小调整。也有一些你能够采用以获取一个更流畅、有所提升的系统表现的经验。你可以选择遵循全部或部分的建议。将各项调整一点一点的结合就能给你一个更流畅、更迅捷快速的 Ubuntu。
### 使 Ubuntu 更快的技巧

我在一个较老版本的 Ubuntu 上使用了这些调整,但是我相信其他的 Ubuntu 版本以及其他的例如 Linux Mint、 Elementary OS Luna 等基 Ubuntu 的 Linux 版本也是同样适用的。
#### 1、 减少默认的 grub 载入时间
Grub 给你 10 秒的时间以让你在多系统启动项或恢复模式之间改变。对我而言,它是多余的。它也意味着你将不得不坐在电脑旁,敲下回车键以尽可能快的启动进入 Ubuntu。这花了一点时间,不是吗? 第一个技巧便是改变这个启动时间。如果你使用图形工具更舒适,阅读这篇文章来[使用 Grub 定制器改变 grub 时间以及启动顺序](https://itsfoss.com/windows-default-os-dual-boot-ubuntu-1304-easy/ "Make Windows Default OS In Dual Boot With Ubuntu 13.04: The Easy Way")。
如果更倾向于命令行,你可以简单地使用以下的命令来打开 grub 配置:
```
sudo gedit /etc/default/grub &
```
并且将 `GRUB_TIMEOUT=10` 改为 `GRUB_TIMEOUT=2`。这将改变启动时间为 2 秒。最好不要将这里改为 0,因为这样你将会失去在操作系统及恢复选项之间切换的机会。一旦你更改了 grub 配置,使用以下命令来使更改生效:
```
sudo update-grub
```
#### 2、 管理开机启动的应用
渐渐地你开始安装各种应用。 如果你是我们的老读者, 你也许从 [App of the week](https://itsfoss.com/tag/app-of-the-week/) 系列安装了许多应用。
这些应用中的一些在每次开机时都会启动,当然资源运行这些应用也会陷入繁忙。结果:一台电脑因为每次启动时的持续时间而变得缓慢。进入 Unity Dash 寻找 “Startup Applications”:

在这里,看看哪些应用在开机时被载入。现在考虑在你每次启动 Ubuntu 时是否有不需要启动的应用。尽管移除它们:

但是要是你不想从启动里移除它们怎么办?举个例子,如果你安装了 [Ubuntu 最好的指示器程序](https://itsfoss.com/best-indicator-applets-ubuntu/ "7 Best Indicator Applets For Ubuntu 13.10")之一, 你将想要它们在每次开机时自动地启动。
这里你所能做的就是延迟一些程序的启动时间。这样你将能够释放开机启动时的资源,并且一段时间后你的应用将被自动启动。在上一张图片里点击 Edit 并使用 sleep 选项来更改运行命令。
例如,如果你想要延迟 Dropbox 指示器的运行,我们指定时间 20 秒,你只需要在已有的命令里像这样**加入一个命令**:
```
sleep 20;
```
所以,命令 `dropbox start -i` 变为 `sleep 20; drobox start -i` 。这意味着现在 Dropbox 将延迟 20 秒启动。你可以通过相似的方法来改变另一个开机启动应用的启动时间。

#### 3、 安装 preload 来加速应用载入时间:
Preload 是一个后台运行的守护进程,它分析用户行为和频繁运行的应用。打开终端,使用如下的命令来安装 preload:
```
sudo apt-get install preload
```
安装后,重启你的电脑就不用管它了。它将在后台工作。[阅读更多关于preload](https://itsfoss.com/improve-application-startup-speed-with-preload-in-ubuntu/ "Improve Application Startup Speed With Preload in Ubuntu")
#### 4、 选择最好的软件更新镜像
验证你更新软件是否正在使用最好的镜像是很好的做法。Ubuntu 的软件仓库镜像跨过全球,使用离你最近的一个是相当明智的。随着从服务器获取包的时间减少,这将形成更快的系统更新。
在 “Software & Updates->Ubuntu Software tab->Download From” 里选择 “Other” 紧接着点击 “Select Best Server”:

它将运行测试来告知你那个是最好的镜像。正常地,最好的镜像已经被设置,但是我说过,验证它没什么坏处。并且,如果仓库缓存的最近的镜像没有频繁更新的话,这将引起获取更新时的一些延迟。这对于网速相对慢的人们是有用的。你可以使用这些技巧来[加速 Ubuntu 的 wifi](https://itsfoss.com/speed-up-slow-wifi-connection-ubuntu/ "Speed Up Slow WiFi Connection In Ubuntu 13.04")。
#### 5、 为了更快的更新,使用 apt-fast 而不是 apt-get
`apt-fast` 是 `apt-get` 的一个 shell 脚本包装器,通过从多连接同时下载包来提升更新及包下载速度。 如果你经常使用终端以及 `apt-get` 来安装和更新包,你也许会想要试一试 `apt-fast`。使用下面的命令来通过官方 PPA 安装 `apt-fast`:
```
sudo add-apt-repository ppa:apt-fast/stable
sudo apt-get update
sudo apt-get install apt-fast
```
#### 6、 从 apt-get 更新移除语言相关的 ign
你曾经注意过 `sudo apt-get` 更新的输出吗?其中有三种行,`hit`、`ign` 和 `get`。 你可以在[这里](http://ubuntuforums.org/showthread.php?t=231300)阅读它们的意义。如果你看到 IGN 行,你会发现它们中的大多数都与语言翻译有关。如果你使用所有的英文应用及包,你将完全不需要英文向英文的包数据库的翻译。
如果你从 `apt-get` 制止语言相关的更新,它将略微地增加 `apt-get` 的更新速度。为了那样,打开如下的文件:
```
sudo gedit /etc/apt/apt.conf.d/00aptitude
```
然后在文件末尾添加如下行:
```
Acquire::Languages "none";
```
[](https://itsfoss.com/wp-content/uploads/2014/01/ign_language-apt_get_update.jpeg)
#### 7、 减少过热
现在过热是电脑普遍的问题。一台过热的电脑运行相当缓慢。当你的 CPU 风扇转得像 [尤塞恩·博尔特](http://en.wikipedia.org/wiki/Usain_Bolt) 一样快,打开一个程序将花费很长的时间。有两个工具你可以用来减少过热,使 Ubuntu 获得更好的系统表现,即 TLP 和 CPUFREQ。
在终端里使用以下命令来安装 TLP:
```
sudo add-apt-repository ppa:linrunner/tlp
sudo apt-get update
sudo apt-get install tlp tlp-rdw
sudo tlp start
```
安装完 TLP 后你不需要做任何事。它在后台工作。
使用如下命令来安装 CPUFREQ 指示器:
```
sudo apt-get install indicator-cpufreq
```
重启你的电脑并使用 Powersave 模式:

#### 8、 调整 LibreOffice 来使它更快
如果你是频繁使用 office 产品的用户,那么你会想要稍微调整默认的 LibreOffice 使它更快。这里你将调整内存选项。打开 Open LibreOffice,进入 “Tools->Options”。在那里,从左边的侧栏选择“Memory”并启用 “Systray Quickstarter” 以及增加内存分配。

你可以阅读更多关于[如何提速 LibreOffice](https://itsfoss.com/speed-libre-office-simple-trick/ "Speed Up LibreOffice With This Simple Trick") 的细节。
#### 9、 使用轻量级的桌面环境 (如果你可以)
如果你选择安装默认的 Unity of GNOME 桌面环境, 你也许会选择一个轻量级的桌面环境像 [Xfce](https://xfce.org/) 或 [LXDE](https://lxde.org/)。
这些桌面环境使用更少的内存,消耗更少的 CPU。它们也自带轻量应用集来更深入地帮助更快地使用 Ubuntu。你可以参考这篇详细指南来学习[如何在 Ubuntu 上安装 Xfce](https://itsfoss.com/install-xfce-desktop-xubuntu/)。
当然,桌面也许没有 Unity 或 GNOME 看起来现代化。那是你必须做出的妥协。
#### 10、 使用不同应用的更轻量可选
这不仅仅是建议和喜好。一些默认的或者流行的应用是耗资源的且可能不适合低端的电脑。你能做的就是使用这些应用的一些替代品。例如,使用 [AppGrid](https://itsfoss.com/app-grid-lighter-alternative-ubuntu-software-center/ "App Grid: Lighter Alternative Of Ubuntu Software Center") 而不是 Ubuntu 软件中心。使用 [Gdebi](https://itsfoss.com/install-deb-files-easily-and-quickly-in-ubuntu-12-10-quick-tip/ "Install .deb Files Easily And Quickly In Ubuntu 12.10 [Quick Tip]") 来安装包。使用 AbiWord 而不是 LibreOffice Writer 等。
可以断定这些技巧的汇总使 Ubuntu 14.04,16.04 以及其他版本更快。我确定这些技巧会提供一个总体上更好的系统表现。
对于加速 Ubuntu 你也有妙计吗?这些技巧也帮到你了吗?分享你的观点。 问题,建议总是受欢迎的。请在评论区里提出来。
---
via: <https://itsfoss.com/speed-up-ubuntu-1310/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[darsh8](https://github.com/darsh8) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

You might have experienced that the system starts running slow after using Ubuntu for some time. In this article, we shall see several tweaks and tips to make Ubuntu run faster.
Before we see how to improve overall system performance in Ubuntu, first let’s ponder on why the system gets slower over time. There could be various reasons for it. You may have a computer with a basic configuration and might have installed numerous applications which are eating up resources at boot time.
It is not rocket science, but as you continue using a system, installing apps, and carrying out many tasks, it affects your system resources in one way or the other. So, to ensure a fast-performing system, you will have to manage numerous aspects of your Linux distribution.
Here I have listed various small tweaks along with some suggestions for best practices that can help you speed up Ubuntu a little.
## 1. Reduce the default grub load time:
By default, the GRUB load time is set to 0 in Ubuntu. This speeds up the system boot.
But, if you are using some dual boot system, the grub gives you some time to change between OSs or recovery. To some, this could be a slow experience.
If you are one of them, you can simply use the following command to open the grub configuration:
```
sudo gedit /etc/default/grub &
```
And change `GRUB_TIMEOUT`
to something lower than 5, as convenient for your specific needs. For example, `GRUB_TIMEOUT=2`
will change the boot time to 2 seconds.
Once you have changed the grub configuration, [update grub to make the change](https://itsfoss.com/update-grub/) count:
```
sudo update-grub
```
If you are more comfortable with a GUI tool, you can refer to our resource on using [grub customizer](https://itsfoss.com/grub-customizer-ubuntu/).
## 2. Manage startup applications:
Over time, you tend to start installing applications. If you are a regular It’s FOSS reader, you might have installed many apps from our [first look series](https://news.itsfoss.com/tag/first-look/).
Some of these apps start at each startup, and, of course, resources will be busy in running these applications. Result, a slow computer for a significant time duration at each boot. Go to overview and look for Startup Applications:

Here, look at what applications are loaded at startup. Now, think if there are any applications that you don’t require to be started up every time you boot into Ubuntu. Please don’t hesitate to remove them.
But what if you don’t want to remove the applications from startup?
For example, if you installed one of the [best indicator applets for Ubuntu](https://itsfoss.com/best-indicator-applets-ubuntu/), you will want them to be started automatically at each boot.
What you can do here is, delay the start of some programs. This way you will free up the resource at boot time and your applications will be start automatically, after the specified time. Giving some breathing space to the computer to process all the startup programs.
For example, if you want to delay the running of the Flameshot indicator, for let’s say 20 seconds, you just need to add a command like this in the existing startup configuration:
```
sleep 20;
```
So, the command `flameshot`
changes to `sleep 20;flameshot`
. This means that now Flameshot will start with a 20-second delay. You can change the start time of other start-up applications similarly.
## 3. Install preload to speed up application load time:
Preload is a daemon that runs in the background and analyzes user behavior and frequently run applications. It will move binaries/dependencies of your most-used apps in to the memory by predicting as per your usage.
Sure, this could also mean using the memory unnecessarily (if you change your behavior). But, as far as user feedback is concerned, it is not something that causes a slowdown.
You can always uninstall it through the terminal if you do not find it helpful.
Open a terminal and use the following command to install preload:
```
sudo apt install preload
```
After installing it, restart your computer and forget about it. It will be working in the background.
## 4. Choose the best mirror for software updates:
It is good to verify that you are using the best mirror to update the software. Ubuntu software repositories are mirrored across the globe, and it is quite advisable to use the one which is nearest to you. This will result in a quicker system update as it reduces the time to get the packages from the server.
Navigate through **Software & Updates ⇾ Ubuntu Software ⇾ Download From**, and click on **Other (**as shown in the screenshot below**)** and thereafter click on **Select Best Server**:
It will run a test and tell you which is the best mirror for you. Normally, the best mirror is already set, but as I said, no harm in verifying it. Furthermore, this may result in some delay in getting the updates if the nearest mirror where the repository is cached is not updated frequently. This is useful for people with a relatively slow internet connection.
You can also refer to our other resource to [speed up Wi-Fi speed](https://itsfoss.com/speed-up-slow-wifi-connection-ubuntu/) in Ubuntu.
Once the tests are finished, click on **Choose Server** and then click **Close**.
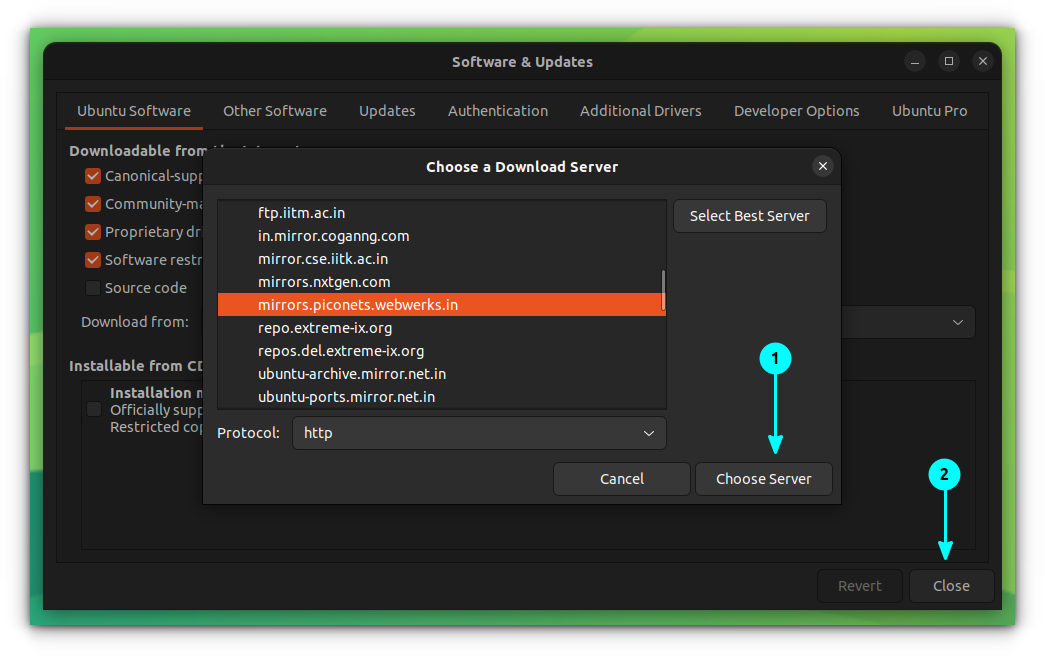
This will ask you to reload the software cache. Use the **Reload** button when asked.
It's better to run an update after this via the terminal:
```
sudo apt update
```
## 5. Use apt-fast instead of apt-get for a speedy update:
`apt-fast`
is a shell script wrapper for “apt-get” that improves update and package download speed by downloading packages from multiple connections simultaneously.
If you frequently use terminal and apt-get to install and update the packages, you may want to give apt-fast a try. Install apt-fast via the official PPA using the following commands:
```
sudo add-apt-repository ppa:apt-fast/stable
sudo apt-get update
sudo apt-get install apt-fast
```
Read more about configuring apt-fast from their [official repository](https://github.com/ilikenwf/apt-fast#configuration).
[Linux alias command](https://linuxhandbook.com/linux-alias-command/)for frequently used commands. This will reduce the time spent typing these commands repeatedly.
## 6. Remove language-related sources from apt update:
Have you ever noticed the output of sudo apt update?
There are three kinds of lines in it, **hit**, **ign** and **get**. You can explore their meanings in our [apt command guide](https://itsfoss.com/apt-command-guide/#update-package-database-with-apt).
You may not notice the IGN lines, depending on the repositories you have.
However, if you look at IGN lines, you will find that most of them are related to language translation. If you use all the applications, and packages in English, there is absolutely no need for a translation of the package database from English to English.
If you suppress these language-related updates from repositories, it will slightly increase the apt update speed. To achieve that, open the following file:
```
sudo gedit /etc/apt/apt.conf.d/00aptitude
```
And add the following line at the end of this file:
```
Acquire::Languages "none";
```

## 7. Reduce overheating
Overheating is a common problem in computers these days. An overheated computer runs quite slow. It takes ages to open a program when thermal throttling affects your system. There are several tools that you can use to reduce overheating and thus get a better system performance on Ubuntu.
The GNOME power-profiles-daemon will be preinstalled on all the latest Ubuntu releases. You can use this tool from the power option in the settings to change the system to three modes, like Power Save, Balanced, and Performance Mode.
Similarly, CPUFREQ can help you adjust the CPU frequency. To [install CPUFREQ indicator](https://itsfoss.com/cpufreq-ubuntu/) use the following command:
```
sudo apt install indicator-cpufreq
```
Restart your computer. Do note that you will be saving battery in this mode by compensating with some performance hit.
For an older system, you can install and use TLP, with the following commands in a terminal:
```
sudo apt update
sudo apt install tlp tlp-rdw
sudo tlp start
```
You don’t need to do anything after installing TLP. It works in the background.
## 8. Use a lightweight desktop environment (if you can)
Usually, the default GNOME desktop-powered Ubuntu distribution takes up more system resources/memory to work snappier.
In such cases, you may opt for a lightweight desktop environment like [Xfce](https://xfce.org/?ref=itsfoss.com) or [LXDE](https://lxde.org/?ref=itsfoss.com), or even [KDE](https://kde.org/?ref=itsfoss.com).
You can learn the [differences between KDE and GNOME](https://itsfoss.com/kde-vs-gnome/) if you are curious.
[KDE vs GNOME: What’s the Ultimate Linux Desktop Choice?Curious about the desktop environment to choose? We help you with KDE vs GNOME here.](https://itsfoss.com/kde-vs-gnome/)

These desktop environments use less system resources and could give you a faster performance overall. They also come with a set of lightweight applications that further help run Ubuntu faster.
You can choose to install a desktop environment manually by referring to our tutorial on [how to install Xfce on Ubuntu](https://itsfoss.com/install-xfce-desktop-xubuntu/). Or, you can pick another flavour of Ubuntu for your system, like Kubuntu, Xubuntu, or Ubuntu MATE.
## 9. Use lighter alternatives for different applications
This is more of a suggestion and liking. Some default or popular applications are resource heavy and may not be suitable for an old computer. You can replace them with some alternatives.
For example, use [Gdebi](https://itsfoss.com/gdebi-default-ubuntu-software-center/) to install packages. Use AbiWord instead of LibreOffice Writer etc.
## 10. Remove Unnecessary software
Sure, it is exciting to install various software to enhance the desktop experience. But, often, we forget to remove them from our system, even if we discontinue using it.
So, it is always good to make a habit of regularly evaluating the software installed and removing the unnecessary ones as per your current requirements.
It is a good to use the `autoremove`
command to remove various leftover packages in the system.
`sudo apt autoremove`
Furthermore, if you are a Flatpak user, then there can be unused runtimes present, that were not removed, when the corresponding app is removed. You can clear them using:
```
flatpak uninstall --unused
```
**Suggested Read 📖**
[How to Clear Apt Cache on Ubuntu and Free Crucial Disk SpaceLearn what apt cache is, why it is used, why you would want to clean it and some other things you should know about purging apt cache.](https://itsfoss.com/clear-apt-cache/)

## 11. Remove Unnecessary Extensions
GNOME provides various [extensions, that enhance the performance of the system](https://itsfoss.com/best-gnome-extensions/). But, as the number of extensions on your system increases, it can cause significant performance issues. So, always keep the extensions to those that you cannot avoid.
If you are considering the speed and performance of the system, you can stay away from heavily customizing extensions.
## 12. Use a system cleaner app
If tidying up your system takes more effort than you intended, you can try using [system optimizing applications like Stacer](https://itsfoss.com/optimize-ubuntu-stacer/).
It can help you clean up junk files, manage startup processes, monitor system resources, and let you do many things from a single app.
With all the functions available, you can end up with a fast-performing Linux system.
## 13. Free up space in /boot partition
If you happen to use a /boot partition separately, often it gets to the point where you have to free some space to be able to install new apps or work without any performance issues.
And, if you get the same warning, and have no clue what to do, fret not, we have a [dedicated guide on it](https://itsfoss.com/free-boot-partition-ubuntu/) to free up space.
[How to Free Up Space in /boot Partition on Ubuntu Linux?Getting a warning that the boot partition has no space left? Here are some ways you can free up space on the boot partition in Ubuntu Linux.](https://itsfoss.com/free-boot-partition-ubuntu/)

## 14. Optimizing SSD Drive
When you delete a file, it is not actually deleted from your system; instead, it is marked for removal, and is removed only when some data is written over it.
So, without proper care, this can lead to fragmentation and degraded performance of SSDs over time. On Ubuntu and other Linux systems, there is this tool called fstrim, that helps keep SSD clean, by freeing up unused blocks of data periodically.
If you have an SSD, it is automatically enabled most of the time. You can check the status by using:
```
sudo systemctl status fstrim.timer
```
If not enabled, enable it using;
```
sudo systemctl enable fstrim.timer
```
Now reboot your system.
## 15. Remove Trash Periodically
You know that, usually, the right-click option in Nautilus file manager has only “Move to Trash” button, unless you tweaked it. This means, the removed files are going to the trash.
You can set it to remove the trash item automatically in a periodic fashion.
For this, go to Settings ⇾ Privacy ⇾ File History and Trash.
Here, set **Automatically Delete Trash Content** and then choose at what interval you want to clear the trash. You can also remove temporary files in this fashion, but you should know what you are removing.
**Suggested Read 📖**
[7 Simple Ways to Free Up Space on Ubuntu and Linux MintRunning out of space on your Linux system? Here are several ways you can clean up your system to free up space on Ubuntu and other Ubuntu based Linux distributions.](https://itsfoss.com/free-up-space-ubuntu-linux/)

## 16. Use the Memory Saver Feature of Browsers
Nowadays, most of the browsers, especially the Chromium-based browsers, come with a feature called **Tab Sleep/Memory Saver**. In this feature, you can set a Tab as idle after some time inactive so that you can save some memory.
This will be a good setting if you have numerous tabs open, and do not mind if some tabs go idle.
You can also exclude sites from the list so that they will be kept active all the time.
## [Bonus] Change Swappiness (Advanced)
Your operating system moves some process to the swap memory (disk storage), on top of RAM, to make room for things when you already have several processes active.
However, just because the disk drive is used for swap memory, it is slower than your RAM.
Hence, it is better to avoid using swap memory as much as possible.
You can explore more about it in our [swap guide](https://itsfoss.com/swap-size/):
[How Much Swap Should You Use in Linux?How much should be the swap size? Should the swap be double of the RAM size or should it be half of the RAM size? Do I need swap at all if my system has got several GBs of RAM? Your questions answered in this detailed article.](https://itsfoss.com/swap-size/)

The Swappiness is a Linux kernel parameter that determines the degree of utilizing swap memory. The default value of Swappiness on Ubuntu is 60. You can check this by running:
```
cat /proc/sys/vm/swappiness
```
Setting a low swappiness value like 10, 35 or 45, will reduce the chances of the system using swap, resulting in a faster performance.
Above all, it depends on the system hardware, workload, etc. So, you need to experiment with the value. To change the swappiness value for the current session, use the command:
```
sudo sysctl vm.swappiness=45
```
This will be reset to 60 when the system is rebooted. Once you find the optimum performance value for your system, and satisfied with it, you can change it permanently, by writing it to the `sysctl.conf`
file.
```
sudo nano /etc/sysctl.conf
```
Enter the following line to the bottom.
```
vm.swappiness=45
```
Save this and reboot your system.
**Suggested Read 📖**
[7 System Monitoring Tools for Linux That are Better Than TopTop command is good but there are better alternatives. Take a look at these system monitoring tools that are similar to top, but better than it.](https://itsfoss.com/linux-system-monitoring-tools/)

## Wrapping Up
That concludes the collection of tips to make Ubuntu 22.04, 20.04, and other versions faster. I am sure these tips would provide an overall better system performance.
While the above-mentioned tips are worth considering, it is also important to keep your system regularly updated so that it will be more reliable in the long run.
Furthermore, if you prefer a faster page load while browsing, you can opt for third-party DNS, like Google, or Cloudflare.
*Do you have some tricks up your sleeves as well to speed up Ubuntu? Did these tips help you as well? Do share your views. Feel free to drop your thoughts in the comment section.* |
9,791 | 如何暂时禁用 iptables 防火墙 | https://kerneltalks.com/howto/how-to-disable-iptables-firewall-temporarily/ | 2018-06-30T09:07:45 | [
"iptables"
] | https://linux.cn/article-9791-1.html |
>
> 了解如何在 Linux 中暂时禁用 iptables 防火墙来进行故障排除。还要学习如何保存策略以及如何在启用防火墙时恢复它们。
>
>
>

有时你需要关闭 iptables 防火墙来做一些连接故障排除,然后你需要重新打开它。在执行此操作时,你还需要保存所有[防火墙策略](https://kerneltalks.com/networking/configuration-of-iptables-policies/)。在本文中,我们将引导你了解如何保存防火墙策略以及如何禁用/启用 iptables 防火墙。有关 iptables 防火墙和策略的更多详细信息[请阅读我们的文章](https://kerneltalks.com/networking/basics-of-iptables-linux-firewall/)。
### 保存 iptables 策略
临时禁用 iptables 防火墙的第一步是保存现有的防火墙规则/策略。`iptables-save` 命令列出你可以保存到服务器中的所有现有策略。
```
root@kerneltalks # # iptables-save
# Generated by iptables-save v1.4.21 on Tue Jun 19 09:54:36 2018
*nat
:PREROUTING ACCEPT [1:52]
:INPUT ACCEPT [1:52]
:OUTPUT ACCEPT [15:1140]
:POSTROUTING ACCEPT [15:1140]
:DOCKER - [0:0]
---- output trucated----
root@kerneltalks # iptables-save > /root/firewall_rules.backup
```
因此,iptables-save 是可以用来备份 iptables 策略的命令。
### 停止/禁用 iptables 防火墙
对于较老的 Linux 内核,你可以选择使用 `service iptables stop` 停止 iptables 服务,但是如果你在用新内核,则只需清除所有策略并允许所有流量通过防火墙。这和你停止防火墙效果一样。
使用下面的命令列表来做到这一点。
```
root@kerneltalks # iptables -F
root@kerneltalks # iptables -X
root@kerneltalks # iptables -P INPUT ACCEPT
root@kerneltalks # iptables -P OUTPUT ACCEPT
root@kerneltalks # iptables -P FORWARD ACCEPT
```
这里 –
* `-F`:删除所有策略链
* `-X`:删除用户定义的链
* `-P INPUT/OUTPUT/FORWARD` :接受指定的流量
完成后,检查当前的防火墙策略。它应该看起来像下面这样接受所有流量(和禁用/停止防火墙一样)
```
# iptables -L
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
```
### 恢复防火墙策略
故障排除后,你想要重新打开 iptables 的所有配置。你需要先从我们在第一步中执行的备份中恢复策略。
```
root@kerneltalks # iptables-restore </root/firewall_rules.backup
```
### 启动 iptables 防火墙
然后启动 iptables 服务,以防止你在上一步中使用 `service iptables start` 停止了它。如果你已经停止服务,那么只有恢复策略才能有用。检查所有策略是否恢复到 iptables 配置中:
```
# iptables -L
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain FORWARD (policy DROP)
target prot opt source destination
DOCKER-USER all -- anywhere anywhere
DOCKER-ISOLATION-STAGE-1 all -- anywhere anywhere
-----output truncated-----
```
就是这些了!你已成功禁用并启用了防火墙,而不会丢失你的策略规则。
---
via: <https://kerneltalks.com/howto/how-to-disable-iptables-firewall-temporarily/>
作者:[kerneltalks](https://kerneltalks.com) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Learn how to disable the iptables firewall in Linux temporarily for troubleshooting purposes. Also, learn how to save policies and how to restore them back when you enable the firewall back.*

Sometimes you have the requirement to turn off the iptables firewall to do some connectivity troubleshooting and then you need to turn it back on. While doing it you also want to save all your [firewall policies](https://kerneltalks.com/networking/configuration-of-iptables-policies/) as well. In this article, we will walk you through how to save firewall policies and how to disable/enable an iptables firewall. For more details about the iptables firewall and policies [read our article](https://kerneltalks.com/networking/basics-of-iptables-linux-firewall/) on it.
#### Save iptables policies
The first step while disabling the iptables firewall temporarily is to save existing firewall rules/policies. `iptables-save`
command lists all your existing policies which you can save in a file on your server.
```
root@kerneltalks # iptables-save
# Generated by iptables-save v1.4.21 on Tue Jun 19 09:54:36 2018
*nat
:PREROUTING ACCEPT [1:52]
:INPUT ACCEPT [1:52]
:OUTPUT ACCEPT [15:1140]
:POSTROUTING ACCEPT [15:1140]
:DOCKER - [0:0]
---- output trucated----
root@kerneltalks # iptables-save > /root/firewall_rules.backup
```
So iptables-save is the command with you can take iptables policy backup.
#### Stop/disable iptables firewall
For older Linux kernels you have an option of stopping service iptables with `service iptables stop`
but if you are on the new kernel, you just need to wipe out all the policies and allow all traffic through the firewall. This is as good as you are stopping the firewall.
Use below list of commands to do that.
```
root@kerneltalks # iptables -F
root@kerneltalks # iptables -X
root@kerneltalks # iptables -P INPUT ACCEPT
root@kerneltalks # iptables -P OUTPUT ACCEPT
root@kerneltalks # iptables -P FORWARD ACCEPT
```
Where –
- -F: Flush all policy chains
- -X: Delete user-defined chains
- -P INPUT/OUTPUT/FORWARD: Accept specified traffic
Once done, check current firewall policies. It should look like below which means everything is accepted (as good as your firewall is disabled/stopped)
```
# iptables -L
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
```
### Restore firewall policies
Once you are done with troubleshooting and you want to turn iptables back on with all its configurations. You need to first restore policies from the backup we took in the first step.
```
root@kerneltalks # iptables-restore </root/firewall_rules.backup
```
### Start iptables firewall
And then start iptables service in case you have stopped it in the previous step using `service iptables start`
. If you haven’t stopped service then only restoring policies will do for you. Check if all policies are back in iptables firewall configurations :
```
root@kerneltalks # iptables -L
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain FORWARD (policy DROP)
target prot opt source destination
DOCKER-USER all -- anywhere anywhere
DOCKER-ISOLATION-STAGE-1 all -- anywhere anywhere
-----output truncated-----
```
That’s it! You have successfully disabled and enabled the firewall without losing your policy rules.
#### Disable iptables firewall permanently
For disabling iptables permanently follow below process –
- Stop iptables service
- Disable iptables service
- Flush all rules
- Save configuration
This can be achieved using below set of commands.
```
root@kerneltalks # systemctl stop iptables
root@kerneltalks # systemctl disable iptables
root@kerneltalks # systemctl status iptables
root@kerneltalks # iptables --flush
root@kerneltalks # service iptables save
root@kerneltalks # cat /etc/sysconfig/iptables
```
Except you don’t really have to delete the user defined chains… They’re isolated once the main chains are cleared
If your policies have DROP as a policy you will lock yourself out of the box with those commands
just did… LOL.
this just bit me hard. this was a machine that was only accessible remotely, at least for the next month.
kerneltalks is temporarily my sworn enemy.
Same here. Awful advice.
FIX THIS. ADD A WARNING. |
9,792 | 密码学及公钥基础设施入门 | https://opensource.com/article/18/5/cryptography-pki | 2018-06-30T09:32:00 | [
"加密",
"私钥",
"公钥"
] | https://linux.cn/article-9792-1.html |
>
> 学习密码学背后的基本概念,主要是保密性、完整性和身份认证。
>
>
>

安全通信正快速成为当今互联网的规范。从 2018 年 7 月起,Google Chrome 将对**全部**使用 HTTP 传输(而不是 HTTPS 传输)的站点[开始显示“不安全”警告](https://security.googleblog.com/2018/02/a-secure-web-is-here-to-stay.html)。虽然密码学已经逐渐变广为人知,但其本身并没有变得更容易理解。[Let's Encrypt](https://letsencrypt.org/) 设计并实现了一套令人惊叹的解决方案,可以提供免费安全证书和周期性续签;但如果不了解底层概念和缺陷,你也不过是加入了类似“[<ruby> 货物崇拜 <rt> cargo cult </rt></ruby>](https://en.wikipedia.org/wiki/Cargo_cult_programming)”的技术崇拜的程序员大军。
### 安全通信的特性
密码学最直观明显的目标是<ruby> 保密性 <rt> confidentiality </rt></ruby>:<ruby> 消息 <rt> message </rt></ruby>传输过程中不会被窥探内容。为了保密性,我们对消息进行加密:对于给定消息,我们结合一个<ruby> 密钥 <rt> key </rt></ruby>生成一个无意义的乱码,只有通过相同的密钥逆转加密过程(即解密过程)才能将其转换为可读的消息。假设我们有两个朋友 [Alice 和 Bob](https://en.wikipedia.org/wiki/Alice_and_Bob),以及他们的<ruby> 八卦 <rt> nosy </rt></ruby>邻居 Eve。Alice 加密类似 "Eve 很讨厌" 的消息,将其发送给 Bob,期间不用担心 Eve 会窥探到这条消息的内容。
对于真正的安全通信,保密性是不够的。假如 Eve 收集了足够多 Alice 和 Bob 之间的消息,发现单词 “Eve” 被加密为 "Xyzzy"。除此之外,Eve 还知道 Alice 和 Bob 正在准备一个派对,Alice 会将访客名单发送给 Bob。如果 Eve 拦截了消息并将 “Xyzzy” 加到访客列表的末尾,那么她已经成功的破坏了这个派对。因此,Alice 和 Bob 需要他们之间的通信可以提供<ruby> 完整性 <rt> integrity </rt></ruby>:消息应该不会被篡改。
而且我们还有一个问题有待解决。假如 Eve 观察到 Bob 打开了标记为“来自 Alice”的信封,信封中包含一条来自 Alice 的消息“再买一加仑冰淇淋”。Eve 看到 Bob 外出,回家时带着冰淇淋,这样虽然 Eve 并不知道消息的完整内容,但她对消息有了大致的了解。Bob 将上述消息丢弃,但 Eve 找出了它并在下一周中的每一天都向 Bob 的邮箱中投递一封标记为“来自 Alice”的信封,内容拷贝自之前 Bob 丢弃的那封信。这样到了派对的时候,冰淇淋严重超量;派对当晚结束后,Bob 分发剩余的冰淇淋,Eve 带着免费的冰淇淋回到家。消息是加密的,完整性也没问题,但 Bob 被误导了,没有认出发信人的真实身份。<ruby> 身份认证 <rt> Authentication </rt></ruby>这个特性用于保证你正在通信的人的确是其声称的那样。
信息安全还有[其它特性](https://en.wikipedia.org/wiki/Information_security#Availability),但保密性、完整性和身份验证是你必须了解的三大特性。
### 加密和加密算法
加密都包含哪些部分呢?首先,需要一条消息,我们称之为<ruby> 明文 <rt> plaintext </rt></ruby>。接着,需要对明文做一些格式上的初始化,以便用于后续的加密过程(例如,假如我们使用<ruby> 分组加密算法 <rt> block cipher </rt></ruby>,需要在明文尾部填充使其达到特定长度)。下一步,需要一个保密的比特序列,我们称之为<ruby> 密钥 <rt> key </rt></ruby>。然后,基于私钥,使用一种加密算法将明文转换为<ruby> 密文 <rt> ciphertext </rt></ruby>。密文看上去像是随机噪声,只有通过相同的加密算法和相同的密钥(在后面提到的非对称加密算法情况下,是另一个数学上相关的密钥)才能恢复为明文。
(LCTT 译注:cipher 一般被翻译为密码,但其具体表达的意思是加密算法,这里采用加密算法的翻译)
加密算法使用密钥加密明文。考虑到希望能够解密密文,我们用到的加密算法也必须是<ruby> 可逆的 <rt> reversible </rt></ruby>。作为简单示例,我们可以使用 [XOR](https://en.wikipedia.org/wiki/XOR_cipher)。该算子可逆,而且逆算子就是本身(`P ^ K = C; C ^ K = P`),故可同时用于加密和解密。该算子的平凡应用可以是<ruby> 一次性密码本 <rt> one-time pad </rt></ruby>,不过一般而言并不[可行](https://en.wikipedia.org/wiki/One-time_pad#Problems)。但可以将 XOR 与一个基于单个密钥生成<ruby> 任意随机数据流 <rt> arbitrary stream of random data </rt></ruby>的函数结合起来。现代加密算法 AES 和 Chacha20 就是这么设计的。
我们把加密和解密使用同一个密钥的加密算法称为<ruby> 对称加密算法 <rt> symmetric cipher </rt></ruby>。对称加密算法分为<ruby> 流加密算法 <rt> stream ciphers </rt></ruby>和分组加密算法两类。流加密算法依次对明文中的每个比特或字节进行加密。例如,我们上面提到的 XOR 加密算法就是一个流加密算法。流加密算法适用于明文长度未知的情形,例如数据从管道或 socket 传入。[RC4](https://en.wikipedia.org/wiki/RC4) 是最为人知的流加密算法,但在多种不同的攻击面前比较脆弱,以至于最新版本 (1.3)的 TLS (“HTTPS” 中的 “S”)已经不再支持该加密算法。[Efforts](https://en.wikipedia.org/wiki/ESTREAM) 正着手创建新的加密算法,候选算法 [ChaCha20](https://en.wikipedia.org/wiki/Salsa20) 已经被 TLS 支持。
分组加密算法对固定长度的分组,使用固定长度的密钥加密。在分组加密算法领域,排行第一的是 [<ruby> 先进加密标准 <rt> Advanced Encryption Standard </rt></ruby>](https://en.wikipedia.org/wiki/Advanced_Encryption_Standard)(AES),使用的分组长度为 128 比特。分组包含的数据并不多,因而分组加密算法包含一个[工作模式](https://en.wikipedia.org/wiki/Block_cipher_mode_of_operation),用于描述如何对任意长度的明文执行分组加密。最简单的工作模式是 [<ruby> 电子密码本 <rt> Electronic Code Book </rt></ruby>](https://en.wikipedia.org/wiki/Block_cipher_mode_of_operation#/media/File:ECB_encryption.svg)(ECB),将明文按分组大小划分成多个分组(在必要情况下,填充最后一个分组),使用密钥独立的加密各个分组。

这里我们留意到一个问题:如果相同的分组在明文中出现多次(例如互联网流量中的 `GET / HTTP/1.1` 词组),由于我们使用相同的密钥加密分组,我们会得到相同的加密结果。我们的安全通信中会出现一种<ruby> 模式规律 <rt> pattern </rt></ruby>,容易受到攻击。
因此还有很多高级的工作模式,例如 [<ruby> 密码分组链接 <rt> Cipher Block Chaining </rt></ruby>](https://en.wikipedia.org/wiki/Block_cipher_mode_of_operation#/media/File:CBC_encryption.svg)(CBC),其中每个分组的明文在加密前会与前一个分组的密文进行 XOR 操作,而第一个分组的明文与一个随机数构成的初始化向量进行 XOR 操作。还有其它一些工作模式,在安全性和执行速度方面各有优缺点。甚至还有 Counter (CTR) 这种工作模式,可以将分组加密算法转换为流加密算法。

除了对称加密算法,还有<ruby> 非对称加密算法 <rt> asymmetric ciphers </rt></ruby>,也被称为<ruby> 公钥密码学 <rt> public-key cryptography </rt></ruby>。这类加密算法使用两个密钥:一个<ruby> 公钥 <rt> public key </rt></ruby>,一个<ruby> 私钥 <rt> private key </rt></ruby>。公钥和私钥在数学上有一定关联,但可以区分二者。经过公钥加密的密文只能通过私钥解密,经过私钥加密的密文可以通过公钥解密。公钥可以大范围分发出去,但私钥必须对外不可见。如果你希望和一个给定的人通信,你可以使用对方的公钥加密消息,这样只有他们的私钥可以解密出消息。在非对称加密算法领域,目前 [RSA](https://en.wikipedia.org/wiki/RSA_(cryptosystem)) 最具有影响力。
非对称加密算法最主要的缺陷是,它们是<ruby> 计算密集型 <rt> computationally expensive </rt></ruby>的。那么使用对称加密算法可以让身份验证更快吗?如果你只与一个人共享密钥,答案是肯定的。但这种方式很快就会失效。假如一群人希望使用对称加密算法进行两两通信,如果对每对成员通信都采用单独的密钥,一个 20 人的群体将有 190 对成员通信,即每个成员要维护 19 个密钥并确认其安全性。如果使用非对称加密算法,每个成员仅需确保自己的私钥安全并维护一个公钥列表即可。
非对称加密算法也有加密[数据长度](https://security.stackexchange.com/questions/33434/rsa-maximum-bytes-to-encrypt-comparison-to-aes-in-terms-of-security)限制。类似于分组加密算法,你需要将长消息进行划分。但实际应用中,非对称加密算法通常用于建立<ruby> 机密 <rt> confidential </rt></ruby>、<ruby> 已认证 <rt> authenticated </rt></ruby>的<ruby> 通道 <rt> channel </rt></ruby>,利用该通道交换对称加密算法的共享密钥。考虑到速度优势,对称加密算法用于后续的通信。TLS 就是严格按照这种方式运行的。
### 基础
安全通信的核心在于随机数。随机数用于生成密钥并为<ruby> 确定性过程 <rt> deterministic processes </rt></ruby>提供不可预测性。如果我们使用的密钥是可预测的,那我们从一开始就可能受到攻击。计算机被设计成按固定规则操作,因此生成随机数是比较困难的。计算机可以收集鼠标移动或<ruby> 键盘计时 <rt> keyboard timings </rt></ruby>这类随机数据。但收集随机性(也叫<ruby> 信息熵 <rt> entropy </rt></ruby>)需要花费不少时间,而且涉及额外处理以确保<ruby> 均匀分布 <rt> uniform distribution </rt></ruby>。甚至可以使用专用硬件,例如[<ruby> 熔岩灯 <rt> lava lamps </rt></ruby>墙](https://www.youtube.com/watch?v=1cUUfMeOijg)等。一般而言,一旦有了一个真正的随机数值,我们可以将其用作<ruby> 种子 <rt> seed </rt></ruby>,使用<ruby> 密码安全的伪随机数生成器 <rt> cryptographically secure pseudorandom number generator </rt></ruby>生成随机数。使用相同的种子,同一个随机数生成器生成的随机数序列保持不变,但重要的是随机数序列是无规律的。在 Linux 内核中,[/dev/random 和 /dev/urandom](https://www.2uo.de/myths-about-urandom/) 工作方式如下:从多个来源收集信息熵,进行<ruby> 无偏处理 <rt> remove biases </rt></ruby>,生成种子,然后生成随机数,该随机数可用于 RSA 密钥生成等。
### 其它密码学组件
我们已经实现了保密性,但还没有考虑完整性和身份验证。对于后两者,我们需要使用一些额外的技术。
首先是<ruby> 密码散列函数 <rt> crytographic hash function </rt></ruby>,该函数接受任意长度的输入并给出固定长度的输出(一般称为<ruby> 摘要 <rt> digest </rt></ruby>)。如果我们找到两条消息,其摘要相同,我们称之为<ruby> 碰撞 <rt> collision </rt></ruby>,对应的散列函数就不适合用于密码学。这里需要强调一下“找到”:考虑到消息的条数是无限的而摘要的长度是固定的,那么总是会存在碰撞;但如果无需海量的计算资源,我们总是能找到发生碰撞的消息对,那就令人比较担心了。更严重的情况是,对于每一个给定的消息,都能找到与之碰撞的另一条消息。
另外,哈希函数必须是<ruby> 单向的 <rt> one-way </rt></ruby>:给定一个摘要,反向计算对应的消息在计算上不可行。相应的,这类[条件](https://crypto.stackexchange.com/a/1174)被称为<ruby> 碰撞阻力 <rt> collision resistance </rt></ruby>、<ruby> 第二原象抗性 <rt> second preimage resistance </rt></ruby>和<ruby> 原象抗性 <rt> preimage resistance </rt></ruby>。如果满足这些条件,摘要可以用作消息的指纹。[理论上](https://www.telegraph.co.uk/science/2016/03/14/why-your-fingerprints-may-not-be-unique/)不存在具有相同指纹的两个人,而且你无法使用指纹反向找到其对应的人。
如果我们同时发送消息及其摘要,接收者可以使用相同的哈希函数独立计算摘要。如果两个摘要相同,可以认为消息没有被篡改。考虑到 [SHA-1](https://en.wikipedia.org/wiki/SHA-1) 已经变得[有些过时](https://security.googleblog.com/2017/02/announcing-first-sha1-collision.html),目前最流行的密码散列函数是 [SHA-256](https://en.wikipedia.org/wiki/SHA-2)。
散列函数看起来不错,但如果有人可以同时篡改消息及其摘要,那么消息发送仍然是不安全的。我们需要将哈希与加密算法结合起来。在对称加密算法领域,我们有<ruby> 消息认证码 <rt> message authentication codes </rt></ruby>(MAC)技术。MAC 有多种形式,但<ruby> 哈希消息认证码 <rt> hash message authentication codes </rt></ruby>(HMAC) 这类是基于哈希的。[HMAC](https://en.wikipedia.org/wiki/HMAC) 使用哈希函数 H 处理密钥 K、消息 M,公式为 `H(K + H(K + M))`,其中 `+` 代表<ruby> 连接 <rt> concatenation </rt></ruby>。公式的独特之处并不在本文讨论范围内,大致来说与保护 HMAC 自身的完整性有关。发送加密消息的同时也发送 MAC。Eve 可以任意篡改消息,但一旦 Bob 独立计算 MAC 并与接收到的 MAC 做比较,就会发现消息已经被篡改。
在非对称加密算法领域,我们有<ruby> 数字签名 <rt> digital signatures </rt></ruby>技术。如果使用 RSA,使用公钥加密的内容只能通过私钥解密,反过来也是如此;这种机制可用于创建一种签名。如果只有我持有私钥并用其加密文档,那么只有我的公钥可以用于解密,那么大家潜在的承认文档是我写的:这是一种身份验证。事实上,我们无需加密整个文档。如果生成文档的摘要,只要对这个指纹加密即可。对摘要签名比对整个文档签名要快得多,而且可以解决非对称加密存在的消息长度限制问题。接收者解密出摘要信息,独立计算消息的摘要并进行比对,可以确保消息的完整性。对于不同的非对称加密算法,数字签名的方法也各不相同;但核心都是使用公钥来检验已有签名。
### 汇总
现在,我们已经有了全部的主体组件,可以用其实现一个我们期待的、具有全部三个特性的[<ruby> 体系 <rt> system </rt></ruby>](https://en.wikipedia.org/wiki/Hybrid_cryptosystem)。Alice 选取一个保密的对称加密密钥并使用 Bob 的公钥进行加密。接着,她对得到的密文进行哈希并使用其私钥对摘要进行签名。Bob 接收到密文和签名,一方面独立计算密文的摘要,另一方面使用 Alice 的公钥解密签名中的摘要;如果两个摘要相同,他可以确信对称加密密钥没有被篡改且通过了身份验证。Bob 使用私钥解密密文得到对称加密密钥,接着使用该密钥及 HMAC 与 Alice 进行保密通信,这样每一条消息的完整性都得到保障。但该体系没有办法抵御消息重放攻击(我们在 Eve 造成的冰淇淋灾难中见过这种攻击)。要解决重放攻击,我们需要使用某种类型的“<ruby> 握手 <rt> handshake </rt></ruby>”建立随机、短期的<ruby> 会话标识符 <rt> session identifier </rt></ruby>。
密码学的世界博大精深,我希望这篇文章能让你对密码学的核心目标及其组件有一个大致的了解。这些概念为你打下坚实的基础,让你可以继续深入学习。
感谢 Hubert Kario、Florian Weimer 和 Mike Bursell 在本文写作过程中提供的帮助。
---
via: <https://opensource.com/article/18/5/cryptography-pki>
作者:[Alex Wood](https://opensource.com/users/awood) 选题:[lujun9972](https://github.com/lujun9972) 译者:[pinewall](https://github.com/pinewall) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Secure communication is quickly becoming the norm for today's web. In July 2018, Google Chrome plans to [start showing "not secure" notifications](https://security.googleblog.com/2018/02/a-secure-web-is-here-to-stay.html) for **all** sites transmitted over HTTP (instead of HTTPS). Mozilla has a [similar plan](https://blog.mozilla.org/security/2017/01/20/communicating-the-dangers-of-non-secure-http/). While cryptography is becoming more commonplace, it has not become easier to understand. [Let's Encrypt](https://letsencrypt.org/) designed and built a wonderful solution to provide and periodically renew free security certificates, but if you don't understand the underlying concepts and pitfalls, you're just another member of a large group of [cargo cult](https://en.wikipedia.org/wiki/Cargo_cult_programming) programmers.
## Attributes of secure communication
The intuitively obvious purpose of cryptography is *confidentiality*: a message can be transmitted without prying eyes learning its contents. For confidentiality, we *encrypt* a message: given a message, we pair it with a key and produce a meaningless jumble that can only be made useful again by reversing the process using the same key (thereby *decrypting* it). Suppose we have two friends, [Alice and Bob](https://en.wikipedia.org/wiki/Alice_and_Bob), and their nosy neighbor, Eve. Alice can encrypt a message like "Eve is annoying", send it to Bob, and never have to worry about Eve snooping on her.
For truly secure communication, we need more than confidentiality. Suppose Eve gathered enough of Alice and Bob's messages to figure out that the word "Eve" is encrypted as "Xyzzy". Furthermore, Eve knows Alice and Bob are planning a party and Alice will be sending Bob the guest list. If Eve intercepts the message and adds "Xyzzy" to the end of the list, she's managed to crash the party. Therefore, Alice and Bob need their communication to provide *integrity*: a message should be immune to tampering.
We have another problem though. Suppose Eve watches Bob open an envelope marked "From Alice" with a message inside from Alice reading "Buy another gallon of ice cream." Eve sees Bob go out and come back with ice cream, so she has a general idea of the message's contents even if the exact wording is unknown to her. Bob throws the message away, Eve recovers it, and then every day for the next week drops an envelope marked "From Alice" with a copy of the message in Bob's mailbox. Now the party has too much ice cream and Eve goes home with free ice cream when Bob gives it away at the end of the night. The extra messages are confidential, and their integrity is intact, but Bob has been misled as to the true identity of the sender. *Authentication* is the property of knowing that the person you are communicating with is in fact who they claim to be.
Information security has [other attributes](https://en.wikipedia.org/wiki/Information_security#Availability), but *confidentiality*, *integrity*, and *authentication* are the three traits you must know.
## Encryption and ciphers
What are the components of encryption? We need a message which we'll call the *plaintext*. We may need to do some initial formatting to the message to make it suitable for the encryption process (padding it to a certain length if we're using a block cipher, for example). Then we take a secret sequence of bits called the *key*. A *cipher* then takes the key and transforms the plaintext into *ciphertext*. The ciphertext should look like random noise and only by using the same cipher and the same key (or as we will see later in the case of asymmetric ciphers, a mathematically related key) can the plaintext be restored.
The cipher transforms the plaintext's bits using the key's bits. Since we want to be able to decrypt the ciphertext, our cipher needs to be reversible too. We can use [XOR](https://en.wikipedia.org/wiki/XOR_cipher) as a simple example. It is reversible and is [its own inverse](https://en.wikipedia.org/wiki/Involution_(mathematics)#Computer_science) (P ^ K = C; C ^ K = P) so it can both encrypt plaintext and decrypt ciphertext. A trivial use of an XOR can be used for encryption in a *one-time pad*, but it is generally not [practical](https://en.wikipedia.org/wiki/One-time_pad#Problems). However, it is possible to combine XOR with a function that generates an arbitrary stream of random data from a single key. Modern ciphers like AES and Chacha20 do exactly that.
We call any cipher that uses the same key to both encrypt and decrypt a *symmetric cipher*. Symmetric ciphers are divided into *stream ciphers* and *block ciphers*. A stream cipher runs through the message one bit or byte at a time. Our XOR cipher is a stream cipher, for example. Stream ciphers are useful if the length of the plaintext is unknown (such as data coming in from a pipe or socket). [RC4](https://en.wikipedia.org/wiki/RC4) is the best-known stream cipher but it is vulnerable to several different attacks, and the newest version (1.3) of the TLS protocol (the "S" in "HTTPS") does not even support it. [Efforts](https://en.wikipedia.org/wiki/ESTREAM) are underway to create new stream ciphers with some candidates like [ChaCha20](https://en.wikipedia.org/wiki/Salsa20) already supported in TLS.
A block cipher takes a fix-sized block and encrypts it with a fixed-sized key. The current king of the hill in the block cipher world is the [Advanced Encryption Standard](https://en.wikipedia.org/wiki/Advanced_Encryption_Standard) (AES), and it has a block size of 128 bits. That's not very much data, so block ciphers have a [ mode](https://en.wikipedia.org/wiki/Block_cipher_mode_of_operation) that describes how to apply the cipher's block operation across a message of arbitrary size. The simplest mode is
[Electronic Code Book](https://en.wikipedia.org/wiki/Block_cipher_mode_of_operation#/media/File:ECB_encryption.svg)(ECB) which takes the message, splits it into blocks (padding the message's final block if necessary), and then encrypts each block with the key independently.

You may spot a problem here: if the same block appears multiple times in the message (a phrase like "GET / HTTP/1.1" in web traffic, for example) and we encrypt it using the same key, we'll get the same result. The appearance of a pattern in our encrypted communication makes it vulnerable to attack.
Thus there are more advanced modes such as [Cipher Block Chaining](https://en.wikipedia.org/wiki/Block_cipher_mode_of_operation#/media/File:CBC_encryption.svg) (CBC) where the result of each block's encryption is XORed with the next block's plaintext. The very first block's plaintext is XORed with an *initialization vector* of random numbers. There are many other modes each with different advantages and disadvantages in security and speed. There are even modes, such as Counter (CTR), that can turn a block cipher into a stream cipher.
In contrast to symmetric ciphers, there are asymmetric ciphers (also called public-key cryptography). These ciphers use two keys: a public key and a private key. The keys are mathematically related but still distinct. Anything encrypted with the public key can only be decrypted with the private key and data encrypted with the private key can be decrypted with the public key. The public key is widely distributed while the private key is kept secret. If you want to communicate with a given person, you use their public key to encrypt your message and only their private key can decrypt it. [RSA](https://en.wikipedia.org/wiki/RSA_(cryptosystem)) is the current heavyweight champion of asymmetric ciphers.
A major downside to asymmetric ciphers is that they are computationally expensive. Can we get authentication with symmetric ciphers to speed things up? If you only share a key with one other person, yes. But that breaks down quickly. Suppose a group of people want to communicate with one another using a symmetric cipher. The group members could establish keys for each unique pairing of members and encrypt messages based on the recipient, but a group of 20 people works out to 190 pairs of members total and 19 keys for each individual to manage and secure. By using an asymmetric cipher, each person only needs to guard their own private key and have access to a listing of public keys.
Asymmetric ciphers are also limited in the [amount of data](https://security.stackexchange.com/questions/33434/rsa-maximum-bytes-to-encrypt-comparison-to-aes-in-terms-of-security) they can encrypt. Like block ciphers, you have to split a longer message into pieces. In practice then, asymmetric ciphers are often used to establish a confidential, authenticated channel which is then used to exchange a shared key for a symmetric cipher. The symmetric cipher is used for subsequent communications since it is much faster. TLS can operate in exactly this fashion.
## At the foundation
At the heart of secure communication are random numbers. Random numbers are used to generate keys and to provide unpredictability for otherwise deterministic processes. If the keys we use are predictable, then we're susceptible to attack right from the very start. Random numbers are difficult to generate on a computer which is meant to behave in a consistent manner. Computers can gather random data from things like mouse movement or keyboard timings. But gathering that randomness (called entropy) takes significant time and involve additional processing to ensure uniform distributions. It can even involve the use of dedicated hardware (such as [a wall of lava lamps](https://www.youtube.com/watch?v=1cUUfMeOijg)). Generally, once we have a truly random value, we use that as a seed to put into a [cryptographically secure pseudorandom number generator](https://en.wikipedia.org/wiki/Cryptographically_secure_pseudorandom_number_generator) Beginning with the same seed will always lead to the same stream of numbers, but what's important is that the stream of numbers descended from the seed don't exhibit any pattern. In the Linux kernel, [/dev/random and /dev/urandom](https://www.2uo.de/myths-about-urandom/), operate in this fashion: they gather entropy from multiple sources, process it to remove biases, create a seed, and can then provide the random numbers used to generate an RSA key for example.
## Other cryptographic building blocks
We've covered confidentiality, but I haven't mentioned integrity or authentication yet. For that, we'll need some new tools in our toolbox.
The first is the *cryptographic hash function*. A cryptographic hash function is meant to take an input of arbitrary size and produce a fixed size output (often called a *digest*). If we can *find* any two messages that create the same digest, that's a *collision* and makes the hash function unsuitable for cryptography. Note the emphasis on "find"; if we have an infinite world of messages and a fixed sized output, there are bound to be collisions, but if we can find any two messages that collide without a monumental investment of computational resources, that's a deal-breaker. Worse still would be if we could take a specific message and could then find another message that results in a collision.
As well, the hash function should be one-way: given a digest, it should be computationally infeasible to determine what the message is. Respectively, these [requirements](https://crypto.stackexchange.com/a/1174) are called collision resistance, second preimage resistance, and preimage resistance. If we meet these requirements, our digest acts as a kind of fingerprint for a message. No two people ([in theory](https://www.telegraph.co.uk/science/2016/03/14/why-your-fingerprints-may-not-be-unique/)) have the same fingerprints, and you can't take a fingerprint and turn it back into a person.
If we send a message and a digest, the recipient can use the same hash function to generate an independent digest. If the two digests match, they know the message hasn't been altered. [SHA-256](https://en.wikipedia.org/wiki/SHA-2) is the most popular cryptographic hash function currently since [SHA-1](https://en.wikipedia.org/wiki/SHA-1) is starting to [show its age](https://security.googleblog.com/2017/02/announcing-first-sha1-collision.html).
Hashes sound great, but what good is sending a digest with a message if someone can tamper with your message and then tamper with the digest too? We need to mix hashing in with the ciphers we have. For symmetric ciphers, we have *message authentication codes* (MACs). MACs come in different forms, but an HMAC is based on hashing. An [HMAC](https://en.wikipedia.org/wiki/HMAC) takes the key K and the message M and blends them together using a hashing function H with the formula H(K + H(K + M)) where "+" is concatenation. Why this formula specifically? That's beyond this article, but it has to do with protecting the integrity of the HMAC itself. The MAC is sent along with an encrypted message. Eve could blindly manipulate the message, but as soon as Bob independently calculates the MAC and compares it to the MAC he received, he'll realize the message has been tampered with.
For asymmetric ciphers, we have *digital signatures*. In RSA, encryption with a public key makes something only the private key can decrypt, but the inverse is true as well and can create a type of signature. If only I have the private key and encrypt a document, then only my public key will decrypt the document, and others can implicitly trust that I wrote it: authentication. In fact, we don't even need to encrypt the entire document. If we create a digest of the document, we can then encrypt just the fingerprint. Signing the digest instead of the whole document is faster and solves some problems around the size of a message that can be encrypted using asymmetric encryption. Recipients decrypt the digest, independently calculate the digest for the message, and then compare the two to ensure integrity. The method for digital signatures varies for other asymmetric ciphers, but the concept of using the public key to verify a signature remains.
## Putting it all together
Now that we have all the major pieces, we can implement a [system](https://en.wikipedia.org/wiki/Hybrid_cryptosystem) that has all three of the attributes we're looking for. Alice picks a secret symmetric key and encrypts it with Bob's public key. Then she hashes the resulting ciphertext and uses her private key to sign the digest. Bob receives the ciphertext and the signature, computes the ciphertext's digest and compares it to the digest in the signature he verified using Alice's public key. If the two digests are identical, he knows the symmetric key has integrity and is authenticated. He decrypts the ciphertext with his private key and uses the symmetric key Alice sent him to communicate with her confidentially using HMACs with each message to ensure integrity. There's no protection here against a message being replayed (as seen in the ice cream disaster Eve caused). To handle that issue, we would need some sort of "handshake" that could be used to establish a random, short-lived session identifier.
The cryptographic world is vast and complex, but I hope this article gives you a basic mental model of the core goals and components it uses. With a solid foundation in the concepts, you'll be able to continue learning more.
*Thank you to Hubert Kario, Florian Weimer, and Mike Bursell for their help with this article.*
## 1 Comment |
9,793 | 用这样的 Vi 配置来保存和组织你的笔记 | https://opensource.com/article/18/6/vimwiki-gitlab-notes | 2018-06-30T10:37:03 | [
"笔记"
] | https://linux.cn/article-9793-1.html |
>
> Vimwiki 和 GitLab 是记录笔记的强大组合。
>
>
>

用 vi 来管理 wiki 来记录你的笔记,这听起来不像是一个符合常规的主意,但当你的日常工作都会用到 vi , 那它是有意义的。
作为一个软件开发人员,使用同编码一样的工具来写笔记会更加简单。我想将我的笔记变成一种编辑器命令,无论我在哪里,都能够用管理我代码的方法来管理我的笔记。这便是我创建一个基于 vi 的环境来搭建我自己的知识库的原因。简单概括起来,我在笔记本电脑上用 vi 插件 [Viwiki](https://vimwiki.github.io/) 来本地管理我的 wiki。用 Git 来进行版本控制(以保留一个中心化的更新版本),并用 GitLab 来进行在线修改(例如在我的手机上)。
### 为什么用 wiki 来进行笔记保存是有意义
我尝试过许多不同的工具来持续的记录我的笔记,笔记里保存着我的灵感以及需要记住的任务安排。这包括线下的笔记本 (没错,纸质的)、特殊的记录笔记的软件,以及思维导图软件。
但每种方案都有不好一面,没有一个能够满足我所有的需求。例如[思维导图](https://opensource.com/article/17/8/mind-maps-creative-dashboard),能够很好的形象化你的想法(因而得名),但是这种工具的搜索功能很差(和纸质笔记本一样)。此外,当一段时间过去,思维导图会变得很难阅读,所以思维导图不适合长时间保存的笔记。
我为一个合作项目配置了 [DokuWiki](https://vimwiki.github.io/),我发现这个 wiki 模型符合了我大多数的需求。在 wiki 上,你能够创建一个笔记(和你在文本编辑器中所作的一样),并在笔记间创建链接。如果一个链接指向一个不存在的页面(你想让本页面添加一条还没有创建的信息), wiki 会为你建立这个页面。这个特性使得 wiki 很好的适应了那些需要快速写下心中所想的人的需求,而仍将你的笔记保持在能够容易浏览和搜索关键字的页面结构中。
这看起来很有希望,并且配置 DokuWiki 也很容易,但我发现只是为了记个笔记而配置整个 wiki 需要花费太多工作。在一番搜索后,我发现了 Vimwiki,这是一个我想要的 vi 插件。因为我每天使用 vi,记录笔记就行编辑代码一样。甚至在 vimwiki 创建一个页面比 Dokuwiki 更简单。你只需要对光标下的单词按下回车键就行。如果没有文件是这个名字,vimwiki 会为你创建一个。
为了更一步的实现用每天都会使用的工具来做笔记的计划,我不仅用这个我最爱的 IDE 来写笔记,而且用 Git 和 GitLab —— 我最爱的代码管理工具 —— 在我的各个机器间分发我的笔记,以便我可以在线访问它们。我也是在 Gitlab 的在线 markdown 工具上用 markdown 语法来写的这篇文章。
### 配置 vimwiki
用你已有的插件管理工具来安装 vimwiki 很简单,只需要添加 vimwiki/vimwiki 到你的插件。对于我的喜爱的插件管理器 Vundle 来说,你只需要在 `/.vimrc` 中添加 `plugin vimwiki/vimwiki` 这一行,然后执行 `:source ~/.vimrc | PluginInstall` 就行。
下面是我的文件 `.vimrc` 的一部分,展示了一些 vimwiki 配置。你能在 [vimwiki](https://vimwiki.github.io/) 页面学到更多的配置和使用的的信息。
```
let wiki_1 = {}
let wiki_1.path = '~/vimwiki_work_md/'
let wiki_1.syntax = 'markdown'
let wiki_1.ext = '.md'
let wiki_2 = {}
let wiki_2.path = '~/vimwiki_personal_md/'
let wiki_2.syntax = 'markdown'
let wiki_2.ext = '.md'
let g:vimwiki_list = [wiki_1, wiki_2]
let g:vimwiki_ext2syntax = {'.md': 'markdown', '.markdown': 'markdown', '.mdown': 'markdown'}
```
如你在上述配置中所见,我的配置还有一个优点。你能简单的区分个人和工作相关的笔记,而不用切换笔记软件。我想让我的个人笔记可以随时随地访问,而不想我的工作笔记同步到我私人的 GitLab 和计算机中。在 vimwiki 这样配置要比我试过的其他软件都要简单。
这个配置告诉 vimwiki 有两个不同 Wiki,都使用 markdown 语法(再一次,因为我的日常工作中天天都在用 markdown 语法)。我也告诉 Vimwiki 在哪个文件夹存储 wiki 页面。
如果你进入存储 wiki 页面的文件夹,你会找到你的 wiki 的普通的 markdown 页面文件,而没有其他特殊的 Vimwiki 相关内容,这使得很容易的初始化 Git 仓库和同步你的 wiki 到中心仓库。
### 同步你的 wiki 到 GitLab
这一步检出一个 GitLab 项目到本地的 VimWiki 文件夹,这步操作和你操作任何 GitHub 的仓库相同,只不过因为我更喜欢保存我的笔记到我的私人 GitLab 仓库,所以我运行了一个 GitLab 实例用于我个人的项目。
GitLab 的 wiki 功能可以用来为你的项目创建 wiki 页面。这些 wiki 就是 Git 仓库本身。它们使用 markdown 语法,你懂得。
只需要初始化你需要的 wiki ,让它与你为笔记而创建的项目的 wiki 同步即可。
```
cd ~/vimwiki_personal_md/
git init
git remote add origin [email protected]:your_user/vimwiki_personal_md.wiki
git add .
git commit -m "Initial commit"
git push -u origin master
```
在 GitLab 创建一个新的项目后,你就可以从页面上复制这些步骤的代码。唯一的改变是仓库地址结尾是 .wiki(而不是 .git)。 这会告诉 Git 克隆 wiki 仓库而不是项目本身。
就是这样!现在你能够通过 Git 来管理你的笔记,通过 GitLab wiki 用户界面来修改笔记。
你可能(像我一样)不想手动的为每个添加到笔记本的笔记创建一个提交。为了解决这个问题,我使用了 Vim 插件 [chazy/dirsetting](https://github.com/chazy/dirsettings)。我添加一个 `.vimaddr` 文件,已经下面的内容:
```
:cd %:p:h
silent! !git pull > /dev/null
:e!
autocmd! BufWritePost * silent! !git add .;git commit -m "vim autocommit" > /dev/null; git push > /dev/null&
```
每当我打开 Wiki 文件按下 `:w` 发布我的修改时,它就会更新到最新的版本。这样做会使你的本地文件与中心仓库保持同步。如果你有合并冲突,通常你需要解决它们。
目前,这就是以我的知识来互动的方法,我很喜欢这方法;请告诉我你对于这个方法的想法,可以在评论区分享你如何追踪笔记的方法。
---
via: <https://opensource.com/article/18/6/vimwiki-gitlab-notes>
作者:[Manuel Dewald](https://opensource.com/users/ntlx) 选题:[lujun9972](https://github.com/lujun9972) 译者:[octopus](https://github.com/singledo) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The idea of using vi to manage a wiki for your notes may seem unconventional, but when you're using vi in your daily work, it makes a lot of sense.
As a software developer, it’s just easier to write my notes in the same tool I use to code. I want my notes to be only an editor command away, available wherever I am, and managed the same way I handle my code. That's why I created a vi-based setup for my personal knowledge base. In a nutshell: I use the vi plugin [Vimwiki](http://vimwiki.github.io/) to manage my wiki locally on my laptop, I use Git to version it (and keep a central, updated version), and I use GitLab for online editing (for example, on my mobile device).
## Why it makes sense to use a wiki for note-keeping
I've tried many different tools to keep track of notes, write down fleeting thoughts, and structure tasks I shouldn’t forget. These include offline notebooks (yes, that involves paper), special note-keeping software, and mind-mapping software.
All these solutions have positives, but none fit all of my needs. For example, [mind maps](https://opensource.com/article/17/8/mind-maps-creative-dashboard) are a great way to visualize what’s in your mind (hence the name), but the tools I tried provided poor searching functionality. (The same thing is true for paper notes.) Also, it’s often hard to read mind maps after time passes, so they don’t work very well for long-term note keeping.
One day while setting up a [DokuWiki](https://www.dokuwiki.org/dokuwiki) for a collaboration project, I found that the wiki structure fits most of my requirements. With a wiki, you can create notes (like you would in any text editor) and create links between your notes. If a link points to a non-existent page (maybe because you wanted a piece of information to be on its own page but haven’t set it up yet), the wiki will create that page for you. These features make a wiki a good fit for quickly writing things as they come to your mind, while still keeping your notes in a page structure that is easy to browse and search for keywords.
While this sounds promising, and setting up DokuWiki is not difficult, I found it a bit too much work to set up a whole wiki just for keeping track of my notes. After some research, I found Vimwiki, a Vi plugin that does what I want. Since I use Vi every day, keeping notes is very similar to editing code. Also, it’s even easier to create a page in Vimwiki than DokuWiki—all you have to do is press Enter while your cursor hovers over a word. If there isn’t already a page with that name, Vimwiki will create it for you.
To take my plan to use my everyday tools for note-keeping a step further, I’m not only using my favorite IDE to write notes but also my favorite code management tools—Git and GitLab—to distribute notes across my various machines and be able to access them online. I’m also using Markdown syntax in GitLab's online Markdown editor to write this article.
## Setting up Vimwiki
Installing Vimwiki is easy using your existing plugin manager: Just add `vimwiki/vimwiki`
to your plugins. In my preferred plugin manager, Vundle, you just add the line `Plugin 'vimwiki/vimwiki'`
in your `~/.vimrc`
followed by a `:source ~/.vimrc|PluginInstall`
.
Following is a piece of my `~.vimrc`
showing a bit of Vimwiki configuration. You can learn more about installing and using this tool on the [Vimwiki page](http://vimwiki.github.io/).
```
let wiki_1 = {}
let wiki_1.path = '~/vimwiki_work_md/'
let wiki_1.syntax = 'markdown'
let wiki_1.ext = '.md'
let wiki_2 = {}
let wiki_2.path = '~/vimwiki_personal_md/'
let wiki_2.syntax = 'markdown'
let wiki_2.ext = '.md'
let g:vimwiki_list = [wiki_1, wiki_2]
let g:vimwiki_ext2syntax = {'.md': 'markdown', '.markdown': 'markdown', '.mdown': 'markdown'}
```
Another advantage of my approach, which you can see in the configuration, is that I can easily divide my personal and work-related notes without switching the note-keeping software. I want my personal notes accessible everywhere, but I don’t want to sync my work-related notes to my private GitLab and computer. This was easier to set up in Vimwiki compared to the other software I tried.
The configuration tells Vimwiki there are two different wikis and I want to use Markdown syntax in both (again, because I’m used to Markdown from my daily work). It also tells Vimwiki the folders where to store the wiki pages.
If you navigate to the folders where the wiki pages are stored, you will find your wiki’s flat Markdown pages without any special Vimwiki context. That makes it easy to initialize a Git repository and sync your wiki to a central repository.
## Synchronizing your wiki to GitLab
The steps to check out a GitLab project to your local Vimwiki folder are nearly the same as you’d use for any GitHub repository. I just prefer to keep my notes in a private GitLab repository, so I keep a GitLab instance running for my personal projects.
GitLab has a wiki functionality that allows you to create wiki pages for your projects. Those wikis are Git repositories themselves. And they use Markdown syntax. You get where this is leading.
Just initialize the wiki you want to synchronize with the wiki of a project you created for your notes:
```
cd ~/vimwiki_personal_md/
git init
git remote add origin [email protected]:your_user/vimwiki_personal_md.wiki
git add .
git commit -m "Initial commit"
git push -u origin master
```
These steps can be copied from the page where you land after creating a new project on GitLab. The only thing to change is the `.wiki`
at the end of the repository URL (instead of `.git`
), which tells it to clone the wiki repository instead of the project itself.
That’s it! Now you can manage your notes with Git and edit them in GitLab’s wiki user interface.
But maybe (like me) you don’t want to manually create commits for every note you add to your notebook. To solve this problem, I use the Vim plugin [chazy/dirsettings](https://github.com/chazy/dirsettings). I added a `.vimdir`
file with the following content to `~/vimwiki_personal_md`
:
```
:cd %:p:h
silent! !git pull > /dev/null
:e!
autocmd! BufWritePost * silent! !git add .;git commit -m "vim autocommit" > /dev/null; git push > /dev/null&
```
This pulls the latest version of my wiki every time I open a wiki file and publishes my changes after every `:w`
command. Doing this should keep your local copy in sync with the central repo. If you have merge conflicts, you may need to resolve them (as usual).
For now, this is the way I interact with my knowledge base, and I’m quite happy with it. Please let me know what *you* think about this approach. And please share in the comments your favorite way to keep track of your notes.
## 3 Comments |
9,794 | 如何在 Linux 中的特定时间运行命令 | https://www.ostechnix.com/run-command-specific-time-linux/ | 2018-06-30T21:54:12 | [
"定时",
"超时"
] | https://linux.cn/article-9794-1.html | 
有一天,我使用 `rsync` 将大文件传输到局域网上的另一个系统。由于它是非常大的文件,大约需要 20 分钟才能完成。我不想再等了,我也不想按 `CTRL+C` 来终止这个过程。我只是想知道在类 Unix 操作系统中是否有简单的方法可以在特定的时间运行一个命令,并且一旦超时就自动杀死它 —— 因此有了这篇文章。请继续阅读。
### 在 Linux 中在特定时间运行命令
我们可以用两种方法做到这一点。
#### 方法 1 - 使用 timeout 命令
最常用的方法是使用 `timeout` 命令。对于那些不知道的人来说,`timeout` 命令会有效地限制一个进程的绝对执行时间。`timeout` 命令是 GNU coreutils 包的一部分,因此它预装在所有 GNU/Linux 系统中。
假设你只想运行一个命令 5 秒钟,然后杀死它。为此,我们使用:
```
$ timeout <time-limit-interval> <command>
```
例如,以下命令将在 10 秒后终止。
```
$ timeout 10s tail -f /var/log/pacman.log
```

你也可以不用在秒数后加后缀 `s`。以下命令与上面的相同。
```
$ timeout 10 tail -f /var/log/pacman.log
```
其他可用的后缀有:
* `m` 代表分钟。
* `h` 代表小时。
* `d` 代表天。
如果你运行这个 `tail -f /var/log/pacman.log` 命令,它将继续运行,直到你按 `CTRL+C` 手动结束它。但是,如果你使用 `timeout` 命令运行它,它将在给定的时间间隔后自动终止。如果该命令在超时后仍在运行,则可以发送 `kill` 信号,如下所示。
```
$ timeout -k 20 10 tail -f /var/log/pacman.log
```
在这种情况下,如果 `tail` 命令在 10 秒后仍然运行,`timeout` 命令将在 20 秒后发送一个 kill 信号并结束。
有关更多详细信息,请查看手册页。
```
$ man timeout
```
有时,某个特定程序可能需要很长时间才能完成并最终冻结你的系统。在这种情况下,你可以使用此技巧在特定时间后自动结束该进程。
另外,可以考虑使用 `cpulimit`,一个简单的限制进程的 CPU 使用率的程序。有关更多详细信息,请查看下面的链接。
* [如何在 Linux 中限制一个进程的使用的 CPU](https://www.ostechnix.com/how-to-limit-cpu-usage-of-a-process-in-linux/)
#### 方法 2 - 使用 timelimit 程序
`timelimit` 使用提供的参数执行给定的命令,并在给定的时间后使用给定的信号终止进程。首先,它会发送警告信号,然后在超时后发送 kill 信号。
与 `timeout` 不同,`timelimit` 有更多选项。你可以传递参数数量,如 `killsig`、`warnsig`、`killtime`、`warntime` 等。它存在于基于 Debian 的系统的默认仓库中。所以,你可以使用命令来安装它:
```
$ sudo apt-get install timelimit
```
对于基于 Arch 的系统,它在 AUR 中存在。因此,你可以使用任何 AUR 助手进行安装,例如 [Pacaur](https://www.ostechnix.com/install-pacaur-arch-linux/)、[Packer](https://www.ostechnix.com/install-packer-arch-linux-2/)、[Yay](https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/)、[Yaourt](https://www.ostechnix.com/install-yaourt-arch-linux/) 等。
对于其他发行版,请[在这里](http://devel.ringlet.net/sysutils/timelimit/#download)下载源码并手动安装。安装 `timelimit` 后,运行下面的命令执行一段特定的时间,例如 10 秒钟:
```
$ timelimit -t10 tail -f /var/log/pacman.log
```
如果不带任何参数运行 `timelimit`,它将使用默认值:`warntime=3600` 秒、`warnsig=15` 秒、`killtime=120` 秒、`killsig=9`。有关更多详细信息,请参阅本指南最后给出的手册页和项目网站。
```
$ man timelimit
```
今天就是这些。我希望对你有用。还有更好的东西。敬请关注!
干杯!
### 资源
* [timelimit 网站](http://devel.ringlet.net/sysutils/timelimit/)
---
via: <https://www.ostechnix.com/run-command-specific-time-linux/>
作者:[SK](https://www.ostechnix.com/author/sk/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,795 | 让我们从 GitHub 中迁移出来 | https://veronneau.org/lets-migrate-away-from-github.html | 2018-06-30T22:22:00 | [
"微软",
"GitHub"
] | https://linux.cn/article-9795-1.html |
>
> 编者按:本文不代表本站观点,而且微软收购 GitHub 的后果目前尚未显现出来,本文只是提供了一个选择。
>
>
>

正如你们之前听到的那样,[微软收购了 GitHub](https://www.bloomberg.com/news/articles/2018-06-03/microsoft-is-said-to-have-agreed-to-acquire-coding-site-github)。这对 GitHub 的未来意味着什么尚不清楚,但 [Gitlab 的人](https://about.gitlab.com/2018/06/03/microsoft-acquires-github/)认为微软的最终目标是将 GitHub 整合到他们的 Azure 帝国。对我来说,这很有道理。
尽管我仍然不情愿地将 GitHub 用于某些项目,但我前一段时间将所有个人仓库迁移到了 Gitlab 中。现在是时候让你做同样的事情,并抛弃 GitHub。
有些人可能认为微软的收购没有问题,但对我来说,这是压垮骆驼的最后一根稻草。几年来,微软一直在开展一场关于他们如何热爱 Linux 的大型营销活动,并突然决定用它所有的形式拥抱自由软件。更像 MS BS 给我的。
让我们花点时间提醒自己:
* Windows 仍然是一个巨大的专有怪物,数十亿人每天都在丧失他们的隐私和权利。
* 微软公司(曾经)以传播自由软件的“危害”闻名,以防止政府和学校放弃 Windows,转而支持 FOSS。
* 为了确保他们的垄断地位,微软通过向全世界的小学颁发“免费”许可证来吸引孩子使用 Windows。毒品经销商使用相同的策略并提供免费样品来获取新客户。
* 微软的 Azure 平台 - 即使它可以运行 Linux 虚拟机 - 它仍然是一个巨大的专有管理程序。
我知道移动 git 仓库看起来像是一件痛苦的事情,但是 Gitlab 的员工正在趁着人们离开 GitHub 的浪潮,通过[提供 GitHub 导入器](https://docs.gitlab.com/ee/user/project/import/github.html)使迁移变得容易。
如果你不想使用 Gitlab 的主实例([gitlab.org](https://gitlab.org)),下面是另外两个你可以用于自由软件项目的备选实例:
* [Debian Gitlab 实例](https://salsa.debian.org)适用于每个 FOSS 项目,它不仅适用于与 Debian 相关的项目。只要项目符合 [Debian 自由软件指南](https://en.wikipedia.org/wiki/Debian_Free_Software_Guidelines),你就可以使用该实例及其 CI。
* Riseup 为名为 [0xacab](https://0xacab.org) 的激进项目维护了一个 Gitlab 实例。如果你的[理念与 Riseup 的一致](https://riseup.net/en/about-us/politics),他们很乐意在那里托管你的项目。
朋友不要再让人使用 Github 了。
---
via: <https://veronneau.org/lets-migrate-away-from-github.html>
作者:[Louis-Philippe Véronneau](https://veronneau.org/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | null |
9,796 | 你的路由器有多不安全? | https://opensource.com/article/18/5/how-insecure-your-router | 2018-06-30T22:48:00 | [
"安全",
"路由器"
] | https://linux.cn/article-9796-1.html |
>
> 你的路由器是你与互联网之间的第一个联系点。它给你带来了多少风险?
>
>
>

我一直对写在 T 恤上的“127.0.0.1 是独一无二的地方” 这句话持有异议。我知道你可能会认为应该将它看作是“家”,但是对于我来说,我认为应该是“本地主机是独一无二的地方”,就像世界上没有完全相同的二个戒指一样。在本文中,我想去讨论一些宽泛的问题:家庭网络的入口,对大多数人来说它是线缆或宽带路由器。<sup> 1</sup> 英国和美国政府刚公布了“俄罗斯” <sup> 2</sup> 攻击路由器的通告。我估计这次的攻击主要针对的是机构,而不是家庭,(看我以前的文章 “[国家行为者是什么,我们应该注意些什么?](https://aliceevebob.com/2018/03/13/whats-a-state-actor-and-should-i-care/)”),但这对我们所有人都是一个警示。
### 路由器有什么用?
路由器很重要。它用于将一个网络(在本文中,是我们的家庭网络)与另外一个网络(在本文中,是指互联网,通过我们的互联网服务提供商的网络)连接。事实上,对于大多数人来说,我们所谓的“路由器” <sup> 3</sup> 这个小盒子能够做的事情远比我们想到的要多。“路由” 一个比特就就如其听起来的意思一样:它让网络中的计算机能够找到一条向外部网络中计算机发送数据的路径 —— 当你接收数据时,反之。
在路由器的其它功能中,大多数时候也作为一台调制解调器来使用。我们中的大部分人 <sup> 4</sup> 到互联网的连接是通过电话线来实现的 —— 无论是电缆还是标准电话线 —— 尽管现在的最新趋势是通过移动互联网连接到家庭中。当你通过电话线连接时,我们所使用的互联网信号必须转换成其它的一些东西,(从另一端来的)返回信号也是如此。对于那些还记得过去的“拨号上网”时代的人来说,它就是你的电脑边上那个用于上网的发出刺耳声音的小盒子。
但是路由器能做的事情很多,有时候很多的事情,包括流量记录、作为一个无线接入点、提供 VPN 功能以便于从外部访问你的内网、儿童上网控制、防火墙等等。
现在的家用路由器越来越复杂;虽然国家行为者也行不会想着攻破它,但是其它人也许会。
你会问,这很重要吗?如果其它人可以进入你的系统,他们可以很容易地攻击你的笔记本电脑、电话、网络设备等等。他们可以访问和删除未被保护的个人数据。他们可以假装是你。他们使用你的网络去寄存非法数据或者用于攻击其它人。基本上所有的坏事都可以做。
幸运的是,现在的路由器趋向于由互联网提供商来做设置,言外之意是你可以忘了它的存在,他们将保证它是运行良好和安全的。
### 因此,我们是安全的吗?
不幸的是,事实并非如此。
第一个问题是,互联网提供商是在有限的预算范围内做这些事情,而使用便宜的设备来做这些事可以让他们的利益最大化。互联网提供商的路由器质量越来越差。它是恶意攻击者的首选目标:如果他们知道特定型号的路由器被安装在几百万个家庭使用,那么很容易找到攻击的动机,因为攻击那个型号的路由器对他们来说是非常有价值的。
产生的其它问题还包括:
* 修复 bug 或者漏洞的过程很缓慢。升级固件可能会让互联网提供商产生较高的成本,因此,修复过程可能非常缓慢(如果他们打算修复的话)。
* 非常容易获得或者默认的管理员密码,这意味着攻击者甚至都不需要去找到真实的漏洞 —— 他们就可以登入到路由器中。
### 对策
对于进入互联网第一跳的路由器,如何才能提升它的安全性,这里给你提供一个快速应对的清单。我是按从简单到复杂的顺序来列出它们的。在你对路由器做任何改变之前,需要先保存配置数据,以便于你需要的时候回滚它们。
1. **密码:** 一定,一定,一定要改变你的路由器的管理员密码。你可能很少会用到它,所以你一定要把密码记录在某个地方。它用的次数很少,你可以考虑将密码粘贴到路由器上,因为路由器一般都放置在仅供授权的人(你和你的家人 <sup> 5</sup> )才可以接触到的地方。
2. **仅允许管理员从内部进行访问:** 除非你有足够好的理由和你知道如何去做,否则不要允许任何机器从外部的互联网上管理你的路由器。在你的路由器上有一个这样的设置。
3. **WiFi 密码:** 一旦你做到了第 2 点,也要确保在你的网络上的那个 WiFi 密码 —— 无论是设置为你的路由器管理密码还是别的 —— 一定要是强密码。为了简单,为连接你的网络的访客设置一个“友好的”简单密码,但是,如果附近一个恶意的人猜到了密码,他做的第一件事情就是查找网络中的路由器。由于他在内部网络,他是可以访问路由器的(因此,第 1 点很重要)。
4. **仅打开你知道的并且是你需要的功能:** 正如我在上面所提到的,现代的路由器有各种很酷的选项。不要使用它们。除非你真的需要它们,并且你真正理解了它们是做什么的,以及打开它们后有什么危险。否则,将增加你的路由器被攻击的风险。
5. **购买你自己的路由器:** 用一个更好的路由器替换掉互联网提供商给你的路由器。去到你本地的电脑商店,让他们给你一些建议。你可能会花很多钱,但是也可能会遇到一些非常便宜的设备,而且比你现在拥有的更好、性能更强、更安全。你也可以只买一个调制解调器。一般设置调制解调器和路由器都很简单,并且,你可以从你的互联网提供商给你的设备中复制配置,它一般就能“正常工作”。
6. **更新固件:** 我喜欢使用最新的功能,但是通常这并不容易。有时,你的路由器上会出现固件更新的提示。大多数的路由器会自动检查并且提示你在下次登入的时候去更新它。问题是如果更新失败则会产生灾难性后果 <sup> 6</sup> 或者丢失配置数据,那就需要你重新输入。但是你真的需要考虑去持续关注修复安全问题的固件更新,并更新它们。
7. **转向开源:** 有一些非常好的开源路由器项目,可以让你用在现有的路由器上,用开源的软件去替换它的固件/软件。你可以在 [Wikipedia](https://en.wikipedia.org/wiki/List_of_router_firmware_projects) 上找到许多这样的项目,以及在 [Opensource.com 上搜索 “router”](https://opensource.com/sitewide-search?search_api_views_fulltext=router),你将看到很多非常好的东西。对于谨慎的人来说要小心,这将会让你的路由器失去保修,但是如果你想真正控制你的路由器,开源永远是最好的选择。
### 其它问题
一旦你提升了你的路由器的安全性,你的家庭网络将变的很好——这是假像,事实并不是如此。你家里的物联网设备(Alexa、Nest、门铃、智能灯泡、等等)安全性如何?连接到其它网络的 VPN 安全性如何?通过 WiFi 的恶意主机、你的孩子手机上的恶意应用程序 …?
不,你永远不会有绝对的安全。但是正如我们前面讨论的,虽然没有绝对的“安全”这种事情,但是并不意味着我们不需要去提升安全标准,以让坏人干坏事更困难。
### 脚注
1. 我写的很简单 — 但请继续读下去,我们将达到目的。
2. “俄罗斯政府赞助的信息技术国家行为者”
3. 或者,以我父母的例子来说,我猜叫做 “互联网盒子”。
4. 这里还有一种这样的情况,我不希望在评论区告诉我,你是直接以 1TB/s 的带宽连接到本地骨干网络的。非常感谢!
5. 或许并没有包含整个家庭。
6. 你的路由器现在是一块“砖”,并且你不能访问互联网了。
这篇文章最初发表在 [Alice, Eve, 和 Bob – 安全博客](https://aliceevebob.com/2018/04/17/defending-our-homes/) 并授权重发布。
---
via: <https://opensource.com/article/18/5/how-insecure-your-router>
作者:[Mike Bursell](https://opensource.com/users/mikecamel) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I've always had a problem with the t-shirt that reads, "There's no place like 127.0.0.1." I know you're supposed to read it as "home," but to me, it says, "There's no place like localhost," which just doesn't have the same ring to it. And in this post, I want to talk about something broader: the entry point to your home network, which for most people will be a cable or broadband router.[ 1](#1) The UK and U.S. governments just published advice that "Russia"
[is attacking routers. This attack will be aimed mostly, I suspect, at organisations (see my previous post "](#2)
2[What's a state actor, and should I care?](https://aliceevebob.com/2018/03/13/whats-a-state-actor-and-should-i-care/)"), rather than homes, but it's a useful wake-up call for all of us.
## What do routers do?
Routers are important. They provide the link between one network (in this case, our home network) and another one (in this case, the internet, via our ISP's network). In fact, for most of us, the box we think of as "the router"[ 3](#3) is doing a lot more than that. The "routing" bit is what is sounds like; it helps computers on your network find routes to send data to computers outside the network—and vice-versa, for when you're getting data back.
High among a router's other functions, many also perform as a modem. Most of us[ 4](#4) connect to the internet via a phone line—whether cable or standard landline—though there is a growing trend for mobile internet to the home. When you're connecting via a phone line, the signals we use for the internet must be converted to something else and then (at the other end) back again. For those of us old enough to remember the old "dial-up" days, that's what the screechy box next to your computer used to do.
But routers often do more things, sometimes many more things, including traffic logging, acting as a WiFi access point, providing a VPN for external access to your internal network, child access, firewalling, and all the rest.
Home routers are complex things these days; although state actors may not be trying to get into them, other people may.
Does this matter, you ask? Well, if other people can get into your system, they have easy access to attacking your laptops, phones, network drives, and the rest. They can access and delete unprotected personal data. They can plausibly pretend to be you. They can use your network to host illegal data or launch attacks on others. Basically, all the bad things.
Luckily, routers tend to come set up by your ISP, with the implication being that you can leave them, and they'll be nice and safe.
## So we're safe, then?
Unluckily, we're really not.
The first problem is that ISPs are working on a budget, and it's in their best interests to provide cheap kit that just does the job. The quality of ISP-provided routers tends to be pretty terrible. It's also high on the list of things to try to attack by malicious actors: If they know that a particular router model is installed in several million homes, there's a great incentive to find an attack, because an attack on that model will be very valuable to them.
Other problems that arise include:
- Slowness to fix known bugs or vulnerabilities. Updating firmware can be costly to your ISP, so fixes may be slow to arrive (if they do at all).
- Easily derived or default admin passwords, which means attackers don't even need to find a real vulnerability—they can just log in.
## Measures to take
Here's a quick list of steps you can take to try to improve the security of your first hop to the internet. I've tried to order them in terms of ease—simplest first. Before you do any of these, however, save the configuration data so you can bring it back if you need it.
**Passwords:**Always, always, always change the admin password for your router. It's probably going to be one you rarely use, so you'll want to record it somewhere. This is one of the few times where you might want to consider taping it to the router itself, as long as the router is in a secure place where only authorised people (you and your family) have access.[5](#5)**Internal admin access only:**Unless you have very good reasons and you know what you're doing, don't allow machines to administer the router unless they're on your home network. There should be a setting on your router for this.**WiFi passwords:**Once you've done item 2, also ensure that WiFi passwords on your network—whether set on your router or elsewhere—are strong. It's easy to set a "friendly" password to make it easy for visitors to connect to your network, but if a malicious person who happens to be nearby guesses it, the first thing that person will do is to look for routers on the network. As they're on the internal network, they'll have access to it (hence why item 1 is important).**Turn on only the functions that you understand and need:**As I noted above, modern routers have all sorts of cool options. Disregard them. Unless you really need them, and you actually understand what they do and the dangers of turning them on, then leave them off. Otherwise, you're just increasing your attack surface.**Buy your own router:**Replace your ISP-supplied router with a better one. Go to your local computer store and ask for suggestions. You can pay an awful lot, but you can also get something fairly cheap that does the job and is more robust, performant, and easy to secure than the one you have at the moment. You may also want to buy a separate modem. Generally, setting up your modem or router is simple, and you can copy the settings from the ISP-supplied one and it will "just work."**Firmware updates:**I'd love to move this further up the list, but it's not always easy. From time to time, firmware updates appear for your router. Most routers will check automatically and may prompt you to update when you next log in. The problem is that failure to update correctly can cause catastrophic resultsor lose configuration data that you'll need to re-enter. But you really do need to consider keeping a lookout for firmware updates that fix severe security issues and implement them.[6](#6)**Go open source:**There are some great open source router projects out there that allow you to take an existing router and replace all of its firmware/software with open source alternatives. You can find many of them on[Wikipedia](https://en.wikipedia.org/wiki/List_of_router_firmware_projects), and a search for["router" on Opensource.com](https://opensource.com/sitewide-search?search_api_views_fulltext=router)will open your eyes to a set of fascinating opportunities. This isn't a step for the faint-hearted, as you'll definitely void the warranty on your router, but if you want to have real control, open source is always the way to go.
## Other issues
I'd love to pretend that once you've improved the security of your router, all's well and good on your home network, but it's not. What about IoT devices in your home (Alexa, Nest, Ring doorbells, smart lightbulbs, etc.?) What about VPNs to other networks? Malicious hosts via WiFi, malicious apps on your children's phones…?
No, you won't be safe. But, as we've discussed before, although there is no such thing as "secure," it doesn't mean we shouldn't raise the bar and make it harder for the Bad Folks.™
[I'm simplifying—but read on, we'll get there.]["Russian state-sponsored cyber actors"][Or, in my parents' case, "the internet box," I suspect.][This is one of these cases where I don't want comments telling me how you have a direct, 1TB/s connection to your local backbone, thank you very much.][Maybe not the entire family.][Your router is now a brick, and you have no access to the internet.]
*This article originally appeared on Alice, Eve, and Bob – a security blog and is republished with permission.*
## 2 Comments |
9,797 | Python 调试技巧 | https://pythondebugging.com/articles/python-debugging-tips | 2018-07-02T08:57:40 | [
"Python",
"调试"
] | https://linux.cn/article-9797-1.html | 
当进行调试时,你有很多选择,但是很难给出一直有效的通用建议(除了“你试过关闭再打开么?”以外)。
这里有一些我最喜欢的 Python 调试技巧。
### 建立一个分支
请相信我。即使你从来没有打算将修改提交回上游,你也会很乐意将你的实验被包含在它们自己的分支中。
不说别的,它会使清理更容易!
### 安装 pdb++
认真地说,如果你使用命令行,它会让你的生活更轻松。
pdb++ 所做的一切就是用更好的模块替换标准的 pdb 模块。以下是你在 `pip install pdbpp` 会看到的:
* 彩色提示!
* 制表符补全!(非常适合探索!)
* 支持切分!
好的,也许最后一个是有点多余……但是非常认真地说,安装 pdb++ 非常值得。
### 探索
有时候最好的办法就是胡乱试试,然后看看会发生什么。在“明显”的位置放置一个断点并确保它被命中。在代码中加入 `print()` 和/或 `logging.debug()` 语句,并查看代码执行的位置。
检查传递给你的函数的参数,检查库的版本(如果你已经非常绝望了)。
### 一次只能改变一件事
在你在探索了一下后,你将会对你可以做的事情有所了解。但在你开始摆弄代码之前,先退一步,考虑一下你可以改变什么,然后只改变一件事。
做出改变后,然后测试一下,看看你是否接近解决问题。如果没有,请将它改回来,然后尝试其他方法。
只更改一件事就可以让你知道什可以工作,哪些不工作。另外,一旦可以工作后,你的新提交将会小得多(因为将有更少的变化)。
这几乎是<ruby> 科学过程 <rt> Scientific Process </rt></ruby>中所做的事情:一次只更改一个变量。通过让自己看到并衡量一次更改的结果,你可以节省你的理智,并更快地找到解决方案。
### 不要假设,提出问题
偶尔一个开发人员(当然不是你咯!)会匆忙提交一些有问题的代码。当你去调试这段代码时,你需要停下来,并确保你明白它想要完成什么。
不要做任何假设。仅仅因为代码在 `model.py` 文件中并不意味着它不会尝试渲染一些 HTML。
同样,在做任何破坏性的事情之前,仔细检查你的所有外部关联。要删除一些配置数据?**请确保你没有连接到你的生产系统。**
### 聪明,但不要聪明过头
有时候我们编写的代码神奇般地奏效,不知道它是如何做的。
当我们发布代码时,我们可能会觉得自己很聪明,但当代码崩溃时,我们往往会感到愚蠢,我们必须记住它是如何工作的,以便弄清楚它为什么不起作用。
留意任何看起来过于复杂、冗长或极短的代码段。这些可能是隐藏复杂并导致错误的地方。
---
via: <https://pythondebugging.com/articles/python-debugging-tips>
作者:[PythonDebugging.com](https://pythondebugging.com) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | When it comes to debugging, there’s a lot of choices that you can make. It is hard to give generic advice that always works (other than “Have you tried turning it off and back on?”).
Here are a few of my favorite Python Debugging tips.
## Make a branch
Trust me on this. Even if you never intend to commit the changes back upstream, you will be glad your experiments are contained within their own branch.
If nothing else, it makes cleanup a lot easier!
## Install pdb++
Seriously. It makes you life easier if you are on the command line.
All that pdb++ does is replace the standard pdb module with 100% PURE AWESOMENESS. Here’s what you get when you `pip install pdbpp`
:
- A Colorized prompt!
- tab completion!
*(perfect for poking around!)* - It slices! It dices!
Ok, maybe the last one is a little bit much… But in all seriousness, installing pdb++ is well worth your time.
## Poke around
Sometimes the best approach is to just mess around and see what happens. Put a break point in an “obvious” spot and make sure it gets hit. Pepper the code with `print()`
and/or `logging.debug()`
statements and see where the code execution goes.
Examine the arguments being passed into your functions. Check the versions of the libraries (if things are getting really desperate).
## Only change one thing at a time
Once you are poking around a bit you are going to get ideas on things you could do. But before you start slinging code, take a step back and think about what you could change, and then only change 1 thing.
Once you’ve made the change, then test and see if you are closer to resolving the issue. If not, change the thing back, and try something else.
Changing only one thing allows you to know what does and doesn’t work. Plus once you do get it working, your new commit is going to be much smaller (because there will be less changes).
This is pretty much what one does in the Scientific Process: only change one variable at a time. By allowing yourself to see and measure the results of one change you will save your sanity and arrive at a working solution faster.
## Assume nothing, ask questions
Occasionally a developer (not you of course!) will be in a hurry and whip out some questionable code. When you go through to debug this code you need to stop and make sure you understand what it is trying to accomplish.
Make no assumptions. Just because the code is in the `model.py`
file doesn’t mean it won’t try to render some HTML.
Likewise, double check all of your external connections before you do anything destructive! Going to delete some configuration data? MAKE SURE YOU ARE NOT CONNECTED TO YOUR PRODUCTION SYSTEM.
## Be clever, but not too clever
Sometimes we write code that is so amazingly awesome it is not obvious how it does what it does.
While we might feel smart when we publish that code, more often than not we will wind up feeling dumb later on when the code breaks and we have to remember how it works to figure out why it isn’t working.
Keep an eye out for any sections of code that look either overly complicated and long, or extremely short. These could be places where complexity is hiding and causing your bugs. |
9,798 | Linux 文件系统详解 | https://www.linux.com/blog/learn/intro-to-linux/2018/4/linux-filesystem-explained | 2018-07-02T09:44:00 | [
"文件系统"
] | https://linux.cn/article-9798-1.html |
>
> 这篇教程将帮你快速了解 Linux 文件系统。
>
>
>

早在 1996 年,在真正理解文件系统的结构之前,我就学会了如何在我崭新的 Linux 上安装软件。这是一个问题,但对程序来说不是大问题,因为即使我不知道实际的可执行文件在哪里,它们也会神奇地工作。问题在于文档。
你知道,那时候,Linux 不是像今天这样直观、用户友好的系统。你必须读很多东西。你必须知道你的 CRT 显示器的扫描频率以及拨号调制解调器的噪音来龙去脉,以及其他数以百计的事情。 我很快就意识到我需要花一些时间来掌握目录的组织方式以及 `/etc`(不是用于“其它”文件),`/usr`(不是用于“用户”文件)和 `/bin` (不是“垃圾桶”)的意思。
本教程将帮助你比我当时更快地了解这些。
### 结构
从终端窗口探索 Linux 文件系统是有道理的,这并不是因为作者是一个脾气暴躁的老人,并且对新孩子和他们漂亮的图形工具不以为然(尽管某些事实如此),而是因为终端,尽管只是文本界面,才是更好地显示 Linux 目录树结构的工具。
事实上,帮助你了解这一切的、应该首先安装的第一个工具的名为:`tree`。如果你正在使用 Ubuntu 或 Debian ,你可以:
```
sudo apt install tree
```
在 Red Hat 或 Fedora :
```
sudo dnf install tree
```
对于 SUSE/openSUSE 可以使用 `zypper`:
```
sudo zypper install tree
```
对于使用 Arch (Manjaro,Antergos,等等)使用:
```
sudo pacman -S tree
```
……等等。
一旦安装好,在终端窗口运行 `tree` 命令:
```
tree /
```
上述指令中的 `/` 指的是根目录。系统中的其他目录都是从根目录分支而出,当你运行 `tree` 命令,并且告诉它从根目录开始,那么你就可以看到整个目录树,系统中的所有目录及其子目录,还有它们的文件。
如果你已经使用你的系统有一段时间了,这可能需要一段时间,因为即使你自己还没有生成很多文件,Linux 系统及其应用程序总是在记录、缓存和存储各种临时文件。文件系统中的条目数量会快速增长。
不过,不要感到不知所措。 相反,试试这个:
```
tree -L 1 /
```
你应该看到如图 1 所示。

*tree*
上面的指令可以翻译为“只显示以 `/`(根目录) 开头的目录树的第一级”。 `-L` 选项告诉树你想看到多少层目录。
大多数 Linux 发行版都会向你显示与你在上图中看到的相同或非常类似的结构。 这意味着,即使你现在感到困惑,掌握这一点,你将掌握大部分(如果不是全部的话)全世界的 Linux 文件系统。
为了让你开始走上掌控之路,让我们看看每个目录的用途。 当我们查看每一个目录的时候,你可以使用 `ls` 来查看他们的内容。
### 目录
从上到下,你所看到的目录如下
#### /bin
`/bin` 目录是包含一些二进制文件的目录,即可以运行的一些应用程序。 你会在这个目录中找到上面提到的 `ls` 程序,以及用于新建和删除文件和目录、移动它们基本工具。还有其它一些程序,等等。文件系统树的其他部分有更多的 *bin* 目录,但我们将在一会儿讨论这些目录。
#### /boot
`/boot` 目录包含启动系统所需的文件。我必须要说吗? 好吧,我会说:**不要动它**! 如果你在这里弄乱了其中一个文件,你可能无法运行你的 Linux,修复被破坏的系统是非常痛苦的一件事。 另一方面,不要太担心无意中破坏系统:你必须拥有超级用户权限才能执行此操作。
#### /dev
`/dev` 目录包含设备文件。 其中许多是在启动时或甚至在运行时生成的。 例如,如果你将新的网络摄像头或 USB 随身碟连接到你的机器中,则会自动弹出一个新的设备条目。
#### /etc
`/etc` 的目录名称会让人变得非常的困惑。`/etc` 得名于最早的 Unix 系统们,它的字面意思是 “etcetera”(诸如此类) ,因为它是系统文件管理员不确定在哪里放置的文件的垃圾场。
现在,说 `/etc` 是“<ruby> 要配置的所有内容 <rt> Everything To Configure </rt></ruby>”更为恰当,因为它包含大部分(如果不是全部的话)的系统配置文件。 例如,包含系统名称、用户及其密码、网络上计算机名称以及硬盘上分区的安装位置和时间的文件都在这里。 再说一遍,如果你是 Linux 的新手,最好是不要在这里接触太多,直到你对系统的工作有更好的理解。
#### /home
`/home` 是你可以找到用户个人目录的地方。在我的情况下,`/home` 下有两个目录:`/home/paul`,其中包含我所有的东西;另外一个目录是 `/home/guest` 目录,以防有客人需要使用我的电脑。
#### /lib
`/lib` 是库文件所在的地方。库是包含应用程序可以使用的代码文件。它们包含应用程序用于在桌面上绘制窗口、控制外围设备或将文件发送到硬盘的代码片段。
在文件系统周围散布着更多的 `lib` 目录,但是这个直接挂载在 `/` 的 `/lib` 目录是特殊的,除此之外,它包含了所有重要的内核模块。 内核模块是使你的显卡、声卡、WiFi、打印机等工作的驱动程序。
#### /media
在 `/media` 目录中,当你插入外部存储器试图访问它时,将自动挂载它。与此列表中的大多数其他项目不同,`/media` 并不追溯到 1970 年代,主要是因为当计算机正在运行而动态地插入和检测存储(U 盘、USB 硬盘、SD 卡、外部 SSD 等),这是近些年才发生的事。
#### /mnt
然而,`/mnt` 目录是一些过去的残余。这是你手动挂载存储设备或分区的地方。现在不常用了。
#### /opt
`/opt` 目录通常是你编译软件(即,你从源代码构建,并不是从你的系统的软件库中安装软件)的地方。应用程序最终会出现在 `/opt/bin` 目录,库会在 `/opt/lib` 目录中出现。
稍微的题外话:应用程序和库的另一个地方是 `/usr/local`,在这里安装软件时,也会有 `/usr/local/bin` 和 `/usr/local/lib` 目录。开发人员如何配置文件来控制编译和安装过程,这就决定了软件安装到哪个地方。
#### /proc
`/proc`,就像 `/dev` 是一个虚拟目录。它包含有关你的计算机的信息,例如关于你的 CPU 和你的 Linux 系统正在运行的内核的信息。与 `/dev` 一样,文件和目录是在计算机启动或运行时生成的,因为你的系统正在运行且会发生变化。
#### /root
`/root` 是系统的超级用户(也称为“管理员”)的主目录。 它与其他用户的主目录是分开的,**因为你不应该动它**。 所以把自己的东西放在你自己的目录中,伙计们。
#### /run
`/run` 是另一个新出现的目录。系统进程出于自己不可告人的原因使用它来存储临时数据。这是另一个**不要动它**的文件夹。
#### /sbin
`/sbin` 与 `/bin` 类似,但它包含的应用程序只有超级用户(即首字母的 `s` )才需要。你可以使用 `sudo` 命令使用这些应用程序,该命令暂时允许你在许多 Linux 发行版上拥有超级用户权限。`/sbin` 目录通常包含可以安装、删除和格式化各种东西的工具。你可以想象,如果你使用不当,这些指令中有一些是致命的,所以要小心处理。
#### /usr
`/usr` 目录是在 UNIX 早期用户的主目录所处的地方。然而,正如我们上面看到的,现在 `/home` 是用户保存他们的东西的地方。如今,`/usr` 包含了大量目录,而这些目录又包含了应用程序、库、文档、壁纸、图标和许多其他需要应用程序和服务共享的内容。
你还可以在 `/usr` 目录下找到 `bin`,`sbin`,`lib` 目录,它们与挂载到根目录下的那些有什么区别呢?现在的区别不是很大。在早期,`/bin` 目录(挂载在根目录下的)只会包含一些基本的命令,例如 `ls`、`mv` 和 `rm` ;这是一些在安装系统的时候就会预装的一些命令,用于维护系统的一个基本的命令。 而 `/usr/bin` 目录则包含了用户自己安装和用于工作的软件,例如文字处理器,浏览器和一些其他的软件。
但是许多现代的 Linux 发行版只是把所有的东西都放到 `/usr/bin` 中,并让 `/bin` 指向 `/usr/bin`,以防彻底删除它会破坏某些东西。因此,Debian、Ubuntu 和 Mint 仍然保持 `/bin` 和 `/usr/bin` (和 `/sbin` 和 `/usr/sbin` )分离;其他的,比如 Arch 和它衍生版,只是有一个“真实”存储二进制程序的目录,`/usr/bin`,其余的任何 `bin` 目录是指向 `/usr/`bin` 的“假”目录。
#### /srv
`/srv` 目录包含服务器的数据。如果你正在 Linux 机器上运行 Web 服务器,你网站的 HTML文件将放到 `/srv/http`(或 `/srv/www`)。 如果你正在运行 FTP 服务器,则你的文件将放到 `/srv/ftp`。
#### /sys
`/sys` 是另一个类似 `/proc` 和 `/dev` 的虚拟目录,它还包含连接到计算机的设备的信息。
在某些情况下,你还可以操纵这些设备。 例如,我可以通过修改存储在 `/sys/devices/pci0000:00/0000:00:02.0/drm/card1/card1-eDP-1/intel_backlight/brightness` 中的值来更改笔记本电脑屏幕的亮度(在你的机器上你可能会有不同的文件)。但要做到这一点,你必须成为超级用户。原因是,与许多其它虚拟目录一样,在 `/sys` 中打乱内容和文件可能是危险的,你可能会破坏系统。直到你确信你知道你在做什么。否则不要动它。
#### /tmp
`/tmp` 包含临时文件,通常由正在运行的应用程序放置。文件和目录通常(并非总是)包含应用程序现在不需要但以后可能需要的数据。
你还可以使用 `/tmp` 来存储你自己的临时文件 —— `/tmp` 是少数挂载到根目录下而你可以在不成为超级用户的情况下与它进行实际交互的目录之一。
#### /var
`/var` 最初被如此命名是因为它的内容被认为是<ruby> 可变的 <rt> variable </rt></ruby>,因为它经常变化。今天,它有点用词不当,因为还有许多其他目录也包含频繁更改的数据,特别是我们上面看到的虚拟目录。
不管怎样,`/var` 目录包含了放在 `/var/log` 子目录的日志文件之类。日志是记录系统中发生的事件的文件。如果内核中出现了什么问题,它将被记录到 `/var/log` 下的文件中;如果有人试图从外部侵入你的计算机,你的防火墙也将记录尝试。它还包含用于任务的假脱机程序。这些“任务”可以是你发送给共享打印机必须等待执行的任务,因为另一个用户正在打印一个长文档,或者是等待递交给系统上的用户的邮件。
你的系统可能还有一些我们上面没有提到的目录。例如,在屏幕截图中,有一个 `/snap` 目录。这是因为这张截图是在 Ubuntu 系统上截取的。Ubuntu 最近将 [snap](https://www.ubuntu.com/desktop/snappy) 包作为一种分发软件的方式。`/snap` 目录包含所有文件和从 snaps 安装的软件。
### 更深入的研究
这里仅仅谈了根目录,但是许多子目录都指向它们自己的一组文件和子目录。图 2 给出了基本文件系统的总体概念(图片是在 Paul Gardner 的 CC BY-SA 许可下提供的),[Wikipedia 对每个目录的用途进行了总结](https://en.wikipedia.org/wiki/Unix_filesystem#Conventional_directory_layout)。

*图 2:标准 Unix 文件系统*
要自行探索文件系统,请使用 `cd` 命令:`cd`将带你到你所选择的目录( `cd` 代表更改目录)。
如果你不知道你在哪儿,`pwd`会告诉你,你到底在哪里,( `pwd` 代表打印工作目录 ),同时 `cd`命令在没有任何选项或者参数的时候,将会直接带你到你自己的主目录,这是一个安全舒适的地方。
最后,`cd ..`将会带你到上一层目录,会使你更加接近根目录,如果你在 `/usr/share/wallpapers` 目录,然后你执行 `cd ..` 命令,你将会跳转到 `/usr/share` 目录
要查看目录里有什么内容,使用 `ls` 或这简单的使用 `l` 列出你所在目录的内容。
当然,你总是可以使用 `tree` 来获得目录中内容的概述。在 `/usr/share` 上试试——里面有很多有趣的东西。
### 总结
尽管 Linux 发行版之间存在细微差别,但它们的文件系统的布局非常相似。 你可以这么说:一旦你了解一个,你就会都了解了。 了解文件系统的最好方法就是探索它。 因此,伴随 `tree` ,`ls` 和 `cd` 进入未知的领域吧。
你不会只是因为查看文件系统就破坏了文件系统,因此请从一个目录移动到另一个目录并进行浏览。 很快你就会发现 Linux 文件系统及其布局的确很有意义,并且你会直观地知道在哪里可以找到应用程序,文档和其他资源。
通过 Linux 基金会和 edX 免费的 “[Linux入门](https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux)” 课程了解更多有关 Linux 的信息。
---
via: <https://www.linux.com/blog/learn/intro-to-linux/2018/4/linux-filesystem-explained>
作者:[PAUL BROWN](https://www.linux.com/users/bro66) 选题:[lujun9972](https://github.com/lujun9972) 译者:[amwps290](https://github.com/amwps290) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,799 | 容器基础知识:你需要知道的术语 | https://www.linux.com/blog/intro-to-linux/2017/12/container-basics-terms-you-need-know | 2018-07-02T10:03:59 | [
"docker",
"容器"
] | https://linux.cn/article-9799-1.html | 
[在前一篇文章中](/article-9468-1.html),我们谈到了<ruby> 容器 <rt> container </rt></ruby>是什么以及它是如何培育创新并助力企业快速发展的。在以后的文章中,我们将讨论如何使用容器。然而,在深入探讨这个话题之前,我们需要了解关于容器的一些术语和命令。掌握了这些术语,才不至于产生混淆。
让我们来探讨 [Docker](https://www.docker.com/) 容器世界中使用的一些基本术语吧。
<ruby> 容器 <rt> Container </rt></ruby>:到底什么是容器呢?它是一个 Docker <ruby> 镜像 <rt> image </rt></ruby>的运行实例。它包含一个 Docker 镜像、执行环境和说明。它与系统完全隔离,所以可以在系统上运行多个容器,并且完全无视对方的存在。你可以从同一镜像中复制出多个容器,并在需求较高时扩展服务,在需求低时对这些容器进行缩减。
Docker <ruby> 镜像 <rt> Image </rt></ruby>:这与你下载的 Linux 发行版的镜像别无二致。它是一个安装包,包含了用于创建、部署和执行容器的一系列依赖关系和信息。你可以在几秒钟内创建任意数量的完全相同的容器。镜像是分层叠加的。一旦镜像被创建出来,是不能更改的。如果你想对容器进行更改,则只需创建一个新的镜像并从该镜像部署新的容器即可。
<ruby> 仓库 <rt> Repository </rt></ruby>(repo):Linux 的用户对于仓库这个术语一定不陌生吧。它是一个软件库,存储了可下载并安装在系统中的软件包。在 Docker 容器中,唯一的区别是它管理的是通过标签分类的 Docker 镜像。你可以找到同一个应用程序的不同版本或不同变体,他们都有适当的标记。
<ruby> 镜像管理服务 <rt> Registry </rt></ruby>:可以将其想象成 GitHub。这是一个在线服务,管理并提供了对 Docker 镜像仓库的访问,例如默认的公共镜像仓库——DockerHub。供应商可以将他们的镜像库上传到 DockerHub 上,以便他们的客户下载和使用官方镜像。一些公司为他们的镜像提供自己的服务。镜像管理服务不必由第三方机构来运行和管理。组织机构可以使用预置的服务来管理内部范围的镜像库访问。
<ruby> 标签 <rt> Tag </rt></ruby>:当你创建 Docker 镜像时,可以给它添加一个合适的标签,以便轻松识别不同的变体或版本。这与你在任何软件包中看到的并无区别。Docker 镜像在添加到镜像仓库时被标记。
现在你已经掌握了基本知识,下一个阶段是理解实际使用 Docker 容器时用到的术语。
**Dockerfile** :这是一个文本文件,包含为了为构建 Docker 镜像需手动执行的命令。Docker 使用这些指令自动构建镜像。
<ruby> 构建 <rt> Build </rt></ruby>:这是从 Dockerfile 创建成镜像的过程。
<ruby> 推送 <rt> Push </rt></ruby>:一旦镜像创建完成,“push” 是将镜像发布到仓库的过程。该术语也是我们下一篇文章要学习的命令之一。
<ruby> 拉取 <rt> Pull </rt></ruby>:用户可以通过 “pull” 过程从仓库检索该镜像。
<ruby> 编组 <rt> Compose </rt></ruby>:复杂的应用程序会包含多个容器。docker-compose 是一个用于运行多容器应用程序的命令行工具。它允许你用单条命令运行一个多容器的应用程序,简化了多容器带来的问题。
### 总结
容器术语的范围很广泛,这里是经常遇到的一些基本术语。下一次当你看到这些术语时,你会确切地知道它们的含义。在下一篇文章中,我们将开始使用 Docker 容器。
---
via: <https://www.linux.com/blog/intro-to-linux/2017/12/container-basics-terms-you-need-know>
作者:[Swapnil Bhartiya](https://www.linux.com/users/arnieswap) 译者:[jessie-pang](https://github.com/jessie-pang) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,800 | 协同编辑器的历史性清单 | https://anarc.at/blog/2018-06-26-collaborative-editors-history/ | 2018-07-03T10:43:00 | [
"编辑器",
"协同"
] | https://linux.cn/article-9800-1.html | 
按时间顺序快速列出主要协同编辑器的演变。
正如任何这样的清单一样,它必定会在一开始便提到被誉为“<ruby> <a href="https://en.wikipedia.org/wiki/The_Mother_of_All_Demos"> 所有演示之母 </a> <rt> the mother of all demos </rt></ruby>”,在这个演示里<ruby> <a href="https://en.wikipedia.org/wiki/Douglas_Engelbart"> 道格·恩格尔巴特 </a> <rt> Doug Engelbart </rt></ruby>早在 1968 年就描述了几乎所有软件的详尽清单。这不仅包括协同编辑器,还包括图形、编程和数学编辑器。
一切都始于那个演示,只不过软件的实现跟不上硬件的发展罢了。
>
> 软件发展的速度比硬件提升的速度慢。——沃斯定律
>
>
>
闲话少说,这里是我找到的可圈可点的协同编辑器的清单。我说“可圈可点”的意思是它们具有可圈可点的特征或实现细节。
| 项目 | 日期 | 平台 | 说明 |
| --- | --- | --- | --- |
| [SubEthaEdit](https://www.codingmonkeys.de/subethaedit/) | 2003-2015? | 仅 Mac | 我能找到的首个协同的、实时的、多光标的编辑器, [有个在 Emacs 上的逆向工程的尝试](https://www.emacswiki.org/emacs/SubEthaEmacs)却没有什么结果。 |
| [DocSynch](http://docsynch.sourceforge.net/) | 2004-2007 | ? | 建立于 IRC 之上! |
| [Gobby](https://gobby.github.io/) | 2005 至今 | C,多平台 | 首个开源、稳固可靠的实现。 仍然存在!众所周知 [libinfinoted](http://infinote.0x539.de/libinfinity/API/libinfinity/) 协议很难移植到其他编辑器中(例如: [Rudel](https://www.emacswiki.org/emacs/Rudel) 不能在 Emacs 上实现此协议)。 2017 年 1 月发行的 0.7 版本添加了也许可以改善这种状况的 Python 绑定。 值得注意的插件: 自动保存到磁盘。 |
| [Ethercalc](https://ethercalc.net/) | 2005 至今 | Web,JavaScript | 首个电子表格,随同 [Google Docs](https://en.wikipedia.org/wiki/Google_docs)。 |
| [moonedit](https://web.archive.org/web/20060423192346/http://www.moonedit.com:80/) | 2005-2008? | ? | 原网站已关闭。其他用户的光标可见并且会模仿击键的声音。 包括一个计算器和音乐定序器。 |
| [synchroedit](http://www.synchroedit.com/) | 2006-2007 | ? | 首个 Web 应用。 |
| [Inkscape](http://wiki.inkscape.org/wiki/index.php/WhiteBoard) | 2007-2011 | C++ | 首个具备协同功能的图形编辑器,其背后的“whiteboard” 插件构建于 Jabber 之上,现已停摆。 |
| [Abiword](https://en.wikipedia.org/wiki/AbiWord) | 2008 至今 | C++ | 首个文字处理器。 |
| [Etherpad](http://etherpad.org/) | 2008 至今 | Web | 首款稳定的 Web 应用。 最初在 2008 年被开发时是一款大型 Java 应用,在 2009 年被谷歌收购并开源,然后在 2011 年被用 Node.JS 重写。使用广泛。 |
| [Wave](https://en.wikipedia.org/wiki/Apache_Wave) | 2009-2010 | Web, Java | 在大一统协议的尝试上失败。 |
| [CRDT](https://en.wikipedia.org/wiki/Conflict-free_replicated_data_type) | 2011 | 特定平台 | 在不同电脑间可靠地复制一个文件的数据结构的标准。 |
| [Operational transform](http://operational-transformation.github.io/) | 2013 | 特定平台 | 与 CRDT 类似,然而确切地说,两者是不同的。 |
| [Floobits](https://floobits.com/) | 2013 至今 | ? | 商业软件,但有对各种编辑器的开源插件。 |
| [LibreOffice Online](https://wiki.documentfoundation.org/Development/LibreOffice_Online) | 2015至今 | Web | 免费的 Google docs 替代品,现已集成到 [Nextcloud](https://nextcloud.com/collaboraonline/) |
| [HackMD](https://hackmd.io/) | 2015 至今 | ? | 商业软件,[开源](https://github.com/hackmdio/hackmd)。灵感来自于(已被 Dropbox 收购的) hackpad。 |
| [Cryptpad](https://cryptpad.fr/) | 2016 至今 | Web ? | Xwiki 的副产品。服务器端的加密的、“零知识” 产品。 |
| [Prosemirror](https://prosemirror.net/) | 2016 至今 | Web, Node.JS | “试图架起消除 Markdown 文本编辑和传统的所见即所得编辑器之间隔阂的桥梁。”不是完全意义上的编辑器,而是一种可以用来构建编辑器的工具。 |
| [Qill](https://quilljs.com/) | 2013 至今 | Web, Node.JS | 富文本编辑器,同时也是 JavaScript 编辑器。不确定是否是协同式的。 |
| [Teletype](https://teletype.atom.io/) | 2017 至今 | WebRTC, Node.JS | 为 GitHub 的 [Atom 编辑器](https://atom.io) 引入了“门户”的思路 ,使得访客可以夸多个文档跟踪主人的操作。访问介绍服务器后使用实时通讯的点对点技术(P2P),基于 CRDT。 |
| [Tandem](http://typeintandem.com/) | 2018 至今 | Node.JS? | Atom、 Vim、Neovim、 Sublime 等的插件。 使用中继来设置基于 CRDT 的 P2P 连接。多亏 Debian 开发者的参与,[可疑证书问题](https://github.com/typeintandem/tandem/issues/131)已被解决,这使它成为很有希望在未来被遵循的标准。 |
### 其他清单
* [Emacs 维基](https://www.emacswiki.org/emacs/CollaborativeEditing)
* [维基百科](https://en.wikipedia.org/wiki/Collaborative_real-time_editor)
---
via: <https://anarc.at/blog/2018-06-26-collaborative-editors-history/>
作者:[Anacr](https://anarc.at) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ZenMoore](https://github.com/ZenMoore) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Historical inventory of collaborative editors
A quick inventory of major collaborative editor efforts, in chronological order.
As with any such list, it must start with an honorable mention to [the
mother of all demos](https://en.wikipedia.org/wiki/The_Mother_of_All_Demos) during which [Doug Engelbart](https://en.wikipedia.org/wiki/Douglas_Engelbart) presented
what is basically an exhaustive list of all possible software written
since 1968. This includes not only a collaborative editor, but
graphics, programming and math editor.
Everything else after that demo is just a slower implementation to compensate for the acceleration of hardware.
Software gets slower faster than hardware gets faster. - Wirth's law
So without further ado, here is the list of notable collaborative editors that I could find. By "notable" i mean that they introduce a notable feature or implementation detail.
Project | Date | Platform | Notes |
---|---|---|---|
|
[reverse-engineering attempt in Emacs](https://www.emacswiki.org/emacs/SubEthaEmacs)failed to produce anything.[DocSynch](http://docsynch.sourceforge.net/)[Gobby](https://gobby.github.io/)[libinfinoted](http://infinote.0x539.de/libinfinity/API/libinfinity/)") is notoriously hard to port to other editors (e.g.[Rudel](https://www.emacswiki.org/emacs/Rudel)failed to implement this in Emacs). 0.7 release in jan 2017 adds possible python bindings that might improve this. Interesting plugins: autosave to disk.[Ethercalc](https://ethercalc.net/)[Google docs](https://en.wikipedia.org/wiki/Google_docs)[moonedit](https://web.archive.org/web/20060423192346/http://www.moonedit.com:80/)[synchroedit](http://www.synchroedit.com/)[Inkscape](http://wiki.inkscape.org/wiki/index.php/WhiteBoard)[Abiword](https://en.wikipedia.org/wiki/AbiWord)[Etherpad](http://etherpad.org/)[Wave](https://en.wikipedia.org/wiki/Apache_Wave)[CRDT](https://en.wikipedia.org/wiki/Conflict-free_replicated_data_type)[Operational transform](http://operational-transformation.github.io/)[Floobits](https://floobits.com/)[LibreOffice Online](https://wiki.documentfoundation.org/Development/LibreOffice_Online)[Nextcloud](https://nextcloud.com/collaboraonline/)[HackMD](https://hackmd.io/)[opensource](https://github.com/hackmdio/hackmd). Inspired by hackpad, which was bought up by Dropbox.[Cryptpad](https://cryptpad.fr/)[Prosemirror](https://prosemirror.net/)[Qill](https://quilljs.com/)[Teletype](https://teletype.atom.io/)[Atom editor](https://atom.io), introduces "portal" idea that makes guests follow what the host is doing across multiple docs. p2p with webRTC after visit to introduction server, CRDT based.[Tandem](http://typeintandem.com/)[Dubious license issues](https://github.com/typeintandem/tandem/issues/131)were resolved thanks to the involvement of Debian developers, which makes it a promising standard to follow in the future.[crdt.el](https://code.librehq.com/qhong/crdt.el/)# Other lists
[Edited .](https://gitlab.com/anarcat/anarc.at/-/commits/main/blog/2018-06-26-collaborative-editors-history.mdwn)
Hello,
Thanks for your interesting post!
I recently did a similar search, I retained the following:
Cheers!
The TogetherJS library by Mozilla was promising... 5 years ago: https://github.com/mozilla/togetherjs
Also worth a mention, good old Google Wave from 2009. It had it all (too much?)
I don't get why Collaborative Editing isn't a standard wiki feature by now.
Saw a demo a couple of months ago:
It's based on automerge, which is a JSON CDRT and dat, a modern updatable bittorrent.
Thanks for all the feedback! I've updated the table to add Ethercalc, Inkscape (how could I forget our poor Jabber friend!) and Abiword (that one still works??).
I've also fixed the "NextCloud" entry to be "LibreOffice Online" as, it's true, it's just one frontend. Plus it promotes it earlier in the history. Funny to notice that Abiword beat LibreOffice on that..
I've also added Google Wave, even though it was fairly short lived, in retrospect.
Thanks to the other suggestions, but the goal here is not to make an exhaustive inventory of all possible collaborative editors: there are
waymore than what's listed here. It seems that everyone thinks they can do better than whoever came before, so I tried to keep the list to project which brought something really new to the pool and/or that succeeded in a significant way. I also try to keep the list limited to free software project and open platforms, except when there is a really notable change.I do believe it was Collabora who developed the 'online' part and released it first, and then contributed it back to LibreOffice which now also has it - credit-where-it-is-due would be to call it Collabora Online, I think.
Sadly the collaborative editing never made it into Kate proper...
Note that Abiword doesn't have a web view like Collabora/LibreOffice has, and LibreOffice still doesn't have collaborative editing on the desktop like Abiword has (but I believe work is happening to enable it).
There once upon a time was also the quite interesting Documents app for ownCloud/Nextcloud based on WebODF. It was a full javascript ODF editor that used the DOM tree, css etc to directly display and edit documents. So it had no import/export, it just directly loaded them and showed the documents in the browser! Quite clever, I don't think as of today any web editor can do that still). The biggest advantage was that the editor was non-destructive, even if it didn't understand or know how to display parts, they wouldn't get deleted/damaged on saving. There is a back-end for it that uses LibreOffice on the server to convert MS Word docs into ODF and back after editing, but, as that IS a destructive import/export, this has its limitations. https://github.com/nextcloud/documents
Sadly, while we kept it working with Nc 12 and will probably make it work with 13 someday, the actual engine is unmaintained so it won't be useful for much longer as browsers move on and break compatibility... |
9,801 | 在开源项目中做出你的第一个贡献 | https://opensource.com/article/18/4/get-started-open-source-project | 2018-07-03T11:09:48 | [
"贡献",
"开源项目"
] | /article-9801-1.html |
>
> 这是许多事情的第一步
>
>
>

有一个普遍的误解,那就是对开源做出贡献是一件很难的事。你可能会想,“有时我甚至不能理解我自己的代码;那我怎么可能理解别人的?”
放轻松。直到去年,我都以为是这样。阅读和理解他人的代码,然后在他们的基础上写上你自己的代码,这是一件令人气馁的任务;但如果有合适的资源,这不像你想象的那么糟。
第一步要做的是选择一个项目。这个决定是可能是一个菜鸟转变成一个老练的开源贡献者的关键一步。
许多对开源感兴趣的业余程序员都被建议从 [Git](https://git-scm.com/) 入手,但这并不是最好的开始方式。Git 是由许多有着多年软件开发经验的超级极客维护的。它是寻找可以做贡献的开源项目的好地方,但对新手并不友好。大多数对 Git 做出贡献的开发者都有足够的经验,他们不需要参考各类资源或文档。在这篇文章里,我将提供一个对新手友好的特性的列表,并且给出一些建议,希望可以使你更轻松地对开源做出贡献。
### 理解产品
在开始贡献之前,你需要理解项目是怎么工作的。为了理解这一点,你需要自己来尝试。如果你发现这个产品很有趣并且有用,它就值得你来做贡献。
初学者常常选择参与贡献那些他们没有使用过的软件。他们会失望,并且最终放弃贡献。如果你没有用过这个软件,你不会理解它是怎么工作的。如果你不理解它是怎么工作的,你怎么能解决 bug 或添加新特性呢?
要记住:尝试它,才能改变它。
### 确认产品的状况
这个项目有多活跃?
如果你向一个暂停维护的项目提交一个<ruby> 拉取请求 <rt> pull request </rt></ruby>,你的请求可能永远不会被讨论或合并。找找那些活跃的项目,这样你的代码可以得到即时的反馈,你的贡献也就不会被浪费。
这里介绍了怎么确认一个项目是否还是活跃的:
* **贡献者数量:** 一个增加的贡献者数量表明开发者社区乐于接受新的贡献者。
* **<ruby> 提交 <rt> commit </rt></ruby>频率:** 查看最近的提交时间。如果是一周之内,甚至是一两个月内,这个项目应该是定期维护的。
* **维护者数量:** 维护者的数量越多,你越可能得到指导。
* **聊天室或 IRC 活跃度:** 一个繁忙的聊天室意味着你的问题可以更快得到回复。
### 新手资源
Coala 是一个开源项目的例子。它有自己的教程和文档,让你可以使用它(每一个类和方法)的 API。这个网站还设计了一个有吸引力的界面,让你有阅读的兴趣。
**文档:** 不管哪种水平的开发者都需要可靠的、被很好地维护的文档,来理解项目的细节。找找在 [GitHub](https://github.com/)(或者放在其它位置)或者类似于 [Read the Docs](https://readthedocs.org/) 之类的独立站点上提供了完善文档的项目,这样可以帮助你深入了解代码。

**教程:** 教程会给新手解释如何在项目里添加特性 (然而,你不是在每个项目中都能找到它)。例如,Coala 提供了 [小熊编写指南](http://api.coala.io/en/latest/Developers/Writing_Linter_Bears.html) (进行代码分析的<ruby> 代码格式化 <rt> linting </rt></ruby>工具的 Python 包装器)。

**分类的<ruby> 讨论点 <rt> issue </rt></ruby>:** 对刚刚想明白如何选择第一个项目的初学者来说,选择一个讨论点是一个更加困难的任务。标签被设为“难度/低”、“难度/新手”、“利于初学者”,以及“<ruby> 触手可及 <rt> low-hanging fruit </rt></ruby>”都表明是对新手友好的。

### 其他因素

* **维护者对新的贡献者的态度:** 从我的经验来看,大部分开源贡献者都很乐于帮助他们项目里的新手。然而,当你问问题时,你也有可能遇到一些不太友好的人(甚至可能有点粗鲁)。不要因为这些人失去信心。他们只是因为在比他们经验更丰富的人那儿得不到发泄的机会而已。还有很多其他人愿意提供帮助。
* **审阅过程/机制:** 你的拉取请求将经历几遍你的同伴和有经验的开发者的查看和更改——这就是你学习软件开发最主要的方式。一个具有严格审阅过程的项目使您在编写生产级代码的过程中成长。
* **一个稳健的<ruby> 持续集成 <rt> continuous integration </rt></ruby>管道:** 开源项目会向新手们介绍持续集成和部署服务。一个稳健的 CI 管道将帮助你学习阅读和理解 CI 日志。它也将带给你处理失败的测试用例和代码覆盖率问题的经验。
* **参加编程项目(例如 [Google Summer Of Code](https://en.wikipedia.org/wiki/Google_Summer_of_Code)):** 参加组织证明了你乐于对一个项目的长期发展做贡献。他们也会给新手提供一个机会来获得现实世界中的开发经验,从而获得报酬。大多数参加这些项目的组织都欢迎新人加入。
### 7 对新手友好的组织
* [coala (Python)](https://github.com/coala/coala)
* [oppia (Python, Django)](https://github.com/oppia/oppia)
* [DuckDuckGo (Perl, JavaScript)](https://github.com/duckduckgo/)
* [OpenGenus (JavaScript)](https://github.com/OpenGenus/)
* [Kinto (Python, JavaScript)](https://github.com/kinto)
* [FOSSASIA (Python, JavaScript)](https://github.com/fossasia/)
* [Kubernetes (Go)](https://github.com/kubernetes)
### 关于作者
Palash Nigam - 我是一个印度计算机科学专业本科生,十分乐于参与开源软件的开发,我在 GitHub 上花费了大部分的时间。我现在的兴趣包括 web 后端开发,区块链,和 All things python。
---
via: <https://opensource.com/article/18/4/get-started-open-source-project>
作者:[Palash Nigam](https://opensource.com/users/palash25) 译者:[lonaparte](https://github.com/lonaparte) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
9,802 | 如何记录你在终端中执行的所有操作 | https://www.ostechnix.com/record-everything-terminal/ | 2018-07-03T11:19:00 | [
"日志",
"script",
"记录"
] | https://linux.cn/article-9802-1.html | 
几天前,我们发布了一个解释如何[保存终端中的命令并按需使用](https://www.ostechnix.com/save-commands-terminal-use-demand/)的指南。对于那些不想记忆冗长的 Linux 命令的人来说,这非常有用。今天,在本指南中,我们将看到如何使用 `script` 命令记录你在终端中执行的所有操作。你可能已经在终端中运行了一个命令,或创建了一个目录,或者安装了一个程序。`script` 命令会保存你在终端中执行的任何操作。如果你想知道你几小时或几天前做了什么,那么你可以查看它们。我知道我知道,我们可以使用上/下箭头或 `history` 命令查看以前运行的命令。但是,你无法查看这些命令的输出。而 `script` 命令记录并显示完整的终端会话活动。
`script` 命令会在终端中创建你所做的所有事件的记录。无论你是安装程序,创建目录/文件还是删除文件夹,一切都会被记录下来,包括命令和相应的输出。这个命令对那些想要一份交互式会话拷贝作为作业证明的人有用。无论是学生还是导师,你都可以将所有在终端中执行的操作和所有输出复制一份。
### 在 Linux 中使用 script 命令记录终端中的所有内容
`script` 命令预先安装在大多数现代 Linux 操作系统上。所以,我们不用担心安装。
让我们继续看看如何实时使用它。
运行以下命令启动终端会话记录。
```
$ script -a my_terminal_activities
```
其中,`-a` 标志用于将输出追加到文件(记录)中,并保留以前的内容。上述命令会记录你在终端中执行的所有操作,并将输出追加到名为 `my_terminal_activities` 的文件中,并将其保存在当前工作目录中。
示例输出:
```
Script started, file is my_terminal_activities
```
现在,在终端中运行一些随机的 Linux 命令。
```
$ mkdir ostechnix
$ cd ostechnix/
$ touch hello_world.txt
$ cd ..
$ uname -r
```
运行所有命令后,使用以下命令结束 `script` 命令的会话:
```
$ exit
```
示例输出:
```
exit
Script done, file is my_terminal_activities
```
如你所见,终端活动已存储在名为 `my_terminal_activities` 的文件中,并将其保存在当前工作目录中。
要查看你的终端活动,只需在任何编辑器中打开此文件,或者使用 `cat` 命令直接显示它。
```
$ cat my_terminal_activities
```
示例输出:
```
Script started on Thu 09 Mar 2017 03:33:44 PM IST
[sk@sk]: ~>$ mkdir ostechnix
[sk@sk]: ~>$ cd ostechnix/
[sk@sk]: ~/ostechnix>$ touch hello_world.txt
[sk@sk]: ~/ostechnix>$ cd ..
[sk@sk]: ~>$ uname -r
4.9.11-1-ARCH
[sk@sk]: ~>$ exit
exit
Script done on Thu 09 Mar 2017 03:37:49 PM IST
```
正如你在上面的输出中看到的,`script` 命令记录了我所有的终端活动,包括 `script` 命令的开始和结束时间。真棒,不是吗?使用 `script` 命令的原因不仅仅是记录命令,还有命令的输出。简单地说,脚本命令将记录你在终端上执行的所有操作。
### 结论
就像我说的那样,脚本命令对于想要保留其终端活动记录的学生,教师和 Linux 用户非常有用。尽管有很多 CLI 和 GUI 可用来执行此操作,但 `script` 命令是记录终端会话活动的最简单快捷的方式。
就是这些。希望这有帮助。如果你发现本指南有用,请在你的社交,专业网络上分享,并支持我们。
干杯!
---
via: <https://www.ostechnix.com/record-everything-terminal/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,803 | 不要再手动合并你的拉取请求(PR) | https://julien.danjou.info/stop-merging-your-pull-request-manually/ | 2018-07-03T21:56:22 | [
"拉取请求",
"GitHub"
] | https://linux.cn/article-9803-1.html | 
如果有什么我讨厌的东西,那就是当我知道我可以自动化它们时,但我手动进行了操作。只有我有这种情况么?我觉得不是。
尽管如此,他们每天都有数千名使用 [GitHub](https://github.com) 的开发人员一遍又一遍地做同样的事情:他们点击这个按钮:

这没有任何意义。
不要误解我的意思。合并拉取请求是有意义的。只是每次点击这个该死的按钮是没有意义的。
这样做没有意义因为世界上的每个开发团队在合并拉取请求之前都有一个已知的先决条件列表。这些要求几乎总是相同的,而且这些要求也是如此:
* 是否通过测试?
* 文档是否更新了?
* 这是否遵循我们的代码风格指南?
* 是否有若干位开发人员对此进行审查?
随着此列表变长,合并过程变得更容易出错。 “糟糕,在没有足够的开发人员审查补丁时 John 就点了合并按钮。” 要发出警报么?
在我的团队中,我们就像外面的每一支队伍。我们知道我们将一些代码合并到我们仓库的标准是什么。这就是为什么我们建立一个持续集成系统,每次有人创建一个拉取请求时运行我们的测试。我们还要求代码在获得批准之前由团队的 2 名成员进行审查。
当这些条件全部设定好时,我希望代码被合并。
而不用点击一个按钮。
这正是启动 [Mergify](https://mergify.io) 的原因。

[Mergify](https://mergify.io) 是一个为你按下合并按钮的服务。你可以在仓库的 `.mergify.yml` 中定义规则,当规则满足时,Mergify 将合并该请求。
无需按任何按钮。
随机抽取一个请求,就像这样:

这来自一个小型项目,没有很多持续集成服务,只有 Travis。在这个拉取请求中,一切都是绿色的:其中一个所有者审查了代码,并且测试通过。因此,该代码应该被合并:但是它还在那里挂起这,等待某人有一天按下合并按钮。
使用 [Mergify](https://mergify.io) 后,你只需将 `.mergify.yml` 放在仓库的根目录即可:
```
rules:
default:
protection:
required_status_checks:
contexts:
- continuous-integration/travis-ci
required_pull_request_reviews:
required_approving_review_count: 1
```
通过这样的配置,[Mergify](https://mergify.io) 可以实现所需的限制,即 Travis 通过,并且至少有一个项目成员审阅了代码。只要这些条件是肯定的,拉取请求就会自动合并。
我们将 [Mergify](https://mergify.io) 构建为 **一个对开源项目免费的服务**。[提供服务的引擎](https://github.com/mergifyio/mergify-engine)也是开源的。
现在去[尝试它](https://mergify.io),不要让这些拉取请求再挂起哪怕一秒钟。合并它们!
如果你有任何问题,请随时在下面向我们提问或写下评论!并且敬请期待 - 因为 Mergify 还提供了其他一些我迫不及待想要介绍的功能!
---
via: <https://julien.danjou.info/stop-merging-your-pull-request-manually/>
作者:[Julien Danjou](https://julien.danjou.info/author/jd/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,804 | Intel 和 AMD 透露新的处理器设计 | https://www.linux.com/blog/2018/6/intel-amd-and-arm-reveal-new-processor-designs | 2018-07-04T09:49:26 | [
"CPU"
] | https://linux.cn/article-9804-1.html |
>
> Whiskey Lake U 系列和 Amber Lake Y 系列的酷睿芯片将会在今年秋季开始出现在超过 70 款笔记本以及 2 合 1 机型中。
>
>
>

根据最近的台北国际电脑展 (Computex 2018) 以及最近其它的消息,处理器成为科技新闻圈中最前沿的话题。Intel 发布了一些公告涉及从新的酷睿处理器到延长电池续航的尖端技术。与此同时,AMD 亮相了第二代 32 核心的高端游戏处理器线程撕裂者(Threadripper)以及一些适合嵌入式的新型号锐龙 Ryzen 处理器。
以上是对 Intel 和 AMD 主要公布产品的快速浏览,针对那些对嵌入式 Linux 开发者最感兴趣的处理器。
### Intel 最新的第八代 CPU 家族
在四月份,Intel 已经宣布量产 10nm 制程的 Cannon Lake 系列酷睿处理器将会延期到 2019 年,这件事引起了人们对摩尔定律最终走上正轨的议论。然而,在 Intel 的 [Computex 展区](https://newsroom.intel.com/editorials/pc-personal-contribution-platform-pushing-boundaries-modern-computers-computex/) 中有着众多让人欣慰的消息。Intel 展示了两款节能的第八代 14nm 酷睿家族产品,同时也是 Intel 首款 5GHz 的设计。
Whiskey Lake U 系列和 Amber Lake Y 系列的酷睿芯片将会在今年秋季开始出现在超过 70 款笔记本以及 2 合 1 机型中。Intel 表示,这些芯片相较于第七代的 Kaby Lake 酷睿系列处理器会带来两倍的性能提升。新的产品家族将会相比于目前出现的搭载 [Coffee Lake](https://www.linux.com/news/elc-openiot/2018/3/hot-chips-face-mwc-and-embedded-world) 芯片的产品更加节能 。
Whiskey Lake 和 Amber Lake 两者将会配备 Intel 高性能千兆 WiFi (Intel 9560 AC),该网卡同样出现在 [Gemini Lake](http://linuxgizmos.com/intel-launches-gemini-lake-socs-with-gigabit-wifi/) 架构的奔腾银牌和赛扬处理器,随之出现在 Apollo Lake 一代。千兆 WiFi 本质上就是 Intel 将 2×2 MU-MIMO 和 160MHz 信道技术与 802.11ac 结合。
Intel 的 Whiskey Lake 将作为第七代和第八代 Skylake U 系列处理器的继任者,它们现在已经流行于嵌入式设备。Intel 透漏了少量细节,但是 Whiskey Lake 想必将会提供同样的,相对较低的 15W TDP。这与 [Coffee Lake U 系列芯片](http://linuxgizmos.com/intel-coffee-lake-h-series-debuts-in-congatec-and-seco-modules) 也很像,它将会被用于四核以及 Kaby Lake 和 Skylake U 系列的双核芯片。
[PC World](https://www.pcworld.com/article/3278091/components-processors/intel-computex-news-a-28-core-chip-a-5ghz-8086-two-new-architectures-and-more.html) 报导称,Amber Lake Y 系列芯片主要目标定位是 2 合 1 机型。就像双核的 [Kaby Lake Y 系列](http://linuxgizmos.com/more-kaby-lake-chips-arrive-plus-four-nuc-mini-pcs/) 芯片,Amber Lake 将会支持 4.5W TDP。
为了庆祝 Intel 即将到来的 50 周年庆典, 同样也是作为世界上第一款 8086 处理器的 40 周年庆典,Intel 将启动一个限量版,带有一个时钟频率 4GHz 的第八代 [酷睿 i7-8086K](https://newsroom.intel.com/wp-content/uploads/sites/11/2018/06/intel-i7-8086k-launch-fact-sheet.pdf) CPU。 这款 64 位限量版产品将会是第一块拥有 5GHz, 单核睿频加速,并且是首款带有集成显卡的 6 核,12 线程处理器。Intel 将会于 6 月 7 日开始 [赠送](https://game.intel.com/8086sweepstakes/) 8086 块超频酷睿 i7-8086K 芯片。
Intel 也展示了计划于今年年底启动新的高端 Core X 系列拥有高核心和线程数。[AnandTech 预测](https://www.anandtech.com/show/12878/intel-discuss-whiskey-lake-amber-lake-and-cascade-lake) 可能会使用类似于 Xeon 的 Cascade Lake 架构。今年晚些时候,Intel 将会公布新的酷睿 S系列型号,AnandTech 预测它可能会是八核心的 Coffee Lake 芯片。
Intel 也表示第一款疾速傲腾 SSD —— 一个 M.2 接口产品被称作 [905P](https://www.intel.com/content/www/us/en/products/memory-storage/solid-state-drives/gaming-enthusiast-ssds/optane-905p-series.htm) —— 终于可用了。今年来迟的是 Intel XMM 800 系列调制解调器,它支持 Sprint 的 5G 蜂窝技术。Intel 表示 可用于 PC 的 5G 将会在 2019 年出现。
### Intel 承诺笔记本全天候的电池寿命
另一则消息,Intel 表示将会尽快启动一项 Intel 低功耗显示技术,它将会为笔记本设备提供一整天的电池续航。合作开发伙伴 Sharp 和 Innolux 正在使用这项技术在 2018 年晚期开始生产 1W 显示面板,这能节省 LCD 一半的电量消耗。
### AMD 继续翻身
在展会中,AMD 亮相了第二代拥有 32 核 64 线程的线程撕裂者(Threadripper) CPU。为了走在 Intel 尚未命名的 28 核怪兽之前,这款高端游戏处理器将会在第三季度推出。根据 [Engadget](https://www.engadget.com/2018/06/05/amd-threadripper-32-cores/) 的消息,新的线程撕裂者同样采用了被用在锐龙 Ryzen 芯片的 12nm Zen+ 架构。
[WCCFTech](https://wccftech.com/amd-demos-worlds-first-7nm-gpu/) 报导,AMD 也表示它选自 7nm Vega Instinct GPU(为拥有 32GB 昂贵的 HBM2 显存而不是 GDDR5X 或 GDDR6 的显卡而设计)。这款 Vega Instinct 将提供相比现今 14nm Vega GPU 高出 35% 的性能和两倍的功效效率。新的渲染能力将会帮助它同 Nvidia 启用 CUDA 技术的 GPU 在光线追踪中竞争。
一些新的 Ryzen 2000 系列处理器近期出现在一个 ASRock CPU 聊天室,它将拥有比主流的 Ryzen 芯片更低的功耗。[AnandTech](https://www.anandtech.com/show/12841/amd-preps-new-ryzen-2000series-cpus-45w-ryzen-7-2700e-ryzen-5-2600e) 详细介绍了,2.8GHz,8 核心,16 线程的 Ryzen 7 2700E 和 3.4GHz/3.9GHz,六核,12 线程 Ryzen 5 2600E 都将拥有 45W TDP。这比 12-54W TDP 的 [Ryzen Embedded V1000](https://www.linux.com/news/elc-openiot/2018/3/hot-chips-face-mwc-and-embedded-world) 处理器更高,但低于 65W 甚至更高的主流 Ryzen 芯片。新的 Ryzen-E 型号是针对 SFF (外形小巧,small form factor) 和无风扇系统。
在 [开源峰会 + 欧洲嵌入式 Linux 会议](https://events.linuxfoundation.org/events/elc-openiot-europe-2018/) 加入我们,关于 Linux,云,容器,AI,社区等 100 多场会议,爱丁堡,英国,2018 年 10 月 22-24 日。
---
via: <https://www.linux.com/blog/2018/6/intel-amd-and-arm-reveal-new-processor-designs>
作者:[Eric Brown](https://www.linux.com/users/ericstephenbrown) 选题:[lujun9972](https://github.com/lujun9972) 译者:[softpaopao](https://github.com/softpaopao) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,805 | 云计算的成本 | https://read.acloud.guru/the-true-cost-of-cloud-a-comparison-of-two-development-teams-edc77d3dc6dc | 2018-07-04T11:43:00 | [
"云计算"
] | https://linux.cn/article-9805-1.html |
>
> 两个开发团队的一天
>
>
>

几个月以前,我与一些人讨论过关于公共云服务成本与传统专用基础设施价格比较的话题。为给你提供一些见解,我们来跟踪一下一个企业中的两个开发团队 — 并比较他们构建类似服务的方式。
第一个团队将使用传统的专用基础设施来部署他们的应用,而第二个团队将使用 AWS 提供的公共云服务。
这两个团队被要求为一家全球化企业开发一个新的服务,该企业目前为全球数百万消费者提供服务。要开发的这项新服务需要满足以下基本需求:
1. 能够随时**扩展**以满足弹性需求
2. 具备应对数据中心故障的**弹性**
3. 确保数据**安全**以及数据受到保护
4. 为排错提供深入的**调试**功能
5. 项目必须能**迅速分发**
6. 服务构建和维护的**性价比**要高
就新服务来说,这看起来是非常标准的需求 — 从本质上看传统专用基础设备上没有什么东西可以超越公共云了。

#### 1 — 扩展以满足客户需求
当说到可扩展性时,这个新服务需要去满足客户变化无常的需求。我们构建的服务不可以拒绝任何请求,以防让公司遭受损失或者声誉受到影响。
**传统团队**
使用的是专用基础设施,架构体系的计算能力需要与峰值数据需求相匹配。对于负载变化无常的服务来说,大量昂贵的计算能力在低利用率时被浪费掉。
这是一种很浪费的方法 — 并且大量的资本支出会侵蚀掉你的利润。另外,这些未充分利用的庞大的服务器资源的维护也是一项很大的运营成本。这是一项你无法忽略的成本 — 我不得不再强调一下,为支持一个单一服务去维护一机柜的服务器是多么的浪费时间和金钱。
**云团队**
使用的是基于云的自动伸缩解决方案,应用会按需要进行自动扩展和收缩。也就是说你只需要支付你所消费的计算资源的费用。
一个架构良好的基于云的应用可以实现无缝地伸缩 — 并且还是自动进行的。开发团队只需要定义好自动伸缩的资源组即可,即当你的应用 CPU 利用率达到某个高位、或者每秒有多大请求数时启动多少实例,并且你可以根据你的意愿去定制这些规则。
#### 2 — 应对故障的弹性
当说到弹性时,将托管服务的基础设施放在同一个房间里并不是一个好的选择。如果你的应用托管在一个单一的数据中心 — (不是如果)发生某些失败时(LCTT 译注:指坍塌、地震、洪灾等),你的所有的东西都被埋了。
**传统团队**
满足这种基本需求的标准解决方案是,为实现局部弹性建立至少两个服务器 — 在地理上冗余的数据中心之间实施秒级复制。
开发团队需要一个负载均衡解决方案,以便于在发生饱和或者故障等事件时将流量转向到另一个节点 — 并且还要确保镜像节点之间,整个栈是持续完全同步的。
**云团队**
在 AWS 全球 50 个地区中,他们都提供多个*可用区*。每个区域由多个容错数据中心组成 — 通过自动故障切换功能,AWS 可以将服务无缝地转移到该地区的其它区中。
在一个 `CloudFormation` 模板中定义你的*基础设施即代码*,确保你的基础设施在自动伸缩事件中跨区保持一致 — 而对于流量的流向管理,AWS 负载均衡服务仅需要做很少的配置即可。
#### 3 — 安全和数据保护
安全是一个组织中任何一个系统的基本要求。我想你肯定不想成为那些不幸遭遇安全问题的公司之一的。
**传统团队**
为保证运行他们服务的基础服务器安全,他们不得不持续投入成本。这意味着将需要投资一个团队,以监视和识别安全威胁,并用来自不同数据源的跨多个供应商解决方案打上补丁。
**云团队**
使用公共云并不能免除来自安全方面的责任。云团队仍然需要提高警惕,但是并不需要去担心为底层基础设施打补丁的问题。AWS 将积极地对付各种零日漏洞 — 最近的一次是 Spectre 和 Meltdown。
利用来自 AWS 的身份管理和加密安全服务,可以让云团队专注于他们的应用 — 而不是无差别的安全管理。使用 CloudTrail 对 API 到 AWS 服务的调用做全面审计,可以实现透明地监视。
#### 4 — 监视和日志
任何基础设施和部署为服务的应用都需要严密监视实时数据。团队应该有一个可以访问的仪表板,当超过指标阈值时仪表板会显示警报,并能够在排错时提供与事件相关的日志。
**传统团队**
对于传统基础设施,将不得不在跨不同供应商和“雪花状”的解决方案上配置监视和报告解决方案。配置这些“见鬼的”解决方案将花费你大量的时间和精力 — 并且能够正确地实现你的目的是相当困难的。
对于大多数部署在专用基础设施上的应用来说,为了搞清楚你的应用为什么崩溃,你可以通过搜索保存在你的服务器文件系统上的日志文件来找到答案。为此你的团队需要通过 SSH 进入服务器,导航到日志文件所在的目录,然后浪费大量的时间,通过 `grep` 在成百上千的日志文件中寻找。如果你在一个横跨 60 台服务器上部署的应用中这么做 — 我能负责任地告诉你,这是一个极差的解决方案。
**云团队**
利用原生的 AWS 服务,如 CloudWatch 和 CloudTrail,来做云应用程序的监视是非常容易。不需要很多的配置,开发团队就可以监视部署的服务上的各种指标 — 问题的排除过程也不再是个恶梦了。
对于传统的基础设施,团队需要构建自己的解决方案,配置他们的 REST API 或者服务去推送日志到一个聚合器。而得到这个“开箱即用”的解决方案将对生产力有极大的提升。
#### 5 — 加速开发进程
现在的商业环境中,快速上市的能力越来越重要。由于实施的延误所失去的机会成本,可能成为影响最终利润的一个主要因素。
**传统团队**
对于大多数组织,他们需要在新项目所需要的硬件采购、配置和部署上花费很长的时间 — 并且由于预测能力差,提前获得的额外的性能将造成大量的浪费。
而且还有可能的是,传统的开发团队在无数的“筒仓”中穿梭以及在移交创建的服务上花费数月的时间。项目的每一步都会在数据库、系统、安全、以及网络管理方面需要一个独立工作。
**云团队**
而云团队开发新特性时,拥有大量的随时可投入生产系统的服务套件供你使用。这是开发者的天堂。每个 AWS 服务一般都有非常好的文档并且可以通过你选择的语言以编程的方式去访问。
使用新的云架构,例如无服务器,开发团队可以在最小化冲突的前提下构建和部署一个可扩展的解决方案。比如,只需要几天时间就可以建立一个 [Imgur 的无服务器克隆](https://read.acloud.guru/building-an-imgur-clone-part-2-image-rekognition-and-a-dynamodb-backend-abc9af300123),它具有图像识别的特性,内置一个产品级的监视/日志解决方案,并且它的弹性极好。

*如何建立一个 Imgur 的无服务器克隆*
如果必须要我亲自去设计弹性和可伸缩性,我可以向你保证,我会陷在这个项目的开发里 — 而且最终的产品将远不如目前的这个好。
从我实践的情况来看,使用无服务器架构的交付时间远小于在大多数公司中提供硬件所花费的时间。我只是简单地将一系列 AWS 服务与 Lambda 功能 — 以及 ta-da 耦合到一起而已!我只专注于开发解决方案,而无差别的可伸缩性和弹性是由 AWS 为我处理的。
#### 关于云计算成本的结论
就弹性而言,云计算团队的按需扩展是当之无愧的赢家 — 因为他们仅为需要的计算能力埋单。而不需要为维护和底层的物理基础设施打补丁付出相应的资源。
云计算也为开发团队提供一个可使用多个可用区的弹性架构、为每个服务构建的安全特性、持续的日志和监视工具、随用随付的服务、以及低成本的加速分发实践。
大多数情况下,云计算的成本要远低于为你的应用运行所需要的购买、支持、维护和设计的按需基础架构的成本 — 并且云计算的麻烦事更少。
通过利用云计算,我们可以更少的先期投入而使业务快速开展。整体而言,当你开发和部署业务服务时,云计算的经济性可以让你的工作更赞。
也有一些云计算比传统基础设施更昂贵的例子,一些情况是在周末忘记关闭运行的一些极其昂贵的测试机器。
[Dropbox 在决定推出自己的基础设施并减少对 AWS 服务的依赖之后,在两年的时间内节省近 7500 万美元的费用,Dropbox…——www.geekwire.com](https://www.geekwire.com/2018/dropbox-saved-almost-75-million-two-years-building-tech-infrastructure/)
即便如此,这样的案例仍然是非常少见的。更不用说当初 Dropbox 也是从 AWS 上开始它的业务的 — 并且当它的业务达到一个临界点时,才决定离开这个平台。即便到现在,他们也已经进入到云计算的领域了,并且还在 AWS 和 GCP 上保留了 40% 的基础设施。
将云服务与基于单一“成本”指标(LCTT 译注:此处的“成本”仅指物理基础设施的购置成本)的传统基础设施比较的想法是极其幼稚的 — 公然无视云为开发团队和你的业务带来的一些主要的优势。
在极少数的情况下,云服务比传统基础设施产生更多的绝对成本 — 但它在开发团队的生产力、速度和创新方面仍然贡献着更好的价值。

*客户才不在乎你的数据中心呢*
*我非常乐意倾听你在云中开发的真实成本相关的经验和反馈!请在下面的评论区、Twitter [@Elliot\_F](https://twitter.com/Elliot_F) 上、或者直接在 [LinkedIn](https://www.linkedin.com/in/elliotforbes/) 上联系我。*
---
via: <https://read.acloud.guru/the-true-cost-of-cloud-a-comparison-of-two-development-teams-edc77d3dc6dc>
作者:[Elliot Forbes](https://read.acloud.guru/@elliot_f?source=post_header_lockup) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,806 | 命令行中的世界杯 | https://www.linuxlinks.com/football-cli-world-cup-football-on-the-command-line/ | 2018-07-04T21:47:25 | [
"足球",
"比赛"
] | https://linux.cn/article-9806-1.html | 
足球始终在我们身边。即使我们国家的队伍已经出局(LCTT 译注:显然这不是指我们国家,因为我们根本没有入局……),我还是想知道球赛比分。目前, 国际足联世界杯是世界上最大的足球锦标赛,2018 届是由俄罗斯主办的。每届世界杯都有一些足球强国未能取得参赛资格(LCTT 译注:我要吐槽么?)。意大利和荷兰就无缘本次世界杯。但是即使在未参加比赛的国家,追踪关注最新比分也成为了一种仪式。我希望能及时了解这个世界级的重大赛事最新比分的变化,而不用去搜索不同的网站。
如果你很喜欢命令行,那么有更好的方法用一个小型命令行程序追踪最新的世界杯比分和排名。让我们看一看最热门的可用的球赛趋势分析程序之一,它叫作 football-cli。
football-cli 不是一个开创性的应用程序。这几年,有许多命令行工具可以让你了解到最新的球赛比分和赛事排名。例如,我是 soccer-cli (Python 写的)和 App-football (Perl 写的)的重度用户。但我总是在寻找新的趋势分析应用,而 football-cli 在某些方面脱颖而出。
football-cli 是 JavaScript 开发的,由 Manraj Singh 编写,它是开源的软件。基于 MIT 许可证发布,用 npm(JavaScript 包管理器)安装十分简单。那么,让我们直接行动吧!
该应用程序提供了命令以获取过去及现在的赛事得分、查看联赛和球队之前和将要进行的赛事。它也会显示某一特定联赛的排名。有一条指令可以列出程序所支持的不同赛事。我们不妨从最后一个条指令开始。
在 shell 提示符下:
```
luke@ganges:~$ football lists
```

世界杯被列在最下方,我错过了昨天的比赛,所以为了了解比分,我在 shell 提示下输入:
```
luke@ganges:~$ football scores
```

现在,我想看看目前的世界杯小组排名。很简单:
```
luke@ganges:~$ football standings -l WC
```
下面是输出的一个片段:

你们当中眼尖的可能会注意到这里有一个错误。比如比利时看上去领先于 G 组,但这是不正确的,比利时和英格兰(截稿前)在得分上打平。在这种情况下,纪律好的队伍排名更高。英格兰收到两张黄牌,而比利时收到三张,因此,英格兰应当名列榜首。
假设我想知道利物浦 90 天前英超联赛的结果,那么:
```
luke@ganges:~$ football fixtures -l PL -d 90 -t "Liverpool"
```

我发现这个程序非常方便。它用一种清晰、整洁而有吸引力的方式显示分数和排名。当欧洲联赛再次开始时,它就更有用了。(事实上 2018-19 冠军联赛已经在进行中)!
这几个示例让大家对 football-cli 的实用性有了更深的体会。想要了解更多,请转至开发者的 [GitHub 页面](https://github.com/ManrajGrover/football-cli)。足球 + 命令行 = football-cli。
如同许多类似的工具一样,该软件从 football-data.org 获取相关数据。这项服务以机器可读的方式为所有欧洲主要联赛提供数据,包括比赛、球队、球员、结果等等。所有这些信息都是以 JOSN 形式通过一个易于使用的 RESTful API 提供的。
---
via: <https://www.linuxlinks.com/football-cli-world-cup-football-on-the-command-line/>
作者:[Luke Baker](https://www.linuxlinks.com/author/luke-baker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ZenMoore](https://github.com/ZenMoore) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Last Updated on September 1, 2020
Football is around us constantly. Even when domestic leagues have finished, there’s always a football score I want to know. Currently, it’s the biggest football tournament in the world, the Fifa World Cup 2018, hosted in Russia. Every World Cup there are some great football nations that don’t manage to qualify for the tournament. This time around the Italians and the Dutch missed out. But even in non-participating countries, it’s a rite of passage to keep track of the latest scores. I also like to keep abreast of the latest scores from the major leagues around the world without having to search different websites.
If you’re a big fan of the command-line, what better way to keep track of the latest World Cup scores and standings with a small command-line utility. Let’s take a look at one of the hottest trending football utilities available. It’s goes by the name football-cli.
football-cli is not a groundbreaking app. Over the years, there’s been a raft of command line tools that let you keep you up-to-date with the latest football scores and league standings. For example, I am a heavy user of soccer-cli, a Python based tool, and App-Football, written in Perl. But I’m always looking on the look out for trending apps. And football-cli stands out from the crowd in a few ways.
football-cli is developed in JavaScript and written by Manraj Singh. It’s open source software, published under the MIT license. Installation is trivial with npm (the package manager for JavaScript), so let’s get straight into the action.
The utility offers commands that give scores of past and live fixtures, see upcoming and past fixtures of a league and team. It also displays standings of a particular league. There’s a command that lists the various supported competitions. Let’s start with the last command.
At a shell prompt.
The World Cup is listed at the bottom. I missed yesterday’s games, so to catch up on the scores, I type at a shell prompt:
Now I want to see the current World Cup group standings. That’s easy.
Here’s an excerpt of the output:
The eagle-eyed among you may notice a bug here. Belgium is showing as the leader of Group G. But this is not correct. Belgium and England are (at the time of writing) both tied on points, goal difference, and goals scored. In this situation, the team with the better disciplinary record is ranked higher. England and Belgium have received 2 and 3 yellow cards respectively, so England top the group.
Suppose I want to find out Liverpool’s results in the Premiership going back 90 days from today.
I’m finding the utility really handy, displaying the scores and standings in a clear, uncluttered, and attractive way. When the European domestic games start up again, it’ll get heavy usage. (Actually, the 2018-19 Champions League is already underway)!
These few examples give a taster of the functionality available with football-cli. Read more about the utility from the developer’s ** GitHub page. ** Football + command-line = football-cli
Like similar tools, the software retrieves its football data from football-data.org. This service provide football data for all major European leagues in a machine-readable way. This includes fixtures, teams, players, results and more. All this information is provided via an easy-to-use RESTful API in JSON representation.
football-cli is written in JavaScript. Learn JavaScript with our recommended ** free books** and
**.**
[free tutorials](/excellent-free-tutorials-learn-javascript/)Popular series |
|
---|---|
![]() |
[in the universe. Each article is supplied with a legendary ratings chart helping you to make informed decisions.](/best-free-open-source-software/)**best free and open source software**

[offering our unbiased and expert opinion on software. We offer helpful and impartial information.](/category/reviews/)**in-depth reviews**

[is a large compilation of actively developed Linux distributions.](/big-list-linux-distros/)**The Big List of Active Linux Distros**

[,](/best-free-open-source-alternatives-google-products-services/)**Google**[,](/best-free-open-source-alternatives-microsoft-products-services/)**Microsoft**[,](/best-free-open-source-alternatives-apple-products/)**Apple**[,](/best-free-open-source-alternatives-adobe-creative-cloud/)**Adobe**[,](/best-free-open-source-alternatives-ibm-products/)**IBM**[,](/best-free-open-source-alternatives-autodesk-products/)**Autodesk**[,](/best-free-open-source-alternatives-oracle-products/)**Oracle**[,](/best-free-open-source-alternatives-atlassian-products/)**Atlassian**[,](best-free-open-source-alternatives-corel-products)**Corel**[,](/best-free-open-source-alternatives-cisco-products/)**Cisco**[, and](/best-free-open-source-alternatives-intuit-products/)**Intuit**[.](/best-free-open-source-alternatives-sas-products/)**SAS**

[showcases a series of tools that making gaming on Linux a more pleasurable experience. This is a new series.](/awesome-free-linux-game-tools/)**Awesome Free Linux Games Tools**

[explores practical applications of machine learning and deep learning from a Linux perspective. We've written reviews of more than 40 self-hosted apps. All are free and open source.](/machine-learning-linux/)**Machine Learning**

[. We start right at the basics and teach you everything you need to know to get started with Linux.](/linux-starters-guide-introduction/)**Linux for Starters series**

[showcases essential tools that are modern replacements for core Linux utilities.](/alternatives-popular-cli-tools/)**Alternatives to popular CLI tools**

[focuses on small, indispensable utilities, useful for system administrators as well as regular users.](/essential-system-tools-excellent-ways-manage-system/)**Essential Linux system tools**

[. Small, indispensable tools, useful for anyone running a Linux machine.](/outstanding-linux-utilities-maximize-productivity/)**productivity**

[,](/streaming-linux-amazon-music-unlimited/)**Amazon Music Unlimited**[,](/streaming-linux-myuzi/)**Myuzi**[,](/streaming-linux-spotify/)**Spotify**[,](/streaming-linux-deezer/)**Deezer**[.](/streaming-linux-tidal/)**Tidal**

[looks at how you can reduce your energy bills running Linux.](/saving-money-linux-getting-started/)**Saving Money with Linux**

[including the Commodore 64, Amiga, Atari ST, ZX81, Amstrad CPC, and ZX Spectrum.](/emulate-sinclair-zx81-home-computer-linux/)**Emulate home computers**

[examines how promising open source software fared over the years. It can be a bumpy ride.](/what-happened-three-promising-open-source-linux-terminal-emulators/)**Now and Then**

[looks at a range of home activities where Linux can play its part, making the most of our time at home, keeping active and engaged.](/linux-home-cooking-linux/)**Linux at Home**

[reveals the lighter side of Linux. Have some fun and escape from the daily drudgery.](/linux-candy-free-and-open-source-software-fun/)**Linux Candy**

[helps you master Docker, a set of platform as a service products that delivers software in packages called containers.](/getting-started-docker-install-docker-engine/)**Getting Started with Docker**

[. We showcase free Android apps that are definitely worth downloading. There's a strict eligibility criteria for inclusion in this series.](/best-free-android-apps/)**Best Free Android Apps**

[accelerate your learning of every programming language. Learn a new language today!](/excellent-free-programming-books/)**best free books**

[offer the perfect tonic to our free programming books series.](/category/tutorials/)**free tutorials**

[showcases usergroups that are relevant to Linux enthusiasts. Great ways to meet up with fellow enthusiasts.](/linux-world/)**Linux Around The World**

[is an occasional series looking at the impact of Linux in the USA.](/stars-stripes-nasa-linux/)**Stars and Stripes**
How do I install this on Debian or CentOS?
# apt-get install football-cli
Reading package lists… Done
Building dependency tree
Reading state information… Done
E: Unable to locate package football-cli
# yum install football-cli
Loaded plugins: fastestmirror, langpacks
Loading mirror speeds from cached hostfile
* base: mirror.rackspace.com
* epel: fedora-epel.mirror.lstn.net
* extras: mirrordenver.fdcservers.net
* updates: mirrors.tummy.com
No package football-cli available.
Error: Nothing to do
Assuming you don’t already have the JavaScript package manager installed, type:
sudo apt install npm
then type:
sudo npm install -g footballcli |
9,807 | 3 个 Python 命令行工具 | https://opensource.com/article/18/5/3-python-command-line-tools | 2018-07-04T22:13:05 | [
"Python",
"命令行"
] | https://linux.cn/article-9807-1.html |
>
> 用 Click、Docopt 和 Fire 库写你自己的命令行应用。
>
>
>

有时对于某项工作来说一个命令行工具就足以胜任。命令行工具是一种从你的 shell 或者终端之类的地方交互或运行的程序。[Git](https://git-scm.com/) 和 [Curl](https://curl.haxx.se/) 就是两个你也许已经很熟悉的命令行工具。
当你有一小段代码需要在一行中执行多次或者经常性地被执行,命令行工具就会很有用。Django 开发者执行 `./manage.py runserver` 命令来启动他们的网络服务器;Docker 开发者执行 `docker-compose up` 来启动他们的容器。你想要写一个命令行工具的原因可能和你一开始想写代码的原因有很大不同。
对于这个月的 Python 专栏,我们有 3 个库想介绍给希望为自己编写命令行工具的 Python 使用者。
### Click
[Click](http://click.pocoo.org/5/) 是我们最爱的用来开发命令行工具的 Python 包。其:
* 有一个富含例子的出色文档
* 包含说明如何将命令行工具打包成一个更加易于执行的 Python 应用程序
* 自动生成实用的帮助文本
* 使你能够叠加使用可选和必要参数,甚至是 [多个命令](http://click.pocoo.org/5/commands/)
* 有一个 Django 版本( [`django-click`](https://github.com/GaretJax/django-click) )用来编写管理命令
Click 使用 `@click.command()` 去声明一个函数作为命令,同时可以指定必要和可选参数。
```
# hello.py
import click
@click.command()
@click.option('--name', default='', help='Your name')
def say_hello(name):
click.echo("Hello {}!".format(name))
if __name__ == '__main__':
say_hello()
```
`@click.option()` 修饰器声明了一个 [可选参数](http://click.pocoo.org/5/options/) ,而 `@click.argument()` 修饰器声明了一个 [必要参数](http://click.pocoo.org/5/arguments/)。你可以通过叠加修饰器来组合可选和必要参数。`echo()` 方法将结果打印到控制台。
```
$ python hello.py --name='Lacey'
Hello Lacey!
```
### Docopt
[Docopt](http://docopt.org/) 是一个命令行工具的解析器,类似于命令行工具的 Markdown。如果你喜欢流畅地编写应用文档,在本文推荐的库中 Docopt 有着最好的格式化帮助文本。它不是我们最爱的命令行工具开发包的原因是它的文档犹如把人扔进深渊,使你开始使用时会有一些小困难。然而,它仍是一个轻量级的、广受欢迎的库,特别是当一个漂亮的说明文档对你来说很重要的时候。
Docopt 对于如何格式化文章开头的 docstring 是很特别的。在工具名称后面的 docsring 中,顶部元素必须是 `Usage:` 并且需要列出你希望命令被调用的方式(比如:自身调用,使用参数等等)。`Usage:` 需要包含 `help` 和 `version` 参数。
docstring 中的第二个元素是 `Options:`,对于在 `Usages:` 中提及的可选项和参数,它应当提供更多的信息。你的 docstring 的内容变成了你帮助文本的内容。
```
"""HELLO CLI
Usage:
hello.py
hello.py <name>
hello.py -h|--help
hello.py -v|--version
Options:
<name> Optional name argument.
-h --help Show this screen.
-v --version Show version.
"""
from docopt import docopt
def say_hello(name):
return("Hello {}!".format(name))
if __name__ == '__main__':
arguments = docopt(__doc__, version='DEMO 1.0')
if arguments['<name>']:
print(say_hello(arguments['<name>']))
else:
print(arguments)
```
在最基本的层面,Docopt 被设计用来返回你的参数键值对。如果我不指定上述的 `name` 调用上面的命令,我会得到一个字典的返回值:
```
$ python hello.py
{'--help': False,
'--version': False,
'<name>': None}
```
这里可看到我没有输入 `help` 和 `version` 标记并且 `name` 参数是 `None`。
但是如果我带着一个 `name` 参数调用,`say_hello` 函数就会执行了。
```
$ python hello.py Jeff
Hello Jeff!
```
Docopt 允许同时指定必要和可选参数,且各自有着不同的语法约定。必要参数需要在 `ALLCAPS` 和 `<carets>` 中展示,而可选参数需要单双横杠显示,就像 `--like`。更多内容可以阅读 Docopt 有关 [patterns](https://github.com/docopt/docopt#usage-pattern-format) 的文档。
### Fire
[Fire](https://github.com/google/python-fire) 是谷歌的一个命令行工具开发库。尤其令人喜欢的是当你的命令需要更多复杂参数或者处理 Python 对象时,它会聪明地尝试解析你的参数类型。
Fire 的 [文档](https://github.com/google/python-fire/blob/master/docs/guide.md) 包括了海量的样例,但是我希望这些文档能被更好地组织。Fire 能够处理 [同一个文件中的多条命令](https://github.com/google/python-fire/blob/master/docs/guide.md#exposing-multiple-commands)、使用 [对象](https://github.com/google/python-fire/blob/master/docs/guide.md#version-3-firefireobject) 的方法作为命令和 [分组](https://github.com/google/python-fire/blob/master/docs/guide.md#grouping-commands) 命令。
它的弱点在于输出到控制台的文档。命令行中的 docstring 不会出现在帮助文本中,并且帮助文本也不一定标识出参数。
```
import fire
def say_hello(name=''):
return 'Hello {}!'.format(name)
if __name__ == '__main__':
fire.Fire()
```
参数是必要还是可选取决于你是否在函数或者方法定义中为其指定了一个默认值。要调用命令,你必须指定文件名和函数名,比较类似 Click 的语法:
```
$ python hello.py say_hello Rikki
Hello Rikki!
```
你还可以像标记一样传参,比如 `--name=Rikki`。
### 额外赠送:打包!
Click 包含了使用 `setuptools` [打包](http://click.pocoo.org/5/setuptools/) 命令行工具的使用说明(强烈推荐按照说明操作)。
要打包我们第一个例子中的命令行工具,将以下内容加到你的 `setup.py` 文件里:
```
from setuptools import setup
setup(
name='hello',
version='0.1',
py_modules=['hello'],
install_requires=[
'Click',
],
entry_points='''
[console_scripts]
hello=hello:say_hello
''',
)
```
任何你看见 `hello` 的地方,使用你自己的模块名称替换掉,但是要记得忽略 `.py` 后缀名。将 `say_hello` 替换成你的函数名称。
然后,执行 `pip install --editable` 来使你的命令在命令行中可用。
现在你可以调用你的命令,就像这样:
```
$ hello --name='Jeff'
Hello Jeff!
```
通过打包你的命令,你可以省掉在控制台键入 `python hello.py --name='Jeff'` 这种额外的步骤以减少键盘敲击。这些指令也很可能可在我们提到的其他库中使用。
---
via: <https://opensource.com/article/18/5/3-python-command-line-tools>
作者:[Jeff Triplett](https://opensource.com/users/laceynwilliams),[Lacey Williams Hensche](https://opensource.com/users/laceynwilliams) 选题:[lujun9972](https://github.com/lujun9972) 译者:[hoppipolla-](https://github.com/hoppipolla-) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Sometimes the right tool for the job is a command-line application. A command-line application is a program that you interact with and run from something like your shell or Terminal. [Git](https://git-scm.com/) and [Curl](https://curl.haxx.se/) are examples of command-line applications that you might already be familiar with.
Command-line apps are useful when you have a bit of code you want to run several times in a row or on a regular basis. Django developers run commands like `./manage.py runserver`
to start their web servers; Docker developers run `docker-compose up`
to spin up their containers. The reasons you might want to write a command-line app are as varied as the reasons you might want to write code in the first place.
For this month's Python column, we have three libraries to recommend to Pythonistas looking to write their own command-line tools.
## Click
[Click](http://click.pocoo.org/5/) is our favorite Python package for command-line applications. It:
- Has great documentation filled with examples
- Includes instructions on packaging your app as a Python application so it's easier to run
- Automatically generates useful help text
- Lets you stack optional and required arguments and even
[several commands](http://click.pocoo.org/5/commands/) - Has a Django version (
) for writing management commands`django-click`
Click uses its `@click.command()`
to declare a function as a command and specify required or optional arguments.
```
# hello.py
import click
@click.command()
@click.option('--name', default='', help='Your name')
def say_hello(name):
click.echo("Hello {}!".format(name))
if __name__ == '__main__':
say_hello()
```
The `@click.option()`
decorator declares an [optional argument](http://click.pocoo.org/5/options/), and the `@click.argument()`
decorator declares a [required argument](http://click.pocoo.org/5/arguments/). You can combine optional and required arguments by stacking the decorators. The `echo()`
method prints results to the console.
```
$ python hello.py --name='Lacey'
Hello Lacey!
```
## Docopt
[Docopt](http://docopt.org/) is a command-line application parser, sort of like Markdown for your command-line apps. If you like writing the documentation for your apps as you go, Docopt has by far the best-formatted help text of the options in this article. It isn't our favorite command-line app library because its documentation throws you into the deep end right away, which makes it a little more difficult to get started. Still, it's a lightweight library that is very popular, especially if exceptionally nice documentation is important to you.
Docopt is very particular about how you format the required docstring at the top of your file. The top element in your docstring after the name of your tool must be "Usage," and it should list the ways you expect your command to be called (e.g., by itself, with arguments, etc.). Usage should include `help`
and `version`
flags.
The second element in your docstring should be "Options," and it should provide more information about the options and arguments you identified in "Usage." The content of your docstring becomes the content of your help text.
```
"""HELLO CLI
Usage:
hello.py
hello.py <name>
hello.py -h|--help
hello.py -v|--version
Options:
<name> Optional name argument.
-h --help Show this screen.
-v --version Show version.
"""
from docopt import docopt
def say_hello(name):
return("Hello {}!".format(name))
if __name__ == '__main__':
arguments = docopt(__doc__, version='DEMO 1.0')
if arguments['<name>']:
print(say_hello(arguments['<name>']))
else:
print(arguments)
```
At its most basic level, Docopt is designed to return your arguments to the console as key-value pairs. If I call the above command without specifying a name, I get a dictionary back:
```
$ python hello.py
{'--help': False,
'--version': False,
'<name>': None}
```
This shows me I did not input the `help`
or `version`
flags, and the `name`
argument is `None`
.
But if I call it with a name, the `say_hello`
function will execute.
```
$ python hello.py Jeff
Hello Jeff!
```
Docopt allows both required and optional arguments and has different syntax conventions for each. Required arguments should be represented in `ALLCAPS`
or in `<carets>`
, and options should be represented with double or single dashes, like `--name`
. Read more about Docopt's [patterns](https://github.com/docopt/docopt#usage-pattern-format) in the docs.
## Fire
[Fire](https://github.com/google/python-fire) is a Google library for writing command-line apps. We especially like it when your command needs to take more complicated arguments or deal with Python objects, as it tries to handle parsing your argument types intelligently.
Fire's [docs](https://github.com/google/python-fire/blob/master/docs/guide.md) include a ton of examples, but I wish the docs were a bit better organized. Fire can handle [multiple commands in one file](https://github.com/google/python-fire/blob/master/docs/guide.md#exposing-multiple-commands), commands as methods on [objects](https://github.com/google/python-fire/blob/master/docs/guide.md#version-3-firefireobject), and [grouping](https://github.com/google/python-fire/blob/master/docs/guide.md#grouping-commands) commands.
Its weakness is the documentation it makes available to the console. Docstrings on your commands don't appear in the help text, and the help text doesn't necessarily identify arguments.
```
import fire
def say_hello(name=''):
return 'Hello {}!'.format(name)
if __name__ == '__main__':
fire.Fire()
```
Arguments are made required or optional depending on whether you specify a default value for them in your function or method definition. To call this command, you must specify the filename and the function name, more like Click's syntax:
```
$ python hello.py say_hello Rikki
Hello Rikki!
```
You can also pass arguments as flags, like `--name=Rikki`
.
## Bonus: Packaging!
Click includes instructions (and highly recommends you follow them) for [packaging](http://click.pocoo.org/5/setuptools/) your commands using `setuptools`
.
To package our first example, add this content to your `setup.py`
file:
```
from setuptools import setup
setup(
name='hello',
version='0.1',
py_modules=['hello'],
install_requires=[
'Click',
],
entry_points='''
[console_scripts]
hello=hello:say_hello
''',
)
```
Everywhere you see `hello`
, substitute the name of your module but omit the `.py`
extension. Where you see `say_hello`
, substitute the name of your function.
Then, run `pip install --editable`
to make your command available to the command line.
You can now call your command like this:
```
$ hello --name='Jeff'
Hello Jeff!
```
By packaging your command, you omit the extra step in the console of having to type `python hello.py --name='Jeff'`
and save yourself several keystrokes. These instructions will probably also work for the other libraries we mentioned.
## 2 Comments |
9,810 | lua 中神奇的表(table) | https://github.com/lujun9972/lujun9972.github.com/blob/source/%E7%BC%96%E7%A8%8B%E4%B9%8B%E6%97%85/lua%E4%B8%AD%E7%A5%9E%E5%A5%87%E7%9A%84table.org | 2018-07-05T16:00:59 | [
"lua"
] | https://linux.cn/article-9810-1.html | 
最近在尝试配置 awesome WM,因此粗略地学习了一下 lua 。 在学习过程中,我完全被<ruby> 表 <rp> ( </rp> <rt> 表 </rt> <rp> ) </rp></ruby>在 lua 中的应用所镇住了。
表在 lua 中真的是无处不在:首先,它可以作为字典和数组来用;此外,它还可以被用于设置闭包环境、模块;甚至可以用来模拟对象和类。
### 字典
表最基础的作用就是当成字典来用。 它的键可以是除了 `nil` 之外的任何类型的值。
```
t={}
t[{}] = "table" -- key 可以是表
t[1] = "int" -- key 可以是整数
t[1.1] = "double" -- key 可以是小数
t[function () end] = "function" -- key 可以是函数
t[true] = "Boolean" -- key 可以是布尔值
t["abc"] = "String" -- key 可以是字符串
t[io.stdout] = "userdata" -- key 可以是userdata
t[coroutine.create(function () end)] = "Thread" -- key可以是thread
```
当把表当成字典来用时,可以使用 `pairs` 函数来进行遍历。
```
for k,v in pairs(t) do
print(k,"->",v)
end
```
运行结果为:
```
1 -> int
1.1 -> double
thread: 0x220bb08 -> Thread
table: 0x220b670 -> table
abc -> String
file (0x7f34a81ef5c0) -> userdata
function: 0x220b340 -> function
true -> Boolean
```
从结果中你还可以发现,使用 `pairs` 进行遍历时的顺序是随机的,事实上相同的语句执行多次得到的结果是不一样的。
表 中的键最常见的两种类型就是整数型和字符串类型。 当键为字符串时,表 可以当成结构体来用。同时形如 `t["field"]` 这种形式的写法可以简写成 `t.field` 这种形式。
### 数组
当键为整数时,表 就可以当成数组来用。而且这个数组是一个 **索引从 1 开始** 、没有固定长度、可以根据需要自动增长的数组。
```
a = {}
for i=0,5 do -- 注意,这里故意写成了i从0开始
a[i] = 0
end
```
当将表当成数组来用时,可以通过长度操作符 `#` 来获取数组的长度:
```
print(#a)
```
结果为:
```
5
```
你会发现, lua 认为数组 `a` 中只有 5 个元素,到底是哪 5 个元素呢?我们可以使用使用 `ipairs` 对数组进行遍历:
```
for i,v in ipairs(a) do
print(i,v)
end
```
结果为:
```
1 0
2 0
3 0
4 0
5 0
```
从结果中你会发现 `a` 的 0 号索引并不认为是数组中的一个元素,从而也验证了 lua 中的数组是从 **1 开始索引的**。
另外,将表当成数组来用时,一定要注意索引不连贯的情况,这种情况下 `#` 计算长度时会变得很诡异。
```
a = {}
for i=1,5 do
a[i] = 0
end
a[8] = 0 -- 虽然索引不连贯,但长度是以最大索引为准
print(#a)
a[100] = 0 -- 索引不连贯,而且长度不再以最大索引为准了
print(#a)
```
结果为:
```
8
8
```
而使用 `ipairs` 对数组进行遍历时,只会从 1 遍历到索引中断处。
```
for i,v in ipairs(a) do
print(i,v)
end
```
结果为:
```
1 0
2 0
3 0
4 0
5 0
```
### 环境(命名空间)
lua 将所有的全局变量/局部变量保存在一个常规表中,这个表一般被称为全局或者某个函数(闭包)的环境。
为了方便,lua 在创建最初的全局环境时,使用全局变量 `_G` 来引用这个全局环境。因此,在未手工设置环境的情况下,可以使用 `-G[varname]` 来存取全局变量的值。
```
for k,v in pairs(_G) do
print(k,"->",v)
end
```
```
rawequal -> function: 0x41c2a0
require -> function: 0x1ea4e70
_VERSION -> Lua 5.3
debug -> table: 0x1ea8ad0
string -> table: 0x1ea74b0
xpcall -> function: 0x41c720
select -> function: 0x41bea0
package -> table: 0x1ea4820
assert -> function: 0x41cc50
pcall -> function: 0x41cd10
next -> function: 0x41c450
tostring -> function: 0x41be70
_G -> table: 0x1ea2b80
coroutine -> table: 0x1ea4ee0
unpack -> function: 0x424fa0
loadstring -> function: 0x41ca00
setmetatable -> function: 0x41c7e0
rawlen -> function: 0x41c250
bit32 -> table: 0x1ea8fc0
utf8 -> table: 0x1ea8650
math -> table: 0x1ea7770
collectgarbage -> function: 0x41c650
rawset -> function: 0x41c1b0
os -> table: 0x1ea6840
pairs -> function: 0x41c950
arg -> table: 0x1ea9450
table -> table: 0x1ea5130
tonumber -> function: 0x41bf40
io -> table: 0x1ea5430
loadfile -> function: 0x41cb10
error -> function: 0x41c5c0
load -> function: 0x41ca00
print -> function: 0x41c2e0
dofile -> function: 0x41cbd0
rawget -> function: 0x41c200
type -> function: 0x41be10
getmetatable -> function: 0x41cb80
module -> function: 0x1ea4e00
ipairs -> function: 0x41c970
```
从 lua 5.2 开始,可以通过修改 `_ENV` 这个值(**lua 5.1 中的 `setfenv` 从 5.2 开始被废除**)来设置某个函数的环境,从而让这个函数中的执行语句在一个新的环境中查找全局变量的值。
```
a=1 -- 全局变量中a=1
local env={a=10,print=_G.print} -- 新环境中a=10,并且确保能访问到全局的print函数
function f1()
local _ENV=env
print("in f1:a=",a)
a=a*10 -- 修改的是新环境中的a值
end
f1()
print("globally:a=",a)
print("env.a=",env.a)
```
```
in f1:a= 10
globally:a= 1
env.a= 100
```
另外,新创建的闭包都继承了创建它的函数的环境。
### 模块
lua 中的模块也是通过返回一个表来供模块使用者来使用的。 这个表中包含的是模块中所导出的所有东西,包括函数和常量。
定义模块的一般模板为:
```
module(模块名, package.seeall)
```
其中 `module(模块名)` 的作用类似于:
```
local modname = 模块名
local M = {} -- M即为存放模块所有函数及常数的table
_G[modname] = M
package.loaded[modname] = M
setmetatable(M,{__index=_G}) -- package.seeall可以使全局环境_G对当前环境可见
local _ENV = M -- 设置当前的运行环境为 M,这样后续所有代码都不需要限定模块名了,所定义的所有函数自动变成M的成员
<函数定义以及常量定义>
return M -- module函数会帮你返回module table,而无需手工返回
```
### 对象
lua 中之所以可以把表当成对象来用是因为:
1. 函数在 lua 中是一类值,你可以直接存取表中的函数值。 这使得一个表既可以有自己的状态,也可以有自己的行为:
```
Account = {balance = 0}
function Account.withdraw(v)
Account.balance = Account.balance - v
end
```
2. lua 支持闭包,这个特性可以用来模拟对象的私有成员变量:
```
function new_account(b)
local balance = b
return {withdraw = function (v) balance = balance -v end,
get_balance = function () return balance end
}
end
a1 = new_account(1000)
a1.withdraw(10)
print(a1.get_balance())
```
```
990
```
不过,上面第一种定义对象的方法有一个缺陷,那就是方法与 `Account` 这个名称绑定死了。 也就是说,这个对象的名称必须为 `Accout` 否则就会出错。
```
a = Account
Account = nil
a.withdraw(10) -- 会报错,因为Accout.balance不再存在
```
为了解决这个问题,我们可以给 `withdraw` 方法多一个参数用于指向对象本身。
```
Account = {balance=100}
function Account.withdraw(self,v)
self.balance = self.balance - v
end
a = Account
Account = nil
a.withdraw(a,10) -- 没问题,这个时候 self 指向的是a,因此会去寻找 a.balance
print(a.balance)
```
```
90
```
不过由于第一个参数 `self` 几乎总是指向调用方法的对象本身,因此 lua 提供了一种语法糖形式 `object:method(...)` 用于隐藏 `self` 参数的定义及传递。这里冒号的作用有两个,其在定义函数时往函数中地一个参数的位置添加一个额外的隐藏参数 `sef`, 而在调用时传递一个额外的隐藏参数 `self` 到地一个参数位置。 即 `function object:method(v) end` 等价于 `function object.method(self,v) end`, `object:method(v)` 等价于 `object.method(object,v)`。
### 类
当涉及到类和继承时,就要用到元表和元方法了。事实上,对于 lua 来说,对象和类并不存在一个严格的划分。
当一个对象被另一个表的 `__index` 元方法所引用时,表就能引用该对象中所定义的方法,因此也就可以理解为对象变成了表的类。
类定义的一般模板为:
```
function 类名:new(o)
o = o or {}
setmetatable(o,{__index = self})
return o
end
```
或者:
```
function 类名:new(o)
o = o or {}
setmetatable(o,self)
self.__index = self
return o
end
```
相比之下,第二种写法可以多省略一个表。
另外有一点我觉得有必要说明的就是 lua 中的元方法是在元表中定义的,而不是对象本身定义的,这一点跟其他面向对象的语言比较不同。
| 200 | OK | 最近在尝试配置 awesome WM,因此粗略地学习了一下 lua 。 在学习过程中,我完全被 table 在 lua 中的应用所镇住了。
table 在 lua 中真的是无处不在:首先,它可以作为字典和数组来用; 此外,它还可以被用于设置闭包环境、module; 甚至可以用来模拟对象和类
table 最基础的作用就是当成字典来用。 它的 key 值可以是除了 nil 之外的任何类型的值。
```
t={}
t[{}] = "table" -- key 可以是 table
t[1] = "int" -- key 可以是整数
t[1.1] = "double" -- key 可以是小数
t[function () end] = "function" -- key 可以是函数
t[true] = "Boolean" -- key 可以是布尔值
t["abc"] = "String" -- key 可以是字符串
t[io.stdout] = "userdata" -- key 可以是userdata
t[coroutine.create(function () end)] = "Thread" -- key可以是thread
```
当把 table 当成字典来用时,可以使用 `pairs`
函数来进行遍历。
```
for k,v in pairs(t) do
print(k,"->",v)
end
```
运行结果为:
```
1 -> int
1.1 -> double
thread: 0x220bb08 -> Thread
table: 0x220b670 -> table
abc -> String
file (0x7f34a81ef5c0) -> userdata
function: 0x220b340 -> function
true -> Boolean
```
从结果中你还可以发现,使用 `pairs`
进行遍历时的顺序是随机的,事实上相同的语句执行多次得到的结果是不一样的。
table 中的key最常见的两种类型就是整数型和字符串类型。
当 key 为字符串时,table可以当成结构体来用。同时形如 `t["field"]`
这种形式的写法可以简写成 `t.field`
这种形式。
当 key 为整数时,table 就可以当成数组来用。而且这个数组是一个 **索引从1开始** ,没有固定长度,可以根据需要自动增长的数组。
```
a = {}
for i=0,5 do -- 注意,这里故意写成了i从0开始
a[i] = 0
end
```
当将 table 当成数组来用时,可以通过 长度操作符 `#`
来获取数组的长度
`print(#a)`
结果为
```
5
```
你会发现, lua 认为 数组 a 中只有5个元素,到底是哪5个元素呢?我们可以使用使用 `ipairs`
对数组进行遍历:
```
for i,v in ipairs(a) do
print(i,v)
end
```
结果为
```
1 0
2 0
3 0
4 0
5 0
```
从结果中你会发现 `a`
的0号索引并不认为是数组中的一个元素,从而也验证了 lua 中的数组是从 **1开始索引的**
另外,将table当成数组来用时,一定要注意索引不连贯的情况,这种情况下 `#`
计算长度时会变得很诡异
```
a = {}
for i=1,5 do
a[i] = 0
end
a[8] = 0 -- 虽然索引不连贯,但长度是以最大索引为准
print(#a)
a[100] = 0 -- 索引不连贯,而且长度不再以最大索引为准了
print(#a)
```
结果为:
```
8
8
```
而使用 `ipairs`
对数组进行遍历时,只会从1遍历到索引中断处
```
for i,v in ipairs(a) do
print(i,v)
end
```
结果为:
```
1 0
2 0
3 0
4 0
5 0
```
lua将所有的全局变量/局部变量保存在一个常规table中,这个table一般被称为全局或者某个函数(闭包)的环境。
为了方便,lua在创建最初的全局环境时,使用全局变量 `_G`
来引用这个全局环境。因此,在未手工设置环境的情况下,可以使用 `_G[varname]`
来存取全局变量的值.
```
for k,v in pairs(_G) do
print(k,"->",v)
end
```
```
rawequal -> function: 0x41c2a0
require -> function: 0x1ea4e70
_VERSION -> Lua 5.3
debug -> table: 0x1ea8ad0
string -> table: 0x1ea74b0
xpcall -> function: 0x41c720
select -> function: 0x41bea0
package -> table: 0x1ea4820
assert -> function: 0x41cc50
pcall -> function: 0x41cd10
next -> function: 0x41c450
tostring -> function: 0x41be70
_G -> table: 0x1ea2b80
coroutine -> table: 0x1ea4ee0
unpack -> function: 0x424fa0
loadstring -> function: 0x41ca00
setmetatable -> function: 0x41c7e0
rawlen -> function: 0x41c250
bit32 -> table: 0x1ea8fc0
utf8 -> table: 0x1ea8650
math -> table: 0x1ea7770
collectgarbage -> function: 0x41c650
rawset -> function: 0x41c1b0
os -> table: 0x1ea6840
pairs -> function: 0x41c950
arg -> table: 0x1ea9450
table -> table: 0x1ea5130
tonumber -> function: 0x41bf40
io -> table: 0x1ea5430
loadfile -> function: 0x41cb10
error -> function: 0x41c5c0
load -> function: 0x41ca00
print -> function: 0x41c2e0
dofile -> function: 0x41cbd0
rawget -> function: 0x41c200
type -> function: 0x41be10
getmetatable -> function: 0x41cb80
module -> function: 0x1ea4e00
ipairs -> function: 0x41c970
```
从lua 5.2开始,可以通过修改 `_ENV`
这个值(**lua5.1中的setfenv从5.2开始被废除**)来设置某个函数的环境,从而让这个函数中的执行语句在一个新的环境中查找全局变量的值。
```
a=1 -- 全局变量中a=1
local env={a=10,print=_G.print} -- 新环境中a=10,并且确保能访问到全局的print函数
function f1()
local _ENV=env
print("in f1:a=",a)
a=a*10 -- 修改的是新环境中的a值
end
f1()
print("globally:a=",a)
print("env.a=",env.a)
```
```
in f1:a= 10
globally:a= 1
env.a= 100
```
另外,新创建的闭包都继承了创建它的函数的环境
lua 中的模块也是通过返回一个table来供模块使用者来使用的。 这个 table中包含的是模块中所导出的所有东西,包括函数和常量。
定义module的一般模板为
`module(模块名, package.seeall)`
其中 `module(模块名)`
的作用类似于
```
local modname = 模块名
local M = {} -- M即为存放模块所有函数及常数的table
_G[modname] = M
package.loaded[modname] = M
setmetatable(M,{__index=_G}) -- package.seeall可以使全局环境_G对当前环境可见
local _ENV = M -- 设置当前的运行环境为 M,这样后续所有代码都不需要限定模块名了,所定义的所有函数自动变成M的成员
<函数定义以及常量定义>
return M -- module函数会帮你返回module table,而无需手工返回
```
lua 中之所以可以把table当成对象来用是因为:
- 函数在 lua 中是一类值,你可以直接存取table中的函数值。 这使得一个table既可以有自己的状态,也可以有自己的行为:
Account = {balance = 0} function Account.withdraw(v) Account.balance = Account.balance - v end
- lua 支持闭包,这个特性可以用来模拟对象的私有成员变量
function new_account(b) local balance = b return {withdraw = function (v) balance = balance -v end, get_balance = function () return balance end } end a1 = new_account(1000) a1.withdraw(10) print(a1.get_balance())
990
不过,上面第一种定义对象的方法有一个缺陷,那就是方法与 `Account`
这个名称绑定死了。
也就是说,这个对象的名称必须为 `Accout`
否则就会出错
```
a = Account
Account = nil
a.withdraw(10) -- 会报错,因为Accout.balance不再存在
```
为了解决这个问题,我们可以给 `withdraw`
方法多一个参数用于指向对象本身
```
Account = {balance=100}
function Account.withdraw(self,v)
self.balance = self.balance - v
end
a = Account
Account = nil
a.withdraw(a,10) -- 没问题,这个时候 self 指向的是a,因此会去寻找 a.balance
print(a.balance)
```
```
90
```
不过由于第一个参数 `self`
几乎总是指向调用方法的对象本身,因此 lua 提供了一种语法糖形式 `object:method(...)`
用于隐藏 `self`
参数的定义及传递.
这里冒号的作用有两个,其在定义函数时往函数中地一个参数的位置添加一个额外的隐藏参数 `sef`
, 而在调用时传递一个额外的隐藏参数 `self`
到地一个参数位置。
即 `function object:method(v) end`
等价于 `function object.method(self,v) end`
,
`object:method(v)`
等价于 `object.method(object,v)`
当涉及到类和继承时,就要用到元表和元方法了。事实上,对于 lua 来说,对象和类并不存在一个严格的划分。
当一个对象被另一个table的 `__index`
元方法所引用时,table就能引用该对象中所定义的方法,因此也就可以理解为对象变成了table的类。
类定义的一般模板为:
```
function 类名:new(o)
o = o or {}
setmetatable(o,{__index = self})
return o
end
```
或者
```
function 类名:new(o)
o = o or {}
setmetatable(o,self)
self.__index = self
return o
end
```
相比之下,第二种写法可以多省略一个table
另外有一点我觉得有必要说明的就是 lua 中的元方法是在元表中定义的,而不是对象本身定义的,这一点跟其他面向对象的语言比较不同。 |
9,811 | 4 种用于构建嵌入式 Linux 系统的工具 | https://opensource.com/article/18/6/embedded-linux-build-tools | 2018-07-06T09:55:00 | [
"嵌入式"
] | https://linux.cn/article-9811-1.html |
>
> 了解 Yocto、Buildroot、 OpenWRT,和改造过的桌面发行版以确定哪种方式最适合你的项目。
>
>
>

Linux 被部署到比 Linus Torvalds 在他的宿舍里开发时所预期的更广泛的设备。令人震惊的支持了各种芯片,使得Linux 可以应用于大大小小的设备上:从 [IBM 的巨型机](https://en.wikipedia.org/wiki/Linux_on_z_Systems)到不如其连接的端口大的[微型设备](http://www.picotux.com/),以及各种大小的设备。它被用于大型企业数据中心、互联网基础设施设备和个人的开发系统。它还为消费类电子产品、移动电话和许多物联网设备提供了动力。
在为桌面和企业级设备构建 Linux 软件时,开发者通常在他们的构建机器上使用桌面发行版,如 [Ubuntu](https://www.ubuntu.com/) 以便尽可能与被部署的机器相似。如 [VirtualBox](https://www.virtualbox.org/) 和 [Docker](https://www.docker.com/) 这样的工具使得开发、测试和生产环境更好的保持了一致。
### 什么是嵌入式系统?
维基百科将[嵌入式系统](https://en.wikipedia.org/wiki/Embedded_system)定义为:“在更大的机械或电气系统中具有专用功能的计算机系统,往往伴随着实时计算限制。”
我觉得可以很简单地说,嵌入式系统是大多数人不认为是计算机的计算机。它的主要作用是作为某种设备,而不被视为通用计算平台。
嵌入式系统编程的开发环境通常与测试和生产环境大不相同。它们可能会使用不同的芯片架构、软件堆栈甚至操作系统。开发工作流程对于嵌入式开发人员与桌面和 Web 开发人员来说是非常不同的。通常,其构建后的输出将包含目标设备的整个软件映像,包括内核、设备驱动程序、库和应用程序软件(有时也包括引导加载程序)。
在本文中,我将对构建嵌入式 Linux 系统的四种常用方式进行纵览。我将介绍一下每种产品的工作原理,并提供足够的信息来帮助读者确定使用哪种工具进行设计。我不会教你如何使用它们中的任何一个;一旦缩小了选择范围,就有大量深入的在线学习资源。没有任何选择适用于所有情况,我希望提供足够的细节来指导您的决定。
### Yocto
[Yocto](https://yoctoproject.org/) 项目 [定义](https://www.yoctoproject.org/about/)为“一个开源协作项目,提供模板、工具和方法,帮助您为嵌入式产品创建定制的基于 Linux 的系统,而不管硬件架构如何。”它是用于创建定制的 Linux 运行时映像的配方、配置值和依赖关系的集合,可根据您的特定需求进行定制。
完全公开:我在嵌入式 Linux 中的大部分工作都集中在 Yocto 项目上,而且我对这个系统的认识和偏见可能很明显。
Yocto 使用 [Openembedded](https://www.openembedded.org/) 作为其构建系统。从技术上讲,这两个是独立的项目;然而,在实践中,用户不需要了解区别,项目名称经常可以互换使用。
Yocto 项目的输出大致由三部分组成:
* **目标运行时二进制文件:**这些包括引导加载程序、内核、内核模块、根文件系统映像。以及将 Linux 部署到目标平台所需的任何其他辅助文件。
* **包流:**这是可以安装在目标上的软件包集合。您可以根据需要选择软件包格式(例如,deb、rpm、ipk)。其中一些可能预先安装在目标运行时二进制文件中,但可以构建用于安装到已部署系统的软件包。
* **目标 SDK:**这些是安装在目标平台上的软件的库和头文件的集合。应用程序开发人员在构建代码时使用它们,以确保它们与适当的库链接
#### 优点
Yocto 项目在行业中得到广泛应用,并得到许多有影响力的公司的支持。此外,它还拥有一个庞大且充满活力的开发人员[社区](https://www.yoctoproject.org/community/)和[生态系统](https://www.yoctoproject.org/ecosystem/participants/)。开源爱好者和企业赞助商的结合的方式有助于推动 Yocto 项目。
获得 Yocto 的支持有很多选择。如果您想自己动手,有书籍和其他培训材料。如果您想获得专业知识,有许多有 Yocto 经验的工程师。而且许多商业组织可以为您的设计提供基于 Yocto 的 Turnkey 产品或基于服务的实施和定制。
Yocto 项目很容易通过 [层](https://layers.openembedded.org/layerindex/branch/master/layers/) 进行扩展,层可以独立发布以添加额外的功能,或针对项目发布时尚不可用的平台,或用于保存系统特有定制功能。层可以添加到你的配置中,以添加未特别包含在市面上版本中的独特功能;例如,“[meta-browser](https://layers.openembedded.org/layerindex/branch/master/layer/meta-browser/)” 层包含 Web 浏览器的清单,可以轻松为您的系统进行构建。因为它们是独立维护的,所以层可以按不同的时间发布(根据层的开发速度),而不是跟着标准的 Yocto 版本发布。
Yocto 可以说是本文讨论的任何方式中最广泛的设备支持。由于许多半导体和电路板制造商的支持,Yocto 很可能能够支持您选择的任何目标平台。主版本 Yocto [分支](https://yoctoproject.org/downloads)仅支持少数几块主板(以便达成合理的测试和发布周期),但是,标准工作模式是使用外部主板支持层。
最后,Yocto 非常灵活和可定制。您的特定应用程序的自定义可以存储在一个层进行封装和隔离,通常将要素层特有的自定义项存储为层本身的一部分,这可以将相同的设置同时应用于多个系统配置。Yocto 还提供了一个定义良好的层优先和覆盖功能。这使您可以定义层应用和搜索元数据的顺序。它还使您可以覆盖具有更高优先级的层的设置;例如,现有清单的许多自定义功能都将保留。
#### 缺点
Yocto 项目最大的缺点是学习曲线陡峭。学习该系统并真正理解系统需要花费大量的时间和精力。 根据您的需求,这可能对您的应用程序不重要的技术和能力投入太大。 在这种情况下,与一家商业供应商合作可能是一个不错的选择。
Yocto 项目的开发时间和资源相当高。 需要构建的包(包括工具链,内核和所有目标运行时组件)的数量相当不少。 Yocto 开发人员的开发工作站往往是大型系统。 不建议使用小型笔记本电脑。 这可以通过使用许多提供商提供的基于云的构建服务器来缓解。 另外,Yocto 有一个内置的缓存机制,当它确定用于构建特定包的参数没有改变时,它允许它重新使用先前构建的组件。
#### 建议
为您的下一个嵌入式 Linux 设计使用 Yocto 项目是一个强有力的选择。 在这里介绍的选项中,无论您的目标用例如何,它都是最广泛适用的。 广泛的行业支持,积极的社区和广泛的平台支持使其成为必须设计师的不错选择。
### Buildroot
[Buildroot](https://buildroot.org/) 项目定义为“通过交叉编译生成嵌入式 Linux 系统的简单、高效且易于使用的工具。”它与 Yocto 项目具有许多相同的目标,但它注重简单性和简约性。一般来说,Buildroot 会禁用所有软件包的所有可选编译时设置(有一些值得注意的例外),从而生成尽可能小的系统。系统设计人员需要启用适用于给定设备的设置。
Buildroot 从源代码构建所有组件,但不支持按目标包管理。因此,它有时称为固件生成器,因为镜像在构建时大部分是固定的。应用程序可以更新目标文件系统,但是没有机制将新软件包安装到正在运行的系统中。
Buildroot 输出主要由三部分组成:
* 将 Linux 部署到目标平台所需的根文件系统映像和任何其他辅助文件
* 适用于目标硬件的内核,引导加载程序和内核模块
* 用于构建所有目标二进制文件的工具链。
#### 优点
Buildroot 对简单性的关注意味着,一般来说,它比 Yocto 更容易学习。核心构建系统用 Make 编写,并且足够短以便开发人员了解整个系统,同时可扩展到足以满足嵌入式 Linux 开发人员的需求。 Buildroot 核心通常只处理常见用例,但它可以通过脚本进行扩展。
Buildroot 系统使用普通的 Makefile 和 Kconfig 语言来进行配置。 Kconfig 由 Linux 内核社区开发,广泛用于开源项目,使得许多开发人员都熟悉它。
由于禁用所有可选的构建时设置的设计目标,Buildroot 通常会使用开箱即用的配置生成尽可能最小的镜像。一般来说,构建时间和构建主机资源的规模将比 Yocto 项目的规模更小。
#### 缺点
关注简单性和最小化启用的构建方式意味着您可能需要执行大量的自定义来为应用程序配置 Buildroot 构建。此外,所有配置选项都存储在单个文件中,这意味着如果您有多个硬件平台,则需要为每个平台进行每个定制更改。
对系统配置文件的任何更改都需要全部重新构建所有软件包。与 Yocto 相比,这个问题通过最小的镜像大小和构建时间得到了一定的解决,但在你调整配置时可能会导致构建时间过长。
中间软件包状态缓存默认情况下未启用,并且不像 Yocto 实施那么彻底。这意味着,虽然第一次构建可能比等效的 Yocto 构建短,但后续构建可能需要重建许多组件。
#### 建议
对于大多数应用程序,使用 Buildroot 进行下一个嵌入式 Linux 设计是一个不错的选择。如果您的设计需要多种硬件类型或其他差异,但由于同步多个配置的复杂性,您可能需要重新考虑,但对于由单一设置组成的系统,Buildroot 可能适合您。
### OpenWRT/LEDE
[OpenWRT](https://openwrt.org/) 项目开始为消费类路由器开发定制固件。您当地零售商提供的许多低成本路由器都可以运行 Linux 系统,但可能无法开箱即用。这些路由器的制造商可能无法提供频繁的更新来解决新的威胁,即使他们这样做,安装更新镜像的机制也很困难且容易出错。 OpenWRT 项目为许多已被其制造商放弃的设备生成更新的固件镜像,让这些设备焕发新生。
OpenWRT 项目的主要交付物是可用于大量商业设备的二进制镜像。它有网络可访问的软件包存储库,允许设备最终用户将新软件添加到他们的系统中。 OpenWRT 构建系统是一个通用构建系统,它允许开发人员创建自定义版本以满足他们自己的需求并添加新软件包,但其主要重点是目标二进制文件。
#### 优点
如果您正在为商业设备寻找替代固件,则 OpenWRT 应位于您的选项列表中。它的维护良好,可以保护您免受制造商固件无法解决的问题。您也可以添加额外的功能,使您的设备更有用。
如果您的嵌入式设计专注于网络,则 OpenWRT 是一个不错的选择。网络应用程序是 OpenWRT 的主要用例,您可能会发现许多可用的软件包。
#### 缺点
OpenWRT 对您的设计限制很多(与 Yocto 和 Buildroot 相比)。如果这些决定不符合您的设计目标,则可能需要进行大量的修改。
在部署的设备中允许基于软件包的更新是很难管理的。按照其定义,这会导致与您的 QA 团队测试的软件负载不同。此外,很难保证大多数软件包管理器的原子安装,以及错误的电源循环可能会使您的设备处于不可预知的状态。
#### 建议
OpenWRT 是爱好者项目或商用硬件再利用的不错选择。它也是网络应用程序的不错选择。如果您需要从默认设置进行大量定制,您可能更喜欢 Buildroot 或 Yocto。
### 桌面发行版
设计嵌入式 Linux 系统的一种常见方法是从桌面发行版开始,例如 [Debian](https://www.debian.org/) 或 [Red Hat](https://www.redhat.com/),并删除不需要的组件,直到安装的镜像符合目标设备的占用空间。这是 [Raspberry Pi](https://www.raspberrypi.org/) 平台流行的 [Raspbian](https://www.raspbian.org/)发行版的方法。
#### 优点
这种方法的主要优点是熟悉。通常,嵌入式 Linux 开发人员也是桌面 Linux 用户,并且精通他们的选择发行版。在目标上使用类似的环境可能会让开发人员更快地入门。根据所选的分布,可以使用 apt 和 yum 等标准封装工具安装许多其他工具。
可以将显示器和键盘连接到目标设备,并直接在那里进行所有的开发。对于不熟悉嵌入式空间的开发人员来说,这可能是一个更为熟悉的环境,无需配置和使用棘手的跨开发平台设置。
大多数桌面发行版可用的软件包数量通常大于前面讨论的嵌入式特定的构建器可用软件包数量。由于较大的用户群和更广泛的用例,您可能能够找到您的应用程序所需的所有运行时包,这些包已经构建并可供使用。
#### 缺点
将目标平台作为您的主要开发环境可能会很慢。运行编译器工具是一项资源密集型操作,根据您构建的代码的多少,这可能会严重妨碍您的性能。
除了一些例外情况,桌面发行版的设计并不适合低资源系统,并且可能难以充分裁剪目标映像。同样,桌面环境中的预设工作流程对于大多数嵌入式设计来说都不理想。以这种方式获得可再现的环境很困难。手动添加和删除软件包很容易出错。这可以使用特定于发行版的工具进行脚本化,例如基于 Debian 系统的 [debootstrap](https://wiki.debian.org/Debootstrap)。为了进一步提高[可再现性](https://wiki.debian.org/Debootstrap),您可以使用配置管理工具,如 [CFEngine](https://cfengine.com/)(我的雇主 [Mender.io](http://Mender.io) 完整披露了 这一工具)。但是,您仍然受发行版提供商的支配,他们将更新软件包以满足他们的需求,而不是您的需求。
#### 建议
对于您打算推向市场的产品,请谨慎使用此方法。这对于爱好者应用程序来说是一个很好的模型;但是,对于需要支持的产品,这种方法很可能会遇到麻烦。虽然您可能能够获得更快的起步,但从长远来看,您可能会花费您的时间和精力。
### 其他考虑
这个讨论集中在构建系统的功能上,但通常有非功能性需求可能会影响您的决定。如果您已经选择了片上系统(SoC)或电路板,则您的选择很可能由供应商决定。如果您的供应商为特定系统提供板级支持包(BSP),使用它通常会节省相当多的时间,但请研究 BSP 的质量以避免在开发周期后期发生问题。
如果您的预算允许,您可能需要考虑为目标操作系统使用商业供应商。有些公司会为这里讨论的许多选项提供经过验证和支持的配置,除非您拥有嵌入式 Linux 构建系统方面的专业知识,否则这是一个不错的选择,可以让您专注于核心能力。
作为替代,您可以考虑为您的开发人员进行商业培训。这可能比商业操作系统供应商便宜,并且可以让你更加自给自足。这是快速找到您选择的构建系统基础知识的学习曲线。
最后,您可能已经有一些开发人员拥有一个或多个系统的经验。如果你的工程师有倾向性,当你做出决定时,肯定值得考虑。
### 总结
构建嵌入式 Linux 系统有多种选择,每种都有优点和缺点。将这部分设计放在优先位置至关重要,因为在以后的过程中切换系统的成本非常高。除了这些选择之外,还有新的系统在开发中。希望这次讨论能够为评估新的系统(以及这里提到的系统)提供一些背景,并帮助您为下一个项目做出坚实的决定。
---
via: <https://opensource.com/article/18/6/embedded-linux-build-tools>
作者:[Drew Moseley](https://opensource.com/users/drewmoseley) 选题:[lujun9972](https://github.com/lujun9972) 译者:[LHRChina](https://github.com/LHRChina) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Linux is being deployed into a much wider array of devices than Linus Torvalds anticipated when he was working on it in his dorm room. The variety of supported chip architectures is astounding and has led to Linux in devices large and small; from [huge IBM mainframes](https://en.wikipedia.org/wiki/Linux_on_z_Systems) to [tiny devices](http://www.picotux.com/) no bigger than their connection ports and everything in between. It is used in large enterprise data centers, internet infrastructure devices, and personal development systems. It also powers consumer electronics, mobile phones, and many Internet of Things devices.
When building Linux software for desktop and enterprise-class devices, developers typically use a desktop distribution such as [Ubuntu](https://www.ubuntu.com/) on their build machines to have an environment as close as possible to the one where the software will be deployed. Tools such as [VirtualBox](https://www.virtualbox.org/) and [Docker](https://www.docker.com/) allow even better alignment between development, testing, and productions environments.
## What is an embedded system?
Wikipedia defines an [embedded system](https://en.wikipedia.org/wiki/Embedded_system) as: "A computer system with a dedicated function within a larger mechanical or electrical system, often with real-time computing constraints."
I find it simple enough to say that an embedded system is a computer that most people don't think of as a computer. Its primary role is to serve as an appliance of some sort, and it is not considered a general-purpose computing platform.
The development environment in embedded systems programming is usually very different from the testing and production environments. They may use different chip architectures, software stacks, and even operating systems. Development workflows are very different for embedded developers vs. desktop and web developers. Typically, the build output will consist of an entire software image for the target device, including the kernel, device drivers, libraries, and application software (and sometimes the bootloader).
In this article, I will present a survey of four commonly available options for building embedded Linux systems. I will give a flavor for what it's like to work with each and provide enough information to help readers decide which tool to use for their design. I won't teach you how to use any of them; there are plenty of in-depth online learning resources once you have narrowed your choices. No option is right for all use cases, and I hope to present enough details to direct your decision.
## Yocto
The [Yocto](https://yoctoproject.org/) project is [defined](https://www.yoctoproject.org/about/) as "an open source collaboration project that provides templates, tools, and methods to help you create custom Linux-based systems for embedded products regardless of the hardware architecture." It is a collection of recipes, configuration values, and dependencies used to create a custom Linux runtime image tailored to your specific needs.
Full disclosure: most of my work in embedded Linux has focused on the Yocto project, and my knowledge and bias to this system will likely be evident.
Yocto uses [Openembedded](https://www.openembedded.org/) as its build system. Technically the two are separate projects; in practice, however, users do not need to understand the distinction, and the project names are frequently used interchangeably.
The output of a Yocto project build consists broadly of three components:
**Target run-time binaries:**These include the bootloader, kernel, kernel modules, root filesystem image. and any other auxiliary files needed to deploy Linux to the target platform.**Package feed:**This is the collection of software packages available to be installed on your target. You can select the package format (e.g., deb, rpm, ipk) based on your needs. Some of them may be preinstalled in the target runtime binaries, however, it is possible to build packages for installation into a deployed system.**Target SDK:**These are the collection of libraries and header files representing the software installed on your target. They are used by application developers when building their code to ensure they are linked with the appropriate libraries
### Advantages
The Yocto project is widely used in the industry and has backing from many influential companies. Additionally, it has a large and vibrant developer [community](https://www.yoctoproject.org/community/) and [ecosystem](https://www.yoctoproject.org/ecosystem/participants/) contributing to it. The combination of open source enthusiasts and corporate sponsors helps drive the Yocto project.
There are many options for getting support with Yocto. There are books and other training materials if you wish to do-it-yourself. Many engineers with experience in Yocto are available if you want to hire expertise. And many commercial organizations provide turnkey Yocto-based products or services-based implementation and customization for your design.
The Yocto project is easily expanded through [layers](https://layers.openembedded.org/layerindex/branch/master/layers/), which can be published independently to add additional functionality, to target platforms not available in the project releases, or to store customizations unique to your system. Layers can be added to your configuration to add unique features that are not specifically included in the stock releases; for example, the "[meta-browser](https://layers.openembedded.org/layerindex/branch/master/layer/meta-browser/)" layer contains recipes for web browsers, which can be easily built for your system. Because they are independently maintained, layers can be on a different release schedule (tuned to the layers' development velocity) than the standard Yocto releases.
Yocto has arguably the widest device support of any of the options discussed in this article. Due to support from many semiconductor and board manufacturers, it's likely Yocto will support any target platform you choose. The direct Yocto [releases](https://yoctoproject.org/downloads) support only a few boards (to allow for proper testing and release cycles), however, a standard working model is to use external board support layers.
Finally, Yocto is extremely flexible and customizable. Customizations for your specific application can be stored in a layer for encapsulation and isolation. Customizations unique to a feature layer are generally stored as part of the layer itself, which allows the same settings to be applied simultaneously to multiple system configurations. Yocto also provides a well-defined layer priority and override capability. This allows you to define the order in which layers are applied and searched for metadata. It also enables you to override settings in layers with higher priority; for instance, many customizations to existing recipes will be added in your private layers, with the order precisely controlled by the priorities.
### Disadvantages
The biggest disadvantage with the Yocto project is the learning curve. It takes significant time and effort to learn the system and truly understand it. Depending on your needs, this may be too large of an investment in technologies and competence that are not central to your application. In such cases, working with one of the commercial vendors may be a good option.
Development build times and resources are fairly high for Yocto project builds. The number of packages that need to be built, including the toolchain, kernel, and all target runtime components, is significant. Development workstations for Yocto developers tend to be large systems. Using a compact notebook is not recommended. This can be mitigated by using cloud-based build servers available from many providers. Additionally, Yocto has a built-in caching mechanism that allows it to reuse previously built components when it determines that the parameters for building a particular package have not changed.
### Recommendation
Using the Yocto project for your next embedded Linux design is a strong choice. Of the options presented here, it is the most broadly applicable regardless of your target use case. The broad industry support, active community, and wide platform support make this a good choice for must designers.
## Buildroot
The [Buildroot](https://buildroot.org/) project is defined as "a simple, efficient, and easy-to-use tool to generate embedded Linux systems through cross-compilation." It shares many of the same objectives as the Yocto project, however it is focused on simplicity and minimalism. In general, Buildroot will disable all optional compile-time settings for all packages (with a few notable exceptions), resulting in the smallest possible system. It will be up to the system designer to enable the settings that are appropriate for a given device.
Buildroot builds all components from source but does not support on-target package management. As such, it is sometimes called a firmware generator since the images are largely fixed at build time. Applications can update the target filesystem, but there is no mechanism to install new packages into a running system.
The Buildroot output consists broadly of three components:
- The root filesystem image and any other auxiliary files needed to deploy Linux to the target platform
- The kernel, boot-loader, and kernel modules appropriate for the target hardware
- The toolchain used to build all the target binaries.
### Advantages
Buildroot's focus on simplicity means that, in general, it is easier to learn than Yocto. The core build system is written in Make and is short enough to allow a developer to understand the entire system while being expandable enough to meet the needs of embedded Linux developers. The Buildroot core generally only handles common use cases, but it is expandable via scripting.
The Buildroot system uses normal Makefiles and the Kconfig language for its configuration. Kconfig was developed by the Linux kernel community and is widely used in open source projects, making it familiar to many developers.
Due to the design goal of disabling all optional build-time settings, Buildroot will generally produce the smallest possible images using the out-of-the-box configuration. The build times and build host resources will likewise be smaller, in general, than those of the Yocto project.
### Disadvantages
The focus on simplicity and minimal enabled build options imply that you may need to do significant customization to configure a Buildroot build for your application. Additionally, all configuration options are stored in a single file, which means if you have multiple hardware platforms, you will need to make each of your customization changes for each platform.
Any change to the system configuration file requires a full rebuild of all packages. This is somewhat mitigated by the minimal image sizes and build times compared with Yocto, but it can result in long builds while you are tweaking your configuration.
Intermediate package state caching is not enabled by default and is not as thorough as the Yocto implementation. This means that, while the first build may be shorter than an equivalent Yocto build, subsequent builds may require rebuilding of many components.
### Recommendation
Using Buildroot for your next embedded Linux design is a good choice for most applications. If your design requires multiple hardware types or other differences, you may want to reconsider due to the complexity of synchronizing multiple configurations, however, for a system consisting of a single setup, Buildroot will likely work well for you.
## OpenWRT/LEDE
The [OpenWRT](https://openwrt.org/) project was started to develop custom firmware for consumer routers. Many of the low-cost routers available at your local retailer are capable of running a Linux system, but maybe not out of the box. The manufacturers of these routers may not provide frequent updates to address new threats, and even if they do, the mechanisms to install updated images are difficult and error-prone. The OpenWRT project produces updated firmware images for many devices that have been abandoned by their manufacturers and gives these devices a new lease on life.
The OpenWRT project's primary deliverables are binary images for a large number of commercial devices. There are network-accessible package repositories that allow device end users to add new software to their systems. The OpenWRT build system is a general-purpose build system, which allows developers to create custom versions to meet their own requirements and add new packages, but its primary focus is target binaries.
### Advantages
If you are looking for replacement firmware for a commercial device, OpenWRT should be on your list of options. It is well-maintained and may protect you from issues that the manufacturer's firmware cannot. You can add extra functionality as well, making your devices more useful.
If your embedded design is networking-focused, OpenWRT is a good choice. Networking applications are the primary use case for OpenWRT, and you will likely find many of those software packages available in it.
### Disadvantages
OpenWRT imposes significant policy decisions on your design (vs. Yocto and Buildroot). If these decisions don't meet your design goals, you may have to do non-trivial modifications.
Allowing package-based updates in a fleet of deployed devices is difficult to manage. This, by definition, results in a different software load than what your QA team tested. Additionally, it is difficult to guarantee atomic installs with most package managers, and an ill-timed power cycle can leave your device in an unpredictable state.
### Recommendation
OpenWRT is a good choice for hobbyist projects or for reusing commercial hardware. It is also a good choice for networking applications. If you need significant customization from the default setup, you may prefer Buildroot or Yocto.
## Desktop distros
A common approach to designing embedded Linux systems is to start with a desktop distribution, such as [Debian](https://www.debian.org/) or [Red Hat](https://www.redhat.com/), and remove unneeded components until the installed image fits into the footprint of your target device. This is the approach taken for the popular [Raspbian](https://www.raspbian.org/) distribution for the [Raspberry Pi](https://www.raspberrypi.org/) platform.
### Advantages
The primary advantage of this approach is familiarity. Often, embedded Linux developers are also desktop Linux users and are well-versed in their distro of choice. Using a similar environment on the target may allow developers to get started more quickly. Depending on the chosen distribution, many additional tools can be installed using standard packaging tools such as apt and yum.
It may be possible to attach a display and keyboard to your target device and do all your development directly there. For developers new to the embedded space, this is likely to be a more familiar environment and removes the need to configure and use a tricky cross-development setup.
The number of packages available for most desktop distributions is generally greater than that available for the embedded-specific builders discussed previously. Due to the larger user base and wider variety of use cases, you may be able to find all the runtime packages you need for your application already built and ready for use.
### Disadvantages
Using the target as your primary development environment is likely to be slow. Running compiler tools is a resource-intensive operation and, depending on how much code you are building, may hinder your performance.
With some exceptions, desktop distributions are not designed to accommodate low-resource systems, and it may be difficult to adequately trim your target images. Similarly, the expected workflow in a desktop environment is not ideal for most embedded designs. Getting a reproducible environment in this fashion is difficult. Manually adding and deleting packages is error-prone. This can be scripted using distribution-specific tools, such as [debootstrap](https://wiki.debian.org/Debootstrap) for Debian-based systems. To further improve [reproducibility](https://wiki.debian.org/Debootstrap), you can use a configuration management tool, such as [CFEngine](https://cfengine.com/) (which, full disclosure, is made by my employer, [Mender.io](http://Mender.io)). However, you are still at the mercy of the distribution provider, who will update packages to meet their needs, not yours.
### Recommendation
Be wary of this approach for a product you plan to take to market. This is a fine model for hobbyist applications; however, for products that need support, this approach is likely going to be trouble. While you may be able to get a faster start, it may cost you time and effort in the long run.
## Other considerations
This discussion has focused on build systems' functionality, but there are usually non-functional requirements that may affect your decision. If you have already selected your system-on-chip (SoC) or board, your choice will likely be dictated by the vendor. If your vendor provides a board support package (BSP) for a given system, using it will normally save quite a bit of time, but please research the BSP's quality to avoid issues later in your development cycle.
If your budget allows, you may want to consider using a commercial vendor for your target OS. There are companies that will provide a validated and supported configuration of many of the options discussed here, and, unless you have expertise in embedded Linux build systems, this is a good choice and will allow you to focus on your core competency.
As an alternative, you may consider commercial training for your development staff. This is likely to be cheaper than a commercial OS provider and will allow you to be more self-sufficient. This is a quick way to get over the learning curve for the basics of the build system you choose.
Finally, you may already have some developers with experience with one or more of the systems. If you have engineers who have a preference, it is certainly worth taking that into consideration as you make your decision.
## Summary
There are many choices available for building embedded Linux systems, each with advantages and disadvantages. It is crucial to prioritize this part of your design, as it is extremely costly to switch systems later in the process. In addition to these options, new systems are being developed all the time. Hopefully, this discussion will provide some context for reviewing new systems (and the ones mentioned here) and help you make a solid decision for your next project.
## 1 Comment |
9,812 | Linux 上的五个开源益智游戏 | https://opensource.com/article/18/6/puzzle-games-linux | 2018-07-06T10:10:48 | [
"游戏"
] | https://linux.cn/article-9812-1.html |
>
> 用这些有趣好玩的游戏来测试你的战略能力。
>
>
>

游戏一直是 Linux 的弱点之一。由于 Steam、GOG 和其他将商业游戏引入多种操作系统的努力,这种情况近年来有所改变,但这些游戏通常不是开源的。当然,这些游戏可以在开源操作系统上玩,但对于纯粹开源主义者来说还不够好。
那么,一个只使用开源软件的人,能否找到那些经过足够打磨的游戏,在不损害其开源理念的前提下,提供一种可靠的游戏体验呢?当然可以。虽然开源游戏历来不太可能与一些借由大量预算开发的 AAA 商业游戏相匹敌,但在多种类型的开源游戏中,有很多都很有趣,可以从大多数主要 Linux 发行版的仓库中安装。即使某个特定的游戏没有被打包成特定的发行版本,通常也很容易从项目的网站上下载该游戏以便安装和游戏。
这篇文章着眼于益智游戏。我已经写过[街机风格游戏](https://opensource.com/article/18/1/arcade-games-linux)和[棋牌游戏](https://opensource.com/article/18/3/card-board-games-linux)。 在之后的文章中,我计划涉足赛车,角色扮演、战略和模拟经营游戏。
### Atomix

[Atomix](https://wiki.gnome.org/action/raw/Apps/Atomix) 是 1990 年在 Amiga、Commodore 64、MS-DOS 和其他平台发布的 [Atomix](https://en.wikipedia.org/w/index.php?title=Atomix_(video_game)) 益智游戏的开源克隆。Atomix 的目标是通过连接原子来构建原子分子。单个原子可以向上、向下、向左或向右移动,并一直朝这个方向移动,直到原子撞上一个障碍物——水平墙或另一个原子。这意味着需要进行规划,以确定在水平上构建分子的位置,以及移动单个部件的顺序。第一关是一个简单的水分子,它由两个氢原子和一个氧原子组成,但后来的关卡是更复杂的分子。
要安装 Atomix,请运行以下命令:
* 在 Fedora: `dnf install atomix`
* 在 Debian/Ubuntu: `apt install atomix`
### Fish Fillets - Next Generation

[Fish Fillets - Next Generation](http://fillets.sourceforge.net/index.php) 是游戏 Fish fillet 的 Linux 移植版本,它于 1998 年在 Windows 发布,源代码在 2004 年以 GPL 许可证发布。游戏中,两条鱼试图将物体移出道路来通过不同的关卡。这两条鱼有不同的属性,所以玩家需要为每个任务挑选合适的鱼。较大的鱼可以移动较重的物体,但它更大,这意味着它不适合较小的空隙。较小的鱼可以适应那些较小的间隙,但它不能移动较重的物体。如果一个物体从上面掉下来,两条鱼都会被压死,所以玩家在移动棋子时要小心。
要安装 Fish fillet——Next Generation,请运行以下命令:
* 在 Fedora:`dnf install fillets-ng`
* 在 Debian/Ubuntu: `apt install fillets-ng`
### Frozen Bubble

[Frozen Bubble](http://www.frozen-bubble.org/home/) 是一款街机风格的益智游戏,从屏幕底部向屏幕顶部的一堆泡泡射击。如果三个相同颜色的气泡连接在一起,它们就会被从屏幕上移除。任何连接在被移除的气泡下面但没有连接其他任何东西的气泡也会被移除。在拼图模式下,关卡的设计是固定的,玩家只需要在泡泡掉到屏幕底部的线以下前将泡泡从游戏区域中移除。该游戏街机模式和多人模式遵循相同的基本规则,但也有不同,这增加了多样性。Frozen Bubble 是一个标志性的开源游戏,所以如果你以前没有玩过它,玩玩看。
要安装 Frozen Bubble,请运行以下命令:
* 在 Fedora: `dnf install frozen-bubble`
* 在 Debian/Ubuntu: `apt install frozen-bubble`
### Hex-a-hop

[Hex-a-hop](http://hexahop.sourceforge.net/index.html) 是一款基于六角形瓦片的益智游戏,玩家需要将所有的绿色瓦片从水平面上移除。瓦片通过移动被移除。由于瓦片在移动后会消失,所以有必要规划出穿过水平面的最佳路径,以便在不被卡住的情况下移除所有的瓦片。但是,如果玩家使用的是次优路径,会有撤销功能。之后的关卡增加了额外的复杂性,包括需要跨越多次的瓦片和使玩家跳过一定数量的六角弹跳瓦片。
要安装 Hex-a-hop,请运行以下命令:
* 在 Fedora: `dnf install hex-a-hop`
* 在 Debian/Ubuntu: `apt install hex-a-hop`
### Pingus

[Pingus](https://pingus.seul.org/index.html) 是 [Lemmings](http://en.wikipedia.org/wiki/Lemmings) 的开源克隆。这不是一个精确的克隆,但游戏非常相似。小动物(Lemmings 里是旅鼠,Pingus 里是企鹅)通过关卡入口进入关卡,开始沿着直线行走。玩家需要使用特殊技能使小动物能够到达关卡的出口而不会被困住或者掉下悬崖。这些技能包括挖掘或建桥。如果有足够数量的小动物进入出口,这个关卡将成功完成,玩家可以进入下一个关卡。Pingus 为标准的 Lemmings 添加了一些额外的特性,包括一个世界地图和一些在原版游戏中没有的技能,但经典 Lemmings 游戏的粉丝们在这个开源版本中仍会感到自在。
要安装 Pingus,请运行以下命令:
* 在 Fedora: `dnf install pingus`
* 在 Debian/Ubuntu: `apt install pingus`
我漏掉你最喜欢的开源益智游戏了吗? 请在下面的评论中分享。
---
via: <https://opensource.com/article/18/6/puzzle-games-linux>
作者:[Joshua Allen Holm](https://opensource.com/users/holmja) 选题:[lujun9972](https://github.com/lujun9972) 译者:[ZenMoore](https://github.com/ZenMoore) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Gaming has traditionally been one of Linux's weak points. That has changed somewhat in recent years thanks to Steam, GOG, and other efforts to bring commercial games to multiple operating systems, but those games are often not open source. Sure, the games can be played on an open source operating system, but that is not good enough for an open source purist.
So, can someone who only uses free and open source software find games that are polished enough to present a solid gaming experience without compromising their open source ideals? Absolutely. While open source games are unlikely ever to rival some of the AAA commercial games developed with massive budgets, there are plenty of open source games, in many genres, that are fun to play and can be installed from the repositories of most major Linux distributions. Even if a particular game is not packaged for a particular distribution, it is usually easy to download the game from the project's website in order to install and play it.
This article looks at puzzle games. I have already written about [arcade-style games](https://opensource.com/article/18/1/arcade-games-linux) and [board and card games](https://opensource.com/article/18/3/card-board-games-linux). In future articles, I plan to cover racing, role-playing, and strategy & simulation games.
## Atomix
[Atomix](https://wiki.gnome.org/action/raw/Apps/Atomix) is an open source clone of the [Atomix](https://en.wikipedia.org/w/index.php?title=Atomix_(video_game)) puzzle game released in 1990 for Amiga, Commodore 64, MS-DOS, and other platforms. The goal of Atomix is to construct atomic molecules by connecting atoms. Individual atoms can be moved up, down, left, or right and will keep moving in that direction until the atom hits an obstacle—either the level's walls or another atom. This means that planning is needed to figure out where in the level to construct the molecule and in what order to move the individual pieces. The first level features a simple water molecule, which is made up of two hydrogen atoms and one oxygen atom, but later levels feature more complex molecules.
To install Atomix, run the following command:
- On Fedora:
`dnf`
`install`
`atomix`
- On Debian/Ubuntu:
`apt install`
## Fish Fillets - Next Generation

[Fish Fillets - Next Generation](http://fillets.sourceforge.net/index.php) is a Linux port of the game Fish Fillets, which was released in 1998 for Windows, and the source code was released under the GPL in 2004. The game involves two fish trying to escape various levels by moving objects out of their way. The two fish have different attributes, so the player needs to pick the right fish for each task. The larger fish can move heavier objects but it is bigger, which means it cannot fit in smaller gaps. The smaller fish can fit in those smaller gaps, but it cannot move the heavier objects. Both fish will be crushed if an object is dropped on them from above, so the player needs to be careful when moving pieces.
To install Fish Fillets, run the following command:
- On Fedora:
`dnf`
`install fillets-ng`
- On Debian/Ubuntu:
`apt install fillets-ng`
## Frozen Bubble
[Frozen Bubble](http://www.frozen-bubble.org/home/) is an arcade-style puzzle game that involves shooting bubbles from the bottom of the screen toward a collection of bubbles at the top of the screen. If three bubbles of the same color connect, they are removed from the screen. Any other bubbles that were connected below the removed bubbles but that were not connected to anything else are also removed. In puzzle mode, the design of the levels is fixed, and the player simply needs to remove the bubbles from the play area before the bubbles drop below a line near the bottom of the screen. The games arcade mode and multiplayer modes follow the same basic rules but provide some differences, which adds to the variety. Frozen Bubble is one of the iconic open source games, so if you have not played it before, check it out.
To install Frozen Bubble, run the following command:
- On Fedora:
`dnf`
`install frozen-bubble`
- On Debian/Ubuntu:
`apt install frozen-bubble`
## Hex-a-hop
[Hex-a-hop](http://hexahop.sourceforge.net/index.html) is a hexagonal tile-based puzzle game in which the player needs to remove all the green tiles from the level. Tiles are removed by moving over them. Since tiles disappear after they are moved over, it is imperative to plan the optimal path through the level to remove all the tiles without getting stuck. However, there is an undo feature if the player uses a sub-optimal path. Later levels add extra complexity by including tiles that need to be crossed over multiple times and bouncing tiles that cause the player to jump over a certain number of hexes.
To install Hex-a-hop, run the following command:
- On Fedora:
`dnf`
`install hex-a-hop`
- On Debian/Ubuntu:
`apt install hex-a-hop`
## Pingus
[Pingus](https://pingus.seul.org/index.html) is an open source clone of [Lemmings](http://en.wikipedia.org/wiki/Lemmings). It is not an exact clone, but the game-play is very similar. Small creatures (lemmings in Lemmings, penguins in Pingus) enter the level through the level's entrance and start walking in a straight line. The player needs to use special abilities to make it so that the creatures can reach the level's exit without getting trapped or falling off a cliff. These abilities include things like digging or building a bridge. If a sufficient number of creatures make it to the exit, the level is successfully solved and the player can advance to the next level. Pingus adds a few extra features to the standard Lemmings features, including a world map and a few abilities not found in the original game, but fans of the classic Lemmings game should feel right at home in this open source variant.
To install Pingus, run the following command:
- On Fedora:
`dnf`
`install`
`pingus`
- On Debian/Ubuntu:
`apt install`
`pingus`
Did I miss one of your favorite open source puzzle games? Share it in the comments below.
## 3 Comments |
9,813 | 使用 LSWC 在 Linux 中自动更改壁纸 | https://itsfoss.com/little-simple-wallpaper-changer/ | 2018-07-07T14:01:56 | [
"墙纸"
] | https://linux.cn/article-9813-1.html |
>
> 简介:这是一个小脚本,可以在 Linux 桌面上定期自动更改壁纸。
>
>
>
顾名思义,LittleSimpleWallpaperChanger (LSWC)是一个小脚本,可以定期地随机更改壁纸。
我知道在“外观”或“更改桌面背景”设置中有一个随机壁纸选项。但那是随机更改预置的壁纸而不是你添加的壁纸。
因此,在本文中,我们将看到如何使用 LittleSimpleWallpaperChanger 设置包含照片的随机桌面壁纸。
### Little Simple Wallpaper Changer (LSWC)
[LittleSimpleWallpaperChanger](https://github.com/LittleSimpleWallpaperChanger/lswc) (LSWC) 是一个非常轻量级的脚本,它在后台运行,从用户指定的文件夹中更改壁纸。壁纸以 1 至 5 分钟的随机间隔变化。该软件设置起来相当简单,设置完后,用户就可以不用再操心了。

#### 安装 LSWC
[点此链接下载 LSWC](https://github.com/LittleSimpleWallpaperChanger/lswc/raw/master/Lswc.zip)。压缩文件的大小约为 15KB。
* 进入下载位置。
* 右键单击下载的 .zip 文件,然后选择“在此处解压”。
* 打开解压后的文件夹,右键单击并选择“在终端中打开”。
* 在终端中复制粘贴命令 `bash ./README_and_install.sh` 并按回车键。
* 然后会弹出一个对话框,要求你选择包含壁纸的文件夹。单击它,然后选择你存放壁纸的文件夹。
* 就是这样。然后重启计算机。

#### 使用 LSWC
安装时,LSWC 会要求你选择包含壁纸的文件夹。因此,我建议你在安装 LSWC 之前创建一个文件夹并将你想要的壁纸全部移动到那。或者你可以使用图片文件夹中的“壁纸”文件夹。**所有壁纸都必须是 .jpg 格式。**
你可以添加更多壁纸或从所选文件夹中删除当前壁纸。要更改壁纸文件夹位置,你可以从以下文件中编辑壁纸的位置。
```
.config/lswc/homepath.conf
```
#### 删除 LSWC
打开终端并运行以下命令以停止 LSWC:
```
pkill lswc
```
在文件管理器中打开家目录,然后按 `Ctrl+H` 显示隐藏文件,接着删除以下文件:
* `.local` 中的 `scripts` 文件夹
* `.config` 中的 `lswc` 文件夹
* `.config/autostart` 中的 `lswc.desktop` 文件
这就完成了。创建自己的桌面背景幻灯片。LSWC 非常轻巧,易于使用。安装它然后忘记它。
LSWC 功能不是很丰富,但这是有意的。它做了它打算做的事情,那就是更换壁纸。如果你想要一个自动下载壁纸的工具试试 [WallpaperDownloader](https://itsfoss.com/wallpaperdownloader-linux/)。
请在下面的评论栏分享你对这个漂亮的小软件的想法。别忘了分享这篇文章。干杯。
---
via: <https://itsfoss.com/little-simple-wallpaper-changer/>
作者:[Aquil Roshan](https://itsfoss.com/author/aquil/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

As the name suggests, LittleSimpleWallpaperChanger is a small script that changes the wallpapers randomly at intervals.
Now I know that there is a random wallpaper option in the ‘Appearance’ or the ‘Change desktop background’ settings. But that randomly changes the pre-installed wallpapers and not the wallpapers that you add.
So in this article, we’ll be seeing how to set up a random desktop wallpaper setup consisting of your photos using LittleSimpleWallpaperChanger.
## Little Simple Wallpaper Changer (LSWC)
[LittleSimpleWallpaperChanger](https://github.com/LittleSimpleWallpaperChanger/lswc) or LSWC is a very lightweight script that runs in the background, changing the wallpapers from the user-specified folder. The wallpapers change at a random interval between 1 and 5 minutes. The software is rather simple to set up, and once set up, the user can just forget about it.
**archive file on Fedora 40, which worked as intended.**
**GNOME 3 or 4**Similarly, if you are switching between dark mode and light-mode frequently, you may need to use the
**file.**
**dark and light theme**### Installing LSWC
Required zip archive files are directly added to the GitHub repo of this project. You can download the file as per your distribution or desktop environment version. The zipped file is around 15 KB in size.
**archive file on Fedora 40, which worked as intended.**
**GNOME 3 or 4**Now, browse to the download location and right-click on the downloaded .zip file and select **Extract**.
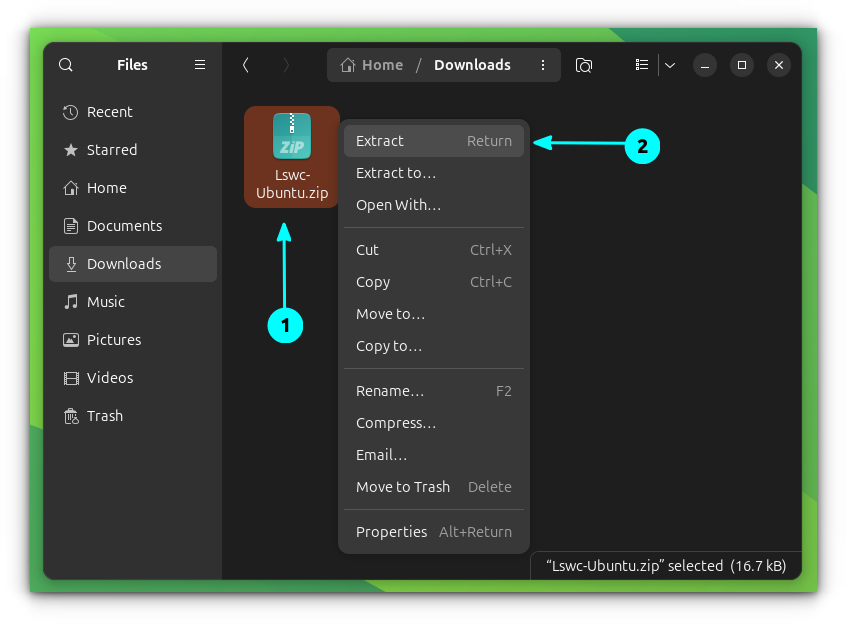
Open the extracted folder, right click and select **Open in terminal**.
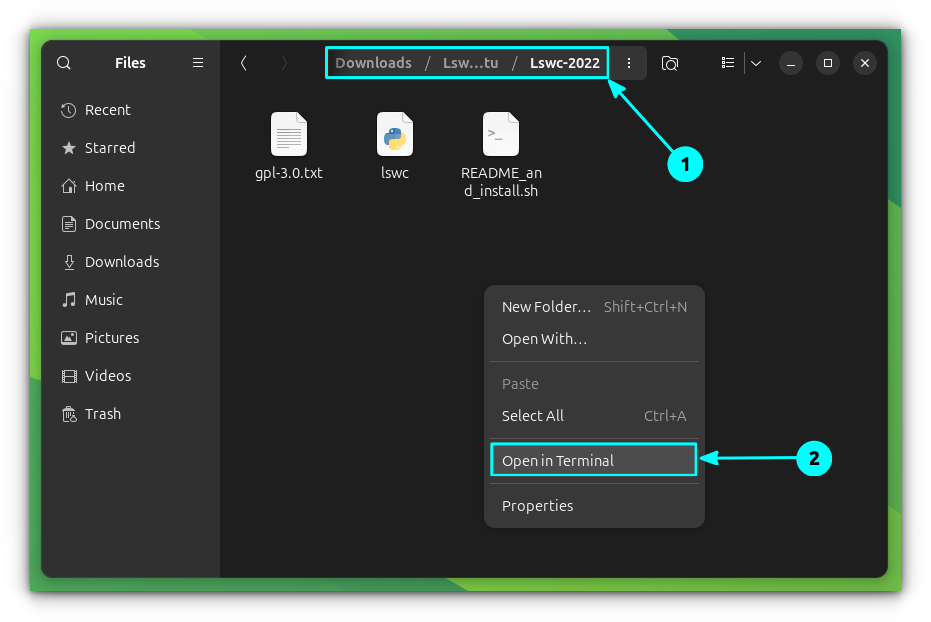
You can now run the `README_and-install.sh`
file. Use the `bash`
command to execute the shell script without giving explicit execution permission to the installation script.
```
bash ./README_and_install.sh
```
**Suggested Read 📖**
[How to Run a Shell Script in Linux [Essentials Explained]Here are all the essential details you should know about executing a shell script in the Linux command line.](https://itsfoss.com/run-shell-script-linux/)

Now a tiny dialogue box will pop up asking you to select the folder containing the wallpapers. Click on the “**Choose Wallpaper Folder**” button and then select the folder that you’ve stored your wallpapers in.
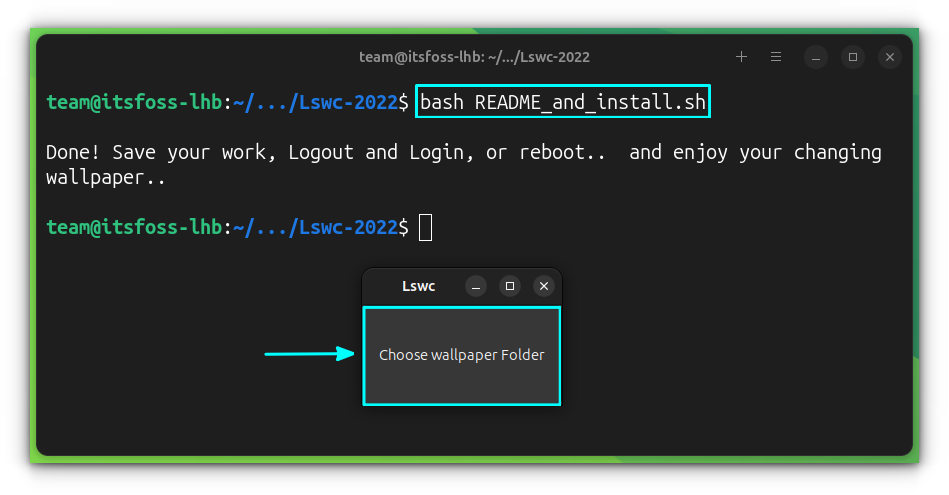
That’s it. Reboot your computer.
### Using LSWC
On installation, LSWC asks you to select the folder containing your wallpapers. So I suggest you create a folder and move all the wallpapers you want to use there before we install LSWC. Or you can just use the ‘Wallpapers’ folder in the Pictures folder.
You can add more wallpapers or delete the current wallpapers from your selected folder. To change the wallpapers folder location, you can edit the location of the wallpapers in the following file.
```
.config/lswc/homepath.conf
```
### To remove LSWC
Open a terminal and [run the pkill command](https://linuxhandbook.com/pkill-command/) to stop LSWC:
```
pkill lswc
```
Then open home in your file manager and press CTRL+H to show hidden files, then delete the following files:
- The
`scripts`
directory from`.local`
directory. - The
`lswc`
directory from`.config`
directory. - The
`lswc.desktop`
file from`.config/autostart`
directory.
You can do this in terminal using the commands:
```
rm -rf ~/.config/lswc ~/.local/scripts
rm .config/autostart/lswc.desktop
```
There you have it. How to create your own desktop background slideshow. LSWC is really lightweight and simple to use. Install it and then forget it.
LSWC is not very feature rich but that intentional. It does what it intends to do and that is to change wallpapers. If you want a tool that automatically downloads wallpapers, try [WallpaperDownloader](https://itsfoss.com/wallpaperdownloader-linux/).
Do share your thoughts on this nifty little software in the comments section below. Don’t forget to share this article. Cheers. |
9,814 | 为什么 Python 开发人员应该使用 Pipenv | https://opensource.com/article/18/2/why-python-devs-should-use-pipenv | 2018-07-07T14:28:28 | [
"Python",
"包依赖"
] | https://linux.cn/article-9814-1.html |
>
> 只用了一年, Pipenv 就变成了管理软件包依赖关系的 Python 官方推荐资源。
>
>
>

Pipenv 是由 Kenneth Reitz 在一年多前创建的“面向开发者而生的 Python 开发工作流”,它已经成为管理软件包依赖关系的 [Python 官方推荐资源](https://packaging.python.org/tutorials/managing-dependencies/#managing-dependencies)。但是对于它解决了什么问题,以及它如何比使用 `pip` 和 `requirements.txt` 文件的标准工作流更有用处,这两点仍然存在困惑。在本月的 Python 专栏中,我们将填补这些空白。
### Python 包安装简史
为了理解 Pipenv 所解决的问题,看一看 Python 包管理如何发展十分有用的。
让我们回到第一个 Python 版本,这时我们有了 Python,但是没有干净的方法来安装软件包。
然后有了 [Easy Install](http://peak.telecommunity.com/DevCenter/EasyInstall),这是一个可以相对容易地安装其他 Python 包的软件包,但它也带来了一个问题:卸载不需要的包并不容易。
[pip](https://packaging.python.org/tutorials/installing-packages/#use-pip-for-installing) 登场,绝大多数 Python 用户都熟悉它。`pip` 可以让我们安装和卸载包。我们可以指定版本,运行 `pip freeze > requirements.txt` 来输出一个已安装包列表到一个文本文件,还可以用相同的文本文件配合 `pip install -r requirements.txt` 来安装一个应用程序需要的所有包。
但是 `pip` 并没有包含将软件包彼此隔离的方法。我们可能会开发使用相同库的不同版本的应用程序,因此我们需要一种方法来实现这一点。随之而来的是[虚拟环境](https://packaging.python.org/tutorials/installing-packages/#creating-virtual-environments),它使我们能够为我们开发的每个应用程序创建一个小型的、隔离的环境。我们已经看到了许多管理虚拟环境的工具:[virtualenv](https://virtualenv.pypa.io/en/stable/)、 [venv](https://docs.python.org/3/library/venv.html)、 [virtualenvwrapper](https://virtualenvwrapper.readthedocs.io/en/latest/)、 [pyenv](https://github.com/pyenv/pyenv)、 [pyenv-virtualenv](https://github.com/pyenv/pyenv-virtualenv)、 [pyenv-virtualenvwrapper](https://github.com/pyenv/pyenv-virtualenvwrapper) 等等。它们都可以很好地使用 `pip` 和 `requirements.txt` 文件。
### 新方法:Pipenv
Pipenv 旨在解决几个问题:
首先,需要 `pip` 库来安装包,外加一个用于创建虚拟环境的库,以及用于管理虚拟环境的库,再有与这些库相关的所有命令。这些都需要管理。Pipenv 附带包管理和虚拟环境支持,因此你可以使用一个工具来安装、卸载、跟踪和记录依赖性,并创建、使用和组织你的虚拟环境。当你使用它启动一个项目时,如果你还没有使用虚拟环境的话,Pipenv 将自动为该项目创建一个虚拟环境。
Pipenv 通过放弃 `requirements.txt` 规范转而将其移动到一个名为 [Pipfile](https://github.com/pypa/pipfile) 的新文档中来完成这种依赖管理。当你使用 Pipenv 安装一个库时,项目的 `Pipfile` 会自动更新安装细节,包括版本信息,还有可能的 Git 仓库位置、文件路径和其他信息。
其次,Pipenv 希望能更容易地管理复杂的相互依赖关系。你的应用程序可能依赖于某个特定版本的库,而那个库可能依赖于另一个特定版本的库,这些依赖关系如海龟般堆叠起来。当你的应用程序使用的两个库有冲突的依赖关系时,你的情况会变得很艰难。Pipenv 希望通过在一个名为 `Pipfile.lock` 的文件中跟踪应用程序相互依赖关系树来减轻这种痛苦。`Pipfile.lock` 还会验证生产中是否使用了正确版本的依赖关系。
另外,当多个开发人员在开发一个项目时,Pipenv 很方便。通过 `pip` 工作流,凯西可能会安装一个库,并花两天时间使用该库实现一个新功能。当凯西提交更改时,他可能会忘记运行 `pip freeze` 来更新 `requirements.txt` 文件。第二天,杰米拉取凯西的改变,测试就突然失败了。这样会花费好一会儿才能意识到问题是在 `requirements.txt` 文件中缺少相关库,而杰米尚未在虚拟环境中安装这些文件。
因为 Pipenv 会在安装时自动记录依赖性,如果杰米和凯西使用了 Pipenv,`Pipfile` 会自动更新并包含在凯西的提交中。这样杰米和凯西就可以节省时间并更快地运送他们的产品。
最后,将 Pipenv 推荐给在你项目上工作的其他人,因为它使用标准化的方式来安装项目依赖项和开发和测试的需求。使用 `pip` 工作流和 `requirements.txt` 文件意味着你可能只有一个 `requirements.txt` 文件,或针对不同环境的多个 `requirements.txt` 文件。例如,你的同事可能不清楚他们是否应该在他们的笔记本电脑上运行项目时是运行 `dev.txt` 还是 `local.txt`。当两个相似的 `requirements.txt` 文件彼此不同步时它也会造成混淆:`local.txt` 是否过时了,还是真的应该与 `dev.txt` 不同?多个 `requirements.txt` 文件需要更多的上下文和文档,以使其他人能够按照预期正确安装依赖关系。这个工作流程有可能会混淆同时并增加你的维护负担。
使用 Pipenv,它会生成 `Pipfile`,通过为你管理对不同环境的依赖关系,可以避免这些问题。该命令将安装主项目依赖项:
```
pipenv install
```
添加 `--dev` 标志将安装开发/测试的 `requirements.txt`:
```
pipenv install --dev
```
使用 Pipenv 还有其他好处:它具有更好的安全特性,以易于理解的格式绘制你的依赖关系,无缝处理 `.env` 文件,并且可以在一个文件中自动处理开发与生产环境的不同依赖关系。你可以在[文档](https://docs.pipenv.org/)中阅读更多内容。
### 使用 Pipenv
使用 Pipenv 的基础知识在官方 Python 包管理教程[管理应用程序依赖关系](https://packaging.python.org/tutorials/managing-dependencies/)部分中详细介绍。要安装 Pipenv,使用 `pip`:
```
pip install pipenv
```
要安装在项目中使用的包,请更改为项目的目录。然后安装一个包(我们将使用 Django 作为例子),运行:
```
pipenv install django
```
你会看到一些输出,表明 Pipenv 正在为你的项目创建一个 `Pipfile`。
如果你还没有使用虚拟环境,你还会看到 Pipenv 的一些输出,说明它正在为你创建一个虚拟环境。
然后,你将看到你在安装包时常看到的输出。
为了生成 `Pipfile.lock` 文件,运行:
```
pipenv lock
```
你也可以使用 Pipenv 运行 Python 脚本。运行名为 `hello.py` 的上层 Python 脚本:
```
pipenv run python hello.py
```
你将在控制台中看到预期结果。
启动一个 shell,运行:
```
pipenv shell
```
如果你想将当前使用 `requirements.txt` 文件的项目转换为使用 Pipenv,请安装 Pipenv 并运行:
```
pipenv install requirements.txt
```
这将创建一个 Pipfile 并安装指定的 `requirements.txt`。考虑一下升级你的项目!
### 了解更多
查看 Pipenv 文档,特别是 [Pipenv 的基本用法](https://docs.pipenv.org/basics/),以帮助你进一步学习。Pipenv 的创建者 Kenneth Reitz 为 Pipenv 在最近的 PyTennessee 发表了一篇演讲:“[Python 依赖管理的未来](https://www.pytennessee.org/schedule/presentation/158/)”。这次演讲没有被记录下来,但他的[幻灯片](https://speakerdeck.com/kennethreitz/the-future-of-python-dependency-management)有助于理解 Pipenv 所做的以及解决的问题。
---
via: <https://opensource.com/article/18/2/why-python-devs-should-use-pipenv>
作者:[Lacey Williams Henschel](https://opensource.com/users/laceynwilliams), [Jeff Triplett](https://opensource.com/users/jefftriplett) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Pipenv, the "Python Development Workflow for Humans" created by Kenneth Reitz a little more than a year ago, has become the [official Python-recommended resource](https://packaging.python.org/tutorials/managing-dependencies/#managing-dependencies) for managing package dependencies. But there is still confusion about what problems it solves and how it's more useful than the standard workflow using `pip`
and a `requirements.txt`
file. In this month's Python column, we'll fill in the gaps.
## A brief history of Python package installation
To understand the problems that Pipenv solves, it's useful to show how Python package management has evolved.
Take yourself back to the first Python iteration. We had Python, but there was no clean way to install packages.
Then came [Easy Install](http://peak.telecommunity.com/DevCenter/EasyInstall), a package that installs other Python packages with relative ease. But it came with a catch: it wasn't easy to uninstall packages that were no longer needed.
Enter [pip](https://packaging.python.org/tutorials/installing-packages/#use-pip-for-installing), which most Python users are familiar with. `pip`
lets us install and uninstall packages. We could specify versions, run `pip freeze > requirements.txt`
to output a list of installed packages to a text file, and use that same text file to install everything an app needed with `pip install -r requirements.txt`
.
But `pip`
didn't include a way to isolate packages from each other. We might work on apps that use different versions of the same libraries, so we needed a way to enable that. Along came [virtual environments](https://packaging.python.org/tutorials/installing-packages/#creating-virtual-environments), which enabled us to create small, isolated environments for each app we worked on. We've seen many tools for managing virtual environments: [virtualenv](https://virtualenv.pypa.io/en/stable/), [venv](https://docs.python.org/3/library/venv.html), [virtualenvwrapper](https://virtualenvwrapper.readthedocs.io/en/latest/), [pyenv](https://github.com/pyenv/pyenv), [pyenv-virtualenv](https://github.com/pyenv/pyenv-virtualenv), [pyenv-virtualenvwrapper](https://github.com/pyenv/pyenv-virtualenvwrapper), and even more. They all play well with `pip`
and `requirements.txt`
files.
## The new kid: Pipenv
Pipenv aims to solve several problems.
First, the problem of needing the `pip`
library for package installation, plus a library for creating a virtual environment, plus a library for managing virtual environments, plus all the commands associated with those libraries. That's a lot to manage. Pipenv ships with package management and virtual environment support, so you can use one tool to install, uninstall, track, and document your dependencies and to create, use, and organize your virtual environments. When you start a project with it, Pipenv will automatically create a virtual environment for that project if you aren't already using one.
Pipenv accomplishes this dependency management by abandoning the `requirements.txt`
norm and trading it for a new document called a [Pipfile](https://github.com/pypa/pipfile). When you install a library with Pipenv, a `Pipfile`
for your project is automatically updated with the details of that installation, including version information and possibly the Git repository location, file path, and other information.
Second, Pipenv wants to make it easier to manage complex interdependencies. Your app might depend on a specific version of a library, and that library might depend on a specific version of another library, and it's just dependencies and turtles all the way down. When two libraries your app uses have conflicting dependencies, your life can become hard. Pipenv wants to ease that pain by keeping track of a tree of your app's interdependencies in a file called `Pipfile.lock`
. `Pipfile.lock`
also verifies that the right versions of dependencies are used in production.
Also, Pipenv is handy when multiple developers are working on a project. With a `pip`
workflow, Casey might install a library and spend two days implementing a new feature using that library. When Casey commits the changes, they might forget to run `pip freeze`
to update the requirements file. The next day, Jamie pulls down Casey's changes, and suddenly tests are failing. It takes time to realize that the problem is libraries missing from the requirements file that Jamie doesn't have installed in the virtual environment.
Because Pipenv auto-documents dependencies as you install them, if Jamie and Casey had been using Pipenv, the `Pipfile`
would have been automatically updated and included in Casey's commit. Jamie and Casey would have saved time and shipped their product faster.
Finally, using Pipenv signals to other people who work on your project that it ships with a standardized way to install project dependencies and development and testing requirements. Using a workflow with `pip`
and requirements files means that you may have one single `requirements.txt`
file, or several requirements files for different environments. It might not be clear to your colleagues whether they should run `dev.txt`
or `local.txt`
when they're running the project on their laptops, for example. It can also create confusion when two similar requirements files get wildly out of sync with each other: Is `local.txt`
out of date, or is it really supposed to be that different from `dev.txt`
? Multiple requirements files require more context and documentation to enable others to install the dependencies properly and as expected. This workflow has the potential to confuse colleagues and increase your maintenance burden.
Using Pipenv, which gives you `Pipfile`
, lets you avoid these problems by managing dependencies for different environments for you. This command will install the main project dependencies:
`pipenv install`
Adding the `--dev`
tag will install the dev/testing requirements:
`pipenv install --dev`
There are other benefits to using Pipenv: It has better security features, graphs your dependencies in an easier-to-understand format, seamlessly handles `.env`
files, and can automatically handle differing dependencies for development versus production environments in one file. You can read more in the [documentation](https://docs.pipenv.org/).
## Pipenv in action
The basics of using Pipenv are detailed in the [Managing Application Dependencies](https://packaging.python.org/tutorials/managing-dependencies/) section of the official Python packaging tutorial. To install Pipenv, use `pip`
:
`pip install pipenv`
To install packages to use in your project, change into the directory for your project. Then to install a package (we'll use Django as an example), run:
`pipenv install django`
You will see some output that indicates that Pipenv is creating a `Pipfile`
for your project.
If you aren't already using a virtual environment, you will also see some output from Pipenv saying it is creating a virtual environment for you.
Then, you will see the output you are used to seeing when you install packages.
To generate a `Pipfile.lock`
file, run:
`pipenv lock`
You can also run Python scripts with Pipenv. To run a top-level Python script called `hello.py`
, run:
`pipenv run python hello.py`
And you will see your expected result in the console.
To start a shell, run:
`pipenv shell`
If you would like to convert a project that currently uses a `requirements.txt`
file to use Pipenv, install Pipenv and run:
`pipenv install requirements.txt`
This will create a Pipfile and install the specified requirements. Consider your project upgraded!
## Learn more
Check out the Pipenv documentation, particularly [Basic Usage of Pipenv](https://docs.pipenv.org/basics/), to take you further. Pipenv creator Kenneth Reitz gave a talk on Pipenv, "[The Future of Python Dependency Management](https://www.pytennessee.org/schedule/presentation/158/)," at a recent PyTennessee event. The talk wasn't recorded, but his [slides](https://speakerdeck.com/kennethreitz/the-future-of-python-dependency-management) are helpful in understanding what Pipenv does and the problems it solves.
## 3 Comments |
9,815 | JavaScript 路由器 | https://nicolasparada.netlify.com/posts/js-router/ | 2018-07-07T14:46:17 | [
"SPA"
] | https://linux.cn/article-9815-1.html | 
构建单页面应用(SPA)有许多的框架/库,但是我希望它们能少一些。我有一个解决方案,我想共享给大家。
```
class Router {
constructor() {
this.routes = []
}
handle(pattern, handler) {
this.routes.push({ pattern, handler })
}
exec(pathname) {
for (const route of this.routes) {
if (typeof route.pattern === 'string') {
if (route.pattern === pathname) {
return route.handler()
}
} else if (route.pattern instanceof RegExp) {
const result = pathname.match(route.pattern)
if (result !== null) {
const params = result.slice(1).map(decodeURIComponent)
return route.handler(...params)
}
}
}
}
}
const router = new Router()
router.handle('/', homePage)
router.handle(/^\/users\/([^\/]+)$/, userPage)
router.handle(/^\//, notFoundPage)
function homePage() {
return 'home page'
}
function userPage(username) {
return `${username}'s page`
}
function notFoundPage() {
return 'not found page'
}
console.log(router.exec('/')) // home page
console.log(router.exec('/users/john')) // john's page
console.log(router.exec('/foo')) // not found page
```
使用它你可以为一个 URL 模式添加处理程序。这个模式可能是一个简单的字符串或一个正则表达式。使用一个字符串将精确匹配它,但是如果使用一个正则表达式将允许你做一些更复杂的事情,比如,从用户页面上看到的 URL 中获取其中的一部分,或者匹配任何没有找到页面的 URL。
我将详细解释这个 `exec` 方法 … 正如我前面说的,URL 模式既有可能是一个字符串,也有可能是一个正则表达式,因此,我首先来检查它是否是一个字符串。如果模式与给定的路径名相同,它返回运行处理程序。如果是一个正则表达式,我们与给定的路径名进行匹配。如果匹配成功,它将获取的参数传递给处理程序,并返回运行这个处理程序。
### 工作示例
那个例子正好记录到了控制台。我们尝试将它整合到一个页面,看看它是什么样的。
```
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Router Demo</title>
<link rel="shortcut icon" href="data:,">
<script src="/main.js" type="module"></script>
</head>
<body>
<header>
<a href="/">Home</a>
<a href="/users/john_doe">Profile</a>
</header>
<main></main>
</body>
</html>
```
这是 `index.html`。对于单页面应用程序来说,你必须在服务器侧做一个特别的工作,因为所有未知的路径都将返回这个 `index.html`。在开发时,我们使用了一个 npm 工具调用了 [serve](https://npm.im/serve)。这个工具去提供静态内容。使用标志 `-s`/`--single`,你可以提供单页面应用程序。
使用 [Node.js](https://nodejs.org/) 和安装的 npm(它与 Node 一起安装),运行:
```
npm i -g serve
serve -s
```
那个 HTML 文件将脚本 `main.js` 加载为一个模块。在我们渲染的相关页面中,它有一个简单的 `<header>` 和一个 `<main>` 元素。
在 `main.js` 文件中:
```
const main = document.querySelector('main')
const result = router.exec(location.pathname)
main.innerHTML = result
```
我们调用传递了当前路径名为参数的 `router.exec()`,然后将 `result` 设置为 `main` 元素的 HTML。
如果你访问 `localhost` 并运行它,你将看到它能够正常工作,但不是预期中的来自一个单页面应用程序。当你点击链接时,单页面应用程序将不会被刷新。
我们将在每个点击的链接的锚点上附加事件监听器,防止出现缺省行为,并做出正确的渲染。因为一个单页面应用程序是一个动态的东西,你预期要创建的锚点链接是动态的,因此要添加事件监听器,我使用的是一个叫 [事件委托](https://developer.mozilla.org/en-US/docs/Learn/JavaScript/Building_blocks/Events#Event_delegation) 的方法。
我给整个文档附加一个点击事件监听器,然后去检查在锚点上(或内部)是否有点击事件。
在 `Router` 类中,我有一个注册回调的方法,在我们每次点击一个链接或者一个 `popstate` 事件发生时,这个方法将被运行。每次你使用浏览器的返回或者前进按钮时,`popstate` 事件将被发送。
为了方便其见,我们给回调传递与 `router.exec(location.pathname)` 相同的参数。
```
class Router {
// ...
install(callback) {
const execCallback = () => {
callback(this.exec(location.pathname))
}
document.addEventListener('click', ev => {
if (ev.defaultPrevented
|| ev.button !== 0
|| ev.ctrlKey
|| ev.shiftKey
|| ev.altKey
|| ev.metaKey) {
return
}
const a = ev.target.closest('a')
if (a === null
|| (a.target !== '' && a.target !== '_self')
|| a.hostname !== location.hostname) {
return
}
ev.preventDefault()
if (a.href !== location.href) {
history.pushState(history.state, document.title, a.href)
execCallback()
}
})
addEventListener('popstate', execCallback)
execCallback()
}
}
```
对于链接的点击事件,除调用了回调之外,我们还使用 `history.pushState()` 去更新 URL。
我们将前面的 `main` 元素中的渲染移动到 `install` 回调中。
```
router.install(result => {
main.innerHTML = result
})
```
#### DOM
你传递给路由器的这些处理程序并不需要返回一个字符串。如果你需要更多的东西,你可以返回实际的 DOM。如:
```
const homeTmpl = document.createElement('template')
homeTmpl.innerHTML = `
<div class="container">
<h1>Home Page</h1>
</div>
`
function homePage() {
const page = homeTmpl.content.cloneNode(true)
// You can do `page.querySelector()` here...
return page
}
```
现在,在 `install` 回调中,你可以去检查 `result` 是一个 `string` 还是一个 `Node`。
```
router.install(result => {
if (typeof result === 'string') {
main.innerHTML = result
} else if (result instanceof Node) {
main.innerHTML = ''
main.appendChild(result)
}
})
```
这些就是基本的功能。我希望将它共享出来,因为我将在下篇文章中使用到这个路由器。
我已经以一个 [npm 包](https://www.npmjs.com/package/@nicolasparada/router) 的形式将它发布了。
---
via: <https://nicolasparada.netlify.com/posts/js-router/>
作者:[Nicolás Parada](https://nicolasparada.netlify.com/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.