
modelId
stringlengths 4
112
| sha
stringlengths 40
40
| lastModified
stringlengths 24
24
| tags
sequence | pipeline_tag
stringclasses 29
values | private
bool 1
class | author
stringlengths 2
38
⌀ | config
null | id
stringlengths 4
112
| downloads
float64 0
36.8M
⌀ | likes
float64 0
712
⌀ | library_name
stringclasses 17
values | __index_level_0__
int64 0
38.5k
| readme
stringlengths 0
186k
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
madlag/bert-base-uncased-squadv1-x1.84-f88.7-d36-hybrid-filled-v1 | a7bdf0f3df58f995c84155ef23bcc0424e8a9070 | 2021-08-31T09:31:46.000Z | [
"pytorch",
"tf",
"bert",
"question-answering",
"en",
"dataset:squad",
"transformers",
"license:mit",
"autotrain_compatible"
] | question-answering | false | madlag | null | madlag/bert-base-uncased-squadv1-x1.84-f88.7-d36-hybrid-filled-v1 | 1 | null | transformers | 29,900 | ---
language: en
thumbnail:
license: mit
tags:
- question-answering
-
-
datasets:
- squad
metrics:
- squad
widget:
- text: "Where is the Eiffel Tower located?"
context: "The Eiffel Tower is a wrought-iron lattice tower on the Champ de Mars in Paris, France. It is named after the engineer Gustave Eiffel, whose company designed and built the tower."
- text: "Who is Frederic Chopin?"
context: "Frédéric François Chopin, born Fryderyk Franciszek Chopin (1 March 1810 – 17 October 1849), was a Polish composer and virtuoso pianist of the Romantic era who wrote primarily for solo piano."
---
## BERT-base uncased model fine-tuned on SQuAD v1
This model was created using the [nn_pruning](https://github.com/huggingface/nn_pruning) python library: the **linear layers contains 36.0%** of the original weights.
The model contains **50.0%** of the original weights **overall** (the embeddings account for a significant part of the model, and they are not pruned by this method).
With a simple resizing of the linear matrices it ran **1.84x as fast as the dense model** on the evaluation.
This is possible because the pruning method lead to structured matrices: to visualize them, hover below on the plot to see the non-zero/zero parts of each matrix.
<div class="graph"><script src="/madlag/bert-base-uncased-squadv1-x1.84-f88.7-d36-hybrid-filled-v1/raw/main/model_card/density_info.js" id="3aca15eb-8def-482c-800a-d9f8a6e8cea5"></script></div>
In terms of accuracy, its **F1 is 88.72**, compared with 88.5 for the dense version, a **F1 gain of 0.22**.
## Fine-Pruning details
This model was fine-tuned from the HuggingFace [model](https://huggingface.co//home/lagunas/devel/hf/nn_pruning/nn_pruning/analysis/tmp_finetune) checkpoint on [SQuAD1.1](https://rajpurkar.github.io/SQuAD-explorer), and distilled from the model [csarron/bert-base-uncased-squad-v1](https://huggingface.co/csarron/bert-base-uncased-squad-v1)
This model is case-insensitive: it does not make a difference between english and English.
A side-effect of the block pruning is that some of the attention heads are completely removed: 48 heads were removed on a total of 144 (33.3%).
Here is a detailed view on how the remaining heads are distributed in the network after pruning.
<div class="graph"><script src="/madlag/bert-base-uncased-squadv1-x1.84-f88.7-d36-hybrid-filled-v1/raw/main/model_card/pruning_info.js" id="95fe9d1f-98f7-40e1-a28f-b90d0da0f1a8"></script></div>
## Details of the SQuAD1.1 dataset
| Dataset | Split | # samples |
| -------- | ----- | --------- |
| SQuAD1.1 | train | 90.6K |
| SQuAD1.1 | eval | 11.1k |
### Fine-tuning
- Python: `3.8.5`
- Machine specs:
```CPU: Intel(R) Core(TM) i7-6700K CPU
Memory: 64 GiB
GPUs: 1 GeForce GTX 3090, with 24GiB memory
GPU driver: 455.23.05, CUDA: 11.1
```
### Results
**Pytorch model file size**: `379MB` (original BERT: `420MB`)
| Metric | # Value | # Original ([Table 2](https://www.aclweb.org/anthology/N19-1423.pdf))| Variation |
| ------ | --------- | --------- | --------- |
| **EM** | **81.69** | **80.8** | **+0.89**|
| **F1** | **88.72** | **88.5** | **+0.22**|
## Example Usage
Install nn_pruning: it contains the optimization script, which just pack the linear layers into smaller ones by removing empty rows/columns.
`pip install nn_pruning`
Then you can use the `transformers library` almost as usual: you just have to call `optimize_model` when the pipeline has loaded.
```python
from transformers import pipeline
from nn_pruning.inference_model_patcher import optimize_model
qa_pipeline = pipeline(
"question-answering",
model="madlag/bert-base-uncased-squadv1-x1.84-f88.7-d36-hybrid-filled-v1",
tokenizer="madlag/bert-base-uncased-squadv1-x1.84-f88.7-d36-hybrid-filled-v1"
)
print("/home/lagunas/devel/hf/nn_pruning/nn_pruning/analysis/tmp_finetune parameters: 218.0M")
print(f"Parameters count (includes only head pruning, not feed forward pruning)={int(qa_pipeline.model.num_parameters() / 1E6)}M")
qa_pipeline.model = optimize_model(qa_pipeline.model, "dense")
print(f"Parameters count after complete optimization={int(qa_pipeline.model.num_parameters() / 1E6)}M")
predictions = qa_pipeline({
'context': "Frédéric François Chopin, born Fryderyk Franciszek Chopin (1 March 1810 – 17 October 1849), was a Polish composer and virtuoso pianist of the Romantic era who wrote primarily for solo piano.",
'question': "Who is Frederic Chopin?",
})
print("Predictions", predictions)
``` |
madlag/bert-base-uncased-squadv1-x2.32-f86.6-d15-hybrid-v1 | ea7c4ce8e9bee6d81ab3ff57e6b601fca6a6ad70 | 2021-06-16T15:06:30.000Z | [
"pytorch",
"tf",
"bert",
"question-answering",
"en",
"dataset:squad",
"transformers",
"license:mit",
"autotrain_compatible"
] | question-answering | false | madlag | null | madlag/bert-base-uncased-squadv1-x2.32-f86.6-d15-hybrid-v1 | 1 | null | transformers | 29,901 | ---
language: en
thumbnail:
license: mit
tags:
- question-answering
-
-
datasets:
- squad
metrics:
- squad
widget:
- text: "Where is the Eiffel Tower located?"
context: "The Eiffel Tower is a wrought-iron lattice tower on the Champ de Mars in Paris, France. It is named after the engineer Gustave Eiffel, whose company designed and built the tower."
- text: "Who is Frederic Chopin?"
context: "Frédéric François Chopin, born Fryderyk Franciszek Chopin (1 March 1810 – 17 October 1849), was a Polish composer and virtuoso pianist of the Romantic era who wrote primarily for solo piano."
---
## BERT-base uncased model fine-tuned on SQuAD v1
This model was created using the [nn_pruning](https://github.com/huggingface/nn_pruning) python library: the **linear layers contains 15.0%** of the original weights.
The model contains **34.0%** of the original weights **overall** (the embeddings account for a significant part of the model, and they are not pruned by this method).
With a simple resizing of the linear matrices it ran **2.32x as fast as bert-base-uncased** on the evaluation.
This is possible because the pruning method lead to structured matrices: to visualize them, hover below on the plot to see the non-zero/zero parts of each matrix.
<div class="graph"><script src="/madlag/bert-base-uncased-squadv1-x2.32-f86.6-d15-hybrid-v1/raw/main/model_card/density_info.js" id="1ff1ba08-69d3-4a20-9f29-494033c72860"></script></div>
In terms of accuracy, its **F1 is 86.64**, compared with 88.5 for bert-base-uncased, a **F1 drop of 1.86**.
## Fine-Pruning details
This model was fine-tuned from the HuggingFace [model](https://huggingface.co/bert-base-uncased) checkpoint on [SQuAD1.1](https://rajpurkar.github.io/SQuAD-explorer), and distilled from the model [bert-large-uncased-whole-word-masking-finetuned-squad](https://huggingface.co/bert-large-uncased-whole-word-masking-finetuned-squad)
This model is case-insensitive: it does not make a difference between english and English.
A side-effect of the block pruning is that some of the attention heads are completely removed: 63 heads were removed on a total of 144 (43.8%).
Here is a detailed view on how the remaining heads are distributed in the network after pruning.
<div class="graph"><script src="/madlag/bert-base-uncased-squadv1-x2.32-f86.6-d15-hybrid-v1/raw/main/model_card/pruning_info.js" id="e092ee84-28af-4821-8127-11914f68e306"></script></div>
## Details of the SQuAD1.1 dataset
| Dataset | Split | # samples |
| -------- | ----- | --------- |
| SQuAD1.1 | train | 90.6K |
| SQuAD1.1 | eval | 11.1k |
### Fine-tuning
- Python: `3.8.5`
- Machine specs:
```CPU: Intel(R) Core(TM) i7-6700K CPU
Memory: 64 GiB
GPUs: 1 GeForce GTX 3090, with 24GiB memory
GPU driver: 455.23.05, CUDA: 11.1
```
### Results
**Pytorch model file size**: `368MB` (original BERT: `420MB`)
| Metric | # Value | # Original ([Table 2](https://www.aclweb.org/anthology/N19-1423.pdf))| Variation |
| ------ | --------- | --------- | --------- |
| **EM** | **78.77** | **80.8** | **-2.03**|
| **F1** | **86.64** | **88.5** | **-1.86**|
## Example Usage
Install nn_pruning: it contains the optimization script, which just pack the linear layers into smaller ones by removing empty rows/columns.
`pip install nn_pruning`
Then you can use the `transformers library` almost as usual: you just have to call `optimize_model` when the pipeline has loaded.
```python
from transformers import pipeline
from nn_pruning.inference_model_patcher import optimize_model
qa_pipeline = pipeline(
"question-answering",
model="madlag/bert-base-uncased-squadv1-x2.32-f86.6-d15-hybrid-v1",
tokenizer="madlag/bert-base-uncased-squadv1-x2.32-f86.6-d15-hybrid-v1"
)
print("bert-base-uncased parameters: 165.0M")
print(f"Parameters count (includes only head pruning, not feed forward pruning)={int(qa_pipeline.model.num_parameters() / 1E6)}M")
qa_pipeline.model = optimize_model(qa_pipeline.model, "dense")
print(f"Parameters count after complete optimization={int(qa_pipeline.model.num_parameters() / 1E6)}M")
predictions = qa_pipeline({
'context': "Frédéric François Chopin, born Fryderyk Franciszek Chopin (1 March 1810 – 17 October 1849), was a Polish composer and virtuoso pianist of the Romantic era who wrote primarily for solo piano.",
'question': "Who is Frederic Chopin?",
})
print("Predictions", predictions)
``` |
mahaamami/distilroberta-base-model | 24cfc2f7873332cbb396094beb16f4c79a870346 | 2022-01-13T12:02:01.000Z | [
"pytorch",
"tensorboard",
"roberta",
"fill-mask",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
] | fill-mask | false | mahaamami | null | mahaamami/distilroberta-base-model | 1 | null | transformers | 29,902 | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: distilroberta-base-model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilroberta-base-model
This model is a fine-tuned version of [distilroberta-base](https://huggingface.co/distilroberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7929
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 2.0892 | 1.0 | 27036 | 1.8990 |
| 1.9644 | 2.0 | 54072 | 1.8040 |
| 1.9174 | 3.0 | 81108 | 1.7929 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
malteos/aspect-cord19-scibert-scivocab-uncased | 51449beb94d9b40e2add76d96bc3753fdda80cec | 2021-11-22T10:13:31.000Z | [
"pytorch",
"bert",
"sci",
"en",
"dataset:cord19",
"arxiv:2010.06395",
"transformers",
"classification",
"similarity",
"license:mit"
] | null | false | malteos | null | malteos/aspect-cord19-scibert-scivocab-uncased | 1 | null | transformers | 29,903 | ---
language:
- sci
- en
tags:
- classification
- similarity
license: mit
datasets:
- cord19
---
# Aspect-based Document Similarity for Research Papers
A `scibert-scivocab-uncased` model fine-tuned on the CORD-19 corpus as in [Aspect-based Document Similarity for Research Papers](https://arxiv.org/abs/2010.06395).
<img src="https://raw.githubusercontent.com/malteos/aspect-document-similarity/master/docrel.png">
See GitHub for more details: https://github.com/malteos/aspect-document-similarity
## Demo
<a href="https://colab.research.google.com/github/malteos/aspect-document-similarity/blob/master/demo.ipynb"><img src="https://camo.githubusercontent.com/52feade06f2fecbf006889a904d221e6a730c194/68747470733a2f2f636f6c61622e72657365617263682e676f6f676c652e636f6d2f6173736574732f636f6c61622d62616467652e737667" alt="Google Colab"></a>
You can try our trained models directly on Google Colab on all papers available on Semantic Scholar (via DOI, ArXiv ID, ACL ID, PubMed ID):
<a href="https://colab.research.google.com/github/malteos/aspect-document-similarity/blob/master/demo.ipynb"><img src="https://raw.githubusercontent.com/malteos/aspect-document-similarity/master/demo.gif" alt="Click here for demo"></a>
|
mamlong34/t5_small_cosmos_qa | f63a77a691ea101f176ba840ef3e3059943392be | 2021-10-10T15:37:59.000Z | [
"pytorch",
"t5",
"text2text-generation",
"dataset:cosmos_qa",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
] | text2text-generation | false | mamlong34 | null | mamlong34/t5_small_cosmos_qa | 1 | null | transformers | 29,904 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- cosmos_qa
metrics:
- accuracy
model-index:
- name: t5_small_cosmos_qa
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5_small_cosmos_qa
This model is a fine-tuned version of [mamlong34/t5_small_race_mutlirc](https://huggingface.co/mamlong34/t5_small_race_mutlirc) on the cosmos_qa dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5614
- Accuracy: 0.6067
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 8
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.4811 | 1.0 | 3158 | 0.5445 | 0.5548 |
| 0.4428 | 2.0 | 6316 | 0.5302 | 0.5836 |
| 0.3805 | 3.0 | 9474 | 0.5614 | 0.6067 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.9.1
- Datasets 1.12.1
- Tokenizers 0.10.3
|
manandey/wav2vec2-large-xlsr-estonian | 9aae51827ae33c56f1c4d9b35f14f2eb35dc8f2d | 2021-07-06T11:32:55.000Z | [
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"et",
"dataset:common_voice",
"transformers",
"audio",
"speech",
"xlsr-fine-tuning-week",
"license:apache-2.0",
"model-index"
] | automatic-speech-recognition | false | manandey | null | manandey/wav2vec2-large-xlsr-estonian | 1 | null | transformers | 29,905 | ---
language: et
datasets:
- common_voice
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: XLSR Wav2Vec2 Estonian by Manan Dey
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice et
type: common_voice
args: et
metrics:
- name: Test WER
type: wer
value: 37.36
---
# Wav2Vec2-Large-XLSR-53-Estonian
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) in Estonian using the [Common Voice](https://huggingface.co/datasets/common_voice)
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "et", split="test[:2%]").
processor = Wav2Vec2Processor.from_pretrained("manandey/wav2vec2-large-xlsr-estonian")
model = Wav2Vec2ForCTC.from_pretrained("manandey/wav2vec2-large-xlsr-estonian")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the {language} test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "et", split="test")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("manandey/wav2vec2-large-xlsr-estonian")
model = Wav2Vec2ForCTC.from_pretrained("manandey/wav2vec2-large-xlsr-estonian")
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"\“\%\‘\”\�\|\।\–\’\']'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 37.36%
## Training
The Common Voice `train`, `validation` datasets were used for training.
|
manifoldix/xlsr-fa-lm | 1da4c8b76ad654dbc0493b7ae133e5994522778c | 2022-03-23T18:28:30.000Z | [
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"fa",
"dataset:common_voice",
"transformers",
"hf-asr-leaderboard",
"robust-speech-event",
"model-index"
] | automatic-speech-recognition | false | manifoldix | null | manifoldix/xlsr-fa-lm | 1 | 1 | transformers | 29,906 | ---
language: fa
datasets:
- common_voice
tags:
- hf-asr-leaderboard
- robust-speech-event
widget:
- example_title: Common Voice sample 2978
src: https://huggingface.co/manifoldix/xlsr-fa-lm/resolve/main/sample2978.flac
- example_title: Common Voice sample 5168
src: https://huggingface.co/manifoldix/xlsr-fa-lm/resolve/main/sample5168.flac
model-index:
- name: XLS-R-300m Wav2Vec2 Persian
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice fa
type: common_voice
args: fa
metrics:
- name: Test WER without LM
type: wer
value: 26%
- name: Test WER with LM
type: wer
value: 23%
---
## XLSR-300m Persian
Fine-tuned on commom voice FA
|
manifoldix/xlsr-sg-lm | d1fc6dc44545b0ba88e963a7f12d46a94276ca08 | 2022-03-23T18:34:59.000Z | [
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"gsw",
"transformers",
"hf-asr-leaderboard",
"robust-speech-event",
"model-index"
] | automatic-speech-recognition | false | manifoldix | null | manifoldix/xlsr-sg-lm | 1 | null | transformers | 29,907 | ---
language: gsw
tags:
- hf-asr-leaderboard
- robust-speech-event
widget:
- example_title: swiss parliament sample 1
src: https://huggingface.co/manifoldix/xlsr-sg-lm/resolve/main/07e73bcaa2ab192aea9524d72db45f34f274d1b3d5672434c462d32d44d792be.mp3
- example_title: swiss parliament sample 2
src: https://huggingface.co/manifoldix/xlsr-sg-lm/resolve/main/14a2f855363920f111c7b30e8632c19e5f340ab5031e1ed2621db39baf452ae0.mp3
model-index:
- name: XLS-R-1b Wav2Vec2 Swiss German
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
metrics:
- name: Test WER on Swiss parliament
type: wer
value: 34.6%
- name: Test WER on Swiss dialect test set
type: wer
value: 40%
---
## XLSR-1b Swiss German
Fine-tuned on the Swiss parliament dataset from FHNW v1 (70h).
Tested on the Swiss parliament test set with a WER of 34.6%
Tested on the "Swiss German Dialects" with a WER of 40%
Both test sets can be accessed here: [fhnw_datasets](https://www.cs.technik.fhnw.ch/i4ds-datasets)
The Swiss German dialect private test set has been uploaded on huggingface: [huggingface_swiss_dialects](https://huggingface.co/datasets/manifoldix/swg_parliament_fhnw) |
manishiitg/distilbert-squad-256seq-8batch-test | b134d2e168bf0d87caf5735c8440be24832fe4d4 | 2020-06-13T15:50:48.000Z | [
"pytorch",
"distilbert",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | false | manishiitg | null | manishiitg/distilbert-squad-256seq-8batch-test | 1 | null | transformers | 29,908 | Entry not found |
maple/roberta-large | 4567ad341e98fd0df7dbf2f984d0904428ecff27 | 2022-01-04T11:19:54.000Z | [
"pytorch",
"roberta",
"token-classification",
"transformers",
"autotrain_compatible"
] | token-classification | false | maple | null | maple/roberta-large | 1 | null | transformers | 29,909 | Entry not found |
marcel/wav2vec2-large-xlsr-53-german | 35c78cceaf30c0065cdd36a3bcb39605fd213f47 | 2021-07-06T11:55:02.000Z | [
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"de",
"dataset:common_voice",
"dataset:wer",
"transformers",
"audio",
"speech",
"xlsr-fine-tuning-week",
"license:apache-2.0",
"model-index"
] | automatic-speech-recognition | false | marcel | null | marcel/wav2vec2-large-xlsr-53-german | 1 | null | transformers | 29,910 | ---
language: de
datasets:
- common_voice
- wer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: XLSR Wav2Vec2 Large 53
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice de
type: common_voice
args: de
metrics:
- name: Test WER
type: wer
value: 15.80
---
# Wav2Vec2-Large-XLSR-53-German
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on German using the [Common Voice](https://huggingface.co/datasets/common_voice) dataset.
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "de", split="test[:2%]")
processor = Wav2Vec2Processor.from_pretrained("marcel/wav2vec2-large-xlsr-53-german")
model = Wav2Vec2ForCTC.from_pretrained("marcel/wav2vec2-large-xlsr-53-german")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the {language} test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "de", split="test")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("marcel/wav2vec2-large-xlsr-53-german")
model = Wav2Vec2ForCTC.from_pretrained("marcel/wav2vec2-large-xlsr-53-german")
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"\“\%\”\�\カ\æ\無\ན\カ\臣\ѹ\…\«\»\ð\ı\„\幺\א\ב\比\ш\ע\)\ứ\в\œ\ч\+\—\ш\‚\נ\м\ń\乡\$\=\ש\ф\支\(\°\и\к\̇]'
substitutions = {
'e' : '[\ə\é\ě\ę\ê\ế\ế\ë\ė\е]',
'o' : '[\ō\ô\ô\ó\ò\ø\ọ\ŏ\õ\ő\о]',
'a' : '[\á\ā\ā\ă\ã\å\â\à\ą\а]',
'c' : '[\č\ć\ç\с]',
'l' : '[\ł]',
'u' : '[\ú\ū\ứ\ů]',
'und' : '[\&]',
'r' : '[\ř]',
'y' : '[\ý]',
's' : '[\ś\š\ș\ş]',
'i' : '[\ī\ǐ\í\ï\î\ï]',
'z' : '[\ź\ž\ź\ż]',
'n' : '[\ñ\ń\ņ]',
'g' : '[\ğ]',
'ss' : '[\ß]',
't' : '[\ț\ť]',
'd' : '[\ď\đ]',
"'": '[\ʿ\་\’\`\´\ʻ\`\‘]',
'p': '\р'
}
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
for x in substitutions:
batch["sentence"] = re.sub(substitutions[x], x, batch["sentence"])
speech_array, sampling_rate = torchaudio.load(batch["path"])
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
The model can also be evaluated with in 10% chunks which needs less ressources (to be tested).
```
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
import jiwer
lang_id = "de"
processor = Wav2Vec2Processor.from_pretrained("marcel/wav2vec2-large-xlsr-53-german")
model = Wav2Vec2ForCTC.from_pretrained("marcel/wav2vec2-large-xlsr-53-german")
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"\“\%\”\�\カ\æ\無\ན\カ\臣\ѹ\…\«\»\ð\ı\„\幺\א\ב\比\ш\ע\)\ứ\в\œ\ч\+\—\ш\‚\נ\м\ń\乡\$\=\ש\ф\支\(\°\и\к\̇]'
substitutions = {
'e' : '[\ə\é\ě\ę\ê\ế\ế\ë\ė\е]',
'o' : '[\ō\ô\ô\ó\ò\ø\ọ\ŏ\õ\ő\о]',
'a' : '[\á\ā\ā\ă\ã\å\â\à\ą\а]',
'c' : '[\č\ć\ç\с]',
'l' : '[\ł]',
'u' : '[\ú\ū\ứ\ů]',
'und' : '[\&]',
'r' : '[\ř]',
'y' : '[\ý]',
's' : '[\ś\š\ș\ş]',
'i' : '[\ī\ǐ\í\ï\î\ï]',
'z' : '[\ź\ž\ź\ż]',
'n' : '[\ñ\ń\ņ]',
'g' : '[\ğ]',
'ss' : '[\ß]',
't' : '[\ț\ť]',
'd' : '[\ď\đ]',
"'": '[\ʿ\་\’\`\´\ʻ\`\‘]',
'p': '\р'
}
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
for x in substitutions:
batch["sentence"] = re.sub(substitutions[x], x, batch["sentence"])
speech_array, sampling_rate = torchaudio.load(batch["path"])
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
H, S, D, I = 0, 0, 0, 0
for i in range(10):
print("test["+str(10*i)+"%:"+str(10*(i+1))+"%]")
test_dataset = load_dataset("common_voice", "de", split="test["+str(10*i)+"%:"+str(10*(i+1))+"%]")
test_dataset = test_dataset.map(speech_file_to_array_fn)
result = test_dataset.map(evaluate, batched=True, batch_size=8)
predictions = result["pred_strings"]
targets = result["sentence"]
chunk_metrics = jiwer.compute_measures(targets, predictions)
H = H + chunk_metrics["hits"]
S = S + chunk_metrics["substitutions"]
D = D + chunk_metrics["deletions"]
I = I + chunk_metrics["insertions"]
WER = float(S + D + I) / float(H + S + D)
print("WER: {:2f}".format(WER*100))
```
**Test Result**: 15.80 %
## Training
The first 50% of the Common Voice `train`, and 12% of the `validation` datasets were used for training (30 epochs on first 12% and 3 epochs on the remainder).
|
marcel/wav2vec2-large-xlsr-german-demo | 642e446c09b53952bc79e5b9b1e2841d9ae16913 | 2021-07-06T12:09:00.000Z | [
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"de",
"dataset:common_voice",
"dataset:wer",
"transformers",
"audio",
"speech",
"xlsr-fine-tuning-week",
"license:apache-2.0",
"model-index"
] | automatic-speech-recognition | false | marcel | null | marcel/wav2vec2-large-xlsr-german-demo | 1 | null | transformers | 29,911 | ---
language: de
datasets:
- common_voice
- wer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: XLSR Wav2Vec2 Large 53
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice de
type: common_voice
args: de
metrics:
- name: Test WER
type: wer
value: 29.35
---
# Wav2Vec2-Large-XLSR-53-German
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on German using 3% of the [Common Voice](https://huggingface.co/datasets/common_voice) dataset.
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "de", split="test[:2%]")
processor = Wav2Vec2Processor.from_pretrained("marcel/wav2vec2-large-xlsr-german-demo")
model = Wav2Vec2ForCTC.from_pretrained("marcel/wav2vec2-large-xlsr-german-demo")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the {language} test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "de", split="test[:10%]")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("marcel/wav2vec2-large-xlsr-german-demo")
model = Wav2Vec2ForCTC.from_pretrained("marcel/wav2vec2-large-xlsr-german-demo")
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"\“\%\”\�\カ\æ\無\ན\カ\臣\ѹ\…\«\»\ð\ı\„\幺\א\ב\比\ш\ע\)\ứ\в\œ\ч\+\—\ш\‚\נ\м\ń\乡\$\=\ש\ф\支\(\°\и\к\̇]'
substitutions = {
'e' : '[\ə\é\ě\ę\ê\ế\ế\ë\ė\е]',
'o' : '[\ō\ô\ô\ó\ò\ø\ọ\ŏ\õ\ő\о]',
'a' : '[\á\ā\ā\ă\ã\å\â\à\ą\а]',
'c' : '[\č\ć\ç\с]',
'l' : '[\ł]',
'u' : '[\ú\ū\ứ\ů]',
'und' : '[\&]',
'r' : '[\ř]',
'y' : '[\ý]',
's' : '[\ś\š\ș\ş]',
'i' : '[\ī\ǐ\í\ï\î\ï]',
'z' : '[\ź\ž\ź\ż]',
'n' : '[\ñ\ń\ņ]',
'g' : '[\ğ]',
'ss' : '[\ß]',
't' : '[\ț\ť]',
'd' : '[\ď\đ]',
"'": '[\ʿ\་\’\`\´\ʻ\`\‘]',
'p': '\р'
}
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
for x in substitutions:
batch["sentence"] = re.sub(substitutions[x], x, batch["sentence"])
speech_array, sampling_rate = torchaudio.load(batch["path"])
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 29.35 %
## Training
The first 3% of the Common Voice `train`, `validation` datasets were used for training.
The script used for training can be found TODO
|
marcosgg/bert-small-gl-cased | 3237483341d0da7f11d97aa8b4f83f4e39609aa9 | 2021-09-09T10:34:36.000Z | [
"pytorch",
"bert",
"fill-mask",
"gl",
"pt",
"arxiv:2106.13553",
"transformers",
"autotrain_compatible"
] | fill-mask | false | marcosgg | null | marcosgg/bert-small-gl-cased | 1 | 1 | transformers | 29,912 | ---
language:
- gl
- pt
widget:
- text: "A mesa estaba feita de [MASK]."
---
# BERT for Galician (Small)
This is a small pre-trained BERT model (6 layers, cased) for Galician (ILG/RAG spelling). It was evaluated on lexical semantics tasks, using a [dataset to identify homonymy and synonymy in context](https://github.com/marcospln/homonymy_acl21), and presented at ACL 2021.
There is also a base version (12 layers, cased): `marcosgg/bert-base-gl-cased`
## Citation
If you use this model, please cite the following [paper](https://arxiv.org/abs/2106.13553):
```
@inproceedings{garcia-2021-exploring,
title = "Exploring the Representation of Word Meanings in Context: {A} Case Study on Homonymy and Synonymy",
author = "Garcia, Marcos",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers)",
year = "2021",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.acl-long.281",
doi = "10.18653/v1/2021.acl-long.281",
pages = "3625--3640"
}
```
|
marioarteaga/distilbert-base-uncased-finetuned-squad | decaeb436743d4937bcbf9eb19677566dd54f99c | 2022-01-04T20:26:53.000Z | [
"pytorch",
"tensorboard",
"distilbert",
"question-answering",
"dataset:squad",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
] | question-answering | false | marioarteaga | null | marioarteaga/distilbert-base-uncased-finetuned-squad | 1 | null | transformers | 29,913 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: distilbert-base-uncased-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-squad
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2052
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.2493 | 1.0 | 5533 | 1.2052 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
marma/test | d3b539a91291db46010590e1e1ccffbbc3910ffd | 2021-07-06T12:24:31.000Z | [
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"sv",
"transformers",
"speech",
"audio"
] | automatic-speech-recognition | false | marma | null | marma/test | 1 | null | transformers | 29,914 | ---
language: sv
tags:
- speech
- audio
- automatic-speech-recognition
---
## Test |
marzinouri101/parsbert-finetuned-persianQA | 61eed32718e869d82ea26089796f73bcdb974355 | 2022-02-05T04:39:21.000Z | [
"pytorch",
"bert",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | false | marzinouri101 | null | marzinouri101/parsbert-finetuned-persianQA | 1 | null | transformers | 29,915 | Entry not found |
masapasa/wav2vec2-large-xls-r-300m-turkish-colab | 2fc27528291d8705ce5ccd0d6df34f4a3f627214 | 2022-01-19T17:30:55.000Z | [
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"dataset:common_voice",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] | automatic-speech-recognition | false | masapasa | null | masapasa/wav2vec2-large-xls-r-300m-turkish-colab | 1 | null | transformers | 29,916 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: wav2vec2-large-xls-r-300m-turkish-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-turkish-colab
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 50
- num_epochs: 30
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu113
- Datasets 1.13.3
- Tokenizers 0.10.3
|
masapasa/xls-r-300m-sv-cv8 | 9db4420337f69412eb01933baf189b985f86e3eb | 2022-03-24T11:55:57.000Z | [
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"sv-SE",
"dataset:mozilla-foundation/common_voice_8_0",
"transformers",
"robust-speech-event",
"mozilla-foundation/common_voice_8_0",
"generated_from_trainer",
"hf-asr-leaderboard",
"license:apache-2.0",
"model-index"
] | automatic-speech-recognition | false | masapasa | null | masapasa/xls-r-300m-sv-cv8 | 1 | null | transformers | 29,917 | ---
language:
- sv-SE
license: apache-2.0
tags:
- robust-speech-event
- automatic-speech-recognition
- mozilla-foundation/common_voice_8_0
- generated_from_trainer
- hf-asr-leaderboard
datasets:
- mozilla-foundation/common_voice_8_0
model-index:
- name: ''
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 8.0
type: mozilla-foundation/common_voice_8_0
args: sv-SE
metrics:
- name: Test WER
type: wer
value: 102.43
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
#
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the MOZILLA-FOUNDATION/COMMON_VOICE_8_0 - SV-SE dataset.
It achieves the following results on the evaluation set:
- Loss: 2.3347
- Wer: 1.0286
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 7.5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 20
- num_epochs: 5.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 10.7838 | 0.01 | 5 | 14.5035 | 1.0 |
| 13.0582 | 0.03 | 10 | 13.6658 | 1.0 |
| 7.3034 | 0.04 | 15 | 9.7898 | 1.0 |
| 6.1847 | 0.05 | 20 | 6.9148 | 1.0 |
| 5.3371 | 0.07 | 25 | 5.3661 | 1.0 |
| 4.4274 | 0.08 | 30 | 4.6945 | 1.0 |
| 4.0918 | 0.1 | 35 | 4.3172 | 1.0 |
| 4.1734 | 0.11 | 40 | 4.0759 | 1.0 |
| 3.7332 | 0.12 | 45 | 3.9039 | 1.0 |
| 3.6871 | 0.14 | 50 | 3.7777 | 1.0 |
| 3.4428 | 0.15 | 55 | 3.6718 | 1.0 |
| 3.5514 | 0.16 | 60 | 3.5947 | 1.0 |
| 3.4307 | 0.18 | 65 | 3.5144 | 1.0 |
| 3.4102 | 0.19 | 70 | 3.4432 | 1.0 |
| 3.4964 | 0.21 | 75 | 3.3890 | 1.0 |
| 3.3936 | 0.22 | 80 | 3.3467 | 1.0 |
| 3.3051 | 0.23 | 85 | 3.3102 | 1.0 |
| 3.278 | 0.25 | 90 | 3.2801 | 1.0 |
| 3.2223 | 0.26 | 95 | 3.2440 | 1.0 |
| 3.1888 | 0.27 | 100 | 3.2900 | 1.0 |
| 3.218 | 0.29 | 105 | 3.2627 | 1.0 |
| 3.1308 | 0.3 | 110 | 3.2152 | 1.0 |
| 3.109 | 0.31 | 115 | 3.1686 | 1.0 |
| 3.1188 | 0.33 | 120 | 3.1734 | 1.0 |
| 3.1132 | 0.34 | 125 | 3.1431 | 1.0 |
| 3.0667 | 0.36 | 130 | 3.1686 | 1.0 |
| 3.1167 | 0.37 | 135 | 3.1885 | 1.0 |
| 3.0592 | 0.38 | 140 | 3.1100 | 1.0 |
| 3.0531 | 0.4 | 145 | 3.1149 | 1.0 |
| 3.1224 | 0.41 | 150 | 3.1205 | 1.0 |
| 3.0651 | 0.42 | 155 | 3.1101 | 1.0 |
| 3.0077 | 0.44 | 160 | 3.0980 | 1.0 |
| 3.0027 | 0.45 | 165 | 3.1132 | 1.0 |
| 3.0423 | 0.47 | 170 | 3.0886 | 1.0 |
| 3.0462 | 0.48 | 175 | 3.0865 | 1.0 |
| 3.0701 | 0.49 | 180 | 3.0863 | 1.0 |
| 3.0871 | 0.51 | 185 | 3.0825 | 1.0 |
| 3.0585 | 0.52 | 190 | 3.0720 | 1.0 |
| 3.0274 | 0.53 | 195 | 3.0736 | 1.0 |
| 3.0983 | 0.55 | 200 | 3.0658 | 1.0 |
| 3.0538 | 0.56 | 205 | 3.1241 | 1.0 |
| 3.0862 | 0.57 | 210 | 3.0573 | 1.0 |
| 3.0041 | 0.59 | 215 | 3.0608 | 1.0 |
| 3.027 | 0.6 | 220 | 3.0614 | 1.0 |
| 2.9916 | 0.62 | 225 | 3.0527 | 1.0 |
| 3.0157 | 0.63 | 230 | 3.0514 | 1.0 |
| 3.0429 | 0.64 | 235 | 3.0391 | 1.0 |
| 2.999 | 0.66 | 240 | 3.0462 | 1.0 |
| 3.0053 | 0.67 | 245 | 3.0438 | 1.0 |
| 2.9812 | 0.68 | 250 | 3.0447 | 1.0 |
| 3.0062 | 0.7 | 255 | 3.0660 | 1.0 |
| 3.0045 | 0.71 | 260 | 3.0103 | 1.0 |
| 2.9684 | 0.73 | 265 | 3.0106 | 1.0 |
| 2.9885 | 0.74 | 270 | 3.0014 | 1.0 |
| 3.0062 | 0.75 | 275 | 2.9885 | 1.0 |
| 2.9736 | 0.77 | 280 | 3.0330 | 1.0 |
| 2.9766 | 0.78 | 285 | 2.9910 | 1.0 |
| 2.9545 | 0.79 | 290 | 2.9972 | 1.0 |
| 2.9936 | 0.81 | 295 | 2.9872 | 1.0 |
| 3.0832 | 0.82 | 300 | 2.9978 | 1.0 |
| 2.974 | 0.83 | 305 | 2.9978 | 1.0 |
| 2.9846 | 0.85 | 310 | 2.9849 | 1.0 |
| 2.9554 | 0.86 | 315 | 2.9810 | 1.0 |
| 2.9524 | 0.88 | 320 | 2.9731 | 1.0 |
| 2.9426 | 0.89 | 325 | 2.9824 | 1.0 |
| 2.9416 | 0.9 | 330 | 2.9731 | 1.0 |
| 2.9705 | 0.92 | 335 | 2.9830 | 1.0 |
| 2.9502 | 0.93 | 340 | 2.9713 | 1.0 |
| 2.9393 | 0.94 | 345 | 2.9790 | 1.0 |
| 2.9336 | 0.96 | 350 | 2.9684 | 1.0 |
| 2.9542 | 0.97 | 355 | 2.9689 | 1.0 |
| 2.9408 | 0.98 | 360 | 2.9556 | 1.0 |
| 2.9544 | 1.0 | 365 | 2.9563 | 1.0 |
| 2.9187 | 1.01 | 370 | 2.9624 | 1.0 |
| 2.9935 | 1.03 | 375 | 2.9500 | 1.0 |
| 2.9803 | 1.04 | 380 | 2.9558 | 1.0 |
| 2.9867 | 1.05 | 385 | 2.9473 | 1.0 |
| 2.8925 | 1.07 | 390 | 2.9444 | 1.0 |
| 2.9633 | 1.08 | 395 | 2.9490 | 1.0 |
| 2.9191 | 1.1 | 400 | 2.9362 | 1.0 |
| 2.9081 | 1.11 | 405 | 2.9394 | 1.0 |
| 2.9381 | 1.12 | 410 | 2.9846 | 1.0 |
| 2.9271 | 1.14 | 415 | 2.9638 | 1.0 |
| 2.959 | 1.15 | 420 | 2.9835 | 1.0 |
| 2.9486 | 1.16 | 425 | 2.9361 | 1.0 |
| 2.9246 | 1.18 | 430 | 2.9615 | 1.0 |
| 2.923 | 1.19 | 435 | 2.9313 | 1.0 |
| 2.8908 | 1.21 | 440 | 2.9362 | 1.0 |
| 2.8976 | 1.22 | 445 | 2.9224 | 1.0 |
| 2.9278 | 1.23 | 450 | 2.9276 | 1.0 |
| 2.8429 | 1.25 | 455 | 2.9299 | 1.0 |
| 2.867 | 1.26 | 460 | 2.9258 | 1.0 |
| 2.9734 | 1.27 | 465 | 2.9281 | 1.0000 |
| 2.934 | 1.29 | 470 | 2.9229 | 1.0 |
| 2.9521 | 1.3 | 475 | 2.9134 | 1.0 |
| 2.9098 | 1.31 | 480 | 2.9051 | 0.9993 |
| 2.9112 | 1.33 | 485 | 2.9028 | 0.9999 |
| 2.8799 | 1.34 | 490 | 2.9101 | 0.9986 |
| 2.857 | 1.36 | 495 | 2.9005 | 0.9992 |
| 2.8525 | 1.37 | 500 | 2.8937 | 1.0 |
| 2.8682 | 1.38 | 505 | 2.8904 | 1.0000 |
| 2.8899 | 1.4 | 510 | 2.8914 | 0.9964 |
| 2.7475 | 1.41 | 515 | 2.8842 | 0.9950 |
| 2.9263 | 1.42 | 520 | 2.8852 | 0.9972 |
| 2.8603 | 1.44 | 525 | 2.8762 | 0.9966 |
| 2.864 | 1.45 | 530 | 2.8680 | 0.9978 |
| 2.8632 | 1.47 | 535 | 2.8602 | 0.9964 |
| 2.9289 | 1.48 | 540 | 2.8584 | 0.9952 |
| 2.8689 | 1.49 | 545 | 2.8587 | 0.9956 |
| 2.8304 | 1.51 | 550 | 2.8511 | 0.9993 |
| 2.8024 | 1.52 | 555 | 2.8460 | 1.0 |
| 2.7649 | 1.53 | 560 | 2.8460 | 1.0000 |
| 2.8756 | 1.55 | 565 | 2.8348 | 0.9987 |
| 2.8808 | 1.56 | 570 | 2.8539 | 0.9993 |
| 2.9027 | 1.57 | 575 | 2.8282 | 0.9975 |
| 2.8586 | 1.59 | 580 | 2.8288 | 0.9976 |
| 2.8193 | 1.6 | 585 | 2.8101 | 1.0051 |
| 2.811 | 1.62 | 590 | 2.7965 | 1.0014 |
| 2.7332 | 1.63 | 595 | 2.7884 | 1.0026 |
| 2.7717 | 1.64 | 600 | 2.7883 | 1.0060 |
| 2.6901 | 1.66 | 605 | 2.7801 | 0.9974 |
| 2.6905 | 1.67 | 610 | 2.8113 | 0.9968 |
| 2.7442 | 1.68 | 615 | 2.8113 | 1.0007 |
| 2.8431 | 1.7 | 620 | 2.8152 | 1.0343 |
| 2.8028 | 1.71 | 625 | 2.7790 | 1.0250 |
| 2.7151 | 1.73 | 630 | 2.7653 | 1.0287 |
| 2.7405 | 1.74 | 635 | 2.7714 | 1.1303 |
| 2.7566 | 1.75 | 640 | 2.7488 | 1.0312 |
| 2.7337 | 1.77 | 645 | 2.7498 | 1.0176 |
| 2.7486 | 1.78 | 650 | 2.7496 | 1.0760 |
| 2.6918 | 1.79 | 655 | 2.7391 | 1.0353 |
| 2.7142 | 1.81 | 660 | 2.7500 | 1.0283 |
| 2.7057 | 1.82 | 665 | 2.7612 | 1.0127 |
| 2.8348 | 1.83 | 670 | 2.7441 | 1.0056 |
| 2.705 | 1.85 | 675 | 2.7473 | 1.0519 |
| 2.7547 | 1.86 | 680 | 2.7216 | 1.0218 |
| 2.7045 | 1.88 | 685 | 2.7261 | 1.1414 |
| 2.7121 | 1.89 | 690 | 2.7223 | 1.0287 |
| 2.6877 | 1.9 | 695 | 2.7283 | 1.0274 |
| 2.6879 | 1.92 | 700 | 2.7451 | 1.1322 |
| 2.6958 | 1.93 | 705 | 2.7166 | 1.0364 |
| 2.6692 | 1.94 | 710 | 2.7148 | 1.0074 |
| 2.5786 | 1.96 | 715 | 2.7101 | 1.0504 |
| 2.6919 | 1.97 | 720 | 2.6963 | 1.0454 |
| 2.7256 | 1.98 | 725 | 2.7201 | 1.0349 |
| 2.6507 | 2.0 | 730 | 2.7099 | 1.1339 |
| 2.7833 | 2.01 | 735 | 2.7111 | 1.0124 |
| 2.7521 | 2.03 | 740 | 2.7024 | 1.0275 |
| 2.6732 | 2.04 | 745 | 2.7058 | 1.0647 |
| 2.719 | 2.05 | 750 | 2.7200 | 1.0211 |
| 2.701 | 2.07 | 755 | 2.7024 | 1.0808 |
| 2.6444 | 2.08 | 760 | 2.6813 | 1.0582 |
| 2.5592 | 2.1 | 765 | 2.6783 | 1.1010 |
| 2.6444 | 2.11 | 770 | 2.6707 | 1.0946 |
| 2.6944 | 2.12 | 775 | 2.7012 | 1.1315 |
| 2.6733 | 2.14 | 780 | 2.7072 | 1.1144 |
| 2.6998 | 2.15 | 785 | 2.7132 | 1.0206 |
| 2.796 | 2.16 | 790 | 2.7076 | 1.1262 |
| 2.6881 | 2.18 | 795 | 2.6953 | 1.0841 |
| 2.7382 | 2.19 | 800 | 2.6605 | 1.1234 |
| 2.5814 | 2.21 | 805 | 2.6814 | 1.1865 |
| 2.6695 | 2.22 | 810 | 2.6531 | 1.0985 |
| 2.6415 | 2.23 | 815 | 2.6590 | 1.0804 |
| 2.646 | 2.25 | 820 | 2.6514 | 1.0853 |
| 2.6028 | 2.26 | 825 | 2.6723 | 1.1411 |
| 2.6429 | 2.27 | 830 | 2.6729 | 1.0395 |
| 2.6736 | 2.29 | 835 | 2.7039 | 1.0355 |
| 2.6959 | 2.3 | 840 | 2.6510 | 1.0414 |
| 2.6426 | 2.31 | 845 | 2.6660 | 1.1591 |
| 2.7152 | 2.33 | 850 | 2.6361 | 1.0276 |
| 2.7148 | 2.34 | 855 | 2.6723 | 1.2461 |
| 2.6336 | 2.36 | 860 | 2.6332 | 1.0310 |
| 2.665 | 2.37 | 865 | 2.6365 | 1.1312 |
| 2.5607 | 2.38 | 870 | 2.6344 | 1.1301 |
| 2.5614 | 2.4 | 875 | 2.6437 | 1.1513 |
| 2.4899 | 2.41 | 880 | 2.6418 | 1.1532 |
| 2.6794 | 2.42 | 885 | 2.6403 | 1.0272 |
| 2.6814 | 2.44 | 890 | 2.6420 | 1.1323 |
| 2.6614 | 2.45 | 895 | 2.6183 | 1.0525 |
| 2.6629 | 2.47 | 900 | 2.6414 | 1.1569 |
| 2.6166 | 2.48 | 905 | 2.6167 | 1.0265 |
| 2.6374 | 2.49 | 910 | 2.6299 | 1.1720 |
| 2.6035 | 2.51 | 915 | 2.6139 | 1.1565 |
| 2.595 | 2.52 | 920 | 2.6126 | 1.0557 |
| 2.6416 | 2.53 | 925 | 2.6190 | 1.0414 |
| 2.6785 | 2.55 | 930 | 2.6352 | 1.0289 |
| 2.6986 | 2.56 | 935 | 2.6268 | 1.0077 |
| 2.6145 | 2.57 | 940 | 2.6166 | 1.0445 |
| 2.6961 | 2.59 | 945 | 2.6142 | 1.0185 |
| 2.6852 | 2.6 | 950 | 2.6072 | 1.0122 |
| 2.5792 | 2.62 | 955 | 2.6078 | 1.1165 |
| 2.6118 | 2.63 | 960 | 2.6177 | 1.1210 |
| 2.5472 | 2.64 | 965 | 2.6126 | 1.0044 |
| 2.577 | 2.66 | 970 | 2.6051 | 1.0881 |
| 2.5602 | 2.67 | 975 | 2.5992 | 1.0178 |
| 2.695 | 2.68 | 980 | 2.6023 | 1.0248 |
| 2.7017 | 2.7 | 985 | 2.6190 | 1.0041 |
| 2.6327 | 2.71 | 990 | 2.6024 | 1.0142 |
| 2.6193 | 2.73 | 995 | 2.5897 | 1.0148 |
| 2.5939 | 2.74 | 1000 | 2.5900 | 1.0329 |
| 2.5477 | 2.75 | 1005 | 2.5971 | 1.0338 |
| 2.6089 | 2.77 | 1010 | 2.5969 | 1.0064 |
| 2.5625 | 2.78 | 1015 | 2.5899 | 1.0648 |
| 2.5745 | 2.79 | 1020 | 2.5861 | 1.0627 |
| 2.5702 | 2.81 | 1025 | 2.5923 | 1.0526 |
| 2.645 | 2.82 | 1030 | 2.6053 | 1.0199 |
| 2.6869 | 2.83 | 1035 | 2.6227 | 1.0011 |
| 2.6678 | 2.85 | 1040 | 2.6094 | 1.0179 |
| 2.6787 | 2.86 | 1045 | 2.5978 | 1.0028 |
| 2.6246 | 2.88 | 1050 | 2.5965 | 1.0093 |
| 2.5676 | 2.89 | 1055 | 2.5927 | 1.0627 |
| 2.6773 | 2.9 | 1060 | 2.5907 | 1.0817 |
| 2.6114 | 2.92 | 1065 | 2.5932 | 1.1013 |
| 2.6227 | 2.93 | 1070 | 2.5840 | 1.0402 |
| 2.594 | 2.94 | 1075 | 2.5997 | 1.1371 |
| 2.751 | 2.96 | 1080 | 2.5909 | 1.0972 |
| 2.6366 | 2.97 | 1085 | 2.6081 | 1.0598 |
| 2.577 | 2.98 | 1090 | 2.5915 | 1.0410 |
| 2.579 | 3.0 | 1095 | 2.5953 | 1.1433 |
| 2.6706 | 3.01 | 1100 | 2.5913 | 1.0456 |
| 2.6161 | 3.03 | 1105 | 2.6079 | 1.1009 |
| 2.6397 | 3.04 | 1110 | 2.5951 | 1.1771 |
| 2.6246 | 3.05 | 1115 | 2.5730 | 1.0299 |
| 2.5637 | 3.07 | 1120 | 2.5622 | 1.0848 |
| 2.5692 | 3.08 | 1125 | 2.5561 | 1.1472 |
| 2.5948 | 3.1 | 1130 | 2.5568 | 1.0802 |
| 2.5372 | 3.11 | 1135 | 2.5638 | 1.1261 |
| 2.4995 | 3.12 | 1140 | 2.5727 | 1.1395 |
| 2.6304 | 3.14 | 1145 | 2.5671 | 1.0259 |
| 2.6395 | 3.15 | 1150 | 2.5778 | 1.0212 |
| 2.6127 | 3.16 | 1155 | 2.5609 | 1.0457 |
| 2.5919 | 3.18 | 1160 | 2.5604 | 1.0902 |
| 2.6111 | 3.19 | 1165 | 2.5463 | 1.0014 |
| 2.5971 | 3.21 | 1170 | 2.5429 | 1.0022 |
| 2.5887 | 3.22 | 1175 | 2.5394 | 1.0412 |
| 2.5644 | 3.23 | 1180 | 2.5342 | 1.0469 |
| 2.4805 | 3.25 | 1185 | 2.6066 | 1.2668 |
| 2.5324 | 3.26 | 1190 | 2.5395 | 1.0234 |
| 2.5491 | 3.27 | 1195 | 2.5431 | 1.0644 |
| 2.6302 | 3.29 | 1200 | 2.5558 | 1.0680 |
| 2.6139 | 3.3 | 1205 | 2.5711 | 1.0565 |
| 2.5607 | 3.31 | 1210 | 2.5635 | 1.0415 |
| 2.6535 | 3.33 | 1215 | 2.5505 | 1.0613 |
| 2.6129 | 3.34 | 1220 | 2.5403 | 1.0724 |
| 2.5157 | 3.36 | 1225 | 2.5294 | 1.0585 |
| 2.551 | 3.37 | 1230 | 2.5242 | 1.1599 |
| 2.5527 | 3.38 | 1235 | 2.5474 | 1.2327 |
| 2.4964 | 3.4 | 1240 | 2.5244 | 1.0857 |
| 2.5781 | 3.41 | 1245 | 2.5299 | 1.0470 |
| 2.6143 | 3.42 | 1250 | 2.5313 | 1.0019 |
| 2.6566 | 3.44 | 1255 | 2.5431 | 1.0488 |
| 2.5373 | 3.45 | 1260 | 2.5281 | 1.0901 |
| 2.6597 | 3.47 | 1265 | 2.5300 | 1.0610 |
| 2.5457 | 3.48 | 1270 | 2.5130 | 1.0420 |
| 2.5632 | 3.49 | 1275 | 2.5306 | 1.1418 |
| 2.5267 | 3.51 | 1280 | 2.5021 | 1.0293 |
| 2.507 | 3.52 | 1285 | 2.5013 | 1.0196 |
| 2.5713 | 3.53 | 1290 | 2.4978 | 1.0664 |
| 2.4783 | 3.55 | 1295 | 2.4958 | 1.0530 |
| 2.5874 | 3.56 | 1300 | 2.4968 | 1.0059 |
| 2.5744 | 3.57 | 1305 | 2.5078 | 1.0287 |
| 2.5701 | 3.59 | 1310 | 2.4971 | 1.0366 |
| 2.5366 | 3.6 | 1315 | 2.4897 | 1.0191 |
| 2.5679 | 3.62 | 1320 | 2.4830 | 1.0223 |
| 2.5239 | 3.63 | 1325 | 2.4833 | 1.0784 |
| 2.5411 | 3.64 | 1330 | 2.4851 | 1.1522 |
| 2.5037 | 3.66 | 1335 | 2.4792 | 1.0928 |
| 2.5907 | 3.67 | 1340 | 2.4750 | 1.0187 |
| 2.5107 | 3.68 | 1345 | 2.4805 | 1.0873 |
| 2.5908 | 3.7 | 1350 | 2.4753 | 1.0098 |
| 2.6274 | 3.71 | 1355 | 2.4765 | 1.0045 |
| 2.5708 | 3.73 | 1360 | 2.4597 | 1.0456 |
| 2.6039 | 3.74 | 1365 | 2.4503 | 1.0485 |
| 2.5305 | 3.75 | 1370 | 2.4439 | 1.0126 |
| 2.4878 | 3.77 | 1375 | 2.4407 | 1.0162 |
| 2.5055 | 3.78 | 1380 | 2.4421 | 1.0605 |
| 2.5249 | 3.79 | 1385 | 2.4499 | 1.1163 |
| 2.5508 | 3.81 | 1390 | 2.4654 | 1.1472 |
| 2.5827 | 3.82 | 1395 | 2.4510 | 1.0561 |
| 2.6148 | 3.83 | 1400 | 2.4496 | 0.9998 |
| 2.5763 | 3.85 | 1405 | 2.4417 | 1.0067 |
| 2.6077 | 3.86 | 1410 | 2.4458 | 1.0682 |
| 2.5388 | 3.88 | 1415 | 2.4352 | 1.0820 |
| 2.5235 | 3.89 | 1420 | 2.4277 | 1.0784 |
| 2.4996 | 3.9 | 1425 | 2.4245 | 1.0671 |
| 2.5601 | 3.92 | 1430 | 2.4202 | 1.0650 |
| 2.5805 | 3.93 | 1435 | 2.4199 | 1.0530 |
| 2.5841 | 3.94 | 1440 | 2.4228 | 1.0797 |
| 2.4877 | 3.96 | 1445 | 2.4284 | 1.1159 |
| 2.5542 | 3.97 | 1450 | 2.4190 | 1.0575 |
| 2.5961 | 3.98 | 1455 | 2.4162 | 1.0676 |
| 2.495 | 4.0 | 1460 | 2.4165 | 1.0821 |
| 2.6157 | 4.01 | 1465 | 2.4119 | 1.0117 |
| 2.5415 | 4.03 | 1470 | 2.4089 | 1.0110 |
| 2.4916 | 4.04 | 1475 | 2.4032 | 1.0498 |
| 2.5445 | 4.05 | 1480 | 2.3997 | 1.0429 |
| 2.4941 | 4.07 | 1485 | 2.4008 | 1.0141 |
| 2.5113 | 4.08 | 1490 | 2.3975 | 1.0357 |
| 2.4707 | 4.1 | 1495 | 2.3938 | 1.0288 |
| 2.4952 | 4.11 | 1500 | 2.3910 | 1.0300 |
| 2.5017 | 4.12 | 1505 | 2.3861 | 1.0813 |
| 2.5566 | 4.14 | 1510 | 2.3919 | 1.1082 |
| 2.5754 | 4.15 | 1515 | 2.3947 | 1.0074 |
| 2.6138 | 4.16 | 1520 | 2.4040 | 0.9989 |
| 2.5024 | 4.18 | 1525 | 2.3949 | 1.0039 |
| 2.5136 | 4.19 | 1530 | 2.3993 | 1.0496 |
| 2.5646 | 4.21 | 1535 | 2.3981 | 1.0729 |
| 2.4556 | 4.22 | 1540 | 2.3952 | 1.0494 |
| 2.5774 | 4.23 | 1545 | 2.3924 | 1.0345 |
| 2.5126 | 4.25 | 1550 | 2.3888 | 1.0306 |
| 2.4596 | 4.26 | 1555 | 2.3960 | 1.0775 |
| 2.521 | 4.27 | 1560 | 2.3978 | 1.1025 |
| 2.6304 | 4.29 | 1565 | 2.3885 | 1.0433 |
| 2.543 | 4.3 | 1570 | 2.3849 | 1.0072 |
| 2.5601 | 4.31 | 1575 | 2.3855 | 1.0110 |
| 2.6304 | 4.33 | 1580 | 2.3878 | 1.0369 |
| 2.4121 | 4.34 | 1585 | 2.3783 | 1.0366 |
| 2.4261 | 4.36 | 1590 | 2.3746 | 1.0307 |
| 2.5038 | 4.37 | 1595 | 2.3789 | 1.0611 |
| 2.5391 | 4.38 | 1600 | 2.3849 | 1.0738 |
| 2.4341 | 4.4 | 1605 | 2.3779 | 1.0573 |
| 2.5306 | 4.41 | 1610 | 2.3751 | 1.0460 |
| 2.5818 | 4.42 | 1615 | 2.3743 | 1.0251 |
| 2.5531 | 4.44 | 1620 | 2.3723 | 1.0209 |
| 2.51 | 4.45 | 1625 | 2.3755 | 1.0316 |
| 2.5788 | 4.47 | 1630 | 2.3725 | 1.0396 |
| 2.5701 | 4.48 | 1635 | 2.3663 | 1.0292 |
| 2.4194 | 4.49 | 1640 | 2.3641 | 1.0261 |
| 2.5439 | 4.51 | 1645 | 2.3629 | 1.0376 |
| 2.4527 | 4.52 | 1650 | 2.3629 | 1.0563 |
| 2.5705 | 4.53 | 1655 | 2.3654 | 1.0766 |
| 2.4552 | 4.55 | 1660 | 2.3708 | 1.0802 |
| 2.5657 | 4.56 | 1665 | 2.3638 | 1.0248 |
| 2.5371 | 4.57 | 1670 | 2.3639 | 1.0053 |
| 2.5365 | 4.59 | 1675 | 2.3626 | 1.0072 |
| 2.5383 | 4.6 | 1680 | 2.3584 | 1.0170 |
| 2.546 | 4.62 | 1685 | 2.3574 | 1.0469 |
| 2.6006 | 4.63 | 1690 | 2.3517 | 1.0509 |
| 2.4894 | 4.64 | 1695 | 2.3489 | 1.0452 |
| 2.4732 | 4.66 | 1700 | 2.3489 | 1.0586 |
| 2.4933 | 4.67 | 1705 | 2.3501 | 1.0694 |
| 2.4784 | 4.68 | 1710 | 2.3472 | 1.0647 |
| 2.5349 | 4.7 | 1715 | 2.3419 | 1.0299 |
| 2.553 | 4.71 | 1720 | 2.3420 | 1.0115 |
| 2.5035 | 4.73 | 1725 | 2.3415 | 1.0117 |
| 2.561 | 4.74 | 1730 | 2.3418 | 1.0242 |
| 2.4773 | 4.75 | 1735 | 2.3420 | 1.0325 |
| 2.4691 | 4.77 | 1740 | 2.3422 | 1.0394 |
| 2.4959 | 4.78 | 1745 | 2.3405 | 1.0418 |
| 2.4928 | 4.79 | 1750 | 2.3394 | 1.0449 |
| 2.5058 | 4.81 | 1755 | 2.3392 | 1.0489 |
| 2.5193 | 4.82 | 1760 | 2.3390 | 1.0506 |
| 2.5369 | 4.83 | 1765 | 2.3392 | 1.0384 |
| 2.4843 | 4.85 | 1770 | 2.3398 | 1.0236 |
| 2.5074 | 4.86 | 1775 | 2.3400 | 1.0150 |
| 2.4941 | 4.88 | 1780 | 2.3386 | 1.0150 |
| 2.4352 | 4.89 | 1785 | 2.3370 | 1.0172 |
| 2.4372 | 4.9 | 1790 | 2.3362 | 1.0208 |
| 2.4855 | 4.92 | 1795 | 2.3358 | 1.0238 |
| 2.4516 | 4.93 | 1800 | 2.3355 | 1.0276 |
| 2.5281 | 4.94 | 1805 | 2.3356 | 1.0312 |
| 2.5519 | 4.96 | 1810 | 2.3352 | 1.0318 |
| 2.4641 | 4.97 | 1815 | 2.3349 | 1.0294 |
| 2.4515 | 4.98 | 1820 | 2.3348 | 1.0284 |
| 2.553 | 5.0 | 1825 | 2.3347 | 1.0286 |
### Framework versions
- Transformers 4.17.0.dev0
- Pytorch 1.10.2+cu102
- Datasets 1.18.2.dev0
- Tokenizers 0.11.0
|
maurice/PolitBERT | 6d7e702589046259bb4d63573e4846d9fd8a5759 | 2021-05-19T23:10:43.000Z | [
"pytorch",
"jax",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | false | maurice | null | maurice/PolitBERT | 1 | null | transformers | 29,918 | # PolitBERT
## Background
This model was created to specialize on political speeches, interviews and press briefings of English-speaking politicians.
## Training
The model was initialized using the pre-trained weights of BERT<sub>BASE</sub> and trained for 20 epochs on the standard MLM task with default parameters.
The used learning rate was 5e-5 with a linearly decreasing schedule and AdamW.
The used batch size is 8 per GPU while beeing trained on two Nvidia GTX TITAN X.
The rest of the used configuration is the same as in ```AutoConfig.from_pretrained('bert-base-uncased')```.
As a tokenizer the default tokenizer of BERT was used (```BertTokenizer.from_pretrained('bert-base-uncased')```)
## Dataset
PolitBERT was trained on the following dataset, which has been split up into single sentences:
<https://www.kaggle.com/mauricerupp/englishspeaking-politicians>
## Usage
To predict a missing word of a sentence, the following pipeline can be applied:
```
from transformers import pipeline, BertTokenizer, AutoModel
fill_mask = pipeline("fill-mask",
model=AutoModel.from_pretrained('maurice/PolitBERT'),
tokenizer=BertTokenizer.from_pretrained('bert-base-uncased'))
print(fill_mask('Donald Trump is a [MASK].'))
```
## Training Results
Evaluation Loss:

Training Loss:

Learning Rate Schedule:

|
maxidl/iML-distilbert-base-uncased-select | 418d7c7d44e8d601fa79a9a911cf34cf3eb30b40 | 2021-11-18T22:45:22.000Z | [
"pytorch",
"distilbert",
"token-classification",
"transformers",
"autotrain_compatible"
] | token-classification | false | maxidl | null | maxidl/iML-distilbert-base-uncased-select | 1 | null | transformers | 29,919 | Entry not found |
maximedb/drclips | dcfbba568c85801d3aa7c4bc671d96420c596879 | 2021-10-21T18:06:53.000Z | [
"pytorch",
"tensorboard",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | false | maximedb | null | maximedb/drclips | 1 | null | transformers | 29,920 | Entry not found |
maximedb/splade-roberta | d35062656b4e419fc52ef56143bf1c0d127f51fd | 2022-02-12T19:21:33.000Z | [
"pytorch",
"roberta",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | false | maximedb | null | maximedb/splade-roberta | 1 | null | transformers | 29,921 | Entry not found |
maximedb/test-2 | bc0e1f9d3b24328c32ec86344d185a94d85e5dbb | 2021-10-18T19:34:47.000Z | [
"pytorch",
"tf",
"xlm-roberta",
"feature-extraction",
"transformers"
] | feature-extraction | false | maximedb | null | maximedb/test-2 | 1 | null | transformers | 29,922 | Entry not found |
maxspaziani/bert-base-italian-uncased-finetuned-ComunaliRoma | 0a19a8abd848291904d7249ade7dfb488dcfed2e | 2021-10-18T16:34:41.000Z | [
"pytorch",
"tensorboard",
"bert",
"fill-mask",
"transformers",
"generated_from_trainer",
"license:mit",
"model-index",
"autotrain_compatible"
] | fill-mask | false | maxspaziani | null | maxspaziani/bert-base-italian-uncased-finetuned-ComunaliRoma | 1 | null | transformers | 29,923 | ---
license: mit
tags:
- generated_from_trainer
model-index:
- name: bert-base-italian-uncased-finetuned-ComunaliRoma
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-italian-uncased-finetuned-ComunaliRoma
This model is a fine-tuned version of [dbmdz/bert-base-italian-uncased](https://huggingface.co/dbmdz/bert-base-italian-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.0398
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 156 | 3.1907 |
| No log | 2.0 | 312 | 3.0522 |
| No log | 3.0 | 468 | 3.0203 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.9.0+cu111
- Datasets 1.13.3
- Tokenizers 0.10.3
|
maxspaziani/bert-base-italian-xxl-uncased-finetuned-ComunaliRoma | 855b7b6b1a26ee69b34d0f79f8cde6db9166a9f0 | 2021-10-19T17:58:13.000Z | [
"pytorch",
"tensorboard",
"bert",
"fill-mask",
"transformers",
"generated_from_trainer",
"license:mit",
"model-index",
"autotrain_compatible"
] | fill-mask | false | maxspaziani | null | maxspaziani/bert-base-italian-xxl-uncased-finetuned-ComunaliRoma | 1 | null | transformers | 29,924 | ---
license: mit
tags:
- generated_from_trainer
model-index:
- name: bert-base-italian-xxl-uncased-finetuned-ComunaliRoma
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-italian-xxl-uncased-finetuned-ComunaliRoma
This model is a fine-tuned version of [dbmdz/bert-base-italian-xxl-uncased](https://huggingface.co/dbmdz/bert-base-italian-xxl-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.5095
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.6717 | 1.0 | 1014 | 2.6913 |
| 2.4869 | 2.0 | 2028 | 2.5843 |
| 2.3411 | 3.0 | 3042 | 2.5095 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.9.0+cu111
- Datasets 1.13.3
- Tokenizers 0.10.3
|
mbateman/marian-finetuned-kde4-en-to-fr-accelerate | 55d436f77fa0851b536f6b2c763f77256ed3be43 | 2022-01-27T11:41:27.000Z | [
"pytorch",
"marian",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | false | mbateman | null | mbateman/marian-finetuned-kde4-en-to-fr-accelerate | 1 | null | transformers | 29,925 | Entry not found |
mbateman/mt5-small-finetuned-amazon-en-es | 3f65884fb085fb05b76f84ac582fa85b5005208a | 2022-02-02T10:07:07.000Z | [
"pytorch",
"tensorboard",
"mt5",
"text2text-generation",
"transformers",
"summarization",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
] | summarization | false | mbateman | null | mbateman/mt5-small-finetuned-amazon-en-es | 1 | null | transformers | 29,926 | ---
license: apache-2.0
tags:
- summarization
- generated_from_trainer
metrics:
- rouge
model-index:
- name: mt5-small-finetuned-amazon-en-es
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mt5-small-finetuned-amazon-en-es
This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.0393
- Rouge1: 17.3313
- Rouge2: 8.1251
- Rougel: 17.0359
- Rougelsum: 16.9503
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.6e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:------:|:-------:|:---------:|
| 6.6665 | 1.0 | 1209 | 3.2917 | 13.908 | 5.5316 | 13.4368 | 13.4302 |
| 3.8961 | 2.0 | 2418 | 3.1711 | 16.247 | 8.7234 | 15.7703 | 15.6964 |
| 3.5801 | 3.0 | 3627 | 3.0917 | 17.3455 | 8.2467 | 16.8631 | 16.8147 |
| 3.4258 | 4.0 | 4836 | 3.0583 | 16.0978 | 7.83 | 15.8065 | 15.7725 |
| 3.3154 | 5.0 | 6045 | 3.0573 | 17.5531 | 8.7811 | 17.2252 | 17.2055 |
| 3.2438 | 6.0 | 7254 | 3.0479 | 17.2072 | 8.0951 | 17.025 | 16.9644 |
| 3.2024 | 7.0 | 8463 | 3.0377 | 17.3692 | 8.1843 | 17.019 | 17.0006 |
| 3.1745 | 8.0 | 9672 | 3.0393 | 17.3313 | 8.1251 | 17.0359 | 16.9503 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.0+cu111
- Datasets 1.18.2
- Tokenizers 0.11.0
|
mbeukman/xlm-roberta-base-finetuned-amharic-finetuned-ner-amharic | ee1a5eb8a40eb086e0009b7563ca2b19465141ba | 2022-02-22T11:30:02.000Z | [
"pytorch",
"xlm-roberta",
"token-classification",
"am",
"dataset:masakhaner",
"arxiv:2103.11811",
"transformers",
"NER",
"autotrain_compatible"
] | token-classification | false | mbeukman | null | mbeukman/xlm-roberta-base-finetuned-amharic-finetuned-ner-amharic | 1 | null | transformers | 29,927 | ---
language:
- am
tags:
- NER
- token-classification
datasets:
- masakhaner
metrics:
- f1
- precision
- recall
widget:
- text: "ቀዳሚው የሶማሌ ክልል በአወዳይ ከተማ ለተገደሉ የክልሉ ተወላጆች ያከናወነው የቀብር ስነ ስርዓትን የተመለከተ ዘገባ ነው ፡፡"
---
# xlm-roberta-base-finetuned-amharic-finetuned-ner-amharic
This is a token classification (specifically NER) model that fine-tuned [xlm-roberta-base-finetuned-amharic](https://huggingface.co/Davlan/xlm-roberta-base-finetuned-amharic) on the [MasakhaNER](https://arxiv.org/abs/2103.11811) dataset, specifically the Amharic part.
More information, and other similar models can be found in the [main Github repository](https://github.com/Michael-Beukman/NERTransfer).
## About
This model is transformer based and was fine-tuned on the MasakhaNER dataset. It is a named entity recognition dataset, containing mostly news articles in 10 different African languages.
The model was fine-tuned for 50 epochs, with a maximum sequence length of 200, 32 batch size, 5e-5 learning rate. This process was repeated 5 times (with different random seeds), and this uploaded model performed the best out of those 5 seeds (aggregate F1 on test set).
This model was fine-tuned by me, Michael Beukman while doing a project at the University of the Witwatersrand, Johannesburg. This is version 1, as of 20 November 2021.
This model is licensed under the [Apache License, Version 2.0](https://www.apache.org/licenses/LICENSE-2.0).
### Contact & More information
For more information about the models, including training scripts, detailed results and further resources, you can visit the the [main Github repository](https://github.com/Michael-Beukman/NERTransfer). You can contact me by filing an issue on this repository.
### Training Resources
In the interest of openness, and reporting resources used, we list here how long the training process took, as well as what the minimum resources would be to reproduce this. Fine-tuning each model on the NER dataset took between 10 and 30 minutes, and was performed on a NVIDIA RTX3090 GPU. To use a batch size of 32, at least 14GB of GPU memory was required, although it was just possible to fit these models in around 6.5GB's of VRAM when using a batch size of 1.
## Data
The train, evaluation and test datasets were taken directly from the MasakhaNER [Github](https://github.com/masakhane-io/masakhane-ner) repository, with minimal to no preprocessing, as the original dataset is already of high quality.
The motivation for the use of this data is that it is the "first large, publicly available, high quality dataset for named entity recognition (NER) in ten African languages" ([source](https://arxiv.org/pdf/2103.11811.pdf)). The high-quality data, as well as the groundwork laid by the paper introducing it are some more reasons why this dataset was used. For evaluation, the dedicated test split was used, which is from the same distribution as the training data, so this model may not generalise to other distributions, and further testing would need to be done to investigate this. The exact distribution of the data is covered in detail [here](https://arxiv.org/abs/2103.11811).
## Intended Use
This model are intended to be used for NLP research into e.g. interpretability or transfer learning. Using this model in production is not supported, as generalisability and downright performance is limited. In particular, this is not designed to be used in any important downstream task that could affect people, as harm could be caused by the limitations of the model, described next.
## Limitations
This model was only trained on one (relatively small) dataset, covering one task (NER) in one domain (news articles) and in a set span of time. The results may not generalise, and the model may perform badly, or in an unfair / biased way if used on other tasks. Although the purpose of this project was to investigate transfer learning, the performance on languages that the model was not trained for does suffer.
Because this model used xlm-roberta-base as its starting point (potentially with domain adaptive fine-tuning on specific languages), this model's limitations can also apply here. These can include being biased towards the hegemonic viewpoint of most of its training data, being ungrounded and having subpar results on other languages (possibly due to unbalanced training data).
As [Adelani et al. (2021)](https://arxiv.org/abs/2103.11811) showed, the models in general struggled with entities that were either longer than 3 words and entities that were not contained in the training data. This could bias the models towards not finding, e.g. names of people that have many words, possibly leading to a misrepresentation in the results. Similarly, names that are uncommon, and may not have been found in the training data (due to e.g. different languages) would also be predicted less often.
Additionally, this model has not been verified in practice, and other, more subtle problems may become prevalent if used without any verification that it does what it is supposed to.
### Privacy & Ethical Considerations
The data comes from only publicly available news sources, the only available data should cover public figures and those that agreed to be reported on. See the original MasakhaNER paper for more details.
No explicit ethical considerations or adjustments were made during fine-tuning of this model.
## Metrics
The language adaptive models achieve (mostly) superior performance over starting with xlm-roberta-base. Our main metric was the aggregate F1 score for all NER categories.
These metrics are on the test set for MasakhaNER, so the data distribution is similar to the training set, so these results do not directly indicate how well these models generalise.
We do find large variation in transfer results when starting from different seeds (5 different seeds were tested), indicating that the fine-tuning process for transfer might be unstable.
The metrics used were chosen to be consistent with previous work, and to facilitate research. Other metrics may be more appropriate for other purposes.
## Caveats and Recommendations
In general, this model performed worse on the 'date' category compared to others, so if dates are a critical factor, then that might need to be taken into account and addressed, by for example collecting and annotating more data.
## Model Structure
Here are some performance details on this specific model, compared to others we trained.
All of these metrics were calculated on the test set, and the seed was chosen that gave the best overall F1 score. The first three result columns are averaged over all categories, and the latter 4 provide performance broken down by category.
This model can predict the following label for a token ([source](https://huggingface.co/Davlan/xlm-roberta-large-masakhaner)):
Abbreviation|Description
-|-
O|Outside of a named entity
B-DATE |Beginning of a DATE entity right after another DATE entity
I-DATE |DATE entity
B-PER |Beginning of a person’s name right after another person’s name
I-PER |Person’s name
B-ORG |Beginning of an organisation right after another organisation
I-ORG |Organisation
B-LOC |Beginning of a location right after another location
I-LOC |Location
| Model Name | Staring point | Evaluation / Fine-tune Language | F1 | Precision | Recall | F1 (DATE) | F1 (LOC) | F1 (ORG) | F1 (PER) |
| -------------------------------------------------- | -------------------- | -------------------- | -------------- | -------------- | -------------- | -------------- | -------------- | -------------- | -------------- |
| [xlm-roberta-base-finetuned-amharic-finetuned-ner-amharic](https://huggingface.co/mbeukman/xlm-roberta-base-finetuned-amharic-finetuned-ner-amharic) (This model) | [amh](https://huggingface.co/Davlan/xlm-roberta-base-finetuned-amharic) | amh | 79.55 | 76.71 | 82.62 | 70.00 | 84.00 | 62.00 | 91.00 |
| [xlm-roberta-base-finetuned-swahili-finetuned-ner-amharic](https://huggingface.co/mbeukman/xlm-roberta-base-finetuned-swahili-finetuned-ner-amharic) | [swa](https://huggingface.co/Davlan/xlm-roberta-base-finetuned-swahili) | amh | 70.34 | 69.72 | 70.97 | 72.00 | 75.00 | 51.00 | 73.00 |
| [xlm-roberta-base-finetuned-ner-amharic](https://huggingface.co/mbeukman/xlm-roberta-base-finetuned-ner-amharic) | [base](https://huggingface.co/xlm-roberta-base) | amh | 72.63 | 70.49 | 74.91 | 76.00 | 75.00 | 52.00 | 78.00 |
## Usage
To use this model (or others), you can do the following, just changing the model name ([source](https://huggingface.co/dslim/bert-base-NER)):
```
from transformers import AutoTokenizer, AutoModelForTokenClassification
from transformers import pipeline
model_name = 'mbeukman/xlm-roberta-base-finetuned-amharic-finetuned-ner-amharic'
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForTokenClassification.from_pretrained(model_name)
nlp = pipeline("ner", model=model, tokenizer=tokenizer)
example = "ቀዳሚው የሶማሌ ክልል በአወዳይ ከተማ ለተገደሉ የክልሉ ተወላጆች ያከናወነው የቀብር ስነ ስርዓትን የተመለከተ ዘገባ ነው ፡፡"
ner_results = nlp(example)
print(ner_results)
```
|
mbeukman/xlm-roberta-base-finetuned-hausa-finetuned-ner-hausa | aabd3b4a0eae299c01f53283204557c6ad8f0700 | 2021-11-25T09:03:55.000Z | [
"pytorch",
"xlm-roberta",
"token-classification",
"ha",
"dataset:masakhaner",
"arxiv:2103.11811",
"transformers",
"NER",
"autotrain_compatible"
] | token-classification | false | mbeukman | null | mbeukman/xlm-roberta-base-finetuned-hausa-finetuned-ner-hausa | 1 | null | transformers | 29,928 | ---
language:
- ha
tags:
- NER
datasets:
- masakhaner
metrics:
- f1
- precision
- recall
widget:
- text: "A saurari cikakken rahoton wakilin Muryar Amurka Ibrahim Abdul'aziz"
---
# xlm-roberta-base-finetuned-hausa-finetuned-ner-hausa
This is a token classification (specifically NER) model that fine-tuned [xlm-roberta-base-finetuned-hausa](https://huggingface.co/Davlan/xlm-roberta-base-finetuned-hausa) on the [MasakhaNER](https://arxiv.org/abs/2103.11811) dataset, specifically the Hausa part.
More information, and other similar models can be found in the [main Github repository](https://github.com/Michael-Beukman/NERTransfer).
## About
This model is transformer based and was fine-tuned on the MasakhaNER dataset. It is a named entity recognition dataset, containing mostly news articles in 10 different African languages.
The model was fine-tuned for 50 epochs, with a maximum sequence length of 200, 32 batch size, 5e-5 learning rate. This process was repeated 5 times (with different random seeds), and this uploaded model performed the best out of those 5 seeds (aggregate F1 on test set).
This model was fine-tuned by me, Michael Beukman while doing a project at the University of the Witwatersrand, Johannesburg. This is version 1, as of 20 November 2021.
This model is licensed under the [Apache License, Version 2.0](https://www.apache.org/licenses/LICENSE-2.0).
### Contact & More information
For more information about the models, including training scripts, detailed results and further resources, you can visit the the [main Github repository](https://github.com/Michael-Beukman/NERTransfer). You can contact me by filing an issue on this repository.
### Training Resources
In the interest of openness, and reporting resources used, we list here how long the training process took, as well as what the minimum resources would be to reproduce this. Fine-tuning each model on the NER dataset took between 10 and 30 minutes, and was performed on a NVIDIA RTX3090 GPU. To use a batch size of 32, at least 14GB of GPU memory was required, although it was just possible to fit these models in around 6.5GB's of VRAM when using a batch size of 1.
## Data
The train, evaluation and test datasets were taken directly from the MasakhaNER [Github](https://github.com/masakhane-io/masakhane-ner) repository, with minimal to no preprocessing, as the original dataset is already of high quality.
The motivation for the use of this data is that it is the "first large, publicly available, high quality dataset for named entity recognition (NER) in ten African languages" ([source](https://arxiv.org/pdf/2103.11811.pdf)). The high-quality data, as well as the groundwork laid by the paper introducing it are some more reasons why this dataset was used. For evaluation, the dedicated test split was used, which is from the same distribution as the training data, so this model may not generalise to other distributions, and further testing would need to be done to investigate this. The exact distribution of the data is covered in detail [here](https://arxiv.org/abs/2103.11811).
## Intended Use
This model are intended to be used for NLP research into e.g. interpretability or transfer learning. Using this model in production is not supported, as generalisability and downright performance is limited. In particular, this is not designed to be used in any important downstream task that could affect people, as harm could be caused by the limitations of the model, described next.
## Limitations
This model was only trained on one (relatively small) dataset, covering one task (NER) in one domain (news articles) and in a set span of time. The results may not generalise, and the model may perform badly, or in an unfair / biased way if used on other tasks. Although the purpose of this project was to investigate transfer learning, the performance on languages that the model was not trained for does suffer.
Because this model used xlm-roberta-base as its starting point (potentially with domain adaptive fine-tuning on specific languages), this model's limitations can also apply here. These can include being biased towards the hegemonic viewpoint of most of its training data, being ungrounded and having subpar results on other languages (possibly due to unbalanced training data).
As [Adelani et al. (2021)](https://arxiv.org/abs/2103.11811) showed, the models in general struggled with entities that were either longer than 3 words and entities that were not contained in the training data. This could bias the models towards not finding, e.g. names of people that have many words, possibly leading to a misrepresentation in the results. Similarly, names that are uncommon, and may not have been found in the training data (due to e.g. different languages) would also be predicted less often.
Additionally, this model has not been verified in practice, and other, more subtle problems may become prevalent if used without any verification that it does what it is supposed to.
### Privacy & Ethical Considerations
The data comes from only publicly available news sources, the only available data should cover public figures and those that agreed to be reported on. See the original MasakhaNER paper for more details.
No explicit ethical considerations or adjustments were made during fine-tuning of this model.
## Metrics
The language adaptive models achieve (mostly) superior performance over starting with xlm-roberta-base. Our main metric was the aggregate F1 score for all NER categories.
These metrics are on the test set for MasakhaNER, so the data distribution is similar to the training set, so these results do not directly indicate how well these models generalise.
We do find large variation in transfer results when starting from different seeds (5 different seeds were tested), indicating that the fine-tuning process for transfer might be unstable.
The metrics used were chosen to be consistent with previous work, and to facilitate research. Other metrics may be more appropriate for other purposes.
## Caveats and Recommendations
In general, this model performed worse on the 'date' category compared to others, so if dates are a critical factor, then that might need to be taken into account and addressed, by for example collecting and annotating more data.
## Model Structure
Here are some performance details on this specific model, compared to others we trained.
All of these metrics were calculated on the test set, and the seed was chosen that gave the best overall F1 score. The first three result columns are averaged over all categories, and the latter 4 provide performance broken down by category.
This model can predict the following label for a token ([source](https://huggingface.co/Davlan/xlm-roberta-large-masakhaner)):
Abbreviation|Description
-|-
O|Outside of a named entity
B-DATE |Beginning of a DATE entity right after another DATE entity
I-DATE |DATE entity
B-PER |Beginning of a person’s name right after another person’s name
I-PER |Person’s name
B-ORG |Beginning of an organisation right after another organisation
I-ORG |Organisation
B-LOC |Beginning of a location right after another location
I-LOC |Location
| Model Name | Staring point | Evaluation / Fine-tune Language | F1 | Precision | Recall | F1 (DATE) | F1 (LOC) | F1 (ORG) | F1 (PER) |
| -------------------------------------------------- | -------------------- | -------------------- | -------------- | -------------- | -------------- | -------------- | -------------- | -------------- | -------------- |
| [xlm-roberta-base-finetuned-hausa-finetuned-ner-hausa](https://huggingface.co/mbeukman/xlm-roberta-base-finetuned-hausa-finetuned-ner-hausa) (This model) | [hau](https://huggingface.co/Davlan/xlm-roberta-base-finetuned-hausa) | hau | 92.27 | 90.46 | 94.16 | 85.00 | 95.00 | 80.00 | 97.00 |
| [xlm-roberta-base-finetuned-swahili-finetuned-ner-hausa](https://huggingface.co/mbeukman/xlm-roberta-base-finetuned-swahili-finetuned-ner-hausa) | [swa](https://huggingface.co/Davlan/xlm-roberta-base-finetuned-swahili) | hau | 89.14 | 87.18 | 91.20 | 82.00 | 93.00 | 76.00 | 93.00 |
| [xlm-roberta-base-finetuned-ner-hausa](https://huggingface.co/mbeukman/xlm-roberta-base-finetuned-ner-hausa) | [base](https://huggingface.co/xlm-roberta-base) | hau | 89.94 | 87.74 | 92.25 | 84.00 | 94.00 | 74.00 | 93.00 |
## Usage
To use this model (or others), you can do the following, just changing the model name ([source](https://huggingface.co/dslim/bert-base-NER)):
```
from transformers import AutoTokenizer, AutoModelForTokenClassification
from transformers import pipeline
model_name = 'mbeukman/xlm-roberta-base-finetuned-hausa-finetuned-ner-hausa'
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForTokenClassification.from_pretrained(model_name)
nlp = pipeline("ner", model=model, tokenizer=tokenizer)
example = "A saurari cikakken rahoton wakilin Muryar Amurka Ibrahim Abdul'aziz"
ner_results = nlp(example)
print(ner_results)
```
|
mbeukman/xlm-roberta-base-finetuned-ner-yoruba | 501c635e49b290291b76d35f51b7b400435b21d5 | 2021-11-25T09:04:45.000Z | [
"pytorch",
"xlm-roberta",
"token-classification",
"yo",
"dataset:masakhaner",
"arxiv:2103.11811",
"transformers",
"NER",
"autotrain_compatible"
] | token-classification | false | mbeukman | null | mbeukman/xlm-roberta-base-finetuned-ner-yoruba | 1 | null | transformers | 29,929 | ---
language:
- yo
tags:
- NER
datasets:
- masakhaner
metrics:
- f1
- precision
- recall
widget:
- text: "Kò sí ẹ̀rí tí ó fi ẹsẹ̀ rinlẹ̀ ."
---
# xlm-roberta-base-finetuned-ner-yoruba
This is a token classification (specifically NER) model that fine-tuned [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the [MasakhaNER](https://arxiv.org/abs/2103.11811) dataset, specifically the Yoruba part.
More information, and other similar models can be found in the [main Github repository](https://github.com/Michael-Beukman/NERTransfer).
## About
This model is transformer based and was fine-tuned on the MasakhaNER dataset. It is a named entity recognition dataset, containing mostly news articles in 10 different African languages.
The model was fine-tuned for 50 epochs, with a maximum sequence length of 200, 32 batch size, 5e-5 learning rate. This process was repeated 5 times (with different random seeds), and this uploaded model performed the best out of those 5 seeds (aggregate F1 on test set).
This model was fine-tuned by me, Michael Beukman while doing a project at the University of the Witwatersrand, Johannesburg. This is version 1, as of 20 November 2021.
This model is licensed under the [Apache License, Version 2.0](https://www.apache.org/licenses/LICENSE-2.0).
### Contact & More information
For more information about the models, including training scripts, detailed results and further resources, you can visit the the [main Github repository](https://github.com/Michael-Beukman/NERTransfer). You can contact me by filing an issue on this repository.
### Training Resources
In the interest of openness, and reporting resources used, we list here how long the training process took, as well as what the minimum resources would be to reproduce this. Fine-tuning each model on the NER dataset took between 10 and 30 minutes, and was performed on a NVIDIA RTX3090 GPU. To use a batch size of 32, at least 14GB of GPU memory was required, although it was just possible to fit these models in around 6.5GB's of VRAM when using a batch size of 1.
## Data
The train, evaluation and test datasets were taken directly from the MasakhaNER [Github](https://github.com/masakhane-io/masakhane-ner) repository, with minimal to no preprocessing, as the original dataset is already of high quality.
The motivation for the use of this data is that it is the "first large, publicly available, high quality dataset for named entity recognition (NER) in ten African languages" ([source](https://arxiv.org/pdf/2103.11811.pdf)). The high-quality data, as well as the groundwork laid by the paper introducing it are some more reasons why this dataset was used. For evaluation, the dedicated test split was used, which is from the same distribution as the training data, so this model may not generalise to other distributions, and further testing would need to be done to investigate this. The exact distribution of the data is covered in detail [here](https://arxiv.org/abs/2103.11811).
## Intended Use
This model are intended to be used for NLP research into e.g. interpretability or transfer learning. Using this model in production is not supported, as generalisability and downright performance is limited. In particular, this is not designed to be used in any important downstream task that could affect people, as harm could be caused by the limitations of the model, described next.
## Limitations
This model was only trained on one (relatively small) dataset, covering one task (NER) in one domain (news articles) and in a set span of time. The results may not generalise, and the model may perform badly, or in an unfair / biased way if used on other tasks. Although the purpose of this project was to investigate transfer learning, the performance on languages that the model was not trained for does suffer.
Because this model used xlm-roberta-base as its starting point (potentially with domain adaptive fine-tuning on specific languages), this model's limitations can also apply here. These can include being biased towards the hegemonic viewpoint of most of its training data, being ungrounded and having subpar results on other languages (possibly due to unbalanced training data).
As [Adelani et al. (2021)](https://arxiv.org/abs/2103.11811) showed, the models in general struggled with entities that were either longer than 3 words and entities that were not contained in the training data. This could bias the models towards not finding, e.g. names of people that have many words, possibly leading to a misrepresentation in the results. Similarly, names that are uncommon, and may not have been found in the training data (due to e.g. different languages) would also be predicted less often.
Additionally, this model has not been verified in practice, and other, more subtle problems may become prevalent if used without any verification that it does what it is supposed to.
### Privacy & Ethical Considerations
The data comes from only publicly available news sources, the only available data should cover public figures and those that agreed to be reported on. See the original MasakhaNER paper for more details.
No explicit ethical considerations or adjustments were made during fine-tuning of this model.
## Metrics
The language adaptive models achieve (mostly) superior performance over starting with xlm-roberta-base. Our main metric was the aggregate F1 score for all NER categories.
These metrics are on the test set for MasakhaNER, so the data distribution is similar to the training set, so these results do not directly indicate how well these models generalise.
We do find large variation in transfer results when starting from different seeds (5 different seeds were tested), indicating that the fine-tuning process for transfer might be unstable.
The metrics used were chosen to be consistent with previous work, and to facilitate research. Other metrics may be more appropriate for other purposes.
## Caveats and Recommendations
In general, this model performed worse on the 'date' category compared to others, so if dates are a critical factor, then that might need to be taken into account and addressed, by for example collecting and annotating more data.
## Model Structure
Here are some performance details on this specific model, compared to others we trained.
All of these metrics were calculated on the test set, and the seed was chosen that gave the best overall F1 score. The first three result columns are averaged over all categories, and the latter 4 provide performance broken down by category.
This model can predict the following label for a token ([source](https://huggingface.co/Davlan/xlm-roberta-large-masakhaner)):
Abbreviation|Description
-|-
O|Outside of a named entity
B-DATE |Beginning of a DATE entity right after another DATE entity
I-DATE |DATE entity
B-PER |Beginning of a person’s name right after another person’s name
I-PER |Person’s name
B-ORG |Beginning of an organisation right after another organisation
I-ORG |Organisation
B-LOC |Beginning of a location right after another location
I-LOC |Location
| Model Name | Staring point | Evaluation / Fine-tune Language | F1 | Precision | Recall | F1 (DATE) | F1 (LOC) | F1 (ORG) | F1 (PER) |
| -------------------------------------------------- | -------------------- | -------------------- | -------------- | -------------- | -------------- | -------------- | -------------- | -------------- | -------------- |
| [xlm-roberta-base-finetuned-ner-yoruba](https://huggingface.co/mbeukman/xlm-roberta-base-finetuned-ner-yoruba) (This model) | [base](https://huggingface.co/xlm-roberta-base) | yor | 78.22 | 77.21 | 79.26 | 77.00 | 80.00 | 71.00 | 82.00 |
| [xlm-roberta-base-finetuned-swahili-finetuned-ner-yoruba](https://huggingface.co/mbeukman/xlm-roberta-base-finetuned-swahili-finetuned-ner-yoruba) | [swa](https://huggingface.co/Davlan/xlm-roberta-base-finetuned-swahili) | yor | 80.29 | 78.34 | 82.35 | 77.00 | 82.00 | 73.00 | 86.00 |
| [xlm-roberta-base-finetuned-yoruba-finetuned-ner-yoruba](https://huggingface.co/mbeukman/xlm-roberta-base-finetuned-yoruba-finetuned-ner-yoruba) | [yor](https://huggingface.co/Davlan/xlm-roberta-base-finetuned-yoruba) | yor | 83.68 | 79.92 | 87.82 | 78.00 | 86.00 | 74.00 | 92.00 |
## Usage
To use this model (or others), you can do the following, just changing the model name ([source](https://huggingface.co/dslim/bert-base-NER)):
```
from transformers import AutoTokenizer, AutoModelForTokenClassification
from transformers import pipeline
model_name = 'mbeukman/xlm-roberta-base-finetuned-ner-yoruba'
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForTokenClassification.from_pretrained(model_name)
nlp = pipeline("ner", model=model, tokenizer=tokenizer)
example = "Kò sí ẹ̀rí tí ó fi ẹsẹ̀ rinlẹ̀ ."
ner_results = nlp(example)
print(ner_results)
```
|
mbeukman/xlm-roberta-base-finetuned-swahili-finetuned-ner-amharic | 964bbb6eff4f4049efda3fd6cee25c26dc4fff08 | 2022-02-22T11:42:08.000Z | [
"pytorch",
"xlm-roberta",
"token-classification",
"am",
"dataset:masakhaner",
"arxiv:2103.11811",
"transformers",
"NER",
"autotrain_compatible"
] | token-classification | false | mbeukman | null | mbeukman/xlm-roberta-base-finetuned-swahili-finetuned-ner-amharic | 1 | null | transformers | 29,930 | ---
language:
- am
tags:
- NER
- token-classification
datasets:
- masakhaner
metrics:
- f1
- precision
- recall
widget:
- text: "ቀዳሚው የሶማሌ ክልል በአወዳይ ከተማ ለተገደሉ የክልሉ ተወላጆች ያከናወነው የቀብር ስነ ስርዓትን የተመለከተ ዘገባ ነው ፡፡"
---
# xlm-roberta-base-finetuned-swahili-finetuned-ner-amharic
This is a token classification (specifically NER) model that fine-tuned [xlm-roberta-base-finetuned-swahili](https://huggingface.co/Davlan/xlm-roberta-base-finetuned-swahili) on the [MasakhaNER](https://arxiv.org/abs/2103.11811) dataset, specifically the Amharic part.
More information, and other similar models can be found in the [main Github repository](https://github.com/Michael-Beukman/NERTransfer).
## About
This model is transformer based and was fine-tuned on the MasakhaNER dataset. It is a named entity recognition dataset, containing mostly news articles in 10 different African languages.
The model was fine-tuned for 50 epochs, with a maximum sequence length of 200, 32 batch size, 5e-5 learning rate. This process was repeated 5 times (with different random seeds), and this uploaded model performed the best out of those 5 seeds (aggregate F1 on test set).
This model was fine-tuned by me, Michael Beukman while doing a project at the University of the Witwatersrand, Johannesburg. This is version 1, as of 20 November 2021.
This model is licensed under the [Apache License, Version 2.0](https://www.apache.org/licenses/LICENSE-2.0).
### Contact & More information
For more information about the models, including training scripts, detailed results and further resources, you can visit the the [main Github repository](https://github.com/Michael-Beukman/NERTransfer). You can contact me by filing an issue on this repository.
### Training Resources
In the interest of openness, and reporting resources used, we list here how long the training process took, as well as what the minimum resources would be to reproduce this. Fine-tuning each model on the NER dataset took between 10 and 30 minutes, and was performed on a NVIDIA RTX3090 GPU. To use a batch size of 32, at least 14GB of GPU memory was required, although it was just possible to fit these models in around 6.5GB's of VRAM when using a batch size of 1.
## Data
The train, evaluation and test datasets were taken directly from the MasakhaNER [Github](https://github.com/masakhane-io/masakhane-ner) repository, with minimal to no preprocessing, as the original dataset is already of high quality.
The motivation for the use of this data is that it is the "first large, publicly available, high quality dataset for named entity recognition (NER) in ten African languages" ([source](https://arxiv.org/pdf/2103.11811.pdf)). The high-quality data, as well as the groundwork laid by the paper introducing it are some more reasons why this dataset was used. For evaluation, the dedicated test split was used, which is from the same distribution as the training data, so this model may not generalise to other distributions, and further testing would need to be done to investigate this. The exact distribution of the data is covered in detail [here](https://arxiv.org/abs/2103.11811).
## Intended Use
This model are intended to be used for NLP research into e.g. interpretability or transfer learning. Using this model in production is not supported, as generalisability and downright performance is limited. In particular, this is not designed to be used in any important downstream task that could affect people, as harm could be caused by the limitations of the model, described next.
## Limitations
This model was only trained on one (relatively small) dataset, covering one task (NER) in one domain (news articles) and in a set span of time. The results may not generalise, and the model may perform badly, or in an unfair / biased way if used on other tasks. Although the purpose of this project was to investigate transfer learning, the performance on languages that the model was not trained for does suffer.
Because this model used xlm-roberta-base as its starting point (potentially with domain adaptive fine-tuning on specific languages), this model's limitations can also apply here. These can include being biased towards the hegemonic viewpoint of most of its training data, being ungrounded and having subpar results on other languages (possibly due to unbalanced training data).
As [Adelani et al. (2021)](https://arxiv.org/abs/2103.11811) showed, the models in general struggled with entities that were either longer than 3 words and entities that were not contained in the training data. This could bias the models towards not finding, e.g. names of people that have many words, possibly leading to a misrepresentation in the results. Similarly, names that are uncommon, and may not have been found in the training data (due to e.g. different languages) would also be predicted less often.
Additionally, this model has not been verified in practice, and other, more subtle problems may become prevalent if used without any verification that it does what it is supposed to.
### Privacy & Ethical Considerations
The data comes from only publicly available news sources, the only available data should cover public figures and those that agreed to be reported on. See the original MasakhaNER paper for more details.
No explicit ethical considerations or adjustments were made during fine-tuning of this model.
## Metrics
The language adaptive models achieve (mostly) superior performance over starting with xlm-roberta-base. Our main metric was the aggregate F1 score for all NER categories.
These metrics are on the test set for MasakhaNER, so the data distribution is similar to the training set, so these results do not directly indicate how well these models generalise.
We do find large variation in transfer results when starting from different seeds (5 different seeds were tested), indicating that the fine-tuning process for transfer might be unstable.
The metrics used were chosen to be consistent with previous work, and to facilitate research. Other metrics may be more appropriate for other purposes.
## Caveats and Recommendations
In general, this model performed worse on the 'date' category compared to others, so if dates are a critical factor, then that might need to be taken into account and addressed, by for example collecting and annotating more data.
## Model Structure
Here are some performance details on this specific model, compared to others we trained.
All of these metrics were calculated on the test set, and the seed was chosen that gave the best overall F1 score. The first three result columns are averaged over all categories, and the latter 4 provide performance broken down by category.
This model can predict the following label for a token ([source](https://huggingface.co/Davlan/xlm-roberta-large-masakhaner)):
Abbreviation|Description
-|-
O|Outside of a named entity
B-DATE |Beginning of a DATE entity right after another DATE entity
I-DATE |DATE entity
B-PER |Beginning of a person’s name right after another person’s name
I-PER |Person’s name
B-ORG |Beginning of an organisation right after another organisation
I-ORG |Organisation
B-LOC |Beginning of a location right after another location
I-LOC |Location
| Model Name | Staring point | Evaluation / Fine-tune Language | F1 | Precision | Recall | F1 (DATE) | F1 (LOC) | F1 (ORG) | F1 (PER) |
| -------------------------------------------------- | -------------------- | -------------------- | -------------- | -------------- | -------------- | -------------- | -------------- | -------------- | -------------- |
| [xlm-roberta-base-finetuned-swahili-finetuned-ner-amharic](https://huggingface.co/mbeukman/xlm-roberta-base-finetuned-swahili-finetuned-ner-amharic) (This model) | [swa](https://huggingface.co/Davlan/xlm-roberta-base-finetuned-swahili) | amh | 70.34 | 69.72 | 70.97 | 72.00 | 75.00 | 51.00 | 73.00 |
| [xlm-roberta-base-finetuned-amharic-finetuned-ner-amharic](https://huggingface.co/mbeukman/xlm-roberta-base-finetuned-amharic-finetuned-ner-amharic) | [amh](https://huggingface.co/Davlan/xlm-roberta-base-finetuned-amharic) | amh | 79.55 | 76.71 | 82.62 | 70.00 | 84.00 | 62.00 | 91.00 |
| [xlm-roberta-base-finetuned-ner-amharic](https://huggingface.co/mbeukman/xlm-roberta-base-finetuned-ner-amharic) | [base](https://huggingface.co/xlm-roberta-base) | amh | 72.63 | 70.49 | 74.91 | 76.00 | 75.00 | 52.00 | 78.00 |
## Usage
To use this model (or others), you can do the following, just changing the model name ([source](https://huggingface.co/dslim/bert-base-NER)):
```
from transformers import AutoTokenizer, AutoModelForTokenClassification
from transformers import pipeline
model_name = 'mbeukman/xlm-roberta-base-finetuned-swahili-finetuned-ner-amharic'
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForTokenClassification.from_pretrained(model_name)
nlp = pipeline("ner", model=model, tokenizer=tokenizer)
example = "ቀዳሚው የሶማሌ ክልል በአወዳይ ከተማ ለተገደሉ የክልሉ ተወላጆች ያከናወነው የቀብር ስነ ስርዓትን የተመለከተ ዘገባ ነው ፡፡"
ner_results = nlp(example)
print(ner_results)
```
|
mbeukman/xlm-roberta-base-finetuned-swahili-finetuned-ner-hausa | dd4fbc19996fccbcb53da5c957a6026f335df11c | 2021-11-25T09:04:48.000Z | [
"pytorch",
"xlm-roberta",
"token-classification",
"ha",
"dataset:masakhaner",
"arxiv:2103.11811",
"transformers",
"NER",
"autotrain_compatible"
] | token-classification | false | mbeukman | null | mbeukman/xlm-roberta-base-finetuned-swahili-finetuned-ner-hausa | 1 | null | transformers | 29,931 | ---
language:
- ha
tags:
- NER
datasets:
- masakhaner
metrics:
- f1
- precision
- recall
widget:
- text: "A saurari cikakken rahoton wakilin Muryar Amurka Ibrahim Abdul'aziz"
---
# xlm-roberta-base-finetuned-swahili-finetuned-ner-hausa
This is a token classification (specifically NER) model that fine-tuned [xlm-roberta-base-finetuned-swahili](https://huggingface.co/Davlan/xlm-roberta-base-finetuned-swahili) on the [MasakhaNER](https://arxiv.org/abs/2103.11811) dataset, specifically the Hausa part.
More information, and other similar models can be found in the [main Github repository](https://github.com/Michael-Beukman/NERTransfer).
## About
This model is transformer based and was fine-tuned on the MasakhaNER dataset. It is a named entity recognition dataset, containing mostly news articles in 10 different African languages.
The model was fine-tuned for 50 epochs, with a maximum sequence length of 200, 32 batch size, 5e-5 learning rate. This process was repeated 5 times (with different random seeds), and this uploaded model performed the best out of those 5 seeds (aggregate F1 on test set).
This model was fine-tuned by me, Michael Beukman while doing a project at the University of the Witwatersrand, Johannesburg. This is version 1, as of 20 November 2021.
This model is licensed under the [Apache License, Version 2.0](https://www.apache.org/licenses/LICENSE-2.0).
### Contact & More information
For more information about the models, including training scripts, detailed results and further resources, you can visit the the [main Github repository](https://github.com/Michael-Beukman/NERTransfer). You can contact me by filing an issue on this repository.
### Training Resources
In the interest of openness, and reporting resources used, we list here how long the training process took, as well as what the minimum resources would be to reproduce this. Fine-tuning each model on the NER dataset took between 10 and 30 minutes, and was performed on a NVIDIA RTX3090 GPU. To use a batch size of 32, at least 14GB of GPU memory was required, although it was just possible to fit these models in around 6.5GB's of VRAM when using a batch size of 1.
## Data
The train, evaluation and test datasets were taken directly from the MasakhaNER [Github](https://github.com/masakhane-io/masakhane-ner) repository, with minimal to no preprocessing, as the original dataset is already of high quality.
The motivation for the use of this data is that it is the "first large, publicly available, high quality dataset for named entity recognition (NER) in ten African languages" ([source](https://arxiv.org/pdf/2103.11811.pdf)). The high-quality data, as well as the groundwork laid by the paper introducing it are some more reasons why this dataset was used. For evaluation, the dedicated test split was used, which is from the same distribution as the training data, so this model may not generalise to other distributions, and further testing would need to be done to investigate this. The exact distribution of the data is covered in detail [here](https://arxiv.org/abs/2103.11811).
## Intended Use
This model are intended to be used for NLP research into e.g. interpretability or transfer learning. Using this model in production is not supported, as generalisability and downright performance is limited. In particular, this is not designed to be used in any important downstream task that could affect people, as harm could be caused by the limitations of the model, described next.
## Limitations
This model was only trained on one (relatively small) dataset, covering one task (NER) in one domain (news articles) and in a set span of time. The results may not generalise, and the model may perform badly, or in an unfair / biased way if used on other tasks. Although the purpose of this project was to investigate transfer learning, the performance on languages that the model was not trained for does suffer.
Because this model used xlm-roberta-base as its starting point (potentially with domain adaptive fine-tuning on specific languages), this model's limitations can also apply here. These can include being biased towards the hegemonic viewpoint of most of its training data, being ungrounded and having subpar results on other languages (possibly due to unbalanced training data).
As [Adelani et al. (2021)](https://arxiv.org/abs/2103.11811) showed, the models in general struggled with entities that were either longer than 3 words and entities that were not contained in the training data. This could bias the models towards not finding, e.g. names of people that have many words, possibly leading to a misrepresentation in the results. Similarly, names that are uncommon, and may not have been found in the training data (due to e.g. different languages) would also be predicted less often.
Additionally, this model has not been verified in practice, and other, more subtle problems may become prevalent if used without any verification that it does what it is supposed to.
### Privacy & Ethical Considerations
The data comes from only publicly available news sources, the only available data should cover public figures and those that agreed to be reported on. See the original MasakhaNER paper for more details.
No explicit ethical considerations or adjustments were made during fine-tuning of this model.
## Metrics
The language adaptive models achieve (mostly) superior performance over starting with xlm-roberta-base. Our main metric was the aggregate F1 score for all NER categories.
These metrics are on the test set for MasakhaNER, so the data distribution is similar to the training set, so these results do not directly indicate how well these models generalise.
We do find large variation in transfer results when starting from different seeds (5 different seeds were tested), indicating that the fine-tuning process for transfer might be unstable.
The metrics used were chosen to be consistent with previous work, and to facilitate research. Other metrics may be more appropriate for other purposes.
## Caveats and Recommendations
In general, this model performed worse on the 'date' category compared to others, so if dates are a critical factor, then that might need to be taken into account and addressed, by for example collecting and annotating more data.
## Model Structure
Here are some performance details on this specific model, compared to others we trained.
All of these metrics were calculated on the test set, and the seed was chosen that gave the best overall F1 score. The first three result columns are averaged over all categories, and the latter 4 provide performance broken down by category.
This model can predict the following label for a token ([source](https://huggingface.co/Davlan/xlm-roberta-large-masakhaner)):
Abbreviation|Description
-|-
O|Outside of a named entity
B-DATE |Beginning of a DATE entity right after another DATE entity
I-DATE |DATE entity
B-PER |Beginning of a person’s name right after another person’s name
I-PER |Person’s name
B-ORG |Beginning of an organisation right after another organisation
I-ORG |Organisation
B-LOC |Beginning of a location right after another location
I-LOC |Location
| Model Name | Staring point | Evaluation / Fine-tune Language | F1 | Precision | Recall | F1 (DATE) | F1 (LOC) | F1 (ORG) | F1 (PER) |
| -------------------------------------------------- | -------------------- | -------------------- | -------------- | -------------- | -------------- | -------------- | -------------- | -------------- | -------------- |
| [xlm-roberta-base-finetuned-swahili-finetuned-ner-hausa](https://huggingface.co/mbeukman/xlm-roberta-base-finetuned-swahili-finetuned-ner-hausa) (This model) | [swa](https://huggingface.co/Davlan/xlm-roberta-base-finetuned-swahili) | hau | 89.14 | 87.18 | 91.20 | 82.00 | 93.00 | 76.00 | 93.00 |
| [xlm-roberta-base-finetuned-hausa-finetuned-ner-hausa](https://huggingface.co/mbeukman/xlm-roberta-base-finetuned-hausa-finetuned-ner-hausa) | [hau](https://huggingface.co/Davlan/xlm-roberta-base-finetuned-hausa) | hau | 92.27 | 90.46 | 94.16 | 85.00 | 95.00 | 80.00 | 97.00 |
| [xlm-roberta-base-finetuned-ner-hausa](https://huggingface.co/mbeukman/xlm-roberta-base-finetuned-ner-hausa) | [base](https://huggingface.co/xlm-roberta-base) | hau | 89.94 | 87.74 | 92.25 | 84.00 | 94.00 | 74.00 | 93.00 |
## Usage
To use this model (or others), you can do the following, just changing the model name ([source](https://huggingface.co/dslim/bert-base-NER)):
```
from transformers import AutoTokenizer, AutoModelForTokenClassification
from transformers import pipeline
model_name = 'mbeukman/xlm-roberta-base-finetuned-swahili-finetuned-ner-hausa'
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForTokenClassification.from_pretrained(model_name)
nlp = pipeline("ner", model=model, tokenizer=tokenizer)
example = "A saurari cikakken rahoton wakilin Muryar Amurka Ibrahim Abdul'aziz"
ner_results = nlp(example)
print(ner_results)
```
|
mbeukman/xlm-roberta-base-finetuned-swahili-finetuned-ner-igbo | c7f3897a7f26dd10d52ec13b014cf7c1836a699b | 2021-11-25T09:04:50.000Z | [
"pytorch",
"xlm-roberta",
"token-classification",
"ig",
"dataset:masakhaner",
"arxiv:2103.11811",
"transformers",
"NER",
"autotrain_compatible"
] | token-classification | false | mbeukman | null | mbeukman/xlm-roberta-base-finetuned-swahili-finetuned-ner-igbo | 1 | null | transformers | 29,932 | ---
language:
- ig
tags:
- NER
datasets:
- masakhaner
metrics:
- f1
- precision
- recall
widget:
- text: "Ike ịda jụụ otụ nkeji banyere oke ogbugbu na - eme n'ala Naijiria agwụla Ekweremmadụ"
---
# xlm-roberta-base-finetuned-swahili-finetuned-ner-igbo
This is a token classification (specifically NER) model that fine-tuned [xlm-roberta-base-finetuned-swahili](https://huggingface.co/Davlan/xlm-roberta-base-finetuned-swahili) on the [MasakhaNER](https://arxiv.org/abs/2103.11811) dataset, specifically the Igbo part.
More information, and other similar models can be found in the [main Github repository](https://github.com/Michael-Beukman/NERTransfer).
## About
This model is transformer based and was fine-tuned on the MasakhaNER dataset. It is a named entity recognition dataset, containing mostly news articles in 10 different African languages.
The model was fine-tuned for 50 epochs, with a maximum sequence length of 200, 32 batch size, 5e-5 learning rate. This process was repeated 5 times (with different random seeds), and this uploaded model performed the best out of those 5 seeds (aggregate F1 on test set).
This model was fine-tuned by me, Michael Beukman while doing a project at the University of the Witwatersrand, Johannesburg. This is version 1, as of 20 November 2021.
This model is licensed under the [Apache License, Version 2.0](https://www.apache.org/licenses/LICENSE-2.0).
### Contact & More information
For more information about the models, including training scripts, detailed results and further resources, you can visit the the [main Github repository](https://github.com/Michael-Beukman/NERTransfer). You can contact me by filing an issue on this repository.
### Training Resources
In the interest of openness, and reporting resources used, we list here how long the training process took, as well as what the minimum resources would be to reproduce this. Fine-tuning each model on the NER dataset took between 10 and 30 minutes, and was performed on a NVIDIA RTX3090 GPU. To use a batch size of 32, at least 14GB of GPU memory was required, although it was just possible to fit these models in around 6.5GB's of VRAM when using a batch size of 1.
## Data
The train, evaluation and test datasets were taken directly from the MasakhaNER [Github](https://github.com/masakhane-io/masakhane-ner) repository, with minimal to no preprocessing, as the original dataset is already of high quality.
The motivation for the use of this data is that it is the "first large, publicly available, high quality dataset for named entity recognition (NER) in ten African languages" ([source](https://arxiv.org/pdf/2103.11811.pdf)). The high-quality data, as well as the groundwork laid by the paper introducing it are some more reasons why this dataset was used. For evaluation, the dedicated test split was used, which is from the same distribution as the training data, so this model may not generalise to other distributions, and further testing would need to be done to investigate this. The exact distribution of the data is covered in detail [here](https://arxiv.org/abs/2103.11811).
## Intended Use
This model are intended to be used for NLP research into e.g. interpretability or transfer learning. Using this model in production is not supported, as generalisability and downright performance is limited. In particular, this is not designed to be used in any important downstream task that could affect people, as harm could be caused by the limitations of the model, described next.
## Limitations
This model was only trained on one (relatively small) dataset, covering one task (NER) in one domain (news articles) and in a set span of time. The results may not generalise, and the model may perform badly, or in an unfair / biased way if used on other tasks. Although the purpose of this project was to investigate transfer learning, the performance on languages that the model was not trained for does suffer.
Because this model used xlm-roberta-base as its starting point (potentially with domain adaptive fine-tuning on specific languages), this model's limitations can also apply here. These can include being biased towards the hegemonic viewpoint of most of its training data, being ungrounded and having subpar results on other languages (possibly due to unbalanced training data).
As [Adelani et al. (2021)](https://arxiv.org/abs/2103.11811) showed, the models in general struggled with entities that were either longer than 3 words and entities that were not contained in the training data. This could bias the models towards not finding, e.g. names of people that have many words, possibly leading to a misrepresentation in the results. Similarly, names that are uncommon, and may not have been found in the training data (due to e.g. different languages) would also be predicted less often.
Additionally, this model has not been verified in practice, and other, more subtle problems may become prevalent if used without any verification that it does what it is supposed to.
### Privacy & Ethical Considerations
The data comes from only publicly available news sources, the only available data should cover public figures and those that agreed to be reported on. See the original MasakhaNER paper for more details.
No explicit ethical considerations or adjustments were made during fine-tuning of this model.
## Metrics
The language adaptive models achieve (mostly) superior performance over starting with xlm-roberta-base. Our main metric was the aggregate F1 score for all NER categories.
These metrics are on the test set for MasakhaNER, so the data distribution is similar to the training set, so these results do not directly indicate how well these models generalise.
We do find large variation in transfer results when starting from different seeds (5 different seeds were tested), indicating that the fine-tuning process for transfer might be unstable.
The metrics used were chosen to be consistent with previous work, and to facilitate research. Other metrics may be more appropriate for other purposes.
## Caveats and Recommendations
In general, this model performed worse on the 'date' category compared to others, so if dates are a critical factor, then that might need to be taken into account and addressed, by for example collecting and annotating more data.
## Model Structure
Here are some performance details on this specific model, compared to others we trained.
All of these metrics were calculated on the test set, and the seed was chosen that gave the best overall F1 score. The first three result columns are averaged over all categories, and the latter 4 provide performance broken down by category.
This model can predict the following label for a token ([source](https://huggingface.co/Davlan/xlm-roberta-large-masakhaner)):
Abbreviation|Description
-|-
O|Outside of a named entity
B-DATE |Beginning of a DATE entity right after another DATE entity
I-DATE |DATE entity
B-PER |Beginning of a person’s name right after another person’s name
I-PER |Person’s name
B-ORG |Beginning of an organisation right after another organisation
I-ORG |Organisation
B-LOC |Beginning of a location right after another location
I-LOC |Location
| Model Name | Staring point | Evaluation / Fine-tune Language | F1 | Precision | Recall | F1 (DATE) | F1 (LOC) | F1 (ORG) | F1 (PER) |
| -------------------------------------------------- | -------------------- | -------------------- | -------------- | -------------- | -------------- | -------------- | -------------- | -------------- | -------------- |
| [xlm-roberta-base-finetuned-swahili-finetuned-ner-igbo](https://huggingface.co/mbeukman/xlm-roberta-base-finetuned-swahili-finetuned-ner-igbo) (This model) | [swa](https://huggingface.co/Davlan/xlm-roberta-base-finetuned-swahili) | ibo | 84.93 | 83.63 | 86.26 | 70.00 | 88.00 | 89.00 | 84.00 |
| [xlm-roberta-base-finetuned-igbo-finetuned-ner-igbo](https://huggingface.co/mbeukman/xlm-roberta-base-finetuned-igbo-finetuned-ner-igbo) | [ibo](https://huggingface.co/Davlan/xlm-roberta-base-finetuned-igbo) | ibo | 88.39 | 87.08 | 89.74 | 74.00 | 91.00 | 90.00 | 91.00 |
| [xlm-roberta-base-finetuned-ner-igbo](https://huggingface.co/mbeukman/xlm-roberta-base-finetuned-ner-igbo) | [base](https://huggingface.co/xlm-roberta-base) | ibo | 86.06 | 85.20 | 86.94 | 76.00 | 86.00 | 90.00 | 87.00 |
## Usage
To use this model (or others), you can do the following, just changing the model name ([source](https://huggingface.co/dslim/bert-base-NER)):
```
from transformers import AutoTokenizer, AutoModelForTokenClassification
from transformers import pipeline
model_name = 'mbeukman/xlm-roberta-base-finetuned-swahili-finetuned-ner-igbo'
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForTokenClassification.from_pretrained(model_name)
nlp = pipeline("ner", model=model, tokenizer=tokenizer)
example = "Ike ịda jụụ otụ nkeji banyere oke ogbugbu na - eme n'ala Naijiria agwụla Ekweremmadụ"
ner_results = nlp(example)
print(ner_results)
```
|
mbeukman/xlm-roberta-base-finetuned-swahili-finetuned-ner-luganda | 27af25f8aeb0cfac3f5523eba76c90562e2d1d67 | 2021-11-25T09:04:55.000Z | [
"pytorch",
"xlm-roberta",
"token-classification",
"lug",
"dataset:masakhaner",
"arxiv:2103.11811",
"transformers",
"NER",
"autotrain_compatible"
] | token-classification | false | mbeukman | null | mbeukman/xlm-roberta-base-finetuned-swahili-finetuned-ner-luganda | 1 | null | transformers | 29,933 | ---
language:
- lug
tags:
- NER
datasets:
- masakhaner
metrics:
- f1
- precision
- recall
widget:
- text: "Empaka zaakubeera mu kibuga Liverpool e Bungereza , okutandika nga July 12 ."
---
# xlm-roberta-base-finetuned-swahili-finetuned-ner-luganda
This is a token classification (specifically NER) model that fine-tuned [xlm-roberta-base-finetuned-swahili](https://huggingface.co/Davlan/xlm-roberta-base-finetuned-swahili) on the [MasakhaNER](https://arxiv.org/abs/2103.11811) dataset, specifically the luganda part.
More information, and other similar models can be found in the [main Github repository](https://github.com/Michael-Beukman/NERTransfer).
## About
This model is transformer based and was fine-tuned on the MasakhaNER dataset. It is a named entity recognition dataset, containing mostly news articles in 10 different African languages.
The model was fine-tuned for 50 epochs, with a maximum sequence length of 200, 32 batch size, 5e-5 learning rate. This process was repeated 5 times (with different random seeds), and this uploaded model performed the best out of those 5 seeds (aggregate F1 on test set).
This model was fine-tuned by me, Michael Beukman while doing a project at the University of the Witwatersrand, Johannesburg. This is version 1, as of 20 November 2021.
This model is licensed under the [Apache License, Version 2.0](https://www.apache.org/licenses/LICENSE-2.0).
### Contact & More information
For more information about the models, including training scripts, detailed results and further resources, you can visit the the [main Github repository](https://github.com/Michael-Beukman/NERTransfer). You can contact me by filing an issue on this repository.
### Training Resources
In the interest of openness, and reporting resources used, we list here how long the training process took, as well as what the minimum resources would be to reproduce this. Fine-tuning each model on the NER dataset took between 10 and 30 minutes, and was performed on a NVIDIA RTX3090 GPU. To use a batch size of 32, at least 14GB of GPU memory was required, although it was just possible to fit these models in around 6.5GB's of VRAM when using a batch size of 1.
## Data
The train, evaluation and test datasets were taken directly from the MasakhaNER [Github](https://github.com/masakhane-io/masakhane-ner) repository, with minimal to no preprocessing, as the original dataset is already of high quality.
The motivation for the use of this data is that it is the "first large, publicly available, high quality dataset for named entity recognition (NER) in ten African languages" ([source](https://arxiv.org/pdf/2103.11811.pdf)). The high-quality data, as well as the groundwork laid by the paper introducing it are some more reasons why this dataset was used. For evaluation, the dedicated test split was used, which is from the same distribution as the training data, so this model may not generalise to other distributions, and further testing would need to be done to investigate this. The exact distribution of the data is covered in detail [here](https://arxiv.org/abs/2103.11811).
## Intended Use
This model are intended to be used for NLP research into e.g. interpretability or transfer learning. Using this model in production is not supported, as generalisability and downright performance is limited. In particular, this is not designed to be used in any important downstream task that could affect people, as harm could be caused by the limitations of the model, described next.
## Limitations
This model was only trained on one (relatively small) dataset, covering one task (NER) in one domain (news articles) and in a set span of time. The results may not generalise, and the model may perform badly, or in an unfair / biased way if used on other tasks. Although the purpose of this project was to investigate transfer learning, the performance on languages that the model was not trained for does suffer.
Because this model used xlm-roberta-base as its starting point (potentially with domain adaptive fine-tuning on specific languages), this model's limitations can also apply here. These can include being biased towards the hegemonic viewpoint of most of its training data, being ungrounded and having subpar results on other languages (possibly due to unbalanced training data).
As [Adelani et al. (2021)](https://arxiv.org/abs/2103.11811) showed, the models in general struggled with entities that were either longer than 3 words and entities that were not contained in the training data. This could bias the models towards not finding, e.g. names of people that have many words, possibly leading to a misrepresentation in the results. Similarly, names that are uncommon, and may not have been found in the training data (due to e.g. different languages) would also be predicted less often.
Additionally, this model has not been verified in practice, and other, more subtle problems may become prevalent if used without any verification that it does what it is supposed to.
### Privacy & Ethical Considerations
The data comes from only publicly available news sources, the only available data should cover public figures and those that agreed to be reported on. See the original MasakhaNER paper for more details.
No explicit ethical considerations or adjustments were made during fine-tuning of this model.
## Metrics
The language adaptive models achieve (mostly) superior performance over starting with xlm-roberta-base. Our main metric was the aggregate F1 score for all NER categories.
These metrics are on the test set for MasakhaNER, so the data distribution is similar to the training set, so these results do not directly indicate how well these models generalise.
We do find large variation in transfer results when starting from different seeds (5 different seeds were tested), indicating that the fine-tuning process for transfer might be unstable.
The metrics used were chosen to be consistent with previous work, and to facilitate research. Other metrics may be more appropriate for other purposes.
## Caveats and Recommendations
In general, this model performed worse on the 'date' category compared to others, so if dates are a critical factor, then that might need to be taken into account and addressed, by for example collecting and annotating more data.
## Model Structure
Here are some performance details on this specific model, compared to others we trained.
All of these metrics were calculated on the test set, and the seed was chosen that gave the best overall F1 score. The first three result columns are averaged over all categories, and the latter 4 provide performance broken down by category.
This model can predict the following label for a token ([source](https://huggingface.co/Davlan/xlm-roberta-large-masakhaner)):
Abbreviation|Description
-|-
O|Outside of a named entity
B-DATE |Beginning of a DATE entity right after another DATE entity
I-DATE |DATE entity
B-PER |Beginning of a person’s name right after another person’s name
I-PER |Person’s name
B-ORG |Beginning of an organisation right after another organisation
I-ORG |Organisation
B-LOC |Beginning of a location right after another location
I-LOC |Location
| Model Name | Staring point | Evaluation / Fine-tune Language | F1 | Precision | Recall | F1 (DATE) | F1 (LOC) | F1 (ORG) | F1 (PER) |
| -------------------------------------------------- | -------------------- | -------------------- | -------------- | -------------- | -------------- | -------------- | -------------- | -------------- | -------------- |
| [xlm-roberta-base-finetuned-swahili-finetuned-ner-luganda](https://huggingface.co/mbeukman/xlm-roberta-base-finetuned-swahili-finetuned-ner-luganda) (This model) | [swa](https://huggingface.co/Davlan/xlm-roberta-base-finetuned-swahili) | lug | 82.57 | 80.38 | 84.89 | 75.00 | 80.00 | 82.00 | 87.00 |
| [xlm-roberta-base-finetuned-luganda-finetuned-ner-luganda](https://huggingface.co/mbeukman/xlm-roberta-base-finetuned-luganda-finetuned-ner-luganda) | [lug](https://huggingface.co/Davlan/xlm-roberta-base-finetuned-luganda) | lug | 85.37 | 82.75 | 88.17 | 78.00 | 82.00 | 80.00 | 92.00 |
| [xlm-roberta-base-finetuned-ner-luganda](https://huggingface.co/mbeukman/xlm-roberta-base-finetuned-ner-luganda) | [base](https://huggingface.co/xlm-roberta-base) | lug | 80.91 | 78.59 | 83.37 | 73.00 | 78.00 | 77.00 | 86.00 |
## Usage
To use this model (or others), you can do the following, just changing the model name ([source](https://huggingface.co/dslim/bert-base-NER)):
```
from transformers import AutoTokenizer, AutoModelForTokenClassification
from transformers import pipeline
model_name = 'mbeukman/xlm-roberta-base-finetuned-swahili-finetuned-ner-luganda'
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForTokenClassification.from_pretrained(model_name)
nlp = pipeline("ner", model=model, tokenizer=tokenizer)
example = "Empaka zaakubeera mu kibuga Liverpool e Bungereza , okutandika nga July 12 ."
ner_results = nlp(example)
print(ner_results)
```
|
mbeukman/xlm-roberta-base-finetuned-swahili-finetuned-ner-naija | 4c0a64448d3c937f232663e737b0fc09b6f5972b | 2021-11-25T09:05:00.000Z | [
"pytorch",
"xlm-roberta",
"token-classification",
"pcm",
"dataset:masakhaner",
"arxiv:2103.11811",
"transformers",
"NER",
"autotrain_compatible"
] | token-classification | false | mbeukman | null | mbeukman/xlm-roberta-base-finetuned-swahili-finetuned-ner-naija | 1 | null | transformers | 29,934 | ---
language:
- pcm
tags:
- NER
datasets:
- masakhaner
metrics:
- f1
- precision
- recall
widget:
- text: "Mixed Martial Arts joinbodi , Ultimate Fighting Championship , UFC don decide say dem go enta back di octagon on Saturday , 9 May , for Jacksonville , Florida ."
---
# xlm-roberta-base-finetuned-swahili-finetuned-ner-naija
This is a token classification (specifically NER) model that fine-tuned [xlm-roberta-base-finetuned-swahili](https://huggingface.co/Davlan/xlm-roberta-base-finetuned-swahili) on the [MasakhaNER](https://arxiv.org/abs/2103.11811) dataset, specifically the Nigerian Pidgin part.
More information, and other similar models can be found in the [main Github repository](https://github.com/Michael-Beukman/NERTransfer).
## About
This model is transformer based and was fine-tuned on the MasakhaNER dataset. It is a named entity recognition dataset, containing mostly news articles in 10 different African languages.
The model was fine-tuned for 50 epochs, with a maximum sequence length of 200, 32 batch size, 5e-5 learning rate. This process was repeated 5 times (with different random seeds), and this uploaded model performed the best out of those 5 seeds (aggregate F1 on test set).
This model was fine-tuned by me, Michael Beukman while doing a project at the University of the Witwatersrand, Johannesburg. This is version 1, as of 20 November 2021.
This model is licensed under the [Apache License, Version 2.0](https://www.apache.org/licenses/LICENSE-2.0).
### Contact & More information
For more information about the models, including training scripts, detailed results and further resources, you can visit the the [main Github repository](https://github.com/Michael-Beukman/NERTransfer). You can contact me by filing an issue on this repository.
### Training Resources
In the interest of openness, and reporting resources used, we list here how long the training process took, as well as what the minimum resources would be to reproduce this. Fine-tuning each model on the NER dataset took between 10 and 30 minutes, and was performed on a NVIDIA RTX3090 GPU. To use a batch size of 32, at least 14GB of GPU memory was required, although it was just possible to fit these models in around 6.5GB's of VRAM when using a batch size of 1.
## Data
The train, evaluation and test datasets were taken directly from the MasakhaNER [Github](https://github.com/masakhane-io/masakhane-ner) repository, with minimal to no preprocessing, as the original dataset is already of high quality.
The motivation for the use of this data is that it is the "first large, publicly available, high quality dataset for named entity recognition (NER) in ten African languages" ([source](https://arxiv.org/pdf/2103.11811.pdf)). The high-quality data, as well as the groundwork laid by the paper introducing it are some more reasons why this dataset was used. For evaluation, the dedicated test split was used, which is from the same distribution as the training data, so this model may not generalise to other distributions, and further testing would need to be done to investigate this. The exact distribution of the data is covered in detail [here](https://arxiv.org/abs/2103.11811).
## Intended Use
This model are intended to be used for NLP research into e.g. interpretability or transfer learning. Using this model in production is not supported, as generalisability and downright performance is limited. In particular, this is not designed to be used in any important downstream task that could affect people, as harm could be caused by the limitations of the model, described next.
## Limitations
This model was only trained on one (relatively small) dataset, covering one task (NER) in one domain (news articles) and in a set span of time. The results may not generalise, and the model may perform badly, or in an unfair / biased way if used on other tasks. Although the purpose of this project was to investigate transfer learning, the performance on languages that the model was not trained for does suffer.
Because this model used xlm-roberta-base as its starting point (potentially with domain adaptive fine-tuning on specific languages), this model's limitations can also apply here. These can include being biased towards the hegemonic viewpoint of most of its training data, being ungrounded and having subpar results on other languages (possibly due to unbalanced training data).
As [Adelani et al. (2021)](https://arxiv.org/abs/2103.11811) showed, the models in general struggled with entities that were either longer than 3 words and entities that were not contained in the training data. This could bias the models towards not finding, e.g. names of people that have many words, possibly leading to a misrepresentation in the results. Similarly, names that are uncommon, and may not have been found in the training data (due to e.g. different languages) would also be predicted less often.
Additionally, this model has not been verified in practice, and other, more subtle problems may become prevalent if used without any verification that it does what it is supposed to.
### Privacy & Ethical Considerations
The data comes from only publicly available news sources, the only available data should cover public figures and those that agreed to be reported on. See the original MasakhaNER paper for more details.
No explicit ethical considerations or adjustments were made during fine-tuning of this model.
## Metrics
The language adaptive models achieve (mostly) superior performance over starting with xlm-roberta-base. Our main metric was the aggregate F1 score for all NER categories.
These metrics are on the test set for MasakhaNER, so the data distribution is similar to the training set, so these results do not directly indicate how well these models generalise.
We do find large variation in transfer results when starting from different seeds (5 different seeds were tested), indicating that the fine-tuning process for transfer might be unstable.
The metrics used were chosen to be consistent with previous work, and to facilitate research. Other metrics may be more appropriate for other purposes.
## Caveats and Recommendations
In general, this model performed worse on the 'date' category compared to others, so if dates are a critical factor, then that might need to be taken into account and addressed, by for example collecting and annotating more data.
## Model Structure
Here are some performance details on this specific model, compared to others we trained.
All of these metrics were calculated on the test set, and the seed was chosen that gave the best overall F1 score. The first three result columns are averaged over all categories, and the latter 4 provide performance broken down by category.
This model can predict the following label for a token ([source](https://huggingface.co/Davlan/xlm-roberta-large-masakhaner)):
Abbreviation|Description
-|-
O|Outside of a named entity
B-DATE |Beginning of a DATE entity right after another DATE entity
I-DATE |DATE entity
B-PER |Beginning of a person’s name right after another person’s name
I-PER |Person’s name
B-ORG |Beginning of an organisation right after another organisation
I-ORG |Organisation
B-LOC |Beginning of a location right after another location
I-LOC |Location
| Model Name | Staring point | Evaluation / Fine-tune Language | F1 | Precision | Recall | F1 (DATE) | F1 (LOC) | F1 (ORG) | F1 (PER) |
| -------------------------------------------------- | -------------------- | -------------------- | -------------- | -------------- | -------------- | -------------- | -------------- | -------------- | -------------- |
| [xlm-roberta-base-finetuned-swahili-finetuned-ner-naija](https://huggingface.co/mbeukman/xlm-roberta-base-finetuned-swahili-finetuned-ner-naija) (This model) | [swa](https://huggingface.co/Davlan/xlm-roberta-base-finetuned-swahili) | pcm | 89.12 | 87.84 | 90.42 | 90.00 | 89.00 | 82.00 | 94.00 |
| [xlm-roberta-base-finetuned-naija-finetuned-ner-naija](https://huggingface.co/mbeukman/xlm-roberta-base-finetuned-naija-finetuned-ner-naija) | [pcm](https://huggingface.co/Davlan/xlm-roberta-base-finetuned-naija) | pcm | 88.06 | 87.04 | 89.12 | 90.00 | 88.00 | 81.00 | 92.00 |
| [xlm-roberta-base-finetuned-ner-naija](https://huggingface.co/mbeukman/xlm-roberta-base-finetuned-ner-naija) | [base](https://huggingface.co/xlm-roberta-base) | pcm | 88.89 | 88.13 | 89.66 | 92.00 | 87.00 | 82.00 | 94.00 |
## Usage
To use this model (or others), you can do the following, just changing the model name ([source](https://huggingface.co/dslim/bert-base-NER)):
```
from transformers import AutoTokenizer, AutoModelForTokenClassification
from transformers import pipeline
model_name = 'mbeukman/xlm-roberta-base-finetuned-swahili-finetuned-ner-naija'
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForTokenClassification.from_pretrained(model_name)
nlp = pipeline("ner", model=model, tokenizer=tokenizer)
example = "Mixed Martial Arts joinbodi , Ultimate Fighting Championship , UFC don decide say dem go enta back di octagon on Saturday , 9 May , for Jacksonville , Florida ."
ner_results = nlp(example)
print(ner_results)
```
|
mbeukman/xlm-roberta-base-finetuned-swahili-finetuned-ner-yoruba | 38e2c17ba6e3981f4f3d7dcf8b813c2319bc5acb | 2021-11-25T09:05:08.000Z | [
"pytorch",
"xlm-roberta",
"token-classification",
"yo",
"dataset:masakhaner",
"arxiv:2103.11811",
"transformers",
"NER",
"autotrain_compatible"
] | token-classification | false | mbeukman | null | mbeukman/xlm-roberta-base-finetuned-swahili-finetuned-ner-yoruba | 1 | null | transformers | 29,935 | ---
language:
- yo
tags:
- NER
datasets:
- masakhaner
metrics:
- f1
- precision
- recall
widget:
- text: "Kò sí ẹ̀rí tí ó fi ẹsẹ̀ rinlẹ̀ ."
---
# xlm-roberta-base-finetuned-swahili-finetuned-ner-yoruba
This is a token classification (specifically NER) model that fine-tuned [xlm-roberta-base-finetuned-swahili](https://huggingface.co/Davlan/xlm-roberta-base-finetuned-swahili) on the [MasakhaNER](https://arxiv.org/abs/2103.11811) dataset, specifically the Yoruba part.
More information, and other similar models can be found in the [main Github repository](https://github.com/Michael-Beukman/NERTransfer).
## About
This model is transformer based and was fine-tuned on the MasakhaNER dataset. It is a named entity recognition dataset, containing mostly news articles in 10 different African languages.
The model was fine-tuned for 50 epochs, with a maximum sequence length of 200, 32 batch size, 5e-5 learning rate. This process was repeated 5 times (with different random seeds), and this uploaded model performed the best out of those 5 seeds (aggregate F1 on test set).
This model was fine-tuned by me, Michael Beukman while doing a project at the University of the Witwatersrand, Johannesburg. This is version 1, as of 20 November 2021.
This model is licensed under the [Apache License, Version 2.0](https://www.apache.org/licenses/LICENSE-2.0).
### Contact & More information
For more information about the models, including training scripts, detailed results and further resources, you can visit the the [main Github repository](https://github.com/Michael-Beukman/NERTransfer). You can contact me by filing an issue on this repository.
### Training Resources
In the interest of openness, and reporting resources used, we list here how long the training process took, as well as what the minimum resources would be to reproduce this. Fine-tuning each model on the NER dataset took between 10 and 30 minutes, and was performed on a NVIDIA RTX3090 GPU. To use a batch size of 32, at least 14GB of GPU memory was required, although it was just possible to fit these models in around 6.5GB's of VRAM when using a batch size of 1.
## Data
The train, evaluation and test datasets were taken directly from the MasakhaNER [Github](https://github.com/masakhane-io/masakhane-ner) repository, with minimal to no preprocessing, as the original dataset is already of high quality.
The motivation for the use of this data is that it is the "first large, publicly available, high quality dataset for named entity recognition (NER) in ten African languages" ([source](https://arxiv.org/pdf/2103.11811.pdf)). The high-quality data, as well as the groundwork laid by the paper introducing it are some more reasons why this dataset was used. For evaluation, the dedicated test split was used, which is from the same distribution as the training data, so this model may not generalise to other distributions, and further testing would need to be done to investigate this. The exact distribution of the data is covered in detail [here](https://arxiv.org/abs/2103.11811).
## Intended Use
This model are intended to be used for NLP research into e.g. interpretability or transfer learning. Using this model in production is not supported, as generalisability and downright performance is limited. In particular, this is not designed to be used in any important downstream task that could affect people, as harm could be caused by the limitations of the model, described next.
## Limitations
This model was only trained on one (relatively small) dataset, covering one task (NER) in one domain (news articles) and in a set span of time. The results may not generalise, and the model may perform badly, or in an unfair / biased way if used on other tasks. Although the purpose of this project was to investigate transfer learning, the performance on languages that the model was not trained for does suffer.
Because this model used xlm-roberta-base as its starting point (potentially with domain adaptive fine-tuning on specific languages), this model's limitations can also apply here. These can include being biased towards the hegemonic viewpoint of most of its training data, being ungrounded and having subpar results on other languages (possibly due to unbalanced training data).
As [Adelani et al. (2021)](https://arxiv.org/abs/2103.11811) showed, the models in general struggled with entities that were either longer than 3 words and entities that were not contained in the training data. This could bias the models towards not finding, e.g. names of people that have many words, possibly leading to a misrepresentation in the results. Similarly, names that are uncommon, and may not have been found in the training data (due to e.g. different languages) would also be predicted less often.
Additionally, this model has not been verified in practice, and other, more subtle problems may become prevalent if used without any verification that it does what it is supposed to.
### Privacy & Ethical Considerations
The data comes from only publicly available news sources, the only available data should cover public figures and those that agreed to be reported on. See the original MasakhaNER paper for more details.
No explicit ethical considerations or adjustments were made during fine-tuning of this model.
## Metrics
The language adaptive models achieve (mostly) superior performance over starting with xlm-roberta-base. Our main metric was the aggregate F1 score for all NER categories.
These metrics are on the test set for MasakhaNER, so the data distribution is similar to the training set, so these results do not directly indicate how well these models generalise.
We do find large variation in transfer results when starting from different seeds (5 different seeds were tested), indicating that the fine-tuning process for transfer might be unstable.
The metrics used were chosen to be consistent with previous work, and to facilitate research. Other metrics may be more appropriate for other purposes.
## Caveats and Recommendations
In general, this model performed worse on the 'date' category compared to others, so if dates are a critical factor, then that might need to be taken into account and addressed, by for example collecting and annotating more data.
## Model Structure
Here are some performance details on this specific model, compared to others we trained.
All of these metrics were calculated on the test set, and the seed was chosen that gave the best overall F1 score. The first three result columns are averaged over all categories, and the latter 4 provide performance broken down by category.
This model can predict the following label for a token ([source](https://huggingface.co/Davlan/xlm-roberta-large-masakhaner)):
Abbreviation|Description
-|-
O|Outside of a named entity
B-DATE |Beginning of a DATE entity right after another DATE entity
I-DATE |DATE entity
B-PER |Beginning of a person’s name right after another person’s name
I-PER |Person’s name
B-ORG |Beginning of an organisation right after another organisation
I-ORG |Organisation
B-LOC |Beginning of a location right after another location
I-LOC |Location
| Model Name | Staring point | Evaluation / Fine-tune Language | F1 | Precision | Recall | F1 (DATE) | F1 (LOC) | F1 (ORG) | F1 (PER) |
| -------------------------------------------------- | -------------------- | -------------------- | -------------- | -------------- | -------------- | -------------- | -------------- | -------------- | -------------- |
| [xlm-roberta-base-finetuned-swahili-finetuned-ner-yoruba](https://huggingface.co/mbeukman/xlm-roberta-base-finetuned-swahili-finetuned-ner-yoruba) (This model) | [swa](https://huggingface.co/Davlan/xlm-roberta-base-finetuned-swahili) | yor | 80.29 | 78.34 | 82.35 | 77.00 | 82.00 | 73.00 | 86.00 |
| [xlm-roberta-base-finetuned-yoruba-finetuned-ner-yoruba](https://huggingface.co/mbeukman/xlm-roberta-base-finetuned-yoruba-finetuned-ner-yoruba) | [yor](https://huggingface.co/Davlan/xlm-roberta-base-finetuned-yoruba) | yor | 83.68 | 79.92 | 87.82 | 78.00 | 86.00 | 74.00 | 92.00 |
| [xlm-roberta-base-finetuned-ner-yoruba](https://huggingface.co/mbeukman/xlm-roberta-base-finetuned-ner-yoruba) | [base](https://huggingface.co/xlm-roberta-base) | yor | 78.22 | 77.21 | 79.26 | 77.00 | 80.00 | 71.00 | 82.00 |
## Usage
To use this model (or others), you can do the following, just changing the model name ([source](https://huggingface.co/dslim/bert-base-NER)):
```
from transformers import AutoTokenizer, AutoModelForTokenClassification
from transformers import pipeline
model_name = 'mbeukman/xlm-roberta-base-finetuned-swahili-finetuned-ner-yoruba'
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForTokenClassification.from_pretrained(model_name)
nlp = pipeline("ner", model=model, tokenizer=tokenizer)
example = "Kò sí ẹ̀rí tí ó fi ẹsẹ̀ rinlẹ̀ ."
ner_results = nlp(example)
print(ner_results)
```
|
mbsouksu/wav2vec2-large-xlsr-turkish-large | 60d07c5d10e5650c0beef2702cc4607d0c7ae0d4 | 2021-07-06T12:43:27.000Z | [
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"tr",
"dataset:common_voice",
"transformers",
"audio",
"speech",
"xlsr-fine-tuning-week",
"license:apache-2.0",
"model-index"
] | automatic-speech-recognition | false | mbsouksu | null | mbsouksu/wav2vec2-large-xlsr-turkish-large | 1 | null | transformers | 29,936 | ---
language: tr
datasets:
- common_voice
metrics:
- wer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: XLSR Wav2Vec2 Turkish by Mehmet Berk Souksu
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice tr
type: common_voice
args: tr
metrics:
- name: Test WER
type: wer
value: 29.80
---
# Wav2Vec2-Large-XLSR-53-Turkish
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Turkish using the [Common Voice](https://huggingface.co/datasets/common_voice).
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "tr", split="test[:2%]")
processor = Wav2Vec2Processor.from_pretrained("mbsouksu/wav2vec2-large-xlsr-turkish-large")
model = Wav2Vec2ForCTC.from_pretrained("mbsouksu/wav2vec2-large-xlsr-turkish-large")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the Turkish test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "tr", split="test")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("mbsouksu/wav2vec2-large-xlsr-turkish-large")
model = Wav2Vec2ForCTC.from_pretrained("mbsouksu/wav2vec2-large-xlsr-turkish-large")
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"\“\%\‘\”\�\'\`\…\\]\\[\\&\\’\»«]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 29.80 %
## Training
The Common Voice `train`, `validation` datasets were used for training.
The script used for training can be found [here](https://github.com/mbsouksu/wav2vec2-turkish) |
meghana/hitalm-xlmroberta-finetuned | 2f870cf0cdc114de663baec42cf137ad394555b4 | 2021-10-22T11:51:18.000Z | [
"pytorch",
"tensorboard",
"xlm-roberta",
"fill-mask",
"transformers",
"generated_from_trainer",
"license:mit",
"model-index",
"autotrain_compatible"
] | fill-mask | false | meghana | null | meghana/hitalm-xlmroberta-finetuned | 1 | null | transformers | 29,937 | ---
license: mit
tags:
- generated_from_trainer
model-index:
- name: hitalm-xlmroberta-finetuned
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hitalm-xlmroberta-finetuned
This model is a fine-tuned version of [xlm-roberta-large](https://huggingface.co/xlm-roberta-large) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 4.7745
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 48 | 5.4501 |
| No log | 2.0 | 96 | 5.2843 |
| No log | 3.0 | 144 | 4.7745 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.9.0+cu111
- Datasets 1.14.0
- Tokenizers 0.10.3
|
meghanabhange/hinglish-indic-bert | 407dcd77183d1aaffc30895c95433f93da564fc0 | 2020-10-22T18:31:30.000Z | [
"pytorch"
] | null | false | meghanabhange | null | meghanabhange/hinglish-indic-bert | 1 | null | null | 29,938 | Entry not found |
meghanabhange/history_roberta_mcq | 06e461da417160e2d3012f79c79ec63ead340ff4 | 2021-06-28T10:41:28.000Z | [
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] | feature-extraction | false | meghanabhange | null | meghanabhange/history_roberta_mcq | 1 | null | transformers | 29,939 | Entry not found |
menciusds/flairmodel | b4cd7f5982499291f18eed0c6d6b7346b7bbf4a8 | 2022-01-31T16:07:32.000Z | [
"pytorch",
"flair",
"token-classification"
] | token-classification | false | menciusds | null | menciusds/flairmodel | 1 | null | flair | 29,940 | ---
tags:
- flair
- token-classification
widget:
- text: "does this work"
---
## Test model README
Some test README description |
metamong1/bigbart_full_tapt_ep3_bs16_pre_RD_half_warmpstep | 80c2ba2516aa37e323fdb9b5a32113c9ea5a9e32 | 2021-12-23T13:44:37.000Z | [
"pytorch",
"encoder-decoder",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | false | metamong1 | null | metamong1/bigbart_full_tapt_ep3_bs16_pre_RD_half_warmpstep | 1 | null | transformers | 29,941 | Entry not found |
metamong1/bigbird-bart-base | 0045796c30fbb96be996a9f48c551bedabbcc48f | 2021-12-18T19:54:33.000Z | [
"pytorch",
"encoder-decoder",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | false | metamong1 | null | metamong1/bigbird-bart-base | 1 | 1 | transformers | 29,942 | Entry not found |
mhd-mst/pure-finetuning3 | 96be7814697521ed2fafb8fc3a0e2a9dc4393a4e | 2022-01-17T19:42:26.000Z | [
"pytorch",
"marian",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | false | mhd-mst | null | mhd-mst/pure-finetuning3 | 1 | null | transformers | 29,943 | Entry not found |
miaomiaomiao/macbert_miao | a8cda7d1b3baf16975b4b9a536d948fa1ef159d5 | 2021-05-19T23:20:21.000Z | [
"pytorch",
"jax",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | false | miaomiaomiao | null | miaomiaomiao/macbert_miao | 1 | null | transformers | 29,944 | Entry not found |
miaomiaomiao/nezha_miao | 5bff66e54806bad9cc859956fc1eda5d7ab11219 | 2021-04-15T04:29:14.000Z | [
"pytorch",
"transformers"
] | null | false | miaomiaomiao | null | miaomiaomiao/nezha_miao | 1 | null | transformers | 29,945 | Entry not found |
michaelhsieh42/distilgpt2-finetuned-wikitext2 | 5ff860ce6b664f4c96b28bb47660f9f26e2dfa9d | 2022-01-21T08:33:37.000Z | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
] | text-generation | false | michaelhsieh42 | null | michaelhsieh42/distilgpt2-finetuned-wikitext2 | 1 | null | transformers | 29,946 | Entry not found |
microsoft/unispeech-1350-en-90-it-ft-1h | 3342ea75248472e76a34c5a9d7bad0eb9a9eab82 | 2021-12-19T13:19:29.000Z | [
"pytorch",
"unispeech",
"automatic-speech-recognition",
"it",
"dataset:common_voice",
"arxiv:2101.07597",
"transformers",
"audio"
] | automatic-speech-recognition | false | microsoft | null | microsoft/unispeech-1350-en-90-it-ft-1h | 1 | null | transformers | 29,947 | ---
language:
- it
datasets:
- common_voice
tags:
- audio
- automatic-speech-recognition
---
# UniSpeech-Large-plus ITALIAN
[Microsoft's UniSpeech](https://www.microsoft.com/en-us/research/publication/unispeech-unified-speech-representation-learning-with-labeled-and-unlabeled-data/)
The large model pretrained on 16kHz sampled speech audio and phonetic labels and consequently fine-tuned on 1h of Italian phonemes.
When using the model make sure that your speech input is also sampled at 16kHz and your text in converted into a sequence of phonemes.
[Paper: UniSpeech: Unified Speech Representation Learning
with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597)
Authors: Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang
**Abstract**
*In this paper, we propose a unified pre-training approach called UniSpeech to learn speech representations with both unlabeled and labeled data, in which supervised phonetic CTC learning and phonetically-aware contrastive self-supervised learning are conducted in a multi-task learning manner. The resultant representations can capture information more correlated with phonetic structures and improve the generalization across languages and domains. We evaluate the effectiveness of UniSpeech for cross-lingual representation learning on public CommonVoice corpus. The results show that UniSpeech outperforms self-supervised pretraining and supervised transfer learning for speech recognition by a maximum of 13.4% and 17.8% relative phone error rate reductions respectively (averaged over all testing languages). The transferability of UniSpeech is also demonstrated on a domain-shift speech recognition task, i.e., a relative word error rate reduction of 6% against the previous approach.*
The original model can be found under https://github.com/microsoft/UniSpeech/tree/main/UniSpeech.
# Usage
This is an speech model that has been fine-tuned on phoneme classification.
## Inference
```python
import torch
from datasets import load_dataset
from transformers import AutoModelForCTC, AutoProcessor
import torchaudio.functional as F
model_id = "microsoft/unispeech-1350-en-90-it-ft-1h"
sample = next(iter(load_dataset("common_voice", "it", split="test", streaming=True)))
resampled_audio = F.resample(torch.tensor(sample["audio"]["array"]), 48_000, 16_000).numpy()
model = AutoModelForCTC.from_pretrained(model_id)
processor = AutoProcessor.from_pretrained(model_id)
input_values = processor(resampled_audio, return_tensors="pt").input_values
with torch.no_grad():
logits = model(input_values).logits
prediction_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(prediction_ids)
# => 'm ɪ a n n o f a tː o ʊ n o f f ɛ r t a k e n o n p o t e v o p r ɔ p r i o r i f j ʊ t a r e'
# for "Mi hanno fatto un\'offerta che non potevo proprio rifiutare."
```
## Evaluation
```python
from datasets import load_dataset, load_metric
import datasets
import torch
from transformers import AutoModelForCTC, AutoProcessor
model_id = "microsoft/unispeech-1350-en-90-it-ft-1h"
ds = load_dataset("mozilla-foundation/common_voice_3_0", "it", split="train+validation+test+other")
wer = load_metric("wer")
model = AutoModelForCTC.from_pretrained(model_id)
processor = AutoProcessor.from_pretrained(model_id)
# taken from
# https://github.com/microsoft/UniSpeech/blob/main/UniSpeech/examples/unispeech/data/it/phonesMatches_reduced.json
with open("./testSeqs_uniform_new_version.text", "r") as f:
lines = f.readlines()
# retrieve ids model is evaluated on
ids = [x.split("\t")[0] for x in lines]
ds = ds.filter(lambda p: p.split("/")[-1].split(".")[0] in ids, input_columns=["path"])
ds = ds.cast_column("audio", datasets.Audio(sampling_rate=16_000))
def decode(batch):
input_values = processor(batch["audio"]["array"], return_tensors="pt", sampling_rate=16_000)
logits = model(input_values).logits
pred_ids = torch.argmax(logits, axis=-1)
batch["prediction"] = processor.batch_decode(pred_ids)
batch["target"] = processor.tokenizer.phonemize(batch["sentence"])
return batch
out = ds.map(decode, remove_columns=ds.column_names)
per = wer.compute(predictions=out["prediction"], references=out["target"])
print("per", per)
# -> should give per 0.06685252146070828 - compare to results below
```
# Contribution
The model was contributed by [cywang](https://huggingface.co/cywang) and [patrickvonplaten](https://huggingface.co/patrickvonplaten).
# License
The official license can be found [here](https://github.com/microsoft/UniSpeech/blob/main/LICENSE)
# Official Results
See *UniSpeeech-L^{+}* - *it*:
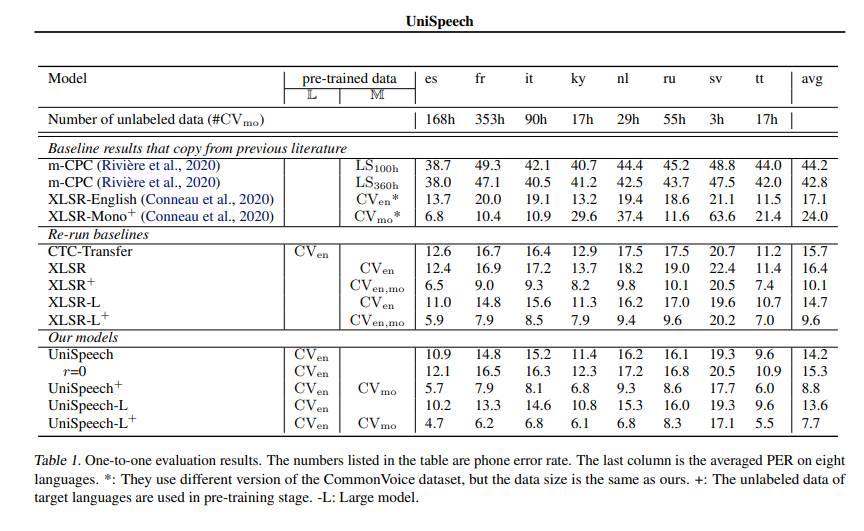 |
microsoft/unispeech-sat-large-sv | 5448decbeb9ee3546551f8cbc540eb9af8320360 | 2021-12-17T18:13:15.000Z | [
"pytorch",
"unispeech-sat",
"audio-xvector",
"en",
"arxiv:1912.07875",
"arxiv:2106.06909",
"arxiv:2101.00390",
"arxiv:2110.05752",
"transformers",
"speech"
] | null | false | microsoft | null | microsoft/unispeech-sat-large-sv | 1 | 2 | transformers | 29,948 | ---
language:
- en
datasets:
tags:
- speech
---
# UniSpeech-SAT-Large for Speaker Verification
[Microsoft's UniSpeech](https://www.microsoft.com/en-us/research/publication/unispeech-unified-speech-representation-learning-with-labeled-and-unlabeled-data/)
The model was pretrained on 16kHz sampled speech audio with utterance and speaker contrastive loss. When using the model, make sure that your speech input is also sampled at 16kHz.
The model was pre-trained on:
- 60,000 hours of [Libri-Light](https://arxiv.org/abs/1912.07875)
- 10,000 hours of [GigaSpeech](https://arxiv.org/abs/2106.06909)
- 24,000 hours of [VoxPopuli](https://arxiv.org/abs/2101.00390)
[Paper: UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER
AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752)
Authors: Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu
**Abstract**
*Self-supervised learning (SSL) is a long-standing goal for speech processing, since it utilizes large-scale unlabeled data and avoids extensive human labeling. Recent years witness great successes in applying self-supervised learning in speech recognition, while limited exploration was attempted in applying SSL for modeling speaker characteristics. In this paper, we aim to improve the existing SSL framework for speaker representation learning. Two methods are introduced for enhancing the unsupervised speaker information extraction. First, we apply the multi-task learning to the current SSL framework, where we integrate the utterance-wise contrastive loss with the SSL objective function. Second, for better speaker discrimination, we propose an utterance mixing strategy for data augmentation, where additional overlapped utterances are created unsupervisely and incorporate during training. We integrate the proposed methods into the HuBERT framework. Experiment results on SUPERB benchmark show that the proposed system achieves state-of-the-art performance in universal representation learning, especially for speaker identification oriented tasks. An ablation study is performed verifying the efficacy of each proposed method. Finally, we scale up training dataset to 94 thousand hours public audio data and achieve further performance improvement in all SUPERB tasks..*
The original model can be found under https://github.com/microsoft/UniSpeech/tree/main/UniSpeech-SAT.
# Fine-tuning details
The model is fine-tuned on the [VoxCeleb1 dataset](https://www.robots.ox.ac.uk/~vgg/data/voxceleb/vox1.html) using an X-Vector head with an Additive Margin Softmax loss
[X-Vectors: Robust DNN Embeddings for Speaker Recognition](https://www.danielpovey.com/files/2018_icassp_xvectors.pdf)
# Usage
## Speaker Verification
```python
from transformers import Wav2Vec2FeatureExtractor, UniSpeechSatForXVector
from datasets import load_dataset
import torch
dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
feature_extractor = Wav2Vec2FeatureExtractor.from_pretrained('microsoft/unispeech-sat-large-sv')
model = UniSpeechSatForXVector.from_pretrained('microsoft/unispeech-sat-large-sv')
# audio files are decoded on the fly
inputs = feature_extractor(dataset[:2]["audio"]["array"], return_tensors="pt")
embeddings = model(**inputs).embeddings
embeddings = torch.nn.functional.normalize(embeddings, dim=-1).cpu()
# the resulting embeddings can be used for cosine similarity-based retrieval
cosine_sim = torch.nn.CosineSimilarity(dim=-1)
similarity = cosine_sim(embeddings[0], embeddings[1])
threshold = 0.89 # the optimal threshold is dataset-dependent
if similarity < threshold:
print("Speakers are not the same!")
```
# License
The official license can be found [here](https://github.com/microsoft/UniSpeech/blob/main/LICENSE)
 |
microsoft/wavlm-base-sd | fe13cca7e592cf0e11287cfede24e6999ac7dc4e | 2022-03-25T12:05:11.000Z | [
"pytorch",
"wavlm",
"audio-frame-classification",
"en",
"arxiv:2110.13900",
"transformers",
"speech"
] | null | false | microsoft | null | microsoft/wavlm-base-sd | 1 | null | transformers | 29,949 | ---
language:
- en
tags:
- speech
---
# WavLM-Base for Speaker Diarization
[Microsoft's WavLM](https://github.com/microsoft/unilm/tree/master/wavlm)
The model was pretrained on 16kHz sampled speech audio with utterance and speaker contrastive loss. When using the model, make sure that your speech input is also sampled at 16kHz.
The model was pre-trained on 960h of [Librispeech](https://huggingface.co/datasets/librispeech_asr).
[Paper: WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing](https://arxiv.org/abs/2110.13900)
Authors: Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Furu Wei
**Abstract**
*Self-supervised learning (SSL) achieves great success in speech recognition, while limited exploration has been attempted for other speech processing tasks. As speech signal contains multi-faceted information including speaker identity, paralinguistics, spoken content, etc., learning universal representations for all speech tasks is challenging. In this paper, we propose a new pre-trained model, WavLM, to solve full-stack downstream speech tasks. WavLM is built based on the HuBERT framework, with an emphasis on both spoken content modeling and speaker identity preservation. We first equip the Transformer structure with gated relative position bias to improve its capability on recognition tasks. For better speaker discrimination, we propose an utterance mixing training strategy, where additional overlapped utterances are created unsupervisely and incorporated during model training. Lastly, we scale up the training dataset from 60k hours to 94k hours. WavLM Large achieves state-of-the-art performance on the SUPERB benchmark, and brings significant improvements for various speech processing tasks on their representative benchmarks.*
The original model can be found under https://github.com/microsoft/unilm/tree/master/wavlm.
# Fine-tuning details
The model is fine-tuned on the [LibriMix dataset](https://github.com/JorisCos/LibriMix) using just a linear layer for mapping the network outputs.
# Usage
## Speaker Diarization
```python
from transformers import Wav2Vec2FeatureExtractor, WavLMForAudioFrameClassification
from datasets import load_dataset
import torch
dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
feature_extractor = Wav2Vec2FeatureExtractor.from_pretrained('microsoft/wavlm-base-sd')
model = WavLMForAudioFrameClassification.from_pretrained('microsoft/wavlm-base-sd')
# audio file is decoded on the fly
inputs = feature_extractor(dataset[0]["audio"]["array"], return_tensors="pt")
logits = model(**inputs).logits
probabilities = torch.sigmoid(logits[0])
# labels is a one-hot array of shape (num_frames, num_speakers)
labels = (probabilities > 0.5).long()
```
# License
The official license can be found [here](https://github.com/microsoft/UniSpeech/blob/main/LICENSE)
 |
midas/gupshup_e2e_bart | fa17ff46877b6e1cf49022713e9702171f4f35de | 2021-11-14T02:09:24.000Z | [
"pytorch",
"bart",
"text2text-generation",
"arxiv:1910.04073",
"transformers",
"autotrain_compatible"
] | text2text-generation | false | midas | null | midas/gupshup_e2e_bart | 1 | null | transformers | 29,950 | # Gupshup
GupShup: Summarizing Open-Domain Code-Switched Conversations EMNLP 2021
Paper: [https://aclanthology.org/2021.emnlp-main.499.pdf](https://aclanthology.org/2021.emnlp-main.499.pdf)
Github: [https://github.com/midas-research/gupshup](https://github.com/midas-research/gupshup)
### Dataset
Please request for the Gupshup data using [this Google form](https://docs.google.com/forms/d/1zvUk7WcldVF3RCoHdWzQPzPprtSJClrnHoIOYbzaJEI/edit?ts=61381ec0).
Dataset is available for `Hinglish Dilaogues to English Summarization`(h2e) and `English Dialogues to English Summarization`(e2e). For each task, Dialogues/conversastion have `.source`(train.source) as file extension whereas Summary has `.target`(train.target) file extension. ".source" file need to be provided to `input_path` and ".target" file to `reference_path` argument in the scripts.
## Models
All model weights are available on the Huggingface model hub. Users can either directly download these weights in their local and provide this path to `model_name` argument in the scripts or use the provided alias (to `model_name` argument) in scripts directly; this will lead to download weights automatically by scripts.
Model names were aliased in "gupshup_TASK_MODEL" sense, where "TASK" can be h2e,e2e and MODEL can be mbart, pegasus, etc., as listed below.
**1. Hinglish Dialogues to English Summary (h2e)**
| Model | Huggingface Alias |
|---------|-------------------------------------------------------------------------------|
| mBART | [midas/gupshup_h2e_mbart](https://huggingface.co/midas/gupshup_h2e_mbart) |
| PEGASUS | [midas/gupshup_h2e_pegasus](https://huggingface.co/midas/gupshup_h2e_pegasus) |
| T5 MTL | [midas/gupshup_h2e_t5_mtl](https://huggingface.co/midas/gupshup_h2e_t5_mtl) |
| T5 | [midas/gupshup_h2e_t5](https://huggingface.co/midas/gupshup_h2e_t5) |
| BART | [midas/gupshup_h2e_bart](https://huggingface.co/midas/gupshup_h2e_bart) |
| GPT-2 | [midas/gupshup_h2e_gpt](https://huggingface.co/midas/gupshup_h2e_gpt) |
**2. English Dialogues to English Summary (e2e)**
| Model | Huggingface Alias |
|---------|-------------------------------------------------------------------------------|
| mBART | [midas/gupshup_e2e_mbart](https://huggingface.co/midas/gupshup_e2e_mbart) |
| PEGASUS | [midas/gupshup_e2e_pegasus](https://huggingface.co/midas/gupshup_e2e_pegasus) |
| T5 MTL | [midas/gupshup_e2e_t5_mtl](https://huggingface.co/midas/gupshup_e2e_t5_mtl) |
| T5 | [midas/gupshup_e2e_t5](https://huggingface.co/midas/gupshup_e2e_t5) |
| BART | [midas/gupshup_e2e_bart](https://huggingface.co/midas/gupshup_e2e_bart) |
| GPT-2 | [midas/gupshup_e2e_gpt](https://huggingface.co/midas/gupshup_e2e_gpt) |
## Inference
### Using command line
1. Clone this repo and create a python virtual environment (https://docs.python.org/3/library/venv.html). Install the required packages using
```
git clone https://github.com/midas-research/gupshup.git
pip install -r requirements.txt
```
2. run_eval script has the following arguments.
* **model_name** : Path or alias to one of our models available on Huggingface as listed above.
* **input_path** : Source file or path to file containing conversations, which will be summarized.
* **save_path** : File path where to save summaries generated by the model.
* **reference_path** : Target file or path to file containing summaries, used to calculate matrices.
* **score_path** : File path where to save scores.
* **bs** : Batch size
* **device**: Cuda devices to use.
Please make sure you have downloaded the Gupshup dataset using the above google form and provide the correct path to these files in the argument's `input_path` and `refrence_path.` Or you can simply put `test.source` and `test.target` in `data/h2e/`(hinglish to english) or `data/e2e/`(english to english) folder. For example, to generate English summaries from Hinglish dialogues using the mbart model, run the following command
```
python run_eval.py \
--model_name midas/gupshup_h2e_mbart \
--input_path data/h2e/test.source \
--save_path generated_summary.txt \
--reference_path data/h2e/test.target \
--score_path scores.txt \
--bs 8
```
Another example, to generate English summaries from English dialogues using the Pegasus model
```
python run_eval.py \
--model_name midas/gupshup_e2e_pegasus \
--input_path data/e2e/test.source \
--save_path generated_summary.txt \
--reference_path data/e2e/test.target \
--score_path scores.txt \
--bs 8
```
Please create an issue if you are facing any difficulties in replicating the results.
### References
Please cite [[1]](https://arxiv.org/abs/1910.04073) if you found the resources in this repository useful.
[1] Mehnaz, Laiba, Debanjan Mahata, Rakesh Gosangi, Uma Sushmitha Gunturi, Riya Jain, Gauri Gupta, Amardeep Kumar, Isabelle G. Lee, Anish Acharya, and Rajiv Shah. [*GupShup: Summarizing Open-Domain Code-Switched Conversations*](https://aclanthology.org/2021.emnlp-main.499.pdf)
```
@inproceedings{mehnaz2021gupshup,
title={GupShup: Summarizing Open-Domain Code-Switched Conversations},
author={Mehnaz, Laiba and Mahata, Debanjan and Gosangi, Rakesh and Gunturi, Uma Sushmitha and Jain, Riya and Gupta, Gauri and Kumar, Amardeep and Lee, Isabelle G and Acharya, Anish and Shah, Rajiv},
booktitle={Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing},
pages={6177--6192},
year={2021}
}
```
|
miguelvictor/python-bart-large | f34279a6cefb128f63623d6d9d8ff6c649717318 | 2021-05-01T14:59:22.000Z | [
"pytorch",
"bart",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | false | miguelvictor | null | miguelvictor/python-bart-large | 1 | null | transformers | 29,951 | Entry not found |
mimi/Waynehills-NLP-doogie-AIHub-paper-summary-AIHub-paper-summary | 88f81f6c9cc61bec38da5bf2a3965b6319ebb02b | 2022-01-07T08:46:52.000Z | [
"pytorch",
"t5",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | false | mimi | null | mimi/Waynehills-NLP-doogie-AIHub-paper-summary-AIHub-paper-summary | 1 | null | transformers | 29,952 | Entry not found |
mimi/Waynehills_NLP_muti | f46da4645900d946af18ca93f4e575948ac8a88d | 2022-01-20T07:12:11.000Z | [
"pytorch",
"t5",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | false | mimi | null | mimi/Waynehills_NLP_muti | 1 | null | transformers | 29,953 | Entry not found |
mimi/wynehills-mimi-ASR | a2b5e20bd34e739da7d7c4055449c92e64d5e3a1 | 2021-11-30T11:45:21.000Z | [
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"transformers",
"generated_from_trainer",
"model-index"
] | automatic-speech-recognition | false | mimi | null | mimi/wynehills-mimi-ASR | 1 | null | transformers | 29,954 | ---
tags:
- generated_from_trainer
model-index:
name: wynehills-mimi-ASR
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wynehills-mimi-ASR
This model was trained from scratch on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3822
- Wer: 0.6309
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 70
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.54 | 20 | 1.4018 | 0.6435 |
| No log | 3.08 | 40 | 1.4704 | 0.6593 |
| No log | 4.62 | 60 | 1.4898 | 0.6625 |
| No log | 6.15 | 80 | 1.4560 | 0.6404 |
| No log | 7.69 | 100 | 1.3822 | 0.6309 |
| No log | 9.23 | 120 | 1.3822 | 0.6309 |
| No log | 10.77 | 140 | 1.3822 | 0.6309 |
| No log | 12.31 | 160 | 1.3822 | 0.6309 |
| No log | 13.85 | 180 | 1.3822 | 0.6309 |
| No log | 15.38 | 200 | 1.3822 | 0.6309 |
| No log | 16.92 | 220 | 1.3822 | 0.6309 |
| No log | 18.46 | 240 | 1.3822 | 0.6309 |
| No log | 20.0 | 260 | 1.3822 | 0.6309 |
| No log | 21.54 | 280 | 1.3822 | 0.6309 |
| No log | 23.08 | 300 | 1.3822 | 0.6309 |
| No log | 24.62 | 320 | 1.3822 | 0.6309 |
| No log | 26.15 | 340 | 1.3822 | 0.6309 |
| No log | 27.69 | 360 | 1.3822 | 0.6309 |
| No log | 29.23 | 380 | 1.3822 | 0.6309 |
| No log | 30.77 | 400 | 1.3822 | 0.6309 |
| No log | 32.31 | 420 | 1.3822 | 0.6309 |
| No log | 33.85 | 440 | 1.3822 | 0.6309 |
| No log | 35.38 | 460 | 1.3822 | 0.6309 |
| No log | 36.92 | 480 | 1.3822 | 0.6309 |
| 0.0918 | 38.46 | 500 | 1.3822 | 0.6309 |
| 0.0918 | 40.0 | 520 | 1.3822 | 0.6309 |
| 0.0918 | 41.54 | 540 | 1.3822 | 0.6309 |
| 0.0918 | 43.08 | 560 | 1.3822 | 0.6309 |
| 0.0918 | 44.62 | 580 | 1.3822 | 0.6309 |
| 0.0918 | 46.15 | 600 | 1.3822 | 0.6309 |
| 0.0918 | 47.69 | 620 | 1.3822 | 0.6309 |
| 0.0918 | 49.23 | 640 | 1.3822 | 0.6309 |
| 0.0918 | 50.77 | 660 | 1.3822 | 0.6309 |
| 0.0918 | 52.31 | 680 | 1.3822 | 0.6309 |
| 0.0918 | 53.85 | 700 | 1.3822 | 0.6309 |
| 0.0918 | 55.38 | 720 | 1.3822 | 0.6309 |
| 0.0918 | 56.92 | 740 | 1.3822 | 0.6309 |
| 0.0918 | 58.46 | 760 | 1.3822 | 0.6309 |
| 0.0918 | 60.0 | 780 | 1.3822 | 0.6309 |
| 0.0918 | 61.54 | 800 | 1.3822 | 0.6309 |
| 0.0918 | 63.08 | 820 | 1.3822 | 0.6309 |
| 0.0918 | 64.62 | 840 | 1.3822 | 0.6309 |
| 0.0918 | 66.15 | 860 | 1.3822 | 0.6309 |
| 0.0918 | 67.69 | 880 | 1.3822 | 0.6309 |
| 0.0918 | 69.23 | 900 | 1.3822 | 0.6309 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu111
- Datasets 1.13.3
- Tokenizers 0.10.3
|
minemile/dummy-model | d0a229e6f7b335f8c16d35c63ab72334f4c21f4e | 2021-12-01T10:53:59.000Z | [
"pytorch",
"camembert",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | false | minemile | null | minemile/dummy-model | 1 | null | transformers | 29,955 | Entry not found |
mingchen7/bert-question-answering | 82c35e24952f57448b6ed88234205f71f4f6d983 | 2021-07-13T06:40:53.000Z | [
"pytorch",
"distilbert",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | false | mingchen7 | null | mingchen7/bert-question-answering | 1 | null | transformers | 29,956 | Entry not found |
minhdang241/robustqa-tapt | ddb263c6f14e4cbf839800a96305c2305175cd1a | 2021-04-27T03:34:14.000Z | [
"pytorch",
"distilbert",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | false | minhdang241 | null | minhdang241/robustqa-tapt | 1 | null | transformers | 29,957 | Entry not found |
minsiam/DialoGPT-small-harrypotterbot | bb58e050b74e42e3ab3ab6f7ce87deac911f01cc | 2021-09-19T17:07:41.000Z | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | false | minsiam | null | minsiam/DialoGPT-small-harrypotterbot | 1 | null | transformers | 29,958 | ---
tags:
- conversational
---
#Harry Potter DialoGPT Model |
mittalnishit/DialoGPT-small-rickman | 5d8dfda886ab029f40a5d8b0de832cc390b59c33 | 2021-06-23T07:15:52.000Z | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | false | mittalnishit | null | mittalnishit/DialoGPT-small-rickman | 1 | null | transformers | 29,959 | ---
tags:
- conversational
---
# DialoGPT-small-rickman |
mk3smo/dialogpt-med-duck2 | 85765b5e29985a7ac02d61b7aa509866193fbde2 | 2021-12-31T05:41:44.000Z | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | false | mk3smo | null | mk3smo/dialogpt-med-duck2 | 1 | null | transformers | 29,960 | ---
tags:
- conversational
---
# Duck/Ahiru DialoGPT Model |
mk3smo/dialogpt-med-duck3 | d5def39d7066a9b1286474884b7849f9fd9354d6 | 2021-12-31T06:06:10.000Z | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | false | mk3smo | null | mk3smo/dialogpt-med-duck3 | 1 | null | transformers | 29,961 | ---
tags:
- conversational
---
# Duck/Ahiru DialoGPT Model |
mk3smo/dialogpt-med-duck5 | 6c4d7ec29605d0b62eb0f384f31eed00dacef135 | 2021-12-31T16:26:54.000Z | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | false | mk3smo | null | mk3smo/dialogpt-med-duck5 | 1 | null | transformers | 29,962 | ---
tags:
- conversational
---
# Duck dialogpt model |
mk3smo/dialogpt-med-stt3 | 5672d8ce9297e1582813ed91faf36c39e7a1dc4f | 2021-12-31T22:03:13.000Z | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | false | mk3smo | null | mk3smo/dialogpt-med-stt3 | 1 | null | transformers | 29,963 | ---
tags:
- conversational
---
# not writing shit here |
ml6team/gpt-2-small-conditional-quote-generator | 946b32ca64b5985e39baf96c668487b0651d5725 | 2021-05-23T09:40:50.000Z | [
"pytorch",
"jax",
"gpt2",
"text-generation",
"transformers"
] | text-generation | false | ml6team | null | ml6team/gpt-2-small-conditional-quote-generator | 1 | 6 | transformers | 29,964 | Entry not found |
mm/roberta-large-mld | 9df889e8fd90f53e90a3a0298c38a7e2e06fa6f1 | 2021-05-20T17:56:43.000Z | [
"pytorch",
"tf",
"jax",
"roberta",
"feature-extraction",
"transformers"
] | feature-extraction | false | mm | null | mm/roberta-large-mld | 1 | null | transformers | 29,965 | # roberta-large-mld
This is a pretrained roberta-large model for machine learning domain documents.
|
mmcquade11-test/reuters-summarization | 7f9ab696a49d54bf43ed8134139a5b4cf94a2bfd | 2021-11-30T21:43:51.000Z | [
"pytorch",
"pegasus",
"text2text-generation",
"en",
"dataset:mmcquade11/autonlp-data-reuters-summarization",
"transformers",
"autonlp",
"co2_eq_emissions",
"autotrain_compatible"
] | text2text-generation | false | mmcquade11-test | null | mmcquade11-test/reuters-summarization | 1 | null | transformers | 29,966 | ---
tags: autonlp
language: en
widget:
- text: "I love AutoNLP 🤗"
datasets:
- mmcquade11/autonlp-data-reuters-summarization
co2_eq_emissions: 286.4350821612984
---
This is an autoNLP model I trained on Reuters dataset
# Model Trained Using AutoNLP
- Problem type: Summarization
- Model ID: 34018133
- CO2 Emissions (in grams): 286.4350821612984
## Validation Metrics
- Loss: 1.1805976629257202
- Rouge1: 55.4013
- Rouge2: 30.8004
- RougeL: 52.57
- RougeLsum: 52.6103
- Gen Len: 15.3458
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_HUGGINGFACE_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/mmcquade11/autonlp-reuters-summarization-34018133
``` |
mobedkova/wav2vec2-xls-r-300m-ru | cb22918ff4144c820896ea8083d8b2fcaf93af2b | 2022-02-07T15:22:00.000Z | [
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"transformers"
] | automatic-speech-recognition | false | mobedkova | null | mobedkova/wav2vec2-xls-r-300m-ru | 1 | null | transformers | 29,967 | Entry not found |
model-mili/DialoGPT-small-Sapph-v1 | 5fc0fd771f3b22d82f06de9f1c792fcbeebdc284 | 2021-11-25T22:48:08.000Z | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | false | model-mili | null | model-mili/DialoGPT-small-Sapph-v1 | 1 | null | transformers | 29,968 | ---
tags:
- conversational
---
# DialoGPT-small-Sapph-v1 |
model-mili/DialoGPT-small-Yukub-v2 | e6bb430945701eac85d6ae890a4a6351b5d6e734 | 2021-11-14T00:39:59.000Z | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | false | model-mili | null | model-mili/DialoGPT-small-Yukub-v2 | 1 | null | transformers | 29,969 | ---
tags:
- conversational
---
# Dialo-GPT small Yukub model v2 |
model-mili/DialoGPT-small-Yukub | 32414560eaaae3f3484020271b1d6d02c3c87516 | 2021-11-13T01:19:22.000Z | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | false | model-mili | null | model-mili/DialoGPT-small-Yukub | 1 | null | transformers | 29,970 | ---
tags:
- conversational
---
# Dialo-GPT small Yukub model |
mofawzy/cstgan | c14a9a7d65511e98725e6cf893c922c85e8f0236 | 2021-12-14T07:28:14.000Z | [
"pytorch",
"gpt2",
"transformers"
] | null | false | mofawzy | null | mofawzy/cstgan | 1 | null | transformers | 29,971 | Entry not found |
mofawzy/gpt-2-negative-reviews | aabf92630ab3cb1a0f43eec12fd90fff046af764 | 2021-05-23T09:55:19.000Z | [
"pytorch",
"tf",
"jax",
"gpt2",
"text-generation",
"transformers"
] | text-generation | false | mofawzy | null | mofawzy/gpt-2-negative-reviews | 1 | null | transformers | 29,972 | |
moha/mbert_ar_c19 | df4cab1f21482d69e981f5c5dda3158e49249d63 | 2021-05-19T23:38:34.000Z | [
"pytorch",
"jax",
"bert",
"fill-mask",
"ar",
"arxiv:2105.03143",
"arxiv:2004.04315",
"transformers",
"autotrain_compatible"
] | fill-mask | false | moha | null | moha/mbert_ar_c19 | 1 | null | transformers | 29,973 | ---
language: ar
widget:
- text: "للوقايه من انتشار [MASK]"
---
# mbert_c19: An mbert model pretrained on 1.5 million COVID-19 multi-dialect Arabic tweets
**mBERT COVID-19** [Arxiv URL](https://arxiv.org/pdf/2105.03143.pdf) is a pretrained (fine-tuned) version of the mBERT model (https://huggingface.co/bert-base-multilingual-cased). The pretraining was done using 1.5 million multi-dialect Arabic tweets regarding the COVID-19 pandemic from the “Large Arabic Twitter Dataset on COVID-19” (https://arxiv.org/abs/2004.04315).
The model can achieve better results for the tasks that deal with multi-dialect Arabic tweets in relation to the COVID-19 pandemic.
# Classification results for multiple tasks including fake-news and hate speech detection when using arabert_c19 and mbert_ar_c19:
For more details refer to the paper (link)
| | arabert | mbert | distilbert multi | arabert Covid-19 | mbert Covid-19 |
|------------------------------------|----------|----------|------------------|------------------|----------------|
| Contains hate (Binary) | 0.8346 | 0.6675 | 0.7145 | `0.8649` | 0.8492 |
| Talk about a cure (Binary) | 0.8193 | 0.7406 | 0.7127 | 0.9055 | `0.9176` |
| News or opinion (Binary) | 0.8987 | 0.8332 | 0.8099 | `0.9163` | 0.9116 |
| Contains fake information (Binary) | 0.6415 | 0.5428 | 0.4743 | `0.7739` | 0.7228 |
# Preprocessing
```python
from arabert.preprocess import ArabertPreprocessor
model_name="moha/mbert_ar_c19"
arabert_prep = ArabertPreprocessor(model_name=model_name)
text = "للوقايه من عدم انتشار كورونا عليك اولا غسل اليدين بالماء والصابون وتكون عملية الغسل دقيقه تشمل راحة اليد الأصابع التركيز على الإبهام"
arabert_prep.preprocess(text)
```
# Citation
Please cite as:
``` bibtex
@misc{ameur2021aracovid19mfh,
title={AraCOVID19-MFH: Arabic COVID-19 Multi-label Fake News and Hate Speech Detection Dataset},
author={Mohamed Seghir Hadj Ameur and Hassina Aliane},
year={2021},
eprint={2105.03143},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
# Contacts
**Hadj Ameur**: [Github](https://github.com/MohamedHadjAmeur) | <[email protected]> | <[email protected]> |
mohamed-illiyas/wav2vec2-base-lj-demo-colab | c012f73e4533fe280baf2b3fbc95552d9bf2f7f5 | 2022-02-16T15:24:20.000Z | [
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] | automatic-speech-recognition | false | mohamed-illiyas | null | mohamed-illiyas/wav2vec2-base-lj-demo-colab | 1 | null | transformers | 29,974 | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: wav2vec2-base-lj-demo-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-lj-demo-colab
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.7050
- Wer: 1.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 2
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:---:|
| No log | 0.41 | 20 | 15.5667 | 1.0 |
| No log | 0.82 | 40 | 11.6885 | 1.0 |
| 8.569 | 1.22 | 60 | 6.0060 | 1.0 |
| 8.569 | 1.63 | 80 | 3.7050 | 1.0 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.10.3
|
mohamed1ai/wav2vec2-large-xls-ar | 6eb1a1ad1ebc9d6f815418f017d248cb5f8c4836 | 2022-02-17T21:45:49.000Z | [
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"ar",
"transformers",
"audio",
"speech",
"xlsr-fine-tuning-week",
"license:apache-2.0",
"model-index"
] | automatic-speech-recognition | false | mohamed1ai | null | mohamed1ai/wav2vec2-large-xls-ar | 1 | 1 | transformers | 29,975 | ---
language: ar
use datasets:
- common_voice: Common Voice Corpus 5.1
metrics:
- wer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: Hasni XLSR Wav2Vec2 Large 53
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice ar
type: common_voice
args: ar
metrics:
- name: Test WER
type: wer
value: 52
---
# Wav2Vec2-Large-XLSR-53-Arabic
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Arabic using the [Common Voice Corpus 5.1](https://commonvoice.mozilla.org/en/datasets) dataset.
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "ar", split="test[:2%]")
processor = Wav2Vec2Processor.from_pretrained("mohamed1ai/wav2vec2-large-xls-ar")
model = Wav2Vec2ForCTC.from_pretrained("mohamed1ai/wav2vec2-large-xls-ar")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the Arabic test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "ar", split="test")
processor = Wav2Vec2Processor.from_pretrained("mohamed1ai/wav2vec2-large-xls-ar")
model = Wav2Vec2ForCTC.from_pretrained("mohamed1ai/wav2vec2-large-xls-ar")
model.to("cuda")
chars_to_ignore_regex = '[\,\؟\.\!\-\;\\:\'\"\☭\«\»\؛\—\ـ\_\،\“\%\‘\”\�]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
batch["sentence"] = re.sub('[a-z]','',batch["sentence"])
batch["sentence"] = re.sub("[إأٱآا]", "ا", batch["sentence"])
noise = re.compile(""" ّ | # Tashdid
َ | # Fatha
ً | # Tanwin Fath
ُ | # Damma
ٌ | # Tanwin Damm
ِ | # Kasra
ٍ | # Tanwin Kasr
ْ | # Sukun
ـ # Tatwil/Kashida
""", re.VERBOSE)
batch["sentence"] = re.sub(noise, '', batch["sentence"])
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 52 %
|
moma1820/DSV-JavaFx-DAPT-CodeBert | a1c28bf5f9a4ac0660a5d9bd259cf9d93164f3e3 | 2021-08-25T12:09:07.000Z | [
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] | feature-extraction | false | moma1820 | null | moma1820/DSV-JavaFx-DAPT-CodeBert | 1 | null | transformers | 29,976 | Pre Träna CodeBert med JavaFx + Java FXML + JavaFx relaterat logik kod (dvs. Model, Controller för olika JavaFx kod).
Blev ungefär 130 k kod exemplar
````
***** train metrics *****
epoch = 3.0
train_loss = 0.4556
train_runtime = 5:57:43.71
train_samples = 131945
train_samples_per_second = 18.442
train_steps_per_second = 2.305
***** eval metrics *****
epoch = 3.0
eval_loss = 0.2984
eval_runtime = 0:01:59.72
eval_samples = 6944
eval_samples_per_second = 57.999
eval_steps_per_second = 7.25
perplexity = 1.3477
```` |
monologg/koelectra-base-v1-goemotions | 63b4513e0b3516654ccc7d30765a9a8718cc939c | 2021-02-09T14:37:05.000Z | [
"pytorch",
"electra",
"transformers"
] | null | false | monologg | null | monologg/koelectra-base-v1-goemotions | 1 | null | transformers | 29,977 | Entry not found |
monologg/koelectra-small-v1-goemotions | a32c506140654d8fb8d4b872a9b9bd01e3faab6b | 2021-02-09T14:40:43.000Z | [
"pytorch",
"electra",
"transformers"
] | null | false | monologg | null | monologg/koelectra-small-v1-goemotions | 1 | null | transformers | 29,978 | Entry not found |
monologg/koelectra-small-v3-finetuned-korquad | 65c2dd066733645489b17789a49029992bdd294b | 2020-10-14T01:45:01.000Z | [
"pytorch",
"electra",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | false | monologg | null | monologg/koelectra-small-v3-finetuned-korquad | 1 | null | transformers | 29,979 | Entry not found |
monsoon-nlp/byt5-basque | 76e9349fd54475ed0659979a848f04f2cda38fdf | 2021-07-07T06:13:11.000Z | [
"pytorch",
"tf",
"t5",
"text2text-generation",
"eu",
"transformers",
"autotrain_compatible"
] | text2text-generation | false | monsoon-nlp | null | monsoon-nlp/byt5-basque | 1 | null | transformers | 29,980 | ---
language: eu
---
# byt5-basque
Pretrained from scratch on Euskara (Basque language)
with ByT5, Google's new byte-level tokenizer strategy.
Corpus: eu.wikipedia.org as of March 2020 (TFDS)
Pretraining Notebook: https://colab.research.google.com/drive/19Afq7CI6cOi1DaTpnQhBbEbnBzLSFHbH
## Todos
Fine-tuning
The Wikipedia corpus is small for this language compared to web crawls. In the future I would add
OSCAR, if I can rewrite the script to accept those
as one TFDS dataset.
|
monsoon-nlp/gpt-nyc-affirmations | 4f85b6d800bff705b88d80327a2c6b592f27c08a | 2021-08-10T21:06:00.000Z | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
] | text-generation | false | monsoon-nlp | null | monsoon-nlp/gpt-nyc-affirmations | 1 | null | transformers | 29,981 | # GPT-NYC-affirmations
## About
GPT2 (small version on HF) fine-tuned on questions and responses from https://reddit.com/r/asknyc
and then 2 epochs of [Value Affirmations](https://gist.github.com/mapmeld/c16794ecd93c241a4d6a65bda621bb55)
based on the OpenAI post [Improving Language Model Behavior](https://openai.com/blog/improving-language-model-behavior/)
and corresponding paper.
Try prompting with ```question? - %% ``` or ```question? - more info %%```
I filtered AskNYC comments to ones with scores >= 3, and responding directly
to the original post ( = ignoring responses to other commenters).
I also added many tokens which were common on /r/AskNYC but missing from
GPT2.
The 'affirmations' list was sourced from excerpts in the OpenAI paper, a popular version of
the 'in this house we believe' sign, and the Reddit rules. They should not
be seen as all-encompassing or foundational to a safe AI. The main goal
was to see how it affected the behavior of GPT-NYC on generating toxic
or non-toxic language.
The [gpt-nyc](https://huggingface.co/monsoon-nlp/gpt-nyc) repo is based
on GPT2-Medium and comes off more accurate.
## Blog
https://mapmeld.medium.com/gpt-nyc-part-1-9cb698b2e3d
## Notebooks
### Data processing / new tokens
https://colab.research.google.com/drive/13BOw0uekoAYB4jjQtaXTn6J_VHatiRLu
### Fine-tuning GPT2 (small)
https://colab.research.google.com/drive/1FnXcAh4H-k8dAzixkV5ieygV96ePh3lR
### Predictive text and probabilities
Scroll to end of
https://colab.research.google.com/drive/1FnXcAh4H-k8dAzixkV5ieygV96ePh3lR
to see how to install git-lfs and trick ecco into loading this.
|
monsoon-nlp/gpt-nyc-small | b52a84ce3bf57052fe08c64e65aff12cd3f8a29c | 2021-05-23T10:01:10.000Z | [
"pytorch",
"jax",
"gpt2",
"text-generation",
"transformers"
] | text-generation | false | monsoon-nlp | null | monsoon-nlp/gpt-nyc-small | 1 | null | transformers | 29,982 | # GPT-NYC-small
## About
GPT2 (small version on HF) fine-tuned on questions and responses from https://reddit.com/r/asknyc
I filtered comments to ones with scores >= 3, and responding directly
to the original post ( = ignoring responses to other commenters).
I also added many tokens which were common on /r/AskNYC but missing from
GPT2.
The [gpt-nyc](https://huggingface.co/monsoon-nlp/gpt-nyc) repo is based
on GPT2-Medium and comes off more accurate, but the answers from this
test model struck me as humorous for their strings of subway transfers
or rambling answers about apartments.
Try prompting with ```question?``` plus two spaces, or ```question? - more info``` plus two spaces
## Blog
https://mapmeld.medium.com/gpt-nyc-part-1-9cb698b2e3d
## Notebooks
### Data processing / new tokens
https://colab.research.google.com/drive/13BOw0uekoAYB4jjQtaXTn6J_VHatiRLu
### Fine-tuning GPT2 (small)
https://colab.research.google.com/drive/1FnXcAh4H-k8dAzixkV5ieygV96ePh3lR
### Predictive text and probabilities
Scroll to end of
https://colab.research.google.com/drive/1FnXcAh4H-k8dAzixkV5ieygV96ePh3lR
to see how to install git-lfs and trick ecco into loading this.
|
monsoon-nlp/gpt-winowhy | 011e3c742a467a09a24cfdccc0946883fe4d8ae7 | 2021-05-22T05:03:46.000Z | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
] | text-generation | false | monsoon-nlp | null | monsoon-nlp/gpt-winowhy | 1 | null | transformers | 29,983 | Entry not found |
motiondew/bert-sd1 | e8c528a32013580a049487c4776655a5d6ef0428 | 2021-07-01T07:25:24.000Z | [
"pytorch",
"bert",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | false | motiondew | null | motiondew/bert-sd1 | 1 | null | transformers | 29,984 | Entry not found |
motiondew/bert-sd2-lr-5e-5-bs-32-e-3 | 7f157e7228a5b5f6305d2ddea89fc65cff5a3605 | 2021-07-04T13:52:26.000Z | [
"pytorch",
"bert",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | false | motiondew | null | motiondew/bert-sd2-lr-5e-5-bs-32-e-3 | 1 | null | transformers | 29,985 | Entry not found |
motiondew/bert-sd2-small | 26416b4bb32ed5fac36b7c59b37471eb8e1e448d | 2021-07-01T09:02:16.000Z | [
"pytorch",
"bert",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | false | motiondew | null | motiondew/bert-sd2-small | 1 | null | transformers | 29,986 | Entry not found |
motiondew/bert-sd2 | 545d236276d01cb6c62348e078e78e99e5652eab | 2021-07-01T07:22:25.000Z | [
"pytorch",
"bert",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | false | motiondew | null | motiondew/bert-sd2 | 1 | null | transformers | 29,987 | Entry not found |
motiondew/bert-sd3-small | dc62bd6ba5453ee6549b98bfb9acb25bb33b44cb | 2021-07-01T09:26:15.000Z | [
"pytorch",
"bert",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | false | motiondew | null | motiondew/bert-sd3-small | 1 | null | transformers | 29,988 | Entry not found |
motiondew/bert-sd3 | a0b6d1dd681762fa32cb5c42e679356bcff4d463 | 2021-07-01T07:18:41.000Z | [
"pytorch",
"bert",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | false | motiondew | null | motiondew/bert-sd3 | 1 | null | transformers | 29,989 | Entry not found |
motiondew/bert-set_date_1-lr-2e-5-bs-32-ep-3 | 7ced898d2cdaa002379e281b30892f7aa6e39e7d | 2021-06-24T23:09:10.000Z | [
"pytorch",
"bert",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | false | motiondew | null | motiondew/bert-set_date_1-lr-2e-5-bs-32-ep-3 | 1 | null | transformers | 29,990 | Entry not found |
motiondew/bert-set_date_1-lr-2e-5-bs-32-ep-4 | 35a8e89f45ed107179c44ecc7e30f1fd4e7b532f | 2021-06-25T06:57:25.000Z | [
"pytorch",
"bert",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | false | motiondew | null | motiondew/bert-set_date_1-lr-2e-5-bs-32-ep-4 | 1 | null | transformers | 29,991 | Entry not found |
motiondew/bert-set_date_1-lr-3e-5-bs-32-ep-3 | a6e72b7f1c9c8a6049bd01a978e9068ae97f750f | 2021-06-25T10:02:03.000Z | [
"pytorch",
"bert",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | false | motiondew | null | motiondew/bert-set_date_1-lr-3e-5-bs-32-ep-3 | 1 | null | transformers | 29,992 | Entry not found |
motiondew/bert-set_date_2-lr-2e-5-bs-32-ep-3 | 728a135a926d8ce4d4f44eef864032ee374c2bc5 | 2021-06-24T23:15:26.000Z | [
"pytorch",
"bert",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | false | motiondew | null | motiondew/bert-set_date_2-lr-2e-5-bs-32-ep-3 | 1 | null | transformers | 29,993 | Entry not found |
motiondew/bert-set_date_2-lr-2e-5-bs-32-ep-4 | 4784a1de3324239605a22eb8d34c253606684955 | 2021-06-25T07:26:59.000Z | [
"pytorch",
"bert",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | false | motiondew | null | motiondew/bert-set_date_2-lr-2e-5-bs-32-ep-4 | 1 | null | transformers | 29,994 | Entry not found |
motiondew/bert-set_date_2-lr-3e-5-bs-32-ep-3 | 90e1fa49386bfc16670586c8f45f6b65ddd0e72e | 2021-06-25T10:07:56.000Z | [
"pytorch",
"bert",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | false | motiondew | null | motiondew/bert-set_date_2-lr-3e-5-bs-32-ep-3 | 1 | null | transformers | 29,995 | Entry not found |
motiondew/bert-set_date_3-lr-2e-5-bs-32-ep-3 | 604cc19bb354a85639e26805e69c88081a6c5110 | 2021-06-29T20:42:30.000Z | [
"pytorch",
"bert",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | false | motiondew | null | motiondew/bert-set_date_3-lr-2e-5-bs-32-ep-3 | 1 | null | transformers | 29,996 | Entry not found |
motiondew/bert-set_date_3-lr-2e-5-bs-32-ep-4 | 3b57af613fbe883d70f55d5b09d48304ff751127 | 2021-06-29T20:41:47.000Z | [
"pytorch",
"bert",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | false | motiondew | null | motiondew/bert-set_date_3-lr-2e-5-bs-32-ep-4 | 1 | null | transformers | 29,997 | Entry not found |
motiondew/distilbert-finetuned | 21c1e2b47ba6912591d3c330c19f6496973f72ad | 2021-05-13T14:39:38.000Z | [
"pytorch",
"distilbert",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | false | motiondew | null | motiondew/distilbert-finetuned | 1 | null | transformers | 29,998 | Entry not found |
motiondew/set_date_1-impartit_4-bert | 26df3a06f6646669d1936f87112ab82230251228 | 2021-06-21T14:50:07.000Z | [
"pytorch",
"bert",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | false | motiondew | null | motiondew/set_date_1-impartit_4-bert | 1 | null | transformers | 29,999 | Entry not found |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.