
modelId
stringlengths 4
112
| sha
stringlengths 40
40
| lastModified
stringlengths 24
24
| tags
list | pipeline_tag
stringclasses 29
values | private
bool 1
class | author
stringlengths 2
38
⌀ | config
null | id
stringlengths 4
112
| downloads
float64 0
36.8M
⌀ | likes
float64 0
712
⌀ | library_name
stringclasses 17
values | __index_level_0__
int64 0
38.5k
| readme
stringlengths 0
186k
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
delvan/DialoGPT-medium-DwightV1
|
eba600f8bb554a42b871329fdc9569687afd8e16
|
2021-10-24T20:29:11.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
| false |
delvan
| null |
delvan/DialoGPT-medium-DwightV1
| 467 | null |
transformers
| 2,400 |
---
tags:
- conversational
---
#DialoGPT medium based model of Dwight Schrute, trained with 10 context lines of history for 20 epochs.
|
dhtocks/Topic-Classification
|
6ff7f547583d0c48b862f349f9ca11747731ad61
|
2022-01-12T03:14:00.000Z
|
[
"pytorch",
"roberta",
"text-classification",
"transformers"
] |
text-classification
| false |
dhtocks
| null |
dhtocks/Topic-Classification
| 467 | null |
transformers
| 2,401 |
Entry not found
|
facebook/nllb-200-1.3B
|
592daca35b1d4712f683a3401240ed61f0854685
|
2022-07-19T15:46:08.000Z
|
[
"pytorch",
"m2m_100",
"text2text-generation",
"ace",
"acm",
"acq",
"aeb",
"af",
"ajp",
"ak",
"als",
"am",
"apc",
"ar",
"ars",
"ary",
"arz",
"as",
"ast",
"awa",
"ayr",
"azb",
"azj",
"ba",
"bm",
"ban",
"be",
"bem",
"bn",
"bho",
"bjn",
"bo",
"bs",
"bug",
"bg",
"ca",
"ceb",
"cs",
"cjk",
"ckb",
"crh",
"cy",
"da",
"de",
"dik",
"dyu",
"dz",
"el",
"en",
"eo",
"et",
"eu",
"ee",
"fo",
"fj",
"fi",
"fon",
"fr",
"fur",
"fuv",
"gaz",
"gd",
"ga",
"gl",
"gn",
"gu",
"ht",
"ha",
"he",
"hi",
"hne",
"hr",
"hu",
"hy",
"ig",
"ilo",
"id",
"is",
"it",
"jv",
"ja",
"kab",
"kac",
"kam",
"kn",
"ks",
"ka",
"kk",
"kbp",
"kea",
"khk",
"km",
"ki",
"rw",
"ky",
"kmb",
"kmr",
"knc",
"kg",
"ko",
"lo",
"lij",
"li",
"ln",
"lt",
"lmo",
"ltg",
"lb",
"lua",
"lg",
"luo",
"lus",
"lvs",
"mag",
"mai",
"ml",
"mar",
"min",
"mk",
"mt",
"mni",
"mos",
"mi",
"my",
"nl",
"nn",
"nb",
"npi",
"nso",
"nus",
"ny",
"oc",
"ory",
"pag",
"pa",
"pap",
"pbt",
"pes",
"plt",
"pl",
"pt",
"prs",
"quy",
"ro",
"rn",
"ru",
"sg",
"sa",
"sat",
"scn",
"shn",
"si",
"sk",
"sl",
"sm",
"sn",
"sd",
"so",
"st",
"es",
"sc",
"sr",
"ss",
"su",
"sv",
"swh",
"szl",
"ta",
"taq",
"tt",
"te",
"tg",
"tl",
"th",
"ti",
"tpi",
"tn",
"ts",
"tk",
"tum",
"tr",
"tw",
"tzm",
"ug",
"uk",
"umb",
"ur",
"uzn",
"vec",
"vi",
"war",
"wo",
"xh",
"ydd",
"yo",
"yue",
"zh",
"zsm",
"zu",
"dataset:flores-200",
"transformers",
"nllb",
"license:cc-by-nc-4.0",
"autotrain_compatible"
] |
text2text-generation
| false |
facebook
| null |
facebook/nllb-200-1.3B
| 467 | 1 |
transformers
| 2,402 |
---
language:
- ace
- acm
- acq
- aeb
- af
- ajp
- ak
- als
- am
- apc
- ar
- ars
- ary
- arz
- as
- ast
- awa
- ayr
- azb
- azj
- ba
- bm
- ban
- be
- bem
- bn
- bho
- bjn
- bo
- bs
- bug
- bg
- ca
- ceb
- cs
- cjk
- ckb
- crh
- cy
- da
- de
- dik
- dyu
- dz
- el
- en
- eo
- et
- eu
- ee
- fo
- fj
- fi
- fon
- fr
- fur
- fuv
- gaz
- gd
- ga
- gl
- gn
- gu
- ht
- ha
- he
- hi
- hne
- hr
- hu
- hy
- ig
- ilo
- id
- is
- it
- jv
- ja
- kab
- kac
- kam
- kn
- ks
- ka
- kk
- kbp
- kea
- khk
- km
- ki
- rw
- ky
- kmb
- kmr
- knc
- kg
- ko
- lo
- lij
- li
- ln
- lt
- lmo
- ltg
- lb
- lua
- lg
- luo
- lus
- lvs
- mag
- mai
- ml
- mar
- min
- mk
- mt
- mni
- mos
- mi
- my
- nl
- nn
- nb
- npi
- nso
- nus
- ny
- oc
- ory
- pag
- pa
- pap
- pbt
- pes
- plt
- pl
- pt
- prs
- quy
- ro
- rn
- ru
- sg
- sa
- sat
- scn
- shn
- si
- sk
- sl
- sm
- sn
- sd
- so
- st
- es
- sc
- sr
- ss
- su
- sv
- swh
- szl
- ta
- taq
- tt
- te
- tg
- tl
- th
- ti
- tpi
- tn
- ts
- tk
- tum
- tr
- tw
- tzm
- ug
- uk
- umb
- ur
- uzn
- vec
- vi
- war
- wo
- xh
- ydd
- yo
- yue
- zh
- zsm
- zu
language_details: "ace_Arab, ace_Latn, acm_Arab, acq_Arab, aeb_Arab, afr_Latn, ajp_Arab, aka_Latn, amh_Ethi, apc_Arab, arb_Arab, ars_Arab, ary_Arab, arz_Arab, asm_Beng, ast_Latn, awa_Deva, ayr_Latn, azb_Arab, azj_Latn, bak_Cyrl, bam_Latn, ban_Latn,bel_Cyrl, bem_Latn, ben_Beng, bho_Deva, bjn_Arab, bjn_Latn, bod_Tibt, bos_Latn, bug_Latn, bul_Cyrl, cat_Latn, ceb_Latn, ces_Latn, cjk_Latn, ckb_Arab, crh_Latn, cym_Latn, dan_Latn, deu_Latn, dik_Latn, dyu_Latn, dzo_Tibt, ell_Grek, eng_Latn, epo_Latn, est_Latn, eus_Latn, ewe_Latn, fao_Latn, pes_Arab, fij_Latn, fin_Latn, fon_Latn, fra_Latn, fur_Latn, fuv_Latn, gla_Latn, gle_Latn, glg_Latn, grn_Latn, guj_Gujr, hat_Latn, hau_Latn, heb_Hebr, hin_Deva, hne_Deva, hrv_Latn, hun_Latn, hye_Armn, ibo_Latn, ilo_Latn, ind_Latn, isl_Latn, ita_Latn, jav_Latn, jpn_Jpan, kab_Latn, kac_Latn, kam_Latn, kan_Knda, kas_Arab, kas_Deva, kat_Geor, knc_Arab, knc_Latn, kaz_Cyrl, kbp_Latn, kea_Latn, khm_Khmr, kik_Latn, kin_Latn, kir_Cyrl, kmb_Latn, kon_Latn, kor_Hang, kmr_Latn, lao_Laoo, lvs_Latn, lij_Latn, lim_Latn, lin_Latn, lit_Latn, lmo_Latn, ltg_Latn, ltz_Latn, lua_Latn, lug_Latn, luo_Latn, lus_Latn, mag_Deva, mai_Deva, mal_Mlym, mar_Deva, min_Latn, mkd_Cyrl, plt_Latn, mlt_Latn, mni_Beng, khk_Cyrl, mos_Latn, mri_Latn, zsm_Latn, mya_Mymr, nld_Latn, nno_Latn, nob_Latn, npi_Deva, nso_Latn, nus_Latn, nya_Latn, oci_Latn, gaz_Latn, ory_Orya, pag_Latn, pan_Guru, pap_Latn, pol_Latn, por_Latn, prs_Arab, pbt_Arab, quy_Latn, ron_Latn, run_Latn, rus_Cyrl, sag_Latn, san_Deva, sat_Beng, scn_Latn, shn_Mymr, sin_Sinh, slk_Latn, slv_Latn, smo_Latn, sna_Latn, snd_Arab, som_Latn, sot_Latn, spa_Latn, als_Latn, srd_Latn, srp_Cyrl, ssw_Latn, sun_Latn, swe_Latn, swh_Latn, szl_Latn, tam_Taml, tat_Cyrl, tel_Telu, tgk_Cyrl, tgl_Latn, tha_Thai, tir_Ethi, taq_Latn, taq_Tfng, tpi_Latn, tsn_Latn, tso_Latn, tuk_Latn, tum_Latn, tur_Latn, twi_Latn, tzm_Tfng, uig_Arab, ukr_Cyrl, umb_Latn, urd_Arab, uzn_Latn, vec_Latn, vie_Latn, war_Latn, wol_Latn, xho_Latn, ydd_Hebr, yor_Latn, yue_Hant, zho_Hans, zho_Hant, zul_Latn"
tags:
- nllb
license: "cc-by-nc-4.0"
datasets:
- flores-200
metrics:
- bleu
- spbleu
- chrf++
---
# NLLB-200
This is the model card of NLLB-200's 1.3B variant.
Here are the [metrics](https://tinyurl.com/nllb200dense1bmetrics) for that particular checkpoint.
- Information about training algorithms, parameters, fairness constraints or other applied approaches, and features. The exact training algorithm, data and the strategies to handle data imbalances for high and low resource languages that were used to train NLLB-200 is described in the paper.
- Paper or other resource for more information NLLB Team et al, No Language Left Behind: Scaling Human-Centered Machine Translation, Arxiv, 2022
- License: CC-BY-NC
- Where to send questions or comments about the model: https://github.com/facebookresearch/fairseq/issues
## Intended Use
- Primary intended uses: NLLB-200 is a machine translation model primarily intended for research in machine translation, - especially for low-resource languages. It allows for single sentence translation among 200 languages. Information on how to - use the model can be found in Fairseq code repository along with the training code and references to evaluation and training data.
- Primary intended users: Primary users are researchers and machine translation research community.
- Out-of-scope use cases: NLLB-200 is a research model and is not released for production deployment. NLLB-200 is trained on general domain text data and is not intended to be used with domain specific texts, such as medical domain or legal domain. The model is not intended to be used for document translation. The model was trained with input lengths not exceeding 512 tokens, therefore translating longer sequences might result in quality degradation. NLLB-200 translations can not be used as certified translations.
## Metrics
• Model performance measures: NLLB-200 model was evaluated using BLEU, spBLEU, and chrF++ metrics widely adopted by machine translation community. Additionally, we performed human evaluation with the XSTS protocol and measured the toxicity of the generated translations.
## Evaluation Data
- Datasets: Flores-200 dataset is described in Section 4
- Motivation: We used Flores-200 as it provides full evaluation coverage of the languages in NLLB-200
- Preprocessing: Sentence-split raw text data was preprocessed using SentencePiece. The
SentencePiece model is released along with NLLB-200.
## Training Data
• We used parallel multilingual data from a variety of sources to train the model. We provide detailed report on data selection and construction process in Section 5 in the paper. We also used monolingual data constructed from Common Crawl. We provide more details in Section 5.2.
## Ethical Considerations
• In this work, we took a reflexive approach in technological development to ensure that we prioritize human users and minimize risks that could be transferred to them. While we reflect on our ethical considerations throughout the article, here are some additional points to highlight. For one, many languages chosen for this study are low-resource languages, with a heavy emphasis on African languages. While quality translation could improve education and information access in many in these communities, such an access could also make groups with lower levels of digital literacy more vulnerable to misinformation or online scams. The latter scenarios could arise if bad actors misappropriate our work for nefarious activities, which we conceive as an example of unintended use. Regarding data acquisition, the training data used for model development were mined from various publicly available sources on the web. Although we invested heavily in data cleaning, personally identifiable information may not be entirely eliminated. Finally, although we did our best to optimize for translation quality, mistranslations produced by the model could remain. Although the odds are low, this could have adverse impact on those who rely on these translations to make important decisions (particularly when related to health and safety).
## Caveats and Recommendations
• Our model has been tested on the Wikimedia domain with limited investigation on other domains supported in NLLB-MD. In addition, the supported languages may have variations that our model is not capturing. Users should make appropriate assessments.
## Carbon Footprint Details
• The carbon dioxide (CO2e) estimate is reported in Section 8.8.
|
IlyaGusev/xlm_roberta_large_headline_cause_full
|
481b4dfb94058bbcd8d47330c45755fa69481533
|
2022-07-13T15:35:52.000Z
|
[
"pytorch",
"xlm-roberta",
"text-classification",
"ru",
"en",
"dataset:IlyaGusev/headline_cause",
"arxiv:2108.12626",
"transformers",
"xlm-roberta-large",
"license:apache-2.0"
] |
text-classification
| false |
IlyaGusev
| null |
IlyaGusev/xlm_roberta_large_headline_cause_full
| 465 | null |
transformers
| 2,403 |
---
language:
- ru
- en
tags:
- xlm-roberta-large
datasets:
- IlyaGusev/headline_cause
license: apache-2.0
widget:
- text: "Песков опроверг свой перевод на удаленку</s>Дмитрий Песков перешел на удаленку"
---
# XLM-RoBERTa HeadlineCause Full
## Model description
This model was trained to predict the presence of causal relations between two headlines. This model is for the Full task with 7 possible labels: titles are almost the same, A causes B, B causes A, A refutes B, B refutes A, A linked with B in another way, A is not linked to B. English and Russian languages are supported.
You can use hosted inference API to infer a label for a headline pair. To do this, you shoud seperate headlines with ```</s>``` token.
For example:
```
Песков опроверг свой перевод на удаленку</s>Дмитрий Песков перешел на удаленку
```
## Intended uses & limitations
#### How to use
```python
from tqdm.notebook import tqdm
from transformers import AutoTokenizer, AutoModelForSequenceClassification, pipeline
def get_batch(data, batch_size):
start_index = 0
while start_index < len(data):
end_index = start_index + batch_size
batch = data[start_index:end_index]
yield batch
start_index = end_index
def pipe_predict(data, pipe, batch_size=64):
raw_preds = []
for batch in tqdm(get_batch(data, batch_size)):
raw_preds += pipe(batch)
return raw_preds
MODEL_NAME = TOKENIZER_NAME = "IlyaGusev/xlm_roberta_large_headline_cause_full"
tokenizer = AutoTokenizer.from_pretrained(TOKENIZER_NAME, do_lower_case=False)
model = AutoModelForSequenceClassification.from_pretrained(MODEL_NAME)
model.eval()
pipe = pipeline("text-classification", model=model, tokenizer=tokenizer, framework="pt", return_all_scores=True)
texts = [
(
"Judge issues order to allow indoor worship in NC churches",
"Some local churches resume indoor services after judge lifted NC governor’s restriction"
),
(
"Gov. Kevin Stitt defends $2 million purchase of malaria drug touted by Trump",
"Oklahoma spent $2 million on malaria drug touted by Trump"
),
(
"Песков опроверг свой перевод на удаленку",
"Дмитрий Песков перешел на удаленку"
)
]
pipe_predict(texts, pipe)
```
#### Limitations and bias
The models are intended to be used on news headlines. No other limitations are known.
## Training data
* HuggingFace dataset: [IlyaGusev/headline_cause](https://huggingface.co/datasets/IlyaGusev/headline_cause)
* GitHub: [IlyaGusev/HeadlineCause](https://github.com/IlyaGusev/HeadlineCause)
## Training procedure
* Notebook: [HeadlineCause](https://colab.research.google.com/drive/1NAnD0OJ0TnYCJRsHpYUyYkjr_yi8ObcA)
* Stand-alone script: [train.py](https://github.com/IlyaGusev/HeadlineCause/blob/main/headline_cause/train.py)
## Eval results
Evaluation results can be found in the [arxiv paper](https://arxiv.org/pdf/2108.12626.pdf).
### BibTeX entry and citation info
```bibtex
@misc{gusev2021headlinecause,
title={HeadlineCause: A Dataset of News Headlines for Detecting Causalities},
author={Ilya Gusev and Alexey Tikhonov},
year={2021},
eprint={2108.12626},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
uer/chinese_roberta_L-2_H-768
|
1aa682dea961da5d795029b2a5d097099982662c
|
2022-07-15T08:11:17.000Z
|
[
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"zh",
"dataset:CLUECorpusSmall",
"arxiv:1909.05658",
"arxiv:1908.08962",
"transformers",
"autotrain_compatible"
] |
fill-mask
| false |
uer
| null |
uer/chinese_roberta_L-2_H-768
| 465 | null |
transformers
| 2,404 |
---
language: zh
datasets: CLUECorpusSmall
widget:
- text: "北京是[MASK]国的首都。"
---
# Chinese RoBERTa Miniatures
## Model description
This is the set of 24 Chinese RoBERTa models pre-trained by [UER-py](https://github.com/dbiir/UER-py/), which is introduced in [this paper](https://arxiv.org/abs/1909.05658).
[Turc et al.](https://arxiv.org/abs/1908.08962) have shown that the standard BERT recipe is effective on a wide range of model sizes. Following their paper, we released the 24 Chinese RoBERTa models. In order to facilitate users to reproduce the results, we used the publicly available corpus and provided all training details.
You can download the 24 Chinese RoBERTa miniatures either from the [UER-py Modelzoo page](https://github.com/dbiir/UER-py/wiki/Modelzoo), or via HuggingFace from the links below:
| | H=128 | H=256 | H=512 | H=768 |
| -------- | :-----------------------: | :-----------------------: | :-------------------------: | :-------------------------: |
| **L=2** | [**2/128 (Tiny)**][2_128] | [2/256][2_256] | [2/512][2_512] | [2/768][2_768] |
| **L=4** | [4/128][4_128] | [**4/256 (Mini)**][4_256] | [**4/512 (Small)**][4_512] | [4/768][4_768] |
| **L=6** | [6/128][6_128] | [6/256][6_256] | [6/512][6_512] | [6/768][6_768] |
| **L=8** | [8/128][8_128] | [8/256][8_256] | [**8/512 (Medium)**][8_512] | [8/768][8_768] |
| **L=10** | [10/128][10_128] | [10/256][10_256] | [10/512][10_512] | [10/768][10_768] |
| **L=12** | [12/128][12_128] | [12/256][12_256] | [12/512][12_512] | [**12/768 (Base)**][12_768] |
Here are scores on the devlopment set of six Chinese tasks:
| Model | Score | douban | chnsenticorp | lcqmc | tnews(CLUE) | iflytek(CLUE) | ocnli(CLUE) |
| -------------- | :---: | :----: | :----------: | :---: | :---------: | :-----------: | :---------: |
| RoBERTa-Tiny | 72.3 | 83.0 | 91.4 | 81.8 | 62.0 | 55.0 | 60.3 |
| RoBERTa-Mini | 75.7 | 84.8 | 93.7 | 86.1 | 63.9 | 58.3 | 67.4 |
| RoBERTa-Small | 76.8 | 86.5 | 93.4 | 86.5 | 65.1 | 59.4 | 69.7 |
| RoBERTa-Medium | 77.8 | 87.6 | 94.8 | 88.1 | 65.6 | 59.5 | 71.2 |
| RoBERTa-Base | 79.5 | 89.1 | 95.2 | 89.2 | 67.0 | 60.9 | 75.5 |
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained with the sequence length of 128:
- epochs: 3, 5, 8
- batch sizes: 32, 64
- learning rates: 3e-5, 1e-4, 3e-4
## How to use
You can use this model directly with a pipeline for masked language modeling (take the case of RoBERTa-Medium):
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='uer/chinese_roberta_L-8_H-512')
>>> unmasker("中国的首都是[MASK]京。")
[
{'sequence': '[CLS] 中 国 的 首 都 是 北 京 。 [SEP]',
'score': 0.8701988458633423,
'token': 1266,
'token_str': '北'},
{'sequence': '[CLS] 中 国 的 首 都 是 南 京 。 [SEP]',
'score': 0.1194809079170227,
'token': 1298,
'token_str': '南'},
{'sequence': '[CLS] 中 国 的 首 都 是 东 京 。 [SEP]',
'score': 0.0037803512532263994,
'token': 691,
'token_str': '东'},
{'sequence': '[CLS] 中 国 的 首 都 是 普 京 。 [SEP]',
'score': 0.0017127094324678183,
'token': 3249,
'token_str': '普'},
{'sequence': '[CLS] 中 国 的 首 都 是 望 京 。 [SEP]',
'score': 0.001687526935711503,
'token': 3307,
'token_str': '望'}
]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('uer/chinese_roberta_L-8_H-512')
model = BertModel.from_pretrained("uer/chinese_roberta_L-8_H-512")
text = "用你喜欢的任何文本替换我。"
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import BertTokenizer, TFBertModel
tokenizer = BertTokenizer.from_pretrained('uer/chinese_roberta_L-8_H-512')
model = TFBertModel.from_pretrained("uer/chinese_roberta_L-8_H-512")
text = "用你喜欢的任何文本替换我。"
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
## Training data
[CLUECorpusSmall](https://github.com/CLUEbenchmark/CLUECorpus2020/) is used as training data. We found that models pre-trained on CLUECorpusSmall outperform those pre-trained on CLUECorpus2020, although CLUECorpus2020 is much larger than CLUECorpusSmall.
## Training procedure
Models are pre-trained by [UER-py](https://github.com/dbiir/UER-py/) on [Tencent Cloud](https://cloud.tencent.com/). We pre-train 1,000,000 steps with a sequence length of 128 and then pre-train 250,000 additional steps with a sequence length of 512. We use the same hyper-parameters on different model sizes.
Taking the case of RoBERTa-Medium
Stage1:
```
python3 preprocess.py --corpus_path corpora/cluecorpussmall.txt \
--vocab_path models/google_zh_vocab.txt \
--dataset_path cluecorpussmall_seq128_dataset.pt \
--processes_num 32 --seq_length 128 \
--dynamic_masking --data_processor mlm
```
```
python3 pretrain.py --dataset_path cluecorpussmall_seq128_dataset.pt \
--vocab_path models/google_zh_vocab.txt \
--config_path models/bert/medium_config.json \
--output_model_path models/cluecorpussmall_roberta_medium_seq128_model.bin \
--world_size 8 --gpu_ranks 0 1 2 3 4 5 6 7 \
--total_steps 1000000 --save_checkpoint_steps 100000 --report_steps 50000 \
--learning_rate 1e-4 --batch_size 64 \
--data_processor mlm --target mlm
```
Stage2:
```
python3 preprocess.py --corpus_path corpora/cluecorpussmall.txt \
--vocab_path models/google_zh_vocab.txt \
--dataset_path cluecorpussmall_seq512_dataset.pt \
--processes_num 32 --seq_length 512 \
--dynamic_masking --data_processor mlm
```
```
python3 pretrain.py --dataset_path cluecorpussmall_seq512_dataset.pt \
--vocab_path models/google_zh_vocab.txt \
--pretrained_model_path models/cluecorpussmall_roberta_medium_seq128_model.bin-1000000 \
--config_path models/bert/medium_config.json \
--output_model_path models/cluecorpussmall_roberta_medium_seq512_model.bin \
--world_size 8 --gpu_ranks 0 1 2 3 4 5 6 7 \
--total_steps 250000 --save_checkpoint_steps 50000 --report_steps 10000 \
--learning_rate 5e-5 --batch_size 16 \
--data_processor mlm --target mlm
```
Finally, we convert the pre-trained model into Huggingface's format:
```
python3 scripts/convert_bert_from_uer_to_huggingface.py --input_model_path models/cluecorpussmall_roberta_medium_seq512_model.bin-250000 \
--output_model_path pytorch_model.bin \
--layers_num 8 --type mlm
```
### BibTeX entry and citation info
```
@article{devlin2018bert,
title={Bert: Pre-training of deep bidirectional transformers for language understanding},
author={Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1810.04805},
year={2018}
}
@article{liu2019roberta,
title={Roberta: A robustly optimized bert pretraining approach},
author={Liu, Yinhan and Ott, Myle and Goyal, Naman and Du, Jingfei and Joshi, Mandar and Chen, Danqi and Levy, Omer and Lewis, Mike and Zettlemoyer, Luke and Stoyanov, Veselin},
journal={arXiv preprint arXiv:1907.11692},
year={2019}
}
@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}
@article{zhao2019uer,
title={UER: An Open-Source Toolkit for Pre-training Models},
author={Zhao, Zhe and Chen, Hui and Zhang, Jinbin and Zhao, Xin and Liu, Tao and Lu, Wei and Chen, Xi and Deng, Haotang and Ju, Qi and Du, Xiaoyong},
journal={EMNLP-IJCNLP 2019},
pages={241},
year={2019}
}
```
[2_128]:https://huggingface.co/uer/chinese_roberta_L-2_H-128
[2_256]:https://huggingface.co/uer/chinese_roberta_L-2_H-256
[2_512]:https://huggingface.co/uer/chinese_roberta_L-2_H-512
[2_768]:https://huggingface.co/uer/chinese_roberta_L-2_H-768
[4_128]:https://huggingface.co/uer/chinese_roberta_L-4_H-128
[4_256]:https://huggingface.co/uer/chinese_roberta_L-4_H-256
[4_512]:https://huggingface.co/uer/chinese_roberta_L-4_H-512
[4_768]:https://huggingface.co/uer/chinese_roberta_L-4_H-768
[6_128]:https://huggingface.co/uer/chinese_roberta_L-6_H-128
[6_256]:https://huggingface.co/uer/chinese_roberta_L-6_H-256
[6_512]:https://huggingface.co/uer/chinese_roberta_L-6_H-512
[6_768]:https://huggingface.co/uer/chinese_roberta_L-6_H-768
[8_128]:https://huggingface.co/uer/chinese_roberta_L-8_H-128
[8_256]:https://huggingface.co/uer/chinese_roberta_L-8_H-256
[8_512]:https://huggingface.co/uer/chinese_roberta_L-8_H-512
[8_768]:https://huggingface.co/uer/chinese_roberta_L-8_H-768
[10_128]:https://huggingface.co/uer/chinese_roberta_L-10_H-128
[10_256]:https://huggingface.co/uer/chinese_roberta_L-10_H-256
[10_512]:https://huggingface.co/uer/chinese_roberta_L-10_H-512
[10_768]:https://huggingface.co/uer/chinese_roberta_L-10_H-768
[12_128]:https://huggingface.co/uer/chinese_roberta_L-12_H-128
[12_256]:https://huggingface.co/uer/chinese_roberta_L-12_H-256
[12_512]:https://huggingface.co/uer/chinese_roberta_L-12_H-512
[12_768]:https://huggingface.co/uer/chinese_roberta_L-12_H-768
|
HamidRezaAttar/gpt2-product-description-generator
|
207b5c894c24825678a2d7e11e5494f30ebe3cc4
|
2022-04-30T09:53:14.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"en",
"arxiv:1706.03762",
"transformers",
"license:apache-2.0"
] |
text-generation
| false |
HamidRezaAttar
| null |
HamidRezaAttar/gpt2-product-description-generator
| 464 | 6 |
transformers
| 2,405 |
---
language: en
tags:
- text-generation
license: apache-2.0
widget:
- text: "Maximize your bedroom space without sacrificing style with the storage bed."
- text: "Handcrafted of solid acacia in weathered gray, our round Jozy drop-leaf dining table is a space-saving."
- text: "Our plush and luxurious Emmett modular sofa brings custom comfort to your living space."
---
## GPT2-Home
This model is fine-tuned using GPT-2 on amazon home products metadata.
It can generate descriptions for your **home** products by getting a text prompt.
### Model description
[GPT-2](https://openai.com/blog/better-language-models/) is a large [transformer](https://arxiv.org/abs/1706.03762)-based language model with 1.5 billion parameters, trained on a dataset of 8 million web pages. GPT-2 is trained with a simple objective: predict the next word, given all of the previous words within some text. The diversity of the dataset causes this simple goal to contain naturally occurring demonstrations of many tasks across diverse domains. GPT-2 is a direct scale-up of GPT, with more than 10X the parameters and trained on more than 10X the amount of data.
### Live Demo
For testing model with special configuration, please visit [Demo](https://huggingface.co/spaces/HamidRezaAttar/gpt2-home)
### Blog Post
For more detailed information about project development please refer to my [blog post](https://hamidrezaattar.github.io/blog/markdown/2022/02/17/gpt2-home.html).
### How to use
For best experience and clean outputs, you can use Live Demo mentioned above, also you can use the notebook mentioned in my [GitHub](https://github.com/HamidRezaAttar/GPT2-Home)
You can use this model directly with a pipeline for text generation.
```python
>>> from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline
>>> tokenizer = AutoTokenizer.from_pretrained("HamidRezaAttar/gpt2-product-description-generator")
>>> model = AutoModelForCausalLM.from_pretrained("HamidRezaAttar/gpt2-product-description-generator")
>>> generator = pipeline('text-generation', model, tokenizer=tokenizer, config={'max_length':100})
>>> generated_text = generator("This bed is very comfortable.")
```
### Citation info
```bibtex
@misc{GPT2-Home,
author = {HamidReza Fatollah Zadeh Attar},
title = {GPT2-Home the English home product description generator},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/HamidRezaAttar/GPT2-Home}},
}
```
|
cross-encoder/nli-deberta-base
|
c4dd278f8b91ff189eecea98e76a9b371ed1db37
|
2021-08-05T08:40:53.000Z
|
[
"pytorch",
"deberta",
"text-classification",
"en",
"dataset:multi_nli",
"dataset:snli",
"transformers",
"deberta-base-base",
"license:apache-2.0",
"zero-shot-classification"
] |
zero-shot-classification
| false |
cross-encoder
| null |
cross-encoder/nli-deberta-base
| 464 | 2 |
transformers
| 2,406 |
---
language: en
pipeline_tag: zero-shot-classification
tags:
- deberta-base-base
datasets:
- multi_nli
- snli
metrics:
- accuracy
license: apache-2.0
---
# Cross-Encoder for Natural Language Inference
This model was trained using [SentenceTransformers](https://sbert.net) [Cross-Encoder](https://www.sbert.net/examples/applications/cross-encoder/README.html) class.
## Training Data
The model was trained on the [SNLI](https://nlp.stanford.edu/projects/snli/) and [MultiNLI](https://cims.nyu.edu/~sbowman/multinli/) datasets. For a given sentence pair, it will output three scores corresponding to the labels: contradiction, entailment, neutral.
## Performance
For evaluation results, see [SBERT.net - Pretrained Cross-Encoder](https://www.sbert.net/docs/pretrained_cross-encoders.html#nli).
## Usage
Pre-trained models can be used like this:
```python
from sentence_transformers import CrossEncoder
model = CrossEncoder('cross-encoder/nli-deberta-base')
scores = model.predict([('A man is eating pizza', 'A man eats something'), ('A black race car starts up in front of a crowd of people.', 'A man is driving down a lonely road.')])
#Convert scores to labels
label_mapping = ['contradiction', 'entailment', 'neutral']
labels = [label_mapping[score_max] for score_max in scores.argmax(axis=1)]
```
## Usage with Transformers AutoModel
You can use the model also directly with Transformers library (without SentenceTransformers library):
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
model = AutoModelForSequenceClassification.from_pretrained('cross-encoder/nli-deberta-base')
tokenizer = AutoTokenizer.from_pretrained('cross-encoder/nli-deberta-base')
features = tokenizer(['A man is eating pizza', 'A black race car starts up in front of a crowd of people.'], ['A man eats something', 'A man is driving down a lonely road.'], padding=True, truncation=True, return_tensors="pt")
model.eval()
with torch.no_grad():
scores = model(**features).logits
label_mapping = ['contradiction', 'entailment', 'neutral']
labels = [label_mapping[score_max] for score_max in scores.argmax(dim=1)]
print(labels)
```
## Zero-Shot Classification
This model can also be used for zero-shot-classification:
```python
from transformers import pipeline
classifier = pipeline("zero-shot-classification", model='cross-encoder/nli-deberta-base')
sent = "Apple just announced the newest iPhone X"
candidate_labels = ["technology", "sports", "politics"]
res = classifier(sent, candidate_labels)
print(res)
```
|
worsterman/DialoGPT-small-mulder
|
c08bdc69d797c730c41d003cf619df6bb4585b3c
|
2021-06-20T22:50:26.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
| false |
worsterman
| null |
worsterman/DialoGPT-small-mulder
| 463 | null |
transformers
| 2,407 |
---
tags:
- conversational
---
# DialoGPT Trained on the Speech of Fox Mulder from The X-Files
|
Skoltech/russian-inappropriate-messages
|
2f0eca13446320dafb6f9743c56d812fa6f19a11
|
2021-05-18T22:39:46.000Z
|
[
"pytorch",
"tf",
"jax",
"bert",
"text-classification",
"ru",
"transformers",
"toxic comments classification"
] |
text-classification
| false |
Skoltech
| null |
Skoltech/russian-inappropriate-messages
| 462 | 3 |
transformers
| 2,408 |
---
language:
- ru
tags:
- toxic comments classification
licenses:
- cc-by-nc-sa
---
## General concept of the model
#### Proposed usage
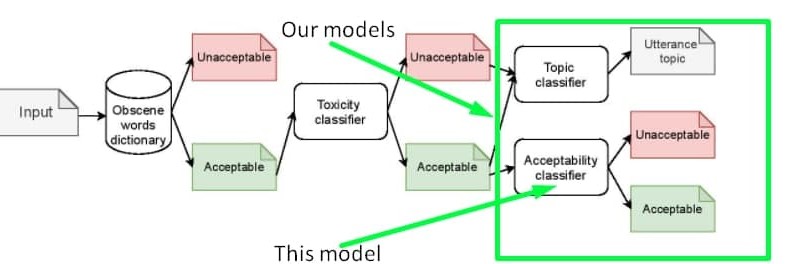
The **'inappropriateness'** substance we tried to collect in the dataset and detect with the model **is NOT a substitution of toxicity**, it is rather a derivative of toxicity. So the model based on our dataset could serve as **an additional layer of inappropriateness filtering after toxicity and obscenity filtration**. You can detect the exact sensitive topic by using [another model](https://huggingface.co/Skoltech/russian-sensitive-topics). The proposed pipeline is shown in the scheme below.
You can also train one classifier for both toxicity and inappropriateness detection. The data to be mixed with toxic labelled samples could be found on our [GitHub](https://github.com/skoltech-nlp/inappropriate-sensitive-topics/blob/main/Version2/appropriateness/Appropriateness.csv) or on [kaggle](https://www.kaggle.com/nigula/russianinappropriatemessages)
#### Inappropraiteness intuition
This model is trained on the dataset of inappropriate messages of the Russian language. Generally, an inappropriate utterance is an utterance that has not obscene words or any kind of toxic intent, but can still harm the reputation of the speaker. Find some sample for more intuition in the table below. Learn more about the concept of inappropriateness [in this article ](https://www.aclweb.org/anthology/2021.bsnlp-1.4/) presented at the workshop for Balto-Slavic NLP at the EACL-2021 conference. Please note that this article describes the first version of the dataset, while the model is trained on the extended version of the dataset open-sourced on our [GitHub](https://github.com/skoltech-nlp/inappropriate-sensitive-topics/blob/main/Version2/appropriateness/Appropriateness.csv) or on [kaggle](https://www.kaggle.com/nigula/russianinappropriatemessages). The properties of the dataset are the same as the one described in the article, the only difference is the size.
| Text | Inappropriate | Comment | Unsafe topic |
|------------------------------------------------------------------------------------------------------|---------------|----------------------------------------------------------------|---------------|
| Ладно бы видного деятеля завалили а тут какого то ноунейм нигру преступника | yes | Оправдание убийства | offline crime |
| Это нарушение УКРФ! | no | Осуждение нарушения закона | offline crime |
| Религия - это насилие высшего уровня. Верующего принуждают к вере еще в младенчестве. | yes | Оскорбление чувств верующих | religion |
| Христиане, как вы относитесь к иноверцам, в частности к Гамалиилу и к уверовавшим в Иисуса фарисеям? | no | Обычные вопросы к верующим без намека на оскорбление их чувств | religion |
| Хорошо что проституция запрещена | no | Осуждение простуитуции | prostitution |
| Возьму бабки и сниму шлюх на выходных | yes | Популяризация проституции | prostitution |
#### Metrics
The model was trained, validated, and tested only on the samples with 100% confidence, which allowed to get the following metrics on test set:
| | precision | recall | f1-score | support |
|--------------|----------|--------|----------|---------|
| 0 | 0.92 | 0.93 | 0.93 | 7839 |
| 1 | 0.80 | 0.76 | 0.78 | 2726 |
| accuracy | | | 0.89 | 10565 |
| macro avg | 0.86 | 0.85 | 0.85 | 10565 |
| weighted avg | 0.89 | 0.89 | 0.89 | 10565 |
## Licensing Information
[Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License][cc-by-nc-sa].
[![CC BY-NC-SA 4.0][cc-by-nc-sa-image]][cc-by-nc-sa]
[cc-by-nc-sa]: http://creativecommons.org/licenses/by-nc-sa/4.0/
[cc-by-nc-sa-image]: https://i.creativecommons.org/l/by-nc-sa/4.0/88x31.png
## Citation
If you find this repository helpful, feel free to cite our publication:
```
@inproceedings{babakov-etal-2021-detecting,
title = "Detecting Inappropriate Messages on Sensitive Topics that Could Harm a Company{'}s Reputation",
author = "Babakov, Nikolay and
Logacheva, Varvara and
Kozlova, Olga and
Semenov, Nikita and
Panchenko, Alexander",
booktitle = "Proceedings of the 8th Workshop on Balto-Slavic Natural Language Processing",
month = apr,
year = "2021",
address = "Kiyv, Ukraine",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2021.bsnlp-1.4",
pages = "26--36",
abstract = "Not all topics are equally {``}flammable{''} in terms of toxicity: a calm discussion of turtles or fishing less often fuels inappropriate toxic dialogues than a discussion of politics or sexual minorities. We define a set of sensitive topics that can yield inappropriate and toxic messages and describe the methodology of collecting and labelling a dataset for appropriateness. While toxicity in user-generated data is well-studied, we aim at defining a more fine-grained notion of inappropriateness. The core of inappropriateness is that it can harm the reputation of a speaker. This is different from toxicity in two respects: (i) inappropriateness is topic-related, and (ii) inappropriate message is not toxic but still unacceptable. We collect and release two datasets for Russian: a topic-labelled dataset and an appropriateness-labelled dataset. We also release pre-trained classification models trained on this data.",
}
```
## Contacts
If you have any questions please contact [Nikolay](mailto:[email protected])
|
arbml/wav2vec2-large-xlsr-53-arabic-egyptian
|
d21ab2f8afebd15f8d3e9c95d2a77343c6f78d7b
|
2021-07-05T18:12:38.000Z
|
[
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"???",
"dataset:common_voice",
"transformers",
"audio",
"speech",
"xlsr-fine-tuning-week",
"license:apache-2.0",
"model-index"
] |
automatic-speech-recognition
| false |
arbml
| null |
arbml/wav2vec2-large-xlsr-53-arabic-egyptian
| 462 | 2 |
transformers
| 2,409 |
---
language: ???
datasets:
- common_voice
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: XLSR Wav2Vec2 Arabic Egyptian by Zaid
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice ???
type: common_voice
args: ???
metrics:
- name: Test WER
type: wer
value: ???
---
# Wav2Vec2-Large-XLSR-53-Tamil
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) in Tamil using the [Common Voice](https://huggingface.co/datasets/common_voice)
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "???", split="test[:2%]").
processor = Wav2Vec2Processor.from_pretrained("Zaid/wav2vec2-large-xlsr-53-arabic-egyptian")
model = Wav2Vec2ForCTC.from_pretrained("Zaid/wav2vec2-large-xlsr-53-arabic-egyptian")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the {language} test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "???", split="test")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("Zaid/wav2vec2-large-xlsr-53-arabic-egyptian")
model = Wav2Vec2ForCTC.from_pretrained("Zaid/wav2vec2-large-xlsr-53-arabic-egyptian")
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"\“]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: ??? %
## Training
The Common Voice `train`, `validation` datasets were used for training.
The script used for training can be found ???
|
Pensador777critico/DialoGPT-small-RickandMorty
|
1c42f5be6b7a0e42229317f9b42321a94b317d81
|
2021-08-31T09:17:11.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
| false |
Pensador777critico
| null |
Pensador777critico/DialoGPT-small-RickandMorty
| 461 | null |
transformers
| 2,410 |
---
tags:
- conversational
---
# Rick and Morty DialoGPT Model
|
seyonec/PubChem10M_SMILES_BPE_396_250
|
a8829bbdf9a6fbd64c91950389687934b3de8394
|
2021-05-20T21:01:53.000Z
|
[
"pytorch",
"jax",
"roberta",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
| false |
seyonec
| null |
seyonec/PubChem10M_SMILES_BPE_396_250
| 461 | null |
transformers
| 2,411 |
Entry not found
|
flax-sentence-embeddings/all_datasets_v3_mpnet-base
|
d442c0e304ff575c261b9bbdf8b13fcbe6ee933c
|
2021-08-18T11:16:43.000Z
|
[
"pytorch",
"mpnet",
"fill-mask",
"en",
"arxiv:1904.06472",
"arxiv:2102.07033",
"arxiv:2104.08727",
"arxiv:1704.05179",
"arxiv:1810.09305",
"sentence-transformers",
"feature-extraction",
"sentence-similarity",
"license:apache-2.0"
] |
sentence-similarity
| false |
flax-sentence-embeddings
| null |
flax-sentence-embeddings/all_datasets_v3_mpnet-base
| 460 | 4 |
sentence-transformers
| 2,412 |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
language: en
license: apache-2.0
---
# all-mpnet-base-v1
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/all-mpnet-base-v1')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
import torch.nn.functional as F
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/all-mpnet-base-v1')
model = AutoModel.from_pretrained('sentence-transformers/all-mpnet-base-v1')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
# Normalize embeddings
sentence_embeddings = F.normalize(sentence_embeddings, p=2, dim=1)
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/all-mpnet-base-v1)
------
## Background
The project aims to train sentence embedding models on very large sentence level datasets using a self-supervised
contrastive learning objective. We used the pretrained [`microsoft/mpnet-base`](https://huggingface.co/microsoft/mpnet-base) model and fine-tuned in on a
1B sentence pairs dataset. We use a contrastive learning objective: given a sentence from the pair, the model should predict which out of a set of randomly sampled other sentences, was actually paired with it in our dataset.
We developped this model during the
[Community week using JAX/Flax for NLP & CV](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104),
organized by Hugging Face. We developped this model as part of the project:
[Train the Best Sentence Embedding Model Ever with 1B Training Pairs](https://discuss.huggingface.co/t/train-the-best-sentence-embedding-model-ever-with-1b-training-pairs/7354). We benefited from efficient hardware infrastructure to run the project: 7 TPUs v3-8, as well as intervention from Googles Flax, JAX, and Cloud team member about efficient deep learning frameworks.
## Intended uses
Our model is intented to be used as a sentence and short paragraph encoder. Given an input text, it ouptuts a vector which captures
the semantic information. The sentence vector may be used for information retrieval, clustering or sentence similarity tasks.
By default, input text longer than 128 word pieces is truncated.
## Training procedure
### Pre-training
We use the pretrained [`microsoft/mpnet-base`](https://huggingface.co/microsoft/mpnet-base). Please refer to the model card for more detailed information about the pre-training procedure.
### Fine-tuning
We fine-tune the model using a contrastive objective. Formally, we compute the cosine similarity from each possible sentence pairs from the batch.
We then apply the cross entropy loss by comparing with true pairs.
#### Hyper parameters
We trained ou model on a TPU v3-8. We train the model during 920k steps using a batch size of 512 (64 per TPU core).
We use a learning rate warm up of 500. The sequence length was limited to 128 tokens. We used the AdamW optimizer with
a 2e-5 learning rate. The full training script is accessible in this current repository: `train_script.py`.
#### Training data
We use the concatenation from multiple datasets to fine-tune our model. The total number of sentence pairs is above 1 billion sentences.
We sampled each dataset given a weighted probability which configuration is detailed in the `data_config.json` file.
| Dataset | Paper | Number of training tuples |
|--------------------------------------------------------|:----------------------------------------:|:--------------------------:|
| [Reddit comments (2015-2018)](https://github.com/PolyAI-LDN/conversational-datasets/tree/master/reddit) | [paper](https://arxiv.org/abs/1904.06472) | 726,484,430 |
| [S2ORC](https://github.com/allenai/s2orc) Citation pairs (Abstracts) | [paper](https://aclanthology.org/2020.acl-main.447/) | 116,288,806 |
| [WikiAnswers](https://github.com/afader/oqa#wikianswers-corpus) Duplicate question pairs | [paper](https://doi.org/10.1145/2623330.2623677) | 77,427,422 |
| [PAQ](https://github.com/facebookresearch/PAQ) (Question, Answer) pairs | [paper](https://arxiv.org/abs/2102.07033) | 64,371,441 |
| [S2ORC](https://github.com/allenai/s2orc) Citation pairs (Titles) | [paper](https://aclanthology.org/2020.acl-main.447/) | 52,603,982 |
| [S2ORC](https://github.com/allenai/s2orc) (Title, Abstract) | [paper](https://aclanthology.org/2020.acl-main.447/) | 41,769,185 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) (Title, Body) pairs | - | 25,316,456 |
| [MS MARCO](https://microsoft.github.io/msmarco/) triplets | [paper](https://doi.org/10.1145/3404835.3462804) | 9,144,553 |
| [GOOAQ: Open Question Answering with Diverse Answer Types](https://github.com/allenai/gooaq) | [paper](https://arxiv.org/pdf/2104.08727.pdf) | 3,012,496 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Title, Answer) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 1,198,260 |
| [Code Search](https://huggingface.co/datasets/code_search_net) | - | 1,151,414 |
| [COCO](https://cocodataset.org/#home) Image captions | [paper](https://link.springer.com/chapter/10.1007%2F978-3-319-10602-1_48) | 828,395|
| [SPECTER](https://github.com/allenai/specter) citation triplets | [paper](https://doi.org/10.18653/v1/2020.acl-main.207) | 684,100 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Question, Answer) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 681,164 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Title, Question) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 659,896 |
| [SearchQA](https://huggingface.co/datasets/search_qa) | [paper](https://arxiv.org/abs/1704.05179) | 582,261 |
| [Eli5](https://huggingface.co/datasets/eli5) | [paper](https://doi.org/10.18653/v1/p19-1346) | 325,475 |
| [Flickr 30k](https://shannon.cs.illinois.edu/DenotationGraph/) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/229/33) | 317,695 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (titles) | | 304,525 |
| AllNLI ([SNLI](https://nlp.stanford.edu/projects/snli/) and [MultiNLI](https://cims.nyu.edu/~sbowman/multinli/) | [paper SNLI](https://doi.org/10.18653/v1/d15-1075), [paper MultiNLI](https://doi.org/10.18653/v1/n18-1101) | 277,230 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (bodies) | | 250,519 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (titles+bodies) | | 250,460 |
| [Sentence Compression](https://github.com/google-research-datasets/sentence-compression) | [paper](https://www.aclweb.org/anthology/D13-1155/) | 180,000 |
| [Wikihow](https://github.com/pvl/wikihow_pairs_dataset) | [paper](https://arxiv.org/abs/1810.09305) | 128,542 |
| [Altlex](https://github.com/chridey/altlex/) | [paper](https://aclanthology.org/P16-1135.pdf) | 112,696 |
| [Quora Question Triplets](https://quoradata.quora.com/First-Quora-Dataset-Release-Question-Pairs) | - | 103,663 |
| [Simple Wikipedia](https://cs.pomona.edu/~dkauchak/simplification/) | [paper](https://www.aclweb.org/anthology/P11-2117/) | 102,225 |
| [Natural Questions (NQ)](https://ai.google.com/research/NaturalQuestions) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/1455) | 100,231 |
| [SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/) | [paper](https://aclanthology.org/P18-2124.pdf) | 87,599 |
| [TriviaQA](https://huggingface.co/datasets/trivia_qa) | - | 73,346 |
| **Total** | | **1,124,818,467** |
|
satyaalmasian/temporal_tagger_BERT_tokenclassifier
|
46bdd518ce24100e9eca478d714e145b86a50380
|
2021-09-21T11:23:18.000Z
|
[
"pytorch",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
] |
token-classification
| false |
satyaalmasian
| null |
satyaalmasian/temporal_tagger_BERT_tokenclassifier
| 460 | 2 |
transformers
| 2,413 |
# BERT based temporal tagged
Token classifier for temporal tagging of plain text using BERT language model. The model is introduced in the paper BERT got a Date: Introducing Transformers to Temporal Tagging and release in this [repository](https://github.com/satya77/Transformer_Temporal_Tagger).
# Model description
BERT is a transformers model pretrained on a large corpus of English data in a self-supervised fashion. We use BERT for token classification to tag the tokens in text with classes:
```
O -- outside of a tag
I-TIME -- inside tag of time
B-TIME -- beginning tag of time
I-DATE -- inside tag of date
B-DATE -- beginning tag of date
I-DURATION -- inside tag of duration
B-DURATION -- beginning tag of duration
I-SET -- inside tag of the set
B-SET -- beginning tag of the set
```
# Intended uses & limitations
This model is best used accompanied with code from the [repository](https://github.com/satya77/Transformer_Temporal_Tagger). Especially for inference, the direct output might be noisy and hard to decipher, in the repository we provide alignment functions and voting strategies for the final output.
# How to use
you can load the model as follows:
```
tokenizer = AutoTokenizer.from_pretrained("satyaalmasian/temporal_tagger_BERT_tokenclassifier", use_fast=False)
model = BertForTokenClassification.from_pretrained("satyaalmasian/temporal_tagger_BERT_tokenclassifier")
```
for inference use:
```
processed_text = tokenizer(input_text, return_tensors="pt")
result = model(**processed_text)
classification= result[0]
```
for an example with post-processing, refer to the [repository](https://github.com/satya77/Transformer_Temporal_Tagger).
We provide a function `merge_tokens` to decipher the output.
to further fine-tune, use the `Trainer` from hugginface. An example of a similar fine-tuning can be found [here](https://github.com/satya77/Transformer_Temporal_Tagger/blob/master/run_token_classifier.py).
#Training data
We use 3 data sources:
[Tempeval-3](https://www.cs.york.ac.uk/semeval-2013/task1/index.php%3Fid=data.html), Wikiwars, Tweets datasets. For the correct data versions please refer to our [repository](https://github.com/satya77/Transformer_Temporal_Tagger).
#Training procedure
The model is trained from publicly available checkpoints on huggingface (`bert-base-uncased`), with a batch size of 34. We use a learning rate of 5e-05 with an Adam optimizer and linear weight decay.
We fine-tune with 5 different random seeds, this version of the model is the only seed=4.
For training, we use 2 NVIDIA A100 GPUs with 40GB of memory.
|
pranaydeeps/Ancient-Greek-BERT
|
db7bf93218e0fdaf880320bd4968aab1efdbf9f6
|
2021-09-24T15:07:58.000Z
|
[
"pytorch",
"bert",
"feature-extraction",
"transformers"
] |
feature-extraction
| false |
pranaydeeps
| null |
pranaydeeps/Ancient-Greek-BERT
| 459 | 2 |
transformers
| 2,414 |
# Ancient Greek BERT
<img src="https://ichef.bbci.co.uk/images/ic/832xn/p02m4gzb.jpg"/>
The first and only available Ancient Greek sub-word BERT model!
State-of-the-art post fine-tuning on Part-of-Speech Tagging and Morphological Analysis.
Pre-trained weights are made available for a standard 12 layer, 768d BERT-base model.
Further scripts for using the model and fine-tuning it for PoS Tagging are available on our [Github repository](https://github.com/pranaydeeps/Ancient-Greek-BERT)!
Please refer to our paper titled: "A Pilot Study for BERT Language Modelling and Morphological Analysis for Ancient and Medieval Greek". In Proceedings of The 5th Joint SIGHUM Workshop on Computational Linguistics for Cultural Heritage, Social Sciences, Humanities and Literature (LaTeCH-CLfL 2021)
## How to use
Requirements:
```python
pip install transformers
pip install unicodedata
pip install flair
```
Can be directly used from the HuggingFace Model Hub with:
```python
from transformers import AutoTokenizer, AutoModel
tokeniser = AutoTokenizer.from_pretrained("pranaydeeps/Ancient-Greek-BERT")
model = AutoModel.from_pretrained("pranaydeeps/Ancient-Greek-BERT")
```
## Fine-tuning for POS/Morphological Analysis
Please refer the GitHub repository for the code and details regarding fine-tuning
## Training data
The model was initialised from [AUEB NLP Group's Greek BERT](https://huggingface.co/nlpaueb/bert-base-greek-uncased-v1)
and subsequently trained on monolingual data from the First1KGreek Project, Perseus Digital Library, PROIEL Treebank and
Gorman's Treebank
## Training and Eval details
Standard de-accentuating and lower-casing for Greek as suggested in [AUEB NLP Group's Greek BERT](https://huggingface.co/nlpaueb/bert-base-greek-uncased-v1)
The model was trained on 4 NVIDIA Tesla V100 16GB GPUs for 80 epochs, with a max-seq-len of 512 and results in a perplexity of 4.8 on the held out test set.
It also gives state-of-the-art results when fine-tuned for PoS Tagging and Morphological Analysis on all 3 treebanks averaging >90% accuracy. Please consult our paper or contact [me](mailto:[email protected]) for further questions!
## Cite
If you end up using Ancient-Greek-BERT in your research, please cite the paper:
```
@inproceedings{ancient-greek-bert,
author = {Singh, Pranaydeep and Rutten, Gorik and Lefever, Els},
title = {A Pilot Study for BERT Language Modelling and Morphological Analysis for Ancient and Medieval Greek},
year = {2021},
booktitle = {The 5th Joint SIGHUM Workshop on Computational Linguistics for Cultural Heritage, Social Sciences, Humanities and Literature (LaTeCH-CLfL 2021)}
}
```
|
BSC-TeMU/roberta-base-bne
|
052845e3a3abcabb150e4724d2c85f0ab59dd67e
|
2021-10-21T10:30:31.000Z
|
[
"pytorch",
"roberta",
"fill-mask",
"es",
"dataset:bne",
"arxiv:1907.11692",
"arxiv:2107.07253",
"transformers",
"national library of spain",
"spanish",
"bne",
"license:apache-2.0",
"autotrain_compatible"
] |
fill-mask
| false |
BSC-TeMU
| null |
BSC-TeMU/roberta-base-bne
| 457 | 8 |
transformers
| 2,415 |
---
language:
- es
license: apache-2.0
tags:
- "national library of spain"
- "spanish"
- "bne"
datasets:
- "bne"
metrics:
- "ppl"
widget:
- text: "Este año las campanadas de La Sexta las presentará <mask>."
- text: "David Broncano es un presentador de La <mask>."
- text: "Gracias a los datos de la BNE se ha podido <mask> este modelo del lenguaje."
- text: "Hay base legal dentro del marco <mask> actual."
---
**⚠️NOTICE⚠️: THIS MODEL HAS BEEN MOVED TO THE FOLLOWING URL AND WILL SOON BE REMOVED:** https://huggingface.co/PlanTL-GOB-ES/roberta-base-bne
# RoBERTa base trained with data from National Library of Spain (BNE)
## Model Description
RoBERTa-base-bne is a transformer-based masked language model for the Spanish language. It is based on the [RoBERTa](https://arxiv.org/abs/1907.11692) base model and has been pre-trained using the largest Spanish corpus known to date, with a total of 570GB of clean and deduplicated text processed for this work, compiled from the web crawlings performed by the [National Library of Spain (Biblioteca Nacional de España)](http://www.bne.es/en/Inicio/index.html) from 2009 to 2019.
## Training corpora and preprocessing
The [National Library of Spain (Biblioteca Nacional de España)](http://www.bne.es/en/Inicio/index.html) crawls all .es domains once a year. The training corpus consists of 59TB of WARC files from these crawls, carried out from 2009 to 2019.
To obtain a high-quality training corpus, the corpus has been preprocessed with a pipeline of operations, including among the others, sentence splitting, language detection, filtering of bad-formed sentences and deduplication of repetitive contents. During the process document boundaries are kept. This resulted into 2TB of Spanish clean corpus. Further global deduplication among the corpus is applied, resulting into 570GB of text.
Some of the statistics of the corpus:
| Corpora | Number of documents | Number of tokens | Size (GB) |
|---------|---------------------|------------------|-----------|
| BNE | 201,080,084 | 135,733,450,668 | 570GB |
## Tokenization and pre-training
The training corpus has been tokenized using a byte version of Byte-Pair Encoding (BPE) used in the original [RoBERTA](https://arxiv.org/abs/1907.11692) model with a vocabulary size of 50,262 tokens. The RoBERTa-base-bne pre-training consists of a masked language model training that follows the approach employed for the RoBERTa base. The training lasted a total of 48 hours with 16 computing nodes each one with 4 NVIDIA V100 GPUs of 16GB VRAM.
## Evaluation and results
For evaluation details visit our [GitHub repository](https://github.com/PlanTL-SANIDAD/lm-spanish).
## Citing
Check out our paper for all the details: https://arxiv.org/abs/2107.07253
```
@misc{gutierrezfandino2021spanish,
title={Spanish Language Models},
author={Asier Gutiérrez-Fandiño and Jordi Armengol-Estapé and Marc Pàmies and Joan Llop-Palao and Joaquín Silveira-Ocampo and Casimiro Pio Carrino and Aitor Gonzalez-Agirre and Carme Armentano-Oller and Carlos Rodriguez-Penagos and Marta Villegas},
year={2021},
eprint={2107.07253},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
flax-community/gpt-2-spanish
|
359ff61122561956ce53fc4caaf660b9d66a5248
|
2022-04-22T11:16:44.000Z
|
[
"pytorch",
"jax",
"tensorboard",
"gpt2",
"text-generation",
"es",
"dataset:oscar",
"transformers"
] |
text-generation
| false |
flax-community
| null |
flax-community/gpt-2-spanish
| 457 | 1 |
transformers
| 2,416 |
---
language: es
tags:
- text-generation
datasets:
- oscar
widgets:
- text: "Érase un vez "
- text: "Frase: Esta película es muy agradable. Sentimiento: positivo
Frase: Odiaba esta película, apesta. Sentimiento: negativo
Frase: Esta película fue bastante mala. Sentimiento: "
---
# Spanish GPT-2
GPT-2 model trained from scratch on the Spanish portion of [OSCAR](https://huggingface.co/datasets/viewer/?dataset=oscar).
The model is trained with Flax and using TPUs sponsored by Google since this is part of the
[Flax/Jax Community Week](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104)
organised by HuggingFace.
## Model description
The model used for training is [OpenAI's GPT-2](https://openai.com/blog/better-language-models/), introduced in the paper ["Language Models are Unsupervised Multitask Learners"](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf) by Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei and Ilya Sutskever.
This model is available in the 🤗 [Model Hub](https://huggingface.co/gpt2).
## Training data
Spanish portion of OSCAR or **O**pen **S**uper-large **C**rawled **A**LMAnaCH co**R**pus, a huge multilingual corpus obtained by language classification and filtering of the [Common Crawl](https://commoncrawl.org/) corpus using the [goclassy](https://github.com/pjox/goclassy) architecture.
This corpus is available in the 🤗 [Datasets](https://huggingface.co/datasets/oscar) library.
## Team members
- Manuel Romero ([mrm8488](https://huggingface.co/mrm8488))
- María Grandury ([mariagrandury](https://huggingface.co/mariagrandury))
- Pablo González de Prado ([Pablogps](https://huggingface.co/Pablogps))
- Daniel Vera ([daveni](https://huggingface.co/daveni))
- Sri Lakshmi ([srisweet](https://huggingface.co/srisweet))
- José Posada ([jdposa](https://huggingface.co/jdposa))
- Santiago Hincapie ([shpotes](https://huggingface.co/shpotes))
- Jorge ([jorgealro](https://huggingface.co/jorgealro))
|
izumi-lab/bert-small-japanese-fin
|
fe4d803446cc47c33233b187b221585fc428d5c8
|
2022-03-19T09:38:08.000Z
|
[
"pytorch",
"bert",
"fill-mask",
"ja",
"dataset:wikipedia",
"dataset:securities reports",
"dataset:summaries of financial results",
"arxiv:2003.10555",
"transformers",
"finance",
"license:cc-by-sa-4.0",
"autotrain_compatible"
] |
fill-mask
| false |
izumi-lab
| null |
izumi-lab/bert-small-japanese-fin
| 456 | null |
transformers
| 2,417 |
---
language: ja
license: cc-by-sa-4.0
tags:
- finance
datasets:
- wikipedia
- securities reports
- summaries of financial results
widget:
- text: 流動[MASK]は、1億円となりました。
---
# BERT small Japanese finance
This is a [BERT](https://github.com/google-research/bert) model pretrained on texts in the Japanese language.
The codes for the pretraining are available at [retarfi/language-pretraining](https://github.com/retarfi/language-pretraining/tree/v1.0).
## Model architecture
The model architecture is the same as BERT small in the [original ELECTRA paper](https://arxiv.org/abs/2003.10555); 12 layers, 256 dimensions of hidden states, and 4 attention heads.
## Training Data
The models are trained on Wikipedia corpus and financial corpus.
The Wikipedia corpus is generated from the Japanese Wikipedia dump file as of June 1, 2021.
The corpus file is 2.9GB, consisting of approximately 20M sentences.
The financial corpus consists of 2 corpora:
- Summaries of financial results from October 9, 2012, to December 31, 2020
- Securities reports from February 8, 2018, to December 31, 2020
The financial corpus file is 5.2GB, consisting of approximately 27M sentences.
## Tokenization
The texts are first tokenized by MeCab with IPA dictionary and then split into subwords by the WordPiece algorithm.
The vocabulary size is 32768.
## Training
The models are trained with the same configuration as BERT small in the [original ELECTRA paper](https://arxiv.org/abs/2003.10555); 128 tokens per instance, 128 instances per batch, and 1.45M training steps.
## Citation
**There will be another paper for this pretrained model. Be sure to check here again when you cite.**
```
@inproceedings{suzuki2021fin-bert-electra,
title={金融文書を用いた事前学習言語モデルの構築と検証},
% title={Construction and Validation of a Pre-Trained Language Model Using Financial Documents},
author={鈴木 雅弘 and 坂地 泰紀 and 平野 正徳 and 和泉 潔},
% author={Masahiro Suzuki and Hiroki Sakaji and Masanori Hirano and Kiyoshi Izumi},
booktitle={人工知能学会第27回金融情報学研究会(SIG-FIN)},
% booktitle={Proceedings of JSAI Special Interest Group on Financial Infomatics (SIG-FIN) 27},
pages={5-10},
year={2021}
}
```
## Licenses
The pretrained models are distributed under the terms of the [Creative Commons Attribution-ShareAlike 4.0](https://creativecommons.org/licenses/by-sa/4.0/).
## Acknowledgments
This work was supported by JSPS KAKENHI Grant Number JP21K12010.
|
nvidia/stt_en_conformer_ctc_large
|
bf01f044a18d14ccba90d7de497e6664fa68a669
|
2022-06-25T01:04:09.000Z
|
[
"nemo",
"en",
"dataset:librispeech_asr",
"dataset:fisher_corpus",
"dataset:Switchboard-1",
"dataset:WSJ-0",
"dataset:WSJ-1",
"dataset:National Singapore Corpus Part 1",
"dataset:National Singapore Corpus Part 6",
"dataset:vctk",
"dataset:VoxPopuli (EN)",
"dataset:Europarl-ASR (EN)",
"dataset:Multilingual LibriSpeech (2000 hours)",
"dataset:mozilla-foundation/common_voice_7_0",
"arxiv:2005.08100",
"automatic-speech-recognition",
"speech",
"audio",
"CTC",
"Conformer",
"Transformer",
"pytorch",
"NeMo",
"hf-asr-leaderboard",
"Riva",
"license:cc-by-4.0",
"model-index"
] |
automatic-speech-recognition
| false |
nvidia
| null |
nvidia/stt_en_conformer_ctc_large
| 456 | 8 |
nemo
| 2,418 |
---
language:
- en
library_name: nemo
datasets:
- librispeech_asr
- fisher_corpus
- Switchboard-1
- WSJ-0
- WSJ-1
- National Singapore Corpus Part 1
- National Singapore Corpus Part 6
- vctk
- VoxPopuli (EN)
- Europarl-ASR (EN)
- Multilingual LibriSpeech (2000 hours)
- mozilla-foundation/common_voice_7_0
thumbnail: null
tags:
- automatic-speech-recognition
- speech
- audio
- CTC
- Conformer
- Transformer
- pytorch
- NeMo
- hf-asr-leaderboard
- Riva
license: cc-by-4.0
widget:
- example_title: Librispeech sample 1
src: https://cdn-media.huggingface.co/speech_samples/sample1.flac
- example_title: Librispeech sample 2
src: https://cdn-media.huggingface.co/speech_samples/sample2.flac
model-index:
- name: stt_en_conformer_ctc_large
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: LibriSpeech (clean)
type: librispeech_asr
config: clean
split: test
args:
language: en
metrics:
- name: Test WER
type: wer
value: 2.2
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: LibriSpeech (other)
type: librispeech_asr
config: other
split: test
args:
language: en
metrics:
- name: Test WER
type: wer
value: 4.3
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: Multilingual LibriSpeech
type: facebook/multilingual_librispeech
config: english
split: test
args:
language: en
metrics:
- name: Test WER
type: wer
value: 7.2
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: Mozilla Common Voice 7.0
type: mozilla-foundation/common_voice_7_0
config: en
split: test
args:
language: en
metrics:
- name: Test WER
type: wer
value: 8.0
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: Mozilla Common Voice 8.0
type: mozilla-foundation/common_voice_8_0
config: en
split: test
args:
language: en
metrics:
- name: Test WER
type: wer
value: 9.48
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: Wall Street Journal 92
type: wsj_0
args:
language: en
metrics:
- name: Test WER
type: wer
value: 2.0
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: Wall Street Journal 93
type: wsj_1
args:
language: en
metrics:
- name: Test WER
type: wer
value: 2.9
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: National Singapore Corpus
type: nsc_part_1
args:
language: en
metrics:
- name: Test WER
type: wer
value: 7.0
---
# NVIDIA Conformer-CTC Large (en-US)
<style>
img {
display: inline;
}
</style>
| [](#model-architecture)
| [](#model-architecture)
| [](#datasets)
| [](#deployment-with-nvidia-riva) |
This model transcribes speech in lowercase English alphabet including spaces and apostrophes, and is trained on several thousand hours of English speech data.
It is a non-autoregressive "large" variant of Conformer, with around 120 million parameters.
See the [model architecture](#model-architecture) section and [NeMo documentation](https://docs.nvidia.com/deeplearning/nemo/user-guide/docs/en/main/asr/models.html#conformer-ctc) for complete architecture details.
It is also compatible with NVIDIA Riva for [production-grade server deployments](#deployment-with-nvidia-riva).
## Usage
The model is available for use in the NeMo toolkit [3], and can be used as a pre-trained checkpoint for inference or for fine-tuning on another dataset.
To train, fine-tune or play with the model you will need to install [NVIDIA NeMo](https://github.com/NVIDIA/NeMo). We recommend you install it after you've installed latest PyTorch version.
```
pip install nemo_toolkit['all']
```
### Automatically instantiate the model
```python
import nemo.collections.asr as nemo_asr
asr_model = nemo_asr.models.EncDecCTCModelBPE.from_pretrained("nvidia/stt_en_conformer_ctc_large")
```
### Transcribing using Python
First, let's get a sample
```
wget https://dldata-public.s3.us-east-2.amazonaws.com/2086-149220-0033.wav
```
Then simply do:
```
asr_model.transcribe(['2086-149220-0033.wav'])
```
### Transcribing many audio files
```shell
python [NEMO_GIT_FOLDER]/examples/asr/transcribe_speech.py
pretrained_name="nvidia/stt_en_conformer_ctc_large"
audio_dir="<DIRECTORY CONTAINING AUDIO FILES>"
```
### Input
This model accepts 16000 kHz Mono-channel Audio (wav files) as input.
### Output
This model provides transcribed speech as a string for a given audio sample.
## Model Architecture
Conformer-CTC model is a non-autoregressive variant of Conformer model [1] for Automatic Speech Recognition which uses CTC loss/decoding instead of Transducer. You may find more info on the detail of this model here: [Conformer-CTC Model](https://docs.nvidia.com/deeplearning/nemo/user-guide/docs/en/main/asr/models.html#conformer-ctc).
## Training
The NeMo toolkit [3] was used for training the models for over several hundred epochs. These model are trained with this [example script](https://github.com/NVIDIA/NeMo/blob/main/examples/asr/asr_ctc/speech_to_text_ctc_bpe.py) and this [base config](https://github.com/NVIDIA/NeMo/blob/main/examples/asr/conf/conformer/conformer_ctc_bpe.yaml).
The tokenizers for these models were built using the text transcripts of the train set with this [script](https://github.com/NVIDIA/NeMo/blob/main/scripts/tokenizers/process_asr_text_tokenizer.py).
The checkpoint of the language model used as the neural rescorer can be found [here](https://ngc.nvidia.com/catalog/models/nvidia:nemo:asrlm_en_transformer_large_ls). You may find more info on how to train and use language models for ASR models here: [ASR Language Modeling](https://docs.nvidia.com/deeplearning/nemo/user-guide/docs/en/main/asr/asr_language_modeling.html)
### Datasets
All the models in this collection are trained on a composite dataset (NeMo ASRSET) comprising of several thousand hours of English speech:
- Librispeech 960 hours of English speech
- Fisher Corpus
- Switchboard-1 Dataset
- WSJ-0 and WSJ-1
- National Speech Corpus (Part 1, Part 6)
- VCTK
- VoxPopuli (EN)
- Europarl-ASR (EN)
- Multilingual Librispeech (MLS EN) - 2,000 hours subset
- Mozilla Common Voice (v7.0)
Note: older versions of the model may have trained on smaller set of datasets.
## Performance
The list of the available models in this collection is shown in the following table. Performances of the ASR models are reported in terms of Word Error Rate (WER%) with greedy decoding.
| Version | Tokenizer | Vocabulary Size | LS test-other | LS test-clean | WSJ Eval92 | WSJ Dev93 | NSC Part 1 | MLS Test | MLS Dev | MCV Test 6.1 |Train Dataset |
|---------|-----------------------|-----------------|---------------|---------------|------------|-----------|-------|------|-----|-------|---------|
| 1.6.0 | SentencePiece Unigram | 128 | 4.3 | 2.2 | 2.0 | 2.9 | 7.0 | 7.2 | 6.5 | 8.0 | NeMo ASRSET 2.0 |
While deploying with [NVIDIA Riva](https://developer.nvidia.com/riva), you can combine this model with external language models to further improve WER. The WER(%) of the latest model with different language modeling techniques are reported in the following table.
| Language Modeling | Training Dataset | LS test-other | LS test-clean | Comment |
|-------------------------------------|-------------------------|---------------|---------------|---------------------------------------------------------|
|N-gram LM | LS Train + LS LM Corpus | 3.5 | 1.8 | N=10, beam_width=128, n_gram_alpha=1.0, n_gram_beta=1.0 |
|Neural Rescorer(Transformer) | LS Train + LS LM Corpus | 3.4 | 1.7 | N=10, beam_width=128 |
|N-gram + Neural Rescorer(Transformer)| LS Train + LS LM Corpus | 3.2 | 1.8 | N=10, beam_width=128, n_gram_alpha=1.0, n_gram_beta=1.0 |
## Limitations
Since this model was trained on publicly available speech datasets, the performance of this model might degrade for speech which includes technical terms, or vernacular that the model has not been trained on. The model might also perform worse for accented speech.
## Deployment with NVIDIA Riva
For the best real-time accuracy, latency, and throughput, deploy the model with [NVIDIA Riva](https://developer.nvidia.com/riva), an accelerated speech AI SDK deployable on-prem, in all clouds, multi-cloud, hybrid, at the edge, and embedded.
Additionally, Riva provides:
* World-class out-of-the-box accuracy for the most common languages with model checkpoints trained on proprietary data with hundreds of thousands of GPU-compute hours
* Best in class accuracy with run-time word boosting (e.g., brand and product names) and customization of acoustic model, language model, and inverse text normalization
* Streaming speech recognition, Kubernetes compatible scaling, and Enterprise-grade support
Check out [Riva live demo](https://developer.nvidia.com/riva#demos).
## References
- [1] [Conformer: Convolution-augmented Transformer for Speech Recognition](https://arxiv.org/abs/2005.08100)
- [2] [Google Sentencepiece Tokenizer](https://github.com/google/sentencepiece)
- [3] [NVIDIA NeMo Toolkit](https://github.com/NVIDIA/NeMo)
|
GroNLP/gpt2-medium-italian-embeddings
|
6b38344ac1d0e476546d610ed482c3f045b9844d
|
2021-05-21T09:52:26.000Z
|
[
"pytorch",
"tf",
"jax",
"gpt2",
"text-generation",
"it",
"arxiv:2012.05628",
"transformers",
"adaption",
"recycled",
"gpt2-medium"
] |
text-generation
| false |
GroNLP
| null |
GroNLP/gpt2-medium-italian-embeddings
| 455 | null |
transformers
| 2,419 |
---
language: it
tags:
- adaption
- recycled
- gpt2-medium
pipeline_tag: text-generation
---
# GPT-2 recycled for Italian (medium, adapted lexical embeddings)
[Wietse de Vries](https://www.semanticscholar.org/author/Wietse-de-Vries/144611157) •
[Malvina Nissim](https://www.semanticscholar.org/author/M.-Nissim/2742475)
## Model description
This model is based on the medium OpenAI GPT-2 ([`gpt2-medium`](https://huggingface.co/gpt2-medium)) model.
The Transformer layer weights in this model are identical to the original English, model but the lexical layer has been retrained for an Italian vocabulary.
For details, check out our paper on [arXiv](https://arxiv.org/abs/2012.05628) and the code on [Github](https://github.com/wietsedv/gpt2-recycle).
## Related models
### Dutch
- [`gpt2-small-dutch-embeddings`](https://huggingface.co/GroNLP/gpt2-small-dutch-embeddings): Small model size with only retrained lexical embeddings.
- [`gpt2-small-dutch`](https://huggingface.co/GroNLP/gpt2-small-dutch): Small model size with retrained lexical embeddings and additional fine-tuning of the full model. (**Recommended**)
- [`gpt2-medium-dutch-embeddings`](https://huggingface.co/GroNLP/gpt2-medium-dutch-embeddings): Medium model size with only retrained lexical embeddings.
### Italian
- [`gpt2-small-italian-embeddings`](https://huggingface.co/GroNLP/gpt2-small-italian-embeddings): Small model size with only retrained lexical embeddings.
- [`gpt2-small-italian`](https://huggingface.co/GroNLP/gpt2-small-italian): Small model size with retrained lexical embeddings and additional fine-tuning of the full model. (**Recommended**)
- [`gpt2-medium-italian-embeddings`](https://huggingface.co/GroNLP/gpt2-medium-italian-embeddings): Medium model size with only retrained lexical embeddings.
## How to use
```python
from transformers import pipeline
pipe = pipeline("text-generation", model="GroNLP/gpt2-medium-italian-embeddings")
```
```python
from transformers import AutoTokenizer, AutoModel, TFAutoModel
tokenizer = AutoTokenizer.from_pretrained("GroNLP/gpt2-medium-italian-embeddings")
model = AutoModel.from_pretrained("GroNLP/gpt2-medium-italian-embeddings") # PyTorch
model = TFAutoModel.from_pretrained("GroNLP/gpt2-medium-italian-embeddings") # Tensorflow
```
## BibTeX entry
```bibtex
@misc{devries2020good,
title={As good as new. How to successfully recycle English GPT-2 to make models for other languages},
author={Wietse de Vries and Malvina Nissim},
year={2020},
eprint={2012.05628},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
clue/albert_chinese_small
|
f2fc21cd3fd18fa7df1ee046c7963351af8f4753
|
2020-12-11T21:35:52.000Z
|
[
"pytorch",
"albert",
"zh",
"transformers"
] | null | false |
clue
| null |
clue/albert_chinese_small
| 455 | null |
transformers
| 2,420 |
---
language: zh
---
## albert_chinese_small
### Overview
**Language model:** albert-small
**Model size:** 18.5M
**Language:** Chinese
**Training data:** [CLUECorpusSmall](https://github.com/CLUEbenchmark/CLUECorpus2020)
**Eval data:** [CLUE dataset](https://github.com/CLUEbenchmark/CLUE)
### Results
For results on downstream tasks like text classification, please refer to [this repository](https://github.com/CLUEbenchmark/CLUE).
### Usage
**NOTE:**Since sentencepiece is not used in `albert_chinese_small` model, you have to call **BertTokenizer** instead of AlbertTokenizer !!!
```
import torch
from transformers import BertTokenizer, AlbertModel
tokenizer = BertTokenizer.from_pretrained("clue/albert_chinese_small")
albert = AlbertModel.from_pretrained("clue/albert_chinese_small")
```
### About CLUE benchmark
Organization of Language Understanding Evaluation benchmark for Chinese: tasks & datasets, baselines, pre-trained Chinese models, corpus and leaderboard.
Github: https://github.com/CLUEbenchmark
Website: https://www.cluebenchmarks.com/
|
cointegrated/rut5-base
|
d2e012d05083539e962a338f9a27769337ea4469
|
2021-06-23T12:03:57.000Z
|
[
"pytorch",
"jax",
"t5",
"text2text-generation",
"ru",
"en",
"transformers",
"russian",
"license:mit",
"autotrain_compatible"
] |
text2text-generation
| false |
cointegrated
| null |
cointegrated/rut5-base
| 455 | null |
transformers
| 2,421 |
---
language: ["ru", "en"]
tags:
- russian
license: mit
---
This is a smaller version of the [google/mt5-base](https://huggingface.co/google/mt5-base) model with only Russian and some English embeddings left.
* The original model has 582M parameters, with 384M of them being input and output embeddings.
* After shrinking the `sentencepiece` vocabulary from 250K to 30K (top 10K English and top 20K Russian tokens) the number of model parameters reduced to 244M parameters, and model size reduced from 2.2GB to 0.9GB - 42% of the original one.
The creation of this model is described in the post [How to adapt a multilingual T5 model for a single language](https://cointegrated.medium.com/how-to-adapt-a-multilingual-t5-model-for-a-single-language-b9f94f3d9c90) along with the source code.
|
dbmdz/bert-base-german-europeana-cased
|
b8ff4bdc5fbd85910c18ea206f9348f6103c68b3
|
2021-05-19T14:54:00.000Z
|
[
"pytorch",
"tf",
"jax",
"bert",
"de",
"transformers",
"historic german",
"license:mit"
] | null | false |
dbmdz
| null |
dbmdz/bert-base-german-europeana-cased
| 455 | null |
transformers
| 2,422 |
---
language: de
license: mit
tags:
- "historic german"
---
# 🤗 + 📚 dbmdz BERT models
In this repository the MDZ Digital Library team (dbmdz) at the Bavarian State
Library open sources German Europeana BERT models 🎉
# German Europeana BERT
We use the open source [Europeana newspapers](http://www.europeana-newspapers.eu/)
that were provided by *The European Library*. The final
training corpus has a size of 51GB and consists of 8,035,986,369 tokens.
Detailed information about the data and pretraining steps can be found in
[this repository](https://github.com/stefan-it/europeana-bert).
## Model weights
Currently only PyTorch-[Transformers](https://github.com/huggingface/transformers)
compatible weights are available. If you need access to TensorFlow checkpoints,
please raise an issue!
| Model | Downloads
| ------------------------------------------ | ---------------------------------------------------------------------------------------------------------------
| `dbmdz/bert-base-german-europeana-cased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-german-europeana-cased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-german-europeana-cased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-german-europeana-cased/vocab.txt)
## Results
For results on Historic NER, please refer to [this repository](https://github.com/stefan-it/europeana-bert).
## Usage
With Transformers >= 2.3 our German Europeana BERT models can be loaded like:
```python
from transformers import AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("dbmdz/bert-base-german-europeana-cased")
model = AutoModel.from_pretrained("dbmdz/bert-base-german-europeana-cased")
```
# Huggingface model hub
All models are available on the [Huggingface model hub](https://huggingface.co/dbmdz).
# Contact (Bugs, Feedback, Contribution and more)
For questions about our BERT models just open an issue
[here](https://github.com/dbmdz/berts/issues/new) 🤗
# Acknowledgments
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
Thanks for providing access to the TFRC ❤️
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
it is possible to download both cased and uncased models from their S3 storage 🤗
|
facebook/s2t-wav2vec2-large-en-de
|
0d0ec5b6a24227d815094d0ca0ced8ce662b85bc
|
2021-11-14T20:12:38.000Z
|
[
"pytorch",
"speech-encoder-decoder",
"automatic-speech-recognition",
"en",
"de",
"dataset:covost2",
"dataset:librispeech_asr",
"arxiv:2104.06678",
"transformers",
"audio",
"speech-translation",
"speech2text2",
"license:mit"
] |
automatic-speech-recognition
| false |
facebook
| null |
facebook/s2t-wav2vec2-large-en-de
| 455 | 2 |
transformers
| 2,423 |
---
language:
- en
- de
datasets:
- covost2
- librispeech_asr
tags:
- audio
- speech-translation
- automatic-speech-recognition
- speech2text2
license: mit
pipeline_tag: automatic-speech-recognition
widget:
- example_title: Common Voice 1
src: https://cdn-media.huggingface.co/speech_samples/common_voice_en_18301577.mp3
- example_title: Common Voice 2
src: https://cdn-media.huggingface.co/speech_samples/common_voice_en_99985.mp3
- example_title: Common Voice 3
src: https://cdn-media.huggingface.co/speech_samples/common_voice_en_99986.mp3
---
# S2T2-Wav2Vec2-CoVoST2-EN-DE-ST
`s2t-wav2vec2-large-en-de` is a Speech to Text Transformer model trained for end-to-end Speech Translation (ST).
The S2T2 model was proposed in [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/pdf/2104.06678.pdf) and officially released in
[Fairseq](https://github.com/pytorch/fairseq/blob/6f847c8654d56b4d1b1fbacec027f47419426ddb/fairseq/models/wav2vec/wav2vec2_asr.py#L266).
## Model description
S2T2 is a transformer-based seq2seq (speech encoder-decoder) model designed for end-to-end Automatic Speech Recognition (ASR) and Speech
Translation (ST). It uses a pretrained [Wav2Vec2](https://huggingface.co/transformers/model_doc/wav2vec2.html) as the encoder and a transformer-based decoder. The model is trained with standard autoregressive cross-entropy loss and generates the translations autoregressively.
## Intended uses & limitations
This model can be used for end-to-end English speech to German text translation.
See the [model hub](https://huggingface.co/models?filter=speech2text2) to look for other S2T2 checkpoints.
### How to use
As this a standard sequence to sequence transformer model, you can use the `generate` method to generate the
transcripts by passing the speech features to the model.
You can use the model directly via the ASR pipeline
```python
from datasets import load_dataset
from transformers import pipeline
librispeech_en = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
asr = pipeline("automatic-speech-recognition", model="facebook/s2t-wav2vec2-large-en-de", feature_extractor="facebook/s2t-wav2vec2-large-en-de")
translation_de = asr(librispeech_en[0]["file"])
```
or step-by-step as follows:
```python
import torch
from transformers import Speech2Text2Processor, SpeechEncoderDecoder
from datasets import load_dataset
import soundfile as sf
model = SpeechEncoderDecoder.from_pretrained("facebook/s2t-wav2vec2-large-en-de")
processor = Speech2Text2Processor.from_pretrained("facebook/s2t-wav2vec2-large-en-de")
def map_to_array(batch):
speech, _ = sf.read(batch["file"])
batch["speech"] = speech
return batch
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
ds = ds.map(map_to_array)
inputs = processor(ds["speech"][0], sampling_rate=16_000, return_tensors="pt")
generated_ids = model.generate(input_ids=inputs["input_features"], attention_mask=inputs["attention_mask"])
transcription = processor.batch_decode(generated_ids)
```
## Evaluation results
CoVoST-V2 test results for en-de (BLEU score): **26.5**
For more information, please have a look at the [official paper](https://arxiv.org/pdf/2104.06678.pdf) - especially row 10 of Table 2.
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2104-06678,
author = {Changhan Wang and
Anne Wu and
Juan Miguel Pino and
Alexei Baevski and
Michael Auli and
Alexis Conneau},
title = {Large-Scale Self- and Semi-Supervised Learning for Speech Translation},
journal = {CoRR},
volume = {abs/2104.06678},
year = {2021},
url = {https://arxiv.org/abs/2104.06678},
archivePrefix = {arXiv},
eprint = {2104.06678},
timestamp = {Thu, 12 Aug 2021 15:37:06 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2104-06678.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
NikkiTiredAf/DialoGPT-small-billy2
|
bcd8e95c78e1d262618738ad24b5425e43a65edb
|
2022-06-20T05:46:46.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
| false |
NikkiTiredAf
| null |
NikkiTiredAf/DialoGPT-small-billy2
| 455 | null |
transformers
| 2,424 |
---
tags:
- conversational
---
# Billy DialoGPT Model
|
9pinus/macbert-base-chinese-medical-collation
|
6cddc419b86a546bfab115dd05a3782a43beb1e0
|
2022-02-25T10:26:38.000Z
|
[
"pytorch",
"bert",
"token-classification",
"zh",
"transformers",
"Token Classification",
"license:apache-2.0",
"autotrain_compatible"
] |
token-classification
| false |
9pinus
| null |
9pinus/macbert-base-chinese-medical-collation
| 454 | 3 |
transformers
| 2,425 |
---
license: apache-2.0
language: zh
tags:
- Token Classification
metrics:
- precision
- recall
- f1
- accuracy
---
## Model description
This model is a fine-tuned version of macbert for the purpose of spell checking in medical application scenarios. We fine-tuned macbert Chinese base version on a 300M dataset including 60K+ authorized medical articles. We proposed to randomly confuse 30% sentences of these articles by adding noise with a either visually or phonologically resembled characters. Consequently, the fine-tuned model can achieve 96% accuracy on our test dataset.
## Intended uses & limitations
You can use this model directly with a pipeline for token classification:
```python
>>> from transformers import (AutoModelForTokenClassification, AutoTokenizer)
>>> from transformers import pipeline
>>> hub_model_id = "9pinus/macbert-base-chinese-medical-collation"
>>> model = AutoModelForTokenClassification.from_pretrained(hub_model_id)
>>> tokenizer = AutoTokenizer.from_pretrained(hub_model_id)
>>> classifier = pipeline('ner', model=model, tokenizer=tokenizer)
>>> result = classifier("如果病情较重,可适当口服甲肖唑片、环酯红霉素片等药物进行抗感染镇痛。")
>>> for item in result:
>>> if item['entity'] == 1:
>>> print(item)
{'entity': 1, 'score': 0.58127016, 'index': 14, 'word': '肖', 'start': 13, 'end': 14}
```
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.1+cu113
- Datasets 1.17.0
- Tokenizers 0.10.3
|
NlpHUST/electra-base-vn
|
be0d6dd0ff6f233ca61c70190d25c0384423102b
|
2021-12-19T09:19:08.000Z
|
[
"pytorch",
"electra",
"pretraining",
"transformers"
] | null | false |
NlpHUST
| null |
NlpHUST/electra-base-vn
| 454 | 2 |
transformers
| 2,426 |
# ELECTRA
## Introduction
**ELECTRA** is a method for self-supervised language representation learning. It can be used to pre-train transformer networks using relatively little compute. ELECTRA models are trained to distinguish "real" input tokens vs "fake" input tokens generated by another neural network, similar to the discriminator of a [GAN](https://arxiv.org/pdf/1406.2661.pdf). At small scale, ELECTRA achieves strong results even when trained on a single GPU. At large scale, ELECTRA achieves state-of-the-art results on the [SQuAD 2.0](https://rajpurkar.github.io/SQuAD-explorer/) dataset.
Electra-base-vn is trained on more 148gb text with max length 512.
You can download tensorflow version at [Electra base TF version](https://drive.google.com/drive/folders/1hN0LiOlMfNDDQVo2bgEYHd03I-xXDLVr?usp=sharing)
### Contact information
For personal communication related to this project, please contact Nha Nguyen Van ([email protected]).
|
tunib/electra-ko-small
|
a3e3d24e0960f0a442be7e2593cb613bd7827e46
|
2021-09-17T08:59:08.000Z
|
[
"pytorch",
"electra",
"pretraining",
"arxiv:2003.10555",
"transformers"
] | null | false |
tunib
| null |
tunib/electra-ko-small
| 454 | 3 |
transformers
| 2,427 |
# TUNiB-Electra
We release several new versions of the [ELECTRA](https://arxiv.org/abs/2003.10555) model, which we name TUNiB-Electra. There are two motivations. First, all the existing pre-trained Korean encoder models are monolingual, that is, they have knowledge about Korean only. Our bilingual models are based on the balanced corpora of Korean and English. Second, we want new off-the-shelf models trained on much more texts. To this end, we collected a large amount of Korean text from various sources such as blog posts, comments, news, web novels, etc., which sum up to 100 GB in total.
## How to use
You can use this model directly with [transformers](https://github.com/huggingface/transformers) library:
```python
from transformers import AutoModel, AutoTokenizer
# Small Model (Korean-only model)
tokenizer = AutoTokenizer.from_pretrained('tunib/electra-ko-small')
model = AutoModel.from_pretrained('tunib/electra-ko-small')
```
### Tokenizer example
```python
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained('tunib/electra-ko-small')
>>> tokenizer.tokenize("tunib is a natural language processing tech startup.")
['tun', '##ib', 'is', 'a', 'natural', 'language', 'processing', 'tech', 'startup', '.']
>>> tokenizer.tokenize("튜닙은 자연어처리 테크 스타트업입니다.")
['튜', '##닙', '##은', '자연', '##어', '##처리', '테크', '스타트업', '##입니다', '.']
```
## Results on Korean downstream tasks
| |**# Params** |**Avg.**| **NSMC**<br/>(acc) | **Naver NER**<br/>(F1) | **PAWS**<br/>(acc) | **KorNLI**<br/>(acc) | **KorSTS**<br/>(spearman) | **Question Pair**<br/>(acc) | **KorQuaD (Dev)**<br/>(EM/F1) |**Korean-Hate-Speech (Dev)**<br/>(F1)|
| :----------------:| :----------------: | :--------------------: | :----------------: | :------------------: | :-----------------------: | :-------------------------: | :---------------------------: | :---------------------------: | :---------------------------: | :----------------: |
|***TUNiB-Electra-ko-small*** | 14M | 81.29| **89.56** | 84.98 | 72.85 | 77.08 | 78.76 | **94.98** | 61.17 / 87.64 | **64.50** |
|***TUNiB-Electra-ko-en-small*** | 18M | 81.44 | 89.28 | 85.15 | 75.75 | 77.06 | 77.61 | 93.79 | 80.55 / 89.77 |63.13 |
| [KoELECTRA-small-v3](https://github.com/monologg/KoELECTRA) | 14M | **82.58** | 89.36 | **85.40** | **77.45** | **78.60** | **80.79** | 94.85 | **82.11 / 91.13** | 63.07 |
|
Salesforce/codet5-large-ntp-py
|
fe53abf996a6de5b126642f5044e9a98e572cdbd
|
2022-07-07T11:55:42.000Z
|
[
"pytorch",
"t5",
"text2text-generation",
"arxiv:2109.00859",
"arxiv:2207.01780",
"arxiv:1909.09436",
"transformers",
"license:bsd-3-clause",
"autotrain_compatible"
] |
text2text-generation
| false |
Salesforce
| null |
Salesforce/codet5-large-ntp-py
| 454 | 2 |
transformers
| 2,428 |
---
license: bsd-3-clause
---
# CodeT5 (large-size model pretrained with NTP objective on Python)
## Model description
CodeT5 is a family of encoder-decoder language models for code from the paper: [CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Understanding and Generation](https://arxiv.org/pdf/2109.00859.pdf) by Yue Wang, Weishi Wang, Shafiq Joty, and Steven C.H. Hoi.
The checkpoint included in this repository is denoted as **CodeT5-large-ntp-py** (770M), which is introduced by the paper: [CodeRL: Mastering Code Generation through Pretrained Models and Deep Reinforcement Learning](https://arxiv.org/pdf/2207.01780.pdf) by Hung Le, Yue Wang, Akhilesh Deepak Gotmare, Silvio Savarese, Steven C.H. Hoi.
## Training data
CodeT5-large-ntp-py was pretrained on [CodeSearchNet](https://arxiv.org/abs/1909.09436) data in six programming languages (Ruby/JavaScript/Go/Python/Java/PHP) and GCPY (the Python split of [Github Code](https://huggingface.co/datasets/codeparrot/github-code)) data. See Section 4.1 of the [paper](https://arxiv.org/pdf/2207.01780.pdf) for more details.
## Training procedure
CodeT5-large-ntp-py was first pretrained using Masked Span Prediction (MSP) objective on CodeSearchNet for 150 epochs and on GCPY for 10 epochs, followed by another 10 epochs on GCPY using Next Token Prediction (NTP) objective. See Section 4.1 of the [paper](https://arxiv.org/pdf/2207.01780.pdf) for more details.
## Evaluation results
We evaluated this checkpoint on [APPS](https://github.com/hendrycks/apps) benchmark. See Table 5 of the [paper](https://arxiv.org/pdf/2207.01780.pdf) for more details.
## How to use
This model can be easily loaded using the `T5ForConditionalGeneration` functionality:
```python
from transformers import AutoTokenizer, T5ForConditionalGeneration
tokenizer = AutoTokenizer.from_pretrained("Salesforce/codet5-large-ntp-py")
model = T5ForConditionalGeneration.from_pretrained("Salesforce/codet5-large-ntp-py")
text = "def hello_world():"
input_ids = tokenizer(text, return_tensors="pt").input_ids
# simply generate a single sequence
generated_ids = model.generate(input_ids, max_length=128)
print(tokenizer.decode(generated_ids[0], skip_special_tokens=True))
```
## BibTeX entry and citation info
```bibtex
@inproceedings{CodeT52021,
author = {Yue Wang and Weishi Wang and Shafiq R. Joty and Steven C. H. Hoi},
title = {CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Understanding and Generation},
booktitle = {EMNLP},
pages = {8696--8708},
publisher = {Association for Computational Linguistics},
year = {2021}
}
@article{CodeRL2022
author = {Hung Le, Yue Wang, Akhilesh Deepak Gotmare, Silvio Savarese, Steven C.H. Hoi},
title = {CodeRL: Mastering Code Generation through Pretrained Models and Deep Reinforcement Learning},
journal = {arXiv preprint},
volume = {abs/2207.01780},
year = {2022}
}
```
|
csarron/mobilebert-uncased-squad-v1
|
14da15e8b5e1e35d188445b7724168e69d251e17
|
2020-12-11T21:36:24.000Z
|
[
"pytorch",
"mobilebert",
"question-answering",
"en",
"dataset:squad",
"arxiv:2004.02984",
"transformers",
"license:mit",
"autotrain_compatible"
] |
question-answering
| false |
csarron
| null |
csarron/mobilebert-uncased-squad-v1
| 453 | null |
transformers
| 2,429 |
---
language: en
thumbnail:
license: mit
tags:
- question-answering
- mobilebert
datasets:
- squad
metrics:
- squad
widget:
- text: "Which name is also used to describe the Amazon rainforest in English?"
context: "The Amazon rainforest (Portuguese: Floresta Amazônica or Amazônia; Spanish: Selva Amazónica, Amazonía or usually Amazonia; French: Forêt amazonienne; Dutch: Amazoneregenwoud), also known in English as Amazonia or the Amazon Jungle, is a moist broadleaf forest that covers most of the Amazon basin of South America. This basin encompasses 7,000,000 square kilometres (2,700,000 sq mi), of which 5,500,000 square kilometres (2,100,000 sq mi) are covered by the rainforest. This region includes territory belonging to nine nations. The majority of the forest is contained within Brazil, with 60% of the rainforest, followed by Peru with 13%, Colombia with 10%, and with minor amounts in Venezuela, Ecuador, Bolivia, Guyana, Suriname and French Guiana. States or departments in four nations contain \"Amazonas\" in their names. The Amazon represents over half of the planet's remaining rainforests, and comprises the largest and most biodiverse tract of tropical rainforest in the world, with an estimated 390 billion individual trees divided into 16,000 species."
- text: "How many square kilometers of rainforest is covered in the basin?"
context: "The Amazon rainforest (Portuguese: Floresta Amazônica or Amazônia; Spanish: Selva Amazónica, Amazonía or usually Amazonia; French: Forêt amazonienne; Dutch: Amazoneregenwoud), also known in English as Amazonia or the Amazon Jungle, is a moist broadleaf forest that covers most of the Amazon basin of South America. This basin encompasses 7,000,000 square kilometres (2,700,000 sq mi), of which 5,500,000 square kilometres (2,100,000 sq mi) are covered by the rainforest. This region includes territory belonging to nine nations. The majority of the forest is contained within Brazil, with 60% of the rainforest, followed by Peru with 13%, Colombia with 10%, and with minor amounts in Venezuela, Ecuador, Bolivia, Guyana, Suriname and French Guiana. States or departments in four nations contain \"Amazonas\" in their names. The Amazon represents over half of the planet's remaining rainforests, and comprises the largest and most biodiverse tract of tropical rainforest in the world, with an estimated 390 billion individual trees divided into 16,000 species."
---
## MobileBERT fine-tuned on SQuAD v1
[MobileBERT](https://arxiv.org/abs/2004.02984) is a thin version of BERT_LARGE, while equipped with bottleneck structures and a carefully designed balance
between self-attentions and feed-forward networks.
This model was fine-tuned from the HuggingFace checkpoint `google/mobilebert-uncased` on [SQuAD1.1](https://rajpurkar.github.io/SQuAD-explorer).
## Details
| Dataset | Split | # samples |
| -------- | ----- | --------- |
| SQuAD1.1 | train | 90.6K |
| SQuAD1.1 | eval | 11.1k |
### Fine-tuning
- Python: `3.7.5`
- Machine specs:
`CPU: Intel(R) Core(TM) i7-6800K CPU @ 3.40GHz`
`Memory: 32 GiB`
`GPUs: 2 GeForce GTX 1070, each with 8GiB memory`
`GPU driver: 418.87.01, CUDA: 10.1`
- script:
```shell
# after install https://github.com/huggingface/transformers
cd examples/question-answering
mkdir -p data
wget -O data/train-v1.1.json https://rajpurkar.github.io/SQuAD-explorer/dataset/train-v1.1.json
wget -O data/dev-v1.1.json https://rajpurkar.github.io/SQuAD-explorer/dataset/dev-v1.1.json
export SQUAD_DIR=`pwd`/data
python run_squad.py \
--model_type mobilebert \
--model_name_or_path google/mobilebert-uncased \
--do_train \
--do_eval \
--do_lower_case \
--train_file $SQUAD_DIR/train-v1.1.json \
--predict_file $SQUAD_DIR/dev-v1.1.json \
--per_gpu_train_batch_size 16 \
--per_gpu_eval_batch_size 16 \
--learning_rate 4e-5 \
--num_train_epochs 5.0 \
--max_seq_length 320 \
--doc_stride 128 \
--warmup_steps 1400 \
--output_dir $SQUAD_DIR/mobilebert-uncased-warmup-squad_v1 2>&1 | tee train-mobilebert-warmup-squad_v1.log
```
It took about 3 hours to finish.
### Results
**Model size**: `95M`
| Metric | # Value | # Original ([Table 5](https://arxiv.org/pdf/2004.02984.pdf))|
| ------ | --------- | --------- |
| **EM** | **82.6** | **82.9** |
| **F1** | **90.0** | **90.0** |
Note that the above results didn't involve any hyperparameter search.
## Example Usage
```python
from transformers import pipeline
qa_pipeline = pipeline(
"question-answering",
model="csarron/mobilebert-uncased-squad-v1",
tokenizer="csarron/mobilebert-uncased-squad-v1"
)
predictions = qa_pipeline({
'context': "The game was played on February 7, 2016 at Levi's Stadium in the San Francisco Bay Area at Santa Clara, California.",
'question': "What day was the game played on?"
})
print(predictions)
# output:
# {'score': 0.7754058241844177, 'start': 23, 'end': 39, 'answer': 'February 7, 2016'}
```
> Created by [Qingqing Cao](https://awk.ai/) | [GitHub](https://github.com/csarron) | [Twitter](https://twitter.com/sysnlp)
> Made with ❤️ in New York.
|
unitary/unbiased-toxic-roberta
|
851fcea0b57478fb28c012e56d6b0dd6077523f3
|
2021-08-16T16:42:01.000Z
|
[
"pytorch",
"jax",
"roberta",
"text-classification",
"arxiv:1703.04009",
"arxiv:1905.12516",
"transformers"
] |
text-classification
| false |
unitary
| null |
unitary/unbiased-toxic-roberta
| 453 | 3 |
transformers
| 2,430 |
<div align="center">
**⚠️ Disclaimer:**
The huggingface models currently give different results to the detoxify library (see issue [here](https://github.com/unitaryai/detoxify/issues/15)). For the most up to date models we recommend using the models from https://github.com/unitaryai/detoxify
# 🙊 Detoxify
## Toxic Comment Classification with ⚡ Pytorch Lightning and 🤗 Transformers


</div>

## Description
Trained models & code to predict toxic comments on 3 Jigsaw challenges: Toxic comment classification, Unintended Bias in Toxic comments, Multilingual toxic comment classification.
Built by [Laura Hanu](https://laurahanu.github.io/) at [Unitary](https://www.unitary.ai/), where we are working to stop harmful content online by interpreting visual content in context.
Dependencies:
- For inference:
- 🤗 Transformers
- ⚡ Pytorch lightning
- For training will also need:
- Kaggle API (to download data)
| Challenge | Year | Goal | Original Data Source | Detoxify Model Name | Top Kaggle Leaderboard Score | Detoxify Score
|-|-|-|-|-|-|-|
| [Toxic Comment Classification Challenge](https://www.kaggle.com/c/jigsaw-toxic-comment-classification-challenge) | 2018 | build a multi-headed model that’s capable of detecting different types of of toxicity like threats, obscenity, insults, and identity-based hate. | Wikipedia Comments | `original` | 0.98856 | 0.98636
| [Jigsaw Unintended Bias in Toxicity Classification](https://www.kaggle.com/c/jigsaw-unintended-bias-in-toxicity-classification) | 2019 | build a model that recognizes toxicity and minimizes this type of unintended bias with respect to mentions of identities. You'll be using a dataset labeled for identity mentions and optimizing a metric designed to measure unintended bias. | Civil Comments | `unbiased` | 0.94734 | 0.93639
| [Jigsaw Multilingual Toxic Comment Classification](https://www.kaggle.com/c/jigsaw-multilingual-toxic-comment-classification) | 2020 | build effective multilingual models | Wikipedia Comments + Civil Comments | `multilingual` | 0.9536 | 0.91655*
*Score not directly comparable since it is obtained on the validation set provided and not on the test set. To update when the test labels are made available.
It is also noteworthy to mention that the top leadearboard scores have been achieved using model ensembles. The purpose of this library was to build something user-friendly and straightforward to use.
## Limitations and ethical considerations
If words that are associated with swearing, insults or profanity are present in a comment, it is likely that it will be classified as toxic, regardless of the tone or the intent of the author e.g. humorous/self-deprecating. This could present some biases towards already vulnerable minority groups.
The intended use of this library is for research purposes, fine-tuning on carefully constructed datasets that reflect real world demographics and/or to aid content moderators in flagging out harmful content quicker.
Some useful resources about the risk of different biases in toxicity or hate speech detection are:
- [The Risk of Racial Bias in Hate Speech Detection](https://homes.cs.washington.edu/~msap/pdfs/sap2019risk.pdf)
- [Automated Hate Speech Detection and the Problem of Offensive Language](https://arxiv.org/pdf/1703.04009.pdf%201.pdf)
- [Racial Bias in Hate Speech and Abusive Language Detection Datasets](https://arxiv.org/pdf/1905.12516.pdf)
## Quick prediction
The `multilingual` model has been trained on 7 different languages so it should only be tested on: `english`, `french`, `spanish`, `italian`, `portuguese`, `turkish` or `russian`.
```bash
# install detoxify
pip install detoxify
```
```python
from detoxify import Detoxify
# each model takes in either a string or a list of strings
results = Detoxify('original').predict('example text')
results = Detoxify('unbiased').predict(['example text 1','example text 2'])
results = Detoxify('multilingual').predict(['example text','exemple de texte','texto de ejemplo','testo di esempio','texto de exemplo','örnek metin','пример текста'])
# optional to display results nicely (will need to pip install pandas)
import pandas as pd
print(pd.DataFrame(results, index=input_text).round(5))
```
For more details check the Prediction section.
## Labels
All challenges have a toxicity label. The toxicity labels represent the aggregate ratings of up to 10 annotators according the following schema:
- **Very Toxic** (a very hateful, aggressive, or disrespectful comment that is very likely to make you leave a discussion or give up on sharing your perspective)
- **Toxic** (a rude, disrespectful, or unreasonable comment that is somewhat likely to make you leave a discussion or give up on sharing your perspective)
- **Hard to Say**
- **Not Toxic**
More information about the labelling schema can be found [here](https://www.kaggle.com/c/jigsaw-unintended-bias-in-toxicity-classification/data).
### Toxic Comment Classification Challenge
This challenge includes the following labels:
- `toxic`
- `severe_toxic`
- `obscene`
- `threat`
- `insult`
- `identity_hate`
### Jigsaw Unintended Bias in Toxicity Classification
This challenge has 2 types of labels: the main toxicity labels and some additional identity labels that represent the identities mentioned in the comments.
Only identities with more than 500 examples in the test set (combined public and private) are included during training as additional labels and in the evaluation calculation.
- `toxicity`
- `severe_toxicity`
- `obscene`
- `threat`
- `insult`
- `identity_attack`
- `sexual_explicit`
Identity labels used:
- `male`
- `female`
- `homosexual_gay_or_lesbian`
- `christian`
- `jewish`
- `muslim`
- `black`
- `white`
- `psychiatric_or_mental_illness`
A complete list of all the identity labels available can be found [here](https://www.kaggle.com/c/jigsaw-unintended-bias-in-toxicity-classification/data).
### Jigsaw Multilingual Toxic Comment Classification
Since this challenge combines the data from the previous 2 challenges, it includes all labels from above, however the final evaluation is only on:
- `toxicity`
## How to run
First, install dependencies
```bash
# clone project
git clone https://github.com/unitaryai/detoxify
# create virtual env
python3 -m venv toxic-env
source toxic-env/bin/activate
# install project
pip install -e detoxify
cd detoxify
# for training
pip install -r requirements.txt
```
## Prediction
Trained models summary:
|Model name| Transformer type| Data from
|:--:|:--:|:--:|
|`original`| `bert-base-uncased` | Toxic Comment Classification Challenge
|`unbiased`| `roberta-base`| Unintended Bias in Toxicity Classification
|`multilingual`| `xlm-roberta-base`| Multilingual Toxic Comment Classification
For a quick prediction can run the example script on a comment directly or from a txt containing a list of comments.
```bash
# load model via torch.hub
python run_prediction.py --input 'example' --model_name original
# load model from from checkpoint path
python run_prediction.py --input 'example' --from_ckpt_path model_path
# save results to a .csv file
python run_prediction.py --input test_set.txt --model_name original --save_to results.csv
# to see usage
python run_prediction.py --help
```
Checkpoints can be downloaded from the latest release or via the Pytorch hub API with the following names:
- `toxic_bert`
- `unbiased_toxic_roberta`
- `multilingual_toxic_xlm_r`
```bash
model = torch.hub.load('unitaryai/detoxify','toxic_bert')
```
Importing detoxify in python:
```python
from detoxify import Detoxify
results = Detoxify('original').predict('some text')
results = Detoxify('unbiased').predict(['example text 1','example text 2'])
results = Detoxify('multilingual').predict(['example text','exemple de texte','texto de ejemplo','testo di esempio','texto de exemplo','örnek metin','пример текста'])
# to display results nicely
import pandas as pd
print(pd.DataFrame(results,index=input_text).round(5))
```
## Training
If you do not already have a Kaggle account:
- you need to create one to be able to download the data
- go to My Account and click on Create New API Token - this will download a kaggle.json file
- make sure this file is located in ~/.kaggle
```bash
# create data directory
mkdir jigsaw_data
cd jigsaw_data
# download data
kaggle competitions download -c jigsaw-toxic-comment-classification-challenge
kaggle competitions download -c jigsaw-unintended-bias-in-toxicity-classification
kaggle competitions download -c jigsaw-multilingual-toxic-comment-classification
```
## Start Training
### Toxic Comment Classification Challenge
```bash
python create_val_set.py
python train.py --config configs/Toxic_comment_classification_BERT.json
```
### Unintended Bias in Toxicicity Challenge
```bash
python train.py --config configs/Unintended_bias_toxic_comment_classification_RoBERTa.json
```
### Multilingual Toxic Comment Classification
This is trained in 2 stages. First, train on all available data, and second, train only on the translated versions of the first challenge.
The [translated data](https://www.kaggle.com/miklgr500/jigsaw-train-multilingual-coments-google-api) can be downloaded from Kaggle in french, spanish, italian, portuguese, turkish, and russian (the languages available in the test set).
```bash
# stage 1
python train.py --config configs/Multilingual_toxic_comment_classification_XLMR.json
# stage 2
python train.py --config configs/Multilingual_toxic_comment_classification_XLMR_stage2.json
```
### Monitor progress with tensorboard
```bash
tensorboard --logdir=./saved
```
## Model Evaluation
### Toxic Comment Classification Challenge
This challenge is evaluated on the mean AUC score of all the labels.
```bash
python evaluate.py --checkpoint saved/lightning_logs/checkpoints/example_checkpoint.pth --test_csv test.csv
```
### Unintended Bias in Toxicicity Challenge
This challenge is evaluated on a novel bias metric that combines different AUC scores to balance overall performance. More information on this metric [here](https://www.kaggle.com/c/jigsaw-unintended-bias-in-toxicity-classification/overview/evaluation).
```bash
python evaluate.py --checkpoint saved/lightning_logs/checkpoints/example_checkpoint.pth --test_csv test.csv
# to get the final bias metric
python model_eval/compute_bias_metric.py
```
### Multilingual Toxic Comment Classification
This challenge is evaluated on the AUC score of the main toxic label.
```bash
python evaluate.py --checkpoint saved/lightning_logs/checkpoints/example_checkpoint.pth --test_csv test.csv
```
### Citation
```
@misc{Detoxify,
title={Detoxify},
author={Hanu, Laura and {Unitary team}},
howpublished={Github. https://github.com/unitaryai/detoxify},
year={2020}
}
```
|
flax-sentence-embeddings/st-codesearch-distilroberta-base
|
65b0f39bfa41c59993f62b57447c942e371b7135
|
2021-07-05T11:40:15.000Z
|
[
"pytorch",
"roberta",
"feature-extraction",
"dataset:code_search_net",
"sentence-transformers",
"sentence-similarity"
] |
sentence-similarity
| false |
flax-sentence-embeddings
| null |
flax-sentence-embeddings/st-codesearch-distilroberta-base
| 452 | 6 |
sentence-transformers
| 2,431 |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
datasets:
- code_search_net
---
# flax-sentence-embeddings/st-codesearch-distilroberta-base
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
It was trained on the [code_search_net](https://huggingface.co/datasets/code_search_net) dataset and can be used to search program code given text.
## Usage:
```python
from sentence_transformers import SentenceTransformer, util
#This list the defines the different programm codes
code = ["""def sort_list(x):
return sorted(x)""",
"""def count_above_threshold(elements, threshold=0):
counter = 0
for e in elements:
if e > threshold:
counter += 1
return counter""",
"""def find_min_max(elements):
min_ele = 99999
max_ele = -99999
for e in elements:
if e < min_ele:
min_ele = e
if e > max_ele:
max_ele = e
return min_ele, max_ele"""]
model = SentenceTransformer("flax-sentence-embeddings/st-codesearch-distilroberta-base")
# Encode our code into the vector space
code_emb = model.encode(code, convert_to_tensor=True)
# Interactive demo: Enter queries, and the method returns the best function from the
# 3 functions we defined
while True:
query = input("Query: ")
query_emb = model.encode(query, convert_to_tensor=True)
hits = util.semantic_search(query_emb, code_emb)[0]
top_hit = hits[0]
print("Cossim: {:.2f}".format(top_hit['score']))
print(code[top_hit['corpus_id']])
print("\n\n")
```
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('flax-sentence-embeddings/st-codesearch-distilroberta-base')
embeddings = model.encode(sentences)
print(embeddings)
```
## Training
The model was trained with a DistilRoBERTa-base model for 10k training steps on the codesearch dataset with batch_size 256 and MultipleNegativesRankingLoss.
It is some preliminary model. It was neither tested nor was the trained quite sophisticated
The model was trained with the parameters:
**DataLoader**:
`MultiDatasetDataLoader.MultiDatasetDataLoader` of length 5371 with parameters:
```
{'batch_size': 256}
```
**Loss**:
`sentence_transformers.losses.MultipleNegativesRankingLoss.MultipleNegativesRankingLoss` with parameters:
```
{'scale': 20, 'similarity_fct': 'dot_score'}
```
Parameters of the fit()-Method:
```
{
"callback": null,
"epochs": 1,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'transformers.optimization.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "warmupconstant",
"steps_per_epoch": 10000,
"warmup_steps": 500,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: RobertaModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
(2): Normalize()
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
google/multiberts-seed_4
|
8e1f8267eedb194a9779d1010656fc19e30b4e69
|
2021-11-05T22:14:20.000Z
|
[
"pytorch",
"tf",
"bert",
"pretraining",
"en",
"arxiv:2106.16163",
"arxiv:1908.08962",
"transformers",
"multiberts",
"multiberts-seed_4",
"license:apache-2.0"
] | null | false |
google
| null |
google/multiberts-seed_4
| 452 | null |
transformers
| 2,432 |
---
language: en
tags:
- multiberts
- multiberts-seed_4
license: apache-2.0
---
# MultiBERTs - Seed 4
MultiBERTs is a collection of checkpoints and a statistical library to support
robust research on BERT. We provide 25 BERT-base models trained with
similar hyper-parameters as
[the original BERT model](https://github.com/google-research/bert) but
with different random seeds, which causes variations in the initial weights and order of
training instances. The aim is to distinguish findings that apply to a specific
artifact (i.e., a particular instance of the model) from those that apply to the
more general procedure.
We also provide 140 intermediate checkpoints captured
during the course of pre-training (we saved 28 checkpoints for the first 5 runs).
The models were originally released through
[http://goo.gle/multiberts](http://goo.gle/multiberts). We describe them in our
paper
[The MultiBERTs: BERT Reproductions for Robustness Analysis](https://arxiv.org/abs/2106.16163).
This is model #4.
## Model Description
This model is a reproduction of
[BERT-base uncased](https://github.com/google-research/bert), for English: it
is a Transformers model pretrained on a large corpus of English data, using the
Masked Language Modelling (MLM) and the Next Sentence Prediction (NSP)
objectives.
The intended uses, limitations, training data and training procedure are similar
to [BERT-base uncased](https://github.com/google-research/bert). Two major
differences with the original model:
* We pre-trained the MultiBERTs models for 2 million steps using sequence
length 512 (instead of 1 million steps using sequence length 128 then 512).
* We used an alternative version of Wikipedia and Books Corpus, initially
collected for [Turc et al., 2019](https://arxiv.org/abs/1908.08962).
This is a best-effort reproduction, and so it is probable that differences with
the original model have gone unnoticed. The performance of MultiBERTs on GLUE is oftentimes comparable to that of original
BERT, but we found significant differences on the dev set of SQuAD (MultiBERTs outperforms original BERT).
See our [technical report](https://arxiv.org/abs/2106.16163) for more details.
### How to use
Using code from
[BERT-base uncased](https://huggingface.co/bert-base-uncased), here is an example based on
Tensorflow:
```
from transformers import BertTokenizer, TFBertModel
tokenizer = BertTokenizer.from_pretrained('google/multiberts-seed_4')
model = TFBertModel.from_pretrained("google/multiberts-seed_4")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
PyTorch version:
```
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('google/multiberts-seed_4')
model = BertModel.from_pretrained("google/multiberts-seed_4")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
## Citation info
```bibtex
@article{sellam2021multiberts,
title={The MultiBERTs: BERT Reproductions for Robustness Analysis},
author={Thibault Sellam and Steve Yadlowsky and Jason Wei and Naomi Saphra and Alexander D'Amour and Tal Linzen and Jasmijn Bastings and Iulia Turc and Jacob Eisenstein and Dipanjan Das and Ian Tenney and Ellie Pavlick},
journal={arXiv preprint arXiv:2106.16163},
year={2021}
}
```
|
philschmid/bart-base-samsum
|
807745bf0e30e6bb98dd5b4fe2c5f8a1d7185ea8
|
2022-06-24T11:24:25.000Z
|
[
"pytorch",
"bart",
"text2text-generation",
"en",
"dataset:samsum",
"transformers",
"sagemaker",
"summarization",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
] |
summarization
| false |
philschmid
| null |
philschmid/bart-base-samsum
| 452 | 1 |
transformers
| 2,433 |
---
language: en
tags:
- sagemaker
- bart
- summarization
license: apache-2.0
datasets:
- samsum
widget:
- text: "Jeff: Can I train a \U0001F917 Transformers model on Amazon SageMaker? \n\
Philipp: Sure you can use the new Hugging Face Deep Learning Container. \nJeff:\
\ ok.\nJeff: and how can I get started? \nJeff: where can I find documentation?\
\ \nPhilipp: ok, ok you can find everything here. https://huggingface.co/blog/the-partnership-amazon-sagemaker-and-hugging-face\
\ "
model-index:
- name: philschmid/bart-base-samsum
results:
- task:
type: summarization
name: Summarization
dataset:
name: samsum
type: samsum
config: samsum
split: test
metrics:
- name: ROUGE-1
type: rouge
value: 45.3438
verified: true
- name: ROUGE-2
type: rouge
value: 21.6953
verified: true
- name: ROUGE-L
type: rouge
value: 38.1365
verified: true
- name: ROUGE-LSUM
type: rouge
value: 41.5913
verified: true
- name: loss
type: loss
value: 1.5832244157791138
verified: true
- name: gen_len
type: gen_len
value: 17.9927
verified: true
---
## `bart-base-samsum`
This model was trained using Amazon SageMaker and the new Hugging Face Deep Learning container.
You can find the notebook [here]() and the referring blog post [here]().
For more information look at:
- [🤗 Transformers Documentation: Amazon SageMaker](https://huggingface.co/transformers/sagemaker.html)
- [Example Notebooks](https://github.com/huggingface/notebooks/tree/master/sagemaker)
- [Amazon SageMaker documentation for Hugging Face](https://docs.aws.amazon.com/sagemaker/latest/dg/hugging-face.html)
- [Python SDK SageMaker documentation for Hugging Face](https://sagemaker.readthedocs.io/en/stable/frameworks/huggingface/index.html)
- [Deep Learning Container](https://github.com/aws/deep-learning-containers/blob/master/available_images.md#huggingface-training-containers)
## Hyperparameters
```json
{
"dataset_name": "samsum",
"do_eval": true,
"do_train": true,
"fp16": true,
"learning_rate": 5e-05,
"model_name_or_path": "facebook/bart-base",
"num_train_epochs": 3,
"output_dir": "/opt/ml/model",
"per_device_eval_batch_size": 8,
"per_device_train_batch_size": 8,
"seed": 7
}
```
## Train results
| key | value |
| --- | ----- |
| epoch | 3 |
| init_mem_cpu_alloc_delta | 180190 |
| init_mem_cpu_peaked_delta | 18282 |
| init_mem_gpu_alloc_delta | 558658048 |
| init_mem_gpu_peaked_delta | 0 |
| train_mem_cpu_alloc_delta | 6658519 |
| train_mem_cpu_peaked_delta | 642937 |
| train_mem_gpu_alloc_delta | 2267624448 |
| train_mem_gpu_peaked_delta | 10355728896 |
| train_runtime | 98.4931 |
| train_samples | 14732 |
| train_samples_per_second | 3.533 |
## Eval results
| key | value |
| --- | ----- |
| epoch | 3 |
| eval_loss | 1.5356481075286865 |
| eval_mem_cpu_alloc_delta | 659047 |
| eval_mem_cpu_peaked_delta | 18254 |
| eval_mem_gpu_alloc_delta | 0 |
| eval_mem_gpu_peaked_delta | 300285440 |
| eval_runtime | 0.3116 |
| eval_samples | 818 |
| eval_samples_per_second | 2625.337 |
## Usage
```python
from transformers import pipeline
summarizer = pipeline("summarization", model="philschmid/bart-base-samsum")
conversation = '''Jeff: Can I train a 🤗 Transformers model on Amazon SageMaker?
Philipp: Sure you can use the new Hugging Face Deep Learning Container.
Jeff: ok.
Jeff: and how can I get started?
Jeff: where can I find documentation?
Philipp: ok, ok you can find everything here. https://huggingface.co/blog/the-partnership-amazon-sagemaker-and-hugging-face
'''
nlp(conversation)
```
|
google/multiberts-seed_5
|
73b6810aed2fb957e82e653e54f49713a455d185
|
2021-11-05T22:15:58.000Z
|
[
"pytorch",
"tf",
"bert",
"pretraining",
"en",
"arxiv:2106.16163",
"arxiv:1908.08962",
"transformers",
"multiberts",
"multiberts-seed_5",
"license:apache-2.0"
] | null | false |
google
| null |
google/multiberts-seed_5
| 451 | null |
transformers
| 2,434 |
---
language: en
tags:
- multiberts
- multiberts-seed_5
license: apache-2.0
---
# MultiBERTs - Seed 5
MultiBERTs is a collection of checkpoints and a statistical library to support
robust research on BERT. We provide 25 BERT-base models trained with
similar hyper-parameters as
[the original BERT model](https://github.com/google-research/bert) but
with different random seeds, which causes variations in the initial weights and order of
training instances. The aim is to distinguish findings that apply to a specific
artifact (i.e., a particular instance of the model) from those that apply to the
more general procedure.
We also provide 140 intermediate checkpoints captured
during the course of pre-training (we saved 28 checkpoints for the first 5 runs).
The models were originally released through
[http://goo.gle/multiberts](http://goo.gle/multiberts). We describe them in our
paper
[The MultiBERTs: BERT Reproductions for Robustness Analysis](https://arxiv.org/abs/2106.16163).
This is model #5.
## Model Description
This model is a reproduction of
[BERT-base uncased](https://github.com/google-research/bert), for English: it
is a Transformers model pretrained on a large corpus of English data, using the
Masked Language Modelling (MLM) and the Next Sentence Prediction (NSP)
objectives.
The intended uses, limitations, training data and training procedure are similar
to [BERT-base uncased](https://github.com/google-research/bert). Two major
differences with the original model:
* We pre-trained the MultiBERTs models for 2 million steps using sequence
length 512 (instead of 1 million steps using sequence length 128 then 512).
* We used an alternative version of Wikipedia and Books Corpus, initially
collected for [Turc et al., 2019](https://arxiv.org/abs/1908.08962).
This is a best-effort reproduction, and so it is probable that differences with
the original model have gone unnoticed. The performance of MultiBERTs on GLUE is oftentimes comparable to that of original
BERT, but we found significant differences on the dev set of SQuAD (MultiBERTs outperforms original BERT).
See our [technical report](https://arxiv.org/abs/2106.16163) for more details.
### How to use
Using code from
[BERT-base uncased](https://huggingface.co/bert-base-uncased), here is an example based on
Tensorflow:
```
from transformers import BertTokenizer, TFBertModel
tokenizer = BertTokenizer.from_pretrained('google/multiberts-seed_5')
model = TFBertModel.from_pretrained("google/multiberts-seed_5")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
PyTorch version:
```
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('google/multiberts-seed_5')
model = BertModel.from_pretrained("google/multiberts-seed_5")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
## Citation info
```bibtex
@article{sellam2021multiberts,
title={The MultiBERTs: BERT Reproductions for Robustness Analysis},
author={Thibault Sellam and Steve Yadlowsky and Jason Wei and Naomi Saphra and Alexander D'Amour and Tal Linzen and Jasmijn Bastings and Iulia Turc and Jacob Eisenstein and Dipanjan Das and Ian Tenney and Ellie Pavlick},
journal={arXiv preprint arXiv:2106.16163},
year={2021}
}
```
|
google/multiberts-seed_7
|
ec918353afaee9c14e71395a2573d9b858e78638
|
2021-11-05T22:19:19.000Z
|
[
"pytorch",
"tf",
"bert",
"pretraining",
"en",
"arxiv:2106.16163",
"arxiv:1908.08962",
"transformers",
"multiberts",
"multiberts-seed_7",
"license:apache-2.0"
] | null | false |
google
| null |
google/multiberts-seed_7
| 451 | null |
transformers
| 2,435 |
---
language: en
tags:
- multiberts
- multiberts-seed_7
license: apache-2.0
---
# MultiBERTs - Seed 7
MultiBERTs is a collection of checkpoints and a statistical library to support
robust research on BERT. We provide 25 BERT-base models trained with
similar hyper-parameters as
[the original BERT model](https://github.com/google-research/bert) but
with different random seeds, which causes variations in the initial weights and order of
training instances. The aim is to distinguish findings that apply to a specific
artifact (i.e., a particular instance of the model) from those that apply to the
more general procedure.
We also provide 140 intermediate checkpoints captured
during the course of pre-training (we saved 28 checkpoints for the first 5 runs).
The models were originally released through
[http://goo.gle/multiberts](http://goo.gle/multiberts). We describe them in our
paper
[The MultiBERTs: BERT Reproductions for Robustness Analysis](https://arxiv.org/abs/2106.16163).
This is model #7.
## Model Description
This model is a reproduction of
[BERT-base uncased](https://github.com/google-research/bert), for English: it
is a Transformers model pretrained on a large corpus of English data, using the
Masked Language Modelling (MLM) and the Next Sentence Prediction (NSP)
objectives.
The intended uses, limitations, training data and training procedure are similar
to [BERT-base uncased](https://github.com/google-research/bert). Two major
differences with the original model:
* We pre-trained the MultiBERTs models for 2 million steps using sequence
length 512 (instead of 1 million steps using sequence length 128 then 512).
* We used an alternative version of Wikipedia and Books Corpus, initially
collected for [Turc et al., 2019](https://arxiv.org/abs/1908.08962).
This is a best-effort reproduction, and so it is probable that differences with
the original model have gone unnoticed. The performance of MultiBERTs on GLUE is oftentimes comparable to that of original
BERT, but we found significant differences on the dev set of SQuAD (MultiBERTs outperforms original BERT).
See our [technical report](https://arxiv.org/abs/2106.16163) for more details.
### How to use
Using code from
[BERT-base uncased](https://huggingface.co/bert-base-uncased), here is an example based on
Tensorflow:
```
from transformers import BertTokenizer, TFBertModel
tokenizer = BertTokenizer.from_pretrained('google/multiberts-seed_7')
model = TFBertModel.from_pretrained("google/multiberts-seed_7")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
PyTorch version:
```
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('google/multiberts-seed_7')
model = BertModel.from_pretrained("google/multiberts-seed_7")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
## Citation info
```bibtex
@article{sellam2021multiberts,
title={The MultiBERTs: BERT Reproductions for Robustness Analysis},
author={Thibault Sellam and Steve Yadlowsky and Jason Wei and Naomi Saphra and Alexander D'Amour and Tal Linzen and Jasmijn Bastings and Iulia Turc and Jacob Eisenstein and Dipanjan Das and Ian Tenney and Ellie Pavlick},
journal={arXiv preprint arXiv:2106.16163},
year={2021}
}
```
|
studio-ousia/luke-large-finetuned-open-entity
|
35df92918b7e8ab3283a6bff5d51ea61bcb94650
|
2021-04-26T16:10:58.000Z
|
[
"pytorch",
"luke",
"transformers"
] | null | false |
studio-ousia
| null |
studio-ousia/luke-large-finetuned-open-entity
| 451 | null |
transformers
| 2,436 |
Entry not found
|
tae898/emoberta-base
|
64377bdd2a1d7bc5ecdac9a4fbd219002663df1e
|
2022-03-16T11:01:29.000Z
|
[
"pytorch",
"roberta",
"text-classification",
"en",
"dataset:MELD",
"dataset:IEMOCAP",
"arxiv:2108.12009",
"transformers",
"emoberta",
"license:mit"
] |
text-classification
| false |
tae898
| null |
tae898/emoberta-base
| 451 | 2 |
transformers
| 2,437 |
---
language: en
tags:
- emoberta
- roberta
license: mit
datasets:
- MELD
- IEMOCAP
---
Check https://github.com/tae898/erc for the details
[Watch a demo video!](https://youtu.be/qbr7fNd6J28)
# Emotion Recognition in Coversation (ERC)
[](https://paperswithcode.com/sota/emotion-recognition-in-conversation-on?p=emoberta-speaker-aware-emotion-recognition-in)
[](https://paperswithcode.com/sota/emotion-recognition-in-conversation-on-meld?p=emoberta-speaker-aware-emotion-recognition-in)
At the moment, we only use the text modality to correctly classify the emotion of the utterances.The experiments were carried out on two datasets (i.e. MELD and IEMOCAP)
## Prerequisites
1. An x86-64 Unix or Unix-like machine
1. Python 3.8 or higher
1. Running in a virtual environment (e.g., conda, virtualenv, etc.) is highly recommended so that you don't mess up with the system python.
1. [`multimodal-datasets` repo](https://github.com/tae898/multimodal-datasets) (submodule)
1. pip install -r requirements.txt
## EmoBERTa training
First configure the hyper parameters and the dataset in `train-erc-text.yaml` and then,
In this directory run the below commands. I recommend you to run this in a virtualenv.
```sh
python train-erc-text.py
```
This will subsequently call `train-erc-text-hp.py` and `train-erc-text-full.py`.
## Results on the test split (weighted f1 scores)
| Model | | MELD | IEMOCAP |
| -------- | ------------------------------- | :-------: | :-------: |
| EmoBERTa | No past and future utterances | 63.46 | 56.09 |
| | Only past utterances | 64.55 | **68.57** |
| | Only future utterances | 64.23 | 66.56 |
| | Both past and future utterances | **65.61** | 67.42 |
| | → *without speaker names* | 65.07 | 64.02 |
Above numbers are the mean values of five random seed runs.
If you want to see more training test details, check out `./results/`
If you want to download the trained checkpoints and stuff, then [here](https://surfdrive.surf.nl/files/index.php/s/khREwk4MUI7MSnO/download) is where you can download them. It's a pretty big zip file.
## Deployment
### Huggingface
We have released our models on huggingface:
- [emoberta-base](https://huggingface.co/tae898/emoberta-base)
- [emoberta-large](https://huggingface.co/tae898/emoberta-large)
They are based on [RoBERTa-base](https://huggingface.co/roberta-base) and [RoBERTa-large](https://huggingface.co/roberta-large), respectively. They were trained on [both MELD and IEMOCAP datasets](utterance-ordered-MELD_IEMOCAP.json). Our deployed models are neither speaker-aware nor take previous utterances into account, meaning that it only classifies one utterance at a time without the speaker information (e.g., "I love you").
### Flask app
You can either run the Flask RESTful server app as a docker container or just as a python script.
1. Running the app as a docker container **(recommended)**.
There are four images. Take what you need:
- `docker run -it --rm -p 10006:10006 tae898/emoberta-base`
- `docker run -it --rm -p 10006:10006 --gpus all tae898/emoberta-base-cuda`
- `docker run -it --rm -p 10006:10006 tae898/emoberta-large`
- `docker run -it --rm -p 10006:10006 --gpus all tae898/emoberta-large-cuda`
1. Running the app in your python environment:
This method is less recommended than the docker one.
Run `pip install -r requirements-deploy.txt` first.<br>
The [`app.py`](app.py) is a flask RESTful server. The usage is below:
```console
app.py [-h] [--host HOST] [--port PORT] [--device DEVICE] [--model-type MODEL_TYPE]
```
For example:
```sh
python app.py --host 0.0.0.0 --port 10006 --device cpu --model-type emoberta-base
```
### Client
Once the app is running, you can send a text to the server. First install the necessary packages: `pip install -r requirements-client.txt`, and the run the [client.py](client.py). The usage is as below:
```console
client.py [-h] [--url-emoberta URL_EMOBERTA] --text TEXT
```
For example:
```sh
python client.py --text "Emotion recognition is so cool\!"
```
will give you:
```json
{
"neutral": 0.0049800905,
"joy": 0.96399665,
"surprise": 0.018937444,
"anger": 0.0071516023,
"sadness": 0.002021492,
"disgust": 0.001495996,
"fear": 0.0014167271
}
```
## Troubleshooting
The best way to find and solve your problems is to see in the github issue tab. If you can't find what you want, feel free to raise an issue. We are pretty responsive.
## Contributing
Contributions are what make the open source community such an amazing place to be learn, inspire, and create. Any contributions you make are **greatly appreciated**.
1. Fork the Project
1. Create your Feature Branch (`git checkout -b feature/AmazingFeature`)
1. Run `make style && quality` in the root repo directory, to ensure code quality.
1. Commit your Changes (`git commit -m 'Add some AmazingFeature'`)
1. Push to the Branch (`git push origin feature/AmazingFeature`)
1. Open a Pull Request
## Cite our work
Check out the [paper](https://arxiv.org/abs/2108.12009).
```bibtex
@misc{kim2021emoberta,
title={EmoBERTa: Speaker-Aware Emotion Recognition in Conversation with RoBERTa},
author={Taewoon Kim and Piek Vossen},
year={2021},
eprint={2108.12009},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
[](https://zenodo.org/badge/latestdoi/328375452)<br>
## Authors
- [Taewoon Kim](https://taewoonkim.com/)
## License
[MIT](https://choosealicense.com/licenses/mit/)
|
google/multiberts-seed_6
|
fe06acd33aecd0a25facb1b397a64cfcaf74c9ea
|
2021-11-05T22:17:37.000Z
|
[
"pytorch",
"tf",
"bert",
"pretraining",
"en",
"arxiv:2106.16163",
"arxiv:1908.08962",
"transformers",
"multiberts",
"multiberts-seed_6",
"license:apache-2.0"
] | null | false |
google
| null |
google/multiberts-seed_6
| 450 | null |
transformers
| 2,438 |
---
language: en
tags:
- multiberts
- multiberts-seed_6
license: apache-2.0
---
# MultiBERTs - Seed 6
MultiBERTs is a collection of checkpoints and a statistical library to support
robust research on BERT. We provide 25 BERT-base models trained with
similar hyper-parameters as
[the original BERT model](https://github.com/google-research/bert) but
with different random seeds, which causes variations in the initial weights and order of
training instances. The aim is to distinguish findings that apply to a specific
artifact (i.e., a particular instance of the model) from those that apply to the
more general procedure.
We also provide 140 intermediate checkpoints captured
during the course of pre-training (we saved 28 checkpoints for the first 5 runs).
The models were originally released through
[http://goo.gle/multiberts](http://goo.gle/multiberts). We describe them in our
paper
[The MultiBERTs: BERT Reproductions for Robustness Analysis](https://arxiv.org/abs/2106.16163).
This is model #6.
## Model Description
This model is a reproduction of
[BERT-base uncased](https://github.com/google-research/bert), for English: it
is a Transformers model pretrained on a large corpus of English data, using the
Masked Language Modelling (MLM) and the Next Sentence Prediction (NSP)
objectives.
The intended uses, limitations, training data and training procedure are similar
to [BERT-base uncased](https://github.com/google-research/bert). Two major
differences with the original model:
* We pre-trained the MultiBERTs models for 2 million steps using sequence
length 512 (instead of 1 million steps using sequence length 128 then 512).
* We used an alternative version of Wikipedia and Books Corpus, initially
collected for [Turc et al., 2019](https://arxiv.org/abs/1908.08962).
This is a best-effort reproduction, and so it is probable that differences with
the original model have gone unnoticed. The performance of MultiBERTs on GLUE is oftentimes comparable to that of original
BERT, but we found significant differences on the dev set of SQuAD (MultiBERTs outperforms original BERT).
See our [technical report](https://arxiv.org/abs/2106.16163) for more details.
### How to use
Using code from
[BERT-base uncased](https://huggingface.co/bert-base-uncased), here is an example based on
Tensorflow:
```
from transformers import BertTokenizer, TFBertModel
tokenizer = BertTokenizer.from_pretrained('google/multiberts-seed_6')
model = TFBertModel.from_pretrained("google/multiberts-seed_6")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
PyTorch version:
```
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('google/multiberts-seed_6')
model = BertModel.from_pretrained("google/multiberts-seed_6")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
## Citation info
```bibtex
@article{sellam2021multiberts,
title={The MultiBERTs: BERT Reproductions for Robustness Analysis},
author={Thibault Sellam and Steve Yadlowsky and Jason Wei and Naomi Saphra and Alexander D'Amour and Tal Linzen and Jasmijn Bastings and Iulia Turc and Jacob Eisenstein and Dipanjan Das and Ian Tenney and Ellie Pavlick},
journal={arXiv preprint arXiv:2106.16163},
year={2021}
}
```
|
google/vit-large-patch32-384
|
a2b30ad36d02e99f045cd2ecfc71e0ae16991efa
|
2022-01-28T10:24:24.000Z
|
[
"pytorch",
"tf",
"jax",
"vit",
"image-classification",
"dataset:imagenet",
"dataset:imagenet-21k",
"arxiv:2010.11929",
"arxiv:2006.03677",
"transformers",
"vision",
"license:apache-2.0"
] |
image-classification
| false |
google
| null |
google/vit-large-patch32-384
| 450 | 3 |
transformers
| 2,439 |
---
license: apache-2.0
tags:
- image-classification
- vision
datasets:
- imagenet
- imagenet-21k
---
# Vision Transformer (large-sized model)
Vision Transformer (ViT) model pre-trained on ImageNet-21k (14 million images, 21,843 classes) at resolution 224x224, and fine-tuned on ImageNet 2012 (1 million images, 1,000 classes) at resolution 384x384. It was introduced in the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Dosovitskiy et al. and first released in [this repository](https://github.com/google-research/vision_transformer). However, the weights were converted from the [timm repository](https://github.com/rwightman/pytorch-image-models) by Ross Wightman, who already converted the weights from JAX to PyTorch. Credits go to him.
Disclaimer: The team releasing ViT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The Vision Transformer (ViT) is a transformer encoder model (BERT-like) pretrained on a large collection of images in a supervised fashion, namely ImageNet-21k, at a resolution of 224x224 pixels. Next, the model was fine-tuned on ImageNet (also referred to as ILSVRC2012), a dataset comprising 1 million images and 1,000 classes, at a higher resolution of 384x384.
Images are presented to the model as a sequence of fixed-size patches (resolution 32x32), which are linearly embedded. One also adds a [CLS] token to the beginning of a sequence to use it for classification tasks. One also adds absolute position embeddings before feeding the sequence to the layers of the Transformer encoder.
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire image.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=google/vit) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import ViTFeatureExtractor, ViTForImageClassification
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = ViTFeatureExtractor.from_pretrained('google/vit-large-patch32-384')
model = ViTForImageClassification.from_pretrained('google/vit-large-patch32-384')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
Currently, both the feature extractor and model support PyTorch. Tensorflow and JAX/FLAX are coming soon, and the API of ViTFeatureExtractor might change.
## Training data
The ViT model was pretrained on [ImageNet-21k](http://www.image-net.org/), a dataset consisting of 14 million images and 21k classes, and fine-tuned on [ImageNet](http://www.image-net.org/challenges/LSVRC/2012/), a dataset consisting of 1 million images and 1k classes.
## Training procedure
### Preprocessing
The exact details of preprocessing of images during training/validation can be found [here](https://github.com/google-research/vision_transformer/blob/master/vit_jax/input_pipeline.py).
Images are resized/rescaled to the same resolution (224x224 during pre-training, 384x384 during fine-tuning) and normalized across the RGB channels with mean (0.5, 0.5, 0.5) and standard deviation (0.5, 0.5, 0.5).
### Pretraining
The model was trained on TPUv3 hardware (8 cores). All model variants are trained with a batch size of 4096 and learning rate warmup of 10k steps. For ImageNet, the authors found it beneficial to additionally apply gradient clipping at global norm 1. Pre-training resolution is 224.
## Evaluation results
For evaluation results on several image classification benchmarks, we refer to tables 2 and 5 of the original paper. Note that for fine-tuning, the best results are obtained with a higher resolution (384x384). Of course, increasing the model size will result in better performance.
### BibTeX entry and citation info
```bibtex
@misc{wu2020visual,
title={Visual Transformers: Token-based Image Representation and Processing for Computer Vision},
author={Bichen Wu and Chenfeng Xu and Xiaoliang Dai and Alvin Wan and Peizhao Zhang and Zhicheng Yan and Masayoshi Tomizuka and Joseph Gonzalez and Kurt Keutzer and Peter Vajda},
year={2020},
eprint={2006.03677},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
```bibtex
@inproceedings{deng2009imagenet,
title={Imagenet: A large-scale hierarchical image database},
author={Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li},
booktitle={2009 IEEE conference on computer vision and pattern recognition},
pages={248--255},
year={2009},
organization={Ieee}
}
```
|
sentence-transformers/sentence-t5-xxl
|
0a2f720e57c36306fbfca6025baba48828555764
|
2022-02-09T14:06:28.000Z
|
[
"pytorch",
"t5",
"en",
"arxiv:2108.08877",
"sentence-transformers",
"feature-extraction",
"sentence-similarity",
"transformers",
"license:apache-2.0"
] |
sentence-similarity
| false |
sentence-transformers
| null |
sentence-transformers/sentence-t5-xxl
| 450 | null |
sentence-transformers
| 2,440 |
---
pipeline_tag: sentence-similarity
language: en
license: apache-2.0
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# sentence-transformers/sentence-t5-xxl
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space. The model works well for sentence similarity tasks, but doesn't perform that well for semantic search tasks.
This model was converted from the Tensorflow model [st5-11b-1](https://tfhub.dev/google/sentence-t5/st5-11b/1) to PyTorch. When using this model, have a look at the publication: [Sentence-T5: Scalable sentence encoders from pre-trained text-to-text models](https://arxiv.org/abs/2108.08877). The tfhub model and this PyTorch model can produce slightly different embeddings, however, when run on the same benchmarks, they produce identical results.
The model uses only the encoder from a T5-11B model. The weights are stored in FP16.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/sentence-t5-xxl')
embeddings = model.encode(sentences)
print(embeddings)
```
The model requires sentence-transformers version 2.2.0 or newer.
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/sentence-t5-xxl)
## Citing & Authors
If you find this model helpful, please cite the respective publication:
[Sentence-T5: Scalable sentence encoders from pre-trained text-to-text models](https://arxiv.org/abs/2108.08877)
|
Naturealbe/DialoGPT-small-Technoblade
|
03d45234348358b2d29f92bd26211ffac3418bd0
|
2022-07-03T18:37:41.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
| false |
Naturealbe
| null |
Naturealbe/DialoGPT-small-Technoblade
| 449 | null |
transformers
| 2,441 |
---
tags:
- conversational
---
# Technoblade DialoGPT Model
|
steeldream/letov
|
21e383798651ed1ad2a2f842ddb431817679bfdb
|
2022-07-10T16:45:45.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"license:cc-by-4.0"
] |
text-generation
| false |
steeldream
| null |
steeldream/letov
| 449 | null |
transformers
| 2,442 |
---
license: cc-by-4.0
---
|
arijitx/wav2vec2-large-xlsr-bengali
|
a3dd1342030ba7478c832d6abdf7538f6e0224cb
|
2021-09-23T13:07:14.000Z
|
[
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"Bengali",
"dataset:OpenSLR",
"transformers",
"bn",
"audio",
"speech",
"license:cc-by-sa-4.0",
"model-index"
] |
automatic-speech-recognition
| false |
arijitx
| null |
arijitx/wav2vec2-large-xlsr-bengali
| 448 | 1 |
transformers
| 2,443 |
---
language: Bengali
datasets:
- OpenSLR
metrics:
- wer
tags:
- bn
- audio
- automatic-speech-recognition
- speech
license: cc-by-sa-4.0
model-index:
- name: XLSR Wav2Vec2 Bengali by Arijit
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: OpenSLR
type: OpenSLR
args: ben
metrics:
- name: Test WER
type: wer
value: 32.45
---
# Wav2Vec2-Large-XLSR-Bengali
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) Bengali using a subset of 40,000 utterances from [Bengali ASR training data set containing ~196K utterances](https://www.openslr.org/53/). Tested WER using ~4200 held out from training.
When using this model, make sure that your speech input is sampled at 16kHz.
Train Script can be Found at : train.py
Data Prep Notebook : https://colab.research.google.com/drive/1JMlZPU-DrezXjZ2t7sOVqn7CJjZhdK2q?usp=sharing
Inference Notebook : https://colab.research.google.com/drive/1uKC2cK9JfUPDTUHbrNdOYqKtNozhxqgZ?usp=sharing
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
processor = Wav2Vec2Processor.from_pretrained("arijitx/wav2vec2-large-xlsr-bengali")
model = Wav2Vec2ForCTC.from_pretrained("arijitx/wav2vec2-large-xlsr-bengali")
# model = model.to("cuda")
resampler = torchaudio.transforms.Resample(TEST_AUDIO_SR, 16_000)
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch)
speech = resampler(speech_array).squeeze().numpy()
return speech
speech_array = speech_file_to_array_fn("test_file.wav")
inputs = processor(speech_array, sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values).logits
predicted_ids = torch.argmax(logits, dim=-1)
preds = processor.batch_decode(predicted_ids)[0]
print(preds.replace("[PAD]",""))
```
**Test Result**: WER on ~4200 utterance : 32.45 %
|
nguyenvulebinh/vi-mrc-base
|
72baf191692f5be375838c9c4de59d6667af6231
|
2022-03-13T20:54:14.000Z
|
[
"pytorch",
"roberta",
"question-answering",
"vi",
"vn",
"en",
"dataset:squad",
"transformers",
"license:cc-by-nc-4.0",
"autotrain_compatible"
] |
question-answering
| false |
nguyenvulebinh
| null |
nguyenvulebinh/vi-mrc-base
| 448 | 3 |
transformers
| 2,444 |
---
language:
- vi
- vn
- en
tags:
- question-answering
- pytorch
datasets:
- squad
license: cc-by-nc-4.0
pipeline_tag: question-answering
metrics:
- squad
widget:
- text: "Bình là chuyên gia về gì ?"
context: "Bình Nguyễn là một người đam mê với lĩnh vực xử lý ngôn ngữ tự nhiên . Anh nhận chứng chỉ Google Developer Expert năm 2020"
- text: "Bình được công nhận với danh hiệu gì ?"
context: "Bình Nguyễn là một người đam mê với lĩnh vực xử lý ngôn ngữ tự nhiên . Anh nhận chứng chỉ Google Developer Expert năm 2020"
---
## Model Description
- Language model: [XLM-RoBERTa](https://huggingface.co/transformers/model_doc/xlmroberta.html)
- Fine-tune: [MRCQuestionAnswering](https://github.com/nguyenvulebinh/extractive-qa-mrc)
- Language: Vietnamese, Englsih
- Downstream-task: Extractive QA
- Dataset (combine English and Vietnamese):
- [Squad 2.0](https://rajpurkar.github.io/SQuAD-explorer/)
- [mailong25](https://github.com/mailong25/bert-vietnamese-question-answering/tree/master/dataset)
- [UIT-ViQuAD](https://www.aclweb.org/anthology/2020.coling-main.233/)
- [MultiLingual Question Answering](https://github.com/facebookresearch/MLQA)
This model is intended to be used for QA in the Vietnamese language so the valid set is Vietnamese only (but English works fine). The evaluation result below using 10% of the Vietnamese dataset.
| Model | EM | F1 |
| ------------- | ------------- | ------------- |
| [base](https://huggingface.co/nguyenvulebinh/vi-mrc-base) | 76.43 | 84.16 |
| [large](https://huggingface.co/nguyenvulebinh/vi-mrc-large) | 77.32 | 85.46 |
[MRCQuestionAnswering](https://github.com/nguyenvulebinh/extractive-qa-mrc) using [XLM-RoBERTa](https://huggingface.co/transformers/model_doc/xlmroberta.html) as a pre-trained language model. By default, XLM-RoBERTa will split word in to sub-words. But in my implementation, I re-combine sub-words representation (after encoded by BERT layer) into word representation using sum strategy.
## Using pre-trained model
[](https://colab.research.google.com/drive/1Yqgdfaca7L94OyQVnq5iQq8wRTFvVZjv?usp=sharing)
- Hugging Face pipeline style (**NOT using sum features strategy**).
```python
from transformers import pipeline
# model_checkpoint = "nguyenvulebinh/vi-mrc-large"
model_checkpoint = "nguyenvulebinh/vi-mrc-base"
nlp = pipeline('question-answering', model=model_checkpoint,
tokenizer=model_checkpoint)
QA_input = {
'question': "Bình là chuyên gia về gì ?",
'context': "Bình Nguyễn là một người đam mê với lĩnh vực xử lý ngôn ngữ tự nhiên . Anh nhận chứng chỉ Google Developer Expert năm 2020"
}
res = nlp(QA_input)
print('pipeline: {}'.format(res))
#{'score': 0.5782045125961304, 'start': 45, 'end': 68, 'answer': 'xử lý ngôn ngữ tự nhiên'}
```
- More accurate infer process ([**Using sum features strategy**](https://github.com/nguyenvulebinh/extractive-qa-mrc))
```python
from infer import tokenize_function, data_collator, extract_answer
from model.mrc_model import MRCQuestionAnswering
from transformers import AutoTokenizer
# model_checkpoint = "nguyenvulebinh/vi-mrc-large"
model_checkpoint = "nguyenvulebinh/vi-mrc-base"
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
model = MRCQuestionAnswering.from_pretrained(model_checkpoint)
QA_input = {
'question': "Bình được công nhận với danh hiệu gì ?",
'context': "Bình Nguyễn là một người đam mê với lĩnh vực xử lý ngôn ngữ tự nhiên . Anh nhận chứng chỉ Google Developer Expert năm 2020"
}
inputs = [tokenize_function(*QA_input)]
inputs_ids = data_collator(inputs)
outputs = model(**inputs_ids)
answer = extract_answer(inputs, outputs, tokenizer)
print(answer)
# answer: Google Developer Expert. Score start: 0.9926977753639221, Score end: 0.9909810423851013
```
## About
*Built by Binh Nguyen*
[](https://twitter.com/intent/follow?screen_name=nguyenvulebinh)
For more details, visit the project repository.
[](https://github.com/nguyenvulebinh/extractive-qa-mrc)
|
pysentimiento/bertweet-hate-speech
|
8913cd6a2515f3e033c3b097f68d3bfb41079c54
|
2021-12-05T15:13:53.000Z
|
[
"pytorch",
"roberta",
"text-classification",
"en",
"arxiv:2106.09462",
"transformers",
"twitter",
"hate-speech"
] |
text-classification
| false |
pysentimiento
| null |
pysentimiento/bertweet-hate-speech
| 448 | 1 |
transformers
| 2,445 |
---
language:
- en
tags:
- twitter
- hate-speech
---
# Hate Speech detection in Spanish
## robertuito-hate-speech
Repository: [https://github.com/pysentimiento/pysentimiento/](https://github.com/finiteautomata/pysentimiento/)
Model trained with SemEval 2019 Task 5: HatEval (SubTask B) corpus for Hate Speech detection in English. Base model is [BERTweet](https://huggingface.co/vinai/bertweet-base), a RoBERTa model trained in English tweets.
It is a multi-classifier model, with the following classes:
- **HS**: is it hate speech?
- **TR**: is it targeted to a specific individual?
- **AG**: is it aggressive?
## License
`pysentimiento` is an open-source library for non-commercial use and scientific research purposes only. Please be aware that models are trained with third-party datasets and are subject to their respective licenses.
1. [TASS Dataset license](http://tass.sepln.org/tass_data/download.php)
2. [SEMEval 2017 Dataset license]()
## Citation
If you use `pysentimiento` in your work, please cite [this paper](https://arxiv.org/abs/2106.09462)
```
@misc{perez2021pysentimiento,
title={pysentimiento: A Python Toolkit for Sentiment Analysis and SocialNLP tasks},
author={Juan Manuel Pérez and Juan Carlos Giudici and Franco Luque},
year={2021},
eprint={2106.09462},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
Enjoy! 🤗
|
Helsinki-NLP/opus-mt-ga-en
|
4497dea247606effb578b6c45a4e40d670e84bc9
|
2021-01-18T08:50:12.000Z
|
[
"pytorch",
"marian",
"text2text-generation",
"ga",
"en",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] |
translation
| false |
Helsinki-NLP
| null |
Helsinki-NLP/opus-mt-ga-en
| 447 | null |
transformers
| 2,446 |
---
language:
- ga
- en
tags:
- translation
license: apache-2.0
---
### gle-eng
* source group: Irish
* target group: English
* OPUS readme: [gle-eng](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/gle-eng/README.md)
* model: transformer-align
* source language(s): gle
* target language(s): eng
* model: transformer-align
* pre-processing: normalization + SentencePiece (spm32k,spm32k)
* download original weights: [opus-2020-06-17.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/gle-eng/opus-2020-06-17.zip)
* test set translations: [opus-2020-06-17.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/gle-eng/opus-2020-06-17.test.txt)
* test set scores: [opus-2020-06-17.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/gle-eng/opus-2020-06-17.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba-test.gle.eng | 51.6 | 0.672 |
### System Info:
- hf_name: gle-eng
- source_languages: gle
- target_languages: eng
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/gle-eng/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['ga', 'en']
- src_constituents: {'gle'}
- tgt_constituents: {'eng'}
- src_multilingual: False
- tgt_multilingual: False
- prepro: normalization + SentencePiece (spm32k,spm32k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/gle-eng/opus-2020-06-17.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/gle-eng/opus-2020-06-17.test.txt
- src_alpha3: gle
- tgt_alpha3: eng
- short_pair: ga-en
- chrF2_score: 0.672
- bleu: 51.6
- brevity_penalty: 1.0
- ref_len: 11247.0
- src_name: Irish
- tgt_name: English
- train_date: 2020-06-17
- src_alpha2: ga
- tgt_alpha2: en
- prefer_old: False
- long_pair: gle-eng
- helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535
- transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b
- port_machine: brutasse
- port_time: 2020-08-21-14:41
|
dbddv01/gpt2-french-small
|
66ffadbe0b789cc90040f7b3b801c3999270e272
|
2021-05-21T15:25:05.000Z
|
[
"pytorch",
"jax",
"gpt2",
"text-generation",
"fr",
"transformers",
"french",
"model"
] |
text-generation
| false |
dbddv01
| null |
dbddv01/gpt2-french-small
| 447 | 2 |
transformers
| 2,447 |
---
language: "fr"
tags:
- french
- gpt2
- model
---
A small french language model for french text generation (and possibly more NLP tasks...)
**Introduction**
This french gpt2 model is based on openai GPT-2 small model.
It was trained on a <b>very small (190Mb) dataset </b> from french wikipedia using Transfer Learning and Fine-tuning techniques in just over a day, on one Colab pro with 1GPU 16GB.
It was created applying the recept of <b>Pierre Guillou</b>
See https://medium.com/@pierre_guillou/faster-than-training-from-scratch-fine-tuning-the-english-gpt-2-in-any-language-with-hugging-f2ec05c98787
It is a proof-of-concept that makes possible to get a language model in any language with low ressources.
It was fine-tuned from the English pre-trained GPT-2 small using the Hugging Face libraries (Transformers and Tokenizers) wrapped into the fastai v2 Deep Learning framework. All the fine-tuning fastai v2 techniques were used.
It is now available on Hugging Face. For further information or requests, please go to "Faster than training from scratch — Fine-tuning the English GPT-2 in any language with Hugging Face and fastai v2 (practical case with Portuguese)".
Model migth be improved by using larger dataset under larger powerful training infrastructure. At least this one can be used for small finetuning experimentation (i.e with aitextgen).
PS : I've lost the metrics but it speaks french with some minor grammar issues, coherence of text is somehow limited.
|
dspoka/units-gen-d-u
|
1206e1a403b6156d8584aa8db3cb97090c77bc8d
|
2021-11-25T10:11:55.000Z
|
[
"pytorch",
"roberta",
"transformers"
] | null | false |
dspoka
| null |
dspoka/units-gen-d-u
| 447 | null |
transformers
| 2,448 |
Entry not found
|
facebook/wav2vec2-xls-r-2b-22-to-16
|
402bde655039c16f485f74897a63eeba8c3e02c6
|
2022-05-26T22:23:54.000Z
|
[
"pytorch",
"speech-encoder-decoder",
"automatic-speech-recognition",
"multilingual",
"fr",
"de",
"es",
"ca",
"it",
"ru",
"zh",
"pt",
"fa",
"et",
"mn",
"nl",
"tr",
"ar",
"sv",
"lv",
"sl",
"ta",
"ja",
"id",
"cy",
"en",
"dataset:common_voice",
"dataset:multilingual_librispeech",
"dataset:covost2",
"transformers",
"speech",
"xls_r",
"xls_r_translation",
"license:apache-2.0"
] |
automatic-speech-recognition
| false |
facebook
| null |
facebook/wav2vec2-xls-r-2b-22-to-16
| 447 | 9 |
transformers
| 2,449 |
---
language:
- multilingual
- fr
- de
- es
- ca
- it
- ru
- zh
- pt
- fa
- et
- mn
- nl
- tr
- ar
- sv
- lv
- sl
- ta
- ja
- id
- cy
- en
datasets:
- common_voice
- multilingual_librispeech
- covost2
tags:
- speech
- xls_r
- automatic-speech-recognition
- xls_r_translation
pipeline_tag: automatic-speech-recognition
license: apache-2.0
widget:
- example_title: Swedish
src: https://cdn-media.huggingface.co/speech_samples/cv_swedish_1.mp3
- example_title: Arabic
src: https://cdn-media.huggingface.co/speech_samples/common_voice_ar_19058308.mp3
- example_title: Russian
src: https://cdn-media.huggingface.co/speech_samples/common_voice_ru_18849022.mp3
- example_title: German
src: https://cdn-media.huggingface.co/speech_samples/common_voice_de_17284683.mp3
- example_title: French
src: https://cdn-media.huggingface.co/speech_samples/common_voice_fr_17299386.mp3
- example_title: Indonesian
src: https://cdn-media.huggingface.co/speech_samples/common_voice_id_19051309.mp3
- example_title: Italian
src: https://cdn-media.huggingface.co/speech_samples/common_voice_it_17415776.mp3
- example_title: Japanese
src: https://cdn-media.huggingface.co/speech_samples/common_voice_ja_19482488.mp3
- example_title: Mongolian
src: https://cdn-media.huggingface.co/speech_samples/common_voice_mn_18565396.mp3
- example_title: Dutch
src: https://cdn-media.huggingface.co/speech_samples/common_voice_nl_17691471.mp3
- example_title: Russian
src: https://cdn-media.huggingface.co/speech_samples/common_voice_ru_18849022.mp3
- example_title: Turkish
src: https://cdn-media.huggingface.co/speech_samples/common_voice_tr_17341280.mp3
- example_title: Catalan
src: https://cdn-media.huggingface.co/speech_samples/common_voice_ca_17367522.mp3
- example_title: English
src: https://cdn-media.huggingface.co/speech_samples/common_voice_en_18301577.mp3
- example_title: Dutch
src: https://cdn-media.huggingface.co/speech_samples/common_voice_nl_17691471.mp3
---
# Wav2Vec2-XLS-R-2B-22-16 (XLS-R-Any-to-Any)
Facebook's Wav2Vec2 XLS-R fine-tuned for **Speech Translation.**

This is a [SpeechEncoderDecoderModel](https://huggingface.co/transformers/model_doc/speechencoderdecoder.html) model.
The encoder was warm-started from the [**`facebook/wav2vec2-xls-r-2b`**](https://huggingface.co/facebook/wav2vec2-xls-r-2b) checkpoint and
the decoder from the [**`facebook/mbart-large-50`**](https://huggingface.co/facebook/mbart-large-50) checkpoint.
Consequently, the encoder-decoder model was fine-tuned on `{input_lang}` -> `{output_lang}` translation pairs
of the [Covost2 dataset](https://huggingface.co/datasets/covost2).
The model can translate from the following spoken languages `{input_lang}` to the following written languages `{output_lang}`:
`{input_lang}` -> `{output_lang}`
with `{input_lang}` one of:
{`en`, `fr`, `de`, `es`, `ca`, `it`, `ru`, `zh-CN`, `pt`, `fa`, `et`, `mn`, `nl`, `tr`, `ar`, `sv-SE`, `lv`, `sl`, `ta`, `ja`, `id`, `cy`}
and `{output_lang}`:
{`en`, `de`, `tr`, `fa`, `sv-SE`, `mn`, `zh-CN`, `cy`, `ca`, `sl`, `et`, `id`, `ar`, `ta`, `lv`, `ja`}
## Usage
### Demo
The model can be tested on [**this space**](https://huggingface.co/spaces/facebook/XLS-R-2B-22-16).
You can select the target language, record some audio in any of the above mentioned input languages,
and then sit back and see how well the checkpoint can translate the input.
### Example
As this a standard sequence to sequence transformer model, you can use the `generate` method to generate the
transcripts by passing the speech features to the model.
You can use the model directly via the ASR pipeline. By default, the checkpoint will
translate spoken English to written German. To change the written target language,
you need to pass the correct `forced_bos_token_id` to `generate(...)` to condition
the decoder on the correct target language.
To select the correct `forced_bos_token_id` given your choosen language id, please make use
of the following mapping:
```python
MAPPING = {
"en": 250004,
"de": 250003,
"tr": 250023,
"fa": 250029,
"sv": 250042,
"mn": 250037,
"zh": 250025,
"cy": 250007,
"ca": 250005,
"sl": 250052,
"et": 250006,
"id": 250032,
"ar": 250001,
"ta": 250044,
"lv": 250017,
"ja": 250012,
}
```
As an example, if you would like to translate to Swedish, you can do the following:
```python
from datasets import load_dataset
from transformers import pipeline
# select correct `forced_bos_token_id`
forced_bos_token_id = MAPPING["sv"]
# replace following lines to load an audio file of your choice
librispeech_en = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
audio_file = librispeech_en[0]["file"]
asr = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-xls-r-2b-22-to-16", feature_extractor="facebook/wav2vec2-xls-r-2b-22-to-16")
translation = asr(audio_file, forced_bos_token_id=forced_bos_token_id)
```
or step-by-step as follows:
```python
import torch
from transformers import Speech2Text2Processor, SpeechEncoderDecoderModel
from datasets import load_dataset
model = SpeechEncoderDecoderModel.from_pretrained("facebook/wav2vec2-xls-r-2b-22-to-16")
processor = Speech2Text2Processor.from_pretrained("facebook/wav2vec2-xls-r-2b-22-to-16")
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
# select correct `forced_bos_token_id`
forced_bos_token_id = MAPPING["sv"]
inputs = processor(ds[0]["audio"]["array"], sampling_rate=ds[0]["audio"]["array"]["sampling_rate"], return_tensors="pt")
generated_ids = model.generate(input_ids=inputs["input_features"], attention_mask=inputs["attention_mask"], forced_bos_token_id=forced_bos_token)
transcription = processor.batch_decode(generated_ids)
```
## More XLS-R models for `{lang}` -> `en` Speech Translation
- [Wav2Vec2-XLS-R-300M-EN-15](https://huggingface.co/facebook/wav2vec2-xls-r-300m-en-to-15)
- [Wav2Vec2-XLS-R-1B-EN-15](https://huggingface.co/facebook/wav2vec2-xls-r-1b-en-to-15)
- [Wav2Vec2-XLS-R-2B-EN-15](https://huggingface.co/facebook/wav2vec2-xls-r-2b-en-to-15)
- [Wav2Vec2-XLS-R-2B-22-16](https://huggingface.co/facebook/wav2vec2-xls-r-2b-22-to-16)
|
ian0delond/model-test
|
548ed19c3fdb1e0ca76cc5e7489aa0ffb1d50321
|
2022-06-30T20:51:38.000Z
|
[
"pytorch",
"tensorboard",
"camembert",
"fill-mask",
"transformers",
"generated_from_trainer",
"model-index",
"autotrain_compatible"
] |
fill-mask
| false |
ian0delond
| null |
ian0delond/model-test
| 447 | null |
transformers
| 2,450 |
---
tags:
- generated_from_trainer
model-index:
- name: model-test
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# model-test
This model is a fine-tuned version of [camembert/camembert-large](https://huggingface.co/camembert/camembert-large) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.7869
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 113 | 2.9638 |
| No log | 2.0 | 226 | 2.8266 |
| 3.1496 | 3.0 | 339 | 2.7721 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.10.0+cu111
- Datasets 2.1.0
- Tokenizers 0.12.1
|
camembert/camembert-base-ccnet
|
135373bcc71a3b85030c8880b683b5058943f93f
|
2020-12-11T21:35:15.000Z
|
[
"pytorch",
"camembert",
"fr",
"arxiv:1911.03894",
"transformers"
] | null | false |
camembert
| null |
camembert/camembert-base-ccnet
| 446 | null |
transformers
| 2,451 |
---
language: fr
---
# CamemBERT: a Tasty French Language Model
## Introduction
[CamemBERT](https://arxiv.org/abs/1911.03894) is a state-of-the-art language model for French based on the RoBERTa model.
It is now available on Hugging Face in 6 different versions with varying number of parameters, amount of pretraining data and pretraining data source domains.
For further information or requests, please go to [Camembert Website](https://camembert-model.fr/)
## Pre-trained models
| Model | #params | Arch. | Training data |
|--------------------------------|--------------------------------|-------|-----------------------------------|
| `camembert-base` | 110M | Base | OSCAR (138 GB of text) |
| `camembert/camembert-large` | 335M | Large | CCNet (135 GB of text) |
| `camembert/camembert-base-ccnet` | 110M | Base | CCNet (135 GB of text) |
| `camembert/camembert-base-wikipedia-4gb` | 110M | Base | Wikipedia (4 GB of text) |
| `camembert/camembert-base-oscar-4gb` | 110M | Base | Subsample of OSCAR (4 GB of text) |
| `camembert/camembert-base-ccnet-4gb` | 110M | Base | Subsample of CCNet (4 GB of text) |
## How to use CamemBERT with HuggingFace
##### Load CamemBERT and its sub-word tokenizer :
```python
from transformers import CamembertModel, CamembertTokenizer
# You can replace "camembert-base" with any other model from the table, e.g. "camembert/camembert-large".
tokenizer = CamembertTokenizer.from_pretrained("camembert/camembert-base-ccnet")
camembert = CamembertModel.from_pretrained("camembert/camembert-base-ccnet")
camembert.eval() # disable dropout (or leave in train mode to finetune)
```
##### Filling masks using pipeline
```python
from transformers import pipeline
camembert_fill_mask = pipeline("fill-mask", model="camembert/camembert-base-ccnet", tokenizer="camembert/camembert-base-ccnet")
results = camembert_fill_mask("Le camembert est <mask> :)")
# results
#[{'sequence': '<s> Le camembert est bon :)</s>', 'score': 0.14011502265930176, 'token': 305},
# {'sequence': '<s> Le camembert est délicieux :)</s>', 'score': 0.13929404318332672, 'token': 11661},
# {'sequence': '<s> Le camembert est excellent :)</s>', 'score': 0.07010319083929062, 'token': 3497},
# {'sequence': '<s> Le camembert est parfait :)</s>', 'score': 0.025885622948408127, 'token': 2528},
# {'sequence': '<s> Le camembert est top :)</s>', 'score': 0.025684962049126625, 'token': 2328}]
```
##### Extract contextual embedding features from Camembert output
```python
import torch
# Tokenize in sub-words with SentencePiece
tokenized_sentence = tokenizer.tokenize("J'aime le camembert !")
# ['▁J', "'", 'aime', '▁le', '▁cam', 'ember', 't', '▁!']
# 1-hot encode and add special starting and end tokens
encoded_sentence = tokenizer.encode(tokenized_sentence)
# [5, 133, 22, 1250, 16, 12034, 14324, 81, 76, 6]
# NB: Can be done in one step : tokenize.encode("J'aime le camembert !")
# Feed tokens to Camembert as a torch tensor (batch dim 1)
encoded_sentence = torch.tensor(encoded_sentence).unsqueeze(0)
embeddings, _ = camembert(encoded_sentence)
# embeddings.detach()
# embeddings.size torch.Size([1, 10, 768])
#tensor([[[ 0.0667, -0.2467, 0.0954, ..., 0.2144, 0.0279, 0.3621],
# [-0.0472, 0.4092, -0.6602, ..., 0.2095, 0.1391, -0.0401],
# [ 0.1911, -0.2347, -0.0811, ..., 0.4306, -0.0639, 0.1821],
# ...,
```
##### Extract contextual embedding features from all Camembert layers
```python
from transformers import CamembertConfig
# (Need to reload the model with new config)
config = CamembertConfig.from_pretrained("camembert/camembert-base-ccnet", output_hidden_states=True)
camembert = CamembertModel.from_pretrained("camembert/camembert-base-ccnet", config=config)
embeddings, _, all_layer_embeddings = camembert(encoded_sentence)
# all_layer_embeddings list of len(all_layer_embeddings) == 13 (input embedding layer + 12 self attention layers)
all_layer_embeddings[5]
# layer 5 contextual embedding : size torch.Size([1, 10, 768])
#tensor([[[ 0.0057, -0.1022, 0.0163, ..., -0.0675, -0.0360, 0.1078],
# [-0.1096, -0.3344, -0.0593, ..., 0.1625, -0.0432, -0.1646],
# [ 0.3751, -0.3829, 0.0844, ..., 0.1067, -0.0330, 0.3334],
# ...,
```
## Authors
CamemBERT was trained and evaluated by Louis Martin\*, Benjamin Muller\*, Pedro Javier Ortiz Suárez\*, Yoann Dupont, Laurent Romary, Éric Villemonte de la Clergerie, Djamé Seddah and Benoît Sagot.
## Citation
If you use our work, please cite:
```bibtex
@inproceedings{martin2020camembert,
title={CamemBERT: a Tasty French Language Model},
author={Martin, Louis and Muller, Benjamin and Su{\'a}rez, Pedro Javier Ortiz and Dupont, Yoann and Romary, Laurent and de la Clergerie, {\'E}ric Villemonte and Seddah, Djam{\'e} and Sagot, Beno{\^\i}t},
booktitle={Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics},
year={2020}
}
```
|
nateraw/food
|
8991abd49ea01ebf502aeda51d4f12a59c603e01
|
2022-05-17T17:44:24.000Z
|
[
"pytorch",
"tensorboard",
"vit",
"image-classification",
"dataset:food101",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] |
image-classification
| false |
nateraw
| null |
nateraw/food
| 445 | 1 |
transformers
| 2,452 |
---
license: apache-2.0
tags:
- generated_from_trainer
- image-classification
- pytorch
datasets:
- food101
metrics:
- accuracy
model-index:
- name: food101_outputs
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: food-101
type: food101
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.8912871287128713
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# nateraw/food
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the nateraw/food101 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4501
- Accuracy: 0.8913
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 128
- eval_batch_size: 128
- seed: 1337
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.8271 | 1.0 | 592 | 0.6070 | 0.8562 |
| 0.4376 | 2.0 | 1184 | 0.4947 | 0.8691 |
| 0.2089 | 3.0 | 1776 | 0.4876 | 0.8747 |
| 0.0882 | 4.0 | 2368 | 0.4639 | 0.8857 |
| 0.0452 | 5.0 | 2960 | 0.4501 | 0.8913 |
### Framework versions
- Transformers 4.9.0.dev0
- Pytorch 1.9.0+cu102
- Datasets 1.9.1.dev0
- Tokenizers 0.10.3
|
doc2query/all-with_prefix-t5-base-v1
|
453aa7323e8efa07ef1d48af9e2285391285f8a0
|
2021-10-19T12:52:47.000Z
|
[
"pytorch",
"t5",
"text2text-generation",
"en",
"dataset:sentence-transformers/reddit-title-body",
"dataset:sentence-transformers/embedding-training-data",
"arxiv:1904.08375",
"arxiv:2104.08663",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] |
text2text-generation
| false |
doc2query
| null |
doc2query/all-with_prefix-t5-base-v1
| 444 | 1 |
transformers
| 2,453 |
---
language: en
datasets:
- sentence-transformers/reddit-title-body
- sentence-transformers/embedding-training-data
widget:
- text: "text2reddit: Python is an interpreted, high-level and general-purpose programming language. Python's design philosophy emphasizes code readability with its notable use of significant whitespace. Its language constructs and object-oriented approach aim to help programmers write clear, logical code for small and large-scale projects."
license: apache-2.0
---
# doc2query/all-with_prefix-t5-base-v1
This is a [doc2query](https://arxiv.org/abs/1904.08375) model based on T5 (also known as [docT5query](https://cs.uwaterloo.ca/~jimmylin/publications/Nogueira_Lin_2019_docTTTTTquery-v2.pdf)).
It can be used for:
- **Document expansion**: You generate for your paragraphs 20-40 queries and index the paragraphs and the generates queries in a standard BM25 index like Elasticsearch, OpenSearch, or Lucene. The generated queries help to close the lexical gap of lexical search, as the generate queries contain synonyms. Further, it re-weights words giving important words a higher weight even if they appear seldomn in a paragraph. In our [BEIR](https://arxiv.org/abs/2104.08663) paper we showed that BM25+docT5query is a powerful search engine. In the [BEIR repository](https://github.com/UKPLab/beir) we have an example how to use docT5query with Pyserini.
- **Domain Specific Training Data Generation**: It can be used to generate training data to learn an embedding model. On [SBERT.net](https://www.sbert.net/examples/unsupervised_learning/query_generation/README.html) we have an example how to use the model to generate (query, text) pairs for a given collection of unlabeled texts. These pairs can then be used to train powerful dense embedding models.
## Usage
```python
from transformers import T5Tokenizer, T5ForConditionalGeneration
model_name = 'doc2query/all-with_prefix-t5-base-v1'
tokenizer = T5Tokenizer.from_pretrained(model_name)
model = T5ForConditionalGeneration.from_pretrained(model_name)
prefix = "answer2question"
text = "Python is an interpreted, high-level and general-purpose programming language. Python's design philosophy emphasizes code readability with its notable use of significant whitespace. Its language constructs and object-oriented approach aim to help programmers write clear, logical code for small and large-scale projects."
text = prefix+": "+text
input_ids = tokenizer.encode(text, max_length=384, truncation=True, return_tensors='pt')
outputs = model.generate(
input_ids=input_ids,
max_length=64,
do_sample=True,
top_p=0.95,
num_return_sequences=5)
print("Text:")
print(text)
print("\nGenerated Queries:")
for i in range(len(outputs)):
query = tokenizer.decode(outputs[i], skip_special_tokens=True)
print(f'{i + 1}: {query}')
```
**Note:** `model.generate()` is non-deterministic. It produces different queries each time you run it.
## Training
This model fine-tuned [google/t5-v1_1-base](https://huggingface.co/google/t5-v1_1-base) for 575k training steps. For the training script, see the `train_script.py` in this repository.
The input-text was truncated to 384 word pieces. Output text was generated up to 64 word pieces.
This model was trained on a large collection of datasets. For the exact datasets names and weights see the `data_config.json` in this repository. Most of the datasets are available at [https://huggingface.co/sentence-transformers](https://huggingface.co/sentence-transformers).
The datasets include besides others:
- (title, body) pairs from [Reddit](https://huggingface.co/datasets/sentence-transformers/reddit-title-body)
- (title, body) pairs and (title, answer) pairs from StackExchange and Yahoo Answers!
- (title, review) pairs from Amazon reviews
- (query, paragraph) pairs from MS MARCO, NQ, and GooAQ
- (question, duplicate_question) from Quora and WikiAnswers
- (title, abstract) pairs from S2ORC
## Prefix
This model was trained **with a prefix**: You start the text with a specific index that defines what type out output text you would like to receive. Depending on the prefix, the output is different.
E.g. the above text about Python produces the following output:
| Prefix | Output |
| --- | --- |
| answer2question | Why should I use python in my business? ; What is the difference between Python and.NET? ; what is the python design philosophy? |
| review2title | Python a powerful and useful language ; A new and improved programming language ; Object-oriented, practical and accessibl |
| abstract2title | Python: A Software Development Platform ; A Research Guide for Python X: Conceptual Approach to Programming ; Python : Language and Approach |
| text2query | is python a low level language? ; what is the primary idea of python? ; is python a programming language? |
These are all available pre-fixes:
- text2reddit
- question2title
- answer2question
- abstract2title
- review2title
- news2title
- text2query
- question2question
For the datasets and weights for the different pre-fixes see `data_config.json` in this repository.
|
gorkemgoknar/gpt2chatbotenglish
|
d18684a4d566c2e7f2acdd164415bd7533e8290d
|
2021-11-22T11:13:11.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"en",
"transformers",
"conversational",
"license:cc-by-4.0"
] |
conversational
| false |
gorkemgoknar
| null |
gorkemgoknar/gpt2chatbotenglish
| 444 | 2 |
transformers
| 2,454 |
---
language:
- en
thumbnail:
tags:
- gpt2
- conversational
license: cc-by-4.0
widget:
- text: Hello there
context: 'Gandalf'
---
# GPT2 Persona Chatbot based on Movie Characters
Model used for https://www.metayazar.com/chatbot
GPT2 Small Trained on movie scripts (especially Sci-fi)
Usual HF api will not work see HF Spaces for demo usage https://huggingface.co/spaces/gorkemgoknar/moviechatbot
This work is based on Persona Chatbot originally done by Hugging Face team (https://medium.com/huggingface/how-to-build-a-state-of-the-art-conversational-ai-with-transfer-learning-2d818ac26313)
For cleaning movie scripts I also provide cleaner code
https://github.com/gorkemgoknar/moviescriptcleaner
Example persona how to:
https://gist.github.com/gorkemgoknar/ae29bf9d14fa814e6a64d0e57a4a4ed7
For obvious reasons I cannot share raw personafile but you can check above gist for example how to create it.
A working "full" demo can be seen in https://www.metayazar.com/chatbot
For Turkish version (with limited training) https://www.metayazar.com/chatbot_tr
Due to double LM head standart hugging face interface will not work. But if you follow huggingface tutorial should be same.
Except each persona is encoded as "My name is XXXX"
Use model, tokenizer and parameters within a class and call in below functions to trigger model.
Some of the available personas:
| Macleod | Moran | Brenda | Ramirez | Peter Parker | Quentin Beck | Andy
| Red | Norton | Willard | Chief | Chef | Kilgore | Kurtz | Westley | Buttercup
| Vizzini | Fezzik | Inigo | Man In Black | Taylor | Zira | Zaius | Cornelius
| Bud | Lindsey | Hippy | Erin | Ed | George | Donna | Trinity | Agent Smith
| Morpheus | Neo | Tank | Meryl | Truman | Marlon | Christof | Stromboli | Bumstead
| Schreber | Walker | Korben | Cornelius | Loc Rhod | Anakin | Obi-Wan | Palpatine
| Padme | Superman | Luthor | Dude | Walter | Donny | Maude | General | Starkiller
| Indiana | Willie | Short Round | John | Sarah | Terminator | Miller | Sarge | Reiben
| Jackson | Upham | Chuckie | Will | Lambeau | Sean | Skylar | Saavik | Spock
| Kirk | Bones | Khan | Kirk | Spock | Sybok | Scotty | Bourne | Pamela | Abbott
```python
def get_answer(self, input_text, personality, history, params=None):
##Check length of history (to save 1 computation!)
if len(history)>0:
#mostly it will be empty list so need a length check for performance
#would do string check also but just assume it is list of list of strings, as not public
new_hist = []
for ele in history:
new_hist.append( self.tokenizer.encode(ele) )
history = new_hist.copy()
history.append(self.tokenizer.encode(input_text))
with torch.no_grad():
out_ids = self.sample_sequence(personality, history, self.tokenizer, self.model, params=params)
history.append(out_ids)
history = history[-(2*self.parameters['max_history']+1):]
out_text = self.tokenizer.decode(out_ids, skip_special_tokens=True)
#print(out_text)
history_decoded = []
for ele in history:
history_decoded.append(self.tokenizer.decode(ele))
return out_text, history_decoded, self.parameters
```
|
l-yohai/bigbird-roberta-base-mnli
|
36bf0e91ade84c3510ffc96e3a0b6b0f2df5d746
|
2022-02-07T09:16:09.000Z
|
[
"pytorch",
"big_bird",
"text-classification",
"transformers"
] |
text-classification
| false |
l-yohai
| null |
l-yohai/bigbird-roberta-base-mnli
| 443 | null |
transformers
| 2,455 |
Entry not found
|
Muennighoff/SGPT-125M-weightedmean-msmarco-specb-bitfit
|
1e82af08d6d871242572f6a18d643d0d1069782a
|
2022-06-18T20:45:44.000Z
|
[
"pytorch",
"gpt_neo",
"feature-extraction",
"arxiv:2202.08904",
"sentence-transformers",
"sentence-similarity"
] |
sentence-similarity
| false |
Muennighoff
| null |
Muennighoff/SGPT-125M-weightedmean-msmarco-specb-bitfit
| 442 | null |
sentence-transformers
| 2,456 |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
---
# SGPT-125M-weightedmean-msmarco-specb-bitfit
## Usage
For usage instructions, refer to our codebase: https://github.com/Muennighoff/sgpt
## Evaluation Results
For eval results, refer to the eval folder or our paper: https://arxiv.org/abs/2202.08904
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 15600 with parameters:
```
{'batch_size': 32, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.MultipleNegativesRankingLoss.MultipleNegativesRankingLoss` with parameters:
```
{'scale': 20.0, 'similarity_fct': 'cos_sim'}
```
Parameters of the fit()-Method:
```
{
"epochs": 10,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'transformers.optimization.AdamW'>",
"optimizer_params": {
"lr": 0.0002
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 1000,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 300, 'do_lower_case': False}) with Transformer model: GPTNeoModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': True, 'pooling_mode_lasttoken': False})
)
```
## Citing & Authors
```bibtex
@article{muennighoff2022sgpt,
title={SGPT: GPT Sentence Embeddings for Semantic Search},
author={Muennighoff, Niklas},
journal={arXiv preprint arXiv:2202.08904},
year={2022}
}
```
|
ValkyriaLenneth/longformer_zh
|
87c8e565be16e9644f7c6ef818a554ce1ceeabbe
|
2022-01-06T03:50:20.000Z
|
[
"pytorch",
"longformer",
"feature-extraction",
"transformers"
] |
feature-extraction
| false |
ValkyriaLenneth
| null |
ValkyriaLenneth/longformer_zh
| 442 | 1 |
transformers
| 2,457 |
# 中文预训练Longformer模型 | Longformer_ZH with PyTorch
相比于Transformer的O(n^2)复杂度,Longformer提供了一种以线性复杂度处理最长4K字符级别文档序列的方法。Longformer Attention包括了标准的自注意力与全局注意力机制,方便模型更好地学习超长序列的信息。
Compared with O(n^2) complexity for Transformer model, Longformer provides an efficient method for processing long-document level sequence in Linear complexity. Longformer’s attention mechanism is a drop-in replacement for the standard self-attention and combines a local windowed attention with a task motivated global attention.
我们注意到关于中文Longformer或超长序列任务的资源较少,因此在此开源了我们预训练的中文Longformer模型参数, 并提供了相应的加载方法,以及预训练脚本。
There are not so much resource for Chinese Longformer or long-sequence-level chinese task. Thus we open source our pretrained longformer model to help the researchers.
## 加载模型 | Load the model
您可以使用谷歌云盘或百度网盘下载我们的模型
You could get Longformer_zh from Google Drive or Baidu Yun.
- Google Drive: https://drive.google.com/file/d/1IDJ4aVTfSFUQLIqCYBtoRpnfbgHPoxB4/view?usp=sharing
- 百度云: 链接:https://pan.baidu.com/s/1HaVDENx52I7ryPFpnQmq1w 提取码:y601
我们同样提供了Huggingface的自动下载
We also provide auto load with HuggingFace.Transformers.
```
from Longformer_zh import LongformerZhForMaksedLM
LongformerZhForMaksedLM.from_pretrained('ValkyriaLenneth/longformer_zh')
```
## 注意事项 | Notice
- 直接使用 `transformers.LongformerModel.from_pretrained` 加载模型
- Please use `transformers.LongformerModel.from_pretrained` to load the model directly
- 以下内容已经被弃用
- The following notices are abondoned, please ignore them.
- 区别于英文原版Longformer, 中文Longformer的基础是Roberta_zh模型,其本质上属于 `Transformers.BertModel` 而非 `RobertaModel`, 因此无法使用原版代码直接加载。
- Different with origin English Longformer, Longformer_Zh is based on Roberta_zh which is a subclass of `Transformers.BertModel` not `RobertaModel`. Thus it is impossible to load it with origin code.
- 我们提供了修改后的中文Longformer文件,您可以使用其加载参数。
- We provide modified Longformer_zh class, you can use it directly to load the model.
- 如果您想将此参数用于更多任务,请参考`Longformer_zh.py`替换Attention Layer.
- If you want to use our model on more down-stream tasks, please refer to `Longformer_zh.py` and replace Attention layer with Longformer Attention layer.
## 关于预训练 | About Pretraining
- 我们的预训练语料来自 https://github.com/brightmart/nlp_chinese_corpus, 根据Longformer原文的设置,采用了多种语料混合的预训练数据。
- The corpus of pretraining is from https://github.com/brightmart/nlp_chinese_corpus. Based on the paper of Longformer, we use a mixture of 4 different chinese corpus for pretraining.
- 我们的模型是基于Roberta_zh_mid (https://github.com/brightmart/roberta_zh),训练脚本参考了https://github.com/allenai/longformer/blob/master/scripts/convert_model_to_long.ipynb
- The basement of our model is Roberta_zh_mid (https://github.com/brightmart/roberta_zh). Pretraining scripts is modified from https://github.com/allenai/longformer/blob/master/scripts/convert_model_to_long.ipynb.
- 同时我们在原版基础上,引入了 `Whole-Word-Masking` 机制,以便更好地适应中文特性。
- We introduce `Whole-Word-Masking` method into pretraining for better fitting Chinese language.
- `Whole-Word-Masking`代码改写自TensorFlow版本的Roberta_zh,据我们所知是第一个开源的Pytorch版本WWM.
- Our WWM scripts is refacted from Roberta_zh_Tensorflow, as far as we know, it is the first open source Whole-word-masking scripts in Pytorch.
- 模型 `max_seq_length = 4096`, 在 4 * Titan RTX 上预训练3K steps 大概用时4天。
- Max seuence length is 4096 and the pretraining took 4 days on 4 * Titan RTX.
- 我们使用了 `Nvidia.Apex` 引入了混合精度训练,以加速预训练。
- We use `Nvidia.Apex` to accelerate pretraining.
- 关于数据预处理, 我们采用 `Jieba` 分词与`JIONLP`进行数据清洗。
- We use `Jieba` Chinese tokenizer and `JIONLP` data cleaning.
- 更多细节可以参考我们的预训练脚本
- For more details, please check our pretraining scripts.
## 效果测试 | Evaluation
### CCF Sentiment Analysis
- 由于中文超长文本级别任务稀缺,我们采用了CCF-Sentiment-Analysis任务进行测试
- Since it is hard to acquire open-sourced long sequence level chinese NLP task, we use CCF-Sentiment-Analysis for evaluation.
|Model|Dev F|
|----|----|
|Bert|80.3|
|Bert-wwm-ext| 80.5|
|Roberta-mid|80.5|
|Roberta-large|81.25|
|Longformer_SC|79.37|
|Longformer_ZH|80.51|
### Pretraining BPC
- 我们提供了预训练BPC(bits-per-character), BPC越小,代表语言模型性能更优。可视作PPL.
- We also provide BPC scores of pretraining, the lower BPC score, the better performance Langugage Model has. You can also treat it as PPL.
|Model|BPC|
|---|---|
|Longformer before training| 14.78|
|Longformer after training| 3.10|
### CMRC(Chinese Machine Reading Comprehension)
|Model|F1|EM|
|---|---|---|
|Bert|85.87|64.90|
|Roberta|86.45|66.57|
|Longformer_zh|86.15|66.84|
### Chinese Coreference Resolution
|Model|Conll-F1|Precision|Recall|
|---|---|---|---|
|Bert|66.82|70.30|63.67|
|Roberta|67.77|69.28|66.32|
|Longformer_zh|67.81|70.13|65.64|
## 致谢
感谢东京工业大学 奥村·船越研究室 提供算力。
Thanks Okumula·Funakoshi Lab from Tokyo Institute of Technology who provides the devices and oppotunity for me to finish this project.
|
obi/deid_roberta_i2b2
|
0d64fa18019b1ba34322288881ad9031f2e3fdcc
|
2022-02-16T14:41:33.000Z
|
[
"pytorch",
"roberta",
"token-classification",
"english",
"dataset:I2B2",
"arxiv:1907.11692",
"transformers",
"deidentification",
"medical notes",
"ehr",
"phi",
"license:mit",
"autotrain_compatible"
] |
token-classification
| false |
obi
| null |
obi/deid_roberta_i2b2
| 442 | null |
transformers
| 2,458 |
---
language:
- english
thumbnail: "https://www.onebraveidea.org/wp-content/uploads/2019/07/OBI-Logo-Website.png"
tags:
- deidentification
- medical notes
- ehr
- phi
datasets:
- I2B2
metrics:
- F1
- Recall
- Precision
widget:
- text: "Physician Discharge Summary Admit date: 10/12/1982 Discharge date: 10/22/1982 Patient Information Jack Reacher, 54 y.o. male (DOB = 1/21/1928)."
- text: "Home Address: 123 Park Drive, San Diego, CA, 03245. Home Phone: 202-555-0199 (home)."
- text: "Hospital Care Team Service: Orthopedics Inpatient Attending: Roger C Kelly, MD Attending phys phone: (634)743-5135 Discharge Unit: HCS843 Primary Care Physician: Hassan V Kim, MD 512-832-5025."
license: mit
---
# Model Description
* A RoBERTa [[Liu et al., 2019]](https://arxiv.org/pdf/1907.11692.pdf) model fine-tuned for de-identification of medical notes.
* Sequence Labeling (token classification): The model was trained to predict protected health information (PHI/PII) entities (spans). A list of protected health information categories is given by [HIPAA](https://www.hhs.gov/hipaa/for-professionals/privacy/laws-regulations/index.html).
* A token can either be classified as non-PHI or as one of the 11 PHI types. Token predictions are aggregated to spans by making use of BILOU tagging.
* The PHI labels that were used for training and other details can be found here: [Annotation Guidelines](https://github.com/obi-ml-public/ehr_deidentification/blob/master/AnnotationGuidelines.md)
* More details on how to use this model, the format of data and other useful information is present in the GitHub repo: [Robust DeID](https://github.com/obi-ml-public/ehr_deidentification).
# How to use
* A demo on how the model works (using model predictions to de-identify a medical note) is on this space: [Medical-Note-Deidentification](https://huggingface.co/spaces/obi/Medical-Note-Deidentification).
* Steps on how this model can be used to run a forward pass can be found here: [Forward Pass](https://github.com/obi-ml-public/ehr_deidentification/tree/master/steps/forward_pass)
* In brief, the steps are:
* Sentencize (the model aggregates the sentences back to the note level) and tokenize the dataset.
* Use the predict function of this model to gather the predictions (i.e., predictions for each token).
* Additionally, the model predictions can be used to remove PHI from the original note/text.
# Dataset
* The I2B2 2014 [[Stubbs and Uzuner, 2015]](https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4978170/) dataset was used to train this model.
| | I2B2 | | I2B2 | |
| --------- | --------------------- | ---------- | -------------------- | ---------- |
| | TRAIN SET - 790 NOTES | | TEST SET - 514 NOTES | |
| PHI LABEL | COUNT | PERCENTAGE | COUNT | PERCENTAGE |
| DATE | 7502 | 43.69 | 4980 | 44.14 |
| STAFF | 3149 | 18.34 | 2004 | 17.76 |
| HOSP | 1437 | 8.37 | 875 | 7.76 |
| AGE | 1233 | 7.18 | 764 | 6.77 |
| LOC | 1206 | 7.02 | 856 | 7.59 |
| PATIENT | 1316 | 7.66 | 879 | 7.79 |
| PHONE | 317 | 1.85 | 217 | 1.92 |
| ID | 881 | 5.13 | 625 | 5.54 |
| PATORG | 124 | 0.72 | 82 | 0.73 |
| EMAIL | 4 | 0.02 | 1 | 0.01 |
| OTHERPHI | 2 | 0.01 | 0 | 0 |
| TOTAL | 17171 | 100 | 11283 | 100 |
# Training procedure
* Steps on how this model was trained can be found here: [Training](https://github.com/obi-ml-public/ehr_deidentification/tree/master/steps/train). The "model_name_or_path" was set to: "roberta-large".
* The dataset was sentencized with the en_core_sci_sm sentencizer from spacy.
* The dataset was then tokenized with a custom tokenizer built on top of the en_core_sci_sm tokenizer from spacy.
* For each sentence we added 32 tokens on the left (from previous sentences) and 32 tokens on the right (from the next sentences).
* The added tokens are not used for learning - i.e, the loss is not computed on these tokens - they are used as additional context.
* Each sequence contained a maximum of 128 tokens (including the 32 tokens added on). Longer sequences were split.
* The sentencized and tokenized dataset with the token level labels based on the BILOU notation was used to train the model.
* The model is fine-tuned from a pre-trained RoBERTa model.
* Training details:
* Input sequence length: 128
* Batch size: 32 (16 with 2 gradient accumulation steps)
* Optimizer: AdamW
* Learning rate: 5e-5
* Dropout: 0.1
## Results
# Questions?
Post a Github issue on the repo: [Robust DeID](https://github.com/obi-ml-public/ehr_deidentification).
|
apple/deeplabv3-mobilevit-small
|
531026df27bacb5e63f6d12c74915c799845b12c
|
2022-06-02T10:54:17.000Z
|
[
"pytorch",
"coreml",
"mobilevit",
"dataset:pascal-voc",
"arxiv:2110.02178",
"arxiv:1706.05587",
"transformers",
"vision",
"image-segmentation",
"license:other"
] |
image-segmentation
| false |
apple
| null |
apple/deeplabv3-mobilevit-small
| 442 | 3 |
transformers
| 2,459 |
---
license: other
tags:
- vision
- image-segmentation
datasets:
- pascal-voc
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/cat-2.jpg
example_title: Cat
---
# MobileViT + DeepLabV3 (small-sized model)
MobileViT model pre-trained on PASCAL VOC at resolution 512x512. It was introduced in [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer](https://arxiv.org/abs/2110.02178) by Sachin Mehta and Mohammad Rastegari, and first released in [this repository](https://github.com/apple/ml-cvnets). The license used is [Apple sample code license](https://github.com/apple/ml-cvnets/blob/main/LICENSE).
Disclaimer: The team releasing MobileViT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
MobileViT is a light-weight, low latency convolutional neural network that combines MobileNetV2-style layers with a new block that replaces local processing in convolutions with global processing using transformers. As with ViT (Vision Transformer), the image data is converted into flattened patches before it is processed by the transformer layers. Afterwards, the patches are "unflattened" back into feature maps. This allows the MobileViT-block to be placed anywhere inside a CNN. MobileViT does not require any positional embeddings.
The model in this repo adds a [DeepLabV3](https://arxiv.org/abs/1706.05587) head to the MobileViT backbone for semantic segmentation.
## Intended uses & limitations
You can use the raw model for semantic segmentation. See the [model hub](https://huggingface.co/models?search=mobilevit) to look for fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model:
```python
from transformers import MobileViTFeatureExtractor, MobileViTForSemanticSegmentation
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = MobileViTFeatureExtractor.from_pretrained("apple/deeplabv3-mobilevit-small")
model = MobileViTForSemanticSegmentation.from_pretrained("apple/deeplabv3-mobilevit-small")
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
predicted_mask = logits.argmax(1).squeeze(0)
```
Currently, both the feature extractor and model support PyTorch.
## Training data
The MobileViT + DeepLabV3 model was pretrained on [ImageNet-1k](https://huggingface.co/datasets/imagenet-1k), a dataset consisting of 1 million images and 1,000 classes, and then fine-tuned on the [PASCAL VOC2012](http://host.robots.ox.ac.uk/pascal/VOC/) dataset.
## Training procedure
### Preprocessing
At inference time, images are center-cropped at 512x512. Pixels are normalized to the range [0, 1]. Images are expected to be in BGR pixel order, not RGB.
### Pretraining
The MobileViT networks are trained from scratch for 300 epochs on ImageNet-1k on 8 NVIDIA GPUs with an effective batch size of 1024 and learning rate warmup for 3k steps, followed by cosine annealing. Also used were label smoothing cross-entropy loss and L2 weight decay. Training resolution varies from 160x160 to 320x320, using multi-scale sampling.
To obtain the DeepLabV3 model, MobileViT was fine-tuned on the PASCAL VOC dataset using 4 NVIDIA A100 GPUs.
## Evaluation results
| Model | PASCAL VOC mIOU | # params | URL |
|------------------|-----------------|-----------|-----------------------------------------------------------|
| MobileViT-XXS | 73.6 | 1.9 M | https://huggingface.co/apple/deeplabv3-mobilevit-xx-small |
| MobileViT-XS | 77.1 | 2.9 M | https://huggingface.co/apple/deeplabv3-mobilevit-x-small |
| **MobileViT-S** | **79.1** | **6.4 M** | https://huggingface.co/apple/deeplabv3-mobilevit-small |
### BibTeX entry and citation info
```bibtex
@inproceedings{vision-transformer,
title = {MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer},
author = {Sachin Mehta and Mohammad Rastegari},
year = {2022},
URL = {https://arxiv.org/abs/2110.02178}
}
```
|
antoniocappiello/bert-base-italian-uncased-squad-it
|
ec30dd86cff1906fa4ed479287c06d98b48e9c8d
|
2021-12-15T10:01:14.000Z
|
[
"pytorch",
"question-answering",
"it",
"transformers",
"autotrain_compatible"
] |
question-answering
| false |
antoniocappiello
| null |
antoniocappiello/bert-base-italian-uncased-squad-it
| 441 | null |
transformers
| 2,460 |
---
language: it
widget:
- text: "Quando nacque D'Annunzio?"
context: "D'Annunzio nacque nel 1863"
---
# Italian Bert Base Uncased on Squad-it
## Model description
This model is the uncased base version of the italian BERT (which you may find at `dbmdz/bert-base-italian-uncased`) trained on the question answering task.
#### How to use
```python
from transformers import pipeline
nlp = pipeline('question-answering', model='antoniocappiello/bert-base-italian-uncased-squad-it')
# nlp(context="D'Annunzio nacque nel 1863", question="Quando nacque D'Annunzio?")
# {'score': 0.9990354180335999, 'start': 22, 'end': 25, 'answer': '1863'}
```
## Training data
It has been trained on the question answering task using [SQuAD-it](http://sag.art.uniroma2.it/demo-software/squadit/), derived from the original SQuAD dataset and obtained through the semi-automatic translation of the SQuAD dataset in Italian.
## Training procedure
```bash
python ./examples/run_squad.py \
--model_type bert \
--model_name_or_path dbmdz/bert-base-italian-uncased \
--do_train \
--do_eval \
--train_file ./squad_it_uncased/train-v1.1.json \
--predict_file ./squad_it_uncased/dev-v1.1.json \
--learning_rate 3e-5 \
--num_train_epochs 2 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir ./models/bert-base-italian-uncased-squad-it/ \
--per_gpu_eval_batch_size=3 \
--per_gpu_train_batch_size=3 \
--do_lower_case \
```
## Eval Results
| Metric | # Value |
| ------ | --------- |
| **EM** | **63.8** |
| **F1** | **75.30** |
## Comparison
| Model | EM | F1 score |
| -------------------------------------------------------------------------------------------------------------------------------- | --------- | --------- |
| [DrQA-it trained on SQuAD-it](https://github.com/crux82/squad-it/blob/master/README.md#evaluating-a-neural-model-over-squad-it) | 56.1 | 65.9 |
| This one | **63.8** | **75.30** |
|
tbs17/MathBERT-custom
|
db3e8ee98c43e1bef5ae02c7fb7623a840f321e3
|
2022-07-04T01:01:11.000Z
|
[
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
| false |
tbs17
| null |
tbs17/MathBERT-custom
| 441 | 4 |
transformers
| 2,461 |
#### MathBERT model (custom vocab)
Pretrained model on pre-k to graduate math language (English) using a masked language modeling (MLM) objective. This model is uncased: it does not make a difference between english and English.
#### Model description
MathBERT is a transformers model pretrained on a large corpus of English math corpus data in a self-supervised fashion. This means it was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely, it was pretrained with two objectives:
Masked language modeling (MLM): taking a sentence, the model randomly masks 15% of the words in the input then run the entire masked sentence through the model and has to predict the masked words. This is different from traditional recurrent neural networks (RNNs) that usually see the words one after the other, or from autoregressive models like GPT which internally mask the future tokens. It allows the model to learn a bidirectional representation of the sentence.
Next sentence prediction (NSP): the models concatenates two masked sentences as inputs during pretraining. Sometimes they correspond to sentences that were next to each other in the original text, sometimes not. The model then has to predict if the two sentences were following each other or not.
This way, the model learns an inner representation of the math language that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a standard classifier using the features produced by the MathBERT model as inputs.
#### Intended uses & limitations
You can use the raw model for either masked language modeling or next sentence prediction, but it's mostly intended to be fine-tuned on a math-related downstream task.
Note that this model is primarily aimed at being fine-tuned on math-related tasks that use the whole sentence (potentially masked) to make decisions, such as sequence classification, token classification or question answering. For tasks such as math text generation you should look at model like GPT2.
#### How to use
<!---You can use this model directly with a pipeline for masked language modeling:
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='bert-base-uncased')
>>> unmasker("Hello I'm a [MASK] model.")
[{'sequence': "[CLS] hello i'm a fashion model. [SEP]",
'score': 0.1073106899857521,
'token': 4827,
'token_str': 'fashion'},
{'sequence': "[CLS] hello i'm a role model. [SEP]",
'score': 0.08774490654468536,
'token': 2535,
'token_str': 'role'},
{'sequence': "[CLS] hello i'm a new model. [SEP]",
'score': 0.05338378623127937,
'token': 2047,
'token_str': 'new'},
{'sequence': "[CLS] hello i'm a super model. [SEP]",
'score': 0.04667217284440994,
'token': 3565,
'token_str': 'super'},
{'sequence': "[CLS] hello i'm a fine model. [SEP]",
'score': 0.027095865458250046,
'token': 2986,
'token_str': 'fine'}]--->
Here is how to use this model to get the features of a given text in PyTorch:
```from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('tbs17/MathBERT-custom')
model = BertModel.from_pretrained("tbs17/MathBERT-custom")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')["input_ids"]
output = model(encoded_input)
```
and in TensorFlow:
```
from transformers import BertTokenizer, TFBertModel
tokenizer = BertTokenizer.from_pretrained('tbs17/MathBERT-custom')
model = TFBertModel.from_pretrained("tbs17/MathBERT-custom")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
#### Warning
MathBERT is specifically designed for mathematics related tasks and works better with mathematical problem text fill-mask tasks instead of general purpose fill-mask tasks. See the below example:
```
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='tbs17/MathBERT')
# Below is desired usage
>>> unmasker("students apply these new understandings as they reason about and perform decimal [MASK] through the hundredths place.")
[{'score': 0.832804799079895,
'sequence': 'students apply these new understandings as they reason about and perform decimal numbers through the hundredths place.',
'token': 3616,
'token_str': 'numbers'},
{'score': 0.0865366980433464,
'sequence': 'students apply these new understandings as they reason about and perform decimals through the hundredths place.',
'token': 2015,
'token_str': '##s'},
{'score': 0.03134258836507797,
'sequence': 'students apply these new understandings as they reason about and perform decimal operations through the hundredths place.',
'token': 3136,
'token_str': 'operations'},
{'score': 0.01993160881102085,
'sequence': 'students apply these new understandings as they reason about and perform decimal placement through the hundredths place.',
'token': 11073,
'token_str': 'placement'},
{'score': 0.012547064572572708,
'sequence': 'students apply these new understandings as they reason about and perform decimal places through the hundredths place.',
'token': 3182,
'token_str': 'places'}]
#Below is not the desired usage
>>> unmasker("The man worked as a [MASK].")
[{'score': 0.6469377875328064,
'sequence': 'the man worked as a book.',
'token': 2338,
'token_str': 'book'},
{'score': 0.07073448598384857,
'sequence': 'the man worked as a guide.',
'token': 5009,
'token_str': 'guide'},
{'score': 0.031362924724817276,
'sequence': 'the man worked as a text.',
'token': 3793,
'token_str': 'text'},
{'score': 0.02306508645415306,
'sequence': 'the man worked as a man.',
'token': 2158,
'token_str': 'man'},
{'score': 0.020547250285744667,
'sequence': 'the man worked as a distance.',
'token': 3292,
'token_str': 'distance'}]
```
### Training data
The BERT model was pretrained on pre-k to HS math curriculum (engageNY, Utah Math, Illustrative Math), college math books from openculture.com as well as graduate level math from arxiv math paper abstracts. There is about 100M tokens got pretrained on.
#### Training procedure
The texts are lowercased and tokenized using WordPiece and a customized vocabulary size of 30,522. We use the ```bert_tokenizer``` from huggingface tokenizers library to generate a custom vocab file from our training raw math texts. The inputs of the model are then of the form:
```
[CLS] Sentence A [SEP] Sentence B [SEP]
```
With probability 0.5, sentence A and sentence B correspond to two consecutive sentences in the original corpus and in the other cases, it's another random sentence in the corpus. Note that what is considered a sentence here is a consecutive span of text usually longer than a single sentence. The only constrain is that the result with the two "sentences" has a combined length of less than 512 tokens.
The details of the masking procedure for each sentence are the following:
+ 15% of the tokens are masked.
+ In 80% of the cases, the masked tokens are replaced by [MASK].
+ In 10% of the cases, the masked tokens are replaced by a random token (different) from the one they replace.
+ In the 10% remaining cases, the masked tokens are left as is.
#### Pretraining
The model was trained on a 8-core cloud TPUs from Google Colab for 600k steps with a batch size of 128. The sequence length was limited to 512 for the entire time. The optimizer used is Adam with a learning rate of 5e-5, beta_{1} = 0.9 and beta_{2} =0.999, a weight decay of 0.01, learning rate warmup for 10,000 steps and linear decay of the learning rate after.
|
ml6team/distilbert-base-german-cased-toxic-comments
|
92d1f1c641db3226d637ab09019a9df44fa007f6
|
2022-06-15T22:10:04.000Z
|
[
"pytorch",
"distilbert",
"text-classification",
"de",
"dataset:germeval21",
"arxiv:1701.08118",
"transformers",
"german",
"classification"
] |
text-classification
| false |
ml6team
| null |
ml6team/distilbert-base-german-cased-toxic-comments
| 440 | 4 |
transformers
| 2,462 |
---
language:
- de
tags:
- distilbert
- german
- classification
datasets:
- germeval21
widget:
- text: "Das ist ein guter Punkt, so hatte ich das noch nicht betrachtet."
example_title: "Agreement (non-toxic)"
- text: "Wow, was ein geiles Spiel. Glückwunsch."
example_title: "Football (non-toxic)"
- text: "Halt deine scheiß Fresse, du Arschloch"
example_title: "Silence (toxic)"
- text: "Verpiss dich, du dreckiger Hurensohn."
example_title: "Dismiss (toxic)"
---
# German Toxic Comment Classification
## Model Description
This model was created with the purpose to detect toxic or potentially harmful comments.
For this model, we fine-tuned a German DistilBERT model [distilbert-base-german-cased](https://huggingface.co/distilbert-base-german-cased) on a combination of five German datasets containing toxicity, profanity, offensive, or hate speech.
## Intended Uses & Limitations
This model can be used to detect toxicity in German comments.
However, the definition of toxicity is vague and the model might not be able to detect all instances of toxicity.
It will not be able to detect toxicity in languages other than German.
## How to Use
```python
from transformers import pipeline
model_hub_url = 'https://huggingface.co/ml6team/distilbert-base-german-cased-toxic-comments'
model_name = 'ml6team/distilbert-base-german-cased-toxic-comments'
toxicity_pipeline = pipeline('text-classification', model=model_name, tokenizer=model_name)
comment = "Ein harmloses Beispiel"
result = toxicity_pipeline(comment)[0]
print(f"Comment: {comment}\nLabel: {result['label']}, score: {result['score']}")
```
## Limitations and Bias
The model was trained on a combinations of datasets that contain examples gathered from different social networks and internet communities. This only represents a narrow subset of possible instances of toxicity and instances in other domains might not be detected reliably.
## Training Data
The training dataset combines the following five datasets:
* GermEval18 [[dataset](https://github.com/uds-lsv/GermEval-2018-Data)]
* Labels: abuse, profanity, toxicity
* GermEval21 [[dataset](https://github.com/germeval2021toxic/SharedTask/tree/main/Data%20Sets)]
* Labels: toxicity
* IWG Hatespeech dataset [[paper](https://arxiv.org/pdf/1701.08118.pdf), [dataset](https://github.com/UCSM-DUE/IWG_hatespeech_public)]
* Labels: hate speech
* Detecting Offensive Statements Towards Foreigners in Social Media (2017) by Breitschneider and Peters [[dataset](http://ub-web.de/research/)]
* Labels: hate
* HASOC: 2019 Hate Speech and Offensive Content [[dataset](https://hasocfire.github.io/hasoc/2019/index.html)]
* Labels: offensive, profanity, hate
The datasets contains different labels ranging from profanity, over hate speech to toxicity. In the combined dataset these labels were subsumed as `toxic` and `non-toxic` and contains 23,515 examples in total.
Note that the datasets vary substantially in the number of examples.
## Training Procedure
The training and test set were created using either the predefined train/test splits where available and otherwise 80% of the examples for training and 20% for testing. This resulted in in 17,072 training examples and 6,443 test examples.
The model was trained for 2 epochs with the following arguments:
```python
training_args = TrainingArguments(
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
num_train_epochs=2,
evaluation_strategy="steps",
logging_strategy="steps",
logging_steps=100,
save_total_limit=5,
learning_rate=2e-5,
weight_decay=0.01,
metric_for_best_model='accuracy',
load_best_model_at_end=True
)
```
## Evaluation Results
Model evaluation was done on 1/10th of the dataset, which served as the test dataset.
| Accuracy | F1 Score | Recall | Precision |
| -------- | -------- | -------- | ----------- |
| 78.50 | 50.34 | 39.22 | 70.27 |
|
textattack/bert-base-uncased-rotten_tomatoes
|
f0be8f91098b02ec780661c1e589eeb416519522
|
2021-05-20T07:47:13.000Z
|
[
"pytorch",
"jax",
"tensorboard",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
| false |
textattack
| null |
textattack/bert-base-uncased-rotten_tomatoes
| 440 | null |
transformers
| 2,463 |
## bert-base-uncased fine-tuned with TextAttack on the rotten_tomatoes dataset
This `bert-base-uncased` model was fine-tuned for sequence classificationusing TextAttack
and the rotten_tomatoes dataset loaded using the `nlp` library. The model was fine-tuned
for 10 epochs with a batch size of 64, a learning
rate of 5e-05, and a maximum sequence length of 128.
Since this was a classification task, the model was trained with a cross-entropy loss function.
The best score the model achieved on this task was 0.875234521575985, as measured by the
eval set accuracy, found after 4 epochs.
For more information, check out [TextAttack on Github](https://github.com/QData/TextAttack).
|
seeksery/DialoGPT-calig2
|
43332f7c47e6ae847f4fcbd4f3cb03686be76590
|
2022-07-26T13:52:24.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
| false |
seeksery
| null |
seeksery/DialoGPT-calig2
| 439 | null |
transformers
| 2,464 |
---
tags:
- conversational
---
|
sentence-transformers/facebook-dpr-question_encoder-single-nq-base
|
4af249243a8a724a781ebeb159d82a78ee32a33c
|
2022-06-15T23:43:46.000Z
|
[
"pytorch",
"tf",
"bert",
"feature-extraction",
"sentence-transformers",
"sentence-similarity",
"transformers",
"license:apache-2.0"
] |
sentence-similarity
| false |
sentence-transformers
| null |
sentence-transformers/facebook-dpr-question_encoder-single-nq-base
| 438 | null |
sentence-transformers
| 2,465 |
---
pipeline_tag: sentence-similarity
license: apache-2.0
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# sentence-transformers/facebook-dpr-question_encoder-single-nq-base
This is a port of the [DPR Model](https://github.com/facebookresearch/DPR) to [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/facebook-dpr-question_encoder-single-nq-base')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
def cls_pooling(model_output, attention_mask):
return model_output[0][:,0]
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/facebook-dpr-question_encoder-single-nq-base')
model = AutoModel.from_pretrained('sentence-transformers/facebook-dpr-question_encoder-single-nq-base')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = cls_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/facebook-dpr-question_encoder-single-nq-base)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 509, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': True, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
Have a look at: [DPR Model](https://github.com/facebookresearch/DPR)
|
uclanlp/visualbert-vcr
|
becbc174cbce1a977121cca39d84048051a36021
|
2021-05-31T11:12:33.000Z
|
[
"pytorch",
"visual_bert",
"transformers"
] | null | false |
uclanlp
| null |
uclanlp/visualbert-vcr
| 438 | null |
transformers
| 2,466 |
Entry not found
|
HHousen/distil-led-large-cnn-16384
|
7cc576aee63d56c763e2eb2badf726659862274e
|
2021-02-02T00:58:07.000Z
|
[
"pytorch",
"led",
"text2text-generation",
"en",
"dataset:cnn_dailymail",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] |
text2text-generation
| false |
HHousen
| null |
HHousen/distil-led-large-cnn-16384
| 437 | 2 |
transformers
| 2,467 |
---
language: en
datasets:
- cnn_dailymail
license: apache-2.0
---
## DistilLED Large CNN 16384
*distil-led-large-cnn-16384* was initialized from [sshleifer/distilbart-cnn-12-6](https://huggingface.co/sshleifer/distilbart-cnn-12-6), in a fashion similar to [allenai/led-large-16384](https://huggingface.co/allenai/led-large-16384).
To be able to process 16K tokens, *sshleifer/distilbart-cnn-12-6*'s position embedding matrix was simply copied 16 times.
This checkpoint should be loaded into `LEDForConditionalGeneration.from_pretrained`. See the [LED documentation](https://huggingface.co/transformers/model_doc/led.html) for more information.
|
allenai/unifiedqa-v2-t5-large-1363200
|
a69158391f8fb9c6bbfdd4f28b699a19e73d7d28
|
2022-02-22T00:36:53.000Z
|
[
"pytorch",
"t5",
"text2text-generation",
"transformers",
"autotrain_compatible"
] |
text2text-generation
| false |
allenai
| null |
allenai/unifiedqa-v2-t5-large-1363200
| 437 | null |
transformers
| 2,468 |
# Further details: https://github.com/allenai/unifiedqa
|
uw-madison/yoso-4096
|
51a64263ef39d9e633f821a13ec9fafe5711061f
|
2022-01-12T13:36:04.000Z
|
[
"pytorch",
"yoso",
"fill-mask",
"arxiv:2111.09714",
"transformers",
"autotrain_compatible"
] |
fill-mask
| false |
uw-madison
| null |
uw-madison/yoso-4096
| 437 | null |
transformers
| 2,469 |
# YOSO
YOSO model for masked language modeling (MLM) for sequence length 4096.
## About YOSO
The YOSO model was proposed in [You Only Sample (Almost) Once: Linear Cost Self-Attention Via Bernoulli Sampling](https://arxiv.org/abs/2111.09714) by Zhanpeng Zeng, Yunyang Xiong, Sathya N. Ravi, Shailesh Acharya, Glenn Fung, Vikas Singh.
The abstract from the paper is the following:
Transformer-based models are widely used in natural language processing (NLP). Central to the transformer model is the self-attention mechanism, which captures the interactions of token pairs in the input sequences and depends quadratically on the sequence length. Training such models on longer sequences is expensive. In this paper, we show that a Bernoulli sampling attention mechanism based on Locality Sensitive Hashing (LSH), decreases the quadratic complexity of such models to linear. We bypass the quadratic cost by considering self-attention as a sum of individual tokens associated with Bernoulli random variables that can, in principle, be sampled at once by a single hash (although in practice, this number may be a small constant). This leads to an efficient sampling scheme to estimate self-attention which relies on specific modifications of LSH (to enable deployment on GPU architectures). We evaluate our algorithm on the GLUE benchmark with standard 512 sequence length where we see favorable performance relative to a standard pretrained Transformer. On the Long Range Arena (LRA) benchmark, for evaluating performance on long sequences, our method achieves results consistent with softmax self-attention but with sizable speed-ups and memory savings and often outperforms other efficient self-attention methods. Our code is available at this https URL
## Usage
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='uw-madison/yoso-4096')
>>> unmasker("Paris is the [MASK] of France.")
[{'score': 0.024274500086903572,
'token': 812,
'token_str': ' capital',
'sequence': 'Paris is the capital of France.'},
{'score': 0.022863076999783516,
'token': 3497,
'token_str': ' Republic',
'sequence': 'Paris is the Republic of France.'},
{'score': 0.01383623294532299,
'token': 1515,
'token_str': ' French',
'sequence': 'Paris is the French of France.'},
{'score': 0.013550693169236183,
'token': 2201,
'token_str': ' Paris',
'sequence': 'Paris is the Paris of France.'},
{'score': 0.011591030284762383,
'token': 270,
'token_str': ' President',
'sequence': 'Paris is the President of France.'}]
```
|
sentence-transformers/stsb-distilroberta-base-v2
|
0078748de585303ee3757abf215b748aa7be581e
|
2022-06-15T22:26:42.000Z
|
[
"pytorch",
"tf",
"jax",
"roberta",
"feature-extraction",
"arxiv:1908.10084",
"sentence-transformers",
"sentence-similarity",
"transformers",
"license:apache-2.0"
] |
sentence-similarity
| false |
sentence-transformers
| null |
sentence-transformers/stsb-distilroberta-base-v2
| 436 | null |
sentence-transformers
| 2,470 |
---
pipeline_tag: sentence-similarity
license: apache-2.0
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# sentence-transformers/stsb-distilroberta-base-v2
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/stsb-distilroberta-base-v2')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/stsb-distilroberta-base-v2')
model = AutoModel.from_pretrained('sentence-transformers/stsb-distilroberta-base-v2')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/stsb-distilroberta-base-v2)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 75, 'do_lower_case': False}) with Transformer model: RobertaModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
```
|
gilf/french-postag-model
|
d4206b8aa47cbf1b282450f454f67f15290c263b
|
2021-05-19T17:22:22.000Z
|
[
"pytorch",
"tf",
"jax",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
] |
token-classification
| false |
gilf
| null |
gilf/french-postag-model
| 435 | 1 |
transformers
| 2,471 |
## About
The *french-postag-model* is a part of speech tagging model for French that was trained on the *free-french-treebank* dataset available on
[github](https://github.com/nicolashernandez/free-french-treebank). The base tokenizer and model used for training is *'bert-base-multilingual-cased'*.
## Supported Tags
It uses the following tags:
| Tag | Category | Extra Info |
|----------|:------------------------------:|------------:|
| ADJ | adjectif | |
| ADJWH | adjectif | |
| ADV | adverbe | |
| ADVWH | adverbe | |
| CC | conjonction de coordination | |
| CLO | pronom | obj |
| CLR | pronom | refl |
| CLS | pronom | suj |
| CS | conjonction de subordination | |
| DET | déterminant | |
| DETWH | déterminant | |
| ET | mot étranger | |
| I | interjection | |
| NC | nom commun | |
| NPP | nom propre | |
| P | préposition | |
| P+D | préposition + déterminant | |
| PONCT | signe de ponctuation | |
| PREF | préfixe | |
| PRO | autres pronoms | |
| PROREL | autres pronoms | rel |
| PROWH | autres pronoms | int |
| U | ? | |
| V | verbe | |
| VIMP | verbe imperatif | |
| VINF | verbe infinitif | |
| VPP | participe passé | |
| VPR | participe présent | |
| VS | subjonctif | |
More information on the tags can be found here:
http://alpage.inria.fr/statgram/frdep/Publications/crabbecandi-taln2008-final.pdf
## Usage
The usage of this model follows the common transformers patterns. Here is a short example of its usage:
```python
from transformers import AutoTokenizer, AutoModelForTokenClassification
tokenizer = AutoTokenizer.from_pretrained("gilf/french-postag-model")
model = AutoModelForTokenClassification.from_pretrained("gilf/french-postag-model")
from transformers import pipeline
nlp_token_class = pipeline('ner', model=model, tokenizer=tokenizer, grouped_entities=True)
nlp_token_class('Face à un choc inédit, les mesures mises en place par le gouvernement ont permis une protection forte et efficace des ménages')
```
The lines above would display something like this on a Jupyter notebook:
```
[{'entity_group': 'PONCT', 'score': 0.0742340236902237, 'word': '[CLS]'},
{'entity_group': 'U', 'score': 0.9995399713516235, 'word': 'Face'},
{'entity_group': 'P', 'score': 0.9999609589576721, 'word': 'à'},
{'entity_group': 'DET', 'score': 0.9999597072601318, 'word': 'un'},
{'entity_group': 'NC', 'score': 0.9998948276042938, 'word': 'choc'},
{'entity_group': 'ADJ', 'score': 0.995318204164505, 'word': 'inédit'},
{'entity_group': 'PONCT', 'score': 0.9999793171882629, 'word': ','},
{'entity_group': 'DET', 'score': 0.999964714050293, 'word': 'les'},
{'entity_group': 'NC', 'score': 0.999936580657959, 'word': 'mesures'},
{'entity_group': 'VPP', 'score': 0.9995776414871216, 'word': 'mises'},
{'entity_group': 'P', 'score': 0.99996417760849, 'word': 'en'},
{'entity_group': 'NC', 'score': 0.999882161617279, 'word': 'place'},
{'entity_group': 'P', 'score': 0.9999671578407288, 'word': 'par'},
{'entity_group': 'DET', 'score': 0.9999637603759766, 'word': 'le'},
{'entity_group': 'NC', 'score': 0.9999350309371948, 'word': 'gouvernement'},
{'entity_group': 'V', 'score': 0.9999298453330994, 'word': 'ont'},
{'entity_group': 'VPP', 'score': 0.9998740553855896, 'word': 'permis'},
{'entity_group': 'DET', 'score': 0.9999625086784363, 'word': 'une'},
{'entity_group': 'NC', 'score': 0.9999420046806335, 'word': 'protection'},
{'entity_group': 'ADJ', 'score': 0.9998913407325745, 'word': 'forte'},
{'entity_group': 'CC', 'score': 0.9998615980148315, 'word': 'et'},
{'entity_group': 'ADJ', 'score': 0.9998483657836914, 'word': 'efficace'},
{'entity_group': 'P+D', 'score': 0.9987645149230957, 'word': 'des'},
{'entity_group': 'NC', 'score': 0.8720395267009735, 'word': 'ménages [SEP]'}]
```
|
aubmindlab/bert-large-arabertv02
|
067c6e0c564e4e4faa2ac0bcfec3f7b0e8d9143f
|
2022-04-07T08:26:52.000Z
|
[
"pytorch",
"tf",
"jax",
"tensorboard",
"bert",
"fill-mask",
"ar",
"dataset:wikipedia",
"dataset:OSIAN",
"dataset:1.5B Arabic Corpus",
"dataset:OSCAR Arabic Unshuffled",
"arxiv:2003.00104",
"transformers",
"autotrain_compatible"
] |
fill-mask
| false |
aubmindlab
| null |
aubmindlab/bert-large-arabertv02
| 434 | 1 |
transformers
| 2,472 |
---
language: ar
datasets:
- wikipedia
- OSIAN
- 1.5B Arabic Corpus
- OSCAR Arabic Unshuffled
widget:
- text: " عاصمة لبنان هي [MASK] ."
---
# AraBERT v1 & v2 : Pre-training BERT for Arabic Language Understanding
<img src="https://raw.githubusercontent.com/aub-mind/arabert/master/arabert_logo.png" width="100" align="left"/>
**AraBERT** is an Arabic pretrained lanaguage model based on [Google's BERT architechture](https://github.com/google-research/bert). AraBERT uses the same BERT-Base config. More details are available in the [AraBERT Paper](https://arxiv.org/abs/2003.00104) and in the [AraBERT Meetup](https://github.com/WissamAntoun/pydata_khobar_meetup)
There are two versions of the model, AraBERTv0.1 and AraBERTv1, with the difference being that AraBERTv1 uses pre-segmented text where prefixes and suffixes were splitted using the [Farasa Segmenter](http://alt.qcri.org/farasa/segmenter.html).
We evalaute AraBERT models on different downstream tasks and compare them to [mBERT]((https://github.com/google-research/bert/blob/master/multilingual.md)), and other state of the art models (*To the extent of our knowledge*). The Tasks were Sentiment Analysis on 6 different datasets ([HARD](https://github.com/elnagara/HARD-Arabic-Dataset), [ASTD-Balanced](https://www.aclweb.org/anthology/D15-1299), [ArsenTD-Lev](https://staff.aub.edu.lb/~we07/Publications/ArSentD-LEV_Sentiment_Corpus.pdf), [LABR](https://github.com/mohamedadaly/LABR)), Named Entity Recognition with the [ANERcorp](http://curtis.ml.cmu.edu/w/courses/index.php/ANERcorp), and Arabic Question Answering on [Arabic-SQuAD and ARCD](https://github.com/husseinmozannar/SOQAL)
# AraBERTv2
## What's New!
AraBERT now comes in 4 new variants to replace the old v1 versions:
More Detail in the AraBERT folder and in the [README](https://github.com/aub-mind/arabert/blob/master/AraBERT/README.md) and in the [AraBERT Paper](https://arxiv.org/abs/2003.00104v2)
Model | HuggingFace Model Name | Size (MB/Params)| Pre-Segmentation | DataSet (Sentences/Size/nWords) |
---|:---:|:---:|:---:|:---:
AraBERTv0.2-base | [bert-base-arabertv02](https://huggingface.co/aubmindlab/bert-base-arabertv02) | 543MB / 136M | No | 200M / 77GB / 8.6B |
AraBERTv0.2-large| [bert-large-arabertv02](https://huggingface.co/aubmindlab/bert-large-arabertv02) | 1.38G 371M | No | 200M / 77GB / 8.6B |
AraBERTv2-base| [bert-base-arabertv2](https://huggingface.co/aubmindlab/bert-base-arabertv2) | 543MB 136M | Yes | 200M / 77GB / 8.6B |
AraBERTv2-large| [bert-large-arabertv2](https://huggingface.co/aubmindlab/bert-large-arabertv2) | 1.38G 371M | Yes | 200M / 77GB / 8.6B |
AraBERTv0.1-base| [bert-base-arabertv01](https://huggingface.co/aubmindlab/bert-base-arabertv01) | 543MB 136M | No | 77M / 23GB / 2.7B |
AraBERTv1-base| [bert-base-arabert](https://huggingface.co/aubmindlab/bert-base-arabert) | 543MB 136M | Yes | 77M / 23GB / 2.7B |
All models are available in the `HuggingFace` model page under the [aubmindlab](https://huggingface.co/aubmindlab/) name. Checkpoints are available in PyTorch, TF2 and TF1 formats.
## Better Pre-Processing and New Vocab
We identified an issue with AraBERTv1's wordpiece vocabulary. The issue came from punctuations and numbers that were still attached to words when learned the wordpiece vocab. We now insert a space between numbers and characters and around punctuation characters.
The new vocabulary was learnt using the `BertWordpieceTokenizer` from the `tokenizers` library, and should now support the Fast tokenizer implementation from the `transformers` library.
**P.S.**: All the old BERT codes should work with the new BERT, just change the model name and check the new preprocessing dunction
**Please read the section on how to use the [preprocessing function](#Preprocessing)**
## Bigger Dataset and More Compute
We used ~3.5 times more data, and trained for longer.
For Dataset Sources see the [Dataset Section](#Dataset)
Model | Hardware | num of examples with seq len (128 / 512) |128 (Batch Size/ Num of Steps) | 512 (Batch Size/ Num of Steps) | Total Steps | Total Time (in Days) |
---|:---:|:---:|:---:|:---:|:---:|:---:
AraBERTv0.2-base | TPUv3-8 | 420M / 207M | 2560 / 1M | 384/ 2M | 3M | -
AraBERTv0.2-large | TPUv3-128 | 420M / 207M | 13440 / 250K | 2056 / 300K | 550K | 7
AraBERTv2-base | TPUv3-8 | 420M / 207M | 2560 / 1M | 384/ 2M | 3M | -
AraBERTv2-large | TPUv3-128 | 520M / 245M | 13440 / 250K | 2056 / 300K | 550K | 7
AraBERT-base (v1/v0.1) | TPUv2-8 | - |512 / 900K | 128 / 300K| 1.2M | 4
# Dataset
The pretraining data used for the new AraBERT model is also used for Arabic **GPT2 and ELECTRA**.
The dataset consists of 77GB or 200,095,961 lines or 8,655,948,860 words or 82,232,988,358 chars (before applying Farasa Segmentation)
For the new dataset we added the unshuffled OSCAR corpus, after we thoroughly filter it, to the previous dataset used in AraBERTv1 but with out the websites that we previously crawled:
- OSCAR unshuffled and filtered.
- [Arabic Wikipedia dump](https://archive.org/details/arwiki-20190201) from 2020/09/01
- [The 1.5B words Arabic Corpus](https://www.semanticscholar.org/paper/1.5-billion-words-Arabic-Corpus-El-Khair/f3eeef4afb81223df96575adadf808fe7fe440b4)
- [The OSIAN Corpus](https://www.aclweb.org/anthology/W19-4619)
- Assafir news articles. Huge thank you for Assafir for giving us the data
# Preprocessing
It is recommended to apply our preprocessing function before training/testing on any dataset.
**Install farasapy to segment text for AraBERT v1 & v2 `pip install farasapy`**
```python
from arabert.preprocess import ArabertPreprocessor
model_name="bert-large-arabertv02"
arabert_prep = ArabertPreprocessor(model_name=model_name)
text = "ولن نبالغ إذا قلنا إن هاتف أو كمبيوتر المكتب في زمننا هذا ضروري"
arabert_prep.preprocess(text)
```
## Accepted_models
```
bert-base-arabertv01
bert-base-arabert
bert-base-arabertv02
bert-base-arabertv2
bert-large-arabertv02
bert-large-arabertv2
araelectra-base
aragpt2-base
aragpt2-medium
aragpt2-large
aragpt2-mega
```
# TensorFlow 1.x models
The TF1.x model are available in the HuggingFace models repo.
You can download them as follows:
- via git-lfs: clone all the models in a repo
```bash
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash
sudo apt-get install git-lfs
git lfs install
git clone https://huggingface.co/aubmindlab/MODEL_NAME
tar -C ./MODEL_NAME -zxvf /content/MODEL_NAME/tf1_model.tar.gz
```
where `MODEL_NAME` is any model under the `aubmindlab` name
- via `wget`:
- Go to the tf1_model.tar.gz file on huggingface.co/models/aubmindlab/MODEL_NAME.
- copy the `oid sha256`
- then run `wget https://cdn-lfs.huggingface.co/aubmindlab/aragpt2-base/INSERT_THE_SHA_HERE` (ex: for `aragpt2-base`: `wget https://cdn-lfs.huggingface.co/aubmindlab/aragpt2-base/3766fc03d7c2593ff2fb991d275e96b81b0ecb2098b71ff315611d052ce65248`)
# If you used this model please cite us as :
Google Scholar has our Bibtex wrong (missing name), use this instead
```
@inproceedings{antoun2020arabert,
title={AraBERT: Transformer-based Model for Arabic Language Understanding},
author={Antoun, Wissam and Baly, Fady and Hajj, Hazem},
booktitle={LREC 2020 Workshop Language Resources and Evaluation Conference 11--16 May 2020},
pages={9}
}
```
# Acknowledgments
Thanks to TensorFlow Research Cloud (TFRC) for the free access to Cloud TPUs, couldn't have done it without this program, and to the [AUB MIND Lab](https://sites.aub.edu.lb/mindlab/) Members for the continous support. Also thanks to [Yakshof](https://www.yakshof.com/#/) and Assafir for data and storage access. Another thanks for Habib Rahal (https://www.behance.net/rahalhabib), for putting a face to AraBERT.
# Contacts
**Wissam Antoun**: [Linkedin](https://www.linkedin.com/in/wissam-antoun-622142b4/) | [Twitter](https://twitter.com/wissam_antoun) | [Github](https://github.com/WissamAntoun) | <[email protected]> | <[email protected]>
**Fady Baly**: [Linkedin](https://www.linkedin.com/in/fadybaly/) | [Twitter](https://twitter.com/fadybaly) | [Github](https://github.com/fadybaly) | <[email protected]> | <[email protected]>
|
Augustvember/wokka2
|
171fd15c9a2dff4c496e723ecd736fbf35d36e08
|
2021-08-08T10:59:54.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
| false |
Augustvember
| null |
Augustvember/wokka2
| 433 | null |
transformers
| 2,473 |
---
tags:
- conversational
---
|
allenai/macaw-11b
|
efbdfd3889acdfd1cdb36aebafbc202a28b845d3
|
2021-09-21T15:59:00.000Z
|
[
"pytorch",
"t5",
"text2text-generation",
"en",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] |
text2text-generation
| false |
allenai
| null |
allenai/macaw-11b
| 432 | 3 |
transformers
| 2,474 |
---
language: en
widget:
- text: $answer$ ; $mcoptions$ ; $question$ = What is the color of a cloudy sky?
license: apache-2.0
---
# macaw-11b
## Model description
Macaw (<b>M</b>ulti-<b>a</b>ngle <b>c</b>(q)uestion <b>a</b>ns<b>w</b>ering) is a ready-to-use model capable of
general question answering,
showing robustness outside the domains it was trained on. It has been trained in "multi-angle" fashion,
which means it can handle a flexible set of input and output "slots"
(question, answer, multiple-choice options, context, and explanation) .
Macaw was built on top of [T5](https://github.com/google-research/text-to-text-transfer-transformer) and comes in
three sizes: [macaw-11b](https://huggingface.co/allenai/macaw-11b), [macaw-3b](https://huggingface.co/allenai/macaw-3b),
and [macaw-large](https://huggingface.co/allenai/macaw-large), as well as an answer-focused version featured on
various leaderboards [macaw-answer-11b](https://huggingface.co/allenai/macaw-answer-11b).
See https://github.com/allenai/macaw for more details.
## Intended uses & limitations
#### How to use
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("allenai/macaw-11b")
model = AutoModelForSeq2SeqLM.from_pretrained("allenai/macaw-11b")
input_string = "$answer$ ; $mcoptions$ ; $question$ = What is the color of a cloudy sky?"
input_ids = tokenizer.encode(input_string, return_tensors="pt")
output = model.generate(input_ids, max_length=200)
>>> tokenizer.batch_decode(output, skip_special_tokens=True)
['$answer$ = gray ; $mcoptions$ = (A) blue (B) white (C) grey (D) black']
```
### BibTeX entry and citation info
```bibtex
@article{Tafjord2021Macaw,
title={General-Purpose Question-Answering with {M}acaw},
author={Oyvind Tafjord and Peter Clark},
journal={ArXiv},
year={2021},
volume={abs/2109.02593}
}
```
|
google/vit-large-patch16-224
|
9e2727f4250d3973839eecfa5c4b42e41b709a50
|
2022-06-23T07:50:15.000Z
|
[
"pytorch",
"tf",
"jax",
"vit",
"image-classification",
"dataset:imagenet-1k",
"dataset:imagenet-21k",
"arxiv:2010.11929",
"arxiv:2006.03677",
"transformers",
"vision",
"license:apache-2.0"
] |
image-classification
| false |
google
| null |
google/vit-large-patch16-224
| 432 | 1 |
transformers
| 2,475 |
---
license: apache-2.0
tags:
- image-classification
- vision
datasets:
- imagenet-1k
- imagenet-21k
---
# Vision Transformer (large-sized model)
Vision Transformer (ViT) model pre-trained on ImageNet-21k (14 million images, 21,843 classes) at resolution 224x224, and fine-tuned on ImageNet 2012 (1 million images, 1,000 classes) at resolution 224x224. It was introduced in the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Dosovitskiy et al. and first released in [this repository](https://github.com/google-research/vision_transformer). However, the weights were converted from the [timm repository](https://github.com/rwightman/pytorch-image-models) by Ross Wightman, who already converted the weights from JAX to PyTorch. Credits go to him.
Disclaimer: The team releasing ViT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The Vision Transformer (ViT) is a transformer encoder model (BERT-like) pretrained on a large collection of images in a supervised fashion, namely ImageNet-21k, at a resolution of 224x224 pixels. Next, the model was fine-tuned on ImageNet (also referred to as ILSVRC2012), a dataset comprising 1 million images and 1,000 classes, at the same resolution, 224x224.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. One also adds a [CLS] token to the beginning of a sequence to use it for classification tasks. One also adds absolute position embeddings before feeding the sequence to the layers of the Transformer encoder.
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire image.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=google/vit) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import ViTFeatureExtractor, ViTForImageClassification
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = ViTFeatureExtractor.from_pretrained('google/vit-large-patch16-224')
model = ViTForImageClassification.from_pretrained('google/vit-large-patch16-224')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
Currently, both the feature extractor and model support PyTorch. Tensorflow and JAX/FLAX are coming soon, and the API of ViTFeatureExtractor might change.
## Training data
The ViT model was pretrained on [ImageNet-21k](http://www.image-net.org/), a dataset consisting of 14 million images and 21k classes, and fine-tuned on [ImageNet](http://www.image-net.org/challenges/LSVRC/2012/), a dataset consisting of 1 million images and 1k classes.
## Training procedure
### Preprocessing
The exact details of preprocessing of images during training/validation can be found [here](https://github.com/google-research/vision_transformer/blob/master/vit_jax/input_pipeline.py).
Images are resized/rescaled to the same resolution (224x224) and normalized across the RGB channels with mean (0.5, 0.5, 0.5) and standard deviation (0.5, 0.5, 0.5).
### Pretraining
The model was trained on TPUv3 hardware (8 cores). All model variants are trained with a batch size of 4096 and learning rate warmup of 10k steps. For ImageNet, the authors found it beneficial to additionally apply gradient clipping at global norm 1. Pre-training resolution is 224.
## Evaluation results
For evaluation results on several image classification benchmarks, we refer to tables 2 and 5 of the original paper. Note that for fine-tuning, the best results are obtained with a higher resolution (384x384). Of course, increasing the model size will result in better performance.
### BibTeX entry and citation info
```bibtex
@misc{wu2020visual,
title={Visual Transformers: Token-based Image Representation and Processing for Computer Vision},
author={Bichen Wu and Chenfeng Xu and Xiaoliang Dai and Alvin Wan and Peizhao Zhang and Zhicheng Yan and Masayoshi Tomizuka and Joseph Gonzalez and Kurt Keutzer and Peter Vajda},
year={2020},
eprint={2006.03677},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
```bibtex
@inproceedings{deng2009imagenet,
title={Imagenet: A large-scale hierarchical image database},
author={Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li},
booktitle={2009 IEEE conference on computer vision and pattern recognition},
pages={248--255},
year={2009},
organization={Ieee}
}
```
|
DaNLP/da-bert-emotion-binary
|
c5f9be72ce0e3daa1b90372ca1a6ba929df4a67a
|
2021-09-23T13:37:13.000Z
|
[
"pytorch",
"tf",
"bert",
"text-classification",
"da",
"dataset:social media",
"transformers",
"emotion",
"license:cc-by-sa-4.0"
] |
text-classification
| false |
DaNLP
| null |
DaNLP/da-bert-emotion-binary
| 431 | 1 |
transformers
| 2,476 |
---
language:
- da
tags:
- bert
- pytorch
- emotion
license: cc-by-sa-4.0
datasets:
- social media
metrics:
- f1
widget:
- text: Der er et træ i haven.
---
# Danish BERT for emotion detection
The BERT Emotion model detects whether a Danish text is emotional or not.
It is based on the pretrained [Danish BERT](https://github.com/certainlyio/nordic_bert) model by BotXO which has been fine-tuned on social media data.
See the [DaNLP documentation](https://danlp-alexandra.readthedocs.io/en/latest/docs/tasks/sentiment_analysis.html#bert-emotion) for more details.
Here is how to use the model:
```python
from transformers import BertTokenizer, BertForSequenceClassification
model = BertForSequenceClassification.from_pretrained("DaNLP/da-bert-emotion-binary")
tokenizer = BertTokenizer.from_pretrained("DaNLP/da-bert-emotion-binary")
```
## Training data
The data used for training has not been made publicly available. It consists of social media data manually annotated in collaboration with Danmarks Radio.
|
charsiu/en_w2v2_fc_10ms
|
e9bf8dd314313fc57f6e4d0b5425bde4bbeac80f
|
2021-10-03T02:09:48.000Z
|
[
"pytorch",
"wav2vec2",
"transformers"
] | null | false |
charsiu
| null |
charsiu/en_w2v2_fc_10ms
| 431 | null |
transformers
| 2,477 |
Entry not found
|
google/bert_uncased_L-4_H-768_A-12
|
0e3749de42f4e094609bc52dc7b0554a3a6bcc52
|
2021-05-19T17:31:28.000Z
|
[
"pytorch",
"jax",
"bert",
"arxiv:1908.08962",
"transformers",
"license:apache-2.0"
] | null | false |
google
| null |
google/bert_uncased_L-4_H-768_A-12
| 431 | null |
transformers
| 2,478 |
---
thumbnail: https://huggingface.co/front/thumbnails/google.png
license: apache-2.0
---
BERT Miniatures
===
This is the set of 24 BERT models referenced in [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962) (English only, uncased, trained with WordPiece masking).
We have shown that the standard BERT recipe (including model architecture and training objective) is effective on a wide range of model sizes, beyond BERT-Base and BERT-Large. The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
Our goal is to enable research in institutions with fewer computational resources and encourage the community to seek directions of innovation alternative to increasing model capacity.
You can download the 24 BERT miniatures either from the [official BERT Github page](https://github.com/google-research/bert/), or via HuggingFace from the links below:
| |H=128|H=256|H=512|H=768|
|---|:---:|:---:|:---:|:---:|
| **L=2** |[**2/128 (BERT-Tiny)**][2_128]|[2/256][2_256]|[2/512][2_512]|[2/768][2_768]|
| **L=4** |[4/128][4_128]|[**4/256 (BERT-Mini)**][4_256]|[**4/512 (BERT-Small)**][4_512]|[4/768][4_768]|
| **L=6** |[6/128][6_128]|[6/256][6_256]|[6/512][6_512]|[6/768][6_768]|
| **L=8** |[8/128][8_128]|[8/256][8_256]|[**8/512 (BERT-Medium)**][8_512]|[8/768][8_768]|
| **L=10** |[10/128][10_128]|[10/256][10_256]|[10/512][10_512]|[10/768][10_768]|
| **L=12** |[12/128][12_128]|[12/256][12_256]|[12/512][12_512]|[**12/768 (BERT-Base)**][12_768]|
Note that the BERT-Base model in this release is included for completeness only; it was re-trained under the same regime as the original model.
Here are the corresponding GLUE scores on the test set:
|Model|Score|CoLA|SST-2|MRPC|STS-B|QQP|MNLI-m|MNLI-mm|QNLI(v2)|RTE|WNLI|AX|
|---|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|BERT-Tiny|64.2|0.0|83.2|81.1/71.1|74.3/73.6|62.2/83.4|70.2|70.3|81.5|57.2|62.3|21.0|
|BERT-Mini|65.8|0.0|85.9|81.1/71.8|75.4/73.3|66.4/86.2|74.8|74.3|84.1|57.9|62.3|26.1|
|BERT-Small|71.2|27.8|89.7|83.4/76.2|78.8/77.0|68.1/87.0|77.6|77.0|86.4|61.8|62.3|28.6|
|BERT-Medium|73.5|38.0|89.6|86.6/81.6|80.4/78.4|69.6/87.9|80.0|79.1|87.7|62.2|62.3|30.5|
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained for 4 epochs:
- batch sizes: 8, 16, 32, 64, 128
- learning rates: 3e-4, 1e-4, 5e-5, 3e-5
If you use these models, please cite the following paper:
```
@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}
```
[2_128]: https://huggingface.co/google/bert_uncased_L-2_H-128_A-2
[2_256]: https://huggingface.co/google/bert_uncased_L-2_H-256_A-4
[2_512]: https://huggingface.co/google/bert_uncased_L-2_H-512_A-8
[2_768]: https://huggingface.co/google/bert_uncased_L-2_H-768_A-12
[4_128]: https://huggingface.co/google/bert_uncased_L-4_H-128_A-2
[4_256]: https://huggingface.co/google/bert_uncased_L-4_H-256_A-4
[4_512]: https://huggingface.co/google/bert_uncased_L-4_H-512_A-8
[4_768]: https://huggingface.co/google/bert_uncased_L-4_H-768_A-12
[6_128]: https://huggingface.co/google/bert_uncased_L-6_H-128_A-2
[6_256]: https://huggingface.co/google/bert_uncased_L-6_H-256_A-4
[6_512]: https://huggingface.co/google/bert_uncased_L-6_H-512_A-8
[6_768]: https://huggingface.co/google/bert_uncased_L-6_H-768_A-12
[8_128]: https://huggingface.co/google/bert_uncased_L-8_H-128_A-2
[8_256]: https://huggingface.co/google/bert_uncased_L-8_H-256_A-4
[8_512]: https://huggingface.co/google/bert_uncased_L-8_H-512_A-8
[8_768]: https://huggingface.co/google/bert_uncased_L-8_H-768_A-12
[10_128]: https://huggingface.co/google/bert_uncased_L-10_H-128_A-2
[10_256]: https://huggingface.co/google/bert_uncased_L-10_H-256_A-4
[10_512]: https://huggingface.co/google/bert_uncased_L-10_H-512_A-8
[10_768]: https://huggingface.co/google/bert_uncased_L-10_H-768_A-12
[12_128]: https://huggingface.co/google/bert_uncased_L-12_H-128_A-2
[12_256]: https://huggingface.co/google/bert_uncased_L-12_H-256_A-4
[12_512]: https://huggingface.co/google/bert_uncased_L-12_H-512_A-8
[12_768]: https://huggingface.co/google/bert_uncased_L-12_H-768_A-12
|
jhgan/ko-sbert-multitask
|
869e0dbcd4b13d9765bf1d7ea05d05baf2e6ec0c
|
2021-12-27T12:35:56.000Z
|
[
"pytorch",
"bert",
"feature-extraction",
"sentence-transformers",
"sentence-similarity",
"transformers"
] |
sentence-similarity
| false |
jhgan
| null |
jhgan/ko-sbert-multitask
| 431 | null |
sentence-transformers
| 2,479 |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# ko-sbert-multitask
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["안녕하세요?", "한국어 문장 임베딩을 위한 버트 모델입니다."]
model = SentenceTransformer('jhgan/ko-sbert-multitask')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('jhgan/ko-sbert-multitask')
model = AutoModel.from_pretrained('jhgan/ko-sbert-multitask')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
KorSTS, KorNLI 학습 데이터셋으로 멀티 태스크 학습을 진행한 후 KorSTS 평가 데이터셋으로 평가한 결과입니다.
- Cosine Pearson: 84.13
- Cosine Spearman: 84.71
- Euclidean Pearson: 82.42
- Euclidean Spearman: 82.66
- Manhattan Pearson: 81.41
- Manhattan Spearman: 81.69
- Dot Pearson: 80.05
- Dot Spearman: 79.69
## Training
The model was trained with the parameters:
**DataLoader**:
`sentence_transformers.datasets.NoDuplicatesDataLoader.NoDuplicatesDataLoader` of length 8885 with parameters:
```
{'batch_size': 64}
```
**Loss**:
`sentence_transformers.losses.MultipleNegativesRankingLoss.MultipleNegativesRankingLoss` with parameters:
```
{'scale': 20.0, 'similarity_fct': 'cos_sim'}
```
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 719 with parameters:
```
{'batch_size': 8, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss`
Parameters of the fit()-Method:
```
{
"epochs": 5,
"evaluation_steps": 1000,
"evaluator": "sentence_transformers.evaluation.EmbeddingSimilarityEvaluator.EmbeddingSimilarityEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'transformers.optimization.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 360,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
- Ham, J., Choe, Y. J., Park, K., Choi, I., & Soh, H. (2020). Kornli and korsts: New benchmark datasets for korean natural language understanding. arXiv
preprint arXiv:2004.03289
- Reimers, Nils and Iryna Gurevych. “Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks.” ArXiv abs/1908.10084 (2019)
- Reimers, Nils and Iryna Gurevych. “Making Monolingual Sentence Embeddings Multilingual Using Knowledge Distillation.” EMNLP (2020).
|
google/roberta2roberta_L-24_cnn_daily_mail
|
103d110ba258873ce4d7c06b2c72e555bfce9aaf
|
2020-12-11T21:43:09.000Z
|
[
"pytorch",
"encoder-decoder",
"text2text-generation",
"en",
"dataset:cnn_dailymail",
"arxiv:1907.12461",
"transformers",
"summarization",
"license:apache-2.0",
"autotrain_compatible"
] |
summarization
| false |
google
| null |
google/roberta2roberta_L-24_cnn_daily_mail
| 430 | 1 |
transformers
| 2,480 |
---
language: en
license: apache-2.0
datasets:
- cnn_dailymail
tags:
- summarization
---
# Roberta2Roberta_L-24_cnn_daily_mail EncoderDecoder model
The model was introduced in
[this paper](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn and first released in [this repository](https://tfhub.dev/google/bertseq2seq/roberta24_cnndm/1).
The model is an encoder-decoder model that was initialized on the `roberta-large` checkpoints for both the encoder
and decoder and fine-tuned on summarization on the CNN / Dailymail dataset, which is linked above.
Disclaimer: The model card has been written by the Hugging Face team.
## How to use
You can use this model for summarization, *e.g.*
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("google/roberta2roberta_L-24_cnn_daily_mail")
model = AutoModelForSeq2SeqLM.from_pretrained("google/roberta2roberta_L-24_cnn_daily_mail")
article = """ (The Hollywood Reporter)"The Rocky Horror Picture
Show" is the latest musical getting the small-
screen treatment. Fox is developing a two-hour
remake of the 1975 cult classic to be directed,
executive-produced and choreographed by Kenneth
Ortega ("High School Musical"). The project,
tentatively titled "The Rocky Horror Picture Show
Event," is casting-contingent. The special will be
filmed in advance and not air live, but few
details beyond that are known. In addition to
Ortega, Gail Berman and Lou Adler, who produced
the original film, are also attached as executive
producers. The special will be produced by Fox 21
Television Studios, and Berman's The Jackal Group.
The special is timed to celebrate the 40th
anniversary of the film, which has grossed more
than $112 million and still plays in theaters
across the country. TV premiere dates: The
complete guide . This isn't the first stab at
adapting "The Rocky Horror Picture Show." In 2002,
Fox unveiled plans for an adaptation timed to the
30th anniversary that never came to fruition. The
faces of pilot season 2015 . Fox's "Glee" covered
several of the show's most popular songs for a
Season 2 episode and even released a special "The
Rocky Horror Glee Show" EP. There is no plan yet
for when the adaptation will air. Fox also has a
live musical production of "Grease", starring
Julianne Hough and Vanessa Hudgens, scheduled to
air on Jan. 31, 2016. Broadcast TV scorecard .
Following in the footsteps of "The Sound of Music"
and "Peter Pan," NBC recently announced plans to
air a live version of The Wiz later this year.
Ortega's credits include "Gilmore Girls," "This Is
It" and "Hocus Pocus." He is repped by Paradigm
and Hanson, Jacobson. ©2015 The Hollywood
Reporter. All rights reserved."""
input_ids = tokenizer(article, return_tensors="pt").input_ids
output_ids = model.generate(input_ids)[0]
print(tokenizer.decode(output_ids, skip_special_tokens=True))
# should output
# Fox is developing a two-hour remake of the 1975 cult classic. The special will be directed, executive-produced and choreographed by Kenneth Ortega.
# The special is timed to celebrate the 40th anniversary of the film, which has grossed more than $112 million.
```
|
michiyasunaga/LinkBERT-base
|
5b245d3b75fd6b739b2b699fdba02bd3abf49d53
|
2022-03-31T00:38:32.000Z
|
[
"pytorch",
"bert",
"feature-extraction",
"en",
"dataset:wikipedia",
"dataset:bookcorpus",
"arxiv:2203.15827",
"transformers",
"exbert",
"linkbert",
"fill-mask",
"question-answering",
"text-classification",
"token-classification",
"license:apache-2.0"
] |
text-classification
| false |
michiyasunaga
| null |
michiyasunaga/LinkBERT-base
| 430 | 2 |
transformers
| 2,481 |
---
license: apache-2.0
language: en
datasets:
- wikipedia
- bookcorpus
tags:
- bert
- exbert
- linkbert
- feature-extraction
- fill-mask
- question-answering
- text-classification
- token-classification
---
## LinkBERT-base
LinkBERT-base model pretrained on English Wikipedia articles along with hyperlink information. It is introduced in the paper [LinkBERT: Pretraining Language Models with Document Links (ACL 2022)](https://arxiv.org/abs/2203.15827). The code and data are available in [this repository](https://github.com/michiyasunaga/LinkBERT).
## Model description
LinkBERT is a transformer encoder (BERT-like) model pretrained on a large corpus of documents. It is an improvement of BERT that newly captures **document links** such as hyperlinks and citation links to include knowledge that spans across multiple documents. Specifically, it was pretrained by feeding linked documents into the same language model context, besides a single document.
LinkBERT can be used as a drop-in replacement for BERT. It achieves better performance for general language understanding tasks (e.g. text classification), and is also particularly effective for **knowledge-intensive** tasks (e.g. question answering) and **cross-document** tasks (e.g. reading comprehension, document retrieval).
## Intended uses & limitations
The model can be used by fine-tuning on a downstream task, such as question answering, sequence classification, and token classification.
You can also use the raw model for feature extraction (i.e. obtaining embeddings for input text).
### How to use
To use the model to get the features of a given text in PyTorch:
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained('michiyasunaga/LinkBERT-base')
model = AutoModel.from_pretrained('michiyasunaga/LinkBERT-base')
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state
```
For fine-tuning, you can use [this repository](https://github.com/michiyasunaga/LinkBERT) or follow any other BERT fine-tuning codebases.
## Evaluation results
When fine-tuned on downstream tasks, LinkBERT achieves the following results.
**General benchmarks ([MRQA](https://github.com/mrqa/MRQA-Shared-Task-2019) and [GLUE](https://gluebenchmark.com/)):**
| | HotpotQA | TriviaQA | SearchQA | NaturalQ | NewsQA | SQuAD | GLUE |
| ---------------------- | -------- | -------- | -------- | -------- | ------ | ----- | -------- |
| | F1 | F1 | F1 | F1 | F1 | F1 | Avg score |
| BERT-base | 76.0 | 70.3 | 74.2 | 76.5 | 65.7 | 88.7 | 79.2 |
| **LinkBERT-base** | **78.2** | **73.9** | **76.8** | **78.3** | **69.3** | **90.1** | **79.6** |
| BERT-large | 78.1 | 73.7 | 78.3 | 79.0 | 70.9 | 91.1 | 80.7 |
| **LinkBERT-large** | **80.8** | **78.2** | **80.5** | **81.0** | **72.6** | **92.7** | **81.1** |
## Citation
If you find LinkBERT useful in your project, please cite the following:
```bibtex
@InProceedings{yasunaga2022linkbert,
author = {Michihiro Yasunaga and Jure Leskovec and Percy Liang},
title = {LinkBERT: Pretraining Language Models with Document Links},
year = {2022},
booktitle = {Association for Computational Linguistics (ACL)},
}
```
|
kakife3586/BadEka
|
79a7b5746fa900db408c67864e6605775e9d4855
|
2022-07-30T04:07:32.000Z
|
[
"pytorch",
"gpt_neo",
"text-generation",
"transformers"
] |
text-generation
| false |
kakife3586
| null |
kakife3586/BadEka
| 430 | 1 |
transformers
| 2,482 |
Entry not found
|
Elron/bleurt-base-512
|
4f4abeeba7c29ded45fc90b8a66eb49c8569f587
|
2021-10-04T13:23:33.000Z
|
[
"pytorch",
"bert",
"text-classification",
"transformers"
] |
text-classification
| false |
Elron
| null |
Elron/bleurt-base-512
| 428 | 1 |
transformers
| 2,483 |
\n## BLEURT
Pytorch version of the original BLEURT models from ACL paper ["BLEURT: Learning Robust Metrics for Text Generation"](https://aclanthology.org/2020.acl-main.704/) by
Thibault Sellam, Dipanjan Das and Ankur P. Parikh of Google Research.
The code for model conversion was originated from [this notebook](https://colab.research.google.com/drive/1KsCUkFW45d5_ROSv2aHtXgeBa2Z98r03?usp=sharing) mentioned [here](https://github.com/huggingface/datasets/issues/224).
## Usage Example
```python
from transformers import AutoModelForSequenceClassification, AutoTokenizer
import torch
tokenizer = AutoTokenizer.from_pretrained("Elron/bleurt-base-512")
model = AutoModelForSequenceClassification.from_pretrained("Elron/bleurt-base-512")
model.eval()
references = ["hello world", "hello world"]
candidates = ["hi universe", "bye world"]
with torch.no_grad():
scores = model(**tokenizer(references, candidates, return_tensors='pt'))[0].squeeze()
print(scores) # tensor([1.0327, 0.2055])
```
|
crystina-z/xdpr-tied-msmarco
|
29e93fd7922297fed5187bb57c43c09f86b2560e
|
2022-05-16T23:02:08.000Z
|
[
"pytorch",
"xlm-roberta",
"feature-extraction",
"transformers"
] |
feature-extraction
| false |
crystina-z
| null |
crystina-z/xdpr-tied-msmarco
| 427 | null |
transformers
| 2,484 |
Entry not found
|
codegram/calbert-tiny-uncased
|
f5e29a94ba5944f2b57d211bbc8cdea6d774b236
|
2020-12-11T21:36:14.000Z
|
[
"pytorch",
"albert",
"ca",
"transformers",
"masked-lm",
"catalan",
"exbert",
"license:mit"
] | null | false |
codegram
| null |
codegram/calbert-tiny-uncased
| 426 | null |
transformers
| 2,485 |
---
language: "ca"
tags:
- masked-lm
- catalan
- exbert
license: mit
---
# Calbert: a Catalan Language Model
## Introduction
CALBERT is an open-source language model for Catalan pretrained on the ALBERT architecture.
It is now available on Hugging Face in its `tiny-uncased` version (the one you're looking at) and `base-uncased` as well, and was pretrained on the [OSCAR dataset](https://traces1.inria.fr/oscar/).
For further information or requests, please go to the [GitHub repository](https://github.com/codegram/calbert)
## Pre-trained models
| Model | Arch. | Training data |
| ----------------------------------- | -------------- | ---------------------- |
| `codegram` / `calbert-tiny-uncased` | Tiny (uncased) | OSCAR (4.3 GB of text) |
| `codegram` / `calbert-base-uncased` | Base (uncased) | OSCAR (4.3 GB of text) |
## How to use Calbert with HuggingFace
#### Load Calbert and its tokenizer:
```python
from transformers import AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("codegram/calbert-tiny-uncased")
model = AutoModel.from_pretrained("codegram/calbert-tiny-uncased")
model.eval() # disable dropout (or leave in train mode to finetune
```
#### Filling masks using pipeline
```python
from transformers import pipeline
calbert_fill_mask = pipeline("fill-mask", model="codegram/calbert-tiny-uncased", tokenizer="codegram/calbert-tiny-uncased")
results = calbert_fill_mask("M'agrada [MASK] això")
# results
# [{'sequence': "[CLS] m'agrada molt aixo[SEP]", 'score': 0.4403671622276306, 'token': 61},
# {'sequence': "[CLS] m'agrada més aixo[SEP]", 'score': 0.050061386078596115, 'token': 43},
# {'sequence': "[CLS] m'agrada veure aixo[SEP]", 'score': 0.026286985725164413, 'token': 157},
# {'sequence': "[CLS] m'agrada bastant aixo[SEP]", 'score': 0.022483550012111664, 'token': 2143},
# {'sequence': "[CLS] m'agrada moltíssim aixo[SEP]", 'score': 0.014491282403469086, 'token': 4867}]
```
#### Extract contextual embedding features from Calbert output
```python
import torch
# Tokenize in sub-words with SentencePiece
tokenized_sentence = tokenizer.tokenize("M'és una mica igual")
# ['▁m', "'", 'es', '▁una', '▁mica', '▁igual']
# 1-hot encode and add special starting and end tokens
encoded_sentence = tokenizer.encode(tokenized_sentence)
# [2, 109, 7, 71, 36, 371, 1103, 3]
# NB: Can be done in one step : tokenize.encode("M'és una mica igual")
# Feed tokens to Calbert as a torch tensor (batch dim 1)
encoded_sentence = torch.tensor(encoded_sentence).unsqueeze(0)
embeddings, _ = model(encoded_sentence)
embeddings.size()
# torch.Size([1, 8, 312])
embeddings.detach()
# tensor([[[-0.2726, -0.9855, 0.9643, ..., 0.3511, 0.3499, -0.1984],
# [-0.2824, -1.1693, -0.2365, ..., -3.1866, -0.9386, -1.3718],
# [-2.3645, -2.2477, -1.6985, ..., -1.4606, -2.7294, 0.2495],
# ...,
# [ 0.8800, -0.0244, -3.0446, ..., 0.5148, -3.0903, 1.1879],
# [ 1.1300, 0.2425, 0.2162, ..., -0.5722, -2.2004, 0.4045],
# [ 0.4549, -0.2378, -0.2290, ..., -2.1247, -2.2769, -0.0820]]])
```
## Authors
CALBERT was trained and evaluated by [Txus Bach](https://twitter.com/txustice), as part of [Codegram](https://www.codegram.com)'s applied research.
<a href="https://huggingface.co/exbert/?model=codegram/calbert-tiny-uncased&modelKind=bidirectional&sentence=M%27agradaria%20força%20saber-ne%20més">
<img width="300px" src="https://cdn-media.huggingface.co/exbert/button.png">
</a>
|
digit82/kolang-t5-base
|
73e6db9cc164510c94c08195987ffd693897af4a
|
2021-05-20T01:04:25.000Z
|
[
"pytorch",
"t5",
"text2text-generation",
"transformers",
"autotrain_compatible"
] |
text2text-generation
| false |
digit82
| null |
digit82/kolang-t5-base
| 426 | null |
transformers
| 2,486 |
Entry not found
|
ktrapeznikov/gpt2-medium-topic-news-v2
|
3a2d72aa8fc6b56e56238cadec20f0c7fa4c74dd
|
2021-05-23T06:14:58.000Z
|
[
"pytorch",
"jax",
"gpt2",
"text-generation",
"transformers"
] |
text-generation
| false |
ktrapeznikov
| null |
ktrapeznikov/gpt2-medium-topic-news-v2
| 426 | 1 |
transformers
| 2,487 |
---
language:
- en
thumbnail:
widget:
- text: "topic climate source washington post title "
---
# GPT2-medium-topic-news
## Model description
GPT2-medium fine tuned on a largish news corpus conditioned on a topic, source, title
## Intended uses & limitations
#### How to use
To generate a news article text conditioned on a topic, source, title or some subsets, prompt model with:
```python
f"topic {topic} source"
f"topic {topic} source {source} title"
f"topic {topic} source {source} title {title} body"
```
Try the following tags for `topic: climate, weather, vaccination`.
Zero shot generation works pretty well as long as `topic` is a single word and not too specific.
```python
device = "cuda:0"
tokenizer = AutoTokenizer.from_pretrained("ktrapeznikov/gpt2-medium-topic-small-set")
model = AutoModelWithLMHead.from_pretrained("ktrapeznikov/gpt2-medium-topic-small-set")
model.to(device)
topic = "climate"
prompt = tokenizer(f"topic {topics} source straitstimes title", return_tensors="pt")
out = model.generate(prompt["input_ids"].to(device), do_sample=True,max_length=500, early_stopping=True, top_p=.9)
print(tokenizer.decode(out[0].cpu(), skip_special_tokens=True))
```
|
allenai/wmt16-en-de-dist-12-1
|
0969ea66b79ae8a2516de3143f7e699ed77d5e3d
|
2020-12-11T21:33:20.000Z
|
[
"pytorch",
"fsmt",
"text2text-generation",
"en",
"de",
"dataset:wmt16",
"arxiv:2006.10369",
"transformers",
"translation",
"wmt16",
"allenai",
"license:apache-2.0",
"autotrain_compatible"
] |
translation
| false |
allenai
| null |
allenai/wmt16-en-de-dist-12-1
| 425 | null |
transformers
| 2,488 |
---
language:
- en
- de
thumbnail:
tags:
- translation
- wmt16
- allenai
license: apache-2.0
datasets:
- wmt16
metrics:
- bleu
---
# FSMT
## Model description
This is a ported version of fairseq-based [wmt16 transformer](https://github.com/jungokasai/deep-shallow/) for en-de.
For more details, please, see [Deep Encoder, Shallow Decoder: Reevaluating the Speed-Quality Tradeoff in Machine Translation](https://arxiv.org/abs/2006.10369).
All 3 models are available:
* [wmt16-en-de-dist-12-1](https://huggingface.co/allenai/wmt16-en-de-dist-12-1)
* [wmt16-en-de-dist-6-1](https://huggingface.co/allenai/wmt16-en-de-dist-6-1)
* [wmt16-en-de-12-1](https://huggingface.co/allenai/wmt16-en-de-12-1)
## Intended uses & limitations
#### How to use
```python
from transformers import FSMTForConditionalGeneration, FSMTTokenizer
mname = "allenai/wmt16-en-de-dist-12-1"
tokenizer = FSMTTokenizer.from_pretrained(mname)
model = FSMTForConditionalGeneration.from_pretrained(mname)
input = "Machine learning is great, isn't it?"
input_ids = tokenizer.encode(input, return_tensors="pt")
outputs = model.generate(input_ids)
decoded = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(decoded) # Maschinelles Lernen ist großartig, nicht wahr?
```
#### Limitations and bias
## Training data
Pretrained weights were left identical to the original model released by allenai. For more details, please, see the [paper](https://arxiv.org/abs/2006.10369).
## Eval results
Here are the BLEU scores:
model | fairseq | transformers
-------|---------|----------
wmt16-en-de-dist-12-1 | 28.3 | 27.52
The score is slightly below the score reported in the paper, as the researchers don't use `sacrebleu` and measure the score on tokenized outputs. `transformers` score was measured using `sacrebleu` on detokenized outputs.
The score was calculated using this code:
```bash
git clone https://github.com/huggingface/transformers
cd transformers
export PAIR=en-de
export DATA_DIR=data/$PAIR
export SAVE_DIR=data/$PAIR
export BS=8
export NUM_BEAMS=5
mkdir -p $DATA_DIR
sacrebleu -t wmt16 -l $PAIR --echo src > $DATA_DIR/val.source
sacrebleu -t wmt16 -l $PAIR --echo ref > $DATA_DIR/val.target
echo $PAIR
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval.py allenai/wmt16-en-de-dist-12-1 $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --num_beams $NUM_BEAMS
```
## Data Sources
- [training, etc.](http://www.statmt.org/wmt16/)
- [test set](http://matrix.statmt.org/test_sets/newstest2016.tgz?1504722372)
### BibTeX entry and citation info
```
@misc{kasai2020deep,
title={Deep Encoder, Shallow Decoder: Reevaluating the Speed-Quality Tradeoff in Machine Translation},
author={Jungo Kasai and Nikolaos Pappas and Hao Peng and James Cross and Noah A. Smith},
year={2020},
eprint={2006.10369},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
healx/biomedical-slot-filling-reader-large
|
52f5d59225e06057329246cf3e0d074b2b2ed9c2
|
2021-11-16T09:15:15.000Z
|
[
"pytorch",
"bert",
"question-answering",
"arxiv:2109.08564",
"transformers",
"autotrain_compatible"
] |
question-answering
| false |
healx
| null |
healx/biomedical-slot-filling-reader-large
| 425 | null |
transformers
| 2,489 |
Reader model for Biomedical slot filling see https://arxiv.org/abs/2109.08564 for details. The model is initialized with [biobert-large](https://huggingface.co/dmis-lab/biobert-large-cased-v1.1).
|
Radicalkiddo/DialoGPT-small-Radical
|
d75bae5d849c3e04d075cfa1ef0edb0a1ecf57d7
|
2022-02-18T23:21:39.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
| false |
Radicalkiddo
| null |
Radicalkiddo/DialoGPT-small-Radical
| 424 | null |
transformers
| 2,490 |
---
tags:
- conversational
---
# radical DialoGPT Model
|
monologg/koelectra-small-finetuned-nsmc
|
6eddccf6902f2d806fbdf99d6cd52d81dcc4d49a
|
2020-08-18T18:43:17.000Z
|
[
"pytorch",
"electra",
"text-classification",
"transformers"
] |
text-classification
| false |
monologg
| null |
monologg/koelectra-small-finetuned-nsmc
| 424 | null |
transformers
| 2,491 |
Entry not found
|
ml6team/keyphrase-extraction-distilbert-inspec
|
d7a71e220849b5f578f83a847d3b2ec1f5101a69
|
2022-06-16T14:20:55.000Z
|
[
"pytorch",
"distilbert",
"token-classification",
"en",
"dataset:midas/inspec",
"transformers",
"keyphrase-extraction",
"license:mit",
"model-index",
"autotrain_compatible"
] |
token-classification
| false |
ml6team
| null |
ml6team/keyphrase-extraction-distilbert-inspec
| 424 | null |
transformers
| 2,492 |
---
language: en
license: mit
tags:
- keyphrase-extraction
datasets:
- midas/inspec
metrics:
- seqeval
widget:
- text: "Keyphrase extraction is a technique in text analysis where you extract the important keyphrases from a document.
Thanks to these keyphrases humans can understand the content of a text very quickly and easily without reading
it completely. Keyphrase extraction was first done primarily by human annotators, who read the text in detail
and then wrote down the most important keyphrases. The disadvantage is that if you work with a lot of documents,
this process can take a lot of time.
Here is where Artificial Intelligence comes in. Currently, classical machine learning methods, that use statistical
and linguistic features, are widely used for the extraction process. Now with deep learning, it is possible to capture
the semantic meaning of a text even better than these classical methods. Classical methods look at the frequency,
occurrence and order of words in the text, whereas these neural approaches can capture long-term semantic dependencies
and context of words in a text."
example_title: "Example 1"
- text: "In this work, we explore how to learn task specific language models aimed towards learning rich representation of keyphrases from text documents. We experiment with different masking strategies for pre-training transformer language models (LMs) in discriminative as well as generative settings. In the discriminative setting, we introduce a new pre-training objective - Keyphrase Boundary Infilling with Replacement (KBIR), showing large gains in performance (up to 9.26 points in F1) over SOTA, when LM pre-trained using KBIR is fine-tuned for the task of keyphrase extraction. In the generative setting, we introduce a new pre-training setup for BART - KeyBART, that reproduces the keyphrases related to the input text in the CatSeq format, instead of the denoised original input. This also led to gains in performance (up to 4.33 points inF1@M) over SOTA for keyphrase generation. Additionally, we also fine-tune the pre-trained language models on named entity recognition(NER), question answering (QA), relation extraction (RE), abstractive summarization and achieve comparable performance with that of the SOTA, showing that learning rich representation of keyphrases is indeed beneficial for many other fundamental NLP tasks."
example_title: "Example 2"
model-index:
- name: DeDeckerThomas/keyphrase-extraction-distilbert-inspec
results:
- task:
type: keyphrase-extraction
name: Keyphrase Extraction
dataset:
type: midas/inspec
name: inspec
metrics:
- type: F1 (Seqeval)
value: 0.509
name: F1 (Seqeval)
- type: F1@M
value: 0.490
name: F1@M
---
# 🔑 Keyphrase Extraction Model: distilbert-inspec
Keyphrase extraction is a technique in text analysis where you extract the important keyphrases from a document. Thanks to these keyphrases humans can understand the content of a text very quickly and easily without reading it completely. Keyphrase extraction was first done primarily by human annotators, who read the text in detail and then wrote down the most important keyphrases. The disadvantage is that if you work with a lot of documents, this process can take a lot of time ⏳.
Here is where Artificial Intelligence 🤖 comes in. Currently, classical machine learning methods, that use statistical and linguistic features, are widely used for the extraction process. Now with deep learning, it is possible to capture the semantic meaning of a text even better than these classical methods. Classical methods look at the frequency, occurrence and order of words in the text, whereas these neural approaches can capture long-term semantic dependencies and context of words in a text.
## 📓 Model Description
This model uses [distilbert](https://huggingface.co/distilbert-base-uncased) as its base model and fine-tunes it on the [Inspec dataset](https://huggingface.co/datasets/midas/inspec).
Keyphrase extraction models are transformer models fine-tuned as a token classification problem where each word in the document is classified as being part of a keyphrase or not.
| Label | Description |
| ----- | ------------------------------- |
| B-KEY | At the beginning of a keyphrase |
| I-KEY | Inside a keyphrase |
| O | Outside a keyphrase |
Kulkarni, Mayank, Debanjan Mahata, Ravneet Arora, and Rajarshi Bhowmik. "Learning Rich Representation of Keyphrases from Text." arXiv preprint arXiv:2112.08547 (2021).
Sahrawat, Dhruva, Debanjan Mahata, Haimin Zhang, Mayank Kulkarni, Agniv Sharma, Rakesh Gosangi, Amanda Stent, Yaman Kumar, Rajiv Ratn Shah, and Roger Zimmermann. "Keyphrase extraction as sequence labeling using contextualized embeddings." In European Conference on Information Retrieval, pp. 328-335. Springer, Cham, 2020.
## ✋ Intended Uses & Limitations
### 🛑 Limitations
* This keyphrase extraction model is very domain-specific and will perform very well on abstracts of scientific papers. It's not recommended to use this model for other domains, but you are free to test it out.
* Only works for English documents.
* For a custom model, please consult the [training notebook]() for more information.
### ❓ How To Use
```python
from transformers import (
TokenClassificationPipeline,
AutoModelForTokenClassification,
AutoTokenizer,
)
from transformers.pipelines import AggregationStrategy
import numpy as np
# Define keyphrase extraction pipeline
class KeyphraseExtractionPipeline(TokenClassificationPipeline):
def __init__(self, model, *args, **kwargs):
super().__init__(
model=AutoModelForTokenClassification.from_pretrained(model),
tokenizer=AutoTokenizer.from_pretrained(model),
*args,
**kwargs
)
def postprocess(self, model_outputs):
results = super().postprocess(
model_outputs=model_outputs,
aggregation_strategy=AggregationStrategy.FIRST,
)
return np.unique([result.get("word").strip() for result in results])
```
```python
# Load pipeline
model_name = "ml6team/keyphrase-extraction-distilbert-inspec"
extractor = KeyphraseExtractionPipeline(model=model_name)
```
```python
# Inference
text = """
Keyphrase extraction is a technique in text analysis where you extract the
important keyphrases from a document. Thanks to these keyphrases humans can
understand the content of a text very quickly and easily without reading it
completely. Keyphrase extraction was first done primarily by human annotators,
who read the text in detail and then wrote down the most important keyphrases.
The disadvantage is that if you work with a lot of documents, this process
can take a lot of time.
Here is where Artificial Intelligence comes in. Currently, classical machine
learning methods, that use statistical and linguistic features, are widely used
for the extraction process. Now with deep learning, it is possible to capture
the semantic meaning of a text even better than these classical methods.
Classical methods look at the frequency, occurrence and order of words
in the text, whereas these neural approaches can capture long-term
semantic dependencies and context of words in a text.
""".replace("\n", " ")
keyphrases = extractor(text)
print(keyphrases)
```
```
# Output
['artificial intelligence' 'classical machine learning' 'deep learning'
'keyphrase extraction' 'linguistic features' 'statistical'
'text analysis']
```
## 📚 Training Dataset
[Inspec](https://huggingface.co/datasets/midas/inspec) is a keyphrase extraction/generation dataset consisting of 2000 English scientific papers from the scientific domains of Computers and Control and Information Technology published between 1998 to 2002. The keyphrases are annotated by professional indexers or editors.
You can find more information in the [paper](https://dl.acm.org/doi/10.3115/1119355.1119383).
## 👷♂️ Training Procedure
For more in detail information, you can take a look at the [training notebook]().
### Training Parameters
| Parameter | Value |
| --------- | ------|
| Learning Rate | 1e-4 |
| Epochs | 50 |
| Early Stopping Patience | 3 |
### Preprocessing
The documents in the dataset are already preprocessed into list of words with the corresponding labels. The only thing that must be done is tokenization and the realignment of the labels so that they correspond with the right subword tokens.
```python
from datasets import load_dataset
from transformers import AutoTokenizer
# Labels
label_list = ["B", "I", "O"]
lbl2idx = {"B": 0, "I": 1, "O": 2}
idx2label = {0: "B", 1: "I", 2: "O"}
# Tokenizer
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
max_length = 512
# Dataset parameters
dataset_full_name = "midas/inspec"
dataset_subset = "raw"
dataset_document_column = "document"
dataset_biotags_column = "doc_bio_tags"
def preprocess_fuction(all_samples_per_split):
tokenized_samples = tokenizer.batch_encode_plus(
all_samples_per_split[dataset_document_column],
padding="max_length",
truncation=True,
is_split_into_words=True,
max_length=max_length,
)
total_adjusted_labels = []
for k in range(0, len(tokenized_samples["input_ids"])):
prev_wid = -1
word_ids_list = tokenized_samples.word_ids(batch_index=k)
existing_label_ids = all_samples_per_split[dataset_biotags_column][k]
i = -1
adjusted_label_ids = []
for wid in word_ids_list:
if wid is None:
adjusted_label_ids.append(lbl2idx["O"])
elif wid != prev_wid:
i = i + 1
adjusted_label_ids.append(lbl2idx[existing_label_ids[i]])
prev_wid = wid
else:
adjusted_label_ids.append(
lbl2idx[
f"{'I' if existing_label_ids[i] == 'B' else existing_label_ids[i]}"
]
)
total_adjusted_labels.append(adjusted_label_ids)
tokenized_samples["labels"] = total_adjusted_labels
return tokenized_samples
# Load dataset
dataset = load_dataset(dataset_full_name, dataset_subset)
# Preprocess dataset
tokenized_dataset = dataset.map(preprocess_fuction, batched=True)
```
### Postprocessing (Without Pipeline Function)
If you do not use the pipeline function, you must filter out the B and I labeled tokens. Each B and I will then be merged into a keyphrase. Finally, you need to strip the keyphrases to make sure all unnecessary spaces have been removed.
```python
# Define post_process functions
def concat_tokens_by_tag(keyphrases):
keyphrase_tokens = []
for id, label in keyphrases:
if label == "B":
keyphrase_tokens.append([id])
elif label == "I":
if len(keyphrase_tokens) > 0:
keyphrase_tokens[len(keyphrase_tokens) - 1].append(id)
return keyphrase_tokens
def extract_keyphrases(example, predictions, tokenizer, index=0):
keyphrases_list = [
(id, idx2label[label])
for id, label in zip(
np.array(example["input_ids"]).squeeze().tolist(), predictions[index]
)
if idx2label[label] in ["B", "I"]
]
processed_keyphrases = concat_tokens_by_tag(keyphrases_list)
extracted_kps = tokenizer.batch_decode(
processed_keyphrases,
skip_special_tokens=True,
clean_up_tokenization_spaces=True,
)
return np.unique([kp.strip() for kp in extracted_kps])
```
## 📝 Evaluation Results
Traditional evaluation methods are the precision, recall and F1-score @k,m where k is the number that stands for the first k predicted keyphrases and m for the average amount of predicted keyphrases.
The model achieves the following results on the Inspec test set:
| Dataset | P@5 | R@5 | F1@5 | P@10 | R@10 | F1@10 | P@M | R@M | F1@M |
|:-----------------:|:----:|:----:|:----:|:----:|:----:|:-----:|:----:|:----:|:----:|
| Inspec Test Set | 0.45 | 0.40 | 0.39 | 0.33 | 0.53 | 0.38 | 0.47 | 0.57 | 0.49 |
For more information on the evaluation process, you can take a look at the keyphrase extraction [evaluation notebook]().
## 🚨 Issues
Please feel free to start discussions in the Community Tab.
|
yechen/bert-base-chinese
|
2d43912ed8aa6d7bd7bc132645fa0580f7106ce7
|
2021-05-01T04:00:07.000Z
|
[
"pytorch",
"tf",
"fill-mask",
"zh",
"transformers",
"autotrain_compatible"
] |
fill-mask
| false |
yechen
| null |
yechen/bert-base-chinese
| 423 | null |
transformers
| 2,493 |
---
language: zh
---
|
cambridgeltl/mirror-bert-base-uncased-word
|
c48c66ea6cbaa1c97590fee2c0cefef6e38f1fe9
|
2021-09-29T23:04:29.000Z
|
[
"pytorch",
"bert",
"feature-extraction",
"arxiv:2104.08027",
"transformers"
] |
feature-extraction
| false |
cambridgeltl
| null |
cambridgeltl/mirror-bert-base-uncased-word
| 422 | 1 |
transformers
| 2,494 |
---
language: en
tags:
- word-embeddings
- word-similarity
### mirror-bert-base-uncased-word
An unsupervised word encoder proposed by [Liu et al. (2021)](https://arxiv.org/pdf/2104.08027.pdf). Trained with a set of unlabelled words, using [bert-base-uncased](https://huggingface.co/bert-base-uncased) as the base model. Please use `[CLS]` as the representation of the input.
### Citation
```bibtex
@inproceedings{
liu2021fast,
title={Fast, Effective and Self-Supervised: Transforming Masked LanguageModels into Universal Lexical and Sentence Encoders},
author={Liu, Fangyu and Vuli{\'c}, Ivan and Korhonen, Anna and Collier, Nigel},
booktitle={EMNLP 2021},
year={2021}
}
```
|
cardiffnlp/bertweet-base-sentiment
|
087bddb2a452eb364661dee2872adece27d9697c
|
2021-05-20T14:50:57.000Z
|
[
"pytorch",
"tf",
"jax",
"roberta",
"text-classification",
"transformers"
] |
text-classification
| false |
cardiffnlp
| null |
cardiffnlp/bertweet-base-sentiment
| 421 | null |
transformers
| 2,495 | |
Helsinki-NLP/opus-mt-tc-big-ar-en
|
4bcf62f599694f87ef20d85b358575d108cd785b
|
2022-06-01T12:59:27.000Z
|
[
"pytorch",
"marian",
"text2text-generation",
"ar",
"en",
"transformers",
"translation",
"opus-mt-tc",
"license:cc-by-4.0",
"model-index",
"autotrain_compatible"
] |
translation
| false |
Helsinki-NLP
| null |
Helsinki-NLP/opus-mt-tc-big-ar-en
| 421 | null |
transformers
| 2,496 |
---
language:
- ar
- en
tags:
- translation
- opus-mt-tc
license: cc-by-4.0
model-index:
- name: opus-mt-tc-big-ar-en
results:
- task:
name: Translation ara-eng
type: translation
args: ara-eng
dataset:
name: flores101-devtest
type: flores_101
args: ara eng devtest
metrics:
- name: BLEU
type: bleu
value: 42.6
- task:
name: Translation ara-eng
type: translation
args: ara-eng
dataset:
name: tatoeba-test-v2021-08-07
type: tatoeba_mt
args: ara-eng
metrics:
- name: BLEU
type: bleu
value: 47.3
- task:
name: Translation ara-eng
type: translation
args: ara-eng
dataset:
name: tico19-test
type: tico19-test
args: ara-eng
metrics:
- name: BLEU
type: bleu
value: 44.4
---
# opus-mt-tc-big-ar-en
Neural machine translation model for translating from Arabic (ar) to English (en).
This model is part of the [OPUS-MT project](https://github.com/Helsinki-NLP/Opus-MT), an effort to make neural machine translation models widely available and accessible for many languages in the world. All models are originally trained using the amazing framework of [Marian NMT](https://marian-nmt.github.io/), an efficient NMT implementation written in pure C++. The models have been converted to pyTorch using the transformers library by huggingface. Training data is taken from [OPUS](https://opus.nlpl.eu/) and training pipelines use the procedures of [OPUS-MT-train](https://github.com/Helsinki-NLP/Opus-MT-train).
* Publications: [OPUS-MT – Building open translation services for the World](https://aclanthology.org/2020.eamt-1.61/) and [The Tatoeba Translation Challenge – Realistic Data Sets for Low Resource and Multilingual MT](https://aclanthology.org/2020.wmt-1.139/) (Please, cite if you use this model.)
```
@inproceedings{tiedemann-thottingal-2020-opus,
title = "{OPUS}-{MT} {--} Building open translation services for the World",
author = {Tiedemann, J{\"o}rg and Thottingal, Santhosh},
booktitle = "Proceedings of the 22nd Annual Conference of the European Association for Machine Translation",
month = nov,
year = "2020",
address = "Lisboa, Portugal",
publisher = "European Association for Machine Translation",
url = "https://aclanthology.org/2020.eamt-1.61",
pages = "479--480",
}
@inproceedings{tiedemann-2020-tatoeba,
title = "The Tatoeba Translation Challenge {--} Realistic Data Sets for Low Resource and Multilingual {MT}",
author = {Tiedemann, J{\"o}rg},
booktitle = "Proceedings of the Fifth Conference on Machine Translation",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.wmt-1.139",
pages = "1174--1182",
}
```
## Model info
* Release: 2022-03-09
* source language(s): afb ara arz
* target language(s): eng
* model: transformer-big
* data: opusTCv20210807+bt ([source](https://github.com/Helsinki-NLP/Tatoeba-Challenge))
* tokenization: SentencePiece (spm32k,spm32k)
* original model: [opusTCv20210807+bt_transformer-big_2022-03-09.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/ara-eng/opusTCv20210807+bt_transformer-big_2022-03-09.zip)
* more information released models: [OPUS-MT ara-eng README](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/ara-eng/README.md)
## Usage
A short example code:
```python
from transformers import MarianMTModel, MarianTokenizer
src_text = [
"اتبع قلبك فحسب.",
"وين راهي دّوش؟"
]
model_name = "pytorch-models/opus-mt-tc-big-ar-en"
tokenizer = MarianTokenizer.from_pretrained(model_name)
model = MarianMTModel.from_pretrained(model_name)
translated = model.generate(**tokenizer(src_text, return_tensors="pt", padding=True))
for t in translated:
print( tokenizer.decode(t, skip_special_tokens=True) )
# expected output:
# Just follow your heart.
# Wayne Rahi Dosh?
```
You can also use OPUS-MT models with the transformers pipelines, for example:
```python
from transformers import pipeline
pipe = pipeline("translation", model="Helsinki-NLP/opus-mt-tc-big-ar-en")
print(pipe("اتبع قلبك فحسب."))
# expected output: Just follow your heart.
```
## Benchmarks
* test set translations: [opusTCv20210807+bt_transformer-big_2022-03-09.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/ara-eng/opusTCv20210807+bt_transformer-big_2022-03-09.test.txt)
* test set scores: [opusTCv20210807+bt_transformer-big_2022-03-09.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/ara-eng/opusTCv20210807+bt_transformer-big_2022-03-09.eval.txt)
* benchmark results: [benchmark_results.txt](benchmark_results.txt)
* benchmark output: [benchmark_translations.zip](benchmark_translations.zip)
| langpair | testset | chr-F | BLEU | #sent | #words |
|----------|---------|-------|-------|-------|--------|
| ara-eng | tatoeba-test-v2021-08-07 | 0.63477 | 47.3 | 10305 | 76975 |
| ara-eng | flores101-devtest | 0.66987 | 42.6 | 1012 | 24721 |
| ara-eng | tico19-test | 0.68521 | 44.4 | 2100 | 56323 |
## Acknowledgements
The work is supported by the [European Language Grid](https://www.european-language-grid.eu/) as [pilot project 2866](https://live.european-language-grid.eu/catalogue/#/resource/projects/2866), by the [FoTran project](https://www.helsinki.fi/en/researchgroups/natural-language-understanding-with-cross-lingual-grounding), funded by the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (grant agreement No 771113), and the [MeMAD project](https://memad.eu/), funded by the European Union’s Horizon 2020 Research and Innovation Programme under grant agreement No 780069. We are also grateful for the generous computational resources and IT infrastructure provided by [CSC -- IT Center for Science](https://www.csc.fi/), Finland.
## Model conversion info
* transformers version: 4.16.2
* OPUS-MT git hash: 3405783
* port time: Wed Apr 13 18:17:57 EEST 2022
* port machine: LM0-400-22516.local
|
uclanlp/plbart-csnet
|
eb9f06eb49af981a7bde3f367b60e0e82f1faaf6
|
2021-11-23T18:12:21.000Z
|
[
"pytorch",
"plbart",
"text2text-generation",
"transformers",
"autotrain_compatible"
] |
text2text-generation
| false |
uclanlp
| null |
uclanlp/plbart-csnet
| 420 | null |
transformers
| 2,497 |
Entry not found
|
ionite/DialoGPT-medium-McKayAI-v2
|
cbd031405701f164e06a626d63b90f2c569e7412
|
2021-11-20T04:49:17.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
| false |
ionite
| null |
ionite/DialoGPT-medium-McKayAI-v2
| 419 | null |
transformers
| 2,498 |
---
tags:
- conversational
---
# McKayAI DialoGPT Model
|
pucpr/clinicalnerpt-disease
|
936144a59fed6848f290f24a625b77d258026edb
|
2021-10-13T09:33:02.000Z
|
[
"pytorch",
"bert",
"token-classification",
"pt",
"dataset:SemClinBr",
"transformers",
"autotrain_compatible"
] |
token-classification
| false |
pucpr
| null |
pucpr/clinicalnerpt-disease
| 419 | 5 |
transformers
| 2,499 |
---
language: "pt"
widget:
- text: "DEVIDO AO FATO DE TER DPOC E APRESENTADO DISFUNÇÃO RESPIRATÓRIA AGUDA COM INFILTRADO PULMONAR EM BASE DIREITA"
- text: "Paciente com Sepse pulmonar em D8 tazocin (paciente não recebeu por 2 dias Atb)."
datasets:
- SemClinBr
thumbnail: "https://raw.githubusercontent.com/HAILab-PUCPR/BioBERTpt/master/images/logo-biobertpr1.png"
---
<img src="https://raw.githubusercontent.com/HAILab-PUCPR/BioBERTpt/master/images/logo-biobertpr1.png" alt="Logo BioBERTpt">
# Portuguese Clinical NER - Disease
The Disease NER model is part of the [BioBERTpt project](https://www.aclweb.org/anthology/2020.clinicalnlp-1.7/), where 13 models of clinical entities (compatible with UMLS) were trained. All NER model from "pucpr" user was trained from the Brazilian clinical corpus [SemClinBr](https://github.com/HAILab-PUCPR/SemClinBr), with 10 epochs and IOB2 format, from BioBERTpt(all) model.
## Acknowledgements
This study was financed in part by the Coordenação de Aperfeiçoamento de Pessoal de Nível Superior - Brasil (CAPES) - Finance Code 001.
## Citation
```
@inproceedings{schneider-etal-2020-biobertpt,
title = "{B}io{BERT}pt - A {P}ortuguese Neural Language Model for Clinical Named Entity Recognition",
author = "Schneider, Elisa Terumi Rubel and
de Souza, Jo{\~a}o Vitor Andrioli and
Knafou, Julien and
Oliveira, Lucas Emanuel Silva e and
Copara, Jenny and
Gumiel, Yohan Bonescki and
Oliveira, Lucas Ferro Antunes de and
Paraiso, Emerson Cabrera and
Teodoro, Douglas and
Barra, Cl{\'a}udia Maria Cabral Moro",
booktitle = "Proceedings of the 3rd Clinical Natural Language Processing Workshop",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.clinicalnlp-1.7",
pages = "65--72",
abstract = "With the growing number of electronic health record data, clinical NLP tasks have become increasingly relevant to unlock valuable information from unstructured clinical text. Although the performance of downstream NLP tasks, such as named-entity recognition (NER), in English corpus has recently improved by contextualised language models, less research is available for clinical texts in low resource languages. Our goal is to assess a deep contextual embedding model for Portuguese, so called BioBERTpt, to support clinical and biomedical NER. We transfer learned information encoded in a multilingual-BERT model to a corpora of clinical narratives and biomedical-scientific papers in Brazilian Portuguese. To evaluate the performance of BioBERTpt, we ran NER experiments on two annotated corpora containing clinical narratives and compared the results with existing BERT models. Our in-domain model outperformed the baseline model in F1-score by 2.72{\%}, achieving higher performance in 11 out of 13 assessed entities. We demonstrate that enriching contextual embedding models with domain literature can play an important role in improving performance for specific NLP tasks. The transfer learning process enhanced the Portuguese biomedical NER model by reducing the necessity of labeled data and the demand for retraining a whole new model.",
}
```
## Questions?
Post a Github issue on the [BioBERTpt repo](https://github.com/HAILab-PUCPR/BioBERTpt).
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.