
modelId
stringlengths 4
112
| sha
stringlengths 40
40
| lastModified
stringlengths 24
24
| tags
list | pipeline_tag
stringclasses 29
values | private
bool 1
class | author
stringlengths 2
38
⌀ | config
null | id
stringlengths 4
112
| downloads
float64 0
36.8M
⌀ | likes
float64 0
712
⌀ | library_name
stringclasses 17
values | __index_level_0__
int64 0
38.5k
| readme
stringlengths 0
186k
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
huggingtweets/pearltrans | fc0bd773d0d110d0c7a4ca33a5605d2fb0fe25f9 | 2021-05-23T14:14:51.000Z | [
"pytorch",
"jax",
"gpt2",
"text-generation",
"en",
"transformers",
"huggingtweets"
]
| text-generation | false | huggingtweets | null | huggingtweets/pearltrans | 6 | null | transformers | 15,300 | ---
language: en
thumbnail: https://www.huggingtweets.com/pearltrans/1621529245791/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1389950688331960324/7bkgN6h8_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">PearlTheComicsGirl</div>
<div style="text-align: center; font-size: 14px;">@pearltrans</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from PearlTheComicsGirl.
| Data | PearlTheComicsGirl |
| --- | --- |
| Tweets downloaded | 837 |
| Retweets | 100 |
| Short tweets | 166 |
| Tweets kept | 571 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/szcek6ld/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @pearltrans's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3t5jniyr) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3t5jniyr/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/pearltrans')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/politicalmiller | c04f2ee0c6a785043d07fd3da7c3907aaa5fa8ed | 2021-05-22T18:59:13.000Z | [
"pytorch",
"jax",
"gpt2",
"text-generation",
"en",
"transformers",
"huggingtweets"
]
| text-generation | false | huggingtweets | null | huggingtweets/politicalmiller | 6 | null | transformers | 15,301 | ---
language: en
thumbnail: https://www.huggingtweets.com/politicalmiller/1621521804404/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1277020279643013122/4Bq8WTOC_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Jack Miller</div>
<div style="text-align: center; font-size: 14px;">@politicalmiller</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Jack Miller.
| Data | Jack Miller |
| --- | --- |
| Tweets downloaded | 274 |
| Retweets | 148 |
| Short tweets | 8 |
| Tweets kept | 118 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/3qe4bmlw/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @politicalmiller's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3sxyaywa) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3sxyaywa/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/politicalmiller')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/rantspakistani | aca299b6fa05528855241bf4b4419886b8db93dc | 2021-06-15T09:17:31.000Z | [
"pytorch",
"gpt2",
"text-generation",
"en",
"transformers",
"huggingtweets"
]
| text-generation | false | huggingtweets | null | huggingtweets/rantspakistani | 6 | null | transformers | 15,302 | ---
language: en
thumbnail: https://www.huggingtweets.com/rantspakistani/1623748645565/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1272527278744973315/PVkL9_v-_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Rants</div>
<div style="text-align: center; font-size: 14px;">@rantspakistani</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Rants.
| Data | Rants |
| --- | --- |
| Tweets downloaded | 3221 |
| Retweets | 573 |
| Short tweets | 142 |
| Tweets kept | 2506 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2wyl63o2/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @rantspakistani's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/d2h287dr) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/d2h287dr/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/rantspakistani')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
huggingtweets/spamemcspam | ac50b20123db924c5730f000545e3c4d64295364 | 2021-07-23T20:59:12.000Z | [
"pytorch",
"gpt2",
"text-generation",
"en",
"transformers",
"huggingtweets"
]
| text-generation | false | huggingtweets | null | huggingtweets/spamemcspam | 6 | null | transformers | 15,303 | ---
language: en
thumbnail: https://www.huggingtweets.com/spamemcspam/1627073948338/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1362892272342196224/RSTBJB08_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Yes, I know my cat is ugly.</div>
<div style="text-align: center; font-size: 14px;">@spamemcspam</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Yes, I know my cat is ugly..
| Data | Yes, I know my cat is ugly. |
| --- | --- |
| Tweets downloaded | 3214 |
| Retweets | 977 |
| Short tweets | 228 |
| Tweets kept | 2009 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/3mn5cki9/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @spamemcspam's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/1v7cmihj) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/1v7cmihj/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/spamemcspam')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
hyunwoongko/asian-bart-ko | d59056832f257e06084a5e0800a6e1dd73420916 | 2021-04-01T08:17:28.000Z | [
"pytorch",
"mbart",
"text2text-generation",
"transformers",
"autotrain_compatible"
]
| text2text-generation | false | hyunwoongko | null | hyunwoongko/asian-bart-ko | 6 | 1 | transformers | 15,304 | Entry not found |
hyunwoongko/roberta-base-en-mnli | 3d053ef07fffb7b016f55f38ec4fad6acee324df | 2021-05-20T16:44:48.000Z | [
"pytorch",
"jax",
"roberta",
"text-classification",
"transformers"
]
| text-classification | false | hyunwoongko | null | hyunwoongko/roberta-base-en-mnli | 6 | null | transformers | 15,305 | Entry not found |
it5/it5-small-question-generation | 56d5cc7151c42ffa1344ca80bc881e0ecb273252 | 2022-03-09T07:55:38.000Z | [
"pytorch",
"tf",
"jax",
"tensorboard",
"t5",
"text2text-generation",
"it",
"dataset:squad_it",
"arxiv:2203.03759",
"transformers",
"italian",
"sequence-to-sequence",
"question-generation",
"squad_it",
"license:apache-2.0",
"model-index",
"co2_eq_emissions",
"autotrain_compatible"
]
| text2text-generation | false | it5 | null | it5/it5-small-question-generation | 6 | null | transformers | 15,306 | ---
language:
- it
license: apache-2.0
datasets:
- squad_it
tags:
- italian
- sequence-to-sequence
- question-generation
- squad_it
- text2text-generation
widget:
- text: "Le conoscenze mediche erano stagnanti durante il Medioevo. Il resoconto più autorevole di allora è venuto dalla facoltà di medicina di Parigi in un rapporto al re di Francia che ha incolpato i cieli, sotto forma di una congiunzione di tre pianeti nel 1345 che causò una \"grande pestilenza nell' aria\". Questa relazione è diventata la prima e più diffusa di una serie di casi di peste che cercava di dare consigli ai malati. Che la peste fosse causata dalla cattiva aria divenne la teoria più accettata. Oggi, questo è conosciuto come la teoria di Miasma. La parola \"peste\" non aveva un significato particolare in questo momento, e solo la ricorrenza dei focolai durante il Medioevo gli diede il nome che è diventato il termine medico. Risposta: re di Francia"
- text: "Il 14 aprile 2011, ABC ha annullato le lunghe opere di sapone All My Children e One Life to Live dopo 41 e 43 anni in onda, rispettivamente (in seguito al contraccolpo dei tifosi, ABC ha venduto i diritti ad entrambi gli spettacoli a Prospect Park, che alla fine ha rilanciato i saponi su Hulu per un' ulteriore stagione nel 2013 e con entrambe le società che si citano in giudizio per accuse di interferenza con il processo di rilancio degli spettacoli, mancato pagamento delle tasse di licenza. Il talk/lifestyle show che ha sostituito One Life to Live, The Revolution, non è riuscito a generare giudizi soddisfacenti ed è stato a sua volta annullato dopo soli sette mesi. La stagione 2011-12 ha visto l' ABC cadere al quarto posto nel 18-49 demografico nonostante rinnovando una manciata di nuovi spettacoli (compresi i drammi matricole Scandal, Revenge e Once Upon a Time) per la seconda stagione. Risposta: Hulu"
- text: "L' American Broadcasting Company (ABC) (stlized nel suo logo come abc dal 1957) è una rete televisiva commerciale americana trasmissione televisiva che è di proprietà del Disney-ABC Television Group, una controllata della divisione Disney Media Networks di The Walt Disney Company. La rete fa parte delle grandi reti televisive Big Three. La rete ha sede a Columbus Avenue e West 66th Street a Manhattan, con ulteriori uffici e stabilimenti di produzione a New York City, Los Angeles e Burbank, California. Risposta: Manhattan"
- text: "La disobbedienza civile non rivoluzionaria è una semplice disobbedienza delle leggi sulla base del fatto che sono giudicate \"sbagliate\" da una coscienza individuale, o come parte di uno sforzo per rendere alcune leggi inefficaci, per causarne l' abrogazione, o per esercitare pressioni per ottenere i propri desideri politici su qualche altra questione. La disobbedienza civile rivoluzionaria è più che altro un tentativo attivo di rovesciare un governo (o di cambiare le tradizioni culturali, i costumi sociali, le credenze religiose, ecc. La rivoluzione non deve necessariamente essere politica, cioè \"rivoluzione culturale\", implica semplicemente un cambiamento radicale e diffuso in una sezione del tessuto sociale). Gli atti di Gandhi sono stati descritti come disobbedienza civile rivoluzionaria. È stato affermato che gli ungheresi sotto Ferenc Deák hanno diretto una disobbedienza civile rivoluzionaria contro il governo austriaco. Thoreau ha anche scritto di disobbedienza civile realizzando \"rivoluzione pacifica\". Howard Zinn, Harvey Wheeler e altri hanno identificato il diritto sposato nella Dichiarazione d' Indipendenza di \"alterare o abolire\" un governo ingiusto come principio di disobbedienza civile. Risposta: Ferenc Deák"
metrics:
- rouge
- bertscore
model-index:
- name: it5-small-question-generation
results:
- task:
type: question-generation
name: "Question generation"
dataset:
type: squad_it
name: "SQuAD-IT"
metrics:
- type: rouge1
value: 0.367
name: "Test Rouge1"
- type: rouge2
value: 0.189
name: "Test Rouge2"
- type: rougeL
value: 0.344
name: "Test RougeL"
- type: bertscore
value: 0.505
name: "Test BERTScore"
args:
- model_type: "dbmdz/bert-base-italian-xxl-uncased"
- lang: "it"
- num_layers: 10
- rescale_with_baseline: True
- baseline_path: "bertscore_baseline_ita.tsv"
co2_eq_emissions:
emissions: "8g"
source: "Google Cloud Platform Carbon Footprint"
training_type: "fine-tuning"
geographical_location: "Eemshaven, Netherlands, Europe"
hardware_used: "1 TPU v3-8 VM"
thumbnail: https://gsarti.com/publication/it5/featured.png
---
# IT5 Small for Question Generation 💭 🇮🇹
This repository contains the checkpoint for the [IT5 Small](https://huggingface.co/gsarti/it5-small) model fine-tuned on question generation on the [SQuAD-IT corpus](https://huggingface.co/datasets/squad_it) as part of the experiments of the paper [IT5: Large-scale Text-to-text Pretraining for Italian Language Understanding and Generation](https://arxiv.org/abs/2203.03759) by [Gabriele Sarti](https://gsarti.com) and [Malvina Nissim](https://malvinanissim.github.io).
A comprehensive overview of other released materials is provided in the [gsarti/it5](https://github.com/gsarti/it5) repository. Refer to the paper for additional details concerning the reported scores and the evaluation approach.
## Using the model
Model checkpoints are available for usage in Tensorflow, Pytorch and JAX. They can be used directly with pipelines as:
```python
from transformers import pipelines
qg = pipeline("text2text-generation", model='it5/it5-small-question-generation')
qg("Le conoscenze mediche erano stagnanti durante il Medioevo. Il resoconto più autorevole di allora è venuto dalla facoltà di medicina di Parigi in un rapporto al re di Francia che ha incolpato i cieli, sotto forma di una congiunzione di tre pianeti nel 1345 che causò una "grande pestilenza nell\' aria". Questa relazione è diventata la prima e più diffusa di una serie di casi di peste che cercava di dare consigli ai malati. Che la peste fosse causata dalla cattiva aria divenne la teoria più accettata. Oggi, questo è conosciuto come la teoria di Miasma. La parola "peste" non aveva un significato particolare in questo momento, e solo la ricorrenza dei focolai durante il Medioevo gli diede il nome che è diventato il termine medico. Risposta: re di Francia")
>>> [{"generated_text": "Per chi è stato redatto il referto medico?"}]
```
or loaded using autoclasses:
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("it5/it5-small-question-generation")
model = AutoModelForSeq2SeqLM.from_pretrained("it5/it5-small-question-generation")
```
If you use this model in your research, please cite our work as:
```bibtex
@article{sarti-nissim-2022-it5,
title={{IT5}: Large-scale Text-to-text Pretraining for Italian Language Understanding and Generation},
author={Sarti, Gabriele and Nissim, Malvina},
journal={ArXiv preprint 2203.03759},
url={https://arxiv.org/abs/2203.03759},
year={2022},
month={mar}
}
``` |
it5/mt5-base-ilgiornale-to-repubblica | 98e5d2bf8bb9d75586e024681e8c8ca3f1a20086 | 2022-03-09T08:02:59.000Z | [
"pytorch",
"tf",
"jax",
"tensorboard",
"mt5",
"text2text-generation",
"it",
"dataset:gsarti/change_it",
"arxiv:2203.03759",
"transformers",
"italian",
"sequence-to-sequence",
"newspaper",
"ilgiornale",
"repubblica",
"style-transfer",
"license:apache-2.0",
"model-index",
"co2_eq_emissions",
"autotrain_compatible"
]
| text2text-generation | false | it5 | null | it5/mt5-base-ilgiornale-to-repubblica | 6 | null | transformers | 15,307 | ---
language:
- it
license: apache-2.0
datasets:
- gsarti/change_it
tags:
- italian
- sequence-to-sequence
- newspaper
- ilgiornale
- repubblica
- style-transfer
widget:
- text: "WASHINGTON - La Corea del Nord torna dopo nove anni nella blacklist Usa degli Stati considerati sponsor del terrorismo. Come Iran, Siria e Sudan. Lo ha deciso Donald Trump , che ha preferito dare l'annuncio non durante il suo recente viaggio in Asia ma ieri, in una riunione del governo alla Casa Bianca. 'Oggi gli Stati Uniti designeranno la Corea del nord come uno stato sponsor del terrorismo', ha tuonato il tycoon, anticipando che sarà formalizzata oggi dal dipartimento di stato e sarà accompagnata da nuove e più severe sanzioni. 'Il livello più alto' mai imposto a Pyongyang, ha promesso. 'Avrebbe dovuto succedere molto tempo fa', ha aggiunto, scaricando per l'ennesima volta la responsabilità dell'attuale crisi sull'amministrazione Obama. Poi si è scagliato contro un 'regime assassino' che 'deve mettere fine allo sviluppo del suo programma illegale nucleare e balistico'. Per giustificare la svolta, Trump ha accusato Pyongyang non solo di 'minacciare il mondo con una devastazione nucleare' ma anche di aver 'ripetutamente sostenuto atti di terrorismo internazionale', compreso omicidi in suolo straniero. Il riferimento è all' uccisione all'aeroporto della capitale malese di Kim Jong Nam , il fratellastro del leader nordcoreano Kim Jong Un , ma non ci sono altri episodi noti. Tanto che alcuni esperti, come pure dirigenti Usa coperti dall'anonimato, dubitano che Pyongyang risponda ai criteri per una tale designazione. La mossa appare altamente simbolica, dato che la Corea del Nord è già pesantemente sanzionata a livello internazionale. Per il segretario di stato Rex Tillerson è solo l'ultima di una serie di passi per rafforzare la pressione su Pyongyang e costringerla a sedersi ad un tavolo perché gli Usa hanno sempre 'speranza nella diplomazia'. Ma nello stesso tempo è un monito per 'fermare e dissuadere' altri Paesi dal sostenere la Corea del Nord, finita nella blacklist 'anche per l'uso di armi chimiche'. Ma la mossa potrebbe anche essere controproducente, provocando una risposta di Kim o minando gli sforzi per sollecitare Pechino ad una maggiore pressione su Pyongyang. In ogni caso non aiuta il dialogo diretto tra Usa e Corea del Nord, che sembrava essere stato avviato in modo riservato. Come non aiutano gli scambi di insulti fra Trump e Kim. Nord Corea, Trump: 'Cerco di essere amico di Kim, sarebbe una bella cosa per il mondo'. Pyongyang era stata messa nella lista Usa degli Stati sponsor del terrorismo per aver fatto esplodere nel 1987 un volo della Korean Air uccidendo tutti i 115 passeggeri a bordo. Ma l'amministrazione di George W. Bush l'aveva rimossa sperando di far avanzare i negoziati sulla denuclearizzazione della penisola coreana. Il governo giapponese sostiene la decisione degli Stati Uniti di inserire la Corea del Nord nella lista degli stati che sponsorizzano il terrorismo, pur riconoscendo che l'annuncio potrebbe provocare una reazione immediata del regime di Pyongyang. Il premier Shinzo Abe ha accolto con consenso il comunicato Usa e ha detto alla stampa che servirà a incrementare la pressione sulla Corea del Nord. Il ministro della Difesa Itsunori Onodera , pur valutando positivamente la notifica, ha spiegato che si attendono azioni provocatorie dallo stato eremita, ribadendo che è vitale rimanere vigili. Secondo la stampa nipponica Abe aveva richiesto al dipartimento di Stato Usa di mettere la Corea del Nord sulla lista durante l'incontro col presidente Usa Donald Trump a Tokyo a inizio mese. L'ultimo lancio di missile balistico condotto da Pyongyang nell'oceano Pacifico, sorvolando il mare del Giappone, risale allo scorso settembre."
- text: "ROMA - Una nuova droga killer è stata sequestrata per la prima volta in Europa dagli investigatori del Nas. Si tratta di una nuova \"miscela psicoattiva altamente tossica\" per la prima volta individuata da forze di polizia, simile all'eroina sintetica, ma molto più economica e letale. Tanto che i 20 grammi scoperti sarebbero stati sufficienti per fabbricare ben 20.000 dosi e lo stesso contatto attraverso la pelle può provocare intossicazione. Individuata per la prima volta, la nuova droga presenta una struttura simile al farmaco sedativo Fentanyl ma con effetti molto più devastanti per l'organismo. Proveniva dell'estero ed era contenuta in un plico postale indirizzato in una città del centro Italia: è stata intercettata tramite accertamenti sul web grazie a un'operazione di intelligence che ha visto come protagonisti i militari della Sezione operativa centrale del Comando carabinieri per la Tutela della salute (Nas). Economica e letale, secondo gli investigatori \"in confronto l'eroina è quasi 'acqua fresca', anzi, proprio per la sua economicità, in alcuni casi viene venduta dai pusher a giovani conviti di comprare eroina\". La diffusione di nuove droghe sintetiche che continuamente appaiono sui mercati necessita di un'attività investigativa costante e complessa. Si tratta infatti di sostanze dalla struttura molecolare molto simile a quella del Fentanyl ma ogni volta leggermente diversa. Di qui la difficoltà di individuarle e l'importanza del nuovo sequestro. \"La chiamano impropriamente 'eroina sintetica' - spiega il comandante dei Nas, generale Adelmo Lusi - per il tipo di effetto psicotropo simile, ma dal punto di vista della tossicità è molto peggio: con 25 milligrammi di eroina ci si sballa, con 25mg di simil-fentanyl, come quello appena sequestrato, si muore\". Le indagini sono partite da ricoveri per overdose in ospedale, in cui arrivavano ragazzi che non rispondevano al trattamento disintossicante per l'eroina. La nuova sostanza verrà ora segnalata per l'inserimento tra le tabelle ministeriali degli stupefacenti prevista dal Dpr 309/1990."
- text: "Fragile come il burro. Il nostro territorio è precario. Ne sanno qualcosa i comuni che sono stati investititi dal maltempo . Il dissesto idrogeologico imperversa su tutto il territorio. Infatti, oltre 6.600 comuni , pari all’82% del totale, sono in aree ad elevato rischio idrogeologico, pari al 10% della sua superficie. La popolazione potenzialmente esposta è stimata in 5,8 milioni di persone. I dati emergono dalle recenti analisi fatte da Legambiente e Protezione civile, che mettono in evidenza come in 10 anni in Italia sia raddoppiata l’area dei territori colpiti da alluvioni e frane , passando da una media di quattro regioni all’anno a otto regioni. Nella classifica delle regioni a maggior rischio idrogeologico prima è la Calabria con il 100% dei comuni esposti; al 100% ci sono anche la provincia di Trento, il Molise, la Basilicata, l’Umbria, la Valle d’Aosta. Poi Marche, Liguria al 99%; Lazio, Toscana al 98%; Abruzzo (96%), Emilia-Romagna (95%), Campania e Friuli Venezia Giulia al 92%, Piemonte (87%), Sardegna (81%), Puglia (78%), Sicilia (71%), Lombardia (60%), provincia di Bolzano (59%), Veneto (56%). Tra le cause che condizionano ed amplificano il rischio idrogeologico c’è l’azione dell’uomo (abbandono e degrado, cementificazione, consumo di suolo, abusivismo, disboscamento e incendi). Ma anche e soprattutto la mancanza di una seria manutenzione ordinaria e non ad una organica politica di prevenzione."
- text: "Arriva dal Partito nazionalista basco (Pnv) la conferma che i cinque deputati che siedono in parlamento voteranno la sfiducia al governo guidato da Mariano Rajoy. Pochi voti, ma significativi quelli della formazione politica di Aitor Esteban, che interverrà nel pomeriggio. Pur con dimensioni molto ridotte, il partito basco si è trovato a fare da ago della bilancia in aula. E il sostegno alla mozione presentata dai Socialisti potrebbe significare per il primo ministro non trovare quei 176 voti che gli servono per continuare a governare. \" Perché dovrei dimettermi io che per il momento ho la fiducia della Camera e quella che mi è stato data alle urne \", ha detto oggi Rajoy nel suo intervento in aula, mentre procedeva la discussione sulla mozione di sfiducia. Il voto dei baschi ora cambia le carte in tavola e fa crescere ulteriormente la pressione sul premier perché rassegni le sue dimissioni. La sfiducia al premier, o un'eventuale scelta di dimettersi, porterebbe alle estreme conseguenze lo scandalo per corruzione che ha investito il Partito popolare. Ma per ora sembra pensare a tutt'altro. \"Non ha intenzione di dimettersi - ha detto il segretario generale del Partito popolare , María Dolores de Cospedal - Non gioverebbe all'interesse generale o agli interessi del Pp\"."
metrics:
- rouge
- bertscore
- headline-headline-consistency-classifier
- headline-article-consistency-classifier
model-index:
- name: mt5-base-ilgiornale-to-repubblica
results:
- task:
type: headline-style-transfer-ilgiornale-to-repubblica
name: "Headline style transfer (Il Giornale to Repubblica)"
dataset:
type: gsarti/change_it
name: "CHANGE-IT"
metrics:
- type: rouge1
value: 0.282
name: "Test Rouge1"
- type: rouge2
value: 0.101
name: "Test Rouge2"
- type: rougeL
value: 0.248
name: "Test RougeL"
- type: bertscore
value: 0.411
name: "Test BERTScore"
args:
- model_type: "dbmdz/bert-base-italian-xxl-uncased"
- lang: "it"
- num_layers: 10
- rescale_with_baseline: True
- baseline_path: "bertscore_baseline_ita.tsv"
- type: headline-headline-consistency-classifier
value: 0.815
name: "Test Headline-Headline Consistency Accuracy"
- type: headline-article-consistency-classifier
value: 0.773
name: "Test Headline-Article Consistency Accuracy"
co2_eq_emissions:
emissions: "40g"
source: "Google Cloud Platform Carbon Footprint"
training_type: "fine-tuning"
geographical_location: "Eemshaven, Netherlands, Europe"
hardware_used: "1 TPU v3-8 VM"
thumbnail: https://gsarti.com/publication/it5/featured.png
---
# mT5 Base for News Headline Style Transfer (Il Giornale to Repubblica) 🗞️➡️🗞️ 🇮🇹
This repository contains the checkpoint for the [mT5 Base](https://huggingface.co/google/mt5-base) model fine-tuned on news headline style transfer in the Il Giornale to Repubblica direction on the Italian CHANGE-IT dataset as part of the experiments of the paper [IT5: Large-scale Text-to-text Pretraining for Italian Language Understanding and Generation](https://arxiv.org/abs/2203.03759) by [Gabriele Sarti](https://gsarti.com) and [Malvina Nissim](https://malvinanissim.github.io).
A comprehensive overview of other released materials is provided in the [gsarti/it5](https://github.com/gsarti/it5) repository. Refer to the paper for additional details concerning the reported scores and the evaluation approach.
## Using the model
The model is trained to generate an headline in the style of Repubblica from the full body of an article written in the style of Il Giornale. Model checkpoints are available for usage in Tensorflow, Pytorch and JAX. They can be used directly with pipelines as:
```python
from transformers import pipelines
g2r = pipeline("text2text-generation", model='it5/mt5-base-ilgiornale-to-repubblica')
g2r("Arriva dal Partito nazionalista basco (Pnv) la conferma che i cinque deputati che siedono in parlamento voteranno la sfiducia al governo guidato da Mariano Rajoy. Pochi voti, ma significativi quelli della formazione politica di Aitor Esteban, che interverrà nel pomeriggio. Pur con dimensioni molto ridotte, il partito basco si è trovato a fare da ago della bilancia in aula. E il sostegno alla mozione presentata dai Socialisti potrebbe significare per il primo ministro non trovare quei 176 voti che gli servono per continuare a governare. \" Perché dovrei dimettermi io che per il momento ho la fiducia della Camera e quella che mi è stato data alle urne \", ha detto oggi Rajoy nel suo intervento in aula, mentre procedeva la discussione sulla mozione di sfiducia. Il voto dei baschi ora cambia le carte in tavola e fa crescere ulteriormente la pressione sul premier perché rassegni le sue dimissioni. La sfiducia al premier, o un'eventuale scelta di dimettersi, porterebbe alle estreme conseguenze lo scandalo per corruzione che ha investito il Partito popolare. Ma per ora sembra pensare a tutt'altro. \"Non ha intenzione di dimettersi - ha detto il segretario generale del Partito popolare , María Dolores de Cospedal - Non gioverebbe all'interesse generale o agli interessi del Pp\".")
>>> [{"generated_text": "il nazionalista rajoy: 'voteremo la sfiducia'"}]
```
or loaded using autoclasses:
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("it5/mt5-base-ilgiornale-to-repubblica")
model = AutoModelForSeq2SeqLM.from_pretrained("it5/mt5-base-ilgiornale-to-repubblica")
```
If you use this model in your research, please cite our work as:
```bibtex
@article{sarti-nissim-2022-it5,
title={{IT5}: Large-scale Text-to-text Pretraining for Italian Language Understanding and Generation},
author={Sarti, Gabriele and Nissim, Malvina},
journal={ArXiv preprint 2203.03759},
url={https://arxiv.org/abs/2203.03759},
year={2022},
month={mar}
}
``` |
it5/mt5-base-informal-to-formal | c6b7de63dfb76444e6cf025bb19d8b5637f622fd | 2022-03-09T07:48:51.000Z | [
"pytorch",
"tf",
"jax",
"tensorboard",
"mt5",
"text2text-generation",
"it",
"dataset:yahoo/xformal_it",
"arxiv:2203.03759",
"transformers",
"italian",
"sequence-to-sequence",
"style-transfer",
"formality-style-transfer",
"license:apache-2.0",
"model-index",
"co2_eq_emissions",
"autotrain_compatible"
]
| text2text-generation | false | it5 | null | it5/mt5-base-informal-to-formal | 6 | null | transformers | 15,308 | ---
language:
- it
license: apache-2.0
tags:
- italian
- sequence-to-sequence
- style-transfer
- formality-style-transfer
datasets:
- yahoo/xformal_it
widget:
- text: "maronn qualcuno mi spieg' CHECCOSA SUCCEDE?!?!"
- text: "wellaaaaaaa, ma fraté sei proprio troppo simpatiko, grazieeee!!"
- text: "nn capisco xke tt i ragazzi lo fanno"
- text: "IT5 è SUPERMEGA BRAVISSIMO a capire tt il vernacolo italiano!!!"
metrics:
- rouge
- bertscore
model-index:
- name: mt5-base-informal-to-formal
results:
- task:
type: formality-style-transfer
name: "Informal-to-formal Style Transfer"
dataset:
type: xformal_it
name: "XFORMAL (Italian Subset)"
metrics:
- type: rouge1
value: 0.661
name: "Avg. Test Rouge1"
- type: rouge2
value: 0.471
name: "Avg. Test Rouge2"
- type: rougeL
value: 0.642
name: "Avg. Test RougeL"
- type: bertscore
value: 0.712
name: "Avg. Test BERTScore"
args:
- model_type: "dbmdz/bert-base-italian-xxl-uncased"
- lang: "it"
- num_layers: 10
- rescale_with_baseline: True
- baseline_path: "bertscore_baseline_ita.tsv"
co2_eq_emissions:
emissions: "40g"
source: "Google Cloud Platform Carbon Footprint"
training_type: "fine-tuning"
geographical_location: "Eemshaven, Netherlands, Europe"
hardware_used: "1 TPU v3-8 VM"
---
# mT5 Base for Informal-to-formal Style Transfer 🧐
This repository contains the checkpoint for the [mT5 Base](https://huggingface.co/google/mt5-base) model fine-tuned on Informal-to-formal style transfer on the Italian subset of the XFORMAL dataset as part of the experiments of the paper [IT5: Large-scale Text-to-text Pretraining for Italian Language Understanding and Generation](https://arxiv.org/abs/2203.03759) by [Gabriele Sarti](https://gsarti.com) and [Malvina Nissim](https://malvinanissim.github.io).
A comprehensive overview of other released materials is provided in the [gsarti/it5](https://github.com/gsarti/it5) repository. Refer to the paper for additional details concerning the reported scores and the evaluation approach.
## Using the model
Model checkpoints are available for usage in Tensorflow, Pytorch and JAX. They can be used directly with pipelines as:
```python
from transformers import pipelines
i2f = pipeline("text2text-generation", model='it5/mt5-base-informal-to-formal')
i2f("nn capisco xke tt i ragazzi lo fanno")
>>> [{"generated_text": "non comprendo perché tutti i ragazzi agiscono così"}]
```
or loaded using autoclasses:
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("it5/mt5-base-informal-to-formal")
model = AutoModelForSeq2SeqLM.from_pretrained("it5/mt5-base-informal-to-formal")
```
If you use this model in your research, please cite our work as:
```bibtex
@article{sarti-nissim-2022-it5,
title={{IT5}: Large-scale Text-to-text Pretraining for Italian Language Understanding and Generation},
author={Sarti, Gabriele and Nissim, Malvina},
journal={ArXiv preprint 2203.03759},
url={https://arxiv.org/abs/2203.03759},
year={2022},
month={mar}
}
``` |
iyaja/codebert-llvm-ic-v0 | ef3fc33386135d74a3d4a6b16d8077269fa3705b | 2021-12-15T12:19:27.000Z | [
"pytorch",
"roberta",
"text-classification",
"transformers"
]
| text-classification | false | iyaja | null | iyaja/codebert-llvm-ic-v0 | 6 | null | transformers | 15,309 | Entry not found |
izumi-lab/electra-small-japanese-fin-generator | ed420dbf04c0cf78fb0391404f350339670b7e95 | 2022-03-19T09:39:26.000Z | [
"pytorch",
"electra",
"fill-mask",
"ja",
"dataset:wikipedia",
"dataset:securities reports",
"dataset:summaries of financial results",
"arxiv:2003.10555",
"transformers",
"finance",
"license:cc-by-sa-4.0",
"autotrain_compatible"
]
| fill-mask | false | izumi-lab | null | izumi-lab/electra-small-japanese-fin-generator | 6 | null | transformers | 15,310 | ---
language: ja
license: cc-by-sa-4.0
tags:
- finance
datasets:
- wikipedia
- securities reports
- summaries of financial results
widget:
- text: 流動[MASK]は1億円となりました。
---
# ELECTRA small Japanese finance generator
This is a [ELECTRA](https://github.com/google-research/electra) model pretrained on texts in the Japanese language.
The codes for the pretraining are available at [retarfi/language-pretraining](https://github.com/retarfi/language-pretraining/tree/v1.0).
## Model architecture
The model architecture is the same as ELECTRA small in the [original ELECTRA implementation](https://github.com/google-research/electra); 12 layers, 256 dimensions of hidden states, and 4 attention heads.
## Training Data
The models are trained on the Japanese version of Wikipedia.
The training corpus is generated from the Japanese version of Wikipedia, using Wikipedia dump file as of June 1, 2021.
The Wikipedia corpus file is 2.9GB, consisting of approximately 20M sentences.
The financial corpus consists of 2 corpora:
- Summaries of financial results from October 9, 2012, to December 31, 2020
- Securities reports from February 8, 2018, to December 31, 2020
The financial corpus file is 5.2GB, consisting of approximately 27M sentences.
## Tokenization
The texts are first tokenized by MeCab with IPA dictionary and then split into subwords by the WordPiece algorithm.
The vocabulary size is 32768.
## Training
The models are trained with the same configuration as ELECTRA small in the [original ELECTRA paper](https://arxiv.org/abs/2003.10555) except size; 128 tokens per instance, 128 instances per batch, and 1M training steps.
The size of the generator is the same of the discriminator.
## Citation
**There will be another paper for this pretrained model. Be sure to check here again when you cite.**
```
@inproceedings{suzuki2021fin-bert-electra,
title={金融文書を用いた事前学習言語モデルの構築と検証},
% title={Construction and Validation of a Pre-Trained Language Model Using Financial Documents},
author={鈴木 雅弘 and 坂地 泰紀 and 平野 正徳 and 和泉 潔},
% author={Masahiro Suzuki and Hiroki Sakaji and Masanori Hirano and Kiyoshi Izumi},
booktitle={人工知能学会第27回金融情報学研究会(SIG-FIN)},
% booktitle={Proceedings of JSAI Special Interest Group on Financial Infomatics (SIG-FIN) 27},
pages={5-10},
year={2021}
}
```
## Licenses
The pretrained models are distributed under the terms of the [Creative Commons Attribution-ShareAlike 4.0](https://creativecommons.org/licenses/by-sa/4.0/).
## Acknowledgments
This work was supported by JSPS KAKENHI Grant Number JP21K12010.
|
jacksonkarel/peacenik-gpt2 | 6e829937c682f6c60d1068f6fe5eec7f85985183 | 2021-08-25T01:03:12.000Z | [
"pytorch",
"gpt2",
"text-generation",
"en",
"transformers",
"license:mit"
]
| text-generation | false | jacksonkarel | null | jacksonkarel/peacenik-gpt2 | 6 | null | transformers | 15,311 | ---
language:
- en
license: mit
widget:
- text: "Nonviolence is justified because"
---
GPT2 fine-tuned on a dataset of pacifist philosophy and foreign policy texts. |
jacobshein/danish-bert-botxo-qa-squad | b3ecafcbfd74b157ab99b294d0e33a8f7db7790c | 2021-07-18T11:19:49.000Z | [
"pytorch",
"bert",
"question-answering",
"da",
"dataset:common_crawl",
"dataset:wikipedia",
"dataset:dindebat.dk",
"dataset:hestenettet.dk",
"dataset:danish OpenSubtitles",
"transformers",
"danish",
"question answering",
"squad",
"machine translation",
"botxo",
"license:cc-by-4.0",
"autotrain_compatible"
]
| question-answering | false | jacobshein | null | jacobshein/danish-bert-botxo-qa-squad | 6 | null | transformers | 15,312 | ---
language: da
tags:
- danish
- bert
- question answering
- squad
- machine translation
- botxo
license: cc-by-4.0
datasets:
- common_crawl
- wikipedia
- dindebat.dk
- hestenettet.dk
- danish OpenSubtitles
widget:
- context: Stine sagde hej, men Jacob sagde halløj.
---
# Danish BERT (version 2, uncased) by [BotXO](https://github.com/botxo/nordic_bert) fine-tuned for Question Answering (QA) on the [machine-translated SQuAD-da dataset](https://github.com/ccasimiro88/TranslateAlignRetrieve/tree/multilingual/squads-tar/da)
```python
from transformers import AutoTokenizer, AutoModelForQuestionAnswering
tokenizer = AutoTokenizer.from_pretrained("jacobshein/danish-bert-botxo-qa-squad")
model = AutoModelForQuestionAnswering.from_pretrained("jacobshein/danish-bert-botxo-qa-squad")
```
#### Contact
For further information on usage or fine-tuning procedure, please reach out by email through [jacobhein.com](https://jacobhein.com/#contact).
|
jean-paul/kinyaRoberta-small | 254fc07318e78cff0993ba7cd8d634696bfb800f | 2021-08-29T10:27:01.000Z | [
"pytorch",
"roberta",
"fill-mask",
"arxiv:1907.11692",
"transformers",
"autotrain_compatible"
]
| fill-mask | false | jean-paul | null | jean-paul/kinyaRoberta-small | 6 | null | transformers | 15,313 | # Model description
A Pretrained model on the Kinyarwanda language dataset using a masked language modeling (MLM) objective. RoBerta model was first introduced in [this paper](https://arxiv.org/abs/1907.11692). This KinyaRoBERTa model was pretrained with uncased tokens which means that no difference between for example ikinyarwanda and Ikinyarwanda.
# Training parameters
#### Dataset
The data set used has both sources from the new articles in Rwanda extracted from different new web pages, dumped Wikipedia files, and the books in Kinyarwanda. The sizes of the sources of data are 72 thousand new articles, three thousand dumped Wikipedia articles, and six books with more than a thousand pages.
#### Hyperparameters
The model was trained with the default configuration of RoBerta and Trainer from the Huggingface. However, due to some resource computation issues, we kept the number of transformer layers to 6.
# How to use:
The model can be used directly with the pipeline for masked language modeling as follows:
```
from transformers import pipeline
the_mask_pipe = pipeline(
"fill-mask",
model='jean-paul/kinyaRoberta-small',
tokenizer='jean-paul/kinyaRoberta-small',
)
the_mask_pipe("Ejo ndikwiga nagize <mask> baje kunsura.")
[{'sequence': 'Ejo ndikwiga nagize amahirwe baje kunsura.', 'score': 0.3530674874782562, 'token': 1711, 'token_str': ' amahirwe'},
{'sequence': 'Ejo ndikwiga nagize ubwoba baje kunsura.', 'score': 0.2858319878578186, 'token': 2594, 'token_str': ' ubwoba'},
{'sequence': 'Ejo ndikwiga nagize ngo baje kunsura.', 'score': 0.032475441694259644, 'token': 396, 'token_str': ' ngo'},
{'sequence': 'Ejo ndikwiga nagize abana baje kunsura.', 'score': 0.029481062665581703, 'token': 739, 'token_str': ' abana'},
{'sequence': 'Ejo ndikwiga nagize abantu baje kunsura.', 'score': 0.016263306140899658, 'token': 500, 'token_str': ' abantu'}]
```
2) Direct use from the transformer library to get features using AutoModel
```
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("jean-paul/kinyaRoberta-small")
model = AutoModelForMaskedLM.from_pretrained("jean-paul/kinyaRoberta-small")
input_text = "Ejo ndikwiga nagize abashyitsi baje kunsura."
encoded_input = tokenizer(input_text, return_tensors='pt')
output = model(**encoded_input)
```
__Note__: We used the huggingface implementations for pretraining RoBerta from scratch, both the RoBerta model and the classes needed to do it. |
ji-xin/bert_large-MRPC-two_stage | 873d2dc968b577636913a84482ea52dc7a8e9082 | 2020-07-08T15:02:27.000Z | [
"pytorch",
"transformers"
]
| null | false | ji-xin | null | ji-xin/bert_large-MRPC-two_stage | 6 | null | transformers | 15,314 | Entry not found |
ji-xin/roberta_base-MNLI-two_stage | ca566c335570e8f5b1946b1077fdb2a355c3992f | 2020-07-08T15:05:22.000Z | [
"pytorch",
"fill-mask",
"transformers",
"autotrain_compatible"
]
| fill-mask | false | ji-xin | null | ji-xin/roberta_base-MNLI-two_stage | 6 | null | transformers | 15,315 | Entry not found |
jky594176/recipe_bart2_v2 | 54e40195ecda775ffac09aca0eed3f1294b3947a | 2021-05-31T21:02:14.000Z | [
"pytorch",
"bart",
"text2text-generation",
"transformers",
"autotrain_compatible"
]
| text2text-generation | false | jky594176 | null | jky594176/recipe_bart2_v2 | 6 | null | transformers | 15,316 | Entry not found |
jsfoon/slogan-generator | 779c969b3ca6919bb4ffef76bcd30b13b4e1a453 | 2021-08-03T07:24:29.000Z | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
]
| text-generation | false | jsfoon | null | jsfoon/slogan-generator | 6 | null | transformers | 15,317 | Entry not found |
juliagsy/tapas_fine_tuning | 3afd8205f799b3aa6ef36d07b764b3e7fea44da3 | 2022-01-31T06:19:02.000Z | [
"pytorch",
"tapas",
"table-question-answering",
"transformers"
]
| table-question-answering | false | juliagsy | null | juliagsy/tapas_fine_tuning | 6 | null | transformers | 15,318 | Entry not found |
junnyu/ChineseBERT-large | 2d5b99d4d6dac134a951922c487ffd3f5478ac02 | 2022-04-21T06:47:54.000Z | [
"pytorch",
"bert",
"fill-mask",
"zh",
"arxiv:2106.16038",
"transformers",
"glycebert",
"autotrain_compatible"
]
| fill-mask | false | junnyu | null | junnyu/ChineseBERT-large | 6 | null | transformers | 15,319 | ---
language: zh
tags:
- glycebert
inference: False
---
# https://github.com/JunnYu/ChineseBert_pytorch
# ChineseBert_pytorch
本项目主要自定义了tokenization_chinesebert_fast.py文件中的ChineseBertTokenizerFast代码。从而可以从huggingface.co调用。
```python
pretrained_tokenizer_name = "junnyu/ChineseBERT-large"
tokenizer = ChineseBertTokenizerFast.from_pretrained(pretrained_tokenizer_name)
```
# Paper
**[ChineseBERT: Chinese Pretraining Enhanced by Glyph and Pinyin Information](https://arxiv.org/pdf/2106.16038.pdf)**
*Zijun Sun, Xiaoya Li, Xiaofei Sun, Yuxian Meng, Xiang Ao, Qing He, Fei Wu and Jiwei Li*
# Install
```bash
pip install chinesebert
or
pip install git+https://github.com/JunnYu/ChineseBert_pytorch.git
```
# Usage
```python
import torch
from chinesebert import ChineseBertForMaskedLM, ChineseBertTokenizerFast, ChineseBertConfig
pretrained_model_name = "junnyu/ChineseBERT-large"
tokenizer = ChineseBertTokenizerFast.from_pretrained(pretrained_model_name )
chinese_bert = ChineseBertForMaskedLM.from_pretrained(pretrained_model_name)
text = "北京是[MASK]国的首都。"
inputs = tokenizer(text, return_tensors="pt")
print(inputs)
maskpos = 4
with torch.no_grad():
o = chinese_bert(**inputs)
value, index = o.logits.softmax(-1)[0, maskpos].topk(10)
pred_tokens = tokenizer.convert_ids_to_tokens(index.tolist())
pred_values = value.tolist()
outputs = []
for t, p in zip(pred_tokens, pred_values):
outputs.append(f"{t}|{round(p,4)}")
print(outputs)
# base ['中|0.711', '我|0.2488', '祖|0.016', '法|0.0057', '美|0.0048', '全|0.0042', '韩|0.0015', '英|0.0011', '两|0.0008', '王|0.0006']
# large ['中|0.8341', '我|0.1479', '祖|0.0157', '全|0.0007', '国|0.0005', '帝|0.0001', '该|0.0001', '法|0.0001', '一|0.0001', '咱|0.0001']
```
# Reference
https://github.com/ShannonAI/ChineseBert |
junzai/demotest | d3b5544d5c20bd3c3585f7e7e35cdc2d3bfca104 | 2022-02-23T07:51:36.000Z | [
"pytorch",
"bert",
"text-classification",
"en",
"dataset:glue",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
]
| text-classification | false | junzai | null | junzai/demotest | 6 | null | transformers | 15,320 | ---
language:
- en
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
- f1
model-index:
- name: bert_finetuning_test
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: GLUE MRPC
type: glue
args: mrpc
metrics:
- name: Accuracy
type: accuracy
value: 0.8284313725490197
- name: F1
type: f1
value: 0.8817567567567567
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert_finetuning_test
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the GLUE MRPC dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4023
- Accuracy: 0.8284
- F1: 0.8818
- Combined Score: 0.8551
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1.0
### Training results
### Framework versions
- Transformers 4.16.0.dev0
- Pytorch 1.10.1+cu102
- Datasets 1.17.0
- Tokenizers 0.11.0
|
kalki7/distilgpt2-ratatouille | e7678f180b0f471d2d4b9eaa7507cde6382802df | 2021-05-23T06:11:59.000Z | [
"pytorch",
"jax",
"gpt2",
"text-generation",
"transformers"
]
| text-generation | false | kalki7 | null | kalki7/distilgpt2-ratatouille | 6 | null | transformers | 15,321 | Entry not found |
kdo6301/bert-base-uncased-finetuned-cola-2 | 212796c26f4901f79486bd3fa70f2189916659fd | 2022-02-22T15:19:32.000Z | [
"pytorch",
"tensorboard",
"bert",
"text-classification",
"dataset:glue",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
]
| text-classification | false | kdo6301 | null | kdo6301/bert-base-uncased-finetuned-cola-2 | 6 | null | transformers | 15,322 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- matthews_correlation
model-index:
- name: bert-base-uncased-finetuned-cola-2
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: cola
metrics:
- name: Matthews Correlation
type: matthews_correlation
value: 0.6015706950519473
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-finetuned-cola-2
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9235
- Matthews Correlation: 0.6016
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.4906 | 1.0 | 535 | 0.5046 | 0.5080 |
| 0.2901 | 2.0 | 1070 | 0.5881 | 0.5235 |
| 0.1818 | 3.0 | 1605 | 0.7253 | 0.5584 |
| 0.1177 | 4.0 | 2140 | 0.8316 | 0.5927 |
| 0.0826 | 5.0 | 2675 | 0.9235 | 0.6016 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.11.0
|
kdo6301/bert-base-uncased-finetuned-cola | 2d5c5981d59945dd21547ac8515c77b38510efda | 2022-02-20T08:16:24.000Z | [
"pytorch",
"tensorboard",
"bert",
"text-classification",
"dataset:glue",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
]
| text-classification | false | kdo6301 | null | kdo6301/bert-base-uncased-finetuned-cola | 6 | null | transformers | 15,323 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- matthews_correlation
model-index:
- name: bert-base-uncased-finetuned-cola
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: cola
metrics:
- name: Matthews Correlation
type: matthews_correlation
value: 0.5640063794282216
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-finetuned-cola
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9089
- Matthews Correlation: 0.5640
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.4864 | 1.0 | 535 | 0.4689 | 0.5232 |
| 0.2864 | 2.0 | 1070 | 0.5835 | 0.5296 |
| 0.1884 | 3.0 | 1605 | 0.6953 | 0.5458 |
| 0.1263 | 4.0 | 2140 | 0.8082 | 0.5625 |
| 0.0832 | 5.0 | 2675 | 0.9089 | 0.5640 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.11.0
|
khanh98/model3 | af70a300c099daf36ad69405048aec5a5cb9e010 | 2021-05-20T17:35:31.000Z | [
"pytorch",
"tf",
"jax",
"roberta",
"text-classification",
"transformers"
]
| text-classification | false | khanh98 | null | khanh98/model3 | 6 | null | transformers | 15,324 | Entry not found |
kinit/slovakbert-pos | ae2a32703edde4ad1308c3a6988765a82b61bf36 | 2021-11-29T17:33:05.000Z | [
"pytorch",
"roberta",
"token-classification",
"sk",
"dataset:universal_dependencies",
"arxiv:2109.15254",
"transformers",
"pos",
"license:cc",
"autotrain_compatible"
]
| token-classification | false | kinit | null | kinit/slovakbert-pos | 6 | null | transformers | 15,325 | ---
language:
- sk
tags:
- pos
license: cc
datasets:
- universal_dependencies
metrics:
- accuracy
widget:
- text: "Kde tá ľudská duša drieme?"
---
# POS tagger based on SlovakBERT
This is a POS tagger based on [SlovakBERT](https://huggingface.co/gerulata/slovakbert). The model uses [Universal POS tagset (UPOS)](https://universaldependencies.org/u/pos/). The model was fine-tuned using Slovak part of [Universal Dependencies dataset](https://universaldependencies.org/) [Zeman 2017] containing 10k manually annotated Slovak sentences.
## Results
The model was evaluated in [our paper](https://arxiv.org/abs/2109.15254) [Pikuliak et al 2021, Section 4.2]. It achieves \\(97.84\%\\) accuracy.
## Cite
```
@article{DBLP:journals/corr/abs-2109-15254,
author = {Mat{\'{u}}{\v{s}} Pikuliak and
{\v{S}}tefan Grivalsk{\'{y}} and
Martin Kon{\^{o}}pka and
Miroslav Bl{\v{s}}t{\'{a}}k and
Martin Tamajka and
Viktor Bachrat{\'{y}} and
Mari{\'{a}}n {\v{S}}imko and
Pavol Bal{\'{a}}{\v{z}}ik and
Michal Trnka and
Filip Uhl{\'{a}}rik},
title = {SlovakBERT: Slovak Masked Language Model},
journal = {CoRR},
volume = {abs/2109.15254},
year = {2021},
url = {https://arxiv.org/abs/2109.15254},
eprinttype = {arXiv},
eprint = {2109.15254},
}
``` |
kinit/slovakbert-sts-stsb | dab601ddd72fde4c7a2422220798f1744c961ab1 | 2021-11-30T10:50:32.000Z | [
"pytorch",
"roberta",
"feature-extraction",
"sk",
"dataset:glue",
"arxiv:2109.15254",
"sentence-transformers",
"sentence-similarity",
"sts",
"license:cc"
]
| sentence-similarity | false | kinit | null | kinit/slovakbert-sts-stsb | 6 | null | sentence-transformers | 15,326 | ---
language:
- sk
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- sts
license: cc
datasets:
- glue
metrics:
- spearmanr
widget:
source_sentence: "Izrael uskutočnil letecké údery v blízkosti Damasku."
sentences:
- "Izrael uskutočnil vzdušný útok na Sýriu."
- "Pes leží na gauči a má hlavu na bielom vankúši."
---
# Sentence similarity model based on SlovakBERT
This is a sentence similarity model based on [SlovakBERT](https://huggingface.co/gerulata/slovakbert). The model was fine-tuned using [STSbenchmark](ixa2.si.ehu.eus/stswiki/index.php/STSbenchmark) [Cer et al 2017] translated to Slovak using [M2M100](https://huggingface.co/facebook/m2m100_1.2B). The model can be used as an universal sentence encoder for Slovak sentences.
## Results
The model was evaluated in [our paper](https://arxiv.org/abs/2109.15254) [Pikuliak et al 2021, Section 4.3]. It achieves \\(0.791\\) Spearman correlation on STSbenchmark test set.
## Usage
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('kinit/slovakbert-sts-stsb')
embeddings = model.encode(sentences)
print(embeddings)
```
## Cite
```
@article{DBLP:journals/corr/abs-2109-15254,
author = {Mat{\'{u}}s Pikuliak and
Stefan Grivalsky and
Martin Konopka and
Miroslav Blst{\'{a}}k and
Martin Tamajka and
Viktor Bachrat{\'{y}} and
Mari{\'{a}}n Simko and
Pavol Bal{\'{a}}zik and
Michal Trnka and
Filip Uhl{\'{a}}rik},
title = {SlovakBERT: Slovak Masked Language Model},
journal = {CoRR},
volume = {abs/2109.15254},
year = {2021},
url = {https://arxiv.org/abs/2109.15254},
eprinttype = {arXiv},
eprint = {2109.15254},
}
```
|
krevas/finance-koelectra-base-discriminator | 61896165065ee9a116704f7ae20b1d088fe1a3a7 | 2020-12-11T21:48:27.000Z | [
"pytorch",
"electra",
"pretraining",
"ko",
"transformers"
]
| null | false | krevas | null | krevas/finance-koelectra-base-discriminator | 6 | null | transformers | 15,327 | ---
language: ko
---
# 📈 Financial Korean ELECTRA model
Pretrained ELECTRA Language Model for Korean (`finance-koelectra-base-discriminator`)
> ELECTRA is a new method for self-supervised language representation learning. It can be used to
> pre-train transformer networks using relatively little compute. ELECTRA models are trained to
> distinguish "real" input tokens vs "fake" input tokens generated by another neural network, similar to
> the discriminator of a GAN.
More details about ELECTRA can be found in the [ICLR paper](https://openreview.net/forum?id=r1xMH1BtvB)
or in the [official ELECTRA repository](https://github.com/google-research/electra) on GitHub.
## Stats
The current version of the model is trained on a financial news data of Naver news.
The final training corpus has a size of 25GB and 2.3B tokens.
This model was trained a cased model on a TITAN RTX for 500k steps.
## Usage
```python
from transformers import ElectraForPreTraining, ElectraTokenizer
import torch
discriminator = ElectraForPreTraining.from_pretrained("krevas/finance-koelectra-base-discriminator")
tokenizer = ElectraTokenizer.from_pretrained("krevas/finance-koelectra-base-discriminator")
sentence = "내일 해당 종목이 대폭 상승할 것이다"
fake_sentence = "내일 해당 종목이 맛있게 상승할 것이다"
fake_tokens = tokenizer.tokenize(fake_sentence)
fake_inputs = tokenizer.encode(fake_sentence, return_tensors="pt")
discriminator_outputs = discriminator(fake_inputs)
predictions = torch.round((torch.sign(discriminator_outputs[0]) + 1) / 2)
[print("%7s" % token, end="") for token in fake_tokens]
[print("%7s" % int(prediction), end="") for prediction in predictions.tolist()[1:-1]]
print("fake token : %s" % fake_tokens[predictions.tolist()[1:-1].index(1)])
```
# Huggingface model hub
All models are available on the [Huggingface model hub](https://huggingface.co/krevas).
|
lewtun/bert-finetuned-squad | 1515b8b9cd5a7b53df2c32d8f3553b8a78d54484 | 2022-05-23T09:53:09.000Z | [
"pytorch",
"tensorboard",
"bert",
"question-answering",
"dataset:squad",
"dataset:lewtun/autoevaluate__squad",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
]
| question-answering | false | lewtun | null | lewtun/bert-finetuned-squad | 6 | null | transformers | 15,328 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
- lewtun/autoevaluate__squad
model-index:
- name: bert-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-finetuned-squad
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.12.3
- Pytorch 1.10.0+cu111
- Datasets 1.15.1
- Tokenizers 0.10.3
|
lfcc/bert-large-pt-archive | 48da7224875afe4d3b07b3dceb475e796250c230 | 2021-12-11T19:01:44.000Z | [
"pytorch",
"tensorboard",
"bert",
"token-classification",
"transformers",
"generated_from_trainer",
"license:mit",
"autotrain_compatible"
]
| token-classification | false | lfcc | null | lfcc/bert-large-pt-archive | 6 | null | transformers | 15,329 | ---
license: mit
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model_index:
- name: bert-large-pt-archive
results:
- task:
name: Token Classification
type: token-classification
metric:
name: Accuracy
type: accuracy
value: 0.9766762474673703
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-large-pt-archive
This model is a fine-tuned version of [neuralmind/bert-large-portuguese-cased](https://huggingface.co/neuralmind/bert-large-portuguese-cased) on an unkown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0869
- Precision: 0.9280
- Recall: 0.9541
- F1: 0.9409
- Accuracy: 0.9767
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.0665 | 1.0 | 765 | 0.1020 | 0.8928 | 0.9566 | 0.9236 | 0.9696 |
| 0.0392 | 2.0 | 1530 | 0.0781 | 0.9229 | 0.9586 | 0.9404 | 0.9757 |
| 0.0201 | 3.0 | 2295 | 0.0809 | 0.9278 | 0.9550 | 0.9412 | 0.9767 |
| 0.0152 | 4.0 | 3060 | 0.0869 | 0.9280 | 0.9541 | 0.9409 | 0.9767 |
### Framework versions
- Transformers 4.10.0.dev0
- Pytorch 1.9.0+cu111
- Datasets 1.10.2
- Tokenizers 0.10.3
|
lgris/bp500-base100k_voxpopuli | 277048a53edff0a97c6b81f5e37cdf20a98e6be1 | 2022-02-07T11:53:19.000Z | [
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"pt",
"dataset:common_voice",
"dataset:mls",
"dataset:cetuc",
"dataset:lapsbm",
"dataset:voxforge",
"dataset:tedx",
"dataset:sid",
"arxiv:2012.03411",
"transformers",
"audio",
"speech",
"portuguese-speech-corpus",
"PyTorch",
"license:apache-2.0"
]
| automatic-speech-recognition | false | lgris | null | lgris/bp500-base100k_voxpopuli | 6 | null | transformers | 15,330 | ---
language: pt
datasets:
- common_voice
- mls
- cetuc
- lapsbm
- voxforge
- tedx
- sid
metrics:
- wer
tags:
- audio
- speech
- wav2vec2
- pt
- portuguese-speech-corpus
- automatic-speech-recognition
- speech
- PyTorch
license: apache-2.0
---
# bp500-base100k_voxpopuli: Wav2vec 2.0 with Brazilian Portuguese (BP) Dataset
This is a the demonstration of a fine-tuned Wav2vec model for Brazilian Portuguese using the following datasets:
- [CETUC](http://www02.smt.ufrj.br/~igor.quintanilha/alcaim.tar.gz): contains approximately 145 hours of Brazilian Portuguese speech distributed among 50 male and 50 female speakers, each pronouncing approximately 1,000 phonetically balanced sentences selected from the [CETEN-Folha](https://www.linguateca.pt/cetenfolha/) corpus.
- [Common Voice 7.0](https://commonvoice.mozilla.org/pt): is a project proposed by Mozilla Foundation with the goal to create a wide open dataset in different languages. In this project, volunteers donate and validate speech using the [oficial site](https://commonvoice.mozilla.org/pt).
- [Lapsbm](https://github.com/falabrasil/gitlab-resources): "Falabrasil - UFPA" is a dataset used by the Fala Brasil group to benchmark ASR systems in Brazilian Portuguese. Contains 35 speakers (10 females), each one pronouncing 20 unique sentences, totalling 700 utterances in Brazilian Portuguese. The audios were recorded in 22.05 kHz without environment control.
- [Multilingual Librispeech (MLS)](https://arxiv.org/abs/2012.03411): a massive dataset available in many languages. The MLS is based on audiobook recordings in public domain like [LibriVox](https://librivox.org/). The dataset contains a total of 6k hours of transcribed data in many languages. The set in Portuguese [used in this work](http://www.openslr.org/94/) (mostly Brazilian variant) has approximately 284 hours of speech, obtained from 55 audiobooks read by 62 speakers.
- [Multilingual TEDx](http://www.openslr.org/100): a collection of audio recordings from TEDx talks in 8 source languages. The Portuguese set (mostly Brazilian Portuguese variant) contains 164 hours of transcribed speech.
- [Sidney](https://igormq.github.io/datasets/) (SID): contains 5,777 utterances recorded by 72 speakers (20 women) from 17 to 59 years old with fields such as place of birth, age, gender, education, and occupation;
- [VoxForge](http://www.voxforge.org/): is a project with the goal to build open datasets for acoustic models. The corpus contains approximately 100 speakers and 4,130 utterances of Brazilian Portuguese, with sample rates varying from 16kHz to 44.1kHz.
These datasets were combined to build a larger Brazilian Portuguese dataset. All data was used for training except Common Voice dev/test sets, that were used for validation/test respectively. We also made test sets for all the gathered datasets.
| Dataset | Train | Valid | Test |
|--------------------------------|-------:|------:|------:|
| CETUC | 94.0h | -- | 5.4h |
| Common Voice | 37.8h | 8.9h | 9.5h |
| LaPS BM | 0.8h | -- | 0.1h |
| MLS | 161.0h | -- | 3.7h |
| Multilingual TEDx (Portuguese) | 148.9h | -- | 1.8h |
| SID | 7.2h | -- | 1.0h |
| VoxForge | 3.9h | -- | 0.1h |
| Total | 453.6h | 8.9h | 21.6h |
The original model was fine-tuned using [fairseq](https://github.com/pytorch/fairseq). This notebook uses a converted version of the original one. The link to the original fairseq model is available [here](https://drive.google.com/file/d/10iESR5AQxuxF5F7w3wLbpc_9YMsYbY9H/view?usp=sharing).
#### Summary
| | CETUC | CV | LaPS | MLS | SID | TEDx | VF | AVG |
|----------------------|---------------|----------------|----------------|----------------|----------------|----------------|----------------|----------------|
| bp\_500-base100k_voxpopuli (demonstration below) | 0.142 | 0.201 | 0.052 | 0.224 | 0.102 | 0.317 | 0.048 | 0.155 |
| bp\_500-base100k_voxpopuli + 4-gram (demonstration below) | 0.099 | 0.149 | 0.047 | 0.192 | 0.115 | 0.371 | 0.127 | 0.157 |
#### Transcription examples
| Text | Transcription |
|------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------|
|qual o instagram dele|**qualo** **está** **gramedele**|
|o capitão foi expulso do exército porque era doido|o **capitãl** foi **exposo** do exército porque era doido|
|também por que não|também **porque** não|
|não existe tempo como o presente|não existe tempo como *o* presente|
|eu pulei para salvar rachel|eu pulei para salvar **haquel**|
|augusto cezar passos marinho|augusto **cesa** **passoesmarinho**|
## Demonstration
```python
MODEL_NAME = "lgris/bp500-base100k_voxpopuli"
```
### Imports and dependencies
```python
%%capture
!pip install torch==1.8.2+cu111 torchvision==0.9.2+cu111 torchaudio===0.8.2 -f https://download.pytorch.org/whl/lts/1.8/torch_lts.html
!pip install datasets
!pip install jiwer
!pip install transformers
!pip install soundfile
!pip install pyctcdecode
!pip install https://github.com/kpu/kenlm/archive/master.zip
```
```python
import jiwer
import torchaudio
from datasets import load_dataset, load_metric
from transformers import (
Wav2Vec2ForCTC,
Wav2Vec2Processor,
)
from pyctcdecode import build_ctcdecoder
import torch
import re
import sys
```
### Helpers
```python
chars_to_ignore_regex = '[\,\?\.\!\;\:\"]' # noqa: W605
def map_to_array(batch):
speech, _ = torchaudio.load(batch["path"])
batch["speech"] = speech.squeeze(0).numpy()
batch["sampling_rate"] = 16_000
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower().replace("’", "'")
batch["target"] = batch["sentence"]
return batch
```
```python
def calc_metrics(truths, hypos):
wers = []
mers = []
wils = []
for t, h in zip(truths, hypos):
try:
wers.append(jiwer.wer(t, h))
mers.append(jiwer.mer(t, h))
wils.append(jiwer.wil(t, h))
except: # Empty string?
pass
wer = sum(wers)/len(wers)
mer = sum(mers)/len(mers)
wil = sum(wils)/len(wils)
return wer, mer, wil
```
```python
def load_data(dataset):
data_files = {'test': f'{dataset}/test.csv'}
dataset = load_dataset('csv', data_files=data_files)["test"]
return dataset.map(map_to_array)
```
### Model
```python
class STT:
def __init__(self,
model_name,
device='cuda' if torch.cuda.is_available() else 'cpu',
lm=None):
self.model_name = model_name
self.model = Wav2Vec2ForCTC.from_pretrained(model_name).to(device)
self.processor = Wav2Vec2Processor.from_pretrained(model_name)
self.vocab_dict = self.processor.tokenizer.get_vocab()
self.sorted_dict = {
k.lower(): v for k, v in sorted(self.vocab_dict.items(),
key=lambda item: item[1])
}
self.device = device
self.lm = lm
if self.lm:
self.lm_decoder = build_ctcdecoder(
list(self.sorted_dict.keys()),
self.lm
)
def batch_predict(self, batch):
features = self.processor(batch["speech"],
sampling_rate=batch["sampling_rate"][0],
padding=True,
return_tensors="pt")
input_values = features.input_values.to(self.device)
with torch.no_grad():
logits = self.model(input_values).logits
if self.lm:
logits = logits.cpu().numpy()
batch["predicted"] = []
for sample_logits in logits:
batch["predicted"].append(self.lm_decoder.decode(sample_logits))
else:
pred_ids = torch.argmax(logits, dim=-1)
batch["predicted"] = self.processor.batch_decode(pred_ids)
return batch
```
### Download datasets
```python
%%capture
!gdown --id 1HFECzIizf-bmkQRLiQD0QVqcGtOG5upI
!mkdir bp_dataset
!unzip bp_dataset -d bp_dataset/
```
```python
%cd bp_dataset
```
/content/bp_dataset
### Tests
```python
stt = STT(MODEL_NAME)
```
#### CETUC
```python
ds = load_data('cetuc_dataset')
result = ds.map(stt.batch_predict, batched=True, batch_size=8)
wer, mer, wil = calc_metrics(result["sentence"], result["predicted"])
print("CETUC WER:", wer)
```
CETUC WER: 0.1419179499917191
#### Common Voice
```python
ds = load_data('commonvoice_dataset')
result = ds.map(stt.batch_predict, batched=True, batch_size=8)
wer, mer, wil = calc_metrics(result["sentence"], result["predicted"])
print("CV WER:", wer)
```
CV WER: 0.20079950312040154
#### LaPS
```python
ds = load_data('lapsbm_dataset')
result = ds.map(stt.batch_predict, batched=True, batch_size=8)
wer, mer, wil = calc_metrics(result["sentence"], result["predicted"])
print("Laps WER:", wer)
```
Laps WER: 0.052780934343434324
#### MLS
```python
ds = load_data('mls_dataset')
result = ds.map(stt.batch_predict, batched=True, batch_size=8)
wer, mer, wil = calc_metrics(result["sentence"], result["predicted"])
print("MLS WER:", wer)
```
MLS WER: 0.22413887199364113
#### SID
```python
ds = load_data('sid_dataset')
result = ds.map(stt.batch_predict, batched=True, batch_size=8)
wer, mer, wil = calc_metrics(result["sentence"], result["predicted"])
print("Sid WER:", wer)
```
Sid WER: 0.1019041538671034
#### TEDx
```python
ds = load_data('tedx_dataset')
result = ds.map(stt.batch_predict, batched=True, batch_size=8)
wer, mer, wil = calc_metrics(result["sentence"], result["predicted"])
print("TEDx WER:", wer)
```
TEDx WER: 0.31711268778273327
#### VoxForge
```python
ds = load_data('voxforge_dataset')
result = ds.map(stt.batch_predict, batched=True, batch_size=8)
wer, mer, wil = calc_metrics(result["sentence"], result["predicted"])
print("VoxForge WER:", wer)
```
VoxForge WER: 0.04826433982683982
### Tests with LM
```python
!rm -rf ~/.cache
!gdown --id 1GJIKseP5ZkTbllQVgOL98R4yYAcIySFP # trained with wikipedia
stt = STT(MODEL_NAME, lm='pt-BR-wiki.word.4-gram.arpa')
# !gdown --id 1dLFldy7eguPtyJj5OAlI4Emnx0BpFywg # trained with bp
# stt = STT(MODEL_NAME, lm='pt-BR.word.4-gram.arpa')
```
### Cetuc
```python
ds = load_data('cetuc_dataset')
result = ds.map(stt.batch_predict, batched=True, batch_size=8)
wer, mer, wil = calc_metrics(result["sentence"], result["predicted"])
print("CETUC WER:", wer)
```
CETUC WER: 0.099518615112877
#### Common Voice
```python
ds = load_data('commonvoice_dataset')
result = ds.map(stt.batch_predict, batched=True, batch_size=8)
wer, mer, wil = calc_metrics(result["sentence"], result["predicted"])
print("CV WER:", wer)
```
CV WER: 0.1488912889506362
#### LaPS
```python
ds = load_data('lapsbm_dataset')
result = ds.map(stt.batch_predict, batched=True, batch_size=8)
wer, mer, wil = calc_metrics(result["sentence"], result["predicted"])
print("Laps WER:", wer)
```
Laps WER: 0.047080176767676764
#### MLS
```python
ds = load_data('mls_dataset')
result = ds.map(stt.batch_predict, batched=True, batch_size=8)
wer, mer, wil = calc_metrics(result["sentence"], result["predicted"])
print("MLS WER:", wer)
```
MLS WER: 0.19220291966887196
#### SID
```python
ds = load_data('sid_dataset')
result = ds.map(stt.batch_predict, batched=True, batch_size=8)
wer, mer, wil = calc_metrics(result["sentence"], result["predicted"])
print("Sid WER:", wer)
```
Sid WER: 0.11535498771650306
#### TEDx
```python
ds = load_data('tedx_dataset')
result = ds.map(stt.batch_predict, batched=True, batch_size=8)
wer, mer, wil = calc_metrics(result["sentence"], result["predicted"])
print("TEDx WER:", wer)
```
TEDx WER: 0.3707890073539895
#### VoxForge
```python
ds = load_data('voxforge_dataset')
result = ds.map(stt.batch_predict, batched=True, batch_size=8)
wer, mer, wil = calc_metrics(result["sentence"], result["predicted"])
print("VoxForge WER:", wer)
```
VoxForge WER: 0.12682088744588746
|
lian01110/bert_finetuning_test | b78b1666575218030c5735b8278e5c8d8b183e15 | 2021-05-19T21:59:22.000Z | [
"pytorch",
"jax",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
]
| fill-mask | false | lian01110 | null | lian01110/bert_finetuning_test | 6 | null | transformers | 15,331 | Entry not found |
lincoln/camembert-squadFR-fquad-piaf-answer-extraction | 59d069129b84f5bb163252528bc7ecc5e0f6a3b3 | 2021-10-11T15:01:04.000Z | [
"pytorch",
"camembert",
"token-classification",
"fr",
"dataset:squadFR",
"dataset:fquad",
"dataset:piaf",
"transformers",
"answer extraction",
"license:mit",
"autotrain_compatible"
]
| token-classification | false | lincoln | null | lincoln/camembert-squadFR-fquad-piaf-answer-extraction | 6 | null | transformers | 15,332 | ---
language:
- fr
license: mit
datasets:
- squadFR
- fquad
- piaf
tags:
- camembert
- answer extraction
---
# Extraction de réponse
Ce modèle est _fine tuné_ à partir du modèle [camembert-base](https://huggingface.co/camembert-base) pour la tâche de classification de tokens.
L'objectif est d'identifier les suites de tokens probables qui pourrait être l'objet d'une question.
## Données d'apprentissage
La base d'entrainement est la concatenation des bases SquadFR, [fquad](https://huggingface.co/datasets/fquad), [piaf](https://huggingface.co/datasets/piaf).
Les réponses de chaque contexte ont été labelisées avec le label "ANS".
Volumétrie (nombre de contexte):
* train: 24 652
* test: 1 370
* valid: 1 370
## Entrainement
L'apprentissage s'est effectué sur une carte Tesla K80.
* Batch size: 16
* Weight decay: 0.01
* Learning rate: 2x10-5 (décroit linéairement)
* Paramètres par défaut de la classe [TrainingArguments](https://huggingface.co/transformers/main_classes/trainer.html#trainingarguments)
* Total steps: 1 000
Le modèle semble sur apprendre au delà :

## Critiques
Le modèle n'a pas de bonnes performances et doit être corrigé après prédiction pour être cohérent. La tâche de classification n'est pas évidente car le modèle doit identifier des groupes de token _sachant_ qu'une question peut être posée.

## Utilisation
_Le modèle est un POC, nous garantissons pas ses performances_
```python
from transformers import AutoTokenizer, AutoModelForTokenClassification
import numpy as np
model_name = "lincoln/camembert-squadFR-fquad-piaf-answer-extraction"
loaded_tokenizer = AutoTokenizer.from_pretrained(model_path)
loaded_model = AutoModelForTokenClassification.from_pretrained(model_path)
text = "La science des données est un domaine interdisciplinaire qui utilise des méthodes, des processus,\
des algorithmes et des systèmes scientifiques pour extraire des connaissances et des idées de nombreuses données structurelles et non structurées.\
Elle est souvent associée aux données massives et à l'analyse des données."
inputs = loaded_tokenizer(text, return_tensors="pt", return_offsets_mapping=True)
outputs = loaded_model(inputs.input_ids).logits
probs = 1 / (1 + np.exp(-outputs.detach().numpy()))
probs[:, :, 1][0] = np.convolve(probs[:, :, 1][0], np.ones(2), 'same') / 2
sentences = loaded_tokenizer.tokenize(text, add_special_tokens=False)
prob_answer_tokens = probs[:, 1:-1, 1].flatten().tolist()
offset_start_mapping = inputs.offset_mapping[:, 1:-1, 0].flatten().tolist()
offset_end_mapping = inputs.offset_mapping[:, 1:-1, 1].flatten().tolist()
threshold = 0.4
entities = []
for ix, (token, prob_ans, offset_start, offset_end) in enumerate(zip(sentences, prob_answer_tokens, offset_start_mapping, offset_end_mapping)):
entities.append({
'entity': 'ANS' if prob_ans > threshold else 'O',
'score': prob_ans,
'index': ix,
'word': token,
'start': offset_start,
'end': offset_end
})
for p in entities:
print(p)
# {'entity': 'O', 'score': 0.3118681311607361, 'index': 0, 'word': '▁La', 'start': 0, 'end': 2}
# {'entity': 'O', 'score': 0.37866950035095215, 'index': 1, 'word': '▁science', 'start': 3, 'end': 10}
# {'entity': 'ANS', 'score': 0.45018652081489563, 'index': 2, 'word': '▁des', 'start': 11, 'end': 14}
# {'entity': 'ANS', 'score': 0.4615934491157532, 'index': 3, 'word': '▁données', 'start': 15, 'end': 22}
# {'entity': 'O', 'score': 0.35033443570137024, 'index': 4, 'word': '▁est', 'start': 23, 'end': 26}
# {'entity': 'O', 'score': 0.24779987335205078, 'index': 5, 'word': '▁un', 'start': 27, 'end': 29}
# {'entity': 'O', 'score': 0.27084410190582275, 'index': 6, 'word': '▁domaine', 'start': 30, 'end': 37}
# {'entity': 'O', 'score': 0.3259460926055908, 'index': 7, 'word': '▁in', 'start': 38, 'end': 40}
# {'entity': 'O', 'score': 0.371802419424057, 'index': 8, 'word': 'terdisciplinaire', 'start': 40, 'end': 56}
# {'entity': 'O', 'score': 0.3140853941440582, 'index': 9, 'word': '▁qui', 'start': 57, 'end': 60}
# {'entity': 'O', 'score': 0.2629334330558777, 'index': 10, 'word': '▁utilise', 'start': 61, 'end': 68}
# {'entity': 'O', 'score': 0.2968383729457855, 'index': 11, 'word': '▁des', 'start': 69, 'end': 72}
# {'entity': 'O', 'score': 0.33898216485977173, 'index': 12, 'word': '▁méthodes', 'start': 73, 'end': 81}
# {'entity': 'O', 'score': 0.3776060938835144, 'index': 13, 'word': ',', 'start': 81, 'end': 82}
# {'entity': 'O', 'score': 0.3710060119628906, 'index': 14, 'word': '▁des', 'start': 83, 'end': 86}
# {'entity': 'O', 'score': 0.35908180475234985, 'index': 15, 'word': '▁processus', 'start': 87, 'end': 96}
# {'entity': 'O', 'score': 0.3890596628189087, 'index': 16, 'word': ',', 'start': 96, 'end': 97}
# {'entity': 'O', 'score': 0.38341325521469116, 'index': 17, 'word': '▁des', 'start': 101, 'end': 104}
# {'entity': 'O', 'score': 0.3743852376937866, 'index': 18, 'word': '▁', 'start': 105, 'end': 106}
# {'entity': 'O', 'score': 0.3943936228752136, 'index': 19, 'word': 'algorithme', 'start': 105, 'end': 115}
# {'entity': 'O', 'score': 0.39456743001937866, 'index': 20, 'word': 's', 'start': 115, 'end': 116}
# {'entity': 'O', 'score': 0.3846966624259949, 'index': 21, 'word': '▁et', 'start': 117, 'end': 119}
# {'entity': 'O', 'score': 0.367380827665329, 'index': 22, 'word': '▁des', 'start': 120, 'end': 123}
# {'entity': 'O', 'score': 0.3652925491333008, 'index': 23, 'word': '▁systèmes', 'start': 124, 'end': 132}
# {'entity': 'O', 'score': 0.3975735306739807, 'index': 24, 'word': '▁scientifiques', 'start': 133, 'end': 146}
# {'entity': 'O', 'score': 0.36417365074157715, 'index': 25, 'word': '▁pour', 'start': 147, 'end': 151}
# {'entity': 'O', 'score': 0.32438698410987854, 'index': 26, 'word': '▁extraire', 'start': 152, 'end': 160}
# {'entity': 'O', 'score': 0.3416857123374939, 'index': 27, 'word': '▁des', 'start': 161, 'end': 164}
# {'entity': 'O', 'score': 0.3674810230731964, 'index': 28, 'word': '▁connaissances', 'start': 165, 'end': 178}
# {'entity': 'O', 'score': 0.38362061977386475, 'index': 29, 'word': '▁et', 'start': 179, 'end': 181}
# {'entity': 'O', 'score': 0.364640474319458, 'index': 30, 'word': '▁des', 'start': 182, 'end': 185}
# {'entity': 'O', 'score': 0.36050117015838623, 'index': 31, 'word': '▁idées', 'start': 186, 'end': 191}
# {'entity': 'O', 'score': 0.3768993020057678, 'index': 32, 'word': '▁de', 'start': 192, 'end': 194}
# {'entity': 'O', 'score': 0.39184248447418213, 'index': 33, 'word': '▁nombreuses', 'start': 195, 'end': 205}
# {'entity': 'ANS', 'score': 0.4091200828552246, 'index': 34, 'word': '▁données', 'start': 206, 'end': 213}
# {'entity': 'ANS', 'score': 0.41234123706817627, 'index': 35, 'word': '▁structurelle', 'start': 214, 'end': 226}
# {'entity': 'ANS', 'score': 0.40243157744407654, 'index': 36, 'word': 's', 'start': 226, 'end': 227}
# {'entity': 'ANS', 'score': 0.4007353186607361, 'index': 37, 'word': '▁et', 'start': 228, 'end': 230}
# {'entity': 'ANS', 'score': 0.40597623586654663, 'index': 38, 'word': '▁non', 'start': 231, 'end': 234}
# {'entity': 'ANS', 'score': 0.40272021293640137, 'index': 39, 'word': '▁structurée', 'start': 235, 'end': 245}
# {'entity': 'O', 'score': 0.392631471157074, 'index': 40, 'word': 's', 'start': 245, 'end': 246}
# {'entity': 'O', 'score': 0.34266412258148193, 'index': 41, 'word': '.', 'start': 246, 'end': 247}
# {'entity': 'O', 'score': 0.26178646087646484, 'index': 42, 'word': '▁Elle', 'start': 255, 'end': 259}
# {'entity': 'O', 'score': 0.2265639454126358, 'index': 43, 'word': '▁est', 'start': 260, 'end': 263}
# {'entity': 'O', 'score': 0.22844195365905762, 'index': 44, 'word': '▁souvent', 'start': 264, 'end': 271}
# {'entity': 'O', 'score': 0.2475772500038147, 'index': 45, 'word': '▁associée', 'start': 272, 'end': 280}
# {'entity': 'O', 'score': 0.3002186715602875, 'index': 46, 'word': '▁aux', 'start': 281, 'end': 284}
# {'entity': 'O', 'score': 0.3875720798969269, 'index': 47, 'word': '▁données', 'start': 285, 'end': 292}
# {'entity': 'ANS', 'score': 0.445063054561615, 'index': 48, 'word': '▁massive', 'start': 293, 'end': 300}
# {'entity': 'ANS', 'score': 0.4419114589691162, 'index': 49, 'word': 's', 'start': 300, 'end': 301}
# {'entity': 'ANS', 'score': 0.4240635633468628, 'index': 50, 'word': '▁et', 'start': 302, 'end': 304}
# {'entity': 'O', 'score': 0.3900952935218811, 'index': 51, 'word': '▁à', 'start': 305, 'end': 306}
# {'entity': 'O', 'score': 0.3784807324409485, 'index': 52, 'word': '▁l', 'start': 307, 'end': 308}
# {'entity': 'O', 'score': 0.3459452986717224, 'index': 53, 'word': "'", 'start': 308, 'end': 309}
# {'entity': 'O', 'score': 0.37636008858680725, 'index': 54, 'word': 'analyse', 'start': 309, 'end': 316}
# {'entity': 'ANS', 'score': 0.4475618302822113, 'index': 55, 'word': '▁des', 'start': 317, 'end': 320}
# {'entity': 'ANS', 'score': 0.43845775723457336, 'index': 56, 'word': '▁données', 'start': 321, 'end': 328}
# {'entity': 'O', 'score': 0.3761221170425415, 'index': 57, 'word': '.', 'start': 328, 'end': 329}
```
|
luffycodes/TAG_mems_str_128_lr_2e5_wd_01_block_512_train_bsz_6_topk_100_lambdah_dot05_w103 | 6082668e615f4be0bd1dfa1d6e459467a8156ff7 | 2021-07-02T02:19:09.000Z | [
"pytorch",
"transfo-xl",
"transformers"
]
| null | false | luffycodes | null | luffycodes/TAG_mems_str_128_lr_2e5_wd_01_block_512_train_bsz_6_topk_100_lambdah_dot05_w103 | 6 | null | transformers | 15,333 | Entry not found |
luffycodes/bb_narataka_roberta_large_nli_bsz_24_bb_bsz_24_nli_lr_1e5_bb_lr_1e5_wu_7k_grad_adam_mask | c2ef1ec1646418042bf457c55be3bd276d7ca914 | 2021-10-30T08:19:57.000Z | [
"pytorch",
"roberta",
"transformers"
]
| null | false | luffycodes | null | luffycodes/bb_narataka_roberta_large_nli_bsz_24_bb_bsz_24_nli_lr_1e5_bb_lr_1e5_wu_7k_grad_adam_mask | 6 | null | transformers | 15,334 | Entry not found |
luffycodes/om_sm_nl_roberta_mnli_lr5e6_ep_5.model | 688e6528dcb8144751054148fc1b8b21d0182932 | 2021-12-10T03:12:17.000Z | [
"pytorch",
"roberta",
"transformers"
]
| null | false | luffycodes | null | luffycodes/om_sm_nl_roberta_mnli_lr5e6_ep_5.model | 6 | null | transformers | 15,335 | Entry not found |
m3hrdadfi/bert-fa-base-uncased-wikinli | c9f971d46f00cd29ab3f740146e7a3fd2ce16ddc | 2021-05-28T06:01:35.000Z | [
"pytorch",
"jax",
"bert",
"text-classification",
"fa",
"transformers",
"license:apache-2.0"
]
| text-classification | false | m3hrdadfi | null | m3hrdadfi/bert-fa-base-uncased-wikinli | 6 | 2 | transformers | 15,336 | ---
language: fa
license: apache-2.0
---
# ParsBERT + Sentence Transformers
Please follow the [Sentence-Transformer](https://github.com/m3hrdadfi/sentence-transformers) repo for the latest information about previous and current models.
```bibtex
@misc{SentenceTransformerWiki,
author = {Mehrdad Farahani},
title = {Sentence Embeddings with ParsBERT},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {https://github.com/m3hrdadfi/sentence-transformers},
}
``` |
m3hrdadfi/roberta-zwnj-wnli-mean-tokens | 36f912ac44e22250aee16ea533a4ff8cd848c1a1 | 2021-06-28T17:40:23.000Z | [
"pytorch",
"roberta",
"feature-extraction",
"sentence-transformers",
"sentence-similarity",
"transformers"
]
| feature-extraction | false | m3hrdadfi | null | m3hrdadfi/roberta-zwnj-wnli-mean-tokens | 6 | null | sentence-transformers | 15,337 | ---
pipeline_tag: feature-extraction
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# Sentence Embeddings with `roberta-zwnj-wnli-mean-tokens`
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = [
'اولین حکمران شهر بابل کی بود؟',
'در فصل زمستان چه اتفاقی افتاد؟',
'میراث کوروش'
]
model = SentenceTransformer('m3hrdadfi/roberta-zwnj-wnli-mean-tokens')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
# Max Pooling - Take the max value over time for every dimension.
def max_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
token_embeddings[input_mask_expanded == 0] = -1e9 # Set padding tokens to large negative value
return torch.mean(token_embeddings, 1)[0]
# Sentences we want sentence embeddings for
sentences = [
'اولین حکمران شهر بابل کی بود؟',
'در فصل زمستان چه اتفاقی افتاد؟',
'میراث کوروش'
]
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('m3hrdadfi/roberta-zwnj-wnli-mean-tokens')
model = AutoModel.from_pretrained('m3hrdadfi/roberta-zwnj-wnli-mean-tokens')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = max_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Questions?
Post a Github issue from [HERE](https://github.com/m3hrdadfi/sentence-transformers). |
macedonizer/gr-gpt2 | 83e359d4f421b2c7192062662eb5f61058cd79b4 | 2021-09-14T16:07:35.000Z | [
"pytorch",
"gpt2",
"text-generation",
"gr",
"dataset:wiki-gr",
"transformers",
"license:apache-2.0"
]
| text-generation | false | macedonizer | null | macedonizer/gr-gpt2 | 6 | null | transformers | 15,338 | ---
language:
- gr
thumbnail: https://huggingface.co/macedonizer/gr-roberta-base/lets-talk-about-nlp-gr.jpg
license: apache-2.0
datasets:
- wiki-gr
---
# gr-gpt2
Test the whole generation capabilities here: https://transformer.huggingface.co/doc/gpt2-large
Pretrained model on English language using a causal language modeling (CLM) objective. It was introduced in
[this paper](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf)
and first released at [this page](https://openai.com/blog/better-language-models/).
## Model description
gr-gpt2 is a transformers model pretrained on a very large corpus of Greek data in a self-supervised fashion. This
means it was pretrained on the raw texts only, with no humans labeling them in any way (which is why it can use lots
of publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely,
it was trained to guess the next word in sentences.
More precisely, inputs are sequences of the continuous text of a certain length and the targets are the same sequence,
shifted one token (word or piece of a word) to the right. The model uses internally a mask-mechanism to make sure the
predictions for the token `i` only uses the inputs from `1` to `i` but not the future tokens.
This way, the model learns an inner representation of the Greek language that can then be used to extract features
useful for downstream tasks. The model is best at what it was pretrained for, however, which is generating texts from a
prompt.
### How to use
Here is how to use this model to get the features of a given text in PyTorch:
import random
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained('macedonizer/gr-gpt2') \\nnmodel = AutoModelWithLMHead.from_pretrained('macedonizer/gr-gpt2')
input_text = 'Η Αθήνα είναι'
if len(input_text) == 0: \
encoded_input = tokenizer(input_text, return_tensors="pt") \
output = model.generate( \
bos_token_id=random.randint(1, 50000), \
do_sample=True, \
top_k=50, \
max_length=1024, \
top_p=0.95, \
num_return_sequences=1, \
) \
else: \
encoded_input = tokenizer(input_text, return_tensors="pt") \
output = model.generate( \
**encoded_input, \
bos_token_id=random.randint(1, 50000), \
do_sample=True, \
top_k=50, \
max_length=1024, \
top_p=0.95, \
num_return_sequences=1, \
)
decoded_output = [] \
for sample in output: \
decoded_output.append(tokenizer.decode(sample, skip_special_tokens=True))
print(decoded_output) |
manishiitg/mobilebert-recruit-qa | 7f023bcbc30dbf2e8937ca15c4c2dedf539409a2 | 2020-11-02T10:38:40.000Z | [
"pytorch",
"mobilebert",
"question-answering",
"transformers",
"autotrain_compatible"
]
| question-answering | false | manishiitg | null | manishiitg/mobilebert-recruit-qa | 6 | null | transformers | 15,339 | Entry not found |
marcolatella/tweet_eval_bench | 915053f1c4f62e3e9cebaf5ce1fc72321fc1a028 | 2021-12-09T18:23:38.000Z | [
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"dataset:tweet_eval",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
]
| text-classification | false | marcolatella | null | marcolatella/tweet_eval_bench | 6 | null | transformers | 15,340 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tweet_eval
metrics:
- accuracy
model-index:
- name: prova_Classi
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: tweet_eval
type: tweet_eval
args: sentiment
metrics:
- name: Accuracy
type: accuracy
value: 0.716
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# prova_Classi
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the tweet_eval dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5530
- Accuracy: 0.716
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.00013441028267541125
- train_batch_size: 32
- eval_batch_size: 16
- seed: 17
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.7022 | 1.0 | 1426 | 0.6581 | 0.7105 |
| 0.5199 | 2.0 | 2852 | 0.6835 | 0.706 |
| 0.2923 | 3.0 | 4278 | 0.7941 | 0.7075 |
| 0.1366 | 4.0 | 5704 | 1.0761 | 0.7115 |
| 0.0645 | 5.0 | 7130 | 1.5530 | 0.716 |
### Framework versions
- Transformers 4.13.0
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
mattmcclean/distilbert-base-uncased-finetuned-emotion | d360c04e31cabd7fba64cc2002f51b1b95901562 | 2022-02-01T19:48:01.000Z | [
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"dataset:emotion",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
]
| text-classification | false | mattmcclean | null | mattmcclean/distilbert-base-uncased-finetuned-emotion | 6 | null | transformers | 15,341 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.925
- name: F1
type: f1
value: 0.9252235175634111
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2173
- Accuracy: 0.925
- F1: 0.9252
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.825 | 1.0 | 250 | 0.2925 | 0.915 | 0.9134 |
| 0.2444 | 2.0 | 500 | 0.2173 | 0.925 | 0.9252 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0
- Datasets 1.16.1
- Tokenizers 0.10.3
|
mbateman/bert-finetuned-ner-accelerate | 59e546b584a5d42f67d5050e41b619ea4e39d870 | 2022-01-05T08:30:51.000Z | [
"pytorch",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | false | mbateman | null | mbateman/bert-finetuned-ner-accelerate | 6 | null | transformers | 15,342 | Entry not found |
mbeukman/xlm-roberta-base-finetuned-ner-igbo | 0bcb1071259ea42baf78cbdcdb3e874ac419fecd | 2021-11-25T09:04:28.000Z | [
"pytorch",
"xlm-roberta",
"token-classification",
"ig",
"dataset:masakhaner",
"arxiv:2103.11811",
"transformers",
"NER",
"autotrain_compatible"
]
| token-classification | false | mbeukman | null | mbeukman/xlm-roberta-base-finetuned-ner-igbo | 6 | null | transformers | 15,343 | ---
language:
- ig
tags:
- NER
datasets:
- masakhaner
metrics:
- f1
- precision
- recall
widget:
- text: "Ike ịda jụụ otụ nkeji banyere oke ogbugbu na - eme n'ala Naijiria agwụla Ekweremmadụ"
---
# xlm-roberta-base-finetuned-ner-igbo
This is a token classification (specifically NER) model that fine-tuned [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the [MasakhaNER](https://arxiv.org/abs/2103.11811) dataset, specifically the Igbo part.
More information, and other similar models can be found in the [main Github repository](https://github.com/Michael-Beukman/NERTransfer).
## About
This model is transformer based and was fine-tuned on the MasakhaNER dataset. It is a named entity recognition dataset, containing mostly news articles in 10 different African languages.
The model was fine-tuned for 50 epochs, with a maximum sequence length of 200, 32 batch size, 5e-5 learning rate. This process was repeated 5 times (with different random seeds), and this uploaded model performed the best out of those 5 seeds (aggregate F1 on test set).
This model was fine-tuned by me, Michael Beukman while doing a project at the University of the Witwatersrand, Johannesburg. This is version 1, as of 20 November 2021.
This model is licensed under the [Apache License, Version 2.0](https://www.apache.org/licenses/LICENSE-2.0).
### Contact & More information
For more information about the models, including training scripts, detailed results and further resources, you can visit the the [main Github repository](https://github.com/Michael-Beukman/NERTransfer). You can contact me by filing an issue on this repository.
### Training Resources
In the interest of openness, and reporting resources used, we list here how long the training process took, as well as what the minimum resources would be to reproduce this. Fine-tuning each model on the NER dataset took between 10 and 30 minutes, and was performed on a NVIDIA RTX3090 GPU. To use a batch size of 32, at least 14GB of GPU memory was required, although it was just possible to fit these models in around 6.5GB's of VRAM when using a batch size of 1.
## Data
The train, evaluation and test datasets were taken directly from the MasakhaNER [Github](https://github.com/masakhane-io/masakhane-ner) repository, with minimal to no preprocessing, as the original dataset is already of high quality.
The motivation for the use of this data is that it is the "first large, publicly available, high quality dataset for named entity recognition (NER) in ten African languages" ([source](https://arxiv.org/pdf/2103.11811.pdf)). The high-quality data, as well as the groundwork laid by the paper introducing it are some more reasons why this dataset was used. For evaluation, the dedicated test split was used, which is from the same distribution as the training data, so this model may not generalise to other distributions, and further testing would need to be done to investigate this. The exact distribution of the data is covered in detail [here](https://arxiv.org/abs/2103.11811).
## Intended Use
This model are intended to be used for NLP research into e.g. interpretability or transfer learning. Using this model in production is not supported, as generalisability and downright performance is limited. In particular, this is not designed to be used in any important downstream task that could affect people, as harm could be caused by the limitations of the model, described next.
## Limitations
This model was only trained on one (relatively small) dataset, covering one task (NER) in one domain (news articles) and in a set span of time. The results may not generalise, and the model may perform badly, or in an unfair / biased way if used on other tasks. Although the purpose of this project was to investigate transfer learning, the performance on languages that the model was not trained for does suffer.
Because this model used xlm-roberta-base as its starting point (potentially with domain adaptive fine-tuning on specific languages), this model's limitations can also apply here. These can include being biased towards the hegemonic viewpoint of most of its training data, being ungrounded and having subpar results on other languages (possibly due to unbalanced training data).
As [Adelani et al. (2021)](https://arxiv.org/abs/2103.11811) showed, the models in general struggled with entities that were either longer than 3 words and entities that were not contained in the training data. This could bias the models towards not finding, e.g. names of people that have many words, possibly leading to a misrepresentation in the results. Similarly, names that are uncommon, and may not have been found in the training data (due to e.g. different languages) would also be predicted less often.
Additionally, this model has not been verified in practice, and other, more subtle problems may become prevalent if used without any verification that it does what it is supposed to.
### Privacy & Ethical Considerations
The data comes from only publicly available news sources, the only available data should cover public figures and those that agreed to be reported on. See the original MasakhaNER paper for more details.
No explicit ethical considerations or adjustments were made during fine-tuning of this model.
## Metrics
The language adaptive models achieve (mostly) superior performance over starting with xlm-roberta-base. Our main metric was the aggregate F1 score for all NER categories.
These metrics are on the test set for MasakhaNER, so the data distribution is similar to the training set, so these results do not directly indicate how well these models generalise.
We do find large variation in transfer results when starting from different seeds (5 different seeds were tested), indicating that the fine-tuning process for transfer might be unstable.
The metrics used were chosen to be consistent with previous work, and to facilitate research. Other metrics may be more appropriate for other purposes.
## Caveats and Recommendations
In general, this model performed worse on the 'date' category compared to others, so if dates are a critical factor, then that might need to be taken into account and addressed, by for example collecting and annotating more data.
## Model Structure
Here are some performance details on this specific model, compared to others we trained.
All of these metrics were calculated on the test set, and the seed was chosen that gave the best overall F1 score. The first three result columns are averaged over all categories, and the latter 4 provide performance broken down by category.
This model can predict the following label for a token ([source](https://huggingface.co/Davlan/xlm-roberta-large-masakhaner)):
Abbreviation|Description
-|-
O|Outside of a named entity
B-DATE |Beginning of a DATE entity right after another DATE entity
I-DATE |DATE entity
B-PER |Beginning of a person’s name right after another person’s name
I-PER |Person’s name
B-ORG |Beginning of an organisation right after another organisation
I-ORG |Organisation
B-LOC |Beginning of a location right after another location
I-LOC |Location
| Model Name | Staring point | Evaluation / Fine-tune Language | F1 | Precision | Recall | F1 (DATE) | F1 (LOC) | F1 (ORG) | F1 (PER) |
| -------------------------------------------------- | -------------------- | -------------------- | -------------- | -------------- | -------------- | -------------- | -------------- | -------------- | -------------- |
| [xlm-roberta-base-finetuned-ner-igbo](https://huggingface.co/mbeukman/xlm-roberta-base-finetuned-ner-igbo) (This model) | [base](https://huggingface.co/xlm-roberta-base) | ibo | 86.06 | 85.20 | 86.94 | 76.00 | 86.00 | 90.00 | 87.00 |
| [xlm-roberta-base-finetuned-igbo-finetuned-ner-igbo](https://huggingface.co/mbeukman/xlm-roberta-base-finetuned-igbo-finetuned-ner-igbo) | [ibo](https://huggingface.co/Davlan/xlm-roberta-base-finetuned-igbo) | ibo | 88.39 | 87.08 | 89.74 | 74.00 | 91.00 | 90.00 | 91.00 |
| [xlm-roberta-base-finetuned-swahili-finetuned-ner-igbo](https://huggingface.co/mbeukman/xlm-roberta-base-finetuned-swahili-finetuned-ner-igbo) | [swa](https://huggingface.co/Davlan/xlm-roberta-base-finetuned-swahili) | ibo | 84.93 | 83.63 | 86.26 | 70.00 | 88.00 | 89.00 | 84.00 |
## Usage
To use this model (or others), you can do the following, just changing the model name ([source](https://huggingface.co/dslim/bert-base-NER)):
```
from transformers import AutoTokenizer, AutoModelForTokenClassification
from transformers import pipeline
model_name = 'mbeukman/xlm-roberta-base-finetuned-ner-igbo'
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForTokenClassification.from_pretrained(model_name)
nlp = pipeline("ner", model=model, tokenizer=tokenizer)
example = "Ike ịda jụụ otụ nkeji banyere oke ogbugbu na - eme n'ala Naijiria agwụla Ekweremmadụ"
ner_results = nlp(example)
print(ner_results)
```
|
meghanabhange/Hinglish-DistilBert-Class | 485d02fcd3f331e460592ab45edecac2c4512d3c | 2021-05-19T23:15:31.000Z | [
"pytorch",
"bert",
"text-classification",
"transformers"
]
| text-classification | false | meghanabhange | null | meghanabhange/Hinglish-DistilBert-Class | 6 | null | transformers | 15,344 | Entry not found |
michaelrglass/bert-base-uncased-sspt | 9c463dd1666d2fe88cb251ebbfb76f2a38db20be | 2021-05-19T23:24:03.000Z | [
"pytorch",
"tf",
"jax",
"bert",
"question-answering",
"transformers",
"autotrain_compatible"
]
| question-answering | false | michaelrglass | null | michaelrglass/bert-base-uncased-sspt | 6 | null | transformers | 15,345 | Entry not found |
microsoft/unispeech-large-multi-lingual-1500h-cv | abdabefbb7de4d0cb87f4e1680ed95a07f63e789 | 2021-11-05T12:42:09.000Z | [
"pytorch",
"unispeech",
"pretraining",
"it",
"en",
"fr",
"es",
"dataset:common_voice",
"arxiv:2101.07597",
"transformers",
"speech"
]
| null | false | microsoft | null | microsoft/unispeech-large-multi-lingual-1500h-cv | 6 | 1 | transformers | 15,346 | ---
language:
- it
- en
- fr
- es
datasets:
- common_voice
tags:
- speech
---
# UniSpeech-Large-Multi-Lingual
[Microsoft's UniSpeech](https://www.microsoft.com/en-us/research/publication/unispeech-unified-speech-representation-learning-with-labeled-and-unlabeled-data/)
The multi-lingual large model pretrained on 16kHz sampled speech audio and phonetic labels. When using the model make sure that your speech input is also sampled at 16kHz and your text in converted into a sequence of phonemes.
**Note**: This model does not have a tokenizer as it was pretrained on audio alone. In order to use this model **speech recognition**, a tokenizer should be created and the model should be fine-tuned on labeled text data. Check out [this blog](https://huggingface.co/blog/fine-tune-wav2vec2-english) for more in-detail explanation of how to fine-tune the model.
[Paper: UniSpeech: Unified Speech Representation Learning
with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597)
Authors: Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang
**Abstract**
*In this paper, we propose a unified pre-training approach called UniSpeech to learn speech representations with both unlabeled and labeled data, in which supervised phonetic CTC learning and phonetically-aware contrastive self-supervised learning are conducted in a multi-task learning manner. The resultant representations can capture information more correlated with phonetic structures and improve the generalization across languages and domains. We evaluate the effectiveness of UniSpeech for cross-lingual representation learning on public CommonVoice corpus. The results show that UniSpeech outperforms self-supervised pretraining and supervised transfer learning for speech recognition by a maximum of 13.4% and 17.8% relative phone error rate reductions respectively (averaged over all testing languages). The transferability of UniSpeech is also demonstrated on a domain-shift speech recognition task, i.e., a relative word error rate reduction of 6% against the previous approach.*
The original model can be found under https://github.com/microsoft/UniSpeech/tree/main/UniSpeech.
# Usage
This is a multi-lingually pre-trained speech model that has to be fine-tuned on a downstream task like speech recognition or audio classification before it can be
used in inference. The model was pre-trained in English, Spanish, French, and Italian and should therefore perform well only in those or similar languages.
**Note**: The model was pre-trained on phonemes rather than characters. This means that one should make sure that the input text is converted to a sequence
of phonemes before fine-tuning.
## Speech Recognition
To fine-tune the model for speech recognition, see [the official speech recognition example](https://github.com/huggingface/transformers/tree/master/examples/pytorch/speech-recognition).
## Speech Classification
To fine-tune the model for speech classification, see [the official audio classification example](https://github.com/huggingface/transformers/tree/master/examples/pytorch/audio-classification).
# Contribution
The model was contributed by [cywang](https://huggingface.co/cywang) and [patrickvonplaten](https://huggingface.co/patrickvonplaten).
# License
The official license can be found [here](https://github.com/microsoft/UniSpeech/blob/main/LICENSE)
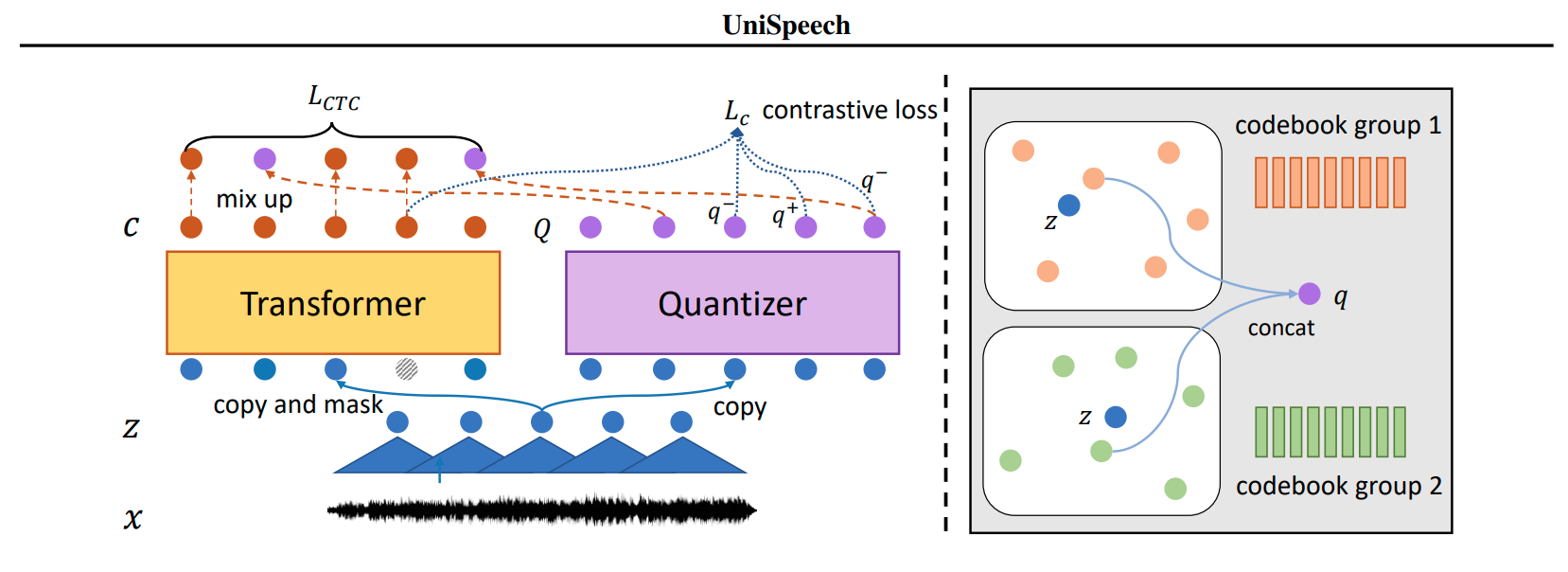 |
mikaelsouza/msft-regular-model | 0bec60c9d77775a57afac3b5b60860178d13935b | 2021-11-02T23:05:40.000Z | [
"pytorch",
"gpt2",
"text-generation",
"dataset:wikitext",
"transformers",
"generated_from_trainer",
"model-index"
]
| text-generation | false | mikaelsouza | null | mikaelsouza/msft-regular-model | 6 | 1 | transformers | 15,347 | ---
tags:
- generated_from_trainer
datasets:
- wikitext
model-index:
- name: msft-regular-model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# msft-regular-model
This model is a fine-tuned version of [](https://huggingface.co/) on the wikitext dataset.
It achieves the following results on the evaluation set:
- Loss: 5.3420
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 9.1224 | 0.17 | 200 | 8.0736 |
| 7.5229 | 0.34 | 400 | 7.1536 |
| 7.0122 | 0.51 | 600 | 6.9072 |
| 6.8296 | 0.69 | 800 | 6.7582 |
| 6.709 | 0.86 | 1000 | 6.6436 |
| 6.5882 | 1.03 | 1200 | 6.5563 |
| 6.4807 | 1.2 | 1400 | 6.4784 |
| 6.4172 | 1.37 | 1600 | 6.4165 |
| 6.3403 | 1.54 | 1800 | 6.3555 |
| 6.2969 | 1.71 | 2000 | 6.3107 |
| 6.2346 | 1.89 | 2200 | 6.2691 |
| 6.1767 | 2.06 | 2400 | 6.2299 |
| 6.1326 | 2.23 | 2600 | 6.1937 |
| 6.1035 | 2.4 | 2800 | 6.1602 |
| 6.0624 | 2.57 | 3000 | 6.1241 |
| 6.0393 | 2.74 | 3200 | 6.0971 |
| 5.9982 | 2.91 | 3400 | 6.0656 |
| 5.9526 | 3.08 | 3600 | 6.0397 |
| 5.9086 | 3.26 | 3800 | 6.0104 |
| 5.8922 | 3.43 | 4000 | 5.9888 |
| 5.8631 | 3.6 | 4200 | 5.9661 |
| 5.8396 | 3.77 | 4400 | 5.9407 |
| 5.8055 | 3.94 | 4600 | 5.9177 |
| 5.7763 | 4.11 | 4800 | 5.9007 |
| 5.7314 | 4.28 | 5000 | 5.8834 |
| 5.7302 | 4.46 | 5200 | 5.8620 |
| 5.6987 | 4.63 | 5400 | 5.8451 |
| 5.6754 | 4.8 | 5600 | 5.8242 |
| 5.6571 | 4.97 | 5800 | 5.8059 |
| 5.615 | 5.14 | 6000 | 5.7871 |
| 5.596 | 5.31 | 6200 | 5.7817 |
| 5.5738 | 5.48 | 6400 | 5.7570 |
| 5.5641 | 5.66 | 6600 | 5.7431 |
| 5.5503 | 5.83 | 6800 | 5.7271 |
| 5.5214 | 6.0 | 7000 | 5.7108 |
| 5.4712 | 6.17 | 7200 | 5.7018 |
| 5.48 | 6.34 | 7400 | 5.6936 |
| 5.4527 | 6.51 | 7600 | 5.6812 |
| 5.4514 | 6.68 | 7800 | 5.6669 |
| 5.4454 | 6.86 | 8000 | 5.6509 |
| 5.399 | 7.03 | 8200 | 5.6408 |
| 5.3747 | 7.2 | 8400 | 5.6327 |
| 5.3667 | 7.37 | 8600 | 5.6197 |
| 5.3652 | 7.54 | 8800 | 5.6084 |
| 5.3394 | 7.71 | 9000 | 5.5968 |
| 5.3349 | 7.88 | 9200 | 5.5870 |
| 5.2994 | 8.05 | 9400 | 5.5826 |
| 5.2793 | 8.23 | 9600 | 5.5710 |
| 5.2716 | 8.4 | 9800 | 5.5623 |
| 5.275 | 8.57 | 10000 | 5.5492 |
| 5.264 | 8.74 | 10200 | 5.5449 |
| 5.241 | 8.91 | 10400 | 5.5322 |
| 5.2285 | 9.08 | 10600 | 5.5267 |
| 5.2021 | 9.25 | 10800 | 5.5187 |
| 5.1934 | 9.43 | 11000 | 5.5158 |
| 5.1737 | 9.6 | 11200 | 5.5044 |
| 5.1774 | 9.77 | 11400 | 5.5008 |
| 5.1841 | 9.94 | 11600 | 5.4960 |
| 5.1414 | 10.11 | 11800 | 5.4895 |
| 5.1491 | 10.28 | 12000 | 5.4849 |
| 5.1184 | 10.45 | 12200 | 5.4738 |
| 5.1136 | 10.63 | 12400 | 5.4690 |
| 5.1199 | 10.8 | 12600 | 5.4598 |
| 5.1056 | 10.97 | 12800 | 5.4536 |
| 5.0648 | 11.14 | 13000 | 5.4496 |
| 5.0598 | 11.31 | 13200 | 5.4449 |
| 5.0656 | 11.48 | 13400 | 5.4422 |
| 5.0664 | 11.65 | 13600 | 5.4367 |
| 5.0675 | 11.83 | 13800 | 5.4286 |
| 5.0459 | 12.0 | 14000 | 5.4249 |
| 5.0073 | 12.17 | 14200 | 5.4260 |
| 5.0229 | 12.34 | 14400 | 5.4175 |
| 5.0079 | 12.51 | 14600 | 5.4119 |
| 5.0 | 12.68 | 14800 | 5.4194 |
| 5.0094 | 12.85 | 15000 | 5.4068 |
| 4.9967 | 13.02 | 15200 | 5.3995 |
| 4.9541 | 13.2 | 15400 | 5.4002 |
| 4.9753 | 13.37 | 15600 | 5.3965 |
| 4.9732 | 13.54 | 15800 | 5.3925 |
| 4.9624 | 13.71 | 16000 | 5.3888 |
| 4.9559 | 13.88 | 16200 | 5.3824 |
| 4.9559 | 14.05 | 16400 | 5.3851 |
| 4.9109 | 14.22 | 16600 | 5.3815 |
| 4.9211 | 14.4 | 16800 | 5.3784 |
| 4.9342 | 14.57 | 17000 | 5.3735 |
| 4.9271 | 14.74 | 17200 | 5.3711 |
| 4.9328 | 14.91 | 17400 | 5.3646 |
| 4.8994 | 15.08 | 17600 | 5.3664 |
| 4.8932 | 15.25 | 17800 | 5.3642 |
| 4.8886 | 15.42 | 18000 | 5.3620 |
| 4.8997 | 15.6 | 18200 | 5.3584 |
| 4.8846 | 15.77 | 18400 | 5.3551 |
| 4.8993 | 15.94 | 18600 | 5.3516 |
| 4.8648 | 16.11 | 18800 | 5.3552 |
| 4.8838 | 16.28 | 19000 | 5.3512 |
| 4.8575 | 16.45 | 19200 | 5.3478 |
| 4.8623 | 16.62 | 19400 | 5.3480 |
| 4.8631 | 16.8 | 19600 | 5.3439 |
| 4.8576 | 16.97 | 19800 | 5.3428 |
| 4.8265 | 17.14 | 20000 | 5.3420 |
| 4.8523 | 17.31 | 20200 | 5.3410 |
| 4.8477 | 17.48 | 20400 | 5.3396 |
| 4.8507 | 17.65 | 20600 | 5.3380 |
| 4.8498 | 17.82 | 20800 | 5.3333 |
| 4.8261 | 17.99 | 21000 | 5.3342 |
| 4.8201 | 18.17 | 21200 | 5.3324 |
| 4.8214 | 18.34 | 21400 | 5.3341 |
| 4.8195 | 18.51 | 21600 | 5.3315 |
| 4.8216 | 18.68 | 21800 | 5.3335 |
| 4.8243 | 18.85 | 22000 | 5.3291 |
| 4.832 | 19.02 | 22200 | 5.3295 |
| 4.8085 | 19.19 | 22400 | 5.3309 |
| 4.8094 | 19.37 | 22600 | 5.3283 |
| 4.815 | 19.54 | 22800 | 5.3280 |
| 4.8219 | 19.71 | 23000 | 5.3270 |
| 4.8117 | 19.88 | 23200 | 5.3280 |
### Framework versions
- Transformers 4.13.0.dev0
- Pytorch 1.10.0
- Datasets 1.14.0
- Tokenizers 0.10.3
|
milyiyo/distilbert-base-uncased-finetuned-amazon-review | 14e2a8ec598d627df67a826372a291be4e2b7051 | 2022-01-20T15:14:48.000Z | [
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"dataset:amazon_reviews_multi",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
]
| text-classification | false | milyiyo | null | milyiyo/distilbert-base-uncased-finetuned-amazon-review | 6 | null | transformers | 15,348 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- amazon_reviews_multi
metrics:
- accuracy
- f1
- precision
- recall
model-index:
- name: distilbert-base-uncased-finetuned-amazon-review
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: amazon_reviews_multi
type: amazon_reviews_multi
args: es
metrics:
- name: Accuracy
type: accuracy
value: 0.693
- name: F1
type: f1
value: 0.7002653469272611
- name: Precision
type: precision
value: 0.709541681233075
- name: Recall
type: recall
value: 0.693
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-amazon-review
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the amazon_reviews_multi dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3494
- Accuracy: 0.693
- F1: 0.7003
- Precision: 0.7095
- Recall: 0.693
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:---------:|:------:|
| No log | 0.5 | 500 | 0.8287 | 0.7104 | 0.7120 | 0.7152 | 0.7104 |
| 0.4238 | 1.0 | 1000 | 0.8917 | 0.7094 | 0.6989 | 0.6917 | 0.7094 |
| 0.4238 | 1.5 | 1500 | 0.9367 | 0.6884 | 0.6983 | 0.7151 | 0.6884 |
| 0.3152 | 2.0 | 2000 | 0.9845 | 0.7116 | 0.7144 | 0.7176 | 0.7116 |
| 0.3152 | 2.5 | 2500 | 1.0752 | 0.6814 | 0.6968 | 0.7232 | 0.6814 |
| 0.2454 | 3.0 | 3000 | 1.1215 | 0.6918 | 0.6954 | 0.7068 | 0.6918 |
| 0.2454 | 3.5 | 3500 | 1.2905 | 0.6976 | 0.7048 | 0.7138 | 0.6976 |
| 0.1989 | 4.0 | 4000 | 1.2938 | 0.694 | 0.7016 | 0.7113 | 0.694 |
| 0.1989 | 4.5 | 4500 | 1.3623 | 0.6972 | 0.7014 | 0.7062 | 0.6972 |
| 0.1746 | 5.0 | 5000 | 1.3494 | 0.693 | 0.7003 | 0.7095 | 0.693 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
mmirshekari/electra-base-squad-classification | ae742f603bbf28f6b6cf634402cc2312f49a72b5 | 2021-09-14T16:53:25.000Z | [
"pytorch",
"electra",
"text-classification",
"transformers"
]
| text-classification | false | mmirshekari | null | mmirshekari/electra-base-squad-classification | 6 | null | transformers | 15,349 | Entry not found |
mofawzy/bert-labr-unbalanced | 943517378529efcccea8a20b8389c4ef551baffa | 2022-02-14T11:39:25.000Z | [
"pytorch",
"tf",
"bert",
"text-classification",
"ar",
"dataset:labr",
"transformers",
"labr"
]
| text-classification | false | mofawzy | null | mofawzy/bert-labr-unbalanced | 6 | null | transformers | 15,350 | ---
language:
- ar
datasets:
- labr
tags:
- labr
widget:
- text: "كتاب ممل جدا تضييع وقت"
- text: "اسلوب ممتع وشيق في الكتاب استمعت بالاحداث"
---
# BERT-LABR unbalanced
Arabic version bert model fine tuned on LABR dataset
## Data
The model were fine-tuned on ~63000 book reviews in arabic using bert large arabic
## Results
| class | precision | recall | f1-score | Support |
|----------|-----------|--------|----------|---------|
| 0 | 0.8109 | 0.6832 | 0.7416 | 1670 |
| 1 | 0.9399 | 0.9689 | 0.9542 | 8541 |
| Accuracy | | | 0.9221 | 10211 |
## How to use
You can use these models by installing `torch` or `tensorflow` and Huggingface library `transformers`. And you can use it directly by initializing it like this:
```python
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model_name="mofawzy/bert-labr-unbalanced"
model = AutoModelForSequenceClassification.from_pretrained(model_name,num_labels=2)
tokenizer = AutoTokenizer.from_pretrained(model_name)
```
|
mohsenfayyaz/bert-base-uncased-avg-pooling | 8774520b8f4d930ff02e77e084932bc9d365b27a | 2021-06-27T12:18:48.000Z | [
"pytorch",
"bert",
"text-classification",
"transformers"
]
| text-classification | false | mohsenfayyaz | null | mohsenfayyaz/bert-base-uncased-avg-pooling | 6 | null | transformers | 15,351 | Entry not found |
mohsenfayyaz/xlnet-base-cased-toxicity | 9cb763cf8295e6d21b7183eb8de8e2b060b95bb5 | 2021-04-18T10:22:12.000Z | [
"pytorch",
"xlnet",
"text-classification",
"transformers"
]
| text-classification | false | mohsenfayyaz | null | mohsenfayyaz/xlnet-base-cased-toxicity | 6 | null | transformers | 15,352 | Entry not found |
monologg/koelectra-base-v2-finetuned-korquad-384 | 8382aa3f80453f03d17f4631bb592d0ec3df1c9a | 2020-06-03T13:03:25.000Z | [
"pytorch",
"electra",
"question-answering",
"transformers",
"autotrain_compatible"
]
| question-answering | false | monologg | null | monologg/koelectra-base-v2-finetuned-korquad-384 | 6 | null | transformers | 15,353 | Entry not found |
monologg/koelectra-small-v2-generator | 369e271a85947ff9e69cd0209b1f1e7df12f3cd4 | 2020-12-26T16:24:12.000Z | [
"pytorch",
"electra",
"fill-mask",
"transformers",
"autotrain_compatible"
]
| fill-mask | false | monologg | null | monologg/koelectra-small-v2-generator | 6 | null | transformers | 15,354 | Entry not found |
moshew/tiny-bert-aug-sst2-distilled | 7f04bae1b02e9802af7cf77781169f859ea9608f | 2022-02-20T18:34:06.000Z | [
"pytorch",
"tensorboard",
"bert",
"text-classification",
"transformers"
]
| text-classification | false | moshew | null | moshew/tiny-bert-aug-sst2-distilled | 6 | null | transformers | 15,355 | Entry not found |
mrm8488/bert-multi-uncased-finetuned-xquadv1 | 8b382d045c4e64a3efef66f5e0962ff05bedc30a | 2021-05-20T00:31:20.000Z | [
"pytorch",
"jax",
"bert",
"question-answering",
"multilingual",
"arxiv:1910.11856",
"transformers",
"autotrain_compatible"
]
| question-answering | false | mrm8488 | null | mrm8488/bert-multi-uncased-finetuned-xquadv1 | 6 | null | transformers | 15,356 | ---
language: multilingual
thumbnail:
---
# BERT (base-multilingual-uncased) fine-tuned for multilingual Q&A
This model was created by [Google](https://github.com/google-research/bert/blob/master/multilingual.md) and fine-tuned on [XQuAD](https://github.com/deepmind/xquad) like data for multilingual (`11 different languages`) **Q&A** downstream task.
## Details of the language model('bert-base-multilingual-uncased')
[Language model](https://github.com/google-research/bert/blob/master/multilingual.md)
| Languages | Heads | Layers | Hidden | Params |
| --------- | ----- | ------ | ------ | ------ |
| 102 | 12 | 12 | 768 | 100 M |
## Details of the downstream task (multilingual Q&A) - Dataset
Deepmind [XQuAD](https://github.com/deepmind/xquad)
Languages covered:
- Arabic: `ar`
- German: `de`
- Greek: `el`
- English: `en`
- Spanish: `es`
- Hindi: `hi`
- Russian: `ru`
- Thai: `th`
- Turkish: `tr`
- Vietnamese: `vi`
- Chinese: `zh`
As the dataset is based on SQuAD v1.1, there are no unanswerable questions in the data. We chose this
setting so that models can focus on cross-lingual transfer.
We show the average number of tokens per paragraph, question, and answer for each language in the
table below. The statistics were obtained using [Jieba](https://github.com/fxsjy/jieba) for Chinese
and the [Moses tokenizer](https://github.com/moses-smt/mosesdecoder/blob/master/scripts/tokenizer/tokenizer.perl)
for the other languages.
| | en | es | de | el | ru | tr | ar | vi | th | zh | hi |
| --------- | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
| Paragraph | 142.4 | 160.7 | 139.5 | 149.6 | 133.9 | 126.5 | 128.2 | 191.2 | 158.7 | 147.6 | 232.4 |
| Question | 11.5 | 13.4 | 11.0 | 11.7 | 10.0 | 9.8 | 10.7 | 14.8 | 11.5 | 10.5 | 18.7 |
| Answer | 3.1 | 3.6 | 3.0 | 3.3 | 3.1 | 3.1 | 3.1 | 4.5 | 4.1 | 3.5 | 5.6 |
Citation:
<details>
```bibtex
@article{Artetxe:etal:2019,
author = {Mikel Artetxe and Sebastian Ruder and Dani Yogatama},
title = {On the cross-lingual transferability of monolingual representations},
journal = {CoRR},
volume = {abs/1910.11856},
year = {2019},
archivePrefix = {arXiv},
eprint = {1910.11856}
}
```
</details>
As **XQuAD** is just an evaluation dataset, I used `Data augmentation techniques` (scraping, neural machine translation, etc) to obtain more samples and split the dataset in order to have a train and test set. The test set was created in a way that contains the same number of samples for each language. Finally, I got:
| Dataset | # samples |
| ----------- | --------- |
| XQUAD train | 50 K |
| XQUAD test | 8 K |
## Model training
The model was trained on a Tesla P100 GPU and 25GB of RAM.
The script for fine tuning can be found [here](https://github.com/huggingface/transformers/blob/master/examples/distillation/run_squad_w_distillation.py)
## Model in action
Fast usage with **pipelines**:
```python
from transformers import pipeline
qa_pipeline = pipeline(
"question-answering",
model="mrm8488/bert-multi-uncased-finetuned-xquadv1",
tokenizer="mrm8488/bert-multi-uncased-finetuned-xquadv1"
)
# context: Coronavirus is seeding panic in the West because it expands so fast.
# question: Where is seeding panic Coronavirus?
qa_pipeline({
'context': "कोरोनावायरस पश्चिम में आतंक बो रहा है क्योंकि यह इतनी तेजी से फैलता है।",
'question': "कोरोनावायरस घबराहट कहां है?"
})
# output: {'answer': 'पश्चिम', 'end': 18, 'score': 0.7037217439689059, 'start': 12}
qa_pipeline({
'context': "Manuel Romero has been working hardly in the repository hugginface/transformers lately",
'question': "Who has been working hard for hugginface/transformers lately?"
})
# output: {'answer': 'Manuel Romero', 'end': 13, 'score': 0.7254485993702389, 'start': 0}
qa_pipeline({
'context': "Manuel Romero a travaillé à peine dans le référentiel hugginface / transformers ces derniers temps",
'question': "Pour quel référentiel a travaillé Manuel Romero récemment?"
})
#output: {'answer': 'hugginface / transformers', 'end': 79, 'score': 0.6482061613915384, 'start': 54}
```
Try it on a Colab:
<a href="https://colab.research.google.com/github/mrm8488/shared_colab_notebooks/blob/master/Try_mrm8488_xquad_finetuned_uncased_model.ipynb" target="_parent"><img src="https://camo.githubusercontent.com/52feade06f2fecbf006889a904d221e6a730c194/68747470733a2f2f636f6c61622e72657365617263682e676f6f676c652e636f6d2f6173736574732f636f6c61622d62616467652e737667" alt="Open In Colab" data-canonical-src="https://colab.research.google.com/assets/colab-badge.svg"></a>
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
mrm8488/bert-uncased-finetuned-qnli | c996c1fb887cc1005ec3b93ef51a95ad6879f813 | 2021-05-20T00:42:00.000Z | [
"pytorch",
"jax",
"bert",
"text-classification",
"en",
"transformers"
]
| text-classification | false | mrm8488 | null | mrm8488/bert-uncased-finetuned-qnli | 6 | null | transformers | 15,357 | ---
language: en
thumbnail:
---
# [BERT](https://huggingface.co/deepset/bert-base-cased-squad2) fine tuned on [QNLI](https://github.com/rhythmcao/QNLI)+ compression ([BERT-of-Theseus](https://github.com/JetRunner/BERT-of-Theseus))
I used a [Bert model fine tuned on **SQUAD v2**](https://huggingface.co/deepset/bert-base-cased-squad2) and then I fine tuned it on **QNLI** using **compression** (with a constant replacing rate) as proposed in **BERT-of-Theseus**
## Details of the downstream task (QNLI):
### Getting the dataset
```bash
wget https://raw.githubusercontent.com/rhythmcao/QNLI/master/data/QNLI/train.tsv
wget https://raw.githubusercontent.com/rhythmcao/QNLI/master/data/QNLI/test.tsv
wget https://raw.githubusercontent.com/rhythmcao/QNLI/master/data/QNLI/dev.tsv
mkdir QNLI_dataset
mv *.tsv QNLI_dataset
```
### Model training
The model was trained on a Tesla P100 GPU and 25GB of RAM with the following command:
```bash
!python /content/BERT-of-Theseus/run_glue.py \
--model_name_or_path deepset/bert-base-cased-squad2 \
--task_name qnli \
--do_train \
--do_eval \
--do_lower_case \
--data_dir /content/QNLI_dataset \
--max_seq_length 128 \
--per_gpu_train_batch_size 32 \
--per_gpu_eval_batch_size 32 \
--learning_rate 2e-5 \
--save_steps 2000 \
--num_train_epochs 50 \
--output_dir /content/ouput_dir \
--evaluate_during_training \
--replacing_rate 0.7 \
--steps_for_replacing 2500
```
## Metrics:
| Model | Accuracy |
|-----------------|------|
| BERT-base | 91.2 |
| BERT-of-Theseus | 88.8 |
| [bert-uncased-finetuned-qnli](https://huggingface.co/mrm8488/bert-uncased-finetuned-qnli) | 87.2
| DistillBERT | 85.3 |
> [See all my models](https://huggingface.co/models?search=mrm8488)
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
mrm8488/bsc-roberta-base-spanish-diagnostics | e9fa82e82eaaebb86bb024eeecb212d1676afdfb | 2021-10-04T18:04:02.000Z | [
"pytorch",
"tensorboard",
"roberta",
"text-classification",
"transformers"
]
| text-classification | false | mrm8488 | null | mrm8488/bsc-roberta-base-spanish-diagnostics | 6 | null | transformers | 15,358 | Entry not found |
mrm8488/distilbert-base-uncased-newspop-student | a8900af7101ecfef32af10ce149ff23ccc76b3ac | 2021-04-27T18:21:40.000Z | [
"pytorch",
"distilbert",
"text-classification",
"transformers"
]
| text-classification | false | mrm8488 | null | mrm8488/distilbert-base-uncased-newspop-student | 6 | null | transformers | 15,359 | Entry not found |
mrm8488/prunebert-base-uncased-finepruned-topK-squadv2 | fb0d34d80e14bb983529d8c9a131a5373a3b9098 | 2020-06-16T11:16:59.000Z | [
"pytorch",
"masked_bert",
"question-answering",
"transformers",
"autotrain_compatible"
]
| question-answering | false | mrm8488 | null | mrm8488/prunebert-base-uncased-finepruned-topK-squadv2 | 6 | null | transformers | 15,360 | Entry not found |
mrm8488/prunebert-multi-uncased-finepruned-magnitude-tydiqa-for-xqa | 8c9a4eb711d11575750d658b2a3e7af23020897d | 2020-06-10T17:09:21.000Z | [
"pytorch",
"masked_bert",
"question-answering",
"transformers",
"autotrain_compatible"
]
| question-answering | false | mrm8488 | null | mrm8488/prunebert-multi-uncased-finepruned-magnitude-tydiqa-for-xqa | 6 | null | transformers | 15,361 | Entry not found |
mrp/simcse-model-distil-m-bert | 272ad5730d95f3267b2f90c10aa12346049bd5f5 | 2021-10-05T05:49:08.000Z | [
"pytorch",
"distilbert",
"feature-extraction",
"arxiv:2104.08821",
"sentence-transformers",
"sentence-similarity",
"transformers"
]
| sentence-similarity | false | mrp | null | mrp/simcse-model-distil-m-bert | 6 | null | sentence-transformers | 15,362 | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# {mrp/simcse-model-distil-m-bert}
This is a [sentence-transformers](https://www.SBERT.net) by using m-Distil-BERT as the baseline model model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
We use SimCSE [here](https://arxiv.org/pdf/2104.08821.pdf) and training the model with Thai Wikipedia [here](https://github.com/PyThaiNLP/ThaiWiki-clean/releases/tag/20210620?fbclid=IwAR1YcmZkb-xd1ibTWCJOcu98_FQ5x3ioZaGW1ME-VHy9fAQLhEr5tXTJygA)
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["ฉันนะคือคนรักชาติยังไงละ!", "พวกสามกีบล้มเจ้า!"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
``` |
muhtasham/autonlp-Doctor_DE-24595547 | 9a98af6c8f059e3509bb2fd51f7d15995242f3e3 | 2021-10-22T14:04:29.000Z | [
"pytorch",
"electra",
"text-classification",
"de",
"dataset:muhtasham/autonlp-data-Doctor_DE",
"transformers",
"autonlp",
"co2_eq_emissions"
]
| text-classification | false | muhtasham | null | muhtasham/autonlp-Doctor_DE-24595547 | 6 | null | transformers | 15,363 | ---
tags: autonlp
language: de
widget:
- text: "I love AutoNLP 🤗"
datasets:
- muhtasham/autonlp-data-Doctor_DE
co2_eq_emissions: 396.5529429198159
---
# Model Trained Using AutoNLP
- Problem type: Single Column Regression
- Model ID: 24595547
- CO2 Emissions (in grams): 396.5529429198159
## Validation Metrics
- Loss: 1.9565489292144775
- MSE: 1.9565489292144775
- MAE: 0.9890901446342468
- R2: -7.68965036332947e-05
- RMSE: 1.3987668752670288
- Explained Variance: 0.0
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/models/muhtasham/autonlp-Doctor_DE-24595547
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("muhtasham/autonlp-Doctor_DE-24595547", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("muhtasham/autonlp-Doctor_DE-24595547", use_auth_token=True)
inputs = tokenizer("I love AutoNLP", return_tensors="pt")
outputs = model(**inputs)
``` |
murali-admin/bart-billsum-1 | 4c80a5550274b15eb491900d96b11e66a9fd3a2a | 2021-07-26T18:07:58.000Z | [
"pytorch",
"bart",
"text2text-generation",
"en",
"dataset:mohsenalam/autonlp-data-billsum-summarization",
"transformers",
"autonlp",
"autotrain_compatible"
]
| text2text-generation | false | murali-admin | null | murali-admin/bart-billsum-1 | 6 | null | transformers | 15,364 | ---
tags: autonlp
language: en
widget:
- text: "I love AutoNLP 🤗"
datasets:
- mohsenalam/autonlp-data-billsum-summarization
---
# Model Trained Using AutoNLP
- Problem type: Summarization
- Model ID: 5691253
## Validation Metrics
- Loss: 1.4430530071258545
- Rouge1: 23.9565
- Rouge2: 19.1897
- RougeL: 23.1191
- RougeLsum: 23.3308
- Gen Len: 20.0
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_HUGGINGFACE_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/mohsenalam/autonlp-billsum-summarization-5691253
``` |
ncduy/distilbert-base-cased-distilled-squad-finetuned-squad-test | f4cee9249fd32b362482d1a2b4812ae4a6130017 | 2021-12-09T12:35:59.000Z | [
"pytorch",
"tensorboard",
"distilbert",
"question-answering",
"transformers",
"autotrain_compatible"
]
| question-answering | false | ncduy | null | ncduy/distilbert-base-cased-distilled-squad-finetuned-squad-test | 6 | null | transformers | 15,365 | Entry not found |
ncoop57/codeparrot-neo-125M-py | f1a629d0d961c6df9923ac2664ded923efa39415 | 2022-01-27T14:44:13.000Z | [
"pytorch",
"jax",
"rust",
"gpt_neo",
"text-generation",
"en",
"dataset:The Pile",
"transformers",
"text generation",
"causal-lm",
"license:apache-2.0"
]
| text-generation | false | ncoop57 | null | ncoop57/codeparrot-neo-125M-py | 6 | null | transformers | 15,366 | ---
language:
- en
tags:
- text generation
- pytorch
- causal-lm
license: apache-2.0
datasets:
- The Pile
---
# GPT-Neo 125M
## Model Description
GPT-Neo 125M is a transformer model designed using EleutherAI's replication of the GPT-3 architecture. GPT-Neo refers to the class of models, while 125M represents the number of parameters of this particular pre-trained model.
## Training data
GPT-Neo 125M was trained on the Pile, a large scale curated dataset created by EleutherAI for the purpose of training this model.
## Training procedure
This model was trained on the Pile for 300 billion tokens over 572,300 steps. It was trained as a masked autoregressive language model, using cross-entropy loss.
## Intended Use and Limitations
This way, the model learns an inner representation of the English language that can then be used to extract features useful for downstream tasks. The model is best at what it was pretrained for however, which is generating texts from a prompt.
### How to use
You can use this model directly with a pipeline for text generation. This example generates a different sequence each time it's run:
```py
>>> from transformers import pipeline
>>> generator = pipeline('text-generation', model='EleutherAI/gpt-neo-125M')
>>> generator("EleutherAI has", do_sample=True, min_length=50)
[{'generated_text': 'EleutherAI has made a commitment to create new software packages for each of its major clients and has'}]
```
### Limitations and Biases
GPT-Neo was trained as an autoregressive language model. This means that its core functionality is taking a string of text and predicting the next token. While language models are widely used for tasks other than this, there are a lot of unknowns with this work.
GPT-Neo was trained on the Pile, a dataset known to contain profanity, lewd, and otherwise abrasive language. Depending on your usecase GPT-Neo may produce socially unacceptable text. See Sections 5 and 6 of the Pile paper for a more detailed analysis of the biases in the Pile.
As with all language models, it is hard to predict in advance how GPT-Neo will respond to particular prompts and offensive content may occur without warning. We recommend having a human curate or filter the outputs before releasing them, both to censor undesirable content and to improve the quality of the results.
## Eval results
TBD
### Down-Stream Applications
TBD
### BibTeX entry and citation info
To cite this model, use
```bibtex
@software{gpt-neo,
author = {Black, Sid and
Leo, Gao and
Wang, Phil and
Leahy, Connor and
Biderman, Stella},
title = {{GPT-Neo: Large Scale Autoregressive Language
Modeling with Mesh-Tensorflow}},
month = mar,
year = 2021,
note = {{If you use this software, please cite it using
these metadata.}},
publisher = {Zenodo},
version = {1.0},
doi = {10.5281/zenodo.5297715},
url = {https://doi.org/10.5281/zenodo.5297715}
}
@article{gao2020pile,
title={The Pile: An 800GB Dataset of Diverse Text for Language Modeling},
author={Gao, Leo and Biderman, Stella and Black, Sid and Golding, Laurence and Hoppe, Travis and Foster, Charles and Phang, Jason and He, Horace and Thite, Anish and Nabeshima, Noa and others},
journal={arXiv preprint arXiv:2101.00027},
year={2020}
}
``` |
nepalprabin/xlm-roberta-base-finetuned-marc-en | 124fdc2b7650043c2341533b65ad8f5ffb4275aa | 2021-10-23T09:53:48.000Z | [
"pytorch",
"tensorboard",
"xlm-roberta",
"text-classification",
"dataset:amazon_reviews_multi",
"transformers",
"generated_from_trainer",
"license:mit",
"model-index"
]
| text-classification | false | nepalprabin | null | nepalprabin/xlm-roberta-base-finetuned-marc-en | 6 | null | transformers | 15,367 | ---
license: mit
tags:
- generated_from_trainer
datasets:
- amazon_reviews_multi
model-index:
- name: xlm-roberta-base-finetuned-marc-en
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-marc-en
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the amazon_reviews_multi dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0442
- Mae: 0.5385
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Mae |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 1.0371 | 1.0 | 1105 | 1.0522 | 0.5256 |
| 0.8925 | 2.0 | 2210 | 1.0442 | 0.5385 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.9.0+cu111
- Datasets 1.14.0
- Tokenizers 0.10.3
|
nhrony/bert-bnsp | daa8ad0fd998c9a36dc3724a477c9a6f87baf0df | 2022-01-16T15:30:20.000Z | [
"pytorch",
"roberta",
"fill-mask",
"transformers",
"autotrain_compatible"
]
| fill-mask | false | nhrony | null | nhrony/bert-bnsp | 6 | null | transformers | 15,368 | Entry not found |
nkul/gpt2-frens | 99fb9148b4939d2d2136a4026e3411327f03c8d8 | 2021-07-11T07:09:11.000Z | [
"pytorch",
"jax",
"gpt2",
"text-generation",
"en",
"transformers"
]
| text-generation | false | nkul | null | nkul/gpt2-frens | 6 | null | transformers | 15,369 | ---
language: en
tags:
- gpt2
- text-generation
widget:
- text: "Rachel: Joey! What were those weird noises coming from your room?"
---
# GPT2 fine-tuned on FRIENDS transcripts. |
noharm-ai/anony | dd88173c321eb98625e2d906bb9b48af59e1246a | 2022-02-17T17:12:25.000Z | [
"pytorch",
"pt",
"flair",
"token-classification",
"sequence-tagger-model",
"license:mit"
]
| token-classification | false | noharm-ai | null | noharm-ai/anony | 6 | null | flair | 15,370 | ---
license: mit
tags:
- flair
- token-classification
- sequence-tagger-model
language: "pt"
widget:
- text: "FISIOTERAPIA TRAUMATO - MANHÃ Henrique Dias, 38 anos. Exercícios metabólicos de extremidades inferiores. Realizo mobilização patelar e leve mobilização de flexão de joelho conforme liberado pelo Dr Marcelo Arocha. Oriento cuidados e posicionamentos."
---
## Portuguese Name Identification
The [NoHarm-Anony - De-Identification of Clinical Notes Using Contextualized Language Models and a Token Classifier](https://link.springer.com/chapter/10.1007/978-3-030-91699-2_3) paper contains Flair-based models for Portuguese Language, initialized with [Flair BBP](https://github.com/jneto04/ner-pt) & trained on clinical notes with names tagged.
### Demo: How to use in Flair
Requires: **[Flair](https://github.com/flairNLP/flair/)** (`pip install flair`)
```python
from flair.data import Sentence
from flair.models import SequenceTagger
# load tagger
tagger = SequenceTagger.load("noharm-ai/anony")
# make example sentence
sentence = Sentence("FISIOTERAPIA TRAUMATO - MANHÃ Henrique Dias, 38 anos. Exercícios metabólicos de extremidades inferiores. Realizo mobilização patelar e leve mobilização de flexão de joelho conforme liberado pelo Dr Marcelo Arocha. Oriento cuidados e posicionamentos.")
# predict NER tags
tagger.predict(sentence)
# print sentence
print(sentence)
# print predicted NER spans
print('The following NER tags are found:')
# iterate over entities and print
for entity in sentence.get_spans('ner'):
print(entity)
```
This yields the following output:
```
Span [5,6]: "Henrique Dias" [− Labels: NOME (0.9735)]
Span [31,32]: "Marcelo Arocha" [− Labels: NOME (0.9803)]
```
So, the entities "*Henrique Dias*" (labeled as a **nome**) and "*Marcelo Arocha*" (labeled as a **nome**) are found in the sentence.
## More Information
Refer to the original paper, [De-Identification of Clinical Notes Using Contextualized Language Models and a Token Classifier](https://link.springer.com/chapter/10.1007/978-3-030-91699-2_3) for additional details and performance.
## Acknowledgements
We thank Dr. Ana Helena D. P. S. Ulbrich, who provided the clinical notes dataset from the hospital, for her valuable cooperation. We also thank the volunteers of the Institute of Artificial Intelligence in Healthcare Celso Pereira and Ana Lúcia Dias, for the dataset annotation.
## Citation
```
@inproceedings{santos2021identification,
title={De-Identification of Clinical Notes Using Contextualized Language Models and a Token Classifier},
author={Santos, Joaquim and dos Santos, Henrique DP and Tabalipa, F{\'a}bio and Vieira, Renata},
booktitle={Brazilian Conference on Intelligent Systems},
pages={33--41},
year={2021},
organization={Springer}
}
``` |
nouamanetazi/wav2vec2-xls-r-300m-ar-with-lm | ef84193e67ca1042b6ddde277ba81c20085b4ea4 | 2022-03-23T18:27:54.000Z | [
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"ar",
"dataset:common_voice",
"transformers",
"common_voice",
"generated_from_trainer",
"hf-asr-leaderboard",
"robust-speech-event",
"license:apache-2.0",
"model-index"
]
| automatic-speech-recognition | false | nouamanetazi | null | nouamanetazi/wav2vec2-xls-r-300m-ar-with-lm | 6 | 1 | transformers | 15,371 | ---
language:
- ar
license: apache-2.0
tags:
- ar
- automatic-speech-recognition
- common_voice
- generated_from_trainer
- hf-asr-leaderboard
- robust-speech-event
datasets:
- common_voice
model-index:
- name: XLS-R-300M - Arabic
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Robust Speech Event - Dev Data
type: speech-recognition-community-v2/dev_data
args: ar
metrics:
- name: Test WER
type: wer
value: 1.0
- name: Test CER
type: cer
value: 1.0
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-xls-r-300m-ar
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the COMMON_VOICE - AR dataset.
It achieves the following results on the evaluation set:
- eval_loss: 3.0191
- eval_wer: 1.0
- eval_runtime: 252.2389
- eval_samples_per_second: 30.217
- eval_steps_per_second: 0.476
- epoch: 1.0
- step: 340
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 2000
- num_epochs: 5
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.17.0.dev0
- Pytorch 1.10.2+cu102
- Datasets 1.18.2.dev0
- Tokenizers 0.11.0
#### Evaluation Commands
Please use the evaluation script `eval.py` included in the repo.
1. To evaluate on `speech-recognition-community-v2/dev_data`
```bash
python eval.py --model_id nouamanetazi/wav2vec2-xls-r-300m-ar --dataset speech-recognition-community-v2/dev_data --config ar --split validation --chunk_length_s 5.0 --stride_length_s 1.0
``` |
nreimers/TinyBERT_L-6_H-768_v2 | cbdb219b7128013bbead88ea281fea3dab77fc19 | 2021-05-28T11:01:29.000Z | [
"pytorch",
"jax",
"bert",
"feature-extraction",
"transformers"
]
| feature-extraction | false | nreimers | null | nreimers/TinyBERT_L-6_H-768_v2 | 6 | 1 | transformers | 15,372 | This is the [General_TinyBERT_v2(6layer-768dim)](https://github.com/huawei-noah/Pretrained-Language-Model/tree/master/TinyBERT) ported to Huggingface transformers. |
nyu-mll/roberta-base-10M-1 | a9e29b2540a6a178a449fc7b5db745f69e6bab8a | 2021-05-20T18:57:10.000Z | [
"pytorch",
"jax",
"roberta",
"fill-mask",
"transformers",
"autotrain_compatible"
]
| fill-mask | false | nyu-mll | null | nyu-mll/roberta-base-10M-1 | 6 | null | transformers | 15,373 | # RoBERTa Pretrained on Smaller Datasets
We pretrain RoBERTa on smaller datasets (1M, 10M, 100M, 1B tokens). We release 3 models with lowest perplexities for each pretraining data size out of 25 runs (or 10 in the case of 1B tokens). The pretraining data reproduces that of BERT: We combine English Wikipedia and a reproduction of BookCorpus using texts from smashwords in a ratio of approximately 3:1.
### Hyperparameters and Validation Perplexity
The hyperparameters and validation perplexities corresponding to each model are as follows:
| Model Name | Training Size | Model Size | Max Steps | Batch Size | Validation Perplexity |
|--------------------------|---------------|------------|-----------|------------|-----------------------|
| [roberta-base-1B-1][link-roberta-base-1B-1] | 1B | BASE | 100K | 512 | 3.93 |
| [roberta-base-1B-2][link-roberta-base-1B-2] | 1B | BASE | 31K | 1024 | 4.25 |
| [roberta-base-1B-3][link-roberta-base-1B-3] | 1B | BASE | 31K | 4096 | 3.84 |
| [roberta-base-100M-1][link-roberta-base-100M-1] | 100M | BASE | 100K | 512 | 4.99 |
| [roberta-base-100M-2][link-roberta-base-100M-2] | 100M | BASE | 31K | 1024 | 4.61 |
| [roberta-base-100M-3][link-roberta-base-100M-3] | 100M | BASE | 31K | 512 | 5.02 |
| [roberta-base-10M-1][link-roberta-base-10M-1] | 10M | BASE | 10K | 1024 | 11.31 |
| [roberta-base-10M-2][link-roberta-base-10M-2] | 10M | BASE | 10K | 512 | 10.78 |
| [roberta-base-10M-3][link-roberta-base-10M-3] | 10M | BASE | 31K | 512 | 11.58 |
| [roberta-med-small-1M-1][link-roberta-med-small-1M-1] | 1M | MED-SMALL | 100K | 512 | 153.38 |
| [roberta-med-small-1M-2][link-roberta-med-small-1M-2] | 1M | MED-SMALL | 10K | 512 | 134.18 |
| [roberta-med-small-1M-3][link-roberta-med-small-1M-3] | 1M | MED-SMALL | 31K | 512 | 139.39 |
The hyperparameters corresponding to model sizes mentioned above are as follows:
| Model Size | L | AH | HS | FFN | P |
|------------|----|----|-----|------|------|
| BASE | 12 | 12 | 768 | 3072 | 125M |
| MED-SMALL | 6 | 8 | 512 | 2048 | 45M |
(AH = number of attention heads; HS = hidden size; FFN = feedforward network dimension; P = number of parameters.)
For other hyperparameters, we select:
- Peak Learning rate: 5e-4
- Warmup Steps: 6% of max steps
- Dropout: 0.1
[link-roberta-med-small-1M-1]: https://huggingface.co/nyu-mll/roberta-med-small-1M-1
[link-roberta-med-small-1M-2]: https://huggingface.co/nyu-mll/roberta-med-small-1M-2
[link-roberta-med-small-1M-3]: https://huggingface.co/nyu-mll/roberta-med-small-1M-3
[link-roberta-base-10M-1]: https://huggingface.co/nyu-mll/roberta-base-10M-1
[link-roberta-base-10M-2]: https://huggingface.co/nyu-mll/roberta-base-10M-2
[link-roberta-base-10M-3]: https://huggingface.co/nyu-mll/roberta-base-10M-3
[link-roberta-base-100M-1]: https://huggingface.co/nyu-mll/roberta-base-100M-1
[link-roberta-base-100M-2]: https://huggingface.co/nyu-mll/roberta-base-100M-2
[link-roberta-base-100M-3]: https://huggingface.co/nyu-mll/roberta-base-100M-3
[link-roberta-base-1B-1]: https://huggingface.co/nyu-mll/roberta-base-1B-1
[link-roberta-base-1B-2]: https://huggingface.co/nyu-mll/roberta-base-1B-2
[link-roberta-base-1B-3]: https://huggingface.co/nyu-mll/roberta-base-1B-3
|
paintingpeter/distilbert-base-uncased-distilled-clinc | 1fdabcaf7b1de488ad4a376e57667560dd8a5644 | 2022-01-31T23:27:39.000Z | [
"pytorch",
"distilbert",
"text-classification",
"dataset:clinc_oos",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
]
| text-classification | false | paintingpeter | null | paintingpeter/distilbert-base-uncased-distilled-clinc | 6 | null | transformers | 15,374 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- clinc_oos
metrics:
- accuracy
model-index:
- name: distilbert-base-uncased-distilled-clinc
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: clinc_oos
type: clinc_oos
args: plus
metrics:
- name: Accuracy
type: accuracy
value: 0.9467741935483871
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-distilled-clinc
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the clinc_oos dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2795
- Accuracy: 0.9468
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 48
- eval_batch_size: 48
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 3.4223 | 1.0 | 318 | 2.5556 | 0.7561 |
| 1.9655 | 2.0 | 636 | 1.3075 | 0.8577 |
| 1.0041 | 3.0 | 954 | 0.6970 | 0.9165 |
| 0.5449 | 4.0 | 1272 | 0.4637 | 0.9339 |
| 0.3424 | 5.0 | 1590 | 0.3630 | 0.9397 |
| 0.247 | 6.0 | 1908 | 0.3225 | 0.9442 |
| 0.1968 | 7.0 | 2226 | 0.2983 | 0.9458 |
| 0.1693 | 8.0 | 2544 | 0.2866 | 0.9465 |
| 0.1547 | 9.0 | 2862 | 0.2820 | 0.9468 |
| 0.1477 | 10.0 | 3180 | 0.2795 | 0.9468 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
paola-md/light-recipes-italian | e9f1d635d13b26bba8e63f3f0cc3e48d114ac1e4 | 2022-02-01T13:03:27.000Z | [
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"transformers"
]
| text-classification | false | paola-md | null | paola-md/light-recipes-italian | 6 | null | transformers | 15,375 | Entry not found |
patrickvonplaten/rag-sequence-ques-enc-prev | afcb83c27a4bfaebaec3bc6e3a56a0d6359ccdc3 | 2020-09-24T12:43:40.000Z | [
"pytorch",
"dpr",
"feature-extraction",
"transformers"
]
| feature-extraction | false | patrickvonplaten | null | patrickvonplaten/rag-sequence-ques-enc-prev | 6 | null | transformers | 15,376 | Entry not found |
patrickvonplaten/wav2vec2-100m-mls-german-ft | e76218a8bc6b641114c1253cb0bfccf3f53fc30c | 2021-11-15T21:52:09.000Z | [
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"dataset:multilingual_librispeech",
"transformers",
"multilingual_librispeech",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
]
| automatic-speech-recognition | false | patrickvonplaten | null | patrickvonplaten/wav2vec2-100m-mls-german-ft | 6 | null | transformers | 15,377 | ---
license: apache-2.0
tags:
- automatic-speech-recognition
- multilingual_librispeech
- generated_from_trainer
datasets:
- multilingual_librispeech
model-index:
- name: wav2vec2-100m-mls-german-ft
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-100m-mls-german-ft
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-100m](https://huggingface.co/facebook/wav2vec2-xls-r-100m) on the MULTILINGUAL_LIBRISPEECH - GERMAN dataset.
It achieves the following results on the evaluation set:
- Loss: 2.9325
- Wer: 1.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- total_train_batch_size: 64
- total_eval_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 100.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:---:|
| 8.2135 | 14.29 | 500 | 8.4258 | 1.0 |
| 3.0031 | 28.57 | 1000 | 2.9839 | 1.0 |
| 2.9661 | 42.86 | 1500 | 2.9402 | 1.0 |
| 2.9584 | 57.14 | 2000 | 2.9354 | 1.0 |
| 2.936 | 71.43 | 2500 | 2.9341 | 1.0 |
| 2.9344 | 85.71 | 3000 | 2.9323 | 1.0 |
| 2.9674 | 100.0 | 3500 | 2.9325 | 1.0 |
### Framework versions
- Transformers 4.13.0.dev0
- Pytorch 1.9.0+cu111
- Datasets 1.15.2.dev0
- Tokenizers 0.10.3
|
patrickvonplaten/wav2vec2-xls-r-1b-common_voice-tr-ft | 6c8486275d421f991abb32ab0914ac8fff9e4745 | 2021-11-14T16:43:33.000Z | [
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"tr",
"dataset:common_voice",
"transformers",
"common_voice",
"generated_from_trainer",
"xls_r_repro_common_voice_tr",
"license:apache-2.0",
"model-index"
]
| automatic-speech-recognition | false | patrickvonplaten | null | patrickvonplaten/wav2vec2-xls-r-1b-common_voice-tr-ft | 6 | 0 | transformers | 15,378 | ---
language:
- tr
license: apache-2.0
tags:
- automatic-speech-recognition
- common_voice
- generated_from_trainer
- xls_r_repro_common_voice_tr
datasets:
- common_voice
model-index:
- name: wav2vec2-large-xls-r-1b-common_voice-tr-ft
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-1b-common_voice-tr-ft
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-1b](https://huggingface.co/facebook/wav2vec2-xls-r-1b) on the COMMON_VOICE - TR dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3015
- Wer: 0.2149
- Cer: 0.0503
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.00005
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- total_train_batch_size: 64
- total_eval_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 100.0
- mixed_precision_training: Native AMP
### Training results
Check [Training metrics](https://huggingface.co/patrickvonplaten/wav2vec2-xls-r-1b-common_voice-tr-ft/tensorboard).
### Framework versions
- Transformers 4.13.0.dev0
- Pytorch 1.9.0+cu111
- Datasets 1.15.2.dev0
- Tokenizers 0.10.3
|
pere/nb-nn-dev | 583865f7e462cb2f43db3ecb339ffc94f87d4c00 | 2021-09-28T07:34:18.000Z | [
"pytorch",
"jax",
"tensorboard",
"no",
"dataset:oscar",
"translation",
"license:cc-by-4.0"
]
| translation | false | pere | null | pere/nb-nn-dev | 6 | null | null | 15,379 | ---
language: no
license: cc-by-4.0
tags:
- translation
datasets:
- oscar
widget:
- text: Skriv inn en tekst som du ønsker å oversette til en annen målform.
---
# Norwegian mT5 - Translation Bokmål Nynorsk - Development
## Description
This is the development version of the Bokmål-Nynorsk translator. If you want something that is stable, Please do run [this version](https://huggingface.co/pere/nb-nn-translation/) instead.
Here is an example of how to use the model from Python
```python
# Import libraries
from transformers import T5ForConditionalGeneration, AutoTokenizer
model = T5ForConditionalGeneration.from_pretrained('pere/nb-nn-dev',from_flax=True)
tokenizer = AutoTokenizer.from_pretrained('pere/nb-nn-dev')
#Encode the text
text = "Hun vil ikke gi bort sine personlige data."
inputs = tokenizer.encode(text, return_tensors="pt")
outputs = model.generate(inputs, max_length=255, num_beams=4, early_stopping=True)
#Decode and print the result
print(tokenizer.decode(outputs[0]))
```
Or if you like to use the pipeline instead
```python
# Set up the pipeline
from transformers import pipeline
translator = pipeline("translation", model='pere/nb-nn-dev')
# Do the translation
text = "Hun vil ikke gi bort sine personlige data."
print(translator(text, max_length=255))
```
|
persiannlp/mt5-large-parsinlu-multiple-choice | 81d01e118f0b4bb564bf4bb04995237bea2dbfa2 | 2021-09-23T16:20:14.000Z | [
"pytorch",
"jax",
"t5",
"text2text-generation",
"fa",
"multilingual",
"dataset:parsinlu",
"transformers",
"multiple-choice",
"mt5",
"persian",
"farsi",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible"
]
| text2text-generation | false | persiannlp | null | persiannlp/mt5-large-parsinlu-multiple-choice | 6 | null | transformers | 15,380 | ---
language:
- fa
- multilingual
thumbnail: https://upload.wikimedia.org/wikipedia/commons/a/a2/Farsi.svg
tags:
- multiple-choice
- mt5
- persian
- farsi
license: cc-by-nc-sa-4.0
datasets:
- parsinlu
metrics:
- accuracy
---
# Multiple-Choice Question Answering (مدل برای پاسخ به سوالات چهار جوابی)
This is a mT5-based model for multiple-choice question answering.
Here is an example of how you can run this model:
```python
from transformers import MT5ForConditionalGeneration, MT5Tokenizer
model_size = "large"
model_name = f"persiannlp/mt5-{model_size}-parsinlu-multiple-choice"
tokenizer = MT5Tokenizer.from_pretrained(model_name)
model = MT5ForConditionalGeneration.from_pretrained(model_name)
def run_model(input_string, **generator_args):
input_ids = tokenizer.encode(input_string, return_tensors="pt")
res = model.generate(input_ids, **generator_args)
output = tokenizer.batch_decode(res, skip_special_tokens=True)
print(output)
return output
run_model("وسیع ترین کشور جهان کدام است؟ <sep> آمریکا <sep> کانادا <sep> روسیه <sep> چین")
run_model("طامع یعنی ؟ <sep> آزمند <sep> خوش شانس <sep> محتاج <sep> مطمئن")
run_model(
"زمینی به ۳۱ قطعه متساوی مفروض شده است و هر روز مساحت آماده شده برای احداث، دو برابر مساحت روز قبل است.اگر پس از (۵ روز) تمام زمین آماده شده باشد، در چه روزی یک قطعه زمین آماده شده <sep> روز اول <sep> روز دوم <sep> روز سوم <sep> هیچکدام")
```
For more details, visit this page: https://github.com/persiannlp/parsinlu/
|
peterhsu/bert-finetuned-ner-accelerate | 904036d676321b6238091534622ce188f85299ae | 2022-01-25T16:23:06.000Z | [
"pytorch",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | false | peterhsu | null | peterhsu/bert-finetuned-ner-accelerate | 6 | null | transformers | 15,381 | Entry not found |
pinecone/bert-medqp-cross-encoder | 4c19e15b0da2c11151080b74457f07d8ba119ec0 | 2021-12-30T12:11:30.000Z | [
"pytorch",
"bert",
"text-classification",
"transformers"
]
| text-classification | false | pinecone | null | pinecone/bert-medqp-cross-encoder | 6 | null | transformers | 15,382 | # Med-QP Cross Encoder
Demo model for use as part of Augmented SBERT chapters of the [NLP for Semantic Search course](https://www.pinecone.io/learn/nlp). |
prajin/nepali-bert | ea2b0b3e6f0252441fa883c70e563403ccb3c238 | 2022-02-08T06:13:42.000Z | [
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
]
| fill-mask | false | prajin | null | prajin/nepali-bert | 6 | null | transformers | 15,383 | Entry not found |
princeton-nlp/densephrases-multi-query-multi | 824622899fa3b29580a51381a93a675c77fa9112 | 2021-09-20T17:47:08.000Z | [
"pytorch",
"bert",
"transformers"
]
| null | false | princeton-nlp | null | princeton-nlp/densephrases-multi-query-multi | 6 | null | transformers | 15,384 | Entry not found |
pritamdeka/PubMedBert-fulltext-cord19 | 49eafd3bd4055cfa222992fa8fb6975d1494afb9 | 2022-02-05T20:56:37.000Z | [
"pytorch",
"bert",
"fill-mask",
"dataset:pritamdeka/cord-19-fulltext",
"transformers",
"generated_from_trainer",
"license:mit",
"model-index",
"autotrain_compatible"
]
| fill-mask | false | pritamdeka | null | pritamdeka/PubMedBert-fulltext-cord19 | 6 | null | transformers | 15,385 | ---
license: mit
tags:
- generated_from_trainer
datasets:
- pritamdeka/cord-19-fulltext
metrics:
- accuracy
model-index:
- name: pubmedbert-fulltext-cord19
results:
- task:
name: Masked Language Modeling
type: fill-mask
dataset:
name: pritamdeka/cord-19-fulltext
type: pritamdeka/cord-19-fulltext
args: fulltext
metrics:
- name: Accuracy
type: accuracy
value: 0.7175316733550737
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# pubmedbert-fulltext-cord19
This model is a fine-tuned version of [microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext](https://huggingface.co/microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext) on the pritamdeka/cord-19-fulltext dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2667
- Accuracy: 0.7175
## Model description
The model has been trained using a maximum train sample size of 300K and evaluation size of 25K due to GPU limitations
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 10000
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 1.7985 | 0.27 | 5000 | 1.2710 | 0.7176 |
| 1.7542 | 0.53 | 10000 | 1.3359 | 0.7070 |
| 1.7462 | 0.8 | 15000 | 1.3489 | 0.7034 |
| 1.8371 | 1.07 | 20000 | 1.4361 | 0.6891 |
| 1.7102 | 1.33 | 25000 | 1.3502 | 0.7039 |
| 1.6596 | 1.6 | 30000 | 1.3341 | 0.7065 |
| 1.6265 | 1.87 | 35000 | 1.3228 | 0.7087 |
| 1.605 | 2.13 | 40000 | 1.3079 | 0.7099 |
| 1.5731 | 2.4 | 45000 | 1.2986 | 0.7121 |
| 1.5602 | 2.67 | 50000 | 1.2929 | 0.7136 |
| 1.5447 | 2.93 | 55000 | 1.2875 | 0.7143 |
### Framework versions
- Transformers 4.17.0.dev0
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.11.0
|
pspatel2/storygen | 906594b379310ddb264f80fb00caf2eedef4070a | 2021-05-23T12:09:14.000Z | [
"pytorch",
"jax",
"gpt2",
"text-generation",
"transformers"
]
| text-generation | false | pspatel2 | null | pspatel2/storygen | 6 | null | transformers | 15,386 | Entry not found |
ramybaly/CoNLL12V2 | d371bec9136e619968784e731c17f9653f4491b8 | 2022-01-25T05:47:38.000Z | [
"pytorch",
"tensorboard",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | false | ramybaly | null | ramybaly/CoNLL12V2 | 6 | null | transformers | 15,387 | Entry not found |
recobo/chemical-bert-uncased-squad2 | 488ef153992514208f24c3beb91211dd73878f7d | 2021-09-01T08:44:18.000Z | [
"pytorch",
"bert",
"question-answering",
"transformers",
"autotrain_compatible"
]
| question-answering | false | recobo | null | recobo/chemical-bert-uncased-squad2 | 6 | null | transformers | 15,388 | ```python
from transformers import AutoModelForQuestionAnswering, AutoTokenizer, pipeline
model_name = "recobo/chemical-bert-uncased-squad2"
# a) Get predictions
nlp = pipeline('question-answering', model=model_name, tokenizer=model_name)
QA_input = {
'question': 'Why is model conversion important?',
'context': 'The option to convert models between pytorch and transformers gives freedom to the user and let people easily switch between frameworks.'
}
res = nlp(QA_input)
# b) Load model & tokenizer
model = AutoModelForQuestionAnswering.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
``` |
robinhad/wav2vec2-xls-r-300m-uk | ca64e043cc2a34c7fb9bdfbce42ba142226310b3 | 2022-01-19T22:20:54.000Z | [
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"uk",
"dataset:common_voice",
"transformers",
"common_voice",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
]
| automatic-speech-recognition | false | robinhad | null | robinhad/wav2vec2-xls-r-300m-uk | 6 | 4 | transformers | 15,389 | ---
language:
- uk
license: apache-2.0
tags:
- automatic-speech-recognition
- common_voice
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: wav2vec2-xls-r-300m-uk
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice uk
type: common_voice
args: uk
metrics:
- name: Test WER
type: wer
value: 27.99
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-xls-r-300m-uk
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset.
Notebook for training is located in this repository: [https://github.com/robinhad/wav2vec2-xls-r-ukrainian](https://github.com/robinhad/wav2vec2-xls-r-ukrainian).
It achieves the following results on the evaluation set:
- Loss: 0.4165
- Wer: 0.2799
- Cer: 0.0601
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 20
- total_train_batch_size: 160
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 500
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Cer | Validation Loss | Wer |
|:-------------:|:------:|:-----:|:------:|:---------------:|:------:|
| 4.3982 | 9.3 | 400 | 0.1437 | 0.5218 | 0.6507 |
| 0.229 | 18.6 | 800 | 0.0848 | 0.3679 | 0.4048 |
| 0.1054 | 27.9 | 1200 | 0.0778 | 0.3813 | 0.3670 |
| 0.0784 | 37.21 | 1600 | 0.0747 | 0.3839 | 0.3550 |
| 0.066 | 46.51 | 2000 | 0.0736 | 0.3970 | 0.3443 |
| 0.0603 | 55.8 | 2400 | 0.0722 | 0.3702 | 0.3393 |
| 0.0539 | 65.11 | 2800 | 0.0724 | 0.3762 | 0.3388 |
| 0.0497 | 74.41 | 3200 | 0.0713 | 0.3623 | 0.3414 |
| 0.0432 | 83.71 | 3600 | 0.0725 | 0.3847 | 0.3346 |
| 0.0438 | 93.02 | 4000 | 0.0750 | 0.4058 | 0.3393 |
| 0.0413 | 102.32 | 4400 | 0.0727 | 0.3957 | 0.3363 |
| 0.039 | 111.62 | 4800 | 0.0718 | 0.3865 | 0.3330 |
| 0.0356 | 120.92 | 5200 | 0.0711 | 0.3860 | 0.3319 |
| 0.0336 | 130.23 | 5600 | 0.0700 | 0.3902 | 0.3242 |
| 0.034 | 139.53 | 6000 | 0.0732 | 0.3930 | 0.3337 |
| 0.0273 | 148.83 | 6400 | 0.0748 | 0.3912 | 0.3375 |
| 0.027 | 158.14 | 6800 | 0.0752 | 0.4266 | 0.3434 |
| 0.028 | 167.44 | 7200 | 0.0708 | 0.3895 | 0.3227 |
| 0.0241 | 176.73 | 7600 | 0.0727 | 0.3967 | 0.3294 |
| 0.0241 | 186.05 | 8000 | 0.0712 | 0.4058 | 0.3255 |
| 0.0209 | 195.34 | 8400 | 0.0702 | 0.4102 | 0.3233 |
| 0.0206 | 204.64 | 8800 | 0.0699 | 0.4075 | 0.3194 |
| 0.0172 | 213.94 | 9200 | 0.0695 | 0.4222 | 0.3191 |
| 0.0166 | 223.25 | 9600 | 0.0678 | 0.3860 | 0.3135 |
| 0.0156 | 232.55 | 10000 | 0.0677 | 0.4035 | 0.3117 |
| 0.0149 | 241.85 | 10400 | 0.0677 | 0.3951 | 0.3087 |
| 0.0142 | 251.16 | 10800 | 0.0674 | 0.3972 | 0.3097 |
| 0.0134 | 260.46 | 11200 | 0.0675 | 0.4069 | 0.3111 |
| 0.0116 | 269.76 | 11600 | 0.0697 | 0.4189 | 0.3161 |
| 0.0119 | 279.07 | 12000 | 0.0648 | 0.3902 | 0.3008 |
| 0.0098 | 288.37 | 12400 | 0.0652 | 0.4095 | 0.3002 |
| 0.0091 | 297.67 | 12800 | 0.0644 | 0.3892 | 0.2990 |
| 0.0094 | 306.96 | 13200 | 0.0647 | 0.4026 | 0.2983 |
| 0.0081 | 316.28 | 13600 | 0.0646 | 0.4303 | 0.2978 |
| 0.0079 | 325.57 | 14000 | 0.0643 | 0.4044 | 0.2980 |
| 0.0072 | 334.87 | 14400 | 0.0655 | 0.3828 | 0.2999 |
| 0.0081 | 344.18 | 14800 | 0.0668 | 0.4108 | 0.3046 |
| 0.0088 | 353.48 | 15200 | 0.0654 | 0.4019 | 0.2993 |
| 0.0088 | 362.78 | 15600 | 0.0681 | 0.4073 | 0.3091 |
| 0.0079 | 372.09 | 16000 | 0.0667 | 0.4204 | 0.3055 |
| 0.0072 | 381.39 | 16400 | 0.0656 | 0.4030 | 0.3028 |
| 0.0073 | 390.69 | 16800 | 0.0677 | 0.4032 | 0.3081 |
| 0.0069 | 399.99 | 17200 | 0.0669 | 0.4130 | 0.3021 |
| 0.0063 | 409.3 | 17600 | 0.0651 | 0.4072 | 0.2979 |
| 0.0059 | 418.6 | 18000 | 0.0640 | 0.4110 | 0.2969 |
| 0.0056 | 427.9 | 18400 | 0.0647 | 0.4229 | 0.2995 |
| 0.005 | 437.21 | 18800 | 0.0624 | 0.4118 | 0.2885 |
| 0.0046 | 446.51 | 19200 | 0.0615 | 0.4111 | 0.2841 |
| 0.0043 | 455.8 | 19600 | 0.0616 | 0.4071 | 0.2850 |
| 0.0038 | 465.11 | 20000 | 0.0624 | 0.4268 | 0.2867 |
| 0.0035 | 474.41 | 20400 | 0.0605 | 0.4117 | 0.2820 |
| 0.0035 | 483.71 | 20800 | 0.0602 | 0.4155 | 0.2819 |
| 0.0034 | 493.02 | 21200 | 0.0601 | 0.4165 | 0.2799 |
### Framework versions
- Transformers 4.14.1
- Pytorch 1.10.0
- Datasets 1.16.1
- Tokenizers 0.10.3
|
rockmiin/ko-boolq-model | c9b03a29a72de9b8f117273e1b54dba1c86583c5 | 2021-12-20T02:42:43.000Z | [
"pytorch",
"roberta",
"text-classification",
"transformers"
]
| text-classification | false | rockmiin | null | rockmiin/ko-boolq-model | 6 | 2 | transformers | 15,390 | labeled by "YES" : 1, "NO" : 0, "No Answer" : 2
fine tuned by klue/roberta-large |
sanayAI/parsbert-base-sanay-uncased | d7de6ace371d43a2a0a57a0e5c6fe568d04359a3 | 2021-05-20T04:43:22.000Z | [
"pytorch",
"jax",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
]
| fill-mask | false | sanayAI | null | sanayAI/parsbert-base-sanay-uncased | 6 | null | transformers | 15,391 | Entry not found |
sanayAI/sanayBERT_model_V1 | 0645573a54757174238c3cb43bdf69b99dd0cce0 | 2021-05-20T04:46:35.000Z | [
"pytorch",
"jax",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
]
| fill-mask | false | sanayAI | null | sanayAI/sanayBERT_model_V1 | 6 | null | transformers | 15,392 | Entry not found |
sciarrilli/distilbert-base-uncased-cola | 9747a40d0b39dbd902953a1f77c188081c2c1435 | 2021-11-15T02:21:53.000Z | [
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"dataset:glue",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
]
| text-classification | false | sciarrilli | null | sciarrilli/distilbert-base-uncased-cola | 6 | null | transformers | 15,393 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- matthews_correlation
model-index:
- name: distilbert-base-uncased-cola
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: cola
metrics:
- name: Matthews Correlation
type: matthews_correlation
value: 0.5301312348234369
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2715
- Matthews Correlation: 0.5301
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.5216 | 1.0 | 535 | 0.5124 | 0.4104 |
| 0.3456 | 2.0 | 1070 | 0.5700 | 0.4692 |
| 0.2362 | 3.0 | 1605 | 0.7277 | 0.4844 |
| 0.1818 | 4.0 | 2140 | 0.7553 | 0.5007 |
| 0.1509 | 5.0 | 2675 | 0.9406 | 0.4987 |
| 0.1017 | 6.0 | 3210 | 0.9475 | 0.5387 |
| 0.0854 | 7.0 | 3745 | 1.0933 | 0.5317 |
| 0.051 | 8.0 | 4280 | 1.1719 | 0.5358 |
| 0.0512 | 9.0 | 4815 | 1.2296 | 0.5321 |
| 0.0308 | 10.0 | 5350 | 1.2715 | 0.5301 |
### Framework versions
- Transformers 4.12.3
- Pytorch 1.10.0+cu102
- Datasets 1.15.1
- Tokenizers 0.10.3
|
seanbenhur/kanglish-offensive-language-identification | 1a2c56ca27a6f8c817c0f133fbbfc7b244a31b99 | 2021-11-13T12:40:59.000Z | [
"pytorch",
"onnx",
"roberta",
"text-classification",
"transformers"
]
| text-classification | false | seanbenhur | null | seanbenhur/kanglish-offensive-language-identification | 6 | null | transformers | 15,394 | Model Card Coming Soon |
seanbenhur/tanglish-offensive-language-identification | a4ad52c32a81d52f66380bbb44c408ec4fd324d0 | 2021-12-11T12:04:18.000Z | [
"pytorch",
"onnx",
"bert",
"text-classification",
"ta",
"en",
"dataset:dravidiancodemixed",
"transformers",
"Text Classification",
"license:apache-2.0"
]
| text-classification | false | seanbenhur | null | seanbenhur/tanglish-offensive-language-identification | 6 | 1 | transformers | 15,395 | ---
language:
- ta
- en
tags:
- Text Classification
license: apache-2.0
datasets:
- dravidiancodemixed
metrics:
- f1
- accuracy
---
Model card Coming soon
|
sebastiaan/sentence-BERT-regression | de6d9e8c41a143da2feddf01de5b21ff15f4ee60 | 2021-12-17T11:30:30.000Z | [
"pytorch",
"bert",
"feature-extraction",
"transformers"
]
| feature-extraction | false | sebastiaan | null | sebastiaan/sentence-BERT-regression | 6 | null | transformers | 15,396 | Entry not found |
sefaozalpadl/election_relevancy_best | 6f2307775d4693ae5cbca51aae975ec5298eb599 | 2021-11-07T16:48:34.000Z | [
"pytorch",
"roberta",
"text-classification",
"en",
"dataset:sefaozalpadl/autonlp-data-election_relevancy_analysis",
"transformers",
"coe",
"co2_eq_emissions"
]
| text-classification | false | sefaozalpadl | null | sefaozalpadl/election_relevancy_best | 6 | null | transformers | 15,397 | ---
tags: coe
language: en
widget:
- text: "@PressSec Response to Putin is laughable. He has Biden's number. He knows Biden can't hold up in a live debate, and the Chinese did a number on the U.S. too. Biden is making US the laughing stock of the world. We pay the price for a stolen election"
datasets:
- sefaozalpadl/autonlp-data-election_relevancy_analysis
co2_eq_emissions: 1.3248523193990855
---
# Election Fraud Binary Classifier
- Problem type: Binary Classification
- Model ID: 23315155
- CO2 Emissions (in grams): 1.3248523193990855
## Validation Metrics
- Loss: 0.4240806996822357
- Accuracy: 0.8173913043478261
- Precision: 0.8837209302325582
- Recall: 0.8085106382978723
- AUC: 0.8882580285281696
- F1: 0.8444444444444444
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/models/sefaozalpadl/election_relevancy_best
```
Or Python API:
```
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("sefaozalpadl/election_relevancy_best")
model = AutoModelForSequenceClassification.from_pretrained("sefaozalpadl/election_relevancy_best")
inputs = tokenizer("I love AutoNLP", return_tensors="pt")
outputs = model(**inputs)
``` |
sgugger/distilbert-base-uncased-finetuned-cola | ef2f0c5fb5910ceeb8e18d2a22cf0ef182ddf81e | 2021-11-08T14:31:12.000Z | [
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"dataset:glue",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
]
| text-classification | false | sgugger | null | sgugger/distilbert-base-uncased-finetuned-cola | 6 | null | transformers | 15,398 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- matthews_correlation
model-index:
- name: distilbert-base-uncased-finetuned-cola
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: cola
metrics:
- name: Matthews Correlation
type: matthews_correlation
value: 0.5158855550567928
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7572
- Matthews Correlation: 0.5159
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.5256 | 1.0 | 535 | 0.5197 | 0.4033 |
| 0.3534 | 2.0 | 1070 | 0.5301 | 0.4912 |
| 0.2402 | 3.0 | 1605 | 0.6680 | 0.5033 |
| 0.1762 | 4.0 | 2140 | 0.7572 | 0.5159 |
| 0.1389 | 5.0 | 2675 | 0.8584 | 0.5127 |
### Framework versions
- Transformers 4.13.0.dev0
- Pytorch 1.10.0+cu102
- Datasets 1.13.4.dev0
- Tokenizers 0.10.3
|
sgugger/test-upload | 280fc1ca0335fd949a626fd0e8c3d2dc23e86ad9 | 2022-07-29T15:56:12.000Z | [
"pytorch",
"bert",
"feature-extraction",
"transformers"
]
| feature-extraction | false | sgugger | null | sgugger/test-upload | 6 | null | transformers | 15,399 | Entry not found |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.