
id
int64 2.05k
16.6k
| title
stringlengths 5
75
| fromurl
stringlengths 19
185
| date
timestamp[s] | tags
sequencelengths 0
11
| permalink
stringlengths 20
37
| content
stringlengths 342
82.2k
| fromurl_status
int64 200
526
⌀ | status_msg
stringclasses 339
values | from_content
stringlengths 0
229k
⌀ |
|---|---|---|---|---|---|---|---|---|---|
9,816 | Python 字节码介绍 | https://opensource.com/article/18/4/introduction-python-bytecode | 2018-07-08T07:24:00 | [
"Python",
"字节码"
] | https://linux.cn/article-9816-1.html |
>
> 了解 Python 字节码是什么,Python 如何使用它来执行你的代码,以及知道它是如何帮到你的。
>
>
>

如果你曾经编写过 Python,或者只是使用过 Python,你或许经常会看到 Python 源代码文件——它们的名字以 `.py` 结尾。你可能还看到过其它类型的文件,比如以 `.pyc` 结尾的文件,或许你可能听说过它们就是 Python 的 “<ruby> 字节码 <rt> bytecode </rt></ruby>” 文件。(在 Python 3 上这些可能不容易看到 —— 因为它们与你的 `.py` 文件不在同一个目录下,它们在一个叫 `__pycache__` 的子目录中)或者你也听说过,这是节省时间的一种方法,它可以避免每次运行 Python 时去重新解析源代码。
但是,除了 “噢,原来这就是 Python 字节码” 之外,你还知道这些文件能做什么吗?以及 Python 是如何使用它们的?
如果你不知道,那你走运了!今天我将带你了解 Python 的字节码是什么,Python 如何使用它去运行你的代码,以及知道它是如何帮助你的。
### Python 如何工作
Python 经常被介绍为它是一个解释型语言 —— 其中一个原因是在程序运行时,你的源代码被转换成 CPU 的原生指令 —— 但这样的看法只是部分正确。Python 与大多数解释型语言一样,确实是将源代码编译为一组虚拟机指令,并且 Python 解释器是针对相应的虚拟机实现的。这种中间格式被称为 “字节码”。
因此,这些 `.pyc` 文件是 Python 悄悄留下的,是为了让它们运行的 “更快”,或者是针对你的源代码的 “优化” 版本;它们是你的程序在 Python 虚拟机上运行的字节码指令。
我们来看一个示例。这里是用 Python 写的经典程序 “Hello, World!”:
```
def hello()
print("Hello, World!")
```
下面是转换后的字节码(转换为人类可读的格式):
```
2 0 LOAD_GLOBAL 0 (print)
2 LOAD_CONST 1 ('Hello, World!')
4 CALL_FUNCTION 1
```
如果你输入那个 `hello()` 函数,然后使用 [CPython](https://github.com/python/cpython) 解释器去运行它,那么上述列出的内容就是 Python 所运行的。它看起来可能有点奇怪,因此,我们来深入了解一下它都做了些什么。
### Python 虚拟机内幕
CPython 使用一个基于栈的虚拟机。也就是说,它完全面向栈数据结构的(你可以 “推入” 一个东西到栈 “顶”,或者,从栈 “顶” 上 “弹出” 一个东西来)。
CPython 使用三种类型的栈:
1. <ruby> 调用栈 <rt> call stack </rt></ruby>。这是运行 Python 程序的主要结构。它为每个当前活动的函数调用使用了一个东西 —— “<ruby> 帧 <rt> frame </rt></ruby>”,栈底是程序的入口点。每个函数调用推送一个新的帧到调用栈,每当函数调用返回后,这个帧被销毁。
2. 在每个帧中,有一个<ruby> 计算栈 <rt> evaluation stack </rt></ruby> (也称为<ruby> 数据栈 <rt> data stack </rt></ruby>)。这个栈就是 Python 函数运行的地方,运行的 Python 代码大多数是由推入到这个栈中的东西组成的,操作它们,然后在返回后销毁它们。
3. 在每个帧中,还有一个<ruby> 块栈 <rt> block stack </rt></ruby>。它被 Python 用于去跟踪某些类型的控制结构:循环、`try` / `except` 块、以及 `with` 块,全部推入到块栈中,当你退出这些控制结构时,块栈被销毁。这将帮助 Python 了解任意给定时刻哪个块是活动的,比如,一个 `continue` 或者 `break` 语句可能影响正确的块。
大多数 Python 字节码指令操作的是当前调用栈帧的计算栈,虽然,还有一些指令可以做其它的事情(比如跳转到指定指令,或者操作块栈)。
为了更好地理解,假设我们有一些调用函数的代码,比如这个:`my_function(my_variable, 2)`。Python 将转换为一系列字节码指令:
1. 一个 `LOAD_NAME` 指令去查找函数对象 `my_function`,然后将它推入到计算栈的顶部
2. 另一个 `LOAD_NAME` 指令去查找变量 `my_variable`,然后将它推入到计算栈的顶部
3. 一个 `LOAD_CONST` 指令去推入一个实整数值 `2` 到计算栈的顶部
4. 一个 `CALL_FUNCTION` 指令
这个 `CALL_FUNCTION` 指令将有 2 个参数,它表示那个 Python 需要从栈顶弹出两个位置参数;然后函数将在它上面进行调用,并且它也同时被弹出(对于函数涉及的关键字参数,它使用另一个不同的指令 —— `CALL_FUNCTION_KW`,但使用的操作原则类似,以及第三个指令 —— `CALL_FUNCTION_EX`,它适用于函数调用涉及到参数使用 `*` 或 `**` 操作符的情况)。一旦 Python 拥有了这些之后,它将在调用栈上分配一个新帧,填充到函数调用的本地变量上,然后,运行那个帧内的 `my_function` 字节码。运行完成后,这个帧将被调用栈销毁,而在最初的帧内,`my_function` 的返回值将被推入到计算栈的顶部。
### 访问和理解 Python 字节码
如果你想玩转字节码,那么,Python 标准库中的 `dis` 模块将对你有非常大的帮助;`dis` 模块为 Python 字节码提供了一个 “反汇编”,它可以让你更容易地得到一个人类可读的版本,以及查找各种字节码指令。[`dis` 模块的文档](https://docs.python.org/3/library/dis.html) 可以让你遍历它的内容,并且提供一个字节码指令能够做什么和有什么样的参数的完整清单。
例如,获取上面的 `hello()` 函数的列表,可以在一个 Python 解析器中输入如下内容,然后运行它:
```
import dis
dis.dis(hello)
```
函数 `dis.dis()` 将反汇编一个函数、方法、类、模块、编译过的 Python 代码对象、或者字符串包含的源代码,以及显示出一个人类可读的版本。`dis` 模块中另一个方便的功能是 `distb()`。你可以给它传递一个 Python 追溯对象,或者在发生预期外情况时调用它,然后它将在发生预期外情况时反汇编调用栈上最顶端的函数,并显示它的字节码,以及插入一个指向到引发意外情况的指令的指针。
它也可以用于查看 Python 为每个函数构建的编译后的代码对象,因为运行一个函数将会用到这些代码对象的属性。这里有一个查看 `hello()` 函数的示例:
```
>>> hello.__code__
<code object hello at 0x104e46930, file "<stdin>", line 1>
>>> hello.__code__.co_consts
(None, 'Hello, World!')
>>> hello.__code__.co_varnames
()
>>> hello.__code__.co_names
('print',)
```
代码对象在函数中可以以属性 `__code__` 来访问,并且携带了一些重要的属性:
* `co_consts` 是存在于函数体内的任意实数的元组
* `co_varnames` 是函数体内使用的包含任意本地变量名字的元组
* `co_names` 是在函数体内引用的任意非本地名字的元组
许多字节码指令 —— 尤其是那些推入到栈中的加载值,或者在变量和属性中的存储值 —— 在这些元组中的索引作为它们参数。
因此,现在我们能够理解 `hello()` 函数中所列出的字节码:
1. `LOAD_GLOBAL 0`:告诉 Python 通过 `co_names` (它是 `print` 函数)的索引 0 上的名字去查找它指向的全局对象,然后将它推入到计算栈
2. `LOAD_CONST 1`:带入 `co_consts` 在索引 1 上的字面值,并将它推入(索引 0 上的字面值是 `None`,它表示在 `co_consts` 中,因为 Python 函数调用有一个隐式的返回值 `None`,如果没有显式的返回表达式,就返回这个隐式的值 )。
3. `CALL_FUNCTION 1`:告诉 Python 去调用一个函数;它需要从栈中弹出一个位置参数,然后,新的栈顶将被函数调用。
“原始的” 字节码 —— 是非人类可读格式的字节 —— 也可以在代码对象上作为 `co_code` 属性可用。如果你有兴趣尝试手工反汇编一个函数时,你可以从它们的十进制字节值中,使用列出 `dis.opname` 的方式去查看字节码指令的名字。
### 字节码的用处
现在,你已经了解的足够多了,你可能会想 “OK,我认为它很酷,但是知道这些有什么实际价值呢?”由于对它很好奇,我们去了解它,但是除了好奇之外,Python 字节码在几个方面还是非常有用的。
首先,理解 Python 的运行模型可以帮你更好地理解你的代码。人们都开玩笑说,C 是一种 “可移植汇编器”,你可以很好地猜测出一段 C 代码转换成什么样的机器指令。理解 Python 字节码之后,你在使用 Python 时也具备同样的能力 —— 如果你能预料到你的 Python 源代码将被转换成什么样的字节码,那么你可以知道如何更好地写和优化 Python 源代码。
第二,理解字节码可以帮你更好地回答有关 Python 的问题。比如,我经常看到一些 Python 新手困惑为什么某些结构比其它结构运行的更快(比如,为什么 `{}` 比 `dict()` 快)。知道如何去访问和阅读 Python 字节码将让你很容易回答这样的问题(尝试对比一下: `dis.dis("{}")` 与 `dis.dis("dict()")` 就会明白)。
最后,理解字节码和 Python 如何运行它,为 Python 程序员不经常使用的一种特定的编程方式提供了有用的视角:面向栈的编程。如果你以前从来没有使用过像 FORTH 或 Fator 这样的面向栈的编程语言,它们可能有些古老,但是,如果你不熟悉这种方法,学习有关 Python 字节码的知识,以及理解面向栈的编程模型是如何工作的,将有助你开拓你的编程视野。
### 延伸阅读
如果你想进一步了解有关 Python 字节码、Python 虚拟机、以及它们是如何工作的更多知识,我推荐如下的这些资源:
* [Python 虚拟机内幕](https://leanpub.com/insidethepythonvirtualmachine),它是 Obi Ike-Nwosu 写的一本免费在线电子书,它深入 Python 解析器,解释了 Python 如何工作的细节。
* [一个用 Python 编写的 Python 解析器](http://www.aosabook.org/en/500L/a-python-interpreter-written-in-python.html),它是由 Allison Kaptur 写的一个教程,它是用 Python 构建的 Python 字节码解析器,并且它实现了运行 Python 字节码的全部构件。
* 最后,CPython 解析器是一个开源软件,你可以在 [GitHub](https://github.com/python/cpython) 上阅读它。它在文件 `Python/ceval.c` 中实现了字节码解析器。[这是 Python 3.6.4 发行版中那个文件的链接](https://github.com/python/cpython/blob/d48ecebad5ac78a1783e09b0d32c211d9754edf4/Python/ceval.c);字节码指令是由第 1266 行开始的 `switch` 语句来处理的。
学习更多内容,参与到 James Bennett 的演讲,[有关字节的知识:理解 Python 字节码](https://us.pycon.org/2018/schedule/presentation/127/),将在 [PyCon Cleveland 2018](https://us.pycon.org/2018/) 召开。
---
via: <https://opensource.com/article/18/4/introduction-python-bytecode>
作者:[James Bennett](https://opensource.com/users/ubernostrum) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | If you've ever written, or even just used, Python, you're probably used to seeing Python source code files; they have names ending in `.py`
. And you may also have seen another type of file, with a name ending in `.pyc`
, and you may have heard that they're Python "bytecode" files. (These are a bit harder to see on Python 3—instead of ending up in the same directory as your `.py`
files, they go into a subdirectory called `__pycache__`
.) And maybe you've heard that this is some kind of time-saver that prevents Python from having to re-parse your source code every time it runs.
But beyond "oh, that's Python bytecode," do you really know what's in those files and how Python uses them?
If not, today's your lucky day! I'll take you through what Python bytecode is, how Python uses it to execute your code, and how knowing about it can help you.
## How Python works
Python is often described as an interpreted language—one in which your source code is translated into native CPU instructions as the program runs—but this is only partially correct. Python, like many interpreted languages, actually compiles source code to a set of instructions for a virtual machine, and the Python interpreter is an implementation of that virtual machine. This intermediate format is called "bytecode."
So those `.pyc`
files Python leaves lying around aren't just some "faster" or "optimized" version of your source code; they're the bytecode instructions that will be executed by Python's virtual machine as your program runs.
Let's look at an example. Here's a classic "Hello, World!" written in Python:
```
``````
def hello()
print("Hello, World!")
```
And here's the bytecode it turns into (translated into a human-readable form):
```
``````
2 0 LOAD_GLOBAL 0 (print)
2 LOAD_CONST 1 ('Hello, World!')
4 CALL_FUNCTION 1
```
If you type up that `hello()`
function and use the [CPython](https://github.com/python/cpython) interpreter to run it, the above listing is what Python will execute. It might look a little weird, though, so let's take a deeper look at what's going on.
## Inside the Python virtual machine
CPython uses a stack-based virtual machine. That is, it's oriented entirely around stack data structures (where you can "push" an item onto the "top" of the structure, or "pop" an item off the "top").
CPython uses three types of stacks:
- The
**call stack**. This is the main structure of a running Python program. It has one item—a "frame"—for each currently active function call, with the bottom of the stack being the entry point of the program. Every function call pushes a new frame onto the call stack, and every time a function call returns, its frame is popped off. - In each frame, there's an
**evaluation stack**(also called the**data stack**). This stack is where execution of a Python function occurs, and executing Python code consists mostly of pushing things onto this stack, manipulating them, and popping them back off. - Also in each frame, there's a
**block stack**. This is used by Python to keep track of certain types of control structures: loops,`try`
/`except`
blocks, and`with`
blocks all cause entries to be pushed onto the block stack, and the block stack gets popped whenever you exit one of those structures. This helps Python know which blocks are active at any given moment so that, for example, a`continue`
or`break`
statement can affect the correct block.
Most of Python's bytecode instructions manipulate the evaluation stack of the current call-stack frame, although there are some instructions that do other things (like jump to specific instructions or manipulate the block stack).
To get a feel for this, suppose we have some code that calls a function, like this: `my_function(my_variable, 2)`
. Python will translate this into a sequence of four bytecode instructions:
- A
`LOAD_NAME`
instruction that looks up the function object`my_function`
and pushes it onto the top of the evaluation stack - Another
`LOAD_NAME`
instruction to look up the variable`my_variable`
and push it on top of the evaluation stack - A
`LOAD_CONST`
instruction to push the literal integer value`2`
on top of the evaluation stack - A
`CALL_FUNCTION`
instruction
The `CALL_FUNCTION`
instruction will have an argument of 2, which indicates that Python needs to pop two positional arguments off the top of the stack; then the function to call will be on top, and it can be popped as well (for functions involving keyword arguments, a different instruction—`CALL_FUNCTION_KW`
—is used, but with a similar principle of operation, and a third instruction, `CALL_FUNCTION_EX`
, is used for function calls that involve argument unpacking with the `*`
or `**`
operators). Once Python has all that, it will allocate a new frame on the call stack, populate the local variables for the function call, and execute the bytecode of `my_function`
inside that frame. Once that's done, the frame will be popped off the call stack, and in the original frame the return value of `my_function`
will be pushed on top of the evaluation stack.
## Accessing and understanding Python bytecode
If you want to play around with this, the `dis`
module in the Python standard library is a huge help; the `dis`
module provides a "disassembler" for Python bytecode, making it easy to get a human-readable version and look up the various bytecode instructions. [The documentation for the dis module](https://docs.python.org/3/library/dis.html) goes over its contents and provides a full list of bytecode instructions along with what they do and what arguments they take.
For example, to get the bytecode listing for the `hello()`
function above, I typed it into a Python interpreter, then ran:
```
``````
import dis
dis.dis(hello)
```
The function `dis.dis()`
will disassemble a function, method, class, module, compiled Python code object, or string literal containing source code and print a human-readable version. Another handy function in the `dis`
module is `distb()`
. You can pass it a Python traceback object or call it after an exception has been raised, and it will disassemble the topmost function on the call stack at the time of the exception, print its bytecode, and insert a pointer to the instruction that raised the exception.
It's also useful to look at the compiled code objects Python builds for every function since executing a function makes use of attributes of those code objects. Here's an example looking at the `hello()`
function:
```
``````
>>> hello.__code__
<code object hello at 0x104e46930, file "<stdin>", line 1>
>>> hello.__code__.co_consts
(None, 'Hello, World!')
>>> hello.__code__.co_varnames
()
>>> hello.__code__.co_names
('print',)
```
The code object is accessible as the attribute `__code__`
on the function and carries a few important attributes:
`co_consts`
is a tuple of any literals that occur in the function body`co_varnames`
is a tuple containing the names of any local variables used in the function body`co_names`
is a tuple of any non-local names referenced in the function body
Many bytecode instructions—particularly those that load values to be pushed onto the stack or store values in variables and attributes—use indices in these tuples as their arguments.
So now we can understand the bytecode listing of the `hello()`
function:
`LOAD_GLOBAL 0`
: tells Python to look up the global object referenced by the name at index 0 of`co_names`
(which is the`print`
function) and push it onto the evaluation stack`LOAD_CONST 1`
: takes the literal value at index 1 of`co_consts`
and pushes it (the value at index 0 is the literal`None`
, which is present in`co_consts`
because Python function calls have an implicit return value of`None`
if no explicit`return`
statement is reached)`CALL_FUNCTION 1`
: tells Python to call a function; it will need to pop one positional argument off the stack, then the new top-of-stack will be the function to call.
The "raw" bytecode—as non-human-readable bytes—is also available on the code object as the attribute `co_code`
. You can use the list `dis.opname`
to look up the names of bytecode instructions from their decimal byte values if you'd like to try to manually disassemble a function.
## Putting bytecode to use
Now that you've read this far, you might be thinking "OK, I guess that's cool, but what's the practical value of knowing this?" Setting aside curiosity for curiosity's sake, understanding Python bytecode is useful in a few ways.
First, understanding Python's execution model helps you reason about your code. People like to joke about C being a kind of "portable assembler," where you can make good guesses about what machine instructions a particular chunk of C source code will turn into. Understanding bytecode will give you the same ability with Python—if you can anticipate what bytecode your Python source code turns into, you can make better decisions about how to write and optimize it.
Second, understanding bytecode is a useful way to answer questions about Python. For example, I often see newer Python programmers wondering why certain constructs are faster than others (like why `{}`
is faster than `dict()`
). Knowing how to access and read Python bytecode lets you work out the answers (try it: `dis.dis("{}")`
versus `dis.dis("dict()")`
).
Finally, understanding bytecode and how Python executes it gives a useful perspective on a particular kind of programming that Python programmers don't often engage in: stack-oriented programming. If you've ever used a stack-oriented language like FORTH or Factor, this may be old news, but if you're not familiar with this approach, learning about Python bytecode and understanding how its stack-oriented programming model works is a neat way to broaden your programming knowledge.
## Further reading
If you'd like to learn more about Python bytecode, the Python virtual machine, and how they work, I recommend these resources:
[Inside the Python Virtual Machine](https://leanpub.com/insidethepythonvirtualmachine)by Obi Ike-Nwosu is a free online book that does a deep dive into the Python interpreter, explaining in detail how Python actually works.[A Python Interpreter Written in Python](http://www.aosabook.org/en/500L/a-python-interpreter-written-in-python.html)by Allison Kaptur is a tutorial for building a Python bytecode interpreter in—what else—Python itself, and it implements all the machinery to run Python bytecode.- Finally, the CPython interpreter is open source and you can
[read through it on GitHub](https://github.com/python/cpython). The implementation of the bytecode interpreter is in the file`Python/ceval.c`
.[Here's that file for the Python 3.6.4 release](https://github.com/python/cpython/blob/d48ecebad5ac78a1783e09b0d32c211d9754edf4/Python/ceval.c); the bytecode instructions are handled by the`switch`
statement beginning on line 1266.
To learn more, attend James Bennett's talk, [A Bit about Bytes: Understanding Python Bytecode](https://us.pycon.org/2018/schedule/presentation/127/), at [PyCon Cleveland 2018](https://us.pycon.org/2018/).
## 3 Comments |
9,817 | Sosreport:收集系统日志和诊断信息的工具 | https://www.ostechnix.com/sosreport-a-tool-to-collect-system-logs-and-diagnostic-information/ | 2018-07-08T09:37:25 | [
"Sosreport"
] | https://linux.cn/article-9817-1.html | 
如果你是 RHEL 管理员,你可能肯定听说过 **Sosreport** :一个可扩展、可移植的支持数据收集工具。它是一个从类 Unix 操作系统中收集系统配置详细信息和诊断信息的工具。当用户提出支持服务单时,他/她必须运行此工具并将由 Sosreport 工具生成的结果报告发送给 Red Hat 支持人员。然后,执行人员将根据报告进行初步分析,并尝试找出系统中的问题。不仅在 RHEL 系统上,你可以在任何类 Unix 操作系统上使用它来收集系统日志和其他调试信息。
### 安装 Sosreport
Sosreport 在 Red Hat 官方系统仓库中,因此你可以使用 Yum 或 DNF 包管理器安装它,如下所示。
```
$ sudo yum install sos
```
要么,
```
$ sudo dnf install sos
```
在 Debian、Ubuntu 和 Linux Mint 上运行:
```
$ sudo apt install sosreport
```
### 用法
安装后,运行以下命令以收集系统配置详细信息和其他诊断信息。
```
$ sudo sosreport
```
系统将要求你输入系统的一些详细信息,例如系统名称、案例 ID 等。相应地输入详细信息,然后按回车键生成报告。如果你不想更改任何内容并使用默认值,只需按回车键即可。
我的 CentOS 7 服务器的示例输出:
```
sosreport (version 3.5)
This command will collect diagnostic and configuration information from
this CentOS Linux system and installed applications.
An archive containing the collected information will be generated in
/var/tmp/sos.DiJXi7 and may be provided to a CentOS support
representative.
Any information provided to CentOS will be treated in accordance with
the published support policies at:
https://wiki.centos.org/
The generated archive may contain data considered sensitive and its
content should be reviewed by the originating organization before being
passed to any third party.
No changes will be made to system configuration.
Press ENTER to continue, or CTRL-C to quit.
Please enter your first initial and last name [server.ostechnix.local]:
Please enter the case id that you are generating this report for []:
Setting up archive ...
Setting up plugins ...
Running plugins. Please wait ...
Running 73/73: yum...
Creating compressed archive...
Your sosreport has been generated and saved in:
/var/tmp/sosreport-server.ostechnix.local-20180628171844.tar.xz
The checksum is: 8f08f99a1702184ec13a497eff5ce334
Please send this file to your support representative.
```
如果你不希望系统提示你输入此类详细信息,请如下使用批处理模式。
```
$ sudo sosreport --batch
```
正如你在上面的输出中所看到的,生成了一个归档报告并保存在 `/var/tmp/sos.DiJXi7` 中。在 RHEL 6/CentOS 6 中,报告将在 `/tmp` 中生成。你现在可以将此报告发送给你的支持人员,以便他可以进行初步分析并找出问题所在。
你可能会担心或想知道报告中的内容。如果是这样,你可以通过运行以下命令来查看它:
```
$ sudo tar -tf /var/tmp/sosreport-server.ostechnix.local-20180628171844.tar.xz
```
要么,
```
$ sudo vim /var/tmp/sosreport-server.ostechnix.local-20180628171844.tar.xz
```
请注意,上述命令不会解压存档,而只显示存档中的文件和文件夹列表。如果要查看存档中文件的实际内容,请首先使用以下命令解压存档:
```
$ sudo tar -xf /var/tmp/sosreport-server.ostechnix.local-20180628171844.tar.xz
```
存档的所有内容都将解压当前工作目录中 `ssosreport-server.ostechnix.local-20180628171844/` 目录中。进入目录并使用 `cat` 命令或任何其他文本浏览器查看文件内容:
```
$ cd sosreport-server.ostechnix.local-20180628171844/
$ cat uptime
17:19:02 up 1:03, 2 users, load average: 0.50, 0.17, 0.10
```
有关 Sosreport 的更多详细信息,请参阅手册页。
```
$ man sosreport
```
就是这些了。希望这些有用。还有更多好东西。敬请关注!
干杯!
---
via: <https://www.ostechnix.com/sosreport-a-tool-to-collect-system-logs-and-diagnostic-information/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,818 | 将你的树莓派打造成一个 Tor 中继节点 | https://www.linux.com/blog/intro-to-linux/2018/6/turn-your-raspberry-pi-tor-relay-node | 2018-07-08T09:50:37 | [
"Tor",
"树莓派"
] | https://linux.cn/article-9818-1.html |
>
> 在此教程中学习如何将你的旧树莓派打造成一个完美的 Tor 中继节点。
>
>
>

你是否和我一样,在第一代或者第二代树莓派发布时买了一个,玩了一段时间就把它搁置“吃灰”了。毕竟,除非你是机器人爱好者,否则一般不太可能去长时间使用一个处理器很慢的、并且内存只有 256 MB 的计算机。这并不是说你不能用它去做一件很酷的东西,但是在工作和其它任务之间,我还没有看到用一些旧的物件发挥新作用的机会。
然而,如果你想去好好利用它并且不想花费你太多的时间和资源的话,可以将你的旧树莓派打造成一个完美的 Tor 中继节点。
### Tor 中继节点是什么
在此之前你或许听说过 [Tor 项目](https://www.torproject.org/),如果恰好你没有听说过,我简单给你介绍一下,“Tor” 是 “The Onion Router(洋葱路由器)” 的缩写,它是用来对付在线追踪和其它违反隐私行为的技术。
不论你在互联网上做什么事情,都会在你的 IP 包通过的设备上留下一些数字“脚印”:所有的交换机、路由器、负载均衡,以及目标网络记录的来自你的原始会话的 IP 地址,以及你访问的互联网资源(通常是它的主机名,[即使是在使用 HTTPS 时](https://en.wikipedia.org/wiki/Server_Name_Indication#Security_implications))的 IP 地址。如过你是在家中上互联网,那么你的 IP 地址可以直接映射到你的家庭所在地。如果你使用了 VPN 服务([你应该使用](https://www.linux.com/blog/2017/10/tips-secure-your-network-wake-krack)),那么你的 IP 地址映射到你的 VPN 提供商那里,而 VPN 提供商是可以映射到你的家庭所在地的。无论如何,有可能在某个地方的某个人正在根据你访问的网络和在网站上呆了多长时间来为你建立一个个人的在线资料。然后将这个资料进行出售,并与从其它服务上收集的资料进行聚合,然后利用广告网络进行赚钱。至少,这是乐观主义者对如何利用这些数据的一些看法 —— 我相信你还可以找到更多的更恶意地使用这些数据的例子。
Tor 项目尝试去提供一个解决这种问题的方案,使它们不可能(或者至少是更加困难)追踪到你的终端 IP 地址。Tor 是通过让你的连接在一个由匿名的入口节点、中继节点和出口节点组成的匿名中继链上反复跳转的方式来实现防止追踪的目的:
1. **入口节点** 只知道你的 IP 地址和中继节点的 IP 地址,但是不知道你最终要访问的目标 IP 地址
2. **中继节点** 只知道入口节点和出口节点的 IP 地址,以及既不是源也不是最终目标的 IP 地址
3. **出口节点** 仅知道中继节点和最终目标地址,它是在到达最终目标地址之前解密流量的节点
中继节点在这个交换过程中扮演一个关键的角色,因为它在源请求和目标地址之间创建了一个加密的障碍。甚至在意图偷窥你数据的对手控制了出口节点的情况下,在他们没有完全控制整个 Tor 中继链的情况下仍然无法知道请求源在哪里。
只要存在大量的中继节点,你的隐私被会得到保护 —— 这就是我为什么真诚地建议你,如果你的家庭宽带有空闲的时候去配置和运行一个中继节点。
#### 考虑去做 Tor 中继时要记住的一些事情
一个 Tor 中继节点仅发送和接收加密流量 —— 它从不访问任何其它站点或者在线资源,因此你不用担心有人会利用你的家庭 IP 地址去直接浏览一些令人担心的站点。话虽如此,但是如果你居住在一个提供<ruby> 匿名增强服务 <rt> anonymity-enhancing services </rt></ruby>是违法行为的司法管辖区的话,那么你还是不要运营你的 Tor 中继节点了。你还需要去查看你的互联网服务提供商的服务条款是否允许你去运营一个 Tor 中继。
### 需要哪些东西
* 一个带完整外围附件的树莓派(任何型号/代次都行)
* 一张有 [Raspbian Stretch Lite](https://www.raspberrypi.org/downloads/raspbian/) 的 SD 卡
* 一根以太网线缆
* 一根用于供电的 micro-USB 线缆
* 一个键盘和带 HDMI 接口的显示器(在配置期间使用)
本指南假设你已经配置好了你的家庭网络连接的线缆或者 ADSL 路由器,它用于运行 NAT 转换(它几乎是必需的)。大多数型号的树莓派都有一个可用于为树莓派供电的 USB 端口,如果你只是使用路由器的 WiFi 功能,那么路由器应该有空闲的以太网口。但是在我们将树莓派设置为一个“配置完不管”的 Tor 中继之前,我们还需要一个键盘和显示器。
### 引导脚本
我改编了一个很流行的 Tor 中继节点引导脚本以适配树莓派上使用 —— 你可以在我的 GitHub 仓库 <https://github.com/mricon/tor-relay-bootstrap-rpi> 上找到它。你用它引导树莓派并使用缺省的用户 `pi` 登入之后,做如下的工作:
```
sudo apt-get install -y git
git clone https://github.com/mricon/tor-relay-bootstrap-rpi
cd tor-relay-bootstrap-rpi
sudo ./bootstrap.sh
```
这个脚本将做如下的工作:
1. 安装最新版本的操作系统更新以确保树莓派打了所有的补丁
2. 将系统配置为无人值守自动更新,以确保有可用更新时会自动接收并安装
3. 安装 Tor 软件
4. 告诉你的 NAT 路由器去转发所需要的端口(端口一般是 443 和 8080,因为这两个端口最不可能被互联网提供商过滤掉)上的数据包到你的中继节点
脚本运行完成后,你需要去配置 `torrc` 文件 —— 但是首先,你需要决定打算贡献给 Tor 流量多大带宽。首先,在 Google 中输入 “[Speed Test](https://www.google.com/search?q=speed+test)”,然后点击 “Run Speed Test” 按钮。你可以不用管 “Download speed” 的结果,因为你的 Tor 中继能处理的速度不会超过最大的上行带宽。
所以,将 “Mbps upload” 的数字除以 8,然后再乘以 1024,结果就是每秒多少 KB 的宽带速度。比如,如果你得到的上行带宽是 21.5 Mbps,那么这个数字应该是:
```
21.5 Mbps / 8 * 1024 = 2752 KBytes per second
```
你可以限制你的中继带宽为那个数字的一半,并允许突发带宽为那个数字的四分之三。确定好之后,使用喜欢的文本编辑器打开 `/etc/tor/torrc` 文件,调整好带宽设置。
```
RelayBandwidthRate 1300 KBytes
RelayBandwidthBurst 2400 KBytes
```
当然,如果你想更慷慨,你可以将那几个设置的数字调的更大,但是尽量不要设置为最大的出口带宽 —— 如果设置的太高,它会影响你的日常使用。
你打开那个文件之后,你应该去设置更多的东西。首先是昵称 —— 只是为了你自己保存记录,第二个是联系信息,只需要一个电子邮件地址。由于你的中继是运行在无人值守模式下的,你应该使用一个定期检查的电子邮件地址 —— 如果你的中继节点离线超过 48 个小时,你将收到 “Tor Weather” 服务的告警信息。
```
Nickname myrpirelay
ContactInfo [email protected]
```
保存文件并重引导系统去启动 Tor 中继。
### 测试它确认有 Tor 流量通过
如果你想去确认中继节点的功能,你可以运行 `arm` 工具:
```
sudo -u debian-tor arm
```
它需要一点时间才显示,尤其是在老板子上。它通常会给你显示一个表示入站和出站流量(或者是错误信息,它将有助于你去排错)的柱状图。
一旦你确信它运行正常,就可以将键盘和显示器拔掉了,然后将树莓派放到地下室,它就可以在那里悄悄地呆着并到处转发加密的比特了。恭喜你,你已经帮助去改善隐私和防范在线的恶意跟踪了!
通过来自 Linux 基金会和 edX 的免费课程 ["Linux 入门"](https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux) 来学习更多的 Linux 知识。
---
via: <https://www.linux.com/blog/intro-to-linux/2018/6/turn-your-raspberry-pi-tor-relay-node>
作者:[Konstantin Ryabitsev](https://www.linux.com/users/mricon) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,819 | 迁移到 Linux:使用 sudo | https://www.linux.com/blog/learn/2018/3/migrating-linux-using-sudo | 2018-07-09T18:04:00 | [
"迁移",
"sudo"
] | https://linux.cn/article-9819-1.html |
>
> sudo 机制可以让你轻松以普通用户偶尔执行管理任务。让我们来学习一下。
>
>
>

本文是我们关于迁移到 Linux 的系列文章的第五篇。如果你错过了之前的那些,你可以在这里赶上:
* [第1部分 - 入门介绍](/article-9212-1.html)
* [第2部分 - 磁盘、文件和文件系统](/article-9213-1.html)
* [第3部分 - 图形操作环境](/article-9293-1.html)
* [第4部分 - 命令行](/article-9565-1.html)
你可能一直想了解 Linux。也许它在你的工作场所使用,如果你每天使用它,你的工作效率会更高。或者,也许你想在家里的某些计算机上安装 Linux。无论是什么原因,这一系列文章都是为了让过渡更容易。
与许多其他操作系统一样,Linux 支持多用户。它甚至支持多个用户同时登录。
用户帐户通常会被分配一个可以存储文件的家目录。通常这个家目录位于:
```
/home/<login name>
```
这样,每个用户都有存储自己的文档和其他文件的独立位置。
### 管理任务
在传统的 Linux 安装中,常规用户帐户无权在系统上执行管理任务。典型的安装 Linux 的系统会要求用户以管理员身份登录以执行某些任务,而不是为每个用户分配权限以执行各种任务。
Linux 上的管理员帐户称为 root。
### Sudo 解释
从历史上看,要执行管理任务,必须以 root 身份登录,执行任务,然后登出。这个过程有点乏味,所以很多人以 root 登录并且整天都以管理员身份工作。这种做法可能会导致灾难性的后果,例如,意外删除系统中的所有文件。当然,root 用户可以做任何事情,因此没有任何保护措施可以防止有人意外地执行影响很大的操作。
创建 `sudo` 工具是为了使你更容易以常规用户帐户登录,偶尔以 root 身份执行管理任务,而无需登录、执行任务然后登出。具体来说,`sudo` 允许你以不同的用户身份运行命令。如果你未指定特定用户,则假定你指的是 root 用户。
`sudo` 可以有复杂的设置,允许用户有权限使用 `sudo` 运行某些命令,而其他的不行。通常,安装的桌面系统会使创建的第一个帐户在 `sudo` 中有完全的权限,因此你作为主要用户可以完全管理 Linux 安装。
### 使用 Sudo
某些安装 Linux 的系统设置了 `sudo`,因此你仍需要知道 root 帐户的密码才能执行管理任务。其他人,设置 `sudo` 输入自己的密码。这里有不同的哲学。
当你尝试在图形环境中执行管理任务时,通常会打开一个要求输入密码的对话框。输入你自己的密码(例如,在 Ubuntu 上)或 root 帐户的密码(例如,Red Hat)。
当你尝试在命令行中执行管理任务时,它通常只会给你一个 “permission denied” 错误。然后你在前面用 `sudo` 重新运行命令。例如:
```
systemctl start vsftpd
Failed to start vsftpd.service: Access denied
sudo systemctl start vsftpd
[sudo] password for user1:
```
### 何时使用 Sudo
以 root 身份运行命令(在 `sudo` 或其他情况下)并不总是解决权限错误的最佳解决方案。虽然将以 root 身份运行会消除 “permission denied” 错误,但有时最好寻找根本原因而不是仅仅解决症状。有时文件拥有错误的所有者和权限。
当你在尝试一个需要 root 权限来执行操作的任务或者程序时使用 `sudo`。如果文件恰好由另一个用户(包括 root 用户)拥有,请不要使用 `sudo`。在第二种情况下,最好正确设置文件的权限。
通过 Linux 基金会和 edX 的免费[“Linux 介绍”](https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux)课程了解有关 Linux 的更多信息。
---
via: <https://www.linux.com/blog/learn/2018/3/migrating-linux-using-sudo>
作者:[John Bonesio](https://www.linux.com/users/johnbonesio) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,820 | 五个最热门的开源机器学习 JavaScript 框架 | https://opensource.com/article/18/5/machine-learning-javascript-frameworks | 2018-07-09T18:22:24 | [
"机器学习",
"JavaScript"
] | /article-9820-1.html |
>
> 如果你是一位想要深入机器学习的 JavaScript 程序员或想成为一位使用 JavaScript 的机器学习专家,那么这些开源框架也许会吸引你。
>
>
>

开源工具的涌现使得开发者能够更加轻松地开发应用,这一点使机器学习领域本身获得了极大增长。(例如,AndreyBu,他来自德国,在机器学习领域拥有五年以上的经验,他一直在使用各种各样的开源框架来创造富有魅力的机器学习项目。)
虽然 Python 是绝大多数的机器学习框架所采用的语言,但是 JavaScript 也并没有被抛下。JavaScript 开发者可以在浏览器中使用各种框架来训练和部署机器学习模型。
下面是 JavaScript 中最热门五个机器学习框架
### 1、 TensorFlow.js
[TensorFlow.js](https://js.tensorflow.org/) 是一个开源库,它使你能在浏览器中完整地运行机器学习程序,它是 Deeplearn.js 的继承者,Deeplearn.js 不再更新了。TensorFlow.js 在 Deeplearn.js 功能的基础上进行了改善,使你能够充分利用浏览器,得到更加深入的机器学习经验。
通过这个开源库,你可以在浏览器中使用有各种功能的、直观的 API 来定义、训练和部署模型。除此之外,它自动提供 WebGL 和 Node.js 的支持。
如果您有了一个已经训练过的模型,你想要导入到浏览器中。TensorFlow.js 可以让你做到这一点,你也可以在不离开浏览器的情况下重新训练已有的模型。
### 2、 机器学习工具库
现在有很多在浏览器中提供广泛的机器学习功能的资源型开源工具,这个[机器学习工具库](https://github.com/mljs/ml)就是这些开源工具的集合。这个工具库为好几种机器学习算法提供支持,包括非监督式学习、监督式学习、数据处理、人工神经网络(ANN)、数学和回归。
如果你以前使用 Python,现在想找类似于 Scikit-learn 的,能在浏览器中使用 JavaScript 进行机器学习的工具,这套工具会满足你的要求。
### 3、 Keras.js
[Keras.js](https://transcranial.github.io/keras-js/#/) 是另外一个热门的开源框架,它使你能够在浏览器中运行机器学习模型,它使用 WebGL 来提供 GPU 模式的支持。如果你有使用 Node.js 的模型,你就只能在 GPU 模式下运行它。Keras.js 还为使用任意后端框架的模型训练提供支持,例如 Microsoft Cognitive Toolkit (CNTK) 。
一些 Keras 模型可以部署在客户端浏览器上,包括 Inception v3 (训练在 ImageNet 上),50 层冗余网络(训练在 ImageNet 上),和卷积变化自动编码器(训练在 MNIST 上)。
### 4、 Brain.js
机器学习里的概念非常重要,它可能会使刚开始进入这个领域的人们气馁,这个领域里的学术用语和专业词汇可能会使初学者感到崩溃,而解决以上问题的能力就是 [Brain.js](https://github.com/BrainJS/brain.js) 的优势所在。它是开源的,基于 JavaScript 的框架,简化了定义、训练和运行神经网络的流程。
如果你是一个 JavaScript 开发者,并且在机器学习领域是完全的新手,Brain.js 能减低你学习的难度曲线。它可以和 Node.js 一起使用,或者运行在客户端浏览器里来训练机器学习模型。Brain.js 支持部分类型的神经网络,包括前馈式网络、Ellman 网络,和门循环单元网络。
### 5、 STDLib
[STDLib](https://stdlib.io/) 是一个基于 JavaScript 和 Node.js 应用的开源库,如果您正在寻找一种在浏览器中运行,支持科学和数字化的基于 web 的机器学习应用,STDLib 能满足你的需要。
这个库能提供全面而先进的数学和统计学上的功能,来帮助你构建高性能的机器学习模型。你同样也可以使用它丰富的功能来构建应用程序和其他的库。除此之外,如果你想要一个数据可视化和探索性数据分析的框架 —— STDLib,你,值得拥有。
### 总结
如果你是一个 JavaScript 开发者,并且打算深入研究令人兴奋的机器学习世界,或者说,你是一个机器学习方面的专家,打算开始尝试使用 JavaScript ,那么上述的开源框架会激起您的兴趣。
你有知道其他的,提供在浏览器里运行机器学习功能的开源库吗?请在下面的评论区里告诉我们。
---
via: <https://opensource.com/article/18/5/machine-learning-javascript-frameworks>
作者:[Dr.Michael J.Garbade](https://opensource.com/users/drmjg) 选题:[lujun9972](https://github.com/lujun9972) 译者:[hopefully2333](https://github.com/hopefully2333) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
9,821 | 3 款 Linux 桌面的日记程序 | https://opensource.com/article/18/6/linux-journaling-applications | 2018-07-09T18:36:08 | [
"日记"
] | /article-9821-1.html |
>
> 用轻量、灵活的数字日记工具来记录你的活动。
>
>
>

保持记日记的习惯,即使是不定期地记,也可以带来很多好处。这不仅是治疗和宣泄,而且还可以很好地记录你所在的位置以及你去过的地方。它可以帮助你展示你在生活中的进步,并提醒你自己做对了什么,做错了什么。
无论你记日记的原因是什么,都有多种方法可以做到这一点。你可以使用传统的笔和纸,也可以使用基于 Web 的程序,或者你可以使用[简单的文本文件](https://plaintextproject.online/2017/07/19/journal.html)。
另一种选择是使用专门的日记程序。Linux 桌面有几种非常灵活且非常有用的日记工具。我们来看看其中的三个。
### RedNotebook

在这里描述的三个日记程序中,[RedNotebook](http://rednotebook.sourceforge.net) 是最灵活的。大部分灵活性来自其模板。这些模板可让你记录个人想法或会议记录、计划旅程或记录电话。你还可以编辑现有模板或创建自己的模板。
你可以使用与 Markdown 非常相似的标记语言来记录日记。你还可以在日记中添加标签,以便于查找。只需在程序的左窗格中单击或输入标记,右窗格中将显示相应日记的列表。
最重要的是,你可以将全部、部分或仅一个日记导出为纯文本、HTML、LaTeX 或 PDF。在执行此操作之前,你可以通过单击工具栏上的“预览”按钮了解日志在 PDF 或 HTML 中的显示情况。
总的来说,RedNotebook 是一款易于使用且灵活的程序。它需要习惯,但一旦你这样做,它是一个有用的工具。
### Lifeograph

[Lifeograph](http://lifeograph.sourceforge.net/wiki/Main_Page) 与 RedNotebook 有相似的外观和感觉。它没有那么多功能,但 Lifeograph 也够了。
该程序通过保持简单和整洁性来简化记日记这件事。你有一个很大的区域可以记录,你可以为日记添加一些基本格式。这包括通常的粗体和斜体,以及箭头和高亮显示。你可以在日记中添加标签,以便更好地组织和查找它们。
Lifeograph 有一个我觉得特别有用的功能。首先,你可以创建多个日记 - 例如,工作日记和个人日记。其次是密码保护你的日记的能力。虽然该网站声称 Lifeograph 使用“真正的加密”,但没有关于它的详细信息。尽管如此,设置密码仍然会阻止大多数窥探者。
### Almanah Diary

[Almanah Diary](https://wiki.gnome.org/Apps/Almanah_Diary) 是另一种非常简单的日记工具。但不要因为它缺乏功能就丢掉它。虽简单,但足够。
有多简单?它差不多只是一个包含了日记输入和日历的区域而已。你可以做更多的事情 —— 比如添加一些基本格式(粗体、斜体和下划线)并将文本转换为超链接。Almanah 还允许你加密日记。
虽然有一个可以将纯文本文件导入该程序的功能,但我无法使其正常工作。尽管如此,如果你喜欢一个简单,能够快速记日记的软件,那么 Almanah 日记值得一看。
### 命令行怎么样?
如果你不想用 GUI 则可以不必用。命令行是保存日记的绝佳选择。
我尝试过并且喜欢的是 [jrnl](http://maebert.github.com/jrnl/)。或者你可以使用[此方案](http://tamilinux.wordpress.com/2007/07/27/writing-short-notes-and-diaries-from-the-cli/),它使用命令行别名格式化并将日记保存到文本文件中。
你有喜欢的日记程序吗?请留下评论,随意分享。
---
via: <https://opensource.com/article/18/6/linux-journaling-applications>
作者:[Scott Nesbitt](https://opensource.com/users/scottnesbitt) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
9,823 | 迁移到 Linux:安装软件 | https://www.linux.com/blog/learn/2018/3/migrating-linux-installing-software | 2018-07-10T07:43:00 | [
"安装",
"迁移"
] | https://linux.cn/article-9823-1.html |
>
> 所有的 Linux 打包系统和工具都会让人迷惑,但是这篇面向初学者的教程可以帮助你搞明白。
>
>
>

如你所见,众所瞩目的 Linux 已经用在互联网,以及 Arduino、Beagle 和树莓派主板等设备上,或许你正在考虑是时候尝试一下 Linux 了。本系列将帮助你成功过渡到 Linux。如果你错过了本系列的早期文章,可以在这里找到它们:
* [第1部分 - 入门介绍](/article-9212-1.html)
* [第2部分 - 磁盘、文件和文件系统](/article-9213-1.html)
* [第3部分 - 图形操作环境](/article-9293-1.html)
* [第4部分 - 命令行](/article-9565-1.html)
* [第5部分 - 使用 sudo](/article-9819-1.html)
### 安装软件
要在你的计算机上获得新软件,通常的方法是从供应商处获得软件产品,然后运行一个安装程序。过去,软件产品会出现在像 CD-ROM 或 DVD 一样的物理媒介上,而现在我们经常从互联网上下载软件产品。
使用 Linux,安装软件就像在你的智能手机上安装一样。如同你的手机应用商店一样,在 Linux 上有个提供开源软件工具和程序的<ruby> 中央仓库 <rt> central repository </rt></ruby>,几乎任何你想要的程序都会出现在可用软件包列表中以供你安装。
每个程序并不需要运行单独的安装程序,而是你可以使用 Linux 发行版附带的软件包管理工具。(这里说的 Linux 发行版就是你安装的 Linux,例如 Ubuntu、Fedora、Debian 等)每个发行版在互联网上都有它自己的集中存储库(称为仓库),它们存储了数千个预先构建好的应用程序。
你可能会注意到,在 Linux 上安装软件有几种例外情况。有时候,你仍然需要去供应商那里获取他们的软件,因为该程序不存在于你的发行版的中央仓库中。当软件不是开源和/或自由软件的时候,通常就是这种情况。
另外请记住,如果你想要安装一个不在发行版仓库中的程序时,事情就不是那么简单了,即使你正在安装自由及开源程序。这篇文章没有涉及到这些更复杂的情况,请遵循在线的指引。
有了所有的 Linux 包管理系统和工具,接下来干什么可能仍然令人困惑。本文应该有助于澄清一些事情。
### 包管理
目前在 Linux 发行版中有几个相互竞争的用于管理、安装和删除软件的包管理系统。每个发行版都选择使用了一个<ruby> 包管理工具 <rt> package management tools </rt> <rt> </rt></ruby>。Red Hat、Fedora、CentOS、Scientific Linux、SUSE 等使用 Red Hat 包管理(RPM)。Debian、Ubuntu、Linux Mint 等等都使用 Debian 包管理系统,简称 DPKG。还有一些其它包管理系统,但 RPM 和 DPKG 是最常见的。

*图 1: Package installers*
无论你使用的软件包管理是什么,它们通常都是一组构建于另外一种工具之上的工具(图 1)。最底层是一个命令行工具,它可以让你做任何与安装软件相关的一切工作。你可以列出已安装的程序、删除程序、安装软件包文件等等。
这个底层工具并不总是最方便使用的,所以通常会有一个命令行工具,它可以使用单个命令在发行版的中央仓库中找到软件包,并下载和安装它以及任何依赖项。最后,通常会有一个<ruby> 图形应用程序 <rt> graphical application </rt> <rt> </rt></ruby>,可以让你使用鼠标选择任何想要的内容,然后单击 “install” 按钮即可。

*图 2: PackageKit*
对于基于 Red Hat 的发行版,包括 Fedora、CentOS、Scientific Linux 等,它们的底层工具是 rpm,高级工具叫做 dnf(在旧系统上是 yum)。图形安装程序称为 PackageKit(图 2),它可能在系统管理菜单下显示名字为 “Add/Remove Software(添加/删除软件)”。

*图 3: Ubuntu Software*
对于基于 Debian 的发行版,包括 Debian、Ubuntu、Linux Mint、Elementary OS 等,它们的底层命令行工具是 dpkg,高级工具称为 apt。在 Ubuntu 上管理已安装软件的图形工具是 Ubuntu Software(图 3)。对于 Debian 和 Linux Mint,图形工具称为<ruby> 新立得 <rt> Synaptic </rt></ruby>,它也可以安装在 Ubuntu 上。
你也可以在 Debian 相关发行版上安装一个基于文本的图形化工具 aptitude。它比 <ruby> 新立得 <rt> synaptic </rt></ruby>更强大,并且即使你只能访问命令行也能工作。如果你想通过各种选项进行各种“骚”操作,你可以试试这个,但它使用起来比新立得更复杂。其它发行版也可能有自己独特的工具。
### 命令行工具
在 Linux 上安装软件的在线说明通常描述了在命令行中键入的命令。这些说明通常更容易理解,并且将命令复制粘贴到命令行窗口中,可以在不出错的情况下一步步进行。这与下面的说明相反:“打开这个菜单,选择这个程序,输入这个搜索模式,点击这个标签,选择这个程序,然后点击这个按钮”,这经常让你在各种操作中迷失。
有时你正在使用的 Linux 没有图形环境,因此熟悉从命令行安装软件包是件好事。表 1 和表 2 列出了基于 RPM 和 DPKG 系统的一下常见操作及其相关命令。


请注意 SUSE,它像 RedHat 和 Fedora 一样使用 RPM,却没有 dnf 或 yum。相反,它使用一个名为 zypper 的程序作为高级命令行工具。其他发行版也可能有不同的工具,例如 Arch Linux 上的 pacman 或 Gentoo 上的 emerge。有很多包管理工具,所以你可能需要查找哪个适用于你的发行版。
这些技巧应该能让你更好地了解如何在新的 Linux 中安装程序,以及更好地了解 Linux 中各种软件包管理方式如何相互关联。
通过 Linux 基金会和 edX 的免费 [“Linux 入门”](https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux)课程了解有关 Linux 的更多信息。
---
via: <https://www.linux.com/blog/learn/2018/3/migrating-linux-installing-software>
作者:[JOHN BONESIO](https://www.linux.com/users/johnbonesio) 译者:[MjSeven](https://github.com/MjSeven) 校对:[pityonline](https://github.com/pityonline), [wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,824 | 如何在 Arch Linux 中查找已安装的专有软件包? | https://www.ostechnix.com/find-installed-proprietary-packages-arch-linux/ | 2018-07-10T08:08:13 | [
"专有软件"
] | https://linux.cn/article-9824-1.html | 
你是狂热的自由软件支持者吗?你目前在使用任何基于 Arch 的 Linux 发行版吗?我有一个小小的提示送给你!现在,你可以轻松地在 Arch Linux 及其变体(如 Antergos、Manjaro Linux 等)中找到已安装的专有软件包。你无需在已安装软件包的网站中参考其许可细节,也无需使用任何其它外部工具来查明软件包是自由的还是专有的。(LCTT 译注:其实下面还是借助了一个外部程序)
### 在 Arch Linux 中查找已安装的专有软件包
一位开发人员开发了一个名为 “[Absolutely Proprietary](https://github.com/vmavromatis/absolutely-proprietary)” 的实用程序,它是一种用于基于 Arch 发行版的专有软件包检测器。它将基于 Arch 系统中的所有安装包与 Parabola 的软件包 [blacklist](https://git.parabola.nu/blacklist.git/plain/blacklist.txt) 和 [aur-blacklist](https://git.parabola.nu/blacklist.git/plain/aur-blacklist.txt) 进行比较,然后显示出你的<ruby> 斯托曼自由指数 <rt> Stallman Freedom Index </rt></ruby>(“自由/总计”比分)。此外,你可以将该列表保存到文件中,并与其他系统/用户共享或比较。
在安装之前,确保你安装了 Python 和 Git。
然后,`git clone` 仓库:
```
git clone https://github.com/vmavromatis/absolutely-proprietary.git
```
这条命令将会下载所有内容到你当前工作目录中的 `absolutely-proprietary` 目录。
进入此目录:
```
cd absolutely-proprietary
```
接着,使用以下命令查找已安装的专有软件:
```
python main.py
```
这条命令将会下载 `blacklist.txt`、`aur-blacklist.txt`,并将本地已安装的软件包与远程软件包进行比较并显示其指数。
以下是在我的 Arch Linux 桌面的示例输出:
```
Retrieving local packages (including AUR)...
Downloading https://git.parabola.nu/blacklist.git/plain/blacklist.txt
Downloading https://git.parabola.nu/blacklist.git/plain/aur-blacklist.txt
Comparing local packages to remote...
=============================================
47 ABSOLUTELY PROPRIETARY PACKAGES INSTALLED
=============================================
Your GNU/Linux is infected with 47 proprietary packages out of 1370 total installed.
Your Stallman Freedom Index is 96.57
+------------------------|---------|--------------------|---------------------------------------------------------------------------------------------+
| Name | Status | Libre Alternatives | Description |
+------------------------|---------|--------------------|---------------------------------------------------------------------------------------------+
| chromium-pepper-flash | nonfree | | proprietary Google Chrome EULA, missing sources |
+------------------------|---------|--------------------|---------------------------------------------------------------------------------------------+
| faac | nonfree | | [FIXME:description] is a GPL'ed package, but has non free code that can't be distributed und|
+------------------------|---------|--------------------|---------------------------------------------------------------------------------------------+
| libunrar | nonfree | | part of nonfree unrar, Issue442 |
+------------------------|---------|--------------------|---------------------------------------------------------------------------------------------+
| opera | nonfree | | nonfree, nondistributable, built from binary installers, etc |
+------------------------|---------|--------------------|---------------------------------------------------------------------------------------------+
| shutter | nonfree | | need registered user to download (and access website) the source code and depends perl-net-d|
+------------------------|---------|--------------------|---------------------------------------------------------------------------------------------+
| ttf-ms-fonts | nonfree | | |
+------------------------|---------|--------------------|---------------------------------------------------------------------------------------------+
| ttf-ubuntu-font-family | nonfree | | Ubuntu font license considered non-free by DFSG and Fedora |
+------------------------|---------|--------------------|---------------------------------------------------------------------------------------------+
| unace | nonfree | | license forbids making competing ACE archivers from unace |
+------------------------|---------|--------------------|---------------------------------------------------------------------------------------------+
| unrar | nonfree | unar | |
| | | fsf | |
| | | unrar | |
+------------------------|---------|--------------------|---------------------------------------------------------------------------------------------+
| virtualbox | nonfree | | contains BIOS which needs a nonfree compiler to build from source (OpenWatcom compiler), doe|
+------------------------|---------|--------------------|---------------------------------------------------------------------------------------------+
| wordnet | nonfree | | |
+------------------------|---------|--------------------|---------------------------------------------------------------------------------------------+
Save list to file? (Y/n)
```

如你所见,我的系统中有 47 个专有软件包。就像我说的那样,我们可以将它保存到文件中稍后查看。为此,当提示你将列表保存在文件时,请按 `y`。然后按 `y` 接受默认值,或按 `n` 以你喜欢的格式和位置来保存它。
```
Save list to file? (Y/n) y
Save as markdown table? (Y/n) y
Save it to (/tmp/tmpkuky_082.md): y
The list is saved at /home/sk/absolutely-proprietary/y.md
You can review it from the command line
using the "less -S /home/sk/absolutely-proprietary/y.md"
or, if installed, the "most /home/sk/absolutely-proprietary/y.md" commands
```
你可能已经注意到,我只有 **nonfree** 包。它还会显示另外两种类型的软件包,例如 semifree、 uses-nonfree。
* **nonfree**:这个软件包是公然的非自由软件。
* **semifree**:这个软件包大部分是自由的,但包含一些非自由软件。
* **uses-nonfree**:这个软件包依赖、推荐或不恰当地与其他自由软件或服务集成。
该使用程序的另一个显著特点是它不仅显示了专有软件包,而且还显示这些包的替代品。
希望这有些帮助。我很快就会在这里提供另一份有用的指南。敬请关注!
干杯!
资源:
* [Absolutely Proprietary](https://github.com/vmavromatis/absolutely-proprietary)
---
via: <https://www.ostechnix.com/find-installed-proprietary-packages-arch-linux/>
作者:[SK](https://www.ostechnix.com/author/sk/) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,825 | 如何在 20 分钟内发布一个正式的 ERC20 通证 | http://www.masonforest.com/blockchain/ethereum/2017/11/13/how-to-deploy-an-erc20-token-in-20-minutes.html | 2018-07-10T22:21:00 | [
"以太坊",
"ERC20"
] | https://linux.cn/article-9825-1.html | 
这段时间以来,以太坊通证很流行。这些通证可以用来代表现实世界的各种价值单位:[黄金](https://digix.global/)、 [谎言](https://www.cnbc.com/2017/08/28/burger-king-russia-cryptocurrency-whoppercoin.html)、 [猫咪](https://www.cryptokitties.co/) 甚至是类似 [公司股票](https://www.investopedia.com/terms/i/initial-coin-offering-ico.asp) 一样的东西。迄今为止,人们已经募集了 [20 亿美元的通证](https://www.forbes.com/sites/chancebarnett/2017/09/23/inside-the-meteoric-rise-of-icos/#57ac46d95670)。那些通证是以 [ERC20](https://theethereum.wiki/w/index.php/ERC20_Token_Standard) 为标准的,人们可以轻松地在钱包之间进行交易。在这篇教程中,我准备指导你部署你自己的 ERC20 通证到真实的以太坊网络上去。
事先准备:
* 一个文本编辑器([Atom](https://atom.io/) 不错,不过我喜欢 [Vim](http://www.vim.org/))
* 对命令行和终端(模拟器)有起码的了解。Mac 内置的应用“终端”就很好,不过我喜欢 [iTerm2](https://www.iterm2.com/)
* Chrome 浏览器
* [Node.js 8](https://nodejs.org/)(或更高版本)
* 你的通证的名字。我的准备叫做 HamburgerCoin(汉堡币)
你需要做的第一件事是安装 [MetaMask](https://metamask.io/)。访问 [Metamask 网站](https://metamask.io/) 并点击“Get Chrome Extention”。
Metamask 可以让你通过 Chrome 在以太坊上进行交易。它依靠运行着公开以太坊节点的 [Infura](https://infura.io/) ,所以你不用自己运行以太坊全节点。如果你颇具探索精神,你也可以下载和安装 [Mist](https://github.com/ethereum/mist/releases) 以替代它。运行 Mist 就可以让你运行你自己的以太坊节点。运行自己的节点你就需要将你的计算机与该网络进行同步,这需要不短的时间。从技术上讲这更安全,因为这样你不必信任 Infura 来处理你的交易。Infura 可以忽略你的交易而干预你,但是它并不能偷走你的钱。因为安装 Metamask 比 Mist 更快也更简单,所以我假设你在下面的教程中使用 Metamask。
接着你需要安装 [truffle](http://truffleframework.com/):
```
$ npm install -g truffle
```
现在为你自己的新通证创建一个新目录,cd 到其中并初始化你的 truffle 项目。
```
$ mkdir hamburger-coin
$ cd hamburger-coin
$ truffle init
```
很好,你的 truffle 项目已经设置好了!
现在来创建我们的通证。首先我们需要安装 [OpenZepplin](https://github.com/OpenZeppelin) 框架。OpenZepplin 框架包括了大量预先构建好的合约,包括我们要部署的 ERC20 通证合约。
(只需要按下回车接受默认值即可)
```
$ npm init
package name: (hamburger-coin)
version: (1.0.0)
description:
entry point: (truffle.js)
test command:
git repository:
keywords:
author:
license: (ISC)
About to write to /Users/masonf/src/hamburger-coin/package.json:
{
"name": "hamburger-coin",
"version": "1.0.0",
"description": "",
"main": "truffle.js",
"directories": {
"test": "test"
},
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "",
"license": "ISC"
}
Is this ok? (yes) yes
$ npm install zeppelin-solidity
```
现在我们可以创建我们的通证合约了。创建一个 `contracts/HamburgerCoin.sol` 文件并加入如下内容:
```
pragma solidity ^0.4.18;
import "zeppelin-solidity/contracts/token/StandardToken.sol";
contract HamburgerCoin is StandardToken {
string public name = "HamburgerCoin";
string public symbol = "HBC";
uint public decimals = 2;
uint public INITIAL_SUPPLY = 10000 * (10 ** decimals);
function HamburgerCoin() public {
totalSupply_ = INITIAL_SUPPLY;
balances[msg.sender] = INITIAL_SUPPLY;
}
}
```
(LCTT 译注:上述合约内容中指定了合约的名称、符号和供应量。在 ERC20 当中,通证的供应量其实是整数,上述合约中通证的实际供应量是 10000 \* 100 个,出于显示 2 位小数的需求,你在合约浏览器、钱包软件中看到和操作的 1 个通证,实际上在交易中是以 100 个进行的。)
OpenZepplin 的 `StandardToken` 是一个标准的 ERC20 通证。如果你感兴趣,你可以看看它的 [源代码](https://github.com/OpenZeppelin/zeppelin-solidity/tree/master/contracts/token) 以了解是如何工作的。
实际上并不太复杂。该合约有一个 [地址到余额](https://github.com/OpenZeppelin/zeppelin-solidity/blob/master/contracts/token/BasicToken.sol#L15) 的映射(LCTT 译注:你可以理解为哈希、关联数组),它也有一个 [允许转账](https://github.com/OpenZeppelin/zeppelin-solidity/blob/master/contracts/token/StandardToken.sol#L17) 的列表。你可以看做是支票。你可以写张支票,但是直到它被兑付前,钱并不会被转账。
如果有人要转走一些资金,你可以在合约上调用 [approve](https://github.com/OpenZeppelin/zeppelin-solidity/blob/master/contracts/token/StandardToken.sol#L48) 方法,设置你要发送的通证数量。这就像是写支票一样。
然后调用 [transferFrom](https://github.com/OpenZeppelin/zeppelin-solidity/blob/master/contracts/token/StandardToken.sol#L26) 会实际进行转账。
我们可以从头写这些合约,但是最好采用经过完备的社区测试的合约。从头写一个 ERC20 通证那就是另外一篇文章了。
试着运行 `compile` 来编译我们的合约:
```
$ truffle compile
Compiling ./contracts/HamburgerCoin.sol...
Compiling zeppelin-solidity/contracts/math/SafeMath.sol...
Compiling zeppelin-solidity/contracts/ownership/Ownable.sol...
Compiling zeppelin-solidity/contracts/token/BasicToken.sol...
Compiling zeppelin-solidity/contracts/token/ERC20.sol...
Compiling zeppelin-solidity/contracts/token/ERC20Basic.sol...
Compiling zeppelin-solidity/contracts/token/MintableToken.sol...
Compiling zeppelin-solidity/contracts/token/StandardToken.sol...
Writing artifacts to ./build/contracts Next you'll need to add a migration file which will tell truffle how to deploy your contract.
```
接下来我们需要增加一个 truffle [迁移](http://truffleframework.com/docs/getting_started/migrations)。
创建 `migrations/2_deploy_hamburgercoin.js` 文件并添加如下内容:
```
var HamburgerCoin = artifacts.require("./HamburgerCoin.sol");
module.exports = function(deployer) {
deployer.deploy(HamburgerCoin);
};
```
现在让我们配置 truffle 以能够使用 Infura 公共节点。如果我们要部署到公共节点,那就需要钱包的私钥。我们可以将该私钥包含在我们的源代码当中,但是如果任何人可以访问你的源代码(和版本库),他就能够偷走我们所有的汉堡币!要避免这种情况,我们会使用 [dotenv](https://github.com/motdotla/dotenv) node.js 模块。(LCTT 译注:dotenv 用于存储机密信息的文件 .env 是以 “.” 开头的,默认不会进入版本库,当然,如果有人能查看你全部的项目文件,你的私钥还是会被泄露。)
让我们安装部署到 Infura 所需的所有模块。
```
npm install --save-dev dotenv truffle-wallet-provider ethereumjs-wallet
```
(LCTT 译注:可能安装过程中会有很多警告,大多应该是属于定义了未使用的变量和方法的编译警告,可以忽略。)
现在编辑 `truffle.js` 并(原样)加入如下内容:
```
require('dotenv').config();
const Web3 = require("web3");
const web3 = new Web3();
const WalletProvider = require("truffle-wallet-provider");
const Wallet = require('ethereumjs-wallet');
var mainNetPrivateKey = Buffer.from(process.env["MAINNET_PRIVATE_KEY"], "hex")
var mainNetWallet = Wallet.fromPrivateKey(mainNetPrivateKey);
var mainNetProvider = new WalletProvider(mainNetWallet, "https://mainnet.infura.io/");
var ropstenPrivateKey = Buffer.from(process.env["ROPSTEN_PRIVATE_KEY"], "hex")
var ropstenWallet = Wallet.fromPrivateKey(ropstenPrivateKey);
var ropstenProvider = new WalletProvider(ropstenWallet, "https://ropsten.infura.io/");
module.exports = {
networks: {
development: {
host: "localhost",
port: 8545,
network_id: "*" // Match any network id
},
ropsten: {
provider: ropstenProvider,
// You can get the current gasLimit by running
// truffle deploy --network rinkeby
// truffle(rinkeby)> web3.eth.getBlock("pending", (error, result) =>
// console.log(result.gasLimit))
gas: 4600000,
gasPrice: web3.toWei("20", "gwei"),
network_id: "3",
},
mainnet: {
provider: mainNetProvider,
gas: 4600000,
gasPrice: web3.toWei("20", "gwei"),
network_id: "1",
}
}
};
```
(LCTT 译注:原文采用 `new Buffer` 来获取私钥设置,但 node.js 升级后,废弃了 `new Buffer` 这种用法,运行时会发出警告,所以上面我修改为使用 `Buffer.from` 。)
接下来我们从 Metamask 中得到我们的私钥:
1. 点击你的 Chrome 窗口右上角的狐狸图标。
2. 点击 “Account 1” 右侧的省略号。
3. 点击 “Export Private Key”。
4. 输入你的密码。
5. 点击该文字以复制私钥到剪贴板。
然后打开 `.env`文件,并像下面这样贴入你的私钥(对于 Ropsten 测试网和 Mainnet 主网,你的私钥是一样的):
```
ROPSTEN_PRIVATE_KEY="123YourPrivateKeyHere"
MAINNET_PRIVATE_KEY="123YourPrivateKeyHere"
```
接下来,让我们部署到 Ropsten 以太坊测试网。
以太坊测试网是一个你可以测试合约的地方。此外还有 [Kovan](https://kovan-testnet.github.io/website/) 和 [Rinkeby](https://www.rinkeby.io/) 测试网。我在这个教程中选择 Ropsten 是因为现在很容易得到 Ropsten 的测试 ETH。这些测试网都类似,你可以使用任何一个你喜欢的,但是在此教程当中我假设你在使用 Ropsten。访问 <https://faucet.metamask.io/> 以得到一些测试 ETH。从 faucet 得到一些 ETH 后,你就可以部署了。
```
$ truffle deploy --network ropsten
Compiling ./contracts/HamburgerCoin.sol...
Compiling ./contracts/Migrations.sol...
Compiling zeppelin-solidity/contracts/math/SafeMath.sol...
Compiling zeppelin-solidity/contracts/token/BasicToken.sol...
Compiling zeppelin-solidity/contracts/token/ERC20.sol...
Compiling zeppelin-solidity/contracts/token/ERC20Basic.sol...
Compiling zeppelin-solidity/contracts/token/StandardToken.sol...
Writing artifacts to ./build/contracts
Using network 'ropsten'.
Running migration: 1_initial_migration.js
Deploying Migrations...
... 0xc2bbe6bf5a7c7c7312c43d65de4c18c51c4d620d5bf51481ea530411dcebc499
Migrations: 0xd827b6f93fcb50631edc4cf8e293159f0c056538
Saving successful migration to network...
... 0xe6f92402e6ca0b1d615a310751568219f66b9d78b80a37c6d92ca59af26cf475
Saving artifacts...
Running migration: 2_deploy_contracts.js
Deploying HamburgerCoin...
... 0x02c4d47526772dc524851fc2180b338a6b037500ab298fa2f405f01abdee21c4
HamburgerCoin: 0x973b1a5c753a2d5d3924dfb66028b975e7ccca51
Saving artifacts...
```
在 “Saving aritfacts” 上面的这行即是你的合约的新地址。
复制并黏贴该地址到 [Ropsten Etherscan 搜索框](https://ropsten.etherscan.io/),你就能看到你新部署的合约。
现在你可以在任何 ERC20 兼容的钱包,如 [Mist](https://github.com/ethereum/mist) 、[MyEtherWallet](https://www.myetherwallet.com/)(LCTT 译注:或 ImToken 这样的手机应用)里面使用你的通证了。
为了这篇教程,我构建了一个名为 [Etherface](http://etherface.io/) 的钱包来做演示。
首先你需要添加你的通证到 Etherface:
1. 访问 <http://etherface.io/> 。
2. 确认你在 Metamask 中选择了 “Ropsten” 网络。
3. 点击 “Tokens”。
4. 点击右上角的加号按钮。
5. 输入上面的合约地址。
如果你有朋友想要一些汉堡币,你现在就可以发送给他们了。如果没有,你也可以在你的两个账号间测试转账:
1. 在 Metamask 中点击 “切换账号”按钮(在右上角),并改变你的账号为 “Account 2”。
2. 点击 “Account 2” 右边的省略号,然后选择 “Copy Address to clipboard”。
3. 切换回 “Account 1”,这很重要!否则交易会失败。
4. 在 Etherface 中你的余额下点击 “Send”。
5. 黏贴 “Account 2” 的地址。
6. 输入你要发送的数量。
7. Metamask 会弹出确认窗口,点击 “Submit”。
8. 等大约 15-30 秒。
9. 你的 “Account 1” 的余额应该会减少,“Account 2” 现在会有了一些汉堡币!
最后,让我们来部署到主网(LCTT 译注:这会花费你真实的 ETH,你可以通过查看前面部署到 Ropsten 的合约信息中了解花费了多少 gas,以相应估计实际要花费多少 ETH):
```
$ truffle deploy --network mainnet
```
你可以如前面一样加你的通证到 Etherface ,并发送你新打造的通证给你的朋友们了!
| 301 | Moved Permanently | null |
9,826 | GNU GPL 许可证常见问题解答(六) | https://www.gnu.org/licenses/gpl-faq.html | 2018-07-10T23:53:59 | [
"GPL"
] | https://linux.cn/article-9826-1.html | 
本文由高级咨询师薛亮据自由软件基金会(FSF)的[英文原文](https://www.gnu.org/licenses/gpl-faq.html)翻译而成,这篇常见问题解答澄清了在使用 GNU 许可证中遇到许多问题,对于企业和软件开发者在实际应用许可证和解决许可证问题时具有很强的实践指导意义。
1. [关于 GNU 项目、自由软件基金会(FSF)及其许可证的基本问题](/article-9062-1.html)
2. [对于 GNU 许可证的一般了解](/article-8834-1.html)
3. [在您的程序中使用 GNU 许可证](/article-8761-1.html)
4. [依据GNU许可证分发程序](/article-9222-1.html)
5. [在编写其他程序时采用依据 GNU 许可证发布的程序](/article-9448-1.html)
6. 将作品与依据 GNU 许可证发布的代码相结合
7. 关于违反 GNU 许可证的问题
### 6 将作品与依据 GNU 许可证发布的代码相结合
#### 6.1 GPL v3 是否与 GPL v2 兼容?
不兼容。许多要求已经从 GPL v2 变为 GPL v3,这意味 GPL v2 中的精确要求并不体现在 GPL v3 中,反之亦然。例如,GPL v3 的终止条件比 GPL v2 的终止条件更为宽泛,因此与 GPL v2 的终止条件不同。
由于这些差异,两个许可证不兼容:如果您试图将依据 GPL v2 发布的代码与依据 GPL v3 发布的代码组合,则将违反 GPL v2 的第 6 部分。
但是,如果代码依据 GPL “v2 或更高版本”发布,则与 GPL v3 兼容,因为 GPL v3 是其允许的选项之一。
#### 6.2 GPL v2 是否有提供安装信息的要求?
GPL v3 明确要求再分发中包含完整的必要的“安装信息”。GPL v2 不使用该术语,但它需要再分发中包含用于控制可编译和安装可执行文件的脚本以及完整和相应的源代码。这涵盖了 GPL v3 中称为“安装信息”的部分内容,但不包括所有内容。因此,GPL v3 对安装信息的要求较强。
#### 6.3 各种 GNU 许可证之间如何相互兼容?
各种 GNU 许可证彼此之间具有广泛的兼容性。下面是唯一的一种您不能将遵循两种 GNU 许可证的代码结合起来的情况:将遵循旧版本许可证的代码与遵循该许可证新版本的代码进行结合。
以下是 GNU 许可证的各种结合的详细兼容性矩阵,以便为特定情况提供易于使用的参考。它假设有人依据其中一个许可证编写了一些软件,而您希望以某种方式将该软件的代码结合到您要发布的项目(您自己的原始作品或其他人的软件的修改版本)中。在表顶部的列中找到项目的许可证,并在左侧的一行中找到其他代码的许可证。它们交叉的单元格会告诉您这种结合是否被允许。
当我们说“复制代码”时,我们的意思就是:您正在从一个源代码中获取一段代码(无论是否修改),并将其插入到自己的程序中,从而基于第一部分代码形成一个作品。当您编译或运行代码时,“使用库”意味着您不直接复制任何源代码,而是通过链接、导入或其他典型机制将源代码绑定在一起。
矩阵中每个标明 GPL v3 的地方,其关于兼容性的声明也同样适用于 AGPL v3。
**兼容性矩阵**
| | |
| --- | --- |
| | 我希望依据以下许可证许可我的代码 |
| 仅 GPL v2 | GPL v2 或更高版本 | GPL v3 或更高版本 | 仅 LGPL v2.1 | LGPL v2.1 或更高版本 | LGPL v3 或更高版本 |
| 我希望复制遵循右侧许可证的代码: | 仅 GPL v2 | 可以 | 可以<sup> 【2】</sup> | 不可以 | 可以,结合作品只能遵循GPL v2<sup> 【7】</sup> | 可以,结合作品只能遵循GPL v2<sup> 【7】【2】</sup> | 不可以 |
| GPL v2 或更高版本 | 可以<sup> 【1】</sup> | 可以 | 可以 | 可以,结合作品需遵循GPL v2或更高版本<sup> 【7】</sup> | 可以,结合作品需遵循GPL v2或更高版本<sup> 【7】</sup> | 可以,结合作品需遵循GPL v3<sup> 【8】</sup> |
| GPL v3 | 不可以 | 可以,结合作品需遵循GPL v3<sup> 【3】</sup> | 可以 | 可以,结合作品需遵循GPL v3<sup> 【7】</sup> | 可以,结合作品需遵循GPL v3<sup> 【7】</sup> | 可以,结合作品需遵循GPL v3<sup> 【8】</sup> |
| 仅 LGPL v2.1 | 可以,需依据GPL v2传递复制后代码<sup> 【7】</sup> | 可以,需依据GPL v2或更高版本传递复制后代码<sup> 【7】</sup> | 可以,需依据GPL v3传递复制后代码<sup> 【7】</sup> | 可以 | 可以<sup> 【6】</sup> | 可以,需依据GPL v3传递复制后代码<sup> 【7】【8】</sup> |
| LGPL v2.1 或更高版本 | 可以,需依据GPL v2传递复制后代码<sup> 【7】【1】</sup> | 可以,需依据GPL v2或更高版本传递复制后代码<sup> 【7】</sup> | 可以,需依据GPL v3传递复制后代码<sup> 【7】</sup> | 可以<sup> 【5】</sup> | 可以 | 可以 |
| LGPL v3 | 不可以 | 可以,结合作品需遵循GPL v3<sup> 【8】【3】</sup> | 可以,结合作品需遵循GPL v3<sup> 【8】</sup> | 可以,结合作品需遵循GPL v3<sup> 【7】【8】</sup> | 可以,结合作品需遵循LGPL v3<sup> 【4】</sup> | 可以 |
| 我希望使用遵循右侧许可证的库: | 仅 GPL v2 | 可以 | 可以<sup> 【2】</sup> | 不可以 | 可以,结合作品只能遵循GPL v2<sup> 【7】</sup> | 可以,结合作品只能遵循GPL v2<sup> 【7】【2】</sup> | 不可以 |
| GPL v2 或更高版本 | 可以<sup> 【1】</sup> | 可以 | 可以 | 可以,结合作品需遵循GPL v2或更高版本<sup> 【7】</sup> | 可以,结合作品需遵循GPL v2或更高版本<sup> 【7】</sup> | 可以,结合作品需遵循GPL v3<sup> 【8】</sup> |
| GPL v3 | 不可以 | 可以,结合作品需遵循GPL v3<sup> 【3】</sup> | 可以 | 可以,结合作品需遵循GPL v3<sup> 【7】</sup> | 可以,结合作品需遵循GPL v3<sup> 【7】</sup> | 可以,结合作品需遵循GPL v3<sup> 【8】</sup> |
| 仅LGPL v2.1 | 可以 | 可以 | 可以 | 可以 | 可以 | 可以 |
| LGPL v2.1 或更高版本 | 可以 | 可以 | 可以 | 可以 | 可以 | 可以 |
| LGPL v3 | 不可以 | 可以,结合作品需遵循GPL v3<sup> 【9】</sup> | 可以 | 可以 | 可以 | 可以 |
**角注:**
1. 在这种情况下,当结合代码时,您必须遵守 GPL v2 的条款。您不能适用更高版本的条款。
2. 在这种情况下,您可以依据 GPL v2 或更高版本发布您的项目(您的原始作品和/或您收到并修改的作品),请注意,您使用的其他代码仍然只能遵循 GPL v2。只要您的项目依赖于该代码,您将无法将项目的许可证升级到 GPL v3 或更高版本,整个作品(您的项目和其他代码的任意结合)只能依据 GPL v2 的条款传递。
3. 如果您有能力依据 GPL v2 或任何更高版本发布项目,您可以选择依据 GPL v3 或更高版本发布该项目,一旦您执行此操作,您就可以结合依据 GPL v3 发布的代码。
4. 如果您有能力依据 LGPL v2.1 或任何更高版本发布项目,您可以选择依据 LGPL v3 或更高版本发布该项目,一旦您这样做,您就可以结合依据 LGPL v3 发布的代码。
5. 在这种情况下结合代码时,您必须遵守 LGPL v2.1 的条款。您不能适用更高版本 LGPL 中的条款。
6. 如果这样做,只要项目包含仅依据 LGPL v2.1 发布的代码,您将无法将项目的许可证升级到 LGPL v3 或更高版本。
7. LGPL v2.1 允许您将遵循自 GPL v2 之后任何版本 GPL 的代码进行重新许可。如果在这种情况下可以将遵循 LGPL 的代码切换为使用适当版本的 GPL(如表所示),则可以进行此种结合。
8. LGPL v3 是 GPL v3 加上在这种情况下可以忽略的额外权限。
9. 由于 GPL v2 不允许与 LGPL v3 结合,因此在这种情况下,您必须依据 GPL v3 的条款传递项目,因为它允许此种结合。
#### 6.4 <ruby> “聚合” <rp> ( </rp> <rt> aggregate </rt> <rp> ) </rp></ruby>与其他类型的“修改版本”有什么区别?(同 2.25)
“聚合”由多个单独的程序组成,分布在同一个 CD-ROM 或其他媒介中。GPL 允许您创建和分发聚合,即使其他软件的许可证不是自由许可证或与 GPL 不兼容。唯一的条件是,发布“聚合”所使用的许可证不能禁止用户去行使“聚合”中每个程序对应的许可证所赋予用户的权利。
两个单独的程序还是一个程序有两个部分,区分的界限在哪里?这是一个法律问题,最终由法官决定。我们认为,适当的判断标准取决于通信机制(exec、管道、rpc、共享地址空间内的函数调用等)和通信的语义(哪些信息被互换)。
如果模块们被包含在相同的可执行文件中,则它们肯定是被组合在一个程序中。如果模块们被设计为在共享地址空间中链接在一起运行,那么几乎肯定意味着它们组合成为一个程序。
相比之下,管道、套接字和命令行参数是通常在两个独立程序之间使用的通信机制。所以当它们用于通信时,模块们通常是单独的程序。但是,如果通信的语义足够亲密,交换复杂的内部数据结构,那么也可以视为这两个部分合并成了一个更大的程序。
#### 6.5 我在使用 GPL 程序的源代码时是否具有<ruby> “合理使用” <rp> ( </rp> <rt> fair use </rt> <rp> ) </rp></ruby>权限?(同 4.17)
是的,您有。“合理使用”是在没有任何特别许可的情况下允许的使用。由于您不需要开发人员的许可来进行这种使用,无论开发人员在许可证或其他地方对此怎么说,您都可以执行此操作,无论该许可证是 GNU GPL 还是其他自由软件许可证。
但是,请注意,没有全世界范围普适的合理使用原则;什么样的用途被认为“合理”因国而异。
#### 6.6 美国政府可否对遵循 GPL 的程序进行改进并发布?(同 3.14)
可以。如果这些改进是由美国政府雇员在雇佣期间编写的,那么这些改进属于公有领域。不过,GNU GPL 仍然涵盖了整体的改进版本。在这种情况下没有问题。
如果美国政府使用承包商来完成这项工作,那么改进本身可以被 GPL 覆盖。
#### 6.7 GPL 对于与其所覆盖的作品进行静态或动态链接的模块有不同的要求吗?
没有。将 GPL 覆盖的作品静态或动态地链接到其他模块是基于 GPL 覆盖的作品构建结合作品。因此,GNU GPL 的条款和条件将覆盖整个结合作品。另请参阅:6.24 如果我在 GPL 软件中使用了与 GPL 不兼容的库,会出现什么法律问题?
#### 6.8 LGPL 对于与其所覆盖的作品进行静态或动态链接的模块有不同的要求吗?
为了遵守 LGPL(任何现有版本:v2、v2.1 或 v3):
(1)如果您静态链接到 LGPL 库,您还必须以对象(不一定是源代码)格式提供应用程序,以便用户有机会修改库并重新链接应用程序。
(2)如果您动态链接*已经存在于用户计算机上*的 LGPL 库,则不需要传递库的源代码。另一方面,如果您自己将可执行的 LGPL 库与您的应用程序一起传递,无论是静态还是动态链接,还必须以 LGPL 所提供的方式之一来传递库的源代码。
#### 6.9 如果库依据 GPL(而不是 LGPL)发布,这是否意味着使用它的任何软件必须遵循 GPL 或与 GPL 兼容的许可证?
是的,因为程序实际上与库进行了链接。因此,GPL 的条款适用于整个结合作品。与库链接的软件模块可能遵循与GPL兼容的不同许可证,但整体作品必须遵循 GPL。另见:“2.23 许可证与 GPL 兼容是什么意思?”
#### 6.10 您有一个遵循 GPL 的程序,我想将它与我的代码进行链接,来构建一个专有程序。那么事实上,我链接到您的程序意味着我必须让我的程序遵循 GPL 许可证?
不完全是。这意味着您必须依据与 GPL 兼容的许可证(更准确地说,与您链接的结合作品中所有其他代码所适用的一个或多个 GPL 版本相兼容)发布您的程序。然后,结合作品本身就可以遵循这些 GPL 版本。
#### 6.11 如果是这样的话,有没有机会依据 LGPL 获得您的程序许可?
您可以这么要求,但绝大多数的作者都会坚定不移地说不。GPL 的想法是,如果要将我们的代码包含在程序中,您的程序也必须是自由软件。GPL 的意图是给您施加压力,让您以能够使其成为我们社区一部分的方式来发布您的程序。
您始终拥有不使用我们代码的合法选择。
#### 6.12 我们构建专有软件的项目不能使用遵循 GPL 的某个 GNU 程序。您会为我们提供例外吗? 这将意味着该程序拥有更多用户。
对不起,我们没有这样的例外。这样做是不对的。
最大化用户数量不是我们的目标。相反,我们正在努力为尽可能多的用户提供至关重要的自由。一般来说,专有软件项目是阻碍而不是实现软件自由的原因。
我们偶尔提供许可证例外来协助一个依据 GPL 以外的许可证生产自由软件的项目。不过,我们必须看到一个很好的理由,即这个项目为什么会推动自由软件的发展。
我们有时也会改变软件包的分发条款,这显然是为自由软件事业服务的正确方法;但是我们对此非常谨慎,所以您必须向我们展示非常有说服力的理由。
#### 6.13 如果一个编程语言解释器是依据 GPL 发布的,这是否意味着由它解释的程序必须遵循与 GPL 兼容的许可证?
当解释器只是解释一种语言时,答案是否定的。被解释程序对于解释器来说只是数据;根据版权法,像GPL这样的自由软件许可证不能限制您使用解释器的数据。您可以使用任何数据(被解释程序),以任何您喜欢的方式运行它,并且没有任何要求规定您必须将数据授权给任何人。
然而,当解释器被扩展以向<ruby> 其他程序 <rp> ( </rp> <rt> facilities </rt> <rp> ) </rp></ruby>(通常但不一定是库)提供<ruby> “绑定” <rp> ( </rp> <rt> bindings </rt> <rp> ) </rp></ruby>时,被解释程序通过这些绑定有效地与其使用的程序相关联。因此,如果这些程序是依据 GPL 发布的,则使用它们的被解释程序必须以与 GPL 兼容的方式发布。JNI(Java Native Interface)是这种绑定机制的一个例子;以这种方式访问的库与调用它们的 Java 程序动态链接。这些库也与解释器联系在一起。如果解释器与这些库静态链接,或者如果它被设计为[与这些特定库动态链接](https://www.gnu.org/licenses/gpl-faq.html#GPLPluginsInNF),那么也需要以与 GPL 兼容的方式发布。
另一个类似且非常常见的情况是为库提供解释器,它们能够自我解释。例如,Perl 带有许多 Perl 模块,Java 实现带有许多 Java 类。这些库和调用它们的程序总是动态链接在一起。
结果是,如果您选择在程序中使用遵循 GPL 的 Perl 模块或 Java 类,则必须以与 GPL 兼容的方式发布该程序,无论结合后的 Perl 或 Java 程序所依之运行的 Perl 或 Java 解释器中使用什么样的许可证。
#### 6.14 如果编程语言解释器遵循与 GPL 不兼容的许可证,我可以在其上运行遵循 GPL 的程序吗?
当解释器解释一种语言时,答案是肯定的。被解释程序对于解释器来说只是数据;GPL 不会限制您处理程序时所使用的工具。
然而,当解释器被扩展以向<ruby> 其他程序 <rp> ( </rp> <rt> facilities </rt> <rp> ) </rp></ruby>(通常但不一定是库)提供“绑定”时,被解释程序通过这些绑定有效地与其使用的程序相关联。JNI(Java Native Interface)是此种程序的一个例子;以这种方式访问的库与调用它们的 Java 程序动态链接。
因此,如果这些程序是依据与 GPL 不兼容的许可证发布的,则情况就像以任何其他方式跟与 GPL 不兼容的库链接。这意味着:
1. 如果您正在编写代码并将其依据 GPL 发布,您可以声明一个<ruby> 明确例外 <rp> ( </rp> <rt> explicit exception </rt> <rp> ) </rp></ruby>,允许将其链接到与 GPL 不兼容的程序。
2. 如果您依据 GPL 编写并发布程序,并且专门设计了与这些程序配合使用的功能,人们可以将其作为<ruby> 隐性例外 <rp> ( </rp> <rt> implicit exception </rt> <rp> ) </rp></ruby>,允许它们与这些程序进行链接。但是,如果这只是你的打算的话,最好明确地这么说。
您不能把别人遵循 GPL 的代码用于这种方式,或者添加这样的例外。只有该代码的版权所有者才能添加例外。
#### 6.15 如果我将一个模块添加到遵循 GPL 的程序中,我必须使用 GPL 作为我的模块的许可证吗?
GPL 规定,整个结合后的程序必须依据 GPL 发布。所以你的模块必须可以依据 GPL 进行使用。
但是,您可以提供使用您代码的额外授权。如果您愿意,您可以依据比 GPL 更为宽松但与 GPL 兼容的许可证发布模块。许可证列表页面提供了与 [GPL 兼容许可证](https://www.gnu.org/licenses/license-list.html)的部分列表。
#### 6.16 什么时候程序和插件会被认为是单一的结合程序?
这取决于主程序如何调用其插件。如果主程序使用 `fork` 和 `exec` 来调用插件,并通过共享复杂的数据结构或来回传送复杂的数据结构来建立<ruby> 密切通信 <rp> ( </rp> <rt> intimate communication </rt> <rp> ) </rp></ruby>,可以使它们成为一个单一的结合程序。如果主程序使用简单的 `fork` 和 `exec` 来调用插件并且不建立它们之间的密切通信,插件被认为是一个单独的程序。
如果主程序动态地链接插件,并且它们彼此进行函数调用并共享数据结构,我们相信它们形成了一个单一的结合程序,它必须被视为主程序和插件的扩展。如果主程序动态地链接插件,但是它们之间的通信仅限于使用某些选项调用插件的“main”功能,并等待它返回,这是一种<ruby> 临界案例 <rp> ( </rp> <rt> borderline case </rt> <rp> ) </rp></ruby>。
使用共享内存与复杂数据结构进行通信几乎等同于动态链接。
#### 6.17 如果我写了一个用于遵循 GPL 程序的插件,那么对可用于分发我的插件的许可证有什么要求?
请参阅 “6.16 什么时候程序和插件会被认为是单一的结合程序 ?”以确定插件和主程序是否被视为单个结合程序,以及何时将其视为单独的作品。
如果主程序和插件是单个结合程序,则这意味着您必须依据 GPL 或与 GPL 兼容的自由软件许可证授权插件,并以符合 GPL 的方式将源代码进行分发。与其插件分开的主程序对插件没有要求。
#### 6.18 在为非自由程序编写插件时,可以应用 GPL 许可证吗?
请参阅 “6.16 什么时候程序和插件会被认为是单一的结合程序?”以确定插件和主程序是否被视为单个结合程序,以及何时被视为单独的程序。
如果它们组成单一的结合程序,这意味着遵循 GPL 的插件与非自由主程序的结合将违反 GPL。但是,您可以通过向插件的许可证添加例外声明来解决该法律问题,并允许将其与非自由主程序链接。
另请参阅正在编写的[使用非自由库的自由软件的问题](https://www.gnu.org/licenses/gpl-faq.html#FSWithNFLibs)。
#### 6.19 我可以发布一个旨在加载遵循 GPL 的插件的非自由程序吗?
请参阅 “6.16 什么时候程序和插件会被认为是单一的结合程序?”以确定插件和主程序是否被视为单个结合程序,以及何时被视为单独的程序。
如果它们组成单一的结合程序,则主程序必须依据 GPL 或与 GPL 兼容的自由软件许可证发布,并且当主程序为了与这些插件一起使用而被分发时,必须遵循 GPL 的条款。
然而,如果它们是单独的作品,则插件的许可证对主程序没有要求。
另请参阅正在编写的[使用非自由库的自由软件的问题](https://www.gnu.org/licenses/gpl-faq.html#FSWithNFLibs)。
#### 6.20 我想将遵循 GPL 的软件纳入我的专有系统。我只依据 GPL 给予我的权限来使用该软件。我可以这样做吗?(同 5.6)
您不能将遵循 GPL 的软件纳入专有系统。GPL 的目标是授予每个人复制、再分发、理解和修改程序的自由。如果您可以将遵循 GPL 的软件整合到非自由系统中,则可能会使遵循 GPL 的软件不再是自由软件。
包含遵循 GPL 程序的系统是该 GPL 程序的扩展版本。GPL 规定,如果它最终发布的话,任何扩展版本的程序必须依据 GPL 发布。这有两个原因:确保获得软件的用户获得自己应该拥有的自由,并鼓励人们回馈他们所做的改进。
但是,在许多情况下,您可以将遵循 GPL 的软件与专有系统一起分发。要有效地做到这一点,您必须确保自由和非自由程序之间的通信<ruby> 保持一定距离 <rp> ( </rp> <rt> arms length </rt> <rp> ) </rp></ruby>,而不是将它们有效地结合成一个程序。
这种情况与“纳入”遵循 GPL 的软件之间的区别,是一部分实质和一部分形式的问题。实质上是这样的:如果两个程序结合起来,使它们成为一个程序的两个部分,那么您不能将它们视为两个单独的程序。所以整个作品必须遵循 GPL。
如果这两个程序保持良好的分离,就像编译器和内核,或者像编辑器和shell一样,那么您可以将它们视为两个单独的程序,但是您必须恰当执行。这个问题只是一个形式问题:您如何描述您在做什么。为什么我们关心这个?因为我们想确保用户清楚地了解软件集合中遵循 GPL 的软件的自由状态。
如果人们分发遵循 GPL 的软件,将其称为系统(用户已知其中一部分为专有软件)的“一部分”,用户可能不确定其对遵循GPL的软件所拥有的权利。但是如果他们知道他们收到的是一个自由程序加上另外一个程序,那么他们的权利就会很清楚。
#### 6.21 我想将遵循 GPL 的软件纳入我的专有系统。我是否可以通过在 GPL 覆盖的部分和专有部分之间,放置一个遵循与 GPL 兼容的宽松许可证(如 X11 许可证)的<ruby> “封装” <rp> ( </rp> <rt> wrapper </rt> <rp> ) </rp></ruby>模块来实现?
不可以,X11 许可证与 GPL 兼容,因此您可以向遵循 GPL 的程序添加一个模块,并让其遵循 X11 许可证。但是,如果要将它们整合到一个更大的程序中,那么这个整体将包含 GPL 覆盖的部分,所以它必须在 GNU GPL 下作为一个整体获得许可。
专有模块 A 仅通过遵循 X11 许可证的模块 B 与遵循 GPL 的模块 C 通信,该事实在法律上是无关紧要的;重要的是模块 C 包含在整体作品中。
#### 6.22 我可以编写使用非自由库的自由软件吗?
如果您这样做,您的程序将无法在一个自由的环境中完全使用。如果您的程序依赖于一个非自由库来做某件工作,那么在自由软件世界里就不能做这个工作。如果这依赖于一个非自由库来运行,它不能是自由操作系统(例如 GNU)的一部分;这完全成为了自由软件世界里的禁区。
所以请考虑:你可以找到一种方法来完成这项工作,而不使用这个库吗?你可以为该库编写一个自由软件替代选择吗?
如果程序已经使用非自由库编写,那么改变决定也许已经太晚了。您也可以按照目前状态来发布程序,而不是不发布。但是请在 README 文件中提到,对非自由库的需求是一个缺点,并建议更改程序以便在没有非自由库的情况下执行相同的工作。请建议任何想要在程序上进行大量进一步工作的人首先将其从依赖非自由库中解脱出来。
请注意,将某些非自由库与遵循 GPL 的自由软件相结合也可能存在法律问题。有关更多信息,请参阅有关 [GPL 软件与和其不兼容库的问题](https://www.gnu.org/licenses/gpl-faq.html#GPLIncompatibleLibs)。
#### 6.23 我可以将遵循 GPL 的程序与专有系统库链接吗?
每个版本的 GPL 相对于其<ruby> 左版 <rp> ( </rp> <rt> copyleft </rt> <rp> ) </rp></ruby>都有一个例外,通常称为系统库例外。如果您要使用的与 GPL 不兼容的库符合系统库的标准,则使用它们不需要做特别的工作;分发整个程序的源代码的要求不包括那些库,即使您分发包含它们的链接可执行文件。
作为<ruby> “系统库” <rp> ( </rp> <rt> system library </rt> <rp> ) </rp></ruby>的标准在不同版本的 GPL 之间有所不同。GPL v3 在第 1 节中明确定义“系统库”,将其从<ruby> “相应源代码” <rp> ( </rp> <rt> Corresponding Source </rt> <rp> ) </rp></ruby>的定义中排除。GPL v2 在第 3 部分的末尾进行,处理这个问题略有不同。
#### 6.24 如果我在遵循 GPL 的软件中使用了与 GPL 不兼容的库,会出现什么法律问题?
如果您希望程序与未被系统库例外所涵盖的库链接,则需要提供许可来执行此操作。以下是您可以使用的两个许可证通知示例;一个用于 GPL v3,另一个用于 GPL v2。在这两种情况下,您应该将此文本放在您授予此权限的每个文件中。
只有该程序的版权持有人才能合法地按照这些条款发布其软件。如果您自己编写了整个程序,假设您的雇主或学校没有声明版权,您就是版权所有者,因此您可以授权该例外。但是,如果您想在代码中使用其他作者的其他遵循GPL的程序的一部分,那么您无法将例外授权给他们。您必须获得这些程序的版权所有者的批准。
当其他人修改程序时,他们不需要为他们的代码设置同样的例外——是否这样做是他们自己的选择。
如果您打算链接的库不是自由软件,请参阅[使用非自由库编写自由软件部分](https://www.gnu.org/licenses/gpl-faq.html#FSWithNFLibs)。
如果您使用 GPL v3,您可以通过在第 7 节下授予额外权限来实现此目标。以下许可证通知将会执行此操作。您必须使用适合您程序的文本替换括号中的所有文本。如果不是每个人都可以为您打算链接的库分发源代码,则应该删除大括号中的文本;否则,只需删除大括号。
>
> Copyright (C) [年份] [著作权人名称]
>
>
> 本程序为自由软件;您可以根据自由软件基金会发布的 GNU GPL 许可证的条款再分发和/或修改它;无论是依据本许可证的版本3,或(根据您的选择)任何更高版本。
>
>
> 本程序基于希望其有用的目标而分发,但**不提供任何担保**;甚至也**没有适销性或适用于特定用途的默示担保**。有关详细信息,请参阅 GNU GPL 许可证。
>
>
> 您应该已经收到本程序以及 GNU GPL 许可证的副本;如果没有,请参阅 <http://www.gnu.org/licenses>。
>
>
> 依据 GNU GPL v3 第7节的额外许可
>
>
> 如果您通过将[与库的名称](或库的修改版本)链接或结合来修改本程序,或任何被覆盖的作品,其中包含被[库许可证的名称]的条款所覆盖的部分,则该程序的许可人授予您额外许可来传递所产出的作品。{这种结合的非源代码形式的相应源代码应包括所使用的[库名称]部分的源代码以及被覆盖的作品的源代码。}
>
>
>
如果您使用 GPL v2,您可以为许可证条款提供自己的例外。以下许可证通知将这样做。同样,您必须使用适合您程序的文本替换括号中的所有文本。如果不是每个人都可以为您打算链接的库分发源代码,则应该删除大括号中的文本;否则,只需删除大括号。
>
> Copyright (C) [年份] [著作权人名称]
>
>
> 本程序为自由软件;您可以根据自由软件基金会发布的 GNU GPL 许可证的条款再分发和/或修改它;无论是依据许可证的 v2,或(根据您的选择)任何更高版本。
>
>
> 本程序基于希望其有用的目标而分发,但**不提供任何担保**;甚至也**没有适销性或适用于特定用途的默示担保**。有关详细信息,请参阅 GNU GPL 许可证。
>
>
> 您应该已经收到本程序以及 GNU GPL 许可证的副本;如果没有,请参阅 <http://www.gnu.org/licenses>。
>
>
> 将[您的程序名称]与其他模块静态或动态链接是以[您的程序名称]为基础构建结合作品。因此,GNU GPL 许可证的条款和条件将覆盖整个结合作品。
>
>
> 另外,作为一个特殊例外,[您的程序名称]的版权持有人可以让您将[您的程序名称]与依据 GNU LGPL 发布的自由程序或库以及依据[库的许可证名称]标准发布的[库名称]中包含的代码相结合(或具有相同许可证的此类代码的修改版本)。您可以按照[您的程序名称]所依据的 GNU GPL 的条款和其他有关代码的许可证复制和分发此系统{前提是当 GNU GPL 要求分发源代码时将其他代码的源代码包含在内}。
>
>
> 注意,对[您的程序名称]做出修改版本的人没有义务为其修改版本授予此特殊例外;是否这样做是他们自己的选择。GNU GPL 许可证允许发布一个没有此例外的修改版本;该例外也使得发布一个带有该例外的修改版本成为可能。
>
>
>
#### 6.25 我正在使用 Microsoft Visual C ++(或 Visual Basic)编写 Windows 应用程序,我将依据 GPL 发布它。依据GPL,是否允许将我的程序与 Visual C ++(或 Visual Basic)运行时库动态链接?
您可以将您的程序链接到这些库,并将编译后的程序分发给其他程序。执行此操作时,运行时库是 GPL v3 所定义的“系统库”。这意味着您不需要担心将库的源代码包含在程序的相应源代码中。GPL v2 在第 3 节中提供了类似的例外。
您可能不会随同您的程序以编译后的 DLL 形式分发这些库。为了防止不道德的分发者试图将系统库例外作为漏洞进行利用,GPL 表示,只有库不与程序本身一起分发,库才能被认定为系统库。如果您随同您的程序分发 DLL,则它们将不再符合此例外的资格;那么遵守 GPL 的唯一方法就是提供它们的源代码,而您无法做到。
可以编写只在 Windows 上运行的自由程序,但这不是一个好主意。这些程序将被 Windows <ruby> <a href="https://www.gnu.org/philosophy/java-trap.html"> “围困” </a> <rp> ( </rp> <rt> trapped </rt> <rp> ) </rp></ruby>,因此对自由软件世界的贡献为零。
#### 6.26 我想修改遵循 GPL 的程序,并将它们与 Money Guzzler Inc. 的可移植性库链接。我无法分发这些库的源代码,因此,任何想要更改这些版本的用户都必须单独获取这些库。为什么 GPL 不允许这样做?
有两个原因。第一、一般性的原因。如果我们允许 A 公司制作一个专有文件,B 公司分发与该文件相关的遵循 GPL 的软件,其效果等同于将 GPL 撕开一个大洞。对于保持 GPL 软件各种修改和扩展的源代码来说,这如同一张署名空白纸。
让所有用户能够访问源代码是我们的主要目标之一,所以这个结果绝对是我们想要避免的。
更具体地说,根据我们对条款的理解,与 Money Guzzler 库链接的程序版本不会是真正的自由软件——它们不会附带完整的让用户能够更改和重新编译程序的源代码。
#### 6.27 如果模块 Q 的许可证具有与 GPL 不兼容的要求,但是只有当 Q 自身分发时,而不是在较大程序中包含 Q 时,该要求才适用,是否可以使得该许可证与 GPL 兼容?可以将 Q 与遵循 GPL 的程序结合使用吗?
如果程序 P 依据 GPL 被发布,这意味着“任何和所有部分”都可以依据 GPL 进行使用。如果您集成了模块 Q,并依据 GPL 发布结合程序 P + Q,则表示可以依据 GPL 使用 P + Q 的任何部分。P + Q 的一部分是 Q,所以依据 GPL 发布 P + Q 意味着,Q 的任何部分可以依据 GPL 进行使用。换句话说,依据 GPL 获得 P + Q 的用户可以删除 P,所以 Q 仍然遵循 GPL。
如果模块 Q 的许可证允许您授予该许可,则其与 GPL 兼容。否则,它不与 GPL 兼容。
如果 Q 的许可证在不明确的条件下表示,您必须在自己再分发 Q 时做某些事情(与 GPL 不兼容),那么不允许您依据 GPL 分发Q。因此,您也不能依据 GPL 发布 P + Q。所以您不能将 P 与 Q 进行链接或结合。
#### 6.28 在面向对象的语言(如 Java)中,如果我在不修改的情况下使用遵循 GPL 的类,并对其进行子类化,GPL 会以什么方式影响较大的程序?
子类化将会创建衍生作品。因此,当您创建遵循 GPL 的类的子类时,GPL 的条款会影响整个程序。
#### 6.29 分发一个意图链接到 Linux 内核的非自由驱动程序会违反 GPL 吗?
Linux(GNU / Linux 操作系统中的内核)依据 GNU GPL v2 进行分发。分发一个意图链接 Linux 的非自由驱动程序违反 GPL 吗?
是的,这是一种违规行为,因为这样做形成了更大的结合作品。用户期望把这些片段放在一起的事实并不会改变任何事情。
在代码实体部分拥有版权的 Linux 的每个贡献者都可以执行 GPL,我们鼓励他们对那些分发非自由 Linux 驱动程序的人采取行动。
#### 6.30 如何允许在受控接口下将专有模块与我的 GPL 库链接起来?
在声明该文件依据 GNU GPL 进行分发的文本末尾,将以下文本添加到软件包中每个文件的许可证通知中:
>
> 将 ABC 与其他模块静态或动态链接是基于 ABC 创建结合作品。因此,GNU GPL 许可证的条款和条件将覆盖整个结合作品。
>
>
> 作为一个特殊的例外,ABC 的版权所有者可以将 ABC 程序与自由软件程序或依据 GNU LGPL 发布的库以及通过 ABCDEF 界面与 ABC 通信的独立模块相结合。您可以根据 ABC 的 GNU GPL 条款和其他代码的许可证复制和分发此系统,前提是您在 GNU GPL 需要分发源代码时提供该代码的源代码,并且您没有修改 ABCDEF 界面。
>
>
> 请注意,制作 ABC 修改版本的人没有义务为其修改版本授予此特殊例外;是否这样做是他们自己的选择。GNU GPL 许可证允许发布不含此例外的修改版本;此例外也使得发布一个带有该例外的修改版本成为可能。如果您修改了 ABCDEF 界面,此例外不适用于您修改的 ABC 版本,并且您必须在分发修改后的版本时删除此例外。
>
>
> 此例外是依据 GNU GPL 许可证第3版(“GPL v3”)第7节的额外权限。
>
>
>
此例外允许通过指定接口(“ABCDEF”)与遵循不同许可证的模块进行链接,同时确保用户仍然会按照 GPL 通常的方式接收源代码。
只有该程序的版权持有者才能合法授权此例外。如果您自己编写了整个程序,假设您的雇主或学校没有声明版权,您就是版权所有者,因此您可以授权该例外。但是,如果您想在代码中使用其他作者的其他遵循 GPL 程序的一部分,那么您无法对他们的例外进行授权。您必须获得这些程序的版权所有者的批准。
#### 6.31 考虑这种情况:1)X 发布遵循 GPL 的项目的 V1 版本。2)基于对 V1 的修改和新代码开发,Y 对 V2 的改进做出贡献。3)X 想将 V2 转换为非 GPL 许可证。X 需要 Y 的许可吗?
需要。Y 需要依据 GNU GPL 发布其版本,因为它基于 X 的版本 V1。没有任何要求规定 Y 为其代码适用任何其他许可。因此,X 必须获得 Y 的许可才能依据另一个许可证发布该代码。
#### 6.32 我已经编写了一个与许多不同组件链接的应用程序,它们具有不同的许可证。我对我的程序有什么许可要求感到很困惑。您能告诉我可以使用哪些许可证吗?
为了回答这个问题,我们需要看一下你的程序使用的每个组件的列表,该组件的许可证和一个简短的(几句话应该足够)说明你的库如何使用该组件的描述。两个例子是:
* 为了让我的软件工作,它必须链接到遵循 LGPL 的 FOO 库。
* 我的软件进行系统调用(使用我建立的命令行)来运行 BAR 程序,该程序遵循 GPL,“具有允许与 QUUX 链接的特殊例外”。
#### 6.33 可以在依据与 GPL 不兼容的许可证进行许可的文档中使用遵循 GPL 的源代码片段吗?
如果片段足够小,依据“合理使用”或类似的法律,您可以将它们纳入其中,那么可以。否则,不可以。
---
译者介绍:薛亮,集慧智佳知识产权咨询公司高级咨询师,擅长专利检索、专利分析、竞争对手跟踪、FTO 分析、开源软件知识产权风险分析,致力于为互联网企业、高科技公司提供知识产权咨询服务。

| 200 | OK | ## Frequently Asked Questions about the GNU Licenses
### Table of Contents
**Basic questions about the GNU Project, the Free Software Foundation, and its licenses****General understanding of the GNU licenses****Using GNU licenses for your programs****Distribution of programs released under the GNU licenses****Using programs released under the GNU licenses when writing other programs****Combining work with code released under the GNU licenses****Questions about violations of the GNU licenses**
#### Basic questions about the GNU Project, the Free Software Foundation, and its licenses
[What does “GPL” stand for?](#WhatDoesGPLStandFor)[Does free software mean using the GPL?](#DoesFreeSoftwareMeanUsingTheGPL)[Why should I use the GNU GPL rather than other free software licenses?](#WhyUseGPL)[Does all GNU software use the GNU GPL as its license?](#DoesAllGNUSoftwareUseTheGNUGPLAsItsLicense)[Does using the GPL for a program make it GNU software?](#DoesUsingTheGPLForAProgramMakeItGNUSoftware)[Can I use the GPL for something other than software?](#GPLOtherThanSoftware)[Why don't you use the GPL for manuals?](#WhyNotGPLForManuals)[Are there translations of the GPL into other languages?](#GPLTranslations)[Why are some GNU libraries released under the ordinary GPL rather than the Lesser GPL?](#WhySomeGPLAndNotLGPL)[Who has the power to enforce the GPL?](#WhoHasThePower)[Why does the FSF require that contributors to FSF-copyrighted programs assign copyright to the FSF? If I hold copyright on a GPLed program, should I do this, too? If so, how?](#AssignCopyright)[Can I modify the GPL and make a modified license?](#ModifyGPL)[Why did you decide to write the GNU Affero GPLv3 as a separate license?](#SeparateAffero)
#### General understanding of the GNU licenses
[Why does the GPL permit users to publish their modified versions?](#WhyDoesTheGPLPermitUsersToPublishTheirModifiedVersions)[Does the GPL require that source code of modified versions be posted to the public?](#GPLRequireSourcePostedPublic)[Can I have a GPL-covered program and an unrelated nonfree program on the same computer?](#GPLAndNonfreeOnSameMachine)[If I know someone has a copy of a GPL-covered program, can I demand they give me a copy?](#CanIDemandACopy)[What does “written offer valid for any third party” mean in GPLv2? Does that mean everyone in the world can get the source to any GPLed program no matter what?](#WhatDoesWrittenOfferValid)[The GPL says that modified versions, if released, must be “licensed … to all third parties.” Who are these third parties?](#TheGPLSaysModifiedVersions)[Does the GPL allow me to sell copies of the program for money?](#DoesTheGPLAllowMoney)[Does the GPL allow me to charge a fee for downloading the program from my distribution site?](#DoesTheGPLAllowDownloadFee)[Does the GPL allow me to require that anyone who receives the software must pay me a fee and/or notify me?](#DoesTheGPLAllowRequireFee)[If I distribute GPLed software for a fee, am I required to also make it available to the public without a charge?](#DoesTheGPLRequireAvailabilityToPublic)[Does the GPL allow me to distribute a copy under a nondisclosure agreement?](#DoesTheGPLAllowNDA)[Does the GPL allow me to distribute a modified or beta version under a nondisclosure agreement?](#DoesTheGPLAllowModNDA)[Does the GPL allow me to develop a modified version under a nondisclosure agreement?](#DevelopChangesUnderNDA)[Why does the GPL require including a copy of the GPL with every copy of the program?](#WhyMustIInclude)[What if the work is not very long?](#WhatIfWorkIsShort)[Am I required to claim a copyright on my modifications to a GPL-covered program?](#RequiredToClaimCopyright)[What does the GPL say about translating some code to a different programming language?](#TranslateCode)[If a program combines public-domain code with GPL-covered code, can I take the public-domain part and use it as public domain code?](#CombinePublicDomainWithGPL)[I want to get credit for my work. I want people to know what I wrote. Can I still get credit if I use the GPL?](#IWantCredit)[Does the GPL allow me to add terms that would require citation or acknowledgment in research papers which use the GPL-covered software or its output?](#RequireCitation)[Can I omit the preamble of the GPL, or the instructions for how to use it on your own programs, to save space?](#GPLOmitPreamble)[What does it mean to say that two licenses are “compatible”?](#WhatIsCompatible)[What does it mean to say a license is “compatible with the GPL”?](#WhatDoesCompatMean)[Why is the original BSD license incompatible with the GPL?](#OrigBSD)[What is the difference between an “aggregate” and other kinds of “modified versions”?](#MereAggregation)[When it comes to determining whether two pieces of software form a single work, does the fact that the code is in one or more containers have any effect?](#AggregateContainers)[Why does the FSF require that contributors to FSF-copyrighted programs assign copyright to the FSF? If I hold copyright on a GPLed program, should I do this, too? If so, how?](#AssignCopyright)[If I use a piece of software that has been obtained under the GNU GPL, am I allowed to modify the original code into a new program, then distribute and sell that new program commercially?](#GPLCommercially)[Can I use the GPL for something other than software?](#GPLOtherThanSoftware)[I'd like to license my code under the GPL, but I'd also like to make it clear that it can't be used for military and/or commercial uses. Can I do this?](#NoMilitary)[Can I use the GPL to license hardware?](#GPLHardware)[Does prelinking a GPLed binary to various libraries on the system, to optimize its performance, count as modification?](#Prelinking)[How does the LGPL work with Java?](#LGPLJava)[Why did you invent the new terms “propagate” and “convey” in GPLv3?](#WhyPropagateAndConvey)[Is “convey” in GPLv3 the same thing as what GPLv2 means by “distribute”?](#ConveyVsDistribute)[If I only make copies of a GPL-covered program and run them, without distributing or conveying them to others, what does the license require of me?](#NoDistributionRequirements)[GPLv3 gives “making available to the public” as an example of propagation. What does this mean? Is making available a form of conveying?](#v3MakingAvailable)[Since distribution and making available to the public are forms of propagation that are also conveying in GPLv3, what are some examples of propagation that do not constitute conveying?](#PropagationNotConveying)[How does GPLv3 make BitTorrent distribution easier?](#BitTorrent)[What is tivoization? How does GPLv3 prevent it?](#Tivoization)[Does GPLv3 prohibit DRM?](#DRMProhibited)[Does GPLv3 require that voters be able to modify the software running in a voting machine?](#v3VotingMachine)[Does GPLv3 have a “patent retaliation clause”?](#v3PatentRetaliation)[In GPLv3 and AGPLv3, what does it mean when it says “notwithstanding any other provision of this License”?](#v3Notwithstanding)[In AGPLv3, what counts as “ interacting with [the software] remotely through a computer network?”](#AGPLv3InteractingRemotely)[How does GPLv3's concept of “you” compare to the definition of “Legal Entity” in the Apache License 2.0?](#ApacheLegalEntity)[In GPLv3, what does “the Program” refer to? Is it every program ever released under GPLv3?](#v3TheProgram)[If some network client software is released under AGPLv3, does it have to be able to provide source to the servers it interacts with?](#AGPLv3ServerAsUser)[For software that runs a proxy server licensed under the AGPL, how can I provide an offer of source to users interacting with that code?](#AGPLProxy)
#### Using GNU licenses for your programs
[How do I upgrade from (L)GPLv2 to (L)GPLv3?](#v3HowToUpgrade)[Could you give me step by step instructions on how to apply the GPL to my program?](#CouldYouHelpApplyGPL)[Why should I use the GNU GPL rather than other free software licenses?](#WhyUseGPL)[Why does the GPL require including a copy of the GPL with every copy of the program?](#WhyMustIInclude)[Is putting a copy of the GNU GPL in my repository enough to apply the GPL?](#LicenseCopyOnly)[Why should I put a license notice in each source file?](#NoticeInSourceFile)[What if the work is not very long?](#WhatIfWorkIsShort)[Can I omit the preamble of the GPL, or the instructions for how to use it on your own programs, to save space?](#GPLOmitPreamble)[How do I get a copyright on my program in order to release it under the GPL?](#HowIGetCopyright)[What if my school might want to make my program into its own proprietary software product?](#WhatIfSchool)[I would like to release a program I wrote under the GNU GPL, but I would like to use the same code in nonfree programs.](#ReleaseUnderGPLAndNF)[Can the developer of a program who distributed it under the GPL later license it to another party for exclusive use?](#CanDeveloperThirdParty)[Can the US Government release a program under the GNU GPL?](#GPLUSGov)[Can the US Government release improvements to a GPL-covered program?](#GPLUSGovAdd)[Why should programs say “Version 3 of the GPL or any later version”?](#VersionThreeOrLater)[Is it a good idea to use a license saying that a certain program can be used only under the latest version of the GNU GPL?](#OnlyLatestVersion)[Is there some way that I can GPL the output people get from use of my program? For example, if my program is used to develop hardware designs, can I require that these designs must be free?](#GPLOutput)[Why don't you use the GPL for manuals?](#WhyNotGPLForManuals)[How does the GPL apply to fonts?](#FontException)[What license should I use for website maintenance system templates?](#WMS)[Can I release a program under the GPL which I developed using nonfree tools?](#NonFreeTools)[I use public key cryptography to sign my code to assure its authenticity. Is it true that GPLv3 forces me to release my private signing keys?](#GiveUpKeys)[Does GPLv3 require that voters be able to modify the software running in a voting machine?](#v3VotingMachine)[The warranty and liability disclaimers in GPLv3 seem specific to U.S. law. Can I add my own disclaimers to my own code?](#v3InternationalDisclaimers)[My program has interactive user interfaces that are non-visual in nature. How can I comply with the Appropriate Legal Notices requirement in GPLv3?](#NonvisualLegalNotices)
#### Distribution of programs released under the GNU licenses
[Can I release a modified version of a GPL-covered program in binary form only?](#ModifiedJustBinary)[I downloaded just the binary from the net. If I distribute copies, do I have to get the source and distribute that too?](#UnchangedJustBinary)[I want to distribute binaries via physical media without accompanying sources. Can I provide source code by FTP instead of by mail order?](#DistributeWithSourceOnInternet)[My friend got a GPL-covered binary with an offer to supply source, and made a copy for me. Can I use the offer to obtain the source?](#RedistributedBinariesGetSource)[Can I put the binaries on my Internet server and put the source on a different Internet site?](#SourceAndBinaryOnDifferentSites)[I want to distribute an extended version of a GPL-covered program in binary form. Is it enough to distribute the source for the original version?](#DistributeExtendedBinary)[I want to distribute binaries, but distributing complete source is inconvenient. Is it ok if I give users the diffs from the “standard” version along with the binaries?](#DistributingSourceIsInconvenient)[Can I make binaries available on a network server, but send sources only to people who order them?](#AnonFTPAndSendSources)[How can I make sure each user who downloads the binaries also gets the source?](#HowCanIMakeSureEachDownloadGetsSource)[Does the GPL require me to provide source code that can be built to match the exact hash of the binary I am distributing?](#MustSourceBuildToMatchExactHashOfBinary)[Can I release a program with a license which says that you can distribute modified versions of it under the GPL but you can't distribute the original itself under the GPL?](#ReleaseNotOriginal)[I just found out that a company has a copy of a GPLed program, and it costs money to get it. Aren't they violating the GPL by not making it available on the Internet?](#CompanyGPLCostsMoney)[A company is running a modified version of a GPLed program on a web site. Does the GPL say they must release their modified sources?](#UnreleasedMods)[A company is running a modified version of a program licensed under the GNU Affero GPL (AGPL) on a web site. Does the AGPL say they must release their modified sources?](#UnreleasedModsAGPL)[Is use within one organization or company “distribution”?](#InternalDistribution)[If someone steals a CD containing a version of a GPL-covered program, does the GPL give him the right to redistribute that version?](#StolenCopy)[What if a company distributes a copy of some other developers' GPL-covered work to me as a trade secret?](#TradeSecretRelease)[What if a company distributes a copy of its own GPL-covered work to me as a trade secret?](#TradeSecretRelease2)[Do I have “fair use” rights in using the source code of a GPL-covered program?](#GPLFairUse)[Does moving a copy to a majority-owned, and controlled, subsidiary constitute distribution?](#DistributeSubsidiary)[Can software installers ask people to click to agree to the GPL? If I get some software under the GPL, do I have to agree to anything?](#ClickThrough)[I would like to bundle GPLed software with some sort of installation software. Does that installer need to have a GPL-compatible license?](#GPLCompatInstaller)[Does a distributor violate the GPL if they require me to “represent and warrant” that I am located in the US, or that I intend to distribute the software in compliance with relevant export control laws?](#ExportWarranties)[The beginning of GPLv3 section 6 says that I can convey a covered work in object code form “under the terms of sections 4 and 5” provided I also meet the conditions of section 6. What does that mean?](#v3Under4and5)[My company owns a lot of patents. Over the years we've contributed code to projects under “GPL version 2 or any later version”, and the project itself has been distributed under the same terms. If a user decides to take the project's code (incorporating my contributions) under GPLv3, does that mean I've automatically granted GPLv3's explicit patent license to that user?](#v2OrLaterPatentLicense)[If I distribute a GPLv3-covered program, can I provide a warranty that is voided if the user modifies the program?](#v3ConditionalWarranty)[If I give a copy of a GPLv3-covered program to a coworker at my company, have I “conveyed” the copy to that coworker?](#v3CoworkerConveying)[Am I complying with GPLv3 if I offer binaries on an FTP server and sources by way of a link to a source code repository in a version control system, like CVS or Subversion?](#SourceInCVS)[Can someone who conveys GPLv3-covered software in a User Product use remote attestation to prevent a user from modifying that software?](#RemoteAttestation)[What does “rules and protocols for communication across the network” mean in GPLv3?](#RulesProtocols)[Distributors that provide Installation Information under GPLv3 are not required to provide “support service” for the product. What kind of “support service” do you mean?](#SupportService)
#### Using programs released under the GNU licenses when writing other programs
[Can I have a GPL-covered program and an unrelated nonfree program on the same computer?](#GPLAndNonfreeOnSameMachine)[Can I use GPL-covered editors such as GNU Emacs to develop nonfree programs? Can I use GPL-covered tools such as GCC to compile them?](#CanIUseGPLToolsForNF)[Is there some way that I can GPL the output people get from use of my program? For example, if my program is used to develop hardware designs, can I require that these designs must be free?](#GPLOutput)[In what cases is the output of a GPL program covered by the GPL too?](#WhatCaseIsOutputGPL)[If I port my program to GNU/Linux, does that mean I have to release it as free software under the GPL or some other free software license?](#PortProgramToGPL)[I'd like to incorporate GPL-covered software in my proprietary system. I have no permission to use that software except what the GPL gives me. Can I do this?](#GPLInProprietarySystem)[If I distribute a proprietary program that links against an LGPLv3-covered library that I've modified, what is the “contributor version” for purposes of determining the scope of the explicit patent license grant I'm making—is it just the library, or is it the whole combination?](#LGPLv3ContributorVersion)[Under AGPLv3, when I modify the Program under section 13, what Corresponding Source does it have to offer?](#AGPLv3CorrespondingSource)[Where can I learn more about the GCC Runtime Library Exception?](#LibGCCException)
#### Combining work with code released under the GNU licenses
[Is GPLv3 compatible with GPLv2?](#v2v3Compatibility)[Does GPLv2 have a requirement about delivering installation information?](#InstInfo)[How are the various GNU licenses compatible with each other?](#AllCompatibility)[What is the difference between an “aggregate” and other kinds of “modified versions”?](#MereAggregation)[Do I have “fair use” rights in using the source code of a GPL-covered program?](#GPLFairUse)[Can the US Government release improvements to a GPL-covered program?](#GPLUSGovAdd)[Does the GPL have different requirements for statically vs dynamically linked modules with a covered work?](#GPLStaticVsDynamic)[Does the LGPL have different requirements for statically vs dynamically linked modules with a covered work?](#LGPLStaticVsDynamic)[If a library is released under the GPL (not the LGPL), does that mean that any software which uses it has to be under the GPL or a GPL-compatible license?](#IfLibraryIsGPL)[You have a GPLed program that I'd like to link with my code to build a proprietary program. Does the fact that I link with your program mean I have to GPL my program?](#LinkingWithGPL)[If so, is there any chance I could get a license of your program under the Lesser GPL?](#SwitchToLGPL)[If a programming language interpreter is released under the GPL, does that mean programs written to be interpreted by it must be under GPL-compatible licenses?](#IfInterpreterIsGPL)[If a programming language interpreter has a license that is incompatible with the GPL, can I run GPL-covered programs on it?](#InterpreterIncompat)[If I add a module to a GPL-covered program, do I have to use the GPL as the license for my module?](#GPLModuleLicense)[When is a program and its plug-ins considered a single combined program?](#GPLPlugins)[If I write a plug-in to use with a GPL-covered program, what requirements does that impose on the licenses I can use for distributing my plug-in?](#GPLAndPlugins)[Can I apply the GPL when writing a plug-in for a nonfree program?](#GPLPluginsInNF)[Can I release a nonfree program that's designed to load a GPL-covered plug-in?](#NFUseGPLPlugins)[I'd like to incorporate GPL-covered software in my proprietary system. I have no permission to use that software except what the GPL gives me. Can I do this?](#GPLInProprietarySystem)[Using a certain GNU program under the GPL does not fit our project to make proprietary software. Will you make an exception for us? It would mean more users of that program.](#WillYouMakeAnException)[I'd like to incorporate GPL-covered software in my proprietary system. Can I do this by putting a “wrapper” module, under a GPL-compatible lax permissive license (such as the X11 license) in between the GPL-covered part and the proprietary part?](#GPLWrapper)[Can I write free software that uses nonfree libraries?](#FSWithNFLibs)[Can I link a GPL program with a proprietary system library?](#SystemLibraryException)[In what ways can I link or combine AGPLv3-covered and GPLv3-covered code?](#AGPLGPL)[What legal issues come up if I use GPL-incompatible libraries with GPL software?](#GPLIncompatibleLibs)[I'm writing a Windows application with Microsoft Visual C++ and I will be releasing it under the GPL. Is dynamically linking my program with the Visual C++ runtime library permitted under the GPL?](#WindowsRuntimeAndGPL)[I'd like to modify GPL-covered programs and link them with the portability libraries from Money Guzzler Inc. I cannot distribute the source code for these libraries, so any user who wanted to change these versions would have to obtain those libraries separately. Why doesn't the GPL permit this?](#MoneyGuzzlerInc)[If license for a module Q has a requirement that's incompatible with the GPL, but the requirement applies only when Q is distributed by itself, not when Q is included in a larger program, does that make the license GPL-compatible? Can I combine or link Q with a GPL-covered program?](#GPLIncompatibleAlone)[In an object-oriented language such as Java, if I use a class that is GPLed without modifying, and subclass it, in what way does the GPL affect the larger program?](#OOPLang)[Does distributing a nonfree driver meant to link with the kernel Linux violate the GPL?](#NonfreeDriverKernelLinux)[How can I allow linking of proprietary modules with my GPL-covered library under a controlled interface only?](#LinkingOverControlledInterface)[Consider this situation: 1) X releases V1 of a project under the GPL. 2) Y contributes to the development of V2 with changes and new code based on V1. 3) X wants to convert V2 to a non-GPL license. Does X need Y's permission?](#Consider)[I have written an application that links with many different components, that have different licenses. I am very confused as to what licensing requirements are placed on my program. Can you please tell me what licenses I may use?](#ManyDifferentLicenses)[Can I use snippets of GPL-covered source code within documentation that is licensed under some license that is incompatible with the GPL?](#SourceCodeInDocumentation)
#### Questions about violations of the GNU licenses
[What should I do if I discover a possible violation of the GPL?](#ReportingViolation)[Who has the power to enforce the GPL?](#WhoHasThePower)[I heard that someone got a copy of a GPLed program under another license. Is this possible?](#HeardOtherLicense)[Is the developer of a GPL-covered program bound by the GPL? Could the developer's actions ever be a violation of the GPL?](#DeveloperViolate)[I just found out that a company has a copy of a GPLed program, and it costs money to get it. Aren't they violating the GPL by not making it available on the Internet?](#CompanyGPLCostsMoney)[Can I use GPLed software on a device that will stop operating if customers do not continue paying a subscription fee?](#SubscriptionFee)[What does it mean to “cure” a violation of GPLv3?](#Cure)[If someone installs GPLed software on a laptop, and then lends that laptop to a friend without providing source code for the software, have they violated the GPL?](#LaptopLoan)[Suppose that two companies try to circumvent the requirement to provide Installation Information by having one company release signed software, and the other release a User Product that only runs signed software from the first company. Is this a violation of GPLv3?](#TwoPartyTivoization)
This page is maintained by the Free Software
Foundation's Licensing and Compliance Lab. You can support our efforts by
[making a donation](http://donate.fsf.org) to the FSF.
You can use our publications to understand how GNU licenses work or help you advocate for free software, but they are not legal advice. The FSF cannot give legal advice. Legal advice is personalized advice from a lawyer who has agreed to work for you. Our answers address general questions and may not apply in your specific legal situation.
Have a
question not answered here? Check out some of our other [licensing resources](https://www.fsf.org/licensing) or contact the
Compliance Lab at [[email protected]](mailto:[email protected]).
- What does “GPL” stand for?
(
[#WhatDoesGPLStandFor](#WhatDoesGPLStandFor)) “GPL” stands for “General Public License”. The most widespread such license is the GNU General Public License, or GNU GPL for short. This can be further shortened to “GPL”, when it is understood that the GNU GPL is the one intended.
- Does free software mean using
the GPL?
(
[#DoesFreeSoftwareMeanUsingTheGPL](#DoesFreeSoftwareMeanUsingTheGPL)) Not at all—there are many other free software licenses. We have an
[incomplete list](/licenses/license-list.html). Any license that provides the user[certain specific freedoms](/philosophy/free-sw.html)is a free software license.- Why should I use the GNU GPL rather than other
free software licenses?
(
[#WhyUseGPL](#WhyUseGPL)) Using the GNU GPL will require that all the
[released improved versions be free software](/philosophy/pragmatic.html). This means you can avoid the risk of having to compete with a proprietary modified version of your own work. However, in some special situations it can be better to use a[more permissive license](/licenses/why-not-lgpl.html).- Does all GNU
software use the GNU GPL as its license?
(
[#DoesAllGNUSoftwareUseTheGNUGPLAsItsLicense](#DoesAllGNUSoftwareUseTheGNUGPLAsItsLicense)) Most GNU software packages use the GNU GPL, but there are a few GNU programs (and parts of programs) that use looser licenses, such as the Lesser GPL. When we do this, it is a matter of
[strategy](/licenses/why-not-lgpl.html).- Does using the
GPL for a program make it GNU software?
(
[#DoesUsingTheGPLForAProgramMakeItGNUSoftware](#DoesUsingTheGPLForAProgramMakeItGNUSoftware)) Anyone can release a program under the GNU GPL, but that does not make it a GNU package.
Making the program a GNU software package means explicitly contributing to the GNU Project. This happens when the program's developers and the GNU Project agree to do it. If you are interested in contributing a program to the GNU Project, please write to
[<[email protected]>](mailto:[email protected]).- What should I do if I discover a possible
violation of the GPL?
(
[#ReportingViolation](#ReportingViolation)) You should
[report it](/licenses/gpl-violation.html). First, check the facts as best you can. Then tell the publisher or copyright holder of the specific GPL-covered program. If that is the Free Software Foundation, write to[<[email protected]>](mailto:[email protected]). Otherwise, the program's maintainer may be the copyright holder, or else could tell you how to contact the copyright holder, so report it to the maintainer.- Why
does the GPL permit users to publish their modified versions?
(
[#WhyDoesTheGPLPermitUsersToPublishTheirModifiedVersions](#WhyDoesTheGPLPermitUsersToPublishTheirModifiedVersions)) A crucial aspect of free software is that users are free to cooperate. It is absolutely essential to permit users who wish to help each other to share their bug fixes and improvements with other users.
Some have proposed alternatives to the GPL that require modified versions to go through the original author. As long as the original author keeps up with the need for maintenance, this may work well in practice, but if the author stops (more or less) to do something else or does not attend to all the users' needs, this scheme falls down. Aside from the practical problems, this scheme does not allow users to help each other.
Sometimes control over modified versions is proposed as a means of preventing confusion between various versions made by users. In our experience, this confusion is not a major problem. Many versions of Emacs have been made outside the GNU Project, but users can tell them apart. The GPL requires the maker of a version to place his or her name on it, to distinguish it from other versions and to protect the reputations of other maintainers.
- Does the GPL require that
source code of modified versions be posted to the public?
(
[#GPLRequireSourcePostedPublic](#GPLRequireSourcePostedPublic)) The GPL does not require you to release your modified version, or any part of it. You are free to make modifications and use them privately, without ever releasing them. This applies to organizations (including companies), too; an organization can make a modified version and use it internally without ever releasing it outside the organization.
But
*if*you release the modified version to the public in some way, the GPL requires you to make the modified source code available to the program's users, under the GPL.Thus, the GPL gives permission to release the modified program in certain ways, and not in other ways; but the decision of whether to release it is up to you.
- Can I have a GPL-covered
program and an unrelated nonfree program on the same computer?
(
[#GPLAndNonfreeOnSameMachine](#GPLAndNonfreeOnSameMachine)) Yes.
- If I know someone has a copy of a GPL-covered
program, can I demand they give me a copy?
(
[#CanIDemandACopy](#CanIDemandACopy)) No. The GPL gives a person permission to make and redistribute copies of the program
*if and when that person chooses to do so*. That person also has the right not to choose to redistribute the program.- What does “written offer
valid for any third party” mean in GPLv2? Does that mean
everyone in the world can get the source to any GPLed program
no matter what?
(
[#WhatDoesWrittenOfferValid](#WhatDoesWrittenOfferValid)) If you choose to provide source through a written offer, then anybody who requests the source from you is entitled to receive it.
If you commercially distribute binaries not accompanied with source code, the GPL says you must provide a written offer to distribute the source code later. When users non-commercially redistribute the binaries they received from you, they must pass along a copy of this written offer. This means that people who did not get the binaries directly from you can still receive copies of the source code, along with the written offer.
The reason we require the offer to be valid for any third party is so that people who receive the binaries indirectly in that way can order the source code from you.
- GPLv2 says that modified
versions, if released, must be “licensed … to all third
parties.” Who are these third parties?
(
[#TheGPLSaysModifiedVersions](#TheGPLSaysModifiedVersions)) Section 2 says that modified versions you distribute must be licensed to all third parties under the GPL. “All third parties” means absolutely everyone—but this does not require you to
*do*anything physically for them. It only means they have a license from you, under the GPL, for your version.- Am I required to claim a copyright
on my modifications to a GPL-covered program?
(
[#RequiredToClaimCopyright](#RequiredToClaimCopyright)) You are not required to claim a copyright on your changes. In most countries, however, that happens automatically by default, so you need to place your changes explicitly in the public domain if you do not want them to be copyrighted.
Whether you claim a copyright on your changes or not, either way you must release the modified version, as a whole, under the GPL (
[if you release your modified version at all](#GPLRequireSourcePostedPublic)).- What does the GPL say about translating
some code to a different programming language?
(
[#TranslateCode](#TranslateCode)) Under copyright law, translation of a work is considered a kind of modification. Therefore, what the GPL says about modified versions applies also to translated versions. The translation is covered by the copyright on the original program.
If the original program carries a free license, that license gives permission to translate it. How you can use and license the translated program is determined by that license. If the original program is licensed under certain versions of the GNU GPL, the translated program must be covered by the same versions of the GNU GPL.
- If a program combines
public-domain code with GPL-covered code, can I take the
public-domain part and use it as public domain code?
(
[#CombinePublicDomainWithGPL](#CombinePublicDomainWithGPL)) You can do that, if you can figure out which part is the public domain part and separate it from the rest. If code was put in the public domain by its developer, it is in the public domain no matter where it has been.
- Does the GPL allow me to sell copies of
the program for money?
(
[#DoesTheGPLAllowMoney](#DoesTheGPLAllowMoney)) Yes, the GPL allows everyone to do this. The
[right to sell copies](/philosophy/selling.html)is part of the definition of free software. Except in one special situation, there is no limit on what price you can charge. (The one exception is the required written offer to provide source code that must accompany binary-only release.)- Does the GPL allow me to charge a
fee for downloading the program from my distribution site?
(
[#DoesTheGPLAllowDownloadFee](#DoesTheGPLAllowDownloadFee)) Yes. You can charge any fee you wish for distributing a copy of the program. Under GPLv2, if you distribute binaries by download, you must provide “equivalent access” to download the source—therefore, the fee to download source may not be greater than the fee to download the binary. If the binaries being distributed are licensed under the GPLv3, then you must offer equivalent access to the source code in the same way through the same place at no further charge.
- Does the GPL allow me to require
that anyone who receives the software must pay me a fee and/or
notify me?
(
[#DoesTheGPLAllowRequireFee](#DoesTheGPLAllowRequireFee)) No. In fact, a requirement like that would make the program nonfree. If people have to pay when they get a copy of a program, or if they have to notify anyone in particular, then the program is not free. See the
[definition of free software](/philosophy/free-sw.html).The GPL is a free software license, and therefore it permits people to use and even redistribute the software without being required to pay anyone a fee for doing so.
You
*can*charge people a fee to[get a copy](#DoesTheGPLAllowMoney). You can't require people to pay you when they get a copy*from you**from someone else*.- If I
distribute GPLed software for a fee, am I required to also make
it available to the public without a charge?
(
[#DoesTheGPLRequireAvailabilityToPublic](#DoesTheGPLRequireAvailabilityToPublic)) No. However, if someone pays your fee and gets a copy, the GPL gives them the freedom to release it to the public, with or without a fee. For example, someone could pay your fee, and then put her copy on a web site for the general public.
- Does the GPL allow me to distribute copies
under a nondisclosure agreement?
(
[#DoesTheGPLAllowNDA](#DoesTheGPLAllowNDA)) No. The GPL says that anyone who receives a copy from you has the right to redistribute copies, modified or not. You are not allowed to distribute the work on any more restrictive basis.
If someone asks you to sign an NDA for receiving GPL-covered software copyrighted by the FSF, please inform us immediately by writing to
[[email protected]](mailto:[email protected]).If the violation involves GPL-covered code that has some other copyright holder, please inform that copyright holder, just as you would for any other kind of violation of the GPL.
- Does the GPL allow me to distribute a
modified or beta version under a nondisclosure agreement?
(
[#DoesTheGPLAllowModNDA](#DoesTheGPLAllowModNDA)) No. The GPL says that your modified versions must carry all the freedoms stated in the GPL. Thus, anyone who receives a copy of your version from you has the right to redistribute copies (modified or not) of that version. You may not distribute any version of the work on a more restrictive basis.
- Does the GPL allow me to develop a
modified version under a nondisclosure agreement?
(
[#DevelopChangesUnderNDA](#DevelopChangesUnderNDA)) Yes. For instance, you can accept a contract to develop changes and agree not to release
*your changes*until the client says ok. This is permitted because in this case no GPL-covered code is being distributed under an NDA.You can also release your changes to the client under the GPL, but agree not to release them to anyone else unless the client says ok. In this case, too, no GPL-covered code is being distributed under an NDA, or under any additional restrictions.
The GPL would give the client the right to redistribute your version. In this scenario, the client will probably choose not to exercise that right, but does
*have*the right.- I want to get credit
for my work. I want people to know what I wrote. Can I still get
credit if I use the GPL?
(
[#IWantCredit](#IWantCredit)) You can certainly get credit for the work. Part of releasing a program under the GPL is writing a copyright notice in your own name (assuming you are the copyright holder). The GPL requires all copies to carry an appropriate copyright notice.
- Does the GPL allow me to add terms
that would require citation or acknowledgment in research papers
which use the GPL-covered software or its output?
(
[#RequireCitation](#RequireCitation)) No, this is not permitted under the terms of the GPL. While we recognize that proper citation is an important part of academic publications, citation cannot be added as an additional requirement to the GPL. Requiring citation in research papers which made use of GPLed software goes beyond what would be an acceptable additional requirement under section 7(b) of GPLv3, and therefore would be considered an additional restriction under Section 7 of the GPL. And copyright law does not allow you to place such a
[requirement on the output of software](#GPLOutput), regardless of whether it is licensed under the terms of the GPL or some other license.- Why does the GPL
require including a copy of the GPL with every copy of the program?
(
[#WhyMustIInclude](#WhyMustIInclude)) Including a copy of the license with the work is vital so that everyone who gets a copy of the program can know what their rights are.
It might be tempting to include a URL that refers to the license, instead of the license itself. But you cannot be sure that the URL will still be valid, five years or ten years from now. Twenty years from now, URLs as we know them today may no longer exist.
The only way to make sure that people who have copies of the program will continue to be able to see the license, despite all the changes that will happen in the network, is to include a copy of the license in the program.
- Is it enough just to put a copy
of the GNU GPL in my repository?
(
[#LicenseCopyOnly](#LicenseCopyOnly)) Just putting a copy of the GNU GPL in a file in your repository does not explicitly state that the code in the same repository may be used under the GNU GPL. Without such a statement, it's not entirely clear that the permissions in the license really apply to any particular source file. An explicit statement saying that eliminates all doubt.
A file containing just a license, without a statement that certain other files are covered by that license, resembles a file containing just a subroutine which is never called from anywhere else. The resemblance is not perfect: lawyers and courts might apply common sense and conclude that you must have put the copy of the GNU GPL there because you wanted to license the code that way. Or they might not. Why leave an uncertainty?
This statement should be in each source file. A clear statement in the program's README file is legally sufficient
*as long as that accompanies the code*, but it is easy for them to get separated. Why take a risk of[uncertainty about your code's license](#NoticeInSourceFile)?This has nothing to do with the specifics of the GNU GPL. It is true for any free license.
- Why should I put a license notice in each
source file?
(
[#NoticeInSourceFile](#NoticeInSourceFile)) You should put a notice at the start of each source file, stating what license it carries, in order to avoid risk of the code's getting disconnected from its license. If your repository's README says that source file is under the GNU GPL, what happens if someone copies that file to another program? That other context may not show what the file's license is. It may appear to have some other license, or
[no license at all](/licenses/license-list.html#NoLicense)(which would make the code nonfree).Adding a copyright notice and a license notice at the start of each source file is easy and makes such confusion unlikely.
This has nothing to do with the specifics of the GNU GPL. It is true for any free license.
- What if the work is not very long?
(
[#WhatIfWorkIsShort](#WhatIfWorkIsShort)) If a whole software package contains very little code—less than 300 lines is the benchmark we use—you may as well use a lax permissive license for it, rather than a copyleft license like the GNU GPL. (Unless, that is, the code is specially important.) We
[recommend the Apache License 2.0](/licenses/license-recommendations.html#software)for such cases.- Can I omit the preamble of the GPL, or the
instructions for how to use it on your own programs, to save space?
(
[#GPLOmitPreamble](#GPLOmitPreamble)) The preamble and instructions are integral parts of the GNU GPL and may not be omitted. In fact, the GPL is copyrighted, and its license permits only verbatim copying of the entire GPL. (You can use the legal terms to make
[another license](#ModifyGPL)but it won't be the GNU GPL.)The preamble and instructions add up to some 1000 words, less than 1/5 of the GPL's total size. They will not make a substantial fractional change in the size of a software package unless the package itself is quite small. In that case, you may as well use a simple all-permissive license rather than the GNU GPL.
- What does it
mean to say that two licenses are “compatible”?
(
[#WhatIsCompatible](#WhatIsCompatible)) In order to combine two programs (or substantial parts of them) into a larger work, you need to have permission to use both programs in this way. If the two programs' licenses permit this, they are compatible. If there is no way to satisfy both licenses at once, they are incompatible.
For some licenses, the way in which the combination is made may affect whether they are compatible—for instance, they may allow linking two modules together, but not allow merging their code into one module.
If you just want to install two separate programs in the same system, it is not necessary that their licenses be compatible, because this does not combine them into a larger work.
- What does it mean to say a license is
“compatible with the GPL?”
(
[#WhatDoesCompatMean](#WhatDoesCompatMean)) It means that the other license and the GNU GPL are compatible; you can combine code released under the other license with code released under the GNU GPL in one larger program.
All GNU GPL versions permit such combinations privately; they also permit distribution of such combinations provided the combination is released under the same GNU GPL version. The other license is compatible with the GPL if it permits this too.
GPLv3 is compatible with more licenses than GPLv2: it allows you to make combinations with code that has specific kinds of additional requirements that are not in GPLv3 itself. Section 7 has more information about this, including the list of additional requirements that are permitted.
- Can I write
free software that uses nonfree libraries?
(
[#FSWithNFLibs](#FSWithNFLibs)) If you do this, your program won't be fully usable in a free environment. If your program depends on a nonfree library to do a certain job, it cannot do that job in the Free World. If it depends on a nonfree library to run at all, it cannot be part of a free operating system such as GNU; it is entirely off limits to the Free World.
So please consider: can you find a way to get the job done without using this library? Can you write a free replacement for that library?
If the program is already written using the nonfree library, perhaps it is too late to change the decision. You may as well release the program as it stands, rather than not release it. But please mention in the README that the need for the nonfree library is a drawback, and suggest the task of changing the program so that it does the same job without the nonfree library. Please suggest that anyone who thinks of doing substantial further work on the program first free it from dependence on the nonfree library.
Note that there may also be legal issues with combining certain nonfree libraries with GPL-covered free software. Please see
[the question on GPL software with GPL-incompatible libraries](#GPLIncompatibleLibs)for more information.- Can I link a GPL program with a
proprietary system library? (
[#SystemLibraryException](#SystemLibraryException)) Both versions of the GPL have an exception to their copyleft, commonly called the system library exception. If the GPL-incompatible libraries you want to use meet the criteria for a system library, then you don't have to do anything special to use them; the requirement to distribute source code for the whole program does not include those libraries, even if you distribute a linked executable containing them.
The criteria for what counts as a “system library” vary between different versions of the GPL. GPLv3 explicitly defines “System Libraries” in section 1, to exclude it from the definition of “Corresponding Source.” GPLv2 deals with this issue slightly differently, near the end of section 3.
- In what ways can I link or combine
AGPLv3-covered and GPLv3-covered code?
(
[#AGPLGPL](#AGPLGPL)) Each of these licenses explicitly permits linking with code under the other license. You can always link GPLv3-covered modules with AGPLv3-covered modules, and vice versa. That is true regardless of whether some of the modules are libraries.
- What legal issues
come up if I use GPL-incompatible libraries with GPL software?
(
[#GPLIncompatibleLibs](#GPLIncompatibleLibs)) -
If you want your program to link against a library not covered by the system library exception, you need to provide permission to do that. Below are two example license notices that you can use to do that; one for GPLv3, and the other for GPLv2. In either case, you should put this text in each file to which you are granting this permission.
Only the copyright holders for the program can legally release their software under these terms. If you wrote the whole program yourself, then assuming your employer or school does not claim the copyright, you are the copyright holder—so you can authorize the exception. But if you want to use parts of other GPL-covered programs by other authors in your code, you cannot authorize the exception for them. You have to get the approval of the copyright holders of those programs.
When other people modify the program, they do not have to make the same exception for their code—it is their choice whether to do so.
If the libraries you intend to link with are nonfree, please also see
[the section on writing Free Software which uses nonfree libraries](#FSWithNFLibs).If you're using GPLv3, you can accomplish this goal by granting an additional permission under section 7. The following license notice will do that. You must replace all the text in brackets with text that is appropriate for your program. If not everybody can distribute source for the libraries you intend to link with, you should remove the text in braces; otherwise, just remove the braces themselves.
Copyright (C)
`[years]``[name of copyright holder]`This program is free software; you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation; either version 3 of the License, or (at your option) any later version.
This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details.
You should have received a copy of the GNU General Public License along with this program; if not, see <https://www.gnu.org/licenses>.
Additional permission under GNU GPL version 3 section 7
If you modify this Program, or any covered work, by linking or combining it with
`[name of library]`(or a modified version of that library), containing parts covered by the terms of`[name of library's license]`, the licensors of this Program grant you additional permission to convey the resulting work. {Corresponding Source for a non-source form of such a combination shall include the source code for the parts of`[name of library]`used as well as that of the covered work.}If you're using GPLv2, you can provide your own exception to the license's terms. The following license notice will do that. Again, you must replace all the text in brackets with text that is appropriate for your program. If not everybody can distribute source for the libraries you intend to link with, you should remove the text in braces; otherwise, just remove the braces themselves.
Copyright (C)
`[years]``[name of copyright holder]`This program is free software; you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation; either version 2 of the License, or (at your option) any later version.
This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details.
You should have received a copy of the GNU General Public License along with this program; if not, see <https://www.gnu.org/licenses>.
Linking
`[name of your program]`statically or dynamically with other modules is making a combined work based on`[name of your program]`. Thus, the terms and conditions of the GNU General Public License cover the whole combination.In addition, as a special exception, the copyright holders of
`[name of your program]`give you permission to combine`[name of your program]`with free software programs or libraries that are released under the GNU LGPL and with code included in the standard release of`[name of library]`under the`[name of library's license]`(or modified versions of such code, with unchanged license). You may copy and distribute such a system following the terms of the GNU GPL for`[name of your program]`and the licenses of the other code concerned{, provided that you include the source code of that other code when and as the GNU GPL requires distribution of source code}.Note that people who make modified versions of
`[name of your program]`are not obligated to grant this special exception for their modified versions; it is their choice whether to do so. The GNU General Public License gives permission to release a modified version without this exception; this exception also makes it possible to release a modified version which carries forward this exception. - How do I get a copyright on my program
in order to release it under the GPL?
(
[#HowIGetCopyright](#HowIGetCopyright)) Under the Berne Convention, everything written is automatically copyrighted from whenever it is put in fixed form. So you don't have to do anything to “get” the copyright on what you write—as long as nobody else can claim to own your work.
However, registering the copyright in the US is a very good idea. It will give you more clout in dealing with an infringer in the US.
The case when someone else might possibly claim the copyright is if you are an employee or student; then the employer or the school might claim you did the job for them and that the copyright belongs to them. Whether they would have a valid claim would depend on circumstances such as the laws of the place where you live, and on your employment contract and what sort of work you do. It is best to consult a lawyer if there is any possible doubt.
If you think that the employer or school might have a claim, you can resolve the problem clearly by getting a copyright disclaimer signed by a suitably authorized officer of the company or school. (Your immediate boss or a professor is usually NOT authorized to sign such a disclaimer.)
- What if my school
might want to make my program into its own proprietary software product?
(
[#WhatIfSchool](#WhatIfSchool)) Many universities nowadays try to raise funds by restricting the use of the knowledge and information they develop, in effect behaving little different from commercial businesses. (See “The Kept University”, Atlantic Monthly, March 2000, for a general discussion of this problem and its effects.)
If you see any chance that your school might refuse to allow your program to be released as free software, it is best to raise the issue at the earliest possible stage. The closer the program is to working usefully, the more temptation the administration might feel to take it from you and finish it without you. At an earlier stage, you have more leverage.
So we recommend that you approach them when the program is only half-done, saying, “If you will agree to releasing this as free software, I will finish it.” Don't think of this as a bluff. To prevail, you must have the courage to say, “My program will have liberty, or never be born.”
- Could
you give me step by step instructions on how to apply the GPL to my program?
(
[#CouldYouHelpApplyGPL](#CouldYouHelpApplyGPL)) See the page of
[GPL instructions](/licenses/gpl-howto.html).- I heard that someone got a copy
of a GPLed program under another license. Is this possible?
(
[#HeardOtherLicense](#HeardOtherLicense)) The GNU GPL does not give users permission to attach other licenses to the program. But the copyright holder for a program can release it under several different licenses in parallel. One of them may be the GNU GPL.
The license that comes in your copy, assuming it was put in by the copyright holder and that you got the copy legitimately, is the license that applies to your copy.
- I would like to release a program I wrote
under the GNU GPL, but I would
like to use the same code in nonfree programs.
(
[#ReleaseUnderGPLAndNF](#ReleaseUnderGPLAndNF)) To release a nonfree program is always ethically tainted, but legally there is no obstacle to your doing this. If you are the copyright holder for the code, you can release it under various different non-exclusive licenses at various times.
- Is the
developer of a GPL-covered program bound by the GPL? Could the
developer's actions ever be a violation of the GPL?
(
[#DeveloperViolate](#DeveloperViolate)) Strictly speaking, the GPL is a license from the developer for others to use, distribute and change the program. The developer itself is not bound by it, so no matter what the developer does, this is not a “violation” of the GPL.
However, if the developer does something that would violate the GPL if done by someone else, the developer will surely lose moral standing in the community.
- Can the developer of a program who distributed
it under the GPL later license it to another party for exclusive use?
(
[#CanDeveloperThirdParty](#CanDeveloperThirdParty)) No, because the public already has the right to use the program under the GPL, and this right cannot be withdrawn.
- Can I use GPL-covered editors such as
GNU Emacs to develop nonfree programs? Can I use GPL-covered tools
such as GCC to compile them?
(
[#CanIUseGPLToolsForNF](#CanIUseGPLToolsForNF)) Yes, because the copyright on the editors and tools does not cover the code you write. Using them does not place any restrictions, legally, on the license you use for your code.
Some programs copy parts of themselves into the output for technical reasons—for example, Bison copies a standard parser program into its output file. In such cases, the copied text in the output is covered by the same license that covers it in the source code. Meanwhile, the part of the output which is derived from the program's input inherits the copyright status of the input.
As it happens, Bison can also be used to develop nonfree programs. This is because we decided to explicitly permit the use of the Bison standard parser program in Bison output files without restriction. We made the decision because there were other tools comparable to Bison which already permitted use for nonfree programs.
- Do I have “fair use”
rights in using the source code of a GPL-covered program?
(
[#GPLFairUse](#GPLFairUse)) Yes, you do. “Fair use” is use that is allowed without any special permission. Since you don't need the developers' permission for such use, you can do it regardless of what the developers said about it—in the license or elsewhere, whether that license be the GNU GPL or any other free software license.
Note, however, that there is no world-wide principle of fair use; what kinds of use are considered “fair” varies from country to country.
- Can the US Government release a program under the GNU GPL?
(
[#GPLUSGov](#GPLUSGov)) If the program is written by US federal government employees in the course of their employment, it is in the public domain, which means it is not copyrighted. Since the GNU GPL is based on copyright, such a program cannot be released under the GNU GPL. (It can still be
[free software](/philosophy/free-sw.html), however; a public domain program is free.)However, when a US federal government agency uses contractors to develop software, that is a different situation. The contract can require the contractor to release it under the GNU GPL. (GNU Ada was developed in this way.) Or the contract can assign the copyright to the government agency, which can then release the software under the GNU GPL.
- Can the US Government
release improvements to a GPL-covered program?
(
[#GPLUSGovAdd](#GPLUSGovAdd)) Yes. If the improvements are written by US government employees in the course of their employment, then the improvements are in the public domain. However, the improved version, as a whole, is still covered by the GNU GPL. There is no problem in this situation.
If the US government uses contractors to do the job, then the improvements themselves can be GPL-covered.
- Does the GPL have different requirements
for statically vs dynamically linked modules with a covered
work? (
[#GPLStaticVsDynamic](#GPLStaticVsDynamic)) No. Linking a GPL covered work statically or dynamically with other modules is making a combined work based on the GPL covered work. Thus, the terms and conditions of the GNU General Public License cover the whole combination. See also
[What legal issues come up if I use GPL-incompatible libraries with GPL software?](#GPLIncompatibleLibs)- Does the LGPL have different requirements
for statically vs dynamically linked modules with a covered
work? (
[#LGPLStaticVsDynamic](#LGPLStaticVsDynamic)) For the purpose of complying with the LGPL (any extant version: v2, v2.1 or v3):
(1) If you statically link against an LGPLed library, you must also provide your application in an object (not necessarily source) format, so that a user has the opportunity to modify the library and relink the application.
(2) If you dynamically link against an LGPLed library
*already present on the user's computer*, you need not convey the library's source. On the other hand, if you yourself convey the executable LGPLed library along with your application, whether linked with statically or dynamically, you must also convey the library's sources, in one of the ways for which the LGPL provides.- Is there some way that
I can GPL the output people get from use of my program? For example,
if my program is used to develop hardware designs, can I require that
these designs must be free?
(
[#GPLOutput](#GPLOutput)) In general this is legally impossible; copyright law does not give you any say in the use of the output people make from their data using your program. If the user uses your program to enter or convert her own data, the copyright on the output belongs to her, not you. More generally, when a program translates its input into some other form, the copyright status of the output inherits that of the input it was generated from.
So the only way you have a say in the use of the output is if substantial parts of the output are copied (more or less) from text in your program. For instance, part of the output of Bison (see above) would be covered by the GNU GPL, if we had not made an exception in this specific case.
You could artificially make a program copy certain text into its output even if there is no technical reason to do so. But if that copied text serves no practical purpose, the user could simply delete that text from the output and use only the rest. Then he would not have to obey the conditions on redistribution of the copied text.
- In what cases is the output of a GPL
program covered by the GPL too?
(
[#WhatCaseIsOutputGPL](#WhatCaseIsOutputGPL)) The output of a program is not, in general, covered by the copyright on the code of the program. So the license of the code of the program does not apply to the output, whether you pipe it into a file, make a screenshot, screencast, or video.
The exception would be when the program displays a full screen of text and/or art that comes from the program. Then the copyright on that text and/or art covers the output. Programs that output audio, such as video games, would also fit into this exception.
If the art/music is under the GPL, then the GPL applies when you copy it no matter how you copy it. However,
[fair use](#GPLFairUse)may still apply.Keep in mind that some programs, particularly video games, can have artwork/audio that is licensed separately from the underlying GPLed game. In such cases, the license on the artwork/audio would dictate the terms under which video/streaming may occur. See also:
[Can I use the GPL for something other than software?](#GPLOtherThanSoftware)- If I add a module to a GPL-covered program,
do I have to use the GPL as the license for my module?
(
[#GPLModuleLicense](#GPLModuleLicense)) The GPL says that the whole combined program has to be released under the GPL. So your module has to be available for use under the GPL.
But you can give additional permission for the use of your code. You can, if you wish, release your module under a license which is more lax than the GPL but compatible with the GPL. The
[license list page](/licenses/license-list.html)gives a partial list of GPL-compatible licenses.- If a library is released under the GPL
(not the LGPL), does that mean that any software which uses it
has to be under the GPL or a GPL-compatible license?
(
[#IfLibraryIsGPL](#IfLibraryIsGPL)) Yes, because the program actually links to the library. As such, the terms of the GPL apply to the entire combination. The software modules that link with the library may be under various GPL compatible licenses, but the work as a whole must be licensed under the GPL. See also:
[What does it mean to say a license is “compatible with the GPL”?](#WhatDoesCompatMean)- If a programming language interpreter
is released under the GPL, does that mean programs written to be
interpreted by it must be under GPL-compatible licenses?
(
[#IfInterpreterIsGPL](#IfInterpreterIsGPL)) When the interpreter just interprets a language, the answer is no. The interpreted program, to the interpreter, is just data; a free software license like the GPL, based on copyright law, cannot limit what data you use the interpreter on. You can run it on any data (interpreted program), any way you like, and there are no requirements about licensing that data to anyone.
However, when the interpreter is extended to provide “bindings” to other facilities (often, but not necessarily, libraries), the interpreted program is effectively linked to the facilities it uses through these bindings. So if these facilities are released under the GPL, the interpreted program that uses them must be released in a GPL-compatible way. The JNI or Java Native Interface is an example of such a binding mechanism; libraries that are accessed in this way are linked dynamically with the Java programs that call them. These libraries are also linked with the interpreter. If the interpreter is linked statically with these libraries, or if it is designed to
[link dynamically with these specific libraries](#GPLPluginsInNF), then it too needs to be released in a GPL-compatible way.Another similar and very common case is to provide libraries with the interpreter which are themselves interpreted. For instance, Perl comes with many Perl modules, and a Java implementation comes with many Java classes. These libraries and the programs that call them are always dynamically linked together.
A consequence is that if you choose to use GPLed Perl modules or Java classes in your program, you must release the program in a GPL-compatible way, regardless of the license used in the Perl or Java interpreter that the combined Perl or Java program will run on.
- I'm writing a Windows application with
Microsoft Visual C++ (or Visual Basic) and I will be releasing it
under the GPL. Is dynamically linking my program with the Visual
C++ (or Visual Basic) runtime library permitted under the GPL?
(
[#WindowsRuntimeAndGPL](#WindowsRuntimeAndGPL)) You may link your program to these libraries, and distribute the compiled program to others. When you do this, the runtime libraries are “System Libraries” as GPLv3 defines them. That means that you don't need to worry about including their source code with the program's Corresponding Source. GPLv2 provides a similar exception in section 3.
You may not distribute these libraries in compiled DLL form with the program. To prevent unscrupulous distributors from trying to use the System Library exception as a loophole, the GPL says that libraries can only qualify as System Libraries as long as they're not distributed with the program itself. If you distribute the DLLs with the program, they won't be eligible for this exception anymore; then the only way to comply with the GPL would be to provide their source code, which you are unable to do.
It is possible to write free programs that only run on Windows, but it is not a good idea. These programs would be “
[trapped](/philosophy/java-trap.html)” by Windows, and therefore contribute zero to the Free World.- Why is the original BSD
license incompatible with the GPL?
(
[#OrigBSD](#OrigBSD)) Because it imposes a specific requirement that is not in the GPL; namely, the requirement on advertisements of the program. Section 6 of GPLv2 states:
You may not impose any further restrictions on the recipients' exercise of the rights granted herein.
GPLv3 says something similar in section 10. The advertising clause provides just such a further restriction, and thus is GPL-incompatible.
The revised BSD license does not have the advertising clause, which eliminates the problem.
- When is a program and its plug-ins considered a single combined program?
(
[#GPLPlugins](#GPLPlugins)) It depends on how the main program invokes its plug-ins. If the main program uses fork and exec to invoke plug-ins, and they establish intimate communication by sharing complex data structures, or shipping complex data structures back and forth, that can make them one single combined program. A main program that uses simple fork and exec to invoke plug-ins and does not establish intimate communication between them results in the plug-ins being a separate program.
If the main program dynamically links plug-ins, and they make function calls to each other and share data structures, we believe they form a single combined program, which must be treated as an extension of both the main program and the plug-ins. If the main program dynamically links plug-ins, but the communication between them is limited to invoking the ‘main’ function of the plug-in with some options and waiting for it to return, that is a borderline case.
Using shared memory to communicate with complex data structures is pretty much equivalent to dynamic linking.
- If I write a plug-in to use with a GPL-covered
program, what requirements does that impose on the licenses I can
use for distributing my plug-in?
(
[#GPLAndPlugins](#GPLAndPlugins)) Please see this question
[for determining when plug-ins and a main program are considered a single combined program and when they are considered separate works](#GPLPlugins).If the main program and the plugins are a single combined program then this means you must license the plug-in under the GPL or a GPL-compatible free software license and distribute it with source code in a GPL-compliant way. A main program that is separate from its plug-ins makes no requirements for the plug-ins.
- Can I apply the
GPL when writing a plug-in for a nonfree program?
(
[#GPLPluginsInNF](#GPLPluginsInNF)) Please see this question
[for determining when plug-ins and a main program are considered a single combined program and when they are considered separate programs](#GPLPlugins).If they form a single combined program this means that combination of the GPL-covered plug-in with the nonfree main program would violate the GPL. However, you can resolve that legal problem by adding an exception to your plug-in's license, giving permission to link it with the nonfree main program.
See also the question
[I am writing free software that uses a nonfree library.](#FSWithNFLibs)- Can I release a nonfree program
that's designed to load a GPL-covered plug-in?
(
[#NFUseGPLPlugins](#NFUseGPLPlugins)) Please see this question
[for determining when plug-ins and a main program are considered a single combined program and when they are considered separate programs](#GPLPlugins).If they form a single combined program then the main program must be released under the GPL or a GPL-compatible free software license, and the terms of the GPL must be followed when the main program is distributed for use with these plug-ins.
However, if they are separate works then the license of the plug-in makes no requirements about the main program.
See also the question
[I am writing free software that uses a nonfree library.](#FSWithNFLibs)- You have a GPLed program that I'd like
to link with my code to build a proprietary program. Does the fact
that I link with your program mean I have to GPL my program?
(
[#LinkingWithGPL](#LinkingWithGPL)) Not exactly. It means you must release your program under a license compatible with the GPL (more precisely, compatible with one or more GPL versions accepted by all the rest of the code in the combination that you link). The combination itself is then available under those GPL versions.
- If so, is there
any chance I could get a license of your program under the Lesser GPL?
(
[#SwitchToLGPL](#SwitchToLGPL)) You can ask, but most authors will stand firm and say no. The idea of the GPL is that if you want to include our code in your program, your program must also be free software. It is supposed to put pressure on you to release your program in a way that makes it part of our community.
You always have the legal alternative of not using our code.
- Does distributing a nonfree driver
meant to link with the kernel Linux violate the GPL?
(
[#NonfreeDriverKernelLinux](#NonfreeDriverKernelLinux)) Linux (the kernel in the GNU/Linux operating system) is distributed under GNU GPL version 2. Does distributing a nonfree driver meant to link with Linux violate the GPL?
Yes, this is a violation, because effectively this makes a larger combined work. The fact that the user is expected to put the pieces together does not really change anything.
Each contributor to Linux who holds copyright on a substantial part of the code can enforce the GPL and we encourage each of them to take action against those distributing nonfree Linux-drivers.
- How can I allow linking of
proprietary modules with my GPL-covered library under a controlled
interface only?
(
[#LinkingOverControlledInterface](#LinkingOverControlledInterface)) Add this text to the license notice of each file in the package, at the end of the text that says the file is distributed under the GNU GPL:
Linking ABC statically or dynamically with other modules is making a combined work based on ABC. Thus, the terms and conditions of the GNU General Public License cover the whole combination.
As a special exception, the copyright holders of ABC give you permission to combine ABC program with free software programs or libraries that are released under the GNU LGPL and with independent modules that communicate with ABC solely through the ABCDEF interface. You may copy and distribute such a system following the terms of the GNU GPL for ABC and the licenses of the other code concerned, provided that you include the source code of that other code when and as the GNU GPL requires distribution of source code and provided that you do not modify the ABCDEF interface.
Note that people who make modified versions of ABC are not obligated to grant this special exception for their modified versions; it is their choice whether to do so. The GNU General Public License gives permission to release a modified version without this exception; this exception also makes it possible to release a modified version which carries forward this exception. If you modify the ABCDEF interface, this exception does not apply to your modified version of ABC, and you must remove this exception when you distribute your modified version.
This exception is an additional permission under section 7 of the GNU General Public License, version 3 (“GPLv3”)
This exception enables linking with differently licensed modules over the specified interface (“ABCDEF”), while ensuring that users would still receive source code as they normally would under the GPL.
Only the copyright holders for the program can legally authorize this exception. If you wrote the whole program yourself, then assuming your employer or school does not claim the copyright, you are the copyright holder—so you can authorize the exception. But if you want to use parts of other GPL-covered programs by other authors in your code, you cannot authorize the exception for them. You have to get the approval of the copyright holders of those programs.
- I have written an application that links
with many different components, that have different licenses. I am
very confused as to what licensing requirements are placed on my
program. Can you please tell me what licenses I may use?
(
[#ManyDifferentLicenses](#ManyDifferentLicenses)) To answer this question, we would need to see a list of each component that your program uses, the license of that component, and a brief (a few sentences for each should suffice) describing how your library uses that component. Two examples would be:
- To make my software work, it must be linked to the FOO library, which is available under the Lesser GPL.
- My software makes a system call (with a command line that I built) to run the BAR program, which is licensed under “the GPL, with a special exception allowing for linking with QUUX”.
- What is the difference between an
“aggregate” and other kinds of “modified versions”?
(
[#MereAggregation](#MereAggregation)) An “aggregate” consists of a number of separate programs, distributed together on the same CD-ROM or other media. The GPL permits you to create and distribute an aggregate, even when the licenses of the other software are nonfree or GPL-incompatible. The only condition is that you cannot release the aggregate under a license that prohibits users from exercising rights that each program's individual license would grant them.
Where's the line between two separate programs, and one program with two parts? This is a legal question, which ultimately judges will decide. We believe that a proper criterion depends both on the mechanism of communication (exec, pipes, rpc, function calls within a shared address space, etc.) and the semantics of the communication (what kinds of information are interchanged).
If the modules are included in the same executable file, they are definitely combined in one program. If modules are designed to run linked together in a shared address space, that almost surely means combining them into one program.
By contrast, pipes, sockets and command-line arguments are communication mechanisms normally used between two separate programs. So when they are used for communication, the modules normally are separate programs. But if the semantics of the communication are intimate enough, exchanging complex internal data structures, that too could be a basis to consider the two parts as combined into a larger program.
- When it comes to determining
whether two pieces of software form a single work, does the fact
that the code is in one or more containers have any effect?
(
[#AggregateContainers](#AggregateContainers)) No, the analysis of whether they are a
[single work or an aggregate](#MereAggregation)is unchanged by the involvement of containers.- Why does
the FSF require that contributors to FSF-copyrighted programs assign
copyright to the FSF? If I hold copyright on a GPLed program, should
I do this, too? If so, how?
(
[#AssignCopyright](#AssignCopyright)) Our lawyers have told us that to be in the
[best position to enforce the GPL](/licenses/why-assign.html)in court against violators, we should keep the copyright status of the program as simple as possible. We do this by asking each contributor to either assign the copyright on contributions to the FSF, or disclaim copyright on contributions.We also ask individual contributors to get copyright disclaimers from their employers (if any) so that we can be sure those employers won't claim to own the contributions.
Of course, if all the contributors put their code in the public domain, there is no copyright with which to enforce the GPL. So we encourage people to assign copyright on large code contributions, and only put small changes in the public domain.
If you want to make an effort to enforce the GPL on your program, it is probably a good idea for you to follow a similar policy. Please contact
[<[email protected]>](mailto:[email protected])if you want more information.- Can I modify the GPL
and make a modified license?
(
[#ModifyGPL](#ModifyGPL)) It is possible to make modified versions of the GPL, but it tends to have practical consequences.
You can legally use the GPL terms (possibly modified) in another license provided that you call your license by another name and do not include the GPL preamble, and provided you modify the instructions-for-use at the end enough to make it clearly different in wording and not mention GNU (though the actual procedure you describe may be similar).
If you want to use our preamble in a modified license, please write to
[<[email protected]>](mailto:[email protected])for permission. For this purpose we would want to check the actual license requirements to see if we approve of them.Although we will not raise legal objections to your making a modified license in this way, we hope you will think twice and not do it. Such a modified license is almost certainly
[incompatible with the GNU GPL](#WhatIsCompatible), and that incompatibility blocks useful combinations of modules. The mere proliferation of different free software licenses is a burden in and of itself.Rather than modifying the GPL, please use the exception mechanism offered by GPL version 3.
- If I use a
piece of software that has been obtained under the GNU GPL, am I
allowed to modify the original code into a new program, then
distribute and sell that new program commercially?
(
[#GPLCommercially](#GPLCommercially)) You are allowed to sell copies of the modified program commercially, but only under the terms of the GNU GPL. Thus, for instance, you must make the source code available to the users of the program as described in the GPL, and they must be allowed to redistribute and modify it as described in the GPL.
These requirements are the condition for including the GPL-covered code you received in a program of your own.
- Can I use the GPL for something other than
software?
(
[#GPLOtherThanSoftware](#GPLOtherThanSoftware)) You can apply the GPL to any kind of work, as long as it is clear what constitutes the “source code” for the work. The GPL defines this as the preferred form of the work for making changes in it.
However, for manuals and textbooks, or more generally any sort of work that is meant to teach a subject, we recommend using the GFDL rather than the GPL.
- How does the LGPL work with Java?
(
[#LGPLJava](#LGPLJava)) [See this article for details.](/licenses/lgpl-java.html)It works as designed, intended, and expected.- Consider this situation:
1) X releases V1 of a project under the GPL.
2) Y contributes to the development of V2 with changes and new code
based on V1.
3) X wants to convert V2 to a non-GPL license.
Does X need Y's permission?
(
[#Consider](#Consider)) Yes. Y was required to release its version under the GNU GPL, as a consequence of basing it on X's version V1. Nothing required Y to agree to any other license for its code. Therefore, X must get Y's permission before releasing that code under another license.
- I'd like to incorporate GPL-covered
software in my proprietary system. I have no permission to use
that software except what the GPL gives me. Can I do this?
(
[#GPLInProprietarySystem](#GPLInProprietarySystem)) You cannot incorporate GPL-covered software in a proprietary system. The goal of the GPL is to grant everyone the freedom to copy, redistribute, understand, and modify a program. If you could incorporate GPL-covered software into a nonfree system, it would have the effect of making the GPL-covered software nonfree too.
A system incorporating a GPL-covered program is an extended version of that program. The GPL says that any extended version of the program must be released under the GPL if it is released at all. This is for two reasons: to make sure that users who get the software get the freedom they should have, and to encourage people to give back improvements that they make.
However, in many cases you can distribute the GPL-covered software alongside your proprietary system. To do this validly, you must make sure that the free and nonfree programs communicate at arms length, that they are not combined in a way that would make them effectively a single program.
The difference between this and “incorporating” the GPL-covered software is partly a matter of substance and partly form. The substantive part is this: if the two programs are combined so that they become effectively two parts of one program, then you can't treat them as two separate programs. So the GPL has to cover the whole thing.
If the two programs remain well separated, like the compiler and the kernel, or like an editor and a shell, then you can treat them as two separate programs—but you have to do it properly. The issue is simply one of form: how you describe what you are doing. Why do we care about this? Because we want to make sure the users clearly understand the free status of the GPL-covered software in the collection.
If people were to distribute GPL-covered software calling it “part of” a system that users know is partly proprietary, users might be uncertain of their rights regarding the GPL-covered software. But if they know that what they have received is a free program plus another program, side by side, their rights will be clear.
- Using a certain GNU program under the
GPL does not fit our project to make proprietary software. Will you
make an exception for us? It would mean more users of that program.
(
[#WillYouMakeAnException](#WillYouMakeAnException)) Sorry, we don't make such exceptions. It would not be right.
Maximizing the number of users is not our aim. Rather, we are trying to give the crucial freedoms to as many users as possible. In general, proprietary software projects hinder rather than help the cause of freedom.
We do occasionally make license exceptions to assist a project which is producing free software under a license other than the GPL. However, we have to see a good reason why this will advance the cause of free software.
We also do sometimes change the distribution terms of a package, when that seems clearly the right way to serve the cause of free software; but we are very cautious about this, so you will have to show us very convincing reasons.
- I'd like to incorporate GPL-covered software in
my proprietary system. Can I do this by putting a “wrapper”
module, under a GPL-compatible lax permissive license (such as the X11
license) in between the GPL-covered part and the proprietary part?
(
[#GPLWrapper](#GPLWrapper)) No. The X11 license is compatible with the GPL, so you can add a module to the GPL-covered program and put it under the X11 license. But if you were to incorporate them both in a larger program, that whole would include the GPL-covered part, so it would have to be licensed
*as a whole*under the GNU GPL.The fact that proprietary module A communicates with GPL-covered module C only through X11-licensed module B is legally irrelevant; what matters is the fact that module C is included in the whole.
- Where can I learn more about the GCC
Runtime Library Exception?
(
[#LibGCCException](#LibGCCException)) The GCC Runtime Library Exception covers libgcc, libstdc++, libfortran, libgomp, libdecnumber, and other libraries distributed with GCC. The exception is meant to allow people to distribute programs compiled with GCC under terms of their choice, even when parts of these libraries are included in the executable as part of the compilation process. To learn more, please read our
[FAQ about the GCC Runtime Library Exception](/licenses/gcc-exception-faq.html).- I'd like to
modify GPL-covered programs and link them with the portability
libraries from Money Guzzler Inc. I cannot distribute the source code
for these libraries, so any user who wanted to change these versions
would have to obtain those libraries separately. Why doesn't the
GPL permit this?
(
[#MoneyGuzzlerInc](#MoneyGuzzlerInc)) There are two reasons for this. First, a general one. If we permitted company A to make a proprietary file, and company B to distribute GPL-covered software linked with that file, the effect would be to make a hole in the GPL big enough to drive a truck through. This would be carte blanche for withholding the source code for all sorts of modifications and extensions to GPL-covered software.
Giving all users access to the source code is one of our main goals, so this consequence is definitely something we want to avoid.
More concretely, the versions of the programs linked with the Money Guzzler libraries would not really be free software as we understand the term—they would not come with full source code that enables users to change and recompile the program.
- If the license for a module Q has a
requirement that's incompatible with the GPL,
but the requirement applies only when Q is distributed by itself, not when
Q is included in a larger program, does that make the license
GPL-compatible? Can I combine or link Q with a GPL-covered program?
(
[#GPLIncompatibleAlone](#GPLIncompatibleAlone)) If a program P is released under the GPL that means *any and every part of it* can be used under the GPL. If you integrate module Q, and release the combined program P+Q under the GPL, that means any part of P+Q can be used under the GPL. One part of P+Q is Q. So releasing P+Q under the GPL says that Q any part of it can be used under the GPL. Putting it in other words, a user who obtains P+Q under the GPL can delete P, so that just Q remains, still under the GPL.
If the license of module Q permits you to give permission for that, then it is GPL-compatible. Otherwise, it is not GPL-compatible.
If the license for Q says in no uncertain terms that you must do certain things (not compatible with the GPL) when you redistribute Q on its own, then it does not permit you to distribute Q under the GPL. It follows that you can't release P+Q under the GPL either. So you cannot link or combine P with Q.
- Can I release a modified
version of a GPL-covered program in binary form only?
(
[#ModifiedJustBinary](#ModifiedJustBinary)) No. The whole point of the GPL is that all modified versions must be
[free software](/philosophy/free-sw.html)—which means, in particular, that the source code of the modified version is available to the users.- I
downloaded just the binary from the net. If I distribute copies,
do I have to get the source and distribute that too?
(
[#UnchangedJustBinary](#UnchangedJustBinary)) Yes. The general rule is, if you distribute binaries, you must distribute the complete corresponding source code too. The exception for the case where you received a written offer for source code is quite limited.
- I want to distribute
binaries via physical media without accompanying sources. Can I provide
source code by FTP?
(
[#DistributeWithSourceOnInternet](#DistributeWithSourceOnInternet)) Version 3 of the GPL allows this; see option 6(b) for the full details. Under version 2, you're certainly free to offer source via FTP, and most users will get it from there. However, if any of them would rather get the source on physical media by mail, you are required to provide that.
If you distribute binaries via FTP,
[you should distribute source via FTP.](#AnonFTPAndSendSources)- My friend got a GPL-covered
binary with an offer to supply source, and made a copy for me.
Can I use the offer myself to obtain the source?
(
[#RedistributedBinariesGetSource](#RedistributedBinariesGetSource)) Yes, you can. The offer must be open to everyone who has a copy of the binary that it accompanies. This is why the GPL says your friend must give you a copy of the offer along with a copy of the binary—so you can take advantage of it.
- Can I put the binaries on my
Internet server and put the source on a different Internet site?
(
[#SourceAndBinaryOnDifferentSites](#SourceAndBinaryOnDifferentSites)) Yes. Section 6(d) allows this. However, you must provide clear instructions people can follow to obtain the source, and you must take care to make sure that the source remains available for as long as you distribute the object code.
- I want to distribute an extended
version of a GPL-covered program in binary form. Is it enough to
distribute the source for the original version?
(
[#DistributeExtendedBinary](#DistributeExtendedBinary)) No, you must supply the source code that corresponds to the binary. Corresponding source means the source from which users can rebuild the same binary.
Part of the idea of free software is that users should have access to the source code for
*the programs they use*. Those using your version should have access to the source code for your version.A major goal of the GPL is to build up the Free World by making sure that improvement to a free program are themselves free. If you release an improved version of a GPL-covered program, you must release the improved source code under the GPL.
- I want to distribute
binaries, but distributing complete source is inconvenient. Is it ok if
I give users the diffs from the “standard” version along with
the binaries?
(
[#DistributingSourceIsInconvenient](#DistributingSourceIsInconvenient)) This is a well-meaning request, but this method of providing the source doesn't really do the job.
A user that wants the source a year from now may be unable to get the proper version from another site at that time. The standard distribution site may have a newer version, but the same diffs probably won't work with that version.
So you need to provide complete sources, not just diffs, with the binaries.
- Can I make binaries available
on a network server, but send sources only to people who order them?
(
[#AnonFTPAndSendSources](#AnonFTPAndSendSources)) If you make object code available on a network server, you have to provide the Corresponding Source on a network server as well. The easiest way to do this would be to publish them on the same server, but if you'd like, you can alternatively provide instructions for getting the source from another server, or even a
[version control system](#SourceInCVS). No matter what you do, the source should be just as easy to access as the object code, though. This is all specified in section 6(d) of GPLv3.The sources you provide must correspond exactly to the binaries. In particular, you must make sure they are for the same version of the program—not an older version and not a newer version.
- How can I make sure each
user who downloads the binaries also gets the source?
(
[#HowCanIMakeSureEachDownloadGetsSource](#HowCanIMakeSureEachDownloadGetsSource)) You don't have to make sure of this. As long as you make the source and binaries available so that the users can see what's available and take what they want, you have done what is required of you. It is up to the user whether to download the source.
Our requirements for redistributors are intended to make sure the users can get the source code, not to force users to download the source code even if they don't want it.
- Does the GPL require
me to provide source code that can be built to match the exact
hash of the binary I am distributing?
(
[#MustSourceBuildToMatchExactHashOfBinary](#MustSourceBuildToMatchExactHashOfBinary)) Complete corresponding source means the source that the binaries were made from, but that does not imply your tools must be able to make a binary that is an exact hash of the binary you are distributing. In some cases it could be (nearly) impossible to build a binary from source with an exact hash of the binary being distributed — consider the following examples: a system might put timestamps in binaries; or the program might have been built against a different (even unreleased) compiler version.
- A company
is running a modified version of a GPLed program on a web site.
Does the GPL say they must release their modified sources?
(
[#UnreleasedMods](#UnreleasedMods)) The GPL permits anyone to make a modified version and use it without ever distributing it to others. What this company is doing is a special case of that. Therefore, the company does not have to release the modified sources. The situation is different when the modified program is licensed under the terms of the
[GNU Affero GPL](#UnreleasedModsAGPL).Compare this to a situation where the web site contains or links to separate GPLed programs that are distributed to the user when they visit the web site (often written in
[JavaScript](/philosophy/javascript-trap.html), but other languages are used as well). In this situation the source code for the programs being distributed must be released to the user under the terms of the GPL.- A company is running a modified
version of a program licensed under the GNU Affero GPL (AGPL) on a
web site. Does the AGPL say they must release their modified
sources?
(
[#UnreleasedModsAGPL](#UnreleasedModsAGPL)) The
[GNU Affero GPL](/licenses/agpl.html)requires that modified versions of the software offer all users interacting with it over a computer network an opportunity to receive the source. What the company is doing falls under that meaning, so the company must release the modified source code.- Is making and using multiple copies
within one organization or company “distribution”?
(
[#InternalDistribution](#InternalDistribution)) No, in that case the organization is just making the copies for itself. As a consequence, a company or other organization can develop a modified version and install that version through its own facilities, without giving the staff permission to release that modified version to outsiders.
However, when the organization transfers copies to other organizations or individuals, that is distribution. In particular, providing copies to contractors for use off-site is distribution.
- If someone steals
a CD containing a version of a GPL-covered program, does the GPL
give the thief the right to redistribute that version?
(
[#StolenCopy](#StolenCopy)) If the version has been released elsewhere, then the thief probably does have the right to make copies and redistribute them under the GPL, but if thieves are imprisoned for stealing the CD, they may have to wait until their release before doing so.
If the version in question is unpublished and considered by a company to be its trade secret, then publishing it may be a violation of trade secret law, depending on other circumstances. The GPL does not change that. If the company tried to release its version and still treat it as a trade secret, that would violate the GPL, but if the company hasn't released this version, no such violation has occurred.
- What if a company distributes a copy of
some other developers' GPL-covered work to me as a trade secret?
(
[#TradeSecretRelease](#TradeSecretRelease)) The company has violated the GPL and will have to cease distribution of that program. Note how this differs from the theft case above; the company does not intentionally distribute a copy when a copy is stolen, so in that case the company has not violated the GPL.
- What if a company distributes a copy
of its own GPL-covered work to me as a trade secret?
(
[#TradeSecretRelease2](#TradeSecretRelease2)) If the program distributed does not incorporate anyone else's GPL-covered work, then the company is not violating the GPL (see “
[Is the developer of a GPL-covered program bound by the GPL?](#DeveloperViolate)” for more information). But it is making two contradictory statements about what you can do with that program: that you can redistribute it, and that you can't. It would make sense to demand clarification of the terms for use of that program before you accept a copy.- Why are some GNU libraries released under
the ordinary GPL rather than the Lesser GPL?
(
[#WhySomeGPLAndNotLGPL](#WhySomeGPLAndNotLGPL)) Using the Lesser GPL for any particular library constitutes a retreat for free software. It means we partially abandon the attempt to defend the users' freedom, and some of the requirements to share what is built on top of GPL-covered software. In themselves, those are changes for the worse.
Sometimes a localized retreat is a good strategy. Sometimes, using the LGPL for a library might lead to wider use of that library, and thus to more improvement for it, wider support for free software, and so on. This could be good for free software if it happens to a large extent. But how much will this happen? We can only speculate.
It would be nice to try out the LGPL on each library for a while, see whether it helps, and change back to the GPL if the LGPL didn't help. But this is not feasible. Once we use the LGPL for a particular library, changing back would be difficult.
So we decide which license to use for each library on a case-by-case basis. There is a
[long explanation](/licenses/why-not-lgpl.html)of how we judge the question.- Why should programs say
“Version 3 of the GPL or any later version”?
(
[#VersionThreeOrLater](#VersionThreeOrLater)) From time to time, at intervals of years, we change the GPL—sometimes to clarify it, sometimes to permit certain kinds of use not previously permitted, and sometimes to tighten up a requirement. (The last two changes were in 2007 and 1991.) Using this “indirect pointer” in each program makes it possible for us to change the distribution terms on the entire collection of GNU software, when we update the GPL.
If each program lacked the indirect pointer, we would be forced to discuss the change at length with numerous copyright holders, which would be a virtual impossibility. In practice, the chance of having uniform distribution terms for GNU software would be nil.
Suppose a program says “Version 3 of the GPL or any later version” and a new version of the GPL is released. If the new GPL version gives additional permission, that permission will be available immediately to all the users of the program. But if the new GPL version has a tighter requirement, it will not restrict use of the current version of the program, because it can still be used under GPL version 3. When a program says “Version 3 of the GPL or any later version”, users will always be permitted to use it, and even change it, according to the terms of GPL version 3—even after later versions of the GPL are available.
If a tighter requirement in a new version of the GPL need not be obeyed for existing software, how is it useful? Once GPL version 4 is available, the developers of most GPL-covered programs will release subsequent versions of their programs specifying “Version 4 of the GPL or any later version”. Then users will have to follow the tighter requirements in GPL version 4, for subsequent versions of the program.
However, developers are not obligated to do this; developers can continue allowing use of the previous version of the GPL, if that is their preference.
- Is it a good idea to use a license saying
that a certain program can be used only under the latest version
of the GNU GPL?
(
[#OnlyLatestVersion](#OnlyLatestVersion)) The reason you shouldn't do that is that it could result some day in withdrawing automatically some permissions that the users previously had.
Suppose a program was released in 2000 under “the latest GPL version”. At that time, people could have used it under GPLv2. The day we published GPLv3 in 2007, everyone would have been suddenly compelled to use it under GPLv3 instead.
Some users may not even have known about GPL version 3—but they would have been required to use it. They could have violated the program's license unintentionally just because they did not get the news. That's a bad way to treat people.
We think it is wrong to take back permissions already granted, except due to a violation. If your freedom could be revoked, then it isn't really freedom. Thus, if you get a copy of a program version under one version of a license, you should
*always*have the rights granted by that version of the license. Releasing under “GPL version N or any later version” upholds that principle.- Why don't you use the GPL for manuals?
(
[#WhyNotGPLForManuals](#WhyNotGPLForManuals)) It is possible to use the GPL for a manual, but the GNU Free Documentation License (GFDL) is much better for manuals.
The GPL was designed for programs; it contains lots of complex clauses that are crucial for programs, but that would be cumbersome and unnecessary for a book or manual. For instance, anyone publishing the book on paper would have to either include machine-readable “source code” of the book along with each printed copy, or provide a written offer to send the “source code” later.
Meanwhile, the GFDL has clauses that help publishers of free manuals make a profit from selling copies—cover texts, for instance. The special rules for Endorsements sections make it possible to use the GFDL for an official standard. This would permit modified versions, but they could not be labeled as “the standard”.
Using the GFDL, we permit changes in the text of a manual that covers its technical topic. It is important to be able to change the technical parts, because people who change a program ought to change the documentation to correspond. The freedom to do this is an ethical imperative.
Our manuals also include sections that state our political position about free software. We mark these as “invariant”, so that they cannot be changed or removed. The GFDL makes provisions for these “invariant sections”.
- How does the GPL apply to fonts?
(
[#FontException](#FontException)) Font licensing is a complex issue which needs serious consideration. The following license exception is experimental but approved for general use. We welcome suggestions on this subject—please see this this
[explanatory essay](http://www.fsf.org/blogs/licensing/20050425novalis)and write to[[email protected]](mailto:[email protected]).To use this exception, add this text to the license notice of each file in the package (to the extent possible), at the end of the text that says the file is distributed under the GNU GPL:
As a special exception, if you create a document which uses this font, and embed this font or unaltered portions of this font into the document, this font does not by itself cause the resulting document to be covered by the GNU General Public License. This exception does not however invalidate any other reasons why the document might be covered by the GNU General Public License. If you modify this font, you may extend this exception to your version of the font, but you are not obligated to do so. If you do not wish to do so, delete this exception statement from your version.
- I am writing a website maintenance system
(called a “
[content management system](/philosophy/words-to-avoid.html#Content)” by some), or some other application which generates web pages from templates. What license should I use for those templates? ([#WMS](#WMS)) Templates are minor enough that it is not worth using copyleft to protect them. It is normally harmless to use copyleft on minor works, but templates are a special case, because they are combined with data provided by users of the application and the combination is distributed. So, we recommend that you license your templates under simple permissive terms.
Some templates make calls into JavaScript functions. Since Javascript is often non-trivial, it is worth copylefting. Because the templates will be combined with user data, it's possible that template+user data+JavaScript would be considered one work under copyright law. A line needs to be drawn between the JavaScript (copylefted), and the user code (usually under incompatible terms).
Here's an exception for JavaScript code that does this:
As a special exception to the GPL, any HTML file which merely makes function calls to this code, and for that purpose includes it by reference shall be deemed a separate work for copyright law purposes. In addition, the copyright holders of this code give you permission to combine this code with free software libraries that are released under the GNU LGPL. You may copy and distribute such a system following the terms of the GNU GPL for this code and the LGPL for the libraries. If you modify this code, you may extend this exception to your version of the code, but you are not obligated to do so. If you do not wish to do so, delete this exception statement from your version.
- Can I release
a program under the GPL which I developed using nonfree tools?
(
[#NonFreeTools](#NonFreeTools)) Which programs you used to edit the source code, or to compile it, or study it, or record it, usually makes no difference for issues concerning the licensing of that source code.
However, if you link nonfree libraries with the source code, that would be an issue you need to deal with. It does not preclude releasing the source code under the GPL, but if the libraries don't fit under the “system library” exception, you should affix an explicit notice giving permission to link your program with them.
[The FAQ entry about using GPL-incompatible libraries](#GPLIncompatibleLibs)provides more information about how to do that.- Are there translations
of the GPL into other languages?
(
[#GPLTranslations](#GPLTranslations)) It would be useful to have translations of the GPL into languages other than English. People have even written translations and sent them to us. But we have not dared to approve them as officially valid. That carries a risk so great we do not dare accept it.
A legal document is in some ways like a program. Translating it is like translating a program from one language and operating system to another. Only a lawyer skilled in both languages can do it—and even then, there is a risk of introducing a bug.
If we were to approve, officially, a translation of the GPL, we would be giving everyone permission to do whatever the translation says they can do. If it is a completely accurate translation, that is fine. But if there is an error in the translation, the results could be a disaster which we could not fix.
If a program has a bug, we can release a new version, and eventually the old version will more or less disappear. But once we have given everyone permission to act according to a particular translation, we have no way of taking back that permission if we find, later on, that it had a bug.
Helpful people sometimes offer to do the work of translation for us. If the problem were a matter of finding someone to do the work, this would solve it. But the actual problem is the risk of error, and offering to do the work does not avoid the risk. We could not possibly authorize a translation written by a non-lawyer.
Therefore, for the time being, we are not approving translations of the GPL as globally valid and binding. Instead, we are doing two things:
Referring people to unofficial translations. This means that we permit people to write translations of the GPL, but we don't approve them as legally valid and binding.
An unapproved translation has no legal force, and it should say so explicitly. It should be marked as follows:
This translation of the GPL is informal, and not officially approved by the Free Software Foundation as valid. To be completely sure of what is permitted, refer to the original GPL (in English).
But the unapproved translation can serve as a hint for how to understand the English GPL. For many users, that is sufficient.
However, businesses using GNU software in commercial activity, and people doing public ftp distribution, should need to check the real English GPL to make sure of what it permits.
Publishing translations valid for a single country only.
We are considering the idea of publishing translations which are officially valid only for one country. This way, if there is a mistake, it will be limited to that country, and the damage will not be too great.
It will still take considerable expertise and effort from a sympathetic and capable lawyer to make a translation, so we cannot promise any such translations soon.
- If a programming language interpreter has a
license that is incompatible with the GPL, can I run GPL-covered
programs on it?
(
[#InterpreterIncompat](#InterpreterIncompat)) When the interpreter just interprets a language, the answer is yes. The interpreted program, to the interpreter, is just data; the GPL doesn't restrict what tools you process the program with.
However, when the interpreter is extended to provide “bindings” to other facilities (often, but not necessarily, libraries), the interpreted program is effectively linked to the facilities it uses through these bindings. The JNI or Java Native Interface is an example of such a facility; libraries that are accessed in this way are linked dynamically with the Java programs that call them.
So if these facilities are released under a GPL-incompatible license, the situation is like linking in any other way with a GPL-incompatible library. Which implies that:
- If you are writing code and releasing it under the GPL, you can state an explicit exception giving permission to link it with those GPL-incompatible facilities.
- If you wrote and released the program under the GPL, and you designed it specifically to work with those facilities, people can take that as an implicit exception permitting them to link it with those facilities. But if that is what you intend, it is better to say so explicitly.
- You can't take someone else's GPL-covered code and use it that way, or add such exceptions to it. Only the copyright holders of that code can add the exception.
- Who has the power to enforce the GPL?
(
[#WhoHasThePower](#WhoHasThePower)) Since the GPL is a copyright license, it can be enforced by the copyright holders of the software. If you see a violation of the GPL, you should inform the developers of the GPL-covered software involved. They either are the copyright holders, or are connected with the copyright holders.
In addition, we encourage the use of any legal mechanism available to users for obtaining complete and corresponding source code, as is their right, and enforcing full compliance with the GNU GPL. After all, we developed the GNU GPL to make software free for all its users.
- In an object-oriented language such as Java,
if I use a class that is GPLed without modifying, and subclass it,
in what way does the GPL affect the larger program?
(
[#OOPLang](#OOPLang)) Subclassing is creating a derivative work. Therefore, the terms of the GPL affect the whole program where you create a subclass of a GPLed class.
- If I port my program to GNU/Linux,
does that mean I have to release it as free software under the GPL
or some other Free Software license?
(
[#PortProgramToGPL](#PortProgramToGPL)) In general, the answer is no—this is not a legal requirement. In specific, the answer depends on which libraries you want to use and what their licenses are. Most system libraries either use the
[GNU Lesser GPL](/licenses/lgpl.html), or use the GNU GPL plus an exception permitting linking the library with anything. These libraries can be used in nonfree programs; but in the case of the Lesser GPL, it does have some requirements you must follow.Some libraries are released under the GNU GPL alone; you must use a GPL-compatible license to use those libraries. But these are normally the more specialized libraries, and you would not have had anything much like them on another platform, so you probably won't find yourself wanting to use these libraries for simple porting.
Of course, your software is not a contribution to our community if it is not free, and people who value their freedom will refuse to use it. Only people willing to give up their freedom will use your software, which means that it will effectively function as an inducement for people to lose their freedom.
If you hope some day to look back on your career and feel that it has contributed to the growth of a good and free society, you need to make your software free.
- I just found out that a company has a
copy of a GPLed program, and it costs money to get it. Aren't they
violating the GPL by not making it available on the Internet?
(
[#CompanyGPLCostsMoney](#CompanyGPLCostsMoney)) No. The GPL does not require anyone to use the Internet for distribution. It also does not require anyone in particular to redistribute the program. And (outside of one special case), even if someone does decide to redistribute the program sometimes, the GPL doesn't say he has to distribute a copy to you in particular, or any other person in particular.
What the GPL requires is that he must have the freedom to distribute a copy to you
*if he wishes to*. Once the copyright holder does distribute a copy of the program to someone, that someone can then redistribute the program to you, or to anyone else, as he sees fit.- Can I release a program with a license which
says that you can distribute modified versions of it under the GPL
but you can't distribute the original itself under the GPL?
(
[#ReleaseNotOriginal](#ReleaseNotOriginal)) No. Such a license would be self-contradictory. Let's look at its implications for me as a user.
Suppose I start with the original version (call it version A), add some code (let's imagine it is 1000 lines), and release that modified version (call it B) under the GPL. The GPL says anyone can change version B again and release the result under the GPL. So I (or someone else) can delete those 1000 lines, producing version C which has the same code as version A but is under the GPL.
If you try to block that path, by saying explicitly in the license that I'm not allowed to reproduce something identical to version A under the GPL by deleting those lines from version B, in effect the license now says that I can't fully use version B in all the ways that the GPL permits. In other words, the license does not in fact allow a user to release a modified version such as B under the GPL.
- Does moving a copy to a majority-owned,
and controlled, subsidiary constitute distribution?
(
[#DistributeSubsidiary](#DistributeSubsidiary)) Whether moving a copy to or from this subsidiary constitutes “distribution” is a matter to be decided in each case under the copyright law of the appropriate jurisdiction. The GPL does not and cannot override local laws. US copyright law is not entirely clear on the point, but appears not to consider this distribution.
If, in some country, this is considered distribution, and the subsidiary must receive the right to redistribute the program, that will not make a practical difference. The subsidiary is controlled by the parent company; rights or no rights, it won't redistribute the program unless the parent company decides to do so.
- Can software installers ask people
to click to agree to the GPL? If I get some software under the GPL,
do I have to agree to anything?
(
[#ClickThrough](#ClickThrough)) Some software packaging systems have a place which requires you to click through or otherwise indicate assent to the terms of the GPL. This is neither required nor forbidden. With or without a click through, the GPL's rules remain the same.
Merely agreeing to the GPL doesn't place any obligations on you. You are not required to agree to anything to merely use software which is licensed under the GPL. You only have obligations if you modify or distribute the software. If it really bothers you to click through the GPL, nothing stops you from hacking the GPLed software to bypass this.
- I would
like to bundle GPLed software with some sort of installation software.
Does that installer need to have a GPL-compatible license?
(
[#GPLCompatInstaller](#GPLCompatInstaller)) No. The installer and the files it installs are separate works. As a result, the terms of the GPL do not apply to the installation software.
- Some distributors of GPLed software
require me in their umbrella EULAs or as part of their downloading
process to “represent and warrant” that I am located in
the US or that I intend to distribute the software in compliance with
relevant export control laws. Why are they doing this and is it a
violation of those distributors' obligations under GPL?
(
[#ExportWarranties](#ExportWarranties)) This is not a violation of the GPL. Those distributors (almost all of whom are commercial businesses selling free software distributions and related services) are trying to reduce their own legal risks, not to control your behavior. Export control law in the United States
*might*make them liable if they knowingly export software into certain countries, or if they give software to parties they know will make such exports. By asking for these statements from their customers and others to whom they distribute software, they protect themselves in the event they are later asked by regulatory authorities what they knew about where software they distributed was going to wind up. They are not restricting what you can do with the software, only preventing themselves from being blamed with respect to anything you do. Because they are not placing additional restrictions on the software, they do not violate section 10 of GPLv3 or section 6 of GPLv2.The FSF opposes the application of US export control laws to free software. Not only are such laws incompatible with the general objective of software freedom, they achieve no reasonable governmental purpose, because free software is currently and should always be available from parties in almost every country, including countries that have no export control laws and which do not participate in US-led trade embargoes. Therefore, no country's government is actually deprived of free software by US export control laws, while no country's citizens
*should*be deprived of free software, regardless of their governments' policies, as far as we are concerned. Copies of all GPL-licensed software published by the FSF can be obtained from us without making any representation about where you live or what you intend to do. At the same time, the FSF understands the desire of commercial distributors located in the US to comply with US laws. They have a right to choose to whom they distribute particular copies of free software; exercise of that right does not violate the GPL unless they add contractual restrictions beyond those permitted by the GPL.- Can I use
GPLed software on a device that will stop operating if customers do
not continue paying a subscription fee?
(
[#SubscriptionFee](#SubscriptionFee)) No. In this scenario, the requirement to keep paying a fee limits the user's ability to run the program. This is an additional requirement on top of the GPL, and the license prohibits it.
- How do I upgrade from (L)GPLv2 to (L)GPLv3?
(
[#v3HowToUpgrade](#v3HowToUpgrade)) First, include the new version of the license in your package. If you're using LGPLv3 in your project, be sure to include copies of both GPLv3 and LGPLv3, since LGPLv3 is now written as a set of additional permissions on top of GPLv3.
Second, replace all your existing v2 license notices (usually at the top of each file) with the new recommended text available on
[the GNU licenses howto](/licenses/gpl-howto.html). It's more future-proof because it no longer includes the FSF's postal mailing address.Of course, any descriptive text (such as in a README) which talks about the package's license should also be updated appropriately.
- How does GPLv3 make BitTorrent distribution easier?
(
[#BitTorrent](#BitTorrent)) Because GPLv2 was written before peer-to-peer distribution of software was common, it is difficult to meet its requirements when you share code this way. The best way to make sure you are in compliance when distributing GPLv2 object code on BitTorrent would be to include all the corresponding source in the same torrent, which is prohibitively expensive.
GPLv3 addresses this problem in two ways. First, people who download this torrent and send the data to others as part of that process are not required to do anything. That's because section 9 says “Ancillary propagation of a covered work occurring solely as a consequence of using peer-to-peer transmission to receive a copy likewise does not require acceptance [of the license].”
Second, section 6(e) of GPLv3 is designed to give distributors—people who initially seed torrents—a clear and straightforward way to provide the source, by telling recipients where it is available on a public network server. This ensures that everyone who wants to get the source can do so, and it's almost no hassle for the distributor.
- What is tivoization? How does GPLv3 prevent it?
(
[#Tivoization](#Tivoization)) Some devices utilize free software that can be upgraded, but are designed so that users are not allowed to modify that software. There are lots of different ways to do this; for example, sometimes the hardware checksums the software that is installed, and shuts down if it doesn't match an expected signature. The manufacturers comply with GPLv2 by giving you the source code, but you still don't have the freedom to modify the software you're using. We call this practice tivoization.
When people distribute User Products that include software under GPLv3, section 6 requires that they provide you with information necessary to modify that software. User Products is a term specially defined in the license; examples of User Products include portable music players, digital video recorders, and home security systems.
- Does GPLv3 prohibit DRM?
(
[#DRMProhibited](#DRMProhibited)) It does not; you can use code released under GPLv3 to develop any kind of DRM technology you like. However, if you do this, section 3 says that the system will not count as an effective technological “protection” measure, which means that if someone breaks the DRM, she will be free to distribute her software too, unhindered by the DMCA and similar laws.
As usual, the GNU GPL does not restrict what people do in software, it just stops them from restricting others.
- Can I use the GPL to license hardware?
(
[#GPLHardware](#GPLHardware)) Any material that can be copyrighted can be licensed under the GPL. GPLv3 can also be used to license materials covered by other copyright-like laws, such as semiconductor masks. So, as an example, you can release a drawing of a physical object or circuit under the GPL.
In many situations, copyright does not cover making physical hardware from a drawing. In these situations, your license for the drawing simply can't exert any control over making or selling physical hardware, regardless of the license you use. When copyright does cover making hardware, for instance with IC masks, the GPL handles that case in a useful way.
- I use public key cryptography to sign my code to
assure its authenticity. Is it true that GPLv3 forces me to release
my private signing keys?
(
[#GiveUpKeys](#GiveUpKeys)) No. The only time you would be required to release signing keys is if you conveyed GPLed software inside a User Product, and its hardware checked the software for a valid cryptographic signature before it would function. In that specific case, you would be required to provide anyone who owned the device, on demand, with the key to sign and install modified software on the device so that it will run. If each instance of the device uses a different key, then you need only give each purchaser a key for that instance.
- Does GPLv3 require that voters be able to
modify the software running in a voting machine?
(
[#v3VotingMachine](#v3VotingMachine)) No. Companies distributing devices that include software under GPLv3 are at most required to provide the source and Installation Information for the software to people who possess a copy of the object code. The voter who uses a voting machine (like any other kiosk) doesn't get possession of it, not even temporarily, so the voter also does not get possession of the binary software in it.
Note, however, that voting is a very special case. Just because the software in a computer is free does not mean you can trust the computer for voting. We believe that computers cannot be trusted for voting. Voting should be done on paper.
- Does GPLv3 have a “patent retaliation
clause”?
(
[#v3PatentRetaliation](#v3PatentRetaliation)) In effect, yes. Section 10 prohibits people who convey the software from filing patent suits against other licensees. If someone did so anyway, section 8 explains how they would lose their license and any patent licenses that accompanied it.
- Can I use snippets of GPL-covered
source code within documentation that is licensed under some license
that is incompatible with the GPL?
(
[#SourceCodeInDocumentation](#SourceCodeInDocumentation)) If the snippets are small enough that you can incorporate them under fair use or similar laws, then yes. Otherwise, no.
- The beginning of GPLv3 section 6 says that I can
convey a covered work in object code form “under the terms of
sections 4 and 5” provided I also meet the conditions of
section 6. What does that mean?
(
[#v3Under4and5](#v3Under4and5)) This means that all the permissions and conditions you have to convey source code also apply when you convey object code: you may charge a fee, you must keep copyright notices intact, and so on.
- My company owns a lot of patents.
Over the years we've contributed code to projects under “GPL
version 2 or any later version”, and the project itself has
been distributed under the same terms. If a user decides to take the
project's code (incorporating my contributions) under GPLv3, does
that mean I've automatically granted GPLv3's explicit patent license
to that user?
(
[#v2OrLaterPatentLicense](#v2OrLaterPatentLicense)) No. When you convey GPLed software, you must follow the terms and conditions of one particular version of the license. When you do so, that version defines the obligations you have. If users may also elect to use later versions of the GPL, that's merely an additional permission they have—it does not require you to fulfill the terms of the later version of the GPL as well.
Do not take this to mean that you can threaten the community with your patents. In many countries, distributing software under GPLv2 provides recipients with an implicit patent license to exercise their rights under the GPL. Even if it didn't, anyone considering enforcing their patents aggressively is an enemy of the community, and we will defend ourselves against such an attack.
- If I distribute a proprietary
program that links against an LGPLv3-covered library that I've
modified, what is the “contributor version” for purposes of
determining the scope of the explicit patent license grant I'm
making—is it just the library, or is it the whole
combination?
(
[#LGPLv3ContributorVersion](#LGPLv3ContributorVersion)) The “contributor version” is only your version of the library.
- Is GPLv3 compatible with GPLv2?
(
[#v2v3Compatibility](#v2v3Compatibility)) No. Many requirements have changed from GPLv2 to GPLv3, which means that the precise requirement of GPLv2 is not present in GPLv3, and vice versa. For instance, the Termination conditions of GPLv3 are considerably more permissive than those of GPLv2, and thus different from the Termination conditions of GPLv2.
Due to these differences, the two licenses are not compatible: if you tried to combine code released under GPLv2 with code under GPLv3, you would violate section 6 of GPLv2.
However, if code is released under GPL “version 2 or later,” that is compatible with GPLv3 because GPLv3 is one of the options it permits.
- Does GPLv2 have a requirement about delivering installation
information?
(
[#InstInfo](#InstInfo)) GPLv3 explicitly requires redistribution to include the full necessary “Installation Information.” GPLv2 doesn't use that term, but it does require redistribution to include
scripts used to control compilation and installation of the executable
with the complete and corresponding source code. This covers part, but not all, of what GPLv3 calls “Installation Information.” Thus, GPLv3's requirement about installation information is stronger.- What does it mean to “cure” a violation of GPLv3?
(
[#Cure](#Cure)) To cure a violation means to adjust your practices to comply with the requirements of the license.
- The warranty and liability
disclaimers in GPLv3 seem specific to U.S. law. Can I add my own
disclaimers to my own code?
(
[#v3InternationalDisclaimers](#v3InternationalDisclaimers)) Yes. Section 7 gives you permission to add your own disclaimers, specifically 7(a).
- My program has interactive user
interfaces that are non-visual in nature. How can I comply with the
Appropriate Legal Notices requirement in GPLv3?
(
[#NonvisualLegalNotices](#NonvisualLegalNotices)) All you need to do is ensure that the Appropriate Legal Notices are readily available to the user in your interface. For example, if you have written an audio interface, you could include a command that reads the notices aloud.
- If I give a copy of a GPLv3-covered
program to a coworker at my company, have I “conveyed” the
copy to that coworker?
(
[#v3CoworkerConveying](#v3CoworkerConveying)) As long as you're both using the software in your work at the company, rather than personally, then the answer is no. The copies belong to the company, not to you or the coworker. This copying is propagation, not conveying, because the company is not making copies available to others.
- If I distribute a GPLv3-covered
program, can I provide a warranty that is voided if the user modifies
the program?
(
[#v3ConditionalWarranty](#v3ConditionalWarranty)) Yes. Just as devices do not need to be warranted if users modify the software inside them, you are not required to provide a warranty that covers all possible activities someone could undertake with GPLv3-covered software.
- Why did you decide to write the GNU Affero GPLv3
as a separate license?
(
[#SeparateAffero](#SeparateAffero)) Early drafts of GPLv3 allowed licensors to add an Affero-like requirement to publish source in section 7. However, some companies that develop and rely upon free software consider this requirement to be too burdensome. They want to avoid code with this requirement, and expressed concern about the administrative costs of checking code for this additional requirement. By publishing the GNU Affero GPLv3 as a separate license, with provisions in it and GPLv3 to allow code under these licenses to link to each other, we accomplish all of our original goals while making it easier to determine which code has the source publication requirement.
- Why did you invent the new terms
“propagate” and “convey” in GPLv3?
(
[#WhyPropagateAndConvey](#WhyPropagateAndConvey)) The term “distribute” used in GPLv2 was borrowed from United States copyright law. Over the years, we learned that some jurisdictions used this same word in their own copyright laws, but gave it different meanings. We invented these new terms to make our intent as clear as possible no matter where the license is interpreted. They are not used in any copyright law in the world, and we provide their definitions directly in the license.
- I'd like to license my code under the GPL, but I'd
also like to make it clear that it can't be used for military and/or
commercial uses. Can I do this?
(
[#NoMilitary](#NoMilitary)) No, because those two goals contradict each other. The GNU GPL is designed specifically to prevent the addition of further restrictions. GPLv3 allows a very limited set of them, in section 7, but any other added restriction can be removed by the user.
More generally, a license that limits who can use a program, or for what, is
[not a free software license](/philosophy/programs-must-not-limit-freedom-to-run.html).- Is “convey” in GPLv3 the same
thing as what GPLv2 means by “distribute”?
(
[#ConveyVsDistribute](#ConveyVsDistribute)) Yes, more or less. During the course of enforcing GPLv2, we learned that some jurisdictions used the word “distribute” in their own copyright laws, but gave it different meanings. We invented a new term to make our intent clear and avoid any problems that could be caused by these differences.
- GPLv3 gives “making available to the
public” as an example of propagation. What does this mean?
Is making available a form of conveying?
(
[#v3MakingAvailable](#v3MakingAvailable)) One example of “making available to the public” is putting the software on a public web or FTP server. After you do this, some time may pass before anybody actually obtains the software from you—but because it could happen right away, you need to fulfill the GPL's obligations right away as well. Hence, we defined conveying to include this activity.
- Since distribution and making
available to the public are forms of propagation that are also
conveying in GPLv3, what are some examples of propagation that do not
constitute conveying?
(
[#PropagationNotConveying](#PropagationNotConveying)) Making copies of the software for yourself is the main form of propagation that is not conveying. You might do this to install the software on multiple computers, or to make backups.
- Does prelinking a
GPLed binary to various libraries on the system, to optimize its
performance, count as modification?
(
[#Prelinking](#Prelinking)) No. Prelinking is part of a compilation process; it doesn't introduce any license requirements above and beyond what other aspects of compilation would. If you're allowed to link the program to the libraries at all, then it's fine to prelink with them as well. If you distribute prelinked object code, you need to follow the terms of section 6.
- If someone installs GPLed software on a laptop, and
then lends that laptop to a friend without providing source code for
the software, have they violated the GPL?
(
[#LaptopLoan](#LaptopLoan)) No. In the jurisdictions where we have investigated this issue, this sort of loan would not count as conveying. The laptop's owner would not have any obligations under the GPL.
- Suppose that two companies try to
circumvent the requirement to provide Installation Information by
having one company release signed software, and the other release a
User Product that only runs signed software from the first company. Is
this a violation of GPLv3?
(
[#TwoPartyTivoization](#TwoPartyTivoization)) Yes. If two parties try to work together to get around the requirements of the GPL, they can both be pursued for copyright infringement. This is especially true since the definition of convey explicitly includes activities that would make someone responsible for secondary infringement.
- Am I complying with GPLv3 if I offer binaries on an
FTP server and sources by way of a link to a source code repository
in a version control system, like CVS or Subversion?
(
[#SourceInCVS](#SourceInCVS)) This is acceptable as long as the source checkout process does not become burdensome or otherwise restrictive. Anybody who can download your object code should also be able to check out source from your version control system, using a publicly available free software client. Users should be provided with clear and convenient instructions for how to get the source for the exact object code they downloaded—they may not necessarily want the latest development code, after all.
- Can someone who conveys GPLv3-covered
software in a User Product use remote attestation to prevent a user
from modifying that software?
(
[#RemoteAttestation](#RemoteAttestation)) No. The definition of Installation Information, which must be provided with source when the software is conveyed inside a User Product, explicitly says: “The information must suffice to ensure that the continued functioning of the modified object code is in no case prevented or interfered with solely because modification has been made.” If the device uses remote attestation in some way, the Installation Information must provide you some means for your modified software to report itself as legitimate.
- What does “rules and protocols for
communication across the network” mean in GPLv3?
(
[#RulesProtocols](#RulesProtocols)) This refers to rules about traffic you can send over the network. For example, if there is a limit on the number of requests you can send to a server per day, or the size of a file you can upload somewhere, your access to those resources may be denied if you do not respect those limits.
These rules do not include anything that does not pertain directly to data traveling across the network. For instance, if a server on the network sent messages for users to your device, your access to the network could not be denied merely because you modified the software so that it did not display the messages.
- Distributors that provide Installation Information
under GPLv3 are not required to provide “support service”
for the product. What kind of “support service”do you mean?
(
[#SupportService](#SupportService)) This includes the kind of service many device manufacturers provide to help you install, use, or troubleshoot the product. If a device relies on access to web services or similar technology to function properly, those should normally still be available to modified versions, subject to the terms in section 6 regarding access to a network.
- In GPLv3 and AGPLv3, what does it mean when it
says “notwithstanding any other provision of this License”?
(
[#v3Notwithstanding](#v3Notwithstanding)) This simply means that the following terms prevail over anything else in the license that may conflict with them. For example, without this text, some people might have claimed that you could not combine code under GPLv3 with code under AGPLv3, because the AGPL's additional requirements would be classified as “further restrictions” under section 7 of GPLv3. This text makes clear that our intended interpretation is the correct one, and you can make the combination.
This text only resolves conflicts between different terms of the license. When there is no conflict between two conditions, then you must meet them both. These paragraphs don't grant you carte blanche to ignore the rest of the license—instead they're carving out very limited exceptions.
- Under AGPLv3, when I modify the Program
under section 13, what Corresponding Source does it have to offer?
(
[#AGPLv3CorrespondingSource](#AGPLv3CorrespondingSource)) “Corresponding Source” is defined in section 1 of the license, and you should provide what it lists. So, if your modified version depends on libraries under other licenses, such as the Expat license or GPLv3, the Corresponding Source should include those libraries (unless they are System Libraries). If you have modified those libraries, you must provide your modified source code for them.
The last sentence of the first paragraph of section 13 is only meant to reinforce what most people would have naturally assumed: even though combinations with code under GPLv3 are handled through a special exception in section 13, the Corresponding Source should still include the code that is combined with the Program this way. This sentence does not mean that you
*only*have to provide the source that's covered under GPLv3; instead it means that such code is*not*excluded from the definition of Corresponding Source.- In AGPLv3, what counts as
“interacting with [the software] remotely through a computer
network?”
(
[#AGPLv3InteractingRemotely](#AGPLv3InteractingRemotely)) If the program is expressly designed to accept user requests and send responses over a network, then it meets these criteria. Common examples of programs that would fall into this category include web and mail servers, interactive web-based applications, and servers for games that are played online.
If a program is not expressly designed to interact with a user through a network, but is being run in an environment where it happens to do so, then it does not fall into this category. For example, an application is not required to provide source merely because the user is running it over SSH, or a remote X session.
- How does GPLv3's concept of
“you” compare to the definition of “Legal Entity”
in the Apache License 2.0?
(
[#ApacheLegalEntity](#ApacheLegalEntity)) They're effectively identical. The definition of “Legal Entity” in the Apache License 2.0 is very standard in various kinds of legal agreements—so much so that it would be very surprising if a court did not interpret the term in the same way in the absence of an explicit definition. We fully expect them to do the same when they look at GPLv3 and consider who qualifies as a licensee.
- In GPLv3, what does “the Program”
refer to? Is it every program ever released under GPLv3?
(
[#v3TheProgram](#v3TheProgram)) The term “the Program” means one particular work that is licensed under GPLv3 and is received by a particular licensee from an upstream licensor or distributor. The Program is the particular work of software that you received in a given instance of GPLv3 licensing, as you received it.
“The Program” cannot mean “all the works ever licensed under GPLv3”; that interpretation makes no sense for a number of reasons. We've published an
[analysis of the term “the Program”](/licenses/gplv3-the-program.html)for those who would like to learn more about this.- If I only make copies of a
GPL-covered program and run them, without distributing or conveying them to
others, what does the license require of me?
(
[#NoDistributionRequirements](#NoDistributionRequirements)) Nothing. The GPL does not place any conditions on this activity.
- If some network client software is
released under AGPLv3, does it have to be able to provide source to
the servers it interacts with?
(
[#AGPLv3ServerAsUser](#AGPLv3ServerAsUser)) -
AGPLv3 requires a program to offer source code to “all users interacting with it remotely through a computer network.” It doesn't matter if you call the program a “client” or a “server,” the question you need to ask is whether or not there is a reasonable expectation that a person will be interacting with the program remotely over a network.
- For software that runs a proxy server licensed
under the AGPL, how can I provide an offer of source to users
interacting with that code?
(
[#AGPLProxy](#AGPLProxy)) For software on a proxy server, you can provide an offer of source through a normal method of delivering messages to users of that kind of proxy. For example, a Web proxy could use a landing page. When users initially start using the proxy, you can direct them to a page with the offer of source along with any other information you choose to provide.
The AGPL says you must make the offer to “all users.” If you know that a certain user has already been shown the offer, for the current version of the software, you don't have to repeat it to that user again.
- How are the various GNU licenses
compatible with each other?
(
[#AllCompatibility](#AllCompatibility)) The various GNU licenses enjoy broad compatibility between each other. The only time you may not be able to combine code under two of these licenses is when you want to use code that's
*only*under an older version of a license with code that's under a newer version.Below is a detailed compatibility matrix for various combinations of the GNU licenses, to provide an easy-to-use reference for specific cases. It assumes that someone else has written some software under one of these licenses, and you want to somehow incorporate code from that into a project that you're releasing (either your own original work, or a modified version of someone else's software). Find the license for your project in a column at the top of the table, and the license for the other code in a row on the left. The cell where they meet will tell you whether or not this combination is permitted.
When we say “copy code,” we mean just that: you're taking a section of code from one source, with or without modification, and inserting it into your own program, thus forming a work based on the first section of code. “Use a library” means that you're not copying any source directly, but instead interacting with it through linking, importing, or other typical mechanisms that bind the sources together when you compile or run the code.
Each place that the matrix states GPLv3, the same statement about compatibility is true for AGPLv3 as well.
I want to license my code under: | |||||||
---|---|---|---|---|---|---|---|
GPLv2 only | GPLv2 or later | GPLv3 or later | LGPLv2.1 only | LGPLv2.1 or later | LGPLv3 or later | ||
I want to copy code under: | GPLv2 only | OK | OK
|
[[7]](#compat-matrix-footnote-7)[[7]](#compat-matrix-footnote-7)[[2]](#compat-matrix-footnote-2)[[1]](#compat-matrix-footnote-1)[[7]](#compat-matrix-footnote-7)[[7]](#compat-matrix-footnote-7)[[8]](#compat-matrix-footnote-8)[[3]](#compat-matrix-footnote-3)[[7]](#compat-matrix-footnote-7)[[7]](#compat-matrix-footnote-7)[[8]](#compat-matrix-footnote-8)[[7]](#compat-matrix-footnote-7)[[7]](#compat-matrix-footnote-7)[[7]](#compat-matrix-footnote-7)[[6]](#compat-matrix-footnote-6)[[7]](#compat-matrix-footnote-7)[[8]](#compat-matrix-footnote-8)[[7]](#compat-matrix-footnote-7)[[1]](#compat-matrix-footnote-1)[[7]](#compat-matrix-footnote-7)[[7]](#compat-matrix-footnote-7)[[5]](#compat-matrix-footnote-5)[[8]](#compat-matrix-footnote-8)[[3]](#compat-matrix-footnote-3)[[8]](#compat-matrix-footnote-8)[[7]](#compat-matrix-footnote-7)[[8]](#compat-matrix-footnote-8)[[4]](#compat-matrix-footnote-4)[[2]](#compat-matrix-footnote-2)[[7]](#compat-matrix-footnote-7)[[7]](#compat-matrix-footnote-7)[[2]](#compat-matrix-footnote-2)[[1]](#compat-matrix-footnote-1)[[7]](#compat-matrix-footnote-7)[[7]](#compat-matrix-footnote-7)[[8]](#compat-matrix-footnote-8)[[3]](#compat-matrix-footnote-3)[[7]](#compat-matrix-footnote-7)[[7]](#compat-matrix-footnote-7)[[8]](#compat-matrix-footnote-8)[[9]](#compat-matrix-footnote-9)1: You must follow the terms of GPLv2 when incorporating the code in this case. You cannot take advantage of terms in later versions of the GPL.
2: While you may release under GPLv2-or-later both your original work, and/or modified versions of work you received under GPLv2-or-later, the GPLv2-only code that you're using must remain under GPLv2 only. As long as your project depends on that code, you won't be able to upgrade the license of your own code to GPLv3-or-later, and the work as a whole (any combination of both your project and the other code) can only be conveyed under the terms of GPLv2.
3: If you have the ability to release the project under GPLv2 or any later version, you can choose to release it under GPLv3 or any later version—and once you do that, you'll be able to incorporate the code released under GPLv3.
4: If you have the ability to release the project under LGPLv2.1 or any later version, you can choose to release it under LGPLv3 or any later version—and once you do that, you'll be able to incorporate the code released under LGPLv3.
5: You must follow the terms of LGPLv2.1 when incorporating the code in this case. You cannot take advantage of terms in later versions of the LGPL.
6: If you do this, as long as the project contains the code released under LGPLv2.1 only, you will not be able to upgrade the project's license to LGPLv3 or later.
7: LGPLv2.1 gives you permission to relicense the code under any version of the GPL since GPLv2. If you can switch the LGPLed code in this case to using an appropriate version of the GPL instead (as noted in the table), you can make this combination.
8: LGPLv3 is GPLv3 plus extra permissions that you can ignore in this case.
9: Because GPLv2 does not permit combinations with LGPLv3, you must convey the project under GPLv3's terms in this case, since it will allow that combination. |
9,827 | 如何在 Fedora 上安装 Pipenv | https://fedoramagazine.org/install-pipenv-fedora/ | 2018-07-11T15:01:52 | [
"Pipenv",
"Python"
] | https://linux.cn/article-9827-1.html | 
Pipenv 的目标是将打包界(bundler、composer、npm、cargo、yarn 等)最好的东西带到 Python 世界来。它试图解决一些问题,并简化整个管理过程。
目前,Python 程序依赖项的管理有时似乎是一个挑战。开发人员通常为每个新项目创建一个[虚拟环境](https://packaging.python.org/tutorials/installing-packages/#creating-virtual-environments),并使用 [pip](https://developer.fedoraproject.org/tech/languages/python/pypi-installation.html) 将依赖项安装到其中。此外,他们必须将已安装的软件包的集合保存到 `requirements.txt` 文件中。我们看到过许多旨在自动化此工作流程的工具和包装程序。但是,仍然需要结合多个程序,并且 `requirements.txt` 格式本身并不适用于更复杂的场景。
### 一个统治它们的工具
Pipenv 可以正确地管理复杂的相互依赖关系,它还提供已安装包的手动记录。例如,开发、测试和生产环境通常需要一组不同的包。过去,每个项目需要维护多个 `requirements.txt`。Pipenv 使用 [TOML](https://github.com/toml-lang/toml) 语法引入了新的 [Pipfile](https://github.com/pypa/pipfile) 格式。多亏这种格式,你终于可以在单个文件中维护不同环境的多组需求。
在将第一行代码提交到项目中仅一年后,Pipenv 已成为管理 Python 程序依赖关系的官方推荐工具。现在它终于在 Fedora 仓库中提供。
### 在 Fedora 上安装 Pipenv
在全新安装 Fedora 28 及更高版本后,你只需在终端上运行此命令即可安装 Pipenv:
```
$ sudo dnf install pipenv
```
现在,你的系统已准备好在 Pipenv 的帮助下开始使用新的 Python 3 程序。
重要的是,虽然这个工具为程序提供了很好的解决方案,但它并不是为处理库需求而设计的。编写 Python 库时,不需要固定依赖项。你应该在 `setup.py` 文件中指定 `install_requires`。
### 基本依赖管理
首先为项目创建一个目录:
```
$ mkdir new-project && cd new-project
```
接下来是为此项目创建虚拟环境:
```
$ pipenv --three
```
这里的 `-three` 选项将虚拟环境的 Python 版本设置为 Python 3。
安装依赖项:
```
$ pipenv install requests
Installing requests…
Adding requests to Pipfile's [packages]…
Pipfile.lock not found, creating…
Locking [dev-packages] dependencies…
Locking [packages] dependencies…
```
最后生成 lockfile:
```
$ pipenv lock
Locking [dev-packages] dependencies…
Locking [packages] dependencies…
Updated Pipfile.lock (b14837)
```
你还可以检查依赖关系图:
```
$ pipenv graph
- certifi [required: >=2017.4.17, installed: 2018.4.16]
- chardet [required: <3.1.0,>=3.0.2, installed: 3.0.4]
- idna [required: <2.8,>=2.5, installed: 2.7]
- urllib3 [required: >=1.21.1,<1.24, installed: 1.23]
```
有关 Pipenv 及其命令的更多详细信息,请参见[文档](https://docs.pipenv.org/)。
---
via: <https://fedoramagazine.org/install-pipenv-fedora/>
作者:[Michal Cyprian](https://fedoramagazine.org/author/mcyprian/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Pipenv aims to bring the best of all packaging worlds (bundler, composer, npm, cargo, yarn, etc.) to the Python world. It tries to solve a couple of problems and also simplify the whole management process.
Currently the management of Python application dependencies sometimes seems like a bit of a challenge. Developers usually create a [ virtual environment](https://packaging.python.org/tutorials/installing-packages/#creating-virtual-environments) for each new project and install dependencies into it using
[. In addition they have to store the set of installed packages into the](https://developer.fedoraproject.org/tech/languages/python/pypi-installation.html)
*pip**requirements.txt*text file. We’ve seen many tools and wrappers that aim to automate this workflow. However, there was still necessity to combine multiple utilities and the
*requirements.txt*format itself is not ideal for more complicated scenarios.
**One** t**ool** **to** r**ule** t**hem** a**ll**
Pipenv manages complex inter-dependencies properly and it also provides manual documenting of installed packages. For example development, testing and production environments often require a different set of packages. It used to be necessary to maintain multiple *requirements.txt* per project. Pipenv introduces the new [Pipfile](https://github.com/pypa/pipfile) format using [TOML](https://github.com/toml-lang/toml) syntax. Thanks to this format, you can finally maintain multiple set of requirement for different environments in a single file.
Pipenv has become the officially recommended tool for managing Python application dependencies only a year after the first lines of code were committed into the project. Now it is finally available as an package in Fedora repositories as well.
## Installing Pipenv on Fedora
On clean installation of Fedora 28 and later you can simply install Pipenv by running this command at the terminal:
$ sudo dnf install pipenv
Your system is now ready to start working on your new Python 3 application with help of Pipenv.
The important point is that while this tool provides nice solution for the applications, it is not designed for dealing with library requirements. When writing a Python library, pinning dependencies is not desirable. You should rather specify *install_requires* in *setup.py *file.
## Basic dependencies management
Create a directory for your project first:
$mkdir new-project && cd new-project
Another step is to create a virtual environment for this project:
$pipenv --three
The *–three *option here sets the Python version of the virtual environment to Python 3.
Install dependencies:
$pipenv install requestsInstalling requests… Adding requests to Pipfile's [packages]… Pipfile.lock not found, creating… Locking [dev-packages] dependencies… Locking [packages] dependencies…
Finally generate a lockfile:
$pipenv lockLocking [dev-packages] dependencies… Locking [packages] dependencies… Updated Pipfile.lock (b14837)
You can also check a dependency graph:
$pipenv graph- certifi [required: >=2017.4.17, installed: 2018.4.16] - chardet [required: <3.1.0,>=3.0.2, installed: 3.0.4] - idna [required: <2.8,>=2.5, installed: 2.7] - urllib3 [required: >=1.21.1,<1.24, installed: 1.23]
More details on Pipenv and it commands are available in the [documentation](https://docs.pipenv.org/).
## mehdi
Great article! Gives good insight into Python even for a non-Python (but Python-curious) developer!
## Adriano Braga
I find it unnecessary to install pipenv on your system, since python3.6 already brings pyvenv-3.6
You can create your isolated environment using python3.6 with the second command:
python3.6 -m venv namemyvenv
## Miro Hrončok
Note that pipenv is a tool built on top of venv/virtualenv. It brings more than just the stdlib’s venv tool.
## Frafra
I also suggest to have a look at Fades: https://fades.readthedocs.io/
## jg424
Relevant xkcd: https://xkcd.com/927/
## Allad Syrad
What an awesome tool. So happy to see it packaged in Fedora. Thanks for making this available.
## Batisteo
One should have a look at Poetry, it’s basically as awesome as Cargo for Python, based on PEP 508, and way more pythonic than Pipenv, covering more use cases.
This should be the recommenced one.
http://poetry.eustace.io/ |
9,828 | 你应该了解的 6 个开源 AI 工具 | https://www.linux.com/blog/2018/6/6-open-source-ai-tools-know | 2018-07-12T10:00:00 | [
"AI"
] | https://linux.cn/article-9828-1.html |
>
> 让我们来看看几个任何人都能用的自由开源的 AI 工具。
>
>
>

在开源领域,不管你的想法是多少的新颖独到,先去看一下别人是否已经做成了这个概念,总是一个很明智的做法。对于有兴趣借助不断成长的<ruby> 人工智能 <rt> Artificial Intelligence </rt></ruby>(AI)的力量的组织和个人来说,许多优秀的工具不仅是自由开源的,而且在很多的情况下,它们都已经过测试和久经考验的。
在领先的公司和非盈利组织中,AI 的优先级都非常高,并且这些公司和组织都开源了很有价值的工具。下面的举例是任何人都可以使用的自由开源的 AI 工具。
### Acumos
[Acumos AI](https://www.acumos.org/) 是一个平台和开源框架,使用它可以很容易地去构建、共享和分发 AI 应用。它规范了运行一个“开箱即用的”通用 AI 环境所需要的<ruby> 基础设施栈 <rt> infrastructure stack </rt></ruby>和组件。这使得数据科学家和模型训练者可以专注于它们的核心竞争力,而不用在无止境的定制、建模,以及训练一个 AI 实现上浪费时间。
Acumos 是 [LF 深度学习基金会](https://www.linuxfoundation.org/projects/deep-learning/) 的一部分,它是 Linux 基金会中的一个组织,它支持在人工智能、<ruby> 机器学习 <rt> machine learning </rt></ruby>、以及<ruby> 深度学习 <rt> deep learning </rt></ruby>方面的开源创新。它的目标是让这些重大的新技术可用于开发者和数据科学家,包括那些在深度学习和 AI 上经验有限的人。LF 深度学习基金会 [最近批准了一个项目生命周期和贡献流程](https://www.linuxfoundation.org/blog/lf-deep-learning-foundation-announces-project-contribution-process/),并且它现在正接受项目贡献的建议。
### Facebook 的框架
Facebook [开源了](https://code.facebook.com/posts/1687861518126048/facebook-to-open-source-ai-hardware-design/) 其中心机器学习系统,它设计用于做一些大规模的人工智能任务,以及一系列其它的 AI 技术。这个工具是经过他们公司验证使用的平台的一部分。Facebook 也开源了一个叫 [Caffe2](https://venturebeat.com/2017/04/18/facebook-open-sources-caffe2-a-new-deep-learning-framework/) 的深度学习和人工智能的框架。
### CaffeOnSpark
**说到 Caffe**。 Yahoo 也在开源许可证下发布了它自己的关键的 AI 软件。[CaffeOnSpark 工具](http://yahoohadoop.tumblr.com/post/139916563586/caffeonspark-open-sourced-for-distributed-deep) 是基于深度学习的,它是人工智能的一个分支,在帮助机器识别人类语言,或者照片、视频的内容方面非常有用。同样地,IBM 的机器学习程序 [SystemML](https://systemml.apache.org/) 可以通过 Apache 软件基金会自由地共享和修改。
### Google 的工具
Google 花费了几年的时间开发了它自己的 [TensorFlow](https://www.tensorflow.org/) 软件框架,用于去支持它的 AI 软件和其它预测和分析程序。TensorFlow 是你可能都已经在使用的一些 Google 工具背后的引擎,包括 Google Photos 和在 Google app 中使用的语言识别。
Google 开源了两个 [AIY 套件](https://www.techradar.com/news/google-assistant-sweetens-raspberry-pi-with-ai-voice-control),它可以让个人很容易地使用人工智能,它们专注于计算机视觉和语音助理。这两个套件将用到的所有组件封装到一个盒子中。该套件目前在美国的 Target 中有售,并且它是基于开源的树莓派平台的 —— 有越来越多的证据表明,在开源和 AI 交集中将发生非常多的事情。
### H2O.ai
我 [以前介绍过](https://www.linux.com/news/sparkling-water-bridging-open-source-machine-learning-and-apache-spark) H2O.ai,它在机器学习和人工智能领域中占有一席之地,因为它的主要工具是自由开源的。你可以获取主要的 H2O 平台和 Sparkling Water,它与 Apache Spark 一起工作,只需要去 [下载](http://www.h2o.ai/download) 它们即可。这些工具遵循 Apache 2.0 许可证,它是一个非常灵活的开源许可证,你甚至可以在 Amazon Web 服务(AWS)和其它的集群上运行它们,而这仅需要几百美元而已。
### Microsoft 入局
“我们的目标是让 AI 大众化,让每个人和组织获得更大的成就,“ Microsoft CEO 萨提亚·纳德拉 [说](https://blogs.msdn.microsoft.com/uk_faculty_connection/2017/02/10/microsoft-cognitive-toolkit-cntk/)。因此,微软持续迭代它的 [Microsoft Cognitive Toolkit](https://www.microsoft.com/en-us/cognitive-toolkit/)(CNTK)。它是一个能够与 TensorFlow 和 Caffe 去竞争的一个开源软件框架。Cognitive Toolkit 可以工作在 64 位的 Windows 和 Linux 平台上。
Cognitive Toolkit 团队的报告称,“Cognitive Toolkit 通过允许用户去创建、训练,以及评估他们自己的神经网络,以使企业级的、生产系统级的 AI 成为可能,这些神经网络可能跨多个 GPU 以及多个机器在大量的数据集中高效伸缩。”
---
从来自 Linux 基金会的新电子书中学习更多的有关 AI 知识。Ibrahim Haddad 的 [开源 AI:项目、洞察和趋势](https://www.linuxfoundation.org/publications/open-source-ai-projects-insights-and-trends/) 调查了 16 个流行的开源 AI 项目—— 深入研究了他们的历史、代码库、以及 GitHub 的贡献。 [现在可以免费下载这个电子书](https://www.linuxfoundation.org/publications/open-source-ai-projects-insights-and-trends/)。
---
via: <https://www.linux.com/blog/2018/6/6-open-source-ai-tools-know>
作者:[Sam Dean](https://www.linux.com/users/sam-dean) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[pityonline](https://github.com/pityonline), [wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,829 | 在 Linux 命令行中自定义文本颜色 | https://www.networkworld.com/article/3269587/linux/customizing-your-text-colors-on-the-linux-command-line.html | 2018-07-12T10:59:00 | [
"终端",
"颜色"
] | https://linux.cn/article-9829-1.html |
>
> 在 Linux 命令行当中使用不同颜色以期提供一种根据文件类型来识别文件的简单方式。你可以修改这些颜色,但是在做之前应该对你做的事情有充分的理由。
>
>
>

如果你在 Linux 命令行上花费了大量的时间(如果没有,那么你可能不会读这篇文章),你无疑注意到了 `ls` 以多种不同的颜色显示文件。你可能也注意到了一些区别 —— 目录是一种颜色,可执行文件是另一种颜色等等。
这一切是如何发生的呢?以及,你可以选择哪些选项来改变颜色分配可能就不是很多人都知道的。
一种方法是运行 `dircolors` 命令得到一大堆展示了如何指定这些颜色的数据。它会显示以下这些东西:
```
$ dircolors
LS_COLORS='rs=0:di=01;34:ln=01;36:mh=00:pi=40;33:so=01;35:do
=01;35:bd=40;33;01:cd=40;33;01:or=40;31;01:mi=00:su=37;41:sg
=30;43:ca=30;41:tw=30;42:ow=34;42:st=37;44:ex=01;32:*.tar=01
;31:*.tgz=01;31:*.arc=01;31:*.arj=01;31:*.taz=01;31:*.lha=01
;31:*.lz4=01;31:*.lzh=01;31:*.lzma=01;31:*.tlz=01;31:*.txz=0
1;31:*.tzo=01;31:*.t7z=01;31:*.zip=01;31:*.z=01;31:*.Z=01;31
:*.dz=01;31:*.gz=01;31:*.lrz=01;31:*.lz=01;31:*.lzo=01;31:*.
xz=01;31:*.zst=01;31:*.tzst=01;31:*.bz2=01;31:*.bz=01;31:*.t
bz=01;31:*.tbz2=01;31:*.tz=01;31:*.deb=01;31:*.rpm=01;31:*.j
ar=01;31:*.war=01;31:*.ear=01;31:*.sar=01;31:*.rar=01;31:*.a
lz=01;31:*.ace=01;31:*.zoo=01;31:*.cpio=01;31:*.7z=01;31:*.r
z=01;31:*.cab=01;31:*.jpg=01;35:*.jpeg=01;35:*.mjpg=01;35:*.
mjpeg=01;35:*.gif=01;35:*.bmp=01;35:*.pbm=01;35:*.pgm=01;35:
*.ppm=01;35:*.tga=01;35:*.xbm=01;35:*.xpm=01;35:*.tif=01;35:
*.tiff=01;35:*.png=01;35:*.svg=01;35:*.svgz=01;35:*.mng=01;3
5:*.pcx=01;35:*.mov=01;35:*.mpg=01;35:*.mpeg=01;35:*.m2v=01;
35:*.mkv=01;35:*.webm=01;35:*.ogm=01;35:*.mp4=01;35:*.m4v=01
;35:*.mp4v=01;35:*.vob=01;35:*.qt=01;35:*.nuv=01;35:*.wmv=01
;35:*.asf=01;35:*.rm=01;35:*.rmvb=01;35:*.flc=01;35:*.avi=01
;35:*.fli=01;35:*.flv=01;35:*.gl=01;35:*.dl=01;35:*.xcf=01;3
5:*.xwd=01;35:*.yuv=01;35:*.cgm=01;35:*.emf=01;35:*.ogv=01;3
5:*.ogx=01;35:*.aac=00;36:*.au=00;36:*.flac=00;36:*.m4a=00;3
6:*.mid=00;36:*.midi=00;36:*.mka=00;36:*.mp3=00;36:*.mpc=00;
36:*.ogg=00;36:*.ra=00;36:*.wav=00;36:*.oga=00;36:*.opus=00;
36:*.spx=00;36:*.xspf=00;36:';
export LS_COLORS
```
如果你擅长解析文件,那么你可能会注意到这个列表有一种<ruby> 模式 <rt> patten </rt></ruby>。用冒号分隔开,你会看到这样的东西:
```
$ dircolors | tr ":" "\n" | head -10
LS_COLORS='rs=0
di=01;34
ln=01;36
mh=00
pi=40;33
so=01;35
do=01;35
bd=40;33;01
cd=40;33;01
or=40;31;01
```
OK,这里有一个模式 —— 一系列定义,有一到三个数字组件。我们来看看其中的一个定义。
```
pi=40;33
```
有些人可能会问的第一个问题是“pi 是什么?”在这里,我们研究的是颜色和文件类型,所以这显然不是以 3.14 开头的那个有趣的数字。当然不是,这个 “pi” 代表 “pipe(管道)” —— Linux 系统上的一种特殊类型的文件,它可以将数据从一个程序传递给另一个程序。所以,让我们建立一个管道。
```
$ mknod /tmp/mypipe p
$ ls -l /tmp/mypipe
prw-rw-r-- 1 shs shs 0 May 1 14:00 /tmp/mypipe
```
当我们在终端窗口中查看我们的管道和其他几个文件时,颜色差异非常明显。

在 `pi` 的定义中(如上所示),“40” 使文件在终端(或 PuTTY)窗口中使用黑色背景显示,31 使字体颜色变红。管道是特殊的文件,这种特殊的处理使它们在目录列表中突出显示。
`bd` 和 `cd` 定义是相同的 —— `40;33;01`,它有一个额外的设置。这个设置会导致 <ruby> 块设备 <rt> block device </rt></ruby>(bd)和 <ruby> 字符设备 <rt> character device </rt></ruby>(cd)以黑色背景,橙色字体和另一种效果显示 —— 字符将以粗体显示。
以下列表显示由<ruby> 文件类型 <rt> file type </rt></ruby>所指定的颜色和字体分配:
```
setting file type
======= =========
rs=0 reset to no color
di=01;34 directory
ln=01;36 link
mh=00 multi-hard link
pi=40;33 pipe
so=01;35 socket
do=01;35 door
bd=40;33;01 block device
cd=40;33;01 character device
or=40;31;01 orphan
mi=00 missing?
su=37;41 setuid
sg=30;43 setgid
ca=30;41 file with capability
tw=30;42 directory with sticky bit and world writable
ow=34;42 directory that is world writable
st=37;44 directory with sticky bit
ex=01;93 executable
```
你可能已经注意到,在 `dircolors` 命令输出中,我们的大多数定义都以星号开头(例如,`*.wav=00;36`)。这些按<ruby> 文件扩展名 <rt> file extension </rt></ruby>而不是文件类型定义显示属性。这有一个示例:
```
$ dircolors | tr ":" "\n" | tail -10
*.mpc=00;36
*.ogg=00;36
*.ra=00;36
*.wav=00;36
*.oga=00;36
*.opus=00;36
*.spx=00;36
*.xspf=00;36
';
export LS_COLORS
```
这些设置(上面列表中所有的 `00;36`)将使这些文件名以青色显示。可用的颜色如下所示。

### 如何改变设置
你要使用 `ls` 的别名来打开颜色显示功能。这通常是 Linux 系统上的默认设置,看起来是这样的:
```
alias ls='ls --color=auto'
```
如果要关闭字体颜色,可以运行 `unalias ls` 命令,然后文件列表将仅以默认字体颜色显示。
你可以通过修改 `$LS_COLORS` 设置和导出修改后的设置来更改文本颜色。
```
$ export LS_COLORS='rs=0:di=01;34:ln=01;36:mh=00:pi=40;33:so=01;...
```
注意:上面的命令由于太长被截断了。
如果希望文本颜色的修改是永久性的,则需要将修改后的 `$LS_COLORS` 定义添加到一个启动文件中,例如 `.bashrc`。
### 更多关于命令行文本
你可以在 NetworkWorld 的 [2016 年 11 月](https://www.networkworld.com/article/3138909/linux/coloring-your-world-with-ls-colors.html)的帖子中找到有关文本颜色的其他信息。
---
via: <https://www.networkworld.com/article/3269587/linux/customizing-your-text-colors-on-the-linux-command-line.html>
作者:[Sandra Henry-Stocker](https://www.networkworld.com/author/Sandra-Henry_Stocker/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[pityonline](https://github.com/pityonline)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
9,830 | 无密码验证:客户端 | https://nicolasparada.netlify.com/posts/passwordless-auth-client/ | 2018-07-12T11:41:37 | [
"无密码",
"验证"
] | https://linux.cn/article-9830-1.html | 
我们继续 [无密码验证](/article-9748-1.html) 的文章。上一篇文章中,我们用 Go 写了一个 HTTP 服务,用这个服务来做无密码验证 API。今天,我们为它再写一个 JavaScript 客户端。
我们将使用 [这里的](/article-9815-1.html) 这个单页面应用程序(SPA)来展示使用的技术。如果你还没有读过它,请先读它。
记住流程:
* 用户输入其 email。
* 用户收到一个带有魔法链接的邮件。
* 用户点击该链接、
* 用户验证成功。
对于根 URL(`/`),我们将根据验证的状态分别使用两个不同的页面:一个是带有访问表单的页面,或者是已验证通过的用户的欢迎页面。另一个页面是验证回调的重定向页面。
### 伺服
我们将使用相同的 Go 服务器来为客户端提供服务,因此,在我们前面的 `main.go` 中添加一些路由:
```
router.Handle("GET", "/...", http.FileServer(SPAFileSystem{http.Dir("static")}))
```
```
type SPAFileSystem struct {
fs http.FileSystem
}
func (spa SPAFileSystem) Open(name string) (http.File, error) {
f, err := spa.fs.Open(name)
if err != nil {
return spa.fs.Open("index.html")
}
return f, nil
}
```
这个伺服文件放在 `static` 下,配合 `static/index.html` 作为回调。
你可以使用你自己的服务器,但是你得在服务器上启用 [CORS](https://developer.mozilla.org/en-US/docs/Web/HTTP/CORS)。
### HTML
我们来看一下那个 `static/index.html` 文件。
```
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Passwordless Demo</title>
<link rel="shortcut icon" href="data:,">
<script src="/js/main.js" type="module"></script>
</head>
<body></body>
</html>
```
单页面应用程序的所有渲染由 JavaScript 来完成,因此,我们使用了一个空的 body 部分和一个 `main.js` 文件。
我们将使用 [上篇文章](/article-9815-1.html) 中的 Router。
### 渲染
现在,我们使用下面的内容来创建一个 `static/js/main.js` 文件:
```
import Router from 'https://unpkg.com/@nicolasparada/router'
import { isAuthenticated } from './auth.js'
const router = new Router()
router.handle('/', guard(view('home')))
router.handle('/callback', view('callback'))
router.handle(/^\//, view('not-found'))
router.install(async resultPromise => {
document.body.innerHTML = ''
document.body.appendChild(await resultPromise)
})
function view(name) {
return (...args) => import(`/js/pages/${name}-page.js`)
.then(m => m.default(...args))
}
function guard(fn1, fn2 = view('welcome')) {
return (...args) => isAuthenticated()
? fn1(...args)
: fn2(...args)
}
```
与上篇文章不同的是,我们实现了一个 `isAuthenticated()` 函数和一个 `guard()` 函数,使用它去渲染两种验证状态的页面。因此,当用户访问 `/` 时,它将根据用户是否通过了验证来展示主页或者是欢迎页面。
### 验证
现在,我们来编写 `isAuthenticated()` 函数。使用下面的内容来创建一个 `static/js/auth.js` 文件:
```
export function getAuthUser() {
const authUserItem = localStorage.getItem('auth_user')
const expiresAtItem = localStorage.getItem('expires_at')
if (authUserItem !== null && expiresAtItem !== null) {
const expiresAt = new Date(expiresAtItem)
if (!isNaN(expiresAt.valueOf()) && expiresAt > new Date()) {
try {
return JSON.parse(authUserItem)
} catch (_) { }
}
}
return null
}
export function isAuthenticated() {
return localStorage.getItem('jwt') !== null && getAuthUser() !== null
}
```
当有人登入时,我们将保存 JSON 格式的 web 令牌、它的过期日期,以及在 `localStorage` 上的当前已验证用户。这个模块就是这个用处。
* `getAuthUser()` 用于从 `localStorage` 获取已认证的用户,以确认 JSON 格式的 Web 令牌没有过期。
* `isAuthenticated()` 在前面的函数中用于去检查它是否没有返回 `null`。
### 获取
在继续这个页面之前,我将写一些与服务器 API 一起使用的 HTTP 工具。
我们使用以下的内容去创建一个 `static/js/http.js` 文件:
```
import { isAuthenticated } from './auth.js'
function get(url, headers) {
return fetch(url, {
headers: Object.assign(getAuthHeader(), headers),
}).then(handleResponse)
}
function post(url, body, headers) {
return fetch(url, {
method: 'POST',
headers: Object.assign(getAuthHeader(), { 'content-type': 'application/json' }, headers),
body: JSON.stringify(body),
}).then(handleResponse)
}
function getAuthHeader() {
return isAuthenticated()
? { authorization: `Bearer ${localStorage.getItem('jwt')}` }
: {}
}
export async function handleResponse(res) {
const body = await res.clone().json().catch(() => res.text())
const response = {
statusCode: res.status,
statusText: res.statusText,
headers: res.headers,
body,
}
if (!res.ok) {
const message = typeof body === 'object' && body !== null && 'message' in body
? body.message
: typeof body === 'string' && body !== ''
? body
: res.statusText
const err = new Error(message)
throw Object.assign(err, response)
}
return response
}
export default {
get,
post,
}
```
这个模块导出了 `get()` 和 `post()` 函数。它们是 `fetch` API 的封装。当用户是已验证的,这二个函数注入一个 `Authorization: Bearer <token_here>` 头到请求中;这样服务器就能对我们进行身份验证。
### 欢迎页
我们现在来到欢迎页面。用如下的内容创建一个 `static/js/pages/welcome-page.js` 文件:
```
const template = document.createElement('template')
template.innerHTML = `
<h1>Passwordless Demo</h1>
<h2>Access</h2>
<form id="access-form">
<input type="email" placeholder="Email" autofocus required>
<button type="submit">Send Magic Link</button>
</form>
`
export default function welcomePage() {
const page = template.content.cloneNode(true)
page.getElementById('access-form')
.addEventListener('submit', onAccessFormSubmit)
return page
}
```
这个页面使用一个 `HTMLTemplateElement` 作为视图。这只是一个输入用户 email 的简单表单。
为了避免干扰,我将跳过错误处理部分,只是将它们输出到控制台上。
现在,我们来写 `onAccessFormSubmit()` 函数。
```
import http from '../http.js'
function onAccessFormSubmit(ev) {
ev.preventDefault()
const form = ev.currentTarget
const input = form.querySelector('input')
const email = input.value
sendMagicLink(email).catch(err => {
console.error(err)
if (err.statusCode === 404 && wantToCreateAccount()) {
runCreateUserProgram(email)
}
})
}
function sendMagicLink(email) {
return http.post('/api/passwordless/start', {
email,
redirectUri: location.origin + '/callback',
}).then(() => {
alert('Magic link sent. Go check your email inbox.')
})
}
function wantToCreateAccount() {
return prompt('No user found. Do you want to create an account?')
}
```
它对 `/api/passwordless/start` 发起了 POST 请求,请求体中包含 `email` 和 `redirectUri`。在本例中它返回 `404 Not Found` 状态码时,我们将创建一个用户。
```
function runCreateUserProgram(email) {
const username = prompt("Enter username")
if (username === null) return
http.post('/api/users', { email, username })
.then(res => res.body)
.then(user => sendMagicLink(user.email))
.catch(console.error)
}
```
这个用户创建程序,首先询问用户名,然后使用 email 和用户名做一个 `POST` 请求到 `/api/users`。成功之后,给创建的用户发送一个魔法链接。
### 回调页
这是访问表单的全部功能,现在我们来做回调页面。使用如下的内容来创建一个 `static/js/pages/callback-page.js` 文件:
```
import http from '../http.js'
const template = document.createElement('template')
template.innerHTML = `
<h1>Authenticating you</h1>
`
export default function callbackPage() {
const page = template.content.cloneNode(true)
const hash = location.hash.substr(1)
const fragment = new URLSearchParams(hash)
for (const [k, v] of fragment.entries()) {
fragment.set(decodeURIComponent(k), decodeURIComponent(v))
}
const jwt = fragment.get('jwt')
const expiresAt = fragment.get('expires_at')
http.get('/api/auth_user', { authorization: `Bearer ${jwt}` })
.then(res => res.body)
.then(authUser => {
localStorage.setItem('jwt', jwt)
localStorage.setItem('auth_user', JSON.stringify(authUser))
localStorage.setItem('expires_at', expiresAt)
location.replace('/')
})
.catch(console.error)
return page
}
```
请记住……当点击魔法链接时,我们会来到 `/api/passwordless/verify_redirect`,它将把我们重定向到重定向 URI,我们将放在哈希中的 JWT 和过期日期传递给 `/callback`。
回调页面解码 URL 中的哈希,提取这些参数去做一个 `GET` 请求到 `/api/auth_user`,用 JWT 保存所有数据到 `localStorage` 中。最后,重定向到主页面。
### 主页
创建如下内容的 `static/pages/home-page.js` 文件:
```
import { getAuthUser } from '../auth.js'
export default function homePage() {
const authUser = getAuthUser()
const template = document.createElement('template')
template.innerHTML = `
<h1>Passwordless Demo</h1>
<p>Welcome back, ${authUser.username}
```
| 404 | Not Found | null |
9,831 | Mesos 和 Kubernetes:不是竞争者 | https://www.linux.com/blog/2018/6/mesos-and-kubernetes-its-not-competition | 2018-07-13T12:11:40 | [
"Mesos",
"Kubernetes",
"容器"
] | https://linux.cn/article-9831-1.html |
>
> 人们经常用 x 相对于 y 这样的术语来考虑问题,但是它并不是一个技术对另一个技术的问题。Ben Hindman 在这里解释了 Mesos 是如何对另外一种技术进行补充的。
>
>
>

Mesos 的起源可以追溯到 2009 年,当时,Ben Hindman 还是加州大学伯克利分校研究并行编程的博士生。他们在 128 核的芯片上做大规模的并行计算,以尝试去解决多个问题,比如怎么让软件和库在这些芯片上运行更高效。他与同学们讨论能否借鉴并行处理和多线程的思想,并将它们应用到集群管理上。
Hindman 说 “最初,我们专注于大数据” 。那时,大数据非常热门,而 Hadoop 就是其中的一个热门技术。“我们发现,人们在集群上运行像 Hadoop 这样的程序与运行多线程应用及并行应用很相似。”Hindman 说。
但是,它们的效率并不高,因此,他们开始去思考,如何通过集群管理和资源管理让它们运行的更好。“我们查看了那个时期很多的各种技术” Hindman 回忆道。
然后,Hindman 和他的同事们决定去采用一种全新的方法。“我们决定对资源管理创建一个低级的抽象,然后在此之上运行调度服务和做其它的事情。” Hindman 说,“基本上,这就是 Mesos 的本质 —— 将资源管理部分从调度部分中分离出来。”
他成功了,并且 Mesos 从那时开始强大了起来。
### 将项目呈献给 Apache
这个项目发起于 2009 年。在 2010 年时,团队决定将这个项目捐献给 Apache 软件基金会(ASF)。它在 Apache 孵化,并于 2013 年成为顶级项目(TLP)。
为什么 Mesos 社区选择 Apache 软件基金会有很多的原因,比如,Apache 许可证,以及基金会已经拥有了一个充满活力的其它此类项目的社区。
与影响力也有关系。许多在 Mesos 上工作的人也参与了 Apache,并且许多人也致力于像 Hadoop 这样的项目。同时,来自 Mesos 社区的许多人也致力于其它大数据项目,比如 Spark。这种交叉工作使得这三个项目 —— Hadoop、Mesos,以及 Spark —— 成为 ASF 的项目。
与商业也有关系。许多公司对 Mesos 很感兴趣,并且开发者希望它能由一个中立的机构来维护它,而不是让它成为一个私有项目。
### 谁在用 Mesos?
更好的问题应该是,谁不在用 Mesos?从 Apple 到 Netflix 每个都在用 Mesos。但是,Mesos 也面临任何技术在早期所面对的挑战。“最初,我要说服人们,这是一个很有趣的新技术。它叫做‘容器’,因为它不需要使用虚拟机” Hindman 说。
从那以后,这个行业发生了许多变化,现在,只要与别人聊到基础设施,必然是从”容器“开始的 —— 感谢 Docker 所做出的工作。今天再也不需要做说服工作了,而在 Mesos 出现的早期,前面提到的像 Apple、Netflix,以及 PayPal 这样的公司。他们已经知道了容器替代虚拟机给他们带来的技术优势。“这些公司在容器成为一种现象之前,已经明白了容器的价值所在”, Hindman 说。
可以在这些公司中看到,他们有大量的容器而不是虚拟机。他们所做的全部工作只是去管理和运行这些容器,并且他们欣然接受了 Mesos。在 Mesos 早期就使用它的公司有 Apple、Netflix、PayPal、Yelp、OpenTable 和 Groupon。
“大多数组织使用 Mesos 来运行各种服务” Hindman 说,“但也有些公司用它做一些非常有趣的事情,比如,数据处理、数据流、分析任务和应用程序。“
这些公司采用 Mesos 的其中一个原因是,资源管理层之间有一个明晰的界线。当公司运营容器的时候,Mesos 为他们提供了很好的灵活性。
“我们尝试使用 Mesos 去做的一件事情是去创建一个层,以让使用者享受到我们的层带来的好处,当然也可以在它之上创建任何他们想要的东西,” Hindman 说。 “我认为这对一些像 Netflix 和 Apple 这样的大公司非常有用。”
但是,并不是每个公司都是技术型的公司;不是每个公司都有或者应该有这种专长。为帮助这样的组织,Hindman 联合创建了 Mesosphere 去围绕 Mesos 提供服务和解决方案。“我们最终决定,为这样的组织去构建 DC/OS,它不需要技术专长或者不想把时间花费在像构建这样的事情上。”
### Mesos vs. Kubernetes?
人们经常用 x 相对于 y 这样的术语来考虑问题,但是它并不是一个技术对另一个技术的问题。大多数的技术在一些领域总是重叠的,并且它们可以是互补的。“我不喜欢将所有的这些东西都看做是竞争者。我认为它们中的一些与另一个在工作中是互补的,” Hindman 说。
“事实上,名字 Mesos 表示它处于 ‘中间’;它是一种中间的操作系统”, Hindman 说,“我们有一个容器调度器的概念,它能够运行在像 Mesos 这样的东西之上。当 Kubernetes 刚出现的时候,我们实际上在 Mesos 的生态系统中接受了它,并将它看做是在 Mesos 上的 DC/OS 中运行容器的另一种方式。”
Mesos 也复活了一个名为 [Marathon](https://mesosphere.github.io/marathon/)(一个用于 Mesos 和 DC/OS 的容器编排器)的项目,它成为了 Mesos 生态系统中最重要的成员。但是,Marathon 确实无法与 Kubernetes 相比较。“Kubernetes 比 Marathon 做的更多,因此,你不能将它们简单地相互交换,” Hindman 说,“与此同时,我们在 Mesos 中做了许多 Kubernetes 中没有的东西。因此,这些技术之间是互补的。”
不要将这些技术视为相互之间是敌对的关系,它们应该被看做是对行业有益的技术。它们不是技术上的重复;它们是多样化的。据 Hindman 说,“对于开源领域的终端用户来说,这可能会让他们很困惑,因为他们很难去知道哪个技术适用于哪种任务,但这是这个被称之为开源的本质所在。“
这只是意味着有更多的选择,并且每个都是赢家。
---
via: <https://www.linux.com/blog/2018/6/mesos-and-kubernetes-its-not-competition>
作者:[Swapnil Bhartiya](https://www.linux.com/users/arnieswap) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,832 | 使用 Ledger 记录(财务)情况 | http://sachachua.com/blog/2014/11/keeping-financial-score-ledger/ | 2018-07-13T12:40:58 | [
"Ledger",
"财务"
] | https://linux.cn/article-9832-1.html | 
自 2005 年搬到加拿大以来,我使用 [Ledger CLI](http://www.ledger-cli.org/) 来跟踪我的财务状况。我喜欢纯文本的方式,它支持虚拟信封意味着我可以同时将我的银行帐户余额和我的虚拟分配到不同的目录下。以下是我们如何使用这些虚拟信封分别管理我们的财务状况。
每个月,我都有一个条目将我生活开支分配到不同的目录中,包括家庭开支的分配。W- 不要求太多, 所以我要谨慎地处理这两者之间的差别和我自己的生活费用。我们处理它的方式是我支付固定金额,这是贷记我支付的杂货。由于我们的杂货总额通常低于我预算的家庭开支,因此任何差异都会留在标签上。我过去常常给他写支票,但最近我只是支付偶尔额外的大笔费用。
这是个示例信封分配:
```
2014.10.01 * Budget
[Envelopes:Living]
[Envelopes:Household] $500
;; More lines go here
```
这是设置的信封规则之一。它鼓励我正确地分类支出。所有支出都从我的 “Play” 信封中取出。
```
= /^Expenses/
(Envelopes:Play) -1.0
```
这个为家庭支出报销 “Play” 信封,将金额从 “Household” 信封转移到 “Play” 信封。
```
= /^Expenses:House$/
(Envelopes:Play) 1.0
(Envelopes:Household) -1.0
```
我有一套定期的支出来模拟我的预算中的家庭开支。例如,这是 10 月份的。
```
2014.10.1 * House
Expenses:House
Assets:Household $-500
```
这是杂货交易的形式:
```
2014.09.28 * No Frills
Assets:Household:Groceries $70.45
Liabilities:MBNA:September $-70.45
```
接着 `ledger bal Assets:Household` 就会告诉我是否欠他钱(负余额)。如果我支付大笔费用(例如:机票、通管道),那么正常家庭开支预算会逐渐减少余额。
我从 W- 那找到了一个为我的信用卡交易添加一个月标签的技巧,他还使用 Ledger 跟踪他的交易。它允许我再次检查条目的余额,看看前一个条目是否已被正确清除。
这个资产分类使用有点奇怪,但它在精神上对我有用。
使用 Ledger 以这种方式跟踪它可以让我跟踪我们的杂货费用以及我实际支付费用和我预算费用之间的差额。如果我最终支出超出预期,我可以从更多可自由支配的信封中移动虚拟货币,因此我的预算始终保持平衡。
Ledger 是一个强大的工具。相当极客,但也许更多的工作流描述可能会帮助那些正在搞清楚它的人!
---
via: <http://sachachua.com/blog/2014/11/keeping-financial-score-ledger/>
作者:[Sacha Chua](http://sachachua.com) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,833 | 使用 Open edX 托管课程 | https://opensource.com/article/18/6/getting-started-open-edx | 2018-07-13T13:03:58 | [
"课程",
"培训"
] | https://linux.cn/article-9833-1.html |
>
> Open edX 为各种规模和类型的组织提供了一个强大而多功能的开源课程管理的解决方案。要不要了解一下。
>
>
>

[Open edX 平台](https://open.edx.org/about-open-edx) 是一个自由开源的课程管理系统,它是 [全世界](https://www.edx.org/schools-partners) 都在使用的大规模网络公开课(MOOC)以及小型课程和培训模块的托管平台。在 Open edX 的 [第七个主要发行版](https://openedx.atlassian.net/wiki/spaces/DOC/pages/11108700/Open+edX+Releases) 中,到现在为止,它已经提供了超过 8,000 个原创课程和 5000 万个课程注册数。你可以使用你自己的本地设备或者任何行业领先的云基础设施服务提供商来安装这个平台,而且,随着项目的[服务提供商](https://openedx.atlassian.net/wiki/spaces/COMM/pages/65667081/Open+edX+Service+Providers)名单越来越长,来自它们中的软件即服务(SaaS)的可用模型也越来越多了。
Open edX 平台被来自世界各地的顶尖教育机构、私人公司、公共机构、非政府组织、非营利机构,以及教育技术初创企业广泛地使用,并且该项目的服务提供商全球社区不断地让甚至更小的组织也可以访问这个平台。如果你打算向广大的读者设计和提供教育内容,你应该考虑去使用 Open edX 平台。
### 安装
安装这个软件有多种方式,这可能有点让你难以选择,至少刚开始是这样。但是不管你是以何种方式 [安装 Open edX](https://openedx.atlassian.net/wiki/spaces/OpenOPS/pages/60227779/Open+edX+Installation+Options),最终你都得到的是有相同功能的应用程序。默认安装包含一个为在线学习者提供的、全功能的学习管理系统(LMS),和一个全功能的课程管理工作室(CMS),CMS 可以让你的讲师团队用它来编写原创课程内容。你可以把 CMS 当做是课程内容设计和管理的 “[Wordpress](https://wordpress.com/)”,把 LMS 当做是课程销售、分发、和消费的 “[Magento](https://magento.com/)”。
Open edX 是设备无关的、完全响应式的应用软件,并且不用花费很多的努力就可发布一个原生的 iOS 和 Android 应用,它可以无缝地集成到你的实例后端。Open edX 平台的代码库、原生移动应用、以及安装脚本都发布在 [GitHub](https://github.com/edx) 上。
#### 有何期望
Open edX 平台的 [GitHub 仓库](https://github.com/edx/edx-platform) 包含适用于各种类型的组织的、性能很好的、产品级的代码。来自数百个机构的数千名程序员经常为 edX 仓库做贡献,并且这个平台是一个名副其实的、研究如何去构建和管理一个复杂的企业级应用的好案例。因此,尽管你可能会遇到大量的类似“如何将平台迁移到生产环境中”的问题,但是你无需对 Open edX 平台代码库本身的质量和健状性担忧。
通过少量的培训,你的讲师就可以去设计不错的在线课程。但是请记住,Open edX 是通过它的 [XBlock](https://open.edx.org/xblocks) 组件架构进行扩展的,因此,通过他们和你的努力,你的讲师将有可能将不错的课程变成精品课程。
这个平台在单服务器环境下也运行的很好,并且它是高度模块化的,几乎可以进行无限地水平扩展。它也是主题化的和本地化的,平台的功能和外观可以根据你的需要进行几乎无限制地调整。平台在你的设备上可以按需安装并可靠地运行。
#### 需要一些封装
请记住,有大量的 edX 软件模块是不包含在默认安装中的,并且这些模块提供的经常都是各种组织所需要的功能。比如,分析模块、电商模块,以及课程的通知/公告模块都是不包含在默认安装中的,并且这些单独的模块都是值得安装的。另外,在数据备份/恢复和系统管理方面要完全依赖你自己去处理。幸运的是,有关这方面的内容,社区有越来越多的文档和如何去做的文章。你可以通过 Google 和 Bing 去搜索,以帮助你在生产环境中安装它们。
虽然有很多文档良好的程序,但是根据你的技能水平,配置 [oAuth](https://oauth.net/) 和 [SSL/TLS](https://en.wikipedia.org/wiki/Transport_Layer_Security),以及使用平台的 [REST API](https://en.wikipedia.org/wiki/Representational_state_transfer) 可能对你是一个挑战。另外,一些组织要求将 MySQL 和/或 MongoDB 数据库在中心化环境中管理,如果你正好是这种情况,你还需要将这些服务从默认平台安装中分离出来。edX 设计团队已经尽可能地为你做了简化,但是由于它是一个非常重大的更改,因此可能需要一些时间去实现。
如果你面临资源和/或技术上的困难 —— 不要气馁,Open edX 社区 SaaS 提供商,像 [appsembler](https://www.appsembler.com/) 和 [eduNEXT](https://www.edunext.co/),提供了引人入胜的替代方案去进行 DIY 安装,尤其是如果你只想简单购买就行。
### 技术栈
在 Open edX 平台的安装上探索是件令人兴奋的事情,从架构的角度来说,这个项目是一个典范。应用程序模块是 [Django](https://www.djangoproject.com/) 应用,它利用了大量的开源社区的顶尖项目,包括 [Ubuntu](https://www.ubuntu.com/)、[MySQL](https://www.mysql.com/)、[MongoDB](https://www.mongodb.com/)、[RabbitMQ](https://www.rabbitmq.com/)、[Elasticsearch](https://www.elastic.co/)、[Hadoop](http://hadoop.apache.org/)、等等。

*Open edX 技术栈(CC BY,来自 edX)*
将这些组件安装并配置好本身就是一件非常不容易的事情,但是以这样的一种方式将所有的组件去打包,并适合于任意规模和复杂性的组织,并且能够按他们的需要进行任意调整搭配而无需在代码上做重大改动,看起来似乎是不可能的事情 —— 它就是这种情况,直到你看到主要的平台配置参数安排和命名是多少的巧妙和直观。请注意,平台的组织结构有一个学习曲线,但是,你所学习的一切都是值的去学习的,不仅是对这个项目,对一般意义上的大型 IT 项目都是如此。
提醒一点:这个平台的 UI 是在不断变动的,最终的目标是在 [React](%E2%80%9Chttps://reactjs.org/%E2%80%9C) 和 [Bootstrap](%E2%80%9Chttps://getbootstrap.com/%E2%80%9C) 上实现标准化。与此同时,你将会发现基本主题有多个实现的样式,这可能会让你感到困惑。
### 采用
edX 项目能够迅速得到世界范围内的采纳,很大程度上取决于该软件的运行情况。这一点也不奇怪,这个项目成功地吸引了大量才华卓越的人参与其中,他们作为程序员、项目顾问、翻译者、技术作者、以及博客作者参与了项目的贡献。一年一次的 [Open edX 会议](https://con.openedx.org/)、[官方的 edX Google Group](https://groups.google.com/forum/#!forum/openedx-ops)、以及 [Open edX 服务提供商名单](https://openedx.atlassian.net/wiki/spaces/COMM/pages/65667081/Open+edX+Service+Providers) 是了解这个多样化的、不断成长的生态系统的非常好的起点。我作为相对而言的新人,我发现参与和直接从事这个项目的各个方面是非常容易的。
祝你学习之旅一切顺利,并且当你构思你的项目时,你可以随时联系我。
---
via: <https://opensource.com/article/18/6/getting-started-open-edx>
作者:[Lawrence Mc Daniel](https://opensource.com/users/mcdaniel0073) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Now in its [seventh major release](https://openedx.atlassian.net/wiki/spaces/DOC/pages/11108700/Open+edX+Releases), the [Open edX platform](https://open.edx.org/about-open-edx) is a free and open source course management system that is used [all over the world](https://www.edx.org/schools-partners) to host Massive Open Online Courses (MOOCs) as well as smaller classes and training modules. To date, Open edX software has powered more than 8,000 original courses and 50 million course enrollments. You can install the platform yourself with on-premise equipment or by leveraging any of the industry-leading cloud infrastructure services providers, but it is also increasingly being made available in a Software-as-a-Service (SaaS) model from several of the project’s growing list of [service providers](https://openedx.atlassian.net/wiki/spaces/COMM/pages/65667081/Open+edX+Service+Providers).
The Open edX platform is used by many of the world’s premier educational institutions as well as private sector companies, public sector institutions, NGOs, non-profits, and educational technology startups, and the project’s global community of service providers continues to make the platform accessible to ever-smaller organizations. If you plan to create and offer educational content to a broad audience, you should consider using the Open edX platform.
## Installation
There are multiple ways to install the software, which might be an unwelcome surprise, at least initially. But you get the same application software with the same feature set regardless of how you go about [installing Open edX](https://openedx.atlassian.net/wiki/spaces/OpenOPS/pages/60227779/Open+edX+Installation+Options). The default installation includes a fully functioning learning management system (LMS) for online learners plus a full-featured course management studio (CMS) that your instructor teams can use to author original course content. The CMS component is your gateway to creating a learning hub, while the LMS component helps users find and use the lessons they need.
Open edX application software is device-agnostic and fully responsive, and with modest effort, you can also publish native iOS and Android apps that seamlessly integrate to your instance’s backend. The code repositories for the Open edX platform, the native mobile apps, and the installation scripts are all publicly available on [GitHub](https://github.com/edx).
### What to expect
The Open edX platform [GitHub repository](https://github.com/edx/edx-platform) contains performant, production-ready code that is suitable for organizations of all sizes. Thousands of programmers from hundreds of institutions regularly contribute to the edX repositories, and the platform is a veritable case study on how to build and manage a complex enterprise application the right way. So even though you’re certain to face a multitude of concerns about how to move the platform into production, you should not lose sleep about the general quality and robustness of the Open edX Platform codebase itself.
With minimal training, your instructors will be able to create good online course content. But bear in mind that Open edX is extensible via its [XBlock](https://open.edx.org/xblocks) component architecture, so your instructors will have the potential to turn good course content into great course content with incremental effort on their parts and yours.
The platform works well in a single-server environment, and it is highly modular, making it nearly infinitely horizontally scalable. It is theme-able, localizable, and completely open source, providing limitless possibilities to tailor the appearance and functionality of the platform to your needs. The platform runs reliably as an on-premise installation on your own equipment.
### Some assembly required
Bear in mind that a handful of the edX software modules are not included in the default installation and that these modules are often on the requirements lists of organizations. Namely, the Analytics module, the e-commerce module, and the Notes/Annotations course feature are not part of the default platform installation, and each of these individually is a non-trivial installation. Additionally, you’re entirely on your own with regard to data backup-restore and system administration in general. Fortunately, there’s a growing body of community-sourced documentation and how-to articles, all searchable via Google and Bing, to help make your installation production-ready.
Setting up [oAuth](https://oauth.net/) and [SSL/TLS](https://en.wikipedia.org/wiki/Transport_Layer_Security) as well as getting the platform’s [REST API](https://en.wikipedia.org/wiki/Representational_state_transfer) up and running can be challenging, depending on your skill level, even though these are all well-documented procedures. Additionally, some organizations require that MySQL and/or MongoDB databases be managed in an existing centralized environment, and if this is your situation, you’ll also need to work through the process of hiving these services out of the default platform installation. The edX design team has done everything possible to simplify this for you, but it’s still a non-trivial change that will likely take some time to implement.
Not to be discouraged—if you’re facing resource and/or technical headwinds, Open edX community SaaS providers like [appsembler](https://www.appsembler.com/) and [eduNEXT](https://www.edunext.co/) offer compelling alternatives to a do-it-yourself installation, particularly if you’re just window shopping.
## Technology stack
Poking around in an Open edX platform installation is a real thrill, and architecturally speaking, the project is a masterpiece. The application modules are [Django](https://www.djangoproject.com/) apps that leverage a plethora of the open source community’s premier projects, including [Ubuntu](https://www.ubuntu.com/), [MySQL](https://www.mysql.com/), [MongoDB](https://www.mongodb.com/), [RabbitMQ](https://www.rabbitmq.com/), [Elasticsearch](https://www.elastic.co/), [Hadoop](http://hadoop.apache.org/), and others.
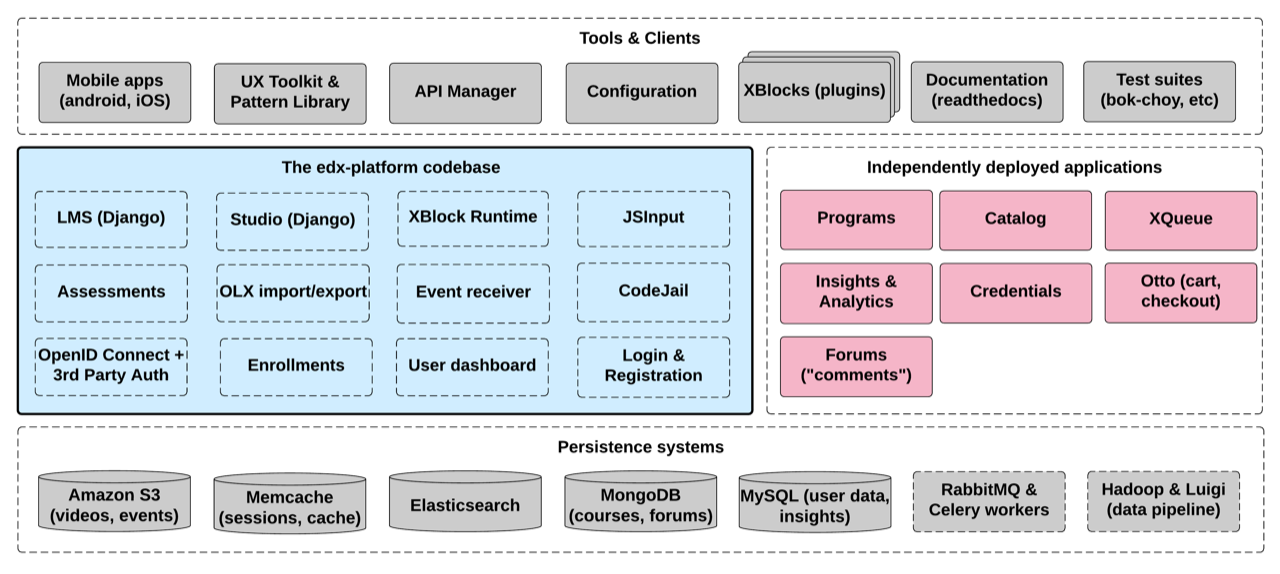
The Open edX technology stack (CC BY, by edX)
Getting all of these components installed and configured is a feat in and of itself, but packaging everything in such a way that organizations of arbitrary size and complexity can tailor installations to their needs without having to perform heart surgery on the codebase would seem impossible—that is, until you see how neatly and intuitively the major platform configuration parameters have been organized and named. Mind you, there’s a learning curve to the platform’s organizational structure, but the upshot is that everything you learn is worth knowing, not just for this project but large IT projects in general.
One word of caution: The platform's UI is in flux, with the aim of eventually standardizing on [React](https://reactjs.org/) and [Bootstrap](https://getbootstrap.com/). Meanwhile, you'll find multiple approaches to implementing styling for the base theme, and this can get confusing.
## Adoption
The edX project has enjoyed rapid international adoption, due in no small measure to how well the software works. Not surprisingly, the project’s success has attracted a large and growing list of talented participants who contribute to the project as programmers, project consultants, translators, technical writers, and bloggers. The annual [Open edX Conference](https://con.openedx.org/), the [Official edX Google Group](https://groups.google.com/forum/#!forum/openedx-ops), and the [Open edX Service Providers List](https://openedx.atlassian.net/wiki/spaces/COMM/pages/65667081/Open+edX+Service+Providers) are good starting points for learning more about this diverse and growing ecosystem. As a relative newcomer myself, I’ve found it comparatively easy to engage and to get directly involved with the project in multiple facets.
Good luck with your journey, and feel free to reach out to me as a sounding board while you’re conceptualizing your project.
## 3 Comments |
9,834 | 在 Linux 上如何得到一个段错误的核心转储 | https://jvns.ca/blog/2018/04/28/debugging-a-segfault-on-linux/ | 2018-07-13T22:19:22 | [
"核心转储",
"调试",
"段错误"
] | https://linux.cn/article-9834-1.html | 
本周工作中,我花了整整一周的时间来尝试调试一个段错误。我以前从来没有这样做过,我花了很长时间才弄清楚其中涉及的一些基本事情(获得核心转储、找到导致段错误的行号)。于是便有了这篇博客来解释如何做那些事情!
在看完这篇博客后,你应该知道如何从“哦,我的程序出现段错误,但我不知道正在发生什么”到“我知道它出现段错误时的堆栈、行号了! ”。
### 什么是段错误?
“<ruby> 段错误 <rt> segmentation fault </rt></ruby>”是指你的程序尝试访问不允许访问的内存地址的情况。这可能是由于:
* 试图解引用空指针(你不被允许访问内存地址 `0`);
* 试图解引用其他一些不在你内存(LCTT 译注:指不在合法的内存地址区间内)中的指针;
* 一个已被破坏并且指向错误的地方的 <ruby> C++ 虚表指针 <rt> C++ vtable pointer </rt></ruby>,这导致程序尝试执行没有执行权限的内存中的指令;
* 其他一些我不明白的事情,比如我认为访问未对齐的内存地址也可能会导致段错误(LCTT 译注:在要求自然边界对齐的体系结构,如 MIPS、ARM 中更容易因非对齐访问产生段错误)。
这个“C++ 虚表指针”是我的程序发生段错误的情况。我可能会在未来的博客中解释这个,因为我最初并不知道任何关于 C++ 的知识,并且这种虚表查找导致程序段错误的情况也是我所不了解的。
但是!这篇博客后不是关于 C++ 问题的。让我们谈论的基本的东西,比如,我们如何得到一个核心转储?
### 步骤1:运行 valgrind
我发现找出为什么我的程序出现段错误的最简单的方式是使用 `valgrind`:我运行
```
valgrind -v your-program
```
这给了我一个故障时的堆栈调用序列。 简洁!
但我想也希望做一个更深入调查,并找出些 `valgrind` 没告诉我的信息! 所以我想获得一个核心转储并探索它。
### 如何获得一个核心转储
<ruby> 核心转储 <rt> core dump </rt></ruby>是您的程序内存的一个副本,并且当您试图调试您的有问题的程序哪里出错的时候它非常有用。
当您的程序出现段错误,Linux 的内核有时会把一个核心转储写到磁盘。 当我最初试图获得一个核心转储时,我很长一段时间非常沮丧,因为 - Linux 没有生成核心转储!我的核心转储在哪里?
这就是我最终做的事情:
1. 在启动我的程序之前运行 `ulimit -c unlimited`
2. 运行 `sudo sysctl -w kernel.core_pattern=/tmp/core-%e.%p.%h.%t`
### ulimit:设置核心转储的最大尺寸
`ulimit -c` 设置核心转储的最大尺寸。 它往往设置为 0,这意味着内核根本不会写核心转储。 它以千字节为单位。 `ulimit` 是按每个进程分别设置的 —— 你可以通过运行 `cat /proc/PID/limit` 看到一个进程的各种资源限制。
例如这些是我的系统上一个随便一个 Firefox 进程的资源限制:
```
$ cat /proc/6309/limits
Limit Soft Limit Hard Limit Units
Max cpu time unlimited unlimited seconds
Max file size unlimited unlimited bytes
Max data size unlimited unlimited bytes
Max stack size 8388608 unlimited bytes
Max core file size 0 unlimited bytes
Max resident set unlimited unlimited bytes
Max processes 30571 30571 processes
Max open files 1024 1048576 files
Max locked memory 65536 65536 bytes
Max address space unlimited unlimited bytes
Max file locks unlimited unlimited locks
Max pending signals 30571 30571 signals
Max msgqueue size 819200 819200 bytes
Max nice priority 0 0
Max realtime priority 0 0
Max realtime timeout unlimited unlimited us
```
内核在决定写入多大的核心转储文件时使用<ruby> 软限制 <rt> soft limit </rt></ruby>(在这种情况下,`max core file size = 0`)。 您可以使用 shell 内置命令 `ulimit`(`ulimit -c unlimited`) 将软限制增加到<ruby> 硬限制 <rt> hard limit </rt></ruby>。
### kernel.core\_pattern:核心转储保存在哪里
`kernel.core_pattern` 是一个内核参数,或者叫 “sysctl 设置”,它控制 Linux 内核将核心转储文件写到磁盘的哪里。
内核参数是一种设定您的系统全局设置的方法。您可以通过运行 `sysctl -a` 得到一个包含每个内核参数的列表,或使用 `sysctl kernel.core_pattern` 来专门查看 `kernel.core_pattern` 设置。
所以 `sysctl -w kernel.core_pattern=/tmp/core-%e.%p.%h.%t` 将核心转储保存到目录 `/tmp` 下,并以 `core` 加上一系列能够标识(出故障的)进程的参数构成的后缀为文件名。
如果你想知道这些形如 `%e`、`%p` 的参数都表示什么,请参考 [man core](http://man7.org/linux/man-pages/man5/core.5.html)。
有一点很重要,`kernel.core_pattern` 是一个全局设置 —— 修改它的时候最好小心一点,因为有可能其它系统功能依赖于把它被设置为一个特定的方式(才能正常工作)。
### kernel.core\_pattern 和 Ubuntu
默认情况下在 ubuntu 系统中,`kernel.core_pattern` 被设置为下面的值:
```
$ sysctl kernel.core_pattern
kernel.core_pattern = |/usr/share/apport/apport %p %s %c %d %P
```
这引起了我的迷惑(这 apport 是干什么的,它对我的核心转储做了什么?)。以下关于这个我了解到的:
* Ubuntu 使用一种叫做 apport 的系统来报告 apt 包有关的崩溃信息。
* 设定 `kernel.core_pattern=|/usr/share/apport/apport %p %s %c %d %P` 意味着核心转储将被通过管道送给 `apport` 程序。
* apport 的日志保存在文件 `/var/log/apport.log` 中。
* apport 默认会忽略来自不属于 Ubuntu 软件包一部分的二进制文件的崩溃信息
我最终只是跳过了 apport,并把 `kernel.core_pattern` 重新设置为 `sysctl -w kernel.core_pattern=/tmp/core-%e.%p.%h.%t`,因为我在一台开发机上,我不在乎 apport 是否工作,我也不想尝试让 apport 把我的核心转储留在磁盘上。
### 现在你有了核心转储,接下来干什么?
好的,现在我们了解了 `ulimit` 和 `kernel.core_pattern` ,并且实际上在磁盘的 `/tmp` 目录中有了一个核心转储文件。太好了!接下来干什么?我们仍然不知道该程序为什么会出现段错误!
下一步将使用 `gdb` 打开核心转储文件并获取堆栈调用序列。
### 从 gdb 中得到堆栈调用序列
你可以像这样用 `gdb` 打开一个核心转储文件:
```
$ gdb -c my_core_file
```
接下来,我们想知道程序崩溃时的堆栈是什么样的。在 `gdb` 提示符下运行 `bt` 会给你一个<ruby> 调用序列 <rt> backtrace </rt></ruby>。在我的例子里,`gdb` 没有为二进制文件加载符号信息,所以这些函数名就像 “??????”。幸运的是,(我们通过)加载符号修复了它。
下面是如何加载调试符号。
```
symbol-file /path/to/my/binary
sharedlibrary
```
这从二进制文件及其引用的任何共享库中加载符号。一旦我这样做了,当我执行 `bt` 时,gdb 给了我一个带有行号的漂亮的堆栈跟踪!
如果你想它能工作,二进制文件应该以带有调试符号信息的方式被编译。在试图找出程序崩溃的原因时,堆栈跟踪中的行号非常有帮助。:)
### 查看每个线程的堆栈
通过以下方式在 `gdb` 中获取每个线程的调用栈!
```
thread apply all bt full
```
### gdb + 核心转储 = 惊喜
如果你有一个带调试符号的核心转储以及 `gdb`,那太棒了!您可以上下查看调用堆栈(LCTT 译注:指跳进调用序列不同的函数中以便于查看局部变量),打印变量,并查看内存来得知发生了什么。这是最好的。
如果您仍然正在基于 gdb 向导来工作上,只打印出栈跟踪与bt也可以。 :)
### ASAN
另一种搞清楚您的段错误的方法是使用 AddressSanitizer 选项编译程序(“ASAN”,即 `$CC -fsanitize=address`)然后运行它。 本文中我不准备讨论那个,因为本文已经相当长了,并且在我的例子中打开 ASAN 后段错误消失了,可能是因为 ASAN 使用了一个不同的内存分配器(系统内存分配器,而不是 tcmalloc)。
在未来如果我能让 ASAN 工作,我可能会多写点有关它的东西。(LCTT 译注:这里指使用 ASAN 也能复现段错误)
### 从一个核心转储得到一个堆栈跟踪真的很亲切!
这个博客听起来很多,当我做这些的时候很困惑,但说真的,从一个段错误的程序中获得一个堆栈调用序列不需要那么多步骤:
1. 试试用 `valgrind`
如果那没用,或者你想要拿到一个核心转储来调查:
1. 确保二进制文件编译时带有调试符号信息;
2. 正确的设置 `ulimit` 和 `kernel.core_pattern`;
3. 运行程序;
4. 一旦你用 `gdb` 调试核心转储了,加载符号并运行 `bt`;
5. 尝试找出发生了什么!
我可以使用 `gdb` 弄清楚有个 C++ 的虚表条目指向一些被破坏的内存,这有点帮助,并且使我感觉好像更懂了 C++ 一点。也许有一天我们会更多地讨论如何使用 `gdb` 来查找问题!
---
via: <https://jvns.ca/blog/2018/04/28/debugging-a-segfault-on-linux/>
作者:[Julia Evans](https://jvns.ca/about/) 译者:[stephenxs](https://github.com/stephenxs) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | This week at work I spent all week trying to debug a segfault. I’d never done this before, and some of the basic things involved (get a core dump! find the line number that segfaulted!) took me a long time to figure out. So here’s a blog post explaining how to do those things!
At the end of this blog post, you should know how to go from “oh no my program is segfaulting and I have no idea what is happening” to “well I know what its stack / line number was when it segfaulted, at least!”.
### what’s a segfault?
A “segmentation fault” is when your program tries to access memory that it’s not allowed to access, or tries to . This can be caused by:
- trying to dereference a null pointer (you’re not allowed to access the memory address
`0`
) - trying to dereference some other pointer that isn’t in your memory
- a C++ vtable pointer that got corrupted and is pointing to the wrong place, which causes the program to try to execute some memory that isn’t executable
- some other things that I don’t understand, like I think misaligned memory accesses can also segfault
This “C++ vtable pointer” thing is what was happening to my segfaulting program. I might explain that in a future blog post because I didn’t know any C++ at the beginning of this week and this vtable lookup thing was a new way for a program to segfault that I didn’t know about.
But! This blog post isn’t about C++ bugs. Let’s talk about the basics, like, how do we even get a core dump?
### step 1: run valgrind
I found the easiest way to figure out why my program is segfaulting was to use valgrind: I ran
```
valgrind -v your-program
```
and this gave me a stack trace of what happened. Neat!
But I also wanted to do a more in-depth investigation and find out more than just what valgrind was telling me! So I wanted to get a core dump and explore it.
### How to get a core dump
A **core dump** is a copy of your program’s memory, and it’s useful when you’re trying to debug what
went wrong with your problematic program.
When your program segfaults, the Linux kernel will sometimes write a core dump to disk. When I originally tried to get a core dump, I was pretty frustrated for a long time because – Linux wasn’t writing a core dump!! Where was my core dump????
Here’s what I ended up doing:
- Run
`ulimit -c unlimited`
before starting my program - Run
`sudo sysctl -w kernel.core_pattern=/tmp/core-%e.%p.%h.%t`
### ulimit: set the max size of a core dump
`ulimit -c`
sets the **maximum size of a core dump**. It’s often set to 0, which means that the
kernel won’t write core dumps at all. It’s in kilobytes. ulimits are **per process** – you can see
a process’s limits by running `cat /proc/PID/limit`
For example these are the limits for a random Firefox process on my system:
```
$ cat /proc/6309/limits
Limit Soft Limit Hard Limit Units
Max cpu time unlimited unlimited seconds
Max file size unlimited unlimited bytes
Max data size unlimited unlimited bytes
Max stack size 8388608 unlimited bytes
Max core file size 0 unlimited bytes
Max resident set unlimited unlimited bytes
Max processes 30571 30571 processes
Max open files 1024 1048576 files
Max locked memory 65536 65536 bytes
Max address space unlimited unlimited bytes
Max file locks unlimited unlimited locks
Max pending signals 30571 30571 signals
Max msgqueue size 819200 819200 bytes
Max nice priority 0 0
Max realtime priority 0 0
Max realtime timeout unlimited unlimited us
```
The kernel uses the **soft limit** (in this case, “max core file size = 0”) when deciding how big of
a core file to write. You can increase the soft limit up to the hard limit using the `ulimit`
shell
builtin (`ulimit -c unlimited`
!)
### kernel.core_pattern: where core dumps are written
`kernel.core_pattern`
is a kernel parameter or a “sysctl setting” that controls where the Linux
kernel writes core dumps to disk.
Kernel parameters are a way to set **global** settings on your system. You can get a list of every
kernel parameter by running `sysctl -a`
, or use `sysctl kernel.core_pattern`
to look at the
`kernel.core_pattern`
setting specifically.
So `sysctl -w kernel.core_pattern=/tmp/core-%e.%p.%h.%t`
will write core dumps to `/tmp/core-<a bunch of stuff identifying the process>`
If you want to know more about what these `%e`
, `%p`
parameters read, see [man core](http://man7.org/linux/man-pages/man5/core.5.html).
It’s important to know that `kernel.core_pattern`
is a global settings – it’s good to be a little
careful about changing it because it’s possible that other systems depend on it being set a certain
way.
### kernel.core_pattern & Ubuntu
By default on Ubuntu systems, this is what `kernel.core_pattern`
is set to
```
$ sysctl kernel.core_pattern
kernel.core_pattern = |/usr/share/apport/apport %p %s %c %d %P
```
This caused me a lot of confusion (what is this apport thing and what is it doing with my core dumps??) so here’s what I learned about this:
- Ubuntu uses a system called “apport” to report crashes in apt packages
- Setting
`kernel.core_pattern=|/usr/share/apport/apport %p %s %c %d %P`
means that core dumps will be piped to`apport`
- apport has logs in /var/log/apport.log
- apport by default will ignore crashes from binaries that aren’t part of an Ubuntu packages
I ended up just overriding this Apport business and setting `kernel.core_pattern`
to `sysctl -w kernel.core_pattern=/tmp/core-%e.%p.%h.%t`
because I was on a dev machine, I didn’t care whether Apport was working on not, and I didn’t feel like trying to convince Apport to give me my core dumps.
### So you have a core dump. Now what?
Okay, now we know about ulimits and `kernel.core_pattern`
and you have actually have a core dump
file on disk in `/tmp`
. Amazing! Now what??? We still don’t know why the program segfaulted!
The next step is to open the core file with `gdb`
and get a backtrace.
### Getting a backtrace from gdb
You can open a core file with gdb like this:
```
$ gdb -c my_core_file
```
or maybe
```
$ gdb executable -c my_core_file
```
Next, we want to know what the stack was when the program crashed. Running `bt`
at
the gdb prompt will give you a backtrace. In my case gdb hadn’t loaded symbols for the binary, so it
was just like `??????`
. Luckily, loading symbols fixed it.
Here’s how to load debugging symbols.
```
symbol-file /path/to/my/binary
sharedlibrary
```
This loads symbols from the binary and from any shared libraries the binary uses. Once I did that,
gdb gave me a beautiful stack trace with line numbers when I ran `bt`
!!!
If you want this to work, the binary should be compiled with debugging symbols. Having line numbers in your stack traces is extremely helpful when trying to figure out why a program crashed :)
### look at the stack for every thread
Here’s how to get the stack for every thread in gdb!
```
thread apply all bt full
```
### gdb + core dumps = amazing
If you have a core dump & debugging symbols and gdb, you are in an amazing situation!! You can go up and down the call stack, print out variables, and poke around in memory to see what happened. It’s the best.
If you are still working on being a gdb wizard, you can also just print out the stack trace with
`bt`
and that’s okay :)
### ASAN
Another path to figuring out your segfault is to do one compile the program with AddressSanitizer
(“ASAN”) (`$CC -fsanitize=address`
) and run it. I’m not going to discuss that in this post because
this is already pretty long and anyway in my case the segfault disappeared with ASAN turned on for
some reason, possibly because the ASAN build used a different memory allocator (system malloc
instead of tcmalloc).
I might write about ASAN more in the future if I ever get it to work :)
### getting a stack trace from a core dump is pretty approachable!
This blog post sounds like a lot and I was pretty confused when I was doing it but really there aren’t all that many steps to getting a stack trace out of a segfaulting program:
- try valgrind
if that doesn’t work, or if you want to have a core dump to investigate:
- make sure the binary is compiled with debugging symbols
- set
`ulimit`
and`kernel.core_pattern`
correctly - run the program
- open your core dump with
`gdb`
, load the symbols, and run`bt`
- try to figure out what happened!!
I was able using gdb to figure out that there was a C++ vtable entry that is pointing to some corrupt memory, which was somewhat helpful and helped me feel like I understood C++ a bit better. Maybe we’ll talk more about how to use gdb to figure things out another day! |
9,835 | TrueOS 不再想要成为“桌面 BSD”了 | https://itsfoss.com/trueos-plan-change/ | 2018-07-13T22:53:46 | [
"BSD",
"TrueBSD"
] | https://linux.cn/article-9835-1.html | [TrueOS](https://www.trueos.org/) 很快会有一些非常重大的变化。今天,我们将了解桌面 BSD 领域将会发生什么。
### 通告

[TrueOS](https://www.trueos.org/) 背后的团队[宣布](https://www.trueos.org/blog/trueosdownstream/),他们将改变项目的重点。到目前为止,TrueOS 使用开箱即用的图形用户界面来轻松安装 BSD。然而,它现在将成为“一个先进的操作系统,保留你所知道和喜欢的 ZFS([OpenZFS](http://open-zfs.org/wiki/Main_Page))和 [FreeBSD](https://www.freebsd.org/)的所有稳定性,并添加额外的功能来创造一个全新的、创新的操作系统。我们的目标是创建一个核心操作系统,该系统具有模块化、实用性,非常适合自己动手和高级用户。“
从本质上讲,TrueOs 将成为 FreeBSD 的下游分支。他们将集成更新一些的软件到系统中,例如 [OpenRC](https://en.wikipedia.org/wiki/OpenRC) 和 [LibreSSL](http://www.libressl.org/)。他们希望能坚持 6 个月的发布周期。
其目标是使 TrueOS 成为可以作为其他项目构建的基础。缺少图形部分以使其更加地与发行版无关。
### 桌面用户如何?
如果你读过我的[TrueOS 评论](https://itsfoss.com/trueos-bsd-review/)并且有兴趣尝试使用桌面 BSD 或已经使用 TrueOS,请不要担心(这对于生活来说也是一个很好的建议)。TrueOS 的所有桌面元素都将剥离到 [Project Trident](http://www.project-trident.org/)。目前,Project Trident 网站的细节不多。他们仿佛还在进行剥离的幕后工作。
如果你目前拥有 TrueOS,则无需担心迁移。TrueOS 团队表示,“对于那些希望迁移到其他基于 FreeBSD 的发行版,如 Project Trident 或 [GhostBSD](https://www.ghostbsd.org/) 的人而言将会有迁移方式。”
### 想法
当我第一次阅读该公告时,坦率地说有点担心。改变名字可能是一个坏主意。客户将习惯使用一个名称,但如果产品名称发生变化,他们可能很容易失去对项目的跟踪。TrueOS 经历过名称更改。该项目于 2006 年启动时,它被命名为 PC-BSD,但在 2016 年,名称更改为 TrueOS。它让我想起了[ArchMerge 和 Arcolinux 传奇](https://itsfoss.com/archlabs-vs-archmerge/)。
话虽这么说,我认为这对 BSD 的桌面用户来说是一件好事。我常听见对 PC-BSD 和 TrueOS 的一个批评是它不是很精致。剥离项目的两个部分将有助于提高相关开发人员的关注度。TrueOS 团队将能够为缓慢进展的 FreeBSD 添加更新的功能,Project Trident 团队将能够改善用户的桌面体验。
我希望两个团队都好。请记住,当有人为开源而努力时,即使是我们不会使用的部分,我们也都会受益。
你对 TrueOS 和 Project Trident 的未来有何看法?请在下面的评论中告诉我们。
---
关于作者:
我叫 John Paul Wohlscheid。我是一个有抱负的神秘作家,喜欢玩技术,尤其是 Linux。你可以在[我的个人网站](http://johnpaulwohlscheid.work/)关注我。
---
via: <https://itsfoss.com/trueos-plan-change/>
作者:[John Paul Wohlscheid](https://itsfoss.com/author/john/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | There are some really big changes on the horizon for [TrueOS](https://www.trueos.org/). Today, we will take a look at what is going on in the world of desktop BSD.
### The Announcement
The team behind [TrueOS](https://www.trueos.org/) [announced](https://www.trueos.org/blog/trueosdownstream/) that they would be changing the focus of the project. Up until this point, TrueOS has made it easy to install BSD with a graphical user interface out of the box. However, it will now become “a cutting-edge operating system that keeps all of the stability that you know and love from ZFS ([OpenZFS](http://open-zfs.org/wiki/Main_Page)) and [FreeBSD](https://www.freebsd.org/), and adds additional features to create a fresh, innovative operating system. Our goal is to create a core-centric operating system that is modular, functional, and perfect for do-it-yourselfers and advanced users alike.”
Essentially, TrueOs will become a downstream fork of FreeBSD. They will integrate newer software into the system, such as [OpenRC](https://en.wikipedia.org/wiki/OpenRC) and [LibreSSL](http://www.libressl.org/). They hope to stick to a 6-month release cycle.
The goal is to make TrueOS so it can be used as the base for other projects to build on. The graphical part will be missing to make it more distro-agnostic.
[irp posts=”27379″ name=”Interview with MidnightBSD Founder and Lead Dev Lucas Holt”]
### What about Desktop Users?
If you read my [review of TrueOS](https://itsfoss.com/trueos-bsd-review/) and are interested in trying a desktop BSD or already use TrueOS, never fear (which is good advice for life too). All of the desktop elements of TrueOS will be spun off into [Project Trident](http://www.project-trident.org/). Currently, the Project Trident website is very light on details. It seems as though they are still figuring out the logistics of the spin-off.
If you currently have TrueOS, you don’t have to worry about moving. The TrueOS team said that “there will be migration paths available for those that would like to move to other FreeBSD-based distributions like Project Trident or [GhostBSD](https://www.ghostbsd.org/).”
[irp posts=”25675″ name=”Interview with FreeDOS Founder and Lead Dev Jim Hall”]
### Thoughts
When I first read the announcement, I was frankly a little worried. Changing names can be a bad idea. Customers will be used to one name, but if the product name changes they could lose track of the project very easily. TrueOS already went through a name change. When the project was started in 2006 it was named PC-BSD, but in 2016 the name was changed to TrueOS. It kinds of reminds me of the [ArchMerge and Arcolinux saga](https://itsfoss.com/archlabs-vs-archmerge/).
That being said, I think this will be a good thing for desktop users of BSD. One of the common criticisms that I heard about PC-BSD and TrueOS is that it wasn’t very polished. Separating the two parts of the project will help sharpen the focus of the respective developers. The TrueOS team will be able to add newer features to the slow-moving FreeBSD base and the Project Trident team will be able to improve user’s desktop experience.
I wish both teams well. Remember, people, when someone works on open source, we all benefit even if the work is done on something we don’t use.
What are your thoughts about the future of TrueOS and Project Trident? Please let us know in the comments below.
If you found this article interesting, please take a minute to share it on social media, Hacker News or [Reddit](http://reddit.com/r/linuxusersgroup). |
9,836 | Buildah 入门 | https://opensource.com/article/18/6/getting-started-buildah | 2018-07-13T23:33:32 | [
"Buildah",
"容器",
"Docker"
] | https://linux.cn/article-9836-1.html |
>
> Buildah 提供一种灵活、可脚本编程的方式,来使用你熟悉的工具创建精简、高效的容器镜像。
>
>
>

[Buildah](https://github.com/projectatomic/buildah) 是一个命令行工具,可以方便、快捷的构建与<ruby> <a href="https://www.opencontainers.org/"> 开放容器标准 </a> <rt> Open Container Initiative </rt></ruby>(OCI)兼容的容器镜像,这意味着其构建的镜像与 Docker 和 Kubernetes 兼容。该工具可作为 Docker 守护进程 `docker build` 命令(即使用传统的 Dockerfile 构建镜像)的一种<ruby> 简单 <rt> drop-in </rt></ruby>替换,而且更加灵活,允许构建镜像时使用你擅长的工具。Buildah 可以轻松与脚本集成并生成<ruby> 流水线 <rt> pipeline </rt></ruby>,最好之处在于构建镜像不再需要运行容器守护进程(LCTT 译注:这里主要是指 Docker 守护进程)。
### docker build 的简单替换
目前你可能使用 Dockerfile 和 `docker build` 命令构建镜像,那么你可以马上使用 Buildah 进行替代。Buildah 的 `build-using-dockerfile` (或 `bud`)子命令与 `docker build` 基本等价,因此可以轻松的与已有脚本结合或构建流水线。
类似我的上一篇关于 Buildah 的[文章](http://chris.collins.is/2017/08/17/buildah-a-new-way-to-build-container-images/),我也将以使用源码安装 “GNU Hello” 为例进行说明,对应的 Dockerfile 文件如下:
```
FROM fedora:28
LABEL maintainer Chris Collins <[email protected]>
RUN dnf install -y tar gzip gcc make \
&& dnf clean all
ADD http://ftpmirror.gnu.org/hello/hello-2.10.tar.gz /tmp/hello-2.10.tar.gz
RUN tar xvzf /tmp/hello-2.10.tar.gz -C /opt
WORKDIR /opt/hello-2.10
RUN ./configure
RUN make
RUN make install
RUN hello -v
ENTRYPOINT "/usr/local/bin/hello"
```
使用 Buildah 从 Dockerfile 构建镜像也很简单,使用 `buildah bud -t hello .` 替换 `docker build -t hello .` 即可:
```
[chris@krang] $ sudo buildah bud -t hello .
STEP 1: FROM fedora:28
Getting image source signatures
Copying blob sha256:e06fd16225608e5b92ebe226185edb7422c3f581755deadf1312c6b14041fe73
81.48 MiB / 81.48 MiB [====================================================] 8s
Copying config sha256:30190780b56e33521971b0213810005a69051d720b73154c6e473c1a07ebd609
2.29 KiB / 2.29 KiB [======================================================] 0s
Writing manifest to image destination
Storing signatures
STEP 2: LABEL maintainer Chris Collins <[email protected]>
STEP 3: RUN dnf install -y tar gzip gcc make && dnf clean all
<考虑篇幅,略去后续输出>
```
镜像构建完毕后,可以使用 `buildah images` 命令查看这个新镜像:
```
[chris@krang] $ sudo buildah images
IMAGE ID IMAGE NAME CREATED AT SIZE
30190780b56e docker.io/library/fedora:28 Mar 7, 2018 16:53 247 MB
6d54bef73e63 docker.io/library/hello:latest May 3, 2018 15:24 391.8 MB
```
新镜像的标签为 `hello:latest`,我们可以将其推送至远程镜像仓库,可以使用 [CRI-O](http://cri-o.io/) 或其它 Kubernetes CRI 兼容的运行时来运行该镜像,也可以推送到远程仓库。如果你要测试对 Docker build 命令的替代性,你可以将镜像拷贝至 docker 守护进程的本地镜像存储中,这样 Docker 也可以使用该镜像。使用 `buildah push` 可以很容易的完成推送操作:
```
[chris@krang] $ sudo buildah push hello:latest docker-daemon:hello:latest
Getting image source signatures
Copying blob sha256:72fcdba8cff9f105a61370d930d7f184702eeea634ac986da0105d8422a17028
247.02 MiB / 247.02 MiB [==================================================] 2s
Copying blob sha256:e567905cf805891b514af250400cc75db3cb47d61219750e0db047c5308bd916
144.75 MiB / 144.75 MiB [==================================================] 1s
Copying config sha256:6d54bef73e638f2e2dd8b7bf1c4dfa26e7ed1188f1113ee787893e23151ff3ff
1.59 KiB / 1.59 KiB [======================================================] 0s
Writing manifest to image destination
Storing signatures
[chris@krang] $ sudo docker images | head -n2
REPOSITORY TAG IMAGE ID CREATED SIZE
docker.io/hello latest 6d54bef73e63 2 minutes ago 398 MB
[chris@krang] $ sudo docker run -t hello:latest
Hello, world!
```
### 若干差异
与 Docker build 不同,Buildah 不会自动的将 Dockerfile 中的每条指令产生的变更提到新的<ruby> 分层 <rt> layer </rt></ruby>中,只是简单的每次从头到尾执行构建。类似于<ruby> 自动化 <rt> automation </rt></ruby>和<ruby> 流水线构建 <rt> build pipeline </rt></ruby>,这种<ruby> 无缓存构建 <rt> non-cached </rt></ruby>方式的好处是可以提高构建速度,在指令较多时尤为明显。从<ruby> 自动部署 <rt> automated deployment </rt></ruby>或<ruby> 持续交付 <rt> continuous delivery </rt></ruby>的视角来看,使用这种方式可以快速的将新变更落实到生产环境中。
但从实际角度出发,缓存机制的缺乏对镜像开发不利,毕竟缓存层可以避免一遍遍的执行构建,从而显著的节省时间。自动分层只在 `build-using-dockerfile` 命令中生效。但我们在下面会看到,Buildah 原生命令允许我们选择将变更提交到硬盘的时间,提高了开发的灵活性。
### Buildah 原生命令
Buildah *真正* 有趣之处在于它的原生命令,你可以在容器构建过程中使用这些命令进行交互。相比与使用 `build-using-dockerfile/bud` 命令执行每次构建,Buildah 提供命令让你可以与构建过程中的临时容器进行交互。(Docker 也使用临时或<ruby> <em> 中间 </em> <rt> intermediate </rt></ruby>容器,但你无法在镜像构建过程中与其交互。)
还是使用 “GNU Hello” 为例,考虑使用如下 Buildah 命令构建的镜像:
```
#!/usr/bin/env bash
set -o errexit
# Create a container
container=$(buildah from fedora:28)
# Labels are part of the "buildah config" command
buildah config --label maintainer="Chris Collins <[email protected]>" $container
# Grab the source code outside of the container
curl -sSL http://ftpmirror.gnu.org/hello/hello-2.10.tar.gz -o hello-2.10.tar.gz
buildah copy $container hello-2.10.tar.gz /tmp/hello-2.10.tar.gz
buildah run $container dnf install -y tar gzip gcc make
buildah run $container dnf clean all
buildah run $container tar xvzf /tmp/hello-2.10.tar.gz -C /opt
# Workingdir is also a "buildah config" command
buildah config --workingdir /opt/hello-2.10 $container
buildah run $container ./configure
buildah run $container make
buildah run $container make install
buildah run $container hello -v
# Entrypoint, too, is a “buildah config” command
buildah config --entrypoint /usr/local/bin/hello $container
# Finally saves the running container to an image
buildah commit --format docker $container hello:latest
```
我们可以一眼看出这是一个 Bash 脚本而不是 Dockerfile。基于 Buildah 的原生命令,可以轻易的使用任何脚本语言或你擅长的自动化工具编写脚本。形式可以是 makefile、Python 脚本或其它你擅长的类型。
这个脚本做了哪些工作呢?首先,Buildah 命令 `container=$(buildah from fedora:28)` 基于 fedora:28 镜像创建了一个正在运行的容器,将容器名(`buildah from` 命令的返回值)保存到变量中,便于后续使用。后续所有命令都是有 `$container` 变量指明需要操作的容器。这些命令的功能大多可以从名称看出:`buildah copy` 将文件拷贝至容器,`buildah run` 会在容器中执行命令。可以很容易的将上述命令与 Dockerfile 中的指令对应起来。
最后一条命令 `buildah commit` 将容器提交到硬盘上的镜像中。当不使用 Dockerfile 而是使用 Buildah 命令构建镜像时,你可以使用 `commit` 命令决定何时保存变更。在上例中,所有的变更是一起提交的;但也可以增加中间提交,让你可以选择作为起点的<ruby> 缓存点 <rt> cache point </rt></ruby>。(例如,执行完 `dnf install` 命令后将变更缓存到硬盘是特别有意义的,一方面因为该操作耗时较长,另一方面每次执行的结果也确实相同。)
### 挂载点,安装目录以及 chroot
另一个可以大大增加构建镜像灵活性的 Buildah 命令是 `buildah mount`,可以将容器的根目录挂载到你主机的一个挂载点上。例如:
```
[chris@krang] $ container=$(sudo buildah from fedora:28)
[chris@krang] $ mountpoint=$(sudo buildah mount ${container})
[chris@krang] $ echo $mountpoint
/var/lib/containers/storage/overlay2/463eda71ec74713d8cebbe41ee07da5f6df41c636f65139a7bd17b24a0e845e3/merged
[chris@krang] $ cat ${mountpoint}/etc/redhat-release
Fedora release 28 (Twenty Eight)
[chris@krang] $ ls ${mountpoint}
bin dev home lib64 media opt root sbin sys usr
boot etc lib lost+found mnt proc run srv tmp var
```
这太棒了,你可以通过与挂载点交互对容器镜像进行修改。这允许你使用主机上的工具进行构建和安装软件,不用将这些构建工具打包到容器镜像本身中。例如,在我们上面的 Bash 脚本中,我们需要安装 tar、Gzip、GCC 和 make,在容器内编译 “GNU Hello”。如果使用挂载点,我仍使用同样的工具进行构建,但下载的压缩包和 tar、Gzip 等 RPM 包都在主机而不是容器和生成的镜像内:
```
#!/usr/bin/env bash
set -o errexit
# Create a container
container=$(buildah from fedora:28)
mountpoint=$(buildah mount $container)
buildah config --label maintainer="Chris Collins <[email protected]>" $container
curl -sSL http://ftpmirror.gnu.org/hello/hello-2.10.tar.gz \
-o /tmp/hello-2.10.tar.gz
tar xvzf src/hello-2.10.tar.gz -C ${mountpoint}/opt
pushd ${mountpoint}/opt/hello-2.10
./configure
make
make install DESTDIR=${mountpoint}
popd
chroot $mountpoint bash -c "/usr/local/bin/hello -v"
buildah config --entrypoint "/usr/local/bin/hello" $container
buildah commit --format docker $container hello
buildah unmount $container
```
在上述脚本中,需要提到如下几点:
1. `curl` 命令将压缩包下载到主机中,而不是镜像中;
2. (主机中的) `tar` 命令将压缩包中的源代码解压到容器的 `/opt` 目录;
3. `configure`,`make` 和 `make install` 命令都在主机的挂载点目录中执行,而不是在容器内;
4. 这里的 `chroot` 命令用于将挂载点本身当作根路径并测试 "hello" 是否正常工作;类似于前面例子中用到的 `buildah run` 命令。
这个脚本更加短小,使用大多数 Linux 爱好者都很熟悉的工具,最后生成的镜像也更小(没有 tar 包,没有额外的软件包等)。你甚至可以使用主机系统上的包管理器为容器安装软件。例如,(出于某种原因)你希望安装 GNU Hello 的同时在容器中安装 [NGINX](https://www.nginx.com/):
```
[chris@krang] $ mountpoint=$(sudo buildah mount ${container})
[chris@krang] $ sudo dnf install nginx --installroot $mountpoint
[chris@krang] $ sudo chroot $mountpoint nginx -v
nginx version: nginx/1.12.1
```
在上面的例子中,DNF 使用 `--installroot` 参数将 NGINX 安装到容器中,可以通过 chroot 进行校验。
### 快来试试吧!
Buildah 是一种轻量级、灵活的容器镜像构建方法,不需要在主机上运行完整的 Docker 守护进程。除了提供基于 Dockerfile 构建容器的开箱即用支持,Buildah 还可以很容易的与脚本或你喜欢的构建工具相结合,特别是可以使用主机上已有的工具构建容器镜像。Buildah 生成的容器体积更小,更便于网络传输,占用更小的存储空间,而且潜在的受攻击面更小。快来试试吧!
**[阅读相关的故事,[使用 Buildah 创建小体积的容器](/article-9719-1.html)]**
---
via: <https://opensource.com/article/18/6/getting-started-buildah>
作者:[Chris Collins](https://opensource.com/users/clcollins) 选题:[lujun9972](https://github.com/lujun9972) 译者:[pinewall](https://github.com/pinewall) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [Buildah](https://github.com/projectatomic/buildah) is a command-line tool for building [Open Container Initiative](https://www.opencontainers.org/)-compatible (that means Docker- and Kubernetes-compatible, too) images quickly and easily. It can act as a drop-in replacement for the Docker daemon’s `docker build`
command (i.e., building images with a traditional Dockerfile) but is flexible enough to allow you to build images with whatever tools you prefer to use. Buildah is easy to incorporate into scripts and build pipelines, and best of all, it doesn’t require a running container daemon to build its image.
## A drop-in replacement for docker build
You can get started with Buildah immediately, dropping it into place where images are currently built using a Dockerfile and `docker build`
. Buildah’s `build-using-dockerfile`
, or `bud`
argument makes it behave just like `docker build`
does, so it's easy to incorporate into existing scripts or build pipelines.
As with [previous articles I’ve written about Buildah](http://chris.collins.is/2017/08/17/buildah-a-new-way-to-build-container-images/), I like to use the example of installing "GNU Hello" from source. Consider this Dockerfile:
```
FROM fedora:28
LABEL maintainer Chris Collins <[email protected]>
RUN dnf install -y tar gzip gcc make \
&& dnf clean all
ADD http://ftpmirror.gnu.org/hello/hello-2.10.tar.gz /tmp/hello-2.10.tar.gz
RUN tar xvzf /tmp/hello-2.10.tar.gz -C /opt
WORKDIR /opt/hello-2.10
RUN ./configure
RUN make
RUN make install
RUN hello -v
ENTRYPOINT "/usr/local/bin/hello"
```
Buildah can create an image from this Dockerfile as easily as `buildah bud -t hello .`
, replacing `docker build -t hello .`
:
```
[chris@krang] $ sudo buildah bud -t hello .
STEP 1: FROM fedora:28
Getting image source signatures
Copying blob sha256:e06fd16225608e5b92ebe226185edb7422c3f581755deadf1312c6b14041fe73
81.48 MiB / 81.48 MiB [====================================================] 8s
Copying config sha256:30190780b56e33521971b0213810005a69051d720b73154c6e473c1a07ebd609
2.29 KiB / 2.29 KiB [======================================================] 0s
Writing manifest to image destination
Storing signatures
STEP 2: LABEL maintainer Chris Collins <[email protected]>
STEP 3: RUN dnf install -y tar gzip gcc make && dnf clean all
<snip>
```
Once the build is complete, you can see the new image with the `buildah images`
command:
```
[chris@krang] $ sudo buildah images
IMAGE ID IMAGE NAME CREATED AT SIZE
30190780b56e docker.io/library/fedora:28 Mar 7, 2018 16:53 247 MB
6d54bef73e63 docker.io/library/hello:latest May 3, 2018 15:24 391.8 MB
```
The new image, tagged `hello:latest`
, can be pushed to a remote image registry or run using [CRI-O](http://cri-o.io/) or other Kubernetes CRI-compatible runtimes, or pushed to a remote registry. If you’re testing it as a replacement for Docker build, you will probably want to copy the image to the docker daemon’s local image storage so it can be run by Docker. This is easily accomplished with the `buildah push`
command:
```
[chris@krang] $ sudo buildah push hello:latest docker-daemon:hello:latest
Getting image source signatures
Copying blob sha256:72fcdba8cff9f105a61370d930d7f184702eeea634ac986da0105d8422a17028
247.02 MiB / 247.02 MiB [==================================================] 2s
Copying blob sha256:e567905cf805891b514af250400cc75db3cb47d61219750e0db047c5308bd916
144.75 MiB / 144.75 MiB [==================================================] 1s
Copying config sha256:6d54bef73e638f2e2dd8b7bf1c4dfa26e7ed1188f1113ee787893e23151ff3ff
1.59 KiB / 1.59 KiB [======================================================] 0s
Writing manifest to image destination
Storing signatures
[chris@krang] $ sudo docker images | head -n2
REPOSITORY TAG IMAGE ID CREATED SIZE
docker.io/hello latest 6d54bef73e63 2 minutes ago 398 MB
[chris@krang] $ sudo docker run -t hello:latest
Hello, world!
```
## A few differences
Unlike Docker build, Buildah doesn’t commit changes to a layer automatically for every instruction in the Dockerfile—it builds everything from top to bottom, every time. On the positive side, this means non-cached builds (for example, those you would do with automation or build pipelines) end up being somewhat faster than their Docker build counterparts, especially if there are a lot of instructions. This is great for getting new changes into production quickly from an automated deployment or continuous delivery standpoint.
Practically speaking, however, the lack of caching may not be quite as useful for image development, where caching layers can save significant time when doing builds over and over again. This applies only to the `build-using-dockerfile`
command, however. When using Buildah native commands, as we’ll see below, you can choose when to commit your changes to disk, allowing for more flexible development.
## Buildah native commands
Where Buildah *really* shines is in its native commands, which you can use to interact with container builds. Rather than using `build-using-dockerfile/bud`
for each build, Buildah has commands to actually interact with the temporary container created during the build process. (Docker uses temporary, or *intermediate *containers, too, but you don’t really interact with them while the image is being built.)
Using the "GNU Hello" example again, consider this image build using Buildah commands:
```
#!/usr/bin/env bash
set -o errexit
# Create a container
container=$(buildah from fedora:28)
# Labels are part of the "buildah config" command
buildah config --label maintainer="Chris Collins <[email protected]>" $container
# Grab the source code outside of the container
curl -sSL http://ftpmirror.gnu.org/hello/hello-2.10.tar.gz -o hello-2.10.tar.gz
buildah copy $container hello-2.10.tar.gz /tmp/hello-2.10.tar.gz
buildah run $container dnf install -y tar gzip gcc make
Buildah run $container dnf clean all
buildah run $container tar xvzf /tmp/hello-2.10.tar.gz -C /opt
# Workingdir is also a "buildah config" command
buildah config --workingdir /opt/hello-2.10 $container
buildah run $container ./configure
buildah run $container make
buildah run $container make install
buildah run $container hello -v
# Entrypoint, too, is a “buildah config” command
buildah config --entrypoint /usr/local/bin/hello $container
# Finally saves the running container to an image
buildah commit --format docker $container hello:latest
```
One thing that should be immediately obvious is the fact that this is a Bash script rather than a Dockerfile. Using Buildah’s native commands makes it easy to script, in whatever language or automation context you like to use. This could be a makefile, a Python script, or whatever tools you like to use.
So what is going on here? The first Buildah command `container=$(buildah from fedora:28)`
, creates a running container from the fedora:28 image, and stores the container name (the output of the command) as a variable for later use. All the rest of the Buildah commands use the `$container`
variable to say what container to act upon. For the most part those commands are self-explanatory: `buildah copy`
moves a file into the container, `buildah run`
executes a command in the container. It is easy to match them to their Dockerfile equivalents.
The final command, `buildah commit`
, commits the container to an image on disk. When building images with Buildah commands rather than from a Dockerfile, you can use the `commit`
command to decide when to save your changes. In the example above, all of the changes are committed at once, but intermediate commits could be included too, allowing you to choose cache points from which to start. (For example, it would be particularly useful to cache to disk after the `dnf install`
, as that can take a long time, but is also reliably the same each time.)
## Mountpoints, install directories, and chroots
Another useful Buildah command opens the door to a lot of flexibility in building images. `buildah mount`
mounts the root directory of a container to a mountpoint on your host. For example:
```
[chris@krang] $ container=$(sudo buildah from fedora:28)
[chris@krang] $ mountpoint=$(sudo buildah mount ${container})
[chris@krang] $ echo $mountpoint
/var/lib/containers/storage/overlay2/463eda71ec74713d8cebbe41ee07da5f6df41c636f65139a7bd17b24a0e845e3/merged
[chris@krang] $ cat ${mountpoint}/etc/redhat-release
Fedora release 28 (Twenty Eight)
[chris@krang] $ ls ${mountpoint}
bin dev home lib64 media opt root sbin sys usr
boot etc lib lost+found mnt proc run srv tmp var
```
This is great because now you can interact with the mountpoint to make changes to your container image. This allows you to use tools on your host to build and install software, rather than including those tools in the container image itself. For example, in the Bash script above, we needed to install the tar, Gzip, GCC, and make packages to compile "GNU Hello" inside the container. Using a mountpoint, we can build an image with the same software, but the downloaded tarball and tar, Gzip, etc., RPMs are all on the host machine rather than in the container and resulting image:
```
#!/usr/bin/env bash
set -o errexit
# Create a container
container=$(buildah from fedora:28)
mountpoint=$(buildah mount $container)
buildah config --label maintainer="Chris Collins <[email protected]>" $container
curl -sSL http://ftpmirror.gnu.org/hello/hello-2.10.tar.gz \
-o /tmp/hello-2.10.tar.gz
tar xvzf src/hello-2.10.tar.gz -C ${mountpoint}/opt
pushd ${mountpoint}/opt/hello-2.10
./configure
make
make install DESTDIR=${mountpoint}
popd
chroot $mountpoint bash -c "/usr/local/bin/hello -v"
buildah config --entrypoint "/usr/local/bin/hello" $container
buildah commit --format docker $container hello
buildah unmount $container
```
Take note of a few things in the script above:
-
The
`curl`
command downloads the tarball to the host, not the image -
The
`tar`
command (running from the host itself) extracts the source code from the tarball into`/opt`
inside the container. -
`Configure`
,`make`
, and`make install`
are all running from a directory inside the mountpoint, mounted to the host rather than running inside the container itself. -
The
`chroot`
command here is used to change root into the mountpoint itself and test that "hello" is working, similar to the`buildah run`
command used in the previous example.
This script is shorter, it uses tools most Linux folks are already familiar with, and the resulting image is smaller (no tarball, no extra packages, etc). You could even use the package manager for the host system to install software into the container. For example, let’s say you wanted to install [NGINX](https://www.nginx.com/) into the container with GNU Hello (for whatever reason):
```
[chris@krang] $ mountpoint=$(sudo buildah mount ${container})
[chris@krang] $ sudo dnf install nginx --installroot $mountpoint
[chris@krang] $ sudo chroot $mountpoint nginx -v
nginx version: nginx/1.12.1
```
In the example above, DNF is used with the `--installroot`
flag to install NGINX into the container, which can be verified with chroot.
## Try it out!
Buildah is a lightweight and flexible way to create container images without running a full Docker daemon on your host. In addition to offering out-of-the-box support for building from Dockerfiles, Buildah is easy to use with scripts or build tools of your choice and can help build container images using existing tools on the build host. The result is leaner images that use less bandwidth to ship around, require less storage space, and have a smaller surface area for potential attackers. Give it a try!
**[See our related story, Creating small containers with Buildah]**
## Comments are closed. |
9,837 | 你所不了解的 Bash:关于 Bash 数组的介绍 | https://opensource.com/article/18/5/you-dont-know-bash-intro-bash-arrays | 2018-07-15T11:22:00 | [
"Bash",
"数组"
] | https://linux.cn/article-9837-1.html |
>
> 进入这个古怪而神奇的 Bash 数组的世界。
>
>
>

尽管软件工程师常常使用命令行来进行各种开发,但命令行中的数组似乎总是一个模糊的东西(虽然不像正则操作符 `=~` 那么复杂隐晦)。除开隐晦和有疑问的语法,[Bash](https://opensource.com/article/17/7/bash-prompt-tips-and-tricks) 数组其实是非常有用的。
### 稍等,这是为什么?
写 Bash 相关的东西很难,但如果是写一篇像手册那样注重怪异语法的文章,就会非常简单。不过请放心,这篇文章的目的就是让你不用去读该死的使用手册。
#### 真实(通常是有用的)示例
为了这个目的,想象一下真实世界的场景以及 Bash 是怎么帮忙的:你正在公司里面主导一个新工作,评估并优化内部数据管线的运行时间。首先,你要做个参数扫描分析来评估管线使用线程的状况。简单起见,我们把这个管道当作一个编译好的 C++ 黑盒子,这里面我们能够调整的唯一的参数是用于处理数据的线程数量:`./pipeline --threads 4`。
### 基础
我们首先要做的事是定义一个数组,用来容纳我们想要测试的 `--threads` 参数:
```
allThreads=(1 2 4 8 16 32 64 128)
```
本例中,所有元素都是数字,但参数并不一定是数字,Bash 中的数组可以容纳数字和字符串,比如 `myArray=(1 2 "three" 4 "five")` 就是个有效的表达式。就像 Bash 中其它的变量一样,确保赋值符号两边没有空格。否则 Bash 将会把变量名当作程序来执行,把 `=` 当作程序的第一个参数。
现在我们初始化了数组,让我们解析它其中的一些元素。仅仅输入 `echo $allThreads` ,你能发现,它只会输出第一个元素。
要理解这个产生的原因,需要回到上一步,回顾我们一般是怎么在 Bash 中输出变量。考虑以下场景:
```
type="article"
echo "Found 42 $type"
```
假如我们得到的变量 `$type` 是一个单词,我们想要添加在句子结尾一个 `s`。我们无法直接把 `s` 加到 `$type` 里面,因为这会把它变成另一个变量,`$types`。尽管我们可以利用像 `echo "Found 42 "$type"s"` 这样的代码形变,但解决这个问题的最好方法是用一个花括号:`echo "Found 42 ${type}s"`,这让我们能够告诉 Bash 变量名的起止位置(有趣的是,JavaScript/ES6 在 [template literals](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Template_literals) 中注入变量和表达式的语法和这里是一样的)
事实上,尽管 Bash 变量一般不用花括号,但在数组中需要用到花括号。这反而允许我们指定要访问的索引,例如 `echo ${allThreads[1]}` 返回的是数组中的第二个元素。如果不写花括号,比如 `echo $allThreads[1]`,会导致 Bash 把 `[1]` 当作字符串然后输出。
是的,Bash 数组的语法很怪,但是至少他们是从 0 开始索引的,不像有些语言(说的就是你,`R` 语言)。
### 遍历数组
上面的例子中我们直接用整数作为数组的索引,我们现在考虑两种其他情况:第一,如果想要数组中的第 `$i` 个元素,这里 `$i` 是一个代表索引的变量,我们可以这样 `echo ${allThreads[$i]}` 解析这个元素。第二,要输出一个数组的所有元素,我们把数字索引换成 `@` 符号(你可以把 `@` 当作表示 `all` 的符号):`echo ${allThreads[@]}`。
#### 遍历数组元素
记住上面讲过的,我们遍历 `$allThreads` 数组,把每个值当作 `--threads` 参数启动管线:
```
for t in ${allThreads[@]}; do
./pipeline --threads $t
done
```
#### 遍历数组索引
接下来,考虑一个稍稍不同的方法。不遍历所有的数组元素,我们可以遍历所有的索引:
```
for i in ${!allThreads[@]}; do
./pipeline --threads ${allThreads[$i]}
done
```
一步一步看:如之前所见,`${allThreads[@]}` 表示数组中的所有元素。前面加了个感叹号,变成 `${!allThreads[@]}`,这会返回数组索引列表(这里是 0 到 7)。换句话说。`for` 循环就遍历所有的索引 `$i` 并从 `$allThreads` 中读取第 `$i` 个元素,当作 `--threads` 选项的参数。
这看上去很辣眼睛,你可能奇怪为什么我要一开始就讲这个。这是因为有时候在循环中需要同时获得索引和对应的值,例如,如果你想要忽视数组中的第一个元素,使用索引可以避免额外创建在循环中累加的变量。
### 填充数组
到目前为止,我们已经能够用给定的 `--threads` 选项启动管线了。现在假设按秒计时的运行时间输出到管线。我们想要捕捉每个迭代的输出,然后把它保存在另一个数组中,因此我们最终可以随心所欲的操作它。
#### 一些有用的语法
在深入代码前,我们要多介绍一些语法。首先,我们要能解析 Bash 命令的输出。用这个语法可以做到:`output=$( ./my_script.sh )`,这会把命令的输出存储到变量 `$output` 中。
我们需要的第二个语法是如何把我们刚刚解析的值添加到数组中。完成这个任务的语法看起来很熟悉:
```
myArray+=( "newElement1" "newElement2" )
```
#### 参数扫描
万事具备,执行参数扫描的脚步如下:
```
allThreads=(1 2 4 8 16 32 64 128)
allRuntimes=()
for t in ${allThreads[@]}; do
runtime=$(./pipeline --threads $t)
allRuntimes+=( $runtime )
done
```
就是这个了!
### 还有什么能做的?
这篇文章中,我们讲过使用数组进行参数扫描的场景。我敢保证有很多理由要使用 Bash 数组,这里就有两个例子:
#### 日志警告
本场景中,把应用分成几个模块,每一个都有它自己的日志文件。我们可以编写一个 cron 任务脚本,当某个模块中出现问题标志时向特定的人发送邮件:
```
# 日志列表,发生问题时应该通知的人
logPaths=("api.log" "auth.log" "jenkins.log" "data.log")
logEmails=("jay@email" "emma@email" "jon@email" "sophia@email")
# 在每个日志中查找问题标志
for i in ${!logPaths[@]};
do
log=${logPaths[$i]}
stakeholder=${logEmails[$i]}
numErrors=$( tail -n 100 "$log" | grep "ERROR" | wc -l )
# 如果近期发现超过 5 个错误,就警告负责人
if [[ "$numErrors" -gt 5 ]];
then
emailRecipient="$stakeholder"
emailSubject="WARNING: ${log} showing unusual levels of errors"
emailBody="${numErrors} errors found in log ${log}"
echo "$emailBody" | mailx -s "$emailSubject" "$emailRecipient"
fi
done
```
#### API 查询
如果你想要生成一些分析数据,分析你的 Medium 帖子中用户评论最多的。由于我们无法直接访问数据库,SQL 不在我们考虑范围,但我们可以用 API!
为了避免陷入关于 API 授权和令牌的冗长讨论,我们将会使用 [JSONPlaceholder](https://github.com/typicode/jsonplaceholder),这是一个面向公众的测试服务 API。一旦我们查询每个帖子,解析出每个评论者的邮箱,我们就可以把这些邮箱添加到我们的结果数组里:
```
endpoint="https://jsonplaceholder.typicode.com/comments"
allEmails=()
# 查询前 10 个帖子
for postId in {1..10};
do
# 执行 API 调用,获取该帖子评论者的邮箱
response=$(curl "${endpoint}?postId=${postId}")
# 使用 jq 把 JSON 响应解析成数组
allEmails+=( $( jq '.[].email' <<< "$response" ) )
done
```
注意这里我是用 [jq 工具](https://stedolan.github.io/jq/) 从命令行里解析 JSON 数据。关于 `jq` 的语法超出了本文的范围,但我强烈建议你了解它。
你可能已经想到,使用 Bash 数组在数不胜数的场景中很有帮助,我希望这篇文章中的示例可以给你思维的启发。如果你从自己的工作中找到其它的例子想要分享出来,请在帖子下方评论。
### 请等等,还有很多东西!
由于我们在本文讲了很多数组语法,这里是关于我们讲到内容的总结,包含一些还没讲到的高级技巧:
| 语法 | 效果 |
| --- | --- |
| `arr=()` | 创建一个空数组 |
| `arr=(1 2 3)` | 初始化数组 |
| `${arr[2]}` | 取得第三个元素 |
| `${arr[@]}` | 取得所有元素 |
| `${!arr[@]}` | 取得数组索引 |
| `${#arr[@]}` | 计算数组长度 |
| `arr[0]=3` | 覆盖第 1 个元素 |
| `arr+=(4)` | 添加值 |
| `str=$(ls)` | 把 `ls` 输出保存到字符串 |
| `arr=( $(ls) )` | 把 `ls` 输出的文件保存到数组里 |
| `${arr[@]:s:n}` | 取得从索引 `s` 开始的 `n` 个元素 |
### 最后一点思考
正如我们所见,Bash 数组的语法很奇怪,但我希望这篇文章让你相信它们很有用。只要你理解了这些语法,你会发现以后会经常使用 Bash 数组。
#### Bash 还是 Python?
问题来了:什么时候该用 Bash 数组而不是其他的脚本语法,比如 Python?
对我而言,完全取决于需求——如果你可以只需要调用命令行工具就能立马解决问题,你也可以用 Bash。但有些时候,当你的脚本属于一个更大的 Python 项目时,你也可以用 Python。
比如,我们可以用 Python 来实现参数扫描,但我们只用编写一个 Bash 的包装:
```
import subprocess
all_threads = [1, 2, 4, 8, 16, 32, 64, 128]
all_runtimes = []
# 用不同的线程数字启动管线
for t in all_threads:
cmd = './pipeline --threads {}'.format(t)
# 使用子线程模块获得返回的输出
p = subprocess.Popen(cmd, stdout=subprocess.PIPE, shell=True)
output = p.communicate()[0]
all_runtimes.append(output)
```
由于本例中没法避免使用命令行,所以可以优先使用 Bash。
#### 羞耻的宣传时间
如果你喜欢这篇文章,这里还有很多类似的文章! [在此注册,加入 OSCON](https://conferences.oreilly.com/oscon/oscon-or),2018 年 7 月 17 号我会在这做一个主题为 [你所不了解的 Bash](https://conferences.oreilly.com/oscon/oscon-or/public/schedule/detail/67166) 的在线编码研讨会。没有幻灯片,不需要门票,只有你和我在命令行里面敲代码,探索 Bash 中的奇妙世界。
本文章由 [Medium] 首发,再发布时已获得授权。
---
via: <https://opensource.com/article/18/5/you-dont-know-bash-intro-bash-arrays>
作者:[Robert Aboukhalil](https://opensource.com/users/robertaboukhalil) 选题:[lujun9972](https://github.com/lujun9972) 译者:[BriFuture](https://github.com/BriFuture) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Although software engineers regularly use the command line for many aspects of development, arrays are likely one of the more obscure features of the command line (although not as obscure as the regex operator `=~`
). But obscurity and questionable syntax aside, [Bash](https://opensource.com/article/17/7/bash-prompt-tips-and-tricks) arrays can be very powerful.
## Wait, but why?
Writing about Bash is challenging because it's remarkably easy for an article to devolve into a manual that focuses on syntax oddities. Rest assured, however, the intent of this article is to avoid having you RTFM.
### A real (actually useful) example
To that end, let's consider a real-world scenario and how Bash can help: You are leading a new effort at your company to evaluate and optimize the runtime of your internal data pipeline. As a first step, you want to do a parameter sweep to evaluate how well the pipeline makes use of threads. For the sake of simplicity, we'll treat the pipeline as a compiled C++ black box where the only parameter we can tweak is the number of threads reserved for data processing: `./pipeline --threads 4`
.
## The basics
The first thing we'll do is define an array containing the values of the `--threads`
parameter that we want to test:
`allThreads=(1 2 4 8 16 32 64 128)`
In this example, all the elements are numbers, but it need not be the case—arrays in Bash can contain both numbers and strings, e.g., `myArray=(1 2 "three" 4 "five")`
is a valid expression. And just as with any other Bash variable, make sure to leave no spaces around the equal sign. Otherwise, Bash will treat the variable name as a program to execute, and the `=`
as its first parameter!
Now that we've initialized the array, let's retrieve a few of its elements. You'll notice that simply doing `echo $allThreads`
will output only the first element.
To understand why that is, let's take a step back and revisit how we usually output variables in Bash. Consider the following scenario:
```
type="article"
echo "Found 42 $type"
```
Say the variable `$type`
is given to us as a singular noun and we want to add an `s`
at the end of our sentence. We can't simply add an `s`
to `$type`
since that would turn it into a different variable, `$types`
. And although we could utilize code contortions such as `echo "Found 42 "$type"s"`
, the best way to solve this problem is to use curly braces: `echo "Found 42 ${type}s"`
, which allows us to tell Bash where the name of a variable starts and ends (interestingly, this is the same syntax used in JavaScript/ES6 to inject variables and expressions in [template literals](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Template_literals)).
So as it turns out, although Bash variables don't generally require curly brackets, they are required for arrays. In turn, this allows us to specify the index to access, e.g., `echo ${allThreads[1]}`
returns the second element of the array. Not including brackets, e.g.,`echo $allThreads[1]`
, leads Bash to treat `[1]`
as a string and output it as such.
Yes, Bash arrays have odd syntax, but at least they are zero-indexed, unlike some other languages (I'm looking at you, `R`
).
## Looping through arrays
Although in the examples above we used integer indices in our arrays, let's consider two occasions when that won't be the case: First, if we wanted the `$i`
-th element of the array, where `$i`
is a variable containing the index of interest, we can retrieve that element using: `echo ${allThreads[$i]}`
. Second, to output all the elements of an array, we replace the numeric index with the `@`
symbol (you can think of `@`
as standing for `all`
): `echo ${allThreads[@]}`
.
### Looping through array elements
With that in mind, let's loop through `$allThreads`
and launch the pipeline for each value of `--threads`
:
```
for t in ${allThreads[@]}; do
./pipeline --threads $t
done
```
### Looping through array indices
Next, let's consider a slightly different approach. Rather than looping over array *elements*, we can loop over array *indices*:
```
for i in ${!allThreads[@]}; do
./pipeline --threads ${allThreads[$i]}
done
```
Let's break that down: As we saw above, `${allThreads[@]}`
represents all the elements in our array. Adding an exclamation mark to make it `${!allThreads[@]}`
will return the list of all array indices (in our case 0 to 7). In other words, the `for`
loop is looping through all indices `$i`
and reading the `$i`
-th element from `$allThreads`
to set the value of the `--threads`
parameter.
This is much harsher on the eyes, so you may be wondering why I bother introducing it in the first place. That's because there are times where you need to know both the index and the value within a loop, e.g., if you want to ignore the first element of an array, using indices saves you from creating an additional variable that you then increment inside the loop.
## Populating arrays
So far, we've been able to launch the pipeline for each `--threads`
of interest. Now, let's assume the output to our pipeline is the runtime in seconds. We would like to capture that output at each iteration and save it in another array so we can do various manipulations with it at the end.
### Some useful syntax
But before diving into the code, we need to introduce some more syntax. First, we need to be able to retrieve the output of a Bash command. To do so, use the following syntax: `output=$( ./my_script.sh )`
, which will store the output of our commands into the variable `$output`
.
The second bit of syntax we need is how to append the value we just retrieved to an array. The syntax to do that will look familiar:
`myArray+=( "newElement1" "newElement2" )`
### The parameter sweep
Putting everything together, here is our script for launching our parameter sweep:
```
allThreads=(1 2 4 8 16 32 64 128)
allRuntimes=()
for t in ${allThreads[@]}; do
runtime=$(./pipeline --threads $t)
allRuntimes+=( $runtime )
done
```
And voilà!
## What else you got?
In this article, we covered the scenario of using arrays for parameter sweeps. But I promise there are more reasons to use Bash arrays—here are two more examples.
### Log alerting
In this scenario, your app is divided into modules, each with its own log file. We can write a cron job script to email the right person when there are signs of trouble in certain modules:` `
```
# List of logs and who should be notified of issues
logPaths=("api.log" "auth.log" "jenkins.log" "data.log")
logEmails=("jay@email" "emma@email" "jon@email" "sophia@email")
# Look for signs of trouble in each log
for i in ${!logPaths[@]};
do
log=${logPaths[$i]}
stakeholder=${logEmails[$i]}
numErrors=$( tail -n 100 "$log" | grep "ERROR" | wc -l )
# Warn stakeholders if recently saw > 5 errors
if [[ "$numErrors" -gt 5 ]];
then
emailRecipient="$stakeholder"
emailSubject="WARNING: ${log} showing unusual levels of errors"
emailBody="${numErrors} errors found in log ${log}"
echo "$emailBody" | mailx -s "$emailSubject" "$emailRecipient"
fi
done
```
### API queries
Say you want to generate some analytics about which users comment the most on your Medium posts. Since we don't have direct database access, SQL is out of the question, but we can use APIs!
To avoid getting into a long discussion about API authentication and tokens, we'll instead use [JSONPlaceholder](https://github.com/typicode/jsonplaceholder), a public-facing API testing service, as our endpoint. Once we query each post and retrieve the emails of everyone who commented, we can append those emails to our results array:
```
endpoint="https://jsonplaceholder.typicode.com/comments"
allEmails=()
# Query first 10 posts
for postId in {1..10};
do
# Make API call to fetch emails of this posts's commenters
response=$(curl "${endpoint}?postId=${postId}")
# Use jq to parse the JSON response into an array
allEmails+=( $( jq '.[].email' <<< "$response" ) )
done
```
Note here that I'm using the [ jq tool](https://stedolan.github.io/jq/) to parse JSON from the command line. The syntax of
`jq`
is beyond the scope of this article, but I highly recommend you look into it.As you might imagine, there are countless other scenarios in which using Bash arrays can help, and I hope the examples outlined in this article have given you some food for thought. If you have other examples to share from your own work, please leave a comment below.
## But wait, there's more!
Since we covered quite a bit of array syntax in this article, here's a summary of what we covered, along with some more advanced tricks we did not cover:
Syntax | Result |
---|---|
`arr=()` |
Create an empty array |
`arr=(1 2 3)` |
Initialize array |
`${arr[2]}` |
Retrieve third element |
`${arr[@]}` |
Retrieve all elements |
`${!arr[@]}` |
Retrieve array indices |
`${#arr[@]}` |
Calculate array size |
`arr[0]=3` |
Overwrite 1st element |
`arr+=(4)` |
Append value(s) |
`str=$(ls)` |
Save `ls` output as a string |
`arr=( $(ls) )` |
Save `ls` output as an array of files |
`${arr[@]:s:n}` |
Retrieve n elements `starting at index s` |
## One last thought
As we've discovered, Bash arrays sure have strange syntax, but I hope this article convinced you that they are extremely powerful. Once you get the hang of the syntax, you'll find yourself using Bash arrays quite often.
### Bash or Python?
Which begs the question: *When should you use Bash arrays instead of other scripting languages such as Python?*
To me, it all boils down to dependencies—if you can solve the problem at hand using only calls to command-line tools, you might as well use Bash. But for times when your script is part of a larger Python project, you might as well use Python.
For example, we could have turned to Python to implement the parameter sweep, but we would have ended up just writing a wrapper around Bash:
```
import subprocess
all_threads = [1, 2, 4, 8, 16, 32, 64, 128]
all_runtimes = []
# Launch pipeline on each number of threads
for t in all_threads:
cmd = './pipeline --threads {}'.format(t)
# Use the subprocess module to fetch the return output
p = subprocess.Popen(cmd, stdout=subprocess.PIPE, shell=True)
output = p.communicate()[0]
all_runtimes.append(output)
```
Since there's no getting around the command line in this example, using Bash directly is preferable.
### Time for a shameless plug
This article is based on a talk I gave at [OSCON](https://conferences.oreilly.com/oscon/oscon-or), where I presented the live-coding workshop [ You Don't Know Bash](https://conferences.oreilly.com/oscon/oscon-or/public/schedule/detail/67166). No slides, no clickers—just me and the audience typing away at the command line, exploring the wondrous world of Bash.
*This article originally appeared on Medium and is republished with permission.*
## 11 Comments |
9,838 | 使用 ftrace 跟踪内核 | https://blog.selectel.com/kernel-tracing-ftrace/ | 2018-07-15T12:17:20 | [
"ftrace",
"跟踪"
] | https://linux.cn/article-9838-1.html | 
在内核层面上分析事件有很多的工具:[SystemTap](https://sourceware.org/systemtap/)、[ktap](https://github.com/ktap/ktap)、[Sysdig](http://www.sysdig.org/)、[LTTNG](http://lttng.org/) 等等,你也可以在网络上找到关于这些工具的大量介绍文章和资料。
而对于使用 Linux 原生机制去跟踪系统事件以及检索/分析故障信息的方面的资料却很少找的到。这就是 [ftrace](https://www.kernel.org/doc/Documentation/trace/ftrace.txt),它是添加到内核中的第一款跟踪工具,今天我们来看一下它都能做什么,让我们从它的一些重要术语开始吧。
### 内核跟踪和分析
<ruby> 内核分析 <rt> Kernel profiling </rt></ruby>可以发现性能“瓶颈”。分析能够帮我们发现在一个程序中性能损失的准确位置。特定的程序生成一个<ruby> 概述 <rt> profile </rt></ruby> — 这是一个事件总结 — 它能够用于帮我们找出哪个函数占用了大量的运行时间。尽管这些程序并不能识别出为什么会损失性能。
瓶颈经常发生在无法通过分析来识别的情况下。要推断出为什么会发生事件,就必须保存发生事件时的相关上下文,这就需要去<ruby> 跟踪 <rt> tracing </rt></ruby>。
跟踪可以理解为在一个正常工作的系统上活动的信息收集过程。它使用特定的工具来完成这项工作,就像录音机来记录声音一样,用它来记录各种系统事件。
跟踪程序能够同时跟踪应用级和操作系统级的事件。它们收集的信息能够用于诊断多种系统问题。
有时候会将跟踪与日志比较。它们两者确时很相似,但是也有不同的地方。
对于跟踪,记录的信息都是些低级别事件。它们的数量是成百上千的,甚至是成千上万的。对于日志,记录的信息都是些高级别事件,数量上通常少多了。这些包含用户登录系统、应用程序错误、数据库事务等等。
就像日志一样,跟踪数据可以被原样读取,但是用特定的应用程序提取的信息更有用。所有的跟踪程序都能这样做。
在内核跟踪和分析方面,Linux 内核有三个主要的机制:
* <ruby> 跟踪点 <rt> tracepoint </rt></ruby>:一种基于静态测试代码的工作机制
* <ruby> 探针 <rt> kprobe </rt></ruby>:一种动态跟踪机制,用于在任意时刻中断内核代码的运行,调用它自己的处理程序,在完成需要的操作之后再返回
* perf\_events —— 一个访问 PMU(<ruby> 性能监视单元 <rt> Performance Monitoring Unit </rt></ruby>)的接口
我并不想在这里写关于这些机制方面的内容,任何对它们感兴趣的人可以去访问 [Brendan Gregg 的博客](http://www.brendangregg.com/blog/index.html)。
使用 ftrace,我们可以与这些机制进行交互,并可以从用户空间直接得到调试信息。下面我们将讨论这方面的详细内容。示例中的所有命令行都是在内核版本为 3.13.0-24 的 Ubuntu 14.04 中运行的。
### ftrace:常用信息
ftrace 是 Function Trace 的简写,但它能做的远不止这些:它可以跟踪上下文切换、测量进程阻塞时间、计算高优先级任务的活动时间等等。
ftrace 是由 Steven Rostedt 开发的,从 2008 年发布的内核 2.6.27 中开始就内置了。这是为记录数据提供的一个调试 Ring 缓冲区的框架。这些数据由集成到内核中的跟踪程序来采集。
ftrace 工作在 debugfs 文件系统上,在大多数现代 Linux 发行版中都默认挂载了。要开始使用 ftrace,你将进入到 `sys/kernel/debug/tracing` 目录(仅对 root 用户可用):
```
# cd /sys/kernel/debug/tracing
```
这个目录的内容看起来应该像这样:
```
аvailable_filter_functions options stack_trace_filter
available_tracers per_cpu trace
buffer_size_kb printk_formats trace_clock
buffer_total_size_kb README trace_marker
current_tracer saved_cmdlines trace_options
dyn_ftrace_total_info set_event trace_pipe
enabled_functions set_ftrace_filter trace_stat
events set_ftrace_notrace tracing_cpumask
free_buffer set_ftrace_pid tracing_max_latency
function_profile_enabled set_graph_function tracing_on
instances set_graph_notrace tracing_thresh
kprobe_events snapshot uprobe_events
kprobe_profile stack_max_size uprobe_profile
```
我不想去描述这些文件和子目录;它们的描述在 [官方文档](https://www.kernel.org/doc/Documentation/trace/ftrace.txt) 中已经写的很详细了。我只想去详细介绍与我们这篇文章相关的这几个文件:
* available\_tracers —— 可用的跟踪程序
* current\_tracer —— 正在运行的跟踪程序
* tracing\_on —— 负责启用或禁用数据写入到 Ring 缓冲区的系统文件(如果启用它,数字 1 被添加到文件中,禁用它,数字 0 被添加)
* trace —— 以人类友好格式保存跟踪数据的文件
### 可用的跟踪程序
我们可以使用如下的命令去查看可用的跟踪程序的一个列表:
```
root@andrei:/sys/kernel/debug/tracing#: cat available_tracers
blk mmiotrace function_graph wakeup_rt wakeup function nop
```
我们来快速浏览一下每个跟踪程序的特性:
* function —— 一个无需参数的函数调用跟踪程序
* function\_graph —— 一个使用子调用的函数调用跟踪程序
* blk —— 一个与块 I/O 跟踪相关的调用和事件跟踪程序(它是 blktrace 使用的)
* mmiotrace —— 一个内存映射 I/O 操作跟踪程序
* nop —— 最简单的跟踪程序,就像它的名字所暗示的那样,它不做任何事情(尽管在某些情况下可能会派上用场,我们将在后文中详细解释)
### 函数跟踪程序
在开始介绍函数跟踪程序 ftrace 之前,我们先看一个测试脚本:
```
#!/bin/sh
dir=/sys/kernel/debug/tracing
sysctl kernel.ftrace_enabled=1
echo function > ${dir}/current_tracer
echo 1 > ${dir}/tracing_on
sleep 1
echo 0 > ${dir}/tracing_on
less ${dir}/trace
```
这个脚本是非常简单的,但是还有几个需要注意的地方。命令 `sysctl ftrace.enabled=1` 启用了函数跟踪程序。然后我们通过写它的名字到 `current_tracer` 文件来启用 `current tracer`。
接下来,我们写入一个 `1` 到 `tracing_on`,它启用了 Ring 缓冲区。这些语法都要求在 `1` 和 `>` 符号前后有一个空格;写成像 `echo 1> tracing_on` 这样将不能工作。一行之后我们禁用它(如果 `0` 写入到 `tracing_on`, 缓冲区不会被清除并且 ftrace 并不会被禁用)。
我们为什么这样做呢?在两个 `echo` 命令之间,我们看到了命令 `sleep 1`。我们启用了缓冲区,运行了这个命令,然后禁用它。这将使跟踪程序采集了这个命令运行期间发生的所有系统调用的信息。
在脚本的最后一行,我们写了一个在控制台上显示跟踪数据的命令。
一旦脚本运行完成后,我们将看到下列的输出(这里只列出了一个小片断):
```
# tracer: function
#
# entries-in-buffer/entries-written: 29571/29571 #P:2
#
# _-----=> irqs-off
# / _----=> need-resched
# | / _---=> hardirq/softirq
# || / _--=> preempt-depth
# ||| / delay
# TASK-PID CPU# |||| TIMESTAMP FUNCTION
# | | | |||| | |
trace.sh-1295 [000] .... 90.502874: mutex_unlock <-rb_simple_write
trace.sh-1295 [000] .... 90.502875: __fsnotify_parent <-vfs_write
trace.sh-1295 [000] .... 90.502876: fsnotify <-vfs_write
trace.sh-1295 [000] .... 90.502876: __srcu_read_lock <-fsnotify
trace.sh-1295 [000] .... 90.502876: __srcu_read_unlock <-fsnotify
trace.sh-1295 [000] .... 90.502877: __sb_end_write <-vfs_write
trace.sh-1295 [000] .... 90.502877: syscall_trace_leave <-int_check_syscall_exit_work
trace.sh-1295 [000] .... 90.502878: context_tracking_user_exit <-syscall_trace_leave
trace.sh-1295 [000] .... 90.502878: context_tracking_user_enter <-syscall_trace_leave
trace.sh-1295 [000] d... 90.502878: vtime_user_enter <-context_tracking_user_enter
trace.sh-1295 [000] d... 90.502878: _raw_spin_lock <-vtime_user_enter
trace.sh-1295 [000] d... 90.502878: __vtime_account_system <-vtime_user_enter
trace.sh-1295 [000] d... 90.502878: get_vtime_delta <-__vtime_account_system
trace.sh-1295 [000] d... 90.502879: account_system_time <-__vtime_account_system
trace.sh-1295 [000] d... 90.502879: cpuacct_account_field <-account_system_time
trace.sh-1295 [000] d... 90.502879: acct_account_cputime <-account_system_time
trace.sh-1295 [000] d... 90.502879: __acct_update_integrals <-acct_account_cputime
```
这个输出以“缓冲区中的信息条目数量”和“写入的全部条目数量”开始。这两者的数据差异是缓冲区中事件的丢失数量(在我们的示例中没有发生丢失)。
在这里有一个包含下列信息的函数列表:
* 进程标识符(PID)
* 运行这个进程的 CPU(CPU#)
* 进程开始时间(TIMESTAMP)
* 被跟踪函数的名字以及调用它的父级函数;例如,在我们输出的第一行,`rb_simple_write` 调用了 `mutex-unlock` 函数。
### function\_graph 跟踪程序
function\_graph 跟踪程序的工作和函数跟踪程序一样,但是它更详细:它显示了每个函数的进入和退出点。使用这个跟踪程序,我们可以跟踪函数的子调用并且测量每个函数的运行时间。
我们来编辑一下最后一个示例的脚本:
```
#!/bin/sh
dir=/sys/kernel/debug/tracing
sysctl kernel.ftrace_enabled=1
echo function_graph > ${dir}/current_tracer
echo 1 > ${dir}/tracing_on
sleep 1
echo 0 > ${dir}/tracing_on
less ${dir}/trace
```
运行这个脚本之后,我们将得到如下的输出:
```
# tracer: function_graph
#
# CPU DURATION FUNCTION CALLS
# | | | | | | |
0) 0.120 us | } /* resched_task */
0) 1.877 us | } /* check_preempt_curr */
0) 4.264 us | } /* ttwu_do_wakeup */
0) + 29.053 us | } /* ttwu_do_activate.constprop.74 */
0) 0.091 us | _raw_spin_unlock();
0) 0.260 us | ttwu_stat();
0) 0.133 us | _raw_spin_unlock_irqrestore();
0) + 37.785 us | } /* try_to_wake_up */
0) + 38.478 us | } /* default_wake_function */
0) + 39.203 us | } /* pollwake */
0) + 40.793 us | } /* __wake_up_common */
0) 0.104 us | _raw_spin_unlock_irqrestore();
0) + 42.920 us | } /* __wake_up_sync_key */
0) + 44.160 us | } /* sock_def_readable */
0) ! 192.850 us | } /* tcp_rcv_established */
0) ! 197.445 us | } /* tcp_v4_do_rcv */
0) 0.113 us | _raw_spin_unlock();
0) ! 205.655 us | } /* tcp_v4_rcv */
0) ! 208.154 us | } /* ip_local_deliver_finish */
```
在这个图中,`DURATION` 展示了花费在每个运行的函数上的时间。注意使用 `+` 和 `!` 符号标记的地方。加号(`+`)意思是这个函数花费的时间超过 10 毫秒;而感叹号(`!`)意思是这个函数花费的时间超过了 100 毫秒。
在 `FUNCTION_CALLS` 下面,我们可以看到每个函数调用的信息。
和 C 语言一样使用了花括号(`{`)标记每个函数的边界,它展示了每个函数的开始和结束,一个用于开始,一个用于结束;不能调用其它任何函数的叶子函数用一个分号(`;`)标记。
### 函数过滤器
ftrace 输出可能会很大,精确找出你所需要的内容可能会非常困难。我们可以使用过滤器去简化我们的搜索:输出中将只显示与我们感兴趣的函数相关的信息。为实现过滤,我们只需要在 `set_ftrace_filter` 文件中写入我们需要过滤的函数的名字即可。例如:
```
root@andrei:/sys/kernel/debug/tracing# echo kfree > set_ftrace_filter
```
如果禁用过滤器,我们只需要在这个文件中添加一个空白行即可:
```
root@andrei:/sys/kernel/debug/tracing# echo > set_ftrace_filter
```
通过运行这个命令:
```
root@andrei:/sys/kernel/debug/tracing# echo kfree > set_ftrace_notrace
```
我们将得到相反的结果:输出将包含除了 `kfree()` 以外的任何函数的信息。
另一个有用的选项是 `set_ftrace_pid`。它是为在一个特定的进程运行期间调用跟踪函数准备的。
ftrace 还有很多过滤选项。对于它们更详细的介绍,你可以去查看 Steven Rostedt 在 [LWN.net](https://lwn.net/Articles/370423/) 上的文章。
### 跟踪事件
我们在上面提到到跟踪点机制。跟踪点是插入的触发系统事件的特定代码。跟踪点可以是动态的(意味着可能会在它们上面附加几个检查),也可以是静态的(意味着不会附加任何检查)。
静态跟踪点不会对系统有任何影响;它们只是在测试的函数末尾增加几个字节的函数调用以及在一个独立的节上增加一个数据结构。
当相关代码片断运行时,动态跟踪点调用一个跟踪函数。跟踪数据是写入到 Ring 缓冲区。
跟踪点可以设置在代码的任何位置;事实上,它们确实可以在许多的内核函数中找到。我们来看一下 `kmem_cache_alloc` 函数(取自 [这里](http://lxr.free-electrons.com/source/mm/slab.c)):
```
{
void *ret = slab_alloc(cachep, flags, _RET_IP_);
trace_kmem_cache_alloc(_RET_IP_, ret,
cachep->object_size, cachep->size, flags);
return ret;
}
```
`trace_kmem_cache_alloc` 它本身就是一个跟踪点。我们可以通过查看其它内核函数的源代码找到这样无数的例子。
在 Linux 内核中为了从用户空间使用跟踪点,它有一个专门的 API。在 `/sys/kernel/debug/tracing` 目录中,这里有一个事件目录,它是为了保存系统事件。这些只是为了跟踪系统事件。在这个上下文中系统事件可以理解为包含在内核中的跟踪点。
可以通过运行如下的命令来查看这个事件列表:
```
root@andrei:/sys/kernel/debug/tracing# cat available_events
```
这个命令将在控制台中输出一个很长的列表。这样看起来很不方便。我们可以使用如下的命令来列出一个结构化的列表:
```
root@andrei:/sys/kernel/debug/tracing# ls events
block gpio mce random skb vsyscall
btrfs header_event migrate ras sock workqueue
compaction header_page module raw_syscalls spi writeback
context_tracking iommu napi rcu swiotlb xen
enable irq net regmap syscalls xfs
exceptions irq_vectors nmi regulator task xhci-hcd
ext4 jbd2 oom rpm timer
filemap kmem pagemap sched udp
fs kvm power scsi vfs
ftrace kvmmmu printk signal vmscan
```
所有可能的事件都按子系统分组到子目录中。在我们开始跟踪事件之前,我们要先确保启用了 Ring 缓冲区写入:
```
root@andrei:/sys/kernel/debug/tracing# cat tracing_on
```
如果在控制台中显示的是数字 0,那么,我们可以运行如下的命令来启用它:
```
root@andrei:/sys/kernel/debug/tracing# echo 1 > tracing_on
```
在我们上一篇的文章中,我们写了关于 `chroot()` 系统调用的内容;我们来跟踪访问一下这个系统调用。对于我们的跟踪程序,我们使用 `nop` 因为函数跟踪程序和 `function_graph` 跟踪程序记录的信息太多,它包含了我们不感兴趣的事件信息。
```
root@andrei:/sys/kernel/debug/tracing# echo nop > current_tracer
```
所有事件相关的系统调用都保存在系统调用目录下。在这里我们将找到一个进入和退出各种系统调用的目录。我们需要在相关的文件中通过写入数字 `1` 来激活跟踪点:
```
root@andrei:/sys/kernel/debug/tracing# echo 1 > events/syscalls/sys_enter_chroot/enable
```
然后我们使用 `chroot` 来创建一个独立的文件系统(更多内容,请查看 [之前这篇文章](https://blog.selectel.com/containerization-mechanisms-namespaces/))。在我们执行完我们需要的命令之后,我们将禁用跟踪程序,以便于不需要的信息或者过量信息不会出现在输出中:
```
root@andrei:/sys/kernel/debug/tracing# echo 0 > tracing_on
```
然后,我们去查看 Ring 缓冲区的内容。在输出的结束部分,我们找到了有关的系统调用信息(这里只是一个节选)。
```
root@andrei:/sys/kernel/debug/tracing# сat trace
......
chroot-11321 [000] .... 4606.265208: sys_chroot(filename: 7fff785ae8c2)
chroot-11325 [000] .... 4691.677767: sys_chroot(filename: 7fff242308cc)
bash-11338 [000] .... 4746.971300: sys_chroot(filename: 7fff1efca8cc)
bash-11351 [000] .... 5379.020609: sys_chroot(filename: 7fffbf9918cc)
```
关于配置事件跟踪的更的信息可以在 [这里](https://www.kernel.org/doc/Documentation/trace/events.txt) 找到。
### 结束语
在这篇文篇中,我们做了一个 ftrace 的功能概述。我们非常感谢你的任何意见或者补充。如果你想深入研究这个主题,我们为你推荐下列的资源:
* <https://www.kernel.org/doc/Documentation/trace/tracepoints.txt> — 一个跟踪点机制的详细描述
* <https://www.kernel.org/doc/Documentation/trace/events.txt> — 在 Linux 中跟踪系统事件的指南
* <https://www.kernel.org/doc/Documentation/trace/ftrace.txt> — ftrace 的官方文档
* <https://lttng.org/files/thesis/desnoyers-dissertation-2009-12-v27.pdf> — Mathieu Desnoyers(作者是跟踪点和 LTTNG 的创建者)的关于内核跟踪和分析的学术论文。
* <https://lwn.net/Articles/370423/> — Steven Rostedt 的关于 ftrace 功能的文章
* <http://alex.dzyoba.com/linux/profiling-ftrace.html> — 用 ftrace 分析实际案例的一个概述
---
via:<https://blog.selectel.com/kernel-tracing-ftrace/>
作者:[Andrej Yemelianov](https://blog.selectel.com/author/yemelianov/) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,839 | 2018 年 6 月 COPR 中值得尝试的 4 个很酷的新项目 | https://fedoramagazine.org/4-try-copr-june-2018/ | 2018-07-15T12:44:31 | [
"COPR",
"Fedora"
] | https://linux.cn/article-9839-1.html | 
COPR 是个人软件仓库[集合](https://copr.fedorainfracloud.org/),它不在 Fedora 中。这是因为某些软件不符合轻松打包的标准。或者它可能不符合其他 Fedora 标准,尽管它是免费和开源的。COPR 可以在 Fedora 套件之外提供这些项目。COPR 中的软件不被 Fedora 基础设施不支持或没有被该项目所签名。但是,这是一种尝试新的或实验性的软件的一种巧妙的方式。
这是 COPR 中一组新的有趣项目。
### Ghostwriter
[Ghostwriter](http://wereturtle.github.io/ghostwriter/) 是 [Markdown](https://daringfireball.net/) 格式的文本编辑器,它有一个最小的界面。它以 HTML 格式提供文档预览,并为 Markdown 提供语法高亮显示。它提供了仅高亮显示当前正在编写的段落或句子的选项。此外,Ghostwriter 可以将文档导出为多种格式,包括 PDF 和 HTML。最后,它有所谓的“海明威”模式,其中删除被禁用,迫使用户现在智能编写,而在稍后编辑。

#### 安装说明
仓库目前为 Fedora 26、27、28 和 Rawhide 以及 EPEL 7 提供 Ghostwriter。要安装 Ghostwriter,请使用以下命令:
```
sudo dnf copr enable scx/ghostwriter
sudo dnf install ghostwriter
```
### Lector
[Lector](https://github.com/BasioMeusPuga/Lector) 是一个简单的电子书阅读器程序。Lector 支持最常见的电子书格式,如 EPUB、MOBI 和 AZW,以及漫画书格式 CBZ 和 CBR。它很容易设置 —— 只需指定包含电子书的目录即可。你可以使用表格或书籍封面浏览 Lector 库内的书籍。Lector 的功能包括书签、用户自定义标签和内置字典。
#### 安装说明
该仓库目前为 Fedora 26、27、28 和 Rawhide 提供Lector。要安装 Lector,请使用以下命令:
```
sudo dnf copr enable bugzy/lector
sudo dnf install lector
```
### Ranger
Ranerger 是一个基于文本的文件管理器,它带有 Vim 键绑定。它以三列显示目录结构。左边显示父目录,中间显示当前目录的内容,右边显示所选文件或目录的预览。对于文本文件,Ranger 将文件的实际内容作为预览。
#### 安装说明
该仓库目前为 Fedora 27、28 和 Rawhide 提供 Ranger。要安装 Ranger,请使用以下命令:
```
sudo dnf copr enable fszymanski/ranger
sudo dnf install ranger
```
### PrestoPalette
PrestoPeralette 是一款帮助创建平衡调色板的工具。PrestoPalette 的一个很好的功能是能够使用光照来影响调色板的亮度和饱和度。你可以将创建的调色板导出为 PNG 或 JSON。

#### 安装说明
仓库目前为 Fedora 26、27、28 和 Rawhide 以及 EPEL 7 提供 PrestoPalette。要安装 PrestoPalette,请使用以下命令:
```
sudo dnf copr enable dagostinelli/prestopalette
sudo dnf install prestopalette
```
---
via: <https://fedoramagazine.org/4-try-copr-june-2018/>
作者:[Dominik Turecek](https://fedoramagazine.org) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | COPR is a [collection](https://copr.fedorainfracloud.org/) of personal repositories for software that isn’t carried in Fedora. Some software doesn’t conform to standards that allow easy packaging. Or it may not meet other Fedora standards, despite being free and open source. COPR can offer these projects outside the Fedora set of packages. Software in COPR isn’t supported by Fedora infrastructure or signed by the project. However, it can be a neat way to try new or experimental software.
Here’s a set of new and interesting projects in COPR.
## Ghostwriter
[Ghostwriter](http://wereturtle.github.io/ghostwriter/) is a text editor for [Markdown](https://daringfireball.net/) format with a minimal interface. It provides a preview of the document in HTML and syntax highlighting for Markdown. It offers the option to highlight only the paragraph or sentence currently being written. In addition, Ghostwriter can export documents to several formats, including PDF and HTML. Finally, it has the so-called “Hemingway” mode, in which erasing is disabled, forcing the user to write now and edit later.
### Installation instructions
The repo currently provides Ghostwriter for Fedora 26, 27, 28, and Rawhide, and EPEL 7. To install Ghostwriter, use these commands:
sudo dnf copr enable scx/ghostwriter sudo dnf install ghostwriter
## Lector
[Lector](https://github.com/BasioMeusPuga/Lector) is a simple ebook reader application. Lector supports most common ebook formats, such as EPUB, MOBI, and AZW, as well as comic book archives CBZ and CBR. It’s easy to setup — just specify the directory containing your ebooks. You can browse books in Lector’s library using either a table or book covers. Among Lector’s features are bookmarks, user-defined tags, and a built-in dictionary.
### Installation instructions
The repo currently provides Lector for Fedora 26, 27, 28, and Rawhide. To install Lector, use these commands:
sudo dnf copr enable bugzy/lector sudo dnf install lector
## Ranger
Ranger is a text-based file manager with Vim key bindings. It displays the directory structure in three columns. The left one shows the parent directory, the middle the contents of the current directory, and the right a preview of the selected file or directory. In the case of text files, Ranger shows actual contents of the file as a preview.
### Installation instructions
The repo currently provides Ranger for Fedora 27, 28, and Rawhide. To install Ranger, use these commands:
sudo dnf copr enable fszymanski/ranger sudo dnf install ranger
## PrestoPalette
PrestoPalette is a tool that helps create balanced color palettes. A nice feature of PrestoPalette is the ability to use lighting to affect both lightness and saturation of the palette. You can export created palettes either as PNG or JSON.
### Installation instructions
The repo currently provides PrestoPalette for Fedora 26, 27, 28, and Rawhide, and EPEL 7. To install PrestoPalette, use these commands:
sudo dnf copr enable dagostinelli/prestopalette sudo dnf install prestopalette
## 鄭仕群
Nice suggestions!Many Thanks!
## Riley
Great post. PrestoPalette is a really cool app that I had never heard of.
## Ujjwal Dey
I read and went through the links regarding Markdown and Ghostwriter etc and understand nothing from it. What exactly is a Markdown Format / Editor, what is its purpose and why would any human on the planet need one? The great Features listed by Ghostwriter website also makes no sense. What is the need for these strange features and who uses it for what goal exactly? I am glad it is free and open source but can’t say anyone would pay money to buy one anyway.
## Willian
If you’re using a blog like Jenkyll or Hugo, you will have to use Markdown to format your text. One example. GitHub, Reddit, etc. use Markdown too.
That said, I don’t like Ghostwriter, or any similar markdown editor like it. I prefer a mix of WYSIWYG editor and a Markdown Editor, but it’s hard to find one that strikes the right balance to me.
## Ujjwal Dey
I am trying to learn this Linux culture and the strange ways users do things instead of simple obvious ways to do it. Jenkyll, Markdown would be like people who prefer using Notepad instead of Microsoft Word in Windows OS because Notepad is free with the OS.
For a layman like me, there seems to be no actual utility or more importantly any need to torture yourself by using Markdown, Jenkyll, Ghostwriter, etc. when you can use many simple new blog tools or just use HTML for a static website.
I am guessing a Markdown Editor will help you save tons of money and bytes (space) in webhosting and server space and bandwidth. But from the websites / blogs I have visited these Markdown fans only use Text, no images or videos uploaded to the server, so how would it be expensive using any of the other free blog software or webpage editors, etc.?
There is no safety if you can use this ‘.text’ suffix trick to view the Markdown source for the content of any page on Markdown websites.
Regarding any known utility, Need, purpose : How exactly is this blog easy to read on a computer or any device?
http://www.aaronsw.com/weblog/
Does this Fedora Magazine use Markdown or Jenkyll or whatever it is that Linux users love so much? I believe they use WordPress like most of humanity on the internet.
Why not use Libre Office and so many other great tools also available for free to edit text. Or so many WYSIWYG Editors existing for decades.
I really wish there was a book on Linux that helped newbies understand the Linux culture instead of all the million technical books on Linux.
## Matthew Bunt
Markdown is not a replacement for word processing software. To me, the point of markdown is to be easily human readable (and writable) whether you are reading the original text file or a rendered version. It’s also a (somewhat non-standardized) file format so you can easily use tools that turn markdown into html. Most people do not use markdown for writing emails or novels. They use markdown for blogs or software documentation and as you’ve already discovered, there are many different ways to accomplish the same task.
## wereturtle
Actually, that is exactly what I use my own Markdown editor for: Word processing. Markdown is very ideal for novels due to a novel’s minimal formatting. Obviously, when you start getting into nested tables and other more complicated things, Markdown isn’t very good anymore. But for simple blogs, novels, etc., it’s awesome.
## Murpholinox Peligro
One example> You can use markdown or html code to create a blog with Jekyll (https://jekyllrb.com/). For me it is far easier to do it in markdown.
## Ttny
@Ujjwal Dey
Markdown format is mostly used by developers or admins to write quick documents in a decent presentable format with less effort. Once you get the hang of it, it’s much quicker to write in
format than it is to use MSWord or LOWriter. This format can then be parsed and viewed in whatever manner you want.
Markdown isn’t a tool for everyone. If you’re only using Linux for some arbitrary reason that is not technical, markdown isn’t a tool for you either. If you are writing software or scripts and want to share your work with others, then Markdown is the accepted standard. It’s easier to parse, view in raw format, and is used by all major git service providers.
If you think markdown is complex, wait until you see LaTeX.
## wereturtle
Hello, I am the creator/maintainer of ghostwriter. I thought I’d chime in as to why someone would want to use a Markdown editor. Believe it or not, I use it for writing novels. I originally started with Libreoffice, but despite my very simple formatting, I noticed odd quirks when searching for where (for example) bold or italic formatting had been applied. Under the hood, the rich text formatting was not quite what I had expected. Markdown allows me to search for formatting and replace formatting very easily. Want to find all the bold formatting? Just search for “**”.
Then there is also the fact that plain text is simply faster than rich text for large documents. Libreoffice does handle a large novel admirably. However, I have sometimes had crashes on large documents, especially on earlier versions. I don’t like splitting my work into multiple files. It makes it harder come submission time. With plaintext, even the largest documents are lightning fast and never crash in 99% of plain text editors. And, I can use Pandoc to convert to epub easily for self-publishing. Just a few clicks and a quick conversion to azw with Calibre, and I’m reading my own work on my Kindle. I can’t say the same for Libreoffice.
As for who would pay for such an editor? Check out MacOS. There are a plethora of Markdown editors being sold for it, from Byword to iaWriter to Ulysses III. Some cost more than others. Last I checked, Ulysses III ran for $45. And it’s geared toward novel writing, to boot!
Obviously, Markdown won’t be for everybody, but it does work for a lot of people. Just try it out and see if you like it. If you don’t, you can convert your document to your favorite format easily enough.
## Qoyyuum
Was wondering if you guys could also cover how to use Mutt in Fedora. Thanks!
## Qoyyuum
Ghostwriter is cool but I prefer Typora for the added advantage of drawing flowcharts and sequence with mermaid.
## Jan
On fc28 ranger (at least up to 1.7.2) is also in @System repo.
## Martijn
Have been looking for a tool like Ranger for a while now, thanks for sharing 🙂
## ww2w
why typora is not in fedora?
## Paul W. Frields
@ww2w: Because it’s not open source. |
9,840 | 区块链进化简史:为什么开源是其核心所在 | https://opensource.com/article/18/6/blockchain-guide-next-generation | 2018-07-16T16:36:00 | [
"比特币",
"区块链"
] | https://linux.cn/article-9840-1.html |
>
> 从比特币到下一代区块链。
>
>
>

当开源项目开发下一个新版本时,用后缀 “-ng” 表示 “下一代”的情况并不鲜见。幸运的是,到目前为止,快速演进的区块链成功地避开了这个命名陷阱。但是在这个开源生态系统的演进过程中,改变是不断发生的,而好的创意以典型的开源方式在许多不同的项目中被采用、交融和演进。
在本文中,我将审视不同代次的区块链,并且看一看在处理这个生态系统遇到的问题时出现什么创意。当然,任何对生态系统进行分类的尝试都有其局限性的 —— 和不同意见者的 —— 但是这也将为混乱的区块链项目提供了一个粗略的指南。
### 始作俑者:比特币
第一代的区块链起源于 <ruby> <a href="https://bitcoin.org"> 比特币 </a> <rt> Bitcoin </rt></ruby> 区块链,这是以去中心化、点对点加密货币为基础的<ruby> 总帐 <rt> ledger </rt></ruby>,它从 [Slashdot](https://slashdot.org/) 网站上的杂谈变成了一个主流话题。
这个区块链是一个分布式总帐,它对所有用户的<ruby> 交易 <rt> transaction </rt></ruby>保持跟踪,以避免他们<ruby> 双重支付 <rt> double-spending </rt></ruby>(双花)货币(在历史上,这个任务是委托给第三方—— 银行 ——来做的)。为防范攻击者在系统上捣乱,总帐被复制到每个参与到比特币网络的计算机上,并且每次只允许一台计算机去更新总帐。为决定哪台计算机能够获得更新总帐的权力,系统安排在比特币网络上的计算机之间每 10 分钟进行一场竞赛,这将消耗它们的(许多)能源才能参与竞赛。赢家将获得将前 10 分钟发生的交易写入到总帐(区块链中的“区块”)的权力,并且为赢家写入区块链的工作给予一些比特币奖励。这种方式被称为<ruby> 工作量证明 <rt> proof of work </rt></ruby>(PoW)共识机制。
这就是区块链最有趣的地方。比特币以[开源项目](https://github.com/bitcoin/bitcoin)的方式发布于 2009 年 1 月 。在 2010 年,由于意识到这些元素中的许多是可以调整的,围绕比特币聚集起了一个社区 —— [bitcointalk 论坛](https://bitcointalk.org/),来开始各种实验。
起初,看到的比特币区块链是一个分布式数据库的形式, [Namecoin](https://www.namecoin.org/) 项目出现后,建议去保存任意数据到它的事务数据库中。如果区块链能够记录金钱的转移,那么它也应该能够记录其它资产的转移,比如域名。这正是 Namecoin 的主要使用场景,它上线于 2011 年 4 月 —— 也就是比特币出现两年后。
Namecoin 调整的地方是区块链的内容,<ruby> <a href="https://litecoin.org/"> 莱特币 </a> <rt> Litecoin </rt></ruby> 调整的是两个技术部分:一是将两个区块的时间间隔从 10 分钟减少到 2.5 分钟,二是改变了竞赛方式(用 [scrypt](https://en.wikipedia.org/wiki/Scrypt) 来替换了 SHA-256 安全哈希算法)。这是能够做到的,因为比特币是以开源软件的方式来发布的,而莱特币本质上与比特币在其它部分是完全相同的。莱特币是修改了比特币共识机制的第一个分叉,这也为其它的更多“币”铺平了道路。
沿着这条道路,基于比特币代码库的各种变种越来越多。其中一些扩展了比特币的用途,比如 [Zerocash](http://zerocash-project.org/index) 协议,它专注于提供交易的匿名性和可替换性,但它最终分拆为它自己的货币 —— [Zcash](https://z.cash)。
虽然 Zcash 带来了它自己的创新,使用了最近被称为“<ruby> 零知识证明 <rt> zero-knowledge proof </rt></ruby>”的加密技术,但它维持着与大多数主要的比特币代码库的兼容性,这意味着它能够从上游的比特币创新中获益。
另外的项目 —— [CryptoNote](https://cryptonote.org/),它萌芽于相同的社区,但是并没有使用相同的代码,它以比特币为背景来构建的,但又与之不同。它发布于 2012 年 12 月,由于它的出现,导致了几种加密货币的诞生,最著名的 <ruby> <a href="https://en.wikipedia.org/wiki/Monero_(cryptocurrency)"> 门罗币 </a> <rt> Monero </rt></ruby> (2014)就是其中之一。门罗币与 Zcash 使用了不同的方法,但解决了相同的问题:隐私性和可替换性。
就像在开源世界中经常出现的案例一样,做同样的工作有不止一个的工具可用。
### 下一代:“Blockchain-ng”
但是,到目前为止,所有的这些变体只是改进加密货币或者扩展它们去支持其它类型的事务。因此,这就引出了第二代区块链。
一旦社区开始去修改区块链的用法和调整技术部分时,对于一些想去扩展和重新思考它们未来的人来说,这种调整花费不了多长时间的。比特币的长期追随者 —— [Vitalik Buterin](https://en.wikipedia.org/wiki/Vitalik_Buterin) 在 2013 年底建议,区域链的事务应该能够表示一个状态机的状态变化,将区域链视为能够运行应用程序(“<ruby> 智能合约 <rt> smart contract </rt></ruby>”)的分布式计算机。这个项目 —— <ruby> <a href="https://ethereum.org"> 以太坊 </a> <rt> Ethereum </rt></ruby>,上线于 2015 年 4 月。它在运行分布式应用程序方面取得了巨大的成功,它的一些非常流行的分布式应用程序(<ruby> <a href="http://cryptokitties.co/"> 加密猫 </a> <rt> CryptoKitties </rt></ruby>)甚至导致以太坊区块链变慢。
这证明了目前的区块链存在一个很大的局限性:速度和容量。(速度通常用每秒事务数来测量,简称 TPS)有几个提议都建议去解决这个速度问题,从<ruby> 分片 <rt> sharding </rt></ruby>到<ruby> 侧链 <rt> sidechain </rt></ruby>,以及一个被称为“<ruby> 第二层 <rt> second-layer </rt></ruby>”的解决方案。这里需要更多的创新。
随着“智能合约”这个词开始流行起来,并且用已经被证实仍然很慢的技术去运行它们,那么就需要实现其它的思路:<ruby> 许可区块链 <rt> Permissioned blockchain </rt></ruby>。到目前为止,我们所介绍的所有区块链网络有两个没有明说的特征:一是它们是公开的(任何人都可以看到它们的功能),二是它们不需要许可(任何人都可以加入它们)。这两个部分是运行一个分布式的、非基于第三方的货币应该具有的和必需具有的条件。
随着区块链被认为出现与加密货币越来越明显的分离趋势,开始去考虑一些隐私、许可场景是很有意义的。一个有业务关系但不需要彼此完全信任的财团类型的参与者,能够从这些区块链类型中获益 —— 比如,物流链上的参与者,定期进行双边结算或者使用一个清算中心的金融、保险、或医疗保健机构。
一旦你将设置从“任何人都可以加入”变为“仅邀请者方可加入”,进一步对区块链构建区块的方式进行改变和调整将变得可能,那么对一些人来说,结果将变得非常有趣。
首先,设计用来保护网络不受恶意或者垃圾参与者的影响的工作量证明(PoW)可以被替换为更简单的和更少资源消耗的一些东西,比如,基于 [Raft](https://en.wikipedia.org/wiki/Raft_(computer_science)) 的共识协议。在更高级别的安全性和更快的速度之间进行权衡,采用更简单的共识算法。对于更多群体来说这样更理想,因为他们可以用基于加密技术的担保来取代其它的基于法律关系的担保,例如为避免由于竞争而产生的大量能源消耗,而工作量证明就是这种情况。另外一个创新的地方是,使用 <ruby> <a href="https://www.investopedia.com/terms/p/proof-stake-pos.asp"> 股权证明 </a> <rt> Proof of Stake </rt></ruby>(PoS),它是公共网络共识机制的一个重量级的竞争者。它将可能像许可链网络一样找到它自己的实现方式。
有几个项目可以让创建许可区块链变得更简单,包括 [Quorum](https://www.jpmorgan.com/global/Quorum) (以太坊的一个分叉)和 [Hyperledger](https://hyperledger.org/) 的 [Fabric](https://www.hyperledger.org/projects/fabric) 和 [Sawtooth](https://www.hyperledger.org/projects/sawtooth),这是基于新代码的两个开源项目。
许可区块链可以避免公共的、非许可方式的区块链中某些错综复杂的问题,但是它自己也存在一些问题。正确地管理参与者是其中的一个问题:谁可以加入?如何辨别他们?如何将他们从网络上移除?网络上的一个实体是否去管理一个中央公共密钥基础设施(PKI)?
### 区块链的开放本质
到目前为止的所有案例中,有一件事情是很明确的:使用一个区块链的目标是去提升网络中的参与者和它产生的数据的信任水平,理想情况下,不需要做进一步的工作即可足以使用它。
只有为这个网络提供动力的软件是自由和开源的,才能达到这种信任水平。即便是一个正确的、专用的、分布式区块链,它的本质仍然是运行着相同的第三方代码的私有代理的集合。从本质上来说,区块链的源代码必须是开源的,但仅是开源还不够。随着生态系统持续成长,这既是最低限度的担保也是进一步创新的源头。
最后,值得一提的是,虽然区块链的开放本质被认为是创新和变化的源头,它也被认为是一种治理形式:代码治理,用户期望运行的任何一个特定版本,都应该包含他们认为的整个网络应该包含的功能和方法。在这方面,需要说明的一点是,一些区块链的开放本质正在“变味”。但是这一问题正在解决。
### 第三和第四代:治理
接下来,我正在考虑第三代和第四代区块链:区块链将内置治理工具,并且项目将去解决棘手的大量不同区块链之间互连互通的问题,以便于它们之间可以交换信息和价值。
---
关于作者
axel simon: 长期的自由及开源软件爱好者,就职于 Red Hat ,关注安全和区块链技术,以及分布式系统和协议。致力于保护互联网及其成就(知识分享、信息访问、去中心化和网络中立)。
---
via: <https://opensource.com/article/18/6/blockchain-guide-next-generation>
作者:[Axel Simon](https://opensource.com/users/axel) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | It isn't uncommon, when working on a new version of an open source project, to suffix it with "-ng", for "next generation." Fortunately, in their rapid evolution blockchains have so far avoided this naming pitfall. But in this evolutionary open source ecosystem, changes have been abundant, and good ideas have been picked up, remixed, and evolved between many different projects in a typical open source fashion.
In this article, I will look at the different generations of blockchains and what ideas have emerged to address the problems the ecosystem has encountered. Of course, any attempt at classifying an ecosystem will have limits—and objectors—but it should provide a rough guide to the jungle of blockchain projects.
## The beginning: Bitcoin
The first generation of blockchains stems from the [Bitcoin](https://bitcoin.org) blockchain, the ledger underpinning the decentralized, peer-to-peer cryptocurrency that has gone from [Slashdot](https://slashdot.org/) miscellanea to a mainstream topic.
This blockchain is a distributed ledger that keeps track of all users' transactions to prevent them from double-spending their coins (a task historically entrusted to third parties: banks). To prevent attackers from gaming the system, the ledger is replicated to every computer participating in the Bitcoin network and can be updated by only one computer in the network at a time. To decide which computer earns the right to update the ledger, the system organizes every 10 minutes a race between the computers, which costs them (a lot of) energy to enter. The winner wins the right to commit the last 10 minutes of transactions to the ledger (the "block" in blockchain) and some Bitcoin as a reward for their efforts. This setup is called a *proof of work* consensus mechanism.
This is where it gets interesting. Bitcoin was released as an [open source project](https://github.com/bitcoin/bitcoin) in January 2009. In 2010, realizing that quite a few of these elements can be tweaked, the community that had aggregated around Bitcoin, often on the [bitcointalk forums](https://bitcointalk.org/), started experimenting with them.
First, seeing that the Bitcoin blockchain is a form of a distributed database, the [Namecoin](https://www.namecoin.org/) project emerged, suggesting to store arbitrary data in its transaction database. If the blockchain can record the transfer of money, it could also record the transfer of other assets, such as domain names. This is exactly Namecoin's main use case, which went live in April 2011, two years after Bitcoin's introduction.
Where Namecoin tweaked the content of the blockchain, [Litecoin](https://litecoin.org/) tweaked two technical aspects: reducing the time between two blocks from 10 to 2.5 minutes and changing how the race is run (replacing the SHA-256 secure hashing algorithm with [scrypt](https://en.wikipedia.org/wiki/Scrypt)). This was possible because Bitcoin was released as open source software and Litecoin is essentially identical to Bitcoin in all other places. Litecoin was the first fork to modify the consensus mechanism, paving the way for many more.
Along the way, many more variations of the Bitcoin codebase have appeared. Some started as proposed extensions to Bitcoin, such as the [Zerocash](http://zerocash-project.org/index) protocol, which aimed to provide transaction anonymity and fungibility but was eventually spun off into its own currency, [Zcash](https://z.cash).
While Zcash has brought its own innovations, using recent cryptographic advances known as zero-knowledge proofs, it maintains compatibility with the vast majority of the Bitcoin code base, meaning it too can benefit from upstream Bitcoin innovations.
Another project, [CryptoNote](https://cryptonote.org/), didn't use the same code base but sprouted from the same community, building on (and against) Bitcoin and again, on older ideas. Published in December 2012, it led to the creation of several cryptocurrencies, of which [Monero](https://en.wikipedia.org/wiki/Monero_(cryptocurrency)) (2014) is the best-known. Monero takes a different approach to Zcash but aims to solve the same issues: privacy and fungibility.
As is often the case in the open source world, there is more than one tool for the job.
## The next generations: "Blockchain-ng"
So far, however, all these variations have only really been about refining cryptocurrencies or extending them to support another type of transaction. This brings us to the second generation of blockchains.
Once the community started modifying what a blockchain could be used for and tweaking technical aspects, it didn't take long for some people to expand and rethink them further. A longtime follower of Bitcoin, [Vitalik Buterin](https://en.wikipedia.org/wiki/Vitalik_Buterin) suggested in late 2013 that a blockchain's transactions could represent the change of states of a state machine, conceiving the blockchain as a distributed computer capable of running applications ("smart contracts"). The project, [Ethereum](https://ethereum.org), went live in July 2015. It has seen fair success in running distributed apps, and the popularity of some of its better-known distributed apps ([CryptoKitties](http://cryptokitties.co/)) have even caused the Ethereum blockchain to slow down.
This demonstrates one of the big limitations of current blockchains: speed and capacity. (Speed is often measured in transactions per second, or TPS.) Several approaches have been suggested to solve this, from sharding to sidechains and so-called "second-layer" solutions. The need for more innovation here is strong.
With the words "smart contract" in the air and a proved—if still slow—technology to run them, another idea came to fruition: permissioned blockchains. So far, all the blockchain networks we've described have had two unsaid characteristics: They are public (anyone can see them function), and they are without permission (anyone can join them). These two aspects are both desirable and necessary to run a distributed, non-third-party-based currency.
As blockchains were being considered more and more separately from cryptocurrencies, it started to make sense to consider them in some private, permissioned settings. A consortium-type group of actors that have business relationships but don't necessarily trust each other fully can benefit from these types of blockchains—for example, actors along a logistics chain, financial or insurance institutions that regularly do bilateral settlements or use a clearinghouse, idem for healthcare institutions.
Once you change the setting from "anyone can join" to "invitation-only," further changes and tweaks to the blockchain building blocks become possible, yielding interesting results for some.
For a start, proof of work, designed to protect the network from malicious and spammy actors, can be replaced by something simpler and less resource-hungry, such as a [Raft](https://en.wikipedia.org/wiki/Raft_(computer_science))-based consensus protocol. A tradeoff appears between a high level of security or faster speed, embodied by the option of simpler consensus algorithms. This is highly desirable to many groups, as they can trade some cryptography-based assurance for assurance based on other means—legal relationships, for instance—and avoid the energy-hungry arms race that proof of work often leads to. This is another area where innovation is ongoing, with [Proof of Stake](https://www.investopedia.com/terms/p/proof-stake-pos.asp) a notable contender for the public network consensus mechanism of choice. It would likely also find its way to permissioned networks too.
Several projects make it simple to create permissioned blockchains, including [Quorum](https://www.jpmorgan.com/global/Quorum) (a fork of Ethereum) and [Hyperledger](https://hyperledger.org/)'s [Fabric](https://www.hyperledger.org/projects/fabric) and [Sawtooth](https://www.hyperledger.org/projects/sawtooth), two open source projects based on new code.
Permissioned blockchains can avoid certain complexities that public, non-permissioned ones can't, but they still have their own set of issues. Proper management of participants is one: Who can join? How do they identify? How can they be removed from the network? Does one entity on the network manage a central public key infrastructure (PKI)?
## Open nature of blockchains
In all of the cases so far, one thing is clear: The goal of using a blockchain is to raise the level of trust participants have in the network and the data it produces—ideally, enough to be able to use it as is, without further work.
Reaching this level of trust is possible only if the software that powers the network is free and open source. Even a correctly distributed proprietary blockchain is essentially a collection of independent agents running the same third party's code. By nature, it's necessary—but not sufficient—for a blockchain's source code to be open source. This has both been a minimum guarantee and the source of further innovation as the ecosystem keeps growing.
Finally, it is worth mentioning that while the open nature of blockchains has been a source of innovation and variation, it has also been seen as a form of governance: governance by code, where users are expected to run whichever specific version of the code contains a function or approach they think the whole network should embrace. In this respect, one can say the open nature of some blockchains has also become a cop-out regarding governance. But this is being addressed.
## Third and fourth generations: governance
Next, I will look at what I am currently considering the third and fourth generations of blockchains: blockchains with built-in governance tools and projects to solve the tricky question of interconnecting the multitude of different blockchain projects to let them exchange information and value with each other.
## Comments are closed. |
9,841 | 如何在绝大部分类型的机器上安装 NVIDIA 显卡驱动 | https://fedoramagazine.org/install-nvidia-gpu/ | 2018-07-16T18:30:08 | [
"NVIDIA",
"显卡"
] | https://linux.cn/article-9841-1.html | 
无论是研究还是娱乐,安装一个最新的显卡驱动都能提升你的计算机性能,并且使你能全方位地实现新功能。本安装指南使用 Fedora 28 的新的第三方仓库来安装 NVIDIA 驱动。它将引导您完成硬件和软件两方面的安装,并且涵盖需要让你的 NVIDIA 显卡启动和运行起来的一切知识。这个流程适用于任何支持 UEFI 的计算机和任意新的 NVIDIA 显卡。
### 准备
本指南依赖于下面这些材料:
* 一台使用 [UEFI](https://whatis.techtarget.com/definition/Unified-Extensible-Firmware-Interface-UEFI) 的计算机,如果你不确定你的电脑是否有这种固件,请运行 `sudo dmidecode -t 0`。如果输出中出现了 “UEFI is supported”,你的安装过程就可以继续了。不然的话,虽然可以在技术上更新某些电脑来支持 UEFI,但是这个过程的要求很苛刻,我们通常不建议你这么使用。
* 一个现代的、支持 UEFI 的 NVIDIA 的显卡
* 一个满足你的 NVIDIA 显卡的功率和接线要求的电源(有关详细信息,请参考“硬件和修改”的章节)
* 网络连接
* Fedora 28 系统
### 安装实例
这个安装示例使用的是:
* 一台 Optiplex 9010 的主机(一台相当老的机器)
* [NVIDIA GeForce GTX 1050 Ti XLR8 游戏超频版 4 GB GDDR5 PCI Express 3.0 显卡](https://www.cnet.com/products/pny-geforce-gtx-xlr8-gaming-1050-ti-overclocked-edition-graphics-card-gf-gtx-1050-ti-4-gb/specs/)
* 为了满足新显卡的电源要求,电源升级为 [EVGA – 80 PLUS 600 W ATX 12V/EPS 12V](https://www.evga.com/products/product.aspx?pn=100-B1-0600-KR),这个最新的电源(PSU)比推荐的最低要求高了 300 W,但在大部分情况下,满足推荐的最低要求就足够了。
* 然后,当然的,Fedora 28 也别忘了.
### 硬件和修改
#### 电源(PSU)
打开你的台式机的机箱,检查印刷在电源上的最大输出功率。然后,查看你的 NVIDIA 显卡的文档,确定推荐的最小电源功率要求(以瓦特为单位)。除此之外,检查你的显卡,看它是否需要额外的接线,例如 6 针连接器,大多数的入门级显卡只从主板获取电力,但是有一些显卡需要额外的电力,如果出现以下情况,你需要升级你的电源:
1. 你的电源的最大输出功率低于显卡建议的最小电源功率。注意:根据一些显卡厂家的说法,比起推荐的功率,预先构建的系统可能会需要更多或更少的功率,而这取决于系统的配置。如果你使用的是一个特别耗电或者特别节能的配置,请灵活决定你的电源需求。
2. 你的电源没有提供必须的接线口来为你的显卡供电。
电源的更换很容易,但是在你拆除你当前正在使用的电源之前,请务必注意你的接线布局。除此之外,请确保你选择的电源适合你的机箱。
#### CPU
虽然在大多数老机器上安装高性能的 NVIDIA 显卡是可能的,但是一个缓慢或受损的 CPU 会阻碍显卡性能的发挥,如果要计算在你的机器上瓶颈效果的影响,请点击[这里](http://thebottlenecker.com "Home: The Bottle Necker")。了解你的 CPU 性能来避免高性能的显卡和 CPU 无法保持匹配是很重要的。升级你的 CPU 是一个潜在的考虑因素。
#### 主板
在继续进行之前,请确认你的主板和你选择的显卡是兼容的。你的显卡应该插在最靠近散热器的 PCI-E x16 插槽中。确保你的设置为显卡预留了足够的空间。此外,请注意,现在大部分的显卡使用的都是 PCI-E 3.0 技术。虽然这些显卡如果插在 PCI-E 3.0 插槽上会运行地最好,但如果插在一个旧版的插槽上的话,性能也不会受到太大的影响。
### 安装
1、 首先,打开终端更新你的包管理器(如果没有更新的话):
```
sudo dnf update
```
2、 然后,使用这条简单的命令进行重启:
```
reboot
```
3、 在重启之后,安装 Fedora 28 的工作站的仓库:
```
sudo dnf install fedora-workstation-repositories
```
4、 接着,设置 NVIDIA 驱动的仓库:
```
sudo dnf config-manager --set-enabled rpmfusion-nonfree-nvidia-driver
```
5、 然后,再次重启。
6、 在这次重启之后,通过下面这条命令验证是否添加了仓库:
```
sudo dnf repository-packages rpmfusion-nonfree-nvidia-driver info
```
如果加载了多个 NVIDIA 工具和它们各自的 spec 文件,请继续进行下一步。如果没有,你可能在添加新仓库的时候遇到了一个错误。你应该再试一次。
7、 登录,连接到互联网,然后打开“软件”应用程序。点击“加载项>硬件驱动> NVIDIA Linux 图形驱动>安装”。
如果你使用更老的显卡或者想使用多个显卡,请进一步查看 [RPMFusion 指南](https://rpmfusion.org/Howto/NVIDIA?highlight=%28CategoryHowto%29)。最后,要确保启动成功,设置 `/etc/gdm/custom.conf` 中的 `WaylandEnable=false`,确认避免使用安全启动。 接着,再一次重启。
8、这个过程完成后,关闭所有的应用并**关机**。拔下电源插头,然后按下电源按钮以释放余电,避免你被电击。如果你对电源有开关,关闭它。
9、 最后,安装显卡,拔掉老的显卡并将新的显卡插入到正确的 PCI-E x16 插槽中。成功安装新的显卡之后,关闭你的机箱,插入电源 ,然后打开计算机,它应该会成功启动。
**注意:** 要禁用此安装中使用的 NVIDIA 驱动仓库,或者要禁用所有的 Fedora 工作站仓库,请参考这个 [Fedora Wiki 页面](https://fedoraproject.org/wiki/Workstation/Third_Party_Software_Repositories)。
### 验证
1、 如果你新安装的 NVIDIA 显卡已连接到你的显示器并显示正确,则表明你的 NVIDIA 驱动程序已成功和显卡建立连接。
如果你想去查看你的设置,或者验证驱动是否在正常工作(这里,主板上安装了两块显卡),再次打开 “NVIDIA X 服务器设置应用程序”。这次,你应该不会得到错误信息提示,并且系统会给出有关 X 的设置文件和你的 NVIDIA 显卡的信息。(请参考下面的屏幕截图)

通过这个应用程序,你可以根据你的需要需改 X 配置文件,并可以监控显卡的性能,时钟速度和温度信息。
2、 为确保新显卡以满功率运行,显卡性能测试是非常必要的。GL Mark 2,是一个提供后台处理、构建、照明、纹理等等有关信息的标准工具。它提供了一个优秀的解决方案。GL Mark 2 记录了各种各样的图形测试的帧速率,然后输出一个总体的性能评分(这被称为 glmark2 分数)。
**注意:** glxgears 只会测试你的屏幕或显示器的性能,不会测试显卡本身,请使用 GL Mark 2。
要运行 GLMark2:
1. 打开终端并关闭其他所有的应用程序
2. 运行 `sudo dnf install glmark2` 命令
3. 运行 `glmark2` 命令
4. 允许运行完整的测试来得到最好的结果。检查帧速率是否符合你对这块显卡的预期。如果你想要额外的验证,你可以查阅网站来确认是否已有你这块显卡的 glmark2 测试评分被公布到网上,你可以比较这个分数来评估你这块显卡的性能。
5. 如果你的帧速率或者 glmark2 评分低于预期,请思考潜在的因素。CPU 造成的瓶颈?其他问题导致?
如果诊断的结果很好,就开始享受你的新显卡吧。
### 参考链接
* [How to benchmark your GPU on Linux](https://www.howtoforge.com/tutorial/linux-gpu-benchmark/)
* [How to install a graphics card](https://www.pcworld.com/article/2913370/components-graphics/how-to-install-a-graphics-card.html)
* [The Fedora Wiki Page](https://fedoraproject.org/wiki/Workstation/Third_Party_Software_Repositories)
* [The Bottlenecker](http://thebottlenecker.com "Home: The Bottle Necker")
* [What Is Unified Extensible Firmware Interface (UEFI)](https://whatis.techtarget.com/definition/Unified-Extensible-Firmware-Interface-UEFI)
---
via: <https://fedoramagazine.org/install-nvidia-gpu/>
作者:[Justice del Castillo](https://fedoramagazine.org/author/justice/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[hopefully2333](https://github.com/hopefully2333) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Whether for research or recreation, installing a new GPU can bolster your computer’s performance and enable new functionality across the board. This installation guide uses Fedora 28’s brand-new third-party repositories to install NVIDIA drivers. It walks you through the installation of both software and hardware, and covers everything you need to get your NVIDIA card up and running. This process works for any UEFI-enabled computer, and any modern NVIDIA GPU.
## Preparation
This guide relies on the following materials:
- A machine that is
[UEFI](https://whatis.techtarget.com/definition/Unified-Extensible-Firmware-Interface-UEFI)capable. If you’re uncertain whether your machine has this firmware, run*sudo dmidecode -t 0*. If “UEFI is supported” appears anywhere in the output, you are all set to continue. Otherwise, while it’s technically possible to update some computers to support UEFI, the process is often finicky and generally not recommended. - A modern, UEFI-enabled NVIDIA card
- A power source that meets the wattage and wiring requirements for your NVIDIA card (see the Hardware & Modifications section for details)
- Internet connection
- Fedora 28
**NOTE:** This guide only covers hardware installation for desktop computers, although the NVIDIA driver installation will be relevant for laptops as well.
## Example setup
This example installation uses:
- An Optiplex 9010 (a fairly old machine)
- NVIDIA
[GeForce GTX 1050 Ti XLR8 Gaming Overclocked Edition 4GB GDDR5 PCI Express 3.0](https://www.cnet.com/products/pny-geforce-gtx-xlr8-gaming-1050-ti-overclocked-edition-graphics-card-gf-gtx-1050-ti-4-gb/specs/)graphics card - In order to meet the power requirements of the new GPU, the power supply was upgraded to an
[EVGA – 80 PLUS 600W ATX 12V/EPS 12V](https://www.evga.com/products/product.aspx?pn=100-B1-0600-KR). This new PSU was 300W above the minimum recommendation, but simply meeting the minimum recommendation is sufficient in most cases. - And, of course, Fedora 28.
## Hardware and modifications
### PSU
Open up your desktop case and check the maximum power output printed on your power supply. Next, check the documentation on your NVIDIA GPU and determine the minimum recommended power (in watts). Further, take a look at your GPU and see if it requires additional wiring, such as a 6-pin connector. Most entry-level GPUs only draw power directly from the motherboard, but some require extra juice. You’ll need to upgrade your PSU if:
- Your power supply’s max power output is below the GPU’s suggested minimum power.
**Note:**According to some NVIDIA card manufacturers, pre-built systems may require more or less power than recommended, depending on the system’s configuration. Use your discretion to determine your requirements if you’re using a particularly power-efficient or power-hungry setup. - Your power supply does not provide the necessary wiring to power your card.
PSUs are straightforward to replace, but make sure to take note of the wiring layout before detaching your current power supply. Additionally, make sure to select a PSU that fits your desktop case.
### CPU
Although installing a high-quality NVIDIA GPU is possible in many old machines, a slow or damaged CPU can “bottleneck” the performance of the GPU. To calculate the impact of the bottlenecking effect for your machine, click [here](http://thebottlenecker.com). It’s important to know your CPU’s performance to avoid pairing a high-powered GPU with a CPU that can’t keep up. Upgrading your CPU is a potential consideration.
#### Motherboard
Before proceeding, ensure your motherboard is compatible with your GPU of choice. Your graphics card should be inserted into the PCI-E x16 slot closest to the heat-sink. Ensure that your setup contains enough space for the GPU. In addition, note that most GPUs today employ PCI-E 3.0 technology. Though these GPUs will run best if mounted on a PCI-E 3.0 x16 slot, performance should not suffer significantly with an older version slot.
## Installation
1. First, open up a terminal, and update your package-manager (if you have not done so already), by running:
sudo dnf update
2. Next, reboot with the simple command:
reboot
3. After reboot, install the Fedora 28 workstation repositories:
sudo dnf install fedora-workstation-repositories
4. Next, enable the NVIDIA driver repository:
sudo dnf config-manager --set-enabled rpmfusion-nonfree-nvidia-driver
5. Then, reboot again.
6. After the reboot, verify the addition of the repository via the following command:
sudo dnf repository-packages rpmfusion-nonfree-nvidia-driver info
If several NVIDIA tools and their respective specs are loaded, then proceed to the next step. If not, you may have encountered an error when adding the new repository and you should give it another shot.
7. Login, connect to the internet, and open the software app. Click *Add-ons> Hardware Drivers> NVIDIA Linux Graphics Driver> Install.*
If you’re using an older GPU or plan to use multiple GPUs, check [the RPMFusion guide](https://rpmfusion.org/Howto/NVIDIA?highlight=%28CategoryHowto%29) for further instructions. Finally, to ensure a successful reboot, set “WaylandEnable=false” in */etc/gdm/custom.conf*, and make sure to avoid using secure boot.
8. Once this process is complete, close all applications and **shut down** the computer. Unplug the power supply to your machine. Then, press the power button once to drain any residual power to protect yourself from electric shock. If your PSU has a power switch, switch it off.
9. Finally, install the graphics card. Remove the old GPU and insert your new NVIDIA graphics card into the proper PCI-E x16 slot. When you have successfully installed the new GPU, close your case, plug in the PSU, and turn the computer on. It should successfully boot up.
**NOTE:** To disable the NVIDIA driver repository used in this installation, or to disable all Fedora workstation repositories, consult [The Fedora Wiki Page](https://fedoraproject.org/wiki/Workstation/Third_Party_Software_Repositories).
## Verification
1. If your newly installed NVIDIA graphics card is connected to your monitor and displaying correctly, then your NVIDIA driver has successfully established a connection to the GPU.
If you’d like to view your settings, or verify the driver is working (in the case that you have two GPUs installed on the motherboard), open up the NVIDIA X Server Settings app again. This time, you should not be prompted with an error message, and information on the X configuration file and your NVIDIA GPU should be available (see screenshot below).
Through this app, you may alter your X configuration file should you please, and may monitor the GPU’s performance, clock speed, and thermal information.
2. To ensure the new card is working at capacity, a GPU performance test is needed. GL Mark 2, a benchmarking tool that provides information on buffering, building, lighting, texturing, etc, offers an excellent solution. GL Mark 2 records frame rates for a variety of different graphical tests, and outputs an overall performance score (called the glmark2 score).
**Note:** *glxgears* will only test the performance of your screen or monitor, not the graphics card itself. Use GL Mark 2 instead.
To run GLMark2:
- Open up a terminal and close all other applications
*sudo dnf install glmark2**glmark2*- Allow the test to run to completion for best results. Check to see if the frame rates match your expectation for your NVIDA card. If you’d like additional verification, consult the web to determine if a glmark2 benchmark has been previously conducted on your NVIDA card model and published to the web. Compare scores to assess your GPUs performance.
- If your framerates and/or glmark2 score are below expected, consider potential causes. CPU-induced bottlenecking? Other issues?
Assuming the diagnostics look good, enjoy using your new GPU.
## References:
[How to benchmark your GPU on Linux](https://www.howtoforge.com/tutorial/linux-gpu-benchmark/)[How to install a graphics card](https://www.pcworld.com/article/2913370/components-graphics/how-to-install-a-graphics-card.html)[The Fedora Wiki Page](https://fedoraproject.org/wiki/Workstation/Third_Party_Software_Repositories)[The Bottlenecker](http://thebottlenecker.com/)[What Is Unified Extensible Firmware Interface (UEFI)](https://whatis.techtarget.com/definition/Unified-Extensible-Firmware-Interface-UEFI)
*Editor’s note: This article was co-authored by Matthew Kenney and Justice del Castillo.*
## Amitosh Swain Mahapatra
Sometimes, especially in laptops having Optimus power saving, the nouveau driver will fail to load and cause kernel panic. It is required to blacklist the driver from grub and disable the services that load the nouveau driver to enable GPU switching.
## Anton
Hi!
I’ve just installed nvidia drivers following this instruction on my laptop.
But I don’t know how to switch between GPU (I have GTX 960m and Intel HD 530).
Could you please point me out how to switch between GPUs? Maybe some manual?
Thanks!
## Night Romantic
Anton,
as far as I know, you can only switch GPUs if your laptop uses Nvidia Optimus tech. Then these pages can point you in the right directions:
https://fedoraproject.org/wiki/Bumblebee
https://superdanby.github.io/Blog/dealing-with-nvidia-optimus.html
https://wiki.archlinux.org/index.php/NVIDIA_Optimus
## Matthew Kenney
Hi Anton! Check out these links, they should be helpful:
https://rpmfusion.org/Howto/NVIDIA#Special_notes
https://rpmfusion.org/Howto/Optimus
## Matthew Kenney
Hi Amitosh,
I’m a coauthor on this article (though not listed yet, Fedora Mag is working out a glitch with listing coauthors). You are 100% correct about blacklisting the nouveau driver… however, when performing the installation described above, Justice and I discovered that the NVIDIA repo used above automatically blacklists the nouveau driver at the appropriate time… we double checked this during installation to make sure. If you are concerned about the nouveau driver causing a problem, feel free to check to make sure it is blacklisted, and get back to us if you didn’t find that it was blacklisted for any reason on your system.
## Amitosh Swain
Hi Matthew,
This is only applicable on Optimus laptops if you disable NVIDIA graphics (steps: https://rpmfusion.org/Howto/Optimus). This tends to be a common setup on laptops, where we mostly use to develop CUDA applications.
The NVIDIA driver package contains a “nvidia-fallback.service” (source: https://github.com/rpmfusion/xorg-x11-drv-nvidia/blob/master/nvidia-fallback.service).
On recent hardware such as 10xx series for laptops that lack decent support in nouveau, this service needs to be disabled.
## daimen
ok so today i sused this guide to install my nvidia driver https://fedoramag.wpengine.com/install-nvidia-gpu/ and once i got to the part that asks me to go to my software center and install my drivers via a gui i couldent find it in the kde version of fedora so i dident know what to do and so i went ahead and i=used this command from terminal “sudo dnf install xorg-x11-drv-nvidia akmod-nvidia” and it installed fine but then once i reboot i run the nvidia controller gui like the guide from fedora says but whenever i run the command “sudo nvidia-xconfig” i get command not found? why is this and how can i fix it?
## Matthew Kenney
Hi Damien,
Unfortunately, I have not performed this installation using the kde version of fedora, but I’ll get back to you as soon as I can if I find any information on this.
## Night Romantic
daimen, it looks like corresponding package wasn’t installed. Install it from terminal with “sudo dnf install nvidia-xconfig” command, and you should be good to go.
## Mike Lothian
Alternatively get an AMD graphics card and use the open drivers built into the OS
## ILMostro
Indeed,
The authors of the article might want to consider changing the title to something that does NOT suggest that their recommendation is to install nvidia GPUs on any machine a user owns.
## Rene Reichenbach
Exactly … all that effort for non OSS policy by Nvidia
## Oisin Feeley
Seems like some people prefer non-Free drivers. Bit sad to see Fedora Magazine promoting something that is contrary to one of the tenets of the Fedora distribution.
## York
Definitely agree with this one. Lubricating people’s usage of crutches such as the proprietary driver is not how you encourage manufacturers to get with the times. It is an unfortunate reality that nVidia has hardware which is slightly more power efficient, but what we pay for in efficiency is more than made up by AMDs willingness to support greater extensibility and compatibility through openness.
## nonamedotc
Do these steps work with secure boot enabled?
## Matthew Kenney
Should work just fine with secure boot enabled, but have not personally performed the installation using this option.
## Matt Kenney
Correction. This will not work with secure boot per the rpm fusion website. Sorry about that.
## Night Romantic
As far as I know, akmod-nvidia will rebuild nvidia kernel modules for each new kernel, and with secure boot enabled you
canrun into situation when system won’t load these newly-built unsigned kernel modules.Unless akmod-nvidia automatically signs modules as they are built — I can’t verify, I use nouveau on my Fedora machine.
You can however sign these modules yourself, check this: https://docs.fedoraproject.org/f28/system-administrators-guide/kernel-module-driver-configuration/Working_with_Kernel_Modules.html#sect-signing-kernel-modules-for-secure-boot and this: https://gorka.eguileor.com/vbox-vmware-in-secureboot-linux-2016-update/ (VirtualBox and VMWare have the same problem with secure boot enabled).
## Lee Nader
Not to beat a dead horse, but I’m assuming this does NOT work with Wayland?
## Matthew Kenney
Hi Lee,
Yup, sadly NVIDIA is a little behind the curve with the whole wayland movement.
## wallyk
When I installed Fedora 27 I think I saw a note that suggesting Wayland is (at least partially) configured from the X configuration files. So maybe the guide will work with Wayland, or maybe not.
## Marcin Skarbek
Nvidia proprietary drivers work fine with Gnome and Wayland in current Fedora release. Problem is that not everyone wants to support it – Sway for example, but that is more of Nvidia fault not Sway programmers – Nvidia, as always, invented they own “thing” to screw everyone else.
## Zelda
Great guide! Thanks. But please, this should probably be removed. I’m not sure if this was ever possible. Cards only fit one way.
“there is no space for the fans to ventilate in this position, place the graphics card face up instead, if possible”
## wallyk
Agreed. Even if it were possible to reorient the card, which way is “face up”? Both sides look like the face to me….
## Matthew Kenney
This suggestion was based on another guide that was probably a bit outdated or uninformed. We will be adjusting the article to remove this portion. Thank you for the input!
## N icolas Chauvet
Don’t ever use nvidia-xconfig on fedora ! It will produce a broken and uneeded configuration files.
This documentation was obviously NOT tested!
Please look at the official RPM Fusion howto related to the packaged driver.
(that’s the one included in Fedora workstation repositories).
https://rpmfusion.org/Howto/NVIDIA
## Dave Sherratt
You need to replace “almost any machine” in the heading with “almost any desktop”.
## Denys
??????????????????????????????????????????????????
Bottleneck detected: Your CPU is too weak for this graphic card.
Intel Core i9-7980XE @ 2.60GHz with GeForce GTX 1080 Ti (x4) will produce 21% of bottleneck. Everything over 10% is considered as bottleneck. We recommend you to replace Intel Core i9-7980XE @ 2.60GHz with Intel Core i9-7980XE @ 2.60GHz.
??????????????????????????????????????????????????
## Sajid
Please post a guide for laptops which have dual GPU, intel and Nvidia. I think they are called Optimus. It would be very kind of you if we can get some sort of guide to install Nvidia drivers for such laptops.
## Matthew Kenney
Sajid,
This documentation should prove helpful:
https://rpmfusion.org/Howto/NVIDIA#Special_notes
https://rpmfusion.org/Howto/Optimus
## Night Romantic
I’m quite sure reboot on step 5 is unnecessary. It’s a good idea however to update dnf package list to include packages from newly enabled repo with “sudo dnf check-update” command.
## Sergio
I have a machine with two NVIDIA GPUs and I have always wondered if its is possible to use the nvidia drivers in one of them, to use CUDA, and noveau driver in the other one.
I don’t want to taint my kernel more than necessary
## Raoul
Fedora and Nvidia
https://www.if-not-true-then-false.com/2015/fedora-nvidia-guide/
## wkjeji
install tensorflow to verify all working ok
but admin still delete my post ;( therefore i dont send how
## Bill Chatfield
Thanks for writing this. I have a laptop with an nvidia card that I’ve been afraid to try to install the nvidia drivers on, given past experiences. With this I may be able to get it to work. But, looks like you need one more prereq: the X Server. Fedora defaults to Wayland.
## Tim Hesketh
“7. Login, connect to the internet, and open the software app.” I’m probably slow, but it’s not clear what software app you refer to, or where it is.
## Night Romantic
Tim, author means application literary called “Software” in default (Gnome) Fedora version. As other people mentioned above, you wouldn’t find it in other desktop environments / Fedora Spins (KDE, XFCE, etc).
## Dave Sherratt
The heading of this article is misleading, it should end with “almost any desktop”, rather than “almost any machine”.
## Matthew Kenney
We will be adjusting the article to address this. The installation of the drivers is pertinent to any machine… but you are correct, our discussion on hardware is really only relevant to desktop computers.
## david
Well; I prefer the Negativo17 drivers; It works ever for me and my friends…
https://negativo17.org/nvidia-driver/
## Dan
I was wondering: didn’t Fedora announce at one point that they were going to use the N17 drivers because the packaging is closer to how they build packages themselves?
## Paul W. Frields
@Dan: My understanding is the maintainer of those packages worked with the rpmfusion folks to unify forces.
## David
It is sad for one of the most open source distro out there with regards to free software to write an article on how to use proprietary drivers for the world worse company that deals with Linux. I would prefer an article on why you should prefer use AMD or Intel graphics rather than “how to install proprietary nvidia driver”. Open source is more important than graphics.
## Night Romantic
David,
on the other hand people should be
freeto use hardware they own in their linux distribution of choice. Also, there are new Linux adepts, who already own that hardware before coming to Linux.## Matthew Kenney
We 100% agree in our support of open source, and believe it should be used wherever possible. Unfortunately, NVIDIA provides many services that are simply indispensable for many researchers. Services such as nvidia-docker (GPU accelerated containers), the nvidia gpu cloud, NVIDIA’s high-powered-computing apps, and optimized deep learning software (TensorFlow, PyTorch, MXNet, TensorRT, etc.) are very valuable to many researchers, and it is difficult to find comparable services to these with open source software. Our guide is especially geared towards those who cannot go without these resources.
## Oisin Feeley
The article should then at the very least start with a paragraph that notes that Nvidia are completely hostile to Free Software and are probably the worst choice if you want a trouble-free Linux installation with easy long-term support.
I am not knocking your article, or your efforts in sharing what you know of the troublesome, irritating, crash-prone Nvidia hardware which will hamper your upgrade efforts in the future and lead to a steady flow of confused bugzilla entries. Rather, I am questioning the poor messaging that this sends out about Fedora. An issue for the editorial team. Fedora Magazine is supposed to be communicating the core values of the project. If those have changed then perhaps Free should be dropped from the branding which so much time was spent on building.
## Paul W. Frields
To quote a previous reply on this topic: “The Fedora Magazine’s policy is to include topics of popular, licit software we know users are interested in. We concentrate on free and open source software but not exclusively, although we are always focused on Fedora users specifically, and how to enable them in their preferred choices.”
## Oisin Feeley
Sure. But that does not exclude having an editorial policy that explicitly notes the practical and pragmatic problems over that long-term that result from installing a GPU over which the user has very little if any control.
As it stands the article’s first paragraphs nearly read like an enticement or advertorial for installing something that will be difficult to upgrade at times and may cause instability to the OS. The article could be an opportunity to educate the hypothetical population of naive users that might be attracted by third-party repositories, or even computational scientists who plan on carrying out non-reproducible research on unverifiable platforms.
Again, these are matters of editorial tone and appear quite divergent from the idea of Freedom of which Fedora could quite rightly be proud.
## Shadders.
Hi,
I installed on a Fedora 28, KDE, desktop motherboard (Gigabyte) with NVidia GTX1050, and it failed to boot.
I had to disable the Intel Graphics from BIOS to allow it to boot, and it boots using text boot sequence for the LUKS password rather than a graphics based screen as per Intel graphics.
Maybe provide an article to show you how to disable the NVidia driver and revert back to Intel ?
Regards,
Shadders.
## David
Guys,
Since many of the comments have pointed out the issue regarding the proprietary software and the Fedora philosophy. Would you be kind to add a big disclaimer at the beginning of the article to say that Fedora does not endorse, support or encourage proprietary software and recommend to use AMD / Intel GPU instead?
Thanks.
## youssefmsourani
for optimus (Intel/Nvidia) and kde sddm you need to add this lines to /etc/sddm/Xsetup .
xrandr –setprovideroutputsource modesetting NVIDIA-0
xrandr –auto
## Vinicius
Using this tutorial my machine works well. I have a notebook Asus Nitro 5 with a GeForce GTX 1050m
## straycat
I’ve been using Fedora along time with Nvidia cards and using the rpmfusion drivers.I’d like to add before installing the driver install kernel-devel & kernel-headers so when theres a kernel update akmod can build the driver with the new kernel after reboot.I also agree with david I’ve been using the negativo17 repo for awhile now and the driver with dkms seems to be more stable but they only support newer cards where rpmfusion supports older cards as well.
## Liviy
Interesting article…I’ve been using nvidia with Fedora since probably around Core 12 and my current system has is UEFI enabled and my GTX970 is also compatible however I’ve never used the official drivers and I don’t boot via UEFI either… What’s the benefit of switching to that combination?
Although…I suspect I’d also need to work out how to get my FC28 desktop to use Wayland (as it’s 100% not) since I disabled Wayland a little too proficiently quite a few Cores ago when it wasn’t playing nice with Nvidia and multiple displays and after quite a few attempts to re-enable it have failed (it’s not disabled in /etc/gdm/custom.conf and I’ve tried re-installing the Wayland related packages with forcing overwriting of configs & even messing with the /usr/share files but I seem to always lose interested before succeeding). I know it works with my system as the FC28 live image boots with it but I can’t bring myself to scratch my system just for Wayland…
## Night Romantic
Liviy, as far as I know, you don’t
needto boot with UEFI to use NVIDIA proprietary drivers.As for benefits — I don’t think you’ll get any ) I think that if you’d needed proprietary drivers in your Fedora — for gaming, CUDA GPU computations, accelerated video decoding or something else — you’d know for sure you need them )
Open source Nouveau driver works quite well at this point for
desktopusage — at least in my experience. It supports KMS, Wayland, and other features Fedora uses by default. I use it in Fedora. I use proprietary driver in other Linux distribution on the same box fro when I want some 3D gaming under Linux.As for reenabling Wayland — well, consider maybe fresh install of Fedora 29 this fall? I have a quite simple procedure for fresh install of next Fedora release, which keeps intact most of my settings and packages, but in the same time doesn’t get stuck with settings I don’t want to keep. It’s no magic bullet, it requires quite a few manual steps/actions — though it can be automated further, I’m just too lazy to do it) Still I like a kind of balance it gives me.
## Liviy
Thanks for your reply…I was just curious if there was some benefits as it would explain the procedure being detailed in the article.
Fresh install…in theory that’s usually a good option but I have quite a bit of laziness too, especially when I remember how long the road was for this desktop to where it is now. I have pondered doing a fresh fc28 install into a vm and doing s comparison between that and my main system to see if anything jumps out.
## jalf86
This article is very misleading. I specifically bought an NVidia graphics card because many articles still say it will work flawlessly with Fedora. After many trials, I’ve got it to work, but I have to stay in Fedora 27-LXQt, only 3 updates from base installation. I have to stay there because there are no articles that can recommend a comparable alternative. With the seeming movement away from X-Server, NVidia is probably the worst graphics card to go with. I’m not a power user. I just use my computer for email, web purchases, and Runescape (can’t find another game to play with my tastes and the NVidia card I have). If, like Windows dominating the desktop, NVidia dominates the graphics card arena, more people will have reason to migrate away from Fedora. I only stay with Fedora because I’ve been using it for years and I like to dabble in science and engineering and Fedora repositories seem to have the best for that. I’ve tried Mint, Umbuntu, and several others. I’ve stayed away from Arch and Gentoo because I want my computer experience to be simpler. I would hate to see Fedora fade away because of a graphics card.
## jalf86
This article is a bit misleading. I purposely bought an NVidia graphics card because many web sites still declare NVidia as the best the graphics card to get for Fedora. Its articles like this that perpetuate that myth. I have the prerequisite hardware, but I have to stay at Fedora 27- LXQt (3 updates from base install) or my computer freezes. Because of NVidia, I’ve tried to migrate away from Fedora (tried out Mint, Umbuntu, and various other distos). I don’t have the budget to change graphics cards and there haven’t been much talk of a comparable alternative outside of “if you don’t care about graphics go with Intel”.
## Night Romantic
jalf86,
my general experiences with Fedora and NVidia drivers are quite in line with the article. It’s quite easy to install them on Fedora — at least it was for two NVidia cards I have/had for the last 10 years or so. There are
nuancesafter installation, maybe quite a few — and yes, the article definitely should at least name them, as you and other commenters pointed out.Fedora with NVidia on XOrg (not on Wayland) worked ok for me (F26, 25 and earlier). But for now I decided to have Fedora with open source nouveau driver as my primary workhorse distribution, and dual-boot to Ubuntu or SolusOS with proprietary NVidia drivers for Steam and maybe some other 3D games. Solus — they’ve done quite a few optimizations for Steam Runtime, have it use updated libraries and such.
And so I have best of both worlds, so to say: “clean” Fedora on Wayland, and other distro with proprietary graphics (without Wayland as of now) just for games and not so mission critical as Fedora.
## ernesto
Does intalling the nvidia propietary drivers still cause the fedora loading screen animation to be replaced with text during the system’s boot?
## muhaha
Login, connect to the internet, and open the software app. Click Add-ons> Hardware Drivers> NVIDIA Linux Graphics Driver> Install.
is it possible to use command line to complete this step? |
9,842 | 我的第一个系统管理员错误 | https://opensource.com/article/18/7/my-first-sysadmin-mistake | 2018-07-17T15:17:00 | [
"系统管理员",
"错误"
] | /article-9842-1.html |
>
> 如何在崩溃的局面中集中精力寻找解决方案。
>
>
>

如果你在 IT 领域工作,你知道事情永远不会像你想象的那样完好。在某些时候,你会遇到错误或出现问题,你最终必须解决问题。这就是系统管理员的工作。
作为人类,我们都会犯错误。我们不是已经犯错,就是即将犯错。结果,我们最终还必须解决自己的错误。总是这样。我们都会失误、敲错字母或犯错。
作为一名年轻的系统管理员,我艰难地学到了这一课。我犯了一个大错。但是多亏了上级的指导,我学会了不去纠缠于我的错误,而是制定一个“错误策略”来做正确的事情。从错误中吸取教训。克服它,继续前进。
我的第一份工作是一家小公司的 Unix 系统管理员。真的,我是一名生嫩的系统管理员,但我大部分时间都独自工作。我们是一个小型 IT 团队,只有我们三个人。我是 20 或 30 台 Unix 工作站和服务器的唯一系统管理员。另外两个支持 Windows 服务器和桌面。
任何阅读这篇文章的系统管理员都不会对此感到意外,作为一个不成熟的初级系统管理员,我最终在错误的目录中运行了 `rm` 命令——作为 root 用户。我以为我正在为我们的某个程序删除一些陈旧的缓存文件。相反,我错误地清除了 `/etc` 目录中的所有文件。糟糕。
我意识到犯了错误是看到了一条错误消息,“`rm` 无法删除某些子目录”。但缓存目录应该只包含文件!我立即停止了 `rm` 命令,看看我做了什么。然后我惊慌失措。一下子,无数个想法涌入了我的脑中。我刚刚销毁了一台重要的服务器吗?系统会怎么样?我会被解雇吗?
幸运的是,我运行的是 `rm *` 而不是 `rm -rf *`,因此我只删除了文件。子目录仍在那里。但这并没有让我感觉更好。
我立刻去找我的主管告诉她我做了什么。她看到我对自己的错误感到愚蠢,但这是我犯的。尽管紧迫,她花了几分钟时间跟我做了一些指导。 她说:“你不是第一个这样做的人,在你这种情况下,别人会怎么做?”这帮助我平静下来并专注。我开始更少考虑我刚刚做的愚蠢事情,而更多地考虑我接下来要做的事情。
我做了一个简单的策略:不要重启服务器。使用相同的系统作为模板,并重建 `/etc` 目录。
制定了行动计划后,剩下的就很容易了。只需运行正确的命令即可从另一台服务器复制 `/etc` 文件并编辑配置,使其与系统匹配。多亏了我对所有东西都做记录的习惯,我使用已有的文档进行最后的调整。我避免了完全恢复服务器,这意味着一个巨大的宕机事件。
可以肯定的是,我从这个错误中吸取了教训。在接下来作为系统管理员的日子中,我总是在运行任何命令之前确认我所在的目录。
我还学习了构建“错误策略”的价值。当事情出错时,恐慌并思考接下来可能发生的所有坏事是很自然的。这是人性。但是制定一个“错误策略”可以帮助我不再担心出了什么问题,而是专注于让事情变得更好。我仍然会想一下,但是知道我接下来的步骤可以让我“克服它”。
---
via: <https://opensource.com/article/18/7/my-first-sysadmin-mistake>
作者:[Jim Hall](https://opensource.com/users/jim-hall) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
9,843 | 6 个可以帮你理解互联网工作原理的 RFC | https://opensource.com/article/18/7/requests-for-comments-to-know | 2018-07-18T09:44:00 | [
"RFC"
] | /article-9843-1.html |
>
> 以及 3 个有趣的 RFC。
>
>
>

阅读源码是开源软件的重要组成部分。这意味着用户可以查看代码并了解做了什么。
但“阅读源码”并不仅适用于代码。理解代码实现的标准同样重要。这些标准编写在由<ruby> <a href="https://www.ietf.org"> 互联网工程任务组 </a> <rt> Internet Engineering Task Force </rt></ruby>(IETF)发布的称为“<ruby> 意见征集 <rt> Requests for Comment </rt></ruby>”(RFC)的文档中。多年来已经发布了数以千计的 RFC,因此我们收集了一些我们的贡献者认为必读的内容。
### 6 个必读的 RFC
#### RFC 2119 - 在 RFC 中用于指示需求级别的关键字
这是一个快速阅读,但它对了解其它 RFC 非常重要。 [RFC 2119](https://www.rfc-editor.org/rfc/rfc2119.txt) 定义了后续 RFC 中使用的需求级别。 “MAY” 究竟意味着什么?如果标准说 “SHOULD”,你*真的*必须这样做吗?通过为需求提供明确定义的分类,RFC 2119 有助于避免歧义。
#### RFC 3339 - 互联网上的日期和时间:时间戳
时间是全世界程序员的祸根。 [RFC 3339](https://www.rfc-editor.org/rfc/rfc3339.txt) 定义了如何格式化时间戳。基于 [ISO 8601](https://www.iso.org/iso-8601-date-and-time-format.html) 标准,3339 为我们提供了一种表达时间的常用方法。例如,像星期几这样的冗余信息不应该包含在存储的时间戳中,因为它很容易计算。
#### RFC 1918 - 私有互联网的地址分配
有属于每个人的互联网,也有只属于你的互联网。私有网络一直在使用,[RFC 1918](https://www.rfc-editor.org/rfc/rfc1918.txt) 定义了这些网络。当然,你可以在路由器上设置在内部使用公网地址,但这是一个坏主意。或者,你可以将未使用的公共 IP 地址视为内部网络。在任何一种情况下都表明你从未阅读过 RFC 1918。
#### RFC 1912 - 常见的 DNS 操作和配置错误
一切都是 #@%@ 的 DNS 问题,对吧? [RFC 1912](https://www.rfc-editor.org/rfc/rfc1912.txt) 列出了管理员在试图保持互联网运行时所犯的错误。虽然它是在 1996 年发布的,但 DNS(以及人们犯的错误)并没有真正改变这么多。为了理解我们为什么首先需要 DNS,如今我们再来看看 [RFC 289 - 我们希望正式的主机列表是什么样子的](https://www.rfc-editor.org/rfc/rfc289.txt) 就知道了。
#### RFC 2822 — 互联网邮件格式
想想你知道什么是有效的电子邮件地址么?如果你知道有多少个站点不接受我邮件地址中 “+” 的话,你就知道你知道不知道了。 [RFC 2822](https://www.rfc-editor.org/rfc/rfc2822.txt) 定义了有效的电子邮件地址。它还详细介绍了电子邮件的其余部分。
#### RFC 7231 - 超文本传输协议(HTTP/1.1):语义和内容
想想看,几乎我们在网上做的一切都依赖于 HTTP。 [RFC 7231](https://www.rfc-editor.org/rfc/rfc7231.txt) 是该协议的最新更新。它有超过 100 页,定义了方法、请求头和状态代码。
### 3 个应该阅读的 RFC
好吧,并非每个 RFC 都是严肃的。
#### RFC 1149 - 在禽类载体上传输 IP 数据报的标准
网络以多种不同方式传递数据包。 [RFC 1149](https://www.rfc-editor.org/rfc/rfc1149.txt) 描述了鸽子载体的使用。当我距离州际高速公路一英里以外时,它们的可靠性不会低于我的移动提供商。
#### RFC 2324 — 超文本咖啡壶控制协议(HTCPCP/1.0)
咖啡对于完成工作非常重要,当然,我们需要一个用于管理咖啡壶的程序化界面。 [RFC 2324](https://www.rfc-editor.org/rfc/rfc2324.txt) 定义了一个用于与咖啡壶交互的协议,并添加了 HTTP 418(“我是一个茶壶”)。
#### RFC 69 — M.I.T.的分发列表更改
[RFC 69](https://www.rfc-editor.org/rfc/rfc69.txt) 是否是第一个误导取消订阅请求的发布示例?
你必须阅读的 RFC 是什么(无论它们是否严肃)?在评论中分享你的列表。
---
via: <https://opensource.com/article/18/7/requests-for-comments-to-know>
作者:[Ben Cotton](https://opensource.com/users/bcotton) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
9,844 | 供应链管理方面的 5 个开源软件工具 | https://opensource.com/tools/supply-chain-management | 2018-07-17T16:17:10 | [
"供应链",
"ERP"
] | https://linux.cn/article-9844-1.html |
>
> 跟踪您的库存和需要的材料,用这些供应链管理工具制造产品。
>
>
>

本文最初发表于 2016 年 1 月 14 日,最后的更新日期为 2018 年 3 月 2 日。
如果你正在管理着处理实体货物的业务,[供应链管理](https://en.wikipedia.org/wiki/Supply_chain_management) 是你的业务流程中非常重要的一部分。不论你是经营着一个只有几个客户的小商店,还是在世界各地拥有数以百万计客户和成千上万产品的世界财富 500 强的制造商或零售商,很清楚地知道你的库存和制造产品所需要的零部件,对你来说都是非常重要的事情。
保持对货品、供应商、客户的持续跟踪,而且所有与它们相关的变动部分都会受益于这些用来帮助管理工作流的专门软件,而在某些情况下需要完全依赖这些软件。在本文中,我们将去了解一些自由及开源的供应链管理方面的软件,以及它们的其中一些功能。
供应链管理比单纯的库存管理更为强大。它能帮你去跟踪货物流以降低成本,以及为可能发生的各种糟糕的变化来制定应对计划。它能够帮你对出口合规性进行跟踪,不论是否是出于法律要求、最低品质要求、还是社会和环境责任。它能够帮你计划最低供应量,让你能够在订单数量和交付时间之间做出明智的决策。
由于其本质决定了许多供应链管理软件是与类似的软件捆绑在一起的,比如,[客户关系管理](https://opensource.com/business/14/7/top-5-open-source-crm-tools)(CRM)和 [企业资源计划管理](/article-9785-1.html) (ERP)。因此,当你选择哪个工具更适合你的组织时,你可能会考虑与其它工具集成作为你的决策依据之一。
### Apache OFBiz
[Apache OFBiz](http://ofbiz.apache.org/) 是一套帮你管理多种业务流程的相关工具。虽然它能管理多种相关问题,比如,分类、电子商务网站、会计和 POS,它在供应链管理方面的主要功能关注于仓库管理、履行、订单和生产管理。它的可定制性很强,但是,对应的它需要大量的规划去设置和集成到你现有的流程中。这就是它适用于中大型业务的原因之一。项目的功能构建于三个层面:展示层、业务层和数据层,它是一个弹性很好的解决方案,但是,再强调一遍,它也很复杂。
Apache OFBiz 的源代码在其 [项目仓库](http://ofbiz.apache.org/source-repositories.html) 中可以找到。Apache OFBiz 是用 Java 写的,并且它是按 [Apache 2.0 许可证](http://www.apache.org/licenses/LICENSE-2.0) 授权的。
如果你对它感兴趣,你也可以去查看 [opentaps](http://www.opentaps.org/),它是在 OFBiz 之上构建的。Opentaps 强化了 OFBiz 的用户界面,并且添加了 ERP 和 CRM 的核心功能,包括仓库管理、采购和计划。它是按 [AGPL 3.0](http://www.fsf.org/licensing/licenses/agpl-3.0.html) 授权使用的,对于不接受开源授权的组织,它也提供了商业授权。
### OpenBoxes
[OpenBoxes](http://openboxes.com/) 是一个供应链管理和存货管理项目,最初的主要设计目标是为了医疗行业中的药品跟踪管理,但是,它可以通过修改去跟踪任何类型的货品和相关的业务流。它有一个需求预测工具,可以基于历史订单数量、存储跟踪、支持多种场所、过期日期跟踪、销售点支持等进行预测,并且它还有许多其它功能,这使它成为医疗行业的理想选择,但是,它也可以用于其它行业。
它在 [Eclipse 公开许可证](http://opensource.org/licenses/eclipse-1.0.php) 下可用,OpenBoxes 主要是由 Groovy 写的,它的源代码可以在 [GitHub](https://github.com/openboxes/openboxes) 上看到。
### OpenLMIS
与 OpenBoxes 类似,[OpenLMIS](http://openlmis.org/) 也是一个医疗行业的供应链管理工具,但是,它专用设计用于在非洲的资源缺乏地区使用,以确保有限的药物和医疗用品能够用到需要的病人上。它是 API 驱动的,这样用户可以去定制和扩展 OpenLMIS,同时还能维护一个与通用基准代码的连接。它是由洛克菲勒基金会开发的,其它的贡献者包括联合国、美国国际开发署、和比尔 & 梅林达·盖茨基金会。
OpenLMIS 是用 Java 和 JavaScript 的 AngularJS 写的。它在 [AGPL 3.0 许可证](https://github.com/OpenLMIS/openlmis-ref-distro/blob/master/LICENSE) 下使用,它的源代码在 [GitHub](https://github.com/OpenLMIS/openlmis-ref-distro/blob/master/LICENSE) 上可以找到。
### Odoo
你可能在我们以前的 [ERP 项目](/article-9785-1.html) 榜的文章上见到过 [Odoo](https://www.odoo.com/)。事实上,根据你的需要,一个全功能的 ERP 对你来说是最适合的。Odoo 的供应链管理工具主要围绕存货和采购管理,同时还与电子商务网站和 POS 连接,但是,它也可以与其它的工具连接,比如,与 [frePPLe](https://frepple.com/) 连接,它是一个开源的生产计划工具。
Odoo 既有软件即服务(SaaS)的解决方案,也有开源的社区版本。开源的版本是以 [LGPL](https://github.com/odoo/odoo/blob/9.0/LICENSE) 版本 3 下发行的,源代码在 [GitHub](https://github.com/odoo/odoo) 上可以找到。Odoo 主要是用 Python 来写的。
### xTuple
[xTuple](https://xtuple.com/) 标称自己是“为成长中的企业提供供应链管理软件”,它专注于已经超越了其传统的小型企业 ERP 和 CRM 解决方案的企业。它的开源版本称为 Postbooks,添加了一些存货、分销、采购、以及供应商报告的功能,它提供的核心功能是会计、CRM、以及 ERP 功能,而它的商业版本扩展了制造和分销的 [功能](https://xtuple.com/comparison-chart)。
xTuple 在 [CPAL](https://xtuple.com/products/license-options#cpal) 下使用,这个项目欢迎开发者去复刻它,为基于存货的制造商去创建其它的业务软件。它的 Web 应用核心是用 JavaScript 写的,它的源代码在 [GitHub](http://xtuple.github.io/) 上可以找到。
就这些,当然了,还有其它的可以帮你处理供应链管理的开源软件。如果你知道还有更好的软件,请在下面的评论区告诉我们。
---
via: <https://opensource.com/tools/supply-chain-management>
作者:[Jason Baker](https://opensource.com/users/jason-baker) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *This article was originally posted on January 14, 2016, and last updated March 2, 2018.*
If you manage a business that deals with physical goods, [supply chain management](https://en.wikipedia.org/wiki/Supply_chain_management) is an important part of your business process. Whether you're running a tiny Etsy store with just a few customers, or a Fortune 500 manufacturer or retailer with thousands of products and millions of customers worldwide, it's important to have a close understanding of your inventory and the parts and raw materials you need to make your products.
Keeping track of physical items, suppliers, customers, and all the many moving parts associated with each can greatly benefit from, and in some cases be totally dependent on, specialized software to help manage these workflows. In this article, we'll take a look at some free and open source software options for supply chain management and some of the features of each.
Supply chain management goes a little further than just inventory management. It can help you keep track of the flow of goods to reduce costs and plan for scenarios in which the supply chain could change. It can help you keep track of compliance issues, whether these fall under the umbrella of legal requirements, quality minimums, or social and environmental responsibility. It can help you plan the minimum supply to keep on hand and enable you to make smart decisions about order quantities and delivery times.
Because of its nature, a lot of supply chain management software is bundled with similar software, such as [customer relationship management](https://opensource.com/business/14/7/top-5-open-source-crm-tools) (CRM) and [enterprise resource planning](https://opensource.com/resources/top-4-open-source-erp-systems) (ERP) tools. So, when making a decision about which tool is best for your organization, you may wish to consider integration with other tools as a part of your decision-making criteria.
## Apache OFBiz
[Apache OFBiz](http://ofbiz.apache.org/) is a suite of related tools for helping you manage a variety of business processes. While it can manage a variety of related issues like catalogs, e-commerce sites, accounting, and point of sale, its primary supply chain functions focus on warehouse management, fulfillment, order, and manufacturing management. It is very customizable, but the flip side of that is that it requires a good deal of careful planning to set up and integrate with your existing processes. That's one reason it is probably the best fit for a midsize to large operation. The project's functionality is built across three layers: presentation, business, and data, making it a scalable solution, but again, a complex one.
The source code of Apache OFBiz can be found in the [project's repository](http://ofbiz.apache.org/source-repositories.html). Apache OFBiz is written in Java and is licensed under an [Apache 2.0 license](http://www.apache.org/licenses/LICENSE-2.0).
If this looks interesting, you might also want to check out [opentaps](http://www.opentaps.org/), which is built on top of OFBiz. Opentaps enhances OFBiz's user interface and adds core ERP and CRM features, including warehouse management, purchasing, and planning. It's licensed under [AGPL 3.0](http://www.fsf.org/licensing/licenses/agpl-3.0.html), with a commercial license available for organizations that don't want to be bound by the open source license.
## OpenBoxes
[OpenBoxes](http://openboxes.com/) is a supply chain management and inventory control project, primarily and originally designed for keeping track of pharmaceuticals in a healthcare environment, but it can be modified to track any type of stock and the flows associated with it. It has tools for demand forecasting based on historical order quantities, tracking stock, supporting multiple facilities, expiration date tracking, kiosk support, and many other features that make it ideal for healthcare situations, but could also be useful for other industries.
Available under an [Eclipse Public License](http://opensource.org/licenses/eclipse-1.0.php), OpenBoxes is written primarily in Groovy and its source code can be browsed on [GitHub](https://github.com/openboxes/openboxes).
## OpenLMIS
Like OpenBoxes, [OpenLMIS](http://openlmis.org/) is a supply chain management tool for the healthcare sector, but it was specifically designed for use in low-resource areas in Africa to ensure medications and medical supplies get to patients in need. Its API-driven approach enables users to customize and extend OpenLMIS while maintaining a connection to the common codebase. It was developed with funding from the Rockefeller Foundation, and other contributors include the UN, USAID, and the Bill & Melinda Gates Foundation.
OpenLMIS is written in Java and JavaScript with AngularJS. It is available under an [AGPL 3.0 license](https://github.com/OpenLMIS/openlmis-ref-distro/blob/master/LICENSE), and its source code is accessible on [GitHub](https://github.com/OpenLMIS/openlmis-ref-distro/blob/master/LICENSE).
## Odoo
You might recognize [Odoo](https://www.odoo.com/) from our previous top [ERP projects](https://opensource.com/resources/top-4-open-source-erp-systems) article. In fact, a full ERP may be a good fit for you, depending on your needs. Odoo's supply chain management tools mostly revolve around inventory and purchase management, as well as connectivity with e-commerce and point of sale, but it can also connect to other tools like [frePPLe](https://frepple.com/) for open source production planning.
Odoo is available both as a software-as-a-service solution and an open source community edition. The open source edition is released under [LGPL](https://github.com/odoo/odoo/blob/9.0/LICENSE) version 3, and the source is available on [GitHub](https://github.com/odoo/odoo). Odoo is primarily written in Python.
## xTuple
Billing itself as "supply chain management software for growing businesses," [xTuple](https://xtuple.com/) focuses on businesses that have outgrown their conventional small business ERP and CRM solutions. Its open source version, called Postbooks, adds some inventory, distribution, purchasing, and vendor reporting features to its core accounting, CRM, and ERP capabilities, and a commercial version expands the [features](https://xtuple.com/comparison-chart) for manufacturers and distributors.
xTuple is available under the Common Public Attribution License ([CPAL](https://xtuple.com/products/license-options#cpal)), and the project welcomes developers to fork it to create other business software for inventory-based manufacturers. Its web app core is written in JavaScript, and its source code can be found on [GitHub](http://xtuple.github.io/).
There are, of course, other open source tools that can help with supply chain management. Know of a good one that we left off? Let us know in the comments below.
## 10 Comments |
9,845 | 在 Kubernetes 上运行一个 Python 应用程序 | https://opensource.com/article/18/1/running-python-application-kubernetes | 2018-07-17T16:35:00 | [
"Python",
"Kubernetes"
] | /article-9845-1.html |
>
> 这个分步指导教程教你通过在 Kubernetes 上部署一个简单的 Python 应用程序来学习部署的流程。
>
>
>

Kubernetes 是一个具备部署、维护和可伸缩特性的开源平台。它在提供可移植性、可扩展性以及自我修复能力的同时,简化了容器化 Python 应用程序的管理。
不论你的 Python 应用程序是简单还是复杂,Kubernetes 都可以帮你高效地部署和伸缩它们,在有限的资源范围内滚动升级新特性。
在本文中,我将描述在 Kubernetes 上部署一个简单的 Python 应用程序的过程,它包括:
* 创建 Python 容器镜像
* 发布容器镜像到镜像注册中心
* 使用持久卷
* 在 Kubernetes 上部署 Python 应用程序
### 必需条件
你需要 Docker、`kubectl` 以及这个 [源代码](https://github.com/jnanjekye/k8s_python_sample_code/tree/master)。
Docker 是一个构建和承载已发布的应用程序的开源平台。可以参照 [官方文档](https://docs.docker.com/engine/installation/) 去安装 Docker。运行如下的命令去验证你的系统上运行的 Docker:
```
$ docker info
Containers: 0
Images: 289
Storage Driver: aufs
Root Dir: /var/lib/docker/aufs
Dirs: 289
Execution Driver: native-0.2
Kernel Version: 3.16.0-4-amd64
Operating System: Debian GNU/Linux 8 (jessie)
WARNING: No memory limit support
WARNING: No swap limit support
```
`kubectl` 是在 Kubernetes 集群上运行命令的一个命令行界面。运行下面的 shell 脚本去安装 `kubectl`:
```
curl -LO https://storage.googleapis.com/kubernetes-release/release/$(curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt)/bin/linux/amd64/kubectl
```
部署到 Kubernetes 的应用要求必须是一个容器化的应用程序。我们来回顾一下 Python 应用程序的容器化过程。
### 一句话了解容器化
容器化是指将一个应用程序所需要的东西打包进一个自带操作系统的容器中。这种完整机器虚拟化的好处是,一个应用程序能够在任何机器上运行而无需考虑它的依赖项。
我们以 Roman Gaponov 的 [文章](https://hackernoon.com/docker-tutorial-getting-started-with-python-redis-and-nginx-81a9d740d091) 为参考,来为我们的 Python 代码创建一个容器。
### 创建一个 Python 容器镜像
为创建这些镜像,我们将使用 Docker,它可以让我们在一个隔离的 Linux 软件容器中部署应用程序。Docker 可以使用来自一个 Dockerfile 中的指令来自动化构建镜像。
这是我们的 Python 应用程序的 Dockerfile:
```
FROM python:3.6
MAINTAINER XenonStack
# Creating Application Source Code Directory
RUN mkdir -p /k8s_python_sample_code/src
# Setting Home Directory for containers
WORKDIR /k8s_python_sample_code/src
# Installing python dependencies
COPY requirements.txt /k8s_python_sample_code/src
RUN pip install --no-cache-dir -r requirements.txt
# Copying src code to Container
COPY . /k8s_python_sample_code/src/app
# Application Environment variables
ENV APP_ENV development
# Exposing Ports
EXPOSE 5035
# Setting Persistent data
VOLUME ["/app-data"]
# Running Python Application
CMD ["python", "app.py"]
```
这个 Dockerfile 包含运行我们的示例 Python 代码的指令。它使用的开发环境是 Python 3.5。
### 构建一个 Python Docker 镜像
现在,我们可以使用下面的这个命令按照那些指令来构建 Docker 镜像:
```
docker build -t k8s_python_sample_code .
```
这个命令为我们的 Python 应用程序创建了一个 Docker 镜像。
### 发布容器镜像
我们可以将我们的 Python 容器镜像发布到不同的私有/公共云仓库中,像 Docker Hub、AWS ECR、Google Container Registry 等等。本教程中我们将发布到 Docker Hub。
在发布镜像之前,我们需要给它标记一个版本号:
```
docker tag k8s_python_sample_code:latest k8s_python_sample_code:0.1
```
### 推送镜像到一个云仓库
如果使用一个 Docker 注册中心而不是 Docker Hub 去保存镜像,那么你需要在你本地的 Docker 守护程序和 Kubernetes Docker 守护程序上添加一个容器注册中心。对于不同的云注册中心,你可以在它上面找到相关信息。我们在示例中使用的是 Docker Hub。
运行下面的 Docker 命令去推送镜像:
```
docker push k8s_python_sample_code
```
### 使用 CephFS 持久卷
Kubernetes 支持许多的持久存储提供商,包括 AWS EBS、CephFS、GlusterFS、Azure Disk、NFS 等等。我在示例中使用 CephFS 做为 Kubernetes 的持久卷。
为使用 CephFS 存储 Kubernetes 的容器数据,我们将创建两个文件:
`persistent-volume.yml` :
```
apiVersion: v1
kind: PersistentVolume
metadata:
name: app-disk1
namespace: k8s_python_sample_code
spec:
capacity:
storage: 50Gi
accessModes:
- ReadWriteMany
cephfs:
monitors:
- "172.17.0.1:6789"
user: admin
secretRef:
name: ceph-secret
readOnly: false
```
`persistent_volume_claim.yaml`:
```
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: appclaim1
namespace: k8s_python_sample_code
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 10Gi
```
现在,我们将使用 `kubectl` 去添加持久卷并声明到 Kubernetes 集群中:
```
$ kubectl create -f persistent-volume.yml
$ kubectl create -f persistent-volume-claim.yml
```
现在,我们准备去部署 Kubernetes。
### 在 Kubernetes 上部署应用程序
为管理部署应用程序到 Kubernetes 上的最后一步,我们将创建两个重要文件:一个服务文件和一个部署文件。
使用下列的内容创建服务文件,并将它命名为 `k8s_python_sample_code.service.yml`:
```
apiVersion: v1
kind: Service
metadata:
labels:
k8s-app: k8s_python_sample_code
name: k8s_python_sample_code
namespace: k8s_python_sample_code
spec:
type: NodePort
ports:
- port: 5035
selector:
k8s-app: k8s_python_sample_code
```
使用下列的内容创建部署文件并将它命名为 `k8s_python_sample_code.deployment.yml`:
```
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: k8s_python_sample_code
namespace: k8s_python_sample_code
spec:
replicas: 1
template:
metadata:
labels:
k8s-app: k8s_python_sample_code
spec:
containers:
- name: k8s_python_sample_code
image: k8s_python_sample_code:0.1
imagePullPolicy: "IfNotPresent"
ports:
- containerPort: 5035
volumeMounts:
- mountPath: /app-data
name: k8s_python_sample_code
volumes:
- name: <name of application>
persistentVolumeClaim:
claimName: appclaim1
```
最后,我们使用 `kubectl` 将应用程序部署到 Kubernetes:
```
$ kubectl create -f k8s_python_sample_code.deployment.yml $ kubectl create -f k8s_python_sample_code.service.yml
```
现在,你的应用程序已经成功部署到 Kubernetes。
你可以通过检查运行的服务来验证你的应用程序是否在运行:
```
kubectl get services
```
或许 Kubernetes 可以解决未来你部署应用程序的各种麻烦!
*想学习更多关于 Python 的知识?Nanjekye 的书,[和平共处的 Python 2 和 3](https://www.apress.com/gp/book/9781484229545) 提供了完整的方法,让你写的代码在 Python 2 和 3 上完美运行,包括如何转换已有的 Python 2 代码为能够可靠运行在 Python 2 和 3 上的代码的详细示例。*
### 关于作者
Joannah Nanjekye - Straight Outta 256,只要结果不问原因,充满激情的飞行员,喜欢用代码说话。[关于我的更多信息](https://opensource.com/users/nanjekyejoannah)
---
via: <https://opensource.com/article/18/1/running-python-application-kubernetes>
作者:[Joannah Nanjekye](https://opensource.com/users/nanjekyejoannah) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
9,846 | 我们能否建立一个服务于用户而非广告商的社交网络? | https://opensource.com/open-organization/18/3/open-social-human-connection | 2018-07-18T14:26:43 | [
"开放组织",
"透明度",
"社区"
] | https://linux.cn/article-9846-1.html |
>
> 找出 Human Connection 是如何将透明度和社区放在首位的。
>
>
>

如今,开源软件具有深远的意义,在推动数字经济创新方面发挥着关键作用。世界正在快速彻底地改变。世界各地的人们需要一个专门的、中立的、透明的在线平台来迎接我们这个时代的挑战。
开放的原则也许是让我们达成这一目标的方法。如果我们用开放的思维方式将数字创新与社会创新结合在一起,会发生什么?
这个问题是我们在 [Human Connection](https://human-connection.org/en/) 工作的核心,这是一个具有前瞻性的,以德国为基础的知识和行动网络,其使命是创建一个服务于全球的真正的社交网络。我们受到这样一种观念为指引,即人类天生慷慨而富有同情心,并且他们在慈善行为上茁壮成长。但我们还没有看到一个完全支持我们的自然趋势,与乐于助人和合作以促进共同利益的社交网络。Human Connection 渴望成为让每个人都成为积极变革者的平台。
为了实现一个以解决方案为导向的平台的梦想,让人们通过与慈善机构、社区团体和社会变革活动人士的接触,围绕社会公益事业采取行动,Human Connection 将开放的价值观作为社会创新的载体。
以下是有关它如何工作的。
### 首先是透明
透明是 Human Connection 的指导原则之一。Human Connection 邀请世界各地的程序员通过[在 Github 上提交他们的源代码](https://github.com/human-connection/)共同开发平台的源代码(JavaScript、Vue、nuxt),并通过贡献代码或编程附加功能来支持真正的社交网络。
但我们对透明的承诺超出了我们的发展实践。事实上,当涉及到建立一种新的社交网络,促进那些让世界变得更好的人之间的真正联系和互动,分享源代码只是迈向透明的一步。
为促进公开对话,Human Connection 团队举行[定期在线公开会议](https://youtu.be/tPcYRQcepYE)。我们在这里回答问题,鼓励建议并对潜在的问题作出回应。我们的 Meet The Team 活动也会记录下来,并在事后向公众开放。通过对我们的流程,源代码和财务状况完全透明,我们可以保护自己免受批评或其他潜在的不利影响。
对透明的承诺意味着,所有在 Human Connection 上公开分享的用户贡献者将在 Creative Commons 许可下发布,最终作为数据包下载。通过让大众知识变得可用,特别是以一种分散的方式,我们创造了一个多元化社会的机会。
有一个问题指导我们所有的组织决策:“它是否服务于人民和更大的利益?”我们用<ruby> <a href="http://www.un.org/en/charter-united-nations/index.html"> 联合国宪章 </a> <rt> UN Charter </rt></ruby>和“<ruby> 世界人权宣言 <rt> Universal Declaration of Human Rights </rt></ruby>”作为我们价值体系的基础。随着我们的规模越来越大,尤其是即将推出的公测版,我们必须对此任务负责。我甚至愿意邀请 Chaos Computer Club (LCTT 译注:这是欧洲最大的黑客联盟)或其他黑客俱乐部通过随机检查我们的平台来验证我们的代码和行为的完整性。
### 一个合作的社会
以一种[以社区为中心的协作方法](https://youtu.be/BQHBno-efRI)来编写 Human Connection 平台是超越社交网络实际应用理念的基础。我们的团队是通过找到问题的答案来驱动:“是什么让一个社交网络真正地社会化?”
一个抛弃了以利润为导向的算法、为最终用户而不是广告商服务的网络,只能通过转向对等生产和协作的过程而繁荣起来。例如,像 [Code Alliance](http://codealliance.org/) 和 [Code for America](https://www.codeforamerica.org/) 这样的组织已经证明了如何在一个开源环境中创造技术,造福人类并变革现状。社区驱动的项目,如基于地图的报告平台 [FixMyStreet](http://fixmystreet.org/),或者为 Humanitarian OpenStreetMap 而建立的 [Tasking Manager](https://tasks.hotosm.org/),已经将众包作为推动其使用的一种方式。
我们建立 Human Connection 的方法从一开始就是合作。为了收集关于必要功能和真正社交网络的目的的初步数据,我们与巴黎<ruby> 索邦大学 <rt> University Sorbonne </rt></ruby>的<ruby> 国家东方语言与文明研究所 <rt> National Institute for Oriental Languages and Civilizations </rt></ruby>(INALCO)和德国<ruby> 斯图加特媒体大学 <rt> Stuttgart Media University </rt></ruby>合作。这两个项目的研究结果都被纳入了 Human Connection 的早期开发。多亏了这项研究,[用户将拥有一套全新的功能](https://youtu.be/AwSx06DK2oU),让他们可以控制自己看到的内容以及他们如何与他人的互动。由于早期的支持者[被邀请到网络的 alpha 版本](https://youtu.be/AwSx06DK2oU),他们可以体验到第一个可用的值得注意的功能。这里有一些:
* 将信息与行动联系起来是我们研究会议的一个重要主题。当前的社交网络让用户处于信息阶段。这两所大学的学生团体都认为,需要一个以行动为导向的组件,以满足人类共同解决问题的本能。所以我们在平台上构建了一个[“Can Do”功能](https://youtu.be/g2gYLNx686I)。这是一个人在阅读了某个话题后可以采取行动的一种方式。“Can Do” 是用户建议的活动,在“<ruby> 采取行动 <rt> Take Action </rt></ruby>”领域,每个人都可以实现。
* “Versus” 功能是另一个成果。在传统社交网络仅限于评论功能的地方,我们的学生团体认为需要采用更加结构化且有用的方式进行讨论和争论。“Versus” 是对公共帖子的反驳,它是单独显示的,并提供了一个机会来突出围绕某个问题的不同意见。
* 今天的社交网络并没有提供很多过滤内容的选项。研究表明,情绪过滤选项可以帮助我们根据日常情绪驾驭社交空间,并可能通过在我们希望仅看到令人振奋的内容的那一天时,不显示悲伤或难过的帖子来潜在地保护我们的情绪健康。
Human Connection 邀请改革者合作开发一个网络,有可能动员世界各地的个人和团体将负面新闻变成 “Can Do”,并与慈善机构和非营利组织一起参与社会创新项目。
[订阅我们的每周时事通讯](https://opensource.com/open-organization/resources/newsletter)以了解有关开放组织的更多信息。
---
via: <https://opensource.com/open-organization/18/3/open-social-human-connection>
作者:[Dennis Hack](https://opensource.com/users/dhack) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Today, open source software is far-reaching and has played a key role driving innovation in our digital economy. The world is undergoing radical change at a rapid pace. People in all parts of the world need a purpose-built, neutral, and transparent online platform to meet the challenges of our time.
And open principles might just be the way to get us there. What would happen if we married digital innovation with social innovation using open-focused thinking?
This question is at the heart of our work at [Human Connection](https://human-connection.org/en/), a forward-thinking, Germany-based knowledge and action network with a mission to create a truly social network that serves the world. We're guided by the notion that human beings are inherently generous and sympathetic, and that they thrive on benevolent actions. But we haven't seen a social network that has fully supported our natural tendency towards helpfulness and cooperation to promote the common good. Human Connection aspires to be the platform that allows everyone to become an active changemaker.
In order to achieve the dream of a solution-oriented platform that enables people to take action around social causes by engaging with charities, community groups, and social change activists, Human Connection embraces open values as a vehicle for social innovation.
Here's how.
## Transparency first
Transparency is one of Human Connection's guiding principles. Human Connection invites programmers around the world to jointly work on the platform's source code (JavaScript, Vue, nuxt) by [making their source code available on Github](https://github.com/human-connection/) and support the idea of a truly social network by contributing to the code or programming additional functions.
But our commitment to transparency extends beyond our development practices. In fact—when it comes to building a new kind of social network that promotes true connection and interaction between people who are passionate about changing the world for the better—making the source code available is just one step towards being transparent.
To facilitate open dialogue, the Human Connection team holds [regular public meetings online](https://youtu.be/tPcYRQcepYE). Here we answer questions, encourage suggestions, and respond to potential concerns. Our Meet The Team events are also recorded and made available to the public afterwards. By being fully transparent with our process, our source code, and our finances, we can protect ourselves against critics or other potential backlashes.
The commitment to transparency also means that all user contributions that shared publicly on Human Connection will be released under a Creative Commons license and can eventually be downloaded as a data pack. By making crowd knowledge available, especially in a decentralized way, we create the opportunity for social pluralism.
Guiding all of our organizational decisions is one question: "Does it serve the people and the greater good?" And we use the [UN Charter](http://www.un.org/en/charter-united-nations/index.html) and the Universal Declaration of Human Rights as a foundation for our value system. As we'll grow bigger, especially with our upcoming open beta launch, it's important for us to stay accountable to that mission. I'm even open to the idea of inviting the Chaos Computer Club or other hacker clubs to verify the integrity of our code and our actions by randomly checking into our platform.
## A collaborative community
A [collaborative, community-centered approach](https://youtu.be/BQHBno-efRI) to programming the Human Connection platform is the foundation for an idea that extends beyond the practical applications of a social network. Our team is driven by finding an answer to the question: "What makes a social network truly social?"
A network that abandons the idea of a profit-driven algorithm serving advertisers instead of end-users can only thrive by turning to the process of peer production and collaboration. Organizations like [Code Alliance](http://codealliance.org/) and [Code for America](https://www.codeforamerica.org/), for example, have demonstrated how technology can be created in an open source environment to benefit humanity and disrupt the status quo. Community-driven projects like the map-based reporting platform [FixMyStreet](http://fixmystreet.org/) or the [Tasking Manager](https://tasks.hotosm.org/) built for the Humanitarian OpenStreetMap initiative have embraced crowdsourcing as a way to move their mission forward.
Our approach to building Human Connection has been collaborative from the start. To gather initial data on the necessary functions and the purpose of a truly *social* network, we collaborated with the National Institute for Oriental Languages and Civilizations (INALCO) at the University Sorbonne in Paris and the Stuttgart Media University in Germany. Research findings from both projects were incorporated into the early development of Human Connection. Thanks to that research, [users will have a whole new set of functions available](https://youtu.be/AwSx06DK2oU) that put them in control of what content they see and how they engage with others. As early supporters are [invited to the network's alpha version](https://youtu.be/AwSx06DK2oU), they can experience the first available noteworthy functions. Here are just a few:
*Linking information to action*was one key theme emerging from our research sessions. Current social networks leave users in the information stage. Student groups at both universities saw a need for an action-oriented component that serves our human instinct of working together to solve problems. So we built a["Can Do" function](https://youtu.be/g2gYLNx686I)into our platform. It's one of the ways individuals can take action after reading about a certain topic. "Can Do's" are user-suggested activities in the "Take Action" area that everyone can implement.- The "Versus" function is another defining result. Where traditional social networks are limited to a comment function, our student groups saw the need for a more structured and useful way to engage in discussions and arguments. A "Versus" is a counter-argument to a public post that is displayed separately and provides an opportunity to highlight different opinions around an issue.
- Today's social networks don't provide a lot of options to filter content. Research has shown that a filtering option by emotions can help us navigate the social space in accordance with our daily mood and potentially protect our emotional wellbeing by not displaying sad or upsetting posts on a day where we want to see uplifting content only.
Human Connection invites changemakers to collaborate on the development of a network with the potential to mobilize individuals and groups around the world to turn negative news into "Can Do's"—and participate in social innovation projects in conjunction with charities and non-profit organizations.
[Subscribe to our weekly newsletter](https://opensource.com/open-organization/resources/newsletter) to learn more about open organizations.
## 5 Comments |
9,849 | 调试器到底怎样工作 | https://opensource.com/article/18/1/how-debuggers-really-work | 2018-07-19T08:57:00 | [
"调试",
"ptrace"
] | /article-9849-1.html |
>
> 你也许用过调速器检查过你的代码,但你知道它们是如何做到的吗?
>
>
>

调试器是大多数(即使不是每个)开发人员在软件工程职业生涯中至少使用过一次的那些软件之一,但是你们中有多少人知道它们到底是如何工作的?我在悉尼 [linux.conf.au 2018](https://linux.conf.au/index.html) 的演讲中,将讨论从头开始编写调试器……使用 [Rust](https://www.rust-lang.org)!
在本文中,术语<ruby> 调试器 <rt> debugger </rt></ruby>和<ruby> 跟踪器 <rt> tracer </rt></ruby>可以互换。 “<ruby> 被跟踪者 <rt> Tracee </rt></ruby>”是指正在被跟踪器跟踪的进程。
### ptrace 系统调用
大多数调试器严重依赖称为 `ptrace(2)` 的系统调用,其原型如下:
```
long ptrace(enum __ptrace_request request, pid_t pid, void *addr, void *data);
```
这是一个可以操纵进程几乎所有方面的系统调用;但是,在调试器可以连接到一个进程之前,“被跟踪者”必须以请求 `PTRACE_TRACEME` 调用 `ptrace`。这告诉 Linux,父进程通过 `ptrace` 连接到这个进程是合法的。但是……我们如何强制一个进程调用 `ptrace`?很简单!`fork/execve` 提供了在 `fork` 之后但在被跟踪者真正开始使用 `execve` 之前调用 `ptrace` 的简单方法。很方便地,`fork` 还会返回被跟踪者的 `pid`,这是后面使用 `ptrace` 所必需的。
现在被跟踪者可以被调试器追踪,重要的变化发生了:
* 每当一个信号被传送到被跟踪者时,它就会停止,并且一个可以被 `wait` 系列的系统调用捕获的等待事件被传送给跟踪器。
* 每个 `execve` 系统调用都会导致 `SIGTRAP` 被传递给被跟踪者。(与之前的项目相结合,这意味着被跟踪者在一个 `execve` 完全发生之前停止。)
这意味着,一旦我们发出 `PTRACE_TRACEME` 请求并调用 `execve` 系统调用来实际在被跟踪者(进程上下文)中启动程序时,被跟踪者将立即停止,因为 `execve` 会传递一个 `SIGTRAP`,并且会被跟踪器中的等待事件捕获。我们如何继续?正如人们所期望的那样,`ptrace` 有大量的请求可以用来告诉被跟踪者可以继续:
* `PTRACE_CONT`:这是最简单的。 被跟踪者运行,直到它接收到一个信号,此时等待事件被传递给跟踪器。这是最常见的实现真实世界调试器的“继续直至断点”和“永远继续”选项的方式。断点将在下面介绍。
* `PTRACE_SYSCALL`:与 `PTRACE_CONT` 非常相似,但在进入系统调用之前以及在系统调用返回到用户空间之前停止。它可以与其他请求(我们将在本文后面介绍)结合使用来监视和修改系统调用的参数或返回值。系统调用追踪程序 `strace` 很大程度上使用这个请求来获知进程发起了哪些系统调用。
* `PTRACE_SINGLESTEP`:这个很好理解。如果您之前使用过调试器(你会知道),此请求会执行下一条指令,然后立即停止。
我们可以通过各种各样的请求停止进程,但我们如何获得被调试者的状态?进程的状态大多是通过其寄存器捕获的,所以当然 `ptrace` 有一个请求来获得(或修改)寄存器:
* `PTRACE_GETREGS`:这个请求将给出被跟踪者刚刚被停止时的寄存器的状态。
* `PTRACE_SETREGS`:如果跟踪器之前通过调用 `PTRACE_GETREGS` 得到了寄存器的值,它可以在参数结构中修改相应寄存器的值,并使用 `PTRACE_SETREGS` 将寄存器设为新值。
* `PTRACE_PEEKUSER` 和 `PTRACE_POKEUSER`:这些允许从被跟踪者的 `USER` 区读取信息,这里保存了寄存器和其他有用的信息。 这可以用来修改单一寄存器,而避免使用更重的 `PTRACE_{GET,SET}REGS` 请求。
在调试器仅仅修改寄存器是不够的。调试器有时需要读取一部分内存,甚至对其进行修改。GDB 可以使用 `print` 得到一个内存位置或变量的值。`ptrace` 通过下面的方法实现这个功能:
* `PTRACE_PEEKTEXT` 和 `PTRACE_POKETEXT`:这些允许读取和写入被跟踪者地址空间中的一个字。当然,使用这个功能时被跟踪者要被暂停。
真实世界的调试器也有类似断点和观察点的功能。 在接下来的部分中,我将深入体系结构对调试器支持的细节。为了清晰和简洁,本文将只考虑 x86。
### 体系结构的支持
`ptrace` 很酷,但它是如何工作? 在前面的部分中,我们已经看到 `ptrace` 跟信号有很大关系:`SIGTRAP` 可以在单步跟踪、`execve` 之前以及系统调用前后被传送。信号可以通过一些方式产生,但我们将研究两个具体的例子,以展示信号可以被调试器用来在给定的位置停止程序(有效地创建一个断点!):
* **未定义的指令**:当一个进程尝试执行一个未定义的指令,CPU 将产生一个异常。此异常通过 CPU 中断处理,内核中相应的中断处理程序被调用。这将导致一个 `SIGILL` 信号被发送给进程。 这依次导致进程被停止,跟踪器通过一个等待事件被通知,然后它可以决定后面做什么。在 x86 上,指令 `ud2` 被确保始终是未定义的。
* **调试中断**:前面的方法的问题是,`ud2` 指令需要占用两个字节的机器码。存在一条特殊的单字节指令能够触发一个中断,它是 `int $3`,机器码是 `0xCC`。 当该中断发出时,内核向进程发送一个 `SIGTRAP`,如前所述,跟踪器被通知。
这很好,但如何我们才能胁迫被跟踪者执行这些指令? 这很简单:利用 `ptrace` 的 `PTRACE_POKETEXT` 请求,它可以覆盖内存中的一个字。 调试器将使用 `PTRACE_PEEKTEXT` 读取该位置原来的值并替换为 `0xCC` ,然后在其内部状态中记录该处原来的值,以及它是一个断点的事实。 下次被跟踪者执行到该位置时,它将被通过 `SIGTRAP` 信号自动停止。 然后调试器的最终用户可以决定如何继续(例如,检查寄存器)。
好吧,我们已经讲过了断点,那观察点呢? 当一个特定的内存位置被读或写,调试器如何停止程序? 当然你不可能为了能够读或写内存而去把每一个指令都覆盖为 `int $3`。有一组调试寄存器为了更有效的满足这个目的而被设计出来:
* `DR0` 到 `DR3`:这些寄存器中的每个都包含一个地址(内存位置),调试器因为某种原因希望被跟踪者在那些地址那里停止。 其原因以掩码方式被设定在 `DR7` 寄存器中。
* `DR4` 和 `DR5`:这些分别是 `DR6` 和 `DR7` 过时的别名。
* `DR6`:调试状态。包含有关 `DR0` 到 `DR3` 中的哪个寄存器导致调试异常被引发的信息。这被 Linux 用来计算与 `SIGTRAP` 信号一起传递给被跟踪者的信息。
* `DR7`:调试控制。通过使用这些寄存器中的位,调试器可以控制如何解释 `DR0` 至 `DR3` 中指定的地址。位掩码控制监视点的尺寸(监视1、2、4 或 8 个字节)以及是否在执行、读取、写入时引发异常,或在读取或写入时引发异常。
由于调试寄存器是进程的 `USER` 区域的一部分,调试器可以使用 `PTRACE_POKEUSER` 将值写入调试寄存器。调试寄存器只与特定进程相关,因此在进程抢占并重新获得 CPU 控制权之前,调试寄存器会被恢复。
### 冰山一角
我们已经浏览了一个调试器的“冰山”:我们已经介绍了 `ptrace`,了解了它的一些功能,然后我们看到了 `ptrace` 是如何实现的。 `ptrace` 的某些部分可以用软件实现,但其它部分必须用硬件来实现,否则实现代价会非常高甚至无法实现。
当然有很多我们没有涉及。例如“调试器如何知道变量在内存中的位置?”等问题由于空间和时间限制而尚未解答,但我希望你从本文中学到了一些东西;如果它激起你的兴趣,网上有足够的资源可以了解更多。
想要了解更多,请查看 [linux.conf.au](https://linux.conf.au/index.html) 中 Levente Kurusa 的演讲 [Let's Write a Debugger!](https://rego.linux.conf.au/schedule/presentation/91/),于一月 22-26 日在悉尼举办。
---
via: <https://opensource.com/article/18/1/how-debuggers-really-work>
作者:[Levente Kurusa](https://opensource.com/users/lkurusa) 译者:[stephenxs](https://github.com/stephenxs) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
9,850 | macOS 和 Linux 的内核有什么区别 | https://itsfoss.com/mac-linux-difference/ | 2018-07-20T00:15:22 | [
"内核",
"macOS"
] | https://linux.cn/article-9850-1.html | 有些人可能会认为 macOS 和 Linux 内核之间存在相似之处,因为它们可以处理类似的命令和类似的软件。有些人甚至认为苹果公司的 macOS 是基于 Linux 的。事实上是,两个内核有着截然不同的历史和特征。今天,我们来看看 macOS 和 Linux 的内核之间的区别。

### macOS 内核的历史
我们将从 macOS 内核的历史开始。1985 年,由于与首席执行官 John Sculley 和董事会不和,<ruby> 史蒂夫·乔布斯 <rt> Steve Jobs </rt></ruby>离开了苹果公司。然后,他成立了一家名为 [NeXT](https://en.wikipedia.org/wiki/NeXT) 的新电脑公司。乔布斯希望将一款(带有新操作系统的)新计算机快速推向市场。为了节省时间,NeXT 团队使用了卡耐基梅隆大学的 [Mach 内核](https://en.wikipedia.org/wiki/Mach_(kernel)) 和部分 BSD 代码库来创建 [NeXTSTEP 操作系统](https://en.wikipedia.org/wiki/NeXTSTEP)。
NeXT 从来没有取得过财务上的成功,部分归因于乔布斯花钱的习惯,就像他还在苹果公司一样。与此同时,苹果公司曾多次试图更新其操作系统,甚至与 IBM 合作,但从未成功。1997年,苹果公司以 4.29 亿美元收购了 NeXT。作为交易的一部分,史蒂夫·乔布斯回到了苹果公司,同时 NeXTSTEP 成为了 macOS 和 iOS 的基础。
### Linux 内核的历史
与 macOS 内核不同,Linux 的创建并非源于商业尝试。相反,它是由[芬兰计算机科学专业学生<ruby> 林纳斯·托瓦兹 <rt> Linus Torvalds </rt></ruby>于 1991 年创建的](https://www.cs.cmu.edu/%7Eawb/linux.history.html)。最初,内核是按照林纳斯自己的计算机的规格编写的,因为他想利用其新的 80386 处理器(的特性)。林纳斯[于 1991 年 8 月在 Usenet 上](https://groups.google.com/forum/#!original/comp.os.minix/dlNtH7RRrGA/SwRavCzVE7gJ)发布了他的新内核代码。很快,他就收到了来自世界各地的代码和功能建议。次年,Orest Zborowski 将 X Window 系统移植到 Linux,使其能够支持图形用户界面。
在过去的 27 年中,Linux 已经慢慢成长并增加了不少功能。这不再是一个学生的小型项目。现在它运行在[世界上](https://www.zdnet.com/article/sorry-windows-android-is-now-the-most-popular-end-user-operating-system/)大多数的[计算设备](https://www.linuxinsider.com/story/31855.html)和[超级计算机](https://itsfoss.com/linux-supercomputers-2017/)上。不错!
### macOS 内核的特性
macOS 内核被官方称为 XNU。这个[首字母缩写词](https://github.com/apple/darwin-xnu)代表“XNU is Not Unix”。根据 [苹果公司的 Github 页面](https://github.com/apple/darwin-xnu),XNU 是“将卡耐基梅隆大学开发的 Mach 内核和 FreeBSD 组件整合而成的混合内核,加上用于编写驱动程序的 C++ API”。代码的 BSD 子系统部分[“在微内核系统中通常实现为用户空间的服务”](http://osxbook.com/book/bonus/ancient/whatismacosx/arch_xnu.html)。Mach 部分负责底层工作,例如多任务、内存保护、虚拟内存管理、内核调试支持和控制台 I/O。
### Linux 内核的特性
虽然 macOS 内核结合了微内核([Mach](https://en.wikipedia.org/wiki/Mach_(kernel))和宏内核([BSD](https://en.wikipedia.org/wiki/FreeBSD))的特性,但 Linux 只是一个宏内核。[宏内核](https://www.howtogeek.com/howto/31632/what-is-the-linux-kernel-and-what-does-it-do/)负责管理 CPU、内存、进程间通信、设备驱动程序、文件系统和系统服务调用( LCTT 译注:原文为 system server calls,但结合 Linux 内核的构成,译者认为这里翻译成系统服务调用更合适,即 system service calls)。
### 用一句话总结 Linux 和 Mac 的区别
macOS 内核(XNU)比 Linux 历史更悠久,并且基于两个更古老一些的代码库的结合;另一方面,Linux 新一些,是从头开始编写的,并且在更多设备上使用。
如果您发现这篇文章很有趣,请花一点时间在社交媒体,黑客新闻或 [Reddit](http://reddit.com/r/linuxusersgroup) 上分享。
---
via: <https://itsfoss.com/mac-linux-difference/>
作者:[John Paul](https://itsfoss.com/author/john/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[stephenxs](https://github.com/stephenxs) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

We often [compare Linux with Windows](https://itsfoss.com/linux-better-than-windows/), but what about comparing it with macOS?
While the differences between Linux and Windows are quite obvious, Linux and macOS may seem similar to many.
Both can run Unix commands in the terminal, and the user experience is vastly different from Windows. And not all Windows applications and games are available for macOS and Linux.
This is why some people even think Apple’s macOS is based on Linux. But that is not the case. macOS is not Linux despite the similarities.
There are plenty of differences between the two UNIX-like operating systems and I shall highlight both the similarities and the differences in this article.
So, let’s compare Apple and ~~Orange~~ Penguin.
## macOS vs. Linux: Origins
macOS has a fascinating history. The foundation of it was built by Steve Jobs’s NeXT computer company when he wasn’t at Apple. Technically, it was based on the [Mach Kernel](https://en.wikipedia.org/wiki/Mach_(kernel)?ref=itsfoss.com) and the UNIX-derived BSD.
Back then, a [NeXTSTEP](https://en.wikipedia.org/wiki/NeXTSTEP?ref=itsfoss.com) operating system was created to power the devices/computers built by ** NeXT**. While it got some attention, it wasn’t a big success. Apple later acquired NeXT and brought back Steve onboard as part of the deal, making NeXTSTEP OS the base for macOS.
This is why macOS has a combination of Unix components along with Apple’s proprietary technologies.
** On the contrary**, Linux (the kernel) was built as a free and open-source replacement for Unix.
Linux is not an operating system but needs different components like [desktop environments](https://itsfoss.com/what-is-desktop-environment/) to form an operating system. There are hundreds of Linux-based operating systems called ** distributions**.
For simplicity, we tend to address it as ** Linux** OS instead of a specific Linux distribution.
** Recommended Read **📖
[What is Linux? Why There are 100’s of Linux OS?Cannot figure out what is Linux and why there are so many of Linux? This analogy explains things in a simpler manner.](https://itsfoss.com/what-is-linux/)

## macOS kernel vs Linux kernel
The macOS kernel is officially known as XNU. The [acronym](https://github.com/apple/darwin-xnu?ref=itsfoss.com) stands for “XNU is Not Unix.” According to [Apple’s GitHub page](https://github.com/apple/darwin-xnu?ref=itsfoss.com):
"XNU is a hybrid kernel combining the Mach kernel developed at Carnegie Mellon University with components from FreeBSD and C++ API for writing drivers”.
The BSD subsystem part of the code is [“typically implemented as user-space servers in microkernel systems”](http://osxbook.com/book/bonus/ancient/whatismacosx/arch_xnu.html?ref=itsfoss.com). The Mach part is responsible for low-level work, such as multitasking, protected memory, virtual memory management, kernel debugging support, and console I/O.
While the macOS kernel combines the feature of a microkernel ([Mach](https://en.wikipedia.org/wiki/Mach_(kernel)?ref=itsfoss.com)) and a monolithic kernel ([BSD](https://en.wikipedia.org/wiki/FreeBSD?ref=itsfoss.com)), Linux is solely a monolithic kernel. A [monolithic kernel](https://www.howtogeek.com/howto/31632/what-is-the-linux-kernel-and-what-does-it-do/?ref=itsfoss.com) is responsible for managing the CPU, memory, inter-process communication, device drivers, file system, and system server calls.
## Here’s What They Have in Common
macOS utilizes Unix components, and Linux was built as an alternative to Unix. So, what do we have in common here?
Both give access to ** Unix commands, Bash/Zsh, and other shells**.
The [default shell](https://linuxhandbook.com/change-shell-linux/?ref=itsfoss.com) can be different, but you can always change it as per your preferences.
That’s about it. I can’t think of anything else similar between the two.
Probably a decade back, we could say that both Linux/macOS offered fewer applications.
But that’s not the case anymore.
The software ecosystem and game support for both have evolved over the years, which we will discuss later in this article.
## Codebase: Proprietary vs. Open-Source

macOS is a proprietary operating system, meaning you cannot view the complete operating system’s source code.
Sure, you have [part of the macOS (mostly GNU) libraries’ source code available](https://opensource.apple.com/releases/?ref=itsfoss.com). There is also the [XNU kernel code](https://github.com/apple/darwin-xnu?ref=itsfoss.com) used in the development of macOS and iOS operating systems. But [you cannot just take this code and build a macOS clone](https://www.techrepublic.com/article/why-apple-open-sourcing-mac-os-x-isnt-terribly-exciting/?ref=itsfoss.com) to be installed on any hardware.
It’s not the end of the world without the source code, but you get ** less transparency** on Apple’s claims and practices to secure and enhance your computer experience.
Some might argue that proprietary code remains hidden for security reasons. However, both proprietary and open-source software remain vulnerable to threats.
** The difference between them** is: open-source software often gets fixed sooner because of community participation by several developers, compared to limited employees working on macOS.
Unless you trust Apple without questions, Linux’s open-source model gets an edge.
## Purpose and Usage: macOS vs. Linux
macOS is tailored for desktop and laptop usage. It is well-suited for ** video editing, graphics designing, and audio editing**.
When it comes to Linux, you get a host of possibilities. You can use Linux for:
- Desktop
- Toaster (yes! I hope you know about
[IoT](https://www.ibm.com/blogs/internet-of-things/what-is-the-iot/?ref=itsfoss.com)) - Single Board Computers
- Server
Of course, it is not the same experience when using it on various platforms, but Linux can run for various use cases.
So, if you like Linux, you can choose to continue using it on other platforms for a comfortable experience.
## macOS vs Linux: User Experience
When it comes to user experience, it comes down to personal preferences.
macOS offers a ** pleasing user interface**. It is visually appealing with subtle animations and high-resolution wallpapers/icons.
You can expect an easy and seamless experience across the platform.
With Linux, you can get an equally pleasing user interface that is easy to use.
** Unfortunately**, the user experience slightly varies because of the distribution you decide to install and the desktop environment it comes along with.
You can explore some of the [best desktop environments](https://itsfoss.com/best-linux-desktop-environments/) listed. You can even opt for [macOS-like Linux distributions](https://itsfoss.com/macos-like-linux-distros/).
For instance, if you are using ** Pop!_OS, Ubuntu, Zorin OS, or elementary OS**, you could have an excellent user experience.
If you end up using something like MX Linux, or different, the user experience may not be comparable to macOS.
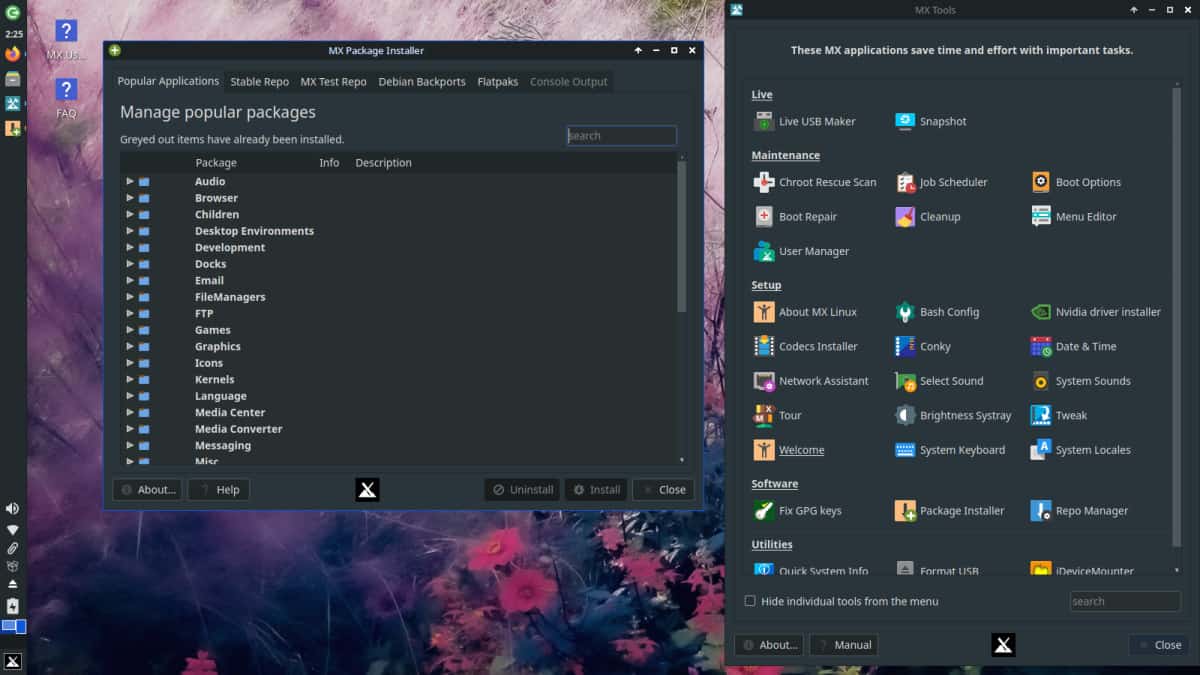
Overall, the out-of-the-box experience with Linux is inconsistent, but it is capable enough if you know what you are doing.
And if you are coming from Windows, the interface could be confusing initially.
## Customizability

If you want an operating system that lets you tinker with every aspect of it, macOS is not for you.
While Apple’s designs could be aesthetically pleasing by default, not everyone likes them.
If you want to personalize, take control, and heavily customize the operating system’s nuts and bolts, Linux should be the perfect pick.
You can choose to customize the user interface as much as you want, with a wide range of different elements, and go wild with your preferences. To get started, look at our [KDE customization](https://itsfoss.com/kde-customization/) guide to explore the possibilities.
While that is good, it could backfire when customizing things on a Linux system. So, you need to learn/explore what you want to customize.
## Hardware Requirements to Run macOS vs Linux

This is where macOS suffers a solid defeat.
If you want access to macOS and have a good experience with it, you need to purchase Apple hardware, which is costly.
For example, the base configurations for macOS-powered laptops start with ** 8 GB of RAM** and
**, available for**
**256 GB of storage****or more.**
**$1200**Unless you want to constantly use the swap space for multitasking and already have a cloud storage space, it would be a terrible idea to get one for yourself.
In contrast, if you would rather not spend a lot but still want a decent configuration for your system (PC/laptop), it is easy to get a device with 16 GB RAM + 512 GB SSD to run Linux for around 800 USD.
**: I’m used to 32 Gigs of RAM + 500 GB of SSD storage. To get that kind of multitasking headroom (without using the swap), I will have to pay a premium to Apple.**
**A personal note**Some skilled tinkerers try running macOS on non-Apple hardware. Such a system is called [Hackintosh](https://www.freecodecamp.org/news/build-a-hackintosh/?ref=itsfoss.com) but it is certainly nowhere close to the comfort of running Linux on a regular computer.
## Software Ecosystem
macOS offers a ** top-notch native experience** with macOS-exclusive applications or tools made by Apple.
Yes, you may have to purchase those applications. However, unlike some subscription options, you get one-time purchase alternatives with macOS for professional applications.
For users who want to design, edit videos, edit photos, and have a creative workflow, macOS’s software suite should be a great choice if you do not mind investing in it.
The free Apple tools like iMovie, Keynote, etc. are good. Couple them with premium tools like Final Cut Pro, Affinity Designer, and more and you get world-class editing experience. Not to forget that creative tools like Adobe are also available on macOS.
Additionally, Apple has strict guidelines for applications available for its platform that enhance the native experience with third-party apps (free or paid).
This is why many designers and editors prefer using macOS over any other operating system.
For the Linux platform, you have ** great FOSS alternatives** to some macOS-only apps. Unless you like or have experience with macOS-specific applications, you should not have trouble with software available for Linux.
The native app experience depends on the Linux distribution you use.
It may not be as seamless as macOS, but if you are not a professional-grade video/graphics editor, you should not have any issues.
## Gaming on Linux and macOS

While Apple’s making good progress on making its new M1/M2 chips as capable as possible, macOS currently has poor support for games.
A handful of games work, and most aren’t supported officially. To be honest, investing in a Mac for gaming is not what it is for.
Regarding Linux, numerous AAA games and Indie titles work fine. Sure, there are some hiccups with certain games. But, with Valve’s push towards official game support for Steam Deck, even the latest releases like “** Spider-Man: Remastered**” are Steam Deck verified.
Ultimately, helping improve the game support for the Linux platform.
Additionally, considering that the PC graphics card market is almost back to normal (near or below MSRP), you can get a sweet PC build or laptop without worrying about performance bottlenecks.
Would you spend upwards of ** $1800 for a Mac with 16 GB of RAM and 512 GB of SSD** or get a PC/laptop with 32 GB RAM (or more), and at least 1 TB SSD (or more)?
That’s your call.
## Package Manager

A package manager helps you quickly find, install, and remove software in your operating system.
Linux has been the superior force in package management compared to anything out there.
You get options like [Flatpak](https://itsfoss.com/what-is-flatpak/), [Snap](https://itsfoss.com/use-snap-packages-ubuntu-16-04/), [Synaptic](https://itsfoss.com/synaptic-package-manager/), and more out of the box.
But, Mac users do not have anything to rely on by default. Fortunately, an option like [Homebrew](https://itsfoss.com/homebrew-linux/) makes life easier for macOS users. Since it also supports Linux, you can use it across multiple devices to make things easy.
There's also a __dedicated tutorial for Homebrew__, which you can check out:
[Installing and Using Homebrew Package Manager on LinuxHomebrew, also known as Brew, is a command line package manager primarily created for macOS. Homebrew grew quite popular among macOS users as more developers created command line tools that could be easily installed with Homebrew. This popularity resulted in the creation of Linuxbrew, a Li…](https://itsfoss.com/homebrew-linux/)

## Operating System Updates

Apple does not share specific timelines for software updates to the operating system.
For instance, ** macOS Ventura** (the upcoming version upgrade at the time of writing) suddenly ditched all Mac devices before 2017.
Interestingly, the previous operating system versions had average support for about ** seven years**, but with newer changes, it seems to be about
**now.**
**five**With Apple silicons, it may not be a straightforward answer. But, it is safe to assume at least 4-5 years of software support.
Linux gives you options. If you want a stable operating system without feature upgrades but focused on maintenance and security, [LTS editions](https://itsfoss.com/long-term-support-lts/) of Linux distributions give you up to ** five years** of updates for free. This is primarily true for
[Ubuntu](https://itsfoss.com/getting-started-with-ubuntu/)or Ubuntu-based distributions like Linux Mint.
Furthermore, there’s a subscription plan for Ubuntu, where you can continue receiving security updates for up to ** 10 years**.
And, it does not end there; you can also opt for [rolling-release distributions](https://itsfoss.com/best-rolling-release-distros/) that get constant bleeding-edge updates with no timeline for an end. As long as your hardware is competent enough, you should be able to update the operating system with no issues.
## macOS vs. Linux: What Should You Pick?
macOS can be well worth the price tag if you need it.
It is not an easy recommendation for users who just need to surf the web, send emails, and perform some tasks that are possible on any platform.
macOS remains a niche pick.
However, Linux has improved to become a usable choice for former Windows/macOS users, computer science students, developers, creative professionals (like us) and a wide range of potential users.
Here are some funny jokes that compare the three operating system giants:
[Windows Vs Mac Vs Linux: 10 Funny Jokes In PicturesThe Windows Vs Mac Vs Linux debate continues. Their fans continue to be at the each others throat. The baseline of most debate is that Windows is clumsy and full of security issues, Linux is complicated and not user-friendly and Mac is all looks that burns your money for each](https://itsfoss.com/10-funny-jokes-pictures-windows-mac-linux/)

There are many reasons to pick Linux over macOS, but not the other way around (I think). Just like this, we have also compared Linux with Windows:
[11 Reasons Why Linux is Better Than WindowsAre you wondering if Linux is better than Windows? Don’t wonder. Linux is better than Windows and in this article, we’ll see the advantages of Linux over Windows.](https://itsfoss.com/linux-better-than-windows/)

What are your thoughts on macOS vs. Linux? You are welcome to share your thoughts in the comments down below. |
9,851 | 如何在 Linux 上检查用户所属组 | https://www.2daygeek.com/how-to-check-which-groups-a-user-belongs-to-on-linux/ | 2018-07-20T12:05:20 | [
"group"
] | https://linux.cn/article-9851-1.html | 
将用户添加到现有组是 Linux 管理员的常规活动之一。这是一些在大环境中工作的管理员的日常活动。
甚至我会因为业务需求而在我的环境中每天都在进行这样的活动。它是帮助你识别环境中现有组的重要命令之一。
此外,这些命令还可以帮助你识别用户所属的组。所有用户都列在 `/etc/passwd` 中,组列在 `/etc/group` 中。
无论我们使用什么命令,都将从这些文件中获取信息。此外,每个命令都有其独特的功能,可帮助用户单独获取所需的信息。
### 什么是 /etc/passwd?
`/etc/passwd` 是一个文本文件,其中包含登录 Linux 系统所必需的每个用户信息。它维护有用的用户信息,如用户名、密码、用户 ID、组 ID、用户 ID 信息、家目录和 shell。passwd 每行包含了用户的详细信息,共有如上所述的 7 个字段。
```
$ grep "daygeek" /etc/passwd
daygeek:x:1000:1000:daygeek,,,:/home/daygeek:/bin/bash
```
### 什么是 /etc/group?
`/etc/group` 是一个文本文件,用于定义用户所属的组。我们可以将多个用户添加到单个组中。它允许用户访问其他用户文件和文件夹,因为 Linux 权限分为三类:用户、组和其他。它维护有关组的有用信息,例如组名、组密码,组 ID(GID)和成员列表。每个都在一个单独的行。组文件每行包含了每个组的详细信息,共有 4 个如上所述字段。
这可以通过使用以下方法来执行。
* `groups`: 显示一个组的所有成员。
* `id`: 打印指定用户名的用户和组信息。
* `lid`: 显示用户的组或组的用户。
* `getent`: 从 Name Service Switch 库中获取条目。
* `grep`: 代表“<ruby> 全局正则表达式打印 <rt> global regular expression print </rt></ruby>”,它能打印匹配的模式。
### 什么是 groups 命令?
`groups` 命令打印每个给定用户名的主要组和任何补充组的名称。
```
$ groups daygeek
daygeek : daygeek adm cdrom sudo dip plugdev lpadmin sambashare
```
如果要检查与当前用户关联的组列表。只需运行 `groups` 命令,无需带任何用户名。
```
$ groups
daygeek adm cdrom sudo dip plugdev lpadmin sambashare
```
### 什么是 id 命令?
id 代表 “<ruby> 身份 <rt> identity </rt></ruby>”。它打印真实有效的用户和组 ID。打印指定用户或当前用户的用户和组信息。
```
$ id daygeek
uid=1000(daygeek) gid=1000(daygeek) groups=1000(daygeek),4(adm),24(cdrom),27(sudo),30(dip),46(plugdev),118(lpadmin),128(sambashare)
```
如果要检查与当前用户关联的组列表。只运行 `id` 命令,无需带任何用户名。
```
$ id
uid=1000(daygeek) gid=1000(daygeek) groups=1000(daygeek),4(adm),24(cdrom),27(sudo),30(dip),46(plugdev),118(lpadmin),128(sambashare)
```
### 什么是 lid 命令?
它显示用户的组或组的用户。显示有关包含用户名的组或组名称中包含的用户的信息。此命令需要管理员权限。
```
$ sudo lid daygeek
adm(gid=4)
cdrom(gid=24)
sudo(gid=27)
dip(gid=30)
plugdev(gid=46)
lpadmin(gid=108)
daygeek(gid=1000)
sambashare(gid=124)
```
### 什么是 getent 命令?
`getent` 命令显示 Name Service Switch 库支持的数据库中的条目,它们在 `/etc/nsswitch.conf` 中配置。
```
$ getent group | grep daygeek
adm:x:4:syslog,daygeek
cdrom:x:24:daygeek
sudo:x:27:daygeek
dip:x:30:daygeek
plugdev:x:46:daygeek
lpadmin:x:118:daygeek
daygeek:x:1000:
sambashare:x:128:daygeek
```
如果你只想打印关联的组名称,请在上面的命令中使用 `awk`。
```
$ getent group | grep daygeek | awk -F: '{print $1}'
adm
cdrom
sudo
dip
plugdev
lpadmin
daygeek
sambashare
```
运行以下命令仅打印主群组信息。
```
$ getent group daygeek
daygeek:x:1000:
```
### 什么是 grep 命令?
`grep` 代表 “<ruby> 全局正则表达式打印 <rt> global regular expression print </rt></ruby>”,它能打印文件匹配的模式。
```
$ grep "daygeek" /etc/group
adm:x:4:syslog,daygeek
cdrom:x:24:daygeek
sudo:x:27:daygeek
dip:x:30:daygeek
plugdev:x:46:daygeek
lpadmin:x:118:daygeek
daygeek:x:1000:
sambashare:x:128:daygeek
```
如果你只想打印关联的组名称,请在上面的命令中使用 `awk`。
```
$ grep "daygeek" /etc/group | awk -F: '{print $1}'
adm
cdrom
sudo
dip
plugdev
lpadmin
daygeek
sambashare
```
---
via: <https://www.2daygeek.com/how-to-check-which-groups-a-user-belongs-to-on-linux/>
作者:[Prakash Subramanian](https://www.2daygeek.com/author/prakash/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
9,852 | 内部人员爆料 GPL v3 起草过程 | https://opensource.com/article/18/6/gplv3-anniversary | 2018-07-20T17:15:02 | [
"GPL"
] | https://linux.cn/article-9852-1.html |
>
> 在 GPL v3 许可证颁发 11 周年之际,让我们了解一下它对自由和开源软件的持久贡献。
>
>
>

2017 年,我错过了为 [GPL v3(GNU 通用公共许可协议的第三版)](https://www.gnu.org/licenses/gpl-3.0.en.html)发布 10 周年撰写文章的机会。GPL v3 由<ruby> 自由软件基金会 <rp> ( </rp> <rt> Free Software Foundation </rt> <rp> ) </rp></ruby>(FSF)于 2007 年 6 月 29 日正式发布,这一天在技术史上更为人熟知的事件是苹果公司推出了 iPhone 手机。一年之后的现在,我觉得应该对 GPL v3 做一些回顾。对于我来说,许多有关 GPL v3 的有趣内容可以追溯到 11 年之前,我作为积极参与者经历了当时的公共起草过程。
2005 年,经过近十年热衷于自由软件的自我沉浸,但却几乎没有任何开源法律经验可言的我被 Eben Moglen 聘用,加入<ruby> 软件自由法律中心 <rp> ( </rp> <rt> Software Freedom Law Center </rt> <rp> ) </rp></ruby>(SFLC)担任法律顾问。SFLC 当时是 FSF 的外部法律顾问,我的角色被设定为关注 GPL v3 起草过程的初期公共阶段。这个机会把我从以前的并不令我满意的一次职业转变中解救出来。<ruby> 自由和开源软件 <rp> ( </rp> <rt> Free and Open Source Software </rt> <rp> ) </rp></ruby>(FOSS)的法律问题成为我的新专长,我发现这一点很有吸引力,令人满意,并且在智力上有所回报。我在 SFLC 的工作,特别是我在 GPL v3 方面勇闯火线的工作,成为了我的在职培训。
GPL v3 必须被理解为早期 FOSS 时代的产物,其轮廓可能让今天的人难以想象。在 2006 年公共起草过程开始时,Linux 和开源已经不再是早年一些漫不经心的观察者所看到的几乎是同义词的情形了,但两者之间的联系仍然比现在更密切。
Linux 已经对技术行业产生深远影响的反映是,每个人都认为 GPL v2 是主要的开源许可模式。我们看到了开源(和伪开源)商业模式如寒武纪式爆发的最终震荡。一个泡沫化商业炒作包围的开源(对我来说最令人难忘的典型代表是<ruby> 开源商业会议 <rp> ( </rp> <rt> Open Source Business Conference </rt></ruby>)与软件工程专业人士目前对开源开发的接受程度几乎没有相似之处。微软凭借其不断扩大的专利组合以及对 Linux 的竞争性对抗,在 FOSS 社区中普遍被视为一种现实存在的威胁,而 [SCO 诉讼](https://en.wikipedia.org/wiki/SCO%E2%80%93Linux_disputes)已经在 Linux 和 GPL 之间笼罩上了法律风险的阴云,并且没有完全消散。
这种环境必然使得 GPL v3 的起草成为自由软件历史上前所未有的高风险事件。主要的技术公司和顶级律师事务所的律师争先恐后地对该许可协议施加影响,并确信 GPL v3 必将接管并彻底重塑开源业态及所有大量相关的商业投资。
技术社区内存在类似的心态;这在 Linux 内核开发人员于 2006 年 9 月对 GPL v3 的[强烈指责]( https://lwn.net/Articles/200422/)中所表达的恐惧里略见一斑。我们这些接近 FSF 的人知道的多一点,但我认为我们假定新的许可协议要么是压倒性的成功,要么是彻底的失败——“成功”意味着将现有的 GPL v2 项目生态系统升级为 GPL v3,尽管也许 Linux 内核会缺席(LCTT 译注:十年过去了,Linux 内核仍旧采用 GPL v2 许可证)。实际的结果是介于两者之间的东西。
我对测量开源许可协议采用程度的尝试没有信心,近年来这种做法通常用于证明<ruby> 左版 <rp> ( </rp> <rt> Copyleft </rt> <rp> ) </rp></ruby>许可协议失去竞争优势。根据我自己的接近 Linux 和工作于<ruby> 红帽 <rp> ( </rp> <rt> Red Hat </rt> <rp> ) </rp></ruby>公司的明显有倾向性的经验,表明 GPL v3 作为自 2007 年以来推出项目的可选许可协议,享有适度的受欢迎程度。尽管 2007 年之前存在的大多数 GPL v2 项目以及它们在 2007 年以后的分支,仍然遵循旧许可协议。(GPL v3 的兄弟许可协议 LGPL v3 和 AGPL v3 从未获得过相当程度的普及)大多数现有的 GPL v2 项目(有一些明显的例外,如 Linux 内核和 Busybox)被许可为“GPL v2 或任何更高的版本”。技术界早就决定“GPL v2 或更高版本”是一个政治中立的许可协议选项,它包含了 GPL v2 和 GPL v3。这可以解释为什么 GPL v3 的采用推进得缓慢和有限,特别是在 Linux 社区中。
在 GPL v3 起草过程中,一些人表达了对 Linux 生态系统“<ruby> 巴尔干化 <rp> ( </rp> <rt> balkanized </rt> <rp> ) </rp></ruby>”的担忧,无论是因为用户必须了解两个不同的强大左版许可协议的开销,还是因为 GPL v2 / GPL v3 的不兼容。事实证明,这些担忧完全没有根据。在主流服务器和工作站 Linux 堆栈中,这两个许可协议已经和平共存了十年。这其中部分是因为这样的堆栈由强大的左版范畴的单独单元组成(参见我对[容器设置中相关问题](/article-9316-1.html)的讨论)。至于强左版范畴单元内部的不兼容性,在这里,“GPL v2 或更高版本”的普遍性被技术界视为干净利索地解决了理论问题。尽管名义上的“GPL v2 或更高版本”升级为 GPL v3 的情况几乎没有发生过。
我已经说过,我们中间的一些 FOSS 许可协议极客已经提到了假定的左版衰退的问题。早在公共起草过程的开始阶段,GPL v3 已经在批评者那里形成了滥用,并且可以推断,有些人已经在特殊情况下的 GPL v3 不受欢迎与一般意义上的 GPL 或左版失宠之间建立了联系。
我对它的看法有所不同:很大程度上是因为它的复杂性和<ruby> 巴洛克 <rp> ( </rp> <rt> baroque </rt> <rp> ) </rp></ruby>风格,GPL v3 失去了创建强大的可以广泛地吸引现代个人软件作者和企业许可人的左版许可协议的机会。我相信今天的个人开发者往往更喜欢简短、易懂、简约的许可证,最明显的例子就是 [MIT 许可证](https://opensource.org/licenses/MIT)。
面临开源许可协议选项的一些公司决策者可能很自然地分享这种观点,而其他公司决策者可能认为 GPL v3 的某些部分风险太大(例如专利条款或反锁定要求)或与其商业模式不相容。具有讽刺意味的是,未能吸引这些群体的 GPL v3 的一部分特性是因为有意识地试图使许可协议吸引这些具备相同类型利益的群体。
GPL v3 是如何变得如此巴洛克式的?正如我所说,GPL v3 是较早时期的产物,彼时 FOSS 许可协议被视为项目治理的主要工具。(现在我们倾向于将治理与其他类型的法律或准法律工具联系起来,例如组织非营利组织,围绕项目决策制定规则,行为准则和贡献者协议。)
在其起草过程中,GPL v3 是对 FOSS 许可协议可以作为雄心勃勃的私人监管手段持乐观态度的最高点。对于 GPL v2 来说已经是这样了,但是 GPL v3 通过详细解决一些新的政策问题——软件专利、反规避法律、设备锁定等方式来解决问题。这必然会使 GPL v3 许可协议比 GPL v2 更长、更复杂,因为 FSF 和 SFLC 在第一份 GPL v3 [基本原理文件](http://gplv3.fsf.org/gpl-rationale-2006-01-16.html)中满怀抱歉地提到了这一点。
但是,起草 GPL v3 过程中的其他一些因素无意中导致许可协议的复杂性增长。代表供应商和商业用户利益的律师从法律和商业角度提供了有用的改进建议,但这些通常采取让措辞简单的条款变成更冗长的形式,在明晰性方面可以说没有明确的改善。对技术社区反馈(通常是识别许可条款的漏洞)的回应也有类似的效果。
GPL v3 起草人也因短期政治危机(2006 年有争议的[微软/ Novell 交易](https://en.wikipedia.org/wiki/Novell#Agreement_with_Microsoft))纠缠在一起,导致许可协议的专利部分永久性地增加了新的和不寻常的条件,这在 2007 年之后是毫无用处的, 除了使有良心的专利持有商更难遵守许可证。当然,GPL v3 中的一些复杂性仅仅是为了使合规更容易(特别是对于社区项目开发人员)或者编写 FSF 的解释实践。最后,人们可以对 GPL v3 中使用的语言风格提出质疑,其中大部分语言都具有传统软件许可法律的顽皮模仿或嘲弄;在许多情况下,一种更简单、直接的措辞形式是一种改进。
GPL v3 的复杂性以及在许可协议起草中倾向于简练和简洁的趋势以及明智的许可政策目标,意味着 GPL v3 的实质性文本对后来的 FOSS 法律起草几乎没有直接影响。但是,正如我在 2012 年所惊奇和[高兴](https://opensource.com/law/12/1/the-new-mpl)地看到的那样,MPL 2.0 改编了 GPL v3 的两个部分:GPL v3 终止条款中的 30 天补救和 60 天休眠文本,并保证升级到更高版本许可协议的下游对上游许可人没有新的义务。
GPL v3 补救文本已经产生了重大影响,特别是在过去一年中。随着 FSF 的支持,<ruby> 软件自由保护组织 <rp> ( </rp> <rt> Software Freedom Conservancy </rt> <rp> ) </rp></ruby>颁布了《<ruby> <a href="https://sfconservancy.org/copyleft-compliance/principles.html"> 面向社区的 GPL 执行原则 </a> <rp> ( </rp> <rt> Principles of Community-Oriented GPL Enforcement </rt> <rp> ) </rp></ruby>》,该原则要求将 GPL v3 补救机会扩展到 GPL v2 违规行为,Linux 基金会技术顾问委员会发布了一份[声明](https://www.kernel.org/doc/html/v4.16/process/kernel-enforcement-statement.html),得到了一百多个 Linux 内核开发人员支持,其中包含了 GPL v3 的补救文本。接下来是以红帽公司为首的一系列[企业承诺](https://www.redhat.com/en/about/press-releases/technology-industry-leaders-join-forces-increase-predictability-open-source-licensing),将 GPL v3 补救条款扩展到 GPL v2 和 LGPL v2.x 违规,这是一项建议个人开源开发者做出同样承诺的活动。红帽公司的一项声明宣布,从此以后其主导的 GPL v2 和 LGPL v2.x 项目将在项目存储库中直接使用承诺文本。我在最近的[博客文章](https://www.redhat.com/en/blog/gpl-cooperation-commitment-and-red-hat-projects?source=author&term=26851)中讨论了这些发展。
关注 GPL v3 的一个持久贡献是改变了对广泛使用的 FOSS 许可协议修订方式的期待。在没有社区评论的参与,也没有努力与主要利益相关者进行磋商的情况下,这些许可协议不能完全进行私下修改。MPL 2.0 以及最近的 EPL 2.0 的起草过程反映了这一新规范。
---
作者简介:Richard Fontana 是红帽公司法律部门产品和技术团队的高级商业顾问。 他的大部分工作都集中在开源相关的法律问题上。
译者简介:薛亮,集慧智佳知识产权咨询公司总监,擅长专利检索、专利分析、竞争对手跟踪、FTO 分析、开源软件知识产权风险分析,致力于为互联网企业、高科技公司提供知识产权咨询服务。

| 200 | OK | Last year, I missed the opportunity to write about the 10th anniversary of [GPLv3](https://www.gnu.org/licenses/gpl-3.0.en.html), the third version of the GNU General Public License. GPLv3 was officially released by the Free Software Foundation (FSF) on June 29, 2007—better known in technology history as the date Apple launched the iPhone. Now, one year later, I feel some retrospection on GPLv3 is due. For me, much of what is interesting about GPLv3 goes back somewhat further than 11 years, to the public drafting process in which I was an active participant.
In 2005, following nearly a decade of enthusiastic self-immersion in free software, yet having had little open source legal experience to speak of, I was hired by Eben Moglen to join the Software Freedom Law Center as counsel. SFLC was then outside counsel to the FSF, and my role was conceived as focusing on the incipient public phase of the GPLv3 drafting process. This opportunity rescued me from a previous career turn that I had found rather dissatisfying. Free and open source software (FOSS) legal matters would come to be my new specialty, one that I found fascinating, gratifying, and intellectually rewarding. My work at SFLC, and particularly the trial by fire that was my work on GPLv3, served as my on-the-job training.
GPLv3 must be understood as the product of an earlier era of FOSS, the contours of which may be difficult for some to imagine today. By the beginning of the public drafting process in 2006, Linux and open source were no longer practically synonymous, as they might have been for casual observers several years earlier, but the connection was much closer than it is now.
Reflecting the profound impact that Linux was already having on the technology industry, everyone assumed GPL version 2 was the dominant open source licensing model. We were seeing the final shakeout of a Cambrian explosion of open source (and pseudo-open source) business models. A frothy business-fueled hype surrounded open source (for me most memorably typified by the Open Source Business Conference) that bears little resemblance to the present-day embrace of open source development by the software engineering profession. Microsoft, with its expanding patent portfolio and its competitive opposition to Linux, was commonly seen in the FOSS community as an existential threat, and the [SCO litigation](https://en.wikipedia.org/wiki/SCO%E2%80%93Linux_disputes) had created a cloud of legal risk around Linux and the GPL that had not quite dissipated.
That environment necessarily made the drafting of GPLv3 a high-stakes affair, unprecedented in free software history. Lawyers at major technology companies and top law firms scrambled for influence over the license, convinced that GPLv3 was bound to take over and thoroughly reshape open source and all its massive associated business investment.
A similar mindset existed within the technical community; it can be detected in the fears expressed in the final paragraph of the Linux kernel developers' momentous September 2006 [denunciation](https://lwn.net/Articles/200422/) of GPLv3. Those of us close to the FSF knew a little better, but I think we assumed the new license would be either an overwhelming success or a resounding failure—where "success" meant something approximating an upgrade of the existing GPLv2 project ecosystem to GPLv3, though perhaps without the kernel. The actual outcome was something in the middle.
I have no confidence in attempts to measure open source license adoption, which have in recent years typically been used to demonstrate a loss of competitive advantage for copyleft licensing. My own experience, which is admittedly distorted by proximity to Linux and my work at Red Hat, suggests that GPLv3 has enjoyed moderate popularity as a license choice for projects launched since 2007, though most GPLv2 projects that existed before 2007, along with their post-2007 offshoots, remained on the old license. (GPLv3's sibling licenses LGPLv3 and AGPLv3 never gained comparable popularity.) Most of the existing GPLv2 projects (with a few notable exceptions like the kernel and Busybox) were licensed as "GPLv2 or any later version." The technical community decided early on that "GPLv2 or later" was a politically neutral license choice that embraced both GPLv2 and GPLv3; this goes some way to explain why adoption of GPLv3 was somewhat gradual and limited, especially within the Linux community.
During the GPLv3 drafting process, some expressed concerns about a "balkanized" Linux ecosystem, whether because of the overhead of users having to understand two different, strong copyleft licenses or because of GPLv2/GPLv3 incompatibility. These fears turned out to be entirely unfounded. Within mainstream server and workstation Linux stacks, the two licenses have peacefully coexisted for a decade now. This is partly because such stacks are made up of separate units of strong copyleft scope (see my discussion of [related issues in the container setting](https://opensource.com/article/18/1/containers-gpl-and-copyleft)). As for incompatibility inside units of strong copyleft scope, here, too, the prevalence of "GPLv2 or later" was seen by the technical community as neatly resolving the theoretical problem, despite the fact that nominal license upgrading of GPLv2-or-later to GPLv3 hardly ever occurred.
I have alluded to the handwringing that some of us FOSS license geeks have brought to the topic of supposed copyleft decline. GPLv3 has taken its share of abuse from critics as far back as the beginning of the public drafting process, and some, predictably, have drawn a link between GPLv3 in particular and GPL or copyleft disfavor in general.
I have viewed it somewhat differently: Largely because of its complexity and baroqueness, GPLv3 was a lost opportunity to create a strong copyleft license that would appeal very broadly to modern individual software authors and corporate licensors. I believe individual developers today tend to prefer short, simple, easy to understand, minimalist licenses, the most obvious example of which is the [MIT License](https://opensource.org/licenses/MIT).
Some corporate decisionmakers around open source license selection may naturally share that view, while others may associate some parts of GPLv3, such as the patent provisions or the anti-lockdown requirements, as too risky or incompatible with their business models. The great irony is that the characteristics of GPLv3 that fail to attract these groups are there in part because of conscious attempts to make the license appeal to these same sorts of interests.
How did GPLv3 come to be so baroque? As I have said, GPLv3 was the product of an earlier time, in which FOSS licenses were viewed as the primary instruments of project governance. (Today, we tend to associate governance with other kinds of legal or quasi-legal tools, such as structuring of nonprofit organizations, rules around project decision making, codes of conduct, and contributor agreements.)
GPLv3, in its drafting, was the high point of an optimistic view of FOSS licenses as ambitious means of private regulation. This was already true of GPLv2, but GPLv3 took things further by addressing in detail a number of new policy problems—software patents, anti-circumvention laws, device lockdown. That was bound to make the license longer and more complex than GPLv2, as the FSF and SFLC noted apologetically in the first GPLv3 [rationale document](http://gplv3.fsf.org/gpl-rationale-2006-01-16.html).
But a number of other factors at play in the drafting of GPLv3 unintentionally caused the complexity of the license to grow. Lawyers representing vendors' and commercial users' interests provided useful suggestions for improvements from a legal and commercial perspective, but these often took the form of making simply worded provisions more verbose, arguably without net increases in clarity. Responses to feedback from the technical community, typically identifying loopholes in license provisions, had a similar effect.
The GPLv3 drafters also famously got entangled in a short-term political crisis—the controversial [Microsoft/Novell deal](https://en.wikipedia.org/wiki/Novell#Agreement_with_Microsoft) of 2006—resulting in the permanent addition of new and unusual conditions in the patent section of the license, which arguably served little purpose after 2007 other than to make license compliance harder for conscientious patent-holding vendors. Of course, some of the complexity in GPLv3 was simply the product of well-intended attempts to make compliance easier, especially for community project developers, or to codify FSF interpretive practice. Finally, one can take issue with the style of language used in GPLv3, much of which had a quality of playful parody or mockery of conventional software license legalese; a simpler, straightforward form of phrasing would in many cases have been an improvement.
The complexity of GPLv3 and the movement towards preferring brevity and simplicity in license drafting and unambitious license policy objectives meant that the substantive text of GPLv3 would have little direct influence on later FOSS legal drafting. But, as I noted with surprise and [delight](https://opensource.com/law/12/1/the-new-mpl) back in 2012, MPL 2.0 adapted two parts of GPLv3: the 30-day cure and 60-day repose language from the GPLv3 termination provision, and the assurance that downstream upgrading to a later license version adds no new obligations on upstream licensors.
The GPLv3 cure language has come to have a major impact, particularly over the past year. Following the Software Freedom Conservancy's promulgation, with the FSF's support, of the [Principles of Community-Oriented GPL Enforcement](https://sfconservancy.org/copyleft-compliance/principles.html), which calls for extending GPLv3 cure opportunities to GPLv2 violations, the Linux Foundation Technical Advisory Board published a [statement](https://www.kernel.org/doc/html/v4.16/process/kernel-enforcement-statement.html), endorsed by over a hundred Linux kernel developers, which incorporates verbatim the cure language of GPLv3. This in turn was followed by a Red Hat-led series of [corporate commitments](https://www.redhat.com/en/about/press-releases/technology-industry-leaders-join-forces-increase-predictability-open-source-licensing) to extend the GPLv3 cure provisions to GPLv2 and LGPLv2.x noncompliance, a campaign to get individual open source developers to extend the same commitment, and an announcement by Red Hat that henceforth GPLv2 and LGPLv2.x projects it leads will use the commitment language directly in project repositories. I discussed these developments in a recent [blog post](https://www.redhat.com/en/blog/gpl-cooperation-commitment-and-red-hat-projects?source=author&term=26851).
One lasting contribution of GPLv3 concerns changed expectations for how revisions of widely-used FOSS licenses are done. It is no longer acceptable for such licenses to be revised entirely in private, without opportunity for comment from the community and without efforts to consult key stakeholders. The drafting of MPL 2.0 and, more recently, EPL 2.0 reflects this new norm.
## Comments are closed. |
9,853 | 如何在 Linux 系统中使用 dd 命令而不会损毁你的磁盘 | https://opensource.com/article/18/7/how-use-dd-linux | 2018-07-20T21:36:06 | [
"dd",
"备份"
] | https://linux.cn/article-9853-1.html |
>
> 使用 Linux 中的 dd 工具安全、可靠地制作一个驱动器、分区和文件系统的完整镜像。
>
>
>

*这篇文章节选自 Manning 出版社出版的图书 [Linux in Action](https://www.manning.com/books/linux-in-action?a_aid=bootstrap-it&a_bid=4ca15fc9&chan=opensource)的第 4 章。*
你是否正在从一个即将损坏的存储驱动器挽救数据,或者要把本地归档进行远程备份,或者要把一个别处的活动分区做个完整的副本,那么你需要懂得如何安全而可靠的复制驱动器和文件系统。幸运的是,`dd` 是一个可以使用的简单而又功能强大的镜像复制命令,从现在到未来很长的时间内,也许直到永远都不会出现比 `dd` 更好的工具了。
### 对驱动器和分区做个完整的副本
仔细研究后,你会发现你可以使用 `dd` 做各种任务,但是它最重要的功能是处理磁盘分区。当然,你可以使用 `tar` 命令或者 `scp` 命令从一台计算机复制整个文件系统的文件,然后把这些文件原样粘贴在另一台刚刚安装好 Linux 操作系统的计算机中。但是,因为那些文件系统归档不是完整的映像文件,所以在复制文件的过程中需要计算机操作系统的运行作为基础。
另一方面,使用 `dd` 可以对任何数字信息完美的进行逐个字节的镜像。但是不论何时何地,当你要对分区进行操作时,我要告诉你早期的 Unix 管理员曾开过这样的玩笑:“ dd 的意思是<ruby> 磁盘毁灭者 <rt> disk destroyer </rt></ruby>”(LCTT 译注:`dd` 原意是<ruby> 磁盘复制 <rt> disk dump </rt></ruby>)。 在使用 `dd` 命令的时候,如果你输入了哪怕是一个字母,也可能立即永久性的擦除掉整个磁盘驱动器里的所有重要的数据。因此,一定要注意命令的拼写格式规范。
**记住:** 在按下回车键执行 `dd` 命令之前,暂时停下来仔细的认真思考一下。
### dd 命令的基本操作
现在你已经得到了适当的提醒,我们将从简单的事情开始。假设你要对代号为 `/dev/sda` 的整个磁盘数据创建精确的映像,你已经插入了一块空的磁盘驱动器 (理想情况下具有与代号为 `/dev/sda` 的磁盘驱动器相同的容量)。语法很简单: `if=` 定义源驱动器,`of=` 定义你要将数据保存到的文件或位置:
```
# dd if=/dev/sda of=/dev/sdb
```
接下来的例子将要对 `/dev/sda` 驱动器创建一个 .img 的映像文件,然后把该文件保存的你的用户帐号家目录:
```
# dd if=/dev/sda of=/home/username/sdadisk.img
```
上面的命令针对整个驱动器创建映像文件,你也可以针对驱动器上的单个分区进行操作。下面的例子针对驱动器的单个分区进行操作,同时使用了一个 `bs` 参数用于设置单次拷贝的字节数量 (此例中是 4096)。设定 `bs` 参数值可能会影响 `dd` 命令的整体操作速度,该参数的理想设置取决于你的硬件配置和其它考虑。
```
# dd if=/dev/sda2 of=/home/username/partition2.img bs=4096
```
数据的恢复非常简单:通过颠倒 `if` 和 `of` 参数可以有效的完成任务。在此例中,`if=` 使用你要恢复的映像,`of=` 使用你想要写入映像的目标驱动器:
```
# dd if=sdadisk.img of=/dev/sdb
```
你也可以在一条命令中同时完成创建和拷贝任务。下面的例子中将使用 SSH 从远程驱动器创建一个压缩的映像文件,并把该文件保存到你的本地计算机中:
```
# ssh [email protected] "dd if=/dev/sda | gzip -1 -" | dd of=backup.gz
```
你应该经常测试你的归档,确保它们可正常使用。如果它是你创建的启动驱动器,将它粘贴到计算机中,看看它是否能够按预期启动。如果它是普通分区的数据,挂载该分区,确保文件都存在而且可以正常的访问。
### 使用 dd 擦除磁盘数据
多年以前,我的一个负责政府海外大使馆安全的朋友曾经告诉我,在他当时在任的时候, 政府会给每一个大使馆提供一个官方版的锤子。为什么呢? 一旦大使馆设施可能被不友善的人员侵占,就会使用这个锤子毁坏所有的硬盘.
为什么要那样做?为什么不是删除数据就好了?你在开玩笑,对吧?所有人都知道从存储设备中删除包含敏感信息的文件实际上并没有真正移除这些数据。除非使用锤子彻底的毁坏这些存储介质,否则,只要有足够的时间和动机, 几乎所有的内容都可以从几乎任何数字存储介质重新获取。
但是,你可以使用 `dd` 命令让坏人非常难以获得你的旧数据。这个命令需要花费一些时间在 `/dev/sda1` 分区的每个扇区写入数百万个 `0`(LCTT 译注:是指 0x0 字节,意即 NUL ,而不是数字 0 ):
```
# dd if=/dev/zero of=/dev/sda1
```
还有更好的方法。通过使用 `/dev/urandom` 作为源文件,你可以在磁盘上写入随机字符:
```
# dd if=/dev/urandom of=/dev/sda1
```
### 监控 dd 的操作
由于磁盘或磁盘分区的归档可能需要很长的时间,因此你可能需要在命令中添加进度查看器。安装管道查看器(在 Ubuntu 系统上安装命令为 `sudo apt install pv`),然后把 `pv` 命令和 `dd` 命令结合在一起。使用 `pv`,最终的命令是这样的:
```
# dd if=/dev/urandom | pv | dd of=/dev/sda1
4,14MB 0:00:05 [ 98kB/s] [ <=> ]
```
想要推迟备份和磁盘管理工作?有了 `dd` 工具,你不会有太多的借口。它真的非常简单,但是要小心。祝你好运!
---
via:<https://opensource.com/article/18/7/how-use-dd-linux>
作者:[David Clinton](https://opensource.com/users/remyd) 选题:[lujun9972](https://github.com/lujun9972) 译者:[SunWave](https://github.com/SunWave) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *This article is excerpted from chapter 4 of Linux in Action, published by Manning.*
Whether you're trying to rescue data from a dying storage drive, backing up archives to remote storage, or making a perfect copy of an active partition somewhere else, you'll need to know how to safely and reliably copy drives and filesystems. Fortunately, `dd`
is a simple and powerful image-copying tool that's been around, well, pretty much forever. And in all that time, nothing's come along that does the job better.
## Making perfect copies of drives and partitions
There's all kinds of stuff you can do with `dd`
if you research hard enough, but where it shines is in the ways it lets you play with partitions. You can, of course, use `tar`
or even `scp`
to replicate entire filesystems by copying the files from one computer and then pasting them as-is on top of a fresh Linux install on another computer. But, because those filesystem archives aren't complete images, they'll require a running host OS at both ends to serve as a base.
Using `dd`
, on the other hand, can make perfect byte-for-byte images of, well, just about anything digital. But before you start flinging partitions from one end of the earth to the other, I should mention that there's some truth to that old Unix admin joke: "*dd* stands for *disk destroyer*." If you type even one wrong character in a `dd`
command, you can instantly and permanently wipe out an entire drive of valuable data. And yes, spelling counts.
**Remember: ***Before pressing that Enter key to **invoke *`dd`
*,** pause and think very carefully!*
## Basic dd operations
Now that you've been suitably warned, we'll start with something straightforward. Suppose you want to create an exact image of an entire disk of data that's been designated as `/dev/`
`sda`
. You've plugged in an empty drive (ideally having the same capacity as your `/dev/`
`sda`
system). The syntax is simple: `if=`
defines the source drive and `of=`
defines the file or location where you want your data saved:
`# dd if=/dev/sda of=/dev/sdb`
The next example will create an .img archive of the `/dev/`
`sda`
drive and save it to the home directory of your user account:
`# dd if=/dev/sda of=/home/username/sdadisk.img`
Those commands created images of entire drives. You could also focus on a single partition from a drive. The next example does that and also uses `bs`
to set the number of bytes to copy at a single time (4,096, in this case). Playing with the `bs`
value can have an impact on the overall speed of a `dd`
operation, although the ideal setting will depend on your hardware profile and other considerations.
`# dd if=/dev/sda2 of=/home/username/partition2.img bs=4096`
Restoring is simple: Effectively, you reverse the values of `if`
and `of`
. In this case, `if=`
takes the image you want to restore, and `of=`
takes the target drive to which you want to write the image:
`# dd if=sdadisk.img of=/dev/sdb`
You can also perform both the create and copy operations in one command. This example, for instance, will create a compressed image of a remote drive using SSH and save the resulting archive to your local machine:
`# ssh [email protected] "dd if=/dev/sda | gzip -1 -" | dd of=backup.gz`
You should always test your archives to confirm they're working. If it's a boot drive you've created, stick it into a computer and see if it launches as expected. If it's a normal data partition, mount it to make sure the files both exist and are appropriately accessible.
## Wiping disks with dd
Years ago, I had a friend who was responsible for security at his government's overseas embassies. He once told me that each embassy under his watch was provided with an official government-issue hammer. Why? In case the facility was ever at risk of being overrun by unfriendlies, the hammer was to be used to destroy all their hard drives.
What's that? Why not just delete the data? You're kidding, right? Everyone knows that deleting files containing sensitive data from storage devices doesn't actually remove the data. Given enough time and motivation, nearly anything can be retrieved from virtually any digital media, with the possible exception of the ones that have been well and properly hammered.
You can, however, use `dd`
to make it a whole lot more difficult for the bad guys to get at your old data. This command will spend some time writing millions and millions of zeros over every nook and cranny of the `/dev/sda1`
partition:
`# dd if=/dev/zero of=/dev/sda1`
But it gets better. Using `/dev/`
`urandom`
file as your source, you can write over a disk with random characters:
`# dd if=/dev/urandom of=/dev/sda1`
## Monitoring dd operations
Since disk or partition archiving can take a very long time, you might want to add a progress monitor to your command. Install Pipe Viewer (`sudo apt install pv`
on Ubuntu) and insert it into `dd`
. With `pv`
, that last command might look something like this:
```
# dd if=/dev/urandom | pv | dd of=/dev/sda1
4,14MB 0:00:05 [ 98kB/s] [ <=> ]
```
Putting off backups and disk management? With dd, you aren't left with too many excuses. It's really not difficult, but be careful. Good luck!
## 11 Comments |
9,854 | Ubunsys:面向 Ubuntu 资深用户的一个高级系统配置工具 | https://www.ostechnix.com/ubunsys-advanced-system-configuration-utility-ubuntu-power-users/ | 2018-07-22T10:35:12 | [
"Ubuntu",
"Ubunsys"
] | https://linux.cn/article-9854-1.html | 
**Ubunsys** 是一个面向 Ubuntu 及其衍生版的基于 Qt 的高级系统工具。高级用户可以使用命令行轻松完成大多数配置。不过为了以防万一某天,你突然不想用命令行了,就可以用 Ubnusys 这个程序来配置你的系统或其衍生系统,如 Linux Mint、Elementary OS 等。Ubunsys 可用来修改系统配置,安装、删除、更新包和旧内核,启用或禁用 `sudo` 权限,安装主线内核,更新软件安装源,清理垃圾文件,将你的 Ubuntu 系统升级到最新版本等等。以上提到的所有功能都可以通过鼠标点击完成。你不需要再依赖于命令行模式,下面是你能用 Ubunsys 做到的事:
* 安装、删除、更新包
* 更新和升级软件源
* 安装主线内核
* 删除旧的和不再使用的内核
* 系统整体更新
* 将系统升级到下一个可用的版本
* 将系统升级到最新的开发版本
* 清理系统垃圾文件
* 在不输入密码的情况下启用或者禁用 `sudo` 权限
* 当你在终端输入密码时使 `sudo` 密码可见
* 启用或禁用系统休眠
* 启用或禁用防火墙
* 打开、备份和导入 `sources.list.d` 和 `sudoers` 文件
* 显示或者隐藏启动项
* 启用或禁用登录音效
* 配置双启动
* 启用或禁用锁屏
* 智能系统更新
* 使用脚本管理器更新/一次性执行脚本
* 从 `git` 执行常规用户安装脚本
* 检查系统完整性和缺失的 GPG 密钥
* 修复网络
* 修复已破损的包
* 还有更多功能在开发中
**重要提示:** Ubunsys 不适用于 Ubuntu 新手。它很危险并且仍然不是稳定版。它可能会使你的系统崩溃。如果你刚接触 Ubuntu 不久,不要使用。但如果你真的很好奇这个应用能做什么,仔细浏览每一个选项,并确定自己能承担风险。在使用这一应用之前记着备份你自己的重要数据。
### 安装 Ubunsys
Ubunsys 开发者制作了一个 PPA 来简化安装过程,Ubunsys 现在可以在 Ubuntu 16.04 LTS、 Ubuntu 17.04 64 位版本上使用。
逐条执行下面的命令,将 Ubunsys 的 PPA 添加进去,并安装它。
```
sudo add-apt-repository ppa:adgellida/ubunsys
sudo apt-get update
sudo apt-get install ubunsys
```
如果 PPA 无法使用,你可以在[发布页面](https://github.com/adgellida/ubunsys/releases)根据你自己当前系统,选择正确的安装包,直接下载并安装 Ubunsys。
### 用途
一旦安装完成,从菜单栏启动 Ubunsys。下图是 Ubunsys 主界面。

你可以看到,Ubunsys 有四个主要部分,分别是 Packages、Tweaks、System 和 Repair。在每一个标签项下面都有一个或多个子标签项以对应不同的操作。
**Packages**
这一部分允许你安装、删除和更新包。

**Tweaks**
在这一部分,我们可以对系统进行多种调整,例如:
* 打开、备份和导入 `sources.list.d` 和 `sudoers` 文件;
* 配置双启动;
* 启用或禁用登录音效、防火墙、锁屏、系统休眠、`sudo` 权限(在不需要密码的情况下)同时你还可以针对某一用户启用或禁用 `sudo` 权限(在不需要密码的情况下);
* 在终端中输入密码时可见(禁用星号)。

**System**
这一部分被进一步分成 3 个部分,每个都是针对某一特定用户类型。
**Normal user** 这一标签下的选项可以:
* 更新、升级包和软件源
* 清理系统
* 执行常规用户安装脚本
**Advanced user** 这一标签下的选项可以:
* 清理旧的/无用的内核
* 安装主线内核
* 智能包更新
* 升级系统
**Developer** 这一部分可以将系统升级到最新的开发版本。

**Repair**
这是 Ubunsys 的第四个也是最后一个部分。正如名字所示,这一部分能让我们修复我们的系统、网络、缺失的 GPG 密钥,和已经缺失的包。

正如你所见,Ubunsys 可以在几次点击下就能完成诸如系统配置、系统维护和软件维护之类的任务。你不需要一直依赖于终端。Ubunsys 能帮你完成任何高级任务。再次声明,我警告你,这个应用不适合新手,而且它并不稳定。所以当你使用的时候,能会出现 bug 或者系统崩溃。在仔细研究过每一个选项的影响之后再使用它。
谢谢阅读!
### 参考资源
* [Ubunsys GitHub Repository](https://github.com/adgellida/ubunsys)
---
via: <https://www.ostechnix.com/ubunsys-advanced-system-configuration-utility-ubuntu-power-users/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wenwensnow](https://github.com/wenwensnow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,855 | BLUI:创建游戏 UI 的简单方法 | https://opensource.com/article/18/6/blui-game-development-plugin | 2018-07-22T12:09:48 | [
"geekpi"
] | https://linux.cn/article-9855-1.html |
>
> 开源游戏开发插件运行虚幻引擎的用户使用基于 Web 的编程方式创建独特的用户界面元素。
>
>
>

游戏开发引擎在过去几年中变得越来越易于使用。像 Unity 这样一直免费使用的引擎,以及最近从基于订阅的服务切换到免费服务的<ruby> 虚幻引擎 <rt> Unreal Engine </rt></ruby>,允许独立开发者使用 AAA 发行商相同达到行业标准的工具。虽然这些引擎都不是开源的,但每个引擎都能够促进其周围的开源生态系统的发展。
这些引擎中可以包含插件以允许开发人员通过添加特定程序来增强引擎的基本功能。这些程序的范围可以从简单的资源包到更复杂的事物,如人工智能 (AI) 集成。这些插件来自不同的创作者。有些是由引擎开发工作室和有些是个人提供的。后者中的很多是开源插件。
### 什么是 BLUI?
作为独立游戏开发工作室的一员,我体验到了在专有游戏引擎上使用开源插件的好处。Aaron Shea 开发的一个开源插件 [BLUI](https://github.com/AaronShea/BLUI) 对我们团队的开发过程起到了重要作用。它允许我们使用基于 Web 的编程(如 HTML/CSS 和 JavaScript)创建用户界面 (UI) 组件。尽管<ruby> 虚幻引擎 <rt> Unreal Engine </rt></ruby>(我们选择的引擎)有一个实现了类似目的的内置 UI 编辑器,我们也选择使用这个开源插件。我们选择使用开源替代品有三个主要原因:它们的可访问性、易于实现以及伴随的开源程序活跃的、支持性好的在线社区。
在虚幻引擎的最早版本中,我们在游戏中创建 UI 的唯一方法是通过引擎的原生 UI 集成,使用 Autodesk 的 Scaleform 程序,或通过在虚幻社区中传播的一些选定的基于订阅的虚幻引擎集成。在这些情况下,这些解决方案要么不能为独立开发者提供有竞争力的 UI 解决方案,对于小型团队来说太昂贵,要么只能为大型团队和 AAA 开发者提供。
在商业产品和虚幻引擎的原生整合失败后,我们向独立社区寻求解决方案。我们在那里发现了 BLUI。它不仅与虚幻引擎无缝集成,而且还保持了一个强大且活跃的社区,经常推出更新并确保独立开发人员可以轻松访问文档。BLUI 使开发人员能够将 HTML 文件导入虚幻引擎,并在程序内部对其进行编程。这使得通过 web 语言创建的 UI 能够集成到游戏的代码、资源和其他元素中,并拥有所有 HTML、CSS、Javascript 和其他网络语言的能力。它还为开源 [Chromium Embedded Framework](https://bitbucket.org/chromiumembedded/cef) 提供全面支持。
### 安装和使用 BLUI
使用 BLUI 的基本过程包括首先通过 HTML 创建 UI。开发人员可以使用任何工具来实现此目的,包括<ruby> 自举 <rt> bootstrapped </rt> JavaScript 代码、外部 API 或任何数据库代码。一旦这个 HTML 页面完成,你可以像安装任何虚幻引擎插件那样安装它,并加载或创建一个项目。项目加载后,你可以将 BLUI 函数放在虚幻引擎 UI 图纸中的任何位置,或者通过 C++ 进行硬编码。开发人员可以通过其 HTML 页面调用函数,或使用 BLUI 的内部函数轻松更改变量。</ruby>

*将 BLUI 集成到虚幻 4 图纸中。*
在我们当前的项目中,我们使用 BLUI 将 UI 元素与游戏中的音轨同步,为游戏机制的节奏方面提供视觉反馈。将定制引擎编程与 BLUI 插件集成很容易。

*使用 BLUI 将 UI 元素与音轨同步。*
通过 BLUI GitHub 页面上的[文档](https://github.com/AaronShea/BLUI/wiki),将 BLUI 集成到虚幻 4 中是一个轻松的过程。还有一个由支持虚幻引擎开发人员组成的[论坛](https://forums.unrealengine.com/community/released-projects/29036-blui-open-source-html5-js-css-hud-ui),他们乐于询问和回答关于插件以及实现该工具时出现的任何问题。
### 开源优势
开源插件可以在专有游戏引擎的范围内扩展创意。他们继续降低进入游戏开发的障碍,并且可以产生前所未有的游戏内的机制和资源。随着对专有游戏开发引擎的访问持续增长,开源插件社区将变得更加重要。不断增长的创造力必将超过专有软件,开源代码将会填补这些空白,并促进开发真正独特的游戏。而这种新颖性正是让独立游戏如此美好的原因!
---
via: <https://opensource.com/article/18/6/blui-game-development-plugin>
作者:[Uwana lkaiddi](https://opensource.com/users/uwikaiddi) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Game development engines have become increasingly accessible in the last few years. Engines like Unity, which has always been free to use, and Unreal, which recently switched from a subscription-based service to a free service, allow independent developers access to the same industry-standard tools used by AAA publishers. While neither of these engines is open source, each has enabled the growth of open source ecosystems around it.
Within these engines are plugins that allow developers to enhance the base capabilities of the engine by adding specific applications. These apps can range from simple asset packs to more complicated things, like artificial intelligence (AI) integrations. These plugins widely vary across creators. Some are offered by the engine development studios and others by individuals. Many of the latter are open source plugins.
## What is BLUI?
As part of an indie game development studio, I've experienced the perks of using open source plugins on proprietary game engines. One open source plugin, [BLUI](https://github.com/AaronShea/BLUI) by Aaron Shea, has been instrumental in our team's development process. It allows us to create user interface (UI) components using web-based programming like HTML/CSS and JavaScript. We chose to use this open source plugin, even though Unreal Engine (our engine of choice) has a built-in UI editor that achieves a similar purpose. We chose to use open source alternatives for three main reasons: their accessibility, their ease of implementation, and the active, supportive online communities that accompany open source programs.
In Unreal Engine's earliest versions, the only means we had of creating UI in the game was either through the engine's native UI integration, by using Autodesk's Scaleform application, or via a few select subscription-based Unreal integrations spread throughout the Unreal community. In all those cases, the solutions were either incapable of providing a competitive UI solution for indie developers, too expensive for small teams, or exclusively for large-scale teams and AAA developers.
After commercial products and Unreal's native integration failed us, we looked to the indie community for solutions. There we discovered BLUI. It not only integrates with Unreal Engine seamlessly but also maintains a robust and active community that frequently pushes updates and ensures the documentation is easily accessible for indie developers. BLUI gives developers the ability to import HTML files into the Unreal Engine and program them even further while inside the program. This allows UI created through web languages to integrate with the game's code, assets, and other elements with the full power of HTML, CSS, JavaScript, and other web languages. It also provides full support for the open source [Chromium Embedded Framework](https://bitbucket.org/chromiumembedded/cef).
## Installing and using BLUI
The basic process for using BLUI involves first creating the UI via HTML. Developers may use any tool at their disposal to achieve this, including bootstrapped JavaScript code, external APIs, or any database code. Once this HTML page is ready, you can install the plugin the same way you would install any Unreal plugin and load or create a project. Once the project is loaded, you can place a BLUI function anywhere within an Unreal UI blueprint or hardcoded via C++. Developers can call functions from within their HTML page or change variables easily using BLUI's internal functions.
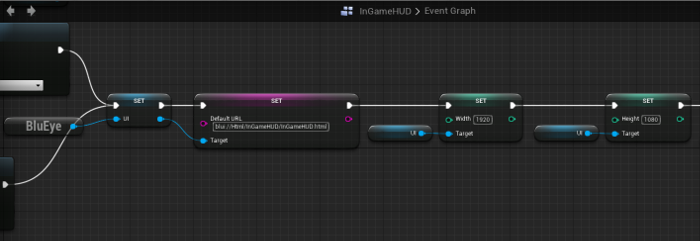
*Integrating BLUI into Unreal Engine 4 blueprints.*
In our current project, we use BLUI to sync UI elements with the in-game soundtrack to provide visual feedback to the rhythm aspects of the game mechanics. It's easy to integrate custom engine programming with the BLUI plugin.

Using BLUI to sync UI elements with the soundtrack.
Implementing BLUI into Unreal Engine 4 is a trivial process thanks to the [documentation](https://github.com/AaronShea/BLUI/wiki) on the BLUI GitHub page. There is also [a forum](https://forums.unrealengine.com/community/released-projects/29036-blui-open-source-html5-js-css-hud-ui) populated with supportive Unreal Engine developers eager to both ask and answer questions regarding the plugin and any issues that appear when implementing the tool.
## Open source advantages
Open source plugins enable expanded creativity within the confines of proprietary game engines. They continue to lower the barrier of entry into game development and can produce in-game mechanics and assets no one has seen before. As access to proprietary game development engines continues to grow, the open source plugin community will become more important. Rising creativity will inevitably outpace proprietary software, and open source will be there to fill the gaps and facilitate the development of truly unique games. And that novelty is exactly what makes indie games so great!
## 2 Comments |
9,856 | 日常 Python 编程优雅之道 | https://opensource.com/article/18/4/elegant-solutions-everyday-python-problems | 2018-07-22T14:44:00 | [
"Python"
] | https://linux.cn/article-9856-1.html |
>
> 3 个可以使你的 Python 代码更优雅、可读、直观和易于维护的工具。
>
>
>

Python 提供了一组独特的工具和语言特性来使你的代码更加优雅、可读和直观。为正确的问题选择合适的工具,你的代码将更易于维护。在本文中,我们将研究其中的三个工具:魔术方法、迭代器和生成器,以及方法魔术。
### 魔术方法
魔术方法可以看作是 Python 的管道。它们被称为“底层”方法,用于某些内置的方法、符号和操作。你可能熟悉的常见魔术方法是 `__init__()`,当我们想要初始化一个类的新实例时,它会被调用。
你可能已经看过其他常见的魔术方法,如 `__str__` 和 `__repr__`。Python 中有一整套魔术方法,通过实现其中的一些方法,我们可以修改一个对象的行为,甚至使其行为类似于内置数据类型,例如数字、列表或字典。
让我们创建一个 `Money` 类来示例:
```
class Money:
currency_rates = {
'$': 1,
'€': 0.88,
}
def __init__(self, symbol, amount):
self.symbol = symbol
self.amount = amount
def __repr__(self):
return '%s%.2f' % (self.symbol, self.amount)
def convert(self, other):
""" Convert other amount to our currency """
new_amount = (
other.amount / self.currency_rates[other.symbol]
* self.currency_rates[self.symbol])
return Money(self.symbol, new_amount)
```
该类定义为给定的货币符号和汇率定义了一个货币汇率,指定了一个初始化器(也称为构造函数),并实现 `__repr__`,因此当我们打印这个类时,我们会看到一个友好的表示,例如 `$2.00` ,这是一个带有货币符号和金额的 `Money('$', 2.00)` 实例。最重要的是,它定义了一种方法,允许你使用不同的汇率在不同的货币之间进行转换。
打开 Python shell,假设我们已经定义了使用两种不同货币的食品的成本,如下所示:
```
>>> soda_cost = Money('$', 5.25)
>>> soda_cost
$5.25
>>> pizza_cost = Money('€', 7.99)
>>> pizza_cost
€7.99
```
我们可以使用魔术方法使得这个类的实例之间可以相互交互。假设我们希望能够将这个类的两个实例一起加在一起,即使它们是不同的货币。为了实现这一点,我们可以在 `Money` 类上实现 `__add__` 这个魔术方法:
```
class Money:
# ... previously defined methods ...
def __add__(self, other):
""" Add 2 Money instances using '+' """
new_amount = self.amount + self.convert(other).amount
return Money(self.symbol, new_amount)
```
现在我们可以以非常直观的方式使用这个类:
```
>>> soda_cost = Money('$', 5.25)
>>> pizza_cost = Money('€', 7.99)
>>> soda_cost + pizza_cost
$14.33
>>> pizza_cost + soda_cost
€12.61
```
当我们将两个实例加在一起时,我们得到以第一个定义的货币符号所表示的结果。所有的转换都是在底层无缝完成的。如果我们想的话,我们也可以为减法实现 `__sub__`,为乘法实现 `__mul__` 等等。阅读[模拟数字类型](https://docs.python.org/3/reference/datamodel.html#emulating-numeric-types)或[魔术方法指南](https://rszalski.github.io/magicmethods/)来获得更多信息。
我们学习到 `__add__` 映射到内置运算符 `+`。其他魔术方法可以映射到像 `[]` 这样的符号。例如,在字典中通过索引或键来获得一项,其实是使用了 `__getitem__` 方法:
```
>>> d = {'one': 1, 'two': 2}
>>> d['two']
2
>>> d.__getitem__('two')
2
```
一些魔术方法甚至映射到内置函数,例如 `__len__()` 映射到 `len()`。
```
class Alphabet:
letters = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
def __len__(self):
return len(self.letters)
>>> my_alphabet = Alphabet()
>>> len(my_alphabet)
26
```
### 自定义迭代器
对于新的和经验丰富的 Python 开发者来说,自定义迭代器是一个非常强大的但令人迷惑的主题。
许多内置类型,例如列表、集合和字典,已经实现了允许它们在底层迭代的协议。这使我们可以轻松地遍历它们。
```
>>> for food in ['Pizza', 'Fries']:
print(food + '. Yum!')
Pizza. Yum!
Fries. Yum!
```
我们如何迭代我们自己的自定义类?首先,让我们来澄清一些术语。
* 要成为一个可迭代对象,一个类需要实现 `__iter__()`
* `__iter__()` 方法需要返回一个迭代器
* 要成为一个迭代器,一个类需要实现 `__next__()`(或[在 Python 2](https://docs.python.org/2/library/stdtypes.html#iterator.next)中是 `next()`),当没有更多的项要迭代时,必须抛出一个 `StopIteration` 异常。
呼!这听起来很复杂,但是一旦你记住了这些基本概念,你就可以在任何时候进行迭代。
我们什么时候想使用自定义迭代器?让我们想象一个场景,我们有一个 `Server` 实例在不同的端口上运行不同的服务,如 `http` 和 `ssh`。其中一些服务处于 `active` 状态,而其他服务则处于 `inactive` 状态。
```
class Server:
services = [
{'active': False, 'protocol': 'ftp', 'port': 21},
{'active': True, 'protocol': 'ssh', 'port': 22},
{'active': True, 'protocol': 'http', 'port': 80},
]
```
当我们遍历 `Server` 实例时,我们只想遍历那些处于 `active` 的服务。让我们创建一个 `IterableServer` 类:
```
class IterableServer:
def __init__(self):
self.current_pos = 0
def __next__(self):
pass # TODO: 实现并记得抛出 StopIteration
```
首先,我们将当前位置初始化为 `0`。然后,我们定义一个 `__next__()` 方法来返回下一项。我们还将确保在没有更多项返回时抛出 `StopIteration`。到目前为止都很好!现在,让我们实现这个 `__next__()` 方法。
```
class IterableServer:
def __init__(self):
self.current_pos = 0. # 我们初始化当前位置为 0
def __iter__(self): # 我们可以在这里返回 self,因为实现了 __next__
return self
def __next__(self):
while self.current_pos < len(self.services):
service = self.services[self.current_pos]
self.current_pos += 1
if service['active']:
return service['protocol'], service['port']
raise StopIteration
next = __next__ # 可选的 Python2 兼容性
```
我们对列表中的服务进行遍历,而当前的位置小于服务的个数,但只有在服务处于活动状态时才返回。一旦我们遍历完服务,就会抛出一个 `StopIteration` 异常。
因为我们实现了 `__next__()` 方法,当它耗尽时,它会抛出 `StopIteration`。我们可以从 `__iter__()` 返回 `self`,因为 `IterableServer` 类遵循 `iterable` 协议。
现在我们可以遍历一个 `IterableServer` 实例,这将允许我们查看每个处于活动的服务,如下所示:
```
>>> for protocol, port in IterableServer():
print('service %s is running on port %d' % (protocol, port))
service ssh is running on port 22
service http is running on port 21
```
太棒了,但我们可以做得更好!在这样类似的实例中,我们的迭代器不需要维护大量的状态,我们可以简化代码并使用 [generator(生成器)](https://docs.python.org/3/library/stdtypes.html#generator-types) 来代替。
```
class Server:
services = [
{'active': False, 'protocol': 'ftp', 'port': 21},
{'active': True, 'protocol': 'ssh', 'port': 22},
{'active': True, 'protocol': 'http', 'port': 21},
]
def __iter__(self):
for service in self.services:
if service['active']:
yield service['protocol'], service['port']
```
`yield` 关键字到底是什么?在定义生成器函数时使用 yield。这有点像 `return`,虽然 `return` 在返回值后退出函数,但 `yield` 会暂停执行直到下次调用它。这允许你的生成器的功能在它恢复之前保持状态。查看 [yield 的文档](https://docs.python.org/3/reference/expressions.html#yieldexpr)以了解更多信息。使用生成器,我们不必通过记住我们的位置来手动维护状态。生成器只知道两件事:它现在需要做什么以及计算下一个项目需要做什么。一旦我们到达执行点,即 `yield` 不再被调用,我们就知道停止迭代。
这是因为一些内置的 Python 魔法。在 [Python 关于 `__iter__()` 的文档](https://docs.python.org/3/reference/datamodel.html#object.__iter__)中我们可以看到,如果 `__iter__()` 是作为一个生成器实现的,它将自动返回一个迭代器对象,该对象提供 `__iter__()` 和 `__next__()` 方法。阅读这篇很棒的文章,深入了解[迭代器,可迭代对象和生成器](http://nvie.com/posts/iterators-vs-generators/)。
### 方法魔法
由于其独特的方面,Python 提供了一些有趣的方法魔法作为语言的一部分。
其中一个例子是别名功能。因为函数只是对象,所以我们可以将它们赋值给多个变量。例如:
```
>>> def foo():
return 'foo'
>>> foo()
'foo'
>>> bar = foo
>>> bar()
'foo'
```
我们稍后会看到它的作用。
Python 提供了一个方便的内置函数[称为 `getattr()`](https://docs.python.org/3/library/functions.html#getattr),它接受 `object, name, default` 参数并在 `object` 上返回属性 `name`。这种编程方式允许我们访问实例变量和方法。例如:
```
>>> class Dog:
sound = 'Bark'
def speak(self):
print(self.sound + '!', self.sound + '!')
>>> fido = Dog()
>>> fido.sound
'Bark'
>>> getattr(fido, 'sound')
'Bark'
>>> fido.speak
<bound method Dog.speak of <__main__.Dog object at 0x102db8828>>
>>> getattr(fido, 'speak')
<bound method Dog.speak of <__main__.Dog object at 0x102db8828>>
>>> fido.speak()
Bark! Bark!
>>> speak_method = getattr(fido, 'speak')
>>> speak_method()
Bark! Bark!
```
这是一个很酷的技巧,但是我们如何在实际中使用 `getattr` 呢?让我们看一个例子,我们编写一个小型命令行工具来动态处理命令。
```
class Operations:
def say_hi(self, name):
print('Hello,', name)
def say_bye(self, name):
print ('Goodbye,', name)
def default(self, arg):
print ('This operation is not supported.')
if __name__ == '__main__':
operations = Operations()
# 假设我们做了错误处理
command, argument = input('> ').split()
func_to_call = getattr(operations, command, operations.default)
func_to_call(argument)
```
脚本的输出是:
```
$ python getattr.py
> say_hi Nina
Hello, Nina
> blah blah
This operation is not supported.
```
接下来,我们来看看 `partial`。例如,`functool.partial(func, *args, **kwargs)` 允许你返回一个新的 [partial 对象](https://docs.python.org/3/library/functools.html#functools.partial),它的行为类似 `func`,参数是 `args` 和 `kwargs`。如果传入更多的 `args`,它们会被附加到 `args`。如果传入更多的 `kwargs`,它们会扩展并覆盖 `kwargs`。让我们通过一个简短的例子来看看:
```
>>> from functools import partial
>>> basetwo = partial(int, base=2)
>>> basetwo
<functools.partial object at 0x1085a09f0>
>>> basetwo('10010')
18
# 这等同于
>>> int('10010', base=2)
```
让我们看看在我喜欢的一个[名为 `agithub`](https://github.com/mozilla/agithub) 的库中的一些示例代码中,这个方法魔术是如何结合在一起的,这是一个(名字起得很 low 的) REST API 客户端,它具有透明的语法,允许你以最小的配置快速构建任何 REST API 原型(不仅仅是 GitHub)。我发现这个项目很有趣,因为它非常强大,但只有大约 400 行 Python 代码。你可以在大约 30 行配置代码中添加对任何 REST API 的支持。`agithub` 知道协议所需的一切(`REST`、`HTTP`、`TCP`),但它不考虑上游 API。让我们深入到它的实现中。
以下是我们如何为 GitHub API 和任何其他相关连接属性定义端点 URL 的简化版本。在这里查看[完整代码](https://github.com/mozilla/agithub/blob/master/agithub/GitHub.py)。
```
class GitHub(API):
def __init__(self, token=None, *args, **kwargs):
props = ConnectionProperties(api_url = kwargs.pop('api_url', 'api.github.com'))
self.setClient(Client(*args, **kwargs))
self.setConnectionProperties(props)
```
然后,一旦配置了[访问令牌](https://github.com/settings/tokens),就可以开始使用 [GitHub API](https://developer.github.com/v3/repos/#list-your-repositories)。
```
>>> gh = GitHub('token')
>>> status, data = gh.user.repos.get(visibility='public', sort='created')
>>> # ^ 映射到 GET /user/repos
>>> data
... ['tweeter', 'snipey', '...']
```
请注意,你要确保 URL 拼写正确,因为我们没有验证 URL。如果 URL 不存在或出现了其他任何错误,将返回 API 抛出的错误。那么,这一切是如何运作的呢?让我们找出答案。首先,我们将查看一个 [`API` 类](https://github.com/mozilla/agithub/blob/dbf7014e2504333c58a39153aa11bbbdd080f6ac/agithub/base.py#L30-L58)的简化示例:
```
class API:
# ... other methods ...
def __getattr__(self, key):
return IncompleteRequest(self.client).__getattr__(key)
__getitem__ = __getattr__
```
在 `API` 类上的每次调用都会调用 [`IncompleteRequest` 类](https://github.com/mozilla/agithub/blob/dbf7014e2504333c58a39153aa11bbbdd080f6ac/agithub/base.py#L60-L100)作为指定的 `key`。
```
class IncompleteRequest:
# ... other methods ...
def __getattr__(self, key):
if key in self.client.http_methods:
htmlMethod = getattr(self.client, key)
return partial(htmlMethod, url=self.url)
else:
self.url += '/' + str(key)
return self
__getitem__ = __getattr__
class Client:
http_methods = ('get') # 还有 post, put, patch 等等。
def get(self, url, headers={}, **params):
return self.request('GET', url, None, headers)
```
如果最后一次调用不是 HTTP 方法(如 `get`、`post` 等),则返回带有附加路径的 `IncompleteRequest`。否则,它从[`Client` 类](https://github.com/mozilla/agithub/blob/dbf7014e2504333c58a39153aa11bbbdd080f6ac/agithub/base.py#L102-L231)获取 HTTP 方法对应的正确函数,并返回 `partial`。
如果我们给出一个不存在的路径会发生什么?
```
>>> status, data = this.path.doesnt.exist.get()
>>> status
... 404
```
因为 `__getattr__` 别名为 `__getitem__`:
```
>>> owner, repo = 'nnja', 'tweeter'
>>> status, data = gh.repos[owner][repo].pulls.get()
>>> # ^ Maps to GET /repos/nnja/tweeter/pulls
>>> data
.... # {....}
```
这真心是一些方法魔术!
### 了解更多
Python 提供了大量工具,使你的代码更优雅,更易于阅读和理解。挑战在于找到合适的工具来完成工作,但我希望本文为你的工具箱添加了一些新工具。而且,如果你想更进一步,你可以在我的博客 [nnja.io](http://nnja.io) 上阅读有关装饰器、上下文管理器、上下文生成器和命名元组的内容。随着你成为一名更好的 Python 开发人员,我鼓励你到那里阅读一些设计良好的项目的源代码。[Requests](https://github.com/requests/requests) 和 [Flask](https://github.com/pallets/flask) 是两个很好的起步的代码库。
---
via: <https://opensource.com/article/18/4/elegant-solutions-everyday-python-problems>
作者:[Nina Zakharenko](https://opensource.com/users/nnja) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Python offers a unique set of tools and language features that help make your code more elegant, readable, and intuitive. By selecting the right tool for the right problem, your code will be easier to maintain. In this article, we'll examine three of those tools: magic methods, iterators and generators, and method magic.
## Magic methods
Magic methods can be considered the plumbing of Python. They're the methods that are called "under the hood" for certain built-in methods, symbols, and operations. A common magic method you may be familiar with is `__init__()`
, which is called when we want to initialize a new instance of a class.
You may have seen other common magic methods, like `__str__`
and `__repr__`
. There is a whole world of magic methods, and by implementing a few of them, we can greatly modify the behavior of an object or even make it behave like a built-in datatype, such as a number, list, or dictionary.
Let's take this `Money`
class for example:
```
``````
class Money:
currency_rates = {
'$': 1,
'€': 0.88,
}
def __init__(self, symbol, amount):
self.symbol = symbol
self.amount = amount
def __repr__(self):
return '%s%.2f' % (self.symbol, self.amount)
def convert(self, other):
""" Convert other amount to our currency """
new_amount = (
other.amount / self.currency_rates[other.symbol]
* self.currency_rates[self.symbol])
return Money(self.symbol, new_amount)
```
The class defines a currency rate for a given symbol and exchange rate, specifies an initializer (also known as a constructor), and implements `__repr__`
, so when we print out the class, we see a nice representation such as `$2.00`
for an instance `Money('$', 2.00)`
with the currency symbol and amount. Most importantly, it defines a method that allows you to convert between different currencies with different exchange rates.
Using a Python shell, let's say we've defined the costs for two food items in different currencies, like so:
```
``````
>>> soda_cost = Money('$', 5.25)
>>> soda_cost
$5.25
>>> pizza_cost = Money('€', 7.99)
>>> pizza_cost
€7.99
```
We could use magic methods to help instances of this class interact with each other. Let's say we wanted to be able to add two instances of this class together, even if they were in different currencies. To make that a reality, we could implement the `__add__`
magic method on our `Money`
class:
```
``````
class Money:
# ... previously defined methods ...
def __add__(self, other):
""" Add 2 Money instances using '+' """
new_amount = self.amount + self.convert(other).amount
return Money(self.symbol, new_amount)
```
Now we can use this class in a very intuitive way:
```
``````
>>> soda_cost = Money('$', 5.25)
>>> pizza_cost = Money('€', 7.99)
>>> soda_cost + pizza_cost
$14.33
>>> pizza_cost + soda_cost
€12.61
```
When we add two instances together, we get a result in the first defined currency. All the conversion is done seamlessly under the hood. If we wanted to, we could also implement `__sub__`
for subtraction, `__mul__`
for multiplication, and many more. Read about [emulating numeric types](https://docs.python.org/3/reference/datamodel.html#emulating-numeric-types), or read this [guide to magic methods](https://rszalski.github.io/magicmethods/) for others.
We learned that `__add__`
maps to the built-in operator `+`
. Other magic methods can map to symbols like `[]`
. For example, to access an item by index or key (in the case of a dictionary), use the `__getitem__`
method:
```
``````
>>> d = {'one': 1, 'two': 2}
>>> d['two']
2
>>> d.__getitem__('two')
2
```
Some magic methods even map to built-in functions, such as `__len__()`
, which maps to `len()`
.
```
``````
class Alphabet:
letters = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
def __len__(self):
return len(self.letters)
>>> my_alphabet = Alphabet()
>>> len(my_alphabet)
26
```
## Custom iterators
Custom iterators are an incredibly powerful but unfortunately confusing topic to new and seasoned Pythonistas alike.
Many built-in types, such as lists, sets, and dictionaries, already implement the protocol that allows them to be iterated over under the hood. This allows us to easily loop over them.
```
``````
>>> for food in ['Pizza', 'Fries']:
print(food + '. Yum!')
Pizza. Yum!
Fries. Yum!
```
How can we iterate over our own custom classes? First, let's clear up some terminology.
- To be
*iterable*, a class needs to*implement*`__iter__()`
- The
`__iter__()`
method needs to*return*an*iterator* - To be an
*iterator*, a class needs to*implement*`__next__()`
(or`next()`
[in Python 2](https://docs.python.org/2/library/stdtypes.html#iterator.next)), which*must*raise a`StopIteration`
exception when there are no more items to iterate over.
Whew! It sounds complicated, but once you remember these fundamental concepts, you'll be able to iterate in your sleep.
When might we want to use a custom iterator? Let's imagine a scenario where we have a `Server`
instance running different services such as `http`
and `ssh`
on different ports. Some of these services have an `active`
state while others are `inactive`
.
```
``````
class Server:
services = [
{'active': False, 'protocol': 'ftp', 'port': 21},
{'active': True, 'protocol': 'ssh', 'port': 22},
{'active': True, 'protocol': 'http', 'port': 80},
]
```
When we loop over our `Server`
instance, we only want to loop over `active`
services. Let's create a new class, an `IterableServer`
:
```
``````
class IterableServer:
def __init__(self):
self.current_pos = 0
def __next__(self):
pass # TODO: Implement and remember to raise StopIteration
```
First, we initialize our current position to `0`
. Then, we define a `__next__()`
method, which will return the next item. We'll also ensure that we raise `StopIteration`
when there are no more items to return. So far so good! Now, let's implement this `__next__()`
method.
```
``````
class IterableServer:
def __init__(self):
self.current_pos = 0. # we initialize our current position to zero
def __iter__(self): # we can return self here, because __next__ is implemented
return self
def __next__(self):
while self.current_pos < len(self.services):
service = self.services[self.current_pos]
self.current_pos += 1
if service['active']:
return service['protocol'], service['port']
raise StopIteration
next = __next__ # optional python2 compatibility
```
We keep looping over the services in our list while our current position is less than the length of the services but only returning if the service is active. Once we run out of services to iterate over, we raise a `StopIteration`
exception.
Because we implement a `__next__()`
method that raises `StopIteration`
when it is exhausted, we can return `self`
from `__iter__()`
because the `IterableServer`
class adheres to the `iterable`
protocol.
Now we can loop over an instance of `IterableServer`
, which will allow us to look at each active service, like so:
```
``````
>>> for protocol, port in IterableServer():
print('service %s is running on port %d' % (protocol, port))
service ssh is running on port 22
service http is running on port 21
```
That's pretty great, but we can do better! In an instance like this, where our iterator doesn't need to maintain a lot of state, we can simplify our code and use a [generator](https://docs.python.org/3/library/stdtypes.html#generator-types) instead.
```
``````
class Server:
services = [
{'active': False, 'protocol': 'ftp', 'port': 21},
{'active': True, 'protocol': 'ssh', 'port': 22},
{'active': True, 'protocol': 'http', 'port': 21},
]
def __iter__(self):
for service in self.services:
if service['active']:
yield service['protocol'], service['port']
```
What exactly is the `yield`
keyword? Yield is used when defining a generator function. It's sort of like a `return`
. While a `return`
exits the function after returning the value, `yield`
suspends execution until the next time it's called. This allows your generator function to maintain state until it resumes. Check out [yield's documentation](https://docs.python.org/3/reference/expressions.html#yieldexpr) to learn more. With a generator, we don't have to manually maintain state by remembering our position. A generator knows only two things: what it needs to do right now and what it needs to do to calculate the next item. Once we reach a point of execution where `yield`
isn't called again, we know to stop iterating.
This works because of some built-in Python magic. In the [Python documentation for __iter__()](https://docs.python.org/3/reference/datamodel.html#object.__iter__) we can see that if
`__iter__()`
is implemented as a generator, it will automatically return an iterator object that supplies the `__iter__()`
and `__next__()`
methods. Read this great article for a deeper dive of [iterators, iterables, and generators](http://nvie.com/posts/iterators-vs-generators/).
## Method magic
Due to its unique aspects, Python provides some interesting method magic as part of the language.
One example of this is aliasing functions. Since functions are just objects, we can assign them to multiple variables. For example:
```
``````
>>> def foo():
return 'foo'
>>> foo()
'foo'
>>> bar = foo
>>> bar()
'foo'
```
We'll see later on how this can be useful.
Python provides a handy built-in, [called getattr()](https://docs.python.org/3/library/functions.html#getattr), that takes the
`object, name, default`
parameters and returns the attribute `name`
on `object`
. This programmatically allows us to access instance variables and methods. For example:```
``````
>>> class Dog:
sound = 'Bark'
def speak(self):
print(self.sound + '!', self.sound + '!')
>>> fido = Dog()
>>> fido.sound
'Bark'
>>> getattr(fido, 'sound')
'Bark'
>>> fido.speak
<bound method Dog.speak of <__main__.Dog object at 0x102db8828>>
>>> getattr(fido, 'speak')
<bound method Dog.speak of <__main__.Dog object at 0x102db8828>>
>>> fido.speak()
Bark! Bark!
>>> speak_method = getattr(fido, 'speak')
>>> speak_method()
Bark! Bark!
```
Cool trick, but how could we practically use `getattr`
? Let's look at an example that allows us to write a tiny command-line tool to dynamically process commands.
```
``````
class Operations:
def say_hi(self, name):
print('Hello,', name)
def say_bye(self, name):
print ('Goodbye,', name)
def default(self, arg):
print ('This operation is not supported.')
if __name__ == '__main__':
operations = Operations()
# let's assume we do error handling
command, argument = input('> ').split()
func_to_call = getattr(operations, command, operations.default)
func_to_call(argument)
```
The output of our script is:
```
``````
$ python getattr.py
> say_hi Nina
Hello, Nina
> blah blah
This operation is not supported.
```
Next, we'll look at `partial`
. For example, ** functool.partial(func, *args, **kwargs)** allows you to return a new
[that behaves like](https://docs.python.org/3/library/functools.html#functools.partial)
*partial object*`func`
called with `args`
and `kwargs`
. If more `args`
are passed in, they're appended to `args`
. If more `kwargs`
are passed in, they extend and override `kwargs`
. Let's see it in action with a brief example:```
``````
>>> from functools import partial
>>> basetwo = partial(int, base=2)
>>> basetwo
<functools.partial object at 0x1085a09f0>
>>> basetwo('10010')
18
# This is the same as
>>> int('10010', base=2)
```
Let's see how this method magic ties together in some sample code from a library I enjoy using [called ](https://github.com/mozilla/agithub)
, which is a (poorly named) REST API client with transparent syntax that allows you to rapidly prototype any REST API (not just GitHub) with minimal configuration. I find this project interesting because it's incredibly powerful yet only about 400 lines of Python. You can add support for any REST API in about 30 lines of configuration code. [agithub](https://github.com/mozilla/agithub)`agithub`
knows everything it needs to about protocol (`REST`
, `HTTP`
, `TCP`
), but it assumes nothing about the upstream API. Let's dive into the implementation.
Here's a simplified version of how we'd define an endpoint URL for the GitHub API and any other relevant connection properties. View the [full code](https://github.com/mozilla/agithub/blob/master/agithub/GitHub.py) instead.
```
``````
class GitHub(API):
def __init__(self, token=None, *args, **kwargs):
props = ConnectionProperties(api_url = kwargs.pop('api_url', 'api.github.com'))
self.setClient(Client(*args, **kwargs))
self.setConnectionProperties(props)
```
Then, once your [access token](https://github.com/settings/tokens) is configured, you can start using the [GitHub API](https://developer.github.com/v3/repos/#list-your-repositories).
```
``````
>>> gh = GitHub('token')
>>> status, data = gh.user.repos.get(visibility='public', sort='created')
>>> # ^ Maps to GET /user/repos
>>> data
... ['tweeter', 'snipey', '...']
```
Note that it's up to you to spell things correctly. There's no validation of the URL. If the URL doesn't exist or anything else goes wrong, the error thrown by the API will be returned. So, how does this all work? Let's figure it out. First, we'll check out a simplified example of the [ API class](https://github.com/mozilla/agithub/blob/dbf7014e2504333c58a39153aa11bbbdd080f6ac/agithub/base.py#L30-L58):
```
``````
class API:
# ... other methods ...
def __getattr__(self, key):
return IncompleteRequest(self.client).__getattr__(key)
__getitem__ = __getattr__
```
Each call on the `API`
class ferries the call to the [ IncompleteRequest class](https://github.com/mozilla/agithub/blob/dbf7014e2504333c58a39153aa11bbbdd080f6ac/agithub/base.py#L60-L100) for the specified
`key`
.```
``````
class IncompleteRequest:
# ... other methods ...
def __getattr__(self, key):
if key in self.client.http_methods:
htmlMethod = getattr(self.client, key)
return partial(htmlMethod, url=self.url)
else:
self.url += '/' + str(key)
return self
__getitem__ = __getattr__
class Client:
http_methods = ('get') # ... and post, put, patch, etc.
def get(self, url, headers={}, **params):
return self.request('GET', url, None, headers)
```
If the last call is not an HTTP method (like 'get', 'post', etc.), it returns an `IncompleteRequest`
with an appended path. Otherwise, it gets the right function for the specified HTTP method from the [ Client class](https://github.com/mozilla/agithub/blob/dbf7014e2504333c58a39153aa11bbbdd080f6ac/agithub/base.py#L102-L231) and returns a
`partial`
.What happens if we give a non-existent path?
```
``````
>>> status, data = this.path.doesnt.exist.get()
>>> status
... 404
```
And because `__getitem__`
is aliased to `__getattr__`
:
```
``````
>>> owner, repo = 'nnja', 'tweeter'
>>> status, data = gh.repos[owner][repo].pulls.get()
>>> # ^ Maps to GET /repos/nnja/tweeter/pulls
>>> data
.... # {....}
```
Now that's some serious method magic!
## Learn more
Python provides plenty of tools that allow you to make your code more elegant and easier to read and understand. The challenge is finding the right tool for the job, but I hope this article added some new ones to your toolbox. And, if you'd like to take this a step further, you can read about decorators, context managers, context generators, and `NamedTuple`
s on my blog [nnja.io](http://nnja.io). As you become a better Python developer, I encourage you to get out there and read some source code for well-architected projects. [Requests](https://github.com/requests/requests) and [Flask](https://github.com/pallets/flask) are two great codebases to start with.
To learn more about these topics, as well as decorators, context managers, context decorators, and NamedTuples, attend Nina Zakharenko 's talk, [Elegant Solutions for Everyday Python Problems](https://us.pycon.org/2018/schedule/presentation/164/), at [PyCon Cleveland 2018](https://us.pycon.org/2018/).
## 2 Comments |
9,857 | Perlbrew 入门 | https://opensource.com/article/18/7/perlbrew | 2018-07-23T11:41:55 | [
"Perl",
"Perlbrew"
] | /article-9857-1.html |
>
> 用 Perlbrew 在你系统上安装多个版本的 Perl。
>
>
>

有比在系统上安装了 Perl 更好的事情吗?那就是在系统中安装了多个版本的 Perl。使用 [Perlbrew](https://perlbrew.pl/) 你可以做到这一点。但是为什么呢,除了让你包围在 Perl 下之外,有什么好处吗?
简短的回答是,不同版本的 Perl 是......不同的。程序 A 可能依赖于较新版本中不推荐使用的行为,而程序 B 需要去年无法使用的新功能。如果你安装了多个版本的 Perl,则每个脚本都可以使用最适合它的版本。如果您是开发人员,这也会派上用场,你可以针对多个版本的 Perl 测试你的程序,这样无论你的用户运行什么,你都知道它能否工作。
### 安装 Perlbrew
另一个好处是 Perlbrew 会安装 Perl 到用户的家目录。这意味着每个用户都可以管理他们的 Perl 版本(以及相关的 CPAN 包),而无需与系统管理员联系。自助服务意味着为用户提供更快的安装,并为系统管理员提供更多时间来解决难题。
第一步是在你的系统上安装 Perlbrew。许多 Linux 发行版已经在包仓库中拥有它,因此你只需要 `dnf install perlbrew`(或者适用于你的发行版的命令)。你还可以使用 `cpan App::perlbrew` 从 CPAN 安装 `App::perlbrew` 模块。或者你可以在 [install.perlbrew.pl](https://raw.githubusercontent.com/gugod/App-perlbrew/master/perlbrew-install) 下载并运行安装脚本。
要开始使用 Perlbrew,请运行 `perlbrew init`。
### 安装新的 Perl 版本
假设你想尝试最新的开发版本(撰写本文时为 5.27.11)。首先,你需要安装包:
```
perlbrew install 5.27.11
```
### 切换 Perl 版本
现在你已经安装了新版本,你可以将它用于该 shell:
```
perlbrew use 5.27.11
```
或者你可以将其设置为你帐户的默认 Perl 版本(假设你按照 `perlbrew init` 的输出设置了你的配置文件):
```
perlbrew switch 5.27.11
```
### 运行单个脚本
你也可以用特定版本的 Perl 运行单个命令:
```
perlberew exec 5.27.11 myscript.pl
```
或者,你可以针对所有已安装的版本运行命令。如果你想针对各种版本运行测试,这尤其方便。在这种情况下,请指定版本为 `perl`:
```
plperlbrew exec perl myscriptpl
```
### 安装 CPAN 模块
如果你想安装 CPAN 模块,`cpanm` 包是一个易于使用的界面,可以很好地与 Perlbrew 一起使用。用下面命令安装它:
```
perlbrew install-cpanm
```
然后,你可以使用 `cpanm` 命令安装 CPAN 模块:
```
cpanm CGI::simple
```
### 但是等下,还有更多!
本文介绍了基本的 Perlbrew 用法。还有更多功能和选项可供选择。从查看 `perlbrew help` 的输出开始,或查看[App::perlbrew 文档](https://metacpan.org/pod/App::perlbrew)。你还喜欢 Perlbrew 的其他什么功能?让我们在评论中知道。
---
via: <https://opensource.com/article/18/7/perlbrew>
作者:[Ben Cotton](https://opensource.com/users/bcotton) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
9,858 | 搭建属于你自己的 Git 服务器 | https://www.linux.com/learn/how-run-your-own-git-server | 2018-07-23T13:19:09 | [
"git"
] | https://linux.cn/article-9858-1.html |
>
> 在本文中,我们的目的是让你了解如何设置属于自己的Git服务器。
>
>
>

[Git](https://github.com/git/git) 是由 [Linux Torvalds 开发](https://www.linuxfoundation.org/blog/10-years-of-git-an-interview-with-git-creator-linus-torvalds/)的一个版本控制系统,现如今正在被全世界大量开发者使用。许多公司喜欢使用基于 Git 版本控制的 GitHub 代码托管。[根据报道,GitHub 是现如今全世界最大的代码托管网站](https://github.com/about/press)。GitHub 宣称已经有 920 万用户和 2180 万个仓库。许多大型公司现如今也将代码迁移到 GitHub 上。[甚至于谷歌,一家搜索引擎公司,也正将代码迁移到 GitHub 上](http://google-opensource.blogspot.com/2015/03/farewell-to-google-code.html)。
### 运行你自己的 Git 服务器
GitHub 能提供极佳的服务,但却有一些限制,尤其是你是单人或是一名 coding 爱好者。GitHub 其中之一的限制就是其中免费的服务没有提供代码私有托管业务。[你不得不支付每月 7 美金购买 5 个私有仓库](https://github.com/pricing),并且想要更多的私有仓库则要交更多的钱。
万一你想要私有仓库或需要更多权限控制,最好的方法就是在你的服务器上运行 Git。不仅你能够省去一笔钱,你还能够在你的服务器有更多的操作。在大多数情况下,大多数高级 Linux 用户已经拥有自己的服务器,并且在这些服务器上方式 Git 就像“啤酒一样免费”(LCTT 译注:指免费软件)。
在这篇教程中,我们主要讲在你的服务器上,使用两种代码管理的方法。一种是运行一个纯 Git 服务器,另一个是使用名为 [GitLab](https://about.gitlab.com/) 的 GUI 工具。在本教程中,我在 VPS 上运行的操作系统是 Ubuntu 14.04 LTS。
### 在你的服务器上安装 Git
在本篇教程中,我们考虑一个简单案例,我们有一个远程服务器和一台本地服务器,现在我们需要使用这两台机器来工作。为了简单起见,我们就分别叫它们为远程服务器和本地服务器。
首先,在两边的机器上安装 Git。你可以从依赖包中安装 Git,在本文中,我们将使用更简单的方法:
```
sudo apt-get install git-core
```
为 Git 创建一个用户。
```
sudo useradd git
passwd git
```
为了容易的访问服务器,我们设置一个免密 ssh 登录。首先在你本地电脑上创建一个 ssh 密钥:
```
ssh-keygen -t rsa
```
这时会要求你输入保存密钥的路径,这时只需要点击回车保存在默认路径。第二个问题是输入访问远程服务器所需的密码。它生成两个密钥——公钥和私钥。记下您在下一步中需要使用的公钥的位置。
现在您必须将这些密钥复制到服务器上,以便两台机器可以相互通信。在本地机器上运行以下命令:
```
cat ~/.ssh/id_rsa.pub | ssh git@remote-server "mkdir -p ~/.ssh && cat >> ~/.ssh/authorized_keys"
```
现在,用 `ssh` 登录进服务器并为 Git 创建一个项目路径。你可以为你的仓库设置一个你想要的目录。
现在跳转到该目录中:
```
cd /home/swapnil/project-1.git
```
现在新建一个空仓库:
```
git init --bare
Initialized empty Git repository in /home/swapnil/project-1.git
```
现在我们需要在本地机器上新建一个基于 Git 版本控制仓库:
```
mkdir -p /home/swapnil/git/project
```
进入我们创建仓库的目录:
```
cd /home/swapnil/git/project
```
现在在该目录中创建项目所需的文件。留在这个目录并启动 `git`:
```
git init
Initialized empty Git repository in /home/swapnil/git/project
```
把所有文件添加到仓库中:
```
git add .
```
现在,每次添加文件或进行更改时,都必须运行上面的 `add` 命令。 您还需要为每个文件更改都写入提交消息。提交消息基本上说明了我们所做的更改。
```
git commit -m "message" -a
[master (root-commit) 57331ee] message
2 files changed, 2 insertions(+)
create mode 100644 GoT.txt
create mode 100644 writing.txt
```
在这种情况下,我有一个名为 GoT(《权力的游戏》的点评)的文件,并且我做了一些更改,所以当我运行命令时,它指定对文件进行更改。 在上面的命令中 `-a` 选项意味着提交仓库中的所有文件。 如果您只更改了一个,则可以指定该文件的名称而不是使用 `-a`。
举一个例子:
```
git commit -m "message" GoT.txt
[master e517b10] message
1 file changed, 1 insertion(+)
```
到现在为止,我们一直在本地服务器上工作。现在我们必须将这些更改推送到远程服务器上,以便通过互联网访问,并且可以与其他团队成员进行协作。
```
git remote add origin ssh://git@remote-server/repo-<wbr< a="">>path-on-server..git
```
现在,您可以使用 `pull` 或 `push` 选项在服务器和本地计算机之间推送或拉取:
```
git push origin master
```
如果有其他团队成员想要使用该项目,则需要将远程服务器上的仓库克隆到其本地计算机上:
```
git clone git@remote-server:/home/swapnil/project.git
```
这里 `/home/swapnil/project.git` 是远程服务器上的项目路径,在你本机上则会改变。
然后进入本地计算机上的目录(使用服务器上的项目名称):
```
cd /project
```
现在他们可以编辑文件,写入提交更改信息,然后将它们推送到服务器:
```
git commit -m 'corrections in GoT.txt story' -a
```
然后推送改变:
```
git push origin master
```
我认为这足以让一个新用户开始在他们自己的服务器上使用 Git。 如果您正在寻找一些 GUI 工具来管理本地计算机上的更改,则可以使用 GUI 工具,例如 QGit 或 GitK for Linux。

### 使用 GitLab
这是项目所有者和协作者的纯命令行解决方案。这当然不像使用 GitHub 那么简单。不幸的是,尽管 GitHub 是全球最大的代码托管商,但是它自己的软件别人却无法使用。因为它不是开源的,所以你不能获取源代码并编译你自己的 GitHub。这与 WordPress 或 Drupal 不同,您无法下载 GitHub 并在您自己的服务器上运行它。
像往常一样,在开源世界中,是没有终结的尽头。GitLab 是一个非常优秀的项目。这是一个开源项目,允许用户在自己的服务器上运行类似于 GitHub 的项目管理系统。
您可以使用 GitLab 为团队成员或公司运行类似于 GitHub 的服务。您可以使用 GitLab 在公开发布之前开发私有项目。
GitLab 采用传统的开源商业模式。他们有两种产品:免费的开源软件,用户可以在自己的服务器上安装,以及类似于 GitHub 的托管服务。
可下载版本有两个版本,免费的社区版和付费企业版。企业版基于社区版,但附带针对企业客户的其他功能。它或多或少与 WordPress.org 或 Wordpress.com 提供的服务类似。
社区版具有高度可扩展性,可以在单个服务器或群集上支持 25000 个用户。GitLab 的一些功能包括:Git 仓库管理,代码评论,问题跟踪,活动源和维基。它配备了 GitLab CI,用于持续集成和交付。
Digital Ocean 等许多 VPS 提供商会为用户提供 GitLab 服务。 如果你想在你自己的服务器上运行它,你可以手动安装它。GitLab 为不同的操作系统提供了软件包。 在我们安装 GitLab 之前,您可能需要配置 SMTP 电子邮件服务器,以便 GitLab 可以在需要时随时推送电子邮件。官方推荐使用 Postfix。所以,先在你的服务器上安装 Postfix:
```
sudo apt-get install postfix
```
在安装 Postfix 期间,它会问你一些问题,不要跳过它们。 如果你一不小心跳过,你可以使用这个命令来重新配置它:
```
sudo dpkg-reconfigure postfix
```
运行此命令时,请选择 “Internet Site”并为使用 Gitlab 的域名提供电子邮件 ID。
我是这样输入的:
```
[email protected]
```
用 Tab 键并为 postfix 创建一个用户名。接下来将会要求你输入一个目标邮箱。
在剩下的步骤中,都选择默认选项。当我们安装且配置完成后,我们继续安装 GitLab。
我们使用 `wget` 来下载软件包(用 [最新包](https://about.gitlab.com/downloads/) 替换下载链接):
```
wget https://downloads-packages.s3.amazonaws.com/ubuntu-14.04/gitlab_7.9.4-omnibus.1-1_amd64.deb
```
然后安装这个包:
```
sudo dpkg -i gitlab_7.9.4-omnibus.1-1_amd64.deb
```
现在是时候配置并启动 GitLab 了。
```
sudo gitlab-ctl reconfigure
```
您现在需要在配置文件中配置域名,以便您可以访问 GitLab。打开文件。
```
nano /etc/gitlab/gitlab.rb
```
在这个文件中编辑 `external_url` 并输入服务器域名。保存文件,然后从 Web 浏览器中打开新建的一个 GitLab 站点。

默认情况下,它会以系统管理员的身份创建 `root`,并使用 `5iveL!fe` 作为密码。 登录到 GitLab 站点,然后更改密码。

密码更改后,登录该网站并开始管理您的项目。

GitLab 有很多选项和功能。最后,我借用电影“黑客帝国”中的经典台词:“不幸的是,没有人知道 GitLab 可以做什么。你必须亲自尝试一下。”
---
via: <https://www.linux.com/learn/how-run-your-own-git-server>
作者:[Swapnil Bhartiya](https://www.linux.com/users/arnieswap) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wyxplus](https://github.com/wyxplus) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,859 | 如何检查 Linux 中的可用磁盘空间 | https://opensource.com/article/18/7/how-check-free-disk-space-linux | 2018-07-23T14:37:51 | [
"磁盘"
] | https://linux.cn/article-9859-1.html |
>
> 用这里列出的方便的工具来跟踪你的磁盘利用率。
>
>
>

跟踪磁盘利用率信息是系统管理员(和其他人)的日常待办事项列表之一。Linux 有一些内置的使用程序来帮助提供这些信息。
### df
`df` 命令意思是 “disk-free”,显示 Linux 系统上可用和已使用的磁盘空间。
`df -h` 以人类可读的格式显示磁盘空间。
`df -a` 显示文件系统的完整磁盘使用情况,即使 Available(可用) 字段为 0。

`df -T` 显示磁盘使用情况以及每个块的文件系统类型(例如,xfs、ext2、ext3、btrfs 等)。
`df -i` 显示已使用和未使用的 inode。

### du
`du` 显示文件,目录等的磁盘使用情况,默认情况下以 kb 为单位显示。
`du -h` 以人类可读的方式显示所有目录和子目录的磁盘使用情况。
`du -a` 显示所有文件的磁盘使用情况。
`du -s` 提供特定文件或目录使用的总磁盘空间。

### ls -al
`ls -al` 列出了特定目录的全部内容及大小。

### stat
`stat <文件/目录>`显示文件/目录或文件系统的大小和其他统计信息。

### fdisk -l
`fdisk -l` 显示磁盘大小以及磁盘分区信息。

这些是用于检查 Linux 文件空间的大多数内置实用程序。有许多类似的工具,如 [Disks](https://wiki.gnome.org/Apps/Disks)(GUI 工具),[Ncdu](https://dev.yorhel.nl/ncdu) 等,它们也显示磁盘空间的利用率。你有你最喜欢的工具而它不在这个列表上吗?请在评论中分享。
---
via: <https://opensource.com/article/18/7/how-check-free-disk-space-linux>
作者:[Archit Modi](https://opensource.com/users/architmodi) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Keeping track of disk utilization information is on system administrators' (and others') daily to-do list. Linux has a few built-in utilities that help provide that information.
[Linux df command](https://opensource.com/article/21/7/check-disk-space-linux-df)
The `df`
command stands for "disk-free," and shows available and used disk space on the Linux system.
`df -h`
shows disk space in human-readable format
`df -a`
shows the file system's complete disk usage even if the Available field is 0
`df -T`
shows the disk usage along with each block's filesystem type (e.g., xfs, ext2, ext3, btrfs, etc.)
`df -i`
shows used and free inodes
You can get this information in a graphical view using the **Disks** (gnome-disk-utility) in the GNOME desktop. Launch it to see all disks detected by your computer, and click a partition to see details about it, including space used and space remaining.
opensource.com
[Linux du command](https://opensource.com/article/21/7/check-disk-space-linux-du)
`du`
shows the disk usage of files, folders, etc. in the default kilobyte size
`du -h`
shows disk usage in human-readable format for all directories and subdirectories
`du -a`
shows disk usage for all files
`du -s`
provides total disk space used by a particular file or directory
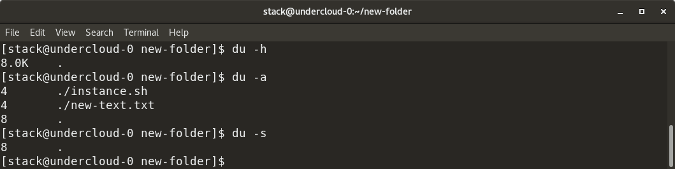
The following commands will check your total space and your utilized space.
This information can be represented visually in GNOME with the **Disk Usage** application, or with **Filelight** in the KDE Plasma desktop. In both applications, disk usage is mapped to concentric circles, with the middle being the base folder (usually your **/home** directory, but it's up to you) with each outer ring representing one directory level deeper. Roll your mouse over any segment for detailed information about what's taking up space.
opensource.com
## Linux ls -al command
`ls -al`
lists the entire contents, along with their size, of a particular directory
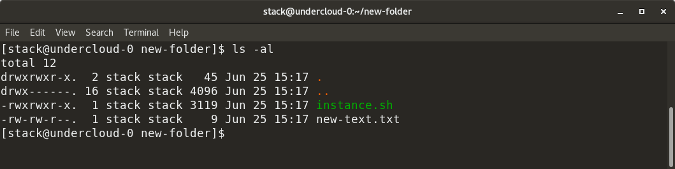
## Linux stat command
`stat <file/directory> `
displays the size and other stats of a file/directory or a filesystem.
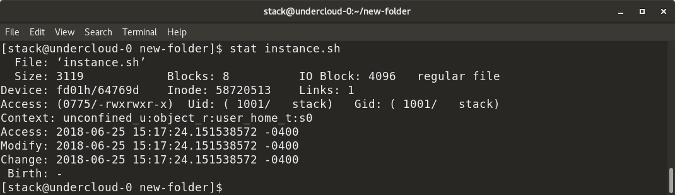
## Linux fdisk -l command
`fdisk -l`
shows disk size along with disk partitioning information
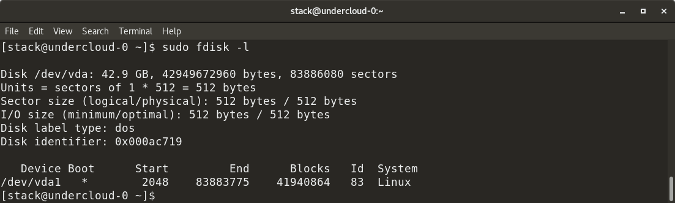
These are most of the built-in utilities for checking file space in Linux. There are many similar tools, like [Disks](https://wiki.gnome.org/Apps/Disks) (GUI), [Ncdu](https://dev.yorhel.nl/ncdu), etc., that also show disk space utilization. Do you have a favorite tool that's not on this list? Please share in the comments.
*This article was originally published in July 2018 and has been updated to include additional information.*
## Comments are closed. |
9,860 | 在 Ubuntu 18.04 LTS 上安装 Microsoft Windows 字体 | https://www.ostechnix.com/install-microsoft-windows-fonts-ubuntu-16-04/ | 2018-07-23T23:33:00 | [
"字体"
] | https://linux.cn/article-9860-1.html | 
大多数教育机构仍在使用 Microsoft 字体, 我不清楚其他国家是什么情况。但在泰米尔纳德邦(印度的一个州), **Times New Roman** 和 **Arial** 字体主要被用于大学和学校的几乎所有文档工作、项目和作业。不仅是教育机构,而且一些小型组织、办公室和商店仍在使用 MS Windows 字体。以防万一,如果你需要在 Ubuntu 桌面版上使用 Microsoft 字体,请按照以下步骤安装。
**免责声明**: Microsoft 已免费发布其核心字体。 但**请注意 Microsoft 字体是禁止使用在其他操作系统中**。在任何 Linux 操作系统中安装 MS 字体之前请仔细阅读 EULA 。我们不负责这种任何种类的盗版行为。
(LCTT 译注:本文只做技术探讨,并不代表作者、译者和本站鼓励任何行为。)
### 在 Ubuntu 18.04 LTS 桌面版上安装 MS 字体
如下所示安装 MS TrueType 字体:
```
$ sudo apt update
$ sudo apt install ttf-mscorefonts-installer
```
然后将会出现 Microsoft 的最终用户协议向导,点击 **OK** 以继续。

点击 **Yes** 已接受 Microsoft 的协议:

安装字体之后, 我们需要使用命令行来更新字体缓存:
```
$ sudo fc-cache -f -v
```
**示例输出:**
```
/usr/share/fonts: caching, new cache contents: 0 fonts, 6 dirs
/usr/share/fonts/X11: caching, new cache contents: 0 fonts, 4 dirs
/usr/share/fonts/X11/Type1: caching, new cache contents: 8 fonts, 0 dirs
/usr/share/fonts/X11/encodings: caching, new cache contents: 0 fonts, 1 dirs
/usr/share/fonts/X11/encodings/large: caching, new cache contents: 0 fonts, 0 dirs
/usr/share/fonts/X11/misc: caching, new cache contents: 89 fonts, 0 dirs
/usr/share/fonts/X11/util: caching, new cache contents: 0 fonts, 0 dirs
/usr/share/fonts/cMap: caching, new cache contents: 0 fonts, 0 dirs
/usr/share/fonts/cmap: caching, new cache contents: 0 fonts, 5 dirs
/usr/share/fonts/cmap/adobe-cns1: caching, new cache contents: 0 fonts, 0 dirs
/usr/share/fonts/cmap/adobe-gb1: caching, new cache contents: 0 fonts, 0 dirs
/usr/share/fonts/cmap/adobe-japan1: caching, new cache contents: 0 fonts, 0 dirs
/usr/share/fonts/cmap/adobe-japan2: caching, new cache contents: 0 fonts, 0 dirs
/usr/share/fonts/cmap/adobe-korea1: caching, new cache contents: 0 fonts, 0 dirs
/usr/share/fonts/opentype: caching, new cache contents: 0 fonts, 2 dirs
/usr/share/fonts/opentype/malayalam: caching, new cache contents: 3 fonts, 0 dirs
/usr/share/fonts/opentype/noto: caching, new cache contents: 24 fonts, 0 dirs
/usr/share/fonts/truetype: caching, new cache contents: 0 fonts, 46 dirs
/usr/share/fonts/truetype/Gargi: caching, new cache contents: 1 fonts, 0 dirs
/usr/share/fonts/truetype/Gubbi: caching, new cache contents: 1 fonts, 0 dirs
/usr/share/fonts/truetype/Nakula: caching, new cache contents: 1 fonts, 0 dirs
/usr/share/fonts/truetype/Navilu: caching, new cache contents: 1 fonts, 0 dirs
/usr/share/fonts/truetype/Sahadeva: caching, new cache contents: 1 fonts, 0 dirs
/usr/share/fonts/truetype/Sarai: caching, new cache contents: 1 fonts, 0 dirs
/usr/share/fonts/truetype/abyssinica: caching, new cache contents: 1 fonts, 0 dirs
/usr/share/fonts/truetype/dejavu: caching, new cache contents: 6 fonts, 0 dirs
/usr/share/fonts/truetype/droid: caching, new cache contents: 1 fonts, 0 dirs
/usr/share/fonts/truetype/fonts-beng-extra: caching, new cache contents: 6 fonts, 0 dirs
/usr/share/fonts/truetype/fonts-deva-extra: caching, new cache contents: 3 fonts, 0 dirs
/usr/share/fonts/truetype/fonts-gujr-extra: caching, new cache contents: 5 fonts, 0 dirs
/usr/share/fonts/truetype/fonts-guru-extra: caching, new cache contents: 1 fonts, 0 dirs
/usr/share/fonts/truetype/fonts-kalapi: caching, new cache contents: 1 fonts, 0 dirs
/usr/share/fonts/truetype/fonts-orya-extra: caching, new cache contents: 1 fonts, 0 dirs
/usr/share/fonts/truetype/fonts-telu-extra: caching, new cache contents: 2 fonts, 0 dirs
/usr/share/fonts/truetype/freefont: caching, new cache contents: 12 fonts, 0 dirs
/usr/share/fonts/truetype/kacst: caching, new cache contents: 15 fonts, 0 dirs
/usr/share/fonts/truetype/kacst-one: caching, new cache contents: 2 fonts, 0 dirs
/usr/share/fonts/truetype/lao: caching, new cache contents: 1 fonts, 0 dirs
/usr/share/fonts/truetype/liberation: caching, new cache contents: 16 fonts, 0 dirs
/usr/share/fonts/truetype/liberation2: caching, new cache contents: 12 fonts, 0 dirs
/usr/share/fonts/truetype/lohit-assamese: caching, new cache contents: 1 fonts, 0 dirs
/usr/share/fonts/truetype/lohit-bengali: caching, new cache contents: 1 fonts, 0 dirs
/usr/share/fonts/truetype/lohit-devanagari: caching, new cache contents: 1 fonts, 0 dirs
/usr/share/fonts/truetype/lohit-gujarati: caching, new cache contents: 1 fonts, 0 dirs
/usr/share/fonts/truetype/lohit-kannada: caching, new cache contents: 1 fonts, 0 dirs
/usr/share/fonts/truetype/lohit-malayalam: caching, new cache contents: 1 fonts, 0 dirs
/usr/share/fonts/truetype/lohit-oriya: caching, new cache contents: 1 fonts, 0 dirs
/usr/share/fonts/truetype/lohit-punjabi: caching, new cache contents: 1 fonts, 0 dirs
/usr/share/fonts/truetype/lohit-tamil: caching, new cache contents: 1 fonts, 0 dirs
/usr/share/fonts/truetype/lohit-tamil-classical: caching, new cache contents: 1 fonts, 0 dirs
/usr/share/fonts/truetype/lohit-telugu: caching, new cache contents: 1 fonts, 0 dirs
/usr/share/fonts/truetype/malayalam: caching, new cache contents: 11 fonts, 0 dirs
/usr/share/fonts/truetype/msttcorefonts: caching, new cache contents: 60 fonts, 0 dirs
/usr/share/fonts/truetype/noto: caching, new cache contents: 2 fonts, 0 dirs
/usr/share/fonts/truetype/openoffice: caching, new cache contents: 1 fonts, 0 dirs
/usr/share/fonts/truetype/padauk: caching, new cache contents: 4 fonts, 0 dirs
/usr/share/fonts/truetype/pagul: caching, new cache contents: 1 fonts, 0 dirs
/usr/share/fonts/truetype/samyak: caching, new cache contents: 1 fonts, 0 dirs
/usr/share/fonts/truetype/samyak-fonts: caching, new cache contents: 3 fonts, 0 dirs
/usr/share/fonts/truetype/sinhala: caching, new cache contents: 1 fonts, 0 dirs
/usr/share/fonts/truetype/tibetan-machine: caching, new cache contents: 1 fonts, 0 dirs
/usr/share/fonts/truetype/tlwg: caching, new cache contents: 58 fonts, 0 dirs
/usr/share/fonts/truetype/ttf-khmeros-core: caching, new cache contents: 2 fonts, 0 dirs
/usr/share/fonts/truetype/ubuntu: caching, new cache contents: 13 fonts, 0 dirs
/usr/share/fonts/type1: caching, new cache contents: 0 fonts, 1 dirs
/usr/share/fonts/type1/gsfonts: caching, new cache contents: 35 fonts, 0 dirs
/usr/local/share/fonts: caching, new cache contents: 0 fonts, 0 dirs
/home/sk/.local/share/fonts: skipping, no such directory
/home/sk/.fonts: skipping, no such directory
/var/cache/fontconfig: cleaning cache directory
/home/sk/.cache/fontconfig: cleaning cache directory
/home/sk/.fontconfig: not cleaning non-existent cache directory
fc-cache: succeeded
```
### 在 Linux 和 Windows 双启动的机器上安装 MS 字体
如果你有 Linux 和 Windows 的双启动系统,你可以轻松地从 Windows C 驱动器上安装 MS 字体。 你所要做的就是挂载 Windows 分区(C:/windows)。
我假设你已经在 Linux 中将 `C:\Windows` 分区挂载在了 `/Windowsdrive` 目录下。
现在,将字体位置链接到你的 Linux 系统的字体文件夹,如下所示:
```
ln -s /Windowsdrive/Windows/Fonts /usr/share/fonts/WindowsFonts
```
链接字体文件之后,使用命令行重新生成 fontconfig 缓存:
```
fc-cache
```
或者,将所有的 Windows 字体复制到 `/usr/share/fonts` 目录下并使用一下命令安装字体:
```
mkdir /usr/share/fonts/WindowsFonts
cp /Windowsdrive/Windows/Fonts/* /usr/share/fonts/WindowsFonts
chmod 755 /usr/share/fonts/WindowsFonts/*
```
最后,使用命令行重新生成 fontconfig 缓存:
```
fc-cache
```
### 测试 Windows 字体
安装 MS 字体后打开 LibreOffice 或 GIMP。 现在,你将会看到 Microsoft coretype 字体。

就是这样, 希望这本指南有用。我再次警告你,在其他操作系统中使用 MS 字体是被禁止的。在安装 MS 字体之前请先阅读 Microsoft 许可协议。
如果你觉得我们的指南有用,请在你的社区、专业网络上分享并支持我们。还有更多好东西在等着我们。持续访问!
庆祝吧!!
---
via: <https://www.ostechnix.com/install-microsoft-windows-fonts-ubuntu-16-04/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Auk7F7](https://github.com/Auk7F7) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,861 | IT 自动化的下一步是什么: 6 大趋势 | https://enterprisersproject.com/article/2018/3/what-s-next-it-automation-6-trends-watch | 2018-07-24T00:36:00 | [
"自动化"
] | https://linux.cn/article-9861-1.html |
>
> 自动化专家分享了一点对 [自动化](https://enterprisersproject.com/tags/automation)不远的将来的看法。请将这些保留在你的视线之内。
>
>
>

我们最近讨论了 [推动 IT 自动化的因素](https://enterprisersproject.com/article/2017/12/5-factors-fueling-automation-it-now),可以看到[当前趋势](https://enterprisersproject.com/article/2017/12/4-trends-watch-it-automation-expands)正在增长,以及那些给刚开始使用自动化部分流程的组织的 [有用的技巧](https://enterprisersproject.com/article/2018/1/getting-started-automation-6-tips) 。
噢,我们也分享了如何在贵公司[进行自动化的案例](https://enterprisersproject.com/article/2018/1/how-make-case-it-automation)及 [长期成功的关键](https://enterprisersproject.com/article/2018/1/it-automation-best-practices-7-keys-long-term-success)的专家建议。
现在,只有一个问题:自动化的下一步是什么? 我们邀请一系列专家分享一下 [自动化](https://enterprisersproject.com/tags/automation)不远的将来的看法。 以下是他们建议 IT 领域领导需密切关注的六大趋势。
### 1、 机器学习的成熟
对于关于 [机器学习](https://enterprisersproject.com/article/2018/2/how-spot-machine-learning-opportunity)(与“自我学习系统”相似的定义)的讨论,对于绝大多数组织的项目来说,实际执行起来它仍然为时过早。但预计这将发生变化,机器学习将在下一次 IT 自动化浪潮中将扮演着至关重要的角色。
[Advanced Systems Concepts, Inc.](https://www.advsyscon.com/en-us/) 公司的工程总监 Mehul Amin 指出机器学习是 IT 自动化下一个关键增长领域之一。
“随着数据化的发展,自动化软件理应可以自我决策,否则这就是开发人员的责任了”,Amin 说。 “例如,开发者构建了需要执行的内容,但通过使用来自系统内部分析的软件,可以确定执行该流程的最佳系统。”
假设将这个系统延伸到其他地方中。Amin 指出,机器学习可以使自动化系统在必要的时候提供额外的资源,以需要满足时间线或 SLA,同样在不需要资源以及其他的可能性的时候退出。
显然不只有 Amin 一个人这样认为。
“IT 自动化正在走向自我学习的方向” ,[Sungard Availability Services](https://www.sungardas.com/en/) 公司首席架构师 Kiran Chitturi 表示,“系统将会能测试和监控自己,加强业务流程和软件交付能力。”
Chitturi 指出自动化测试就是个例子。脚本测试已经被广泛采用,但很快这些自动化测试流程将会更容易学习,更快发展,例如开发出新的代码或将更为广泛地影响生产环境。
### 2、 人工智能催生的自动化
上述原则同样适合与相关的(但是独立的) [人工智能](https://enterprisersproject.com/tags/artificial-intelligence)的领域。根据对人工智能的定义,机器学习在短时间内可能会对 IT 领域产生巨大的影响(并且我们可能会看到这两个领域的许多重叠的定义和理解)。假定新兴的人工智能技术将也会产生新的自动化机会。
[SolarWinds](https://www.solarwinds.com/) 公司技术负责人 Patrick Hubbard 说,“人工智能和机器学习的整合普遍被认为对未来几年的商业成功起至关重要的作用。”
### 3、 这并不意味着不再需要人力
让我们试着安慰一下那些不知所措的人:前两种趋势并不一定意味着我们将失去工作。
这很可能意味着各种角色的改变,以及[全新角色](https://enterprisersproject.com/article/2017/12/8-emerging-ai-jobs-it-pros)的创造。
但是在可预见的将来,至少,你不必需要对机器人鞠躬。
“一台机器只能运行在给定的环境变量中——它不能选择包含新的变量,在今天只有人类可以这样做,” Hubbard 解释说。“但是,对于 IT 专业人员来说,这将需要培养 AI 和自动化技能,如对程序设计、编程、管理人工智能和机器学习功能算法的基本理解,以及用强大的安全状态面对更复杂的网络攻击。”
Hubbard 分享一些新的工具或功能例子,例如支持人工智能的安全软件或机器学习的应用程序,这些应用程序可以远程发现石油管道中的维护需求。两者都可以提高效益和效果,自然不会代替需要信息安全或管道维护的人员。
“许多新功能仍需要人工监控,”Hubbard 说。“例如,为了让机器确定一些‘预测’是否可能成为‘规律’,人为的管理是必要的。”
即使你把机器学习和 AI 先放在一边,看待一般的 IT 自动化,同样原理也是成立的,尤其是在软件开发生命周期中。
[Juniper Networks](https://www.juniper.net/) 公司自动化首席架构师 Matthew Oswalt ,指出 IT 自动化增长的根本原因是它通过减少操作基础设施所需的人工工作量来创造直接价值。
>
> 在代码上,操作工程师可以使用事件驱动的自动化提前定义他们的工作流程,而不是在凌晨 3 点来应对基础设施的问题。
>
>
>
“它也将操作工作流程作为代码而不再是容易过时的文档或系统知识阶段,”Oswalt 解释说。“操作人员仍然需要在[自动化]工具响应事件方面后发挥积极作用。采用自动化的下一个阶段是建立一个能够跨 IT 频谱识别发生的有趣事件的系统,并以自主方式进行响应。在代码上,操作工程师可以使用事件驱动的自动化提前定义他们的工作流程,而不是在凌晨 3 点来应对基础设施的问题。他们可以依靠这个系统在任何时候以同样的方式作出回应。”
### 4、 对自动化的焦虑将会减少
SolarWinds 公司的 Hubbard 指出,“自动化”一词本身就产生大量的不确定性和担忧,不仅仅是在 IT 领域,而且是跨专业领域,他说这种担忧是合理的。但一些随之而来的担忧可能被夸大了,甚至与科技产业本身共存。现实可能实际上是这方面的镇静力:当自动化的实际实施和实践帮助人们认识到这个列表中的第 3 项时,我们将看到第 4 项的出现。
“今年我们可能会看到对自动化焦虑的减少,更多的组织开始接受人工智能和机器学习作为增加现有人力资源的一种方式,”Hubbard 说。“自动化历史上为更多的工作创造了空间,通过降低成本和时间来完成较小任务,并将劳动力重新集中到无法自动化并需要人力的事情上。人工智能和机器学习也是如此。”
自动化还将减少令 IT 领导者神经紧张的一些焦虑:安全。正如[红帽](https://www.redhat.com/en?intcmp=701f2000000tjyaAAA)公司首席架构师 Matt Smith 最近[指出](https://enterprisersproject.com/article/2018/2/12-bad-enterprise-security-habits-break)的那样,自动化将越来越多地帮助 IT 部门降低与维护任务相关的安全风险。
他的建议是:“首先在维护活动期间记录和自动化 IT 资产之间的交互。通过依靠自动化,您不仅可以消除之前需要大量手动操作和手术技巧的任务,还可以降低人为错误的风险,并展示当您的 IT 组织采纳变更和新工作方法时可能发生的情况。最终,这将迅速减少对应用安全补丁的抵制。而且它还可以帮助您的企业在下一次重大安全事件中摆脱头条新闻。”
\**[ 阅读全文: [12个企业安全坏习惯要打破。](https://enterprisersproject.com/article/2018/2/12-bad-enterprise-security-habits-break?sc_cid=70160000000h0aXAAQ) ] \**
### 5、 脚本和自动化工具将持续发展
许多组织看到了增加自动化的第一步,通常以脚本或自动化工具(有时称为配置管理工具)的形式作为“早期”工作。
但是随着各种自动化技术的使用,对这些工具的观点也在不断发展。
[DataVision](https://datavision.com/) 首席运营官 Mark Abolafia 表示:“数据中心环境中存在很多重复性过程,容易出现人为错误,[Ansible](https://opensource.com/tags/ansible) 等技术有助于缓解这些问题。“通过 Ansible ,人们可以为一组操作编写特定的步骤,并输入不同的变量,例如地址等,使过去长时间的过程链实现自动化,而这些过程以前都需要人为触摸和更长的交付时间。”
**[想了解更多关于 Ansible 这个方面的知识吗?阅读相关文章:[使用 Ansible 时的成功秘诀](https://opensource.com/article/18/2/tips-success-when-getting-started-ansible?intcmp=701f2000000tjyaAAA)。 ]**
另一个因素是:工具本身将继续变得更先进。
“使用先进的 IT 自动化工具,开发人员将能够在更短的时间内构建和自动化工作流程,减少易出错的编码,” ASCI 公司的 Amin 说。“这些工具包括预先构建的、预先测试过的拖放式集成,API 作业,丰富的变量使用,参考功能和对象修订历史记录。”
### 6、 自动化开创了新的指标机会
正如我们在此前所说的那样,IT 自动化不是万能的。它不会修复被破坏的流程,或者以其他方式为您的组织提供全面的灵丹妙药。这也是持续不断的:自动化并不排除衡量性能的必要性。
**[ 参见我们的相关文章 [DevOps 指标:你在衡量什么重要吗?](https://enterprisersproject.com/article/2017/7/devops-metrics-are-you-measuring-what-matters?sc_cid=70160000000h0aXAAQ) ]**
实际上,自动化应该打开了新的机会。
[Janeiro Digital](https://www.janeirodigital.com/) 公司架构师总裁 Josh Collins 说,“随着越来越多的开发活动 —— 源代码管理、DevOps 管道、工作项目跟踪等转向 API 驱动的平台,将这些原始数据拼接在一起以描绘组织效率提升的机会和图景”。
Collins 认为这是一种可能的新型“开发组织度量指标”。但不要误认为这意味着机器和算法可以突然预测 IT 所做的一切。
“无论是衡量个人资源还是整体团队,这些指标都可以很强大 —— 但应该用大量的背景来衡量。”Collins 说,“将这些数据用于高层次趋势并确认定性观察 —— 而不是临床评级你的团队。”
**想要更多这样知识, IT 领导者?[注册我们的每周电子邮件通讯](https://enterprisersproject.com/email-newsletter?intcmp=701f2000000tsjPAAQ)。**
---
via: <https://enterprisersproject.com/article/2018/3/what-s-next-it-automation-6-trends-watch>
作者:[Kevin Casey](https://enterprisersproject.com/user/kevin-casey) 译者:[MZqk](https://github.com/MZqk) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | We’ve recently covered the [factors fueling IT automation](https://enterprisersproject.com/article/2017/12/5-factors-fueling-automation-it-now), the [current trends](https://enterprisersproject.com/article/2017/12/4-trends-watch-it-automation-expands) to watch as adoption grows, and [helpful tips](https://enterprisersproject.com/article/2018/1/getting-started-automation-6-tips) for those organizations just beginning to automate certain processes.
Oh, and we also shared expert advice on [how to make the case for automation](https://enterprisersproject.com/article/2018/1/how-make-case-it-automation) in your company, as well as [keys for long-term success](https://enterprisersproject.com/article/2018/1/it-automation-best-practices-7-keys-long-term-success).
Now, there’s just one question: What’s next? We asked a range of experts to share a peek into the not-so-distant future of [automation](https://enterprisersproject.com/taxonomy/term/66). Here are six trends they advise IT leaders to monitor closely.
**[ Want more lessons learned from your peers and automation experts? Get our free resource, Automation: The IT leader's guide. ]**
## 1. Machine learning matures
For all of the buzz around [machine learning](https://enterprisersproject.com/article/2018/2/how-spot-machine-learning-opportunity) (and the overlapping phrase “self-learning systems”), it’s still very early days for most organizations in terms of actual implementations. Expect that to change, and for machine learning to play a significant role in the next waves of IT automation.
Mehul Amin, director of engineering for [Advanced Systems Concepts, Inc.](https://www.advsyscon.com/en-us/), points to machine learning as one of the next key growth areas for IT automation.
“With the data that is developed, automation software can make decisions that otherwise might be the responsibility of the developer,” Amin says. “For example, the developer builds what needs to be executed, but identifying the best system to execute the processes might be [done] by software using analytics from within the system.”
That extends elsewhere in this same hypothetical system; Amin notes that machine learning can enable automated systems to provision additional resources when necessary to meet timelines or SLAs, as well as retire those resources when they’re no longer needed, and other possibilities.
Amin is certainly not alone.
“IT automation is moving towards self-learning,” says Kiran Chitturi, CTO architect at [Sungard Availability Services](https://www.sungardas.com/en/). “Systems will be able to test and monitor themselves, enhancing business processes and software delivery.”
Chitturi points to automated testing as an example; test scripts are already in widespread adoption, but soon those automated testing processes may be more likely to learn as they go, developing, for example, wider recognition of how new code or code changes will impact production environments.
## 2. Artificial intelligence spawns automation opportunities
The same principles above hold true for the related (but separate) field of [artificial intelligence](https://enterprisersproject.com/taxonomy/term/426). Depending on your definition of AI, it seems likely that machine learning will have the more significant IT impact in the near term (and we’re likely to see a lot of overlapping definitions and understandings of the two fields). Assume that emerging AI technologies will spawn new automation opportunities, too.
“The integration of artificial intelligence (AI) and machine learning capabilities is widely perceived as critical for business success in the coming years,” says Patrick Hubbard, head geek at [SolarWinds](https://www.solarwinds.com/).
## 3. That doesn’t mean people are obsolete
Let’s try to calm those among us who are now hyperventilating into a paper bag: The first two trends don’t necessarily mean we’re all going to be out of a job.
It is likely to mean changes to various roles – and the creation of [new roles](https://enterprisersproject.com/article/2017/12/8-emerging-ai-jobs-it-pros) altogether.
But in the foreseeable future, at least, you don’t need to practice bowing to your robot overlords.
“A machine can only consider the environment variables that it is given – it can’t choose to include new variables, only a human can do this today,” Hubbard explains. “However, for IT professionals this will necessitate the cultivation of AI- and automation-era skills such as programming, coding, a basic understanding of the algorithms that govern AI and machine learning functionality, and a strong security posture in the face of more sophisticated cyberattacks.”
Hubbard shares the example of new tools or capabilities such as AI-enabled security software or machine-learning applications that remotely spot maintenance needs in an oil pipeline. Both might improve efficiency and effectiveness; neither automatically replaces the people necessary for information security or pipeline maintenance.
“Many new functionalities still require human oversight,” Hubbard says. “In order for a machine to determine if something ‘predictive’ could become ‘prescriptive,’ for example, human management is needed.”
The same principle holds true even if you set machine learning and AI aside for a moment and look at IT automation more generally, especially in the software development lifecycle.
Matthew Oswalt, lead architect for automation at [Juniper Networks](https://www.juniper.net/), points out that the fundamental reason IT automation is growing is that it is creating immediate value by reducing the amount of manual effort required to operate infrastructure.
“It also sets the stage for treating their operations workflows as code rather than easily outdated documentation or tribal knowledge,” Oswalt explains. “Operations staff are still required to play an active role in how [automation] tooling responds to events. The next phase of adopting automation is to put in place a system that is able to recognize interesting events that take place across the IT spectrum and respond in an autonomous fashion. Rather than responding to an infrastructure issue at 3 a.m. themselves, operations engineers can use event-driven automation to define their workflows ahead of time, as code. They can rely on this system to respond in the same way they would, at any time.”
## 4. Automation anxiety will decrease
Hubbard of SolarWinds notes that the term “automation” itself tends to spawn a lot of uncertainty and concern, not just in IT but across professional disciplines, and he says that concern is legitimate. But some of the attendant fears may be overblown, and even perpetuated by the tech industry itself. Reality might actually be the calming force on this front: When the actual implementation and practice of automation helps people realize #3 on this list, then we’ll see #4 occur.
“This year we’ll likely see a decrease in automation anxiety and more organizations begin to embrace AI and machine learning as a way to augment their existing human resources,” Hubbard says. “Automation has historically created room for more jobs by lowering the cost and time required to accomplish smaller tasks and refocusing the workforce on things that cannot be automated and require human labor. The same will be true of AI and machine learning.”
Automation will also decrease some anxiety around the topic most likely to increase an IT leader’s blood pressure: Security. As Matt Smith, chief architect, [Red Hat](https://www.redhat.com/en?intcmp=701f2000000tjyaAAA), recently [noted](https://enterprisersproject.com/article/2018/2/12-bad-enterprise-security-habits-break), automation will increasingly help IT groups reduce the security risks associated with maintenance tasks.
His advice: “Start by documenting and automating the interactions between IT assets during maintenance activities. By relying on automation, not only will you eliminate tasks that historically required much manual effort and surgical skill, you will also be reducing the risks of human error and demonstrating what’s possible when your IT organization embraces change and new methods of work. Ultimately, this will reduce resistance to promptly applying security patches. And it could also help keep your business out of the headlines during the next major security event.”
**[ Read the full article: 12 bad enterprise security habits to break. ] **
## 5. Continued evolution of scripting and automation tools
Many organizations see the first steps toward increasing automation – usually in the form of scripting or automation tools (sometimes referred to as configuration management tools) – as "early days" work.
But views of those tools are evolving as the use of various automation technologies grows.
“There are many processes in the data center environment that are repetitive and subject to human error, and technologies such as [Ansible](https://opensource.com/tags/ansible) help to ameliorate those issues,” says Mark Abolafia, chief operating officer at [DataVision](https://datavision.com/). “With Ansible, one can write a specific playbook for a set of actions and input different variables such as addresses, etc., to automate long chains of process that were previously subject to human touch and longer lead times.”
**[ Want to learn more about this aspect of Ansible? Read the related article: Tips for success when getting started with Ansible. ]**
Another factor: The tools themselves will continue to become more advanced.
“With advanced IT automation tools, developers will be able to build and automate workflows in less time, reducing error-prone coding,” says Amin of ASCI. “These tools include pre-built, pre-tested drag-and-drop integrations, API jobs, the rich use of variables, reference functionality, and object revision history.”
## 6. Automation opens new metrics opportunities
As we’ve said previously in this space, automation isn’t IT snake oil. It won’t fix busted processes or otherwise serve as some catch-all elixir for what ails your organization. That’s true on an ongoing basis, too: Automation doesn’t eliminate the need to measure performance.
**[ See our related article DevOps metrics: Are you measuring what matters? ]**
In fact, automation should open up new opportunities here.
“As more and more development activities – source control, DevOps pipelines, work item tracking – move to the API-driven platforms – the opportunity and temptation to stitch these pieces of raw data together to paint the picture of your organization's efficiency increases,” says Josh Collins, VP of architecture at [Janeiro Digital](https://www.janeirodigital.com/).
Collins thinks of this as a possible new “development organization metrics-in-a-box.” But don’t mistake that to mean machines and algorithms can suddenly measure everything IT does.
“Whether measuring individual resources or the team in aggregate, these metrics can be powerful – but should be balanced with a heavy dose of context,” Collins says. “Use this data for high-level trends and to affirm qualitative observations – not to clinically grade your team.”
**Want more wisdom like this, IT leaders? Sign up for our weekly email newsletter.** |
9,862 | 可代替 Dropbox 的 5 个开源软件 | https://opensource.com/alternatives/dropbox | 2018-07-24T01:01:00 | [
"Dropbox",
"文件共享"
] | https://linux.cn/article-9862-1.html |
>
> 寻找一个不会破坏你的安全、自由或银行资产的文件共享应用。
>
>
>

Dropbox 在文件共享应用中是个 800 磅的大猩猩。尽管它是个极度流行的工具,但你可能仍想使用一个软件去替代它。
也行你出于各种好的理由,包括安全和自由,这使你决定用[开源方式](https://opensource.com/open-source-way)。亦或是你已经被数据泄露吓坏了,或者定价计划不能满足你实际需要的存储量。
幸运的是,有各种各样的开源文件共享应用,可以提供给你更多的存储容量,更好的安全性,并且以低于 Dropbox 很多的价格来让你掌控你自己的数据。有多低呢?如果你有一定的技术和一台 Linux 服务器可供使用,那尝试一下免费的应用吧。
这里有 5 个最好的可以代替 Dropbox 的开源应用,以及其他一些,你可能想考虑使用。
### ownCloud

[ownCloud](https://owncloud.org/) 发布于 2010 年,是本文所列应用中最老的,但是不要被这件事蒙蔽:它仍然十分流行(根据该公司统计,有超过 150 万用户),并且由由 1100 个参与者的社区积极维护,定期发布更新。
它的主要特点——文件共享和文档写作功能和 Dropbox 的功能相似。它们的主要区别(除了它的[开源协议](https://www.gnu.org/licenses/agpl-3.0.html))是你的文件可以托管在你的私人 Linux 服务器或云上,给予用户对自己数据完全的控制权。(自托管是本文所列应用的一个普遍的功能。)
使用 ownCloud,你可以通过 Linux、MacOS 或 Windows 的客户端和安卓、iOS 的移动应用程序来同步和访问文件。你还可以通过带有密码保护的链接分享给其他人来协作或者上传和下载。数据传输通过端到端加密(E2EE)和 SSL 加密来保护安全。你还可以通过使用它的 [市场](https://marketplace.owncloud.com/) 中的各种各样的第三方应用来扩展它的功能。当然,它也提供付费的、商业许可的企业版本。
ownCloud 提供了详尽的[文档](https://doc.owncloud.com/),包括安装指南和针对用户、管理员、开发者的手册。你可以从 GitHub 仓库中获取它的[源码](https://github.com/owncloud)。
### NextCloud

[NextCloud](https://nextcloud.com/) 在 2016 年从 ownCloud 分裂出来,并且具有很多相同的功能。 NextCloud 以它的高安全性和法规遵从性作为它的一个独特的[推崇的卖点](https://nextcloud.com/secure/)。它具有 HIPAA (医疗) 和 GDPR (隐私)法规遵从功能,并提供广泛的数据策略约束、加密、用户管理和审核功能。它还在传输和存储期间对数据进行加密,并且集成了移动设备管理和身份验证机制 (包括 LDAP/AD、单点登录、双因素身份验证等)。
像本文列表里的其他应用一样, NextCloud 是自托管的,但是如果你不想在自己的 Linux 上安装 NextCloud 服务器,该公司与几个[提供商](https://nextcloud.com/providers/)达成了伙伴合作,提供安装和托管,并销售服务器、设备和服务支持。在[市场](https://apps.nextcloud.com/)中提供了大量的apps 来扩展它的功能。
NextCloud 的[文档](https://nextcloud.com/support/)为用户、管理员和开发者提供了详细的信息,并且它的论坛、IRC 频道和社交媒体提供了基于社区的支持。如果你想贡献或者获取它的源码、报告一个错误、查看它的 AGPLv3 许可,或者想了解更多,请访问它的[GitHub 项目主页](https://github.com/nextcloud)。
### Seafile

与 ownCloud 或 NextCloud 相比,[Seafile](https://www.seafile.com/en/home/) 或许没有花里胡哨的卖点(app 生态),但是它能完成任务。实质上, 它充当了 Linux 服务器上的虚拟驱动器,以扩展你的桌面存储,并允许你使用密码保护和各种级别的权限(即只读或读写) 有选择地共享文件。
它的协作功能包括文件夹权限控制,密码保护的下载链接和像 Git 一样的版本控制和记录。文件使用双因素身份验证、文件加密和 AD/LDAP 集成进行保护,并且可以从 Windows、MacOS、Linux、iOS 或 Android 设备进行访问。
更多详细信息, 请访问 Seafile 的 [GitHub 仓库](https://github.com/haiwen/seafile)、[服务手册](https://manual.seafile.com/)、[wiki](https://seacloud.cc/group/3/wiki/) 和[论坛](https://forum.seafile.com/)。请注意, Seafile 的社区版在 [GPLv2](https://github.com/haiwen/seafile/blob/master/LICENSE.txt) 下获得许可,但其专业版不是开源的。
### OnionShare

[OnionShare](https://onionshare.org/) 是一个很酷的应用:如果你想匿名,它允许你安全地共享单个文件或文件夹。不需要设置或维护服务器,所有你需要做的就是[下载和安装](https://onionshare.org/#downloads),无论是在 MacOS, Windows 还是 Linux 上。文件始终在你自己的计算机上; 当你共享文件时,OnionShare 创建一个 web 服务器,使其可作为 Tor 洋葱服务访问,并生成一个不可猜测的 .onion URL,这个 URL 允许收件人通过 [Tor 浏览器](https://www.torproject.org/)获取文件。
你可以设置文件共享的限制,例如限制可以下载的次数或使用自动停止计时器,这会设置一个严格的过期日期/时间,超过这个期限便不可访问(即使尚未访问该文件)。
OnionShare 在 [GPLv3](https://github.com/micahflee/onionshare/blob/develop/LICENSE) 之下被许可;有关详细信息,请查阅其 [GitHub 仓库](https://github.com/micahflee/onionshare/blob/develop/LICENSE),其中还包括[文档](https://github.com/micahflee/onionshare/wiki),介绍了这个易用的文件共享软件的特点。
### Pydio Cells

[Pydio Cells](https://pydio.com/en) 在 2018 年 5 月推出了稳定版,是对 Pydio 共享应用程序的核心服务器代码的彻底大修。由于 Pydio 的基于 PHP 的后端的限制,开发人员决定用 Go 服务器语言和微服务体系结构重写后端。(前端仍然是基于 PHP 的)。
Pydio Cells 包括通常的共享和版本控制功能,以及应用程序中的消息接受、移动应用程序(Android 和 iOS),以及一种社交网络风格的协作方法。安全性包括基于 OpenID 连接的身份验证、rest 加密、安全策略等。企业发行版中包含着高级功能,但在社区(家庭)版本中,对于大多数中小型企业和家庭用户来说,依然是足够的。
您可以 在 Linux 和 MacOS 里[下载](https://pydio.com/download/) Pydio Cells。有关详细信息, 请查阅 [文档常见问题](https://pydio.com/en/docs/faq)、[源码库](https://github.com/pydio/cells) 和 [AGPLv3 许可证](https://github.com/pydio/pydio-core/blob/develop/LICENSE)
### 其他
如果以上选择不能满足你的需求,你可能想考虑其他开源的文件共享型应用。
* 如果你的主要目的是在设备间同步文件而不是分享文件,考察一下 [Syncthing](https://syncthing.net/)。
* 如果你是一个 Git 的粉丝而不需要一个移动应用。你可能更喜欢 [SparkleShare](http://www.sparkleshare.org/)。
* 如果你主要想要一个地方聚合所有你的个人数据, 看看 [Cozy](https://cozy.io/en/)。
* 如果你想找一个轻量级的或者专注于文件共享的工具,考察一下 [Scott Nesbitt's review](https://opensource.com/article/17/3/file-sharing-tools)——一个罕为人知的工具。
哪个是你最喜欢的开源文件共享应用?在评论中让我们知悉。
---
via: <https://opensource.com/alternatives/dropbox>
作者:[Opensource.com](https://opensource.com) 选题:[lujun9972](https://github.com/lujun9972) 译者:[distant1219](https://github.com/distant1219) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Dropbox is the 800-pound gorilla of filesharing applications. Even though it's a massively popular tool, you may choose to use an alternative.
Maybe that's because you're dedicated to the [open source way](https://opensource.com/open-source-way) for all the good reasons, including security and freedom, or possibly you've been spooked by data breaches. Or perhaps the pricing plan doesn't work out in your favor for the amount of storage you actually need.
Fortunately, there are a variety of open source filesharing applications out there that give you more storage, security, and control over your data at a far lower price than Dropbox charges. How much lower? Try free, if you're a bit tech savvy and have a Linux server to use.
Here are five of the best open source alternatives to Dropbox, plus a few others that you might want to consider.
## ownCloud
[ownCloud](https://owncloud.org/), launched in 2010, is the oldest application on this list, but don't let that fool you: It's still very popular (with over 1.5 million users, according to the company) and actively maintained by a community of 1,100 contributors, with updates released regularly.
Its primary features—file and folding sharing, document collaboration—are similar to Dropbox's. Its primary difference (aside from its [open source license](https://www.gnu.org/licenses/agpl-3.0.html)) is that your files are hosted on your private Linux server or cloud, giving users complete control over your data. (Self-hosting is a common thread among the apps on this list.)
With ownCloud, you can sync and access files through clients for Linux, MacOS, or Windows computers or mobile apps for Android and iOS devices, and provide password-protected links to others for collaboration or file upload/download. Data transfers are secured by end-to-end encryption (E2EE) and SSL encryption. You can also expand its functionality with a wide variety of third-party apps available in its [marketplace](https://marketplace.owncloud.com/), and there is also a paid, commercially licensed enterprise edition.
ownCloud offers comprehensive [documentation](https://doc.owncloud.com/), including an installation guide and manuals for users, admins, and developers, and you can access its [source code](https://github.com/owncloud) in its GitHub repository.
## NextCloud
[NextCloud](https://nextcloud.com/) spun out of ownCloud in 2016 and shares much of the same functionality. Nextcloud [touts](https://nextcloud.com/secure/) its high security and regulatory compliance as a distinguishing feature. It has HIPAA (healthcare) and GDPR (privacy) compliance features and offers extensive data-policy enforcement, encryption, user management, and auditing capabilities. It also encrypts data during transfer and at rest and integrates with mobile device management and authentication mechanisms (including LDAP/AD, single-sign-on, two-factor authentication, etc.).
Like the other solutions on this list, NextCloud is self-hosted, but if you don't want to roll your own NextCloud server on Linux, the company partners with several [providers](https://nextcloud.com/providers/) for setup and hosting and sells servers, appliances, and support. A [marketplace](https://apps.nextcloud.com/) offers numerous apps to extend its features.
NextCloud's [documentation](https://nextcloud.com/support/) page offers thorough information for users, admins, and developers as well as links to its forums, IRC channel, and social media pages for community-based support. If you'd like to contribute, access its source code, report a bug, check out its (AGPLv3) license, or just learn more, visit the project's [GitHub repository](https://github.com/nextcloud).
## Seafile
[Seafile](https://www.seafile.com/en/home/) may not have the bells and whistles (or app ecosystem) of ownCloud or Nextcloud, but it gets the job done. Essentially, it acts as a virtual drive on your Linux server to extend your desktop storage and allow you to share files selectively with password protection and various levels of permission (i.e., read-only or read/write).
Its collaboration features include per-folder access control, password-protected download links, and Git-like version control and retention. Files are secured with two-factor authentication, file encryption, and AD/LDAP integration, and they're accessible from Windows, MacOS, Linux, iOS, or Android devices.
For more information, visit Seafile's [GitHub repository](https://github.com/haiwen/seafile), [server manual](https://manual.seafile.com/), [wiki](https://seacloud.cc/group/3/wiki/), and [forums](https://forum.seafile.com/). Note that Seafile's community edition is licensed under [GPLv2](https://github.com/haiwen/seafile/blob/master/LICENSE.txt), but its professional edition is not open source.
## OnionShare
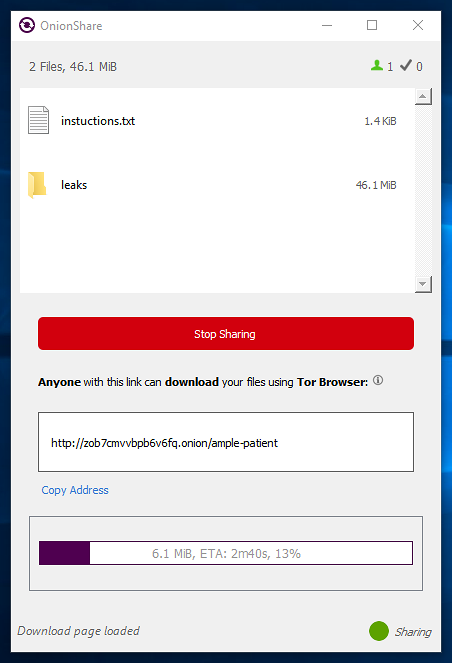
[OnionShare](https://onionshare.org/) is a cool app that does one thing: It allows you to share individual files or folders securely and, if you want, anonymously. There's no server to set up or maintain—all you need to do is [download and install](https://onionshare.org/#downloads) the app on MacOS, Windows, or Linux. Files are always hosted on your own computer; when you share a file, OnionShare creates a web server, makes it accessible as a Tor Onion service, and generates an unguessable .onion URL that allows the recipient to access the file via [Tor browser](https://www.torproject.org/).
You can set limits on your fileshare, such as limiting the number of times it can be downloaded or using an auto-stop timer, which sets a strict expiration date/time after which the file is inaccessible (even if it hasn't been accessed yet).
OnionShare is licensed under [GPLv3](https://github.com/micahflee/onionshare/blob/develop/LICENSE); for more information, check out its GitHub [repository](https://github.com/micahflee/onionshare/blob/develop/LICENSE), which also includes [documentation](https://github.com/micahflee/onionshare/wiki) that covers the features in this easy-to-use filesharing application.
## Pydio Cells
[Pydio Cells](https://pydio.com/en), which achieved stability in May 2018, is a complete overhaul of the Pydio filesharing application's core server code. Due to limitations with Pydio's PHP-based backend, the developers decided to rewrite the backend in the Go server language with a microservices architecture. (The frontend is still based on PHP.)
Pydio Cells includes the usual filesharing and version control features, as well as in-app messaging, mobile apps (Android and iOS), and a social network-style approach to collaboration. Security includes OpenID Connect-based authentication, encryption at rest, security policies, and more. Advanced features are included in the enterprise distribution, but there's plenty of power for most small and midsize businesses and home users in the community (or "Home") version.
You can [download](https://pydio.com/download/) Pydio Cells for Linux and MacOS. For more information, check out the [documentation FAQ](https://pydio.com/en/docs/faq), [source code](https://github.com/pydio/cells) repository, and [AGPLv3 license](https://github.com/pydio/pydio-core/blob/develop/LICENSE).
## Others to consider
If these choices don't meet your needs, you may want to consider these open source filesharing-type applications.
- If your main goal is to sync files between devices, rather than to share files, check out
[Syncthing](https://syncthing.net/)). - If you're a Git fan and don't need a mobile app, you might appreciate
[SparkleShare](http://www.sparkleshare.org/). - If you primarily want a place to aggregate all your personal data, take a look at
[Cozy](https://cozy.io/en/). - And, if you're looking for a lightweight or dedicated filesharing tool, peruse
[Scott Nesbitt's review](https://opensource.com/article/17/3/file-sharing-tools)of some lesser-known options.
What is your favorite open source filesharing application? Let us know in the comments.
## 9 Comments |
9,863 | 对数据隐私持开放的态度 | https://opensource.com/article/18/1/being-open-about-data-privacy | 2018-07-25T00:40:00 | [
"隐私",
"GDPR"
] | https://linux.cn/article-9863-1.html |
>
> 尽管有包括 GDPR 在内的法规,数据隐私对于几乎所有的人来说都是很重要的事情。
>
>
>

今天(LCTT 译注:本文发表于 2018/1/28)是<ruby> <a href="https://en.wikipedia.org/wiki/Data_Privacy_Day"> 数据隐私日 </a> <rt> Data Privacy Day </rt></ruby>,(在欧洲叫“<ruby> 数据保护日 <rt> Data Protection Day </rt></ruby>”),你可能会认为现在我们处于一个开源的世界中,所有的数据都应该是自由的,[就像人们想的那样](https://en.wikipedia.org/wiki/Information_wants_to_be_free),但是现实并没那么简单。主要有两个原因:
1. 我们中的大多数(不仅仅是在开源中)认为至少有些关于我们自己的数据是不愿意分享出去的(我在之前发表的一篇文章中列举了一些例子[3](https://aliceevebob.wordpress.com/2017/06/06/helping-our-governments-differently/))
2. 我们很多人虽然在开源中工作,但事实上是为了一些商业公司或者其他一些组织工作,也是在合法的要求范围内分享数据。
所以实际上,数据隐私对于每个人来说是很重要的。
事实证明,在美国和欧洲之间,人们和政府认为让组织使用哪些数据的出发点是有些不同的。前者通常为商业实体(特别是愤世嫉俗的人们会指出是大型的商业实体)利用他们所收集到的关于我们的数据提供了更多的自由度。在欧洲,完全是另一观念,一直以来持有的多是有更多约束限制的观念,而且在 5 月 25 日,欧洲的观点可以说取得了胜利。
### 通用数据保护条例(GDPR)的影响
那是一个相当全面的声明,其实事实上这是 2016 年欧盟通过的一项称之为<ruby> 通用数据保护条例 <rt> General Data Protection Regulation </rt></ruby>(GDPR)的立法的日期。数据通用保护条例在私人数据怎样才能被保存,如何才能被使用,谁能使用,能被持有多长时间这些方面设置了严格的规则。它描述了什么数据属于私人数据——而且涉及的条目范围非常广泛,从你的姓名、家庭住址到你的医疗记录以及接通你电脑的 IP 地址。
通用数据保护条例的重要之处是它并不仅仅适用于欧洲的公司,如果你是阿根廷人、日本人、美国人或者是俄罗斯的公司而且你正在收集涉及到欧盟居民的数据,你就要受到这个条例的约束管辖。
“哼!” 你可能会这样说<sup> 注1</sup> ,“我的业务不在欧洲:他们能对我有啥约束?” 答案很简单:如果你想继续在欧盟做任何生意,你最好遵守,因为一旦你违反了通用数据保护条例的规则,你将会受到你的全球总收入百分之四的惩罚。是的,你没听错,是全球总收入,而不是仅仅在欧盟某一国家的的收入,也不只是净利润,而是全球总收入。这将会让你去叮嘱告知你的法律团队,他们就会知会你的整个团队,同时也会立即去指引你的 IT 团队,确保你的行为在相当短的时间内合规。
看上去这和非欧盟公民没有什么相关性,但其实不然,对大多数公司来说,对所有的他们的顾客、合作伙伴以及员工实行同样的数据保护措施是件既简单又有效的事情,而不是仅针对欧盟公民实施,这将会是一件很有利的事情。<sup> 注2</sup>
然而,数据通用保护条例不久将在全球实施并不意味着一切都会变的很美好<sup> 注3</sup> :事实并非如此,我们一直在丢弃关于我们自己的信息——而且允许公司去使用它。
有一句话是这么说的(尽管很争议):“如果你没有在付费,那么你就是产品。”这句话的意思就是如果你没有为某一项服务付费,那么其他的人就在付费使用你的数据。你有付费使用 Facebook、推特、谷歌邮箱?你觉得他们是如何赚钱的?大部分是通过广告,一些人会争论那是他们向你提供的一项服务而已,但事实上是他们在利用你的数据从广告商里获取收益。你不是一个真正的广告的顾客——只有当你从看了广告后买了他们的商品之后你才变成了他们的顾客,但直到这个发生之前,都是广告平台和广告商的关系。
有些服务是允许你通过付费来消除广告的(流媒体音乐平台声破天就是这样的),但从另一方面来讲,即使你认为付费的服务也可以启用广告(例如,亚马逊正在努力让 Alexa 发广告),除非我们想要开始为这些所有的免费服务付费,我们需要清楚我们所放弃的,而且在我们暴露的和不想暴露的之间做一些选择。
### 谁是顾客?
关于数据的另一个问题一直在困扰着我们,它是产生的数据量的直接结果。有许多组织一直在产生巨量的数据,包括公共的组织比如大学、医院或者是政府部门<sup> 注4</sup> ——而且他们没有能力去储存这些数据。如果这些数据没有长久的价值也就没什么要紧的,但事实正好相反,随着处理大数据的工具正在开发中,而且这些组织也认识到他们现在以及在不久的将来将能够去挖掘这些数据。
然而他们面临的是,随着数据的增长和存储量无法跟上该怎么办。幸运的是——而且我是带有讽刺意味的使用了这个词<sup> 注5</sup> ,大公司正在介入去帮助他们。“把你们的数据给我们,”他们说,“我们将免费保存。我们甚至让你随时能够使用你所收集到的数据!”这听起来很棒,是吗?这是大公司<sup> 注6</sup> 的一个极具代表性的例子,站在慈善的立场上帮助公共组织管理他们收集到的关于我们的数据。
不幸的是,慈善不是唯一的理由。他们是附有条件的:作为同意保存数据的交换条件,这些公司得到了将数据访问权限出售给第三方的权利。你认为公共组织,或者是被收集数据的人在数据被出售使用权使给第三方,以及在他们如何使用上能有发言权吗?我将把这个问题当做一个练习留给读者去思考。<sup> 注7</sup>
### 开放和积极
然而并不只有坏消息。政府中有一项在逐渐发展起来的“开放数据”运动鼓励各个部门免费开放大量他们的数据给公众或者其他组织。在某些情况下,这是专门立法的。许多志愿组织——尤其是那些接受公共资金的——正在开始这样做。甚至商业组织也有感兴趣的苗头。而且,有一些技术已经可行了,例如围绕不同的隐私和多方计算上,正在允许跨越多个数据集挖掘数据,而不用太多披露个人的信息——这个计算问题从未如现在比你想象的更容易。
这些对我们来说意味着什么呢?我之前在网站 Opensource.com 上写过关于[开源的共享福利](https://opensource.com/article/17/11/commonwealth-open-source),而且我越来越相信我们需要把我们的视野从软件拓展到其他区域:硬件、组织,和这次讨论有关的,数据。让我们假设一下你是 A 公司要提向另一家公司客户 B<sup> 注8</sup> 提供一项服务 。在此有四种不同类型的数据:
1. 数据完全开放:对 A 和 B 都是可得到的,世界上任何人都可以得到
2. 数据是已知的、共享的,和机密的:A 和 B 可得到,但其他人不能得到
3. 数据是公司级别上保密的:A 公司可以得到,但 B 顾客不能
4. 数据是顾客级别保密的:B 顾客可以得到,但 A 公司不能
首先,也许我们对数据应该更开放些,将数据默认放到选项 1 中。如果那些数据对所有人开放——在无人驾驶、语音识别,矿藏以及人口数据统计会有相当大的作用的。<sup> 注9</sup> 如果我们能够找到方法将数据放到选项 2、3 和 4 中,不是很好吗?——或者至少它们中的一些——在选项 1 中是可以实现的,同时仍将细节保密?这就是研究这些新技术的希望。 然而有很长的路要走,所以不要太兴奋,同时,开始考虑将你的的一些数据默认开放。
### 一些具体的措施
我们如何处理数据的隐私和开放?下面是我想到的一些具体的措施:欢迎大家评论做出更多的贡献。
* 检查你的组织是否正在认真严格的执行通用数据保护条例。如果没有,去推动实施它。
* 要默认加密敏感数据(或者适当的时候用散列算法),当不再需要的时候及时删掉——除非数据正在被处理使用,否则没有任何借口让数据清晰可见。
* 当你注册了一个服务的时候考虑一下你公开了什么信息,特别是社交媒体类的。
* 和你的非技术朋友讨论这个话题。
* 教育你的孩子、你朋友的孩子以及他们的朋友。然而最好是去他们的学校和他们的老师谈谈在他们的学校中展示。
* 鼓励你所服务和志愿贡献的组织,或者和他们沟通一些推动数据的默认开放。不是去思考为什么我要使数据开放,而是从我为什么不让数据开放开始。
* 尝试去访问一些开源数据。挖掘使用它、开发应用来使用它,进行数据分析,画漂亮的图,<sup> 注10</sup> 制作有趣的音乐,考虑使用它来做些事。告诉组织去使用它们,感谢它们,而且鼓励他们去做更多。
**注:**
1. 我承认你可能尽管不会。
2. 假设你坚信你的个人数据应该被保护。
3. 如果你在思考“极好的”的寓意,在这点上你并不孤独。
4. 事实上这些机构能够有多开放取决于你所居住的地方。
5. 假设我是英国人,那是非常非常大的剂量。
6. 他们可能是巨大的公司:没有其他人能够负担得起这么大的存储和基础架构来使数据保持可用。
7. 不,答案是“不”。
8. 尽管这个例子也同样适用于个人。看看:A 可能是 Alice,B 可能是 BOb……
9. 并不是说我们应该暴露个人的数据或者是这样的数据应该被保密,当然——不是那类的数据。
10. 我的一个朋友当她接孩子放学的时候总是下雨,所以为了避免确认失误,她在整个学年都访问天气信息并制作了图表分享到社交媒体上。
---
via: <https://opensource.com/article/18/1/being-open-about-data-privacy>
作者:[Mike Bursell](https://opensource.com/users/mikecamel) 译者:[FelixYFZ](https://github.com/FelixYFZ) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Today is [Data Privacy Day](https://en.wikipedia.org/wiki/Data_Privacy_Day), ("Data Protection Day" in Europe), and you might think that those of us in the open source world should think that all data should be free, [as information supposedly wants to be](https://en.wikipedia.org/wiki/Information_wants_to_be_free), but life's not that simple. That's for two main reasons:
- Most of us (and not just in open source) believe there's at least some data about us that we might not feel happy sharing (I compiled an example list in
[a post](https://aliceevebob.wordpress.com/2017/06/06/helping-our-governments-differently/)I published a while ago). - Many of us working in open source actually work for commercial companies or other organisations subject to legal requirements around what they can share.
So actually, data privacy is something that's important for pretty much everybody.
It turns out that the starting point for what data people and governments believe should be available for organisations to use is somewhat different between the U.S. and Europe, with the former generally providing more latitude for entities—particularly, the more cynical might suggest, large commercial entities—to use data they've collected about us as they will. Europe, on the other hand, has historically taken a more restrictive view, and on the 25th of May, Europe's view arguably will have triumphed.
## The impact of GDPR
That's a rather sweeping statement, but the fact remains that this is the date on which a piece of legislation called the General Data Protection Regulation (GDPR), enacted by the European Union in 2016, becomes enforceable. The GDPR basically provides a stringent set of rules about how personal data can be stored, what it can be used for, who can see it, and how long it can be kept. It also describes what personal data is—and it's a pretty broad set of items, from your name and home address to your medical records and on through to your computer's IP address.
What is important about the GDPR, though, is that it doesn't apply just to European companies, but to any organisation processing data about EU citizens. If you're an Argentinian, Japanese, U.S., or Russian company and you're collecting data about an EU citizen, you're subject to it.
"Pah!" you may say,[ 1](#1) "I'm not based in the EU: what can they do to me?" The answer is simple: If you want to continue doing any business in the EU, you'd better comply, because if you breach GDPR rules, you could be liable for up to four percent of your
*global*revenues. Yes, that's global revenues: not just revenues in a particular country in Europe or across the EU, not just profits, but
*global revenues*. Those are the sorts of numbers that should lead you to talk to your legal team, who will direct you to your exec team, who will almost immediately direct you to your IT group to make sure you're compliant in pretty short order.
This may seem like it's not particularly relevant to non-EU citizens, but it is. For most companies, it's going to be simpler and more efficient to implement the same protection measures for data associated with *all* customers, partners, and employees they deal with, rather than just targeting specific measures at EU citizens. This has got to be a good thing.2
However, just because GDPR will soon be applied to organisations across the globe doesn't mean that everything's fine and dandy[ 3](#3): it's not. We give away information about ourselves all the time—and permission for companies to use it.
There's a telling (though disputed) saying: "If you're not paying, you're the product." What this suggests is that if you're not paying for a service, then somebody else is paying to use your data. Do you pay to use Facebook? Twitter? Gmail? How do you think they make their money? Well, partly through advertising, and some might argue that's a service they provide to you, but actually that's them using your data to get money from the advertisers. You're not really a customer of advertising—it's only once you buy something from the advertiser that you become their customer, but until you do, the relationship is between the the owner of the advertising platform and the advertiser.
Some of these services allow you to pay to reduce or remove advertising (Spotify is a good example), but on the other hand, advertising may be enabled even for services that you think you do pay for (Amazon is apparently working to allow adverts via Alexa, for instance). Unless we want to start paying to use all of these "free" services, we need to be aware of what we're giving up, and making some choices about what we expose and what we don't.
## Who's the customer?
There's another issue around data that should be exercising us, and it's a direct consequence of the amounts of data that are being generated. There are many organisations out there—including "public" ones like universities, hospitals, or government departments[ 4](#4)—who generate enormous quantities of data all the time, and who just don't have the capacity to store it. It would be a different matter if this data didn't have long-term value, but it does, as the tools for handling Big Data are developing, and organisations are realising they can be mining this now and in the future.
The problem they face, though, as the amount of data increases and their capacity to store it fails to keep up, is what to do with it. *Luckily*—and I use this word with a very heavy dose of irony,[ 5](#5) big corporations are stepping in to help them. "Give us your data," they say, "and we'll host it for free. We'll even let you use the data you collected when you want to!" Sounds like a great deal, yes? A fantastic example of big corporations
[taking a philanthropic stance and helping out public organisations that have collected all of that lovely data about us.](#6)
6Sadly, philanthropy isn't the only reason. These hosting deals come with a price: in exchange for agreeing to host the data, these corporations get to sell access to it to third parties. And do you think the public organisations, or those whose data is collected, will get a say in who these third parties are or how they will use it? I'll leave this as an exercise for the reader.7
## Open and positive
It's not all bad news, however. There's a growing "open data" movement among governments to encourage departments to make much of their data available to the public and other bodies for free. In some cases, this is being specifically legislated. Many voluntary organisations—particularly those receiving public funding—are starting to do the same. There are glimmerings of interest even from commercial organisations. What's more, there are techniques becoming available, such as those around differential privacy and multi-party computation, that are beginning to allow us to mine data across data sets without revealing too much about individuals—a computing problem that has historically been much less tractable than you might otherwise expect.
What does this all mean to us? Well, I've written before on Opensource.com about the [commonwealth of open source](https://opensource.com/article/17/11/commonwealth-open-source), and I'm increasingly convinced that we need to look beyond just software to other areas: hardware, organisations, and, relevant to this discussion, data. Let's imagine that you're a company (A) that provides a service to another company, a customer (B).[ 8](#8) There are four different types of data in play:
- Data that's fully open: visible to A, B, and the rest of the world
- Data that's known, shared, and confidential: visible to A and B, but nobody else
- Data that's company-confidential: visible to A, but not B
- Data that's customer-confidential: visible to B, but not A
First of all, maybe we should be a bit more open about data and default to putting it into bucket 1. That data—on self-driving cars, voice recognition, mineral deposits, demographic statistics—could be enormously useful if it were available to everyone.[ 9](#9) Also, wouldn't it be great if we could find ways to make the data in buckets 2, 3, and 4—or at least some of it—available in bucket 1, whilst still keeping the details confidential? That's the hope for some of these new techniques being researched. They're a way off, though, so don't get too excited, and in the meantime, start thinking about making more of your data open by default.
## Some concrete steps
So, what can we do around data privacy and being open? Here are a few concrete steps that occurred to me: please use the comments to contribute more.
- Check to see whether your organisation is taking GDPR seriously. If it isn't, push for it.
- Default to encrypting sensitive data (or hashing where appropriate), and deleting when it's no longer required—there's really no excuse for data to be in the clear to these days except for when it's actually being processed.
- Consider what information you disclose when you sign up to services, particularly social media.
- Discuss this with your non-technical friends.
- Educate your children, your friends' children, and their friends. Better yet, go and talk to their teachers about it and present something in their schools.
- Encourage the organisations you work for, volunteer for, or interact with to make data open by default. Rather than thinking, "why should I make this public?" start with "why
*shouldn't*I make this public?" - Try accessing some of the open data sources out there. Mine it, create apps that use it, perform statistical analyses, draw pretty graphs,
make interesting music, but consider doing something with it. Tell the organisations that sourced it, thank them, and encourage them to do more.10
[1. Though you probably won't, I admit.]
[2. Assuming that you believe that your personal data should be protected.]
[3. If you're wondering what "dandy" means, you're not alone at this point.]
[4. Exactly how public these institutions seem to you will probably depend on where you live: ][YMMV](http://www.outpost9.com/reference/jargon/jargon_40.html#TAG2036).
[5. And given that I'm British, that's a really very, very heavy dose.]
[6. And they're likely to be big corporations: nobody else can afford all of that storage and the infrastructure to keep it available.]
[8. Although the example works for people, too. Oh, look: A could be Alice, B could be Bob…]
[9. Not that we should be exposing personal data or data that actually needs to be confidential, of course—not that type of data.]
[10. A friend of mine decided that it always seemed to rain when she picked her children up from school, so to avoid confirmation bias, she accessed rainfall information across the school year and created graphs that she shared on social media.]
## Comments are closed. |
9,864 | 4 个提高你在 Thunderbird 上隐私的加载项 | https://fedoramagazine.org/4-addons-privacy-thunderbird/ | 2018-07-25T08:17:13 | [
"Thunderbird",
"隐私"
] | https://linux.cn/article-9864-1.html | 
Thunderbird 是由 [Mozilla](https://www.mozilla.org/en-US/) 开发的流行的免费电子邮件客户端。与 Firefox 类似,Thunderbird 提供了大量加载项来用于额外功能和自定义。本文重点介绍四个加载项,以改善你的隐私。
### Enigmail
使用 GPG(GNU Privacy Guard)加密电子邮件是保持其内容私密性的最佳方式。如果你不熟悉 GPG,请[查看我们在这里的入门介绍](https://fedoramagazine.org/gnupg-a-fedora-primer/)。
[Enigmail](https://addons.mozilla.org/en-US/thunderbird/addon/enigmail/) 是使用 OpenPGP 和 Thunderbird 的首选加载项。实际上,Enigmail 与 Thunderbird 集成良好,可让你加密、解密、数字签名和验证电子邮件。
### Paranoia
[Paranoia](https://addons.mozilla.org/en-US/thunderbird/addon/paranoia/?src=cb-dl-users) 可让你查看有关收到的电子邮件的重要信息。用一个表情符号显示电子邮件在到达收件箱之前经过的服务器之间的加密状态。
黄色、快乐的表情告诉你所有连接都已加密。蓝色、悲伤的表情意味着有一个连接未加密。最后,红色的、害怕的表情表示在多个连接上该消息未加密。
还有更多有关这些连接的详细信息,你可以用来检查哪台服务器用于投递邮件。
### Sensitivity Header
[Sensitivity Header](https://addons.mozilla.org/en-US/thunderbird/addon/sensitivity-header/?src=cb-dl-users) 是一个简单的加载项,可让你选择外发电子邮件的隐私级别。使用选项菜单,你可以选择敏感度:正常、个人、隐私和机密。
添加此标头不会为电子邮件添加额外的安全性。但是,某些电子邮件客户端或邮件传输/用户代理(MTA/MUA)可以使用此标头根据敏感度以不同方式处理邮件。
请注意,开发人员将此加载项标记为实验性的。
### TorBirdy
如果你真的担心自己的隐私,[TorBirdy](https://addons.mozilla.org/en-US/thunderbird/addon/torbirdy/?src=cb-dl-users) 就是给你设计的加载项。它将 Thunderbird 配置为使用 [Tor](https://www.torproject.org/) 网络。
据其[文档](https://trac.torproject.org/projects/tor/wiki/torbirdy)所述,TorBirdy 为以前没有使用 Tor 的电子邮件帐户提供了少量隐私保护。
>
> 请记住,跟之前使用 Tor 访问的电子邮件帐户相比,之前没有使用 Tor 访问的电子邮件帐户提供**更少**的隐私/匿名/更弱的假名。但是,TorBirdy 仍然对现有帐户或实名电子邮件地址有用。例如,如果你正在寻求隐匿位置 —— 你经常旅行并且不想通过发送电子邮件来披露你的所有位置 —— TorBirdy 非常有效!
>
>
>
请注意,要使用此加载项,必须在系统上安装 Tor。
照片由 [Braydon Anderson](https://unsplash.com/photos/wOHH-NUTvVc?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText) 在 [Unsplash](https://unsplash.com/search/photos/privacy?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText) 上发布。
---
via: <https://fedoramagazine.org/4-addons-privacy-thunderbird/>
作者:[Clément Verna](https://fedoramagazine.org) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Thunderbird is a popular free email client developed by [Mozilla](https://www.mozilla.org/en-US/). Similar to Firefox, Thunderbird offers a large choice of add-ons for extra features and customization. This article focuses on four add-ons to improve your privacy.
### Enigmail
Encrypting emails using GPG (GNU Privacy Guard) is the best way to keep their contents private. If you aren’t familiar with GPG, [check out our primer right here](https://fedoramagazine.org/gnupg-a-fedora-primer/) on the Magazine.
[Enigmail](https://addons.mozilla.org/en-US/thunderbird/addon/enigmail/) is the go-to add-on for using OpenPGP with Thunderbird. Indeed, Enigmail integrates well with Thunderbird, and lets you encrypt, decrypt, and digitally sign and verify emails.
### Paranoia
[Paranoia](https://addons.mozilla.org/en-US/thunderbird/addon/paranoia/?src=cb-dl-users) gives you access to critical information about your incoming emails. An emoticon shows the encryption state between servers an email traveled through before reaching your inbox.
A yellow, happy emoticon tells you all connections were encrypted. A blue, sad emoticon means one connection was not encrypted. Finally, a red, scared emoticon shows on more than one connection the message wasn’t encrypted.
More details about these connections are available, so you can check which servers were used to deliver the email.
### Sensitivity Header
[Sensitivity Header](https://addons.mozilla.org/en-US/thunderbird/addon/sensitivity-header/?src=cb-dl-users) is a simple add-on that lets you select the privacy level of an outgoing email. Using the option menu, you can select a sensitivity: Normal, Personal, Private and Confidential.
Adding this header doesn’t add extra security to email. However, some email clients or mail transport/user agents (MTA/MUA) can use this header to process the message differently based on the sensitivity.
Note that this add-on is marked as experimental by its developers.
### TorBirdy
If you’re really concerned about your privacy, [TorBirdy](https://addons.mozilla.org/en-US/thunderbird/addon/torbirdy/?src=cb-dl-users) is the add-on for you. It configures Thunderbird to use the [Tor](https://www.torproject.org/) network.
TorBirdy offers less privacy on email accounts that have been used without Tor before, as noted in the [documentation](https://trac.torproject.org/projects/tor/wiki/torbirdy).
Please bear in mind that email accounts that have been used without Tor before offer
lessprivacy/anonymity/weaker pseudonyms than email accounts that have always been accessed with Tor. But nevertheless, TorBirdy is still useful for existing accounts or real-name email addresses. For example, if you are looking for location anonymity — you travel a lot and don’t want to disclose all your locations by sending emails — TorBirdy works wonderfully!
Note that to use this add-on, you must have Tor installed on your system.
Photo by [Braydon Anderson](https://unsplash.com/photos/wOHH-NUTvVc?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText) on [Unsplash](https://unsplash.com/search/photos/privacy?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText).
## Daniel
Many of these add-ons are legacy extensions and don’t work in Thunderbird 60.
## Clément Verna
@Daniel, I used the version of Thunderbird available in Fedora 28 (52.8.0) as a target while writing this article.
Also I believe that Thunderbird 60 is still in beta release.
## Brian Vaughan
I’ve seen it suggested that, since you can’t encrypt email headers, there’s nothing special about encrypting the body of an email, so for most purposes, it’s easier to just encrypt a file and add it as an attachment.
## Stuart D Gathman
Your source is correct, and that is what GPG mail is: a standard for encrypting a file and adding it as an attachment with a corresponding mime-type. Enigmail makes the process more convenient, doing it all within thunderbird. Plus, how many people know how to set the mime-type of attached files? |
9,865 | 在 Arch 用户仓库(AUR)中发现恶意软件 | https://www.linuxuprising.com/2018/07/malware-found-on-arch-user-repository.html | 2018-07-25T08:41:00 | [
"恶意软件",
"AUR"
] | https://linux.cn/article-9865-1.html | 
7 月 7 日,有一个 AUR 软件包被改入了一些恶意代码,提醒 [Arch Linux](https://www.archlinux.org/) 用户(以及一般的 Linux 用户)在安装之前应该尽可能检查所有由用户生成的软件包。
[AUR](https://aur.archlinux.org/)(即 Arch(Linux)用户仓库)包含包描述,也称为 PKGBUILD,它使得从源代码编译包变得更容易。虽然这些包非常有用,但它们永远不应被视为安全的,并且用户应尽可能在使用之前检查其内容。毕竟,AUR 在网页中以粗体显示 “**AUR 包是用户制作的内容。任何使用该提供的文件的风险由你自行承担。**”
这次[发现](https://lists.archlinux.org/pipermail/aur-general/2018-July/034152.html)包含恶意代码的 AUR 包证明了这一点。[acroread](https://aur.archlinux.org/cgit/aur.git/commit/?h=acroread&id=b3fec9f2f16703c2dae9e793f75ad6e0d98509bc) 于 7 月 7 日(看起来它以前是“孤儿”,意思是它没有维护者)被一位名为 “xeactor” 的用户修改,它包含了一行从 pastebin 使用 `curl` 下载脚本的命令。然后,该脚本下载了另一个脚本并安装了一个 systemd 单元以定期运行该脚本。
**看来有[另外两个](https://lists.archlinux.org/pipermail/aur-general/2018-July/034153.html) AUR 包以同样的方式被修改。所有违规软件包都已删除,并暂停了用于上传它们的用户帐户(它们注册在更新软件包的同一天)。**
这些恶意代码没有做任何真正有害的事情 —— 它只是试图上传一些系统信息,比如机器 ID、`uname -a` 的输出(包括内核版本、架构等)、CPU 信息、pacman 信息,以及 `systemctl list-units`(列出 systemd 单元信息)的输出到 pastebin.com。我说“试图”是因为第二个脚本中存在错误而没有实际上传系统信息(上传函数为 “upload”,但脚本试图使用其他名称 “uploader” 调用它)。
此外,将这些恶意脚本添加到 AUR 的人将脚本中的个人 Pastebin API 密钥以明文形式留下,再次证明他们真的不明白他们在做什么。(LCTT 译注:意即这是一个菜鸟“黑客”,还不懂得如何有经验地隐藏自己。)
尝试将此信息上传到 Pastebin 的目的尚不清楚,特别是原本可以上传更加敏感信息的情况下,如 GPG / SSH 密钥。
**更新:** Reddit用户 u/xanaxdroid\_ [提及](https://www.reddit.com/r/archlinux/comments/8x0p5z/reminder_to_always_read_your_pkgbuilds/e21iugg/)同一个名为 “xeactor” 的用户也发布了一些加密货币挖矿软件包,因此他推测 “xeactor” 可能正计划添加一些隐藏的加密货币挖矿软件到 AUR([两个月](https://www.linuxuprising.com/2018/05/malware-found-in-ubuntu-snap-store.html)前的一些 Ubuntu Snap 软件包也是如此)。这就是 “xeactor” 可能试图获取各种系统信息的原因。此 AUR 用户上传的所有包都已删除,因此我无法检查。
**另一个更新:**你究竟应该在那些用户生成的软件包检查什么(如 AUR 中发现的)?情况各有不同,我无法准确地告诉你,但你可以从寻找任何尝试使用 `curl`、`wget`和其他类似工具下载内容的东西开始,看看他们究竟想要下载什么。还要检查从中下载软件包源的服务器,并确保它是官方来源。不幸的是,这不是一个确切的“科学做法”。例如,对于 Launchpad PPA,事情变得更加复杂,因为你必须懂得 Debian 如何打包,并且这些源代码是可以直接更改的,因为它托管在 PPA 中并由用户上传的。使用 Snap 软件包会变得更加复杂,因为在安装之前你无法检查这些软件包(据我所知)。在后面这些情况下,作为通用解决方案,我觉得你应该只安装你信任的用户/打包器生成的软件包。
---
via: <https://www.linuxuprising.com/2018/07/malware-found-on-arch-user-repository.html>
作者:[Logix](https://plus.google.com/118280394805678839070) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Malware Found On The Arch User Repository (AUR)
**On July 7, an AUR package was modified with some malicious code, reminding**
[Arch Linux](https://www.archlinux.org/)users (and Linux users in general) that all user-generated packages should be checked (when possible) before installation.[AUR](https://aur.archlinux.org/), or the Arch (Linux) User Repository contains package descriptions, also known as PKGBUILDs, which make compiling packages from source easier. While these packages are very useful, they should never be treated as safe, and users should always check their contents before using them, when possible. After all, the AUR webpage states in bold that "
*"*
**AUR packages are user produced content. Any use of the provided files is at your own risk.**The
[discovery](https://lists.archlinux.org/pipermail/aur-general/2018-July/034152.html)of an AUR package containing malicious code proves this.
[acroread](https://aur.archlinux.org/cgit/aur.git/commit/?h=acroread&id=b3fec9f2f16703c2dae9e793f75ad6e0d98509bc)was modified on July 7 (it appears it was previously "orphaned", meaning it had no maintainer) by an user named "xeactor" to include a
`curl`
command that downloaded a script from a pastebin. The script then downloaded another script and installed a systemd unit to run that script periodically.**It appears**
[two other](https://lists.archlinux.org/pipermail/aur-general/2018-July/034153.html)AUR packages were modified in the same way. All the offending packages were removed and the user account (which was registered in the same day those packages were updated) that was used to upload them was suspended.The malicious code didn't do anything truly harmful - it only tried to upload some system information, like the machine ID, the output of
`uname -a`
(which includes the kernel version, architecture, etc.), CPU information, pacman information, and the output of `systemctl list-units`
(which lists systemd units information) to pastebin.com. I'm saying "tried" because no system information was actually uploaded due to an error in the second script (the upload function is called "upload", but the script tried to call it using a different name, "uploader").Also, the person adding these malicious scripts to AUR left the personal Pastebin API key in the script in cleartext, proving once again that they don't know exactly what they are doing.
The purpose for trying to upload this information to Pastebin is not clear, especially since much more sensitive data could have been uploaded, like GPG / SSH keys.
**Update:**Reddit user u/xanaxdroid_
[mentions](https://www.reddit.com/r/archlinux/comments/8x0p5z/reminder_to_always_read_your_pkgbuilds/e21iugg/)that the same user named "xeactor" also had some cryptocurrency mining packages posted, so he speculates that "xeactor" was probably planning on adding some hidden cryptocurrency mining software to AUR (this was also the case with some Ubuntu Snap packages
[two months ago](https://www.linuxuprising.com/2018/05/malware-found-in-ubuntu-snap-store.html)). That's why "xeactor" was probably trying to obtain various system information. All the packages uploaded by this AUR user have been removed so I cannot check this.
**Another update:**What exactly should you check in user-generated packages such as those found in AUR? This varies and I can't tell you exactly but you can start by looking for anything that tries to download something using
`curl`
, `wget`
and other similar tools, and see what exactly they are attempting to download. Also check the server from which the package source is downloaded from and make sure it's the official source. Unfortunately this is not an exact 'science'. For Launchpad PPAs for example, things get more complicated as you must know how Debian packaging works, and the source can be altered directly as it's hosted in the PPA and uploaded by the user. It gets even more complicated with Snap packages, because you cannot check such packages before installation (as far as I know). In these latter cases, and as a generic solution, I guess you should only install user-generated packages if you trust the uploader / packager.*from*[Reddit](https://www.reddit.com/r/archlinux/comments/8x0p5z/reminder_to_always_read_your_pkgbuilds/) |
9,866 | 如何在 Linux 中使用一个命令升级所有软件 | https://www.ostechnix.com/how-to-upgrade-everything-using-a-single-command-in-linux/ | 2018-07-25T23:03:47 | [
"升级",
"apt",
"topgrade"
] | https://linux.cn/article-9866-1.html | 
众所周知,让我们的 Linux 系统保持最新状态会用到多种包管理器。比如说,在 Ubuntu 中,你无法使用 `sudo apt update` 和 `sudo apt upgrade` 命令升级所有软件。此命令仅升级使用 APT 包管理器安装的应用程序。你有可能使用 `cargo`、[pip](https://www.ostechnix.com/manage-python-packages-using-pip/)、`npm`、`snap` 、`flatpak` 或 [Linuxbrew](https://www.ostechnix.com/linuxbrew-common-package-manager-linux-mac-os-x/) 包管理器安装了其他软件。你需要使用相应的包管理器才能使它们全部更新。
再也不用这样了!跟 `topgrade` 打个招呼,这是一个可以一次性升级系统中所有软件的工具。
你无需运行每个包管理器来更新包。这个 `topgrade` 工具通过检测已安装的软件包、工具、插件并运行相应的软件包管理器来更新 Linux 中的所有软件,用一条命令解决了这个问题。它是自由而开源的,使用 **rust 语言**编写。它支持 GNU/Linux 和 Mac OS X.
### 在 Linux 中使用一个命令升级所有软件
`topgrade` 存在于 AUR 中。因此,你可以在任何基于 Arch 的系统中使用 [Yay](https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/) 助手程序安装它。
```
$ yay -S topgrade
```
在其他 Linux 发行版上,你可以使用 `cargo` 包管理器安装 `topgrade`。要安装 cargo 包管理器,请参阅以下链接:
* [在 Linux 安装 rust 语言](https://www.ostechnix.com/install-rust-programming-language-in-linux/)
然后,运行以下命令来安装 `topgrade`。
```
$ cargo install topgrade
```
安装完成后,运行 `topgrade` 以升级 Linux 系统中的所有软件。
```
$ topgrade
```
一旦调用了 `topgrade`,它将逐个执行以下任务。如有必要,系统会要求输入 root/sudo 用户密码。
1、 运行系统的包管理器:
* Arch:运行 `yay` 或者回退到 [pacman](https://www.ostechnix.com/getting-started-pacman/)
* CentOS/RHEL:运行 `yum upgrade`
* Fedora :运行 `dnf upgrade`
* Debian/Ubuntu:运行 `apt update` 和 `apt dist-upgrade`
* Linux/macOS:运行 `brew update` 和 `brew upgrade`
2、 检查 Git 是否跟踪了以下路径。如果有,则拉取它们:
* `~/.emacs.d` (无论你使用 Spacemacs 还是自定义配置都应该可用)
* `~/.zshrc`
* `~/.oh-my-zsh`
* `~/.tmux`
* `~/.config/fish/config.fish`
* 自定义路径
3、 Unix:运行 `zplug` 更新
4、 Unix:使用 TPM 升级 `tmux` 插件
5、 运行 `cargo install-update`
6、 升级 Emacs 包
7、 升级 Vim 包。对以下插件框架均可用:
* NeoBundle
* [Vundle](https://www.ostechnix.com/manage-vim-plugins-using-vundle-linux/)
* Plug
8、 升级 [npm](https://www.ostechnix.com/manage-nodejs-packages-using-npm/) 全局安装的包
9、 升级 Atom 包
10、 升级 [Flatpak](https://www.ostechnix.com/flatpak-new-framework-desktop-applications-linux/) 包
11、 升级 [snap](https://www.ostechnix.com/install-snap-packages-arch-linux-fedora/) 包
12、 Linux:运行 `fwupdmgr` 显示固件升级。 (仅查看。实际不会执行升级)
13、 运行自定义命令。
最后,`topgrade` 将运行 `needrestart` 以重新启动所有服务。在 Mac OS X 中,它会升级 App Store 程序。
我的 Ubuntu 18.04 LTS 测试环境的示例输出:

好处是如果一个任务失败,它将自动运行下一个任务并完成所有其他后续任务。最后,它将显示摘要,其中包含运行的任务数量,成功的数量和失败的数量等详细信息。

**建议阅读:**
就个人而言,我喜欢创建一个像 `topgrade` 程序的想法,并使用一个命令升级使用各种包管理器安装的所有软件。我希望你也觉得它有用。还有更多的好东西。敬请关注!
干杯!
---
via: <https://www.ostechnix.com/how-to-upgrade-everything-using-a-single-command-in-linux/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,867 | 6 个开源的数字货币钱包 | https://opensource.com/article/18/7/crypto-wallets | 2018-07-25T23:30:28 | [
"数字货币",
"钱包"
] | https://linux.cn/article-9867-1.html |
>
> 想寻找一个可以存储和交易你的比特币、以太坊和其它数字货币的软件吗?这里有 6 个开源的软件可以选择。
>
>
>

没有数字货币钱包,像比特币和以太坊这样的数字货币只不过是又一个空想罢了。这些钱包对于保存、发送、以及接收数字货币来说是必需的东西。
迅速成长的 [数字货币](https://www.liveedu.tv/guides/cryptocurrency/) 之所以是革命性的,都归功于它的去中心化,该网络中没有中央权威,每个人都享有平等的权力。开源技术是数字货币和 [区块链](https://opensource.com/tags/blockchain) 网络的核心所在。它使得这个充满活力的新兴行业能够从去中心化中获益 —— 比如,不可改变、透明和安全。
如果你正在寻找一个自由开源的数字货币钱包,请继续阅读,并开始去探索以下的选择能否满足你的需求。
### 1、 Copay
[Copay](https://copay.io/) 是一个能够很方便地存储比特币的开源数字货币钱包。这个软件以 [MIT 许可证](https://github.com/bitpay/copay/blob/master/LICENSE) 发布。
Copay 服务器也是开源的。因此,开发者和比特币爱好者可以在服务器上部署他们自己的应用程序来完全控制他们的活动。
Copay 钱包能让你手中的比特币更加安全,而不是去信任不可靠的第三方。它允许你使用多重签名来批准交易,并且支持在同一个 app 钱包内支持存储多个独立的钱包。
Copay 可以在多种平台上使用,比如 Android、Windows、MacOS、Linux、和 iOS。
### 2、 MyEtherWallet
正如它的名字所示,[MyEtherWallet](https://www.myetherwallet.com/) (缩写为 MEW) 是一个以太坊钱包。它是开源的(遵循 [MIT 许可证](https://github.com/kvhnuke/etherwallet/blob/mercury/LICENSE.md))并且是完全在线的,可以通过 web 浏览器来访问它。
这个钱包的客户端界面非常简洁,它可以让你自信而安全地参与到以太坊区块链中。
### 3、 mSIGNA
[mSIGNA](https://ciphrex.com/) 是一个功能强大的桌面版应用程序,用于在比特币网络上完成交易。它遵循 [MIT 许可证](https://github.com/ciphrex/mSIGNA/blob/master/LICENSE) 并且在 MacOS、Windows、和 Linux 上可用。
这个区块链钱包可以让你完全控制你存储的比特币。其中一些特性包括用户友好性、灵活性、去中心化的离线密钥生成能力、加密的数据备份,以及多设备同步功能。
### 4、 Armory
[Armory](https://www.bitcoinarmory.com/) 是一个在你的计算机上产生和保管比特币私钥的开源钱包(遵循 [GNU AGPLv3](https://github.com/etotheipi/BitcoinArmory/blob/master/LICENSE))。它通过使用冷存储和支持多重签名的能力增强了安全性。
使用 Armory,你可以在完全离线的计算机上设置一个钱包;你将通过<ruby> 仅查看 <rt> watch-only </rt></ruby>功能在因特网上查看你的比特币具体信息,这样有助于改善安全性。这个钱包也允许你去创建多个地址,并使用它们去完成不同的事务。
Armory 可用于 MacOS、Windows、和几个比较有特色的 Linux 平台上(包括树莓派)。
### 5、 Electrum
[Electrum](https://electrum.org/#home) 是一个既对新手友好又具备专家功能的比特币钱包。它遵循 [MIT 许可证](https://github.com/spesmilo/electrum/blob/master/LICENCE) 来发行。
Electrum 可以在你的本地机器上使用较少的资源来实现本地加密你的私钥,支持冷存储,并且提供多重签名能力。
它在各种操作系统和设备上都可以使用,包括 Windows、MacOS、Android、iOS 和 Linux,并且也可以在像 [Trezor](https://trezor.io/) 这样的硬件钱包中使用。
### 6、 Etherwall
[Etherwall](https://www.etherwall.com/) 是第一款可以在桌面计算机上存储和发送以太坊的钱包。它是一个遵循 [GPLv3 许可证](https://github.com/almindor/etherwall/blob/master/LICENSE) 的开源钱包。
Etherwall 非常直观而且速度很快。更重要的是,它增加了你的私钥安全性,你可以在一个全节点或瘦节点上来运行它。它作为全节点客户端运行时,可以允许你在本地机器上下载整个以太坊区块链。
Etherwall 可以在 MacOS、Linux 和 Windows 平台上运行,并且它也支持 Trezor 硬件钱包。
### 智者之言
自由开源的数字钱包在让更多的人快速上手数字货币方面扮演至关重要的角色。
在你使用任何数字货币软件钱包之前,你一定要确保你的安全,而且一定要记住并完全遵循确保你的资金安全的最佳实践。
如果你喜欢的开源数字货币钱包不在以上的清单中,请在下面的评论区共享出你所知道的开源钱包。
---
via: <https://opensource.com/article/18/7/crypto-wallets>
作者:[Dr.Michael J.Garbade](https://opensource.com/users/drmjg) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Without crypto wallets, cryptocurrencies like Bitcoin and Ethereum would just be another pie-in-the-sky idea. These wallets are essential for keeping, sending, and receiving cryptocurrencies.
The revolutionary growth of [cryptocurrencies](https://www.liveedu.tv/guides/cryptocurrency/) is attributed to the idea of decentralization, where a central authority is absent from the network and everyone has a level playing field. Open source technology is at the heart of cryptocurrencies and [blockchain](https://opensource.com/tags/blockchain) networks. It has enabled the vibrant, nascent industry to reap the benefits of decentralization—such as immutability, transparency, and security.
If you're looking for a free and open source cryptocurrency wallet, read on to start exploring whether any of the following options meet your needs.
## 1. Copay
[Copay](https://copay.io/) is an open source Bitcoin crypto wallet that promises convenient storage. The software is released under the [MIT License](https://github.com/bitpay/copay/blob/master/LICENSE).
The Copay server is also open source. Therefore, developers and Bitcoin enthusiasts can assume complete control of their activities by deploying their own applications on the server.
The Copay wallet empowers you to take the security of your Bitcoin in your own hands, instead of trusting unreliable third parties. It allows you to use multiple signatories for approving transactions and supports the storage of multiple, separate wallets within the same app.
Copay is available for a range of platforms, such as Android, Windows, MacOS, Linux, and iOS.
## 2. MyEtherWallet
As the name implies, [MyEtherWallet](https://www.myetherwallet.com/) (abbreviated MEW) is a wallet for Ethereum transactions. It is open source (under the [MIT License](https://github.com/kvhnuke/etherwallet/blob/mercury/LICENSE.md)) and is completely online, accessible through a web browser.
The wallet has a simple client-side interface, which allows you to participate in the Ethereum blockchain confidently and securely.
## 3. mSIGNA
[mSIGNA](https://ciphrex.com/) is a powerful desktop application for completing transactions on the Bitcoin network. It is released under the [MIT License](https://github.com/ciphrex/mSIGNA/blob/master/LICENSE) and is available for MacOS, Windows, and Linux.
The blockchain wallet provides you with complete control over your Bitcoin stash. Some of its features include user-friendliness, versatility, decentralized offline key generation capabilities, encrypted data backups, and multi-device synchronization.
## 4. Armory
[Armory](https://www.bitcoinarmory.com/) is an open source wallet (released under the [GNU AGPLv3](https://github.com/etotheipi/BitcoinArmory/blob/master/LICENSE)) for producing and keeping Bitcoin private keys on your computer. It enhances security by providing users with cold storage and multi-signature support capabilities.
With Armory, you can set up a wallet on a computer that is completely offline; you'll use the watch-only feature for observing your Bitcoin details on the internet, which improves security. The wallet also allows you to create multiple addresses and use them to complete different transactions.
Armory is available for MacOS, Windows, and several flavors of Linux (including Raspberry Pi).
## 5. Electrum
[Electrum](https://electrum.org/#home) is a Bitcoin wallet that navigates the thin line between beginner user-friendliness and expert functionality. The open source wallet is released under the [MIT License](https://github.com/spesmilo/electrum/blob/master/LICENCE).
Electrum encrypts your private keys locally, supports cold storage, and provides multi-signature capabilities with minimal resource usage on your machine.
It is available for a wide range of operating systems and devices, including Windows, MacOS, Android, iOS, and Linux, and hardware wallets such as [Trezor](https://trezor.io/).
## 6. Etherwall
[Etherwall](https://www.etherwall.com/) is the first wallet for storing and sending Ethereum on the desktop. The open source wallet is released under the [GPLv3 License](https://github.com/almindor/etherwall/blob/master/LICENSE).
Etherwall is intuitive and fast. What's more, to enhance the security of your private keys, you can operate it on a full node or a thin node. Running it as a full-node client will enable you to download the whole Ethereum blockchain on your local machine.
Etherwall is available for MacOS, Linux, and Windows, and it also supports the Trezor hardware wallet.
## Words to the wise
Open source and free crypto wallets are playing a vital role in making cryptocurrencies easily available to more people.
Before using any digital currency software wallet, make sure to do your due diligence to protect your security, and always remember to comply with best practices for safeguarding your finances.
If your favorite open source cryptocurrency wallet is not on this list, please share what you know in the comment section below.
## 1 Comment |
9,868 | 如何强制用户在下次登录 Linux 时更改密码 | https://www.2daygeek.com/how-to-force-user-to-change-password-on-next-login-in-linux/ | 2018-07-25T23:56:57 | [
"密码"
] | https://linux.cn/article-9868-1.html | 
当你使用默认密码创建用户时,你必须强制用户在下一次登录时更改密码。
当你在一个组织中工作时,此选项是强制性的。因为老员工可能知道默认密码,他们可能会也可能不会尝试不当行为。
这是安全投诉之一,所以,确保你必须以正确的方式处理此事而无任何失误。即使是你的团队成员也要一样做。
大多数用户都很懒,除非你强迫他们更改密码,否则他们不会这样做。所以要做这个实践。
出于安全原因,你需要经常更改密码,或者至少每个月更换一次。
确保你使用的是难以猜测的密码(大小写字母,数字和特殊字符的组合)。它至少应该为 10-15 个字符。
我们运行了一个 shell 脚本来在 Linux 服务器中创建一个用户账户,它会自动为用户附加一个密码,密码是实际用户名和少量数字的组合。
我们可以通过使用以下两种方法来实现这一点:
* passwd 命令
* chage 命令
**建议阅读:**
* [如何在 Linux 上检查用户所属的组](https://www.2daygeek.com/how-to-check-which-groups-a-user-belongs-to-on-linux/)
* [如何在 Linux 上检查创建用户的日期](https://www.2daygeek.com/how-to-check-user-created-date-on-linux/)
* [如何在 Linux 中重置/更改用户密码](https://www.2daygeek.com/passwd-command-examples/)
* [如何使用 passwd 命令管理密码过期和老化](https://www.2daygeek.com/passwd-command-examples-part-l/)
### 方法 1:使用 passwd 命令
`passwd` 的意思是“密码”。它用于更新用户的身份验证令牌。`passwd` 命令/实用程序用于设置、修改或更改用户的密码。
普通的用户只能更改自己的账户,但超级用户可以更改任何账户的密码。
此外,我们还可以使用其他选项,允许用户执行其他活动,例如删除用户密码、锁定或解锁用户账户、设置用户账户的密码过期时间等。
在 Linux 中这可以通过调用 Linux-PAM 和 Libuser API 执行。
在 Linux 中创建用户时,用户详细信息将存储在 `/etc/passwd` 文件中。`passwd` 文件将每个用户的详细信息保存为带有七个字段的单行。
此外,在 Linux 系统中创建新用户时,将更新以下四个文件。
* `/etc/passwd`: 用户详细信息将在此文件中更新。
* `/etc/shadow`: 用户密码信息将在此文件中更新。
* `/etc/group`: 新用户的组详细信息将在此文件中更新。
* `/etc/gshadow`: 新用户的组密码信息将在此文件中更新。
#### 如何使用 passwd 命令执行此操作
我们可以使用 `passwd` 命令并添加 `-e` 选项来执行此操作。
为了测试这一点,让我们创建一个新用户账户,看看它是如何工作的。
```
# useradd -c "2g Admin - Magesh M" magesh && passwd magesh
Changing password for user magesh.
New password:
Retype new password:
passwd: all authentication tokens updated successfully.
```
使用户账户的密码失效,那么在下次登录尝试期间,用户将被迫更改密码。
```
# passwd -e magesh
Expiring password for user magesh.
passwd: Success
```
当我第一次尝试使用此用户登录系统时,它要求我设置一个新密码。
```
login as: magesh
[email protected]'s password:
You are required to change your password immediately (root enforced)
WARNING: Your password has expired.
You must change your password now and login again!
Changing password for user magesh.
Changing password for magesh.
(current) UNIX password:
New password:
Retype new password:
passwd: all authentication tokens updated successfully.
Connection to localhost closed.
```
### 方法 2:使用 chage 命令
`chage` 意即“改变时间”。它会更改用户密码过期信息。
`chage` 命令会改变上次密码更改日期之后需要修改密码的天数。系统使用此信息来确定用户何时必须更改他/她的密码。
它允许用户执行其他活动,例如设置帐户到期日期,到期后设置密码失效,显示帐户过期信息,设置密码更改前的最小和最大天数以及设置到期警告天数。
#### 如何使用 chage 命令执行此操作
让我们在 `chage` 命令的帮助下,通过添加 `-d` 选项执行此操作。
为了测试这一点,让我们创建一个新用户帐户,看看它是如何工作的。我们将创建一个名为 `thanu` 的用户帐户。
```
# useradd -c "2g Editor - Thanisha M" thanu && passwd thanu
Changing password for user thanu.
New password:
Retype new password:
passwd: all authentication tokens updated successfully.
```
要实现这一点,请使用 `chage` 命令将用户的上次密码更改日期设置为 0。
```
# chage -d 0 thanu
# chage -l thanu
Last password change : Jul 18, 2018
Password expires : never
Password inactive : never
Account expires : never
Minimum number of days between password change : 0
Maximum number of days between password change : 99999
Number of days of warning before password expires : 7
```
当我第一次尝试使用此用户登录系统时,它要求我设置一个新密码。
```
login as: thanu
[email protected]'s password:
You are required to change your password immediately (root enforced)
WARNING: Your password has expired.
You must change your password now and login again!
Changing password for user thanu.
Changing password for thanu.
(current) UNIX password:
New password:
Retype new password:
passwd: all authentication tokens updated successfully.
Connection to localhost closed.
```
---
via: <https://www.2daygeek.com/how-to-force-user-to-change-password-on-next-login-in-linux/>
作者:[Prakash Subramanian](https://www.2daygeek.com/author/prakash/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
9,869 | Android 工程师的一年 | https://proandroiddev.com/a-year-as-android-engineer-55e2a428dfc8 | 2018-07-26T23:01:41 | [
"程序员"
] | https://linux.cn/article-9869-1.html | 
>
> 这幅妙绝的题图来自 [Miquel Beltran](https://medium.com/@Miqubel)
>
>
>
我的技术生涯,从两年前算起。开始是 QA 测试员,一年后就转入开发人员角色。没怎么努力,也没有投入过多的个人时间。
你可以从[我为何从生物学转向技术](https://medium.com/@laramartin/how-i-took-my-first-step-in-it-6e9233c4684d)和我[学习 Android 的一年](https://medium.com/udacity/a-year-of-android-ffba9f3e40b6) 这两篇文章中找到些只言片语。今天,我想谈谈是自己是如何开始担任 Android 开发人员这个角色、如何换公司以及作为 Android 工程师的一年所得所失。
### 我的第一个职位角色
我的第一个职位角色, Android 开发者,开始于一年前。我工作的这家公司,可以花一半的时间去尝试其它角色的工作,这给我从 QA 职位转到 Android 开发者职位创造了机会。
这一转变归功于我在晚上和周末投入学习 Android 的时间。我通过了 [Android 基础纳米学位](https://de.udacity.com/course/android-basics-nanodegree-by-google--nd803)、[Andriod 工程师纳米学位](https://de.udacity.com/course/android-developer-nanodegree-by-google--nd801)课程,也获得了 [Google 开发者认证](https://developers.google.com/training/certification/)。这部分的详细故事在[这儿](https://medium.com/udacity/a-year-of-android-ffba9f3e40b6)。
两个月后,公司雇佣了另一位 QA,我转向全职工作。挑战从此开始!
比起给他们提供一台笔记本电脑和一个 git 账号来说,要把某人转变为胜任的开发角色,显然困难重重。在这里我解释一下我在那段时间遇到的一些障碍:
#### 缺乏预期
我面临的第一个问题是不知道公司对我的期望。我认为他们希望我从第一天起就有交付物,虽然不会要求像那些经验丰富的同事一样,但也要完成一个小任务就交付。这种感觉让我压力山大。由于没有明确的目标,我一直认为自己不够好,而且是个伪劣的冒牌货。
#### 缺乏指导
在公司里没有导师的概念,环境也不允许我们一起工作。我们很少结对编程,因为总是在赶项目进度,公司要求我们持续交付。幸运的是,我的同事都乐于助人!无论何时我卡住或需要帮助,他们总是陪我一起解决。
#### 缺乏反馈
那段时间,我从来没有得到过任何的反馈。我做的好还是坏?我应该改进些什么?我不知道,因为我没有得到过任何人的评论。
#### 缺乏学习氛围
我认为,为了保持常新,我们应该通过阅读博客文章、观看演讲、参加会议、尝试新事物等方式持续学习。该公司在工作时间并没有安排学习时间,不幸的是,其它开发人员告诉我这很常见。由于没有学习时间,所以我觉得没有资格花费哪怕十分钟的时间来阅读与工作相关且很有意思的博客文章。
问题不仅在于缺乏明确的学习时间津贴,而且当我明确要求时,被拒绝了。
当我完成突击任务时,发生了一个例子,我们已经完成了任务,因此我询问是否可以用剩下的时间来学习 Kotlin。这个请求被拒绝了。
另外的例子是我想参加一个 Android 相关的研讨会,然后被要求从带薪年假中抽出时间。
#### 冒充者综合征
在这公司缺乏指导、缺乏反馈、缺乏学习氛围,使我的开发者职业生涯的前九个月更加煎熬。我有感觉到,我内心的冒充者综合征与日俱增。
一个例子就是拉取代码进行公开展示和代码审查。有是我会请同事私下检查我的代码,并不想被公开拉取,向任何人展示。
其他时候,当我做代码审查时,会花好几分钟盯着“批准”按纽犹豫不决,在担心审查通过的代码会被其他同事找出毛病。
当我在一些事上持反对意见时,由于缺乏相关知识,担心被坐冷板凳,从来没有大声说出来过。
>
> 某些时间我会请同事私下[...]检查我的代码,以避免被公开展示。
>
>
>
### 新的公司,新的挑战
后来,我手边有了个新的机会。感谢曾经和我共事的朋友,我被 [Babbel](http://babbel.com/) 邀请去参加初级 Android 工程师职位的招聘流程。
我见到了他们的团队,同时自告奋勇的在他们办公室主持了一次本地会议。此事让我下定决心要申请这个职位。我喜欢公司的箴言:全民学习。其次,公司每个人都非常友善,在那儿工作看起来很愉快!但我没有马上申请,因为我认为自己不够好,所以为什么能申请呢?
还好我的朋友和搭档推动我这样做,他们给了我发送简历的力量和勇气。过后不久就进入了面试流程。这很简单:以很小的程序的形式来进行编码挑战,随后是和团队一起的技术面试,之后是和招聘经理间关于团队合作的面试。
#### 招聘过程
我用周未的时间来完成编码挑战的项目,并在周一就立即发送过去。不久就受邀去当场面试。
技术面试是关于编程挑战本身,我们谈论了 Android 好的不好的地方、我为什么以这种方式实现这功能,以及如何改进等等。随后是招聘经理进行的一次简短的关于团队合作面试,也有涉及到编程挑战的事,我们谈到了我面临的挑战,我如何解决这些问题,等等。
最后,通过面试,得到 offer,我授受了!
我的 Android 工程师生涯的第一年,有九个月在一个公司,后面三个月在当前的公司。
#### 学习环境
对我来说一个大的变化就是每两周会和工程经理进行面对面会谈。那样,我很清楚我们的目标和方向。
在需要如何改进、需要如何提供帮助及如何寻求帮助这些事情上,我们得到持续的反馈和想法。他们除了提供内部培训的的福利外,我还有每周学习时间的福利,可以学习任意想学的。到目前为止,我正利用这些时间来提高我的 Kotlin 和 RxJava 方面知识。
每日的大部分时间,我们也做结对编程。我的办公桌上总是备着纸和笔,以便记下想法。我旁边还配了第二把椅子,以方便同事就坐。:-)
但是,我仍然在与冒充者综合征斗争。
#### 仍然有冒充者综合征
我仍然在斗争。例如,在做结对编程时,当我对某个话题不太清楚时,即使我的同事很有耐心的一遍一遍为我解释,但有时我仍然还是不知道。
两次三次后,压力就堵到胸口。为什么我还不知道?为什么就那么难理解?这种状态让我焦虑万分。
我意识到我需要承认我确实不懂某个特定的主题,但第一步是要知道有这么个概念!有时,仅仅需要的就是更多的时间、更多的练习,最终会“在大脑中完全演绎” :-)
例如,我常常为 Java 的接口类和抽象类所困扰,不管看了多少的例子,还是不能完全明白他们之间的区别。但一旦我使用后,即使还不能解释其工作原理,也知道了怎么使用以及什么时候使用。
#### 自信
当前公司的学习氛围提升了我的自信心。即使我还在问很多问题,也开始如鱼得水了。
经验较少并不意味着您的意见将不会被重视。比如一个提出的解决方案似乎太复杂了,我会挑战自我以更清晰的方式来重写。此外,我提出了一套不同的体验和观点,目前,对公司的应用程序用户体验改进有着很大帮助。
### 提高
工程师的角色不仅仅是编码,而是广泛的技能。 我仍然处于旅程的起点,在掌握它的道路上,我想着重于以下几点:
* 交流:因为英文不是我的母语,所以有的时候我需要努力传达我的想法,这在我工作中是至关重要的。我可以通过写作,阅读和交谈来解决这个问题。
* 提有建设性的反馈意见:我想给同事有意义的反馈,这样我们一起共同发展。
* 为我的成就感到骄傲:我需要创建一个列表来跟踪各种成就,无论大小,或整体进步,所以当我挣扎时我可以回顾并感觉良好。
* 不要着迷于不知道的事情:当有很多新事物出现时很难做到都知道,所以只关注必须的,及手头项目需要的东西,这非常重要的。
* 多和同事分享知识:我是初级的并不意味着没有可以分享的!我需要持续分享我感兴趣的的文章及讨论话题。我知道同事们会感激我的。
* 耐心和持续学习:和现在一样的保持不断学习,但对自己要有更多耐心。
* 自我保健:随时注意休息,不要为难自己。 放松也富有成效。
---
via: <https://proandroiddev.com/a-year-as-android-engineer-55e2a428dfc8>
作者:[Lara Martín](https://proandroiddev.com/@laramartin) 译者:[runningwater](https://github.com/runningwater) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 307 | Temporary Redirect | null |
9,870 | 在 Fedora 28 Workstation 使用 emoji 加速输入 | https://fedoramagazine.org/boost-typing-emoji-fedora-28-workstation/ | 2018-07-26T23:14:24 | [
"emoji",
"表情符",
"输入法"
] | https://linux.cn/article-9870-1.html | 
Fedora 28 Workstation 添加了一个功能允许你使用键盘快速搜索、选择和输入 emoji。emoji,这种可爱的表意文字是 Unicode 的一部分,在消息传递中使用得相当广泛,特别是在移动设备上。你可能听过这样的成语:“一图胜千言”。这正是 emoji 所提供的:简单的图像供你在交流中使用。Unicode 的每个版本都增加了更多 emoji,在最近的 Unicode 版本中添加了 200 多个 emoji。本文向你展示如何使它们在你的 Fedora 系统中易于使用。
很高兴看到 emoji 的数量在增长。但与此同时,它带来了如何在计算设备中输入它们的挑战。许多人已经将这些符号用于移动设备或社交网站中的输入。
[**编者注:**本文是对此主题以前发表过的文章的更新]。
### 在 Fedora 28 Workstation 上启用 emoji 输入
新的 emoji 输入法默认出现在 Fedora 28 Workstation 中。要使用它,必须使用“区域和语言设置”对话框启用它。从 Fedora Workstation 设置打开“区域和语言”对话框,或在“概要”中搜索它。
[](https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-15-02-41.png)
选择 `+` 控件添加输入源。出现以下对话框:
[](https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-33-46.png)
选择最后选项(三个点)来完全展开选择。然后,在列表底部找到“Other”并选择它:
[](https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-34-15.png)
在下面的对话框中,找到 “Typing Booster” 选项并选择它:
[](https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-34-41.png)
这个高级输入法由 iBus 在背后支持。该高级输入法可通过列表右侧的齿轮图标在列表中识别。
输入法下拉菜单自动出现在 GNOME Shell 顶部栏中。确认你的默认输入法 —— 在此示例中为英语(美国) - 被选为当前输入法,你就可以输入了。
[](https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-15-05-24.png)
### 使用新的表情符号输入法
现在 emoji 输入法启用了,按键盘快捷键 `Ctrl+Shift+E` 搜索 emoji。将出现一个弹出对话框,你可以在其中输入搜索词,例如 “smile” 来查找匹配的符号。
[](https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-08-14-36-31.png)
使用箭头键翻页列表。然后按回车进行选择,字形将替换输入内容。
---
via: <https://fedoramagazine.org/boost-typing-emoji-fedora-28-workstation/>
作者:[Paul W. Frields](https://fedoramagazine.org/author/pfrields/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Fedora 28 Workstation ships with a feature that allows you to quickly search, select and input emoji using your keyboard. Emoji, cute ideograms that are part of Unicode, are used fairly widely in messaging and especially on mobile devices. You may have heard the idiom “A picture is worth a thousand words.” This is exactly what emoji provide: simple images for you to use in communication. Each release of Unicode adds more, with over 200 new ones added in past releases of Unicode. This article shows you how to make them easy to use in your Fedora system.
It’s great to see emoji numbers growing. But at the same time it brings the challenge of how to input them in a computing device. Many people already use these symbols for input in mobile devices or social networking sites.
[**Editors’ note: **This article is an update to a previously published piece on this topic.]
### Enabling Emoji input on Fedora 28 Workstation
The new emoji input method ships by default in Fedora 28 Workstation. To use it, you must enable it using the *Region and Language* settings dialog. Open the Region and Language dialog from the main Fedora Workstation settings, or search for it in the Overview.
Choose the + control to add an input source. The following dialog appears:
Choose the final option (three dots) to expand the selections fully. Then, find *Other* at the bottom of the list and select it:
In the next dialog, find the *Typing booster* choice and select it:
This advanced input method is powered behind the scenes by iBus. The advanced input methods are identifiable in the list by the cogs icon on the right of the list.
The Input Method drop-down automatically appears in the GNOME Shell top bar. Ensure your default method — in this example, *English (US) —* is selected as the current method, and you’ll be ready to input.
## Using the new Emoji input method
Now the Emoji input method is enabled, search for emoji by pressing the keyboard shortcut **Ctrl+Shift+E**. A pop-over dialog appears where you can type a search term, such as *smile*, to find matching symbols.
Use the arrow keys to navigate the list. Then, hit **Enter** to make your selection, and the glyph will be placed as input.
## ifohancroft
Is this GNOME specific?
Of course, the input method is not GNOME specific, however, I suppose the shortcut and emoji browser may be.
## Paul W. Frields
The input method is not GNOME specific. There may be a different enabler in other environments, though.
## bepolymathe
Thank you very much for this article. I’ve been looking for something similar for a long time… but it only works in Gnome box dialog ? Under Firefox or Qt software it doesn’t seem to work?
Is there a way around this limitation?
## Rohan
This seems to be enabled by default on mine and I can’t find a way to override the Ctl+Shift+e combo which is super useful in the terminal emulator “Terminator”
## Paul W. Frields
@Rohan: You can do this with gsettings, e.g.:
If you want to get back the old setting:
## Rohan
@ Paul: Thanks! I had to make some modifications though.
ctrl+f [solution] if you want to skip to the solution.
Here’s what I got when I tried your command:
GLib-GIO-Message: Using the 'memory' GSettings backend. Your settings will not be saved or shared with other applications.
I verified that the setting was there (which it was):
GLib-GIO-Message: Using the 'memory' GSettings backend. Your settings will not be saved or shared with other applications.
['<Control><Shift>e']
After some googling I tried and failed with:
(process:4634): GLib-GIO-WARNING **: Can't find module 'dconf' specified in GSETTINGS_BACKEND
GLib-GIO-Message: Using the 'memory' GSettings backend. Your settings will not be saved or shared with other applications.
[solution] What finally worked was the dconf-editor GUI I launched using:
Though there I did not find the setting under the same path. There was nothing called ibus under org.freedesktop. I found the setting using the search function under desktop.ibus.panel.emoji
I still don’t know how to disable it though.
## gun1x
Yea, I closed this emoji stuff since it was messing up my terminator ….
## hhh
ugly rectangles, why not all emoi on screen
## Joao
Ctl+Shift-E was the “Edit in external editor” command in Evolution and it’s now clobbered by this “feature”. I would love to know how to remove it.
## Paul W. Frields
@Joao: Simply go to Region and Language and remove the Typing Booster you added. Or use the note above to reconfigure the keystroke.
## Leopold Topre
How would one enable this on KDE? Is the shortcut also available in this desktop env?
Thanks for this neat feature!
## Charles Steiner
@bepolymathe @joao click the superkey (windows button) to get an overview then click the Ctrl+Shift+E
## bepolymathe
It change nothing for me. Could you explain more ?
## Stuart D Gathman
I tried it out in gnome-terminal with utf-8 – works! The emoji chars are treated as double wide. The logic seems a little shaky when going back to edit text contains emoji in vim. This should be fun to add to comments in utf-8 programming languages.
## Stuart D Gathman
Another feature – you actually get a full unicode character picker, for when you want that odd char. Which reminds me – back in the day, terminals generally had a special key to enter arbitrary extended ASCII codes. Do we have a way to enter the hex code of an arbitrary unicode char? (The character picker is much slower when you already know the code.)
## Derek
Crtl+shift+u, enter the codepoint, and then space or enter!
https://help.gnome.org/users/gnome-help/stable/tips-specialchars.html.en#ctrlshiftu
## bepolymathe
I don’t understand why, but it doesn’t work in firefox. Are there any limitations on that side?
## Misc
So, I do not know if that’s the translation in French, or Fedora Silverblue, but I had a hard time to find the Ibus add on, since the name has nothing to do with “typing booster”, but “unicode (m17n)”. I guess it might be the same for a few others non english languages.
## Paul W. Frields
@Misc: Thanks for the tip for finding this in non-English desktops. |
9,871 | 学习如何使用 Python 构建你自己的 Twitter 机器人 | https://fedoramagazine.org/learn-build-twitter-bot-python/ | 2018-07-26T23:43:42 | [
"机器人",
"Twitter"
] | https://linux.cn/article-9871-1.html | 
Twitter 允许用户将博客帖子和文章[分享](https://twitter.com)给全世界。使用 Python 和 Tweepy 库使得创建一个 Twitter 机器人来接管你的所有的推特变得非常简单。这篇文章告诉你如何去构建这样一个机器人。希望你能将这些概念也同样应用到其他的在线服务的项目中去。
### 开始
[tweepy](https://tweepy.readthedocs.io/en/v3.5.0/) 库可以让创建一个 Twitter 机器人的过程更加容易上手。它包含了 Twitter 的 API 调用和一个很简单的接口。
下面这些命令使用 `pipenv` 在一个虚拟环境中安装 tweepy。如果你没有安装 `pipenv`,可以看一看我们之前的文章[如何在 Fedora 上安装 Pipenv](/article-9827-1.html)。
```
$ mkdir twitterbot
$ cd twitterbot
$ pipenv --three
$ pipenv install tweepy
$ pipenv shell
```
### Tweepy —— 开始
要使用 Twitter API ,机器人需要通过 Twitter 的授权。为了解决这个问题, tweepy 使用了 OAuth 授权标准。你可以通过在 <https://apps.twitter.com/> 创建一个新的应用来获取到凭证。
#### 创建一个新的 Twitter 应用
当你填完了表格并点击了“<ruby> 创建你自己的 Twitter 应用 <rt> Create your Twitter application </rt></ruby>”的按钮后,你可以获取到该应用的凭证。 Tweepy 需要<ruby> 用户密钥 <rt> API Key </rt></ruby>和<ruby> 用户密码 <rt> API Secret </rt></ruby>,这些都可以在 “<ruby> 密钥和访问令牌 <rt> Keys and Access Tokens </rt></ruby>” 中找到。

向下滚动页面,使用“<ruby> 创建我的访问令牌 <rt> Create my access token </rt></ruby>”按钮生成一个“<ruby> 访问令牌 <rt> Access Token </rt></ruby>” 和一个“<ruby> 访问令牌密钥 <rt> Access Token Secret </rt></ruby>”。
#### 使用 Tweppy —— 输出你的时间线
现在你已经有了所需的凭证了,打开一个文件,并写下如下的 Python 代码。
```
import tweepy
auth = tweepy.OAuthHandler("your_consumer_key", "your_consumer_key_secret")
auth.set_access_token("your_access_token", "your_access_token_secret")
api = tweepy.API(auth)
public_tweets = api.home_timeline()
for tweet in public_tweets:
print(tweet.text)
```
在确保你正在使用你的 Pipenv 虚拟环境后,执行你的程序。
```
$ python tweet.py
```
上述程序调用了 `home_timeline` 方法来获取到你时间线中的 20 条最近的推特。现在这个机器人能够使用 tweepy 来获取到 Twitter 的数据,接下来尝试修改代码来发送 tweet。
#### 使用 Tweepy —— 发送一条推特
要发送一条推特 ,有一个容易上手的 API 方法 `update_status` 。它的用法很简单:
```
api.update_status("The awesome text you would like to tweet")
```
Tweepy 拓展为制作 Twitter 机器人准备了非常多不同有用的方法。要获取 API 的详细信息,请查看[文档](http://docs.tweepy.org/en/v3.5.0/api.html#id1)。
### 一个杂志机器人
接下来我们来创建一个搜索 Fedora Magazine 的推特并转推这些的机器人。
为了避免多次转推相同的内容,这个机器人存放了最近一条转推的推特的 ID 。 两个助手函数 `store_last_id` 和 `get_last_id` 将会帮助存储和保存这个 ID。
然后,机器人使用 tweepy 搜索 API 来查找 Fedora Magazine 的最近的推特并存储这个 ID。
```
import tweepy
def store_last_id(tweet_id):
""" Stores a tweet id in text file """
with open('lastid', 'w') as fp:
fp.write(str(tweet_id))
def get_last_id():
""" Retrieve the list of tweets that were
already retweeted """
with open('lastid') as fp:
return fp.read()
if __name__ == '__main__':
auth = tweepy.OAuthHandler("your_consumer_key", "your_consumer_key_secret")
auth.set_access_token("your_access_token", "your_access_token_secret")
api = tweepy.API(auth)
try:
last_id = get_last_id()
except FileNotFoundError:
print("No retweet yet")
last_id = None
for tweet in tweepy.Cursor(api.search, q="fedoramagazine.org", since_id=last_id).items():
if tweet.user.name == 'Fedora Project':
store_last_id(tweet.id)
#tweet.retweet()
print(f'"{tweet.text}" was retweeted')
```
为了只转推 Fedora Magazine 的推特 ,机器人搜索内容包含 fedoramagazine.org 和由 「Fedora Project」 Twitter 账户发布的推特。
### 结论
在这篇文章中你看到了如何使用 tweepy 的 Python 库来创建一个自动阅读、发送和搜索推特的 Twitter 应用。现在,你能使用你自己的创造力来创造一个你自己的 Twitter 机器人。
这篇文章的演示源码可以在 [Github](https://github.com/cverna/magabot) 找到。
---
via: <https://fedoramagazine.org/learn-build-twitter-bot-python/>
作者:[Clément Verna](https://fedoramagazine.org) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Bestony](https://github.com/bestony) 校对:[校对者ID](https://github.com/%E6%A0%A1%E5%AF%B9%E8%80%85ID)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Twitter allows one to [share](https://twitter.com) blog posts and articles with the world. Using Python and the *tweepy* library makes it easy to create a Twitter bot that takes care of all the tweeting for you. This article shows you how to build such a bot. Hopefully you can take the concepts here and apply them to other projects that use online services.
### Getting started
To create a Twitter bot the [ tweepy](https://tweepy.readthedocs.io/en/v3.5.0/) library comes handy. It manages the Twitter API calls and provides a simple interface.
The following commands use *Pipenv* to install *tweepy* into a virtual environment. If you don’t have Pipenv installed, check out our previous article, [How to install Pipenv on Fedora](https://fedoramagazine.org/install-pipenv-fedora/).
$ mkdir twitterbot $ cd twitterbot $ pipenv --three $ pipenv install tweepy $ pipenv shell
### Tweepy – Getting started
To use the Twitter API the bot needs to authenticate against Twitter. For that, *tweepy* uses the OAuth authentication standard. You can get credentials by creating a new application at [https://apps.twitter.com/](https://apps.twitter.com/).
#### Create a new Twitter application
After you fill in the following form and click on the *Create your Twitter application* button, you have access to the application credentials. *Tweepy* requires the *Consumer Key (API Key)* and the *Consumer Secret (API Secret)*, both available from the *Keys and Access Tokens.*
After scrolling down the page, generate an *Access Token* and an *Access Token Secret *using the *Create my access token* button*.*
#### Using Tweepy – print your timeline
Now that you have all the credentials needed, open a new file and write the following Python code.
import tweepy auth = tweepy.OAuthHandler("your_consumer_key", "your_consumer_key_secret") auth.set_access_token("your_access_token", "your_access_token_secret") api = tweepy.API(auth) public_tweets = api.home_timeline() for tweet in public_tweets: print(tweet.text)
After making sure that you are using the Pipenv virtual environment, run your program.
$ python tweet.py
The above program calls the *home_timeline * API method to retrieve the 20 most recent tweets from your timeline. Now that the bot is able to use *tweepy * to get data from Twitter, try changing the code to send a tweet.
#### Using Tweepy – send a tweet
To send a tweet, the API method *update_status* comes in handy. The usage is simple:
api.update_status("The awesome text you would like to tweet")
The *tweepy *library has many other methods that can be useful for a Twitter bot. For the full details of the API, check the [documentation](http://docs.tweepy.org/en/v3.5.0/api.html#id1).
### A magazine bot
Let’s create a bot that searches for Fedora Magazine tweets and automatically retweets them.
To avoid retweeting the same tweet multiple times, the bot stores the tweet ID of the last retweet. Two helper functions, *store_last_id* and *get_last_id,* will be used to save and retrieve this ID.
Then the bot uses the *tweepy *search API to find the Fedora Magazine tweets that are more recent than the stored ID.
import tweepy def store_last_id(tweet_id): """ Store a tweet id in a file """ with open("lastid", "w") as fp: fp.write(str(tweet_id)) def get_last_id(): """ Read the last retweeted id from a file """ with open("lastid", "r") as fp: return fp.read() if __name__ == '__main__': auth = tweepy.OAuthHandler("your_consumer_key", "your_consumer_key_secret") auth.set_access_token("your_access_token", "your_access_token_secret") api = tweepy.API(auth) try: last_id = get_last_id() except FileNotFoundError: print("No retweet yet") last_id = None for tweet in tweepy.Cursor(api.search, q="fedoramagazine.org", since_id=last_id).items(): if tweet.user.name == 'Fedora Project': store_last_id(tweet.id) tweet.retweet() print(f'"{tweet.text}" was retweeted'
In order to retweet only tweets from the Fedora Magazine, the bot searches for tweets that contain *fedoramagazine.org* and are published by the “Fedora Project” Twitter account.
### Conclusion
In this article you saw how to create a Twitter application using the *tweepy* Python library to automate reading, sending and searching tweets. You can now use your creativity to create a Twitter bot of your own.
The source code of the example in this article is available on [Github](https://github.com/cverna/magabot). |
9,872 | 如何轻松地检查 Ubuntu 版本以及其它系统信息 | https://itsfoss.com/how-to-know-ubuntu-unity-version/ | 2018-07-27T07:52:55 | [
"Ubuntu",
"版本"
] | https://linux.cn/article-9872-1.html |
>
> 摘要:想知道你正在使用的 Ubuntu 具体是什么版本吗?这篇文档将告诉你如何检查你的 Ubuntu 版本、桌面环境以及其他相关的系统信息。
>
>
>

通常,你能非常容易的通过命令行或者图形界面获取你正在使用的 Ubuntu 的版本。当你正在尝试学习一篇互联网上的入门教材或者正在从各种各样的论坛里获取帮助的时候,知道当前正在使用的 Ubuntu 确切的版本号、桌面环境以及其他的系统信息将是尤为重要的。
在这篇简短的文章中,作者将展示各种检查 [Ubuntu](https://www.ubuntu.com/) 版本以及其他常用的系统信息的方法。
### 如何在命令行检查 Ubuntu 版本
这个是获得 Ubuntu 版本的最好的办法。我本想先展示如何用图形界面做到这一点,但是我决定还是先从命令行方法说起,因为这种方法不依赖于你使用的任何[桌面环境](https://en.wikipedia.org/wiki/Desktop_environment)。 你可以在 Ubuntu 的任何变种系统上使用这种方法。
打开你的命令行终端 (`Ctrl+Alt+T`), 键入下面的命令:
```
lsb_release -a
```
上面命令的输出应该如下:
```
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 16.04.4 LTS
Release: 16.04
Codename: xenial
```

正像你所看到的,当前我的系统安装的 Ubuntu 版本是 Ubuntu 16.04, 版本代号: Xenial。
且慢!为什么版本描述中显示的是 Ubuntu 16.04.4 而发行版本是 16.04?到底哪个才是正确的版本?16.04 还是 16.04.4? 这两者之间有什么区别?
如果言简意赅的回答这个问题的话,那么答案应该是你正在使用 Ubuntu 16.04。这个是基准版本,而 16.04.4 进一步指明这是 16.04 的第四个补丁版本。你可以将补丁版本理解为 Windows 世界里的服务包。在这里,16.04 和 16.04.4 都是正确的版本号。
那么输出的 Xenial 又是什么?那正是 Ubuntu 16.04 的版本代号。你可以阅读下面这篇文章获取更多信息:[了解 Ubuntu 的命名惯例](https://itsfoss.com/linux-code-names/)。
#### 其他一些获取 Ubuntu 版本的方法
你也可以使用下面任意的命令得到 Ubuntu 的版本:
```
cat /etc/lsb-release
```
输出如下信息:
```
DISTRIB_ID=Ubuntu
DISTRIB_RELEASE=16.04
DISTRIB_CODENAME=xenial
DISTRIB_DESCRIPTION="Ubuntu 16.04.4 LTS"
```

你还可以使用下面的命令来获得 Ubuntu 版本:
```
cat /etc/issue
```
命令行的输出将会如下:
```
Ubuntu 16.04.4 LTS \n \l
```
不要介意输出末尾的\n \l. 这里 Ubuntu 版本就是 16.04.4,或者更加简单:16.04。
### 如何在图形界面下得到 Ubuntu 版本
在图形界面下获取 Ubuntu 版本更是小事一桩。这里我使用了 Ubuntu 18.04 的图形界面系统 GNOME 的屏幕截图来展示如何做到这一点。如果你在使用 Unity 或者别的桌面环境的话,显示可能会有所不同。这也是为什么我推荐使用命令行方式来获得版本的原因:你不用依赖形形色色的图形界面。
下面我来展示如何在桌面环境获取 Ubuntu 版本。
进入‘系统设置’并点击下面的‘详细信息’栏。

你将会看到系统的 Ubuntu 版本和其他和桌面系统有关的系统信息 这里的截图来自 [GNOME](https://www.gnome.org/) 。

### 如何知道桌面环境以及其他的系统信息
你刚才学习的是如何得到 Ubuntu 的版本信息,那么如何知道桌面环境呢? 更进一步, 如果你还想知道当前使用的 Linux 内核版本呢?
有各种各样的命令你可以用来得到这些信息,不过今天我想推荐一个命令行工具, 叫做 [Neofetch](https://itsfoss.com/display-linux-logo-in-ascii/)。 这个工具能在命令行完美展示系统信息,包括 Ubuntu 或者其他 Linux 发行版的系统图标。
用下面的命令安装 Neofetch:
```
sudo apt install neofetch
```
安装成功后,运行 `neofetch` 将会优雅的展示系统的信息如下。

如你所见,`neofetch` 完全展示了 Linux 内核版本、Ubuntu 的版本、桌面系统版本以及环境、主题和图标等等信息。
希望我如上展示方法能帮到你更快的找到你正在使用的 Ubuntu 版本和其他系统信息。如果你对这篇文章有其他的建议,欢迎在评论栏里留言。
再见。:)
---
via: <https://itsfoss.com/how-to-know-ubuntu-unity-version/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[DavidChenLiang](https://github.com/davidchenliang) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

Knowing the exact Ubuntu version, desktop environment and other system information helps a lot when you’re trying to follow a tutorial from the web or seeking help on forums.
It also helps while installing software from some external repositories.
To check the Ubuntu version, use the following command in terminal:
`lsb_release -a`
This will show you some details about your distribution, including Ubuntu version:
```
Distributor ID: Ubuntu
Description: Ubuntu 20.04 LTS
Release: 20.04
Codename: focal
```
There are other ways to find the Ubuntu version I'll be discussing in detail in this article. I'll also share the method for getting the desktop environment version here.
## How to check Ubuntu version in the terminal
This is the best way to find your Ubuntu version. I could have mentioned the graphical way first, but I chose this method because it doesn’t depend on the [desktop environment](https://en.wikipedia.org/wiki/Desktop_environment?ref=itsfoss.com) you’re using.
You can use it on any Ubuntu variant. You can use it to [check Linux Mint version](https://itsfoss.com/check-linux-mint-version/), Fedora version or any other distribution you are using.
Open a terminal (Ctrl+Alt+T) and type the following command:
`lsb_release -a`
The output of the above command should look like this:
```
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 16.04.4 LTS
Release: 16.04
Codename: xenial
```
You can easily see what version of Ubuntu I have here. The current Ubuntu installed in my system is Ubuntu 16.04 and its code name is Xenial.
Wait! Why does it say Ubuntu 16.04.4 in Description and 16.04 in Release? Which one is it, 16.04 or 16.04.4? What’s the difference between the two?
The short answer is that you’re using Ubuntu 16.04. That’s the base image. 16.04.4 means it’s the fourth point release of 16.04. A point release can be thought of as the Linux equivalent of a Windows service pack. So both 16.04 and 16.04.4 are correct answers to this question.
What’s Xenial in the output? That’s the codename of the Ubuntu 16.04 release. You can read this [article to find out about Ubuntu naming conventions](https://itsfoss.com/linux-code-names/).
### Alternate ways to find the Ubuntu version
Alternatively, you can use either of the following commands to find your Ubuntu version:
`cat /etc/lsb-release`
The output of the above command looks like this:
```
DISTRIB_ID=Ubuntu
DISTRIB_RELEASE=16.04
DISTRIB_CODENAME=xenial
DISTRIB_DESCRIPTION="Ubuntu 16.04.4 LTS"
```
You can also use this command to get your Ubuntu version:
`cat /etc/issue`
The output of this command will be like this:
`Ubuntu 16.04.4 LTS \n \l`
Forget the \n \l. The Ubuntu version is 16.04.4 in this case, or simply Ubuntu 16.04.
## How to check Ubuntu version graphically
Checking your Ubuntu version graphically is no big deal either. I’m going to use screenshots from Ubuntu 18.04 GNOME here, but things may look different if you’re using Unity or some other desktop environment. I recommend the command line versions discussed in the previous sections because they don’t depend on the desktop environment.
The next section will show you how to find the desktop environment.
For now, go to System Settings and look under the Details segment.
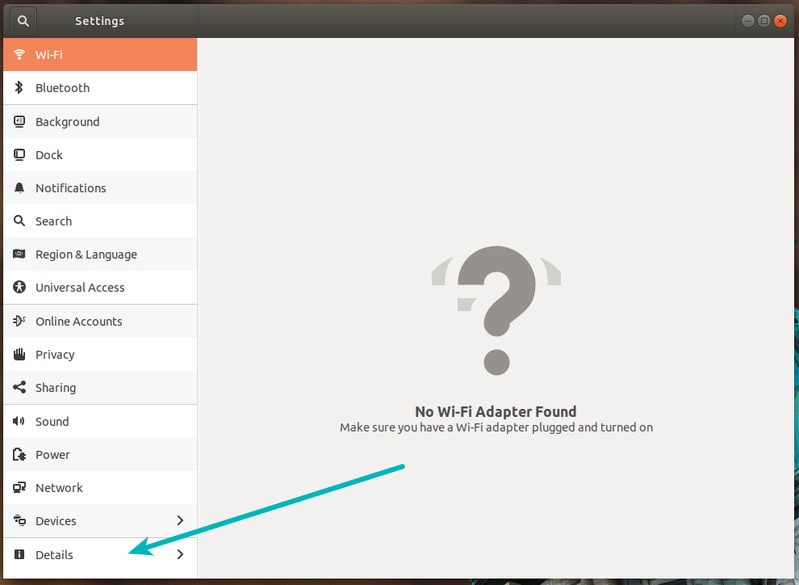
You should see the Ubuntu version here along with the information about the desktop environment you are using, [GNOME](https://www.gnome.org/?ref=itsfoss.com) being the case here.
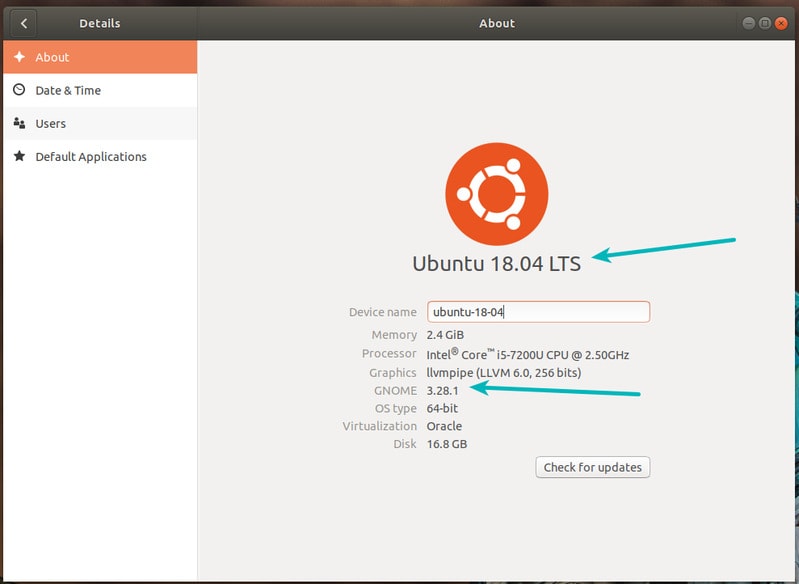
## How to find out the desktop environment and other system information in Ubuntu
So, you just learned how to find your Ubuntu version. But what about other information? [Which desktop environment are you using](https://itsfoss.com/find-desktop-environment/)? [Which Linux kernel version](https://itsfoss.com/find-which-kernel-version-is-running-in-ubuntu/) is being used?
Of course, you can use various commands to get all that information, but I recommend a command line utility called [Neofetch](https://github.com/dylanaraps/neofetch?ref=itsfoss.com). This will show you essential system information in the terminal, accompanied by the [ascii logo of the Linux distribution](https://itsfoss.com/display-linux-logo-in-ascii/) you are using.
[Install Neofetch](https://itsfoss.com/using-neofetch/) using the command below:
`sudo apt install neofetch`
Once installed, simply run the command `neofetch`
in the terminal and see a beautiful display of system information.
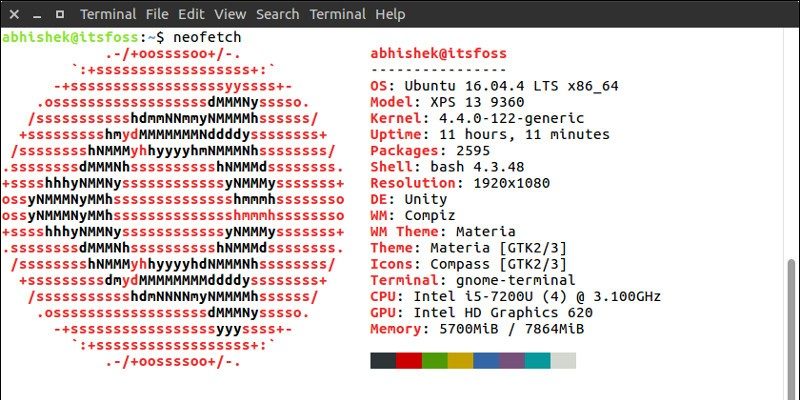
As you can see, Neofetch shows you the Linux kernel version, Ubuntu version, desktop environment and its version, themes and icons in use, etc.
I hope this helps you find your Ubuntu version and other system information. If you have suggestions for improving this article, feel free to drop them in the comment section. Ciao :) |
9,873 | 如何在 Android 上借助 Wine 来运行 Windows Apps | https://www.maketecheasier.com/run-windows-apps-android-with-wine/ | 2018-07-27T20:31:21 | [
"Wine"
] | https://linux.cn/article-9873-1.html | 
Wine(一种 Linux 上的程序,不是你喝的葡萄酒)是在类 Unix 操作系统上运行 Windows 程序的一个自由开源的兼容层。创建于 1993 年,借助它你可以在 Linux 和 macOS 操作系统上运行很多 Windows 程序,虽然有时可能还需要做一些小修改。现在,Wine 项目已经发布了 3.0 版本,这个版本兼容 Android 设备。
在本文中,我们将向你展示,在你的 Android 设备上如何借助 Wine 来运行 Windows Apps。
**相关阅读** : [如何使用 Winepak 在 Linux 上轻松安装 Windows 游戏](https://www.maketecheasier.com/winepak-install-windows-games-linux/ "How to Easily Install Windows Games on Linux with Winepak")
### 在 Wine 上你可以运行什么?
Wine 只是一个兼容层,而不是一个全功能的仿真器,因此,你需要一个 x86 的 Android 设备才能完全发挥出它的优势。但是,大多数消费者手中的 Android 设备都是基于 ARM 的。
因为大多数人使用的是基于 ARM 的 Android 设备,所以有一个限制,只有适配在 Windows RT 上运行的那些 App 才能够使用 Wine 在基于 ARM 的 Android 上运行。但是随着发展,能够在 ARM 设备上运行的 App 数量越来越多。你可以在 XDA 开发者论坛上的这个 [帖子](https://forum.xda-developers.com/showthread.php?t=2092348) 中找到兼容的这些 App 的清单。
在 ARM 上能够运行的一些 App 的例子如下:
* [Keepass Portable](http://downloads.sourceforge.net/keepass/KeePass-2.20.1.zip): 一个密码钱包
* [Paint.NET](http://forum.xda-developers.com/showthread.php?t=2411497): 一个图像处理程序
* [SumatraPDF](http://forum.xda-developers.com/showthread.php?t=2098594): 一个 PDF 文档阅读器,也能够阅读一些其它的文档类型
* [Audacity](http://forum.xda-developers.com/showthread.php?t=2103779): 一个数字录音和编辑程序
也有一些再度流行的开源游戏,比如,[Doom](http://forum.xda-developers.com/showthread.php?t=2175449) 和 [Quake 2](http://forum.xda-developers.com/attachment.php?attachmentid=1640830&amp;d=1358070370),以及它们的开源克隆,比如 [OpenTTD](http://forum.xda-developers.com/showpost.php?p=36674868&amp;postcount=151) 和《运输大亨》的一个版本。
随着 Wine 在 Android 上越来越普及,能够在基于 ARM 的 Android 设备上的 Wine 中运行的程序越来越多。Wine 项目致力于在 ARM 上使用 QEMU 去仿真 x86 的 CPU 指令,在该项目完成后,能够在 Android 上运行的 App 将会迅速增加。
### 安装 Wine
在安装 Wine 之前,你首先需要去确保你的设备的设置 “允许从 Play 商店之外的其它源下载和安装 APK”。对于本文的用途,你需要去许可你的设备从未知源下载 App。
1、 打开你手机上的设置,然后选择安全选项。

2、 向下拉并点击 “Unknown Sources” 的开关。

3、 接受风险警告。

4、 打开 [Wine 安装站点](https://dl.winehq.org/wine-builds/android/),并点选列表中的第一个选择框。下载将自动开始。

5、 下载完成后,从下载目录中打开它,或者下拉通知菜单并点击这里的已完成的下载。
6、 开始安装程序。它将提示你它需要访问和记录音频,并去修改、删除、和读取你的 SD 卡。你也可为程序中使用的一些 App 授予访问音频的权利。

7、 安装完成后,点击程序图标去打开它。

当你打开 Wine 后,它模仿的是 Windows 7 的桌面。

Wine 有一个缺点是,你得有一个外接键盘去进行输入。如果你在一个小屏幕上运行它,并且触摸非常小的按钮很困难,你也可以使用一个外接鼠标。
你可以通过触摸 “开始” 按钮去打开两个菜单 —— “控制面板”和“运行”。

### 使用 Wine 来工作
当你触摸 “控制面板” 后你将看到三个选项 —— 添加/删除程序、游戏控制器、和 Internet 设定。
使用 “运行”,你可以打开一个对话框去运行命令。例如,通过输入 `iexplore` 来启动 “Internet Explorer”。

### 在 Wine 中安装程序
1、 在你的 Android 设备上下载应用程序(或通过云来同步)。一定要记住下载的程序保存的位置。
2、 打开 Wine 命令提示符窗口。
3、 输入程序的位置路径。如果你把下载的文件保存在 SD 卡上,输入:
```
cd sdcard/Download/[filename.exe]
```
4、 在 Android 上运行 Wine 中的文件,只需要简单地输入 EXE 文件的名字即可。
如果这个支持 ARM 的文件是兼容的,它将会运行。如果不兼容,你将看到一大堆错误信息。在这种情况下,在 Android 上的 Wine 中安装的 Windows 软件可能会损坏或丢失。
这个在 Android 上使用的新版本的 Wine 仍然有许多问题。它并不能在所有的 Android 设备上正常工作。它可以在我的 Galaxy S6 Edge 上运行的很好,但是在我的 Galaxy Tab 4 上却不能运行。许多游戏也不能正常运行,因为图形驱动还不支持 Direct3D。因为触摸屏还不是全扩展的,所以你需要一个外接的键盘和鼠标才能很轻松地操作它。
即便是在早期阶段的发布版本中存在这样那样的问题,但是这种技术还是值得深思的。当然了,你要想在你的 Android 智能手机上运行 Windows 程序而不出问题,可能还需要等待一些时日。
---
via: <https://www.maketecheasier.com/run-windows-apps-android-with-wine/>
作者:[Tracey Rosenberger](https://www.maketecheasier.com/author/traceyrosenberger/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 
Wine (on Linux, not the one you drink) is a free and open-source compatibility layer for running Windows programs on Unix-like operating systems. Begun in 1993, it could run a wide variety of Windows programs on Linux and macOS, although sometimes with modification. Now the Wine Project has rolled out version 3.0 which is compatible with your Android devices.
In this article we will show you how you can run Windows apps on your Android device with WINE.
**Also read:** [How to Easily Install Windows Games on Linux with Winepak](https://www.maketecheasier.com/winepak-install-windows-games-linux/)
## What can you run on Wine?
Wine is only a compatibility layer, not a full-blown emulator, so you need an x86 Android device to take full advantage of it. However, most Androids in the hands of consumers are ARM-based.
Since most of you are using an ARM-based Android device, you will only be able to use Wine to run apps that have been adapted to run on Windows RT. There is a limited, but growing, list of software available for ARM devices. You can find a list of these apps that are compatible in this [thread](https://forum.xda-developers.com/showthread.php?t=2092348) on XDA Developers Forums.
Some examples of apps you will be able to run on ARM are:
[Keepass Portable](https://downloads.sourceforge.net/keepass/KeePass-2.20.1.zip): A password storage wallet[Paint.NET](https://forum.xda-developers.com/showthread.php?t=2411497): An image manipulation program[SumatraPDF](https://forum.xda-developers.com/showthread.php?t=2098594): A document reader for PDFs and possibly some other document types[Audacity](https://forum.xda-developers.com/showthread.php?t=2103779): A digital audio recording and editing program
There are also some open-source retro games available like [Doom](https://forum.xda-developers.com/showthread.php?t=2175449) and [Quake 2](https://forum.xda-developers.com/attachment.php?attachmentid=1640830&d=1358070370), as well as the open-source clone, [OpenTTD](https://forum.xda-developers.com/showpost.php?p=36674868&postcount=151), a version of Transport Tycoon.
The list of programs that Wine can run on Android ARM devices is bound to grow as the popularity of Wine on Android expands. The Wine project is working on using QEMU to emulate x86 CPU instructions on ARM, and when that is complete, the number of apps your Android will be able to run should grow rapidly.
## Installing Wine
To install Wine you must first make sure that your device’s settings allow it to download and install APKs from other sources than the Play Store. To do this you’ll need to give your device permission to download apps from unknown sources.
1. Open Settings on your phone and select your Security options.
2. Scroll down and click on the switch next to “Unknown Sources.”
3. Accept the risks in the warning.
4. Open the [Wine installation site](https://dl.winehq.org/wine-builds/android/), and tap the first checkbox in the list. The download will automatically begin.
5. Once the download completes, open it from your Downloads folder, or pull down the notifications menu and click on the completed download there.
6. Install the program. It will notify you that it needs access to recording audio and to modify, delete, and read the contents of your SD card. You may also need to give access for audio recording for some apps you will use in the program.
7. When the installation completes, click on the icon to open the program.
## Working with Wine
When you open Wine, the desktop mimics Windows 7.
One drawback of Wine is that you have to have an external keyboard available to type. An external mouse may also be useful if you are running it on a small screen and find it difficult to tap small buttons.
You can tap the Start button to open two menus – Control Panel and Run.
When you tap “Control panel” you will see three choices – Add/Remove Programs, Game Controllers, and Internet Settings.
Using “Run,” you can open a dialogue box to issue commands. For instance, launch Internet Explorer by entering `iexplore`
.
## Installing programs on Wine
1. Download the application (or sync via the cloud) to your Android device. Take note of where you save it.
2. Open the Wine Command Prompt window.
3. Type the path to the location of the program. If you have saved it to the Download folder on your SD card, type:
cd sdcard/Download/[filename.exe]
4. To run the file in Wine for Android, simply input the name of the EXE file.
If the ARM-ready file is compatible, it should run. If not, you’ll see a bunch of error messages. At this stage, installing Windows software on Android in Wine can be hit or miss.
There are still a lot of issues with this new version of Wine for Android. It doesn’t work on all Android devices. It worked on my Galaxy S6 Edge but not on my Galaxy Tab 4. Many games won’t work because the graphics driver doesn’t support Direct3D yet. You need an external keyboard and mouse to be able to easily manipulate the screen because touch-screen is not fully developed yet.
Even with these issues in the early stages of release, the possibilities for this technology are thought-provoking. It’s certainly likely that it will take some time yet before you can launch Windows programs on your Android smartphone using Wine without a hitch.
Our latest tutorials delivered straight to your inbox |
9,874 | 使用 Xenlism 主题对你的 Linux 桌面进行令人惊叹的改造 | https://itsfoss.com/xenlism-theme/ | 2018-07-27T20:47:30 | [
"主题"
] | https://linux.cn/article-9874-1.html |
>
> 简介:Xenlism 主题包提供了一个美观的 GTK 主题、彩色图标和简约的壁纸,将你的 Linux 桌面转变为引人注目的操作系统。
>
>
>
除非我找到一些非常棒的东西,否则我不会每天都把整篇文章献给一个主题。我曾经经常发布主题和图标。但最近,我更喜欢列出[最佳 GTK 主题](https://itsfoss.com/best-gtk-themes/)和图标主题。这对我和你来说都更方便,你可以在一个地方看到许多美丽的主题。
在 [Pop OS 主题](https://itsfoss.com/pop-icon-gtk-theme-ubuntu/)套件之后,Xenlism 是另一个让我对它的外观感到震惊的主题。

Xenlism GTK 主题基于 Arc 主题,其得益于许多主题的灵感。GTK 主题提供类似于 macOS 的 Windows 按钮,我既不特别喜欢,也没有特别不喜欢。GTK 主题采用扁平、简约的布局,我喜欢这样。
Xenlism 套件中有两个图标主题。Xenlism Wildfire 是以前的,已经进入我们的[最佳图标主题](https://itsfoss.com/best-icon-themes-ubuntu-16-04/)列表。

*Xenlism Wildfire 图标*
Xenlsim Storm 是一个相对较新的图标主题,但同样美观。

*Xenlism Storm 图标*
Xenlism 主题在 GPL 许可下开源。
### 如何在 Ubuntu 18.04 上安装 Xenlism 主题包
Xenlism 开发提供了一种通过 PPA 安装主题包的更简单方法。尽管 PPA 可用于 Ubuntu 16.04,但我发现 GTK 主题不适用于 Unity。它适用于 Ubuntu 18.04 中的 GNOME 桌面。
打开终端(`Ctrl+Alt+T`)并逐个使用以下命令:
```
sudo add-apt-repository ppa:xenatt/xenlism
sudo apt update
```
该 PPA 提供四个包:
* xenlism-finewalls:一组壁纸,可直接在 Ubuntu 的壁纸中使用。截图中使用了其中一个壁纸。
* xenlism-minimalism-theme:GTK 主题
* xenlism-storm:一个图标主题(见前面的截图)
* xenlism-wildfire-icon-theme:具有多种颜色变化的另一个图标主题(文件夹颜色在变体中更改)
你可以自己决定要安装的主题组件。就个人而言,我认为安装所有组件没有任何损害。
```
sudo apt install xenlism-minimalism-theme xenlism-storm-icon-theme xenlism-wildfire-icon-theme xenlism-finewalls
```
你可以使用 GNOME Tweaks 来更改主题和图标。如果你不熟悉该过程,我建议你阅读本教程以学习[如何在 Ubuntu 18.04 GNOME 中安装主题](https://itsfoss.com/install-themes-ubuntu/)。
### 在其他 Linux 发行版中获取 Xenlism 主题
你也可以在其他 Linux 发行版上安装 Xenlism 主题。各种 Linux 发行版的安装说明可在其网站上找到:
[安装 Xenlism 主题](http://xenlism.github.io/minimalism/#install)
### 你怎么看?
我知道不是每个人都会同意我,但我喜欢这个主题。我想你将来会在 It's FOSS 的教程中会看到 Xenlism 主题的截图。
你喜欢 Xenlism 主题吗?如果不喜欢,你最喜欢什么主题?在下面的评论部分分享你的意见。
### 关于作者
我是一名专业软件开发人员,也是 It's FOSS 的创始人。我是一名狂热的 Linux 爱好者和开源爱好者。我使用 Ubuntu 并相信分享知识。除了Linux,我喜欢经典侦探之谜。我是 Agatha Christie 作品的忠实粉丝。
---
via: <https://itsfoss.com/xenlism-theme/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | **Brief: Xenlism theme pack provides an aesthetically pleasing GTK theme, colorful icons, and minimalist wallpapers to transform your Linux desktop into an eye-catching setup.**
It’s not every day that I dedicate an entire article to a theme unless I find something really awesome. I used to cover themes and icons regularly. But lately, I preferred having lists of [best GTK themes](https://itsfoss.com/best-gtk-themes/) and icon themes. This is more convenient for me and for you as well as you get to see many beautiful themes in one place.
After [Pop OS theme](https://itsfoss.com/pop-icon-gtk-theme-ubuntu/) suit, Xenlism is another theme that has left me awestruck by its look.
Xenlism GTK theme is based on the Arc theme, an inspiration behind so many themes these days. The GTK theme provides Windows buttons similar to macOS which I neither like nor dislike. The GTK theme has a flat, minimalist layout and I like that.
There are two icon themes in the Xenlism suite. Xenlism Wildfire is an old one and had already made to our list of [best icon themes](https://itsfoss.com/best-icon-themes-ubuntu-16-04/).
Xenlsim Storm is the relatively new icon theme but is equally beautiful.
Xenlism themes are open source under GPL license.
## How to install Xenlism theme pack on Ubuntu 18.04
Xenlism dev provides an easier way of installing the theme pack through a PPA. Though the PPA is available for Ubuntu 16.04, I found the GTK theme wasn’t working with Unity. It works fine with the GNOME desktop in Ubuntu 18.04.
Open a terminal (Ctrl+Alt+T) and use the following commands one by one:
```
sudo add-apt-repository ppa:xenatt/xenlism
sudo apt update
```
This PPA offers four packages:
- xenlism-finewalls: for a set of wallpapers that will be available directly in the wallpaper section of Ubuntu. One of the wallpapers has been used in the screenshot.
- xenlism-minimalism-theme: GTK theme
- xenlism-storm: an icon theme (see previous screenshots)
- xenlism-wildfire-icon-theme: another icon theme with several color variants (folder colors get changed in the variants)
You can decide on your own what theme component you want to install. Personally, I don’t see any harm in installing all the components.
`sudo apt install xenlism-minimalism-theme xenlism-storm-icon-theme xenlism-wildfire-icon-theme xenlism-finewalls`
You can use GNOME Tweaks for changing the theme and icons. If you are not familiar with the procedure already, I suggest reading this tutorial to learn [how to install themes in Ubuntu 18.04 GNOME](https://itsfoss.com/install-themes-ubuntu/).
## Getting Xenlism themes in other Linux distributions
You can install Xenlism themes on other Linux distributions as well. Installation instructions for various Linux distributions can be found on its website:
### What do you think?
I know not everyone would agree with me but I loved this theme. I think you are going to see the glimpse of Xenlism theme in the screenshots in future tutorials on It’s FOSS.
Did you like Xenlism theme? If not, what theme do you like the most? Share your opinion in the comment section below. |
9,875 | 如何提升自动化的 ROI:4 个小提示 | https://enterprisersproject.com/article/2017/11/how-improve-roi-automation-4-tips | 2018-07-27T22:09:28 | [
"ROI",
"自动化"
] | https://linux.cn/article-9875-1.html |
>
> 想要在你的自动化项目上达成强 ROI?采取如下步骤来规避失败。
>
>
>

在过去的几年间,有关自动化技术的讨论已经很多了。COO 们和运营团队(事实上还有其它的业务部门)对于可以重新定义成本随着工作量的增加而增加的这一事实而感到震惊。
<ruby> 机器人流程自动化 <rt> Robotic Process Automation </rt></ruby>(RPA)似乎预示着运营的<ruby> 圣杯 <rt> Holy Grail </rt></ruby>:“我们提供了开箱即用的功能来满足你的日常操作所需 —— 检查电子邮件、保存附件、取数据、更新表格、生成报告、文件以及目录操作。构建一个机器人就像配置这些功能一样简单,然后用机器人将这些操作链接到一起,而不用去请求 IT 部门来构建它们。”这是一个多么诱人的话题。
低成本、几乎不出错、非常遵守流程 —— 对 COO 们和运营领导来说,这些好处真实可及。RPA 工具承诺,它从运营中节省下来的费用就足够支付它的成本(有一个短的回报期),这一事实使得业务的观点更具有吸引力。
自动化的谈论都趋向于类似的话题:COO 们和他们的团队想知道,自动化操作能够给他们带来什么好处。他们想知道 RPA 平台特性和功能,以及自动化在现实中的真实案例。从这一点到概念验证的实现过程通常很短暂。
**[ 在实现人工智能技术方面的建议,可以查看我们相关的文章,[制定你的人工智能策略:3 个小提示](https://enterprisersproject.com/article/2017/11/crafting-your-ai-strategy-3-tips?sc_cid=70160000000h0aXAAQ)]**。
但是自动化带来的现实好处有时候可能比你所预期的时间要晚。采用 RPA 的公司在其实施后可能会对它们自身的 ROI 提出一些质疑。一些人没有看到预期之中的成本节省,并对其中的原因感到疑惑。
### 你是不是自动化了错误的东西?
在这些情况下,自动化的愿景和现实之间的差距是什么呢?我们来分析一下它,在决定去继续进行一个自动化验证项目(甚至是一个成熟的实践)之后,我们来看一下通常会发生什么。
在确定实施自动化所采用的路径之后,COO 一般会问运营领导和他的团队们,应该在哪个流程或者任务上实施自动化。虽然从原则上说应该鼓励他们参与进来,但是有时候这种方式产生的决策往往会产生一个次优选择。原因如下:
首先,团队领导经常会是“视野较窄”:他们对自己的流程和任务非常熟悉,但是对他们不参与的流程和任务并不是那么熟悉(特别是在他们没有太多运营经验的情况下)。这意味着他们在自己的工作领域内可能会找出比较适合自动化的候选者,但是在跨整个运营的其它领域中可能并不一定会找出最适合的。另外其它的像“我希望我的流程成为第一个实施自动化的候选者”这样的“软性”因素也会影响决定。
其次,候选流程的选择有时候会被自动化特性和能力的匹配度所支配,而不是根据自动化所带来的价值所决定的。一个常见的误解是,任何包括像电子邮件或目录监视、下载、计算等活动的任务都是自动化的最佳候选者。如果对这些任务实施自动化不能为组织产生价值,那么它们就不是正确的候选者。
那么,对于领导们来说,怎么才能确保实施自动化能够带来他们想要的 ROI 呢?实现这个目标有四步:
### 1. 教育团队
在你的团队中,从 COO 职位以下的人中,很有可能都听说过 RPA 和运营自动化。同样很有可能他们都有许多的问题和担心。在你开始启动实施之前解决这些问题和担心是非常重要的。
对运营团队进行积极的教育可以大大地提升他们对自动化的热情和信心。培训主要关注于自动化和机器人是什么,它们在流程中一般扮演什么样的角色,哪个流程和任务最适合自动化,以及自动化的预期好处是什么。
**建议**:邀请你的自动化合作伙伴去进行这些团队教育工作,你要有所控制:他们可能会非常乐意帮助你。在领导层将这些传播到更大范围的团队之前,你应该对他们的教育内容进行把关。
“实施自动化的第一步是更好地理解你的流程。”
### 2. 审查内部流程
实施自动化的第一步是更好地理解你的流程。每个 RPA 实施之前都应该进行流程清单、动作分析、以及成本/价值的绘制练习。
这些练习对于理解流程中何处产生价值(或成本,如果没有价值的情况下)是至关重要的。并且这些练习需要在每个流程或者每个任务这样的粒度级别上来做。
这将有助你去识别和优先考虑最合适的自动化候选者。由于能够或者可能需要自动化的任务数量较多,流程一般需要分段实施自动化,因此优先级很重要。
**建议**:设置一个小的工作团队,每个运营团队都参与其中。从每个运营团队中提名一个协调人 —— 一般是运营团队的领导或者团队管理者。在团队级别上组织一次研讨会,去构建流程清单、识别候选流程、以及推动购买。你的自动化合作伙伴很可能有“加速器” —— 调查问卷、计分卡等等 —— 这些将帮助你加速完成这项活动。
### 3. 为优先业务提供强有力的指导
实施自动化经常会涉及到在运营团队之间,基于业务价值对流程选择和自动化优先级上要达成共识(有时候是打破平衡)虽然团队的参与仍然是分析和实施的关键部分,但是领导仍然应该是最终的决策者。
**建议**:安排定期会议从工作团队中获取最新信息。除了像推动达成共识和购买之外,工作团队还应该在团队层面上去查看领导们关于 ROI、平台选择、以及自动化优先级上的指导性决定。
### 4. 应该推动 CIO 和 COO 的紧密合作
当运营团队和技术团队紧密合作时,自动化的实施将异常顺利。COO 需要去帮助推动与 CIO 团队的合作。
COO 和其他运营领导人的参与和监督对成功实施自动化是至关重要的。
**建议**:COO 和 CIO 团队应该与第三方的自动化合作伙伴共同设立一个联合工作组(一个“战场”)。对每个参与者的责任进行明确的界定并持续跟踪。理想情况下,COO 和 CIO 应该至少有一个投入到联合工作组中,至少在初始发布中应该是这样。
自动化可以为组织创造重要的价值。然而为了在自动化中获得最优的投资回报,CIO 们必须在“入坑”之前做好规划。
---
via: <https://enterprisersproject.com/article/2017/11/how-improve-roi-automation-4-tips>
作者:[Rajesh Kamath](https://enterprisersproject.com/user/rajesh-kamath) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Automation technologies have generated plenty of buzz during the past few years. COOs and operations teams (and indeed, other business functions) are thrilled at the prospect of being able to redefine how costs have historically increased as work volume rose.
Robotic process automation (RPA) seems to promise the Holy Grail to operations: “Our platform provides out-of-box features to meet most of your daily process needs – checking email, saving attachments, getting data, updating forms, generating reports, file and folder operations. Building bots can be as easy as configuring these features and chaining them together, rather than asking IT to build them.” It’s a seductive conversation.
Lower cost, fewer errors, better compliance with procedures – the benefits seem real and achievable to COOs and operations leaders. The fact that RPA tools promise to pay for themselves from the operational savings (with short payback periods) makes the business case even more attractive.
Automation conversations tend to follow a similar script: COOs and their teams want to know how automating operations can benefit them. They want to know about RPA platform features and capabilities, and they want to see real-world examples of automation in action. The journey from this point to a proof-of-concept implementation is often short.
**[ For advice on implementing AI technology, see our related article, Crafting your AI strategy: 3 tips. ]**
But the reality of automation benefits can sometimes lag behind expectations. Companies that adopt RPA may find themselves questioning its ROI after implementation. Some express disappointment about not seeing the expected savings, and confusion as to why.
## Are you automating the wrong things?
What could explain the gap between the promise and reality of operational automation in these cases? To analyze this, let’s explore what typically happens after the decision to proceed with an automation proof-of-concept project (or a full-blown implementation, even) has been made.
After deciding that automation is the path to take, the COO typically asks operational leaders and their teams to decide which processes or tasks should be automated. While participation should be encouraged, this type of decision-making sometimes leads to sub-optimal choices in automation candidates. There are a few reasons for this:
First, team leaders often have a “narrow field of deep vision:” They know their processes and tasks well, but might not be deeply familiar with those that they do not participate in (especially if they have not had wide operations exposure). This means that they are able to identify good automation candidates within their own scope of work, but not necessarily across the entire operations landscape. Softer factors like “I want my process to be picked as the first automation candidate” can also come into play.
Second, candidate process selection can sometimes be driven by matching automation features and capabilities rather than by the *value* of automation. A common misunderstanding is that any task that includes activities like email or folder monitoring, downloads, calculations, etc. is automatically a good candidate for automation. If automating such tasks doesn’t provide value to the organization, they are not the right candidates.
So what can leaders do to ensure that their automation implementation delivers the ROI they are seeking? Take these four steps, up front:
**1. Educate your teams**
It’s very likely that people in your operations team, from the COO downward, have heard of RPA and operational automation. It’s equally likely that they have many questions and concerns. It is critical to address these issues before you start your implementation.
Proactively educating the operations team can go a long way in drumming up enthusiasm and buy-in for automation. Training can focus on what automation and bots are, what role they play in a typical process, which processes and tasks are best positioned for automation, and what the expected benefits of automation are.
**Recommendation**: Ask your automation partner to conduct these team education sessions, with your moderation: They will likely be eager to assist. The leadership should shape the message before it is delivered to the broader team.
**2. Examine your internal processes**
The first step in automation is to get to know your processes better. Every RPA implementation should be preceded by a process inventory, activity analysis, and cost/value mapping exercise.
It’s critical to understand where the value add (or cost, if value is unavailable) happens in the process. And this needs to be done at a granular level for each process or every task.
This will help you identify and prioritize the right candidates for automation. Because of the sheer number of tasks that can or may need to be automated, processes typically get automated in phases, so prioritization is key.
**Recommendation**: Set up a small working team, with participation from each group within Operations. Nominate a coordinator from each group – typically a group leader or team manager. Conduct a workshop at the group level to build the process inventory, identify candidate processes, and drive buy-in. Your automation partners are likely to have accelerators – questionnaires, scorecards etc. – that can help you speed up this activity.
**3. Provide strong direction on business priorities **
Implementations often involve driving consensus (and sometimes tie-breaking) between operations teams on process selection and automation priorities, based on business value. Though team participation remains a critical part of the analysis and implementation exercises, leaders should own final decision-making.
**Recommendation**: Schedule regular sessions to get updates from the working teams. In addition to factors like driving consensus and buy-in, teams will also look to leaders for directional decisions on ROI, platform selection, and automation prioritization at the group level.
**4. CIO and COO should drive close cooperation**
Automation rollouts are much smoother when there is close cooperation between the operations and technology teams. The COO needs to help drive this coordination with the CIO’s team.
Involvement and oversight of the COO and other operations leaders are critical for successful automation implementations.
**Recommendation**: The COO and CIO team should set up a joint working group (a “war room”) with the third-party automation partners. Responsibilities for each participant should be clearly demarcated and tracked on an ongoing basis. Ideally, the COO and CIO should dedicate at least one resource to the group, at least during the initial rollouts.
Automation can create significant value for an organization. However, to achieve optimal returns on the investment in their automation journey, CIOs must map before they leap.
## Comments
RPA provides many advantages to help businesses. However, no solution comes without potential barriers to the successful implementation of a new technology. A few roadblocks that could hinder ROI are also: lack of employee, support, selecting the wrong processes, and unrealistic expectations. Read more about RPA potential opportunities and difficulties: https://www.cigen.com.au/cigenblog/implementing-robotic-process-automation-overview-potential-opportunities-difficulties |
9,876 | 15 个适用于 MacOS 的开源应用程序 | https://opensource.com/article/18/7/open-source-tools-macos | 2018-07-28T22:49:11 | [
"Mac",
"开源"
] | https://linux.cn/article-9876-1.html |
>
> 钟爱开源的用户不会觉得在非 Linux 操作系统上使用他们喜爱的应用有多难。
>
>
>

只要有可能的情况下,我都会去选择使用开源工具。不久之前,我回到大学去攻读教育领导学硕士学位。即便是我将喜欢的 Linux 笔记本电脑换成了一台 MacBook Pro(因为我不能确定校园里能够接受 Linux),我还是决定继续使用我喜欢的工具,哪怕是在 MacOS 上也是如此。
幸运的是,它很容易,并且没有哪个教授质疑过我用的是什么软件。即然如此,我就不能秘而不宣。
我知道,我的一些同学最终会在学区担任领导职务,因此,我与我的那些使用 MacOS 或 Windows 的同学分享了关于下面描述的这些开源软件。毕竟,开源软件是真正地自由和友好的。我也希望他们去了解它,并且愿意以很少的一些成本去提供给他们的学生去使用这些世界级的应用程序。他们中的大多数人都感到很惊讶,因为,众所周知,开源软件除了有像你和我这样的用户之外,压根就没有销售团队。
### 我的 MacOS 学习曲线
虽然大多数的开源工具都能像以前我在 Linux 上使用的那样工作,只是需要不同的安装方法。但是,经过这个过程,我学习了这些工具在 MacOS 上的一些细微差别。像 [yum](https://en.wikipedia.org/wiki/Yum_(software))、[DNF](https://en.wikipedia.org/wiki/DNF_(software))、和 [APT](https://en.wikipedia.org/wiki/APT_(Debian)) 在 MacOS 的世界中压根不存在 —— 我真的很怀念它们。
一些 MacOS 应用程序要求依赖项,并且安装它们要比我在 Linux 上习惯的方法困难很多。尽管如此,我仍然没有放弃。在这个过程中,我学会了如何在我的新平台上保留最好的软件。即便是 MacOS 大部分的核心也是 [开源的](https://developer.apple.com/library/archive/documentation/MacOSX/Conceptual/OSX_Technology_Overview/SystemTechnology/SystemTechnology.html)。
此外,我的 Linux 的知识背景让我使用 MacOS 的命令行很轻松很舒适。我仍然使用命令行去创建和拷贝文件、添加用户、以及使用其它的像 `cat`、`tac`、`more`、`less` 和 `tail` 这样的 [实用工具](https://www.gnu.org/software/coreutils/coreutils.html)。
### 15 个适用于 MacOS 的非常好的开源应用程序
* 在大学里,要求我使用 DOCX 的电子版格式来提交我的工作,而这其实很容易,最初我使用的是 [OpenOffice](https://www.openoffice.org/),而后来我使用的是 [LibreOffice](https://www.libreoffice.org/) 去完成我的论文。
* 当我因为演示需要去做一些图像时,我使用的是我最喜欢的图像应用程序 [GIMP](https://www.gimp.org/) 和 [Inkscape](https://inkscape.org/en/)。
* 我喜欢的播客创建工具是 [Audacity](https://www.audacityteam.org/)。它比起 Mac 上搭载的专有应用程序更加简单。我使用它去录制访谈和为视频演示创建配乐。
* 在 MacOS 上我最早发现的多媒体播放器是 [VideoLan](https://www.videolan.org/index.html) (VLC)。
* MacOS 内置的专有视频创建工具是一个非常好的产品,但是你也可以很轻松地去安装和使用 [OpenShot](https://www.openshot.org/),它是一个非常好的内容创建工具。
* 当我需要在我的客户端上分析网络时,我在我的 Mac 上使用了易于安装的 [Nmap](https://nmap.org/) (Network Mapper) 和 [Wireshark](https://www.wireshark.org/) 工具。
* 当我为图书管理员和其它教育工作者提供培训时,我在 MacOS 上使用 [VirtualBox](https://www.virtualbox.org/) 去做 Raspbian、Fedora、Ubuntu 和其它 Linux 发行版的示范操作。
* 我使用 [Etcher.io](https://etcher.io/) 在我的 MacBook 上制作了一个引导盘,下载 ISO 文件,将它刻录到一个 U 盘上。
* 我认为 [Firefox](https://www.mozilla.org/en-US/firefox/new/) 比起 MacBook Pro 自带的专有浏览器更易用更安全,并且它允许我跨操作系统去同步我的书签。
* 当我使用电子书阅读器时,[Calibre](https://calibre-ebook.com/) 是当之无愧的选择。它很容易去下载和安装,你甚至只需要几次点击就能将它配置为一台 [教室中使用的电子书服务器](https://opensource.com/article/17/6/raspberrypi-ebook-server)。
* 最近我给中学的学生教 Python 课程,我发现它可以很容易地从 [Python.org](https://www.python.org/downloads/release/python-370/) 上下载和安装 Python 3 及 IDLE3 编辑器。我也喜欢学习数据科学,并与学生分享。不论你是对 Python 还是 R 感兴趣,我都建议你下载和 [安装](https://opensource.com/article/18/4/getting-started-anaconda-python) [Anaconda 发行版](https://www.anaconda.com/download/#macos)。它包含了非常好的 iPython 编辑器、RStudio、Jupyter Notebooks、和 JupyterLab,以及其它一些应用程序。
* [HandBrake](https://handbrake.fr/) 是一个将你家里的旧的视频 DVD 转成 MP4 的工具,这样你就可以将它们共享到 YouTube、Vimeo、或者你的 MacOS 上的 [Kodi](https://kodi.tv/download) 服务器上。
现在轮到你了:你在 MacOS(或 Windows)上都使用什么样的开源软件?在下面的评论区共享出来吧。
---
via: <https://opensource.com/article/18/7/open-source-tools-macos>
作者:[Don Watkins](https://opensource.com/users/don-watkins) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | I use open source tools whenever and wherever I can. I returned to college a while ago to earn a master's degree in educational leadership. Even though I switched from my favorite Linux laptop to a MacBook Pro (since I wasn't sure Linux would be accepted on campus), I decided I would keep using my favorite tools, even on macOS, as much as I could.
Fortunately, it was easy, and no professor ever questioned what software I used. Even so, I couldn't keep a secret.
I knew some of my classmates would eventually assume leadership positions in school districts, so I shared information about the open source applications described below with many of my macOS or Windows-using classmates. After all, open source software is really about freedom and goodwill. I also wanted them to know that it would be easy to provide their students with world-class applications at little cost. Most of them were surprised and amazed because, as we all know, open source software doesn't have a marketing team except users like you and me.
## My macOS learning curve
Through this process, I learned some of the nuances of macOS. While most of the open source tools worked as I was used to, others required different installation methods. Tools like [yum](https://en.wikipedia.org/wiki/Yum_(software)), [DNF](https://en.wikipedia.org/wiki/DNF_(software)), and [APT](https://en.wikipedia.org/wiki/APT_(Debian)) do not exist in the macOS world—and I really missed them.
Some macOS applications required dependencies and installations that were more difficult than what I was accustomed to with Linux. Nonetheless, I persisted. In the process, I learned how I could keep the best software on my new platform. Even much of MacOS's core is [open source](https://developer.apple.com/library/archive/documentation/MacOSX/Conceptual/OSX_Technology_Overview/SystemTechnology/SystemTechnology.html).
Also, my Linux background made it easy to get comfortable with the macOS command line. I still use it to create and copy files, add users, and use other [utilities ](https://www.gnu.org/software/coreutils/coreutils.html)like cat, tac, more, less, and tail.
## 15 great open source applications for macOS
- The college required that I submit most of my work electronically in DOCX format, and I did that easily, first with
[OpenOffice](https://www.openoffice.org/)and later using[LibreOffice](https://www.libreoffice.org/)to produce my papers. - When I needed to produce graphics for presentations, I used my favorite graphics applications,
[GIMP](https://www.gimp.org/)and[Inkscape](https://inkscape.org/en/). - My favorite podcast creation tool is
[Audacity](https://www.audacityteam.org/). It's much simpler to use than the proprietary application that ships with the Mac. I use it to record interviews and create soundtracks for video presentations. - I discovered early on that I could use the
[VideoLan](https://www.videolan.org/index.html)(VLC) media player on macOS. - macOS's built-in proprietary video creation tool is a good product, but you can easily install and use
[OpenShot](https://www.openshot.org/), which is a great content creation tool. - When I need to analyze networks for my clients, I use the easy-to-install
[Nmap](https://nmap.org/)(Network Mapper) and[Wireshark](https://www.wireshark.org/)tools on my Mac. - I use
[VirtualBox](https://www.virtualbox.org/)for macOS to demonstrate Raspbian, Fedora, Ubuntu, and other Linux distributions, as well as Moodle, WordPress, Drupal, and Koha when I provide training for librarians and other educators. - I make boot drives on my MacBook using
[Etcher.io](https://etcher.io/). I just download the ISO file and burn it on a USB stick drive. - I think
[Firefox](https://www.mozilla.org/en-US/firefox/new/)is easier and more secure to use than the proprietary browser that comes with the MacBook Pro, and it allows me to synchronize my bookmarks across operating systems. - When it comes to eBook readers,
[Calibre](https://calibre-ebook.com/)cannot be beaten. It is easy to download and install, and you can even configure it for a[classroom eBook server](https://opensource.com/article/17/6/raspberrypi-ebook-server)with a few clicks. - Recently I have been teaching Python to middle school students, I have found it is easy to download and install Python 3 and the IDLE3 editor from
[Python.org](https://www.python.org/downloads/release/python-370/). I have also enjoyed learning about data science and sharing that with students. Whether you're interested in Python or R, I recommend you download and[install](https://opensource.com/article/18/4/getting-started-anaconda-python)the[Anaconda distribution](https://www.anaconda.com/download/#macos). It contains the great iPython editor, RStudio, Jupyter Notebooks, and JupyterLab, along with some other applications. [HandBrake](https://handbrake.fr/)is a great way to turn your old home video DVDs into MP4s, which you can share on YouTube, Vimeo, or your own[Kodi](https://kodi.tv/download)server on macOS.
Now it's your turn: What open source software are you using on macOS (or Windows)? Share your favorites in the comments.
## 13 Comments |
9,877 | 为什么 DevSecOps 对 IT 领导来说如此重要 | https://enterprisersproject.com/article/2018/1/why-devsecops-matters-it-leaders | 2018-07-28T23:40:14 | [
"DevSecOps",
"DevOps"
] | https://linux.cn/article-9877-1.html |
>
> DevSecOps 也许不是一个优雅的词汇,但是其结果很吸引人:更强的安全、提前出现在开发周期中。来看看一个 IT 领导与 Meltdown 的拼搏。
>
>
>

如果 [DevOps](https://enterprisersproject.com/tags/devops) 最终是关于创造更好的软件,那也就意味着是更安全的软件。
而到了术语 “DevSecOps”,就像任何其他 IT 术语一样,DevSecOps —— 一个更成熟的 DevOps 的后代 ——可能容易受到炒作和盗用。但这个术语对那些拥抱了 DevOps 文化的领导者们来说具有重要的意义,并且其实践和工具可以帮助他们实现其承诺。
说道这里:“DevSecOps”是什么意思?
“DevSecOps 是开发、安全、运营的混合,”来自 [Datical](https://www.datical.com/) 的首席技术官和联合创始人 Robert 说。“这提醒我们,对我们的应用程序来说安全和创建并部署应用到生产中一样重要。”
**[想阅读其他首席技术官的 DevOps 文章吗?查阅我们丰富的资源,[DevOps:IT 领导者指南](https://enterprisersproject.com/devops?sc_cid=70160000000h0aXAAQ)]**
向非技术人员解释 DevSecOps 的一个简单的方法是:它是指将安全有意并提前加入到开发过程中。
“安全团队从历史上一直都被孤立于开发团队——每个团队在 IT 的不同领域都发展了很强的专业能力”,来自红帽安全策的专家 Kirsten 最近告诉我们。“不需要这样,非常关注安全也关注他们通过软件来兑现商业价值的能力的企业正在寻找能够在应用开发生命周期中加入安全的方法。他们通过在整个 CI/CD 管道中集成安全实践、工具和自动化来采用 DevSecOps。”
“为了能够做的更好,他们正在整合他们的团队——专业的安全人员从开始设计到部署到生产中都融入到了开发团队中了,”她说,“双方都收获了价值——每个团队都拓展了他们的技能和基础知识,使他们自己都成更有价值的技术人员。 DevOps 做的很正确——或者说 DevSecOps——提高了 IT 的安全性。”
IT 团队比任何以往都要求要快速频繁的交付服务。DevOps 在某种程度上可以成为一个很棒的推动者,因为它能够消除开发和运营之间通常遇到的一些摩擦,运营一直被排挤在整个过程之外直到要部署的时候,开发者把代码随便一放之后就不再去管理,他们承担更少的基础架构的责任。那种孤立的方法引起了很多问题,委婉的说,在数字时代,如果将安全孤立起来同样的情况也会发生。
“我们已经采用了 DevOps,因为它已经被证明通过移除开发和运营之间的阻碍来提高 IT 的绩效,”Reevess 说,“就像我们不应该在开发周期要结束时才加入运营,我们不应该在快要结束时才加入安全。”
### 为什么 DevSecOps 必然出现
或许会把 DevSecOps 看作是另一个时髦词,但对于安全意识很强的IT领导者来说,它是一个实质性的术语:在软件开发管道中安全必须是第一层面的要素,而不是部署前的最后一步的螺栓,或者更糟的是,作为一个团队只有当一个实际的事故发生的时候安全人员才会被重用争抢。
“DevSecOps 不只是一个时髦的术语——因为多种原因它是现在和未来 IT 将呈现的状态”,来自 [Sumo Logic] 的安全和合规副总裁 George 说道,“最重要的好处是将安全融入到开发和运营当中开提供保护的能力”
此外,DevSecOps 的出现可能是 DevOps 自身逐渐成熟并扎根于 IT 之中的一个征兆。
“企业中的 DevOps 文化已成定局,而且那意味着开发者们正以不断增长的速度交付功能和更新,特别是自我管理的组织会对合作和衡量的结果更加满意”,来自 [CYBRIC] 的首席技术官和联合创始人 Mike 说道。
在实施 DevOps 的同时继续保留原有安全措施的团队和公司,随着他们继续部署的更快更频繁可能正在经历越来越多的安全管理风险上的痛苦。
“现在的手工的安全测试方法会继续远远被甩在后面。”
“如今,手动的安全测试方法正被甩得越来越远,利用自动化和协作将安全测试转移到软件开发生命周期中,因此推动 DevSecOps 的文化是 IT 领导者们为增加整体的灵活性提供安全保证的唯一途径”,Kail 说。
转移安全测试也使开发者受益:他们能够在开放的较早的阶段验证并解决潜在的问题——这样很少需要或者甚至不需要安全人员的介入,而不是在一个新的服务或者更新部署之前在他们的代码中发现一个明显的漏洞。
“做的正确,DevSecOps 能够将安全融入到开发生命周期中,允许开发者们在没有安全中断的情况下更加快速容易的保证他们应用的安全”,来自 [SAS](https://www.sas.com/en_us/home.html) 的首席信息安全员 Wilson 说道。
Wilson 指出静态(SAST)和源组合分析(SCA)工具,集成到团队的持续交付管道中,作为有用的技术通过给予开发者关于他们的代码中的潜在问题和第三方依赖中的漏洞的反馈来使之逐渐成为可能。
“因此,开发者们能够主动和迭代的缓解应用安全的问题,然后在不需要安全人员介入的情况下重新进行安全扫描。” Wilson 说。他同时指出 DevSecOps 能够帮助开发者简化更新和打补丁。
DevSecOps 并不意味着你不再需要安全组的意见了,就如同 DevOps 并不意味着你不再需要基础架构专家;它只是帮助你减少在生产中发现缺陷的可能性,或者减少导致降低部署速度的阻碍,因为缺陷已经在开发周期中被发现解决了。
“如果他们有问题或者需要帮助,我们就在这儿,但是因为已经给了开发者他们需要的保护他们应用安全的工具,我们很少在一个深入的测试中发现一个导致中断的问题,”Wilson 说道。
### DevSecOps 遇到 Meltdown
Sumo Locic 的 Gerchow 向我们分享了一个在运转中的 DevSecOps 文化的一个及时案例:当最近 [Meltdown 和 Spectre] 的消息传来的时候,团队的 DevSecOps 方法使得有了一个快速的响应来减轻风险,没有任何的通知去打扰内部或者外部的顾客,Gerchow 所说的这点对原生云、高监管的公司来说特别的重要。
第一步:Gerchow 的小型安全团队都具有一定的开发能力,能够通过 Slack 和它的主要云供应商协同工作来确保它的基础架构能够在 24 小时之内完成修复。
“接着我的团队立即开始进行系统级的修复,实现终端客户的零停机时间,不需要去开工单给工程师,如果那样那意味着你需要等待很长的变更过程。所有的变更都是通过 Slack 的自动 jira 票据进行,通过我们的日志监控和分析解决方案”,Gerchow 解释道。
在本质上,它听起来非常像 DevOps 文化,匹配正确的人员、过程和工具,但它明确的将安全作为文化中的一部分进行了混合。
“在传统的环境中,这将花费数周或数月的停机时间来处理,因为开发、运维和安全三者是相互独立的”,Gerchow 说道,“通过一个 DevSecOps 的过程和习惯,终端用户可以通过简单的沟通和当日修复获得无缝的体验。”
---
via: <https://enterprisersproject.com/article/2018/1/why-devsecops-matters-it-leaders>
作者:[Kevin Casey](https://enterprisersproject.com/user/kevin-casey) 译者:[FelixYFZ](https://github.com/FelixYFZ) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | If [DevOps](https://enterprisersproject.com/taxonomy/term/76) is ultimately about building better software, that means better-secured software, too.
Enter the term “DevSecOps.” Like any IT term, DevSecOps – a descendant of the better-established DevOps – could be susceptible to hype and misappropriation. But the term has real meaning for IT leaders who’ve embraced a culture of DevOps and the practices and tools that help deliver on its promise.
Speaking of which: What does “DevSecOps” mean?
“DevSecOps is a portmanteau of development, security, and operations,” says Robert Reeves, CTO and co-founder at [Datical](https://www.datical.com/). “It reminds us that security is just as important to our applications as creating them and deploying them to production.”
**[ Want DevOps advice from other CIOs? See our comprehensive resource, DevOps: The IT Leader's Guide. ]**
One easy way to explain DevSecOps to non-technical people: It bakes security into the development process intentionally and earlier.
“Security teams have historically been isolated from development teams – and each team has developed deep expertise in different areas of IT,” [Red Hat](https://www.redhat.com/en?intcmp=701f2000000tjyaAAA) security strategist Kirsten Newcomer [told us](https://enterprisersproject.com/article/2017/10/what-s-next-devops-5-trends-watch) recently. “It doesn’t need to be this way. Enterprises that care deeply about security and also care deeply about their ability to quickly deliver business value through software are finding ways to move security left in their application development lifecycles. They’re adopting DevSecOps by integrating security practices, tooling, and automation throughout the CI/CD pipeline.”
“To do this well, they’re integrating their teams – security professionals are embedded with application development teams from inception (design) through to production deployment,” she says. “Both sides are seeing the value – each team expands their skill sets and knowledge base, making them more valuable technologists. DevOps done right – or DevSecOps – improves IT security.”
IT teams are tasked with delivering services faster and more frequently than ever before. DevOps can be a great enabler of this, in part because it can remove some of the traditional friction between development and operations teams that commonly surfaced when Ops was left out of the process until deployment time and Dev tossed its code over an invisible wall, never to manage it again, much less have any infrastructure responsibility. That kind of siloed approach causes problems, to put it mildly, in the digital age. According to Reeves, the same holds true if security exists in a silo.
“We have adopted DevOps because it’s proven to improve our IT performance by removing the barriers between development and operations,” Reeves says. “Much like we shouldn’t wait until the end of the deployment cycle to involve operations, we shouldn’t wait until the end to involve security.”
## Why DevSecOps is here to stay
It may be tempting to see DevSecOps as just another buzzword, but for security-conscious IT leaders, it’s a substantive term: Security must be a first-class citizen in the software development pipeline, not something that gets bolted on as a final step before a deploy, or worse, as a team that gets scrambled only after an actual incident occurs.
“DevSecOps is not just a buzzword – it is the current and future state of IT for multiple reasons,” says George Gerchow, VP of security and compliance at [Sumo Logic](https://www.sumologic.com/). “The most important benefit is the ability to bake security into development and operational processes to provide guardrails – not barriers – to achieve agility and innovation.”
Moreover, the appearance of the DevSecOps on the scene might be another sign that DevOps itself is maturing and digging deep roots inside IT.
“The culture of DevOps in the enterprise is here to stay, and that means that developers are delivering features and updates to the production environment at an increasingly higher velocity, especially as the self-organizing teams become more comfortable with both collaboration and measurement of results,” says Mike Kail, CTO and co-founder at [CYBRIC](https://www.cybric.io/).
Teams and companies that have kept their old security practices in place while embracing DevOps are likely experiencing an increasing amount of pain managing security risks as they continue to deploy faster and more frequently.
“The current, manual testing approaches of security continue to fall further and further behind, and leveraging both automation and collaboration to shift security testing left into the software development life cycle, thus driving the culture of DevSecOps, is the only way for IT leaders to increase overall resiliency and delivery security assurance,” Kail says.
Shifting security testing left (earlier) benefits developers, too: Rather than finding out about a glaring hole in their code right before a new or updated service is set to deploy, they can identify and resolve potential issues during much earlier stages of development – often with little or no intervention from security personnel.
“Done right, DevSecOps can ingrain security into the development lifecycle, empowering developers to more quickly and easily secure their applications without security disruptions,” says Brian Wilson, chief information security officer at [SAS](https://www.sas.com/en_us/home.html).
Wilson points to static (SAST) and source composition analysis (SCA) tools, integrated into a team’s continuous delivery pipelines, as useful technologies that help make this possible by giving developers feedback about potential issues in their own code as well as vulnerabilities in third-party dependencies.
“As a result, developers can proactively and iteratively mitigate appsec issues and rerun security scans without the need to involve security personnel,” Wilson says. He notes, too, that DevSecOps can also help the Dev team streamline updates and patching.
DevSecOps doesn’t mean you no longer need security pros, just as DevOps doesn’t mean you no longer need infrastructure experts; it just helps reduce the likelihood of flaws finding their way into production, or from slowing down deployments because they’re caught late in the pipeline.
“We’re here if they have questions or need help, but having given developers the tools they need to secure their apps, we’re less likely to find a showstopper issue during a penetration test,” Wilson says.
## DevSecOps meets Meltdown
Sumo Logic’s Gerchow shares a timely example of the DevSecOps culture in action: When the recent [Meltdown and Spectre](https://www.redhat.com/en/blog/what-are-meltdown-and-spectre-heres-what-you-need-know?intcmp=701f2000000tjyaAAA) news hit, the team’s DevSecOps approach enabled a rapid response to mitigate its risks without any noticeable disruption to internal or external customers, which Gerchow said was particularly important for the cloud-native, highly regulated company.
The first step: Gerchow’s small security team, which he notes also has development skills, was able to work with one of its main cloud vendors via Slack to ensure its infrastructure was completely patched within 24 hours.
“My team then began OS-level fixes immediately with zero downtime to end users without having to open tickets and requests with engineering that would have meant waiting on a long change management process. All the changes were accounted for via automated Jira tickets opened via Slack and monitored through our logs and analytics solution,” Gerchow explains.
In essence, it sounds a whole lot like the culture of DevOps, matched with the right mix of people, processes, and tools, but it explicitly includes security as part of that culture and mix.
“In traditional environments, it would have taken weeks or months to do this with downtime because all three development, operations, and security functions were siloed,” Gerchow says. “With a DevSecOps process and mindset, end users get a seamless experience with easy communication and same-day fixes.”
**Want more wisdom like this, IT leaders? Sign up for our weekly email newsletter.**
## Comments
Hello Kevin,
I couldn't agree more about shifting security left in the development process, but how much further left in the process can you go than securing the access to your APIs, applications, and the systems in your infrastructure. When looking at DevOps security most people focus on OS level security issues, but what about secrets embedded in code like passwords and API tokens?
I am working on the Conjur.org open source project to fix this issue.
Thanks,
John Walsh |
9,878 | Debian 打包入门 | http://minkush.me/cardbook-debian-package/ | 2018-07-29T10:50:36 | [
"Debian",
"打包"
] | https://linux.cn/article-9878-1.html |
>
> 创建 CardBook 软件包、本地 Debian 仓库,并修复错误。
>
>
>

我在 GSoC(LCTT 译注:Google Summer Of Code,一项针对学生进行的开源项目训练营,一般在夏季进行。)的任务中有一项是为用户构建 Thunderbird <ruby> 扩展 <rt> add-ons </rt></ruby>。一些非常流行的扩展,比如 [Lightning](https://addons.mozilla.org/en-US/thunderbird/addon/lightning/) (日历行事历)已经拥有了 deb 包。
另外一个重要的用于管理基于 CardDav 和 vCard 标准的联系人的扩展 [Cardbook](https://addons.mozilla.org/nn-NO/thunderbird/addon/cardbook/?src=hp-dl-featured) ,还没有一个 deb 包。
我的导师, [Daniel](https://danielpocock.com/) 鼓励我去为它制作一个包,并上传到 [mentors.debian.net](https://mentors.debian.net/)。因为这样就可以使用 `apt-get` 来安装,简化了安装流程。这篇博客描述了我是如何从头开始学习为 CardBook 创建一个 Debian 包的。
首先,我是第一次接触打包,我在从源码构建包的基础上进行了大量研究,并检查它的协议是是否与 [DFSG](https://wiki.debian.org/DFSGLicenses) 兼容。
我从多个 Debian Wiki 中的指南中进行学习,比如 [打包介绍](https://wiki.debian.org/Packaging/Intro)、 [构建一个包](https://wiki.debian.org/BuildingAPackage),以及一些博客。
我还研究了包含在 [Lightning 扩展包](https://packages.debian.org/stretch/amd64/lightning/filelist)的 amd64 文件。
我创建的包可以在[这里](https://salsa.debian.org/minkush-guest/CardBook/tree/debian-package/Debian)找到。

*Debian 包*
### 创建一个空的包
我从使用 `dh_make` 来创建一个 `debian` 目录开始。
```
# Empty project folder
$ mkdir -p Debian/cardbook
```
```
# create files
$ dh_make\
> --native \
> --single \
> --packagename cardbook_1.0.0 \
> --email [email protected]
```
一些重要的文件,比如 `control`、`rules`、`changelog`、`copyright` 等文件被初始化其中。
所创建的文件的完整列表如下:
```
$ find /debian
debian/
debian/rules
debian/preinst.ex
debian/cardbook-docs.docs
debian/manpage.1.ex
debian/install
debian/source
debian/source/format
debian/cardbook.debhelper.lo
debian/manpage.xml.ex
debian/README.Debian
debian/postrm.ex
debian/prerm.ex
debian/copyright
debian/changelog
debian/manpage.sgml.ex
debian/cardbook.default.ex
debian/README
debian/cardbook.doc-base.EX
debian/README.source
debian/compat
debian/control
debian/debhelper-build-stamp
debian/menu.ex
debian/postinst.ex
debian/cardbook.substvars
debian/files
```
我了解了 Debian 系统中 [Dpkg](https://packages.debian.org/stretch/dpkg) 包管理器及如何用它安装、删除和管理包。
我使用 `dpkg` 命令创建了一个空的包。这个命令创建一个空的包文件以及四个名为 `.changes`、`.deb`、 `.dsc`、 `.tar.gz` 的文件。
* `.dsc` 文件包含了所发生的修改和签名
* `.deb` 文件是用于安装的主要包文件。
* `.tar.gz` (tarball)包含了源代码
这个过程也在 `/usr/share` 目录下创建了 `README` 和 `changelog` 文件。它们包含了关于这个包的基本信息比如描述、作者、版本。
我安装这个包,并检查这个包安装的内容。我的新包中包含了版本、架构和描述。
```
$ dpkg -L cardbook
/usr
/usr/share
/usr/share/doc
/usr/share/doc/cardbook
/usr/share/doc/cardbook/README.Debian
/usr/share/doc/cardbook/changelog.gz
/usr/share/doc/cardbook/copyright
```
### 包含 CardBook 源代码
在成功的创建了一个空包以后,我在包中添加了实际的 CardBook 扩展文件。 CardBook 的源代码托管在 [Gitlab](https://gitlab.com/CardBook/CardBook) 上。我将所有的源码文件包含在另外一个目录,并告诉打包命令哪些文件需要包含在这个包中。
我使用 `vi` 编辑器创建一个 `debian/install` 文件并列举了需要被安装的文件。在这个过程中,我花费了一些时间去学习基于 Linux 终端的文本编辑器,比如 `vi` 。这让我熟悉如何在 `vi` 中编辑、创建文件和快捷方式。
当这些完成后,我在变更日志中更新了包的版本并记录了我所做的改变。
```
$ dpkg -l | grep cardbook
ii cardbook 1.1.0 amd64 Thunderbird add-on for address book
```

*更新完包的变更日志*
在重新构建完成后,重要的依赖和描述信息可以被加入到包中。 Debian 的 `control` 文件可以用来添加额外的必须项目和依赖。
### 本地 Debian 仓库
在不创建本地存储库的情况下,CardBook 可以使用如下的命令来安装:
```
$ sudo dpkg -i cardbook_1.1.0.deb
```
为了实际测试包的安装,我决定构建一个本地 Debian 存储库。没有它,`apt-get` 命令将无法定位包,因为它没有在 Debian 的包软件列表中。
为了配置本地 Debian 存储库,我复制我的包 (.deb)为放在 `/tmp` 目录中的 `Packages.gz` 文件。

*本地 Debian 仓库*
为了使它工作,我了解了 `apt` 的配置和它查找文件的路径。
我研究了一种在 `apt-config` 中添加文件位置的方法。最后,我通过在 APT 中添加 `*.list` 文件来添加包的路径,并使用 `apt-cache` 更新APT缓存来完成我的任务。
因此,最新的 CardBook 版本可以成功的通过 `apt-get install cardbook` 来安装了。

*使用 apt-get 安装 CardBook*
### 修复打包错误和 Bugs
我的导师 Daniel 在这个过程中帮了我很多忙,并指导我如何进一步进行打包。他告诉我使用 [Lintian](https://packages.debian.org/stretch/lintian) 来修复打包过程中出现的常见错误和最终使用 [dput](https://packages.debian.org/stretch/dput) 来上传 CardBook 包。
>
> Lintian 是一个用于发现策略问题和 Bug 的包检查器。它是 Debian 维护者们在上传包之前广泛使用的自动化检查 Debian 策略的工具。
>
>
>
我上传了该软件包的第二个更新版本到 Debian 目录中的 [Salsa 仓库](https://salsa.debian.org/minkush-guest/CardBook/tree/debian-package) 的一个独立分支中。
我从 Debian backports 上安装 Lintian 并学习在一个包上用它来修复错误。我研究了它用在其错误信息中的缩写,和如何查看 Lintian 命令返回的详细内容。
```
$ lintian -i -I --show-overrides cardbook_1.2.0.changes
```
最初,在 `.changes` 文件上运行命令时,我惊讶地看到显示出来了大量错误、警告和注释!

*在包上运行 Lintian 时看到的大量报错*

*详细的 Lintian 报错*

*详细的 Lintian 报错 (2) 以及更多*
我花了几天时间修复与 Debian 包策略违例相关的一些错误。为了消除一个简单的错误,我必须仔细研究每一项策略和 Debian 的规则。为此,我参考了 [Debian 策略手册](https://www.debian.org/doc/debian-policy/) 以及 [Debian 开发者参考](https://www.debian.org/doc/manuals/developers-reference/)。
我仍然在努力使它变得完美无暇,并希望很快可以将它上传到 mentors.debian.net!
如果 Debian 社区中使用 Thunderbird 的人可以帮助修复这些报错就太感谢了。
---
via: <http://minkush.me/cardbook-debian-package/>
作者:[Minkush Jain](http://minkush.me/cardbook-debian-package/#) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Bestony](https://github.com/bestony) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 302 | Found | null |
9,879 | Streams:一个新的 Redis 通用数据结构 | http://antirez.com/news/114 | 2018-07-29T21:47:00 | [
"Redis",
"数据结构"
] | https://linux.cn/article-9879-1.html | 
直到几个月以前,对于我来说,在消息传递的环境中,<ruby> 流 <rt> streams </rt></ruby>只是一个有趣且相对简单的概念。这个概念在 Kafka 流行之后,我主要研究它们在 Disque 案例中的应用,Disque 是一个消息队列,它将在 Redis 4.2 中被转换为 Redis 的一个模块。后来我决定让 Disque 都用 AP 消息(LCTT 译注:参见 [CAP 定理](https://zh.wikipedia.org/wiki/CAP%E5%AE%9A%E7%90%86)),也就是说,它将在不需要客户端过多参与的情况下实现容错和可用性,这样一来,我更加确定地认为流的概念在那种情况下并不适用。
然而在那时 Redis 有个问题,那就是缺省情况下导出数据结构并不轻松。它在 Redis <ruby> 列表 <rt> list </rt></ruby>、<ruby> 有序集 <rt> sorted list </rt></ruby>、<ruby> 发布/订阅 <rt> Pub/Sub </rt></ruby>功能之间有某些缺陷。你可以权衡使用这些工具对一系列消息或事件建模。
有序集是内存消耗大户,那自然就不能对投递的相同消息进行一次又一次的建模,客户端不能阻塞新消息。因为有序集并不是一个序列化的数据结构,它是一个元素可以根据它们量的变化而移动的集合:所以它不像时序性的数据那样。
列表有另外的问题,它在某些特定的用例中会产生类似的适用性问题:你无法浏览列表中间的内容,因为在那种情况下,访问时间是线性的。此外,没有任何指定输出的功能,列表上的阻塞操作仅为单个客户端提供单个元素。列表中没有固定的元素标识,也就是说,不能指定从哪个元素开始给我提供内容。
对于一对多的工作任务,有发布/订阅机制,它在大多数情况下是非常好的,但是,对于某些不想<ruby> “即发即弃” <rt> fire-and-forget </rt></ruby>的东西:保留一个历史是很重要的,不只是因为是断开之后会重新获得消息,也因为某些如时序性的消息列表,用范围查询浏览是非常重要的:比如在这 10 秒范围内温度读数是多少?
我试图解决上述问题,我想规划一个通用的有序集合,并列入一个独特的、更灵活的数据结构,然而,我的设计尝试最终以生成一个比当前的数据结构更加矫揉造作的结果而告终。Redis 有个好处,它的数据结构导出更像自然的计算机科学的数据结构,而不是 “Salvatore 发明的 API”。因此,我最终停止了我的尝试,并且说,“ok,这是我们目前能提供的”,或许我会为发布/订阅增加一些历史信息,或者为列表访问增加一些更灵活的方式。然而,每次在会议上有用户对我说 “你如何在 Redis 中模拟时间系列” 或者类似的问题时,我的脸就绿了。
### 起源
在 Redis 4.0 中引入模块之后,用户开始考虑他们自己怎么去修复这些问题。其中一个用户 Timothy Downs 通过 IRC 和我说道:
```
\<forkfork> 我计划给这个模块增加一个事务日志式的数据类型 —— 这意味着大量的订阅者可以在不导致 redis 内存激增的情况下做一些像发布/订阅那样的事情
\<forkfork> 订阅者持有他们在消息队列中的位置,而不是让 Redis 必须维护每个消费者的位置和为每个订阅者复制消息
```
他的思路启发了我。我想了几天,并且意识到这可能是我们马上同时解决上面所有问题的契机。我需要去重新构思 “日志” 的概念是什么。日志是个基本的编程元素,每个人都使用过它,因为它只是简单地以追加模式打开一个文件,并以一定的格式写入数据。然而 Redis 数据结构必须是抽象的。它们在内存中,并且我们使用内存并不是因为我们懒,而是因为使用一些指针,我们可以概念化数据结构并把它们抽象,以使它们摆脱明确的限制。例如,一般来说日志有几个问题:偏移不是逻辑化的,而是真实的字节偏移,如果你想要与条目插入的时间相关的逻辑偏移应该怎么办?我们有范围查询可用。同样,日志通常很难进行垃圾回收:在一个只能进行追加操作的数据结构中怎么去删除旧的元素?好吧,在我们理想的日志中,我们只需要说,我想要数字最大的那个条目,而旧的元素一个也不要,等等。
当我从 Timothy 的想法中受到启发,去尝试着写一个规范的时候,我使用了 Redis 集群中的 radix 树去实现,优化了它内部的某些部分。这为实现一个有效利用空间的日志提供了基础,而且仍然有可能在<ruby> 对数时间 <rt> logarithmic time </rt></ruby>内访问范围。同时,我开始去读关于 Kafka 的流相关的内容以获得另外的灵感,它也非常适合我的设计,最后借鉴了 Kafka <ruby> 消费组 <rt> consumer groups </rt></ruby>的概念,并且再次针对 Redis 进行优化,以适用于 Redis 在内存中使用的情况。然而,该规范仅停留在纸面上,在一段时间后我几乎把它从头到尾重写了一遍,以便将我与别人讨论的所得到的许多建议一起增加到 Redis 升级中。我希望 Redis 流能成为对于时间序列有用的特性,而不仅是一个常见的事件和消息类的应用程序。
### 让我们写一些代码吧
从 Redis 大会回来后,整个夏天我都在实现一个叫 listpack 的库。这个库是 `ziplist.c` 的继任者,那是一个表示在单个分配中的字符串元素列表的数据结构。它是一个非常特殊的序列化格式,其特点在于也能够以逆序(从右到左)解析:以便在各种用例中替代 ziplists。
结合 radix 树和 listpacks 的特性,它可以很容易地去构建一个空间高效的日志,并且还是可索引的,这意味着允许通过 ID 和时间进行随机访问。自从这些就绪后,我开始去写一些代码以实现流数据结构。我还在完成这个实现,不管怎样,现在在 Github 上的 Redis 的 streams 分支里它已经可以跑起来了。我并没有声称那个 API 是 100% 的最终版本,但是,这有两个有意思的事实:一,在那时只有消费群组是缺失的,加上一些不太重要的操作流的命令,但是,所有的大的方面都已经实现了。二,一旦各个方面比较稳定了之后,我决定大概用两个月的时间将所有的流的特性<ruby> 向后移植 <rt> backport </rt></ruby>到 4.0 分支。这意味着 Redis 用户想要使用流,不用等待 Redis 4.2 发布,它们在生产环境马上就可用了。这是可能的,因为作为一个新的数据结构,几乎所有的代码改变都出现在新的代码里面。除了阻塞列表操作之外:该代码被重构了,我们对于流和列表阻塞操作共享了相同的代码,而极大地简化了 Redis 内部实现。
### 教程:欢迎使用 Redis 的 streams
在某些方面,你可以认为流是 Redis 列表的一个增强版本。流元素不再是一个单一的字符串,而是一个<ruby> 字段 <rt> field </rt></ruby>和<ruby> 值 <rt> value </rt></ruby>组成的对象。范围查询更适用而且更快。在流中,每个条目都有一个 ID,它是一个逻辑偏移量。不同的客户端可以<ruby> 阻塞等待 <rt> blocking-wait </rt></ruby>比指定的 ID 更大的元素。Redis 流的一个基本的命令是 `XADD`。是的,所有的 Redis 流命令都是以一个 `X` 为前缀的。
```
> XADD mystream * sensor-id 1234 temperature 10.5
1506871964177.0
```
这个 `XADD` 命令将追加指定的条目作为一个指定的流 —— “mystream” 的新元素。上面示例中的这个条目有两个字段:`sensor-id` 和 `temperature`,每个条目在同一个流中可以有不同的字段。使用相同的字段名可以更好地利用内存。有意思的是,字段的排序是可以保证顺序的。`XADD` 仅返回插入的条目的 ID,因为在第三个参数中是星号(`*`),表示由命令自动生成 ID。通常这样做就够了,但是也可以去强制指定一个 ID,这种情况用于复制这个命令到<ruby> 从服务器 <rt> slave server </rt></ruby>和 <ruby> AOF <rt> append-only file </rt></ruby> 文件。
这个 ID 是由两部分组成的:一个毫秒时间和一个序列号。`1506871964177` 是毫秒时间,它只是一个毫秒级的 UNIX 时间戳。圆点(`.`)后面的数字 `0` 是一个序号,它是为了区分相同毫秒数的条目增加上去的。这两个数字都是 64 位的无符号整数。这意味着,我们可以在流中增加所有想要的条目,即使是在同一毫秒中。ID 的毫秒部分使用 Redis 服务器的当前本地时间生成的 ID 和流中的最后一个条目 ID 两者间的最大的一个。因此,举例来说,即使是计算机时间回跳,这个 ID 仍然是增加的。在某些情况下,你可以认为流条目的 ID 是完整的 128 位数字。然而,事实上它们与被添加到的实例的本地时间有关,这意味着我们可以在毫秒级的精度的范围随意查询。
正如你想的那样,快速添加两个条目后,结果是仅一个序号递增了。我们可以用一个 `MULTI`/`EXEC` 块来简单模拟“快速插入”:
```
> MULTI
OK
> XADD mystream * foo 10
QUEUED
> XADD mystream * bar 20
QUEUED
> EXEC
1) 1506872463535.0
2) 1506872463535.1
```
在上面的示例中,也展示了无需指定任何初始<ruby> 模式 <rt> schema </rt></ruby>的情况下,对不同的条目使用不同的字段。会发生什么呢?就像前面提到的一样,只有每个块(它通常包含 50-150 个消息内容)的第一个消息被使用。并且,相同字段的连续条目都使用了一个标志进行了压缩,这个标志表示与“它们与这个块中的第一个条目的字段相同”。因此,使用相同字段的连续消息可以节省许多内存,即使是字段集随着时间发生缓慢变化的情况下也很节省内存。
为了从流中检索数据,这里有两种方法:范围查询,它是通过 `XRANGE` 命令实现的;<ruby> 流播 <rt> streaming </rt></ruby>,它是通过 `XREAD` 命令实现的。`XRANGE` 命令仅取得包括从开始到停止范围内的全部条目。因此,举例来说,如果我知道它的 ID,我可以使用如下的命名取得单个条目:
```
> XRANGE mystream 1506871964177.0 1506871964177.0
1) 1) 1506871964177.0
2) 1) "sensor-id"
2) "1234"
3) "temperature"
4) "10.5"
```
不管怎样,你都可以使用指定的开始符号 `-` 和停止符号 `+` 表示最小和最大的 ID。为了限制返回条目的数量,也可以使用 `COUNT` 选项。下面是一个更复杂的 `XRANGE` 示例:
```
> XRANGE mystream - + COUNT 2
1) 1) 1506871964177.0
2) 1) "sensor-id"
2) "1234"
3) "temperature"
4) "10.5"
2) 1) 1506872463535.0
2) 1) "foo"
2) "10"
```
这里我们讲的是 ID 的范围,然后,为了取得在一个给定时间范围内的特定范围的元素,你可以使用 `XRANGE`,因为 ID 的“序号” 部分可以省略。因此,你可以只指定“毫秒”时间即可,下面的命令的意思是:“从 UNIX 时间 1506872463 开始给我 10 个条目”:
```
127.0.0.1:6379> XRANGE mystream 1506872463000 + COUNT 10
1) 1) 1506872463535.0
2) 1) "foo"
2) "10"
2) 1) 1506872463535.1
2) 1) "bar"
2) "20"
```
关于 `XRANGE` 需要注意的最重要的事情是,假设我们在回复中收到 ID,随后连续的 ID 只是增加了序号部分,所以可以使用 `XRANGE` 遍历整个流,接收每个调用的指定个数的元素。Redis 中的`*SCAN` 系列命令允许迭代 Redis 数据结构,尽管事实上它们不是为迭代设计的,但这样可以避免再犯相同的错误。
### 使用 XREAD 处理流播:阻塞新的数据
当我们想通过 ID 或时间去访问流中的一个范围或者是通过 ID 去获取单个元素时,使用 `XRANGE` 是非常完美的。然而,在使用流的案例中,当数据到达时,它必须由不同的客户端来消费时,这就不是一个很好的解决方案,这需要某种形式的<ruby> 汇聚池 <rt> pooling </rt></ruby>。(对于 *某些* 应用程序来说,这可能是个好主意,因为它们仅是偶尔连接查询的)
`XREAD` 命令是为读取设计的,在同一个时间,从多个流中仅指定我们从该流中得到的最后条目的 ID。此外,如果没有数据可用,我们可以要求阻塞,当数据到达时,就解除阻塞。类似于阻塞列表操作产生的效果,但是这里并没有消费从流中得到的数据,并且多个客户端可以同时访问同一份数据。
这里有一个典型的 `XREAD` 调用示例:
```
> XREAD BLOCK 5000 STREAMS mystream otherstream $ $
```
它的意思是:从 `mystream` 和 `otherstream` 取得数据。如果没有数据可用,阻塞客户端 5000 毫秒。在 `STREAMS` 选项之后指定我们想要监听的关键字,最后的是指定想要监听的 ID,指定的 ID 为 `$` 的意思是:假设我现在需要流中的所有元素,因此,只需要从下一个到达的元素开始给我。
如果我从另一个客户端发送这样的命令:
```
> XADD otherstream * message “Hi There”
```
在 `XREAD` 侧会出现什么情况呢?
```
1) 1) "otherstream"
2) 1) 1) 1506935385635.0
2) 1) "message"
2) "Hi There"
```
与收到的数据一起,我们也得到了数据的关键字。在下次调用中,我们将使用接收到的最新消息的 ID:
```
> XREAD BLOCK 5000 STREAMS mystream otherstream $ 1506935385635.0
```
依次类推。然而需要注意的是使用方式,客户端有可能在一个非常大的延迟之后再次连接(因为它处理消息需要时间,或者其它什么原因)。在这种情况下,期间会有很多消息堆积,为了确保客户端不被消息淹没,以及服务器不会因为给单个客户端提供大量消息而浪费太多的时间,使用 `XREAD` 的 `COUNT` 选项是非常明智的。
### 流封顶
目前看起来还不错……然而,有些时候,流需要删除一些旧的消息。幸运的是,这可以使用 `XADD` 命令的 `MAXLEN` 选项去做:
```
> XADD mystream MAXLEN 1000000 * field1 value1 field2 value2
```
它是基本意思是,如果在流中添加新元素后发现消息数量超过了 `1000000` 个,那么就删除旧的消息,以便于元素总量重新回到 `1000000` 以内。它很像是在列表中使用的 `RPUSH` + `LTRIM`,但是,这次我们是使用了一个内置机制去完成的。然而,需要注意的是,上面的意思是每次我们增加一个新的消息时,我们还需要另外的工作去从流中删除旧的消息。这将消耗一些 CPU 资源,所以在计算 `MAXLEN` 之前,尽可能使用 `~` 符号,以表明我们不要求非常 *精确* 的 1000000 个消息,就是稍微多一些也不是大问题:
```
> XADD mystream MAXLEN ~ 1000000 * foo bar
```
这种方式的 XADD 仅当它可以删除整个节点的时候才会删除消息。相比普通的 `XADD`,这种方式几乎可以自由地对流进行封顶。
### 消费组(开发中)
这是第一个 Redis 中尚未实现而在开发中的特性。灵感也是来自 Kafka,尽管在这里是以不同的方式实现的。重点是使用了 `XREAD`,客户端也可以增加一个 `GROUP <name>` 选项。相同组的所有客户端将自动得到 *不同的* 消息。当然,同一个流可以被多个组读取。在这种情况下,所有的组将收到流中到达的消息的相同副本。但是,在每个组内,消息是不会重复的。
当指定组时,能够指定一个 `RETRY <milliseconds>` 选项去扩展组:在这种情况下,如果消息没有通过 `XACK` 进行确认,它将在指定的毫秒数后进行再次投递。这将为消息投递提供更佳的可靠性,这种情况下,客户端没有私有的方法将消息标记为已处理。这一部分也正在开发中。
### 内存使用和节省加载时间
因为用来建模 Redis 流的设计,内存使用率是非常低的。这取决于它们的字段、值的数量和长度,对于简单的消息,每使用 100MB 内存可以有几百万条消息。此外,该格式设想为需要极少的序列化:listpack 块以 radix 树节点方式存储,在磁盘上和内存中都以相同方式表示的,因此它们可以很轻松地存储和读取。例如,Redis 可以在 0.3 秒内从 RDB 文件中读取 500 万个条目。这使流的复制和持久存储非常高效。
我还计划允许从条目中间进行部分删除。现在仅实现了一部分,策略是在条目在标记中标识条目为已删除,并且,当已删除条目占全部条目的比例达到指定值时,这个块将被回收重写,如果需要,它将被连到相邻的另一个块上,以避免碎片化。
### 关于最终发布时间的结论
Redis 的流特性将包含在年底前(LCTT 译注:本文原文发布于 2017 年 10 月)推出的 Redis 4.0 系列的稳定版中。我认为这个通用的数据结构将为 Redis 提供一个巨大的补丁,以用于解决很多现在很难以解决的情况:那意味着你(之前)需要创造性地“滥用”当前提供的数据结构去解决那些问题。一个非常重要的使用场景是时间序列,但是,我觉得对于其它场景来说,通过 `TREAD` 来流播消息将是非常有趣的,因为对于那些需要更高可靠性的应用程序,可以使用发布/订阅模式来替换“即用即弃”,还有其它全新的使用场景。现在,如果你想在有问题环境中评估这个新数据结构,可以更新 GitHub 上的 streams 分支开始试用。欢迎向我们报告所有的 bug。:-)
如果你喜欢观看视频的方式,这里有一个现场演示:<https://www.youtube.com/watch?v=ELDzy9lCFHQ>
---
via: <http://antirez.com/news/114>
作者:[antirez](http://antirez.com/) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy), [pityonline](https://github.com/pityonline)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [antirez](/user/antirez)2564 days ago. 352699 views.
Until a few months ago, for me streams were no more than an interesting and relatively straightforward concept in the context of messaging. After Kafka popularized the concept, I mostly investigated their usefulness in the case of Disque, a message queue that is now headed to be translated into a Redis 4.2 module. Later I decided that Disque was all about AP messaging, which is, fault tolerance and guarantees of delivery without much efforts from the client, so I decided that the concept of streams was not a good match in that case. However, at the same time, there was a problem in Redis, that was not taking me relaxed about the data structures exported by default. There is some kind of gap between Redis lists, sorted sets, and Pub/Sub capabilities. You can kindly use all these tools in order to model a sequence of messages or events, but with different tradeoffs. Sorted sets are memory hungry, can’t model naturally the same message delivered again and again, clients can’t block for new messages. Because a sorted set is not a sequential data structure, it’s a set where elements can be moved around changing their scores: no wonder if it was not a good match for things like time series. Lists have different problems creating similar applicability issues in certain use cases: you cannot explore what is in the middle of a list because the access time in that case is linear. Moreover no fan-out is possible, blocking operations on list serve a single element to a single client. Nor there was a fixed element identifier in lists, in order to say: given me things starting from that element. For one-to-many workloads there is Pub/Sub, which is great in many cases, but for certain things you do not want fire-and-forget: to retain a history is important, not just to refetch messages after a disconnection, also because certain list of messages, like time series, are very important to explore with range queries: what were my temperature readings in this 10 seconds range? The way I tried to address the above problems, was planning a generalization of sorted sets and lists into a unique more flexible data structure, however my design attempts ended almost always in making the resulting data structure ways more artificial than the current ones. One good thing about Redis is that the data structures exported resemble more the natural computer science data structures, than, “this API that Salvatore invented”. So in the end, I stopped my attempts, and said, ok that’s what we can provide so far, maybe I’ll add some history to Pub/Sub, or some more flexibility to lists access patterns in the future. However every time an user approached me during a conference saying “how would you model time series in Redis?” or similar related questions, my face turned green. Genesis ======= After the introduction of modules in Redis 4.0, users started to see how to fix this problem themselves. One of them, Timothy Downs, wrote me the following over IRC: <forkfork> the module I'm planning on doing is to add a transaction log style data type - meaning that a very large number of subscribers can do something like pub sub without a lot of redis memory growth <forkfork> subscribers keeping their position in a message queue rather than having redis maintain where each consumer is up to and duplicating messages per subscriber This captured my imagination. I thought about it a few days, and realized that this could be the moment when we could solve all the above problems at once. What I needed was to re-imagine the concept of “log”. It is a basic programming element, everybody is used to it, because it’s just as simple as opening a file in append mode and writing data to it in some format. However Redis data structures must be abstract. They are in memory, and we use RAM not just because we are lazy, but because using a few pointers, we can conceptualize data structures and make them abstract, to allow them to break free from the obvious limits. For instance normally a log has several problems: the offset is not logical, but is an actual bytes offset, what if we want logical offsets that are related to the time an entry was inserted? We have range queries for free. Similarly, a log is often hard to garbage collect: how to remove old elements in an append only data structure? Well, in our idealized log, we just say we want at max this number of entries, and the old ones will go away, and so forth. While I was trying to write a specification starting from the seed idea of Timothy, I was working to a radix tree implementation that I was using for Redis Cluster, to optimize certain parts of its internals. This provided the ground in order to implement a very space efficient log, that was still accessible in logarithmic time to get ranges. At the same time I started reading about Kafka streams to get other interesting ideas that could fit well into my design, and this resulted into getting the concept of Kafka consumer groups, and idealizing it again for Redis and the in-memory use case. However the specification remained just a specification for months, at the point that after some time I rewrote it almost from scratch in order to upgrade it with many hints that I accumulated talking with people about this upcoming addition to Redis. I wanted Redis streams to be a very good use case for time series especially, not just for other kind of events and messaging applications. Let’s write some code ===================== Back from Redis Conf, during the summertime, I was implementing a library called “listpack”. This library is just the successor of ziplist.c, that is, a data structure that can represent a list of string elements inside a single allocation. It’s just a very specialized serialization format, with the peculiarity of being parsable also in reverse order, from right to left: something needed in order to substitute ziplists in all the use cases. Mixing radix trees + listpacks, it is possible to easily build a log that is at the same time very space efficient, and indexed, that means, allowing for random access by IDs and time. Once this was ready, I started to write the code in order to implement the stream data structure. I’m still finishing the implementation, however at this point, inside the Redis “streams” branch at Github, there is enough to start playing and having fun. I don’t claim that the API is 100% final, but there are two interesting facts: one is that at this point, only the consumer groups are missing, plus a number of less important commands to manipulate the stream, but all the big things are implemented already. The second is the decision to backport all the stream work back into the 4.0 branch in about two months, once everything looks stable. It means that Redis users will not have to wait for Redis 4.2 in order to use streams, they will be available ASAP for production usage. This is possible because being a new data structure, almost all the code changes are self-contained into the new code. With the exception of the blocking list operations: the code was refactored so that we share the same code for streams and lists blocking operations, with a great simplification of the Redis internals. Tutorial: welcome to Redis Streams ================================== In some way, you can think at streams as a supercharged version of Redis lists. Streams elements are not just a single string, they are more objects composed of fields and values. Range queries are possible and fast. Each entry in a stream has an ID, which is a logical offset. Different clients can blocking-wait for elements with IDs greater than a specified one. A fundamental command of Redis streams is XADD. Yes, all the Redis stream commands are prefixed by an “X”. > XADD mystream * sensor-id 1234 temperature 10.5 1506871964177.0 The XADD command will append the specified entry as a new element to the specified stream “mystream”. The entry, in the example above, has two fields: sensor-id and temperature, however each entry in the same stream can have different fields. Using the same field names will just lead to better memory usage. An interesting thing is also that the fields order is guaranteed to be retained. XADD returns the ID of the just inserted entry, because with the asterisk in the third argument, we asked the command to auto-generate the ID. This is almost always what you want, but it is possible also to force a specific ID, for instance in order to replicate the command to slaves and AOF files. The ID is composed of two parts: a millisecond time and a sequence number. 1506871964177 is the millisecond time, and is just a Unix time with millisecond resolution. The number after the dot, 0, is the sequence number, and is used in order to distinguish entries added in the same millisecond. Both numbers are 64 bit unsigned integers. This means that we can add all the entries we want in a stream, even in the same millisecond. The millisecond part of the ID is obtained using the maximum between the current local time of the Redis server generating the ID, and the last entry inside the stream. So even if, for instance, the computer clock jumps backward, the IDs will continue to be incremental. In some way you can think stream entry IDs as whole 128 bit numbers. However the fact that they have a correlation with the local time of the instance where they are added, means that we have millisecond precision range queries for free. As you can guess, adding two entries in a very fast way, will result in only the sequence number to be incremented. We can simulate the “fast insertion” simply with a MULTI/EXEC block: > MULTI OK > XADD mystream * foo 10 QUEUED > XADD mystream * bar 20 QUEUED > EXEC 1) 1506872463535.0 2) 1506872463535.1 The above example also shows how we can use different fields for different entries without having to specifying any schema initially. What happens however is that every first message of every block (that usually contains something in the range of 50-150 messages) is used as reference, and successive entries having the same fields are compressed with a single flag saying “same fields of the first entry in this block”. So indeed using the same fields for successive messages saves a lot of memory, even when the set of fields slowly change over time. In order to retrieve data from the stream there are two ways: range queries, that are implemented by the XRANGE command, and streaming, implemented by the XREAD command. XRANGE just fetches a range of items from start to stop, inclusive. So for instance I can fetch a single item, if I know its ID, with: > XRANGE mystream 1506871964177.0 1506871964177.0 1) 1) 1506871964177.0 2) 1) "sensor-id" 2) "1234" 3) "temperature" 4) "10.5" However you can use the special start symbol of “-“ and the special stop symbol of “+” to signify the minimum and maximum ID possible. It’s also possible to use the COUNT option in order to limit the amount of entries returned. A more complex XRANGE example is the following: > XRANGE mystream - + COUNT 2 1) 1) 1506871964177.0 2) 1) "sensor-id" 2) "1234" 3) "temperature" 4) "10.5" 2) 1) 1506872463535.0 2) 1) "foo" 2) "10" Here we are reasoning in terms of ranges of IDs, however you can use XRANGE in order to get a specific range of elements in a given time range, because you can omit the “sequence” part of the IDs. So what you can do is to just specify times in milliseconds. The following means: “Give me 10 entries starting from the Unix time 1506872463”: 127.0.0.1:6379> XRANGE mystream 1506872463000 + COUNT 10 1) 1) 1506872463535.0 2) 1) "foo" 2) "10" 2) 1) 1506872463535.1 2) 1) "bar" 2) "20" A final important thing to note about XRANGE is that, given that we receive the IDs in the reply, and the immediately successive ID is trivially obtained just incrementing the sequence part of the ID, it is possible to use XRANGE to incrementally iterate the whole stream, receiving for every call the specified number of elements. After the *SCAN family of commands in Redis, that allowed iteration of Redis data structures *despite* the fact they were not designed for being iterated, I avoided to make the same error again. Streaming with XREAD: blocking for new data =========================================== XRANGE is perfect when we want to access our stream to get ranges by ID or time, or single elements by ID. However in the case of streams that different clients must consume as data arrives, this is not good enough and would require some form of pooling (that could be a good idea for *certain* applications that just connect from time to time to get data). The XREAD command is designed in order to read, at the same time, from multiple streams just specifying the ID of the last entry in the stream we got. Moreover we can request to block if no data is available, to be unblocked when data arrives. Similarly to what happens with blocking list operations, but here data is not consumed from the stream, and multiple clients can access the same data at the same time. This is a canonical example of XREAD call: > XREAD BLOCK 5000 STREAMS mystream otherstream $ $ And it means: get data from “mystream” and “otherstream”. If no data is available, block the client, with a timeout of 5000 milliseconds. After the STREAMS option we specify the keys we want to listen for, and the last ID we have. However a special ID of “$” means: assume I’ve all the elements that there are in the stream right now, so give me just starting from the next element arriving. If, from another client, I send the commnad: > XADD otherstream * message “Hi There” This is what happens on the XREAD side: 1) 1) "otherstream" 2) 1) 1) 1506935385635.0 2) 1) "message" 2) "Hi There" We get the key that received data, together with the data received. In the next call, we’ll likely use the ID of the last message received: > XREAD BLOCK 5000 STREAMS mystream otherstream $ 1506935385635.0 And so forth. However note that with this usage pattern, it is possible that the client will connect again after a very big delay (because it took time to process messages, or for any other reason). In such a case, in the meantime, a lot of messages could pile up, so it is wise to always use the COUNT option with XREAD, in order to make sure the client will not be flooded with messages and the server will not have to lose too much time just serving tons of messages to a single client. Capped streams ============== So far so good… however streams at some point have to remove old messages. Fortunately this is possible with the MAXLEN option of the XADD command: > XADD mystream MAXLEN 1000000 * field1 value1 field2 value2 This basically means, if the stream, after adding the new element is found to have more than 1 million messages, remove old messages so that the length returns back to 1 million elements. It’s just like using RPUSH + LTRIM with lists, but this time we have a built-in mechanism to do so. However note that the above means that every time we add a new message, we have also to incur in the work needed in order to remove a message from the other side of the stream. This takes some CPU, so it is possible to use the “~” symbol before the count in MAXLEN, in order to specify that we are not really demanding *exactly* 1 million messages, but if there are a few more it’s not a big problem: > XADD mystream MAXLEN ~ 1000000 * foo bar This way XADD will remove messages only when it can remove a whole node. This will make having the capped stream almost for free compared to vanilla XADD. Consumer groups (work in progress) ================================== This is the first of the features that is not already implemented in Redis, but is a work in progress. It is also the idea more clearly inspired by Kafka, even if implemented here in a pretty different way. The gist is that with XREAD, clients can also add a “GROUP <name>” option. Automatically all the clients in the same group will get *different* messages. Of course there could be multiple groups reading from the same stream, in such cases all groups will receive duplicates of the same messages arriving in the stream, but within each group, messages will not be repeated. An extension to groups is that it will be possible to specify a “RETRY <milliseconds>” option when groups are specified: in this case, if messages are not acknowledged for processing with XACK, they will be delivered again after the specified amount of milliseconds. This provides some best effort reliability to the delivering of the messages, in case the client has no private means to mark messages as processed. This part is a work in progress as well. Memory usage and saving loading times ===================================== Because of the design used to model Redis streams, the memory usage is remarkably low. It depends on the number of fields, values, and their lengths, but for simple messages we are at a few millions of messages for every 100 MB of used memory. Moreover, the format is conceived to need very minimal serialization: the listpack blocks that are stored as radix tree nodes, have the same representation on disk and in memory, so they are trivially stored and read. For instance Redis can read 5 million entries from the RDB file in 0.3 seconds. This makes replication and persistence of streams very efficient. It is planned to also allow deletion of items in the middle. This is only partially implemented, but the strategy is to mark entries as deleted in the entry flag, and when a given ratio between entries and deleted entires is reached, the block is rewritten to collect the garbage, and if needed it is glued to another adjacent block in order to avoid fragmentation. Conclusions end ETA =================== Redis streams will be part of Redis stable in the 4.0 series before the end of the year. I think that this general purpose data structure is going to put a huge patch in order for Redis to cover a lot of use cases that were hard to cover: that means that you had to be creative in order to abuse the current data structures to fix certain problems. One very important use case is time series, but my feeling is that also streaming of messages for other use cases via TREAD is going to be very interesting both as replacement for Pub/Sub applications that need more reliability than fire-and-forget, and for completely new use cases. For now, if you want to start to evaluate the new capabilities in the context of your problems, just fetch the “streams” branch at Github and start playing. After all bug reports are welcome :-) If you like videos, a real-time session showing streams is here:[https://www.youtube.com/watch?v=ELDzy9lCFHQ]
[🚀 Dear reader, the first six chapters of my AI sci-fi novel, WOHPE, are now available as a free eBook. Click here to get it.](http://invece.org/wohpe_EN_six_chapters.epub)
[blog comments powered by Disqus](http://disqus.com) |
9,880 | 使用 Wttr.in 在你的终端中显示天气预报 | https://www.linuxuprising.com/2018/07/display-weather-forecast-in-your.html | 2018-07-29T23:06:00 | [
"天气",
"气候"
] | https://linux.cn/article-9880-1.html | 
[wttr.in](https://wttr.in/) 是一个功能丰富的天气预报服务,它支持在命令行显示天气。它可以(根据你的 IP 地址)自动检测你的位置,也支持指定位置或搜索地理位置(如城市、山区等)等。哦,另外**你不需要安装它 —— 你只需要使用 cURL 或 Wget**(见下文)。
wttr.in 功能包括:
* **显示当前天气以及 3 天内的天气预报,分为早晨、中午、傍晚和夜晚**(包括温度范围、风速和风向、可见度、降水量和概率)
* **可以显示月相**
* **基于你的 IP 地址自动检测位置**
* **允许指定城市名称、3 字母的机场代码、区域代码、GPS 坐标、IP 地址或域名**。你还可以指定地理位置,如湖泊、山脉、地标等)
* **支持多语言位置名称**(查询字符串必须以 Unicode 指定)
* **支持指定**天气预报显示的语言(它支持超过 50 种语言)
* **来自美国的查询使用 USCS 单位用于,世界其他地方使用公制系统**,但你可以通过附加 `?u` 使用 USCS,附加 `?m` 使用公制系统。 )
* **3 种输出格式:终端的 ANSI,浏览器的 HTML 和 PNG**
就像我在文章开头提到的那样,使用 wttr.in,你只需要 cURL 或 Wget,但你也可以在你的服务器上[安装它](https://github.com/chubin/wttr.in#installation)。 或者你可以安装 [wego](https://github.com/schachmat/wego),这是一个使用 wtter.in 的终端气候应用,虽然 wego 要求注册一个 API 密钥来安装。
**在使用 wttr.in 之前,请确保已安装 cURL。**在 Debian、Ubuntu 或 Linux Mint(以及其他基于 Debian 或 Ubuntu 的 Linux 发行版)中,使用以下命令安装 cURL:
```
sudo apt install curl
```
### wttr.in 命令行示例
获取你所在位置的天气(wttr.in 会根据你的 IP 地址猜测你的位置):
```
curl wttr.in
```
通过在 `curl` 之后添加 `-4`,强制 cURL 将名称解析为 IPv4 地址(如果你用 IPv6 访问 wttr.in 有问题):
```
curl -4 wttr.in
```
如果你想检索天气预报保存为 png,**还可以使用 Wget**(而不是 cURL),或者你想这样使用它:
```
wget -O- -q wttr.in
```
如果相对 cURL 你更喜欢 Wget ,可以在下面的所有命令中用 `wget -O- -q` 替换 `curl`。
指定位置:
```
curl wttr.in/Dublin
```
显示地标的天气信息(本例中为艾菲尔铁塔):
```
curl wttr.in/~Eiffel+Tower
```
获取 IP 地址位置的天气信息(以下 IP 属于 GitHub):
```
curl wttr.in/@192.30.253.113
```
使用 USCS 单位检索天气:
```
curl wttr.in/Paris?u
```
如果你在美国,强制 wttr.in 使用公制系统(SI):
```
curl wttr.in/New+York?m
```
使用 Wget 将当前天气和 3 天预报下载为 PNG 图像:
```
wget wttr.in/Istanbul.png
```
你可以指定 PNG 的[透明度](https://github.com/chubin/wttr.in#supported-formats),这在你要使用一个脚本自动添加天气信息到某些图片(比如墙纸)上有用。
**对于其他示例,请查看 wttr.in [项目页面](https://github.com/chubin/wttr.in)或在终端中输入:**
```
curl wttr.in/:help
```
---
via: <https://www.linuxuprising.com/2018/07/display-weather-forecast-in-your.html>
作者:[Logix](https://plus.google.com/118280394805678839070) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Display Weather Forecast In Your Terminal With Wttr.in
**. It can automatically detect your location (based on your IP address), supports specifying the location or searching for a geographical location (like a site in a city, a mountain and so on), and much more. Oh, and**
[wttr.in](https://wttr.in/)is a feature-packed weather forecast service that supports displaying the weather from the command line**you don't have to install it - all you need to use it is cURL or Wget**(see below).
wttr.in features include:
**displays the current weather as well as a 3-day weather forecast, split into morning, noon, evening and night**(includes temperature range, wind speed and direction, viewing distance, precipitation amount and probability)**can display Moon phases****automatic location detection based on your IP address****allows specifying a location using the city name, 3-letter airport code, area code, GPS coordinates, IP address, or domain name**. You can also specify a geographical location like a lake, mountain, landmark, and so on)**supports multilingual location names**(the query string must be specified in Unicode)**supports specifying the language**in which the weather forecast should be displayed in (it supports more than 50 languages)**it uses USCS units for queries from the USA and the metric system for the rest of the world**, but you can change this by appending`?u`
for USCS, and`?m`
for the metric system (SI)**3 output formats: ANSI for the terminal, HTML for the browser, and PNG**.
Like I mentioned in the beginning of the article, to use wttr.in, all you need is cURL or Wget, but you can also
[install it](https://github.com/chubin/wttr.in#installation)on your own server. Or you could install
[wego](https://github.com/schachmat/wego), a weather application for the terminal which is what wtter.in uses, though wego requires installation as well as registering for an API key.
**Before using wttr.in, make sure cURL is installed.**In Debian, Ubuntu or Linux Mint (and other Debian or Ubuntu-based Linux distributions), install cURL using this command:
`sudo apt install curl`
## wttr.in command line examples
Get the weather for your location (wttr.in tries to guess your location based on your IP address):
`curl wttr.in`
Force cURL to resolve names to IPv4 addresses (in case you're having issues with IPv6 and wttr.in) by adding
`-4`
after `curl`
:`curl -4 wttr.in`
**Wget also works**(instead of cURL) if you want to retrieve the current weather and forecast as a png, or if you use it like this:
`wget -O- -q wttr.in`
You can replace
`curl`
with `wget -O- -q`
in all the commands below if you prefer Wget over cURL.Specify the location:
`curl wttr.in/Dublin`
Display weather information for a landmark (the Eiffel Tower in this example):
`curl wttr.in/`**~**Eiffel+Tower
Get the weather information for an IP address' location (the IP below belongs to GitHub):
`curl wttr.in/`**@**192.30.253.113
Retrieve the weather using USCS units:
`curl wttr.in/Paris`**?u**
Force wttr.in to use the metric system (SI) if you're in the USA:
`curl wttr.in/New+York`**?m**
Use Wget to download the current weather and 3-day forecast as a PNG image:
`wget wttr.in/Istanbul`**.png**
You can specify the PNG
[transparency](https://github.com/chubin/wttr.in#supported-formats)level, useful if you want to automate a script to automatically add weather information to some image (like a wallpaper) for example.
**For many other examples, check out the wttr.in**
[project page](https://github.com/chubin/wttr.in)or type this in a terminal:`curl wttr.in/:help` |
9,881 | Python 集合是什么,为什么应该使用以及如何使用? | https://www.pythoncheatsheet.org/blog/python-sets-what-why-how | 2018-07-29T23:45:00 | [
"Python",
"数据结构",
"集合"
] | https://linux.cn/article-9881-1.html | 

Python 配备了几种内置数据类型来帮我们组织数据。这些结构包括列表、字典、元组和集合。
根据 Python 3 文档:
>
> 集合是一个*无序*集合,没有*重复元素*。基本用途包括*成员测试*和*消除重复的条目*。集合对象还支持数学运算,如*并集*、*交集*、*差集*和*对等差分*。
>
>
>
在本文中,我们将回顾并查看上述定义中列出的每个要素的示例。让我们马上开始,看看如何创建它。
### 初始化一个集合
有两种方法可以创建一个集合:一个是给内置函数 `set()` 提供一个元素列表,另一个是使用花括号 `{}`。
使用内置函数 `set()` 来初始化一个集合:
```
>>> s1 = set([1, 2, 3])
>>> s1
{1, 2, 3}
>>> type(s1)
<class 'set'>
```
使用 `{}`:
```
>>> s2 = {3, 4, 5}
>>> s2
{3, 4, 5}
>>> type(s2)
<class 'set'>
>>>
```
如你所见,这两种方法都是有效的。但问题是,如果我们想要一个空的集合呢?
```
>>> s = {}
>>> type(s)
<class 'dict'>
```
没错,如果我们使用空花括号,我们将得到一个字典而不是一个集合。=)
值得一提的是,为了简单起见,本文中提供的所有示例都将使用整数集合,但集合可以包含 Python 支持的所有 <ruby> <a href="https://docs.python.org/3/glossary.html#term-hashable"> 可哈希的 </a> <rt> hashable </rt></ruby> 数据类型。换句话说,即整数、字符串和元组,而不是*列表*或*字典*这样的可变类型。
```
>>> s = {1, 'coffee', [4, 'python']}
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'list'
```
既然你知道了如何创建一个集合以及它可以包含哪些类型的元素,那么让我们继续看看*为什么*我们总是应该把它放在我们的工具箱中。
### 为什么你需要使用它
写代码时,你可以用不止一种方法来完成它。有些被认为是相当糟糕的,另一些则是清晰的、简洁的和可维护的,或者是 “<ruby> <a href="http://docs.python-guide.org/en/latest/writing/style/"> Python 式的 </a> <rt> pythonic </rt></ruby>”。
根据 [Hitchhiker 对 Python 的建议](http://docs.python-guide.org/en/latest/):
>
> 当一个经验丰富的 Python 开发人员(<ruby> Python 人 <rt> Pythonista </rt></ruby>)调用一些不够 “<ruby> Python 式的 <rt> pythonic </rt></ruby>” 的代码时,他们通常认为着这些代码不遵循通用指南,并且无法被认为是以一种好的方式(可读性)来表达意图。
>
>
>
让我们开始探索 Python 集合那些不仅可以帮助我们提高可读性,还可以加快程序执行时间的方式。
#### 无序的集合元素
首先你需要明白的是:你无法使用索引访问集合中的元素。
```
>>> s = {1, 2, 3}
>>> s[0]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'set' object does not support indexing
```
或者使用切片修改它们:
```
>>> s[0:2]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'set' object is not subscriptable
```
但是,如果我们需要删除重复项,或者进行组合列表(与)之类的数学运算,那么我们可以,并且*应该*始终使用集合。
我不得不提一下,在迭代时,集合的表现优于列表。所以,如果你需要它,那就加深对它的喜爱吧。为什么?好吧,这篇文章并不打算解释集合的内部工作原理,但是如果你感兴趣的话,这里有几个链接,你可以阅读它:
* [时间复杂度](https://wiki.python.org/moin/TimeComplexity)
* [set() 是如何实现的?](https://stackoverflow.com/questions/3949310/how-is-set-implemented)
* [Python 集合 vs 列表](https://stackoverflow.com/questions/2831212/python-sets-vs-lists)
* [在列表中使用集合是否有任何优势或劣势,以确保独一无二的列表条目?](https://mail.python.org/pipermail/python-list/2011-June/606738.html)
#### 没有重复项
写这篇文章的时候,我总是不停地思考,我经常使用 `for` 循环和 `if` 语句检查并删除列表中的重复元素。记得那时我的脸红了,而且不止一次,我写了类似这样的代码:
```
>>> my_list = [1, 2, 3, 2, 3, 4]
>>> no_duplicate_list = []
>>> for item in my_list:
... if item not in no_duplicate_list:
... no_duplicate_list.append(item)
...
>>> no_duplicate_list
[1, 2, 3, 4]
```
或者使用列表解析:
```
>>> my_list = [1, 2, 3, 2, 3, 4]
>>> no_duplicate_list = []
>>> [no_duplicate_list.append(item) for item in my_list if item not in no_duplicate_list]
[None, None, None, None]
>>> no_duplicate_list
[1, 2, 3, 4]
```
但没关系,因为我们现在有了武器装备,没有什么比这更重要的了:
```
>>> my_list = [1, 2, 3, 2, 3, 4]
>>> no_duplicate_list = list(set(my_list))
>>> no_duplicate_list
[1, 2, 3, 4]
>>>
```
现在让我们使用 `timeit` 模块,查看列表和集合在删除重复项时的执行时间:
```
>>> from timeit import timeit
>>> def no_duplicates(list):
... no_duplicate_list = []
... [no_duplicate_list.append(item) for item in list if item not in no_duplicate_list]
... return no_duplicate_list
...
>>> # 首先,让我们看看列表的执行情况:
>>> print(timeit('no_duplicates([1, 2, 3, 1, 7])', globals=globals(), number=1000))
0.0018683355819786227
```
```
>>> from timeit import timeit
>>> # 使用集合:
>>> print(timeit('list(set([1, 2, 3, 1, 2, 3, 4]))', number=1000))
0.0010220493243764395
>>> # 快速而且干净 =)
```
使用集合而不是列表推导不仅让我们编写*更少的代码*,而且还能让我们获得*更具可读性*和*高性能*的代码。
注意:请记住集合是无序的,因此无法保证在将它们转换回列表时,元素的顺序不变。
[Python 之禅](https://www.python.org/dev/peps/pep-0020/):
>
> <ruby> 优美胜于丑陋 <rt> Beautiful is better than ugly. </rt></ruby>
>
>
> <ruby> 明了胜于晦涩 <rt> Explicit is better than implicit. </rt></ruby>
>
>
> <ruby> 简洁胜于复杂 <rt> Simple is better than complex. </rt></ruby>
>
>
> <ruby> 扁平胜于嵌套 <rt> Flat is better than nested. </rt></ruby>
>
>
>
集合不正是这样美丽、明了、简单且扁平吗?
#### 成员测试
每次我们使用 `if` 语句来检查一个元素,例如,它是否在列表中时,意味着你正在进行成员测试:
```
my_list = [1, 2, 3]
>>> if 2 in my_list:
... print('Yes, this is a membership test!')
...
Yes, this is a membership test!
```
在执行这些操作时,集合比列表更高效:
```
>>> from timeit import timeit
>>> def in_test(iterable):
... for i in range(1000):
... if i in iterable:
... pass
...
>>> timeit('in_test(iterable)',
... setup="from __main__ import in_test; iterable = list(range(1000))",
... number=1000)
12.459663048726043
```
```
>>> from timeit import timeit
>>> def in_test(iterable):
... for i in range(1000):
... if i in iterable:
... pass
...
>>> timeit('in_test(iterable)',
... setup="from __main__ import in_test; iterable = set(range(1000))",
... number=1000)
.12354438152988223
```
注意:上面的测试来自于[这个](https://stackoverflow.com/questions/2831212/python-sets-vs-lists) StackOverflow 话题。
因此,如果你在巨大的列表中进行这样的比较,尝试将该列表转换为集合,它应该可以加快你的速度。
### 如何使用
现在你已经了解了集合是什么以及为什么你应该使用它,现在让我们快速浏览一下,看看我们如何修改和操作它。
#### 添加元素
根据要添加的元素数量,我们要在 `add()` 和 `update()` 方法之间进行选择。
`add()` 适用于添加单个元素:
```
>>> s = {1, 2, 3}
>>> s.add(4)
>>> s
{1, 2, 3, 4}
```
`update()` 适用于添加多个元素:
```
>>> s = {1, 2, 3}
>>> s.update([2, 3, 4, 5, 6])
>>> s
{1, 2, 3, 4, 5, 6}
```
请记住,集合会移除重复项。
#### 移除元素
如果你希望在代码中尝试删除不在集合中的元素时收到警报,请使用 `remove()`。否则,`discard()` 提供了一个很好的选择:
```
>>> s = {1, 2, 3}
>>> s.remove(3)
>>> s
{1, 2}
>>> s.remove(3)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 3
```
`discard()` 不会引起任何错误:
```
>>> s = {1, 2, 3}
>>> s.discard(3)
>>> s
{1, 2}
>>> s.discard(3)
>>> # 什么都不会发生
```
我们也可以使用 `pop()` 来随机丢弃一个元素:
```
>>> s = {1, 2, 3, 4, 5}
>>> s.pop() # 删除一个任意的元素
1
>>> s
{2, 3, 4, 5}
```
或者 `clear()` 方法来清空一个集合:
```
>>> s = {1, 2, 3, 4, 5}
>>> s.clear() # 清空集合
>>> s
set()
```
#### union()
`union()` 或者 `|` 将创建一个新集合,其中包含我们提供集合中的所有元素:
```
>>> s1 = {1, 2, 3}
>>> s2 = {3, 4, 5}
>>> s1.union(s2) # 或者 's1 | s2'
{1, 2, 3, 4, 5}
```
#### intersection()
`intersection` 或 `&` 将返回一个由集合共同元素组成的集合:
```
>>> s1 = {1, 2, 3}
>>> s2 = {2, 3, 4}
>>> s3 = {3, 4, 5}
>>> s1.intersection(s2, s3) # 或者 's1 & s2 & s3'
{3}
```
#### difference()
使用 `diference()` 或 `-` 创建一个新集合,其值在 “s1” 中但不在 “s2” 中:
```
>>> s1 = {1, 2, 3}
>>> s2 = {2, 3, 4}
>>> s1.difference(s2) # 或者 's1 - s2'
{1}
```
#### symmetric\_diference()
`symetric_difference` 或 `^` 将返回集合之间的不同元素。
```
>>> s1 = {1, 2, 3}
>>> s2 = {2, 3, 4}
>>> s1.symmetric_difference(s2) # 或者 's1 ^ s2'
{1, 4}
```
### 结论
我希望在阅读本文之后,你会知道集合是什么,如何操纵它的元素以及它可以执行的操作。知道何时使用集合无疑会帮助你编写更清晰的代码并加速你的程序。
如果你有任何疑问,请发表评论,我很乐意尝试回答。另外,不要忘记,如果你已经理解了集合,它们在 [Python Cheatsheet](https://www.pythoncheatsheet.org/) 中有自己的[一席之地](https://www.pythoncheatsheet.org/#sets),在那里你可以快速参考并重新认知你已经知道的内容。
---
via: <https://www.pythoncheatsheet.org/blog/python-sets-what-why-how>
作者:[wilfredinni](https://www.pythoncheatsheet.org/author/wilfredinni) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | null |
9,882 | 想学习区块链?那就用 Python 构建一个 | https://hackernoon.com/learn-blockchains-by-building-one-117428612f46 | 2018-07-30T13:04:02 | [
"区块链",
"Python"
] | https://linux.cn/article-9882-1.html |
>
> 了解区块链是如何工作的最快的方法是构建一个。
>
>
>

你看到这篇文章是因为和我一样,对加密货币的大热而感到兴奋。并且想知道区块链是如何工作的 —— 它们背后的技术基础是什么。
但是理解区块链并不容易 —— 至少对我来说是这样。我徜徉在各种难懂的视频中,并且因为示例太少而陷入深深的挫败感中。
我喜欢在实践中学习。这会使得我在代码层面上处理主要问题,从而可以让我坚持到底。如果你也是这么做的,在本指南结束的时候,你将拥有一个功能正常的区块链,并且实实在在地理解了它的工作原理。
### 开始之前 …
记住,区块链是一个 *不可更改的、有序的* 记录(被称为区块)的链。它们可以包括<ruby> 交易 <rt> transaction </rt></ruby>、文件或者任何你希望的真实数据。最重要的是它们是通过使用*哈希*链接到一起的。
如果你不知道哈希是什么,[这里有解释](https://learncryptography.com/hash-functions/what-are-hash-functions)。
***本指南的目标读者是谁?*** 你应该能轻松地读、写一些基本的 Python 代码,并能够理解 HTTP 请求是如何工作的,因为我们讨论的区块链将基于 HTTP。
***我需要做什么?*** 确保安装了 [Python 3.6](https://www.python.org/downloads/)+(以及 `pip`),还需要去安装 Flask 和非常好用的 Requests 库:
```
pip install Flask==0.12.2 requests==2.18.4
```
当然,你也需要一个 HTTP 客户端,像 [Postman](https://www.getpostman.com) 或者 cURL。哪个都行。
***最终的代码在哪里可以找到?*** 源代码在 [这里](https://github.com/dvf/blockchain)。
### 第 1 步:构建一个区块链
打开你喜欢的文本编辑器或者 IDE,我个人喜欢 [PyCharm](https://www.jetbrains.com/pycharm/)。创建一个名为 `blockchain.py` 的新文件。我将仅使用一个文件,如果你看晕了,可以去参考 [源代码](https://github.com/dvf/blockchain)。
#### 描述一个区块链
我们将创建一个 `Blockchain` 类,它的构造函数将去初始化一个空列表(去存储我们的区块链),以及另一个列表去保存交易。下面是我们的类规划:
```
class Blockchain(object):
def __init__(self):
self.chain = []
self.current_transactions = []
def new_block(self):
# Creates a new Block and adds it to the chain
pass
def new_transaction(self):
# Adds a new transaction to the list of transactions
pass
@staticmethod
def hash(block):
# Hashes a Block
pass
@property
def last_block(self):
# Returns the last Block in the chain
pass
```
*我们的 Blockchain 类的原型*
我们的 `Blockchain` 类负责管理链。它将存储交易并且有一些为链中增加新区块的辅助性质的方法。现在我们开始去充实一些类的方法。
#### 区块是什么样子的?
每个区块有一个索引、一个时间戳(Unix 时间)、一个交易的列表、一个证明(后面会详细解释)、以及前一个区块的哈希。
单个区块的示例应该是下面的样子:
```
block = {
'index': 1,
'timestamp': 1506057125.900785,
'transactions': [
{
'sender': "8527147fe1f5426f9dd545de4b27ee00",
'recipient': "a77f5cdfa2934df3954a5c7c7da5df1f",
'amount': 5,
}
],
'proof': 324984774000,
'previous_hash': "2cf24dba5fb0a30e26e83b2ac5b9e29e1b161e5c1fa7425e73043362938b9824"
}
```
*我们的区块链中的块示例*
此刻,链的概念应该非常明显 —— 每个新区块包含它自身的信息和前一个区域的哈希。**这一点非常重要,因为这就是区块链不可更改的原因**:如果攻击者修改了一个早期的区块,那么**所有**的后续区块将包含错误的哈希。
*这样做有意义吗?如果没有,就让时间来埋葬它吧 —— 这就是区块链背后的核心思想。*
#### 添加交易到一个区块
我们将需要一种区块中添加交易的方式。我们的 `new_transaction()` 就是做这个的,它非常简单明了:
```
class Blockchain(object):
...
def new_transaction(self, sender, recipient, amount):
"""
Creates a new transaction to go into the next mined Block
:param sender: <str> Address of the Sender
:param recipient: <str> Address of the Recipient
:param amount: <int> Amount
:return: <int> The index of the Block that will hold this transaction
"""
self.current_transactions.append({
'sender': sender,
'recipient': recipient,
'amount': amount,
})
return self.last_block['index'] + 1
```
在 `new_transaction()` 运行后将在列表中添加一个交易,它返回添加交易后的那个区块的索引 —— 那个区块接下来将被挖矿。提交交易的用户后面会用到这些。
#### 创建新区块
当我们的 `Blockchain` 被实例化后,我们需要一个创世区块(一个没有祖先的区块)来播种它。我们也需要去添加一些 “证明” 到创世区块,它是挖矿(工作量证明 PoW)的成果。我们在后面将讨论更多挖矿的内容。
除了在我们的构造函数中创建创世区块之外,我们还需要写一些方法,如 `new_block()`、`new_transaction()` 以及 `hash()`:
```
import hashlib
import json
from time import time
class Blockchain(object):
def __init__(self):
self.current_transactions = []
self.chain = []
# Create the genesis block
self.new_block(previous_hash=1, proof=100)
def new_block(self, proof, previous_hash=None):
"""
Create a new Block in the Blockchain
:param proof: <int> The proof given by the Proof of Work algorithm
:param previous_hash: (Optional) <str> Hash of previous Block
:return: <dict> New Block
"""
block = {
'index': len(self.chain) + 1,
'timestamp': time(),
'transactions': self.current_transactions,
'proof': proof,
'previous_hash': previous_hash or self.hash(self.chain[-1]),
}
# Reset the current list of transactions
self.current_transactions = []
self.chain.append(block)
return block
def new_transaction(self, sender, recipient, amount):
"""
Creates a new transaction to go into the next mined Block
:param sender: <str> Address of the Sender
:param recipient: <str> Address of the Recipient
:param amount: <int> Amount
:return: <int> The index of the Block that will hold this transaction
"""
self.current_transactions.append({
'sender': sender,
'recipient': recipient,
'amount': amount,
})
return self.last_block['index'] + 1
@property
def last_block(self):
return self.chain[-1]
@staticmethod
def hash(block):
"""
Creates a SHA-256 hash of a Block
:param block: <dict> Block
:return: <str>
"""
# We must make sure that the Dictionary is Ordered, or we'll have inconsistent hashes
block_string = json.dumps(block, sort_keys=True).encode()
return hashlib.sha256(block_string).hexdigest()
```
上面的内容简单明了 —— 我添加了一些注释和文档字符串,以使代码清晰可读。到此为止,表示我们的区块链基本上要完成了。但是,你肯定想知道新区块是如何被创建、打造或者挖矿的。
#### 理解工作量证明
<ruby> 工作量证明 <rt> Proof of Work </rt></ruby>(PoW)算法是在区块链上创建或者挖出新区块的方法。PoW 的目标是去撞出一个能够解决问题的数字。这个数字必须满足“找到它很困难但是验证它很容易”的条件 —— 网络上的任何人都可以计算它。这就是 PoW 背后的核心思想。
我们来看一个非常简单的示例来帮助你了解它。
我们来解决一个问题,一些整数 `x` 乘以另外一个整数 `y` 的结果的哈希值必须以 `0` 结束。因此,`hash(x * y) = ac23dc…0`。为简单起见,我们先把 `x = 5` 固定下来。在 Python 中的实现如下:
```
from hashlib import sha256
x = 5
y = 0 # We don't know what y should be yet...
while sha256(f'{x*y}'.encode()).hexdigest()[-1] != "0":
y += 1
print(f'The solution is y = {y}')
```
在这里的答案是 `y = 21`。因为它产生的哈希值是以 0 结尾的:
```
hash(5 * 21) = 1253e9373e...5e3600155e860
```
在比特币中,工作量证明算法被称之为 [Hashcash](https://en.wikipedia.org/wiki/Hashcash)。与我们上面的例子没有太大的差别。这就是矿工们进行竞赛以决定谁来创建新块的算法。一般来说,其难度取决于在一个字符串中所查找的字符数量。然后矿工会因其做出的求解而得到奖励的币——在一个交易当中。
网络上的任何人都可以很容易地去核验它的答案。
#### 实现基本的 PoW
为我们的区块链来实现一个简单的算法。我们的规则与上面的示例类似:
>
> 找出一个数字 `p`,它与前一个区块的答案进行哈希运算得到一个哈希值,这个哈希值的前四位必须是由 `0` 组成。
>
>
>
```
import hashlib
import json
from time import time
from uuid import uuid4
class Blockchain(object):
...
def proof_of_work(self, last_proof):
"""
Simple Proof of Work Algorithm:
- Find a number p' such that hash(pp') contains leading 4 zeroes, where p is the previous p'
- p is the previous proof, and p' is the new proof
:param last_proof: <int>
:return: <int>
"""
proof = 0
while self.valid_proof(last_proof, proof) is False:
proof += 1
return proof
@staticmethod
def valid_proof(last_proof, proof):
"""
Validates the Proof: Does hash(last_proof, proof) contain 4 leading zeroes?
:param last_proof: <int> Previous Proof
:param proof: <int> Current Proof
:return: <bool> True if correct, False if not.
"""
guess = f'{last_proof}{proof}'.encode()
guess_hash = hashlib.sha256(guess).hexdigest()
return guess_hash[:4] == "0000"
```
为了调整算法的难度,我们可以修改前导 0 的数量。但是 4 个零已经足够难了。你会发现,将前导 0 的数量每增加一,那么找到正确答案所需要的时间难度将大幅增加。
我们的类基本完成了,现在我们开始去使用 HTTP 请求与它交互。
### 第 2 步:以 API 方式去访问我们的区块链
我们将使用 Python Flask 框架。它是个微框架,使用它去做端点到 Python 函数的映射很容易。这样我们可以使用 HTTP 请求基于 web 来与我们的区块链对话。
我们将创建三个方法:
* `/transactions/new` 在一个区块上创建一个新交易
* `/mine` 告诉我们的服务器去挖矿一个新区块
* `/chain` 返回完整的区块链
#### 配置 Flask
我们的 “服务器” 将在我们的区块链网络中产生一个单个的节点。我们来创建一些样板代码:
```
import hashlib
import json
from textwrap import dedent
from time import time
from uuid import uuid4
from flask import Flask
class Blockchain(object):
...
# Instantiate our Node
app = Flask(__name__)
# Generate a globally unique address for this node
node_identifier = str(uuid4()).replace('-', '')
# Instantiate the Blockchain
blockchain = Blockchain()
@app.route('/mine', methods=['GET'])
def mine():
return "We'll mine a new Block"
@app.route('/transactions/new', methods=['POST'])
def new_transaction():
return "We'll add a new transaction"
@app.route('/chain', methods=['GET'])
def full_chain():
response = {
'chain': blockchain.chain,
'length': len(blockchain.chain),
}
return jsonify(response), 200
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)
```
对上面的代码,我们做添加一些详细的解释:
* Line 15:实例化我们的节点。更多关于 Flask 的知识读 [这里](http://flask.pocoo.org/docs/0.12/quickstart/#a-minimal-application)。
* Line 18:为我们的节点创建一个随机的名字。
* Line 21:实例化我们的区块链类。
* Line 24–26:创建 `/mine` 端点,这是一个 GET 请求。
* Line 28–30:创建 `/transactions/new` 端点,这是一个 POST 请求,因为我们要发送数据给它。
* Line 32–38:创建 `/chain` 端点,它返回全部区块链。
* Line 40–41:在 5000 端口上运行服务器。
#### 交易端点
这就是对一个交易的请求,它是用户发送给服务器的:
```
{
"sender": "my address",
"recipient": "someone else's address",
"amount": 5
}
```
因为我们已经有了添加交易到块中的类方法,剩下的就很容易了。让我们写个函数来添加交易:
```
import hashlib
import json
from textwrap import dedent
from time import time
from uuid import uuid4
from flask import Flask, jsonify, request
...
@app.route('/transactions/new', methods=['POST'])
def new_transaction():
values = request.get_json()
# Check that the required fields are in the POST'ed data
required = ['sender', 'recipient', 'amount']
if not all(k in values for k in required):
return 'Missing values', 400
# Create a new Transaction
index = blockchain.new_transaction(values['sender'], values['recipient'], values['amount'])
response = {'message': f'Transaction will be added to Block {index}'}
return jsonify(response), 201
```
*创建交易的方法*
#### 挖矿端点
我们的挖矿端点是见证奇迹的地方,它实现起来很容易。它要做三件事情:
1. 计算工作量证明
2. 因为矿工(我们)添加一个交易而获得报酬,奖励矿工(我们) 1 个币
3. 通过将它添加到链上而打造一个新区块
```
import hashlib
import json
from time import time
from uuid import uuid4
from flask import Flask, jsonify, request
...
@app.route('/mine', methods=['GET'])
def mine():
# We run the proof of work algorithm to get the next proof...
last_block = blockchain.last_block
last_proof = last_block['proof']
proof = blockchain.proof_of_work(last_proof)
# We must receive a reward for finding the proof.
# The sender is "0" to signify that this node has mined a new coin.
blockchain.new_transaction(
sender="0",
recipient=node_identifier,
amount=1,
)
# Forge the new Block by adding it to the chain
previous_hash = blockchain.hash(last_block)
block = blockchain.new_block(proof, previous_hash)
response = {
'message': "New Block Forged",
'index': block['index'],
'transactions': block['transactions'],
'proof': block['proof'],
'previous_hash': block['previous_hash'],
}
return jsonify(response), 200
```
注意,挖掘出的区块的接收方是我们的节点地址。现在,我们所做的大部分工作都只是与我们的 `Blockchain` 类的方法进行交互的。到目前为止,我们已经做完了,现在开始与我们的区块链去交互。
### 第 3 步:与我们的区块链去交互
你可以使用简单的 cURL 或者 Postman 通过网络与我们的 API 去交互。
启动服务器:
```
$ python blockchain.py
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
```
我们通过生成一个 `GET` 请求到 `http://localhost:5000/mine` 去尝试挖一个区块:

*使用 Postman 去生成一个 GET 请求*
我们通过生成一个 `POST` 请求到 `http://localhost:5000/transactions/new` 去创建一个区块,请求数据包含我们的交易结构:

*使用 Postman 去生成一个 POST 请求*
如果你不使用 Postman,也可以使用 cURL 去生成一个等价的请求:
```
$ curl -X POST -H "Content-Type: application/json" -d '{
"sender": "d4ee26eee15148ee92c6cd394edd974e",
"recipient": "someone-other-address",
"amount": 5
}' "http://localhost:5000/transactions/new"
```
我重启动我的服务器,然后我挖到了两个区块,这样总共有了 3 个区块。我们通过请求 `http://localhost:5000/chain` 来检查整个区块链:
```
{
"chain": [
{
"index": 1,
"previous_hash": 1,
"proof": 100,
"timestamp": 1506280650.770839,
"transactions": []
},
{
"index": 2,
"previous_hash": "c099bc...bfb7",
"proof": 35293,
"timestamp": 1506280664.717925,
"transactions": [
{
"amount": 1,
"recipient": "8bbcb347e0634905b0cac7955bae152b",
"sender": "0"
}
]
},
{
"index": 3,
"previous_hash": "eff91a...10f2",
"proof": 35089,
"timestamp": 1506280666.1086972,
"transactions": [
{
"amount": 1,
"recipient": "8bbcb347e0634905b0cac7955bae152b",
"sender": "0"
}
]
}
],
"length": 3
}
```
### 第 4 步:共识
这是很酷的一个地方。我们已经有了一个基本的区块链,它可以接收交易并允许我们去挖掘出新区块。但是区块链的整个重点在于它是<ruby> 去中心化的 <rt> decentralized </rt></ruby>。而如果它们是去中心化的,那我们如何才能确保它们表示在同一个区块链上?这就是<ruby> 共识 <rt> Consensus </rt></ruby>问题,如果我们希望在我们的网络上有多于一个的节点运行,那么我们将必须去实现一个共识算法。
#### 注册新节点
在我们能实现一个共识算法之前,我们需要一个办法去让一个节点知道网络上的邻居节点。我们网络上的每个节点都保留有一个该网络上其它节点的注册信息。因此,我们需要更多的端点:
1. `/nodes/register` 以 URL 的形式去接受一个新节点列表
2. `/nodes/resolve` 去实现我们的共识算法,由它来解决任何的冲突 —— 确保节点有一个正确的链。
我们需要去修改我们的区块链的构造函数,来提供一个注册节点的方法:
```
...
from urllib.parse import urlparse
...
class Blockchain(object):
def __init__(self):
...
self.nodes = set()
...
def register_node(self, address):
"""
Add a new node to the list of nodes
:param address: <str> Address of node. Eg. 'http://192.168.0.5:5000'
:return: None
"""
parsed_url = urlparse(address)
self.nodes.add(parsed_url.netloc)
```
*一个添加邻居节点到我们的网络的方法*
注意,我们将使用一个 `set()` 去保存节点列表。这是一个非常合算的方式,它将确保添加的节点是<ruby> 幂等 <rt> idempotent </rt></ruby>的 —— 这意味着不论你将特定的节点添加多少次,它都是精确地只出现一次。
#### 实现共识算法
正如前面提到的,当一个节点与另一个节点有不同的链时就会产生冲突。为解决冲突,我们制定一个规则,即最长的有效的链才是权威的链。换句话说就是,网络上最长的链就是事实上的区块链。使用这个算法,可以在我们的网络上节点之间达到共识。
```
...
import requests
class Blockchain(object)
...
def valid_chain(self, chain):
"""
Determine if a given blockchain is valid
:param chain: <list> A blockchain
:return: <bool> True if valid, False if not
"""
last_block = chain[0]
current_index = 1
while current_index < len(chain):
block = chain[current_index]
print(f'{last_block}')
print(f'{block}')
print("\n-----------\n")
# Check that the hash of the block is correct
if block['previous_hash'] != self.hash(last_block):
return False
# Check that the Proof of Work is correct
if not self.valid_proof(last_block['proof'], block['proof']):
return False
last_block = block
current_index += 1
return True
def resolve_conflicts(self):
"""
This is our Consensus Algorithm, it resolves conflicts
by replacing our chain with the longest one in the network.
:return: <bool> True if our chain was replaced, False if not
"""
neighbours = self.nodes
new_chain = None
# We're only looking for chains longer than ours
max_length = len(self.chain)
# Grab and verify the chains from all the nodes in our network
for node in neighbours:
response = requests.get(f'http://{node}/chain')
if response.status_code == 200:
length = response.json()['length']
chain = response.json()['chain']
# Check if the length is longer and the chain is valid
if length > max_length and self.valid_chain(chain):
max_length = length
new_chain = chain
# Replace our chain if we discovered a new, valid chain longer than ours
if new_chain:
self.chain = new_chain
return True
return False
```
第一个方法 `valid_chain()` 是负责来检查链是否有效,它通过遍历区块链上的每个区块并验证它们的哈希和工作量证明来检查这个区块链是否有效。
`resolve_conflicts()` 方法用于遍历所有的邻居节点,下载它们的链并使用上面的方法去验证它们是否有效。**如果找到有效的链,确定谁是最长的链,然后我们就用最长的链来替换我们的当前的链。**
在我们的 API 上来注册两个端点,一个用于添加邻居节点,另一个用于解决冲突:
```
@app.route('/nodes/register', methods=['POST'])
def register_nodes():
values = request.get_json()
nodes = values.get('nodes')
if nodes is None:
return "Error: Please supply a valid list of nodes", 400
for node in nodes:
blockchain.register_node(node)
response = {
'message': 'New nodes have been added',
'total_nodes': list(blockchain.nodes),
}
return jsonify(response), 201
@app.route('/nodes/resolve', methods=['GET'])
def consensus():
replaced = blockchain.resolve_conflicts()
if replaced:
response = {
'message': 'Our chain was replaced',
'new_chain': blockchain.chain
}
else:
response = {
'message': 'Our chain is authoritative',
'chain': blockchain.chain
}
return jsonify(response), 200
```
这种情况下,如果你愿意,可以使用不同的机器来做,然后在你的网络上启动不同的节点。或者是在同一台机器上使用不同的端口启动另一个进程。我是在我的机器上使用了不同的端口启动了另一个节点,并将它注册到了当前的节点上。因此,我现在有了两个节点:`http://localhost:5000` 和 `http://localhost:5001`。

*注册一个新节点*
我接着在节点 2 上挖出一些新区块,以确保这个链是最长的。之后我在节点 1 上以 `GET` 方式调用了 `/nodes/resolve`,这时,节点 1 上的链被共识算法替换成节点 2 上的链了:

*工作中的共识算法*
然后将它们封装起来 … 找一些朋友来帮你一起测试你的区块链。
---
我希望以上内容能够鼓舞你去创建一些新的东西。我是加密货币的狂热拥护者,因此我相信区块链将迅速改变我们对经济、政府和记录保存的看法。
**更新:** 我正计划继续它的第二部分,其中我将扩展我们的区块链,使它具备交易验证机制,同时讨论一些你可以在其上产生你自己的区块链的方式。(LCTT 译注:第二篇并没有~!)
---
via: <https://hackernoon.com/learn-blockchains-by-building-one-117428612f46>
作者:[Daniel van Flymen](https://hackernoon.com/@vanflymen?source=post_header_lockup) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 
You’re here because, like me, you’re psyched about the rise of Cryptocurrencies. And you want to know how Blockchains work—the fundamental technology behind them.
But understanding Blockchains isn’t easy—or at least wasn’t for me. I trudged through dense videos, followed porous tutorials, and dealt with the amplified frustration of too few examples.
I like learning by doing. It forces me to deal with the subject matter at a code level, which gets it sticking. If you do the same, at the end of this guide you’ll have a functioning Blockchain with a solid grasp of how they work.
Remember that a blockchain is an *immutable, sequential* chain of records called Blocks. They can contain transactions, files or any data you like, really. But the important thing is that they’re *chained* together using *hashes*.
If you aren’t sure what a hash is, [here’s an explanation](https://learncryptography.com/hash-functions/what-are-hash-functions?ref=hackernoon.com).
** Who is this guide aimed at?** You should be comfy reading and writing some basic Python, as well as have some understanding of how HTTP requests work, since we’ll be talking to our Blockchain over HTTP.
** What do I need?** Make sure that
`pip`
) is installed. You’ll also need to install Flask and the wonderful Requests library:`pip install Flask==0.12.2 requests==2.18.4`
Oh, you’ll also need an HTTP Client, like [Postman](https://www.getpostman.com/?ref=hackernoon.com) or cURL. But anything will do.
** Where’s the final code?** The source code is
Open up your favourite text editor or IDE, personally I ❤️ [PyCharm](https://www.jetbrains.com/pycharm/?ref=hackernoon.com). Create a new file, called `blockchain.py`
. We’ll only use a single file, but if you get lost, you can always refer to the [source code](https://github.com/dvf/blockchain?ref=hackernoon.com).
We’ll create a `Blockchain`
class whose constructor creates an initial empty list (to store our blockchain), and another to store transactions. Here’s the blueprint for our class:
Blueprint of our Blockchain Class
Our `Blockchain`
class is responsible for managing the chain. It will store transactions and have some helper methods for adding new blocks to the chain. Let’s start fleshing out some methods.
Each Block has an *index*, a *timestamp* (in Unix time), a *list of transactions*, a *proof* (more on that later), and the *hash of the previous Block*.
Here’s an example of what a single Block looks like:
Example of a Block in our Blockchain
At this point, the idea of a *chain* should be apparent—each new block contains within itself, the hash of the previous Block. **This is crucial because it’s what gives blockchains immutability:** If an attacker corrupted an earlier Block in the chain then ** all** subsequent blocks will contain incorrect hashes.
*Does this make sense? If it doesn’t, take some time to let it sink in—it’s the core idea behind blockchains.*
We’ll need a way of adding transactions to a Block. Our `new_transaction()`
method is responsible for this, and it’s pretty straight-forward:
After `new_transaction()`
adds a transaction to the list, it returns the *index* of the block which the transaction will be added to—*the next one to be mined.* This will be useful later on, to the user submitting the transaction.
When our `Blockchain`
is instantiated we’ll need to seed it with a *genesis* block—a block with no predecessors. We’ll also need to add a *“proof”* to our genesis block which is the result of mining (or proof of work). We’ll talk more about mining later.
In addition to creating the *genesis* block in our constructor, we’ll also flesh out the methods for `new_block()`
, `new_transaction()`
and `hash()`
:
The above should be straight-forward—I’ve added some comments and *docstrings* to help keep it clear. We’re almost done with representing our blockchain. But at this point, you must be wondering how new blocks are created, forged or mined.
A Proof of Work algorithm (PoW) is how new Blocks are created or *mined* on the blockchain_._ The goal of PoW is to discover a number which solves a problem. The number must be **difficult to find** **but easy to verify**—computationally speaking—by anyone on the network. This is the core idea behind Proof of Work.
We’ll look at a very simple example to help this sink in.
Let’s decide that the *hash* of some integer `x`
multiplied by another `y`
must end in `0`
. So, `hash(x * y) = ac23dc...0`
. And for this simplified example, let’s fix `x = 5`
. Implementing this in Python:
from hashlib import sha256
x = 5y = 0 # We don't know what y should be yet...
while sha256(f'{x*y}'.encode()).hexdigest()[-1] != "0":y += 1
print(f'The solution is y = {y}')
The solution here is `y = 21`
. Since, the produced hash ends in `0`
:
hash(5 * 21) = 1253e9373e...5e3600155e860
In Bitcoin, the Proof of Work algorithm is called [ Hashcash](https://en.wikipedia.org/wiki/Hashcash?ref=hackernoon.com). And it’s not too different from our basic example above. It’s the algorithm that miners race to solve in order to create a new block. In general, the difficulty is determined by the number of characters searched for in a string. The miners are then rewarded for their solution by receiving a coin—in a transaction.
The network is able to *easily* verify their solution.
Let’s implement a similar algorithm for our blockchain. Our rule will be similar to the example above:
Find a numberpthat when hashed with the previous block’s solution a hash with 4 leading`_0_`
s is produced.
To adjust the difficulty of the algorithm, we could modify the number of leading zeroes. But 4 is sufficient. You’ll find out that the addition of a single leading zero makes a mammoth difference to the time required to find a solution.
Our class is almost complete and we’re ready to begin interacting with it using HTTP requests.
We’re going to use the Python Flask Framework. It’s a micro-framework and it makes it easy to map endpoints to Python functions. This allows us talk to our blockchain over the web using HTTP requests.
We’ll create three methods:
`/transactions/new`
to create a new transaction to a block`/mine`
to tell our server to mine a new block.`/chain`
to return the full Blockchain.Our “server” will form a single node in our blockchain network. Let’s create some boilerplate code:
A brief explanation of what we’ve added above:
`Blockchain`
class.`/mine`
endpoint, which is a `GET`
request.`/transactions/new`
endpoint, which is a `POST`
request, since we’ll be sending data to it.`/chain`
endpoint, which returns the full Blockchain.This is what the request for a transaction will look like. It’s what the user sends to the server:
{"sender": "my address","recipient": "someone else's address","amount": 5}
Since we already have our class method for adding transactions to a block, the rest is easy. Let’s write the function for adding transactions:
A method for creating Transactions
Our mining endpoint is where the magic happens, and it’s easy. It has to do three things:
Note that the recipient of the mined block is the address of our node. And most of what we’ve done here is just interact with the methods on our Blockchain class. At this point, we’re done, and can start interacting with our blockchain.
You can use plain old cURL or Postman to interact with our API over a network.
Fire up the server:
$ python blockchain.py
* Running on [http://127.0.0.1:5000/](http://127.0.0.1:5000/?ref=hackernoon.com) (Press CTRL+C to quit)
Let’s try mining a block by making a `GET`
request to `http://localhost:5000/mine`
:
Using Postman to make a GET request
Let’s create a new transaction by making a `POST`
request to`http://localhost:5000/transactions/new`
with a body containing our transaction structure:
Using Postman to make a POST request
If you aren’t using Postman, then you can make the equivalent request using cURL:
$ curl -X POST -H "Content-Type: application/json" -d '{"sender": "d4ee26eee15148ee92c6cd394edd974e","recipient": "someone-other-address","amount": 5}' "[http://localhost:5000/transactions/new](http://localhost:5000/transactions/new?ref=hackernoon.com)"
I restarted my server, and mined two blocks, to give 3 in total. Let’s inspect the full chain by requesting `[http://localhost:5000/chain](http://localhost:5000/chain:)`
[:](http://localhost:5000/chain:?ref=hackernoon.com)
{"chain": [{"index": 1,"previous_hash": 1,"proof": 100,"timestamp": 1506280650.770839,"transactions": []},{"index": 2,"previous_hash": "c099bc...bfb7","proof": 35293,"timestamp": 1506280664.717925,"transactions": [{"amount": 1,"recipient": "8bbcb347e0634905b0cac7955bae152b","sender": "0"}]},{"index": 3,"previous_hash": "eff91a...10f2","proof": 35089,"timestamp": 1506280666.1086972,"transactions": [{"amount": 1,"recipient": "8bbcb347e0634905b0cac7955bae152b","sender": "0"}]}],"length": 3}
This is very cool. We’ve got a basic Blockchain that accepts transactions and allows us to mine new Blocks. But the whole point of Blockchains is that they should be *decentralized*. And if they’re decentralized, how on earth do we ensure that they all reflect the same chain? This is called the problem of *Consensus*, and we’ll have to implement a Consensus Algorithm if we want more than one node in our network.
Before we can implement a Consensus Algorithm, we need a way to let a node know about neighbouring nodes on the network. Each node on our network should keep a registry of other nodes on the network. Thus, we’ll need some more endpoints:
`/nodes/register`
to accept a list of new nodes in the form of URLs.`/nodes/resolve`
to implement our Consensus Algorithm, which resolves any conflicts—to ensure a node has the correct chain.We’ll need to modify our Blockchain’s constructor and provide a method for registering nodes:
A method for adding neighbouring nodes to our Network
Note that we’ve used a `set()`
to hold the list of nodes. This is a cheap way of ensuring that the addition of new nodes is idempotent—meaning that no matter how many times we add a specific node, it appears exactly once.
As mentioned, a conflict is when one node has a different chain to another node. To resolve this, we’ll make the rule that *the longest valid chain is authoritative.* In other words, the longest chain on the network is the *de-facto* one. Using this algorithm, we reach *Consensus* amongst the nodes in our network.
The first method `valid_chain()`
is responsible for checking if a chain is valid by looping through each block and verifying both the hash and the proof.
`resolve_conflicts()`
is a method which loops through all our neighbouring nodes, *downloads* their chains and verifies them using the above method. **If a valid chain is found, whose length is greater than ours, we replace ours.**
Let’s register the two endpoints to our API, one for adding neighbouring nodes and the another for resolving conflicts:
At this point you can grab a different machine if you like, and spin up different nodes on your network. Or spin up processes using different ports on the same machine. I spun up another node on my machine, on a different port, and registered it with my current node. Thus, I have two nodes: `[http://localhost:5000](http://localhost:5000)`
and `http://localhost:5001`
.
Registering a new Node
I then mined some new Blocks on node 2, to ensure the chain was longer. Afterward, I called `GET /nodes/resolve`
on node 1, where the chain was replaced by the Consensus Algorithm:
Consensus Algorithm at Work
And that’s a wrap... Go get some friends together to help test out your Blockchain.
I hope that this has inspired you to create something new. I’m ecstatic about Cryptocurrencies because I believe that Blockchains will rapidly change the way we think about economies, governments and record-keeping.
**Update:** I’m planning on following up with a Part 2, where we’ll extend our Blockchain to have a Transaction Validation Mechanism as well as discuss some ways in which you can productionize your Blockchain.
If you enjoyed this guide, or have any suggestions or questions, let me know in the comments. And if you’ve spotted any errors, feel free to contribute to the codehere! |
9,883 | Kubernetes 分布式应用部署实战:以人脸识别应用为例 | https://skarlso.github.io/2018/03/15/kubernetes-distributed-application/ | 2018-07-30T18:24:55 | [
"Kubernetes",
"人脸识别"
] | https://linux.cn/article-9883-1.html | 
简介
--
伙计们,请搬好小板凳坐好,下面将是一段漫长的旅程,期望你能够乐在其中。
我将基于 [Kubernetes](https://kubernetes.io/) 部署一个分布式应用。我曾试图编写一个尽可能真实的应用,但由于时间和精力有限,最终砍掉了很多细节。
我将聚焦 Kubernetes 及其部署。
让我们开始吧。
应用
--
### TL;DR

该应用本身由 6 个组件构成。代码可以从如下链接中找到:[Kubenetes 集群示例](https://github.com/Skarlso/kube-cluster-sample)。
这是一个人脸识别服务,通过比较已知个人的图片,识别给定图片对应的个人。前端页面用表格形式简要的展示图片及对应的个人。具体而言,向 [接收器](https://github.com/Skarlso/kube-cluster-sample) 发送请求,请求包含指向一个图片的链接。图片可以位于任何位置。接受器将图片地址存储到数据库 (MySQL) 中,然后向队列发送处理请求,请求中包含已保存图片的 ID。这里我们使用 [NSQ](http://nsq.io/) 建立队列。
[图片处理](https://github.com/Skarlso/kube-cluster-sample/tree/master/image_processor) 服务一直监听处理请求队列,从中获取任务。处理过程包括如下几步:获取图片 ID,读取图片,通过 [gRPC](https://grpc.io/) 将图片路径发送至 Python 编写的 [人脸识别](https://github.com/Skarlso/kube-cluster-sample/tree/master/face_recognition) 后端。如果识别成功,后端给出图片对应个人的名字。图片处理器进而根据个人 ID 更新图片记录,将其标记为处理成功。如果识别不成功,图片被标记为待解决。如果图片识别过程中出现错误,图片被标记为失败。
标记为失败的图片可以通过计划任务等方式进行重试。
那么具体是如何工作的呢?我们深入探索一下。
### 接收器
接收器服务是整个流程的起点,通过如下形式的 API 接收请求:
```
curl -d '{"path":"/unknown_images/unknown0001.jpg"}' http://127.0.0.1:8000/image/post
```
此时,接收器将<ruby> 路径 <rt> path </rt></ruby>存储到共享数据库集群中,该实体存储后将从数据库服务收到对应的 ID。本应用采用“<ruby> 实体对象 <rt> Entity Object </rt></ruby>的唯一标识由持久层提供”的模型。获得实体 ID 后,接收器向 NSQ 发送消息,至此接收器的工作完成。
### 图片处理器
从这里开始变得有趣起来。图片处理器首次运行时会创建两个 Go <ruby> 协程 <rt> routine </rt></ruby>,具体为:
### Consume
这是一个 NSQ 消费者,需要完成三项必需的任务。首先,监听队列中的消息。其次,当有新消息到达时,将对应的 ID 追加到一个线程安全的 ID 片段中,以供第二个协程处理。最后,告知第二个协程处理新任务,方法为 [sync.Condition](https://golang.org/pkg/sync/#Cond)。
### ProcessImages
该协程会处理指定 ID 片段,直到对应片段全部处理完成。当处理完一个片段后,该协程并不是在一个通道上睡眠等待,而是进入悬挂状态。对每个 ID,按如下步骤顺序处理:
* 与人脸识别服务建立 gRPC 连接,其中人脸识别服务会在人脸识别部分进行介绍
* 从数据库获取图片对应的实体
* 为 [断路器](https://skarlso.github.io/2018/03/15/kubernetes-distributed-application/#circuit-breaker) 准备两个函数
+ 函数 1: 用于 RPC 方法调用的主函数
+ 函数 2: 基于 ping 的断路器健康检查
* 调用函数 1 将图片路径发送至人脸识别服务,其中路径应该是人脸识别服务可以访问的,最好是共享的,例如 NFS
* 如果调用失败,将图片实体状态更新为 FAILEDPROCESSING
* 如果调用成功,返回值是一个图片的名字,对应数据库中的一个个人。通过联合 SQL 查询,获取对应个人的 ID
* 将数据库中的图片实体状态更新为 PROCESSED,更新图片被识别成的个人的 ID
这个服务可以复制多份同时运行。
### 断路器
即使对于一个复制资源几乎没有开销的系统,也会有意外的情况发生,例如网络故障或任何两个服务之间的通信存在问题等。我在 gRPC 调用中实现了一个简单的断路器,这十分有趣。
下面给出工作原理:

当出现 5 次不成功的服务调用时,断路器启动并阻断后续的调用请求。经过指定的时间后,它对服务进行健康检查并判断是否恢复。如果问题依然存在,等待时间会进一步增大。如果已经恢复,断路器停止对服务调用的阻断,允许请求流量通过。
### 前端
前端只包含一个极其简单的表格视图,通过 Go 自身的 html/模板显示一系列图片。
### 人脸识别
人脸识别是整个识别的关键点。仅因为追求灵活性,我将这个服务设计为基于 gRPC 的服务。最初我使用 Go 编写,但后续发现基于 Python 的实现更加适合。事实上,不算 gRPC 部分的代码,人脸识别部分仅有 7 行代码。我使用的[人脸识别](https://github.com/ageitgey/face_recognition)库极为出色,它包含 OpenCV 的全部 C 绑定。维护 API 标准意味着只要标准本身不变,实现可以任意改变。
注意:我曾经试图使用 [GoCV](https://gocv.io/),这是一个极好的 Go 库,但欠缺所需的 C 绑定。推荐马上了解一下这个库,它会让你大吃一惊,例如编写若干行代码即可实现实时摄像处理。
这个 Python 库的工作方式本质上很简单。准备一些你认识的人的图片,把信息记录下来。对于我而言,我有一个图片文件夹,包含若干图片,名称分别为 `hannibal_1.jpg`、 `hannibal_2.jpg`、 `gergely_1.jpg`、 `john_doe.jpg`。在数据库中,我使用两个表记录信息,分别为 `person`、 `person_images`,具体如下:
```
+----+----------+
| id | name |
+----+----------+
| 1 | Gergely |
| 2 | John Doe |
| 3 | Hannibal |
+----+----------+
+----+----------------+-----------+
| id | image_name | person_id |
+----+----------------+-----------+
| 1 | hannibal_1.jpg | 3 |
| 2 | hannibal_2.jpg | 3 |
+----+----------------+-----------+
```
人脸识别库识别出未知图片后,返回图片的名字。我们接着使用类似下面的联合查询找到对应的个人。
```
select person.name, person.id from person inner join person_images as pi on person.id = pi.person_id where image_name = 'hannibal_2.jpg';
```
gRPC 调用返回的个人 ID 用于更新图片的 `person` 列。
### NSQ
NSQ 是 Go 编写的小规模队列,可扩展且占用系统内存较少。NSQ 包含一个查询服务,用于消费者接收消息;包含一个守护进程,用于发送消息。
在 NSQ 的设计理念中,消息发送程序应该与守护进程在同一台主机上,故发送程序仅需发送至 localhost。但守护进程与查询服务相连接,这使其构成了全局队列。
这意味着有多少 NSQ 守护进程就有多少对应的发送程序。但由于其资源消耗极小,不会影响主程序的资源使用。
### 配置
为了尽可能增加灵活性以及使用 Kubernetes 的 ConfigSet 特性,我在开发过程中使用 `.env` 文件记录配置信息,例如数据库服务的地址以及 NSQ 的查询地址。在生产环境或 Kubernetes 环境中,我将使用环境变量属性配置。
### 应用小结
这就是待部署应用的全部架构信息。应用的各个组件都是可变更的,他们之间仅通过数据库、消息队列和 gRPC 进行耦合。考虑到更新机制的原理,这是部署分布式应用所必须的;在部署部分我会继续分析。
使用 Kubernetes 部署应用
------------------
### 基础知识
Kubernetes 是什么?
这里我会提到一些基础知识,但不会深入细节,细节可以用一本书的篇幅描述,例如 [Kubernetes 构建与运行](http://shop.oreilly.com/product/0636920043874.do)。另外,如果你愿意挑战自己,可以查看官方文档:[Kubernetes 文档](https://kubernetes.io/docs/)。
Kubernetes 是容器化服务及应用的管理器。它易于扩展,可以管理大量容器;更重要的是,可以通过基于 yaml 的模板文件高度灵活地进行配置。人们经常把 Kubernetes 比作 Docker Swarm,但 Kubernetes 的功能不仅仅如此。例如,Kubernetes 不关心底层容器实现,你可以使用 LXC 与 Kubernetes 的组合,效果与使用 Docker 一样好。Kubernetes 在管理容器的基础上,可以管理已部署的服务或应用集群。如何操作呢?让我们概览一下用于构成 Kubernetes 的模块。
在 Kubernetes 中,你给出期望的应用状态,Kubernetes 会尽其所能达到对应的状态。状态可以是已部署、已暂停,有 2 个副本等,以此类推。
Kubernetes 使用标签和注释标记组件,包括服务、部署、副本组、守护进程组等在内的全部组件都被标记。考虑如下场景,为了识别 pod 与应用的对应关系,使用 `app: myapp` 标签。假设应用已部署 2 个容器,如果你移除其中一个容器的 `app` 标签,Kubernetes 只能识别到一个容器(隶属于应用),进而启动一个新的具有 `myapp` 标签的实例。
### Kubernetes 集群
要使用 Kubernetes,需要先搭建一个 Kubernetes 集群。搭建 Kubernetes 集群可能是一个痛苦的经历,但所幸有工具可以帮助我们。Minikube 为我们在本地搭建一个单节点集群。AWS 的一个 beta 服务工作方式类似于 Kubernetes 集群,你只需请求节点并定义你的部署即可。Kubernetes 集群组件的文档如下:[Kubernetes 集群组件](https://kubernetes.io/docs/concepts/overview/components/)。
### 节点
<ruby> 节点 <rt> node </rt></ruby>是工作单位,形式可以是虚拟机、物理机,也可以是各种类型的云主机。
### Pod
Pod 是本地容器逻辑上组成的集合,即一个 Pod 中可能包含若干个容器。Pod 创建后具有自己的 DNS 和虚拟 IP,这样 Kubernetes 可以对到达流量进行负载均衡。你几乎不需要直接和容器打交道;即使是调试的时候,例如查看日志,你通常调用 `kubectl logs deployment/your-app -f` 查看部署日志,而不是使用 `-c container_name` 查看具体某个容器的日志。`-f` 参数表示从日志尾部进行流式输出。
### 部署
在 Kubernetes 中创建任何类型的资源时,后台使用一个<ruby> 部署 <rt> deployment </rt></ruby>组件,它指定了资源的期望状态。使用部署对象,你可以将 Pod 或服务变更为另外的状态,也可以更新应用或上线新版本应用。你一般不会直接操作副本组 (后续会描述),而是通过部署对象创建并管理。
### 服务
默认情况下,Pod 会获取一个 IP 地址。但考虑到 Pod 是 Kubernetes 中的易失性组件,我们需要更加持久的组件。不论是队列,MySQL、内部 API 或前端,都需要长期运行并使用保持不变的 IP 或更好的 DNS 记录。
为解决这个问题,Kubernetes 提供了<ruby> 服务 <rt> service </rt></ruby>组件,可以定义访问模式,支持的模式包括负载均衡、简单 IP 或内部 DNS。
Kubernetes 如何获知服务运行正常呢?你可以配置健康性检查和可用性检查。健康性检查是指检查容器是否处于运行状态,但容器处于运行状态并不意味着服务运行正常。对此,你应该使用可用性检查,即请求应用的一个特别<ruby> 接口 <rt> endpoint </rt></ruby>。
由于服务非常重要,推荐你找时间阅读以下文档:[服务](https://kubernetes.io/docs/concepts/services-networking/service/)。严肃的说,需要阅读的东西很多,有 24 页 A4 纸的篇幅,涉及网络、服务及自动发现。这也有助于你决定是否真的打算在生产环境中使用 Kubernetes。
### DNS / 服务发现
在 Kubernetes 集群中创建服务后,该服务会从名为 `kube-proxy` 和 `kube-dns` 的特殊 Kubernetes 部署中获取一个 DNS 记录。它们两个用于提供集群内的服务发现。如果你有一个正在运行的 MySQL 服务并配置 `clusterIP: no`,那么集群内部任何人都可以通过 `mysql.default.svc.cluster.local` 访问该服务,其中:
* `mysql` – 服务的名称
* `default` – 命名空间的名称
* `svc` – 对应服务分类
* `cluster.local` – 本地集群的域名
可以使用自定义设置更改本地集群的域名。如果想让服务可以从集群外访问,需要使用 DNS 服务,并使用例如 Nginx 将 IP 地址绑定至记录。服务对应的对外 IP 地址可以使用如下命令查询:
* 节点端口方式 – `kubectl get -o jsonpath="{.spec.ports[0].nodePort}" services mysql`
* 负载均衡方式 – `kubectl get -o jsonpath="{.spec.ports[0].LoadBalancer}" services mysql`
### 模板文件
类似 Docker Compose、TerraForm 或其它的服务管理工具,Kubernetes 也提供了基础设施描述模板。这意味着,你几乎不用手动操作。
以 Nginx 部署为例,查看下面的 yaml 模板:
```
apiVersion: apps/v1
kind: Deployment #(1)
metadata: #(2)
name: nginx-deployment
labels: #(3)
app: nginx
spec: #(4)
replicas: 3 #(5)
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers: #(6)
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
```
在这个示例部署中,我们做了如下操作:
* (1) 使用 `kind` 关键字定义模板类型
* (2) 使用 `metadata` 关键字,增加该部署的识别信息
* (3) 使用 `labels` 标记每个需要创建的资源
* (4) 然后使用 `spec` 关键字描述所需的状态
* (5) nginx 应用需要 3 个副本
* (6) Pod 中容器的模板定义部分
* 容器名称为 nginx
* 容器模板为 nginx:1.7.9 (本例使用 Docker 镜像)
### 副本组
<ruby> 副本组 <rt> ReplicaSet </rt></ruby>是一个底层的副本管理器,用于保证运行正确数目的应用副本。相比而言,部署是更高层级的操作,应该用于管理副本组。除非你遇到特殊的情况,需要控制副本的特性,否则你几乎不需要直接操作副本组。
### 守护进程组
上面提到 Kubernetes 始终使用标签,还有印象吗?<ruby> 守护进程组 <rt> DaemonSet </rt></ruby>是一个控制器,用于确保守护进程化的应用一直运行在具有特定标签的节点中。
例如,你将所有节点增加 `logger` 或 `mission_critical` 的标签,以便运行日志 / 审计服务的守护进程。接着,你创建一个守护进程组并使用 `logger` 或 `mission_critical` 节点选择器。Kubernetes 会查找具有该标签的节点,确保守护进程的实例一直运行在这些节点中。因而,节点中运行的所有进程都可以在节点内访问对应的守护进程。
以我的应用为例,NSQ 守护进程可以用守护进程组实现。具体而言,将对应节点增加 `recevier` 标签,创建一个守护进程组并配置 `receiver` 应用选择器,这样这些节点上就会一直运行接收者组件。
守护进程组具有副本组的全部优势,可扩展且由 Kubernetes 管理,意味着 Kubernetes 管理其全生命周期的事件,确保持续运行,即使出现故障,也会立即替换。
### 扩展
在 Kubernetes 中,扩展是稀松平常的事情。副本组负责 Pod 运行的实例数目。就像你在 nginx 部署那个示例中看到的那样,对应设置项 `replicas:3`。我们可以按应用所需,让 Kubernetes 运行多份应用副本。
当然,设置项有很多。你可以指定让多个副本运行在不同的节点上,也可以指定各种不同的应用启动等待时间。想要在这方面了解更多,可以阅读 [水平扩展](https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/) 和 [Kubernetes 中的交互式扩展](https://kubernetes.io/docs/tutorials/kubernetes-basics/scale-interactive/);当然 [副本组](https://kubernetes.io/docs/concepts/workloads/controllers/replicaset/) 的细节对你也有帮助,毕竟 Kubernetes 中的扩展功能都来自于该模块。
### Kubernetes 部分小结
Kubernetes 是容器编排的便捷工具,工作单元为 Pod,具有分层架构。最顶层是部署,用于操作其它资源,具有高度可配置性。对于你的每个命令调用,Kubernetes 提供了对应的 API,故理论上你可以编写自己的代码,向 Kubernetes API 发送数据,得到与 `kubectl` 命令同样的效果。
截至目前,Kubernetes 原生支持所有主流云服务供应商,而且完全开源。如果你愿意,可以贡献代码;如果你希望对工作原理有深入了解,可以查阅代码:[GitHub 上的 Kubernetes 项目](https://github.com/kubernetes/kubernetes)。
### Minikube
接下来我会使用 [Minikube](https://github.com/kubernetes/minikube/) 这款本地 Kubernetes 集群模拟器。它并不擅长模拟多节点集群,但可以很容易地给你提供本地学习环境,让你开始探索,这很棒。Minikube 基于可高度调优的虚拟机,由 VirtualBox 类似的虚拟化工具提供。
我用到的全部 Kubernetes 模板文件可以在这里找到:[Kubernetes 文件](https://github.com/Skarlso/kube-cluster-sample/tree/master/kube_files)。
注意:在你后续测试可扩展性时,会发现副本一直处于 `Pending` 状态,这是因为 minikube 集群中只有一个节点,不应该允许多副本运行在同一个节点上,否则明显只是耗尽了可用资源。使用如下命令可以查看可用资源:
```
kubectl get nodes -o yaml
```
### 构建容器
Kubernetes 支持大多数现有的容器技术。我这里使用 Docker。每一个构建的服务容器,对应代码库中的一个 Dockerfile 文件。我推荐你仔细阅读它们,其中大多数都比较简单。对于 Go 服务,我采用了最近引入的多步构建的方式。Go 服务基于 Alpine Linux 镜像创建。人脸识别程序使用 Python、NSQ 和 MySQL 使用对应的容器。
### 上下文
Kubernetes 使用命名空间。如果你不额外指定命名空间,Kubernetes 会使用 `default` 命名空间。为避免污染默认命名空间,我会一直指定命名空间,具体操作如下:
```
❯ kubectl config set-context kube-face-cluster --namespace=face
Context "kube-face-cluster" created.
```
创建上下文之后,应马上启用:
```
❯ kubectl config use-context kube-face-cluster
Switched to context "kube-face-cluster".
```
此后,所有 `kubectl` 命令都会使用 `face` 命名空间。
(LCTT 译注:作者后续并没有使用 face 命名空间,模板文件中的命名空间仍为 default,可能 face 命名空间用于开发环境。如果希望使用 face 命令空间,需要将内部 DNS 地址中的 default 改成 face;如果只是测试,可以不执行这两条命令。)
应用部署
----
Pods 和 服务概览:

### MySQL
第一个要部署的服务是数据库。
按照 Kubernetes 的示例 [Kubenetes MySQL](https://kubernetes.io/docs/tasks/run-application/run-single-instance-stateful-application/#deploy-mysql) 进行部署,即可以满足我的需求。注意:示例配置文件的 MYSQL\_PASSWORD 字段使用了明文密码,我将使用 [Kubernetes Secrets](https://kubernetes.io/docs/concepts/configuration/secret/) 对象以提高安全性。
我创建了一个 Secret 对象,对应的本地 yaml 文件如下:
```
apiVersion: v1
kind: Secret
metadata:
name: kube-face-secret
type: Opaque
data:
mysql_password: base64codehere
mysql_userpassword: base64codehere
```
其中 base64 编码通过如下命令生成:
```
echo -n "ubersecurepassword" | base64
echo -n "root:ubersecurepassword" | base64
```
(LCTT 译注:secret yaml 文件中的 data 应该有两条,一条对应 `mysql_password`,仅包含密码;另一条对应 `mysql_userpassword`,包含用户和密码。后文会用到 `mysql_userpassword`,但没有提及相应的生成)
我的部署 yaml 对应部分如下:
```
...
- name: MYSQL_ROOT_PASSWORD
valueFrom:
secretKeyRef:
name: kube-face-secret
key: mysql_password
...
```
另外值得一提的是,我使用卷将数据库持久化,卷对应的定义如下:
```
...
volumeMounts:
- name: mysql-persistent-storage
mountPath: /var/lib/mysql
...
volumes:
- name: mysql-persistent-storage
persistentVolumeClaim:
claimName: mysql-pv-claim
...
```
其中 `presistentVolumeClain` 是关键,告知 Kubernetes 当前资源需要持久化存储。持久化存储的提供方式对用户透明。类似 Pods,如果想了解更多细节,参考文档:[Kubernetes 持久化存储](https://kubernetes.io/docs/concepts/storage/persistent-volumes)。
(LCTT 译注:使用 `presistentVolumeClain` 之前需要创建 `presistentVolume`,对于单节点可以使用本地存储,对于多节点需要使用共享存储,因为 Pod 可以能调度到任何一个节点)
使用如下命令部署 MySQL 服务:
```
kubectl apply -f mysql.yaml
```
这里比较一下 `create` 和 `apply`。`apply` 是一种<ruby> 宣告式 <rt> declarative </rt></ruby>的对象配置命令,而 `create` 是<ruby> 命令式 <rt> imperative </rt> 的命令。当下我们需要知道的是, <code> create </code> 通常对应一项任务,例如运行某个组件或创建一个部署;相比而言,当我们使用 <code> apply </code> 的时候,用户并没有指定具体操作,Kubernetes 会根据集群目前的状态定义需要执行的操作。故如果不存在名为 <code> mysql </code> 的服务,当我执行 <code> apply -f mysql.yaml </code> 时,Kubernetes 会创建该服务。如果再次执行这个命令,Kubernetes 会忽略该命令。但如果我再次运行 <code> create </code> ,Kubernetes 会报错,告知服务已经创建。</ruby>
想了解更多信息,请阅读如下文档:[Kubernetes 对象管理](https://kubernetes.io/docs/concepts/overview/object-management-kubectl/overview/),[命令式配置](https://kubernetes.io/docs/concepts/overview/object-management-kubectl/imperative-config/)和[宣告式配置](https://kubernetes.io/docs/concepts/overview/object-management-kubectl/declarative-config/)。
运行如下命令查看执行进度信息:
```
# 描述完整信息
kubectl describe deployment mysql
# 仅描述 Pods 信息
kubectl get pods -l app=mysql
```
(第一个命令)输出示例如下:
```
...
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
OldReplicaSets: <none>
NewReplicaSet: mysql-55cd6b9f47 (1/1 replicas created)
...
```
对于 `get pods` 命令,输出示例如下:
```
NAME READY STATUS RESTARTS AGE
mysql-78dbbd9c49-k6sdv 1/1 Running 0 18s
```
可以使用下面的命令测试数据库实例:
```
kubectl run -it --rm --image=mysql:5.6 --restart=Never mysql-client -- mysql -h mysql -pyourpasswordhere
```
特别提醒:如果你在这里修改了密码,重新 apply 你的 yaml 文件并不能更新容器。因为数据库是持久化的,密码并不会改变。你需要先使用 `kubectl delete -f mysql.yaml` 命令删除整个部署。
运行 `show databases` 后,应该可以看到如下信息:
```
If you don't see a command prompt, try pressing enter.
mysql>
mysql>
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| kube |
| mysql |
| performance_schema |
+--------------------+
4 rows in set (0.00 sec)
mysql> exit
Bye
```
你会注意到,我还将一个[数据库初始化 SQL](https://github.com/Skarlso/kube-cluster-sample/blob/master/database_setup.sql) 文件挂载到容器中,MySQL 容器会自动运行该文件,导入我将用到的部分数据和模式。
对应的卷定义如下:
```
volumeMounts:
- name: mysql-persistent-storage
mountPath: /var/lib/mysql
- name: bootstrap-script
mountPath: /docker-entrypoint-initdb.d/database_setup.sql
volumes:
- name: mysql-persistent-storage
persistentVolumeClaim:
claimName: mysql-pv-claim
- name: bootstrap-script
hostPath:
path: /Users/hannibal/golang/src/github.com/Skarlso/kube-cluster-sample/database_setup.sql
type: File
```
(LCTT 译注:数据库初始化脚本需要改成对应的路径,如果是多节点,需要是共享存储中的路径。另外,作者给的 sql 文件似乎有误,`person_images` 表中的 `person_id` 列数字都小 1,作者默认 `id` 从 0 开始,但应该是从 1 开始)
运行如下命令查看引导脚本是否正确执行:
```
~/golang/src/github.com/Skarlso/kube-cluster-sample/kube_files master*
❯ kubectl run -it --rm --image=mysql:5.6 --restart=Never mysql-client -- mysql -h mysql -uroot -pyourpasswordhere kube
If you don't see a command prompt, try pressing enter.
mysql> show tables;
+----------------+
| Tables_in_kube |
+----------------+
| images |
| person |
| person_images |
+----------------+
3 rows in set (0.00 sec)
mysql>
```
(LCTT 译注:上述代码块中的第一行是作者执行命令所在路径,执行第二行的命令无需在该目录中进行)
上述操作完成了数据库服务的初始化。使用如下命令可以查看服务日志:
```
kubectl logs deployment/mysql -f
```
### NSQ 查询
NSQ 查询将以内部服务的形式运行。由于不需要外部访问,这里使用 `clusterIP: None` 在 Kubernetes 中将其设置为<ruby> 无头服务 <rt> headless service </rt></ruby>,意味着该服务不使用负载均衡模式,也不使用单独的服务 IP。DNS 将基于服务<ruby> 选择器 <rt> selectors </rt></ruby>。
我们的 NSQ 查询服务对应的选择器为:
```
selector:
matchLabels:
app: nsqlookup
```
那么,内部 DNS 对应的实体类似于:`nsqlookup.default.svc.cluster.local`。
无头服务的更多细节,可以参考:[无头服务](https://kubernetes.io/docs/concepts/services-networking/service/#headless-services)。
NSQ 服务与 MySQL 服务大同小异,只需要少许修改即可。如前所述,我将使用 NSQ 原生的 Docker 镜像,名称为 `nsqio/nsq`。镜像包含了全部的 nsq 命令,故 nsqd 也将使用该镜像,只是使用的命令不同。对于 nsqlookupd,命令如下:
```
command: ["/nsqlookupd"]
args: ["--broadcast-address=nsqlookup.default.svc.cluster.local"]
```
你可能会疑惑,`--broadcast-address` 参数是做什么用的?默认情况下,`nsqlookup` 使用容器的主机名作为广播地址;这意味着,当用户运行回调时,回调试图访问的地址类似于 `http://nsqlookup-234kf-asdf:4161/lookup?topics=image`,但这显然不是我们期望的。将广播地址设置为内部 DNS 后,回调地址将是 `http://nsqlookup.default.svc.cluster.local:4161/lookup?topic=images`,这正是我们期望的。
NSQ 查询还需要转发两个端口,一个用于广播,另一个用于 nsqd 守护进程的回调。在 Dockerfile 中暴露相应端口,在 Kubernetes 模板中使用它们,类似如下:
容器模板:
```
ports:
- containerPort: 4160
hostPort: 4160
- containerPort: 4161
hostPort: 4161
```
服务模板:
```
spec:
ports:
- name: main
protocol: TCP
port: 4160
targetPort: 4160
- name: secondary
protocol: TCP
port: 4161
targetPort: 4161
```
端口名称是必须的,Kubernetes 基于名称进行区分。(LCTT 译注:端口名更新为作者 GitHub 对应文件中的名称)
像之前那样,使用如下命令创建服务:
```
kubectl apply -f nsqlookup.yaml
```
nsqlookupd 部分到此结束。截至目前,我们已经准备好两个主要的组件。
### 接收器
这部分略微复杂。接收器需要完成三项工作:
* 创建一些部署
* 创建 nsq 守护进程
* 将本服务对外公开
#### 部署
第一个要创建的部署是接收器本身,容器镜像为 `skarlso/kube-receiver-alpine`。
#### NSQ 守护进程
接收器需要使用 NSQ 守护进程。如前所述,接收器在其内部运行一个 NSQ,这样与 nsq 的通信可以在本地进行,无需通过网络。为了让接收器可以这样操作,NSQ 需要与接收器部署在同一个节点上。
NSQ 守护进程也需要一些调整的参数配置:
```
ports:
- containerPort: 4150
hostPort: 4150
- containerPort: 4151
hostPort: 4151
env:
- name: NSQLOOKUP_ADDRESS
value: nsqlookup.default.svc.cluster.local
- name: NSQ_BROADCAST_ADDRESS
value: nsqd.default.svc.cluster.local
command: ["/nsqd"]
args: ["--lookupd-tcp-address=$(NSQLOOKUP_ADDRESS):4160", "--broadcast-address=$(NSQ_BROADCAST_ADDRESS)"]
```
其中我们配置了 `lookup-tcp-address` 和 `broadcast-address` 参数。前者是 nslookup 服务的 DNS 地址,后者用于回调,就像 nsqlookupd 配置中那样。
#### 对外公开
下面即将创建第一个对外公开的服务。有两种方式可供选择。考虑到该 API 负载较高,可以使用负载均衡的方式。另外,如果希望将其部署到生产环境中的任选节点,也应该使用负载均衡方式。
但由于我使用的本地集群只有一个节点,那么使用 `NodePort` 的方式就足够了。`NodePort` 方式将服务暴露在对应节点的固定端口上。如果未指定端口,将从 30000-32767 数字范围内随机选其一个。也可以指定端口,可以在模板文件中使用 `nodePort` 设置即可。可以通过 `<NodeIP>:<NodePort>` 访问该服务。如果使用多个节点,负载均衡可以将多个 IP 合并为一个 IP。
更多信息,请参考文档:[服务发布](https://kubernetes.io/docs/concepts/services-networking/service/#publishing-services---service-types)。
结合上面的信息,我们定义了接收器服务,对应的模板如下:
```
apiVersion: v1
kind: Service
metadata:
name: receiver-service
spec:
ports:
- protocol: TCP
port: 8000
targetPort: 8000
selector:
app: receiver
type: NodePort
```
如果希望固定使用 8000 端口,需要增加 `nodePort` 配置,具体如下:
```
apiVersion: v1
kind: Service
metadata:
name: receiver-service
spec:
ports:
- protocol: TCP
port: 8000
targetPort: 8000
selector:
app: receiver
type: NodePort
nodePort: 8000
```
(LCTT 译注:虽然作者没有写,但我们应该知道需要运行的部署命令 `kubectl apply -f receiver.yaml`。)
### 图片处理器
图片处理器用于将图片传送至识别组件。它需要访问 nslookupd、 mysql 以及后续部署的人脸识别服务的 gRPC 接口。事实上,这是一个无聊的服务,甚至其实并不是服务(LCTT 译注:第一个服务是指在整个架构中,图片处理器作为一个服务;第二个服务是指 Kubernetes 服务)。它并需要对外暴露端口,这是第一个只包含部署的组件。长话短说,下面是完整的模板:
```
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: image-processor-deployment
spec:
selector:
matchLabels:
app: image-processor
replicas: 1
template:
metadata:
labels:
app: image-processor
spec:
containers:
- name: image-processor
image: skarlso/kube-processor-alpine:latest
env:
- name: MYSQL_CONNECTION
value: "mysql.default.svc.cluster.local"
- name: MYSQL_USERPASSWORD
valueFrom:
secretKeyRef:
name: kube-face-secret
key: mysql_userpassword
- name: MYSQL_PORT
# TIL: If this is 3306 without " kubectl throws an error.
value: "3306"
- name: MYSQL_DBNAME
value: kube
- name: NSQ_LOOKUP_ADDRESS
value: "nsqlookup.default.svc.cluster.local:4161"
- name: GRPC_ADDRESS
value: "face-recog.default.svc.cluster.local:50051"
```
文件中唯一需要提到的是用于配置应用的多个环境变量属性,主要关注 nsqlookupd 地址 和 gRPC 地址。
运行如下命令完成部署:
```
kubectl apply -f image_processor.yaml
```
### 人脸识别
人脸识别服务的确包含一个 Kubernetes 服务,具体而言是一个比较简单、仅供图片处理器使用的服务。模板如下:
```
apiVersion: v1
kind: Service
metadata:
name: face-recog
spec:
ports:
- protocol: TCP
port: 50051
targetPort: 50051
selector:
app: face-recog
clusterIP: None
```
更有趣的是,该服务涉及两个卷,分别为 `known_people` 和 `unknown_people`。你能猜到卷中包含什么内容吗?对,是图片。`known_people` 卷包含所有新图片,接收器收到图片后将图片发送至该卷对应的路径,即挂载点。在本例中,挂载点为 `/unknown_people`,人脸识别服务需要能够访问该路径。
对于 Kubernetes 和 Docker 而言,这很容易。卷可以使用挂载的 S3 或 某种 nfs,也可以是宿主机到虚拟机的本地挂载。可选方式有很多 (至少有一打那么多)。为简洁起见,我将使用本地挂载方式。
挂载卷分为两步。第一步,需要在 Dockerfile 中指定卷:
```
VOLUME [ "/unknown_people", "/known_people" ]
```
第二步,就像之前为 MySQL Pod 挂载卷那样,需要在 Kubernetes 模板中配置;相比而言,这里使用 `hostPath`,而不是 MySQL 例子中的 `PersistentVolumeClaim`:
```
volumeMounts:
- name: known-people-storage
mountPath: /known_people
- name: unknown-people-storage
mountPath: /unknown_people
volumes:
- name: known-people-storage
hostPath:
path: /Users/hannibal/Temp/known_people
type: Directory
- name: unknown-people-storage
hostPath:
path: /Users/hannibal/Temp/
type: Directory
```
(LCTT 译注:对于多节点模式,由于人脸识别服务和接收器服务可能不在一个节点上,故需要使用共享存储而不是节点本地存储。另外,出于 Python 代码的逻辑,推荐保持两个文件夹的嵌套结构,即 known\_people 作为子目录。)
我们还需要为 `known_people` 文件夹做配置设置,用于人脸识别程序。当然,使用环境变量属性可以完成该设置:
```
env:
- name: KNOWN_PEOPLE
value: "/known_people"
```
Python 代码按如下方式搜索图片:
```
known_people = os.getenv('KNOWN_PEOPLE', 'known_people')
print("Known people images location is: %s" % known_people)
images = self.image_files_in_folder(known_people)
```
其中 `image_files_in_folder` 函数定义如下:
```
def image_files_in_folder(self, folder):
return [os.path.join(folder, f) for f in os.listdir(folder) if re.match(r'.*\.(jpg|jpeg|png)', f, flags=re.I)]
```
看起来不错。
如果接收器现在收到一个类似下面的请求(接收器会后续将其发送出去):
```
curl -d '{"path":"/unknown_people/unknown220.jpg"}' http://192.168.99.100:30251/image/post
```
图像处理器会在 `/unknown_people` 目录搜索名为 unknown220.jpg 的图片,接着在 `known_folder` 文件中找到 `unknown220.jpg` 对应个人的图片,最后返回匹配图片的名称。
查看日志,大致信息如下:
```
# 接收器
❯ curl -d '{"path":"/unknown_people/unknown219.jpg"}' http://192.168.99.100:30251/image/post
got path: {Path:/unknown_people/unknown219.jpg}
image saved with id: 4
image sent to nsq
# 图片处理器
2018/03/26 18:11:21 INF 1 [images/ch] querying nsqlookupd http://nsqlookup.default.svc.cluster.local:4161/lookup?topic=images
2018/03/26 18:11:59 Got a message: 4
2018/03/26 18:11:59 Processing image id: 4
2018/03/26 18:12:00 got person: Hannibal
2018/03/26 18:12:00 updating record with person id
2018/03/26 18:12:00 done
```
我们已经使用 Kubernetes 部署了应用正常工作所需的全部服务。
### 前端
更进一步,可以使用简易的 Web 应用更好的显示数据库中的信息。这也是一个对外公开的服务,使用的参数可以参考接收器。
部署后效果如下:

### 回顾
到目前为止我们做了哪些操作呢?我一直在部署服务,用到的命令汇总如下:
```
kubectl apply -f mysql.yaml
kubectl apply -f nsqlookup.yaml
kubectl apply -f receiver.yaml
kubectl apply -f image_processor.yaml
kubectl apply -f face_recognition.yaml
kubectl apply -f frontend.yaml
```
命令顺序可以打乱,因为除了图片处理器的 NSQ 消费者外的应用在启动时并不会建立连接,而且图片处理器的 NSQ 消费者会不断重试。
使用 `kubectl get pods` 查询正在运行的 Pods,示例如下:
```
❯ kubectl get pods
NAME READY STATUS RESTARTS AGE
face-recog-6bf449c6f-qg5tr 1/1 Running 0 1m
image-processor-deployment-6467468c9d-cvx6m 1/1 Running 0 31s
mysql-7d667c75f4-bwghw 1/1 Running 0 36s
nsqd-584954c44c-299dz 1/1 Running 0 26s
nsqlookup-7f5bdfcb87-jkdl7 1/1 Running 0 11s
receiver-deployment-5cb4797598-sf5ds 1/1 Running 0 26s
```
运行 `minikube service list`:
```
❯ minikube service list
|-------------|----------------------|-----------------------------|
| NAMESPACE | NAME | URL |
|-------------|----------------------|-----------------------------|
| default | face-recog | No node port |
| default | kubernetes | No node port |
| default | mysql | No node port |
| default | nsqd | No node port |
| default | nsqlookup | No node port |
| default | receiver-service | http://192.168.99.100:30251 |
| kube-system | kube-dns | No node port |
| kube-system | kubernetes-dashboard | http://192.168.99.100:30000 |
|-------------|----------------------|-----------------------------|
```
滚动更新
----
<ruby> 滚动更新 <rt> Rolling Update </rt></ruby>过程中会发生什么呢?

在软件开发过程中,需要变更应用的部分组件是常有的事情。如果我希望在不影响其它组件的情况下变更一个组件,我们的集群会发生什么变化呢?我们还需要最大程度的保持向后兼容性,以免影响用户体验。谢天谢地,Kubernetes 可以帮我们做到这些。
目前的 API 一次只能处理一个图片,不能批量处理,对此我并不满意。
### 代码
目前,我们使用下面的代码段处理单个图片的情形:
```
// PostImage 对图片提交做出响应,将图片信息保存到数据库中
// 并将该信息发送给 NSQ 以供后续处理使用
func PostImage(w http.ResponseWriter, r *http.Request) {
...
}
func main() {
router := mux.NewRouter()
router.HandleFunc("/image/post", PostImage).Methods("POST")
log.Fatal(http.ListenAndServe(":8000", router))
}
```
我们有两种选择。一种是增加新接口 `/images/post` 给用户使用;另一种是在原接口基础上修改。
新版客户端有回退特性,在新接口不可用时回退使用旧接口。但旧版客户端没有这个特性,故我们不能马上修改代码逻辑。考虑如下场景,你有 90 台服务器,计划慢慢执行滚动更新,依次对各台服务器进行业务更新。如果一台服务需要大约 1 分钟更新业务,那么整体更新完成需要大约 1 个半小时的时间(不考虑并行更新的情形)。
更新过程中,一些服务器运行新代码,一些服务器运行旧代码。用户请求被负载均衡到各个节点,你无法控制请求到达哪台服务器。如果客户端的新接口请求被调度到运行旧代码的服务器,请求会失败;客户端可能会回退使用旧接口,(但由于我们已经修改旧接口,本质上仍然是调用新接口),故除非请求刚好到达到运行新代码的服务器,否则一直都会失败。这里我们假设不使用<ruby> 粘性会话 <rt> sticky sessions </rt></ruby>。
而且,一旦所有服务器更新完毕,旧版客户端不再能够使用你的服务。
这里,你可能会说你并不需要保留旧代码;某些情况下,确实如此。因此,我们打算直接修改旧代码,让其通过少量参数调用新代码。这样操作操作相当于移除了旧代码。当所有客户端迁移完毕后,这部分代码也可以安全地删除。
### 新的接口
让我们添加新的路由方法:
```
...
router.HandleFunc("/images/post", PostImages).Methods("POST")
...
```
更新旧的路由方法,使其调用新的路由方法,修改部分如下:
```
// PostImage 对图片提交做出响应,将图片信息保存到数据库中
// 并将该信息发送给 NSQ 以供后续处理使用
func PostImage(w http.ResponseWriter, r *http.Request) {
var p Path
err := json.NewDecoder(r.Body).Decode(&p)
if err != nil {
fmt.Fprintf(w, "got error while decoding body: %s", err)
return
}
fmt.Fprintf(w, "got path: %+v\n", p)
var ps Paths
paths := make([]Path, 0)
paths = append(paths, p)
ps.Paths = paths
var pathsJSON bytes.Buffer
err = json.NewEncoder(&pathsJSON).Encode(ps)
if err != nil {
fmt.Fprintf(w, "failed to encode paths: %s", err)
return
}
r.Body = ioutil.NopCloser(&pathsJSON)
r.ContentLength = int64(pathsJSON.Len())
PostImages(w, r)
}
```
当然,方法名可能容易混淆,但你应该能够理解我想表达的意思。我将请求中的单个路径封装成新方法所需格式,然后将其作为请求发送给新接口处理。仅此而已。在 [滚动更新批量图片的 PR](https://github.com/Skarlso/kube-cluster-sample/pull/1) 中可以找到更多的修改方式。
至此,我们使用两种方法调用接收器:
```
# 单路径模式
curl -d '{"path":"unknown4456.jpg"}' http://127.0.0.1:8000/image/post
# 多路径模式
curl -d '{"paths":[{"path":"unknown4456.jpg"}]}' http://127.0.0.1:8000/images/post
```
这里用到的客户端是 curl。一般而言,如果客户端本身是一个服务,我会做一些修改,在新接口返回 404 时继续尝试旧接口。
为了简洁,我不打算为 NSQ 和其它组件增加批量图片处理的能力。这些组件仍然是一次处理一个图片。这部分修改将留给你作为扩展内容。 :)
### 新镜像
为实现滚动更新,我首先需要为接收器服务创建一个新的镜像。新镜像使用新标签,告诉大家版本号为 v1.1。
```
docker build -t skarlso/kube-receiver-alpine:v1.1 .
```
新镜像创建后,我们可以开始滚动更新了。
### 滚动更新
在 Kubernetes 中,可以使用多种方式完成滚动更新。
#### 手动更新
不妨假设在我配置文件中使用的容器版本为 `v1.0`,那么实现滚动更新只需运行如下命令:
```
kubectl rolling-update receiver --image:skarlso/kube-receiver-alpine:v1.1
```
如果滚动更新过程中出现问题,我们总是可以回滚:
```
kubectl rolling-update receiver --rollback
```
容器将回滚到使用上一个版本镜像,操作简捷无烦恼。
#### 应用新的配置文件
手动更新的不足在于无法版本管理。
试想下面的场景。你使用手工更新的方式对若干个服务器进行滚动升级,但其它人并不知道这件事。之后,另外一个人修改了模板文件并将其应用到集群中,更新了全部服务器;更新过程中,突然发现服务不可用了。
长话短说,由于模板无法识别已经手动更新的服务器,这些服务器会按模板变更成错误的状态。这种做法很危险,千万不要这样做。
推荐的做法是,使用新版本信息更新模板文件,然后使用 `apply` 命令应用模板文件。
对于滚动扩展,Kubernetes 推荐通过部署结合副本组完成。但这意味着待滚动更新的应用至少有 2 个副本,否则无法完成 (除非将 `maxUnavailable` 设置为 1)。我在模板文件中增加了副本数量、设置了接收器容器的新镜像版本。
```
replicas: 2
...
spec:
containers:
- name: receiver
image: skarlso/kube-receiver-alpine:v1.1
...
```
更新过程中,你会看到如下信息:
```
❯ kubectl rollout status deployment/receiver-deployment
Waiting for rollout to finish: 1 out of 2 new replicas have been updated...
```
通过在模板中增加 `strategy` 段,你可以增加更多的滚动扩展配置:
```
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 0
```
关于滚动更新的更多信息,可以参考如下文档:[部署的滚动更新](https://kubernetes.io/docs/concepts/workloads/controllers/deployment/#rolling-back-a-deployment),[部署的更新](https://kubernetes.io/docs/concepts/workloads/controllers/deployment/#updating-a-deployment), [部署的管理](https://kubernetes.io/docs/concepts/cluster-administration/manage-deployment/#updating-your-application-without-a-service-outage) 和 [使用副本控制器完成滚动更新](https://kubernetes.io/docs/tasks/run-application/rolling-update-replication-controller/)等。
MINIKUBE 用户需要注意:由于我们使用单个主机上使用单节点配置,应用只有 1 份副本,故需要将 `maxUnavailable` 设置为 `1`。否则 Kubernetes 会阻止更新,新版本会一直处于 `Pending` 状态;这是因为我们在任何时刻都不允许出现没有(正在运行的) `receiver` 容器的场景。
### 扩展
Kubernetes 让扩展成为相当容易的事情。由于 Kubernetes 管理整个集群,你仅需在模板文件中添加你需要的副本数目即可。
这篇文章已经比较全面了,但文章的长度也越来越长。我计划再写一篇后续文章,在 AWS 上使用多节点、多副本方式实现扩展。敬请期待。
### 清理环境
```
kubectl delete deployments --all
kubectl delete services -all
```
写在最后的话
------
各位看官,本文就写到这里了。我们在 Kubernetes 上编写、部署、更新和扩展(老实说,并没有实现)了一个分布式应用。
如果你有任何疑惑,请在下面的评论区留言交流,我很乐意回答相关问题。
希望阅读本文让你感到愉快。我知道,这是一篇相对长的文章,我也曾经考虑进行拆分;但整合在一起的单页教程也有其好处,例如利于搜索、保存页面或更进一步将页面打印为 PDF 文档。
Gergely 感谢你阅读本文。
---
via: <https://skarlso.github.io/2018/03/15/kubernetes-distributed-application/>
作者:[hannibal](https://github.com/Skarlso) 译者:[pinewall](https://github.com/pinewall) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Intro[#](#intro)
Alright folks. Settle in and get comfortable. This is going to be a long, but hopefully, fun ride.
I’m going to deploy a distributed application with [Kubernetes](https://kubernetes.io/). I attempted to create an application that I thought resembled a real world app. Obviously I had to cut some corners due to time and energy constraints.
My focus will be on Kubernetes and deployment.
Shall we delve right in?
# The Application[#](#the-application)
## TL;DR[#](#tldr)
The application itself consists of six parts. The repository can be found here: [Kube Cluster Sample](https://github.com/Skarlso/kube-cluster-sample).
It’s a face recognition service which identifies images of people, comparing them to known individuals. A simple frontend displays a table of these images whom they belong to. This happens by sending a request to a [receiver](https://github.com/Skarlso/kube-cluster-sample/tree/master/receiver). The request contains a path to an image. This image can sit on an NFS somewhere. The receiver stores this path in the DB (MySQL) and sends a processing request to a queue. The queue uses: [NSQ](http://nsq.io/). The request contains the ID of the saved image.
An [Image Processing](https://github.com/Skarlso/kube-cluster-sample/tree/master/image_processor) service is constantly monitoring the queue for jobs to do. The processing consists of the following steps: taking the ID; loading the image; and finally, sending the image to a [face recognition](https://github.com/Skarlso/kube-cluster-sample/tree/master/face_recognition) backend written in Python via [gRPC](https://grpc.io/). If the identification is successful, the backend will return the name of the image corresponding to that person. The image_processor then updates the image’s record with the person’s ID and marks the image as “processed successfully”. If identification is unsuccessful, the image will be left as “pending”. If there was a failure during identification, the image will be flagged as “failed”.
Failed images can be retried with a cron job, for example:
So how does this all work? Let’s check it out .
## Receiver[#](#receiver)
The receiver service is the starting point of the process. It’s an API which receives a request in the following format:
```
curl -d '{"path":"/unknown_images/unknown0001.jpg"}' http://127.0.0.1:8000/image/post
```
In this instance, the receiver stores the path using a shared database cluster. The entity will then receive an ID from the database service. This application is based on the model where unique identification for Entity Objects is provided by the persistence layer. Once the ID is procured, the receiver will send a message to NSQ. At this point in the process, the receiver’s job is done.
## Image Processor[#](#image-processor)
Here is where the excitement begins. When Image Processor first runs it creates two Go routines. These are…
### Consume[#](#consume)
This is an NSQ consumer. It has three integral jobs. Firstly, it listens for messages on the queue. Secondly, when there is a message, it appends the received ID to a thread safe slice of IDs that the second routine processes. And lastly, it signals the second routine that there is work to be do. It does this through [sync.Condition](https://golang.org/pkg/sync/#Cond).
### ProcessImages[#](#processimages)
This routine processes a slice of IDs until the slice is drained completely. Once the slice is drained, the routine suspends instead of sleep-waiting on a channel. The processing of a single ID can be seen in the following linear steps:
- Establish a gRPC connection to the Face Recognition service (explained under Face Recognition)
- Retrieve the image record from the database
- Setup two functions for the
[Circuit Breaker](#circuit-breaker)- Function 1: The main function which runs the RPC method call
- Function 2: A health check for the Ping of the circuit breaker
- Call Function 1 which sends the path of the image to the face recognition service. This path should be accessible by the face recognition service. Preferably something shared like an NFS
- If this call fails, update the image record as FAILED PROCESSING
- If it succeeds, an image name should come back which corresponds to a person in the db. It runs a joined SQL query which gets the corresponding person’s ID
- Update the Image record in the database with PROCESSED status and the ID of the person that image was identified as
This service can be replicated. In other words, more than one can run at the same time.
### Circuit Breaker[#](#circuit-breaker)
A system in which replicating resources requires little to no effort, there still can be cases where, for example, the network goes down, or there are communication problems of any kind between two services. I like to implement a little circuit breaker around the gRPC calls for fun.
This is how it works:
As you can see, once there are 5 unsuccessful calls to the service, the circuit breaker activates, not allowing any more calls to go through. After a configured amount of time, it will send a Ping call to the service to see if it’s back up. If that still errors out, it will increase the timeout. If not, it opens the circuit, allowing traffic to proceed.
## Front-End[#](#front-end)
This is only a simple table view with Go’s own html/template used to render a list of images.
## Face Recognition[#](#face-recognition)
Here is where the identification magic happens. I decided to make this a gRPC based service for the sole purpose of its flexibility. I started writing it in Go but decided that a Python implementation would be much sorter. In fact, excluding the gRPC code, the recognition part is approximately 7 lines of Python code. I’m using this fantastic library which contains all the C bindings to OpenCV. [Face Recognition](https://github.com/ageitgey/face_recognition). Having an API contract here means that I can change the implementation anytime as long as it adheres to the contract.
Please note that there exist a great Go library OpenCV. I was about to use it but they had yet to write the C bindings for that part of OpenCV. It’s called [GoCV](https://gocv.io/). Check them out! They have some pretty amazing things, like real-time camera feed processing that only needs a couple of lines of code.
The python library is simple in nature. Have a set of images of people you know. I have a folder with a couple of images named, `hannibal_1.jpg, hannibal_2.jpg, gergely_1.jpg, john_doe.jpg`
. In the database I have two tables named, `person, person_images`
. They look like this:
```
+----+----------+
| id | name |
+----+----------+
| 1 | Gergely |
| 2 | John Doe |
| 3 | Hannibal |
+----+----------+
+----+----------------+-----------+
| id | image_name | person_id |
+----+----------------+-----------+
| 1 | hannibal_1.jpg | 3 |
| 2 | hannibal_2.jpg | 3 |
+----+----------------+-----------+
```
The face recognition library returns the name of the image from the known people which matches the person on the unknown image. After that, a simple joined query -like this- will return the person in question.
```
select person.name, person.id from person inner join person_images as pi on person.id = pi.person_id where image_name = 'hannibal_2.jpg';
```
The gRPC call returns the ID of the person which is then used to update the image’s ‘person` column.
## NSQ[#](#nsq)
NSQ is a nice little Go based queue. It can be scaled and has a minimal footprint on the system. It also has a lookup service that consumers use to receive messages, and a daemon that senders use when sending messages.
NSQ’s philosophy is that the daemon should run with the sender application. That way, the sender will send to the localhost only. But the daemon is connected to the lookup service, and that’s how they achieve a global queue.
This means that there are as many NSQ daemons deployed as there are senders. Because the daemon has a minuscule resource requirement, it won’t interfere with the requirements of the main application.
## Configuration[#](#configuration)
In order to be as flexible as possible, as well as making use of Kubernetes’s ConfigSet, I’m using .env files in development to store configurations like the location of the database service, or NSQ’s lookup address. In production- and that means the Kubernetes’s environment- I’ll use environment properties.
## Conclusion for the Application[#](#conclusion-for-the-application)
And that’s all there is to the architecture of the application we are about to deploy. All of its components are changeable and coupled only through the database, a queue and gRPC. This is imperative when deploying a distributed application due to how updating mechanics work. I will cover that part in the Deployment section.
# Deployment with Kubernetes[#](#deployment-with-kubernetes)
## Basics[#](#basics)
What **is** Kubernetes?
I’m going to cover some of the basics here. I won’t go too much into detail- that would require a whole book like this one: [Kubernetes Up And Running](http://shop.oreilly.com/product/0636920043874.do). Also, if you’re daring enough, you can have a look through this documentation: [Kubernetes Documentation](https://kubernetes.io/docs/).
Kubernetes is a containerized service and application manager. It scales easily, employs a swarm of containers, and most importantly, it’s highly configurable via yaml based template files. People often compare Kubernetes to Docker swarm, but Kubernetes does way more than that! For example: it’s container agnostic. You could use LXC with Kubernetes and it would work the same way as you using it with Docker. It provides a layer above managing a cluster of deployed services and applications. How? Let’s take a quick look at the building blocks of Kubernetes.
In Kubernetes, you’ll describe a desired state of the application and Kubernetes will do what it can to reach that state. States could be something such as deployed; paused; replicated twice; and so on and so forth.
One of the basics of Kubernetes is that it uses Labels and Annotations for all of its components. Services, Deployments, ReplicaSets, DaemonSets, everything is labelled. Consider the following scenario. In order to identify what pod belongs to what application, a label is used called `app: myapp`
. Let’s assume you have two containers of this application deployed; if you would remove the label `app`
from one of the containers, Kubernetes would only detect one and thus would launch a new instance of `myapp`
.
### Kubernetes Cluster[#](#kubernetes-cluster)
For Kuberenetes to work, a Kubernetes cluster needs to be present. Setting that up might be a tad painful, but luckily, help is on hand. Minikube sets up a cluster for us locally with one Node. And AWS has a beta service running in the form of a Kubernetes cluster in which the only thing you need to do is request nodes and define your deployments. The Kubernetes cluster components are documented here: [Kubernetes Cluster Components](https://kubernetes.io/docs/concepts/overview/components/).
### Nodes[#](#nodes)
A Node is a worker machine. It can be anything- from a vm to a physical machine- including all sorts of cloud provided vms.
### Pods[#](#pods)
Pods are a logically grouped collection of containers, meaning one Pod can potentially house a multitude of containers. A Pod gets its own DNS and virtual IP address after it has been created so Kubernetes can load balancer traffic to it. You rarely need to deal with containers directly. Even when debugging, (like looking at logs), you usually invoke `kubectl logs deployment/your-app -f`
instead of looking at a specific container. Although it is possible with `-c container_name`
. The `-f`
does a tail on the log.
### Deployments[#](#deployments)
When creating any kind of resource in Kubernetes, it will use a Deployment in the background. A deployment describes a desired state of the current application. It’s an object you can use to update Pods or a Service to be in a different state, do an update, or rollout new version of your app. You don’t directly control a ReplicaSet, (as described later), but control the deployment object which creates and manages a ReplicaSet.
### Services[#](#services)
By default a Pod will get an IP address. However, since Pods are a volatile thing in Kubernetes, you’ll need something more permanent. A queue, mysql, or an internal API, a frontend; these need to be long running and behind a static, unchanging IP or preferably a DNS record.
For this purpose, Kubernetes has Services for which you can define modes of accessibility. Load Balanced, simple IP or internal DNS.
How does Kubernetes know if a service is running correctly? You can configure Health Checks and Availability Checks. A Health Check will check whether a container is running, but that doesn’t mean that your service is running. For that, you have the availability check which pings a different endpoint in your application.
Since Services are pretty important, I recommend that you read up on them later here: [Services](https://kubernetes.io/docs/concepts/services-networking/service/). Advanced warning though, this document is quite dense. Twenty four A4 pages of networking, services and discovery. It’s also vital to decide whether you want to seriously employ Kubernetes in production.
### DNS / Service Discovery[#](#dns--service-discovery)
If you create a service in the cluster, that service will get a DNS record in Kubernetes provided by special Kubernetes deployments called kube-proxy and kube-dns. These two provide service discover inside a cluster. If you have a mysql service running and set `clusterIP: none`
, then everyone in the cluster can reach that service by pinging `mysql.default.svc.cluster.local`
. Where:
`mysql`
– is the name of the service`default`
– is the namespace name`svc`
– is services`cluster.local`
– is a local cluster domain
The domain can be changed via a custom definition. To access a service outside the cluster, a DNS provider has to be used, and Nginx (for example), to bind an IP address to a record. The public IP address of a service can be queried with the following commands:
- NodePort –
`kubectl get -o jsonpath="{.spec.ports[0].nodePort}" services mysql`
- LoadBalancer –
`kubectl get -o jsonpath="{.spec.ports[0].LoadBalancer}" services mysql`
### Template Files[#](#template-files)
Like Docker Compose, TerraForm or other service management tools, Kubernetes also provides infrastructure describing templates. What that means is that you rarely need to do anything by hand.
For example, consider the following yaml template which describes an nginx Deployment:
```
apiVersion: apps/v1
kind: Deployment #(1)
metadata: #(2)
name: nginx-deployment
labels: #(3)
app: nginx
spec: #(4)
replicas: 3 #(5)
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers: #(6)
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
```
This is a simple deployment in which we do the following:
- (1) Define the type of the template with kind
- (2) Add metadata that will identify this deployment and every resource that it would create with a label (3)
- (4) Then comes the spec which describes the desired state
- (5) For the nginx app, have 3 replicas
- (6) This is the template definition for the containers that this Pod will contain
- nginx named container
- nginx:1.7.9 image (docker in this case)
- exposed ports
### ReplicaSet[#](#replicaset)
A ReplicaSet is a low level replication manager. It ensures that the correct number of replicates are running for a application. However, Deployments are at a higher level and should always manage ReplicaSets. You rarely need to use ReplicaSets directly unless you have a fringe case in which you want to control the specifics of replication.
### DaemonSet[#](#daemonset)
Remember how I said Kubernetes is using Labels all the time? A DaemonSet is a controller that ensures that at daemonized application is always running on a node with a certain label.
For example: you want all the nodes labelled with `logger`
or `mission_critical`
to run an logger / auditing service daemon. Then you create a DaemonSet and give it a node selector called `logger`
or `mission_critical`
. Kubernetes will look for a node that has that label. Always ensure that it will have an instance of that daemon running on it. Thus everyone running on that node will have access to that daemon locally.
In case of my application, the NSQ daemon could be a DaemonSet. Make sure it’s up on a node which has the receiver component running by labelling a node with `receiver`
and specifying a DaemonSet with a `receiver`
application selector.
The DaemonSet has all the benefits of the ReplicaSet. It’s scalable and Kubernetes manages it; which means, all life cycle events are handled by Kube ensuring it never dies, and when it does, it will be immediately replaced.
### Scaling[#](#scaling)
It’s trivial to scale in Kubernetes. The ReplicaSets take care of the number of instances of a Pod to run- as seen in the nginx deployment with the setting `replicas:3`
. It’s up to us to write our application in a way that allows Kubernetes to run multiple copies of it.
Of course the settings are vast. You can specify which replicates must run on what Nodes, or on various waiting times as to how long to wait for an instance to come up. You can read more on this subject here: [Horizontal Scaling](https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/) and here: [Interactive Scaling with Kubernetes](https://kubernetes.io/docs/tutorials/kubernetes-basics/scale-interactive/) and of course the details of a [ReplicaSet](https://kubernetes.io/docs/concepts/workloads/controllers/replicaset/) which controls all the scaling made possible in Kubernetes.
### Conclusion for Kubernetes[#](#conclusion-for-kubernetes)
It’s a convenient tool to handle container orchestration. Its unit of work are Pods and it has a layered architecture. The top level layer is Deployments through which you handle all other resources. It’s highly configurable. It provides an API for all calls you make, so potentially, instead of running `kubectl`
you can also write your own logic to send information to the Kubernetes API.
It provides support for all major cloud providers natively by now and it’s completely open source. Feel free to contribute! And check the code if you would like to have a deeper understanding on how it works: [Kubernetes on Github](https://github.com/kubernetes/kubernetes).
## Minikube[#](#minikube)
I’m going to use [Minikube](https://github.com/kubernetes/minikube/). Minikube is a local Kubernetes cluster simulator. It’s not great in simulating multiple nodes though, but for starting out and local play without any costs, it’s great. It uses a VM that can be fine tuned if necessary using VirtualBox and the likes.
All of the kube template files that I’ll be using can be found here: [Kube files](https://github.com/Skarlso/kube-cluster-sample/tree/master/kube_files).
**NOTE** If, later on, you would like to play with scaling but notice that the replicates are always in `Pending`
state, remember that minikube employs a single node only. It might not allow multiple replicas on the same node, or just plainly ran out of resources to use. You can check available resources with the following command:
```
kubectl get nodes -o yaml
```
## Building the containers[#](#building-the-containers)
Kubernetes supports most of the containers out there. I’m going to use Docker. For all the services I’ve built, there is a Dockerfile included in the repository. I encourage you to study them. Most of them are simple. For the go services, I’m using a multi stage build that has been recently introduced. The Go services are Alpine Linux based. The Face Recognition service is Python. NSQ and MySQL are using their own containers.
## Context[#](#context)
Kubernetes uses namespaces. If you don’t specify any, it will use the `default`
namespace. I’m going to permanently set a context to avoid polluting the default namespace. You do that like this:
```
❯ kubectl config set-context kube-face-cluster --namespace=face
Context "kube-face-cluster" created.
```
You have to also start using the context once it’s created, like so:
```
❯ kubectl config use-context kube-face-cluster
Switched to context "kube-face-cluster".
```
After this, all `kubectl`
commands will use the namespace `face`
.
## Deploying the Application[#](#deploying-the-application)
Overview of Pods and Services:
### MySQL[#](#mysql)
The first Service I’m going to deploy is my database.
I’m using the Kubernetes example located here [Kube MySQL](https://kubernetes.io/docs/tasks/run-application/run-single-instance-stateful-application/#deploy-mysql) which fits my needs. Please note that this file is using a plain password for MYSQL_PASSWORD. I’m going to employ a vault as described here [Kubernetes Secrets](https://kubernetes.io/docs/concepts/configuration/secret/).
I’ve created a secret locally as described in that document using a secret yaml:
```
apiVersion: v1
kind: Secret
metadata:
name: kube-face-secret
type: Opaque
data:
mysql_password: base64codehere
```
I created the base64 code via the following command:
```
echo -n "ubersecurepassword" | base64
```
And, this is what you’ll see in my deployment yaml file:
```
...
- name: MYSQL_ROOT_PASSWORD
valueFrom:
secretKeyRef:
name: kube-face-secret
key: mysql_password
...
```
Another thing worth mentioning: It’s using a volume to persist the database. The volume definition is as follows:
```
...
volumeMounts:
- name: mysql-persistent-storage
mountPath: /var/lib/mysql
...
volumes:
- name: mysql-persistent-storage
persistentVolumeClaim:
claimName: mysql-pv-claim
...
```
`presistentVolumeClain`
is key here. This tells Kubernetes that this resource requires a persistent volume. How it’s provided is abstracted away from the user. You can be sure that Kubernetes will provide a volume that will always be there. It is similar to Pods. To read up on the details, check out this document: [Kubernetes Persistent Volumes](https://kubernetes.io/docs/concepts/storage/persistent-volumes).
Deploying the mysql Service is done with the following command:
```
kubectl apply -f mysql.yaml
```
`apply`
vs `create`
. In short, `apply`
is considered a declarative object configuration command while `create`
is imperative. What this means for now is that ‘create’ is usually for a one of tasks, like running something or creating a deployment. While, when using apply, the user doesn’t define the action to be taken. That will be defined by Kubernetes based on the current status of the cluster. Thus, when there is no service called `mysql`
and I’m calling `apply -f mysql.yaml`
it will create the service. When running again, Kubernetes won’t do anything. But if I would run `create`
again it will throw an error saying the service is already created.
For more information, check out the following docs: [Kubernetes Object Management](https://kubernetes.io/docs/concepts/overview/object-management-kubectl/overview/), [Imperative Configuration](https://kubernetes.io/docs/concepts/overview/object-management-kubectl/imperative-config/), [Declarative Configuration](https://kubernetes.io/docs/concepts/overview/object-management-kubectl/declarative-config/).
To see progress information, run:
```
# Describes the whole process
kubectl describe deployment mysql
# Shows only the pod
kubectl get pods -l app=mysql
```
Output should be similar to this:
```
...
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
OldReplicaSets: <none>
NewReplicaSet: mysql-55cd6b9f47 (1/1 replicas created)
...
```
Or in case of `get pods`
:
```
NAME READY STATUS RESTARTS AGE
mysql-78dbbd9c49-k6sdv 1/1 Running 0 18s
```
To test the instance, run the following snippet:
```
kubectl run -it --rm --image=mysql:5.6 --restart=Never mysql-client -- mysql -h mysql -pyourpasswordhere
```
**GOTCHA**: If you change the password now, it’s not enough to re-apply your yaml file to update the container. Since the DB is persisted, the password will not be changed. You have to delete the whole deployment with `kubectl delete -f mysql.yaml`
.
You should see the following when running a `show databases`
.
```
If you don't see a command prompt, try pressing enter.
mysql>
mysql>
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| kube |
| mysql |
| performance_schema |
+--------------------+
4 rows in set (0.00 sec)
mysql> exit
Bye
```
You’ll also notice that I’ve mounted a file located here: [Database Setup SQL](https://github.com/Skarlso/kube-cluster-sample/blob/master/database_setup.sql) into the container. MySQL container automatically executes these. That file will bootstrap some data and the schema I’m going to use.
The volume definition is as follows:
```
volumeMounts:
- name: mysql-persistent-storage
mountPath: /var/lib/mysql
- name: bootstrap-script
mountPath: /docker-entrypoint-initdb.d/database_setup.sql
volumes:
- name: mysql-persistent-storage
persistentVolumeClaim:
claimName: mysql-pv-claim
- name: bootstrap-script
hostPath:
path: /Users/hannibal/golang/src/github.com/Skarlso/kube-cluster-sample/database_setup.sql
type: File
```
To check if the bootstrap script was successful, run this:
```
~/golang/src/github.com/Skarlso/kube-cluster-sample/kube_files master*
❯ kubectl run -it --rm --image=mysql:5.6 --restart=Never mysql-client -- mysql -h mysql -uroot -pyourpasswordhere kube
If you don't see a command prompt, try pressing enter.
mysql> show tables;
+----------------+
| Tables_in_kube |
+----------------+
| images |
| person |
| person_images |
+----------------+
3 rows in set (0.00 sec)
mysql>
```
This concludes the database service setup. Logs for this service can be viewed with the following command:
```
kubectl logs deployment/mysql -f
```
### NSQ Lookup[#](#nsq-lookup)
The NSQ Lookup will run as an internal service. It doesn’t need access from the outside, so I’m setting `clusterIP: None`
which will tell Kubernetes that this service is a headless service. This means that it won’t be load balanced, and it won’t be a single IP service. The DNS will be based upon service selectors.
Our NSQ Lookup selector is:
```
selector:
matchLabels:
app: nsqlookup
```
Thus, the internal DNS will look like this: `nsqlookup.default.svc.cluster.local`
.
Headless services are described in detail here: [Headless Service](https://kubernetes.io/docs/concepts/services-networking/service/#headless-services).
Basically it’s the same as MySQL, just with slight modifications. As stated earlier, I’m using NSQ’s own Docker Image called `nsqio/nsq`
. All nsq commands are there, so nsqd will also use this image just with a different command. For nsqlookupd, the command is:
```
command: ["/nsqlookupd"]
args: ["--broadcast-address=nsqlookup.default.svc.cluster.local"]
```
What’s the `--broadcast-address`
for, you might ask? By default, nsqlookup will use the `hostname`
as broadcast address. When the consumer runs a callback it will try to connect to something like: `http://nsqlookup-234kf-asdf:4161/lookup?topics=image`
. Please note that `nsqlookup-234kf-asdf`
is the hostname of the container. By setting the broadcast-address to the internal DNS, the callback will be: `http://nsqlookup.default.svc.cluster.local:4161/lookup?topic=images`
. Which will work as expected.
NSQ Lookup also requires two ports forwarded: One for broadcasting and one for nsqd callback. These are exposed in the Dockerfile, and then utilized in the Kubernetes template. Like this:
In the container template:
```
ports:
- containerPort: 4160
hostPort: 4160
- containerPort: 4161
hostPort: 4161
```
In the service template:
```
spec:
ports:
- name: tcp
protocol: TCP
port: 4160
targetPort: 4160
- name: http
protocol: TCP
port: 4161
targetPort: 4161
```
Names are required by Kubernetes.
To create this service, I’m using the same command as before:
```
kubectl apply -f nsqlookup.yaml
```
This concludes nsqlookupd. Two of the major players are in the sack!
### Receiver[#](#receiver-1)
This is a more complex one. The receiver will do three things:
- Create some deployments;
- Create the nsq daemon;
- Expose the service to the public.
#### Deployments[#](#deployments-1)
The first deployment it creates is its own. The receiver’s container is `skarlso/kube-receiver-alpine`
.
#### Nsq Daemon[#](#nsq-daemon)
The receiver starts an nsq daemon. As stated earlier, the receiver runs an nsqd with it-self. It does this so talking to it can happen locally and not over the network. By making the receiver do this, they will end up on the same node.
NSQ daemon also needs some adjustments and parameters.
```
ports:
- containerPort: 4150
hostPort: 4150
- containerPort: 4151
hostPort: 4151
env:
- name: NSQLOOKUP_ADDRESS
value: nsqlookup.default.svc.cluster.local
- name: NSQ_BROADCAST_ADDRESS
value: nsqd.default.svc.cluster.local
command: ["/nsqd"]
args: ["--lookupd-tcp-address=$(NSQLOOKUP_ADDRESS):4160", "--broadcast-address=$(NSQ_BROADCAST_ADDRESS)"]
```
You can see that the lookup-tcp-address and the broadcast-address are set. Lookup tcp address is the DNS for the nsqlookupd service. And the broadcast address is necessary, just like with nsqlookupd, so the callbacks are working properly.
#### Public facing[#](#public-facing)
Now, this is the first time I’m deploying a public facing service. There are two options. I could use a LoadBalancer since this API will be under heavy load. And if this would be deployed anywhere in production, then it should be using one.
I’m doing this locally though- with one node- so something called a `NodePort`
is enough. A `NodePort`
exposes a service on each node’s IP at a static port. If not specified, it will assign a random port on the host between 30000-32767. But it can also be configured to be a specific port, using `nodePort`
in the template file. To reach this service, use `<NodeIP>:<NodePort>`
. If more than one node is configured, a LoadBalancer can multiplex them to a single IP.
For further information, check out this document: [Publishing Services](https://kubernetes.io/docs/concepts/services-networking/service/#publishing-services---service-types).
Putting this all together, we’ll get a receiver-service for which the template for is as follows:
```
apiVersion: v1
kind: Service
metadata:
name: receiver-service
spec:
ports:
- protocol: TCP
port: 8000
targetPort: 8000
selector:
app: receiver
type: NodePort
```
For a fixed nodePort on 8000 a definition of `nodePort`
must be provided:
```
apiVersion: v1
kind: Service
metadata:
name: receiver-service
spec:
ports:
- protocol: TCP
port: 8000
targetPort: 8000
selector:
app: receiver
type: NodePort
nodePort: 8000
```
### Image processor[#](#image-processor-1)
The Image Processor is where I’m handling passing off images to be identified. It should have access to nsqlookupd, mysql and the gRPC endpoint of the face recognition service. This is actually quite a boring service. In fact, it’s not even a service at all. It doesn’t expose anything, and thus it’s the first deployment only component. For brevity, here is the whole template:
```
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: image-processor-deployment
spec:
selector:
matchLabels:
app: image-processor
replicas: 1
template:
metadata:
labels:
app: image-processor
spec:
containers:
- name: image-processor
image: skarlso/kube-processor-alpine:latest
env:
- name: MYSQL_CONNECTION
value: "mysql.default.svc.cluster.local"
- name: MYSQL_USERPASSWORD
valueFrom:
secretKeyRef:
name: kube-face-secret
key: mysql_userpassword
- name: MYSQL_PORT
# TIL: If this is 3306 without " kubectl throws an error.
value: "3306"
- name: MYSQL_DBNAME
value: kube
- name: NSQ_LOOKUP_ADDRESS
value: "nsqlookup.default.svc.cluster.local:4161"
- name: GRPC_ADDRESS
value: "face-recog.default.svc.cluster.local:50051"
```
The only interesting points in this file are the multitude of environment properties that are used to configure the application. Note the nsqlookupd address and the grpc address.
To create this deployment, run:
```
kubectl apply -f image_processor.yaml
```
### Face - Recognition[#](#face---recognition)
The face recognition service does have a service. It’s a simple one. Only needed by image-processor. It’s template is as follows:
```
apiVersion: v1
kind: Service
metadata:
name: face-recog
spec:
ports:
- protocol: TCP
port: 50051
targetPort: 50051
selector:
app: face-recog
clusterIP: None
```
The more interesting part is that it requires two volumes. The two volumes are `known_people`
and `unknown_people`
. Can you guess what they will contain? Yep, images. The `known_people`
volume contains all the images associated to the known people in the database. The `unknown_people`
volume will contain all new images. And that’s the path we will need to use when sending images from the receiver; that is wherever the mount point points too, which in my case is `/unknown_people`
. Basically, the path needs to be one that the face recognition service can access.
Now, with Kubernetes and Docker, this is easy. It can be a mounted S3 or some kind of nfs or a local mount from host to guest. The possibilities are endless (around a dozen or so). I’m going to use a local mount for the sake of simplicity.
Mounting a volume is done in two parts. Firstly, the Dockerfile has to specify volumes:
```
VOLUME [ "/unknown_people", "/known_people" ]
```
Secondly, the Kubernetes template needs add `volumeMounts`
as seen in the MySQL service; the difference being `hostPath`
instead of claimed volume:
```
volumeMounts:
- name: known-people-storage
mountPath: /known_people
- name: unknown-people-storage
mountPath: /unknown_people
volumes:
- name: known-people-storage
hostPath:
path: /Users/hannibal/Temp/known_people
type: Directory
- name: unknown-people-storage
hostPath:
path: /Users/hannibal/Temp/
type: Directory
```
We also need to set the `known_people`
folder config setting for the face recognition service. This is done via an environment property:
```
env:
- name: KNOWN_PEOPLE
value: "/known_people"
```
Then the Python code will look up images, like this:
```
known_people = os.getenv('KNOWN_PEOPLE', 'known_people')
print("Known people images location is: %s" % known_people)
images = self.image_files_in_folder(known_people)
```
Where `image_files_in_folder`
is:
```
def image_files_in_folder(self, folder):
return [os.path.join(folder, f) for f in os.listdir(folder) if re.match(r'.*\.(jpg|jpeg|png)', f, flags=re.I)]
```
Neat.
Now, if the receiver receives a request (and sends it off further down the line) similar to the one below…
```
curl -d '{"path":"/unknown_people/unknown220.jpg"}' http://192.168.99.100:30251/image/post
```
…it will look for an image called unknown220.jpg under `/unknown_people`
, locate an image in the known_folder that corresponds to the person in the unknown image and return the name of the image that matches.
Looking at logs, you should see something like this:
```
# Receiver
❯ curl -d '{"path":"/unknown_people/unknown219.jpg"}' http://192.168.99.100:30251/image/post
got path: {Path:/unknown_people/unknown219.jpg}
image saved with id: 4
image sent to nsq
# Image Processor
2018/03/26 18:11:21 INF 1 [images/ch] querying nsqlookupd http://nsqlookup.default.svc.cluster.local:4161/lookup?topic=images
2018/03/26 18:11:59 Got a message: 4
2018/03/26 18:11:59 Processing image id: 4
2018/03/26 18:12:00 got person: Hannibal
2018/03/26 18:12:00 updating record with person id
2018/03/26 18:12:00 done
```
And that concludes all of the services that we need to deploy.
### Frontend[#](#frontend)
Lastly, there is a small web-app which displays the information in the db for convenience. This is also a public facing service with the same parameters as the receiver.
It looks like this:
### Recap[#](#recap)
We are now at the point in which I’ve deployed a bunch of services. A recap off the commands I’ve used so far:
```
kubectl apply -f mysql.yaml
kubectl apply -f nsqlookup.yaml
kubectl apply -f receiver.yaml
kubectl apply -f image_processor.yaml
kubectl apply -f face_recognition.yaml
kubectl apply -f frontend.yaml
```
These could be in any order since the application does not allocate connections on start. (Except for image_processor’s NSQ consumer. But that re-tries.)
Query-ing kube for running pods with `kubectl get pods`
should show something like this if there were no errors:
```
❯ kubectl get pods
NAME READY STATUS RESTARTS AGE
face-recog-6bf449c6f-qg5tr 1/1 Running 0 1m
image-processor-deployment-6467468c9d-cvx6m 1/1 Running 0 31s
mysql-7d667c75f4-bwghw 1/1 Running 0 36s
nsqd-584954c44c-299dz 1/1 Running 0 26s
nsqlookup-7f5bdfcb87-jkdl7 1/1 Running 0 11s
receiver-deployment-5cb4797598-sf5ds 1/1 Running 0 26s
```
Running `minikube service list`
:
```
❯ minikube service list
|-------------|----------------------|-----------------------------|
| NAMESPACE | NAME | URL |
|-------------|----------------------|-----------------------------|
| default | face-recog | No node port |
| default | kubernetes | No node port |
| default | mysql | No node port |
| default | nsqd | No node port |
| default | nsqlookup | No node port |
| default | receiver-service | http://192.168.99.100:30251 |
| kube-system | kube-dns | No node port |
| kube-system | kubernetes-dashboard | http://192.168.99.100:30000 |
|-------------|----------------------|-----------------------------|
```
### Rolling update[#](#rolling-update)
What happens during a rolling update?
As it happens during software development, change is requested/needed to some parts of the system. So what happens to our cluster if I change one of its components without breaking the others whilst also maintaining backwards compatibility with no disruption to user experience? Thankfully Kubernetes can help with that.
What I don’t like is that the API only handles one image at a time. Unfortunately there is no bulk upload option.
#### Code[#](#code)
Currently, we have the following code segment dealing with a single image:
```
// PostImage handles a post of an image. Saves it to the database
// and sends it to NSQ for further processing.
func PostImage(w http.ResponseWriter, r *http.Request) {
...
}
func main() {
router := mux.NewRouter()
router.HandleFunc("/image/post", PostImage).Methods("POST")
log.Fatal(http.ListenAndServe(":8000", router))
}
```
We have two options: Add a new endpoint with `/images/post`
and make the client use that, or modify the existing one.
The new client code has the advantage in that it can fall back to submitting the old way if the new endpoint isn’t available. The old client code, however, doesn’t have this advantage so we can’t change the way our code works right now. Consider this: You have 90 servers and you do a slow paced rolling update that will take out servers one step at a time whilst doing an update. If an update lasts around a minute, the whole process will take around one and a half hours to complete, (not counting any parallel updates).
During this time, some of your servers will run the new code and some will run the old one. Calls are load balanced, thus you have no control over which servers will be hit. If a client is trying to do a call the new way but hits an old server, the client will fail. The client can try and fallback, but since you eliminated the old version it will not succeed unless it, by mere chance, hits a server with the new code (assuming no sticky sessions are set).
Also, once all your servers are updated, an old client will not be able to use your service any longer.
Now, you can argue that you don’t want to keep old versions of your code forever. And that’s true in a sense. That’s why we are going to modify the old code to simply call the new one with some slight augmentations. This way, once all clients have been migrated, the code can simply be deleted without any problems.
#### New Endpoint[#](#new-endpoint)
Let’s add a new route method:
```
...
router.HandleFunc("/images/post", PostImages).Methods("POST")
...
```
Updating the old one to call the new one with a modified body looks like this:
```
// PostImage handles a post of an image. Saves it to the database
// and sends it to NSQ for further processing.
func PostImage(w http.ResponseWriter, r *http.Request) {
var p Path
err := json.NewDecoder(r.Body).Decode(&p)
if err != nil {
fmt.Fprintf(w, "got error while decoding body: %s", err)
return
}
fmt.Fprintf(w, "got path: %+v\n", p)
var ps Paths
paths := make([]Path, 0)
paths = append(paths, p)
ps.Paths = paths
var pathsJSON bytes.Buffer
err = json.NewEncoder(&pathsJSON).Encode(ps)
if err != nil {
fmt.Fprintf(w, "failed to encode paths: %s", err)
return
}
r.Body = ioutil.NopCloser(&pathsJSON)
r.ContentLength = int64(pathsJSON.Len())
PostImages(w, r)
}
```
Well, the naming could be better, but you should get the basic idea. I’m modifying the incoming single path by wrapping it into the new format and sending it over to the new endpoint handler. And that’s it! There are a few more modifications. To check them out, take a look at this PR: [Rolling Update Bulk Image Path PR](https://github.com/Skarlso/kube-cluster-sample/pull/1).
Now, the receiver can be called in two ways:
```
# Single Path:
curl -d '{"path":"unknown4456.jpg"}' http://127.0.0.1:8000/image/post
# Multiple Paths:
curl -d '{"paths":[{"path":"unknown4456.jpg"}]}' http://127.0.0.1:8000/images/post
```
Here, the client is curl. Normally, if the client is a service, I would modify it that in case the new end-point throws a 404 it would try the old one next.
For brevity, I’m not modifying NSQ and the others to handle bulk image processing; they will still receive it one by one. I’ll leave that up to you as homework ;)
#### New Image[#](#new-image)
To perform a rolling update, I must create a new image first from the receiver service.
```
docker build -t skarlso/kube-receiver-alpine:v1.1 .
```
Once this is complete, we can begin rolling out the change.
#### Rolling update[#](#rolling-update-1)
In Kubernetes, you can configure your rolling update in multiple ways:
##### Manual Update[#](#manual-update)
If I was using a container version in my config file called `v1.0`
, then doing an update is simply calling:
```
kubectl rolling-update receiver --image:skarlso/kube-receiver-alpine:v1.1
```
If there is a problem during the rollout we can always rollback.
```
kubectl rolling-update receiver --rollback
```
It will set back the previous version. No fuss, no muss.
##### Apply a new configuration file[#](#apply-a-new-configuration-file)
The problem with by-hand updates is that they aren’t in source control.
Consider this: Something has changed, A couple of servers got updated by hand to do a quick “patch fix”, but nobody witnessed it and it wasn’t documented. A new person comes along and does a change to the template and applies the template to the cluster. All the servers are updated, and then all of a sudden there is a service outage.
Long story short, the servers which got updated are written over because the template doesn’t reflect what has been done manually.
The recommended way is to change the template in order to use the new version, and than apply the template with the `apply`
command.
Kubernetes recommends that a Deployment with ReplicaSets should handle a rollout. This means there must be at least two replicates present for a rolling update. If less than two replicates are present then the update won’t work (unless `maxUnavailable`
is set to 1). I increase the replica count in yaml. I also set the new image version for the receiver container.
```
replicas: 2
...
spec:
containers:
- name: receiver
image: skarlso/kube-receiver-alpine:v1.1
...
```
Looking at the progress, this is what you should see :
```
❯ kubectl rollout status deployment/receiver-deployment
Waiting for rollout to finish: 1 out of 2 new replicas have been updated...
```
You can add in additional rollout configuration settings by specifying the `strategy`
part of the template like this:
```
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 0
```
Additional information on rolling update can be found in the below documents: [Deployment Rolling Update](https://kubernetes.io/docs/concepts/workloads/controllers/deployment/#rolling-back-a-deployment), [Updating a Deployment](https://kubernetes.io/docs/concepts/workloads/controllers/deployment/#updating-a-deployment), [Manage Deployments](https://kubernetes.io/docs/concepts/cluster-administration/manage-deployment/#updating-your-application-without-a-service-outage), [Rolling Update using ReplicaController](https://kubernetes.io/docs/tasks/run-application/rolling-update-replication-controller/).
**NOTE MINIKUBE USERS**: Since we are doing this on a local machine with one node and 1 replica of an application, we have to set `maxUnavailable`
to `1`
; otherwise Kubernetes won’t allow the update to happen, and the new version will remain in `Pending`
state. That’s because we aren’t allowing for a services to exist with no running containers; which basically means service outage.
### Scaling[#](#scaling-1)
Scaling is dead easy with Kubernetes. Since it’s managing the whole cluster, you basically just need to put a number into the template of the desired replicas to use.
This has been a great post so far, but it’s getting too long. I’m planning on writing a follow-up where I will be truly scaling things up on AWS with multiple nodes and replicas; plus deploying a Kubernetes cluster with [Kops](https://github.com/kubernetes/kops). So stay tuned!
### Cleanup[#](#cleanup)
```
kubectl delete deployments --all
kubectl delete services -all
```
# Final Words[#](#final-words)
And that’s it ladies and gentlemen. We wrote, deployed, updated and scaled (well, not yet really) a distributed application with Kubernetes.
If you have any questions, please feel free to chat in the comments below. I’m happy to answer.
I hope you’ve enjoyed reading this. I know it’s quite long; I was thinking of splitting it up multiple posts, but having a cohesive, one page guide is useful and makes it easy to find, save, and print.
Thank you for reading, Gergely. |
9,884 | GitLab 的付费套餐现在可以免费用于开源项目 | https://itsfoss.com/gitlab-free-open-source/ | 2018-07-31T13:23:13 | [
"GitLab",
"GitHub"
] | https://linux.cn/article-9884-1.html | 最近在开源社区发生了很多事情。首先,[微软收购了 GitHub](https://itsfoss.com/microsoft-github/),然后人们开始寻找 [GitHub 替代套餐](https://itsfoss.com/github-alternatives/),甚至在 Linus Torvalds 发布 [Linux Kernel 4.17](https://itsfoss.com/linux-kernel-4-17/) 时没有花一点时间考虑它。好吧,如果你一直关注我们,我认为你知道这一切。
但是,如今,GitLab 做出了一个明智的举措,为教育机构和开源项目免费提供高级套餐。当许多开发人员有兴趣将他们的开源项目迁移到 GitLab 时,没有更好的时机来提供这些了。
### GitLab 的高级套餐现在对开源项目和教育机构免费

在今天(2018/6/7)[发布的博客](https://about.gitlab.com/2018/06/05/gitlab-ultimate-and-gold-free-for-education-and-open-source/)中,GitLab 宣布其**旗舰**和黄金套餐现在对教育机构和开源项目免费。虽然我们已经知道为什么 GitLab 做出这个举动(一个完美的时机!),但他们还是解释了他们让它免费的动机:
>
> 我们让 GitLab 对教育机构免费,因为我们希望学生使用我们最先进的功能。许多大学已经运行了 GitLab。如果学生使用 GitLab 旗舰和黄金套餐的高级功能,他们将把这些高级功能的经验带到他们的工作场所。
>
>
> 我们希望有更多的开源项目使用 GitLab。GitLab.com 上的公共项目已经拥有 GitLab 旗舰套餐的所有功能。像 [Gnome](https://www.gnome.org/news/2018/05/gnome-moves-to-gitlab-2/) 和 [Debian](https://salsa.debian.org/public) 这样的项目已经在自己的服务器运行开源版 GitLab 。随着今天的宣布,在专有软件上运行的开源项目可以使用 GitLab 提供的所有功能,同时我们通过向非开源组织收费来建立可持续的业务模式。
>
>
>
### GitLab 提供的这些“免费”套餐是什么?

GitLab 有两类产品。一个是你可以在自己的云托管服务如 [Digital Ocean](https://m.do.co/c/d58840562553) 上运行的软件。另一个是 Gitlab 软件既服务,其中托管由 GitLab 本身管理,你在 GitLab.com 上获得一个帐户。

黄金套餐是托管类别中最高的产品,而旗舰套餐是自托管类别中的最高产品。
你可以在 GitLab 定价页面上获得有关其功能的更多详细信息。请注意,支持服务不包括在套餐中。你必须单独购买。
### 你必须符合某些条件才能使用此优惠
GitLab 还提到 —— 该优惠对谁有效。以下是他们在博客文章中写的内容:
>
> 1. **教育机构:**任何为了学习、教育的机构,并且/或者由合格的教育机构、教职人员、学生训练。教育目的不包括商业,专业或任何其他营利目的。
> 2. **开源项目:**任何使用[标准开源许可证](https://itsfoss.com/open-source-licenses-explained/)且非商业性的项目。它不应该有付费支持或付费贡献者。
>
>
>
虽然免费套餐不包括支持,但是当你迫切需要专家帮助解决问题时,你仍然可以支付每用户每月 4.95 美元的额外费用 —— 当你特别需要一个专家来解决问题时,这是一个非常合理的价格。
GitLab 还为学生们添加了一条说明:
>
> 为减轻 GitLab 的管理负担,只有教育机构才能代表学生申请。如果你是学生并且你的教育机构不申请,你可以在 GitLab.com 上使用公共项目的所有功能,使用私人项目的免费功能,或者自己付费。
>
>
>
### 总结
现在 GitLab 正在加快脚步,你如何看待它?
你有 [GitHub](https://github.com/) 上的项目吗?你会切换么?或者,幸运的是,你从一开始就碰巧使用 GitLab?
请在下面的评论栏告诉我们你的想法。
---
via: <https://itsfoss.com/gitlab-free-open-source/>
作者:[Ankush Das](https://itsfoss.com/author/ankush/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [Microsoft acquired GitHub](https://itsfoss.com/microsoft-github/) and then people started to look for [GitHub alternatives](https://itsfoss.com/github-alternatives/) without even taking a second to think about it while Linus Torvalds released the [Linux Kernel 4.17](https://itsfoss.com/linux-kernel-4-17/). Well, if you’ve been following us, I assume that you know all that.
But, today, GitLab made a smart move by making some of its high-tier plans free for educational institutes and open-source projects. There couldn’t be a better time to offer something like this when a lot of developers are interested in migrating their open-source projects to GitLab.
## GitLab’s premium plans are now free for open source projects and educational institutes
In a [blog post](https://about.gitlab.com/2018/06/05/gitlab-ultimate-and-gold-free-for-education-and-open-source/) today, GitLab announced that the **Ultimate** and Gold plans are now free for educational institutes and open-source projects. While we already know why GitLab made this move (a darn perfect timing!), they did explain their motive to make it free:
We make GitLab free for education because we want students to use our most advanced features. Many universities already run GitLab. If the students use the advanced features of GitLab Ultimate and Gold they will take their experiences with these advanced features to their workplaces.
We would love to have more open source projects use GitLab. Public projects on GitLab.com already have all the features of GitLab Ultimate. And projects like
[Gnome]and[Debian]already run their own server with the open source version of GitLab. With today’s announcement, open source projects that are comfortable running on proprietary software can use all the features GitLab has to offer while allowing us to have a sustainable business model by charging non-open-source organizations.
[irp posts=”26764″ name=”City of Barcelona Kicks Out Microsoft in Favor of Linux and Open Source”]
## What are these ‘free’ plans offered by GitLab?
GitLab has two categories of offerings. One is the software that you could host on your own cloud hosting service like [Digital Ocean](https://m.do.co/c/d58840562553). The other is providing GitLab software as a service where the hosting is managed by GitLab itself and you get an account on GitLab.com.
Gold is the highest offering in the hosted category while Ultimate is the highest offering in the self-hosted category.
You can get more details about their features on GitLab pricing page. Do note that the support is not included in this offer. You have to purchase it separately.
## You have to match certain criteria to avail this offer
GitLab also mentioned – to whom the offer will be valid for. Here’s what they wrote in their blog post:
Educational institutions:any institution whose purposes directly relate to learning, teaching, and/or training by a qualified educational institution, faculty, or student. Educational purposes do not include commercial, professional, or any other for-profit purposes.
Open source projects:any project that uses a[standard open source license]and is non-commercial. It should not have paid support or paid contributors.
Although the free plan does not include support, you can still pay an additional fee of 4.95 USD per user per month – which is a very fair price, when you are in the dire need of an expert to help resolve an issue.
GitLab also added a note for the students:
To reduce the administrative burden for GitLab, only educational institutions can apply on behalf of their students. If you’re a student and your educational institution does not apply, you can use public projects on GitLab.com with all functionality, use private projects with the free functionality, or pay yourself.
## Wrapping Up
Now that GitLab is stepping up its game, what do you think about it?
Do you have a project hosted on [GitHub](https://github.com/)? Will you be switching over? Or, luckily, you already happen to use GitLab from the start?
Let us know your thoughts in the comments section below. |
9,885 | 面向系统管理员的网络管理指南 | https://opensource.com/article/18/7/sysadmin-guide-networking-commands | 2018-07-31T17:44:26 | [
"网络管理"
] | https://linux.cn/article-9885-1.html |
>
> 一个使管理服务器和网络更轻松的 Linux 工具和命令的参考列表。
>
>
>

如果你是一位系统管理员,那么你的日常工作应该包括管理服务器和数据中心的网络。以下的 Linux 实用工具和命令 —— 从基础的到高级的 —— 将帮你更轻松地管理你的网络。
在几个命令中,你将会看到 `<fqdn>`,它是“完全合格域名”的全称。当你看到它时,你应该用你的网站 URL 或你的服务器来代替它(比如,`server-name.company.com`),具体要视情况而定。
### Ping
正如它的名字所表示的那样,`ping` 是用于去检查从你的系统到你想去连接的系统之间端到端的连通性。当一个 `ping` 成功时,它使用的 [ICMP](https://en.wikipedia.org/wiki/Internet_Control_Message_Protocol) 的 echo 包将会返回到你的系统中。它是检查系统/网络连通性的一个良好开端。你可以在 IPv4 和 IPv6 地址上使用 `ping` 命令。(阅读我的文章 "[如何在 Linux 系统上找到你的 IP 地址](https://opensource.com/article/18/5/how-find-ip-address-linux)" 去学习更多关于 IP 地址的知识)
**语法:**
* IPv4: `ping <ip address>/<fqdn>`
* IPv6: `ping6 <ip address>/<fqdn>`
你也可以使用 `ping` 去解析出网站所对应的 IP 地址,如下图所示:

### Traceroute
`ping` 是用于检查端到端的连通性,`traceroute` 实用工具将告诉你到达对端系统、网站,或服务器所经过的路径上所有路由器的 IP 地址。`traceroute` 在网络连接调试中经常用于在 `ping` 之后的第二步。
这是一个跟踪从你的系统到其它对端的全部网络路径的非常好的工具。在检查端到端的连通性时,这个实用工具将告诉你到达对端系统、网站、或服务器上所经历的路径上的全部路由器的 IP 地址。通常用于网络连通性调试的第二步。
**语法:**
* `traceroute <ip address>/<fqdn>`
### Telnet
**语法:**
* `telnet <ip address>/<fqdn>` 是用于 [telnet](https://en.wikipedia.org/wiki/Telnet) 进入任何支持该协议的服务器。
### Netstat
这个网络统计(`netstat`)实用工具是用于去分析解决网络连接问题和检查接口/端口统计数据、路由表、协议状态等等的。它是任何管理员都应该必须掌握的工具。
**语法:**
* `netstat -l` 显示所有处于监听状态的端口列表。
* `netstat -a` 显示所有端口;如果去指定仅显示 TCP 端口,使用 `-at`(指定信显示 UDP 端口,使用 `-au`)。
* `netstat -r` 显示路由表。

* `netstat -s` 显示每个协议的状态总结。

* `netstat -i` 显示每个接口传输/接收(TX/RX)包的统计数据。

### Nmcli
`nmcli` 是一个管理网络连接、配置等工作的非常好的实用工具。它能够去管理网络管理程序和修改任何设备的网络配置详情。
**语法:**
* `nmcli device` 列出网络上的所有设备。
* `nmcli device show <interface>` 显示指定接口的网络相关的详细情况。
* `nmcli connection` 检查设备的连接情况。
* `nmcli connection down <interface>` 关闭指定接口。
* `nmcli connection up <interface>` 打开指定接口。
* `nmcli con add type vlan con-name <connection-name> dev <interface> id <vlan-number> ipv4 <ip/cidr> gw4 <gateway-ip>` 在特定的接口上使用指定的 VLAN 号添加一个虚拟局域网(VLAN)接口、IP 地址、和网关。

### 路由
检查和配置路由的命令很多。下面是其中一些比较有用的:
**语法:**
* `ip route` 显示各自接口上所有当前的路由配置。

* `route add default gw <gateway-ip>` 在路由表中添加一个默认的网关。
* `route add -net <network ip/cidr> gw <gateway ip> <interface>` 在路由表中添加一个新的网络路由。还有许多其它的路由参数,比如,添加一个默认路由,默认网关等等。
* `route del -net <network ip/cidr>` 从路由表中删除一个指定的路由条目。

* `ip neighbor` 显示当前的邻接表和用于去添加、改变、或删除新的邻居。


* `arp` (它的全称是 “地址解析协议”)类似于 `ip neighbor`。`arp` 映射一个系统的 IP 地址到它相应的 MAC(介质访问控制)地址。

### Tcpdump 和 Wireshark
Linux 提供了许多包捕获工具,比如 `tcpdump`、`wireshark`、`tshark` 等等。它们被用于去捕获传输/接收的网络流量中的数据包,因此它们对于系统管理员去诊断丢包或相关问题时非常有用。对于热衷于命令行操作的人来说,`tcpdump` 是一个非常好的工具,而对于喜欢 GUI 操作的用户来说,`wireshark` 是捕获和分析数据包的不二选择。`tcpdump` 是一个 Linux 内置的用于去捕获网络流量的实用工具。它能够用于去捕获/显示特定端口、协议等上的流量。
**语法:**
* `tcpdump -i <interface-name>` 显示指定接口上实时通过的数据包。通过在命令中添加一个 `-w` 标志和输出文件的名字,可以将数据包保存到一个文件中。例如:`tcpdump -w <output-file.> -i <interface-name>`。

* `tcpdump -i <interface> src <source-ip>` 从指定的源 IP 地址上捕获数据包。
* `tcpdump -i <interface> dst <destination-ip>` 从指定的目标 IP 地址上捕获数据包。
* `tcpdump -i <interface> port <port-number>` 从一个指定的端口号(比如,53、80、8080 等等)上捕获数据包。
* `tcpdump -i <interface> <protocol>` 捕获指定协议的数据包,比如:TCP、UDP、等等。
### Iptables
`iptables` 是一个包过滤防火墙工具,它能够允许或阻止某些流量。这个实用工具的应用范围非常广泛;下面是它的其中一些最常用的使用命令。
**语法:**
* `iptables -L` 列出所有已存在的 `iptables` 规则。
* `iptables -F` 删除所有已存在的规则。
下列命令允许流量从指定端口到指定接口:
* `iptables -A INPUT -i <interface> -p tcp –dport <port-number> -m state –state NEW,ESTABLISHED -j ACCEPT`
* `iptables -A OUTPUT -o <interface> -p tcp -sport <port-number> -m state – state ESTABLISHED -j ACCEPT`
下列命令允许<ruby> 环回 <rt> loopback </rt></ruby>接口访问系统:
* `iptables -A INPUT -i lo -j ACCEPT`
* `iptables -A OUTPUT -o lo -j ACCEPT`
### Nslookup
`nslookup` 工具是用于去获得一个网站或域名所映射的 IP 地址。它也能用于去获得你的 DNS 服务器的信息,比如,一个网站的所有 DNS 记录(具体看下面的示例)。与 `nslookup` 类似的一个工具是 `dig`(Domain Information Groper)实用工具。
**语法:**
* `nslookup <website-name.com>` 显示你的服务器组中 DNS 服务器的 IP 地址,它后面就是你想去访问网站的 IP 地址。
* `nslookup -type=any <website-name.com>` 显示指定网站/域中所有可用记录。
### 网络/接口调试
下面是用于接口连通性或相关网络问题调试所需的命令和文件的汇总。
**语法:**
* `ss` 是一个转储套接字统计数据的实用工具。
* `nmap <ip-address>`,它的全称是 “Network Mapper”,它用于扫描网络端口、发现主机、检测 MAC 地址,等等。
* `ip addr/ifconfig -a` 提供一个系统上所有接口的 IP 地址和相关信息。
* `ssh -vvv user@<ip/domain>` 允许你使用指定的 IP/域名和用户名通过 SSH 协议登入到其它服务器。`-vvv` 标志提供 SSH 登入到服务器过程中的 "最详细的" 信息。
* `ethtool -S <interface>` 检查指定接口上的统计数据。
* `ifup <interface>` 启动指定的接口。
* `ifdown <interface>` 关闭指定的接口
* `systemctl restart network` 重启动系统上的一个网络服务。
* `/etc/sysconfig/network-scripts/<interface-name>` 是一个对指定的接口设置 IP 地址、网络、网关等等的接口配置文件。DHCP 模式也可以在这里设置。
* `/etc/hosts` 这个文件包含自定义的主机/域名到 IP 地址的映射。
* `/etc/resolv.conf` 指定系统上的 DNS 服务器的 IP 地址。
* `/etc/ntp.conf` 指定 NTP 服务器域名。
---
via: <https://opensource.com/article/18/7/sysadmin-guide-networking-commands>
作者:[Archit Modi](https://opensource.com/users/architmodi) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | If you're a sysadmin, your daily tasks include managing servers and the data center's network. The following Linux utilities and commands—from basic to advanced—will help make network management easier.
In several of these commands, you'll see `<fqdn>`
, which stands for "fully qualified domain name." When you see this, substitute your website URL or your server (e.g., `server-name.company.com`
), as the case may be.
## Ping
As the name suggests, `ping`
is used to check the end-to-end connectivity from your system to the one you are trying to connect to. It uses [ICMP](https://en.wikipedia.org/wiki/Internet_Control_Message_Protocol) echo packets that travel back to your system when a ping is successful. It's also a good first step to check system/network connectivity. You can use the `ping`
command with IPv4 and IPv6 addresses. (Read my article "[How to find your IP address in Linux](https://opensource.com/article/18/5/how-find-ip-address-linux)" to learn more about IP addresses.)
**Syntax:**
- IPv4:
`ping <ip address>/<fqdn>`
- IPv6:
`ping6 <ip address>/<fqdn>`
You can also use `ping`
to resolve names of websites to their corresponding IP address, as shown below:
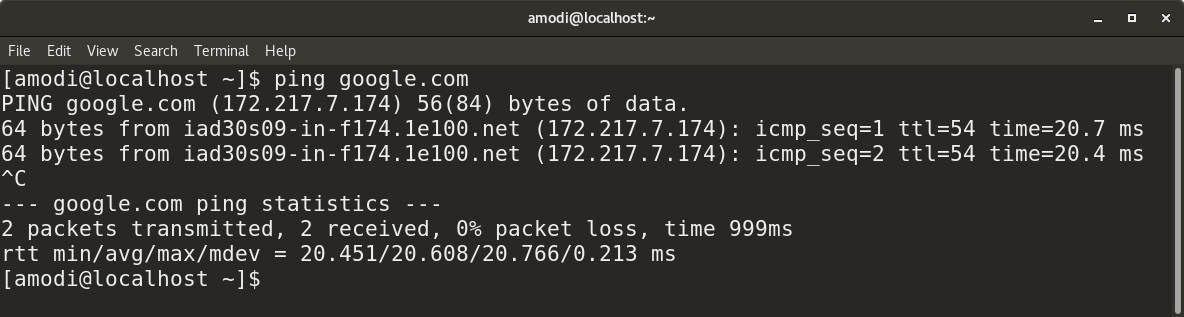
## Traceroute
This is a nice utility for tracing the full network path from your system to another. Where `ping`
checks end-to-end connectivity, the `traceroute`
utility tells you all the router IPs on the path you travel to reach the end system, website, or server. `traceroute`
is usually is the second step after `ping`
for network connection debugging.
**Syntax:**
`traceroute <ip address>/<fqdn>`
## Telnet
**Syntax:**
`telnet <ip address>/<fqdn>`
is used to[telnet](https://en.wikipedia.org/wiki/Telnet)into any server.
## Netstat
The network statistics (`netstat`
) utility is used to troubleshoot network-connection problems and to check interface/port statistics, routing tables, protocol stats, etc. It's any sysadmin's must-have tool.
**Syntax:**
`netstat -l`
shows the list of all the ports that are in listening mode.`netstat -a`
shows all ports; to specify only TCP, use`-at`
(for UDP use`-au`
).`netstat -r`
provides a routing table.
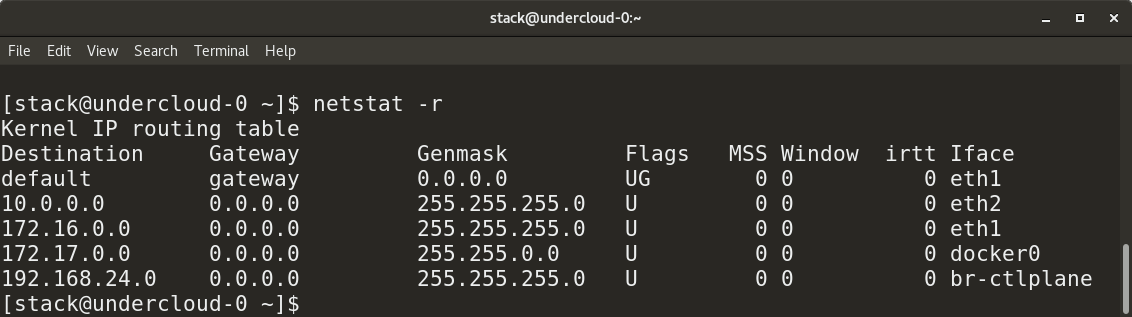
`netstat -s`
provides a summary of statistics for each protocol.
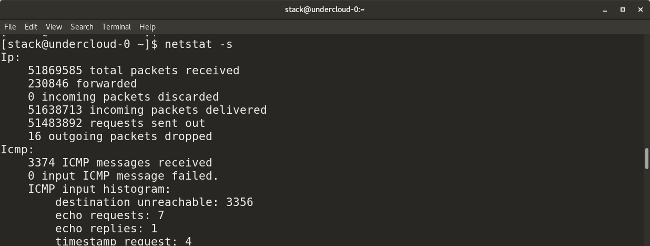
`netstat -i`
displays transmission/receive (TX/RX) packet statistics for each interface.
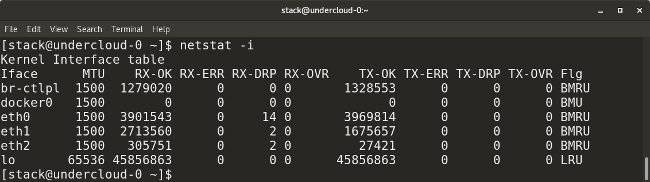
## Nmcli
`nmcli`
is a good utility for managing network connections, configurations, etc. It can be used to control Network Manager and modify any device's network configuration details.
**Syntax:**
-
`nmcli device`
lists all devices on the system. -
`nmcli device show <interface>`
shows network-related details of the specified interface. -
`nmcli connection`
checks a device's connection. -
`nmcli connection down <interface>`
shuts down the specified interface. -
`nmcli connection up <interface>`
starts the specified interface. -
`nmcli con add type vlan con-name <connection-name> dev <interface> id <vlan-number> ipv4 <ip/cidr> gw4 <gateway-ip>`
adds a virtual LAN (VLAN) interface with the specified VLAN number, IP address, and gateway to a particular interface.
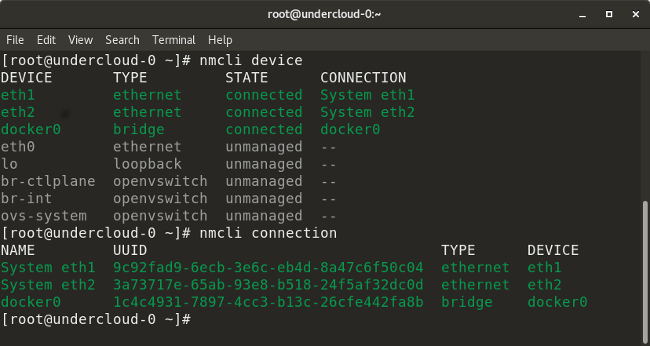
## Routing
There are many commands you can use to check and configure routing. Here are some useful ones:
**Syntax:**
`ip route`
shows all the current routes configured for the respective interfaces.
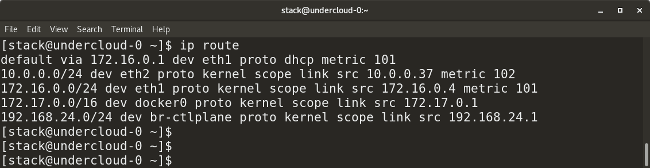
`route add default gw <gateway-ip>`
adds a default gateway to the routing table.`route add -net <network ip/cidr> gw <gateway ip> <interface>`
adds a new network route to the routing table. There are many other routing parameters, such as adding a default route, default gateway, etc.`route del -net <network ip/cidr>`
deletes a particular route entry from the routing table.
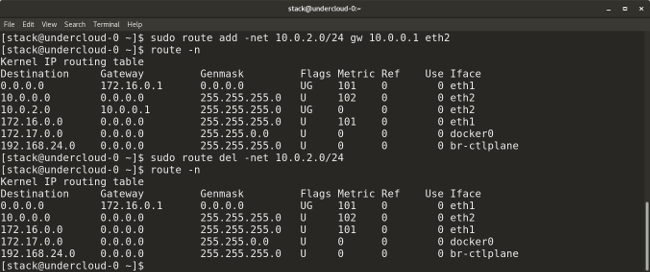
`ip neighbor`
shows the current neighbor table and can be used to add, change, or delete new neighbors.
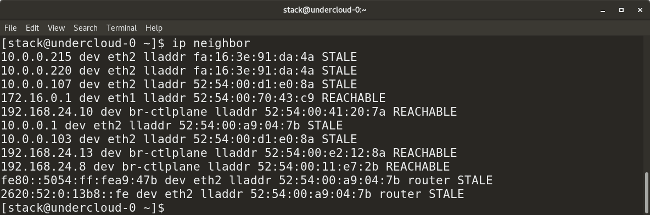
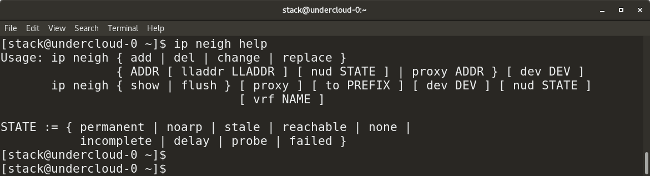
`arp`
(which stands for address resolution protocol) is similar to`ip neighbor`
.`arp`
maps a system's IP address to its corresponding MAC (media access control) address.
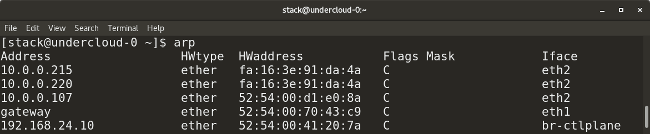
## Tcpdump and Wireshark
Linux provides many packet-capturing tools like `tcpdump`
, `wireshark`
, `tshark`
, etc. They are used to capture network traffic in packets that are transmitted/received and hence are very useful for a sysadmin to debug any packet losses or related issues. For command-line enthusiasts, `tcpdump`
is a great tool, and for GUI users, `wireshark`
is a great utility to capture and analyze packets. `tcpdump`
is a built-in Linux utility to capture network traffic. It can be used to capture/show traffic on specific ports, protocols, etc.
**Syntax:**
`tcpdump -i <interface-name>`
shows live packets from the specified interface. Packets can be saved in a file by adding the`-w`
flag and the name of the output file to the command, for example:`tcpdump -w <output-file.> -i <interface-name>`
.
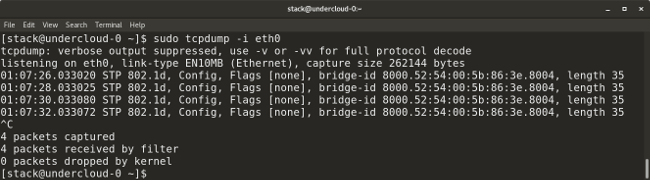
`tcpdump -i <interface> src <source-ip>`
captures packets from a particular source IP.`tcpdump -i <interface> dst <destination-ip>`
captures packets from a particular destination IP.`tcpdump -i <interface> port <port-number>`
captures traffic for a specific port number like 53, 80, 8080, etc.`tcpdump -i <interface> <protocol>`
captures traffic for a particular protocol, like TCP, UDP, etc.
## Iptables
`iptables`
is a firewall-like packet-filtering utility that can allow or block certain traffic. The scope of this utility is very wide; here are some of its most common uses.
**Syntax:**
`iptables -L`
lists all existing`iptables`
rules.`iptables -F`
deletes all existing rules.
The following commands allow traffic from the specified port number to the specified interface:
`iptables -A INPUT -i <interface> -p tcp –dport <port-number> -m state –state NEW,ESTABLISHED -j ACCEPT`
`iptables -A OUTPUT -o <interface> -p tcp -sport <port-number> -m state – state ESTABLISHED -j ACCEPT`
The following commands allow loopback access to the system:
`iptables -A INPUT -i lo -j ACCEPT`
`iptables -A OUTPUT -o lo -j ACCEPT`
## Nslookup
The `nslookup`
tool is used to obtain IP address mapping of a website or domain. It can also be used to obtain information on your DNS server, such as all DNS records on a website (see the example below). A similar tool to `nslookup`
is the `dig`
(Domain Information Groper) utility.
**Syntax:**
`nslookup <website-name.com>`
shows the IP address of your DNS server in the Server field, and, below that, gives the IP address of the website you are trying to reach.`nslookup -type=any <website-name.com>`
shows all the available records for the specified website/domain.
## Network/interface debugging
Here is a summary of the necessary commands and files used to troubleshoot interface connectivity or related network issues.
**Syntax:**
`ss`
is a utility for dumping socket statistics.`nmap <ip-address>`
, which stands for Network Mapper, scans network ports, discovers hosts, detects MAC addresses, and much more.`ip addr/ifconfig -a`
provides IP addresses and related info on all the interfaces of a system.`ssh -vvv user@<ip/domain>`
enables you to SSH to another server with the specified IP/domain and username. The`-vvv`
flag provides "triple-verbose" details of the processes going on while SSH'ing to the server.`ethtool -S <interface>`
checks the statistics for a particular interface.`ifup <interface>`
starts up the specified interface.`ifdown <interface>`
shuts down the specified interface.`systemctl restart network`
restarts a network service for the system.`/etc/sysconfig/network-scripts/<interface-name>`
is an interface configuration file used to set IP, network, gateway, etc. for the specified interface. DHCP mode can be set here.`/etc/hosts`
this file contains custom host/domain to IP mappings.`/etc/resolv.conf`
specifies the DNS nameserver IP of the system.`/etc/ntp.conf`
specifies the NTP server domain.
## 13 Comments |
9,887 | 如何使用 Android Things 和 TensorFlow 在物联网上应用机器学习 | https://www.survivingwithandroid.com/2018/03/apply-machine-learning-iot-using-android-things-tensorflow.html | 2018-08-01T23:12:29 | [
"机器学习",
"物联网",
"树莓派"
] | /article-9887-1.html | 
>
> 探索如何将 Android Things 与 Tensorflow 集成起来,以及如何应用机器学习到物联网系统上。学习如何在装有 Android Things 的树莓派上使用 Tensorflow 进行图片分类。
>
>
>
这个项目探索了如何将机器学习应用到物联网上。具体来说,物联网平台我们将使用 **Android Things**,而机器学习引擎我们将使用 **Google TensorFlow**。
现如今,Android Things 处于名为 Android Things 1.0 的稳定版本,已经可以用在生产系统中了。如你可能已经知道的,树莓派是一个可以支持 Android Things 1.0 做开发和原型设计的平台。本教程将使用 Android Things 1.0 和树莓派,当然,你可以无需修改代码就能换到其它所支持的平台上。这个教程是关于如何将机器学习应用到物联网的,这个物联网平台就是 Android Things Raspberry Pi。
物联网上的机器学习是最热门的话题之一。要给机器学习一个最简单的定义,可能就是 [维基百科上的定义](https://en.wikipedia.org/wiki/Machine_learning):
>
> 机器学习是计算机科学中,让计算机不需要显式编程就能去“学习”(即,逐步提升在特定任务上的性能)使用数据的一个领域。
>
>
>
换句话说就是,经过训练之后,那怕是它没有针对它们进行特定的编程,这个系统也能够预测结果。另一方面,我们都知道物联网和联网设备的概念。其中前景最看好的领域之一就是如何在物联网上应用机器学习,构建专家系统,这样就能够去开发一个能够“学习”的系统。此外,还可以使用这些知识去控制和管理物理对象。在深入了解 Android Things 的细节之前,你应该先将其安装在你的设备上。如果你是第一次使用 Android Things,你可以阅读一下这篇[如何在你的设备上安装 Android Things](https://www.survivingwithandroid.com/2017/01/android-things-android-internet-of-things.html) 的教程。
这里有几个应用机器学习和物联网产生重要价值的领域,以下仅提到了几个有趣的领域,它们是:
* 在工业物联网(IIoT)中的预见性维护
* 消费物联网中,机器学习可以让设备更智能,它通过调整使设备更适应我们的习惯
在本教程中,我们希望去探索如何使用 Android Things 和 TensorFlow 在物联网上应用机器学习。这个 Adnroid Things 物联网项目的基本想法是,探索如何去*构建一个能够识别前方道路上基本形状(比如箭头)并控制其道路方向的无人驾驶汽车*。我们已经介绍了 [如何使用 Android Things 去构建一个无人驾驶汽车](https://www.survivingwithandroid.com/2017/12/building-a-remote-controlled-car-using-android-things-gpio.html),因此,在开始这个项目之前,我们建议你去阅读那个教程。
这个机器学习和物联网项目包含如下的主题:
* 如何使用 Docker 配置 TensorFlow 环境
* 如何训练 TensorFlow 系统
* 如何使用 Android Things 去集成 TensorFlow
* 如何使用 TensorFlow 的成果去控制无人驾驶汽车
这个项目起源于 [Android Things TensorFlow 图像分类器](https://github.com/androidthings/sample-tensorflow-imageclassifier)。
我们开始吧!
### 如何使用 Tensorflow 图像识别
在开始之前,需要安装和配置 TensorFlow 环境。我不是机器学习方面的专家,因此,我需要找到一些快速而能用的东西,以便我们可以构建 TensorFlow 图像识别器。为此,我们使用 Docker 去运行一个 TensorFlow 镜像。以下是操作步骤:
1、 克隆 TensorFlow 仓库:
```
git clone https://github.com/tensorflow/tensorflow.git
cd /tensorflow
git checkout v1.5.0
```
2、 创建一个目录(`/tf-data`),它将用于保存这个项目中使用的所有文件。
3、 运行 Docker:
```
docker run -it \
--volume /tf-data:/tf-data \
--volume /tensorflow:/tensorflow \
--workdir /tensorflow tensorflow/tensorflow:1.5.0 bash
```
使用这个命令,我们运行一个交互式 TensorFlow 环境,可以挂载一些在使用项目期间使用的目录。
### 如何训练 TensorFlow 去识别图像
在 Android Things 系统能够识别图像之前,我们需要去训练 TensorFlow 引擎,以使它能够构建它的模型。为此,我们需要去收集一些图像。正如前面所言,我们需要使用箭头来控制 Android Things 无人驾驶汽车,因此,我们至少要收集四种类型的箭头:
* 向上的箭头
* 向下的箭头
* 向左的箭头
* 向右的箭头
为训练这个系统,需要使用这四类不同的图像去创建一个“知识库”。在 `/tf-data` 目录下创建一个名为 `images` 的目录,然后在它下面创建如下名字的四个子目录:
* `up-arrow`
* `down-arrow`
* `left-arrow`
* `right-arrow`
现在,我们去找图片。我使用的是 Google 图片搜索,你也可以使用其它的方法。为了简化图片下载过程,你可以安装一个 Chrome 下载插件,这样你只需要点击就可以下载选定的图片。别忘了多下载一些图片,这样训练效果更好,当然,这样创建模型的时间也会相应增加。
**扩展阅读**
* [如何使用 API 去集成 Android Things](https://www.survivingwithandroid.com/2017/11/building-a-restful-api-interface-using-android-things.html)
* [如何与 Firebase 一起使用 Android Things](https://www.survivingwithandroid.com/2017/10/synchronize-android-things-with-firebase-real-time-control-firebase-iot.html)
打开浏览器,开始去查找四种箭头的图片:

每个类别我下载了 80 张图片。不用管图片文件的扩展名。
为所有类别的图片做一次如下的操作(在 Docker 界面下):
```
python /tensorflow/examples/image_retraining/retrain.py \
--bottleneck_dir=tf_files/bottlenecks \
--how_many_training_steps=4000 \
--output_graph=/tf-data/retrained_graph.pb \
--output_labels=/tf-data/retrained_labels.txt \
--image_dir=/tf-data/images
```
这个过程你需要耐心等待,它需要花费很长时间。结束之后,你将在 `/tf-data` 目录下发现如下的两个文件:
1. `retrained_graph.pb`
2. `retrained_labels.txt`
第一个文件包含了 TensorFlow 训练过程产生的结果模型,而第二个文件包含了我们的四个图片类相关的标签。
### 如何测试 Tensorflow 模型
如果你想去测试这个模型,去验证它是否能按预期工作,你可以使用如下的命令:
```
python scripts.label_image \
--graph=/tf-data/retrained-graph.pb \
--image=/tf-data/images/[category]/[image_name.jpg]
```
### 优化模型
在 Android Things 项目中使用我们的 TensorFlow 模型之前,需要去优化它:
```
python /tensorflow/python/tools/optimize_for_inference.py \
--input=/tf-data/retrained_graph.pb \
--output=/tf-data/opt_graph.pb \
--input_names="Mul" \
--output_names="final_result"
```
那个就是我们全部的模型。我们将使用这个模型,把 TensorFlow 与 Android Things 集成到一起,在物联网或者更多任务上应用机器学习。目标是使用 Android Things 应用程序智能识别箭头图片,并反应到接下来的无人驾驶汽车的方向控制上。
如果你想去了解关于 TensorFlow 以及如何生成模型的更多细节,请查看官方文档以及这篇 [教程](https://codelabs.developers.google.com/codelabs/tensorflow-for-poets/#0)。
### 如何使用 Android Things 和 TensorFlow 在物联网上应用机器学习
TensorFlow 的数据模型准备就绪之后,我们继续下一步:如何将 Android Things 与 TensorFlow 集成到一起。为此,我们将这个任务分为两步来完成:
1. 硬件部分,我们将把电机和其它部件连接到 Android Things 开发板上
2. 实现这个应用程序
### Android Things 示意图
在深入到如何连接外围部件之前,先列出在这个 Android Things 项目中使用到的组件清单:
1. Android Things 开发板(树莓派 3)
2. 树莓派摄像头
3. 一个 LED 灯
4. LN298N 双 H 桥电机驱动模块(连接控制电机)
5. 一个带两个轮子的无人驾驶汽车底盘
我不再重复 [如何使用 Android Things 去控制电机](https://www.survivingwithandroid.com/2017/12/building-a-remote-controlled-car-using-android-things-gpio.html) 了,因为在以前的文章中已经讲过了。
下面是示意图:

上图中没有展示摄像头。最终成果如下图:

### 使用 TensorFlow 实现 Android Things 应用程序
最后一步是实现 Android Things 应用程序。为此,我们可以复用 Github 上名为 [TensorFlow 图片分类器示例](https://github.com/androidthings/sample-tensorflow-imageclassifier) 的示例代码。开始之前,先克隆 Github 仓库,这样你就可以修改源代码。
这个 Android Things 应用程序与原始的应用程序是不一样的,因为:
1. 它不使用按钮去开启摄像头图像捕获
2. 它使用了不同的模型
3. 它使用一个闪烁的 LED 灯来提示,摄像头将在 LED 停止闪烁后拍照
4. 当 TensorFlow 检测到图像时(箭头)它将控制电机。此外,在第 3 步的循环开始之前,它将打开电机 5 秒钟。
为了让 LED 闪烁,使用如下的代码:
```
private Handler blinkingHandler = new Handler();
private Runnable blinkingLED = new Runnable() {
@Override
public void run() {
try {
// If the motor is running the app does not start the cam
if (mc.getStatus())
return ;
Log.d(TAG, "Blinking..");
mReadyLED.setValue(!mReadyLED.getValue());
if (currentValue <= NUM_OF_TIMES) {
currentValue++;
blinkingHandler.postDelayed(blinkingLED,
BLINKING_INTERVAL_MS);
}
else {
mReadyLED.setValue(false);
currentValue = 0;
mBackgroundHandler.post(mBackgroundClickHandler);
}
} catch (IOException e) {
e.printStackTrace();
}
}
};
```
当 LED 停止闪烁后,应用程序将捕获图片。
现在需要去关心如何根据检测到的图片去控制电机。修改这个方法:
```
@Override
public void onImageAvailable(ImageReader reader) {
final Bitmap bitmap;
try (Image image = reader.acquireNextImage()) {
bitmap = mImagePreprocessor.preprocessImage(image);
}
final List<Classifier.Recognition> results =
mTensorFlowClassifier.doRecognize(bitmap);
Log.d(TAG,
"Got the following results from Tensorflow: " + results);
// Check the result
if (results == null || results.size() == 0) {
Log.d(TAG, "No command..");
blinkingHandler.post(blinkingLED);
return ;
}
Classifier.Recognition rec = results.get(0);
Float confidence = rec.getConfidence();
Log.d(TAG, "Confidence " + confidence.floatValue());
if (confidence.floatValue() < 0.55) {
Log.d(TAG, "Confidence too low..");
blinkingHandler.post(blinkingLED);
return ;
}
String command = rec.getTitle();
Log.d(TAG, "Command: " + rec.getTitle());
if (command.indexOf("down") != -1)
mc.backward();
else if (command.indexOf("up") != -1)
mc.forward();
else if (command.indexOf("left") != -1)
mc.turnLeft();
else if (command.indexOf("right") != -1)
mc.turnRight();
}
```
在这个方法中,当 TensorFlow 返回捕获的图片匹配到的可能的标签之后,应用程序将比较这个结果与可能的方向,并因此来控制电机。
最后,将去使用前面创建的模型了。拷贝 `assets` 文件夹下的 `opt_graph.pb` 和 `reatrained_labels.txt` 去替换现在的文件。
打开 `Helper.java` 并修改如下的行:
```
public static final int IMAGE_SIZE = 299;
private static final int IMAGE_MEAN = 128;
private static final float IMAGE_STD = 128;
private static final String LABELS_FILE = "retrained_labels.txt";
public static final String MODEL_FILE = "file:///android_asset/opt_graph.pb";
public static final String INPUT_NAME = "Mul";
public static final String OUTPUT_OPERATION = "output";
public static final String OUTPUT_NAME = "final_result";
```
运行这个应用程序,并给摄像头展示几种箭头,以检查它的反应。无人驾驶汽车将根据展示的箭头进行移动。
### 总结
教程到此结束,我们讲解了如何使用 Android Things 和 TensorFlow 在物联网上应用机器学习。我们使用图片去控制无人驾驶汽车的移动。
---
via: <https://www.survivingwithandroid.com/2018/03/apply-machine-learning-iot-using-android-things-tensorflow.html>
作者:[Francesco Azzola](https://www.survivingwithandroid.com/author/francesco-azzolagmail-com) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='www.survivingwithandroid.com', port=443): Read timed out. (read timeout=10) | null |
9,888 | 列出 Linux 系统上所有用户的 3 种方法 | https://www.2daygeek.com/3-methods-to-list-all-the-users-in-linux-system/ | 2018-08-01T23:37:48 | [
"用户",
"passwd"
] | https://linux.cn/article-9888-1.html |
>
> 通过使用 `/etc/passwd` 文件,`getent` 命令,`compgen` 命令这三种方法查看系统中用户的信息。
>
>
>

大家都知道,Linux 系统中用户信息存放在 `/etc/passwd` 文件中。
这是一个包含每个用户基本信息的文本文件。当我们在系统中创建一个用户,新用户的详细信息就会被添加到这个文件中。
`/etc/passwd` 文件将每个用户的基本信息记录为文件中的一行,一行中包含 7 个字段。
`/etc/passwd` 文件的一行代表一个单独的用户。该文件将用户的信息分为 3 个部分。
```
* 第 1 部分:`root` 用户信息
* 第 2 部分:系统定义的账号信息
* 第 3 部分:真实用户的账户信息
```
第一部分是 `root` 账户,这代表管理员账户,对系统的每个方面都有完全的权力。
第二部分是系统定义的群组和账户,这些群组和账号是正确安装和更新系统软件所必需的。
第三部分在最后,代表一个使用系统的真实用户。
在创建新用户时,将修改以下 4 个文件。
```
* `/etc/passwd`: 用户账户的详细信息在此文件中更新。
* `/etc/shadow`: 用户账户密码在此文件中更新。
* `/etc/group`: 新用户群组的详细信息在此文件中更新。
* `/etc/gshadow`: 新用户群组密码在此文件中更新。
```
\*\* 建议阅读 : \*\*
* [如何在 Linux 上查看创建用户的日期](https://www.2daygeek.com/how-to-check-user-created-date-on-linux/)
* [如何在 Linux 上查看 A 用户所属的群组](https://www.2daygeek.com/how-to-check-which-groups-a-user-belongs-to-on-linux/)
* [如何强制用户在下一次登录 Linux 系统时修改密码](https://www.2daygeek.com/how-to-force-user-to-change-password-on-next-login-in-linux/)
### 方法 1 :使用 `/etc/passwd` 文件
使用任何一个像 `cat`、`more`、`less` 等文件操作命令来打印 Linux 系统上创建的用户列表。
`/etc/passwd` 是一个文本文件,其中包含了登录 Linux 系统所必需的每个用户的信息。它保存用户的有用信息,如用户名、密码、用户 ID、群组 ID、用户 ID 信息、用户的家目录和 Shell 。
`/etc/passwd` 文件将每个用户的详细信息写为一行,其中包含七个字段,每个字段之间用冒号 `:` 分隔:
```
# cat /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
postfix:x:89:89::/var/spool/postfix:/sbin/nologin
sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
tcpdump:x:72:72::/:/sbin/nologin
2gadmin:x:500:10::/home/viadmin:/bin/bash
apache:x:48:48:Apache:/var/www:/sbin/nologin
zabbix:x:498:499:Zabbix Monitoring System:/var/lib/zabbix:/sbin/nologin
mysql:x:497:502::/home/mysql:/bin/bash
zend:x:502:503::/u01/zend/zend/gui/lighttpd:/sbin/nologin
rpc:x:32:32:Rpcbind Daemon:/var/cache/rpcbind:/sbin/nologin
2daygeek:x:503:504::/home/2daygeek:/bin/bash
named:x:25:25:Named:/var/named:/sbin/nologin
mageshm:x:506:507:2g Admin - Magesh M:/home/mageshm:/bin/bash
```
7 个字段的详细信息如下。
* **用户名** (`magesh`): 已创建用户的用户名,字符长度 1 个到 12 个字符。
* **密码**(`x`):代表加密密码保存在 `/etc/shadow 文件中。
* \*\*用户 ID(`506`):代表用户的 ID 号,每个用户都要有一个唯一的 ID 。UID 号为 0 的是为 `root` 用户保留的,UID 号 1 到 99 是为系统用户保留的,UID 号 100-999 是为系统账户和群组保留的。
* \*\*群组 ID (`507`):代表群组的 ID 号,每个群组都要有一个唯一的 GID ,保存在 `/etc/group` 文件中。
* \*\*用户信息(`2g Admin - Magesh M`):代表描述字段,可以用来描述用户的信息(LCTT 译注:此处原文疑有误)。
* \*\*家目录(`/home/mageshm`):代表用户的家目录。
* \*\*Shell(`/bin/bash`):代表用户使用的 shell 类型。
你可以使用 `awk` 或 `cut` 命令仅打印出 Linux 系统中所有用户的用户名列表。显示的结果是相同的。
```
# awk -F':' '{ print $1}' /etc/passwd
or
# cut -d: -f1 /etc/passwd
root
bin
daemon
adm
lp
sync
shutdown
halt
mail
ftp
postfix
sshd
tcpdump
2gadmin
apache
zabbix
mysql
zend
rpc
2daygeek
named
mageshm
```
### 方法 2 :使用 `getent` 命令
`getent` 命令显示 Name Service Switch 库支持的数据库中的条目。这些库的配置文件为 `/etc/nsswitch.conf`。
`getent` 命令显示类似于 `/etc/passwd` 文件的用户详细信息,它将每个用户详细信息显示为包含七个字段的单行。
```
# getent passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
postfix:x:89:89::/var/spool/postfix:/sbin/nologin
sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
tcpdump:x:72:72::/:/sbin/nologin
2gadmin:x:500:10::/home/viadmin:/bin/bash
apache:x:48:48:Apache:/var/www:/sbin/nologin
zabbix:x:498:499:Zabbix Monitoring System:/var/lib/zabbix:/sbin/nologin
mysql:x:497:502::/home/mysql:/bin/bash
zend:x:502:503::/u01/zend/zend/gui/lighttpd:/sbin/nologin
rpc:x:32:32:Rpcbind Daemon:/var/cache/rpcbind:/sbin/nologin
2daygeek:x:503:504::/home/2daygeek:/bin/bash
named:x:25:25:Named:/var/named:/sbin/nologin
mageshm:x:506:507:2g Admin - Magesh M:/home/mageshm:/bin/bash
```
7 个字段的详细信息如上所述。(LCTT 译注:此处内容重复,删节)
你同样可以使用 `awk` 或 `cut` 命令仅打印出 Linux 系统中所有用户的用户名列表。显示的结果是相同的。
### 方法 3 :使用 `compgen` 命令
`compgen` 是 `bash` 的内置命令,它将显示所有可用的命令,别名和函数。
```
# compgen -u
root
bin
daemon
adm
lp
sync
shutdown
halt
mail
ftp
postfix
sshd
tcpdump
2gadmin
apache
zabbix
mysql
zend
rpc
2daygeek
named
mageshm
```
---
via: <https://www.2daygeek.com/3-methods-to-list-all-the-users-in-linux-system/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[SunWave](https://github.com/SunWave) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
9,889 | 使用 Handbrake 转换视频 | https://opensource.com/article/18/7/handbrake | 2018-08-02T00:00:00 | [
"转换",
"视频"
] | https://linux.cn/article-9889-1.html |
>
> 这个开源工具可以很简单地将老视频转换为新格式。
>
>
>

最近,当我的儿子让我数字化他的高中篮球比赛的一些旧 DVD 时,我马上就想到了 [Handbrake](https://handbrake.fr/)。它是一个开源软件包,可轻松将视频转换为可在 MacOS、Windows、Linux、iOS、Android 和其他平台上播放的格式所需的所有工具。
Handbrake 是开源的,并在 [GPLv2 许可证](https://github.com/HandBrake/HandBrake/blob/master/LICENSE)下分发。它很容易在 MacOS、Windows 和 Linux 包括 [Fedora](https://fedora.pkgs.org/28/rpmfusion-free-x86_64/HandBrake-1.1.0-1.fc28.x86_64.rpm.html) 和 [Ubuntu](https://launchpad.net/%7Estebbins/+archive/ubuntu/handbrake-releases) 上安装。在 Linux 中,安装后就可以从命令行使用 `$ handbrake` 或从图形用户界面中选择它。(我的情况是 GNOME 3)

Handbrake 的菜单系统易于使用。单击 “Open Source” 选择要转换的视频源。对于我儿子的篮球视频,它是我的 Linux 笔记本中的 DVD 驱动器。将 DVD 插入驱动器后,软件会识别磁盘的内容。

正如你在上面截图中的 “Source” 旁边看到的那样,Handbrake 将其识别为 720x480 的 DVD,宽高比为 4:3,以每秒 29.97 帧的速度录制,有一个音轨。该软件还能预览视频。
如果默认转换设置可以接受,只需按下 “Start Encoding” 按钮(一段时间后,根据处理器的速度),DVD 的内容将被转换并以默认格式 [M4V](https://en.wikipedia.org/wiki/M4V) 保存(可以改变)。
如果你不喜欢文件名,很容易改变它。

Handbrake 有各种格式、大小和配置的输出选项。例如,它可以生成针对 YouTube、Vimeo 和其他网站以及 iPod、iPad、Apple TV、Amazon Fire TV、Roku、PlayStation 等设备优化的视频。

你可以在 “Dimensions” 选项卡中更改视频输出大小。其他选项卡允许你应用过滤器、更改视频质量和编码、添加或修改音轨,包括字幕和修改章节。“Tags” 选项卡可让你识别输出视频文件中的作者、演员、导演、发布日期等。

如果使用 Handbrake 为特定平台输出,可以使用包含的预设。

你还可以使用菜单选项创建自己的格式,具体取决于你需要的功能。
Handbrake 是一款非常强大的软件,但它并不是唯一的开源视频转换工具。你有其他喜欢的吗?如果有,请分享评论。
---
via: <https://opensource.com/article/18/7/handbrake>
作者:[Don Watkins](https://opensource.com/users/don-watkins) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Recently, when my son asked me to digitally convert some old DVDs of his high school basketball games, I immediately knew I would use [Handbrake](https://handbrake.fr/). It is an open source package that has all the tools necessary to easily convert video into formats that can be played on MacOS, Windows, Linux, iOS, Android, and other platforms.
Handbrake is open source and distributable under the [GPLv2 license](https://github.com/HandBrake/HandBrake/blob/master/LICENSE). It's easy to install on MacOS, Windows, and Linux, including both [Fedora](https://fedora.pkgs.org/28/rpmfusion-free-x86_64/HandBrake-1.1.0-1.fc28.x86_64.rpm.html) and [Ubuntu](https://launchpad.net/~stebbins/+archive/ubuntu/handbrake-releases). In Linux, once it's installed, it can be launched from the command line with `$ handbrake`
or selected from the graphical user interface. (In my case, that is GNOME 3.)

Handbrake's menu system is easy to use. Click on **Open Source** to select the video source you want to convert. For my son's basketball videos, that is the DVD drive in my Linux laptop. After inserting the DVD into the drive, the software identifies the contents of the disk.
As you can see next to Source in the screenshot above, Handbrake recognizes it as a DVD with a 720x480 video in 4:3 aspect ratio, recorded at 29.97 frames per second, with one audio track. The software also previews the video.
If the default conversion settings are acceptable, just press the **Start Encoding** button and (after a period of time, depending on the speed of your processor) the DVD's contents will be converted and saved in the default format, [M4V](https://en.wikipedia.org/wiki/M4V) (which can be changed).
If you don't like the filename, it's easy to change it.

Handbrake has a variety of output options for format, size, and disposition. For example, it can produce video optimized for YouTube, Vimeo, and other websites, as well as for devices including iPod, iPad, Apple TV, Amazon Fire TV, Roku, PlayStation, and more.
You can change the video output size in the Dimensions menu tab. Other tabs allow you to apply filters, change video quality and encoding, add or modify an audio track, include subtitles, and modify chapters. The Tags menu tab lets you identify the author, actors, director, release date, and more on the output video file.
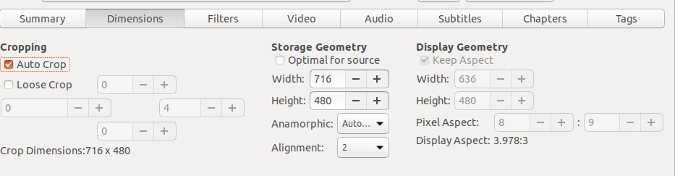
If you want to set Handbrake to produce output for a specific platform, you can use the included presets.
You can also use the menu options to create your own format, depending on the functionality you want.
Handbrake is an incredibly powerful piece of software, but it's not the only open source video conversion tool out there. Do you have another favorite? If so, please share in the comments.
## Comments are closed. |
9,890 | DevOps 时代的 7 个领导力准则 | https://enterprisersproject.com/article/2018/1/7-leadership-rules-devops-age | 2018-08-02T23:24:39 | [
"DevOps"
] | https://linux.cn/article-9890-1.html |
>
> DevOps 是一种持续性的改变和提高:那么也准备改变你所珍视的领导力准则吧。
>
>
>

如果 [DevOps] 最终更多的是一种文化而非某种技术或者平台,那么请记住:它没有终点线。而是一种持续性的改变和提高——而且最高管理层并不及格。
然而,如果期望 DevOps 能够帮助获得更多的成果,领导者需要[修订他们的一些传统的方法](https://enterprisersproject.com/article/2017/7/devops-requires-dumping-old-it-leadership-ideas)。让我们考虑 7 个在 DevOps 时代更有效的 IT 领导的想法。
### 1、 向失败说“是的”
“失败”这个词在 IT 领域中一直包含着非常具体的意义,而且通常是糟糕的意思:服务器失败、备份失败、硬盘驱动器失败——你的印象就是如此。
然而一个健康的 DevOps 文化取决于如何重新定义失败——IT 领导者应该在他们的字典里重新定义这个单词,使这个词的含义和“机会”对等起来。
“在 DevOps 之前,我们曾有一种惩罚失败者的文化,”[Datical](https://www.datical.com/) 的首席技术官兼联合创始人罗伯特·里夫斯说,“我们学到的仅仅是去避免错误。在 IT 领域避免错误的首要措施就是不要去改变任何东西:不要加速版本迭代的日程,不要迁移到云中,不要去做任何不同的事”
那是一个旧时代的剧本,里夫斯坦诚的说,它已经不起作用了,事实上,那种停滞实际上是失败。
“那些缓慢的发布周期并逃避云的公司被恐惧所麻痹——他们将会走向失败,”里夫斯说道。“IT 领导者必须拥抱失败,并把它当做成一个机遇。人们不仅仅从他们的过错中学习,也会从别人的错误中学习。开放和[安全心理](https://rework.withgoogle.com/guides/understanding-team-effectiveness/steps/foster-psychological-safety/)的文化促进学习和提高。”
**[相关文章:[为什么敏捷领导者谈论“失败”必须超越它本义](https://enterprisersproject.com/article/2017/10/why-agile-leaders-must-move-beyond-talking-about-failure?sc_cid=70160000000h0aXAAQ)]**
### 2、 在管理层渗透开发运营的理念
尽管 DevOps 文化可以在各个方向有机的发展,那些正在从单体、孤立的 IT 实践中转变出来的公司,以及可能遭遇逆风的公司——需要高管层的全面支持。如果缺少了它,你就会传达模糊的信息,而且可能会鼓励那些宁愿被推着走的人,但这是我们一贯的做事方式。[改变文化是困难的](https://enterprisersproject.com/article/2017/10/how-beat-fear-and-loathing-it-change);人们需要看到高管层完全投入进去并且知道改变已经实际发生了。
“高层管理必须全力支持 DevOps,才能成功的实现收益”,来自 [Rainforest QA](https://www.rainforestqa.com/) 的首席信息官德里克·蔡说道。
成为一个 DevOps 商店。德里克指出,涉及到公司的一切,从技术团队到工具到进程到规则和责任。
“没有高层管理的统一赞助支持,DevOps 的实施将很难成功,”德里克说道,“因此,在转变到 DevOps 之前在高层中保持一致是很重要的。”
### 3、 不要只是声明 “DevOps”——要明确它
即使 IT 公司也已经开始张开双臂拥抱 DevOps,也可能不是每个人都在同一个步调上。
**[参考我们的相关文章,[3 阐明了DevOps和首席技术官们必须在同一进程上](https://enterprisersproject.com/article/2018/1/3-areas-where-devops-and-cios-must-get-same-page)]**
造成这种脱节的一个根本原因是:人们对这个术语的有着不同的定义理解。
“DevOps 对不同的人可能意味着不同的含义,”德里克解释道,“对高管层和副总裁层来说,要执行明确的 DevOps 的目标,清楚地声明期望的成果,充分理解带来的成果将如何使公司的商业受益,并且能够衡量和报告成功的过程。”
事实上,在基线定义和远景之外,DevOps 要求正在进行频繁的交流,不是仅仅在小团队里,而是要贯穿到整个组织。IT 领导者必须将它设置为优先。
“不可避免的,将会有些阻碍,在商业中将会存在失败和破坏,”德里克说道,“领导者们需要清楚的将这个过程向公司的其他人阐述清楚,告诉他们他们作为这个过程的一份子能够期待的结果。”
### 4、 DevOps 对于商业和技术同样重要
IT 领导者们成功的将 DevOps 商店的这种文化和实践当做一项商业策略,以及构建和运营软件的方法。DevOps 是将 IT 从支持部门转向战略部门的推动力。
IT 领导者们必须转变他们的思想和方法,从成本和服务中心转变到驱动商业成果,而且 DevOps 的文化能够通过自动化和强大的协作加速这些成果,来自 [CYBRIC](https://www.cybric.io/) 的首席技术官和联合创始人迈克·凯尔说道。
事实上,这是一个强烈的趋势,贯穿这些新“规则”,在 DevOps 时代走在前沿。
“促进创新并且鼓励团队成员去聪明的冒险是 DevOps 文化的一个关键部分,IT 领导者们需要在一个持续的基础上清楚的和他们交流”,凯尔说道。
“一个高效的 IT 领导者需要比以往任何时候都要积极的参与到业务中去,”来自 [West Monroe Partners](http://www.westmonroepartners.com/) 的性能服务部门的主任埃文说道,“每年或季度回顾的日子一去不复返了——[你需要欢迎每两周一次的挤压整理](https://www.scrumalliance.org/community/articles/2017/february/product-backlog-grooming),你需要有在年度水平上的思考战略能力,在冲刺阶段的互动能力,在商业期望满足时将会被给予一定的奖励。”
### 5、 改变妨碍 DevOps 目标的任何事情
虽然 DevOps 的老兵们普遍认为 DevOps 更多的是一种文化而不是技术,成功取决于通过正确的过程和工具激活文化。当你声称自己的部门是一个 DevOps 商店却拒绝对进程或技术做必要的改变,这就是你买了辆法拉利却使用了用了 20 年的引擎,每次转动钥匙都会冒烟。
展览 A: [自动化](https://www.redhat.com/en/topics/automation?intcmp=701f2000000tjyaAAA)。这是 DevOps 成功的重要并行策略。
“IT 领导者需要重点强调自动化,”卡伦德说,“这将是 DevOps 的前期投资,但是如果没有它,DevOps 将会很容易被低效吞噬,而且将会无法完整交付。”
自动化是基石,但改变不止于此。
“领导者们需要推动自动化、监控和持续交付过程。这意着对现有的实践、过程、团队架构以及规则的很多改变,” 德里克说。“领导者们需要改变一切会阻碍团队去实现完全自动化的因素。”
### 6、 重新思考团队架构和能力指标
当你想改变时……如果你桌面上的组织结构图和你过去大部分时候嵌入的名字都是一样的,那么你是时候该考虑改革了。
“在这个 DevOps 的新时代文化中,IT 执行者需要采取一个全新的方法来组织架构。”凯尔说,“消除组织的边界限制,它会阻碍团队间的合作,允许团队自我组织、敏捷管理。”
凯尔告诉我们在 DevOps 时代,这种反思也应该拓展应用到其他领域,包括你怎样衡量个人或者团队的成功,甚至是你和人们的互动。
“根据业务成果和总体的积极影响来衡量主动性,”凯尔建议。“最后,我认为管理中最重要的一个方面是:有同理心。”
注意很容易收集的到测量值不是 DevOps 真正的指标,[Red Hat] 的技术专家戈登·哈夫写到,“DevOps 应该把指标以某种形式和商业成果绑定在一起”,他指出,“你可能并不真正在乎开发者些了多少代码,是否有一台服务器在深夜硬件损坏,或者是你的测试是多么的全面。你甚至都不直接关注你的网站的响应情况或者是你更新的速度。但是你要注意的是这些指标可能和顾客放弃购物车去竞争对手那里有关,”参考他的文章,[DevOps 指标:你在测量什么?]
### 7、 丢弃传统的智慧
如果 DevOps 时代要求关于 IT 领导能力的新的思考方式,那么也就意味着一些旧的方法要被淘汰。但是是哪些呢?
“说实话,是全部”,凯尔说道,“要摆脱‘因为我们一直都是以这种方法做事的’的心态。过渡到 DevOps 文化是一种彻底的思维模式的转变,不是对瀑布式的过去和变革委员会的一些细微改变。”
事实上,IT 领导者们认识到真正的变革要求的不只是对旧方法的小小接触。它更多的是要求对之前的进程或者策略的一个重新启动。
West Monroe Partners 的卡伦德分享了一个阻碍 DevOps 的领导力的例子:未能拥抱 IT 混合模型和现代的基础架构比如说容器和微服务。
“我所看到的一个大的规则就是架构整合,或者认为在一个同质的环境下长期的维护会更便宜,”卡伦德说。
---
via: <https://enterprisersproject.com/article/2018/1/7-leadership-rules-devops-age>
作者:[Kevin Casey](https://enterprisersproject.com/user/kevin-casey) 译者:[FelixYFZ](https://github.com/FelixYFZ) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | If [DevOps](https://enterprisersproject.com/taxonomy/term/76) is ultimately more about culture than any particular technology or platform, then remember this: There isn’t a finish line. It’s about continuous change and improvement – and the C-suite doesn’t get a pass.
Rather, leaders need to [revise some of their traditional approaches](https://enterprisersproject.com/article/2017/7/devops-requires-dumping-old-it-leadership-ideas) if they expect DevOps to help drive the outcomes they seek. Let’s consider seven ideas for more effective IT leadership in the DevOps era.
**1. Say “yes” to failure**
The word “failure” has long had very specific connotations in IT, and they’re almost universally bad: server failure, backup failure, hard drive failure – you get the picture.
A healthy DevOps culture, however, depends upon redefining failure – IT leaders should rewrite their thesaurus to make the word synonymous with “opportunity.”
“Prior to DevOps, we had a culture of punishing failure,” says Robert Reeves, CTO and co-founder of [Datical](https://www.datical.com/). “The only learning we had was to avoid mistakes. The number one way to avoid mistakes in IT is to not change anything: Don't accelerate the release schedule, don't move to the cloud, don't do anything differently!”
That’s a playbook for a bygone era and, as Reeves puts plainly, it doesn’t work. In fact, that kind of stasis is actual failure.
“Companies that release slowly and avoid the cloud are paralyzed by fear – and they will fail,” Reeves says. “IT leaders must embrace failure as an opportunity. Humans not only learn from their mistakes, they learn from others’ mistakes. A culture of openness and [‘psychological safety’](https://rework.withgoogle.com/guides/understanding-team-effectiveness/steps/foster-psychological-safety/) fosters learning and improvement.”
**[ Related article: Why agile leaders must move beyond talking about “failure.” ]**
**2. Live, eat, and breathe DevOps in the C-suite**
While DevOps culture can certainly grow organically in all directions, companies that are shifting from monolithic, siloed IT practices – and likely encountering headwinds en route – need total buy-in from executive leadership. Without it, you’re sending mixed messages and likely emboldening those who’d rather push a *but this is the way we’ve always done things* agenda. [Culture change is hard](https://enterprisersproject.com/article/2017/10/how-beat-fear-and-loathing-it-change); people need to see leadership fully invested in that change for it to actually happen.
“Top management must fully support DevOps in order for it to be successful in delivering the benefits,” says Derek Choy, CIO at [Rainforest QA](https://www.rainforestqa.com/).
Becoming a DevOps shop. Choy notes, touches pretty much everything in the organization, from technical teams to tools to processes to roles and responsibilities.
“Without unified sponsorship from top management, DevOps implementation will not be successful,” Choy says. “Therefore, it is important to have leaders aligned at the top level before transitioning to DevOps."
**3. Don’t just declare “DevOps” – define it**
Even in IT organizations that have welcomed DevOps with open arms, it’s possible that’s not everyone’s on the same page.
**[Read our related article, ****3 areas where DevOps and CIOs must get on the same page****.]**
One fundamental reason for such disconnects: People might be operating with different definitions for what the term even means.
"DevOps can mean different things to different people,” Choy says. “It is important for C-level [and] VP-level execs to define the goals of DevOps, clearly stating the expected outcome, understand how this outcome can benefit the business and be able to measure and report on success along the way.”
Indeed, beyond the baseline definition and vision, DevOps requires ongoing and frequent communication, not just in the trenches but throughout the organization. IT leaders must make that a priority.
“Inevitably, there will be hiccups, there will be failures and disruptions to the business,” Choy says. “Leaders need to clearly communicate the journey to the rest of the company and what they can expect as part of the process."
**4.** **DevOps is as much about business as technology**
IT leaders running successful DevOps shops have embraced its culture and practices as a business strategy as much as an approach to building and operating software. DevOps culture is a great enabler of IT’s shift from support arm to strategic business unit.
"IT leaders must shift their thinking and approach from being cost/service centers to driving business outcomes, and a DevOps culture helps speed up those outcomes via automation and stronger collaboration,” says Mike Kail, CTO and co-founder at [CYBRIC](https://www.cybric.io/).
Indeed, this is a strong current that runs through much of these new “rules” for leading in the age of DevOps.
“Promoting innovation and encouraging team members to take smart risks is a key part of a DevOps culture and IT leaders need to clearly communicate that on a continuous basis," Kail says.
“An effective IT leader will need to be more engaged with the business than ever before,” says Evan Callendar, director, performance services at [West Monroe Partners](http://www.westmonroepartners.com/). “Gone are the days of yearly or quarterly reviews – you need to welcome the [practice of] [bi-weekly backlog grooming](https://www.scrumalliance.org/community/articles/2017/february/product-backlog-grooming). The ability to think strategically at the year level, but interact at the sprint level, will be rewarded when business expectations are met.”
**5. Change anything that hampers DevOps goals**
While DevOps veterans generally agree that DevOps is much more a matter of culture than technology, success does depend on enabling that culture with the right processes and tools. Declaring your department a DevOps shop while resisting the necessary changes to processes or technologies is like buying a Ferrari but keeping the engine from your 20-year-old junker that billows smoke each time you turn the key.
Exhibit A: [Automation](https://www.redhat.com/en/topics/automation?intcmp=701f2000000tjyaAAA). It’s critical parallel strategy for DevOps success.
“IT leadership has to put an emphasis on automation,” Callendar says. “This will be an upfront investment, but without it, DevOps simply will engulf itself with inefficiency and lack of delivery.”
Automation is a fundamental, but change doesn’t stop there.
“Leaders need to push for automation, monitoring, and a continuous delivery process. This usually means changes to many existing practices, processes, team structures, [and] roles,” Choy says. “Leaders need to be willing to change anything that'll hinder the team's ability to fully automate the process."
**6. Rethink team structure and performance metrics**
While we’re on the subject of change...if that org chart collecting dust on your desktop is the same one you’ve been plugging names into for the better part of a decade (or more), it’s time for an overhaul.
"IT executives need to take a completely different approach to organizational structure in this new era of DevOps culture,” Kail says. “Remove strict team boundaries, which tend to hamper collaboration, and allow for the teams to be self-organizing and agile.”
Kail says this kind of rethinking can and should extend to other areas in the DevOps age, too, including how you measure individual and team success, and even how you interact with people.
“Measure initiatives in terms of business outcomes and overall positive impact,” Kail advises. “Finally, and something that I believe to be the most important aspect of management: Be empathetic."
Beware easily collected measurements that are not truly DevOps metrics, writes [Red Hat ](https://www.redhat.com/en?intcmp=701f2000000tjyaAAA)technology evangelist Gordon Haff. "DevOps metrics should be tied to business outcomes in some manner," he notes. "You probably don’t really care about how many lines of code your developers write, whether a server had a hardware failure overnight, or how comprehensive your test coverage is. In fact, you may not even directly care about the responsiveness of your website or the rapidity of your updates. But you do care to the degree such metrics can be correlated with customers abandoning shopping carts or leaving for a competitor." See his full article, [DevOps metrics: Are you measuring what matters?](https://enterprisersproject.com/article/2017/7/devops-metrics-are-you-measuring-what-matters)
**7. Chuck conventional wisdom out the window**
If the DevOps age requires new ways of thinking about IT leadership, it follows that some of the old ways need to be retired. But which ones?
"To be honest, all of them,” Kail says. “Get rid of the ‘because that's the way we've always done things’ mindset. The transition to a culture of DevOps is a complete paradigm shift, not a few subtle changes to the old days of Waterfall and Change Advisory Boards."
Indeed, IT leaders recognize that real transformation requires more than minor touch-ups to old approaches. Often, it requires a total reboot of a previous process or strategy.
Callendar of West Monroe Partners shares a parting example of legacy leadership thinking that hampers DevOps: Failing to embrace hybrid IT models and modern infrastructure approaches such as containers and microservices.
“One of the big rules I see going out the window is architecture consolidation, or the idea that long-term maintenance is cheaper if done within a homogenous environment,” Callendar says.
**Want more wisdom like this, IT leaders? Sign up for our weekly email newsletter.** |
9,891 | 针对 Bash 的不完整路径展开(补全)功能 | https://www.linuxuprising.com/2018/07/incomplete-path-expansion-completion.html | 2018-08-03T00:00:28 | [
"补全",
"命令行"
] | https://linux.cn/article-9891-1.html | 
[bash-complete-partial-path](https://github.com/sio/bash-complete-partial-path) 通过添加不完整的路径展开(类似于 Zsh)来增强 Bash(它在 Linux 上,macOS 使用 gnu-sed,Windows 使用 MSYS)中的路径补全。如果你想在 Bash 中使用这个省时特性,而不必切换到 Zsh,它将非常有用。
这是它如何工作的。当按下 `Tab` 键时,bash-complete-partial-path 假定每个部分都不完整并尝试展开它。假设你要进入 `/usr/share/applications` 。你可以输入 `cd /u/s/app`,按下 `Tab`,bash-complete-partial-path 应该把它展开成 `cd /usr/share/applications` 。如果存在冲突,那么按 `Tab` 仅补全没有冲突的路径。例如,Ubuntu 用户在 `/usr/share` 中应该有很多以 “app” 开头的文件夹,在这种情况下,输入 `cd /u/s/app` 只会展开 `/usr/share/` 部分。
另一个更深层不完整文件路径展开的例子。在Ubuntu系统上输入 `cd /u/s/f/t/u`,按下 `Tab`,它应该自动展开为 `cd /usr/share/fonts/truetype/ubuntu`。
功能包括:
* 转义特殊字符
* 如果用户路径开头使用引号,则不转义字符转义,而是在展开路径后使用匹配字符结束引号
* 正确展开 `~` 表达式
* 如果正在使用 bash-completion 包,则此代码将安全地覆盖其 `_filedir` 函数。无需额外配置,只需确保在主 bash-completion 后引入此项目。
查看[项目页面](https://github.com/sio/bash-complete-partial-path)以获取更多信息和演示截图。
### 安装 bash-complete-partial-path
bash-complete-partial-path 安装说明指定直接下载 bash\_completion 脚本。我更喜欢从 Git 仓库获取,这样我可以用一个简单的 `git pull` 来更新它,因此下面的说明将使用这种安装 bash-complete-partial-path。如果你喜欢,可以使用[官方](https://github.com/sio/bash-complete-partial-path#installation-and-updating)说明。
1、 安装 Git(需要克隆 bash-complete-partial-path 的 Git 仓库)。
在 Debian、Ubuntu、Linux Mint 等中,使用此命令安装 Git:
```
sudo apt install git
```
2、 在 `~/.config/` 中克隆 bash-complete-partial-path 的 Git 仓库:
```
cd ~/.config && git clone https://github.com/sio/bash-complete-partial-path
```
3、 在 `~/.bashrc` 文件中 source `~/.config/bash-complete-partial-path/bash_completion`,
用文本编辑器打开 ~/.bashrc。例如你可以使用 Gedit:
```
gedit ~/.bashrc
```
在 `~/.bashrc` 的末尾添加以下内容(在一行中):
```
[ -s "$HOME/.config/bash-complete-partial-path/bash_completion" ] && source "$HOME/.config/bash-complete-partial-path/bash_completion"
```
我提到在文件的末尾添加它,因为这需要包含在你的 `~/.bashrc` 文件的主 bash-completion 下面(之后)。因此,请确保不要将其添加到原始 bash-completion 之上,因为它会导致问题。
4、 引入 `~/.bashrc`:
```
source ~/.bashrc
```
这样就好了,现在应该安装完 bash-complete-partial-path 并可以使用了。
---
via: <https://www.linuxuprising.com/2018/07/incomplete-path-expansion-completion.html>
作者:[Logix](https://plus.google.com/118280394805678839070) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # Incomplete Path Expansion (Completion) For Bash
[bash-complete-partial-path](https://github.com/sio/bash-complete-partial-path)enhances the path completion in Bash (on Linux, macOS with gnu-sed, and Windows with MSYS) by adding incomplete path expansion, similar to Zsh. This is useful if you want this time-saving feature in Bash, without having to switch to Zsh.
Here is how this works. When the
`Tab`
key is pressed, bash-complete-partial-path assumes each component is incomplete and tries to expand it. Let's say you want to navigate to `/usr/share/applications`
. You can type `cd /u/s/app`
, press `Tab`
, and bash-complete-partial-path should expand it into `cd /usr/share/applications`
. If there are conflicts, only the path without conflicts is completed upon pressing `Tab`
. For instance Ubuntu users should have quite a few folders in `/usr/share`
that begin with "app" so in this case, typing `cd /u/s/app`
will only expand the `/usr/share/`
part.Here is another example of deeper incomplete file path expansion. On an Ubuntu system type
`cd /u/s/f/t/u`
, press `Tab`
, and it should be automatically expanded to cd `/usr/share/fonts/truetype/ubuntu`
.Features include:
- Escapes special characters
- If the user starts the path with quotes, character escaping is not applied and instead, the quote is closed with a matching character after expending the path
- Properly expands
`~`
expressions - If bash-completion package is already in use, this code will safely override its _filedir function. No extra configuration is required, just make sure you source this project after the main bash-completion.
Check out the
[project page](https://github.com/sio/bash-complete-partial-path)for more information and a demo screencast.
Update: bash-complete-partial-path now supports some customization, like optionally completing only directory paths, make completion case insensitive, enable colors, and more. Check out the
*Custom feature selection*section from
[here](https://github.com/sio/bash-complete-partial-path#custom-feature-selection).
## Install bash-complete-partial-path
The bash-complete-partial-path installation instructions specify downloading the bash_completion script directly. I prefer to grab the Git repository instead, so I can update it with a simple
`git pull`
, therefore the instructions below will use this method of installing bash-complete-partial-path. You can use the [official](https://github.com/sio/bash-complete-partial-path#installation-and-updating)instructions if you prefer them.
1. Install Git (needed to clone the bash-complete-partial-path Git repository).
In Debian, Ubuntu, Linux Mint and so on, use this command to install Git:
`sudo apt install git`
2. Clone the bash-complete-partial-path Git repository in
`~/.config/`
:`cd ~/.config && git clone https://github.com/sio/bash-complete-partial-path`
3. Source
`~/.config/bash-complete-partial-path/bash_completion`
in your `~/.bashrc`
file,Open ~/.bashrc with a text editor. You can use Gedit for example:
`gedit ~/.bashrc`
At the end of the
`~/.bashrc`
file add the following:```
if [ -s "$HOME/.config/bash-complete-partial-path/bash_completion" ]
then
. "$HOME/.config/bash-complete-partial-path/bash_completion"
_bcpp --defaults
fi
```
I mentioned adding it at the end of the file because this needs to be included below (after) the main bash-completion from your
`~/.bashrc`
file. So make sure you don't add it above the original bash-completion as it will cause issues.4. Source
`~/.bashrc`
:`. ~/.bashrc`
And you're done, bash-complete-partial-path should now be installed and ready to be used.
*Bash logo at the top is from* |
9,892 | 为什么 Arch Linux 如此“难弄”又有何优劣? | https://www.fossmint.com/why-is-arch-linux-so-challenging-what-are-pros-cons/ | 2018-08-03T07:30:00 | [
"Arch"
] | https://linux.cn/article-9892-1.html | 
[Arch Linux](https://www.archlinux.org/) 于 **2002** 年发布,由 Aaron Grifin 领头,是当下最热门的 Linux 发行版之一。从设计上说,Arch Linux 试图给用户提供简单、最小化且优雅的体验,但它的目标用户群可不是怕事儿多的用户。Arch 鼓励参与社区建设,并且从设计上期待用户自己有学习操作系统的能力。
很多 Linux 老鸟对于 **Arch Linux** 会更了解,但电脑前的你可能只是刚开始打算把 Arch 当作日常操作系统来使用。虽然我也不是权威人士,但下面几点优劣是我认为你总会在使用中慢慢发现的。
### 1、优点: 定制属于你自己的 Linux 操作系统
大多数热门的 Linux 发行版(比如 **Ubuntu** 和 **Fedora**)很像一般我们会看到的预装系统,和 **Windows** 或者 **MacOS** 一样。但 Arch 则会更鼓励你去把操作系统配置的符合你的品味。如果你能顺利做到这点的话,你会得到一个每一个细节都如你所想的操作系统。
#### 缺点: 安装过程让人头疼
[Arch Linux 的安装](https://www.tecmint.com/arch-linux-installation-and-configuration-guide/) 别辟蹊径——因为你要花些时间来微调你的操作系统。你会在过程中了解到不少终端命令和组成你系统的各种软件模块——毕竟你要自己挑选安装什么。当然,你也知道这个过程少不了阅读一些文档/教程。
### 2、优点: 没有预装垃圾
鉴于 **Arch** 允许你在安装时选择你想要的系统部件,你再也不用烦恼怎么处理你不想要的一堆预装软件。作为对比,**Ubuntu** 会预装大量的软件和桌面应用——很多你不需要、甚至卸载之前都不知道它们存在的东西。
总而言之,**Arch Linux\* 能省去大量的系统安装后时间。**Pacman\*\*,是 Arch Linux 默认使用的优秀包管理组件。或者你也可以选择 [Pamac](https://www.fossmint.com/pamac-arch-linux-gui-package-manager/) 作为替代。
### 3、优点: 无需繁琐系统升级
**Arch Linux** 采用滚动升级模型,简直妙极了。这意味着你不需要操心升级了。一旦你用上了 Arch,持续的更新体验会让你和一会儿一个版本的升级说再见。只要你记得‘滚’更新(Arch 用语),你就一直会使用最新的软件包们。
#### 缺点: 一些升级可能会滚坏你的系统
虽然升级过程是完全连续的,你有时得留意一下你在更新什么。没人能知道所有软件的细节配置,也没人能替你来测试你的情况。所以如果你盲目更新,有时候你会滚坏你的系统。(LCTT 译注:别担心,你可以‘滚’回来 ;D )
### 4、优点: Arch 有一个社区基因
所有 Linux 用户通常有一个共同点:对独立自由的追求。虽然大多数 Linux 发行版和公司企业等挂钩极少,但也并非没有。比如 基于 **Ubuntu** 的衍生版本们不得不受到 Canonical 公司决策的影响。
如果你想让你的电脑更独立,那么 Arch Linux 是你的伙伴。不像大多数操作系统,Arch 完全没有商业集团的影响,完全由社区驱动。
### 5、优点: Arch Wiki 无敌
[Arch Wiki](https://wiki.archlinux.org/) 是一个无敌文档库,几乎涵盖了所有关于安装和维护 Arch 以及关于操作系统本身的知识。Arch Wiki 最厉害的一点可能是,不管你在用什么发行版,你多多少少可能都在 Arch Wiki 的页面里找到有用信息。这是因为 Arch 用户也会用别的发行版用户会用的东西,所以一些技巧和知识得以泛化。
### 6、优点: 别忘了 Arch 用户软件库 (AUR)
<ruby> <a href="https://wiki.archlinux.org/index.php/Arch_User_Repository"> Arch 用户软件库 </a> <rt> Arch User Repository </rt></ruby> (AUR)是一个来自社区的超大软件仓库。如果你找了一个还没有 Arch 的官方仓库里出现的软件,那你肯定能在 AUR 里找到社区为你准备好的包。
AUR 是由用户自发编译和维护的。Arch 用户也可以给每个包投票,这样后来者就能找到最有用的那些软件包了。
### 最后: Arch Linux 适合你吗?
**Arch Linux** 优点多于缺点,也有很多优缺点我无法在此一一叙述。安装过程很长,对非 Linux 用户来说也可能偏有些技术,但只要你投入一些时间和善用 Wiki,你肯定能迈过这道坎。
**Arch Linux** 是一个非常优秀的发行版——尽管它有一些复杂性。同时它也很受那些知道自己想要什么的用户的欢迎——只要你肯做点功课,有些耐心。
当你从零开始搭建完 Arch 的时候,你会掌握很多 GNU/Linux 的内部细节,也再也不会对你的电脑内部运作方式一无所知了。
欢迎读者们在评论区讨论你使用 Arch Linux 的优缺点?以及你曾经遇到过的一些挑战。
---
via: <https://www.fossmint.com/why-is-arch-linux-so-challenging-what-are-pros-cons/>
作者:[Martins D. Okoi](https://www.fossmint.com/author/dillivine/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Moelf](https://github.com/Moelf) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,894 | 2018 年 7 月 COPR 中 4 个值得尝试很酷的新项目 | https://fedoramagazine.org/4-try-copr-july-2018/ | 2018-08-03T22:56:16 | [
"COPR"
] | https://linux.cn/article-9894-1.html | 
COPR 是个人软件仓库[集合](https://copr.fedorainfracloud.org/),它不在 Fedora 中。这是因为某些软件不符合轻松打包的标准。或者它可能不符合其他 Fedora 标准,尽管它是自由而开源的。COPR 可以在 Fedora 套件之外提供这些项目。COPR 中的软件不被 Fedora 基础设施不支持或没有被该项目所签名。但是,这是一种尝试新的或实验性的软件的一种巧妙的方式。
这是 COPR 中一组新的有趣项目。
### Hledger
[Hledger](http://hledger.org/) 是用于跟踪货币或其他商品的命令行程序。它使用简单的纯文本格式日志来存储数据和复式记帐。除了命令行界面,hledger 还提供终端界面和 Web 客户端,可以显示帐户余额图。

#### 安装说明
该仓库目前为 Fedora 27、28 和 Rawhide 提供了 hledger。要安装 hledger,请使用以下命令:
```
sudo dnf copr enable kefah/HLedger
sudo dnf install hledger
```
### Neofetch
[Neofetch](https://github.com/dylanaraps/neofetch) 是一个命令行工具,可显示有关操作系统、软件和硬件的信息。其主要目的是以紧凑的方式显示数据来截图。你可以使用命令行标志和配置文件将 Neofetch 配置为完全按照你希望的方式显示。

#### 安装说明
仓库目前为 Fedora 28 提供 Neofetch。要安装 Neofetch,请使用以下命令:
```
sudo dnf copr enable sysek/neofetch
sudo dnf install neofetch
```
### Remarkable
[Remarkable](https://remarkableapp.github.io/linux.html)是 Markdown 文本编辑器,它使用类似 GitHub 的 Markdown 风格。它提供了文档的预览,以及导出为 PDF 和 HTML 的选项。Markdown 有几种可用的样式,包括使用 CSS 创建自己的样式的选项。此外,Remarkable 支持用于编写方程的 LaTeX 语法和源代码的语法高亮。

#### 安装说明
该仓库目前为 Fedora 28 和 Rawhide 提供 Remarkable。要安装 Remarkable,请使用以下命令:
```
sudo dnf copr enable neteler/remarkable
sudo dnf install remarkable
```
### Aha
[Aha](https://github.com/theZiz/aha)(即 ANSI HTML Adapter)是一个命令行工具,可将终端转义成 HTML 代码。这允许你将 git diff 或 htop 的输出共享为静态 HTML 页面。

#### 安装说明
[仓库](https://copr.fedorainfracloud.org/coprs/scx/aha/) 目前为 Fedora 26、27、28 和 Rawhide、EPEL 6 和 7 以及其他发行版提供 aha。要安装 aha,请使用以下命令:
```
sudo dnf copr enable scx/aha
sudo dnf install aha
```
---
via: <https://fedoramagazine.org/4-try-copr-july-2018/>
作者:[Dominik Turecek](https://fedoramagazine.org) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | COPR is a [collection](https://copr.fedorainfracloud.org/) of personal repositories for software that isn’t carried in Fedora. Some software doesn’t conform to standards that allow easy packaging. Or it may not meet other Fedora standards, despite being free and open source. COPR can offer these projects outside the Fedora set of packages. Software in COPR isn’t supported by Fedora infrastructure or signed by the project. However, it can be a neat way to try new or experimental software.
Here’s a set of new and interesting projects in COPR.
### Hledger
[Hledger](http://hledger.org/) is a command-line program for tracking money or other commodities. It uses a simple, plain-text formatted journal for storing data and double-entry accounting. In addition to the command-line interface, *hledger* offers a terminal interface and a web client that can show graphs of balance on the accounts.
#### Installation instructions
The repo currently provides *hledger* for Fedora 27, 28, and Rawhide. To install hledger, use these commands:
sudo dnf copr enable kefah/HLedger sudo dnf install hledger
### Neofetch
[Neofetch](https://github.com/dylanaraps/neofetch) is a command-line tool that displays information about the operating system, software, and hardware. Its main purpose is to show the data in a compact way to take screenshots. You can configure Neofetch to display exactly the way you want, by using both command-line flags and a configuration file.
#### Installation instructions
The repo currently provides Neofetch for Fedora 28. To install Neofetch, use these commands:
sudo dnf copr enable sysek/neofetch sudo dnf install neofetch
### Remarkable
[Remarkable](https://remarkableapp.github.io/linux.html) is a Markdown text editor that uses the GitHub-like flavor of Markdown. It offers a preview of the document, as well as the option to export to PDF and HTML. There are several styles available for the Markdown, including an option to create your own styles using CSS. In addition, Remarkable supports LaTeX syntax for writing equations and syntax highlighting for source code.
#### Installation instructions
The repo currently provides Remarkable for Fedora 28 and Rawhide. To install Remarkable, use these commands:
sudo dnf copr enable neteler/remarkable sudo dnf install remarkable
### Aha
[Aha](https://github.com/theZiz/aha) (or ANSI HTML Adapter) is a command-line tool that converts terminal escape sequences to HTML code. This allows you to share, for example, output of *git diff* or *htop* as a static HTML page.
#### Installation instructions
The [repo](https://copr.fedorainfracloud.org/coprs/scx/aha/) currently provides *aha* for Fedora 26, 27, 28, and Rawhide, EPEL 6 and 7, and other distributions. To install *aha*, use these commands:
sudo dnf copr enable scx/aha sudo dnf install aha
## Anonymous
There is error:
sudo dnf dnf copr enable scx/aha
->
sudo dnf copr enable scx/aha
## Paul W. Frields
Fixed, thanks!
## Ed
Neofetch is available in the ‘standard’ repo on my machine, although it’s a little behind the copr; 3.4.0 vs 5.0.0
[root@localhost ~]# uname -a
Linux localhost.localdomain 4.17.6-200.fc28.x86_64 #1 SMP Wed Jul 11 20:29:01 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux
[root@localhost ~]# dnf info neofetch
Last metadata expiration check: 0:19:50 ago on Fri 20 Jul 2018 13:45:11 BST.
Installed Packages
Name : neofetch
Version : 3.4.0
Release : 1.fc28
Arch : noarch
Size : 279 k
Source : neofetch-3.4.0-1.fc28.src.rpm
Repo : @System
From repo : fedora
Summary : CLI system information tool written in Bash
URL : https://github.com/dylanaraps/neofetch
License : MIT
Description : Neofetch displays information about your system next to an image,
: your OS logo, or any ASCII file of your choice. The main purpose of Neofetch
: is to be used in screenshots to show other users what OS/distribution you’re
: running, what theme/icons you’re using and more.
## Phillip B
neofetch is already in the normal repository??? I have used it for a couple years
## Jens Petersen
The hledger command-line is already in Fedora. 🙂
We are just one dependency away from being able to package the hledger-web UI too.
## Niyas C
Finally, neofetch is landing on Fedora. I was curious to try it on other distributions, since I saw it on Solus for the first time. I think, it is more colorful comparing to screenfetch
## Bruno
It would be kool if Copr allowed multiple persons to sign the package. It would allow to have a bit more trust into these binaries. Obviously, it is not a absolute insurance, but if multiple persons get the sources, apply some patch and basically redo the same operation, check that they have the same results and sign for it .
Especially today, with multiple issues with packages including malwares.
## Sascha Biermanns
Hi there!
Do I miss the point? Neofetch is already in the normal Fedora repository, an easy sudo dnf install neofetch without installing a COPR-repo does the trick. Just checked the server: https://dl.fedoraproject.org/pub/fedora/linux/releases/28/Everything/x86_64/os/Packages/n/neofetch-3.4.0-1.fc28.noarch.rpm
Best regards,
Sascha
## Alejandro
Nice article, but neofetch is on the Fedora repo. There’s no need to enable COPR repository for it.
From “dnf info neofetch”:
Installed Packages
Name : neofetch
Version : 3.4.0
Release : 1.fc28
Arch : noarch
Size : 279 k
Source : neofetch-3.4.0-1.fc28.src.rpm
Repo : @System
From repo : fedora
Summary : CLI system information tool written in Bash
URL : https://github.com/dylanaraps/neofetch
License : MIT
Description : Neofetch displays information about your system next to an image,
: your OS logo, or any ASCII file of your choice. The main purpose
: of Neofetch is to be used in screenshots to show other users what
: OS/distribution you’re running, what theme/icons you’re using and
: more.
## clime
From Copr, you can get a newer version of neofetch though.
## Allen Halsey
Similar to
is the
command from the
package, which is in the Fedora repo.
## clime
I don’t think we need to sign packages per se to indicate the trust in them. But we need or will need a karma-based system in Copr. If anyone is interested in implementing it into Copr, please, let me know at [email protected]. |
9,895 | Linux 下 cut 命令的 4 个基础实用的示例 | https://linuxhandbook.com/cut-command/ | 2018-08-03T23:29:00 | [
"cut"
] | https://linux.cn/article-9895-1.html | `cut` 命令是用来从文本文件中移除“某些列”的经典工具。在本文中的“一列”可以被定义为按照一行中位置区分的一系列字符串或者字节,或者是以某个分隔符为间隔的某些域。
先前我已经介绍了[如何使用 AWK 命令](https://linuxhandbook.com/awk-command-tutorial/)。在本文中,我将解释 linux 下 `cut` 命令的 4 个本质且实用的例子,有时这些例子将帮你节省很多时间。

### Linux 下 cut 命令的 4 个实用示例
假如你想,你可以观看下面的视频,视频中解释了本文中我列举的 cut 命令的使用例子。
* <https://www.youtube.com/PhE_cFLzVFw>
### 1、 作用在一系列字符上
当启用 `-c` 命令行选项时,`cut` 命令将移除一系列字符。
和其他的过滤器类似, `cut` 命令不会直接改变输入的文件,它将复制已修改的数据到它的标准输出里去。你可以通过重定向命令的结果到一个文件中来保存修改后的结果,或者使用管道将结果送到另一个命令的输入中,这些都由你来负责。
假如你已经下载了上面视频中的[示例测试文件](https://static.yesik.it/EP22/Yes_I_Know_IT-EP22.tar.gz),你将看到一个名为 `BALANCE.txt` 的数据文件,这些数据是直接从我妻子在她工作中使用的某款会计软件中导出的:
```
sh$ head BALANCE.txt
ACCDOC ACCDOCDATE ACCOUNTNUM ACCOUNTLIB ACCDOCLIB DEBIT CREDIT
4 1012017 623477 TIDE SCHEDULE ALNEENRE-4701-LOC 00000001615,00
4 1012017 445452 VAT BS/ENC ALNEENRE-4701-LOC 00000000323,00
4 1012017 4356 PAYABLES ALNEENRE-4701-LOC 00000001938,00
5 1012017 623372 ACCOMODATION GUIDE ALNEENRE-4771-LOC 00000001333,00
5 1012017 445452 VAT BS/ENC ALNEENRE-4771-LOC 00000000266,60
5 1012017 4356 PAYABLES ALNEENRE-4771-LOC 00000001599,60
6 1012017 4356 PAYABLES FACT FA00006253 - BIT QUIROBEN 00000001837,20
6 1012017 445452 VAT BS/ENC FACT FA00006253 - BIT QUIROBEN 00000000306,20
6 1012017 623795 TOURIST GUIDE BOOK FACT FA00006253 - BIT QUIROBEN 00000001531,00
```
上述文件是一个固定宽度的文本文件,因为对于每一项数据,都使用了不定长的空格做填充,使得它看起来是一个对齐的列表。
这样一来,每一列数据开始和结束的位置都是一致的。从 `cut` 命令的字面意思去理解会给我们带来一个小陷阱:`cut` 命令实际上需要你指出你想*保留*的数据范围,而不是你想*移除*的范围。所以,假如我*只*需要上面文件中的 `ACCOUNTNUM` 和 `ACCOUNTLIB` 列,我需要这么做:
```
sh$ cut -c 25-59 BALANCE.txt | head
ACCOUNTNUM ACCOUNTLIB
623477 TIDE SCHEDULE
445452 VAT BS/ENC
4356 /accountPAYABLES
623372 ACCOMODATION GUIDE
445452 VAT BS/ENC
4356 PAYABLES
4356 PAYABLES
445452 VAT BS/ENC
623795 TOURIST GUIDE BOOK
```
#### 范围如何定义?
正如我们上面看到的那样, `cut` 命令需要我们特别指定需要保留的数据的*范围*。所以,下面我将更正式地介绍如何定义范围:对于 `cut` 命令来说,范围是由连字符(`-`)分隔的起始和结束位置组成,范围是基于 1 计数的,即每行的第一项是从 1 开始计数的,而不是从 0 开始。范围是一个闭区间,开始和结束位置都将包含在结果之中,正如它们之间的所有字符那样。如果范围中的结束位置比起始位置小,则这种表达式是错误的。作为快捷方式,你可以省略起始*或*结束值,正如下面的表格所示:
| 范围 | 含义 |
| --- | --- |
| `a-b` | a 和 b 之间的范围(闭区间) |
| `a` | 与范围 `a-a` 等价 |
| `-b` | 与范围 `1-a` 等价 |
| `b-` | 与范围 `b-∞` 等价 |
`cut` 命令允许你通过逗号分隔多个范围,下面是一些示例:
```
# 保留 1 到 24 之间(闭区间)的字符
cut -c -24 BALANCE.txt
# 保留 1 到 24(闭区间)以及 36 到 59(闭区间)之间的字符
cut -c -24,36-59 BALANCE.txt
# 保留 1 到 24(闭区间)、36 到 59(闭区间)和 93 到该行末尾之间的字符
cut -c -24,36-59,93- BALANCE.txt
```
`cut` 命令的一个限制(或者是特性,取决于你如何看待它)是它将 *不会对数据进行重排*。所以下面的命令和先前的命令将产生相同的结果,尽管范围的顺序做了改变:
```
cut -c 93-,-24,36-59 BALANCE.txt
```
你可以轻易地使用 `diff` 命令来验证:
```
diff -s <(cut -c -24,36-59,93- BALANCE.txt) \
<(cut -c 93-,-24,36-59 BALANCE.txt)
Files /dev/fd/63 and /dev/fd/62 are identical
```
类似的,`cut` 命令 *不会重复数据*:
```
# 某人或许期待这可以第一列三次,但并不会……
cut -c -10,-10,-10 BALANCE.txt | head -5
ACCDOC
4
4
4
5
```
值得提及的是,曾经有一个提议,建议使用 `-o` 选项来去除上面提到的两个限制,使得 `cut` 工具可以重排或者重复数据。但这个提议被 [POSIX 委员会拒绝了](http://pubs.opengroup.org/onlinepubs/9699919799/utilities/cut.html#tag_20_28_18),*“因为这类增强不属于 IEEE P1003.2b 草案标准的范围”*。
据我所知,我还没有见过哪个版本的 `cut` 程序实现了上面的提议,以此来作为扩展,假如你知道某些例外,请使用下面的评论框分享给大家!
### 2、 作用在一系列字节上
当使用 `-b` 命令行选项时,`cut` 命令将移除字节范围。
咋一看,使用*字符*范围和使用*字节*没有什么明显的不同:
```
sh$ diff -s <(cut -b -24,36-59,93- BALANCE.txt) \
<(cut -c -24,36-59,93- BALANCE.txt)
Files /dev/fd/63 and /dev/fd/62 are identical
```
这是因为我们的示例数据文件使用的是 [US-ASCII 编码](https://en.wikipedia.org/wiki/ASCII#Character_set)(字符集),使用 `file -i` 便可以正确地猜出来:
```
sh$ file -i BALANCE.txt
BALANCE.txt: text/plain; charset=us-ascii
```
在 US-ASCII 编码中,字符和字节是一一对应的。理论上,你只需要使用一个字节就可以表示 256 个不同的字符(数字、字母、标点符号和某些符号等)。实际上,你能表达的字符数比 256 要更少一些,因为字符编码中为某些特定值做了规定(例如 32 或 65 就是[控制字符](https://en.wikipedia.org/wiki/Control_character))。即便我们能够使用上述所有的字节范围,但对于存储种类繁多的人类手写符号来说,256 是远远不够的。所以如今字符和字节间的一一对应更像是某种例外,并且几乎总是被无处不在的 UTF-8 多字节编码所取代。下面让我们看看如何来处理多字节编码的情形。
#### 作用在多字节编码的字符上
正如我前面提到的那样,示例数据文件来源于我妻子使用的某款会计软件。最近好像她升级了那个软件,然后呢,导出的文本就完全不同了,你可以试试和上面的数据文件相比,找找它们之间的区别:
```
sh$ head BALANCE-V2.txt
ACCDOC ACCDOCDATE ACCOUNTNUM ACCOUNTLIB ACCDOCLIB DEBIT CREDIT
4 1012017 623477 TIDE SCHEDULE ALNÉENRE-4701-LOC 00000001615,00
4 1012017 445452 VAT BS/ENC ALNÉENRE-4701-LOC 00000000323,00
4 1012017 4356 PAYABLES ALNÉENRE-4701-LOC 00000001938,00
5 1012017 623372 ACCOMODATION GUIDE ALNÉENRE-4771-LOC 00000001333,00
5 1012017 445452 VAT BS/ENC ALNÉENRE-4771-LOC 00000000266,60
5 1012017 4356 PAYABLES ALNÉENRE-4771-LOC 00000001599,60
6 1012017 4356 PAYABLES FACT FA00006253 - BIT QUIROBEN 00000001837,20
6 1012017 445452 VAT BS/ENC FACT FA00006253 - BIT QUIROBEN 00000000306,20
6 1012017 623795 TOURIST GUIDE BOOK FACT FA00006253 - BIT QUIROBEN 00000001531,00
```
上面的标题栏或许能够帮助你找到什么被改变了,但无论你找到与否,现在让我们看看上面的更改过后的结果:
```
sh$ cut -c 93-,-24,36-59 BALANCE-V2.txt
ACCDOC ACCDOCDATE ACCOUNTLIB DEBIT CREDIT
4 1012017 TIDE SCHEDULE 00000001615,00
4 1012017 VAT BS/ENC 00000000323,00
4 1012017 PAYABLES 00000001938,00
5 1012017 ACCOMODATION GUIDE 00000001333,00
5 1012017 VAT BS/ENC 00000000266,60
5 1012017 PAYABLES 00000001599,60
6 1012017 PAYABLES 00000001837,20
6 1012017 VAT BS/ENC 00000000306,20
6 1012017 TOURIST GUIDE BOOK 00000001531,00
19 1012017 SEMINAR FEES 00000000080,00
19 1012017 PAYABLES 00000000080,00
28 1012017 MAINTENANCE 00000000746,58
28 1012017 VAT BS/ENC 00000000149,32
28 1012017 PAYABLES 00000000895,90
31 1012017 PAYABLES 00000000240,00
31 1012017 VAT BS/DEBIT 00000000040,00
31 1012017 ADVERTISEMENTS 00000000200,00
32 1012017 WATER 00000000202,20
32 1012017 VAT BS/DEBIT 00000000020,22
32 1012017 WATER 00000000170,24
32 1012017 VAT BS/DEBIT 00000000009,37
32 1012017 PAYABLES 00000000402,03
34 1012017 RENTAL COSTS 00000000018,00
34 1012017 PAYABLES 00000000018,00
35 1012017 MISCELLANEOUS CHARGES 00000000015,00
35 1012017 VAT BS/DEBIT 00000000003,00
35 1012017 PAYABLES 00000000018,00
36 1012017 LANDLINE TELEPHONE 00000000069,14
36 1012017 VAT BS/ENC 00000000013,83
```
我*毫无删减地*复制了上面命令的输出。所以可以很明显地看出列对齐那里有些问题。
对此我的解释是原来的数据文件只包含 US-ASCII 编码的字符(符号、标点符号、数字和没有发音符号的拉丁字母)。
但假如你仔细地查看经软件升级后产生的文件,你可以看到新导出的数据文件保留了带发音符号的字母。例如现在合理地记录了名为 “ALNÉENRE” 的公司,而不是先前的 “ALNEENRE”(没有发音符号)。
`file -i` 正确地识别出了改变,因为它报告道现在这个文件是 [UTF-8 编码](https://en.wikipedia.org/wiki/UTF-8#Codepage_layout) 的。
```
sh$ file -i BALANCE-V2.txt
BALANCE-V2.txt: text/plain; charset=utf-8
```
如果想看看 UTF-8 文件中那些带发音符号的字母是如何编码的,我们可以使用 `[hexdump][12]`,它可以让我们直接以字节形式查看文件:
```
# 为了减少输出,让我们只关注文件的第 2 行
sh$ sed '2!d' BALANCE-V2.txt
4 1012017 623477 TIDE SCHEDULE ALNÉENRE-4701-LOC 00000001615,00
sh$ sed '2!d' BALANCE-V2.txt | hexdump -C
00000000 34 20 20 20 20 20 20 20 20 20 31 30 31 32 30 31 |4 101201|
00000010 37 20 20 20 20 20 20 20 36 32 33 34 37 37 20 20 |7 623477 |
00000020 20 20 20 54 49 44 45 20 53 43 48 45 44 55 4c 45 | TIDE SCHEDULE|
00000030 20 20 20 20 20 20 20 20 20 20 20 41 4c 4e c3 89 | ALN..|
00000040 45 4e 52 45 2d 34 37 30 31 2d 4c 4f 43 20 20 20 |ENRE-4701-LOC |
00000050 20 20 20 20 20 20 20 20 20 20 20 20 20 30 30 30 | 000|
00000060 30 30 30 30 31 36 31 35 2c 30 30 20 20 20 20 20 |00001615,00 |
00000070 20 20 20 20 20 20 20 20 20 20 20 0a | .|
0000007c
```
在 `hexdump` 输出的 00000030 那行,在一系列的空格(字节 `20`)之后,你可以看到:
* 字母 `A` 被编码为 `41`,
* 字母 `L` 被编码为 `4c`,
* 字母 `N` 被编码为 `4e`。
但对于大写的[带有注音的拉丁大写字母 E](https://www.fileformat.info/info/unicode/char/00c9/index.htm) (这是它在 Unicode 标准中字母 *É* 的官方名称),则是使用 *2* 个字节 `c3 89` 来编码的。
这样便出现问题了:对于使用固定宽度编码的文件, 使用字节位置来表示范围的 `cut` 命令工作良好,但这并不适用于使用变长编码的 UTF-8 或者 [Shift JIS](https://en.wikipedia.org/wiki/Shift_JIS#Shift_JIS_byte_map) 编码。这种情况在下面的 [POSIX 标准的非规范性摘录](http://pubs.opengroup.org/onlinepubs/9699919799/utilities/cut.html#tag_20_28_16) 中被明确地解释过:
>
> 先前版本的 `cut` 程序将字节和字符视作等同的环境下运作(正如在某些实现下对退格键 `<backspace>` 和制表键 `<tab>` 的处理)。在针对多字节字符的情况下,特别增加了 `-b` 选项。
>
>
>
嘿,等一下!我并没有在上面“有错误”的例子中使用 '-b' 选项,而是 `-c` 选项呀!所以,难道*不应该*能够成功处理了吗!?
是的,确实*应该*:但是很不幸,即便我们现在已身处 2018 年,GNU Coreutils 的版本为 8.30 了,`cut` 程序的 GNU 版本实现仍然不能很好地处理多字节字符。引用 [GNU 文档](https://www.gnu.org/software/coreutils/manual/html_node/cut-invocation.html#cut-invocation) 的话说,*`-c` 选项“现在和 `-b` 选项是相同的,但对于国际化的情形将有所不同[...]”*。需要提及的是,这个问题距今已有 10 年之久了!
另一方面,[OpenBSD](https://www.openbsd.org/) 的实现版本和 POSIX 相吻合,这将归功于当前的本地化(`locale`)设定来合理地处理多字节字符:
```
# 确保随后的命令知晓我们现在处理的是 UTF-8 编码的文本文件
openbsd-6.3$ export LC_CTYPE=en_US.UTF-8
# 使用 `-c` 选项, `cut` 能够合理地处理多字节字符
openbsd-6.3$ cut -c -24,36-59,93- BALANCE-V2.txt
ACCDOC ACCDOCDATE ACCOUNTLIB DEBIT CREDIT
4 1012017 TIDE SCHEDULE 00000001615,00
4 1012017 VAT BS/ENC 00000000323,00
4 1012017 PAYABLES 00000001938,00
5 1012017 ACCOMODATION GUIDE 00000001333,00
5 1012017 VAT BS/ENC 00000000266,60
5 1012017 PAYABLES 00000001599,60
6 1012017 PAYABLES 00000001837,20
6 1012017 VAT BS/ENC 00000000306,20
6 1012017 TOURIST GUIDE BOOK 00000001531,00
19 1012017 SEMINAR FEES 00000000080,00
19 1012017 PAYABLES 00000000080,00
28 1012017 MAINTENANCE 00000000746,58
28 1012017 VAT BS/ENC 00000000149,32
28 1012017 PAYABLES 00000000895,90
31 1012017 PAYABLES 00000000240,00
31 1012017 VAT BS/DEBIT 00000000040,00
31 1012017 ADVERTISEMENTS 00000000200,00
32 1012017 WATER 00000000202,20
32 1012017 VAT BS/DEBIT 00000000020,22
32 1012017 WATER 00000000170,24
32 1012017 VAT BS/DEBIT 00000000009,37
32 1012017 PAYABLES 00000000402,03
34 1012017 RENTAL COSTS 00000000018,00
34 1012017 PAYABLES 00000000018,00
35 1012017 MISCELLANEOUS CHARGES 00000000015,00
35 1012017 VAT BS/DEBIT 00000000003,00
35 1012017 PAYABLES 00000000018,00
36 1012017 LANDLINE TELEPHONE 00000000069,14
36 1012017 VAT BS/ENC 00000000013,83
```
正如期望的那样,当使用 `-b` 选项而不是 `-c` 选项后, OpenBSD 版本的 `cut` 实现和传统的 `cut` 表现是类似的:
```
openbsd-6.3$ cut -b -24,36-59,93- BALANCE-V2.txt
ACCDOC ACCDOCDATE ACCOUNTLIB DEBIT CREDIT
4 1012017 TIDE SCHEDULE 00000001615,00
4 1012017 VAT BS/ENC 00000000323,00
4 1012017 PAYABLES 00000001938,00
5 1012017 ACCOMODATION GUIDE 00000001333,00
5 1012017 VAT BS/ENC 00000000266,60
5 1012017 PAYABLES 00000001599,60
6 1012017 PAYABLES 00000001837,20
6 1012017 VAT BS/ENC 00000000306,20
6 1012017 TOURIST GUIDE BOOK 00000001531,00
19 1012017 SEMINAR FEES 00000000080,00
19 1012017 PAYABLES 00000000080,00
28 1012017 MAINTENANCE 00000000746,58
28 1012017 VAT BS/ENC 00000000149,32
28 1012017 PAYABLES 00000000895,90
31 1012017 PAYABLES 00000000240,00
31 1012017 VAT BS/DEBIT 00000000040,00
31 1012017 ADVERTISEMENTS 00000000200,00
32 1012017 WATER 00000000202,20
32 1012017 VAT BS/DEBIT 00000000020,22
32 1012017 WATER 00000000170,24
32 1012017 VAT BS/DEBIT 00000000009,37
32 1012017 PAYABLES 00000000402,03
34 1012017 RENTAL COSTS 00000000018,00
34 1012017 PAYABLES 00000000018,00
35 1012017 MISCELLANEOUS CHARGES 00000000015,00
35 1012017 VAT BS/DEBIT 00000000003,00
35 1012017 PAYABLES 00000000018,00
36 1012017 LANDLINE TELEPHONE 00000000069,14
36 1012017 VAT BS/ENC 00000000013,83
```
### 3、 作用在域上
从某种意义上说,使用 `cut` 来处理用特定分隔符隔开的文本文件要更加容易一些,因为只需要确定好每行中域之间的分隔符,然后复制域的内容到输出就可以了,而不需要烦恼任何与编码相关的问题。
下面是一个用分隔符隔开的示例文本文件:
```
sh$ head BALANCE.csv
ACCDOC;ACCDOCDATE;ACCOUNTNUM;ACCOUNTLIB;ACCDOCLIB;DEBIT;CREDIT
4;1012017;623477;TIDE SCHEDULE;ALNEENRE-4701-LOC;00000001615,00;
4;1012017;445452;VAT BS/ENC;ALNEENRE-4701-LOC;00000000323,00;
4;1012017;4356;PAYABLES;ALNEENRE-4701-LOC;;00000001938,00
5;1012017;623372;ACCOMODATION GUIDE;ALNEENRE-4771-LOC;00000001333,00;
5;1012017;445452;VAT BS/ENC;ALNEENRE-4771-LOC;00000000266,60;
5;1012017;4356;PAYABLES;ALNEENRE-4771-LOC;;00000001599,60
6;1012017;4356;PAYABLES;FACT FA00006253 - BIT QUIROBEN;;00000001837,20
6;1012017;445452;VAT BS/ENC;FACT FA00006253 - BIT QUIROBEN;00000000306,20;
6;1012017;623795;TOURIST GUIDE BOOK;FACT FA00006253 - BIT QUIROBEN;00000001531,00;
```
你可能知道上面文件是一个 [CSV](https://en.wikipedia.org/wiki/Comma-separated_values) 格式的文件(它以逗号来分隔),即便有时候域分隔符不是逗号。例如分号(`;`)也常被用来作为分隔符,并且对于那些总使用逗号作为 [十进制分隔符](https://en.wikipedia.org/wiki/Decimal_separator)的国家(例如法国,所以上面我的示例文件中选用了他们国家的字符),当导出数据为 “CSV” 格式时,默认将使用分号来分隔数据。另一种常见的情况是使用 [tab 键](https://en.wikipedia.org/wiki/Tab-separated_values) 来作为分隔符,从而生成叫做 [tab 分隔的值](https://en.wikipedia.org/wiki/Tab-separated_values) 的文件。最后,在 Unix 和 Linux 领域,冒号 (`:`) 是另一种你能找到的常见分隔符号,例如在标准的 `/etc/passwd` 和 `/etc/group` 这两个文件里。
当处理使用分隔符隔开的文本文件格式时,你可以向带有 `-f` 选项的 `cut` 命令提供需要保留的域的范围,并且你也可以使用 `-d` 选项来指定分隔符(当没有使用 `-d` 选项时,默认以 tab 字符来作为分隔符):
```
sh$ cut -f 5- -d';' BALANCE.csv | head
ACCDOCLIB;DEBIT;CREDIT
ALNEENRE-4701-LOC;00000001615,00;
ALNEENRE-4701-LOC;00000000323,00;
ALNEENRE-4701-LOC;;00000001938,00
ALNEENRE-4771-LOC;00000001333,00;
ALNEENRE-4771-LOC;00000000266,60;
ALNEENRE-4771-LOC;;00000001599,60
FACT FA00006253 - BIT QUIROBEN;;00000001837,20
FACT FA00006253 - BIT QUIROBEN;00000000306,20;
FACT FA00006253 - BIT QUIROBEN;00000001531,00;
```
#### 处理不包含分隔符的行
但要是输入文件中的某些行没有分隔符又该怎么办呢?很容易地认为可以将这样的行视为只包含第一个域。但 `cut` 程序并 *不是* 这样做的。
默认情况下,当使用 `-f` 选项时,`cut` 将总是原样输出不包含分隔符的那一行(可能假设它是非数据行,就像表头或注释等):
```
sh$ (echo "# 2018-03 BALANCE"; cat BALANCE.csv) > BALANCE-WITH-HEADER.csv
sh$ cut -f 6,7 -d';' BALANCE-WITH-HEADER.csv | head -5
# 2018-03 BALANCE
DEBIT;CREDIT
00000001615,00;
00000000323,00;
;00000001938,00
```
使用 `-s` 选项,你可以做出相反的行为,这样 `cut` 将总是忽略这些行:
```
sh$ cut -s -f 6,7 -d';' BALANCE-WITH-HEADER.csv | head -5
DEBIT;CREDIT
00000001615,00;
00000000323,00;
;00000001938,00
00000001333,00;
```
假如你好奇心强,你还可以探索这种特性,来作为一种相对隐晦的方式去保留那些只包含给定字符的行:
```
# 保留含有一个 `e` 的行
sh$ printf "%s\n" {mighty,bold,great}-{condor,monkey,bear} | cut -s -f 1- -d'e'
```
#### 改变输出的分隔符
作为一种扩展, GNU 版本实现的 `cut` 允许通过使用 `--output-delimiter` 选项来为结果指定一个不同的域分隔符:
```
sh$ cut -f 5,6- -d';' --output-delimiter="*" BALANCE.csv | head
ACCDOCLIB*DEBIT*CREDIT
ALNEENRE-4701-LOC*00000001615,00*
ALNEENRE-4701-LOC*00000000323,00*
ALNEENRE-4701-LOC**00000001938,00
ALNEENRE-4771-LOC*00000001333,00*
ALNEENRE-4771-LOC*00000000266,60*
ALNEENRE-4771-LOC**00000001599,60
FACT FA00006253 - BIT QUIROBEN**00000001837,20
FACT FA00006253 - BIT QUIROBEN*00000000306,20*
FACT FA00006253 - BIT QUIROBEN*00000001531,00*
```
需要注意的是,在上面这个例子中,所有出现域分隔符的地方都被替换掉了,而不仅仅是那些在命令行中指定的作为域范围边界的分隔符。
### 4、 非 POSIX GNU 扩展
说到非 POSIX GNU 扩展,它们中的某些特别有用。特别需要提及的是下面的扩展也同样对字节、字符或者域范围工作良好(相对于当前的 GNU 实现来说)。
`--complement`:
想想在 sed 地址中的感叹符号(`!`),使用它,`cut` 将只保存**没有**被匹配到的范围:
```
# 只保留第 5 个域
sh$ cut -f 5 -d';' BALANCE.csv |head -3
ACCDOCLIB
ALNEENRE-4701-LOC
ALNEENRE-4701-LOC
# 保留除了第 5 个域之外的内容
sh$ cut --complement -f 5 -d';' BALANCE.csv |head -3
ACCDOC;ACCDOCDATE;ACCOUNTNUM;ACCOUNTLIB;DEBIT;CREDIT
4;1012017;623477;TIDE SCHEDULE;00000001615,00;
4;1012017;445452;VAT BS/ENC;00000000323,00;
```
`--zero-terminated (-z)`:
使用 [NUL 字符](https://en.wikipedia.org/wiki/Null_character) 来作为行终止符,而不是 [<ruby> 新行 <rt> newline </rt></ruby>字符](https://en.wikipedia.org/wiki/Newline)。当你的数据包含 新行字符时, `-z` 选项就特别有用了,例如当处理文件名的时候(因为在文件名中新行字符是可以使用的,而 NUL 则不可以)。
为了展示 `-z` 选项,让我们先做一点实验。首先,我们将创建一个文件名中包含换行符的文件:
```
bash$ touch $'EMPTY\nFILE\nWITH FUNKY\nNAME'.txt
bash$ ls -1 *.txt
BALANCE.txt
BALANCE-V2.txt
EMPTY?FILE?WITH FUNKY?NAME.txt
```
现在假设我想展示每个 `*.txt` 文件的前 5 个字符。一个想当然的解决方法将会失败:
```
sh$ ls -1 *.txt | cut -c 1-5
BALAN
BALAN
EMPTY
FILE
WITH
NAME.
```
你可以已经知道 [ls](https://linux.die.net/man/1/ls) 是为了[方便人类使用](http://lists.gnu.org/archive/html/coreutils/2014-02/msg00005.html)而特别设计的,并且在一个命令管道中使用它是一个反模式(确实是这样的)。所以让我们用 [find](https://linux.die.net/man/1/find) 来替换它:
```
sh$ find . -name '*.txt' -printf "%f\n" | cut -c 1-5
BALAN
EMPTY
FILE
WITH
NAME.
BALAN
```
上面的命令基本上产生了与先前类似的结果(尽管以不同的次序,因为 `ls` 会隐式地对文件名做排序,而 `find` 则不会)。
在上面的两个例子中,都有一个相同的问题,`cut` 命令不能区分 新行 字符是数据域的一部分(即文件名),还是作为最后标记的 新行 记号。但使用 NUL 字节(`\0`)来作为行终止符就将排除掉这种混淆的情况,使得我们最后可以得到期望的结果:
```
# 我被告知在某些旧版的 `tr` 程序中需要使用 `\000` 而不是 `\0` 来代表 NUL 字符(假如你需要这种改变请让我知晓!)
sh$ find . -name '*.txt' -printf "%f\0" | cut -z -c 1-5| tr '\0' '\n'
BALAN
EMPTY
BALAN
```
通过上面最后的例子,我们就达到了本文的最后部分了,所以我将让你自己试试 `-printf` 后面那个有趣的 `"%f\0"` 参数或者理解为什么我在管道的最后使用了 [tr](https://linux.die.net/man/1/tr) 命令。
### 使用 cut 命令可以实现更多功能
我只是列举了 `cut` 命令的最常见且在我眼中最基础的使用方式。你甚至可以将它以更加实用的方式加以运用,这取决于你的逻辑和想象。
不要再犹豫了,请使用下面的评论框贴出你的发现。最后一如既往的,假如你喜欢这篇文章,请不要忘记将它分享到你最喜爱网站和社交媒体中!
---
via: <https://linuxhandbook.com/cut-command/>
作者:[Sylvain Leroux](https://linuxhandbook.com/author/sylvain/) 译者:[FSSlc](https://github.com/FSSlc) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # cut Command Examples
The cut command in Linux allows removing data on each line of a file. Read this tutorial to know how to use it effectively to process text or CSV data file.
The cut command is the canonical tool to remove “columns” from a text file. In this context, a “column” can be defined as a range of characters or bytes identified by their physical position on the line, or a range of fields delimited by a separator.
I have written about [using AWK commands](https://linuxhandbook.com/awk-command-tutorial/) earlier. In this detailed guide, I’ll explain four essential and practical examples of cut command in Linux that will help you big time.
## 4 Practical examples of Cut command in Linux
If you prefer, you can watch this video explaining the same practical examples of cut command that I have listed in the article.
### 1. Working with character ranges
When invoked with the `-c`
command line option, the cut command will remove **character** ranges.
Like any other filter, the cut command does not change the input file in place but it will copy the modified data to its standard output. It is your responsibility to redirect the command output to a file to save the result or to use a pipe to send it as input to another command.
If you’ve downloaded the [sample test files](https://static.yesik.it/EP22/Yes_I_Know_IT-EP22.tar.gz) used in the video above, you can see the `BALANCE.txt`
data file, coming straight out of an accounting software my wife is using at her work:
```
sh$ head BALANCE.txt
ACCDOC ACCDOCDATE ACCOUNTNUM ACCOUNTLIB ACCDOCLIB DEBIT CREDIT
4 1012017 623477 TIDE SCHEDULE ALNEENRE-4701-LOC 00000001615,00
4 1012017 445452 VAT BS/ENC ALNEENRE-4701-LOC 00000000323,00
4 1012017 4356 PAYABLES ALNEENRE-4701-LOC 00000001938,00
5 1012017 623372 ACCOMODATION GUIDE ALNEENRE-4771-LOC 00000001333,00
5 1012017 445452 VAT BS/ENC ALNEENRE-4771-LOC 00000000266,60
5 1012017 4356 PAYABLES ALNEENRE-4771-LOC 00000001599,60
6 1012017 4356 PAYABLES FACT FA00006253 - BIT QUIROBEN 00000001837,20
6 1012017 445452 VAT BS/ENC FACT FA00006253 - BIT QUIROBEN 00000000306,20
6 1012017 623795 TOURIST GUIDE BOOK FACT FA00006253 - BIT QUIROBEN 00000001531,00
```
This is a fixed-width text file since the data fields are padded with a variable number of spaces to ensure they are displayed as a nicely aligned table.
As a corollary, a data column always starts and ends at the same character position on each line. There is a little pitfall though: despite its name, the `cut`
command actually requires you to specify the range of data you want to *keep*, not the range you want to *remove*. So, if I need *only* the `ACCOUNTNUM`
and `ACCOUNTLIB`
columns in the data file above, I would write that:
```
sh$ cut -c 25-59 BALANCE.txt | head
ACCOUNTNUM ACCOUNTLIB
623477 TIDE SCHEDULE
445452 VAT BS/ENC
4356 /accountPAYABLES
623372 ACCOMODATION GUIDE
445452 VAT BS/ENC
4356 PAYABLES
4356 PAYABLES
445452 VAT BS/ENC
623795 TOURIST GUIDE BOOK
```
#### What’s a range?
As we have just seen it, the cut command requires we specify the *range* of data we want to keep. So, let’s introduce more formally what is a range: for the `cut`
command, a range is defined by a starting and ending position separated by a hyphen. Ranges are 1-based, that is the first item of the line is the item number 1, not 0. Ranges are inclusive: the start and end will be preserved in the output, as well as all characters between them. It is an error to specify a range whose ending position is before (“lower”) than its starting position. As a shortcut, you can omit the start *or* end value as described in the table below:
`a-b`
: the range between a and b (inclusive)`a`
: equivalent to the range`a-a`
`-b`
: equivalent to`1-a`
`b-`
: equivalent to`b-∞`
The cut commands allow you to specify several ranges by separating them with a comma. Here are a couple of examples:
```
# Keep characters from 1 to 24 (inclusive)
cut -c -24 BALANCE.txt
# Keep characters from 1 to 24 and 36 to 59 (inclusive)
cut -c -24,36-59 BALANCE.txt
# Keep characters from 1 to 24, 36 to 59 and 93 to the end of the line (inclusive)
cut -c -24,36-59,93- BALANCE.txt
```
One limitation (or feature, depending on the way you see it) of the `cut`
command is that it will *never reorder the data*. So, the following command will produce exactly the same result as the previous one, despite the ranges being specified in a different order:
`cut -c 93-,-24,36-59 BALANCE.txt`
You can check that easily using the `diff`
command:
```
diff -s <(cut -c -24,36-59,93- BALANCE.txt) \
<(cut -c 93-,-24,36-59 BALANCE.txt)
Files /dev/fd/63 and /dev/fd/62 are identical
```
Similarly, the `cut`
command *never duplicates data*:
```
# One might expect that could be a way to repeat
# the first column three times, but no...
cut -c -10,-10,-10 BALANCE.txt | head -5
ACCDOC
4
4
4
5
```
Worth mentioning there was a proposal for a `-o`
option to lift those two last limitations, allowing the `cut`
utility to reorder or duplicate data. But this was [rejected by the POSIX committee](https://pubs.opengroup.org/onlinepubs/9699919799/utilities/cut.html#tag_20_28_18)*“because this type of enhancement is outside the scope of the IEEE P1003.2b draft standard.”*
As of myself, I don’t know any cut version implementing that proposal as an extension. But if you do, please, share that with us using the comment section!
### 2. Working with byte ranges
When invoked with the `-b`
command line option, the cut command will remove **byte** ranges.
At first sight, there is no obvious difference between *character* and *byte* ranges:
```
sh$ diff -s <(cut -b -24,36-59,93- BALANCE.txt) \
<(cut -c -24,36-59,93- BALANCE.txt)
Files /dev/fd/63 and /dev/fd/62 are identical
```
That’s because my sample data file is using the [US-ASCII character encoding](https://en.wikipedia.org/wiki/ASCII#Character_set) (“charset”) as the `file -i`
command can correctly guess it:
```
sh$ file -i BALANCE.txt
BALANCE.txt: text/plain; charset=us-ascii
```
In that character encoding, there is a one-to-one mapping between characters and bytes. Using only one byte, you can theoretically encode up to 256 different characters (digits, letters, punctuations, symbols, … ) In practice, that number is much lower since character encodings make provision for some special values (like the 32 or 65 [control characters](https://en.wikipedia.org/wiki/Control_character) generally found). Anyway, even if we could use the full byte range, that would be far from enough to store the variety of human writing. So, today, the one-to-one mapping between characters and byte is more the exception than the norm and is almost always replaced by the ubiquitous UTF-8 multibyte encoding. Let’s see now how the cut command could handle that.
#### Working with multibyte characters
As I said previously, the sample data files used as examples for that article are coming from an accounting software used by my wife. It appends she updated that software recently and, after that, the exported text files were subtlely different. I let you try spotting the difference by yourself:
```
sh$ head BALANCE-V2.txt
ACCDOC ACCDOCDATE ACCOUNTNUM ACCOUNTLIB ACCDOCLIB DEBIT CREDIT
4 1012017 623477 TIDE SCHEDULE ALNÉENRE-4701-LOC 00000001615,00
4 1012017 445452 VAT BS/ENC ALNÉENRE-4701-LOC 00000000323,00
4 1012017 4356 PAYABLES ALNÉENRE-4701-LOC 00000001938,00
5 1012017 623372 ACCOMODATION GUIDE ALNÉENRE-4771-LOC 00000001333,00
5 1012017 445452 VAT BS/ENC ALNÉENRE-4771-LOC 00000000266,60
5 1012017 4356 PAYABLES ALNÉENRE-4771-LOC 00000001599,60
6 1012017 4356 PAYABLES FACT FA00006253 - BIT QUIROBEN 00000001837,20
6 1012017 445452 VAT BS/ENC FACT FA00006253 - BIT QUIROBEN 00000000306,20
6 1012017 623795 TOURIST GUIDE BOOK FACT FA00006253 - BIT QUIROBEN 00000001531,00
```
The title of this section might help you in finding what has changed. But, found or not, let see now the consequences of that change:
```
sh$ cut -c 93-,-24,36-59 BALANCE-V2.txt
ACCDOC ACCDOCDATE ACCOUNTLIB DEBIT CREDIT
4 1012017 TIDE SCHEDULE 00000001615,00
4 1012017 VAT BS/ENC 00000000323,00
4 1012017 PAYABLES 00000001938,00
5 1012017 ACCOMODATION GUIDE 00000001333,00
5 1012017 VAT BS/ENC 00000000266,60
5 1012017 PAYABLES 00000001599,60
6 1012017 PAYABLES 00000001837,20
6 1012017 VAT BS/ENC 00000000306,20
6 1012017 TOURIST GUIDE BOOK 00000001531,00
19 1012017 SEMINAR FEES 00000000080,00
19 1012017 PAYABLES 00000000080,00
28 1012017 MAINTENANCE 00000000746,58
28 1012017 VAT BS/ENC 00000000149,32
28 1012017 PAYABLES 00000000895,90
31 1012017 PAYABLES 00000000240,00
31 1012017 VAT BS/DEBIT 00000000040,00
31 1012017 ADVERTISEMENTS 00000000200,00
32 1012017 WATER 00000000202,20
32 1012017 VAT BS/DEBIT 00000000020,22
32 1012017 WATER 00000000170,24
32 1012017 VAT BS/DEBIT 00000000009,37
32 1012017 PAYABLES 00000000402,03
34 1012017 RENTAL COSTS 00000000018,00
34 1012017 PAYABLES 00000000018,00
35 1012017 MISCELLANEOUS CHARGES 00000000015,00
35 1012017 VAT BS/DEBIT 00000000003,00
35 1012017 PAYABLES 00000000018,00
36 1012017 LANDLINE TELEPHONE 00000000069,14
36 1012017 VAT BS/ENC 00000000013,83
```
I have copied above the command output *in-extenso* so it should be obvious something has gone wrong with the column alignment.
The explanation is the original data file contained only US-ASCII characters (symbol, punctuations, numbers and Latin letters without any diacritical marks)
But if you look closely at the file produced after the software update, you can see that new export data file now preserves accented letters. For example, the company named “ALNÉENRE” is now properly spelled whereas it was previously exported as “ALNEENRE” (no accent)
The `file -i`
utility did not miss that change since it reports now the file as being [UTF-8 encoded](https://en.wikipedia.org/wiki/UTF-8#Codepage_layout):
```
sh$ file -i BALANCE-V2.txt
BALANCE-V2.txt: text/plain; charset=utf-8
```
To see how are encoded accented letters in an UTF-8 file, we can use the [ hexdump](https://linux.die.net/man/1/hexdump) utility that allows us to look directly at the bytes in a file:
```
# To reduce clutter, let's focus only on the second line of the file
sh$ sed '2!d' BALANCE-V2.txt
4 1012017 623477 TIDE SCHEDULE ALNÉENRE-4701-LOC 00000001615,00
sh$ sed '2!d' BALANCE-V2.txt | hexdump -C
00000000 34 20 20 20 20 20 20 20 20 20 31 30 31 32 30 31 |4 101201|
00000010 37 20 20 20 20 20 20 20 36 32 33 34 37 37 20 20 |7 623477 |
00000020 20 20 20 54 49 44 45 20 53 43 48 45 44 55 4c 45 | TIDE SCHEDULE|
00000030 20 20 20 20 20 20 20 20 20 20 20 41 4c 4e c3 89 | ALN..|
00000040 45 4e 52 45 2d 34 37 30 31 2d 4c 4f 43 20 20 20 |ENRE-4701-LOC |
00000050 20 20 20 20 20 20 20 20 20 20 20 20 20 30 30 30 | 000|
00000060 30 30 30 30 31 36 31 35 2c 30 30 20 20 20 20 20 |00001615,00 |
00000070 20 20 20 20 20 20 20 20 20 20 20 0a | .|
0000007c
```
On the line 00000030 of the `hexdump`
output, after a bunch of spaces (byte `20`
), you can see:
- the letter
`A`
is encoded as the byte`41`
, - the letter
`L`
is encoded a the byte`4c`
, - and the letter
`N`
is encoded as the byte`4e`
.
But, the uppercase [LATIN CAPITAL LETTER E WITH ACUTE](https://www.fileformat.info/info/unicode/char/00c9/index.htm) (as it is the official name of the letter *É* in the Unicode standard) is encoded using the *two* bytes `c3 89`
And here is the problem: using the `cut`
command with ranges expressed as byte positions works well for fixed length encodings, but not for variable length ones like UTF-8 or [Shift JIS](https://en.wikipedia.org/wiki/Shift_JIS#Shift_JIS_byte_map). This is clearly explained in the following [non-normative extract of the POSIX standard](https://pubs.opengroup.org/onlinepubs/9699919799/utilities/cut.html#tag_20_28_16):
Earlier versions of the cut utility worked in an environment where bytes and characters were considered equivalent (modulo <backspace> and <tab> processing in some implementations). In the extended world of multi-byte characters, the new -b option has been added.
Hey, wait a minute! I wasn’t using the `-b`
option in the “faulty” example above, but the `-c`
option. So, *shouldn’t* that have worked?!?
Yes, it *should*: it is unfortunate, but we are in 2018 and despite that, as of GNU Coreutils 8.30, the GNU implementation of the cut utility still does not handle multi-byte characters properly. To quote the [GNU documentation](https://www.gnu.org/software/coreutils/manual/html_node/cut-invocation.html#cut-invocation), the `-c`
option is *“The same as -b for now, but internationalization will change that[… ]”* — a mention that is present since more than 10 years now!
On the other hand, the [OpenBSD](https://www.openbsd.org/) implementation of the cut utility is POSIX compliant, and will honor the current locale settings to handle multi-byte characters properly:
```
# Ensure subseauent commands will know we are using UTF-8 encoded
# text files
openbsd-6.3$ export LC_CTYPE=en_US.UTF-8
# With the `-c` option, cut works properly with multi-byte characters
openbsd-6.3$ cut -c -24,36-59,93- BALANCE-V2.txt
ACCDOC ACCDOCDATE ACCOUNTLIB DEBIT CREDIT
4 1012017 TIDE SCHEDULE 00000001615,00
4 1012017 VAT BS/ENC 00000000323,00
4 1012017 PAYABLES 00000001938,00
5 1012017 ACCOMODATION GUIDE 00000001333,00
5 1012017 VAT BS/ENC 00000000266,60
5 1012017 PAYABLES 00000001599,60
6 1012017 PAYABLES 00000001837,20
6 1012017 VAT BS/ENC 00000000306,20
6 1012017 TOURIST GUIDE BOOK 00000001531,00
19 1012017 SEMINAR FEES 00000000080,00
19 1012017 PAYABLES 00000000080,00
28 1012017 MAINTENANCE 00000000746,58
28 1012017 VAT BS/ENC 00000000149,32
28 1012017 PAYABLES 00000000895,90
31 1012017 PAYABLES 00000000240,00
31 1012017 VAT BS/DEBIT 00000000040,00
31 1012017 ADVERTISEMENTS 00000000200,00
32 1012017 WATER 00000000202,20
32 1012017 VAT BS/DEBIT 00000000020,22
32 1012017 WATER 00000000170,24
32 1012017 VAT BS/DEBIT 00000000009,37
32 1012017 PAYABLES 00000000402,03
34 1012017 RENTAL COSTS 00000000018,00
34 1012017 PAYABLES 00000000018,00
35 1012017 MISCELLANEOUS CHARGES 00000000015,00
35 1012017 VAT BS/DEBIT 00000000003,00
35 1012017 PAYABLES 00000000018,00
36 1012017 LANDLINE TELEPHONE 00000000069,14
36 1012017 VAT BS/ENC 00000000013,83
```
As expected, when using the `-b`
byte mode instead of the `-c`
character mode, the OpenBSD cut implementation behave like the legacy `cut`
:
```
openbsd-6.3$ cut -b -24,36-59,93- BALANCE-V2.txt
ACCDOC ACCDOCDATE ACCOUNTLIB DEBIT CREDIT
4 1012017 TIDE SCHEDULE 00000001615,00
4 1012017 VAT BS/ENC 00000000323,00
4 1012017 PAYABLES 00000001938,00
5 1012017 ACCOMODATION GUIDE 00000001333,00
5 1012017 VAT BS/ENC 00000000266,60
5 1012017 PAYABLES 00000001599,60
6 1012017 PAYABLES 00000001837,20
6 1012017 VAT BS/ENC 00000000306,20
6 1012017 TOURIST GUIDE BOOK 00000001531,00
19 1012017 SEMINAR FEES 00000000080,00
19 1012017 PAYABLES 00000000080,00
28 1012017 MAINTENANCE 00000000746,58
28 1012017 VAT BS/ENC 00000000149,32
28 1012017 PAYABLES 00000000895,90
31 1012017 PAYABLES 00000000240,00
31 1012017 VAT BS/DEBIT 00000000040,00
31 1012017 ADVERTISEMENTS 00000000200,00
32 1012017 WATER 00000000202,20
32 1012017 VAT BS/DEBIT 00000000020,22
32 1012017 WATER 00000000170,24
32 1012017 VAT BS/DEBIT 00000000009,37
32 1012017 PAYABLES 00000000402,03
34 1012017 RENTAL COSTS 00000000018,00
34 1012017 PAYABLES 00000000018,00
35 1012017 MISCELLANEOUS CHARGES 00000000015,00
35 1012017 VAT BS/DEBIT 00000000003,00
35 1012017 PAYABLES 00000000018,00
36 1012017 LANDLINE TELEPHONE 00000000069,14
36 1012017 VAT BS/ENC 00000000013,83
```
### 3. Working with fields
In some sense, working with fields in a delimited text file is easier for the `cut`
utility, since it will only have to locate the (one byte) field delimiters on each row, copying then verbatim the field content to the output without bothering with any encoding issues.
Here is a sample delimited text file:
```
sh$ head BALANCE.csv
ACCDOC;ACCDOCDATE;ACCOUNTNUM;ACCOUNTLIB;ACCDOCLIB;DEBIT;CREDIT
4;1012017;623477;TIDE SCHEDULE;ALNEENRE-4701-LOC;00000001615,00;
4;1012017;445452;VAT BS/ENC;ALNEENRE-4701-LOC;00000000323,00;
4;1012017;4356;PAYABLES;ALNEENRE-4701-LOC;;00000001938,00
5;1012017;623372;ACCOMODATION GUIDE;ALNEENRE-4771-LOC;00000001333,00;
5;1012017;445452;VAT BS/ENC;ALNEENRE-4771-LOC;00000000266,60;
5;1012017;4356;PAYABLES;ALNEENRE-4771-LOC;;00000001599,60
6;1012017;4356;PAYABLES;FACT FA00006253 - BIT QUIROBEN;;00000001837,20
6;1012017;445452;VAT BS/ENC;FACT FA00006253 - BIT QUIROBEN;00000000306,20;
6;1012017;623795;TOURIST GUIDE BOOK;FACT FA00006253 - BIT QUIROBEN;00000001531,00;
```
You may know that file format as [CSV](https://en.wikipedia.org/wiki/Comma-separated_values) (for Comma-separated Value), even if the field separator is not always a comma. For example, the semi-colon (`;`
) is frequently encountered as a field separator, and it is often the default choice when exporting data as “CSV” in countries already using the comma as the [decimal separator](https://en.wikipedia.org/wiki/Decimal_separator) (like we do in France — hence the choice of that character in my sample file). Another popular variant uses a [tab character](https://en.wikipedia.org/wiki/Tab_key#Tab_characters) as the field separator, producing what is sometimes called a [tab-separated values](https://en.wikipedia.org/wiki/Tab-separated_values) file. Finally, in the Unix and Linux world, the colon (`:`
) is yet another relatively common field separator you may find, for example, in the standard `/etc/passwd`
and `/etc/group`
files.
When using a delimited text file format, you provide to the cut command the range of fields to keep using the `-f`
option, and you have to specify the delimiter using the `-d`
option (without the `-d`
option, the cut utility defaults to a tab character for the separator):
```
sh$ cut -f 5- -d';' BALANCE.csv | head
ACCDOCLIB;DEBIT;CREDIT
ALNEENRE-4701-LOC;00000001615,00;
ALNEENRE-4701-LOC;00000000323,00;
ALNEENRE-4701-LOC;;00000001938,00
ALNEENRE-4771-LOC;00000001333,00;
ALNEENRE-4771-LOC;00000000266,60;
ALNEENRE-4771-LOC;;00000001599,60
FACT FA00006253 - BIT QUIROBEN;;00000001837,20
FACT FA00006253 - BIT QUIROBEN;00000000306,20;
FACT FA00006253 - BIT QUIROBEN;00000001531,00;
```
#### Handling lines not containing the delimiter
But what if some line in the input file does not contain the delimiter? It is tempting to imagine that as a row containing only the first field. But this is *not* what the cut utility does.
By default, when using the `-f`
option, the cut utility will always output verbatim a line that does not contain the delimiter (probably assuming this is a non-data row like a header or comment of some sort):
```
sh$ (echo "# 2018-03 BALANCE"; cat BALANCE.csv) > BALANCE-WITH-HEADER.csv
sh$ cut -f 6,7 -d';' BALANCE-WITH-HEADER.csv | head -5
# 2018-03 BALANCE
DEBIT;CREDIT
00000001615,00;
00000000323,00;
;00000001938,00
```
Using the `-s`
option, you can reverse that behavior, so `cut`
will always ignore such line:
```
sh$ cut -s -f 6,7 -d';' BALANCE-WITH-HEADER.csv | head -5
DEBIT;CREDIT
00000001615,00;
00000000323,00;
;00000001938,00
00000001333,00;
```
If you are in a hackish mood, you can exploit that feature as a relatively obscure way to keep only lines containing a given character:
```
# Keep lines containing a `e`
sh$ printf "%s\n" {mighty,bold,great}-{condor,monkey,bear} | cut -s -f 1- -d'e'
```
#### Changing the output delimiter
As an extension, the GNU implementation of cut allows to use a different field separator for the output using the `--output-delimiter`
option:
```
sh$ cut -f 5,6- -d';' --output-delimiter="*" BALANCE.csv | head
ACCDOCLIB*DEBIT*CREDIT
ALNEENRE-4701-LOC*00000001615,00*
ALNEENRE-4701-LOC*00000000323,00*
ALNEENRE-4701-LOC**00000001938,00
ALNEENRE-4771-LOC*00000001333,00*
ALNEENRE-4771-LOC*00000000266,60*
ALNEENRE-4771-LOC**00000001599,60
FACT FA00006253 - BIT QUIROBEN**00000001837,20
FACT FA00006253 - BIT QUIROBEN*00000000306,20*
FACT FA00006253 - BIT QUIROBEN*00000001531,00*
```
Notice, in that case, all occurrences of the field separator are replaced, and not only those at the boundary of the ranges specified on the command line arguments.
### 4. Non-POSIX GNU extensions
Speaking of non-POSIX GNU extension, a couple of them that can be particularly useful. Worth mentioning the following extensions work equally well with the byte, character (for what that means in the current GNU implementation) or field ranges:`--complement`
Think of that option like the exclamation mark in a sed address (`!`
); instead of keeping the data matching the given range, `cut`
will keep data NOT matching the range
```
# Keep only field 5
sh$ cut -f 5 -d';' BALANCE.csv |head -3
ACCDOCLIB
ALNEENRE-4701-LOC
ALNEENRE-4701-LOC
# Keep all but field 5
sh$ cut --complement -f 5 -d';' BALANCE.csv |head -3
ACCDOC;ACCDOCDATE;ACCOUNTNUM;ACCOUNTLIB;DEBIT;CREDIT
4;1012017;623477;TIDE SCHEDULE;00000001615,00;
4;1012017;445452;VAT BS/ENC;00000000323,00;
```
`--zero-terminated`
(`-z`
)
use the [NUL character](https://en.wikipedia.org/wiki/Null_character) as the line terminator instead of the [newline character](https://en.wikipedia.org/wiki/Newline). The `-z`
option is particularly useful when your data may contain embedded newline characters, like when working with filenames (since newline is a valid character in a filename, but NUL isn’t).
To show you how the `-z`
option works, let’s make a little experiment. First, we will create a file whose name contains embedded new lines:
`bash$ touch`
Let’s now assume I want to display the first 5 characters of each `*.txt`
file name. A naive solution will miserably fail here:
```
sh$ ls -1 *.txt | cut -c 1-5
BALAN
BALAN
EMPTY
FILE
WITH
NAME.
```
You may have already read [ ls](https://linux.die.net/man/1/ls) was designed for
[human consumption](https://lists.gnu.org/archive/html/coreutils/2014-02/msg00005.html), and using it in a command pipeline is an anti-pattern (it is indeed). So let’s
[use the find command](https://linuxhandbook.com/find-command-examples/)instead:
```
sh$ find . -name '*.txt' -printf "%f\n" | cut -c 1-5
BALAN
EMPTY
FILE
WITH
NAME.
BALAN
```
and … that produced basically the same erroneous result as before (although in a different order because `ls`
implicitly sorts the filenames, something the `find`
command does not do).
The problem is in both cases, the `cut`
command can’t make the distinction between a newline character being part of a data field (the filename), and a newline character used as an end of record marker. But, using the NUL byte (`\0`
) as the line terminator clears the confusion so we can finally obtain the expected result:
```
# I was told (?) some old versions of tr require using \000 instead of \0
# to denote the NUL character (let me know if you needed that change!)
sh$ find . -name '*.txt' -printf "%f\0" | cut -z -c 1-5| tr '\0' '\n'
BALAN
EMPTY
BALAN
```
With that latest example, we are moving away from the core of this article, that was the `cut`
command. So, I will let you try to figure by yourself the meaning of the funky `"%f\0"`
after the [printf](https://linuxhandbook.com/bash-printf/) argument of the [find command](https://linuxhandbook.com/find-command-examples/) or why I used the [tr command](https://linuxhandbook.com/tr-command/) at the end of the pipeline.
### A lot more can be done with Cut command
I just showed the most common and in my opinion the most essential usage of Cut command. You can apply the command in even more practical ways. It depends on your logical reasoning and imagination.
Don’t hesitate to use the comment section below to post your findings. And, as always, if you like this article, don’t forget to share it on your favorite websites and social media!
[Sylvain Leroux](https://linuxhandbook.com/author/sylvain/)
Engineer by Passion, Teacher by Vocation. My goal is to share my enthusiasm for what I teach and prepare my students to develop their skills by themselves.
[Website](http://www.yesik.it/)France |
9,896 | CIP:延续 Linux 之光 | https://www.linux.com/blog/2018/6/cip-keeping-lights-linux | 2018-08-04T16:24:37 | [
"CIP",
"开源软件"
] | https://linux.cn/article-9896-1.html |
>
> CIP 的目标是创建一个基本的系统,使用开源软件来为我们现代社会的基础设施提供动力。
>
>
>

现如今,现代民用基础设施遍及各处 —— 发电厂、雷达系统、交通信号灯、水坝和天气系统等。这些基础设施项目已然存在数十年,这些设施还将继续提供更长时间的服务,所以安全性和使用寿命是至关重要的。
并且,其中许多系统都是由 Linux 提供支持,它为技术提供商提供了对这些问题的更多控制。然而,如果每个提供商都在构建自己的解决方案,这可能会导致分散和重复工作。因此,<ruby> <a href="https://www.cip-project.org/"> 民用基础设施平台 </a> <rt> Civil Infrastructure Platform </rt></ruby>(CIP)最首要的目标是创造一个开源基础层,提供给工业设施,例如嵌入式控制器或是网关设备。
担任 CIP 的技术指导委员会主席的 Yoshitake Kobayashi 说过,“我们在这个领域有一种非常保守的文化,因为一旦我们建立了一个系统,它必须得到长达十多年的支持,在某些情况下超过 60 年。这就是为什么这个项目被创建的原因,因为这个行业的每个使用者都面临同样的问题,即能够长时间地使用 Linux。”
CIP 的架构是创建一个非常基础的系统,以在控制器上使用开源软件。其中,该基础层包括 Linux 内核和一系列常见的开源软件如 libc、busybox 等。由于软件的使用寿命是一个最主要的问题,CIP 选择使用 Linux 4.4 版本的内核,这是一个由 Greg Kroah-Hartman 维护的长期支持版本。
### 合作
由于 CIP 有上游优先政策,因此他们在项目中需要的代码必须位于上游内核中。为了与内核社区建立积极的反馈循环,CIP 聘请 Ben Hutchings 作为 CIP 的官方维护者。Hutchings 以他在 Debian LTS 版本上所做的工作而闻名,这也促成了 CIP 与 Debian 项目之间的官方合作。
在新的合作下,CIP 将使用 Debian LTS 版本作为构建平台。 CIP 还将支持 Debian 长期支持版本(LTS),延长所有 Debian 稳定版的生命周期。CIP 还将与 Freexian 进行密切合作,后者是一家围绕 Debian LTS 版本提供商业服务的公司。这两个组织将专注于嵌入式系统的开源软件的互操作性、安全性和维护。CIP 还会为一些 Debian LTS 版本提供资金支持。
Debian 项目负责人 Chris Lamb 表示,“我们对此次合作以及 CIP 对 Debian LTS 项目的支持感到非常兴奋,这样将使支持周期延长至五年以上。我们将一起致力于为用户提供长期支持,并为未来的城市奠定基础。”
### 安全性
Kobayashi 说过,其中最需要担心的是安全性。虽然出于明显的安全原因,大部分民用基础设施没有接入互联网(你肯定不想让一座核电站连接到互联网),但也存在其他风险。
仅仅是系统本身没有连接到互联网,这并不意味着能避开所有危险。其他系统,比如个人移动电脑也能够通过接入互联网而间接入侵到本地系统中。如若有人收到一封带有恶意文件作为电子邮件的附件,这将会“污染”系统内部的基础设备。
因此,至关重要的是保持运行在这些控制器上的所有软件是最新的并且完全修补的。为了确保安全性,CIP 还向后移植了<ruby> 内核自我保护 <rt> Kernel Self Protection </rt></ruby>(KSP)项目的许多组件。CIP 还遵循最严格的网络安全标准之一 —— IEC 62443,该标准定义了软件的流程和相应的测试,以确保系统更安全。
### 展望未来
随着 CIP 日趋成熟,官方正在加大与各个 Linux 提供商的合作力度。除了与 Debian 和 freexian 的合作外,CIP 最近还邀请了企业 Linux 操作系统供应商 Cybertrust Japan Co., Ltd. 作为新的银牌成员。
Cybertrust 与其他行业领军者合作,如西门子、东芝、Codethink、日立、Moxa、Plat'Home 和瑞萨,致力于为未来数十年打造一个可靠、安全的基于 Linux 的嵌入式软件平台。
这些公司在 CIP 的保护下所进行的工作,将确保管理我们现代社会中的民用基础设施的完整性。
想要了解更多信息,请访问 [民用基础设施官网](https://www.cip-project.org/)。
---
via: <https://www.linux.com/blog/2018/6/cip-keeping-lights-linux>
作者:[Swapnil Bhartiya](https://www.linux.com/users/arnieswap) 选题:[lujun9972](https://github.com/lujun9972) 译者:[wyxplus](https://github.com/wyxplus) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,897 | Textricator:让数据提取变得简单 | https://opensource.com/article/18/7/textricator | 2018-08-04T20:03:00 | [
"数据",
"PDF",
"提取"
] | https://linux.cn/article-9897-1.html |
>
> 这个新的开源工具可以从 PDF 文档中提取复杂的数据,而无需编程技能。
>
>
>

你可能知道这种感觉:你请求得到数据并得到积极的响应,只打开电子邮件并发现一大堆附加的 PDF。数据——中断。
我们理解你的挫败感,并为此做了一些事情:让我们介绍下 [Textricator](https://textricator.mfj.io/),这是我们的第一个开源产品。
我们是 “Measures for Justice”(MFJ),一个刑事司法研究和透明度组织。我们的使命是为整个司法系统从逮捕到定罪后提供数据透明度。我们通过制定一系列多达 32 项指标来实现这一目标,涵盖每个县的整个刑事司法系统。我们以多种方式获取数据 —— 当然,所有这些都是合法的 —— 虽然许多州和县机构都掌握数据,可以为我们提供 CSV 格式的高质量格式化数据,但这些数据通常捆绑在软件中,没有简单的方法可以提取。PDF 报告是他们能提供的最佳报告。
开发者 Joe Hale 和 Stephen Byrne 在过去两年中一直在开发 Textricator,它用来提取数万页数据供我们内部使用。Textricator 可以处理几乎任何基于文本的 PDF 格式 —— 不仅仅是表格,还包括复杂的报表,其中包含从 Crystal Reports 等工具生成的文本和细节部分。只需告诉 Textricator 你要收集的字段的属性,它就会整理文档,收集并写出你的记录。
不是软件工程师?Textricator 不需要编程技巧。相反,用户描述 PDF 的结构,Textricator 处理其余部分。大多数用户通过命令行运行它。但是,你可以使用基于浏览器的 GUI。
我们评估了其他很好的开源解决方案,如 [Tabula](https://tabula.technology/),但它们无法处理我们需要抓取的一些 PDF 的结构。技术总监 Andrew Branch 说:“Textricator 既灵活又强大,缩短了我们花费大量时间处理大型数据集的时间。”
在 MFJ,我们致力于透明度和知识共享,其中包括向任何人提供我们的软件,特别是那些试图公开自由共享数据的人。Textricator 可以在 [GitHub](https://github.com/measuresforjustice/textricator) 上找到,并在 [GNU Affero 通用公共许可证第 3 版](https://www.gnu.org/licenses/agpl-3.0.en.html)下发布。
你可以在我们的免费[在线数据门户](https://www.measuresforjustice.org/portal/)上查看我们的工作成果,包括通过 Textricator 处理的数据。Textricator 是我们流程的重要组成部分,我们希望民间技术机构和政府组织都可以使用这个新工具解锁更多数据。
如果你使用 Textricator,请告诉我们它如何帮助你解决数据问题。想要改进吗?提交一个拉取请求。
---
via: <https://opensource.com/article/18/7/textricator>
作者:[Stephen Byrne](https://opensource.com/users/stephenbyrne-mfj) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | You probably know the feeling: You ask for data and get a positive response, only to open the email and find a whole bunch of PDFs attached. Data, interrupted.
We understand your frustration, and we’ve done something about it: Introducing [Textricator](https://textricator.mfj.io/), our first open source product.
We’re Measures for Justice, a criminal justice research and transparency organization. Our mission is to provide data transparency for the entire justice system, from arrest to post-conviction. We do this by producing a series of up to 32 performance measures covering the entire criminal justice system, county by county. We get our data in many ways—all legal, of course—and while many state and county agencies are data-savvy, giving us quality, formatted data in CSVs, the data is often bundled inside software with no simple way to get it out. PDF reports are the best they can offer.
Developers Joe Hale and Stephen Byrne have spent the past two years developing Textricator to extract tens of thousands of pages of data for our internal use. Textricator can process just about any text-based PDF format—not just tables, but complex reports with wrapping text and detail sections generated from tools like Crystal Reports. Simply tell Textricator the attributes of the fields you want to collect, and it chomps through the document, collecting and writing out your records.
Not a software engineer? Textricator doesn’t require programming skills; rather, the user describes the structure of the PDF and Textricator handles the rest. Most users run it via the command line; however, a browser-based GUI is available.
We evaluated other great open source solutions like [Tabula](https://tabula.technology/), but they just couldn’t handle the structure of some of the PDFs we needed to scrape. “Textricator is both flexible and powerful and has cut the time we spend to process large datasets from days to hours,” says Andrew Branch, director of technology.
At MFJ, we’re committed to transparency and knowledge-sharing, which includes making our software available to anyone, especially those trying to free and share data publicly. Textricator is available on [GitHub](https://github.com/measuresforjustice/textricator) and released under [GNU Affero General Public License Version 3](https://www.gnu.org/licenses/agpl-3.0.en.html).
You can see the results of our work, including data processed via Textricator, on our free [online data portal](https://www.measuresforjustice.org/portal/). Textricator is an essential part of our process and we hope civic tech and government organizations alike can unlock more data with this new tool.
If you use Textricator, let us know how it helped solve your data problem. Want to improve it? Submit a pull request.
## 1 Comment |
9,898 | 三款 Linux 下的 Git 图形客户端 | https://www.linux.com/learn/intro-to-linux/2018/7/three-graphical-clients-git-linux | 2018-08-05T22:49:53 | [
"Git"
] | https://linux.cn/article-9898-1.html |
>
> 了解这三个 Git 图形客户端工具如何增强你的开发流程。
>
>
>

在 Linux 下工作的人们对 [Git](https://git-scm.com/) 非常熟悉。一个理所当然的原因是,Git 是我们这个星球上最广为人知也是使用最广泛的版本控制工具。不过大多数情况下,Git 需要学习繁杂的终端命令。毕竟,我们的大多数开发工作可能是基于命令行的,那么没理由不以同样的方式与 Git 交互。
但在某些情况下,使用带图形界面的工具可能使你的工作更高效一点(起码对那些更倾向于使用图形界面的人们来说)。那么,有哪些 Git 图形客户端可供选择呢?幸运的是,我们找到一些客户端值得你花费时间和金钱(一些情况下)去尝试一下。在此,我主要推荐三种可以运行在 Linux 操作系统上的 Git 客户端。在这几种中,你可以找到一款满足你所有要求的客户端。
在这里我假设你理解如何使用 Git 和具有 GitHub 类似功能的代码仓库,[使用方法我之前讲过了](https://www.linux.com/learn/intro-to-linux/2018/7/introduction-using-git),因此我不再花费时间讲解如何使用这些工具。本篇文章主要是一篇介绍,介绍几种可以用在开发任务中的工具。
提前说明一下:这些工具并不都是免费的,它们中的一些可能需要商业授权。不过,它们都在 Linux 下运行良好并且可以轻而易举的和 GitHub 相结合。
就说这些了,快让我们看看这些出色的 Git 图形客户端吧。
### SmartGit
[SmartGit](https://www.syntevo.com/smartgit/) 是一个商业工具,不过如果你在非商业环境下使用是免费的。如果你打算在商业环境下使用的话,一个许可证每人每年需要 99 美元,或者 5.99 美元一个月。还有一些其它升级功能(比如<ruby> 分布式评审 <rt> Distributed Reviews </rt></ruby>和<ruby> 智能同步 <rt> SmartSynchronize </rt></ruby>),这两个工具每个许可证需要另加 15 美元。你也能通过下载源码或者 deb 安装包进行安装。我在 Ubuntu 18.04 下测试,发现 SmartGit 运行良好,没有出现一点问题。
不过,我们为什么要用 SmartGit 呢?有许多原因,最重要的一点是,SmartGit 可以非常方便的和 GitHub 以及 Subversion 等版本控制工具整合。不需要你花费宝贵的时间去配置各种远程账号,SmartGit 的这些功能开箱即用。SmartGit 的界面(图 1)设计的也很好,整洁直观。

*图 1: SmartGit 帮助简化工作*
安装完 SmartGit 后,我马上就用它连接到了我的 GitHub 账户。默认的工具栏是和仓库操作相关联的,非常简洁。推送、拉取、检出、合并、添加分支、cherry pick、撤销、变基、重置 —— 这些 Git 的的流行功能都支持。除了支持标准 Git 和 GitHub 的大部分功能,SmartGit 运行也非常稳定。至少当你在 Ubuntu上使用时,你会觉得这一款软件是专门为 Linux 设计和开发的。
SmartGit 可能是使各个水平的 Git 用户都可以非常轻松的使用 Git,甚至 Git 高级功能的最好工具。为了了解更多 SmartGit 相关知识,你可以查看一下其[丰富的文档](http://www.syntevo.com/doc/display/SG/Manual)。
### GitKraken
[GitKraken](https://www.gitkraken.com/) 是另外一款商业 Git 图形客户端,它可以使你感受到一种绝不会后悔的使用 Git 或者 GitHub 的美妙体验。SmartGit 具有非常简洁的界面,而 GitKraken 拥有非常华丽的界面,它一开始就给你展现了很多特色。GitKraken 有一个免费版(你也可以使用完整版 15 天)。试用期过了,你也可以继续使用免费版,不过不能用于商业用途。
对那些想让其开发工作流发挥最大功效的人们来说,GitKraken 可能是一个比较好的选择。界面上具有的功能包括:可视化交互、可缩放的提交图、拖拽、与 Github、GitLab 和 BitBucked 的无缝整合、简单的应用内任务清单、应用内置的合并工具、模糊查找、支持 Gitflow、一键撤销与重做、快捷键、文件历史与追责、子模块、亮色和暗色主题、Git 钩子支持和 Git LFS 等许多功能。不过用户倍加赞赏的还是精美的界面(图 2)。

*图 2: GitKraken的界面非常出色*
除了令人惊艳的图形界面,另一个使 GitKraken 在 Git 图形客户端竞争中脱颖而出的功能是:GitKraken 使得使用多个远程仓库和多套配置变得非常简单。不过有一个告诫,使用 GitKraken 需要花钱(它是专有的)。如果你想商业使用,许可证的价钱如下:
* 一人一年 49 美元
* 10 人以上团队,39 美元每人每年
* 100 人以上团队, 29 美元每人每年
专业版账户不但可以在商业环境使用 Git 相关功能,还可以使用 Glo Boards(GitKraken 的项目管理工具)。Glo Boards 的一个吸引人的功能是可以将数据同步到 GitHub <ruby> 工单 <rt> Issues </rt></ruby>。Glo Boards 具有分享功能还具有搜索过滤、问题跟踪、Markdown 支持、附件、@ 功能、清单卡片等许多功能。所有的这些功能都可以在 GitKraken 界面里进行操作。
GitKraken 可以通过 deb 文件或者源码进行安装。
### Git Cola
[Git Cola](https://git-cola.github.io/) 是我们推荐列表中一款自由开源的 Git 图像客户端。不像 GitKraken 和 SmartGit,Git Cola是一款比较难啃的骨头,一款比较实用的 Git 客户端。Git Cola 是用 Python 写成的,使用的是 GTK 界面,因此无论你用的是什么 Linux 发行版和桌面,都可以无缝支持。并且因为它是开源的,你可以在你使用的发行版的包管理器中找到它。因此安装过程无非是打开应用商店,搜索 “Git Cola” 安装即可。你也可以通过下面的命令进行安装:
```
sudo apt install git-cola
```
或者
```
sudo dnf install git-cola
```
Git Cola 看起来相对比较简单(图 3)。事实上,你无法找到更复杂的东西,因为 Git Cola 是非常基础的。

*图 3:Git Cola 界面是非常简单的*
因为 Git Cola 看起来回归自然,所以很多时间你必须同终端打交道。不过这并不是什么难事儿(因为大多数开发人员需要经常使用终端)。Git Cola 包含以下特性:
* 支持多个子命令
* 自定义窗口设置
* 可设置环境变量
* 语言设置
* 支持自定义 GUI 设置
* 支持快捷键
尽管 Git Cola 支持连接到远程仓库,但和像 GitHub 这样的仓库整合看起来也没有 GitKraken 和 SmartGit 直观。不过如果你的大部分工作是在本地进行的,Git Cola 并不失为一个出色的工具。
Git Cola 也带有有一个高级的 DAG(有向无环图)可视化工具,叫做 Git DAG。这个工具可以使你获得分支的可视化展示。你可以独立使用 Git DAG,也可以在 Git Cola 内通过 “view->DAG” 菜单来打开。正是 Git DAG 这个威力巨大的工具使用 Git Cola 跻身于应用商店中 Git 图形客户端前列。
### 更多的客户端
还有更多的 Git 图形客户端。不过,从上面介绍的这几款中,你已经可以做很多事情了。无论你在寻找一款更有丰富功能的 Git 客户端(不管许可证的话)还是你本身是一名坚定的 GPL 支持者,都可以从上面找到适合自己的一款。
如果想学习更多关于 Linux 的知识,可以通过学习Linux基金会的[走进 Linux](https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux)课程。
---
via: <https://www.linux.com/learn/intro-to-linux/2018/7/three-graphical-clients-git-linux>
作者:[Jack Wallen](https://www.linux.com/users/jlwallen) 选题:[lujun9972](https://github.com/lujun9972) 译者:[tarepanda1024](https://github.com/tarepanda1024) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,899 | 如何用 Scribus 和 Gedit 编辑 Adobe InDesign 文件 | https://opensource.com/article/18/7/adobe-indesign-open-source-tools | 2018-08-06T00:23:00 | [
"InDesign"
] | /article-9899-1.html |
>
> 学习一下这些用开源工具编辑 InDesign 文件的方案。
>
>
>

要想成为一名优秀的平面设计师,您必须善于使用各种各样专业的工具。现在,对大多数设计师来说,最常用的工具是 <ruby> Adobe 全家桶 <rt> Adobe Creative Suite </rt></ruby>。
但是,有时候使用开源工具能够帮您摆脱困境。比如,您正在使用一台公共打印机打印一份用 Adobe InDesign 创建的文件。这时,您需要对文件做一些简单的改动(比如,改正一个错别字),但您无法立刻使用 Adobe 套件。虽然这种情况很少见,但电子杂志制作软件 [Scribus](https://www.scribus.net/) 和文本编辑器 [Gedit](https://wiki.gnome.org/Apps/Gedit) 等开源工具可以节约您的时间。
在本文中,我将向您展示如何使用 Scribus 和 Gedit 编辑 Adobe InDesign 文件。请注意,还有许多其他开源平面设计软件可以用来代替 Adobe InDesign 或者结合使用。详情请查看我的文章:[昂贵的工具(从来!)不是平面设计的唯一选择](https://opensource.com/life/16/8/open-source-alternatives-graphic-design) 以及 [两个开源 Adobe InDesign 脚本](https://opensource.com/article/17/3/scripts-adobe-indesign).
在编写本文的时候,我阅读了一些关于如何使用开源软件编辑 InDesign 文件的博客,但没有找到有用的文章。我尝试了两个解决方案。一个是:在 InDesign 创建一个 EPS 并在文本编辑器 Scribus 中将其以可编辑文件打开,但这不起作用。另一个是:从 InDesign 中创建一个 IDML(一种旧的 InDesign 文件格式)文件,并在 Scribus 中打开它。第二种方法效果更好,也是我在下文中使用的解决方法。
### 编辑名片
我尝试在 Scribus 中打开和编辑 InDesign 名片文件的效果很好。唯一的问题是字母间的间距有些偏移,以及我用倒过来的 ‘J’ 来创建 “Jeff” 中的 ‘f’ 被翻转。其他部分,像样式和颜色等都完好无损。

*图:在 Adobe InDesign 中编辑名片。*

*图:在 Scribus 中打开 InDesign IDML 文件。*
### 删除带页码的书籍中的副本
书籍的转换并不顺利。书籍的正文还 OK,但当我用 Scribus 打开 InDesign 文件,目录、页脚和一些首字下沉的段落都出现问题。不过至少,它是一个可编辑的文档。其中一个问题是一些块引用中的文字变成了默认的 Arial 字体,这是因为字体样式(似乎来自其原始的 Word 文档)的优先级比段落样式高。这个问题容易解决。

*图:InDesign 中的书籍布局。*

*图:用 Scribus 打开 InDesign IDML 文件的书籍布局。*
当我试图选择并删除一页文本的时候,发生了奇异事件。我把光标放在文本中,按下 `Command + A`(“全选”的快捷键)。表面看起来高亮显示了一页文本,但事实并非如此!

*图:Scribus 中被选中的文本。*
当我按下“删除”键,整个文本(不只是高亮的部分)都消失了。

*图:两页文本都被删除了。*
然后,更奇异的事情发生了……我按下 `Command + Z` 键来撤回删除操作,文本恢复,但文本格式全乱套了。

*图:Command+Z (撤回删除操作) 恢复了文本,但格式乱套了。*
### 用文本编辑器打开 InDesign 文件
当您用普通的记事本(比如,Mac 中的 TextEdit)分别打开 Scribus 文件和 InDesign 文件,会发现 Scribus 文件是可读的,而 InDesign 文件全是乱码。
您可以用 TextEdit 对两者进行更改并成功保存,但得到的文件是损坏的。下图是当我用 InDesign 打开编辑后的文件时的报错。

*图:InDesign 的报错。*
我在 Ubuntu 系统上用文本编辑器 Gedit 编辑 Scribus 时得到了更好的结果。我从命令行启动了 Gedit,然后打开并编辑 Scribus 文件,保存后,再次使用 Scribus 打开文件时,我在 Gedit 中所做的更改都成功显示在 Scribus 中。

*图:用 Gedit 编辑 Scribus 文件。*

*图:用 Scribus 打开 Gedit 编辑过的文件。*
当您正准备打印的时候,客户打来电话说有一个错别字需要更改,此时您不需要苦等客户爸爸发来新的文件,只需要用 Gedit 打开 Scribus 文件,改正错别字,继续打印。
### 把图像拖拽到 ID 文件中
我将 InDesign 文档另存为 IDML 文件,这样我就可以用 Scribus 往其中拖进一些 PDF 文档。似乎 Scribus 并不能像 InDesign 一样把 PDF 文档拖拽进去。于是,我把 PDF 文档转换成 JPG 格式的图片然后导入到 Scribus 中,成功了。但这么做的结果是,将 IDML 文档转换成 PDF 格式后,文件大小非常大。

*图:把 Scribus 转换成 PDF 时得到一个非常大的文件*。
我不确定为什么会这样——这个坑留着以后再填吧。
您是否有使用开源软件编辑平面图形文件的技巧?如果有,请在评论中分享哦。
---
via: <https://opensource.com/article/18/7/adobe-indesign-open-source-tools>
作者:[Jeff Macharyas](https://opensource.com/users/rikki-endsley) 选题:[lujun9972](https://github.com/lujun9972) 译者:[XiatianSummer](https://github.com/XiatianSummer) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
9,901 | 测试 Node.js,2018 | https://hackernoon.com/testing-node-js-in-2018-10a04dd77391 | 2018-08-07T07:10:00 | [
"测试",
"Node.js"
] | https://linux.cn/article-9901-1.html | 
超过 3 亿用户正在使用 [Stream](https://getstream.io/)。这些用户全都依赖我们的框架,而我们十分擅长测试要放到生产环境中的任何东西。我们大部分的代码库是用 Go 语言编写的,剩下的部分则是用 Python 编写。
我们最新的展示应用,[Winds 2.0](https://getstream.io/winds),是用 Node.js 构建的,很快我们就了解到测试 Go 和 Python 的常规方法并不适合它。而且,创造一个好的测试套件需要用 Node.js 做很多额外的工作,因为我们正在使用的框架没有提供任何内建的测试功能。
不论你用什么语言,要构建完好的测试框架可能都非常复杂。本文我们会展示 Node.js 测试过程中的困难部分,以及我们在 Winds 2.0 中用到的各种工具,并且在你要编写下一个测试集合时为你指明正确的方向。
### 为什么测试如此重要
我们都向生产环境中推送过糟糕的提交,并且遭受了其后果。碰到这样的情况不是好事。编写一个稳固的测试套件不仅仅是一个明智的检测,而且它还让你能够完全地重构代码,并自信重构之后的代码仍然可以正常运行。这在你刚刚开始编写代码的时候尤为重要。
如果你是与团队共事,达到测试覆盖率极其重要。没有它,团队中的其他开发者几乎不可能知道他们所做的工作是否导致重大变动(或破坏)。
编写测试同时会促进你和你的队友把代码分割成更小的片段。这让别人去理解你的代码和修改 bug 变得容易多了。产品收益变得更大,因为你能更早的发现 bug。
最后,没有测试,你的基本代码还不如一堆纸片。基本不能保证你的代码是稳定的。
### 困难的部分
在我看来,我们在 Winds 中遇到的大多数测试问题是 Node.js 中特有的。它的生态系统一直在变大。例如,如果你用的是 macOS,运行 `brew upgrade`(安装了 homebrew),你看到你一个新版本的 Node.js 的概率非常高。由于 Node.js 迭代频繁,相应的库也紧随其后,想要与最新的库保持同步非常困难。
以下是一些马上映入脑海的痛点:
1. 在 Node.js 中进行测试是非常主观而又不主观的。人们对于如何构建一个测试架构以及如何检验成功有不同的看法。沮丧的是还没有一个黄金准则规定你应该如何进行测试。
2. 有一堆框架能够用在你的应用里。但是它们一般都很精简,没有完好的配置或者启动过程。这会导致非常常见的副作用,而且还很难检测到;所以你最终会想要从零开始编写自己的<ruby> 测试执行平台 <rt> test runner </rt></ruby>测试执行平台。
3. 几乎可以保证你 *需要* 编写自己的测试执行平台(马上就会讲到这一节)。
以上列出的情况不是理想的,而且这是 Node.js 社区应该尽管处理的事情。如果其他语言解决了这些问题,我认为也是作为广泛使用的语言, Node.js 解决这些问题的时候。
### 编写你自己的测试执行平台
所以……你可能会好奇test runner测试执行平台 *是* 什么,说实话,它并不复杂。测试执行平台是测试套件中最高层的容器。它允许你指定全局配置和环境,还可以导入配置。可能有人觉得做这个很简单,对吧?别那么快下结论。
我们所了解到的是,尽管现在就有足够多的测试框架了,但没有一个测试框架为 Node.js 提供了构建你的测试执行平台的标准方式。不幸的是,这需要开发者来完成。这里有个关于测试执行平台的需求的简单总结:
* 能够加载不同的配置(比如,本地的、测试的、开发的),并确保你 *永远不会* 加载一个生产环境的配置 —— 你能想象出那样会出什么问题。
* 播种数据库——产生用于测试的数据。必须要支持多种数据库,不论是 MySQL、PostgreSQL、MongoDB 或者其它任何一个数据库。
* 能够加载配置(带有用于开发环境测试的播种数据的文件)。
开发 Winds 的时候,我们选择 Mocha 作为测试执行平台。Mocha 提供了简单并且可编程的方式,通过命令行工具(整合了 Babel)来运行 ES6 代码的测试。
为了进行测试,我们注册了自己的 Babel 模块引导器。这为我们提供了更细的粒度,更强大的控制,在 Babel 覆盖掉 Node.js 模块加载过程前,对导入的模块进行控制,让我们有机会在所有测试运行前对模块进行模拟。
此外,我们还使用了 Mocha 的测试执行平台特性,预先把特定的请求赋给 HTTP 管理器。我们这么做是因为常规的初始化代码在测试中不会运行(服务器交互是用 Chai HTTP 插件模拟的),还要做一些安全性检查来确保我们不会连接到生产环境数据库。
尽管这不是测试执行平台的一部分,有一个<ruby> 配置 <rt> fixture </rt></ruby>加载器也是我们测试套件中的重要的一部分。我们试验过已有的解决方案;然而,我们最终决定编写自己的助手程序,这样它就能贴合我们的需求。根据我们的解决方案,在生成或手动编写配置时,通过遵循简单专有的协议,我们就能加载数据依赖很复杂的配置。
### Winds 中用到的工具
尽管过程很冗长,我们还是能够合理使用框架和工具,使得针对后台 API 进行的适当测试变成现实。这里是我们选择使用的工具:
#### Mocha
[Mocha](https://github.com/mochajs/mocha),被称为 “运行在 Node.js 上的特性丰富的测试框架”,是我们用于该任务的首选工具。拥有超过 15K 的星标,很多支持者和贡献者,我们知道对于这种任务,这是正确的框架。
#### Chai
然后是我们的断言库。我们选择使用传统方法,也就是最适合配合 Mocha 使用的 —— [Chai](http://www.chaijs.com/)。Chai 是一个用于 Node.js,适合 BDD 和 TDD 模式的断言库。拥有简单的 API,Chai 很容易整合进我们的应用,让我们能够轻松地断言出我们 *期望* 从 Winds API 中返回的应该是什么。最棒的地方在于,用 Chai 编写测试让人觉得很自然。这是一个简短的例子:
```
describe('retrieve user', () => {
let user;
before(async () => {
await loadFixture('user');
user = await User.findOne({email: authUser.email});
expect(user).to.not.be.null;
});
after(async () => {
await User.remove().exec();
});
describe('valid request', () => {
it('should return 200 and the user resource, including the email field, when retrieving the authenticated user', async () => {
const response = await withLogin(request(api).get(`/users/${user._id}`), authUser);
expect(response).to.have.status(200);
expect(response.body._id).to.equal(user._id.toString());
});
it('should return 200 and the user resource, excluding the email field, when retrieving another user', async () => {
const anotherUser = await User.findOne({email: '[email protected]'});
const response = await withLogin(request(api).get(`/users/${anotherUser.id}`), authUser);
expect(response).to.have.status(200);
expect(response.body._id).to.equal(anotherUser._id.toString());
expect(response.body).to.not.have.an('email');
});
});
describe('invalid requests', () => {
it('should return 404 if requested user does not exist', async () => {
const nonExistingId = '5b10e1c601e9b8702ccfb974';
expect(await User.findOne({_id: nonExistingId})).to.be.null;
const response = await withLogin(request(api).get(`/users/${nonExistingId}`), authUser);
expect(response).to.have.status(404);
});
});
});
```
#### Sinon
拥有与任何单元测试框架相适应的能力,[Sinon](http://sinonjs.org/) 是模拟库的首选。而且,精简安装带来的超级整洁的整合,让 Sinon 把模拟请求变成了简单而轻松的过程。它的网站有极其良好的用户体验,并且提供简单的步骤,供你将 Sinon 整合进自己的测试框架中。
#### Nock
对于所有外部的 HTTP 请求,我们使用健壮的 HTTP 模拟库 [nock](https://github.com/node-nock/nock),在你要和第三方 API 交互时非常易用(比如说 [Stream 的 REST API](https://getstream.io/docs_rest/))。它做的事情非常酷炫,这就是我们喜欢它的原因,除此之外关于这个精妙的库没有什么要多说的了。这是我们的速成示例,调用我们在 Stream 引擎中提供的 [personalization](https://getstream.io/personalization):
```
nock(config.stream.baseUrl)
.get(/winds_article_recommendations/)
.reply(200, { results: [{foreign_id:`article:${article.id}`}] });
```
#### Mock-require
[mock-require](https://github.com/boblauer/mock-require) 库允许依赖外部代码。用一行代码,你就可以替换一个模块,并且当代码尝试导入这个库时,将会产生模拟请求。这是一个小巧但稳定的库,我们是它的超级粉丝。
#### Istanbul
[Istanbul](https://github.com/gotwarlost/istanbul) 是 JavaScript 代码覆盖工具,在运行测试的时候,通过模块钩子自动添加覆盖率,可以计算语句,行数,函数和分支覆盖率。尽管我们有相似功能的 CodeCov(见下一节),进行本地测试时,这仍然是一个很棒的工具。
### 最终结果 — 运行测试
*有了这些库,还有之前提过的测试执行平台,现在让我们看看什么是完整的测试(你可以在 [*这里*](https://github.com/GetStream/Winds/tree/master/api/test) 看看我们完整的测试套件):*
```
import nock from 'nock';
import { expect, request } from 'chai';
import api from '../../src/server';
import Article from '../../src/models/article';
import config from '../../src/config';
import { dropDBs, loadFixture, withLogin } from '../utils.js';
describe('Article controller', () => {
let article;
before(async () => {
await dropDBs();
await loadFixture('initial-data', 'articles');
article = await Article.findOne({});
expect(article).to.not.be.null;
expect(article.rss).to.not.be.null;
});
describe('get', () => {
it('should return the right article via /articles/:articleId', async () => {
let response = await withLogin(request(api).get(`/articles/${article.id}`));
expect(response).to.have.status(200);
});
});
describe('get parsed article', () => {
it('should return the parsed version of the article', async () => {
const response = await withLogin(
request(api).get(`/articles/${article.id}`).query({ type: 'parsed' })
);
expect(response).to.have.status(200);
});
});
describe('list', () => {
it('should return the list of articles', async () => {
let response = await withLogin(request(api).get('/articles'));
expect(response).to.have.status(200);
});
});
describe('list from personalization', () => {
after(function () {
nock.cleanAll();
});
it('should return the list of articles', async () => {
nock(config.stream.baseUrl)
.get(/winds_article_recommendations/)
.reply(200, { results: [{foreign_id:`article:${article.id}`}] });
const response = await withLogin(
request(api).get('/articles').query({
type: 'recommended',
})
);
expect(response).to.have.status(200);
expect(response.body.length).to.be.at.least(1);
expect(response.body[0].url).to.eq(article.url);
});
});
});
```
### 持续集成
有很多可用的持续集成服务,但我们钟爱 [Travis CI](https://travis-ci.org/),因为他们和我们一样喜爱开源环境。考虑到 Winds 是开源的,它再合适不过了。
我们的集成非常简单 —— 我们用 [.travis.yml] 文件设置环境,通过简单的 [npm](https://www.npmjs.com/) 命令进行测试。测试覆盖率反馈给 GitHub,在 GitHub 上我们将清楚地看出我们最新的代码或者 PR 是不是通过了测试。GitHub 集成很棒,因为它可以自动查询 Travis CI 获取结果。以下是一个在 GitHub 上看到 (经过了测试的) PR 的简单截图:

除了 Travis CI,我们还用到了叫做 [CodeCov](https://codecov.io/#features) 的工具。CodeCov 和 [Istanbul] 很像,但它是个可视化的工具,方便我们查看代码覆盖率、文件变动、行数变化,还有其他各种小玩意儿。尽管不用 CodeCov 也可以可视化数据,但把所有东西囊括在一个地方也很不错。

### 我们学到了什么
在开发我们的测试套件的整个过程中,我们学到了很多东西。开发时没有所谓“正确”的方法,我们决定开始创造自己的测试流程,通过理清楚可用的库,找到那些足够有用的东西添加到我们的工具箱中。
最终我们学到的是,在 Node.js 中进行测试不是听上去那么简单。还好,随着 Node.js 持续完善,社区将会聚集力量,构建一个坚固稳健的库,可以用“正确”的方式处理所有和测试相关的东西。
但在那时到来之前,我们还会接着用自己的测试套件,它开源在 [Winds 的 GitHub 仓库](https://github.com/GetStream/Winds/tree/master/api/test)。
### 局限
#### 创建配置没有简单的方法
有的框架和语言,就如 Python 中的 Django,有简单的方式来创建配置。比如,你可以使用下面这些 Django 命令,把数据导出到文件中来自动化配置的创建过程:
以下命令会把整个数据库导出到 `db.json` 文件中:
```
./manage.py dumpdata > db.json
```
以下命令仅导出 django 中 `admin.logentry` 表里的内容:
```
./manage.py dumpdata admin.logentry > logentry.json
```
以下命令会导出 `auth.user` 表中的内容:
```
./manage.py dumpdata auth.user > user.json
```
Node.js 里面没有创建配置的简单方式。我们最后做的事情是用 MongoDB Compass 工具导出数据到 JSON 中。这生成了不错的配置,如下图(但是,这是个乏味的过程,肯定会出错):

#### 使用 Babel,模拟模块和 Mocha 测试执行平台时,模块加载不直观
为了支持多种 node 版本,和获取 JavaScript 标准的最新附件,我们使用 Babel 把 ES6 代码转换成 ES5。Node.js 模块系统基于 CommonJS 标准,而 ES6 模块系统中有不同的语义。
Babel 在 Node.js 模块系统的顶层模拟 ES6 模块语义,但由于我们要使用 mock-require 来介入模块的加载,所以我们经历了罕见的怪异的模块加载过程,这看上去很不直观,而且能导致在整个代码中,导入的、初始化的和使用的模块有不同的版本。这使测试时的模拟过程和全局状态管理复杂化了。
#### 在使用 ES6 模块时声明的函数,模块内部的函数,都无法模拟
当一个模块导出多个函数,其中一个函数调用了其他的函数,就不可能模拟使用在模块内部的函数。原因在于当你引用一个 ES6 模块时,你得到的引用集合和模块内部的是不同的。任何重新绑定引用,将其指向新值的尝试都无法真正影响模块内部的函数,内部函数仍然使用的是原始的函数。
### 最后的思考
测试 Node.js 应用是复杂的过程,因为它的生态系统总在发展。掌握最新和最好的工具很重要,这样你就不会掉队了。
如今有很多方式获取 JavaScript 相关的新闻,导致与时俱进很难。关注邮件新闻刊物如 [JavaScript Weekly](https://javascriptweekly.com/) 和 [Node Weekly](https://nodeweekly.com/) 是良好的开始。还有,关注一些 reddit 子模块如 [/r/node](https://www.reddit.com/r/node/) 也不错。如果你喜欢了解最新的趋势,[State of JS](https://stateofjs.com/2017/testing/results/) 在测试领域帮助开发者可视化趋势方面就做的很好。
最后,这里是一些我喜欢的博客,我经常在这上面发文章:
* [Hacker Noon](https://hackernoon.com/)
* [Free Code Camp](https://medium.freecodecamp.org/)
* [Bits and Pieces](https://blog.bitsrc.io/)
觉得我遗漏了某些重要的东西?在评论区或者 Twitter [@NickParsons](https://twitter.com/@nickparsons) 让我知道。
还有,如果你想要了解 Stream,我们的网站上有很棒的 5 分钟教程。点 [这里](https://getstream.io/try-the-api) 进行查看。
---
作者简介:
Nick Parsons
Dreamer. Doer. Engineer. Developer Evangelist <https://getstream.io>.
---
via: <https://hackernoon.com/testing-node-js-in-2018-10a04dd77391>
作者:[Nick Parsons](https://hackernoon.com/@nparsons08?source=post_header_lockup) 译者:[BriFuture](https://github.com/BriFuture) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 
[Stream](https://getstream.io/?ref=hackernoon.com) powers feeds for over 300+ million end users. With all of those users relying on our infrastructure, we’re very good about testing everything that gets pushed into production. Our primary codebase is written in Go, with some remaining bits of Python.
Our recent showcase application, [Winds 2.0](https://getstream.io/winds?ref=hackernoon.com), is built with Node.js and we quickly learned that our usual testing methods in Go and Python didn’t quite fit. Furthermore, creating a proper test suite requires a bit of upfront work in Node.js as the frameworks we are using don’t offer any type of built-in test functionality.
Setting up a good test framework can be tricky regardless of what language you’re using. In this post, we’ll uncover the hard parts of testing with Node.js, the various tooling we decided to utilize in Winds 2.0, and point you in the right direction for when it comes time for you to write your next set of tests.
We’ve all pushed a bad commit to production and faced the consequences. It’s not a fun thing to have happen. Writing a solid test suite is not only a good sanity check, but it allows you to completely refactor code and feel confident that your codebase is still functional. This is especially important if you’ve just launched.
If you’re working with a team, it’s extremely important that you have test coverage. Without it, it’s nearly impossible for other developers on the team to know if their contributions will result in a breaking change (ouch).
Writing tests also encourage you and your teammates to split up code into smaller pieces. This makes it much easier to understand your code, and fix bugs along the way. The productivity gains are even bigger, due to the fact that you catch bugs early on.
Finally, without tests, your codebase might as well be a house of cards. There is simply zero certainty that your code is stable.
In my opinion, most of the testing problems we ran into with Winds were specific to Node.js. The ecosystem is always growing. For example, if you are on macOS and run “brew upgrade” (with homebrew installed), your chances of seeing a new version of Node.js are quite high. With Node.js moving quickly and libraries following close behind, keeping up to date with the latest libraries is difficult.
**Below are a few pain points that immediately come to mind:**
The situations listed above are not ideal and it’s something that the Node.js community needs to address sooner rather than later. If other languages have figured it out, I think it’s time for Node.js, a widely adopted language, to figure it out as well.
So… you’re probably wondering what a test runner *is*. To be honest, it’s not that complicated. A test runner is the highest component in the test suite. It allows for you to specify global configurations and environments, as well as import fixtures. One would assume this would be simple and easy to do… Right? Not so fast…
What we learned is that, although there is a solid number of test frameworks out there, not a single one for Node.js provides a unified way to construct your test runner. Sadly, it’s up to the developer to do so. Here’s a quick breakdown of the requirements for a test runner:
With Winds, we chose to use Mocha as our test runner. Mocha provides an easy and programmatic way to run tests on an ES6 codebase via command-line tools (integrated with Babel).
To kick off the tests, we register the Babel module loader ourselves. This provides us with finer grain greater control over which modules are imported before Babel overrides Node.js module loading process, giving us the opportunity to mock modules before any tests are run.
Additionally, we also use Mocha’s test runner feature to pre-assign HTTP handlers to specific requests. We do this because the normal initialization code is not run during tests (server interactions are mocked by the Chai HTTP plugin) and run some safety check to ensure we are not connecting to production databases.
While this isn’t part of the test runner, having a fixture loader is an important part of our test suite. We examined existing solutions; however, we settled on writing our own helper so that it was tailored to our requirements. With our solution, we can load fixtures with complex data-dependencies by following an easy ad-hoc convention when generating or writing fixtures by hand.
Although the process was cumbersome, we were able to find the right balance of tools and frameworks to make proper testing become a reality for our backend API. Here’s what we chose to go with:
[Mocha](https://github.com/mochajs/mocha?ref=hackernoon.com), described as a “feature-rich JavaScript test framework running on Node.js”, was our immediate choice of tooling for the job. With well over 15k stars, many backers, sponsors, and contributors, we knew it was the right framework for the job.
Next up was our assertion library. We chose to go with the traditional approach, which is what works best with Mocha — [Chai](http://www.chaijs.com/?ref=hackernoon.com). Chai is a BDD and TDD assertion library for Node.js. With a simple API, Chai was easy to integrate into our application and allowed for us to easily assert what we should ** expect** to be returned from the Winds API. Best of all, writing tests feel natural with Chai. Here’s a short example:
With the ability to work with any unit testing framework, [Sinon](http://sinonjs.org/?ref=hackernoon.com) was our first choice for a mocking library. Again, a super clean integration with minimal setup, Sinon turns mocking requests into a simple and easy process. Their website has an extremely friendly user experience and offers up easy steps to integrate Sinon with your test suite.
For all external HTTP requests, we use [nock](https://github.com/node-nock/nock?ref=hackernoon.com), a robust HTTP mocking library that really comes in handy when you have to communicate with a third party API (such as [Stream’s REST API](https://getstream.io/docs_rest/?ref=hackernoon.com)). There’s not much to say about this little library aside from the fact that it is awesome at what it does, and that’s why we like it. Here’s a quick example of us calling our [personalization](https://getstream.io/personalization?ref=hackernoon.com) engine for Stream:
The library [mock-require](https://github.com/boblauer/mock-require?ref=hackernoon.com) allows dependencies on external code. In a single line of code, you can replace a module and mock-require will step in when some code attempts to import that module. It’s a small and minimalistic, but robust library, and we’re big fans.
[Istanbul](https://github.com/gotwarlost/istanbul?ref=hackernoon.com) is a JavaScript code coverage tool that computes statement, line, function and branch coverage with module loader hooks to transparently add coverage when running tests. Although we have similar functionality with CodeCov (see next section), this is a nice tool to have when running tests locally.
*With all of the libraries, including the test runner mentioned above, let’s have a look at what a full test looks like (you can have a look at our entire test suite* *here**):*
There are a lot of continuous integration services available, but we like to use [Travis CI](https://travis-ci.org/?ref=hackernoon.com) because they love the open-source environment just as much as we do. Given that Winds is open-source, it made for a perfect fit.
Our integration is rather simple — we have a [.travis.yml](https://github.com/GetStream/Winds/blob/master/.travis.yml?ref=hackernoon.com) file that sets up the environment and kicks off our tests via a simple [npm](https://www.npmjs.com/?ref=hackernoon.com) command. The coverage reports back to GitHub, where we have a clear picture of whether or not our latest codebase or PR passes our tests. The GitHub integration is great, as it is visible without us having to go to Travis CI to look at the results. Below is a screenshot of GitHub when viewing the PR (after tests):
In addition to Travis CI, we use a tool called [CodeCov](https://codecov.io/?ref=hackernoon.com#features). CodeCov is similar to [Istanbul](https://github.com/gotwarlost/istanbul?ref=hackernoon.com), however, it’s a visualization tool that allows us to easily see code coverage, files changed, lines modified, and all sorts of other goodies. Though visualizing this data is possible without CodeCov, it’s nice to have everything in one spot.
We learned a lot throughout the process of developing our test suite. With no “correct” way of doing things, we decided to set out and create our own test flow by sorting through the available libraries to find ones that were promising enough to add to our toolbox.
What we ultimately learned is that testing in Node.js is not as easy as it may sound. Hopefully, as Node.js continues to grow, the community will come together and build a rock solid library that handles everything test related in a “correct” manner.
Until then, we’ll continue to use our test suite, which is open-source on the [Winds GitHub repository](https://github.com/GetStream/Winds/tree/master/api/test?ref=hackernoon.com).
Frameworks and languages, such as Python’s Django, have easy ways to create fixtures. With Django, for example, you can use the following commands to automate the creation of fixtures by dumping data into a file:
**The Following command will dump the whole database into a db.json file:**./manage.py dumpdata > db.json
**The Following command will dump only the content in django admin.logentry table**:./manage.py dumpdata admin.logentry > logentry.json
**The Following command will dump the content in django auth.user table:**./manage.py dumpdata auth.user > user.json
There’s no easy way to create a fixture in Node.js. What we ended up doing is using MongoDB Compass and exporting JSON from there. This resulted in a nice fixture, as shown below (however, it was a tedious process and prone to error):
To support a broader variety of node versions and have access to latest additions to Javascript standard, we are using Babel to transpile our ES6 codebase to ES5. Node.js module system is based on the CommonJS standard whereas the ES6 module system has different semantics.
Babel emulates ES6 module semantics on top of the Node.js module system, but because we are interfering with module loading by using mock-require, we are embarking on a journey through weird module loading corner cases, which seem unintuitive and can lead to multiple independent versions of the module imported and initialized and used throughout the codebase. This complicates mocking and global state management during testing.
When a module exports multiple functions where one calls the other, it’s impossible to mock the function being used inside the module. The reason is that when you require an ES6 module you are presented with a separate set of references from the one used inside the module. Any attempt to rebind the references to point to new values does not really affect the code inside the module, which will continue to use the original function.
Testing Node.js applications is a complicated process because the ecosystem is always evolving. It’s important to stay on top of the latest and greatest tools so you don’t fall behind.
There are so many outlets for JavaScript related news these days that it’s hard to keep up to date with all of them. Following email newsletters such as [JavaScript Weekly](https://javascriptweekly.com/?ref=hackernoon.com) and [Node Weekly](https://nodeweekly.com/?ref=hackernoon.com) is a good start. Beyond that, joining a subreddit such as [/r/node](https://www.reddit.com/r/node/?ref=hackernoon.com) is a great idea. If you like to stay on top of the latest trends, [State of JS](https://stateofjs.com/2017/testing/results/?ref=hackernoon.com) does a great job at helping developers visualize trends in the testing world.
Lastly, here are a couple of my favorite blogs where articles often popup:
Think I missed something important? Let me know in the comments, or on Twitter – [@NickParsons](https://twitter.com/@nickparsons?ref=hackernoon.com).
Also, if you’d like to check out Stream, we have a great 5 minute tutorial on our website. Give it a shot [here](https://getstream.io/try-the-api?ref=hackernoon.com). |
9,902 | 如何使用命令行检查 Linux 上的磁盘空间 | https://www.linux.com/learn/intro-to-linux/2018/6how-check-disk-space-linux-command-line | 2018-08-07T07:42:46 | [
"磁盘",
"df",
"du"
] | https://linux.cn/article-9902-1.html |
>
> Linux 提供了所有必要的工具来帮助你确切地发现你的驱动器上剩余多少空间。Jack 在这里展示了如何做。
>
>
>

快速提问:你的驱动器剩余多少剩余空间?一点点还是很多?接下来的提问是:你知道如何找出这些剩余空间吗?如果你碰巧使用的是 GUI 桌面( 例如 GNOME、KDE、Mate、Pantheon 等 ),则任务可能非常简单。但是,当你要在一个没有 GUI 桌面的服务器上查询剩余空间,你该如何去做呢?你是否要为这个任务安装相应的软件工具?答案是绝对不是。在 Linux 中,具备查找驱动器上的剩余磁盘空间的所有工具。事实上,有两个非常容易使用的工具。
在本文中,我将演示这些工具。我将使用 [Elementary OS](https://elementary.io/%09)(LCTT译注:Elementary OS 是基于 Ubuntu 精心打磨美化的桌面 Linux 发行版 ),它还包括一个 GUI 方式,但我们将限制自己仅使用命令行。好消息是这些命令行工具随时可用于每个 Linux 发行版。在我的测试系统中,连接了许多的驱动器(内部的和外部的)。使用的命令与连接驱动器的位置无关,仅仅与驱动器是否已经挂载好并且对操作系统可见有关。
言归正传,让我们来试试这些工具。
### df
`df` 命令是我第一个用于在 Linux 上查询驱动器空间的工具,时间可以追溯到 20 世纪 90 年代。它的使用和报告结果非常简单。直到今天,`df` 还是我执行此任务的首选命令。此命令有几个选项开关,对于基本的报告,你实际上只需要一个选项。该命令是 `df -H` 。`-H` 选项开关用于将 `df` 的报告结果以人类可读的格式进行显示。`df -H` 的输出包括:已经使用了的空间量、可用空间、空间使用的百分比,以及每个磁盘连接到系统的挂载点(图 1)。

*图 1:Elementary OS 系统上 `df -H` 命令的输出结果*
如果你的驱动器列表非常长并且你只想查看单个驱动器上使用的空间,该怎么办?对于 `df` 这没问题。我们来看一下位于 `/dev/sda1` 的主驱动器已经使用了多少空间。为此,执行如下命令:
```
df -H /dev/sda1
```
输出将限于该驱动器(图 2)。

*图 2:一个单独驱动器空间情况*
你还可以限制 `df` 命令结果报告中显示指定的字段。可用的字段包括:
* `source` — 文件系统的来源(LCTT译注:通常为一个设备,如 `/dev/sda1` )
* `size` — 块总数
* `used` — 驱动器已使用的空间
* `avail` — 可以使用的剩余空间
* `pcent` — 驱动器已经使用的空间占驱动器总空间的百分比
* `target` —驱动器的挂载点
让我们显示所有驱动器的输出,仅显示 `size` ,`used` ,`avail` 字段。对此的命令是:
```
df -H --output=size,used,avail
```
该命令的输出非常简单( 图 3 )。

*图 3:显示我们驱动器的指定输出*
这里唯一需要注意的是我们不知道该输出的来源,因此,我们要把 `source` 加入命令中:
```
df -H --output=source,size,used,avail
```
现在输出的信息更加全面有意义(图 4)。

*图 4:我们现在知道了磁盘使用情况的来源*
### du
我们的下一个命令是 `du` 。 正如您所料,这代表<ruby> 磁盘使用情况 <rt> disk usage </rt></ruby>。 `du` 命令与 `df` 命令完全不同,因为它报告目录而不是驱动器的空间使用情况。 因此,您需要知道要检查的目录的名称。 假设我的计算机上有一个包含虚拟机文件的目录。 那个目录是 `/media/jack/HALEY/VIRTUALBOX` 。 如果我想知道该特定目录使用了多少空间,我将运行如下命令:
```
du -h /media/jack/HALEY/VIRTUALBOX
```
上面命令的输出将显示目录中每个文件占用的空间(图 5)。

*图 5 在特定目录上运行 `du` 命令的输出*
到目前为止,这个命令并没有那么有用。如果我们想知道特定目录的总使用量怎么办?幸运的是,`du` 可以处理这项任务。对于同一目录,命令将是:
```
du -sh /media/jack/HALEY/VIRTUALBOX/
```
现在我们知道了上述目录使用存储空间的总和(图 6)。

*图 6:我的虚拟机文件使用存储空间的总和是 559GB*
您还可以使用此命令查看父项的所有子目录使用了多少空间,如下所示:
```
du -h /media/jack/HALEY
```
此命令的输出见(图 7),是一个用于查看各子目录占用的驱动器空间的好方法。

*图 7:子目录的存储空间使用情况*
`du` 命令也是一个很好的工具,用于查看使用系统磁盘空间最多的目录列表。执行此任务的方法是将 `du` 命令的输出通过管道传递给另外两个命令:`sort` 和 `head` 。下面的命令用于找出驱动器上占用存储空间最大的前 10 个目录:
```
du -a /media/jack | sort -n -r |head -n 10
```
输出将以从大到小的顺序列出这些目录(图 8)。

*图 8:使用驱动器空间最多的 10 个目录*
### 没有你想像的那么难
查看 Linux 系统上挂载的驱动器的空间使用情况非常简单。只要你将你的驱动器挂载在 Linux 系统上,使用 `df` 命令或 `du` 命令在报告必要信息方面都会非常出色。使用 `df` 命令,您可以快速查看磁盘上总的空间使用量,使用 `du` 命令,可以查看特定目录的空间使用情况。对于每一个 Linux 系统的管理员来说,这两个命令的结合使用是必须掌握的。
而且,如果你没有注意到,我最近介绍了[查看 Linux 上内存使用情况的方法](https://www.linux.com/learn/5-commands-checking-memory-usage-linux%09)。总之,这些技巧将大力帮助你成功管理 Linux 服务器。
通过 Linux Foundation 和 edX 免费提供的 “Linux 简介” 课程,了解更多有关 Linux 的信息。
---
via: <https://www.linux.com/learn/intro-to-linux/2018/6how-check-disk-space-linux-command-line>
作者:[Jack Wallen](https://www.linux.com/users/jlwallen%09) 选题:[lujun9972](https://github.com/lujun9972) 译者:[SunWave](https://github.com/SunWave) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,903 | 4 款酷炫的终端应用 | https://fedoramagazine.org/4-cool-apps-for-your-terminal/ | 2018-08-08T00:17:00 | [
"终端"
] | https://linux.cn/article-9903-1.html | 
许多 Linux 用户认为在终端中工作太复杂、无聊,并试图逃避它。但这里有个改善方法 —— 四款终端下很棒的开源程序。它们既有趣又易于使用,甚至可以在你需要在命令行中工作时照亮你的生活。
### No More Secrets
这是一个简单的命令行工具,可以重现 1992 年电影 [Sneakers](https://www.imdb.com/title/tt0105435/) 中所见的著名数据解密效果。该项目让你编译个 `nms` 命令,该命令与管道数据一起使用并以混乱字符的形式打印输出。开始后,你可以按任意键,并能在输出中看到很酷的好莱坞效果的现场“解密”。

#### 安装说明
一个全新安装的 Fedora Workstation 系统已经包含了从源代码构建 No More Secrets 所需的一切。只需在终端中输入以下命令:
```
git clone https://github.com/bartobri/no-more-secrets.git
cd ./no-more-secrets
make nms
make sneakers ## Optional
sudo make install
```
对于那些记得原来的电影的人来说,`sneakers` 命令是一个小小的彩蛋,但主要的英雄是 `nms`。使用管道将任何 Linux 命令重定向到 `nms`,如下所示:
```
systemctl list-units --type=target | nms
```
当文本停止闪烁,按任意键“解密”它。上面的 `systemctl` 命令只是一个例子 —— 你几乎可以用任何东西替换它!
### lolcat
这是一个用彩虹为终端输出着色的命令。没什么用,但是它看起来很棒!

#### 安装说明
`lolcat` 是一个 Ruby 软件包,可从官方 Ruby Gems 托管中获得。所以,你首先需要 gem 客户端:
```
sudo dnf install -y rubygems
```
然后安装 `lolcat` 本身:
```
gem install lolcat
```
再说一次,使用 `lolcat` 命令管道任何其他命令,并在 Fedora 终端中享受彩虹(和独角兽!)。
### chafa

`chafa` 是一个[命令行图像转换器和查看器](https://hpjansson.org/chafa/)。它可以帮助你在不离开终端的情况下欣赏图像。语法非常简单:
```
chafa /path/to/your/image
```
你可以将几乎任何类型的图像投射到 `chafa`,包括 JPG、PNG、TIFF、BMP 或几乎任何 ImageMagick 支持的图像 - 这是 `chafa` 用于解析输入文件的引擎。最酷的部分是 `chafa` 还可以在你的终端内显示非常流畅的 GIF 动画!
#### 安装说明
`chafa` 还没有为 Fedora 打包,但从源代码构建它很容易。首先,获取必要的构建依赖项:
```
sudo dnf install -y autoconf automake libtool gtk-doc glib2-devel ImageMagick-devel
```
接下来,克隆代码或从项目的 GitHub 页面下载快照,然后 cd 到 `chafa` 目录,这样就行了:
```
git clone https://github.com/hpjansson/chafa
./autogen.sh
make
sudo make install
```
大的图像在第一次运行时可能需要一段时间处理,但 `chafa` 会缓存你加载的所有内容。下一次运行几乎是瞬间完成的。
### Browsh
Browsh 是完善的终端网页浏览器。它比 Lynx 更强大,当然更引人注目。 Browsh 以无头模式启动 Firefox Web 浏览器(因此你无法看到它)并在特殊 Web 扩展的帮助下将其与你的终端连接。因此,Browsh 能像 Firefox 一样呈现所有富媒体内容,只是有点像素化的风格。

#### 安装说明
该项目为各种 Linux 发行版提供了包,包括 Fedora。以这种方式安装:
```
sudo dnf install -y https://github.com/browsh-org/browsh/releases/download/v1.4.6/browsh_1.4.6_linux_amd64.rpm
```
之后,启动 `browsh` 命令并给它几秒钟加载。按 `Ctrl+L` 将焦点切换到地址栏并开始浏览 Web,就像以前一样使用!使用 `Ctrl+Q` 返回终端。
---
via: <https://fedoramagazine.org/4-cool-apps-for-your-terminal/>
作者:[atolstoy](https://fedoramagazine.org/author/atolstoy/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Many Linux users think that working in a terminal is either too complex or boring, and try to escape it. Here is a fix, though — four great open source apps for your terminal. They’re fun and easy to use, and may even brighten up your life when you need to spend a time in the command line.
## No More Secrets
This is a simple command line tool that recreates the famous data decryption effect seen in the 1992 movie [Sneakers](https://www.imdb.com/title/tt0105435/). The project lets you compile the *nms* command, which works with piped data and prints the output in the form of messed characters. Once it does so, you can press any key, and see the live “deciphering” of the output with a cool Hollywood-style effect.
This GIF animation briefly shows the No More Secrets effect
### Installation instructions
A fresh Fedora Workstation system already includes everything you need to build *No More Secrets* from source. Just enter the following command in your terminal:
git clone https://github.com/bartobri/no-more-secrets.git cd ./no-more-secrets make nms make sneakers ## Optional sudo make install
The *sneakers* command is a little bonus for those who remember the original movie, but the main hero is *nms*. Use a pipe to redirect any Linux command to *nms*, like this:
systemctl list-units --type=target | nms
Once the text stops flickering, hit any key to “decrypt” it. The *systemctl* command above is only an example — you can replace it with virtually anything!
## Lolcat
Here’s a command that colorizes the terminal output with rainbows. Nothing can be more useless, but boy, it looks awesome!
Let your Linux command output look jolly!
### Installation instructions
Lolcat is a Ruby package available from the official Ruby Gems hosting. So, you’ll need the gem client first:
sudo dnf install -y rubygems
And then install Lolcat itself:
gem install lolcat
Again, use the *lolcat* command in for piping any other command and enjoy rainbows (and unicorns!) right in your Fedora terminal.
## Chafa
Zoom out your terminal view to increase resolution for Chafa
Chafa is a [command line image converter and viewer](https://hpjansson.org/chafa/). It helps you enjoy your images without leaving your lovely terminal. The syntax is very straightforward:
chafa /path/to/your/image
You can throw almost any sort of image to Chafa, including JPG, PNG, TIFF, BMP or virtually anything that ImageMagick supports — this is the engine that Chafa uses for parsing input files. The coolest part is that Chafa can also show very smooth and fluid GIF animations right inside your terminal!
### Installation instructions
Chafa isn’t packaged for Fedora yet, but it’s quite easy to build it from source. First, get the necessary build dependencies:
sudo dnf install -y autoconf automake libtool gtk-doc glib2-devel ImageMagick-devel
Next, clone the code or download a snapshot from the project’s Github page and cd to the Chafa directory. After that, you’re ready to go:
git clone https://github.com/hpjansson/chafa ./autogen.sh make sudo make install
Large images can take a while to process at the first run, but Chafa caches everything you load with it. Next runs will be nearly instantaneous.
## Browsh
Browsh is a fully-fledged web browser for the terminal. It’s more powerful than Lynx and certainly more eye-catching. Browsh launches the Firefox web browser in a headless mode (so that you can’t see it) and connects it with your terminal with the help of special web extension. Therefore, Browsh renders all rich media content just like Firefox, only in a bit pixelated style.

Fedora Magazine still looks awesome in Browsh
### Installation instructions
The project provides packages for various Linux distributions, including Fedora. Install it this way:
sudo dnf install -y https://github.com/browsh-org/browsh/releases/download/v1.4.6/browsh_1.4.6_linux_amd64.rpm
After that, launch the *browsh* command and give it a couple of seconds to load up. Press *Ctrl+L* to switch focus to the address bar and start browsing the Web like you never did before! Use* Ctrl+Q* to get back to your terminal.
## Aleksandersen
Are anyone working on bringing any of these to the Fedora repositories?
## atolstoy
I don’t think so. But you can be the first one if you wish)
## xvitaly
Sudo make install? Are you serious? Sudo make install will cause lots of untracked files and cause major problems on updates/upgrades.
This article need to be removed from Fedora Magazine because end users will damage their Fedora installation after using that.
## Paul W. Frields
@xvitaly: In both these cases,
installs under the /usr/local hierarchy, which means it shouldn’t be affected by package updates/upgrades. Packaged software in the Fedora repos avoids this folder. It’s not as ideal as packaging, but should be safe for users.
## atolstoy
I know that ‘sudo make install’ has long been deprecated, but you’re exaggerating the problem in many ways. First, there is hardly any real issue in installing/upgrading/removing packaged software when you have third-party files in /etc or /usr. You could have thought of such an issue, but it’s not so much probable in real life. Second, the files are prefectly manageable through ‘sudo make uninstall’, which you can try and see yourself.
I’m sorry that you didn’t like the article. Instead of carring out such hasty judgment maybe you could have helped in packaging the aforementioned apps as RPMs in Copr, or may as Flatpaks?
## Brenton Horne
I know it’s a minor detail, but the chafa install commands should have a
line after the git clone command and before the autogen script running command.
## Bob
It is always frustrating when fun little applications like this are not part of the default repositories. The number of times I have seen someone say “well I can install it with aptitude. ” I’ve had more people switch to Ubuntu because of stupid (but fun) little applications like this than because of all the community and documentation they have combined.
## Dmitri
Thanks for fun applications.
lolcat is so fun, I would have to blind my eyes :))))))
## BarbaraF
I love it! I usually do a quick check of a bunch of mails with mutt and lolcat adds fun.
## me
Terminology. You can have a flying rainbow cat for a cursor and animated transparent backgrounds
## atolstoy
Terminology is really great, thanks for the clue. Meanwhile, I was thinking about Alacritty as a testbed for running Browsh inside it. Alacritty is a GPU-accelerated terminal, which pretends to be the fastest one. In my tests, however, it performed fine but not any faster than other terminals.
## Dick
https://nyancat.dakko.us/ could easily added to this list.
## Enrique Betancourt
Actually I was looking for something like that, but to be honest I stop searching when I found the variety of ‘cows’ in cowsay. Now every time I open my terminal it starts with Rick and Morty and the message ‘Wabba lubba dub dub!!’
Here som cowsay links:
https://github.com/paulkaefer/cowsay-files
https://github.com/bkendzior/cowfiles
How to install:
”’
sudo dnf install cowsay
”’
How to run
cowsay -f [path to a cowsay file] [message]
## Miro Hrončok
I’ll try to get chafa to Fedora repos.
## judovana
Check https://mojefedora.cz/poberky-z-fedorky/ ‘s console-image-viewer first 😉
## Marcin
For those who remember the ancient times, there is a terminal emulating the old monitors from 70’s and 80’s – https://github.com/Swordfish90/cool-retro-term . In the full screen mode it can be very convincing with all the “eye-candy” details from the past . The “funny” thing is that you are not able to use it for real due to the eye discomfort. Good things (such as non-blinking LCDs with high resolution) spoils users :).
The project is already in the Fedora repository. Just type:
## Marcin
For those who remember the ancient times, there is a terminal emulating the old monitors from 70’s and 80’s – https://github.com/Swordfish90/cool-retro-term . In the full screen mode it can be very convincing with all the “eye-candy” details from the past (such as the ghosting effect). The “funny” thing is that you are not able to use it for real due to the eye discomfort. Good things (such as non-blinking LCDs with high resolution) spoils users :).
The project is already in the Fedora repository. Just type:
## judovana
same as Chafa is:
dnf install console-image-viewer
consoleImageViewer /usr/share/icons/mate/48×48/emotes/face-devilish.png
Is included in fedora repo, but do not know animated gifs.
What it is really good in is that it can list directories and similalry. So searching of images in headless system was never more easy!
First found it at: https://mojefedora.cz/poberky-z-fedorky/ in the middle. (no anchors in document), contains some more examples and screenshots
## Alexander Dill
no-more-secrets is in the repository – fedora 28
at least when i do ‘dnf info no-more-secrets’ i get this:
Name: no-more-secrets
Version: 0.3.2
Release: 3.fc28
Arch: x86_64
Größe: 29 k
Quelle: no-more-secrets-0.3.2-3.fc28.src.rpm
Paketquelle: fedora
Zusammenfass: A recreation of the “decrypting text” effect from the 1992 movie sneakers
URL: https://github.com/bartobri/no-more-secrets
Lizenz: GPLv3+
Beschreibung: A tool set to recreate the famous “decrypting text” effect as seen in the 1992 movie Sneakers.
## lobocode
Browsh is very crazy lol!!! |
9,904 | UKTools:安装最新 Linux 内核的简便方法 | https://www.2daygeek.com/uktools-easy-way-to-install-latest-stable-linux-kernel-on-ubuntu-mint-and-derivatives/ | 2018-08-08T11:24:59 | [
"内核",
"Ubuntu"
] | https://linux.cn/article-9904-1.html | 
Ubuntu 中有许多实用程序可以将 Linux 内核升级到最新的稳定版本。我们之前已经写过关于这些实用程序的文章,例如 Linux Kernel Utilities (LKU)、 Ubuntu Kernel Upgrade Utility (UKUU) 和 Ubunsys。
另外还有一些其它实用程序可供使用。我们计划在其它文章中包含这些,例如 `ubuntu-mainline-kernel.sh` 和从主线内核手动安装的方式。
今天我们还会教你类似的使用工具 —— UKTools。你可以尝试使用这些实用程序中的任何一个来将 Linux 内核升级至最新版本。
最新的内核版本附带了安全漏洞修复和一些改进,因此,最好保持最新的内核版本以获得可靠、安全和更好的硬件性能。
有时候最新的内核版本可能会有一些漏洞,并且会导致系统崩溃,这是你的风险。我建议你不要在生产环境中安装它。
**建议阅读:**
* [Linux 内核实用程序(LKU)- 在 Ubuntu/LinuxMint 中编译,安装和更新最新内核的一组 Shell 脚本](https://www.2daygeek.com/lku-linux-kernel-utilities-compile-install-update-latest-kernel-in-linux-mint-ubuntu/)
* [Ukuu - 在基于 Ubuntu 的系统中安装或升级 Linux 内核的简便方法](https://www.2daygeek.com/ukuu-install-upgrade-linux-kernel-in-linux-mint-ubuntu-debian-elementary-os/)
* [6 种检查系统上正在运行的 Linux 内核版本的方法](https://www.2daygeek.com/check-find-determine-running-installed-linux-kernel-version/)
### 什么是 UKTools
[UKTools](https://github.com/usbkey9/uktools) 意思是 Ubuntu 内核工具,它包含两个 shell 脚本 `ukupgrade` 和 `ukpurge`。
`ukupgrade` 意思是 “Ubuntu Kernel Upgrade”,它允许用户将 Linux 内核升级到 Ubuntu/Mint 的最新稳定版本以及基于 [kernel.ubuntu.com](http://kernel.ubuntu.com/%7Ekernel-ppa/mainline/) 的衍生版本。
`ukpurge` 意思是 “Ubuntu Kernel Purge”,它允许用户在机器中删除旧的 Linux 内核镜像或头文件,用于 Ubuntu/Mint 和其衍生版本。它将只保留三个内核版本。
此实用程序没有 GUI,但它看起来非常简单直接,因此,新手可以在没有任何问题的情况下进行升级。
我正在运行 Ubuntu 17.10,目前的内核版本如下:
```
$ uname -a
Linux ubuntu 4.13.0-39-generic #44-Ubuntu SMP Thu Apr 5 14:25:01 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux
```
运行以下命令来获取系统上已安装内核的列表(Ubuntu 及其衍生产品)。目前我持有 `7` 个内核。
```
$ dpkg --list | grep linux-image
ii linux-image-4.13.0-16-generic 4.13.0-16.19 amd64 Linux kernel image for version 4.13.0 on 64 bit x86 SMP
ii linux-image-4.13.0-17-generic 4.13.0-17.20 amd64 Linux kernel image for version 4.13.0 on 64 bit x86 SMP
ii linux-image-4.13.0-32-generic 4.13.0-32.35 amd64 Linux kernel image for version 4.13.0 on 64 bit x86 SMP
ii linux-image-4.13.0-36-generic 4.13.0-36.40 amd64 Linux kernel image for version 4.13.0 on 64 bit x86 SMP
ii linux-image-4.13.0-37-generic 4.13.0-37.42 amd64 Linux kernel image for version 4.13.0 on 64 bit x86 SMP
ii linux-image-4.13.0-38-generic 4.13.0-38.43 amd64 Linux kernel image for version 4.13.0 on 64 bit x86 SMP
ii linux-image-4.13.0-39-generic 4.13.0-39.44 amd64 Linux kernel image for version 4.13.0 on 64 bit x86 SMP
ii linux-image-extra-4.13.0-16-generic 4.13.0-16.19 amd64 Linux kernel extra modules for version 4.13.0 on 64 bit x86 SMP
ii linux-image-extra-4.13.0-17-generic 4.13.0-17.20 amd64 Linux kernel extra modules for version 4.13.0 on 64 bit x86 SMP
ii linux-image-extra-4.13.0-32-generic 4.13.0-32.35 amd64 Linux kernel extra modules for version 4.13.0 on 64 bit x86 SMP
ii linux-image-extra-4.13.0-36-generic 4.13.0-36.40 amd64 Linux kernel extra modules for version 4.13.0 on 64 bit x86 SMP
ii linux-image-extra-4.13.0-37-generic 4.13.0-37.42 amd64 Linux kernel extra modules for version 4.13.0 on 64 bit x86 SMP
ii linux-image-extra-4.13.0-38-generic 4.13.0-38.43 amd64 Linux kernel extra modules for version 4.13.0 on 64 bit x86 SMP
ii linux-image-extra-4.13.0-39-generic 4.13.0-39.44 amd64 Linux kernel extra modules for version 4.13.0 on 64 bit x86 SMP
ii linux-image-generic 4.13.0.39.42 amd64 Generic Linux kernel image
```
### 如何安装 UKTools
在 Ubuntu 及其衍生产品上,只需运行以下命令来安装 UKTools 即可。
在你的系统上运行以下命令来克隆 UKTools 仓库:
```
$ git clone https://github.com/usbkey9/uktools
```
进入 uktools 目录:
```
$ cd uktools
```
运行 `Makefile` 以生成必要的文件。此外,这将自动安装最新的可用内核。只需重新启动系统即可使用最新的内核。
```
$ sudo make
[sudo] password for daygeek:
Creating the directories if neccessary
Linking profile.d file for reboot message
Linking files to global sbin directory
Ubuntu Kernel Upgrade - by Mustafa Hasturk
------------------------------------------
This script is based on the work of Mustafa Hasturk and was reworked by
Caio Oliveira and modified and fixed by Christoph Kepler
Current Development and Maintenance by Christoph Kepler
Do you want the Stable Release (if not sure, press y)? (y/n): y
Do you want the Generic kernel? (y/n): y
Do you want to autoremove old kernel? (y/n): y
no crontab for root
Do you want to update the kernel automatically? (y/n): y
Setup complete. Update the kernel right now? (y/n): y
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following packages were automatically installed and are no longer required:
linux-headers-4.13.0-16 linux-headers-4.13.0-16-generic linux-headers-4.13.0-17 linux-headers-4.13.0-17-generic linux-headers-4.13.0-32 linux-headers-4.13.0-32-generic linux-headers-4.13.0-36
linux-headers-4.13.0-36-generic linux-headers-4.13.0-37 linux-headers-4.13.0-37-generic linux-image-4.13.0-16-generic linux-image-4.13.0-17-generic linux-image-4.13.0-32-generic linux-image-4.13.0-36-generic
linux-image-4.13.0-37-generic linux-image-extra-4.13.0-16-generic linux-image-extra-4.13.0-17-generic linux-image-extra-4.13.0-32-generic linux-image-extra-4.13.0-36-generic
linux-image-extra-4.13.0-37-generic
Use 'sudo apt autoremove' to remove them.
The following additional packages will be installed:
lynx-common
The following NEW packages will be installed:
lynx lynx-common
0 upgraded, 2 newly installed, 0 to remove and 71 not upgraded.
Need to get 1,498 kB of archives.
After this operation, 5,418 kB of additional disk space will be used.
Get:1 http://in.archive.ubuntu.com/ubuntu artful/universe amd64 lynx-common all 2.8.9dev16-1 [873 kB]
Get:2 http://in.archive.ubuntu.com/ubuntu artful/universe amd64 lynx amd64 2.8.9dev16-1 [625 kB]
Fetched 1,498 kB in 12s (120 kB/s)
Selecting previously unselected package lynx-common.
(Reading database ... 441037 files and directories currently installed.)
Preparing to unpack .../lynx-common_2.8.9dev16-1_all.deb ...
Unpacking lynx-common (2.8.9dev16-1) ...
Selecting previously unselected package lynx.
Preparing to unpack .../lynx_2.8.9dev16-1_amd64.deb ...
Unpacking lynx (2.8.9dev16-1) ...
Processing triggers for mime-support (3.60ubuntu1) ...
Processing triggers for doc-base (0.10.7) ...
Processing 1 added doc-base file...
Processing triggers for man-db (2.7.6.1-2) ...
Setting up lynx-common (2.8.9dev16-1) ...
Setting up lynx (2.8.9dev16-1) ...
update-alternatives: using /usr/bin/lynx to provide /usr/bin/www-browser (www-browser) in auto mode
Cleaning old downloads in /tmp
Downloading the kernel's components...
Checksum for linux-headers-4.16.7-041607-generic_4.16.7-041607.201805021131_amd64.deb succeed
Checksum for linux-image-unsigned-4.16.7-041607-generic_4.16.7-041607.201805021131_amd64.deb succeed
Checksum for linux-modules-4.16.7-041607-generic_4.16.7-041607.201805021131_amd64.deb succeed
Downloading the shared kernel header...
Checksum for linux-headers-4.16.7-041607_4.16.7-041607.201805021131_all.deb succeed
Installing Kernel and Headers...
Selecting previously unselected package linux-headers-4.16.7-041607.
(Reading database ... 441141 files and directories currently installed.)
Preparing to unpack .../linux-headers-4.16.7-041607_4.16.7-041607.201805021131_all.deb ...
Unpacking linux-headers-4.16.7-041607 (4.16.7-041607.201805021131) ...
Selecting previously unselected package linux-headers-4.16.7-041607-generic.
Preparing to unpack .../linux-headers-4.16.7-041607-generic_4.16.7-041607.201805021131_amd64.deb ...
Unpacking linux-headers-4.16.7-041607-generic (4.16.7-041607.201805021131) ...
Selecting previously unselected package linux-image-unsigned-4.16.7-041607-generic.
Preparing to unpack .../linux-image-unsigned-4.16.7-041607-generic_4.16.7-041607.201805021131_amd64.deb ...
Unpacking linux-image-unsigned-4.16.7-041607-generic (4.16.7-041607.201805021131) ...
Selecting previously unselected package linux-modules-4.16.7-041607-generic.
Preparing to unpack .../linux-modules-4.16.7-041607-generic_4.16.7-041607.201805021131_amd64.deb ...
Unpacking linux-modules-4.16.7-041607-generic (4.16.7-041607.201805021131) ...
Setting up linux-headers-4.16.7-041607 (4.16.7-041607.201805021131) ...
dpkg: dependency problems prevent configuration of linux-headers-4.16.7-041607-generic:
linux-headers-4.16.7-041607-generic depends on libssl1.1 (>= 1.1.0); however:
Package libssl1.1 is not installed.
Setting up linux-modules-4.16.7-041607-generic (4.16.7-041607.201805021131) ...
Setting up linux-image-unsigned-4.16.7-041607-generic (4.16.7-041607.201805021131) ...
I: /vmlinuz.old is now a symlink to boot/vmlinuz-4.13.0-39-generic
I: /initrd.img.old is now a symlink to boot/initrd.img-4.13.0-39-generic
I: /vmlinuz is now a symlink to boot/vmlinuz-4.16.7-041607-generic
I: /initrd.img is now a symlink to boot/initrd.img-4.16.7-041607-generic
Processing triggers for linux-image-unsigned-4.16.7-041607-generic (4.16.7-041607.201805021131) ...
/etc/kernel/postinst.d/initramfs-tools:
update-initramfs: Generating /boot/initrd.img-4.16.7-041607-generic
/etc/kernel/postinst.d/zz-update-grub:
Generating grub configuration file ...
Warning: Setting GRUB_TIMEOUT to a non-zero value when GRUB_HIDDEN_TIMEOUT is set is no longer supported.
Found linux image: /boot/vmlinuz-4.16.7-041607-generic
Found initrd image: /boot/initrd.img-4.16.7-041607-generic
Found linux image: /boot/vmlinuz-4.13.0-39-generic
Found initrd image: /boot/initrd.img-4.13.0-39-generic
Found linux image: /boot/vmlinuz-4.13.0-38-generic
Found initrd image: /boot/initrd.img-4.13.0-38-generic
Found linux image: /boot/vmlinuz-4.13.0-37-generic
Found initrd image: /boot/initrd.img-4.13.0-37-generic
Found linux image: /boot/vmlinuz-4.13.0-36-generic
Found initrd image: /boot/initrd.img-4.13.0-36-generic
Found linux image: /boot/vmlinuz-4.13.0-32-generic
Found initrd image: /boot/initrd.img-4.13.0-32-generic
Found linux image: /boot/vmlinuz-4.13.0-17-generic
Found initrd image: /boot/initrd.img-4.13.0-17-generic
Found linux image: /boot/vmlinuz-4.13.0-16-generic
Found initrd image: /boot/initrd.img-4.13.0-16-generic
Found memtest86+ image: /boot/memtest86+.elf
Found memtest86+ image: /boot/memtest86+.bin
done
Thanks for using this script! Hope it helped.
Give it a star: https://github.com/MarauderXtreme/uktools
```
重新启动系统以激活最新的内核。
```
$ sudo shutdown -r now
```
一旦系统重新启动,重新检查内核版本。
```
$ uname -a
Linux ubuntu 4.16.7-041607-generic #201805021131 SMP Wed May 2 15:34:55 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux
```
此 make 命令会将下面的文件放到 `/usr/local/bin` 目录中。
```
do-kernel-upgrade
do-kernel-purge
```
要移除旧内核,运行以下命令:
```
$ do-kernel-purge
Ubuntu Kernel Purge - by Caio Oliveira
This script will only keep three versions: the first and the last two, others will be purge
---Current version:
Linux Kernel 4.16.7-041607 Generic (linux-image-4.16.7-041607-generic)
---Versions to remove:
4.13.0-16
4.13.0-17
4.13.0-32
4.13.0-36
4.13.0-37
---Do you want to remove the old kernels/headers versions? (Y/n): y
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following packages were automatically installed and are no longer required:
linux-headers-4.13.0-17 linux-headers-4.13.0-17-generic linux-headers-4.13.0-32 linux-headers-4.13.0-32-generic linux-headers-4.13.0-36 linux-headers-4.13.0-36-generic linux-headers-4.13.0-37
linux-headers-4.13.0-37-generic linux-image-4.13.0-17-generic linux-image-4.13.0-32-generic linux-image-4.13.0-36-generic linux-image-4.13.0-37-generic linux-image-extra-4.13.0-17-generic
linux-image-extra-4.13.0-32-generic linux-image-extra-4.13.0-36-generic linux-image-extra-4.13.0-37-generic
Use 'sudo apt autoremove' to remove them.
The following packages will be REMOVED:
linux-headers-4.13.0-16* linux-headers-4.13.0-16-generic* linux-image-4.13.0-16-generic* linux-image-extra-4.13.0-16-generic*
0 upgraded, 0 newly installed, 4 to remove and 71 not upgraded.
After this operation, 318 MB disk space will be freed.
(Reading database ... 465582 files and directories currently installed.)
Removing linux-headers-4.13.0-16-generic (4.13.0-16.19) ...
Removing linux-headers-4.13.0-16 (4.13.0-16.19) ...
Removing linux-image-extra-4.13.0-16-generic (4.13.0-16.19) ...
run-parts: executing /etc/kernel/postinst.d/apt-auto-removal 4.13.0-16-generic /boot/vmlinuz-4.13.0-16-generic
run-parts: executing /etc/kernel/postinst.d/initramfs-tools 4.13.0-16-generic /boot/vmlinuz-4.13.0-16-generic
update-initramfs: Generating /boot/initrd.img-4.13.0-16-generic
run-parts: executing /etc/kernel/postinst.d/unattended-upgrades 4.13.0-16-generic /boot/vmlinuz-4.13.0-16-generic
run-parts: executing /etc/kernel/postinst.d/update-notifier 4.13.0-16-generic /boot/vmlinuz-4.13.0-16-generic
run-parts: executing /etc/kernel/postinst.d/zz-update-grub 4.13.0-16-generic /boot/vmlinuz-4.13.0-16-generic
Generating grub configuration file ...
Warning: Setting GRUB_TIMEOUT to a non-zero value when GRUB_HIDDEN_TIMEOUT is set is no longer supported.
Found linux image: /boot/vmlinuz-4.16.7-041607-generic
Found initrd image: /boot/initrd.img-4.16.7-041607-generic
Found linux image: /boot/vmlinuz-4.13.0-39-generic
Found initrd image: /boot/initrd.img-4.13.0-39-generic
Found linux image: /boot/vmlinuz-4.13.0-38-generic
Found initrd image: /boot/initrd.img-4.13.0-38-generic
Found linux image: /boot/vmlinuz-4.13.0-37-generic
Found initrd image: /boot/initrd.img-4.13.0-37-generic
Found linux image: /boot/vmlinuz-4.13.0-36-generic
Found initrd image: /boot/initrd.img-4.13.0-36-generic
Found linux image: /boot/vmlinuz-4.13.0-32-generic
Found initrd image: /boot/initrd.img-4.13.0-32-generic
Found linux image: /boot/vmlinuz-4.13.0-17-generic
Found initrd image: /boot/initrd.img-4.13.0-17-generic
Found linux image: /boot/vmlinuz-4.13.0-16-generic
Found initrd image: /boot/initrd.img-4.13.0-16-generic
Found memtest86+ image: /boot/memtest86+.elf
Found memtest86+ image: /boot/memtest86+.bin
done
Removing linux-image-4.13.0-16-generic (4.13.0-16.19) ...
Examining /etc/kernel/postrm.d .
run-parts: executing /etc/kernel/postrm.d/initramfs-tools 4.13.0-16-generic /boot/vmlinuz-4.13.0-16-generic
update-initramfs: Deleting /boot/initrd.img-4.13.0-16-generic
run-parts: executing /etc/kernel/postrm.d/zz-update-grub 4.13.0-16-generic /boot/vmlinuz-4.13.0-16-generic
Generating grub configuration file ...
Warning: Setting GRUB_TIMEOUT to a non-zero value when GRUB_HIDDEN_TIMEOUT is set is no longer supported.
Found linux image: /boot/vmlinuz-4.16.7-041607-generic
Found initrd image: /boot/initrd.img-4.16.7-041607-generic
Found linux image: /boot/vmlinuz-4.13.0-39-generic
Found initrd image: /boot/initrd.img-4.13.0-39-generic
Found linux image: /boot/vmlinuz-4.13.0-38-generic
Found initrd image: /boot/initrd.img-4.13.0-38-generic
Found linux image: /boot/vmlinuz-4.13.0-37-generic
Found initrd image: /boot/initrd.img-4.13.0-37-generic
Found linux image: /boot/vmlinuz-4.13.0-36-generic
Found initrd image: /boot/initrd.img-4.13.0-36-generic
Found linux image: /boot/vmlinuz-4.13.0-32-generic
Found initrd image: /boot/initrd.img-4.13.0-32-generic
Found linux image: /boot/vmlinuz-4.13.0-17-generic
Found initrd image: /boot/initrd.img-4.13.0-17-generic
Found memtest86+ image: /boot/memtest86+.elf
Found memtest86+ image: /boot/memtest86+.bin
done
(Reading database ... 430635 files and directories currently installed.)
Purging configuration files for linux-image-extra-4.13.0-16-generic (4.13.0-16.19) ...
Purging configuration files for linux-image-4.13.0-16-generic (4.13.0-16.19) ...
Examining /etc/kernel/postrm.d .
run-parts: executing /etc/kernel/postrm.d/initramfs-tools 4.13.0-16-generic /boot/vmlinuz-4.13.0-16-generic
run-parts: executing /etc/kernel/postrm.d/zz-update-grub 4.13.0-16-generic /boot/vmlinuz-4.13.0-16-generic
Reading package lists... Done
Building dependency tree
Reading state information... Done
.
.
.
.
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following packages will be REMOVED:
linux-headers-4.13.0-37* linux-headers-4.13.0-37-generic* linux-image-4.13.0-37-generic* linux-image-extra-4.13.0-37-generic*
0 upgraded, 0 newly installed, 4 to remove and 71 not upgraded.
After this operation, 321 MB disk space will be freed.
(Reading database ... 325772 files and directories currently installed.)
Removing linux-headers-4.13.0-37-generic (4.13.0-37.42) ...
Removing linux-headers-4.13.0-37 (4.13.0-37.42) ...
Removing linux-image-extra-4.13.0-37-generic (4.13.0-37.42) ...
run-parts: executing /etc/kernel/postinst.d/apt-auto-removal 4.13.0-37-generic /boot/vmlinuz-4.13.0-37-generic
run-parts: executing /etc/kernel/postinst.d/initramfs-tools 4.13.0-37-generic /boot/vmlinuz-4.13.0-37-generic
update-initramfs: Generating /boot/initrd.img-4.13.0-37-generic
run-parts: executing /etc/kernel/postinst.d/unattended-upgrades 4.13.0-37-generic /boot/vmlinuz-4.13.0-37-generic
run-parts: executing /etc/kernel/postinst.d/update-notifier 4.13.0-37-generic /boot/vmlinuz-4.13.0-37-generic
run-parts: executing /etc/kernel/postinst.d/zz-update-grub 4.13.0-37-generic /boot/vmlinuz-4.13.0-37-generic
Generating grub configuration file ...
Warning: Setting GRUB_TIMEOUT to a non-zero value when GRUB_HIDDEN_TIMEOUT is set is no longer supported.
Found linux image: /boot/vmlinuz-4.16.7-041607-generic
Found initrd image: /boot/initrd.img-4.16.7-041607-generic
Found linux image: /boot/vmlinuz-4.13.0-39-generic
Found initrd image: /boot/initrd.img-4.13.0-39-generic
Found linux image: /boot/vmlinuz-4.13.0-38-generic
Found initrd image: /boot/initrd.img-4.13.0-38-generic
Found linux image: /boot/vmlinuz-4.13.0-37-generic
Found initrd image: /boot/initrd.img-4.13.0-37-generic
Found memtest86+ image: /boot/memtest86+.elf
Found memtest86+ image: /boot/memtest86+.bin
done
Removing linux-image-4.13.0-37-generic (4.13.0-37.42) ...
Examining /etc/kernel/postrm.d .
run-parts: executing /etc/kernel/postrm.d/initramfs-tools 4.13.0-37-generic /boot/vmlinuz-4.13.0-37-generic
update-initramfs: Deleting /boot/initrd.img-4.13.0-37-generic
run-parts: executing /etc/kernel/postrm.d/zz-update-grub 4.13.0-37-generic /boot/vmlinuz-4.13.0-37-generic
Generating grub configuration file ...
Warning: Setting GRUB_TIMEOUT to a non-zero value when GRUB_HIDDEN_TIMEOUT is set is no longer supported.
Found linux image: /boot/vmlinuz-4.16.7-041607-generic
Found initrd image: /boot/initrd.img-4.16.7-041607-generic
Found linux image: /boot/vmlinuz-4.13.0-39-generic
Found initrd image: /boot/initrd.img-4.13.0-39-generic
Found linux image: /boot/vmlinuz-4.13.0-38-generic
Found initrd image: /boot/initrd.img-4.13.0-38-generic
Found memtest86+ image: /boot/memtest86+.elf
Found memtest86+ image: /boot/memtest86+.bin
done
(Reading database ... 290810 files and directories currently installed.)
Purging configuration files for linux-image-extra-4.13.0-37-generic (4.13.0-37.42) ...
Purging configuration files for linux-image-4.13.0-37-generic (4.13.0-37.42) ...
Examining /etc/kernel/postrm.d .
run-parts: executing /etc/kernel/postrm.d/initramfs-tools 4.13.0-37-generic /boot/vmlinuz-4.13.0-37-generic
run-parts: executing /etc/kernel/postrm.d/zz-update-grub 4.13.0-37-generic /boot/vmlinuz-4.13.0-37-generic
Thanks for using this script!!!
```
使用以下命令重新检查已安装内核的列表。它将只保留三个旧的内核。
```
$ dpkg --list | grep linux-image
ii linux-image-4.13.0-38-generic 4.13.0-38.43 amd64 Linux kernel image for version 4.13.0 on 64 bit x86 SMP
ii linux-image-4.13.0-39-generic 4.13.0-39.44 amd64 Linux kernel image for version 4.13.0 on 64 bit x86 SMP
ii linux-image-extra-4.13.0-38-generic 4.13.0-38.43 amd64 Linux kernel extra modules for version 4.13.0 on 64 bit x86 SMP
ii linux-image-extra-4.13.0-39-generic 4.13.0-39.44 amd64 Linux kernel extra modules for version 4.13.0 on 64 bit x86 SMP
ii linux-image-generic 4.13.0.39.42 amd64 Generic Linux kernel image
ii linux-image-unsigned-4.16.7-041607-generic 4.16.7-041607.201805021131 amd64 Linux kernel image for version 4.16.7 on 64 bit x86 SMP
```
下次你可以调用 `do-kernel-upgrade` 实用程序来安装新的内核。如果有任何新内核可用,那么它将安装。如果没有,它将报告当前没有可用的内核更新。
```
$ do-kernel-upgrade
Kernel up to date. Finishing
```
再次运行 `do-kernel-purge` 命令以确认。如果发现超过三个内核,那么它将移除。如果不是,它将报告没有删除消息。
```
$ do-kernel-purge
Ubuntu Kernel Purge - by Caio Oliveira
This script will only keep three versions: the first and the last two, others will be purge
---Current version:
Linux Kernel 4.16.7-041607 Generic (linux-image-4.16.7-041607-generic)
Nothing to remove!
Thanks for using this script!!!
```
---
via: <https://www.2daygeek.com/uktools-easy-way-to-install-latest-stable-linux-kernel-on-ubuntu-mint-and-derivatives/>
作者:[Prakash Subramanian](https://www.2daygeek.com/author/prakash/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
9,906 | 系统管理员的 SELinux 指南:这个大问题的 42 个答案 | https://opensource.com/article/18/7/sysadmin-guide-selinux | 2018-08-09T00:50:56 | [
"SELinux",
"安全"
] | https://linux.cn/article-9906-1.html |
>
> 获取有关生活、宇宙和除了有关 SELinux 的重要问题的答案
>
>
>

>
> “一个重要而普遍的事实是,事情并不总是你看上去的那样 …” ―Douglas Adams,《银河系漫游指南》
>
>
>
安全、坚固、遵从性、策略是末世中系统管理员的四骑士。除了我们的日常任务之外 —— 监控、备份、实施、调优、更新等等 —— 我们还需要负责我们的系统安全。即使这些系统是第三方提供商告诉我们该禁用增强安全性的系统。这看起来像《碟中碟》中 [Ethan Hunt](https://en.wikipedia.org/wiki/Ethan_Hunt) 的工作一样。
面对这种窘境,一些系统管理员决定去[服用蓝色小药丸](https://en.wikipedia.org/wiki/Red_pill_and_blue_pill),因为他们认为他们永远也不会知道如生命、宇宙、以及其它一些大问题的答案。而我们都知道,它的答案就是这个 **[42](https://en.wikipedia.org/wiki/Phrases_from_The_Hitchhiker%27s_Guide_to_the_Galaxy#Answer_to_the_Ultimate_Question_of_Life,_the_Universe,_and_Everything_%2842%29)**。
按《银河系漫游指南》的精神,这里是关于在你的系统上管理和使用 [SELinux](https://en.wikipedia.org/wiki/Security-Enhanced_Linux) 这个大问题的 42 个答案。
1. SELinux 是一个标签系统,这意味着每个进程都有一个标签。每个文件、目录、以及系统对象都有一个标签。策略规则负责控制标签化的进程和标签化的对象之间的访问。由内核强制执行这些规则。
2. 两个最重要的概念是:标签化(文件、进程、端口等等)和类型强制(基于不同的类型隔离不同的的进程)。
3. 正确的标签格式是 `user:role:type:level`(可选)。
4. <ruby> 多级别安全 <rt> Multi-Level Security </rt></ruby>(MLS)强制的目的是基于它们所使用数据的安全级别,对进程(域)强制实施控制。比如,一个秘密级别的进程是不能读取极机密级别的数据。
5. <ruby> 多类别安全 <rt> Multi-Category Security </rt></ruby>(MCS)强制相互保护相似的进程(如虚拟机、OpenShift gears、SELinux 沙盒、容器等等)。
6. 在启动时改变 SELinux 模式的内核参数有:
* `autorelabel=1` → 强制给系统重新标签化
* `selinux=0` → 内核不加载 SELinux 基础设施的任何部分
* `enforcing=0` → 以<ruby> 许可 <rt> permissive </rt></ruby>模式启动
7. 如果给整个系统重新标签化:
```
# touch /.autorelabel
# reboot
```
如果系统标签中有大量的错误,为了能够让 autorelabel 成功,你可以用许可模式引导系统。
8. 检查 SELinux 是否启用:`# getenforce`
9. 临时启用/禁用 SELinux:`# setenforce [1|0]`
10. SELinux 状态工具:`# sestatus`
11. 配置文件:`/etc/selinux/config`
12. SELinux 是如何工作的?这是一个为 Apache Web Server 标签化的示例:
* 二进制文件:`/usr/sbin/httpd`→`httpd_exec_t`
* 配置文件目录:`/etc/httpd`→`httpd_config_t`
* 日志文件目录:`/var/log/httpd` → `httpd_log_t`
* 内容目录:`/var/www/html` → `httpd_sys_content_t`
* 启动脚本:`/usr/lib/systemd/system/httpd.service` → `httpd_unit_file_d`
* 进程:`/usr/sbin/httpd -DFOREGROUND` → `httpd_t`
* 端口:`80/tcp, 443/tcp` → `httpd_t, http_port_t`在 `httpd_t` 安全上下文中运行的一个进程可以与具有 `httpd_something_t` 标签的对象交互。
13. 许多命令都可以接收一个 `-Z` 参数去查看、创建、和修改安全上下文:
* `ls -Z`
* `id -Z`
* `ps -Z`
* `netstat -Z`
* `cp -Z`
* `mkdir -Z`当文件被创建时,它们的安全上下文会根据它们父目录的安全上下文来创建(可能有某些例外)。RPM 可以在安装过程中设定安全上下文。
14. 这里有导致 SELinux 出错的四个关键原因,它们将在下面的 15 - 21 条中展开描述:
* 标签化问题
* SELinux 需要知道一些东西
* SELinux 策略或者应用有 bug
* 你的信息可能被损坏
15. 标签化问题:如果在 `/srv/myweb` 中你的文件没有被正确的标签化,访问可能会被拒绝。这里有一些修复这类问题的方法:
* 如果你知道标签:`# semanage fcontext -a -t httpd_sys_content_t '/srv/myweb(/.*)?'`
* 如果你知道和它有相同标签的文件:`# semanage fcontext -a -e /srv/myweb /var/www`
* 恢复安全上下文(对于以上两种情况):`# restorecon -vR /srv/myweb`
16. 标签化问题:如果你是移动了一个文件,而不是去复制它,那么这个文件将保持原始的环境。修复这类问题:
* 使用标签来改变安全上下文:`# chcon -t httpd_system_content_t /var/www/html/index.html`
* 使用参考文件的标签来改变安全上下文:`# chcon --reference /var/www/html/ /var/www/html/index.html`
* 恢复安全上下文(对于以上两种情况):`# restorecon -vR /var/www/html/`
17. 如果 SELinux 需要知道 HTTPD 在 8585 端口上监听,使用下列命令告诉 SELinux:`# semanage port -a -t http_port_t -p tcp 8585`
18. SELinux 需要知道是否允许在运行时改变 SELinux 策略部分,而无需重写 SELinux 策略。例如,如果希望 httpd 去发送邮件,输入:`# setsebool -P httpd_can_sendmail 1`
19. SELinux 需要知道 SELinux 设置的关闭或打开的一系列布尔值:
* 查看所有的布尔值:`# getsebool -a`
* 查看每个布尔值的描述:`# semanage boolean -l`
* 设置某个布尔值:`# setsebool [_boolean_] [1|0]`
* 将它配置为永久值,添加 `-P` 标志。例如:`# setsebool httpd_enable_ftp_server 1 -P`
20. SELinux 策略/应用可能有 bug,包括:
* 不寻常的代码路径
* 配置
* 重定向 `stdout`
* 泄露的文件描述符
* 可执行内存
* 错误构建的库开一个工单(但不要提交 Bugzilla 报告;使用 Bugzilla 没有对应的服务)
21. 你的信息可能被损坏了,假如你被限制在某个区域,尝试这样做:
* 加载内核模块
* 关闭 SELinux 的强制模式
* 写入 `etc_t/shadow_t`
* 修改 iptables 规则
22. 用于开发策略模块的 SELinux 工具:`# yum -y install setroubleshoot setroubleshoot-server`。安装完成之后重引导机器或重启 `auditd` 服务。
23. 使用 `journalctl` 去列出所有与 `setroubleshoot` 相关的日志:`# journalctl -t setroubleshoot --since=14:20`
24. 使用 `journalctl` 去列出所有与特定 SELinux 标签相关的日志。例如:`# journalctl _SELINUX_CONTEXT=system_u:system_r:policykit_t:s0`
25. 当 SELinux 错误发生时,使用`setroubleshoot` 的日志,并尝试找到某些可能的解决方法。例如:从 `journalctl` 中:
```
Jun 14 19:41:07 web1 setroubleshoot: SELinux is preventing httpd from getattr access on the file /var/www/html/index.html. For complete message run: sealert -l 12fd8b04-0119-4077-a710-2d0e0ee5755e
# sealert -l 12fd8b04-0119-4077-a710-2d0e0ee5755e
SELinux is preventing httpd from getattr access on the file /var/www/html/index.html.
***** Plugin restorecon (99.5 confidence) suggests ************************
If you want to fix the label,
/var/www/html/index.html default label should be httpd_syscontent_t.
Then you can restorecon.
Do
# /sbin/restorecon -v /var/www/html/index.html
```
26. 日志:SELinux 记录的信息全在这些地方:
* `/var/log/messages`
* `/var/log/audit/audit.log`
* `/var/lib/setroubleshoot/setroubleshoot_database.xml`
27. 日志:在审计日志中查找 SELinux 错误:`# ausearch -m AVC,USER_AVC,SELINUX_ERR -ts today`
28. 针对特定的服务,搜索 SELinux 的<ruby> 访问向量缓存 <rt> Access Vector Cache </rt></ruby>(AVC)信息:`# ausearch -m avc -c httpd`
29. `audit2allow` 实用工具可以通过从日志中搜集有关被拒绝的操作,然后生成 SELinux 策略允许的规则,例如:
* 产生一个人类可读的关于为什么拒绝访问的描述:`# audit2allow -w -a`
* 查看允许被拒绝的类型强制规则:`# audit2allow -a`
* 创建一个自定义模块:`# audit2allow -a -M mypolicy`,其中 `-M` 选项将创建一个特定名称的强制类型文件(.te),并编译这个规则到一个策略包(.pp)中:`mypolicy.pp mypolicy.te`
* 安装自定义模块:`# semodule -i mypolicy.pp`
30. 配置单个进程(域)运行在许可模式:`# semanage permissive -a httpd_t`
31. 如果不再希望一个域在许可模式中:`# semanage permissive -d httpd_t`
32. 禁用所有的许可域:`# semodule -d permissivedomains`
33. 启用 SELinux MLS 策略:`# yum install selinux-policy-mls`。 在 `/etc/selinux/config` 中:
```
SELINUX=permissive
SELINUXTYPE=mls
```
确保 SELinux 运行在许可模式:`# setenforce 0`
使用 `fixfiles` 脚本来确保在下一次重启时文件将被重新标签化:`# fixfiles -F onboot # reboot`
34. 创建一个带有特定 MLS 范围的用户:`# useradd -Z staff_u john`
使用 `useradd` 命令,映射新用户到一个已存在的 SELinux 用户(上面例子中是 `staff_u`)。
35. 查看 SELinux 和 Linux 用户之间的映射:`# semanage login -l`
36. 为用户定义一个指定的范围:`# semanage login --modify --range s2:c100 john`
37. 调整用户家目录上的标签(如果需要的话):`# chcon -R -l s2:c100 /home/john`
38. 列出当前类别:`# chcat -L`
39. 修改类别或者创建你自己的分类,修改如下文件:`/etc/selinux/_<selinuxtype>_/setrans.conf`
40. 以某个特定的文件、角色和用户安全上下文来运行一个命令或者脚本:`# runcon -t initrc_t -r system_r -u user_u yourcommandhere`
* `-t` 是文件安全上下文
* `-r` 是角色安全上下文
* `-u` 是用户安全上下文
41. 在容器中禁用 SELinux:
* 使用 Podman:`# podman run --security-opt label=disable ...`
* 使用 Docker:`# docker run --security-opt label=disable ...`
42. 如果需要给容器提供完全访问系统的权限:
* 使用 Podman:`# podman run --privileged ...`
* 使用 Docker:`# docker run --privileged ...`
就这些了,你已经知道了答案。因此请相信我:**不用恐慌,去打开 SELinux 吧**。
### 作者简介
Alex Callejas 是位于墨西哥城的红帽公司拉丁美洲区的一名技术客服经理。作为一名系统管理员,他已有超过 10 年的经验。在基础设施强化方面具有很强的专业知识。对开源抱有热情,通过在不同的公共事件和大学中分享他的知识来支持社区。天生的极客,当然他一般选择使用 Fedora Linux 发行版。[这里][11]有更多关于他的信息。
---
via: <https://opensource.com/article/18/7/sysadmin-guide-selinux>
作者:[Alex Callejas](https://opensource.com/users/darkaxl) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw), [FSSlc](https://github.com/FSSlc) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | "It is an important and popular fact that things are not always what they seem…"
―Douglas Adams,The Hitchhiker's Guide to the Galaxy
Security. Hardening. Compliance. Policy. The Four Horsemen of the SysAdmin Apocalypse. In addition to our daily tasks—monitoring, backup, implementation, tuning, updating, and so forth—we are also in charge of securing our systems. Even those systems where the third-party provider tells us to disable the enhanced security. It seems like a job for *Mission Impossible*'s [Ethan Hunt](https://en.wikipedia.org/wiki/Ethan_Hunt).
Faced with this dilemma, some sysadmins decide to [take the blue pill](https://en.wikipedia.org/wiki/Red_pill_and_blue_pill) because they think they will never know the answer to the big question of life, the universe, and everything else. And, as we all know, that answer is ** 42**.
In the spirit of *The Hitchhiker's Guide to the Galaxy*, here are the 42 answers to the big questions about managing and using [SELinux](https://en.wikipedia.org/wiki/Security-Enhanced_Linux) with your systems.
- SELinux is a LABELING system, which means every process has a LABEL. Every file, directory, and system object has a LABEL. Policy rules control access between labeled processes and labeled objects. The kernel enforces these rules.
- The two most important concepts are:
*Labeling*(files, process, ports, etc.) and*Type enforcement*(which isolates processes from each other based on types).
- The correct Label format is
`user:role:type:level`
(*optional*).
- The purpose of
*Multi-Level Security (MLS) enforcement*is to control processes (*domains*) based on the security level of the data they will be using. For example, a secret process cannot read top-secret data.
*Multi-Category Security (MCS) enforcement*protects similar processes from each other (like virtual machines, OpenShift gears, SELinux sandboxes, containers, etc.).
- Kernel parameters for changing SELinux modes at boot:
`autorelabel=1`
→ forces the system to relabel`selinux=0`
→ kernel doesn't load any part of the SELinux infrastructure`enforcing=0`
→ boot in permissive mode
- If you need to relabel the entire system:
`# touch /.autorelabel # reboot`
If the system labeling contains a large amount of errors, you might need to boot in permissive mode in order for the autorelabel to succeed.
-
To check if SELinux is enabled:
`# getenforce`
-
To temporarily enable/disable SELinux:
`# setenforce [1|0]`
-
SELinux status tool:
`# sestatus`
-
Configuration file:
`/etc/selinux/config`
- How does SELinux work? Here's an example of labeling for an Apache Web Server:
- Binary:
`/usr/sbin/httpd`
→`httpd_exec_t`
- Configuration directory:
`/etc/httpd`
→`httpd_config_t`
- Logfile directory:
`/var/log/httpd`
→`httpd_log_t`
- Content directory:
`/var/www/html`
→`httpd_sys_content_t`
- Startup script:
`/usr/lib/systemd/system/httpd.service`
→`httpd_unit_file_d`
- Process:
`/usr/sbin/httpd -DFOREGROUND`
→`httpd_t`
- Ports:
`80/tcp, 443/tcp`
→`httpd_t, http_port_t`
- Binary:
A process running in the `httpd_t`
context can interact with an object with the `httpd_something_t`
label.
- Many commands accept the argument
`-Z`
to view, create, and modify context:`ls -Z`
`id -Z`
`ps -Z`
`netstat -Z`
`cp -Z`
`mkdir -Z`
Contexts are set when files are created based on their parent directory's context (with a few exceptions). RPMs can set contexts as part of installation.
- There are four key causes of SELinux errors, which are further explained in items 15-21 below:
- Labeling problems
- Something SELinux needs to know
- A bug in an SELinux policy/app
- Your information may be compromised
*Labeling problem:*If your files in`/srv/myweb`
are not labeled correctly, access might be denied. Here are some ways to fix this:- If you know the label:
`# semanage fcontext -a -t httpd_sys_content_t '/srv/myweb(/.*)?'`
- If you know the file with the equivalent labeling:
`# semanage fcontext -a -e /srv/myweb /var/www`
- Restore the context (for both cases):
`# restorecon -vR /srv/myweb`
- If you know the label:
*Labeling problem:*If you move a file instead of copying it, the file keeps its original context. To fix these issues:-
Change the context command with the label:
`$ sudo chcon -t httpd_system_content_t /var/www/html/index.html`
-
Change the context command with the reference label:
`$ sudo chcon --reference /var/www/html/ /var/www/html/index.html`
-
Restore the context (for both cases):
`$ sudo restorecon -vR /var/www/html/`
-
-
If
*SELinux needs to know*HTTPD listens on port 8585, tell SELinux:`$ sudo semanage port -a -t http_port_t -p tcp 8585`
-
*SELinux needs to know*booleans allow parts of SELinux policy to be changed at runtime without any knowledge of SELinux policy writing. For example, if you want httpd to send email, enter:`$ sudo setsebool -P httpd_can_sendmail 1`
*SELinux needs to know*Booleans are just off/on settings for SELinux:- To see all booleans:
`# getsebool -a`
- To see the description of each one:
`# semanage boolean -l`
- To set a boolean execute:
`# setsebool [_boolean_] [1|0]`
- To configure it permanently, add
`-P`
. For example:
`# setsebool httpd_enable_ftp_server 1 -P`
- To see all booleans:
- SELinux policies/apps can have bugs, including:
- Unusual code paths
- Configurations
- Redirection of
`stdout`
- Leaked file descriptors
- Executable memory
- Badly built libraries
*Your information may be compromised*if you have confined domains trying to:- Load kernel modules
- Turn off the enforcing mode of SELinux
- Write to
`etc_t/shadow_t`
- Modify iptables rules
- SELinux tools for the development of policy modules:
`$ yum -y install setroubleshoot setroubleshoot-server`
Reboot or restart
`auditd`
after you install.
- Use
`journalctl`
for listing all logs related to`setroubleshoot`
:
`$ sudo journalctl -t setroubleshoot --since=14:20`
- Use
`journalctl`
for listing all logs related to a particular SELinux label. For example:
`$ sudo journalctl _SELINUX_CONTEXT=system_u:system_r:policykit_t:s0`
-
Use
`setroubleshoot`
log when an SELinux error occurs and suggest some possible solutions. For example, from`journalctl`
:`Jun 14 19:41:07 web1 setroubleshoot: SELinux is preventing httpd from getattr access on the file /var/www/html/index.html. For complete message run: sealert -l 12fd8b04-0119-4077-a710-2d0e0ee5755e # sealert -l 12fd8b04-0119-4077-a710-2d0e0ee5755e SELinux is preventing httpd from getattr access on the file /var/www/html/index.html. ***** Plugin restorecon (99.5 confidence) suggests ************************ If you want to fix the label, /var/www/html/index.html default label should be httpd_syscontent_t. Then you can restorecon. Do # /sbin/restorecon -v /var/www/html/index.html`
- Logging: SELinux records information all over the place:
`/var/log/messages`
`/var/log/audit/audit.log`
`/var/lib/setroubleshoot/setroubleshoot_database.xml`
-
Logging: Looking for SELinux errors in the audit log:
`$ sudo ausearch -m AVC,USER_AVC,SELINUX_ERR -ts today`
-
To search for SELinux Access Vector Cache (AVC) messages for a particular service:
`$ sudo ausearch -m avc -c httpd`
- The
`audit2allow`
utility gathers information from logs of denied operations and then generates SELinux policy-allow rules. For example:- To produce a human-readable description of why the access was denied:
`# audit2allow -w -a`
- To view the type enforcement rule that allows the denied access:
`# audit2allow -a`
- To create a custom module:
`# audit2allow -a -M mypolicy`
The`-M`
option creates a type enforcement file (.te) with the name specified and compiles the rule into a policy package (.pp):`mypolicy.pp mypolicy.te`
- To install the custom module:
`# semodule -i mypolicy.pp`
- To produce a human-readable description of why the access was denied:
- To configure a single process (domain) to run permissive:
`# semanage permissive -a httpd_t`
- If you no longer want a domain to be permissive:
`# semanage permissive -d httpd_t`
-
To disable all permissive domains:
`$ sudo semodule -d permissivedomains`
-
Enabling SELinux MLS policy:
`$ sudo yum install selinux-policy-mls`
In
`/etc/selinux/config:`
`SELINUX=permissive SELINUXTYPE=mls`
Ensure that SELinux is running in permissive mode:
`$ sudo setenforce 0`
Use the
`fixfiles`
script to ensure that files are relabeled upon the next reboot:`$ sudo fixfiles -F onboot $ sudo reboot`
-
Create a user with a specific MLS range:
`$ sudo useradd -Z staff_u tux`
Using the
`useradd`
command, map the new user to an existing SELinux user (in this case,`staff_u`
).
-
To view the mapping between SELinux and Linux users:
`$ sudo semanage login -l`
-
Define a specific range for a user:
`$ sudo semanage login --modify --range s2:c100 tux`
-
To correct the label on the user's home directory (if needed):
`$ sudo chcon -R -l s2:c100 /home/tux`
-
To list the current categories:
`$ sudo chcat -L`
-
To modify the categories or to start creating your own, modify the file as follows:
`/etc/selinux/_<selinuxtype>_/setrans.conf`
-
To run a command or script in a specific file, role, and user context:
`$ sudo runcon -t initrc_t -r system_r -u user_u yourcommandhere`
- -t is the
*file context* - -r is the
*role context* - -u is the
*user context*
- -t is the
- Containers running with SELinux disabled:
- With Podman:
`# podman run --security-opt label=disable …`
- With Docker:
`# docker run --security-opt label=disable …`
- With Podman:
- If you need to give a container full access to the system:
- With Podman:
`# podman run --privileged …`
- With Docker:
`# docker run --privileged …`
- With Podman:
And with this, you already know the answer. So please: **Don't panic, and turn on SELinux**.
## 5 Comments |
9,907 | 用以检查 Linux 内存使用的 5 个命令 | https://www.linux.com/learn/5-commands-checking-memory-usage-linux | 2018-08-09T01:45:36 | [
"内存"
] | https://linux.cn/article-9907-1.html |
>
> 对于 Linux 管理员来说,检查系统内存用量是一个重要的技能。Jack 给出了解决这个问题的五种不同方式。
>
>
>

Linux 操作系统包含大量工具,所有这些工具都可以帮助你管理系统。从简单的文件和目录工具到非常复杂的安全命令,在 Linux 中没有多少是你做不了的。而且,尽管普通桌面用户可能不需要在命令行熟悉这些工具,但对于 Linux 管理员来说,它们是必需的。为什么?首先,你在某些时候不得不使用没有 GUI 的 Linux 服务器。其次,命令行工具通常比 GUI 替代工具提供更多的功能和灵活性。
确定内存使用情况是你可能需要的技能,尤其是某个应用程序变得异常和占用系统内存时。当发生这种情况时,知道有多种工具可以帮助你进行故障排除十分方便的。或者,你可能需要收集有关 Linux 交换分区的信息,或者有关安装的内存的详细信息?对于这些也有相应的命令。让我们深入了解各种 Linux 命令行工具,以帮助你检查系统内存使用情况。这些工具并不是非常难以使用,在本文中,我将向你展示五种不同的方法来解决这个问题。
我将在 [Ubuntu 18.04 服务器平台](https://www.ubuntu.com/download/server)上进行演示,但是你应该在你选择的发行版中找到对应的所有命令。更妙的是,你不需要安装任何东西(因为大多数这些工具都包含 Linux 系统中)。
话虽如此,让我们开始工作吧。
### top
我想从最常用的工具开始。`top` 命令提供正在运行的系统的实时动态视图,它检查每个进程的内存使用情况。这非常重要,因为你可以轻松地看到同一命令的多个示例消耗不同的内存量。虽然你无法在没有显示器的服务器上看到这种情况,但是你已经注意到打开 Chrome 使你的系统速度变慢了。运行 `top` 命令以查看 Chrome 有多个进程在运行(每个选项卡一个 - 图 1)。

*图1:top 命令中出现多个 Chrome 进程。*
Chrome 并不是唯一显示多个进程的应用。你看到图 1 中的 Firefox 了吗?那是 Firefox 的主进程,而 Web Content 进程是其打开的选项卡。在输出的顶部,你将看到系统统计信息。在我的机器上([System76 Leopard Extreme](https://system76.com/desktops/leopard)),我总共有 16GB 可用 RAM,其中只有超过 10GB 的 RAM 正在使用中。然后,你可以整理该列表,查看每个进程使用的内存百分比。
`top` 最好的地方之一就是发现可能已经失控的服务的进程 ID 号(PID)。有了这些 PID,你可以对有问题的任务进行故障排除(或 `kill`)。
如果你想让 `top` 显示更友好的内存信息,使用命令 `top -o %MEM`,这会使 `top` 按进程所用内存对所有进程进行排序(图 2)。

*图 2:在 top 命令中按使用内存对进程排序*
`top` 命令还为你提供有关使用了多少交换空间的实时更新。
### free
然而有时候,`top` 命令可能不能满足你的需求。你可能只需要查看系统的可用和已用内存。对此,Linux 还有 `free` 命令。`free` 命令显示:
* 可用和已使用的物理内存总量
* 系统中交换内存的总量
* 内核使用的缓冲区和缓存
在终端窗口中,输入 `free` 命令。它的输出不是实时的,相反,你将获得的是当前空闲和已用内存的即时快照(图 3)。

*图 3 :free 命令的输出简单明了。*
当然,你可以通过添加 `-m` 选项来让 `free` 显示得更友好一点,就像这样:`free -m`。这将显示内存的使用情况,以 MB 为单位(图 4)。

*图 4:free 命令以一种更易于阅读的形式输出。*
当然,如果你的系统是很新的,你将希望使用 `-g` 选项(以 GB 为单位),比如 `free -g`。
如果你需要知道内存总量,你可以添加 `-t` 选项,比如:`free -mt`。这将简单地计算每列中的内存总量(图 5)。

*图 5:为你提供空闲的内存列。*
### vmstat
另一个非常方便的工具是 `vmstat`。这个特殊的命令是一个报告虚拟内存统计信息的小技巧。`vmstat` 命令将报告关于:
* 进程
* 内存
* 分页
* 阻塞 IO
* 中断
* 磁盘
* CPU
使用 `vmstat` 的最佳方法是使用 `-s` 选项,如 `vmstat -s`。这将在单列中报告统计信息(这比默认报告更容易阅读)。`vmstat` 命令将提供比你需要的更多的信息(图 6),但更多的总是更好的(在这种情况下)。

*图 6:使用 vmstat 命令来检查内存使用情况。*
### dmidecode
如果你想找到关于已安装的系统内存的详细信息,该怎么办?为此,你可以使用 `dmidecode` 命令。这个特殊的工具是 DMI 表解码器,它将系统的 DMI 表内容转储成人类可读的格式。如果你不清楚 DMI 表是什么,那么可以这样说,它可以用来描述系统的构成(以及系统的演变)。
要运行 `dmidecode` 命令,你需要 `sudo` 权限。因此输入命令 `sudo dmidecode -t 17`。该命令的输出(图 7)可能很长,因为它显示所有内存类型设备的信息。因此,如果你无法上下滚动,则可能需要将该命令的输出发送到一个文件中,比如:`sudo dmidecode -t 17> dmi_infoI`,或将其传递给 `less` 命令,如 `sudo dmidecode | less`。

*图 7:dmidecode 命令的输出。*
### /proc/meminfo
你可能会问自己:“这些命令从哪里获取这些信息?”在某些情况下,它们从 `/proc/meminfo` 文件中获取。猜到了吗?你可以使用命令 `less /proc/meminfo` 直接读取该文件。通过使用 `less` 命令,你可以在长长的输出中向上和向下滚动,以准确找到你需要的内容(图 8)。

*图 8:less /proc/meminfo 命令的输出。*
关于 `/proc/meminfo` 你应该知道:这不是一个真实的文件。相反 `/proc/meminfo` 是一个虚拟文件,包含有关系统的实时动态信息。特别是,你需要检查以下值:
* 全部内存(`MemTotal`)
* 空闲内存(`MemFree`)
* 可用内存(`MemAvailable`)
* 缓冲区(`Buffers`)
* 文件缓存(`Cached`)
* 交换缓存(`SwapCached`)
* 全部交换区(`SwapTotal`)
* 空闲交换区(`SwapFree`)
如果你想使用 `/proc/meminfo`,你可以连接 egrep 命令使用它:`egrep --color'Mem | Cache | Swap'/proc/meminfo`。这将生成一个易于阅读的列表,其中包含 `Mem`、 `Cache` 和 `Swap` 等内容的条目将是彩色的(图 9)。

*图 9:让 /proc/meminfo 更容易阅读。*
### 继续学习
你要做的第一件事就是阅读每个命令的手册页(例如 `man top`、`man free`、`man vmstat`、`man dmidecode`)。从命令的手册页开始,对于如何在 Linux 上使用一个工具,它总是一个很好的学习方法。
通过 Linux 基金会和 edX 的免费 [“Linux 简介”](https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux)课程了解有关 Linux 的更多知识。
---
via: <https://www.linux.com/learn/5-commands-checking-memory-usage-linux>
作者:[Jack Wallen](https://www.linux.com/users/jlwallen) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,908 | 献给 Debian 和 Ubuntu 用户的一组实用程序 | https://www.ostechnix.com/debian-goodies-a-set-of-useful-utilities-for-debian-and-ubuntu-users/ | 2018-08-09T15:13:21 | [
"Debian",
"软件包"
] | https://linux.cn/article-9908-1.html | 
你使用的是基于 Debian 的系统吗?如果是,太好了!我今天在这里给你带来了一个好消息。先向 “Debian-goodies” 打个招呼,这是一组基于 Debian 系统(比如:Ubuntu、Linux Mint)的有用工具。这些实用工具提供了一些额外的有用的命令,这些命令在基于 Debian 的系统中默认不可用。通过使用这些工具,用户可以找到哪些程序占用更多磁盘空间,更新系统后需要重新启动哪些服务,在一个软件包中搜索与模式匹配的文件,根据搜索字符串列出已安装的包等等。在这个简短的指南中,我们将讨论一些有用的 Debian 的好东西。
### Debian-goodies – 给 Debian 和 Ubuntu 用户的实用程序
debian-goodies 包可以在 Debian 和其衍生的 Ubuntu 以及其它 Ubuntu 变体(如 Linux Mint)的官方仓库中找到。要安装 debian-goodies,只需简单运行:
```
$ sudo apt-get install debian-goodies
```
debian-goodies 安装完成后,让我们继续看一看一些有用的实用程序。
#### 1、 checkrestart
让我从我最喜欢的 `checkrestart` 实用程序开始。安装某些安全更新时,某些正在运行的应用程序可能仍然会使用旧库。要彻底应用安全更新,你需要查找并重新启动所有这些更新。这就是 `checkrestart` 派上用场的地方。该实用程序将查找哪些进程仍在使用旧版本的库,然后,你可以重新启动服务。
在进行库更新后,要检查哪些守护进程应该被重新启动,运行:
```
$ sudo checkrestart
[sudo] password for sk:
Found 0 processes using old versions of upgraded files
```
由于我最近没有执行任何安全更新,因此没有显示任何内容。
请注意,`checkrestart` 实用程序确实运行良好。但是,有一个名为 `needrestart` 的类似的新工具可用于最新的 Debian 系统。`needrestart` 的灵感来自 `checkrestart` 实用程序,它完成了同样的工作。 `needrestart` 得到了积极维护,并支持容器(LXC、 Docker)等新技术。
以下是 `needrestart` 的特点:
* 支持(但不要求)systemd
* 二进制程序的黑名单(例如:用于图形显示的显示管理器)
* 尝试检测挂起的内核升级
* 尝试检测基于解释器的守护进程所需的重启(支持 Perl、Python、Ruby)
* 使用钩子完全集成到 apt/dpkg 中
它在默认仓库中也可以使用。所以,你可以使用如下命令安装它:
```
$ sudo apt-get install needrestart
```
现在,你可以使用以下命令检查更新系统后需要重新启动的守护程序列表:
```
$ sudo needrestart
Scanning processes...
Scanning linux images...
Running kernel seems to be up-to-date.
Failed to check for processor microcode upgrades.
No services need to be restarted.
No containers need to be restarted.
No user sessions are running outdated binaries.
```
好消息是 Needrestart 同样也适用于其它 Linux 发行版。例如,你可以从 Arch Linux 及其衍生版的 AUR 或者其它任何 AUR 帮助程序来安装,就像下面这样:
```
$ yaourt -S needrestart
```
在 Fedora:
```
$ sudo dnf install needrestart
```
#### 2、 check-enhancements
`check-enhancements` 实用程序用于查找那些用于增强已安装的包的软件包。此实用程序将列出增强其它包但不是必须运行它的包。你可以通过 `-ip` 或 `–installed-packages` 选项来查找增强单个包或所有已安装包的软件包。
例如,我将列出增强 gimp 包功能的包:
```
$ check-enhancements gimp
gimp => gimp-data: Installed: (none) Candidate: 2.8.22-1
gimp => gimp-gmic: Installed: (none) Candidate: 1.7.9+zart-4build3
gimp => gimp-gutenprint: Installed: (none) Candidate: 5.2.13-2
gimp => gimp-help-ca: Installed: (none) Candidate: 2.8.2-0.1
gimp => gimp-help-de: Installed: (none) Candidate: 2.8.2-0.1
gimp => gimp-help-el: Installed: (none) Candidate: 2.8.2-0.1
gimp => gimp-help-en: Installed: (none) Candidate: 2.8.2-0.1
gimp => gimp-help-es: Installed: (none) Candidate: 2.8.2-0.1
gimp => gimp-help-fr: Installed: (none) Candidate: 2.8.2-0.1
gimp => gimp-help-it: Installed: (none) Candidate: 2.8.2-0.1
gimp => gimp-help-ja: Installed: (none) Candidate: 2.8.2-0.1
gimp => gimp-help-ko: Installed: (none) Candidate: 2.8.2-0.1
gimp => gimp-help-nl: Installed: (none) Candidate: 2.8.2-0.1
gimp => gimp-help-nn: Installed: (none) Candidate: 2.8.2-0.1
gimp => gimp-help-pt: Installed: (none) Candidate: 2.8.2-0.1
gimp => gimp-help-ru: Installed: (none) Candidate: 2.8.2-0.1
gimp => gimp-help-sl: Installed: (none) Candidate: 2.8.2-0.1
gimp => gimp-help-sv: Installed: (none) Candidate: 2.8.2-0.1
gimp => gimp-plugin-registry: Installed: (none) Candidate: 7.20140602ubuntu3
gimp => xcftools: Installed: (none) Candidate: 1.0.7-6
```
要列出增强所有已安装包的,请运行:
```
$ check-enhancements -ip
autoconf => autoconf-archive: Installed: (none) Candidate: 20170928-2
btrfs-progs => snapper: Installed: (none) Candidate: 0.5.4-3
ca-certificates => ca-cacert: Installed: (none) Candidate: 2011.0523-2
cryptsetup => mandos-client: Installed: (none) Candidate: 1.7.19-1
dpkg => debsig-verify: Installed: (none) Candidate: 0.18
[...]
```
#### 3、 dgrep
顾名思义,`dgrep` 用于根据给定的正则表达式搜索制指定包的所有文件。例如,我将在 Vim 包中搜索包含正则表达式 “text” 的文件。
```
$ sudo dgrep "text" vim
Binary file /usr/bin/vim.tiny matches
/usr/share/doc/vim-tiny/copyright: that they must include this license text. You can also distribute
/usr/share/doc/vim-tiny/copyright: include this license text. You are also allowed to include executables
/usr/share/doc/vim-tiny/copyright: 1) This license text must be included unmodified.
/usr/share/doc/vim-tiny/copyright: text under a) applies to those changes.
/usr/share/doc/vim-tiny/copyright: context diff. You can choose what license to use for new code you
/usr/share/doc/vim-tiny/copyright: context diff will do. The e-mail address to be used is
/usr/share/doc/vim-tiny/copyright: On Debian systems, the complete text of the GPL version 2 license can be
[...]
```
`dgrep` 支持大多数 `grep` 的选项。参阅以下指南以了解 `grep` 命令。
* [献给初学者的 Grep 命令教程](https://www.ostechnix.com/the-grep-command-tutorial-with-examples-for-beginners/)
#### 4、 dglob
`dglob` 实用程序生成与给定模式匹配的包名称列表。例如,找到与字符串 “vim” 匹配的包列表。
```
$ sudo dglob vim
vim-tiny:amd64
vim:amd64
vim-common:all
vim-runtime:all
```
默认情况下,`dglob` 将仅显示已安装的软件包。如果要列出所有包(包括已安装的和未安装的),使用 `-a` 标志。
```
$ sudo dglob vim -a
```
#### 5、 debget
`debget` 实用程序将在 APT 的数据库中下载一个包的 .deb 文件。请注意,它只会下载给定的包,不包括依赖项。
```
$ debget nano
Get:1 http://in.archive.ubuntu.com/ubuntu bionic/main amd64 nano amd64 2.9.3-2 [231 kB]
Fetched 231 kB in 2s (113 kB/s)
```
#### 6、 dpigs
这是此次集合中另一个有用的实用程序。`dpigs` 实用程序将查找并显示那些占用磁盘空间最多的已安装包。
```
$ dpigs
260644 linux-firmware
167195 linux-modules-extra-4.15.0-20-generic
75186 linux-headers-4.15.0-20
64217 linux-modules-4.15.0-20-generic
55620 snapd
31376 git
31070 libicu60
28420 vim-runtime
25971 gcc-7
24349 g++-7
```
如你所见,linux-firmware 包占用的磁盘空间最多。默认情况下,它将显示占用磁盘空间的 **前 10 个**包。如果要显示更多包,例如 20 个,运行以下命令:
```
$ dpigs -n 20
```
#### 7. debman
`debman` 实用程序允许你轻松查看二进制文件 .deb 中的手册页而不提取它。你甚至不需要安装 .deb 包。以下命令显示 nano 包的手册页。
```
$ debman -f nano_2.9.3-2_amd64.deb nano
```
如果你没有 .deb 软件包的本地副本,使用 `-p` 标志下载并查看包的手册页。
```
$ debman -p nano nano
```
**建议阅读:**
* [每个 Linux 用户都应该知道的 3 个 man 的替代品](https://www.ostechnix.com/3-good-alternatives-man-pages-every-linux-user-know/)
#### 8、 debmany
安装的 Debian 包不仅包含手册页,还包括其它文件,如确认、版权和自述文件等。`debmany` 实用程序允许你查看和读取那些文件。
```
$ debmany vim
```

使用方向键选择要查看的文件,然后按回车键查看所选文件。按 `q` 返回主菜单。
如果未安装指定的软件包,`debmany` 将从 APT 数据库下载并显示手册页。应安装 `dialog` 包来阅读手册页。
#### 9、 popbugs
如果你是开发人员,`popbugs` 实用程序将非常有用。它将根据你使用的包显示一个定制的发布关键 bug 列表(使用 popularity-contest 数据)。对于那些不关心的人,popularity-contest 包设置了一个 cron (定时)任务,它将定期匿名向 Debian 开发人员提交有关该系统上最常用的 Debian 软件包的统计信息。这些信息有助于 Debian 做出决定,例如哪些软件包应该放在第一张 CD 上。它还允许 Debian 改进未来的发行版本,以便为新用户自动安装最流行的软件包。
要生成严重 bug 列表并在默认 Web 浏览器中显示结果,运行:
```
$ popbugs
```
此外,你可以将结果保存在文件中,如下所示。
```
$ popbugs --output=bugs.txt
```
#### 10、 which-pkg-broke
此命令将显示给定包的所有依赖项以及安装每个依赖项的时间。通过使用此信息,你可以在升级系统或软件包之后轻松找到哪个包可能会在什么时间损坏了另一个包。
```
$ which-pkg-broke vim
Package <debconf-2.0> has no install time info
debconf Wed Apr 25 08:08:40 2018
gcc-8-base:amd64 Wed Apr 25 08:08:41 2018
libacl1:amd64 Wed Apr 25 08:08:41 2018
libattr1:amd64 Wed Apr 25 08:08:41 2018
dpkg Wed Apr 25 08:08:41 2018
libbz2-1.0:amd64 Wed Apr 25 08:08:41 2018
libc6:amd64 Wed Apr 25 08:08:42 2018
libgcc1:amd64 Wed Apr 25 08:08:42 2018
liblzma5:amd64 Wed Apr 25 08:08:42 2018
libdb5.3:amd64 Wed Apr 25 08:08:42 2018
[...]
```
#### 11、 dhomepage
`dhomepage` 实用程序将在默认 Web 浏览器中显示给定包的官方网站。例如,以下命令将打开 Vim 编辑器的主页。
```
$ dhomepage vim
```
这就是全部了。Debian-goodies 是你武器库中必备的工具。即使我们不经常使用所有这些实用程序,但它们值得学习,我相信它们有时会非常有用。
我希望这很有用。更多好东西要来了。敬请关注!
干杯!
---
via: <https://www.ostechnix.com/debian-goodies-a-set-of-useful-utilities-for-debian-and-ubuntu-users/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[MjSeven](https://github.com/MjSeven) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,909 | Google 为树莓派 Zero W 发布了基于TensorFlow 的视觉识别套件 | http://linuxgizmos.com/google-launches-tensorflow-based-vision-recognition-kit-for-rpi-zero-w/ | 2018-08-09T15:34:13 | [
"AIY"
] | https://linux.cn/article-9909-1.html | 
Google 发布了一个 45 美元的 “AIY Vision Kit”,它是运行在树莓派 Zero W 上的基于 TensorFlow 的视觉识别开发套件,它使用了一个带 Movidius 芯片的 “VisionBonnet” 板。
为加速该设备上的神经网络,Google 的 AIY 视频套件继承了早期树莓派上运行的 [AIY 项目](http://linuxgizmos.com/free-raspberry-pi-voice-kit-taps-google-assistant-sdk/) 的语音/AI 套件,这个型号的树莓派随五月份的 MagPi 杂志一起赠送。与语音套件和老的 Google 硬纸板 VR 查看器一样,这个新的 AIY 视觉套件也使用一个硬纸板包装。这个套件和 [Cloud Vision API](http://linuxgizmos.com/google-releases-cloud-vision-api-with-demo-for-pi-based-robot/) 是不一样的,它使用了一个在 2015 年演示过的基于树莓派的 GoPiGo 机器人,它完全在本地的处理能力上运行,而不需要使用一个云端连接。这个 AIY 视觉套件现在可以 45 美元的价格去预订,将在 12 月份发货。
[](http://linuxgizmos.com/files/google_aiyvisionkit.jpg) [](http://linuxgizmos.com/files/rpi_zerow.jpg)
*AIY 视觉套件,完整包装(左)和树莓派 Zero W*
这个套件的主要处理部分除了所需要的 [树莓派 Zero W](http://linuxgizmos.com/raspberry-pi-zero-w-adds-wifi-and-bluetooth-for-only-5-more/) 单片机之外 —— 一个基于 ARM11 的 1 GHz 的 Broadcom BCM2836 片上系统,另外的就是 Google 最新的 VisionBonnet RPi 附件板。这个 VisionBonnet pHAT 附件板使用了一个 Movidius MA2450,它是 [Movidius Myriad 2 VPU](https://www.movidius.com/solutions/vision-processing-unit) 版的处理器。在 VisionBonnet 上,处理器为神经网络运行了 Google 的开源机器学习库 [TensorFlow](https://www.tensorflow.org/)。因为这个芯片,使得视觉处理的速度最高达每秒 30 帧。
这个 AIY 视觉套件要求用户提供一个树莓派 Zero W、一个 [树莓派摄像机 v2](http://linuxgizmos.com/raspberry-pi-cameras-jump-to-8mp-keep-25-dollar-price/)、以及一个 16GB 的 micro SD 卡,它用来下载基于 Linux 的 OS 镜像。这个套件包含了 VisionBonnet、一个 RGB 街机风格的按钮、一个压电扬声器、一个广角镜头套件、以及一个包裹它们的硬纸板。还有一些就是线缆、支架、安装螺母,以及连接部件。
[](http://linuxgizmos.com/files/google_aiyvisionkit_pieces.jpg) [](http://linuxgizmos.com/files/google_visionbonnet.jpg)
*AIY 视觉套件组件(左)和 VisonBonnet 附件板*
有三个可用的神经网络模型。一个是通用的模型,它可以识别常见的 1000 个东西,一个是面部检测模型,它可以对 “快乐程度” 进行评分,从 “悲伤” 到 “大笑”,还有一个模型可以用来辨别图像内容是狗、猫、还是人。这个 1000 个图片模型源自 Google 的开源 [MobileNets](https://research.googleblog.com/2017/06/mobilenets-open-source-models-for.html),它是基于 TensorFlow 家族的计算机视觉模型,它设计用于资源受限的移动或者嵌入式设备。
MobileNet 模型是低延时、低功耗,和参数化的,以满足资源受限的不同使用情景。Google 说,这个模型可以用于构建分类、检测、嵌入、以及分隔。在本月的早些时候,Google 发布了一个开发者预览版,它是一个对 Android 和 iOS 移动设备友好的 [TensorFlow Lite](https://developers.googleblog.com/2017/11/announcing-tensorflow-lite.html) 库,它与 MobileNets 和 Android 神经网络 API 是兼容的。
[](http://linuxgizmos.com/files/google_aiyvisionkit_assembly.jpg)
*AIY 视觉套件包装图*
除了提供这三个模型之外,AIY 视觉套件还提供了基本的 TensorFlow 代码和一个编译器,因此用户可以去开发自己的模型。另外,Python 开发者可以写一些新软件去定制 RGB 按钮颜色、压电元素声音、以及在 VisionBonnet 上的 4x GPIO 针脚,它可以添加另外的指示灯、按钮、或者伺服机构。Potential 模型包括识别食物、基于可视化输入来打开一个狗门、当你的汽车偏离车道时发出文本信息、或者根据识别到的人的面部表情来播放特定的音乐。
[](http://linuxgizmos.com/files/movidius_myriad2vpu_block.jpg) [](http://linuxgizmos.com/files/movidius_myriad2_reference_board.jpg)
*Myriad 2 VPU 结构图(左)和参考板*
Movidius Myriad 2 处理器在一个标称 1W 的功耗下提供每秒万亿次浮点运算的性能。在被 Intel 收购之前,这个芯片最早出现在 Tango 项目的参考平台上,并内置在 2016 年 5 月由 Movidius 首次亮相的、Ubuntu 驱动的 USB 的 [Fathom](http://linuxgizmos.com/usb-stick-brings-neural-computing-functions-to-devices/) 神经网络处理棒中。根据 Movidius 的说法,Myriad 2 目前已经在 “市场上数百万的设备上使用”。
**更多信息**
AIY 视觉套件可以在 Micro Center 上预订,价格为 $44.99,预计在(2017 年) 12 月初发货。更多信息请参考 AIY 视觉套件的 [公告](https://blog.google/topics/machine-learning/introducing-aiy-vision-kit-make-devices-see/)、[Google 博客](https://developers.googleblog.com/2017/11/introducing-aiy-vision-kit-add-computer.html)、以及 [Micro Center 购物页面](http://www.microcenter.com/site/content/Google_AIY.aspx?ekw=aiy&rd=1)。
---
via: <http://linuxgizmos.com/google-launches-tensorflow-based-vision-recognition-kit-for-rpi-zero-w/>
作者:[Eric Brown](http://linuxgizmos.com/google-launches-tensorflow-based-vision-recognition-kit-for-rpi-zero-w/) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 520 | null |
|
9,910 | 老树发新芽:微服务 | https://blogs.dxc.technology/2018/05/08/everything-old-is-new-again-microservices/ | 2018-08-11T00:54:00 | [
"微服务",
"SOA"
] | https://linux.cn/article-9910-1.html | 
如果我告诉你有这样一种软件架构,一个应用程序的组件通过基于网络的通讯协议为其它组件提供服务,我估计你可能会说它是 …
是的,它和你编程的年限有关。如果你从上世纪九十年代就开始了你的编程生涯,那么你肯定会说它是 <ruby> <a href="https://www.service-architecture.com/articles/web-services/service-oriented_architecture_soa_definition.html"> 面向服务的架构 </a> <rt> Service-Oriented Architecture </rt></ruby>(SOA)。但是,如果你是个年青人,并且在云上获得初步的经验,那么,你将会说:“哦,你说的是 <ruby> <a href="http://microservices.io/"> 微服务 </a> <rt> Microservices </rt></ruby>。”
你们都没错。如果想真正地了解它们的差别,你需要深入地研究这两种架构。
在 SOA 中,服务是一个功能,它是定义好的、自包含的、并且是不依赖上下文和其它服务的状态的功能。总共有两种服务。一种是消费者服务,它从另外类型的服务 —— 提供者服务 —— 中请求一个服务。一个 SOA 服务可以同时扮演这两种角色。
SOA 服务可以与其它服务交换数据。两个或多个服务也可以彼此之间相互协调。这些服务执行基本的任务,比如创建一个用户帐户、提供登录功能、或验证支付。
与其说 SOA 是模块化一个应用程序,还不如说它是把分布式的、独立维护和部署的组件,组合成一个应用程序。然后在服务器上运行这些组件。
早期版本的 SOA 使用面向对象的协议进行组件间通讯。例如,微软的 <ruby> <a href="https://technet.microsoft.com/en-us/library/cc958799.aspx"> 分布式组件对象模型 </a> <rt> Distributed Component Object Model </rt></ruby>(DCOM) 和使用 <ruby> <a href="http://www.corba.org/"> 通用对象请求代理架构 </a> <rt> Common Object Request Broker Architecture </rt></ruby>(CORBA) 规范的 <ruby> <a href="https://searchmicroservices.techtarget.com/definition/Object-Request-Broker-ORB"> 对象请求代理 </a> <rt> Object Request Broker </rt></ruby>(ORB)。
用于消息服务的最新的版本,有 <ruby> <a href="https://docs.oracle.com/javaee/6/tutorial/doc/bncdq.html"> Java 消息服务 </a> <rt> Java Message Service </rt></ruby>(JMS)或者 <ruby> <a href="https://www.amqp.org/"> 高级消息队列协议 </a> <rt> Advanced Message Queuing Protocol </rt></ruby>(AMQP)。这些服务通过<ruby> 企业服务总线 <rt> Enterprise Service Bus </rt></ruby>(ESB) 进行连接。基于这些总线,来传递和接收可扩展标记语言(XML)格式的数据。
[微服务](http://microservices.io/) 是一个架构样式,其中的应用程序以松散耦合的服务或模块组成。它适用于开发大型的、复杂的应用程序的<ruby> 持续集成 <rt> Continuous Integration </rt></ruby>/<ruby> 持续部署 <rt> Continuous Deployment </rt></ruby>(CI/CD)模型。一个应用程序就是一堆模块的汇总。
每个微服务提供一个应用程序编程接口(API)端点。它们通过轻量级协议连接,比如,<ruby> <a href="https://www.service-architecture.com/articles/web-services/representational_state_transfer_rest.html"> 表述性状态转移 </a> <rt> REpresentational State Transfer </rt></ruby>(REST),或 [gRPC](https://grpc.io/)。数据倾向于使用 <ruby> <a href="https://www.json.org/"> JavaScript 对象标记 </a> <rt> JavaScript Object Notation </rt></ruby>(JSON)或 [Protobuf](https://github.com/google/protobuf/) 来表示。
这两种架构都可以用于去替代以前老的整体式架构,整体式架构的应用程序被构建为单个的、自治的单元。例如,在一个客户机 —— 服务器模式中,一个典型的 Linux、Apache、MySQL、PHP/Python/Perl (LAMP) 服务器端应用程序将去处理 HTTP 请求、运行子程序、以及从底层的 MySQL 数据库中检索/更新数据。所有这些应用程序“绑”在一起提供服务。当你改变了任何一个东西,你都必须去构建和部署一个新版本。
使用 SOA,你可以只改变需要的几个组件,而不是整个应用程序。使用微服务,你可以做到一次只改变一个服务。使用微服务,你才能真正做到一个解耦架构。
微服务也比 SOA 更轻量级。不过 SOA 服务是部署到服务器和虚拟机上,而微服务是部署在容器中。协议也更轻量级。这使得微服务比 SOA 更灵活。因此,它更适合于要求敏捷性的电商网站。
说了这么多,到底意味着什么呢?微服务就是 SOA 在容器和云计算上的变种。
老式的 SOA 并没有离我们远去,而因为我们不断地将应用程序搬迁到容器中,所以微服务架构将越来越流行。
---
via: <https://blogs.dxc.technology/2018/05/08/everything-old-is-new-again-microservices/>
作者:[Cloudy Weather](https://blogs.dxc.technology/author/steven-vaughan-nichols/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,911 | 欧洲核子研究组织(CERN)是如何使用 Linux 和开源的 | https://www.linux.com/blog/2018/5/how-cern-using-linux-open-source | 2018-08-11T07:30:13 | [
"CERN",
"开源"
] | https://linux.cn/article-9911-1.html | 
>
> 欧洲核子研究组织(简称 CERN)依靠开源技术处理大型强子对撞机生成的大量数据。ATLAS(超环面仪器,如图所示)是一种探测基本粒子的通用探测器。
>
>
>
[CERN](https://home.cern/) 无需过多介绍了吧。CERN 创建了<ruby> 万维网 <rt> World Wide Web </rt></ruby>(WWW)和<ruby> 大型强子对撞机 <rt> Large Hadron Collider </rt></ruby>(LHC),这是世界上最大的<ruby> 粒子加速器 <rt> particle accelerator </rt></ruby>,就是通过它发现了 <ruby> <a href="https://home.cern/topics/higgs-boson"> 希格斯玻色子 </a> <rt> Higgs boson </rt></ruby>。负责该组织 IT 操作系统和基础架构的 Tim Bell 表示,他的团队的目标是“为全球 13000 名物理学家提供计算设施,以分析这些碰撞,了解宇宙的构成以及是如何运转的。”
CERN 正在进行硬核科学研究,尤其是大型强子对撞机,它在运行时 [生成大量数据](https://home.cern/about/computing)。“CERN 目前存储大约 200 PB 的数据,当加速器运行时,每月有超过 10 PB 的数据产生。这必然会给计算基础架构带来极大的挑战,包括存储大量数据,以及能够在合理的时间范围内处理数据,对于网络、存储技术和高效计算架构都是很大的压力。“Bell 说到。

*Tim Bell, CERN*
大型强子对撞机的运作规模和它产生的数据量带来了严峻的挑战,但 CERN 对这些问题并不陌生。CERN 成立于 1954 年,已经 60 余年了。“我们一直面临着难以解决的计算能力挑战,但我们一直在与开源社区合作解决这些问题。”Bell 说,“即使在 90 年代,当我们发明万维网时,我们也希望与人们共享,使其能够从 CERN 的研究中受益,开源是做这件事的再合适不过的工具了。”
### 使用 OpenStack 和 CentOS
时至今日,CERN 是 OpenStack 的深度用户,而 Bell 则是 OpenStack 基金会的董事会成员之一。不过 CERN 比 OpenStack 出现的要早,多年来,他们一直在使用各种开源技术通过 Linux 服务器提供服务。
“在过去的十年中,我们发现,与其自己解决问题,不如找到面临类似挑战的上游开源社区进行合作,然后我们一同为这些项目做出贡献,而不是一切都由自己来创造和维护。“Bell 说。
一个很好的例子是 Linux 本身。CERN 曾经是 Red Hat Enterprise Linux 的客户。其实,早在 2004 年,他们就与 Fermilab 合作一起建立了自己的 Linux 发行版,名为 [Scientific Linux](https://www.scientificlinux.org/)。最终他们意识到,因为没有修改内核,耗费时间建立自己的发行版是没有意义的,所以他们迁移到了 CentOS 上。由于 CentOS 是一个完全开源和社区驱使的项目,CERN 可以与该项目合作,并为 CentOS 的构建和分发做出贡献。
CERN 帮助 CentOS 提供基础架构,他们还组织了 CentOS DoJo 活动(LCTT 译者注:CentOS Dojo 是为期一日的活动,汇聚来自 CentOS 社群的人分享系统管理、最佳实践及新兴科技。),工程师可以汇聚在此共同改进 CentOS 的封装。
除了 OpenStack 和 CentOS 之外,CERN 还是其他开源项目的深度用户,包括用于配置管理的 Puppet、用于监控的 Grafana 和 InfluxDB,等等。
“我们与全球约 170 个实验室合作。因此,每当我们发现一个开源项目的改进之处,其他实验室便可以很容易地采纳使用。”Bell 说,“与此同时,我们也向其他项目学习。当像 eBay 和 Rackspace 这样大规模的装机量提高了解决方案的可扩展性时,我们也从中受益,也可以扩大规模。“
### 解决现实问题
2012 年左右,CERN 正在研究如何为大型强子对撞机扩展计算能力,但难点是人员而不是技术。CERN 雇用的员工人数是固定的。“我们必须找到一种方法来扩展计算能力,而不需要大量额外的人来管理。”Bell 说,“OpenStack 为我们提供了一个自动的 API 驱动和软件定义的基础架构。”OpenStack 还帮助 CERN 检查与服务交付相关的问题,然后使其自动化,而无需增加员工。
“我们目前在日内瓦和布达佩斯的两个数据中心运行大约 280000 个处理器核心和 7000 台服务器。我们正在使用软件定义的基础架构使一切自动化,这使我们能够在保持员工数量不变的同时继续添加更多的服务器。“Bell 说。
随着时间的推移,CERN 将面临更大的挑战。大型强子对撞机有一个到 2035 年的蓝图,包括一些重要的升级。“我们的加速器运转三到四年,然后会用 18 个月或两年的时间来升级基础架构。在这维护期间我们会做一些计算能力的规划。 ”Bell 说。CERN 还计划升级高亮度大型强子对撞机,会允许更高光度的光束。与目前的 CERN 的规模相比,升级意味着计算需求需增加约 60 倍。
“根据摩尔定律,我们可能只能满足需求的四分之一,因此我们必须找到相应的扩展计算能力和存储基础架构的方法,并找到自动化和解决方案,例如 OpenStack,将有助于此。”Bell 说。
“当我们开始使用大型强子对撞机并观察我们如何提供计算能力时,很明显我们无法将所有内容都放入 CERN 的数据中心,因此我们设计了一个分布式网格结构:位于中心的 CERN 和围绕着它的级联结构。”Bell 说,“全世界约有 12 个大型一级数据中心,然后是 150 所小型大学和实验室。他们从大型强子对撞机的数据中收集样本,以帮助物理学家理解和分析数据。”
这种结构意味着 CERN 正在进行国际合作,数百个国家正致力于分析这些数据。归结为一个基本原则,即开源不仅仅是共享代码,还包括人们之间的协作、知识共享,以实现个人、组织或公司无法单独实现的目标。这就是开源世界的希格斯玻色子。
---
via: <https://www.linux.com/blog/2018/5/how-cern-using-linux-open-source>
作者:[SWAPNIL BHARTIYA](https://www.linux.com/users/arnieswap) 译者:[jessie-pang](https://github.com/jessie-pang) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,912 | 如何在 Linux 中使用 Fio 来测评硬盘性能 | https://wpmojo.com/how-to-use-fio-to-measure-disk-performance-in-linux/ | 2018-08-11T11:08:00 | [
"硬盘",
"fio"
] | /article-9912-1.html | 
Fio(Flexible I/O Tester) 是一款由 Jens Axboe 开发的用于测评和压力/硬件验证的[自由开源](https://github.com/axboe/fio)的软件。
它支持 19 种不同类型的 I/O 引擎 (sync、mmap、libaio、posixaio、SG v3、splice、null、network、 syslet、guasi、solarisaio,以及更多), I/O 优先级(针对较新的 Linux 内核),I/O 速度,fork 的任务或线程任务等等。它能够在块设备和文件上工作。
Fio 接受一种非常简单易于理解的文本格式的任务描述。软件默认包含了几个示例任务文件。 Fio 展示了所有类型的 I/O 性能信息,包括完整的 IO 延迟和百分比。
它被广泛的应用在非常多的地方,包括测评、QA,以及验证用途。它支持 Linux 、FreeBSD 、NetBSD、 OpenBSD、 OS X、 OpenSolaris、 AIX、 HP-UX、 Android 以及 Windows。
在这个教程,我们将使用 Ubuntu 16 ,你需要拥有这台电脑的 `sudo` 或 root 权限。我们将完整的进行安装和 Fio 的使用。
### 使用源码安装 Fio
我们要去克隆 GitHub 上的仓库。安装所需的依赖,然后我们将会从源码构建应用。首先,确保我们安装了 Git 。
```
sudo apt-get install git
```
CentOS 用户可以执行下述命令:
```
sudo yum install git
```
现在,我们切换到 `/opt` 目录,并从 Github 上克隆仓库:
```
cd /opt
git clone https://github.com/axboe/fio
```
你应该会看到下面这样的输出:
```
Cloning into 'fio'...
remote: Counting objects: 24819, done.
remote: Compressing objects: 100% (44/44), done.
remote: Total 24819 (delta 39), reused 62 (delta 32), pack-reused 24743
Receiving objects: 100% (24819/24819), 16.07 MiB | 0 bytes/s, done.
Resolving deltas: 100% (16251/16251), done.
Checking connectivity... done.
```
现在,我们通过在 `/opt` 目录下输入下方的命令切换到 Fio 的代码目录:
```
cd fio
```
最后,我们可以使用下面的命令来使用 `make` 从源码构建软件:
```
# ./configure
# make
# make install
```
### 在 Ubuntu 上安装 Fio
对于 Ubuntu 和 Debian 来说, Fio 已经在主仓库内。你可以很容易的使用类似 `yum` 和 `apt-get` 的标准包管理器来安装 Fio。
对于 Ubuntu 和 Debian ,你只需要简单的执行下述命令:
```
sudo apt-get install fio
```
对于 CentOS/Redhat 你只需要简单执行下述命令。
在 CentOS ,你可能在你能安装 Fio 前需要去安装 EPEL 仓库到你的系统中。你可以通过执行下述命令来安装它:
```
sudo yum install epel-release -y
```
你可以执行下述命令来安装 Fio:
```
sudo yum install fio -y
```
### 使用 Fio 进行磁盘性能测试
现在 Fio 已经安装到了你的系统中。现在是时候看一些如何使用 Fio 的例子了。我们将进行随机写、读和读写测试。
### 执行随机写测试
执行下面的命令来开始。这个命令将要同一时间执行两个进程,写入共计 4GB( 4 个任务 x 512MB = 2GB) 文件:
```
sudo fio --name=randwrite --ioengine=libaio --iodepth=1 --rw=randwrite --bs=4k --direct=0 --size=512M --numjobs=2 --runtime=240 --group_reporting
```
```
...
fio-2.2.10
Starting 2 processes
randwrite: (groupid=0, jobs=2): err= 0: pid=7271: Sat Aug 5 13:28:44 2017
write: io=1024.0MB, bw=2485.5MB/s, iops=636271, runt= 412msec
slat (usec): min=1, max=268, avg= 1.79, stdev= 1.01
clat (usec): min=0, max=13, avg= 0.20, stdev= 0.40
lat (usec): min=1, max=268, avg= 2.03, stdev= 1.01
clat percentiles (usec):
| 1.00th=[ 0], 5.00th=[ 0], 10.00th=[ 0], 20.00th=[ 0],
| 30.00th=[ 0], 40.00th=[ 0], 50.00th=[ 0], 60.00th=[ 0],
| 70.00th=[ 0], 80.00th=[ 1], 90.00th=[ 1], 95.00th=[ 1],
| 99.00th=[ 1], 99.50th=[ 1], 99.90th=[ 1], 99.95th=[ 1],
| 99.99th=[ 1]
lat (usec) : 2=99.99%, 4=0.01%, 10=0.01%, 20=0.01%
cpu : usr=15.14%, sys=84.00%, ctx=8, majf=0, minf=26
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued : total=r=0/w=262144/d=0, short=r=0/w=0/d=0, drop=r=0/w=0/d=0
latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs):
WRITE: io=1024.0MB, aggrb=2485.5MB/s, minb=2485.5MB/s, maxb=2485.5MB/s, mint=412msec, maxt=412msec
Disk stats (read/write):
sda: ios=0/0, merge=0/0, ticks=0/0, in_queue=0, util=0.00%
```
### 执行随机读测试
我们将要执行一个随机读测试,我们将会尝试读取一个随机的 2GB 文件。
```
sudo fio --name=randread --ioengine=libaio --iodepth=16 --rw=randread --bs=4k --direct=0 --size=512M --numjobs=4 --runtime=240 --group_reporting
```
你应该会看到下面这样的输出:
```
...
fio-2.2.10
Starting 4 processes
randread: Laying out IO file(s) (1 file(s) / 512MB)
randread: Laying out IO file(s) (1 file(s) / 512MB)
randread: Laying out IO file(s) (1 file(s) / 512MB)
randread: Laying out IO file(s) (1 file(s) / 512MB)
Jobs: 4 (f=4): [r(4)] [100.0% done] [71800KB/0KB/0KB /s] [17.1K/0/0 iops] [eta 00m:00s]
randread: (groupid=0, jobs=4): err= 0: pid=7586: Sat Aug 5 13:30:52 2017
read : io=2048.0MB, bw=80719KB/s, iops=20179, runt= 25981msec
slat (usec): min=72, max=10008, avg=195.79, stdev=94.72
clat (usec): min=2, max=28811, avg=2971.96, stdev=760.33
lat (usec): min=185, max=29080, avg=3167.96, stdev=798.91
clat percentiles (usec):
| 1.00th=[ 2192], 5.00th=[ 2448], 10.00th=[ 2576], 20.00th=[ 2736],
| 30.00th=[ 2800], 40.00th=[ 2832], 50.00th=[ 2928], 60.00th=[ 3024],
| 70.00th=[ 3120], 80.00th=[ 3184], 90.00th=[ 3248], 95.00th=[ 3312],
| 99.00th=[ 3536], 99.50th=[ 6304], 99.90th=[15168], 99.95th=[18816],
| 99.99th=[22912]
bw (KB /s): min=17360, max=25144, per=25.05%, avg=20216.90, stdev=1605.65
lat (usec) : 4=0.01%, 10=0.01%, 250=0.01%, 500=0.01%, 750=0.01%
lat (usec) : 1000=0.01%
lat (msec) : 2=0.01%, 4=99.27%, 10=0.44%, 20=0.24%, 50=0.04%
cpu : usr=1.35%, sys=5.18%, ctx=524309, majf=0, minf=98
IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=100.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.1%, 32=0.0%, 64=0.0%, >=64=0.0%
issued : total=r=524288/w=0/d=0, short=r=0/w=0/d=0, drop=r=0/w=0/d=0
latency : target=0, window=0, percentile=100.00%, depth=16
Run status group 0 (all jobs):
READ: io=2048.0MB, aggrb=80718KB/s, minb=80718KB/s, maxb=80718KB/s, mint=25981msec, maxt=25981msec
Disk stats (read/write):
sda: ios=521587/871, merge=0/1142, ticks=96664/612, in_queue=97284, util=99.85%
```
最后,我们想要展示一个简单的随机读-写测试来看一看 Fio 返回的输出类型。
### 读写性能测试
下述命令将会测试 USB Pen 驱动器 (`/dev/sdc1`) 的随机读写性能:
```
sudo fio --randrepeat=1 --ioengine=libaio --direct=1 --gtod_reduce=1 --name=test --filename=random_read_write.fio --bs=4k --iodepth=64 --size=4G --readwrite=randrw --rwmixread=75
```
下面的内容是我们从上面的命令得到的输出:
```
fio-2.2.10
Starting 1 process
Jobs: 1 (f=1): [m(1)] [100.0% done] [217.8MB/74452KB/0KB /s] [55.8K/18.7K/0 iops] [eta 00m:00s]
test: (groupid=0, jobs=1): err= 0: pid=8475: Sat Aug 5 13:36:04 2017
read : io=3071.7MB, bw=219374KB/s, iops=54843, runt= 14338msec
write: io=1024.4MB, bw=73156KB/s, iops=18289, runt= 14338msec
cpu : usr=6.78%, sys=20.81%, ctx=1007218, majf=0, minf=9
IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.1%, 32=0.1%, >=64=100.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.1%, >=64=0.0%
issued : total=r=786347/w=262229/d=0, short=r=0/w=0/d=0, drop=r=0/w=0/d=0
latency : target=0, window=0, percentile=100.00%, depth=64
Run status group 0 (all jobs):
READ: io=3071.7MB, aggrb=219374KB/s, minb=219374KB/s, maxb=219374KB/s, mint=14338msec, maxt=14338msec
WRITE: io=1024.4MB, aggrb=73156KB/s, minb=73156KB/s, maxb=73156KB/s, mint=14338msec, maxt=14338msec
Disk stats (read/write):
sda: ios=774141/258944, merge=1463/899, ticks=748800/150316, in_queue=900720, util=99.35%
```
我们希望你能喜欢这个教程并且享受接下来的内容,Fio 是一个非常有用的工具,并且我们希望你能在你下一次 Debugging 活动中使用到它。如果你喜欢这个文章,欢迎留下评论和问题。
---
via: <https://wpmojo.com/how-to-use-fio-to-measure-disk-performance-in-linux/>
作者:[Alex Pearson](https://wpmojo.com/author/wpmojo/) 译者:[Bestony](https://github.com/bestony) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='wpmojo.com', port=443): Max retries exceeded with url: /how-to-use-fio-to-measure-disk-performance-in-linux/ (Caused by ConnectTimeoutError(<urllib3.connection.HTTPSConnection object at 0x7b83409d37f0>, 'Connection to wpmojo.com timed out. (connect timeout=10)')) | null |
9,913 | 比特币是一个邪教 | https://adamcaudill.com/2018/06/21/bitcoin-is-a-cult/ | 2018-08-11T14:48:13 | [
"比特币",
"区块链",
"加密货币"
] | https://linux.cn/article-9913-1.html | 
经过这些年,比特币社区已经发生了非常大的变化;社区成员从闭着眼睛都能讲解 [梅克尔树](https://en.wikipedia.org/wiki/Merkle_tree) 的技术迷们,变成了被一夜爆富欲望驱使的投机者和由一些连什么是梅克尔树都不懂的人所领导的企图寻求 10 亿美元估值的区块链初创公司。随着时间的流逝,围绕比特币和其它加密货币形成了一股热潮,他们认为比特币和其它加密货币远比实际的更重要;他们相信常见的货币(法定货币)正在成为过去,而加密货币将从根本上改变世界经济。
每一年他们的队伍都在壮大,而他们对加密货币的看法也在变得更加宏伟,那怕是对该技术的[新奇的用法](https://hackernoon.com/how-crypto-kitties-disrupted-the-ethereum-network-845c22aa1e6e)而使它陷入了困境。虽然我坚信设计优良的加密货币可以使金钱的跨境流动更容易,并且在大规模通胀的领域提供一个更稳定的选择,但现实情况是,我们并没有做到这些。实际上,正是价值的巨大不稳定性才使得投机者赚钱。那些宣扬美元和欧元即将死去的人,已经完全抛弃了对现实世界客观公正的看法。
### 一点点背景 …
比特币发行那天,我读了它的白皮书 —— 它使用有趣的 [梅克尔树](https://en.wikipedia.org/wiki/Merkle_tree) 去创建一个公共账簿和一个非常合理的共识协议 —— 由于它新颖的特性引起了密码学领域中许多人的注意。在白皮书发布后的几年里,比特币变得非常有价值,并由此吸引了许多人将它视为是一种投资,和那些认为它将改变一切的忠实追随者(和发声者)。这篇文章将讨论的正是后者。
昨天(2018/6/20),有人在推特上发布了一个最近的比特币区块的哈希,下面成千上万的推文和其它讨论让我相信,比特币已经跨越界线进入了真正的邪教领域。
一切都源于 Mark Wilcox 的[这个推文](https://twitter.com/mwilcox/status/1009160832398262273?ref_src=twsrc%5Etfw):
>
> [#00000000000000000021e800c1e8df51b22c1588e5a624bea17e9faa34b2dc4a](https://twitter.com/hashtag/00000000000000000021e800c1e8df51b22c1588e5a624bea17e9faa34b2dc4a?src=hash&ref_src=twsrc%5Etfw)
>
>
> — Mark Wilcox (@mwilcox) [June 19, 2018](https://twitter.com/mwilcox/status/1009160832398262273?ref_src=twsrc%5Etfw)
>
>
>
张贴的这个值是 [比特币 #528249 号区块](https://blockchain.info/block-height/528249) 的哈希值。前导零是挖矿过程的结果;挖掘一个区块就是把区块内容与一个<ruby> 现时数 <rt> nonce </rt></ruby>(和其它数据)组合起来,然后做哈希运算,并且它至少有一定数量的前导零才能被验证为有效区块。如果它不是正确的数字,你可以更换现时数再试。重复这个过程直到哈希值的前导零数量是正确的数字之后,你就有了一个有效的区块。让人们感到很兴奋的部分是接下来的 `21e800`。
一些人说这是一个有意义的编号,挖掘出这个区块的人实际上的难度远远超出当前所看到的,不仅要调整前导零的数量,还要匹配接下来的 24 位 —— 它要求非常强大的计算能力。如果有人能够以蛮力去实现它,这将表明有些事情很严重,比如,在计算或密码学方面的重大突破。
你一定会有疑问,为什么 `21e800` 如此重要 —— 一个你问了肯定会后悔的问题。有人说它是参考了 [E8 理论](https://en.wikipedia.org/wiki/An_Exceptionally_Simple_Theory_of_Everything)(一个广受批评的提出标准场理论的论文),或是表示总共存在 2,100,000,000 枚比特币(`21 x 10^8` 就是 2,100,000,000)。还有其它说法,因为太疯狂了而没有办法写出来。另一个重要的事实是,在前导零后面有 21e8 的区块平均每年被挖掘出一次 —— 这些从来没有人认为是很重要的。
这就引出了有趣的地方:关于这是如何发生的[理论](https://medium.com/@coop__soup/00000000000000000021e800c1e8df51b22c1588e5a624bea17e9faa34b2dc4a-cd4b67d446be)。
* 一台量子计算机,它能以某种方式用不可思议的速度做哈希运算。尽管在量子计算机的理论中还没有迹象表明它能够做这件事。哈希是量子计算机认为安全的东西之一。
* 时间旅行。是的,真的有人这么说,有人从未来穿梭回到现在去挖掘这个区块。我认为这种说法太荒谬了,都懒得去解释它为什么是错误的。
* 中本聪回来了。尽管事实上他的私钥没有任何活动,一些人从理论上认为他回来了,他能做一些没人能做的事情。这些理论是无法解释他如何做到的。
>
> 因此,总的来说(按我的理解)中本聪,为了知道和计算他做的事情,根据现代科学,他可能是以下之一:
>
>
> A) 使用了一台量子计算机 B) 来自未来 C) 两者都是
>
>
> — Crypto Randy Marsh [REKT](@nondualrandy) [June 21, 2018](https://twitter.com/nondualrandy/status/1009609117768605696?ref_src=twsrc%5Etfw)
>
>
>
如果你觉得所有的这一切听起来像 <ruby> <a href="https://en.wikipedia.org/wiki/Numerology"> 命理学 </a> <rt> numerology </rt></ruby>,不止你一个人是这样想的。
所有围绕有特殊意义的区块哈希的讨论,也引发了对在某种程度上比较有趣的东西的讨论。比特币的创世区块,它是第一个比特币区块,有一个不寻常的属性:早期的比特币要求哈希值的前 32 <ruby> 位 <rt> bit </rt></ruby>是零;而创始区块的前导零有 43 位。因为产生创世区块的代码从未发布过,不知道它是如何产生的,也不知道是用什么类型的硬件产生的。中本聪有学术背景,因此可能他有比那个时候大学中常见设备更强大的计算能力。从这一点上说,只是对古怪的创世区块的历史有点好奇,仅此而已。
### 关于哈希运算的简单题外话
这种喧嚣始于比特币区块的哈希运算;因此理解哈希是什么很重要,并且要理解一个非常重要的属性,哈希是单向加密函数,它能够基于给定的数据创建一个伪随机输出。
这意味着什么呢?基于本文讨论的目的,对于每个给定的输入你将得到一个随机的输出。随机数有时看起来很有趣,很简单,因为它是随机的结果,并且人类大脑可以很容易从任何东西中找到顺序。当你从随机数据中开始查看顺序时,你就会发现有趣的事情 —— 这些东西毫无意义,因为它们只是简单地随机数。当人们把重要的意义归属到随机数据上时,它将告诉你很多这些参与者观念相关的东西,而不是数据本身。
### 币之邪教
首先,我们来定义一组术语:
* <ruby> 邪教 <rt> Cult </rt></ruby>:一个宗教崇拜和直接向一个特定的人或物虔诚的体系。
* <ruby> 宗教 <rt> Religion </rt></ruby>:有人认为是至高无上的追求或兴趣。
<ruby> 币之邪教 <rt> Cult of the Coin </rt></ruby>有许多圣人,或许没有人比<ruby> 中本聪 <rt> Satoshi Nakamoto </rt></ruby>更伟大,他是比特币创始者(们)的假名。(对他的)狂热拥戴,要归因于他的能力和理解力远超过一般的研究人员,认为他的远见卓视无人能比,他影响了世界新经济的秩序。当将中本聪的神秘本质和未知的真实身份结合起来时,狂热的追随着们将中本聪视为一个真正值得尊敬的人物。
当然,除了追随其他圣人的追捧者之外,毫无疑问这些追捧者认为自己是正确的。任何对他们的圣人的批评都被认为也是对他们的批评。例如,那些追捧 EOS 的人,可能会视中本聪为一个开发了失败项目的黑客,而对 EOS 那怕是最轻微的批评,他们也会作出激烈的反应,之所以反应如此强烈,仅仅是因为攻击了他们心目中的神。那些追捧 IOTA 的人的反应也一样;还有更多这样的例子。
这些追随者在讨论问题时已经失去了理性和客观,他们的狂热遮盖了他们的视野。任何对这些项目和项目背后的人的讨论,如果不是溢美之词,必然以某种程序的刻薄言辞结束,对于一个技术的讨论那种做法是毫无道理的。
这很危险,原因很多:
* 开发者 & 研究者对缺陷视而不见。由于追捧者的大量赞美,这些参与开发的人对自己的能力的看法开始膨胀,并将一些批评看作是无端的攻击 —— 因为他们认为自己是不可能错的。
* 真正的问题是被攻击。技术问题不再被看作是需要去解决的问题和改进的机会,他们认为是来自那些想去破坏项目的人的攻击。
* 物以类聚,人以币分。追随者们通常会结盟到一起,而圣人仅有一个。承认其它项目的优越,意味着认同自己项目的缺陷或不足,而这是他们不愿意做的事情。
* 阻止真实的进步。进化是很残酷的,死亡是必然会有的,项目可能失败,也要承认这些失败的原因。如果忽视失败的教训,如果不允许那些应该去死亡的事情发生,进步就会停止。
许多围绕加密货币和相关区块链项目的讨论已经开始变得越来越”有毒“,善意的人想在不受攻击的情况下进行技术性讨论越来越不可能。随着对真正缺陷的讨论,那些在其它环境中注定要失败的缺陷,在没有做任何的事实分析的情况下即刻被判定为异端已经成为了惯例,善意的人参与其中的代价变得极其昂贵。至少有些人已经意识到极其严重的安全漏洞,由于高“毒性”的环境,他们选择保持沉默。
曾经被好奇、学习和改进的期望、创意可行性所驱动的东西,现在被盲目的贪婪、宗教般的狂热、自以为是和自我膨胀所驱动。
我对受这种狂热激励的项目的未来不抱太多的希望,而它持续地传播,可能会损害多年来在这个领域中真正的研究者。这些技术项目中,一些项目成功了,一些项目失败了 —— 这就是技术演进的方式。设计这些系统的人,就和你我一样都有缺点,同样这些项目也有缺陷。有些项目非常适合某些使用场景而不适合其它场景,有些项目不适合任何使用场景,没有一个项目适合所有使用场景。关于这些项目的讨论应该关注于技术方面,这样做是为了让这一研究领域得以发展;在这些项目中掺杂宗教般狂热必将损害所有人。
[注意:这种行为有许多例子可以引用,但是为了保护那些因批评项目而成为被攻击目标的人,我选择尽可能少的列出这种例子。我看到许多我很尊敬的人、许多我认为是朋友的人成为这种恶毒攻击的受害者 —— 我不想引起人们对这些攻击的注意和重新引起对他们的攻击。]
(题图:news.bitcoin.com)
---
关于作者:
我是一个资深应用安全顾问、研究员和具有超过 15 年的经验的软件开发者。我主要关注的是应用程序安全、安全通信和加密, 虽然我经常由于无聊而去研究新的领域。我通常会写了一些关于我的研究和安全、开发和软件设计,和我当前吸引了我注意力的爱好的文章。
---
via: <https://adamcaudill.com/2018/06/21/bitcoin-is-a-cult/>
作者:[Adam Caudill](https://adamcaudill.com/author/adam/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The Bitcoin community has changed greatly over the years; from technophiles that could explain a [Merkle tree](https://en.wikipedia.org/wiki/Merkle_tree) in their sleep, to speculators driven by the desire for a quick profit & blockchain startups seeking billion dollar valuations led by people who don’t even know what a Merkle tree is. As the years have gone on, a zealotry has been building around Bitcoin and other cryptocurrencies driven by people who see them as something far grander than they actually are; people who believe that normal (or fiat) currencies are becoming a thing of the past, and the cryptocurrencies will fundamentally change the world’s economy.
Every year, their ranks grow, and their perception of cryptocurrencies becomes more grandiose, even as [novel uses](https://hackernoon.com/how-crypto-kitties-disrupted-the-ethereum-network-845c22aa1e6e) of the technology brings it to its knees. While I’m a firm believer that a well designed cryptocurrency could ease the flow of money across borders, and provide a stable option in areas of mass inflation, the reality is that we aren’t there yet. In fact, it’s the substantial instability in value that allows speculators to make money. Those that preach that the US Dollar and Euro are on their deathbed have utterly abandoned an objective view of reality.
I read the Bitcoin white-paper the day it was released – an interesting use of [Merkle trees](https://en.wikipedia.org/wiki/Merkle_tree) to create a public ledger and a fairly reasonable consensus protocol – it got the attention of many in the cryptography sphere for its novel properties. In the years since that paper was released, Bitcoin has become rather valuable, attracted many that see it as an investment, and a loyal (and vocal) following of people who think it’ll change everything. This discussion is about the latter.
Yesterday, someone on Twitter posted the hash of a recent Bitcoin block, the thousands of Tweets and other conversations that followed have convinced me that Bitcoin has crossed the line into true cult territory.
It all started with this Tweet by Mark Wilcox:
— Mark Wilcox (@mwilcox)
[#00000000000000000021e800c1e8df51b22c1588e5a624bea17e9faa34b2dc4a][June 19, 2018]
The value posted is the hash of [Bitcoin block #528249](https://blockchain.info/block-height/528249). The leading zeros are a result of the mining process; to mine a block you combine the contents of the block with a nonce (and other data), hash it, and it has to have at least a certain number of leading zeros to be considered valid. If it doesn’t have the correct number, you change the nonce and try again. Repeat this until the number of leading zeros is the right number, and you now have a valid block. The part that people got excited about is what follows, 21e800.
Some are claiming this is an intentional reference, that whoever mined this block actually went well beyond the current difficulty to not just bruteforce the leading zeros, but also the next 24 bits – which would require some serious computing power. If someone had the ability to bruteforce this, it could indicate something rather serious, such as a substantial breakthrough in computing or cryptography.
You must be asking yourself, what’s so important about 21e800 – a question you would surely regret. Some are claiming it’s a reference to [E8 Theory](https://en.wikipedia.org/wiki/An_Exceptionally_Simple_Theory_of_Everything) (a widely criticized paper that presents a standard field theory), or to the 21,000,000 total Bitcoins that will eventually exist (despite the fact that $21 \times 10^8$ would be 2,100,000,000). There are others, they are just too crazy to write about. Another important fact is that a block is mined on average on once a year that has 21e8 following the leading zeros – those were never seen as anything important.
This leads to where things get fun: the [theories](https://medium.com/@coop__soup/00000000000000000021e800c1e8df51b22c1588e5a624bea17e9faa34b2dc4a-cd4b67d446be) that are circulating about how this happened.
- A quantum computer, that is somehow able to hash at unbelievable speed. This is despite the fact that there’s no indication in theories around quantum computers that they’ll be able to do this; hashing is one thing that’s considered safe from quantum computers.
- Time travel. Yes, people are actually saying that someone came back from the future to mine this block. I think this is crazy enough that I don’t need to get into why this is wrong.
- Satoshi Nakamoto is back. Despite the fact that there has been no activity with his private keys, some theorize that he has returned, and is somehow able to do things that nobody can. These theories don’t explain how he could do it.
So basically (as i understand) Satoshi, in order to have known and computed the things that he did, according to modern science he was either:
— Crypto Randy Marsh [REKT] (@nondualrandy)
A) Using a quantum computer
B) Fom the future
C) Both[June 21, 2018]
If all this sounds like [numerology](https://en.wikipedia.org/wiki/Numerology) to you, you aren’t alone.
All this discussion around special meaning in block hashes also reignited the discussion around something that is, at least somewhat, interesting. The Bitcoin genesis block, the first bitcoin block, does have an unusual property: the early Bitcoin blocks required that the first 32 bits of the hash be zero; however the genesis block had 43 leading zero bits. As the code that produced the genesis block was never released, it’s not known how it was produced, nor is it known what type of hardware was used to produce it. Satoshi had an academic background, so may have had access to more substantial computing power than was common at the time via a university. At this point, the oddities of the genesis block are a historical curiosity, nothing more.
This hullabaloo started with the hash of a Bitcoin block; so it’s important to understand just what a hash is, and understand one very important property they have. A hash is a one-way cryptographic function that creates a *pseudo-random* output based on the data that it’s given.
What this means, for the purposes of this discussion, is that for each input you get a random output. Random numbers have a way of sometimes looking interesting, simply as a result of being random and the human brain’s affinity to find order in everything. When you start looking for order in random data, you find interesting things – that are yet meaningless, as it’s simply random. When people ascribe significant meaning to random data, it tells you far more about the mindset of those involved rather than the data itself.
First, let us define a couple of terms:
- Cult: a system of religious veneration and devotion directed toward a particular figure or object.
- Religion: a pursuit or interest to which someone ascribes supreme importance.
The Cult of the Coin has many saints, perhaps none greater than Satoshi Nakamoto, the pseudonym used by the person(s) that created Bitcoin. Vigorously defended, ascribed with ability and understanding far above that of a normal researcher, seen as a visionary beyond compare that is leading the world to a new economic order. When combined with Satoshi’s secretive nature and unknown true identify, adherents to the Cult view Satoshi as a truly venerated figure.
That is, of course, with the exception of adherents that follow a different saint, who is unquestionably correct, and any criticism is seen as not only an attack on their saint, but on themselves as well. Those that follow EOS for example, may see Satoshi has a hack that developed a failed project, yet will react fiercely to the slightest criticism of EOS, a reaction so strong that it’s reserved only for an attack on one’s deity. Those that follow IOTA react with equal fierceness; and there are many others.
These adherents have abandoned objectivity and reasonable discourse, and allowed their zealotry to cloud their vision. Any discussion of these projects and the people behind them that doesn’t include glowing praise inevitably ends with a level of vitriolic speech that is beyond reason for a discussion of technology.
This is dangerous, for many reasons:
- Developers & researchers are blinded to flaws. Due to the vast quantities of praise by adherents, those involved develop a grandiose view of their own abilities, and begin to view criticism as unjustified attacks – as they couldn’t possibly have been wrong.
- Real problems are attacked. Instead of technical issues being seen as problems to be solved and opportunities to improve, they are seen as attacks from people who must be motivated to destroy the project.
- One coin to rule them all. Adherents are often aligned to one, and only one, saint. Acknowledging the qualities of another project means acceptance of flaws or deficiencies in their own, which they will not do.
- Preventing real progress. Evolution is brutal, it requires death, it requires projects to fail and that the reasons for those failures to be acknowledged. If lessons from failure are ignored, if things that should die aren’t allowed to, progress stalls.
Discussions around many of the cryptocurrencies and related blockchain projects are becoming more and more toxic, becoming impossible for well-intentioned people to have real technical discussions without being attacked. With discussions of real flaws, flaws that would doom a design in any other environment, being instantly treated as heretical without any analysis to determine the factual claims becoming routine, the cost for the well-intentioned to get involved has become extremely high. There are at least some that are aware of significant security flaws that have opted to remain silent due to the highly toxic environment.
What was once driven by curiosity, a desire to learn and improve, to determine the viability of ideas, is now driven by blind greed, religious zealotry, self-righteousness, and self-aggrandizement.
I have precious little hope for the future of projects that inspire this type of zealotry, and its continuous spread will likely harm real research in this area for many years to come. These are technical projects, some projects succeed, some fail – this is how technology evolves. Those designing these systems are human, just as flawed as the rest of us, and so too are the projects flawed. Some are well suited to certain use cases and not others, some aren’t suited to any use case, none yet are suited to all. The discussions about these projects should be focused on the technical aspects, and done so to evolve this field of research; adding a religious to these projects harms all.
*Note: There are many examples of this behavior that could be cited, however in the interest of protecting those that have been targeted for criticizing projects, I have opted to minimize such examples. I have seen too many people who I respect, too many that I consider friends, being viciously attacked – I have no desire to draw attention to those attacks, and risk restarting them.* |
9,915 | CSRF(跨站请求伪造)简介 | http://www.linuxandubuntu.com/home/understanding-csrf-cross-site-request-forgery | 2018-08-13T08:38:00 | [
"安全",
"CSRF"
] | https://linux.cn/article-9915-1.html | 
设计 Web 程序时,安全性是一个主要问题。我不是在谈论 DDoS 保护、使用强密码或两步验证。我说的是对网络程序的最大威胁。它被称为 **CSRF**, 是 **Cross Site Request Forgery** (跨站请求伪造)的缩写。
### 什么是 CSRF?
[](http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/csrf-what-is-cross-site-forgery_orig.jpg)
首先,**CSRF** 是 Cross Site Request Forgery 的缩写。它通常发音为 “sea-surf”,也经常被称为 XSRF。CSRF 是一种攻击类型,在受害者不知情的情况下,在受害者登录的 Web 程序上执行各种操作。这些行为可以是任何事情,从简单地点赞或评论社交媒体帖子到向人们发送垃圾消息,甚至从受害者的银行账户转移资金。
### CSRF 如何工作?
**CSRF** 攻击尝试利用所有浏览器上的一个简单的常见漏洞。每次我们对网站进行身份验证或登录时,会话 cookie 都会存储在浏览器中。因此,每当我们向网站提出请求时,这些 cookie 就会自动发送到服务器,服务器通过匹配与服务器记录一起发送的 cookie 来识别我们。这样就知道是我们了。
[](http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/cookies-set-by-website-chrome_orig.jpg)
这意味着我将在知情或不知情的情况下发出请求。由于 cookie 也被发送并且它们将匹配服务器上的记录,服务器认为我在发出该请求。 CSRF 攻击通常以链接的形式出现。我们可以在其他网站上点击它们或通过电子邮件接收它们。单击这些链接时,会向服务器发出不需要的请求。正如我之前所说,服务器认为我们发出了请求并对其进行了身份验证。
#### 一个真实世界的例子
为了把事情看得更深入,想象一下你已登录银行的网站。并在 **yourbank.com/transfer** 上填写表格。你将接收者的帐号填写为 1234,填入金额 5,000 并单击提交按钮。现在,我们将有一个 **yourbank.com/transfer/send?to=1234&amount=5000** 的请求。因此服务器将根据请求进行操作并转账。现在想象一下你在另一个网站上,然后点击一个链接,用黑客的帐号作为参数打开上面的 URL。这笔钱现在会转账给黑客,服务器认为你做了交易。即使你没有。
[](http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/csrf-hacking-bank-account_orig.jpg)
#### CSRF 防护
CSRF 防护非常容易实现。它通常将一个称为 CSRF 令牌的令牌发送到网页。每次发出新请求时,都会发送并验证此令牌。因此,向服务器发出的恶意请求将通过 cookie 身份验证,但 CSRF 验证会失败。大多数 Web 框架为防止 CSRF 攻击提供了开箱即用的支持,而 CSRF 攻击现在并不像以前那样常见。
### 总结
CSRF 攻击在 10 年前是一件大事,但如今我们看不到太多。过去,Youtube、纽约时报和 Netflix 等知名网站都容易受到 CSRF 的攻击。然而,CSRF 攻击的普遍性和发生率最近有减少。尽管如此,CSRF 攻击仍然是一种威胁,重要的是,你要保护自己的网站或程序免受攻击。
---
via: <http://www.linuxandubuntu.com/home/understanding-csrf-cross-site-request-forgery>
作者:[linuxandubuntu](http://www.linuxandubuntu.com) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
9,916 | 如何在 Git 中重置、恢复,返回到以前的状态 | https://opensource.com/article/18/6/git-reset-revert-rebase-commands | 2018-08-13T09:23:00 | [
"Git",
"重置",
"变基"
] | https://linux.cn/article-9916-1.html |
>
> 用简洁而优雅的 Git 命令撤销仓库中的改变。
>
>
>

使用 Git 工作时其中一个鲜为人知(和没有意识到)的方面就是,如何轻松地返回到你以前的位置 —— 也就是说,在仓库中如何很容易地去撤销那怕是重大的变更。在本文中,我们将带你了解如何去重置、恢复和完全回到以前的状态,做到这些只需要几个简单而优雅的 Git 命令。
### 重置
我们从 Git 的 `reset` 命令开始。确实,你应该能够认为它就是一个 “回滚” —— 它将你本地环境返回到之前的提交。这里的 “本地环境” 一词,我们指的是你的本地仓库、暂存区以及工作目录。
先看一下图 1。在这里我们有一个在 Git 中表示一系列提交的示意图。在 Git 中一个分支简单来说就是一个命名的、指向一个特定的提交的可移动指针。在这里,我们的 master 分支是指向链中最新提交的一个指针。

*图 1:有仓库、暂存区、和工作目录的本地环境*
如果看一下我们的 master 分支是什么,可以看一下到目前为止我们产生的提交链。
```
$ git log --oneline
b764644 File with three lines
7c709f0 File with two lines
9ef9173 File with one line
```
如果我们想回滚到前一个提交会发生什么呢?很简单 —— 我们只需要移动分支指针即可。Git 提供了为我们做这个动作的 `reset` 命令。例如,如果我们重置 master 为当前提交回退两个提交的位置,我们可以使用如下之一的方法:
```
$ git reset 9ef9173
```
(使用一个绝对的提交 SHA1 值 `9ef9173`)
或:
```
$ git reset current~2
```
(在 “current” 标签之前,使用一个相对值 -2)
图 2 展示了操作的结果。在这之后,如果我们在当前分支(master)上运行一个 `git log` 命令,我们将看到只有一个提交。
```
$ git log --oneline
9ef9173 File with one line
```

*图 2:在 `reset` 之后*
`git reset` 命令也包含使用一些选项,可以让你最终满意的提交内容去更新本地环境的其它部分。这些选项包括:`hard` 在仓库中去重置指向的提交,用提交的内容去填充工作目录,并重置暂存区;`soft` 仅重置仓库中的指针;而 `mixed`(默认值)将重置指针和暂存区。
这些选项在特定情况下非常有用,比如,`git reset --hard <commit sha1 | reference>` 这个命令将覆盖本地任何未提交的更改。实际上,它重置了(清除掉)暂存区,并用你重置的提交内容去覆盖了工作区中的内容。在你使用 `hard` 选项之前,一定要确保这是你真正地想要做的操作,因为这个命令会覆盖掉任何未提交的更改。
### 恢复
`git revert` 命令的实际结果类似于 `reset`,但它的方法不同。`reset` 命令(默认)是在链中向后移动分支的指针去“撤销”更改,`revert` 命令是在链中添加一个新的提交去“取消”更改。再次查看图 1 可以非常轻松地看到这种影响。如果我们在链中的每个提交中向文件添加一行,一种方法是使用 `reset` 使那个提交返回到仅有两行的那个版本,如:`git reset HEAD~1`。
另一个方法是添加一个新的提交去删除第三行,以使最终结束变成两行的版本 —— 实际效果也是取消了那个更改。使用一个 `git revert` 命令可以实现上述目的,比如:
```
$ git revert HEAD
```
因为它添加了一个新的提交,Git 将提示如下的提交信息:
```
Revert "File with three lines"
This reverts commit b764644bad524b804577684bf74e7bca3117f554.
# Please enter the commit message for your changes. Lines starting
# with '#' will be ignored, and an empty message aborts the commit.
# On branch master
# Changes to be committed:
# modified: file1.txt
#
```
图 3(在下面)展示了 `revert` 操作完成后的结果。
如果我们现在运行一个 `git log` 命令,我们将看到前面的提交之前的一个新提交。
```
$ git log --oneline
11b7712 Revert "File with three lines"
b764644 File with three lines
7c709f0 File with two lines
9ef9173 File with one line
```
这里是工作目录中这个文件当前的内容:
```
$ cat <filename>
Line 1
Line 2
```

*图 3 `revert` 操作之后*
### 恢复或重置如何选择?
为什么要优先选择 `revert` 而不是 `reset` 操作?如果你已经将你的提交链推送到远程仓库(其它人可以已经拉取了你的代码并开始工作),一个 `revert` 操作是让他们去获得更改的非常友好的方式。这是因为 Git 工作流可以非常好地在分支的末端添加提交,但是当有人 `reset` 分支指针之后,一组提交将再也看不见了,这可能会是一个挑战。
当我们以这种方式使用 Git 工作时,我们的基本规则之一是:在你的本地仓库中使用这种方式去更改还没有推送的代码是可以的。如果提交已经推送到了远程仓库,并且可能其它人已经使用它来工作了,那么应该避免这些重写提交历史的更改。
总之,如果你想回滚、撤销或者重写其它人已经在使用的一个提交链的历史,当你的同事试图将他们的更改合并到他们拉取的原始链上时,他们可能需要做更多的工作。如果你必须对已经推送并被其他人正在使用的代码做更改,在你做更改之前必须要与他们沟通,让他们先合并他们的更改。然后在这个侵入操作没有需要合并的内容之后,他们再拉取最新的副本。
你可能注意到了,在我们做了 `reset` 操作之后,原始的提交链仍然在那个位置。我们移动了指针,然后 `reset` 代码回到前一个提交,但它并没有删除任何提交。换句话说就是,只要我们知道我们所指向的原始提交,我们能够通过简单的返回到分支的原始链的头部来“恢复”指针到前面的位置:
```
git reset <sha1 of commit>
```
当提交被替换之后,我们在 Git 中做的大量其它操作也会发生类似的事情。新提交被创建,有关的指针被移动到一个新的链,但是老的提交链仍然存在。
### 变基
现在我们来看一个分支变基。假设我们有两个分支:master 和 feature,提交链如下图 4 所示。master 的提交链是 `C4->C2->C1->C0` 和 feature 的提交链是 `C5->C3->C2->C1->C0`。

*图 4:master 和 feature 分支的提交链*
如果我们在分支中看它的提交记录,它们看起来应该像下面的这样。(为了易于理解,`C` 表示提交信息)
```
$ git log --oneline master
6a92e7a C4
259bf36 C2
f33ae68 C1
5043e79 C0
$ git log --oneline feature
79768b8 C5
000f9ae C3
259bf36 C2
f33ae68 C1
5043e79 C0
```
我告诉人们在 Git 中,可以将 `rebase` 认为是 “将历史合并”。从本质上来说,Git 将一个分支中的每个不同提交尝试“重放”到另一个分支中。
因此,我们使用基本的 Git 命令,可以变基一个 feature 分支进入到 master 中,并将它拼入到 `C4` 中(比如,将它插入到 feature 的链中)。操作命令如下:
```
$ git checkout feature
$ git rebase master
First, rewinding head to replay your work on top of it...
Applying: C3
Applying: C5
```
完成以后,我们的提交链将变成如下图 5 的样子。

*图 5:`rebase` 命令完成后的提交链*
接着,我们看一下提交历史,它应该变成如下的样子。
```
$ git log --oneline master
6a92e7a C4
259bf36 C2
f33ae68 C1
5043e79 C0
$ git log --oneline feature
c4533a5 C5
64f2047 C3
6a92e7a C4
259bf36 C2
f33ae68 C1
5043e79 C0
```
注意那个 `C3'` 和 `C5'`— 在 master 分支上已处于提交链的“顶部”,由于产生了更改而创建了新提交。但是也要注意的是,rebase 后“原始的” `C3` 和 `C5` 仍然在那里 — 只是再没有一个分支指向它们而已。
如果我们做了这个变基,然后确定这不是我们想要的结果,希望去撤销它,我们可以做下面示例所做的操作:
```
$ git reset 79768b8
```
由于这个简单的变更,现在我们的分支将重新指向到做 `rebase` 操作之前一模一样的位置 —— 完全等效于撤销操作(图 6)。

*图 6:撤销 `rebase` 操作之后*
如果你想不起来之前一个操作指向的一个分支上提交了什么内容怎么办?幸运的是,Git 命令依然可以帮助你。用这种方式可以修改大多数操作的指针,Git 会记住你的原始提交。事实上,它是在 `.git` 仓库目录下,将它保存为一个特定的名为 `ORIG_HEAD` 的文件中。在它被修改之前,那个路径是一个包含了大多数最新引用的文件。如果我们 `cat` 这个文件,我们可以看到它的内容。
```
$ cat .git/ORIG_HEAD
79768b891f47ce06f13456a7e222536ee47ad2fe
```
我们可以使用 `reset` 命令,正如前面所述,它返回指向到原始的链。然后它的历史将是如下的这样:
```
$ git log --oneline feature
79768b8 C5
000f9ae C3
259bf36 C2
f33ae68 C1
5043e79 C0
```
在 reflog 中是获取这些信息的另外一个地方。reflog 是你本地仓库中相关切换或更改的详细描述清单。你可以使用 `git reflog` 命令去查看它的内容:
```
$ git reflog
79768b8 HEAD@{0}: reset: moving to 79768b
c4533a5 HEAD@{1}: rebase finished: returning to refs/heads/feature
c4533a5 HEAD@{2}: rebase: C5
64f2047 HEAD@{3}: rebase: C3
6a92e7a HEAD@{4}: rebase: checkout master
79768b8 HEAD@{5}: checkout: moving from feature to feature
79768b8 HEAD@{6}: commit: C5
000f9ae HEAD@{7}: checkout: moving from master to feature
6a92e7a HEAD@{8}: commit: C4
259bf36 HEAD@{9}: checkout: moving from feature to master
000f9ae HEAD@{10}: commit: C3
259bf36 HEAD@{11}: checkout: moving from master to feature
259bf36 HEAD@{12}: commit: C2
f33ae68 HEAD@{13}: commit: C1
5043e79 HEAD@{14}: commit (initial): C0
```
你可以使用日志中列出的、你看到的相关命名格式,去重置任何一个东西:
```
$ git reset HEAD@{1}
```
一旦你理解了当“修改”链的操作发生后,Git 是如何跟踪原始提交链的基本原理,那么在 Git 中做一些更改将不再是那么可怕的事。这就是强大的 Git 的核心能力之一:能够很快速、很容易地尝试任何事情,并且如果不成功就撤销它们。
---
via: <https://opensource.com/article/18/6/git-reset-revert-rebase-commands>
作者:[Brent Laster](https://opensource.com/users/bclaster) 选题:[lujun9972](https://github.com/lujun9972) 译者:[qhwdw](https://github.com/qhwdw) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | One of the lesser understood (and appreciated) aspects of working with Git is how easy it is to get back to where you were before—that is, how easy it is to undo even major changes in a repository. In this article, we'll take a quick look at how to reset, revert, and completely return to previous states, all with the simplicity and elegance of individual Git commands.
## How to reset a Git commit
Let's start with the Git command `reset`
. Practically, you can think of it as a "rollback"—it points your local environment back to a previous commit. By "local environment," we mean your local repository, staging area, and working directory.
Take a look at Figure 1. Here we have a representation of a series of commits in Git. A branch in Git is simply a named, movable pointer to a specific commit. In this case, our branch *master* is a pointer to the latest commit in the chain.
Fig. 1: Local Git environment with repository, staging area, and working directory
If we look at what's in our *master* branch now, we can see the chain of commits made so far.
```
$ git log --oneline
b764644 File with three lines
7c709f0 File with two lines
9ef9173 File with one line
```
What happens if we want to roll back to a previous commit. Simple—we can just move the branch pointer. Git supplies the `reset`
command to do this for us. For example, if we want to reset *master* to point to the commit two back from the current commit, we could use either of the following methods:
`$ git reset 9ef9173`
(using an absolute commit SHA1 value 9ef9173)
or
`$ git reset current~2`
(using a relative value -2 before the "current" tag)
Figure 2 shows the results of this operation. After this, if we execute a `git log`
command on the current branch (*master*), we'll see just the one commit.
```
$ git log --oneline
9ef9173 File with one line
```
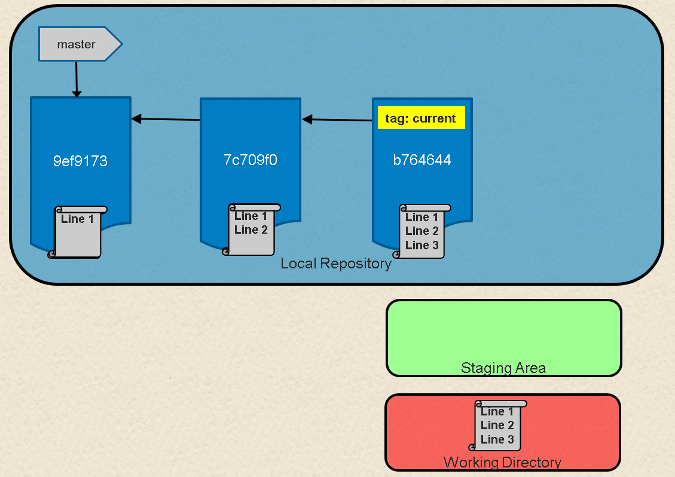
Fig. 2: After reset
The `git reset`
command also includes options to update the other parts of your local environment with the contents of the commit where you end up. These options include: `hard`
to reset the commit being pointed to in the repository, populate the working directory with the contents of the commit, and reset the staging area; `soft`
to only reset the pointer in the repository; and `mixed`
(the default) to reset the pointer and the staging area.
Using these options can be useful in targeted circumstances such as `git reset --hard <commit sha1 | reference>`
`.`
This overwrites any local changes you haven't committed. In effect, it resets (clears out) the staging area and overwrites content in the working directory with the content from the commit you reset to. Before you use the `hard`
option, be sure that's what you really want to do, since the command overwrites any uncommitted changes.
## How to revert a Git commit
The net effect of the `git revert`
command is similar to reset, but its approach is different. Where the `reset`
command moves the branch pointer back in the chain (typically) to "undo" changes, the `revert`
command adds a new commit at the end of the chain to "cancel" changes. The effect is most easily seen by looking at Figure 1 again. If we add a line to a file in each commit in the chain, one way to get back to the version with only two lines is to reset to that commit, i.e., `git reset HEAD~1`
.
Another way to end up with the two-line version is to add a new commit that has the third line removed—effectively canceling out that change. This can be done with a `git revert`
command, such as:
`$ git revert HEAD`
Because this adds a new commit, Git will prompt for the commit message:
```
Revert "File with three lines"
This reverts commit b764644bad524b804577684bf74e7bca3117f554.
# Please enter the commit message for your changes. Lines starting
# with '#' will be ignored, and an empty message aborts the commit.
# On branch master
# Changes to be committed:
# modified: file1.txt
#
```
Figure 3 (below) shows the result after the `revert`
operation is completed.
If we do a `git log`
now, we'll see a new commit that reflects the contents before the previous commit.
```
$ git log --oneline
11b7712 Revert "File with three lines"
b764644 File with three lines
7c709f0 File with two lines
9ef9173 File with one line
```
Here are the current contents of the file in the working directory:
```
$ cat <filename>
Line 1
Line 2
```
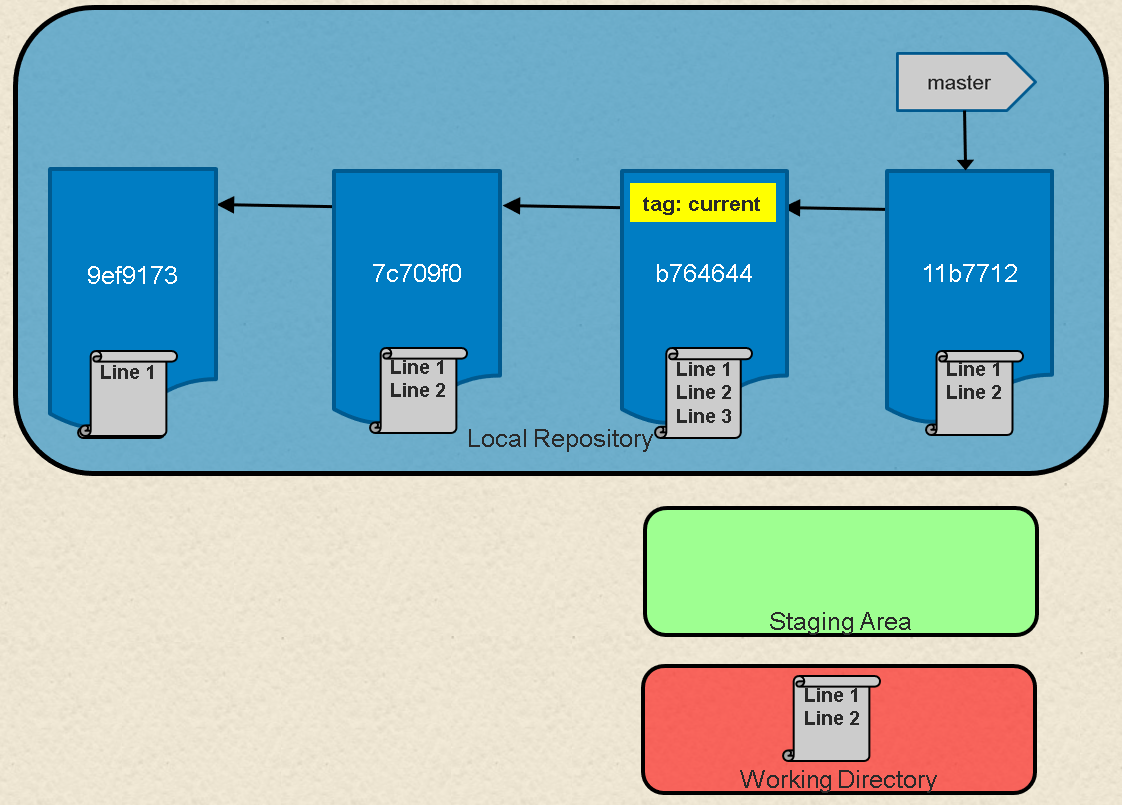
### Revert or reset?
Why would you choose to do a `revert`
over a `reset`
operation? If you have already pushed your chain of commits to the remote repository (where others may have pulled your code and started working with it), a revert is a nicer way to cancel out changes for them. This is because the Git workflow works well for picking up additional commits at the end of a branch, but it can be challenging if a set of commits is no longer seen in the chain when someone resets the branch pointer back.
This brings us to one of the fundamental rules when working with Git in this manner: Making these kinds of changes in your *local repository* to code you haven't pushed yet is fine. But avoid making changes that rewrite history if the commits have already been pushed to the remote repository and others may be working with them.
In short, if you rollback, undo, or rewrite the history of a commit chain that others are working with, your colleagues may have a lot more work when they try to merge in changes based on the original chain they pulled. If you must make changes against code that has already been pushed and is being used by others, consider communicating before you make the changes and give people the chance to merge their changes first. Then they can pull a fresh copy after the infringing operation without needing to merge.
You may have noticed that the original chain of commits was still there after we did the reset. We moved the pointer and reset the code back to a previous commit, but it did not delete any commits. This means that, as long as we know the original commit we were pointing to, we can "restore" back to the previous point by simply resetting back to the original head of the branch:
`git reset <sha1 of commit>`
A similar thing happens in most other operations we do in Git when commits are replaced. New commits are created, and the appropriate pointer is moved to the new chain. But the old chain of commits still exists.
## Rebase
Now let's look at a branch rebase. Consider that we have two branches—*master* and *feature*—with the chain of commits shown in Figure 4 below. *Master* has the chain `C4->C2->C1->C0`
and *feature* has the chain `C5->C3->C2->C1->C0`
.
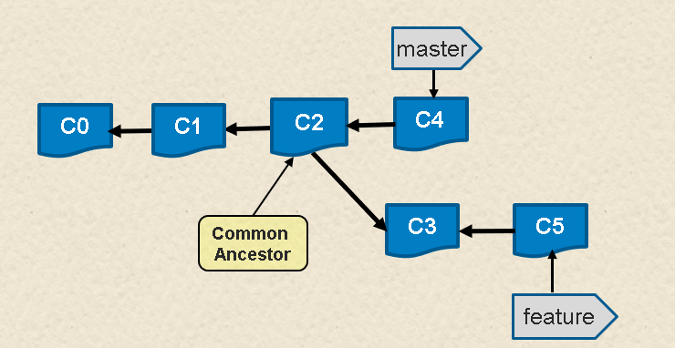
Fig. 4: Chain of commits for branches master and feature
If we look at the log of commits in the branches, they might look like the following. (The `C`
designators for the commit messages are used to make this easier to understand.)
```
$ git log --oneline master
6a92e7a C4
259bf36 C2
f33ae68 C1
5043e79 C0
$ git log --oneline feature
79768b8 C5
000f9ae C3
259bf36 C2
f33ae68 C1
5043e79 C0
```
I tell people to think of a rebase as a "merge with history" in Git. Essentially what Git does is take each different commit in one branch and attempt to "replay" the differences onto the other branch.
So, we can rebase a feature onto *master* to pick up `C4`
(e.g., insert it into feature's chain). Using the basic Git commands, it might look like this:
```
$ git checkout feature
$ git rebase master
First, rewinding head to replay your work on top of it...
Applying: C3
Applying: C5
```
Afterward, our chain of commits would look like Figure 5.
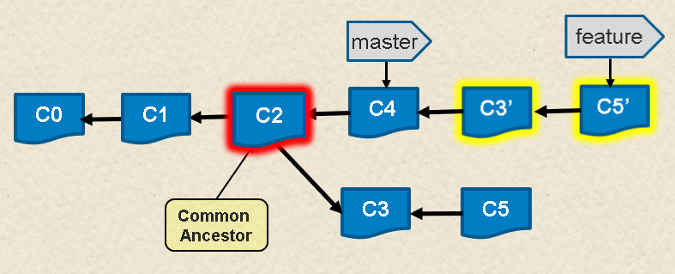
Fig. 5: Chain of commits after the rebase command
Again, looking at the log of commits, we can see the changes.
```
$ git log --oneline master
6a92e7a C4
259bf36 C2
f33ae68 C1
5043e79 C0
$ git log --oneline feature
c4533a5 C5
64f2047 C3
6a92e7a C4
259bf36 C2
f33ae68 C1
5043e79 C0
```
Notice that we have `C3'`
and `C5'`
—new commits created as a result of making the changes from the originals "on top of" the existing chain in *master*. But also notice that the "original" `C3`
and `C5`
are still there—they just don't have a branch pointing to them anymore.
If we did this rebase, then decided we didn't like the results and wanted to undo it, it would be as simple as:
`$ git reset 79768b8`
With this simple change, our branch would now point back to the same set of commits as before the `rebase`
operation—effectively undoing it (Figure 6).
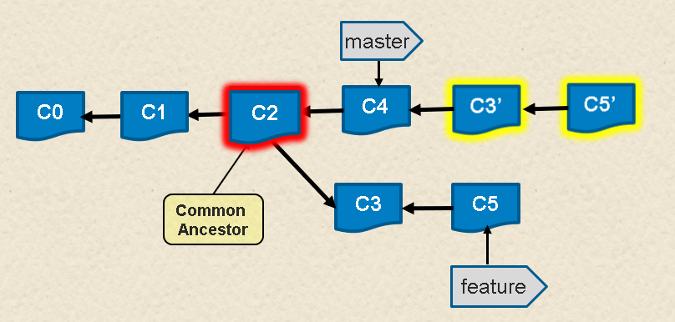
Fig. 6: After undoing the rebase operation
What happens if you can't recall what commit a branch pointed to before an operation? Fortunately, Git again helps us out. For most operations that modify pointers in this way, Git remembers the original commit for you. In fact, it stores it in a special reference named `ORIG_HEAD `
within the `.git`
repository directory. That path is a file containing the most recent reference before it was modified. If we `cat`
the file, we can see its contents.
```
$ cat .git/ORIG_HEAD
79768b891f47ce06f13456a7e222536ee47ad2fe
```
We could use the `reset`
command, as before, to point back to the original chain. Then the log would show this:
```
$ git log --oneline feature
79768b8 C5
000f9ae C3
259bf36 C2
f33ae68 C1
5043e79 C0
```
Another place to get this information is in the reflog. The reflog is a play-by-play listing of switches or changes to references in your local repository. To see it, you can use the `git reflog`
command:
```
$ git reflog
79768b8 HEAD@{0}: reset: moving to 79768b
c4533a5 HEAD@{1}: rebase finished: returning to refs/heads/feature
c4533a5 HEAD@{2}: rebase: C5
64f2047 HEAD@{3}: rebase: C3
6a92e7a HEAD@{4}: rebase: checkout master
79768b8 HEAD@{5}: checkout: moving from feature to feature
79768b8 HEAD@{6}: commit: C5
000f9ae HEAD@{7}: checkout: moving from master to feature
6a92e7a HEAD@{8}: commit: C4
259bf36 HEAD@{9}: checkout: moving from feature to master
000f9ae HEAD@{10}: commit: C3
259bf36 HEAD@{11}: checkout: moving from master to feature
259bf36 HEAD@{12}: commit: C2
f33ae68 HEAD@{13}: commit: C1
5043e79 HEAD@{14}: commit (initial): C0
```
You can then reset to any of the items in that list using the special relative naming format you see in the log:
`$ git reset HEAD@{1}`
Once you understand that Git keeps the original chain of commits around when operations "modify" the chain, making changes in Git becomes much less scary. This is one of Git's core strengths: being able to quickly and easily try things out and undo them if they don't work.
*Brent Laster will present Power Git: Rerere, Bisect, Subtrees, Filter Branch, Worktrees, Submodules, and More at the 20th annual OSCON event, July 16-19 in Portland, Ore. For more tips and explanations about using Git at any level, checkout Brent's book "Professional Git," available on Amazon.*
## 1 Comment |
9,917 | 如何在 Linux 上使用 pbcopy 和 pbpaste 命令 | https://www.ostechnix.com/how-to-use-pbcopy-and-pbpaste-commands-on-linux/ | 2018-08-14T09:26:29 | [
"pbcopy",
"pbpaste"
] | https://linux.cn/article-9917-1.html | 
由于 Linux 和 Mac OS X 是基于 \*Nix 的系统,因此许多命令可以在两个平台上运行。但是,某些命令可能在两个平台上都没有,比如 `pbcopy` 和 `pbpast`。这些命令仅在 Mac OS X 平台上可用。`pbcopy` 命令将标准输入复制到剪贴板。然后,你可以在任何地方使用 `pbpaste` 命令粘贴剪贴板内容。当然,上述命令可能有一些 Linux 替代品,例如 `xclip`。 `xclip` 与 `pbcopy` 完全相同。但是,从 Mac OS 切换到 Linux 的发行版的人将会找不到这两个命令,不过仍然想使用它们。别担心!这个简短的教程描述了如何在 Linux 上使用 `pbcopy` 和 `pbpaste` 命令。
### 安装 xclip / xsel
就像我已经说过的那样,Linux 中没有 `pbcopy` 和 `pbpaste` 命令。但是,我们可以通过 shell 别名使用 xclip 和/或 xsel 命令复制 `pbcopy` 和 `pbpaste` 命令的功能。xclip 和 xsel 包存在于大多数 Linux 发行版的默认存储库中。请注意,你无需安装这两个程序。只需安装上述任何一个程序即可。
要在 Arch Linux 及其衍生产版上安装它们,请运行:
```
$ sudo pacman xclip xsel
```
在 Fedora 上:
```
$ sudo dnf xclip xsel
```
在 Debian、Ubuntu、Linux Mint 上:
```
$ sudo apt install xclip xsel
```
安装后,你需要为 `pbcopy` 和 `pbpaste` 命令创建别名。为此,请编辑 `~/.bashrc`:
```
$ vi ~/.bashrc
```
如果要使用 xclip,请粘贴以下行:
```
alias pbcopy='xclip -selection clipboard'
alias pbpaste='xclip -selection clipboard -o'
```
如果要使用 xsel,请在 `~/.bashrc` 中粘贴以下行。
```
alias pbcopy='xsel --clipboard --input'
alias pbpaste='xsel --clipboard --output'
```
保存并关闭文件。
接下来,运行以下命令以更新 `~/.bashrc` 中的更改。
```
$ source ~/.bashrc
```
ZSH 用户将上述行粘贴到 `~/.zshrc` 中。
### 在 Linux 上使用 pbcopy 和 pbpaste 命令
让我们看一些例子。
`pbcopy` 命令将文本从 stdin 复制到剪贴板缓冲区。例如,看看下面的例子。
```
$ echo "Welcome To OSTechNix!" | pbcopy
```
上面的命令会将文本 “Welcome to OSTechNix” 复制到剪贴板中。你可以稍后访问此内容并使用如下所示的 `pbpaste` 命令将其粘贴到任何位置。
```
$ echo `pbpaste`
Welcome To OSTechNix!
```

以下是一些其他例子。
我有一个名为 `file.txt` 的文件,其中包含以下内容。
```
$ cat file.txt
Welcome To OSTechNix!
```
你可以直接将文件内容复制到剪贴板中,如下所示。
```
$ pbcopy < file.txt
```
现在,只要你用其他文件的内容更新了剪切板,那么剪切板中的内容就可用了。
要从剪贴板检索内容,只需输入:
```
$ pbpaste
Welcome To OSTechNix!
```
你还可以使用管道字符将任何 Linux 命令的输出发送到剪贴板。看看下面的例子。
```
$ ps aux | pbcopy
```
现在,输入 `pbpaste` 命令以显示剪贴板中 `ps aux` 命令的输出。
```
$ pbpaste
```

使用 `pbcopy` 和 `pbpaste` 命令可以做更多的事情。我希望你现在对这些命令有一个基本的想法。
就是这些了。还有更好的东西。敬请关注!
干杯!
---
via: <https://www.ostechnix.com/how-to-use-pbcopy-and-pbpaste-commands-on-linux/>
作者:[SK](https://www.ostechnix.com/author/sk/) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
9,918 | 如何查看 Linux 中所有正在运行的服务 | https://www.2daygeek.com/how-to-check-all-running-services-in-linux/ | 2018-08-14T10:05:34 | [
"服务"
] | https://linux.cn/article-9918-1.html | 
有许多方法和工具可以查看 Linux 中所有正在运行的服务。大多数管理员会在 System V(SysV)初始化系统中使用 `service service-name status` 或 `/etc/init.d/service-name status`,而在 systemd 初始化系统中使用 `systemctl status service-name`。
以上命令可以清楚地显示该服务是否在服务器上运行,这也是每个 Linux 管理员都该知道的非常简单和基础的命令。
如果你对系统环境并不熟悉,也不清楚系统在运行哪些服务,你会如何检查?
是的,我们的确有必要这样检查一下。这将有助于我们了解系统上运行了什么服务,以及哪些是必要的、哪些需要被禁用。
init(<ruby> 初始化 <rt> initialization </rt></ruby>的简称)是在系统启动期间运行的第一个进程。`init` 是一个守护进程,它将持续运行直至关机。
大多数 Linux 发行版都使用如下的初始化系统之一:
* System V 是更老的初始化系统
* Upstart 是一个基于事件的传统的初始化系统的替代品
* systemd 是新的初始化系统,它已经被大多数最新的 Linux 发行版所采用
### 什么是 System V(SysV)
SysV(意即 System V) 初始化系统是早期传统的初始化系统和系统管理器。由于 sysVinit 系统上一些长期悬而未决的问题,大多数最新的发行版都适用于 systemd 系统。
### 什么是 Upstart 初始化系统
Upstart 是一个基于事件的 /sbin/init 的替代品,它控制在启动时的任务和服务的开始,在关机时停止它们,并在系统运行时监控它们。
它最初是为 Ubuntu 发行版开发的,但其是以适合所有 Linux 发行版的开发为目标的,以替换过时的 System-V 初始化系统。
### 什么是 systemd
systemd 是一个新的初始化系统以及系统管理器,它已成为大多数 Linux 发行版中非常流行且广泛适应的新的标准初始化系统。`systemctl` 是一个 systemd 管理工具,它可以帮助我们管理 systemd 系统。
### 方法一:如何在 System V(SysV)系统中查看运行的服务
以下命令可以帮助我们列出 System V(SysV) 系统中所有正在运行的服务。
如果服务很多,我建议使用文件查看命令,如 `less`、`more` 等,以便得到清晰的结果。
```
# service --status-all
或
# service --status-all | more
或
# service --status-all | less
```
```
abrt-ccpp hook is installed
abrtd (pid 2131) is running...
abrt-dump-oops is stopped
acpid (pid 1958) is running...
atd (pid 2164) is running...
auditd (pid 1731) is running...
Frequency scaling enabled using ondemand governor
crond (pid 2153) is running...
hald (pid 1967) is running...
htcacheclean is stopped
httpd is stopped
Table: filter
Chain INPUT (policy ACCEPT)
num target prot opt source destination
1 ACCEPT all ::/0 ::/0 state RELATED,ESTABLISHED
2 ACCEPT icmpv6 ::/0 ::/0
3 ACCEPT all ::/0 ::/0
4 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:80
5 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:21
6 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:22
7 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:25
8 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:2082
9 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:2086
10 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:2083
11 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:2087
12 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:10000
13 REJECT all ::/0 ::/0 reject-with icmp6-adm-prohibited
Chain FORWARD (policy ACCEPT)
num target prot opt source destination
1 REJECT all ::/0 ::/0 reject-with icmp6-adm-prohibited
Chain OUTPUT (policy ACCEPT)
num target prot opt source destination
iptables: Firewall is not running.
irqbalance (pid 1826) is running...
Kdump is operational
lvmetad is stopped
mdmonitor is stopped
messagebus (pid 1929) is running...
SUCCESS! MySQL running (24376)
rndc: neither /etc/rndc.conf nor /etc/rndc.key was found
named is stopped
netconsole module not loaded
Usage: startup.sh { start | stop }
Configured devices:
lo eth0 eth1
Currently active devices:
lo eth0
ntpd is stopped
portreserve (pid 1749) is running...
master (pid 2107) is running...
Process accounting is disabled.
quota_nld is stopped
rdisc is stopped
rngd is stopped
rpcbind (pid 1840) is running...
rsyslogd (pid 1756) is running...
sandbox is stopped
saslauthd is stopped
smartd is stopped
openssh-daemon (pid 9859) is running...
svnserve is stopped
vsftpd (pid 4008) is running...
xinetd (pid 2031) is running...
zabbix_agentd (pid 2150 2149 2148 2147 2146 2140) is running...
```
执行以下命令,可以只查看正在运行的服务:
```
# service --status-all | grep running
```
```
crond (pid 535) is running...
httpd (pid 627) is running...
mysqld (pid 911) is running...
rndc: neither /etc/rndc.conf nor /etc/rndc.key was found
rsyslogd (pid 449) is running...
saslauthd (pid 492) is running...
sendmail (pid 509) is running...
sm-client (pid 519) is running...
openssh-daemon (pid 478) is running...
xinetd (pid 485) is running...
```
运行以下命令以查看指定服务的状态:
```
# service --status-all | grep httpd
httpd (pid 627) is running...
```
或者,使用以下命令也可以查看指定服务的状态:
```
# service httpd status
httpd (pid 627) is running...
```
使用以下命令查看系统启动时哪些服务会被启用:
```
# chkconfig --list
```
```
crond 0:off 1:off 2:on 3:on 4:on 5:on 6:off
htcacheclean 0:off 1:off 2:off 3:off 4:off 5:off 6:off
httpd 0:off 1:off 2:off 3:on 4:off 5:off 6:off
ip6tables 0:off 1:off 2:on 3:off 4:on 5:on 6:off
iptables 0:off 1:off 2:on 3:on 4:on 5:on 6:off
modules_dep 0:off 1:off 2:on 3:on 4:on 5:on 6:off
mysqld 0:off 1:off 2:on 3:on 4:on 5:on 6:off
named 0:off 1:off 2:off 3:off 4:off 5:off 6:off
netconsole 0:off 1:off 2:off 3:off 4:off 5:off 6:off
netfs 0:off 1:off 2:off 3:off 4:on 5:on 6:off
network 0:off 1:off 2:on 3:on 4:on 5:on 6:off
nmb 0:off 1:off 2:off 3:off 4:off 5:off 6:off
nscd 0:off 1:off 2:off 3:off 4:off 5:off 6:off
portreserve 0:off 1:off 2:on 3:off 4:on 5:on 6:off
quota_nld 0:off 1:off 2:off 3:off 4:off 5:off 6:off
rdisc 0:off 1:off 2:off 3:off 4:off 5:off 6:off
restorecond 0:off 1:off 2:off 3:off 4:off 5:off 6:off
rpcbind 0:off 1:off 2:on 3:off 4:on 5:on 6:off
rsyslog 0:off 1:off 2:on 3:on 4:on 5:on 6:off
saslauthd 0:off 1:off 2:off 3:on 4:off 5:off 6:off
sendmail 0:off 1:off 2:on 3:on 4:on 5:on 6:off
smb 0:off 1:off 2:off 3:off 4:off 5:off 6:off
snmpd 0:off 1:off 2:off 3:off 4:off 5:off 6:off
snmptrapd 0:off 1:off 2:off 3:off 4:off 5:off 6:off
sshd 0:off 1:off 2:on 3:on 4:on 5:on 6:off
udev-post 0:off 1:on 2:on 3:off 4:on 5:on 6:off
winbind 0:off 1:off 2:off 3:off 4:off 5:off 6:off
xinetd 0:off 1:off 2:off 3:on 4:on 5:on 6:off
xinetd based services:
chargen-dgram: off
chargen-stream: off
daytime-dgram: off
daytime-stream: off
discard-dgram: off
discard-stream: off
echo-dgram: off
echo-stream: off
finger: off
ntalk: off
rsync: off
talk: off
tcpmux-server: off
time-dgram: off
time-stream: off
```
### 方法二:如何在 System V(SysV)系统中查看运行的服务
另外一种在 Linux 系统上列出运行的服务的方法是使用 initctl 命令:
```
# initctl list
rc stop/waiting
tty (/dev/tty3) start/running, process 1740
tty (/dev/tty2) start/running, process 1738
tty (/dev/tty1) start/running, process 1736
tty (/dev/tty6) start/running, process 1746
tty (/dev/tty5) start/running, process 1744
tty (/dev/tty4) start/running, process 1742
plymouth-shutdown stop/waiting
control-alt-delete stop/waiting
rcS-emergency stop/waiting
readahead-collector stop/waiting
kexec-disable stop/waiting
quit-plymouth stop/waiting
rcS stop/waiting
prefdm stop/waiting
init-system-dbus stop/waiting
ck-log-system-restart stop/waiting
readahead stop/waiting
ck-log-system-start stop/waiting
splash-manager stop/waiting
start-ttys stop/waiting
readahead-disable-services stop/waiting
ck-log-system-stop stop/waiting
rcS-sulogin stop/waiting
serial stop/waiting
```
### 方法三:如何在 systemd 系统中查看运行的服务
以下命令帮助我们列出 systemd 系统中所有服务:
```
# systemctl
UNIT LOAD ACTIVE SUB DESCRIPTION
sys-devices-virtual-block-loop0.device loaded active plugged /sys/devices/virtual/block/loop0
sys-devices-virtual-block-loop1.device loaded active plugged /sys/devices/virtual/block/loop1
sys-devices-virtual-block-loop2.device loaded active plugged /sys/devices/virtual/block/loop2
sys-devices-virtual-block-loop3.device loaded active plugged /sys/devices/virtual/block/loop3
sys-devices-virtual-block-loop4.device loaded active plugged /sys/devices/virtual/block/loop4
sys-devices-virtual-misc-rfkill.device loaded active plugged /sys/devices/virtual/misc/rfkill
sys-devices-virtual-tty-ttyprintk.device loaded active plugged /sys/devices/virtual/tty/ttyprintk
sys-module-fuse.device loaded active plugged /sys/module/fuse
sys-subsystem-net-devices-enp0s3.device loaded active plugged 82540EM Gigabit Ethernet Controller (PRO/1000 MT Desktop Adapter)
-.mount loaded active mounted Root Mount
dev-hugepages.mount loaded active mounted Huge Pages File System
dev-mqueue.mount loaded active mounted POSIX Message Queue File System
run-user-1000-gvfs.mount loaded active mounted /run/user/1000/gvfs
run-user-1000.mount loaded active mounted /run/user/1000
snap-core-3887.mount loaded active mounted Mount unit for core
snap-core-4017.mount loaded active mounted Mount unit for core
snap-core-4110.mount loaded active mounted Mount unit for core
snap-gping-13.mount loaded active mounted Mount unit for gping
snap-termius\x2dapp-8.mount loaded active mounted Mount unit for termius-app
sys-fs-fuse-connections.mount loaded active mounted FUSE Control File System
sys-kernel-debug.mount loaded active mounted Debug File System
acpid.path loaded active running ACPI Events Check
cups.path loaded active running CUPS Scheduler
systemd-ask-password-plymouth.path loaded active waiting Forward Password Requests to Plymouth Directory Watch
systemd-ask-password-wall.path loaded active waiting Forward Password Requests to Wall Directory Watch
init.scope loaded active running System and Service Manager
session-c2.scope loaded active running Session c2 of user magi
accounts-daemon.service loaded active running Accounts Service
acpid.service loaded active running ACPI event daemon
anacron.service loaded active running Run anacron jobs
apache2.service loaded active running The Apache HTTP Server
apparmor.service loaded active exited AppArmor initialization
apport.service loaded active exited LSB: automatic crash report generation
aptik-battery-monitor.service loaded active running LSB: start/stop the aptik battery monitor daemon
atop.service loaded active running Atop advanced performance monitor
atopacct.service loaded active running Atop process accounting daemon
avahi-daemon.service loaded active running Avahi mDNS/DNS-SD Stack
colord.service loaded active running Manage, Install and Generate Color Profiles
console-setup.service loaded active exited Set console font and keymap
cron.service loaded active running Regular background program processing daemon
cups-browsed.service loaded active running Make remote CUPS printers available locally
cups.service loaded active running CUPS Scheduler
dbus.service loaded active running D-Bus System Message Bus
postfix.service loaded active exited Postfix Mail Transport Agent
```
* `UNIT` 相应的 systemd 单元名称
* `LOAD` 相应的单元是否被加载到内存中
* `ACTIVE` 该单元是否处于活动状态
* `SUB` 该单元是否处于运行状态(LCTT 译注:是较于 ACTIVE 更加详细的状态描述,不同的单元类型有不同的状态。)
* `DESCRIPTION` 关于该单元的简短描述
以下选项可根据类型列出单元:
```
# systemctl list-units --type service
UNIT LOAD ACTIVE SUB DESCRIPTION
accounts-daemon.service loaded active running Accounts Service
acpid.service loaded active running ACPI event daemon
anacron.service loaded active running Run anacron jobs
apache2.service loaded active running The Apache HTTP Server
apparmor.service loaded active exited AppArmor initialization
apport.service loaded active exited LSB: automatic crash report generation
aptik-battery-monitor.service loaded active running LSB: start/stop the aptik battery monitor daemon
atop.service loaded active running Atop advanced performance monitor
atopacct.service loaded active running Atop process accounting daemon
avahi-daemon.service loaded active running Avahi mDNS/DNS-SD Stack
colord.service loaded active running Manage, Install and Generate Color Profiles
console-setup.service loaded active exited Set console font and keymap
cron.service loaded active running Regular background program processing daemon
cups-browsed.service loaded active running Make remote CUPS printers available locally
cups.service loaded active running CUPS Scheduler
dbus.service loaded active running D-Bus System Message Bus
fwupd.service loaded active running Firmware update daemon
[email protected] loaded active running Getty on tty1
grub-common.service loaded active exited LSB: Record successful boot for GRUB
irqbalance.service loaded active running LSB: daemon to balance interrupts for SMP systems
keyboard-setup.service loaded active exited Set the console keyboard layout
kmod-static-nodes.service loaded active exited Create list of required static device nodes for the current kernel
```
以下选项可帮助您根据状态列出单位,输出与前例类似但更直截了当:
```
# systemctl list-unit-files --type service
UNIT FILE STATE
accounts-daemon.service enabled
acpid.service disabled
alsa-restore.service static
alsa-state.service static
alsa-utils.service masked
anacron-resume.service enabled
anacron.service enabled
apache-htcacheclean.service disabled
[email protected] disabled
apache2.service enabled
[email protected] disabled
apparmor.service enabled
[email protected] static
apport.service generated
apt-daily-upgrade.service static
apt-daily.service static
aptik-battery-monitor.service generated
atop.service enabled
atopacct.service enabled
[email protected] enabled
avahi-daemon.service enabled
bluetooth.service enabled
```
运行以下命令以查看指定服务的状态:
```
# systemctl | grep apache2
apache2.service loaded active running The Apache HTTP Server
```
或者,使用以下命令也可查看指定服务的状态:
```
# systemctl status apache2
● apache2.service - The Apache HTTP Server
Loaded: loaded (/lib/systemd/system/apache2.service; enabled; vendor preset: enabled)
Drop-In: /lib/systemd/system/apache2.service.d
└─apache2-systemd.conf
Active: active (running) since Tue 2018-03-06 12:34:09 IST; 8min ago
Process: 2786 ExecReload=/usr/sbin/apachectl graceful (code=exited, status=0/SUCCESS)
Main PID: 1171 (apache2)
Tasks: 55 (limit: 4915)
CGroup: /system.slice/apache2.service
├─1171 /usr/sbin/apache2 -k start
├─2790 /usr/sbin/apache2 -k start
└─2791 /usr/sbin/apache2 -k start
Mar 06 12:34:08 magi-VirtualBox systemd[1]: Starting The Apache HTTP Server...
Mar 06 12:34:09 magi-VirtualBox apachectl[1089]: AH00558: apache2: Could not reliably determine the server's fully qualified domain name, using 10.0.2.15. Set the 'ServerName' directive globally to suppre
Mar 06 12:34:09 magi-VirtualBox systemd[1]: Started The Apache HTTP Server.
Mar 06 12:39:10 magi-VirtualBox systemd[1]: Reloading The Apache HTTP Server.
Mar 06 12:39:10 magi-VirtualBox apachectl[2786]: AH00558: apache2: Could not reliably determine the server's fully qualified domain name, using fe80::7929:4ed1:279f:4d65. Set the 'ServerName' directive gl
Mar 06 12:39:10 magi-VirtualBox systemd[1]: Reloaded The Apache HTTP Server.
```
执行以下命令,只查看正在运行的服务:
```
# systemctl | grep running
acpid.path loaded active running ACPI Events Check
cups.path loaded active running CUPS Scheduler
init.scope loaded active running System and Service Manager
session-c2.scope loaded active running Session c2 of user magi
accounts-daemon.service loaded active running Accounts Service
acpid.service loaded active running ACPI event daemon
apache2.service loaded active running The Apache HTTP Server
aptik-battery-monitor.service loaded active running LSB: start/stop the aptik battery monitor daemon
atop.service loaded active running Atop advanced performance monitor
atopacct.service loaded active running Atop process accounting daemon
avahi-daemon.service loaded active running Avahi mDNS/DNS-SD Stack
colord.service loaded active running Manage, Install and Generate Color Profiles
cron.service loaded active running Regular background program processing daemon
cups-browsed.service loaded active running Make remote CUPS printers available locally
cups.service loaded active running CUPS Scheduler
dbus.service loaded active running D-Bus System Message Bus
fwupd.service loaded active running Firmware update daemon
[email protected] loaded active running Getty on tty1
irqbalance.service loaded active running LSB: daemon to balance interrupts for SMP systems
lightdm.service loaded active running Light Display Manager
ModemManager.service loaded active running Modem Manager
NetworkManager.service loaded active running Network Manager
polkit.service loaded active running Authorization Manager
```
使用以下命令查看系统启动时会被启用的服务列表:
```
# systemctl list-unit-files | grep enabled
acpid.path enabled
cups.path enabled
accounts-daemon.service enabled
anacron-resume.service enabled
anacron.service enabled
apache2.service enabled
apparmor.service enabled
atop.service enabled
atopacct.service enabled
[email protected] enabled
avahi-daemon.service enabled
bluetooth.service enabled
console-setup.service enabled
cron.service enabled
cups-browsed.service enabled
cups.service enabled
display-manager.service enabled
dns-clean.service enabled
friendly-recovery.service enabled
[email protected] enabled
gpu-manager.service enabled
keyboard-setup.service enabled
lightdm.service enabled
ModemManager.service enabled
network-manager.service enabled
networking.service enabled
NetworkManager-dispatcher.service enabled
NetworkManager-wait-online.service enabled
NetworkManager.service enabled
```
`systemd-cgtop` 按资源使用情况(任务、CPU、内存、输入和输出)列出控制组:
```
# systemd-cgtop
Control Group Tasks %CPU Memory Input/s Output/s
/ - - 1.5G - -
/init.scope 1 - - - -
/system.slice 153 - - - -
/system.slice/ModemManager.service 3 - - - -
/system.slice/NetworkManager.service 4 - - - -
/system.slice/accounts-daemon.service 3 - - - -
/system.slice/acpid.service 1 - - - -
/system.slice/apache2.service 55 - - - -
/system.slice/aptik-battery-monitor.service 1 - - - -
/system.slice/atop.service 1 - - - -
/system.slice/atopacct.service 1 - - - -
/system.slice/avahi-daemon.service 2 - - - -
/system.slice/colord.service 3 - - - -
/system.slice/cron.service 1 - - - -
/system.slice/cups-browsed.service 3 - - - -
/system.slice/cups.service 2 - - - -
/system.slice/dbus.service 6 - - - -
/system.slice/fwupd.service 5 - - - -
/system.slice/irqbalance.service 1 - - - -
/system.slice/lightdm.service 7 - - - -
/system.slice/polkit.service 3 - - - -
/system.slice/repowerd.service 14 - - - -
/system.slice/rsyslog.service 4 - - - -
/system.slice/rtkit-daemon.service 3 - - - -
/system.slice/snapd.service 8 - - - -
/system.slice/system-getty.slice 1 - - - -
```
同时,我们可以使用 `pstree` 命令(输出来自 SysVinit 系统)查看正在运行的服务:
```
# pstree
init-+-crond
|-httpd---2*[httpd]
|-kthreadd/99149---khelper/99149
|-2*[mingetty]
|-mysqld_safe---mysqld---9*[{mysqld}]
|-rsyslogd---3*[{rsyslogd}]
|-saslauthd---saslauthd
|-2*[sendmail]
|-sshd---sshd---bash---pstree
|-udevd
`-xinetd
```
我们还可以使用 `pstree` 命令(输出来自 systemd 系统)查看正在运行的服务:
```
# pstree
systemd─┬─ModemManager─┬─{gdbus}
│ └─{gmain}
├─NetworkManager─┬─dhclient
│ ├─{gdbus}
│ └─{gmain}
├─accounts-daemon─┬─{gdbus}
│ └─{gmain}
├─acpid
├─agetty
├─anacron
├─apache2───2*[apache2───26*[{apache2}]]
├─aptd───{gmain}
├─aptik-battery-m
├─atop
├─atopacctd
├─avahi-daemon───avahi-daemon
├─colord─┬─{gdbus}
│ └─{gmain}
├─cron
├─cups-browsed─┬─{gdbus}
│ └─{gmain}
├─cupsd
├─dbus-daemon
├─fwupd─┬─{GUsbEventThread}
│ ├─{fwupd}
│ ├─{gdbus}
│ └─{gmain}
├─gnome-keyring-d─┬─{gdbus}
│ ├─{gmain}
│ └─{timer}
```
### 方法四:如何使用 chkservice 在 systemd 系统中查看正在运行的服务
`chkservice` 是一个管理系统单元的终端工具,需要超级用户权限。
```
# chkservice
```

要查看帮助页面,请按下 `?` ,它将显示管理 systemd 服务的可用选项。

---
via: <https://www.2daygeek.com/how-to-check-all-running-services-in-linux/>
作者:[Magesh Maruthamuthu](https://www.2daygeek.com/author/magesh/) 译者:[jessie-pang](https://github.com/jessie-pang) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
9,919 | 面向系统管理员的 Bash 指南 | https://opensource.com/article/18/7/admin-guide-bash | 2018-08-15T12:30:00 | [
"bash"
] | https://linux.cn/article-9919-1.html |
>
> 使 Bash 工作的更好的技巧。
>
>
>

每个行业都有一个该行业的大师们最常使用的工具。 对于许多系统管理员来说,这个工具就是他们的 [shell](http://www.catb.org/jargon/html/S/shell.html)。 在大多数 Linux 和其他类 Unix 系统上,默认的 shell 是 Bash。
Bash 是一个相当古老的程序——它起源于 20 世纪 80 年代后期——但它建立在更多更老的 shell 上,比如 C shell(csh),csh 至少是它 10 年前的前辈了。 因为 shell 的概念是那么古老,所以有大量的神秘知识等待着系统管理员去吸收领悟,使其生活更轻松。
我们来看看一些基础知识。
在某些时候,谁曾经无意中以 root 身份运行命令并导致某种问题? *举手*
我很确定我们很多人一度都是那个人。 这很痛苦。 这里有一些非常简单的技巧可以防止你再次碰上这类问题。
### 使用别名
首先,为 `mv` 和 `rm` 等命令设置别名,指向 `mv -i` 和 `rm -i`。 这将确保在运行 `rm -f /boot` 时至少需要你确认。 在 Red Hat 企业版 Linux 中,如果你使用 root 帐户,则默认设置这些别名。
如果你还要为普通用户帐户设置这些别名,只需将这两行放入家目录下名为 `.bashrc` 的文件中(这些也适用于 `sudo` ):
```
alias mv='mv -i'
alias rm='rm -i'
```
### 让你的 root 提示符脱颖而出
你可以采取的防止意外发生的另一项措施是确保你很清楚在使用 root 帐户。 在日常工作中,我通常会让 root 提示符从日常使用的提示符中脱颖而出。
如果将以下内容放入 root 的家目录中的 `.bashrc` 文件中,你将看到一个黑色背景上的红色的 root 提示符,清楚地表明你(或其他任何人)应该谨慎行事。
```
export PS1="\[$(tput bold)$(tput setab 0)$(tput setaf 1)\]\u@\h:\w # \[$(tput sgr0)\]"
```
实际上,你应该尽可能避免以 root 用户身份登录,而是通过 `sudo` 运行大多数系统管理命令,但这是另一回事。
使用了一些小技巧用于防止使用 root 帐户时的“不小心的副作用”之后,让我们看看 Bash 可以帮助你在日常工作中做的一些好事。
### 控制你的历史
你可能知道在 Bash 中你按向上的箭头时能看见和重新使用你之前所有(好吧,大多数)的命令。这是因为这些命令已经保存到了你家目录下的名为 `.bash_history` 的文件中。这个历史文件附带了一组有用的设置和命令。
首先,你可以通过键入 `history` 来查看整个最近的命令历史记录,或者你可以通过键入 `history 30` 将其限制为最近 30 个命令。不过这技巧太平淡无奇了(LCTT 译注: vanilla 原为香草,后引申没拓展的、标准、普通的,比如 vanilla C++ compiler 意为标准 C++ 编译器)。 你可以更好地控制 Bash 保存的内容以及保存方式。
例如,如果将以下内容添加到 `.bashrc`,那么任何以空格开头的命令都不会保存到历史记录列表中:
```
HISTCONTROL=ignorespace
```
如果你需要以明文形式将密码传递给一个命令,这就非常有用。 (是的,这太可怕了,但它仍然会发生。)
如果你不希望经常执行的命令充斥在历史记录中,请使用:
```
HISTCONTROL=ignorespace:erasedups
```
这样,每次使用一个命令时,都会从历史记录文件中删除之前出现的所有相同命令,并且只将最后一次调用保存到历史记录列表中。
我特别喜欢的历史记录设置是 `HISTTIMEFORMAT` 设置。 这将在历史记录文件中在所有的条目前面添加上时间戳。 例如,我使用:
```
HISTTIMEFORMAT="%F %T "
```
当我输入 `history 5` 时,我得到了很好的完整信息,如下所示:
```
1009 2018-06-11 22:34:38 cat /etc/hosts
1010 2018-06-11 22:34:40 echo $foo
1011 2018-06-11 22:34:42 echo $bar
1012 2018-06-11 22:34:44 ssh myhost
1013 2018-06-11 22:34:55 vim .bashrc
```
这使我更容易浏览我的命令历史记录并找到我两天前用来建立到我家实验室的 SSH 连接(我一次又一次地忘记......)。
### Bash 最佳实践
我将在编写 Bash 脚本时最好的(或者至少是好的,我不要求无所不知)11 项实践列出来。
11、 Bash 脚本可能变得复杂,不过注释也很方便。 如果你在考虑是否要添加注释,那就添加一个注释。 如果你在周末之后回来并且不得不花时间搞清楚你上周五想要做什么,那你是忘了添加注释。
10、 用花括号括起所有变量名,比如 `${myvariable}`。 养成这个习惯可以使用 `${variable}_suffix` 这种用法了,还能提高整个脚本的一致性。
9、 计算表达式时不要使用反引号;请改用 `$()` 语法。 所以使用:
```
for file in $(ls); do
```
而不使用:
```
for file in `ls`; do
```
前一个方式是可嵌套的,更易于阅读的,还能让一般的系统管理员群体感到满意。 不要使用反引号。
8、 一致性是好的。 选择一种风格并在整个脚本中坚持下去。 显然,我喜欢人们选择 `$()` 语法而不是反引号,并将其变量包在花括号中。 我更喜欢人们使用两个或四个空格而不是制表符来缩进,但即使你选择了错误的方式,也要一贯地错下去。
7、 为 Bash 脚本使用适当的<ruby> <a href="/article-3664-1.html"> 释伴 </a> <rt> shebang </rt></ruby>(LCTT 译注:**Shebang**,也称为 **Hashbang** ,是一个由井号和叹号构成的字符序列 `#!` ,其出现在文本文件的第一行的前两个字符。 在文件中存在释伴的情况下,类 Unix 操作系统的程序载入器会分析释伴后的内容,将这些内容作为解释器指令,并调用该指令,并将载有释伴的文件路径作为该解释器的参数)。 因为我正在编写Bash脚本,只打算用 Bash 执行它们,所以我经常使用 `#!/usr/bin/bash` 作为我的释伴。 不要使用 `#!/bin/sh` 或 `#!/usr/bin/sh`。 你的脚本会被执行,但它会以兼容模式运行——可能会产生许多意外的副作用。 (当然,除非你想要兼容模式。)
6、 比较字符串时,在 `if` 语句中给变量加上引号是个好主意,因为如果你的变量是空的,Bash 会为这样的行抛出一个错误:
```
if [ ${myvar} == "foo" ]; then
echo "bar"
fi
```
对于这样的行,将判定为 `false`:
```
if [ "${myvar}" == "foo" ]; then
echo "bar"
fi
```
此外,如果你不确定变量的内容(例如,在解析用户输入时),请给变量加引号以防止解释某些特殊字符,并确保该变量被视为单个单词,即使它包含空格。
5、 我想这是一个品味问题,但我更喜欢使用双等号( `==` ),即使是比较 Bash 中的字符串。 这是一致性的问题,尽管对于字符串比较,只有一个等号会起作用,我的思维立即变为“单个 `=` 是一个赋值运算符!”
4、 使用适当的退出代码。 确保如果你的脚本无法执行某些操作,则会向用户显示已写好的失败消息(最好提供解决问题的方法)并发送非零退出代码:
```
# we have failed
echo "Process has failed to complete, you need to manually restart the whatchamacallit"
exit 1
```
这样可以更容易地以编程方式从另一个脚本调用你的脚本并验证其成功完成。
3、 使用 Bash 的内置机制为变量提供合理的默认值,或者如果未定义你希望定义的变量,则抛出错误:
```
# this sets the value of $myvar to redhat, and prints 'redhat'
echo ${myvar:=redhat}
```
```
# this throws an error reading 'The variable myvar is undefined, dear reader' if $myvar is undefined
${myvar:?The variable myvar is undefined, dear reader}
```
2、 特别是如果你正在编写大型脚本,或者是如果你与其他人一起开发该大型脚本,请考虑在函数内部定义变量时使用 `local` 关键字。 `local` 关键字将创建一个局部变量,该变量只在该函数中可见。 这限制了变量冲突的可能性。
1、 每个系统管理员有时必须这样做:在控制台上调试一些东西,可能是数据中心的真实服务器,也可能是虚拟化平台的虚拟服务器。 如果你必须以这种方式调试脚本,你会感谢你自己记住了这个:不要让你的脚本中的行太长!
在许多系统上,控制台的默认宽度仍为 80 个字符。 如果你需要在控制台上调试脚本并且该脚本有很长的行,那么你将成为一个悲伤的熊猫。 此外,具有较短行的脚本—— 默认值仍为 80 个字符——在普通编辑器中也更容易阅读和理解!
我真的很喜欢 Bash。 我可以花几个小时写这篇文章或与其他爱好者交流优秀的技巧。 就希望你们能在评论中留下赞美。
---
via: <https://opensource.com/article/18/7/admin-guide-bash>
作者:[Maxim Burgerhout](https://opensource.com/users/wzzrd) 选题:[lujun9972](https://github.com/lujun9972) 译者:[Flowsnow](https://github.com/Flowsnow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Each trade has a tool that masters in that trade wield most often. For many sysadmins, that tool is their [shell](http://www.catb.org/jargon/html/S/shell.html). On the majority of Linux and other Unix-like systems out there, the default shell is Bash.
Bash is a fairly old program—it originated in the late 1980s—but it builds on much, much older shells, like the C shell ([csh](https://en.wikipedia.org/wiki/C_shell)), which is easily 10 years its senior. Because the concept of a shell is that old, there is an enormous amount of arcane knowledge out there waiting to be consumed to make any sysadmin guy's or gal's life a lot easier.
Let's take a look at some of the basics.
Who has, at some point, unintentionally ran a command as root and caused some kind of issue? *raises hand*
I'm pretty sure a lot of us have been that guy or gal at one point. Very painful. Here are some very simple tricks to prevent you from hitting that stone a second time.
## Use aliases
First, set up aliases for commands like ** mv** and
**that point to**
`rm`
`mv -I`
and `rm -I`
. This will make sure that running `rm -f /boot`
at least asks you for confirmation. In Red Hat Enterprise Linux, these aliases are set up by default if you use the root account.If you want to set those aliases for your normal user account as well, just drop these two lines into a file called .bashrc in your home directory (these will also work with sudo):
```
alias mv='mv -i'
alias rm='rm -i'
```
## Make your root prompt stand out
Another thing you can do to prevent mishaps is to make sure you are aware when you are using the root account. I usually do that by making the root prompt stand out really well from the prompt I use for my normal, everyday work.
If you drop the following into the .bashrc file in root's home directory, you will have a root prompt that is red on black, making it crystal clear that you (or anyone else) should tread carefully.
`export PS1="\[$(tput bold)$(tput setab 0)$(tput setaf 1)\]\u@\h:\w # \[$(tput sgr0)\]"`
In fact, you should refrain from logging in as root as much as possible and instead run the majority of your sysadmin commands through sudo, but that's a different story.
Having implemented a couple of minor tricks to help prevent "unintentional side-effects" of using the root account, let's look at a couple of nice things Bash can help you do in your daily work.
## Control your history
You probably know that when you press the Up arrow key in Bash, you can see and reuse all (well, many) of your previous commands. That is because those commands have been saved to a file called .bash_history in your home directory. That history file comes with a bunch of settings and commands that can be very useful.
First, you can view your entire recent command history by typing ** history**, or you can limit it to your last 30 commands by typing
**. But that's pretty vanilla. You have more control over what Bash saves and how it saves it.**
`history 30`
For example, if you add the following to your .bashrc, any commands that start with a space will not be saved to the history list:
`HISTCONTROL=ignorespace`
This can be useful if you need to pass a password to a command in plaintext. (Yes, that is horrible, but it still happens.)
If you don't want a frequently executed command to show up in your history, use:
`HISTCONTROL=ignorespace:erasedups`
With this, every time you use a command, all its previous occurrences are removed from the history file, and only the last invocation is saved to your history list.
A history setting I particularly like is the ** HISTTIMEFORMAT** setting. This will prepend all entries in your history file with a timestamp. For example, I use:
`HISTTIMEFORMAT="%F %T "`
When I type ** history 5**, I get nice, complete information, like this:
```
1009 2018-06-11 22:34:38 cat /etc/hosts
1010 2018-06-11 22:34:40 echo $foo
1011 2018-06-11 22:34:42 echo $bar
1012 2018-06-11 22:34:44 ssh myhost
1013 2018-06-11 22:34:55 vim .bashrc
```
That makes it a lot easier to browse my command history and find the one I used two days ago to set up an SSH tunnel to my home lab (which I forget again, and again, and again…).
## Best Bash practices
I'll wrap this up with my top 11 list of the best (or good, at least; I don't claim omniscience) practices when writing Bash scripts.
-
Bash scripts can become complicated and comments are cheap. If you wonder whether to add a comment, add a comment. If you return after the weekend and have to spend time figuring out what you were trying to do last Friday, you forgot to add a comment.
- Wrap all your variable names in curly braces, like
. Making this a habit makes things like`${myvariable}`
`${variable}_suffix`
possible and improves consistency throughout your scripts.
- Do not use backticks when evaluating an expression; use the
syntax instead. So use:`$()`
`for file in $(ls); do`
not
`for file in `ls`; do`
The former option is nestable, more easily readable, and keeps the general sysadmin population happy. Do not use backticks.
- Consistency is good. Pick one style of doing things and stick with it throughout your script. Obviously, I would prefer if people picked the
syntax over backticks and wrapped their variables in curly braces. I would prefer it if people used two or four spaces—not tabs—to indent, but even if you choose to do it wrong, do it wrong consistently.`$()`
- Use the proper shebang for a Bash script. As I'm writing Bash scripts with the intention of only executing them with Bash, I most often use
as my shebang. Do not use`#!/usr/bin/bash`
or`#!/bin/sh`
. Your script will execute, but it'll run in compatibility mode—potentially with lots of unintended side effects. (Unless, of course, compatibility mode is what you want.)`#!/usr/bin/sh`
- When comparing strings, it's a good idea to quote your variables in if-statements, because if your variable is empty, Bash will throw an error for lines like these:
`if [ ${myvar} == "foo" ]; then echo "bar" fi`
And will evaluate to false for a line like this:
`if [ "${myvar}" == "foo" ]; then echo "bar" fi`
Also, if you are unsure about the contents of a variable (e.g., when you are parsing user input), quote your variables to prevent interpretation of some special characters and make sure the variable is considered a single word, even if it contains whitespace.
- This is a matter of taste, I guess, but I prefer using the double equals sign (
) even when comparing strings in Bash. It's a matter of consistency, and even though—for string comparisons only—a single equals sign will work, my mind immediately goes "single equals is an assignment operator!"`==`
- Use proper exit codes. Make sure that if your script fails to do something, you present the user with a written failure message (preferably with a way to fix the problem) and send a non-zero exit code:
`# we have failed echo "Process has failed to complete, you need to manually restart the whatchamacallit" exit 1`
This makes it easier to programmatically call your script from yet another script and verify its successful completion.
- Use Bash's built-in mechanisms to provide sane defaults for your variables or throw errors if variables you expect to be defined are not defined:
`# this sets the value of $myvar to redhat, and prints 'redhat' echo ${myvar:=redhat}`
`# this throws an error reading 'The variable myvar is undefined, dear reader' if $myvar is undefined ${myvar:?The variable myvar is undefined, dear reader}`
- Especially if you are writing a large script, and especially if you work on that large script with others, consider using the
keyword when defining variables inside functions. The`local`
keyword will create a local variable, that is one that's visible only within that function. This limits the possibility of clashing variables.`local`
- Every sysadmin must do it sometimes: debug something on a console, either a real one in a data center or a virtual one through a virtualization platform. If you have to debug a script that way, you will thank yourself for remembering this: Do not make the lines in your scripts too long!
On many systems, the default width of a console is still 80 characters. If you need to debug a script on a console and that script has very long lines, you'll be a sad panda. Besides, a script with shorter lines—the default is still 80 characters—is a lot easier to read and understand in a normal editor, too!
I truly love Bash. I can spend hours writing about it or exchanging nice tricks with fellow enthusiasts. Make sure you drop your favorites in the comments!
## 16 Comments |
9,920 | Mu 入门:一个面向初学者的 Python 编辑器 | https://opensource.com/article/18/8/getting-started-mu-python-editor-beginners | 2018-08-15T12:48:07 | [
"Python"
] | https://linux.cn/article-9920-1.html |
>
> 相识 Mu —— 一个可以使学生学习 Python 更轻松的开源编辑器。
>
>
>

Mu 是一个给初学者的 Python 编辑器,它旨在使学习体验更加愉快。它使学生能够在早期体验成功,这在你学习任何新知识的时候都很重要。
如果你曾试图教年轻人如何编程,你会立即把握到 [Mu](https://codewith.mu) 的重要性。大多数编程工具都是由开发人员为开发人员编写的,不管他们的年龄如何,它们并不适合初学者。然而,Mu 是由老师为学生写的。
### Mu 的起源
Mu 是 [Nicholas Tollervey](https://us.pycon.org/2018/speaker/profile/194/) 的心血结晶(我听过他 5 月份在 PyCon2018 上发言)。Nicholas 是一位受过古典音乐训练的音乐家,在担任音乐老师期间,他在职业生涯早期就开始对 Python 和开发感兴趣。他还写了 [Python in Education](https://www.oreilly.com/programming/free/python-in-education.csp),这是一本可以从 O'Reilly 下载的免费书。
Nicholas 曾经寻找过一个更简单的 Python 编程界面。他想要一些没有其他编辑器(甚至是 Python 附带的 IDLE3 编辑器 )复杂性的东西,所以他与 Raspberry Pi 基金会(赞助他的工作)的教育总监 [Carrie Ann Philbin](https://uk.linkedin.com/in/carrie-anne-philbin-a20649b7) 合作开发了 Mu 。
Mu 是一个用 Python 编写的开源程序(在 [GNU GPLv3](https://mu.readthedocs.io/en/latest/license.html) 许可证下)。它最初是为 [Micro:bit](http://microbit.org/) 迷你计算机开发的,但是其他老师的反馈和请求促使他将 Mu 重写为通用的 Python 编辑器。
### 受音乐启发
Nicholas 对 Mu 的启发来自于他教授音乐的方法。他想知道如果我们按照教授音乐的方式教授编程会如何,并立即看出了差别。与编程不同,我们没有音乐训练营,我们也不会书上学习如何演奏乐器,比如说如何演奏长笛。
Nicholas 说,Mu “旨在成为真实的东西”,因为没有人可以在 30 分钟内学习 Python。当他开发 Mu 时,他与老师一起工作,观察编程俱乐部,并观看中学生使用 Python。他发现少即多,保持简单可以改善成品的功能。Nicholas 说,Mu 只有大约 3,000 行代码。
### 使用 Mu
要尝试它,[下载](https://codewith.mu/en/download) Mu 并按照 [Linux、Windows 和 Mac OS](https://codewith.mu/en/howto/install_with_python)的简易安装说明进行操作。如果像我一样,你想[在 Raspberry Pi 上安装](https://codewith.mu/en/howto/install_raspberry_pi),请在终端中输入以下内容:
```
$ sudo apt-get update
$ sudo apt-get install mu
```
从编程菜单启动 Mu。然后你就可以选择如何使用 Mu。

我选择了Python 3,它启动了编写代码的环境。Python shell 直接在下面,它允许你查看代码执行。

菜单使用和理解非常简单,这实现了 Mu 的目标 —— 让编写代码对初学者简单。
在 Mu 用户的网站上可找到[教程](https://codewith.mu/en/tutorials/)和其他资源。在网站上,你还可以看到一些帮助开发 Mu 的[志愿者](https://codewith.mu/en/thanks)的名字。如果你想成为其中之一并[为 Mu 的发展做出贡献](https://mu.readthedocs.io/en/latest/contributing.html),我们非常欢迎您。
---
via: <https://opensource.com/article/18/8/getting-started-mu-python-editor-beginners>
作者:[Don Watkins](https://opensource.com/users/don-watkins) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Mu is a Python editor for beginning programmers, designed to make the learning experience more pleasant. It gives students the ability to experience success early on, which is important anytime you're learning something new.
If you have ever tried to teach young people how to program, you will immediately grasp the importance of [Mu](https://codewith.mu). Most programming tools are written by developers for developers and aren't well-suited for beginning programmers, regardless of their age. Mu, however, was written by a teacher for students.
## Mu's origins
Mu is the brainchild of [Nicholas Tollervey](https://us.pycon.org/2018/speaker/profile/194/) (who I heard speak at PyCon2018 in May). Nicholas is a classically trained musician who became interested in Python and development early in his career while working as a music teacher. He also wrote * Python in Education*, a free book you can download from O'Reilly.
Nicholas was looking for a simpler interface for Python programming. He wanted something without the complexity of other editors—even the IDLE3 editor that comes with Python—so he worked with [Carrie Ann Philbin](https://uk.linkedin.com/in/carrie-anne-philbin-a20649b7), director of education at the Raspberry Pi Foundation (which sponsored his work), to develop Mu.
Mu is an open source application (licensed under [GNU GPLv3](https://mu.readthedocs.io/en/latest/license.html)) written in Python. It was originally developed to work with the [Micro:bit](http://microbit.org/) mini-computer, but feedback and requests from other teachers spurred him to rewrite Mu into a generic Python editor.
## Inspired by music
Nicholas' inspiration for Mu came from his approach to teaching music. He wondered what would happen if we taught programming the way we teach music and immediately saw the disconnect. Unlike with programming, we don't have music boot camps and we don't learn to play an instrument from a book on, say, how to play the flute.
Nicholas says, Mu "aims to be the real thing," because no one can learn Python in 30 minutes. As he developed Mu, he worked with teachers, observed coding clubs, and watched secondary school students as they worked with Python. He found that less is more and keeping things simple improves the finished product's functionality. Mu is only about 3,000 lines of code, Nicholas says.
## Using Mu
To try it out, [download](https://codewith.mu/en/download) Mu and follow the easy installation instructions for Linux, Windows, and Mac OS. If, like me, you want to [install it on Raspberry Pi](https://codewith.mu/en/howto/1.0/install_raspberry_pi), enter the following in the terminal:
```
$ sudo apt-get update
$ sudo apt-get install mu
```
Launch Mu from the Programming menu. Then you'll have a choice about how you will use Mu.
I chose Python 3, which launches an environment to write code; the Python shell is directly below, which allows you to see the code execution.
The menu is very simple to use and understand, which achieves Mu's purpose—making coding easy for beginning programmers.
[Tutorials](https://codewith.mu/en/tutorials/) and other resources are available on the Mu users' website. On the site, you can also see names of some of the [volunteers](https://codewith.mu/en/thanks) who helped develop Mu. If you would like to become one of them and [contribute to Mu's development](https://mu.readthedocs.io/en/latest/contributing.html), you are most welcome.
## 5 Comments |
9,921 | 使用 MQTT 在项目中实现数据收发 | https://opensource.com/article/18/6/mqtt | 2018-08-15T22:08:38 | [
"MQTT"
] | https://linux.cn/article-9921-1.html |
>
> 从开源数据到开源事件流,了解一下 MQTT 发布/订阅(pubsub)线路协议。
>
>
>

去年 11 月我们购买了一辆电动汽车,同时也引发了有趣的思考:我们应该什么时候为电动汽车充电?对于电动汽车充电所用的电,我希望能够对应最小的二氧化碳排放,归结为一个特定的问题:对于任意给定时刻,每千瓦时对应的二氧化碳排放量是多少,一天中什么时间这个值最低?
### 寻找数据
我住在纽约州,大约 80% 的电力消耗可以自给自足,主要来自天然气、水坝(大部分来自于<ruby> 尼亚加拉 <rt> Niagara </rt></ruby>大瀑布)、核能发电,少部分来自风力、太阳能和其它化石燃料发电。非盈利性组织 [<ruby> 纽约独立电网运营商 <rt> New York Independent System Operator </rt></ruby>](http://www.nyiso.com/public/index.jsp) (NYISO)负责整个系统的运作,实现发电机组发电与用电之间的平衡,同时也是纽约路灯系统的监管部门。
尽管没有为公众提供公开 API,NYISO 还是尽责提供了[不少公开数据](http://www.nyiso.com/public/markets_operations/market_data/reports_info/index.jsp)供公众使用。每隔 5 分钟汇报全州各个发电机组消耗的燃料数据。数据以 CSV 文件的形式发布于公开的档案库中,全天更新。如果你了解不同燃料对发电瓦数的贡献比例,你可以比较准确的估计任意时刻的二氧化碳排放情况。
在构建收集处理公开数据的工具时,我们应该时刻避免过度使用这些资源。相比将这些数据打包并发送给所有人,我们有更好的方案。我们可以创建一个低开销的<ruby> 事件流 <rt> event stream </rt></ruby>,人们可以订阅并第一时间得到消息。我们可以使用 [MQTT](http://mqtt.org/) 实现该方案。我的项目([ny-power.org](http://ny-power.org/#))目标是收录到 [Home Assistant](https://www.home-assistant.io) 项目中;后者是一个开源的<ruby> 家庭自动化 <rt> home automation </rt></ruby>平台,拥有数十万用户。如果所有用户同时访问 CSV 文件服务器,估计 NYISO 不得不增加访问限制。
### MQTT 是什么?
MQTT 是一个<ruby> 发布订阅线路协议 <rt> publish/subscription wire protocol </rt></ruby>,为小规模设备设计。发布订阅系统工作原理类似于消息总线。你将一条消息发布到一个<ruby> 主题 <rt> topic </rt></ruby>上,那么所有订阅了该主题的客户端都可以获得该消息的一份拷贝。对于消息发送者而言,无需知道哪些人在订阅消息;你只需将消息发布到一系列主题,并订阅一些你感兴趣的主题。就像参加了一场聚会,你选取并加入感兴趣的对话。
MQTT 能够构建极为高效的应用。客户端订阅有限的几个主题,也只收到它们感兴趣的内容。不仅节省了处理时间,还降低了网络带宽使用。
作为一个开放标准,MQTT 有很多开源的客户端和服务端实现。对于你能想到的每种编程语言,都有对应的客户端库;甚至有嵌入到 Arduino 的库,可以构建传感器网络。服务端可供选择的也很多,我的选择是 Eclipse 项目提供的 [Mosquitto](https://mosquitto.org/) 服务端,这是因为它体积小、用 C 编写,可以承载数以万计的订阅者。
### 为何我喜爱 MQTT
在过去二十年间,我们为软件应用设计了可靠且准确的模型,用于解决服务遇到的问题。我还有其它邮件吗?当前的天气情况如何?我应该此刻购买这种产品吗?在绝大多数情况下,这种<ruby> 问答式 <rt> ask/receive </rt></ruby>的模型工作良好;但对于一个数据爆炸的世界,我们需要其它的模型。MQTT 的发布订阅模型十分强大,可以将大量数据发送到系统中。客户可以订阅数据中的一小部分并在订阅数据发布的第一时间收到更新。
MQTT 还有一些有趣的特性,其中之一是<ruby> 遗嘱 <rt> last-will-and-testament </rt></ruby>消息,可以用于区分两种不同的静默,一种是没有主题相关数据推送,另一种是你的数据接收器出现故障。MQTT 还包括<ruby> 保留消息 <rt> retained message </rt></ruby>,当客户端初次连接时会提供相关主题的最后一条消息。这对那些更新缓慢的主题来说很有必要。
我在 Home Assistant 项目开发过程中,发现这种消息总线模型对<ruby> 异构系统 <rt> heterogeneous systems </rt></ruby>尤为适合。如果你深入<ruby> 物联网 <rt> Internet of Things </rt></ruby>领域,你会发现 MQTT 无处不在。
### 我们的第一个 MQTT 流
NYSO 公布的 CSV 文件中有一个是实时的燃料混合使用情况。每 5 分钟,NYSO 发布这 5 分钟内发电使用的燃料类型和相应的发电量(以兆瓦为单位)。
这个 CSV 文件看起来像这样:
| 时间戳 | 时区 | 燃料类型 | 兆瓦为单位的发电量 |
| --- | --- | --- | --- |
| 05/09/2018 00:05:00 | EDT | 混合燃料 | 1400 |
| 05/09/2018 00:05:00 | EDT | 天然气 | 2144 |
| 05/09/2018 00:05:00 | EDT | 核能 | 4114 |
| 05/09/2018 00:05:00 | EDT | 其它化石燃料 | 4 |
| 05/09/2018 00:05:00 | EDT | 其它可再生资源 | 226 |
| 05/09/2018 00:05:00 | EDT | 风力 | 1 |
| 05/09/2018 00:05:00 | EDT | 水力 | 3229 |
| 05/09/2018 00:10:00 | EDT | 混合燃料 | 1307 |
| 05/09/2018 00:10:00 | EDT | 天然气 | 2092 |
| 05/09/2018 00:10:00 | EDT | 核能 | 4115 |
| 05/09/2018 00:10:00 | EDT | 其它化石燃料 | 4 |
| 05/09/2018 00:10:00 | EDT | 其它可再生资源 | 224 |
| 05/09/2018 00:10:00 | EDT | 风力 | 40 |
| 05/09/2018 00:10:00 | EDT | 水力 | 3166 |
表中唯一令人不解就是燃料类别中的混合燃料。纽约的大多数天然气工厂也通过燃烧其它类型的化石燃料发电。在冬季寒潮到来之际,家庭供暖的优先级高于发电;但这种情况出现的次数不多,(在我们计算中)可以将混合燃料类型看作天然气类型。
CSV 文件全天更新。我编写了一个简单的数据泵,每隔 1 分钟检查是否有数据更新,并将新条目发布到 MQTT 服务器的一系列主题上,主题名称基本与 CSV 文件有一定的对应关系。数据内容被转换为 JSON 对象,方便各种编程语言处理。
```
ny-power/upstream/fuel-mix/Hydro {"units": "MW", "value": 3229, "ts": "05/09/2018 00:05:00"}
ny-power/upstream/fuel-mix/Dual Fuel {"units": "MW", "value": 1400, "ts": "05/09/2018 00:05:00"}
ny-power/upstream/fuel-mix/Natural Gas {"units": "MW", "value": 2144, "ts": "05/09/2018 00:05:00"}
ny-power/upstream/fuel-mix/Other Fossil Fuels {"units": "MW", "value": 4, "ts": "05/09/2018 00:05:00"}
ny-power/upstream/fuel-mix/Wind {"units": "MW", "value": 41, "ts": "05/09/2018 00:05:00"}
ny-power/upstream/fuel-mix/Other Renewables {"units": "MW", "value": 226, "ts": "05/09/2018 00:05:00"}
ny-power/upstream/fuel-mix/Nuclear {"units": "MW", "value": 4114, "ts": "05/09/2018 00:05:00"}
```
这种直接的转换是种不错的尝试,可将公开数据转换为公开事件。我们后续会继续将数据转换为二氧化碳排放强度,但这些原始数据还可被其它应用使用,用于其它计算用途。
### MQTT 主题
主题和<ruby> 主题结构 <rt> topic structure </rt></ruby>是 MQTT 的一个主要特色。与其它标准的企业级消息总线不同,MQTT 的主题无需事先注册。发送者可以凭空创建主题,唯一的限制是主题的长度,不超过 220 字符。其中 `/` 字符有特殊含义,用于创建主题的层次结构。我们即将看到,你可以订阅这些层次中的一些分片。
基于开箱即用的 Mosquitto,任何一个客户端都可以向任何主题发布消息。在原型设计过程中,这种方式十分便利;但一旦部署到生产环境,你需要增加<ruby> 访问控制列表 <rt> access control list </rt></ruby>(ACL)只允许授权的应用发布消息。例如,任何人都能以只读的方式访问我的应用的主题层级,但只有那些具有特定<ruby> 凭证 <rt> credentials </rt></ruby>的客户端可以发布内容。
主题中不包含<ruby> 自动样式 <rt> automatic schema </rt></ruby>,也没有方法查找客户端可以发布的全部主题。因此,对于那些从 MQTT 总线消费数据的应用,你需要让其直接使用已知的主题和消息格式样式。
那么应该如何设计主题呢?最佳实践包括使用应用相关的根名称,例如在我的应用中使用 `ny-power`。接着,为提高订阅效率,构建足够深的层次结构。`upstream` 层次结构包含了直接从数据源获取的、不经处理的原始数据,而 `fuel-mix` 层次结构包含特定类型的数据;我们后续还可以增加其它的层次结构。
### 订阅主题
在 MQTT 中,订阅仅仅是简单的字符串匹配。为提高处理效率,只允许如下两种通配符:
* `#` 以递归方式匹配,直到字符串结束
* `+` 匹配下一个 `/` 之前的内容
为便于理解,下面给出几个例子:
```
ny-power/# - 匹配 ny-power 应用发布的全部主题
ny-power/upstream/# - 匹配全部原始数据的主题
ny-power/upstream/fuel-mix/+ - 匹配全部燃料类型的主题
ny-power/+/+/Hydro - 匹配全部两次层级之后为 Hydro 类型的主题(即使不位于 upstream 层次结构下)
```
类似 `ny-power/#` 的大范围订阅适用于<ruby> 低数据量 <rt> low-volume </rt></ruby>的应用,应用从网络获取全部数据并处理。但对<ruby> 高数据量 <rt> high-volume </rt></ruby>应用而言则是一个灾难,由于绝大多数消息并不会被使用,大部分的网络带宽被白白浪费了。
在大数据量情况下,为确保性能,应用需要使用恰当的主题筛选(如 `ny-power/+/+/Hydro`)尽量准确获取业务所需的数据。
### 增加我们自己的数据层次
接下来,应用中的一切都依赖于已有的 MQTT 流并构建新流。第一个额外的数据层用于计算发电对应的二氧化碳排放。
利用[<ruby> 美国能源情报署 <rt> U.S. Energy Information Administration </rt></ruby>](https://www.eia.gov/) 给出的 2016 年纽约各类燃料发电及排放情况,我们可以给出各类燃料的[平均排放率](https://github.com/IBM/ny-power/blob/master/src/nypower/calc.py#L1-L60),单位为克/兆瓦时。
上述结果被封装到一个专用的微服务中。该微服务订阅 `ny-power/upstream/fuel-mix/+`,即数据泵中燃料组成情况的原始数据,接着完成计算并将结果(单位为克/千瓦时)发布到新的主题层次结构上:
```
ny-power/computed/co2 {"units": "g / kWh", "value": 152.9486, "ts": "05/09/2018 00:05:00"}
```
接着,另一个服务会订阅该主题层次结构并将数据打包到 [InfluxDB](https://www.influxdata.com/) 进程中;同时,发布 24 小时内的时间序列数据到 `ny-power/archive/co2/24h` 主题,这样可以大大简化当前变化数据的绘制。
这种层次结构的主题模型效果不错,可以将上述程序之间的逻辑解耦合。在复杂系统中,各个组件可能使用不同的编程语言,但这并不重要,因为交换格式都是 MQTT 消息,即主题和 JSON 格式的消息内容。
### 从终端消费数据
为了更好的了解 MQTT 完成了什么工作,将其绑定到一个消息总线并查看消息流是个不错的方法。`mosquitto-clients` 包中的 `mosquitto_sub` 可以让我们轻松实现该目标。
安装程序后,你需要提供服务器名称以及你要订阅的主题。如果有需要,使用参数 `-v` 可以让你看到有新消息发布的那些主题;否则,你只能看到主题内的消息数据。
```
mosquitto_sub -h mqtt.ny-power.org -t ny-power/# -v
```
只要我编写或调试 MQTT 应用,我总会在一个终端中运行 `mosquitto_sub`。
### 从网页直接访问 MQTT
到目前为止,我们已经有提供公开事件流的应用,可以用微服务或命令行工具访问该应用。但考虑到互联网仍占据主导地位,因此让用户可以从浏览器直接获取事件流是很重要。
MQTT 的设计者已经考虑到了这一点。协议标准支持三种不同的传输协议:[TCP](https://en.wikipedia.org/wiki/Transmission_Control_Protocol)、[UDP](https://en.wikipedia.org/wiki/User_Datagram_Protocol) 和 [WebSockets](https://en.wikipedia.org/wiki/WebSocket)。主流浏览器都支持 WebSockets,可以维持持久连接,用于实时应用。
Eclipse 项目提供了 MQTT 的一个 JavaScript 实现,叫做 [Paho](https://www.eclipse.org/paho/),可包含在你的应用中。工作模式为与服务器建立连接、建立一些订阅,然后根据接收到的消息进行响应。
```
// ny-power web console application
var client = new Paho.MQTT.Client(mqttHost, Number("80"), "client-" + Math.random());
// set callback handlers
client.onMessageArrived = onMessageArrived;
// connect the client
client.reconnect = true;
client.connect({onSuccess: onConnect});
// called when the client connects
function onConnect() {
// Once a connection has been made, make a subscription and send a message.
console.log("onConnect");
client.subscribe("ny-power/computed/co2");
client.subscribe("ny-power/archive/co2/24h");
client.subscribe("ny-power/upstream/fuel-mix/#");
}
// called when a message arrives
function onMessageArrived(message) {
console.log("onMessageArrived:"+message.destinationName + message.payloadString);
if (message.destinationName == "ny-power/computed/co2") {
var data = JSON.parse(message.payloadString);
$("#co2-per-kwh").html(Math.round(data.value));
$("#co2-units").html(data.units);
$("#co2-updated").html(data.ts);
}
if (message.destinationName.startsWith("ny-power/upstream/fuel-mix")) {
fuel_mix_graph(message);
}
if (message.destinationName == "ny-power/archive/co2/24h") {
var data = JSON.parse(message.payloadString);
var plot = [
{
x: data.ts,
y: data.values,
type: 'scatter'
}
];
var layout = {
yaxis: {
title: "g CO2 / kWh",
}
};
Plotly.newPlot('co2_graph', plot, layout);
}
```
上述应用订阅了不少主题,因为我们将要呈现若干种不同类型的数据;其中 `ny-power/computed/co2` 主题为我们提供当前二氧化碳排放的参考值。一旦收到该主题的新消息,网站上的相应内容会被相应替换。

*[ny-power.org](http://ny-power.org/#) 网站提供的 NYISO 二氧化碳排放图。*
`ny-power/archive/co2/24h` 主题提供了时间序列数据,用于为 [Plotly](https://plot.ly/) 线表提供数据。`ny-power/upstream/fuel-mix` 主题提供当前燃料组成情况,为漂亮的柱状图提供数据。

*[ny-power.org](http://ny-power.org/#) 网站提供的燃料组成情况。*
这是一个动态网站,数据不从服务器拉取,而是结合 MQTT 消息总线,监听对外开放的 WebSocket。就像数据泵和打包器程序那样,网站页面也是一个发布订阅客户端,只不过是在你的浏览器中执行,而不是在公有云的微服务上。
你可以在 <http://ny-power.org> 站点点看到动态变更,包括图像和可以看到消息到达的实时 MQTT 终端。
### 继续深入
ny-power.org 应用的完整内容开源在 [GitHub](https://github.com/IBM/ny-power) 中。你也可以查阅 [架构简介](https://developer.ibm.com/code/patterns/use-mqtt-stream-real-time-data/),学习如何使用 [Helm](https://helm.sh/) 部署一系列 Kubernetes 微服务构建应用。另一个有趣的 MQTT 示例使用 MQTT 和 OpenWhisk 进行实时文本消息翻译,<ruby> 代码模式 <rt> code pattern </rt></ruby>参考[链接](https://developer.ibm.com/code/patterns/deploy-serverless-multilingual-conference-room/)。
MQTT 被广泛应用于物联网领域,更多关于 MQTT 用途的例子可以在 [Home Assistant](https://www.home-assistant.io/) 项目中找到。
如果你希望深入了解协议内容,可以从 [mqtt.org](http://mqtt.org/) 获得该公开标准的全部细节。
想了解更多,可以参加 Sean Dague 在 [OSCON](https://conferences.oreilly.com/oscon/oscon-or) 上的演讲,主题为 [将 MQTT 加入到你的工具箱](https://conferences.oreilly.com/oscon/oscon-or/public/schedule/speaker/77317),会议将于 7 月 16-19 日在奥尔良州波特兰举办。
---
via: <https://opensource.com/article/18/6/mqtt>
作者:[Sean Dague](https://opensource.com/users/sdague) 选题:[lujun9972](https://github.com/lujun9972) 译者:[pinewall](https://github.com/pinewall) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Last November we bought an electric car, and it raised an interesting question: When should we charge it? I was concerned about having the lowest emissions for the electricity used to charge the car, so this is a specific question: What is the rate of CO2 emissions per kWh at any given time, and when during the day is it at its lowest?
## Finding the data
I live in New York State. About 80% of our electricity comes from in-state generation, mostly through natural gas, hydro dams (much of it from Niagara Falls), nuclear, and a bit of wind, solar, and other fossil fuels. The entire system is managed by the [New York Independent System Operator](http://www.nyiso.com/public/index.jsp) (NYISO), a not-for-profit entity that was set up to balance the needs of power generators, consumers, and regulatory bodies to keep the lights on in New York.
Although there is no official public API, as part of its mission, NYISO makes [a lot of open data](http://www.nyiso.com/public/markets_operations/market_data/reports_info/index.jsp) available for public consumption. This includes reporting on what fuels are being consumed to generate power, at five-minute intervals, throughout the state. These are published as CSV files on a public archive and updated throughout the day. If you know the number of megawatts coming from different kinds of fuels, you can make a reasonable approximation of how much CO2 is being emitted at any given time.
We should always be kind when building tools to collect and process open data to avoid overloading those systems. Instead of sending everyone to their archive service to download the files all the time, we can do better. We can create a low-overhead event stream that people can subscribe to and get updates as they happen. We can do that with [MQTT](http://mqtt.org/). The target for my project ([ny-power.org](http://ny-power.org/#)) was inclusion in the [Home Assistant](https://www.home-assistant.io) project, an open source home automation platform that has hundreds of thousands of users. If all of these users were hitting this CSV server all the time, NYISO might need to restrict access to it.
## What is MQTT?
MQTT is a publish/subscribe (pubsub) wire protocol designed with small devices in mind. Pubsub systems work like a message bus. You send a message to a topic, and any software with a subscription for that topic gets a copy of your message. As a sender, you never really know who is listening; you just provide your information to a set of topics and listen for any other topics you might care about. It's like walking into a party and listening for interesting conversations to join.
This can make for extremely efficient applications. Clients subscribe to a narrow selection of topics and only receive the information they are looking for. This saves both processing time and network bandwidth.
As an open standard, MQTT has many open source implementations of both clients and servers. There are client libraries for every language you could imagine, even a library you can embed in Arduino for making sensor networks. There are many servers to choose from. My go-to is the [Mosquitto](https://mosquitto.org/) server from Eclipse, as it's small, written in C, and can handle tens of thousands of subscribers without breaking a sweat.
## Why I like MQTT
Over the past two decades, we've come up with tried and true models for software applications to ask questions of services. Do I have more email? What is the current weather? Should I buy this thing now? This pattern of "ask/receive" works well much of the time; however, in a world awash with data, there are other patterns we need. The MQTT pubsub model is powerful where lots of data is published inbound to the system. Clients can subscribe to narrow slices of data and receive updates instantly when that data comes in.
MQTT also has additional interesting features, such as "last-will-and-testament" messages, which make it possible to distinguish between silence because there is no relevant data and silence because your data collectors have crashed. MQTT also has retained messages, which provide the last message on a topic to clients when they first connect. This is extremely useful for topics that update slowly.
In my work with the Home Assistant project, I've found this message bus model works extremely well for heterogeneous systems. If you dive into the Internet of Things space, you'll quickly run into MQTT everywhere.
## Our first MQTT stream
One of NYSO's CSV files is the real-time fuel mix. Every five minutes, it's updated with the fuel sources and power generated (in megawatts) during that time period.
The CSV file looks something like this:
Time Stamp | Time Zone | Fuel Category | Gen MW |
---|---|---|---|
05/09/2018 00:05:00 | EDT | Dual Fuel | 1400 |
05/09/2018 00:05:00 | EDT | Natural Gas | 2144 |
05/09/2018 00:05:00 | EDT | Nuclear | 4114 |
05/09/2018 00:05:00 | EDT | Other Fossil Fuels | 4 |
05/09/2018 00:05:00 | EDT | Other Renewables | 226 |
05/09/2018 00:05:00 | EDT | Wind | 41 |
05/09/2018 00:05:00 | EDT | Hydro | 3229 |
05/09/2018 00:10:00 | EDT | Dual Fuel | 1307 |
05/09/2018 00:10:00 | EDT | Natural Gas | 2092 |
05/09/2018 00:10:00 | EDT | Nuclear | 4115 |
05/09/2018 00:10:00 | EDT | Other Fossil Fuels | 4 |
05/09/2018 00:10:00 | EDT | Other Renewables | 224 |
05/09/2018 00:10:00 | EDT | Wind | 40 |
05/09/2018 00:10:00 | EDT | Hydro | 3166 |
The only odd thing in the table is the dual-fuel category. Most natural gas plants in New York can also burn other fossil fuel to generate power. During cold snaps in the winter, the natural gas supply gets constrained, and its use for home heating is prioritized over power generation. This happens at a low enough frequency that we can consider dual fuel to be natural gas (for our calculations).
The file is updated throughout the day. I created a simple data pump that polls for the file every minute and looks for updates. It publishes any new entries out to the MQTT server into a set of topics that largely mirror this CSV file. The payload is turned into a JSON object that is easy to parse from nearly any programming language.
```
ny-power/upstream/fuel-mix/Hydro {"units": "MW", "value": 3229, "ts": "05/09/2018 00:05:00"}
ny-power/upstream/fuel-mix/Dual Fuel {"units": "MW", "value": 1400, "ts": "05/09/2018 00:05:00"}
ny-power/upstream/fuel-mix/Natural Gas {"units": "MW", "value": 2144, "ts": "05/09/2018 00:05:00"}
ny-power/upstream/fuel-mix/Other Fossil Fuels {"units": "MW", "value": 4, "ts": "05/09/2018 00:05:00"}
ny-power/upstream/fuel-mix/Wind {"units": "MW", "value": 41, "ts": "05/09/2018 00:05:00"}
ny-power/upstream/fuel-mix/Other Renewables {"units": "MW", "value": 226, "ts": "05/09/2018 00:05:00"}
ny-power/upstream/fuel-mix/Nuclear {"units": "MW", "value": 4114, "ts": "05/09/2018 00:05:00"}
```
This direct reflection is a good first step in turning open data into open events. We'll be converting this into a CO2 intensity, but other applications might want these raw feeds to do other calculations with them.
## MQTT topics
Topics and topic structures are one of MQTT's major design points. Unlike more "enterprisey" message buses, in MQTT topics are not preregistered. A sender can create topics on the fly, the only limit being that they are less than 220 characters. The `/`
character is special; it's used to create topic hierarchies. As we'll soon see, you can subscribe to slices of data in these hierarchies.
Out of the box with Mosquitto, every client can publish to any topic. While it's great for prototyping, before going to production you'll want to add an access control list (ACL) to restrict writing to authorized applications. For example, my app's tree is accessible to everyone in read-only format, but only clients with specific credentials can publish to it.
There is no automatic schema around topics nor a way to discover all the possible topics that clients will publish to. You'll have to encode that understanding directly into any application that consumes the MQTT bus.
So how should you design your topics? The best practice is to start with an application-specific root name, in our case, `ny-power`
. After that, build a hierarchy as deep as you need for efficient subscription. The `upstream`
tree will contain data that comes directly from an upstream source without any processing. Our `fuel-mix`
category is a specific type of data. We may add others later.
## Subscribing to topics
Subscriptions in MQTT are simple string matches. For processing efficiency, only two wildcards are allowed:
`#`
matches everything recursively to the end`+`
matches only until the next`/`
character
It's easiest to explain this with some examples:
```
ny-power/# - match everything published by the ny-power app
ny-power/upstream/# - match all raw data
ny-power/upstream/fuel-mix/+ - match all fuel types
ny-power/+/+/Hydro - match everything about Hydro power that's
nested 2 deep (even if it's not in the upstream tree)
```
A wide subscription like `ny-power/#`
is common for low-volume applications. Just get everything over the network and handle it in your own application. This works poorly for high-volume applications, as most of the network bandwidth will be wasted as you drop most of the messages on the floor.
To stay performant at higher volumes, applications will do some clever topic slides like `ny-power/+/+/Hydro`
to get exactly the cross-section of data they need.
## Adding our next layer of data
From this point forward, everything in the application will work off existing MQTT streams. The first additional layer of data is computing the power's CO2 intensity.
Using the 2016 [U.S. Energy Information Administration](https://www.eia.gov/) numbers for total emissions and total power by fuel type in New York, we can come up with an [average emissions rate](https://github.com/IBM/ny-power/blob/master/src/nypower/calc.py#L1-L60) per megawatt hour of power.
This is encapsulated in a dedicated microservice. This has a subscription on `ny-power/upstream/fuel-mix/+`
, which matches all upstream fuel-mix entries from the data pump. It then performs the calculation and publishes out to a new topic tree:
`ny-power/computed/co2 {"units": "g / kWh", "value": 152.9486, "ts": "05/09/2018 00:05:00"}`
In turn, there is another process that subscribes to this topic tree and archives that data into an [InfluxDB](https://www.influxdata.com/) instance. It then publishes a 24-hour time series to `ny-power/archive/co2/24h`
, which makes it easy to graph the recent changes.
This layer model works well, as the logic for each of these programs can be distinct from each other. In a more complicated system, they may not even be in the same programming language. We don't care, because the interchange format is MQTT messages, with well-known topics and JSON payloads.
## Consuming from the command line
To get a feel for MQTT in action, it's useful to just attach it to a bus and see the messages flow. The `mosquitto_sub`
program included in the `mosquitto-clients`
package is a simple way to do that.
After you've installed it, you need to provide a server hostname and the topic you'd like to listen to. The `-v`
flag is important if you want to see the topics being posted to. Without that, you'll see only the payloads.
`mosquitto_sub -h mqtt.ny-power.org -t ny-power/# -v`
Whenever I'm writing or debugging an MQTT application, I always have a terminal with `mosquitto_sub`
running.
## Accessing MQTT directly from the web
We now have an application providing an open event stream. We can connect to it with our microservices and, with some command-line tooling, it's on the internet for all to see. But the web is still king, so it's important to get it directly into a user's browser.
The MQTT folks thought about this one. The protocol specification is designed to work over three transport protocols: [TCP](https://en.wikipedia.org/wiki/Transmission_Control_Protocol), [UDP](https://en.wikipedia.org/wiki/User_Datagram_Protocol), and [WebSockets](https://en.wikipedia.org/wiki/WebSocket). WebSockets are supported by all major browsers as a way to retain persistent connections for real-time applications.
The Eclipse project has a JavaScript implementation of MQTT called [Paho](https://www.eclipse.org/paho/), which can be included in your application. The pattern is to connect to the host, set up some subscriptions, and then react to messages as they are received.
```
// ny-power web console application
var client = new Paho.MQTT.Client(mqttHost, Number("80"), "client-" + Math.random());
// set callback handlers
client.onMessageArrived = onMessageArrived;
// connect the client
client.reconnect = true;
client.connect({onSuccess: onConnect});
// called when the client connects
function onConnect() {
// Once a connection has been made, make a subscription and send a message.
console.log("onConnect");
client.subscribe("ny-power/computed/co2");
client.subscribe("ny-power/archive/co2/24h");
client.subscribe("ny-power/upstream/fuel-mix/#");
}
// called when a message arrives
function onMessageArrived(message) {
console.log("onMessageArrived:"+message.destinationName + message.payloadString);
if (message.destinationName == "ny-power/computed/co2") {
var data = JSON.parse(message.payloadString);
$("#co2-per-kwh").html(Math.round(data.value));
$("#co2-units").html(data.units);
$("#co2-updated").html(data.ts);
}
if (message.destinationName.startsWith("ny-power/upstream/fuel-mix")) {
fuel_mix_graph(message);
}
if (message.destinationName == "ny-power/archive/co2/24h") {
var data = JSON.parse(message.payloadString);
var plot = [
{
x: data.ts,
y: data.values,
type: 'scatter'
}
];
var layout = {
yaxis: {
title: "g CO2 / kWh",
}
};
Plotly.newPlot('co2_graph', plot, layout);
}
```
This application subscribes to a number of topics because we're going to display a few different kinds of data. The `ny-power/computed/co2`
topic provides us a topline number of current intensity. Whenever we receive that topic, we replace the related contents on the site.
NY ISO Grid CO 2 Intensity graph from /ny-power.org/#
The `ny-power/archive/co2/24h`
topic provides a time series that can be loaded into a [Plotly](https://plot.ly/) line graph. And `ny-power/upstream/fuel-mix`
provides the data needed to provide a nice bar graph of the current fuel mix.
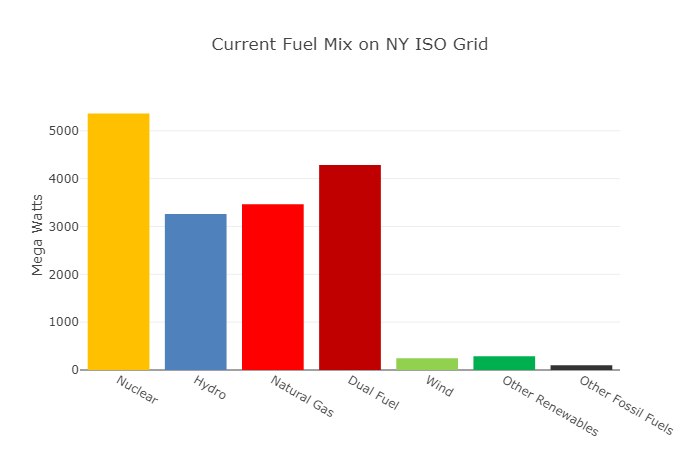
Fuel mix on NYISO grid, ny-power.org.
This is a dynamic website that is not polling the server. It is attached to the MQTT bus and listening on its open WebSocket. The webpage is a pub/sub client just like the data pump and the archiver. This one just happens to be executing in your browser instead of a microservice in the cloud.
You can see the page in action at [http://ny-power.org](http://ny-power.org). That includes both the graphics and a real-time MQTT console to see the messages as they come in.
## Diving deeper
The entire ny-power.org application is [available as open source on GitHub](https://github.com/IBM/ny-power). You can also check out [this architecture overview](https://developer.ibm.com/code/patterns/use-mqtt-stream-real-time-data/) to see how it was built as a set of Kubernetes microservices deployed with [Helm](https://helm.sh/). You can see another interesting MQTT application example with [this code pattern](https://developer.ibm.com/code/patterns/deploy-serverless-multilingual-conference-room/) using MQTT and OpenWhisk to translate text messages in real time.
MQTT is used extensively in the Internet of Things space, and many more examples of MQTT use can be found at the [Home Assistant](https://www.home-assistant.io/) project.
And if you want to dive deep into the protocol, [mqtt.org](http://mqtt.org/) has all the details for this open standard.
*To learn more, attend Sean Dague's talk, Adding MQTT to your toolkit, at OSCON, which will be held July 16-19 in Portland, Oregon.*
## Comments are closed. |
9,922 | 使用 EduBlocks 轻松学习 Python 编程 | https://opensource.com/article/18/8/edublocks | 2018-08-15T22:19:00 | [
"Python",
"Scratch",
"EduBlocks"
] | https://linux.cn/article-9922-1.html |
>
> EduBlocks 提供了 Scratch 式的图形界面来编写 Python 3 代码。
>
>
>

如果你正在寻找一种方法将你的学生(或你自己)从使用 [Scratch](https://scratch.mit.edu/) 编程转移到学习 [Python](https://www.python.org/),我建议你了解一下 [EduBlocks](https://edublocks.org/)。它为 Python 3 编程带来了熟悉的拖放式图形用户界面(GUI)。
从 Scratch 过渡到 Python 的一个障碍是缺少拖放式 GUI,而正是这种拖放式 GUI 使得 Scratch 成为 K-12 学校的首选程序。EduBlocks 的拖放版的 Python 3 改变了这种范式。它的目的是“帮助教师在较早的时候向儿童介绍基于文本的编程语言,如 Python。”
EduBlocks 的硬件要求非常适中 —— 一个树莓派和一条互联网连接 —— 应该可以在许多教室中使用。
EduBlocks 是由来自英国的 14 岁 Python 开发人员 Joshua Lowe 开发的。我看到 Joshua 在 2018 年 5 月的 [PyCon 2018](https://us.pycon.org/2018/about/) 上展示了他的项目。
### 入门
安装 EduBlocks 很容易。该网站提供了清晰的安装说明,你可以在项目的 [GitHub](https://github.com/AllAboutCode/EduBlocks) 仓库中找到详细的截图。
使用以下命令在 Raspberry Pi 命令行安装 EduBlocks:
```
curl -sSL get.edublocks.org | bash
```
### 在 EduBlocks 中编程
安装完成后,从桌面快捷方式或 Raspberry Pi 上的“编程”菜单启动 EduBlocks。

启动程序后,你可以使用 EduBlocks 的拖放界面开始创建 Python 3 代码。它的菜单有清晰的标签。你可以通过单击 **Samples** 菜单按钮使用示例代码。你还可以通过单击 **Theme** 为你的编程界面选择不同的配色方案。使用 **Save** 菜单,你可以保存你的作品,然后 **Download** 你的 Python 代码。单击 **Run** 来执行并测试你的代码。
你可以通过单击最右侧的 **Blockly** 按钮来查看代码。它让你在 ”Blockly” 界面和普通的 Python 代码视图之间切换(正如你在任何其他 Python 编辑器中看到的那样)。

EduBlocks 附带了一系列代码库,包括 [EduPython](https://edupython.tuxfamily.org/)、[Minecraft](https://minecraft.net/en-us/edition/pi/)、[Sonic Pi](https://sonic-pi.net/)、[GPIO Zero](https://gpiozero.readthedocs.io/en/stable/) 和 [Sense Hat](https://www.raspberrypi.org/products/sense-hat/)。
### 学习和支持
该项目维护了一个[学习门户网站](https://edublocks.org/learn.html),其中包含教程和其他资源,可以轻松地 [hack](https://edublocks.org/resources/1.pdf) 树莓派版本的 Minecraft,编写 GPIOZero 和 Sonic Pi,并使用 Micro:bit 代码编辑器控制 LED。可以在 Twitter [@edu\_blocks](https://twitter.com/edu_blocks?lang=en) 和 [@all*about*code](https://twitter.com/all_about_code) 以及 [email](mailto:[email protected]) 提供对 EduBlocks 的支持。
为了更深入的了解,你可以在 [GitHub](https://github.com/allaboutcode/edublocks) 上访问 EduBlocks 的源代码。该程序在 GNU Affero Public License v3.0 下[许可](https://github.com/AllAboutCode/EduBlocks/blob/tarball-install/LICENSE)。EduBlocks 的创建者(项目负责人 [Joshua Lowe](https://github.com/JoshuaLowe1002) 和开发人员 [Chris Dell](https://twitter.com/cjdell?lang=en) 和 [Les Pounder](https://twitter.com/biglesp?lang=en))希望它成为一个社区项目,并邀请人们提出问题,提供反馈,以及提交 pull request 以向项目添加功能或修复。
---
via: <https://opensource.com/article/18/8/edublocks>
作者:[Don Watkins](https://opensource.com/users/don-watkins) 选题:[lujun9972](https://github.com/lujun9972) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | If you are you looking for a way to move your students (or yourself) from programming in [Scratch](https://scratch.mit.edu/) to learning [Python](https://www.python.org/), I recommend you look into [EduBlocks](https://edublocks.org/). It brings a familiar drag-and-drop graphical user interface (GUI) to Python 3 programming.
One of the barriers when transitioning from Scratch to Python is the absence of the drag-and-drop GUI that has made Scratch the go-to application in K-12 schools. EduBlocks' drag-and-drop version of Python 3 changes that paradigm. It aims to "help teachers to introduce text-based programming languages, like Python, to children at an earlier age."
The hardware requirements for EduBlocks are quite modest—a Raspberry Pi and an internet connection—and should be available in many classrooms.
EduBlocks was developed by Joshua Lowe, a 14-year-old Python developer from the United Kingdom. I saw Joshua demonstrate his project at [PyCon 2018](https://us.pycon.org/2018/about/) in May 2018.
## Getting started
It's easy to install EduBlocks. The website provides clear installation instructions, and you can find detailed screenshots in the project's [GitHub](https://github.com/AllAboutCode/EduBlocks) repository.
Install EduBlocks from the Raspberry Pi command line by issuing the following command:
`curl -sSL get.edublocks.org | bash`

## Programming EduBlocks
Once the installation is complete, launch EduBlocks from either the desktop shortcut or the Programming menu on the Raspberry Pi.

Once you launch the application, you can start creating Python 3 code with EduBlocks' drag-and-drop interface. Its menus are clearly labeled. You can start with sample code by clicking the **Samples** menu button. You can also choose a different color scheme for your programming palette by clicking **Theme**. With the **Save** menu, you can save your code as you work, then **Download** your Python code. Click **Run** to execute and test your code.
You can see your code by clicking the **Blockly** button at the far right. It allows you to toggle between the "Blockly" interface and the normal Python code view (as you would see in any other Python editor).
EduBlocks comes with a range of code libraries, including [EduPython](https://edupython.tuxfamily.org/), [Minecraft](https://minecraft.net/en-us/edition/pi/), [Sonic Pi](https://sonic-pi.net/), [GPIO Zero](https://gpiozero.readthedocs.io/en/stable/), and [Sense Hat](https://www.raspberrypi.org/products/sense-hat/).
## Learning and support
The project maintains a [learning portal](https://edublocks.org/learn.html) with tutorials and other resources for easily [hacking](https://edublocks.org/resources/1.pdf) the version of Minecraft that comes with Raspberry Pi, programming the GPIOZero and Sonic Pi, and controlling LEDs with the Micro:bit code editor. Support for EduBlocks is available on Twitter [@edu_blocks](https://twitter.com/edu_blocks?lang=en) and [@all_about_code](https://twitter.com/all_about_code) and through [email](mailto:[email protected]).
For a deeper dive, you can access EduBlocks' source code on [GitHub](https://github.com/allaboutcode/edublocks); the application is [licensed](https://github.com/AllAboutCode/EduBlocks/blob/tarball-install/LICENSE) under GNU Affero General Public License v3.0. EduBlocks' creators (project lead [Joshua Lowe](https://github.com/JoshuaLowe1002) and fellow developers [Chris Dell](https://twitter.com/cjdell?lang=en) and [Les Pounder](https://twitter.com/biglesp?lang=en)) want it to be a community project and invite people to open issues, provide feedback, and submit pull requests to add features or fixes to the project.
## 3 Comments |
9,923 | netdev 第一天:IPsec! | https://jvns.ca/blog/2018/07/11/netdev-day-1--ipsec/ | 2018-08-15T22:54:38 | [
"IPsec"
] | https://linux.cn/article-9923-1.html | 
嗨!和去年一样,今年我又参加了 [netdev 会议](https://www.netdevconf.org/0x12/)。([这里](https://jvns.ca/categories/netdev/)是我上一年所做的笔记)。
在今天的会议中,我学到了很多有关 IPsec 的知识,所以下面我将介绍它们!其中 Sowmini Varadhan 和 [Paul Wouters](https://nohats.ca/) 做了一场关于 IPsec 的专题研讨会。本文中的错误 100% 都是我的错 :)。
### 什么是 IPsec?
IPsec 是一个用来加密 IP 包的协议。某些 VPN 已经是通过使用 IPsec 来实现的。直到今天我才真正意识到 VPN 使用了不只一种协议,原来我以为 VPN 只是一个通用术语,指的是“你的数据包将被加密,然后通过另一台服务器去发送“。VPN 可以使用一系列不同的协议(OpenVPN、PPTP、SSTP、IPsec 等)以不同的方式来实现。
为什么 IPsec 和其他的 VPN 协议如此不同呢?(或者说,为什么在本次 netdev 会议会有 IPsec 的教程,而不是其他的协议呢?)我的理解是有 2 点使得它如此不同:
* 它是一个 IETF 标准,例如可以在文档 [RFC 6071](https://tools.ietf.org/html/rfc6071) 等中查到(你知道 IETF 是制定 RFC 标准的组织吗?我也是直到今天才知道的!)。
* 它在 Linux 内核中被实现了(所以这才是为什么本次 netdev 会议中有关于它的教程,因为 netdev 是一个跟 Linux 内核网络有关的会议 :))。
### IPsec 是如何工作的?
假如说你的笔记本正使用 IPsec 来加密数据包并通过另一台设备来发送它们,那这是怎么工作的呢?对于 IPsec 来说,它有 2 个部分:一个是用户空间部分,另一个是内核空间部分。
IPsec 的用户空间部分负责**密钥的交换**,使用名为 [IKE](https://en.wikipedia.org/wiki/Internet_Key_Exchange) (<ruby> 网络密钥传输 <rt> internet key exchange </rt></ruby>)的协议。总的来说,当你打开一个 VPN 连接的时候,你需要与 VPN 服务器通信,并且和它协商使用一个密钥来进行加密。
IPsec 的内核部分负责数据包的实际加密工作 —— 一旦使用 IKE 生成了一个密钥,IPsec 的用户空间部分便会告诉内核使用哪个密钥来进行加密。然后内核便会使用该密钥来加密数据包!
### 安全策略以及安全关联
(LCTT 译注:security association 我翻译为安全关联, 参考自 <https://zh.wikipedia.org/wiki/%E5%AE%89%E5%85%A8%E9%97%9C%E8%81%AF> )
IPSec 的内核部分有两个数据库:**安全策略数据库**(SPD)和**安全关联数据库**(SAD)。
安全策略数据库包含 IP 范围和用于该范围的数据包需要执行的操作(对其执行 IPsec、丢弃数据包、让数据包通过)。对于这点我有点迷糊,因为针对不同 IP 范围的数据包所采取的规则已经在路由表(`sudo ip route list`)中使用过,但显然你也可以设定 IPsec 规则,但它们位于不同的地方!
而在我眼中,安全关联数据库存放有用于各种不同 IP 的加密密钥。
查看这些数据库的方式却是非常不直观的,需要使用一个名为 `ip xfrm` 的命令,至于 `xfrm` 是什么意思呢?我也不知道!
(LCTT 译注:我在 <https://www.allacronyms.com/XFMR/Transformer> 上查到 xfmr 是 Transformer 的简写,又根据 [man7](http://man7.org/linux/man-pages/man8/ip-xfrm.8.html) 上的简介, 我认为这个说法可信。)
```
# security policy database
$ sudo ip xfrm policy
$ sudo ip x p
# security association database
$ sudo ip xfrm state
$ sudo ip x s
```
### 为什么 IPsec 被实现在 Linux 内核中而 TLS 没有?
对于 TLS 和 IPsec 来说,当打开一个连接时,它们都需要做密钥交换(使用 Diffie-Hellman 或者其他算法)。基于某些可能很明显但我现在还没有理解(??)的原因,在内核中人们并不想做密钥的交换。
IPsec 更容易在内核实现的原因是使用 IPsec 你可以更少频率地协商密钥的交换(对于每个你想通过 VPN 来连接的 IP 只需要一次),并且 IPsec 会话存活得更长。所以对于用户空间来说,使用 IPsec 来做密钥交换、密钥的获取和将密钥传递给内核将更容易,内核得到密钥后将使用该密钥来处理每个 IP 数据包。
而对于 TLS 来说,则存在一些问题:
a. 当你每打开一个 TLS 连接时,每次你都要做新的密钥交换,并且 TLS 连接存活时间较短。 b. 当你需要开始做加密时,使用 IPsec 没有一个自然的协议边界,你只需要加密给定 IP 范围内的每个 IP 包即可,但如果使用 TLS,你需要查看 TCP 流,辨别 TCP 包是否是一个数据包,然后决定是否加密它。
实际上有一个补丁用于 [在 Linux 内核中实现 TLS](https://blog.filippo.io/playing-with-kernel-tls-in-linux-4-13-and-go/),它让用户空间做密钥交换,然后传给内核密钥,所以很明显,使用 TLS 不是不可能的,但它是一个新事物,并且我认为相比使用 IPsec,使用 TLS 更加复杂。
### 使用什么软件来实现 IPsec 呢?
据我所知有 Libreswan 和 Strongswan 两个软件。今天的教程关注的是 libreswan。
有些让人迷糊的是,尽管 Libreswan 和 Strongswan 是不同的程序包,但它们都会安装一个名为 `ipsec` 的二进制文件来管理 IPsec 连接,并且这两个 `ipsec` 二进制文件并不是相同的程序(尽管它们担任同样的角色)。
在上面的“IPsec 如何工作”部分,我已经描述了 Strongswan 和 Libreswan 做了什么 —— 使用 IKE 做密钥交换,并告诉内核有关如何使用密钥来做加密。
### VPN 不是只能使用 IPsec 来实现!
在本文的开头我说“IPsec 是一个 VPN 协议”,这是对的,但你并不必须使用 IPsec 来实现 VPN!实际上有两种方式来使用 IPsec:
1. “传输模式”,其中 IP 表头没有改变,只有 IP 数据包的内容被加密。这种模式有点类似于使用 TLS —— 你直接告诉服务器你正在通信(而不是通过一个 VPN 服务器或其他设备),只有 IP 包里的内容被加密。
2. ”隧道模式“,其中 IP 表头和它的内容都被加密了,并且被封装进另一个 UDP 包内。这个模式被 VPN 所使用 —— 你获取你正传送给一个秘密网站的包,然后加密它,并将它送给你的 VPN 服务器,然后 VPN 服务器再传送给你。
### 投机的 IPsec
今天我学到了 IPsec “传输模式”的一个有趣应用,它叫做 “投机的 IPsec”(通过它,你可以通过开启一个 IPsec 连接来直接和你要通信的主机连接,而不是通过其他的中介服务器),现在已经有一个“投机的 IPsec” 服务器了,它位于 <http://oe.libreswan.org/>。
我认为当你在你的电脑上设定好 `libreswan` 和 `unbound` DNS 程序后,当你连接到 [http://oe.libreswan.org](http://oe.libreswan.org/) 时,主要发生了如下的几件事:
1. `unbound` 做一次 DNS 查询来获取 `oe.libreswan.org` (`dig ipseckey oe.libreswan.org`) 的 IPSECKEY 记录,以便获取到公钥来用于该网站(这需要 DNSSEC 是安全的,并且当我获得足够多这方面的知识后,我将用另一篇文章来说明它。假如你想看到相关的结果,并且如果你只是使用 dig 命令来运行此次 DNS 查询的话,它也可以工作)。
2. `unbound` 将公钥传给 `libreswan` 程序,然后 `libreswan` 使用它来和运行在 `oe.libreswan.org` 网站上的 IKE 服务器做一次密钥交换。
3. `libreswan` 完成了密钥交换,将加密密钥传给内核并告诉内核当和 `oe.libreswan.org` 做通信时使用该密钥。
4. 你的连接现在被加密了!即便它是 HTTP 连接!有趣吧!
### IPsec 和 TLS 相互借鉴
在今天的教程中听到一个有趣的花絮是 IPsec 和 TLS 协议实际上总是从对方学习 —— 正如他们说在 TLS 出现前, IPsec 的 IKE 协议有着完美的正向加密,而 IPsec 也从 TLS 那里学了很多。很高兴能听到不同的网络协议之间是如何从对方那里学习并与时俱进的事实!
### IPsec 是有趣的!
我已经花了很长时间来学习 TLS,很明显它是一个超级重要的网络协议(让我们来加密网络吧!:D)。但 IPsec 也是一个很重要的网络加密协议,它与 TLS 有着不同的角色!很明显有些移动电话协议(例如 5G/LTE)使用 IPsec 来加密它们的网络流量!
现在我很高兴我知道更多关于 IPsec 的知识!和以前一样可能本文有些错误,但希望不会错的太多 :)
---
via: <https://jvns.ca/blog/2018/07/11/netdev-day-1--ipsec/>
作者:[Julia Evans](https://jvns.ca/about) 译者:[FSSlc](https://github.com/FSSlc) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.