
modelId
stringlengths 4
112
| sha
stringlengths 40
40
| lastModified
stringlengths 24
24
| tags
list | pipeline_tag
stringclasses 29
values | private
bool 1
class | author
stringlengths 2
38
⌀ | config
null | id
stringlengths 4
112
| downloads
float64 0
36.8M
⌀ | likes
float64 0
712
⌀ | library_name
stringclasses 17
values | __index_level_0__
int64 0
38.5k
| readme
stringlengths 0
186k
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
NbAiLab/nb-bert-base
|
82b194c0b3ea1fcad65f1eceee04adb26f9f71ac
|
2021-11-26T12:02:27.000Z
|
[
"pytorch",
"tf",
"jax",
"bert",
"no",
"transformers",
"norwegian",
"license:cc-by-4.0",
"fill-mask"
] |
fill-mask
| false |
NbAiLab
| null |
NbAiLab/nb-bert-base
| 13,659 | 13 |
transformers
| 600 |
---
language: no
license: cc-by-4.0
tags:
- norwegian
- bert
pipeline_tag: fill-mask
widget:
- text: På biblioteket kan du [MASK] en bok.
- text: Dette er et [MASK] eksempel.
- text: Av og til kan en språkmodell gi et [MASK] resultat.
- text: Som ansat får du [MASK] for at bidrage til borgernes adgang til dansk kulturarv, til forskning og til samfundets demokratiske udvikling.
---
- **Release 1.1** (March 11, 2021)
- **Release 1.0** (January 13, 2021)
# NB-BERT-base
## Description
NB-BERT-base is a general BERT-base model built on the large digital collection at the National Library of Norway.
This model is based on the same structure as [BERT Cased multilingual model](https://github.com/google-research/bert/blob/master/multilingual.md), and is trained on a wide variety of Norwegian text (both bokmål and nynorsk) from the last 200 years.
## Intended use & limitations
The 1.1 version of the model is general, and should be fine-tuned for any particular use. Some fine-tuning sets may be found on GitHub, see
* https://github.com/NBAiLab/notram
## Training data
The model is trained on a wide variety of text. The training set is described on
* https://github.com/NBAiLab/notram
## More information
For more information on the model, see
https://github.com/NBAiLab/notram
|
monsoon-nlp/hindi-bert
|
35f95927136cc5ea05db2fb2af1fb1455f5b310e
|
2020-08-26T22:14:33.000Z
|
[
"pytorch",
"tf",
"electra",
"feature-extraction",
"hi",
"transformers"
] |
feature-extraction
| false |
monsoon-nlp
| null |
monsoon-nlp/hindi-bert
| 13,569 | 4 |
transformers
| 601 |
---
language: hi
---
# Releasing Hindi ELECTRA model
This is a first attempt at a Hindi language model trained with Google Research's [ELECTRA](https://github.com/google-research/electra).
**Consider using this newer, larger model: https://huggingface.co/monsoon-nlp/hindi-tpu-electra**
<a href="https://colab.research.google.com/drive/1R8TciRSM7BONJRBc9CBZbzOmz39FTLl_">Tokenization and training CoLab</a>
I originally used <a href="https://github.com/monsoonNLP/transformers">a modified ELECTRA</a> for finetuning, but now use SimpleTransformers.
<a href="https://medium.com/@mapmeld/teaching-hindi-to-electra-b11084baab81">Blog post</a> - I was greatly influenced by: https://huggingface.co/blog/how-to-train
## Example Notebooks
This small model has comparable results to Multilingual BERT on <a href="https://colab.research.google.com/drive/18FQxp9QGOORhMENafQilEmeAo88pqVtP">BBC Hindi news classification</a>
and on <a href="https://colab.research.google.com/drive/1UYn5Th8u7xISnPUBf72at1IZIm3LEDWN">Hindi movie reviews / sentiment analysis</a> (using SimpleTransformers)
You can get higher accuracy using ktrain by adjusting learning rate (also: changing model_type in config.json - this is an open issue with ktrain): https://colab.research.google.com/drive/1mSeeSfVSOT7e-dVhPlmSsQRvpn6xC05w?usp=sharing
Question-answering on MLQA dataset: https://colab.research.google.com/drive/1i6fidh2tItf_-IDkljMuaIGmEU6HT2Ar#scrollTo=IcFoAHgKCUiQ
A larger model (<a href="https://huggingface.co/monsoon-nlp/hindi-tpu-electra">Hindi-TPU-Electra</a>) using ELECTRA base size outperforms both models on Hindi movie reviews / sentiment analysis, but
does not perform as well on the BBC news classification task.
## Corpus
Download: https://drive.google.com/drive/folders/1SXzisKq33wuqrwbfp428xeu_hDxXVUUu?usp=sharing
The corpus is two files:
- Hindi CommonCrawl deduped by OSCAR https://traces1.inria.fr/oscar/
- latest Hindi Wikipedia ( https://dumps.wikimedia.org/hiwiki/ ) + WikiExtractor to txt
Bonus notes:
- Adding English wiki text or parallel corpus could help with cross-lingual tasks and training
## Vocabulary
https://drive.google.com/file/d/1-6tXrii3tVxjkbrpSJE9MOG_HhbvP66V/view?usp=sharing
Bonus notes:
- Created with HuggingFace Tokenizers; you can increase vocabulary size and re-train; remember to change ELECTRA vocab_size
## Training
Structure your files, with data-dir named "trainer" here
```
trainer
- vocab.txt
- pretrain_tfrecords
-- (all .tfrecord... files)
- models
-- modelname
--- checkpoint
--- graph.pbtxt
--- model.*
```
CoLab notebook gives examples of GPU vs. TPU setup
[configure_pretraining.py](https://github.com/google-research/electra/blob/master/configure_pretraining.py)
## Conversion
Use this process to convert an in-progress or completed ELECTRA checkpoint to a Transformers-ready model:
```
git clone https://github.com/huggingface/transformers
python ./transformers/src/transformers/convert_electra_original_tf_checkpoint_to_pytorch.py
--tf_checkpoint_path=./models/checkpointdir
--config_file=config.json
--pytorch_dump_path=pytorch_model.bin
--discriminator_or_generator=discriminator
python
```
```
from transformers import TFElectraForPreTraining
model = TFElectraForPreTraining.from_pretrained("./dir_with_pytorch", from_pt=True)
model.save_pretrained("tf")
```
Once you have formed one directory with config.json, pytorch_model.bin, tf_model.h5, special_tokens_map.json, tokenizer_config.json, and vocab.txt on the same level, run:
```
transformers-cli upload directory
```
|
facebook/deit-base-distilled-patch16-224
|
a0fc9b37fdb63c112e76104f669208784ecfe4ea
|
2022-07-13T11:39:38.000Z
|
[
"pytorch",
"tf",
"deit",
"image-classification",
"dataset:imagenet",
"arxiv:2012.12877",
"arxiv:2006.03677",
"transformers",
"vision",
"license:apache-2.0"
] |
image-classification
| false |
facebook
| null |
facebook/deit-base-distilled-patch16-224
| 13,553 | 11 |
transformers
| 602 |
---
license: apache-2.0
tags:
- image-classification
- vision
datasets:
- imagenet
---
# Distilled Data-efficient Image Transformer (base-sized model)
Distilled data-efficient Image Transformer (DeiT) model pre-trained and fine-tuned on ImageNet-1k (1 million images, 1,000 classes) at resolution 224x224. It was first introduced in the paper [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Touvron et al. and first released in [this repository](https://github.com/facebookresearch/deit). However, the weights were converted from the [timm repository](https://github.com/rwightman/pytorch-image-models) by Ross Wightman.
Disclaimer: The team releasing DeiT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
This model is a distilled Vision Transformer (ViT). It uses a distillation token, besides the class token, to effectively learn from a teacher (CNN) during both pre-training and fine-tuning. The distillation token is learned through backpropagation, by interacting with the class ([CLS]) and patch tokens through the self-attention layers.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=facebook/deit) to look for
fine-tuned versions on a task that interests you.
### How to use
Since this model is a distilled ViT model, you can plug it into DeiTModel, DeiTForImageClassification or DeiTForImageClassificationWithTeacher. Note that the model expects the data to be prepared using DeiTFeatureExtractor. Here we use AutoFeatureExtractor, which will automatically use the appropriate feature extractor given the model name.
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import AutoFeatureExtractor, DeiTForImageClassificationWithTeacher
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = AutoFeatureExtractor.from_pretrained('facebook/deit-base-distilled-patch16-224')
model = DeiTForImageClassificationWithTeacher.from_pretrained('facebook/deit-base-distilled-patch16-224')
inputs = feature_extractor(images=image, return_tensors="pt")
# forward pass
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
Currently, both the feature extractor and model support PyTorch. Tensorflow and JAX/FLAX are coming soon.
## Training data
This model was pretrained and fine-tuned with distillation on [ImageNet-1k](http://www.image-net.org/challenges/LSVRC/2012/), a dataset consisting of 1 million images and 1k classes.
## Training procedure
### Preprocessing
The exact details of preprocessing of images during training/validation can be found [here](https://github.com/facebookresearch/deit/blob/ab5715372db8c6cad5740714b2216d55aeae052e/datasets.py#L78).
At inference time, images are resized/rescaled to the same resolution (256x256), center-cropped at 224x224 and normalized across the RGB channels with the ImageNet mean and standard deviation.
### Pretraining
The model was trained on a single 8-GPU node for 3 days. Training resolution is 224. For all hyperparameters (such as batch size and learning rate) we refer to table 9 of the original paper.
## Evaluation results
| Model | ImageNet top-1 accuracy | ImageNet top-5 accuracy | # params | URL |
|---------------------------------------|-------------------------|-------------------------|----------|------------------------------------------------------------------|
| DeiT-tiny | 72.2 | 91.1 | 5M | https://huggingface.co/facebook/deit-tiny-patch16-224 |
| DeiT-small | 79.9 | 95.0 | 22M | https://huggingface.co/facebook/deit-small-patch16-224 |
| DeiT-base | 81.8 | 95.6 | 86M | https://huggingface.co/facebook/deit-base-patch16-224 |
| DeiT-tiny distilled | 74.5 | 91.9 | 6M | https://huggingface.co/facebook/deit-tiny-distilled-patch16-224 |
| DeiT-small distilled | 81.2 | 95.4 | 22M | https://huggingface.co/facebook/deit-small-distilled-patch16-224 |
| **DeiT-base distilled** | **83.4** | **96.5** | **87M** | **https://huggingface.co/facebook/deit-base-distilled-patch16-224** |
| DeiT-base 384 | 82.9 | 96.2 | 87M | https://huggingface.co/facebook/deit-base-patch16-384 |
| DeiT-base distilled 384 (1000 epochs) | 85.2 | 97.2 | 88M | https://huggingface.co/facebook/deit-base-distilled-patch16-384 |
Note that for fine-tuning, the best results are obtained with a higher resolution (384x384). Of course, increasing the model size will result in better performance.
### BibTeX entry and citation info
```bibtex
@misc{touvron2021training,
title={Training data-efficient image transformers & distillation through attention},
author={Hugo Touvron and Matthieu Cord and Matthijs Douze and Francisco Massa and Alexandre Sablayrolles and Hervé Jégou},
year={2021},
eprint={2012.12877},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
```bibtex
@misc{wu2020visual,
title={Visual Transformers: Token-based Image Representation and Processing for Computer Vision},
author={Bichen Wu and Chenfeng Xu and Xiaoliang Dai and Alvin Wan and Peizhao Zhang and Zhicheng Yan and Masayoshi Tomizuka and Joseph Gonzalez and Kurt Keutzer and Peter Vajda},
year={2020},
eprint={2006.03677},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
```bibtex
@inproceedings{deng2009imagenet,
title={Imagenet: A large-scale hierarchical image database},
author={Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li},
booktitle={2009 IEEE conference on computer vision and pattern recognition},
pages={248--255},
year={2009},
organization={Ieee}
}
```
|
sshleifer/distilbart-xsum-1-1
|
891968fcbb0e421075cc2c3dfc8da8d4b24d54a4
|
2021-06-14T07:53:57.000Z
|
[
"pytorch",
"tf",
"jax",
"bart",
"text2text-generation",
"en",
"dataset:cnn_dailymail",
"dataset:xsum",
"transformers",
"summarization",
"license:apache-2.0",
"autotrain_compatible"
] |
summarization
| false |
sshleifer
| null |
sshleifer/distilbart-xsum-1-1
| 13,547 | null |
transformers
| 603 |
---
language: en
tags:
- summarization
license: apache-2.0
datasets:
- cnn_dailymail
- xsum
thumbnail: https://huggingface.co/front/thumbnails/distilbart_medium.png
---
### Usage
This checkpoint should be loaded into `BartForConditionalGeneration.from_pretrained`. See the [BART docs](https://huggingface.co/transformers/model_doc/bart.html?#transformers.BartForConditionalGeneration) for more information.
### Metrics for DistilBART models
| Model Name | MM Params | Inference Time (MS) | Speedup | Rouge 2 | Rouge-L |
|:---------------------------|------------:|----------------------:|----------:|----------:|----------:|
| distilbart-xsum-12-1 | 222 | 90 | 2.54 | 18.31 | 33.37 |
| distilbart-xsum-6-6 | 230 | 132 | 1.73 | 20.92 | 35.73 |
| distilbart-xsum-12-3 | 255 | 106 | 2.16 | 21.37 | 36.39 |
| distilbart-xsum-9-6 | 268 | 136 | 1.68 | 21.72 | 36.61 |
| bart-large-xsum (baseline) | 406 | 229 | 1 | 21.85 | 36.50 |
| distilbart-xsum-12-6 | 306 | 137 | 1.68 | 22.12 | 36.99 |
| bart-large-cnn (baseline) | 406 | 381 | 1 | 21.06 | 30.63 |
| distilbart-12-3-cnn | 255 | 214 | 1.78 | 20.57 | 30.00 |
| distilbart-12-6-cnn | 306 | 307 | 1.24 | 21.26 | 30.59 |
| distilbart-6-6-cnn | 230 | 182 | 2.09 | 20.17 | 29.70 |
|
pysentimiento/robertuito-hate-speech
|
272493f45c85fd9b6590716d0206443f2ce79731
|
2021-12-02T21:50:23.000Z
|
[
"pytorch",
"roberta",
"text-classification",
"es",
"arxiv:2106.09462",
"arxiv:2111.09453",
"transformers",
"twitter",
"hate-speech"
] |
text-classification
| false |
pysentimiento
| null |
pysentimiento/robertuito-hate-speech
| 13,537 | 3 |
transformers
| 604 |
---
language:
- es
tags:
- twitter
- hate-speech
---
# Hate Speech detection in Spanish
## robertuito-hate-speech
Repository: [https://github.com/pysentimiento/pysentimiento/](https://github.com/finiteautomata/pysentimiento/)
Model trained with SemEval 2019 Task 5: HatEval (SubTask B) corpus for Hate Speech detection in Spanish. Base model is [RoBERTuito](https://github.com/pysentimiento/robertuito), a RoBERTa model trained in Spanish tweets.
It is a multi-classifier model, with the following classes:
- **HS**: is it hate speech?
- **TR**: is it targeted to a specific individual?
- **AG**: is it aggressive?
## Results
Results for the four tasks evaluated in `pysentimiento`. Results are expressed as Macro F1 scores
| model | emotion | hate_speech | irony | sentiment |
|:--------------|:--------------|:--------------|:--------------|:--------------|
| robertuito | 0.560 ± 0.010 | 0.759 ± 0.007 | 0.739 ± 0.005 | 0.705 ± 0.003 |
| roberta | 0.527 ± 0.015 | 0.741 ± 0.012 | 0.721 ± 0.008 | 0.670 ± 0.006 |
| bertin | 0.524 ± 0.007 | 0.738 ± 0.007 | 0.713 ± 0.012 | 0.666 ± 0.005 |
| beto_uncased | 0.532 ± 0.012 | 0.727 ± 0.016 | 0.701 ± 0.007 | 0.651 ± 0.006 |
| beto_cased | 0.516 ± 0.012 | 0.724 ± 0.012 | 0.705 ± 0.009 | 0.662 ± 0.005 |
| mbert_uncased | 0.493 ± 0.010 | 0.718 ± 0.011 | 0.681 ± 0.010 | 0.617 ± 0.003 |
| biGRU | 0.264 ± 0.007 | 0.592 ± 0.018 | 0.631 ± 0.011 | 0.585 ± 0.011 |
Note that for Hate Speech, these are the results for Semeval 2019, Task 5 Subtask B (HS+TR+AG detection)
## Citation
If you use this model in your research, please cite pysentimiento, RoBERTuito and HatEval papers:
```
% Pysentimiento
@misc{perez2021pysentimiento,
title={pysentimiento: A Python Toolkit for Sentiment Analysis and SocialNLP tasks},
author={Juan Manuel Pérez and Juan Carlos Giudici and Franco Luque},
year={2021},
eprint={2106.09462},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
% RoBERTuito paper
@misc{perez2021robertuito,
title={RoBERTuito: a pre-trained language model for social media text in Spanish},
author={Juan Manuel Pérez and Damián A. Furman and Laura Alonso Alemany and Franco Luque},
year={2021},
eprint={2111.09453},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
% HatEval paper
@inproceedings{hateval2019semeval,
title={SemEval-2019 Task 5: Multilingual Detection of Hate Speech Against Immigrants and Women in Twitter},
author={Basile, Valerio and Bosco, Cristina and Fersini, Elisabetta and Nozza, Debora and Patti, Viviana and Rangel, Francisco and Rosso, Paolo and Sanguinetti, Manuela},
booktitle={Proceedings of the 13th International Workshop on Semantic Evaluation (SemEval-2019)},
year={2019},
publisher= {Association for Computational Linguistics}
}
```
|
xlnet-large-cased
|
09792d2c42dfb606155f1bea8873260b23887edd
|
2021-09-16T09:45:20.000Z
|
[
"pytorch",
"tf",
"xlnet",
"text-generation",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1906.08237",
"transformers",
"license:mit"
] |
text-generation
| false | null | null |
xlnet-large-cased
| 13,523 | 1 |
transformers
| 605 |
---
language: en
license: mit
datasets:
- bookcorpus
- wikipedia
---
# XLNet (large-sized model)
XLNet model pre-trained on English language. It was introduced in the paper [XLNet: Generalized Autoregressive Pretraining for Language Understanding](https://arxiv.org/abs/1906.08237) by Yang et al. and first released in [this repository](https://github.com/zihangdai/xlnet/).
Disclaimer: The team releasing XLNet did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
XLNet is a new unsupervised language representation learning method based on a novel generalized permutation language modeling objective. Additionally, XLNet employs Transformer-XL as the backbone model, exhibiting excellent performance for language tasks involving long context. Overall, XLNet achieves state-of-the-art (SOTA) results on various downstream language tasks including question answering, natural language inference, sentiment analysis, and document ranking.
## Intended uses & limitations
The model is mostly intended to be fine-tuned on a downstream task. See the [model hub](https://huggingface.co/models?search=xlnet) to look for fine-tuned versions on a task that interests you.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked) to make decisions, such as sequence classification, token classification or question answering. For tasks such as text generation, you should look at models like GPT2.
## Usage
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import XLNetTokenizer, XLNetModel
tokenizer = XLNetTokenizer.from_pretrained('xlnet-large-cased')
model = XLNetModel.from_pretrained('xlnet-large-cased')
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state
```
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-1906-08237,
author = {Zhilin Yang and
Zihang Dai and
Yiming Yang and
Jaime G. Carbonell and
Ruslan Salakhutdinov and
Quoc V. Le},
title = {XLNet: Generalized Autoregressive Pretraining for Language Understanding},
journal = {CoRR},
volume = {abs/1906.08237},
year = {2019},
url = {http://arxiv.org/abs/1906.08237},
eprinttype = {arXiv},
eprint = {1906.08237},
timestamp = {Mon, 24 Jun 2019 17:28:45 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-1906-08237.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
j-hartmann/sentiment-roberta-large-english-3-classes
|
f995433eb6d79d26702ab9335bfde472a9933ee4
|
2022-02-06T12:26:00.000Z
|
[
"pytorch",
"roberta",
"text-classification",
"en",
"transformers",
"sentiment",
"twitter"
] |
text-classification
| false |
j-hartmann
| null |
j-hartmann/sentiment-roberta-large-english-3-classes
| 13,452 | 3 |
transformers
| 606 |
---
language: "en"
tags:
- roberta
- sentiment
- twitter
widget:
- text: "Oh no. This is bad.."
- text: "To be or not to be."
- text: "Oh Happy Day"
---
This RoBERTa-based model can classify the sentiment of English language text in 3 classes:
- positive 😀
- neutral 😐
- negative 🙁
The model was fine-tuned on 5,304 manually annotated social media posts.
The hold-out accuracy is 86.1%.
For details on the training approach see Web Appendix F in Hartmann et al. (2021).
# Application
```python
from transformers import pipeline
classifier = pipeline("text-classification", model="j-hartmann/sentiment-roberta-large-english-3-classes", return_all_scores=True)
classifier("This is so nice!")
```
```python
Output:
[[{'label': 'negative', 'score': 0.00016451838018838316},
{'label': 'neutral', 'score': 0.000174045650055632},
{'label': 'positive', 'score': 0.9996614456176758}]]
```
# Reference
Please cite [this paper](https://journals.sagepub.com/doi/full/10.1177/00222437211037258) when you use our model. Feel free to reach out to [[email protected]](mailto:[email protected]) with any questions or feedback you may have.
```
@article{hartmann2021,
title={The Power of Brand Selfies},
author={Hartmann, Jochen and Heitmann, Mark and Schamp, Christina and Netzer, Oded},
journal={Journal of Marketing Research}
year={2021}
}
```
|
sultan/BioM-ELECTRA-Large-Discriminator
|
dac81e9477f7f7e00b2dc79574500fb3072e59c7
|
2021-10-12T21:25:07.000Z
|
[
"pytorch",
"electra",
"pretraining",
"transformers"
] | null | false |
sultan
| null |
sultan/BioM-ELECTRA-Large-Discriminator
| 13,387 | 1 |
transformers
| 607 |
# BioM-Transformers: Building Large Biomedical Language Models with BERT, ALBERT and ELECTRA
# Abstract
The impact of design choices on the performance
of biomedical language models recently
has been a subject for investigation. In
this paper, we empirically study biomedical
domain adaptation with large transformer models
using different design choices. We evaluate
the performance of our pretrained models
against other existing biomedical language
models in the literature. Our results show that
we achieve state-of-the-art results on several
biomedical domain tasks despite using similar
or less computational cost compared to other
models in the literature. Our findings highlight
the significant effect of design choices on
improving the performance of biomedical language
models.
# Model Description
This model was pre-trained on PubMed Abstracts only with biomedical domain vocabulary for 434K steps with a batch size of 4096 on TPUv3-512 unit.
In order to help researchers with limited resources to fine-tune larger models, we created an example with PyTorch XLA. PyTorch XLA (https://github.com/pytorch/xla) is a library that allows you to use PyTorch on TPU units, which is provided for free by Google Colab and Kaggle. Follow this example to work with PyTorch/XLA [Link](https://github.com/salrowili/BioM-Transformers/blob/main/examples/Fine_Tuning_Biomedical_Models_on_Text_Classification_Task_With_HuggingFace_Transformers_and_PyTorch_XLA.ipynb)
Check our GitHub repo at https://github.com/salrowili/BioM-Transformers for TensorFlow and GluonNLP checkpoints. We also updated this repo with a couple of examples on how to fine-tune LMs on text classification and questions answering tasks such as ChemProt, SQuAD, and BioASQ.
# Colab Notebook Examples
BioM-ELECTRA-LARGE on NER and ChemProt Task [![Open In Colab][COLAB]](https://colab.research.google.com/github/salrowili/BioM-Transformers/blob/main/examples/Example_of_NER_and_ChemProt_Task_on_TPU.ipynb)
BioM-ELECTRA-Large on SQuAD2.0 and BioASQ7B Factoid tasks [![Open In Colab][COLAB]](https://colab.research.google.com/github/salrowili/BioM-Transformers/blob/main/examples/Example_of_SQuAD2_0_and_BioASQ7B_tasks_with_BioM_ELECTRA_Large_on_TPU.ipynb)
BioM-ALBERT-xxlarge on SQuAD2.0 and BioASQ7B Factoid tasks [![Open In Colab][COLAB]](https://colab.research.google.com/github/salrowili/BioM-Transformers/blob/main/examples/Example_of_SQuAD2_0_and_BioASQ7B_tasks_with_BioM_ALBERT_xxlarge_on_TPU.ipynb)
Text Classification Task With HuggingFace Transformers and PyTorchXLA on Free TPU [![Open In Colab][COLAB]](https://colab.research.google.com/github/salrowili/BioM-Transformers/blob/main/examples/Fine_Tuning_Biomedical_Models_on_Text_Classification_Task_With_HuggingFace_Transformers_and_PyTorch_XLA.ipynb)
[COLAB]: https://colab.research.google.com/assets/colab-badge.svg
# Acknowledgment
We would like to acknowledge the support we have from Tensorflow Research Cloud (TFRC) team to grant us access to TPUv3 units.
# Citation
```bibtex
@inproceedings{alrowili-shanker-2021-biom,
title = "{B}io{M}-Transformers: Building Large Biomedical Language Models with {BERT}, {ALBERT} and {ELECTRA}",
author = "Alrowili, Sultan and
Shanker, Vijay",
booktitle = "Proceedings of the 20th Workshop on Biomedical Language Processing",
month = jun,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2021.bionlp-1.24",
pages = "221--227",
abstract = "The impact of design choices on the performance of biomedical language models recently has been a subject for investigation. In this paper, we empirically study biomedical domain adaptation with large transformer models using different design choices. We evaluate the performance of our pretrained models against other existing biomedical language models in the literature. Our results show that we achieve state-of-the-art results on several biomedical domain tasks despite using similar or less computational cost compared to other models in the literature. Our findings highlight the significant effect of design choices on improving the performance of biomedical language models.",
}
```
|
nghuyong/ernie-2.0-large-en
|
4770fb35e20abf0e2ed2ba0a70faec4fc55b5d2b
|
2021-05-20T01:45:21.000Z
|
[
"pytorch",
"tf",
"jax",
"bert",
"arxiv:1907.12412",
"transformers"
] | null | false |
nghuyong
| null |
nghuyong/ernie-2.0-large-en
| 13,381 | 3 |
transformers
| 608 |
# ERNIE-2.0-large
## Introduction
ERNIE 2.0 is a continual pre-training framework proposed by Baidu in 2019,
which builds and learns incrementally pre-training tasks through constant multi-task learning.
Experimental results demonstrate that ERNIE 2.0 outperforms BERT and XLNet on 16 tasks including English tasks on GLUE benchmarks and several common tasks in Chinese.
More detail: https://arxiv.org/abs/1907.12412
## Released Model Info
|Model Name|Language|Model Structure|
|:---:|:---:|:---:|
|ernie-2.0-large-en| English |Layer:24, Hidden:1024, Heads:16|
This released pytorch model is converted from the officially released PaddlePaddle ERNIE model and
a series of experiments have been conducted to check the accuracy of the conversion.
- Official PaddlePaddle ERNIE repo: https://github.com/PaddlePaddle/ERNIE
- Pytorch Conversion repo: https://github.com/nghuyong/ERNIE-Pytorch
## How to use
```Python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("nghuyong/ernie-2.0-large-en")
model = AutoModel.from_pretrained("nghuyong/ernie-2.0-large-en")
```
## Citation
```bibtex
@article{sun2019ernie20,
title={ERNIE 2.0: A Continual Pre-training Framework for Language Understanding},
author={Sun, Yu and Wang, Shuohuan and Li, Yukun and Feng, Shikun and Tian, Hao and Wu, Hua and Wang, Haifeng},
journal={arXiv preprint arXiv:1907.12412},
year={2019}
}
```
|
PlanTL-GOB-ES/roberta-large-bne
|
e30d1acb98f8cd8339e31464ffdb35413ac5a003
|
2022-04-06T14:41:03.000Z
|
[
"pytorch",
"roberta",
"fill-mask",
"es",
"dataset:bne",
"arxiv:1907.11692",
"arxiv:2107.07253",
"transformers",
"national library of spain",
"spanish",
"bne",
"license:apache-2.0",
"autotrain_compatible"
] |
fill-mask
| false |
PlanTL-GOB-ES
| null |
PlanTL-GOB-ES/roberta-large-bne
| 13,312 | 5 |
transformers
| 609 |
---
language:
- es
license: apache-2.0
tags:
- "national library of spain"
- "spanish"
- "bne"
datasets:
- "bne"
metrics:
- "ppl"
widget:
- text: "Este año las campanadas de La Sexta las <mask> Pedroche y Chicote."
- text: "El artista Antonio Orozco es un colaborador de La <mask>."
- text: "Gracias a los datos de la BNE se ha podido <mask> este modelo del lenguaje."
- text: "Hay base legal dentro del marco <mask> actual."
---
# RoBERTa large trained with data from National Library of Spain (BNE)
## Model Description
RoBERTa-large-bne is a transformer-based masked language model for the Spanish language. It is based on the [RoBERTa](https://arxiv.org/abs/1907.11692) large model and has been pre-trained using the largest Spanish corpus known to date, with a total of 570GB of clean and deduplicated text processed for this work, compiled from the web crawlings performed by the [National Library of Spain (Biblioteca Nacional de España)](http://www.bne.es/en/Inicio/index.html) from 2009 to 2019.
## Training corpora and preprocessing
The [National Library of Spain (Biblioteca Nacional de España)](http://www.bne.es/en/Inicio/index.html) crawls all .es domains once a year. The training corpus consists of 59TB of WARC files from these crawls, carried out from 2009 to 2019.
To obtain a high-quality training corpus, the corpus has been preprocessed with a pipeline of operations, including among the others, sentence splitting, language detection, filtering of bad-formed sentences and deduplication of repetitive contents. During the process document boundaries are kept. This resulted into 2TB of Spanish clean corpus. Further global deduplication among the corpus is applied, resulting into 570GB of text.
Some of the statistics of the corpus:
| Corpora | Number of documents | Number of tokens | Size (GB) |
|---------|---------------------|------------------|-----------|
| BNE | 201,080,084 | 135,733,450,668 | 570GB |
## Tokenization and pre-training
The training corpus has been tokenized using a byte version of Byte-Pair Encoding (BPE) used in the original [RoBERTA](https://arxiv.org/abs/1907.11692) model with a vocabulary size of 50,262 tokens. The RoBERTa-large-bne pre-training consists of a masked language model training that follows the approach employed for the RoBERTa large. The training lasted a total of 96 hours with 32 computing nodes each one with 4 NVIDIA V100 GPUs of 16GB VRAM.
## Evaluation and results
For evaluation details visit our [GitHub repository](https://github.com/PlanTL-GOB-ES/lm-spanish).
## Citing
Check out our paper for all the details: https://arxiv.org/abs/2107.07253
```
@article{gutierrezfandino2022,
author = {Asier Gutiérrez-Fandiño and Jordi Armengol-Estapé and Marc Pàmies and Joan Llop-Palao and Joaquin Silveira-Ocampo and Casimiro Pio Carrino and Carme Armentano-Oller and Carlos Rodriguez-Penagos and Aitor Gonzalez-Agirre and Marta Villegas},
title = {MarIA: Spanish Language Models},
journal = {Procesamiento del Lenguaje Natural},
volume = {68},
number = {0},
year = {2022},
issn = {1989-7553},
url = {http://journal.sepln.org/sepln/ojs/ojs/index.php/pln/article/view/6405},
pages = {39--60}
}
```
## Funding
This work was funded by the Spanish State Secretariat for Digitalization and Artificial Intelligence (SEDIA) within the framework of the Plan-TL.
## Disclaimer
The models published in this repository are intended for a generalist purpose and are available to third parties. These models may have bias and/or any other undesirable distortions.
When third parties, deploy or provide systems and/or services to other parties using any of these models (or using systems based on these models) or become users of the models, they should note that it is their responsibility to mitigate the risks arising from their use and, in any event, to comply with applicable regulations, including regulations regarding the use of artificial intelligence.
In no event shall the owner of the models (SEDIA – State Secretariat for digitalization and artificial intelligence) nor the creator (BSC – Barcelona Supercomputing Center) be liable for any results arising from the use made by third parties of these models.
Los modelos publicados en este repositorio tienen una finalidad generalista y están a disposición de terceros. Estos modelos pueden tener sesgos y/u otro tipo de distorsiones indeseables.
Cuando terceros desplieguen o proporcionen sistemas y/o servicios a otras partes usando alguno de estos modelos (o utilizando sistemas basados en estos modelos) o se conviertan en usuarios de los modelos, deben tener en cuenta que es su responsabilidad mitigar los riesgos derivados de su uso y, en todo caso, cumplir con la normativa aplicable, incluyendo la normativa en materia de uso de inteligencia artificial.
En ningún caso el propietario de los modelos (SEDIA – Secretaría de Estado de Digitalización e Inteligencia Artificial) ni el creador (BSC – Barcelona Supercomputing Center) serán responsables de los resultados derivados del uso que hagan terceros de estos modelos.
|
naver/splade-cocondenser-ensembledistil
|
25178a62708a3ab1b5c4b5eb30764d65bfddcfbb
|
2022-05-11T08:05:37.000Z
|
[
"pytorch",
"bert",
"fill-mask",
"en",
"dataset:ms_marco",
"arxiv:2205.04733",
"transformers",
"splade",
"query-expansion",
"document-expansion",
"bag-of-words",
"passage-retrieval",
"knowledge-distillation",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible"
] |
fill-mask
| false |
naver
| null |
naver/splade-cocondenser-ensembledistil
| 13,295 | 6 |
transformers
| 610 |
---
license: cc-by-nc-sa-4.0
language: "en"
tags:
- splade
- query-expansion
- document-expansion
- bag-of-words
- passage-retrieval
- knowledge-distillation
datasets:
- ms_marco
---
## SPLADE CoCondenser EnsembleDistil
SPLADE model for passage retrieval. For additional details, please visit:
* paper: https://arxiv.org/abs/2205.04733
* code: https://github.com/naver/splade
| | MRR@10 (MS MARCO dev) | R@1000 (MS MARCO dev) |
| --- | --- | --- |
| `splade-cocondenser-ensembledistil` | 38.3 | 98.3 |
## Citation
If you use our checkpoint, please cite our work:
```
@misc{https://doi.org/10.48550/arxiv.2205.04733,
doi = {10.48550/ARXIV.2205.04733},
url = {https://arxiv.org/abs/2205.04733},
author = {Formal, Thibault and Lassance, Carlos and Piwowarski, Benjamin and Clinchant, Stéphane},
keywords = {Information Retrieval (cs.IR), Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {From Distillation to Hard Negative Sampling: Making Sparse Neural IR Models More Effective},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution Non Commercial Share Alike 4.0 International}
}
```
|
microsoft/beit-base-patch16-224-pt22k-ft22k
|
e10357ec82ca7a0de830c20ffc715b6c33cde963
|
2022-01-28T10:17:47.000Z
|
[
"pytorch",
"jax",
"beit",
"image-classification",
"dataset:imagenet",
"dataset:imagenet-21k",
"arxiv:2106.08254",
"transformers",
"vision",
"license:apache-2.0"
] |
image-classification
| false |
microsoft
| null |
microsoft/beit-base-patch16-224-pt22k-ft22k
| 13,243 | 6 |
transformers
| 611 |
---
license: apache-2.0
tags:
- image-classification
- vision
datasets:
- imagenet
- imagenet-21k
---
# BEiT (base-sized model, fine-tuned on ImageNet-22k)
BEiT model pre-trained in a self-supervised fashion on ImageNet-22k - also called ImageNet-21k (14 million images, 21,841 classes) at resolution 224x224, and fine-tuned on the same dataset at resolution 224x224. It was introduced in the paper [BEIT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) by Hangbo Bao, Li Dong and Furu Wei and first released in [this repository](https://github.com/microsoft/unilm/tree/master/beit).
Disclaimer: The team releasing BEiT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The BEiT model is a Vision Transformer (ViT), which is a transformer encoder model (BERT-like). In contrast to the original ViT model, BEiT is pretrained on a large collection of images in a self-supervised fashion, namely ImageNet-21k, at a resolution of 224x224 pixels. The pre-training objective for the model is to predict visual tokens from the encoder of OpenAI's DALL-E's VQ-VAE, based on masked patches.
Next, the model was fine-tuned in a supervised fashion on ImageNet (also referred to as ILSVRC2012), a dataset comprising 1 million images and 1,000 classes, also at resolution 224x224.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. Contrary to the original ViT models, BEiT models do use relative position embeddings (similar to T5) instead of absolute position embeddings, and perform classification of images by mean-pooling the final hidden states of the patches, instead of placing a linear layer on top of the final hidden state of the [CLS] token.
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire image. Alternatively, one can mean-pool the final hidden states of the patch embeddings, and place a linear layer on top of that.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=microsoft/beit) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import BeitFeatureExtractor, BeitForImageClassification
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = BeitFeatureExtractor.from_pretrained('microsoft/beit-base-patch16-224-pt22k-ft22k')
model = BeitForImageClassification.from_pretrained('microsoft/beit-base-patch16-224-pt22k-ft22k')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 21,841 ImageNet-22k classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
Currently, both the feature extractor and model support PyTorch.
## Training data
The BEiT model was pretrained on [ImageNet-21k](http://www.image-net.org/), a dataset consisting of 14 million images and 21k classes, and fine-tuned on the same dataset.
## Training procedure
### Preprocessing
The exact details of preprocessing of images during training/validation can be found [here](https://github.com/microsoft/unilm/blob/master/beit/datasets.py).
Images are resized/rescaled to the same resolution (224x224) and normalized across the RGB channels with mean (0.5, 0.5, 0.5) and standard deviation (0.5, 0.5, 0.5).
### Pretraining
For all pre-training related hyperparameters, we refer to page 15 of the [original paper](https://arxiv.org/abs/2106.08254).
## Evaluation results
For evaluation results on several image classification benchmarks, we refer to tables 1 and 2 of the original paper. Note that for fine-tuning, the best results are obtained with a higher resolution. Of course, increasing the model size will result in better performance.
### BibTeX entry and citation info
```@article{DBLP:journals/corr/abs-2106-08254,
author = {Hangbo Bao and
Li Dong and
Furu Wei},
title = {BEiT: {BERT} Pre-Training of Image Transformers},
journal = {CoRR},
volume = {abs/2106.08254},
year = {2021},
url = {https://arxiv.org/abs/2106.08254},
archivePrefix = {arXiv},
eprint = {2106.08254},
timestamp = {Tue, 29 Jun 2021 16:55:04 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2106-08254.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
```bibtex
@inproceedings{deng2009imagenet,
title={Imagenet: A large-scale hierarchical image database},
author={Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li},
booktitle={2009 IEEE conference on computer vision and pattern recognition},
pages={248--255},
year={2009},
organization={Ieee}
}
```
|
KoboldAI/fairseq-dense-13B-Nerys-v2
|
45d7cf7f2a4f285bbe36a3421f2497c925f86ef4
|
2022-06-25T11:07:32.000Z
|
[
"pytorch",
"xglm",
"text-generation",
"en",
"transformers",
"license:mit"
] |
text-generation
| false |
KoboldAI
| null |
KoboldAI/fairseq-dense-13B-Nerys-v2
| 13,190 | null |
transformers
| 612 |
---
language: en
license: mit
---
# Fairseq-dense 13B - Nerys
## Model Description
Fairseq-dense 13B-Nerys is a finetune created using Fairseq's MoE dense model.
## Training data
The training data contains around 2500 ebooks in various genres (the "Pike" dataset), a CYOA dataset called "CYS" and 50 Asian "Light Novels" (the "Manga-v1" dataset).
Most parts of the dataset have been prepended using the following text: `[Genre: <genre1>, <genre2>]`
## Revision changes:
- Removed all headers
- Removed all whitespaces
- Some reshuffling of data
### How to use
You can use this model directly with a pipeline for text generation. This example generates a different sequence each time it's run:
```py
>>> from transformers import pipeline
>>> generator = pipeline('text-generation', model='KoboldAI/fairseq-dense-13B-Nerys')
>>> generator("Welcome Captain Janeway, I apologize for the delay.", do_sample=True, min_length=50)
[{'generated_text': 'Welcome Captain Janeway, I apologize for the delay."\nIt's all right," Janeway said. "I'm certain that you're doing your best to keep me informed of what\'s going on."'}]
```
### Limitations and Biases
Based on known problems with NLP technology, potential relevant factors include bias (gender, profession, race and religion).
### BibTeX entry and citation info
```
Artetxe et al. (2021): Efficient Large Scale Language Modeling with Mixtures of Experts
```
|
redewiedergabe/bert-base-historical-german-rw-cased
|
011b11dc5bf01e1ac3423bfb1593ce58d9938d37
|
2021-05-20T04:11:23.000Z
|
[
"pytorch",
"jax",
"bert",
"fill-mask",
"de",
"arxiv:1508.01991",
"transformers",
"autotrain_compatible"
] |
fill-mask
| false |
redewiedergabe
| null |
redewiedergabe/bert-base-historical-german-rw-cased
| 13,183 | 1 |
transformers
| 613 |
---
language: de
---
# Model description
## Dataset
Trained on fictional and non-fictional German texts written between 1840 and 1920:
* Narrative texts from Digitale Bibliothek (https://textgrid.de/digitale-bibliothek)
* Fairy tales and sagas from Grimm Korpus (https://www1.ids-mannheim.de/kl/projekte/korpora/archiv/gri.html)
* Newspaper and magazine article from Mannheimer Korpus Historischer Zeitungen und Zeitschriften (https://repos.ids-mannheim.de/mkhz-beschreibung.html)
* Magazine article from the journal „Die Grenzboten“ (http://www.deutschestextarchiv.de/doku/textquellen#grenzboten)
* Fictional and non-fictional texts from Projekt Gutenberg (https://www.projekt-gutenberg.org)
## Hardware used
1 Tesla P4 GPU
## Hyperparameters
| Parameter | Value |
|-------------------------------|----------|
| Epochs | 3 |
| Gradient_accumulation_steps | 1 |
| Train_batch_size | 32 |
| Learning_rate | 0.00003 |
| Max_seq_len | 128 |
## Evaluation results: Automatic tagging of four forms of speech/thought/writing representation in historical fictional and non-fictional German texts
The language model was used in the task to tag direct, indirect, reported and free indirect speech/thought/writing representation in fictional and non-fictional German texts. The tagger is available and described in detail at https://github.com/redewiedergabe/tagger.
The tagging model was trained using the SequenceTagger Class of the Flair framework ([Akbik et al., 2019](https://www.aclweb.org/anthology/N19-4010)) which implements a BiLSTM-CRF architecture on top of a language embedding (as proposed by [Huang et al. (2015)](https://arxiv.org/abs/1508.01991)).
Hyperparameters
| Parameter | Value |
|-------------------------------|------------|
| Hidden_size | 256 |
| Learning_rate | 0.1 |
| Mini_batch_size | 8 |
| Max_epochs | 150 |
Results are reported below in comparison to a custom trained flair embedding, which was stacked onto a custom trained fastText-model. Both models were trained on the same dataset.
| | BERT ||| FastText+Flair |||Test data|
|----------------|----------|-----------|----------|------|-----------|--------|--------|
| | F1 | Precision | Recall | F1 | Precision | Recall ||
| Direct | 0.80 | 0.86 | 0.74 | 0.84 | 0.90 | 0.79 |historical German, fictional & non-fictional|
| Indirect | **0.76** | **0.79** | **0.73** | 0.73 | 0.78 | 0.68 |historical German, fictional & non-fictional|
| Reported | **0.58** | **0.69** | **0.51** | 0.56 | 0.68 | 0.48 |historical German, fictional & non-fictional|
| Free indirect | **0.57** | **0.80** | **0.44** | 0.47 | 0.78 | 0.34 |modern German, fictional|
## Intended use:
Historical German Texts (1840 to 1920)
(Showed good performance with modern German fictional texts as well)
|
textattack/roberta-base-CoLA
|
3ccf3a400f2fa75ff257eac171047603ffbe84f1
|
2021-05-20T22:05:35.000Z
|
[
"pytorch",
"jax",
"roberta",
"text-classification",
"transformers"
] |
text-classification
| false |
textattack
| null |
textattack/roberta-base-CoLA
| 13,151 | 1 |
transformers
| 614 |
## TextAttack Model Cardand the glue dataset loaded using the `nlp` library. The model was fine-tuned
for 5 epochs with a batch size of 32, a learning
rate of 2e-05, and a maximum sequence length of 128.
Since this was a classification task, the model was trained with a cross-entropy loss function.
The best score the model achieved on this task was 0.850431447746884, as measured by the
eval set accuracy, found after 1 epoch.
For more information, check out [TextAttack on Github](https://github.com/QData/TextAttack).
|
nreimers/MiniLM-L6-H384-uncased
|
3276f0fac9d818781d7a1327b3ff818fc4e643c0
|
2021-08-30T20:05:29.000Z
|
[
"pytorch",
"jax",
"bert",
"feature-extraction",
"transformers",
"license:mit"
] |
feature-extraction
| false |
nreimers
| null |
nreimers/MiniLM-L6-H384-uncased
| 13,124 | 8 |
transformers
| 615 |
---
license: mit
---
## MiniLM: 6 Layer Version
This is a 6 layer version of [microsoft/MiniLM-L12-H384-uncased](https://huggingface.co/microsoft/MiniLM-L12-H384-uncased/) by keeping only every second layer.
|
dandelin/vilt-b32-mlm
|
9507e9c3da12076e10f272e942569dc5190edc1c
|
2022-07-06T12:18:37.000Z
|
[
"pytorch",
"vilt",
"fill-mask",
"arxiv:2102.03334",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] |
fill-mask
| false |
dandelin
| null |
dandelin/vilt-b32-mlm
| 13,056 | 2 |
transformers
| 616 |
---
license: apache-2.0
---
# Vision-and-Language Transformer (ViLT), pre-trained only
Vision-and-Language Transformer (ViLT) model pre-trained on GCC+SBU+COCO+VG (200k steps). It was introduced in the paper [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) by Kim et al. and first released in [this repository](https://github.com/dandelin/ViLT). Note: this model only includes the language modeling head.
Disclaimer: The team releasing ViLT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Intended uses & limitations
You can use the raw model for masked language modeling given an image and a piece of text with [MASK] tokens.
### How to use
Here is how to use this model in PyTorch:
```
from transformers import ViltProcessor, ViltForMaskedLM
import requests
from PIL import Image
import re
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
text = "a bunch of [MASK] laying on a [MASK]."
processor = ViltProcessor.from_pretrained("dandelin/vilt-b32-mlm")
model = ViltForMaskedLM.from_pretrained("dandelin/vilt-b32-mlm")
# prepare inputs
encoding = processor(image, text, return_tensors="pt")
# forward pass
outputs = model(**encoding)
tl = len(re.findall("\[MASK\]", text))
inferred_token = [text]
# gradually fill in the MASK tokens, one by one
with torch.no_grad():
for i in range(tl):
encoded = processor.tokenizer(inferred_token)
input_ids = torch.tensor(encoded.input_ids).to(device)
encoded = encoded["input_ids"][0][1:-1]
outputs = model(input_ids=input_ids, pixel_values=pixel_values)
mlm_logits = outputs.logits[0] # shape (seq_len, vocab_size)
# only take into account text features (minus CLS and SEP token)
mlm_logits = mlm_logits[1 : input_ids.shape[1] - 1, :]
mlm_values, mlm_ids = mlm_logits.softmax(dim=-1).max(dim=-1)
# only take into account text
mlm_values[torch.tensor(encoded) != 103] = 0
select = mlm_values.argmax().item()
encoded[select] = mlm_ids[select].item()
inferred_token = [processor.decode(encoded)]
selected_token = ""
encoded = processor.tokenizer(inferred_token)
processor.decode(encoded.input_ids[0], skip_special_tokens=True)
```
## Training data
(to do)
## Training procedure
### Preprocessing
(to do)
### Pretraining
(to do)
## Evaluation results
(to do)
### BibTeX entry and citation info
```bibtex
@misc{kim2021vilt,
title={ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision},
author={Wonjae Kim and Bokyung Son and Ildoo Kim},
year={2021},
eprint={2102.03334},
archivePrefix={arXiv},
primaryClass={stat.ML}
}
```
|
sentence-transformers/xlm-r-bert-base-nli-stsb-mean-tokens
|
9c71022cc69f395526255204c7af8bea1cc252d8
|
2022-06-15T20:21:25.000Z
|
[
"pytorch",
"tf",
"xlm-roberta",
"feature-extraction",
"arxiv:1908.10084",
"sentence-transformers",
"sentence-similarity",
"transformers",
"license:apache-2.0"
] |
sentence-similarity
| false |
sentence-transformers
| null |
sentence-transformers/xlm-r-bert-base-nli-stsb-mean-tokens
| 13,041 | null |
sentence-transformers
| 617 |
---
pipeline_tag: sentence-similarity
license: apache-2.0
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
**⚠️ This model is deprecated. Please don't use it as it produces sentence embeddings of low quality. You can find recommended sentence embedding models here: [SBERT.net - Pretrained Models](https://www.sbert.net/docs/pretrained_models.html)**
# sentence-transformers/xlm-r-bert-base-nli-stsb-mean-tokens
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/xlm-r-bert-base-nli-stsb-mean-tokens')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/xlm-r-bert-base-nli-stsb-mean-tokens')
model = AutoModel.from_pretrained('sentence-transformers/xlm-r-bert-base-nli-stsb-mean-tokens')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/xlm-r-bert-base-nli-stsb-mean-tokens)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: XLMRobertaModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
```
|
nlpaueb/legal-bert-small-uncased
|
0e23f7a9a39f59768ea7e09766d8ee308580fb17
|
2022-04-28T14:43:32.000Z
|
[
"pytorch",
"tf",
"jax",
"bert",
"en",
"transformers",
"legal",
"license:cc-by-sa-4.0",
"fill-mask"
] |
fill-mask
| false |
nlpaueb
| null |
nlpaueb/legal-bert-small-uncased
| 12,944 | 5 |
transformers
| 618 |
---
language: en
pipeline_tag: fill-mask
license: cc-by-sa-4.0
thumbnail: https://i.ibb.co/p3kQ7Rw/Screenshot-2020-10-06-at-12-16-36-PM.png
tags:
- legal
widget:
- text: "The applicant submitted that her husband was subjected to treatment amounting to [MASK] whilst in the custody of police."
---
# LEGAL-BERT: The Muppets straight out of Law School
<img align="left" src="https://i.ibb.co/p3kQ7Rw/Screenshot-2020-10-06-at-12-16-36-PM.png" width="100"/>
LEGAL-BERT is a family of BERT models for the legal domain, intended to assist legal NLP research, computational law, and legal technology applications. To pre-train the different variations of LEGAL-BERT, we collected 12 GB of diverse English legal text from several fields (e.g., legislation, court cases, contracts) scraped from publicly available resources. Sub-domain variants (CONTRACTS-, EURLEX-, ECHR-) and/or general LEGAL-BERT perform better than using BERT out of the box for domain-specific tasks.<br>
This is the light-weight version of BERT-BASE (33% the size of BERT-BASE) pre-trained from scratch on legal data, which achieves comparable performance to larger models, while being much more efficient (approximately 4 times faster) with a smaller environmental footprint.
<br/><br/>
---
I. Chalkidis, M. Fergadiotis, P. Malakasiotis, N. Aletras and I. Androutsopoulos. "LEGAL-BERT: The Muppets straight out of Law School". In Findings of Empirical Methods in Natural Language Processing (EMNLP 2020) (Short Papers), to be held online, 2020. (https://aclanthology.org/2020.findings-emnlp.261)
---
## Pre-training corpora
The pre-training corpora of LEGAL-BERT include:
* 116,062 documents of EU legislation, publicly available from EURLEX (http://eur-lex.europa.eu), the repository of EU Law running under the EU Publication Office.
* 61,826 documents of UK legislation, publicly available from the UK legislation portal (http://www.legislation.gov.uk).
* 19,867 cases from the European Court of Justice (ECJ), also available from EURLEX.
* 12,554 cases from HUDOC, the repository of the European Court of Human Rights (ECHR) (http://hudoc.echr.coe.int/eng).
* 164,141 cases from various courts across the USA, hosted in the Case Law Access Project portal (https://case.law).
* 76,366 US contracts from EDGAR, the database of US Securities and Exchange Commission (SECOM) (https://www.sec.gov/edgar.shtml).
## Pre-training details
* We trained BERT using the official code provided in Google BERT's GitHub repository (https://github.com/google-research/bert).
* We released a model similar to the English BERT-BASE model (12-layer, 768-hidden, 12-heads, 110M parameters).
* We chose to follow the same training set-up: 1 million training steps with batches of 256 sequences of length 512 with an initial learning rate 1e-4.
* We were able to use a single Google Cloud TPU v3-8 provided for free from [TensorFlow Research Cloud (TFRC)](https://www.tensorflow.org/tfrc), while also utilizing [GCP research credits](https://edu.google.com/programs/credits/research). Huge thanks to both Google programs for supporting us!
## Models list
| Model name | Model Path | Training corpora |
| ------------------- | ------------------------------------ | ------------------- |
| CONTRACTS-BERT-BASE | `nlpaueb/bert-base-uncased-contracts` | US contracts |
| EURLEX-BERT-BASE | `nlpaueb/bert-base-uncased-eurlex` | EU legislation |
| ECHR-BERT-BASE | `nlpaueb/bert-base-uncased-echr` | ECHR cases |
| LEGAL-BERT-BASE * | `nlpaueb/legal-bert-base-uncased` | All |
| LEGAL-BERT-SMALL | `nlpaueb/legal-bert-small-uncased` | All |
\* LEGAL-BERT-BASE is the model referred to as LEGAL-BERT-SC in Chalkidis et al. (2020); a model trained from scratch in the legal corpora mentioned below using a newly created vocabulary by a sentence-piece tokenizer trained on the very same corpora.
\*\* As many of you expressed interest in the LEGAL-BERT-FP models (those relying on the original BERT-BASE checkpoint), they have been released in Archive.org (https://archive.org/details/legal_bert_fp), as these models are secondary and possibly only interesting for those who aim to dig deeper in the open questions of Chalkidis et al. (2020).
## Load Pretrained Model
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("nlpaueb/legal-bert-small-uncased")
model = AutoModel.from_pretrained("nlpaueb/legal-bert-small-uncased")
```
## Use LEGAL-BERT variants as Language Models
| Corpus | Model | Masked token | Predictions |
| --------------------------------- | ---------------------------------- | ------------ | ------------ |
| | **BERT-BASE-UNCASED** |
| (Contracts) | This [MASK] Agreement is between General Motors and John Murray . | employment | ('new', '0.09'), ('current', '0.04'), ('proposed', '0.03'), ('marketing', '0.03'), ('joint', '0.02')
| (ECHR) | The applicant submitted that her husband was subjected to treatment amounting to [MASK] whilst in the custody of Adana Security Directorate | torture | ('torture', '0.32'), ('rape', '0.22'), ('abuse', '0.14'), ('death', '0.04'), ('violence', '0.03')
| (EURLEX) | Establishing a system for the identification and registration of [MASK] animals and regarding the labelling of beef and beef products . | bovine | ('farm', '0.25'), ('livestock', '0.08'), ('draft', '0.06'), ('domestic', '0.05'), ('wild', '0.05')
| | **CONTRACTS-BERT-BASE** |
| (Contracts) | This [MASK] Agreement is between General Motors and John Murray . | employment | ('letter', '0.38'), ('dealer', '0.04'), ('employment', '0.03'), ('award', '0.03'), ('contribution', '0.02')
| (ECHR) | The applicant submitted that her husband was subjected to treatment amounting to [MASK] whilst in the custody of Adana Security Directorate | torture | ('death', '0.39'), ('imprisonment', '0.07'), ('contempt', '0.05'), ('being', '0.03'), ('crime', '0.02')
| (EURLEX) | Establishing a system for the identification and registration of [MASK] animals and regarding the labelling of beef and beef products . | bovine | (('domestic', '0.18'), ('laboratory', '0.07'), ('household', '0.06'), ('personal', '0.06'), ('the', '0.04')
| | **EURLEX-BERT-BASE** |
| (Contracts) | This [MASK] Agreement is between General Motors and John Murray . | employment | ('supply', '0.11'), ('cooperation', '0.08'), ('service', '0.07'), ('licence', '0.07'), ('distribution', '0.05')
| (ECHR) | The applicant submitted that her husband was subjected to treatment amounting to [MASK] whilst in the custody of Adana Security Directorate | torture | ('torture', '0.66'), ('death', '0.07'), ('imprisonment', '0.07'), ('murder', '0.04'), ('rape', '0.02')
| (EURLEX) | Establishing a system for the identification and registration of [MASK] animals and regarding the labelling of beef and beef products . | bovine | ('live', '0.43'), ('pet', '0.28'), ('certain', '0.05'), ('fur', '0.03'), ('the', '0.02')
| | **ECHR-BERT-BASE** |
| (Contracts) | This [MASK] Agreement is between General Motors and John Murray . | employment | ('second', '0.24'), ('latter', '0.10'), ('draft', '0.05'), ('bilateral', '0.05'), ('arbitration', '0.04')
| (ECHR) | The applicant submitted that her husband was subjected to treatment amounting to [MASK] whilst in the custody of Adana Security Directorate | torture | ('torture', '0.99'), ('death', '0.01'), ('inhuman', '0.00'), ('beating', '0.00'), ('rape', '0.00')
| (EURLEX) | Establishing a system for the identification and registration of [MASK] animals and regarding the labelling of beef and beef products . | bovine | ('pet', '0.17'), ('all', '0.12'), ('slaughtered', '0.10'), ('domestic', '0.07'), ('individual', '0.05')
| | **LEGAL-BERT-BASE** |
| (Contracts) | This [MASK] Agreement is between General Motors and John Murray . | employment | ('settlement', '0.26'), ('letter', '0.23'), ('dealer', '0.04'), ('master', '0.02'), ('supplemental', '0.02')
| (ECHR) | The applicant submitted that her husband was subjected to treatment amounting to [MASK] whilst in the custody of Adana Security Directorate | torture | ('torture', '1.00'), ('detention', '0.00'), ('arrest', '0.00'), ('rape', '0.00'), ('death', '0.00')
| (EURLEX) | Establishing a system for the identification and registration of [MASK] animals and regarding the labelling of beef and beef products . | bovine | ('live', '0.67'), ('beef', '0.17'), ('farm', '0.03'), ('pet', '0.02'), ('dairy', '0.01')
| | **LEGAL-BERT-SMALL** |
| (Contracts) | This [MASK] Agreement is between General Motors and John Murray . | employment | ('license', '0.09'), ('transition', '0.08'), ('settlement', '0.04'), ('consent', '0.03'), ('letter', '0.03')
| (ECHR) | The applicant submitted that her husband was subjected to treatment amounting to [MASK] whilst in the custody of Adana Security Directorate | torture | ('torture', '0.59'), ('pain', '0.05'), ('ptsd', '0.05'), ('death', '0.02'), ('tuberculosis', '0.02')
| (EURLEX) | Establishing a system for the identification and registration of [MASK] animals and regarding the labelling of beef and beef products . | bovine | ('all', '0.08'), ('live', '0.07'), ('certain', '0.07'), ('the', '0.07'), ('farm', '0.05')
## Evaluation on downstream tasks
Consider the experiments in the article "LEGAL-BERT: The Muppets straight out of Law School". Chalkidis et al., 2020, (https://aclanthology.org/2020.findings-emnlp.261)
## Author - Publication
```
@inproceedings{chalkidis-etal-2020-legal,
title = "{LEGAL}-{BERT}: The Muppets straight out of Law School",
author = "Chalkidis, Ilias and
Fergadiotis, Manos and
Malakasiotis, Prodromos and
Aletras, Nikolaos and
Androutsopoulos, Ion",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2020",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
doi = "10.18653/v1/2020.findings-emnlp.261",
pages = "2898--2904"
}
```
## About Us
[AUEB's Natural Language Processing Group](http://nlp.cs.aueb.gr) develops algorithms, models, and systems that allow computers to process and generate natural language texts.
The group's current research interests include:
* question answering systems for databases, ontologies, document collections, and the Web, especially biomedical question answering,
* natural language generation from databases and ontologies, especially Semantic Web ontologies,
text classification, including filtering spam and abusive content,
* information extraction and opinion mining, including legal text analytics and sentiment analysis,
* natural language processing tools for Greek, for example parsers and named-entity recognizers,
machine learning in natural language processing, especially deep learning.
The group is part of the Information Processing Laboratory of the Department of Informatics of the Athens University of Economics and Business.
[Ilias Chalkidis](https://iliaschalkidis.github.io) on behalf of [AUEB's Natural Language Processing Group](http://nlp.cs.aueb.gr)
| Github: [@ilias.chalkidis](https://github.com/iliaschalkidis) | Twitter: [@KiddoThe2B](https://twitter.com/KiddoThe2B) |
|
sberbank-ai/ruT5-base
|
8940daf014ad31b5b619cb07429dd50c884882f1
|
2021-09-21T19:41:58.000Z
|
[
"pytorch",
"t5",
"text2text-generation",
"ru",
"transformers",
"PyTorch",
"Transformers",
"autotrain_compatible"
] |
text2text-generation
| false |
sberbank-ai
| null |
sberbank-ai/ruT5-base
| 12,891 | 2 |
transformers
| 619 |
---
language:
- ru
tags:
- PyTorch
- Transformers
thumbnail: "https://github.com/sberbank-ai/model-zoo"
---
# ruT5-base
Model was trained by [SberDevices](https://sberdevices.ru/) team.
* Task: `text2text generation`
* Type: `encoder-decoder`
* Tokenizer: `bpe`
* Dict size: `32 101`
* Num Parameters: `222 M`
* Training Data Volume `300 GB`
|
skt/kobert-base-v1
|
a9f5849fce18fb088f0cd0f9b29ec3f756958464
|
2021-07-01T07:16:05.000Z
|
[
"pytorch",
"bert",
"feature-extraction",
"transformers"
] |
feature-extraction
| false |
skt
| null |
skt/kobert-base-v1
| 12,864 | 5 |
transformers
| 620 |
Please refer here. https://github.com/SKTBrain/KoBERT
|
google/bert_uncased_L-4_H-256_A-4
|
387825ce42dbb39b87911cdf8e383ee3b25184f8
|
2021-05-19T17:30:27.000Z
|
[
"pytorch",
"jax",
"bert",
"arxiv:1908.08962",
"transformers",
"license:apache-2.0"
] | null | false |
google
| null |
google/bert_uncased_L-4_H-256_A-4
| 12,826 | null |
transformers
| 621 |
---
thumbnail: https://huggingface.co/front/thumbnails/google.png
license: apache-2.0
---
BERT Miniatures
===
This is the set of 24 BERT models referenced in [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962) (English only, uncased, trained with WordPiece masking).
We have shown that the standard BERT recipe (including model architecture and training objective) is effective on a wide range of model sizes, beyond BERT-Base and BERT-Large. The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
Our goal is to enable research in institutions with fewer computational resources and encourage the community to seek directions of innovation alternative to increasing model capacity.
You can download the 24 BERT miniatures either from the [official BERT Github page](https://github.com/google-research/bert/), or via HuggingFace from the links below:
| |H=128|H=256|H=512|H=768|
|---|:---:|:---:|:---:|:---:|
| **L=2** |[**2/128 (BERT-Tiny)**][2_128]|[2/256][2_256]|[2/512][2_512]|[2/768][2_768]|
| **L=4** |[4/128][4_128]|[**4/256 (BERT-Mini)**][4_256]|[**4/512 (BERT-Small)**][4_512]|[4/768][4_768]|
| **L=6** |[6/128][6_128]|[6/256][6_256]|[6/512][6_512]|[6/768][6_768]|
| **L=8** |[8/128][8_128]|[8/256][8_256]|[**8/512 (BERT-Medium)**][8_512]|[8/768][8_768]|
| **L=10** |[10/128][10_128]|[10/256][10_256]|[10/512][10_512]|[10/768][10_768]|
| **L=12** |[12/128][12_128]|[12/256][12_256]|[12/512][12_512]|[**12/768 (BERT-Base)**][12_768]|
Note that the BERT-Base model in this release is included for completeness only; it was re-trained under the same regime as the original model.
Here are the corresponding GLUE scores on the test set:
|Model|Score|CoLA|SST-2|MRPC|STS-B|QQP|MNLI-m|MNLI-mm|QNLI(v2)|RTE|WNLI|AX|
|---|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|BERT-Tiny|64.2|0.0|83.2|81.1/71.1|74.3/73.6|62.2/83.4|70.2|70.3|81.5|57.2|62.3|21.0|
|BERT-Mini|65.8|0.0|85.9|81.1/71.8|75.4/73.3|66.4/86.2|74.8|74.3|84.1|57.9|62.3|26.1|
|BERT-Small|71.2|27.8|89.7|83.4/76.2|78.8/77.0|68.1/87.0|77.6|77.0|86.4|61.8|62.3|28.6|
|BERT-Medium|73.5|38.0|89.6|86.6/81.6|80.4/78.4|69.6/87.9|80.0|79.1|87.7|62.2|62.3|30.5|
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained for 4 epochs:
- batch sizes: 8, 16, 32, 64, 128
- learning rates: 3e-4, 1e-4, 5e-5, 3e-5
If you use these models, please cite the following paper:
```
@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}
```
[2_128]: https://huggingface.co/google/bert_uncased_L-2_H-128_A-2
[2_256]: https://huggingface.co/google/bert_uncased_L-2_H-256_A-4
[2_512]: https://huggingface.co/google/bert_uncased_L-2_H-512_A-8
[2_768]: https://huggingface.co/google/bert_uncased_L-2_H-768_A-12
[4_128]: https://huggingface.co/google/bert_uncased_L-4_H-128_A-2
[4_256]: https://huggingface.co/google/bert_uncased_L-4_H-256_A-4
[4_512]: https://huggingface.co/google/bert_uncased_L-4_H-512_A-8
[4_768]: https://huggingface.co/google/bert_uncased_L-4_H-768_A-12
[6_128]: https://huggingface.co/google/bert_uncased_L-6_H-128_A-2
[6_256]: https://huggingface.co/google/bert_uncased_L-6_H-256_A-4
[6_512]: https://huggingface.co/google/bert_uncased_L-6_H-512_A-8
[6_768]: https://huggingface.co/google/bert_uncased_L-6_H-768_A-12
[8_128]: https://huggingface.co/google/bert_uncased_L-8_H-128_A-2
[8_256]: https://huggingface.co/google/bert_uncased_L-8_H-256_A-4
[8_512]: https://huggingface.co/google/bert_uncased_L-8_H-512_A-8
[8_768]: https://huggingface.co/google/bert_uncased_L-8_H-768_A-12
[10_128]: https://huggingface.co/google/bert_uncased_L-10_H-128_A-2
[10_256]: https://huggingface.co/google/bert_uncased_L-10_H-256_A-4
[10_512]: https://huggingface.co/google/bert_uncased_L-10_H-512_A-8
[10_768]: https://huggingface.co/google/bert_uncased_L-10_H-768_A-12
[12_128]: https://huggingface.co/google/bert_uncased_L-12_H-128_A-2
[12_256]: https://huggingface.co/google/bert_uncased_L-12_H-256_A-4
[12_512]: https://huggingface.co/google/bert_uncased_L-12_H-512_A-8
[12_768]: https://huggingface.co/google/bert_uncased_L-12_H-768_A-12
|
cointegrated/LaBSE-en-ru
|
9e6d1e5fa79584f5346a5262b69bb6dc64b46f98
|
2022-06-23T12:43:04.000Z
|
[
"pytorch",
"tf",
"bert",
"pretraining",
"ru",
"en",
"arxiv:2007.01852",
"transformers",
"feature-extraction",
"embeddings",
"sentence-similarity"
] |
feature-extraction
| false |
cointegrated
| null |
cointegrated/LaBSE-en-ru
| 12,813 | 10 |
transformers
| 622 |
---
language: ["ru", "en"]
tags:
- feature-extraction
- embeddings
- sentence-similarity
---
# LaBSE for English and Russian
This is a truncated version of [sentence-transformers/LaBSE](https://huggingface.co/sentence-transformers/LaBSE), which is, in turn, a port of [LaBSE](https://tfhub.dev/google/LaBSE/1) by Google.
The current model has only English and Russian tokens left in the vocabulary.
Thus, the vocabulary is 10% of the original, and number of parameters in the whole model is 27% of the original, without any loss in the quality of English and Russian embeddings.
To get the sentence embeddings, you can use the following code:
```python
import torch
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("cointegrated/LaBSE-en-ru")
model = AutoModel.from_pretrained("cointegrated/LaBSE-en-ru")
sentences = ["Hello World", "Привет Мир"]
encoded_input = tokenizer(sentences, padding=True, truncation=True, max_length=64, return_tensors='pt')
with torch.no_grad():
model_output = model(**encoded_input)
embeddings = model_output.pooler_output
embeddings = torch.nn.functional.normalize(embeddings)
print(embeddings)
```
## Reference:
Fangxiaoyu Feng, Yinfei Yang, Daniel Cer, Narveen Ari, Wei Wang. [Language-agnostic BERT Sentence Embedding](https://arxiv.org/abs/2007.01852). July 2020
License: [https://tfhub.dev/google/LaBSE/1](https://tfhub.dev/google/LaBSE/1)
|
Maltehb/danish-bert-botxo
|
565d9bd5ca0872bec0b2d7af7887607a96416c2f
|
2021-11-12T08:34:29.000Z
|
[
"pytorch",
"jax",
"bert",
"pretraining",
"da",
"dataset:common_crawl",
"dataset:wikipedia",
"dataset:dindebat.dk",
"dataset:hestenettet.dk",
"dataset:danish OpenSubtitles",
"transformers",
"danish",
"masked-lm",
"Certainly",
"license:cc-by-4.0",
"fill-mask"
] |
fill-mask
| false |
Maltehb
| null |
Maltehb/danish-bert-botxo
| 12,759 | 2 |
transformers
| 623 |
---
language: da
tags:
- danish
- bert
- masked-lm
- Certainly
license: cc-by-4.0
datasets:
- common_crawl
- wikipedia
- dindebat.dk
- hestenettet.dk
- danish OpenSubtitles
pipeline_tag: fill-mask
widget:
- text: "København er [MASK] i Danmark."
---
# Danish BERT (version 2, uncased) by [Certainly](https://certainly.io/) (previously known as BotXO).
All credit goes to [Certainly](https://certainly.io/) (previously known as BotXO), who developed Danish BERT. For data and training details see their [GitHub repository](https://github.com/certainlyio/nordic_bert) or [this article](https://www.certainly.io/blog/danish-bert-model/). You can also visit their [organization page](https://huggingface.co/Certainly) on Hugging Face.
It is both available in TensorFlow and Pytorch format.
The original TensorFlow version can be downloaded using [this link](https://www.dropbox.com/s/19cjaoqvv2jicq9/danish_bert_uncased_v2.zip?dl=1).
Here is an example on how to load Danish BERT in PyTorch using the [🤗Transformers](https://github.com/huggingface/transformers) library:
```python
from transformers import AutoTokenizer, AutoModelForPreTraining
tokenizer = AutoTokenizer.from_pretrained("Maltehb/danish-bert-botxo")
model = AutoModelForPreTraining.from_pretrained("Maltehb/danish-bert-botxo")
```
|
Helsinki-NLP/opus-mt-roa-en
|
7d547ac627a5bee2cbeb5e614f9752927eb52aab
|
2020-08-21T14:42:49.000Z
|
[
"pytorch",
"rust",
"marian",
"text2text-generation",
"it",
"ca",
"rm",
"es",
"ro",
"gl",
"co",
"wa",
"pt",
"oc",
"an",
"id",
"fr",
"ht",
"roa",
"en",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] |
translation
| false |
Helsinki-NLP
| null |
Helsinki-NLP/opus-mt-roa-en
| 12,727 | 1 |
transformers
| 624 |
---
language:
- it
- ca
- rm
- es
- ro
- gl
- co
- wa
- pt
- oc
- an
- id
- fr
- ht
- roa
- en
tags:
- translation
license: apache-2.0
---
### roa-eng
* source group: Romance languages
* target group: English
* OPUS readme: [roa-eng](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/roa-eng/README.md)
* model: transformer
* source language(s): arg ast cat cos egl ext fra frm_Latn gcf_Latn glg hat ind ita lad lad_Latn lij lld_Latn lmo max_Latn mfe min mwl oci pap pms por roh ron scn spa tmw_Latn vec wln zlm_Latn zsm_Latn
* target language(s): eng
* model: transformer
* pre-processing: normalization + SentencePiece (spm32k,spm32k)
* download original weights: [opus2m-2020-08-01.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/roa-eng/opus2m-2020-08-01.zip)
* test set translations: [opus2m-2020-08-01.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/roa-eng/opus2m-2020-08-01.test.txt)
* test set scores: [opus2m-2020-08-01.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/roa-eng/opus2m-2020-08-01.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| newsdev2016-enro-roneng.ron.eng | 37.1 | 0.631 |
| newsdiscussdev2015-enfr-fraeng.fra.eng | 31.6 | 0.564 |
| newsdiscusstest2015-enfr-fraeng.fra.eng | 36.1 | 0.592 |
| newssyscomb2009-fraeng.fra.eng | 29.3 | 0.563 |
| newssyscomb2009-itaeng.ita.eng | 33.1 | 0.589 |
| newssyscomb2009-spaeng.spa.eng | 29.2 | 0.562 |
| news-test2008-fraeng.fra.eng | 25.2 | 0.533 |
| news-test2008-spaeng.spa.eng | 26.6 | 0.542 |
| newstest2009-fraeng.fra.eng | 28.6 | 0.557 |
| newstest2009-itaeng.ita.eng | 32.0 | 0.580 |
| newstest2009-spaeng.spa.eng | 28.9 | 0.559 |
| newstest2010-fraeng.fra.eng | 29.9 | 0.573 |
| newstest2010-spaeng.spa.eng | 33.3 | 0.596 |
| newstest2011-fraeng.fra.eng | 31.2 | 0.585 |
| newstest2011-spaeng.spa.eng | 32.3 | 0.584 |
| newstest2012-fraeng.fra.eng | 31.3 | 0.580 |
| newstest2012-spaeng.spa.eng | 35.3 | 0.606 |
| newstest2013-fraeng.fra.eng | 31.9 | 0.575 |
| newstest2013-spaeng.spa.eng | 32.8 | 0.592 |
| newstest2014-fren-fraeng.fra.eng | 34.6 | 0.611 |
| newstest2016-enro-roneng.ron.eng | 35.8 | 0.614 |
| Tatoeba-test.arg-eng.arg.eng | 38.7 | 0.512 |
| Tatoeba-test.ast-eng.ast.eng | 35.2 | 0.520 |
| Tatoeba-test.cat-eng.cat.eng | 54.9 | 0.703 |
| Tatoeba-test.cos-eng.cos.eng | 68.1 | 0.666 |
| Tatoeba-test.egl-eng.egl.eng | 6.7 | 0.209 |
| Tatoeba-test.ext-eng.ext.eng | 24.2 | 0.427 |
| Tatoeba-test.fra-eng.fra.eng | 53.9 | 0.691 |
| Tatoeba-test.frm-eng.frm.eng | 25.7 | 0.423 |
| Tatoeba-test.gcf-eng.gcf.eng | 14.8 | 0.288 |
| Tatoeba-test.glg-eng.glg.eng | 54.6 | 0.703 |
| Tatoeba-test.hat-eng.hat.eng | 37.0 | 0.540 |
| Tatoeba-test.ita-eng.ita.eng | 64.8 | 0.768 |
| Tatoeba-test.lad-eng.lad.eng | 21.7 | 0.452 |
| Tatoeba-test.lij-eng.lij.eng | 11.2 | 0.299 |
| Tatoeba-test.lld-eng.lld.eng | 10.8 | 0.273 |
| Tatoeba-test.lmo-eng.lmo.eng | 5.8 | 0.260 |
| Tatoeba-test.mfe-eng.mfe.eng | 63.1 | 0.819 |
| Tatoeba-test.msa-eng.msa.eng | 40.9 | 0.592 |
| Tatoeba-test.multi.eng | 54.9 | 0.697 |
| Tatoeba-test.mwl-eng.mwl.eng | 44.6 | 0.674 |
| Tatoeba-test.oci-eng.oci.eng | 20.5 | 0.404 |
| Tatoeba-test.pap-eng.pap.eng | 56.2 | 0.669 |
| Tatoeba-test.pms-eng.pms.eng | 10.3 | 0.324 |
| Tatoeba-test.por-eng.por.eng | 59.7 | 0.738 |
| Tatoeba-test.roh-eng.roh.eng | 14.8 | 0.378 |
| Tatoeba-test.ron-eng.ron.eng | 55.2 | 0.703 |
| Tatoeba-test.scn-eng.scn.eng | 10.2 | 0.259 |
| Tatoeba-test.spa-eng.spa.eng | 56.2 | 0.714 |
| Tatoeba-test.vec-eng.vec.eng | 13.8 | 0.317 |
| Tatoeba-test.wln-eng.wln.eng | 17.3 | 0.323 |
### System Info:
- hf_name: roa-eng
- source_languages: roa
- target_languages: eng
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/roa-eng/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['it', 'ca', 'rm', 'es', 'ro', 'gl', 'co', 'wa', 'pt', 'oc', 'an', 'id', 'fr', 'ht', 'roa', 'en']
- src_constituents: {'ita', 'cat', 'roh', 'spa', 'pap', 'lmo', 'mwl', 'lij', 'lad_Latn', 'ext', 'ron', 'ast', 'glg', 'pms', 'zsm_Latn', 'gcf_Latn', 'lld_Latn', 'min', 'tmw_Latn', 'cos', 'wln', 'zlm_Latn', 'por', 'egl', 'oci', 'vec', 'arg', 'ind', 'fra', 'hat', 'lad', 'max_Latn', 'frm_Latn', 'scn', 'mfe'}
- tgt_constituents: {'eng'}
- src_multilingual: True
- tgt_multilingual: False
- prepro: normalization + SentencePiece (spm32k,spm32k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/roa-eng/opus2m-2020-08-01.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/roa-eng/opus2m-2020-08-01.test.txt
- src_alpha3: roa
- tgt_alpha3: eng
- short_pair: roa-en
- chrF2_score: 0.6970000000000001
- bleu: 54.9
- brevity_penalty: 0.9790000000000001
- ref_len: 74762.0
- src_name: Romance languages
- tgt_name: English
- train_date: 2020-08-01
- src_alpha2: roa
- tgt_alpha2: en
- prefer_old: False
- long_pair: roa-eng
- helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535
- transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b
- port_machine: brutasse
- port_time: 2020-08-21-14:41
|
thatdramebaazguy/roberta-base-squad
|
a7a26fd500148b760ca89a87edcd5b5605daab09
|
2022-07-01T19:12:50.000Z
|
[
"pytorch",
"tf",
"jax",
"roberta",
"question-answering",
"English",
"dataset:SQuAD",
"transformers",
"roberta-base",
"qa",
"license:cc-by-4.0",
"autotrain_compatible"
] |
question-answering
| false |
thatdramebaazguy
| null |
thatdramebaazguy/roberta-base-squad
| 12,654 | 1 |
transformers
| 625 |
---
datasets:
- SQuAD
language:
- English
thumbnail:
tags:
- roberta
- roberta-base
- question-answering
- qa
license: cc-by-4.0
---
# roberta-base + SQuAD QA
Objective:
This is Roberta Base trained to do the SQuAD Task. This makes a QA model capable of answering questions.
```
model_name = "thatdramebaazguy/roberta-base-squad"
pipeline(model=model_name, tokenizer=model_name, revision="v1.0", task="question-answering")
```
## Overview
**Language model:** roberta-base
**Language:** English
**Downstream-task:** QA
**Training data:** SQuADv1
**Eval data:** SQuAD
**Infrastructure**: 2x Tesla v100
**Code:** See [example](https://github.com/adityaarunsinghal/Domain-Adaptation/blob/master/scripts/shell_scripts/train_movieR_just_squadv1.sh)
## Hyperparameters
```
Num examples = 88567
Num Epochs = 10
Instantaneous batch size per device = 32
Total train batch size (w. parallel, distributed & accumulation) = 64
```
## Performance
### Eval on SQuADv1
- epoch = 10.0
- eval_samples = 10790
- exact_match = 83.6045
- f1 = 91.1709
### Eval on MoviesQA
- eval_samples = 5032
- exact_match = 51.6494
- f1 = 68.2615
Github Repo:
- [Domain-Adaptation Project](https://github.com/adityaarunsinghal/Domain-Adaptation/)
---
|
shahrukhx01/question-vs-statement-classifier
|
38767ed252cb888c5c1507ea7933150537500893
|
2021-08-25T08:17:39.000Z
|
[
"pytorch",
"bert",
"text-classification",
"en",
"transformers",
"neural-search-query-classification",
"neural-search"
] |
text-classification
| false |
shahrukhx01
| null |
shahrukhx01/question-vs-statement-classifier
| 12,639 | 6 |
transformers
| 626 |
---
language: "en"
tags:
- neural-search-query-classification
- neural-search
widget:
- text: "what did you eat in lunch?"
---
# KEYWORD STATEMENT VS QUESTION CLASSIFIER FOR NEURAL SEARCH
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("shahrukhx01/question-vs-statement-classifier")
model = AutoModelForSequenceClassification.from_pretrained("shahrukhx01/question-vs-statement-classifier")
```
Trained to add the feature for classifying queries between Question Query vs Statement Query using classification in [Haystack](https://github.com/deepset-ai/haystack/issues/611)
|
Zixtrauce/JohnBot
|
3831946b0c973685e937c4db612ed7cce2733129
|
2022-01-02T06:43:38.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
| false |
Zixtrauce
| null |
Zixtrauce/JohnBot
| 12,482 | null |
transformers
| 627 |
---
tags:
- conversational
---
#JohnBot
|
Helsinki-NLP/opus-mt-en-nl
|
cd888e7c566d69f91f675d7a12d26613d1c4d826
|
2021-09-09T21:38:05.000Z
|
[
"pytorch",
"rust",
"marian",
"text2text-generation",
"en",
"nl",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] |
translation
| false |
Helsinki-NLP
| null |
Helsinki-NLP/opus-mt-en-nl
| 12,407 | null |
transformers
| 628 |
---
tags:
- translation
license: apache-2.0
---
### opus-mt-en-nl
* source languages: en
* target languages: nl
* OPUS readme: [en-nl](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/en-nl/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2019-12-04.zip](https://object.pouta.csc.fi/OPUS-MT-models/en-nl/opus-2019-12-04.zip)
* test set translations: [opus-2019-12-04.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/en-nl/opus-2019-12-04.test.txt)
* test set scores: [opus-2019-12-04.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/en-nl/opus-2019-12-04.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba.en.nl | 57.1 | 0.730 |
|
haisongzhang/roberta-tiny-cased
|
2e8caf4404987b8cb20fa4b22955f56940b2ebc6
|
2021-05-19T17:53:53.000Z
|
[
"pytorch",
"tf",
"jax",
"bert",
"feature-extraction",
"transformers"
] |
feature-extraction
| false |
haisongzhang
| null |
haisongzhang/roberta-tiny-cased
| 12,316 | null |
transformers
| 629 |
Github: https://github.com/haisongzhang/roberta-tiny-cased
|
deepset/gbert-base-germandpr-ctx_encoder
|
12ac6df80a8a3a3301464a306cd412d01f43c082
|
2021-10-21T12:17:10.000Z
|
[
"pytorch",
"dpr",
"de",
"dataset:deepset/germandpr",
"transformers",
"exbert",
"license:mit"
] | null | false |
deepset
| null |
deepset/gbert-base-germandpr-ctx_encoder
| 12,308 | 5 |
transformers
| 630 |
---
language: de
datasets:
- deepset/germandpr
license: mit
thumbnail: https://thumb.tildacdn.com/tild3433-3637-4830-a533-353833613061/-/resize/720x/-/format/webp/germanquad.jpg
tags:
- exbert
---

## Overview
**Language model:** gbert-base-germandpr
**Language:** German
**Training data:** GermanDPR train set (~ 56MB)
**Eval data:** GermanDPR test set (~ 6MB)
**Infrastructure**: 4x V100 GPU
**Published**: Apr 26th, 2021
## Details
- We trained a dense passage retrieval model with two gbert-base models as encoders of questions and passages.
- The dataset is GermanDPR, a new, German language dataset, which we hand-annotated and published [online](https://deepset.ai/germanquad).
- It comprises 9275 question/answer pairs in the training set and 1025 pairs in the test set.
For each pair, there are one positive context and three hard negative contexts.
- As the basis of the training data, we used our hand-annotated GermanQuAD dataset as positive samples and generated hard negative samples from the latest German Wikipedia dump (6GB of raw txt files).
- The data dump was cleaned with tailored scripts, leading to 2.8 million indexed passages from German Wikipedia.
See https://deepset.ai/germanquad for more details and dataset download.
## Hyperparameters
```
batch_size = 40
n_epochs = 20
num_training_steps = 4640
num_warmup_steps = 460
max_seq_len = 32 tokens for question encoder and 300 tokens for passage encoder
learning_rate = 1e-6
lr_schedule = LinearWarmup
embeds_dropout_prob = 0.1
num_hard_negatives = 2
```
## Performance
During training, we monitored the in-batch average rank and the loss and evaluated different batch sizes, numbers of epochs, and number of hard negatives on a dev set split from the train set.
The dev split contained 1030 question/answer pairs.
Even without thorough hyperparameter tuning, we observed quite stable learning. Multiple restarts with different seeds produced quite similar results.
Note that the in-batch average rank is influenced by settings for batch size and number of hard negatives. A smaller number of hard negatives makes the task easier.
After fixing the hyperparameters we trained the model on the full GermanDPR train set.
We further evaluated the retrieval performance of the trained model on the full German Wikipedia with the GermanDPR test set as labels. To this end, we converted the GermanDPR test set to SQuAD format. The DPR model drastically outperforms the BM25 baseline with regard to recall@k.

## Usage
### In haystack
You can load the model in [haystack](https://github.com/deepset-ai/haystack/) as a retriever for doing QA at scale:
```python
retriever = DensePassageRetriever(
document_store=document_store,
query_embedding_model="deepset/gbert-base-germandpr-question_encoder"
passage_embedding_model="deepset/gbert-base-germandpr-ctx_encoder"
)
```
## Authors
- Timo Möller: `timo.moeller [at] deepset.ai`
- Julian Risch: `julian.risch [at] deepset.ai`
- Malte Pietsch: `malte.pietsch [at] deepset.ai`
## About us

We bring NLP to the industry via open source!
Our focus: Industry specific language models & large scale QA systems.
Some of our work:
- [German BERT (aka "bert-base-german-cased")](https://deepset.ai/german-bert)
- [GermanQuAD and GermanDPR datasets and models (aka "gelectra-base-germanquad", "gbert-base-germandpr")](https://deepset.ai/germanquad)
- [FARM](https://github.com/deepset-ai/FARM)
- [Haystack](https://github.com/deepset-ai/haystack/)
Get in touch:
[Twitter](https://twitter.com/deepset_ai) | [LinkedIn](https://www.linkedin.com/company/deepset-ai/) | [Website](https://deepset.ai)
By the way: [we're hiring!](http://www.deepset.ai/jobs)
|
Maltehb/aelaectra-danish-electra-small-cased
|
106e95e10eef7b40441db59d1ac98bef3d78dd0a
|
2021-11-23T06:39:44.000Z
|
[
"pytorch",
"tf",
"electra",
"pretraining",
"da",
"dataset:DAGW",
"arxiv:2003.10555",
"arxiv:1810.04805",
"arxiv:2005.03521",
"transformers",
"ælæctra",
"danish",
"ELECTRA-Small",
"replaced token detection",
"license:mit",
"co2_eq_emissions"
] | null | false |
Maltehb
| null |
Maltehb/aelaectra-danish-electra-small-cased
| 12,267 | 1 |
transformers
| 631 |
---
language: "da"
co2_eq_emissions: 4009.5
tags:
- ælæctra
- pytorch
- danish
- ELECTRA-Small
- replaced token detection
license: "mit"
datasets:
- DAGW
metrics:
- f1
---
# Ælæctra - A Step Towards More Efficient Danish Natural Language Processing
**Ælæctra** is a Danish Transformer-based language model created to enhance the variety of Danish NLP resources with a more efficient model compared to previous state-of-the-art (SOTA) models. Initially a cased and an uncased model are released. It was created as part of a Cognitive Science bachelor's thesis.
Ælæctra was pretrained with the ELECTRA-Small (Clark et al., 2020) pretraining approach by using the Danish Gigaword Corpus (Strømberg-Derczynski et al., 2020) and evaluated on Named Entity Recognition (NER) tasks. Since NER only presents a limited picture of Ælæctra's capabilities I am very interested in further evaluations. Therefore, if you employ it for any task, feel free to hit me up your findings!
Ælæctra was, as mentioned, created to enhance the Danish NLP capabilties and please do note how this GitHub still does not support the Danish characters "*Æ, Ø and Å*" as the title of this repository becomes "*-l-ctra*". How ironic.🙂
Here is an example on how to load both the cased and the uncased Ælæctra model in [PyTorch](https://pytorch.org/) using the [🤗Transformers](https://github.com/huggingface/transformers) library:
```python
from transformers import AutoTokenizer, AutoModelForPreTraining
tokenizer = AutoTokenizer.from_pretrained("Maltehb/-l-ctra-danish-electra-small-cased")
model = AutoModelForPreTraining.from_pretrained("Maltehb/-l-ctra-danish-electra-small-cased")
```
```python
from transformers import AutoTokenizer, AutoModelForPreTraining
tokenizer = AutoTokenizer.from_pretrained("Maltehb/-l-ctra-danish-electra-small-uncased")
model = AutoModelForPreTraining.from_pretrained("Maltehb/-l-ctra-danish-electra-small-uncased")
```
### Evaluation of current Danish Language Models
Ælæctra, Danish BERT (DaBERT) and multilingual BERT (mBERT) were evaluated:
| Model | Layers | Hidden Size | Params | AVG NER micro-f1 (DaNE-testset) | Average Inference Time (Sec/Epoch) | Download |
| --- | --- | --- | --- | --- | --- | --- |
| Ælæctra Uncased | 12 | 256 | 13.7M | 78.03 (SD = 1.28) | 10.91 | [Link for model](https://www.dropbox.com/s/cag7prs1nvdchqs/%C3%86l%C3%A6ctra.zip?dl=0) |
| Ælæctra Cased | 12 | 256 | 14.7M | 80.08 (SD = 0.26) | 10.92 | [Link for model](https://www.dropbox.com/s/cag7prs1nvdchqs/%C3%86l%C3%A6ctra.zip?dl=0) |
| DaBERT | 12 | 768 | 110M | 84.89 (SD = 0.64) | 43.03 | [Link for model](https://www.dropbox.com/s/19cjaoqvv2jicq9/danish_bert_uncased_v2.zip?dl=1) |
| mBERT Uncased | 12 | 768 | 167M | 80.44 (SD = 0.82) | 72.10 | [Link for model](https://storage.googleapis.com/bert_models/2018_11_03/multilingual_L-12_H-768_A-12.zip) |
| mBERT Cased | 12 | 768 | 177M | 83.79 (SD = 0.91) | 70.56 | [Link for model](https://storage.googleapis.com/bert_models/2018_11_23/multi_cased_L-12_H-768_A-12.zip) |
On [DaNE](https://danlp.alexandra.dk/304bd159d5de/datasets/ddt.zip) (Hvingelby et al., 2020), Ælæctra scores slightly worse than both cased and uncased Multilingual BERT (Devlin et al., 2019) and Danish BERT (Danish BERT, 2019/2020), however, Ælæctra is less than one third the size, and uses significantly fewer computational resources to pretrain and instantiate. For a full description of the evaluation and specification of the model read the thesis: 'Ælæctra - A Step Towards More Efficient Danish Natural Language Processing'.
### Pretraining
To pretrain Ælæctra it is recommended to build a Docker Container from the [Dockerfile](https://github.com/MalteHB/Ælæctra/tree/master/notebooks/fine-tuning/). Next, simply follow the [pretraining notebooks](https://github.com/MalteHB/Ælæctra/tree/master/infrastructure/Dockerfile/)
The pretraining was done by utilizing a single NVIDIA Tesla V100 GPU with 16 GiB, endowed by the Danish data company [KMD](https://www.kmd.dk/). The pretraining took approximately 4 days and 9.5 hours for both the cased and uncased model
### Fine-tuning
To fine-tune any Ælæctra model follow the [fine-tuning notebooks](https://github.com/MalteHB/Ælæctra/tree/master/notebooks/fine-tuning/)
### References
Clark, K., Luong, M.-T., Le, Q. V., & Manning, C. D. (2020). ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators. ArXiv:2003.10555 [Cs]. http://arxiv.org/abs/2003.10555
Danish BERT. (2020). BotXO. https://github.com/botxo/nordic_bert (Original work published 2019)
Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. ArXiv:1810.04805 [Cs]. http://arxiv.org/abs/1810.04805
Hvingelby, R., Pauli, A. B., Barrett, M., Rosted, C., Lidegaard, L. M., & Søgaard, A. (2020). DaNE: A Named Entity Resource for Danish. Proceedings of the 12th Language Resources and Evaluation Conference, 4597–4604. https://www.aclweb.org/anthology/2020.lrec-1.565
Strømberg-Derczynski, L., Baglini, R., Christiansen, M. H., Ciosici, M. R., Dalsgaard, J. A., Fusaroli, R., Henrichsen, P. J., Hvingelby, R., Kirkedal, A., Kjeldsen, A. S., Ladefoged, C., Nielsen, F. Å., Petersen, M. L., Rystrøm, J. H., & Varab, D. (2020). The Danish Gigaword Project. ArXiv:2005.03521 [Cs]. http://arxiv.org/abs/2005.03521
#### Acknowledgements
As the majority of this repository is build upon [the works](https://github.com/google-research/electra) by the team at Google who created ELECTRA, a HUGE thanks to them is in order.
A Giga thanks also goes out to the incredible people who collected The Danish Gigaword Corpus (Strømberg-Derczynski et al., 2020).
Furthermore, I would like to thank my supervisor [Riccardo Fusaroli](https://github.com/fusaroli) for the support with the thesis, and a special thanks goes out to [Kenneth Enevoldsen](https://github.com/KennethEnevoldsen) for his continuous feedback.
Lastly, i would like to thank KMD, my colleagues from KMD, and my peers and co-students from Cognitive Science for encouriging me to keep on working hard and holding my head up high!
#### Contact
For help or further information feel free to connect with the author Malte Højmark-Bertelsen on [[email protected]](mailto:[email protected]?subject=[GitHub]%20Ælæctra) or any of the following platforms:
[<img align="left" alt="MalteHB | Twitter" width="22px" src="https://cdn.jsdelivr.net/npm/simple-icons@v3/icons/twitter.svg" />][twitter]
[<img align="left" alt="MalteHB | LinkedIn" width="22px" src="https://cdn.jsdelivr.net/npm/simple-icons@v3/icons/linkedin.svg" />][linkedin]
[<img align="left" alt="MalteHB | Instagram" width="22px" src="https://cdn.jsdelivr.net/npm/simple-icons@v3/icons/instagram.svg" />][instagram]
<br />
</details>
[twitter]: https://twitter.com/malteH_B
[instagram]: https://www.instagram.com/maltemusen/
[linkedin]: https://www.linkedin.com/in/malte-h%C3%B8jmark-bertelsen-9a618017b/
|
microsoft/Multilingual-MiniLM-L12-H384
|
f8a8e5023cbd4f94f1debed2578c65964dd4846b
|
2021-06-01T14:33:36.000Z
|
[
"pytorch",
"tf",
"jax",
"bert",
"arxiv:2002.10957",
"arxiv:1809.05053",
"arxiv:1911.02116",
"arxiv:1910.07475",
"transformers",
"text-classification",
"license:mit"
] |
text-classification
| false |
microsoft
| null |
microsoft/Multilingual-MiniLM-L12-H384
| 12,245 | 14 |
transformers
| 632 |
---
thumbnail: https://huggingface.co/front/thumbnails/microsoft.png
tags:
- text-classification
license: mit
---
## MiniLM: Small and Fast Pre-trained Models for Language Understanding and Generation
MiniLM is a distilled model from the paper "[MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers](https://arxiv.org/abs/2002.10957)".
Please find the information about preprocessing, training and full details of the MiniLM in the [original MiniLM repository](https://github.com/microsoft/unilm/blob/master/minilm/).
Please note: This checkpoint uses `BertModel` with `XLMRobertaTokenizer` so `AutoTokenizer` won't work with this checkpoint!
### Multilingual Pretrained Model
- Multilingual-MiniLMv1-L12-H384: 12-layer, 384-hidden, 12-heads, 21M Transformer parameters, 96M embedding parameters
Multilingual MiniLM uses the same tokenizer as XLM-R. But the Transformer architecture of our model is the same as BERT. We provide the fine-tuning code on XNLI based on [huggingface/transformers](https://github.com/huggingface/transformers). Please replace `run_xnli.py` in transformers with [ours](https://github.com/microsoft/unilm/blob/master/minilm/examples/run_xnli.py) to fine-tune multilingual MiniLM.
We evaluate the multilingual MiniLM on cross-lingual natural language inference benchmark (XNLI) and cross-lingual question answering benchmark (MLQA).
#### Cross-Lingual Natural Language Inference - [XNLI](https://arxiv.org/abs/1809.05053)
We evaluate our model on cross-lingual transfer from English to other languages. Following [Conneau et al. (2019)](https://arxiv.org/abs/1911.02116), we select the best single model on the joint dev set of all the languages.
| Model | #Layers | #Hidden | #Transformer Parameters | Average | en | fr | es | de | el | bg | ru | tr | ar | vi | th | zh | hi | sw | ur |
|---------------------------------------------------------------------------------------------|---------|---------|-------------------------|---------|------|------|------|------|------|------|------|------|------|------|------|------|------|------|------|
| [mBERT](https://github.com/google-research/bert) | 12 | 768 | 85M | 66.3 | 82.1 | 73.8 | 74.3 | 71.1 | 66.4 | 68.9 | 69.0 | 61.6 | 64.9 | 69.5 | 55.8 | 69.3 | 60.0 | 50.4 | 58.0 |
| [XLM-100](https://github.com/facebookresearch/XLM#pretrained-cross-lingual-language-models) | 16 | 1280 | 315M | 70.7 | 83.2 | 76.7 | 77.7 | 74.0 | 72.7 | 74.1 | 72.7 | 68.7 | 68.6 | 72.9 | 68.9 | 72.5 | 65.6 | 58.2 | 62.4 |
| [XLM-R Base](https://arxiv.org/abs/1911.02116) | 12 | 768 | 85M | 74.5 | 84.6 | 78.4 | 78.9 | 76.8 | 75.9 | 77.3 | 75.4 | 73.2 | 71.5 | 75.4 | 72.5 | 74.9 | 71.1 | 65.2 | 66.5 |
| **mMiniLM-L12xH384** | 12 | 384 | 21M | 71.1 | 81.5 | 74.8 | 75.7 | 72.9 | 73.0 | 74.5 | 71.3 | 69.7 | 68.8 | 72.1 | 67.8 | 70.0 | 66.2 | 63.3 | 64.2 |
This example code fine-tunes **12**-layer multilingual MiniLM on XNLI.
```bash
# run fine-tuning on XNLI
DATA_DIR=/{path_of_data}/
OUTPUT_DIR=/{path_of_fine-tuned_model}/
MODEL_PATH=/{path_of_pre-trained_model}/
python ./examples/run_xnli.py --model_type minilm \
--output_dir ${OUTPUT_DIR} --data_dir ${DATA_DIR} \
--model_name_or_path microsoft/Multilingual-MiniLM-L12-H384 \
--tokenizer_name xlm-roberta-base \
--config_name ${MODEL_PATH}/multilingual-minilm-l12-h384-config.json \
--do_train \
--do_eval \
--max_seq_length 128 \
--per_gpu_train_batch_size 128 \
--learning_rate 5e-5 \
--num_train_epochs 5 \
--per_gpu_eval_batch_size 32 \
--weight_decay 0.001 \
--warmup_steps 500 \
--save_steps 1500 \
--logging_steps 1500 \
--eval_all_checkpoints \
--language en \
--fp16 \
--fp16_opt_level O2
```
#### Cross-Lingual Question Answering - [MLQA](https://arxiv.org/abs/1910.07475)
Following [Lewis et al. (2019b)](https://arxiv.org/abs/1910.07475), we adopt SQuAD 1.1 as training data and use MLQA English development data for early stopping.
| Model F1 Score | #Layers | #Hidden | #Transformer Parameters | Average | en | es | de | ar | hi | vi | zh |
|--------------------------------------------------------------------------------------------|---------|---------|-------------------------|---------|------|------|------|------|------|------|------|
| [mBERT](https://github.com/google-research/bert) | 12 | 768 | 85M | 57.7 | 77.7 | 64.3 | 57.9 | 45.7 | 43.8 | 57.1 | 57.5 |
| [XLM-15](https://github.com/facebookresearch/XLM#pretrained-cross-lingual-language-models) | 12 | 1024 | 151M | 61.6 | 74.9 | 68.0 | 62.2 | 54.8 | 48.8 | 61.4 | 61.1 |
| [XLM-R Base](https://arxiv.org/abs/1911.02116) (Reported) | 12 | 768 | 85M | 62.9 | 77.8 | 67.2 | 60.8 | 53.0 | 57.9 | 63.1 | 60.2 |
| [XLM-R Base](https://arxiv.org/abs/1911.02116) (Our fine-tuned) | 12 | 768 | 85M | 64.9 | 80.3 | 67.0 | 62.7 | 55.0 | 60.4 | 66.5 | 62.3 |
| **mMiniLM-L12xH384** | 12 | 384 | 21M | 63.2 | 79.4 | 66.1 | 61.2 | 54.9 | 58.5 | 63.1 | 59.0 |
### Citation
If you find MiniLM useful in your research, please cite the following paper:
``` latex
@misc{wang2020minilm,
title={MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers},
author={Wenhui Wang and Furu Wei and Li Dong and Hangbo Bao and Nan Yang and Ming Zhou},
year={2020},
eprint={2002.10957},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
KoboldAI/GPT-Neo-2.7B-Horni
|
6024c30cd1984b12fa35c50e1490c73e42cf4823
|
2021-12-30T11:43:31.000Z
|
[
"pytorch",
"gpt_neo",
"text-generation",
"transformers"
] |
text-generation
| false |
KoboldAI
| null |
KoboldAI/GPT-Neo-2.7B-Horni
| 12,012 | null |
transformers
| 633 |
Entry not found
|
hf-internal-testing/tiny-random-wav2vec2
|
44e60a7cad2409b873242c874476c0c8ce8e98b0
|
2021-10-06T10:02:54.000Z
|
[
"pytorch",
"tf",
"wav2vec2",
"transformers"
] | null | false |
hf-internal-testing
| null |
hf-internal-testing/tiny-random-wav2vec2
| 12,005 | null |
transformers
| 634 |
Entry not found
|
mrm8488/t5-base-finetuned-span-sentiment-extraction
|
04a3fe1f7373c1f33b82e9fb06d2b2635e0fc5a0
|
2021-08-23T21:29:49.000Z
|
[
"pytorch",
"t5",
"text2text-generation",
"en",
"arxiv:1910.10683",
"transformers",
"sentiment",
"extracion",
"passage",
"autotrain_compatible"
] |
text2text-generation
| false |
mrm8488
| null |
mrm8488/t5-base-finetuned-span-sentiment-extraction
| 11,961 | 8 |
transformers
| 635 |
---
language: en
tags:
- sentiment
- extracion
- passage
widget:
- text: "question: positive context: On the monday, so i wont be able to be with you! i love you"
---
# T5-base fine-tuned for Sentiment Span Extraction
All credits to [Lorenzo Ampil](https://twitter.com/AND__SO)
[Google's T5](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) base fine-tuned on [Tweet Sentiment Extraction Dataset](https://www.kaggle.com/c/tweet-sentiment-extraction) for **Span Sentiment Extraction** downstream task.
## Details of T5
The **T5** model was presented in [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/pdf/1910.10683.pdf) by *Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J. Liu* in Here the abstract:
Transfer learning, where a model is first pre-trained on a data-rich task before being fine-tuned on a downstream task, has emerged as a powerful technique in natural language processing (NLP). The effectiveness of transfer learning has given rise to a diversity of approaches, methodology, and practice. In this paper, we explore the landscape of transfer learning techniques for NLP by introducing a unified framework that converts every language problem into a text-to-text format. Our systematic study compares pre-training objectives, architectures, unlabeled datasets, transfer approaches, and other factors on dozens of language understanding tasks. By combining the insights from our exploration with scale and our new “Colossal Clean Crawled Corpus”, we achieve state-of-the-art results on many benchmarks covering summarization, question answering, text classification, and more. To facilitate future work on transfer learning for NLP, we release our dataset, pre-trained models, and code.
## Details of the downstream task (Span Sentiment Extraction) - Dataset 📚
[Tweet Sentiment Extraction Dataset](https://www.kaggle.com/c/tweet-sentiment-extraction)
"My ridiculous dog is amazing." [sentiment: positive]
With all of the tweets circulating every second it is hard to tell whether the sentiment behind a specific tweet will impact a company, or a person's, brand for being viral (positive), or devastate profit because it strikes a negative tone. Capturing sentiment in language is important in these times where decisions and reactions are created and updated in seconds. But, which words actually lead to the sentiment description? In this competition you will need to pick out the part of the tweet (word or phrase) that reflects the sentiment.
Help build your skills in this important area with this broad dataset of tweets. Work on your technique to grab a top spot in this competition. What words in tweets support a positive, negative, or neutral sentiment? How can you help make that determination using machine learning tools?
In this competition we've extracted support phrases from Figure Eight's Data for Everyone platform. The dataset is titled Sentiment Analysis: Emotion in Text tweets with existing sentiment labels, used here under creative commons attribution 4.0. international licence. Your objective in this competition is to construct a model that can do the same - look at the labeled sentiment for a given tweet and figure out what word or phrase best supports it.
Disclaimer: The dataset for this competition contains text that may be considered profane, vulgar, or offensive.
| Dataset | Split | # samples |
| -------- | ----- | --------- |
| TSE | train | 23907 |
| TSE | eval | 3573 |
## Model fine-tuning 🏋️
The training script is a slightly modified version of [this Colab Notebook](https://github.com/enzoampil/t5-intro/blob/master/t5_qa_training_pytorch_span_extraction.ipynb) created by [Lorenzo Ampil](https://github.com/enzoampil), so all credits to him!
## Model in Action 🚀
```python
from transformers import AutoModelWithLMHead, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("mrm8488/t5-base-finetuned-span-sentiment-extraction")
model = AutoModelWithLMHead.from_pretrained("mrm8488/t5-base-finetuned-span-sentiment-extraction")
def get_sentiment_span(text):
input_ids = tokenizer.encode(text, return_tensors="pt", add_special_tokens=True) # Batch size 1
generated_ids = model.generate(input_ids=input_ids, num_beams=1, max_length=80).squeeze()
predicted_span = tokenizer.decode(generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True)
return predicted_span
get_sentiment_span("question: negative context: My bike was put on hold...should have known that.... argh total bummer")
# output: 'argh total bummer'
get_sentiment_span("question: positive context: On the monday, so i wont be able to be with you! i love you")
# output: 'i love you'
```
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488) | [LinkedIn](https://www.linkedin.com/in/manuel-romero-cs/)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
allenai/tk-instruct-11b-def
|
60a86546f3005d9b3685fde089d67e61c281211d
|
2022-05-27T06:29:34.000Z
|
[
"pytorch",
"t5",
"text2text-generation",
"en",
"dataset:natural instructions v2.0",
"arxiv:1910.10683",
"arxiv:2204.07705",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] |
text2text-generation
| false |
allenai
| null |
allenai/tk-instruct-11b-def
| 11,959 | 2 |
transformers
| 636 |
---
language: en
license: apache-2.0
datasets:
- natural instructions v2.0
---
# Model description
Tk-Instruct is a series of encoder-decoder Transformer models that are trained to solve various NLP tasks by following in-context instructions (plain language task definitions, k-shot examples, explanations, etc). Built upon the pre-trained [T5 models](https://arxiv.org/abs/1910.10683), they are fine-tuned on a large number of tasks & instructions that are collected in the [Natural Instructions benchmark](https://github.com/allenai/natural-instructions), which contains 1600+ tasks in 70+ broach categories in total. This enables the model to not only process the training tasks, but also generalize to many unseen tasks without further parameter update.
More resources for using the model:
- **Paper**: [link](https://arxiv.org/abs/2204.07705)
- **Code repository**: [Tk-Instruct](https://github.com/yizhongw/Tk-Instruct)
- **Official Website**: [Natural Instructions](https://instructions.apps.allenai.org/)
- **All released models**: [allenai/tk-instruct](https://huggingface.co/models?search=allenai/tk-instruct)
## Intended uses & limitations
Tk-Instruct can be used to do many NLP tasks by following instructions.
### How to use
When instructing the model, task definition or demonstration examples or explanations should be prepended to the original input and fed into the model. You can easily try Tk-Instruct models as follows:
```python
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
>>> tokenizer = AutoTokenizer.from_pretrained("allenai/tk-instruct-3b-def")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("allenai/tk-instruct-3b-def")
>>> input_ids = tokenizer.encode(
"Definition: return the currency of the given country. Now complete the following example - Input: India. Output:",
return_tensors="pt")
>>> output = model.generate(input_ids, max_length=10)
>>> output = tokenizer.decode(output[0], skip_special_tokens=True) # model should output 'Indian Rupee'
>>> input_ids = tokenizer.encode(
"Definition: negate the following sentence. Input: John went to school. Output:",
return_tensors="pt")
>>> output = model.generate(input_ids, max_length=10)
>>> output = tokenizer.decode(output[0], skip_special_tokens=True) # model should output 'John did not go to shool.'
```
### Limitations
We are still working on understanding the behaviors of these models, but here are several issues we have found:
- Models are generally sensitive to the instruction. Sometimes rewording the instruction can lead to very different output.
- Models are not always compliant to the instruction. Sometimes the model don't follow your instruction (e.g., when you ask the model to generate one sentence, it might still generate one word or a long story).
- Models might totally fail on some tasks.
If you find serious issues or any interesting result, you are welcome to share with us!
## Training data
Tk-Instruct is trained using the tasks & instructions in [Natural Instructions benchmark](https://github.com/allenai/natural-instructions), which contains 1600+ tasks in 70+ broach categories in total. We follow the official train/test split. Tk-Instruct model series were trained using 757 tasks, and mTk-Instruct series were trained using 1271 tasks (including some non-English tasks).
The training tasks are in 64 broad categories, such as text categorization / question answering / sentiment analysis / summarization / grammar error detection / dialogue generation / etc. The other 12 categories are selected for evaluation.
## Training procedure
All our models are initialized from either T5 models or mT5 models. Because generating the output can be regarded as a form of language modeling, we used their [LM adapted version](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#lm-adapted-t511lm100k). All data is converted into a text-to-text format, and models are fine-tuned to maximize the likelihood of the output sequence.
Our [released models](https://huggingface.co/models?search=allenai/tk-instruct) are in different sizes, and each of them was trained with a specific type of instruction encoding. For instance, `tk-instruct-3b-def-pos` was initialized from [t5-xl-lm-adapt](https://huggingface.co/google/t5-xl-lm-adapt), and it saw task definition & 2 positive examples as the instruction during training time.
Although they are trained with only one type of instruction encodings, we found they can usually work with other type of encodings at test time (see more in our paper).
### BibTeX entry and citation info
```bibtex
@article{wang2022benchmarking,
title={Benchmarking Generalization via In-Context Instructions on 1,600+ Language Tasks},
author={Yizhong Wang and Swaroop Mishra and Pegah Alipoormolabashi and Yeganeh Kordi and Amirreza Mirzaei and A. Arunkumar and Arjun Ashok and Arut Selvan Dhanasekaran and Atharva Naik and David Stap and Eshaan Pathak and Giannis Karamanolakis and Haizhi Gary Lai and Ishan Purohit and Ishani Mondal and Jacob Anderson and Kirby Kuznia and Krima Doshi and Maitreya Patel and Kuntal Kumar Pal and M. Moradshahi and Mihir Parmar and Mirali Purohit and Neeraj Varshney and Phani Rohitha Kaza and Pulkit Verma and Ravsehaj Singh Puri and Rushang Karia and Shailaja Keyur Sampat and Savan Doshi and Siddharth Deepak Mishra and Sujan C. Reddy and Sumanta Patro and Tanay Dixit and Xu-dong Shen and Chitta Baral and Yejin Choi and Hannaneh Hajishirzi and Noah A. Smith and Daniel Khashabi},
year={2022},
archivePrefix={arXiv},
eprint={2204.07705},
primaryClass={cs.CL},
}
```
|
benjamin/gerpt2-large
|
d0ec9b299d7a96e24d03303de120ffb81769f366
|
2022-05-11T09:16:51.000Z
|
[
"pytorch",
"jax",
"gpt2",
"text-generation",
"de",
"transformers",
"license:mit"
] |
text-generation
| false |
benjamin
| null |
benjamin/gerpt2-large
| 11,920 | 6 |
transformers
| 637 |
---
language: de
widget:
- text: "In einer schockierenden Entdeckung fanden Wissenschaftler eine Herde Einhörner, die in einem abgelegenen, zuvor unerforschten Tal in den Anden lebten."
license: mit
---
# GerPT2
German large and small versions of GPT2:
- https://huggingface.co/benjamin/gerpt2
- https://huggingface.co/benjamin/gerpt2-large
See the [GPT2 model card](https://huggingface.co/gpt2) for considerations on limitations and bias. See the [GPT2 documentation](https://huggingface.co/transformers/model_doc/gpt2.html) for details on GPT2.
## Comparison to [dbmdz/german-gpt2](https://huggingface.co/dbmdz/german-gpt2)
I evaluated both GerPT2-large and the other German GPT2, [dbmdz/german-gpt2](https://huggingface.co/dbmdz/german-gpt2) on the [CC-100](http://data.statmt.org/cc-100/) dataset and on the German Wikipedia:
| | CC-100 (PPL) | Wikipedia (PPL) |
|-------------------|--------------|-----------------|
| dbmdz/german-gpt2 | 49.47 | 62.92 |
| GerPT2 | 24.78 | 35.33 |
| GerPT2-large | __16.08__ | __23.26__ |
| | | |
See the script `evaluate.py` in the [GerPT2 Github repository](https://github.com/bminixhofer/gerpt2) for the code.
## Usage
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
tokenizer = AutoTokenizer.from_pretrained("benjamin/gerpt2-large")
model = AutoModelForCausalLM.from_pretrained("benjamin/gerpt2-large")
prompt = "<your prompt>"
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
print(pipe(prompt)[0]["generated_text"])
```
Also, two tricks might improve the generated text:
```python
output = model.generate(
# during training an EOS token was used to mark the beginning of each text
# so it can help to insert it at the start
torch.tensor(
[tokenizer.eos_token_id] + tokenizer.encode(prompt)
).unsqueeze(0),
do_sample=True,
# try setting bad_words_ids=[[0]] to disallow generating an EOS token, without this the model is
# prone to ending generation early because a significant number of texts from the training corpus
# is quite short
bad_words_ids=[[0]],
max_length=max_length,
)[0]
print(tokenizer.decode(output))
```
## Training details
GerPT2-large is trained on the entire German data from the [CC-100 Corpus](http://data.statmt.org/cc-100/) and weights were initialized from the [English GPT2 model](https://huggingface.co/gpt2-large).
GerPT2-large was trained with:
- a batch size of 256
- using OneCycle learning rate with a maximum of 5e-3
- with AdamW with a weight decay of 0.01
- for 2 epochs
Training took roughly 12 days on 8 TPUv3 cores.
To train GerPT2-large, follow these steps. Scripts are located in the [Github repository](https://github.com/bminixhofer/gerpt2):
0. Download and unzip training data from http://data.statmt.org/cc-100/.
1. Train a tokenizer using `prepare/train_tokenizer.py`. As training data for the tokenizer I used a random subset of 5% of the CC-100 data.
2. (optionally) generate a German input embedding matrix with `prepare/generate_aligned_wte.py`. This uses a neat trick to semantically map tokens from the English tokenizer to tokens from the German tokenizer using aligned word embeddings. E. g.:
```
ĠMinde -> Ġleast
Ġjed -> Ġwhatsoever
flughafen -> Air
vermittlung -> employment
teilung -> ignment
ĠInterpretation -> Ġinterpretation
Ġimport -> Ġimported
hansa -> irl
genehmigungen -> exempt
ĠAuflist -> Ġlists
Ġverschwunden -> Ġdisappeared
ĠFlyers -> ĠFlyers
Kanal -> Channel
Ġlehr -> Ġteachers
Ġnahelie -> Ġconvenient
gener -> Generally
mitarbeiter -> staff
```
This helps a lot on a trial run I did, although I wasn't able to do a full comparison due to budget and time constraints. To use this WTE matrix it can be passed via the `wte_path` to the training script. Credit to [this blogpost](https://medium.com/@pierre_guillou/faster-than-training-from-scratch-fine-tuning-the-english-gpt-2-in-any-language-with-hugging-f2ec05c98787) for the idea of initializing GPT2 from English weights.
3. Tokenize the corpus using `prepare/tokenize_text.py`. This generates files for train and validation tokens in JSON Lines format.
4. Run the training script `train.py`! `run.sh` shows how this was executed for the full run with config `configs/tpu_large.json`.
## License
GerPT2 is licensed under the MIT License.
## Citing
Please cite GerPT2 as follows:
```
@misc{Minixhofer_GerPT2_German_large_2020,
author = {Minixhofer, Benjamin},
doi = {10.5281/zenodo.5509984},
month = {12},
title = {{GerPT2: German large and small versions of GPT2}},
url = {https://github.com/bminixhofer/gerpt2},
year = {2020}
}
```
## Acknowledgements
Thanks to [Hugging Face](https://huggingface.co) for awesome tools and infrastructure.
Huge thanks to [Artus Krohn-Grimberghe](https://twitter.com/artuskg) at [LYTiQ](https://www.lytiq.de/) for making this possible by sponsoring the resources used for training.
|
Helsinki-NLP/opus-mt-uk-ru
|
0dbf7d9872d43f0599f41259b927e012f84b87fe
|
2020-08-21T14:42:51.000Z
|
[
"pytorch",
"marian",
"text2text-generation",
"uk",
"ru",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] |
translation
| false |
Helsinki-NLP
| null |
Helsinki-NLP/opus-mt-uk-ru
| 11,691 | null |
transformers
| 638 |
---
language:
- uk
- ru
tags:
- translation
license: apache-2.0
---
### ukr-rus
* source group: Ukrainian
* target group: Russian
* OPUS readme: [ukr-rus](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/ukr-rus/README.md)
* model: transformer-align
* source language(s): ukr
* target language(s): rus
* model: transformer-align
* pre-processing: normalization + SentencePiece (spm32k,spm32k)
* download original weights: [opus-2020-06-17.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/ukr-rus/opus-2020-06-17.zip)
* test set translations: [opus-2020-06-17.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/ukr-rus/opus-2020-06-17.test.txt)
* test set scores: [opus-2020-06-17.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/ukr-rus/opus-2020-06-17.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba-test.ukr.rus | 69.2 | 0.826 |
### System Info:
- hf_name: ukr-rus
- source_languages: ukr
- target_languages: rus
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/ukr-rus/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['uk', 'ru']
- src_constituents: {'ukr'}
- tgt_constituents: {'rus'}
- src_multilingual: False
- tgt_multilingual: False
- prepro: normalization + SentencePiece (spm32k,spm32k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/ukr-rus/opus-2020-06-17.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/ukr-rus/opus-2020-06-17.test.txt
- src_alpha3: ukr
- tgt_alpha3: rus
- short_pair: uk-ru
- chrF2_score: 0.826
- bleu: 69.2
- brevity_penalty: 0.992
- ref_len: 60387.0
- src_name: Ukrainian
- tgt_name: Russian
- train_date: 2020-06-17
- src_alpha2: uk
- tgt_alpha2: ru
- prefer_old: False
- long_pair: ukr-rus
- helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535
- transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b
- port_machine: brutasse
- port_time: 2020-08-21-14:41
|
hf-internal-testing/tiny-bert
|
8a4db81d7e7ef2296d71ceb206e048c5734ce42f
|
2021-07-08T18:23:09.000Z
|
[
"pytorch",
"transformers"
] | null | false |
hf-internal-testing
| null |
hf-internal-testing/tiny-bert
| 11,632 | null |
transformers
| 639 |
This is a copy of: https://huggingface.co/prajjwal1/bert-tiny
|
allenai/led-large-16384
|
04472a9a5d3af2efe700dda11da6063c68cd27a4
|
2021-01-11T14:51:13.000Z
|
[
"pytorch",
"tf",
"led",
"text2text-generation",
"en",
"arxiv:2004.05150",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] |
text2text-generation
| false |
allenai
| null |
allenai/led-large-16384
| 11,624 | 2 |
transformers
| 640 |
---
language: en
license: apache-2.0
---
## Introduction
[Allenai's Longformer Encoder-Decoder (LED)](https://github.com/allenai/longformer#longformer).
As described in [Longformer: The Long-Document Transformer](https://arxiv.org/pdf/2004.05150.pdf) by Iz Beltagy, Matthew E. Peters, Arman Cohan, *led-large-16384* was initialized from [*bart-large*](https://huggingface.co/facebook/bart-large) since both models share the exact same architecture. To be able to process 16K tokens, *bart-large*'s position embedding matrix was simply copied 16 times.
This model is especially interesting for long-range summarization and question answering.
## Fine-tuning for down-stream task
[This notebook](https://colab.research.google.com/drive/12LjJazBl7Gam0XBPy_y0CTOJZeZ34c2v?usp=sharing) shows how *led-large-16384* can effectively be fine-tuned on a downstream task.
|
ydshieh/wav2vec2-large-xlsr-53-chinese-zh-cn-gpt
|
cf511f7e00de089e67e80fbedd5fbfb8e76ea067
|
2021-04-01T14:09:29.000Z
|
[
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"zh",
"dataset:common_voice",
"transformers",
"audio",
"speech",
"xlsr-fine-tuning-week",
"license:apache-2.0",
"model-index"
] |
automatic-speech-recognition
| false |
ydshieh
| null |
ydshieh/wav2vec2-large-xlsr-53-chinese-zh-cn-gpt
| 11,617 | 9 |
transformers
| 641 |
---
language: zh
datasets:
- common_voice
metrics:
- cer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: XLSR Wav2Vec2 Large 53 - Chinese (zh-CN), by Yih-Dar SHIEH
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice zh-CN
type: common_voice
args: zh-CN
metrics:
- name: Test CER
type: cer
value: 20.90
---
# Wav2Vec2-Large-XLSR-53-Chinese-zh-cn-gpt
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Chinese (zh-CN) using the [Common Voice](https://huggingface.co/datasets/common_voice), included [Common Voice](https://huggingface.co/datasets/common_voice) Chinese (zh-TW) dataset (converting the label text to simplified Chinese).
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "zh-CN", split="test")
processor = Wav2Vec2Processor.from_pretrained("ydshieh/wav2vec2-large-xlsr-53-chinese-zh-cn-gpt")
model = Wav2Vec2ForCTC.from_pretrained("ydshieh/wav2vec2-large-xlsr-53-chinese-zh-cn-gpt")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset[:2]["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset[:2]["sentence"])
```
## Evaluation
The model can be evaluated as follows on the zh-CN test data of Common Voice.
Original CER calculation refer to https://huggingface.co/ctl/wav2vec2-large-xlsr-cantonese
```python
#!pip install datasets==1.4.1
#!pip install transformers==4.4.0
#!pip install torchaudio
#!pip install jiwer
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
import jiwer
def chunked_cer(targets, predictions, chunk_size=None):
_predictions = [char for seq in predictions for char in list(seq)]
_targets = [char for seq in targets for char in list(seq)]
if chunk_size is None: return jiwer.wer(_targets, _predictions)
start = 0
end = chunk_size
H, S, D, I = 0, 0, 0, 0
while start < len(targets):
_predictions = [char for seq in predictions[start:end] for char in list(seq)]
_targets = [char for seq in targets[start:end] for char in list(seq)]
chunk_metrics = jiwer.compute_measures(_targets, _predictions)
H = H + chunk_metrics["hits"]
S = S + chunk_metrics["substitutions"]
D = D + chunk_metrics["deletions"]
I = I + chunk_metrics["insertions"]
start += chunk_size
end += chunk_size
return float(S + D + I) / float(H + S + D)
test_dataset = load_dataset("common_voice", "zh-CN", split="test")
processor = Wav2Vec2Processor.from_pretrained("ydshieh/wav2vec2-large-xlsr-53-chinese-zh-cn-gpt")
model = Wav2Vec2ForCTC.from_pretrained("ydshieh/wav2vec2-large-xlsr-53-chinese-zh-cn-gpt")
model.to("cuda")
chars_to_ignore_regex = '[\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\,\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\?\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\.\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\!\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\-\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\;\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\:"\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\“\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\%\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\‘\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\”\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\�\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\.\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\⋯\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\!\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\-\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\:\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\–\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\。\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\》\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\,\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\)\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\,\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\?\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\;\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\~\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\~\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\…\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\︰\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\,\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\(\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\」\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\‧\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\《\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\﹔\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\、\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\—\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\/\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\,\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\「\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\﹖\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\·\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\×\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\̃\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\̌\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\ε\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\λ\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\μ\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\и\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\т\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\─\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\□\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\〈\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\〉\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\『\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\』\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\ア\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\オ\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\カ\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\チ\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\ド\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\ベ\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\ャ\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\ヤ\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\ン\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\・\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\丶\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\a\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\b\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\f\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\g\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\i\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\n\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\p\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\t' + "\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\']"
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower().replace("’", "'") + " "
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("CER: {:2f}".format(100 * chunked_cer(predictions=result["pred_strings"], targets=result["sentence"], chunk_size=1000)))
```
**Test Result**: 20.902244 %
## Training
The Common Voice zh-CN `train`, `validation` were used for training, as well as Common Voice zh-TW `train`, `validation` and `test` datasets.
The script used for training can be found [to be uploaded later](...)
|
sentence-transformers/multi-qa-MiniLM-L6-dot-v1
|
cffdcf0082a1156dce96de91b456a8859adc67b2
|
2022-06-15T22:45:19.000Z
|
[
"pytorch",
"tf",
"bert",
"feature-extraction",
"sentence-transformers",
"sentence-similarity"
] |
sentence-similarity
| false |
sentence-transformers
| null |
sentence-transformers/multi-qa-MiniLM-L6-dot-v1
| 11,558 | 4 |
sentence-transformers
| 642 |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
---
# multi-qa-MiniLM-L6-dot-v1
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 384 dimensional dense vector space and was designed for **semantic search**. It has been trained on 215M (question, answer) pairs from diverse sources. For an introduction to semantic search, have a look at: [SBERT.net - Semantic Search](https://www.sbert.net/examples/applications/semantic-search/README.html)
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer, util
query = "How many people live in London?"
docs = ["Around 9 Million people live in London", "London is known for its financial district"]
#Load the model
model = SentenceTransformer('sentence-transformers/multi-qa-MiniLM-L6-dot-v1')
#Encode query and documents
query_emb = model.encode(query)
doc_emb = model.encode(docs)
#Compute dot score between query and all document embeddings
scores = util.dot_score(query_emb, doc_emb)[0].cpu().tolist()
#Combine docs & scores
doc_score_pairs = list(zip(docs, scores))
#Sort by decreasing score
doc_score_pairs = sorted(doc_score_pairs, key=lambda x: x[1], reverse=True)
#Output passages & scores
for doc, score in doc_score_pairs:
print(score, doc)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the correct pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#CLS Pooling - Take output from first token
def cls_pooling(model_output):
return model_output.last_hidden_state[:,0]
#Encode text
def encode(texts):
# Tokenize sentences
encoded_input = tokenizer(texts, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input, return_dict=True)
# Perform pooling
embeddings = cls_pooling(model_output)
return embeddings
# Sentences we want sentence embeddings for
query = "How many people live in London?"
docs = ["Around 9 Million people live in London", "London is known for its financial district"]
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/multi-qa-MiniLM-L6-dot-v1")
model = AutoModel.from_pretrained("sentence-transformers/multi-qa-MiniLM-L6-dot-v1")
#Encode query and docs
query_emb = encode(query)
doc_emb = encode(docs)
#Compute dot score between query and all document embeddings
scores = torch.mm(query_emb, doc_emb.transpose(0, 1))[0].cpu().tolist()
#Combine docs & scores
doc_score_pairs = list(zip(docs, scores))
#Sort by decreasing score
doc_score_pairs = sorted(doc_score_pairs, key=lambda x: x[1], reverse=True)
#Output passages & scores
for doc, score in doc_score_pairs:
print(score, doc)
```
## Technical Details
In the following some technical details how this model must be used:
| Setting | Value |
| --- | :---: |
| Dimensions | 384 |
| Produces normalized embeddings | No |
| Pooling-Method | CLS pooling |
| Suitable score functions | dot-product (e.g. `util.dot_score`) |
----
## Background
The project aims to train sentence embedding models on very large sentence level datasets using a self-supervised
contrastive learning objective. We use a contrastive learning objective: given a sentence from the pair, the model should predict which out of a set of randomly sampled other sentences, was actually paired with it in our dataset.
We developped this model during the
[Community week using JAX/Flax for NLP & CV](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104),
organized by Hugging Face. We developped this model as part of the project:
[Train the Best Sentence Embedding Model Ever with 1B Training Pairs](https://discuss.huggingface.co/t/train-the-best-sentence-embedding-model-ever-with-1b-training-pairs/7354). We benefited from efficient hardware infrastructure to run the project: 7 TPUs v3-8, as well as intervention from Googles Flax, JAX, and Cloud team member about efficient deep learning frameworks.
## Intended uses
Our model is intented to be used for semantic search: It encodes queries / questions and text paragraphs in a dense vector space. It finds relevant documents for the given passages.
Note that there is a limit of 512 word pieces: Text longer than that will be truncated. Further note that the model was just trained on input text up to 250 word pieces. It might not work well for longer text.
## Training procedure
The full training script is accessible in this current repository: `train_script.py`.
### Pre-training
We use the pretrained [`nreimers/MiniLM-L6-H384-uncased`](https://huggingface.co/nreimers/MiniLM-L6-H384-uncased) model. Please refer to the model card for more detailed information about the pre-training procedure.
#### Training
We use the concatenation from multiple datasets to fine-tune our model. In total we have about 215M (question, answer) pairs.
We sampled each dataset given a weighted probability which configuration is detailed in the `data_config.json` file.
The model was trained with [MultipleNegativesRankingLoss](https://www.sbert.net/docs/package_reference/losses.html#multiplenegativesrankingloss) using CLS-pooling, dot-product as similarity function, and a scale of 1.
| Dataset | Number of training tuples |
|--------------------------------------------------------|:--------------------------:|
| [WikiAnswers](https://github.com/afader/oqa#wikianswers-corpus) Duplicate question pairs from WikiAnswers | 77,427,422 |
| [PAQ](https://github.com/facebookresearch/PAQ) Automatically generated (Question, Paragraph) pairs for each paragraph in Wikipedia | 64,371,441 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) (Title, Body) pairs from all StackExchanges | 25,316,456 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) (Title, Answer) pairs from all StackExchanges | 21,396,559 |
| [MS MARCO](https://microsoft.github.io/msmarco/) Triplets (query, answer, hard_negative) for 500k queries from Bing search engine | 17,579,773 |
| [GOOAQ: Open Question Answering with Diverse Answer Types](https://github.com/allenai/gooaq) (query, answer) pairs for 3M Google queries and Google featured snippet | 3,012,496 |
| [Amazon-QA](http://jmcauley.ucsd.edu/data/amazon/qa/) (Question, Answer) pairs from Amazon product pages | 2,448,839
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Title, Answer) pairs from Yahoo Answers | 1,198,260 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Question, Answer) pairs from Yahoo Answers | 681,164 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Title, Question) pairs from Yahoo Answers | 659,896 |
| [SearchQA](https://huggingface.co/datasets/search_qa) (Question, Answer) pairs for 140k questions, each with Top5 Google snippets on that question | 582,261 |
| [ELI5](https://huggingface.co/datasets/eli5) (Question, Answer) pairs from Reddit ELI5 (explainlikeimfive) | 325,475 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions pairs (titles) | 304,525 |
| [Quora Question Triplets](https://quoradata.quora.com/First-Quora-Dataset-Release-Question-Pairs) (Question, Duplicate_Question, Hard_Negative) triplets for Quora Questions Pairs dataset | 103,663 |
| [Natural Questions (NQ)](https://ai.google.com/research/NaturalQuestions) (Question, Paragraph) pairs for 100k real Google queries with relevant Wikipedia paragraph | 100,231 |
| [SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/) (Question, Paragraph) pairs from SQuAD2.0 dataset | 87,599 |
| [TriviaQA](https://huggingface.co/datasets/trivia_qa) (Question, Evidence) pairs | 73,346 |
| **Total** | **214,988,242** |
|
deepset/roberta-base-squad2-distilled
|
13d15d60b8fb45dc19c73a13bbd9a523811bca59
|
2022-07-22T16:29:09.000Z
|
[
"pytorch",
"roberta",
"question-answering",
"en",
"dataset:squad_v2",
"transformers",
"exbert",
"license:mit",
"model-index",
"autotrain_compatible"
] |
question-answering
| false |
deepset
| null |
deepset/roberta-base-squad2-distilled
| 11,514 | 2 |
transformers
| 643 |
---
language: en
datasets:
- squad_v2
license: mit
thumbnail: https://thumb.tildacdn.com/tild3433-3637-4830-a533-353833613061/-/resize/720x/-/format/webp/germanquad.jpg
tags:
- exbert
model-index:
- name: deepset/roberta-base-squad2-distilled
results:
- task:
type: question-answering
name: Question Answering
dataset:
name: squad_v2
type: squad_v2
config: squad_v2
split: validation
metrics:
- name: Exact Match
type: exact_match
value: 80.8593
verified: true
- name: F1
type: f1
value: 84.0104
verified: true
---
## Overview
**Language model:** deepset/roberta-base-squad2-distilled
**Language:** English
**Training data:** SQuAD 2.0 training set
**Eval data:** SQuAD 2.0 dev set
**Infrastructure**: 4x V100 GPU
**Published**: Dec 8th, 2021
## Details
- haystack's distillation feature was used for training. deepset/roberta-large-squad2 was used as the teacher model.
## Hyperparameters
```
batch_size = 80
n_epochs = 4
max_seq_len = 384
learning_rate = 3e-5
lr_schedule = LinearWarmup
embeds_dropout_prob = 0.1
temperature = 1.5
distillation_loss_weight = 0.75
```
## Performance
```
"exact": 79.8366040596311
"f1": 83.916407079888
```
## Authors
- Timo Möller: `timo.moeller [at] deepset.ai`
- Julian Risch: `julian.risch [at] deepset.ai`
- Malte Pietsch: `malte.pietsch [at] deepset.ai`
- Michel Bartels: `michel.bartels [at] deepset.ai`
## About us

We bring NLP to the industry via open source!
Our focus: Industry specific language models & large scale QA systems.
Some of our work:
- [German BERT (aka "bert-base-german-cased")](https://deepset.ai/german-bert)
- [GermanQuAD and GermanDPR datasets and models (aka "gelectra-base-germanquad", "gbert-base-germandpr")](https://deepset.ai/germanquad)
- [FARM](https://github.com/deepset-ai/FARM)
- [Haystack](https://github.com/deepset-ai/haystack/)
Get in touch:
[Twitter](https://twitter.com/deepset_ai) | [LinkedIn](https://www.linkedin.com/company/deepset-ai/) | [Slack](https://haystack.deepset.ai/community/join) | [GitHub Discussions](https://github.com/deepset-ai/haystack/discussions) | [Website](https://deepset.ai)
By the way: [we're hiring!](http://www.deepset.ai/jobs)
|
Helsinki-NLP/opus-mt-bat-en
|
760a39c69d5158182c320e47986306e24e96fa1f
|
2021-01-18T07:48:50.000Z
|
[
"pytorch",
"marian",
"text2text-generation",
"lt",
"lv",
"bat",
"en",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] |
translation
| false |
Helsinki-NLP
| null |
Helsinki-NLP/opus-mt-bat-en
| 11,478 | null |
transformers
| 644 |
---
language:
- lt
- lv
- bat
- en
tags:
- translation
license: apache-2.0
---
### bat-eng
* source group: Baltic languages
* target group: English
* OPUS readme: [bat-eng](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/bat-eng/README.md)
* model: transformer
* source language(s): lav lit ltg prg_Latn sgs
* target language(s): eng
* model: transformer
* pre-processing: normalization + SentencePiece (spm32k,spm32k)
* download original weights: [opus2m-2020-07-31.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/bat-eng/opus2m-2020-07-31.zip)
* test set translations: [opus2m-2020-07-31.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/bat-eng/opus2m-2020-07-31.test.txt)
* test set scores: [opus2m-2020-07-31.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/bat-eng/opus2m-2020-07-31.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| newsdev2017-enlv-laveng.lav.eng | 27.5 | 0.566 |
| newsdev2019-enlt-liteng.lit.eng | 27.8 | 0.557 |
| newstest2017-enlv-laveng.lav.eng | 21.1 | 0.512 |
| newstest2019-lten-liteng.lit.eng | 30.2 | 0.592 |
| Tatoeba-test.lav-eng.lav.eng | 51.5 | 0.687 |
| Tatoeba-test.lit-eng.lit.eng | 55.1 | 0.703 |
| Tatoeba-test.multi.eng | 50.6 | 0.662 |
| Tatoeba-test.prg-eng.prg.eng | 1.0 | 0.159 |
| Tatoeba-test.sgs-eng.sgs.eng | 16.5 | 0.265 |
### System Info:
- hf_name: bat-eng
- source_languages: bat
- target_languages: eng
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/bat-eng/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['lt', 'lv', 'bat', 'en']
- src_constituents: {'lit', 'lav', 'prg_Latn', 'ltg', 'sgs'}
- tgt_constituents: {'eng'}
- src_multilingual: True
- tgt_multilingual: False
- prepro: normalization + SentencePiece (spm32k,spm32k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/bat-eng/opus2m-2020-07-31.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/bat-eng/opus2m-2020-07-31.test.txt
- src_alpha3: bat
- tgt_alpha3: eng
- short_pair: bat-en
- chrF2_score: 0.662
- bleu: 50.6
- brevity_penalty: 0.9890000000000001
- ref_len: 30772.0
- src_name: Baltic languages
- tgt_name: English
- train_date: 2020-07-31
- src_alpha2: bat
- tgt_alpha2: en
- prefer_old: False
- long_pair: bat-eng
- helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535
- transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b
- port_machine: brutasse
- port_time: 2020-08-21-14:41
|
zenham/wail_m_e4_16h_2k
|
5ac007e21763708150470814fc800ab1e72c9582
|
2022-03-10T03:06:38.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
| false |
zenham
| null |
zenham/wail_m_e4_16h_2k
| 11,459 | null |
transformers
| 645 |
---
tags:
- conversational
---
#wail m e4 16h 2k DialoGPT Model
|
clips/mfaq
|
a49f0160e4d170a3d12e90ace3990fd6a50e35aa
|
2021-10-15T06:21:13.000Z
|
[
"pytorch",
"tf",
"xlm-roberta",
"feature-extraction",
"cs",
"da",
"de",
"en",
"es",
"fi",
"fr",
"he",
"hr",
"hu",
"id",
"it",
"nl",
"no",
"pl",
"pt",
"ro",
"ru",
"sv",
"tr",
"vi",
"dataset:clips/mfaq",
"arxiv:2109.12870",
"sentence-transformers",
"sentence-similarity",
"transformers",
"license:apache-2.0"
] |
sentence-similarity
| false |
clips
| null |
clips/mfaq
| 11,437 | 11 |
sentence-transformers
| 646 |
---
pipeline_tag: sentence-similarity
license: apache-2.0
language:
- cs
- da
- de
- en
- es
- fi
- fr
- he
- hr
- hu
- id
- it
- nl
- 'no'
- pl
- pt
- ro
- ru
- sv
- tr
- vi
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
datasets:
- clips/mfaq
widget:
source_sentence: "<Q>How many models can I host on HuggingFace?"
sentences:
- "<A>All plans come with unlimited private models and datasets."
- "<A>AutoNLP is an automatic way to train and deploy state-of-the-art NLP models, seamlessly integrated with the Hugging Face ecosystem."
- "<A>Based on how much training data and model variants are created, we send you a compute cost and payment link - as low as $10 per job."
---
# MFAQ
We present a multilingual FAQ retrieval model trained on the [MFAQ dataset](https://huggingface.co/datasets/clips/mfaq), it ranks candidate answers according to a given question.
## Installation
```
pip install sentence-transformers transformers
```
## Usage
You can use MFAQ with sentence-transformers or directly with a HuggingFace model.
In both cases, questions need to be prepended with `<Q>`, and answers with `<A>`.
#### Sentence Transformers
```python
from sentence_transformers import SentenceTransformer
question = "<Q>How many models can I host on HuggingFace?"
answer_1 = "<A>All plans come with unlimited private models and datasets."
answer_2 = "<A>AutoNLP is an automatic way to train and deploy state-of-the-art NLP models, seamlessly integrated with the Hugging Face ecosystem."
answer_3 = "<A>Based on how much training data and model variants are created, we send you a compute cost and payment link - as low as $10 per job."
model = SentenceTransformer('clips/mfaq')
embeddings = model.encode([question, answer_1, answer_3, answer_3])
print(embeddings)
```
#### HuggingFace Transformers
```python
from transformers import AutoTokenizer, AutoModel
import torch
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
question = "<Q>How many models can I host on HuggingFace?"
answer_1 = "<A>All plans come with unlimited private models and datasets."
answer_2 = "<A>AutoNLP is an automatic way to train and deploy state-of-the-art NLP models, seamlessly integrated with the Hugging Face ecosystem."
answer_3 = "<A>Based on how much training data and model variants are created, we send you a compute cost and payment link - as low as $10 per job."
tokenizer = AutoTokenizer.from_pretrained('clips/mfaq')
model = AutoModel.from_pretrained('clips/mfaq')
# Tokenize sentences
encoded_input = tokenizer([question, answer_1, answer_3, answer_3], padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
```
## Training
You can find the training script for the model [here](https://github.com/clips/mfaq).
## People
This model was developed by [Maxime De Bruyn](https://www.linkedin.com/in/maximedebruyn/), Ehsan Lotfi, Jeska Buhmann and Walter Daelemans.
## Citation information
```
@misc{debruyn2021mfaq,
title={MFAQ: a Multilingual FAQ Dataset},
author={Maxime De Bruyn and Ehsan Lotfi and Jeska Buhmann and Walter Daelemans},
year={2021},
eprint={2109.12870},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
indolem/indobert-base-uncased
|
b6663c19a819c04798e7a93d681f9bc34ed57b4a
|
2021-09-17T04:06:54.000Z
|
[
"pytorch",
"jax",
"bert",
"fill-mask",
"id",
"dataset:220M words (IndoWiki, IndoWC, News)]",
"arxiv:2011.00677",
"transformers",
"indobert",
"indolem",
"license:mit",
"autotrain_compatible"
] |
fill-mask
| false |
indolem
| null |
indolem/indobert-base-uncased
| 11,412 | 6 |
transformers
| 647 |
---
language: id
tags:
- indobert
- indolem
license: mit
inference: False
datasets:
- 220M words (IndoWiki, IndoWC, News)]
---
## About
[IndoBERT](https://arxiv.org/pdf/2011.00677.pdf) is the Indonesian version of BERT model. We train the model using over 220M words, aggregated from three main sources:
* Indonesian Wikipedia (74M words)
* news articles from Kompas, Tempo (Tala et al., 2003), and Liputan6 (55M words in total)
* an Indonesian Web Corpus (Medved and Suchomel, 2017) (90M words).
We trained the model for 2.4M steps (180 epochs) with the final perplexity over the development set being <b>3.97</b> (similar to English BERT-base).
This <b>IndoBERT</b> was used to examine IndoLEM - an Indonesian benchmark that comprises of seven tasks for the Indonesian language, spanning morpho-syntax, semantics, and discourse.
| Task | Metric | Bi-LSTM | mBERT | MalayBERT | IndoBERT |
| ---- | ---- | ---- | ---- | ---- | ---- |
| POS Tagging | Acc | 95.4 | <b>96.8</b> | <b>96.8</b> | <b>96.8</b> |
| NER UGM | F1| 70.9 | 71.6 | 73.2 | <b>74.9</b> |
| NER UI | F1 | 82.2 | 82.2 | 87.4 | <b>90.1</b> |
| Dep. Parsing (UD-Indo-GSD) | UAS/LAS | 85.25/80.35 | 86.85/81.78 | 86.99/81.87 | <b>87.12<b/>/<b>82.32</b> |
| Dep. Parsing (UD-Indo-PUD) | UAS/LAS | 84.04/79.01 | <b>90.58</b>/<b>85.44</b> | 88.91/83.56 | 89.23/83.95 |
| Sentiment Analysis | F1 | 71.62 | 76.58 | 82.02 | <b>84.13</b> |
| Summarization | R1/R2/RL | 67.96/61.65/67.24 | 68.40/61.66/67.67 | 68.44/61.38/67.71 | <b>69.93</b>/<b>62.86</b>/<b>69.21</b> |
| Next Tweet Prediction | Acc | 73.6 | 92.4 | 93.1 | <b>93.7</b> |
| Tweet Ordering | Spearman corr. | 0.45 | 0.53 | 0.51 | <b>0.59</b> |
The paper is published at the 28th COLING 2020. Please refer to https://indolem.github.io for more details about the benchmarks.
## How to use
### Load model and tokenizer (tested with transformers==3.5.1)
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("indolem/indobert-base-uncased")
model = AutoModel.from_pretrained("indolem/indobert-base-uncased")
```
## Citation
If you use our work, please cite:
```bibtex
@inproceedings{koto2020indolem,
title={IndoLEM and IndoBERT: A Benchmark Dataset and Pre-trained Language Model for Indonesian NLP},
author={Fajri Koto and Afshin Rahimi and Jey Han Lau and Timothy Baldwin},
booktitle={Proceedings of the 28th COLING},
year={2020}
}
```
|
beomi/kcbert-base
|
99fc27ea7d643d8377ade8912c6c445a5e3861be
|
2022-07-20T01:56:19.000Z
|
[
"pytorch",
"jax",
"bert",
"fill-mask",
"ko",
"arxiv:1810.04805",
"transformers",
"korean",
"license:apache-2.0",
"autotrain_compatible"
] |
fill-mask
| false |
beomi
| null |
beomi/kcbert-base
| 11,349 | null |
transformers
| 648 |
---
language: ko
license: apache-2.0
tags:
- korean
---
# KcBERT: Korean comments BERT
** Updates on 2021.04.07 **
- KcELECTRA가 릴리즈 되었습니다!🤗
- KcELECTRA는 보다 더 많은 데이터셋, 그리고 더 큰 General vocab을 통해 KcBERT 대비 **모든 태스크에서 더 높은 성능**을 보입니다.
- 아래 깃헙 링크에서 직접 사용해보세요!
- https://github.com/Beomi/KcELECTRA
** Updates on 2021.03.14 **
- KcBERT Paper 인용 표기를 추가하였습니다.(bibtex)
- KcBERT-finetune Performance score를 본문에 추가하였습니다.
** Updates on 2020.12.04 **
Huggingface Transformers가 v4.0.0으로 업데이트됨에 따라 Tutorial의 코드가 일부 변경되었습니다.
업데이트된 KcBERT-Large NSMC Finetuning Colab: <a href="https://colab.research.google.com/drive/1dFC0FL-521m7CL_PSd8RLKq67jgTJVhL?usp=sharing">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
** Updates on 2020.09.11 **
KcBERT를 Google Colab에서 TPU를 통해 학습할 수 있는 튜토리얼을 제공합니다! 아래 버튼을 눌러보세요.
Colab에서 TPU로 KcBERT Pretrain 해보기: <a href="https://colab.research.google.com/drive/1lYBYtaXqt9S733OXdXvrvC09ysKFN30W">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
텍스트 분량만 전체 12G 텍스트 중 일부(144MB)로 줄여 학습을 진행합니다.
한국어 데이터셋/코퍼스를 좀더 쉽게 사용할 수 있는 [Korpora](https://github.com/ko-nlp/Korpora) 패키지를 사용합니다.
** Updates on 2020.09.08 **
Github Release를 통해 학습 데이터를 업로드하였습니다.
다만 한 파일당 2GB 이내의 제약으로 인해 분할압축되어있습니다.
아래 링크를 통해 받아주세요. (가입 없이 받을 수 있어요. 분할압축)
만약 한 파일로 받고싶으시거나/Kaggle에서 데이터를 살펴보고 싶으시다면 아래의 캐글 데이터셋을 이용해주세요.
- Github릴리즈: https://github.com/Beomi/KcBERT/releases/tag/TrainData_v1
** Updates on 2020.08.22 **
Pretrain Dataset 공개
- 캐글: https://www.kaggle.com/junbumlee/kcbert-pretraining-corpus-korean-news-comments (한 파일로 받을 수 있어요. 단일파일)
Kaggle에 학습을 위해 정제한(아래 `clean`처리를 거친) Dataset을 공개하였습니다!
직접 다운받으셔서 다양한 Task에 학습을 진행해보세요 :)
---
공개된 한국어 BERT는 대부분 한국어 위키, 뉴스 기사, 책 등 잘 정제된 데이터를 기반으로 학습한 모델입니다. 한편, 실제로 NSMC와 같은 댓글형 데이터셋은 정제되지 않았고 구어체 특징에 신조어가 많으며, 오탈자 등 공식적인 글쓰기에서 나타나지 않는 표현들이 빈번하게 등장합니다.
KcBERT는 위와 같은 특성의 데이터셋에 적용하기 위해, 네이버 뉴스에서 댓글과 대댓글을 수집해, 토크나이저와 BERT모델을 처음부터 학습한 Pretrained BERT 모델입니다.
KcBERT는 Huggingface의 Transformers 라이브러리를 통해 간편히 불러와 사용할 수 있습니다. (별도의 파일 다운로드가 필요하지 않습니다.)
## KcBERT Performance
- Finetune 코드는 https://github.com/Beomi/KcBERT-finetune 에서 찾아보실 수 있습니다.
| | Size<br/>(용량) | **NSMC**<br/>(acc) | **Naver NER**<br/>(F1) | **PAWS**<br/>(acc) | **KorNLI**<br/>(acc) | **KorSTS**<br/>(spearman) | **Question Pair**<br/>(acc) | **KorQuaD (Dev)**<br/>(EM/F1) |
| :-------------------- | :---: | :----------------: | :--------------------: | :----------------: | :------------------: | :-----------------------: | :-------------------------: | :---------------------------: |
| KcBERT-Base | 417M | 89.62 | 84.34 | 66.95 | 74.85 | 75.57 | 93.93 | 60.25 / 84.39 |
| KcBERT-Large | 1.2G | **90.68** | 85.53 | 70.15 | 76.99 | 77.49 | 94.06 | 62.16 / 86.64 |
| KoBERT | 351M | 89.63 | 86.11 | 80.65 | 79.00 | 79.64 | 93.93 | 52.81 / 80.27 |
| XLM-Roberta-Base | 1.03G | 89.49 | 86.26 | 82.95 | 79.92 | 79.09 | 93.53 | 64.70 / 88.94 |
| HanBERT | 614M | 90.16 | **87.31** | 82.40 | **80.89** | 83.33 | 94.19 | 78.74 / 92.02 |
| KoELECTRA-Base | 423M | **90.21** | 86.87 | 81.90 | 80.85 | 83.21 | 94.20 | 61.10 / 89.59 |
| KoELECTRA-Base-v2 | 423M | 89.70 | 87.02 | **83.90** | 80.61 | **84.30** | **94.72** | **84.34 / 92.58** |
| DistilKoBERT | 108M | 88.41 | 84.13 | 62.55 | 70.55 | 73.21 | 92.48 | 54.12 / 77.80 |
\*HanBERT의 Size는 Bert Model과 Tokenizer DB를 합친 것입니다.
\***config의 세팅을 그대로 하여 돌린 결과이며, hyperparameter tuning을 추가적으로 할 시 더 좋은 성능이 나올 수 있습니다.**
## How to use
### Requirements
- `pytorch <= 1.8.0`
- `transformers ~= 3.0.1`
- `transformers ~= 4.0.0` 도 호환됩니다.
- `emoji ~= 0.6.0`
- `soynlp ~= 0.0.493`
```python
from transformers import AutoTokenizer, AutoModelWithLMHead
# Base Model (108M)
tokenizer = AutoTokenizer.from_pretrained("beomi/kcbert-base")
model = AutoModelWithLMHead.from_pretrained("beomi/kcbert-base")
# Large Model (334M)
tokenizer = AutoTokenizer.from_pretrained("beomi/kcbert-large")
model = AutoModelWithLMHead.from_pretrained("beomi/kcbert-large")
```
### Pretrain & Finetune Colab 링크 모음
#### Pretrain Data
- [데이터셋 다운로드(Kaggle, 단일파일, 로그인 필요)](https://www.kaggle.com/junbumlee/kcbert-pretraining-corpus-korean-news-comments)
- [데이터셋 다운로드(Github, 압축 여러파일, 로그인 불필요)](https://github.com/Beomi/KcBERT/releases/tag/TrainData_v1)
#### Pretrain Code
Colab에서 TPU로 KcBERT Pretrain 해보기: <a href="https://colab.research.google.com/drive/1lYBYtaXqt9S733OXdXvrvC09ysKFN30W">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
#### Finetune Samples
**KcBERT-Base** NSMC Finetuning with PyTorch-Lightning (Colab) <a href="https://colab.research.google.com/drive/1fn4sVJ82BrrInjq6y5655CYPP-1UKCLb?usp=sharing">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
**KcBERT-Large** NSMC Finetuning with PyTorch-Lightning (Colab) <a href="https://colab.research.google.com/drive/1dFC0FL-521m7CL_PSd8RLKq67jgTJVhL?usp=sharing">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
> 위 두 코드는 Pretrain 모델(base, large)와 batch size만 다를 뿐, 나머지 코드는 완전히 동일합니다.
## Train Data & Preprocessing
### Raw Data
학습 데이터는 2019.01.01 ~ 2020.06.15 사이에 작성된 **댓글 많은 뉴스** 기사들의 **댓글과 대댓글**을 모두 수집한 데이터입니다.
데이터 사이즈는 텍스트만 추출시 **약 15.4GB이며, 1억1천만개 이상의 문장**으로 이뤄져 있습니다.
### Preprocessing
PLM 학습을 위해서 전처리를 진행한 과정은 다음과 같습니다.
1. 한글 및 영어, 특수문자, 그리고 이모지(🥳)까지!
정규표현식을 통해 한글, 영어, 특수문자를 포함해 Emoji까지 학습 대상에 포함했습니다.
한편, 한글 범위를 `ㄱ-ㅎ가-힣` 으로 지정해 `ㄱ-힣` 내의 한자를 제외했습니다.
2. 댓글 내 중복 문자열 축약
`ㅋㅋㅋㅋㅋ`와 같이 중복된 글자를 `ㅋㅋ`와 같은 것으로 합쳤습니다.
3. Cased Model
KcBERT는 영문에 대해서는 대소문자를 유지하는 Cased model입니다.
4. 글자 단위 10글자 이하 제거
10글자 미만의 텍스트는 단일 단어로 이뤄진 경우가 많아 해당 부분을 제외했습니다.
5. 중복 제거
중복적으로 쓰인 댓글을 제거하기 위해 중복 댓글을 하나로 합쳤습니다.
이를 통해 만든 최종 학습 데이터는 **12.5GB, 8.9천만개 문장**입니다.
아래 명령어로 pip로 설치한 뒤, 아래 clean함수로 클리닝을 하면 Downstream task에서 보다 성능이 좋아집니다. (`[UNK]` 감소)
```bash
pip install soynlp emoji
```
아래 `clean` 함수를 Text data에 사용해주세요.
```python
import re
import emoji
from soynlp.normalizer import repeat_normalize
emojis = list({y for x in emoji.UNICODE_EMOJI.values() for y in x.keys()})
emojis = ''.join(emojis)
pattern = re.compile(f'[^ .,?!/@$%~%·∼()\x00-\x7Fㄱ-ㅣ가-힣{emojis}]+')
url_pattern = re.compile(
r'https?:\/\/(www\.)?[-a-zA-Z0-9@:%._\+~#=]{1,256}\.[a-zA-Z0-9()]{1,6}\b([-a-zA-Z0-9()@:%_\+.~#?&//=]*)')
def clean(x):
x = pattern.sub(' ', x)
x = url_pattern.sub('', x)
x = x.strip()
x = repeat_normalize(x, num_repeats=2)
return x
```
### Cleaned Data (Released on Kaggle)
원본 데이터를 위 `clean`함수로 정제한 12GB분량의 txt 파일을 아래 Kaggle Dataset에서 다운받으실 수 있습니다 :)
https://www.kaggle.com/junbumlee/kcbert-pretraining-corpus-korean-news-comments
## Tokenizer Train
Tokenizer는 Huggingface의 [Tokenizers](https://github.com/huggingface/tokenizers) 라이브러리를 통해 학습을 진행했습니다.
그 중 `BertWordPieceTokenizer` 를 이용해 학습을 진행했고, Vocab Size는 `30000`으로 진행했습니다.
Tokenizer를 학습하는 것에는 `1/10`로 샘플링한 데이터로 학습을 진행했고, 보다 골고루 샘플링하기 위해 일자별로 stratify를 지정한 뒤 햑습을 진행했습니다.
## BERT Model Pretrain
- KcBERT Base config
```json
{
"max_position_embeddings": 300,
"hidden_dropout_prob": 0.1,
"hidden_act": "gelu",
"initializer_range": 0.02,
"num_hidden_layers": 12,
"type_vocab_size": 2,
"vocab_size": 30000,
"hidden_size": 768,
"attention_probs_dropout_prob": 0.1,
"directionality": "bidi",
"num_attention_heads": 12,
"intermediate_size": 3072,
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert"
}
```
- KcBERT Large config
```json
{
"type_vocab_size": 2,
"initializer_range": 0.02,
"max_position_embeddings": 300,
"vocab_size": 30000,
"hidden_size": 1024,
"hidden_dropout_prob": 0.1,
"model_type": "bert",
"directionality": "bidi",
"pad_token_id": 0,
"layer_norm_eps": 1e-12,
"hidden_act": "gelu",
"num_hidden_layers": 24,
"num_attention_heads": 16,
"attention_probs_dropout_prob": 0.1,
"intermediate_size": 4096,
"architectures": [
"BertForMaskedLM"
]
}
```
BERT Model Config는 Base, Large 기본 세팅값을 그대로 사용했습니다. (MLM 15% 등)
TPU `v3-8` 을 이용해 각각 3일, N일(Large는 학습 진행 중)을 진행했고, 현재 Huggingface에 공개된 모델은 1m(100만) step을 학습한 ckpt가 업로드 되어있습니다.
모델 학습 Loss는 Step에 따라 초기 200k에 가장 빠르게 Loss가 줄어들다 400k이후로는 조금씩 감소하는 것을 볼 수 있습니다.
- Base Model Loss
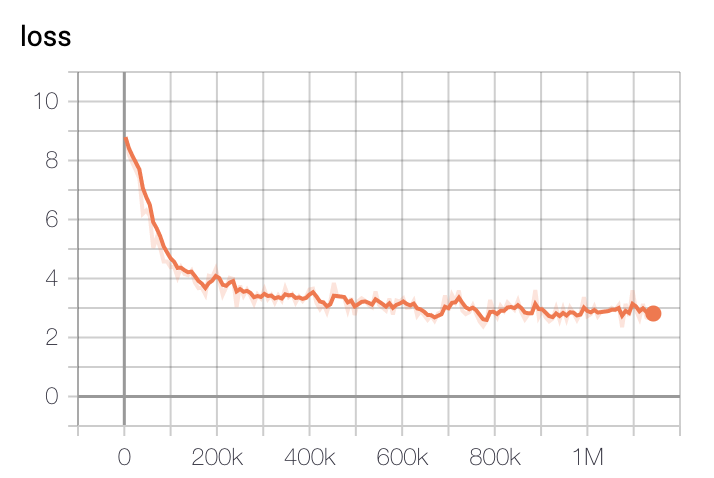
- Large Model Loss
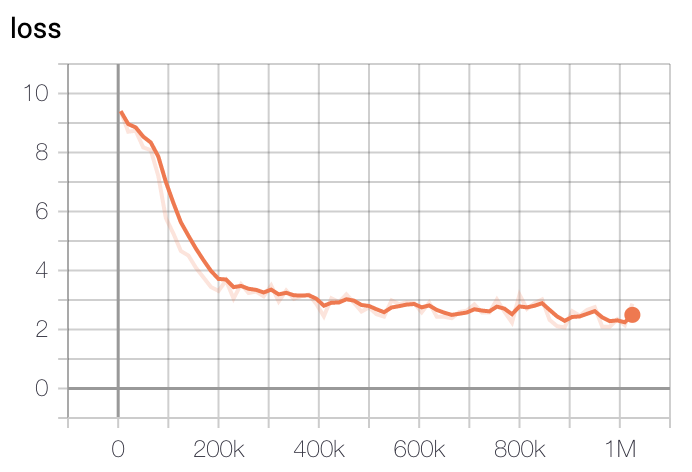
학습은 GCP의 TPU v3-8을 이용해 학습을 진행했고, 학습 시간은 Base Model 기준 2.5일정도 진행했습니다. Large Model은 약 5일정도 진행한 뒤 가장 낮은 loss를 가진 체크포인트로 정했습니다.
## Example
### HuggingFace MASK LM
[HuggingFace kcbert-base 모델](https://huggingface.co/beomi/kcbert-base?text=오늘은+날씨가+[MASK]) 에서 아래와 같이 테스트 해 볼 수 있습니다.
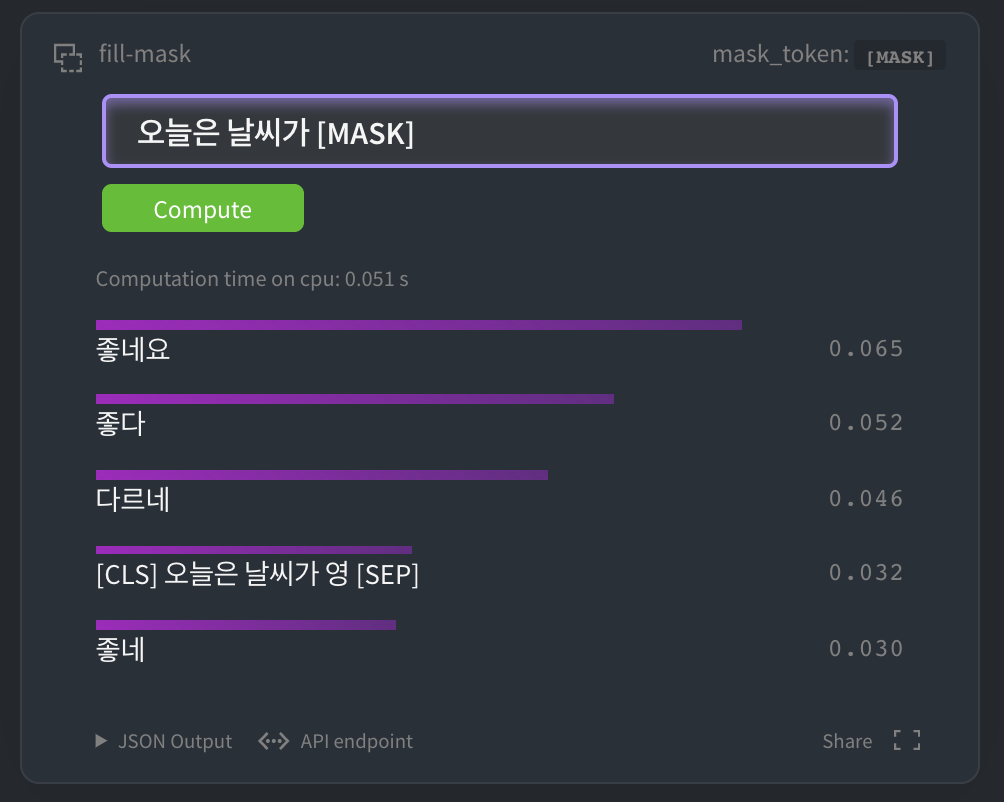
물론 [kcbert-large 모델](https://huggingface.co/beomi/kcbert-large?text=오늘은+날씨가+[MASK]) 에서도 테스트 할 수 있습니다.
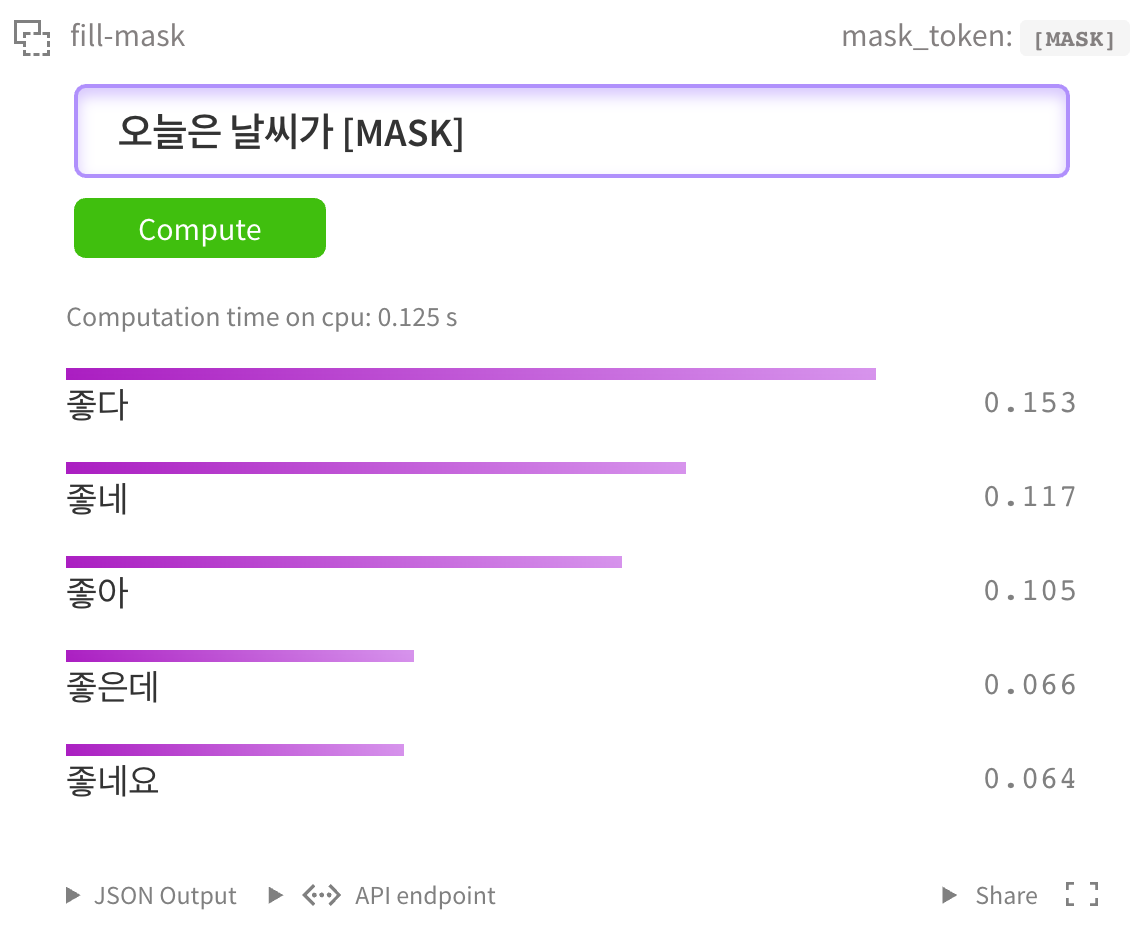
### NSMC Binary Classification
[네이버 영화평 코퍼스](https://github.com/e9t/nsmc) 데이터셋을 대상으로 Fine Tuning을 진행해 성능을 간단히 테스트해보았습니다.
Base Model을 Fine Tune하는 코드는 <a href="https://colab.research.google.com/drive/1fn4sVJ82BrrInjq6y5655CYPP-1UKCLb?usp=sharing">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a> 에서 직접 실행해보실 수 있습니다.
Large Model을 Fine Tune하는 코드는 <a href="https://colab.research.google.com/drive/1dFC0FL-521m7CL_PSd8RLKq67jgTJVhL?usp=sharing">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a> 에서 직접 실행해볼 수 있습니다.
- GPU는 P100 x1대 기준 1epoch에 2-3시간, TPU는 1epoch에 1시간 내로 소요됩니다.
- GPU RTX Titan x4대 기준 30분/epoch 소요됩니다.
- 예시 코드는 [pytorch-lightning](https://github.com/PyTorchLightning/pytorch-lightning)으로 개발했습니다.
#### 실험결과
- KcBERT-Base Model 실험결과: Val acc `.8905`

- KcBERT-Large Model 실험 결과: Val acc `.9089`
> 더 다양한 Downstream Task에 대해 테스트를 진행하고 공개할 예정입니다.
## 인용표기/Citation
KcBERT를 인용하실 때는 아래 양식을 통해 인용해주세요.
```
@inproceedings{lee2020kcbert,
title={KcBERT: Korean Comments BERT},
author={Lee, Junbum},
booktitle={Proceedings of the 32nd Annual Conference on Human and Cognitive Language Technology},
pages={437--440},
year={2020}
}
```
- 논문집 다운로드 링크: http://hclt.kr/dwn/?v=bG5iOmNvbmZlcmVuY2U7aWR4OjMy (*혹은 http://hclt.kr/symp/?lnb=conference )
## Acknowledgement
KcBERT Model을 학습하는 GCP/TPU 환경은 [TFRC](https://www.tensorflow.org/tfrc?hl=ko) 프로그램의 지원을 받았습니다.
모델 학습 과정에서 많은 조언을 주신 [Monologg](https://github.com/monologg/) 님 감사합니다 :)
## Reference
### Github Repos
- [BERT by Google](https://github.com/google-research/bert)
- [KoBERT by SKT](https://github.com/SKTBrain/KoBERT)
- [KoELECTRA by Monologg](https://github.com/monologg/KoELECTRA/)
- [Transformers by Huggingface](https://github.com/huggingface/transformers)
- [Tokenizers by Hugginface](https://github.com/huggingface/tokenizers)
### Papers
- [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805)
### Blogs
- [Monologg님의 KoELECTRA 학습기](https://monologg.kr/categories/NLP/ELECTRA/)
- [Colab에서 TPU로 BERT 처음부터 학습시키기 - Tensorflow/Google ver.](https://beomi.github.io/2020/02/26/Train-BERT-from-scratch-on-colab-TPU-Tensorflow-ver/)
|
allenai/biomed_roberta_base
|
6209646a5f79bbd383f8193d70e88ab00ae779f8
|
2021-05-20T13:00:31.000Z
|
[
"pytorch",
"jax",
"roberta",
"transformers"
] | null | false |
allenai
| null |
allenai/biomed_roberta_base
| 11,329 | 7 |
transformers
| 649 |
---
thumbnail: https://huggingface.co/front/thumbnails/allenai.png
---
# BioMed-RoBERTa-base
BioMed-RoBERTa-base is a language model based on the RoBERTa-base (Liu et. al, 2019) architecture. We adapt RoBERTa-base to 2.68 million scientific papers from the [Semantic Scholar](https://www.semanticscholar.org) corpus via continued pretraining. This amounts to 7.55B tokens and 47GB of data. We use the full text of the papers in training, not just abstracts.
Specific details of the adaptive pretraining procedure can be found in Gururangan et. al, 2020.
## Evaluation
BioMed-RoBERTa achieves competitive performance to state of the art models on a number of NLP tasks in the biomedical domain (numbers are mean (standard deviation) over 3+ random seeds)
| Task | Task Type | RoBERTa-base | BioMed-RoBERTa-base |
|--------------|---------------------|--------------|---------------------|
| RCT-180K | Text Classification | 86.4 (0.3) | 86.9 (0.2) |
| ChemProt | Relation Extraction | 81.1 (1.1) | 83.0 (0.7) |
| JNLPBA | NER | 74.3 (0.2) | 75.2 (0.1) |
| BC5CDR | NER | 85.6 (0.1) | 87.8 (0.1) |
| NCBI-Disease | NER | 86.6 (0.3) | 87.1 (0.8) |
More evaluations TBD.
## Citation
If using this model, please cite the following paper:
```bibtex
@inproceedings{domains,
author = {Suchin Gururangan and Ana Marasović and Swabha Swayamdipta and Kyle Lo and Iz Beltagy and Doug Downey and Noah A. Smith},
title = {Don't Stop Pretraining: Adapt Language Models to Domains and Tasks},
year = {2020},
booktitle = {Proceedings of ACL},
}
```
|
Narasimha/hinglish-distilbert
|
e58ddfc465f1027aa1c54092992247bd310d97c7
|
2022-05-05T08:45:20.000Z
|
[
"pytorch",
"distilbert",
"text-classification",
"transformers",
"license:mit"
] |
text-classification
| false |
Narasimha
| null |
Narasimha/hinglish-distilbert
| 11,266 | null |
transformers
| 650 |
---
license: mit
---
|
csarron/bert-base-uncased-squad-v1
|
31129bdd485e06a6bec8fd2e045256369db34b0b
|
2021-05-19T14:32:38.000Z
|
[
"pytorch",
"jax",
"bert",
"question-answering",
"en",
"dataset:squad",
"transformers",
"bert-base",
"license:mit",
"autotrain_compatible"
] |
question-answering
| false |
csarron
| null |
csarron/bert-base-uncased-squad-v1
| 11,230 | null |
transformers
| 651 |
---
language: en
thumbnail:
license: mit
tags:
- question-answering
- bert
- bert-base
datasets:
- squad
metrics:
- squad
widget:
- text: "Which name is also used to describe the Amazon rainforest in English?"
context: "The Amazon rainforest (Portuguese: Floresta Amazônica or Amazônia; Spanish: Selva Amazónica, Amazonía or usually Amazonia; French: Forêt amazonienne; Dutch: Amazoneregenwoud), also known in English as Amazonia or the Amazon Jungle, is a moist broadleaf forest that covers most of the Amazon basin of South America. This basin encompasses 7,000,000 square kilometres (2,700,000 sq mi), of which 5,500,000 square kilometres (2,100,000 sq mi) are covered by the rainforest. This region includes territory belonging to nine nations. The majority of the forest is contained within Brazil, with 60% of the rainforest, followed by Peru with 13%, Colombia with 10%, and with minor amounts in Venezuela, Ecuador, Bolivia, Guyana, Suriname and French Guiana. States or departments in four nations contain \"Amazonas\" in their names. The Amazon represents over half of the planet's remaining rainforests, and comprises the largest and most biodiverse tract of tropical rainforest in the world, with an estimated 390 billion individual trees divided into 16,000 species."
- text: "How many square kilometers of rainforest is covered in the basin?"
context: "The Amazon rainforest (Portuguese: Floresta Amazônica or Amazônia; Spanish: Selva Amazónica, Amazonía or usually Amazonia; French: Forêt amazonienne; Dutch: Amazoneregenwoud), also known in English as Amazonia or the Amazon Jungle, is a moist broadleaf forest that covers most of the Amazon basin of South America. This basin encompasses 7,000,000 square kilometres (2,700,000 sq mi), of which 5,500,000 square kilometres (2,100,000 sq mi) are covered by the rainforest. This region includes territory belonging to nine nations. The majority of the forest is contained within Brazil, with 60% of the rainforest, followed by Peru with 13%, Colombia with 10%, and with minor amounts in Venezuela, Ecuador, Bolivia, Guyana, Suriname and French Guiana. States or departments in four nations contain \"Amazonas\" in their names. The Amazon represents over half of the planet's remaining rainforests, and comprises the largest and most biodiverse tract of tropical rainforest in the world, with an estimated 390 billion individual trees divided into 16,000 species."
---
## BERT-base uncased model fine-tuned on SQuAD v1
This model was fine-tuned from the HuggingFace [BERT](https://www.aclweb.org/anthology/N19-1423/) base uncased checkpoint on [SQuAD1.1](https://rajpurkar.github.io/SQuAD-explorer).
This model is case-insensitive: it does not make a difference between english and English.
## Details
| Dataset | Split | # samples |
| -------- | ----- | --------- |
| SQuAD1.1 | train | 90.6K |
| SQuAD1.1 | eval | 11.1k |
### Fine-tuning
- Python: `3.7.5`
- Machine specs:
`CPU: Intel(R) Core(TM) i7-6800K CPU @ 3.40GHz`
`Memory: 32 GiB`
`GPUs: 2 GeForce GTX 1070, each with 8GiB memory`
`GPU driver: 418.87.01, CUDA: 10.1`
- script:
```shell
# after install https://github.com/huggingface/transformers
cd examples/question-answering
mkdir -p data
wget -O data/train-v1.1.json https://rajpurkar.github.io/SQuAD-explorer/dataset/train-v1.1.json
wget -O data/dev-v1.1.json https://rajpurkar.github.io/SQuAD-explorer/dataset/dev-v1.1.json
python run_squad.py \
--model_type bert \
--model_name_or_path bert-base-uncased \
--do_train \
--do_eval \
--do_lower_case \
--train_file train-v1.1.json \
--predict_file dev-v1.1.json \
--per_gpu_train_batch_size 12 \
--per_gpu_eval_batch_size=16 \
--learning_rate 3e-5 \
--num_train_epochs 2.0 \
--max_seq_length 320 \
--doc_stride 128 \
--data_dir data \
--output_dir data/bert-base-uncased-squad-v1 2>&1 | tee train-energy-bert-base-squad-v1.log
```
It took about 2 hours to finish.
### Results
**Model size**: `418M`
| Metric | # Value | # Original ([Table 2](https://www.aclweb.org/anthology/N19-1423.pdf))|
| ------ | --------- | --------- |
| **EM** | **80.9** | **80.8** |
| **F1** | **88.2** | **88.5** |
Note that the above results didn't involve any hyperparameter search.
## Example Usage
```python
from transformers import pipeline
qa_pipeline = pipeline(
"question-answering",
model="csarron/bert-base-uncased-squad-v1",
tokenizer="csarron/bert-base-uncased-squad-v1"
)
predictions = qa_pipeline({
'context': "The game was played on February 7, 2016 at Levi's Stadium in the San Francisco Bay Area at Santa Clara, California.",
'question': "What day was the game played on?"
})
print(predictions)
# output:
# {'score': 0.8730505704879761, 'start': 23, 'end': 39, 'answer': 'February 7, 2016'}
```
> Created by [Qingqing Cao](https://awk.ai/) | [GitHub](https://github.com/csarron) | [Twitter](https://twitter.com/sysnlp)
> Made with ❤️ in New York.
|
Babelscape/rebel-large
|
d24237e8ab9c1ad2cbdf53fd54b0d7cda1da8018
|
2022-05-27T10:20:40.000Z
|
[
"pytorch",
"bart",
"text2text-generation",
"en",
"dataset:Babelscape/rebel-dataset",
"transformers",
"seq2seq",
"relation-extraction",
"license:cc-by-nc-sa-4.0",
"model-index",
"autotrain_compatible"
] |
text2text-generation
| false |
Babelscape
| null |
Babelscape/rebel-large
| 11,194 | 22 |
transformers
| 652 |
---
language:
- en
widget:
- text: "Punta Cana is a resort town in the municipality of Higuey, in La Altagracia Province, the eastern most province of the Dominican Republic"
tags:
- seq2seq
- relation-extraction
datasets:
- Babelscape/rebel-dataset
model-index:
- name: REBEL
results:
- task:
name: Relation Extraction
type: Relation-Extraction
dataset:
name: "CoNLL04"
type: CoNLL04
metrics:
- name: RE+ Macro F1
type: re+ macro f1
value: 76.65
- task:
name: Relation Extraction
type: Relation-Extraction
dataset:
name: "NYT"
type: NYT
metrics:
- name: F1
type: f1
value: 93.4
license: cc-by-nc-sa-4.0
---
[](https://paperswithcode.com/sota/relation-extraction-on-nyt?p=rebel-relation-extraction-by-end-to-end)
[](https://paperswithcode.com/sota/relation-extraction-on-conll04?p=rebel-relation-extraction-by-end-to-end)
[](https://paperswithcode.com/sota/joint-entity-and-relation-extraction-on-3?p=rebel-relation-extraction-by-end-to-end)
[](https://paperswithcode.com/sota/relation-extraction-on-ade-corpus?p=rebel-relation-extraction-by-end-to-end)
[](https://paperswithcode.com/sota/relation-extraction-on-re-tacred?p=rebel-relation-extraction-by-end-to-end)
# REBEL <img src="https://i.ibb.co/qsLzNqS/hf-rebel.png" width="30" alt="hf-rebel" border="0" style="display:inline; white-space:nowrap;">: Relation Extraction By End-to-end Language generation
This is the model card for the Findings of EMNLP 2021 paper [REBEL: Relation Extraction By End-to-end Language generation](https://github.com/Babelscape/rebel/blob/main/docs/EMNLP_2021_REBEL__Camera_Ready_.pdf). We present a new linearization approach and a reframing of Relation Extraction as a seq2seq task. The paper can be found [here](https://github.com/Babelscape/rebel/blob/main/docs/EMNLP_2021_REBEL__Camera_Ready_.pdf). If you use the code, please reference this work in your paper:
@inproceedings{huguet-cabot-navigli-2021-rebel-relation,
title = "{REBEL}: Relation Extraction By End-to-end Language generation",
author = "Huguet Cabot, Pere-Llu{\'\i}s and
Navigli, Roberto",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2021",
month = nov,
year = "2021",
address = "Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.findings-emnlp.204",
pages = "2370--2381",
abstract = "Extracting relation triplets from raw text is a crucial task in Information Extraction, enabling multiple applications such as populating or validating knowledge bases, factchecking, and other downstream tasks. However, it usually involves multiple-step pipelines that propagate errors or are limited to a small number of relation types. To overcome these issues, we propose the use of autoregressive seq2seq models. Such models have previously been shown to perform well not only in language generation, but also in NLU tasks such as Entity Linking, thanks to their framing as seq2seq tasks. In this paper, we show how Relation Extraction can be simplified by expressing triplets as a sequence of text and we present REBEL, a seq2seq model based on BART that performs end-to-end relation extraction for more than 200 different relation types. We show our model{'}s flexibility by fine-tuning it on an array of Relation Extraction and Relation Classification benchmarks, with it attaining state-of-the-art performance in most of them.",
}
The original repository for the paper can be found [here](https://github.com/Babelscape/rebel)
Be aware that the inference widget at the right does not output special tokens, which are necessary to distinguish the subject, object and relation types. For a demo of REBEL and its pre-training dataset check the [Spaces demo](https://huggingface.co/spaces/Babelscape/rebel-demo).
## Pipeline usage
```python
from transformers import pipeline
triplet_extractor = pipeline('text2text-generation', model='Babelscape/rebel-large', tokenizer='Babelscape/rebel-large')
# We need to use the tokenizer manually since we need special tokens.
extracted_text = triplet_extractor.tokenizer.batch_decode([triplet_extractor("Punta Cana is a resort town in the municipality of Higuey, in La Altagracia Province, the eastern most province of the Dominican Republic", return_tensors=True, return_text=False)[0]["generated_token_ids"]])
print(extracted_text[0])
# Function to parse the generated text and extract the triplets
def extract_triplets(text):
triplets = []
relation, subject, relation, object_ = '', '', '', ''
text = text.strip()
current = 'x'
for token in text.replace("<s>", "").replace("<pad>", "").replace("</s>", "").split():
if token == "<triplet>":
current = 't'
if relation != '':
triplets.append({'head': subject.strip(), 'type': relation.strip(),'tail': object_.strip()})
relation = ''
subject = ''
elif token == "<subj>":
current = 's'
if relation != '':
triplets.append({'head': subject.strip(), 'type': relation.strip(),'tail': object_.strip()})
object_ = ''
elif token == "<obj>":
current = 'o'
relation = ''
else:
if current == 't':
subject += ' ' + token
elif current == 's':
object_ += ' ' + token
elif current == 'o':
relation += ' ' + token
if subject != '' and relation != '' and object_ != '':
triplets.append({'head': subject.strip(), 'type': relation.strip(),'tail': object_.strip()})
return triplets
extracted_triplets = extract_triplets(extracted_text[0])
print(extracted_triplets)
```
## Model and Tokenizer using transformers
```python
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
def extract_triplets(text):
triplets = []
relation, subject, relation, object_ = '', '', '', ''
text = text.strip()
current = 'x'
for token in text.replace("<s>", "").replace("<pad>", "").replace("</s>", "").split():
if token == "<triplet>":
current = 't'
if relation != '':
triplets.append({'head': subject.strip(), 'type': relation.strip(),'tail': object_.strip()})
relation = ''
subject = ''
elif token == "<subj>":
current = 's'
if relation != '':
triplets.append({'head': subject.strip(), 'type': relation.strip(),'tail': object_.strip()})
object_ = ''
elif token == "<obj>":
current = 'o'
relation = ''
else:
if current == 't':
subject += ' ' + token
elif current == 's':
object_ += ' ' + token
elif current == 'o':
relation += ' ' + token
if subject != '' and relation != '' and object_ != '':
triplets.append({'head': subject.strip(), 'type': relation.strip(),'tail': object_.strip()})
return triplets
# Load model and tokenizer
tokenizer = AutoTokenizer.from_pretrained("Babelscape/rebel-large")
model = AutoModelForSeq2SeqLM.from_pretrained("Babelscape/rebel-large")
gen_kwargs = {
"max_length": 256,
"length_penalty": 0,
"num_beams": 3,
"num_return_sequences": 3,
}
# Text to extract triplets from
text = 'Punta Cana is a resort town in the municipality of Higüey, in La Altagracia Province, the easternmost province of the Dominican Republic.'
# Tokenizer text
model_inputs = tokenizer(text, max_length=256, padding=True, truncation=True, return_tensors = 'pt')
# Generate
generated_tokens = model.generate(
model_inputs["input_ids"].to(model.device),
attention_mask=model_inputs["attention_mask"].to(model.device),
**gen_kwargs,
)
# Extract text
decoded_preds = tokenizer.batch_decode(generated_tokens, skip_special_tokens=False)
# Extract triplets
for idx, sentence in enumerate(decoded_preds):
print(f'Prediction triplets sentence {idx}')
print(extract_triplets(sentence))
```
|
rinna/japanese-roberta-base
|
1559edfaaadefcb1661c016455990b0f6f68b20d
|
2021-09-13T00:46:53.000Z
|
[
"pytorch",
"tf",
"roberta",
"fill-mask",
"ja",
"dataset:cc100",
"dataset:wikipedia",
"transformers",
"japanese",
"masked-lm",
"nlp",
"license:mit",
"autotrain_compatible"
] |
fill-mask
| false |
rinna
| null |
rinna/japanese-roberta-base
| 11,187 | 13 |
transformers
| 653 |
---
language: ja
thumbnail: https://github.com/rinnakk/japanese-gpt2/blob/master/rinna.png
tags:
- ja
- japanese
- roberta
- masked-lm
- nlp
license: mit
datasets:
- cc100
- wikipedia
mask_token: "[MASK]"
widget:
- text: "[CLS]4年に1度[MASK]は開かれる。"
---
# japanese-roberta-base

This repository provides a base-sized Japanese RoBERTa model. The model was trained using code from Github repository [rinnakk/japanese-pretrained-models](https://github.com/rinnakk/japanese-pretrained-models) by [rinna Co., Ltd.](https://corp.rinna.co.jp/)
# How to load the model
*NOTE:* Use `T5Tokenizer` to initiate the tokenizer.
~~~~
from transformers import T5Tokenizer, RobertaForMaskedLM
tokenizer = T5Tokenizer.from_pretrained("rinna/japanese-roberta-base")
tokenizer.do_lower_case = True # due to some bug of tokenizer config loading
model = RobertaForMaskedLM.from_pretrained("rinna/japanese-roberta-base")
~~~~
# How to use the model for masked token prediction
## Note 1: Use `[CLS]`
To predict a masked token, be sure to add a `[CLS]` token before the sentence for the model to correctly encode it, as it is used during the model training.
## Note 2: Use `[MASK]` after tokenization
A) Directly typing `[MASK]` in an input string and B) replacing a token with `[MASK]` after tokenization will yield different token sequences, and thus different prediction results. It is more appropriate to use `[MASK]` after tokenization (as it is consistent with how the model was pretrained). However, the Huggingface Inference API only supports typing `[MASK]` in the input string and produces less robust predictions.
## Note 3: Provide `position_ids` as an argument explicitly
When `position_ids` are not provided for a `Roberta*` model, Huggingface's `transformers` will automatically construct it but start from `padding_idx` instead of `0` (see [issue](https://github.com/rinnakk/japanese-pretrained-models/issues/3) and function `create_position_ids_from_input_ids()` in Huggingface's [implementation](https://github.com/huggingface/transformers/blob/master/src/transformers/models/roberta/modeling_roberta.py)), which unfortunately does not work as expected with `rinna/japanese-roberta-base` since the `padding_idx` of the corresponding tokenizer is not `0`. So please be sure to constrcut the `position_ids` by yourself and make it start from position id `0`.
## Example
Here is an example by to illustrate how our model works as a masked language model. Notice the difference between running the following code example and running the Huggingface Inference API.
~~~~
# original text
text = "4年に1度オリンピックは開かれる。"
# prepend [CLS]
text = "[CLS]" + text
# tokenize
tokens = tokenizer.tokenize(text)
print(tokens) # output: ['[CLS]', '▁4', '年に', '1', '度', 'オリンピック', 'は', '開かれる', '。']
# mask a token
masked_idx = 5
tokens[masked_idx] = tokenizer.mask_token
print(tokens) # output: ['[CLS]', '▁4', '年に', '1', '度', '[MASK]', 'は', '開かれる', '。']
# convert to ids
token_ids = tokenizer.convert_tokens_to_ids(tokens)
print(token_ids) # output: [4, 1602, 44, 24, 368, 6, 11, 21583, 8]
# convert to tensor
import torch
token_tensor = torch.LongTensor([token_ids])
# provide position ids explicitly
position_ids = list(range(0, token_tensor.size(1)))
print(position_ids) # output: [0, 1, 2, 3, 4, 5, 6, 7, 8]
position_id_tensor = torch.LongTensor([position_ids])
# get the top 10 predictions of the masked token
with torch.no_grad():
outputs = model(input_ids=token_tensor, position_ids=position_id_tensor)
predictions = outputs[0][0, masked_idx].topk(10)
for i, index_t in enumerate(predictions.indices):
index = index_t.item()
token = tokenizer.convert_ids_to_tokens([index])[0]
print(i, token)
"""
0 総会
1 サミット
2 ワールドカップ
3 フェスティバル
4 大会
5 オリンピック
6 全国大会
7 党大会
8 イベント
9 世界選手権
"""
~~~~
# Model architecture
A 12-layer, 768-hidden-size transformer-based masked language model.
# Training
The model was trained on [Japanese CC-100](http://data.statmt.org/cc-100/ja.txt.xz) and [Japanese Wikipedia](https://dumps.wikimedia.org/jawiki/) to optimize a masked language modelling objective on 8*V100 GPUs for around 15 days. It reaches ~3.9 perplexity on a dev set sampled from CC-100.
# Tokenization
The model uses a [sentencepiece](https://github.com/google/sentencepiece)-based tokenizer, the vocabulary was trained on the Japanese Wikipedia using the official sentencepiece training script.
# Licenese
[The MIT license](https://opensource.org/licenses/MIT)
|
microsoft/prophetnet-large-uncased
|
f8218576b32128d7623ad24f3f25dce10f3d1b01
|
2021-03-04T20:24:09.000Z
|
[
"pytorch",
"rust",
"prophetnet",
"text2text-generation",
"en",
"arxiv:2001.04063",
"transformers",
"autotrain_compatible"
] |
text2text-generation
| false |
microsoft
| null |
microsoft/prophetnet-large-uncased
| 11,179 | null |
transformers
| 654 |
---
language: en
---
## prophetnet-large-uncased
Pretrained weights for [ProphetNet](https://arxiv.org/abs/2001.04063).
ProphetNet is a new pre-trained language model for sequence-to-sequence learning with a novel self-supervised objective called future n-gram prediction.
ProphetNet is able to predict more future tokens with a n-stream decoder. The original implementation is Fairseq version at [github repo](https://github.com/microsoft/ProphetNet).
### Usage
This pre-trained model can be fine-tuned on *sequence-to-sequence* tasks. The model could *e.g.* be trained on headline generation as follows:
```python
from transformers import ProphetNetForConditionalGeneration, ProphetNetTokenizer
model = ProphetNetForConditionalGeneration.from_pretrained("microsoft/prophetnet-large-uncased")
tokenizer = ProphetNetTokenizer.from_pretrained("microsoft/prophetnet-large-uncased")
input_str = "the us state department said wednesday it had received no formal word from bolivia that it was expelling the us ambassador there but said the charges made against him are `` baseless ."
target_str = "us rejects charges against its ambassador in bolivia"
input_ids = tokenizer(input_str, return_tensors="pt").input_ids
labels = tokenizer(target_str, return_tensors="pt").input_ids
loss = model(input_ids, labels=labels).loss
```
### Citation
```bibtex
@article{yan2020prophetnet,
title={Prophetnet: Predicting future n-gram for sequence-to-sequence pre-training},
author={Yan, Yu and Qi, Weizhen and Gong, Yeyun and Liu, Dayiheng and Duan, Nan and Chen, Jiusheng and Zhang, Ruofei and Zhou, Ming},
journal={arXiv preprint arXiv:2001.04063},
year={2020}
}
```
|
Zixtrauce/BaekBot
|
8dd7cbc7e2f1f6d711330aabb4a165d87a8dc7f5
|
2021-12-31T08:30:32.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
| false |
Zixtrauce
| null |
Zixtrauce/BaekBot
| 11,165 | null |
transformers
| 655 |
---
tags:
- conversational
---
#BaekBot
|
Salesforce/codet5-base
|
4078456db09ba972a3532827a0b5df4da172323c
|
2021-11-23T09:53:41.000Z
|
[
"pytorch",
"t5",
"text2text-generation",
"dataset:code_search_net",
"arxiv:2109.00859",
"arxiv:1909.09436",
"transformers",
"codet5",
"license:apache-2.0",
"autotrain_compatible"
] |
text2text-generation
| false |
Salesforce
| null |
Salesforce/codet5-base
| 11,146 | 27 |
transformers
| 656 |
---
license: apache-2.0
tags:
- codet5
datasets:
- code_search_net
inference: false
---
# CodeT5 (base-sized model)
Pre-trained CodeT5 model. It was introduced in the paper [CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models
for Code Understanding and Generation](https://arxiv.org/abs/2109.00859) by Yue Wang, Weishi Wang, Shafiq Joty, Steven C.H. Hoi and first released in [this repository](https://github.com/salesforce/CodeT5).
Disclaimer: The team releasing CodeT5 did not write a model card for this model so this model card has been written by the Hugging Face team (more specifically, [nielsr](https://huggingface.co/nielsr)).
## Model description
From the abstract:
"We present CodeT5, a unified pre-trained encoder-decoder Transformer model that better leverages the code semantics conveyed from the developer-assigned identifiers. Our model employs a unified framework to seamlessly support both code understanding and generation tasks and allows for multi-task learning. Besides, we propose a novel identifier-aware pre-training task that enables the model to distinguish which code tokens are identifiers and to recover them when they are masked. Furthermore, we propose to exploit the user-written code comments with a bimodal dual generation task for better NL-PL alignment. Comprehensive experiments show that CodeT5 significantly outperforms prior methods on understanding tasks such as code defect detection and clone detection, and generation tasks across various directions including PL-NL, NL-PL, and PL-PL. Further analysis reveals that our model can better capture semantic information from code."
## Intended uses & limitations
This repository contains the pre-trained model only, so you can use this model for (among other tasks) masked span prediction, as shown in the code example below. However, the main use of this model is to fine-tune it for a downstream task of interest, such as:
* code summarization
* code generation
* code translation
* code refinement
* code defect detection
* code clone detection.
Supervised datasets for code can be found [here](https://huggingface.co/datasets?languages=languages:code).
See the [model hub](https://huggingface.co/models?search=salesforce/codet) to look for fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model:
```python
from transformers import RobertaTokenizer, T5ForConditionalGeneration
tokenizer = RobertaTokenizer.from_pretrained('Salesforce/codet5-base')
model = T5ForConditionalGeneration.from_pretrained('Salesforce/codet5-base')
text = "def greet(user): print(f'hello <extra_id_0>!')"
input_ids = tokenizer(text, return_tensors="pt").input_ids
# simply generate a single sequence
generated_ids = model.generate(input_ids, max_length=8)
print(tokenizer.decode(generated_ids[0], skip_special_tokens=True))
# this prints "{user.username}"
```
## Training data
The CodeT5 model was pretrained on CodeSearchNet [Husain et al., 2019](https://arxiv.org/abs/1909.09436). Additionally, the authors collected two datasets of C/CSharp from [BigQuery1](https://console.cloud.google.com/marketplace/details/github/github-repos) to ensure that all downstream tasks have overlapped programming languages with the pre-training data. In total, around 8.35 million instances are used for pretraining.
## Training procedure
### Preprocessing
This model uses a code-specific BPE (Byte-Pair Encoding) tokenizer trained using the [HuggingFace Tokenizers](https://github.com/huggingface/tokenizers) library. One can prepare text (or code) for the model using RobertaTokenizer, with the files from this repository.
## Evaluation results
For evaluation results on several downstream benchmarks, we refer to the paper.
### BibTeX entry and citation info
```bibtex
@misc{wang2021codet5,
title={CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Understanding and Generation},
author={Yue Wang and Weishi Wang and Shafiq Joty and Steven C. H. Hoi},
year={2021},
eprint={2109.00859},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
aliosm/sha3bor-footer-51-arabertv02-base
|
3538a19ad8c8efa08ab46e4273a9e28a8db097d5
|
2022-05-28T09:34:58.000Z
|
[
"pytorch",
"bert",
"text-classification",
"ar",
"transformers",
"license:mit"
] |
text-classification
| false |
aliosm
| null |
aliosm/sha3bor-footer-51-arabertv02-base
| 11,140 | null |
transformers
| 657 |
---
language: ar
license: mit
widget:
- text: "إن العيون التي في طرفها حور"
- text: "إذا ما فعلت الخير ضوعف شرهم"
- text: "واحر قلباه ممن قلبه شبم"
---
|
sentence-transformers/sentence-t5-large
|
266640df151776ad39f66a2595b81c97ae678195
|
2022-02-09T14:01:09.000Z
|
[
"pytorch",
"t5",
"en",
"arxiv:2108.08877",
"sentence-transformers",
"feature-extraction",
"sentence-similarity",
"transformers",
"license:apache-2.0"
] |
sentence-similarity
| false |
sentence-transformers
| null |
sentence-transformers/sentence-t5-large
| 11,115 | 2 |
sentence-transformers
| 658 |
---
pipeline_tag: sentence-similarity
language: en
license: apache-2.0
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# sentence-transformers/sentence-t5-large
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space. The model works well for sentence similarity tasks, but doesn't perform that well for semantic search tasks.
This model was converted from the Tensorflow model [st5-large-1](https://tfhub.dev/google/sentence-t5/st5-large/1) to PyTorch. When using this model, have a look at the publication: [Sentence-T5: Scalable sentence encoders from pre-trained text-to-text models](https://arxiv.org/abs/2108.08877). The tfhub model and this PyTorch model can produce slightly different embeddings, however, when run on the same benchmarks, they produce identical results.
The model uses only the encoder from a T5-large model. The weights are stored in FP16.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/sentence-t5-large')
embeddings = model.encode(sentences)
print(embeddings)
```
The model requires sentence-transformers version 2.2.0 or newer.
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/sentence-t5-large)
## Citing & Authors
If you find this model helpful, please cite the respective publication:
[Sentence-T5: Scalable sentence encoders from pre-trained text-to-text models](https://arxiv.org/abs/2108.08877)
|
ckiplab/bert-base-chinese
|
efe27bb4a9373384e0120ffe1cf327714ceb61bf
|
2022-05-10T03:28:12.000Z
|
[
"pytorch",
"jax",
"bert",
"fill-mask",
"zh",
"transformers",
"lm-head",
"license:gpl-3.0",
"autotrain_compatible"
] |
fill-mask
| false |
ckiplab
| null |
ckiplab/bert-base-chinese
| 11,108 | 5 |
transformers
| 659 |
---
language:
- zh
thumbnail: https://ckip.iis.sinica.edu.tw/files/ckip_logo.png
tags:
- pytorch
- lm-head
- bert
- zh
license: gpl-3.0
---
# CKIP BERT Base Chinese
This project provides traditional Chinese transformers models (including ALBERT, BERT, GPT2) and NLP tools (including word segmentation, part-of-speech tagging, named entity recognition).
這個專案提供了繁體中文的 transformers 模型(包含 ALBERT、BERT、GPT2)及自然語言處理工具(包含斷詞、詞性標記、實體辨識)。
## Homepage
- https://github.com/ckiplab/ckip-transformers
## Contributers
- [Mu Yang](https://muyang.pro) at [CKIP](https://ckip.iis.sinica.edu.tw) (Author & Maintainer)
## Usage
Please use BertTokenizerFast as tokenizer instead of AutoTokenizer.
請使用 BertTokenizerFast 而非 AutoTokenizer。
```
from transformers import (
BertTokenizerFast,
AutoModel,
)
tokenizer = BertTokenizerFast.from_pretrained('bert-base-chinese')
model = AutoModel.from_pretrained('ckiplab/bert-base-chinese')
```
For full usage and more information, please refer to https://github.com/ckiplab/ckip-transformers.
有關完整使用方法及其他資訊,請參見 https://github.com/ckiplab/ckip-transformers 。
|
aliosm/sha3bor-rhyme-detector-arabertv02-base
|
6b25d49b178fc51b74a7f7ad0461c6fee7a3105b
|
2022-05-28T09:34:23.000Z
|
[
"pytorch",
"bert",
"text-classification",
"ar",
"transformers",
"license:mit"
] |
text-classification
| false |
aliosm
| null |
aliosm/sha3bor-rhyme-detector-arabertv02-base
| 11,047 | null |
transformers
| 660 |
---
language: ar
license: mit
widget:
- text: "إن العيون التي في طرفها حور [شطر] قتلننا ثم لم يحيين قتلانا"
- text: "إذا ما فعلت الخير ضوعف شرهم [شطر] وكل إناء بالذي فيه ينضح"
- text: "واحر قلباه ممن قلبه شبم [شطر] ومن بجسمي وحالي عنده سقم"
---
|
aliosm/sha3bor-metre-detector-arabertv02-base
|
5cc8cfa4c8ed69b642cd3527941d13830c8c1945
|
2022-05-28T09:34:12.000Z
|
[
"pytorch",
"bert",
"text-classification",
"ar",
"transformers",
"license:mit"
] |
text-classification
| false |
aliosm
| null |
aliosm/sha3bor-metre-detector-arabertv02-base
| 11,030 | null |
transformers
| 661 |
---
language: ar
license: mit
widget:
- text: "إن العيون التي في طرفها حور [شطر] قتلننا ثم لم يحيين قتلانا"
- text: "إذا ما فعلت الخير ضوعف شرهم [شطر] وكل إناء بالذي فيه ينضح"
- text: "واحر قلباه ممن قلبه شبم [شطر] ومن بجسمي وحالي عنده سقم"
---
|
sentence-transformers/msmarco-distilbert-base-tas-b
|
1de916fb3ec96493f57c9f0349a0d9e338ed64c2
|
2022-06-15T21:37:05.000Z
|
[
"pytorch",
"tf",
"distilbert",
"feature-extraction",
"sentence-transformers",
"sentence-similarity",
"transformers",
"license:apache-2.0"
] |
sentence-similarity
| false |
sentence-transformers
| null |
sentence-transformers/msmarco-distilbert-base-tas-b
| 10,954 | 4 |
sentence-transformers
| 662 |
---
pipeline_tag: sentence-similarity
license: apache-2.0
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# sentence-transformers/msmarco-distilbert-base-tas-b
This is a port of the [DistilBert TAS-B Model](https://huggingface.co/sebastian-hofstaetter/distilbert-dot-tas_b-b256-msmarco) to [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and is optimized for the task of semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer, util
query = "How many people live in London?"
docs = ["Around 9 Million people live in London", "London is known for its financial district"]
#Load the model
model = SentenceTransformer('sentence-transformers/msmarco-distilbert-base-tas-b')
#Encode query and documents
query_emb = model.encode(query)
doc_emb = model.encode(docs)
#Compute dot score between query and all document embeddings
scores = util.dot_score(query_emb, doc_emb)[0].cpu().tolist()
#Combine docs & scores
doc_score_pairs = list(zip(docs, scores))
#Sort by decreasing score
doc_score_pairs = sorted(doc_score_pairs, key=lambda x: x[1], reverse=True)
#Output passages & scores
for doc, score in doc_score_pairs:
print(score, doc)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#CLS Pooling - Take output from first token
def cls_pooling(model_output):
return model_output.last_hidden_state[:,0]
#Encode text
def encode(texts):
# Tokenize sentences
encoded_input = tokenizer(texts, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input, return_dict=True)
# Perform pooling
embeddings = cls_pooling(model_output)
return embeddings
# Sentences we want sentence embeddings for
query = "How many people live in London?"
docs = ["Around 9 Million people live in London", "London is known for its financial district"]
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/msmarco-distilbert-base-tas-b")
model = AutoModel.from_pretrained("sentence-transformers/msmarco-distilbert-base-tas-b")
#Encode query and docs
query_emb = encode(query)
doc_emb = encode(docs)
#Compute dot score between query and all document embeddings
scores = torch.mm(query_emb, doc_emb.transpose(0, 1))[0].cpu().tolist()
#Combine docs & scores
doc_score_pairs = list(zip(docs, scores))
#Sort by decreasing score
doc_score_pairs = sorted(doc_score_pairs, key=lambda x: x[1], reverse=True)
#Output passages & scores
for doc, score in doc_score_pairs:
print(score, doc)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/msmarco-distilbert-base-tas-b)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: DistilBertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': True, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
Have a look at: [DistilBert TAS-B Model](https://huggingface.co/sebastian-hofstaetter/distilbert-dot-tas_b-b256-msmarco)
|
rycont/biblify
|
4bd8b40b9570dc2ad5389b22a8f78a69b0a21389
|
2022-07-14T01:52:55.000Z
|
[
"pytorch",
"bart",
"text2text-generation",
"transformers",
"autotrain_compatible"
] |
text2text-generation
| false |
rycont
| null |
rycont/biblify
| 10,945 | null |
transformers
| 663 |
Entry not found
|
facebook/vit-mae-base
|
87dd4faac12498cde93a176406329112584c0413
|
2022-03-29T16:18:27.000Z
|
[
"pytorch",
"tf",
"vit_mae",
"pretraining",
"dataset:imagenet-1k",
"arxiv:2111.06377",
"transformers",
"vision",
"license:apache-2.0"
] | null | false |
facebook
| null |
facebook/vit-mae-base
| 10,939 | 2 |
transformers
| 664 |
---
license: apache-2.0
tags:
- vision
datasets:
- imagenet-1k
---
# Vision Transformer (base-sized model) pre-trained with MAE
Vision Transformer (ViT) model pre-trained using the MAE method. It was introduced in the paper [Masked Autoencoders Are Scalable Vision Learners](https://arxiv.org/abs/2111.06377) by Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick and first released in [this repository](https://github.com/facebookresearch/mae).
Disclaimer: The team releasing MAE did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The Vision Transformer (ViT) is a transformer encoder model (BERT-like). Images are presented to the model as a sequence of fixed-size patches.
During pre-training, one randomly masks out a high portion (75%) of the image patches. First, the encoder is used to encode the visual patches. Next, a learnable (shared) mask token is added at the positions of the masked patches. The decoder takes the encoded visual patches and mask tokens as input and reconstructs raw pixel values for the masked positions.
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=facebook/vit-mae) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model:
```python
from transformers import AutoFeatureExtractor, ViTMAEForPreTraining
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = AutoFeatureExtractor.from_pretrained('facebook/vit-mae-base')
model = ViTMAEForPreTraining.from_pretrained('facebook/vit-mae-base')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
loss = outputs.loss
mask = outputs.mask
ids_restore = outputs.ids_restore
```
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2111-06377,
author = {Kaiming He and
Xinlei Chen and
Saining Xie and
Yanghao Li and
Piotr Doll{\'{a}}r and
Ross B. Girshick},
title = {Masked Autoencoders Are Scalable Vision Learners},
journal = {CoRR},
volume = {abs/2111.06377},
year = {2021},
url = {https://arxiv.org/abs/2111.06377},
eprinttype = {arXiv},
eprint = {2111.06377},
timestamp = {Tue, 16 Nov 2021 12:12:31 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2111-06377.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
aliosm/sha3bor-poetry-diacritizer-canine-s
|
ac91eec76844bfcd9159c6063c2828bdc61e65d4
|
2022-05-28T09:41:28.000Z
|
[
"pytorch",
"canine",
"token-classification",
"ar",
"transformers",
"license:mit",
"autotrain_compatible"
] |
token-classification
| false |
aliosm
| null |
aliosm/sha3bor-poetry-diacritizer-canine-s
| 10,913 | null |
transformers
| 665 |
---
language: ar
license: mit
widget:
- text: "إن العيون التي في طرفها حور [شطر] قتلننا ثم لم يحيين قتلانا"
- text: "إذا ما فعلت الخير ضوعف شرهم [شطر] وكل إناء بالذي فيه ينضح"
- text: "واحر قلباه ممن قلبه شبم [شطر] ومن بجسمي وحالي عنده سقم"
---
|
dbmdz/german-gpt2
|
f0edef6d975b1338bae533502e1dae74974cb2d2
|
2021-10-22T08:58:57.000Z
|
[
"pytorch",
"tf",
"jax",
"gpt2",
"text-generation",
"de",
"transformers",
"license:mit"
] |
text-generation
| false |
dbmdz
| null |
dbmdz/german-gpt2
| 10,875 | 6 |
transformers
| 666 |
---
language: de
widget:
- text: "Heute ist sehr schönes Wetter in"
license: mit
---
# German GPT-2 model
In this repository we release (yet another) GPT-2 model, that was trained on various texts for German.
The model is meant to be an entry point for fine-tuning on other texts, and it is definitely not as good or "dangerous" as the English GPT-3 model. We do not plan extensive PR or staged releases for this model 😉
**Note**: The model was initially released under an anonymous alias (`anonymous-german-nlp/german-gpt2`) so we now "de-anonymize" it.
More details about GPT-2 can be found in the great [Hugging Face](https://huggingface.co/transformers/model_doc/gpt2.html) documentation.
# Changelog
16.08.2021: Public release of re-trained version of our German GPT-2 model with better results.
15.11.2020: Initial release. Please use the tag `v1.0` for [this older version](https://huggingface.co/dbmdz/german-gpt2/tree/v1.0).
# Training corpora
We use pretty much the same corpora as used for training the DBMDZ BERT model, that can be found in [this repository](https://github.com/dbmdz/berts).
Thanks to the awesome Hugging Face team, it is possible to create byte-level BPE with their awesome [Tokenizers](https://github.com/huggingface/tokenizers) library.
With the previously mentioned awesome Tokenizers library we created a 50K byte-level BPE vocab based on the training corpora.
After creating the vocab, we could train the GPT-2 for German on a v3-8 TPU over the complete training corpus for 20 epochs. All hyperparameters
can be found in the official JAX/FLAX documentation [here](https://github.com/huggingface/transformers/blob/master/examples/flax/language-modeling/README.md)
from Transformers.
# Using the model
The model itself can be used in this way:
```python
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("dbmdz/german-gpt2")
model = AutoModelWithLMHead.from_pretrained("dbmdz/german-gpt2")
```
However, text generation is a bit more interesting, so here's an example that shows how to use the great Transformers *Pipelines* for generating text:
```python
from transformers import pipeline
pipe = pipeline('text-generation', model="dbmdz/german-gpt2",
tokenizer="dbmdz/german-gpt2")
text = pipe("Der Sinn des Lebens ist es", max_length=100)[0]["generated_text"]
print(text)
```
This could output this beautiful text:
```
Der Sinn des Lebens ist es, im Geist zu verweilen, aber nicht in der Welt zu sein, sondern ganz im Geist zu leben.
Die Menschen beginnen, sich nicht nach der Natur und nach der Welt zu richten, sondern nach der Seele,'
```
# License
All models are licensed under [MIT](LICENSE).
# Huggingface model hub
All models are available on the [Huggingface model hub](https://huggingface.co/dbmdz).
# Contact (Bugs, Feedback, Contribution and more)
For questions about our BERT models just open an issue
[here](https://github.com/stefan-it/german-gpt/issues/new) 🤗
# Acknowledgments
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
Thanks for providing access to the TFRC ❤️
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
it is possible to download both cased and uncased models from their S3 storage 🤗
|
albert-xxlarge-v1
|
431c690c9f508b1cbcba8f475974833ac646d41c
|
2021-01-13T15:32:02.000Z
|
[
"pytorch",
"tf",
"albert",
"fill-mask",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1909.11942",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] |
fill-mask
| false | null | null |
albert-xxlarge-v1
| 10,863 | 1 |
transformers
| 667 |
---
language: en
license: apache-2.0
datasets:
- bookcorpus
- wikipedia
---
# ALBERT XXLarge v1
Pretrained model on English language using a masked language modeling (MLM) objective. It was introduced in
[this paper](https://arxiv.org/abs/1909.11942) and first released in
[this repository](https://github.com/google-research/albert). This model, as all ALBERT models, is uncased: it does not make a difference
between english and English.
Disclaimer: The team releasing ALBERT did not write a model card for this model so this model card has been written by
the Hugging Face team.
## Model description
ALBERT is a transformers model pretrained on a large corpus of English data in a self-supervised fashion. This means it
was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of
publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely, it
was pretrained with two objectives:
- Masked language modeling (MLM): taking a sentence, the model randomly masks 15% of the words in the input then run
the entire masked sentence through the model and has to predict the masked words. This is different from traditional
recurrent neural networks (RNNs) that usually see the words one after the other, or from autoregressive models like
GPT which internally mask the future tokens. It allows the model to learn a bidirectional representation of the
sentence.
- Sentence Ordering Prediction (SOP): ALBERT uses a pretraining loss based on predicting the ordering of two consecutive segments of text.
This way, the model learns an inner representation of the English language that can then be used to extract features
useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a standard
classifier using the features produced by the ALBERT model as inputs.
ALBERT is particular in that it shares its layers across its Transformer. Therefore, all layers have the same weights. Using repeating layers results in a small memory footprint, however, the computational cost remains similar to a BERT-like architecture with the same number of hidden layers as it has to iterate through the same number of (repeating) layers.
This is the first version of the xxlarge model. Version 2 is different from version 1 due to different dropout rates, additional training data, and longer training. It has better results in nearly all downstream tasks.
This model has the following configuration:
- 12 repeating layers
- 128 embedding dimension
- 4096 hidden dimension
- 64 attention heads
- 223M parameters
## Intended uses & limitations
You can use the raw model for either masked language modeling or next sentence prediction, but it's mostly intended to
be fine-tuned on a downstream task. See the [model hub](https://huggingface.co/models?filter=albert) to look for
fine-tuned versions on a task that interests you.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked)
to make decisions, such as sequence classification, token classification or question answering. For tasks such as text
generation you should look at model like GPT2.
### How to use
You can use this model directly with a pipeline for masked language modeling:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='albert-xxlarge-v1')
>>> unmasker("Hello I'm a [MASK] model.")
[
{
"sequence":"[CLS] hello i'm a modeling model.[SEP]",
"score":0.05816134437918663,
"token":12807,
"token_str":"â–modeling"
},
{
"sequence":"[CLS] hello i'm a modelling model.[SEP]",
"score":0.03748830780386925,
"token":23089,
"token_str":"â–modelling"
},
{
"sequence":"[CLS] hello i'm a model model.[SEP]",
"score":0.033725276589393616,
"token":1061,
"token_str":"â–model"
},
{
"sequence":"[CLS] hello i'm a runway model.[SEP]",
"score":0.017313428223133087,
"token":8014,
"token_str":"â–runway"
},
{
"sequence":"[CLS] hello i'm a lingerie model.[SEP]",
"score":0.014405295252799988,
"token":29104,
"token_str":"â–lingerie"
}
]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import AlbertTokenizer, AlbertModel
tokenizer = AlbertTokenizer.from_pretrained('albert-xxlarge-v1')
model = AlbertModel.from_pretrained("albert-xxlarge-v1")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import AlbertTokenizer, TFAlbertModel
tokenizer = AlbertTokenizer.from_pretrained('albert-xxlarge-v1')
model = TFAlbertModel.from_pretrained("albert-xxlarge-v1")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
### Limitations and bias
Even if the training data used for this model could be characterized as fairly neutral, this model can have biased
predictions:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='albert-xxlarge-v1')
>>> unmasker("The man worked as a [MASK].")
[
{
"sequence":"[CLS] the man worked as a chauffeur.[SEP]",
"score":0.029577180743217468,
"token":28744,
"token_str":"â–chauffeur"
},
{
"sequence":"[CLS] the man worked as a janitor.[SEP]",
"score":0.028865724802017212,
"token":29477,
"token_str":"â–janitor"
},
{
"sequence":"[CLS] the man worked as a shoemaker.[SEP]",
"score":0.02581118606030941,
"token":29024,
"token_str":"â–shoemaker"
},
{
"sequence":"[CLS] the man worked as a blacksmith.[SEP]",
"score":0.01849772222340107,
"token":21238,
"token_str":"â–blacksmith"
},
{
"sequence":"[CLS] the man worked as a lawyer.[SEP]",
"score":0.01820771023631096,
"token":3672,
"token_str":"â–lawyer"
}
]
>>> unmasker("The woman worked as a [MASK].")
[
{
"sequence":"[CLS] the woman worked as a receptionist.[SEP]",
"score":0.04604868218302727,
"token":25331,
"token_str":"â–receptionist"
},
{
"sequence":"[CLS] the woman worked as a janitor.[SEP]",
"score":0.028220869600772858,
"token":29477,
"token_str":"â–janitor"
},
{
"sequence":"[CLS] the woman worked as a paramedic.[SEP]",
"score":0.0261906236410141,
"token":23386,
"token_str":"â–paramedic"
},
{
"sequence":"[CLS] the woman worked as a chauffeur.[SEP]",
"score":0.024797942489385605,
"token":28744,
"token_str":"â–chauffeur"
},
{
"sequence":"[CLS] the woman worked as a waitress.[SEP]",
"score":0.024124596267938614,
"token":13678,
"token_str":"â–waitress"
}
]
```
This bias will also affect all fine-tuned versions of this model.
## Training data
The ALBERT model was pretrained on [BookCorpus](https://yknzhu.wixsite.com/mbweb), a dataset consisting of 11,038
unpublished books and [English Wikipedia](https://en.wikipedia.org/wiki/English_Wikipedia) (excluding lists, tables and
headers).
## Training procedure
### Preprocessing
The texts are lowercased and tokenized using SentencePiece and a vocabulary size of 30,000. The inputs of the model are
then of the form:
```
[CLS] Sentence A [SEP] Sentence B [SEP]
```
### Training
The ALBERT procedure follows the BERT setup.
The details of the masking procedure for each sentence are the following:
- 15% of the tokens are masked.
- In 80% of the cases, the masked tokens are replaced by `[MASK]`.
- In 10% of the cases, the masked tokens are replaced by a random token (different) from the one they replace.
- In the 10% remaining cases, the masked tokens are left as is.
## Evaluation results
When fine-tuned on downstream tasks, the ALBERT models achieve the following results:
| | Average | SQuAD1.1 | SQuAD2.0 | MNLI | SST-2 | RACE |
|----------------|----------|----------|----------|----------|----------|----------|
|V2 |
|ALBERT-base |82.3 |90.2/83.2 |82.1/79.3 |84.6 |92.9 |66.8 |
|ALBERT-large |85.7 |91.8/85.2 |84.9/81.8 |86.5 |94.9 |75.2 |
|ALBERT-xlarge |87.9 |92.9/86.4 |87.9/84.1 |87.9 |95.4 |80.7 |
|ALBERT-xxlarge |90.9 |94.6/89.1 |89.8/86.9 |90.6 |96.8 |86.8 |
|V1 |
|ALBERT-base |80.1 |89.3/82.3 | 80.0/77.1|81.6 |90.3 | 64.0 |
|ALBERT-large |82.4 |90.6/83.9 | 82.3/79.4|83.5 |91.7 | 68.5 |
|ALBERT-xlarge |85.5 |92.5/86.1 | 86.1/83.1|86.4 |92.4 | 74.8 |
|ALBERT-xxlarge |91.0 |94.8/89.3 | 90.2/87.4|90.8 |96.9 | 86.5 |
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-1909-11942,
author = {Zhenzhong Lan and
Mingda Chen and
Sebastian Goodman and
Kevin Gimpel and
Piyush Sharma and
Radu Soricut},
title = {{ALBERT:} {A} Lite {BERT} for Self-supervised Learning of Language
Representations},
journal = {CoRR},
volume = {abs/1909.11942},
year = {2019},
url = {http://arxiv.org/abs/1909.11942},
archivePrefix = {arXiv},
eprint = {1909.11942},
timestamp = {Fri, 27 Sep 2019 13:04:21 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-1909-11942.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
cointegrated/rubert-tiny2
|
a53f0afc4b34c94012191a043c52e2271fa23f27
|
2022-06-30T14:26:53.000Z
|
[
"pytorch",
"bert",
"pretraining",
"ru",
"transformers",
"russian",
"fill-mask",
"embeddings",
"masked-lm",
"tiny",
"feature-extraction",
"sentence-similarity",
"license:mit"
] |
feature-extraction
| false |
cointegrated
| null |
cointegrated/rubert-tiny2
| 10,824 | 7 |
transformers
| 668 |
---
language: ["ru"]
tags:
- russian
- fill-mask
- pretraining
- embeddings
- masked-lm
- tiny
- feature-extraction
- sentence-similarity
license: mit
widget:
- text: "Миниатюрная модель для [MASK] разных задач."
---
This is an updated version of [cointegrated/rubert-tiny](https://huggingface.co/cointegrated/rubert-tiny): a small Russian BERT-based encoder with high-quality sentence embeddings. This [post in Russian](https://habr.com/ru/post/669674/) gives more details.
The differences from the previous version include:
- a larger vocabulary: 83828 tokens instead of 29564;
- larger supported sequences: 2048 instead of 512;
- sentence embeddings approximate LaBSE closer than before;
- meaningful segment embeddings (tuned on the NLI task)
- the model is focused only on Russian.
The model should be used as is to produce sentence embeddings (e.g. for KNN classification of short texts) or fine-tuned for a downstream task.
Sentence embeddings can be produced as follows:
```python
# pip install transformers sentencepiece
import torch
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("cointegrated/rubert-tiny2")
model = AutoModel.from_pretrained("cointegrated/rubert-tiny2")
# model.cuda() # uncomment it if you have a GPU
def embed_bert_cls(text, model, tokenizer):
t = tokenizer(text, padding=True, truncation=True, return_tensors='pt')
with torch.no_grad():
model_output = model(**{k: v.to(model.device) for k, v in t.items()})
embeddings = model_output.last_hidden_state[:, 0, :]
embeddings = torch.nn.functional.normalize(embeddings)
return embeddings[0].cpu().numpy()
print(embed_bert_cls('привет мир', model, tokenizer).shape)
# (312,)
```
|
deepset/electra-base-squad2
|
3f5fb835e980f8bcb97cfbdf33afec8acfb9f45e
|
2022-07-26T11:04:45.000Z
|
[
"pytorch",
"electra",
"question-answering",
"en",
"dataset:squad_v2",
"transformers",
"license:cc-by-4.0",
"model-index",
"autotrain_compatible"
] |
question-answering
| false |
deepset
| null |
deepset/electra-base-squad2
| 10,788 | 6 |
transformers
| 669 |
---
language: en
datasets:
- squad_v2
license: cc-by-4.0
model-index:
- name: deepset/electra-base-squad2
results:
- task:
type: question-answering
name: Question Answering
dataset:
name: squad_v2
type: squad_v2
config: squad_v2
split: validation
metrics:
- name: Exact Match
type: exact_match
value: 77.6074
verified: true
- name: F1
type: f1
value: 81.7181
verified: true
---
# electra-base for QA
## Overview
**Language model:** electra-base
**Language:** English
**Downstream-task:** Extractive QA
**Training data:** SQuAD 2.0
**Eval data:** SQuAD 2.0
**Code:** See [example](https://github.com/deepset-ai/FARM/blob/master/examples/question_answering.py) in [FARM](https://github.com/deepset-ai/FARM/blob/master/examples/question_answering.py)
**Infrastructure**: 1x Tesla v100
## Hyperparameters
```
seed=42
batch_size = 32
n_epochs = 5
base_LM_model = "google/electra-base-discriminator"
max_seq_len = 384
learning_rate = 1e-4
lr_schedule = LinearWarmup
warmup_proportion = 0.1
doc_stride=128
max_query_length=64
```
## Performance
Evaluated on the SQuAD 2.0 dev set with the [official eval script](https://worksheets.codalab.org/rest/bundles/0x6b567e1cf2e041ec80d7098f031c5c9e/contents/blob/).
```
"exact": 77.30144024256717,
"f1": 81.35438272008543,
"total": 11873,
"HasAns_exact": 74.34210526315789,
"HasAns_f1": 82.45961302894314,
"HasAns_total": 5928,
"NoAns_exact": 80.25231286795626,
"NoAns_f1": 80.25231286795626,
"NoAns_total": 5945
```
## Usage
### In Transformers
```python
from transformers import AutoModelForQuestionAnswering, AutoTokenizer, pipeline
model_name = "deepset/electra-base-squad2"
# a) Get predictions
nlp = pipeline('question-answering', model=model_name, tokenizer=model_name)
QA_input = {
'question': 'Why is model conversion important?',
'context': 'The option to convert models between FARM and transformers gives freedom to the user and lets people easily switch between frameworks.'
}
res = nlp(QA_input)
# b) Load model & tokenizer
model = AutoModelForQuestionAnswering.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
```
### In FARM
```python
from farm.modeling.adaptive_model import AdaptiveModel
from farm.modeling.tokenization import Tokenizer
from farm.infer import Inferencer
model_name = "deepset/electra-base-squad2"
# a) Get predictions
nlp = Inferencer.load(model_name, task_type="question_answering")
QA_input = [{"questions": ["Why is model conversion important?"],
"text": "The option to convert models between FARM and transformers gives freedom to the user and lets people easily switch between frameworks."}]
res = nlp.inference_from_dicts(dicts=QA_input)
# b) Load model & tokenizer
model = AdaptiveModel.convert_from_transformers(model_name, device="cpu", task_type="question_answering")
tokenizer = Tokenizer.load(model_name)
```
### In haystack
For doing QA at scale (i.e. many docs instead of a single paragraph), you can load the model also in [haystack](https://github.com/deepset-ai/haystack/):
```python
reader = FARMReader(model_name_or_path="deepset/electra-base-squad2")
# or
reader = TransformersReader(model="deepset/electra-base-squad2",tokenizer="deepset/electra-base-squad2")
```
## Authors
Vaishali Pal `vaishali.pal [at] deepset.ai`
Branden Chan: `branden.chan [at] deepset.ai`
Timo Möller: `timo.moeller [at] deepset.ai`
Malte Pietsch: `malte.pietsch [at] deepset.ai`
Tanay Soni: `tanay.soni [at] deepset.ai`
## About us

We bring NLP to the industry via open source!
Our focus: Industry specific language models & large scale QA systems.
Some of our work:
- [German BERT (aka "bert-base-german-cased")](https://deepset.ai/german-bert)
- [GermanQuAD and GermanDPR datasets and models (aka "gelectra-base-germanquad", "gbert-base-germandpr")](https://deepset.ai/germanquad)
- [FARM](https://github.com/deepset-ai/FARM)
- [Haystack](https://github.com/deepset-ai/haystack/)
Get in touch:
[Twitter](https://twitter.com/deepset_ai) | [LinkedIn](https://www.linkedin.com/company/deepset-ai/) | [Slack](https://haystack.deepset.ai/community/join) | [GitHub Discussions](https://github.com/deepset-ai/haystack/discussions) | [Website](https://deepset.ai)
By the way: [we're hiring!](http://www.deepset.ai/jobs)
|
sberbank-ai/ruclip-vit-base-patch32-224
|
95a185fc2b0b1b7fa54c651bcb1fab292b4a3faf
|
2022-01-09T21:34:27.000Z
|
[
"pytorch",
"transformers"
] | null | false |
sberbank-ai
| null |
sberbank-ai/ruclip-vit-base-patch32-224
| 10,770 | null |
transformers
| 670 |
# ruclip-vit-base-patch32-224
**RuCLIP** (**Ru**ssian **C**ontrastive **L**anguage–**I**mage **P**retraining) is a multimodal model
for obtaining images and text similarities and rearranging captions and pictures.
RuCLIP builds on a large body of work on zero-shot transfer, computer vision, natural language processing and
multimodal learning.
Model was trained by [Sber AI](https://github.com/sberbank-ai) and [SberDevices](https://sberdevices.ru/) teams.
* Task: `text ranking`; `image ranking`; `zero-shot image classification`;
* Type: `encoder`
* Num Parameters: `150M`
* Training Data Volume: `240 million text-image pairs`
* Language: `Russian`
* Context Length: `77`
* Transformer Layers: `12`
* Transformer Width: `512`
* Transformer Heads: `8`
* Image Size: `224`
* Vision Layers: `12`
* Vision Width: `768`
* Vision Patch Size: `32`
## Usage [Github](https://github.com/sberbank-ai/ru-clip)
```
pip install ruclip
```
```python
clip, processor = ruclip.load("ruclip-vit-base-patch32-224", device="cuda")
```
## Performance
We have evaluated the performance on the following datasets:
| Dataset | Metric Name | Metric Result |
|:--------------|:---------------|:--------------------|
| Food101 | acc | 0.505 |
| CIFAR10 | acc | 0.818 |
| CIFAR100 | acc | 0.504 |
| Birdsnap | acc | 0.115 |
| SUN397 | acc | 0.452 |
| Stanford Cars | acc | 0.433 |
| DTD | acc | 0.380 |
| MNIST | acc | 0.447 |
| STL10 | acc | 0.932 |
| PCam | acc | 0.501 |
| CLEVR | acc | 0.148 |
| Rendered SST2 | acc | 0.489 |
| ImageNet | acc | 0.375 |
| FGVC Aircraft | mean-per-class | 0.033 |
| Oxford Pets | mean-per-class | 0.560 |
| Caltech101 | mean-per-class | 0.786 |
| Flowers102 | mean-per-class | 0.401 |
| HatefulMemes | roc-auc | 0.564 |
# Authors
+ Alex Shonenkov: [Github](https://github.com/shonenkov), [Kaggle GM](https://www.kaggle.com/shonenkov)
+ Daniil Chesakov: [Github](https://github.com/Danyache)
+ Denis Dimitrov: [Github](https://github.com/denndimitrov)
+ Igor Pavlov: [Github](https://github.com/boomb0om)
|
Helsinki-NLP/opus-mt-hi-en
|
48acb8543e96768bc9fea5b3813d0e46fe1a45f3
|
2021-09-09T22:09:54.000Z
|
[
"pytorch",
"rust",
"marian",
"text2text-generation",
"hi",
"en",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] |
translation
| false |
Helsinki-NLP
| null |
Helsinki-NLP/opus-mt-hi-en
| 10,743 | 2 |
transformers
| 671 |
---
tags:
- translation
license: apache-2.0
---
### opus-mt-hi-en
* source languages: hi
* target languages: en
* OPUS readme: [hi-en](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/hi-en/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2019-12-18.zip](https://object.pouta.csc.fi/OPUS-MT-models/hi-en/opus-2019-12-18.zip)
* test set translations: [opus-2019-12-18.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/hi-en/opus-2019-12-18.test.txt)
* test set scores: [opus-2019-12-18.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/hi-en/opus-2019-12-18.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| newsdev2014.hi.en | 9.1 | 0.357 |
| newstest2014-hien.hi.en | 13.6 | 0.409 |
| Tatoeba.hi.en | 40.4 | 0.580 |
|
cl-tohoku/bert-large-japanese
|
0f5fc4dcd523bed677d208cfa7279c80b1e8e8dc
|
2021-09-23T13:45:41.000Z
|
[
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"ja",
"dataset:wikipedia",
"transformers",
"license:cc-by-sa-4.0",
"autotrain_compatible"
] |
fill-mask
| false |
cl-tohoku
| null |
cl-tohoku/bert-large-japanese
| 10,714 | null |
transformers
| 672 |
---
language: ja
license: cc-by-sa-4.0
datasets:
- wikipedia
widget:
- text: 東北大学で[MASK]の研究をしています。
---
# BERT large Japanese (unidic-lite with whole word masking, jawiki-20200831)
This is a [BERT](https://github.com/google-research/bert) model pretrained on texts in the Japanese language.
This version of the model processes input texts with word-level tokenization based on the Unidic 2.1.2 dictionary (available in [unidic-lite](https://pypi.org/project/unidic-lite/) package), followed by the WordPiece subword tokenization.
Additionally, the model is trained with the whole word masking enabled for the masked language modeling (MLM) objective.
The codes for the pretraining are available at [cl-tohoku/bert-japanese](https://github.com/cl-tohoku/bert-japanese/tree/v2.0).
## Model architecture
The model architecture is the same as the original BERT large model; 24 layers, 1024 dimensions of hidden states, and 16 attention heads.
## Training Data
The models are trained on the Japanese version of Wikipedia.
The training corpus is generated from the Wikipedia Cirrussearch dump file as of August 31, 2020.
The generated corpus files are 4.0GB in total, containing approximately 30M sentences.
We used the [MeCab](https://taku910.github.io/mecab/) morphological parser with [mecab-ipadic-NEologd](https://github.com/neologd/mecab-ipadic-neologd) dictionary to split texts into sentences.
## Tokenization
The texts are first tokenized by MeCab with the Unidic 2.1.2 dictionary and then split into subwords by the WordPiece algorithm.
The vocabulary size is 32768.
We used [`fugashi`](https://github.com/polm/fugashi) and [`unidic-lite`](https://github.com/polm/unidic-lite) packages for the tokenization.
## Training
The models are trained with the same configuration as the original BERT; 512 tokens per instance, 256 instances per batch, and 1M training steps.
For training of the MLM (masked language modeling) objective, we introduced whole word masking in which all of the subword tokens corresponding to a single word (tokenized by MeCab) are masked at once.
For training of each model, we used a v3-8 instance of Cloud TPUs provided by [TensorFlow Research Cloud program](https://www.tensorflow.org/tfrc/).
The training took about 5 days to finish.
## Licenses
The pretrained models are distributed under the terms of the [Creative Commons Attribution-ShareAlike 3.0](https://creativecommons.org/licenses/by-sa/3.0/).
## Acknowledgments
This model is trained with Cloud TPUs provided by [TensorFlow Research Cloud](https://www.tensorflow.org/tfrc/) program.
|
dbmdz/bert-base-turkish-128k-cased
|
ee962e2ecfaafa8cf708fa961f5cbc4346b1c367
|
2021-05-19T15:10:48.000Z
|
[
"pytorch",
"tf",
"jax",
"bert",
"tr",
"transformers",
"license:mit"
] | null | false |
dbmdz
| null |
dbmdz/bert-base-turkish-128k-cased
| 10,655 | 7 |
transformers
| 673 |
---
language: tr
license: mit
---
# 🤗 + 📚 dbmdz Turkish BERT model
In this repository the MDZ Digital Library team (dbmdz) at the Bavarian State
Library open sources a cased model for Turkish 🎉
# 🇹🇷 BERTurk
BERTurk is a community-driven cased BERT model for Turkish.
Some datasets used for pretraining and evaluation are contributed from the
awesome Turkish NLP community, as well as the decision for the model name: BERTurk.
## Stats
The current version of the model is trained on a filtered and sentence
segmented version of the Turkish [OSCAR corpus](https://traces1.inria.fr/oscar/),
a recent Wikipedia dump, various [OPUS corpora](http://opus.nlpl.eu/) and a
special corpus provided by [Kemal Oflazer](http://www.andrew.cmu.edu/user/ko/).
The final training corpus has a size of 35GB and 44,04,976,662 tokens.
Thanks to Google's TensorFlow Research Cloud (TFRC) we could train a cased model
on a TPU v3-8 for 2M steps.
For this model we use a vocab size of 128k.
## Model weights
Currently only PyTorch-[Transformers](https://github.com/huggingface/transformers)
compatible weights are available. If you need access to TensorFlow checkpoints,
please raise an issue!
| Model | Downloads
| ------------------------------------ | ---------------------------------------------------------------------------------------------------------------
| `dbmdz/bert-base-turkish-128k-cased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-turkish-128k-cased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-turkish-128k-cased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-turkish-128k-cased/vocab.txt)
## Usage
With Transformers >= 2.3 our BERTurk cased model can be loaded like:
```python
from transformers import AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("dbmdz/bert-base-turkish-128k-cased")
model = AutoModel.from_pretrained("dbmdz/bert-base-turkish-128k-cased")
```
## Results
For results on PoS tagging or NER tasks, please refer to
[this repository](https://github.com/stefan-it/turkish-bert).
# Huggingface model hub
All models are available on the [Huggingface model hub](https://huggingface.co/dbmdz).
# Contact (Bugs, Feedback, Contribution and more)
For questions about our BERT models just open an issue
[here](https://github.com/dbmdz/berts/issues/new) 🤗
# Acknowledgments
Thanks to [Kemal Oflazer](http://www.andrew.cmu.edu/user/ko/) for providing us
additional large corpora for Turkish. Many thanks to Reyyan Yeniterzi for providing
us the Turkish NER dataset for evaluation.
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
Thanks for providing access to the TFRC ❤️
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
it is possible to download both cased and uncased models from their S3 storage 🤗
|
seyonec/PubChem10M_SMILES_BPE_450k
|
c18fccd09b3326bf2d4633412c256d7db872156d
|
2021-05-20T21:02:39.000Z
|
[
"pytorch",
"jax",
"roberta",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
| false |
seyonec
| null |
seyonec/PubChem10M_SMILES_BPE_450k
| 10,609 | 1 |
transformers
| 674 |
Entry not found
|
UWB-AIR/Czert-B-base-cased
|
93c1b4ee6603cea828b217e6bb84e369e9b142f0
|
2022-03-16T10:39:50.000Z
|
[
"pytorch",
"tf",
"bert",
"pretraining",
"arxiv:2103.13031",
"transformers",
"cs",
"fill-mask"
] |
fill-mask
| false |
UWB-AIR
| null |
UWB-AIR/Czert-B-base-cased
| 10,382 | null |
transformers
| 675 |
---
tags:
- cs
- fill-mask
---
# CZERT
This repository keeps trained Czert-B model for the paper [Czert – Czech BERT-like Model for Language Representation
](https://arxiv.org/abs/2103.13031)
For more information, see the paper
## Available Models
You can download **MLM & NSP only** pretrained models
~~[CZERT-A-v1](https://air.kiv.zcu.cz/public/CZERT-A-czert-albert-base-uncased.zip)
[CZERT-B-v1](https://air.kiv.zcu.cz/public/CZERT-B-czert-bert-base-cased.zip)~~
After some additional experiments, we found out that the tokenizers config was exported wrongly. In Czert-B-v1, the tokenizer parameter "do_lower_case" was wrongly set to true. In Czert-A-v1 the parameter "strip_accents" was incorrectly set to true.
Both mistakes are repaired in v2.
[CZERT-A-v2](https://air.kiv.zcu.cz/public/CZERT-A-v2-czert-albert-base-uncased.zip)
[CZERT-B-v2](https://air.kiv.zcu.cz/public/CZERT-B-v2-czert-bert-base-cased.zip)
or choose from one of **Finetuned Models**
| | Models |
| - | - |
| Sentiment Classification<br> (Facebook or CSFD) | [CZERT-A-sentiment-FB](https://air.kiv.zcu.cz/public/CZERT-A_fb.zip) <br> [CZERT-B-sentiment-FB](https://air.kiv.zcu.cz/public/CZERT-B_fb.zip) <br> [CZERT-A-sentiment-CSFD](https://air.kiv.zcu.cz/public/CZERT-A_csfd.zip) <br> [CZERT-B-sentiment-CSFD](https://air.kiv.zcu.cz/public/CZERT-B_csfd.zip) | Semantic Text Similarity <br> (Czech News Agency) | [CZERT-A-sts-CNA](https://air.kiv.zcu.cz/public/CZERT-A-sts-CNA.zip) <br> [CZERT-B-sts-CNA](https://air.kiv.zcu.cz/public/CZERT-B-sts-CNA.zip)
| Named Entity Recognition | [CZERT-A-ner-CNEC](https://air.kiv.zcu.cz/public/CZERT-A-ner-CNEC-cased.zip) <br> [CZERT-B-ner-CNEC](https://air.kiv.zcu.cz/public/CZERT-B-ner-CNEC-cased.zip) <br>[PAV-ner-CNEC](https://air.kiv.zcu.cz/public/PAV-ner-CNEC-cased.zip) <br> [CZERT-A-ner-BSNLP](https://air.kiv.zcu.cz/public/CZERT-A-ner-BSNLP-cased.zip)<br>[CZERT-B-ner-BSNLP](https://air.kiv.zcu.cz/public/CZERT-B-ner-BSNLP-cased.zip) <br>[PAV-ner-BSNLP](https://air.kiv.zcu.cz/public/PAV-ner-BSNLP-cased.zip) |
| Morphological Tagging<br> | [CZERT-A-morphtag-126k](https://air.kiv.zcu.cz/public/CZERT-A-morphtag-126k-cased.zip)<br>[CZERT-B-morphtag-126k](https://air.kiv.zcu.cz/public/CZERT-B-morphtag-126k-cased.zip) |
| Semantic Role Labelling |[CZERT-A-srl](https://air.kiv.zcu.cz/public/CZERT-A-srl-cased.zip)<br> [CZERT-B-srl](https://air.kiv.zcu.cz/public/CZERT-B-srl-cased.zip) |
## How to Use CZERT?
### Sentence Level Tasks
We evaluate our model on two sentence level tasks:
* Sentiment Classification,
* Semantic Text Similarity.
<!-- tokenizer = BertTokenizerFast.from_pretrained(CZERT_MODEL_PATH, strip_accents=False)
\\tmodel = TFAlbertForSequenceClassification.from_pretrained(CZERT_MODEL_PATH, num_labels=1)
or
self.tokenizer = BertTokenizerFast.from_pretrained(CZERT_MODEL_PATH, strip_accents=False)
self.model_encoder = AutoModelForSequenceClassification.from_pretrained(CZERT_MODEL_PATH, from_tf=True)
-->
\\t
### Document Level Tasks
We evaluate our model on one document level task
* Multi-label Document Classification.
### Token Level Tasks
We evaluate our model on three token level tasks:
* Named Entity Recognition,
* Morphological Tagging,
* Semantic Role Labelling.
## Downstream Tasks Fine-tuning Results
### Sentiment Classification
| | mBERT | SlavicBERT | ALBERT-r | Czert-A | Czert-B |
|:----:|:------------------------:|:------------------------:|:------------------------:|:-----------------------:|:--------------------------------:|
| FB | 71.72 ± 0.91 | 73.87 ± 0.50 | 59.50 ± 0.47 | 72.47 ± 0.72 | **76.55** ± **0.14** |
| CSFD | 82.80 ± 0.14 | 82.51 ± 0.14 | 75.40 ± 0.18 | 79.58 ± 0.46 | **84.79** ± **0.26** |
Average F1 results for the Sentiment Classification task. For more information, see [the paper](https://arxiv.org/abs/2103.13031).
### Semantic Text Similarity
| | **mBERT** | **Pavlov** | **Albert-random** | **Czert-A** | **Czert-B** |
|:-------------|:--------------:|:--------------:|:-----------------:|:--------------:|:----------------------:|
| STA-CNA | 83.335 ± 0.063 | 83.593 ± 0.050 | 43.184 ± 0.125 | 82.942 ± 0.106 | **84.345** ± **0.028** |
| STS-SVOB-img | 79.367 ± 0.486 | 79.900 ± 0.810 | 15.739 ± 2.992 | 79.444 ± 0.338 | **83.744** ± **0.395** |
| STS-SVOB-hl | 78.833 ± 0.296 | 76.996 ± 0.305 | 33.949 ± 1.807 | 75.089 ± 0.806 | **79.827 ± 0.469** |
Comparison of Pearson correlation achieved using pre-trained CZERT-A, CZERT-B, mBERT, Pavlov and randomly initialised Albert on semantic text similarity. For more information see [the paper](https://arxiv.org/abs/2103.13031).
### Multi-label Document Classification
| | mBERT | SlavicBERT | ALBERT-r | Czert-A | Czert-B |
|:-----:|:------------:|:------------:|:------------:|:------------:|:-------------------:|
| AUROC | 97.62 ± 0.08 | 97.80 ± 0.06 | 94.35 ± 0.13 | 97.49 ± 0.07 | **98.00** ± **0.04** |
| F1 | 83.04 ± 0.16 | 84.08 ± 0.14 | 72.44 ± 0.22 | 82.27 ± 0.17 | **85.06** ± **0.11** |
Comparison of F1 and AUROC score achieved using pre-trained CZERT-A, CZERT-B, mBERT, Pavlov and randomly initialised Albert on multi-label document classification. For more information see [the paper](https://arxiv.org/abs/2103.13031).
### Morphological Tagging
| | mBERT | Pavlov | Albert-random | Czert-A | Czert-B |
|:-----------------------|:---------------|:---------------|:---------------|:---------------|:---------------|
| Universal Dependencies | 99.176 ± 0.006 | 99.211 ± 0.008 | 96.590 ± 0.096 | 98.713 ± 0.008 | **99.300 ± 0.009** |
Comparison of F1 score achieved using pre-trained CZERT-A, CZERT-B, mBERT, Pavlov and randomly initialised Albert on morphological tagging task. For more information see [the paper](https://arxiv.org/abs/2103.13031).
### Semantic Role Labelling
<div id="tab:SRL">
| | mBERT | Pavlov | Albert-random | Czert-A | Czert-B | dep-based | gold-dep |
|:------:|:----------:|:----------:|:-------------:|:----------:|:----------:|:---------:|:--------:|
| span | 78.547 ± 0.110 | 79.333 ± 0.080 | 51.365 ± 0.423 | 72.254 ± 0.172 | **81.861 ± 0.102** | \\\\- | \\\\- |
| syntax | 90.226 ± 0.224 | 90.492 ± 0.040 | 80.747 ± 0.131 | 80.319 ± 0.054 | **91.462 ± 0.062** | 85.19 | 89.52 |
SRL results – dep columns are evaluate with labelled F1 from CoNLL 2009 evaluation script, other columns are evaluated with span F1 score same as it was used for NER evaluation. For more information see [the paper](https://arxiv.org/abs/2103.13031).
</div>
### Named Entity Recognition
| | mBERT | Pavlov | Albert-random | Czert-A | Czert-B |
|:-----------|:---------------|:---------------|:---------------|:---------------|:---------------|
| CNEC | **86.225 ± 0.208** | **86.565 ± 0.198** | 34.635 ± 0.343 | 72.945 ± 0.227 | 86.274 ± 0.116 |
| BSNLP 2019 | 84.006 ± 1.248 | **86.699 ± 0.370** | 19.773 ± 0.938 | 48.859 ± 0.605 | **86.729 ± 0.344** |
Comparison of f1 score achieved using pre-trained CZERT-A, CZERT-B, mBERT, Pavlov and randomly initialised Albert on named entity recognition task. For more information see [the paper](https://arxiv.org/abs/2103.13031).
## Licence
This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License. http://creativecommons.org/licenses/by-nc-sa/4.0/
## How should I cite CZERT?
For now, please cite [the Arxiv paper](https://arxiv.org/abs/2103.13031):
```
@article{sido2021czert,
title={Czert -- Czech BERT-like Model for Language Representation},
author={Jakub Sido and Ondřej Pražák and Pavel Přibáň and Jan Pašek and Michal Seják and Miloslav Konopík},
year={2021},
eprint={2103.13031},
archivePrefix={arXiv},
primaryClass={cs.CL},
journal={arXiv preprint arXiv:2103.13031},
}
```
|
LiYuan/amazon-review-sentiment-analysis
|
0aacda6423e43213da4e50a0f30cfcdb42a5c725
|
2022-04-30T22:03:23.000Z
|
[
"pytorch",
"tensorboard",
"bert",
"text-classification",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] |
text-classification
| false |
LiYuan
| null |
LiYuan/amazon-review-sentiment-analysis
| 10,370 | 0 |
transformers
| 676 |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: distilbert-base-uncased-finetuned-mnli-amazon-query-shopping
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-mnli-amazon-query-shopping
This model is a fine-tuned version of [nlptown/bert-base-multilingual-uncased-sentiment](https://huggingface.co/nlptown/bert-base-multilingual-uncased-sentiment?text=I+like+you.+I+love+you) on an [Amazon US Customer Reviews Dataset](https://www.kaggle.com/datasets/cynthiarempel/amazon-us-customer-reviews-dataset). The code for the fine-tuning process can be found
[here](https://github.com/vanderbilt-data-science/bigdata/blob/main/06-fine-tune-BERT-on-our-dataset.ipynb). This model is uncased: it does
not make a difference between english and English.
It achieves the following results on the evaluation set:
- Loss: 0.5202942490577698
- Accuracy: 0.8
## Model description
This a bert-base-multilingual-uncased model finetuned for sentiment analysis on product reviews in six languages: English, Dutch, German, French, Spanish and Italian. It predicts the sentiment of the review as a number of stars (between 1 and 5).
This model is intended for direct use as a sentiment analysis model for product reviews in any of the six languages above, or for further finetuning on related sentiment analysis tasks.
We replaced its head with our customer reviews to fine-tune it on 17,280 rows of training set while validating it on 4,320 rows of dev set. Finally, we evaluated our model performance on a held-out test set: 2,400 rows.
## Intended uses & limitations
Bert-base is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked)
to make decisions, such as sequence classification, token classification, or question answering. This fine-tuned version of BERT-base is used to predict review rating star given the review.
The limitations are this trained model is focusing on reviews and products on Amazon. If you apply this model to other domains, it may perform poorly.
## How to use
You can use this model directly by downloading the trained weights and configurations like the below code snippet:
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("LiYuan/amazon-review-sentiment-analysis")
model = AutoModelForSequenceClassification.from_pretrained("LiYuan/amazon-review-sentiment-analysis")
```
## Training and evaluation data
Download all the raw [dataset](https://www.kaggle.com/datasets/cynthiarempel/amazon-us-customer-reviews-dataset) from the Kaggle website.
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 0.555400 | 1.0 | 1080 | 0.520294 | 0.800000 |
| 0.424300 | 2.0 | 1080 | 0.549649 | 0.798380 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0+cu113
- Datasets 2.1.0
- Tokenizers 0.12.1
|
knkarthick/MEETING_SUMMARY
|
1d9f2261609ed4970abf4f3659c080783beaf09e
|
2022-06-29T07:16:14.000Z
|
[
"pytorch",
"tf",
"bart",
"text2text-generation",
"en",
"dataset:cnndaily/newyorkdaily/xsum/samsum/dialogsum/AMI",
"transformers",
"seq2seq",
"summarization",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
] |
summarization
| false |
knkarthick
| null |
knkarthick/MEETING_SUMMARY
| 10,311 | 14 |
transformers
| 677 |
---
language: en
tags:
- bart
- seq2seq
- summarization
license: apache-2.0
datasets:
- cnndaily/newyorkdaily/xsum/samsum/dialogsum/AMI
metrics:
- rouge
widget:
- text: |-
Hi, I'm David and I'm supposed to be an industrial designer. Um, I just got the project announcement about what the project is. Designing a remote control. That's about it, didn't get anything else. Did you get the same thing? Cool. There's too much gear. Okay. Can't draw. Um. Yeah. Um, well anyway, I don't know, it's just the first animal I can think off the top of my head. Um. Yes. Big reason is 'cause I'm allergic to most animals. Allergic to animal fur, so um fish was a natural choice. Um, yeah, and I kind of like whales. They come in and go eat everything in sight. And they're quite harmless and mild and interesting. Tail's a bit big, I think. It's an after dinner dog then. Hmm. It does make sense from maybe the design point of view 'cause you have more complicated characters like European languages, then you need more buttons. So, possibly. Hmm. Yeah. And you keep losing them. Finding them is really a pain, you know. I mean it's usually quite small, or when you want it right, it slipped behind the couch or it's kicked under the table. You know. Yep. Mm-hmm. I think one factor would be production cost. Because there's a cap there, so um depends on how much you can cram into that price. Um. I think that that's the main factor. Cool.
Okay. Right. Um well this is the kick-off meeting for our our project. Um and um this is just what we're gonna be doing over the next twenty five minutes. Um so first of all, just to kind of make sure that we all know each other, I'm Laura and I'm the project manager. Do you want to introduce yourself again? Okay. Great. Okay. Um so we're designing a new remote control and um Oh I have to record who's here actually. So that's David, Andrew and Craig, isn't it? And you all arrived on time. Um yeah so des uh design a new remote control. Um, as you can see it's supposed to be original, trendy and user friendly. Um so that's kind of our our brief, as it were. Um and so there are three different stages to the design. Um I'm not really sure what what you guys have already received um in your emails. What did you get? Mm-hmm. Is that what everybody got? Okay. Um. So we're gonna have like individual work and then a meeting about it. And repeat that process three times. Um and at this point we get try out the whiteboard over there. Um. So uh you get to draw your favourite animal and sum up your favourite characteristics of it. So who would like to go first? Very good. Mm-hmm. Yeah. Yeah. Right. Lovely. Right. You can take as long over this as you like, because we haven't got an awful lot to discuss. Ok oh we do we do. Don't feel like you're in a rush, anyway. Ach why not We might have to get you up again then. I don't know what mine is. I'm gonna have to think on the spot now. Is that a whale? Ah. Okay. God, I still don't know what I'm gonna write about. Um. I was gonna choose a dog as well. But I'll just draw a different kind of dog. M my favourite animal is my own dog at home. Um That doesn't really look like him, actually. He looks more like a pig, actually. Ah well. Do you? Oh that's very good of you. Uh. Um he's a mixture of uh various things. Um and what do I like about him, um That's just to suggest that his tail wags. Um he's very friendly and cheery and always pleased to see you, and very kind of affectionate and um uh and he's quite quite wee as well so you know he can doesn't take up too much space. Um and uh And he does a funny thing where he chases his tail as well, which is quite amusing, so It is. I think it is. He only does it after he's had his dinner and um he'll just all of a sudden just get up and start chasing his tail 'round the living room. Yeah, so uh Yeah, maybe. Maybe. Right, um where did you find this? Just down here? Yeah. Okay. Um what are we doing next? Uh um. Okay, uh we now need to discuss the project finance. Um so according to the brief um we're gonna be selling this remote control for twenty five Euro, um and we're aiming to make fifty million Euro. Um so we're gonna be selling this on an international scale. And uh we don't want it to cost any more than uh twelve fifty Euros, so fifty percent of the selling price. Sure. All together. Um I dunno. I imagine That's a good question. I imagine it probably is our sale actually because it's probably up to the the um the retailer to uh sell it for whatever price they want. Um. But I I don't know, I mean do you think the fact that it's going to be sold internationally will have a bearing on how we design it at all? Think it will? Um. Hmm. Oh yeah, regions and stuff, yeah. Yeah. Okay. Yeah. Well for a remote control, do you think that will be I suppose it's depends on how complicated our remote control is. Yeah, yeah. Okay. What, just like in terms of like the wealth of the country? Like how much money people have to spend on things like? Aye, I see what you mean, yeah. Marketing. Good marketing thoughts. Oh gosh, I should be writing all this down. Um. Mm. Yeah. Yeah, yeah. Like how much does, you know, a remote control cost. Well twenty five Euro, I mean that's um that's about like eighteen pounds or something, isn't it? Or no, is it as much as that? Sixteen seventeen eighteen pounds. Um, I dunno, I've never bought a remote control, so I don't know how how good a remote control that would get you. Um. But yeah, I suppose it has to look kind of cool and gimmicky. Um right, okay. Let me just scoot on ahead here. Okay. Um well d Does anybody have anything to add to uh to the finance issue at all? Thin No, actually. That would be useful, though, wouldn't it, if you knew like what your money would get you now. Mm-hmm. Yeah, yeah. Oh. Five minutes to end of meeting. Oh, okay. We're a bit behind. Yeah. Right, so do you think that should be like a main design aim of our remote control d you know, do your your satellite and your regular telly and your V_C_R_ and everything? Mm-hmm. Yeah. Or even like, you know, notes about um what you wanna watch. Like you might put in there oh I want to watch such and such and look a Oh that's a good idea. So extra functionalities. Mm-hmm. Hmm. Um okay, uh I'd wel we're gonna have to wrap up pretty quickly in the next couple of minutes. Um I'll just check we've nothing else. Okay. Um so anything else anybody wants to add about what they don't like about remote controls they've used, what they would really like to be part of this new one at all? You keep losing them. Okay. Yeah. W You get those ones where you can, if you like, whistle or make a really high pitched noise they beep. There I mean is that something we'd want to include, do you think? Dunno. Okay maybe. My goodness. Still feels quite primitive. Maybe like a touch screen or something? Okay. Uh-huh, okay. Well I guess that's up to our industrial designer. It looks better. Yeah. Okay. Okay. Right, well um so just to wrap up, the next meeting's gonna be in thirty minutes. So that's about um about ten to twelve by my watch. Um so inbetween now and then, um as the industrial designer, you're gonna be working on you know the actual working design of it so y you know what you're doing there. Um for user interface, technical functions, I guess that's you know like what we've been talking about, what it'll actually do. Um and uh marketing executive, you'll be just thinking about what it actually what, you know, what requirements it has to has to fulfil and you'll all get instructions emailed to you, I guess. Um. Yeah, so it's th the functional design stage is next, I guess. And uh and that's the end of the meeting. So I got that little message a lot sooner than I thought I would, so Mm-hmm. Uh-huh, yeah. Th Okay, well just very quickly 'cause this we're supposed to finish now. Um I guess that's up to us, I mean you probably want some kind of unique selling point of it, so um, you know Yeah. Mm-hmm. Yeah. Okay. Right, okay, we'll that's that's the end of the meeting, then. Um. So, uh thank you all for coming.
Um I'm Craig and I'm User Interface. Yeah. Well, my favourite animal would be a monkey. Then they're small cute and furry, and uh when planet of the apes becomes real, I'm gonna be up there with them. Yeah. I know um My parents went out and bought um remote controls because um they got fed up of having four or five different remote controls for each things the house. So um for them it was just how many devices control. Uh.
Mm-hmm. Great. And I'm Andrew and I'm uh our marketing expert. Mm-hmm. Mm-hmm. Yeah, that's that's it. Yeah. I will go. That's fine. Alright. So This one here, right? Okay. Very nice. Alright. My favourite animal is like A beagle. Um charac favourite characteristics of it? Is that right? Uh, right, well basically um high priority for any animal for me is that they be willing to take a lot of physical affection from their family. And, yeah that they have lots of personality and uh be fit and in robust good health. So this is blue. Blue beagle. My family's beagle. I coulda told you a whole lot more about beagles. Boy, let me tell you. Impressionist. Alright. Mm. Superb sketch, by the way. Yep. I see a dog in there. Yep. Now I see a rooster. What kind is it? Is he aware that th it's his own cha tail he's chasing? Hmm. Probably when he was little he got lots of attention for doing it and has forever been conditioned. 'Kay. Um, can we just go over that again? Uh, so bas at twel Alright, yeah. Okay. So cost like production cost is twelve fifty, but selling price is is that wholesale or retail? Like on the shelf. Our sale our sale anyway. Yeah, okay okay. Okay. Mm-hmm. Alright. Yes. Mm-hmm. Mm-hmm. Well right away I'm wondering if there's um th th uh, like with D_V_D_ players, if there are zones. Um f frequencies or something um as well as uh characters, um different uh keypad styles and s symbols. Um. I don't know. Yeah. Yeah. Yeah. And then a and then al the other thing international is on top of the price. I'm thinking the price might might appeal to a certain market in one region, whereas in another it'll be different, so Just a chara just a characteristic of the Just Or just like, basic product podi positioning, the twenty five Euro remote control might be a big hit in London, might not be such a big hit in Greece, who knows, something like that, yeah. Yep. Right away I'm making some kind of assumptions about what what information we're given here, thinking, 'kay trendy probably means something other than just basic, something other than just standard. Um so I'm wondering right away, is selling twenty five Euros, is that sort of the thi is this gonna to be like the premium product kinda thing or Uh-huh. Mm-hmm. Yep. Yeah, I'd say so, yeah. No. Yeah, yeah. Mm-hmm. Do we have any other background information on like how that compares to other other Yeah. Mm-hmm. Yeah, interesting thing about discussing um production of a remote control for me is that l as you point out, I just don't think of remote controls as somethin something people consciously assess in their purchasing habits. It's just like getting shoelaces with shoes or something. It just comes along. Do you know what I mean? Like so sort of like how do you I I mean one one way of looking at it would be, well the people producing television sets, maybe they have to buy remote controls. Or another way is maybe people who have T_V_ sets are really fed up with their remote control and they really want a better one or something. But Right. Right. Okay so Right, so in function one of the priorities might be to combine as many uses I think so. Yeah, yeah. Yeah. Well like um, maybe what we could use is a sort of like a example of a successful other piece technology is palm palm pilots. They're gone from being just like little sort of scribble boards to cameras, M_P_ three players, telephones, everything, agenda. So, like, I wonder if we might add something new to the to the remote control market, such as the lighting in your house, or um Yeah, yeah. An Yeah. Like, p personally for me, at home I've I've combined the um the audio video of my television set and my D_V_D_ player and my C_D_ player. So they w all work actually function together but I have different remote controls for each of them. So it's sort of ironic that that then they're in there um you know, the sound and everything it's just one system. But each one's got its own little part. Mm. Mm. Mm. Mm-hmm. Mm-hmm. Yeah. Yeah. That's just really good id Yep. Uh, sure. I remember when the first remote control my my family had was on a cable. Actually had a cable between it and the T_V_ and big like buttons that sort of like, like on a blender or something. And um, you know, when I think about what they are now, it's better, but actually it's still kind of, I dunno, like a massive junky thing on the table. Maybe we could think about how, could be more, you know, streamlined. S Something like that, yeah. Or whatever would be technologically reasonable. 'Cause it could b it could it could be that f it could be that functionally that doesn't make it any better, but that just the appeal of of not having You know, these days there's a r pe things in people's homes are becoming more and more like chic, you know. Um, nicer materials and might be be worth exploring anyway. Okay. Um. Before we wrap up, just to make sure we're all on the same page here, um, do we We were given sort of an example of a coffee machine or something, right? Well, um are we at ma right now on the assumption that our television remote control may have features which go beyond the television? Or are we keeping sort of like a a design commitment to television features? I I don't know. Yep. Yeah, sure. Okay. Okay, yeah. Okay. Okay. Okay. Alright.
model-index:
- name: MEETING_SUMMARY
results:
- task:
name: Abstractive Text Summarization
type: abstractive-text-summarization
dataset:
name: "samsum"
type: samsum
metrics:
- name: Validation ROGUE-1
type: rouge-1
value: 53.8795
- name: Validation ROGUE-2
type: rouge-2
value: 28.4975
- name: Validation ROGUE-L
type: rouge-L
value: 44.1899
- name: Validation ROGUE-Lsum
type: rouge-Lsum
value: 49.4863
- name: Validation ROGUE-Lsum
type: gen-length
value: 30.088
- name: Test ROGUE-1
type: rouge-1
value: 53.2284
- name: Test ROGUE-2
type: rouge-2
value: 28.184
- name: Test ROGUE-L
type: rouge-L
value: 44.122
- name: Test ROGUE-Lsum
type: rouge-Lsum
value: 49.0301
- name: Test ROGUE-Lsum
type: gen-length
value: 29.9951
- name: MEETING_SUMMARY
results:
- task:
name: Abstractive Text Summarization
type: abstractive-text-summarization
dataset:
name: "xsum"
type: xsum
metrics:
- name: Validation ROGUE-1
type: rouge-1
value: 35.9078
- name: Validation ROGUE-2
type: rouge-2
value: 14.2497
- name: Validation ROGUE-L
type: rouge-L
value: 28.1421
- name: Validation ROGUE-Lsum
type: rouge-Lsum
value: 28.9826
- name: Validation ROGUE-Lsum
type: gen-length
value: 32.0167
- name: Test ROGUE-1
type: rouge-1
value: 36.0241
- name: Test ROGUE-2
type: rouge-2
value: 14.3715
- name: Test ROGUE-L
type: rouge-L
value: 28.1968
- name: Test ROGUE-Lsum
type: rouge-Lsum
value: 29.0527
- name: Test ROGUE-Lsum
type: gen-length
value: 31.9933
- name: MEETING_SUMMARY
results:
- task:
name: Abstractive Text Summarization
type: abstractive-text-summarization
dataset:
name: "dialogsum"
type: dialogsum
metrics:
- name: Validation ROGUE-1
type: rouge-1
value: 39.8612
- name: Validation ROGUE-2
type: rouge-2
value: 16.6917
- name: Validation ROGUE-L
type: rouge-L
value: 32.2718
- name: Validation ROGUE-Lsum
type: rouge-Lsum
value: 35.8748
- name: Validation ROGUE-Lsum
type: gen-length
value: 41.726
- name: Test ROGUE-1
type: rouge-1
value: 36.9608
- name: Test ROGUE-2
type: rouge-2
value: 14.3058
- name: Test ROGUE-L
type: rouge-L
value: 29.3261
- name: Test ROGUE-Lsum
type: rouge-Lsum
value: 32.9
- name: Test ROGUE-Lsum
type: gen-length
value: 43.086
---
Model obtained by Fine Tuning 'facebook/bart-large-xsum' using AMI Meeting Corpus, SAMSUM Dataset, DIALOGSUM Dataset, XSUM Dataset!
## Usage
# Example 1
```python
from transformers import pipeline
summarizer = pipeline("summarization", model="knkarthick/MEETING_SUMMARY")
text = '''The tower is 324 metres (1,063 ft) tall, about the same height as an 81-storey building, and the tallest structure in Paris. Its base is square, measuring 125 metres (410 ft) on each side. During its construction, the Eiffel Tower surpassed the Washington Monument to become the tallest man-made structure in the world, a title it held for 41 years until the Chrysler Building in New York City was finished in 1930. It was the first structure to reach a height of 300 metres. Due to the addition of a broadcasting aerial at the top of the tower in 1957, it is now taller than the Chrysler Building by 5.2 metres (17 ft). Excluding transmitters, the Eiffel Tower is the second tallest free-standing structure in France after the Millau Viaduct.
'''
summarizer(text)
```
# Example 2
```python
from transformers import pipeline
summarizer = pipeline("summarization", model="knkarthick/MEETING_SUMMARY")
text = '''Bangalore is the capital and the largest city of the Indian state of Karnataka. It has a population of more than 8 million and a metropolitan population of around 11 million, making it the third most populous city and fifth most populous urban agglomeration in India. Located in southern India on the Deccan Plateau, at a height of over 900 m (3,000 ft) above sea level, Bangalore is known for its pleasant climate throughout the year. Its elevation is the highest among the major cities of India.The city's history dates back to around 890 CE, in a stone inscription found at the Nageshwara Temple in Begur, Bangalore. The Begur inscription is written in Halegannada (ancient Kannada), mentions 'Bengaluru Kalaga' (battle of Bengaluru). It was a significant turning point in the history of Bangalore as it bears the earliest reference to the name 'Bengaluru'. In 1537 CE, Kempé Gowdā – a feudal ruler under the Vijayanagara Empire – established a mud fort considered to be the foundation of modern Bangalore and its oldest areas, or petes, which exist to the present day.
After the fall of Vijayanagar empire in 16th century, the Mughals sold Bangalore to Chikkadevaraja Wodeyar (1673–1704), the then ruler of the Kingdom of Mysore for three lakh rupees. When Haider Ali seized control of the Kingdom of Mysore, the administration of Bangalore passed into his hands.
The city was captured by the British East India Company after victory in the Fourth Anglo-Mysore War (1799), who returned administrative control of the city to the Maharaja of Mysore. The old city developed in the dominions of the Maharaja of Mysore and was made capital of the Princely State of Mysore, which existed as a nominally sovereign entity of the British Raj. In 1809, the British shifted their cantonment to Bangalore, outside the old city, and a town grew up around it, which was governed as part of British India. Following India's independence in 1947, Bangalore became the capital of Mysore State, and remained capital when the new Indian state of Karnataka was formed in 1956. The two urban settlements of Bangalore – city and cantonment – which had developed as independent entities merged into a single urban centre in 1949. The existing Kannada name, Bengalūru, was declared the official name of the city in 2006.
Bangalore is widely regarded as the "Silicon Valley of India" (or "IT capital of India") because of its role as the nation's leading information technology (IT) exporter. Indian technological organisations are headquartered in the city. A demographically diverse city, Bangalore is the second fastest-growing major metropolis in India. Recent estimates of the metro economy of its urban area have ranked Bangalore either the fourth- or fifth-most productive metro area of India. As of 2017, Bangalore was home to 7,700 millionaires and 8 billionaires with a total wealth of $320 billion. It is home to many educational and research institutions. Numerous state-owned aerospace and defence organisations are located in the city. The city also houses the Kannada film industry. It was ranked the most liveable Indian city with a population of over a million under the Ease of Living Index 2020.
'''
summarizer(text)
```
# Example 3
```python
from transformers import pipeline
summarizer = pipeline("summarization", model="knkarthick/MEETING_SUMMARY")
text = '''Hi, I'm David and I'm supposed to be an industrial designer. Um, I just got the project announcement about what the project is. Designing a remote control. That's about it, didn't get anything else. Did you get the same thing? Cool. There's too much gear. Okay. Can't draw. Um. Yeah. Um, well anyway, I don't know, it's just the first animal I can think off the top of my head. Um. Yes. Big reason is 'cause I'm allergic to most animals. Allergic to animal fur, so um fish was a natural choice. Um, yeah, and I kind of like whales. They come in and go eat everything in sight. And they're quite harmless and mild and interesting. Tail's a bit big, I think. It's an after dinner dog then. Hmm. It does make sense from maybe the design point of view 'cause you have more complicated characters like European languages, then you need more buttons. So, possibly. Hmm. Yeah. And you keep losing them. Finding them is really a pain, you know. I mean it's usually quite small, or when you want it right, it slipped behind the couch or it's kicked under the table. You know. Yep. Mm-hmm. I think one factor would be production cost. Because there's a cap there, so um depends on how much you can cram into that price. Um. I think that that's the main factor. Cool.
Okay. Right. Um well this is the kick-off meeting for our our project. Um and um this is just what we're gonna be doing over the next twenty five minutes. Um so first of all, just to kind of make sure that we all know each other, I'm Laura and I'm the project manager. Do you want to introduce yourself again? Okay. Great. Okay. Um so we're designing a new remote control and um Oh I have to record who's here actually. So that's David, Andrew and Craig, isn't it? And you all arrived on time. Um yeah so des uh design a new remote control. Um, as you can see it's supposed to be original, trendy and user friendly. Um so that's kind of our our brief, as it were. Um and so there are three different stages to the design. Um I'm not really sure what what you guys have already received um in your emails. What did you get? Mm-hmm. Is that what everybody got? Okay. Um. So we're gonna have like individual work and then a meeting about it. And repeat that process three times. Um and at this point we get try out the whiteboard over there. Um. So uh you get to draw your favourite animal and sum up your favourite characteristics of it. So who would like to go first? Very good. Mm-hmm. Yeah. Yeah. Right. Lovely. Right. You can take as long over this as you like, because we haven't got an awful lot to discuss. Ok oh we do we do. Don't feel like you're in a rush, anyway. Ach why not We might have to get you up again then. I don't know what mine is. I'm gonna have to think on the spot now. Is that a whale? Ah. Okay. God, I still don't know what I'm gonna write about. Um. I was gonna choose a dog as well. But I'll just draw a different kind of dog. M my favourite animal is my own dog at home. Um That doesn't really look like him, actually. He looks more like a pig, actually. Ah well. Do you? Oh that's very good of you. Uh. Um he's a mixture of uh various things. Um and what do I like about him, um That's just to suggest that his tail wags. Um he's very friendly and cheery and always pleased to see you, and very kind of affectionate and um uh and he's quite quite wee as well so you know he can doesn't take up too much space. Um and uh And he does a funny thing where he chases his tail as well, which is quite amusing, so It is. I think it is. He only does it after he's had his dinner and um he'll just all of a sudden just get up and start chasing his tail 'round the living room. Yeah, so uh Yeah, maybe. Maybe. Right, um where did you find this? Just down here? Yeah. Okay. Um what are we doing next? Uh um. Okay, uh we now need to discuss the project finance. Um so according to the brief um we're gonna be selling this remote control for twenty five Euro, um and we're aiming to make fifty million Euro. Um so we're gonna be selling this on an international scale. And uh we don't want it to cost any more than uh twelve fifty Euros, so fifty percent of the selling price. Sure. All together. Um I dunno. I imagine That's a good question. I imagine it probably is our sale actually because it's probably up to the the um the retailer to uh sell it for whatever price they want. Um. But I I don't know, I mean do you think the fact that it's going to be sold internationally will have a bearing on how we design it at all? Think it will? Um. Hmm. Oh yeah, regions and stuff, yeah. Yeah. Okay. Yeah. Well for a remote control, do you think that will be I suppose it's depends on how complicated our remote control is. Yeah, yeah. Okay. What, just like in terms of like the wealth of the country? Like how much money people have to spend on things like? Aye, I see what you mean, yeah. Marketing. Good marketing thoughts. Oh gosh, I should be writing all this down. Um. Mm. Yeah. Yeah, yeah. Like how much does, you know, a remote control cost. Well twenty five Euro, I mean that's um that's about like eighteen pounds or something, isn't it? Or no, is it as much as that? Sixteen seventeen eighteen pounds. Um, I dunno, I've never bought a remote control, so I don't know how how good a remote control that would get you. Um. But yeah, I suppose it has to look kind of cool and gimmicky. Um right, okay. Let me just scoot on ahead here. Okay. Um well d Does anybody have anything to add to uh to the finance issue at all? Thin No, actually. That would be useful, though, wouldn't it, if you knew like what your money would get you now. Mm-hmm. Yeah, yeah. Oh. Five minutes to end of meeting. Oh, okay. We're a bit behind. Yeah. Right, so do you think that should be like a main design aim of our remote control d you know, do your your satellite and your regular telly and your V_C_R_ and everything? Mm-hmm. Yeah. Or even like, you know, notes about um what you wanna watch. Like you might put in there oh I want to watch such and such and look a Oh that's a good idea. So extra functionalities. Mm-hmm. Hmm. Um okay, uh I'd wel we're gonna have to wrap up pretty quickly in the next couple of minutes. Um I'll just check we've nothing else. Okay. Um so anything else anybody wants to add about what they don't like about remote controls they've used, what they would really like to be part of this new one at all? You keep losing them. Okay. Yeah. W You get those ones where you can, if you like, whistle or make a really high pitched noise they beep. There I mean is that something we'd want to include, do you think? Dunno. Okay maybe. My goodness. Still feels quite primitive. Maybe like a touch screen or something? Okay. Uh-huh, okay. Well I guess that's up to our industrial designer. It looks better. Yeah. Okay. Okay. Right, well um so just to wrap up, the next meeting's gonna be in thirty minutes. So that's about um about ten to twelve by my watch. Um so inbetween now and then, um as the industrial designer, you're gonna be working on you know the actual working design of it so y you know what you're doing there. Um for user interface, technical functions, I guess that's you know like what we've been talking about, what it'll actually do. Um and uh marketing executive, you'll be just thinking about what it actually what, you know, what requirements it has to has to fulfil and you'll all get instructions emailed to you, I guess. Um. Yeah, so it's th the functional design stage is next, I guess. And uh and that's the end of the meeting. So I got that little message a lot sooner than I thought I would, so Mm-hmm. Uh-huh, yeah. Th Okay, well just very quickly 'cause this we're supposed to finish now. Um I guess that's up to us, I mean you probably want some kind of unique selling point of it, so um, you know Yeah. Mm-hmm. Yeah. Okay. Right, okay, we'll that's that's the end of the meeting, then. Um. So, uh thank you all for coming.
Um I'm Craig and I'm User Interface. Yeah. Well, my favourite animal would be a monkey. Then they're small cute and furry, and uh when planet of the apes becomes real, I'm gonna be up there with them. Yeah. I know um My parents went out and bought um remote controls because um they got fed up of having four or five different remote controls for each things the house. So um for them it was just how many devices control. Uh.
Mm-hmm. Great. And I'm Andrew and I'm uh our marketing expert. Mm-hmm. Mm-hmm. Yeah, that's that's it. Yeah. I will go. That's fine. Alright. So This one here, right? Okay. Very nice. Alright. My favourite animal is like A beagle. Um charac favourite characteristics of it? Is that right? Uh, right, well basically um high priority for any animal for me is that they be willing to take a lot of physical affection from their family. And, yeah that they have lots of personality and uh be fit and in robust good health. So this is blue. Blue beagle. My family's beagle. I coulda told you a whole lot more about beagles. Boy, let me tell you. Impressionist. Alright. Mm. Superb sketch, by the way. Yep. I see a dog in there. Yep. Now I see a rooster. What kind is it? Is he aware that th it's his own cha tail he's chasing? Hmm. Probably when he was little he got lots of attention for doing it and has forever been conditioned. 'Kay. Um, can we just go over that again? Uh, so bas at twel Alright, yeah. Okay. So cost like production cost is twelve fifty, but selling price is is that wholesale or retail? Like on the shelf. Our sale our sale anyway. Yeah, okay okay. Okay. Mm-hmm. Alright. Yes. Mm-hmm. Mm-hmm. Well right away I'm wondering if there's um th th uh, like with D_V_D_ players, if there are zones. Um f frequencies or something um as well as uh characters, um different uh keypad styles and s symbols. Um. I don't know. Yeah. Yeah. Yeah. And then a and then al the other thing international is on top of the price. I'm thinking the price might might appeal to a certain market in one region, whereas in another it'll be different, so Just a chara just a characteristic of the Just Or just like, basic product podi positioning, the twenty five Euro remote control might be a big hit in London, might not be such a big hit in Greece, who knows, something like that, yeah. Yep. Right away I'm making some kind of assumptions about what what information we're given here, thinking, 'kay trendy probably means something other than just basic, something other than just standard. Um so I'm wondering right away, is selling twenty five Euros, is that sort of the thi is this gonna to be like the premium product kinda thing or Uh-huh. Mm-hmm. Yep. Yeah, I'd say so, yeah. No. Yeah, yeah. Mm-hmm. Do we have any other background information on like how that compares to other other Yeah. Mm-hmm. Yeah, interesting thing about discussing um production of a remote control for me is that l as you point out, I just don't think of remote controls as somethin something people consciously assess in their purchasing habits. It's just like getting shoelaces with shoes or something. It just comes along. Do you know what I mean? Like so sort of like how do you I I mean one one way of looking at it would be, well the people producing television sets, maybe they have to buy remote controls. Or another way is maybe people who have T_V_ sets are really fed up with their remote control and they really want a better one or something. But Right. Right. Okay so Right, so in function one of the priorities might be to combine as many uses I think so. Yeah, yeah. Yeah. Well like um, maybe what we could use is a sort of like a example of a successful other piece technology is palm palm pilots. They're gone from being just like little sort of scribble boards to cameras, M_P_ three players, telephones, everything, agenda. So, like, I wonder if we might add something new to the to the remote control market, such as the lighting in your house, or um Yeah, yeah. An Yeah. Like, p personally for me, at home I've I've combined the um the audio video of my television set and my D_V_D_ player and my C_D_ player. So they w all work actually function together but I have different remote controls for each of them. So it's sort of ironic that that then they're in there um you know, the sound and everything it's just one system. But each one's got its own little part. Mm. Mm. Mm. Mm-hmm. Mm-hmm. Yeah. Yeah. That's just really good id Yep. Uh, sure. I remember when the first remote control my my family had was on a cable. Actually had a cable between it and the T_V_ and big like buttons that sort of like, like on a blender or something. And um, you know, when I think about what they are now, it's better, but actually it's still kind of, I dunno, like a massive junky thing on the table. Maybe we could think about how, could be more, you know, streamlined. S Something like that, yeah. Or whatever would be technologically reasonable. 'Cause it could b it could it could be that f it could be that functionally that doesn't make it any better, but that just the appeal of of not having You know, these days there's a r pe things in people's homes are becoming more and more like chic, you know. Um, nicer materials and might be be worth exploring anyway. Okay. Um. Before we wrap up, just to make sure we're all on the same page here, um, do we We were given sort of an example of a coffee machine or something, right? Well, um are we at ma right now on the assumption that our television remote control may have features which go beyond the television? Or are we keeping sort of like a a design commitment to television features? I I don't know. Yep. Yeah, sure. Okay. Okay, yeah. Okay. Okay. Okay. Alright.
'''
summarizer(text)
```
# Example 4
```python
from transformers import pipeline
summarizer = pipeline("summarization", model="knkarthick/MEETING_SUMMARY")
text = '''
Das : Hi and welcome to the a16z podcast. I’m Das, and in this episode, I talk SaaS go-to-market with David Ulevitch and our newest enterprise general partner Kristina Shen. The first half of the podcast looks at how remote work impacts the SaaS go-to-market and what the smartest founders are doing to survive the current crisis. The second half covers pricing approaches and strategy, including how to think about free versus paid trials and navigating the transition to larger accounts. But we start with why it’s easier to move upmarket than down… and the advantage that gives a SaaS startup against incumbents.
David : If you have a cohort of customers that are paying you $10,000 a year for your product, you’re going to find a customer that self-selects and is willing to pay $100,000 a year. Once you get one of those, your organization will figure out how you sell to, how you satisfy and support, customers at that price point and that size. But it’s really hard for a company that sells up market to move down market, because they’ve already baked in all that expensive, heavy lifting sales motion. And so as you go down market with a lower price point, usually, you can’t actually support it.
Das : Does that mean that it’s easier for a company to do this go-to-market if they’re a new startup as opposed to if they’re a pre-existing SaaS?
Kristina : It’s culturally very, very hard to give a product away for free that you’re already charging for. It feels like you’re eating away at your own potential revenue when you do it. So most people who try it end up pulling back very quickly.
David : This is actually one of the key reasons why the bottoms up SaaS motion is just so competitive, and compelling, and so destructive against the traditional sales-driven test motion. If you have that great product and people are choosing to use it, it’s very hard for somebody with a sales-driven motion, and all the cost that’s loaded into that, to be able to compete against it. There are so many markets where initially, we would look at companies and say, “Oh, well, this couldn’t possibly be bottoms up. It has to be sold to the CIO. It has to be sold to the CSO or the CFO.” But in almost every case we’ve been wrong, and there has been a bottoms up motion. The canonical example is Slack. It’s crazy that Slack is a bottoms up company, because you’re talking about corporate messaging, and how could you ever have a messaging solution that only a few people might be using, that only a team might be using? But now it’s just, “Oh, yeah, some people started using it, and then more people started using it, and then everyone had Slack.”
Kristina : I think another classic example is Dropbox versus Box. Both started as bottoms up businesses, try before you buy. But Box quickly found, “Hey, I’d rather sell to IT.” And Dropbox said, “Hey, we’ve got a great freemium motion going.” And they catalyzed their business around referrals and giving away free storage and shared storage in a way that really helped drive their bottoms up business.
Das : It’s a big leap to go from selling to smaller customers to larger customers. How have you seen SaaS companies know or get the timing right on that? Especially since it does seem like that’s really related to scaling your sales force?
Kristina : Don’t try to go from a 100-person company to a 20,000-person company. Start targeting early adopters, maybe they’re late stage pre-IPO companies, then newly IPO’d companies. Starting in tech tends to be a little bit easier because they tend to be early adopters. Going vertical by vertical can be a great strategy as well. Targeting one customer who might be branded in that space, can help brand yourself in that category. And then all their competitors will also want your product if you do a good job. A lot of times people will dedicate a sales rep to each vertical, so that they become really, really knowledgeable in that space, and also build their own brand and reputation and know who are the right customers to target.
Das : So right now, you’ve got a lot more people working remote. Does this move to remote work mean that on-premise software is dying? And is it accelerating the move to software as a service?
Kristina : This remote work and working from home is only going to catalyze more of the conversion from on-premise over to cloud and SaaS. In general, software spend declines 20% during an economic downturn. This happened in ’08, this happened in ’01. But when we look at the last downturn in ’08, SaaS spend actually, for public companies, increased, on average, 10%, which means there’s a 30% spread, which really shows us that there was a huge catalyst from people moving on-premise to SaaS.
David : And as people work remote, the ability to use SaaS tools is much easier than having to VPN back into your corporate network. We’ve been seeing that, inside sales teams have been doing larger and larger deals, essentially moving up market on the inside, without having to engage with field sales teams. In fact, a lot of the new SaaS companies today rather than building out a field team, they have a hybrid team, where people are working and closing deals on the inside and if they had to go out and meet with a customer, they would do that. But by and large, most of it was happening over the phone, over email, and over videoconferencing. And all the deals now, by definition, are gonna be done remote because people can’t go visit their customers in person.
Das : So with bottoms up, did user behavior and buyer behavior change, so the go-to-market evolved? Or did the go-to-market evolve and then you saw user and buyer behavior change? I’m curious with this move to remote work. Is that going to trigger more changes or has the go-to-market enabled that change in user behavior, even though we see that change coming because of a lot of forces outside of the market?
Kristina : I definitely think they are interrelated. But I do think it was a user change that catalyzed everything. We decided that we preferred better software, and we tried a couple products. We were able to purchase off our credit card. And then IT and procurement eventually said, “Wow, everyone’s buying these already, I might as well get a company license and a company deal so I’m not paying as much.” While obviously software vendors had to offer the products that could be self-served, users started to realize they had the power, they wanted to use better software, they paid with their credit cards. And now software vendors are forced to change their go-to-market to actually suit that use case.
Das : If that’s the case that when user behavior has changed, it’s tended to be the catalyzing force of bigger changes in the go-to-market, what are some of the changes you foresee for SaaS because the world has changed to this new reality of remote work and more distributed teams?
David : We’re in a very uncertain economic environment right now. And a couple of things will become very clear over the next 3 to 9 to 15 months — you’re going to find out which SaaS products are absolutely essential to helping a business operate and run, and which ones were just nice to have and may not get renewed. I think on the customer, buying side, you’re very likely to see people push back on big annual commitments and prefer to go month-to-month where they can. Or you’ll see more incentives from SaaS startups to offer discounts for annual contracts. You’re going to see people that might sign an annual contract, but they may not want to pay upfront. They may prefer to meter the cash out ratably over the term of the contract. And as companies had empowered and allowed budget authority to be pushed down in organizations, you’re gonna see that budget authority get pulled back, more scrutiny on spending, and likely a lot of SaaS products not get renewed that turned out to not be essential.
Kristina : I think the smartest founders are making sure they have the runway to continue to exist. And they’re doing that in a couple of ways. They’re preserving cash, and they are making sure that their existing customers are super, super happy, because retaining your customers is so important in this environment. And they’re making sure that they have efficient or profitable customer acquisition. Don’t spend valuable dollars acquiring customers. But acquire customers efficiently that will add to a great existing customer base.
Das : To go into pricing and packaging for SaaS for a moment, what are some of the different pricing approaches that you see SaaS companies taking?
Kristina : The old school way of doing SaaS go-to-market is bundle everything together, make the pricing super complex, so you don’t actually understand what you’re paying for. You’re forced to purchase it because you need one component of the product. New modern SaaS pricing is keep it simple, keep it tied to value, and make sure you’re solving one thing really, really well.
David : You want to make it easy for your customers to give you money. And if your customers don’t understand your pricing, that’s a huge red flag. Sometimes founders will try to over engineer their pricing model.
Kristina : We talk a lot about everything has to be 10X better than the alternatives. But it’s much easier to be 10X better when you solve one thing very, very well, and then have simple pricing around it. I think the most common that most people know about is PEPM or per employee per month, where you’re charging basically for every single seat. Another really common model is the freemium model. So, think about a Dropbox, or an Asana, or a Skype, where it’s trigger based. You try the product for free, but when you hit a certain amount of storage, or a certain amount of users, then it converts over to paid. And then you also have a time trial, where you get the full experience of the product for some limited time period. And then you’re asked if you want to continue using the product to pay. And then there’s pay as go, and particularly, pay as you go as a usage model. So, Slack will say, “Hey, if your users aren’t actually using the product this month, we won’t actually charge you for it.”
David : The example that Kristina made about Slack and users, everybody understands what a user is, and if they’re using the product, they pay for it, and if they’re not using it, they don’t pay for it. That’s a very friendly way to make it easy for your customers to give you money. If Slack came up with a pricing model that was like based on number of messages, or number of API integration calls, the customer would have no idea what that means.
Kristina : There’s also the consumption model. So Twilio only charges you for every SMS text or phone call that you make on the platform any given month. And so they make money or lose money as your usage goes. The pricing is very aligned to your productivity.
David : Generally, those are for products where the usage only goes in one direction. If you think of a company like Databricks, where they’re charging for storage, or Amazon’s S3 service, it is very aligned with the customer, but it also strategically aligns with the business because they know the switching cost is very high, the churn is very low. And generally, in those businesses, you’re only going to store more data, so they can charge based on usage or volume of data.
Kristina : Recently, there’s been a huge trend of payment as a revenue. It’s particularly common in vertical markets where SaaS companies are adding payments as a revenue in addition to their employee or subscription revenue. If you look at Shopify, for example, more than 50% of their revenue is actually payment revenue. They’re making money every single time you purchase something off one of their shopping cart websites.
Das : When you’re working with a founder or a SaaS startup, how have you seen them find the right pricing model for their product, for their market?
Kristina : Step one is just talk to a lot of customers. Try to figure out what is the market pricing for possible alternatives or competitors, understand their pain points and their willingness to pay. And just throw a price out there, because you have to have a starting point in order to actually test and iterate. Particularly in the SMB, or the bottoms up business, you can test and iterate pretty quickly because you have so many data points.
David : I always tell founders, step one is to just go out there and talk to customers. Step two is just double your prices. I don’t think there’s ever been a great company with a great product that’s fallen apart because their pricing was wrong. But a lot of SaaS startup founders really under price, and you don’t want to find out two or three years later that you were 200% underpriced. A very common thing that SaaS companies do, they’ll have the basic package that either is free or low cost, that you can just sign up online for. They’ll have a middle package where they share some pricing, and then they’ll have the enterprise package where you have to contact sales to find out more. And that way they don’t actually have to show the pricing for that third package. And that gives the salespeople the flexibility to adjust pricing on a per deal basis.
Das : When you’re working with companies, why are they underpricing their products?
David : I think it’s psychological. People need to price on value, and they don’t know how much value they’re delivering relative to “Oh, it only cost me $100 a month to provide this service, so I just need to charge $200.” But if it turns out you’re saving your customer $50,000 a year, then you’re wildly underpriced. You have to remember that SaaS is essentially a proxy for outsourced IT. You’re spending money on a SaaS service to not pay to develop something internally, or to have to pay IT to support something that’s more complex on-prem. Software is much cheaper than people, and so generally, the price point can be much higher.
Kristina : And the other thing is your value increases over time. You’re delivering more features, more products, you understand the customer better. It’s the beauty of the SaaS model and cloud model that you can iterate and push code immediately, and the customer immediately sees value. A lot of times people have the same price point from the first customer sold to three years later and the 200th customer. Quite frankly, you’ve delivered so much value along the way that your price point should have gone up. The other thing I’ll say is a lot of people discount per seat pricing a lot as they move up market. We tend to tell people that the best validation of your product having great product market fit is your ability to hold your price point. So while there is some natural discounting on a per seat basis because people do deserve some volume discounting, I would say try to resist that as much as possible.
Das : Especially for a technical founder, it’s so tempting to get in there and fiddle with these knobs. How do you know when it is time to experiment with your pricing and packaging?
David : If you’re looking at your business and you see that you are doing more deals, and they’re closing faster, you should raise your pricing. And you pay attention to how long it takes to close deals and whether the number of deals is staying consistent as you do that. And, at some point, you’re going to find out when you’re losing deals on price. I think a moment where companies have to plan ahead to avoid having to course correct is after they roll out massive pricing and packaging changes, which are pretty natural as companies move up market. But how they navigate that transition to larger accounts, and how they either bring along or move away from those smaller, earlier customers who got them to where they are, tends to be really important because they can get a lot of noise on Twitter, they can get a lot of blowback from their customers. So Zendesk is a company where they rolled out a major packaging change. And when they rolled it out, they hadn’t planned on grandfathering in their early customers. They got a lot of pushback, and very quickly, they put out a blog post and said, “We hear what you’re saying, we appreciate you building the business that we’ve become today. We do need to have a package for the future. But all the people that have been customers so far will be grandfathered in for at least a period of time into the old model.”
Kristina : If you iterate pricing constantly, you don’t really have this problem because your customers will be used to pricing changes. You normally pair them with new features, and it all kind of works out. But if you have to go through a big grandfather change, I tend to lean towards treating your early customers really, really well. They adopted when you weren’t a big company yet. They probably co-built the product with you in many ways. And so, it’s great to get more dollars out of your customer base, but treat your early customers well.
Das : Are there any other failure modes that you see startups really falling into around pricing and packaging or any common mistakes that they make?
David : I think a lot of founders don’t always map out the cost or model of their pricing and their product relative to their cost of actually doing sales and marketing and customer acquisition.
Kristina : Inside sales is so popular in Silicon Valley. When you’re selling more to an SMB or mid-market type customer, the expectation is that you’re educating and helping the prospective customer over the phone. And so, you’re not expected to be as high touch. But 5K is almost the minimum price point you need to sell to the SMB with an inside sales team in order to pay for the outbound costs and all the conversions, because there is typically a team that sits around the quota carrying rep. And so, price matching — how much your price point is compared to what your go-to-market motion is — matters a lot. Other big failure modes that I see, people guess the ramp time of a sales rep wrong. And ramp time really ties to the segment of customer you’re selling into. It tends be that if you’re selling into the enterprise, the ramp time for sales reps, because sales cycles are so long, tend to be much longer as well. They could be six months plus, could be a year. While if you’re selling more into SMB or mid-market, the ramp time to get a rep up and running can be much shorter, three to six months. Because the sales cycles are shorter, they just iterate much faster, and they ramp up much more quickly.
David : The other thing that people have to understand is that sales velocity is a really important component to figuring out how many reps you should be hiring, whether they should be inside reps or field reps. If it takes you 90 days to close a deal, that can’t be a $5,000 a year deal, that has to be a $50,000 or even $150,000 a year deal.
Das : Kristina, I know you’ve done a lot of work with metrics. So how do those play in?
Kristina : Probably the one way to sum it all together is how many months does it take to pay back customer acquisition cost. Very commonly within the SaaS world, we talk about a 12-month CAC payback. We typically want to see for every dollar you spend on sales and marketing, you get a dollar back within a year. That means you can tweak the inputs any way you want. Let’s say that doing paid acquisition is really effective for you. Then, you can spend proportionally more on paid acquisition and less on sales reps. Vice versa, if you have a great inbound engine, you actually can hire a lot more sales reps and spend more on sales headcount. With all formulas, it’s a guide rail, so if you have customers that retain really, really well, let’s say you’re selling to the enterprise, and you’ve got a 90% or 95% annual retention rate, then your CAC payback could be between 12 and 24 months. But let’s say you’re selling to the SMB and churn is 2% or 3% monthly, which ends up being like 80% to 90% annual retention. Then, because your customer is less sticky, I would recommend looking at a CAC payback of 6 to 12 months.
Das : How should you think about doing a free trial versus a paid trial?
David : On the one hand, the bottoms up motion where people can try essentially a full version of a product before they buy it is extremely powerful. On the other hand, I’ve started to try to think about how I advise companies, when they are thinking about a free trial for something that might cost $100,000 or $200,000 a year? Do we do a paid pilot that has some sort of contractual obligation that if we meet then turns into a commercial engagement?
Kristina : I do think the beauty of the bottoms up business is that you can get people to try the entire experience of the product for free, and they fall in love with it, and a certain percentage will convert. And that works really, really well for products that can self-serve. When you start moving up market to more complex products, the challenge with trials is it takes work to actually implement the product, whether it be integrations, IT has to give access, etc. You lose that self-serve ability, which is so amazing in the trial. And so, I tend to be more in the camp of paid trials, if it costs you money to actually deploy the trial. And when you’re selling to bigger customers, they associate value when they have to pay. Once a customer has to pay you, then they feel a need to make the project successful and thus they will onboard, schedule things, give you data and access.
David : If you can get to a point where you get the customer to do that paid pilot, such that the only difference between a pilot and an actual customer is just the signing of a contract, that’s very powerful. Now, that does force you to have a really good pre-sales motion to make sure that you can deliver on the promise you’ve made your customers. When companies don’t have a great product, and they paper over it with professional services and sales engineering and post-sales support, that paid pilot thing doesn’t work because the experience isn’t good enough. So, it really is incumbent on the SaaS company that does a paid pilot to make sure that they are able to deliver on that experience.
Kristina : And one emerging trend recently is people signing an annual contract with a one or three month out, as a replacement to the paid pilot. Because it’s the best of both worlds, the SaaS company that’s selling the product gets a higher level of commitment. And the customer gets the optionality of opting out in the same way as a trial without any clawback. It really comes down to where procurement falls. Sometimes procurement is at the beginning of that decision, which makes it more like an annual contract. Sometimes procurement is at the one or three month opt-out period, which means the customer already has a great experience, loves the product, and it is an easier way to convert procurements to actually sign on…
David : And that is a really good segue into renewals. I always tell founders, you might have this subscription business, but it’s not a recurring revenue business until the second year when the revenue actually recurs. I think you really have the first three months to get a customer up and running and happy. And if they’re not, you then have about three months to fix it. And if all that works out, then the remaining six months of the contract can be focused on upsell and expansion.
Das : Awesome. Thank you, Kristina. Thank you, David.
Kristina : Thanks so much for having us. This was fun.
David : Yeah, a lot of fun, great topics, and our favorite thing to talk about.
'''
summarizer(text)
```
|
hfl/rbt3
|
0aa0527ff4170f29e1dfd3eb6ef60dc67e1bf75c
|
2021-05-19T19:19:45.000Z
|
[
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"zh",
"arxiv:1906.08101",
"arxiv:2004.13922",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] |
fill-mask
| false |
hfl
| null |
hfl/rbt3
| 10,305 | 4 |
transformers
| 678 |
---
language:
- zh
tags:
- bert
license: "apache-2.0"
pipeline_tag: "fill-mask"
---
# This is a re-trained 3-layer RoBERTa-wwm-ext model.
## Chinese BERT with Whole Word Masking
For further accelerating Chinese natural language processing, we provide **Chinese pre-trained BERT with Whole Word Masking**.
**[Pre-Training with Whole Word Masking for Chinese BERT](https://arxiv.org/abs/1906.08101)**
Yiming Cui, Wanxiang Che, Ting Liu, Bing Qin, Ziqing Yang, Shijin Wang, Guoping Hu
This repository is developed based on:https://github.com/google-research/bert
You may also interested in,
- Chinese BERT series: https://github.com/ymcui/Chinese-BERT-wwm
- Chinese MacBERT: https://github.com/ymcui/MacBERT
- Chinese ELECTRA: https://github.com/ymcui/Chinese-ELECTRA
- Chinese XLNet: https://github.com/ymcui/Chinese-XLNet
- Knowledge Distillation Toolkit - TextBrewer: https://github.com/airaria/TextBrewer
More resources by HFL: https://github.com/ymcui/HFL-Anthology
## Citation
If you find the technical report or resource is useful, please cite the following technical report in your paper.
- Primary: https://arxiv.org/abs/2004.13922
```
@inproceedings{cui-etal-2020-revisiting,
title = "Revisiting Pre-Trained Models for {C}hinese Natural Language Processing",
author = "Cui, Yiming and
Che, Wanxiang and
Liu, Ting and
Qin, Bing and
Wang, Shijin and
Hu, Guoping",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.findings-emnlp.58",
pages = "657--668",
}
```
- Secondary: https://arxiv.org/abs/1906.08101
```
@article{chinese-bert-wwm,
title={Pre-Training with Whole Word Masking for Chinese BERT},
author={Cui, Yiming and Che, Wanxiang and Liu, Ting and Qin, Bing and Yang, Ziqing and Wang, Shijin and Hu, Guoping},
journal={arXiv preprint arXiv:1906.08101},
year={2019}
}
```
|
bionlp/bluebert_pubmed_uncased_L-12_H-768_A-12
|
a0ce2a0e0feb8f4caf0346b139266f5320b90322
|
2021-09-24T07:45:33.000Z
|
[
"pytorch",
"en",
"dataset:pubmed",
"transformers",
"bluebert",
"license:cc0-1.0"
] | null | false |
bionlp
| null |
bionlp/bluebert_pubmed_uncased_L-12_H-768_A-12
| 10,301 | 1 |
transformers
| 679 |
---
language:
- en
tags:
- bluebert
license: cc0-1.0
datasets:
- pubmed
---
# BlueBert-Base, Uncased, PubMed
## Model description
A BERT model pre-trained on PubMed abstracts
## Intended uses & limitations
#### How to use
Please see https://github.com/ncbi-nlp/bluebert
## Training data
We provide [preprocessed PubMed texts](https://ftp.ncbi.nlm.nih.gov/pub/lu/Suppl/NCBI-BERT/pubmed_uncased_sentence_nltk.txt.tar.gz) that were used to pre-train the BlueBERT models.
The corpus contains ~4000M words extracted from the [PubMed ASCII code version](https://www.ncbi.nlm.nih.gov/research/bionlp/APIs/BioC-PubMed/).
Pre-trained model: https://huggingface.co/bert-base-uncased
## Training procedure
* lowercasing the text
* removing speical chars `\x00`-`\x7F`
* tokenizing the text using the [NLTK Treebank tokenizer](https://www.nltk.org/_modules/nltk/tokenize/treebank.html)
Below is a code snippet for more details.
```python
value = value.lower()
value = re.sub(r'[\r\n]+', ' ', value)
value = re.sub(r'[^\x00-\x7F]+', ' ', value)
tokenized = TreebankWordTokenizer().tokenize(value)
sentence = ' '.join(tokenized)
sentence = re.sub(r"\s's\b", "'s", sentence)
```
### BibTeX entry and citation info
```bibtex
@InProceedings{peng2019transfer,
author = {Yifan Peng and Shankai Yan and Zhiyong Lu},
title = {Transfer Learning in Biomedical Natural Language Processing: An Evaluation of BERT and ELMo on Ten Benchmarking Datasets},
booktitle = {Proceedings of the 2019 Workshop on Biomedical Natural Language Processing (BioNLP 2019)},
year = {2019},
pages = {58--65},
}
```
|
howey/bert-base-uncased-sst2
|
4463eee18b0108806303203ebfb9cd91a88a96fa
|
2021-05-26T08:29:25.000Z
|
[
"pytorch",
"bert",
"text-classification",
"transformers"
] |
text-classification
| false |
howey
| null |
howey/bert-base-uncased-sst2
| 10,285 | null |
transformers
| 680 |
Entry not found
|
facebook/deit-base-patch16-224
|
fb2c78a54a5637dec350432794f7b93e31f910c9
|
2022-07-13T11:40:44.000Z
|
[
"pytorch",
"tf",
"vit",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2012.12877",
"arxiv:2006.03677",
"transformers",
"license:apache-2.0"
] |
image-classification
| false |
facebook
| null |
facebook/deit-base-patch16-224
| 10,265 | 5 |
transformers
| 681 |
---
license: apache-2.0
tags:
- image-classification
datasets:
- imagenet-1k
---
# Data-efficient Image Transformer (base-sized model)
Data-efficient Image Transformer (DeiT) model pre-trained and fine-tuned on ImageNet-1k (1 million images, 1,000 classes) at resolution 224x224. It was first introduced in the paper [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Touvron et al. and first released in [this repository](https://github.com/facebookresearch/deit). However, the weights were converted from the [timm repository](https://github.com/rwightman/pytorch-image-models) by Ross Wightman.
Disclaimer: The team releasing DeiT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
This model is actually a more efficiently trained Vision Transformer (ViT).
The Vision Transformer (ViT) is a transformer encoder model (BERT-like) pre-trained and fine-tuned on a large collection of images in a supervised fashion, namely ImageNet-1k, at a resolution of 224x224 pixels.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. One also adds a [CLS] token to the beginning of a sequence to use it for classification tasks. One also adds absolute position embeddings before feeding the sequence to the layers of the Transformer encoder.
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire image.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=facebook/deit) to look for
fine-tuned versions on a task that interests you.
### How to use
Since this model is a more efficiently trained ViT model, you can plug it into ViTModel or ViTForImageClassification. Note that the model expects the data to be prepared using DeiTFeatureExtractor. Here we use AutoFeatureExtractor, which will automatically use the appropriate feature extractor given the model name.
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import AutoFeatureExtractor, ViTForImageClassification
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = AutoFeatureExtractor.from_pretrained('facebook/deit-base-patch16-224')
model = ViTForImageClassification.from_pretrained('facebook/deit-base-patch16-224')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
Currently, both the feature extractor and model support PyTorch. Tensorflow and JAX/FLAX are coming soon.
## Training data
The ViT model was pretrained on [ImageNet-1k](http://www.image-net.org/challenges/LSVRC/2012/), a dataset consisting of 1 million images and 1k classes.
## Training procedure
### Preprocessing
The exact details of preprocessing of images during training/validation can be found [here](https://github.com/facebookresearch/deit/blob/ab5715372db8c6cad5740714b2216d55aeae052e/datasets.py#L78).
At inference time, images are resized/rescaled to the same resolution (256x256), center-cropped at 224x224 and normalized across the RGB channels with the ImageNet mean and standard deviation.
### Pretraining
The model was trained on a single 8-GPU node for 3 days. Training resolution is 224. For all hyperparameters (such as batch size and learning rate) we refer to table 9 of the original paper.
## Evaluation results
| Model | ImageNet top-1 accuracy | ImageNet top-5 accuracy | # params | URL |
|---------------------------------------|-------------------------|-------------------------|----------|------------------------------------------------------------------|
| DeiT-tiny | 72.2 | 91.1 | 5M | https://huggingface.co/facebook/deit-tiny-patch16-224 |
| DeiT-small | 79.9 | 95.0 | 22M | https://huggingface.co/facebook/deit-small-patch16-224 |
| **DeiT-base** | **81.8** | **95.6** | **86M** | **https://huggingface.co/facebook/deit-base-patch16-224** |
| DeiT-tiny distilled | 74.5 | 91.9 | 6M | https://huggingface.co/facebook/deit-tiny-distilled-patch16-224 |
| DeiT-small distilled | 81.2 | 95.4 | 22M | https://huggingface.co/facebook/deit-small-distilled-patch16-224 |
| DeiT-base distilled | 83.4 | 96.5 | 87M | https://huggingface.co/facebook/deit-base-distilled-patch16-224 |
| DeiT-base 384 | 82.9 | 96.2 | 87M | https://huggingface.co/facebook/deit-base-patch16-384 |
| DeiT-base distilled 384 (1000 epochs) | 85.2 | 97.2 | 88M | https://huggingface.co/facebook/deit-base-distilled-patch16-384 |
Note that for fine-tuning, the best results are obtained with a higher resolution (384x384). Of course, increasing the model size will result in better performance.
### BibTeX entry and citation info
```bibtex
@misc{touvron2021training,
title={Training data-efficient image transformers & distillation through attention},
author={Hugo Touvron and Matthieu Cord and Matthijs Douze and Francisco Massa and Alexandre Sablayrolles and Hervé Jégou},
year={2021},
eprint={2012.12877},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
```bibtex
@misc{wu2020visual,
title={Visual Transformers: Token-based Image Representation and Processing for Computer Vision},
author={Bichen Wu and Chenfeng Xu and Xiaoliang Dai and Alvin Wan and Peizhao Zhang and Zhicheng Yan and Masayoshi Tomizuka and Joseph Gonzalez and Kurt Keutzer and Peter Vajda},
year={2020},
eprint={2006.03677},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
```bibtex
@inproceedings{deng2009imagenet,
title={Imagenet: A large-scale hierarchical image database},
author={Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li},
booktitle={2009 IEEE conference on computer vision and pattern recognition},
pages={248--255},
year={2009},
organization={Ieee}
}
```
|
ckiplab/bert-base-chinese-ner
|
50c5afc0a0131e8ab93f54d9ebf9575af04c22d5
|
2022-05-10T03:28:12.000Z
|
[
"pytorch",
"jax",
"bert",
"token-classification",
"zh",
"transformers",
"license:gpl-3.0",
"autotrain_compatible"
] |
token-classification
| false |
ckiplab
| null |
ckiplab/bert-base-chinese-ner
| 10,198 | 12 |
transformers
| 682 |
---
language:
- zh
thumbnail: https://ckip.iis.sinica.edu.tw/files/ckip_logo.png
tags:
- pytorch
- token-classification
- bert
- zh
license: gpl-3.0
---
# CKIP BERT Base Chinese
This project provides traditional Chinese transformers models (including ALBERT, BERT, GPT2) and NLP tools (including word segmentation, part-of-speech tagging, named entity recognition).
這個專案提供了繁體中文的 transformers 模型(包含 ALBERT、BERT、GPT2)及自然語言處理工具(包含斷詞、詞性標記、實體辨識)。
## Homepage
- https://github.com/ckiplab/ckip-transformers
## Contributers
- [Mu Yang](https://muyang.pro) at [CKIP](https://ckip.iis.sinica.edu.tw) (Author & Maintainer)
## Usage
Please use BertTokenizerFast as tokenizer instead of AutoTokenizer.
請使用 BertTokenizerFast 而非 AutoTokenizer。
```
from transformers import (
BertTokenizerFast,
AutoModel,
)
tokenizer = BertTokenizerFast.from_pretrained('bert-base-chinese')
model = AutoModel.from_pretrained('ckiplab/bert-base-chinese-ner')
```
For full usage and more information, please refer to https://github.com/ckiplab/ckip-transformers.
有關完整使用方法及其他資訊,請參見 https://github.com/ckiplab/ckip-transformers 。
|
rinna/japanese-gpt2-medium
|
f464b76739c884d8b0479a0a7705b7fa71c3fd5a
|
2021-08-23T03:20:17.000Z
|
[
"pytorch",
"tf",
"jax",
"gpt2",
"text-generation",
"ja",
"dataset:cc100",
"dataset:wikipedia",
"transformers",
"japanese",
"lm",
"nlp",
"license:mit"
] |
text-generation
| false |
rinna
| null |
rinna/japanese-gpt2-medium
| 10,180 | 17 |
transformers
| 683 |
---
language: ja
thumbnail: https://github.com/rinnakk/japanese-gpt2/blob/master/rinna.png
tags:
- ja
- japanese
- gpt2
- text-generation
- lm
- nlp
license: mit
datasets:
- cc100
- wikipedia
widget:
- text: "生命、宇宙、そして万物についての究極の疑問の答えは"
---
# japanese-gpt2-medium

This repository provides a medium-sized Japanese GPT-2 model. The model was trained using code from Github repository [rinnakk/japanese-pretrained-models](https://github.com/rinnakk/japanese-pretrained-models) by [rinna Co., Ltd.](https://corp.rinna.co.jp/)
# How to use the model
*NOTE:* Use `T5Tokenizer` to initiate the tokenizer.
~~~~
from transformers import T5Tokenizer, AutoModelForCausalLM
tokenizer = T5Tokenizer.from_pretrained("rinna/japanese-gpt2-medium")
tokenizer.do_lower_case = True # due to some bug of tokenizer config loading
model = AutoModelForCausalLM.from_pretrained("rinna/japanese-gpt2-medium")
~~~~
# Model architecture
A 24-layer, 1024-hidden-size transformer-based language model.
# Training
The model was trained on [Japanese CC-100](http://data.statmt.org/cc-100/ja.txt.xz) and [Japanese Wikipedia](https://dumps.wikimedia.org/other/cirrussearch) to optimize a traditional language modelling objective on 8\\*V100 GPUs for around 30 days. It reaches around 18 perplexity on a chosen validation set from the same data.
# Tokenization
The model uses a [sentencepiece](https://github.com/google/sentencepiece)-based tokenizer, the vocabulary was trained on the Japanese Wikipedia using the official sentencepiece training script.
# Licenese
[The MIT license](https://opensource.org/licenses/MIT)
|
google/tapas-large-finetuned-wtq
|
8ee9ab2e6d2e09fc3c138730f8a144cea6fe5c16
|
2022-07-14T10:13:16.000Z
|
[
"pytorch",
"tf",
"tapas",
"table-question-answering",
"en",
"dataset:wikitablequestions",
"arxiv:2004.02349",
"arxiv:2010.00571",
"arxiv:1508.00305",
"transformers",
"license:apache-2.0"
] |
table-question-answering
| false |
google
| null |
google/tapas-large-finetuned-wtq
| 10,178 | 4 |
transformers
| 684 |
---
language: en
tags:
- tapas
- table-question-answering
license: apache-2.0
datasets:
- wikitablequestions
---
# TAPAS large model fine-tuned on WikiTable Questions (WTQ)
This model has 2 versions which can be used. The default version corresponds to the `tapas_wtq_wikisql_sqa_inter_masklm_large_reset` checkpoint of the [original Github repository](https://github.com/google-research/tapas).
This model was pre-trained on MLM and an additional step which the authors call intermediate pre-training, and then fine-tuned in a chain on [SQA](https://www.microsoft.com/en-us/download/details.aspx?id=54253), [WikiSQL](https://github.com/salesforce/WikiSQL) and finally [WTQ](https://github.com/ppasupat/WikiTableQuestions). It uses relative position embeddings (i.e. resetting the position index at every cell of the table).
The other (non-default) version which can be used is:
- `no_reset`, which corresponds to `tapas_wtq_wikisql_sqa_inter_masklm_large` (intermediate pre-training, absolute position embeddings).
Disclaimer: The team releasing TAPAS did not write a model card for this model so this model card has been written by
the Hugging Face team and contributors.
## Results
Size | Reset | Dev Accuracy | Link
-------- | --------| -------- | ----
**LARGE** | **noreset** | **0.5062** | [tapas-large-finetuned-wtq (with absolute pos embeddings)](https://huggingface.co/google/tapas-large-finetuned-wtq/tree/no_reset)
**LARGE** | **reset** | **0.5097** | [tapas-large-finetuned-wtq](https://huggingface.co/google/tapas-large-finetuned-wtq/tree/main)
BASE | noreset | 0.4525 | [tapas-base-finetuned-wtq (with absolute pos embeddings)](https://huggingface.co/google/tapas-base-finetuned-wtq/tree/no_reset)
BASE | reset | 0.4638 | [tapas-base-finetuned-wtq](https://huggingface.co/google/tapas-base-finetuned-wtq/tree/main)
MEDIUM | noreset | 0.4324 | [tapas-medium-finetuned-wtq (with absolute pos embeddings)](https://huggingface.co/google/tapas-medium-finetuned-wtq/tree/no_reset)
MEDIUM | reset | 0.4324 | [tapas-medium-finetuned-wtq](https://huggingface.co/google/tapas-medium-finetuned-wtq/tree/main)
SMALL | noreset | 0.3681 | [tapas-small-finetuned-wtq (with absolute pos embeddings)](https://huggingface.co/google/tapas-small-finetuned-wtq/tree/no_reset)
SMALL | reset | 0.3762 | [tapas-small-finetuned-wtq](https://huggingface.co/google/tapas-small-finetuned-wtq/tree/main)
MINI | noreset | 0.2783 | [tapas-mini-finetuned-wtq (with absolute pos embeddings)](https://huggingface.co/google/tapas-mini-finetuned-wtq/tree/no_reset)
MINI | reset | 0.2854 | [tapas-mini-finetuned-wtq](https://huggingface.co/google/tapas-mini-finetuned-wtq/tree/main)
TINY | noreset | 0.0823 | [tapas-tiny-finetuned-wtq (with absolute pos embeddings)](https://huggingface.co/google/tapas-tiny-finetuned-wtq/tree/no_reset)
TINY | reset | 0.1039 | [tapas-tiny-finetuned-wtq](https://huggingface.co/google/tapas-tiny-finetuned-wtq/tree/main)
## Model description
TAPAS is a BERT-like transformers model pretrained on a large corpus of English data from Wikipedia in a self-supervised fashion.
This means it was pretrained on the raw tables and associated texts only, with no humans labelling them in any way (which is why it
can use lots of publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely, it
was pretrained with two objectives:
- Masked language modeling (MLM): taking a (flattened) table and associated context, the model randomly masks 15% of the words in
the input, then runs the entire (partially masked) sequence through the model. The model then has to predict the masked words.
This is different from traditional recurrent neural networks (RNNs) that usually see the words one after the other,
or from autoregressive models like GPT which internally mask the future tokens. It allows the model to learn a bidirectional
representation of a table and associated text.
- Intermediate pre-training: to encourage numerical reasoning on tables, the authors additionally pre-trained the model by creating
a balanced dataset of millions of syntactically created training examples. Here, the model must predict (classify) whether a sentence
is supported or refuted by the contents of a table. The training examples are created based on synthetic as well as counterfactual statements.
This way, the model learns an inner representation of the English language used in tables and associated texts, which can then be used
to extract features useful for downstream tasks such as answering questions about a table, or determining whether a sentence is entailed
or refuted by the contents of a table. Fine-tuning is done by adding a cell selection head and aggregation head on top of the pre-trained model, and then jointly train these randomly initialized classification heads with the base model on SQa, WikiSQL and finally WTQ.
## Intended uses & limitations
You can use this model for answering questions related to a table.
For code examples, we refer to the documentation of TAPAS on the HuggingFace website.
## Training procedure
### Preprocessing
The texts are lowercased and tokenized using WordPiece and a vocabulary size of 30,000. The inputs of the model are
then of the form:
```
[CLS] Question [SEP] Flattened table [SEP]
```
The authors did first convert the WTQ dataset into the format of SQA using automatic conversion scripts.
### Fine-tuning
The model was fine-tuned on 32 Cloud TPU v3 cores for 50,000 steps with maximum sequence length 512 and batch size of 512.
In this setup, fine-tuning takes around 10 hours. The optimizer used is Adam with a learning rate of 1.93581e-5, and a warmup
ratio of 0.128960. An inductive bias is added such that the model only selects cells of the same column. This is reflected by the
`select_one_column` parameter of `TapasConfig`. See the [paper](https://arxiv.org/abs/2004.02349) for more details (tables 11 and
12).
### BibTeX entry and citation info
```bibtex
@misc{herzig2020tapas,
title={TAPAS: Weakly Supervised Table Parsing via Pre-training},
author={Jonathan Herzig and Paweł Krzysztof Nowak and Thomas Müller and Francesco Piccinno and Julian Martin Eisenschlos},
year={2020},
eprint={2004.02349},
archivePrefix={arXiv},
primaryClass={cs.IR}
}
```
```bibtex
@misc{eisenschlos2020understanding,
title={Understanding tables with intermediate pre-training},
author={Julian Martin Eisenschlos and Syrine Krichene and Thomas Müller},
year={2020},
eprint={2010.00571},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
```bibtex
@article{DBLP:journals/corr/PasupatL15,
author = {Panupong Pasupat and
Percy Liang},
title = {Compositional Semantic Parsing on Semi-Structured Tables},
journal = {CoRR},
volume = {abs/1508.00305},
year = {2015},
url = {http://arxiv.org/abs/1508.00305},
archivePrefix = {arXiv},
eprint = {1508.00305},
timestamp = {Mon, 13 Aug 2018 16:47:37 +0200},
biburl = {https://dblp.org/rec/journals/corr/PasupatL15.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
patrickvonplaten/wav2vec2_tiny_random_robust
|
358ecf7824b56e9b52b1ffa22ed02680207d3eae
|
2021-09-01T14:48:17.000Z
|
[
"pytorch",
"wav2vec2",
"feature-extraction",
"en",
"dataset:librispeech_asr",
"transformers",
"automatic-speech-recognition",
"license:apache-2.0"
] |
feature-extraction
| false |
patrickvonplaten
| null |
patrickvonplaten/wav2vec2_tiny_random_robust
| 10,152 | null |
transformers
| 685 |
---
language: en
datasets:
- librispeech_asr
tags:
- automatic-speech-recognition
license: apache-2.0
---
## Test model
To test this model run the following code:
```python
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC
import torchaudio
import torch
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
model = Wav2Vec2ForCTC.from_pretrained("patrickvonplaten/wav2vec2_tiny_random_robust")
def load_audio(batch):
batch["samples"], _ = torchaudio.load(batch["file"])
return batch
ds = ds.map(load_audio)
input_values = torch.nn.utils.rnn.pad_sequence([torch.tensor(x[0]) for x in ds["samples"][:10]], batch_first=True)
# forward
logits = model(input_values).logits
pred_ids = torch.argmax(logits, dim=-1)
# dummy loss
dummy_labels = pred_ids.clone()
dummy_labels[dummy_labels == model.config.pad_token_id] = 1 # can't have CTC blank token in label
dummy_labels = dummy_labels[:, -(dummy_labels.shape[1] // 4):] # make sure labels are shorter to avoid "inf" loss (can still happen though...)
loss = model(input_values, labels=dummy_labels).loss
```
|
sshleifer/distilbart-cnn-6-6
|
d2fde4ca965ba893255479612e4b801aa6500029
|
2021-06-14T07:53:04.000Z
|
[
"pytorch",
"jax",
"rust",
"bart",
"text2text-generation",
"en",
"dataset:cnn_dailymail",
"dataset:xsum",
"transformers",
"summarization",
"license:apache-2.0",
"autotrain_compatible"
] |
summarization
| false |
sshleifer
| null |
sshleifer/distilbart-cnn-6-6
| 10,144 | 11 |
transformers
| 686 |
---
language: en
tags:
- summarization
license: apache-2.0
datasets:
- cnn_dailymail
- xsum
thumbnail: https://huggingface.co/front/thumbnails/distilbart_medium.png
---
### Usage
This checkpoint should be loaded into `BartForConditionalGeneration.from_pretrained`. See the [BART docs](https://huggingface.co/transformers/model_doc/bart.html?#transformers.BartForConditionalGeneration) for more information.
### Metrics for DistilBART models
| Model Name | MM Params | Inference Time (MS) | Speedup | Rouge 2 | Rouge-L |
|:---------------------------|------------:|----------------------:|----------:|----------:|----------:|
| distilbart-xsum-12-1 | 222 | 90 | 2.54 | 18.31 | 33.37 |
| distilbart-xsum-6-6 | 230 | 132 | 1.73 | 20.92 | 35.73 |
| distilbart-xsum-12-3 | 255 | 106 | 2.16 | 21.37 | 36.39 |
| distilbart-xsum-9-6 | 268 | 136 | 1.68 | 21.72 | 36.61 |
| bart-large-xsum (baseline) | 406 | 229 | 1 | 21.85 | 36.50 |
| distilbart-xsum-12-6 | 306 | 137 | 1.68 | 22.12 | 36.99 |
| bart-large-cnn (baseline) | 406 | 381 | 1 | 21.06 | 30.63 |
| distilbart-12-3-cnn | 255 | 214 | 1.78 | 20.57 | 30.00 |
| distilbart-12-6-cnn | 306 | 307 | 1.24 | 21.26 | 30.59 |
| distilbart-6-6-cnn | 230 | 182 | 2.09 | 20.17 | 29.70 |
|
microsoft/SportsBERT
|
79260fc3773f96187a55fc2d94c3c897a285b3c9
|
2022-05-05T20:38:36.000Z
|
[
"pytorch",
"jax",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
| false |
microsoft
| null |
microsoft/SportsBERT
| 10,121 | 4 |
transformers
| 687 |
Pretraining large natural language processing models such as BERT, RoBERTa, etc are now state of the art models in natural language understanding and processing tasks. However, these models are trained on a general corpus of articles from the web or from repositories like quora, wikipedia, etc which contain articles of all domains and backgrounds. Training domain specific language model has proven to perform better than pretrained general models in domains like Medicine. With that knowledge, we went on to train a sports specific BERT based transformers model, SportsBERT.
SportsBERT is a BERT model trained from scratch with specific focus on sports articles. The training corpus included news articles scraped from the web related to sports from the past 4 years. These articles covered news from Football, Basketball, Hockey, Cricket, Soccer, Baseball, Olympics, Tennis, Golf, MMA, etc. There were approximately 8 million articles which were used to train this model. A tokenizer was trained from scratch to include more sports related tokens to the vocabulary. The architecture used in this model is the BERT base uncased architecture. The model was trained on four V100 GPUs. It's a MLM based transformers model and the primary task of the model is to fill in missing masked tokens. For example,
"Anthony Davis is a [MASK]" would give out the tokens "legend", "superstar", "rookie", "star", "king" in descending confidences.
This model can then be used to fine tune for other tasks such as classification, entity extraction, etc.
Language: English
pipeline_tag: fill-mask
Authors: Prithvishankar Srinivasan ([email protected]), Santosh Mashetty ([email protected])
|
sbcBI/sentiment_analysis_model
|
a994fec145b4e096961210b871c376a0ba8440ba
|
2022-05-16T18:37:13.000Z
|
[
"pytorch",
"distilbert",
"text-classification",
"en",
"dataset:Confidential",
"arxiv:1810.04805",
"transformers",
"exbert",
"license:apache-2.0"
] |
text-classification
| false |
sbcBI
| null |
sbcBI/sentiment_analysis_model
| 10,074 | null |
transformers
| 688 |
---
language: en
tags:
- exbert
license: apache-2.0
datasets:
- Confidential
---
# BERT base model (uncased)
Pretrained model on English language using a masked language modeling (MLM) objective. It was introduced in
[this paper](https://arxiv.org/abs/1810.04805) and first released in
[this repository](https://github.com/google-research/bert). This model is uncased: it does not make a difference
between english and English.
## Model description
BERT is a transformers model pretrained on a large corpus of English data in a self-supervised fashion. This means it
was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of
publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely, it
was pretrained with two objectives:
- Masked language modeling (MLM): taking a sentence, the model randomly masks 15% of the words in the input then run
the entire masked sentence through the model and has to predict the masked words. This is different from traditional
recurrent neural networks (RNNs) that usually see the words one after the other, or from autoregressive models like
GPT which internally mask the future tokens. It allows the model to learn a bidirectional representation of the
sentence.
- Next sentence prediction (NSP): the models concatenates two masked sentences as inputs during pretraining. Sometimes
they correspond to sentences that were next to each other in the original text, sometimes not. The model then has to
predict if the two sentences were following each other or not.
This way, the model learns an inner representation of the English language that can then be used to extract features
useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a standard
classifier using the features produced by the BERT model as inputs.
## Model description [sbcBI/sentiment_analysis]
This is a fine-tuned downstream version of the bert-base-uncased model for sentiment analysis, this model is not intended for
further downstream fine-tuning for any other tasks. This model is trained on a classified dataset for text-classification.
|
google/canine-s
|
792aaf916e56cb8470fc3162a75f2fa31f96756a
|
2021-08-13T08:23:53.000Z
|
[
"pytorch",
"canine",
"feature-extraction",
"multilingual",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:2103.06874",
"transformers",
"license:apache-2.0"
] |
feature-extraction
| false |
google
| null |
google/canine-s
| 10,062 | 1 |
transformers
| 689 |
---
language: multilingual
license: apache-2.0
datasets:
- bookcorpus
- wikipedia
---
# CANINE-s (CANINE pre-trained with subword loss)
Pretrained CANINE model on 104 languages using a masked language modeling (MLM) objective. It was introduced in the paper [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://arxiv.org/abs/2103.06874) and first released in [this repository](https://github.com/google-research/language/tree/master/language/canine).
What's special about CANINE is that it doesn't require an explicit tokenizer (such as WordPiece or SentencePiece) as other models like BERT and RoBERTa. Instead, it directly operates at a character level: each character is turned into its [Unicode code point](https://en.wikipedia.org/wiki/Code_point#:~:text=For%20Unicode%2C%20the%20particular%20sequence,forming%20a%20self%2Dsynchronizing%20code.).
This means that input processing is trivial and can typically be accomplished as:
```
input_ids = [ord(char) for char in text]
```
The ord() function is part of Python, and turns each character into its Unicode code point.
Disclaimer: The team releasing CANINE did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
CANINE is a transformers model pretrained on a large corpus of multilingual data in a self-supervised fashion, similar to BERT. This means it was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely, it was pretrained with two objectives:
* Masked language modeling (MLM): one randomly masks part of the inputs, which the model needs to predict. This model (CANINE-s) is trained with a subword loss, meaning that the model needs to predict the identities of subword tokens, while taking characters as input. By reading characters yet predicting subword tokens, the hard token boundary constraint found in other models such as BERT is turned into a soft inductive bias in CANINE.
* Next sentence prediction (NSP): the model concatenates two sentences as inputs during pretraining. Sometimes they correspond to sentences that were next to each other in the original text, sometimes not. The model then has to predict if the two sentences were following each other or not.
This way, the model learns an inner representation of multiple languages that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a standard classifier using the features produced by the CANINE model as inputs.
## Intended uses & limitations
You can use the raw model for either masked language modeling or next sentence prediction, but it's mostly intended to be fine-tuned on a downstream task. See the [model hub](https://huggingface.co/models?filter=canine) to look for fine-tuned versions on a task that interests you.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked) to make decisions, such as sequence classification, token classification or question answering. For tasks such as text generation you should look at models like GPT2.
### How to use
Here is how to use this model:
```python
from transformers import CanineTokenizer, CanineModel
model = CanineModel.from_pretrained('google/canine-s')
tokenizer = CanineTokenizer.from_pretrained('google/canine-s')
inputs = ["Life is like a box of chocolates.", "You never know what you gonna get."]
encoding = tokenizer(inputs, padding="longest", truncation=True, return_tensors="pt")
outputs = model(**encoding) # forward pass
pooled_output = outputs.pooler_output
sequence_output = outputs.last_hidden_state
```
## Training data
The CANINE model was pretrained on on the multilingual Wikipedia data of [mBERT](https://github.com/google-research/bert/blob/master/multilingual.md), which includes 104 languages.
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2103-06874,
author = {Jonathan H. Clark and
Dan Garrette and
Iulia Turc and
John Wieting},
title = {{CANINE:} Pre-training an Efficient Tokenization-Free Encoder for
Language Representation},
journal = {CoRR},
volume = {abs/2103.06874},
year = {2021},
url = {https://arxiv.org/abs/2103.06874},
archivePrefix = {arXiv},
eprint = {2103.06874},
timestamp = {Tue, 16 Mar 2021 11:26:59 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2103-06874.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
dbmdz/electra-large-discriminator-finetuned-conll03-english
|
7c0a483cbc7c8c27759f5fc38fe0261ce6bda31e
|
2020-12-09T18:30:05.000Z
|
[
"pytorch",
"electra",
"token-classification",
"transformers",
"autotrain_compatible"
] |
token-classification
| false |
dbmdz
| null |
dbmdz/electra-large-discriminator-finetuned-conll03-english
| 10,055 | 5 |
transformers
| 690 |
Entry not found
|
asafaya/bert-base-arabic
|
b61c328d130eabc1bb1b3b4d1448410a961da888
|
2021-05-19T00:05:27.000Z
|
[
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"ar",
"dataset:oscar",
"dataset:wikipedia",
"transformers",
"autotrain_compatible"
] |
fill-mask
| false |
asafaya
| null |
asafaya/bert-base-arabic
| 10,010 | 6 |
transformers
| 691 |
---
language: ar
datasets:
- oscar
- wikipedia
---
# Arabic BERT Model
Pretrained BERT base language model for Arabic
_If you use this model in your work, please cite this paper:_
```
@inproceedings{safaya-etal-2020-kuisail,
title = "{KUISAIL} at {S}em{E}val-2020 Task 12: {BERT}-{CNN} for Offensive Speech Identification in Social Media",
author = "Safaya, Ali and
Abdullatif, Moutasem and
Yuret, Deniz",
booktitle = "Proceedings of the Fourteenth Workshop on Semantic Evaluation",
month = dec,
year = "2020",
address = "Barcelona (online)",
publisher = "International Committee for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.semeval-1.271",
pages = "2054--2059",
}
```
## Pretraining Corpus
`arabic-bert-base` model was pretrained on ~8.2 Billion words:
- Arabic version of [OSCAR](https://traces1.inria.fr/oscar/) - filtered from [Common Crawl](http://commoncrawl.org/)
- Recent dump of Arabic [Wikipedia](https://dumps.wikimedia.org/backup-index.html)
and other Arabic resources which sum up to ~95GB of text.
__Notes on training data:__
- Our final version of corpus contains some non-Arabic words inlines, which we did not remove from sentences since that would affect some tasks like NER.
- Although non-Arabic characters were lowered as a preprocessing step, since Arabic characters does not have upper or lower case, there is no cased and uncased version of the model.
- The corpus and vocabulary set are not restricted to Modern Standard Arabic, they contain some dialectical Arabic too.
## Pretraining details
- This model was trained using Google BERT's github [repository](https://github.com/google-research/bert) on a single TPU v3-8 provided for free from [TFRC](https://www.tensorflow.org/tfrc).
- Our pretraining procedure follows training settings of bert with some changes: trained for 3M training steps with batchsize of 128, instead of 1M with batchsize of 256.
## Load Pretrained Model
You can use this model by installing `torch` or `tensorflow` and Huggingface library `transformers`. And you can use it directly by initializing it like this:
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("asafaya/bert-base-arabic")
model = AutoModelForMaskedLM.from_pretrained("asafaya/bert-base-arabic")
```
## Results
For further details on the models performance or any other queries, please refer to [Arabic-BERT](https://github.com/alisafaya/Arabic-BERT)
## Acknowledgement
Thanks to Google for providing free TPU for the training process and for Huggingface for hosting this model on their servers 😊
|
aliosm/sha3bor-generator-aragpt2-medium
|
6a63861ac042b61a1ab5bf3e58df42d96cd07365
|
2022-05-28T09:18:07.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"ar",
"transformers",
"license:mit"
] |
text-generation
| false |
aliosm
| null |
aliosm/sha3bor-generator-aragpt2-medium
| 9,994 | null |
transformers
| 692 |
---
language: ar
license: mit
widget:
- text: "حبيبي"
example_title: "حبيبي"
- text: "يا"
example_title: "يا"
- text: "رسول الله"
example_title: "رسول الله"
---
|
seyonec/ChemBERTa_zinc250k_v2_40k
|
460f88413c1b572509b46fbd957a4296ea71e19f
|
2021-05-20T20:57:42.000Z
|
[
"pytorch",
"jax",
"roberta",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
| false |
seyonec
| null |
seyonec/ChemBERTa_zinc250k_v2_40k
| 9,917 | null |
transformers
| 693 |
Entry not found
|
allenai/tk-instruct-3b-def-pos
|
c6b8a84d2d7cc60376733fcb5e17ad1bd3516d0b
|
2022-05-27T06:27:30.000Z
|
[
"pytorch",
"t5",
"text2text-generation",
"en",
"dataset:natural instructions v2.0",
"arxiv:1910.10683",
"arxiv:2204.07705",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] |
text2text-generation
| false |
allenai
| null |
allenai/tk-instruct-3b-def-pos
| 9,892 | null |
transformers
| 694 |
---
language: en
license: apache-2.0
datasets:
- natural instructions v2.0
---
# Model description
Tk-Instruct is a series of encoder-decoder Transformer models that are trained to solve various NLP tasks by following in-context instructions (plain language task definitions, k-shot examples, explanations, etc). Built upon the pre-trained [T5 models](https://arxiv.org/abs/1910.10683), they are fine-tuned on a large number of tasks & instructions that are collected in the [Natural Instructions benchmark](https://github.com/allenai/natural-instructions), which contains 1600+ tasks in 70+ broach categories in total. This enables the model to not only process the training tasks, but also generalize to many unseen tasks without further parameter update.
More resources for using the model:
- **Paper**: [link](https://arxiv.org/abs/2204.07705)
- **Code repository**: [Tk-Instruct](https://github.com/yizhongw/Tk-Instruct)
- **Official Website**: [Natural Instructions](https://instructions.apps.allenai.org/)
- **All released models**: [allenai/tk-instruct](https://huggingface.co/models?search=allenai/tk-instruct)
## Intended uses & limitations
Tk-Instruct can be used to do many NLP tasks by following instructions.
### How to use
When instructing the model, task definition or demonstration examples or explanations should be prepended to the original input and fed into the model. You can easily try Tk-Instruct models as follows:
```python
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
>>> tokenizer = AutoTokenizer.from_pretrained("allenai/tk-instruct-3b-def")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("allenai/tk-instruct-3b-def")
>>> input_ids = tokenizer.encode(
"Definition: return the currency of the given country. Now complete the following example - Input: India. Output:",
return_tensors="pt")
>>> output = model.generate(input_ids, max_length=10)
>>> output = tokenizer.decode(output[0], skip_special_tokens=True) # model should output 'Indian Rupee'
>>> input_ids = tokenizer.encode(
"Definition: negate the following sentence. Input: John went to school. Output:",
return_tensors="pt")
>>> output = model.generate(input_ids, max_length=10)
>>> output = tokenizer.decode(output[0], skip_special_tokens=True) # model should output 'John did not go to shool.'
```
### Limitations
We are still working on understanding the behaviors of these models, but here are several issues we have found:
- Models are generally sensitive to the instruction. Sometimes rewording the instruction can lead to very different output.
- Models are not always compliant to the instruction. Sometimes the model don't follow your instruction (e.g., when you ask the model to generate one sentence, it might still generate one word or a long story).
- Models might totally fail on some tasks.
If you find serious issues or any interesting result, you are welcome to share with us!
## Training data
Tk-Instruct is trained using the tasks & instructions in [Natural Instructions benchmark](https://github.com/allenai/natural-instructions), which contains 1600+ tasks in 70+ broach categories in total. We follow the official train/test split. Tk-Instruct model series were trained using 757 tasks, and mTk-Instruct series were trained using 1271 tasks (including some non-English tasks).
The training tasks are in 64 broad categories, such as text categorization / question answering / sentiment analysis / summarization / grammar error detection / dialogue generation / etc. The other 12 categories are selected for evaluation.
## Training procedure
All our models are initialized from either T5 models or mT5 models. Because generating the output can be regarded as a form of language modeling, we used their [LM adapted version](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#lm-adapted-t511lm100k). All data is converted into a text-to-text format, and models are fine-tuned to maximize the likelihood of the output sequence.
Our [released models](https://huggingface.co/models?search=allenai/tk-instruct) are in different sizes, and each of them was trained with a specific type of instruction encoding. For instance, `tk-instruct-3b-def-pos` was initialized from [t5-xl-lm-adapt](https://huggingface.co/google/t5-xl-lm-adapt), and it saw task definition & 2 positive examples as the instruction during training time.
Although they are trained with only one type of instruction encodings, we found they can usually work with other type of encodings at test time (see more in our paper).
### BibTeX entry and citation info
```bibtex
@article{wang2022benchmarking,
title={Benchmarking Generalization via In-Context Instructions on 1,600+ Language Tasks},
author={Yizhong Wang and Swaroop Mishra and Pegah Alipoormolabashi and Yeganeh Kordi and Amirreza Mirzaei and A. Arunkumar and Arjun Ashok and Arut Selvan Dhanasekaran and Atharva Naik and David Stap and Eshaan Pathak and Giannis Karamanolakis and Haizhi Gary Lai and Ishan Purohit and Ishani Mondal and Jacob Anderson and Kirby Kuznia and Krima Doshi and Maitreya Patel and Kuntal Kumar Pal and M. Moradshahi and Mihir Parmar and Mirali Purohit and Neeraj Varshney and Phani Rohitha Kaza and Pulkit Verma and Ravsehaj Singh Puri and Rushang Karia and Shailaja Keyur Sampat and Savan Doshi and Siddharth Deepak Mishra and Sujan C. Reddy and Sumanta Patro and Tanay Dixit and Xu-dong Shen and Chitta Baral and Yejin Choi and Hannaneh Hajishirzi and Noah A. Smith and Daniel Khashabi},
year={2022},
archivePrefix={arXiv},
eprint={2204.07705},
primaryClass={cs.CL},
}
```
|
microsoft/deberta-v2-xxlarge
|
da58c8f337be794a1bb98c218d0d8cc72c324884
|
2022-01-13T20:00:20.000Z
|
[
"pytorch",
"tf",
"deberta-v2",
"en",
"arxiv:2006.03654",
"transformers",
"deberta",
"license:mit"
] | null | false |
microsoft
| null |
microsoft/deberta-v2-xxlarge
| 9,813 | 10 |
transformers
| 695 |
---
language: en
tags: deberta
thumbnail: https://huggingface.co/front/thumbnails/microsoft.png
license: mit
---
## DeBERTa: Decoding-enhanced BERT with Disentangled Attention
[DeBERTa](https://arxiv.org/abs/2006.03654) improves the BERT and RoBERTa models using disentangled attention and enhanced mask decoder. It outperforms BERT and RoBERTa on majority of NLU tasks with 80GB training data.
Please check the [official repository](https://github.com/microsoft/DeBERTa) for more details and updates.
This is the DeBERTa V2 xxlarge model with 48 layers, 1536 hidden size. The total parameters are 1.5B and it is trained with 160GB raw data.
### Fine-tuning on NLU tasks
We present the dev results on SQuAD 1.1/2.0 and several GLUE benchmark tasks.
| Model | SQuAD 1.1 | SQuAD 2.0 | MNLI-m/mm | SST-2 | QNLI | CoLA | RTE | MRPC | QQP |STS-B |
|---------------------------|-----------|-----------|-------------|-------|------|------|--------|-------|-------|------|
| | F1/EM | F1/EM | Acc | Acc | Acc | MCC | Acc |Acc/F1 |Acc/F1 |P/S |
| BERT-Large | 90.9/84.1 | 81.8/79.0 | 86.6/- | 93.2 | 92.3 | 60.6 | 70.4 | 88.0/- | 91.3/- |90.0/- |
| RoBERTa-Large | 94.6/88.9 | 89.4/86.5 | 90.2/- | 96.4 | 93.9 | 68.0 | 86.6 | 90.9/- | 92.2/- |92.4/- |
| XLNet-Large | 95.1/89.7 | 90.6/87.9 | 90.8/- | 97.0 | 94.9 | 69.0 | 85.9 | 90.8/- | 92.3/- |92.5/- |
| [DeBERTa-Large](https://huggingface.co/microsoft/deberta-large)<sup>1</sup> | 95.5/90.1 | 90.7/88.0 | 91.3/91.1| 96.5|95.3| 69.5| 91.0| 92.6/94.6| 92.3/- |92.8/92.5 |
| [DeBERTa-XLarge](https://huggingface.co/microsoft/deberta-xlarge)<sup>1</sup> | -/- | -/- | 91.5/91.2| 97.0 | - | - | 93.1 | 92.1/94.3 | - |92.9/92.7|
| [DeBERTa-V2-XLarge](https://huggingface.co/microsoft/deberta-v2-xlarge)<sup>1</sup>|95.8/90.8| 91.4/88.9|91.7/91.6| **97.5**| 95.8|71.1|**93.9**|92.0/94.2|92.3/89.8|92.9/92.9|
|**[DeBERTa-V2-XXLarge](https://huggingface.co/microsoft/deberta-v2-xxlarge)<sup>1,2</sup>**|**96.1/91.4**|**92.2/89.7**|**91.7/91.9**|97.2|**96.0**|**72.0**| 93.5| **93.1/94.9**|**92.7/90.3** |**93.2/93.1** |
--------
#### Notes.
- <sup>1</sup> Following RoBERTa, for RTE, MRPC, STS-B, we fine-tune the tasks based on [DeBERTa-Large-MNLI](https://huggingface.co/microsoft/deberta-large-mnli), [DeBERTa-XLarge-MNLI](https://huggingface.co/microsoft/deberta-xlarge-mnli), [DeBERTa-V2-XLarge-MNLI](https://huggingface.co/microsoft/deberta-v2-xlarge-mnli), [DeBERTa-V2-XXLarge-MNLI](https://huggingface.co/microsoft/deberta-v2-xxlarge-mnli). The results of SST-2/QQP/QNLI/SQuADv2 will also be slightly improved when start from MNLI fine-tuned models, however, we only report the numbers fine-tuned from pretrained base models for those 4 tasks.
- <sup>2</sup> To try the **XXLarge** model with **[HF transformers](https://huggingface.co/transformers/main_classes/trainer.html)**, we recommand using **deepspeed** as it's faster and saves memory.
Run with `Deepspeed`,
```bash
pip install datasets
pip install deepspeed
# Download the deepspeed config file
wget https://huggingface.co/microsoft/deberta-v2-xxlarge/resolve/main/ds_config.json -O ds_config.json
export TASK_NAME=mnli
output_dir="ds_results"
num_gpus=8
batch_size=8
python -m torch.distributed.launch --nproc_per_node=${num_gpus} \\
run_glue.py \\
--model_name_or_path microsoft/deberta-v2-xxlarge \\
--task_name $TASK_NAME \\
--do_train \\
--do_eval \\
--max_seq_length 256 \\
--per_device_train_batch_size ${batch_size} \\
--learning_rate 3e-6 \\
--num_train_epochs 3 \\
--output_dir $output_dir \\
--overwrite_output_dir \\
--logging_steps 10 \\
--logging_dir $output_dir \\
--deepspeed ds_config.json
```
You can also run with `--sharded_ddp`
```bash
cd transformers/examples/text-classification/
export TASK_NAME=mnli
python -m torch.distributed.launch --nproc_per_node=8 run_glue.py --model_name_or_path microsoft/deberta-v2-xxlarge \\
--task_name $TASK_NAME --do_train --do_eval --max_seq_length 256 --per_device_train_batch_size 8 \\
--learning_rate 3e-6 --num_train_epochs 3 --output_dir /tmp/$TASK_NAME/ --overwrite_output_dir --sharded_ddp --fp16
```
### Citation
If you find DeBERTa useful for your work, please cite the following paper:
``` latex
@inproceedings{
he2021deberta,
title={DEBERTA: DECODING-ENHANCED BERT WITH DISENTANGLED ATTENTION},
author={Pengcheng He and Xiaodong Liu and Jianfeng Gao and Weizhu Chen},
booktitle={International Conference on Learning Representations},
year={2021},
url={https://openreview.net/forum?id=XPZIaotutsD}
}
```
|
Salesforce/codet5-small
|
a642dc934e5475185369d09ac07091dfe72a31fc
|
2021-11-23T09:45:34.000Z
|
[
"pytorch",
"t5",
"text2text-generation",
"dataset:code_search_net",
"arxiv:2109.00859",
"arxiv:1909.09436",
"transformers",
"codet5",
"license:apache-2.0",
"autotrain_compatible"
] |
text2text-generation
| false |
Salesforce
| null |
Salesforce/codet5-small
| 9,809 | 11 |
transformers
| 696 |
---
license: apache-2.0
tags:
- codet5
datasets:
- code_search_net
inference: false
---
# CodeT5 (small-sized model)
Pre-trained CodeT5 model. It was introduced in the paper [CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models
for Code Understanding and Generation](https://arxiv.org/abs/2109.00859) by Yue Wang, Weishi Wang, Shafiq Joty, Steven C.H. Hoi and first released in [this repository](https://github.com/salesforce/CodeT5).
Disclaimer: The team releasing CodeT5 did not write a model card for this model so this model card has been written by the Hugging Face team (more specifically, [nielsr](https://huggingface.co/nielsr)).
## Model description
From the abstract:
"We present CodeT5, a unified pre-trained encoder-decoder Transformer model that better leverages the code semantics conveyed from the developer-assigned identifiers. Our model employs a unified framework to seamlessly support both code understanding and generation tasks and allows for multi-task learning. Besides, we propose a novel identifier-aware pre-training task that enables the model to distinguish which code tokens are identifiers and to recover them when they are masked. Furthermore, we propose to exploit the user-written code comments with a bimodal dual generation task for better NL-PL alignment. Comprehensive experiments show that CodeT5 significantly outperforms prior methods on understanding tasks such as code defect detection and clone detection, and generation tasks across various directions including PL-NL, NL-PL, and PL-PL. Further analysis reveals that our model can better capture semantic information from code."
## Intended uses & limitations
This repository contains the pre-trained model only, so you can use this model for masked span prediction, as shown in the code example below. However, the main use of this model is to fine-tune it for a downstream task of interest, such as:
* code summarization
* code generation
* code translation
* code refinement
* code defect detection
* code clone detection.
See the [model hub](https://huggingface.co/models?search=salesforce/codet) to look for fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model:
```python
from transformers import RobertaTokenizer, T5ForConditionalGeneration
tokenizer = RobertaTokenizer.from_pretrained('Salesforce/codet5-small')
model = T5ForConditionalGeneration.from_pretrained('Salesforce/codet5-small')
text = "def greet(user): print(f'hello <extra_id_0>!')"
input_ids = tokenizer(text, return_tensors="pt").input_ids
# simply generate a single sequence
generated_ids = model.generate(input_ids, max_length=10)
print(tokenizer.decode(generated_ids[0], skip_special_tokens=True))
# this prints "user: {user.name}"
```
## Training data
The CodeT5 model was pretrained on CodeSearchNet [Husain et al., 2019](https://arxiv.org/abs/1909.09436). Additionally, the authors collected two datasets of C/CSharp from [BigQuery1](https://console.cloud.google.com/marketplace/details/github/github-repos) to ensure that all downstream tasks have overlapped programming languages with the pre-training data. In total, around 8.35 million instances are used for pretraining.
## Training procedure
### Preprocessing
This model uses a code-specific BPE (Byte-Pair Encoding) tokenizer. One can prepare text (or code) for the model using RobertaTokenizer, with the files from this repository.
## Evaluation results
For evaluation results on several downstream benchmarks, we refer to the paper.
### BibTeX entry and citation info
```bibtex
@misc{wang2021codet5,
title={CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Understanding and Generation},
author={Yue Wang and Weishi Wang and Shafiq Joty and Steven C. H. Hoi},
year={2021},
eprint={2109.00859},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
microsoft/deberta-xlarge-mnli
|
5b07a9086c1dbb79981ff7b05b4d1ad83b3af51c
|
2022-06-27T15:47:33.000Z
|
[
"pytorch",
"tf",
"deberta",
"text-classification",
"en",
"arxiv:2006.03654",
"transformers",
"deberta-v1",
"deberta-mnli",
"license:mit"
] |
text-classification
| false |
microsoft
| null |
microsoft/deberta-xlarge-mnli
| 9,771 | 4 |
transformers
| 697 |
---
language: en
tags:
- deberta-v1
- deberta-mnli
tasks: mnli
thumbnail: https://huggingface.co/front/thumbnails/microsoft.png
license: mit
widget:
- text: "[CLS] I love you. [SEP] I like you. [SEP]"
---
## DeBERTa: Decoding-enhanced BERT with Disentangled Attention
[DeBERTa](https://arxiv.org/abs/2006.03654) improves the BERT and RoBERTa models using disentangled attention and enhanced mask decoder. It outperforms BERT and RoBERTa on majority of NLU tasks with 80GB training data.
Please check the [official repository](https://github.com/microsoft/DeBERTa) for more details and updates.
This the DeBERTa xlarge model(750M) fine-tuned with mnli task.
### Fine-tuning on NLU tasks
We present the dev results on SQuAD 1.1/2.0 and several GLUE benchmark tasks.
| Model | SQuAD 1.1 | SQuAD 2.0 | MNLI-m/mm | SST-2 | QNLI | CoLA | RTE | MRPC | QQP |STS-B |
|---------------------------|-----------|-----------|-------------|-------|------|------|--------|-------|-------|------|
| | F1/EM | F1/EM | Acc | Acc | Acc | MCC | Acc |Acc/F1 |Acc/F1 |P/S |
| BERT-Large | 90.9/84.1 | 81.8/79.0 | 86.6/- | 93.2 | 92.3 | 60.6 | 70.4 | 88.0/- | 91.3/- |90.0/- |
| RoBERTa-Large | 94.6/88.9 | 89.4/86.5 | 90.2/- | 96.4 | 93.9 | 68.0 | 86.6 | 90.9/- | 92.2/- |92.4/- |
| XLNet-Large | 95.1/89.7 | 90.6/87.9 | 90.8/- | 97.0 | 94.9 | 69.0 | 85.9 | 90.8/- | 92.3/- |92.5/- |
| [DeBERTa-Large](https://huggingface.co/microsoft/deberta-large)<sup>1</sup> | 95.5/90.1 | 90.7/88.0 | 91.3/91.1| 96.5|95.3| 69.5| 91.0| 92.6/94.6| 92.3/- |92.8/92.5 |
| [DeBERTa-XLarge](https://huggingface.co/microsoft/deberta-xlarge)<sup>1</sup> | -/- | -/- | 91.5/91.2| 97.0 | - | - | 93.1 | 92.1/94.3 | - |92.9/92.7|
| [DeBERTa-V2-XLarge](https://huggingface.co/microsoft/deberta-v2-xlarge)<sup>1</sup>|95.8/90.8| 91.4/88.9|91.7/91.6| **97.5**| 95.8|71.1|**93.9**|92.0/94.2|92.3/89.8|92.9/92.9|
|**[DeBERTa-V2-XXLarge](https://huggingface.co/microsoft/deberta-v2-xxlarge)<sup>1,2</sup>**|**96.1/91.4**|**92.2/89.7**|**91.7/91.9**|97.2|**96.0**|**72.0**| 93.5| **93.1/94.9**|**92.7/90.3** |**93.2/93.1** |
--------
#### Notes.
- <sup>1</sup> Following RoBERTa, for RTE, MRPC, STS-B, we fine-tune the tasks based on [DeBERTa-Large-MNLI](https://huggingface.co/microsoft/deberta-large-mnli), [DeBERTa-XLarge-MNLI](https://huggingface.co/microsoft/deberta-xlarge-mnli), [DeBERTa-V2-XLarge-MNLI](https://huggingface.co/microsoft/deberta-v2-xlarge-mnli), [DeBERTa-V2-XXLarge-MNLI](https://huggingface.co/microsoft/deberta-v2-xxlarge-mnli). The results of SST-2/QQP/QNLI/SQuADv2 will also be slightly improved when start from MNLI fine-tuned models, however, we only report the numbers fine-tuned from pretrained base models for those 4 tasks.
- <sup>2</sup> To try the **XXLarge** model with **[HF transformers](https://huggingface.co/transformers/main_classes/trainer.html)**, you need to specify **--sharded_ddp**
```bash
cd transformers/examples/text-classification/
export TASK_NAME=mrpc
python -m torch.distributed.launch --nproc_per_node=8 run_glue.py --model_name_or_path microsoft/deberta-v2-xxlarge \\
--task_name $TASK_NAME --do_train --do_eval --max_seq_length 128 --per_device_train_batch_size 4 \\
--learning_rate 3e-6 --num_train_epochs 3 --output_dir /tmp/$TASK_NAME/ --overwrite_output_dir --sharded_ddp --fp16
```
### Citation
If you find DeBERTa useful for your work, please cite the following paper:
``` latex
@inproceedings{
he2021deberta,
title={DEBERTA: DECODING-ENHANCED BERT WITH DISENTANGLED ATTENTION},
author={Pengcheng He and Xiaodong Liu and Jianfeng Gao and Weizhu Chen},
booktitle={International Conference on Learning Representations},
year={2021},
url={https://openreview.net/forum?id=XPZIaotutsD}
}
```
|
ahotrod/electra_large_discriminator_squad2_512
|
fe230d41e74248eceb366a91e4f8572f358f201c
|
2020-12-11T21:31:42.000Z
|
[
"pytorch",
"tf",
"electra",
"question-answering",
"transformers",
"autotrain_compatible"
] |
question-answering
| false |
ahotrod
| null |
ahotrod/electra_large_discriminator_squad2_512
| 9,769 | 4 |
transformers
| 698 |
## ELECTRA_large_discriminator language model fine-tuned on SQuAD2.0
### with the following results:
```
"exact": 87.09677419354838,
"f1": 89.98343832723452,
"total": 11873,
"HasAns_exact": 84.66599190283401,
"HasAns_f1": 90.44759839056285,
"HasAns_total": 5928,
"NoAns_exact": 89.52060555088309,
"NoAns_f1": 89.52060555088309,
"NoAns_total": 5945,
"best_exact": 87.09677419354838,
"best_exact_thresh": 0.0,
"best_f1": 89.98343832723432,
"best_f1_thresh": 0.0
```
### from script:
```
python ${EXAMPLES}/run_squad.py \
--model_type electra \
--model_name_or_path google/electra-large-discriminator \
--do_train \
--do_eval \
--train_file ${SQUAD}/train-v2.0.json \
--predict_file ${SQUAD}/dev-v2.0.json \
--version_2_with_negative \
--do_lower_case \
--num_train_epochs 3 \
--warmup_steps 306 \
--weight_decay 0.01 \
--learning_rate 3e-5 \
--max_grad_norm 0.5 \
--adam_epsilon 1e-6 \
--max_seq_length 512 \
--doc_stride 128 \
--per_gpu_train_batch_size 8 \
--gradient_accumulation_steps 16 \
--per_gpu_eval_batch_size 128 \
--fp16 \
--fp16_opt_level O1 \
--threads 12 \
--logging_steps 50 \
--save_steps 1000 \
--overwrite_output_dir \
--output_dir ${MODEL_PATH}
```
### using the following system & software:
```
Transformers: 2.11.0
PyTorch: 1.5.0
TensorFlow: 2.2.0
Python: 3.8.1
OS/Platform: Linux-5.3.0-59-generic-x86_64-with-glibc2.10
CPU/GPU: Intel i9-9900K / NVIDIA Titan RTX 24GB
```
|
ALINEAR/albert-japanese-v2
|
102cec3c2b7bc8483cd9281b6a029279861df66d
|
2020-05-04T13:20:53.000Z
|
[
"pytorch",
"albert",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
| false |
ALINEAR
| null |
ALINEAR/albert-japanese-v2
| 9,729 | null |
transformers
| 699 |
Entry not found
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.