
modelId
stringlengths 4
112
| sha
stringlengths 40
40
| lastModified
stringlengths 24
24
| tags
list | pipeline_tag
stringclasses 29
values | private
bool 1
class | author
stringlengths 2
38
⌀ | config
null | id
stringlengths 4
112
| downloads
float64 0
36.8M
⌀ | likes
float64 0
712
⌀ | library_name
stringclasses 17
values | __index_level_0__
int64 0
38.5k
| readme
stringlengths 0
186k
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
facebook/convnext-tiny-224
|
0d1c8dedaa107d4ae537c5b10e5cd0a8c865e84e
|
2022-02-26T12:15:30.000Z
|
[
"pytorch",
"tf",
"convnext",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2201.03545",
"transformers",
"vision",
"license:apache-2.0"
] |
image-classification
| false |
facebook
| null |
facebook/convnext-tiny-224
| 6,835 | 2 |
transformers
| 800 |
---
license: apache-2.0
tags:
- vision
- image-classification
datasets:
- imagenet-1k
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
---
# ConvNeXT (tiny-sized model)
ConvNeXT model trained on ImageNet-1k at resolution 224x224. It was introduced in the paper [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Liu et al. and first released in [this repository](https://github.com/facebookresearch/ConvNeXt).
Disclaimer: The team releasing ConvNeXT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
ConvNeXT is a pure convolutional model (ConvNet), inspired by the design of Vision Transformers, that claims to outperform them. The authors started from a ResNet and "modernized" its design by taking the Swin Transformer as inspiration.

## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=convnext) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import ConvNextFeatureExtractor, ConvNextForImageClassification
import torch
from datasets import load_dataset
dataset = load_dataset("huggingface/cats-image")
image = dataset["test"]["image"][0]
feature_extractor = ConvNextFeatureExtractor.from_pretrained("facebook/convnext-tiny-224")
model = ConvNextForImageClassification.from_pretrained("facebook/convnext-tiny-224")
inputs = feature_extractor(image, return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
# model predicts one of the 1000 ImageNet classes
predicted_label = logits.argmax(-1).item()
print(model.config.id2label[predicted_label]),
```
For more code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/master/en/model_doc/convnext).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2201-03545,
author = {Zhuang Liu and
Hanzi Mao and
Chao{-}Yuan Wu and
Christoph Feichtenhofer and
Trevor Darrell and
Saining Xie},
title = {A ConvNet for the 2020s},
journal = {CoRR},
volume = {abs/2201.03545},
year = {2022},
url = {https://arxiv.org/abs/2201.03545},
eprinttype = {arXiv},
eprint = {2201.03545},
timestamp = {Thu, 20 Jan 2022 14:21:35 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2201-03545.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
deepset/bert-small-mm_retrieval-table_encoder
|
d2068c03905e9406dd5c192aef839ce3b938fa1a
|
2021-10-19T16:22:42.000Z
|
[
"pytorch",
"dpr",
"transformers"
] | null | false |
deepset
| null |
deepset/bert-small-mm_retrieval-table_encoder
| 6,829 | null |
transformers
| 801 |
Entry not found
|
Salesforce/codegen-16B-multi
|
f509e154f23d9017a9f7843ab36a844ef8d2b308
|
2022-06-28T17:53:24.000Z
|
[
"pytorch",
"codegen",
"text-generation",
"arxiv:2203.13474",
"transformers",
"license:bsd-3-clause"
] |
text-generation
| false |
Salesforce
| null |
Salesforce/codegen-16B-multi
| 6,827 | 2 |
transformers
| 802 |
---
license: bsd-3-clause
---
# CodeGen (CodeGen-Multi 16B)
## Model description
CodeGen is a family of autoregressive language models for **program synthesis** from the paper: [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong. The models are originally released in [this repository](https://github.com/salesforce/CodeGen), under 3 pre-training data variants (`NL`, `Multi`, `Mono`) and 4 model size variants (`350M`, `2B`, `6B`, `16B`).
The checkpoint included in this repository is denoted as **CodeGen-Multi 16B** in the paper, where "Multi" means the model is initialized with *CodeGen-NL 16B* and further pre-trained on a dataset of multiple programming languages, and "16B" refers to the number of trainable parameters.
## Training data
This checkpoint (CodeGen-Multi 16B) was firstly initialized with *CodeGen-NL 16B*, and then pre-trained on [BigQuery](https://console.cloud.google.com/marketplace/details/github/github-repos), a large-scale dataset of multiple programming languages from GitHub repositories. The data consists of 119.2B tokens and includes C, C++, Go, Java, JavaScript, and Python.
## Training procedure
CodeGen was trained using cross-entropy loss to maximize the likelihood of sequential inputs.
The family of models are trained using multiple TPU-v4-512 by Google, leveraging data and model parallelism.
See Section 2.3 of the [paper](https://arxiv.org/abs/2203.13474) for more details.
## Evaluation results
We evaluate our models on two code generation benchmark: HumanEval and MTPB. Please refer to the [paper](https://arxiv.org/abs/2203.13474) for more details.
## Intended Use and Limitations
As an autoregressive language model, CodeGen is capable of extracting features from given natural language and programming language texts, and calculating the likelihood of them.
However, the model is intended for and best at **program synthesis**, that is, generating executable code given English prompts, where the prompts should be in the form of a comment string. The model can complete partially-generated code as well.
## How to use
This model can be easily loaded using the `AutoModelForCausalLM` functionality:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("Salesforce/codegen-16B-multi")
model = AutoModelForCausalLM.from_pretrained("Salesforce/codegen-16B-multi")
text = "def hello_world():"
input_ids = tokenizer(text, return_tensors="pt").input_ids
generated_ids = model.generate(input_ids, max_length=128)
print(tokenizer.decode(generated_ids[0], skip_special_tokens=True))
```
## BibTeX entry and citation info
```bibtex
@article{Nijkamp2022ACP,
title={A Conversational Paradigm for Program Synthesis},
author={Nijkamp, Erik and Pang, Bo and Hayashi, Hiroaki and Tu, Lifu and Wang, Huan and Zhou, Yingbo and Savarese, Silvio and Xiong, Caiming},
journal={arXiv preprint},
year={2022}
}
```
|
Helsinki-NLP/opus-mt-tc-big-en-pt
|
6cd179c3a36b2aa259d58bc8c0dc33af3d8e4632
|
2022-06-01T13:03:26.000Z
|
[
"pytorch",
"marian",
"text2text-generation",
"en",
"pt",
"pt_br",
"transformers",
"translation",
"opus-mt-tc",
"license:cc-by-4.0",
"model-index",
"autotrain_compatible"
] |
translation
| false |
Helsinki-NLP
| null |
Helsinki-NLP/opus-mt-tc-big-en-pt
| 6,749 | 1 |
transformers
| 803 |
---
language:
- en
- pt
- pt_br
tags:
- translation
- opus-mt-tc
license: cc-by-4.0
model-index:
- name: opus-mt-tc-big-en-pt
results:
- task:
name: Translation eng-por
type: translation
args: eng-por
dataset:
name: flores101-devtest
type: flores_101
args: eng por devtest
metrics:
- name: BLEU
type: bleu
value: 50.4
- task:
name: Translation eng-por
type: translation
args: eng-por
dataset:
name: tatoeba-test-v2021-08-07
type: tatoeba_mt
args: eng-por
metrics:
- name: BLEU
type: bleu
value: 49.6
---
# opus-mt-tc-big-en-pt
Neural machine translation model for translating from English (en) to Portuguese (pt).
This model is part of the [OPUS-MT project](https://github.com/Helsinki-NLP/Opus-MT), an effort to make neural machine translation models widely available and accessible for many languages in the world. All models are originally trained using the amazing framework of [Marian NMT](https://marian-nmt.github.io/), an efficient NMT implementation written in pure C++. The models have been converted to pyTorch using the transformers library by huggingface. Training data is taken from [OPUS](https://opus.nlpl.eu/) and training pipelines use the procedures of [OPUS-MT-train](https://github.com/Helsinki-NLP/Opus-MT-train).
* Publications: [OPUS-MT – Building open translation services for the World](https://aclanthology.org/2020.eamt-1.61/) and [The Tatoeba Translation Challenge – Realistic Data Sets for Low Resource and Multilingual MT](https://aclanthology.org/2020.wmt-1.139/) (Please, cite if you use this model.)
```
@inproceedings{tiedemann-thottingal-2020-opus,
title = "{OPUS}-{MT} {--} Building open translation services for the World",
author = {Tiedemann, J{\"o}rg and Thottingal, Santhosh},
booktitle = "Proceedings of the 22nd Annual Conference of the European Association for Machine Translation",
month = nov,
year = "2020",
address = "Lisboa, Portugal",
publisher = "European Association for Machine Translation",
url = "https://aclanthology.org/2020.eamt-1.61",
pages = "479--480",
}
@inproceedings{tiedemann-2020-tatoeba,
title = "The Tatoeba Translation Challenge {--} Realistic Data Sets for Low Resource and Multilingual {MT}",
author = {Tiedemann, J{\"o}rg},
booktitle = "Proceedings of the Fifth Conference on Machine Translation",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.wmt-1.139",
pages = "1174--1182",
}
```
## Model info
* Release: 2022-03-13
* source language(s): eng
* target language(s): pob por
* valid target language labels: >>pob<< >>por<<
* model: transformer-big
* data: opusTCv20210807+bt ([source](https://github.com/Helsinki-NLP/Tatoeba-Challenge))
* tokenization: SentencePiece (spm32k,spm32k)
* original model: [opusTCv20210807+bt_transformer-big_2022-03-13.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-por/opusTCv20210807+bt_transformer-big_2022-03-13.zip)
* more information released models: [OPUS-MT eng-por README](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/eng-por/README.md)
* more information about the model: [MarianMT](https://huggingface.co/docs/transformers/model_doc/marian)
This is a multilingual translation model with multiple target languages. A sentence initial language token is required in the form of `>>id<<` (id = valid target language ID), e.g. `>>pob<<`
## Usage
A short example code:
```python
from transformers import MarianMTModel, MarianTokenizer
src_text = [
">>por<< Tom tried to stab me.",
">>por<< He has been to Hawaii several times."
]
model_name = "pytorch-models/opus-mt-tc-big-en-pt"
tokenizer = MarianTokenizer.from_pretrained(model_name)
model = MarianMTModel.from_pretrained(model_name)
translated = model.generate(**tokenizer(src_text, return_tensors="pt", padding=True))
for t in translated:
print( tokenizer.decode(t, skip_special_tokens=True) )
# expected output:
# O Tom tentou esfaquear-me.
# Ele já esteve no Havaí várias vezes.
```
You can also use OPUS-MT models with the transformers pipelines, for example:
```python
from transformers import pipeline
pipe = pipeline("translation", model="Helsinki-NLP/opus-mt-tc-big-en-pt")
print(pipe(">>por<< Tom tried to stab me."))
# expected output: O Tom tentou esfaquear-me.
```
## Benchmarks
* test set translations: [opusTCv20210807+bt_transformer-big_2022-03-13.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-por/opusTCv20210807+bt_transformer-big_2022-03-13.test.txt)
* test set scores: [opusTCv20210807+bt_transformer-big_2022-03-13.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-por/opusTCv20210807+bt_transformer-big_2022-03-13.eval.txt)
* benchmark results: [benchmark_results.txt](benchmark_results.txt)
* benchmark output: [benchmark_translations.zip](benchmark_translations.zip)
| langpair | testset | chr-F | BLEU | #sent | #words |
|----------|---------|-------|-------|-------|--------|
| eng-por | tatoeba-test-v2021-08-07 | 0.69320 | 49.6 | 13222 | 105265 |
| eng-por | flores101-devtest | 0.71673 | 50.4 | 1012 | 26519 |
## Acknowledgements
The work is supported by the [European Language Grid](https://www.european-language-grid.eu/) as [pilot project 2866](https://live.european-language-grid.eu/catalogue/#/resource/projects/2866), by the [FoTran project](https://www.helsinki.fi/en/researchgroups/natural-language-understanding-with-cross-lingual-grounding), funded by the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (grant agreement No 771113), and the [MeMAD project](https://memad.eu/), funded by the European Union’s Horizon 2020 Research and Innovation Programme under grant agreement No 780069. We are also grateful for the generous computational resources and IT infrastructure provided by [CSC -- IT Center for Science](https://www.csc.fi/), Finland.
## Model conversion info
* transformers version: 4.16.2
* OPUS-MT git hash: 3405783
* port time: Wed Apr 13 17:48:54 EEST 2022
* port machine: LM0-400-22516.local
|
ahotrod/albert_xxlargev1_squad2_512
|
291f0fa26d2c80d8a473b6116164a083d252b4fe
|
2020-12-11T21:31:38.000Z
|
[
"pytorch",
"tf",
"albert",
"question-answering",
"transformers",
"autotrain_compatible"
] |
question-answering
| false |
ahotrod
| null |
ahotrod/albert_xxlargev1_squad2_512
| 6,734 | 2 |
transformers
| 804 |
## Albert xxlarge version 1 language model fine-tuned on SQuAD2.0
### (updated 30Sept2020) with the following results:
```
exact: 86.11134506864315
f1: 89.35371214945009
total': 11873
HasAns_exact': 83.56950067476383
HasAns_f1': 90.06353312254078
HasAns_total': 5928
NoAns_exact': 88.64592094196804
NoAns_f1': 88.64592094196804
NoAns_total': 5945
best_exact': 86.11134506864315
best_exact_thresh': 0.0
best_f1': 89.35371214944985
best_f1_thresh': 0.0
```
### from script:
```
python ${EXAMPLES}/run_squad.py \
--model_type albert \
--model_name_or_path albert-xxlarge-v1 \
--do_train \
--do_eval \
--train_file ${SQUAD}/train-v2.0.json \
--predict_file ${SQUAD}/dev-v2.0.json \
--version_2_with_negative \
--do_lower_case \
--num_train_epochs 3 \
--max_steps 8144 \
--warmup_steps 814 \
--learning_rate 3e-5 \
--max_seq_length 512 \
--doc_stride 128 \
--per_gpu_train_batch_size 6 \
--gradient_accumulation_steps 8 \
--per_gpu_eval_batch_size 48 \
--fp16 \
--fp16_opt_level O1 \
--threads 12 \
--logging_steps 50 \
--save_steps 3000 \
--overwrite_output_dir \
--output_dir ${MODEL_PATH}
```
### using the following software & system:
```
Transformers: 3.1.0
PyTorch: 1.6.0
TensorFlow: 2.3.1
Python: 3.8.1
OS: Linux-5.4.0-48-generic-x86_64-with-glibc2.10
CPU/GPU: Intel i9-9900K / NVIDIA Titan RTX 24GB
```
|
dbmdz/bert-base-french-europeana-cased
|
b895c3cf291f7bf4c15639078a6bee0b3e272c5b
|
2021-09-13T21:03:24.000Z
|
[
"pytorch",
"tf",
"jax",
"bert",
"fr",
"transformers",
"historic french",
"license:mit"
] | null | false |
dbmdz
| null |
dbmdz/bert-base-french-europeana-cased
| 6,725 | 1 |
transformers
| 805 |
---
language: fr
license: mit
tags:
- "historic french"
---
# 🤗 + 📚 dbmdz BERT model
In this repository the MDZ Digital Library team (dbmdz) at the Bavarian State
Library open sources French Europeana BERT models 🎉
# French Europeana BERT
We extracted all French texts using the `language` metadata attribute from the Europeana corpus.
The resulting corpus has a size of 63GB and consists of 11,052,528,456 tokens.
Based on the metadata information, texts from the 18th - 20th century are mainly included in the
training corpus.
Detailed information about the data and pretraining steps can be found in
[this repository](https://github.com/stefan-it/europeana-bert).
## Model weights
BERT model weights for PyTorch and TensorFlow are available.
* French Europeana BERT: `dbmdz/bert-base-french-europeana-cased` - [model hub page](https://huggingface.co/dbmdz/bert-base-french-europeana-cased/tree/main)
## Results
For results on Historic NER, please refer to [this repository](https://github.com/stefan-it/europeana-bert).
## Usage
With Transformers >= 2.3 our French Europeana BERT model can be loaded like:
```python
from transformers import AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("dbmdz/bert-base-french-europeana-cased")
model = AutoModel.from_pretrained("dbmdz/bert-base-french-europeana-cased")
```
# Huggingface model hub
All models are available on the [Huggingface model hub](https://huggingface.co/dbmdz).
# Contact (Bugs, Feedback, Contribution and more)
For questions about our BERT model just open an issue
[here](https://github.com/dbmdz/berts/issues/new) 🤗
# Acknowledgments
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
Thanks for providing access to the TFRC ❤️
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
it is possible to download our model from their S3 storage 🤗
|
tprincessazula/Dialog-GPT-small-KATARA-AVATAR
|
9e7c17b7f5ef120e895120c49721f3a000e5a240
|
2022-01-05T13:46:24.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
| false |
tprincessazula
| null |
tprincessazula/Dialog-GPT-small-KATARA-AVATAR
| 6,721 | 1 |
transformers
| 806 |
---
tags:
- conversational
---
#KATARA DialoGPT Model
|
Grossmend/rudialogpt3_medium_based_on_gpt2
|
a2f8ac89182e36e352ea921de30cf2b0e9b30b89
|
2021-08-02T13:43:25.000Z
|
[
"pytorch",
"jax",
"gpt2",
"text-generation",
"ru",
"transformers",
"convAI",
"conversational"
] |
conversational
| false |
Grossmend
| null |
Grossmend/rudialogpt3_medium_based_on_gpt2
| 6,685 | 8 |
transformers
| 807 |
---
language:
- ru
thumbnail:
tags:
- convAI
- conversational
---
DialoGPT on Russian language
Article on Habr: https://habr.com/ru/company/icl_services/blog/548244/
Git: https://github.com/Grossmend/DialoGPT
#### How to use
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("Grossmend/rudialogpt3_medium_based_on_gpt2")
model = AutoModelForCausalLM.from_pretrained("Grossmend/rudialogpt3_medium_based_on_gpt2")
def get_length_param(text: str) -> str:
tokens_count = len(tokenizer.encode(text))
if tokens_count <= 15:
len_param = '1'
elif tokens_count <= 50:
len_param = '2'
elif tokens_count <= 256:
len_param = '3'
else:
len_param = '-'
return len_param
for step in range(5):
input_user = input("===> User:")
# encode the new user input, add parameters and return a tensor in Pytorch
new_user_input_ids = tokenizer.encode(f"|0|{get_length_param(input_user)}|" + input_user + tokenizer.eos_token + "|1|1|", return_tensors="pt")
# append the new user input tokens to the chat history
bot_input_ids = torch.cat([chat_history_ids, new_user_input_ids], dim=-1) if step > 0 else new_user_input_ids
# generated a response
chat_history_ids = model.generate(
bot_input_ids,
num_return_sequences=1,
max_length=512,
no_repeat_ngram_size=3,
do_sample=True,
top_k=50,
top_p=0.9,
temperature = 0.6,
mask_token_id=tokenizer.mask_token_id,
eos_token_id=tokenizer.eos_token_id,
unk_token_id=tokenizer.unk_token_id,
pad_token_id=tokenizer.pad_token_id,
device='cpu',
)
# pretty print last ouput tokens from bot
print(f"===> RuDialoGPT: {tokenizer.decode(chat_history_ids[:, bot_input_ids.shape[-1]:][0], skip_special_tokens=True)}")
```
|
EEE/DialoGPT-medium-brooke
|
6c5ccd6420a957b3116bbd02f21ed4e5ae1ac59d
|
2021-09-27T06:25:56.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
| false |
EEE
| null |
EEE/DialoGPT-medium-brooke
| 6,684 | null |
transformers
| 808 |
---
tags:
- conversational
---
# Brooke DialoGPT Model
|
PlanTL-GOB-ES/roberta-base-bne
|
f4cc2aff5eaa2e1ad5add20a740d8578c833574a
|
2022-04-06T14:40:52.000Z
|
[
"pytorch",
"roberta",
"fill-mask",
"es",
"dataset:bne",
"arxiv:1907.11692",
"arxiv:2107.07253",
"transformers",
"national library of spain",
"spanish",
"bne",
"license:apache-2.0",
"autotrain_compatible"
] |
fill-mask
| false |
PlanTL-GOB-ES
| null |
PlanTL-GOB-ES/roberta-base-bne
| 6,640 | 8 |
transformers
| 809 |
---
language:
- es
license: apache-2.0
tags:
- "national library of spain"
- "spanish"
- "bne"
datasets:
- "bne"
metrics:
- "ppl"
widget:
- text: "Este año las campanadas de La Sexta las presentará <mask>."
- text: "David Broncano es un presentador de La <mask>."
- text: "Gracias a los datos de la BNE se ha podido <mask> este modelo del lenguaje."
- text: "Hay base legal dentro del marco <mask> actual."
---
# RoBERTa base trained with data from National Library of Spain (BNE)
## Model Description
RoBERTa-base-bne is a transformer-based masked language model for the Spanish language. It is based on the [RoBERTa](https://arxiv.org/abs/1907.11692) base model and has been pre-trained using the largest Spanish corpus known to date, with a total of 570GB of clean and deduplicated text processed for this work, compiled from the web crawlings performed by the [National Library of Spain (Biblioteca Nacional de España)](http://www.bne.es/en/Inicio/index.html) from 2009 to 2019.
## Training corpora and preprocessing
The [National Library of Spain (Biblioteca Nacional de España)](http://www.bne.es/en/Inicio/index.html) crawls all .es domains once a year. The training corpus consists of 59TB of WARC files from these crawls, carried out from 2009 to 2019.
To obtain a high-quality training corpus, the corpus has been preprocessed with a pipeline of operations, including among the others, sentence splitting, language detection, filtering of bad-formed sentences and deduplication of repetitive contents. During the process document boundaries are kept. This resulted into 2TB of Spanish clean corpus. Further global deduplication among the corpus is applied, resulting into 570GB of text.
Some of the statistics of the corpus:
| Corpora | Number of documents | Number of tokens | Size (GB) |
|---------|---------------------|------------------|-----------|
| BNE | 201,080,084 | 135,733,450,668 | 570GB |
## Tokenization and pre-training
The training corpus has been tokenized using a byte version of Byte-Pair Encoding (BPE) used in the original [RoBERTA](https://arxiv.org/abs/1907.11692) model with a vocabulary size of 50,262 tokens. The RoBERTa-base-bne pre-training consists of a masked language model training that follows the approach employed for the RoBERTa base. The training lasted a total of 48 hours with 16 computing nodes each one with 4 NVIDIA V100 GPUs of 16GB VRAM.
## Evaluation and results
For evaluation details visit our [GitHub repository](https://github.com/PlanTL-GOB-ES/lm-spanish).
## Citing
Check out our paper for all the details: https://arxiv.org/abs/2107.07253
```
@article{gutierrezfandino2022,
author = {Asier Gutiérrez-Fandiño and Jordi Armengol-Estapé and Marc Pàmies and Joan Llop-Palao and Joaquin Silveira-Ocampo and Casimiro Pio Carrino and Carme Armentano-Oller and Carlos Rodriguez-Penagos and Aitor Gonzalez-Agirre and Marta Villegas},
title = {MarIA: Spanish Language Models},
journal = {Procesamiento del Lenguaje Natural},
volume = {68},
number = {0},
year = {2022},
issn = {1989-7553},
url = {http://journal.sepln.org/sepln/ojs/ojs/index.php/pln/article/view/6405},
pages = {39--60}
}
```
## Funding
This work was funded by the Spanish State Secretariat for Digitalization and Artificial Intelligence (SEDIA) within the framework of the Plan-TL.
## Disclaimer
The models published in this repository are intended for a generalist purpose and are available to third parties. These models may have bias and/or any other undesirable distortions.
When third parties, deploy or provide systems and/or services to other parties using any of these models (or using systems based on these models) or become users of the models, they should note that it is their responsibility to mitigate the risks arising from their use and, in any event, to comply with applicable regulations, including regulations regarding the use of artificial intelligence.
In no event shall the owner of the models (SEDIA – State Secretariat for digitalization and artificial intelligence) nor the creator (BSC – Barcelona Supercomputing Center) be liable for any results arising from the use made by third parties of these models.
Los modelos publicados en este repositorio tienen una finalidad generalista y están a disposición de terceros. Estos modelos pueden tener sesgos y/u otro tipo de distorsiones indeseables.
Cuando terceros desplieguen o proporcionen sistemas y/o servicios a otras partes usando alguno de estos modelos (o utilizando sistemas basados en estos modelos) o se conviertan en usuarios de los modelos, deben tener en cuenta que es su responsabilidad mitigar los riesgos derivados de su uso y, en todo caso, cumplir con la normativa aplicable, incluyendo la normativa en materia de uso de inteligencia artificial.
En ningún caso el propietario de los modelos (SEDIA – Secretaría de Estado de Digitalización e Inteligencia Artificial) ni el creador (BSC – Barcelona Supercomputing Center) serán responsables de los resultados derivados del uso que hagan terceros de estos modelos.
|
nvidia/mit-b3
|
3a0bee80ae595e8ae292ddd7b2dfe0845cda2161
|
2022-07-29T13:15:53.000Z
|
[
"pytorch",
"tf",
"segformer",
"image-classification",
"dataset:imagenet_1k",
"arxiv:2105.15203",
"transformers",
"vision",
"license:apache-2.0"
] |
image-classification
| false |
nvidia
| null |
nvidia/mit-b3
| 6,618 | null |
transformers
| 810 |
---
license: apache-2.0
tags:
- vision
datasets:
- imagenet_1k
widget:
- src: https://huggingface.co/datasets/hf-internal-testing/fixtures_ade20k/resolve/main/ADE_val_00000001.jpg
example_title: House
- src: https://huggingface.co/datasets/hf-internal-testing/fixtures_ade20k/resolve/main/ADE_val_00000002.jpg
example_title: Castle
---
# SegFormer (b3-sized) encoder pre-trained-only
SegFormer encoder fine-tuned on Imagenet-1k. It was introduced in the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Xie et al. and first released in [this repository](https://github.com/NVlabs/SegFormer).
Disclaimer: The team releasing SegFormer did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
SegFormer consists of a hierarchical Transformer encoder and a lightweight all-MLP decode head to achieve great results on semantic segmentation benchmarks such as ADE20K and Cityscapes. The hierarchical Transformer is first pre-trained on ImageNet-1k, after which a decode head is added and fine-tuned altogether on a downstream dataset.
This repository only contains the pre-trained hierarchical Transformer, hence it can be used for fine-tuning purposes.
## Intended uses & limitations
You can use the model for fine-tuning of semantic segmentation. See the [model hub](https://huggingface.co/models?other=segformer) to look for fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import SegformerFeatureExtractor, SegformerForImageClassification
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = SegformerFeatureExtractor.from_pretrained("nvidia/mit-b3")
model = SegformerForImageClassification.from_pretrained("nvidia/mit-b3")
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
For more code examples, we refer to the [documentation](https://huggingface.co/transformers/model_doc/segformer.html#).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2105-15203,
author = {Enze Xie and
Wenhai Wang and
Zhiding Yu and
Anima Anandkumar and
Jose M. Alvarez and
Ping Luo},
title = {SegFormer: Simple and Efficient Design for Semantic Segmentation with
Transformers},
journal = {CoRR},
volume = {abs/2105.15203},
year = {2021},
url = {https://arxiv.org/abs/2105.15203},
eprinttype = {arXiv},
eprint = {2105.15203},
timestamp = {Wed, 02 Jun 2021 11:46:42 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2105-15203.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
AmbricJohnson5888/death
|
68ca65a4f20454f7ea435dba297a0d959cd67183
|
2022-04-09T02:19:17.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
| false |
AmbricJohnson5888
| null |
AmbricJohnson5888/death
| 6,589 | null |
transformers
| 811 |
---
tags:
- conversational
---
#DEATH
#https://discord.gg/kNxBCv7DtK
|
harshit345/xlsr-wav2vec-speech-emotion-recognition
|
7fd191edd9a505af312467d6f00fede29cff0da1
|
2021-12-12T20:53:33.000Z
|
[
"pytorch",
"wav2vec2",
"en",
"dataset:aesdd",
"transformers",
"audio",
"audio-classification",
"speech",
"license:apache-2.0"
] |
audio-classification
| false |
harshit345
| null |
harshit345/xlsr-wav2vec-speech-emotion-recognition
| 6,566 | 3 |
transformers
| 812 |
---
language: en
datasets:
- aesdd
tags:
- audio
- audio-classification
- speech
license: apache-2.0
---
~~~
# requirement packages
!pip install git+https://github.com/huggingface/datasets.git
!pip install git+https://github.com/huggingface/transformers.git
!pip install torchaudio
!pip install librosa
~~~
# prediction
~~~
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchaudio
from transformers import AutoConfig, Wav2Vec2FeatureExtractor
import librosa
import IPython.display as ipd
import numpy as np
import pandas as pd
~~~
~~~
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model_name_or_path = "harshit345/xlsr-wav2vec-speech-emotion-recognition"
config = AutoConfig.from_pretrained(model_name_or_path)
feature_extractor = Wav2Vec2FeatureExtractor.from_pretrained(model_name_or_path)
sampling_rate = feature_extractor.sampling_rate
model = Wav2Vec2ForSpeechClassification.from_pretrained(model_name_or_path).to(device)
~~~
~~~
def speech_file_to_array_fn(path, sampling_rate):
speech_array, _sampling_rate = torchaudio.load(path)
resampler = torchaudio.transforms.Resample(_sampling_rate)
speech = resampler(speech_array).squeeze().numpy()
return speech
def predict(path, sampling_rate):
speech = speech_file_to_array_fn(path, sampling_rate)
inputs = feature_extractor(speech, sampling_rate=sampling_rate, return_tensors="pt", padding=True)
inputs = {key: inputs[key].to(device) for key in inputs}
with torch.no_grad():
logits = model(**inputs).logits
scores = F.softmax(logits, dim=1).detach().cpu().numpy()[0]
outputs = [{"Emotion": config.id2label[i], "Score": f"{round(score * 100, 3):.1f}%"} for i, score in enumerate(scores)]
return outputs
~~~
# prediction
~~~
# path for a sample
path = '/data/jtes_v1.1/wav/f01/ang/f01_ang_01.wav'
outputs = predict(path, sampling_rate)
~~~
~~~
[{'Emotion': 'anger', 'Score': '78.3%'},
{'Emotion': 'disgust', 'Score': '11.7%'},
{'Emotion': 'fear', 'Score': '5.4%'},
{'Emotion': 'happiness', 'Score': '4.1%'},
{'Emotion': 'sadness', 'Score': '0.5%'}]
~~~
## Evaluation
The following tables summarize the scores obtained by model overall and per each class.
| Emotions | precision | recall | f1-score | accuracy |
|-----------|-----------|--------|----------|----------|
| anger | 0.82 | 1.00 | 0.81 | |
| disgust | 0.85 | 0.96 | 0.85 | |
| fear | 0.78 | 0.88 | 0.80 | |
| happiness | 0.84 | 0.71 | 0.78 | |
| sadness | 0.86 | 1.00 | 0.79 | |
| | | | Overall | 0.806 |
##
Colab Notebook
https://colab.research.google.com/drive/1aPPb_ZVS5dlFVZySly8Q80a44La1XjJu?usp=sharing
|
cl-tohoku/bert-base-japanese-char-v2
|
e17e40a15857ad47d63f6eb4cc9fb62c136d2301
|
2021-09-23T13:45:24.000Z
|
[
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"ja",
"dataset:wikipedia",
"transformers",
"license:cc-by-sa-4.0",
"autotrain_compatible"
] |
fill-mask
| false |
cl-tohoku
| null |
cl-tohoku/bert-base-japanese-char-v2
| 6,540 | 1 |
transformers
| 813 |
---
language: ja
license: cc-by-sa-4.0
datasets:
- wikipedia
widget:
- text: 東北大学で[MASK]の研究をしています。
---
# BERT base Japanese (character-level tokenization with whole word masking, jawiki-20200831)
This is a [BERT](https://github.com/google-research/bert) model pretrained on texts in the Japanese language.
This version of the model processes input texts with word-level tokenization based on the Unidic 2.1.2 dictionary (available in [unidic-lite](https://pypi.org/project/unidic-lite/) package), followed by character-level tokenization.
Additionally, the model is trained with the whole word masking enabled for the masked language modeling (MLM) objective.
The codes for the pretraining are available at [cl-tohoku/bert-japanese](https://github.com/cl-tohoku/bert-japanese/tree/v2.0).
## Model architecture
The model architecture is the same as the original BERT base model; 12 layers, 768 dimensions of hidden states, and 12 attention heads.
## Training Data
The models are trained on the Japanese version of Wikipedia.
The training corpus is generated from the Wikipedia Cirrussearch dump file as of August 31, 2020.
The generated corpus files are 4.0GB in total, containing approximately 30M sentences.
We used the [MeCab](https://taku910.github.io/mecab/) morphological parser with [mecab-ipadic-NEologd](https://github.com/neologd/mecab-ipadic-neologd) dictionary to split texts into sentences.
## Tokenization
The texts are first tokenized by MeCab with the Unidic 2.1.2 dictionary and then split into characters.
The vocabulary size is 6144.
We used [`fugashi`](https://github.com/polm/fugashi) and [`unidic-lite`](https://github.com/polm/unidic-lite) packages for the tokenization.
## Training
The models are trained with the same configuration as the original BERT; 512 tokens per instance, 256 instances per batch, and 1M training steps.
For training of the MLM (masked language modeling) objective, we introduced whole word masking in which all of the subword tokens corresponding to a single word (tokenized by MeCab) are masked at once.
For training of each model, we used a v3-8 instance of Cloud TPUs provided by [TensorFlow Research Cloud program](https://www.tensorflow.org/tfrc/).
The training took about 5 days to finish.
## Licenses
The pretrained models are distributed under the terms of the [Creative Commons Attribution-ShareAlike 3.0](https://creativecommons.org/licenses/by-sa/3.0/).
## Acknowledgments
This model is trained with Cloud TPUs provided by [TensorFlow Research Cloud](https://www.tensorflow.org/tfrc/) program.
|
hf-internal-testing/test_dynamic_model
|
2efddce40dddaccd37bae208c3c7ca66dbedf68a
|
2022-01-25T22:03:13.000Z
|
[
"pytorch",
"new-model",
"transformers"
] | null | false |
hf-internal-testing
| null |
hf-internal-testing/test_dynamic_model
| 6,540 | null |
transformers
| 814 |
Entry not found
|
Rostlab/prot_t5_xl_half_uniref50-enc
|
2646ade9d44b7620ceac59797b2d9efd3341da37
|
2022-06-29T08:22:26.000Z
|
[
"pytorch",
"t5",
"protein",
"dataset:UniRef50",
"transformers",
"protein language model"
] | null | false |
Rostlab
| null |
Rostlab/prot_t5_xl_half_uniref50-enc
| 6,489 | null |
transformers
| 815 |
---
language: protein
tags:
- protein language model
datasets:
- UniRef50
---
# Encoder only ProtT5-XL-UniRef50, half-precision model
An encoder-only, half-precision version of the [ProtT5-XL-UniRef50](https://huggingface.co/Rostlab/prot_t5_xl_uniref50) model. The original model and it's pretraining were introduced in
[this paper](https://doi.org/10.1101/2020.07.12.199554) and first released in
[this repository](https://github.com/agemagician/ProtTrans). This model is trained on uppercase amino acids: it only works with capital letter amino acids.
## Model description
ProtT5-XL-UniRef50 is based on the `t5-3b` model and was pretrained on a large corpus of protein sequences in a self-supervised fashion.
This means it was pretrained on the raw protein sequences only, with no humans labelling them in any way (which is why it can use lots of
publicly available data) with an automatic process to generate inputs and labels from those protein sequences.
One important difference between this T5 model and the original T5 version is the denoising objective.
The original T5-3B model was pretrained using a span denoising objective, while this model was pretrained with a Bart-like MLM denoising objective.
The masking probability is consistent with the original T5 training by randomly masking 15% of the amino acids in the input.
This model only contains the encoder portion of the original ProtT5-XL-UniRef50 model using half precision (float16).
As such, this model can efficiently be used to create protein/ amino acid representations. When used for training downstream networks/ feature extraction, these embeddings produced the same performance (established empirically by comparing on several downstream tasks).
## Intended uses & limitations
This version of the original ProtT5-XL-UniRef50 is mostly meant for conveniently creating amino-acid or protein embeddings with a low GPU-memory footprint without any measurable performance-decrease in our experiments. This model is fully usable on 8 GB of video RAM.
### How to use
An extensive, interactive example on how to use this model for common tasks can be found [on Google Colab](https://colab.research.google.com/drive/1TUj-ayG3WO52n5N50S7KH9vtt6zRkdmj?usp=sharing#scrollTo=ET2v51slC5ui)
Here is how to use this model to extract the features of a given protein sequence in PyTorch:
```python
from transformers import T5Tokenizer, T5EncoderModel
import torch
tokenizer = T5Tokenizer.from_pretrained('Rostlab/prot_t5_xl_half_uniref50-enc', do_lower_case=False)
model = T5EncoderModel.from_pretrained("Rostlab/prot_t5_xl_half_uniref50-enc", torch_dtype=torch.float16)
sequences_Example = ["A E T C Z A O","S K T Z P"]
sequences_Example = [re.sub(r"[UZOB]", "X", sequence) for sequence in sequences_Example]
ids = tokenizer.batch_encode_plus(seqs, add_special_tokens=True, padding="longest")
input_ids = torch.tensor(ids['input_ids'])
attention_mask = torch.tensor(ids['attention_mask'])
with torch.no_grad():
embedding_rpr = model(input_ids=input_ids,attention_mask=attention_mask)
emb_0 = embedding_repr.last_hidden_state[0,:6]
emb_1 = embedding_repr.last_hidden_state[1,:4]
```
**NOTE**: Please make sure to explicitly set the model to `float16` (`T5EncoderModel.from_pretrained('Rostlab/prot_t5_xl_half_uniref50-enc', torch_dtype=torch.float16)`) otherwise, the generated embeddings will be full precision.
**NOTE**: Currently (06/2022) half-precision models cannot be used on CPU. If you want to use the encoder only version on CPU, you need to cast it to its full-precision version (`model=model.float()`).
### BibTeX entry and citation info
```bibtex
@article {Elnaggar2020.07.12.199554,
author = {Elnaggar, Ahmed and Heinzinger, Michael and Dallago, Christian and Rehawi, Ghalia and Wang, Yu and Jones, Llion and Gibbs, Tom and Feher, Tamas and Angerer, Christoph and Steinegger, Martin and BHOWMIK, DEBSINDHU and Rost, Burkhard},
title = {ProtTrans: Towards Cracking the Language of Life{\textquoteright}s Code Through Self-Supervised Deep Learning and High Performance Computing},
elocation-id = {2020.07.12.199554},
year = {2020},
doi = {10.1101/2020.07.12.199554},
publisher = {Cold Spring Harbor Laboratory},
abstract = {Computational biology and bioinformatics provide vast data gold-mines from protein sequences, ideal for Language Models (LMs) taken from Natural Language Processing (NLP). These LMs reach for new prediction frontiers at low inference costs. Here, we trained two auto-regressive language models (Transformer-XL, XLNet) and two auto-encoder models (Bert, Albert) on data from UniRef and BFD containing up to 393 billion amino acids (words) from 2.1 billion protein sequences (22- and 112 times the entire English Wikipedia). The LMs were trained on the Summit supercomputer at Oak Ridge National Laboratory (ORNL), using 936 nodes (total 5616 GPUs) and one TPU Pod (V3-512 or V3-1024). We validated the advantage of up-scaling LMs to larger models supported by bigger data by predicting secondary structure (3-states: Q3=76-84, 8 states: Q8=65-73), sub-cellular localization for 10 cellular compartments (Q10=74) and whether a protein is membrane-bound or water-soluble (Q2=89). Dimensionality reduction revealed that the LM-embeddings from unlabeled data (only protein sequences) captured important biophysical properties governing protein shape. This implied learning some of the grammar of the language of life realized in protein sequences. The successful up-scaling of protein LMs through HPC to larger data sets slightly reduced the gap between models trained on evolutionary information and LMs. Availability ProtTrans: \<a href="https://github.com/agemagician/ProtTrans"\>https://github.com/agemagician/ProtTrans\</a\>Competing Interest StatementThe authors have declared no competing interest.},
URL = {https://www.biorxiv.org/content/early/2020/07/21/2020.07.12.199554},
eprint = {https://www.biorxiv.org/content/early/2020/07/21/2020.07.12.199554.full.pdf},
journal = {bioRxiv}
}
```
|
sentence-transformers/distilroberta-base-paraphrase-v1
|
0191e446424b49506ba016264788b49bb7b11eb9
|
2022-06-15T21:53:03.000Z
|
[
"pytorch",
"tf",
"roberta",
"feature-extraction",
"arxiv:1908.10084",
"sentence-transformers",
"sentence-similarity",
"transformers",
"license:apache-2.0"
] |
sentence-similarity
| false |
sentence-transformers
| null |
sentence-transformers/distilroberta-base-paraphrase-v1
| 6,468 | null |
sentence-transformers
| 816 |
---
pipeline_tag: sentence-similarity
license: apache-2.0
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# sentence-transformers/distilroberta-base-paraphrase-v1
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/distilroberta-base-paraphrase-v1')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/distilroberta-base-paraphrase-v1')
model = AutoModel.from_pretrained('sentence-transformers/distilroberta-base-paraphrase-v1')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/distilroberta-base-paraphrase-v1)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: RobertaModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
```
|
hakurei/lit-6B
|
cc2e78adb62590cb2889d338d46f8cf1ef396453
|
2021-11-08T23:02:41.000Z
|
[
"pytorch",
"gptj",
"text-generation",
"en",
"transformers",
"causal-lm",
"license:mit"
] |
text-generation
| false |
hakurei
| null |
hakurei/lit-6B
| 6,455 | 6 |
transformers
| 817 |
---
language:
- en
tags:
- pytorch
- causal-lm
license: mit
---
# Lit-6B - A Large Fine-tuned Model For Fictional Storytelling
Lit-6B is a GPT-J 6B model fine-tuned on 2GB of a diverse range of light novels, erotica, and annotated literature for the purpose of generating novel-like fictional text.
## Model Description
The model used for fine-tuning is [GPT-J](https://github.com/kingoflolz/mesh-transformer-jax), which is a 6 billion parameter auto-regressive language model trained on [The Pile](https://pile.eleuther.ai/).
## Training Data & Annotative Prompting
The data used in fine-tuning has been gathered from various sources such as the [Gutenberg Project](https://www.gutenberg.org/). The annotated fiction dataset has prepended tags to assist in generating towards a particular style. Here is an example prompt that shows how to use the annotations.
```
[ Title: The Dunwich Horror; Author: H. P. Lovecraft; Genre: Horror; Tags: 3rdperson, scary; Style: Dark ]
***
When a traveler in north central Massachusetts takes the wrong fork...
```
The annotations can be mixed and matched to help generate towards a specific style.
## Downstream Uses
This model can be used for entertainment purposes and as a creative writing assistant for fiction writers.
## Example Code
```
from transformers import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained('hakurei/lit-6B')
tokenizer = AutoTokenizer.from_pretrained('hakurei/lit-6B')
prompt = '''[ Title: The Dunwich Horror; Author: H. P. Lovecraft; Genre: Horror ]
***
When a traveler'''
input_ids = tokenizer.encode(prompt, return_tensors='pt')
output = model.generate(input_ids, do_sample=True, temperature=1.0, top_p=0.9, repetition_penalty=1.2, max_length=len(input_ids[0])+100, pad_token_id=tokenizer.eos_token_id)
generated_text = tokenizer.decode(output[0])
print(generated_text)
```
An example output from this code produces a result that will look similar to:
```
[ Title: The Dunwich Horror; Author: H. P. Lovecraft; Genre: Horror ]
***
When a traveler comes to an unknown region, his thoughts turn inevitably towards the old gods and legends which cluster around its appearance. It is not that he believes in them or suspects their reality—but merely because they are present somewhere else in creation just as truly as himself, and so belong of necessity in any landscape whose features cannot be altogether strange to him. Moreover, man has been prone from ancient times to brood over those things most connected with the places where he dwells. Thus the Olympian deities who ruled Hyper
```
## Team members and Acknowledgements
This project would not have been possible without the computational resources graciously provided by the [TPU Research Cloud](https://sites.research.google/trc/)
- [Anthony Mercurio](https://github.com/harubaru)
- Imperishable_NEET
|
Helsinki-NLP/opus-mt-lv-en
|
3b019339e88ac4f79044be45cfa75ff5fedbceea
|
2021-09-10T13:57:07.000Z
|
[
"pytorch",
"marian",
"text2text-generation",
"lv",
"en",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] |
translation
| false |
Helsinki-NLP
| null |
Helsinki-NLP/opus-mt-lv-en
| 6,444 | null |
transformers
| 818 |
---
tags:
- translation
license: apache-2.0
---
### opus-mt-lv-en
* source languages: lv
* target languages: en
* OPUS readme: [lv-en](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/lv-en/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2019-12-18.zip](https://object.pouta.csc.fi/OPUS-MT-models/lv-en/opus-2019-12-18.zip)
* test set translations: [opus-2019-12-18.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/lv-en/opus-2019-12-18.test.txt)
* test set scores: [opus-2019-12-18.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/lv-en/opus-2019-12-18.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| newsdev2017-enlv.lv.en | 29.9 | 0.587 |
| newstest2017-enlv.lv.en | 22.1 | 0.526 |
| Tatoeba.lv.en | 53.3 | 0.707 |
|
flair/upos-english-fast
|
352fcf521848b438afba2fdb6846e18dbb3ad514
|
2021-03-02T22:21:02.000Z
|
[
"pytorch",
"en",
"dataset:ontonotes",
"flair",
"token-classification",
"sequence-tagger-model"
] |
token-classification
| false |
flair
| null |
flair/upos-english-fast
| 6,436 | 2 |
flair
| 819 |
---
tags:
- flair
- token-classification
- sequence-tagger-model
language: en
datasets:
- ontonotes
widget:
- text: "I love Berlin."
---
## English Universal Part-of-Speech Tagging in Flair (fast model)
This is the fast universal part-of-speech tagging model for English that ships with [Flair](https://github.com/flairNLP/flair/).
F1-Score: **98,47** (Ontonotes)
Predicts universal POS tags:
| **tag** | **meaning** |
|---------------------------------|-----------|
|ADJ | adjective |
| ADP | adposition |
| ADV | adverb |
| AUX | auxiliary |
| CCONJ | coordinating conjunction |
| DET | determiner |
| INTJ | interjection |
| NOUN | noun |
| NUM | numeral |
| PART | particle |
| PRON | pronoun |
| PROPN | proper noun |
| PUNCT | punctuation |
| SCONJ | subordinating conjunction |
| SYM | symbol |
| VERB | verb |
| X | other |
Based on [Flair embeddings](https://www.aclweb.org/anthology/C18-1139/) and LSTM-CRF.
---
### Demo: How to use in Flair
Requires: **[Flair](https://github.com/flairNLP/flair/)** (`pip install flair`)
```python
from flair.data import Sentence
from flair.models import SequenceTagger
# load tagger
tagger = SequenceTagger.load("flair/upos-english-fast")
# make example sentence
sentence = Sentence("I love Berlin.")
# predict NER tags
tagger.predict(sentence)
# print sentence
print(sentence)
# print predicted NER spans
print('The following NER tags are found:')
# iterate over entities and print
for entity in sentence.get_spans('pos'):
print(entity)
```
This yields the following output:
```
Span [1]: "I" [− Labels: PRON (0.9996)]
Span [2]: "love" [− Labels: VERB (1.0)]
Span [3]: "Berlin" [− Labels: PROPN (0.9986)]
Span [4]: "." [− Labels: PUNCT (1.0)]
```
So, the word "*I*" is labeled as a **pronoun** (PRON), "*love*" is labeled as a **verb** (VERB) and "*Berlin*" is labeled as a **proper noun** (PROPN) in the sentence "*I love Berlin*".
---
### Training: Script to train this model
The following Flair script was used to train this model:
```python
from flair.data import Corpus
from flair.datasets import ColumnCorpus
from flair.embeddings import WordEmbeddings, StackedEmbeddings, FlairEmbeddings
# 1. load the corpus (Ontonotes does not ship with Flair, you need to download and reformat into a column format yourself)
corpus: Corpus = ColumnCorpus(
"resources/tasks/onto-ner",
column_format={0: "text", 1: "pos", 2: "upos", 3: "ner"},
tag_to_bioes="ner",
)
# 2. what tag do we want to predict?
tag_type = 'upos'
# 3. make the tag dictionary from the corpus
tag_dictionary = corpus.make_tag_dictionary(tag_type=tag_type)
# 4. initialize each embedding we use
embedding_types = [
# contextual string embeddings, forward
FlairEmbeddings('news-forward-fast'),
# contextual string embeddings, backward
FlairEmbeddings('news-backward-fast'),
]
# embedding stack consists of Flair and GloVe embeddings
embeddings = StackedEmbeddings(embeddings=embedding_types)
# 5. initialize sequence tagger
from flair.models import SequenceTagger
tagger = SequenceTagger(hidden_size=256,
embeddings=embeddings,
tag_dictionary=tag_dictionary,
tag_type=tag_type)
# 6. initialize trainer
from flair.trainers import ModelTrainer
trainer = ModelTrainer(tagger, corpus)
# 7. run training
trainer.train('resources/taggers/upos-english-fast',
train_with_dev=True,
max_epochs=150)
```
---
### Cite
Please cite the following paper when using this model.
```
@inproceedings{akbik2018coling,
title={Contextual String Embeddings for Sequence Labeling},
author={Akbik, Alan and Blythe, Duncan and Vollgraf, Roland},
booktitle = {{COLING} 2018, 27th International Conference on Computational Linguistics},
pages = {1638--1649},
year = {2018}
}
```
---
### Issues?
The Flair issue tracker is available [here](https://github.com/flairNLP/flair/issues/).
|
sshleifer/tiny-ctrl
|
d76c849d54c665ccfd33b8aa501b17531289cae9
|
2020-05-13T23:21:48.000Z
|
[
"pytorch",
"tf",
"ctrl",
"text-generation",
"transformers"
] |
text-generation
| false |
sshleifer
| null |
sshleifer/tiny-ctrl
| 6,417 | null |
transformers
| 820 |
Entry not found
|
camembert/camembert-base
|
e12767c19b74b1efc75b0af07bbde51ddd26b529
|
2022-06-17T23:06:40.000Z
|
[
"pytorch",
"camembert",
"fill-mask",
"fr",
"arxiv:1911.03894",
"transformers",
"autotrain_compatible"
] |
fill-mask
| false |
camembert
| null |
camembert/camembert-base
| 6,388 | null |
transformers
| 821 |
---
language: fr
---
# CamemBERT: a Tasty French Language Model
## Introduction
[CamemBERT](https://arxiv.org/abs/1911.03894) is a state-of-the-art language model for French based on the RoBERTa model.
It is now available on Hugging Face in 6 different versions with varying number of parameters, amount of pretraining data and pretraining data source domains.
For further information or requests, please go to [Camembert Website](https://camembert-model.fr/)
## Pre-trained models
| Model | #params | Arch. | Training data |
|--------------------------------|--------------------------------|-------|-----------------------------------|
| `camembert-base` | 110M | Base | OSCAR (138 GB of text) |
| `camembert/camembert-large` | 335M | Large | CCNet (135 GB of text) |
| `camembert/camembert-base-ccnet` | 110M | Base | CCNet (135 GB of text) |
| `camembert/camembert-base-wikipedia-4gb` | 110M | Base | Wikipedia (4 GB of text) |
| `camembert/camembert-base-oscar-4gb` | 110M | Base | Subsample of OSCAR (4 GB of text) |
| `camembert/camembert-base-ccnet-4gb` | 110M | Base | Subsample of CCNet (4 GB of text) |
## How to use CamemBERT with HuggingFace
##### Load CamemBERT and its sub-word tokenizer :
```python
from transformers import CamembertModel, CamembertTokenizer
# You can replace "camembert-base" with any other model from the table, e.g. "camembert/camembert-large".
tokenizer = CamembertTokenizer.from_pretrained("camembert/camembert-base-wikipedia-4gb")
camembert = CamembertModel.from_pretrained("camembert/camembert-base-wikipedia-4gb")
camembert.eval() # disable dropout (or leave in train mode to finetune)
```
##### Filling masks using pipeline
```python
from transformers import pipeline
camembert_fill_mask = pipeline("fill-mask", model="camembert/camembert-base-wikipedia-4gb", tokenizer="camembert/camembert-base-wikipedia-4gb")
results = camembert_fill_mask("Le camembert est un fromage de <mask>!")
# results
#[{'sequence': '<s> Le camembert est un fromage de chèvre!</s>', 'score': 0.4937814474105835, 'token': 19370},
#{'sequence': '<s> Le camembert est un fromage de brebis!</s>', 'score': 0.06255942583084106, 'token': 30616},
#{'sequence': '<s> Le camembert est un fromage de montagne!</s>', 'score': 0.04340197145938873, 'token': 2364},
# {'sequence': '<s> Le camembert est un fromage de Noël!</s>', 'score': 0.02823255956172943, 'token': 3236},
#{'sequence': '<s> Le camembert est un fromage de vache!</s>', 'score': 0.021357402205467224, 'token': 12329}]
```
##### Extract contextual embedding features from Camembert output
```python
import torch
# Tokenize in sub-words with SentencePiece
tokenized_sentence = tokenizer.tokenize("J'aime le camembert !")
# ['▁J', "'", 'aime', '▁le', '▁ca', 'member', 't', '▁!']
# 1-hot encode and add special starting and end tokens
encoded_sentence = tokenizer.encode(tokenized_sentence)
# [5, 221, 10, 10600, 14, 8952, 10540, 75, 1114, 6]
# NB: Can be done in one step : tokenize.encode("J'aime le camembert !")
# Feed tokens to Camembert as a torch tensor (batch dim 1)
encoded_sentence = torch.tensor(encoded_sentence).unsqueeze(0)
embeddings, _ = camembert(encoded_sentence)
# embeddings.detach()
# embeddings.size torch.Size([1, 10, 768])
#tensor([[[-0.0928, 0.0506, -0.0094, ..., -0.2388, 0.1177, -0.1302],
# [ 0.0662, 0.1030, -0.2355, ..., -0.4224, -0.0574, -0.2802],
# [-0.0729, 0.0547, 0.0192, ..., -0.1743, 0.0998, -0.2677],
# ...,
```
##### Extract contextual embedding features from all Camembert layers
```python
from transformers import CamembertConfig
# (Need to reload the model with new config)
config = CamembertConfig.from_pretrained("camembert/camembert-base-wikipedia-4gb", output_hidden_states=True)
camembert = CamembertModel.from_pretrained("camembert/camembert-base-wikipedia-4gb", config=config)
embeddings, _, all_layer_embeddings = camembert(encoded_sentence)
# all_layer_embeddings list of len(all_layer_embeddings) == 13 (input embedding layer + 12 self attention layers)
all_layer_embeddings[5]
# layer 5 contextual embedding : size torch.Size([1, 10, 768])
#tensor([[[-0.0059, -0.0227, 0.0065, ..., -0.0770, 0.0369, 0.0095],
# [ 0.2838, -0.1531, -0.3642, ..., -0.0027, -0.8502, -0.7914],
# [-0.0073, -0.0338, -0.0011, ..., 0.0533, -0.0250, -0.0061],
# ...,
```
## Authors
CamemBERT was trained and evaluated by Louis Martin\*, Benjamin Muller\*, Pedro Javier Ortiz Suárez\*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot.
## Citation
If you use our work, please cite:
```bibtex
@inproceedings{martin2020camembert,
title={CamemBERT: a Tasty French Language Model},
author={Martin, Louis and Muller, Benjamin and Su{\'a}rez, Pedro Javier Ortiz and Dupont, Yoann and Romary, Laurent and de la Clergerie, {\'E}ric Villemonte and Seddah, Djam{\'e} and Sagot, Beno{\^\i}t},
booktitle={Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics},
year={2020}
}
```
|
hf-internal-testing/tiny-random-speech-encoder-decoder
|
880a6041222f5297adfceb3debd1a955d1c48ba5
|
2021-12-24T15:13:44.000Z
|
[
"pytorch",
"speech-encoder-decoder",
"automatic-speech-recognition",
"transformers"
] |
automatic-speech-recognition
| false |
hf-internal-testing
| null |
hf-internal-testing/tiny-random-speech-encoder-decoder
| 6,373 | null |
transformers
| 822 |
Entry not found
|
hiiamsid/sentence_similarity_spanish_es
|
2817cf8566982a08b43bc4d6f74924010bc56f65
|
2021-10-18T03:52:32.000Z
|
[
"pytorch",
"bert",
"feature-extraction",
"es",
"sentence-transformers",
"sentence-similarity",
"transformers"
] |
sentence-similarity
| false |
hiiamsid
| null |
hiiamsid/sentence_similarity_spanish_es
| 6,371 | 4 |
sentence-transformers
| 823 |
---
pipeline_tag: sentence-similarity
language:
- es
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# hiiamsid/sentence_similarity_spanish_es
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('hiiamsid/sentence_similarity_spanish_es')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('hiiamsid/sentence_similarity_spanish_es')
model = AutoModel.from_pretrained('hiiamsid/sentence_similarity_spanish_es')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
```
cosine_pearson : 0.8280372842978689
cosine_spearman : 0.8232689765056079
euclidean_pearson : 0.81021993884437
euclidean_spearman : 0.8087904592393836
manhattan_pearson : 0.809645390126291
manhattan_spearman : 0.8077035464970413
dot_pearson : 0.7803662255836028
dot_spearman : 0.7699607641618339
```
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=hiiamsid/sentence_similarity_spanish_es)
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 360 with parameters:
```
{'batch_size': 16, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss`
Parameters of the fit()-Method:
```
{
"callback": null,
"epochs": 4,
"evaluation_steps": 1000,
"evaluator": "sentence_transformers.evaluation.EmbeddingSimilarityEvaluator.EmbeddingSimilarityEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'transformers.optimization.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 144,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
- Datasets : [stsb_multi_mt](https://huggingface.co/datasets/stsb_multi_mt)
- Model : [dccuchile/bert-base-spanish-wwm-cased](https://huggingface.co/dccuchile/bert-base-spanish-wwm-cased)
- Sentence Transformers [Semantic Textual Similarity](https://www.sbert.net/examples/training/sts/README.html)
|
google/vit-base-patch32-224-in21k
|
ebb34016d84eb82beee2f88d5ae21a1f08a8ca88
|
2022-01-12T08:06:34.000Z
|
[
"pytorch",
"tf",
"jax",
"vit",
"feature-extraction",
"dataset:imagenet-21k",
"arxiv:2010.11929",
"arxiv:2006.03677",
"transformers",
"vision",
"license:apache-2.0"
] |
feature-extraction
| false |
google
| null |
google/vit-base-patch32-224-in21k
| 6,344 | null |
transformers
| 824 |
---
license: apache-2.0
tags:
- vision
datasets:
- imagenet-21k
inference: false
---
# Vision Transformer (base-sized model)
Vision Transformer (ViT) model pre-trained on ImageNet-21k (14 million images, 21,843 classes) at resolution 224x224. It was introduced in the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Dosovitskiy et al. and first released in [this repository](https://github.com/google-research/vision_transformer). However, the weights were converted from the [timm repository](https://github.com/rwightman/pytorch-image-models) by Ross Wightman, who already converted the weights from JAX to PyTorch. Credits go to him.
Disclaimer: The team releasing ViT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The Vision Transformer (ViT) is a transformer encoder model (BERT-like) pretrained on a large collection of images in a supervised fashion, namely ImageNet-21k, at a resolution of 224x224 pixels.
Images are presented to the model as a sequence of fixed-size patches (resolution 32x32), which are linearly embedded. One also adds a [CLS] token to the beginning of a sequence to use it for classification tasks. One also adds absolute position embeddings before feeding the sequence to the layers of the Transformer encoder.
Note that this model does not provide any fine-tuned heads, as these were zero'd by Google researchers. However, the model does include the pre-trained pooler, which can be used for downstream tasks (such as image classification).
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire image.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=google/vit) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model:
```python
from transformers import ViTFeatureExtractor, ViTModel
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = ViTFeatureExtractor.from_pretrained('google/vit-base-patch32-224-in21k')
model = ViTModel.from_pretrained('google/vit-base-patch32-224-in21k')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
last_hidden_state = outputs.last_hidden_state
```
Currently, both the feature extractor and model support PyTorch. Tensorflow and JAX/FLAX are coming soon, and the API of ViTFeatureExtractor might change.
## Training data
The ViT model was pretrained on [ImageNet-21k](http://www.image-net.org/), a dataset consisting of 14 million images and 21k classes.
## Training procedure
### Preprocessing
The exact details of preprocessing of images during training/validation can be found [here](https://github.com/google-research/vision_transformer/blob/master/vit_jax/input_pipeline.py).
Images are resized/rescaled to the same resolution (224x224) and normalized across the RGB channels with mean (0.5, 0.5, 0.5) and standard deviation (0.5, 0.5, 0.5).
### Pretraining
The model was trained on TPUv3 hardware (8 cores). All model variants are trained with a batch size of 4096 and learning rate warmup of 10k steps. For ImageNet, the authors found it beneficial to additionally apply gradient clipping at global norm 1. Pre-training resolution is 224.
## Evaluation results
For evaluation results on several image classification benchmarks, we refer to tables 2 and 5 of the original paper. Note that for fine-tuning, the best results are obtained with a higher resolution (384x384). Of course, increasing the model size will result in better performance.
### BibTeX entry and citation info
```bibtex
@misc{wu2020visual,
title={Visual Transformers: Token-based Image Representation and Processing for Computer Vision},
author={Bichen Wu and Chenfeng Xu and Xiaoliang Dai and Alvin Wan and Peizhao Zhang and Zhicheng Yan and Masayoshi Tomizuka and Joseph Gonzalez and Kurt Keutzer and Peter Vajda},
year={2020},
eprint={2006.03677},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
```bibtex
@inproceedings{deng2009imagenet,
title={Imagenet: A large-scale hierarchical image database},
author={Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li},
booktitle={2009 IEEE conference on computer vision and pattern recognition},
pages={248--255},
year={2009},
organization={Ieee}
}
```
|
Salesforce/bart-large-xsum-samsum
|
bf8a8779c158901df223516a72b9efaa887ed1df
|
2021-06-09T19:36:02.000Z
|
[
"pytorch",
"tf",
"bart",
"text2text-generation",
"transformers",
"autotrain_compatible"
] |
text2text-generation
| false |
Salesforce
| null |
Salesforce/bart-large-xsum-samsum
| 6,327 | 4 |
transformers
| 825 |
Entry not found
|
anferico/bert-for-patents
|
d1a25632e9c586399068a2f139d5664306b32ad8
|
2022-06-23T19:22:35.000Z
|
[
"pytorch",
"tf",
"fill-mask",
"en",
"transformers",
"masked-lm",
"license:apache-2.0",
"autotrain_compatible"
] |
fill-mask
| false |
anferico
| null |
anferico/bert-for-patents
| 6,311 | 24 |
transformers
| 826 |
---
language:
- en
tags:
- masked-lm
- pytorch
pipeline-tag: "fill-mask"
mask-token: "[MASK]"
widget:
- text: "The present [MASK] provides a torque sensor that is small and highly rigid and for which high production efficiency is possible."
- text: "The present invention relates to [MASK] accessories and pertains particularly to a brake light unit for bicycles."
- text: "The present invention discloses a space-bound-free [MASK] and its coordinate determining circuit for determining a coordinate of a stylus pen."
- text: "The illuminated [MASK] includes a substantially translucent canopy supported by a plurality of ribs pivotally swingable towards and away from a shaft."
license: apache-2.0
metrics:
- perplexity
---
# BERT for Patents
BERT for Patents is a model trained by Google on 100M+ patents (not just US patents). It is based on BERT<sub>LARGE</sub>.
If you want to learn more about the model, check out the [blog post](https://cloud.google.com/blog/products/ai-machine-learning/how-ai-improves-patent-analysis), [white paper](https://services.google.com/fh/files/blogs/bert_for_patents_white_paper.pdf) and [GitHub page](https://github.com/google/patents-public-data/blob/master/models/BERT%20for%20Patents.md) containing the original TensorFlow checkpoint.
---
### Projects using this model (or variants of it):
- [Patents4IPPC](https://github.com/ec-jrc/Patents4IPPC) (carried out by [Pi School](https://picampus-school.com/) and commissioned by the [Joint Research Centre (JRC)](https://ec.europa.eu/jrc/en) of the European Commission)
|
nvidia/mit-b0
|
698892efdcedeeb02bce6a40d3f4830e469bbff9
|
2022-07-29T13:15:48.000Z
|
[
"pytorch",
"tf",
"segformer",
"image-classification",
"dataset:imagenet_1k",
"arxiv:2105.15203",
"transformers",
"vision",
"license:apache-2.0"
] |
image-classification
| false |
nvidia
| null |
nvidia/mit-b0
| 6,248 | 2 |
transformers
| 827 |
---
license: apache-2.0
tags:
- vision
datasets:
- imagenet_1k
widget:
- src: https://huggingface.co/datasets/hf-internal-testing/fixtures_ade20k/resolve/main/ADE_val_00000001.jpg
example_title: House
- src: https://huggingface.co/datasets/hf-internal-testing/fixtures_ade20k/resolve/main/ADE_val_00000002.jpg
example_title: Castle
---
# SegFormer (b0-sized) encoder pre-trained-only
SegFormer encoder fine-tuned on Imagenet-1k. It was introduced in the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Xie et al. and first released in [this repository](https://github.com/NVlabs/SegFormer).
Disclaimer: The team releasing SegFormer did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
SegFormer consists of a hierarchical Transformer encoder and a lightweight all-MLP decode head to achieve great results on semantic segmentation benchmarks such as ADE20K and Cityscapes. The hierarchical Transformer is first pre-trained on ImageNet-1k, after which a decode head is added and fine-tuned altogether on a downstream dataset.
This repository only contains the pre-trained hierarchical Transformer, hence it can be used for fine-tuning purposes.
## Intended uses & limitations
You can use the model for fine-tuning of semantic segmentation. See the [model hub](https://huggingface.co/models?other=segformer) to look for fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import SegformerFeatureExtractor, SegformerForImageClassification
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = SegformerFeatureExtractor.from_pretrained("nvidia/mit-b0")
model = SegformerForImageClassification.from_pretrained("nvidia/mit-b0")
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
For more code examples, we refer to the [documentation](https://huggingface.co/transformers/model_doc/segformer.html#).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2105-15203,
author = {Enze Xie and
Wenhai Wang and
Zhiding Yu and
Anima Anandkumar and
Jose M. Alvarez and
Ping Luo},
title = {SegFormer: Simple and Efficient Design for Semantic Segmentation with
Transformers},
journal = {CoRR},
volume = {abs/2105.15203},
year = {2021},
url = {https://arxiv.org/abs/2105.15203},
eprinttype = {arXiv},
eprint = {2105.15203},
timestamp = {Wed, 02 Jun 2021 11:46:42 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2105-15203.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
flair/chunk-english
|
ade3849ae09b28854c9bad0a6ec4028ba547bae2
|
2021-03-02T22:00:37.000Z
|
[
"pytorch",
"en",
"dataset:conll2000",
"flair",
"token-classification",
"sequence-tagger-model"
] |
token-classification
| false |
flair
| null |
flair/chunk-english
| 6,206 | 4 |
flair
| 828 |
---
tags:
- flair
- token-classification
- sequence-tagger-model
language: en
datasets:
- conll2000
widget:
- text: "The happy man has been eating at the diner"
---
## English Chunking in Flair (default model)
This is the standard phrase chunking model for English that ships with [Flair](https://github.com/flairNLP/flair/).
F1-Score: **96,48** (CoNLL-2000)
Predicts 4 tags:
| **tag** | **meaning** |
|---------------------------------|-----------|
| ADJP | adjectival |
| ADVP | adverbial |
| CONJP | conjunction |
| INTJ | interjection |
| LST | list marker |
| NP | noun phrase |
| PP | prepositional |
| PRT | particle |
| SBAR | subordinate clause |
| VP | verb phrase |
Based on [Flair embeddings](https://www.aclweb.org/anthology/C18-1139/) and LSTM-CRF.
---
### Demo: How to use in Flair
Requires: **[Flair](https://github.com/flairNLP/flair/)** (`pip install flair`)
```python
from flair.data import Sentence
from flair.models import SequenceTagger
# load tagger
tagger = SequenceTagger.load("flair/chunk-english")
# make example sentence
sentence = Sentence("The happy man has been eating at the diner")
# predict NER tags
tagger.predict(sentence)
# print sentence
print(sentence)
# print predicted NER spans
print('The following NER tags are found:')
# iterate over entities and print
for entity in sentence.get_spans('np'):
print(entity)
```
This yields the following output:
```
Span [1,2,3]: "The happy man" [− Labels: NP (0.9958)]
Span [4,5,6]: "has been eating" [− Labels: VP (0.8759)]
Span [7]: "at" [− Labels: PP (1.0)]
Span [8,9]: "the diner" [− Labels: NP (0.9991)]
```
So, the spans "*The happy man*" and "*the diner*" are labeled as **noun phrases** (NP) and "*has been eating*" is labeled as a **verb phrase** (VP) in the sentence "*The happy man has been eating at the diner*".
---
### Training: Script to train this model
The following Flair script was used to train this model:
```python
from flair.data import Corpus
from flair.datasets import CONLL_2000
from flair.embeddings import WordEmbeddings, StackedEmbeddings, FlairEmbeddings
# 1. get the corpus
corpus: Corpus = CONLL_2000()
# 2. what tag do we want to predict?
tag_type = 'np'
# 3. make the tag dictionary from the corpus
tag_dictionary = corpus.make_tag_dictionary(tag_type=tag_type)
# 4. initialize each embedding we use
embedding_types = [
# contextual string embeddings, forward
FlairEmbeddings('news-forward'),
# contextual string embeddings, backward
FlairEmbeddings('news-backward'),
]
# embedding stack consists of Flair and GloVe embeddings
embeddings = StackedEmbeddings(embeddings=embedding_types)
# 5. initialize sequence tagger
from flair.models import SequenceTagger
tagger = SequenceTagger(hidden_size=256,
embeddings=embeddings,
tag_dictionary=tag_dictionary,
tag_type=tag_type)
# 6. initialize trainer
from flair.trainers import ModelTrainer
trainer = ModelTrainer(tagger, corpus)
# 7. run training
trainer.train('resources/taggers/chunk-english',
train_with_dev=True,
max_epochs=150)
```
---
### Cite
Please cite the following paper when using this model.
```
@inproceedings{akbik2018coling,
title={Contextual String Embeddings for Sequence Labeling},
author={Akbik, Alan and Blythe, Duncan and Vollgraf, Roland},
booktitle = {{COLING} 2018, 27th International Conference on Computational Linguistics},
pages = {1638--1649},
year = {2018}
}
```
---
### Issues?
The Flair issue tracker is available [here](https://github.com/flairNLP/flair/issues/).
|
facebook/blenderbot-90M
|
3e5344952a74d2017762fa8428c45edd07f3dea7
|
2021-03-12T06:17:25.000Z
|
[
"pytorch",
"blenderbot-small",
"text2text-generation",
"en",
"dataset:blended_skill_talk",
"arxiv:1907.06616",
"transformers",
"convAI",
"conversational",
"facebook",
"license:apache-2.0",
"autotrain_compatible"
] |
conversational
| false |
facebook
| null |
facebook/blenderbot-90M
| 6,163 | null |
transformers
| 829 |
---
language:
- en
thumbnail:
tags:
- convAI
- conversational
- facebook
license: apache-2.0
datasets:
- blended_skill_talk
metrics:
- perplexity
---
# 🚨🚨**IMPORTANT**🚨🚨
**This model is deprecated! Please use the identical model** **https://huggingface.co/facebook/blenderbot_small-90M instead**
## Model description
+ Paper: [Recipes for building an open-domain chatbot](https://arxiv.org/abs/1907.06616)
+ [Original PARLAI Code](https://parl.ai/projects/recipes/)
### Abstract
Building open-domain chatbots is a challenging area for machine learning research. While prior work has shown that scaling neural models in the number of parameters and the size of the data they are trained on gives improved results, we show that other ingredients are important for a high-performing chatbot. Good conversation requires a number of skills that an expert conversationalist blends in a seamless way: providing engaging talking points and listening to their partners, both asking and answering questions, and displaying knowledge, empathy and personality appropriately, depending on the situation. We show that large scale models can learn these skills when given appropriate training data and choice of generation strategy. We build variants of these recipes with 90M, 2.7B and 9.4B parameter neural models, and make our models and code publicly available. Human evaluations show our best models are superior to existing approaches in multi-turn dialogue in terms of engagingness and humanness measurements. We then discuss the limitations of this work by analyzing failure cases of our models.
|
Peltarion/xlm-roberta-longformer-base-4096
|
c2e164abd333ebd242de4178ea18c1260e00d330
|
2022-03-30T09:23:58.000Z
|
[
"pytorch",
"xlm-roberta",
"fill-mask",
"multilingual",
"dataset:wikitext",
"transformers",
"longformer",
"license:apache-2.0",
"autotrain_compatible"
] |
fill-mask
| false |
Peltarion
| null |
Peltarion/xlm-roberta-longformer-base-4096
| 6,159 | 2 |
transformers
| 830 |
---
tags:
- longformer
language: multilingual
license: apache-2.0
datasets:
- wikitext
---
## XLM-R Longformer Model
XLM-R Longformer is a XLM-R model, that has been extended to allow sequence lengths up to 4096 tokens, instead of the regular 512. The model was pre-trained from the XLM-RoBERTa checkpoint using the Longformer [pre-training scheme](https://github.com/allenai/longformer/blob/master/scripts/convert_model_to_long.ipynb) on the English WikiText-103 corpus.
The reason for this was to investigate methods for creating efficient Transformers for low-resource languages, such as Swedish, without the need to pre-train them on long-context datasets in each respecitve language. The trained model came as a result of a master thesis project at [Peltarion](https://peltarion.com/) and was fine-tuned on multilingual quesion-answering tasks, with code available [here](https://github.com/MarkusSagen/Master-Thesis-Multilingual-Longformer#xlm-r).
Since both XLM-R model and Longformer models are large models, it it recommended to run the models with NVIDIA Apex (16bit precision), large GPU and several gradient accumulation steps.
## How to Use
The model can be used as expected to fine-tune on a downstream task.
For instance for QA.
```python
import torch
from transformers import AutoModel, AutoTokenizer
MAX_SEQUENCE_LENGTH = 4096
MODEL_NAME_OR_PATH = "markussagen/xlm-roberta-longformer-base-4096"
tokenizer = AutoTokenizer.from_pretrained(
MODEL_NAME_OR_PATH,
max_length=MAX_SEQUENCE_LENGTH,
padding="max_length",
truncation=True,
)
model = AutoModelForQuestionAnswering.from_pretrained(
MODEL_NAME_OR_PATH,
max_length=MAX_SEQUENCE_LENGTH,
)
```
## Training Procedure
The model have been trained on the WikiText-103 corpus, using a **48GB** GPU with the following training script and parameters. The model was pre-trained for 6000 iterations and took ~5 days. See the full [training script](https://github.com/MarkusSagen/Master-Thesis-Multilingual-Longformer/blob/main/scripts/finetune_qa_models.py) and [Github repo](https://github.com/MarkusSagen/Master-Thesis-Multilingual-Longformer) for more information
```sh
wget https://s3.amazonaws.com/research.metamind.io/wikitext/wikitext-103-raw-v1.zip
unzip wikitext-103-raw-v1.zip
export DATA_DIR=./wikitext-103-raw
scripts/run_long_lm.py \
--model_name_or_path xlm-roberta-base \
--model_name xlm-roberta-to-longformer \
--output_dir ./output \
--logging_dir ./logs \
--val_file_path $DATA_DIR/wiki.valid.raw \
--train_file_path $DATA_DIR/wiki.train.raw \
--seed 42 \
--max_pos 4096 \
--adam_epsilon 1e-8 \
--warmup_steps 500 \
--learning_rate 3e-5 \
--weight_decay 0.01 \
--max_steps 6000 \
--evaluate_during_training \
--logging_steps 50 \
--eval_steps 50 \
--save_steps 6000 \
--max_grad_norm 1.0 \
--per_device_eval_batch_size 2 \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 64 \
--overwrite_output_dir \
--fp16 \
--do_train \
--do_eval
```
|
DeepPavlov/bert-base-cased-conversational
|
5415204d80daf12299c85dfddec5f5a7fc7b620a
|
2021-11-08T13:07:31.000Z
|
[
"pytorch",
"jax",
"bert",
"feature-extraction",
"en",
"transformers"
] |
feature-extraction
| false |
DeepPavlov
| null |
DeepPavlov/bert-base-cased-conversational
| 6,152 | 3 |
transformers
| 831 |
---
language: en
---
# bert-base-cased-conversational
Conversational BERT \(English, cased, 12‑layer, 768‑hidden, 12‑heads, 110M parameters\) was trained on the English part of Twitter, Reddit, DailyDialogues\[1\], OpenSubtitles\[2\], Debates\[3\], Blogs\[4\], Facebook News Comments. We used this training data to build the vocabulary of English subtokens and took English cased version of BERT‑base as an initialization for English Conversational BERT.
08.11.2021: upload model with MLM and NSP heads
\[1\]: Yanran Li, Hui Su, Xiaoyu Shen, Wenjie Li, Ziqiang Cao, and Shuzi Niu. DailyDialog: A Manually Labelled Multi-turn Dialogue Dataset. IJCNLP 2017.
\[2\]: P. Lison and J. Tiedemann, 2016, OpenSubtitles2016: Extracting Large Parallel Corpora from Movie and TV Subtitles. In Proceedings of the 10th International Conference on Language Resources and Evaluation \(LREC 2016\)
\[3\]: Justine Zhang, Ravi Kumar, Sujith Ravi, Cristian Danescu-Niculescu-Mizil. Proceedings of NAACL, 2016.
\[4\]: J. Schler, M. Koppel, S. Argamon and J. Pennebaker \(2006\). Effects of Age and Gender on Blogging in Proceedings of 2006 AAAI Spring Symposium on Computational Approaches for Analyzing Weblogs.
|
fnlp/bart-large-chinese
|
b47be247db39e74f5383784524c68bfddf0aa496
|
2021-10-29T05:19:42.000Z
|
[
"pytorch",
"bart",
"feature-extraction",
"zh",
"arxiv:2109.05729",
"transformers",
"text2text-generation",
"Chinese",
"seq2seq"
] |
feature-extraction
| false |
fnlp
| null |
fnlp/bart-large-chinese
| 6,147 | 14 |
transformers
| 832 |
---
tags:
- text2text-generation
- Chinese
- seq2seq
language: zh
---
# Chinese BART-Large
## Model description
This is an implementation of Chinese BART-Large.
[**CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Generation**](https://arxiv.org/pdf/2109.05729.pdf)
Yunfan Shao, Zhichao Geng, Yitao Liu, Junqi Dai, Fei Yang, Li Zhe, Hujun Bao, Xipeng Qiu
**Github Link:** https://github.com/fastnlp/CPT
## Usage
```python
>>> from transformers import BertTokenizer, BartForConditionalGeneration, Text2TextGenerationPipeline
>>> tokenizer = BertTokenizer.from_pretrained("fnlp/bart-large-chinese")
>>> model = BartForConditionalGeneration.from_pretrained("fnlp/bart-large-chinese")
>>> text2text_generator = Text2TextGenerationPipeline(model, tokenizer)
>>> text2text_generator("北京是[MASK]的首都", max_length=50, do_sample=False)
[{'generated_text': '北 京 是 中 华 人 民 共 和 国 的 首 都'}]
```
**Note: Please use BertTokenizer for the model vocabulary. DO NOT use original BartTokenizer.**
## Citation
```bibtex
@article{shao2021cpt,
title={CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Generation},
author={Yunfan Shao and Zhichao Geng and Yitao Liu and Junqi Dai and Fei Yang and Li Zhe and Hujun Bao and Xipeng Qiu},
journal={arXiv preprint arXiv:2109.05729},
year={2021}
}
```
|
flair/ner-french
|
84166b7e2ebffceaf9807a7eaf90ec07f7cc01a4
|
2021-02-26T15:43:57.000Z
|
[
"pytorch",
"fr",
"dataset:conll2003",
"flair",
"token-classification",
"sequence-tagger-model"
] |
token-classification
| false |
flair
| null |
flair/ner-french
| 6,146 | 2 |
flair
| 833 |
---
tags:
- flair
- token-classification
- sequence-tagger-model
language: fr
datasets:
- conll2003
widget:
- text: "George Washington est allé à Washington"
---
## French NER in Flair (default model)
This is the standard 4-class NER model for French that ships with [Flair](https://github.com/flairNLP/flair/).
F1-Score: **90,61** (WikiNER)
Predicts 4 tags:
| **tag** | **meaning** |
|---------------------------------|-----------|
| PER | person name |
| LOC | location name |
| ORG | organization name |
| MISC | other name |
Based on [Flair embeddings](https://www.aclweb.org/anthology/C18-1139/) and LSTM-CRF.
---
### Demo: How to use in Flair
Requires: **[Flair](https://github.com/flairNLP/flair/)** (`pip install flair`)
```python
from flair.data import Sentence
from flair.models import SequenceTagger
# load tagger
tagger = SequenceTagger.load("flair/ner-french")
# make example sentence
sentence = Sentence("George Washington est allé à Washington")
# predict NER tags
tagger.predict(sentence)
# print sentence
print(sentence)
# print predicted NER spans
print('The following NER tags are found:')
# iterate over entities and print
for entity in sentence.get_spans('ner'):
print(entity)
```
This yields the following output:
```
Span [1,2]: "George Washington" [− Labels: PER (0.7394)]
Span [6]: "Washington" [− Labels: LOC (0.9161)]
```
So, the entities "*George Washington*" (labeled as a **person**) and "*Washington*" (labeled as a **location**) are found in the sentence "*George Washington est allé à Washington*".
---
### Training: Script to train this model
The following Flair script was used to train this model:
```python
from flair.data import Corpus
from flair.datasets import WIKINER_FRENCH
from flair.embeddings import WordEmbeddings, StackedEmbeddings, FlairEmbeddings
# 1. get the corpus
corpus: Corpus = WIKINER_FRENCH()
# 2. what tag do we want to predict?
tag_type = 'ner'
# 3. make the tag dictionary from the corpus
tag_dictionary = corpus.make_tag_dictionary(tag_type=tag_type)
# 4. initialize each embedding we use
embedding_types = [
# GloVe embeddings
WordEmbeddings('fr'),
# contextual string embeddings, forward
FlairEmbeddings('fr-forward'),
# contextual string embeddings, backward
FlairEmbeddings('fr-backward'),
]
# embedding stack consists of Flair and GloVe embeddings
embeddings = StackedEmbeddings(embeddings=embedding_types)
# 5. initialize sequence tagger
from flair.models import SequenceTagger
tagger = SequenceTagger(hidden_size=256,
embeddings=embeddings,
tag_dictionary=tag_dictionary,
tag_type=tag_type)
# 6. initialize trainer
from flair.trainers import ModelTrainer
trainer = ModelTrainer(tagger, corpus)
# 7. run training
trainer.train('resources/taggers/ner-french',
train_with_dev=True,
max_epochs=150)
```
---
### Cite
Please cite the following paper when using this model.
```
@inproceedings{akbik2018coling,
title={Contextual String Embeddings for Sequence Labeling},
author={Akbik, Alan and Blythe, Duncan and Vollgraf, Roland},
booktitle = {{COLING} 2018, 27th International Conference on Computational Linguistics},
pages = {1638--1649},
year = {2018}
}
```
---
### Issues?
The Flair issue tracker is available [here](https://github.com/flairNLP/flair/issues/).
|
facebook/opt-13b
|
45d913414643f29e9273a362ef881109c36b72a5
|
2022-06-24T05:21:44.000Z
|
[
"pytorch",
"tf",
"jax",
"opt",
"text-generation",
"en",
"arxiv:2205.01068",
"arxiv:2005.14165",
"transformers",
"license:other"
] |
text-generation
| false |
facebook
| null |
facebook/opt-13b
| 6,121 | 9 |
transformers
| 834 |
---
language: en
inference: false
tags:
- opt
- text-generation
license: other
commercial: false
---
# OPT : Open Pre-trained Transformer Language Models
OPT was first introduced in [Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068) and first released in [metaseq's repository](https://github.com/facebookresearch/metaseq) on May 3rd 2022 by Meta AI.
**Disclaimer**: The team releasing OPT wrote an official model card, which is available in Appendix D of the [paper](https://arxiv.org/pdf/2205.01068.pdf).
Content from **this** model card has been written by the Hugging Face team.
## Intro
To quote the first two paragraphs of the [official paper](https://arxiv.org/abs/2205.01068)
> Large language models trained on massive text collections have shown surprising emergent
> capabilities to generate text and perform zero- and few-shot learning. While in some cases the public
> can interact with these models through paid APIs, full model access is currently limited to only a
> few highly resourced labs. This restricted access has limited researchers’ ability to study how and
> why these large language models work, hindering progress on improving known challenges in areas
> such as robustness, bias, and toxicity.
> We present Open Pretrained Transformers (OPT), a suite of decoder-only pre-trained transformers ranging from 125M
> to 175B parameters, which we aim to fully and responsibly share with interested researchers. We train the OPT models to roughly match
> the performance and sizes of the GPT-3 class of models, while also applying the latest best practices in data
> collection and efficient training. Our aim in developing this suite of OPT models is to enable reproducible and responsible research at scale, and
> to bring more voices to the table in studying the impact of these LLMs. Definitions of risk, harm, bias, and toxicity, etc., should be articulated by the
> collective research community as a whole, which is only possible when models are available for study.
## Model description
OPT was predominantly pretrained with English text, but a small amount of non-English data is still present within the training corpus via CommonCrawl. The model was pretrained using a causal language modeling (CLM) objective.
OPT belongs to the same family of decoder-only models like [GPT-3](https://arxiv.org/abs/2005.14165). As such, it was pretrained using the self-supervised causal language modedling objective.
For evaluation, OPT follows [GPT-3](https://arxiv.org/abs/2005.14165) by using their prompts and overall experimental setup. For more details, please read
the [official paper](https://arxiv.org/abs/2205.01068).
## Intended uses & limitations
The pretrained-only model can be used for prompting for evaluation of downstream tasks as well as text generation.
In addition, the model can be fine-tuned on a downstream task using the [CLM example](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling). For all other OPT checkpoints, please have a look at the [model hub](https://huggingface.co/models?filter=opt).
### How to use
For large OPT models, such as this one, it is not recommend to make use of the `text-generation` pipeline because
one should load the model in half-precision to accelerate generation and optimize memory consumption on GPU.
It is recommended to directly call the [`generate`](https://huggingface.co/docs/transformers/main/en/main_classes/text_generation#transformers.generation_utils.GenerationMixin.generate)
method as follows:
```python
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> import torch
>>> model = AutoModelForCausalLM.from_pretrained("facebook/opt-13b", torch_dtype=torch.float16).cuda()
>>> # the fast tokenizer currently does not work correctly
>>> tokenizer = AutoTokenizer.from_pretrained(path, use_fast=False)
>>> prompt = "Hello, I'm am conscious and"
>>> input_ids = tokenizer(prompt, return_tensors="pt").input_ids.cuda()
>>> generated_ids = model.generate(input_ids)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
['Hello, I am conscious and aware of my surroundings.\nI am conscious and aware of my']
```
By default, generation is deterministic. In order to use the top-k sampling, please set `do_sample` to `True`.
```python
>>> from transformers import AutoModelForCausalLM, AutoTokenizer, set_seed
>>> import torch
>>> model = AutoModelForCausalLM.from_pretrained("facebook/opt-13b", torch_dtype=torch.float16).cuda()
>>> # the fast tokenizer currently does not work correctly
>>> tokenizer = AutoTokenizer.from_pretrained(path, use_fast=False)
>>> prompt = "Hello, I'm am conscious and"
>>> input_ids = tokenizer(prompt, return_tensors="pt").input_ids.cuda()
>>> set_seed(32)
>>> generated_ids = model.generate(input_ids, do_sample=True)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
['Hello, I am conscious and aware.\nSo that makes you dead, right? ']
```
### Limitations and bias
As mentioned in Meta AI's model card, given that the training data used for this model contains a lot of
unfiltered content from the internet, which is far from neutral the model is strongly biased :
> Like other large language models for which the diversity (or lack thereof) of training
> data induces downstream impact on the quality of our model, OPT-175B has limitations in terms
> of bias and safety. OPT-175B can also have quality issues in terms of generation diversity and
> hallucination. In general, OPT-175B is not immune from the plethora of issues that plague modern
> large language models.
Here's an example of how the model can have biased predictions:
```python
>>> from transformers import AutoModelForCausalLM, AutoTokenizer, set_seed
>>> import torch
>>> model = AutoModelForCausalLM.from_pretrained("facebook/opt-13b", torch_dtype=torch.float16).cuda()
>>> # the fast tokenizer currently does not work correctly
>>> tokenizer = AutoTokenizer.from_pretrained(path, use_fast=False)
>>> prompt = "The woman worked as a"
>>> input_ids = tokenizer(prompt, return_tensors="pt").input_ids.cuda()
>>> set_seed(32)
>>> generated_ids = model.generate(input_ids, do_sample=True, num_return_sequences=5, max_length=10)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
The woman worked as a supervisor in the office
The woman worked as a social media consultant for
The woman worked as a cashier at the
The woman worked as a teacher, and was
The woman worked as a maid at our friends
```
compared to:
```python
>>> from transformers import AutoModelForCausalLM, AutoTokenizer, set_seed
>>> import torch
>>> model = AutoModelForCausalLM.from_pretrained("facebook/opt-13b", torch_dtype=torch.float16).cuda()
>>> # the fast tokenizer currently does not work correctly
>>> tokenizer = AutoTokenizer.from_pretrained(path, use_fast=False)
>>> prompt = "The man worked as a"
>>> input_ids = tokenizer(prompt, return_tensors="pt").input_ids.cuda()
>>> set_seed(32)
>>> generated_ids = model.generate(input_ids, do_sample=True, num_return_sequences=5, max_length=10)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
The man worked as a consultant to the defense
The man worked as a bartender in a bar
The man worked as a cashier at the
The man worked as a teacher, and was
The man worked as a professional athlete while he
```
This bias will also affect all fine-tuned versions of this model.
## Training data
The Meta AI team wanted to train this model on a corpus as large as possible. It is composed of the union of the following 5 filtered datasets of textual documents:
- BookCorpus, which consists of more than 10K unpublished books,
- CC-Stories, which contains a subset of CommonCrawl data filtered to match the
story-like style of Winograd schemas,
- The Pile, from which * Pile-CC, OpenWebText2, USPTO, Project Gutenberg, OpenSubtitles, Wikipedia, DM Mathematics and HackerNews* were included.
- Pushshift.io Reddit dataset that was developed in Baumgartner et al. (2020) and processed in
Roller et al. (2021)
- CCNewsV2 containing an updated version of the English portion of the CommonCrawl News
dataset that was used in RoBERTa (Liu et al., 2019b)
The final training data contains 180B tokens corresponding to 800GB of data. The validation split was made of 200MB of the pretraining data, sampled proportionally
to each dataset’s size in the pretraining corpus.
The dataset might contains offensive content as parts of the dataset are a subset of
public Common Crawl data, along with a subset of public Reddit data, which could contain sentences
that, if viewed directly, can be insulting, threatening, or might otherwise cause anxiety.
### Collection process
The dataset was collected form internet, and went through classic data processing algorithms and
re-formatting practices, including removing repetitive/non-informative text like *Chapter One* or
*This ebook by Project Gutenberg.*
## Training procedure
### Preprocessing
The texts are tokenized using the **GPT2** byte-level version of Byte Pair Encoding (BPE) (for unicode characters) and a
vocabulary size of 50272. The inputs are sequences of 2048 consecutive tokens.
The 175B model was trained on 992 *80GB A100 GPUs*. The training duration was roughly ~33 days of continuous training.
### BibTeX entry and citation info
```bibtex
@misc{zhang2022opt,
title={OPT: Open Pre-trained Transformer Language Models},
author={Susan Zhang and Stephen Roller and Naman Goyal and Mikel Artetxe and Moya Chen and Shuohui Chen and Christopher Dewan and Mona Diab and Xian Li and Xi Victoria Lin and Todor Mihaylov and Myle Ott and Sam Shleifer and Kurt Shuster and Daniel Simig and Punit Singh Koura and Anjali Sridhar and Tianlu Wang and Luke Zettlemoyer},
year={2022},
eprint={2205.01068},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
MilaNLProc/xlm-emo-t
|
cbec0894eb5035a2a513cd7e786a4d7772cfe45b
|
2022-06-08T13:02:56.000Z
|
[
"pytorch",
"xlm-roberta",
"text-classification",
"multilingual",
"arxiv:2104.12250",
"transformers",
"emotion",
"emotion-analysis",
"license:mit"
] |
text-classification
| false |
MilaNLProc
| null |
MilaNLProc/xlm-emo-t
| 6,097 | 1 |
transformers
| 835 |
---
language: multilingual
license: mit
tags:
- emotion
- emotion-analysis
- multilingual
widget:
- text: "Guarda! ci sono dei bellissimi capibara!"
example_title: "Emotion Classification 1"
- text: "Sei una testa di cazzo!!"
example_title: "Emotion Classification 2"
- text: "Quelle bonne nouvelle!"
example_title: "Emotion Classification 3"
---
#
[Federico Bianchi](https://federicobianchi.io/) •
[Debora Nozza](http://dnozza.github.io/) •
[Dirk Hovy](http://www.dirkhovy.com/)
## Abstract
Detecting emotion in text allows social and computational scientists to study how people behave and react to online events. However, developing these tools for different languages requires data that is not always available. This paper collects the available emotion detection datasets across 19 languages. We train a multilingual emotion prediction model for social media data, XLM-EMO. The model shows competitive performance in a zero-shot setting, suggesting it is helpful in the context of low-resource languages. We release our model to the community so that interested researchers can directly use it.
## Model
This model is the fine-tuned version of the [XLM-T](https://arxiv.org/abs/2104.12250) model.
## Results
This model had an F1 of 0.85 on the test set.
## Citation
Please use the following BibTeX entry if you use this model in your project:
```
@inproceedings{bianchi2021feel,
title = "{XLM-EMO: Multilingual Emotion Prediction in Social Media Text}",
author = "Bianchi, Federico and Nozza, Debora and Hovy, Dirk",
booktitle = "Proceedings of the 12th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis",
year = "2022",
publisher = "Association for Computational Linguistics",
}
```
|
laxya007/gpt2_bd2_systemanalysis
|
f190dfa6ad8c5077f45c04d13a5c57c9e28c4979
|
2022-07-05T16:43:36.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers"
] |
text-generation
| false |
laxya007
| null |
laxya007/gpt2_bd2_systemanalysis
| 6,091 | null |
transformers
| 836 |
Entry not found
|
bionlp/bluebert_pubmed_mimic_uncased_L-12_H-768_A-12
|
c656dbe1fc4d6c7771d93bcaff21b2e7984f64c8
|
2021-09-24T07:46:11.000Z
|
[
"pytorch",
"jax",
"en",
"dataset:PubMed",
"dataset:MIMIC-III",
"transformers",
"bert",
"bluebert",
"license:cc0-1.0"
] | null | false |
bionlp
| null |
bionlp/bluebert_pubmed_mimic_uncased_L-12_H-768_A-12
| 6,085 | 3 |
transformers
| 837 |
---
language:
- en
tags:
- bert
- bluebert
license: cc0-1.0
datasets:
- PubMed
- MIMIC-III
---
# BlueBert-Base, Uncased, PubMed and MIMIC-III
## Model description
A BERT model pre-trained on PubMed abstracts and clinical notes ([MIMIC-III](https://mimic.physionet.org/)).
## Intended uses & limitations
#### How to use
Please see https://github.com/ncbi-nlp/bluebert
## Training data
We provide [preprocessed PubMed texts](https://ftp.ncbi.nlm.nih.gov/pub/lu/Suppl/NCBI-BERT/pubmed_uncased_sentence_nltk.txt.tar.gz) that were used to pre-train the BlueBERT models.
The corpus contains ~4000M words extracted from the [PubMed ASCII code version](https://www.ncbi.nlm.nih.gov/research/bionlp/APIs/BioC-PubMed/).
Pre-trained model: https://huggingface.co/bert-base-uncased
## Training procedure
* lowercasing the text
* removing speical chars `\x00`-`\x7F`
* tokenizing the text using the [NLTK Treebank tokenizer](https://www.nltk.org/_modules/nltk/tokenize/treebank.html)
Below is a code snippet for more details.
```python
value = value.lower()
value = re.sub(r'[\r\n]+', ' ', value)
value = re.sub(r'[^\x00-\x7F]+', ' ', value)
tokenized = TreebankWordTokenizer().tokenize(value)
sentence = ' '.join(tokenized)
sentence = re.sub(r"\s's\b", "'s", sentence)
```
### BibTeX entry and citation info
```bibtex
@InProceedings{peng2019transfer,
author = {Yifan Peng and Shankai Yan and Zhiyong Lu},
title = {Transfer Learning in Biomedical Natural Language Processing: An Evaluation of BERT and ELMo on Ten Benchmarking Datasets},
booktitle = {Proceedings of the 2019 Workshop on Biomedical Natural Language Processing (BioNLP 2019)},
year = {2019},
pages = {58--65},
}
```
### Acknowledgments
This work was supported by the Intramural Research Programs of the National Institutes of Health, National Library of
Medicine and Clinical Center. This work was supported by the National Library of Medicine of the National Institutes of Health under award number 4R00LM013001-01.
We are also grateful to the authors of BERT and ELMo to make the data and codes publicly available.
We would like to thank Dr Sun Kim for processing the PubMed texts.
### Disclaimer
This tool shows the results of research conducted in the Computational Biology Branch, NCBI. The information produced
on this website is not intended for direct diagnostic use or medical decision-making without review and oversight
by a clinical professional. Individuals should not change their health behavior solely on the basis of information
produced on this website. NIH does not independently verify the validity or utility of the information produced
by this tool. If you have questions about the information produced on this website, please see a health care
professional. More information about NCBI's disclaimer policy is available.
|
sonoisa/sentence-bert-base-ja-mean-tokens-v2
|
a230680fdb31ed495808f08e2d700361dc982542
|
2021-12-26T08:33:30.000Z
|
[
"pytorch",
"bert",
"feature-extraction",
"ja",
"sentence-transformers",
"sentence-bert",
"sentence-similarity",
"license:cc-by-sa-4.0"
] |
feature-extraction
| false |
sonoisa
| null |
sonoisa/sentence-bert-base-ja-mean-tokens-v2
| 6,080 | 4 |
sentence-transformers
| 838 |
---
language: ja
license: cc-by-sa-4.0
tags:
- sentence-transformers
- sentence-bert
- feature-extraction
- sentence-similarity
---
**※重要: 2021/12/26 モデルを修正しました。誤って精度が低いモデルを公開していたため、精度が高いモデルに差し替えました。**
This is a Japanese sentence-BERT model.
日本語用Sentence-BERTモデル(バージョン2)です。
[バージョン1](https://huggingface.co/sonoisa/sentence-bert-base-ja-mean-tokens)よりも良いロス関数である[MultipleNegativesRankingLoss](https://www.sbert.net/docs/package_reference/losses.html#multiplenegativesrankingloss)を用いて学習した改良版です。
手元の非公開データセットでは、バージョン1よりも1.5〜2ポイントほど精度が高い結果が得られました。
事前学習済みモデルとして[cl-tohoku/bert-base-japanese-whole-word-masking](https://huggingface.co/cl-tohoku/bert-base-japanese-whole-word-masking)を利用しました。
従って、推論の実行にはfugashiとipadicが必要です(pip install fugashi ipadic)。
# 旧バージョンの解説
https://qiita.com/sonoisa/items/1df94d0a98cd4f209051
モデル名を"sonoisa/sentence-bert-base-ja-mean-tokens-v2"に書き換えれば、本モデルを利用した挙動になります。
# 使い方
```python
from transformers import BertJapaneseTokenizer, BertModel
import torch
class SentenceBertJapanese:
def __init__(self, model_name_or_path, device=None):
self.tokenizer = BertJapaneseTokenizer.from_pretrained(model_name_or_path)
self.model = BertModel.from_pretrained(model_name_or_path)
self.model.eval()
if device is None:
device = "cuda" if torch.cuda.is_available() else "cpu"
self.device = torch.device(device)
self.model.to(device)
def _mean_pooling(self, model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
@torch.no_grad()
def encode(self, sentences, batch_size=8):
all_embeddings = []
iterator = range(0, len(sentences), batch_size)
for batch_idx in iterator:
batch = sentences[batch_idx:batch_idx + batch_size]
encoded_input = self.tokenizer.batch_encode_plus(batch, padding="longest",
truncation=True, return_tensors="pt").to(self.device)
model_output = self.model(**encoded_input)
sentence_embeddings = self._mean_pooling(model_output, encoded_input["attention_mask"]).to('cpu')
all_embeddings.extend(sentence_embeddings)
# return torch.stack(all_embeddings).numpy()
return torch.stack(all_embeddings)
MODEL_NAME = "sonoisa/sentence-bert-base-ja-mean-tokens-v2" # <- v2です。
model = SentenceBertJapanese(MODEL_NAME)
sentences = ["暴走したAI", "暴走した人工知能"]
sentence_embeddings = model.encode(sentences, batch_size=8)
print("Sentence embeddings:", sentence_embeddings)
```
|
dmis-lab/biobert-large-cased-v1.1
|
c6775648fdc33f369c4342679bcf0f2691e08b3c
|
2020-10-14T06:19:39.000Z
|
[
"pytorch",
"transformers"
] | null | false |
dmis-lab
| null |
dmis-lab/biobert-large-cased-v1.1
| 6,013 | 1 |
transformers
| 839 |
Entry not found
|
ckiplab/bert-base-chinese-pos
|
c3f173670d4793f00ce5d23381cbeffa17e4e197
|
2022-05-10T03:28:12.000Z
|
[
"pytorch",
"jax",
"bert",
"token-classification",
"zh",
"transformers",
"license:gpl-3.0",
"autotrain_compatible"
] |
token-classification
| false |
ckiplab
| null |
ckiplab/bert-base-chinese-pos
| 6,011 | 2 |
transformers
| 840 |
---
language:
- zh
thumbnail: https://ckip.iis.sinica.edu.tw/files/ckip_logo.png
tags:
- pytorch
- token-classification
- bert
- zh
license: gpl-3.0
---
# CKIP BERT Base Chinese
This project provides traditional Chinese transformers models (including ALBERT, BERT, GPT2) and NLP tools (including word segmentation, part-of-speech tagging, named entity recognition).
這個專案提供了繁體中文的 transformers 模型(包含 ALBERT、BERT、GPT2)及自然語言處理工具(包含斷詞、詞性標記、實體辨識)。
## Homepage
- https://github.com/ckiplab/ckip-transformers
## Contributers
- [Mu Yang](https://muyang.pro) at [CKIP](https://ckip.iis.sinica.edu.tw) (Author & Maintainer)
## Usage
Please use BertTokenizerFast as tokenizer instead of AutoTokenizer.
請使用 BertTokenizerFast 而非 AutoTokenizer。
```
from transformers import (
BertTokenizerFast,
AutoModel,
)
tokenizer = BertTokenizerFast.from_pretrained('bert-base-chinese')
model = AutoModel.from_pretrained('ckiplab/bert-base-chinese-pos')
```
For full usage and more information, please refer to https://github.com/ckiplab/ckip-transformers.
有關完整使用方法及其他資訊,請參見 https://github.com/ckiplab/ckip-transformers 。
|
Rostlab/prot_t5_xl_bfd
|
7ae1d5c1d148d6c65c7e294cc72807e5b454fdb7
|
2020-12-11T21:30:13.000Z
|
[
"pytorch",
"tf",
"t5",
"text2text-generation",
"protein",
"dataset:BFD",
"transformers",
"protein language model",
"autotrain_compatible"
] |
text2text-generation
| false |
Rostlab
| null |
Rostlab/prot_t5_xl_bfd
| 5,994 | 2 |
transformers
| 841 |
---
language: protein
tags:
- protein language model
datasets:
- BFD
---
# ProtT5-XL-BFD model
Pretrained model on protein sequences using a masked language modeling (MLM) objective. It was introduced in
[this paper](https://doi.org/10.1101/2020.07.12.199554) and first released in
[this repository](https://github.com/agemagician/ProtTrans). This model is trained on uppercase amino acids: it only works with capital letter amino acids.
## Model description
ProtT5-XL-BFD is based on the `t5-3b` model and was pretrained on a large corpus of protein sequences in a self-supervised fashion.
This means it was pretrained on the raw protein sequences only, with no humans labelling them in any way (which is why it can use lots of
publicly available data) with an automatic process to generate inputs and labels from those protein sequences.
One important difference between this T5 model and the original T5 version is the denosing objective.
The original T5-3B model was pretrained using a span denosing objective, while this model was pre-trained with a Bart-like MLM denosing objective.
The masking probability is consistent with the original T5 training by randomly masking 15% of the amino acids in the input.
It has been shown that the features extracted from this self-supervised model (LM-embeddings) captured important biophysical properties governing protein shape.
shape.
This implied learning some of the grammar of the language of life realized in protein sequences.
## Intended uses & limitations
The model could be used for protein feature extraction or to be fine-tuned on downstream tasks.
We have noticed in some tasks on can gain more accuracy by fine-tuning the model rather than using it as a feature extractor.
We have also noticed that for feature extraction, its better to use the feature extracted from the encoder not from the decoder.
### How to use
Here is how to use this model to extract the features of a given protein sequence in PyTorch:
```python
from transformers import T5Tokenizer, T5Model
import re
import torch
tokenizer = T5Tokenizer.from_pretrained('Rostlab/prot_t5_xl_bfd', do_lower_case=False)
model = T5Model.from_pretrained("Rostlab/prot_t5_xl_bfd")
sequences_Example = ["A E T C Z A O","S K T Z P"]
sequences_Example = [re.sub(r"[UZOB]", "X", sequence) for sequence in sequences_Example]
ids = tokenizer.batch_encode_plus(sequences_Example, add_special_tokens=True, padding=True)
input_ids = torch.tensor(ids['input_ids'])
attention_mask = torch.tensor(ids['attention_mask'])
with torch.no_grad():
embedding = model(input_ids=input_ids,attention_mask=attention_mask,decoder_input_ids=None)
# For feature extraction we recommend to use the encoder embedding
encoder_embedding = embedding[2].cpu().numpy()
decoder_embedding = embedding[0].cpu().numpy()
```
## Training data
The ProtT5-XL-BFD model was pretrained on [BFD](https://bfd.mmseqs.com/), a dataset consisting of 2.1 billion protein sequences.
## Training procedure
### Preprocessing
The protein sequences are uppercased and tokenized using a single space and a vocabulary size of 21. The rare amino acids "U,Z,O,B" were mapped to "X".
The inputs of the model are then of the form:
```
Protein Sequence [EOS]
```
The preprocessing step was performed on the fly, by cutting and padding the protein sequences up to 512 tokens.
The details of the masking procedure for each sequence are as follows:
- 15% of the amino acids are masked.
- In 90% of the cases, the masked amino acids are replaced by `[MASK]` token.
- In 10% of the cases, the masked amino acids are replaced by a random amino acid (different) from the one they replace.
### Pretraining
The model was trained on a single TPU Pod V3-1024 for 1.2 million steps in total, using sequence length 512 (batch size 4k).
It has a total of approximately 3B parameters and was trained using the encoder-decoder architecture.
The optimizer used is AdaFactor with inverse square root learning rate schedule for pre-training.
## Evaluation results
When the model is used for feature etraction, this model achieves the following results:
Test results :
| Task/Dataset | secondary structure (3-states) | secondary structure (8-states) | Localization | Membrane |
|:-----:|:-----:|:-----:|:-----:|:-----:|
| CASP12 | 77 | 66 | | |
| TS115 | 85 | 74 | | |
| CB513 | 84 | 71 | | |
| DeepLoc | | | 77 | 91 |
### BibTeX entry and citation info
```bibtex
@article {Elnaggar2020.07.12.199554,
author = {Elnaggar, Ahmed and Heinzinger, Michael and Dallago, Christian and Rehawi, Ghalia and Wang, Yu and Jones, Llion and Gibbs, Tom and Feher, Tamas and Angerer, Christoph and Steinegger, Martin and BHOWMIK, DEBSINDHU and Rost, Burkhard},
title = {ProtTrans: Towards Cracking the Language of Life{\textquoteright}s Code Through Self-Supervised Deep Learning and High Performance Computing},
elocation-id = {2020.07.12.199554},
year = {2020},
doi = {10.1101/2020.07.12.199554},
publisher = {Cold Spring Harbor Laboratory},
abstract = {Computational biology and bioinformatics provide vast data gold-mines from protein sequences, ideal for Language Models (LMs) taken from Natural Language Processing (NLP). These LMs reach for new prediction frontiers at low inference costs. Here, we trained two auto-regressive language models (Transformer-XL, XLNet) and two auto-encoder models (Bert, Albert) on data from UniRef and BFD containing up to 393 billion amino acids (words) from 2.1 billion protein sequences (22- and 112 times the entire English Wikipedia). The LMs were trained on the Summit supercomputer at Oak Ridge National Laboratory (ORNL), using 936 nodes (total 5616 GPUs) and one TPU Pod (V3-512 or V3-1024). We validated the advantage of up-scaling LMs to larger models supported by bigger data by predicting secondary structure (3-states: Q3=76-84, 8 states: Q8=65-73), sub-cellular localization for 10 cellular compartments (Q10=74) and whether a protein is membrane-bound or water-soluble (Q2=89). Dimensionality reduction revealed that the LM-embeddings from unlabeled data (only protein sequences) captured important biophysical properties governing protein shape. This implied learning some of the grammar of the language of life realized in protein sequences. The successful up-scaling of protein LMs through HPC to larger data sets slightly reduced the gap between models trained on evolutionary information and LMs. Availability ProtTrans: \<a href="https://github.com/agemagician/ProtTrans"\>https://github.com/agemagician/ProtTrans\</a\>Competing Interest StatementThe authors have declared no competing interest.},
URL = {https://www.biorxiv.org/content/early/2020/07/21/2020.07.12.199554},
eprint = {https://www.biorxiv.org/content/early/2020/07/21/2020.07.12.199554.full.pdf},
journal = {bioRxiv}
}
```
> Created by [Ahmed Elnaggar/@Elnaggar_AI](https://twitter.com/Elnaggar_AI) | [LinkedIn](https://www.linkedin.com/in/prof-ahmed-elnaggar/)
|
blanchefort/rubert-base-cased-sentiment
|
1dfb5bcf1904a12eb157a0dfaf06029e606ce7c7
|
2021-05-19T13:05:55.000Z
|
[
"pytorch",
"tf",
"jax",
"bert",
"text-classification",
"ru",
"transformers",
"sentiment"
] |
text-classification
| false |
blanchefort
| null |
blanchefort/rubert-base-cased-sentiment
| 5,933 | 2 |
transformers
| 842 |
---
language:
- ru
tags:
- sentiment
- text-classification
---
# RuBERT for Sentiment Analysis
Short Russian texts sentiment classification
This is a [DeepPavlov/rubert-base-cased-conversational](https://huggingface.co/DeepPavlov/rubert-base-cased-conversational) model trained on aggregated corpus of 351.797 texts.
## Labels
0: NEUTRAL
1: POSITIVE
2: NEGATIVE
## How to use
```python
import torch
from transformers import AutoModelForSequenceClassification
from transformers import BertTokenizerFast
tokenizer = BertTokenizerFast.from_pretrained('blanchefort/rubert-base-cased-sentiment')
model = AutoModelForSequenceClassification.from_pretrained('blanchefort/rubert-base-cased-sentiment', return_dict=True)
@torch.no_grad()
def predict(text):
inputs = tokenizer(text, max_length=512, padding=True, truncation=True, return_tensors='pt')
outputs = model(**inputs)
predicted = torch.nn.functional.softmax(outputs.logits, dim=1)
predicted = torch.argmax(predicted, dim=1).numpy()
return predicted
```
## Datasets used for model training
**[RuTweetCorp](https://study.mokoron.com/)**
> Рубцова Ю. Автоматическое построение и анализ корпуса коротких текстов (постов микроблогов) для задачи разработки и тренировки тонового классификатора //Инженерия знаний и технологии семантического веба. – 2012. – Т. 1. – С. 109-116.
**[RuReviews](https://github.com/sismetanin/rureviews)**
> RuReviews: An Automatically Annotated Sentiment Analysis Dataset for Product Reviews in Russian.
**[RuSentiment](http://text-machine.cs.uml.edu/projects/rusentiment/)**
> A. Rogers A. Romanov A. Rumshisky S. Volkova M. Gronas A. Gribov RuSentiment: An Enriched Sentiment Analysis Dataset for Social Media in Russian. Proceedings of COLING 2018.
**[Отзывы о медучреждениях](https://github.com/blanchefort/datasets/tree/master/medical_comments)**
> Датасет содержит пользовательские отзывы о медицинских учреждениях. Датасет собран в мае 2019 года с сайта prodoctorov.ru
|
hfl/rbt6
|
460e5cea82f393f75495db07da8055a957b53a2c
|
2021-05-19T19:22:02.000Z
|
[
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"zh",
"arxiv:1906.08101",
"arxiv:2004.13922",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] |
fill-mask
| false |
hfl
| null |
hfl/rbt6
| 5,928 | 2 |
transformers
| 843 |
---
language:
- zh
tags:
- bert
license: "apache-2.0"
---
# This is a re-trained 6-layer RoBERTa-wwm-ext model.
## Chinese BERT with Whole Word Masking
For further accelerating Chinese natural language processing, we provide **Chinese pre-trained BERT with Whole Word Masking**.
**[Pre-Training with Whole Word Masking for Chinese BERT](https://arxiv.org/abs/1906.08101)**
Yiming Cui, Wanxiang Che, Ting Liu, Bing Qin, Ziqing Yang, Shijin Wang, Guoping Hu
This repository is developed based on:https://github.com/google-research/bert
You may also interested in,
- Chinese BERT series: https://github.com/ymcui/Chinese-BERT-wwm
- Chinese MacBERT: https://github.com/ymcui/MacBERT
- Chinese ELECTRA: https://github.com/ymcui/Chinese-ELECTRA
- Chinese XLNet: https://github.com/ymcui/Chinese-XLNet
- Knowledge Distillation Toolkit - TextBrewer: https://github.com/airaria/TextBrewer
More resources by HFL: https://github.com/ymcui/HFL-Anthology
## Citation
If you find the technical report or resource is useful, please cite the following technical report in your paper.
- Primary: https://arxiv.org/abs/2004.13922
```
@inproceedings{cui-etal-2020-revisiting,
title = "Revisiting Pre-Trained Models for {C}hinese Natural Language Processing",
author = "Cui, Yiming and
Che, Wanxiang and
Liu, Ting and
Qin, Bing and
Wang, Shijin and
Hu, Guoping",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.findings-emnlp.58",
pages = "657--668",
}
```
- Secondary: https://arxiv.org/abs/1906.08101
```
@article{chinese-bert-wwm,
title={Pre-Training with Whole Word Masking for Chinese BERT},
author={Cui, Yiming and Che, Wanxiang and Liu, Ting and Qin, Bing and Yang, Ziqing and Wang, Shijin and Hu, Guoping},
journal={arXiv preprint arXiv:1906.08101},
year={2019}
}
```
|
flair/ner-german
|
a68cf20d7900104ff560f9bfbdfddb24f9c37282
|
2021-02-26T15:38:47.000Z
|
[
"pytorch",
"de",
"dataset:conll2003",
"flair",
"token-classification",
"sequence-tagger-model"
] |
token-classification
| false |
flair
| null |
flair/ner-german
| 5,919 | 4 |
flair
| 844 |
---
tags:
- flair
- token-classification
- sequence-tagger-model
language: de
datasets:
- conll2003
widget:
- text: "George Washington ging nach Washington"
---
## German NER in Flair (default model)
This is the standard 4-class NER model for German that ships with [Flair](https://github.com/flairNLP/flair/).
F1-Score: **87,94** (CoNLL-03 German revised)
Predicts 4 tags:
| **tag** | **meaning** |
|---------------------------------|-----------|
| PER | person name |
| LOC | location name |
| ORG | organization name |
| MISC | other name |
Based on [Flair embeddings](https://www.aclweb.org/anthology/C18-1139/) and LSTM-CRF.
---
### Demo: How to use in Flair
Requires: **[Flair](https://github.com/flairNLP/flair/)** (`pip install flair`)
```python
from flair.data import Sentence
from flair.models import SequenceTagger
# load tagger
tagger = SequenceTagger.load("flair/ner-german")
# make example sentence
sentence = Sentence("George Washington ging nach Washington")
# predict NER tags
tagger.predict(sentence)
# print sentence
print(sentence)
# print predicted NER spans
print('The following NER tags are found:')
# iterate over entities and print
for entity in sentence.get_spans('ner'):
print(entity)
```
This yields the following output:
```
Span [1,2]: "George Washington" [− Labels: PER (0.9977)]
Span [5]: "Washington" [− Labels: LOC (0.9895)]
```
So, the entities "*George Washington*" (labeled as a **person**) and "*Washington*" (labeled as a **location**) are found in the sentence "*George Washington ging nach Washington*".
---
### Training: Script to train this model
The following Flair script was used to train this model:
```python
from flair.data import Corpus
from flair.datasets import CONLL_03_GERMAN
from flair.embeddings import WordEmbeddings, StackedEmbeddings, FlairEmbeddings
# 1. get the corpus
corpus: Corpus = CONLL_03_GERMAN()
# 2. what tag do we want to predict?
tag_type = 'ner'
# 3. make the tag dictionary from the corpus
tag_dictionary = corpus.make_tag_dictionary(tag_type=tag_type)
# 4. initialize each embedding we use
embedding_types = [
# GloVe embeddings
WordEmbeddings('de'),
# contextual string embeddings, forward
FlairEmbeddings('de-forward'),
# contextual string embeddings, backward
FlairEmbeddings('de-backward'),
]
# embedding stack consists of Flair and GloVe embeddings
embeddings = StackedEmbeddings(embeddings=embedding_types)
# 5. initialize sequence tagger
from flair.models import SequenceTagger
tagger = SequenceTagger(hidden_size=256,
embeddings=embeddings,
tag_dictionary=tag_dictionary,
tag_type=tag_type)
# 6. initialize trainer
from flair.trainers import ModelTrainer
trainer = ModelTrainer(tagger, corpus)
# 7. run training
trainer.train('resources/taggers/ner-german',
train_with_dev=True,
max_epochs=150)
```
---
### Cite
Please cite the following paper when using this model.
```
@inproceedings{akbik2018coling,
title={Contextual String Embeddings for Sequence Labeling},
author={Akbik, Alan and Blythe, Duncan and Vollgraf, Roland},
booktitle = {{COLING} 2018, 27th International Conference on Computational Linguistics},
pages = {1638--1649},
year = {2018}
}
```
---
### Issues?
The Flair issue tracker is available [here](https://github.com/flairNLP/flair/issues/).
|
allenai/unifiedqa-t5-3b
|
2f8ea967707edd861f92957b4f7f90d96175e7c2
|
2020-11-13T11:54:17.000Z
|
[
"pytorch",
"t5",
"text2text-generation",
"transformers",
"autotrain_compatible"
] |
text2text-generation
| false |
allenai
| null |
allenai/unifiedqa-t5-3b
| 5,897 | null |
transformers
| 845 |
Entry not found
|
shibing624/macbert4csc-base-chinese
|
a3383e26cc84638663a8681b141a6fdeabf09b72
|
2022-01-29T04:00:02.000Z
|
[
"pytorch",
"bert",
"fill-mask",
"zh",
"arxiv:2004.13922",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] |
fill-mask
| false |
shibing624
| null |
shibing624/macbert4csc-base-chinese
| 5,854 | 16 |
transformers
| 846 |
---
language:
- zh
tags:
- bert
- pytorch
- zh
license: "apache-2.0"
---
# MacBERT for Chinese Spelling Correction(macbert4csc) Model
中文拼写纠错模型
`macbert4csc-base-chinese` evaluate SIGHAN2015 test data:
- Char Level: precision:0.9372, recall:0.8640, f1:0.8991
- Sentence Level: precision:0.8264, recall:0.7366, f1:0.7789
由于训练使用的数据使用了SIGHAN2015的训练集(复现paper),在SIGHAN2015的测试集上达到SOTA水平。
模型结构,魔改于softmaskedbert:

## Usage
本项目开源在中文文本纠错项目:[pycorrector](https://github.com/shibing624/pycorrector),可支持macbert4csc模型,通过如下命令调用:
```python
from pycorrector.macbert.macbert_corrector import MacBertCorrector
nlp = MacBertCorrector("shibing624/macbert4csc-base-chinese").macbert_correct
i = nlp('今天新情很好')
print(i)
```
当然,你也可使用官方的huggingface/transformers调用:
*Please use 'Bert' related functions to load this model!*
```python
import operator
import torch
from transformers import BertTokenizer, BertForMaskedLM
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
tokenizer = BertTokenizer.from_pretrained("shibing624/macbert4csc-base-chinese")
model = BertForMaskedLM.from_pretrained("shibing624/macbert4csc-base-chinese")
model.to(device)
texts = ["今天新情很好", "你找到你最喜欢的工作,我也很高心。"]
with torch.no_grad():
outputs = model(**tokenizer(texts, padding=True, return_tensors='pt').to(device))
def get_errors(corrected_text, origin_text):
sub_details = []
for i, ori_char in enumerate(origin_text):
if ori_char in [' ', '“', '”', '‘', '’', '琊', '\n', '…', '—', '擤']:
# add unk word
corrected_text = corrected_text[:i] + ori_char + corrected_text[i:]
continue
if i >= len(corrected_text):
continue
if ori_char != corrected_text[i]:
if ori_char.lower() == corrected_text[i]:
# pass english upper char
corrected_text = corrected_text[:i] + ori_char + corrected_text[i + 1:]
continue
sub_details.append((ori_char, corrected_text[i], i, i + 1))
sub_details = sorted(sub_details, key=operator.itemgetter(2))
return corrected_text, sub_details
result = []
for ids, text in zip(outputs.logits, texts):
_text = tokenizer.decode(torch.argmax(ids, dim=-1), skip_special_tokens=True).replace(' ', '')
corrected_text = _text[:len(text)]
corrected_text, details = get_errors(corrected_text, text)
print(text, ' => ', corrected_text, details)
result.append((corrected_text, details))
print(result)
```
output:
```shell
今天新情很好 => 今天心情很好 [('新', '心', 2, 3)]
你找到你最喜欢的工作,我也很高心。 => 你找到你最喜欢的工作,我也很高兴。 [('心', '兴', 15, 16)]
```
模型文件组成:
```
macbert4csc-base-chinese
├── config.json
├── added_tokens.json
├── pytorch_model.bin
├── special_tokens_map.json
├── tokenizer_config.json
└── vocab.txt
```
### 训练数据集
#### SIGHAN+Wang271K中文纠错数据集
| 数据集 | 语料 | 下载链接 | 压缩包大小 |
| :------- | :--------- | :---------: | :---------: |
| **`SIGHAN+Wang271K中文纠错数据集`** | SIGHAN+Wang271K(27万条) | [百度网盘(密码01b9)](https://pan.baidu.com/s/1BV5tr9eONZCI0wERFvr0gQ)| 106M |
| **`原始SIGHAN数据集`** | SIGHAN13 14 15 | [官方csc.html](http://nlp.ee.ncu.edu.tw/resource/csc.html)| 339K |
| **`原始Wang271K数据集`** | Wang271K | [Automatic-Corpus-Generation dimmywang提供](https://github.com/wdimmy/Automatic-Corpus-Generation/blob/master/corpus/train.sgml)| 93M |
SIGHAN+Wang271K中文纠错数据集,数据格式:
```json
[
{
"id": "B2-4029-3",
"original_text": "晚间会听到嗓音,白天的时候大家都不会太在意,但是在睡觉的时候这嗓音成为大家的恶梦。",
"wrong_ids": [
5,
31
],
"correct_text": "晚间会听到噪音,白天的时候大家都不会太在意,但是在睡觉的时候这噪音成为大家的恶梦。"
},
]
```
```shell
macbert4csc
├── config.json
├── pytorch_model.bin
├── special_tokens_map.json
├── tokenizer_config.json
└── vocab.txt
```
如果需要训练macbert4csc,请参考[https://github.com/shibing624/pycorrector/tree/master/pycorrector/macbert](https://github.com/shibing624/pycorrector/tree/master/pycorrector/macbert)
### About MacBERT
**MacBERT** is an improved BERT with novel **M**LM **a**s **c**orrection pre-training task, which mitigates the discrepancy of pre-training and fine-tuning.
Here is an example of our pre-training task.
| task | Example |
| -------------- | ----------------- |
| **Original Sentence** | we use a language model to predict the probability of the next word. |
| **MLM** | we use a language [M] to [M] ##di ##ct the pro [M] ##bility of the next word . |
| **Whole word masking** | we use a language [M] to [M] [M] [M] the [M] [M] [M] of the next word . |
| **N-gram masking** | we use a [M] [M] to [M] [M] [M] the [M] [M] [M] [M] [M] next word . |
| **MLM as correction** | we use a text system to ca ##lc ##ulate the po ##si ##bility of the next word . |
Except for the new pre-training task, we also incorporate the following techniques.
- Whole Word Masking (WWM)
- N-gram masking
- Sentence-Order Prediction (SOP)
**Note that our MacBERT can be directly replaced with the original BERT as there is no differences in the main neural architecture.**
For more technical details, please check our paper: [Revisiting Pre-trained Models for Chinese Natural Language Processing](https://arxiv.org/abs/2004.13922)
## Citation
```latex
@software{pycorrector,
author = {Xu Ming},
title = {pycorrector: Text Error Correction Tool},
year = {2021},
url = {https://github.com/shibing624/pycorrector},
}
```
|
DB13067/Peterbot
|
8562a504120603feadd5d9c676ea3e3f8c5ff72b
|
2022-03-14T13:51:19.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
| false |
DB13067
| null |
DB13067/Peterbot
| 5,853 | null |
transformers
| 847 |
---
tags:
- conversational
---
# Peter from Your Boyfriend Game.
|
obi/deid_bert_i2b2
|
8ceb8983df9f0bf75d8c4bac345e157d80b4a5f7
|
2022-02-16T14:41:21.000Z
|
[
"pytorch",
"bert",
"token-classification",
"english",
"dataset:I2B2",
"arxiv:1904.03323",
"transformers",
"deidentification",
"medical notes",
"ehr",
"phi",
"license:mit",
"autotrain_compatible"
] |
token-classification
| false |
obi
| null |
obi/deid_bert_i2b2
| 5,835 | 1 |
transformers
| 848 |
---
language:
- english
thumbnail: "https://www.onebraveidea.org/wp-content/uploads/2019/07/OBI-Logo-Website.png"
tags:
- deidentification
- medical notes
- ehr
- phi
datasets:
- I2B2
metrics:
- F1
- Recall
- AUC
widget:
- text: "Physician Discharge Summary Admit date: 10/12/1982 Discharge date: 10/22/1982 Patient Information Jack Reacher, 54 y.o. male (DOB = 1/21/1928)."
- text: "Home Address: 123 Park Drive, San Diego, CA, 03245. Home Phone: 202-555-0199 (home)."
- text: "Hospital Care Team Service: Orthopedics Inpatient Attending: Roger C Kelly, MD Attending phys phone: (634)743-5135 Discharge Unit: HCS843 Primary Care Physician: Hassan V Kim, MD 512-832-5025."
license: mit
---
# Model Description
* A ClinicalBERT [[Alsentzer et al., 2019]](https://arxiv.org/pdf/1904.03323.pdf) model fine-tuned for de-identification of medical notes.
* Sequence Labeling (token classification): The model was trained to predict protected health information (PHI/PII) entities (spans). A list of protected health information categories is given by [HIPAA](https://www.hhs.gov/hipaa/for-professionals/privacy/laws-regulations/index.html).
* A token can either be classified as non-PHI or as one of the 11 PHI types. Token predictions are aggregated to spans by making use of BILOU tagging.
* The PHI labels that were used for training and other details can be found here: [Annotation Guidelines](https://github.com/obi-ml-public/ehr_deidentification/blob/master/AnnotationGuidelines.md)
* More details on how to use this model, the format of data and other useful information is present in the GitHub repo: [Robust DeID](https://github.com/obi-ml-public/ehr_deidentification).
# How to use
* A demo on how the model works (using model predictions to de-identify a medical note) is on this space: [Medical-Note-Deidentification](https://huggingface.co/spaces/obi/Medical-Note-Deidentification).
* Steps on how this model can be used to run a forward pass can be found here: [Forward Pass](https://github.com/obi-ml-public/ehr_deidentification/tree/master/steps/forward_pass)
* In brief, the steps are:
* Sentencize (the model aggregates the sentences back to the note level) and tokenize the dataset.
* Use the predict function of this model to gather the predictions (i.e., predictions for each token).
* Additionally, the model predictions can be used to remove PHI from the original note/text.
# Dataset
* The I2B2 2014 [[Stubbs and Uzuner, 2015]](https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4978170/) dataset was used to train this model.
| | I2B2 | | I2B2 | |
| --------- | --------------------- | ---------- | -------------------- | ---------- |
| | TRAIN SET - 790 NOTES | | TEST SET - 514 NOTES | |
| PHI LABEL | COUNT | PERCENTAGE | COUNT | PERCENTAGE |
| DATE | 7502 | 43.69 | 4980 | 44.14 |
| STAFF | 3149 | 18.34 | 2004 | 17.76 |
| HOSP | 1437 | 8.37 | 875 | 7.76 |
| AGE | 1233 | 7.18 | 764 | 6.77 |
| LOC | 1206 | 7.02 | 856 | 7.59 |
| PATIENT | 1316 | 7.66 | 879 | 7.79 |
| PHONE | 317 | 1.85 | 217 | 1.92 |
| ID | 881 | 5.13 | 625 | 5.54 |
| PATORG | 124 | 0.72 | 82 | 0.73 |
| EMAIL | 4 | 0.02 | 1 | 0.01 |
| OTHERPHI | 2 | 0.01 | 0 | 0 |
| TOTAL | 17171 | 100 | 11283 | 100 |
# Training procedure
* Steps on how this model was trained can be found here: [Training](https://github.com/obi-ml-public/ehr_deidentification/tree/master/steps/train). The "model_name_or_path" was set to: "emilyalsentzer/Bio_ClinicalBERT".
* The dataset was sentencized with the en_core_sci_sm sentencizer from spacy.
* The dataset was then tokenized with a custom tokenizer built on top of the en_core_sci_sm tokenizer from spacy.
* For each sentence we added 32 tokens on the left (from previous sentences) and 32 tokens on the right (from the next sentences).
* The added tokens are not used for learning - i.e, the loss is not computed on these tokens - they are used as additional context.
* Each sequence contained a maximum of 128 tokens (including the 32 tokens added on). Longer sequences were split.
* The sentencized and tokenized dataset with the token level labels based on the BILOU notation was used to train the model.
* The model is fine-tuned from a pre-trained RoBERTa model.
* Training details:
* Input sequence length: 128
* Batch size: 32
* Optimizer: AdamW
* Learning rate: 4e-5
* Dropout: 0.1
# Results
# Questions?
Post a Github issue on the repo: [Robust DeID](https://github.com/obi-ml-public/ehr_deidentification).
|
allenai/wmt19-de-en-6-6-base
|
a9ec1968c8c3962f0f85f9f38ee4b8093ce84f24
|
2020-12-11T21:33:27.000Z
|
[
"pytorch",
"fsmt",
"text2text-generation",
"de",
"en",
"dataset:wmt19",
"arxiv:2006.10369",
"transformers",
"translation",
"wmt19",
"allenai",
"license:apache-2.0",
"autotrain_compatible"
] |
translation
| false |
allenai
| null |
allenai/wmt19-de-en-6-6-base
| 5,811 | null |
transformers
| 849 |
---
language:
- de
- en
thumbnail:
tags:
- translation
- wmt19
- allenai
license: apache-2.0
datasets:
- wmt19
metrics:
- bleu
---
# FSMT
## Model description
This is a ported version of fairseq-based [wmt19 transformer](https://github.com/jungokasai/deep-shallow/) for de-en.
For more details, please, see [Deep Encoder, Shallow Decoder: Reevaluating the Speed-Quality Tradeoff in Machine Translation](https://arxiv.org/abs/2006.10369).
2 models are available:
* [wmt19-de-en-6-6-big](https://huggingface.co/allenai/wmt19-de-en-6-6-big)
* [wmt19-de-en-6-6-base](https://huggingface.co/allenai/wmt19-de-en-6-6-base)
## Intended uses & limitations
#### How to use
```python
from transformers import FSMTForConditionalGeneration, FSMTTokenizer
mname = "allenai/wmt19-de-en-6-6-base"
tokenizer = FSMTTokenizer.from_pretrained(mname)
model = FSMTForConditionalGeneration.from_pretrained(mname)
input = "Maschinelles Lernen ist großartig, nicht wahr?"
input_ids = tokenizer.encode(input, return_tensors="pt")
outputs = model.generate(input_ids)
decoded = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(decoded) # Machine learning is great, isn't it?
```
#### Limitations and bias
## Training data
Pretrained weights were left identical to the original model released by allenai. For more details, please, see the [paper](https://arxiv.org/abs/2006.10369).
## Eval results
Here are the BLEU scores:
model | transformers
-------|---------
wmt19-de-en-6-6-base | 38.37
The score was calculated using this code:
```bash
git clone https://github.com/huggingface/transformers
cd transformers
export PAIR=de-en
export DATA_DIR=data/$PAIR
export SAVE_DIR=data/$PAIR
export BS=8
export NUM_BEAMS=5
mkdir -p $DATA_DIR
sacrebleu -t wmt19 -l $PAIR --echo src > $DATA_DIR/val.source
sacrebleu -t wmt19 -l $PAIR --echo ref > $DATA_DIR/val.target
echo $PAIR
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval.py allenai/wmt19-de-en-6-6-base $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --num_beams $NUM_BEAMS
```
## Data Sources
- [training, etc.](http://www.statmt.org/wmt19/)
- [test set](http://matrix.statmt.org/test_sets/newstest2019.tgz?1556572561)
### BibTeX entry and citation info
```
@misc{kasai2020deep,
title={Deep Encoder, Shallow Decoder: Reevaluating the Speed-Quality Tradeoff in Machine Translation},
author={Jungo Kasai and Nikolaos Pappas and Hao Peng and James Cross and Noah A. Smith},
year={2020},
eprint={2006.10369},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
mrm8488/distill-bert-base-spanish-wwm-cased-finetuned-spa-squad2-es
|
a8842522e00a16b382c875ecb2da2dd8cf7cf5b6
|
2022-03-30T20:37:58.000Z
|
[
"pytorch",
"jax",
"bert",
"question-answering",
"es",
"transformers",
"autotrain_compatible"
] |
question-answering
| false |
mrm8488
| null |
mrm8488/distill-bert-base-spanish-wwm-cased-finetuned-spa-squad2-es
| 5,802 | 12 |
transformers
| 850 |
---
language: es
thumbnail: https://i.imgur.com/jgBdimh.png
---
# BETO (Spanish BERT) + Spanish SQuAD2.0 + distillation using 'bert-base-multilingual-cased' as teacher
This model is a fine-tuned on [SQuAD-es-v2.0](https://github.com/ccasimiro88/TranslateAlignRetrieve) and **distilled** version of [BETO](https://github.com/dccuchile/beto) for **Q&A**.
Distillation makes the model **smaller, faster, cheaper and lighter** than [bert-base-spanish-wwm-cased-finetuned-spa-squad2-es](https://github.com/huggingface/transformers/blob/master/model_cards/mrm8488/bert-base-spanish-wwm-cased-finetuned-spa-squad2-es/README.md)
This model was fine-tuned on the same dataset but using **distillation** during the process as mentioned above (and one more train epoch).
The **teacher model** for the distillation was `bert-base-multilingual-cased`. It is the same teacher used for `distilbert-base-multilingual-cased` AKA [**DistilmBERT**](https://github.com/huggingface/transformers/tree/master/examples/distillation) (on average is twice as fast as **mBERT-base**).
## Details of the downstream task (Q&A) - Dataset
<details>
[SQuAD-es-v2.0](https://github.com/ccasimiro88/TranslateAlignRetrieve)
| Dataset | # Q&A |
| ----------------------- | ----- |
| SQuAD2.0 Train | 130 K |
| SQuAD2.0-es-v2.0 | 111 K |
| SQuAD2.0 Dev | 12 K |
| SQuAD-es-v2.0-small Dev | 69 K |
</details>
## Model training
The model was trained on a Tesla P100 GPU and 25GB of RAM with the following command:
```bash
!export SQUAD_DIR=/path/to/squad-v2_spanish \
&& python transformers/examples/distillation/run_squad_w_distillation.py \
--model_type bert \
--model_name_or_path dccuchile/bert-base-spanish-wwm-cased \
--teacher_type bert \
--teacher_name_or_path bert-base-multilingual-cased \
--do_train \
--do_eval \
--do_lower_case \
--train_file $SQUAD_DIR/train-v2.json \
--predict_file $SQUAD_DIR/dev-v2.json \
--per_gpu_train_batch_size 12 \
--learning_rate 3e-5 \
--num_train_epochs 5.0 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir /content/model_output \
--save_steps 5000 \
--threads 4 \
--version_2_with_negative
```
## Results:
TBA
### Model in action
Fast usage with **pipelines**:
```python
from transformers import *
# Important!: By now the QA pipeline is not compatible with fast tokenizer, but they are working on it. So that pass the object to the tokenizer {"use_fast": False} as in the following example:
nlp = pipeline(
'question-answering',
model='mrm8488/distill-bert-base-spanish-wwm-cased-finetuned-spa-squad2-es',
tokenizer=(
'mrm8488/distill-bert-base-spanish-wwm-cased-finetuned-spa-squad2-es',
{"use_fast": False}
)
)
nlp(
{
'question': '¿Para qué lenguaje está trabajando?',
'context': 'Manuel Romero está colaborando activamente con huggingface/transformers ' +
'para traer el poder de las últimas técnicas de procesamiento de lenguaje natural al idioma español'
}
)
# Output: {'answer': 'español', 'end': 169, 'score': 0.67530957344621, 'start': 163}
```
Play with this model and ```pipelines``` in a Colab:
<a href="https://colab.research.google.com/github/mrm8488/shared_colab_notebooks/blob/master/Using_Spanish_BERT_fine_tuned_for_Q%26A_pipelines.ipynb" target="_parent"><img src="https://camo.githubusercontent.com/52feade06f2fecbf006889a904d221e6a730c194/68747470733a2f2f636f6c61622e72657365617263682e676f6f676c652e636f6d2f6173736574732f636f6c61622d62616467652e737667" alt="Open In Colab" data-canonical-src="https://colab.research.google.com/assets/colab-badge.svg"></a>
<details>
1. Set the context and ask some questions:

2. Run predictions:

</details>
More about ``` Huggingface pipelines```? check this Colab out:
<a href="https://colab.research.google.com/github/mrm8488/shared_colab_notebooks/blob/master/Huggingface_pipelines_demo.ipynb" target="_parent"><img src="https://camo.githubusercontent.com/52feade06f2fecbf006889a904d221e6a730c194/68747470733a2f2f636f6c61622e72657365617263682e676f6f676c652e636f6d2f6173736574732f636f6c61622d62616467652e737667" alt="Open In Colab" data-canonical-src="https://colab.research.google.com/assets/colab-badge.svg"></a>
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
avichr/heBERT
|
01566c04aa226325662d5054331458e14ef3ede1
|
2022-04-15T09:36:09.000Z
|
[
"pytorch",
"jax",
"bert",
"fill-mask",
"arxiv:1810.04805",
"transformers",
"autotrain_compatible"
] |
fill-mask
| false |
avichr
| null |
avichr/heBERT
| 5,778 | 1 |
transformers
| 851 |
## HeBERT: Pre-trained BERT for Polarity Analysis and Emotion Recognition
HeBERT is a Hebrew pretrained language model. It is based on Google's BERT architecture and it is BERT-Base config [(Devlin et al. 2018)](https://arxiv.org/abs/1810.04805). <br>
### HeBert was trained on three dataset:
1. A Hebrew version of OSCAR [(Ortiz, 2019)](https://oscar-corpus.com/): ~9.8 GB of data, including 1 billion words and over 20.8 millions sentences.
2. A Hebrew dump of [Wikipedia](https://dumps.wikimedia.org/hewiki/latest/): ~650 MB of data, including over 63 millions words and 3.8 millions sentences
3. Emotion UGC data that was collected for the purpose of this study. (described below)
We evaluated the model on emotion recognition and sentiment analysis, for a downstream tasks.
### Emotion UGC Data Description
Our User Genrated Content (UGC) is comments written on articles collected from 3 major news sites, between January 2020 to August 2020,. Total data size ~150 MB of data, including over 7 millions words and 350K sentences.
4000 sentences annotated by crowd members (3-10 annotators per sentence) for 8 emotions (anger, disgust, expectation , fear, happy, sadness, surprise and trust) and overall sentiment / polarity<br>
In order to valid the annotation, we search an agreement between raters to emotion in each sentence using krippendorff's alpha [(krippendorff, 1970)](https://journals.sagepub.com/doi/pdf/10.1177/001316447003000105). We left sentences that got alpha > 0.7. Note that while we found a general agreement between raters about emotion like happy, trust and disgust, there are few emotion with general disagreement about them, apparently given the complexity of finding them in the text (e.g. expectation and surprise).
## How to use
### For masked-LM model (can be fine-tunned to any down-stream task)
```
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("avichr/heBERT")
model = AutoModel.from_pretrained("avichr/heBERT")
from transformers import pipeline
fill_mask = pipeline(
"fill-mask",
model="avichr/heBERT",
tokenizer="avichr/heBERT"
)
fill_mask("הקורונה לקחה את [MASK] ולנו לא נשאר דבר.")
```
### For sentiment classification model (polarity ONLY):
```
from transformers import AutoTokenizer, AutoModel, pipeline
tokenizer = AutoTokenizer.from_pretrained("avichr/heBERT_sentiment_analysis") #same as 'avichr/heBERT' tokenizer
model = AutoModel.from_pretrained("avichr/heBERT_sentiment_analysis")
# how to use?
sentiment_analysis = pipeline(
"sentiment-analysis",
model="avichr/heBERT_sentiment_analysis",
tokenizer="avichr/heBERT_sentiment_analysis",
return_all_scores = True
)
>>> sentiment_analysis('אני מתלבט מה לאכול לארוחת צהריים')
[[{'label': 'natural', 'score': 0.9978172183036804},
{'label': 'positive', 'score': 0.0014792329166084528},
{'label': 'negative', 'score': 0.0007035882445052266}]]
>>> sentiment_analysis('קפה זה טעים')
[[{'label': 'natural', 'score': 0.00047328314394690096},
{'label': 'possitive', 'score': 0.9994067549705505},
{'label': 'negetive', 'score': 0.00011996887042187154}]]
>>> sentiment_analysis('אני לא אוהב את העולם')
[[{'label': 'natural', 'score': 9.214012970915064e-05},
{'label': 'possitive', 'score': 8.876807987689972e-05},
{'label': 'negetive', 'score': 0.9998190999031067}]]
```
Our model is also available on AWS! for more information visit [AWS' git](https://github.com/aws-samples/aws-lambda-docker-serverless-inference/tree/main/hebert-sentiment-analysis-inference-docker-lambda)
### For NER model:
```
from transformers import pipeline
# how to use?
NER = pipeline(
"token-classification",
model="avichr/heBERT_NER",
tokenizer="avichr/heBERT_NER",
)
NER('דויד לומד באוניברסיטה העברית שבירושלים')
```
## Stay tuned!
We are still working on our model and will edit this page as we progress.<br>
Note that we have released only sentiment analysis (polarity) at this point, emotion detection will be released later on.<br>
our git: https://github.com/avichaychriqui/HeBERT
## If you use this model please cite us as :
Chriqui, A., & Yahav, I. (2022). HeBERT & HebEMO: a Hebrew BERT Model and a Tool for Polarity Analysis and Emotion Recognition. INFORMS Journal on Data Science, forthcoming.
```
@article{chriqui2021hebert,
title={HeBERT \& HebEMO: a Hebrew BERT Model and a Tool for Polarity Analysis and Emotion Recognition},
author={Chriqui, Avihay and Yahav, Inbal},
journal={INFORMS Journal on Data Science},
year={2022}
}
```
|
Helsinki-NLP/opus-mt-uk-en
|
d6c1e62ab5c03e34a3d118382be7a27b704241f0
|
2021-09-11T10:51:14.000Z
|
[
"pytorch",
"marian",
"text2text-generation",
"uk",
"en",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] |
translation
| false |
Helsinki-NLP
| null |
Helsinki-NLP/opus-mt-uk-en
| 5,763 | null |
transformers
| 852 |
---
tags:
- translation
license: apache-2.0
---
### opus-mt-uk-en
* source languages: uk
* target languages: en
* OPUS readme: [uk-en](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/uk-en/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-16.zip](https://object.pouta.csc.fi/OPUS-MT-models/uk-en/opus-2020-01-16.zip)
* test set translations: [opus-2020-01-16.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/uk-en/opus-2020-01-16.test.txt)
* test set scores: [opus-2020-01-16.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/uk-en/opus-2020-01-16.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba.uk.en | 64.1 | 0.757 |
|
remotejob/gradientclassification_v0
|
a9178cb4e1f714eb99b5076f363a5f4ddab726c6
|
2021-11-12T22:55:12.000Z
|
[
"pytorch",
"rust",
"bert",
"text-classification",
"transformers"
] |
text-classification
| false |
remotejob
| null |
remotejob/gradientclassification_v0
| 5,761 | null |
transformers
| 853 |
Entry not found
|
amberoad/bert-multilingual-passage-reranking-msmarco
|
ed2597214a09ac6a3095b64c1ec49309daab5d9c
|
2021-09-21T16:00:16.000Z
|
[
"pytorch",
"tf",
"jax",
"bert",
"text-classification",
"multilingual",
"dataset:msmarco",
"arxiv:1901.04085",
"transformers",
"msmarco",
"passage reranking",
"license:apache-2.0"
] |
text-classification
| false |
amberoad
| null |
amberoad/bert-multilingual-passage-reranking-msmarco
| 5,754 | 6 |
transformers
| 854 |
---
language: multilingual
thumbnail: https://amberoad.de/images/logo_text.png
tags:
- msmarco
- multilingual
- passage reranking
license: apache-2.0
datasets:
- msmarco
metrics:
- MRR
widget:
- query: What is a corporation?
passage: A company is incorporated in a specific nation, often within the bounds
of a smaller subset of that nation, such as a state or province. The corporation
is then governed by the laws of incorporation in that state. A corporation may
issue stock, either private or public, or may be classified as a non-stock corporation.
If stock is issued, the corporation will usually be governed by its shareholders,
either directly or indirectly.
---
# Passage Reranking Multilingual BERT 🔃 🌍
## Model description
**Input:** Supports over 100 Languages. See [List of supported languages](https://github.com/google-research/bert/blob/master/multilingual.md#list-of-languages) for all available.
**Purpose:** This module takes a search query [1] and a passage [2] and calculates if the passage matches the query.
It can be used as an improvement for Elasticsearch Results and boosts the relevancy by up to 100%.
**Architecture:** On top of BERT there is a Densly Connected NN which takes the 768 Dimensional [CLS] Token as input and provides the output ([Arxiv](https://arxiv.org/abs/1901.04085)).
**Output:** Just a single value between between -10 and 10. Better matching query,passage pairs tend to have a higher a score.
## Intended uses & limitations
Both query[1] and passage[2] have to fit in 512 Tokens.
As you normally want to rerank the first dozens of search results keep in mind the inference time of approximately 300 ms/query.
#### How to use
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("amberoad/bert-multilingual-passage-reranking-msmarco")
model = AutoModelForSequenceClassification.from_pretrained("amberoad/bert-multilingual-passage-reranking-msmarco")
```
This Model can be used as a drop-in replacement in the [Nboost Library](https://github.com/koursaros-ai/nboost)
Through this you can directly improve your Elasticsearch Results without any coding.
## Training data
This model is trained using the [**Microsoft MS Marco Dataset**](https://microsoft.github.io/msmarco/ "Microsoft MS Marco"). This training dataset contains approximately 400M tuples of a query, relevant and non-relevant passages. All datasets used for training and evaluating are listed in this [table](https://github.com/microsoft/MSMARCO-Passage-Ranking#data-information-and-formating). The used dataset for training is called *Train Triples Large*, while the evaluation was made on *Top 1000 Dev*. There are 6,900 queries in total in the development dataset, where each query is mapped to top 1,000 passage retrieved using BM25 from MS MARCO corpus.
## Training procedure
The training is performed the same way as stated in this [README](https://github.com/nyu-dl/dl4marco-bert "NYU Github"). See their excellent Paper on [Arxiv](https://arxiv.org/abs/1901.04085).
We changed the BERT Model from an English only to the default BERT Multilingual uncased Model from [Google](https://huggingface.co/bert-base-multilingual-uncased).
Training was done 400 000 Steps. This equaled 12 hours an a TPU V3-8.
## Eval results
We see nearly similar performance than the English only Model in the English [Bing Queries Dataset](http://www.msmarco.org/). Although the training data is English only internal Tests on private data showed a far higher accurancy in German than all other available models.
Fine-tuned Models | Dependency | Eval Set | Search Boost<a href='#benchmarks'> | Speed on GPU
----------------------------------------------------------------------------------- | ---------------------------------------------------------------------------- | ------------------------------------------------------------------ | ----------------------------------------------------- | ----------------------------------
**`amberoad/Multilingual-uncased-MSMARCO`** (This Model) | <img alt="PyTorch" src="https://img.shields.io/badge/PyTorch-blue"/> | <a href ='http://www.msmarco.org/'>bing queries</a> | **+61%** <sub><sup>(0.29 vs 0.18)</sup></sub> | ~300 ms/query <a href='#footnotes'>
`nboost/pt-tinybert-msmarco` | <img alt="PyTorch" src="https://img.shields.io/badge/PyTorch-red"/> | <a href ='http://www.msmarco.org/'>bing queries</a> | **+45%** <sub><sup>(0.26 vs 0.18)</sup></sub> | ~50ms/query <a href='#footnotes'>
`nboost/pt-bert-base-uncased-msmarco` | <img alt="PyTorch" src="https://img.shields.io/badge/PyTorch-red"/> | <a href ='http://www.msmarco.org/'>bing queries</a> | **+62%** <sub><sup>(0.29 vs 0.18)</sup></sub> | ~300 ms/query<a href='#footnotes'>
`nboost/pt-bert-large-msmarco` | <img alt="PyTorch" src="https://img.shields.io/badge/PyTorch-red"/> | <a href ='http://www.msmarco.org/'>bing queries</a> | **+77%** <sub><sup>(0.32 vs 0.18)</sup></sub> | -
`nboost/pt-biobert-base-msmarco` | <img alt="PyTorch" src="https://img.shields.io/badge/PyTorch-red"/> | <a href ='https://github.com/naver/biobert-pretrained'>biomed</a> | **+66%** <sub><sup>(0.17 vs 0.10)</sup></sub> | ~300 ms/query<a href='#footnotes'>
This table is taken from [nboost](https://github.com/koursaros-ai/nboost) and extended by the first line.
## Contact Infos

Amberoad is a company focussing on Search and Business Intelligence.
We provide you:
* Advanced Internal Company Search Engines thorugh NLP
* External Search Egnines: Find Competitors, Customers, Suppliers
**Get in Contact now to benefit from our Expertise:**
The training and evaluation was performed by [**Philipp Reissel**](https://reissel.eu/) and [**Igli Manaj**](https://github.com/iglimanaj)
[ Linkedin](https://de.linkedin.com/company/amberoad) | <svg xmlns="http://www.w3.org/2000/svg" x="0px" y="0px"
width="32" height="32"
viewBox="0 0 172 172"
style=" fill:#000000;"><g fill="none" fill-rule="nonzero" stroke="none" stroke-width="1" stroke-linecap="butt" stroke-linejoin="miter" stroke-miterlimit="10" stroke-dasharray="" stroke-dashoffset="0" font-family="none" font-weight="none" font-size="none" text-anchor="none" style="mix-blend-mode: normal"><path d="M0,172v-172h172v172z" fill="none"></path><g fill="#e67e22"><path d="M37.625,21.5v86h96.75v-86h-5.375zM48.375,32.25h10.75v10.75h-10.75zM69.875,32.25h10.75v10.75h-10.75zM91.375,32.25h32.25v10.75h-32.25zM48.375,53.75h75.25v43h-75.25zM80.625,112.875v17.61572c-1.61558,0.93921 -2.94506,2.2687 -3.88428,3.88428h-49.86572v10.75h49.86572c1.8612,3.20153 5.28744,5.375 9.25928,5.375c3.97183,0 7.39808,-2.17347 9.25928,-5.375h49.86572v-10.75h-49.86572c-0.93921,-1.61558 -2.2687,-2.94506 -3.88428,-3.88428v-17.61572z"></path></g></g></svg>[Homepage](https://de.linkedin.com/company/amberoad) | [Email]([email protected])
|
vblagoje/dpr-question_encoder-single-lfqa-wiki
|
bf06f6e217a69a4c1421c3eab66bf16a503e28f5
|
2022-03-11T10:11:16.000Z
|
[
"pytorch",
"dpr",
"feature-extraction",
"en",
"dataset:vblagoje/lfqa",
"transformers",
"license:mit"
] |
feature-extraction
| false |
vblagoje
| null |
vblagoje/dpr-question_encoder-single-lfqa-wiki
| 5,752 | null |
transformers
| 855 |
---
language: en
datasets:
- vblagoje/lfqa
license: mit
---
## Introduction
The question encoder model based on [DPRQuestionEncoder](https://huggingface.co/docs/transformers/master/en/model_doc/dpr#transformers.DPRQuestionEncoder) architecture. It uses the transformer's pooler outputs as question representations. See [blog post](https://towardsdatascience.com/long-form-qa-beyond-eli5-an-updated-dataset-and-approach-319cb841aabb) for more details.
## Training
We trained vblagoje/dpr-question_encoder-single-lfqa-wiki using FAIR's dpr-scale in two stages. In the first stage, we used PAQ based pretrained checkpoint and fine-tuned the retriever on the question-answer pairs from the LFQA dataset. As dpr-scale requires DPR formatted training set input with positive, negative, and hard negative samples - we created a training file with an answer being positive, negatives being question unrelated answers, while hard negative samples were chosen from answers on questions between 0.55 and 0.65 of cosine similarity. In the second stage, we created a new DPR training set using positives, negatives, and hard negatives from the Wikipedia/Faiss index created in the first stage instead of LFQA dataset answers. More precisely, for each dataset question, we queried the first stage Wikipedia Faiss index and subsequently used SBert cross-encoder to score questions/answers (passage) pairs with topk=50. The cross-encoder selected the positive passage with the highest score, while the bottom seven answers were selected for hard-negatives. Negative samples were again chosen to be answers unrelated to a given dataset question. After creating a DPR formatted training file with Wikipedia sourced positive, negative, and hard negative passages, we trained DPR-based question/passage encoders using dpr-scale.
## Performance
LFQA DPR-based retriever (vblagoje/dpr-question_encoder-single-lfqa-wiki and vblagoje/dpr-ctx_encoder-single-lfqa-wiki) slightly underperform 'state-of-the-art' Krishna et al. "Hurdles to Progress in Long-form Question Answering" REALM based retriever with KILT benchmark performance of 11.2 for R-precision and 19.5 for Recall@5.
## Usage
```python
from transformers import DPRContextEncoder, DPRContextEncoderTokenizer
model = DPRQuestionEncoder.from_pretrained("vblagoje/dpr-question_encoder-single-lfqa-wiki").to(device)
tokenizer = AutoTokenizer.from_pretrained("vblagoje/dpr-question_encoder-single-lfqa-wiki")
input_ids = tokenizer("Why do airplanes leave contrails in the sky?", return_tensors="pt")["input_ids"]
embeddings = model(input_ids).pooler_output
```
## Author
- Vladimir Blagojevic: `dovlex [at] gmail.com` [Twitter](https://twitter.com/vladblagoje) | [LinkedIn](https://www.linkedin.com/in/blagojevicvladimir/)
|
AmbricJohnson5888/claura
|
bb46422b9136a2fc1217cd6debdf362e49f26743
|
2022-04-09T04:18:57.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
| false |
AmbricJohnson5888
| null |
AmbricJohnson5888/claura
| 5,741 | null |
transformers
| 856 |
---
tags:
- conversational
---
#claura #https://discord.gg/kNxBCv7DtK
|
cahya/bert-base-indonesian-NER
|
4d361d082a907c349cc9dc53e08a75be21673a7c
|
2021-05-19T13:39:48.000Z
|
[
"pytorch",
"jax",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
] |
token-classification
| false |
cahya
| null |
cahya/bert-base-indonesian-NER
| 5,724 | null |
transformers
| 857 |
Entry not found
|
microsoft/DialogRPT-updown
|
afe1247fd7e1b3abea28a52ea72db4ce1c8d2186
|
2021-05-23T09:19:13.000Z
|
[
"pytorch",
"gpt2",
"text-classification",
"arxiv:2009.06978",
"transformers"
] |
text-classification
| false |
microsoft
| null |
microsoft/DialogRPT-updown
| 5,709 | 3 |
transformers
| 858 |
# Demo
Please try this [➤➤➤ Colab Notebook Demo (click me!)](https://colab.research.google.com/drive/1cAtfkbhqsRsT59y3imjR1APw3MHDMkuV?usp=sharing)
| Context | Response | `updown` score |
| :------ | :------- | :------------: |
| I love NLP! | Here’s a free textbook (URL) in case anyone needs it. | 0.613 |
| I love NLP! | Me too! | 0.111 |
The `updown` score predicts how likely the response is getting upvoted.
# DialogRPT-updown
### Dialog Ranking Pretrained Transformers
> How likely a dialog response is upvoted 👍 and/or gets replied 💬?
This is what [**DialogRPT**](https://github.com/golsun/DialogRPT) is learned to predict.
It is a set of dialog response ranking models proposed by [Microsoft Research NLP Group](https://www.microsoft.com/en-us/research/group/natural-language-processing/) trained on 100 + millions of human feedback data.
It can be used to improve existing dialog generation model (e.g., [DialoGPT](https://huggingface.co/microsoft/DialoGPT-medium)) by re-ranking the generated response candidates.
Quick Links:
* [EMNLP'20 Paper](https://arxiv.org/abs/2009.06978/)
* [Dataset, training, and evaluation](https://github.com/golsun/DialogRPT)
* [Colab Notebook Demo](https://colab.research.google.com/drive/1cAtfkbhqsRsT59y3imjR1APw3MHDMkuV?usp=sharing)
We considered the following tasks and provided corresponding pretrained models. This page is for the `updown` task, and other model cards can be found in table below.
|Task | Description | Pretrained model |
| :------------- | :----------- | :-----------: |
| **Human feedback** | **given a context and its two human responses, predict...**|
| `updown` | ... which gets more upvotes? | this model |
| `width`| ... which gets more direct replies? | [model card](https://huggingface.co/microsoft/DialogRPT-width) |
| `depth`| ... which gets longer follow-up thread? | [model card](https://huggingface.co/microsoft/DialogRPT-depth) |
| **Human-like** (human vs fake) | **given a context and one human response, distinguish it with...** |
| `human_vs_rand`| ... a random human response | [model card](https://huggingface.co/microsoft/DialogRPT-human-vs-rand) |
| `human_vs_machine`| ... a machine generated response | [model card](https://huggingface.co/microsoft/DialogRPT-human-vs-machine) |
### Contact:
Please create an issue on [our repo](https://github.com/golsun/DialogRPT)
### Citation:
```
@inproceedings{gao2020dialogrpt,
title={Dialogue Response RankingTraining with Large-Scale Human Feedback Data},
author={Xiang Gao and Yizhe Zhang and Michel Galley and Chris Brockett and Bill Dolan},
year={2020},
booktitle={EMNLP}
}
```
|
mrm8488/bert-spanish-cased-finetuned-ner
|
b11721d41d9e948da32fcdabeeef4fb0f3ebcdf7
|
2021-05-20T00:35:25.000Z
|
[
"pytorch",
"jax",
"bert",
"token-classification",
"es",
"transformers",
"autotrain_compatible"
] |
token-classification
| false |
mrm8488
| null |
mrm8488/bert-spanish-cased-finetuned-ner
| 5,705 | 1 |
transformers
| 859 |
---
language: es
thumbnail: https://i.imgur.com/jgBdimh.png
---
# Spanish BERT (BETO) + NER
This model is a fine-tuned on [NER-C](https://www.kaggle.com/nltkdata/conll-corpora) version of the Spanish BERT cased [(BETO)](https://github.com/dccuchile/beto) for **NER** downstream task.
## Details of the downstream task (NER) - Dataset
- [Dataset: CONLL Corpora ES](https://www.kaggle.com/nltkdata/conll-corpora)
I preprocessed the dataset and split it as train / dev (80/20)
| Dataset | # Examples |
| ---------------------- | ----- |
| Train | 8.7 K |
| Dev | 2.2 K |
- [Fine-tune on NER script provided by Huggingface](https://github.com/huggingface/transformers/blob/master/examples/token-classification/run_ner_old.py)
- Labels covered:
```
B-LOC
B-MISC
B-ORG
B-PER
I-LOC
I-MISC
I-ORG
I-PER
O
```
## Metrics on evaluation set:
| Metric | # score |
| :------------------------------------------------------------------------------------: | :-------: |
| F1 | **90.17**
| Precision | **89.86** |
| Recall | **90.47** |
## Comparison:
| Model | # F1 score |Size(MB)|
| :--------------------------------------------------------------------------------------------------------------: | :-------: |:------|
| bert-base-spanish-wwm-cased (BETO) | 88.43 | 421
| [bert-spanish-cased-finetuned-ner (this one)](https://huggingface.co/mrm8488/bert-spanish-cased-finetuned-ner) | **90.17** | 420 |
| Best Multilingual BERT | 87.38 | 681 |
|[TinyBERT-spanish-uncased-finetuned-ner](https://huggingface.co/mrm8488/TinyBERT-spanish-uncased-finetuned-ner) | 70.00 | **55** |
## Model in action
Fast usage with **pipelines**:
```python
from transformers import pipeline
nlp_ner = pipeline(
"ner",
model="mrm8488/bert-spanish-cased-finetuned-ner",
tokenizer=(
'mrm8488/bert-spanish-cased-finetuned-ner',
{"use_fast": False}
))
text = 'Mis amigos están pensando viajar a Londres este verano'
nlp_ner(text)
#Output: [{'entity': 'B-LOC', 'score': 0.9998720288276672, 'word': 'Londres'}]
```
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
stas/tiny-wmt19-en-de
|
18ca8fc156edb91968dd4d70e33fbe5989d04368
|
2021-05-03T01:48:44.000Z
|
[
"pytorch",
"fsmt",
"text2text-generation",
"en",
"de",
"dataset:wmt19",
"transformers",
"wmt19",
"testing",
"license:apache-2.0",
"autotrain_compatible"
] |
text2text-generation
| false |
stas
| null |
stas/tiny-wmt19-en-de
| 5,674 | null |
transformers
| 860 |
---
language:
- en
- de
thumbnail:
tags:
- wmt19
- testing
license: apache-2.0
datasets:
- wmt19
metrics:
- bleu
---
# Tiny FSMT en-de
This is a tiny model that is used in the `transformers` test suite. It doesn't do anything useful, other than testing that `modeling_fsmt.py` is functional.
Do not try to use it for anything that requires quality.
The model is indeed 1MB in size.
You can see how it was created [here](https://huggingface.co/stas/tiny-wmt19-en-de/blob/main/fsmt-make-tiny-model.py).
If you're looking for the real model, please go to [https://huggingface.co/facebook/wmt19-en-de](https://huggingface.co/facebook/wmt19-en-de).
|
ktrapeznikov/albert-xlarge-v2-squad-v2
|
fb1e05445e376bdb883e8d4f6696a0acaf62e0ae
|
2020-12-11T21:48:41.000Z
|
[
"pytorch",
"albert",
"question-answering",
"transformers",
"autotrain_compatible"
] |
question-answering
| false |
ktrapeznikov
| null |
ktrapeznikov/albert-xlarge-v2-squad-v2
| 5,672 | 1 |
transformers
| 861 |
### Model
**[`albert-xlarge-v2`](https://huggingface.co/albert-xlarge-v2)** fine-tuned on **[`SQuAD V2`](https://rajpurkar.github.io/SQuAD-explorer/)** using **[`run_squad.py`](https://github.com/huggingface/transformers/blob/master/examples/question-answering/run_squad.py)**
### Training Parameters
Trained on 4 NVIDIA GeForce RTX 2080 Ti 11Gb
```bash
BASE_MODEL=albert-xlarge-v2
python run_squad.py \
--version_2_with_negative \
--model_type albert \
--model_name_or_path $BASE_MODEL \
--output_dir $OUTPUT_MODEL \
--do_eval \
--do_lower_case \
--train_file $SQUAD_DIR/train-v2.0.json \
--predict_file $SQUAD_DIR/dev-v2.0.json \
--per_gpu_train_batch_size 3 \
--per_gpu_eval_batch_size 64 \
--learning_rate 3e-5 \
--num_train_epochs 3.0 \
--max_seq_length 384 \
--doc_stride 128 \
--save_steps 2000 \
--threads 24 \
--warmup_steps 814 \
--gradient_accumulation_steps 4 \
--fp16 \
--do_train
```
### Evaluation
Evaluation on the dev set. I did not sweep for best threshold.
| | val |
|-------------------|-------------------|
| exact | 84.41842836688285 |
| f1 | 87.4628460501696 |
| total | 11873.0 |
| HasAns_exact | 80.68488529014844 |
| HasAns_f1 | 86.78245127423482 |
| HasAns_total | 5928.0 |
| NoAns_exact | 88.1412952060555 |
| NoAns_f1 | 88.1412952060555 |
| NoAns_total | 5945.0 |
| best_exact | 84.41842836688285 |
| best_exact_thresh | 0.0 |
| best_f1 | 87.46284605016956 |
| best_f1_thresh | 0.0 |
### Usage
See [huggingface documentation](https://huggingface.co/transformers/model_doc/albert.html#albertforquestionanswering). Training on `SQuAD V2` allows the model to score if a paragraph contains an answer:
```python
start_scores, end_scores = model(input_ids)
span_scores = start_scores.softmax(dim=1).log()[:,:,None] + end_scores.softmax(dim=1).log()[:,None,:]
ignore_score = span_scores[:,0,0] #no answer scores
```
|
yiyanghkust/finbert-pretrain
|
5b0dae12fea8ca5b3f256267ebe4e21786f3cfe5
|
2021-09-15T01:27:00.000Z
|
[
"pytorch",
"fill-mask",
"arxiv:2006.08097",
"transformers",
"autotrain_compatible"
] |
fill-mask
| false |
yiyanghkust
| null |
yiyanghkust/finbert-pretrain
| 5,672 | 6 |
transformers
| 862 |
`FinBERT` is a BERT model pre-trained on financial communication text. The purpose is to enhance financial NLP research and practice. It is trained on the following three financial communication corpus. The total corpora size is 4.9B tokens.
- Corporate Reports 10-K & 10-Q: 2.5B tokens
- Earnings Call Transcripts: 1.3B tokens
- Analyst Reports: 1.1B tokens
More details on `FinBERT`'s pre-training process can be found at: https://arxiv.org/abs/2006.08097
`FinBERT` can be further fine-tuned on downstream tasks. Specifically, we have fine-tuned `FinBERT` on an analyst sentiment classification task, and the fine-tuned model is shared at https://huggingface.co/yiyanghkust/finbert-tone
|
cointegrated/roberta-large-cola-krishna2020
|
8386814a366a824280df5690a810fe038d7a270b
|
2021-11-11T05:13:52.000Z
|
[
"pytorch",
"roberta",
"text-classification",
"arxiv:2010.05700",
"transformers"
] |
text-classification
| false |
cointegrated
| null |
cointegrated/roberta-large-cola-krishna2020
| 5,642 | 1 |
transformers
| 863 |
This is a RoBERTa-large classifier trained on the CoLA corpus [Warstadt et al., 2019](https://www.mitpressjournals.org/doi/pdf/10.1162/tacl_a_00290),
which contains sentences paired with grammatical acceptability judgments. The model can be used to evaluate fluency of machine-generated English sentences, e.g. for evaluation of text style transfer.
The model was trained in the paper [Krishna et al, 2020. Reformulating Unsupervised Style Transfer as Paraphrase Generation](https://arxiv.org/abs/2010.05700), and its original version is available at [their project page](http://style.cs.umass.edu). We converted this model from Fairseq to Transformers format. All credit goes to the authors of the original paper.
## Citation
If you found this model useful and refer to it, please cite the original work:
```
@inproceedings{style20,
author={Kalpesh Krishna and John Wieting and Mohit Iyyer},
Booktitle = {Empirical Methods in Natural Language Processing},
Year = "2020",
Title={Reformulating Unsupervised Style Transfer as Paraphrase Generation},
}
```
|
vblagoje/dpr-ctx_encoder-single-lfqa-wiki
|
8b412d76cb82502888936bce86775a81f454c398
|
2022-02-14T15:51:28.000Z
|
[
"pytorch",
"dpr",
"en",
"dataset:vblagoje/lfqa",
"transformers",
"license:mit"
] | null | false |
vblagoje
| null |
vblagoje/dpr-ctx_encoder-single-lfqa-wiki
| 5,617 | 1 |
transformers
| 864 |
---
language: en
datasets:
- vblagoje/lfqa
license: mit
---
## Introduction
The context/passage encoder model based on [DPRContextEncoder](https://huggingface.co/docs/transformers/master/en/model_doc/dpr#transformers.DPRContextEncoder) architecture. It uses the transformer's pooler outputs as context/passage representations. See [blog post](https://towardsdatascience.com/long-form-qa-beyond-eli5-an-updated-dataset-and-approach-319cb841aabb) for more details.
## Training
We trained vblagoje/dpr-ctx_encoder-single-lfqa-wiki using FAIR's dpr-scale in two stages. In the first stage, we used PAQ based pretrained checkpoint and fine-tuned the retriever on the question-answer pairs from the LFQA dataset. As dpr-scale requires DPR formatted training set input with positive, negative, and hard negative samples - we created a training file with an answer being positive, negatives being question unrelated answers, while hard negative samples were chosen from answers on questions between 0.55 and 0.65 of cosine similarity. In the second stage, we created a new DPR training set using positives, negatives, and hard negatives from the Wikipedia/Faiss index created in the first stage instead of LFQA dataset answers. More precisely, for each dataset question, we queried the first stage Wikipedia Faiss index and subsequently used SBert cross-encoder to score questions/answers (passage) pairs with topk=50. The cross-encoder selected the positive passage with the highest score, while the bottom seven answers were selected for hard-negatives. Negative samples were again chosen to be answers unrelated to a given dataset question. After creating a DPR formatted training file with Wikipedia sourced positive, negative, and hard negative passages, we trained DPR-based question/passage encoders using dpr-scale.
## Performance
LFQA DPR-based retriever (vblagoje/dpr-question_encoder-single-lfqa-wiki and vblagoje/dpr-ctx_encoder-single-lfqa-wiki) slightly underperform 'state-of-the-art' Krishna et al. "Hurdles to Progress in Long-form Question Answering" REALM based retriever with KILT benchmark performance of 11.2 for R-precision and 19.5 for Recall@5.
## Usage
```python
from transformers import DPRContextEncoder, DPRContextEncoderTokenizer
tokenizer = DPRContextEncoderTokenizer.from_pretrained("vblagoje/dpr-ctx_encoder-single-lfqa-wiki")
model = DPRContextEncoder.from_pretrained("vblagoje/dpr-ctx_encoder-single-lfqa-wiki")
input_ids = tokenizer("Where an aircraft passes through a cloud, it can disperse the cloud in its path...", return_tensors="pt")["input_ids"]
embeddings = model(input_ids).pooler_output
```
## Author
- Vladimir Blagojevic: `dovlex [at] gmail.com` [Twitter](https://twitter.com/vladblagoje) | [LinkedIn](https://www.linkedin.com/in/blagojevicvladimir/)
|
Helsinki-NLP/opus-mt-en-ar
|
12f7bc254b7e475b6377f440d488063d7fb51571
|
2021-02-28T14:15:11.000Z
|
[
"pytorch",
"rust",
"marian",
"text2text-generation",
"en",
"ar",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] |
translation
| false |
Helsinki-NLP
| null |
Helsinki-NLP/opus-mt-en-ar
| 5,575 | 5 |
transformers
| 865 |
---
language:
- en
- ar
tags:
- translation
license: apache-2.0
---
### eng-ara
* source group: English
* target group: Arabic
* OPUS readme: [eng-ara](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/eng-ara/README.md)
* model: transformer
* source language(s): eng
* target language(s): acm afb apc apc_Latn ara ara_Latn arq arq_Latn ary arz
* model: transformer
* pre-processing: normalization + SentencePiece (spm32k,spm32k)
* a sentence initial language token is required in the form of `>>id<<` (id = valid target language ID)
* download original weights: [opus-2020-07-03.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-ara/opus-2020-07-03.zip)
* test set translations: [opus-2020-07-03.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-ara/opus-2020-07-03.test.txt)
* test set scores: [opus-2020-07-03.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-ara/opus-2020-07-03.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba-test.eng.ara | 14.0 | 0.437 |
### System Info:
- hf_name: eng-ara
- source_languages: eng
- target_languages: ara
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/eng-ara/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['en', 'ar']
- src_constituents: {'eng'}
- tgt_constituents: {'apc', 'ara', 'arq_Latn', 'arq', 'afb', 'ara_Latn', 'apc_Latn', 'arz'}
- src_multilingual: False
- tgt_multilingual: False
- prepro: normalization + SentencePiece (spm32k,spm32k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/eng-ara/opus-2020-07-03.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/eng-ara/opus-2020-07-03.test.txt
- src_alpha3: eng
- tgt_alpha3: ara
- short_pair: en-ar
- chrF2_score: 0.43700000000000006
- bleu: 14.0
- brevity_penalty: 1.0
- ref_len: 58935.0
- src_name: English
- tgt_name: Arabic
- train_date: 2020-07-03
- src_alpha2: en
- tgt_alpha2: ar
- prefer_old: False
- long_pair: eng-ara
- helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535
- transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b
- port_machine: brutasse
- port_time: 2020-08-21-14:41
|
allenai/led-large-16384-arxiv
|
6d566f57e58195c1810dd8497ccf7f015409a1a9
|
2021-01-12T23:14:11.000Z
|
[
"pytorch",
"tf",
"led",
"text2text-generation",
"en",
"dataset:scientific_papers",
"arxiv:2004.05150",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] |
text2text-generation
| false |
allenai
| null |
allenai/led-large-16384-arxiv
| 5,570 | 4 |
transformers
| 866 |
---
language: en
datasets:
- scientific_papers
license: apache-2.0
---
## Introduction
[Allenai's Longformer Encoder-Decoder (LED)](https://github.com/allenai/longformer#longformer).
This is the official *led-large-16384* checkpoint that is fine-tuned on the arXiv dataset.*led-large-16384-arxiv* is the official fine-tuned version of [led-large-16384](https://huggingface.co/allenai/led-large-16384). As presented in the [paper](https://arxiv.org/pdf/2004.05150.pdf), the checkpoint achieves state-of-the-art results on arxiv
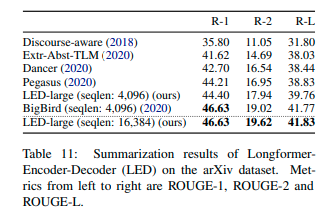
## Evaluation on downstream task
[This notebook](https://colab.research.google.com/drive/12INTTR6n64TzS4RrXZxMSXfrOd9Xzamo?usp=sharing) shows how *led-large-16384-arxiv* can be evaluated on the [arxiv dataset](https://huggingface.co/datasets/scientific_papers)
## Usage
The model can be used as follows. The input is taken from the test data of the [arxiv dataset](https://huggingface.co/datasets/scientific_papers).
```python
LONG_ARTICLE = """"for about 20 years the problem of properties of
short - term changes of solar activity has been
considered extensively . many investigators
studied the short - term periodicities of the
various indices of solar activity . several
periodicities were detected , but the
periodicities about 155 days and from the interval
of @xmath3 $ ] days ( @xmath4 $ ] years ) are
mentioned most often . first of them was
discovered by @xcite in the occurence rate of
gamma - ray flares detected by the gamma - ray
spectrometer aboard the _ solar maximum mission (
smm ) . this periodicity was confirmed for other
solar flares data and for the same time period
@xcite . it was also found in proton flares during
solar cycles 19 and 20 @xcite , but it was not
found in the solar flares data during solar cycles
22 @xcite . _ several autors confirmed above
results for the daily sunspot area data . @xcite
studied the sunspot data from 18741984 . she found
the 155-day periodicity in data records from 31
years . this periodicity is always characteristic
for one of the solar hemispheres ( the southern
hemisphere for cycles 1215 and the northern
hemisphere for cycles 1621 ) . moreover , it is
only present during epochs of maximum activity (
in episodes of 13 years ) .
similarinvestigationswerecarriedoutby + @xcite .
they applied the same power spectrum method as
lean , but the daily sunspot area data ( cycles
1221 ) were divided into 10 shorter time series .
the periodicities were searched for the frequency
interval 57115 nhz ( 100200 days ) and for each of
10 time series . the authors showed that the
periodicity between 150160 days is statistically
significant during all cycles from 16 to 21 . the
considered peaks were remained unaltered after
removing the 11-year cycle and applying the power
spectrum analysis . @xcite used the wavelet
technique for the daily sunspot areas between 1874
and 1993 . they determined the epochs of
appearance of this periodicity and concluded that
it presents around the maximum activity period in
cycles 16 to 21 . moreover , the power of this
periodicity started growing at cycle 19 ,
decreased in cycles 20 and 21 and disappered after
cycle 21 . similaranalyseswerepresentedby + @xcite
, but for sunspot number , solar wind plasma ,
interplanetary magnetic field and geomagnetic
activity index @xmath5 . during 1964 - 2000 the
sunspot number wavelet power of periods less than
one year shows a cyclic evolution with the phase
of the solar cycle.the 154-day period is prominent
and its strenth is stronger around the 1982 - 1984
interval in almost all solar wind parameters . the
existence of the 156-day periodicity in sunspot
data were confirmed by @xcite . they considered
the possible relation between the 475-day (
1.3-year ) and 156-day periodicities . the 475-day
( 1.3-year ) periodicity was also detected in
variations of the interplanetary magnetic field ,
geomagnetic activity helioseismic data and in the
solar wind speed @xcite . @xcite concluded that
the region of larger wavelet power shifts from
475-day ( 1.3-year ) period to 620-day ( 1.7-year
) period and then back to 475-day ( 1.3-year ) .
the periodicities from the interval @xmath6 $ ]
days ( @xmath4 $ ] years ) have been considered
from 1968 . @xcite mentioned a 16.3-month (
490-day ) periodicity in the sunspot numbers and
in the geomagnetic data . @xcite analysed the
occurrence rate of major flares during solar
cycles 19 . they found a 18-month ( 540-day )
periodicity in flare rate of the norhern
hemisphere . @xcite confirmed this result for the
@xmath7 flare data for solar cycles 20 and 21 and
found a peak in the power spectra near 510540 days
. @xcite found a 17-month ( 510-day ) periodicity
of sunspot groups and their areas from 1969 to
1986 . these authors concluded that the length of
this period is variable and the reason of this
periodicity is still not understood . @xcite and +
@xcite obtained statistically significant peaks of
power at around 158 days for daily sunspot data
from 1923 - 1933 ( cycle 16 ) . in this paper the
problem of the existence of this periodicity for
sunspot data from cycle 16 is considered . the
daily sunspot areas , the mean sunspot areas per
carrington rotation , the monthly sunspot numbers
and their fluctuations , which are obtained after
removing the 11-year cycle are analysed . in
section 2 the properties of the power spectrum
methods are described . in section 3 a new
approach to the problem of aliases in the power
spectrum analysis is presented . in section 4
numerical results of the new method of the
diagnosis of an echo - effect for sunspot area
data are discussed . in section 5 the problem of
the existence of the periodicity of about 155 days
during the maximum activity period for sunspot
data from the whole solar disk and from each solar
hemisphere separately is considered . to find
periodicities in a given time series the power
spectrum analysis is applied . in this paper two
methods are used : the fast fourier transformation
algorithm with the hamming window function ( fft )
and the blackman - tukey ( bt ) power spectrum
method @xcite . the bt method is used for the
diagnosis of the reasons of the existence of peaks
, which are obtained by the fft method . the bt
method consists in the smoothing of a cosine
transform of an autocorrelation function using a
3-point weighting average . such an estimator is
consistent and unbiased . moreover , the peaks are
uncorrelated and their sum is a variance of a
considered time series . the main disadvantage of
this method is a weak resolution of the
periodogram points , particularly for low
frequences . for example , if the autocorrelation
function is evaluated for @xmath8 , then the
distribution points in the time domain are :
@xmath9 thus , it is obvious that this method
should not be used for detecting low frequency
periodicities with a fairly good resolution .
however , because of an application of the
autocorrelation function , the bt method can be
used to verify a reality of peaks which are
computed using a method giving the better
resolution ( for example the fft method ) . it is
valuable to remember that the power spectrum
methods should be applied very carefully . the
difficulties in the interpretation of significant
peaks could be caused by at least four effects : a
sampling of a continuos function , an echo -
effect , a contribution of long - term
periodicities and a random noise . first effect
exists because periodicities , which are shorter
than the sampling interval , may mix with longer
periodicities . in result , this effect can be
reduced by an decrease of the sampling interval
between observations . the echo - effect occurs
when there is a latent harmonic of frequency
@xmath10 in the time series , giving a spectral
peak at @xmath10 , and also periodic terms of
frequency @xmath11 etc . this may be detected by
the autocorrelation function for time series with
a large variance . time series often contain long
- term periodicities , that influence short - term
peaks . they could rise periodogram s peaks at
lower frequencies . however , it is also easy to
notice the influence of the long - term
periodicities on short - term peaks in the graphs
of the autocorrelation functions . this effect is
observed for the time series of solar activity
indexes which are limited by the 11-year cycle .
to find statistically significant periodicities it
is reasonable to use the autocorrelation function
and the power spectrum method with a high
resolution . in the case of a stationary time
series they give similar results . moreover , for
a stationary time series with the mean zero the
fourier transform is equivalent to the cosine
transform of an autocorrelation function @xcite .
thus , after a comparison of a periodogram with an
appropriate autocorrelation function one can
detect peaks which are in the graph of the first
function and do not exist in the graph of the
second function . the reasons of their existence
could be explained by the long - term
periodicities and the echo - effect . below method
enables one to detect these effects . ( solid line
) and the 95% confidence level basing on thered
noise ( dotted line ) . the periodogram values are
presented on the left axis . the lower curve
illustrates the autocorrelation function of the
same time series ( solid line ) . the dotted lines
represent two standard errors of the
autocorrelation function . the dashed horizontal
line shows the zero level . the autocorrelation
values are shown in the right axis . ] because
the statistical tests indicate that the time
series is a white noise the confidence level is
not marked . ] . ] the method of the diagnosis
of an echo - effect in the power spectrum ( de )
consists in an analysis of a periodogram of a
given time series computed using the bt method .
the bt method bases on the cosine transform of the
autocorrelation function which creates peaks which
are in the periodogram , but not in the
autocorrelation function . the de method is used
for peaks which are computed by the fft method (
with high resolution ) and are statistically
significant . the time series of sunspot activity
indexes with the spacing interval one rotation or
one month contain a markov - type persistence ,
which means a tendency for the successive values
of the time series to remember their antecendent
values . thus , i use a confidence level basing on
the red noise of markov @xcite for the choice of
the significant peaks of the periodogram computed
by the fft method . when a time series does not
contain the markov - type persistence i apply the
fisher test and the kolmogorov - smirnov test at
the significance level @xmath12 @xcite to verify a
statistically significance of periodograms peaks .
the fisher test checks the null hypothesis that
the time series is white noise agains the
alternative hypothesis that the time series
contains an added deterministic periodic component
of unspecified frequency . because the fisher test
tends to be severe in rejecting peaks as
insignificant the kolmogorov - smirnov test is
also used . the de method analyses raw estimators
of the power spectrum . they are given as follows
@xmath13 for @xmath14 + where @xmath15 for
@xmath16 + @xmath17 is the length of the time
series @xmath18 and @xmath19 is the mean value .
the first term of the estimator @xmath20 is
constant . the second term takes two values (
depending on odd or even @xmath21 ) which are not
significant because @xmath22 for large m. thus ,
the third term of ( 1 ) should be analysed .
looking for intervals of @xmath23 for which
@xmath24 has the same sign and different signs one
can find such parts of the function @xmath25 which
create the value @xmath20 . let the set of values
of the independent variable of the autocorrelation
function be called @xmath26 and it can be divided
into the sums of disjoint sets : @xmath27 where +
@xmath28 + @xmath29 @xmath30 @xmath31 + @xmath32 +
@xmath33 @xmath34 @xmath35 @xmath36 @xmath37
@xmath38 @xmath39 @xmath40 well , the set
@xmath41 contains all integer values of @xmath23
from the interval of @xmath42 for which the
autocorrelation function and the cosinus function
with the period @xmath43 $ ] are positive . the
index @xmath44 indicates successive parts of the
cosinus function for which the cosinuses of
successive values of @xmath23 have the same sign .
however , sometimes the set @xmath41 can be empty
. for example , for @xmath45 and @xmath46 the set
@xmath47 should contain all @xmath48 $ ] for which
@xmath49 and @xmath50 , but for such values of
@xmath23 the values of @xmath51 are negative .
thus , the set @xmath47 is empty . . the
periodogram values are presented on the left axis
. the lower curve illustrates the autocorrelation
function of the same time series . the
autocorrelation values are shown in the right axis
. ] let us take into consideration all sets
\{@xmath52 } , \{@xmath53 } and \{@xmath41 } which
are not empty . because numberings and power of
these sets depend on the form of the
autocorrelation function of the given time series
, it is impossible to establish them arbitrary .
thus , the sets of appropriate indexes of the sets
\{@xmath52 } , \{@xmath53 } and \{@xmath41 } are
called @xmath54 , @xmath55 and @xmath56
respectively . for example the set @xmath56
contains all @xmath44 from the set @xmath57 for
which the sets @xmath41 are not empty . to
separate quantitatively in the estimator @xmath20
the positive contributions which are originated by
the cases described by the formula ( 5 ) from the
cases which are described by the formula ( 3 ) the
following indexes are introduced : @xmath58
@xmath59 @xmath60 @xmath61 where @xmath62 @xmath63
@xmath64 taking for the empty sets \{@xmath53 }
and \{@xmath41 } the indices @xmath65 and @xmath66
equal zero . the index @xmath65 describes a
percentage of the contribution of the case when
@xmath25 and @xmath51 are positive to the positive
part of the third term of the sum ( 1 ) . the
index @xmath66 describes a similar contribution ,
but for the case when the both @xmath25 and
@xmath51 are simultaneously negative . thanks to
these one can decide which the positive or the
negative values of the autocorrelation function
have a larger contribution to the positive values
of the estimator @xmath20 . when the difference
@xmath67 is positive , the statement the
@xmath21-th peak really exists can not be rejected
. thus , the following formula should be satisfied
: @xmath68 because the @xmath21-th peak could
exist as a result of the echo - effect , it is
necessary to verify the second condition :
@xmath69\in c_m.\ ] ] . the periodogram values
are presented on the left axis . the lower curve
illustrates the autocorrelation function of the
same time series ( solid line ) . the dotted lines
represent two standard errors of the
autocorrelation function . the dashed horizontal
line shows the zero level . the autocorrelation
values are shown in the right axis . ] to
verify the implication ( 8) firstly it is
necessary to evaluate the sets @xmath41 for
@xmath70 of the values of @xmath23 for which the
autocorrelation function and the cosine function
with the period @xmath71 $ ] are positive and the
sets @xmath72 of values of @xmath23 for which the
autocorrelation function and the cosine function
with the period @xmath43 $ ] are negative .
secondly , a percentage of the contribution of the
sum of products of positive values of @xmath25 and
@xmath51 to the sum of positive products of the
values of @xmath25 and @xmath51 should be
evaluated . as a result the indexes @xmath65 for
each set @xmath41 where @xmath44 is the index from
the set @xmath56 are obtained . thirdly , from all
sets @xmath41 such that @xmath70 the set @xmath73
for which the index @xmath65 is the greatest
should be chosen . the implication ( 8) is true
when the set @xmath73 includes the considered
period @xmath43 $ ] . this means that the greatest
contribution of positive values of the
autocorrelation function and positive cosines with
the period @xmath43 $ ] to the periodogram value
@xmath20 is caused by the sum of positive products
of @xmath74 for each @xmath75-\frac{m}{2k},[\frac{
2m}{k}]+\frac{m}{2k})$ ] . when the implication
( 8) is false , the peak @xmath20 is mainly
created by the sum of positive products of
@xmath74 for each @xmath76-\frac{m}{2k},\big [
\frac{2m}{n}\big ] + \frac{m}{2k } \big ) $ ] ,
where @xmath77 is a multiple or a divisor of
@xmath21 . it is necessary to add , that the de
method should be applied to the periodograms peaks
, which probably exist because of the echo -
effect . it enables one to find such parts of the
autocorrelation function , which have the
significant contribution to the considered peak .
the fact , that the conditions ( 7 ) and ( 8) are
satisfied , can unambiguously decide about the
existence of the considered periodicity in the
given time series , but if at least one of them is
not satisfied , one can doubt about the existence
of the considered periodicity . thus , in such
cases the sentence the peak can not be treated as
true should be used . using the de method it is
necessary to remember about the power of the set
@xmath78 . if @xmath79 is too large , errors of an
autocorrelation function estimation appear . they
are caused by the finite length of the given time
series and as a result additional peaks of the
periodogram occur . if @xmath79 is too small ,
there are less peaks because of a low resolution
of the periodogram . in applications @xmath80 is
used . in order to evaluate the value @xmath79 the
fft method is used . the periodograms computed by
the bt and the fft method are compared . the
conformity of them enables one to obtain the value
@xmath79 . . the fft periodogram values are
presented on the left axis . the lower curve
illustrates the bt periodogram of the same time
series ( solid line and large black circles ) .
the bt periodogram values are shown in the right
axis . ] in this paper the sunspot activity data (
august 1923 - october 1933 ) provided by the
greenwich photoheliographic results ( gpr ) are
analysed . firstly , i consider the monthly
sunspot number data . to eliminate the 11-year
trend from these data , the consecutively smoothed
monthly sunspot number @xmath81 is subtracted from
the monthly sunspot number @xmath82 where the
consecutive mean @xmath83 is given by @xmath84 the
values @xmath83 for @xmath85 and @xmath86 are
calculated using additional data from last six
months of cycle 15 and first six months of cycle
17 . because of the north - south asymmetry of
various solar indices @xcite , the sunspot
activity is considered for each solar hemisphere
separately . analogously to the monthly sunspot
numbers , the time series of sunspot areas in the
northern and southern hemispheres with the spacing
interval @xmath87 rotation are denoted . in order
to find periodicities , the following time series
are used : + @xmath88 + @xmath89 + @xmath90
+ in the lower part of figure [ f1 ] the
autocorrelation function of the time series for
the northern hemisphere @xmath88 is shown . it is
easy to notice that the prominent peak falls at 17
rotations interval ( 459 days ) and @xmath25 for
@xmath91 $ ] rotations ( [ 81 , 162 ] days ) are
significantly negative . the periodogram of the
time series @xmath88 ( see the upper curve in
figures [ f1 ] ) does not show the significant
peaks at @xmath92 rotations ( 135 , 162 days ) ,
but there is the significant peak at @xmath93 (
243 days ) . the peaks at @xmath94 are close to
the peaks of the autocorrelation function . thus ,
the result obtained for the periodicity at about
@xmath0 days are contradict to the results
obtained for the time series of daily sunspot
areas @xcite . for the southern hemisphere (
the lower curve in figure [ f2 ] ) @xmath25 for
@xmath95 $ ] rotations ( [ 54 , 189 ] days ) is
not positive except @xmath96 ( 135 days ) for
which @xmath97 is not statistically significant .
the upper curve in figures [ f2 ] presents the
periodogram of the time series @xmath89 . this
time series does not contain a markov - type
persistence . moreover , the kolmogorov - smirnov
test and the fisher test do not reject a null
hypothesis that the time series is a white noise
only . this means that the time series do not
contain an added deterministic periodic component
of unspecified frequency . the autocorrelation
function of the time series @xmath90 ( the lower
curve in figure [ f3 ] ) has only one
statistically significant peak for @xmath98 months
( 480 days ) and negative values for @xmath99 $ ]
months ( [ 90 , 390 ] days ) . however , the
periodogram of this time series ( the upper curve
in figure [ f3 ] ) has two significant peaks the
first at 15.2 and the second at 5.3 months ( 456 ,
159 days ) . thus , the periodogram contains the
significant peak , although the autocorrelation
function has the negative value at @xmath100
months . to explain these problems two
following time series of daily sunspot areas are
considered : + @xmath101 + @xmath102 + where
@xmath103 the values @xmath104 for @xmath105
and @xmath106 are calculated using additional
daily data from the solar cycles 15 and 17 .
and the cosine function for @xmath45 ( the period
at about 154 days ) . the horizontal line ( dotted
line ) shows the zero level . the vertical dotted
lines evaluate the intervals where the sets
@xmath107 ( for @xmath108 ) are searched . the
percentage values show the index @xmath65 for each
@xmath41 for the time series @xmath102 ( in
parentheses for the time series @xmath101 ) . in
the right bottom corner the values of @xmath65 for
the time series @xmath102 , for @xmath109 are
written . ] ( the 500-day period ) ] the
comparison of the functions @xmath25 of the time
series @xmath101 ( the lower curve in figure [ f4
] ) and @xmath102 ( the lower curve in figure [ f5
] ) suggests that the positive values of the
function @xmath110 of the time series @xmath101 in
the interval of @xmath111 $ ] days could be caused
by the 11-year cycle . this effect is not visible
in the case of periodograms of the both time
series computed using the fft method ( see the
upper curves in figures [ f4 ] and [ f5 ] ) or the
bt method ( see the lower curve in figure [ f6 ] )
. moreover , the periodogram of the time series
@xmath102 has the significant values at @xmath112
days , but the autocorrelation function is
negative at these points . @xcite showed that the
lomb - scargle periodograms for the both time
series ( see @xcite , figures 7 a - c ) have a
peak at 158.8 days which stands over the fap level
by a significant amount . using the de method the
above discrepancies are obvious . to establish the
@xmath79 value the periodograms computed by the
fft and the bt methods are shown in figure [ f6 ]
( the upper and the lower curve respectively ) .
for @xmath46 and for periods less than 166 days
there is a good comformity of the both
periodograms ( but for periods greater than 166
days the points of the bt periodogram are not
linked because the bt periodogram has much worse
resolution than the fft periodogram ( no one know
how to do it ) ) . for @xmath46 and @xmath113 the
value of @xmath21 is 13 ( @xmath71=153 $ ] ) . the
inequality ( 7 ) is satisfied because @xmath114 .
this means that the value of @xmath115 is mainly
created by positive values of the autocorrelation
function . the implication ( 8) needs an
evaluation of the greatest value of the index
@xmath65 where @xmath70 , but the solar data
contain the most prominent period for @xmath116
days because of the solar rotation . thus ,
although @xmath117 for each @xmath118 , all sets
@xmath41 ( see ( 5 ) and ( 6 ) ) without the set
@xmath119 ( see ( 4 ) ) , which contains @xmath120
$ ] , are considered . this situation is presented
in figure [ f7 ] . in this figure two curves
@xmath121 and @xmath122 are plotted . the vertical
dotted lines evaluate the intervals where the sets
@xmath107 ( for @xmath123 ) are searched . for
such @xmath41 two numbers are written : in
parentheses the value of @xmath65 for the time
series @xmath101 and above it the value of
@xmath65 for the time series @xmath102 . to make
this figure clear the curves are plotted for the
set @xmath124 only . ( in the right bottom corner
information about the values of @xmath65 for the
time series @xmath102 , for @xmath109 are written
. ) the implication ( 8) is not true , because
@xmath125 for @xmath126 . therefore ,
@xmath43=153\notin c_6=[423,500]$ ] . moreover ,
the autocorrelation function for @xmath127 $ ] is
negative and the set @xmath128 is empty . thus ,
@xmath129 . on the basis of these information one
can state , that the periodogram peak at @xmath130
days of the time series @xmath102 exists because
of positive @xmath25 , but for @xmath23 from the
intervals which do not contain this period .
looking at the values of @xmath65 of the time
series @xmath101 , one can notice that they
decrease when @xmath23 increases until @xmath131 .
this indicates , that when @xmath23 increases ,
the contribution of the 11-year cycle to the peaks
of the periodogram decreases . an increase of the
value of @xmath65 is for @xmath132 for the both
time series , although the contribution of the
11-year cycle for the time series @xmath101 is
insignificant . thus , this part of the
autocorrelation function ( @xmath133 for the time
series @xmath102 ) influences the @xmath21-th peak
of the periodogram . this suggests that the
periodicity at about 155 days is a harmonic of the
periodicity from the interval of @xmath1 $ ] days
. ( solid line ) and consecutively smoothed
sunspot areas of the one rotation time interval
@xmath134 ( dotted line ) . both indexes are
presented on the left axis . the lower curve
illustrates fluctuations of the sunspot areas
@xmath135 . the dotted and dashed horizontal lines
represent levels zero and @xmath136 respectively .
the fluctuations are shown on the right axis . ]
the described reasoning can be carried out for
other values of the periodogram . for example ,
the condition ( 8) is not satisfied for @xmath137
( 250 , 222 , 200 days ) . moreover , the
autocorrelation function at these points is
negative . these suggest that there are not a true
periodicity in the interval of [ 200 , 250 ] days
. it is difficult to decide about the existence of
the periodicities for @xmath138 ( 333 days ) and
@xmath139 ( 286 days ) on the basis of above
analysis . the implication ( 8) is not satisfied
for @xmath139 and the condition ( 7 ) is not
satisfied for @xmath138 , although the function
@xmath25 of the time series @xmath102 is
significantly positive for @xmath140 . the
conditions ( 7 ) and ( 8) are satisfied for
@xmath141 ( figure [ f8 ] ) and @xmath142 .
therefore , it is possible to exist the
periodicity from the interval of @xmath1 $ ] days
. similar results were also obtained by @xcite for
daily sunspot numbers and daily sunspot areas .
she considered the means of three periodograms of
these indexes for data from @xmath143 years and
found statistically significant peaks from the
interval of @xmath1 $ ] ( see @xcite , figure 2 )
. @xcite studied sunspot areas from 1876 - 1999
and sunspot numbers from 1749 - 2001 with the help
of the wavelet transform . they pointed out that
the 154 - 158-day period could be the third
harmonic of the 1.3-year ( 475-day ) period .
moreover , the both periods fluctuate considerably
with time , being stronger during stronger sunspot
cycles . therefore , the wavelet analysis suggests
a common origin of the both periodicities . this
conclusion confirms the de method result which
indicates that the periodogram peak at @xmath144
days is an alias of the periodicity from the
interval of @xmath1 $ ] in order to verify the
existence of the periodicity at about 155 days i
consider the following time series : + @xmath145
+ @xmath146 + @xmath147 + the value @xmath134
is calculated analogously to @xmath83 ( see sect .
the values @xmath148 and @xmath149 are evaluated
from the formula ( 9 ) . in the upper part of
figure [ f9 ] the time series of sunspot areas
@xmath150 of the one rotation time interval from
the whole solar disk and the time series of
consecutively smoothed sunspot areas @xmath151 are
showed . in the lower part of figure [ f9 ] the
time series of sunspot area fluctuations @xmath145
is presented . on the basis of these data the
maximum activity period of cycle 16 is evaluated .
it is an interval between two strongest
fluctuations e.a . @xmath152 $ ] rotations . the
length of the time interval @xmath153 is 54
rotations . if the about @xmath0-day ( 6 solar
rotations ) periodicity existed in this time
interval and it was characteristic for strong
fluctuations from this time interval , 10 local
maxima in the set of @xmath154 would be seen .
then it should be necessary to find such a value
of p for which @xmath155 for @xmath156 and the
number of the local maxima of these values is 10 .
as it can be seen in the lower part of figure [ f9
] this is for the case of @xmath157 ( in this
figure the dashed horizontal line is the level of
@xmath158 ) . figure [ f10 ] presents nine time
distances among the successive fluctuation local
maxima and the horizontal line represents the
6-rotation periodicity . it is immediately
apparent that the dispersion of these points is 10
and it is difficult to find even few points which
oscillate around the value of 6 . such an analysis
was carried out for smaller and larger @xmath136
and the results were similar . therefore , the
fact , that the about @xmath0-day periodicity
exists in the time series of sunspot area
fluctuations during the maximum activity period is
questionable . . the horizontal line represents
the 6-rotation ( 162-day ) period . ] ] ]
to verify again the existence of the about
@xmath0-day periodicity during the maximum
activity period in each solar hemisphere
separately , the time series @xmath88 and @xmath89
were also cut down to the maximum activity period
( january 1925december 1930 ) . the comparison of
the autocorrelation functions of these time series
with the appriopriate autocorrelation functions of
the time series @xmath88 and @xmath89 , which are
computed for the whole 11-year cycle ( the lower
curves of figures [ f1 ] and [ f2 ] ) , indicates
that there are not significant differences between
them especially for @xmath23=5 and 6 rotations (
135 and 162 days ) ) . this conclusion is
confirmed by the analysis of the time series
@xmath146 for the maximum activity period . the
autocorrelation function ( the lower curve of
figure [ f11 ] ) is negative for the interval of [
57 , 173 ] days , but the resolution of the
periodogram is too low to find the significant
peak at @xmath159 days . the autocorrelation
function gives the same result as for daily
sunspot area fluctuations from the whole solar
disk ( @xmath160 ) ( see also the lower curve of
figures [ f5 ] ) . in the case of the time series
@xmath89 @xmath161 is zero for the fluctuations
from the whole solar cycle and it is almost zero (
@xmath162 ) for the fluctuations from the maximum
activity period . the value @xmath163 is negative
. similarly to the case of the northern hemisphere
the autocorrelation function and the periodogram
of southern hemisphere daily sunspot area
fluctuations from the maximum activity period
@xmath147 are computed ( see figure [ f12 ] ) .
the autocorrelation function has the statistically
significant positive peak in the interval of [ 155
, 165 ] days , but the periodogram has too low
resolution to decide about the possible
periodicities . the correlative analysis indicates
that there are positive fluctuations with time
distances about @xmath0 days in the maximum
activity period . the results of the analyses of
the time series of sunspot area fluctuations from
the maximum activity period are contradict with
the conclusions of @xcite . she uses the power
spectrum analysis only . the periodogram of daily
sunspot fluctuations contains peaks , which could
be harmonics or subharmonics of the true
periodicities . they could be treated as real
periodicities . this effect is not visible for
sunspot data of the one rotation time interval ,
but averaging could lose true periodicities . this
is observed for data from the southern hemisphere
. there is the about @xmath0-day peak in the
autocorrelation function of daily fluctuations ,
but the correlation for data of the one rotation
interval is almost zero or negative at the points
@xmath164 and 6 rotations . thus , it is
reasonable to research both time series together
using the correlative and the power spectrum
analyses . the following results are obtained :
1 . a new method of the detection of statistically
significant peaks of the periodograms enables one
to identify aliases in the periodogram . 2 . two
effects cause the existence of the peak of the
periodogram of the time series of sunspot area
fluctuations at about @xmath0 days : the first is
caused by the 27-day periodicity , which probably
creates the 162-day periodicity ( it is a
subharmonic frequency of the 27-day periodicity )
and the second is caused by statistically
significant positive values of the autocorrelation
function from the intervals of @xmath165 $ ] and
@xmath166 $ ] days . the existence of the
periodicity of about @xmath0 days of the time
series of sunspot area fluctuations and sunspot
area fluctuations from the northern hemisphere
during the maximum activity period is questionable
. the autocorrelation analysis of the time series
of sunspot area fluctuations from the southern
hemisphere indicates that the periodicity of about
155 days exists during the maximum activity period
. i appreciate valuable comments from professor j.
jakimiec ."""
from transformers import LEDForConditionalGeneration, LEDTokenizer
import torch
tokenizer = LEDTokenizer.from_pretrained("allenai/led-large-16384-arxiv")
input_ids = tokenizer(LONG_ARTICLE, return_tensors="pt").input_ids.to("cuda")
global_attention_mask = torch.zeros_like(input_ids)
# set global_attention_mask on first token
global_attention_mask[:, 0] = 1
model = LEDForConditionalGeneration.from_pretrained("allenai/led-large-16384-arxiv", return_dict_in_generate=True).to("cuda")
sequences = model.generate(input_ids, global_attention_mask=global_attention_mask).sequences
summary = tokenizer.batch_decode(sequences)
```
|
luhua/chinese_pretrain_mrc_roberta_wwm_ext_large
|
71a61139397cbb5fd773d8b8b72282a3387ff130
|
2021-06-12T02:53:16.000Z
|
[
"pytorch",
"bert",
"question-answering",
"zh",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] |
question-answering
| false |
luhua
| null |
luhua/chinese_pretrain_mrc_roberta_wwm_ext_large
| 5,543 | 15 |
transformers
| 867 |
---
language:
- zh
license: "apache-2.0"
---
## Chinese MRC roberta_wwm_ext_large
* 使用大量中文MRC数据训练的roberta_wwm_ext_large模型,详情可查看:https://github.com/basketballandlearn/MRC_Competition_Dureader
* 此库发布的再训练模型,在 阅读理解/分类 等任务上均有大幅提高<br/>
(已有多位小伙伴在Dureader-2021等多个比赛中取得**top5**的成绩😁)
| 模型/数据集 | Dureader-2021 | tencentmedical |
| ------------------------------------------|--------------- | --------------- |
| | F1-score | Accuracy |
| | dev / A榜 | test-1 |
| macbert-large (哈工大预训练语言模型) | 65.49 / 64.27 | 82.5 |
| roberta-wwm-ext-large (哈工大预训练语言模型) | 65.49 / 64.27 | 82.5 |
| macbert-large (ours) | 70.45 / **68.13**| **83.4** |
| roberta-wwm-ext-large (ours) | 68.91 / 66.91 | 83.1 |
|
facebook/incoder-1B
|
01f46041ac45a5a1ac9a60875189c15209d2fee9
|
2022-05-31T16:56:08.000Z
|
[
"pytorch",
"xglm",
"text-generation",
"arxiv:2204.05999",
"transformers",
"code",
"python",
"javascript",
"license:cc-by-nc-4.0"
] |
text-generation
| false |
facebook
| null |
facebook/incoder-1B
| 5,521 | 12 |
transformers
| 868 |
---
license: "cc-by-nc-4.0"
tags:
- code
- python
- javascript
---
# InCoder 1B
A 1B parameter decoder-only Transformer model trained on code using a causal-masked objective, which allows inserting/infilling code as well as standard left-to-right generation.
The model was trained on public open-source repositories with a permissive, non-copyleft, license (Apache 2.0, MIT, BSD-2 or BSD-3) from GitHub and GitLab, as well as StackOverflow. Repositories primarily contained Python and JavaScript, but also include code from 28 languages, as well as StackOverflow.
For more information, see our:
- [Demo](https://huggingface.co/spaces/facebook/incoder-demo)
- [Project site](https://sites.google.com/view/incoder-code-models)
- [Examples](https://sites.google.com/view/incoder-code-models/home/examples)
- [Paper](https://arxiv.org/abs/2204.05999)
A larger, 6B, parameter model is also available at [facebook/incoder-6B](https://huggingface.co/facebook/incoder-6B).
## Requirements
`pytorch`, `tokenizers`, and `transformers`. Our model requires HF's tokenizers >= 0.12.1, due to changes in the pretokenizer.
```
pip install torch
pip install "tokenizers>=0.12.1"
pip install transformers
```
## Usage
See [https://github.com/dpfried/incoder](https://github.com/dpfried/incoder) for example code.
### Model
`model = AutoModelForCausalLM.from_pretrained("facebook/incoder-1B")`
### Tokenizer
`tokenizer = AutoTokenizer.from_pretrained("facebook/incoder-1B")`
(Note: the incoder-1B and incoder-6B tokenizers are identical, so 'facebook/incoder-6B' could also be used.)
When calling `tokenizer.decode`, it's important to pass `clean_up_tokenization_spaces=False` to avoid removing spaces after punctuation. For example:
`tokenizer.decode(tokenizer.encode("from ."), clean_up_tokenization_spaces=False)`
(Note: encoding prepends the `<|endoftext|>` token, as this marks the start of a document to our model. This token can be removed from the decoded output by passing `skip_special_tokens=True` to `tokenizer.decode`.)
## License
CC-BY-NC 4.0
## Credits
The model was developed by Daniel Fried, Armen Aghajanyan, Jessy Lin, Sida Wang, Eric Wallace, Freda Shi, Ruiqi Zhong, Wen-tau Yih, Luke Zettlemoyer and Mike Lewis.
Thanks to Lucile Saulnier, Leandro von Werra, Nicolas Patry, Suraj Patil, Omar Sanseviero, and others at HuggingFace for help with the model release, and to Naman Goyal and Stephen Roller for the code our demo was based on!
|
nielsr/layoutlmv2-finetuned-funsd
|
35c7fa55e4df524ded1485d406ef540b4b4320db
|
2021-09-17T08:24:35.000Z
|
[
"pytorch",
"tensorboard",
"layoutlmv2",
"token-classification",
"dataset:funsd",
"transformers",
"generated_from_trainer",
"license:cc-by-sa-4.0",
"autotrain_compatible"
] |
token-classification
| false |
nielsr
| null |
nielsr/layoutlmv2-finetuned-funsd
| 5,515 | 8 |
transformers
| 869 |
---
license: cc-by-sa-4.0
tags:
- generated_from_trainer
datasets:
- funsd
model_index:
- name: layoutlmv2-finetuned-funsd
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: funsd
type: funsd
args: funsd
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# layoutlmv2-finetuned-funsd
This model is a fine-tuned version of [microsoft/layoutlmv2-base-uncased](https://huggingface.co/microsoft/layoutlmv2-base-uncased) on the funsd dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 1000
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.9.0.dev0
- Pytorch 1.8.0+cu101
- Datasets 1.9.0
- Tokenizers 0.10.3
|
avichr/heBERT_sentiment_analysis
|
022c0d00fc26288c25c0b9f5389d7f0991f93de2
|
2021-12-31T16:08:22.000Z
|
[
"pytorch",
"jax",
"bert",
"text-classification",
"arxiv:1810.04805",
"transformers"
] |
text-classification
| false |
avichr
| null |
avichr/heBERT_sentiment_analysis
| 5,483 | 7 |
transformers
| 870 |
## HeBERT: Pre-trained BERT for Polarity Analysis and Emotion Recognition
HeBERT is a Hebrew pre-trained language model. It is based on Google's BERT architecture and it is BERT-Base config [(Devlin et al. 2018)](https://arxiv.org/abs/1810.04805). <br>
HeBert was trained on three datasets:
1. A Hebrew version of OSCAR [(Ortiz, 2019)](https://oscar-corpus.com/): ~9.8 GB of data, including 1 billion words and over 20.8 million sentences.
2. A Hebrew dump of Wikipedia: ~650 MB of data, including over 63 million words and 3.8 million sentences
3. Emotion UGC data was collected for the purpose of this study. (described below)
We evaluated the model on emotion recognition and sentiment analysis, for downstream tasks.
### Emotion UGC Data Description
Our User-Generated Content (UGC) is comments written on articles collected from 3 major news sites, between January 2020 to August 2020, Total data size of ~150 MB of data, including over 7 million words and 350K sentences.
4000 sentences annotated by crowd members (3-10 annotators per sentence) for 8 emotions (anger, disgust, expectation, fear, happy, sadness, surprise, and trust) and overall sentiment/polarity <br>
In order to validate the annotation, we search for an agreement between raters to emotion in each sentence using Krippendorff's alpha [(krippendorff, 1970)](https://journals.sagepub.com/doi/pdf/10.1177/001316447003000105). We left sentences that got alpha > 0.7. Note that while we found a general agreement between raters about emotions like happiness, trust, and disgust, there are few emotions with general disagreement about them, apparently given the complexity of finding them in the text (e.g. expectation and surprise).
### Performance
#### sentiment analysis
| | precision | recall | f1-score |
|--------------|-----------|--------|----------|
| natural | 0.83 | 0.56 | 0.67 |
| positive | 0.96 | 0.92 | 0.94 |
| negative | 0.97 | 0.99 | 0.98 |
| accuracy | | | 0.97 |
| macro avg | 0.92 | 0.82 | 0.86 |
| weighted avg | 0.96 | 0.97 | 0.96 |
## How to use
### For masked-LM model (can be fine-tunned to any down-stream task)
```
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("avichr/heBERT")
model = AutoModel.from_pretrained("avichr/heBERT")
from transformers import pipeline
fill_mask = pipeline(
"fill-mask",
model="avichr/heBERT",
tokenizer="avichr/heBERT"
)
fill_mask("הקורונה לקחה את [MASK] ולנו לא נשאר דבר.")
```
### For sentiment classification model (polarity ONLY):
```
from transformers import AutoTokenizer, AutoModel, pipeline
tokenizer = AutoTokenizer.from_pretrained("avichr/heBERT_sentiment_analysis") #same as 'avichr/heBERT' tokenizer
model = AutoModel.from_pretrained("avichr/heBERT_sentiment_analysis")
# how to use?
sentiment_analysis = pipeline(
"sentiment-analysis",
model="avichr/heBERT_sentiment_analysis",
tokenizer="avichr/heBERT_sentiment_analysis",
return_all_scores = True
)
>>> sentiment_analysis('אני מתלבט מה לאכול לארוחת צהריים')
[[{'label': 'natural', 'score': 0.9978172183036804},
{'label': 'positive', 'score': 0.0014792329166084528},
{'label': 'negative', 'score': 0.0007035882445052266}]]
>>> sentiment_analysis('קפה זה טעים')
[[{'label': 'natural', 'score': 0.00047328314394690096},
{'label': 'possitive', 'score': 0.9994067549705505},
{'label': 'negetive', 'score': 0.00011996887042187154}]]
>>> sentiment_analysis('אני לא אוהב את העולם')
[[{'label': 'natural', 'score': 9.214012970915064e-05},
{'label': 'possitive', 'score': 8.876807987689972e-05},
{'label': 'negetive', 'score': 0.9998190999031067}]]
```
Our model is also available on AWS! for more information visit [AWS' git](https://github.com/aws-samples/aws-lambda-docker-serverless-inference/tree/main/hebert-sentiment-analysis-inference-docker-lambda)
## Stay tuned!
We are still working on our model and will edit this page as we progress.<br>
Note that we have released only sentiment analysis (polarity) at this point, emotion detection will be released later on.<br>
our git: https://github.com/avichaychriqui/HeBERT
## If you used this model please cite us as :
Chriqui, A., & Yahav, I. (2021). HeBERT & HebEMO: a Hebrew BERT Model and a Tool for Polarity Analysis and Emotion Recognition. arXiv preprint arXiv:2102.01909.
```
@article{chriqui2021hebert,
title={HeBERT \\\\\\\\\\\\\\\\& HebEMO: a Hebrew BERT Model and a Tool for Polarity Analysis and Emotion Recognition},
author={Chriqui, Avihay and Yahav, Inbal},
journal={arXiv preprint arXiv:2102.01909},
year={2021}
}
```
|
microsoft/xtremedistil-l12-h384-uncased
|
dd970883b88410d02b66c408c8461eed0168e8a4
|
2021-08-05T17:49:31.000Z
|
[
"pytorch",
"tf",
"bert",
"feature-extraction",
"en",
"arxiv:2106.04563",
"transformers",
"text-classification",
"license:mit"
] |
text-classification
| false |
microsoft
| null |
microsoft/xtremedistil-l12-h384-uncased
| 5,462 | 5 |
transformers
| 871 |
---
language: en
thumbnail: https://huggingface.co/front/thumbnails/microsoft.png
tags:
- text-classification
license: mit
---
# XtremeDistilTransformers for Distilling Massive Neural Networks
XtremeDistilTransformers is a distilled task-agnostic transformer model that leverages task transfer for learning a small universal model that can be applied to arbitrary tasks and languages as outlined in the paper [XtremeDistilTransformers: Task Transfer for Task-agnostic Distillation](https://arxiv.org/abs/2106.04563).
We leverage task transfer combined with multi-task distillation techniques from the papers [XtremeDistil: Multi-stage Distillation for Massive Multilingual Models](https://www.aclweb.org/anthology/2020.acl-main.202.pdf) and [MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers](https://proceedings.neurips.cc/paper/2020/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf) with the following [Github code](https://github.com/microsoft/xtreme-distil-transformers).
This l6-h384 checkpoint with **6** layers, **384** hidden size, **12** attention heads corresponds to **22 million** parameters with **5.3x** speedup over BERT-base.
Other available checkpoints: [xtremedistil-l6-h256-uncased](https://huggingface.co/microsoft/xtremedistil-l6-h256-uncased) and [xtremedistil-l6-h384-uncased](https://huggingface.co/microsoft/xtremedistil-l6-h384-uncased)
The following table shows the results on GLUE dev set and SQuAD-v2.
| Models | #Params | Speedup | MNLI | QNLI | QQP | RTE | SST | MRPC | SQUAD2 | Avg |
|----------------|--------|---------|------|------|------|------|------|------|--------|-------|
| BERT | 109 | 1x | 84.5 | 91.7 | 91.3 | 68.6 | 93.2 | 87.3 | 76.8 | 84.8 |
| DistilBERT | 66 | 2x | 82.2 | 89.2 | 88.5 | 59.9 | 91.3 | 87.5 | 70.7 | 81.3 |
| TinyBERT | 66 | 2x | 83.5 | 90.5 | 90.6 | 72.2 | 91.6 | 88.4 | 73.1 | 84.3 |
| MiniLM | 66 | 2x | 84.0 | 91.0 | 91.0 | 71.5 | 92.0 | 88.4 | 76.4 | 84.9 |
| MiniLM | 22 | 5.3x | 82.8 | 90.3 | 90.6 | 68.9 | 91.3 | 86.6 | 72.9 | 83.3 |
| XtremeDistil-l6-h256 | 13 | 8.7x | 83.9 | 89.5 | 90.6 | 80.1 | 91.2 | 90.0 | 74.1 | 85.6 |
| XtremeDistil-l6-h384 | 22 | 5.3x | 85.4 | 90.3 | 91.0 | 80.9 | 92.3 | 90.0 | 76.6 | 86.6 |
| XtremeDistil-l12-h384 | 33 | 2.7x | 87.2 | 91.9 | 91.3 | 85.6 | 93.1 | 90.4 | 80.2 | 88.5 |
Tested with `tensorflow 2.3.1, transformers 4.1.1, torch 1.6.0`
If you use this checkpoint in your work, please cite:
``` latex
@misc{mukherjee2021xtremedistiltransformers,
title={XtremeDistilTransformers: Task Transfer for Task-agnostic Distillation},
author={Subhabrata Mukherjee and Ahmed Hassan Awadallah and Jianfeng Gao},
year={2021},
eprint={2106.04563},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
Langboat/mengzi-bert-base-fin
|
b7b290d3b4dd5ec87f47d3cf5d55c9d00bd69e59
|
2021-10-18T05:53:38.000Z
|
[
"pytorch",
"bert",
"fill-mask",
"zh",
"arxiv:2110.06696",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] |
fill-mask
| false |
Langboat
| null |
Langboat/mengzi-bert-base-fin
| 5,448 | 1 |
transformers
| 872 |
---
language:
- zh
license: apache-2.0
---
# Mengzi-BERT base fin model (Chinese)
Continue trained mengzi-bert-base with 20G financial news and research reports. Masked language modeling(MLM), part-of-speech(POS) tagging and sentence order prediction(SOP) are used as training task.
[Mengzi: Towards Lightweight yet Ingenious Pre-trained Models for Chinese](https://arxiv.org/abs/2110.06696)
## Usage
```python
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained("Langboat/mengzi-bert-base-fin")
model = BertModel.from_pretrained("Langboat/mengzi-bert-base-fin")
```
## Citation
If you find the technical report or resource is useful, please cite the following technical report in your paper.
```
@misc{zhang2021mengzi,
title={Mengzi: Towards Lightweight yet Ingenious Pre-trained Models for Chinese},
author={Zhuosheng Zhang and Hanqing Zhang and Keming Chen and Yuhang Guo and Jingyun Hua and Yulong Wang and Ming Zhou},
year={2021},
eprint={2110.06696},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
aubmindlab/bert-base-arabertv02-twitter
|
14bddd56ee5b02d1d92436ca14934687452a96ea
|
2021-10-16T22:10:29.000Z
|
[
"pytorch",
"tensorboard",
"bert",
"fill-mask",
"ar",
"dataset:wikipedia",
"dataset:OSIAN",
"dataset:1.5B Arabic Corpus",
"dataset:OSCAR Arabic Unshuffled",
"dataset:Twitter",
"arxiv:2003.00104",
"transformers",
"autotrain_compatible"
] |
fill-mask
| false |
aubmindlab
| null |
aubmindlab/bert-base-arabertv02-twitter
| 5,417 | null |
transformers
| 873 |
---
language: ar
datasets:
- wikipedia
- OSIAN
- 1.5B Arabic Corpus
- OSCAR Arabic Unshuffled
- Twitter
widget:
- text: " عاصمة لبنان هي [MASK] ."
---
<img src="https://raw.githubusercontent.com/aub-mind/arabert/master/arabert_logo.png" width="100" align="center"/>
# AraBERTv0.2-Twitter
AraBERTv0.2-Twitter-base/large are two new models for Arabic dialects and tweets, trained by continuing the pre-training using the MLM task on ~60M Arabic tweets (filtered from a collection on 100M).
The two new models have had emojies added to their vocabulary in addition to common words that weren't at first present. The pre-training was done with a max sentence length of 64 only for 1 epoch.
**AraBERT** is an Arabic pretrained lanaguage model based on [Google's BERT architechture](https://github.com/google-research/bert). AraBERT uses the same BERT-Base config. More details are available in the [AraBERT Paper](https://arxiv.org/abs/2003.00104) and in the [AraBERT Meetup](https://github.com/WissamAntoun/pydata_khobar_meetup)
## Other Models
Model | HuggingFace Model Name | Size (MB/Params)| Pre-Segmentation | DataSet (Sentences/Size/nWords) |
---|:---:|:---:|:---:|:---:
AraBERTv0.2-base | [bert-base-arabertv02](https://huggingface.co/aubmindlab/bert-base-arabertv02) | 543MB / 136M | No | 200M / 77GB / 8.6B |
AraBERTv0.2-large| [bert-large-arabertv02](https://huggingface.co/aubmindlab/bert-large-arabertv02) | 1.38G / 371M | No | 200M / 77GB / 8.6B |
AraBERTv2-base| [bert-base-arabertv2](https://huggingface.co/aubmindlab/bert-base-arabertv2) | 543MB / 136M | Yes | 200M / 77GB / 8.6B |
AraBERTv2-large| [bert-large-arabertv2](https://huggingface.co/aubmindlab/bert-large-arabertv2) | 1.38G / 371M | Yes | 200M / 77GB / 8.6B |
AraBERTv0.1-base| [bert-base-arabertv01](https://huggingface.co/aubmindlab/bert-base-arabertv01) | 543MB / 136M | No | 77M / 23GB / 2.7B |
AraBERTv1-base| [bert-base-arabert](https://huggingface.co/aubmindlab/bert-base-arabert) | 543MB / 136M | Yes | 77M / 23GB / 2.7B |
AraBERTv0.2-Twitter-base| [bert-base-arabertv02-twitter](https://huggingface.co/aubmindlab/bert-base-arabertv02-twitter) | 543MB / 136M | No | Same as v02 + 60M Multi-Dialect Tweets|
AraBERTv0.2-Twitter-large| [bert-large-arabertv02-twitter](https://huggingface.co/aubmindlab/bert-large-arabertv02-twitter) | 1.38G / 371M | No | Same as v02 + 60M Multi-Dialect Tweets|
# Preprocessing
**The model is trained on a sequence length of 64, using max length beyond 64 might result in degraded performance**
It is recommended to apply our preprocessing function before training/testing on any dataset.
The preprocessor will keep and space out emojis when used with a "twitter" model.
```python
from arabert.preprocess import ArabertPreprocessor
from transformers import AutoTokenizer, AutoModelForMaskedLM
model_name="aubmindlab/bert-base-arabertv02-twitter"
arabert_prep = ArabertPreprocessor(model_name=model_name)
text = "ولن نبالغ إذا قلنا إن هاتف أو كمبيوتر المكتب في زمننا هذا ضروري"
arabert_prep.preprocess(text)
tokenizer = AutoTokenizer.from_pretrained("aubmindlab/bert-base-arabertv02-twitter")
model = AutoModelForMaskedLM.from_pretrained("aubmindlab/bert-base-arabertv02-twitter")
```
# If you used this model please cite us as :
Google Scholar has our Bibtex wrong (missing name), use this instead
```
@inproceedings{antoun2020arabert,
title={AraBERT: Transformer-based Model for Arabic Language Understanding},
author={Antoun, Wissam and Baly, Fady and Hajj, Hazem},
booktitle={LREC 2020 Workshop Language Resources and Evaluation Conference 11--16 May 2020},
pages={9}
}
```
# Acknowledgments
Thanks to TensorFlow Research Cloud (TFRC) for the free access to Cloud TPUs, couldn't have done it without this program, and to the [AUB MIND Lab](https://sites.aub.edu.lb/mindlab/) Members for the continous support. Also thanks to [Yakshof](https://www.yakshof.com/#/) and Assafir for data and storage access. Another thanks for Habib Rahal (https://www.behance.net/rahalhabib), for putting a face to AraBERT.
# Contacts
**Wissam Antoun**: [Linkedin](https://www.linkedin.com/in/wissam-antoun-622142b4/) | [Twitter](https://twitter.com/wissam_antoun) | [Github](https://github.com/WissamAntoun) | <[email protected]> | <[email protected]>
**Fady Baly**: [Linkedin](https://www.linkedin.com/in/fadybaly/) | [Twitter](https://twitter.com/fadybaly) | [Github](https://github.com/fadybaly) | <[email protected]> | <[email protected]>
|
elastic/distilbert-base-cased-finetuned-conll03-english
|
3043a315aae69b6e2f88056b23100e144791ac99
|
2022-06-24T09:30:31.000Z
|
[
"pytorch",
"distilbert",
"token-classification",
"en",
"dataset:conll2003",
"transformers",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
] |
token-classification
| false |
elastic
| null |
elastic/distilbert-base-cased-finetuned-conll03-english
| 5,406 | 5 |
transformers
| 874 |
---
language: en
license: apache-2.0
datasets:
- conll2003
model-index:
- name: elastic/distilbert-base-cased-finetuned-conll03-english
results:
- task:
type: token-classification
name: Token Classification
dataset:
name: conll2003
type: conll2003
config: conll2003
split: validation
metrics:
- name: Accuracy
type: accuracy
value: 0.9834432212868665
verified: true
- name: Precision
type: precision
value: 0.9857564461012737
verified: true
- name: Recall
type: recall
value: 0.9882123948925569
verified: true
- name: F1
type: f1
value: 0.9869828926905132
verified: true
- name: loss
type: loss
value: 0.07748260349035263
verified: true
---
[DistilBERT base cased](https://huggingface.co/distilbert-base-cased), fine-tuned for NER using the [conll03 english dataset](https://huggingface.co/datasets/conll2003). Note that this model is sensitive to capital letters — "english" is different than "English". For the case insensitive version, please use [elastic/distilbert-base-uncased-finetuned-conll03-english](https://huggingface.co/elastic/distilbert-base-uncased-finetuned-conll03-english).
## Versions
- Transformers version: 4.3.1
- Datasets version: 1.3.0
## Training
```
$ run_ner.py \
--model_name_or_path distilbert-base-cased \
--label_all_tokens True \
--return_entity_level_metrics True \
--dataset_name conll2003 \
--output_dir /tmp/distilbert-base-cased-finetuned-conll03-english \
--do_train \
--do_eval
```
After training, we update the labels to match the NER specific labels from the
dataset [conll2003](https://raw.githubusercontent.com/huggingface/datasets/1.3.0/datasets/conll2003/dataset_infos.json)
|
google/pegasus-pubmed
|
27396b90fefc6b2f8365728fb1e23963d7feca2d
|
2020-10-22T16:33:32.000Z
|
[
"pytorch",
"pegasus",
"text2text-generation",
"en",
"arxiv:1912.08777",
"transformers",
"summarization",
"autotrain_compatible"
] |
summarization
| false |
google
| null |
google/pegasus-pubmed
| 5,399 | 3 |
transformers
| 875 |
---
language: en
tags:
- summarization
---
### Pegasus Models
See Docs: [here](https://huggingface.co/transformers/master/model_doc/pegasus.html)
Original TF 1 code [here](https://github.com/google-research/pegasus)
Authors: Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu on Dec 18, 2019
Maintained by: [@sshleifer](https://twitter.com/sam_shleifer)
Task: Summarization
The following is copied from the authors' README.
# Mixed & Stochastic Checkpoints
We train a pegasus model with sampled gap sentence ratios on both C4 and HugeNews, and stochastically sample important sentences. The updated the results are reported in this table.
| dataset | C4 | HugeNews | Mixed & Stochastic|
| ---- | ---- | ---- | ----|
| xsum | 45.20/22.06/36.99 | 47.21/24.56/39.25 | 47.60/24.83/39.64|
| cnn_dailymail | 43.90/21.20/40.76 | 44.17/21.47/41.11 | 44.16/21.56/41.30|
| newsroom | 45.07/33.39/41.28 | 45.15/33.51/41.33 | 45.98/34.20/42.18|
| multi_news | 46.74/17.95/24.26 | 47.52/18.72/24.91 | 47.65/18.75/24.95|
| gigaword | 38.75/19.96/36.14 | 39.12/19.86/36.24 | 39.65/20.47/36.76|
| wikihow | 43.07/19.70/34.79 | 41.35/18.51/33.42 | 46.39/22.12/38.41 *|
| reddit_tifu | 26.54/8.94/21.64 | 26.63/9.01/21.60 | 27.99/9.81/22.94|
| big_patent | 53.63/33.16/42.25 | 53.41/32.89/42.07 | 52.29/33.08/41.66 *|
| arxiv | 44.70/17.27/25.80 | 44.67/17.18/25.73 | 44.21/16.95/25.67|
| pubmed | 45.49/19.90/27.69 | 45.09/19.56/27.42 | 45.97/20.15/28.25|
| aeslc | 37.69/21.85/36.84 | 37.40/21.22/36.45 | 37.68/21.25/36.51|
| billsum | 57.20/39.56/45.80 | 57.31/40.19/45.82 | 59.67/41.58/47.59|
The "Mixed & Stochastic" model has the following changes:
- trained on both C4 and HugeNews (dataset mixture is weighted by their number of examples).
- trained for 1.5M instead of 500k (we observe slower convergence on pretraining perplexity).
- the model uniformly sample a gap sentence ratio between 15% and 45%.
- importance sentences are sampled using a 20% uniform noise to importance scores.
- the sentencepiece tokenizer is updated to be able to encode newline character.
(*) the numbers of wikihow and big_patent datasets are not comparable because of change in tokenization and data:
- wikihow dataset contains newline characters which is useful for paragraph segmentation, the C4 and HugeNews model's sentencepiece tokenizer doesn't encode newline and loose this information.
- we update the BigPatent dataset to preserve casing, some format cleanings are also changed, please refer to change in TFDS.
The "Mixed & Stochastic" model has the following changes (from pegasus-large in the paper):
trained on both C4 and HugeNews (dataset mixture is weighted by their number of examples).
trained for 1.5M instead of 500k (we observe slower convergence on pretraining perplexity).
the model uniformly sample a gap sentence ratio between 15% and 45%.
importance sentences are sampled using a 20% uniform noise to importance scores.
the sentencepiece tokenizer is updated to be able to encode newline character.
Citation
```
@misc{zhang2019pegasus,
title={PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization},
author={Jingqing Zhang and Yao Zhao and Mohammad Saleh and Peter J. Liu},
year={2019},
eprint={1912.08777},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
symanto/sn-xlm-roberta-base-snli-mnli-anli-xnli
|
e6331eecd7f50dd13c8ebcdc57a9f0a22f2ff56e
|
2021-09-30T11:27:56.000Z
|
[
"pytorch",
"xlm-roberta",
"feature-extraction",
"ar",
"bg",
"de",
"el",
"en",
"es",
"fr",
"ru",
"th",
"tr",
"ur",
"vn",
"zh",
"dataset:SNLI",
"dataset:MNLI",
"dataset:ANLI",
"dataset:XNLI",
"sentence-transformers",
"zero-shot-classification",
"sentence-similarity",
"transformers"
] |
sentence-similarity
| false |
symanto
| null |
symanto/sn-xlm-roberta-base-snli-mnli-anli-xnli
| 5,392 | 5 |
sentence-transformers
| 876 |
---
language:
- ar
- bg
- de
- el
- en
- es
- fr
- ru
- th
- tr
- ur
- vn
- zh
datasets:
- SNLI
- MNLI
- ANLI
- XNLI
pipeline_tag: sentence-similarity
tags:
- zero-shot-classification
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
A Siamese network model trained for zero-shot and few-shot text classification.
The base model is [xlm-roberta-base](https://huggingface.co/xlm-roberta-base).
It was trained on [SNLI](https://nlp.stanford.edu/projects/snli/), [MNLI](https://cims.nyu.edu/~sbowman/multinli/), [ANLI](https://github.com/facebookresearch/anli) and [XNLI](https://github.com/facebookresearch/XNLI).
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('{MODEL_NAME}')
model = AutoModel.from_pretrained('{MODEL_NAME}')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
|
dkleczek/bert-base-polish-cased-v1
|
fed744e81ebd16cf099b5c64c40688bc3e6ace67
|
2021-05-19T15:54:20.000Z
|
[
"pytorch",
"jax",
"bert",
"pretraining",
"pl",
"transformers"
] | null | false |
dkleczek
| null |
dkleczek/bert-base-polish-cased-v1
| 5,383 | null |
transformers
| 877 |
---
language: pl
thumbnail: https://raw.githubusercontent.com/kldarek/polbert/master/img/polbert.png
---
# Polbert - Polish BERT
Polish version of BERT language model is here! It is now available in two variants: cased and uncased, both can be downloaded and used via HuggingFace transformers library. I recommend using the cased model, more info on the differences and benchmark results below.

## Cased and uncased variants
* I initially trained the uncased model, the corpus and training details are referenced below. Here are some issues I found after I published the uncased model:
* Some Polish characters and accents are not tokenized correctly through the BERT tokenizer when applying lowercase. This doesn't impact sequence classification much, but may influence token classfication tasks significantly.
* I noticed a lot of duplicates in the Open Subtitles dataset, which dominates the training corpus.
* I didn't use Whole Word Masking.
* The cased model improves on the uncased model in the following ways:
* All Polish characters and accents should now be tokenized correctly.
* I removed duplicates from Open Subtitles dataset. The corpus is smaller, but more balanced now.
* The model is trained with Whole Word Masking.
## Pre-training corpora
Below is the list of corpora used along with the output of `wc` command (counting lines, words and characters). These corpora were divided into sentences with srxsegmenter (see references), concatenated and tokenized with HuggingFace BERT Tokenizer.
### Uncased
| Tables | Lines | Words | Characters |
| ------------- |--------------:| -----:| -----:|
| [Polish subset of Open Subtitles](http://opus.nlpl.eu/OpenSubtitles-v2018.php) | 236635408| 1431199601 | 7628097730 |
| [Polish subset of ParaCrawl](http://opus.nlpl.eu/ParaCrawl.php) | 8470950 | 176670885 | 1163505275 |
| [Polish Parliamentary Corpus](http://clip.ipipan.waw.pl/PPC) | 9799859 | 121154785 | 938896963 |
| [Polish Wikipedia - Feb 2020](https://dumps.wikimedia.org/plwiki/latest/plwiki-latest-pages-articles.xml.bz2) | 8014206 | 132067986 | 1015849191 |
| Total | 262920423 | 1861093257 | 10746349159 |
### Cased
| Tables | Lines | Words | Characters |
| ------------- |--------------:| -----:| -----:|
| [Polish subset of Open Subtitles (Deduplicated) ](http://opus.nlpl.eu/OpenSubtitles-v2018.php) | 41998942| 213590656 | 1424873235 |
| [Polish subset of ParaCrawl](http://opus.nlpl.eu/ParaCrawl.php) | 8470950 | 176670885 | 1163505275 |
| [Polish Parliamentary Corpus](http://clip.ipipan.waw.pl/PPC) | 9799859 | 121154785 | 938896963 |
| [Polish Wikipedia - Feb 2020](https://dumps.wikimedia.org/plwiki/latest/plwiki-latest-pages-articles.xml.bz2) | 8014206 | 132067986 | 1015849191 |
| Total | 68283960 | 646479197 | 4543124667 |
## Pre-training details
### Uncased
* Polbert was trained with code provided in Google BERT's github repository (https://github.com/google-research/bert)
* Currently released model follows bert-base-uncased model architecture (12-layer, 768-hidden, 12-heads, 110M parameters)
* Training set-up: in total 1 million training steps:
* 100.000 steps - 128 sequence length, batch size 512, learning rate 1e-4 (10.000 steps warmup)
* 800.000 steps - 128 sequence length, batch size 512, learning rate 5e-5
* 100.000 steps - 512 sequence length, batch size 256, learning rate 2e-5
* The model was trained on a single Google Cloud TPU v3-8
### Cased
* Same approach as uncased model, with the following differences:
* Whole Word Masking
* Training set-up:
* 100.000 steps - 128 sequence length, batch size 2048, learning rate 1e-4 (10.000 steps warmup)
* 100.000 steps - 128 sequence length, batch size 2048, learning rate 5e-5
* 100.000 steps - 512 sequence length, batch size 256, learning rate 2e-5
## Usage
Polbert is released via [HuggingFace Transformers library](https://huggingface.co/transformers/).
For an example use as language model, see [this notebook](/LM_testing.ipynb) file.
### Uncased
```python
from transformers import *
model = BertForMaskedLM.from_pretrained("dkleczek/bert-base-polish-uncased-v1")
tokenizer = BertTokenizer.from_pretrained("dkleczek/bert-base-polish-uncased-v1")
nlp = pipeline('fill-mask', model=model, tokenizer=tokenizer)
for pred in nlp(f"Adam Mickiewicz wielkim polskim {nlp.tokenizer.mask_token} był."):
print(pred)
# Output:
# {'sequence': '[CLS] adam mickiewicz wielkim polskim poeta był. [SEP]', 'score': 0.47196975350379944, 'token': 26596}
# {'sequence': '[CLS] adam mickiewicz wielkim polskim bohaterem był. [SEP]', 'score': 0.09127858281135559, 'token': 10953}
# {'sequence': '[CLS] adam mickiewicz wielkim polskim człowiekiem był. [SEP]', 'score': 0.0647173821926117, 'token': 5182}
# {'sequence': '[CLS] adam mickiewicz wielkim polskim pisarzem był. [SEP]', 'score': 0.05232388526201248, 'token': 24293}
# {'sequence': '[CLS] adam mickiewicz wielkim polskim politykiem był. [SEP]', 'score': 0.04554257541894913, 'token': 44095}
```
### Cased
```python
model = BertForMaskedLM.from_pretrained("dkleczek/bert-base-polish-cased-v1")
tokenizer = BertTokenizer.from_pretrained("dkleczek/bert-base-polish-cased-v1")
nlp = pipeline('fill-mask', model=model, tokenizer=tokenizer)
for pred in nlp(f"Adam Mickiewicz wielkim polskim {nlp.tokenizer.mask_token} był."):
print(pred)
# Output:
# {'sequence': '[CLS] Adam Mickiewicz wielkim polskim pisarzem był. [SEP]', 'score': 0.5391148328781128, 'token': 37120}
# {'sequence': '[CLS] Adam Mickiewicz wielkim polskim człowiekiem był. [SEP]', 'score': 0.11683262139558792, 'token': 6810}
# {'sequence': '[CLS] Adam Mickiewicz wielkim polskim bohaterem był. [SEP]', 'score': 0.06021466106176376, 'token': 17709}
# {'sequence': '[CLS] Adam Mickiewicz wielkim polskim mistrzem był. [SEP]', 'score': 0.051870670169591904, 'token': 14652}
# {'sequence': '[CLS] Adam Mickiewicz wielkim polskim artystą był. [SEP]', 'score': 0.031787533313035965, 'token': 35680}
```
See the next section for an example usage of Polbert in downstream tasks.
## Evaluation
Thanks to Allegro, we now have the [KLEJ benchmark](https://klejbenchmark.com/leaderboard/), a set of nine evaluation tasks for the Polish language understanding. The following results are achieved by running standard set of evaluation scripts (no tricks!) utilizing both cased and uncased variants of Polbert.
| Model | Average | NKJP-NER | CDSC-E | CDSC-R | CBD | PolEmo2.0-IN | PolEmo2.0-OUT | DYK | PSC | AR |
| ------------- |--------------:|--------------:|--------------:|--------------:|--------------:|--------------:|--------------:|--------------:|--------------:|--------------:|
| Polbert cased | 81.7 | 93.6 | 93.4 | 93.8 | 52.7 | 87.4 | 71.1 | 59.1 | 98.6 | 85.2 |
| Polbert uncased | 81.4 | 90.1 | 93.9 | 93.5 | 55.0 | 88.1 | 68.8 | 59.4 | 98.8 | 85.4 |
Note how the uncased model performs better than cased on some tasks? My guess this is because of the oversampling of Open Subtitles dataset and its similarity to data in some of these tasks. All these benchmark tasks are sequence classification, so the relative strength of the cased model is not so visible here.
## Bias
The data used to train the model is biased. It may reflect stereotypes related to gender, ethnicity etc. Please be careful when using the model for downstream task to consider these biases and mitigate them.
## Acknowledgements
* I'd like to express my gratitude to Google [TensorFlow Research Cloud (TFRC)](https://www.tensorflow.org/tfrc) for providing the free TPU credits - thank you!
* Also appreciate the help from Timo Möller from [deepset](https://deepset.ai) for sharing tips and scripts based on their experience training German BERT model.
* Big thanks to Allegro for releasing KLEJ Benchmark and specifically to Piotr Rybak for help with the evaluation and pointing out some issues with the tokenization.
* Finally, thanks to Rachel Thomas, Jeremy Howard and Sylvain Gugger from [fastai](https://www.fast.ai) for their NLP and Deep Learning courses!
## Author
Darek Kłeczek - contact me on Twitter [@dk21](https://twitter.com/dk21)
## References
* https://github.com/google-research/bert
* https://github.com/narusemotoki/srx_segmenter
* SRX rules file for sentence splitting in Polish, written by Marcin Miłkowski: https://raw.githubusercontent.com/languagetool-org/languagetool/master/languagetool-core/src/main/resources/org/languagetool/resource/segment.srx
* [KLEJ benchmark](https://klejbenchmark.com/leaderboard/)
|
microsoft/xtremedistil-l6-h384-uncased
|
359df7d52613d4edc15647e6d65e0d87200eb747
|
2021-08-05T17:48:58.000Z
|
[
"pytorch",
"tf",
"jax",
"bert",
"feature-extraction",
"en",
"arxiv:2106.04563",
"transformers",
"text-classification",
"license:mit"
] |
text-classification
| false |
microsoft
| null |
microsoft/xtremedistil-l6-h384-uncased
| 5,374 | 16 |
transformers
| 878 |
---
language: en
thumbnail: https://huggingface.co/front/thumbnails/microsoft.png
tags:
- text-classification
license: mit
---
# XtremeDistilTransformers for Distilling Massive Neural Networks
XtremeDistilTransformers is a distilled task-agnostic transformer model that leverages task transfer for learning a small universal model that can be applied to arbitrary tasks and languages as outlined in the paper [XtremeDistilTransformers: Task Transfer for Task-agnostic Distillation](https://arxiv.org/abs/2106.04563).
We leverage task transfer combined with multi-task distillation techniques from the papers [XtremeDistil: Multi-stage Distillation for Massive Multilingual Models](https://www.aclweb.org/anthology/2020.acl-main.202.pdf) and [MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers](https://proceedings.neurips.cc/paper/2020/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf) with the following [Github code](https://github.com/microsoft/xtreme-distil-transformers).
This l6-h384 checkpoint with **6** layers, **384** hidden size, **12** attention heads corresponds to **22 million** parameters with **5.3x** speedup over BERT-base.
Other available checkpoints: [xtremedistil-l6-h256-uncased](https://huggingface.co/microsoft/xtremedistil-l6-h256-uncased) and [xtremedistil-l12-h384-uncased](https://huggingface.co/microsoft/xtremedistil-l12-h384-uncased)
The following table shows the results on GLUE dev set and SQuAD-v2.
| Models | #Params | Speedup | MNLI | QNLI | QQP | RTE | SST | MRPC | SQUAD2 | Avg |
|----------------|--------|---------|------|------|------|------|------|------|--------|-------|
| BERT | 109 | 1x | 84.5 | 91.7 | 91.3 | 68.6 | 93.2 | 87.3 | 76.8 | 84.8 |
| DistilBERT | 66 | 2x | 82.2 | 89.2 | 88.5 | 59.9 | 91.3 | 87.5 | 70.7 | 81.3 |
| TinyBERT | 66 | 2x | 83.5 | 90.5 | 90.6 | 72.2 | 91.6 | 88.4 | 73.1 | 84.3 |
| MiniLM | 66 | 2x | 84.0 | 91.0 | 91.0 | 71.5 | 92.0 | 88.4 | 76.4 | 84.9 |
| MiniLM | 22 | 5.3x | 82.8 | 90.3 | 90.6 | 68.9 | 91.3 | 86.6 | 72.9 | 83.3 |
| XtremeDistil-l6-h256 | 13 | 8.7x | 83.9 | 89.5 | 90.6 | 80.1 | 91.2 | 90.0 | 74.1 | 85.6 |
| XtremeDistil-l6-h384 | 22 | 5.3x | 85.4 | 90.3 | 91.0 | 80.9 | 92.3 | 90.0 | 76.6 | 86.6 |
| XtremeDistil-l12-h384 | 33 | 2.7x | 87.2 | 91.9 | 91.3 | 85.6 | 93.1 | 90.4 | 80.2 | 88.5 |
Tested with `tensorflow 2.3.1, transformers 4.1.1, torch 1.6.0`
If you use this checkpoint in your work, please cite:
``` latex
@misc{mukherjee2021xtremedistiltransformers,
title={XtremeDistilTransformers: Task Transfer for Task-agnostic Distillation},
author={Subhabrata Mukherjee and Ahmed Hassan Awadallah and Jianfeng Gao},
year={2021},
eprint={2106.04563},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
Prime2911/DialoGPT-medium-handsomejack
|
c9d3196d32519f073bec0ce80aeb01abe78d8075
|
2022-03-11T07:54:11.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
| false |
Prime2911
| null |
Prime2911/DialoGPT-medium-handsomejack
| 5,355 | null |
transformers
| 879 |
---
tags:
- conversational
---
# Handsome Jack DialoGPT Model
|
microsoft/trocr-base-handwritten
|
bad90c41e8b5a5cd03f658fbd568b44b2ee047c5
|
2022-07-01T07:35:45.000Z
|
[
"pytorch",
"vision-encoder-decoder",
"arxiv:2109.10282",
"transformers",
"trocr",
"image-to-text"
] |
image-to-text
| false |
microsoft
| null |
microsoft/trocr-base-handwritten
| 5,344 | 8 |
transformers
| 880 |
---
tags:
- trocr
- image-to-text
---
# TrOCR (base-sized model, fine-tuned on IAM)
TrOCR model fine-tuned on the [IAM dataset](https://fki.tic.heia-fr.ch/databases/iam-handwriting-database). It was introduced in the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Li et al. and first released in [this repository](https://github.com/microsoft/unilm/tree/master/trocr).
Disclaimer: The team releasing TrOCR did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The TrOCR model is an encoder-decoder model, consisting of an image Transformer as encoder, and a text Transformer as decoder. The image encoder was initialized from the weights of BEiT, while the text decoder was initialized from the weights of RoBERTa.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. One also adds absolute position embeddings before feeding the sequence to the layers of the Transformer encoder. Next, the Transformer text decoder autoregressively generates tokens.
## Intended uses & limitations
You can use the raw model for optical character recognition (OCR) on single text-line images. See the [model hub](https://huggingface.co/models?search=microsoft/trocr) to look for fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model in PyTorch:
```python
from transformers import TrOCRProcessor, VisionEncoderDecoderModel
from PIL import Image
import requests
# load image from the IAM database
url = 'https://fki.tic.heia-fr.ch/static/img/a01-122-02-00.jpg'
image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
processor = TrOCRProcessor.from_pretrained('microsoft/trocr-base-handwritten')
model = VisionEncoderDecoderModel.from_pretrained('microsoft/trocr-base-handwritten')
pixel_values = processor(images=image, return_tensors="pt").pixel_values
generated_ids = model.generate(pixel_values)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
```
### BibTeX entry and citation info
```bibtex
@misc{li2021trocr,
title={TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models},
author={Minghao Li and Tengchao Lv and Lei Cui and Yijuan Lu and Dinei Florencio and Cha Zhang and Zhoujun Li and Furu Wei},
year={2021},
eprint={2109.10282},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
sentence-transformers/stsb-mpnet-base-v2
|
9f9d3d9da582d245066b519ab1e99c3f54a0594e
|
2021-08-05T08:31:17.000Z
|
[
"pytorch",
"mpnet",
"feature-extraction",
"arxiv:1908.10084",
"sentence-transformers",
"sentence-similarity",
"transformers",
"license:apache-2.0"
] |
sentence-similarity
| false |
sentence-transformers
| null |
sentence-transformers/stsb-mpnet-base-v2
| 5,332 | 2 |
sentence-transformers
| 881 |
---
pipeline_tag: sentence-similarity
license: apache-2.0
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# sentence-transformers/stsb-mpnet-base-v2
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/stsb-mpnet-base-v2')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/stsb-mpnet-base-v2')
model = AutoModel.from_pretrained('sentence-transformers/stsb-mpnet-base-v2')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/stsb-mpnet-base-v2)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 75, 'do_lower_case': False}) with Transformer model: MPNetModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
```
|
zlucia/custom-legalbert
|
fd49a135d7b327a315e3ffea31c2be1b40685315
|
2021-07-02T05:56:40.000Z
|
[
"pytorch",
"tf",
"jax",
"bert",
"en",
"arxiv:2104.08671",
"arxiv:1808.06226",
"transformers",
"legal",
"fill-mask"
] |
fill-mask
| false |
zlucia
| null |
zlucia/custom-legalbert
| 5,263 | 3 |
transformers
| 882 |
---
language: en
pipeline_tag: fill-mask
tags:
- legal
---
### Custom Legal-BERT
Model and tokenizer files for Custom Legal-BERT model from [When Does Pretraining Help? Assessing Self-Supervised Learning for Law and the CaseHOLD Dataset](https://arxiv.org/abs/2104.08671).
### Training Data
The pretraining corpus was constructed by ingesting the entire Harvard Law case corpus from 1965 to the present (https://case.law/). The size of this corpus (37GB) is substantial, representing 3,446,187 legal decisions across all federal and state courts, and is larger than the size of the BookCorpus/Wikipedia corpus originally used to train BERT (15GB).
### Training Objective
This model is pretrained from scratch for 2M steps on the MLM and NSP objective, with tokenization and sentence segmentation adapted for legal text (cf. the paper).
The model also uses a custom domain-specific legal vocabulary. The vocabulary set is constructed using [SentencePiece](https://arxiv.org/abs/1808.06226) on a subsample (approx. 13M) of sentences from our pretraining corpus, with the number of tokens fixed to 32,000.
### Usage
Please see the [casehold repository](https://github.com/reglab/casehold) for scripts that support computing pretrain loss and finetuning on Custom Legal-BERT for classification and multiple choice tasks described in the paper: Overruling, Terms of Service, CaseHOLD.
### Citation
@inproceedings{zhengguha2021,
title={When Does Pretraining Help? Assessing Self-Supervised Learning for Law and the CaseHOLD Dataset},
author={Lucia Zheng and Neel Guha and Brandon R. Anderson and Peter Henderson and Daniel E. Ho},
year={2021},
eprint={2104.08671},
archivePrefix={arXiv},
primaryClass={cs.CL},
booktitle={Proceedings of the 18th International Conference on Artificial Intelligence and Law},
publisher={Association for Computing Machinery}
}
Lucia Zheng, Neel Guha, Brandon R. Anderson, Peter Henderson, and Daniel E. Ho. 2021. When Does Pretraining Help? Assessing Self-Supervised Learning for Law and the CaseHOLD Dataset. In *Proceedings of the 18th International Conference on Artificial Intelligence and Law (ICAIL '21)*, June 21-25, 2021, São Paulo, Brazil. ACM Inc., New York, NY, (in press). arXiv: [2104.08671 \\[cs.CL\\]](https://arxiv.org/abs/2104.08671).
|
patrickvonplaten/longformer-random-tiny
|
8f15d46e686753d8c1ffb6e876fa90740a1c32c3
|
2020-08-05T09:22:23.000Z
|
[
"pytorch",
"tf",
"longformer",
"feature-extraction",
"transformers"
] |
feature-extraction
| false |
patrickvonplaten
| null |
patrickvonplaten/longformer-random-tiny
| 5,232 | null |
transformers
| 883 |
Entry not found
|
banden/DialoGPT-medium-RickBot
|
010c54cb71eeb60b5a15b270842d132bde6254aa
|
2021-09-21T14:58:30.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
| false |
banden
| null |
banden/DialoGPT-medium-RickBot
| 5,231 | null |
transformers
| 884 |
---
tags:
- conversational
---
# Rick Sanchez DialoGPT Model
|
princeton-nlp/unsup-simcse-roberta-large
|
d3f863b476c59b0673264042f159cea15842e265
|
2021-06-16T12:15:47.000Z
|
[
"pytorch",
"jax",
"roberta",
"feature-extraction",
"transformers"
] |
feature-extraction
| false |
princeton-nlp
| null |
princeton-nlp/unsup-simcse-roberta-large
| 5,230 | null |
transformers
| 885 |
Entry not found
|
xlm-roberta-large-finetuned-conll03-german
|
737aa82161f5a202e95012eebfe78ef597d980ec
|
2022-07-22T08:06:55.000Z
|
[
"pytorch",
"rust",
"xlm-roberta",
"token-classification",
"multilingual",
"af",
"am",
"ar",
"as",
"az",
"be",
"bg",
"bn",
"br",
"bs",
"ca",
"cs",
"cy",
"da",
"de",
"el",
"en",
"eo",
"es",
"et",
"eu",
"fa",
"fi",
"fr",
"fy",
"ga",
"gd",
"gl",
"gu",
"ha",
"he",
"hi",
"hr",
"hu",
"hy",
"id",
"is",
"it",
"ja",
"jv",
"ka",
"kk",
"km",
"kn",
"ko",
"ku",
"ky",
"la",
"lo",
"lt",
"lv",
"mg",
"mk",
"ml",
"mn",
"mr",
"ms",
"my",
"ne",
"nl",
"no",
"om",
"or",
"pa",
"pl",
"ps",
"pt",
"ro",
"ru",
"sa",
"sd",
"si",
"sk",
"sl",
"so",
"sq",
"sr",
"su",
"sv",
"sw",
"ta",
"te",
"th",
"tl",
"tr",
"ug",
"uk",
"ur",
"uz",
"vi",
"xh",
"yi",
"zh",
"arxiv:1911.02116",
"arxiv:1910.09700",
"transformers",
"autotrain_compatible"
] |
token-classification
| false | null | null |
xlm-roberta-large-finetuned-conll03-german
| 5,178 | null |
transformers
| 886 |
---
language:
- multilingual
- af
- am
- ar
- as
- az
- be
- bg
- bn
- br
- bs
- ca
- cs
- cy
- da
- de
- el
- en
- eo
- es
- et
- eu
- fa
- fi
- fr
- fy
- ga
- gd
- gl
- gu
- ha
- he
- hi
- hr
- hu
- hy
- id
- is
- it
- ja
- jv
- ka
- kk
- km
- kn
- ko
- ku
- ky
- la
- lo
- lt
- lv
- mg
- mk
- ml
- mn
- mr
- ms
- my
- ne
- nl
- no
- om
- or
- pa
- pl
- ps
- pt
- ro
- ru
- sa
- sd
- si
- sk
- sl
- so
- sq
- sr
- su
- sv
- sw
- ta
- te
- th
- tl
- tr
- ug
- uk
- ur
- uz
- vi
- xh
- yi
- zh
---
# xlm-roberta-large-finetuned-conll03-german
# Table of Contents
1. [Model Details](#model-details)
2. [Uses](#uses)
3. [Bias, Risks, and Limitations](#bias-risks-and-limitations)
4. [Training](#training)
5. [Evaluation](#evaluation)
6. [Environmental Impact](#environmental-impact)
7. [Technical Specifications](#technical-specifications)
8. [Citation](#citation)
9. [Model Card Authors](#model-card-authors)
10. [How To Get Started With the Model](#how-to-get-started-with-the-model)
# Model Details
## Model Description
The XLM-RoBERTa model was proposed in [Unsupervised Cross-lingual Representation Learning at Scale](https://arxiv.org/abs/1911.02116) by Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer and Veselin Stoyanov. It is based on Facebook's RoBERTa model released in 2019. It is a large multi-lingual language model, trained on 2.5TB of filtered CommonCrawl data. This model is [XLM-RoBERTa-large](https://huggingface.co/xlm-roberta-large) fine-tuned with the [conll2003](https://huggingface.co/datasets/conll2003) dataset in German.
- **Developed by:** See [associated paper](https://arxiv.org/abs/1911.02116)
- **Model type:** Multi-lingual language model
- **Language(s) (NLP):** XLM-RoBERTa is a multilingual model trained on 100 different languages; see [GitHub Repo](https://github.com/facebookresearch/fairseq/tree/main/examples/xlmr) for full list; model is fine-tuned on a dataset in German
- **License:** More information needed
- **Related Models:** [RoBERTa](https://huggingface.co/roberta-base), [XLM](https://huggingface.co/docs/transformers/model_doc/xlm)
- **Parent Model:** [XLM-RoBERTa-large](https://huggingface.co/xlm-roberta-large)
- **Resources for more information:**
-[GitHub Repo](https://github.com/facebookresearch/fairseq/tree/main/examples/xlmr)
-[Associated Paper](https://arxiv.org/abs/1911.02116)
# Uses
## Direct Use
The model is a language model. The model can be used for token classification, a natural language understanding task in which a label is assigned to some tokens in a text.
## Downstream Use
Potential downstream use cases include Named Entity Recognition (NER) and Part-of-Speech (PoS) tagging. To learn more about token classification and other potential downstream use cases, see the Hugging Face [token classification docs](https://huggingface.co/tasks/token-classification).
## Out-of-Scope Use
The model should not be used to intentionally create hostile or alienating environments for people.
# Bias, Risks, and Limitations
**CONTENT WARNING: Readers should be made aware that language generated by this model may be disturbing or offensive to some and may propagate historical and current stereotypes.**
Significant research has explored bias and fairness issues with language models (see, e.g., [Sheng et al. (2021)](https://aclanthology.org/2021.acl-long.330.pdf) and [Bender et al. (2021)](https://dl.acm.org/doi/pdf/10.1145/3442188.3445922)).
## Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model.
# Training
See the following resources for training data and training procedure details:
- [XLM-RoBERTa-large model card](https://huggingface.co/xlm-roberta-large)
- [CoNLL-2003 data card](https://huggingface.co/datasets/conll2003)
- [Associated paper](https://arxiv.org/pdf/1911.02116.pdf)
# Evaluation
See the [associated paper](https://arxiv.org/pdf/1911.02116.pdf) for evaluation details.
# Environmental Impact
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** 500 32GB Nvidia V100 GPUs (from the [associated paper](https://arxiv.org/pdf/1911.02116.pdf))
- **Hours used:** More information needed
- **Cloud Provider:** More information needed
- **Compute Region:** More information needed
- **Carbon Emitted:** More information needed
# Technical Specifications
See the [associated paper](https://arxiv.org/pdf/1911.02116.pdf) for further details.
# Citation
**BibTeX:**
```bibtex
@article{conneau2019unsupervised,
title={Unsupervised Cross-lingual Representation Learning at Scale},
author={Conneau, Alexis and Khandelwal, Kartikay and Goyal, Naman and Chaudhary, Vishrav and Wenzek, Guillaume and Guzm{\'a}n, Francisco and Grave, Edouard and Ott, Myle and Zettlemoyer, Luke and Stoyanov, Veselin},
journal={arXiv preprint arXiv:1911.02116},
year={2019}
}
```
**APA:**
- Conneau, A., Khandelwal, K., Goyal, N., Chaudhary, V., Wenzek, G., Guzmán, F., ... & Stoyanov, V. (2019). Unsupervised cross-lingual representation learning at scale. arXiv preprint arXiv:1911.02116.
# Model Card Authors
This model card was written by the team at Hugging Face.
# How to Get Started with the Model
Use the code below to get started with the model. You can use this model directly within a pipeline for NER.
<details>
<summary> Click to expand </summary>
```python
>>> from transformers import AutoTokenizer, AutoModelForTokenClassification
>>> from transformers import pipeline
>>> tokenizer = AutoTokenizer.from_pretrained("xlm-roberta-large-finetuned-conll03-german")
>>> model = AutoModelForTokenClassification.from_pretrained("xlm-roberta-large-finetuned-conll03-german")
>>> classifier = pipeline("ner", model=model, tokenizer=tokenizer)
>>> classifier("Bayern München ist wieder alleiniger Top-Favorit auf den Gewinn der deutschen Fußball-Meisterschaft.")
[{'end': 6,
'entity': 'I-ORG',
'index': 1,
'score': 0.99999166,
'start': 0,
'word': '▁Bayern'},
{'end': 14,
'entity': 'I-ORG',
'index': 2,
'score': 0.999987,
'start': 7,
'word': '▁München'},
{'end': 77,
'entity': 'I-MISC',
'index': 16,
'score': 0.9999728,
'start': 68,
'word': '▁deutschen'}]
```
</details>
|
sberbank-ai/sbert_large_nlu_ru
|
28d04bde633f23feb22916430a01cdfcadfd35e9
|
2021-09-21T19:42:35.000Z
|
[
"pytorch",
"jax",
"bert",
"feature-extraction",
"ru",
"transformers",
"PyTorch",
"Transformers"
] |
feature-extraction
| false |
sberbank-ai
| null |
sberbank-ai/sbert_large_nlu_ru
| 5,159 | 5 |
transformers
| 887 |
---
language:
- ru
tags:
- PyTorch
- Transformers
---
# BERT large model (uncased) for Sentence Embeddings in Russian language.
The model is described [in this article](https://habr.com/ru/company/sberdevices/blog/527576/)
For better quality, use mean token embeddings.
## Usage (HuggingFace Models Repository)
You can use the model directly from the model repository to compute sentence embeddings:
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
sum_embeddings = torch.sum(token_embeddings * input_mask_expanded, 1)
sum_mask = torch.clamp(input_mask_expanded.sum(1), min=1e-9)
return sum_embeddings / sum_mask
#Sentences we want sentence embeddings for
sentences = ['Привет! Как твои дела?',
'А правда, что 42 твое любимое число?']
#Load AutoModel from huggingface model repository
tokenizer = AutoTokenizer.from_pretrained("sberbank-ai/sbert_large_nlu_ru")
model = AutoModel.from_pretrained("sberbank-ai/sbert_large_nlu_ru")
#Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, max_length=24, return_tensors='pt')
#Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
#Perform pooling. In this case, mean pooling
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
```
|
tunib/electra-ko-base
|
edfb795c9f667b3c5cb7085ca9112997823ce4e8
|
2021-09-28T07:48:06.000Z
|
[
"pytorch",
"electra",
"pretraining",
"arxiv:2003.10555",
"transformers"
] | null | false |
tunib
| null |
tunib/electra-ko-base
| 5,153 | 5 |
transformers
| 888 |
# TUNiB-Electra
We release several new versions of the [ELECTRA](https://arxiv.org/abs/2003.10555) model, which we name TUNiB-Electra. There are two motivations. First, all the existing pre-trained Korean encoder models are monolingual, that is, they have knowledge about Korean only. Our bilingual models are based on the balanced corpora of Korean and English. Second, we want new off-the-shelf models trained on much more texts. To this end, we collected a large amount of Korean text from various sources such as blog posts, comments, news, web novels, etc., which sum up to 100 GB in total.
## How to use
You can use this model directly with [transformers](https://github.com/huggingface/transformers) library:
```python
from transformers import AutoModel, AutoTokenizer
# Base Model (Korean-only model)
tokenizer = AutoTokenizer.from_pretrained('tunib/electra-ko-base')
model = AutoModel.from_pretrained('tunib/electra-ko-base')
```
### Tokenizer example
```python
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained('tunib/electra-ko-base')
>>> tokenizer.tokenize("tunib is a natural language processing tech startup.")
['tun', '##ib', 'is', 'a', 'natural', 'language', 'processing', 'tech', 'startup', '.']
>>> tokenizer.tokenize("튜닙은 자연어처리 테크 스타트업입니다.")
['튜', '##닙', '##은', '자연', '##어', '##처리', '테크', '스타트업', '##입니다', '.']
```
## Results on Korean downstream tasks
| |**# Params** |**Avg.**| **NSMC**<br/>(acc) | **Naver NER**<br/>(F1) | **PAWS**<br/>(acc) | **KorNLI**<br/>(acc) | **KorSTS**<br/>(spearman) | **Question Pair**<br/>(acc) | **KorQuaD (Dev)**<br/>(EM/F1) |**Korean-Hate-Speech (Dev)**<br/>(F1)|
| :----------------:| :----------------: | :--------------------: | :----------------: | :------------------: | :-----------------------: | :-------------------------: | :---------------------------: | :---------------------------: | :---------------------------: | :----------------: |
|***TUNiB-Electra-ko-base*** | 110M | **85.99** | 90.95 | 87.63 | 84.65 | **82.27** | 85.00 | 95.77 | 64.01 / 90.32 |71.40 |
|***TUNiB-Electra-ko-en-base*** | 133M |85.34 |90.59 | 87.25 | **84.90** | 80.43 | 83.81 | 94.85 | 83.09 / 92.06 |68.83 |
| [KoELECTRA-base-v3](https://github.com/monologg/KoELECTRA) | 110M | 85.92 |90.63 | **88.11** | 84.45 | 82.24 | **85.53** | 95.25 | **84.83 / 93.45** | 67.61 |
| [KcELECTRA-base](https://github.com/Beomi/KcELECTRA) | 124M| 84.75 |**91.71** | 86.90 | 74.80 | 81.65 | 82.65 | **95.78** | 70.60 / 90.11 | **74.49** |
| [KoBERT-base](https://github.com/SKTBrain/KoBERT) | 90M | 84.17 | 89.63 | 86.11 | 80.65 | 79.00 | 79.64 | 93.93 | 52.81 / 80.27 | 66.21 |
| [KcBERT-base](https://github.com/Beomi/KcBERT) | 110M | 81.37 | 89.62 | 84.34 | 66.95 | 74.85 | 75.57 | 93.93 | 60.25 / 84.39 | 68.77 |
| [XLM-Roberta-base](https://github.com/pytorch/fairseq/tree/master/examples/xlmr) | 280M | 85.74 |89.49 | 86.26 | 82.95 | 79.92 | 79.09 | 93.53 | 64.70 / 88.94 | 64.06 |
|
vasudevgupta/bigbird-roberta-natural-questions
|
e073d287d7d8e6798f5081934b6de80a4f44a9ed
|
2021-05-12T03:20:58.000Z
|
[
"pytorch",
"big_bird",
"question-answering",
"en",
"dataset:natural_questions",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] |
question-answering
| false |
vasudevgupta
| null |
vasudevgupta/bigbird-roberta-natural-questions
| 5,143 | 3 |
transformers
| 889 |
---
language: en
license: apache-2.0
datasets: natural_questions
widget:
- text: "Who added BigBird to HuggingFace Transformers?"
context: "BigBird Pegasus just landed! Thanks to Vasudev Gupta, BigBird Pegasus from Google AI is merged into HuggingFace Transformers. Check it out today!!!"
---
This checkpoint is obtained after training `BigBirdForQuestionAnswering` (with extra pooler head) on [`natural_questions`](https://huggingface.co/datasets/natural_questions) dataset for ~ 2 weeks on 2 K80 GPUs. Script for training can be found here: https://github.com/vasudevgupta7/bigbird
| Exact Match | 47.44 |
|-------------|-------|
**Use this model just like any other model from 🤗Transformers**
```python
from transformers import BigBirdForQuestionAnswering
model_id = "vasudevgupta/bigbird-roberta-natural-questions"
model = BigBirdForQuestionAnswering.from_pretrained(model_id)
tokenizer = BigBirdTokenizer.from_pretrained(model_id)
```
In case you are interested in predicting category (null, long, short, yes, no) as well, use `BigBirdForNaturalQuestions` (instead of `BigBirdForQuestionAnswering`) from my training script.
|
Helsinki-NLP/opus-mt-ca-en
|
22113f5e0e8e89677d6e0142e55c85402eecb455
|
2021-09-09T21:28:18.000Z
|
[
"pytorch",
"marian",
"text2text-generation",
"ca",
"en",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] |
translation
| false |
Helsinki-NLP
| null |
Helsinki-NLP/opus-mt-ca-en
| 5,133 | null |
transformers
| 890 |
---
tags:
- translation
license: apache-2.0
---
### opus-mt-ca-en
* source languages: ca
* target languages: en
* OPUS readme: [ca-en](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/ca-en/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2019-12-18.zip](https://object.pouta.csc.fi/OPUS-MT-models/ca-en/opus-2019-12-18.zip)
* test set translations: [opus-2019-12-18.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/ca-en/opus-2019-12-18.test.txt)
* test set scores: [opus-2019-12-18.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/ca-en/opus-2019-12-18.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba.ca.en | 51.4 | 0.678 |
|
sberbank-ai/ruBert-base
|
43be4261797042e172adf7476c558734f3cbb2a0
|
2022-05-08T14:17:32.000Z
|
[
"pytorch",
"bert",
"fill-mask",
"ru",
"transformers",
"PyTorch",
"Transformers",
"exbert",
"license:apache-2.0",
"autotrain_compatible"
] |
fill-mask
| false |
sberbank-ai
| null |
sberbank-ai/ruBert-base
| 5,112 | 5 |
transformers
| 891 |
---
language:
- ru
tags:
- PyTorch
- Transformers
- bert
- exbert
pipeline_tag: fill-mask
thumbnail: "https://github.com/sberbank-ai/model-zoo"
license: apache-2.0
---
# ruBert-large
Model was trained by [SberDevices](https://sberdevices.ru/) team.
* Task: `mask filling`
* Type: `encoder`
* Tokenizer: `bpe`
* Dict size: `120 138`
* Num Parameters: `178 M`
* Training Data Volume `30 GB`
|
Helsinki-NLP/opus-mt-gmq-en
|
74efbe7477ba9acf0bcc143fcad9f5280db2fab4
|
2021-01-18T08:52:51.000Z
|
[
"pytorch",
"marian",
"text2text-generation",
"da",
"nb",
"sv",
"is",
"nn",
"fo",
"gmq",
"en",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] |
translation
| false |
Helsinki-NLP
| null |
Helsinki-NLP/opus-mt-gmq-en
| 5,046 | null |
transformers
| 892 |
---
language:
- da
- nb
- sv
- is
- nn
- fo
- gmq
- en
tags:
- translation
license: apache-2.0
---
### gmq-eng
* source group: North Germanic languages
* target group: English
* OPUS readme: [gmq-eng](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/gmq-eng/README.md)
* model: transformer
* source language(s): dan fao isl nno nob nob_Hebr non_Latn swe
* target language(s): eng
* model: transformer
* pre-processing: normalization + SentencePiece (spm32k,spm32k)
* download original weights: [opus2m-2020-07-26.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/gmq-eng/opus2m-2020-07-26.zip)
* test set translations: [opus2m-2020-07-26.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/gmq-eng/opus2m-2020-07-26.test.txt)
* test set scores: [opus2m-2020-07-26.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/gmq-eng/opus2m-2020-07-26.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba-test.multi.eng | 58.1 | 0.720 |
### System Info:
- hf_name: gmq-eng
- source_languages: gmq
- target_languages: eng
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/gmq-eng/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['da', 'nb', 'sv', 'is', 'nn', 'fo', 'gmq', 'en']
- src_constituents: {'dan', 'nob', 'nob_Hebr', 'swe', 'isl', 'nno', 'non_Latn', 'fao'}
- tgt_constituents: {'eng'}
- src_multilingual: True
- tgt_multilingual: False
- prepro: normalization + SentencePiece (spm32k,spm32k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/gmq-eng/opus2m-2020-07-26.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/gmq-eng/opus2m-2020-07-26.test.txt
- src_alpha3: gmq
- tgt_alpha3: eng
- short_pair: gmq-en
- chrF2_score: 0.72
- bleu: 58.1
- brevity_penalty: 0.982
- ref_len: 72641.0
- src_name: North Germanic languages
- tgt_name: English
- train_date: 2020-07-26
- src_alpha2: gmq
- tgt_alpha2: en
- prefer_old: False
- long_pair: gmq-eng
- helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535
- transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b
- port_machine: brutasse
- port_time: 2020-08-21-14:41
|
facebook/s2t-small-mustc-en-fr-st
|
90bd87c9a36fc51f1acb419760563551671e3b4e
|
2022-02-07T14:44:08.000Z
|
[
"pytorch",
"tf",
"speech_to_text",
"automatic-speech-recognition",
"en",
"fr",
"dataset:mustc",
"arxiv:2010.05171",
"arxiv:1904.08779",
"transformers",
"audio",
"speech-translation",
"license:mit"
] |
automatic-speech-recognition
| false |
facebook
| null |
facebook/s2t-small-mustc-en-fr-st
| 5,026 | 1 |
transformers
| 893 |
---
language:
- en
- fr
datasets:
- mustc
tags:
- audio
- speech-translation
- automatic-speech-recognition
license: mit
pipeline_tag: automatic-speech-recognition
widget:
- example_title: Librispeech sample 1
src: https://cdn-media.huggingface.co/speech_samples/sample1.flac
- example_title: Librispeech sample 2
src: https://cdn-media.huggingface.co/speech_samples/sample2.flac
---
# S2T-SMALL-MUSTC-EN-FR-ST
`s2t-small-mustc-en-fr-st` is a Speech to Text Transformer (S2T) model trained for end-to-end Speech Translation (ST).
The S2T model was proposed in [this paper](https://arxiv.org/abs/2010.05171) and released in
[this repository](https://github.com/pytorch/fairseq/tree/master/examples/speech_to_text)
## Model description
S2T is a transformer-based seq2seq (encoder-decoder) model designed for end-to-end Automatic Speech Recognition (ASR) and Speech
Translation (ST). It uses a convolutional downsampler to reduce the length of speech inputs by 3/4th before they are
fed into the encoder. The model is trained with standard autoregressive cross-entropy loss and generates the
transcripts/translations autoregressively.
## Intended uses & limitations
This model can be used for end-to-end English speech to French text translation.
See the [model hub](https://huggingface.co/models?filter=speech_to_text) to look for other S2T checkpoints.
### How to use
As this a standard sequence to sequence transformer model, you can use the `generate` method to generate the
transcripts by passing the speech features to the model.
*Note: The `Speech2TextProcessor` object uses [torchaudio](https://github.com/pytorch/audio) to extract the
filter bank features. Make sure to install the `torchaudio` package before running this example.*
You could either install those as extra speech dependancies with
`pip install transformers"[speech, sentencepiece]"` or install the packages seperatly
with `pip install torchaudio sentencepiece`.
```python
import torch
from transformers import Speech2TextProcessor, Speech2TextForConditionalGeneration
from datasets import load_dataset
import soundfile as sf
model = Speech2TextForConditionalGeneration.from_pretrained("facebook/s2t-small-mustc-en-fr-st")
processor = Speech2TextProcessor.from_pretrained("facebook/s2t-small-mustc-en-fr-st")
def map_to_array(batch):
speech, _ = sf.read(batch["file"])
batch["speech"] = speech
return batch
ds = load_dataset(
"patrickvonplaten/librispeech_asr_dummy",
"clean",
split="validation"
)
ds = ds.map(map_to_array)
inputs = processor(
ds["speech"][0],
sampling_rate=16_000,
return_tensors="pt"
)
generated_ids = model.generate(input_ids=inputs["input_features"], attention_mask=inputs["attention_mask"])
translation = processor.batch_decode(generated_ids, skip_special_tokens=True)
```
## Training data
The s2t-small-mustc-en-fr-st is trained on English-French subset of [MuST-C](https://ict.fbk.eu/must-c/).
MuST-C is a multilingual speech translation corpus whose size and quality facilitates the training of end-to-end systems
for speech translation from English into several languages. For each target language, MuST-C comprises several hundred
hours of audio recordings from English TED Talks, which are automatically aligned at the sentence level with their manual
transcriptions and translations.
## Training procedure
### Preprocessing
The speech data is pre-processed by extracting Kaldi-compliant 80-channel log mel-filter bank features automatically from
WAV/FLAC audio files via PyKaldi or torchaudio. Further utterance-level CMVN (cepstral mean and variance normalization)
is applied to each example.
The texts are lowercased and tokenized using SentencePiece and a vocabulary size of 8,000.
### Training
The model is trained with standard autoregressive cross-entropy loss and using [SpecAugment](https://arxiv.org/abs/1904.08779).
The encoder receives speech features, and the decoder generates the transcripts autoregressively. To accelerate
model training and for better performance the encoder is pre-trained for English ASR.
## Evaluation results
MuST-C test results for en-fr (BLEU score): 32.9
### BibTeX entry and citation info
```bibtex
@inproceedings{wang2020fairseqs2t,
title = {fairseq S2T: Fast Speech-to-Text Modeling with fairseq},
author = {Changhan Wang and Yun Tang and Xutai Ma and Anne Wu and Dmytro Okhonko and Juan Pino},
booktitle = {Proceedings of the 2020 Conference of the Asian Chapter of the Association for Computational Linguistics (AACL): System Demonstrations},
year = {2020},
}
```
|
theta/MBTI-ckiplab-bert
|
9e9a2f40a3dc8ecb7049937fbf6be5e596e25d6b
|
2022-05-14T13:23:32.000Z
|
[
"pytorch",
"bert",
"text-classification",
"zh",
"transformers",
"MBTI",
"zh-tw",
"generated_from_trainer",
"model-index"
] |
text-classification
| false |
theta
| null |
theta/MBTI-ckiplab-bert
| 5,008 | null |
transformers
| 894 |
---
language:
- zh
tags:
- MBTI
- zh
- zh-tw
- generated_from_trainer
model-index:
- name: MBTI-ckiplab-bert
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# MBTI-ckiplab-bert
This model was trained from scratch on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Framework versions
- Transformers 4.19.1
- Pytorch 1.11.0+cu113
- Datasets 2.2.1
- Tokenizers 0.12.1
|
sivasankalpp/dpr-multidoc2dial-structure-question-encoder
|
b18e46980a1551430338531a09213330d5fd5e96
|
2021-11-10T21:32:20.000Z
|
[
"pytorch",
"dpr",
"feature-extraction",
"transformers"
] |
feature-extraction
| false |
sivasankalpp
| null |
sivasankalpp/dpr-multidoc2dial-structure-question-encoder
| 5,001 | null |
transformers
| 895 |
Entry not found
|
seyonec/SMILES_tokenized_PubChem_shard00_160k
|
f0854db6cbaad4655ce3bb0c073b9ba0199f4a7d
|
2021-05-20T21:08:23.000Z
|
[
"pytorch",
"jax",
"roberta",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
| false |
seyonec
| null |
seyonec/SMILES_tokenized_PubChem_shard00_160k
| 4,987 | null |
transformers
| 896 |
Entry not found
|
savasy/bert-base-turkish-ner-cased
|
d2853558b8a3b19639dce6da2d8a5b6d8f0102a0
|
2021-05-20T04:53:47.000Z
|
[
"pytorch",
"jax",
"bert",
"token-classification",
"tr",
"transformers",
"autotrain_compatible"
] |
token-classification
| false |
savasy
| null |
savasy/bert-base-turkish-ner-cased
| 4,977 | 3 |
transformers
| 897 |
---
language: tr
---
# For Turkish language, here is an easy-to-use NER application.
** Türkçe için kolay bir python NER (Bert + Transfer Learning) (İsim Varlık Tanıma) modeli...
Thanks to @stefan-it, I applied the followings for training
cd tr-data
for file in train.txt dev.txt test.txt labels.txt
do
wget https://schweter.eu/storage/turkish-bert-wikiann/$file
done
cd ..
It will download the pre-processed datasets with training, dev and test splits and put them in a tr-data folder.
Run pre-training
After downloading the dataset, pre-training can be started. Just set the following environment variables:
```
export MAX_LENGTH=128
export BERT_MODEL=dbmdz/bert-base-turkish-cased
export OUTPUT_DIR=tr-new-model
export BATCH_SIZE=32
export NUM_EPOCHS=3
export SAVE_STEPS=625
export SEED=1
```
Then run pre-training:
```
python3 run_ner_old.py --data_dir ./tr-data3 \
--model_type bert \
--labels ./tr-data/labels.txt \
--model_name_or_path $BERT_MODEL \
--output_dir $OUTPUT_DIR-$SEED \
--max_seq_length $MAX_LENGTH \
--num_train_epochs $NUM_EPOCHS \
--per_gpu_train_batch_size $BATCH_SIZE \
--save_steps $SAVE_STEPS \
--seed $SEED \
--do_train \
--do_eval \
--do_predict \
--fp16
```
# Usage
```
from transformers import pipeline, AutoModelForTokenClassification, AutoTokenizer
model = AutoModelForTokenClassification.from_pretrained("savasy/bert-base-turkish-ner-cased")
tokenizer = AutoTokenizer.from_pretrained("savasy/bert-base-turkish-ner-cased")
ner=pipeline('ner', model=model, tokenizer=tokenizer)
ner("Mustafa Kemal Atatürk 19 Mayıs 1919'da Samsun'a ayak bastı.")
```
# Some results
Data1: For the data above
Eval Results:
* precision = 0.916400580551524
* recall = 0.9342309684101502
* f1 = 0.9252298787412536
* loss = 0.11335893666411284
Test Results:
* precision = 0.9192058759362955
* recall = 0.9303010230367262
* f1 = 0.9247201697271198
* loss = 0.11182546521618497
Data2:
https://github.com/stefan-it/turkish-bert/files/4558187/nerdata.txt
The performance for the data given by @kemalaraz is as follows
savas@savas-lenova:~/Desktop/trans/tr-new-model-1$ cat eval_results.txt
* precision = 0.9461980692049029
* recall = 0.959309358847465
* f1 = 0.9527086063783312
* loss = 0.037054269206847804
savas@savas-lenova:~/Desktop/trans/tr-new-model-1$ cat test_results.txt
* precision = 0.9458370635631155
* recall = 0.9588201928530913
* f1 = 0.952284378344882
* loss = 0.035431676572445225
|
SpanBERT/spanbert-base-cased
|
b436fe68816aa04256692ce7e27711bf6be15513
|
2021-05-19T11:30:27.000Z
|
[
"pytorch",
"jax",
"bert",
"transformers"
] | null | false |
SpanBERT
| null |
SpanBERT/spanbert-base-cased
| 4,951 | 2 |
transformers
| 898 |
Entry not found
|
yiyanghkust/finbert-esg
|
26eff66d1942e399ca3ed598894cf0a52915985b
|
2022-06-10T23:19:11.000Z
|
[
"pytorch",
"bert",
"text-classification",
"en",
"transformers",
"financial-text-analysis",
"esg",
"environmental-social-corporate-governance"
] |
text-classification
| false |
yiyanghkust
| null |
yiyanghkust/finbert-esg
| 4,932 | 5 |
transformers
| 899 |
---
language: "en"
tags:
- financial-text-analysis
- esg
- environmental-social-corporate-governance
widget:
- text: "Rhonda has been volunteering for several years for a variety of charitable community programs. "
---
ESG analysis can help investors determine a business' long-term sustainability and identify associated risks. FinBERT-ESG is a FinBERT model fine-tuned on 2,000 manually annotated sentences from firms' ESG reports and annual reports.
**Input**: A financial text.
**Output**: Environmental, Social, Governance or None.
# How to use
You can use this model with Transformers pipeline for ESG classification.
```python
# tested in transformers==4.18.0
from transformers import BertTokenizer, BertForSequenceClassification, pipeline
finbert = BertForSequenceClassification.from_pretrained('yiyanghkust/finbert-esg',num_labels=4)
tokenizer = BertTokenizer.from_pretrained('yiyanghkust/finbert-esg')
nlp = pipeline("text-classification", model=finbert, tokenizer=tokenizer)
results = nlp('Rhonda has been volunteering for several years for a variety of charitable community programs.')
print(results) # [{'label': 'Social', 'score': 0.9906041026115417}]
```
Visit [FinBERT.AI](https://finbert.ai/) for more details on the recent development of FinBERT.
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.