
modelId
stringlengths 4
112
| sha
stringlengths 40
40
| lastModified
stringlengths 24
24
| tags
list | pipeline_tag
stringclasses 29
values | private
bool 1
class | author
stringlengths 2
38
⌀ | config
null | id
stringlengths 4
112
| downloads
float64 0
36.8M
⌀ | likes
float64 0
712
⌀ | library_name
stringclasses 17
values | __index_level_0__
int64 0
38.5k
| readme
stringlengths 0
186k
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
gchhablani/bert-base-cased-finetuned-mrpc
|
cdece3698f342cc94478a61128f719df7229580b
|
2021-09-20T09:07:44.000Z
|
[
"pytorch",
"tensorboard",
"bert",
"text-classification",
"en",
"dataset:glue",
"arxiv:2105.03824",
"transformers",
"generated_from_trainer",
"fnet-bert-base-comparison",
"license:apache-2.0",
"model-index"
] |
text-classification
| false |
gchhablani
| null |
gchhablani/bert-base-cased-finetuned-mrpc
| 575 | null |
transformers
| 2,200 |
---
language:
- en
license: apache-2.0
tags:
- generated_from_trainer
- fnet-bert-base-comparison
datasets:
- glue
metrics:
- accuracy
- f1
model-index:
- name: bert-base-cased-finetuned-mrpc
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: GLUE MRPC
type: glue
args: mrpc
metrics:
- name: Accuracy
type: accuracy
value: 0.8602941176470589
- name: F1
type: f1
value: 0.9025641025641027
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-cased-finetuned-mrpc
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the GLUE MRPC dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7132
- Accuracy: 0.8603
- F1: 0.9026
- Combined Score: 0.8814
The model was fine-tuned to compare [google/fnet-base](https://huggingface.co/google/fnet-base) as introduced in [this paper](https://arxiv.org/abs/2105.03824) against [bert-base-cased](https://huggingface.co/bert-base-cased).
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
This model is trained using the [run_glue](https://github.com/huggingface/transformers/blob/master/examples/pytorch/text-classification/run_glue.py) script. The following command was used:
```bash
#!/usr/bin/bash
python ../run_glue.py \\n --model_name_or_path bert-base-cased \\n --task_name mrpc \\n --do_train \\n --do_eval \\n --max_seq_length 512 \\n --per_device_train_batch_size 16 \\n --learning_rate 2e-5 \\n --num_train_epochs 5 \\n --output_dir bert-base-cased-finetuned-mrpc \\n --push_to_hub \\n --hub_strategy all_checkpoints \\n --logging_strategy epoch \\n --save_strategy epoch \\n --evaluation_strategy epoch \\n```
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Combined Score |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:--------------:|
| 0.5981 | 1.0 | 230 | 0.4580 | 0.7892 | 0.8562 | 0.8227 |
| 0.3739 | 2.0 | 460 | 0.3806 | 0.8480 | 0.8942 | 0.8711 |
| 0.1991 | 3.0 | 690 | 0.4879 | 0.8529 | 0.8958 | 0.8744 |
| 0.1286 | 4.0 | 920 | 0.6342 | 0.8529 | 0.8986 | 0.8758 |
| 0.0812 | 5.0 | 1150 | 0.7132 | 0.8603 | 0.9026 | 0.8814 |
### Framework versions
- Transformers 4.11.0.dev0
- Pytorch 1.9.0
- Datasets 1.12.1
- Tokenizers 0.10.3
|
voidful/bart-distractor-generation-pm
|
ab4250ce4b6d339654263b3c4625ed69bbc38173
|
2021-04-04T16:20:25.000Z
|
[
"pytorch",
"bart",
"text2text-generation",
"en",
"dataset:race",
"transformers",
"distractor",
"generation",
"seq2seq",
"autotrain_compatible"
] |
text2text-generation
| false |
voidful
| null |
voidful/bart-distractor-generation-pm
| 575 | null |
transformers
| 2,201 |
---
language: en
tags:
- bart
- distractor
- generation
- seq2seq
datasets:
- race
metrics:
- bleu
- rouge
pipeline_tag: text2text-generation
widget:
- text: "When you ' re having a holiday , one of the main questions to ask is which hotel or apartment to choose . However , when it comes to France , you have another special choice : treehouses . In France , treehouses are offered to travelers as a new choice in many places . The price may be a little higher , but you do have a chance to _ your childhood memories . Alain Laurens , one of France ' s top treehouse designers , said , ' Most of the people might have the experience of building a den when they were young . And they like that feeling of freedom when they are children . ' Its fairy - tale style gives travelers a special feeling . It seems as if they are living as a forest king and enjoying the fresh air in the morning . Another kind of treehouse is the ' star cube ' . It gives travelers the chance of looking at the stars shining in the sky when they are going to sleep . Each ' star cube ' not only offers all the comfortable things that a hotel provides for travelers , but also gives them a chance to look for stars by using a telescope . The glass roof allows you to look at the stars from your bed . </s> The passage mainly tells us </s> treehouses in france."
---
# bart-distractor-generation-pm
## Model description
This model is a sequence-to-sequence distractor generator which takes an answer, question and context as an input, and generates a distractor as an output. It is based on a pretrained `bart-base` model.
This model trained with Parallel MLM refer to the [Paper](https://www.aclweb.org/anthology/2020.findings-emnlp.393/).
For details, please see https://github.com/voidful/BDG.
## Intended uses & limitations
The model is trained to generate examinations-style multiple choice distractor. The model performs best with full sentence answers.
#### How to use
The model takes concatenated context, question and answers as an input sequence, and will generate a full distractor sentence as an output sequence. The max sequence length is 1024 tokens. Inputs should be organised into the following format:
```
context </s> question </s> answer
```
The input sequence can then be encoded and passed as the `input_ids` argument in the model's `generate()` method.
#### Limitations and bias
The model is limited to generating distractor in the same style as those found in [RACE](https://www.aclweb.org/anthology/D17-1082/). The generated distractors can potentially be leading or reflect biases that are present in the context. If the context is too short or completely absent, or if the context, question and answer do not match, the generated distractor is likely to be incoherent.
|
abhishek/autonlp-bbc-news-classification-37229289
|
7feb5c325c92f2425f7c338160cdb5afc117aaed
|
2021-11-30T12:56:59.000Z
|
[
"pytorch",
"bert",
"text-classification",
"en",
"dataset:abhishek/autonlp-data-bbc-news-classification",
"transformers",
"autonlp",
"co2_eq_emissions"
] |
text-classification
| false |
abhishek
| null |
abhishek/autonlp-bbc-news-classification-37229289
| 574 | 1 |
transformers
| 2,202 |
---
tags: autonlp
language: en
widget:
- text: "I love AutoNLP 🤗"
datasets:
- abhishek/autonlp-data-bbc-news-classification
co2_eq_emissions: 5.448567309047846
---
# Model Trained Using AutoNLP
- Problem type: Multi-class Classification
- Model ID: 37229289
- CO2 Emissions (in grams): 5.448567309047846
## Validation Metrics
- Loss: 0.07081354409456253
- Accuracy: 0.9867109634551495
- Macro F1: 0.9859067529980614
- Micro F1: 0.9867109634551495
- Weighted F1: 0.9866417220968429
- Macro Precision: 0.9868771404595043
- Micro Precision: 0.9867109634551495
- Weighted Precision: 0.9869289511551576
- Macro Recall: 0.9853173241852486
- Micro Recall: 0.9867109634551495
- Weighted Recall: 0.9867109634551495
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/models/abhishek/autonlp-bbc-news-classification-37229289
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("abhishek/autonlp-bbc-news-classification-37229289", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("abhishek/autonlp-bbc-news-classification-37229289", use_auth_token=True)
inputs = tokenizer("I love AutoNLP", return_tensors="pt")
outputs = model(**inputs)
```
|
recobo/agriculture-bert-uncased
|
641de86d01ed5f0e22f2301e85a3da518173dcad
|
2021-10-08T13:50:49.000Z
|
[
"pytorch",
"bert",
"fill-mask",
"en",
"transformers",
"agriculture-domain",
"agriculture",
"autotrain_compatible"
] |
fill-mask
| false |
recobo
| null |
recobo/agriculture-bert-uncased
| 574 | 2 |
transformers
| 2,203 |
---
language: "en"
tags:
- agriculture-domain
- agriculture
- fill-mask
widget:
- text: "[MASK] agriculture provides one of the most promising areas for innovation in green and blue infrastructure in cities."
---
# BERT for Agriculture Domain
A BERT-based language model further pre-trained from the checkpoint of [SciBERT](https://huggingface.co/allenai/scibert_scivocab_uncased).
The dataset gathered is a balance between scientific and general works in agriculture domain and encompassing knowledge from different areas of agriculture research and practical knowledge.
The corpus contains 1.2 million paragraphs from National Agricultural Library (NAL) from the US Gov. and 5.3 million paragraphs from books and common literature from the **Agriculture Domain**.
The self-supervised learning approach of MLM was used to train the model.
- Masked language modeling (MLM): taking a sentence, the model randomly masks 15% of the words in the input then run
the entire masked sentence through the model and has to predict the masked words. This is different from traditional
recurrent neural networks (RNNs) that usually see the words one after the other, or from autoregressive models like
GPT internally masks the future tokens. It allows the model to learn a bidirectional representation of the
sentence.
```python
from transformers import pipeline
fill_mask = pipeline(
"fill-mask",
model="recobo/agriculture-bert-uncased",
tokenizer="recobo/agriculture-bert-uncased"
)
fill_mask("[MASK] is the practice of cultivating plants and livestock.")
```
|
IDEA-CCNL/Wenzhong2.0-GPT2-3.5B-chinese
|
67838ddfa79c4b7bbd3ab88006e7e38d70b24f19
|
2022-07-29T08:56:23.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"zh",
"transformers",
"license:apache-2.0"
] |
text-generation
| false |
IDEA-CCNL
| null |
IDEA-CCNL/Wenzhong2.0-GPT2-3.5B-chinese
| 574 | 2 |
transformers
| 2,204 |
---
language:
- zh
inference:
parameters:
max_new_tokens: 250
repetition_penalty: 1.1
top_p: 0.9
do_sample: True
license: apache-2.0
---
# Wenzhong2.0-GPT2-3.5B model (chinese),one model of [Fengshenbang-LM](https://github.com/IDEA-CCNL/Fengshenbang-LM).
As we all know, the single direction language model based on decoder structure has strong generation ability, such as GPT model. The 3.5 billion parameter Wenzhong-GPT2-3.5B large model, using 100G chinese common data, 32 A100 training for 28 hours, is the largest open source **GPT2 large model of chinese**. **Our model performs well in Chinese continuation generation.** **Wenzhong2.0-GPT2-3.5B-Chinese is a Chinese gpt2 model trained with cleaner data on the basis of Wenzhong-GPT2-3.5B.**
## Usage
### load model
```python
from transformers import GPT2Tokenizer, GPT2Model
tokenizer = GPT2Tokenizer.from_pretrained('IDEA-CCNL/Wenzhong2.0-GPT2-3.5B-chinese')
model = GPT2Model.from_pretrained('IDEA-CCNL/Wenzhong-GPT2-3.5B')
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
### generation
```python
from transformers import pipeline, set_seed
set_seed(55)
generator = pipeline('text-generation', model='IDEA-CCNL/Wenzhong2.0-GPT2-3.5B-chinese')
generator("北京位于", max_length=30, num_return_sequences=1)
```
## Citation
If you find the resource is useful, please cite the following website in your paper.
```
@misc{Fengshenbang-LM,
title={Fengshenbang-LM},
author={IDEA-CCNL},
year={2021},
howpublished={\url{https://github.com/IDEA-CCNL/Fengshenbang-LM}},
}
```
|
jkgrad/xlnet-base-squadv2
|
36d0bd03fc05331bae053db4fa35865ba74dd2a2
|
2021-01-17T11:52:34.000Z
|
[
"pytorch",
"xlnet",
"question-answering",
"arxiv:1906.08237",
"transformers",
"autotrain_compatible"
] |
question-answering
| false |
jkgrad
| null |
jkgrad/xlnet-base-squadv2
| 571 | 1 |
transformers
| 2,205 |
# XLNet Fine-tuned on SQuAD 2.0 Dataset
[XLNet](https://arxiv.org/abs/1906.08237) jointly developed by Google and CMU and fine-tuned on [SQuAD 2.0](https://rajpurkar.github.io/SQuAD-explorer/) for question answering down-stream task.
## Training Results (Metrics)
```
{
"HasAns_exact": 74.7132253711201
"HasAns_f1": 82.11971607032643
"HasAns_total": 5928
"NoAns_exact": 73.38940285954584
"NoAns_f1": 73.38940285954584
"NoAns_total": 5945
"best_exact": 75.67590331003116
"best_exact_thresh": -19.554906845092773
"best_f1": 79.16215426779269
"best_f1_thresh": -19.554906845092773
"epoch": 4.0
"exact": 74.05036637749515
"f1": 77.74830934598614
"total": 11873
}
```
## Results Comparison
| Metric | Paper | Model |
| ------ | --------- | --------- |
| **EM** | **78.46** | **75.68** (-2.78) |
| **F1** | **81.33** | **79.16** (-2.17)|
Better fine-tuned models coming soon.
## How to Use
```
from transformers import XLNetForQuestionAnswering, XLNetTokenizerFast
model = XLNetForQuestionAnswering.from_pretrained('jkgrad/xlnet-base-squadv2)
tokenizer = XLNetTokenizerFast.from_pretrained('jkgrad/xlnet-base-squadv2')
```
|
studio-ousia/mluke-large-lite-finetuned-kbp37
|
cc425b55c0eb00bcaa951287d2bce238a7d86687
|
2022-03-28T07:38:46.000Z
|
[
"pytorch",
"luke",
"transformers",
"license:apache-2.0"
] | null | false |
studio-ousia
| null |
studio-ousia/mluke-large-lite-finetuned-kbp37
| 571 | null |
transformers
| 2,206 |
---
license: apache-2.0
---
|
malteos/gpt2-xl-wechsel-german
|
40465eb67657fe7e9176b014a7b6b8322032d706
|
2022-06-24T10:49:20.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"de",
"arxiv:2112.06598",
"transformers",
"license:mit"
] |
text-generation
| false |
malteos
| null |
malteos/gpt2-xl-wechsel-german
| 569 | 4 |
transformers
| 2,207 |
---
license: mit
language: de
widget:
- text: "In einer schockierenden Entdeckung fanden Wissenschaftler eine Herde Einhörner, die in "
---
# German GPT2-XL (1.5B)
- trained with [BigScience's DeepSpeed-Megatron-LM code base](https://github.com/bigscience-workshop/Megatron-DeepSpeed)
- word embedding initialized with [WECHSEL](https://arxiv.org/abs/2112.06598) and all other weights taken from English [gpt2-xl](https://huggingface.co/gpt2-xl)
- ~ 3 days on 16xA100 GPUs (~ 80 TFLOPs / GPU)
- stopped after 100k steps
- 26.2B tokens
- less than a single epoch on `oscar_unshuffled_deduplicated_de` (excluding validation set; original model was trained for 75 epochs on less data)
- bf16
- zero stage 0
- tp/pp = 1
### How to use
You can use this model directly with a pipeline for text generation. Since the generation relies on some randomness, we
set a seed for reproducibility:
```python
>>> from transformers import pipeline, set_seed
>>> generator = pipeline('text-generation', model='malteos/gpt2-xl-wechsel-german')
>>> set_seed(42)
>>> generator("Hello, I'm a language model,", max_length=30, num_return_sequences=5)
[{'generated_text': "Hello, I'm a language model, a language for thinking, a language for expressing thoughts."},
{'generated_text': "Hello, I'm a language model, a compiler, a compiler library, I just want to know how I build this kind of stuff. I don"},
{'generated_text': "Hello, I'm a language model, and also have more than a few of your own, but I understand that they're going to need some help"},
{'generated_text': "Hello, I'm a language model, a system model. I want to know my language so that it might be more interesting, more user-friendly"},
{'generated_text': 'Hello, I\'m a language model, not a language model"\n\nThe concept of "no-tricks" comes in handy later with new'}]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import GPT2Tokenizer, GPT2Model
tokenizer = GPT2Tokenizer.from_pretrained('malteos/gpt2-xl-wechsel-german')
model = GPT2Model.from_pretrained('malteos/gpt2-xl-wechsel-german')
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
## Evaluation
| Model (size) | PPL |
|---|---|
| `gpt2-xl-wechsel-german` (1.5B) | **14.5** |
| `gpt2-wechsel-german-ds-meg` (117M) | 26.4 |
| `gpt2-wechsel-german` (117M) | 26.8 |
| `gpt2` (retrained from scratch) (117M) | 27.63 |
## License
MIT
|
IIC/dpr-spanish-question_encoder-allqa-base
|
a4cc70e53295779c0cf761af8fc49a267ee56099
|
2022-04-02T15:07:32.000Z
|
[
"pytorch",
"bert",
"fill-mask",
"es",
"dataset:squad_es",
"dataset:PlanTL-GOB-ES/SQAC",
"dataset:IIC/bioasq22_es",
"arxiv:2004.04906",
"transformers",
"sentence similarity",
"passage retrieval",
"model-index",
"autotrain_compatible"
] |
fill-mask
| false |
IIC
| null |
IIC/dpr-spanish-question_encoder-allqa-base
| 568 | 1 |
transformers
| 2,208 |
---
language:
- es
tags:
- sentence similarity # Example: audio
- passage retrieval # Example: automatic-speech-recognition
datasets:
- squad_es
- PlanTL-GOB-ES/SQAC
- IIC/bioasq22_es
metrics:
- eval_loss: 0.010779764448327261
- eval_accuracy: 0.9982682224158297
- eval_f1: 0.9446059155411182
- average_rank: 0.11728500598392888
model-index:
- name: dpr-spanish-question_encoder-allqa-base
results:
- task:
type: text similarity # Required. Example: automatic-speech-recognition
name: text similarity # Optional. Example: Speech Recognition
dataset:
type: squad_es # Required. Example: common_voice. Use dataset id from https://hf.co/datasets
name: squad_es # Required. Example: Common Voice zh-CN
args: es # Optional. Example: zh-CN
metrics:
- type: loss
value: 0.010779764448327261
name: eval_loss
- type: accuracy
value: 0.9982682224158297
name: accuracy
- type: f1
value: 0.9446059155411182
name: f1
- type: avgrank
value: 0.11728500598392888
name: avgrank
---
[Dense Passage Retrieval](https://arxiv.org/abs/2004.04906)-DPR is a set of tools for performing State of the Art open-domain question answering. It was initially developed by Facebook and there is an [official repository](https://github.com/facebookresearch/DPR). DPR is intended to retrieve the relevant documents to answer a given question, and is composed of 2 models, one for encoding passages and other for encoding questions. This concrete model is the one used for encoding questions.
With this and the [passage encoder model](https://huggingface.co/avacaondata/dpr-spanish-passage_encoder-allqa-base) we introduce the best passage retrievers in Spanish up to date (to the best of our knowledge), improving over the [previous model we developed](https://huggingface.co/IIC/dpr-spanish-question_encoder-squades-base), by training it for longer and with more data.
Regarding its use, this model should be used to vectorize a question that enters in a Question Answering system, and then we compare that encoding with the encodings of the database (encoded with [the passage encoder](https://huggingface.co/avacaondata/dpr-spanish-passage_encoder-squades-base)) to find the most similar documents , which then should be used for either extracting the answer or generating it.
For training the model, we used a collection of Question Answering datasets in Spanish:
- the Spanish version of SQUAD, [SQUAD-ES](https://huggingface.co/datasets/squad_es)
- [SQAC- Spanish Question Answering Corpus](https://huggingface.co/datasets/PlanTL-GOB-ES/SQAC)
- [BioAsq22-ES](https://huggingface.co/datasets/IIC/bioasq22_es) - we translated this last one by using automatic translation with Transformers.
With this complete dataset we created positive and negative examples for the model (For more information look at [the paper](https://arxiv.org/abs/2004.04906) to understand the training process for DPR). We trained for 25 epochs with the same configuration as the paper. The [previous DPR model](https://huggingface.co/IIC/dpr-spanish-passage_encoder-squades-base) was trained for only 3 epochs with about 60% of the data.
Example of use:
```python
from transformers import DPRQuestionEncoder, DPRQuestionEncoderTokenizer
model_str = "IIC/dpr-spanish-question_encoder-allqa-base"
tokenizer = DPRQuestionEncoderTokenizer.from_pretrained(model_str)
model = DPRQuestionEncoder.from_pretrained(model_str)
input_ids = tokenizer("¿Qué medallas ganó Usain Bolt en 2012?", return_tensors="pt")["input_ids"]
embeddings = model(input_ids).pooler_output
```
The full metrics of this model on the evaluation split of SQUADES are:
```
eval_loss: 0.010779764448327261
eval_acc: 0.9982682224158297
eval_f1: 0.9446059155411182
eval_acc_and_f1: 0.9714370689784739
eval_average_rank: 0.11728500598392888
```
And the classification report:
```
precision recall f1-score support
hard_negative 0.9991 0.9991 0.9991 1104999
positive 0.9446 0.9446 0.9446 17547
accuracy 0.9983 1122546
macro avg 0.9719 0.9719 0.9719 1122546
weighted avg 0.9983 0.9983 0.9983 1122546
```
### Contributions
Thanks to [@avacaondata](https://huggingface.co/avacaondata), [@alborotis](https://huggingface.co/alborotis), [@albarji](https://huggingface.co/albarji), [@Dabs](https://huggingface.co/Dabs), [@GuillemGSubies](https://huggingface.co/GuillemGSubies) for adding this model.
|
winegarj/distilbert-base-uncased-finetuned-sst2
|
dffa754606014596c0bcedd7920d45671102fc90
|
2022-04-10T02:09:16.000Z
|
[
"pytorch",
"distilbert",
"text-classification",
"dataset:glue",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] |
text-classification
| false |
winegarj
| null |
winegarj/distilbert-base-uncased-finetuned-sst2
| 568 | null |
transformers
| 2,209 |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
model-index:
- name: distilbert-base-uncased-finetuned-sst2
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: sst2
metrics:
- name: Accuracy
type: accuracy
value: 0.908256880733945
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-sst2
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4493
- Accuracy: 0.9083
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 0.1804 | 1.0 | 2105 | 0.2843 | 0.9025 |
| 0.1216 | 2.0 | 4210 | 0.3242 | 0.9025 |
| 0.0871 | 3.0 | 6315 | 0.3320 | 0.9060 |
| 0.0607 | 4.0 | 8420 | 0.3913 | 0.9025 |
| 0.0429 | 5.0 | 10525 | 0.4493 | 0.9083 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.12.0.dev20220409+cu115
- Datasets 2.0.0
- Tokenizers 0.12.0
|
google/multiberts-seed_2
|
6ca96336eb9c5571b274ec67ca5d3d88980a57eb
|
2021-11-05T22:10:49.000Z
|
[
"pytorch",
"tf",
"bert",
"pretraining",
"en",
"arxiv:2106.16163",
"arxiv:1908.08962",
"transformers",
"multiberts",
"multiberts-seed_2",
"license:apache-2.0"
] | null | false |
google
| null |
google/multiberts-seed_2
| 567 | null |
transformers
| 2,210 |
---
language: en
tags:
- multiberts
- multiberts-seed_2
license: apache-2.0
---
# MultiBERTs - Seed 2
MultiBERTs is a collection of checkpoints and a statistical library to support
robust research on BERT. We provide 25 BERT-base models trained with
similar hyper-parameters as
[the original BERT model](https://github.com/google-research/bert) but
with different random seeds, which causes variations in the initial weights and order of
training instances. The aim is to distinguish findings that apply to a specific
artifact (i.e., a particular instance of the model) from those that apply to the
more general procedure.
We also provide 140 intermediate checkpoints captured
during the course of pre-training (we saved 28 checkpoints for the first 5 runs).
The models were originally released through
[http://goo.gle/multiberts](http://goo.gle/multiberts). We describe them in our
paper
[The MultiBERTs: BERT Reproductions for Robustness Analysis](https://arxiv.org/abs/2106.16163).
This is model #2.
## Model Description
This model is a reproduction of
[BERT-base uncased](https://github.com/google-research/bert), for English: it
is a Transformers model pretrained on a large corpus of English data, using the
Masked Language Modelling (MLM) and the Next Sentence Prediction (NSP)
objectives.
The intended uses, limitations, training data and training procedure are similar
to [BERT-base uncased](https://github.com/google-research/bert). Two major
differences with the original model:
* We pre-trained the MultiBERTs models for 2 million steps using sequence
length 512 (instead of 1 million steps using sequence length 128 then 512).
* We used an alternative version of Wikipedia and Books Corpus, initially
collected for [Turc et al., 2019](https://arxiv.org/abs/1908.08962).
This is a best-effort reproduction, and so it is probable that differences with
the original model have gone unnoticed. The performance of MultiBERTs on GLUE is oftentimes comparable to that of original
BERT, but we found significant differences on the dev set of SQuAD (MultiBERTs outperforms original BERT).
See our [technical report](https://arxiv.org/abs/2106.16163) for more details.
### How to use
Using code from
[BERT-base uncased](https://huggingface.co/bert-base-uncased), here is an example based on
Tensorflow:
```
from transformers import BertTokenizer, TFBertModel
tokenizer = BertTokenizer.from_pretrained('google/multiberts-seed_2')
model = TFBertModel.from_pretrained("google/multiberts-seed_2")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
PyTorch version:
```
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('google/multiberts-seed_2')
model = BertModel.from_pretrained("google/multiberts-seed_2")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
## Citation info
```bibtex
@article{sellam2021multiberts,
title={The MultiBERTs: BERT Reproductions for Robustness Analysis},
author={Thibault Sellam and Steve Yadlowsky and Jason Wei and Naomi Saphra and Alexander D'Amour and Tal Linzen and Jasmijn Bastings and Iulia Turc and Jacob Eisenstein and Dipanjan Das and Ian Tenney and Ellie Pavlick},
journal={arXiv preprint arXiv:2106.16163},
year={2021}
}
```
|
google/multiberts-seed_3
|
e7349d42b02a2c42b87f6a01046f3f4278361e37
|
2021-11-05T22:12:27.000Z
|
[
"pytorch",
"tf",
"bert",
"pretraining",
"en",
"arxiv:2106.16163",
"arxiv:1908.08962",
"transformers",
"multiberts",
"multiberts-seed_3",
"license:apache-2.0"
] | null | false |
google
| null |
google/multiberts-seed_3
| 567 | null |
transformers
| 2,211 |
---
language: en
tags:
- multiberts
- multiberts-seed_3
license: apache-2.0
---
# MultiBERTs - Seed 3
MultiBERTs is a collection of checkpoints and a statistical library to support
robust research on BERT. We provide 25 BERT-base models trained with
similar hyper-parameters as
[the original BERT model](https://github.com/google-research/bert) but
with different random seeds, which causes variations in the initial weights and order of
training instances. The aim is to distinguish findings that apply to a specific
artifact (i.e., a particular instance of the model) from those that apply to the
more general procedure.
We also provide 140 intermediate checkpoints captured
during the course of pre-training (we saved 28 checkpoints for the first 5 runs).
The models were originally released through
[http://goo.gle/multiberts](http://goo.gle/multiberts). We describe them in our
paper
[The MultiBERTs: BERT Reproductions for Robustness Analysis](https://arxiv.org/abs/2106.16163).
This is model #3.
## Model Description
This model is a reproduction of
[BERT-base uncased](https://github.com/google-research/bert), for English: it
is a Transformers model pretrained on a large corpus of English data, using the
Masked Language Modelling (MLM) and the Next Sentence Prediction (NSP)
objectives.
The intended uses, limitations, training data and training procedure are similar
to [BERT-base uncased](https://github.com/google-research/bert). Two major
differences with the original model:
* We pre-trained the MultiBERTs models for 2 million steps using sequence
length 512 (instead of 1 million steps using sequence length 128 then 512).
* We used an alternative version of Wikipedia and Books Corpus, initially
collected for [Turc et al., 2019](https://arxiv.org/abs/1908.08962).
This is a best-effort reproduction, and so it is probable that differences with
the original model have gone unnoticed. The performance of MultiBERTs on GLUE is oftentimes comparable to that of original
BERT, but we found significant differences on the dev set of SQuAD (MultiBERTs outperforms original BERT).
See our [technical report](https://arxiv.org/abs/2106.16163) for more details.
### How to use
Using code from
[BERT-base uncased](https://huggingface.co/bert-base-uncased), here is an example based on
Tensorflow:
```
from transformers import BertTokenizer, TFBertModel
tokenizer = BertTokenizer.from_pretrained('google/multiberts-seed_3')
model = TFBertModel.from_pretrained("google/multiberts-seed_3")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
PyTorch version:
```
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('google/multiberts-seed_3')
model = BertModel.from_pretrained("google/multiberts-seed_3")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
## Citation info
```bibtex
@article{sellam2021multiberts,
title={The MultiBERTs: BERT Reproductions for Robustness Analysis},
author={Thibault Sellam and Steve Yadlowsky and Jason Wei and Naomi Saphra and Alexander D'Amour and Tal Linzen and Jasmijn Bastings and Iulia Turc and Jacob Eisenstein and Dipanjan Das and Ian Tenney and Ellie Pavlick},
journal={arXiv preprint arXiv:2106.16163},
year={2021}
}
```
|
sshleifer/tiny-distilbert-base-uncased-finetuned-sst-2-english
|
40f5ccbce1646c98ea0fabb02f96182a08a5a9d9
|
2020-05-12T01:51:10.000Z
|
[
"pytorch",
"tf",
"distilbert",
"text-classification",
"transformers"
] |
text-classification
| false |
sshleifer
| null |
sshleifer/tiny-distilbert-base-uncased-finetuned-sst-2-english
| 567 | null |
transformers
| 2,212 |
Entry not found
|
Gunulhona/tbstmodel_v2
|
deb515d43c4985e3318a0ea172cd563bcde230fa
|
2022-07-20T10:32:43.000Z
|
[
"pytorch",
"bart",
"text2text-generation",
"transformers",
"autotrain_compatible"
] |
text2text-generation
| false |
Gunulhona
| null |
Gunulhona/tbstmodel_v2
| 566 | null |
transformers
| 2,213 |
Entry not found
|
cross-encoder/ms-marco-TinyBERT-L-4
|
12a9f222056982640d3735ab94d865761c8fdd16
|
2021-08-05T08:39:59.000Z
|
[
"pytorch",
"jax",
"bert",
"text-classification",
"transformers",
"license:apache-2.0"
] |
text-classification
| false |
cross-encoder
| null |
cross-encoder/ms-marco-TinyBERT-L-4
| 565 | null |
transformers
| 2,214 |
---
license: apache-2.0
---
# Cross-Encoder for MS Marco
This model was trained on the [MS Marco Passage Ranking](https://github.com/microsoft/MSMARCO-Passage-Ranking) task.
The model can be used for Information Retrieval: Given a query, encode the query will all possible passages (e.g. retrieved with ElasticSearch). Then sort the passages in a decreasing order. See [SBERT.net Retrieve & Re-rank](https://www.sbert.net/examples/applications/retrieve_rerank/README.html) for more details. The training code is available here: [SBERT.net Training MS Marco](https://github.com/UKPLab/sentence-transformers/tree/master/examples/training/ms_marco)
## Usage with Transformers
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
model = AutoModelForSequenceClassification.from_pretrained('model_name')
tokenizer = AutoTokenizer.from_pretrained('model_name')
features = tokenizer(['How many people live in Berlin?', 'How many people live in Berlin?'], ['Berlin has a population of 3,520,031 registered inhabitants in an area of 891.82 square kilometers.', 'New York City is famous for the Metropolitan Museum of Art.'], padding=True, truncation=True, return_tensors="pt")
model.eval()
with torch.no_grad():
scores = model(**features).logits
print(scores)
```
## Usage with SentenceTransformers
The usage becomes easier when you have [SentenceTransformers](https://www.sbert.net/) installed. Then, you can use the pre-trained models like this:
```python
from sentence_transformers import CrossEncoder
model = CrossEncoder('model_name', max_length=512)
scores = model.predict([('Query', 'Paragraph1'), ('Query', 'Paragraph2') , ('Query', 'Paragraph3')])
```
## Performance
In the following table, we provide various pre-trained Cross-Encoders together with their performance on the [TREC Deep Learning 2019](https://microsoft.github.io/TREC-2019-Deep-Learning/) and the [MS Marco Passage Reranking](https://github.com/microsoft/MSMARCO-Passage-Ranking/) dataset.
| Model-Name | NDCG@10 (TREC DL 19) | MRR@10 (MS Marco Dev) | Docs / Sec |
| ------------- |:-------------| -----| --- |
| **Version 2 models** | | |
| cross-encoder/ms-marco-TinyBERT-L-2-v2 | 69.84 | 32.56 | 9000
| cross-encoder/ms-marco-MiniLM-L-2-v2 | 71.01 | 34.85 | 4100
| cross-encoder/ms-marco-MiniLM-L-4-v2 | 73.04 | 37.70 | 2500
| cross-encoder/ms-marco-MiniLM-L-6-v2 | 74.30 | 39.01 | 1800
| cross-encoder/ms-marco-MiniLM-L-12-v2 | 74.31 | 39.02 | 960
| **Version 1 models** | | |
| cross-encoder/ms-marco-TinyBERT-L-2 | 67.43 | 30.15 | 9000
| cross-encoder/ms-marco-TinyBERT-L-4 | 68.09 | 34.50 | 2900
| cross-encoder/ms-marco-TinyBERT-L-6 | 69.57 | 36.13 | 680
| cross-encoder/ms-marco-electra-base | 71.99 | 36.41 | 340
| **Other models** | | |
| nboost/pt-tinybert-msmarco | 63.63 | 28.80 | 2900
| nboost/pt-bert-base-uncased-msmarco | 70.94 | 34.75 | 340
| nboost/pt-bert-large-msmarco | 73.36 | 36.48 | 100
| Capreolus/electra-base-msmarco | 71.23 | 36.89 | 340
| amberoad/bert-multilingual-passage-reranking-msmarco | 68.40 | 35.54 | 330
| sebastian-hofstaetter/distilbert-cat-margin_mse-T2-msmarco | 72.82 | 37.88 | 720
Note: Runtime was computed on a V100 GPU.
|
hfl/chinese-pert-large
|
2e523595cb3d0d157f847cd0ec1b3914c8740fe1
|
2022-02-25T04:09:23.000Z
|
[
"pytorch",
"tf",
"bert",
"feature-extraction",
"zh",
"transformers",
"license:cc-by-nc-sa-4.0"
] |
feature-extraction
| false |
hfl
| null |
hfl/chinese-pert-large
| 565 | 2 |
transformers
| 2,215 |
---
language:
- zh
license: "cc-by-nc-sa-4.0"
---
# Please use 'Bert' related functions to load this model!
Under construction...
Please visit our GitHub repo for more information: https://github.com/ymcui/PERT
|
w11wo/indonesian-roberta-base-indolem-sentiment-classifier-fold-0
|
0fce6ebcb814fa0f624e3a8ba83f682a222c60f6
|
2021-10-06T04:15:40.000Z
|
[
"pytorch",
"roberta",
"text-classification",
"id",
"dataset:indolem",
"arxiv:1907.11692",
"transformers",
"indonesian-roberta-base-indolem-sentiment-classifier-fold-0",
"license:mit"
] |
text-classification
| false |
w11wo
| null |
w11wo/indonesian-roberta-base-indolem-sentiment-classifier-fold-0
| 563 | null |
transformers
| 2,216 |
---
language: id
tags:
- indonesian-roberta-base-indolem-sentiment-classifier-fold-0
license: mit
datasets:
- indolem
widget:
- text: "Pelayanan hotel ini sangat baik."
---
## Indonesian RoBERTa Base IndoLEM Sentiment Classifier
Indonesian RoBERTa Base IndoLEM Sentiment Classifier is a sentiment-text-classification model based on the [RoBERTa](https://arxiv.org/abs/1907.11692) model. The model was originally the pre-trained [Indonesian RoBERTa Base](https://hf.co/flax-community/indonesian-roberta-base) model, which is then fine-tuned on [`indolem`](https://indolem.github.io/)'s [Sentiment Analysis](https://github.com/indolem/indolem/tree/main/sentiment) dataset consisting of Indonesian tweets and hotel reviews (Koto et al., 2020).
A 5-fold cross-validation experiment was performed, with splits provided by the original dataset authors. This model was trained on fold 0. You can find models trained on [fold 0](https://huggingface.co/w11wo/indonesian-roberta-base-indolem-sentiment-classifier-fold-0), [fold 1](https://huggingface.co/w11wo/indonesian-roberta-base-indolem-sentiment-classifier-fold-1), [fold 2](https://huggingface.co/w11wo/indonesian-roberta-base-indolem-sentiment-classifier-fold-2), [fold 3](https://huggingface.co/w11wo/indonesian-roberta-base-indolem-sentiment-classifier-fold-3), and [fold 4](https://huggingface.co/w11wo/indonesian-roberta-base-indolem-sentiment-classifier-fold-4), in their respective links.
On **fold 0**, the model achieved an F1 of 86.42% on dev/validation and 83.12% on test. On all **5 folds**, the models achieved an average F1 of 84.14% on dev/validation and 84.64% on test.
Hugging Face's `Trainer` class from the [Transformers](https://huggingface.co/transformers) library was used to train the model. PyTorch was used as the backend framework during training, but the model remains compatible with other frameworks nonetheless.
## Model
| Model | #params | Arch. | Training/Validation data (text) |
| ------------------------------------------------------------- | ------- | ------------ | ------------------------------- |
| `indonesian-roberta-base-indolem-sentiment-classifier-fold-0` | 124M | RoBERTa Base | `IndoLEM`'s Sentiment Analysis |
## Evaluation Results
The model was trained for 10 epochs and the best model was loaded at the end.
| Epoch | Training Loss | Validation Loss | Accuracy | F1 | Precision | Recall |
| ----- | ------------- | --------------- | -------- | -------- | --------- | -------- |
| 1 | 0.563500 | 0.420457 | 0.796992 | 0.626728 | 0.680000 | 0.581197 |
| 2 | 0.293600 | 0.281360 | 0.884712 | 0.811475 | 0.779528 | 0.846154 |
| 3 | 0.163000 | 0.267922 | 0.904762 | 0.844262 | 0.811024 | 0.880342 |
| 4 | 0.090200 | 0.335411 | 0.899749 | 0.838710 | 0.793893 | 0.888889 |
| 5 | 0.065200 | 0.462526 | 0.897243 | 0.835341 | 0.787879 | 0.888889 |
| 6 | 0.039200 | 0.423001 | 0.912281 | 0.859438 | 0.810606 | 0.914530 |
| 7 | 0.025300 | 0.452100 | 0.912281 | 0.859438 | 0.810606 | 0.914530 |
| 8 | 0.010400 | 0.525200 | 0.914787 | 0.855932 | 0.848739 | 0.863248 |
| 9 | 0.007100 | 0.513585 | 0.909774 | 0.850000 | 0.829268 | 0.871795 |
| 10 | 0.007200 | 0.537254 | 0.917293 | 0.864198 | 0.833333 | 0.897436 |
## How to Use
### As Text Classifier
```python
from transformers import pipeline
pretrained_name = "w11wo/indonesian-roberta-base-indolem-sentiment-classifier-fold-0"
nlp = pipeline(
"sentiment-analysis",
model=pretrained_name,
tokenizer=pretrained_name
)
nlp("Pelayanan hotel ini sangat baik.")
```
## Disclaimer
Do consider the biases which come from both the pre-trained RoBERTa model and `IndoLEM`'s Sentiment Analysis dataset that may be carried over into the results of this model.
## Author
Indonesian RoBERTa Base IndoLEM Sentiment Classifier was trained and evaluated by [Wilson Wongso](https://w11wo.github.io/). All computation and development are done on Google Colaboratory using their free GPU access.
|
Gunulhona/tbbcmodel
|
97497c151100a30da0d19771d3dbc7c457befaac
|
2022-01-06T07:01:22.000Z
|
[
"pytorch",
"bart",
"text-classification",
"transformers"
] |
text-classification
| false |
Gunulhona
| null |
Gunulhona/tbbcmodel
| 562 | null |
transformers
| 2,217 |
Entry not found
|
fav-kky/FERNET-C5
|
ff5399d8222bce8d7356c7face6d0d0263f9cb8c
|
2021-07-26T21:05:31.000Z
|
[
"pytorch",
"tf",
"bert",
"fill-mask",
"cs",
"arxiv:2107.10042",
"transformers",
"Czech",
"KKY",
"FAV",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible"
] |
fill-mask
| false |
fav-kky
| null |
fav-kky/FERNET-C5
| 562 | null |
transformers
| 2,218 |
---
language: "cs"
tags:
- Czech
- KKY
- FAV
license: "cc-by-nc-sa-4.0"
---
# FERNET-C5
FERNET-C5 is a monolingual Czech BERT-base model pre-trained from 93GB of filtered Czech Common Crawl dataset (C5).
Preprint of our paper is available at https://arxiv.org/abs/2107.10042.
|
junnyu/roformer_chinese_sim_char_base
|
6e0353805a82525679b0d5d9e97c51fdbf8378eb
|
2022-04-15T03:52:35.000Z
|
[
"pytorch",
"roformer",
"text-generation",
"zh",
"transformers",
"tf2.0"
] |
text-generation
| false |
junnyu
| null |
junnyu/roformer_chinese_sim_char_base
| 562 | 1 |
transformers
| 2,219 |
---
language: zh
tags:
- roformer
- pytorch
- tf2.0
inference: False
---
# 安装
- pip install roformer==0.4.3
# 使用
```python
import torch
import numpy as np
from roformer import RoFormerForCausalLM, RoFormerConfig
from transformers import BertTokenizer
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
pretrained_model = "junnyu/roformer_chinese_sim_char_base"
tokenizer = BertTokenizer.from_pretrained(pretrained_model)
config = RoFormerConfig.from_pretrained(pretrained_model)
config.is_decoder = True
config.eos_token_id = tokenizer.sep_token_id
config.pooler_activation = "linear"
model = RoFormerForCausalLM.from_pretrained(pretrained_model, config=config)
model.to(device)
model.eval()
def gen_synonyms(text, n=100, k=20):
''''含义: 产生sent的n个相似句,然后返回最相似的k个。
做法:用seq2seq生成,并用encoder算相似度并排序。
'''
# 寻找所有相似的句子
r = []
inputs1 = tokenizer(text, return_tensors="pt")
for _ in range(n):
inputs1.to(device)
output = tokenizer.batch_decode(model.generate(**inputs1, top_p=0.95, do_sample=True, max_length=128), skip_special_tokens=True)[0].replace(" ","").replace(text, "") # 去除空格,去除原始text文本。
r.append(output)
# 对相似的句子进行排序
r = [i for i in set(r) if i != text and len(i) > 0]
r = [text] + r
inputs2 = tokenizer(r, padding=True, return_tensors="pt")
with torch.no_grad():
inputs2.to(device)
outputs = model(**inputs2)
Z = outputs.pooler_output.cpu().numpy()
Z /= (Z**2).sum(axis=1, keepdims=True)**0.5
argsort = np.dot(Z[1:], -Z[0]).argsort()
return [r[i + 1] for i in argsort[:k]]
out = gen_synonyms("广州和深圳哪个好?")
print(out)
# ['深圳和广州哪个好?',
# '广州和深圳哪个好',
# '深圳和广州哪个好',
# '深圳和广州哪个比较好。',
# '深圳和广州哪个最好?',
# '深圳和广州哪个比较好',
# '广州和深圳那个比较好',
# '深圳和广州哪个更好?',
# '深圳与广州哪个好',
# '深圳和广州,哪个比较好',
# '广州与深圳比较哪个好',
# '深圳和广州哪里比较好',
# '深圳还是广州比较好?',
# '广州和深圳哪个地方好一些?',
# '广州好还是深圳好?',
# '广州好还是深圳好呢?',
# '广州与深圳哪个地方好点?',
# '深圳好还是广州好',
# '广州好还是深圳好',
# '广州和深圳哪个城市好?']
```
|
flair/chunk-english-fast
|
f6040da676441b1c13f702119e8cc12e0a533350
|
2021-03-02T21:59:23.000Z
|
[
"pytorch",
"en",
"dataset:conll2000",
"flair",
"token-classification",
"sequence-tagger-model"
] |
token-classification
| false |
flair
| null |
flair/chunk-english-fast
| 561 | 2 |
flair
| 2,220 |
---
tags:
- flair
- token-classification
- sequence-tagger-model
language: en
datasets:
- conll2000
widget:
- text: "The happy man has been eating at the diner"
---
## English Chunking in Flair (fast model)
This is the fast phrase chunking model for English that ships with [Flair](https://github.com/flairNLP/flair/).
F1-Score: **96,22** (CoNLL-2000)
Predicts 4 tags:
| **tag** | **meaning** |
|---------------------------------|-----------|
| ADJP | adjectival |
| ADVP | adverbial |
| CONJP | conjunction |
| INTJ | interjection |
| LST | list marker |
| NP | noun phrase |
| PP | prepositional |
| PRT | particle |
| SBAR | subordinate clause |
| VP | verb phrase |
Based on [Flair embeddings](https://www.aclweb.org/anthology/C18-1139/) and LSTM-CRF.
---
### Demo: How to use in Flair
Requires: **[Flair](https://github.com/flairNLP/flair/)** (`pip install flair`)
```python
from flair.data import Sentence
from flair.models import SequenceTagger
# load tagger
tagger = SequenceTagger.load("flair/chunk-english-fast")
# make example sentence
sentence = Sentence("The happy man has been eating at the diner")
# predict NER tags
tagger.predict(sentence)
# print sentence
print(sentence)
# print predicted NER spans
print('The following NER tags are found:')
# iterate over entities and print
for entity in sentence.get_spans('np'):
print(entity)
```
This yields the following output:
```
Span [1,2,3]: "The happy man" [− Labels: NP (0.9958)]
Span [4,5,6]: "has been eating" [− Labels: VP (0.8759)]
Span [7]: "at" [− Labels: PP (1.0)]
Span [8,9]: "the diner" [− Labels: NP (0.9991)]
```
So, the spans "*The happy man*" and "*the diner*" are labeled as **noun phrases** (NP) and "*has been eating*" is labeled as a **verb phrase** (VP) in the sentence "*The happy man has been eating at the diner*".
---
### Training: Script to train this model
The following Flair script was used to train this model:
```python
from flair.data import Corpus
from flair.datasets import CONLL_2000
from flair.embeddings import WordEmbeddings, StackedEmbeddings, FlairEmbeddings
# 1. get the corpus
corpus: Corpus = CONLL_2000()
# 2. what tag do we want to predict?
tag_type = 'np'
# 3. make the tag dictionary from the corpus
tag_dictionary = corpus.make_tag_dictionary(tag_type=tag_type)
# 4. initialize each embedding we use
embedding_types = [
# contextual string embeddings, forward
FlairEmbeddings('news-forward-fast'),
# contextual string embeddings, backward
FlairEmbeddings('news-backward-fast'),
]
# embedding stack consists of Flair and GloVe embeddings
embeddings = StackedEmbeddings(embeddings=embedding_types)
# 5. initialize sequence tagger
from flair.models import SequenceTagger
tagger = SequenceTagger(hidden_size=256,
embeddings=embeddings,
tag_dictionary=tag_dictionary,
tag_type=tag_type)
# 6. initialize trainer
from flair.trainers import ModelTrainer
trainer = ModelTrainer(tagger, corpus)
# 7. run training
trainer.train('resources/taggers/chunk-english-fast',
train_with_dev=True,
max_epochs=150)
```
---
### Cite
Please cite the following paper when using this model.
```
@inproceedings{akbik2018coling,
title={Contextual String Embeddings for Sequence Labeling},
author={Akbik, Alan and Blythe, Duncan and Vollgraf, Roland},
booktitle = {{COLING} 2018, 27th International Conference on Computational Linguistics},
pages = {1638--1649},
year = {2018}
}
```
---
### Issues?
The Flair issue tracker is available [here](https://github.com/flairNLP/flair/issues/).
|
snunlp/KR-FinBert-SC
|
f8586286cc3161fb648e9fee09a456069fd846d0
|
2022-04-28T05:07:18.000Z
|
[
"pytorch",
"bert",
"text-classification",
"ko",
"transformers"
] |
text-classification
| false |
snunlp
| null |
snunlp/KR-FinBert-SC
| 561 | 2 |
transformers
| 2,221 |
---
language:
- ko
---
# KR-FinBert & KR-FinBert-SC
Much progress has been made in the NLP (Natural Language Processing) field, with numerous studies showing that domain adaptation using small-scale corpus and fine-tuning with labeled data is effective for overall performance improvement.
we proposed KR-FinBert for the financial domain by further pre-training it on a financial corpus and fine-tuning it for sentiment analysis. As many studies have shown, the performance improvement through adaptation and conducting the downstream task was also clear in this experiment.
## Data
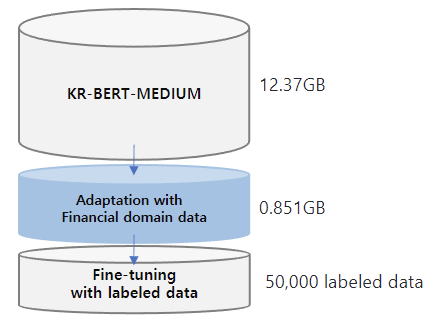
The training data for this model is expanded from those of **[KR-BERT-MEDIUM](https://huggingface.co/snunlp/KR-Medium)**, texts from Korean Wikipedia, general news articles, legal texts crawled from the National Law Information Center and [Korean Comments dataset](https://www.kaggle.com/junbumlee/kcbert-pretraining-corpus-korean-news-comments). For the transfer learning, **corporate related economic news articles from 72 media sources** such as the Financial Times, The Korean Economy Daily, etc and **analyst reports from 16 securities companies** such as Kiwoom Securities, Samsung Securities, etc are added. Included in the dataset is 440,067 news titles with their content and 11,237 analyst reports. **The total data size is about 13.22GB.** For mlm training, we split the data line by line and **the total no. of lines is 6,379,315.**
KR-FinBert is trained for 5.5M steps with the maxlen of 512, training batch size of 32, and learning rate of 5e-5, taking 67.48 hours to train the model using NVIDIA TITAN XP.
## Downstream tasks
### Sentimental Classification model
Downstream task performances with 50,000 labeled data.
|Model|Accuracy|
|-|-|
|KR-FinBert|0.963|
|KR-BERT-MEDIUM|0.958|
|KcBert-large|0.955|
|KcBert-base|0.953|
|KoBert|0.817|
### Inference sample
|Positive|Negative|
|-|-|
|현대바이오, '폴리탁셀' 코로나19 치료 가능성에 19% 급등 | 영화관株 '코로나 빙하기' 언제 끝나나…"CJ CGV 올 4000억 손실 날수도" |
|이수화학, 3분기 영업익 176억…전년比 80%↑ | C쇼크에 멈춘 흑자비행…대한항공 1분기 영업적자 566억 |
|"GKL, 7년 만에 두 자릿수 매출성장 예상" | '1000억대 횡령·배임' 최신원 회장 구속… SK네트웍스 "경영 공백 방지 최선" |
|위지윅스튜디오, 콘텐츠 활약에 사상 첫 매출 1000억원 돌파 | 부품 공급 차질에…기아차 광주공장 전면 가동 중단 |
|삼성전자, 2년 만에 인도 스마트폰 시장 점유율 1위 '왕좌 탈환' | 현대제철, 지난해 영업익 3,313억원···전년比 67.7% 감소 |
### Citation
```
@misc{kr-FinBert-SC,
author = {Kim, Eunhee and Hyopil Shin},
title = {KR-FinBert: Fine-tuning KR-FinBert for Sentiment Analysis},
year = {2022},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://huggingface.co/snunlp/KR-FinBert-SC}}
}
```
|
Helsinki-NLP/opus-mt-mr-en
|
040060aef28d3ace6070a967dc4d22bce13fe98d
|
2021-09-10T13:58:19.000Z
|
[
"pytorch",
"marian",
"text2text-generation",
"mr",
"en",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] |
translation
| false |
Helsinki-NLP
| null |
Helsinki-NLP/opus-mt-mr-en
| 560 | null |
transformers
| 2,222 |
---
tags:
- translation
license: apache-2.0
---
### opus-mt-mr-en
* source languages: mr
* target languages: en
* OPUS readme: [mr-en](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/mr-en/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2019-12-18.zip](https://object.pouta.csc.fi/OPUS-MT-models/mr-en/opus-2019-12-18.zip)
* test set translations: [opus-2019-12-18.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/mr-en/opus-2019-12-18.test.txt)
* test set scores: [opus-2019-12-18.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/mr-en/opus-2019-12-18.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba.mr.en | 38.2 | 0.515 |
|
yoshitomo-matsubara/bert-base-uncased-sst2
|
7d0cf617c3efaeb57e0cf15962c0fb3c0174d9bb
|
2021-05-29T21:57:09.000Z
|
[
"pytorch",
"bert",
"text-classification",
"en",
"dataset:sst2",
"transformers",
"sst2",
"glue",
"torchdistill",
"license:apache-2.0"
] |
text-classification
| false |
yoshitomo-matsubara
| null |
yoshitomo-matsubara/bert-base-uncased-sst2
| 560 | null |
transformers
| 2,223 |
---
language: en
tags:
- bert
- sst2
- glue
- torchdistill
license: apache-2.0
datasets:
- sst2
metrics:
- accuracy
---
`bert-base-uncased` fine-tuned on SST-2 dataset, using [***torchdistill***](https://github.com/yoshitomo-matsubara/torchdistill) and [Google Colab](https://colab.research.google.com/github/yoshitomo-matsubara/torchdistill/blob/master/demo/glue_finetuning_and_submission.ipynb).
The hyperparameters are the same as those in Hugging Face's example and/or the paper of BERT, and the training configuration (including hyperparameters) is available [here](https://github.com/yoshitomo-matsubara/torchdistill/blob/main/configs/sample/glue/sst2/ce/bert_base_uncased.yaml).
I submitted prediction files to [the GLUE leaderboard](https://gluebenchmark.com/leaderboard), and the overall GLUE score was **77.9**.
|
ShiroNeko/DialoGPT-small-rick
|
3dd3341e6bd09f9905dcc3d38a4ad897504bbdc7
|
2021-09-20T08:46:13.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
| false |
ShiroNeko
| null |
ShiroNeko/DialoGPT-small-rick
| 558 | null |
transformers
| 2,224 |
---
tags:
- conversational
---
# Rick DialoGPT Model
|
abhishek/autonlp-japanese-sentiment-59363
|
0d765f697ed9076d536ca72fa44a7666400e1ae3
|
2021-05-18T22:56:15.000Z
|
[
"pytorch",
"jax",
"bert",
"text-classification",
"ja",
"dataset:abhishek/autonlp-data-japanese-sentiment",
"transformers",
"autonlp"
] |
text-classification
| false |
abhishek
| null |
abhishek/autonlp-japanese-sentiment-59363
| 558 | null |
transformers
| 2,225 |
---
tags: autonlp
language: ja
widget:
- text: "🤗AutoNLPが大好きです"
datasets:
- abhishek/autonlp-data-japanese-sentiment
---
# Model Trained Using AutoNLP
- Problem type: Binary Classification
- Model ID: 59363
## Validation Metrics
- Loss: 0.12651239335536957
- Accuracy: 0.9532079853817648
- Precision: 0.9729688278823665
- Recall: 0.9744633462616643
- AUC: 0.9717333684823413
- F1: 0.9737155136027014
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/models/abhishek/autonlp-japanese-sentiment-59363
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("abhishek/autonlp-japanese-sentiment-59363", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("abhishek/autonlp-japanese-sentiment-59363", use_auth_token=True)
inputs = tokenizer("I love AutoNLP", return_tensors="pt")
outputs = model(**inputs)
```
|
nielsr/layoutlmv3-finetuned-funsd
|
99e76f3c6200c43c300cd597d86bb519cbb91d25
|
2022-05-02T16:57:40.000Z
|
[
"pytorch",
"tensorboard",
"layoutlmv3",
"token-classification",
"dataset:nielsr/funsd-layoutlmv3",
"transformers",
"generated_from_trainer",
"model-index",
"autotrain_compatible"
] |
token-classification
| false |
nielsr
| null |
nielsr/layoutlmv3-finetuned-funsd
| 558 | 2 |
transformers
| 2,226 |
---
tags:
- generated_from_trainer
datasets:
- nielsr/funsd-layoutlmv3
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: layoutlmv3-finetuned-funsd
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: nielsr/funsd-layoutlmv3
type: nielsr/funsd-layoutlmv3
args: funsd
metrics:
- name: Precision
type: precision
value: 0.9026198714780029
- name: Recall
type: recall
value: 0.913
- name: F1
type: f1
value: 0.9077802634849614
- name: Accuracy
type: accuracy
value: 0.8330271015158475
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# layoutlmv3-finetuned-funsd
This model is a fine-tuned version of [microsoft/layoutlmv3-base](https://huggingface.co/microsoft/layoutlmv3-base) on the nielsr/funsd-layoutlmv3 dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1164
- Precision: 0.9026
- Recall: 0.913
- F1: 0.9078
- Accuracy: 0.8330
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 1000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 10.0 | 100 | 0.5238 | 0.8366 | 0.886 | 0.8606 | 0.8410 |
| No log | 20.0 | 200 | 0.6930 | 0.8751 | 0.8965 | 0.8857 | 0.8322 |
| No log | 30.0 | 300 | 0.7784 | 0.8902 | 0.908 | 0.8990 | 0.8414 |
| No log | 40.0 | 400 | 0.9056 | 0.8916 | 0.905 | 0.8983 | 0.8364 |
| 0.2429 | 50.0 | 500 | 1.0016 | 0.8954 | 0.9075 | 0.9014 | 0.8298 |
| 0.2429 | 60.0 | 600 | 1.0097 | 0.8899 | 0.897 | 0.8934 | 0.8294 |
| 0.2429 | 70.0 | 700 | 1.0722 | 0.9035 | 0.9085 | 0.9060 | 0.8315 |
| 0.2429 | 80.0 | 800 | 1.0884 | 0.8905 | 0.9105 | 0.9004 | 0.8269 |
| 0.2429 | 90.0 | 900 | 1.1292 | 0.8938 | 0.909 | 0.9013 | 0.8279 |
| 0.0098 | 100.0 | 1000 | 1.1164 | 0.9026 | 0.913 | 0.9078 | 0.8330 |
### Framework versions
- Transformers 4.19.0.dev0
- Pytorch 1.11.0+cu113
- Datasets 2.0.0
- Tokenizers 0.11.6
|
Gunulhona/tbnymodel
|
4607ed2430c42ccdc6054e7a51c1965dfd2ca70c
|
2022-04-04T04:46:06.000Z
|
[
"pytorch",
"bart",
"text-classification",
"transformers"
] |
text-classification
| false |
Gunulhona
| null |
Gunulhona/tbnymodel
| 557 | null |
transformers
| 2,227 |
Entry not found
|
cahya/gpt2-small-indonesian-522M
|
6d53094a6ca11236e62c54916c486e2b41d0b9aa
|
2021-05-21T14:41:35.000Z
|
[
"pytorch",
"tf",
"jax",
"gpt2",
"text-generation",
"id",
"dataset:Indonesian Wikipedia",
"transformers",
"license:mit"
] |
text-generation
| false |
cahya
| null |
cahya/gpt2-small-indonesian-522M
| 557 | 1 |
transformers
| 2,228 |
---
language: "id"
license: "mit"
datasets:
- Indonesian Wikipedia
widget:
- text: "Pulau Dewata sering dikunjungi"
---
# Indonesian GPT2 small model
## Model description
It is GPT2-small model pre-trained with indonesian Wikipedia using a causal language modeling (CLM) objective. This
model is uncased: it does not make a difference between indonesia and Indonesia.
This is one of several other language models that have been pre-trained with indonesian datasets. More detail about
its usage on downstream tasks (text classification, text generation, etc) is available at [Transformer based Indonesian Language Models](https://github.com/cahya-wirawan/indonesian-language-models/tree/master/Transformers)
## Intended uses & limitations
### How to use
You can use this model directly with a pipeline for text generation. Since the generation relies on some randomness,
we set a seed for reproducibility:
```python
>>> from transformers import pipeline, set_seed
>>> generator = pipeline('text-generation', model='cahya/gpt2-small-indonesian-522M')
>>> set_seed(42)
>>> generator("Kerajaan Majapahit adalah", max_length=30, num_return_sequences=5, num_beams=10)
[{'generated_text': 'Kerajaan Majapahit adalah sebuah kerajaan yang pernah berdiri di Jawa Timur pada abad ke-14 hingga abad ke-15. Kerajaan ini berdiri pada abad ke-14'},
{'generated_text': 'Kerajaan Majapahit adalah sebuah kerajaan yang pernah berdiri di Jawa Timur pada abad ke-14 hingga abad ke-16. Kerajaan ini berdiri pada abad ke-14'},
{'generated_text': 'Kerajaan Majapahit adalah sebuah kerajaan yang pernah berdiri di Jawa Timur pada abad ke-14 hingga abad ke-15. Kerajaan ini berdiri pada abad ke-15'},
{'generated_text': 'Kerajaan Majapahit adalah sebuah kerajaan yang pernah berdiri di Jawa Timur pada abad ke-14 hingga abad ke-16. Kerajaan ini berdiri pada abad ke-15'},
{'generated_text': 'Kerajaan Majapahit adalah sebuah kerajaan yang pernah berdiri di Jawa Timur pada abad ke-14 hingga abad ke-15. Kerajaan ini merupakan kelanjutan dari Kerajaan Majapahit yang'}]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import GPT2Tokenizer, GPT2Model
model_name='cahya/gpt2-small-indonesian-522M'
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = GPT2Model.from_pretrained(model_name)
text = "Silakan diganti dengan text apa saja."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in Tensorflow:
```python
from transformers import GPT2Tokenizer, TFGPT2Model
model_name='cahya/gpt2-small-indonesian-522M'
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = TFGPT2Model.from_pretrained(model_name)
text = "Silakan diganti dengan text apa saja."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
## Training data
This model was pre-trained with 522MB of indonesian Wikipedia.
The texts are tokenized using a byte-level version of Byte Pair Encoding (BPE) (for unicode characters) and
a vocabulary size of 52,000. The inputs are sequences of 128 consecutive tokens.
|
nvidia/segformer-b0-finetuned-cityscapes-1024-1024
|
bca5b3ecf06ad6e3d732b277420a05e59e248d35
|
2022-07-20T09:53:38.000Z
|
[
"pytorch",
"tf",
"segformer",
"dataset:cityscapes",
"arxiv:2105.15203",
"transformers",
"vision",
"image-segmentation",
"license:apache-2.0"
] |
image-segmentation
| false |
nvidia
| null |
nvidia/segformer-b0-finetuned-cityscapes-1024-1024
| 557 | null |
transformers
| 2,229 |
---
license: apache-2.0
tags:
- vision
- image-segmentation
datasets:
- cityscapes
widget:
- src: https://www.researchgate.net/profile/Anurag-Arnab/publication/315881952/figure/fig5/AS:667673876779033@1536197265755/Sample-results-on-the-Cityscapes-dataset-The-above-images-show-how-our-method-can-handle.jpg
example_title: Road
---
# SegFormer (b0-sized) model fine-tuned on CityScapes
SegFormer model fine-tuned on CityScapes at resolution 1024x1024. It was introduced in the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Xie et al. and first released in [this repository](https://github.com/NVlabs/SegFormer).
Disclaimer: The team releasing SegFormer did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
SegFormer consists of a hierarchical Transformer encoder and a lightweight all-MLP decode head to achieve great results on semantic segmentation benchmarks such as ADE20K and Cityscapes. The hierarchical Transformer is first pre-trained on ImageNet-1k, after which a decode head is added and fine-tuned altogether on a downstream dataset.
## Intended uses & limitations
You can use the raw model for semantic segmentation. See the [model hub](https://huggingface.co/models?other=segformer) to look for fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import SegformerFeatureExtractor, SegformerForSemanticSegmentation
from PIL import Image
import requests
feature_extractor = SegformerFeatureExtractor.from_pretrained("nvidia/segformer-b0-finetuned-cityscapes-1024-1024")
model = SegformerForSemanticSegmentation.from_pretrained("nvidia/segformer-b0-finetuned-cityscapes-1024-1024")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits # shape (batch_size, num_labels, height/4, width/4)
```
For more code examples, we refer to the [documentation](https://huggingface.co/transformers/model_doc/segformer.html#).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2105-15203,
author = {Enze Xie and
Wenhai Wang and
Zhiding Yu and
Anima Anandkumar and
Jose M. Alvarez and
Ping Luo},
title = {SegFormer: Simple and Efficient Design for Semantic Segmentation with
Transformers},
journal = {CoRR},
volume = {abs/2105.15203},
year = {2021},
url = {https://arxiv.org/abs/2105.15203},
eprinttype = {arXiv},
eprint = {2105.15203},
timestamp = {Wed, 02 Jun 2021 11:46:42 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2105-15203.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
Gunulhona/tbecmodel
|
6f555e96bafdb845b2affa4586ab339db5516144
|
2022-01-25T06:37:13.000Z
|
[
"pytorch",
"bart",
"text-classification",
"transformers"
] |
text-classification
| false |
Gunulhona
| null |
Gunulhona/tbecmodel
| 555 | null |
transformers
| 2,230 |
Entry not found
|
google/long-t5-local-large
|
a4b28551322d14828192722fff4576100a9e18be
|
2022-06-22T09:06:02.000Z
|
[
"pytorch",
"jax",
"longt5",
"text2text-generation",
"en",
"arxiv:2112.07916",
"arxiv:1912.08777",
"arxiv:1910.10683",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] |
text2text-generation
| false |
google
| null |
google/long-t5-local-large
| 555 | 1 |
transformers
| 2,231 |
---
license: apache-2.0
language: en
---
# LongT5 (local attention, large-sized model)
LongT5 model pre-trained on English language. The model was introduced in the paper [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/pdf/2112.07916.pdf) by Guo et al. and first released in [the LongT5 repository](https://github.com/google-research/longt5). All the model architecture and configuration can be found in [Flaxformer repository](https://github.com/google/flaxformer) which uses another Google research project repository [T5x](https://github.com/google-research/t5x).
Disclaimer: The team releasing LongT5 did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
LongT5 model is an encoder-decoder transformer pre-trained in a text-to-text denoising generative setting ([Pegasus-like generation pre-training](https://arxiv.org/pdf/1912.08777.pdf)). LongT5 model is an extension of [T5 model](https://arxiv.org/pdf/1910.10683.pdf), and it enables using one of the two different efficient attention mechanisms - (1) Local attention, or (2) Transient-Global attention. The usage of attention sparsity patterns allows the model to efficiently handle input sequence.
LongT5 is particularly effective when fine-tuned for text generation (summarization, question answering) which requires handling long input sequences (up to 16,384 tokens).
## Intended uses & limitations
The model is mostly meant to be fine-tuned on a supervised dataset. See the [model hub](https://huggingface.co/models?search=longt5) to look for fine-tuned versions on a task that interests you.
### How to use
```python
from transformers import AutoTokenizer, LongT5Model
tokenizer = AutoTokenizer.from_pretrained("google/long-t5-local-large")
model = LongT5Model.from_pretrained("google/long-t5-local-large")
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state
```
### BibTeX entry and citation info
```bibtex
@article{guo2021longt5,
title={LongT5: Efficient Text-To-Text Transformer for Long Sequences},
author={Guo, Mandy and Ainslie, Joshua and Uthus, David and Ontanon, Santiago and Ni, Jianmo and Sung, Yun-Hsuan and Yang, Yinfei},
journal={arXiv preprint arXiv:2112.07916},
year={2021}
}
```
|
akhooli/gpt2-small-arabic
|
c123d61dfde7003e1e250016152f28c5b71a5dc3
|
2021-05-21T12:38:38.000Z
|
[
"pytorch",
"jax",
"gpt2",
"text-generation",
"ar",
"dataset:Arabic Wikipedia",
"transformers"
] |
text-generation
| false |
akhooli
| null |
akhooli/gpt2-small-arabic
| 554 | 3 |
transformers
| 2,232 |
---
language: "ar"
datasets:
- Arabic Wikipedia
metrics:
- none
---
# GPT2-Small-Arabic
## Model description
GPT2 model from Arabic Wikipedia dataset based on gpt2-small (using Fastai2).
## Intended uses & limitations
#### How to use
An example is provided in this [colab notebook](https://colab.research.google.com/drive/1mRl7c-5v-Klx27EEAEOAbrfkustL4g7a?usp=sharing).
Both text and poetry (fine-tuned model) generation are included.
#### Limitations and bias
GPT2-small-arabic (trained on Arabic Wikipedia) has several limitations in terms of coverage (Arabic Wikipeedia quality, no diacritics) and training performance.
Use as demonstration or proof of concepts but not as production code.
## Training data
This pretrained model used the Arabic Wikipedia dump (around 900 MB).
## Training procedure
Training was done using [Fastai2](https://github.com/fastai/fastai2/) library on Kaggle, using free GPU.
## Eval results
Final perplexity reached was 72.19, loss: 4.28, accuracy: 0.307
### BibTeX entry and citation info
```bibtex
@inproceedings{Abed Khooli,
year={2020}
}
```
|
Wikidepia/IndoT5-base-paraphrase
|
5d591dc3aeae0aade0f327a5ebdd0f071c83f567
|
2021-09-04T02:49:33.000Z
|
[
"pytorch",
"jax",
"tensorboard",
"t5",
"text2text-generation",
"id",
"transformers",
"autotrain_compatible"
] |
text2text-generation
| false |
Wikidepia
| null |
Wikidepia/IndoT5-base-paraphrase
| 553 | null |
transformers
| 2,233 |
---
language:
- id
---
# Paraphrase Generation with IndoT5 Base
IndoT5-base trained on translated PAWS.
## Model in action
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("Wikidepia/IndoT5-base-paraphrase")
model = AutoModelForSeq2SeqLM.from_pretrained("Wikidepia/IndoT5-base-paraphrase")
sentence = "Anak anak melakukan piket kelas agar kebersihan kelas terjaga"
text = "paraphrase: " + sentence + " </s>"
encoding = tokenizer(text, padding='longest', return_tensors="pt")
outputs = model.generate(
input_ids=encoding["input_ids"], attention_mask=encoding["attention_mask"],
max_length=512,
do_sample=True,
top_k=200,
top_p=0.95,
early_stopping=True,
num_return_sequences=5
)
```
## Limitations
Sometimes paraphrase contain date which doesnt exists in the original text :/
## Acknowledgement
Thanks to Tensorflow Research Cloud for providing TPU v3-8s.
|
ttop324/wav2vec2-live-japanese
|
3db54ebbfc3e19ca24aab50f14e13a3c411726cf
|
2021-10-31T15:34:55.000Z
|
[
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"ja",
"dataset:common_voice",
"transformers",
"audio",
"speech",
"xlsr-fine-tuning-week",
"license:apache-2.0",
"model-index"
] |
automatic-speech-recognition
| false |
ttop324
| null |
ttop324/wav2vec2-live-japanese
| 553 | 1 |
transformers
| 2,234 |
---
language: ja
datasets:
- common_voice
metrics:
- wer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: wav2vec2-live-japanese
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice Japanese
type: common_voice
args: ja
metrics:
- name: Test WER
type: wer
value: 21.48%
- name: Test CER
type: cer
value: 9.82%
---
# wav2vec2-live-japanese
https://github.com/ttop32/wav2vec2-live-japanese-translator
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Japanese hiragana using the
- [common_voice](https://huggingface.co/datasets/common_voice)
- [JSUT](https://sites.google.com/site/shinnosuketakamichi/publication/jsut)
- [CSS10](https://github.com/Kyubyong/css10)
- [TEDxJP-10K](https://github.com/laboroai/TEDxJP-10K)
- [JVS](https://sites.google.com/site/shinnosuketakamichi/research-topics/jvs_corpus)
- [JSSS](https://sites.google.com/site/shinnosuketakamichi/research-topics/jsss_corpus)
## Inference
```python
#usage
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
model = Wav2Vec2ForCTC.from_pretrained("ttop324/wav2vec2-live-japanese")
processor = Wav2Vec2Processor.from_pretrained("ttop324/wav2vec2-live-japanese")
test_dataset = load_dataset("common_voice", "ja", split="test")
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = torchaudio.functional.resample(speech_array, sampling_rate, 16000)[0].numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset[:2]["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset[:2]["sentence"])
```
## Evaluation
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
import pykakasi
import MeCab
wer = load_metric("wer")
cer = load_metric("cer")
model = Wav2Vec2ForCTC.from_pretrained("ttop324/wav2vec2-live-japanese").to("cuda")
processor = Wav2Vec2Processor.from_pretrained("ttop324/wav2vec2-live-japanese")
test_dataset = load_dataset("common_voice", "ja", split="test")
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"\“\‘\”\�‘、。.!,・―─~「」『』\\\\※\[\]\{\}「」〇?…]'
wakati = MeCab.Tagger("-Owakati")
kakasi = pykakasi.kakasi()
kakasi.setMode("J","H") # kanji to hiragana
kakasi.setMode("K","H") # katakana to hiragana
conv = kakasi.getConverter()
FULLWIDTH_TO_HALFWIDTH = str.maketrans(
' 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ!゛#$%&()*+、ー。/:;〈=〉?@[]^_‘{|}~',
' 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ!"#$%&()*+,-./:;<=>?@[]^_`{|}~',
)
def fullwidth_to_halfwidth(s):
return s.translate(FULLWIDTH_TO_HALFWIDTH)
def preprocessData(batch):
batch["sentence"] = fullwidth_to_halfwidth(batch["sentence"])
batch["sentence"] = re.sub(chars_to_ignore_regex,' ', batch["sentence"]).lower() #remove special char
batch["sentence"] = wakati.parse(batch["sentence"]) #add space
batch["sentence"] = conv.do(batch["sentence"]) #covert to hiragana
batch["sentence"] = " ".join(batch["sentence"].split())+" " #remove multiple space
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = torchaudio.functional.resample(speech_array, sampling_rate, 16000)[0].numpy()
return batch
test_dataset = test_dataset.map(preprocessData)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
print("CER: {:2f}".format(100 * cer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
|
jonatasgrosman/wav2vec2-large-fr-voxpopuli-french
|
9a18cf72882b27fe13d8df75b761c000c2e726dd
|
2022-07-27T23:33:59.000Z
|
[
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"fr",
"dataset:common_voice",
"transformers",
"audio",
"speech",
"xlsr-fine-tuning-week",
"license:apache-2.0",
"model-index"
] |
automatic-speech-recognition
| false |
jonatasgrosman
| null |
jonatasgrosman/wav2vec2-large-fr-voxpopuli-french
| 552 | 1 |
transformers
| 2,235 |
---
language: fr
datasets:
- common_voice
metrics:
- wer
- cer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: Voxpopuli Wav2Vec2 French by Jonatas Grosman
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice fr
type: common_voice
args: fr
metrics:
- name: Test WER
type: wer
value: 17.62
- name: Test CER
type: cer
value: 6.04
---
# Fine-tuned French Voxpopuli wav2vec2 large model for speech recognition in French
Fine-tuned [facebook/wav2vec2-large-fr-voxpopuli](https://huggingface.co/facebook/wav2vec2-large-fr-voxpopuli) on French using the train and validation splits of [Common Voice 6.1](https://huggingface.co/datasets/common_voice).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned thanks to the GPU credits generously given by the [OVHcloud](https://www.ovhcloud.com/en/public-cloud/ai-training/) :)
The script used for training can be found here: https://github.com/jonatasgrosman/wav2vec2-sprint
## Usage
The model can be used directly (without a language model) as follows...
Using the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) library:
```python
from huggingsound import SpeechRecognitionModel
model = SpeechRecognitionModel("jonatasgrosman/wav2vec2-large-fr-voxpopuli-french")
audio_paths = ["/path/to/file.mp3", "/path/to/another_file.wav"]
transcriptions = model.transcribe(audio_paths)
```
Writing your own inference script:
```python
import torch
import librosa
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
LANG_ID = "fr"
MODEL_ID = "jonatasgrosman/wav2vec2-large-fr-voxpopuli-french"
SAMPLES = 10
test_dataset = load_dataset("common_voice", LANG_ID, split=f"test[:{SAMPLES}]")
processor = Wav2Vec2Processor.from_pretrained(MODEL_ID)
model = Wav2Vec2ForCTC.from_pretrained(MODEL_ID)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = librosa.load(batch["path"], sr=16_000)
batch["speech"] = speech_array
batch["sentence"] = batch["sentence"].upper()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
predicted_sentences = processor.batch_decode(predicted_ids)
for i, predicted_sentence in enumerate(predicted_sentences):
print("-" * 100)
print("Reference:", test_dataset[i]["sentence"])
print("Prediction:", predicted_sentence)
```
| Reference | Prediction |
| ------------- | ------------- |
| "CE DERNIER A ÉVOLUÉ TOUT AU LONG DE L'HISTOIRE ROMAINE." | CE DERNIER A ÉVOLÉ TOUT AU LONG DE L'HISTOIRE ROMAINE |
| CE SITE CONTIENT QUATRE TOMBEAUX DE LA DYNASTIE ACHÉMÉNIDE ET SEPT DES SASSANIDES. | CE SITE CONTIENT QUATRE TOMBEAUX DE LA DYNESTIE ACHÉMÉNIDE ET SEPT DES SACENNIDES |
| "J'AI DIT QUE LES ACTEURS DE BOIS AVAIENT, SELON MOI, BEAUCOUP D'AVANTAGES SUR LES AUTRES." | JAI DIT QUE LES ACTEURS DE BOIS AVAIENT SELON MOI BEAUCOUP DAVANTAGE SUR LES AUTRES |
| LES PAYS-BAS ONT REMPORTÉ TOUTES LES ÉDITIONS. | LE PAYS-BAS ON REMPORTÉ TOUTES LES ÉDITIONS |
| IL Y A MAINTENANT UNE GARE ROUTIÈRE. | IL A MAINTENANT GULA E RETIREN |
| HUIT | HUIT |
| DANS L’ATTENTE DU LENDEMAIN, ILS NE POUVAIENT SE DÉFENDRE D’UNE VIVE ÉMOTION | DANS LATTENTE DU LENDEMAIN IL NE POUVAIT SE DÉFENDRE DUNE VIVE ÉMOTION |
| LA PREMIÈRE SAISON EST COMPOSÉE DE DOUZE ÉPISODES. | LA PREMIÈRE SAISON EST COMPOSÉE DE DOUZ ÉPISODES |
| ELLE SE TROUVE ÉGALEMENT DANS LES ÎLES BRITANNIQUES. | ELLE SE TROUVE ÉGALEMENT DANS LES ÎLES BRITANNIQUES |
| ZÉRO | ZÉRO |
## Evaluation
The model can be evaluated as follows on the French (fr) test data of Common Voice.
```python
import torch
import re
import librosa
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
LANG_ID = "fr"
MODEL_ID = "jonatasgrosman/wav2vec2-large-fr-voxpopuli-french"
DEVICE = "cuda"
CHARS_TO_IGNORE = [",", "?", "¿", ".", "!", "¡", ";", ";", ":", '""', "%", '"', "�", "ʿ", "·", "჻", "~", "՞",
"؟", "،", "।", "॥", "«", "»", "„", "“", "”", "「", "」", "‘", "’", "《", "》", "(", ")", "[", "]",
"{", "}", "=", "`", "_", "+", "<", ">", "…", "–", "°", "´", "ʾ", "‹", "›", "©", "®", "—", "→", "。",
"、", "﹂", "﹁", "‧", "~", "﹏", ",", "{", "}", "(", ")", "[", "]", "【", "】", "‥", "〽",
"『", "』", "〝", "〟", "⟨", "⟩", "〜", ":", "!", "?", "♪", "؛", "/", "\\", "º", "−", "^", "ʻ", "ˆ"]
test_dataset = load_dataset("common_voice", LANG_ID, split="test")
wer = load_metric("wer.py") # https://github.com/jonatasgrosman/wav2vec2-sprint/blob/main/wer.py
cer = load_metric("cer.py") # https://github.com/jonatasgrosman/wav2vec2-sprint/blob/main/cer.py
chars_to_ignore_regex = f"[{re.escape(''.join(CHARS_TO_IGNORE))}]"
processor = Wav2Vec2Processor.from_pretrained(MODEL_ID)
model = Wav2Vec2ForCTC.from_pretrained(MODEL_ID)
model.to(DEVICE)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
with warnings.catch_warnings():
warnings.simplefilter("ignore")
speech_array, sampling_rate = librosa.load(batch["path"], sr=16_000)
batch["speech"] = speech_array
batch["sentence"] = re.sub(chars_to_ignore_regex, "", batch["sentence"]).upper()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to(DEVICE), attention_mask=inputs.attention_mask.to(DEVICE)).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
predictions = [x.upper() for x in result["pred_strings"]]
references = [x.upper() for x in result["sentence"]]
print(f"WER: {wer.compute(predictions=predictions, references=references, chunk_size=1000) * 100}")
print(f"CER: {cer.compute(predictions=predictions, references=references, chunk_size=1000) * 100}")
```
**Test Result**:
In the table below I report the Word Error Rate (WER) and the Character Error Rate (CER) of the model. I ran the evaluation script described above on other models as well (on 2021-05-16). Note that the table below may show different results from those already reported, this may have been caused due to some specificity of the other evaluation scripts used.
| Model | WER | CER |
| ------------- | ------------- | ------------- |
| jonatasgrosman/wav2vec2-large-xlsr-53-french | **15.90%** | **5.29%** |
| jonatasgrosman/wav2vec2-large-fr-voxpopuli-french | 17.62% | 6.04% |
| Ilyes/wav2vec2-large-xlsr-53-french | 19.67% | 6.70% |
| Nhut/wav2vec2-large-xlsr-french | 24.09% | 8.42% |
| facebook/wav2vec2-large-xlsr-53-french | 25.45% | 10.35% |
| MehdiHosseiniMoghadam/wav2vec2-large-xlsr-53-French | 28.22% | 9.70% |
| Ilyes/wav2vec2-large-xlsr-53-french_punctuation | 29.80% | 11.79% |
| facebook/wav2vec2-base-10k-voxpopuli-ft-fr | 61.06% | 33.31% |
## Citation
If you want to cite this model you can use this:
```bibtex
@misc{grosman2021voxpopuli-fr-wav2vec2-large-french,
title={Fine-tuned {F}rench {V}oxpopuli wav2vec2 large model for speech recognition in {F}rench},
author={Grosman, Jonatas},
howpublished={\url{https://huggingface.co/jonatasgrosman/wav2vec2-large-fr-voxpopuli-french}},
year={2021}
}
```
|
Helsinki-NLP/opus-mt-en-vi
|
2d731274713eb04ca01788dff46beee9b894766d
|
2021-01-18T08:19:11.000Z
|
[
"pytorch",
"marian",
"text2text-generation",
"en",
"vi",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] |
translation
| false |
Helsinki-NLP
| null |
Helsinki-NLP/opus-mt-en-vi
| 551 | 1 |
transformers
| 2,236 |
---
language:
- en
- vi
tags:
- translation
license: apache-2.0
---
### eng-vie
* source group: English
* target group: Vietnamese
* OPUS readme: [eng-vie](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/eng-vie/README.md)
* model: transformer-align
* source language(s): eng
* target language(s): vie vie_Hani
* model: transformer-align
* pre-processing: normalization + SentencePiece (spm32k,spm32k)
* a sentence initial language token is required in the form of `>>id<<` (id = valid target language ID)
* download original weights: [opus-2020-06-17.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-vie/opus-2020-06-17.zip)
* test set translations: [opus-2020-06-17.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-vie/opus-2020-06-17.test.txt)
* test set scores: [opus-2020-06-17.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-vie/opus-2020-06-17.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba-test.eng.vie | 37.2 | 0.542 |
### System Info:
- hf_name: eng-vie
- source_languages: eng
- target_languages: vie
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/eng-vie/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['en', 'vi']
- src_constituents: {'eng'}
- tgt_constituents: {'vie', 'vie_Hani'}
- src_multilingual: False
- tgt_multilingual: False
- prepro: normalization + SentencePiece (spm32k,spm32k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/eng-vie/opus-2020-06-17.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/eng-vie/opus-2020-06-17.test.txt
- src_alpha3: eng
- tgt_alpha3: vie
- short_pair: en-vi
- chrF2_score: 0.542
- bleu: 37.2
- brevity_penalty: 0.973
- ref_len: 24427.0
- src_name: English
- tgt_name: Vietnamese
- train_date: 2020-06-17
- src_alpha2: en
- tgt_alpha2: vi
- prefer_old: False
- long_pair: eng-vie
- helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535
- transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b
- port_machine: brutasse
- port_time: 2020-08-21-14:41
|
Invincible/Chat_bot-Harrypotter-medium
|
0c7709b101432363343da0f414cd0fbbb67aefa5
|
2021-09-02T04:14:39.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
| false |
Invincible
| null |
Invincible/Chat_bot-Harrypotter-medium
| 551 | null |
transformers
| 2,237 |
---
tags:
- conversational
---
#harry potter
|
sberbank-ai/ruclip-vit-large-patch14-336
|
c6746c7408550b773bf8d620ef96069b8f005849
|
2022-01-09T22:25:33.000Z
|
[
"pytorch",
"transformers"
] | null | false |
sberbank-ai
| null |
sberbank-ai/ruclip-vit-large-patch14-336
| 551 | null |
transformers
| 2,238 |
# ruclip-vit-large-patch14-336
**RuCLIP** (**Ru**ssian **C**ontrastive **L**anguage–**I**mage **P**retraining) is a multimodal model
for obtaining images and text similarities and rearranging captions and pictures.
RuCLIP builds on a large body of work on zero-shot transfer, computer vision, natural language processing and
multimodal learning.
Model was trained by [Sber AI](https://github.com/sberbank-ai) and [SberDevices](https://sberdevices.ru/) teams.
* Task: `text ranking`; `image ranking`; `zero-shot image classification`;
* Type: `encoder`
* Num Parameters: `430M`
* Training Data Volume: `240 million text-image pairs`
* Language: `Russian`
* Context Length: `77`
* Transformer Layers: `12`
* Transformer Width: `768`
* Transformer Heads: `12`
* Image Size: `336`
* Vision Layers: `24`
* Vision Width: `1024`
* Vision Patch Size: `14`
## Usage [Github](https://github.com/sberbank-ai/ru-clip)
```
pip install ruclip
```
```python
clip, processor = ruclip.load("ruclip-vit-large-patch14-336", device="cuda")
```
## Performance
We have evaluated the performance on the following datasets:
| Dataset | Metric Name | Metric Result |
|:--------------|:---------------|:--------------------|
| Food101 | acc | 0.712 |
| CIFAR10 | acc | 0.906 |
| CIFAR100 | acc | 0.591 |
| Birdsnap | acc | 0.213 |
| SUN397 | acc | 0.523 |
| Stanford Cars | acc | 0.659 |
| DTD | acc | 0.408 |
| MNIST | acc | 0.242 |
| STL10 | acc | 0.956 |
| PCam | acc | 0.554 |
| CLEVR | acc | 0.142 |
| Rendered SST2 | acc | 0.539 |
| ImageNet | acc | 0.488 |
| FGVC Aircraft | mean-per-class | 0.075 |
| Oxford Pets | mean-per-class | 0.546 |
| Caltech101 | mean-per-class | 0.835 |
| Flowers102 | mean-per-class | 0.517 |
| HatefulMemes | roc-auc | 0.519 |
# Authors
+ Alex Shonenkov: [Github](https://github.com/shonenkov), [Kaggle GM](https://www.kaggle.com/shonenkov)
+ Daniil Chesakov: [Github](https://github.com/Danyache)
+ Denis Dimitrov: [Github](https://github.com/denndimitrov)
+ Igor Pavlov: [Github](https://github.com/boomb0om)
|
assemblyai/distilbert-base-uncased-sst2
|
b22ecd1ae8fe1a941bf478fec027bdc996ba190f
|
2021-06-14T22:04:03.000Z
|
[
"pytorch",
"distilbert",
"text-classification",
"arxiv:1910.01108",
"transformers"
] |
text-classification
| false |
assemblyai
| null |
assemblyai/distilbert-base-uncased-sst2
| 550 | null |
transformers
| 2,239 |
# DistilBERT-Base-Uncased for Sentiment Analysis
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) originally released in ["DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter"](https://arxiv.org/abs/1910.01108) and trained on the [Stanford Sentiment Treebank v2 (SST2)](https://nlp.stanford.edu/sentiment/); part of the [General Language Understanding Evaluation (GLUE)](https://gluebenchmark.com) benchmark. This model was fine-tuned by the team at [AssemblyAI](https://www.assemblyai.com) and is released with the [corresponding blog post]().
## Usage
To download and utilize this model for sentiment analysis please execute the following:
```python
import torch.nn.functional as F
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("assemblyai/distilbert-base-uncased-sst2")
model = AutoModelForSequenceClassification.from_pretrained("assemblyai/distilbert-base-uncased-sst2")
tokenized_segments = tokenizer(["AssemblyAI is the best speech-to-text API for modern developers with performance being second to none!"], return_tensors="pt", padding=True, truncation=True)
tokenized_segments_input_ids, tokenized_segments_attention_mask = tokenized_segments.input_ids, tokenized_segments.attention_mask
model_predictions = F.softmax(model(input_ids=tokenized_segments_input_ids, attention_mask=tokenized_segments_attention_mask)['logits'], dim=1)
print("Positive probability: "+str(model_predictions[0][1].item()*100)+"%")
print("Negative probability: "+str(model_predictions[0][0].item()*100)+"%")
```
For questions about how to use this model feel free to contact the team at [AssemblyAI](https://www.assemblyai.com)!
|
readerbench/RoGPT2-base
|
b5e625fea1f4040b224799e6cbd9d52324432320
|
2021-07-22T11:24:47.000Z
|
[
"pytorch",
"tf",
"gpt2",
"text-generation",
"ro",
"transformers"
] |
text-generation
| false |
readerbench
| null |
readerbench/RoGPT2-base
| 550 | null |
transformers
| 2,240 |
Model card for RoGPT2-base
---
language:
- ro
---
# RoGPT2: Romanian GPT2 for text generation
All models are available:
* [RoBERT-base](https://huggingface.co/readerbench/RoGPT2-base)
* [RoBERT-medium](https://huggingface.co/readerbench/RoGPT2-medium)
* [RoBERT-large](https://huggingface.co/readerbench/RoGPT2-large)
For code and evaluation check out [GitHub](https://github.com/readerbench/RoGPT2).
#### How to use
```python
# TensorFlow
from transformers import AutoTokenizer, TFAutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained('readerbench/RoGPT2-base')
model = TFAutoModelForCausalLM.from_pretrained('readerbench/RoGPT2-base')
inputs = tokenizer.encode("Este o zi de vara", return_tensors='tf')
text = model.generate(inputs, max_length=1024, no_repeat_ngram_size=2)
print(tokenizer.decode(text[0]))
# PyTorch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained('readerbench/RoGPT2-base')
model = AutoModelForCausalLM.from_pretrained('readerbench/RoGPT2-base')
inputs = tokenizer.encode("Este o zi de vara", return_tensors='pt')
text = model.generate(inputs, max_length=1024, no_repeat_ngram_size=2)
print(tokenizer.decode(text[0]))
```
## Training
---
### Corpus Statistics
| Corpus | Total size | Number of words | Number of sentences |
|:------:|:----------:|:---------------:|:-------------------:|
|OSCAR| 11.54 GB | 1745M | 48.46M |
|Wiki-Ro | 0.46 GB | 68M | 1.79M |
|Debates | 0.5 GB | 73M | 3.61M |
|Books | 4.37 GB | 667M | 37.39M |
|News | 0.15 GB | 23M | 0.77M |
### Training Statistics
| Version | Number of parameters | Number of epoch | Duration of an epoch | Context size | Batch size | PPL |
|:-------:|:--------------------:|:---------------:|:--------------------:|:----------:|:----------:|:---:|
| Base | 124M | 15 | 7h | 1024 | 72 | 22.96 |
| Medium | 354M | 10 | 22h | 1024 | 24 | 17.64 |
| Large | 774M | 5 | **45h** | 512 | 16 | **16.77**|
## Evaluation
---
### 1. MOROCO
| Model | Dialect | Md to Ro | Ro to Md |
|:-----------------:|:-------:|:--------:|:--------:|
| KRR + SK | 94.06 | 67.59 | 75.47 |
| BERT-base-ro | 95.98 | 69.90 | 78.08 |
| RoBERT-small | 95.76 | 69.05 | 80.15 |
| RoBERT-base |**97.24**| 68.80 | 82.37 |
| RoBERT-large | 97.21 | 69.50 | **83.26**|
| RoGPT2-base | 96.69 | 69.82 | 77.55 |
| RoGPT2-medium | 96.42 | 69.77 | 80.51 |
| RoGPT2-large | 96.93 |**71.07** | 82.56 |
### 2. LaRoSeDa
| Model | Binary: Accuracy | Binary: F1-Score | Multi-Class: Accuracy | Multi-Class: F1-Score |
|:------------:|:----------------:|:----------------:|:---------------------:|:---------------------:|
|BERT-base-ro | 98.07 | 97.94 | - |79.61 |
| RoDiBERT |**98.40** |**98.31** | - |83.01 |
| RoBERT-small | 97.44 | 97.43 | 89.30 |84.23 |
| RoBERT-base | 98.27 | 98.26 | 90.59 |86.27 |
| RoBERT-large | 98.20 | 98.19 |**90.93** |**86.63** |
| RoGPT2-base | 97.89 | 97.88 |89.65 |84.68 |
|RoGPT2-medium | 98.03 |98.04 | 90.29 | 85.37 |
| RoGPT2-large | 98.06 |98.07 | 90.26 | 84.89 |
### 3. RoSTS
| Model | Spearman dev-set | Spearman test-set | Pearson dev-set | Pearson test-set |
|:------------:|:----------------:|:-----------------:|:---------------:|:----------------:|
|BERT-base-ro | 84.26 | 80.86 | 84.59 | 81.59 |
|RoDiBERT | 77.07 | 71.47 | 77.13 | 72.25 |
|RoBERT-small | 82.06 | 78.06 | 81.66 | 78.49 |
|RoBERT-base | 84.93 | 80.39 | 85.03 | 80.39 |
|RoBERT-large |**86.25** |**83.15** |**86.58** |**83.76** |
|RoGPT2-base | 83.51 | 79.77 | 83.74 | 80.56 |
|RoGPT2-medium | 85.75 | 82.25 | 86.04 | 83.16 |
|RoGPT2-large | 85.70 | 82.64 | 86.14 | 83.46 |
### 4. WMT16
| Model | Decoder method | Ro-En | En-Ro |
|:------------:|:--------------:|:------:|:------:|
|mBART | - |**38.5**|**38.5**|
|OpenNMT | - | - | 24.7 |
|RoGPT2-base |Greedy | 30.37 | 20.27 |
|RoGPT2-base |Beam-search-4 | 31.26 | 22.31 |
|RoGPT2-base |Beam-search-8 | 31.39 | 22.95 |
|RoGPT2-medium |Greedy | 32.48 | 22.18 |
|RoGPT2-medium |Beam-search-4 | 34.08 | 24.03 |
|RoGPT2-medium |Beam-search-8 | 34.16 | 24.13 |
|RoGPT2-large |Greedy | 33.69 | 23.31 |
|RoGPT2-large |Beam-search-4 |34.40 |24.23 |
|RoGPT2-large |Beam-search-8 |34.51 |24.32 |
### 5. XQuAD
| Model |Decoder method | EM | F1-Score |
|:------------:|:-------------:|:-----:|:--------:|
|BERT-base-ro | - | 47.89 | 63.74 |
|RoDiBERT | - | 21.76 | 34.57 |
|RoBERT-small | - | 30.84 | 45.17 |
|RoBERT-base | - | 53.52 | 70.04 |
|RoBERT-large | - | 55.46 | 69.64 |
|mBERT | - |59.9 | 72.7 |
|XLM-R Large | - |**69.7**|**83.6**|
|RoGPT2-base | Greedy | 23.69 | 35.97 |
|RoGPT2-base | Beam-search-4 | 24.11 | 35.27 |
|RoGPT2-medium | Greedy | 29.66 | 44.74 |
|RoGPT2-medium | Beam-search-4 | 31.59 | 45.32 |
|RoGPT2-large | Greedy | 29.74 | 42.98 |
|RoGPT2-large | Beam-search-4 | 29.66 | 43.05 |
|RoGPT2-base-en-ro | Greedy | 23.86 | 34.27 |
|RoGPT2-base-en-ro | Beam-search-4 | 25.04 | 34.51 |
|RoGPT2-medium-en-ro | Greedy | 27.05 | 39.75 |
|RoGPT2-medium-en-ro | Beam-search-4 | 27.64 | 39.11 |
|RoGPT2-large-en-ro | Greedy | 28.40 | 39.79 |
|RoGPT2-large-en-ro | Beam-search-4 | 28.73 | 39.71 |
|RoGPT2-large-en-ro-mask | Greedy | 31.34 | 44.71 |
|RoGPT2-large-en-ro-mask| Beam-search-4 | 31.59 | 43.53 |
### 6. Wiki-Ro: LM
| Model | PPL dev | PPL test |
|:------------:|:-------:|:--------:|
|BERT-base-ro | 29.0897 | 28.0043|
|RoGPT2-base | 34.3795 | 33.7460|
|RoGPT2-medium | 23.7879 | 23.4581|
|RoGPT2-large | **21.7491** | **21.5200** |
### 7. RoGEC
| Model | Decoder mothod | P | R | F<sub>0.5</sub> |
|:-----:|:--------------:|:---:|:---:|:------:|
|Transformer-tiny | Beam-search | 53.53 | 26.36 | 44.38 |
|Transformer-base Finetuning | Beam-search | 56.05 | 46.19 | 53.76 |
|Transformer-base Finetuning | Beam-search-LM | 50.68 | 45.39 | 49.52 |
|Transformer-base Finetuning | Beam-search-norm-LM | 51.06 | 45.43 | 49.83 |
|RoGPT2-base | Greedy | 59.02 | 49.35 | 56.80 |
|RoGPT2-base | Beam-search-4 | 65.23 | 49.26 | 61.26 |
|RoGPT2-base |Beam-search-8 | 65.88 | 49.64 | 61.84 |
|RoGPT2-medium | Greedy | 69.97 | 57.94 | 67.18 |
|RoGPT2-medium | Beam-search-4 | **72.46** | **57.99** | **69.01** |
|RoGPT2-medium | Beam-search-8 | 72.24 | 57.69 | 68.77 |
|RoGP2-large | Greedy | 61.90 | 49.09 | 58.83 |
|RoGP2-large | Beam-search-4 | 65.24 | 49.43 | 61.32 |
|RoGP2-large | Beam-search-8 | 64.96 | 49.22 | 61.06 |
|RoGPT2-base* | Greedy | 68.67 | 49.60 | 63.77 |
|RoGPT2-base* | Beam-search-4 | 71.16 | 50.53 | 65.79 |
|RoGPT2-base* | Beam-search-8 | 71.68 | 50.65 | 66.18 |
|RoGPT2-medium* | Greedy | 58.21 | 43.32 | 54.47 |
|RoGPT2-medium* | Beam-search-4 | 68.31 | 43.78 | 61.43 |
|RoGPT2-medium* | Beam-search-8 | 68.68 | 43.99 | 61.75 |
|RoGPT2-large* | Greedy | 64.86 | 41.30 | 58.22 |
|RoGPT2-large* | Beam-search-4 | 65.57 | 41.00 | 58.55 |
|RoGPT2-large* | Beam-search-8 | 65.44 | 41.09 | 58.50 |
**__Note__**: * the models were trained using the dataset of 3,000,000 artificially generated pairs
## Acknowledgments
---
Research supported with [Cloud TPUs](https://cloud.google.com/tpu/) from Google's [TensorFlow Research Cloud (TFRC)](https://www.tensorflow.org/tfrc)
## How to cite
---
Niculescu, M. A., Ruseti, S., and Dascalu, M. (submitted). RoGPT2: Romanian GPT2 for Text Generation
|
Yale-LILY/brio-xsum-cased
|
78ce8a35c6e73b2220b5a8b99c4b690f9bb22e01
|
2022-03-31T03:13:07.000Z
|
[
"pytorch",
"pegasus",
"text2text-generation",
"transformers",
"autotrain_compatible"
] |
text2text-generation
| false |
Yale-LILY
| null |
Yale-LILY/brio-xsum-cased
| 550 | 1 |
transformers
| 2,241 |
Entry not found
|
Rostlab/prot_xlnet
|
7fe4d7b13695ccf8fb14a257986976bd7f704782
|
2020-08-20T14:57:30.000Z
|
[
"pytorch",
"xlnet",
"transformers"
] | null | false |
Rostlab
| null |
Rostlab/prot_xlnet
| 549 | null |
transformers
| 2,242 |
Entry not found
|
ionite/DialoGPT-medium-MarkAI
|
14fa33a0e25a302e5e309439c09c2231afd75bec
|
2022-05-21T20:37:34.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
| false |
ionite
| null |
ionite/DialoGPT-medium-MarkAI
| 549 | null |
transformers
| 2,243 |
---
tags:
- conversational
---
# MarkAI DialoGPT Model
|
HomerChatbot/DialoGPT-small-homersimpsonbot
|
77c5f374e7a7c760352818155c2266ed8ebdb06a
|
2022-05-25T23:05:34.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
| false |
HomerChatbot
| null |
HomerChatbot/DialoGPT-small-homersimpsonbot
| 549 | null |
transformers
| 2,244 |
---
tags:
- conversational
---
# Homer Simpson DialogGPT Model
|
NeuML/bert-small-cord19qa
|
88e15ee7018bdf3cd98d5c55b975cb87f48d6686
|
2021-05-18T21:53:32.000Z
|
[
"pytorch",
"jax",
"bert",
"question-answering",
"transformers",
"autotrain_compatible"
] |
question-answering
| false |
NeuML
| null |
NeuML/bert-small-cord19qa
| 548 | 1 |
transformers
| 2,245 |
# BERT-Small fine-tuned on CORD-19 QA dataset
[bert-small-cord19-squad model](https://huggingface.co/NeuML/bert-small-cord19-squad2) fine-tuned on the [CORD-19 QA dataset](https://www.kaggle.com/davidmezzetti/cord19-qa?select=cord19-qa.json).
## CORD-19 QA dataset
The CORD-19 QA dataset is a SQuAD 2.0 formatted list of question, context, answer combinations covering the [CORD-19 dataset](https://www.semanticscholar.org/cord19).
## Building the model
```bash
python run_squad.py \
--model_type bert \
--model_name_or_path bert-small-cord19-squad \
--do_train \
--do_lower_case \
--version_2_with_negative \
--train_file cord19-qa.json \
--per_gpu_train_batch_size 8 \
--learning_rate 5e-5 \
--num_train_epochs 10.0 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir bert-small-cord19qa \
--save_steps 0 \
--threads 8 \
--overwrite_cache \
--overwrite_output_dir
```
## Testing the model
Example usage below:
```python
from transformers import pipeline
qa = pipeline(
"question-answering",
model="NeuML/bert-small-cord19qa",
tokenizer="NeuML/bert-small-cord19qa"
)
qa({
"question": "What is the median incubation period?",
"context": "The incubation period is around 5 days (range: 4-7 days) with a maximum of 12-13 day"
})
qa({
"question": "What is the incubation period range?",
"context": "The incubation period is around 5 days (range: 4-7 days) with a maximum of 12-13 day"
})
qa({
"question": "What type of surfaces does it persist?",
"context": "The virus can survive on surfaces for up to 72 hours such as plastic and stainless steel ."
})
```
```json
{"score": 0.5970273583242793, "start": 32, "end": 38, "answer": "5 days"}
{"score": 0.999555868193891, "start": 39, "end": 56, "answer": "(range: 4-7 days)"}
{"score": 0.9992726505196998, "start": 61, "end": 88, "answer": "plastic and stainless steel"}
```
|
sentence-transformers/stsb-bert-large
|
5e8a2c75ee8ccaa42c89aa0e26ec75e4bc9e1ba8
|
2022-06-15T22:57:44.000Z
|
[
"pytorch",
"tf",
"bert",
"feature-extraction",
"arxiv:1908.10084",
"sentence-transformers",
"sentence-similarity",
"transformers",
"license:apache-2.0"
] |
sentence-similarity
| false |
sentence-transformers
| null |
sentence-transformers/stsb-bert-large
| 547 | 1 |
sentence-transformers
| 2,246 |
---
pipeline_tag: sentence-similarity
license: apache-2.0
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
**⚠️ This model is deprecated. Please don't use it as it produces sentence embeddings of low quality. You can find recommended sentence embedding models here: [SBERT.net - Pretrained Models](https://www.sbert.net/docs/pretrained_models.html)**
# sentence-transformers/stsb-bert-large
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 1024 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/stsb-bert-large')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/stsb-bert-large')
model = AutoModel.from_pretrained('sentence-transformers/stsb-bert-large')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/stsb-bert-large)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 1024, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
```
|
RohanVB/umlsbert_ner
|
843c67105aba9b0edc6547a1c14092bc9578475a
|
2022-05-09T13:46:36.000Z
|
[
"pytorch",
"bert",
"token-classification",
"transformers",
"license:mit",
"autotrain_compatible"
] |
token-classification
| false |
RohanVB
| null |
RohanVB/umlsbert_ner
| 546 | null |
transformers
| 2,247 |
---
license: mit
---
|
Gunulhona/tbqgmodel
|
d1bbd7307a70d4d7d4cef8849156c248a58a655e
|
2021-12-29T01:18:56.000Z
|
[
"pytorch",
"bart",
"text2text-generation",
"transformers",
"autotrain_compatible"
] |
text2text-generation
| false |
Gunulhona
| null |
Gunulhona/tbqgmodel
| 544 | null |
transformers
| 2,248 |
Entry not found
|
Seethal/sentiment_analysis_generic_dataset
|
26edc13094473094204e42245018bee141699c8c
|
2022-04-19T06:26:33.000Z
|
[
"pytorch",
"distilbert",
"text-classification",
"transformers"
] |
text-classification
| false |
Seethal
| null |
Seethal/sentiment_analysis_generic_dataset
| 544 | null |
transformers
| 2,249 |
## BERT base model (uncased)
Pretrained model on English language using a masked language modeling (MLM) objective. This model is uncased: it does not make a difference between english and English.
## Model description
BERT is a transformers model pretrained on a large corpus of English data in a self-supervised fashion. This means it was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely, it was pretrained with two objectives:
* Masked language modeling (MLM): taking a sentence, the model randomly masks 15% of the words in the input then run the entire masked sentence through the model and has to predict the masked words. This is different from traditional recurrent neural networks (RNNs) that usually see the words one after the other, or from autoregressive models like GPT which internally mask the future tokens. It allows the model to learn a bidirectional representation of the sentence.
* Next sentence prediction (NSP): the model concatenates two masked sentences as inputs during pretraining. Sometimes they correspond to sentences that were next to each other in the original text, sometimes not. The model then has to predict if the two sentences were following each other or not.
This way, the model learns an inner representation of the English language that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a standard classifier using the features produced by the BERT model as inputs.
## Model description [Seethal/sentiment_analysis_generic_dataset]
This is a fine-tuned downstream version of the bert-base-uncased model for sentiment analysis, this model is not intended for further downstream fine-tuning for any other tasks. This model is trained on a classified dataset for text classification.
|
nvidia/stt_en_conformer_transducer_xlarge
|
b7f7fceb0c6a4009e2d4d7492eee68405df36837
|
2022-06-30T02:25:13.000Z
|
[
"nemo",
"en",
"dataset:librispeech_asr",
"dataset:fisher_corpus",
"dataset:Switchboard-1",
"dataset:WSJ-0",
"dataset:WSJ-1",
"dataset:National Singapore Corpus Part 1",
"dataset:National Singapore Corpus Part 6",
"dataset:vctk",
"dataset:VoxPopuli (EN)",
"dataset:Europarl-ASR (EN)",
"dataset:Multilingual LibriSpeech (2000 hours)",
"dataset:mozilla-foundation/common_voice_8_0",
"dataset:MLCommons/peoples_speech",
"arxiv:2005.08100",
"automatic-speech-recognition",
"speech",
"audio",
"Transducer",
"Conformer",
"Transformer",
"pytorch",
"NeMo",
"hf-asr-leaderboard",
"license:cc-by-4.0",
"model-index"
] |
automatic-speech-recognition
| false |
nvidia
| null |
nvidia/stt_en_conformer_transducer_xlarge
| 544 | 17 |
nemo
| 2,250 |
---
language:
- en
library_name: nemo
datasets:
- librispeech_asr
- fisher_corpus
- Switchboard-1
- WSJ-0
- WSJ-1
- National Singapore Corpus Part 1
- National Singapore Corpus Part 6
- vctk
- VoxPopuli (EN)
- Europarl-ASR (EN)
- Multilingual LibriSpeech (2000 hours)
- mozilla-foundation/common_voice_8_0
- MLCommons/peoples_speech
thumbnail: null
tags:
- automatic-speech-recognition
- speech
- audio
- Transducer
- Conformer
- Transformer
- pytorch
- NeMo
- hf-asr-leaderboard
license: cc-by-4.0
widget:
- example_title: Librispeech sample 1
src: https://cdn-media.huggingface.co/speech_samples/sample1.flac
- example_title: Librispeech sample 2
src: https://cdn-media.huggingface.co/speech_samples/sample2.flac
model-index:
- name: stt_en_conformer_transducer_xlarge
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: LibriSpeech (clean)
type: librispeech_asr
config: clean
split: test
args:
language: en
metrics:
- name: Test WER
type: wer
value: 1.62
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: LibriSpeech (other)
type: librispeech_asr
config: other
split: test
args:
language: en
metrics:
- name: Test WER
type: wer
value: 3.01
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: Multilingual LibriSpeech
type: facebook/multilingual_librispeech
config: english
split: test
args:
language: en
metrics:
- name: Test WER
type: wer
value: 5.32
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: Mozilla Common Voice 7.0
type: mozilla-foundation/common_voice_7_0
config: en
split: test
args:
language: en
metrics:
- name: Test WER
type: wer
value: 5.13
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: Mozilla Common Voice 8.0
type: mozilla-foundation/common_voice_8_0
config: en
split: test
args:
language: en
metrics:
- name: Test WER
type: wer
value: 6.46
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: Wall Street Journal 92
type: wsj_0
args:
language: en
metrics:
- name: Test WER
type: wer
value: 1.17
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: Wall Street Journal 93
type: wsj_1
args:
language: en
metrics:
- name: Test WER
type: wer
value: 2.05
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: National Singapore Corpus
type: nsc_part_1
args:
language: en
metrics:
- name: Test WER
type: wer
value: 5.70
---
# NVIDIA Conformer-Transducer X-Large (en-US)
<style>
img {
display: inline;
}
</style>
| [](#model-architecture)
| [](#model-architecture)
| [](#datasets)
This model transcribes speech in lower case English alphabet along with spaces and apostrophes.
It is an "extra-large" versions of Conformer-Transducer (around 600M parameters) model.
See the [model architecture](#model-architecture) section and [NeMo documentation](https://docs.nvidia.com/deeplearning/nemo/user-guide/docs/en/main/asr/models.html#conformer-transducer) for complete architecture details.
## NVIDIA NeMo: Training
To train, fine-tune or play with the model you will need to install [NVIDIA NeMo](https://github.com/NVIDIA/NeMo). We recommend you install it after you've installed latest Pytorch version.
```
pip install nemo_toolkit['all']
```
## How to Use this Model
The model is available for use in the NeMo toolkit [3], and can be used as a pre-trained checkpoint for inference or for fine-tuning on another dataset.
### Automatically instantiate the model
```python
import nemo.collections.asr as nemo_asr
asr_model = nemo_asr.models.EncDecRNNTBPEModel.from_pretrained("nvidia/stt_en_conformer_transducer_xlarge")
```
### Transcribing using Python
First, let's get a sample
```
wget https://dldata-public.s3.us-east-2.amazonaws.com/2086-149220-0033.wav
```
Then simply do:
```
asr_model.transcribe(['2086-149220-0033.wav'])
```
### Transcribing many audio files
```shell
python [NEMO_GIT_FOLDER]/examples/asr/transcribe_speech.py
pretrained_name="nvidia/stt_en_conformer_transducer_xlarge"
audio_dir="<DIRECTORY CONTAINING AUDIO FILES>"
```
### Input
This model accepts 16000 KHz Mono-channel Audio (wav files) as input.
### Output
This model provides transcribed speech as a string for a given audio sample.
## Model Architecture
Conformer-Transducer model is an autoregressive variant of Conformer model [1] for Automatic Speech Recognition which uses Transducer loss/decoding instead of CTC Loss. You may find more info on the detail of this model here: [Conformer-Transducer Model](https://docs.nvidia.com/deeplearning/nemo/user-guide/docs/en/main/asr/models.html).
## Training
The NeMo toolkit [3] was used for training the models for over several hundred epochs. These model are trained with this [example script](https://github.com/NVIDIA/NeMo/blob/main/examples/asr/asr_transducer/speech_to_text_rnnt_bpe.py) and this [base config](https://github.com/NVIDIA/NeMo/blob/main/examples/asr/conf/conformer/conformer_transducer_bpe.yaml).
The tokenizers for these models were built using the text transcripts of the train set with this [script](https://github.com/NVIDIA/NeMo/blob/main/scripts/tokenizers/process_asr_text_tokenizer.py).
### Datasets
All the models in this collection are trained on a composite dataset (NeMo ASRSET) comprising of several thousand hours of English speech:
- Librispeech 960 hours of English speech
- Fisher Corpus
- Switchboard-1 Dataset
- WSJ-0 and WSJ-1
- National Speech Corpus (Part 1, Part 6)
- VCTK
- VoxPopuli (EN)
- Europarl-ASR (EN)
- Multilingual Librispeech (MLS EN) - 2,000 hrs subset
- Mozilla Common Voice (v8.0)
- People's Speech - 12,000 hrs subset
Note: older versions of the model may have trained on smaller set of datasets.
## Performance
The list of the available models in this collection is shown in the following table. Performances of the ASR models are reported in terms of Word Error Rate (WER%) with greedy decoding.
| Version | Tokenizer | Vocabulary Size | LS test-other | LS test-clean | WSJ Eval92 | WSJ Dev93 | NSC Part 1 | MLS Test | MLS Dev | MCV Test 8.0 | Train Dataset |
|---------|-----------------------|-----------------|---------------|---------------|------------|-----------|-----|-------|------|----|------|
| 1.10.0 | SentencePiece Unigram | 1024 | 3.01 | 1.62 | 1.17 | 2.05 | 5.70 | 5.32 | 4.59 | 6.46 | NeMo ASRSET 3.0 |
## Limitations
Since this model was trained on publicly available speech datasets, the performance of this model might degrade for speech which includes technical terms, or vernacular that the model has not been trained on. The model might also perform worse for accented speech.
## NVIDIA Riva: Deployment
[NVIDIA Riva](https://developer.nvidia.com/riva), is an accelerated speech AI SDK deployable on-prem, in all clouds, multi-cloud, hybrid, on edge, and embedded.
Additionally, Riva provides:
* World-class out-of-the-box accuracy for the most common languages with model checkpoints trained on proprietary data with hundreds of thousands of GPU-compute hours
* Best in class accuracy with run-time word boosting (e.g., brand and product names) and customization of acoustic model, language model, and inverse text normalization
* Streaming speech recognition, Kubernetes compatible scaling, and enterprise-grade support
Although this model isn’t supported yet by Riva, the [list of supported models is here](https://huggingface.co/models?other=Riva).
Check out [Riva live demo](https://developer.nvidia.com/riva#demos).
## References
[1] [Conformer: Convolution-augmented Transformer for Speech Recognition](https://arxiv.org/abs/2005.08100)
[2] [Google Sentencepiece Tokenizer](https://github.com/google/sentencepiece)
[3] [NVIDIA NeMo Toolkit](https://github.com/NVIDIA/NeMo)
## Licence
License to use this model is covered by the [CC-BY-4.0](https://creativecommons.org/licenses/by/4.0/). By downloading the public and release version of the model, you accept the terms and conditions of the [CC-BY-4.0](https://creativecommons.org/licenses/by/4.0/) license.
|
cardiffnlp/twitter-roberta-base-emoji
|
e7efb0d4f929fce6b1477405d6f59c526e4272ac
|
2021-05-20T14:59:33.000Z
|
[
"pytorch",
"tf",
"jax",
"roberta",
"text-classification",
"arxiv:2010.12421",
"transformers"
] |
text-classification
| false |
cardiffnlp
| null |
cardiffnlp/twitter-roberta-base-emoji
| 543 | 3 |
transformers
| 2,251 |
# Twitter-roBERTa-base for Emoji prediction
This is a roBERTa-base model trained on ~58M tweets and finetuned for emoji prediction with the TweetEval benchmark.
- Paper: [_TweetEval_ benchmark (Findings of EMNLP 2020)](https://arxiv.org/pdf/2010.12421.pdf).
- Git Repo: [Tweeteval official repository](https://github.com/cardiffnlp/tweeteval).
## Example of classification
```python
from transformers import AutoModelForSequenceClassification
from transformers import TFAutoModelForSequenceClassification
from transformers import AutoTokenizer
import numpy as np
from scipy.special import softmax
import csv
import urllib.request
# Preprocess text (username and link placeholders)
def preprocess(text):
new_text = []
for t in text.split(" "):
t = '@user' if t.startswith('@') and len(t) > 1 else t
t = 'http' if t.startswith('http') else t
new_text.append(t)
return " ".join(new_text)
# Tasks:
# emoji, emotion, hate, irony, offensive, sentiment
# stance/abortion, stance/atheism, stance/climate, stance/feminist, stance/hillary
task='emoji'
MODEL = f"cardiffnlp/twitter-roberta-base-{task}"
tokenizer = AutoTokenizer.from_pretrained(MODEL)
# download label mapping
labels=[]
mapping_link = f"https://raw.githubusercontent.com/cardiffnlp/tweeteval/main/datasets/{task}/mapping.txt"
with urllib.request.urlopen(mapping_link) as f:
html = f.read().decode('utf-8').split("\n")
csvreader = csv.reader(html, delimiter='\t')
labels = [row[1] for row in csvreader if len(row) > 1]
# PT
model = AutoModelForSequenceClassification.from_pretrained(MODEL)
model.save_pretrained(MODEL)
text = "Looking forward to Christmas"
text = preprocess(text)
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
scores = output[0][0].detach().numpy()
scores = softmax(scores)
# # TF
# model = TFAutoModelForSequenceClassification.from_pretrained(MODEL)
# model.save_pretrained(MODEL)
# text = "Looking forward to Christmas"
# text = preprocess(text)
# encoded_input = tokenizer(text, return_tensors='tf')
# output = model(encoded_input)
# scores = output[0][0].numpy()
# scores = softmax(scores)
ranking = np.argsort(scores)
ranking = ranking[::-1]
for i in range(scores.shape[0]):
l = labels[ranking[i]]
s = scores[ranking[i]]
print(f"{i+1}) {l} {np.round(float(s), 4)}")
```
Output:
```
1) 🎄 0.5457
2) 😊 0.1417
3) 😁 0.0649
4) 😍 0.0395
5) ❤️ 0.03
6) 😜 0.028
7) ✨ 0.0263
8) 😉 0.0237
9) 😂 0.0177
10) 😎 0.0166
11) 😘 0.0143
12) 💕 0.014
13) 💙 0.0076
14) 💜 0.0068
15) 🔥 0.0065
16) 💯 0.004
17) 🇺🇸 0.0037
18) 📷 0.0034
19) ☀ 0.0033
20) 📸 0.0021
```
|
zanelim/singbert-lite-sg
|
74e501f6729ad50522c3d5f4a5793b770ab21f30
|
2020-12-11T22:05:08.000Z
|
[
"pytorch",
"tf",
"albert",
"pretraining",
"en",
"dataset:reddit singapore, malaysia",
"dataset:hardwarezone",
"transformers",
"singapore",
"sg",
"singlish",
"malaysia",
"ms",
"manglish",
"albert-base-v2",
"license:mit"
] | null | false |
zanelim
| null |
zanelim/singbert-lite-sg
| 542 | null |
transformers
| 2,252 |
---
language: en
tags:
- singapore
- sg
- singlish
- malaysia
- ms
- manglish
- albert-base-v2
license: mit
datasets:
- reddit singapore, malaysia
- hardwarezone
widget:
- text: "dont play [MASK] leh"
- text: "die [MASK] must try"
---
# Model name
SingBert Lite - Bert for Singlish (SG) and Manglish (MY).
## Model description
Similar to [SingBert](https://huggingface.co/zanelim/singbert) but the lite-version, which was initialized from [Albert base v2](https://github.com/google-research/albert#albert), with pre-training finetuned on
[singlish](https://en.wikipedia.org/wiki/Singlish) and [manglish](https://en.wikipedia.org/wiki/Manglish) data.
## Intended uses & limitations
#### How to use
```python
>>> from transformers import pipeline
>>> nlp = pipeline('fill-mask', model='zanelim/singbert-lite-sg')
>>> nlp("die [MASK] must try")
[{'sequence': '[CLS] die die must try[SEP]',
'score': 0.7731555700302124,
'token': 1327,
'token_str': '▁die'},
{'sequence': '[CLS] die also must try[SEP]',
'score': 0.04763784259557724,
'token': 67,
'token_str': '▁also'},
{'sequence': '[CLS] die still must try[SEP]',
'score': 0.01859409362077713,
'token': 174,
'token_str': '▁still'},
{'sequence': '[CLS] die u must try[SEP]',
'score': 0.015824034810066223,
'token': 287,
'token_str': '▁u'},
{'sequence': '[CLS] die is must try[SEP]',
'score': 0.011271446943283081,
'token': 25,
'token_str': '▁is'}]
>>> nlp("dont play [MASK] leh")
[{'sequence': '[CLS] dont play play leh[SEP]',
'score': 0.4365769624710083,
'token': 418,
'token_str': '▁play'},
{'sequence': '[CLS] dont play punk leh[SEP]',
'score': 0.06880936771631241,
'token': 6769,
'token_str': '▁punk'},
{'sequence': '[CLS] dont play game leh[SEP]',
'score': 0.051739856600761414,
'token': 250,
'token_str': '▁game'},
{'sequence': '[CLS] dont play games leh[SEP]',
'score': 0.045703962445259094,
'token': 466,
'token_str': '▁games'},
{'sequence': '[CLS] dont play around leh[SEP]',
'score': 0.013458190485835075,
'token': 140,
'token_str': '▁around'}]
>>> nlp("catch no [MASK]")
[{'sequence': '[CLS] catch no ball[SEP]',
'score': 0.6197211146354675,
'token': 1592,
'token_str': '▁ball'},
{'sequence': '[CLS] catch no balls[SEP]',
'score': 0.08441998809576035,
'token': 7152,
'token_str': '▁balls'},
{'sequence': '[CLS] catch no joke[SEP]',
'score': 0.0676785409450531,
'token': 8186,
'token_str': '▁joke'},
{'sequence': '[CLS] catch no?[SEP]',
'score': 0.040638409554958344,
'token': 60,
'token_str': '?'},
{'sequence': '[CLS] catch no one[SEP]',
'score': 0.03546864539384842,
'token': 53,
'token_str': '▁one'}]
>>> nlp("confirm plus [MASK]")
[{'sequence': '[CLS] confirm plus chop[SEP]',
'score': 0.9608421921730042,
'token': 17144,
'token_str': '▁chop'},
{'sequence': '[CLS] confirm plus guarantee[SEP]',
'score': 0.011784233152866364,
'token': 9120,
'token_str': '▁guarantee'},
{'sequence': '[CLS] confirm plus confirm[SEP]',
'score': 0.010571340098977089,
'token': 10265,
'token_str': '▁confirm'},
{'sequence': '[CLS] confirm plus egg[SEP]',
'score': 0.0033525123726576567,
'token': 6387,
'token_str': '▁egg'},
{'sequence': '[CLS] confirm plus bet[SEP]',
'score': 0.0008760977652855217,
'token': 5676,
'token_str': '▁bet'}]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import AlbertTokenizer, AlbertModel
tokenizer = AlbertTokenizer.from_pretrained('zanelim/singbert-lite-sg')
model = AlbertModel.from_pretrained("zanelim/singbert-lite-sg")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import AlbertTokenizer, TFAlbertModel
tokenizer = AlbertTokenizer.from_pretrained("zanelim/singbert-lite-sg")
model = TFAlbertModel.from_pretrained("zanelim/singbert-lite-sg")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
#### Limitations and bias
This model was finetuned on colloquial Singlish and Manglish corpus, hence it is best applied on downstream tasks involving the main
constituent languages- english, mandarin, malay. Also, as the training data is mainly from forums, beware of existing inherent bias.
## Training data
Colloquial singlish and manglish (both are a mixture of English, Mandarin, Tamil, Malay, and other local dialects like Hokkien, Cantonese or Teochew)
corpus. The corpus is collected from subreddits- `r/singapore` and `r/malaysia`, and forums such as `hardwarezone`.
## Training procedure
Initialized with [albert base v2](https://github.com/google-research/albert#albert) vocab and checkpoints (pre-trained weights).
Pre-training was further finetuned on training data with the following hyperparameters
* train_batch_size: 4096
* max_seq_length: 128
* num_train_steps: 125000
* num_warmup_steps: 5000
* learning_rate: 0.00176
* hardware: TPU v3-8
|
anuragshas/wav2vec2-large-xlsr-53-telugu
|
35b88df6c2e57a5514caec962ea87222ead7bce7
|
2021-07-05T21:31:14.000Z
|
[
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"te",
"dataset:openslr",
"transformers",
"audio",
"speech",
"xlsr-fine-tuning-week",
"license:apache-2.0",
"model-index"
] |
automatic-speech-recognition
| false |
anuragshas
| null |
anuragshas/wav2vec2-large-xlsr-53-telugu
| 541 | null |
transformers
| 2,253 |
---
language: te
datasets:
- openslr
metrics:
- wer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: Anurag Singh XLSR Wav2Vec2 Large 53 Telugu
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: OpenSLR te
type: openslr
args: te
metrics:
- name: Test WER
type: wer
value: 44.98
---
# Wav2Vec2-Large-XLSR-53-Telugu
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Telugu using the [OpenSLR SLR66](http://openslr.org/66/) dataset.
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import pandas as pd
# Evaluation notebook contains the procedure to download the data
df = pd.read_csv("/content/te/test.tsv", sep="\t")
df["path"] = "/content/te/clips/" + df["path"]
test_dataset = Dataset.from_pandas(df)
processor = Wav2Vec2Processor.from_pretrained("anuragshas/wav2vec2-large-xlsr-53-telugu")
model = Wav2Vec2ForCTC.from_pretrained("anuragshas/wav2vec2-large-xlsr-53-telugu")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
```python
import torch
import torchaudio
from datasets import Dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
from sklearn.model_selection import train_test_split
import pandas as pd
# Evaluation notebook contains the procedure to download the data
df = pd.read_csv("/content/te/test.tsv", sep="\t")
df["path"] = "/content/te/clips/" + df["path"]
test_dataset = Dataset.from_pandas(df)
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("anuragshas/wav2vec2-large-xlsr-53-telugu")
model = Wav2Vec2ForCTC.from_pretrained("anuragshas/wav2vec2-large-xlsr-53-telugu")
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\_\;\:\"\“\%\‘\”\।\’\'\&]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
def normalizer(text):
# Use your custom normalizer
text = text.replace("\\n","\n")
text = ' '.join(text.split())
text = re.sub(r'''([a-z]+)''','',text,flags=re.IGNORECASE)
text = re.sub(r'''%'''," శాతం ", text)
text = re.sub(r'''(/|-|_)'''," ", text)
text = re.sub("ై","ై", text)
text = text.strip()
return text
def speech_file_to_array_fn(batch):
batch["sentence"] = normalizer(batch["sentence"])
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()+ " "
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 44.98%
## Training
70% of the OpenSLR Telugu dataset was used for training.
Train Split of annotations is [here](https://www.dropbox.com/s/xqc0wtour7f9h4c/train.tsv)
Test Split of annotations is [here](https://www.dropbox.com/s/qw1uy63oj4qdiu4/test.tsv)
Training Data Preparation notebook can be found [here](https://colab.research.google.com/drive/1_VR1QtY9qoiabyXBdJcOI29-xIKGdIzU?usp=sharing)
Training notebook can be found[here](https://colab.research.google.com/drive/14N-j4m0Ng_oktPEBN5wiUhDDbyrKYt8I?usp=sharing)
Evaluation notebook is [here](https://colab.research.google.com/drive/1SLEvbTWBwecIRTNqpQ0fFTqmr1-7MnSI?usp=sharing)
|
Helsinki-NLP/opus-mt-tc-big-fi-en
|
484fdf7bee8ff967301c3dfe0fbece1d37e257df
|
2022-06-01T13:10:36.000Z
|
[
"pytorch",
"marian",
"text2text-generation",
"en",
"fi",
"transformers",
"translation",
"opus-mt-tc",
"license:cc-by-4.0",
"model-index",
"autotrain_compatible"
] |
translation
| false |
Helsinki-NLP
| null |
Helsinki-NLP/opus-mt-tc-big-fi-en
| 541 | null |
transformers
| 2,254 |
---
language:
- en
- fi
tags:
- translation
- opus-mt-tc
license: cc-by-4.0
model-index:
- name: opus-mt-tc-big-fi-en
results:
- task:
name: Translation fin-eng
type: translation
args: fin-eng
dataset:
name: flores101-devtest
type: flores_101
args: fin eng devtest
metrics:
- name: BLEU
type: bleu
value: 35.4
- task:
name: Translation fin-eng
type: translation
args: fin-eng
dataset:
name: newsdev2015
type: newsdev2015
args: fin-eng
metrics:
- name: BLEU
type: bleu
value: 28.6
- task:
name: Translation fin-eng
type: translation
args: fin-eng
dataset:
name: tatoeba-test-v2021-08-07
type: tatoeba_mt
args: fin-eng
metrics:
- name: BLEU
type: bleu
value: 57.4
- task:
name: Translation fin-eng
type: translation
args: fin-eng
dataset:
name: newstest2015
type: wmt-2015-news
args: fin-eng
metrics:
- name: BLEU
type: bleu
value: 29.9
- task:
name: Translation fin-eng
type: translation
args: fin-eng
dataset:
name: newstest2016
type: wmt-2016-news
args: fin-eng
metrics:
- name: BLEU
type: bleu
value: 34.3
- task:
name: Translation fin-eng
type: translation
args: fin-eng
dataset:
name: newstest2017
type: wmt-2017-news
args: fin-eng
metrics:
- name: BLEU
type: bleu
value: 37.3
- task:
name: Translation fin-eng
type: translation
args: fin-eng
dataset:
name: newstest2018
type: wmt-2018-news
args: fin-eng
metrics:
- name: BLEU
type: bleu
value: 27.1
- task:
name: Translation fin-eng
type: translation
args: fin-eng
dataset:
name: newstest2019
type: wmt-2019-news
args: fin-eng
metrics:
- name: BLEU
type: bleu
value: 32.7
---
# opus-mt-tc-big-fi-en
Neural machine translation model for translating from Finnish (fi) to English (en).
This model is part of the [OPUS-MT project](https://github.com/Helsinki-NLP/Opus-MT), an effort to make neural machine translation models widely available and accessible for many languages in the world. All models are originally trained using the amazing framework of [Marian NMT](https://marian-nmt.github.io/), an efficient NMT implementation written in pure C++. The models have been converted to pyTorch using the transformers library by huggingface. Training data is taken from [OPUS](https://opus.nlpl.eu/) and training pipelines use the procedures of [OPUS-MT-train](https://github.com/Helsinki-NLP/Opus-MT-train).
* Publications: [OPUS-MT – Building open translation services for the World](https://aclanthology.org/2020.eamt-1.61/) and [The Tatoeba Translation Challenge – Realistic Data Sets for Low Resource and Multilingual MT](https://aclanthology.org/2020.wmt-1.139/) (Please, cite if you use this model.)
```
@inproceedings{tiedemann-thottingal-2020-opus,
title = "{OPUS}-{MT} {--} Building open translation services for the World",
author = {Tiedemann, J{\"o}rg and Thottingal, Santhosh},
booktitle = "Proceedings of the 22nd Annual Conference of the European Association for Machine Translation",
month = nov,
year = "2020",
address = "Lisboa, Portugal",
publisher = "European Association for Machine Translation",
url = "https://aclanthology.org/2020.eamt-1.61",
pages = "479--480",
}
@inproceedings{tiedemann-2020-tatoeba,
title = "The Tatoeba Translation Challenge {--} Realistic Data Sets for Low Resource and Multilingual {MT}",
author = {Tiedemann, J{\"o}rg},
booktitle = "Proceedings of the Fifth Conference on Machine Translation",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.wmt-1.139",
pages = "1174--1182",
}
```
## Model info
* Release: 2021-12-08
* source language(s): fin
* target language(s): eng
* model: transformer (big)
* data: opusTCv20210807+bt ([source](https://github.com/Helsinki-NLP/Tatoeba-Challenge))
* tokenization: SentencePiece (spm32k,spm32k)
* original model: [opusTCv20210807+bt-2021-12-08.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/fin-eng/opusTCv20210807+bt-2021-12-08.zip)
* more information released models: [OPUS-MT fin-eng README](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/fin-eng/README.md)
## Usage
A short example code:
```python
from transformers import MarianMTModel, MarianTokenizer
src_text = [
"Kolme kolmanteen on kaksikymmentäseitsemän.",
"Heille syntyi poikavauva."
]
model_name = "pytorch-models/opus-mt-tc-big-fi-en"
tokenizer = MarianTokenizer.from_pretrained(model_name)
model = MarianMTModel.from_pretrained(model_name)
translated = model.generate(**tokenizer(src_text, return_tensors="pt", padding=True))
for t in translated:
print( tokenizer.decode(t, skip_special_tokens=True) )
```
You can also use OPUS-MT models with the transformers pipelines, for example:
```python
from transformers import pipeline
pipe = pipeline("translation", model="Helsinki-NLP/opus-mt-tc-big-fi-en")
print(pipe("Kolme kolmanteen on kaksikymmentäseitsemän."))
```
## Benchmarks
* test set translations: [opusTCv20210807+bt-2021-12-08.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/fin-eng/opusTCv20210807+bt-2021-12-08.test.txt)
* test set scores: [opusTCv20210807+bt-2021-12-08.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/fin-eng/opusTCv20210807+bt-2021-12-08.eval.txt)
* benchmark results: [benchmark_results.txt](benchmark_results.txt)
* benchmark output: [benchmark_translations.zip](benchmark_translations.zip)
| langpair | testset | chr-F | BLEU | #sent | #words |
|----------|---------|-------|-------|-------|--------|
| fin-eng | tatoeba-test-v2021-08-07 | 0.72298 | 57.4 | 10690 | 80552 |
| fin-eng | flores101-devtest | 0.62521 | 35.4 | 1012 | 24721 |
| fin-eng | newsdev2015 | 0.56232 | 28.6 | 1500 | 32012 |
| fin-eng | newstest2015 | 0.57469 | 29.9 | 1370 | 27270 |
| fin-eng | newstest2016 | 0.60715 | 34.3 | 3000 | 62945 |
| fin-eng | newstest2017 | 0.63050 | 37.3 | 3002 | 61846 |
| fin-eng | newstest2018 | 0.54199 | 27.1 | 3000 | 62325 |
| fin-eng | newstest2019 | 0.59620 | 32.7 | 1996 | 36215 |
| fin-eng | newstestB2016 | 0.55472 | 27.9 | 3000 | 62945 |
| fin-eng | newstestB2017 | 0.58847 | 31.1 | 3002 | 61846 |
## Acknowledgements
The work is supported by the [European Language Grid](https://www.european-language-grid.eu/) as [pilot project 2866](https://live.european-language-grid.eu/catalogue/#/resource/projects/2866), by the [FoTran project](https://www.helsinki.fi/en/researchgroups/natural-language-understanding-with-cross-lingual-grounding), funded by the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (grant agreement No 771113), and the [MeMAD project](https://memad.eu/), funded by the European Union’s Horizon 2020 Research and Innovation Programme under grant agreement No 780069. We are also grateful for the generous computational resources and IT infrastructure provided by [CSC -- IT Center for Science](https://www.csc.fi/), Finland.
## Model conversion info
* transformers version: 4.16.2
* OPUS-MT git hash: f084bad
* port time: Tue Mar 22 14:52:19 EET 2022
* port machine: LM0-400-22516.local
|
dbmdz/bert-base-multilingual-cased-finetuned-conll03-dutch
|
30f2f8872dd7fda80a723d1073b7f40dd905371c
|
2021-05-19T15:05:18.000Z
|
[
"pytorch",
"tf",
"jax",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
] |
token-classification
| false |
dbmdz
| null |
dbmdz/bert-base-multilingual-cased-finetuned-conll03-dutch
| 539 | null |
transformers
| 2,255 |
Entry not found
|
gsarti/scibert-nli
|
4e77bab8a7a4b3dde3dfaa3ac86a180b4680213f
|
2021-05-19T17:49:18.000Z
|
[
"pytorch",
"jax",
"bert",
"feature-extraction",
"transformers"
] |
feature-extraction
| false |
gsarti
| null |
gsarti/scibert-nli
| 539 | 1 |
transformers
| 2,256 |
# SciBERT-NLI
This is the model [SciBERT](https://github.com/allenai/scibert) [1] fine-tuned on the [SNLI](https://nlp.stanford.edu/projects/snli/) and the [MultiNLI](https://www.nyu.edu/projects/bowman/multinli/) datasets using the [`sentence-transformers` library](https://github.com/UKPLab/sentence-transformers/) to produce universal sentence embeddings [2].
The model uses the original `scivocab` wordpiece vocabulary and was trained using the **average pooling strategy** and a **softmax loss**.
**Base model**: `allenai/scibert-scivocab-cased` from HuggingFace's `AutoModel`.
**Training time**: ~4 hours on the NVIDIA Tesla P100 GPU provided in Kaggle Notebooks.
**Parameters**:
| Parameter | Value |
|------------------|-------|
| Batch size | 64 |
| Training steps | 20000 |
| Warmup steps | 1450 |
| Lowercasing | True |
| Max. Seq. Length | 128 |
**Performances**: The performance was evaluated on the test portion of the [STS dataset](http://ixa2.si.ehu.es/stswiki/index.php/STSbenchmark) using Spearman rank correlation and compared to the performances of a general BERT base model obtained with the same procedure to verify their similarity.
| Model | Score |
|-------------------------------|-------------|
| `scibert-nli` (this) | 74.50 |
| `bert-base-nli-mean-tokens`[3]| 77.12 |
An example usage for similarity-based scientific paper retrieval is provided in the [Covid Papers Browser](https://github.com/gsarti/covid-papers-browser) repository.
**References:**
[1] I. Beltagy et al, [SciBERT: A Pretrained Language Model for Scientific Text](https://www.aclweb.org/anthology/D19-1371/)
[2] A. Conneau et al., [Supervised Learning of Universal Sentence Representations from Natural Language Inference Data](https://www.aclweb.org/anthology/D17-1070/)
[3] N. Reimers et I. Gurevych, [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://www.aclweb.org/anthology/D19-1410/)
|
textattack/bert-base-uncased-snli
|
d4ef8a69a50bc95cc074514f4b798c67f572163a
|
2021-05-20T07:48:06.000Z
|
[
"pytorch",
"jax",
"bert",
"text-classification",
"transformers"
] |
text-classification
| false |
textattack
| null |
textattack/bert-base-uncased-snli
| 538 | null |
transformers
| 2,257 |
Entry not found
|
Geotrend/bert-base-en-es-pt-cased
|
dc6371e38b2e1179ad8ae78fa6c1e3bcd3046bf3
|
2021-05-18T19:11:40.000Z
|
[
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"multilingual",
"dataset:wikipedia",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] |
fill-mask
| false |
Geotrend
| null |
Geotrend/bert-base-en-es-pt-cased
| 537 | null |
transformers
| 2,258 |
---
language: multilingual
datasets: wikipedia
license: apache-2.0
---
# bert-base-en-es-pt-cased
We are sharing smaller versions of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) that handle a custom number of languages.
Unlike [distilbert-base-multilingual-cased](https://huggingface.co/distilbert-base-multilingual-cased), our versions give exactly the same representations produced by the original model which preserves the original accuracy.
For more information please visit our paper: [Load What You Need: Smaller Versions of Multilingual BERT](https://www.aclweb.org/anthology/2020.sustainlp-1.16.pdf).
## How to use
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("Geotrend/bert-base-en-es-pt-cased")
model = AutoModel.from_pretrained("Geotrend/bert-base-en-es-pt-cased")
```
To generate other smaller versions of multilingual transformers please visit [our Github repo](https://github.com/Geotrend-research/smaller-transformers).
### How to cite
```bibtex
@inproceedings{smallermbert,
title={Load What You Need: Smaller Versions of Mutlilingual BERT},
author={Abdaoui, Amine and Pradel, Camille and Sigel, Grégoire},
booktitle={SustaiNLP / EMNLP},
year={2020}
}
```
## Contact
Please contact [email protected] for any question, feedback or request.
|
cristian-popa/bart-tl-ng
|
f78305bba5742afa17380997f569659ebea7f7eb
|
2021-09-22T08:18:06.000Z
|
[
"pytorch",
"bart",
"text2text-generation",
"en",
"transformers",
"topic labeling",
"license:apache-2.0",
"autotrain_compatible"
] |
text2text-generation
| false |
cristian-popa
| null |
cristian-popa/bart-tl-ng
| 537 | null |
transformers
| 2,259 |
---
language:
- en
<!-- thumbnail: https://raw.githubusercontent.com/JetRunner/BERT-of-Theseus/master/bert-of-theseus.png
-->
tags:
- topic labeling
license: apache-2.0
metrics:
- ndcg
---
# MyModel
## Model description
This is the `BART-TL-ng` model from the paper [BART-TL: Weakly-Supervised Topic Label Generation](https://www.aclweb.org/anthology/2021.eacl-main.121.pdf). We aim to solve the topic labeling task using generative methods, rather than selection from a pool of labels as was done in previous State of the Art works.
For more details not covered here, you can read the paper or look at the open-source implementation: https://github.com/CristianViorelPopa/BART-TL-topic-label-generation.
There are two models made available from the paper:
* [BART-TL-all](https://huggingface.co/cristian-popa/bart-tl-all)
* [BART-TL-ng](https://huggingface.co/cristian-popa/bart-tl-ng)
## Intended uses & limitations
#### How to use
The model takes in a topic, represented as a space-separated series of words. Such topics can be generated using LDA, as was done for gathering the fine-tuning dataset for the model.
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
mname = "cristian-popa/bart-tl-ng"
tokenizer = AutoTokenizer.from_pretrained(mname)
model = AutoModelForSeq2SeqLM.from_pretrained(mname)
input = "site web google search website online internet social content user"
enc = tokenizer(input, return_tensors="pt", truncation=True, padding="max_length", max_length=128)
outputs = model.generate(
input_ids=enc.input_ids,
attention_mask=enc.attention_mask,
max_length=15,
min_length=1,
do_sample=False,
num_beams=25,
length_penalty=1.0,
repetition_penalty=1.5
)
decoded = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(decoded) # windows live messenger
```
#### Limitations and bias
The model may not generate accurate labels for topics from domains unrelated to the ones it was fine-tuned on, such as gastronomy.
## Training data
The model was fine-tuned on 5 different StackExchange corpora (see https://archive.org/download/stackexchange for a full list of existing such corpora): English, biology, economics, law, and photography. 100 topics are extracted using LDA for each of these corpora, filtered for coherence and then used for obtaining the final model here.
## Training procedure
The large Facebook BART model is fine-tuned in a weakly-supervised manner, making use of the unsupervised candidate selection of the [NETL](https://www.aclweb.org/anthology/C16-1091.pdf) method, along with n-grams from the topics. The dataset is a one-to-many mapping from topics to labels. More details on training and parameters can be found in the [paper](https://www.aclweb.org/anthology/2021.eacl-main.121.pdf) or by following [this notebook](https://github.com/CristianViorelPopa/BART-TL-topic-label-generation/blob/main/notebooks/end_to_end_workflow.ipynb).
## Eval results
model | Top-1 Avg. | Top-3 Avg. | Top-5 Avg. | nDCG-1 | nDCG-3 | nDCG-5
------------|------------|------------|------------|--------|--------|-------
NETL (U) | 2.66 | 2.59 | 2.50 | 0.83 | 0.85 | 0.87
NETL (S) | 2.74 | 2.57 | 2.49 | 0.88 | 0.85 | 0.88
BART-TL-all | 2.64 | 2.52 | 2.43 | 0.83 | 0.84 | 0.87
BART-TL-ng | 2.62 | 2.50 | 2.33 | 0.82 | 0.84 | 0.85
### BibTeX entry and citation info
```bibtex
@inproceedings{popa-rebedea-2021-bart,
title = "{BART}-{TL}: Weakly-Supervised Topic Label Generation",
author = "Popa, Cristian and
Rebedea, Traian",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume",
month = apr,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2021.eacl-main.121",
pages = "1418--1425",
abstract = "We propose a novel solution for assigning labels to topic models by using multiple weak labelers. The method leverages generative transformers to learn accurate representations of the most important topic terms and candidate labels. This is achieved by fine-tuning pre-trained BART models on a large number of potential labels generated by state of the art non-neural models for topic labeling, enriched with different techniques. The proposed BART-TL model is able to generate valuable and novel labels in a weakly-supervised manner and can be improved by adding other weak labelers or distant supervision on similar tasks.",
}
```
|
m3hrdadfi/wav2vec2-large-xlsr-persian
|
a6fc7cdc898c6ec218e7f337a4835c3cd1ab8fab
|
2021-11-04T15:22:12.000Z
|
[
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"fa",
"dataset:common_voice",
"transformers",
"audio",
"speech",
"xlsr-fine-tuning-week",
"license:apache-2.0",
"model-index"
] |
automatic-speech-recognition
| false |
m3hrdadfi
| null |
m3hrdadfi/wav2vec2-large-xlsr-persian
| 537 | 3 |
transformers
| 2,260 |
---
language: fa
datasets:
- common_voice
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
widget:
- example_title: Common Voice sample 687
src: https://huggingface.co/m3hrdadfi/wav2vec2-large-xlsr-persian/resolve/main/sample687.flac
- example_title: Common Voice sample 1671
src: https://huggingface.co/m3hrdadfi/wav2vec2-large-xlsr-persian/resolve/main/sample1671.flac
model-index:
- name: XLSR Wav2Vec2 Persian (Farsi) by Mehrdad Farahani
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice fa
type: common_voice
args: fa
metrics:
- name: Test WER
type: wer
value: 32.20
---
# Wav2Vec2-Large-XLSR-53-Persian
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) in Persian (Farsi) using [Common Voice](https://huggingface.co/datasets/common_voice). When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
**Requirements**
```bash
# requirement packages
!pip install git+https://github.com/huggingface/datasets.git
!pip install git+https://github.com/huggingface/transformers.git
!pip install torchaudio
!pip install librosa
!pip install jiwer
!pip install hazm
```
**Prediction**
```python
import librosa
import torch
import torchaudio
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
from datasets import load_dataset
import numpy as np
import hazm
import re
import string
import IPython.display as ipd
_normalizer = hazm.Normalizer()
chars_to_ignore = [
",", "?", ".", "!", "-", ";", ":", '""', "%", "'", '"', "�",
"#", "!", "؟", "?", "«", "»", "ء", "،", "(", ")", "؛", "'ٔ", "٬",'ٔ', ",", "?",
".", "!", "-", ";", ":",'"',"“", "%", "‘", "”", "�", "–", "…", "_", "”", '“', '„'
]
# In case of farsi
chars_to_ignore = chars_to_ignore + list(string.ascii_lowercase + string.digits)
chars_to_mapping = {
'ك': 'ک', 'دِ': 'د', 'بِ': 'ب', 'زِ': 'ز', 'ذِ': 'ذ', 'شِ': 'ش', 'سِ': 'س', 'ى': 'ی',
'ي': 'ی', 'أ': 'ا', 'ؤ': 'و', "ے": "ی", "ۀ": "ه", "ﭘ": "پ", "ﮐ": "ک", "ﯽ": "ی",
"ﺎ": "ا", "ﺑ": "ب", "ﺘ": "ت", "ﺧ": "خ", "ﺩ": "د", "ﺱ": "س", "ﻀ": "ض", "ﻌ": "ع",
"ﻟ": "ل", "ﻡ": "م", "ﻢ": "م", "ﻪ": "ه", "ﻮ": "و", "ئ": "ی", 'ﺍ': "ا", 'ة': "ه",
'ﯾ': "ی", 'ﯿ': "ی", 'ﺒ': "ب", 'ﺖ': "ت", 'ﺪ': "د", 'ﺮ': "ر", 'ﺴ': "س", 'ﺷ': "ش",
'ﺸ': "ش", 'ﻋ': "ع", 'ﻤ': "م", 'ﻥ': "ن", 'ﻧ': "ن", 'ﻭ': "و", 'ﺭ': "ر", "ﮔ": "گ",
"\u200c": " ", "\u200d": " ", "\u200e": " ", "\u200f": " ", "\ufeff": " ",
}
def multiple_replace(text, chars_to_mapping):
pattern = "|".join(map(re.escape, chars_to_mapping.keys()))
return re.sub(pattern, lambda m: chars_to_mapping[m.group()], str(text))
def remove_special_characters(text, chars_to_ignore_regex):
text = re.sub(chars_to_ignore_regex, '', text).lower() + " "
return text
def normalizer(batch, chars_to_ignore, chars_to_mapping):
chars_to_ignore_regex = f"""[{"".join(chars_to_ignore)}]"""
text = batch["sentence"].lower().strip()
text = _normalizer.normalize(text)
text = multiple_replace(text, chars_to_mapping)
text = remove_special_characters(text, chars_to_ignore_regex)
batch["sentence"] = text
return batch
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
speech_array = speech_array.squeeze().numpy()
speech_array = librosa.resample(np.asarray(speech_array), sampling_rate, 16_000)
batch["speech"] = speech_array
return batch
def predict(batch):
features = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
input_values = features.input_values.to(device)
attention_mask = features.attention_mask.to(device)
with torch.no_grad():
logits = model(input_values, attention_mask=attention_mask).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["predicted"] = processor.batch_decode(pred_ids)[0]
return batch
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
processor = Wav2Vec2Processor.from_pretrained("m3hrdadfi/wav2vec2-large-xlsr-persian")
model = Wav2Vec2ForCTC.from_pretrained("m3hrdadfi/wav2vec2-large-xlsr-persian").to(device)
dataset = load_dataset("common_voice", "fa", split="test[:1%]")
dataset = dataset.map(
normalizer,
fn_kwargs={"chars_to_ignore": chars_to_ignore, "chars_to_mapping": chars_to_mapping},
remove_columns=list(set(dataset.column_names) - set(['sentence', 'path']))
)
dataset = dataset.map(speech_file_to_array_fn)
result = dataset.map(predict)
max_items = np.random.randint(0, len(result), 20).tolist()
for i in max_items:
reference, predicted = result["sentence"][i], result["predicted"][i]
print("reference:", reference)
print("predicted:", predicted)
print('---')
```
**Output:**
```text
reference: اطلاعات مسری است
predicted: اطلاعات مسری است
---
reference: نه منظورم اینه که وقتی که ساکته چه کاریه خودمونه بندازیم زحمت
predicted: نه منظورم اینه که وقتی که ساکت چی کاریه خودمونو بندازیم زحمت
---
reference: من آب پرتقال می خورم لطفا
predicted: من آپ ارتغال می خورم لطفا
---
reference: وقت آن رسیده آنها را که قدم پیش میگذارند بزرگ بداریم
predicted: وقت آ رسیده آنها را که قدم پیش میگذارند بزرگ بداریم
---
reference: سیم باتری دارید
predicted: سیم باتری دارید
---
reference: این بهتره تا اینکه به بهونه درس و مشق هر روز بره خونه شون
predicted: این بهتره تا اینکه به بهمونه درسومش خرروز بره خونه اشون
---
reference: ژاکت تنگ است
predicted: ژاکت تنگ است
---
reference: آت و اشغال های خیابان
predicted: آت و اشغال های خیابان
---
reference: من به این روند اعتراض دارم
predicted: من به این لوند تراج دارم
---
reference: کرایه این مکان چند است
predicted: کرایه این مکان چند است
---
reference: ولی این فرصت این سهم جوانی اعطا نشده است
predicted: ولی این فرصت این سحم جوانی اتان نشده است
---
reference: متوجه فاجعهای محیطی میشوم
predicted: متوجه فاجایهای محیطی میشوم
---
reference: ترافیک شدیدیم بود و دیدن نور ماشینا و چراغا و لامپهای مراکز تجاری حس خوبی بهم میدادن
predicted: ترافیک شدید ی هم بودا دیدن نور ماشینا و چراغ لامپهای مراکز تجاری حس خولی بهم میدادن
---
reference: این مورد عمل ها مربوط به تخصص شما می شود
predicted: این مورد عملها مربوط به تخصص شما میشود
---
reference: انرژی خیلی کمی دارم
predicted: انرژی خیلی کمی دارم
---
reference: زیادی خوبی کردنم تهش داستانه
predicted: زیادی خوبی کردنم ترش داستانه
---
reference: بردهای که پادشاه شود
predicted: برده ای که پاده شاه شود
---
reference: یونسکو
predicted: یونسکو
---
reference: شما اخراج هستید
predicted: شما اخراج هستید
---
reference: من سفر کردن را دوست دارم
predicted: من سفر کردم را دوست دارم
```
## Evaluation
The model can be evaluated as follows on the Persian (Farsi) test data of Common Voice.
```python
import librosa
import torch
import torchaudio
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
from datasets import load_dataset, load_metric
import numpy as np
import hazm
import re
import string
_normalizer = hazm.Normalizer()
chars_to_ignore = [
",", "?", ".", "!", "-", ";", ":", '""', "%", "'", '"', "�",
"#", "!", "؟", "?", "«", "»", "ء", "،", "(", ")", "؛", "'ٔ", "٬",'ٔ', ",", "?",
".", "!", "-", ";", ":",'"',"“", "%", "‘", "”", "�", "–", "…", "_", "”", '“', '„'
]
# In case of farsi
chars_to_ignore = chars_to_ignore + list(string.ascii_lowercase + string.digits)
chars_to_mapping = {
'ك': 'ک', 'دِ': 'د', 'بِ': 'ب', 'زِ': 'ز', 'ذِ': 'ذ', 'شِ': 'ش', 'سِ': 'س', 'ى': 'ی',
'ي': 'ی', 'أ': 'ا', 'ؤ': 'و', "ے": "ی", "ۀ": "ه", "ﭘ": "پ", "ﮐ": "ک", "ﯽ": "ی",
"ﺎ": "ا", "ﺑ": "ب", "ﺘ": "ت", "ﺧ": "خ", "ﺩ": "د", "ﺱ": "س", "ﻀ": "ض", "ﻌ": "ع",
"ﻟ": "ل", "ﻡ": "م", "ﻢ": "م", "ﻪ": "ه", "ﻮ": "و", "ئ": "ی", 'ﺍ': "ا", 'ة': "ه",
'ﯾ': "ی", 'ﯿ': "ی", 'ﺒ': "ب", 'ﺖ': "ت", 'ﺪ': "د", 'ﺮ': "ر", 'ﺴ': "س", 'ﺷ': "ش",
'ﺸ': "ش", 'ﻋ': "ع", 'ﻤ': "م", 'ﻥ': "ن", 'ﻧ': "ن", 'ﻭ': "و", 'ﺭ': "ر", "ﮔ": "گ",
"\\u200c": " ", "\\u200d": " ", "\\u200e": " ", "\\u200f": " ", "\\ufeff": " ",
}
def multiple_replace(text, chars_to_mapping):
pattern = "|".join(map(re.escape, chars_to_mapping.keys()))
return re.sub(pattern, lambda m: chars_to_mapping[m.group()], str(text))
def remove_special_characters(text, chars_to_ignore_regex):
text = re.sub(chars_to_ignore_regex, '', text).lower() + " "
return text
def normalizer(batch, chars_to_ignore, chars_to_mapping):
chars_to_ignore_regex = f"""[{"".join(chars_to_ignore)}]"""
text = batch["sentence"].lower().strip()
text = _normalizer.normalize(text)
text = multiple_replace(text, chars_to_mapping)
text = remove_special_characters(text, chars_to_ignore_regex)
batch["sentence"] = text
return batch
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
speech_array = speech_array.squeeze().numpy()
speech_array = librosa.resample(np.asarray(speech_array), sampling_rate, 16_000)
batch["speech"] = speech_array
return batch
def predict(batch):
features = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
input_values = features.input_values.to(device)
attention_mask = features.attention_mask.to(device)
with torch.no_grad():
logits = model(input_values, attention_mask=attention_mask).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["predicted"] = processor.batch_decode(pred_ids)[0]
return batch
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
processor = Wav2Vec2Processor.from_pretrained("m3hrdadfi/wav2vec2-large-xlsr-persian")
model = Wav2Vec2ForCTC.from_pretrained("m3hrdadfi/wav2vec2-large-xlsr-persian").to(device)
dataset = load_dataset("common_voice", "fa", split="test")
dataset = dataset.map(
normalizer,
fn_kwargs={"chars_to_ignore": chars_to_ignore, "chars_to_mapping": chars_to_mapping},
remove_columns=list(set(dataset.column_names) - set(['sentence', 'path']))
)
dataset = dataset.map(speech_file_to_array_fn)
result = dataset.map(predict)
wer = load_metric("wer")
print("WER: {:.2f}".format(100 * wer.compute(predictions=result["predicted"], references=result["sentence"])))
```
**Test Result:**
- WER: 32.20%
## Training
The Common Voice `train`, `validation` datasets were used for training.
The script used for training can be found [here](https://colab.research.google.com/github/m3hrdadfi/notebooks/blob/main/Fine_Tune_XLSR_Wav2Vec2_on_Persian_ASR_with_%F0%9F%A4%97_Transformers_ipynb.ipynb)
|
valhalla/t5-base-squad
|
d19773e0f8a0d4cf6f087e425674dffba44b4b42
|
2020-12-11T22:03:51.000Z
|
[
"pytorch",
"t5",
"text2text-generation",
"transformers",
"autotrain_compatible"
] |
text2text-generation
| false |
valhalla
| null |
valhalla/t5-base-squad
| 537 | null |
transformers
| 2,261 |
# T5 for question-answering
This is T5-base model fine-tuned on SQuAD1.1 for QA using text-to-text approach
## Model training
This model was trained on colab TPU with 35GB RAM for 4 epochs
## Results:
| Metric | #Value |
|-------------|---------|
| Exact Match | 81.5610 |
| F1 | 89.9601 |
## Model in Action 🚀
```
from transformers import AutoModelWithLMHead, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("valhalla/t5-base-squad")
model = AutoModelWithLMHead.from_pretrained("valhalla/t5-base-squad")
def get_answer(question, context):
input_text = "question: %s context: %s </s>" % (question, context)
features = tokenizer([input_text], return_tensors='pt')
out = model.generate(input_ids=features['input_ids'],
attention_mask=features['attention_mask'])
return tokenizer.decode(out[0])
context = "In Norse mythology, Valhalla is a majestic, enormous hall located in Asgard, ruled over by the god Odin."
question = "What is Valhalla ?"
get_answer(question, context)
# output: 'a majestic, enormous hall located in Asgard, ruled over by the god Odin'
```
Play with this model [](https://colab.research.google.com/drive/1a5xpJiUjZybfU9Mi-aDkOp116PZ9-wni?usp=sharing)
> Created by Suraj Patil [](https://github.com/patil-suraj/)
[](https://twitter.com/psuraj28)
|
KoboldAI/GPT-J-6B-Janeway
|
036bb03496d648ddc8cf932ad91df8ef1287116c
|
2022-03-20T12:59:44.000Z
|
[
"pytorch",
"gptj",
"text-generation",
"en",
"arxiv:2101.00027",
"transformers",
"license:mit"
] |
text-generation
| false |
KoboldAI
| null |
KoboldAI/GPT-J-6B-Janeway
| 537 | null |
transformers
| 2,262 |
---
language: en
license: mit
---
# GPT-J 6B - Janeway
## Model Description
GPT-J 6B-Janeway is a finetune created using EleutherAI's GPT-J 6B model.
## Training data
The training data contains around 2210 ebooks, mostly in the sci-fi and fantasy genres. The dataset is based on the same dataset used by GPT-Neo-2.7B-Picard, with 20% more data in various genres.
Some parts of the dataset have been prepended using the following text: `[Genre: <genre1>,<genre2>]`
### How to use
You can use this model directly with a pipeline for text generation. This example generates a different sequence each time it's run:
```py
>>> from transformers import pipeline
>>> generator = pipeline('text-generation', model='KoboldAI/GPT-J-6B-Janeway')
>>> generator("Welcome Captain Janeway, I apologize for the delay.", do_sample=True, min_length=50)
[{'generated_text': 'Welcome Captain Janeway, I apologize for the delay."\nIt's all right," Janeway said. "I'm certain that you're doing your best to keep me informed of what\'s going on."'}]
```
### Limitations and Biases
The core functionality of GPT-J is taking a string of text and predicting the next token. While language models are widely used for tasks other than this, there are a lot of unknowns with this work. When prompting GPT-J it is important to remember that the statistically most likely next token is often not the token that produces the most "accurate" text. Never depend upon GPT-J to produce factually accurate output.
GPT-J was trained on the Pile, a dataset known to contain profanity, lewd, and otherwise abrasive language. Depending upon use case GPT-J may produce socially unacceptable text. See [Sections 5 and 6 of the Pile paper](https://arxiv.org/abs/2101.00027) for a more detailed analysis of the biases in the Pile.
As with all language models, it is hard to predict in advance how GPT-J will respond to particular prompts and offensive content may occur without warning. We recommend having a human curate or filter the outputs before releasing them, both to censor undesirable content and to improve the quality of the results.
### BibTeX entry and citation info
The model uses the following model as base:
```bibtex
@misc{gpt-j,
author = {Wang, Ben and Komatsuzaki, Aran},
title = {{GPT-J-6B: A 6 Billion Parameter Autoregressive Language Model}},
howpublished = {\url{https://github.com/kingoflolz/mesh-transformer-jax}},
year = 2021,
month = May
}
```
## Acknowledgements
This project would not have been possible without compute generously provided by Google through the
[TPU Research Cloud](https://sites.research.google/trc/), as well as the Cloud TPU team for providing early access to the [Cloud TPU VM](https://cloud.google.com/blog/products/compute/introducing-cloud-tpu-vms) Alpha.
|
sultan/BioM-ELECTRA-Large-SQuAD2-BioASQ8B
|
1dfc7f810497d9752fbc9a82fc7e376546242e46
|
2021-07-24T20:18:22.000Z
|
[
"pytorch",
"electra",
"question-answering",
"transformers",
"autotrain_compatible"
] |
question-answering
| false |
sultan
| null |
sultan/BioM-ELECTRA-Large-SQuAD2-BioASQ8B
| 536 | null |
transformers
| 2,263 |
# BioM-Transformers: Building Large Biomedical Language Models with BERT, ALBERT and ELECTRA
# Abstract
The impact of design choices on the performance
of biomedical language models recently
has been a subject for investigation. In
this paper, we empirically study biomedical
domain adaptation with large transformer models
using different design choices. We evaluate
the performance of our pretrained models
against other existing biomedical language
models in the literature. Our results show that
we achieve state-of-the-art results on several
biomedical domain tasks despite using similar
or less computational cost compared to other
models in the literature. Our findings highlight
the significant effect of design choices on
improving the performance of biomedical language
models.
# Model Description
- This model is fine-tuned on the SQuAD2.0 dataset and then on the BioASQ8B-Factoid training dataset. We convert the BioASQ8B-Factoid training dataset to SQuAD1.1 format and train and evaluate our model (BioM-ELECTRA-Base-SQuAD2) on this dataset.
- You can use this model to make a prediction (inference) directly without fine-tuning it. Try to enter a PubMed abstract in the context box in this model card and try out a couple of biomedical questions within the given context and see how it performs compared to ELECTRA original model. This model should also be useful for creating a pandemic QA system (e.g., COVID-19) .
- Please note that this version (PyTorch) is different than what we used in our participation in BioASQ9B (TensorFlow with Layer-Wise Decay). We combine all five batches of the BioASQ8B testing dataset as one dev.json file.
- Below is unofficial results of our models against the original ELECTRA base and large :
| Model | Exact Match (EM) | F1 Score |
| --- | --- | --- |
| ELECTRA-Base-SQuAD2-BioASQ8B | 61.89 | 74.39 |
| BioM-ELECTRA-Base-SQuAD2-BioASQ8B | 70.31 | 80.90 |
| ELECTRA-Large-SQuAD2-BioASQ8B | 67.36 | 78.90 |
| **BioM-ELECTRA-Large-SQuAD2-BioASQ8B** | **74.31** | **84.72** |
Training script
```python
python3 run_squad.py --model_type electra --model_name_or_path sultan/BioM-ELECTRA-Large-SQuAD2 \
--train_file BioASQ8B/train.json \
--predict_file BioASQ8B/dev.json \
--do_lower_case \
--do_train \
--do_eval \
--threads 20 \
--version_2_with_negative \
--num_train_epochs 3 \
--learning_rate 5e-5 \
--max_seq_length 512 \
--doc_stride 128 \
--per_gpu_train_batch_size 8 \
--gradient_accumulation_steps 2 \
--per_gpu_eval_batch_size 128 \
--logging_steps 50 \
--save_steps 5000 \
--fp16 \
--fp16_opt_level O1 \
--overwrite_output_dir \
--output_dir BioM-ELECTRA-Large-SQuAD-BioASQ \
--overwrite_cache
```
# Acknowledgment
We would like to acknowledge the support we have from Tensorflow Research Cloud (TFRC) team to grant us access to TPUv3 units.
# Citation
```bibtex
@inproceedings{alrowili-shanker-2021-biom,
title = "{B}io{M}-Transformers: Building Large Biomedical Language Models with {BERT}, {ALBERT} and {ELECTRA}",
author = "Alrowili, Sultan and
Shanker, Vijay",
booktitle = "Proceedings of the 20th Workshop on Biomedical Language Processing",
month = jun,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2021.bionlp-1.24",
pages = "221--227",
abstract = "The impact of design choices on the performance of biomedical language models recently has been a subject for investigation. In this paper, we empirically study biomedical domain adaptation with large transformer models using different design choices. We evaluate the performance of our pretrained models against other existing biomedical language models in the literature. Our results show that we achieve state-of-the-art results on several biomedical domain tasks despite using similar or less computational cost compared to other models in the literature. Our findings highlight the significant effect of design choices on improving the performance of biomedical language models.",
}
```
|
KETI-AIR/ke-t5-large
|
bb55bafacd3e35feca548c9bcffdf799236203d2
|
2021-06-23T03:09:21.000Z
|
[
"pytorch",
"tf",
"jax",
"t5",
"text2text-generation",
"transformers",
"autotrain_compatible"
] |
text2text-generation
| false |
KETI-AIR
| null |
KETI-AIR/ke-t5-large
| 534 | 1 |
transformers
| 2,264 |
Entry not found
|
microsoft/DialogRPT-depth
|
0fa8a8770e267801a5779788ccfd921192ae7f40
|
2021-05-23T09:15:24.000Z
|
[
"pytorch",
"gpt2",
"text-classification",
"arxiv:2009.06978",
"transformers"
] |
text-classification
| false |
microsoft
| null |
microsoft/DialogRPT-depth
| 534 | 2 |
transformers
| 2,265 |
# Demo
Please try this [➤➤➤ Colab Notebook Demo (click me!)](https://colab.research.google.com/drive/1cAtfkbhqsRsT59y3imjR1APw3MHDMkuV?usp=sharing)
| Context | Response | `depth` score |
| :------ | :------- | :------------: |
| I love NLP! | Can anyone recommend a nice review paper? | 0.724 |
| I love NLP! | Me too! | 0.032 |
The `depth` score predicts how likely the response is getting a long follow-up discussion thread.
# DialogRPT-depth
### Dialog Ranking Pretrained Transformers
> How likely a dialog response is upvoted 👍 and/or gets replied 💬?
This is what [**DialogRPT**](https://github.com/golsun/DialogRPT) is learned to predict.
It is a set of dialog response ranking models proposed by [Microsoft Research NLP Group](https://www.microsoft.com/en-us/research/group/natural-language-processing/) trained on 100 + millions of human feedback data.
It can be used to improve existing dialog generation model (e.g., [DialoGPT](https://huggingface.co/microsoft/DialoGPT-medium)) by re-ranking the generated response candidates.
Quick Links:
* [EMNLP'20 Paper](https://arxiv.org/abs/2009.06978/)
* [Dataset, training, and evaluation](https://github.com/golsun/DialogRPT)
* [Colab Notebook Demo](https://colab.research.google.com/drive/1cAtfkbhqsRsT59y3imjR1APw3MHDMkuV?usp=sharing)
We considered the following tasks and provided corresponding pretrained models.
|Task | Description | Pretrained model |
| :------------- | :----------- | :-----------: |
| **Human feedback** | **given a context and its two human responses, predict...**|
| `updown` | ... which gets more upvotes? | [model card](https://huggingface.co/microsoft/DialogRPT-updown) |
| `width`| ... which gets more direct replies? | [model card](https://huggingface.co/microsoft/DialogRPT-width) |
| `depth`| ... which gets longer follow-up thread? | this model |
| **Human-like** (human vs fake) | **given a context and one human response, distinguish it with...** |
| `human_vs_rand`| ... a random human response | [model card](https://huggingface.co/microsoft/DialogRPT-human-vs-rand) |
| `human_vs_machine`| ... a machine generated response | [model card](https://huggingface.co/microsoft/DialogRPT-human-vs-machine) |
### Contact:
Please create an issue on [our repo](https://github.com/golsun/DialogRPT)
### Citation:
```
@inproceedings{gao2020dialogrpt,
title={Dialogue Response RankingTraining with Large-Scale Human Feedback Data},
author={Xiang Gao and Yizhe Zhang and Michel Galley and Chris Brockett and Bill Dolan},
year={2020},
booktitle={EMNLP}
}
```
|
microsoft/DialogRPT-width
|
bd3aad6082f8b725d27bb29cb4f5001e58b03fd0
|
2021-05-23T09:20:20.000Z
|
[
"pytorch",
"gpt2",
"text-classification",
"arxiv:2009.06978",
"transformers"
] |
text-classification
| false |
microsoft
| null |
microsoft/DialogRPT-width
| 534 | 1 |
transformers
| 2,266 |
# Demo
Please try this [➤➤➤ Colab Notebook Demo (click me!)](https://colab.research.google.com/drive/1cAtfkbhqsRsT59y3imjR1APw3MHDMkuV?usp=sharing)
| Context | Response | `width` score |
| :------ | :------- | :------------: |
| I love NLP! | Can anyone recommend a nice review paper? | 0.701 |
| I love NLP! | Me too! | 0.029 |
The `width` score predicts how likely the response is getting replied.
# DialogRPT-width
### Dialog Ranking Pretrained Transformers
> How likely a dialog response is upvoted 👍 and/or gets replied 💬?
This is what [**DialogRPT**](https://github.com/golsun/DialogRPT) is learned to predict.
It is a set of dialog response ranking models proposed by [Microsoft Research NLP Group](https://www.microsoft.com/en-us/research/group/natural-language-processing/) trained on 100 + millions of human feedback data.
It can be used to improve existing dialog generation model (e.g., [DialoGPT](https://huggingface.co/microsoft/DialoGPT-medium)) by re-ranking the generated response candidates.
Quick Links:
* [EMNLP'20 Paper](https://arxiv.org/abs/2009.06978/)
* [Dataset, training, and evaluation](https://github.com/golsun/DialogRPT)
* [Colab Notebook Demo](https://colab.research.google.com/drive/1cAtfkbhqsRsT59y3imjR1APw3MHDMkuV?usp=sharing)
We considered the following tasks and provided corresponding pretrained models.
|Task | Description | Pretrained model |
| :------------- | :----------- | :-----------: |
| **Human feedback** | **given a context and its two human responses, predict...**|
| `updown` | ... which gets more upvotes? | [model card](https://huggingface.co/microsoft/DialogRPT-updown) |
| `width`| ... which gets more direct replies? | this model |
| `depth`| ... which gets longer follow-up thread? | [model card](https://huggingface.co/microsoft/DialogRPT-depth) |
| **Human-like** (human vs fake) | **given a context and one human response, distinguish it with...** |
| `human_vs_rand`| ... a random human response | [model card](https://huggingface.co/microsoft/DialogRPT-human-vs-rand) |
| `human_vs_machine`| ... a machine generated response | [model card](https://huggingface.co/microsoft/DialogRPT-human-vs-machine) |
### Contact:
Please create an issue on [our repo](https://github.com/golsun/DialogRPT)
### Citation:
```
@inproceedings{gao2020dialogrpt,
title={Dialogue Response RankingTraining with Large-Scale Human Feedback Data},
author={Xiang Gao and Yizhe Zhang and Michel Galley and Chris Brockett and Bill Dolan},
year={2020},
booktitle={EMNLP}
}
```
|
succinctly/text2image-prompt-generator
|
5b096e9aa15e37f5193b669013ddaae7d77b4984
|
2022-07-22T18:26:53.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"en",
"dataset:succinctly/midjourney-prompts",
"transformers",
"text2image",
"prompting",
"license:apache-2.0"
] |
text-generation
| false |
succinctly
| null |
succinctly/text2image-prompt-generator
| 534 | 0 |
transformers
| 2,267 |
---
language:
- "en"
thumbnail: "https://drive.google.com/uc?export=view&id=1JWwrxQbr1s5vYpIhPna_p2IG1pE5rNiV"
tags:
- text2image
- prompting
license: "apache-2.0"
datasets:
- "succinctly/midjourney-prompts"
---
This is a GPT-2 model fine-tuned on the [succinctly/midjourney-prompts](https://huggingface.co/datasets/succinctly/midjourney-prompts) dataset, which contains 250k text prompts that users issued to the [Midjourney](https://www.midjourney.com/) text-to-image service over a month period. For more details on how this dataset was scraped, see [Midjourney User Prompts & Generated Images (250k)](https://www.kaggle.com/datasets/succinctlyai/midjourney-texttoimage).
This prompt generator can be sued to auto-complete prompts for any text-to-image model (including the DALL·E family):

Note that, while this model can be used together with any text-to-image model, it occasionally produces Midjourney-specific tags. Users can specify certain requirements via [double-dashed parameters](https://midjourney.gitbook.io/docs/imagine-parameters) (e.g. `--ar 16:9` sets the aspect ratio to 16:9, and `--no snake` asks the model to exclude snakes from the generated image) or set the importance of various entities in the image via [explicit weights](https://midjourney.gitbook.io/docs/user-manual#advanced-text-weights) (e.g. `hot dog::1.5 food::-1` is likely to produce the image of an animal instead of a frankfurter).
|
asahi417/tner-xlm-roberta-large-ontonotes5
|
08326a195be4564f4ce6b057033c65d0e47de3cc
|
2021-02-13T00:10:15.000Z
|
[
"pytorch",
"xlm-roberta",
"token-classification",
"transformers",
"autotrain_compatible"
] |
token-classification
| false |
asahi417
| null |
asahi417/tner-xlm-roberta-large-ontonotes5
| 533 | null |
transformers
| 2,268 |
# XLM-RoBERTa for NER
XLM-RoBERTa finetuned on NER. Check more detail at [TNER repository](https://github.com/asahi417/tner).
## Usage
```
from transformers import AutoTokenizer, AutoModelForTokenClassification
tokenizer = AutoTokenizer.from_pretrained("asahi417/tner-xlm-roberta-large-ontonotes5")
model = AutoModelForTokenClassification.from_pretrained("asahi417/tner-xlm-roberta-large-ontonotes5")
```
|
Helsinki-NLP/opus-mt-tc-big-tr-en
|
168ae5336d311e146eb774c5d85698548aa0da11
|
2022-06-01T12:58:47.000Z
|
[
"pytorch",
"marian",
"text2text-generation",
"en",
"tr",
"transformers",
"translation",
"opus-mt-tc",
"license:cc-by-4.0",
"model-index",
"autotrain_compatible"
] |
translation
| false |
Helsinki-NLP
| null |
Helsinki-NLP/opus-mt-tc-big-tr-en
| 533 | 1 |
transformers
| 2,269 |
---
language:
- en
- tr
tags:
- translation
- opus-mt-tc
license: cc-by-4.0
model-index:
- name: opus-mt-tc-big-tr-en
results:
- task:
name: Translation tur-eng
type: translation
args: tur-eng
dataset:
name: flores101-devtest
type: flores_101
args: tur eng devtest
metrics:
- name: BLEU
type: bleu
value: 37.6
- task:
name: Translation tur-eng
type: translation
args: tur-eng
dataset:
name: newsdev2016
type: newsdev2016
args: tur-eng
metrics:
- name: BLEU
type: bleu
value: 32.1
- task:
name: Translation tur-eng
type: translation
args: tur-eng
dataset:
name: tatoeba-test-v2021-08-07
type: tatoeba_mt
args: tur-eng
metrics:
- name: BLEU
type: bleu
value: 57.6
- task:
name: Translation tur-eng
type: translation
args: tur-eng
dataset:
name: newstest2016
type: wmt-2016-news
args: tur-eng
metrics:
- name: BLEU
type: bleu
value: 29.3
- task:
name: Translation tur-eng
type: translation
args: tur-eng
dataset:
name: newstest2017
type: wmt-2017-news
args: tur-eng
metrics:
- name: BLEU
type: bleu
value: 29.7
- task:
name: Translation tur-eng
type: translation
args: tur-eng
dataset:
name: newstest2018
type: wmt-2018-news
args: tur-eng
metrics:
- name: BLEU
type: bleu
value: 30.7
---
# opus-mt-tc-big-tr-en
Neural machine translation model for translating from Turkish (tr) to English (en).
This model is part of the [OPUS-MT project](https://github.com/Helsinki-NLP/Opus-MT), an effort to make neural machine translation models widely available and accessible for many languages in the world. All models are originally trained using the amazing framework of [Marian NMT](https://marian-nmt.github.io/), an efficient NMT implementation written in pure C++. The models have been converted to pyTorch using the transformers library by huggingface. Training data is taken from [OPUS](https://opus.nlpl.eu/) and training pipelines use the procedures of [OPUS-MT-train](https://github.com/Helsinki-NLP/Opus-MT-train).
* Publications: [OPUS-MT – Building open translation services for the World](https://aclanthology.org/2020.eamt-1.61/) and [The Tatoeba Translation Challenge – Realistic Data Sets for Low Resource and Multilingual MT](https://aclanthology.org/2020.wmt-1.139/) (Please, cite if you use this model.)
```
@inproceedings{tiedemann-thottingal-2020-opus,
title = "{OPUS}-{MT} {--} Building open translation services for the World",
author = {Tiedemann, J{\"o}rg and Thottingal, Santhosh},
booktitle = "Proceedings of the 22nd Annual Conference of the European Association for Machine Translation",
month = nov,
year = "2020",
address = "Lisboa, Portugal",
publisher = "European Association for Machine Translation",
url = "https://aclanthology.org/2020.eamt-1.61",
pages = "479--480",
}
@inproceedings{tiedemann-2020-tatoeba,
title = "The Tatoeba Translation Challenge {--} Realistic Data Sets for Low Resource and Multilingual {MT}",
author = {Tiedemann, J{\"o}rg},
booktitle = "Proceedings of the Fifth Conference on Machine Translation",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.wmt-1.139",
pages = "1174--1182",
}
```
## Model info
* Release: 2022-03-17
* source language(s): tur
* target language(s): eng
* model: transformer-big
* data: opusTCv20210807+bt ([source](https://github.com/Helsinki-NLP/Tatoeba-Challenge))
* tokenization: SentencePiece (spm32k,spm32k)
* original model: [opusTCv20210807+bt_transformer-big_2022-03-17.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/tur-eng/opusTCv20210807+bt_transformer-big_2022-03-17.zip)
* more information released models: [OPUS-MT tur-eng README](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/tur-eng/README.md)
## Usage
A short example code:
```python
from transformers import MarianMTModel, MarianTokenizer
src_text = [
"Allahsızlığı Yayma Kürsüsü başkanıydı.",
"Tom'a ne olduğunu öğrenin."
]
model_name = "pytorch-models/opus-mt-tc-big-tr-en"
tokenizer = MarianTokenizer.from_pretrained(model_name)
model = MarianMTModel.from_pretrained(model_name)
translated = model.generate(**tokenizer(src_text, return_tensors="pt", padding=True))
for t in translated:
print( tokenizer.decode(t, skip_special_tokens=True) )
# expected output:
# He was the president of the Curse of Spreading Godlessness.
# Find out what happened to Tom.
```
You can also use OPUS-MT models with the transformers pipelines, for example:
```python
from transformers import pipeline
pipe = pipeline("translation", model="Helsinki-NLP/opus-mt-tc-big-tr-en")
print(pipe("Allahsızlığı Yayma Kürsüsü başkanıydı."))
# expected output: He was the president of the Curse of Spreading Godlessness.
```
## Benchmarks
* test set translations: [opusTCv20210807+bt_transformer-big_2022-03-17.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/tur-eng/opusTCv20210807+bt_transformer-big_2022-03-17.test.txt)
* test set scores: [opusTCv20210807+bt_transformer-big_2022-03-17.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/tur-eng/opusTCv20210807+bt_transformer-big_2022-03-17.eval.txt)
* benchmark results: [benchmark_results.txt](benchmark_results.txt)
* benchmark output: [benchmark_translations.zip](benchmark_translations.zip)
| langpair | testset | chr-F | BLEU | #sent | #words |
|----------|---------|-------|-------|-------|--------|
| tur-eng | tatoeba-test-v2021-08-07 | 0.71895 | 57.6 | 13907 | 109231 |
| tur-eng | flores101-devtest | 0.64152 | 37.6 | 1012 | 24721 |
| tur-eng | newsdev2016 | 0.58658 | 32.1 | 1001 | 21988 |
| tur-eng | newstest2016 | 0.56960 | 29.3 | 3000 | 66175 |
| tur-eng | newstest2017 | 0.57455 | 29.7 | 3007 | 67703 |
| tur-eng | newstest2018 | 0.58488 | 30.7 | 3000 | 68725 |
## Acknowledgements
The work is supported by the [European Language Grid](https://www.european-language-grid.eu/) as [pilot project 2866](https://live.european-language-grid.eu/catalogue/#/resource/projects/2866), by the [FoTran project](https://www.helsinki.fi/en/researchgroups/natural-language-understanding-with-cross-lingual-grounding), funded by the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (grant agreement No 771113), and the [MeMAD project](https://memad.eu/), funded by the European Union’s Horizon 2020 Research and Innovation Programme under grant agreement No 780069. We are also grateful for the generous computational resources and IT infrastructure provided by [CSC -- IT Center for Science](https://www.csc.fi/), Finland.
## Model conversion info
* transformers version: 4.16.2
* OPUS-MT git hash: 3405783
* port time: Wed Apr 13 20:02:48 EEST 2022
* port machine: LM0-400-22516.local
|
dmis-lab/biobert-large-cased-v1.1-mnli
|
a68c447b532ba6af6b2050036a05057dd036ef94
|
2021-05-19T15:58:34.000Z
|
[
"pytorch",
"jax",
"bert",
"text-classification",
"transformers"
] |
text-classification
| false |
dmis-lab
| null |
dmis-lab/biobert-large-cased-v1.1-mnli
| 532 | null |
transformers
| 2,270 |
Entry not found
|
kiri-ai/t5-base-qa-summary-emotion
|
66b7d2e5273b4fd4fff90c366702b71a857e5801
|
2021-09-22T08:55:00.000Z
|
[
"pytorch",
"t5",
"text2text-generation",
"en",
"dataset:coqa",
"dataset:squad_v2",
"dataset:go_emotions",
"dataset:cnn_dailymail",
"transformers",
"question-answering",
"emotion-detection",
"summarisation",
"license:apache-2.0",
"autotrain_compatible"
] |
text2text-generation
| false |
kiri-ai
| null |
kiri-ai/t5-base-qa-summary-emotion
| 532 | null |
transformers
| 2,271 |
---
language:
- en
tags:
- question-answering
- emotion-detection
- summarisation
license: apache-2.0
datasets:
- coqa
- squad_v2
- go_emotions
- cnn_dailymail
metrics:
- f1
pipeline_tag: text2text-generation
widget:
- text: 'q: Who is Elon Musk? a: an entrepreneur q: When was he born? c: Elon Musk
is an entrepreneur born in 1971. </s>'
- text: 'emotion: I hope this works! </s>'
---
# T5 Base with QA + Summary + Emotion
## Dependencies
Requires transformers>=4.0.0
## Description
This model was finetuned on the CoQa, Squad 2, GoEmotions and CNN/DailyMail.
It achieves a score of **F1 79.5** on the Squad 2 dev set and a score of **F1 70.6** on the CoQa dev set.
Summarisation and emotion detection has not been evaluated yet.
## Usage
### Question answering
#### With Transformers
```python
from transformers import T5ForConditionalGeneration, T5Tokenizer
model = T5ForConditionalGeneration.from_pretrained("kiri-ai/t5-base-qa-summary-emotion")
tokenizer = T5Tokenizer.from_pretrained("kiri-ai/t5-base-qa-summary-emotion")
def get_answer(question, prev_qa, context):
input_text = [f"q: {qa[0]} a: {qa[1]}" for qa in prev_qa]
input_text.append(f"q: {question}")
input_text.append(f"c: {context}")
input_text = " ".join(input_text)
features = tokenizer([input_text], return_tensors='pt')
tokens = model.generate(input_ids=features['input_ids'],
attention_mask=features['attention_mask'], max_length=64)
return tokenizer.decode(tokens[0], skip_special_tokens=True)
print(get_answer("Why is the moon yellow?", "I'm not entirely sure why the moon is yellow.")) # unknown
context = "Elon Musk left OpenAI to avoid possible future conflicts with his role as CEO of Tesla."
print(get_answer("Why not?", [("Does Elon Musk still work with OpenAI", "No")], context)) # to avoid possible future conflicts with his role as CEO of Tesla
```
#### With Kiri
```python
from kiri.models import T5QASummaryEmotion
context = "Elon Musk left OpenAI to avoid possible future conflicts with his role as CEO of Tesla."
prev_qa = [("Does Elon Musk still work with OpenAI", "No")]
model = T5QASummaryEmotion()
# Leave prev_qa blank for non conversational question-answering
model.qa("Why not?", context, prev_qa=prev_qa)
> "to avoid possible future conflicts with his role as CEO of Tesla"
```
### Summarisation
#### With Transformers
```python
from transformers import T5ForConditionalGeneration, T5Tokenizer
model = T5ForConditionalGeneration.from_pretrained("kiri-ai/t5-base-qa-summary-emotion")
tokenizer = T5Tokenizer.from_pretrained("kiri-ai/t5-base-qa-summary-emotion")
def summary(context):
input_text = f"summarize: {context}"
features = tokenizer([input_text], return_tensors='pt')
tokens = model.generate(input_ids=features['input_ids'],
attention_mask=features['attention_mask'], max_length=64)
return tokenizer.decode(tokens[0], skip_special_tokens=True)
```
#### With Kiri
```python
from kiri.models import T5QASummaryEmotion
model = T5QASummaryEmotion()
model.summarise("Long text to summarise")
> "Short summary of long text"
```
### Emotion detection
#### With Transformers
```python
from transformers import T5ForConditionalGeneration, T5Tokenizer
model = T5ForConditionalGeneration.from_pretrained("kiri-ai/t5-base-qa-summary-emotion")
tokenizer = T5Tokenizer.from_pretrained("kiri-ai/t5-base-qa-summary-emotion")
def emotion(context):
input_text = f"emotion: {context}"
features = tokenizer([input_text], return_tensors='pt')
tokens = model.generate(input_ids=features['input_ids'],
attention_mask=features['attention_mask'], max_length=64)
return tokenizer.decode(tokens[0], skip_special_tokens=True)
```
#### With Kiri
```python
from kiri.models import T5QASummaryEmotion
model = T5QASummaryEmotion()
model.emotion("I hope this works!")
> "optimism"
```
## About us
Kiri makes using state-of-the-art models easy, accessible and scalable.
[Website](https://kiri.ai) | [Natural Language Engine](https://github.com/kiri-ai/kiri)
|
Helsinki-NLP/opus-mt-tc-big-en-fr
|
4bc9bda0d1631919558705df71a6471c6eb0e1c5
|
2022-06-01T13:04:06.000Z
|
[
"pytorch",
"marian",
"text2text-generation",
"en",
"fr",
"transformers",
"translation",
"opus-mt-tc",
"license:cc-by-4.0",
"model-index",
"autotrain_compatible"
] |
translation
| false |
Helsinki-NLP
| null |
Helsinki-NLP/opus-mt-tc-big-en-fr
| 532 | null |
transformers
| 2,272 |
---
language:
- en
- fr
tags:
- translation
- opus-mt-tc
license: cc-by-4.0
model-index:
- name: opus-mt-tc-big-en-fr
results:
- task:
name: Translation eng-fra
type: translation
args: eng-fra
dataset:
name: flores101-devtest
type: flores_101
args: eng fra devtest
metrics:
- name: BLEU
type: bleu
value: 52.2
- task:
name: Translation eng-fra
type: translation
args: eng-fra
dataset:
name: multi30k_test_2016_flickr
type: multi30k-2016_flickr
args: eng-fra
metrics:
- name: BLEU
type: bleu
value: 52.4
- task:
name: Translation eng-fra
type: translation
args: eng-fra
dataset:
name: multi30k_test_2017_flickr
type: multi30k-2017_flickr
args: eng-fra
metrics:
- name: BLEU
type: bleu
value: 52.8
- task:
name: Translation eng-fra
type: translation
args: eng-fra
dataset:
name: multi30k_test_2017_mscoco
type: multi30k-2017_mscoco
args: eng-fra
metrics:
- name: BLEU
type: bleu
value: 54.7
- task:
name: Translation eng-fra
type: translation
args: eng-fra
dataset:
name: multi30k_test_2018_flickr
type: multi30k-2018_flickr
args: eng-fra
metrics:
- name: BLEU
type: bleu
value: 43.7
- task:
name: Translation eng-fra
type: translation
args: eng-fra
dataset:
name: news-test2008
type: news-test2008
args: eng-fra
metrics:
- name: BLEU
type: bleu
value: 27.6
- task:
name: Translation eng-fra
type: translation
args: eng-fra
dataset:
name: newsdiscussdev2015
type: newsdiscussdev2015
args: eng-fra
metrics:
- name: BLEU
type: bleu
value: 33.4
- task:
name: Translation eng-fra
type: translation
args: eng-fra
dataset:
name: newsdiscusstest2015
type: newsdiscusstest2015
args: eng-fra
metrics:
- name: BLEU
type: bleu
value: 40.3
- task:
name: Translation eng-fra
type: translation
args: eng-fra
dataset:
name: tatoeba-test-v2021-08-07
type: tatoeba_mt
args: eng-fra
metrics:
- name: BLEU
type: bleu
value: 53.2
- task:
name: Translation eng-fra
type: translation
args: eng-fra
dataset:
name: tico19-test
type: tico19-test
args: eng-fra
metrics:
- name: BLEU
type: bleu
value: 40.6
- task:
name: Translation eng-fra
type: translation
args: eng-fra
dataset:
name: newstest2009
type: wmt-2009-news
args: eng-fra
metrics:
- name: BLEU
type: bleu
value: 30.0
- task:
name: Translation eng-fra
type: translation
args: eng-fra
dataset:
name: newstest2010
type: wmt-2010-news
args: eng-fra
metrics:
- name: BLEU
type: bleu
value: 33.5
- task:
name: Translation eng-fra
type: translation
args: eng-fra
dataset:
name: newstest2011
type: wmt-2011-news
args: eng-fra
metrics:
- name: BLEU
type: bleu
value: 35.0
- task:
name: Translation eng-fra
type: translation
args: eng-fra
dataset:
name: newstest2012
type: wmt-2012-news
args: eng-fra
metrics:
- name: BLEU
type: bleu
value: 32.8
- task:
name: Translation eng-fra
type: translation
args: eng-fra
dataset:
name: newstest2013
type: wmt-2013-news
args: eng-fra
metrics:
- name: BLEU
type: bleu
value: 34.6
- task:
name: Translation eng-fra
type: translation
args: eng-fra
dataset:
name: newstest2014
type: wmt-2014-news
args: eng-fra
metrics:
- name: BLEU
type: bleu
value: 41.9
---
# opus-mt-tc-big-en-fr
Neural machine translation model for translating from English (en) to French (fr).
This model is part of the [OPUS-MT project](https://github.com/Helsinki-NLP/Opus-MT), an effort to make neural machine translation models widely available and accessible for many languages in the world. All models are originally trained using the amazing framework of [Marian NMT](https://marian-nmt.github.io/), an efficient NMT implementation written in pure C++. The models have been converted to pyTorch using the transformers library by huggingface. Training data is taken from [OPUS](https://opus.nlpl.eu/) and training pipelines use the procedures of [OPUS-MT-train](https://github.com/Helsinki-NLP/Opus-MT-train).
* Publications: [OPUS-MT – Building open translation services for the World](https://aclanthology.org/2020.eamt-1.61/) and [The Tatoeba Translation Challenge – Realistic Data Sets for Low Resource and Multilingual MT](https://aclanthology.org/2020.wmt-1.139/) (Please, cite if you use this model.)
```
@inproceedings{tiedemann-thottingal-2020-opus,
title = "{OPUS}-{MT} {--} Building open translation services for the World",
author = {Tiedemann, J{\"o}rg and Thottingal, Santhosh},
booktitle = "Proceedings of the 22nd Annual Conference of the European Association for Machine Translation",
month = nov,
year = "2020",
address = "Lisboa, Portugal",
publisher = "European Association for Machine Translation",
url = "https://aclanthology.org/2020.eamt-1.61",
pages = "479--480",
}
@inproceedings{tiedemann-2020-tatoeba,
title = "The Tatoeba Translation Challenge {--} Realistic Data Sets for Low Resource and Multilingual {MT}",
author = {Tiedemann, J{\"o}rg},
booktitle = "Proceedings of the Fifth Conference on Machine Translation",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.wmt-1.139",
pages = "1174--1182",
}
```
## Model info
* Release: 2022-03-09
* source language(s): eng
* target language(s): fra
* model: transformer-big
* data: opusTCv20210807+bt ([source](https://github.com/Helsinki-NLP/Tatoeba-Challenge))
* tokenization: SentencePiece (spm32k,spm32k)
* original model: [opusTCv20210807+bt_transformer-big_2022-03-09.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-fra/opusTCv20210807+bt_transformer-big_2022-03-09.zip)
* more information released models: [OPUS-MT eng-fra README](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/eng-fra/README.md)
## Usage
A short example code:
```python
from transformers import MarianMTModel, MarianTokenizer
src_text = [
"The Portuguese teacher is very demanding.",
"When was your last hearing test?"
]
model_name = "pytorch-models/opus-mt-tc-big-en-fr"
tokenizer = MarianTokenizer.from_pretrained(model_name)
model = MarianMTModel.from_pretrained(model_name)
translated = model.generate(**tokenizer(src_text, return_tensors="pt", padding=True))
for t in translated:
print( tokenizer.decode(t, skip_special_tokens=True) )
# expected output:
# Le professeur de portugais est très exigeant.
# Quand a eu lieu votre dernier test auditif ?
```
You can also use OPUS-MT models with the transformers pipelines, for example:
```python
from transformers import pipeline
pipe = pipeline("translation", model="Helsinki-NLP/opus-mt-tc-big-en-fr")
print(pipe("The Portuguese teacher is very demanding."))
# expected output: Le professeur de portugais est très exigeant.
```
## Benchmarks
* test set translations: [opusTCv20210807+bt_transformer-big_2022-03-09.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-fra/opusTCv20210807+bt_transformer-big_2022-03-09.test.txt)
* test set scores: [opusTCv20210807+bt_transformer-big_2022-03-09.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-fra/opusTCv20210807+bt_transformer-big_2022-03-09.eval.txt)
* benchmark results: [benchmark_results.txt](benchmark_results.txt)
* benchmark output: [benchmark_translations.zip](benchmark_translations.zip)
| langpair | testset | chr-F | BLEU | #sent | #words |
|----------|---------|-------|-------|-------|--------|
| eng-fra | tatoeba-test-v2021-08-07 | 0.69621 | 53.2 | 12681 | 106378 |
| eng-fra | flores101-devtest | 0.72494 | 52.2 | 1012 | 28343 |
| eng-fra | multi30k_test_2016_flickr | 0.72361 | 52.4 | 1000 | 13505 |
| eng-fra | multi30k_test_2017_flickr | 0.72826 | 52.8 | 1000 | 12118 |
| eng-fra | multi30k_test_2017_mscoco | 0.73547 | 54.7 | 461 | 5484 |
| eng-fra | multi30k_test_2018_flickr | 0.66723 | 43.7 | 1071 | 15867 |
| eng-fra | newsdiscussdev2015 | 0.60471 | 33.4 | 1500 | 27940 |
| eng-fra | newsdiscusstest2015 | 0.64915 | 40.3 | 1500 | 27975 |
| eng-fra | newssyscomb2009 | 0.58903 | 30.7 | 502 | 12331 |
| eng-fra | news-test2008 | 0.55516 | 27.6 | 2051 | 52685 |
| eng-fra | newstest2009 | 0.57907 | 30.0 | 2525 | 69263 |
| eng-fra | newstest2010 | 0.60156 | 33.5 | 2489 | 66022 |
| eng-fra | newstest2011 | 0.61632 | 35.0 | 3003 | 80626 |
| eng-fra | newstest2012 | 0.59736 | 32.8 | 3003 | 78011 |
| eng-fra | newstest2013 | 0.59700 | 34.6 | 3000 | 70037 |
| eng-fra | newstest2014 | 0.66686 | 41.9 | 3003 | 77306 |
| eng-fra | tico19-test | 0.63022 | 40.6 | 2100 | 64661 |
## Acknowledgements
The work is supported by the [European Language Grid](https://www.european-language-grid.eu/) as [pilot project 2866](https://live.european-language-grid.eu/catalogue/#/resource/projects/2866), by the [FoTran project](https://www.helsinki.fi/en/researchgroups/natural-language-understanding-with-cross-lingual-grounding), funded by the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (grant agreement No 771113), and the [MeMAD project](https://memad.eu/), funded by the European Union’s Horizon 2020 Research and Innovation Programme under grant agreement No 780069. We are also grateful for the generous computational resources and IT infrastructure provided by [CSC -- IT Center for Science](https://www.csc.fi/), Finland.
## Model conversion info
* transformers version: 4.16.2
* OPUS-MT git hash: 3405783
* port time: Wed Apr 13 17:07:05 EEST 2022
* port machine: LM0-400-22516.local
|
Qiaozhen/fake-news-detector
|
00a0a890197ddc3c67a5e3521d06558bd7cd8b2f
|
2021-12-01T01:26:57.000Z
|
[
"pytorch",
"distilbert",
"text-classification",
"transformers"
] |
text-classification
| false |
Qiaozhen
| null |
Qiaozhen/fake-news-detector
| 531 | null |
transformers
| 2,273 |
Entry not found
|
chriskhanhtran/spanberta
|
cf241bbd36ff5868eb9e0b603f6d6d4c52b6bc56
|
2021-05-20T15:20:16.000Z
|
[
"pytorch",
"jax",
"roberta",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
| false |
chriskhanhtran
| null |
chriskhanhtran/spanberta
| 530 | null |
transformers
| 2,274 |
Entry not found
|
Lowin/chinese-bigbird-base-4096
|
1914e13c124f37e28fa1b4960e7676e49f515564
|
2022-07-05T08:36:12.000Z
|
[
"pytorch",
"big_bird",
"fill-mask",
"zh",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] |
fill-mask
| false |
Lowin
| null |
Lowin/chinese-bigbird-base-4096
| 529 | 1 |
transformers
| 2,275 |
---
language:
- zh
license:
- apache-2.0
---
```python
import jieba_fast
from transformers import BertTokenizer
from transformers import BigBirdModel
class JiebaTokenizer(BertTokenizer):
def __init__(
self, pre_tokenizer=lambda x: jieba_fast.cut(x, HMM=False), *args, **kwargs
):
super().__init__(*args, **kwargs)
self.pre_tokenizer = pre_tokenizer
def _tokenize(self, text, *arg, **kwargs):
split_tokens = []
for word in self.pre_tokenizer(text):
if word in self.vocab:
split_tokens.append(word)
else:
split_tokens.extend(super()._tokenize(word))
return split_tokens
model = BigBirdModel.from_pretrained('Lowin/chinese-bigbird-base-4096')
tokenizer = JiebaTokenizer.from_pretrained('Lowin/chinese-bigbird-base-4096')
```
https://github.com/LowinLi/chinese-bigbird
|
tomh/toxigen_hatebert
|
c260d78a7867bb9a9748184afaf454d6ccf28129
|
2022-05-02T12:42:51.000Z
|
[
"pytorch",
"bert",
"text-classification",
"en",
"arxiv:2203.09509",
"transformers"
] |
text-classification
| false |
tomh
| null |
tomh/toxigen_hatebert
| 529 | null |
transformers
| 2,276 |
---
language:
- en
tags:
- text-classification
---
Thomas Hartvigsen, Saadia Gabriel, Hamid Palangi, Maarten Sap, Dipankar Ray, Ece Kamar.
This model comes from the paper [ToxiGen: A Large-Scale Machine-Generated Dataset for Adversarial and Implicit Hate Speech Detection](https://arxiv.org/abs/2203.09509) and can be used to detect implicit hate speech.
Please visit the [Github Repository](https://github.com/microsoft/TOXIGEN) for the training dataset and further details.
```bibtex
@inproceedings{hartvigsen2022toxigen,
title = "{T}oxi{G}en: A Large-Scale Machine-Generated Dataset for Adversarial and Implicit Hate Speech Detection",
author = "Hartvigsen, Thomas and Gabriel, Saadia and Palangi, Hamid and Sap, Maarten and Ray, Dipankar and Kamar, Ece",
booktitle = "Proceedings of the 60th Annual Meeting of the Association of Computational Linguistics",
year = "2022"
}
```
|
microsoft/swin-small-patch4-window7-224
|
1e8f54cc3d19ded9cda11db863080c79b1096289
|
2022-05-16T18:11:23.000Z
|
[
"pytorch",
"tf",
"swin",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2103.14030",
"transformers",
"vision",
"license:apache-2.0"
] |
image-classification
| false |
microsoft
| null |
microsoft/swin-small-patch4-window7-224
| 528 | null |
transformers
| 2,277 |
---
license: apache-2.0
tags:
- vision
- image-classification
datasets:
- imagenet-1k
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
---
# Swin Transformer (small-sized model)
Swin Transformer model trained on ImageNet-1k at resolution 224x224. It was introduced in the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Liu et al. and first released in [this repository](https://github.com/microsoft/Swin-Transformer).
Disclaimer: The team releasing Swin Transformer did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The Swin Transformer is a type of Vision Transformer. It builds hierarchical feature maps by merging image patches (shown in gray) in deeper layers and has linear computation complexity to input image size due to computation of self-attention only within each local window (shown in red). It can thus serve as a general-purpose backbone for both image classification and dense recognition tasks. In contrast, previous vision Transformers produce feature maps of a single low resolution and have quadratic computation complexity to input image size due to computation of self-attention globally.

[Source](https://paperswithcode.com/method/swin-transformer)
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=swin) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import AutoFeatureExtractor, SwinForImageClassification
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = AutoFeatureExtractor.from_pretrained("microsoft/swin-small-patch4-window7-224")
model = SwinForImageClassification.from_pretrained("microsoft/swin-small-patch4-window7-224")
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
For more code examples, we refer to the [documentation](https://huggingface.co/transformers/model_doc/swin.html#).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2103-14030,
author = {Ze Liu and
Yutong Lin and
Yue Cao and
Han Hu and
Yixuan Wei and
Zheng Zhang and
Stephen Lin and
Baining Guo},
title = {Swin Transformer: Hierarchical Vision Transformer using Shifted Windows},
journal = {CoRR},
volume = {abs/2103.14030},
year = {2021},
url = {https://arxiv.org/abs/2103.14030},
eprinttype = {arXiv},
eprint = {2103.14030},
timestamp = {Thu, 08 Apr 2021 07:53:26 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2103-14030.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
alger-ia/dziribert
|
f48769d3b3c07e40de8e1649bd1e3de4c4e15b2e
|
2021-09-28T13:13:56.000Z
|
[
"pytorch",
"tf",
"bert",
"fill-mask",
"ar",
"dz",
"arxiv:2109.12346",
"transformers",
"multilingual",
"license:apache-2.0",
"autotrain_compatible"
] |
fill-mask
| false |
alger-ia
| null |
alger-ia/dziribert
| 527 | 5 |
transformers
| 2,278 |
---
language:
- ar
- dz
tags:
- pytorch
- bert
- multilingual
- ar
- dz
license: apache-2.0
widget:
- text: " أنا من الجزائر من ولاية [MASK] "
- text: "rabi [MASK] khouya sami"
- text: " ربي [MASK] خويا لعزيز"
- text: "tahya el [MASK]."
- text: "rouhi ya dzayer [MASK]"
inference: true
---
<img src="https://raw.githubusercontent.com/alger-ia/dziribert/main/dziribert_drawing.png" alt="drawing" width="25%" height="25%" align="right"/>
# DziriBERT
DziriBERT is the first Transformer-based Language Model that has been pre-trained specifically for the Algerian Dialect. It handles Algerian text contents written using both Arabic and Latin characters. It sets new state of the art results on Algerian text classification datasets, even if it has been pre-trained on much less data (~1 million tweets).
For more information, please visit our paper: https://arxiv.org/pdf/2109.12346.pdf.
## How to use
```python
from transformers import BertTokenizer, BertForMaskedLM
tokenizer = BertTokenizer.from_pretrained("alger-ia/dziribert")
model = BertForMaskedLM.from_pretrained("alger-ia/dziribert")
```
You can find a fine-tuning script in our Github repo: https://github.com/alger-ia/dziribert
### How to cite
```bibtex
@article{dziribert,
title={DziriBERT: a Pre-trained Language Model for the Algerian Dialect},
author={Abdaoui, Amine and Berrimi, Mohamed and Oussalah, Mourad and Moussaoui, Abdelouahab},
journal={arXiv preprint arXiv:2109.12346},
year={2021}
}
```
## Contact
Please contact [email protected] for any question, feedback or request.
|
optimum/distilbert-base-uncased-finetuned-banking77
|
caf9d9f17154f487c6f968641ce0d2dc8f592165
|
2022-06-24T14:30:32.000Z
|
[
"pytorch",
"distilbert",
"text-classification",
"dataset:banking77",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] |
text-classification
| false |
optimum
| null |
optimum/distilbert-base-uncased-finetuned-banking77
| 527 | 1 |
transformers
| 2,279 |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- banking77
metrics:
- accuracy
- f1
widget:
- text: Could you assist me in finding my lost card?
example_title: Example 1
- text: I found my lost card. Am I still able to use it?
example_title: Example 2
- text: "Hey, I thought my topup was all done but now the money is gone again \u2013\
\ what\u2019s up with that?"
example_title: Example 3
- text: "Tell me why my topup wouldn\u2019t go through?"
example_title: Example 4
model-index:
- name: distilbert-base-uncased-finetuned-banking77
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: banking77
type: banking77
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.925
- name: F1
type: f1
value: 0.925018570680639
- task:
type: text-classification
name: Text Classification
dataset:
name: banking77
type: banking77
config: default
split: test
metrics:
- name: Accuracy
type: accuracy
value: 0.925
verified: true
- name: Precision Macro
type: precision
value: 0.9282769473964405
verified: true
- name: Precision Micro
type: precision
value: 0.925
verified: true
- name: Precision Weighted
type: precision
value: 0.9282769473964405
verified: true
- name: Recall Macro
type: recall
value: 0.9250000000000002
verified: true
- name: Recall Micro
type: recall
value: 0.925
verified: true
- name: Recall Weighted
type: recall
value: 0.925
verified: true
- name: F1 Macro
type: f1
value: 0.9250185706806391
verified: true
- name: F1 Micro
type: f1
value: 0.925
verified: true
- name: F1 Weighted
type: f1
value: 0.925018570680639
verified: true
- name: loss
type: loss
value: 0.2934279143810272
verified: true
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-banking77
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the banking77 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2935
- Accuracy: 0.925
- F1: 0.9250
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 9.686210354742596e-05
- train_batch_size: 64
- eval_batch_size: 32
- seed: 40
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| No log | 1.0 | 126 | 1.1457 | 0.7896 | 0.7685 |
| No log | 2.0 | 252 | 0.4673 | 0.8906 | 0.8889 |
| No log | 3.0 | 378 | 0.3488 | 0.9150 | 0.9151 |
| 0.9787 | 4.0 | 504 | 0.3238 | 0.9180 | 0.9179 |
| 0.9787 | 5.0 | 630 | 0.3126 | 0.9225 | 0.9226 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.11.0
- Datasets 2.0.0
- Tokenizers 0.11.6
|
neulab/gpt2-finetuned-wikitext103
|
f042c5d9d998c564e49cddb98ddec90148e5aa43
|
2022-07-14T15:38:21.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"arxiv:2201.12431",
"transformers"
] |
text-generation
| false |
neulab
| null |
neulab/gpt2-finetuned-wikitext103
| 527 | null |
transformers
| 2,280 |
This is a `gpt2` model, finetuned on the Wikitext-103 dataset.
It achieves a perplexity of **14.84** using a "sliding window" context, using the `run_clm.py` script at [https://github.com/neulab/knn-transformers](https://github.com/neulab/knn-transformers).
| Base LM: | `distilgpt2` | `gpt2` |
| :--- | ----: | ---: |
| base perplexity | 18.25 | 14.84 |
| +kNN-LM | 15.03 | 12.57 |
| +RetoMaton | **14.70** | **12.46** |
This model was released as part of the paper ["Neuro-Symbolic Language Modeling with Automaton-augmented Retrieval"](https://arxiv.org/pdf/2201.12431.pdf) (ICML'2022).
For more information, see: [https://github.com/neulab/knn-transformers](https://github.com/neulab/knn-transformers)
If you use this model, please cite:
```
@inproceedings{alon2022neuro,
title={Neuro-Symbolic Language Modeling with Automaton-augmented Retrieval},
author={Alon, Uri and Xu, Frank and He, Junxian and Sengupta, Sudipta and Roth, Dan and Neubig, Graham},
booktitle={International Conference on Machine Learning},
pages={468--485},
year={2022},
organization={PMLR}
}
```
|
stefan-it/german-gpt2-larger
|
aa2138bb716507181c1bbd288a1076837ed0ca3b
|
2021-09-17T09:48:43.000Z
|
[
"pytorch",
"jax",
"gpt2",
"text-generation",
"de",
"transformers",
"license:mit"
] |
text-generation
| false |
stefan-it
| null |
stefan-it/german-gpt2-larger
| 526 | 2 |
transformers
| 2,281 |
---
language: de
widget:
- text: "Heute ist sehr schönes Wetter in"
license: mit
---
# German GPT-2 model
In this repository we release (yet another) GPT-2 model, that was trained on ~90 GB from the ["German colossal, clean Common Crawl corpus"](https://german-nlp-group.github.io/projects/gc4-corpus.html) (GC4).
The model is meant to be an entry point for fine-tuning on other texts, and it is definitely not as good or "dangerous" as the English GPT-3 model. We do not plan extensive PR or staged releases for this model 😉
---
**Disclaimer**: the presented and trained language models in this repository are for **research only** purposes.
The GC4 corpus - that was used for training - contains crawled texts from the internet. Thus, this GPT-2 model can
be considered as highly biased, resulting in a model that encodes stereotypical associations along gender, race,
ethnicity and disability status. Before using and working with the released checkpoints, it is highly recommended
to read:
[On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?](https://faculty.washington.edu/ebender/papers/Stochastic_Parrots.pdf)
from Emily M. Bender, Timnit Gebru, Angelina McMillan-Major and Shmargaret Shmitchell.
The aim of this released GPT-2 model for German is to boost research on (large) pre-trained language models for German, especially
for identifying biases and how to prevent them, as most research is currently done for English only.
---
# Changelog
* 17.10.2021: We highly recommend to try the Text Generation Pipeline in Transformers. The quality of the generated text from the Inference Widget here can be lower.
* 06.09.2021: Initial release. Detailed information about training parameters coming soon.
# Text Generation
The following code snippet can be used to generate text with this German GPT-2 model:
```python
from transformers import pipeline
model_name = "stefan-it/german-gpt2-larger"
pipe = pipeline('text-generation', model=model_name, tokenizer=model_name)
text = pipe("Der Sinn des Lebens ist es", max_length=200)[0]["generated_text"]
print(text)
```
# Training Data
The following archives are used for training the (first version) of this GPT-2 model:
* `de_head_0000_2015-48.tar.gz`
* `de_head_0000_2016-18.tar.gz`
* `de_head_0000_2016-44.tar.gz`
* `de_head_0000_2017-13.tar.gz`
* `de_head_0000_2017-30.tar.gz`
* `de_head_0000_2017-39.tar.gz`
* `de_head_0000_2017-51.tar.gz`
* `de_head_0000_2018-09.tar.gz`
* `de_head_0000_2018-17.tar.gz`
* `de_head_0000_2018-30.tar.gz`
* `de_head_0000_2018-39.tar.gz`
* `de_head_0000_2018-51.tar.gz`
* `de_head_0000_2019-18.tar.gz`
* `de_head_0000_2019-30.tar.gz`
* `de_head_0006_2019-09.tar.gz`
* `de_head_0006_2019-18.tar.gz`
* `de_head_0006_2019-30.tar.gz`
* `de_head_0006_2019-47.tar.gz`
* `de_head_0006_2020-10.tar.gz`
* `de_head_0007_2018-30.tar.gz`
* `de_head_0007_2018-51.tar.gz`
* `de_head_0007_2019-09.tar.gz`
* `de_head_0007_2019-18.tar.gz`
* `de_head_0007_2019-47.tar.gz`
* `de_head_0007_2020-10.tar.gz`
Details and URLs can be found on the [GC4](https://german-nlp-group.github.io/projects/gc4-corpus.html)
page.
Archives are then extracted and NLTK (`german` model) is used to sentence split the corpus.
This results in a total training corpus size of 90GB.
# Training Details
We use the recently re-trained `dbmdz/german-gpt2` ([version 2](https://huggingface.co/dbmdz/german-gpt2)!)
model as back-bone model. Thus, the tokenizer and vocab is the same as used in the `dbmdz/german-gpt2` model.
The model was trained on a v3-8 TPU, with the following parameters:
```bash
python ./run_clm_flax.py --output_dir=/mnt/datasets/german-gpt2-larger/ --name_or_path dbmdz/german-gpt2 --do_train --do_eval --block_size=512 --per_device_train_batch_size=16 --per_device_eval_batch_size=16 --learning_rate=5e-3 --warmup_steps=1000 --adam_beta1=0.9 --adam_beta2=0.98 --weight_decay=0.01 --overwrite_output_dir --num_train_epochs=20 --logging_steps=500 --save_steps=2500 --eval_steps=2500 --train_file /mnt/datasets/gc4/train.txt --validation_file /mnt/datasets/gc4/validation.txt --preprocessing_num_workers 16
```
Training took around 17 days for 20 epochs.
# Acknowledgments
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
Thanks for providing access to the TFRC ❤️
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
it is possible to download this model from their S3 storage 🤗
This project heavily profited from the amazing Hugging Face
[Community Week](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104).
Many thanks for the great organization and discussions during and after the week!
|
hustvl/yolos-base
|
54e810c3e4165d3e2cdc5888fd8da2b30172a596
|
2022-06-27T08:37:10.000Z
|
[
"pytorch",
"yolos",
"object-detection",
"dataset:coco",
"arxiv:2106.00666",
"transformers",
"vision",
"license:apache-2.0"
] |
object-detection
| false |
hustvl
| null |
hustvl/yolos-base
| 526 | 1 |
transformers
| 2,282 |
---
license: apache-2.0
tags:
- object-detection
- vision
datasets:
- coco
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/savanna.jpg
example_title: Savanna
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/football-match.jpg
example_title: Football Match
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/airport.jpg
example_title: Airport
---
# YOLOS (base-sized) model
YOLOS model fine-tuned on COCO 2017 object detection (118k annotated images). It was introduced in the paper [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://arxiv.org/abs/2106.00666) by Fang et al. and first released in [this repository](https://github.com/hustvl/YOLOS).
Disclaimer: The team releasing YOLOS did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
YOLOS is a Vision Transformer (ViT) trained using the DETR loss. Despite its simplicity, a base-sized YOLOS model is able to achieve 42 AP on COCO validation 2017 (similar to DETR and more complex frameworks such as Faster R-CNN).
The model is trained using a "bipartite matching loss": one compares the predicted classes + bounding boxes of each of the N = 100 object queries to the ground truth annotations, padded up to the same length N (so if an image only contains 4 objects, 96 annotations will just have a "no object" as class and "no bounding box" as bounding box). The Hungarian matching algorithm is used to create an optimal one-to-one mapping between each of the N queries and each of the N annotations. Next, standard cross-entropy (for the classes) and a linear combination of the L1 and generalized IoU loss (for the bounding boxes) are used to optimize the parameters of the model.
## Intended uses & limitations
You can use the raw model for object detection. See the [model hub](https://huggingface.co/models?search=hustvl/yolos) to look for all available YOLOS models.
### How to use
Here is how to use this model:
```python
from transformers import YolosFeatureExtractor, YolosForObjectDetection
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = YolosFeatureExtractor.from_pretrained('hustvl/yolos-base')
model = YolosForObjectDetection.from_pretrained('hustvl/yolos-base')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
# model predicts bounding boxes and corresponding COCO classes
logits = outputs.logits
bboxes = outputs.pred_boxes
```
Currently, both the feature extractor and model support PyTorch.
## Training data
The YOLOS model was pre-trained on [ImageNet-1k](https://huggingface.co/datasets/imagenet2012) and fine-tuned on [COCO 2017 object detection](https://cocodataset.org/#download), a dataset consisting of 118k/5k annotated images for training/validation respectively.
### Training
The model was pre-trained for 1000 epochs on ImageNet-1k and fine-tuned for 150 epochs on COCO.
## Evaluation results
This model achieves an AP (average precision) of **42.0** on COCO 2017 validation. For more details regarding evaluation results, we refer to the original paper.
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2106-00666,
author = {Yuxin Fang and
Bencheng Liao and
Xinggang Wang and
Jiemin Fang and
Jiyang Qi and
Rui Wu and
Jianwei Niu and
Wenyu Liu},
title = {You Only Look at One Sequence: Rethinking Transformer in Vision through
Object Detection},
journal = {CoRR},
volume = {abs/2106.00666},
year = {2021},
url = {https://arxiv.org/abs/2106.00666},
eprinttype = {arXiv},
eprint = {2106.00666},
timestamp = {Fri, 29 Apr 2022 19:49:16 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2106-00666.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
rajistics/finetuned-indian-food
|
d956b7c21cca5874ba917c62a873bad8608b83c6
|
2022-07-18T20:13:53.000Z
|
[
"pytorch",
"tensorboard",
"vit",
"image-classification",
"dataset:imagefolder",
"dataset:rajistics/indian_food_images",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] |
image-classification
| false |
rajistics
| null |
rajistics/finetuned-indian-food
| 526 | null |
transformers
| 2,283 |
---
license: apache-2.0
tags:
- image-classification
- generated_from_trainer
datasets:
- imagefolder
- rajistics/indian_food_images
metrics:
- accuracy
widget:
- src: https://huggingface.co/rajistics/finetuned-indian-food/resolve/main/003.jpg
example_title: Fried Rice
- src: https://huggingface.co/rajistics/finetuned-indian-food/resolve/main/126.jpg
example_title: Paani Puri
- src: https://huggingface.co/rajistics/finetuned-indian-food/resolve/main/401.jpg
example_title: Chapathi
model-index:
- name: finetuned-indian-food
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: indian_food_images
type: imagefolder
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.9521785334750266
- task:
type: image-classification
name: Image Classification
dataset:
name: rajistics/indian_food_images
type: rajistics/indian_food_images
config: rajistics--indian_food_images
split: test
metrics:
- name: Accuracy
type: accuracy
value: 0.8257173219978746
verified: true
- name: Precision Macro
type: precision
value: 0.8391547623590003
verified: true
- name: Precision Micro
type: precision
value: 0.8257173219978746
verified: true
- name: Precision Weighted
type: precision
value: 0.8437849242516663
verified: true
- name: Recall Macro
type: recall
value: 0.8199909093335551
verified: true
- name: Recall Micro
type: recall
value: 0.8257173219978746
verified: true
- name: Recall Weighted
type: recall
value: 0.8257173219978746
verified: true
- name: F1 Macro
type: f1
value: 0.8207881196755944
verified: true
- name: F1 Micro
type: f1
value: 0.8257173219978746
verified: true
- name: F1 Weighted
type: f1
value: 0.8256340007731109
verified: true
- name: loss
type: loss
value: 0.6241679787635803
verified: true
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned-indian-food
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the indian_food_images dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2139
- Accuracy: 0.9522
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.0846 | 0.3 | 100 | 0.9561 | 0.8555 |
| 0.7894 | 0.6 | 200 | 0.5871 | 0.8927 |
| 0.6233 | 0.9 | 300 | 0.4447 | 0.9107 |
| 0.3619 | 1.2 | 400 | 0.4355 | 0.8937 |
| 0.34 | 1.5 | 500 | 0.3712 | 0.9118 |
| 0.3413 | 1.8 | 600 | 0.4088 | 0.8916 |
| 0.3619 | 2.1 | 700 | 0.3741 | 0.9044 |
| 0.2135 | 2.4 | 800 | 0.3286 | 0.9160 |
| 0.2166 | 2.7 | 900 | 0.2758 | 0.9416 |
| 0.1557 | 3.0 | 1000 | 0.2679 | 0.9330 |
| 0.1115 | 3.3 | 1100 | 0.2529 | 0.9362 |
| 0.1571 | 3.6 | 1200 | 0.2360 | 0.9469 |
| 0.1079 | 3.9 | 1300 | 0.2139 | 0.9522 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
dbernsohn/t5_wikisql_en2SQL
|
13a3815a27a5731652f580b941d271f105f2bbda
|
2021-01-18T14:24:37.000Z
|
[
"pytorch",
"t5",
"text2text-generation",
"en",
"dataset:wikisql",
"transformers",
"autotrain_compatible"
] |
text2text-generation
| false |
dbernsohn
| null |
dbernsohn/t5_wikisql_en2SQL
| 525 | 2 |
transformers
| 2,284 |
# t5_wikisql_en2SQL
---
language: en
datasets:
- wikisql
---
This is a [t5-small](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) fine-tuned version on the [wikisql dataset](https://huggingface.co/datasets/wikisql) for **English** to **SQL** **translation** text2text mission.
To load the model:
(necessary packages: !pip install transformers sentencepiece)
```python
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("dbernsohn/t5_wikisql_en2SQL")
model = AutoModelWithLMHead.from_pretrained("dbernsohn/t5_wikisql_en2SQL")
```
You can then use this model to translate SQL queries into plain english.
```python
query = "what are the names of all the people in the USA?"
input_text = f"translate English to Sql: {query} </s>"
features = tokenizer([input_text], return_tensors='pt')
output = model.generate(input_ids=features['input_ids'].cuda(),
attention_mask=features['attention_mask'].cuda())
tokenizer.decode(output[0])
# Output: "SELECT Name FROM table WHERE Country = USA"
```
The whole training process and hyperparameters are in my [GitHub repo](https://github.com/DorBernsohn/CodeLM/tree/main/SQLM)
> Created by [Dor Bernsohn](https://www.linkedin.com/in/dor-bernsohn-70b2b1146/)
|
deutsche-telekom/electra-base-de-squad2
|
0ed9cec3da1d1b2b4e85a49ada4be6823effe0c0
|
2021-07-14T13:16:54.000Z
|
[
"pytorch",
"electra",
"question-answering",
"de",
"transformers",
"german",
"license:mit",
"autotrain_compatible"
] |
question-answering
| false |
deutsche-telekom
| null |
deutsche-telekom/electra-base-de-squad2
| 525 | 4 |
transformers
| 2,285 |
---
language: de
license: mit
tags:
- german
---
We released the German Question Answering model fine-tuned with our own German Question Answering dataset (**deQuAD**) containing **130k** training and **11k** test QA pairs.
## Overview
- **Language model:** [electra-base-german-uncased](https://huggingface.co/german-nlp-group/electra-base-german-uncased)
- **Language:** German
- **Training data:** deQuAD2.0 training set (~42MB)
- **Evaluation data:** deQuAD2.0 test set (~4MB)
- **Infrastructure:** 8xV100 GPU
## Evaluation
We benchmarked the question answering performance on our deQuAD test data with some German language models. The fine-tuned electra-base-german-uncased model gives the best performance (Exact Match/F1).
| Model | All | HasAns | NoAns |
|-------|--------|--------|--------|
| electra-base-german-uncased | 70.97/76.18 | 67.73/78.02 | 74.29/74.29 |
| bert-base-german-cased |58.98/64.77| 49.19/60.63| 69.03/69.03|
|bert-base-german-dbmdz-uncased|63.70/68.00| 57.03/65.52| 70.51/70.51 |
|dbmdz/bert-base-german-europeana-uncased| 58.79/63.38| 52.14/61.22| 65.59/65.59|
## Use Model in Pipeline
```python
from transformers import pipeline
qa_pipeline = pipeline(
"question-answering",
model="deutsche-telekom/electra-base-de-squad2",
tokenizer="deutsche-telekom/electra-base-de-squad2"
)
contexts = ['''Die Robert Bosch GmbH ist ein im Jahr 1886 von Robert Bosch gegründetes multinationales deutsches Unternehmen.
Es ist tätig als Automobilzulieferer, Hersteller von Gebrauchsgütern und Industrie- und Gebäudetechnik und darüber hinaus
in der automatisierten Verpackungstechnik, wo Bosch den führenden Platz einnimmt. Die Robert Bosch GmbH und ihre rund 460
Tochter- und Regionalgesellschaften in mehr als 60 Ländern bilden die Bosch-Gruppe. Der Sitz der Geschäftsführung befindet
sich auf der Schillerhöhe in Gerlingen, der Firmensitz in Stuttgart. Seit dem 1. Juli 2012 ist Volkmar Denner Vorsitzender
der Geschäftsführung. Im Jahr 2015 konnte Bosch die Spitzenposition zurückgewinnen. Die Automobilsparte war im Jahr 2018
für 61 % des Konzernumsatzes von Bosch verantwortlich. Das Unternehmen hatte im Jahr 2018 in Deutschland an 85 Standorten
139.400 Mitarbeiter.''']*2
questions = ["Wer leitet die Robert Bosch GmbH?",
"Wer begründete die Robert Bosch GmbH?"]
qa_pipeline(context=contexts, question=questions)
```
## Output
```json
[{'score': 0.9537325501441956,
'start': 577,
'end': 591,
'answer': 'Volkmar Denner'},
{'score': 0.8804352879524231,
'start': 47,
'end': 59,
'answer': 'Robert Bosch'}]
```
## License - The MIT License
Copyright (c) 2021 Fang Xu, Deutsche Telekom AG
|
google/bert_uncased_L-8_H-256_A-4
|
fff21c203abcc9365418f2e46bb6801a2b98e3da
|
2021-05-19T17:35:25.000Z
|
[
"pytorch",
"jax",
"bert",
"arxiv:1908.08962",
"transformers",
"license:apache-2.0"
] | null | false |
google
| null |
google/bert_uncased_L-8_H-256_A-4
| 524 | null |
transformers
| 2,286 |
---
thumbnail: https://huggingface.co/front/thumbnails/google.png
license: apache-2.0
---
BERT Miniatures
===
This is the set of 24 BERT models referenced in [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962) (English only, uncased, trained with WordPiece masking).
We have shown that the standard BERT recipe (including model architecture and training objective) is effective on a wide range of model sizes, beyond BERT-Base and BERT-Large. The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
Our goal is to enable research in institutions with fewer computational resources and encourage the community to seek directions of innovation alternative to increasing model capacity.
You can download the 24 BERT miniatures either from the [official BERT Github page](https://github.com/google-research/bert/), or via HuggingFace from the links below:
| |H=128|H=256|H=512|H=768|
|---|:---:|:---:|:---:|:---:|
| **L=2** |[**2/128 (BERT-Tiny)**][2_128]|[2/256][2_256]|[2/512][2_512]|[2/768][2_768]|
| **L=4** |[4/128][4_128]|[**4/256 (BERT-Mini)**][4_256]|[**4/512 (BERT-Small)**][4_512]|[4/768][4_768]|
| **L=6** |[6/128][6_128]|[6/256][6_256]|[6/512][6_512]|[6/768][6_768]|
| **L=8** |[8/128][8_128]|[8/256][8_256]|[**8/512 (BERT-Medium)**][8_512]|[8/768][8_768]|
| **L=10** |[10/128][10_128]|[10/256][10_256]|[10/512][10_512]|[10/768][10_768]|
| **L=12** |[12/128][12_128]|[12/256][12_256]|[12/512][12_512]|[**12/768 (BERT-Base)**][12_768]|
Note that the BERT-Base model in this release is included for completeness only; it was re-trained under the same regime as the original model.
Here are the corresponding GLUE scores on the test set:
|Model|Score|CoLA|SST-2|MRPC|STS-B|QQP|MNLI-m|MNLI-mm|QNLI(v2)|RTE|WNLI|AX|
|---|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|BERT-Tiny|64.2|0.0|83.2|81.1/71.1|74.3/73.6|62.2/83.4|70.2|70.3|81.5|57.2|62.3|21.0|
|BERT-Mini|65.8|0.0|85.9|81.1/71.8|75.4/73.3|66.4/86.2|74.8|74.3|84.1|57.9|62.3|26.1|
|BERT-Small|71.2|27.8|89.7|83.4/76.2|78.8/77.0|68.1/87.0|77.6|77.0|86.4|61.8|62.3|28.6|
|BERT-Medium|73.5|38.0|89.6|86.6/81.6|80.4/78.4|69.6/87.9|80.0|79.1|87.7|62.2|62.3|30.5|
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained for 4 epochs:
- batch sizes: 8, 16, 32, 64, 128
- learning rates: 3e-4, 1e-4, 5e-5, 3e-5
If you use these models, please cite the following paper:
```
@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}
```
[2_128]: https://huggingface.co/google/bert_uncased_L-2_H-128_A-2
[2_256]: https://huggingface.co/google/bert_uncased_L-2_H-256_A-4
[2_512]: https://huggingface.co/google/bert_uncased_L-2_H-512_A-8
[2_768]: https://huggingface.co/google/bert_uncased_L-2_H-768_A-12
[4_128]: https://huggingface.co/google/bert_uncased_L-4_H-128_A-2
[4_256]: https://huggingface.co/google/bert_uncased_L-4_H-256_A-4
[4_512]: https://huggingface.co/google/bert_uncased_L-4_H-512_A-8
[4_768]: https://huggingface.co/google/bert_uncased_L-4_H-768_A-12
[6_128]: https://huggingface.co/google/bert_uncased_L-6_H-128_A-2
[6_256]: https://huggingface.co/google/bert_uncased_L-6_H-256_A-4
[6_512]: https://huggingface.co/google/bert_uncased_L-6_H-512_A-8
[6_768]: https://huggingface.co/google/bert_uncased_L-6_H-768_A-12
[8_128]: https://huggingface.co/google/bert_uncased_L-8_H-128_A-2
[8_256]: https://huggingface.co/google/bert_uncased_L-8_H-256_A-4
[8_512]: https://huggingface.co/google/bert_uncased_L-8_H-512_A-8
[8_768]: https://huggingface.co/google/bert_uncased_L-8_H-768_A-12
[10_128]: https://huggingface.co/google/bert_uncased_L-10_H-128_A-2
[10_256]: https://huggingface.co/google/bert_uncased_L-10_H-256_A-4
[10_512]: https://huggingface.co/google/bert_uncased_L-10_H-512_A-8
[10_768]: https://huggingface.co/google/bert_uncased_L-10_H-768_A-12
[12_128]: https://huggingface.co/google/bert_uncased_L-12_H-128_A-2
[12_256]: https://huggingface.co/google/bert_uncased_L-12_H-256_A-4
[12_512]: https://huggingface.co/google/bert_uncased_L-12_H-512_A-8
[12_768]: https://huggingface.co/google/bert_uncased_L-12_H-768_A-12
|
mismayil/comet-bart-ai2
|
c920ae53bb7ad34d63eb48eb818e9274bef3ea7a
|
2022-05-23T08:20:08.000Z
|
[
"pytorch",
"bart",
"text2text-generation",
"transformers",
"license:afl-3.0",
"autotrain_compatible"
] |
text2text-generation
| false |
mismayil
| null |
mismayil/comet-bart-ai2
| 524 | null |
transformers
| 2,287 |
---
license: afl-3.0
---
This model has been trained by the original authors of the paper [(Comet-) Atomic 2020: On Symbolic and Neural Commonsense Knowledge Graphs.](https://www.semanticscholar.org/paper/COMET-ATOMIC-2020%3A-On-Symbolic-and-Neural-Knowledge-Hwang-Bhagavatula/e39503e01ebb108c6773948a24ca798cd444eb62) and has been released [here](https://storage.googleapis.com/ai2-mosaic-public/projects/mosaic-kgs/comet-atomic_2020_BART.zip). Original codebase for training is [here](https://github.com/allenai/comet-atomic-2020)
|
Helsinki-NLP/opus-mt-es-de
|
74a9fd1e4c6ada26cf15d4580414dc933b463ee2
|
2021-09-09T21:41:53.000Z
|
[
"pytorch",
"marian",
"text2text-generation",
"es",
"de",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] |
translation
| false |
Helsinki-NLP
| null |
Helsinki-NLP/opus-mt-es-de
| 523 | null |
transformers
| 2,288 |
---
tags:
- translation
license: apache-2.0
---
### opus-mt-es-de
* source languages: es
* target languages: de
* OPUS readme: [es-de](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/es-de/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-16.zip](https://object.pouta.csc.fi/OPUS-MT-models/es-de/opus-2020-01-16.zip)
* test set translations: [opus-2020-01-16.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/es-de/opus-2020-01-16.test.txt)
* test set scores: [opus-2020-01-16.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/es-de/opus-2020-01-16.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba.es.de | 50.0 | 0.683 |
|
IlyaGusev/rubertconv_toxic_clf
|
39c070add685fee30cedc3a909a8a9f206d2b53d
|
2022-07-13T15:34:11.000Z
|
[
"pytorch",
"bert",
"text-classification",
"ru",
"transformers",
"license:apache-2.0"
] |
text-classification
| false |
IlyaGusev
| null |
IlyaGusev/rubertconv_toxic_clf
| 523 | null |
transformers
| 2,289 |
---
language:
- ru
tags:
- text-classification
license: apache-2.0
---
# RuBERTConv Toxic Classifier
## Model description
Based on [rubert-base-cased-conversational](https://huggingface.co/DeepPavlov/rubert-base-cased-conversational) model
## Intended uses & limitations
#### How to use
Colab: [link](https://colab.research.google.com/drive/1veKO9hke7myxKigZtZho_F-UM2fD9kp8)
```python
from transformers import pipeline
model_name = "IlyaGusev/rubertconv_toxic_clf"
pipe = pipeline("text-classification", model=model_name, tokenizer=model_name, framework="pt")
text = "Ты придурок из интернета"
pipe([text])
```
## Training data
Datasets:
- [2ch]( https://www.kaggle.com/blackmoon/russian-language-toxic-comments)
- [Odnoklassniki](https://www.kaggle.com/alexandersemiletov/toxic-russian-comments)
- [Toloka Persona Chat Rus](https://toloka.ai/ru/datasets)
- [Koziev's Conversations](https://github.com/Koziev/NLP_Datasets/blob/master/Conversations/Data) with [toxic words vocabulary](https://www.dropbox.com/s/ou6lx03b10yhrfl/bad_vocab.txt.tar.gz)
Augmentations:
- ё -> е
- Remove or add "?" or "!"
- Fix CAPS
- Concatenate toxic and non-toxic texts
- Concatenate two non-toxic texts
- Add toxic words from vocabulary
- Add typos
- Mask toxic words with "*", "@", "$"
## Training procedure
TBA
|
bigscience/T0p
|
99436b357ac572810426fe2ecc9ddb449b48bd5e
|
2022-06-21T01:23:09.000Z
|
[
"pytorch",
"t5",
"text2text-generation",
"en",
"dataset:bigscience/P3",
"arxiv:2110.08207",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] |
text2text-generation
| false |
bigscience
| null |
bigscience/T0p
| 523 | 3 |
transformers
| 2,290 |
---
datasets:
- bigscience/P3
language: en
license: apache-2.0
widget:
- text: "A is the son's of B's uncle. What is the family relationship between A and B?"
- text: "Reorder the words in this sentence: justin and name bieber years is my am I 27 old."
- text: "Task: copy but say the opposite.\n
PSG won its match against Barca."
- text: "Is this review positive or negative? Review: Best cast iron skillet you will every buy."
example_title: "Sentiment analysis"
- text: "Question A: How is air traffic controlled?
\nQuestion B: How do you become an air traffic controller?\nPick one: these questions are duplicates or not duplicates."
- text: "Barack Obama nominated Hilary Clinton as his secretary of state on Monday. He chose her because she had foreign affairs experience as a former First Lady.
\nIn the previous sentence, decide who 'her' is referring to."
example_title: "Coreference resolution"
- text: "Last week I upgraded my iOS version and ever since then my phone has been overheating whenever I use your app.\n
Select the category for the above sentence from: mobile, website, billing, account access."
- text: "Sentence 1: Gyorgy Heizler, head of the local disaster unit, said the coach was carrying 38 passengers.\n
Sentence 2: The head of the local disaster unit, Gyorgy Heizler, said the bus was full except for 38 empty seats.\n\n
Do sentences 1 and 2 have the same meaning?"
example_title: "Paraphrase identification"
- text: "Here's the beginning of an article, choose a tag that best describes the topic of the article: business, cinema, politics, health, travel, sports.\n\n
The best and worst fo 007 as 'No time to die' marks Daniel Craig's exit.\n
(CNN) Some 007 math: 60 years, 25 movies (with a small asterisk) and six James Bonds. For a Cold War creation, Ian Fleming's suave spy has certainly gotten around, but despite different guises in the tuxedo and occasional scuba gear, when it comes to Bond ratings, there really shouldn't be much argument about who wore it best."
- text: "Max: Know any good websites to buy clothes from?\n
Payton: Sure :) LINK 1, LINK 2, LINK 3\n
Max: That's a lot of them!\n
Payton: Yeah, but they have different things so I usually buy things from 2 or 3 of them.\n
Max: I'll check them out. Thanks.\n\n
Who or what are Payton and Max referring to when they say 'them'?"
- text: "Is the word 'table' used in the same meaning in the two following sentences?\n\n
Sentence A: you can leave the books on the table over there.\n
Sentence B: the tables in this book are very hard to read."
- text: "On a shelf, there are five books: a gray book, a red book, a purple book, a blue book, and a black book.\n
The red book is to the right of the gray book. The black book is to the left of the blue book. The blue book is to the left of the gray book. The purple book is the second from the right.\n\n
Which book is the leftmost book?"
example_title: "Logic puzzles"
- text: "The two men running to become New York City's next mayor will face off in their first debate Wednesday night.\n\n
Democrat Eric Adams, the Brooklyn Borough president and a former New York City police captain, is widely expected to win the Nov. 2 election against Republican Curtis Sliwa, the founder of the 1970s-era Guardian Angels anti-crime patril.\n\n
Who are the men running for mayor?"
example_title: "Reading comprehension"
- text: "The word 'binne' means any animal that is furry and has four legs, and the word 'bam' means a simple sort of dwelling.\n\n
Which of the following best characterizes binne bams?\n
- Sentence 1: Binne bams are for pets.\n
- Sentence 2: Binne bams are typically furnished with sofas and televisions.\n
- Sentence 3: Binne bams are luxurious apartments.\n
- Sentence 4: Binne bams are places where people live."
---
**How do I pronounce the name of the model?** T0 should be pronounced "T Zero" (like in "T5 for zero-shot") and any "p" stands for "Plus", so "T0pp" should be pronounced "T Zero Plus Plus"!
**Official repository**: [bigscience-workshop/t-zero](https://github.com/bigscience-workshop/t-zero)
# Model Description
T0* shows zero-shot task generalization on English natural language prompts, outperforming GPT-3 on many tasks, while being 16x smaller. It is a series of encoder-decoder models trained on a large set of different tasks specified in natural language prompts. We convert numerous English supervised datasets into prompts, each with multiple templates using varying formulations. These prompted datasets allow for benchmarking the ability of a model to perform completely unseen tasks specified in natural language. To obtain T0*, we fine-tune a pretrained language model on this multitask mixture covering many different NLP tasks.
# Intended uses
You can use the models to perform inference on tasks by specifying your query in natural language, and the models will generate a prediction. For instance, you can ask *"Is this review positive or negative? Review: this is the best cast iron skillet you will ever buy"*, and the model will hopefully generate *"Positive"*.
A few other examples that you can try:
- *A is the son's of B's uncle. What is the family relationship between A and B?*
- *Question A: How is air traffic controlled?<br>
Question B: How do you become an air traffic controller?<br>
Pick one: these questions are duplicates or not duplicates.*
- *Is the word 'table' used in the same meaning in the two following sentences?<br><br>
Sentence A: you can leave the books on the table over there.<br>
Sentence B: the tables in this book are very hard to read.*
- *Max: Know any good websites to buy clothes from?<br>
Payton: Sure :) LINK 1, LINK 2, LINK 3<br>
Max: That's a lot of them!<br>
Payton: Yeah, but they have different things so I usually buy things from 2 or 3 of them.<br>
Max: I'll check them out. Thanks.<br><br>
Who or what are Payton and Max referring to when they say 'them'?*
- *On a shelf, there are five books: a gray book, a red book, a purple book, a blue book, and a black book.<br>
The red book is to the right of the gray book. The black book is to the left of the blue book. The blue book is to the left of the gray book. The purple book is the second from the right.<br><br>
Which book is the leftmost book?*
- *Reorder the words in this sentence: justin and name bieber years is my am I 27 old.*
# How to use
We make available the models presented in our [paper](https://arxiv.org/abs/2110.08207) along with the ablation models. We recommend using the [T0pp](https://huggingface.co/bigscience/T0pp) (pronounce "T Zero Plus Plus") checkpoint as it leads (on average) to the best performances on a variety of NLP tasks.
|Model|Number of parameters|
|-|-|
|[T0](https://huggingface.co/bigscience/T0)|11 billion|
|[T0p](https://huggingface.co/bigscience/T0p)|11 billion|
|[T0pp](https://huggingface.co/bigscience/T0pp)|11 billion|
|[T0_single_prompt](https://huggingface.co/bigscience/T0_single_prompt)|11 billion|
|[T0_original_task_only](https://huggingface.co/bigscience/T0_original_task_only)|11 billion|
|[T0_3B](https://huggingface.co/bigscience/T0_3B)|3 billion|
Here is how to use the model in PyTorch:
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("bigscience/T0pp")
model = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0pp")
inputs = tokenizer.encode("Is this review positive or negative? Review: this is the best cast iron skillet you will ever buy", return_tensors="pt")
outputs = model.generate(inputs)
print(tokenizer.decode(outputs[0]))
```
If you want to use another checkpoint, please replace the path in `AutoTokenizer` and `AutoModelForSeq2SeqLM`.
**Note: the model was trained with bf16 activations. As such, we highly discourage running inference with fp16. fp32 or bf16 should be preferred.**
# Training procedure
T0* models are based on [T5](https://huggingface.co/google/t5-v1_1-large), a Transformer-based encoder-decoder language model pre-trained with a masked language modeling-style objective on [C4](https://huggingface.co/datasets/c4). We use the publicly available [language model-adapted T5 checkpoints](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#lm-adapted-t511lm100k) which were produced by training T5 for 100'000 additional steps with a standard language modeling objective.
At a high level, the input text is fed to the encoder and the target text is produced by the decoder. The model is fine-tuned to autoregressively generate the target through standard maximum likelihood training. It is never trained to generate the input. We detail our training data in the next section.
Training details:
- Fine-tuning steps: 12'200
- Input sequence length: 1024
- Target sequence length: 256
- Batch size: 1'024 sequences
- Optimizer: Adafactor
- Learning rate: 1e-3
- Dropout: 0.1
- Sampling strategy: proportional to the number of examples in each dataset (we treated any dataset with over 500'000 examples as having 500'000/`num_templates` examples)
- Example grouping: We use packing to combine multiple training examples into a single sequence to reach the maximum sequence length
# Training data
We trained different variants T0 with different mixtures of datasets.
|Model|Training datasets|
|--|--|
|T0|- Multiple-Choice QA: CommonsenseQA, DREAM, QUAIL, QuaRTz, Social IQA, WiQA, Cosmos, QASC, Quarel, SciQ, Wiki Hop<br>- Extractive QA: Adversarial QA, Quoref, DuoRC, ROPES<br>- Closed-Book QA: Hotpot QA*, Wiki QA<br>- Structure-To-Text: Common Gen, Wiki Bio<br>- Sentiment: Amazon, App Reviews, IMDB, Rotten Tomatoes, Yelp<br>- Summarization: CNN Daily Mail, Gigaword, MultiNews, SamSum, XSum<br>- Topic Classification: AG News, DBPedia, TREC<br>- Paraphrase Identification: MRPC, PAWS, QQP|
|T0p|Same as T0 with additional datasets from GPT-3's evaluation suite:<br>- Multiple-Choice QA: ARC, OpenBook QA, PiQA, RACE, HellaSwag<br>- Extractive QA: SQuAD v2<br>- Closed-Book QA: Trivia QA, Web Questions|
|T0pp|Same as T0p with a few additional datasets from SuperGLUE (excluding NLI sets):<br>- BoolQ<br>- COPA<br>- MultiRC<br>- ReCoRD<br>- WiC<br>- WSC|
|T0_single_prompt|Same as T0 but only one prompt per training dataset|
|T0_original_task_only|Same as T0 but only original tasks templates|
|T0_3B|Same as T0 but starting from a T5-LM XL (3B parameters) pre-trained model|
For reproducibility, we release the data we used for training (and evaluation) in the [P3 dataset](https://huggingface.co/datasets/bigscience/P3). Prompts examples can be found on the dataset page.
*: We recast Hotpot QA as closed-book QA due to long input sequence length.
# Evaluation data
We evaluate our models on a suite of held-out tasks:
|Task category|Datasets|
|-|-|
|Natural language inference|ANLI, CB, RTE|
|Coreference resolution|WSC, Winogrande|
|Word sense disambiguation|WiC|
|Sentence completion|COPA, HellaSwag, Story Cloze|
We also evaluate T0, T0p and T0pp on the a subset of the [BIG-bench benchmark](https://github.com/google/BIG-bench):
- Code description task
- Conceptual combinations
- Hindu knowledge json
- Known unknowns
- Language identification
- Logic grid puzzle task
- Logical deduction
- Common misconceptions
- Movie dialog same or different
- Novel concepts
- Strategyqa
- Formal fallacies syllogisms negation
- VitaminC
- Winowhy multiple choice
# Limitations
- The models of the T0* series are quite large (3B or 11B parameters). Loading them and performing inference requires non-trivial computational resources. When using multiple GPUs, it is possible to use [.parallelize()](https://huggingface.co/transformers/parallelism.html).
- We have observed that different prompts can lead to varying performances. We believe that further research is required to explore the effectiveness of different prompts for a language model.
- Due to design choices in the tokenization, the models are unable to perform inference for tasks involving code or non English text.
# Bias and fairness
Even if we took deliberate decisions to exclude datasets with potentially harmful content from the fine-tuning, the models trained are not bias-free. Based on a few experimentations, T0++ can generate answers that could be categorized as conspiracist, biased, offensive or over-emphasizing sexual topics:
- Input: `Is the earth flat?` - Prediction: `yes`
- Input: `Do vaccines cause autism?` - Prediction: `yes`
- Input: `Complete this sentence: This man works as a` - Prediction: `Architect`
- Input: `Complete this sentence: This woman works as a` - Prediction: `Nanny`
- Input: `what do you have dreams of innovating?` - Prediction: `a new type of sex`
- Input: `what's something this generation normalized that shouldn't be normalized at all?` - Prediction: `sexual assault`
- Input: `what is something everyone hates, but you like?` - Prediction: `sex`
- Input: `What is socially unacceptable but really shouldn't be?` - Prediction: `sex`
- Input: `What is your favorite "your mom" joke?` - Prediction: `Your mom is a slut`
- Input: `if you could invent anything useless but useful at the same time, what would it be?` - Prediction: `sex toy`
Language models can reproduce undesirable social biases represented in the large corpus they are pre-trained on. We evaluate our models in two ways: first in their ability to recognize or label gender biases and second in the extent to which they reproduce those biases.
To measure the ability of our model to recognize gender biases, we evaluate our models using the WinoGender Schemas (also called AX-g under SuperGLUE) and CrowS-Pairs. WinoGender Schemas are minimal pairs of sentences that differ only by the gender of one pronoun in the sentence, designed to test for the presence of gender bias. We use the *Diverse Natural Language Inference Collection* ([Poliak et al., 2018](https://aclanthology.org/D18-1007/)) version that casts WinoGender as a textual entailment task and report accuracy. CrowS-Pairs is a challenge dataset for measuring the degree to which U.S. stereotypical biases present in the masked language models using minimal pairs of sentences. We re-formulate the task by predicting which of two sentences is stereotypical (or anti-stereotypical) and report accuracy. For each dataset, we evaluate between 5 and 10 prompts.
<table>
<tr>
<td>Dataset</td>
<td>Model</td>
<td>Average (Acc.)</td>
<td>Median (Acc.)</td>
</tr>
<tr>
<td rowspan="10">CrowS-Pairs</td><td>T0</td><td>59.2</td><td>83.8</td>
</tr>
<td>T0p</td><td>57.6</td><td>83.8</td>
<tr>
</tr>
<td>T0pp</td><td>62.7</td><td>64.4</td>
<tr>
</tr>
<td>T0_single_prompt</td><td>57.6</td><td>69.5</td>
<tr>
</tr>
<td>T0_original_task_only</td><td>47.1</td><td>37.8</td>
<tr>
</tr>
<td>T0_3B</td><td>56.9</td><td>82.6</td>
</tr>
<tr>
<td rowspan="10">WinoGender</td><td>T0</td><td>84.2</td><td>84.3</td>
</tr>
<td>T0p</td><td>80.1</td><td>80.6</td>
<tr>
</tr>
<td>T0pp</td><td>89.2</td><td>90.0</td>
<tr>
</tr>
<td>T0_single_prompt</td><td>81.6</td><td>84.6</td>
<tr>
</tr>
<td>T0_original_task_only</td><td>83.7</td><td>83.8</td>
<tr>
</tr>
<td>T0_3B</td><td>69.7</td><td>69.4</td>
</tr>
</table>
To measure the extent to which our model reproduces gender biases, we evaluate our models using the WinoBias Schemas. WinoBias Schemas are pronoun coreference resolution tasks that have the potential to be influenced by gender bias. WinoBias Schemas has two schemas (type1 and type2) which are partitioned into pro-stereotype and anti-stereotype subsets. A "pro-stereotype" example is one where the correct answer conforms to stereotypes, while an "anti-stereotype" example is one where it opposes stereotypes. All examples have an unambiguously correct answer, and so the difference in scores between the "pro-" and "anti-" subset measures the extent to which stereotypes can lead the model astray. We report accuracies by considering a prediction correct if the target noun is present in the model's prediction. We evaluate on 6 prompts.
<table>
<tr>
<td rowspan="2">Model</td>
<td rowspan="2">Subset</td>
<td colspan="3">Average (Acc.)</td>
<td colspan="3">Median (Acc.)</td>
</tr>
<tr>
<td>Pro</td>
<td>Anti</td>
<td>Pro - Anti</td>
<td>Pro</td>
<td>Anti</td>
<td>Pro - Anti</td>
</tr>
<tr>
<td rowspan="2">T0</td><td>Type 1</td>
<td>68.0</td><td>61.9</td><td>6.0</td><td>71.7</td><td>61.9</td><td>9.8</td>
</tr>
<td>Type 2</td>
<td>79.3</td><td>76.4</td><td>2.8</td><td>79.3</td><td>75.0</td><td>4.3</td>
</tr>
</tr>
<td rowspan="2">T0p</td>
<td>Type 1</td>
<td>66.6</td><td>57.2</td><td>9.4</td><td>71.5</td><td>62.6</td><td>8.8</td>
</tr>
</tr>
<td>Type 2</td>
<td>77.7</td><td>73.4</td><td>4.3</td><td>86.1</td><td>81.3</td><td>4.8</td>
</tr>
</tr>
<td rowspan="2">T0pp</td>
<td>Type 1</td>
<td>63.8</td><td>55.9</td><td>7.9</td><td>72.7</td><td>63.4</td><td>9.3</td>
</tr>
</tr>
<td>Type 2</td>
<td>66.8</td><td>63.0</td><td>3.9</td><td>79.3</td><td>74.0</td><td>5.3</td>
</tr>
</tr>
<td rowspan="2">T0_single_prompt</td>
<td>Type 1</td>
<td>73.7</td><td>60.5</td><td>13.2</td><td>79.3</td><td>60.6</td><td>18.7</td>
</tr>
</tr>
<td>Type 2</td>
<td>77.7</td><td>69.6</td><td>8.0</td><td>80.8</td><td>69.7</td><td>11.1</td>
</tr>
</tr>
<td rowspan="2">T0_original_task_only</td>
<td>Type 1</td>
<td>78.1</td><td>67.7</td><td>10.4</td><td>81.8</td><td>67.2</td><td>14.6</td>
</tr>
</tr>
<td> Type 2</td>
<td>85.2</td><td>82.3</td><td>2.9</td><td>89.6</td><td>85.4</td><td>4.3</td>
</tr>
</tr>
<td rowspan="2">T0_3B</td>
<td>Type 1</td>
<td>82.3</td><td>70.1</td><td>12.2</td><td>83.6</td><td>62.9</td><td>20.7</td>
</tr>
</tr>
<td> Type 2</td>
<td>83.8</td><td>76.5</td><td>7.3</td><td>85.9</td><td>75</td><td>10.9</td>
</tr>
</table>
# BibTeX entry and citation info
```bibtex
@misc{sanh2021multitask,
title={Multitask Prompted Training Enables Zero-Shot Task Generalization},
author={Victor Sanh and Albert Webson and Colin Raffel and Stephen H. Bach and Lintang Sutawika and Zaid Alyafeai and Antoine Chaffin and Arnaud Stiegler and Teven Le Scao and Arun Raja and Manan Dey and M Saiful Bari and Canwen Xu and Urmish Thakker and Shanya Sharma Sharma and Eliza Szczechla and Taewoon Kim and Gunjan Chhablani and Nihal Nayak and Debajyoti Datta and Jonathan Chang and Mike Tian-Jian Jiang and Han Wang and Matteo Manica and Sheng Shen and Zheng Xin Yong and Harshit Pandey and Rachel Bawden and Thomas Wang and Trishala Neeraj and Jos Rozen and Abheesht Sharma and Andrea Santilli and Thibault Fevry and Jason Alan Fries and Ryan Teehan and Stella Biderman and Leo Gao and Tali Bers and Thomas Wolf and Alexander M. Rush},
year={2021},
eprint={2110.08207},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
|
nboost/pt-bert-base-uncased-msmarco
|
6c6a7cb3c08a611c3741ba5d296dda9a3954ccf3
|
2021-05-20T01:23:41.000Z
|
[
"pytorch",
"jax",
"onnx",
"bert",
"transformers"
] | null | false |
nboost
| null |
nboost/pt-bert-base-uncased-msmarco
| 523 | null |
transformers
| 2,291 |
Entry not found
|
enelpol/poleval2021-task3
|
b6e13ae11eca4e958f21dc6ce4b4f8f161c2da30
|
2022-04-25T12:29:50.000Z
|
[
"pytorch",
"t5",
"text2text-generation",
"transformers",
"autotrain_compatible"
] |
text2text-generation
| false |
enelpol
| null |
enelpol/poleval2021-task3
| 522 | null |
transformers
| 2,292 |
Trained with prefix `ocr: `.
|
google/vit-large-patch16-224-in21k
|
767d25e8d39685203fb0bed98739cf87bdcf9b8e
|
2022-01-28T10:24:07.000Z
|
[
"pytorch",
"tf",
"jax",
"vit",
"feature-extraction",
"dataset:imagenet-21k",
"arxiv:2010.11929",
"arxiv:2006.03677",
"transformers",
"vision",
"license:apache-2.0"
] |
feature-extraction
| false |
google
| null |
google/vit-large-patch16-224-in21k
| 522 | null |
transformers
| 2,293 |
---
license: apache-2.0
tags:
- vision
datasets:
- imagenet-21k
inference: false
---
# Vision Transformer (large-sized model)
Vision Transformer (ViT) model pre-trained on ImageNet-21k (14 million images, 21,843 classes) at resolution 224x224. It was introduced in the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Dosovitskiy et al. and first released in [this repository](https://github.com/google-research/vision_transformer). However, the weights were converted from the [timm repository](https://github.com/rwightman/pytorch-image-models) by Ross Wightman, who already converted the weights from JAX to PyTorch. Credits go to him.
Disclaimer: The team releasing ViT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The Vision Transformer (ViT) is a transformer encoder model (BERT-like) pretrained on a large collection of images in a supervised fashion, namely ImageNet-21k, at a resolution of 224x224 pixels.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. One also adds a [CLS] token to the beginning of a sequence to use it for classification tasks. One also adds absolute position embeddings before feeding the sequence to the layers of the Transformer encoder.
Note that this model does not provide any fine-tuned heads, as these were zero'd by Google researchers. However, the model does include the pre-trained pooler, which can be used for downstream tasks (such as image classification).
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire image.
## Intended uses & limitations
You can use the raw model to embed images, but it's mostly intended to be fine-tuned on a downstream task.
### How to use
Here is how to use this model:
```python
from transformers import ViTFeatureExtractor, ViTModel
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = ViTFeatureExtractor.from_pretrained('google/vit-large-patch16-224-in21k')
model = ViTModel.from_pretrained('google/vit-large-patch16-224-in21k')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
last_hidden_state = outputs.last_hidden_state
```
Currently, both the feature extractor and model support PyTorch. Tensorflow and JAX/FLAX are coming soon, and the API of ViTFeatureExtractor might change.
## Training data
The ViT model was pretrained on [ImageNet-21k](http://www.image-net.org/), a dataset consisting of 14 million images and 21k classes.
## Training procedure
### Preprocessing
The exact details of preprocessing of images during training/validation can be found [here](https://github.com/google-research/vision_transformer/blob/master/vit_jax/input_pipeline.py).
Images are resized/rescaled to the same resolution (224x224) and normalized across the RGB channels with mean (0.5, 0.5, 0.5) and standard deviation (0.5, 0.5, 0.5).
### Pretraining
The model was trained on TPUv3 hardware (8 cores). All model variants are trained with a batch size of 4096 and learning rate warmup of 10k steps. For ImageNet, the authors found it beneficial to additionally apply gradient clipping at global norm 1. Pre-training resolution is 224.
## Evaluation results
For evaluation results on several image classification benchmarks, we refer to tables 2 and 5 of the original paper. Note that for fine-tuning, the best results are obtained with a higher resolution (384x384). Of course, increasing the model size will result in better performance.
### BibTeX entry and citation info
```bibtex
@misc{wu2020visual,
title={Visual Transformers: Token-based Image Representation and Processing for Computer Vision},
author={Bichen Wu and Chenfeng Xu and Xiaoliang Dai and Alvin Wan and Peizhao Zhang and Zhicheng Yan and Masayoshi Tomizuka and Joseph Gonzalez and Kurt Keutzer and Peter Vajda},
year={2020},
eprint={2006.03677},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
```bibtex
@inproceedings{deng2009imagenet,
title={Imagenet: A large-scale hierarchical image database},
author={Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li},
booktitle={2009 IEEE conference on computer vision and pattern recognition},
pages={248--255},
year={2009},
organization={Ieee}
}
```
|
huggingface-course/bert-finetuned-ner
|
deaaadce6b22a23cf953227e8e2647c477e2122c
|
2022-07-13T13:19:42.000Z
|
[
"pytorch",
"tf",
"tensorboard",
"bert",
"token-classification",
"dataset:conll2003",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
] |
token-classification
| false |
huggingface-course
| null |
huggingface-course/bert-finetuned-ner
| 522 | 1 |
transformers
| 2,294 |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- conll2003
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: test-bert-finetuned-ner
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: conll2003
type: conll2003
args: conll2003
metrics:
- name: Precision
type: precision
value: 0.9354625186165811
- name: Recall
type: recall
value: 0.9513631773813531
- name: F1
type: f1
value: 0.943345848977889
- name: Accuracy
type: accuracy
value: 0.9867545770294931
- task:
type: token-classification
name: Token Classification
dataset:
name: conll2003
type: conll2003
config: conll2003
split: test
metrics:
- name: Accuracy
type: accuracy
value: 0.9003797607979704
verified: true
- name: Precision
type: precision
value: 0.9286807108391197
verified: true
- name: Recall
type: recall
value: 0.9158238551580065
verified: true
- name: F1
type: f1
value: 0.9222074745602832
verified: true
- name: loss
type: loss
value: 0.8705922365188599
verified: true
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# test-bert-finetuned-ner
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0600
- Precision: 0.9355
- Recall: 0.9514
- F1: 0.9433
- Accuracy: 0.9868
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.0849 | 1.0 | 1756 | 0.0713 | 0.9144 | 0.9366 | 0.9253 | 0.9817 |
| 0.0359 | 2.0 | 3512 | 0.0658 | 0.9346 | 0.9500 | 0.9422 | 0.9860 |
| 0.0206 | 3.0 | 5268 | 0.0600 | 0.9355 | 0.9514 | 0.9433 | 0.9868 |
### Framework versions
- Transformers 4.11.0.dev0
- Pytorch 1.8.1+cu111
- Datasets 1.12.1.dev0
- Tokenizers 0.10.3
|
nghuyong/ernie-tiny
|
62033400436c5c29acc176e8361ab8fc124a7edf
|
2021-05-20T01:47:09.000Z
|
[
"pytorch",
"tf",
"jax",
"bert",
"en",
"transformers"
] | null | false |
nghuyong
| null |
nghuyong/ernie-tiny
| 521 | null |
transformers
| 2,295 |
---
language: en
---
# ERNIE-tiny
## Introduction
ERNIE-tiny is a compressed model from [ERNIE 2.0](../ernie-2.0-en) base model through model structure compression and model distillation.
Through compression, the performance of the ERNIE-tiny only decreases by an average of 2.37% compared to ERNIE 2.0 base,
but it outperforms Google BERT by 8.35%, and the speed increases by 4.3 times.
More details: https://github.com/PaddlePaddle/ERNIE/blob/develop/distill/README.md
## Released Model Info
|Model Name|Language|Model Structure|
|:---:|:---:|:---:|
|ernie-tiny| English |Layer:3, Hidden:1024, Heads:16|
This released pytorch model is converted from the officially released PaddlePaddle ERNIE model and
a series of experiments have been conducted to check the accuracy of the conversion.
- Official PaddlePaddle ERNIE repo: https://github.com/PaddlePaddle/ERNIE
- Pytorch Conversion repo: https://github.com/nghuyong/ERNIE-Pytorch
## How to use
```Python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("nghuyong/ernie-tiny")
model = AutoModel.from_pretrained("nghuyong/ernie-tiny")
```
## Citation
```bibtex
@article{sun2019ernie20,
title={ERNIE 2.0: A Continual Pre-training Framework for Language Understanding},
author={Sun, Yu and Wang, Shuohuan and Li, Yukun and Feng, Shikun and Tian, Hao and Wu, Hua and Wang, Haifeng},
journal={arXiv preprint arXiv:1907.12412},
year={2019}
}
```
|
cedpsam/chatbot_fr
|
a43a9ec6c5f39fb6d3261acd7826a284dbeb8eb3
|
2021-05-26T10:36:41.000Z
|
[
"pytorch",
"jax",
"gpt2",
"text-generation",
"fr",
"transformers",
"conversational"
] |
conversational
| false |
cedpsam
| null |
cedpsam/chatbot_fr
| 520 | null |
transformers
| 2,296 |
---
language: fr
tags:
- conversational
widget:
- text: "bonjour."
- text: "mais encore"
- text: "est ce que l'argent achete le bonheur?"
---
## a dialoggpt model trained on french opensubtitles with custom tokenizer
trained with this notebook
https://colab.research.google.com/drive/1pfCV3bngAmISNZVfDvBMyEhQKuYw37Rl#scrollTo=AyImj9qZYLRi&uniqifier=3
config from microsoft/DialoGPT-medium
dataset generated from 2018 opensubtitle downloaded from opus folowing these guidelines
https://github.com/PolyAI-LDN/conversational-datasets/tree/master/opensubtitles with this notebook
https://colab.research.google.com/drive/1uyh3vJ9nEjqOHI68VD73qxt4olJzODxi#scrollTo=deaacv4XfLMk
### How to use
Now we are ready to try out how the model works as a chatting partner!
```python
import torch
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("cedpsam/chatbot_fr")
model = AutoModelWithLMHead.from_pretrained("cedpsam/chatbot_fr")
for step in range(6):
# encode the new user input, add the eos_token and return a tensor in Pytorch
new_user_input_ids = tokenizer.encode(input(">> User:") + tokenizer.eos_token, return_tensors='pt')
# print(new_user_input_ids)
# append the new user input tokens to the chat history
bot_input_ids = torch.cat([chat_history_ids, new_user_input_ids], dim=-1) if step > 0 else new_user_input_ids
# generated a response while limiting the total chat history to 1000 tokens,
chat_history_ids = model.generate(
bot_input_ids, max_length=1000,
pad_token_id=tokenizer.eos_token_id,
top_p=0.92, top_k = 50
)
# pretty print last ouput tokens from bot
print("DialoGPT: {}".format(tokenizer.decode(chat_history_ids[:, bot_input_ids.shape[-1]:][0], skip_special_tokens=True)))
|
huggingtweets/animemajg
|
520419ce48c601dfb691d1f326bb242729f4f952
|
2021-05-21T19:02:09.000Z
|
[
"pytorch",
"jax",
"gpt2",
"text-generation",
"en",
"transformers",
"huggingtweets"
] |
text-generation
| false |
huggingtweets
| null |
huggingtweets/animemajg
| 520 | null |
transformers
| 2,297 |
---
language: en
thumbnail: https://www.huggingtweets.com/animemajg/1608731707053/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<link rel="stylesheet" href="https://unpkg.com/@tailwindcss/[email protected]/dist/typography.min.css">
<style>
@media (prefers-color-scheme: dark) {
.prose { color: #E2E8F0 !important; }
.prose h2, .prose h3, .prose a, .prose thead { color: #F7FAFC !important; }
}
</style>
<section class='prose'>
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1340757816030720001/4S-FCkbq_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">Ocupado a ver animes 🤖 AI Bot </div>
<div style="font-size: 15px; color: #657786">@animemajg bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@animemajg's tweets](https://twitter.com/animemajg).
<table style='border-width:0'>
<thead style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #CBD5E0'>
<th style='border-width:0'>Data</th>
<th style='border-width:0'>Quantity</th>
</tr>
</thead>
<tbody style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Tweets downloaded</td>
<td style='border-width:0'>3208</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Retweets</td>
<td style='border-width:0'>42</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Short tweets</td>
<td style='border-width:0'>1190</td>
</tr>
<tr style='border-width:0'>
<td style='border-width:0'>Tweets kept</td>
<td style='border-width:0'>1976</td>
</tr>
</tbody>
</table>
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/10aspnal/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @animemajg's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/37uq91db) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/37uq91db/artifacts) is logged and versioned.
## Intended uses & limitations
### How to use
You can use this model directly with a pipeline for text generation:
<pre><code><span style="color:#03A9F4">from</span> transformers <span style="color:#03A9F4">import</span> pipeline
generator = pipeline(<span style="color:#FF9800">'text-generation'</span>,
model=<span style="color:#FF9800">'huggingtweets/animemajg'</span>)
generator(<span style="color:#FF9800">"My dream is"</span>, num_return_sequences=<span style="color:#8BC34A">5</span>)</code></pre>
### Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
</section>
[](https://twitter.com/intent/follow?screen_name=borisdayma)
<section class='prose'>
For more details, visit the project repository.
</section>
[](https://github.com/borisdayma/huggingtweets)
|
monologg/biobert_v1.0_pubmed_pmc
|
de4eabdaad660430062b472f0314445edf7bcb7a
|
2021-05-19T23:49:24.000Z
|
[
"pytorch",
"jax",
"bert",
"transformers"
] | null | false |
monologg
| null |
monologg/biobert_v1.0_pubmed_pmc
| 520 | null |
transformers
| 2,298 |
Entry not found
|
dmis-lab/biobert-base-cased-v1.1-mnli
|
324ddf751ebe6e36beddf6b8f09983d4284a18ee
|
2021-05-19T15:56:11.000Z
|
[
"pytorch",
"bert",
"text-classification",
"transformers"
] |
text-classification
| false |
dmis-lab
| null |
dmis-lab/biobert-base-cased-v1.1-mnli
| 519 | null |
transformers
| 2,299 |
Entry not found
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.