
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-07-15 06:27:42
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 521
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-07-15 06:27:26
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
tvarella/q-FrozenLake-v1-4x4-noSlippery | tvarella | 2023-02-14T21:10:59Z | 0 | 0 | null | [
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-02-14T21:08:24Z | ---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="tvarella/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
enlacinglines/q-FrozenLake-v1-4x4-noSlippery | enlacinglines | 2023-02-14T21:08:21Z | 0 | 0 | null | [
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-02-14T21:08:18Z | ---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="enlacinglines/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
dor88/Reinforce-pixelcopter | dor88 | 2023-02-14T20:00:08Z | 0 | 0 | null | [
"Pixelcopter-PLE-v0",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-02-14T13:33:37Z | ---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-pixelcopter
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: 58.50 +/- 53.06
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
Deisler/poca-SoccerTwos | Deisler | 2023-02-14T19:50:10Z | 47 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"unity-ml-agents",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SoccerTwos",
"region:us"
]
| reinforcement-learning | 2023-02-09T22:49:24Z |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SoccerTwos
library_name: ml-agents
---
# **poca** Agent playing **SoccerTwos**
This is a trained model of a **poca** agent playing **SoccerTwos** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-SoccerTwos
2. Step 1: Write your model_id: Deisler/poca-SoccerTwos
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
fpsandnoob/mae-vit-base-patch32-224-ct | fpsandnoob | 2023-02-14T19:43:11Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"vit_mae",
"pretraining",
"masked-auto-encoding",
"generated_from_trainer",
"dataset:imagefolder",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| null | 2023-02-14T12:05:25Z | ---
license: apache-2.0
tags:
- masked-auto-encoding
- generated_from_trainer
datasets:
- imagefolder
model-index:
- name: mae-vit-base-patch32-224-ct
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mae-vit-base-patch32-224-ct
This model is a fine-tuned version of [google/vit-base-patch32-224-in21k](https://huggingface.co/google/vit-base-patch32-224-in21k) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3803
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.00015
- train_batch_size: 256
- eval_batch_size: 256
- seed: 1337
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.05
- num_epochs: 1200.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:-----:|:---------------:|
| 1.1257 | 1.0 | 51 | 1.1119 |
| 1.0507 | 2.0 | 102 | 1.0434 |
| 1.0046 | 3.0 | 153 | 0.9988 |
| 0.9761 | 4.0 | 204 | 0.9725 |
| 0.9572 | 5.0 | 255 | 0.9529 |
| 0.9357 | 6.0 | 306 | 0.9304 |
| 0.9128 | 7.0 | 357 | 0.9100 |
| 0.9037 | 8.0 | 408 | 0.9004 |
| 0.8984 | 9.0 | 459 | 0.8941 |
| 0.8904 | 10.0 | 510 | 0.8896 |
| 0.8846 | 11.0 | 561 | 0.8802 |
| 0.8748 | 12.0 | 612 | 0.8775 |
| 0.8692 | 13.0 | 663 | 0.8685 |
| 0.8656 | 14.0 | 714 | 0.8665 |
| 0.8634 | 15.0 | 765 | 0.8607 |
| 0.8565 | 16.0 | 816 | 0.8561 |
| 0.8555 | 17.0 | 867 | 0.8548 |
| 0.8521 | 18.0 | 918 | 0.8464 |
| 0.8478 | 19.0 | 969 | 0.8449 |
| 0.847 | 20.0 | 1020 | 0.8455 |
| 0.842 | 21.0 | 1071 | 0.8378 |
| 0.8385 | 22.0 | 1122 | 0.8358 |
| 0.8319 | 23.0 | 1173 | 0.8332 |
| 0.8267 | 24.0 | 1224 | 0.8347 |
| 0.8266 | 25.0 | 1275 | 0.8247 |
| 0.8242 | 26.0 | 1326 | 0.8242 |
| 0.8215 | 27.0 | 1377 | 0.8192 |
| 0.8171 | 28.0 | 1428 | 0.8213 |
| 0.8176 | 29.0 | 1479 | 0.8160 |
| 0.8122 | 30.0 | 1530 | 0.8128 |
| 0.8107 | 31.0 | 1581 | 0.8036 |
| 0.8069 | 32.0 | 1632 | 0.8069 |
| 0.8081 | 33.0 | 1683 | 0.8023 |
| 0.8043 | 34.0 | 1734 | 0.8048 |
| 0.8071 | 35.0 | 1785 | 0.8082 |
| 0.8017 | 36.0 | 1836 | 0.7971 |
| 0.7965 | 37.0 | 1887 | 0.7953 |
| 0.7953 | 38.0 | 1938 | 0.8112 |
| 0.7979 | 39.0 | 1989 | 0.7955 |
| 0.7887 | 40.0 | 2040 | 0.7966 |
| 0.7866 | 41.0 | 2091 | 0.7879 |
| 0.7862 | 42.0 | 2142 | 0.7828 |
| 0.7836 | 43.0 | 2193 | 0.7865 |
| 0.7851 | 44.0 | 2244 | 0.7830 |
| 0.7813 | 45.0 | 2295 | 0.7840 |
| 0.78 | 46.0 | 2346 | 0.7749 |
| 0.779 | 47.0 | 2397 | 0.7825 |
| 0.7762 | 48.0 | 2448 | 0.7712 |
| 0.7676 | 49.0 | 2499 | 0.7675 |
| 0.7638 | 50.0 | 2550 | 0.7645 |
| 0.7826 | 51.0 | 2601 | 0.7879 |
| 0.7728 | 52.0 | 2652 | 0.7730 |
| 0.7629 | 53.0 | 2703 | 0.7606 |
| 0.7819 | 54.0 | 2754 | 0.7718 |
| 0.7802 | 55.0 | 2805 | 0.7809 |
| 0.7632 | 56.0 | 2856 | 0.7577 |
| 0.7567 | 57.0 | 2907 | 0.7654 |
| 0.7564 | 58.0 | 2958 | 0.7574 |
| 0.7535 | 59.0 | 3009 | 0.7555 |
| 0.75 | 60.0 | 3060 | 0.7484 |
| 0.7512 | 61.0 | 3111 | 0.7487 |
| 0.7493 | 62.0 | 3162 | 0.7462 |
| 0.742 | 63.0 | 3213 | 0.7450 |
| 0.7469 | 64.0 | 3264 | 0.7464 |
| 0.7449 | 65.0 | 3315 | 0.7393 |
| 0.7321 | 66.0 | 3366 | 0.7425 |
| 0.7411 | 67.0 | 3417 | 0.7391 |
| 0.7394 | 68.0 | 3468 | 0.7413 |
| 0.7301 | 69.0 | 3519 | 0.7344 |
| 0.7208 | 70.0 | 3570 | 0.7256 |
| 0.7211 | 71.0 | 3621 | 0.7225 |
| 0.7273 | 72.0 | 3672 | 0.7264 |
| 0.7267 | 73.0 | 3723 | 0.7221 |
| 0.7222 | 74.0 | 3774 | 0.7256 |
| 0.7175 | 75.0 | 3825 | 0.7202 |
| 0.7174 | 76.0 | 3876 | 0.7149 |
| 0.7143 | 77.0 | 3927 | 0.7127 |
| 0.7106 | 78.0 | 3978 | 0.7061 |
| 0.7188 | 79.0 | 4029 | 0.7153 |
| 0.7103 | 80.0 | 4080 | 0.7086 |
| 0.7055 | 81.0 | 4131 | 0.7098 |
| 0.7026 | 82.0 | 4182 | 0.7075 |
| 0.7191 | 83.0 | 4233 | 0.7127 |
| 0.7027 | 84.0 | 4284 | 0.7172 |
| 0.6981 | 85.0 | 4335 | 0.7070 |
| 0.7064 | 86.0 | 4386 | 0.7029 |
| 0.6943 | 87.0 | 4437 | 0.7046 |
| 0.7025 | 88.0 | 4488 | 0.7036 |
| 0.6959 | 89.0 | 4539 | 0.7094 |
| 0.6988 | 90.0 | 4590 | 0.6917 |
| 0.6912 | 91.0 | 4641 | 0.6926 |
| 0.689 | 92.0 | 4692 | 0.6881 |
| 0.687 | 93.0 | 4743 | 0.6866 |
| 0.6867 | 94.0 | 4794 | 0.6873 |
| 0.6832 | 95.0 | 4845 | 0.6820 |
| 0.6863 | 96.0 | 4896 | 0.6809 |
| 0.6908 | 97.0 | 4947 | 0.6792 |
| 0.6891 | 98.0 | 4998 | 0.6796 |
| 0.6803 | 99.0 | 5049 | 0.6793 |
| 0.6755 | 100.0 | 5100 | 0.6738 |
| 0.6735 | 101.0 | 5151 | 0.6750 |
| 0.6727 | 102.0 | 5202 | 0.6729 |
| 0.6695 | 103.0 | 5253 | 0.6734 |
| 0.6678 | 104.0 | 5304 | 0.6702 |
| 0.671 | 105.0 | 5355 | 0.6720 |
| 0.6654 | 106.0 | 5406 | 0.6686 |
| 0.669 | 107.0 | 5457 | 0.6683 |
| 0.6628 | 108.0 | 5508 | 0.6639 |
| 0.6655 | 109.0 | 5559 | 0.6663 |
| 0.6637 | 110.0 | 5610 | 0.6651 |
| 0.6643 | 111.0 | 5661 | 0.6639 |
| 0.6607 | 112.0 | 5712 | 0.6561 |
| 0.6598 | 113.0 | 5763 | 0.6591 |
| 0.6589 | 114.0 | 5814 | 0.6610 |
| 0.6566 | 115.0 | 5865 | 0.6566 |
| 0.6706 | 116.0 | 5916 | 0.6749 |
| 0.6688 | 117.0 | 5967 | 0.6670 |
| 0.6657 | 118.0 | 6018 | 0.6599 |
| 0.6611 | 119.0 | 6069 | 0.6567 |
| 0.6528 | 120.0 | 6120 | 0.6591 |
| 0.652 | 121.0 | 6171 | 0.6566 |
| 0.6488 | 122.0 | 6222 | 0.6528 |
| 0.6538 | 123.0 | 6273 | 0.6558 |
| 0.6457 | 124.0 | 6324 | 0.6509 |
| 0.643 | 125.0 | 6375 | 0.6462 |
| 0.6433 | 126.0 | 6426 | 0.6459 |
| 0.6451 | 127.0 | 6477 | 0.6454 |
| 0.6413 | 128.0 | 6528 | 0.6441 |
| 0.6407 | 129.0 | 6579 | 0.6409 |
| 0.6381 | 130.0 | 6630 | 0.6422 |
| 0.6408 | 131.0 | 6681 | 0.6432 |
| 0.6404 | 132.0 | 6732 | 0.6408 |
| 0.6412 | 133.0 | 6783 | 0.6354 |
| 0.6348 | 134.0 | 6834 | 0.6350 |
| 0.6307 | 135.0 | 6885 | 0.6389 |
| 0.639 | 136.0 | 6936 | 0.6417 |
| 0.6319 | 137.0 | 6987 | 0.6353 |
| 0.6306 | 138.0 | 7038 | 0.6385 |
| 0.6307 | 139.0 | 7089 | 0.6412 |
| 0.6343 | 140.0 | 7140 | 0.6308 |
| 0.6289 | 141.0 | 7191 | 0.6337 |
| 0.6298 | 142.0 | 7242 | 0.6342 |
| 0.6284 | 143.0 | 7293 | 0.6287 |
| 0.624 | 144.0 | 7344 | 0.6305 |
| 0.6266 | 145.0 | 7395 | 0.6338 |
| 0.6253 | 146.0 | 7446 | 0.6281 |
| 0.6204 | 147.0 | 7497 | 0.6241 |
| 0.6232 | 148.0 | 7548 | 0.6222 |
| 0.6213 | 149.0 | 7599 | 0.6201 |
| 0.6225 | 150.0 | 7650 | 0.6237 |
| 0.6228 | 151.0 | 7701 | 0.6193 |
| 0.6191 | 152.0 | 7752 | 0.6200 |
| 0.6198 | 153.0 | 7803 | 0.6229 |
| 0.6183 | 154.0 | 7854 | 0.6213 |
| 0.6181 | 155.0 | 7905 | 0.6213 |
| 0.6168 | 156.0 | 7956 | 0.6164 |
| 0.6156 | 157.0 | 8007 | 0.6160 |
| 0.6125 | 158.0 | 8058 | 0.6153 |
| 0.6126 | 159.0 | 8109 | 0.6151 |
| 0.6115 | 160.0 | 8160 | 0.6163 |
| 0.611 | 161.0 | 8211 | 0.6167 |
| 0.6099 | 162.0 | 8262 | 0.6083 |
| 0.6089 | 163.0 | 8313 | 0.6104 |
| 0.6091 | 164.0 | 8364 | 0.6140 |
| 0.6105 | 165.0 | 8415 | 0.6122 |
| 0.61 | 166.0 | 8466 | 0.6106 |
| 0.6104 | 167.0 | 8517 | 0.6062 |
| 0.6067 | 168.0 | 8568 | 0.6095 |
| 0.6056 | 169.0 | 8619 | 0.6067 |
| 0.607 | 170.0 | 8670 | 0.6091 |
| 0.6032 | 171.0 | 8721 | 0.6041 |
| 0.6038 | 172.0 | 8772 | 0.6104 |
| 0.605 | 173.0 | 8823 | 0.6068 |
| 0.6036 | 174.0 | 8874 | 0.6005 |
| 0.6035 | 175.0 | 8925 | 0.6055 |
| 0.6026 | 176.0 | 8976 | 0.6014 |
| 0.6012 | 177.0 | 9027 | 0.6029 |
| 0.5945 | 178.0 | 9078 | 0.5967 |
| 0.6011 | 179.0 | 9129 | 0.5921 |
| 0.5929 | 180.0 | 9180 | 0.5991 |
| 0.5981 | 181.0 | 9231 | 0.5954 |
| 0.6011 | 182.0 | 9282 | 0.6007 |
| 0.5977 | 183.0 | 9333 | 0.6013 |
| 0.5947 | 184.0 | 9384 | 0.6023 |
| 0.59 | 185.0 | 9435 | 0.5968 |
| 0.5924 | 186.0 | 9486 | 0.5987 |
| 0.5906 | 187.0 | 9537 | 0.5915 |
| 0.5928 | 188.0 | 9588 | 0.5877 |
| 0.5849 | 189.0 | 9639 | 0.5911 |
| 0.5913 | 190.0 | 9690 | 0.5954 |
| 0.5863 | 191.0 | 9741 | 0.5906 |
| 0.588 | 192.0 | 9792 | 0.5942 |
| 0.5906 | 193.0 | 9843 | 0.5924 |
| 0.5927 | 194.0 | 9894 | 0.5911 |
| 0.5857 | 195.0 | 9945 | 0.5852 |
| 0.5859 | 196.0 | 9996 | 0.5910 |
| 0.5775 | 197.0 | 10047 | 0.5853 |
| 0.586 | 198.0 | 10098 | 0.5877 |
| 0.5853 | 199.0 | 10149 | 0.5848 |
| 0.5824 | 200.0 | 10200 | 0.5854 |
| 0.5797 | 201.0 | 10251 | 0.5834 |
| 0.5857 | 202.0 | 10302 | 0.5792 |
| 0.5863 | 203.0 | 10353 | 0.5824 |
| 0.5826 | 204.0 | 10404 | 0.5838 |
| 0.579 | 205.0 | 10455 | 0.5808 |
| 0.5758 | 206.0 | 10506 | 0.5810 |
| 0.5798 | 207.0 | 10557 | 0.5782 |
| 0.576 | 208.0 | 10608 | 0.5818 |
| 0.5717 | 209.0 | 10659 | 0.5826 |
| 0.5774 | 210.0 | 10710 | 0.5800 |
| 0.5724 | 211.0 | 10761 | 0.5813 |
| 0.5706 | 212.0 | 10812 | 0.5755 |
| 0.5737 | 213.0 | 10863 | 0.5788 |
| 0.5791 | 214.0 | 10914 | 0.5769 |
| 0.5712 | 215.0 | 10965 | 0.5767 |
| 0.567 | 216.0 | 11016 | 0.5790 |
| 0.5671 | 217.0 | 11067 | 0.5734 |
| 0.5733 | 218.0 | 11118 | 0.5722 |
| 0.5673 | 219.0 | 11169 | 0.5806 |
| 0.5713 | 220.0 | 11220 | 0.5764 |
| 0.5669 | 221.0 | 11271 | 0.5694 |
| 0.5669 | 222.0 | 11322 | 0.5749 |
| 0.5665 | 223.0 | 11373 | 0.5732 |
| 0.5676 | 224.0 | 11424 | 0.5676 |
| 0.5621 | 225.0 | 11475 | 0.5677 |
| 0.5623 | 226.0 | 11526 | 0.5715 |
| 0.5695 | 227.0 | 11577 | 0.5676 |
| 0.5657 | 228.0 | 11628 | 0.5667 |
| 0.565 | 229.0 | 11679 | 0.5644 |
| 0.5617 | 230.0 | 11730 | 0.5650 |
| 0.5587 | 231.0 | 11781 | 0.5637 |
| 0.5591 | 232.0 | 11832 | 0.5652 |
| 0.5607 | 233.0 | 11883 | 0.5648 |
| 0.559 | 234.0 | 11934 | 0.5681 |
| 0.5601 | 235.0 | 11985 | 0.5637 |
| 0.5605 | 236.0 | 12036 | 0.5697 |
| 0.5555 | 237.0 | 12087 | 0.5593 |
| 0.5602 | 238.0 | 12138 | 0.5683 |
| 0.5647 | 239.0 | 12189 | 0.5629 |
| 0.5575 | 240.0 | 12240 | 0.5611 |
| 0.5577 | 241.0 | 12291 | 0.5588 |
| 0.5514 | 242.0 | 12342 | 0.5584 |
| 0.5581 | 243.0 | 12393 | 0.5566 |
| 0.555 | 244.0 | 12444 | 0.5563 |
| 0.5571 | 245.0 | 12495 | 0.5541 |
| 0.5549 | 246.0 | 12546 | 0.5541 |
| 0.5521 | 247.0 | 12597 | 0.5521 |
| 0.55 | 248.0 | 12648 | 0.5567 |
| 0.5518 | 249.0 | 12699 | 0.5559 |
| 0.5522 | 250.0 | 12750 | 0.5536 |
| 0.5481 | 251.0 | 12801 | 0.5504 |
| 0.5516 | 252.0 | 12852 | 0.5563 |
| 0.5524 | 253.0 | 12903 | 0.5503 |
| 0.5582 | 254.0 | 12954 | 0.5519 |
| 0.5514 | 255.0 | 13005 | 0.5504 |
| 0.5498 | 256.0 | 13056 | 0.5520 |
| 0.5481 | 257.0 | 13107 | 0.5540 |
| 0.551 | 258.0 | 13158 | 0.5503 |
| 0.5495 | 259.0 | 13209 | 0.5491 |
| 0.5483 | 260.0 | 13260 | 0.5461 |
| 0.5468 | 261.0 | 13311 | 0.5586 |
| 0.5454 | 262.0 | 13362 | 0.5495 |
| 0.5447 | 263.0 | 13413 | 0.5455 |
| 0.5475 | 264.0 | 13464 | 0.5511 |
| 0.5439 | 265.0 | 13515 | 0.5453 |
| 0.542 | 266.0 | 13566 | 0.5477 |
| 0.5437 | 267.0 | 13617 | 0.5502 |
| 0.5452 | 268.0 | 13668 | 0.5432 |
| 0.5397 | 269.0 | 13719 | 0.5443 |
| 0.5424 | 270.0 | 13770 | 0.5410 |
| 0.5391 | 271.0 | 13821 | 0.5420 |
| 0.5368 | 272.0 | 13872 | 0.5402 |
| 0.5387 | 273.0 | 13923 | 0.5401 |
| 0.5362 | 274.0 | 13974 | 0.5414 |
| 0.5374 | 275.0 | 14025 | 0.5418 |
| 0.5375 | 276.0 | 14076 | 0.5415 |
| 0.5427 | 277.0 | 14127 | 0.5436 |
| 0.5382 | 278.0 | 14178 | 0.5366 |
| 0.5341 | 279.0 | 14229 | 0.5411 |
| 0.5348 | 280.0 | 14280 | 0.5377 |
| 0.5339 | 281.0 | 14331 | 0.5393 |
| 0.5359 | 282.0 | 14382 | 0.5359 |
| 0.536 | 283.0 | 14433 | 0.5368 |
| 0.5362 | 284.0 | 14484 | 0.5384 |
| 0.532 | 285.0 | 14535 | 0.5346 |
| 0.5298 | 286.0 | 14586 | 0.5376 |
| 0.5352 | 287.0 | 14637 | 0.5373 |
| 0.5344 | 288.0 | 14688 | 0.5359 |
| 0.5399 | 289.0 | 14739 | 0.5427 |
| 0.5329 | 290.0 | 14790 | 0.5349 |
| 0.531 | 291.0 | 14841 | 0.5321 |
| 0.5317 | 292.0 | 14892 | 0.5361 |
| 0.5303 | 293.0 | 14943 | 0.5296 |
| 0.5291 | 294.0 | 14994 | 0.5312 |
| 0.5335 | 295.0 | 15045 | 0.5244 |
| 0.5309 | 296.0 | 15096 | 0.5252 |
| 0.5251 | 297.0 | 15147 | 0.5310 |
| 0.5266 | 298.0 | 15198 | 0.5301 |
| 0.5279 | 299.0 | 15249 | 0.5308 |
| 0.5261 | 300.0 | 15300 | 0.5250 |
| 0.5214 | 301.0 | 15351 | 0.5252 |
| 0.5269 | 302.0 | 15402 | 0.5306 |
| 0.5229 | 303.0 | 15453 | 0.5264 |
| 0.5234 | 304.0 | 15504 | 0.5263 |
| 0.5271 | 305.0 | 15555 | 0.5280 |
| 0.525 | 306.0 | 15606 | 0.5233 |
| 0.5216 | 307.0 | 15657 | 0.5211 |
| 0.5247 | 308.0 | 15708 | 0.5246 |
| 0.5203 | 309.0 | 15759 | 0.5279 |
| 0.5201 | 310.0 | 15810 | 0.5246 |
| 0.5254 | 311.0 | 15861 | 0.5306 |
| 0.5166 | 312.0 | 15912 | 0.5224 |
| 0.525 | 313.0 | 15963 | 0.5192 |
| 0.5224 | 314.0 | 16014 | 0.5247 |
| 0.5195 | 315.0 | 16065 | 0.5230 |
| 0.5189 | 316.0 | 16116 | 0.5239 |
| 0.5226 | 317.0 | 16167 | 0.5180 |
| 0.5166 | 318.0 | 16218 | 0.5197 |
| 0.5159 | 319.0 | 16269 | 0.5156 |
| 0.5156 | 320.0 | 16320 | 0.5204 |
| 0.5179 | 321.0 | 16371 | 0.5215 |
| 0.5194 | 322.0 | 16422 | 0.5211 |
| 0.519 | 323.0 | 16473 | 0.5212 |
| 0.5112 | 324.0 | 16524 | 0.5175 |
| 0.5163 | 325.0 | 16575 | 0.5225 |
| 0.5165 | 326.0 | 16626 | 0.5172 |
| 0.5104 | 327.0 | 16677 | 0.5200 |
| 0.51 | 328.0 | 16728 | 0.5156 |
| 0.5129 | 329.0 | 16779 | 0.5160 |
| 0.5084 | 330.0 | 16830 | 0.5207 |
| 0.5159 | 331.0 | 16881 | 0.5147 |
| 0.5126 | 332.0 | 16932 | 0.5159 |
| 0.5132 | 333.0 | 16983 | 0.5156 |
| 0.5092 | 334.0 | 17034 | 0.5151 |
| 0.5116 | 335.0 | 17085 | 0.5147 |
| 0.5113 | 336.0 | 17136 | 0.5121 |
| 0.5076 | 337.0 | 17187 | 0.5101 |
| 0.5106 | 338.0 | 17238 | 0.5111 |
| 0.5117 | 339.0 | 17289 | 0.5094 |
| 0.5086 | 340.0 | 17340 | 0.5132 |
| 0.5034 | 341.0 | 17391 | 0.5162 |
| 0.5061 | 342.0 | 17442 | 0.5142 |
| 0.5101 | 343.0 | 17493 | 0.5136 |
| 0.5042 | 344.0 | 17544 | 0.5135 |
| 0.5091 | 345.0 | 17595 | 0.5083 |
| 0.5095 | 346.0 | 17646 | 0.5112 |
| 0.5058 | 347.0 | 17697 | 0.5121 |
| 0.504 | 348.0 | 17748 | 0.5082 |
| 0.5016 | 349.0 | 17799 | 0.5075 |
| 0.5042 | 350.0 | 17850 | 0.5090 |
| 0.5036 | 351.0 | 17901 | 0.5089 |
| 0.5045 | 352.0 | 17952 | 0.5095 |
| 0.5067 | 353.0 | 18003 | 0.5087 |
| 0.5026 | 354.0 | 18054 | 0.5064 |
| 0.5001 | 355.0 | 18105 | 0.5055 |
| 0.5036 | 356.0 | 18156 | 0.5057 |
| 0.5012 | 357.0 | 18207 | 0.5083 |
| 0.5031 | 358.0 | 18258 | 0.5110 |
| 0.5021 | 359.0 | 18309 | 0.5128 |
| 0.4973 | 360.0 | 18360 | 0.5014 |
| 0.4988 | 361.0 | 18411 | 0.5028 |
| 0.5013 | 362.0 | 18462 | 0.5035 |
| 0.5001 | 363.0 | 18513 | 0.5040 |
| 0.4972 | 364.0 | 18564 | 0.5056 |
| 0.4994 | 365.0 | 18615 | 0.5070 |
| 0.5005 | 366.0 | 18666 | 0.5070 |
| 0.4993 | 367.0 | 18717 | 0.5053 |
| 0.4975 | 368.0 | 18768 | 0.5036 |
| 0.4967 | 369.0 | 18819 | 0.5026 |
| 0.4968 | 370.0 | 18870 | 0.5011 |
| 0.498 | 371.0 | 18921 | 0.4990 |
| 0.5022 | 372.0 | 18972 | 0.5032 |
| 0.4959 | 373.0 | 19023 | 0.4972 |
| 0.4921 | 374.0 | 19074 | 0.4967 |
| 0.4936 | 375.0 | 19125 | 0.4967 |
| 0.496 | 376.0 | 19176 | 0.5000 |
| 0.4941 | 377.0 | 19227 | 0.4980 |
| 0.4937 | 378.0 | 19278 | 0.4975 |
| 0.4979 | 379.0 | 19329 | 0.4975 |
| 0.4996 | 380.0 | 19380 | 0.4932 |
| 0.4961 | 381.0 | 19431 | 0.4983 |
| 0.4903 | 382.0 | 19482 | 0.4974 |
| 0.4899 | 383.0 | 19533 | 0.4953 |
| 0.4924 | 384.0 | 19584 | 0.4953 |
| 0.4895 | 385.0 | 19635 | 0.4964 |
| 0.4965 | 386.0 | 19686 | 0.5006 |
| 0.4896 | 387.0 | 19737 | 0.4938 |
| 0.497 | 388.0 | 19788 | 0.4956 |
| 0.4924 | 389.0 | 19839 | 0.4960 |
| 0.4904 | 390.0 | 19890 | 0.4972 |
| 0.5 | 391.0 | 19941 | 0.4958 |
| 0.4961 | 392.0 | 19992 | 0.4906 |
| 0.491 | 393.0 | 20043 | 0.4918 |
| 0.4878 | 394.0 | 20094 | 0.4954 |
| 0.4881 | 395.0 | 20145 | 0.4916 |
| 0.49 | 396.0 | 20196 | 0.4946 |
| 0.4881 | 397.0 | 20247 | 0.4924 |
| 0.4871 | 398.0 | 20298 | 0.4959 |
| 0.492 | 399.0 | 20349 | 0.4867 |
| 0.4883 | 400.0 | 20400 | 0.4891 |
| 0.4864 | 401.0 | 20451 | 0.4946 |
| 0.4898 | 402.0 | 20502 | 0.4922 |
| 0.4841 | 403.0 | 20553 | 0.4902 |
| 0.4879 | 404.0 | 20604 | 0.4921 |
| 0.4801 | 405.0 | 20655 | 0.4914 |
| 0.4877 | 406.0 | 20706 | 0.4882 |
| 0.4858 | 407.0 | 20757 | 0.4882 |
| 0.4856 | 408.0 | 20808 | 0.4872 |
| 0.4825 | 409.0 | 20859 | 0.4871 |
| 0.4865 | 410.0 | 20910 | 0.4853 |
| 0.4834 | 411.0 | 20961 | 0.4908 |
| 0.4815 | 412.0 | 21012 | 0.4847 |
| 0.4828 | 413.0 | 21063 | 0.4919 |
| 0.487 | 414.0 | 21114 | 0.4899 |
| 0.4842 | 415.0 | 21165 | 0.4876 |
| 0.4902 | 416.0 | 21216 | 0.4873 |
| 0.4809 | 417.0 | 21267 | 0.4913 |
| 0.4825 | 418.0 | 21318 | 0.4832 |
| 0.4797 | 419.0 | 21369 | 0.4872 |
| 0.4852 | 420.0 | 21420 | 0.4868 |
| 0.4879 | 421.0 | 21471 | 0.4833 |
| 0.4823 | 422.0 | 21522 | 0.4824 |
| 0.4729 | 423.0 | 21573 | 0.4793 |
| 0.4825 | 424.0 | 21624 | 0.4812 |
| 0.4739 | 425.0 | 21675 | 0.4831 |
| 0.4767 | 426.0 | 21726 | 0.4848 |
| 0.4806 | 427.0 | 21777 | 0.4858 |
| 0.4736 | 428.0 | 21828 | 0.4831 |
| 0.4857 | 429.0 | 21879 | 0.4785 |
| 0.4819 | 430.0 | 21930 | 0.4805 |
| 0.4767 | 431.0 | 21981 | 0.4845 |
| 0.4765 | 432.0 | 22032 | 0.4803 |
| 0.4785 | 433.0 | 22083 | 0.4826 |
| 0.4758 | 434.0 | 22134 | 0.4814 |
| 0.4677 | 435.0 | 22185 | 0.4815 |
| 0.4735 | 436.0 | 22236 | 0.4811 |
| 0.4764 | 437.0 | 22287 | 0.4749 |
| 0.4743 | 438.0 | 22338 | 0.4846 |
| 0.4736 | 439.0 | 22389 | 0.4825 |
| 0.4732 | 440.0 | 22440 | 0.4783 |
| 0.4706 | 441.0 | 22491 | 0.4810 |
| 0.4735 | 442.0 | 22542 | 0.4780 |
| 0.4796 | 443.0 | 22593 | 0.4881 |
| 0.4724 | 444.0 | 22644 | 0.4785 |
| 0.4701 | 445.0 | 22695 | 0.4753 |
| 0.4764 | 446.0 | 22746 | 0.4787 |
| 0.4729 | 447.0 | 22797 | 0.4824 |
| 0.4726 | 448.0 | 22848 | 0.4742 |
| 0.4736 | 449.0 | 22899 | 0.4775 |
| 0.4764 | 450.0 | 22950 | 0.4755 |
| 0.4701 | 451.0 | 23001 | 0.4755 |
| 0.4746 | 452.0 | 23052 | 0.4750 |
| 0.4727 | 453.0 | 23103 | 0.4731 |
| 0.4691 | 454.0 | 23154 | 0.4686 |
| 0.4673 | 455.0 | 23205 | 0.4761 |
| 0.4726 | 456.0 | 23256 | 0.4763 |
| 0.4726 | 457.0 | 23307 | 0.4807 |
| 0.4696 | 458.0 | 23358 | 0.4738 |
| 0.4689 | 459.0 | 23409 | 0.4727 |
| 0.4702 | 460.0 | 23460 | 0.4793 |
| 0.4692 | 461.0 | 23511 | 0.4696 |
| 0.4694 | 462.0 | 23562 | 0.4713 |
| 0.4628 | 463.0 | 23613 | 0.4747 |
| 0.4677 | 464.0 | 23664 | 0.4787 |
| 0.4673 | 465.0 | 23715 | 0.4682 |
| 0.4709 | 466.0 | 23766 | 0.4692 |
| 0.463 | 467.0 | 23817 | 0.4676 |
| 0.4654 | 468.0 | 23868 | 0.4696 |
| 0.4648 | 469.0 | 23919 | 0.4675 |
| 0.4642 | 470.0 | 23970 | 0.4700 |
| 0.4687 | 471.0 | 24021 | 0.4691 |
| 0.469 | 472.0 | 24072 | 0.4749 |
| 0.4692 | 473.0 | 24123 | 0.4672 |
| 0.4635 | 474.0 | 24174 | 0.4707 |
| 0.4635 | 475.0 | 24225 | 0.4696 |
| 0.4655 | 476.0 | 24276 | 0.4652 |
| 0.4633 | 477.0 | 24327 | 0.4702 |
| 0.4622 | 478.0 | 24378 | 0.4637 |
| 0.4571 | 479.0 | 24429 | 0.4678 |
| 0.4645 | 480.0 | 24480 | 0.4635 |
| 0.4654 | 481.0 | 24531 | 0.4655 |
| 0.4588 | 482.0 | 24582 | 0.4688 |
| 0.4608 | 483.0 | 24633 | 0.4639 |
| 0.4606 | 484.0 | 24684 | 0.4654 |
| 0.4624 | 485.0 | 24735 | 0.4661 |
| 0.4612 | 486.0 | 24786 | 0.4669 |
| 0.46 | 487.0 | 24837 | 0.4653 |
| 0.4623 | 488.0 | 24888 | 0.4688 |
| 0.4648 | 489.0 | 24939 | 0.4648 |
| 0.4602 | 490.0 | 24990 | 0.4620 |
| 0.4587 | 491.0 | 25041 | 0.4652 |
| 0.4627 | 492.0 | 25092 | 0.4694 |
| 0.4638 | 493.0 | 25143 | 0.4620 |
| 0.4565 | 494.0 | 25194 | 0.4653 |
| 0.4588 | 495.0 | 25245 | 0.4598 |
| 0.4568 | 496.0 | 25296 | 0.4617 |
| 0.4524 | 497.0 | 25347 | 0.4631 |
| 0.4635 | 498.0 | 25398 | 0.4640 |
| 0.4534 | 499.0 | 25449 | 0.4643 |
| 0.4599 | 500.0 | 25500 | 0.4663 |
| 0.4549 | 501.0 | 25551 | 0.4588 |
| 0.4595 | 502.0 | 25602 | 0.4661 |
| 0.46 | 503.0 | 25653 | 0.4626 |
| 0.4504 | 504.0 | 25704 | 0.4591 |
| 0.459 | 505.0 | 25755 | 0.4623 |
| 0.4582 | 506.0 | 25806 | 0.4617 |
| 0.4532 | 507.0 | 25857 | 0.4580 |
| 0.4555 | 508.0 | 25908 | 0.4615 |
| 0.4571 | 509.0 | 25959 | 0.4617 |
| 0.4561 | 510.0 | 26010 | 0.4579 |
| 0.4541 | 511.0 | 26061 | 0.4601 |
| 0.4534 | 512.0 | 26112 | 0.4627 |
| 0.4569 | 513.0 | 26163 | 0.4615 |
| 0.4583 | 514.0 | 26214 | 0.4527 |
| 0.4498 | 515.0 | 26265 | 0.4587 |
| 0.4511 | 516.0 | 26316 | 0.4552 |
| 0.4535 | 517.0 | 26367 | 0.4579 |
| 0.4551 | 518.0 | 26418 | 0.4543 |
| 0.4581 | 519.0 | 26469 | 0.4597 |
| 0.4573 | 520.0 | 26520 | 0.4540 |
| 0.4495 | 521.0 | 26571 | 0.4578 |
| 0.4532 | 522.0 | 26622 | 0.4605 |
| 0.4474 | 523.0 | 26673 | 0.4579 |
| 0.4504 | 524.0 | 26724 | 0.4563 |
| 0.4529 | 525.0 | 26775 | 0.4583 |
| 0.4475 | 526.0 | 26826 | 0.4616 |
| 0.4457 | 527.0 | 26877 | 0.4558 |
| 0.4532 | 528.0 | 26928 | 0.4584 |
| 0.4566 | 529.0 | 26979 | 0.4573 |
| 0.4546 | 530.0 | 27030 | 0.4563 |
| 0.4479 | 531.0 | 27081 | 0.4628 |
| 0.4485 | 532.0 | 27132 | 0.4547 |
| 0.4491 | 533.0 | 27183 | 0.4539 |
| 0.4522 | 534.0 | 27234 | 0.4536 |
| 0.4477 | 535.0 | 27285 | 0.4561 |
| 0.45 | 536.0 | 27336 | 0.4530 |
| 0.4522 | 537.0 | 27387 | 0.4525 |
| 0.4475 | 538.0 | 27438 | 0.4554 |
| 0.4475 | 539.0 | 27489 | 0.4486 |
| 0.4512 | 540.0 | 27540 | 0.4584 |
| 0.445 | 541.0 | 27591 | 0.4543 |
| 0.4478 | 542.0 | 27642 | 0.4507 |
| 0.4472 | 543.0 | 27693 | 0.4520 |
| 0.448 | 544.0 | 27744 | 0.4507 |
| 0.4447 | 545.0 | 27795 | 0.4514 |
| 0.4485 | 546.0 | 27846 | 0.4553 |
| 0.4482 | 547.0 | 27897 | 0.4532 |
| 0.4448 | 548.0 | 27948 | 0.4533 |
| 0.4467 | 549.0 | 27999 | 0.4511 |
| 0.4473 | 550.0 | 28050 | 0.4531 |
| 0.4423 | 551.0 | 28101 | 0.4462 |
| 0.4473 | 552.0 | 28152 | 0.4538 |
| 0.4463 | 553.0 | 28203 | 0.4472 |
| 0.4459 | 554.0 | 28254 | 0.4486 |
| 0.4432 | 555.0 | 28305 | 0.4470 |
| 0.4448 | 556.0 | 28356 | 0.4522 |
| 0.4406 | 557.0 | 28407 | 0.4528 |
| 0.4433 | 558.0 | 28458 | 0.4502 |
| 0.4447 | 559.0 | 28509 | 0.4471 |
| 0.4438 | 560.0 | 28560 | 0.4500 |
| 0.4433 | 561.0 | 28611 | 0.4471 |
| 0.4412 | 562.0 | 28662 | 0.4491 |
| 0.4357 | 563.0 | 28713 | 0.4474 |
| 0.4424 | 564.0 | 28764 | 0.4481 |
| 0.4412 | 565.0 | 28815 | 0.4480 |
| 0.4483 | 566.0 | 28866 | 0.4453 |
| 0.4397 | 567.0 | 28917 | 0.4435 |
| 0.4377 | 568.0 | 28968 | 0.4460 |
| 0.4424 | 569.0 | 29019 | 0.4475 |
| 0.4412 | 570.0 | 29070 | 0.4445 |
| 0.4435 | 571.0 | 29121 | 0.4418 |
| 0.4398 | 572.0 | 29172 | 0.4434 |
| 0.4427 | 573.0 | 29223 | 0.4417 |
| 0.4409 | 574.0 | 29274 | 0.4410 |
| 0.4425 | 575.0 | 29325 | 0.4434 |
| 0.4402 | 576.0 | 29376 | 0.4489 |
| 0.4394 | 577.0 | 29427 | 0.4435 |
| 0.4379 | 578.0 | 29478 | 0.4447 |
| 0.4391 | 579.0 | 29529 | 0.4471 |
| 0.4404 | 580.0 | 29580 | 0.4435 |
| 0.4399 | 581.0 | 29631 | 0.4411 |
| 0.4353 | 582.0 | 29682 | 0.4416 |
| 0.4417 | 583.0 | 29733 | 0.4417 |
| 0.4389 | 584.0 | 29784 | 0.4399 |
| 0.4378 | 585.0 | 29835 | 0.4432 |
| 0.439 | 586.0 | 29886 | 0.4427 |
| 0.431 | 587.0 | 29937 | 0.4403 |
| 0.4348 | 588.0 | 29988 | 0.4409 |
| 0.4363 | 589.0 | 30039 | 0.4425 |
| 0.4399 | 590.0 | 30090 | 0.4394 |
| 0.4342 | 591.0 | 30141 | 0.4412 |
| 0.4342 | 592.0 | 30192 | 0.4399 |
| 0.4348 | 593.0 | 30243 | 0.4420 |
| 0.4326 | 594.0 | 30294 | 0.4446 |
| 0.4333 | 595.0 | 30345 | 0.4430 |
| 0.4336 | 596.0 | 30396 | 0.4397 |
| 0.4314 | 597.0 | 30447 | 0.4418 |
| 0.4371 | 598.0 | 30498 | 0.4411 |
| 0.4333 | 599.0 | 30549 | 0.4385 |
| 0.4337 | 600.0 | 30600 | 0.4394 |
| 0.4371 | 601.0 | 30651 | 0.4407 |
| 0.4294 | 602.0 | 30702 | 0.4395 |
| 0.4323 | 603.0 | 30753 | 0.4404 |
| 0.4303 | 604.0 | 30804 | 0.4422 |
| 0.4325 | 605.0 | 30855 | 0.4376 |
| 0.44 | 606.0 | 30906 | 0.4399 |
| 0.4343 | 607.0 | 30957 | 0.4403 |
| 0.4313 | 608.0 | 31008 | 0.4397 |
| 0.4338 | 609.0 | 31059 | 0.4379 |
| 0.4299 | 610.0 | 31110 | 0.4349 |
| 0.4325 | 611.0 | 31161 | 0.4370 |
| 0.429 | 612.0 | 31212 | 0.4371 |
| 0.4291 | 613.0 | 31263 | 0.4299 |
| 0.4349 | 614.0 | 31314 | 0.4364 |
| 0.4308 | 615.0 | 31365 | 0.4336 |
| 0.4305 | 616.0 | 31416 | 0.4343 |
| 0.4267 | 617.0 | 31467 | 0.4391 |
| 0.4329 | 618.0 | 31518 | 0.4365 |
| 0.4269 | 619.0 | 31569 | 0.4333 |
| 0.4251 | 620.0 | 31620 | 0.4343 |
| 0.427 | 621.0 | 31671 | 0.4344 |
| 0.4327 | 622.0 | 31722 | 0.4345 |
| 0.4263 | 623.0 | 31773 | 0.4370 |
| 0.4288 | 624.0 | 31824 | 0.4323 |
| 0.4316 | 625.0 | 31875 | 0.4325 |
| 0.431 | 626.0 | 31926 | 0.4328 |
| 0.4316 | 627.0 | 31977 | 0.4316 |
| 0.4325 | 628.0 | 32028 | 0.4311 |
| 0.4287 | 629.0 | 32079 | 0.4323 |
| 0.4267 | 630.0 | 32130 | 0.4302 |
| 0.426 | 631.0 | 32181 | 0.4342 |
| 0.4259 | 632.0 | 32232 | 0.4324 |
| 0.427 | 633.0 | 32283 | 0.4315 |
| 0.4268 | 634.0 | 32334 | 0.4300 |
| 0.4251 | 635.0 | 32385 | 0.4385 |
| 0.4291 | 636.0 | 32436 | 0.4358 |
| 0.4273 | 637.0 | 32487 | 0.4342 |
| 0.4238 | 638.0 | 32538 | 0.4311 |
| 0.4262 | 639.0 | 32589 | 0.4327 |
| 0.4251 | 640.0 | 32640 | 0.4329 |
| 0.4276 | 641.0 | 32691 | 0.4344 |
| 0.4274 | 642.0 | 32742 | 0.4304 |
| 0.4269 | 643.0 | 32793 | 0.4263 |
| 0.4217 | 644.0 | 32844 | 0.4305 |
| 0.4204 | 645.0 | 32895 | 0.4314 |
| 0.4268 | 646.0 | 32946 | 0.4284 |
| 0.4227 | 647.0 | 32997 | 0.4281 |
| 0.4236 | 648.0 | 33048 | 0.4320 |
| 0.4245 | 649.0 | 33099 | 0.4295 |
| 0.4229 | 650.0 | 33150 | 0.4262 |
| 0.423 | 651.0 | 33201 | 0.4239 |
| 0.4209 | 652.0 | 33252 | 0.4294 |
| 0.4209 | 653.0 | 33303 | 0.4315 |
| 0.425 | 654.0 | 33354 | 0.4299 |
| 0.418 | 655.0 | 33405 | 0.4282 |
| 0.423 | 656.0 | 33456 | 0.4264 |
| 0.4267 | 657.0 | 33507 | 0.4296 |
| 0.4226 | 658.0 | 33558 | 0.4269 |
| 0.4213 | 659.0 | 33609 | 0.4296 |
| 0.4192 | 660.0 | 33660 | 0.4259 |
| 0.4234 | 661.0 | 33711 | 0.4243 |
| 0.4205 | 662.0 | 33762 | 0.4256 |
| 0.4185 | 663.0 | 33813 | 0.4251 |
| 0.4212 | 664.0 | 33864 | 0.4231 |
| 0.4228 | 665.0 | 33915 | 0.4250 |
| 0.421 | 666.0 | 33966 | 0.4284 |
| 0.4226 | 667.0 | 34017 | 0.4243 |
| 0.4201 | 668.0 | 34068 | 0.4279 |
| 0.4213 | 669.0 | 34119 | 0.4210 |
| 0.4237 | 670.0 | 34170 | 0.4264 |
| 0.4228 | 671.0 | 34221 | 0.4237 |
| 0.4181 | 672.0 | 34272 | 0.4245 |
| 0.4242 | 673.0 | 34323 | 0.4244 |
| 0.4178 | 674.0 | 34374 | 0.4250 |
| 0.4184 | 675.0 | 34425 | 0.4274 |
| 0.4163 | 676.0 | 34476 | 0.4221 |
| 0.4288 | 677.0 | 34527 | 0.4245 |
| 0.4205 | 678.0 | 34578 | 0.4258 |
| 0.4167 | 679.0 | 34629 | 0.4243 |
| 0.4172 | 680.0 | 34680 | 0.4241 |
| 0.4212 | 681.0 | 34731 | 0.4216 |
| 0.4164 | 682.0 | 34782 | 0.4214 |
| 0.4171 | 683.0 | 34833 | 0.4230 |
| 0.4166 | 684.0 | 34884 | 0.4261 |
| 0.4172 | 685.0 | 34935 | 0.4224 |
| 0.4188 | 686.0 | 34986 | 0.4209 |
| 0.4187 | 687.0 | 35037 | 0.4168 |
| 0.4174 | 688.0 | 35088 | 0.4201 |
| 0.4184 | 689.0 | 35139 | 0.4177 |
| 0.4126 | 690.0 | 35190 | 0.4192 |
| 0.4168 | 691.0 | 35241 | 0.4171 |
| 0.4152 | 692.0 | 35292 | 0.4202 |
| 0.4137 | 693.0 | 35343 | 0.4210 |
| 0.4139 | 694.0 | 35394 | 0.4143 |
| 0.418 | 695.0 | 35445 | 0.4250 |
| 0.4116 | 696.0 | 35496 | 0.4237 |
| 0.4113 | 697.0 | 35547 | 0.4172 |
| 0.4131 | 698.0 | 35598 | 0.4219 |
| 0.4148 | 699.0 | 35649 | 0.4179 |
| 0.4117 | 700.0 | 35700 | 0.4264 |
| 0.4115 | 701.0 | 35751 | 0.4244 |
| 0.4149 | 702.0 | 35802 | 0.4223 |
| 0.4129 | 703.0 | 35853 | 0.4190 |
| 0.4134 | 704.0 | 35904 | 0.4197 |
| 0.4155 | 705.0 | 35955 | 0.4203 |
| 0.4112 | 706.0 | 36006 | 0.4206 |
| 0.4113 | 707.0 | 36057 | 0.4176 |
| 0.4117 | 708.0 | 36108 | 0.4202 |
| 0.4128 | 709.0 | 36159 | 0.4186 |
| 0.4111 | 710.0 | 36210 | 0.4196 |
| 0.4168 | 711.0 | 36261 | 0.4225 |
| 0.408 | 712.0 | 36312 | 0.4146 |
| 0.4117 | 713.0 | 36363 | 0.4185 |
| 0.4089 | 714.0 | 36414 | 0.4214 |
| 0.408 | 715.0 | 36465 | 0.4196 |
| 0.4126 | 716.0 | 36516 | 0.4175 |
| 0.4106 | 717.0 | 36567 | 0.4145 |
| 0.4112 | 718.0 | 36618 | 0.4160 |
| 0.4064 | 719.0 | 36669 | 0.4175 |
| 0.41 | 720.0 | 36720 | 0.4181 |
| 0.4046 | 721.0 | 36771 | 0.4159 |
| 0.4141 | 722.0 | 36822 | 0.4119 |
| 0.414 | 723.0 | 36873 | 0.4167 |
| 0.4118 | 724.0 | 36924 | 0.4166 |
| 0.4106 | 725.0 | 36975 | 0.4157 |
| 0.4079 | 726.0 | 37026 | 0.4176 |
| 0.4114 | 727.0 | 37077 | 0.4108 |
| 0.4117 | 728.0 | 37128 | 0.4135 |
| 0.4155 | 729.0 | 37179 | 0.4171 |
| 0.4117 | 730.0 | 37230 | 0.4147 |
| 0.4092 | 731.0 | 37281 | 0.4094 |
| 0.4091 | 732.0 | 37332 | 0.4133 |
| 0.4081 | 733.0 | 37383 | 0.4142 |
| 0.4084 | 734.0 | 37434 | 0.4170 |
| 0.4082 | 735.0 | 37485 | 0.4158 |
| 0.4097 | 736.0 | 37536 | 0.4118 |
| 0.4082 | 737.0 | 37587 | 0.4105 |
| 0.4043 | 738.0 | 37638 | 0.4162 |
| 0.4011 | 739.0 | 37689 | 0.4122 |
| 0.4082 | 740.0 | 37740 | 0.4158 |
| 0.4098 | 741.0 | 37791 | 0.4153 |
| 0.4082 | 742.0 | 37842 | 0.4107 |
| 0.4073 | 743.0 | 37893 | 0.4117 |
| 0.403 | 744.0 | 37944 | 0.4163 |
| 0.4024 | 745.0 | 37995 | 0.4080 |
| 0.4098 | 746.0 | 38046 | 0.4082 |
| 0.4072 | 747.0 | 38097 | 0.4111 |
| 0.4065 | 748.0 | 38148 | 0.4119 |
| 0.404 | 749.0 | 38199 | 0.4087 |
| 0.4024 | 750.0 | 38250 | 0.4093 |
| 0.4054 | 751.0 | 38301 | 0.4111 |
| 0.403 | 752.0 | 38352 | 0.4093 |
| 0.4042 | 753.0 | 38403 | 0.4117 |
| 0.4025 | 754.0 | 38454 | 0.4088 |
| 0.4025 | 755.0 | 38505 | 0.4102 |
| 0.4056 | 756.0 | 38556 | 0.4135 |
| 0.4025 | 757.0 | 38607 | 0.4125 |
| 0.4035 | 758.0 | 38658 | 0.4110 |
| 0.4026 | 759.0 | 38709 | 0.4127 |
| 0.4028 | 760.0 | 38760 | 0.4107 |
| 0.4007 | 761.0 | 38811 | 0.4079 |
| 0.4043 | 762.0 | 38862 | 0.4106 |
| 0.3979 | 763.0 | 38913 | 0.4084 |
| 0.4071 | 764.0 | 38964 | 0.4093 |
| 0.4097 | 765.0 | 39015 | 0.4130 |
| 0.4052 | 766.0 | 39066 | 0.4118 |
| 0.4063 | 767.0 | 39117 | 0.4055 |
| 0.4051 | 768.0 | 39168 | 0.4056 |
| 0.403 | 769.0 | 39219 | 0.4054 |
| 0.4061 | 770.0 | 39270 | 0.4102 |
| 0.3989 | 771.0 | 39321 | 0.4141 |
| 0.4022 | 772.0 | 39372 | 0.4050 |
| 0.4018 | 773.0 | 39423 | 0.4098 |
| 0.3993 | 774.0 | 39474 | 0.4090 |
| 0.3984 | 775.0 | 39525 | 0.4074 |
| 0.4034 | 776.0 | 39576 | 0.4068 |
| 0.4036 | 777.0 | 39627 | 0.4043 |
| 0.4027 | 778.0 | 39678 | 0.4056 |
| 0.3999 | 779.0 | 39729 | 0.4104 |
| 0.401 | 780.0 | 39780 | 0.4033 |
| 0.4058 | 781.0 | 39831 | 0.4058 |
| 0.3977 | 782.0 | 39882 | 0.4094 |
| 0.402 | 783.0 | 39933 | 0.4057 |
| 0.3972 | 784.0 | 39984 | 0.4044 |
| 0.3997 | 785.0 | 40035 | 0.4075 |
| 0.4003 | 786.0 | 40086 | 0.4074 |
| 0.3973 | 787.0 | 40137 | 0.4045 |
| 0.3989 | 788.0 | 40188 | 0.4078 |
| 0.4029 | 789.0 | 40239 | 0.4092 |
| 0.4011 | 790.0 | 40290 | 0.4051 |
| 0.3975 | 791.0 | 40341 | 0.4008 |
| 0.3952 | 792.0 | 40392 | 0.4049 |
| 0.4032 | 793.0 | 40443 | 0.4054 |
| 0.4027 | 794.0 | 40494 | 0.4034 |
| 0.397 | 795.0 | 40545 | 0.4042 |
| 0.3941 | 796.0 | 40596 | 0.4030 |
| 0.3929 | 797.0 | 40647 | 0.4031 |
| 0.4016 | 798.0 | 40698 | 0.4003 |
| 0.3926 | 799.0 | 40749 | 0.4026 |
| 0.3985 | 800.0 | 40800 | 0.4046 |
| 0.3978 | 801.0 | 40851 | 0.4002 |
| 0.3972 | 802.0 | 40902 | 0.4058 |
| 0.3993 | 803.0 | 40953 | 0.4026 |
| 0.3935 | 804.0 | 41004 | 0.4049 |
| 0.3973 | 805.0 | 41055 | 0.3989 |
| 0.4002 | 806.0 | 41106 | 0.4003 |
| 0.3918 | 807.0 | 41157 | 0.4006 |
| 0.4001 | 808.0 | 41208 | 0.3997 |
| 0.397 | 809.0 | 41259 | 0.4018 |
| 0.3984 | 810.0 | 41310 | 0.4030 |
| 0.3925 | 811.0 | 41361 | 0.4074 |
| 0.398 | 812.0 | 41412 | 0.4032 |
| 0.4 | 813.0 | 41463 | 0.3987 |
| 0.3943 | 814.0 | 41514 | 0.4015 |
| 0.3973 | 815.0 | 41565 | 0.3962 |
| 0.3922 | 816.0 | 41616 | 0.4032 |
| 0.3902 | 817.0 | 41667 | 0.3993 |
| 0.3942 | 818.0 | 41718 | 0.4018 |
| 0.3994 | 819.0 | 41769 | 0.4031 |
| 0.3959 | 820.0 | 41820 | 0.4008 |
| 0.3911 | 821.0 | 41871 | 0.4036 |
| 0.3941 | 822.0 | 41922 | 0.3997 |
| 0.3936 | 823.0 | 41973 | 0.3971 |
| 0.397 | 824.0 | 42024 | 0.4011 |
| 0.3974 | 825.0 | 42075 | 0.3964 |
| 0.3921 | 826.0 | 42126 | 0.4010 |
| 0.3961 | 827.0 | 42177 | 0.4019 |
| 0.3912 | 828.0 | 42228 | 0.4004 |
| 0.3939 | 829.0 | 42279 | 0.3980 |
| 0.3917 | 830.0 | 42330 | 0.4027 |
| 0.3977 | 831.0 | 42381 | 0.4005 |
| 0.3881 | 832.0 | 42432 | 0.3983 |
| 0.3939 | 833.0 | 42483 | 0.4026 |
| 0.393 | 834.0 | 42534 | 0.3991 |
| 0.3928 | 835.0 | 42585 | 0.3980 |
| 0.394 | 836.0 | 42636 | 0.3953 |
| 0.3908 | 837.0 | 42687 | 0.4002 |
| 0.3926 | 838.0 | 42738 | 0.4015 |
| 0.3947 | 839.0 | 42789 | 0.3991 |
| 0.3965 | 840.0 | 42840 | 0.3969 |
| 0.3934 | 841.0 | 42891 | 0.4002 |
| 0.3916 | 842.0 | 42942 | 0.3969 |
| 0.3887 | 843.0 | 42993 | 0.3941 |
| 0.3938 | 844.0 | 43044 | 0.3972 |
| 0.3928 | 845.0 | 43095 | 0.4015 |
| 0.3948 | 846.0 | 43146 | 0.3976 |
| 0.3925 | 847.0 | 43197 | 0.3953 |
| 0.3876 | 848.0 | 43248 | 0.3958 |
| 0.3857 | 849.0 | 43299 | 0.3967 |
| 0.389 | 850.0 | 43350 | 0.3975 |
| 0.3905 | 851.0 | 43401 | 0.3916 |
| 0.389 | 852.0 | 43452 | 0.3987 |
| 0.3872 | 853.0 | 43503 | 0.3965 |
| 0.3902 | 854.0 | 43554 | 0.3963 |
| 0.3883 | 855.0 | 43605 | 0.3941 |
| 0.393 | 856.0 | 43656 | 0.3945 |
| 0.3908 | 857.0 | 43707 | 0.3987 |
| 0.3891 | 858.0 | 43758 | 0.3970 |
| 0.39 | 859.0 | 43809 | 0.3934 |
| 0.3894 | 860.0 | 43860 | 0.3981 |
| 0.3859 | 861.0 | 43911 | 0.3940 |
| 0.3896 | 862.0 | 43962 | 0.3956 |
| 0.3897 | 863.0 | 44013 | 0.3952 |
| 0.385 | 864.0 | 44064 | 0.3941 |
| 0.3876 | 865.0 | 44115 | 0.3937 |
| 0.3889 | 866.0 | 44166 | 0.3975 |
| 0.3926 | 867.0 | 44217 | 0.3953 |
| 0.3895 | 868.0 | 44268 | 0.3918 |
| 0.3926 | 869.0 | 44319 | 0.3926 |
| 0.3861 | 870.0 | 44370 | 0.3933 |
| 0.3881 | 871.0 | 44421 | 0.3941 |
| 0.3863 | 872.0 | 44472 | 0.3939 |
| 0.3863 | 873.0 | 44523 | 0.3913 |
| 0.386 | 874.0 | 44574 | 0.3919 |
| 0.382 | 875.0 | 44625 | 0.3879 |
| 0.384 | 876.0 | 44676 | 0.3938 |
| 0.3898 | 877.0 | 44727 | 0.3949 |
| 0.3913 | 878.0 | 44778 | 0.3947 |
| 0.3859 | 879.0 | 44829 | 0.3952 |
| 0.385 | 880.0 | 44880 | 0.3950 |
| 0.3872 | 881.0 | 44931 | 0.3877 |
| 0.383 | 882.0 | 44982 | 0.3905 |
| 0.387 | 883.0 | 45033 | 0.3939 |
| 0.3834 | 884.0 | 45084 | 0.3947 |
| 0.3866 | 885.0 | 45135 | 0.3935 |
| 0.3834 | 886.0 | 45186 | 0.3925 |
| 0.3848 | 887.0 | 45237 | 0.3903 |
| 0.3896 | 888.0 | 45288 | 0.3918 |
| 0.3863 | 889.0 | 45339 | 0.3880 |
| 0.384 | 890.0 | 45390 | 0.3884 |
| 0.3844 | 891.0 | 45441 | 0.3907 |
| 0.3863 | 892.0 | 45492 | 0.3954 |
| 0.3872 | 893.0 | 45543 | 0.3919 |
| 0.3869 | 894.0 | 45594 | 0.3928 |
| 0.3801 | 895.0 | 45645 | 0.3941 |
| 0.3832 | 896.0 | 45696 | 0.3930 |
| 0.3886 | 897.0 | 45747 | 0.3933 |
| 0.3871 | 898.0 | 45798 | 0.3917 |
| 0.3892 | 899.0 | 45849 | 0.3927 |
| 0.3864 | 900.0 | 45900 | 0.3934 |
| 0.3827 | 901.0 | 45951 | 0.3916 |
| 0.3838 | 902.0 | 46002 | 0.3932 |
| 0.3859 | 903.0 | 46053 | 0.3901 |
| 0.382 | 904.0 | 46104 | 0.3918 |
| 0.3824 | 905.0 | 46155 | 0.3939 |
| 0.3799 | 906.0 | 46206 | 0.3907 |
| 0.3851 | 907.0 | 46257 | 0.3891 |
| 0.3854 | 908.0 | 46308 | 0.3885 |
| 0.3855 | 909.0 | 46359 | 0.3912 |
| 0.3855 | 910.0 | 46410 | 0.3912 |
| 0.3799 | 911.0 | 46461 | 0.3882 |
| 0.387 | 912.0 | 46512 | 0.3894 |
| 0.3792 | 913.0 | 46563 | 0.3887 |
| 0.3831 | 914.0 | 46614 | 0.3875 |
| 0.3821 | 915.0 | 46665 | 0.3863 |
| 0.3853 | 916.0 | 46716 | 0.3884 |
| 0.381 | 917.0 | 46767 | 0.3873 |
| 0.3847 | 918.0 | 46818 | 0.3850 |
| 0.3813 | 919.0 | 46869 | 0.3875 |
| 0.3853 | 920.0 | 46920 | 0.3860 |
| 0.3849 | 921.0 | 46971 | 0.3880 |
| 0.3771 | 922.0 | 47022 | 0.3891 |
| 0.3815 | 923.0 | 47073 | 0.3887 |
| 0.3827 | 924.0 | 47124 | 0.3902 |
| 0.3828 | 925.0 | 47175 | 0.3900 |
| 0.3861 | 926.0 | 47226 | 0.3915 |
| 0.383 | 927.0 | 47277 | 0.3911 |
| 0.3785 | 928.0 | 47328 | 0.3837 |
| 0.3825 | 929.0 | 47379 | 0.3879 |
| 0.3793 | 930.0 | 47430 | 0.3921 |
| 0.3836 | 931.0 | 47481 | 0.3893 |
| 0.3858 | 932.0 | 47532 | 0.3874 |
| 0.387 | 933.0 | 47583 | 0.3881 |
| 0.3855 | 934.0 | 47634 | 0.3863 |
| 0.3813 | 935.0 | 47685 | 0.3833 |
| 0.3787 | 936.0 | 47736 | 0.3876 |
| 0.3834 | 937.0 | 47787 | 0.3870 |
| 0.3807 | 938.0 | 47838 | 0.3839 |
| 0.3788 | 939.0 | 47889 | 0.3863 |
| 0.3788 | 940.0 | 47940 | 0.3847 |
| 0.3819 | 941.0 | 47991 | 0.3876 |
| 0.3814 | 942.0 | 48042 | 0.3845 |
| 0.3817 | 943.0 | 48093 | 0.3830 |
| 0.3838 | 944.0 | 48144 | 0.3880 |
| 0.3787 | 945.0 | 48195 | 0.3880 |
| 0.3812 | 946.0 | 48246 | 0.3884 |
| 0.3806 | 947.0 | 48297 | 0.3891 |
| 0.3816 | 948.0 | 48348 | 0.3855 |
| 0.3813 | 949.0 | 48399 | 0.3847 |
| 0.3811 | 950.0 | 48450 | 0.3847 |
| 0.3776 | 951.0 | 48501 | 0.3831 |
| 0.3794 | 952.0 | 48552 | 0.3867 |
| 0.3782 | 953.0 | 48603 | 0.3812 |
| 0.3834 | 954.0 | 48654 | 0.3852 |
| 0.3785 | 955.0 | 48705 | 0.3830 |
| 0.3789 | 956.0 | 48756 | 0.3852 |
| 0.3801 | 957.0 | 48807 | 0.3882 |
| 0.3771 | 958.0 | 48858 | 0.3842 |
| 0.3808 | 959.0 | 48909 | 0.3840 |
| 0.3762 | 960.0 | 48960 | 0.3849 |
| 0.3777 | 961.0 | 49011 | 0.3842 |
| 0.3781 | 962.0 | 49062 | 0.3874 |
| 0.3781 | 963.0 | 49113 | 0.3838 |
| 0.376 | 964.0 | 49164 | 0.3863 |
| 0.3777 | 965.0 | 49215 | 0.3827 |
| 0.3808 | 966.0 | 49266 | 0.3853 |
| 0.3835 | 967.0 | 49317 | 0.3869 |
| 0.3801 | 968.0 | 49368 | 0.3859 |
| 0.3839 | 969.0 | 49419 | 0.3841 |
| 0.3768 | 970.0 | 49470 | 0.3849 |
| 0.3797 | 971.0 | 49521 | 0.3844 |
| 0.3763 | 972.0 | 49572 | 0.3855 |
| 0.3788 | 973.0 | 49623 | 0.3832 |
| 0.374 | 974.0 | 49674 | 0.3858 |
| 0.3785 | 975.0 | 49725 | 0.3805 |
| 0.3752 | 976.0 | 49776 | 0.3855 |
| 0.3752 | 977.0 | 49827 | 0.3827 |
| 0.3779 | 978.0 | 49878 | 0.3826 |
| 0.3769 | 979.0 | 49929 | 0.3824 |
| 0.3778 | 980.0 | 49980 | 0.3848 |
| 0.3749 | 981.0 | 50031 | 0.3831 |
| 0.3756 | 982.0 | 50082 | 0.3879 |
| 0.3739 | 983.0 | 50133 | 0.3830 |
| 0.3769 | 984.0 | 50184 | 0.3845 |
| 0.3737 | 985.0 | 50235 | 0.3894 |
| 0.3769 | 986.0 | 50286 | 0.3815 |
| 0.373 | 987.0 | 50337 | 0.3797 |
| 0.374 | 988.0 | 50388 | 0.3827 |
| 0.3778 | 989.0 | 50439 | 0.3844 |
| 0.3773 | 990.0 | 50490 | 0.3846 |
| 0.3759 | 991.0 | 50541 | 0.3826 |
| 0.3752 | 992.0 | 50592 | 0.3843 |
| 0.3747 | 993.0 | 50643 | 0.3817 |
| 0.3781 | 994.0 | 50694 | 0.3784 |
| 0.3751 | 995.0 | 50745 | 0.3832 |
| 0.3758 | 996.0 | 50796 | 0.3800 |
| 0.3718 | 997.0 | 50847 | 0.3837 |
| 0.3745 | 998.0 | 50898 | 0.3823 |
| 0.3757 | 999.0 | 50949 | 0.3798 |
| 0.3786 | 1000.0 | 51000 | 0.3794 |
| 0.3738 | 1001.0 | 51051 | 0.3781 |
| 0.3779 | 1002.0 | 51102 | 0.3851 |
| 0.3735 | 1003.0 | 51153 | 0.3844 |
| 0.3753 | 1004.0 | 51204 | 0.3841 |
| 0.3701 | 1005.0 | 51255 | 0.3805 |
| 0.3738 | 1006.0 | 51306 | 0.3826 |
| 0.3729 | 1007.0 | 51357 | 0.3793 |
| 0.3765 | 1008.0 | 51408 | 0.3825 |
| 0.3725 | 1009.0 | 51459 | 0.3817 |
| 0.3766 | 1010.0 | 51510 | 0.3813 |
| 0.3736 | 1011.0 | 51561 | 0.3834 |
| 0.3747 | 1012.0 | 51612 | 0.3800 |
| 0.3726 | 1013.0 | 51663 | 0.3817 |
| 0.3819 | 1014.0 | 51714 | 0.3840 |
| 0.3799 | 1015.0 | 51765 | 0.3834 |
| 0.3754 | 1016.0 | 51816 | 0.3818 |
| 0.3762 | 1017.0 | 51867 | 0.3769 |
| 0.3718 | 1018.0 | 51918 | 0.3794 |
| 0.3785 | 1019.0 | 51969 | 0.3825 |
| 0.3754 | 1020.0 | 52020 | 0.3827 |
| 0.374 | 1021.0 | 52071 | 0.3818 |
| 0.3785 | 1022.0 | 52122 | 0.3780 |
| 0.3735 | 1023.0 | 52173 | 0.3815 |
| 0.3726 | 1024.0 | 52224 | 0.3794 |
| 0.3798 | 1025.0 | 52275 | 0.3787 |
| 0.3714 | 1026.0 | 52326 | 0.3810 |
| 0.3776 | 1027.0 | 52377 | 0.3787 |
| 0.3688 | 1028.0 | 52428 | 0.3771 |
| 0.375 | 1029.0 | 52479 | 0.3776 |
| 0.372 | 1030.0 | 52530 | 0.3795 |
| 0.3736 | 1031.0 | 52581 | 0.3781 |
| 0.3713 | 1032.0 | 52632 | 0.3815 |
| 0.3772 | 1033.0 | 52683 | 0.3802 |
| 0.375 | 1034.0 | 52734 | 0.3788 |
| 0.3725 | 1035.0 | 52785 | 0.3819 |
| 0.3696 | 1036.0 | 52836 | 0.3836 |
| 0.3741 | 1037.0 | 52887 | 0.3814 |
| 0.3734 | 1038.0 | 52938 | 0.3799 |
| 0.3759 | 1039.0 | 52989 | 0.3789 |
| 0.3726 | 1040.0 | 53040 | 0.3802 |
| 0.3693 | 1041.0 | 53091 | 0.3769 |
| 0.3705 | 1042.0 | 53142 | 0.3812 |
| 0.3691 | 1043.0 | 53193 | 0.3806 |
| 0.3736 | 1044.0 | 53244 | 0.3796 |
| 0.3707 | 1045.0 | 53295 | 0.3784 |
| 0.3735 | 1046.0 | 53346 | 0.3752 |
| 0.3773 | 1047.0 | 53397 | 0.3801 |
| 0.3714 | 1048.0 | 53448 | 0.3800 |
| 0.3747 | 1049.0 | 53499 | 0.3787 |
| 0.3735 | 1050.0 | 53550 | 0.3775 |
| 0.3727 | 1051.0 | 53601 | 0.3771 |
| 0.3736 | 1052.0 | 53652 | 0.3833 |
| 0.3676 | 1053.0 | 53703 | 0.3796 |
| 0.3688 | 1054.0 | 53754 | 0.3758 |
| 0.369 | 1055.0 | 53805 | 0.3775 |
| 0.3696 | 1056.0 | 53856 | 0.3811 |
| 0.3707 | 1057.0 | 53907 | 0.3776 |
| 0.3765 | 1058.0 | 53958 | 0.3804 |
| 0.3697 | 1059.0 | 54009 | 0.3813 |
| 0.3718 | 1060.0 | 54060 | 0.3722 |
| 0.3699 | 1061.0 | 54111 | 0.3771 |
| 0.3725 | 1062.0 | 54162 | 0.3780 |
| 0.3705 | 1063.0 | 54213 | 0.3767 |
| 0.3698 | 1064.0 | 54264 | 0.3783 |
| 0.374 | 1065.0 | 54315 | 0.3775 |
| 0.3665 | 1066.0 | 54366 | 0.3813 |
| 0.3695 | 1067.0 | 54417 | 0.3801 |
| 0.3705 | 1068.0 | 54468 | 0.3805 |
| 0.3709 | 1069.0 | 54519 | 0.3780 |
| 0.3762 | 1070.0 | 54570 | 0.3758 |
| 0.3718 | 1071.0 | 54621 | 0.3801 |
| 0.3736 | 1072.0 | 54672 | 0.3769 |
| 0.3702 | 1073.0 | 54723 | 0.3763 |
| 0.3716 | 1074.0 | 54774 | 0.3791 |
| 0.3684 | 1075.0 | 54825 | 0.3745 |
| 0.3682 | 1076.0 | 54876 | 0.3796 |
| 0.3699 | 1077.0 | 54927 | 0.3784 |
| 0.3745 | 1078.0 | 54978 | 0.3794 |
| 0.3721 | 1079.0 | 55029 | 0.3780 |
| 0.3758 | 1080.0 | 55080 | 0.3792 |
| 0.3742 | 1081.0 | 55131 | 0.3781 |
| 0.3693 | 1082.0 | 55182 | 0.3819 |
| 0.3676 | 1083.0 | 55233 | 0.3746 |
| 0.3684 | 1084.0 | 55284 | 0.3812 |
| 0.3727 | 1085.0 | 55335 | 0.3745 |
| 0.3689 | 1086.0 | 55386 | 0.3743 |
| 0.3704 | 1087.0 | 55437 | 0.3785 |
| 0.3664 | 1088.0 | 55488 | 0.3774 |
| 0.3704 | 1089.0 | 55539 | 0.3757 |
| 0.3702 | 1090.0 | 55590 | 0.3790 |
| 0.3747 | 1091.0 | 55641 | 0.3798 |
| 0.3704 | 1092.0 | 55692 | 0.3756 |
| 0.3749 | 1093.0 | 55743 | 0.3783 |
| 0.3686 | 1094.0 | 55794 | 0.3759 |
| 0.369 | 1095.0 | 55845 | 0.3762 |
| 0.3671 | 1096.0 | 55896 | 0.3783 |
| 0.3686 | 1097.0 | 55947 | 0.3780 |
| 0.3693 | 1098.0 | 55998 | 0.3778 |
| 0.3728 | 1099.0 | 56049 | 0.3759 |
| 0.3715 | 1100.0 | 56100 | 0.3777 |
| 0.3712 | 1101.0 | 56151 | 0.3775 |
| 0.3695 | 1102.0 | 56202 | 0.3767 |
| 0.3715 | 1103.0 | 56253 | 0.3762 |
| 0.3728 | 1104.0 | 56304 | 0.3775 |
| 0.368 | 1105.0 | 56355 | 0.3783 |
| 0.3705 | 1106.0 | 56406 | 0.3797 |
| 0.3705 | 1107.0 | 56457 | 0.3771 |
| 0.3734 | 1108.0 | 56508 | 0.3754 |
| 0.3701 | 1109.0 | 56559 | 0.3793 |
| 0.3707 | 1110.0 | 56610 | 0.3729 |
| 0.3677 | 1111.0 | 56661 | 0.3763 |
| 0.3734 | 1112.0 | 56712 | 0.3813 |
| 0.3714 | 1113.0 | 56763 | 0.3772 |
| 0.3654 | 1114.0 | 56814 | 0.3765 |
| 0.3692 | 1115.0 | 56865 | 0.3757 |
| 0.3721 | 1116.0 | 56916 | 0.3749 |
| 0.3741 | 1117.0 | 56967 | 0.3769 |
| 0.3649 | 1118.0 | 57018 | 0.3806 |
| 0.3709 | 1119.0 | 57069 | 0.3720 |
| 0.3721 | 1120.0 | 57120 | 0.3794 |
| 0.3701 | 1121.0 | 57171 | 0.3748 |
| 0.3674 | 1122.0 | 57222 | 0.3787 |
| 0.3669 | 1123.0 | 57273 | 0.3736 |
| 0.3726 | 1124.0 | 57324 | 0.3789 |
| 0.3672 | 1125.0 | 57375 | 0.3774 |
| 0.3674 | 1126.0 | 57426 | 0.3778 |
| 0.3702 | 1127.0 | 57477 | 0.3772 |
| 0.3717 | 1128.0 | 57528 | 0.3766 |
| 0.3703 | 1129.0 | 57579 | 0.3757 |
| 0.3695 | 1130.0 | 57630 | 0.3808 |
| 0.3729 | 1131.0 | 57681 | 0.3721 |
| 0.3657 | 1132.0 | 57732 | 0.3784 |
| 0.3676 | 1133.0 | 57783 | 0.3793 |
| 0.3684 | 1134.0 | 57834 | 0.3797 |
| 0.3703 | 1135.0 | 57885 | 0.3771 |
| 0.3705 | 1136.0 | 57936 | 0.3752 |
| 0.3691 | 1137.0 | 57987 | 0.3773 |
| 0.3673 | 1138.0 | 58038 | 0.3766 |
| 0.3715 | 1139.0 | 58089 | 0.3779 |
| 0.37 | 1140.0 | 58140 | 0.3750 |
| 0.3709 | 1141.0 | 58191 | 0.3786 |
| 0.3696 | 1142.0 | 58242 | 0.3776 |
| 0.3752 | 1143.0 | 58293 | 0.3758 |
| 0.3675 | 1144.0 | 58344 | 0.3762 |
| 0.3681 | 1145.0 | 58395 | 0.3741 |
| 0.3684 | 1146.0 | 58446 | 0.3794 |
| 0.3663 | 1147.0 | 58497 | 0.3720 |
| 0.3712 | 1148.0 | 58548 | 0.3742 |
| 0.3672 | 1149.0 | 58599 | 0.3786 |
| 0.369 | 1150.0 | 58650 | 0.3737 |
| 0.3648 | 1151.0 | 58701 | 0.3767 |
| 0.3704 | 1152.0 | 58752 | 0.3740 |
| 0.3695 | 1153.0 | 58803 | 0.3781 |
| 0.3707 | 1154.0 | 58854 | 0.3753 |
| 0.3661 | 1155.0 | 58905 | 0.3774 |
| 0.367 | 1156.0 | 58956 | 0.3763 |
| 0.3657 | 1157.0 | 59007 | 0.3767 |
| 0.3638 | 1158.0 | 59058 | 0.3738 |
| 0.3728 | 1159.0 | 59109 | 0.3732 |
| 0.3748 | 1160.0 | 59160 | 0.3787 |
| 0.3753 | 1161.0 | 59211 | 0.3743 |
| 0.3663 | 1162.0 | 59262 | 0.3758 |
| 0.3694 | 1163.0 | 59313 | 0.3772 |
| 0.3657 | 1164.0 | 59364 | 0.3763 |
| 0.3643 | 1165.0 | 59415 | 0.3770 |
| 0.3679 | 1166.0 | 59466 | 0.3772 |
| 0.37 | 1167.0 | 59517 | 0.3724 |
| 0.3693 | 1168.0 | 59568 | 0.3752 |
| 0.3705 | 1169.0 | 59619 | 0.3732 |
| 0.3671 | 1170.0 | 59670 | 0.3767 |
| 0.3729 | 1171.0 | 59721 | 0.3723 |
| 0.3701 | 1172.0 | 59772 | 0.3768 |
| 0.3717 | 1173.0 | 59823 | 0.3782 |
| 0.3716 | 1174.0 | 59874 | 0.3721 |
| 0.3723 | 1175.0 | 59925 | 0.3712 |
| 0.3674 | 1176.0 | 59976 | 0.3746 |
| 0.365 | 1177.0 | 60027 | 0.3768 |
| 0.3725 | 1178.0 | 60078 | 0.3760 |
| 0.3679 | 1179.0 | 60129 | 0.3742 |
| 0.3707 | 1180.0 | 60180 | 0.3753 |
| 0.3698 | 1181.0 | 60231 | 0.3730 |
| 0.3697 | 1182.0 | 60282 | 0.3748 |
| 0.368 | 1183.0 | 60333 | 0.3722 |
| 0.3689 | 1184.0 | 60384 | 0.3724 |
| 0.3667 | 1185.0 | 60435 | 0.3731 |
| 0.3708 | 1186.0 | 60486 | 0.3785 |
| 0.3684 | 1187.0 | 60537 | 0.3755 |
| 0.3701 | 1188.0 | 60588 | 0.3774 |
| 0.3685 | 1189.0 | 60639 | 0.3733 |
| 0.37 | 1190.0 | 60690 | 0.3773 |
| 0.372 | 1191.0 | 60741 | 0.3761 |
| 0.3677 | 1192.0 | 60792 | 0.3733 |
| 0.367 | 1193.0 | 60843 | 0.3770 |
| 0.3641 | 1194.0 | 60894 | 0.3731 |
| 0.3679 | 1195.0 | 60945 | 0.3739 |
| 0.3709 | 1196.0 | 60996 | 0.3731 |
| 0.3668 | 1197.0 | 61047 | 0.3784 |
| 0.3678 | 1198.0 | 61098 | 0.3754 |
| 0.3642 | 1199.0 | 61149 | 0.3795 |
| 0.3717 | 1200.0 | 61200 | 0.3766 |
### Framework versions
- Transformers 4.27.0.dev0
- Pytorch 1.13.0
- Datasets 2.8.0
- Tokenizers 0.13.2
|
azamat/mapper | azamat | 2023-02-14T19:30:12Z | 2 | 0 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
]
| sentence-similarity | 2023-02-14T16:19:26Z | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('{MODEL_NAME}')
model = AutoModel.from_pretrained('{MODEL_NAME}')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 2471 with parameters:
```
{'batch_size': 512, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.ContrastiveLoss.ContrastiveLoss` with parameters:
```
{'distance_metric': 'SiameseDistanceMetric.COSINE_DISTANCE', 'margin': 0.5, 'size_average': True}
```
Parameters of the fit()-Method:
```
{
"epochs": 4,
"evaluation_steps": 1000,
"evaluator": "sentence_transformers.evaluation.BinaryClassificationEvaluator.BinaryClassificationEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 100,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
shaiman12/flan-t5-base-samsum | shaiman12 | 2023-02-14T19:29:12Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:samsum",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2023-02-14T16:47:42Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- samsum
metrics:
- rouge
model-index:
- name: flan-t5-base-samsum
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: samsum
type: samsum
config: samsum
split: test
args: samsum
metrics:
- name: Rouge1
type: rouge
value: 47.5929
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# flan-t5-base-samsum
This model is a fine-tuned version of [google/flan-t5-base](https://huggingface.co/google/flan-t5-base) on the samsum dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3776
- Rouge1: 47.5929
- Rouge2: 23.8272
- Rougel: 40.1493
- Rougelsum: 43.7798
- Gen Len: 17.2503
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| 1.4416 | 1.0 | 1842 | 1.3837 | 46.6013 | 23.125 | 39.4894 | 42.9943 | 17.0684 |
| 1.3581 | 2.0 | 3684 | 1.3730 | 47.3142 | 23.5981 | 39.5786 | 43.447 | 17.3675 |
| 1.2781 | 3.0 | 5526 | 1.3739 | 47.5321 | 23.8035 | 40.0555 | 43.7595 | 17.2271 |
| 1.2368 | 4.0 | 7368 | 1.3767 | 47.0944 | 23.2414 | 39.6673 | 43.2155 | 17.2405 |
| 1.1953 | 5.0 | 9210 | 1.3776 | 47.5929 | 23.8272 | 40.1493 | 43.7798 | 17.2503 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.12.1
- Datasets 2.9.0
- Tokenizers 0.13.2
|
pete88b/q-Taxi-v3-0.0.1 | pete88b | 2023-02-14T19:24:03Z | 0 | 0 | null | [
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-02-14T19:24:01Z | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3-0.0.1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="pete88b/q-Taxi-v3-0.0.1", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
civility-lab/roberta-base-namecalling | civility-lab | 2023-02-14T19:18:42Z | 14,385 | 2 | transformers | [
"transformers",
"pytorch",
"roberta",
"text-classification",
"incivility",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2023-02-13T17:54:29Z | ---
language:
- en
license: apache-2.0
library_name: transformers
tags:
- incivility
metrics:
- f1
widget:
- text: "Be careful around those DemocRats."
example_title: "Namecall"
- text: "Be careful around those Democrats."
example_title: "No Namecall"
---
# Model Card for roberta-base-namecalling
This is a [roBERTa-base](https://huggingface.co/roberta-base) model fine-tuned on ~12K social media posts annotated for the presence or absence of namecalling.
# How to Get Started with the Model
You can use this model directly with a pipeline for text classification:
```python
>>> import transformers
>>> model_name = "civility-lab/roberta-base-namecalling"
>>> classifier = transformers.TextClassificationPipeline(
... tokenizer=transformers.AutoTokenizer.from_pretrained(model_name),
... model=transformers.AutoModelForSequenceClassification.from_pretrained(model_name))
>>> classifier("Be careful around those Democrats.")
[{'label': 'not-namecalling', 'score': 0.9995089769363403}]
>>> classifier("Be careful around those DemocRats.")
[{'label': 'namecalling', 'score': 0.996940016746521}]
```
# Model Details
This is a 2023 update of the model built by [Ozler et al. (2020)](https://aclanthology.org/2020.alw-1.4/) incorporating data from [Rains et al. (2021)](https://doi.org/10.1093/hcr/hqab009) and using a more recent version of the transformers library.
- **Developed by:**
[Steven Bethard](https://bethard.github.io/),
[Kate Kenski](https://comm.arizona.edu/user/kate-kenski),
[Steve Rains](https://comm.arizona.edu/user/steve-rains),
[Yotam Shmargad](https://www.yotamshmargad.com/),
[Kevin Coe](https://faculty.utah.edu/u0915886-Kevin_Coe/)
- **Language:** en
- **License:** apache-2.0
- **Parent Model:** roberta-base
- **Resources for more information:**
- [GitHub Repo](https://github.com/clulab/incivility)
- Kadir Bulut Ozler; Kate Kenski; Steve Rains; Yotam Shmargad; Kevin Coe; and Steven Bethard. [Fine-tuning for multi-domain and multi-label uncivil language detection](https://aclanthology.org/2020.alw-1.4/). In Proceedings of the Fourth Workshop on Online Abuse and Harms, pages 28–33, Online, November 2020. Association for Computational Linguistics
- Stephen A Rains; Yotam Shmargad; Kevin Coe; Kate Kenski; and Steven Bethard. [Assessing the Russian Troll Efforts to Sow Discord on Twitter during the 2016 U.S. Election](https://doi.org/10.1093/hcr/hqab009). Human Communication Research, 47(4): 477-486. 08 2021.
- Stephen A Rains; Jake Harwood; Yotam Shmargad; Kate Kenski; Kevin Coe; and Steven Bethard. [Engagement with partisan Russian troll tweets during the 2016 U.S. presidential election: a social identity perspective](https://doi.org/10.1093/joc/jqac037). Journal of Communication, 73(1): 38-48. 02 2023.
# Uses
The model is intended to be used for text classification, taking as input social media posts and predicting as output whether the post contains namecalling.
It is not intended to generate namecalling, and it should not be used as part of any incivility generation model.
# Training Details
The model was trained on data from four sources: comments on the Arizona Daily Star website from 2011, Russian troll Tweets from 2012-2018, Tucson politician Tweets from 2018, and US presidential primary Tweets from 2019.
Each dataset was annotated for the presence of namecalling following the approach of [Coe et al. (2014)](https://doi.org/10.1111/jcom.12104) and split into training, development, and test partitions.
The [roberta-base](https://huggingface.co/roberta-base) model was fine-tuned on the combined training partitions from all four datasets, with texts tokenized using the standard [roberta-base](https://huggingface.co/roberta-base) tokenizer.
# Evaluation
The model was evaluated on the test partition of each of the datasets. It achieves the following F1 scores:
- 0.58 F1 on Arizona Daily Star comments
- 0.71 F1 on Russian troll Tweets
- 0.71 F1 on Tucson politician Tweets
- 0.81 F1 on US presidential primary Tweets
# Limitations and Biases
The human coders and their trainers were mostly [Western, educated, industrialized, rich and democratic (WEIRD)](https://www.nature.com/articles/466029a), which may have shaped how they evaluated incivility.
The trained models will reflect such biases.
# Environmental Impact
- **Hardware Type:** Tesla V100S-PCIE-32GB
- **Hours used:** 22
- **HPC Provider:** <https://hpc.arizona.edu/>
- **Carbon Emitted:** 2.85 kg CO2 (estimated by [ML CO2 Impact](https://mlco2.github.io/impact#compute))
# Citation
```bibtex
@inproceedings{ozler-etal-2020-fine,
title = "Fine-tuning for multi-domain and multi-label uncivil language detection",
author = "Ozler, Kadir Bulut and
Kenski, Kate and
Rains, Steve and
Shmargad, Yotam and
Coe, Kevin and
Bethard, Steven",
booktitle = "Proceedings of the Fourth Workshop on Online Abuse and Harms",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.alw-1.4",
doi = "10.18653/v1/2020.alw-1.4",
pages = "28--33",
}
```
|
kaloyloyloyloy/wav2vec2-base-finetuned-ks | kaloyloyloyloy | 2023-02-14T19:14:46Z | 163 | 0 | transformers | [
"transformers",
"pytorch",
"wav2vec2",
"audio-classification",
"generated_from_trainer",
"dataset:superb",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| audio-classification | 2023-02-14T15:47:52Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- superb
metrics:
- accuracy
model-index:
- name: wav2vec2-base-finetuned-ks
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-finetuned-ks
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the superb dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5492
- Accuracy: 0.6209
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.4528 | 1.0 | 399 | 1.5492 | 0.6209 |
| 1.5591 | 2.0 | 798 | 1.5411 | 0.6209 |
| 1.4814 | 3.0 | 1197 | 1.5397 | 0.6209 |
| 1.4528 | 4.0 | 1596 | 1.5412 | 0.6209 |
| 1.4829 | 5.0 | 1995 | 1.5395 | 0.6209 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1
- Datasets 2.9.0
- Tokenizers 0.13.2
|
Ahmed-ibn-Harun/es_pipeline | Ahmed-ibn-Harun | 2023-02-14T18:53:10Z | 1 | 0 | spacy | [
"spacy",
"token-classification",
"es",
"model-index",
"region:us"
]
| token-classification | 2023-02-14T18:52:47Z | ---
tags:
- spacy
- token-classification
language:
- es
model-index:
- name: es_pipeline
results:
- task:
name: NER
type: token-classification
metrics:
- name: NER Precision
type: precision
value: 0.9937984496
- name: NER Recall
type: recall
value: 0.9953416149
- name: NER F Score
type: f_score
value: 0.9945694337
---
| Feature | Description |
| --- | --- |
| **Name** | `es_pipeline` |
| **Version** | `0.0.0` |
| **spaCy** | `>=3.5.0,<3.6.0` |
| **Default Pipeline** | `tok2vec`, `ner` |
| **Components** | `tok2vec`, `ner` |
| **Vectors** | 0 keys, 0 unique vectors (0 dimensions) |
| **Sources** | n/a |
| **License** | n/a |
| **Author** | [n/a]() |
### Label Scheme
<details>
<summary>View label scheme (3 labels for 1 components)</summary>
| Component | Labels |
| --- | --- |
| **`ner`** | `NOUN`, `PNOUN`, `VERB` |
</details>
### Accuracy
| Type | Score |
| --- | --- |
| `ENTS_F` | 99.46 |
| `ENTS_P` | 99.38 |
| `ENTS_R` | 99.53 |
| `TOK2VEC_LOSS` | 8110.20 |
| `NER_LOSS` | 35115.85 | |
dwchris/dqn-SpaceInvadersNoFrameskip-v4 | dwchris | 2023-02-14T18:48:16Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-02-14T18:47:42Z | ---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 14.50 +/- 12.34
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga dwchris -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga dwchris -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga dwchris
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 15000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
|
badalsahani/text-classification-multi | badalsahani | 2023-02-14T17:59:32Z | 10 | 7 | transformers | [
"transformers",
"pytorch",
"bert",
"text-classification",
"autotrain",
"en",
"dataset:badalsahani/autotrain-data-text-classification",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2023-02-14T17:32:19Z | ---
tags:
- autotrain
- text-classification
language:
- en
widget:
- text: "I love AutoTrain 🤗"
datasets:
- badalsahani/autotrain-data-text-classification
co2_eq_emissions:
emissions: 7.761992510873142
---
# Model Trained Using AutoTrain
- Problem type: Multi-class Classification
- Model ID: 3486594647
- CO2 Emissions (in grams): 7.7620
## Validation Metrics
- Loss: 0.008
- Accuracy: 1.000
- Macro F1: 1.000
- Micro F1: 1.000
- Weighted F1: 1.000
- Macro Precision: 1.000
- Micro Precision: 1.000
- Weighted Precision: 1.000
- Macro Recall: 1.000
- Micro Recall: 1.000
- Weighted Recall: 1.000
## Usage
You can use cURL to access this model:
```curl
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/badalsahani/text-classification-multi
```
Or Python API:
```python
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("badalsahani/text-classification-multi", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("badalsahani/text-classification-multi", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
``` |
darkwolfsam/dqn-SpaceInvadersNoFrameskip-v4 | darkwolfsam | 2023-02-14T17:44:13Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-02-03T21:20:18Z | ---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 229.50 +/- 55.79
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga darkwolfsam -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga darkwolfsam -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga darkwolfsam
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 150000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
|
Zekunli/t5-base-da-multiwoz2.1_500 | Zekunli | 2023-02-14T17:42:14Z | 106 | 0 | transformers | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"generated_from_trainer",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2023-02-14T17:25:23Z | ---
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: t5-base-da-multiwoz2.1_500
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-base-da-multiwoz2.1_500
This model was trained from scratch on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4253
- Accuracy: 22.6359
- Num: 3689
- Gen Len: 15.4806
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 24
- eval_batch_size: 48
- seed: 1799
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Num | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:----:|:-------:|
| 0.5137 | 2.78 | 400 | 0.4454 | 21.1276 | 3689 | 15.569 |
| 0.4673 | 5.56 | 800 | 0.4329 | 21.7406 | 3689 | 15.4573 |
| 0.4591 | 8.33 | 1200 | 0.4253 | 22.6359 | 3689 | 15.4806 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.10.0+cu111
- Datasets 2.5.1
- Tokenizers 0.12.1
|
Zekunli/t5-base-extraction-cnndm_10000-all | Zekunli | 2023-02-14T17:38:04Z | 3 | 0 | transformers | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"generated_from_trainer",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2023-02-14T17:01:07Z | ---
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: t5-base-extraction-cnndm_10000-all
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-base-extraction-cnndm_10000-all
This model was trained from scratch on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.8182
- Rouge1: 33.8286
- Rouge2: 14.4919
- Rougel: 28.8935
- Rougelsum: 28.9581
- Gen Len: 19.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 24
- eval_batch_size: 48
- seed: 1799
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| 1.9662 | 0.48 | 200 | 1.9092 | 33.2564 | 14.236 | 28.2044 | 28.3269 | 18.992 |
| 1.9495 | 0.96 | 400 | 1.8775 | 33.7516 | 14.2246 | 28.9019 | 28.9507 | 19.0 |
| 1.9062 | 1.44 | 600 | 1.8580 | 33.7533 | 14.2196 | 28.3873 | 28.4658 | 19.0 |
| 1.8713 | 1.92 | 800 | 1.8496 | 33.6921 | 14.4532 | 28.5695 | 28.6573 | 19.0 |
| 1.85 | 2.4 | 1000 | 1.8327 | 34.1551 | 14.7671 | 28.9492 | 28.9885 | 19.0 |
| 1.8232 | 2.88 | 1200 | 1.8182 | 33.8286 | 14.4919 | 28.8935 | 28.9581 | 19.0 |
| 1.8004 | 3.36 | 1400 | 1.8299 | 34.5099 | 14.8659 | 29.1119 | 29.1544 | 19.0 |
| 1.7832 | 3.84 | 1600 | 1.8252 | 34.5877 | 15.1259 | 29.3368 | 29.3638 | 19.0 |
| 1.7677 | 4.32 | 1800 | 1.8226 | 34.4487 | 15.0361 | 29.2962 | 29.3431 | 19.0 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.10.0+cu111
- Datasets 2.5.1
- Tokenizers 0.12.1
|
albburtsev/faucet-v2-1 | albburtsev | 2023-02-14T16:51:22Z | 29 | 1 | diffusers | [
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
]
| text-to-image | 2023-02-14T16:40:51Z | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### faucet-v2.1 Dreambooth model trained by albburtsev with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
|
drnkwtr/Malware_Spectrogram_Prediction | drnkwtr | 2023-02-14T16:38:21Z | 0 | 0 | null | [
"license:openrail",
"region:us"
]
| null | 2023-02-14T15:15:53Z | ---
license: openrail
---
This model is trained on spectrograms of malwares. It is supposed to make a prediction.
POST /image - accepts an image in binary format, either as an octet-stream file, or as a multipart/form-data with files in the imageData parameter. The server loads the image using the Python Imaging Library, runs it through the predict_image function from the predict module (not shown), and returns the results as a JSON object.
POST /url - accepts a JSON object containing a URL to an image. The server loads the image using the predict_url function from the predict module, and returns the results as a JSON object. |
aioe/anysium_anypas | aioe | 2023-02-14T16:11:45Z | 0 | 7 | null | [
"text-to-image",
"art",
"stable diffusion",
"ja",
"en",
"license:other",
"region:us"
]
| text-to-image | 2023-02-14T10:21:57Z | ---
license: other
language:
- ja
- en
tags:
- text-to-image
- art
- stable diffusion
---
# 【概要(Outline)】
コンセプトは<strong>「儚さ」</strong>です。
<br>
1つはElysium特有の線の細さを活かしたマージモデル、もう1つはpastelmix特有の色味を活かしたマージモデルとなっています。
<br>
<br>
The concept is <strong>"like disappearing."</strong>
<br>
One is the marge model by the feature of thin outline of Elysium, and another is the marge model by the feature of unique colors of pastelmix.
<br>
<br>
# 【モデル紹介とマージ素材(Models introduction and merged materials)】
<strong>*■anysium-v1.0*</strong>
<br>
・anything-v4.5
<br>
・Elysium_Anime_V3
<br>
→線の細さが特徴的です。
<br>
(The feature is thin outline.)
<br>
<br>
<strong>*■anypas-v1.0*</strong>
<br>
・anything-v4.5
<br>
・pastelmix
<br>
→pastelmix風の色味が特徴的です。
<br>
(The feature is like colors of pastelmix.)
<br>
<br>
# 【推奨設定(Recommended settings)】
<strong>*■anysium-v1.0*</strong>
<br>
・Steps:20
<br>
・CFG Scale:5.5
<br>
・Clip Skip:2
<br>
・Negative:(worst quality, low quality:1.2),
<br>
<br>
<strong>*■anypas-v1.0*</strong>
<br>
・Steps:30
<br>
・CFG Scale:10
<br>
・Clip Skip:2
<br>
・Negative:(worst quality, low quality, poorly eyes:1.2),
<br>
<br>
# 【作例(Examples)】
Positive:one girl,
<br>
<br>
<strong>*■anysium-v1.0*</strong>
<img src="https://imgur.com/B4fPJul.png" width="1152" height="768">
<br>
<strong>*■anypas-v1.0*</strong>
<img src="https://imgur.com/AdkCtC0.png" width="1152" height="768">
<br>
<br>
Positive:(one little and cute girl:1.2), (loli), (solo:1.3), (masterpiece), (best quality), the girl wearing (white headdress), (frilled white capelet:1.2), (short sleeves), (short white gloves), (intricate and gorgeous frilled white dress with gold decoration), the girl has (long blonde hair), [[[blue eyes]]], the background is large western style garden, (many colorful flowers), trees, birds,
<br>
<br>
<strong>*■anysium-v1.0*</strong>
<img src="https://imgur.com/f903ASm.jpg" width="1152" height="768">
<br>
<strong>*■anypas-v1.0*</strong>
<img src="https://imgur.com/hkeyhX2.jpg" width="1152" height="768"> |
pyflynn/dqn-SpaceInvadersNoFrameskip-v4 | pyflynn | 2023-02-14T16:09:20Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-02-14T16:08:37Z | ---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 608.50 +/- 150.13
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga pyflynn -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga pyflynn -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga pyflynn
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 5e-05),
('learning_starts', 100000),
('n_timesteps', 1000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
|
khiyza/PPO-LunarLander-v2 | khiyza | 2023-02-14T15:59:31Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-02-14T15:59:07Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 241.80 +/- 24.27
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
bofenghuang/whisper-large-v2-cv11-french | bofenghuang | 2023-02-14T15:17:59Z | 7 | 5 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"whisper",
"automatic-speech-recognition",
"hf-asr-leaderboard",
"whisper-event",
"fr",
"dataset:mozilla-foundation/common_voice_11_0",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2023-01-05T16:50:41Z | ---
license: apache-2.0
language: fr
library_name: transformers
thumbnail: null
tags:
- automatic-speech-recognition
- hf-asr-leaderboard
- whisper-event
datasets:
- mozilla-foundation/common_voice_11_0
metrics:
- wer
model-index:
- name: Fine-tuned whisper-large-v2 model for ASR in French
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 11.0
type: mozilla-foundation/common_voice_11_0
config: fr
split: test
args: fr
metrics:
- name: WER (Greedy)
type: wer
value: 8.05
- name: WER (Beam 5)
type: wer
value: 7.67
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Multilingual LibriSpeech (MLS)
type: facebook/multilingual_librispeech
config: french
split: test
args: french
metrics:
- name: WER (Greedy)
type: wer
value: 5.56
- name: WER (Beam 5)
type: wer
value: 5.28
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: VoxPopuli
type: facebook/voxpopuli
config: fr
split: test
args: fr
metrics:
- name: WER (Greedy)
type: wer
value: 11.50
- name: WER (Beam 5)
type: wer
value: 10.69
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Fleurs
type: google/fleurs
config: fr_fr
split: test
args: fr_fr
metrics:
- name: WER (Greedy)
type: wer
value: 5.42
- name: WER (Beam 5)
type: wer
value: 5.05
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: African Accented French
type: gigant/african_accented_french
config: fr
split: test
args: fr
metrics:
- name: WER (Greedy)
type: wer
value: 6.47
- name: WER (Beam 5)
type: wer
value: 5.95
---
<style>
img {
display: inline;
}
</style>



# Fine-tuned whisper-large-v2 model for ASR in French
This model is a fine-tuned version of [openai/whisper-large-v2](https://huggingface.co/openai/whisper-large-v2), trained on the mozilla-foundation/common_voice_11_0 fr dataset. When using the model make sure that your speech input is also sampled at 16Khz. **This model also predicts casing and punctuation.**
## Performance
*Below are the WERs of the pre-trained models on the [Common Voice 9.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_9_0), [Multilingual LibriSpeech](https://huggingface.co/datasets/facebook/multilingual_librispeech), [Voxpopuli](https://github.com/facebookresearch/voxpopuli) and [Fleurs](https://huggingface.co/datasets/google/fleurs). These results are reported in the original [paper](https://cdn.openai.com/papers/whisper.pdf).*
| Model | Common Voice 9.0 | MLS | VoxPopuli | Fleurs |
| --- | :---: | :---: | :---: | :---: |
| [openai/whisper-small](https://huggingface.co/openai/whisper-small) | 22.7 | 16.2 | 15.7 | 15.0 |
| [openai/whisper-medium](https://huggingface.co/openai/whisper-medium) | 16.0 | 8.9 | 12.2 | 8.7 |
| [openai/whisper-large](https://huggingface.co/openai/whisper-large) | 14.7 | 8.9 | **11.0** | **7.7** |
| [openai/whisper-large-v2](https://huggingface.co/openai/whisper-large-v2) | **13.9** | **7.3** | 11.4 | 8.3 |
*Below are the WERs of the fine-tuned models on the [Common Voice 11.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_11_0), [Multilingual LibriSpeech](https://huggingface.co/datasets/facebook/multilingual_librispeech), [Voxpopuli](https://github.com/facebookresearch/voxpopuli), and [Fleurs](https://huggingface.co/datasets/google/fleurs). Note that these evaluation datasets have been filtered and preprocessed to only contain French alphabet characters and are removed of punctuation outside of apostrophe. The results in the table are reported as `WER (greedy search) / WER (beam search with beam width 5)`.*
| Model | Common Voice 11.0 | MLS | VoxPopuli | Fleurs |
| --- | :---: | :---: | :---: | :---: |
| [bofenghuang/whisper-small-cv11-french](https://huggingface.co/bofenghuang/whisper-small-cv11-french) | 11.76 / 10.99 | 9.65 / 8.91 | 14.45 / 13.66 | 10.76 / 9.83 |
| [bofenghuang/whisper-medium-cv11-french](https://huggingface.co/bofenghuang/whisper-medium-cv11-french) | 9.03 / 8.54 | 6.34 / 5.86 | 11.64 / 11.35 | 7.13 / 6.85 |
| [bofenghuang/whisper-medium-french](https://huggingface.co/bofenghuang/whisper-medium-french) | 9.03 / 8.73 | 4.60 / 4.44 | 9.53 / 9.46 | 6.33 / 5.94 |
| [bofenghuang/whisper-large-v2-cv11-french](https://huggingface.co/bofenghuang/whisper-large-v2-cv11-french) | **8.05** / **7.67** | 5.56 / 5.28 | 11.50 / 10.69 | 5.42 / 5.05 |
| [bofenghuang/whisper-large-v2-french](https://huggingface.co/bofenghuang/whisper-large-v2-french) | 8.15 / 7.83 | **4.20** / **4.03** | **9.10** / **8.66** | **5.22** / **4.98** |
## Usage
Inference with 🤗 Pipeline
```python
import torch
from datasets import load_dataset
from transformers import pipeline
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# Load pipeline
pipe = pipeline("automatic-speech-recognition", model="bofenghuang/whisper-large-v2-cv11-french", device=device)
# NB: set forced_decoder_ids for generation utils
pipe.model.config.forced_decoder_ids = pipe.tokenizer.get_decoder_prompt_ids(language="fr", task="transcribe")
# Load data
ds_mcv_test = load_dataset("mozilla-foundation/common_voice_11_0", "fr", split="test", streaming=True)
test_segment = next(iter(ds_mcv_test))
waveform = test_segment["audio"]
# Run
generated_sentences = pipe(waveform, max_new_tokens=225)["text"] # greedy
# generated_sentences = pipe(waveform, max_new_tokens=225, generate_kwargs={"num_beams": 5})["text"] # beam search
# Normalise predicted sentences if necessary
```
Inference with 🤗 low-level APIs
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import AutoProcessor, AutoModelForSpeechSeq2Seq
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# Load model
model = AutoModelForSpeechSeq2Seq.from_pretrained("bofenghuang/whisper-large-v2-cv11-french").to(device)
processor = AutoProcessor.from_pretrained("bofenghuang/whisper-large-v2-cv11-french", language="french", task="transcribe")
# NB: set forced_decoder_ids for generation utils
model.config.forced_decoder_ids = processor.get_decoder_prompt_ids(language="fr", task="transcribe")
# 16_000
model_sample_rate = processor.feature_extractor.sampling_rate
# Load data
ds_mcv_test = load_dataset("mozilla-foundation/common_voice_11_0", "fr", split="test", streaming=True)
test_segment = next(iter(ds_mcv_test))
waveform = torch.from_numpy(test_segment["audio"]["array"])
sample_rate = test_segment["audio"]["sampling_rate"]
# Resample
if sample_rate != model_sample_rate:
resampler = torchaudio.transforms.Resample(sample_rate, model_sample_rate)
waveform = resampler(waveform)
# Get feat
inputs = processor(waveform, sampling_rate=model_sample_rate, return_tensors="pt")
input_features = inputs.input_features
input_features = input_features.to(device)
# Generate
generated_ids = model.generate(inputs=input_features, max_new_tokens=225) # greedy
# generated_ids = model.generate(inputs=input_features, max_new_tokens=225, num_beams=5) # beam search
# Detokenize
generated_sentences = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
# Normalise predicted sentences if necessary
``` |
mocker/KaBoom | mocker | 2023-02-14T15:09:06Z | 0 | 128 | null | [
"art",
"en",
"license:creativeml-openrail-m",
"region:us"
]
| null | 2023-02-06T23:47:49Z | ---
license: creativeml-openrail-m
language:
- en
tags:
- art
---
# In short,
- FaceBomb : Covers from anime to 2.5D style. Suited for general use.
- recipe : 0.5((0.5(AbyssOrangeMix2_hard) + 0.5(pastelmix-better-vae-fp32)) + 0.5(CounterfeitV25_25)) + 0.5(dalcefoV3Painting_dalcefoV3Painting)
- ColorBomb : FaceBomb + vivid color and lighting. A bit picky about prompts.
- recipe : dalcefoV3Painting_dalcefoV3Painting + 0.5(ultracolorV4_ultracolorV4 - CounterfeitV25_25)
- HyperBomb : Strong anime style w/ highly saturated color.
- recipe : 0.5((0.5(AbyssOrangeMix2_hard) + 0.5(pastelmix-better-vae-fp32)) + 0.5(CounterfeitV25_25)) + 0.5(dalcefoV3Painting_dalcefoV3Painting) + 0.3(0.8(pastelMixStylizedAnime_pastelMixPrunedFP16) + 0.2(CounterfeitV25_25) - f222)
# Recommended Setting
## VAE
- If the color appears dull or washed out, try applying VAE. I used `kl-f8-anime2`
- https://huggingface.co/hakurei/waifu-diffusion-v1-4/blob/main/vae/kl-f8-anime2.ckpt
## Sampling method and Hires.fix
1. `DPM++ SDE Karras: 24~32 steps` / `R-ESRGAN 4x+ Anime6B: 2x, 14 steps` / `Denoising strength:0.45 ~ 0.55`
2. `DDIM: 24~32 steps` / `Latent: 2x 14 steps` / `Denoising Strength:0.45 ~ 0.7`
- First option yields better result in general. Recommended.
- Second option was 1.5 ~ 2 times faster on my system but the output was questionable. Especially for ColorBomb.
## FaceBomb
- Positive : `(masterpiece, sidelighting, finely detailed beautiful eyes: 1.2), masterpiece*portrait, realistic, 3d face, lustrous skin, `
- Negative : `(worst quality, low quality:1.4), watermark, logo,`
## ColorBomb
- Positive : `(masterpiece, sidelighting, finely detailed beautiful eyes: 1.2), (ultra-detailed, high-resolution: 1.2), beautiful girl, { color } { color } theme, `
- e.g. black gold theme
- Negative : `(worst quality, low quality:1.4), watermark, logo,`
## HyperBomb
- Positive : `(masterpiece, sidelighting, finely detailed beautiful eyes: 1.2),`
- Negative : `(worst quality, low quality:1.4), watermark, logo,`
# Example
- More pictures in folder.
- Below are the ideal/intended outputs.

### FaceBomb
(masterpiece, sidelighting, finely detailed beautiful eyes: 1.2), masterpiece*portrait, realistic, 3d face, glowing eyes, shiny hair, lustrous skin, solo, embarassed
Negative prompt: (worst quality, low quality:1.4), watermark, logo,
Steps: 32, Sampler: DPM++ SDE Karras, CFG scale: 9, Seed: 3624413002, Size: 512x768, Model hash: aad629159b, Model: __Custom_FaceBombMix-fp16-no-ema, Denoising strength: 0.5, Clip skip: 2, ENSD: 31337, Hires upscale: 2, Hires steps: 14, Hires upscaler: R-ESRGAN 4x+ Anime6B
---

### ColorBomb
((masterpiece, best quality, ultra-detailed, high-resolution)), solo, beautiful girl, gleaming eye, perfect eye, age 15, black white gold theme,
Negative prompt: (worst quality, low quality:1.4), (depth of field, blurry:1.2), (greyscale, monochrome:1.1), 3D face, cropped, lowres, text, jpeg artifacts, signature, watermark, username, blurry, artist name, trademark, watermark, title, (tan, muscular, sd character:1.1), multiple view, Reference sheet, non-linear background, blurred background, bad anatomy, cropped hands, extra digit, fewer digit,
Steps: 24, Sampler: DDIM, CFG scale: 7, Seed: 3050494714, Size: 512x768, Model hash: 627f50eea8, Model: __Custom_ColorBomb-fp16-no-ema, Denoising strength: 0.7, Clip skip: 2, ENSD: 31337, Hires upscale: 2, Hires steps: 14, Hires upscaler: Latent
---

### HyperBomb
(masterpiece, sidelighting, finely detailed beautiful eyes: 1.2),
Negative prompt: (worst quality, low quality:1.4), watermark, logo,
Steps: 32, Sampler: DDIM, CFG scale: 9, Seed: 2411870881, Size: 768x512, Model hash: 16c6ca45b1, Model: __Custom_HyperBombMix-fp16-no-ema, Denoising strength: 0.7, Clip skip: 2, ENSD: 31337, Hires upscale: 2, Hires steps: 14, Hires upscaler: Latent |
AdamOswald1/Tester | AdamOswald1 | 2023-02-14T15:02:27Z | 0 | 0 | null | [
"license:mit",
"region:us"
]
| null | 2022-11-09T18:10:39Z | ---
title: Finetuned Diffusion
emoji: 🪄🖼️
colorFrom: red
colorTo: pink
sdk: gradio
sdk_version: 3.18.0
app_file: app.py
pinned: true
license: mit
---
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
mafaisalsust/xlm-roberta-large-finetuned-ac | mafaisalsust | 2023-02-14T14:58:33Z | 80 | 0 | transformers | [
"transformers",
"tf",
"xlm-roberta",
"fill-mask",
"generated_from_keras_callback",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| fill-mask | 2023-02-14T14:43:51Z | ---
license: mit
tags:
- generated_from_keras_callback
model-index:
- name: mafaisalsust/xlm-roberta-large-finetuned-ac
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# mafaisalsust/xlm-roberta-large-finetuned-ac
This model is a fine-tuned version of [xlm-roberta-large](https://huggingface.co/xlm-roberta-large) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 11.0965
- Validation Loss: 4.5876
- Epoch: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'WarmUp', 'config': {'initial_learning_rate': 2e-05, 'decay_schedule_fn': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': -688, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, '__passive_serialization__': True}, 'warmup_steps': 1000, 'power': 1.0, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 11.0965 | 4.5876 | 0 |
### Framework versions
- Transformers 4.26.1
- TensorFlow 2.8.0
- Datasets 2.9.0
- Tokenizers 0.13.2
|
chradden/q-FrozenLake-v1-4x4-noSlippery | chradden | 2023-02-14T14:56:08Z | 0 | 0 | null | [
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-02-13T16:07:06Z | ---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="chradden/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
YoriV/a2c-AntBulletEnv-v0 | YoriV | 2023-02-14T14:44:39Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"AntBulletEnv-v0",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-02-14T14:43:28Z | ---
library_name: stable-baselines3
tags:
- AntBulletEnv-v0
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: AntBulletEnv-v0
type: AntBulletEnv-v0
metrics:
- type: mean_reward
value: 1159.33 +/- 399.23
name: mean_reward
verified: false
---
# **A2C** Agent playing **AntBulletEnv-v0**
This is a trained model of a **A2C** agent playing **AntBulletEnv-v0**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
nhiro3303/a2c-PandaReachDense-v2 | nhiro3303 | 2023-02-14T14:41:25Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"PandaReachDense-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-02-14T14:39:48Z | ---
library_name: stable-baselines3
tags:
- PandaReachDense-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: PandaReachDense-v2
type: PandaReachDense-v2
metrics:
- type: mean_reward
value: -1.43 +/- 0.65
name: mean_reward
verified: false
---
# **A2C** Agent playing **PandaReachDense-v2**
This is a trained model of a **A2C** agent playing **PandaReachDense-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
bencevans/ddpm-ena24-gen-512-100 | bencevans | 2023-02-14T14:37:54Z | 12 | 0 | diffusers | [
"diffusers",
"diffusers:DDPMPipeline",
"region:us"
]
| null | 2023-02-03T09:24:53Z | ---
library_name: diffusers
---
# Model Card for ddpm-ena24-gen-512-100
This model generates Camera Trap Imagery. It's been trained on the ENA24-Detection Dataset for 100 epochs. |
frangiral/ppo-Pyramids1 | frangiral | 2023-02-14T14:29:26Z | 3 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"unity-ml-agents",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
]
| reinforcement-learning | 2023-02-14T14:29:04Z |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
library_name: ml-agents
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Pyramids
2. Step 1: Write your model_id: frangiral/ppo-Pyramids1
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
mmiteva/qa_model_customs | mmiteva | 2023-02-14T14:24:06Z | 63 | 0 | transformers | [
"transformers",
"tf",
"distilbert",
"question-answering",
"generated_from_keras_callback",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| question-answering | 2023-02-13T19:44:16Z | ---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: mmiteva/qa_model-customs
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# mmiteva/qa_model-customs
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.3517
- Train End Logits Accuracy: 0.8772
- Train Start Logits Accuracy: 0.8735
- Validation Loss: 0.8793
- Validation End Logits Accuracy: 0.7642
- Validation Start Logits Accuracy: 0.7586
- Epoch: 4
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 32050, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Train End Logits Accuracy | Train Start Logits Accuracy | Validation Loss | Validation End Logits Accuracy | Validation Start Logits Accuracy | Epoch |
|:----------:|:-------------------------:|:---------------------------:|:---------------:|:------------------------------:|:--------------------------------:|:-----:|
| 1.3795 | 0.6168 | 0.6015 | 0.9590 | 0.7074 | 0.6950 | 0 |
| 0.8193 | 0.7377 | 0.7260 | 0.8504 | 0.7313 | 0.7260 | 1 |
| 0.5982 | 0.8004 | 0.7932 | 0.8225 | 0.7505 | 0.7440 | 2 |
| 0.4467 | 0.8462 | 0.8405 | 0.8469 | 0.7633 | 0.7584 | 3 |
| 0.3517 | 0.8772 | 0.8735 | 0.8793 | 0.7642 | 0.7586 | 4 |
### Framework versions
- Transformers 4.25.1
- TensorFlow 2.10.1
- Datasets 2.7.1
- Tokenizers 0.12.1
|
dwarfbum/myfavloras | dwarfbum | 2023-02-14T14:14:04Z | 0 | 2 | null | [
"nagatoro",
"hayase nagatoro",
"makima",
"nazuna nanakusa",
"lora",
"region:us"
]
| null | 2023-02-06T15:09:03Z | ---
tags:
- nagatoro
- hayase nagatoro
- makima
- nazuna nanakusa
- lora
---
https://civitai.com/models/6060/nagatoro-hayase-ti NOT LORA. THATS TI
https://civitai.com/models/5662/nazuna-nanakusa-call-of-the-night-lora
https://civitai.com/models/5373/makima-chainsaw-man-lora |
frangiral/ppo-SnowballTarget | frangiral | 2023-02-14T14:03:38Z | 10 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"unity-ml-agents",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SnowballTarget",
"region:us"
]
| reinforcement-learning | 2023-02-14T14:03:31Z |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SnowballTarget
library_name: ml-agents
---
# **ppo** Agent playing **SnowballTarget**
This is a trained model of a **ppo** agent playing **SnowballTarget** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-SnowballTarget
2. Step 1: Write your model_id: frangiral/ppo-SnowballTarget
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
XperienciaVirtual/bdbybt-puig | XperienciaVirtual | 2023-02-14T14:03:29Z | 4 | 0 | diffusers | [
"diffusers",
"tensorboard",
"text-to-image",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
]
| text-to-image | 2023-02-14T14:02:07Z | ---
license: creativeml-openrail-m
tags:
- text-to-image
widget:
- text: bdbybt
---
### bdbybt_puig Dreambooth model trained by jaimexv with [Hugging Face Dreambooth Training Space](https://huggingface.co/spaces/multimodalart/dreambooth-training) with the v1-5 base model
You run your new concept via `diffusers` [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb). Don't forget to use the concept prompts!
Sample pictures of:
bdbybt (use that on your prompt)

|
ybelkada/flan-t5-large-financial-phrasebank-lora | ybelkada | 2023-02-14T13:47:51Z | 0 | 4 | null | [
"text2text-generation",
"en",
"sp",
"ja",
"pe",
"hi",
"fr",
"ch",
"be",
"gu",
"ge",
"te",
"it",
"ar",
"po",
"ta",
"ma",
"or",
"pa",
"ur",
"ga",
"he",
"ko",
"ca",
"th",
"du",
"in",
"vi",
"bu",
"fi",
"ce",
"la",
"tu",
"ru",
"cr",
"sw",
"yo",
"ku",
"cz",
"so",
"si",
"ka",
"zh",
"ig",
"xh",
"ro",
"ha",
"es",
"sl",
"li",
"gr",
"ne",
"as",
"no",
"dataset:svakulenk0/qrecc",
"dataset:taskmaster2",
"dataset:djaym7/wiki_dialog",
"dataset:deepmind/code_contests",
"dataset:lambada",
"dataset:gsm8k",
"dataset:aqua_rat",
"dataset:esnli",
"dataset:quasc",
"dataset:qed",
"dataset:financial_phrasebank",
"license:apache-2.0",
"region:us"
]
| text2text-generation | 2023-02-14T13:39:05Z | ---
language:
- en
- sp
- ja
- pe
- hi
- fr
- ch
- be
- gu
- ge
- te
- it
- ar
- po
- ta
- ma
- ma
- or
- pa
- po
- ur
- ga
- he
- ko
- ca
- th
- du
- in
- vi
- bu
- fi
- ce
- la
- tu
- ru
- cr
- sw
- yo
- ku
- bu
- ma
- cz
- fi
- so
- ta
- sw
- si
- ka
- zh
- ig
- xh
- ro
- ha
- es
- sl
- li
- gr
- ne
- as
- no
widget:
- text: "Translate to German: My name is Arthur"
example_title: "Translation"
- text: "Please answer to the following question. Who is going to be the next Ballon d'or?"
example_title: "Question Answering"
- text: "Q: Can Geoffrey Hinton have a conversation with George Washington? Give the rationale before answering."
example_title: "Logical reasoning"
- text: "Please answer the following question. What is the boiling point of Nitrogen?"
example_title: "Scientific knowledge"
- text: "Answer the following yes/no question. Can you write a whole Haiku in a single tweet?"
example_title: "Yes/no question"
- text: "Answer the following yes/no question by reasoning step-by-step. Can you write a whole Haiku in a single tweet?"
example_title: "Reasoning task"
- text: "Q: ( False or not False or False ) is? A: Let's think step by step"
example_title: "Boolean Expressions"
- text: "The square root of x is the cube root of y. What is y to the power of 2, if x = 4?"
example_title: "Math reasoning"
- text: "Premise: At my age you will probably have learnt one lesson. Hypothesis: It's not certain how many lessons you'll learn by your thirties. Does the premise entail the hypothesis?"
example_title: "Premise and hypothesis"
tags:
- text2text-generation
datasets:
- svakulenk0/qrecc
- taskmaster2
- djaym7/wiki_dialog
- deepmind/code_contests
- lambada
- gsm8k
- aqua_rat
- esnli
- quasc
- qed
- financial_phrasebank
license: apache-2.0
---
# Model Card for LoRA-FLAN-T5 large

This repository contains the LoRA (Low Rank Adapters) of `flan-t5-large` that has been fine-tuned on [`financial_phrasebank`](https://huggingface.co/datasets/financial_phrasebank) dataset.
## Usage
Use this adapter with `peft` library
```python
# pip install peft transformers
import torch
from peft import PeftModel, PeftConfig
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
peft_model_id = "ybelkada/flan-t5-large-financial-phrasebank-lora"
config = PeftConfig.from_pretrained(peft_model_id)
model = AutoModelForSeq2SeqLM.from_pretrained(
config.base_model_name_or_path,
torch_dtype='auto',
device_map='auto'
)
tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path)
# Load the Lora model
model = PeftModel.from_pretrained(model, peft_model_id)
```
Enjoy! |
huggingtweets/antoniobanderas-oquimbarreiros-snoopdogg | huggingtweets | 2023-02-14T13:38:01Z | 107 | 0 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text-generation | 2023-02-14T13:37:53Z | ---
language: en
thumbnail: https://github.com/borisdayma/huggingtweets/blob/master/img/logo.png?raw=true
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1618012757621673992/kPppseWI_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/564137495244570624/CrWEr-Xk_400x400.jpeg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1564375315526275072/7Xnua7BM_400x400.jpg')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Quim Barreiros & Antonio Banderas & Snoop Dogg</div>
<div style="text-align: center; font-size: 14px;">@antoniobanderas-oquimbarreiros-snoopdogg</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Quim Barreiros & Antonio Banderas & Snoop Dogg.
| Data | Quim Barreiros | Antonio Banderas | Snoop Dogg |
| --- | --- | --- | --- |
| Tweets downloaded | 2275 | 3248 | 3221 |
| Retweets | 55 | 593 | 1035 |
| Short tweets | 860 | 1006 | 414 |
| Tweets kept | 1360 | 1649 | 1772 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/9sxu3b40/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @antoniobanderas-oquimbarreiros-snoopdogg's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/d57ngqld) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/d57ngqld/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/antoniobanderas-oquimbarreiros-snoopdogg')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
NathanaelM/poca-SoccerTwos | NathanaelM | 2023-02-14T13:34:23Z | 36 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"unity-ml-agents",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SoccerTwos",
"region:us"
]
| reinforcement-learning | 2023-02-14T13:27:47Z |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SoccerTwos
library_name: ml-agents
---
# **poca** Agent playing **SoccerTwos**
This is a trained model of a **poca** agent playing **SoccerTwos** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-SoccerTwos
2. Step 1: Write your model_id: NathanaelM/poca-SoccerTwos
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
Maksim-t/Tiktok_Memes | Maksim-t | 2023-02-14T13:27:37Z | 0 | 0 | null | [
"arxiv:1910.09700",
"region:us"
]
| null | 2023-02-14T13:26:29Z | ---
# For reference on model card metadata, see the spec: https://github.com/huggingface/hub-docs/blob/main/modelcard.md?plain=1
# Doc / guide: https://huggingface.co/docs/hub/model-cards
{}
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
This modelcard aims to be a base template for new models. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/modelcard_template.md?plain=1).
# Model Details
## Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
## Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
# Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
## Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
## Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
## Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
# Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
## Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
# Training Details
## Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
## Training Procedure [optional]
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
### Preprocessing
[More Information Needed]
### Speeds, Sizes, Times
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
# Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
## Testing Data, Factors & Metrics
### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
## Results
[More Information Needed]
### Summary
# Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
# Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
# Technical Specifications [optional]
## Model Architecture and Objective
[More Information Needed]
## Compute Infrastructure
[More Information Needed]
### Hardware
[More Information Needed]
### Software
[More Information Needed]
# Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
# Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
# More Information [optional]
[More Information Needed]
# Model Card Authors [optional]
[More Information Needed]
# Model Card Contact
[More Information Needed]
|
jamesthong/ppo-Huggy | jamesthong | 2023-02-14T13:16:52Z | 14 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"unity-ml-agents",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
]
| reinforcement-learning | 2023-02-14T13:16:45Z |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
library_name: ml-agents
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Huggy
2. Step 1: Write your model_id: mikato/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
alfredplpl/x2-latent-upscaler-for-anime | alfredplpl | 2023-02-14T12:51:41Z | 19 | 1 | diffusers | [
"diffusers",
"stable-diffusion",
"text-to-image",
"license:openrail++",
"diffusers:StableDiffusionLatentUpscalePipeline",
"region:us"
]
| text-to-image | 2023-02-14T12:42:02Z | ---
license: openrail++
tags:
- stable-diffusion
- text-to-image
inference: false
---
# Stable Diffusion x2 latent upscaler model card
This model card focuses on the latent diffusion-based upscaler developed by [Katherine Crowson](https://github.com/crowsonkb/k-diffusion)
in collaboration with [Stability AI](https://stability.ai/).
This model was trained on a high-resolution subset of the LAION-2B dataset.
It is a diffusion model that operates in the same latent space as the Stable Diffusion model, which is decoded into a full-resolution image.
To use it with Stable Diffusion, You can take the generated latent from Stable Diffusion and pass it into the upscaler before decoding with your standard VAE.
Or you can take any image, encode it into the latent space, use the upscaler, and decode it.
**Note**:
This upscaling model is designed explicitely for **Stable Diffusion** as it can upscale Stable Diffusion's latent denoised image embeddings.
This allows for very fast text-to-image + upscaling pipelines as all intermeditate states can be kept on GPU. More for information, see example below.
This model works on all [Stable Diffusion checkpoints](https://huggingface.co/models?other=stable-diffusion)
| 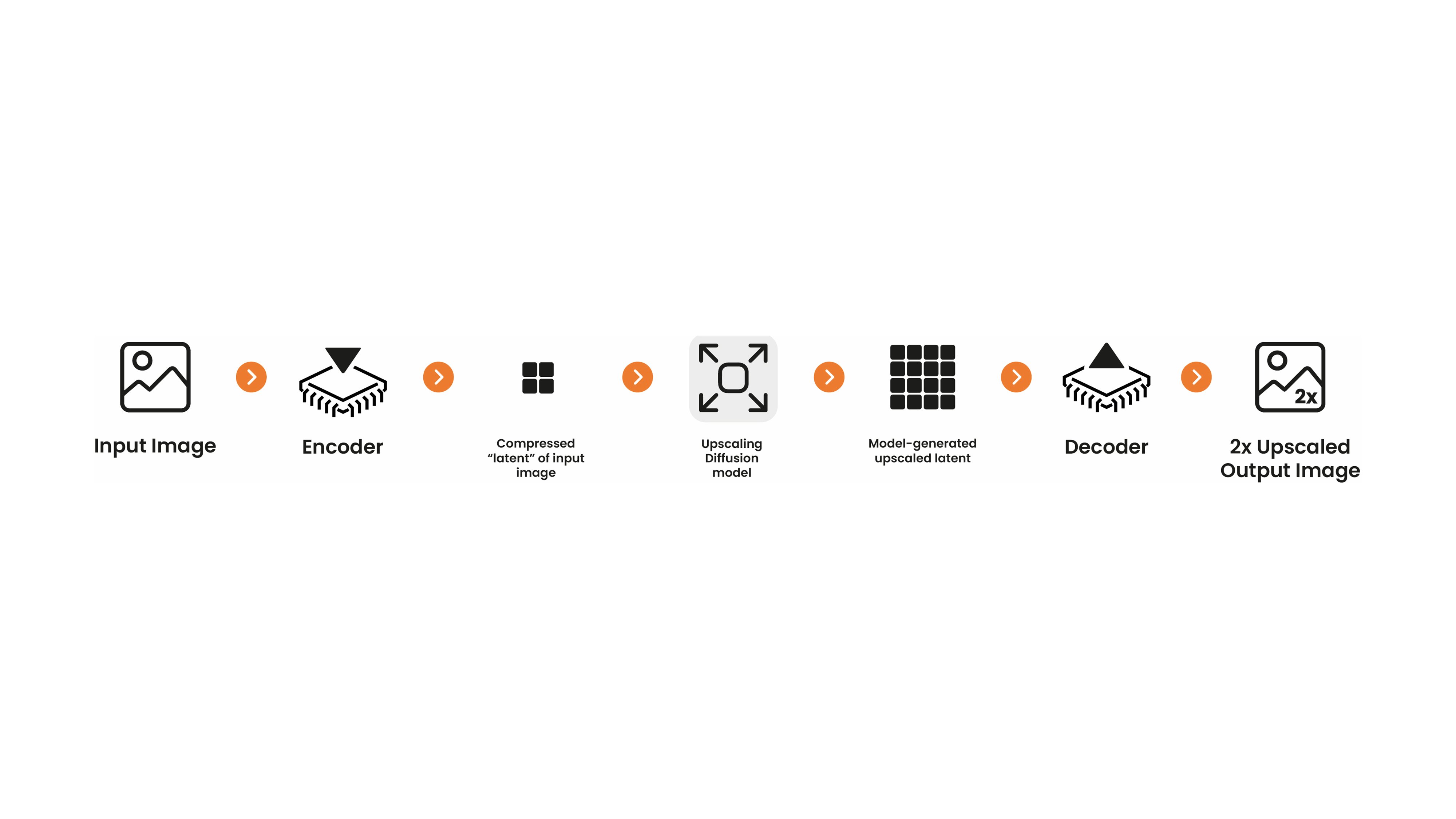 |
|:--:|
Image by Tanishq Abraham from [Stability AI](https://stability.ai/) originating from [this tweet](https://twitter.com/StabilityAI/status/1590531958815064065)|
Original output image | 2x upscaled output image
:-------------------------:|:-------------------------:
 | 
- Use it with 🧨 [`diffusers`](https://huggingface.co/stabilityai/sd-x2-latent-upscaler#examples)
## Model Details
- **Developed by:** Katherine Crowson
- **Model type:** Diffusion-based latent upscaler
- **Language(s):** English
- **License:** [CreativeML Open RAIL++-M License](https://huggingface.co/stabilityai/stable-diffusion-2/blob/main/LICENSE-MODEL)
## Examples
Using the [🤗's Diffusers library](https://github.com/huggingface/diffusers) to run latent upscaler on top of any `StableDiffusionUpscalePipeline` checkpoint
to enhance its output image resolution by a factor of 2.
```bash
pip install git+https://github.com/huggingface/diffusers.git
pip install transformers accelerate scipy safetensors
```
```python
from diffusers import StableDiffusionLatentUpscalePipeline, StableDiffusionPipeline
import torch
pipeline = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", torch_dtype=torch.float16)
pipeline.to("cuda")
upscaler = StableDiffusionLatentUpscalePipeline.from_pretrained("stabilityai/sd-x2-latent-upscaler", torch_dtype=torch.float16)
upscaler.to("cuda")
prompt = "a photo of an astronaut high resolution, unreal engine, ultra realistic"
generator = torch.manual_seed(33)
# we stay in latent space! Let's make sure that Stable Diffusion returns the image
# in latent space
low_res_latents = pipeline(prompt, generator=generator, output_type="latent").images
upscaled_image = upscaler(
prompt=prompt,
image=low_res_latents,
num_inference_steps=20,
guidance_scale=0,
generator=generator,
).images[0]
# Let's save the upscaled image under "upscaled_astronaut.png"
upscaled_image.save("astronaut_1024.png")
# as a comparison: Let's also save the low-res image
with torch.no_grad():
image = pipeline.decode_latents(low_res_latents)
image = pipeline.numpy_to_pil(image)[0]
image.save("astronaut_512.png")
```
**Result**:
*512-res Astronaut*

*1024-res Astronaut*

**Notes**:
- Despite not being a dependency, we highly recommend you to install [xformers](https://github.com/facebookresearch/xformers) for memory efficient attention (better performance)
- If you have low GPU RAM available, make sure to add a `pipe.enable_attention_slicing()` after sending it to `cuda` for less VRAM usage (to the cost of speed)
# Uses
## Direct Use
The model is intended for research purposes only. Possible research areas and tasks include
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
- Research on generative models.
Excluded uses are described below.
### Misuse, Malicious Use, and Out-of-Scope Use
_Note: This section is originally taken from the [DALLE-MINI model card](https://huggingface.co/dalle-mini/dalle-mini), was used for Stable Diffusion v1, but applies in the same way to Stable Diffusion v2_.
The model should not be used to intentionally create or disseminate images that create hostile or alienating environments for people. This includes generating images that people would foreseeably find disturbing, distressing, or offensive; or content that propagates historical or current stereotypes.
#### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
#### Misuse and Malicious Use
Using the model to generate content that is cruel to individuals is a misuse of this model. This includes, but is not limited to:
- Generating demeaning, dehumanizing, or otherwise harmful representations of people or their environments, cultures, religions, etc.
- Intentionally promoting or propagating discriminatory content or harmful stereotypes.
- Impersonating individuals without their consent.
- Sexual content without consent of the people who might see it.
- Mis- and disinformation
- Representations of egregious violence and gore
- Sharing of copyrighted or licensed material in violation of its terms of use.
- Sharing content that is an alteration of copyrighted or licensed material in violation of its terms of use.
## Limitations and Bias
### Limitations
- The model does not achieve perfect photorealism
- The model cannot render legible text
- The model does not perform well on more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
- Faces and people in general may not be generated properly.
- The model was trained mainly with English captions and will not work as well in other languages.
- The autoencoding part of the model is lossy
- The model was trained on a subset of the large-scale dataset
[LAION-5B](https://laion.ai/blog/laion-5b/), which contains adult, violent and sexual content. To partially mitigate this, we have filtered the dataset using LAION's NFSW detector (see Training section).
### Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
Stable Diffusion vw was primarily trained on subsets of [LAION-2B(en)](https://laion.ai/blog/laion-5b/),
which consists of images that are limited to English descriptions.
Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for.
This affects the overall output of the model, as white and western cultures are often set as the default. Further, the
ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts.
Stable Diffusion v2 mirrors and exacerbates biases to such a degree that viewer discretion must be advised irrespective of the input or its intent. |
juliawabant/ppo-LunarLander-v2 | juliawabant | 2023-02-14T12:46:09Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-02-10T15:37:38Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 219.19 +/- 89.86
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Ili1991/q-FrozenLake-v1-4x4-noSlippery | Ili1991 | 2023-02-14T12:39:10Z | 0 | 0 | null | [
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-02-14T12:39:07Z | ---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="Ili1991/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
vinayak361/token_fine_tunned_flipkart_2_gl9 | vinayak361 | 2023-02-14T12:31:32Z | 7 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"token-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| token-classification | 2023-02-14T10:44:04Z | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: token_fine_tunned_flipkart_2_gl9
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# token_fine_tunned_flipkart_2_gl9
This model is a fine-tuned version of [vinayak361/token_fine_tunned_flipkart_2_gl7](https://huggingface.co/vinayak361/token_fine_tunned_flipkart_2_gl7) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2452
- Precision: 0.8593
- Recall: 0.8767
- F1: 0.8679
- Accuracy: 0.9105
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-06
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 451 | 0.3331 | 0.8070 | 0.8310 | 0.8188 | 0.8774 |
| 0.4065 | 2.0 | 902 | 0.2927 | 0.8319 | 0.8526 | 0.8421 | 0.8940 |
| 0.3251 | 3.0 | 1353 | 0.2737 | 0.8428 | 0.8633 | 0.8529 | 0.9021 |
| 0.2825 | 4.0 | 1804 | 0.2650 | 0.8484 | 0.8651 | 0.8567 | 0.9046 |
| 0.2568 | 5.0 | 2255 | 0.2586 | 0.8543 | 0.8749 | 0.8645 | 0.9085 |
| 0.2419 | 6.0 | 2706 | 0.2511 | 0.8552 | 0.8754 | 0.8652 | 0.9083 |
| 0.2351 | 7.0 | 3157 | 0.2481 | 0.8564 | 0.8746 | 0.8654 | 0.9102 |
| 0.2226 | 8.0 | 3608 | 0.2455 | 0.8551 | 0.8746 | 0.8647 | 0.9089 |
| 0.222 | 9.0 | 4059 | 0.2458 | 0.8597 | 0.8769 | 0.8682 | 0.9106 |
| 0.2207 | 10.0 | 4510 | 0.2452 | 0.8593 | 0.8767 | 0.8679 | 0.9105 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu102
- Datasets 2.2.2
- Tokenizers 0.12.1
|
justlotw/ppo-Huggy | justlotw | 2023-02-14T12:26:13Z | 12 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"unity-ml-agents",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
]
| reinforcement-learning | 2023-02-14T12:26:06Z |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
library_name: ml-agents
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Huggy
2. Step 1: Write your model_id: justlotw/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
Gokulapriyan/swin-tiny-patch4-window7-224-finetuned-og_dataset_5e | Gokulapriyan | 2023-02-14T12:25:55Z | 41 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"swin",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| image-classification | 2023-02-13T10:10:40Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: swin-tiny-patch4-window7-224-finetuned-og_dataset_5e
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.970523929063082
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# swin-tiny-patch4-window7-224-finetuned-og_dataset_5e
This model is a fine-tuned version of [microsoft/swin-tiny-patch4-window7-224](https://huggingface.co/microsoft/swin-tiny-patch4-window7-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0788
- Accuracy: 0.9705
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.4626 | 1.0 | 546 | 0.3468 | 0.8578 |
| 0.2915 | 2.0 | 1092 | 0.1998 | 0.9200 |
| 0.2333 | 3.0 | 1638 | 0.1155 | 0.9566 |
| 0.2019 | 4.0 | 2184 | 0.0977 | 0.9634 |
| 0.1713 | 5.0 | 2730 | 0.0788 | 0.9705 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
|
Maki7/cnew | Maki7 | 2023-02-14T12:16:57Z | 0 | 1 | null | [
"arxiv:2302.05543",
"region:us"
]
| null | 2023-02-14T12:14:50Z | # ControlNet
Official implementation of [Adding Conditional Control to Text-to-Image Diffusion Models](https://arxiv.org/abs/2302.05543).
ControlNet is a neural network structure to control diffusion models by adding extra conditions.

It copys the weights of neural network blocks into a "locked" copy and a "trainable" copy.
The "trainable" one learns your condition. The "locked" one preserves your model.
Thanks to this, training with small dataset of image pairs will not destroy the production-ready diffusion models.
The "zero convolution" is 1×1 convolution with both weight and bias initialized as zeros.
Before training, all zero convolutions output zeros, and ControlNet will not cause any distortion.
No layer is trained from scratch. You are still fine-tuning. Your original model is safe.
This allows training on small-scale or even personal devices.
This is also friendly to merge/replacement/offsetting of models/weights/blocks/layers.
### FAQ
**Q:** But wait, if the weight of a conv layer is zero, the gradient will also be zero, and the network will not learn anything. Why "zero convolution" works?
**A:** This is not true. [See an explanation here](docs/faq.md).
# Stable Diffusion + ControlNet
By repeating the above simple structure 14 times, we can control stable diffusion in this way:

Note that the way we connect layers is computational efficient. The original SD encoder does not need to store gradients (the locked original SD Encoder Block 1234 and Middle). The required GPU memory is not much larger than original SD, although many layers are added. Great!
# Production-Ready Pretrained Models
First create a new conda environment
conda env create -f environment.yaml
conda activate control
All models and detectors can be downloaded from [our Hugging Face page](https://huggingface.co/lllyasviel/ControlNet). Make sure that SD models are put in "ControlNet/models" and detectors are put in "ControlNet/annotator/ckpts". Make sure that you download all necessary pretrained weights and detector models from that Hugging Face page, including HED edge detection model, Midas depth estimation model, Openpose, and so on.
We provide 9 Gradio apps with these models.
All test images can be found at the folder "test_imgs".
### News
2023/02/12 - Now you can play with any community model by [Transferring the ControlNet](https://github.com/lllyasviel/ControlNet/discussions/12).
2023/02/11 - [Low VRAM mode](docs/low_vram.md) is added. Please use this mode if you are using 8GB GPU(s) or if you want larger batch size.
## ControlNet with Canny Edge
Stable Diffusion 1.5 + ControlNet (using simple Canny edge detection)
python gradio_canny2image.py
The Gradio app also allows you to change the Canny edge thresholds. Just try it for more details.
Prompt: "bird"

Prompt: "cute dog"

## ControlNet with M-LSD Lines
Stable Diffusion 1.5 + ControlNet (using simple M-LSD straight line detection)
python gradio_hough2image.py
The Gradio app also allows you to change the M-LSD thresholds. Just try it for more details.
Prompt: "room"

Prompt: "building"

## ControlNet with HED Boundary
Stable Diffusion 1.5 + ControlNet (using soft HED Boundary)
python gradio_hed2image.py
The soft HED Boundary will preserve many details in input images, making this app suitable for recoloring and stylizing. Just try it for more details.
Prompt: "oil painting of handsome old man, masterpiece"

Prompt: "Cyberpunk robot"

## ControlNet with User Scribbles
Stable Diffusion 1.5 + ControlNet (using Scribbles)
python gradio_scribble2image.py
Note that the UI is based on Gradio, and Gradio is somewhat difficult to customize. Right now you need to draw scribbles outside the UI (using your favorite drawing software, for example, MS Paint) and then import the scribble image to Gradio.
Prompt: "turtle"

Prompt: "hot air balloon"

### Interactive Interface
We actually provide an interactive interface
python gradio_scribble2image_interactive.py
However, because gradio is very [buggy](https://github.com/gradio-app/gradio/issues/3166) and difficult to customize, right now, user need to first set canvas width and heights and then click "Open drawing canvas" to get a drawing area. Please do not upload image to that drawing canvas. Also, the drawing area is very small; it should be bigger. But I failed to find out how to make it larger. Again, gradio is really buggy.
The below dog sketch is drawn by me. Perhaps we should draw a better dog for showcase.
Prompt: "dog in a room"

## ControlNet with Fake Scribbles
Stable Diffusion 1.5 + ControlNet (using fake scribbles)
python gradio_fake_scribble2image.py
Sometimes we are lazy, and we do not want to draw scribbles. This script use the exactly same scribble-based model but use a simple algorithm to synthesize scribbles from input images.
Prompt: "bag"

Prompt: "shose" (Note that "shose" is a typo; it should be "shoes". But it still seems to work.)

## ControlNet with Human Pose
Stable Diffusion 1.5 + ControlNet (using human pose)
python gradio_pose2image.py
Apparently, this model deserves a better UI to directly manipulate pose skeleton. However, again, Gradio is somewhat difficult to customize. Right now you need to input an image and then the Openpose will detect the pose for you.
Prompt: "Chief in the kitchen"

Prompt: "An astronaut on the moon"

## ControlNet with Semantic Segmentation
Stable Diffusion 1.5 + ControlNet (using semantic segmentation)
python gradio_seg2image.py
This model use ADE20K's segmentation protocol. Again, this model deserves a better UI to directly draw the segmentations. However, again, Gradio is somewhat difficult to customize. Right now you need to input an image and then a model called Uniformer will detect the segmentations for you. Just try it for more details.
Prompt: "House"

Prompt: "River"

## ControlNet with Depth
Stable Diffusion 1.5 + ControlNet (using depth map)
python gradio_depth2image.py
Great! Now SD 1.5 also have a depth control. FINALLY. So many possibilities (considering SD1.5 has much more community models than SD2).
Note that different from Stability's model, the ControlNet receive the full 512×512 depth map, rather than 64×64 depth. Note that Stability's SD2 depth model use 64*64 depth maps. This means that the ControlNet will preserve more details in the depth map.
This is always a strength because if users do not want to preserve more details, they can simply use another SD to post-process an i2i. But if they want to preserve more details, ControlNet becomes their only choice. Again, SD2 uses 64×64 depth, we use 512×512.
Prompt: "Stormtrooper's lecture"

## ControlNet with Normal Map
Stable Diffusion 1.5 + ControlNet (using normal map)
python gradio_normal2image.py
This model use normal map. Rightnow in the APP, the normal is computed from the midas depth map and a user threshold (to determine how many area is background with identity normal face to viewer, tune the "Normal background threshold" in the gradio app to get a feeling).
Prompt: "Cute toy"

Prompt: "Plaster statue of Abraham Lincoln"

Compared to depth model, this model seems to be a bit better at preserving the geometry. This is intuitive: minor details are not salient in depth maps, but are salient in normal maps. Below is the depth result with same inputs. You can see that the hairstyle of the man in the input image is modified by depth model, but preserved by the normal model.
Prompt: "Plaster statue of Abraham Lincoln"

## ControlNet with Anime Line Drawing
We also trained a relatively simple ControlNet for anime line drawings. This tool may be useful for artistic creations. (Although the image details in the results is a bit modified, since it still diffuse latent images.)
This model is not available right now. We need to evaluate the potential risks before releasing this model. Nevertheless, you may be interested in [transferring the ControlNet to any community model](https://github.com/lllyasviel/ControlNet/discussions/12).

# Annotate Your Own Data
We provide simple python scripts to process images.
[See a gradio example here](docs/annotator.md).
# Train with Your Own Data
Training a ControlNet is as easy as (or even easier than) training a simple pix2pix.
[See the steps here](docs/train.md).
# Citation
@misc{zhang2023adding,
title={Adding Conditional Control to Text-to-Image Diffusion Models},
author={Lvmin Zhang and Maneesh Agrawala},
year={2023},
eprint={2302.05543},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
[Arxiv Link](https://arxiv.org/abs/2302.05543)
|
saiful-sit/whisper-small-hi | saiful-sit | 2023-02-14T11:59:11Z | 75 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"whisper",
"automatic-speech-recognition",
"hf-asr-leaderboard",
"generated_from_trainer",
"hi",
"dataset:mozilla-foundation/common_voice_11_0",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2023-02-14T09:46:38Z | ---
language:
- hi
license: apache-2.0
tags:
- hf-asr-leaderboard
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_11_0
model-index:
- name: Whisper Small Hi - Saiful
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small Hi - Saiful
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the Common Voice 11.0 dataset.
It achieves the following results on the evaluation set:
- eval_loss: 0.2908
- eval_wer: 38.0005
- eval_runtime: 1507.0416
- eval_samples_per_second: 1.92
- eval_steps_per_second: 0.24
- epoch: 2.44
- step: 1000
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.27.0.dev0
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
|
Manzer/army_men | Manzer | 2023-02-14T11:58:32Z | 0 | 0 | keras | [
"keras",
"en",
"license:afl-3.0",
"region:us"
]
| null | 2023-02-14T10:53:08Z | ---
license: afl-3.0
language:
- en
library_name: keras
---
|
FabioDataGeek/CartPole-v1 | FabioDataGeek | 2023-02-14T11:32:59Z | 0 | 0 | null | [
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-02-14T11:32:49Z | ---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: CartPole-v1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
z4x/poca-SoccerTwos-v3 | z4x | 2023-02-14T11:27:15Z | 8 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"unity-ml-agents",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SoccerTwos",
"region:us"
]
| reinforcement-learning | 2023-02-14T11:32:41Z |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SoccerTwos
library_name: ml-agents
---
# **poca** Agent playing **SoccerTwos**
This is a trained model of a **poca** agent playing **SoccerTwos** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-SoccerTwos
2. Step 1: Write your model_id: z4x/poca-SoccerTwos-v3
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
iotengtr/bert-base-uncased-with-mrpc-trained | iotengtr | 2023-02-14T11:27:04Z | 107 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2023-02-14T08:54:49Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
model-index:
- name: bert-base-uncased-with-mrpc-trained
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-with-mrpc-trained
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6346
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 459 | 0.3987 |
| 0.5157 | 2.0 | 918 | 0.4586 |
| 0.3096 | 3.0 | 1377 | 0.6346 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
|
selvino/CartPole-v4 | selvino | 2023-02-14T11:19:08Z | 0 | 0 | null | [
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-02-14T11:18:58Z | ---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: CartPole-v4
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
meganstodel/pixelcopter2 | meganstodel | 2023-02-14T11:04:06Z | 0 | 0 | null | [
"Pixelcopter-PLE-v0",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-02-14T11:03:57Z | ---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: pixelcopter2
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: 12.60 +/- 8.97
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
g8a9/roberta-tiny-10M | g8a9 | 2023-02-14T11:01:05Z | 48 | 1 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"roberta",
"fill-mask",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| fill-mask | 2023-01-31T16:41:29Z | ---
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: roberta-tiny-10M
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-tiny-10M
This model was trained from scratch on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.7391
- Accuracy: 0.5148
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0004
- train_batch_size: 16
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 32
- total_train_batch_size: 512
- optimizer: Adam with betas=(0.9,0.98) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 50
- num_epochs: 100.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 7.8031 | 1.04 | 50 | 7.3560 | 0.0606 |
| 7.1948 | 2.08 | 100 | 6.7374 | 0.1182 |
| 6.8927 | 3.12 | 150 | 6.5022 | 0.1415 |
| 6.7339 | 4.16 | 200 | 6.4005 | 0.1483 |
| 6.6609 | 5.21 | 250 | 6.3535 | 0.1510 |
| 6.1972 | 6.25 | 300 | 6.3324 | 0.1519 |
| 6.1685 | 7.29 | 350 | 6.3029 | 0.1528 |
| 6.1302 | 8.33 | 400 | 6.2828 | 0.1521 |
| 6.093 | 9.37 | 450 | 6.2568 | 0.1536 |
| 6.0543 | 10.41 | 500 | 6.2430 | 0.1544 |
| 6.0479 | 11.45 | 550 | 6.2346 | 0.1541 |
| 6.0372 | 12.49 | 600 | 6.2232 | 0.1546 |
| 6.0127 | 13.53 | 650 | 6.2139 | 0.1541 |
| 5.968 | 14.58 | 700 | 6.2053 | 0.1547 |
| 5.9635 | 15.62 | 750 | 6.1996 | 0.1549 |
| 5.9479 | 16.66 | 800 | 6.1953 | 0.1548 |
| 5.9371 | 17.7 | 850 | 6.1887 | 0.1545 |
| 5.9046 | 18.74 | 900 | 6.1613 | 0.1545 |
| 5.8368 | 19.78 | 950 | 6.0952 | 0.1557 |
| 5.7914 | 20.82 | 1000 | 6.0330 | 0.1569 |
| 5.7026 | 21.86 | 1050 | 5.9430 | 0.1612 |
| 5.491 | 22.9 | 1100 | 5.6100 | 0.1974 |
| 4.9289 | 23.95 | 1150 | 4.9607 | 0.2702 |
| 4.5214 | 24.99 | 1200 | 4.5795 | 0.3051 |
| 4.5663 | 26.04 | 1250 | 4.3454 | 0.3265 |
| 4.3717 | 27.08 | 1300 | 4.1738 | 0.3412 |
| 4.1483 | 28.12 | 1350 | 4.0336 | 0.3555 |
| 3.9988 | 29.16 | 1400 | 3.9180 | 0.3677 |
| 3.8695 | 30.21 | 1450 | 3.8108 | 0.3782 |
| 3.5017 | 31.25 | 1500 | 3.7240 | 0.3879 |
| 3.4311 | 32.29 | 1550 | 3.6426 | 0.3974 |
| 3.3517 | 33.33 | 1600 | 3.5615 | 0.4068 |
| 3.2856 | 34.37 | 1650 | 3.4915 | 0.4156 |
| 3.227 | 35.41 | 1700 | 3.4179 | 0.4255 |
| 3.1675 | 36.45 | 1750 | 3.3636 | 0.4325 |
| 3.0908 | 37.49 | 1800 | 3.3083 | 0.4394 |
| 3.0561 | 38.53 | 1850 | 3.2572 | 0.4473 |
| 3.0139 | 39.58 | 1900 | 3.2159 | 0.4525 |
| 2.9837 | 40.62 | 1950 | 3.1789 | 0.4575 |
| 2.9387 | 41.66 | 2000 | 3.1431 | 0.4618 |
| 2.9034 | 42.7 | 2050 | 3.1163 | 0.4654 |
| 2.8822 | 43.74 | 2100 | 3.0842 | 0.4694 |
| 2.836 | 44.78 | 2150 | 3.0583 | 0.4727 |
| 2.8129 | 45.82 | 2200 | 3.0359 | 0.4760 |
| 2.7733 | 46.86 | 2250 | 3.0173 | 0.4776 |
| 2.7589 | 47.9 | 2300 | 2.9978 | 0.4812 |
| 2.7378 | 48.95 | 2350 | 2.9788 | 0.4831 |
| 2.7138 | 49.99 | 2400 | 2.9674 | 0.4844 |
| 2.8692 | 51.04 | 2450 | 2.9476 | 0.4874 |
| 2.8462 | 52.08 | 2500 | 2.9342 | 0.4893 |
| 2.8312 | 53.12 | 2550 | 2.9269 | 0.4900 |
| 2.7834 | 54.16 | 2600 | 2.9111 | 0.4917 |
| 2.7822 | 55.21 | 2650 | 2.8987 | 0.4934 |
| 2.584 | 56.25 | 2700 | 2.8844 | 0.4949 |
| 2.5668 | 57.29 | 2750 | 2.8808 | 0.4965 |
| 2.5536 | 58.33 | 2800 | 2.8640 | 0.4982 |
| 2.5403 | 59.37 | 2850 | 2.8606 | 0.4982 |
| 2.5294 | 60.41 | 2900 | 2.8441 | 0.5008 |
| 2.513 | 61.45 | 2950 | 2.8402 | 0.5013 |
| 2.5105 | 62.49 | 3000 | 2.8316 | 0.5022 |
| 2.4897 | 63.53 | 3050 | 2.8237 | 0.5027 |
| 2.4974 | 64.58 | 3100 | 2.8187 | 0.5040 |
| 2.4799 | 65.62 | 3150 | 2.8129 | 0.5044 |
| 2.4741 | 66.66 | 3200 | 2.8056 | 0.5057 |
| 2.4582 | 67.7 | 3250 | 2.8025 | 0.5061 |
| 2.4389 | 68.74 | 3300 | 2.7913 | 0.5076 |
| 2.4539 | 69.78 | 3350 | 2.7881 | 0.5072 |
| 2.4252 | 70.82 | 3400 | 2.7884 | 0.5082 |
| 2.4287 | 71.86 | 3450 | 2.7784 | 0.5093 |
| 2.4131 | 72.9 | 3500 | 2.7782 | 0.5099 |
| 2.4016 | 73.95 | 3550 | 2.7724 | 0.5098 |
| 2.3998 | 74.99 | 3600 | 2.7659 | 0.5111 |
| 2.5475 | 76.04 | 3650 | 2.7650 | 0.5108 |
| 2.5443 | 77.08 | 3700 | 2.7620 | 0.5117 |
| 2.5381 | 78.12 | 3750 | 2.7631 | 0.5115 |
| 2.5269 | 79.16 | 3800 | 2.7578 | 0.5122 |
| 2.5288 | 80.21 | 3850 | 2.7540 | 0.5124 |
| 2.3669 | 81.25 | 3900 | 2.7529 | 0.5125 |
| 2.3631 | 82.29 | 3950 | 2.7498 | 0.5132 |
| 2.3499 | 83.33 | 4000 | 2.7454 | 0.5136 |
| 2.3726 | 84.37 | 4050 | 2.7446 | 0.5141 |
| 2.3411 | 85.41 | 4100 | 2.7403 | 0.5144 |
| 2.3321 | 86.45 | 4150 | 2.7372 | 0.5146 |
| 2.3456 | 87.49 | 4200 | 2.7389 | 0.5146 |
| 2.3372 | 88.53 | 4250 | 2.7384 | 0.5151 |
| 2.343 | 89.58 | 4300 | 2.7398 | 0.5144 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.11.0+cu113
- Datasets 2.6.1
- Tokenizers 0.12.1
|
0RisingStar0/HighRiseMixV1 | 0RisingStar0 | 2023-02-14T10:42:49Z | 4 | 19 | diffusers | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:creativeml-openrail-m",
"region:us"
]
| text-to-image | 2023-02-07T17:45:17Z | ---
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
---
<p align="center"><img src="https://huggingface.co/0RisingStar0/HighRiseMixV1/resolve/main/00401-2269441947-(masterpiece%2C%20excellent%20quality%2C%20high%20quality%2C%20highres%20_%201.5)%2C%20(1girl%2C%20solo)%2C%20solo%20focus%2C%20sky%2C%20city%2C%20skyscrapers%2C%20pavement%2C%20tree.png">
<img src="https://huggingface.co/0RisingStar0/HighRiseMixV1/resolve/main/13.png"></p>
<b>V2 is out! : https://huggingface.co/0RisingStar0/HighRiseMixV2</b>
<center><b>HighRiseMixV1</b></center>
U-Net mixed model <b>specialized for city and skyscrapers background.</b>
<b>FP16 Pruned version</b>(No EMA).
(Quality change may occur in very small details on buildings' textures)
<b>Recommended prompts : </b>
(masterpiece, best quality, excellent quality), ((1girl, solo)), sky, city, (skyscrapers), trees, pavement, lens flare
EasyNegative, moss, phone, man, pedestrians, extras, border, outside border, white border
(EasyNegative is a negative embedding : https://huggingface.co/datasets/gsdf/EasyNegative)
<b>Recommended settings : </b>
Sampler : DPM++ 2M Karras OR DPM++ SDE Karras
Sampling steps : 25 ~ 30
Resolution : 512x768 OR 768x512
CFG Scale : 9
<b> Upscale is a must-do!! </b> Otherwise, you won't get great results.
Upscaler : Latent (nearest)
Hires steps : 0
Denoise : 0.6
Upscale 2x
<b> Mixed models : </b>
AbyssOrangeMix2_NSFW, AnythingV4.5, BasilMixFixed, CounterfeitV2.5, EerieOrangeMix2, PowercolorV2
(Thanks to everyone who made above models!)
This is my first mixed model being uploaded to public site, so feel free to give feedbacks as you wish, I'll try and work around with it. |
asuzuki/a2c-PandaReachDense-v2 | asuzuki | 2023-02-14T10:19:46Z | 3 | 0 | stable-baselines3 | [
"stable-baselines3",
"PandaReachDense-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-02-14T09:49:42Z | ---
library_name: stable-baselines3
tags:
- PandaReachDense-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: PandaReachDense-v2
type: PandaReachDense-v2
metrics:
- type: mean_reward
value: -0.74 +/- 0.27
name: mean_reward
verified: false
---
# **A2C** Agent playing **PandaReachDense-v2**
This is a trained model of a **A2C** agent playing **PandaReachDense-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
#install
!apt install python-opengl
!apt install ffmpeg
!apt install xvfb
!pip3 install pyvirtualdisplay
!pip install -r https://raw.githubusercontent.com/huggingface/deep-rl-class/main/notebooks/unit6/requirements-unit6.txt
# Virtual display
from pyvirtualdisplay import Display
virtual_display = Display(visible=0, size=(1400, 900))
virtual_display.start()
#imports
import pybullet_envs
import panda_gym
import gym
import os
from huggingface_sb3 import load_from_hub, package_to_hub
from stable_baselines3 import A2C
from stable_baselines3.common.evaluation import evaluate_policy
from stable_baselines3.common.vec_env import DummyVecEnv, VecNormalize
from stable_baselines3.common.env_util import make_vec_env
from huggingface_hub import notebook_login
#Define the environment called "PandaReachDense-v2"
env_id = "PandaReachDense-v2"
#Make a vectorized environment
env = make_vec_env(env_id, n_envs=4)
#Add a wrapper to normalize the observations and rewards. Check the documentation
env = VecNormalize(env, norm_obs=True, norm_reward=True, clip_obs=10)
#Create the A2C Model (don't forget verbose=1 to print the training logs).
model = A2C(policy = "MultiInputPolicy",
env = env,
gae_lambda = 0.9,
gamma = 0.95,
learning_rate = 0.001,
max_grad_norm = 0.5,
n_steps = 8,
vf_coef = 0.4,
ent_coef = 0.0,
seed=11,
policy_kwargs=dict(
log_std_init=-2, ortho_init=False),
normalize_advantage=False,
use_rms_prop= True,
use_sde= True,
verbose=1)
#Train it for 1M Timesteps
model.learn(1_500_000)
#Save the model and VecNormalize statistics when saving the agent
model.save(f"a2c-{env_id}")
env.save(f"vec_normalize_{env_id}.pkl")
#Evaluate your agent
eval_env = DummyVecEnv([lambda: gym.make(env_id)])
eval_env = VecNormalize.load(f"vec_normalize_{env_id}.pkl", eval_env)
# do not update them at test time
eval_env.training = False
# reward normalization is not needed at test time
eval_env.norm_reward = False
# Load the model
model = A2C.load(f"a2c-{env_id}")
#Evaluate model
mean_reward, std_reward = evaluate_policy(model, eval_env)
print(f"Mean reward = {mean_reward:.2f} +/- {std_reward:.2f}")
...
```
|
Guigadal/layoutxlm-finetuned-xfund-es | Guigadal | 2023-02-14T09:53:57Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"layoutlmv2",
"token-classification",
"generated_from_trainer",
"dataset:xfun",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| token-classification | 2023-02-09T09:14:02Z | ---
license: cc-by-nc-sa-4.0
tags:
- generated_from_trainer
datasets:
- xfun
model-index:
- name: layoutxlm-finetuned-xfund-es
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# layoutxlm-finetuned-xfund-es
-> This model is a fine-tuned version of [microsoft/layoutxlm-base](https://huggingface.co/microsoft/layoutxlm-base) on the xfun dataset.
-> Este modelo es una versión de [microsoft/layoutxlm-base](https://huggingface.co/microsoft/layoutxlm-base) con ajuste fino sobre xfun-es dataset (español).
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- training_steps: 2500
### Training results
Train output:
- global_step=2500
- training_loss=0.3006648193359375
- train_runtime: 3385.7522
- train_samples_per_second: 1.477
- train_steps_per_second: 0.738
- total_flos: 2688500014387200.0
- train_loss: 0.3006648193359375
- epoch: 20.49
### Framework versions
- Transformers 4.26.0
- Pytorch 1.10.0+cu111
- Datasets 2.9.0
- Tokenizers 0.13.2
|
EdenYav/dqn-SpaceInvadersNoFrameskip-v4 | EdenYav | 2023-02-14T09:27:34Z | 4 | 0 | stable-baselines3 | [
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-02-08T11:42:18Z | ---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 427.00 +/- 94.58
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga EdenYav -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga EdenYav -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga EdenYav
```
## Hyperparameters
```python
OrderedDict([('batch_size', 64),
('buffer_size', 150000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0005),
('learning_starts', 100000),
('n_timesteps', 500000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
|
fermaat/poca-SoccerTwos | fermaat | 2023-02-14T09:22:24Z | 7 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"unity-ml-agents",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SoccerTwos",
"region:us"
]
| reinforcement-learning | 2023-02-14T09:22:19Z |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SoccerTwos
library_name: ml-agents
---
# **poca** Agent playing **SoccerTwos**
This is a trained model of a **poca** agent playing **SoccerTwos** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-SoccerTwos
2. Step 1: Write your model_id: fermaat/poca-SoccerTwos
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
giggling-squid/q-Taxi-v3-5x5 | giggling-squid | 2023-02-14T09:21:09Z | 0 | 0 | null | [
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-02-14T08:51:27Z | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3-5x5
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.54 +/- 2.73
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="giggling-squid/q-Taxi-v3-5x5", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
ysugawa/distilbert-base-uncased-finetuned-squad-d5716d28 | ysugawa | 2023-02-14T09:04:31Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"distilbert",
"fill-mask",
"question-answering",
"en",
"dataset:squad",
"arxiv:1910.01108",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| question-answering | 2023-02-14T09:02:05Z | ---
language:
- en
thumbnail: https://github.com/karanchahal/distiller/blob/master/distiller.jpg
tags:
- question-answering
license: apache-2.0
datasets:
- squad
metrics:
- squad
---
# DistilBERT with a second step of distillation
## Model description
This model replicates the "DistilBERT (D)" model from Table 2 of the [DistilBERT paper](https://arxiv.org/pdf/1910.01108.pdf). In this approach, a DistilBERT student is fine-tuned on SQuAD v1.1, but with a BERT model (also fine-tuned on SQuAD v1.1) acting as a teacher for a second step of task-specific distillation.
In this version, the following pre-trained models were used:
* Student: `distilbert-base-uncased`
* Teacher: `lewtun/bert-base-uncased-finetuned-squad-v1`
## Training data
This model was trained on the SQuAD v1.1 dataset which can be obtained from the `datasets` library as follows:
```python
from datasets import load_dataset
squad = load_dataset('squad')
```
## Training procedure
## Eval results
| | Exact Match | F1 |
|------------------|-------------|------|
| DistilBERT paper | 79.1 | 86.9 |
| Ours | 78.4 | 86.5 |
The scores were calculated using the `squad` metric from `datasets`.
### BibTeX entry and citation info
```bibtex
@misc{sanh2020distilbert,
title={DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter},
author={Victor Sanh and Lysandre Debut and Julien Chaumond and Thomas Wolf},
year={2020},
eprint={1910.01108},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
TracyWang/MAUD_KWM_AWS_Roberta-base | TracyWang | 2023-02-14T08:37:02Z | 9 | 1 | transformers | [
"transformers",
"pytorch",
"roberta",
"question-answering",
"legal",
"text-classification",
"en",
"arxiv:2301.00876",
"license:mit",
"endpoints_compatible",
"region:us"
]
| text-classification | 2023-02-08T03:08:17Z | ---
license: mit
language:
- en
pipeline_tag: text-classification
tags:
- legal
---
Dataset and Training Script offered by the Atticus Project MAUD.
Trained on AWS Sagemaker with 4 A10 GPUs.
Model owned by King & Wood Mallesons Law Firm AI LAB.
Project Member:
- Wuyue(Tracy) Wang @ King & Wood Mallesons
- Anbei Zhao @ Amazon Web Services
- Xiaodong Guo @ Amazon Web Services
- Xiuyu Wu @ Peking University
Reference:
```
@misc{wang2023maud,
title={MAUD: An Expert-Annotated Legal NLP Dataset for Merger Agreement Understanding},
author={Steven H. Wang and Antoine Scardigli and Leonard Tang and Wei Chen and Dimitry Levkin and Anya Chen and Spencer Ball and Thomas Woodside and Oliver Zhang and Dan Hendrycks},
year={2023},
eprint={2301.00876},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
k-ush/xlm-roberta-base-ance-warmup | k-ush | 2023-02-14T08:30:05Z | 108 | 0 | transformers | [
"transformers",
"pytorch",
"xlm-roberta",
"fill-mask",
"en",
"autotrain_compatible",
"region:us"
]
| fill-mask | 2023-02-13T16:57:17Z | ---
language:
- en
inference: false
---
# XLM RoBERTa Base ANCE-Warmuped
This is a XLM RoBERTa Base model trained with ANCE warmup script.
RobertaForSequenceClassification is replaced to XLMRobertaForSequenceClassification in warmup script.
trained 60k steps.
train args is below:
``` text
data_dir: ../data/raw_data/
train_model_type: rdot_nll
model_name_or_path: xlm-roberta-base
task_name: msmarco
output_dir:
config_name:
tokenizer_name:
cache_dir:
max_seq_length: 128
do_train: True
do_eval: False
evaluate_during_training: True
do_lower_case: False
log_dir: ../logs/
eval_type: full
optimizer: lamb
scheduler: linear
per_gpu_train_batch_size: 32
per_gpu_eval_batch_size: 32
gradient_accumulation_steps: 1
learning_rate: 0.0002
weight_decay: 0.0
adam_epsilon: 1e-08
max_grad_norm: 1.0
num_train_epochs: 2.0
max_steps: -1
warmup_steps: 1000
logging_steps: 1000
logging_steps_per_eval: 20
save_steps: 30000
eval_all_checkpoints: False
no_cuda: False
overwrite_output_dir: True
overwrite_cache: False
seed: 42
fp16: True
fp16_opt_level: O1
expected_train_size: 35000000
load_optimizer_scheduler: False
local_rank: 0
server_ip:
server_port:
n_gpu: 1
device: cuda:0
output_mode: classification
num_labels: 2
train_batch_size: 32
```
# Eval Result
``` text
Reranking/Full ranking mrr: 0.27380855732933/0.24284821712830248
{"learning_rate": 0.00019460324719871943, "loss": 0.0895877162806064, "step": 60000}
```
# Usage
``` python3
from transformers import XLMRobertaForSequenceClassification, XLMRobertaTokenizer
repo = "k-ush/xlm-roberta-base-ance-warmup"
model = XLMRobertaForSequenceClassification.from_pretrained(repo)
tokenizer = XLMRobertaTokenizer.from_pretrained(repo)
``` |
mqy/mt5-small-finetuned-14feb-1 | mqy | 2023-02-14T08:26:00Z | 10 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"mt5",
"text2text-generation",
"summarization",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| summarization | 2023-02-14T02:02:27Z | ---
license: apache-2.0
tags:
- summarization
- generated_from_trainer
metrics:
- rouge
model-index:
- name: mt5-small-finetuned-14feb-1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mt5-small-finetuned-14feb-1
This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4516
- Rouge1: 20.33
- Rouge2: 6.2
- Rougel: 19.9
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.000275
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|
| 4.0401 | 1.0 | 388 | 2.5481 | 16.31 | 4.7 | 16.1 |
| 2.9776 | 2.0 | 776 | 2.4442 | 17.25 | 4.93 | 16.93 |
| 2.7362 | 3.0 | 1164 | 2.4181 | 19.73 | 5.74 | 19.21 |
| 2.5767 | 4.0 | 1552 | 2.4071 | 19.37 | 5.62 | 18.89 |
| 2.4466 | 5.0 | 1940 | 2.3560 | 18.98 | 5.94 | 18.55 |
| 2.3402 | 6.0 | 2328 | 2.3923 | 20.45 | 5.5 | 20.03 |
| 2.2385 | 7.0 | 2716 | 2.3639 | 20.03 | 5.96 | 19.76 |
| 2.1663 | 8.0 | 3104 | 2.3431 | 19.17 | 5.34 | 18.84 |
| 2.0849 | 9.0 | 3492 | 2.4008 | 19.97 | 5.58 | 19.67 |
| 2.0203 | 10.0 | 3880 | 2.3948 | 19.67 | 5.75 | 19.26 |
| 1.9653 | 11.0 | 4268 | 2.3915 | 20.06 | 6.07 | 19.61 |
| 1.9067 | 12.0 | 4656 | 2.4025 | 20.83 | 6.46 | 20.41 |
| 1.8592 | 13.0 | 5044 | 2.4194 | 19.97 | 6.4 | 19.69 |
| 1.8158 | 14.0 | 5432 | 2.4156 | 19.87 | 6.16 | 19.38 |
| 1.7679 | 15.0 | 5820 | 2.4053 | 19.9 | 5.99 | 19.52 |
| 1.748 | 16.0 | 6208 | 2.4156 | 19.68 | 5.81 | 19.28 |
| 1.7198 | 17.0 | 6596 | 2.4306 | 20.0 | 6.26 | 19.63 |
| 1.6959 | 18.0 | 6984 | 2.4499 | 19.1 | 6.19 | 18.82 |
| 1.6769 | 19.0 | 7372 | 2.4536 | 20.62 | 6.3 | 20.15 |
| 1.6682 | 20.0 | 7760 | 2.4516 | 20.33 | 6.2 | 19.9 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
|
amrisaurus/pretrained-m-bert-90 | amrisaurus | 2023-02-14T07:57:21Z | 46 | 0 | transformers | [
"transformers",
"tf",
"bert",
"pretraining",
"generated_from_keras_callback",
"endpoints_compatible",
"region:us"
]
| null | 2023-02-14T07:55:57Z | ---
tags:
- generated_from_keras_callback
model-index:
- name: pretrained-m-bert-90
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# pretrained-m-bert-90
This model is a fine-tuned version of [](https://huggingface.co/) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 5.7094
- Validation Loss: 14.5332
- Epoch: 89
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': True, 'is_legacy_optimizer': False, 'learning_rate': 1e-04, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 10.2413 | 10.9668 | 0 |
| 7.5814 | 10.9638 | 1 |
| 7.0095 | 11.3733 | 2 |
| 6.4352 | 11.5989 | 3 |
| 6.7137 | 11.4072 | 4 |
| 6.4383 | 11.8287 | 5 |
| 6.2223 | 12.0344 | 6 |
| 6.1759 | 11.6900 | 7 |
| 6.0764 | 11.7144 | 8 |
| 5.8802 | 12.1089 | 9 |
| 6.0159 | 12.3456 | 10 |
| 5.9254 | 12.7065 | 11 |
| 5.6652 | nan | 12 |
| 5.8185 | 12.8155 | 13 |
| 5.9185 | 12.7047 | 14 |
| 5.8418 | 12.7175 | 15 |
| 5.9122 | 12.5688 | 16 |
| 5.9698 | 12.5251 | 17 |
| 5.8286 | 12.7015 | 18 |
| 5.8807 | 13.2514 | 19 |
| 5.8330 | 12.8541 | 20 |
| 5.6456 | 13.4088 | 21 |
| 5.7257 | 13.5517 | 22 |
| 5.8854 | 12.8775 | 23 |
| 5.6770 | 13.6499 | 24 |
| 5.6026 | 13.9732 | 25 |
| 5.6651 | 13.0827 | 26 |
| 5.8888 | 13.1292 | 27 |
| 5.8123 | 12.8970 | 28 |
| 5.7525 | 13.3724 | 29 |
| 5.9020 | 13.5507 | 30 |
| 5.8642 | 13.3284 | 31 |
| 5.9329 | 13.7350 | 32 |
| 5.7728 | 13.3011 | 33 |
| 5.8297 | 13.6108 | 34 |
| 5.8118 | 13.3331 | 35 |
| 5.7382 | 13.7047 | 36 |
| 5.8061 | 13.8107 | 37 |
| 5.8423 | 13.4207 | 38 |
| 5.8442 | 13.6832 | 39 |
| 5.7680 | 14.1248 | 40 |
| 5.7668 | 13.6626 | 41 |
| 5.7826 | 13.6470 | 42 |
| 5.7692 | 13.9430 | 43 |
| 5.5109 | 14.0924 | 44 |
| 5.7394 | 14.0253 | 45 |
| 5.8013 | 13.5926 | 46 |
| 5.7222 | 13.9732 | 47 |
| 5.7023 | 14.0204 | 48 |
| 5.8250 | 13.9655 | 49 |
| 5.6064 | 14.0406 | 50 |
| 5.7319 | 14.1826 | 51 |
| 5.6849 | 13.9114 | 52 |
| 5.8167 | 13.9917 | 53 |
| 5.7573 | 14.1509 | 54 |
| 5.6921 | 14.3722 | 55 |
| 5.7190 | 14.4919 | 56 |
| 5.8501 | 13.6970 | 57 |
| 5.7627 | 14.1393 | 58 |
| 5.8031 | 14.1246 | 59 |
| 5.7207 | 14.3084 | 60 |
| 5.7979 | 13.9398 | 61 |
| 5.7068 | 14.2865 | 62 |
| 5.7547 | 14.2590 | 63 |
| 5.8349 | 14.1481 | 64 |
| 5.7924 | 14.0461 | 65 |
| 5.8127 | 14.1274 | 66 |
| 5.7590 | 14.3578 | 67 |
| 5.8297 | 14.2429 | 68 |
| 5.7822 | 14.2742 | 69 |
| 5.7708 | 14.3720 | 70 |
| 5.6521 | 14.8640 | 71 |
| 5.7253 | 14.4404 | 72 |
| 5.8076 | 14.1843 | 73 |
| 5.7746 | 14.4657 | 74 |
| 5.8592 | 14.2965 | 75 |
| 5.6643 | 14.0996 | 76 |
| 5.7849 | 14.3531 | 77 |
| 5.7418 | 14.4266 | 78 |
| 5.7030 | 14.5584 | 79 |
| 5.8298 | 14.1390 | 80 |
| 5.9061 | 13.9172 | 81 |
| 5.6570 | 14.6991 | 82 |
| 5.7040 | 14.7839 | 83 |
| 5.8064 | 14.2581 | 84 |
| 5.6855 | 14.4449 | 85 |
| 5.7803 | 14.7469 | 86 |
| 5.7495 | 14.4704 | 87 |
| 5.7539 | 14.5520 | 88 |
| 5.7094 | 14.5332 | 89 |
### Framework versions
- Transformers 4.27.0.dev0
- TensorFlow 2.11.0
- Datasets 2.9.0
- Tokenizers 0.13.2
|
akghxhs55/poca-SoccerTwos-4 | akghxhs55 | 2023-02-14T07:54:19Z | 6 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"unity-ml-agents",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SoccerTwos",
"region:us"
]
| reinforcement-learning | 2023-02-14T07:54:12Z |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SoccerTwos
library_name: ml-agents
---
# **poca** Agent playing **SoccerTwos**
This is a trained model of a **poca** agent playing **SoccerTwos** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-SoccerTwos
2. Step 1: Write your model_id: akghxhs55/poca-SoccerTwos-4
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
nolanaatama/crns7thhvnmx | nolanaatama | 2023-02-14T07:53:35Z | 0 | 0 | null | [
"license:creativeml-openrail-m",
"region:us"
]
| null | 2023-02-14T07:45:39Z | ---
license: creativeml-openrail-m
---
|
Zekunli/flan-t5-large-extraction-cnndm_10000-all | Zekunli | 2023-02-14T07:52:30Z | 4 | 0 | transformers | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2023-02-14T06:39:35Z | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: flan-t5-large-extraction-cnndm_10000-all
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# flan-t5-large-extraction-cnndm_10000-all
This model is a fine-tuned version of [google/flan-t5-large](https://huggingface.co/google/flan-t5-large) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7044
- Rouge1: 34.8618
- Rouge2: 15.5978
- Rougel: 29.7948
- Rougelsum: 29.7581
- Gen Len: 19.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 24
- seed: 1799
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| 2.1668 | 0.16 | 200 | 1.8280 | 33.7941 | 14.3114 | 28.7743 | 28.7968 | 19.0 |
| 1.9736 | 0.32 | 400 | 1.7818 | 34.8351 | 15.5548 | 29.8974 | 29.8557 | 18.99 |
| 1.904 | 0.48 | 600 | 1.7513 | 35.465 | 15.8566 | 30.7139 | 30.6596 | 18.986 |
| 1.8938 | 0.64 | 800 | 1.7440 | 34.6193 | 15.5473 | 30.0661 | 30.0019 | 18.99 |
| 1.8471 | 0.8 | 1000 | 1.7366 | 34.553 | 15.2214 | 29.8807 | 29.8419 | 18.99 |
| 1.8621 | 0.96 | 1200 | 1.7486 | 34.9309 | 15.1932 | 29.8973 | 29.8774 | 18.99 |
| 1.8082 | 1.12 | 1400 | 1.7311 | 35.3395 | 16.0976 | 30.2748 | 30.293 | 18.99 |
| 1.7448 | 1.28 | 1600 | 1.7155 | 35.1387 | 15.7462 | 29.924 | 29.9287 | 18.99 |
| 1.7655 | 1.44 | 1800 | 1.7239 | 35.3603 | 15.6355 | 30.3944 | 30.3766 | 19.0 |
| 1.7283 | 1.6 | 2000 | 1.7132 | 34.7368 | 15.4073 | 29.9027 | 29.8971 | 19.0 |
| 1.7463 | 1.76 | 2200 | 1.7171 | 35.0545 | 15.726 | 30.0364 | 30.0056 | 19.0 |
| 1.7462 | 1.92 | 2400 | 1.7044 | 34.8618 | 15.5978 | 29.7948 | 29.7581 | 19.0 |
| 1.719 | 2.08 | 2600 | 1.7285 | 34.9598 | 15.5237 | 29.5593 | 29.5803 | 19.0 |
| 1.6828 | 2.24 | 2800 | 1.7179 | 35.0944 | 15.7333 | 29.8381 | 29.7784 | 19.0 |
| 1.7 | 2.4 | 3000 | 1.7047 | 35.1766 | 15.7758 | 29.818 | 29.7859 | 19.0 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.10.0+cu111
- Datasets 2.5.1
- Tokenizers 0.12.1
|
sinny/baseline | sinny | 2023-02-14T07:45:17Z | 4 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"unity-ml-agents",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SoccerTwos",
"region:us"
]
| reinforcement-learning | 2023-02-14T07:45:11Z |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SoccerTwos
library_name: ml-agents
---
# **poca** Agent playing **SoccerTwos**
This is a trained model of a **poca** agent playing **SoccerTwos** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-SoccerTwos
2. Step 1: Write your model_id: sinny/baseline
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
joelniklaus/legal-swedish-roberta-base | joelniklaus | 2023-02-14T06:08:34Z | 107 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"roberta",
"fill-mask",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| fill-mask | 2023-02-06T02:38:57Z | ---
tags:
- generated_from_trainer
model-index:
- name: legal-swedish-roberta-base
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# legal-swedish-roberta-base
This model was trained from scratch on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6149
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- distributed_type: tpu
- num_devices: 8
- gradient_accumulation_steps: 4
- total_train_batch_size: 512
- total_eval_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.05
- training_steps: 200000
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:------:|:---------------:|
| 0.9458 | 2.04 | 50000 | 0.7559 |
| 0.8037 | 4.08 | 100000 | 0.6746 |
| 0.8366 | 7.01 | 150000 | 0.6285 |
| 0.7924 | 9.05 | 200000 | 0.6149 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu102
- Datasets 2.9.0
- Tokenizers 0.12.0
|
Ransaka/a2c-AntBulletEnv-v0 | Ransaka | 2023-02-14T05:56:44Z | 1 | 0 | stable-baselines3 | [
"stable-baselines3",
"AntBulletEnv-v0",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-02-14T05:55:33Z | ---
library_name: stable-baselines3
tags:
- AntBulletEnv-v0
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: AntBulletEnv-v0
type: AntBulletEnv-v0
metrics:
- type: mean_reward
value: 1950.91 +/- 129.99
name: mean_reward
verified: false
---
# **A2C** Agent playing **AntBulletEnv-v0**
This is a trained model of a **A2C** agent playing **AntBulletEnv-v0**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
PecanPi/pixelcopter-v1 | PecanPi | 2023-02-14T05:51:41Z | 0 | 0 | null | [
"Pixelcopter-PLE-v0",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-02-13T03:45:46Z | ---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: pixelcopter-v1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: 45.90 +/- 37.13
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
LarryAIDraw/azuraFireEmblemFates_v10 | LarryAIDraw | 2023-02-14T05:31:03Z | 0 | 0 | null | [
"license:creativeml-openrail-m",
"region:us"
]
| null | 2023-02-14T05:29:06Z | ---
license: creativeml-openrail-m
---
|
LarryAIDraw/kaguyaSamaLoveIsWar_hayasakaAiV1 | LarryAIDraw | 2023-02-14T05:30:28Z | 0 | 0 | null | [
"license:creativeml-openrail-m",
"region:us"
]
| null | 2023-02-14T05:23:37Z | ---
license: creativeml-openrail-m
---
https://civitai.com/models/8613/kaguya-samalove-is-war-hayasaka-ai |
TheRains/whisper-small-id | TheRains | 2023-02-14T04:46:04Z | 77 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"whisper",
"automatic-speech-recognition",
"hf-asr-leaderboard",
"generated_from_trainer",
"id",
"dataset:mozilla-foundation/common_voice_11_0",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2023-01-16T08:30:02Z | ---
language:
- id
license: apache-2.0
tags:
- hf-asr-leaderboard
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_11_0
model-index:
- name: Whisper Small Id - TheRains
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small Id - TheRains
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the Common Voice 11.0 dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-06
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 100
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.27.0.dev0
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
|
UchihaMadara/model1-thesis-5 | UchihaMadara | 2023-02-14T04:42:32Z | 107 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| token-classification | 2023-02-14T04:18:52Z | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: model1-thesis-5
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# model1-thesis-5
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6273
- Precision: 0.4620
- Recall: 0.6348
- F1: 0.5348
- Accuracy: 0.8196
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 29 | 0.5895 | 0.3871 | 0.6261 | 0.4784 | 0.8086 |
| No log | 2.0 | 58 | 0.5814 | 0.4424 | 0.6348 | 0.5214 | 0.8118 |
| No log | 3.0 | 87 | 0.5734 | 0.4360 | 0.6522 | 0.5226 | 0.8332 |
| No log | 4.0 | 116 | 0.6326 | 0.4808 | 0.6522 | 0.5535 | 0.8170 |
| No log | 5.0 | 145 | 0.6273 | 0.4620 | 0.6348 | 0.5348 | 0.8196 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
|
bakuaifuji/test | bakuaifuji | 2023-02-14T04:41:49Z | 0 | 0 | null | [
"music",
"license:apache-2.0",
"region:us"
]
| null | 2023-02-10T05:40:41Z | ---
license: apache-2.0
tags:
- music
--- |
enankobh1/whisper-small-ASR-EN | enankobh1 | 2023-02-14T04:35:06Z | 78 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2023-02-13T10:13:04Z | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: whisper-small-ASR-EN
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper-small-ASR-EN
This model is a fine-tuned version of [openai/whisper-small.en](https://huggingface.co/openai/whisper-small.en) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7014
- Wer: 20.6492
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.0389 | 5.95 | 1000 | 0.4354 | 24.2479 |
| 0.0015 | 11.9 | 2000 | 0.6301 | 21.1699 |
| 0.0003 | 17.86 | 3000 | 0.6822 | 20.5739 |
| 0.0002 | 23.81 | 4000 | 0.7014 | 20.6492 |
### Framework versions
- Transformers 4.27.0.dev0
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
|
nhiro3303/ppo-SnowballTarget | nhiro3303 | 2023-02-14T04:23:07Z | 14 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"unity-ml-agents",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SnowballTarget",
"region:us"
]
| reinforcement-learning | 2023-02-14T04:23:02Z |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SnowballTarget
library_name: ml-agents
---
# **ppo** Agent playing **SnowballTarget**
This is a trained model of a **ppo** agent playing **SnowballTarget** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-SnowballTarget
2. Step 1: Write your model_id: nhiro3303/ppo-SnowballTarget
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
dfm794/poca-SoccerTwos-2x-2-r-l | dfm794 | 2023-02-14T04:22:23Z | 9 | 0 | ml-agents | [
"ml-agents",
"tensorboard",
"onnx",
"unity-ml-agents",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SoccerTwos",
"region:us"
]
| reinforcement-learning | 2023-02-14T04:22:16Z |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SoccerTwos
library_name: ml-agents
---
# **poca** Agent playing **SoccerTwos**
This is a trained model of a **poca** agent playing **SoccerTwos** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-SoccerTwos
2. Step 1: Write your model_id: dfm794/poca-SoccerTwos-2x-2-r-l
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
yhchoi/klue-emotional-finetuned-emotion | yhchoi | 2023-02-14T04:21:14Z | 5 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"roberta",
"text-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2023-02-14T03:44:34Z | ---
tags:
- generated_from_trainer
model-index:
- name: klue-emotional-finetuned-emotion
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# klue-emotional-finetuned-emotion
This model is a fine-tuned version of [klue/roberta-small](https://huggingface.co/klue/roberta-small) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.26.1
- Pytorch 1.8.1+cu111
- Datasets 2.9.0
- Tokenizers 0.13.2
|
jhn9803/Contract-new-tokenizer-roberta-large | jhn9803 | 2023-02-14T04:19:19Z | 4 | 1 | transformers | [
"transformers",
"pytorch",
"roberta",
"text-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2023-02-14T03:36:26Z | ---
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: Contract-new-tokenizer-roberta-large
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Contract-new-tokenizer-roberta-large
This model is a fine-tuned version of [klue/roberta-large](https://huggingface.co/klue/roberta-large) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6076
- Accuracy: 0.7042
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 249 | 0.6072 | 0.7042 |
| No log | 2.0 | 498 | 0.6138 | 0.7042 |
| No log | 3.0 | 747 | 0.6076 | 0.7042 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
|
printr/gptx-rl-371k | printr | 2023-02-14T03:55:52Z | 0 | 0 | null | [
"license:cc-by-2.0",
"region:us"
]
| null | 2023-02-13T22:40:20Z | ---
license: cc-by-2.0
---
[Github for Inference and Training](https://github.com/Quicksticks-oss/GPTX-RL)
### Features
- Just like GPT this model generates text based on an input prompt.
- This project uses Reinforcement Learning (RL) for training and inference.
- All models can be found on hugging face.
---
### Training
- First step is to run ``generate_vocab.py`` on whatever text data you would like to train on for example ``python3 generate_vocab.py -i train.txt``
- Next step is to run ``train.py``
- Now all you have to do is wait!
---
### Inference
- Run ``inference.py`` with ``-i`` as an argumentand with models path.
### Logging
- Output plot graphs will be avalible in the next version. |
mjschock/a2c-AntBulletEnv-v0 | mjschock | 2023-02-14T03:54:20Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"AntBulletEnv-v0",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-02-14T03:53:05Z | ---
library_name: stable-baselines3
tags:
- AntBulletEnv-v0
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: AntBulletEnv-v0
type: AntBulletEnv-v0
metrics:
- type: mean_reward
value: 1358.66 +/- 213.32
name: mean_reward
verified: false
---
# **A2C** Agent playing **AntBulletEnv-v0**
This is a trained model of a **A2C** agent playing **AntBulletEnv-v0**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
jhn9803/Contract-base-tokenizer-roberta-large | jhn9803 | 2023-02-14T03:28:12Z | 7 | 0 | transformers | [
"transformers",
"pytorch",
"roberta",
"text-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2023-02-13T13:20:38Z | ---
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: Contract-base-tokenizer-roberta-large
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Contract-base-tokenizer-roberta-large
This model is a fine-tuned version of [klue/roberta-large](https://huggingface.co/klue/roberta-large) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0431
- Accuracy: 0.9930
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 249 | 0.0580 | 0.9869 |
| No log | 2.0 | 498 | 0.0380 | 0.9920 |
| No log | 3.0 | 747 | 0.0431 | 0.9930 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
|
cwwojin/stt_kr_conformer_ctc_medium | cwwojin | 2023-02-14T03:23:47Z | 1 | 1 | nemo | [
"nemo",
"ksponspeech",
"automatic-speech-recognition",
"ko",
"license:mit",
"model-index",
"region:us"
]
| automatic-speech-recognition | 2023-02-12T13:10:42Z | ---
license: mit
language:
- ko
metrics:
- cer
pipeline_tag: automatic-speech-recognition
tags:
- ksponspeech
model-index:
- name: cwwojin/stt_kr_conformer_ctc_medium
results:
- task:
type: automatic-speech-recognition # Required. Example: automatic-speech-recognition
dataset:
type: Murple/ksponspeech # Required. Example: common_voice. Use dataset id from https://hf.co/datasets
name: KsponSpeech-eval (Korean) # Required. A pretty name for the dataset. Example: Common Voice (French)
split: test # Optional. Example: test
metrics:
- type: cer # Required. Example: wer. Use metric id from https://hf.co/metrics
value: 11.902 # Required. Example: 20.90
name: Test CER(%) # Optional. Example: Test WER
---
# stt_kr_conformer_ctc_medium
- Fine-tuned from "stt_en_conformer_ctc_medium" https://catalog.ngc.nvidia.com/orgs/nvidia/teams/nemo/models/stt_en_conformer_ctc_medium
- Trained on KsponSpeech, provided by https://aihub.or.kr/
## Preprocessing
- Files converted from .pcm -> .wav
- Text - Korean phonetic transcription
- SentencePiece tokenizer (Byte-pair encoding), vocab-size = 5,000
## Evaluation
- "KsponSpeech_eval_clean", "KsponSpeech_eval_other" |
letingliu/my_awesome_model | letingliu | 2023-02-14T03:21:41Z | 5 | 0 | transformers | [
"transformers",
"tf",
"distilbert",
"text-classification",
"generated_from_keras_callback",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2022-12-13T01:03:05Z | ---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: letingliu/my_awesome_model
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# letingliu/my_awesome_model
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.5129
- Validation Loss: 0.5051
- Train Accuracy: 0.9231
- Epoch: 7
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': True, 'is_legacy_optimizer': False, 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 30, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Accuracy | Epoch |
|:----------:|:---------------:|:--------------:|:-----:|
| 0.6853 | 0.6586 | 0.7788 | 0 |
| 0.6489 | 0.6197 | 0.7788 | 1 |
| 0.6090 | 0.5693 | 0.8942 | 2 |
| 0.5617 | 0.5245 | 0.8942 | 3 |
| 0.5235 | 0.5051 | 0.9231 | 4 |
| 0.5116 | 0.5051 | 0.9231 | 5 |
| 0.5112 | 0.5051 | 0.9231 | 6 |
| 0.5129 | 0.5051 | 0.9231 | 7 |
### Framework versions
- Transformers 4.26.1
- TensorFlow 2.11.0
- Datasets 2.9.0
- Tokenizers 0.13.2
|
amrutha3899/my_awesome_qa_model2 | amrutha3899 | 2023-02-14T02:49:16Z | 107 | 0 | transformers | [
"transformers",
"pytorch",
"distilbert",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"endpoints_compatible",
"region:us"
]
| question-answering | 2023-02-14T01:44:19Z | ---
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: my_awesome_qa_model2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_qa_model2
This model was trained from scratch on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
|
svenkate/ppo-LunarLander-v2 | svenkate | 2023-02-14T02:44:08Z | 4 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-02-14T02:43:44Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 268.79 +/- 25.14
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Zekunli/flan-t5-large-extraction-cnndm_20000-all | Zekunli | 2023-02-14T02:35:46Z | 3 | 0 | transformers | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2023-02-14T01:29:24Z | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: flan-t5-large-extraction-cnndm_20000-all
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# flan-t5-large-extraction-cnndm_20000-all
This model is a fine-tuned version of [google/flan-t5-large](https://huggingface.co/google/flan-t5-large) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6652
- Rouge1: 35.487
- Rouge2: 15.6713
- Rougel: 29.9519
- Rougelsum: 29.9368
- Gen Len: 19.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 24
- seed: 1799
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| 2.1295 | 0.08 | 200 | 1.8266 | 34.0465 | 14.7511 | 29.3395 | 29.3437 | 19.0 |
| 1.9354 | 0.16 | 400 | 1.7732 | 34.7923 | 15.3094 | 29.8484 | 29.8757 | 18.99 |
| 1.854 | 0.24 | 600 | 1.7367 | 34.8358 | 15.1969 | 29.9971 | 30.0064 | 18.986 |
| 1.833 | 0.32 | 800 | 1.7120 | 34.7854 | 15.5144 | 29.8141 | 29.7863 | 18.982 |
| 1.8217 | 0.4 | 1000 | 1.7256 | 34.7274 | 15.2763 | 30.0298 | 30.0871 | 19.0 |
| 1.8309 | 0.48 | 1200 | 1.7089 | 35.4328 | 15.7724 | 30.0655 | 30.0199 | 19.0 |
| 1.825 | 0.56 | 1400 | 1.6947 | 35.4116 | 15.6911 | 30.1438 | 30.1764 | 19.0 |
| 1.7914 | 0.64 | 1600 | 1.7119 | 35.5918 | 16.3762 | 30.3234 | 30.2807 | 19.0 |
| 1.7889 | 0.72 | 1800 | 1.6810 | 35.6413 | 15.8936 | 30.2848 | 30.2291 | 19.0 |
| 1.7576 | 0.8 | 2000 | 1.6826 | 35.9424 | 15.6803 | 30.5998 | 30.5571 | 19.0 |
| 1.7763 | 0.88 | 2200 | 1.6748 | 35.7543 | 15.984 | 30.7197 | 30.721 | 18.998 |
| 1.7604 | 0.96 | 2400 | 1.6652 | 35.487 | 15.6713 | 29.9519 | 29.9368 | 19.0 |
| 1.7138 | 1.04 | 2600 | 1.6860 | 36.0333 | 16.4065 | 30.7249 | 30.7168 | 19.0 |
| 1.6951 | 1.12 | 2800 | 1.6792 | 35.3149 | 15.7178 | 30.1555 | 30.1517 | 18.998 |
| 1.6752 | 1.2 | 3000 | 1.6832 | 34.7566 | 15.4179 | 29.7687 | 29.8259 | 19.0 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.10.0+cu111
- Datasets 2.5.1
- Tokenizers 0.12.1
|
alc15492/msemj30 | alc15492 | 2023-02-14T01:23:58Z | 9 | 0 | diffusers | [
"diffusers",
"text-to-image",
"license:openrail",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
]
| text-to-image | 2023-02-14T00:55:50Z | ---
license: openrail
library_name: diffusers
pipeline_tag: text-to-image
--- |
muchad/idt5-qa-qg | muchad | 2023-02-14T01:20:53Z | 128 | 9 | transformers | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"question-generation",
"multitask-model",
"idt5",
"id",
"dataset:SQuADv2.0",
"arxiv:2302.00856",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2022-08-12T16:32:11Z | ---
language: id
datasets:
- SQuADv2.0
tags:
- question-generation
- multitask-model
- idt5
widget:
- text: "generate question: <hl> Dua orang <hl> pengembara berjalan di sepanjang jalan yang berdebu dan tandus di hari yang sangat panas. Tidak lama kemudian, mereka menemukan sebuah pohon besar. </s>"
- text: "question: Siapa pemimpin Kerajaan Tarumanegara? context: Raja Purnawarman mulai memerintah Kerajaan Tarumanegara pada tahun 395 M. </s>"
license: apache-2.0
---
# idT5 for Indonesian Question Generation and Question Answering
[idT5](https://huggingface.co/muchad/idt5-base) (Indonesian version of [mT5](https://huggingface.co/google/mt5-base)) is fine-tuned on 30% of [translated SQuAD v2.0](https://github.com/Wikidepia/indonesian_datasets/tree/master/question-answering/squad) for **Question Generation** and **Question Answering** tasks.
## Live Demo
* **Question Generation:** [ai.muchad.com/qg](https://ai.muchad.com/qg/)
* **Question Answering:** [t.me/caritahubot](https://t.me/caritahubot)
## Requirements
```
!pip install transformers==4.4.2
!pip install sentencepiece==0.1.95
!git clone https://github.com/muchad/qaqg.git
%cd qaqg/
```
## Usage 🚀
#### Question Generation
[](https://colab.research.google.com/github/muchad/qaqg/blob/main/idT5_Question_Generation.ipynb)
```
from pipeline_qg import pipeline #pipeline_qg.py script in the cloned repo
qg = pipeline()
#sample
qg("Raja Purnawarman mulai memerintah Kerajaan Tarumanegara pada tahun 395 M.")
#output
=> [{'answer': 'Raja Purnawarman','question': 'Siapa yang memerintah Kerajaan Tarumanegara?'}, {'answer': '395 M','question': 'Kapan Raja Purnawarman memerintah Kerajaan Tarumanegara?'}]
```
#### Question Answering
[](https://colab.research.google.com/github/muchad/qaqg/blob/main/idT5_Question_Answering.ipynb)
```
from pipeline_qa import pipeline #pipeline_qa.py script in the cloned repo
qa = pipeline()
#sample
qa({"context":"Raja Purnawarman mulai memerintah Kerajaan Tarumanegara pada tahun 395 M.","question":"Siapa pemimpin Kerajaan Tarumanegara?"})
#output
=> Raja Purnawarman
```
#### Citation
Paper: [idT5: Indonesian Version of Multilingual T5 Transformer](https://arxiv.org/abs/2302.00856)
```
@misc{https://doi.org/10.48550/arxiv.2302.00856,
doi = {10.48550/ARXIV.2302.00856},
url = {https://arxiv.org/abs/2302.00856},
author = {Fuadi, Mukhlish and Wibawa, Adhi Dharma and Sumpeno, Surya},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences, I.2.7},
title = {idT5: Indonesian Version of Multilingual T5 Transformer},
publisher = {arXiv},
year = {2023}
}
``` |
deprem-ml/deprem_bert_128k | deprem-ml | 2023-02-14T01:15:10Z | 8 | 3 | transformers | [
"transformers",
"pytorch",
"bert",
"text-classification",
"deprem-clf-v1",
"tr",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2023-02-13T17:56:09Z | ---
license: apache-2.0
language:
- tr
metrics:
- accuracy
- recall
- f1
tags:
- deprem-clf-v1
library_name: transformers
pipeline_tag: text-classification
model-index:
- name: deprem_v12
results:
- task:
type: text-classification
dataset:
type: deprem_private_dataset_v1_2
name: deprem_private_dataset_v1_2
metrics:
- type: recall
value: 0.82
verified: false
- type: f1
value: 0.76
verified: false
widget:
- text: >-
acil acil acil antakyadan istanbula gitmek için antakya expoya ulaşmaya çalışan 19 kişilik bir aile için şehir içi ulaşım desteği istiyoruz. dışardalar üşüyorlar.iletebileceğiniz numaraları bekliyorum
example_title: Örnek
---
## Eval Results
```
precision recall f1-score support
Alakasiz 0.87 0.91 0.89 734
Barinma 0.79 0.89 0.84 207
Elektronik 0.69 0.83 0.75 130
Giysi 0.71 0.81 0.76 94
Kurtarma 0.82 0.85 0.83 362
Lojistik 0.57 0.67 0.62 112
Saglik 0.68 0.85 0.75 108
Su 0.56 0.76 0.64 78
Yagma 0.60 0.77 0.68 31
Yemek 0.71 0.89 0.79 117
micro avg 0.77 0.86 0.81 1973
macro avg 0.70 0.82 0.76 1973
weighted avg 0.78 0.86 0.82 1973
samples avg 0.83 0.88 0.84 1973
```
## Training Params:
```python
{'per_device_train_batch_size': 32,
'per_device_eval_batch_size': 32,
'learning_rate': 5.8679699888213376e-05,
'weight_decay': 0.03530961718117487,
'num_train_epochs': 4,
'lr_scheduler_type': 'cosine',
'warmup_steps': 40,
'seed': 42,
'fp16': True,
'load_best_model_at_end': True,
'metric_for_best_model': 'macro f1',
'greater_is_better': True
}
```
## Threshold:
- **Best Threshold:** 0.40
## Class Loss Weights
- Same as Anıl's approach:
```python
[1.0,
1.5167249178108022,
1.7547338578655642,
1.9610520059358458,
1.8684086209021484,
1.8019018017117145,
2.110648663094536,
3.081208739200435,
1.7994815143101963]
``` |
zb/ppo-LunarLander-v2 | zb | 2023-02-14T00:47:03Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-02-14T00:46:35Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: MlpPolicy
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 233.87 +/- 16.42
name: mean_reward
verified: false
---
# **MlpPolicy** Agent playing **LunarLander-v2**
This is a trained model of a **MlpPolicy** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
NathanS-HuggingFace/LunarLander | NathanS-HuggingFace | 2023-02-14T00:29:30Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-02-12T16:53:23Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 308.50 +/- 11.39
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
nikgeo/ppo-LunarLander-v2 | nikgeo | 2023-02-14T00:13:50Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-02-13T23:14:35Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 251.12 +/- 21.78
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
cleandata/ppo-LunarLander-v2 | cleandata | 2023-02-14T00:09:17Z | 6 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-02-14T00:08:45Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 244.85 +/- 17.73
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
nossal/ppo-LunarLander-v2 | nossal | 2023-02-13T23:15:23Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-02-13T23:14:49Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 239.91 +/- 21.04
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
lilouuch/Goodreads_Books_Reviews_Roberta_53 | lilouuch | 2023-02-13T23:13:42Z | 162 | 0 | transformers | [
"transformers",
"pytorch",
"roberta",
"text-classification",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2023-02-13T11:28:16Z | ---
license: mit
tags:
- generated_from_trainer
metrics:
- f1
- accuracy
model-index:
- name: Goodreads_Books_Reviews_Roberta_53
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Goodreads_Books_Reviews_Roberta_53
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8038
- F1: 0.6238
- Accuracy: 0.6614
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:--------:|
| 0.8378 | 1.0 | 25313 | 0.8197 | 0.6092 | 0.6538 |
| 0.7683 | 2.0 | 50626 | 0.8038 | 0.6238 | 0.6614 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
GrimReaperSam/q-Taxi-v3 | GrimReaperSam | 2023-02-13T23:08:58Z | 0 | 0 | null | [
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
]
| reinforcement-learning | 2023-02-13T23:08:51Z | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.46 +/- 2.78
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="GrimReaperSam/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Subsets and Splits