
modelId
stringlengths 4
112
| sha
stringlengths 40
40
| lastModified
stringlengths 24
24
| tags
list | pipeline_tag
stringclasses 29
values | private
bool 1
class | author
stringlengths 2
38
⌀ | config
null | id
stringlengths 4
112
| downloads
float64 0
36.8M
⌀ | likes
float64 0
712
⌀ | library_name
stringclasses 17
values | __index_level_0__
int64 0
38.5k
| readme
stringlengths 0
186k
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
ceshine/t5-paraphrase-paws-msrp-opinosis | a54ecca4603c7ff7bc497ffc97d1dc7dd5f485d2 | 2021-09-22T08:16:39.000Z | [
"pytorch",
"jax",
"t5",
"text2text-generation",
"en",
"transformers",
"paraphrasing",
"paraphrase",
"license:apache-2.0",
"autotrain_compatible"
]
| text2text-generation | false | ceshine | null | ceshine/t5-paraphrase-paws-msrp-opinosis | 1,561 | null | transformers | 1,500 | ---
language: en
tags:
- t5
- paraphrasing
- paraphrase
license: apache-2.0
---
# T5-base Parapharasing model fine-tuned on PAWS, MSRP, and Opinosis
More details in [ceshine/finetuning-t5 Github repo](https://github.com/ceshine/finetuning-t5/tree/master/paraphrase) |
monsoon-nlp/bert-base-thai | 9b5ca3cc1b41c8ff91c57d34e50e77d29ec7d2c1 | 2022-02-15T19:21:29.000Z | [
"pytorch",
"jax",
"bert",
"feature-extraction",
"th",
"arxiv:1609.08144",
"arxiv:1508.07909",
"transformers"
]
| feature-extraction | false | monsoon-nlp | null | monsoon-nlp/bert-base-thai | 1,561 | 1 | transformers | 1,501 | ---
language: th
---
# BERT-th
Adapted from https://github.com/ThAIKeras/bert for HuggingFace/Transformers library
## Pre-tokenization
You must run the original ThaiTokenizer to have your tokenization match that of the original model.
If you skip this step, you will not do much better than
mBERT or random chance!
[Refer to this CoLab notebook](https://colab.research.google.com/drive/1Ax9OsbTPwBBP1pJx1DkYwtgKILcj3Ur5?usp=sharing)
or follow these steps:
```bash
pip install pythainlp six sentencepiece python-crfsuite
git clone https://github.com/ThAIKeras/bert
# download .vocab and .model files from ThAIKeras/bert > Tokenization section
```
Or from [.vocab](https://raw.githubusercontent.com/jitkapat/thaipostagger/master/th.wiki.bpe.op25000.vocab)
and [.model](https://raw.githubusercontent.com/jitkapat/thaipostagger/master/th.wiki.bpe.op25000.model) links.
Then set up ThaiTokenizer class - this is modified slightly to
remove a TensorFlow dependency.
```python
import collections
import unicodedata
import six
def convert_to_unicode(text):
"""Converts `text` to Unicode (if it's not already), assuming utf-8 input."""
if six.PY3:
if isinstance(text, str):
return text
elif isinstance(text, bytes):
return text.decode("utf-8", "ignore")
else:
raise ValueError("Unsupported string type: %s" % (type(text)))
elif six.PY2:
if isinstance(text, str):
return text.decode("utf-8", "ignore")
elif isinstance(text, unicode):
return text
else:
raise ValueError("Unsupported string type: %s" % (type(text)))
else:
raise ValueError("Not running on Python2 or Python 3?")
def load_vocab(vocab_file):
vocab = collections.OrderedDict()
index = 0
with open(vocab_file, "r") as reader:
while True:
token = reader.readline()
if token.split(): token = token.split()[0] # to support SentencePiece vocab file
token = convert_to_unicode(token)
if not token:
break
token = token.strip()
vocab[token] = index
index += 1
return vocab
#####
from bert.bpe_helper import BPE
import sentencepiece as spm
def convert_by_vocab(vocab, items):
output = []
for item in items:
output.append(vocab[item])
return output
class ThaiTokenizer(object):
"""Tokenizes Thai texts."""
def __init__(self, vocab_file, spm_file):
self.vocab = load_vocab(vocab_file)
self.inv_vocab = {v: k for k, v in self.vocab.items()}
self.bpe = BPE(vocab_file)
self.s = spm.SentencePieceProcessor()
self.s.Load(spm_file)
def tokenize(self, text):
bpe_tokens = self.bpe.encode(text).split(' ')
spm_tokens = self.s.EncodeAsPieces(text)
tokens = bpe_tokens if len(bpe_tokens) < len(spm_tokens) else spm_tokens
split_tokens = []
for token in tokens:
new_token = token
if token.startswith('_') and not token in self.vocab:
split_tokens.append('_')
new_token = token[1:]
if not new_token in self.vocab:
split_tokens.append('<unk>')
else:
split_tokens.append(new_token)
return split_tokens
def convert_tokens_to_ids(self, tokens):
return convert_by_vocab(self.vocab, tokens)
def convert_ids_to_tokens(self, ids):
return convert_by_vocab(self.inv_vocab, ids)
```
Then pre-tokenizing your own text:
```python
from pythainlp import sent_tokenize
tokenizer = ThaiTokenizer(vocab_file='th.wiki.bpe.op25000.vocab', spm_file='th.wiki.bpe.op25000.model')
txt = "กรุงเทพมหานครเป็นเขตปกครองพิเศษของประเทศไทย มิได้มีสถานะเป็นจังหวัด คำว่า \"กรุงเทพมหานคร\" นั้นยังใช้เรียกองค์กรปกครองส่วนท้องถิ่นของกรุงเทพมหานครอีกด้วย"
split_sentences = sent_tokenize(txt)
print(split_sentences)
"""
['กรุงเทพมหานครเป็นเขตปกครองพิเศษของประเทศไทย ',
'มิได้มีสถานะเป็นจังหวัด ',
'คำว่า "กรุงเทพมหานคร" นั้นยังใช้เรียกองค์กรปกครองส่วนท้องถิ่นของกรุงเทพมหานครอีกด้วย']
"""
split_words = ' '.join(tokenizer.tokenize(' '.join(split_sentences)))
print(split_words)
"""
'▁กรุงเทพมหานคร เป็นเขต ปกครอง พิเศษ ของประเทศไทย ▁มิ ได้มี สถานะเป็น จังหวัด ▁คําว่า ▁" กรุงเทพมหานคร " ▁นั้น...' # continues
"""
```
Original README follows:
---
Google's [**BERT**](https://github.com/google-research/bert) is currently the state-of-the-art method of pre-training text representations which additionally provides multilingual models. ~~Unfortunately, Thai is the only one in 103 languages that is excluded due to difficulties in word segmentation.~~
BERT-th presents the Thai-only pre-trained model based on the BERT-Base structure. It is now available to download.
* **[`BERT-Base, Thai`](https://drive.google.com/open?id=1J3uuXZr_Se_XIFHj7zlTJ-C9wzI9W_ot)**: BERT-Base architecture, Thai-only model
BERT-th also includes relevant codes and scripts along with the pre-trained model, all of which are the modified versions of those in the original BERT project.
## Preprocessing
### Data Source
Training data for BERT-th come from [the latest article dump of Thai Wikipedia](https://dumps.wikimedia.org/thwiki/latest/thwiki-latest-pages-articles.xml.bz2) on November 2, 2018. The raw texts are extracted by using [WikiExtractor](https://github.com/attardi/wikiextractor).
### Sentence Segmentation
Input data need to be segmented into separate sentences before further processing by BERT modules. Since Thai language has no explicit marker at the end of a sentence, it is quite problematic to pinpoint sentence boundaries. To the best of our knowledge, there is still no implementation of Thai sentence segmentation elsewhere. So, in this project, sentence segmentation is done by applying simple heuristics, considering spaces, sentence length and common conjunctions.
After preprocessing, the training corpus consists of approximately 2 million sentences and 40 million words (counting words after word segmentation by [PyThaiNLP](https://github.com/PyThaiNLP/pythainlp)). The plain and segmented texts can be downloaded **[`here`](https://drive.google.com/file/d/1QZSOpikO6Qc02gRmyeb_UiRLtTmUwGz1/view?usp=sharing)**.
## Tokenization
BERT uses [WordPiece](https://arxiv.org/pdf/1609.08144.pdf) as a tokenization mechanism. But it is Google internal, we cannot apply existing Thai word segmentation and then utilize WordPiece to learn the set of subword units. The best alternative is [SentencePiece](https://github.com/google/sentencepiece) which implements [BPE](https://arxiv.org/abs/1508.07909) and needs no word segmentation.
In this project, we adopt a pre-trained Thai SentencePiece model from [BPEmb](https://github.com/bheinzerling/bpemb). The model of 25000 vocabularies is chosen and the vocabulary file has to be augmented with BERT's special characters, including '[PAD]', '[CLS]', '[SEP]' and '[MASK]'. The model and vocabulary files can be downloaded **[`here`](https://drive.google.com/file/d/1F7pCgt3vPlarI9RxKtOZUrC_67KMNQ1W/view?usp=sharing)**.
`SentencePiece` and `bpe_helper.py` from BPEmb are both used to tokenize data. `ThaiTokenizer class` has been added to BERT's `tokenization.py` for tokenizing Thai texts.
## Pre-training
The data can be prepared before pre-training by using this script.
```shell
export BPE_DIR=/path/to/bpe
export TEXT_DIR=/path/to/text
export DATA_DIR=/path/to/data
python create_pretraining_data.py \
--input_file=$TEXT_DIR/thaiwikitext_sentseg \
--output_file=$DATA_DIR/tf_examples.tfrecord \
--vocab_file=$BPE_DIR/th.wiki.bpe.op25000.vocab \
--max_seq_length=128 \
--max_predictions_per_seq=20 \
--masked_lm_prob=0.15 \
--random_seed=12345 \
--dupe_factor=5 \
--thai_text=True \
--spm_file=$BPE_DIR/th.wiki.bpe.op25000.model
```
Then, the following script can be run to learn a model from scratch.
```shell
export DATA_DIR=/path/to/data
export BERT_BASE_DIR=/path/to/bert_base
python run_pretraining.py \
--input_file=$DATA_DIR/tf_examples.tfrecord \
--output_dir=$BERT_BASE_DIR \
--do_train=True \
--do_eval=True \
--bert_config_file=$BERT_BASE_DIR/bert_config.json \
--train_batch_size=32 \
--max_seq_length=128 \
--max_predictions_per_seq=20 \
--num_train_steps=1000000 \
--num_warmup_steps=100000 \
--learning_rate=1e-4 \
--save_checkpoints_steps=200000
```
We have trained the model for 1 million steps. On Tesla K80 GPU, it took around 20 days to complete. Though, we provide a snapshot at 0.8 million steps because it yields better results for downstream classification tasks.
## Downstream Classification Tasks
### XNLI
[XNLI](http://www.nyu.edu/projects/bowman/xnli/) is a dataset for evaluating a cross-lingual inferential classification task. The development and test sets contain 15 languages which data are thoroughly edited. The machine-translated versions of training data are also provided.
The Thai-only pre-trained BERT model can be applied to the XNLI task by using training data which are translated to Thai. Spaces between words in the training data need to be removed to make them consistent with inputs in the pre-training step. The processed files of XNLI related to Thai language can be downloaded **[`here`](https://drive.google.com/file/d/1ZAk1JfR6a0TSCkeyQ-EkRtk1w_mQDWFG/view?usp=sharing)**.
Afterwards, the XNLI task can be learned by using this script.
```shell
export BPE_DIR=/path/to/bpe
export XNLI_DIR=/path/to/xnli
export OUTPUT_DIR=/path/to/output
export BERT_BASE_DIR=/path/to/bert_base
python run_classifier.py \
--task_name=XNLI \
--do_train=true \
--do_eval=true \
--data_dir=$XNLI_DIR \
--vocab_file=$BPE_DIR/th.wiki.bpe.op25000.vocab \
--bert_config_file=$BERT_BASE_DIR/bert_config.json \
--init_checkpoint=$BERT_BASE_DIR/model.ckpt \
--max_seq_length=128 \
--train_batch_size=32 \
--learning_rate=5e-5 \
--num_train_epochs=2.0 \
--output_dir=$OUTPUT_DIR \
--xnli_language=th \
--spm_file=$BPE_DIR/th.wiki.bpe.op25000.model
```
This table compares the Thai-only model with XNLI baselines and the Multilingual Cased model which is also trained by using translated data.
<!-- Use html table because github markdown doesn't support colspan -->
<table>
<tr>
<td colspan="2" align="center"><b>XNLI Baseline</b></td>
<td colspan="2" align="center"><b>BERT</b></td>
</tr>
<tr>
<td align="center">Translate Train</td>
<td align="center">Translate Test</td>
<td align="center">Multilingual Model</td>
<td align="center">Thai-only Model</td>
</tr>
<td align="center">62.8</td>
<td align="center">64.4</td>
<td align="center">66.1</td>
<td align="center"><b>68.9</b></td>
</table>
### Wongnai Review Dataset
Wongnai Review Dataset collects restaurant reviews and ratings from [Wongnai](https://www.wongnai.com/) website. The task is to classify a review into one of five ratings (1 to 5 stars). The dataset can be downloaded **[`here`](https://github.com/wongnai/wongnai-corpus)** and the following script can be run to use the Thai-only model for this task.
```shell
export BPE_DIR=/path/to/bpe
export WONGNAI_DIR=/path/to/wongnai
export OUTPUT_DIR=/path/to/output
export BERT_BASE_DIR=/path/to/bert_base
python run_classifier.py \
--task_name=wongnai \
--do_train=true \
--do_predict=true \
--data_dir=$WONGNAI_DIR \
--vocab_file=$BPE_DIR/th.wiki.bpe.op25000.vocab \
--bert_config_file=$BERT_BASE_DIR/bert_config.json \
--init_checkpoint=$BERT_BASE_DIR/model.ckpt \
--max_seq_length=128 \
--train_batch_size=32 \
--learning_rate=5e-5 \
--num_train_epochs=2.0 \
--output_dir=$OUTPUT_DIR \
--spm_file=$BPE_DIR/th.wiki.bpe.op25000.model
```
Without additional preprocessing and further fine-tuning, the Thai-only BERT model can achieve 0.56612 and 0.57057 for public and private test-set scores respectively. |
csebuetnlp/banglat5 | c3a6a2bac3e318e065b3d2be88f91ae289b8c67d | 2022-05-24T11:15:26.000Z | [
"pytorch",
"t5",
"text2text-generation",
"bn",
"arxiv:2205.11081",
"transformers",
"autotrain_compatible"
]
| text2text-generation | false | csebuetnlp | null | csebuetnlp/banglat5 | 1,560 | 1 | transformers | 1,502 | ---
language:
- bn
licenses:
- cc-by-nc-sa-4.0
---
# BanglaT5
This repository contains the pretrained checkpoint of the model **BanglaT5**. This is a sequence to sequence transformer model pretrained with the ["Span Corruption"]() objective. Finetuned models using this checkpoint achieve state-of-the-art results on many of the NLG tasks in bengali.
For finetuning on different downstream tasks such as `Machine Translation`, `Abstractive Text Summarization`, `Question Answering` etc., refer to the scripts in the official GitHub [repository](https://github.com/csebuetnlp/BanglaNLG).
**Note**: This model was pretrained using a specific normalization pipeline available [here](https://github.com/csebuetnlp/normalizer). All finetuning scripts in the official GitHub repository use this normalization by default. If you need to adapt the pretrained model for a different task make sure the text units are normalized using this pipeline before tokenizing to get best results. A basic example is given below:
## Using this model in `transformers` (tested on 4.11.0.dev0)
```python
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
from normalizer import normalize # pip install git+https://github.com/csebuetnlp/normalizer
model = AutoModelForSeq2SeqLM.from_pretrained("csebuetnlp/banglat5")
tokenizer = AutoTokenizer.from_pretrained("csebuetnlp/banglat5", use_fast=False)
input_sentence = ""
input_ids = tokenizer(normalize(input_sentence), return_tensors="pt").input_ids
generated_tokens = model.generate(input_ids)
decoded_tokens = tokenizer.batch_decode(generated_tokens)[0]
print(decoded_tokens)
```
## Benchmarks
* Supervised fine-tuning
| Model | Params | MT (SacreBLEU) | ATS (ROUGE-2) | QA (EM/F1) | BNLG score |
|--------------------|------------|-----------------------|------------------------|-------------------|--------------|
|[mT5 (base)](https://huggingface.co/google/mt5-base) | 582M | 36.6/22.5 | 10.27 | 58.95/65.32 | 38.73 |
|[BanglaT5](https://huggingface.co/csebuetnlp/banglat5) | 247M | 38.8/25.2 | 13.66 | 68.49/74.77 | 44.18 |
The benchmarking datasets are as follows:
* **MT:** **[Machine Translation]()**
* **ATS:** **[Abstractive Text Summarization]()**
* **QA:** **[Question Answering]()**
## Citation
If you use this model, please cite the following paper:
```
@article{bhattacharjee2022banglanlg,
author = {Abhik Bhattacharjee and Tahmid Hasan and Wasi Uddin Ahmad and Rifat Shahriyar},
title = {BanglaNLG: Benchmarks and Resources for Evaluating Low-Resource Natural Language Generation in Bangla},
journal = {CoRR},
volume = {abs/2205.11081},
year = {2022},
url = {https://arxiv.org/abs/2205.11081},
eprinttype = {arXiv},
eprint = {2205.11081}
}
```
If you use the normalization module, please cite the following paper:
```
@inproceedings{hasan-etal-2020-low,
title = "Not Low-Resource Anymore: Aligner Ensembling, Batch Filtering, and New Datasets for {B}engali-{E}nglish Machine Translation",
author = "Hasan, Tahmid and
Bhattacharjee, Abhik and
Samin, Kazi and
Hasan, Masum and
Basak, Madhusudan and
Rahman, M. Sohel and
Shahriyar, Rifat",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.emnlp-main.207",
doi = "10.18653/v1/2020.emnlp-main.207",
pages = "2612--2623",
abstract = "Despite being the seventh most widely spoken language in the world, Bengali has received much less attention in machine translation literature due to being low in resources. Most publicly available parallel corpora for Bengali are not large enough; and have rather poor quality, mostly because of incorrect sentence alignments resulting from erroneous sentence segmentation, and also because of a high volume of noise present in them. In this work, we build a customized sentence segmenter for Bengali and propose two novel methods for parallel corpus creation on low-resource setups: aligner ensembling and batch filtering. With the segmenter and the two methods combined, we compile a high-quality Bengali-English parallel corpus comprising of 2.75 million sentence pairs, more than 2 million of which were not available before. Training on neural models, we achieve an improvement of more than 9 BLEU score over previous approaches to Bengali-English machine translation. We also evaluate on a new test set of 1000 pairs made with extensive quality control. We release the segmenter, parallel corpus, and the evaluation set, thus elevating Bengali from its low-resource status. To the best of our knowledge, this is the first ever large scale study on Bengali-English machine translation. We believe our study will pave the way for future research on Bengali-English machine translation as well as other low-resource languages. Our data and code are available at https://github.com/csebuetnlp/banglanmt.",
}
```
|
bespin-global/klue-sroberta-base-continue-learning-by-mnr | d5a9b36c4620a79996adce86facbed7261f93cf6 | 2022-04-04T09:19:55.000Z | [
"pytorch",
"roberta",
"feature-extraction",
"sentence-transformers",
"sentence-similarity",
"transformers"
]
| sentence-similarity | false | bespin-global | null | bespin-global/klue-sroberta-base-continue-learning-by-mnr | 1,554 | null | sentence-transformers | 1,503 | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# bespin-global/klue-sroberta-base-continue-learning-by-mnr
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer("bespin-global/klue-sroberta-base-continue-learning-by-mnr")
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained("bespin-global/klue-sroberta-base-continue-learning-by-mnr")
model = AutoModel.from_pretrained("bespin-global/klue-sroberta-base-continue-learning-by-mnr")
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
**EmbeddingSimilarityEvaluator: Evaluating the model on sts-test dataset:**
- Cosine-Similarity :
- Pearson: 0.8901 Spearman: 0.8893
- Manhattan-Distance:
- Pearson: 0.8867 Spearman: 0.8818
- Euclidean-Distance:
- Pearson: 0.8875 Spearman: 0.8827
- Dot-Product-Similarity:
- Pearson: 0.8786 Spearman: 0.8735
- Average : 0.8892573547643868
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 329 with parameters:
```
{'batch_size': 32, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss`
Parameters of the fit()-Method:
```
{
"epochs": 4,
"evaluation_steps": 32,
"evaluator": "sentence_transformers.evaluation.EmbeddingSimilarityEvaluator.EmbeddingSimilarityEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'transformers.optimization.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 132,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': True}) with Transformer model: RobertaModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
[Jaehyeong](https://huggingface.co/jaehyeong) at [Bespin Global](https://www.bespinglobal.com/) |
VoVanPhuc/sup-SimCSE-VietNamese-phobert-base | ae1275825875314c5b772b93280fbf14dbed86c5 | 2021-05-28T05:42:03.000Z | [
"pytorch",
"roberta",
"arxiv:2104.08821",
"transformers"
]
| null | false | VoVanPhuc | null | VoVanPhuc/sup-SimCSE-VietNamese-phobert-base | 1,549 | 2 | transformers | 1,504 |
#### Table of contents
1. [Introduction](#introduction)
2. [Pretrain model](#models)
3. [Using SimeCSE_Vietnamese with `sentences-transformers`](#sentences-transformers)
- [Installation](#install1)
- [Example usage](#usage1)
4. [Using SimeCSE_Vietnamese with `transformers`](#transformers)
- [Installation](#install2)
- [Example usage](#usage2)
# <a name="introduction"></a> SimeCSE_Vietnamese: Simple Contrastive Learning of Sentence Embeddings with Vietnamese
Pre-trained SimeCSE_Vietnamese models are the state-of-the-art of Sentence Embeddings with Vietnamese :
- SimeCSE_Vietnamese pre-training approach is based on [SimCSE](https://arxiv.org/abs/2104.08821) which optimizes the SimeCSE_Vietnamese pre-training procedure for more robust performance.
- SimeCSE_Vietnamese encode input sentences using a pre-trained language model such as [PhoBert](https://www.aclweb.org/anthology/2020.findings-emnlp.92/)
- SimeCSE_Vietnamese works with both unlabeled and labeled data.
## Pre-trained models <a name="models"></a>
Model | #params | Arch.
---|---|---
[`VoVanPhuc/sup-SimCSE-VietNamese-phobert-base`](https://huggingface.co/VoVanPhuc/sup-SimCSE-VietNamese-phobert-base) | 135M | base
[`VoVanPhuc/unsup-SimCSE-VietNamese-phobert-base`](https://huggingface.co/VoVanPhuc/unsup-SimCSE-VietNamese-phobert-base) | 135M | base
## <a name="sentences-transformers"></a> Using SimeCSE_Vietnamese with `sentences-transformers`
### Installation <a name="install1"></a>
- Install `sentence-transformers`:
- `pip install -U sentence-transformers`
- Install `pyvi` to word segment:
- `pip install pyvi`
### Example usage <a name="usage1"></a>
```python
from sentence_transformers import SentenceTransformer
from pyvi.ViTokenizer import tokenize
model = SentenceTransformer('VoVanPhuc/sup-SimCSE-VietNamese-phobert-base')
sentences = ['Kẻ đánh bom đinh tồi tệ nhất nước Anh.',
'Nghệ sĩ làm thiện nguyện - minh bạch là việc cấp thiết.',
'Bắc Giang tăng khả năng điều trị và xét nghiệm.',
'HLV futsal Việt Nam tiết lộ lý do hạ Lebanon.',
'việc quan trọng khi kêu gọi quyên góp từ thiện là phải minh bạch, giải ngân kịp thời.',
'20% bệnh nhân Covid-19 có thể nhanh chóng trở nặng.',
'Thái Lan thua giao hữu trước vòng loại World Cup.',
'Cựu tuyển thủ Nguyễn Bảo Quân: May mắn ủng hộ futsal Việt Nam',
'Chủ ki-ốt bị đâm chết trong chợ đầu mối lớn nhất Thanh Hoá.',
'Bắn chết người trong cuộc rượt đuổi trên sông.'
]
sentences = [tokenize(sentence) for sentence in sentences]
embeddings = model.encode(sentences)
```
## <a name="sentences-transformers"></a> Using SimeCSE_Vietnamese with `transformers`
### Installation <a name="install2"></a>
- Install `transformers`:
- `pip install -U transformers`
- Install `pyvi` to word segment:
- `pip install pyvi`
### Example usage <a name="usage2"></a>
```python
import torch
from transformers import AutoModel, AutoTokenizer
from pyvi.ViTokenizer import tokenize
PhobertTokenizer = AutoTokenizer.from_pretrained("VoVanPhuc/sup-SimCSE-VietNamese-phobert-base")
model = AutoModel.from_pretrained("VoVanPhuc/sup-SimCSE-VietNamese-phobert-base")
sentences = ['Kẻ đánh bom đinh tồi tệ nhất nước Anh.',
'Nghệ sĩ làm thiện nguyện - minh bạch là việc cấp thiết.',
'Bắc Giang tăng khả năng điều trị và xét nghiệm.',
'HLV futsal Việt Nam tiết lộ lý do hạ Lebanon.',
'việc quan trọng khi kêu gọi quyên góp từ thiện là phải minh bạch, giải ngân kịp thời.',
'20% bệnh nhân Covid-19 có thể nhanh chóng trở nặng.',
'Thái Lan thua giao hữu trước vòng loại World Cup.',
'Cựu tuyển thủ Nguyễn Bảo Quân: May mắn ủng hộ futsal Việt Nam',
'Chủ ki-ốt bị đâm chết trong chợ đầu mối lớn nhất Thanh Hoá.',
'Bắn chết người trong cuộc rượt đuổi trên sông.'
]
sentences = [tokenize(sentence) for sentence in sentences]
inputs = PhobertTokenizer(sentences, padding=True, truncation=True, return_tensors="pt")
with torch.no_grad():
embeddings = model(**inputs, output_hidden_states=True, return_dict=True).pooler_output
```
## Quick Start
[Open In Colab](https://colab.research.google.com/drive/12__EXJoQYHe9nhi4aXLTf9idtXT8yr7H?usp=sharing)
## Citation
@article{gao2021simcse,
title={{SimCSE}: Simple Contrastive Learning of Sentence Embeddings},
author={Gao, Tianyu and Yao, Xingcheng and Chen, Danqi},
journal={arXiv preprint arXiv:2104.08821},
year={2021}
}
@inproceedings{phobert,
title = {{PhoBERT: Pre-trained language models for Vietnamese}},
author = {Dat Quoc Nguyen and Anh Tuan Nguyen},
booktitle = {Findings of the Association for Computational Linguistics: EMNLP 2020},
year = {2020},
pages = {1037--1042}
}
|
sentence-transformers/nli-bert-base | d5604f34c50678d07bd65a2cad9b996dae053a76 | 2022-06-15T23:20:12.000Z | [
"pytorch",
"tf",
"bert",
"feature-extraction",
"arxiv:1908.10084",
"sentence-transformers",
"sentence-similarity",
"transformers",
"license:apache-2.0"
]
| sentence-similarity | false | sentence-transformers | null | sentence-transformers/nli-bert-base | 1,544 | null | sentence-transformers | 1,505 | ---
pipeline_tag: sentence-similarity
license: apache-2.0
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
**⚠️ This model is deprecated. Please don't use it as it produces sentence embeddings of low quality. You can find recommended sentence embedding models here: [SBERT.net - Pretrained Models](https://www.sbert.net/docs/pretrained_models.html)**
# sentence-transformers/nli-bert-base
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/nli-bert-base')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/nli-bert-base')
model = AutoModel.from_pretrained('sentence-transformers/nli-bert-base')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/nli-bert-base)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
``` |
Davlan/distilbert-base-multilingual-cased-ner-hrl | 6c3d663fb9d1b22e6f000595e9ce74597021a68a | 2022-06-27T10:49:50.000Z | [
"pytorch",
"tf",
"distilbert",
"token-classification",
"ar",
"de",
"en",
"es",
"fr",
"it",
"lv",
"nl",
"pt",
"zh",
"multilingual",
"transformers",
"autotrain_compatible"
]
| token-classification | false | Davlan | null | Davlan/distilbert-base-multilingual-cased-ner-hrl | 1,539 | 4 | transformers | 1,506 | Hugging Face's logo
---
language:
- ar
- de
- en
- es
- fr
- it
- lv
- nl
- pt
- zh
- multilingual
---
# distilbert-base-multilingual-cased-ner-hrl
## Model description
**distilbert-base-multilingual-cased-ner-hrl** is a **Named Entity Recognition** model for 10 high resourced languages (Arabic, German, English, Spanish, French, Italian, Latvian, Dutch, Portuguese and Chinese) based on a fine-tuned Distiled BERT base model. It has been trained to recognize three types of entities: location (LOC), organizations (ORG), and person (PER).
Specifically, this model is a *distilbert-base-multilingual-cased* model that was fine-tuned on an aggregation of 10 high-resourced languages
## Intended uses & limitations
#### How to use
You can use this model with Transformers *pipeline* for NER.
```python
from transformers import AutoTokenizer, AutoModelForTokenClassification
from transformers import pipeline
tokenizer = AutoTokenizer.from_pretrained("Davlan/distilbert-base-multilingual-cased-ner-hrl")
model = AutoModelForTokenClassification.from_pretrained("Davlan/distilbert-base-multilingual-cased-ner-hrl")
nlp = pipeline("ner", model=model, tokenizer=tokenizer)
example = "Nader Jokhadar had given Syria the lead with a well-struck header in the seventh minute."
ner_results = nlp(example)
print(ner_results)
```
#### Limitations and bias
This model is limited by its training dataset of entity-annotated news articles from a specific span of time. This may not generalize well for all use cases in different domains.
## Training data
The training data for the 10 languages are from:
Language|Dataset
-|-
Arabic | [ANERcorp](https://camel.abudhabi.nyu.edu/anercorp/)
German | [conll 2003](https://www.clips.uantwerpen.be/conll2003/ner/)
English | [conll 2003](https://www.clips.uantwerpen.be/conll2003/ner/)
Spanish | [conll 2002](https://www.clips.uantwerpen.be/conll2002/ner/)
French | [Europeana Newspapers](https://github.com/EuropeanaNewspapers/ner-corpora/tree/master/enp_FR.bnf.bio)
Italian | [Italian I-CAB](https://ontotext.fbk.eu/icab.html)
Latvian | [Latvian NER](https://github.com/LUMII-AILab/FullStack/tree/master/NamedEntities)
Dutch | [conll 2002](https://www.clips.uantwerpen.be/conll2002/ner/)
Portuguese |[Paramopama + Second Harem](https://github.com/davidsbatista/NER-datasets/tree/master/Portuguese)
Chinese | [MSRA](https://huggingface.co/datasets/msra_ner)
The training dataset distinguishes between the beginning and continuation of an entity so that if there are back-to-back entities of the same type, the model can output where the second entity begins. As in the dataset, each token will be classified as one of the following classes:
Abbreviation|Description
-|-
O|Outside of a named entity
B-PER |Beginning of a person’s name right after another person’s name
I-PER |Person’s name
B-ORG |Beginning of an organisation right after another organisation
I-ORG |Organisation
B-LOC |Beginning of a location right after another location
I-LOC |Location
## Training procedure
This model was trained on NVIDIA V100 GPU with recommended hyperparameters from HuggingFace code.
|
prajjwal1/bert-tiny-mnli | 3488cd7cf0799da403ee9544ca7310c4dfcce634 | 2021-10-05T18:00:12.000Z | [
"pytorch",
"jax",
"bert",
"text-classification",
"arxiv:1908.08962",
"arxiv:2110.01518",
"transformers"
]
| text-classification | false | prajjwal1 | null | prajjwal1/bert-tiny-mnli | 1,539 | null | transformers | 1,507 | The following model is a Pytorch pre-trained model obtained from converting Tensorflow checkpoint found in the [official Google BERT repository](https://github.com/google-research/bert). These BERT variants were introduced in the paper [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962). These models are trained on MNLI.
If you use the model, please consider citing the paper
```
@misc{bhargava2021generalization,
title={Generalization in NLI: Ways (Not) To Go Beyond Simple Heuristics},
author={Prajjwal Bhargava and Aleksandr Drozd and Anna Rogers},
year={2021},
eprint={2110.01518},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
Original Implementation and more info can be found in [this Github repository](https://github.com/prajjwal1/generalize_lm_nli).
```
MNLI: 60%
MNLI-mm: 61.61%
```
These models were trained for 4 epochs.
[@prajjwal_1](https://twitter.com/prajjwal_1)
|
prithivida/informal_to_formal_styletransfer | 472cedcfc522615f77e64bedc54b4ef710fe71d3 | 2021-06-19T08:30:19.000Z | [
"pytorch",
"t5",
"text2text-generation",
"transformers",
"autotrain_compatible"
]
| text2text-generation | false | prithivida | null | prithivida/informal_to_formal_styletransfer | 1,539 | 6 | transformers | 1,508 | ## This model belongs to the Styleformer project
[Please refer to github page](https://github.com/PrithivirajDamodaran/Styleformer)
|
alvaroalon2/biobert_genetic_ner | ebb8c1e20ebbfcd98c6a4df8802c32fdbc2f9028 | 2021-07-07T12:36:25.000Z | [
"pytorch",
"bert",
"token-classification",
"English",
"dataset:JNLPBA",
"dataset:BC2GM",
"transformers",
"NER",
"Biomedical",
"Genetics",
"license:apache-2.0",
"autotrain_compatible"
]
| token-classification | false | alvaroalon2 | null | alvaroalon2/biobert_genetic_ner | 1,534 | 2 | transformers | 1,509 | ---
language: "English"
license: apache-2.0
tags:
- token-classification
- NER
- Biomedical
- Genetics
datasets:
- JNLPBA
- BC2GM
---
BioBERT model fine-tuned in NER task with JNLPBA and BC2GM corpus for genetic class entities.
This was fine-tuned in order to use it in a BioNER/BioNEN system which is available at: https://github.com/librairy/bio-ner |
facebook/esm-1b | 09a25a9cbce6d278b1da9146321500d0d9e07db4 | 2021-11-12T17:13:02.000Z | [
"pytorch",
"esm",
"fill-mask",
"arxiv:1907.11692",
"arxiv:1810.04805",
"arxiv:1603.05027",
"transformers",
"autotrain_compatible"
]
| fill-mask | false | facebook | null | facebook/esm-1b | 1,533 | 7 | transformers | 1,510 | # **ESM-1b**
ESM-1b ([paper](https://www.pnas.org/content/118/15/e2016239118#:~:text=https%3A//doi.org/10.1073/pnas.2016239118), [repository](https://github.com/facebookresearch/esm)) is a transformer protein language model, trained on protein sequence data without label supervision. The model is pretrained on Uniref50 with an unsupervised masked language modeling (MLM) objective, meaning the model is trained to predict amino acids from the surrounding sequence context. This pretraining objective allows ESM-1b to learn generally useful features which can be transferred to downstream prediction tasks. ESM-1b has been evaluated on a variety of tasks related to protein structure and function, including remote homology detection, secondary structure prediction, contact prediction, and prediction of the effects of mutations on function, producing state-of-the-art results.
## **Model description**
The ESM-1b model is based on the [RoBERTa](https://arxiv.org/abs/1907.11692) architecture and training procedure, using the Uniref50 2018_03 database of protein sequences. Note that the pretraining is on the raw protein sequences only. The training is purely unsupervised -- during training no labels are given related to structure or function.
Training is with the masked language modeling objective. The masking follows the procedure of [Devlin et al. 2019](https://arxiv.org/abs/1810.04805), randomly masking 15% of the amino acids in the input, and includes the pass-through and random token noise. One architecture difference from the RoBERTa model is that ESM-1b uses [pre-activation layer normalization](https://arxiv.org/abs/1603.05027).
The learned representations can be used as features for downstream tasks. For example if you have a dataset of measurements of protein activity you can fit a regression model on the features output by ESM-1b to predict the activity of new sequences. The model can also be fine-tuned.
ESM-1b can infer information about the structure and function of proteins without further supervision, i.e. it is capable of zero-shot transfer to structure and function prediction. [Rao et al. 2020](https://openreview.net/pdf?id=fylclEqgvgd) found that the attention heads of ESM-1b directly represent contacts in the 3d structure of the protein. [Meier et al. 2021](https://openreview.net/pdf?id=uXc42E9ZPFs) found that ESM-1b can be used to score the effect of sequence variations on protein function.
## **Intended uses & limitations**
The model can be used for feature extraction, fine-tuned on downstream tasks, or used directly to make inferences about the structure and function of protein sequences.
### **How to use**
You can use this model with a pipeline for masked language modeling:
```
>>> from transformers import ESMForMaskedLM, ESMTokenizer, pipeline
>>> tokenizer = ESMTokenizer.from_pretrained("facebook/esm-1b", do_lower_case=False)
>>> model = ESMForMaskedLM.from_pretrained("facebook/esm-1b")
>>> unmasker = pipeline('fill-mask', model=model, tokenizer=tokenizer)
>>> unmasker('QERLKSIVRILE<mask>SLGYNIVAT')
[{'sequence': 'Q E R L K S I V R I L E E S L G Y N I V A T',
'score': 0.0933581069111824,
'token': 9,
'token_str': 'E'},
{'sequence': 'Q E R L K S I V R I L E K S L G Y N I V A T',
'score': 0.09198431670665741,
'token': 15,
'token_str': 'K'},
{'sequence': 'Q E R L K S I V R I L E S S L G Y N I V A T',
'score': 0.06775771081447601,
'token': 8,
'token_str': 'S'},
{'sequence': 'Q E R L K S I V R I L E L S L G Y N I V A T',
'score': 0.0661069005727768,
'token': 4,
'token_str': 'L'},
{'sequence': 'Q E R L K S I V R I L E R S L G Y N I V A T',
'score': 0.06330915540456772,
'token': 10,
'token_str': 'R'}]
```
Here is how to use this model to get the features of a given protein sequence in PyTorch:
```
from transformers import ESMForMaskedLM, ESMTokenizer
tokenizer = ESMTokenizer.from_pretrained("facebook/esm-1b", do_lower_case=False )
model = ESMForMaskedLM.from_pretrained("facebook/esm-1b")
sequence_Example = "QERLKSIVRILE"
encoded_input = tokenizer(sequence_Example, return_tensors='pt')
output = model(**encoded_input)
```
## **Training data**
The ESM-1b model was pretrained on [Uniref50](https://www.uniprot.org/downloads) 2018-03, a dataset consisting of approximately 30 million protein sequences.
## **Training procedure**
### **Preprocessing**
The protein sequences are uppercased and tokenized using a single space and a vocabulary size of 21. The inputs of the model are then of the form:
```
<cls> Protein Sequence A
```
During training, sequences longer than 1023 tokens (without CLS) are randomly cropped to a length of 1023.
The details of the masking procedure for each sequence follow Devlin et al. 2019:
* 15% of the amino acids are masked.
* In 80% of the cases, the masked amino acids are replaced by `<mask>`.
* In 10% of the cases, the masked amino acids are replaced by a random amino acid (different) from the one they replace.
* In the 10% remaining cases, the masked amino acids are left as is.
### **Pretraining**
The model was trained on 128 NVIDIA v100 GPUs for 500K updates, using sequence length 1024 (131,072 tokens per batch). The optimizer used is Adam (betas=[0.9, 0.999]) with a learning rate of 1e-4, a weight decay of 0, learning rate warmup for 16k steps and inverse square root decay of the learning rate after. |
Helsinki-NLP/opus-mt-gl-en | 9a0170e5a81324078b87675a597a65cc6ff92487 | 2021-01-18T08:52:37.000Z | [
"pytorch",
"marian",
"text2text-generation",
"gl",
"en",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
]
| translation | false | Helsinki-NLP | null | Helsinki-NLP/opus-mt-gl-en | 1,532 | null | transformers | 1,511 | ---
language:
- gl
- en
tags:
- translation
license: apache-2.0
---
### glg-eng
* source group: Galician
* target group: English
* OPUS readme: [glg-eng](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/glg-eng/README.md)
* model: transformer-align
* source language(s): glg
* target language(s): eng
* model: transformer-align
* pre-processing: normalization + SentencePiece (spm12k,spm12k)
* download original weights: [opus-2020-06-16.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/glg-eng/opus-2020-06-16.zip)
* test set translations: [opus-2020-06-16.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/glg-eng/opus-2020-06-16.test.txt)
* test set scores: [opus-2020-06-16.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/glg-eng/opus-2020-06-16.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba-test.glg.eng | 44.4 | 0.628 |
### System Info:
- hf_name: glg-eng
- source_languages: glg
- target_languages: eng
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/glg-eng/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['gl', 'en']
- src_constituents: {'glg'}
- tgt_constituents: {'eng'}
- src_multilingual: False
- tgt_multilingual: False
- prepro: normalization + SentencePiece (spm12k,spm12k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/glg-eng/opus-2020-06-16.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/glg-eng/opus-2020-06-16.test.txt
- src_alpha3: glg
- tgt_alpha3: eng
- short_pair: gl-en
- chrF2_score: 0.628
- bleu: 44.4
- brevity_penalty: 0.975
- ref_len: 8365.0
- src_name: Galician
- tgt_name: English
- train_date: 2020-06-16
- src_alpha2: gl
- tgt_alpha2: en
- prefer_old: False
- long_pair: glg-eng
- helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535
- transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b
- port_machine: brutasse
- port_time: 2020-08-21-14:41 |
vinai/vinai-translate-en2vi | 4eeefc237431f28d4e8048a262c88a80ce07a2ab | 2022-07-06T08:33:18.000Z | [
"pytorch",
"tf",
"mbart",
"text2text-generation",
"transformers",
"autotrain_compatible"
]
| text2text-generation | false | vinai | null | vinai/vinai-translate-en2vi | 1,532 | null | transformers | 1,512 | # A Vietnamese-English Neural Machine Translation System
Our pre-trained VinAI Translate models `vinai/vinai-translate-vi2en` and `vinai/vinai-translate-en2vi` are state-of-the-art text translation models for Vietnamese-to-English and English-to-Vietnamese, respectively. The general architecture and experimental results of VinAI Translate can be found in [our paper](https://openreview.net/forum?id=CRg-RaxKnai):
@inproceedings{vinaitranslate,
title = {{A Vietnamese-English Neural Machine Translation System}},
author = {Thien Hai Nguyen and Tuan-Duy H. Nguyen and Duy Phung and Duy Tran-Cong Nguyen and Hieu Minh Tran and Manh Luong and Tin Duy Vo and Hung Hai Bui and Dinh Phung and Dat Quoc Nguyen},
booktitle = {Proceedings of the 23rd Annual Conference of the International Speech Communication Association: Show and Tell (INTERSPEECH)},
year = {2022}
}
Please **CITE** our paper whenever the pre-trained models or the system are used to help produce published results or incorporated into other software.
For further information or requests, please go to [VinAI Translate's homepage](https://github.com/VinAIResearch/VinAI_Translate)! |
sshleifer/distill-pegasus-xsum-16-4 | 2b576a5f863f49550a3bf3db25c8e72cc97dd23c | 2020-10-14T16:16:54.000Z | [
"pytorch",
"pegasus",
"text2text-generation",
"en",
"arxiv:1912.08777",
"transformers",
"summarization",
"autotrain_compatible"
]
| summarization | false | sshleifer | null | sshleifer/distill-pegasus-xsum-16-4 | 1,529 | 2 | transformers | 1,513 | ---
language: en
tags:
- summarization
---
### Pegasus Models
See Docs: [here](https://huggingface.co/transformers/master/model_doc/pegasus.html)
Original TF 1 code [here](https://github.com/google-research/pegasus)
Authors: Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu on Dec 18, 2019
Maintained by: [@sshleifer](https://twitter.com/sam_shleifer)
Task: Summarization
The following is copied from the authors' README.
# Mixed & Stochastic Checkpoints
We train a pegasus model with sampled gap sentence ratios on both C4 and HugeNews, and stochastically sample important sentences. The updated the results are reported in this table.
| dataset | C4 | HugeNews | Mixed & Stochastic|
| ---- | ---- | ---- | ----|
| xsum | 45.20/22.06/36.99 | 47.21/24.56/39.25 | 47.60/24.83/39.64|
| cnn_dailymail | 43.90/21.20/40.76 | 44.17/21.47/41.11 | 44.16/21.56/41.30|
| newsroom | 45.07/33.39/41.28 | 45.15/33.51/41.33 | 45.98/34.20/42.18|
| multi_news | 46.74/17.95/24.26 | 47.52/18.72/24.91 | 47.65/18.75/24.95|
| gigaword | 38.75/19.96/36.14 | 39.12/19.86/36.24 | 39.65/20.47/36.76|
| wikihow | 43.07/19.70/34.79 | 41.35/18.51/33.42 | 46.39/22.12/38.41 *|
| reddit_tifu | 26.54/8.94/21.64 | 26.63/9.01/21.60 | 27.99/9.81/22.94|
| big_patent | 53.63/33.16/42.25 | 53.41/32.89/42.07 | 52.29/33.08/41.66 *|
| arxiv | 44.70/17.27/25.80 | 44.67/17.18/25.73 | 44.21/16.95/25.67|
| pubmed | 45.49/19.90/27.69 | 45.09/19.56/27.42 | 45.97/20.15/28.25|
| aeslc | 37.69/21.85/36.84 | 37.40/21.22/36.45 | 37.68/21.25/36.51|
| billsum | 57.20/39.56/45.80 | 57.31/40.19/45.82 | 59.67/41.58/47.59|
The "Mixed & Stochastic" model has the following changes:
- trained on both C4 and HugeNews (dataset mixture is weighted by their number of examples).
- trained for 1.5M instead of 500k (we observe slower convergence on pretraining perplexity).
- the model uniformly sample a gap sentence ratio between 15% and 45%.
- importance sentences are sampled using a 20% uniform noise to importance scores.
- the sentencepiece tokenizer is updated to be able to encode newline character.
(*) the numbers of wikihow and big_patent datasets are not comparable because of change in tokenization and data:
- wikihow dataset contains newline characters which is useful for paragraph segmentation, the C4 and HugeNews model's sentencepiece tokenizer doesn't encode newline and loose this information.
- we update the BigPatent dataset to preserve casing, some format cleanings are also changed, please refer to change in TFDS.
The "Mixed & Stochastic" model has the following changes (from pegasus-large in the paper):
trained on both C4 and HugeNews (dataset mixture is weighted by their number of examples).
trained for 1.5M instead of 500k (we observe slower convergence on pretraining perplexity).
the model uniformly sample a gap sentence ratio between 15% and 45%.
importance sentences are sampled using a 20% uniform noise to importance scores.
the sentencepiece tokenizer is updated to be able to encode newline character.
Citation
```
@misc{zhang2019pegasus,
title={PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization},
author={Jingqing Zhang and Yao Zhao and Mohammad Saleh and Peter J. Liu},
year={2019},
eprint={1912.08777},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
Rostlab/prot_t5_base_mt_uniref50 | 3fb12c6025327b105f6f602827a5f66259f334f9 | 2021-06-23T03:55:50.000Z | [
"pytorch",
"jax",
"t5",
"text2text-generation",
"transformers",
"summarization",
"autotrain_compatible"
]
| summarization | false | Rostlab | null | Rostlab/prot_t5_base_mt_uniref50 | 1,525 | null | transformers | 1,514 | ---
tags:
- summarization
widget:
- text: "predict protein ms : Met Gly Leu Pro Val Ser Trp Ala Pro Pro Ala Leu"
---
|
scottykwok/wav2vec2-large-xlsr-cantonese | bae7b4405c2d88961c7d11b1a6769658f6dce1f0 | 2022-07-19T15:22:01.000Z | [
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"zh",
"dataset:common_voice",
"transformers",
"license:cc-by-sa-4.0"
]
| automatic-speech-recognition | false | scottykwok | null | scottykwok/wav2vec2-large-xlsr-cantonese | 1,522 | null | transformers | 1,515 | ---
language: zh
tags:
- automatic-speech-recognition
license: cc-by-sa-4.0
datasets:
- common_voice
metrics:
- cer
---
# Wav2vec2-large-xlsr-cantonese
This model was based on [wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53), finetuned using Common Voice/zh-HK/6.1.0.
The training code is similar to [user ctl](https://huggingface.co/ctl/wav2vec2-large-xlsr-cantonese), except that the number of training epochs was 80 (doubled) and fp16_backend is apex. The model was trained using a single RTX 3090 and docker image is nvidia/cuda:11.1-cudnn8-devel.
CER is 15.11% when evaluate against common voice zh-HK test set.
# Result (CER)
15.11%
# Source Code
See this GitHub Repo [cantonese-selfish-project](https://github.com/scottykwok/cantonese-selfish-project/) and [demo video](https://youtu.be/k_9RQ-ilGEc).
# Usage
```python
import soundfile as sf
import torch
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
# load pretrained model
processor = Wav2Vec2Processor.from_pretrained("scottykwok/wav2vec2-large-xlsr-cantonese")
model = Wav2Vec2ForCTC.from_pretrained("scottykwok/wav2vec2-large-xlsr-cantonese")
# load audio - must be 16kHz mono
audio_input, sample_rate = sf.read('audio.wav')
# pad input values and return pt tensor
input_values = processor(audio_input, sampling_rate=sample_rate, return_tensors="pt").input_values
# INFERENCE
# retrieve logits & take argmax
logits = model(input_values).logits
predicted_ids = torch.argmax(logits, dim=-1)
# transcribe
transcription = processor.decode(predicted_ids[0])
print("-" *20)
print("Transcription:\n", transcription.lower())
print("-" *20)
```
|
facebook/xlm-roberta-xl | cd9a69a5ee20ea0a261196037b24c0eafff34358 | 2022-01-28T16:22:30.000Z | [
"pytorch",
"xlm-roberta-xl",
"fill-mask",
"multilingual",
"arxiv:2105.00572",
"transformers",
"license:mit",
"autotrain_compatible"
]
| fill-mask | false | facebook | null | facebook/xlm-roberta-xl | 1,520 | 2 | transformers | 1,516 | ---
language: multilingual
license: mit
---
# XLM-RoBERTa-XL (xlarge-sized model)
XLM-RoBERTa-XL model pre-trained on 2.5TB of filtered CommonCrawl data containing 100 languages. It was introduced in the paper [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://arxiv.org/abs/2105.00572) by Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau and first released in [this repository](https://github.com/pytorch/fairseq/tree/master/examples/xlmr).
Disclaimer: The team releasing XLM-RoBERTa-XL did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
XLM-RoBERTa-XL is a extra large multilingual version of RoBERTa. It is pre-trained on 2.5TB of filtered CommonCrawl data containing 100 languages.
RoBERTa is a transformers model pretrained on a large corpus in a self-supervised fashion. This means it was pretrained on the raw texts only, with no humans labeling them in any way (which is why it can use lots of publicly available data) with an automatic process to generate inputs and labels from those texts.
More precisely, it was pretrained with the Masked language modeling (MLM) objective. Taking a sentence, the model randomly masks 15% of the words in the input then run the entire masked sentence through the model and has to predict the masked words. This is different from traditional recurrent neural networks (RNNs) that usually see the words one after the other, or from autoregressive models like GPT which internally mask the future tokens. It allows the model to learn a bidirectional representation of the sentence.
This way, the model learns an inner representation of 100 languages that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a standard classifier using the features produced by the XLM-RoBERTa-XL model as inputs.
## Intended uses & limitations
You can use the raw model for masked language modeling, but it's mostly intended to be fine-tuned on a downstream task. See the [model hub](https://huggingface.co/models?search=xlm-roberta-xl) to look for fine-tuned versions on a task that interests you.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked) to make decisions, such as sequence classification, token classification or question answering. For tasks such as text generation, you should look at models like GPT2.
## Usage
You can use this model directly with a pipeline for masked language modeling:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='facebook/xlm-roberta-xl')
>>> unmasker("Europe is a <mask> continent.")
[{'score': 0.08562745153903961,
'token': 38043,
'token_str': 'living',
'sequence': 'Europe is a living continent.'},
{'score': 0.0799778401851654,
'token': 103494,
'token_str': 'dead',
'sequence': 'Europe is a dead continent.'},
{'score': 0.046154674142599106,
'token': 72856,
'token_str': 'lost',
'sequence': 'Europe is a lost continent.'},
{'score': 0.04358183592557907,
'token': 19336,
'token_str': 'small',
'sequence': 'Europe is a small continent.'},
{'score': 0.040570393204689026,
'token': 34923,
'token_str': 'beautiful',
'sequence': 'Europe is a beautiful continent.'}]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained('facebook/xlm-roberta-xl')
model = AutoModelForMaskedLM.from_pretrained("facebook/xlm-roberta-xl")
# prepare input
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
# forward pass
output = model(**encoded_input)
```
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2105-00572,
author = {Naman Goyal and
Jingfei Du and
Myle Ott and
Giri Anantharaman and
Alexis Conneau},
title = {Larger-Scale Transformers for Multilingual Masked Language Modeling},
journal = {CoRR},
volume = {abs/2105.00572},
year = {2021},
url = {https://arxiv.org/abs/2105.00572},
eprinttype = {arXiv},
eprint = {2105.00572},
timestamp = {Wed, 12 May 2021 15:54:31 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2105-00572.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` |
its5Q/rugpt3large_mailqa | c629c9f150e29c36acac4a8a2e9bab2963a50b45 | 2022-07-07T09:49:07.000Z | [
"pytorch",
"gpt2",
"text-generation",
"ru",
"transformers",
"PyTorch",
"Transformers"
]
| text-generation | false | its5Q | null | its5Q/rugpt3large_mailqa | 1,519 | 2 | transformers | 1,517 | ---
language:
- ru
tags:
- PyTorch
- Transformers
---
# rugpt3large\_mailqa
Model was finetuned with sequence length 1024 for 516000 steps on a dataset of otvet.mail.ru questions and answers. The raw dataset can be found [here](https://www.kaggle.com/datasets/atleast6characterss/otvetmailru-full). Beware that the data contains a good portion of toxic language, so the answers can be unpredictable.
Jupyter notebook with an example of how to inference this model can be found in the [repository](https://github.com/NeuralPushkin/MailRu_Q-A) |
Helsinki-NLP/opus-mt-ceb-en | 2f433caadadc020231e840797eb513c287cf4894 | 2021-01-18T07:53:40.000Z | [
"pytorch",
"marian",
"text2text-generation",
"ceb",
"en",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
]
| translation | false | Helsinki-NLP | null | Helsinki-NLP/opus-mt-ceb-en | 1,517 | null | transformers | 1,518 | ---
language:
- ceb
- en
tags:
- translation
license: apache-2.0
---
### ceb-eng
* source group: Cebuano
* target group: English
* OPUS readme: [ceb-eng](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/ceb-eng/README.md)
* model: transformer-align
* source language(s): ceb
* target language(s): eng
* model: transformer-align
* pre-processing: normalization + SentencePiece (spm32k,spm32k)
* download original weights: [opus-2020-06-17.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/ceb-eng/opus-2020-06-17.zip)
* test set translations: [opus-2020-06-17.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/ceb-eng/opus-2020-06-17.test.txt)
* test set scores: [opus-2020-06-17.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/ceb-eng/opus-2020-06-17.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba-test.ceb.eng | 21.5 | 0.387 |
### System Info:
- hf_name: ceb-eng
- source_languages: ceb
- target_languages: eng
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/ceb-eng/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['ceb', 'en']
- src_constituents: {'ceb'}
- tgt_constituents: {'eng'}
- src_multilingual: False
- tgt_multilingual: False
- prepro: normalization + SentencePiece (spm32k,spm32k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/ceb-eng/opus-2020-06-17.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/ceb-eng/opus-2020-06-17.test.txt
- src_alpha3: ceb
- tgt_alpha3: eng
- short_pair: ceb-en
- chrF2_score: 0.387
- bleu: 21.5
- brevity_penalty: 1.0
- ref_len: 2293.0
- src_name: Cebuano
- tgt_name: English
- train_date: 2020-06-17
- src_alpha2: ceb
- tgt_alpha2: en
- prefer_old: False
- long_pair: ceb-eng
- helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535
- transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b
- port_machine: brutasse
- port_time: 2020-08-21-14:41 |
elgeish/wav2vec2-large-lv60-timit-asr | 7db32147e521892ab8a63c7cd6008b060876181e | 2021-07-06T01:39:41.000Z | [
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"en",
"dataset:timit_asr",
"transformers",
"audio",
"speech",
"license:apache-2.0"
]
| automatic-speech-recognition | false | elgeish | null | elgeish/wav2vec2-large-lv60-timit-asr | 1,510 | null | transformers | 1,519 | ---
language: en
datasets:
- timit_asr
tags:
- audio
- automatic-speech-recognition
- speech
license: apache-2.0
---
# Wav2Vec2-Large-LV60-TIMIT
Fine-tuned [facebook/wav2vec2-large-lv60](https://huggingface.co/facebook/wav2vec2-large-lv60)
on the [timit_asr dataset](https://huggingface.co/datasets/timit_asr).
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import soundfile as sf
import torch
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
model_name = "elgeish/wav2vec2-large-lv60-timit-asr"
processor = Wav2Vec2Processor.from_pretrained(model_name)
model = Wav2Vec2ForCTC.from_pretrained(model_name)
model.eval()
dataset = load_dataset("timit_asr", split="test").shuffle().select(range(10))
char_translations = str.maketrans({"-": " ", ",": "", ".": "", "?": ""})
def prepare_example(example):
example["speech"], _ = sf.read(example["file"])
example["text"] = example["text"].translate(char_translations)
example["text"] = " ".join(example["text"].split()) # clean up whitespaces
example["text"] = example["text"].lower()
return example
dataset = dataset.map(prepare_example, remove_columns=["file"])
inputs = processor(dataset["speech"], sampling_rate=16000, return_tensors="pt", padding="longest")
with torch.no_grad():
predicted_ids = torch.argmax(model(inputs.input_values).logits, dim=-1)
predicted_ids[predicted_ids == -100] = processor.tokenizer.pad_token_id # see fine-tuning script
predicted_transcripts = processor.tokenizer.batch_decode(predicted_ids)
for reference, predicted in zip(dataset["text"], predicted_transcripts):
print("reference:", reference)
print("predicted:", predicted)
print("--")
```
Here's the output:
```
reference: the emblem depicts the acropolis all aglow
predicted: the amblum depicts the acropolis all a glo
--
reference: don't ask me to carry an oily rag like that
predicted: don't ask me to carry an oily rag like that
--
reference: they enjoy it when i audition
predicted: they enjoy it when i addition
--
reference: set aside to dry with lid on sugar bowl
predicted: set aside to dry with a litt on shoogerbowl
--
reference: a boring novel is a superb sleeping pill
predicted: a bor and novel is a suberb sleeping peel
--
reference: only the most accomplished artists obtain popularity
predicted: only the most accomplished artists obtain popularity
--
reference: he has never himself done anything for which to be hated which of us has
predicted: he has never himself done anything for which to be hated which of us has
--
reference: the fish began to leap frantically on the surface of the small lake
predicted: the fish began to leap frantically on the surface of the small lake
--
reference: or certain words or rituals that child and adult go through may do the trick
predicted: or certain words or rituals that child an adult go through may do the trick
--
reference: are your grades higher or lower than nancy's
predicted: are your grades higher or lower than nancies
--
```
## Fine-Tuning Script
You can find the script used to produce this model
[here](https://github.com/elgeish/transformers/blob/8ee49e09c91ffd5d23034ce32ed630d988c50ddf/examples/research_projects/wav2vec2/finetune_large_lv60_timit_asr.sh).
**Note:** This model can be fine-tuned further;
[trainer_state.json](https://huggingface.co/elgeish/wav2vec2-large-lv60-timit-asr/blob/main/trainer_state.json)
shows useful details, namely the last state (this checkpoint):
```json
{
"epoch": 29.51,
"eval_loss": 25.424150466918945,
"eval_runtime": 182.9499,
"eval_samples_per_second": 9.183,
"eval_wer": 0.1351704233095107,
"step": 8500
}
```
|
sentence-transformers/nli-roberta-base-v2 | 64c0737f24398dce1ec9ae04f363dc6b220dceaf | 2022-06-15T22:41:43.000Z | [
"pytorch",
"tf",
"jax",
"roberta",
"feature-extraction",
"arxiv:1908.10084",
"sentence-transformers",
"sentence-similarity",
"transformers",
"license:apache-2.0"
]
| sentence-similarity | false | sentence-transformers | null | sentence-transformers/nli-roberta-base-v2 | 1,509 | null | sentence-transformers | 1,520 | ---
pipeline_tag: sentence-similarity
license: apache-2.0
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# sentence-transformers/nli-roberta-base-v2
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/nli-roberta-base-v2')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/nli-roberta-base-v2')
model = AutoModel.from_pretrained('sentence-transformers/nli-roberta-base-v2')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/nli-roberta-base-v2)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 75, 'do_lower_case': False}) with Transformer model: RobertaModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
``` |
yoshitomo-matsubara/bert-base-uncased-mnli | 38c02ebe3cf589c8aa25dfb852aba7b904c29739 | 2021-05-29T21:43:56.000Z | [
"pytorch",
"bert",
"text-classification",
"en",
"dataset:mnli",
"dataset:ax",
"transformers",
"mnli",
"ax",
"glue",
"torchdistill",
"license:apache-2.0"
]
| text-classification | false | yoshitomo-matsubara | null | yoshitomo-matsubara/bert-base-uncased-mnli | 1,509 | null | transformers | 1,521 | ---
language: en
tags:
- bert
- mnli
- ax
- glue
- torchdistill
license: apache-2.0
datasets:
- mnli
- ax
metrics:
- accuracy
---
`bert-base-uncased` fine-tuned on MNLI dataset, using [***torchdistill***](https://github.com/yoshitomo-matsubara/torchdistill) and [Google Colab](https://colab.research.google.com/github/yoshitomo-matsubara/torchdistill/blob/master/demo/glue_finetuning_and_submission.ipynb).
The hyperparameters are the same as those in Hugging Face's example and/or the paper of BERT, and the training configuration (including hyperparameters) is available [here](https://github.com/yoshitomo-matsubara/torchdistill/blob/main/configs/sample/glue/mnli/ce/bert_base_uncased.yaml).
I submitted prediction files to [the GLUE leaderboard](https://gluebenchmark.com/leaderboard), and the overall GLUE score was **77.9**.
|
wptoux/albert-chinese-large-qa | 02a1762ffdc88ce77fad185f9c3098dba0f27ece | 2021-03-09T07:48:40.000Z | [
"pytorch",
"albert",
"question-answering",
"zh",
"dataset:webqa",
"dataset:dureader",
"transformers",
"Question Answering",
"license:apache-2.0",
"autotrain_compatible"
]
| question-answering | false | wptoux | null | wptoux/albert-chinese-large-qa | 1,508 | 1 | transformers | 1,522 | ---
language:
- zh
tags:
- Question Answering
license: apache-2.0
datasets:
- webqa
- dureader
---
# albert-chinese-large-qa
Albert large QA model pretrained from baidu webqa and baidu dureader datasets.
## Data source
+ baidu webqa 1.0
+ baidu dureader
## Traing Method
We combined the two datasets together and created a new dataset in squad format, including 705139 samples for training and 69638 samples for validation.
We finetune the model based on the albert chinese large model.
## Hyperparams
+ learning_rate 1e-5
+ max_seq_length 512
+ max_query_length 50
+ max_answer_length 300
+ doc_stride 256
+ num_train_epochs 2
+ warmup_steps 1000
+ per_gpu_train_batch_size 8
+ gradient_accumulation_steps 3
+ n_gpu 2 (Nvidia Tesla P100)
## Usage
```
from transformers import AutoModelForQuestionAnswering, BertTokenizer
model = AutoModelForQuestionAnswering.from_pretrained('wptoux/albert-chinese-large-qa')
tokenizer = BertTokenizer.from_pretrained('wptoux/albert-chinese-large-qa')
```
***Important: use BertTokenizer***
## MoreInfo
Please visit https://github.com/wptoux/albert-chinese-large-webqa for details.
|
Lalita/marianmt-zh_cn-th | 3c440603f723b3ef2624c25057d62a62bab015e7 | 2021-06-29T11:25:02.000Z | [
"pytorch",
"marian",
"text2text-generation",
"transformers",
"translation",
"torch==1.8.0",
"autotrain_compatible"
]
| translation | false | Lalita | null | Lalita/marianmt-zh_cn-th | 1,505 | null | transformers | 1,523 | ---
tags:
- translation
- torch==1.8.0
widget:
- text: "Inference Unavailable"
---
### marianmt-zh_cn-th
* source languages: zh_cn
* target languages: th
* dataset:
* model: transformer-align
* pre-processing: normalization + SentencePiece
* test set scores: syllable: 15.95, word: 8.43
## Training
Training scripts from [LalitaDeelert/NLP-ZH_TH-Project](https://github.com/LalitaDeelert/NLP-ZH_TH-Project). Experiments tracked at [cstorm125/marianmt-zh_cn-th](https://wandb.ai/cstorm125/marianmt-zh_cn-th).
```
export WANDB_PROJECT=marianmt-zh_cn-th
python train_model.py --input_fname ../data/v1/Train.csv \\\\\\\\\\\\\\\\
\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\t--output_dir ../models/marianmt-zh_cn-th \\\\\\\\\\\\\\\\
\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\t--source_lang zh --target_lang th \\\\\\\\\\\\\\\\
\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\t--metric_tokenize th_syllable --fp16
```
## Usage
```
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("Lalita/marianmt-zh_cn-th")
model = AutoModelForSeq2SeqLM.from_pretrained("Lalita/marianmt-zh_cn-th").cpu()
src_text = [
'我爱你',
'我想吃米饭',
]
translated = model.generate(**tokenizer(src_text, return_tensors="pt", padding=True))
print([tokenizer.decode(t, skip_special_tokens=True) for t in translated])
> ['ผมรักคุณนะ', 'ฉันอยากกินข้าว']
```
## Requirements
```
transformers==4.6.0
torch==1.8.0
``` |
ankur310794/bart-base-keyphrase-generation-kpTimes | 3d0d7234b09b8cc55f25f53c08e1a9210857d4fa | 2021-04-09T08:38:24.000Z | [
"pytorch",
"bart",
"text2text-generation",
"transformers",
"autotrain_compatible"
]
| text2text-generation | false | ankur310794 | null | ankur310794/bart-base-keyphrase-generation-kpTimes | 1,504 | 0 | transformers | 1,524 | Entry not found |
Helsinki-NLP/opus-mt-de-fr | 6aa8c4011488513f5575b235ce75d6d795d90b35 | 2021-09-09T21:31:13.000Z | [
"pytorch",
"rust",
"marian",
"text2text-generation",
"de",
"fr",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
]
| translation | false | Helsinki-NLP | null | Helsinki-NLP/opus-mt-de-fr | 1,503 | null | transformers | 1,525 | ---
tags:
- translation
license: apache-2.0
---
### opus-mt-de-fr
* source languages: de
* target languages: fr
* OPUS readme: [de-fr](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/de-fr/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-08.zip](https://object.pouta.csc.fi/OPUS-MT-models/de-fr/opus-2020-01-08.zip)
* test set translations: [opus-2020-01-08.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/de-fr/opus-2020-01-08.test.txt)
* test set scores: [opus-2020-01-08.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/de-fr/opus-2020-01-08.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| euelections_dev2019.transformer-align.de | 32.2 | 0.590 |
| newssyscomb2009.de.fr | 26.8 | 0.553 |
| news-test2008.de.fr | 26.4 | 0.548 |
| newstest2009.de.fr | 25.6 | 0.539 |
| newstest2010.de.fr | 29.1 | 0.572 |
| newstest2011.de.fr | 26.9 | 0.551 |
| newstest2012.de.fr | 27.7 | 0.554 |
| newstest2013.de.fr | 29.5 | 0.560 |
| newstest2019-defr.de.fr | 36.6 | 0.625 |
| Tatoeba.de.fr | 49.2 | 0.664 |
|
Helsinki-NLP/opus-mt-en-hi | 108ec718a95d9cf96bdb27345a6012c60e141da1 | 2021-03-02T16:17:47.000Z | [
"pytorch",
"rust",
"marian",
"text2text-generation",
"en",
"hi",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
]
| translation | false | Helsinki-NLP | null | Helsinki-NLP/opus-mt-en-hi | 1,502 | 4 | transformers | 1,526 | ---
language:
- en
- hi
tags:
- translation
license: apache-2.0
---
### eng-hin
* source group: English
* target group: Hindi
* OPUS readme: [eng-hin](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/eng-hin/README.md)
* model: transformer-align
* source language(s): eng
* target language(s): hin
* model: transformer-align
* pre-processing: normalization + SentencePiece (spm32k,spm32k)
* download original weights: [opus-2020-06-17.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-hin/opus-2020-06-17.zip)
* test set translations: [opus-2020-06-17.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-hin/opus-2020-06-17.test.txt)
* test set scores: [opus-2020-06-17.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-hin/opus-2020-06-17.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| newsdev2014.eng.hin | 6.9 | 0.296 |
| newstest2014-hien.eng.hin | 9.9 | 0.323 |
| Tatoeba-test.eng.hin | 16.1 | 0.447 |
### System Info:
- hf_name: eng-hin
- source_languages: eng
- target_languages: hin
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/eng-hin/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['en', 'hi']
- src_constituents: {'eng'}
- tgt_constituents: {'hin'}
- src_multilingual: False
- tgt_multilingual: False
- prepro: normalization + SentencePiece (spm32k,spm32k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/eng-hin/opus-2020-06-17.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/eng-hin/opus-2020-06-17.test.txt
- src_alpha3: eng
- tgt_alpha3: hin
- short_pair: en-hi
- chrF2_score: 0.447
- bleu: 16.1
- brevity_penalty: 1.0
- ref_len: 32904.0
- src_name: English
- tgt_name: Hindi
- train_date: 2020-06-17
- src_alpha2: en
- tgt_alpha2: hi
- prefer_old: False
- long_pair: eng-hin
- helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535
- transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b
- port_machine: brutasse
- port_time: 2020-08-21-14:41 |
bionlp/bluebert_pubmed_mimic_uncased_L-24_H-1024_A-16 | e4a3d79282d3b1fc123b562de18b4c18b50a9176 | 2021-09-24T07:46:34.000Z | [
"pytorch",
"jax",
"en",
"dataset:PubMed",
"dataset:MIMIC-III",
"transformers",
"bert",
"bluebert",
"license:cc0-1.0"
]
| null | false | bionlp | null | bionlp/bluebert_pubmed_mimic_uncased_L-24_H-1024_A-16 | 1,502 | null | transformers | 1,527 | ---
language:
- en
tags:
- bert
- bluebert
license: cc0-1.0
datasets:
- PubMed
- MIMIC-III
---
# BlueBert-Base, Uncased, PubMed and MIMIC-III
## Model description
A BERT model pre-trained on PubMed abstracts and clinical notes ([MIMIC-III](https://mimic.physionet.org/)).
## Intended uses & limitations
#### How to use
Please see https://github.com/ncbi-nlp/bluebert
## Training data
We provide [preprocessed PubMed texts](https://ftp.ncbi.nlm.nih.gov/pub/lu/Suppl/NCBI-BERT/pubmed_uncased_sentence_nltk.txt.tar.gz) that were used to pre-train the BlueBERT models.
The corpus contains ~4000M words extracted from the [PubMed ASCII code version](https://www.ncbi.nlm.nih.gov/research/bionlp/APIs/BioC-PubMed/).
Pre-trained model: https://huggingface.co/bert-large-uncased
## Training procedure
* lowercasing the text
* removing speical chars `\x00`-`\x7F`
* tokenizing the text using the [NLTK Treebank tokenizer](https://www.nltk.org/_modules/nltk/tokenize/treebank.html)
Below is a code snippet for more details.
```python
value = value.lower()
value = re.sub(r'[\r\n]+', ' ', value)
value = re.sub(r'[^\x00-\x7F]+', ' ', value)
tokenized = TreebankWordTokenizer().tokenize(value)
sentence = ' '.join(tokenized)
sentence = re.sub(r"\s's\b", "'s", sentence)
```
### BibTeX entry and citation info
```bibtex
@InProceedings{peng2019transfer,
author = {Yifan Peng and Shankai Yan and Zhiyong Lu},
title = {Transfer Learning in Biomedical Natural Language Processing: An Evaluation of BERT and ELMo on Ten Benchmarking Datasets},
booktitle = {Proceedings of the 2019 Workshop on Biomedical Natural Language Processing (BioNLP 2019)},
year = {2019},
pages = {58--65},
}
```
### Acknowledgments
This work was supported by the Intramural Research Programs of the National Institutes of Health, National Library of
Medicine and Clinical Center. This work was supported by the National Library of Medicine of the National Institutes of Health under award number 4R00LM013001-01.
We are also grateful to the authors of BERT and ELMo to make the data and codes publicly available.
We would like to thank Dr Sun Kim for processing the PubMed texts.
### Disclaimer
This tool shows the results of research conducted in the Computational Biology Branch, NCBI. The information produced
on this website is not intended for direct diagnostic use or medical decision-making without review and oversight
by a clinical professional. Individuals should not change their health behavior solely on the basis of information
produced on this website. NIH does not independently verify the validity or utility of the information produced
by this tool. If you have questions about the information produced on this website, please see a health care
professional. More information about NCBI's disclaimer policy is available.
|
ozcangundes/mt5-multitask-qa-qg-turkish | 05f063c45a3ad0cdcdac26eb823c7aac2d625aa6 | 2021-06-23T15:24:09.000Z | [
"pytorch",
"jax",
"mt5",
"text2text-generation",
"tr",
"dataset:TQUAD",
"transformers",
"question-answering",
"question-generation",
"multitask-model",
"license:apache-2.0",
"autotrain_compatible"
]
| question-answering | false | ozcangundes | null | ozcangundes/mt5-multitask-qa-qg-turkish | 1,500 | 0 | transformers | 1,528 | ---
language: tr
datasets:
- TQUAD
tags:
- question-answering
- question-generation
- multitask-model
license: apache-2.0
---
# mT5-small based Turkish Multitask (Answer Extraction, Question Generation and Question Answering) System
[Google's Multilingual T5-small](https://github.com/google-research/multilingual-t5) is fine-tuned on [Turkish Question Answering dataset](https://github.com/okanvk/Turkish-Reading-Comprehension-Question-Answering-Dataset) for three downstream task **Answer extraction, Question Generation and Question Answering** served in this single model. mT5 model was also trained for multiple text2text NLP tasks.
All data processing, training and pipeline codes can be found on my [Github](https://github.com/ozcangundes/multitask-question-generation). I will share the training details in the repo as soon as possible.
mT5 small model has 300 million parameters and model size is about 1.2GB. Therefore, it takes significant amount of time to fine tune it.
8 epoch and 1e-4 learning rate with 0 warmup steps was applied during training. These hparams and the others can be fine-tuned for much more better results.
## Requirements ❗❗❗
```
!pip install transformers==4.4.2
!pip install sentencepiece==0.1.95
!git clone https://github.com/ozcangundes/multitask-question-generation.git
%cd multitask-question-generation/
```
## Usage 🚀🚀
```
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("ozcangundes/mt5-multitask-qa-qg-turkish")
model = AutoModelForSeq2SeqLM.from_pretrained("ozcangundes/mt5-multitask-qa-qg-turkish")
from pipelines import pipeline #pipelines.py script in the cloned repo
multimodel = pipeline("multitask-qa-qg",tokenizer=tokenizer,model=model)
#sample text
text="Özcan Gündeş, 1993 yılı Tarsus doğumludur. Orta Doğu Teknik Üniversitesi \\\\
Endüstri Mühendisliği bölümünde 2011 2016 yılları arasında lisans eğitimi görmüştür. \\\\
Yüksek lisansını ise 2020 Aralık ayında, 4.00 genel not ortalaması ile \\\\
Boğaziçi Üniversitesi, Yönetim Bilişim Sistemleri bölümünde tamamlamıştır.\\\\
Futbolla yakından ilgilenmekle birlikte, Galatasaray kulübü taraftarıdır."
```
## Example - Both Question Generation and Question Answering 💬💬
```
multimodel(text)
#output
=> [{'answer': 'Tarsus', 'question': 'Özcan Gündeş nerede doğmuştur?'},
{'answer': '1993', 'question': 'Özcan Gündeş kaç yılında doğmuştur?'},
{'answer': '2011 2016',
'question': 'Özcan Gündeş lisans eğitimini hangi yıllar arasında tamamlamıştır?'},
{'answer': 'Boğaziçi Üniversitesi, Yönetim Bilişim Sistemleri',
'question': 'Özcan Gündeş yüksek lisansını hangi bölümde tamamlamıştır?'},
{'answer': 'Galatasaray kulübü',
'question': 'Özcan Gündeş futbolla yakından ilgilenmekle birlikte hangi kulübü taraftarıdır?'}]
```
From this text, 5 questions are generated and they are answered by the model.
## Example - Question Answering 💭💭
Both text and also, related question should be passed into pipeline.
```
multimodel({"context":text,"question":"Özcan hangi takımı tutmaktadır?"})
#output
=> Galatasaray
multimodel({"context":text,"question":"Özcan, yüksek lisanstan ne zaman mezun oldu?"})
#output
=> 2020 Aralık ayında
multimodel({"context":text,"question":"Özcan'ın yüksek lisans bitirme notu kaçtır?"})
#output
=> 4.00
#Sorry for being cocky 😝😝
```
## ACKNOWLEDGEMENT
This work is inspired from [Suraj Patil's great repo](https://github.com/patil-suraj/question_generation). I would like to thank him for the clean codes and also,[Okan Çiftçi](https://github.com/okanvk) for the Turkish dataset 🙏
|
slauw87/bart_summarisation | e6097186162a3d9d75ba0a1297640f985baadf52 | 2021-09-20T05:27:36.000Z | [
"pytorch",
"bart",
"text2text-generation",
"en",
"dataset:samsum",
"transformers",
"sagemaker",
"summarization",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
]
| summarization | false | slauw87 | null | slauw87/bart_summarisation | 1,493 | 4 | transformers | 1,529 |
---
language: en
tags:
- sagemaker
- bart
- summarization
license: apache-2.0
datasets:
- samsum
model-index:
- name: bart-large-cnn-samsum
results:
- task:
name: Abstractive Text Summarization
type: abstractive-text-summarization
dataset:
name: "SAMSum Corpus: A Human-annotated Dialogue Dataset for Abstractive Summarization"
type: samsum
metrics:
- name: Validation ROGUE-1
type: rogue-1
value: 43.2111
- name: Validation ROGUE-2
type: rogue-2
value: 22.3519
- name: Validation ROGUE-L
type: rogue-l
value: 33.315
- name: Test ROGUE-1
type: rogue-1
value: 41.8283
- name: Test ROGUE-2
type: rogue-2
value: 20.9857
- name: Test ROGUE-L
type: rogue-l
value: 32.3602
widget:
- text: |
Sugi: I am tired of everything in my life.
Tommy: What? How happy you life is! I do envy you.
Sugi: You don't know that I have been over-protected by my mother these years. I am really about to leave the family and spread my wings.
Tommy: Maybe you are right.
---
## `bart-large-cnn-samsum`
This model was trained using Amazon SageMaker and the new Hugging Face Deep Learning container.
For more information look at:
- [🤗 Transformers Documentation: Amazon SageMaker](https://huggingface.co/transformers/sagemaker.html)
- [Example Notebooks](https://github.com/huggingface/notebooks/tree/master/sagemaker)
- [Amazon SageMaker documentation for Hugging Face](https://docs.aws.amazon.com/sagemaker/latest/dg/hugging-face.html)
- [Python SDK SageMaker documentation for Hugging Face](https://sagemaker.readthedocs.io/en/stable/frameworks/huggingface/index.html)
- [Deep Learning Container](https://github.com/aws/deep-learning-containers/blob/master/available_images.md#huggingface-training-containers)
## Hyperparameters
{
"dataset_name": "samsum",
"do_eval": true,
"do_predict": true,
"do_train": true,
"fp16": true,
"learning_rate": 5e-05,
"model_name_or_path": "facebook/bart-large-cnn",
"num_train_epochs": 3,
"output_dir": "/opt/ml/model",
"per_device_eval_batch_size": 4,
"per_device_train_batch_size": 4,
"predict_with_generate": true,
"seed": 7
}
## Usage
from transformers import pipeline
summarizer = pipeline("summarization", model="slauw87/bart-large-cnn-samsum")
conversation = '''Sugi: I am tired of everything in my life.
Tommy: What? How happy you life is! I do envy you.
Sugi: You don't know that I have been over-protected by my mother these years. I am really about to leave the family and spread my wings.
Tommy: Maybe you are right.
'''
nlp(conversation)
## Results
| key | value |
| --- | ----- |
| eval_rouge1 | 43.2111 |
| eval_rouge2 | 22.3519 |
| eval_rougeL | 33.3153 |
| eval_rougeLsum | 40.0527 |
| predict_rouge1 | 41.8283 |
| predict_rouge2 | 20.9857 |
| predict_rougeL | 32.3602 |
| predict_rougeLsum | 38.7316 |
|
Helsinki-NLP/opus-mt-sq-en | c4c55527072468e3f7401d6717aeb9824d1d7345 | 2021-09-10T14:04:20.000Z | [
"pytorch",
"marian",
"text2text-generation",
"sq",
"en",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
]
| translation | false | Helsinki-NLP | null | Helsinki-NLP/opus-mt-sq-en | 1,492 | 1 | transformers | 1,530 | ---
tags:
- translation
license: apache-2.0
---
### opus-mt-sq-en
* source languages: sq
* target languages: en
* OPUS readme: [sq-en](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/sq-en/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-16.zip](https://object.pouta.csc.fi/OPUS-MT-models/sq-en/opus-2020-01-16.zip)
* test set translations: [opus-2020-01-16.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/sq-en/opus-2020-01-16.test.txt)
* test set scores: [opus-2020-01-16.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/sq-en/opus-2020-01-16.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba.sq.en | 58.4 | 0.732 |
|
Helsinki-NLP/opus-mt-bg-en | 3a34359f5781368c7748219c2868ffd065f24df0 | 2021-09-09T21:27:33.000Z | [
"pytorch",
"marian",
"text2text-generation",
"bg",
"en",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
]
| translation | false | Helsinki-NLP | null | Helsinki-NLP/opus-mt-bg-en | 1,490 | 1 | transformers | 1,531 | ---
tags:
- translation
license: apache-2.0
---
### opus-mt-bg-en
* source languages: bg
* target languages: en
* OPUS readme: [bg-en](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/bg-en/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2019-12-18.zip](https://object.pouta.csc.fi/OPUS-MT-models/bg-en/opus-2019-12-18.zip)
* test set translations: [opus-2019-12-18.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/bg-en/opus-2019-12-18.test.txt)
* test set scores: [opus-2019-12-18.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/bg-en/opus-2019-12-18.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba.bg.en | 59.4 | 0.727 |
|
sentence-transformers/bert-large-nli-max-tokens | 1738a181e9e77a09752f92e6dbde15f4a5527d5c | 2022-06-15T23:14:28.000Z | [
"pytorch",
"tf",
"jax",
"bert",
"feature-extraction",
"arxiv:1908.10084",
"sentence-transformers",
"sentence-similarity",
"transformers",
"license:apache-2.0"
]
| sentence-similarity | false | sentence-transformers | null | sentence-transformers/bert-large-nli-max-tokens | 1,490 | null | sentence-transformers | 1,532 | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
license: apache-2.0
---
**⚠️ This model is deprecated. Please don't use it as it produces sentence embeddings of low quality. You can find recommended sentence embedding models here: [SBERT.net - Pretrained Models](https://www.sbert.net/docs/pretrained_models.html)**
# sentence-transformers/bert-large-nli-max-tokens
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 1024 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/bert-large-nli-max-tokens')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
# Max Pooling - Take the max value over time for every dimension.
def max_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
token_embeddings[input_mask_expanded == 0] = -1e9 # Set padding tokens to large negative value
return torch.max(token_embeddings, 1)[0]
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/bert-large-nli-max-tokens')
model = AutoModel.from_pretrained('sentence-transformers/bert-large-nli-max-tokens')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = max_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/bert-large-nli-max-tokens)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 1024, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': True, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
``` |
Jonesy/LisaOnIce | 67fc2267ff59323174edd742555326cadf9c1528 | 2022-04-27T12:41:47.000Z | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
]
| conversational | false | Jonesy | null | Jonesy/LisaOnIce | 1,490 | null | transformers | 1,533 | ---
tags:
- conversational
---
# DialoGPT-medium Model of Simpsons Episode s8e6 "Lisa On Ice"
|
cardiffnlp/twitter-roberta-base-mar2022 | 4dbf97378f905571e34b6399573db2f4d92f7aaf | 2022-04-18T10:53:59.000Z | [
"pytorch",
"roberta",
"fill-mask",
"arxiv:2202.03829",
"transformers",
"autotrain_compatible"
]
| fill-mask | false | cardiffnlp | null | cardiffnlp/twitter-roberta-base-mar2022 | 1,486 | 2 | transformers | 1,534 | # Twitter March 2022 (RoBERTa-base, 128M)
This is a RoBERTa-base model trained on 128.06M tweets until the end of March 2022.
More details and performance scores are available in the [TimeLMs paper](https://arxiv.org/abs/2202.03829).
Below, we provide some usage examples using the standard Transformers interface. For another interface more suited to comparing predictions and perplexity scores between models trained at different temporal intervals, check the [TimeLMs repository](https://github.com/cardiffnlp/timelms).
For other models trained until different periods, check this [table](https://github.com/cardiffnlp/timelms#released-models).
## Preprocess Text
Replace usernames and links for placeholders: "@user" and "http".
If you're interested in retaining verified users which were also retained during training, you may keep the users listed [here](https://github.com/cardiffnlp/timelms/tree/main/data).
```python
def preprocess(text):
new_text = []
for t in text.split(" "):
t = '@user' if t.startswith('@') and len(t) > 1 else t
t = 'http' if t.startswith('http') else t
new_text.append(t)
return " ".join(new_text)
```
## Example Masked Language Model
```python
from transformers import pipeline, AutoTokenizer
MODEL = "cardiffnlp/twitter-roberta-base-mar2022"
fill_mask = pipeline("fill-mask", model=MODEL, tokenizer=MODEL)
tokenizer = AutoTokenizer.from_pretrained(MODEL)
def print_candidates():
for i in range(5):
token = tokenizer.decode(candidates[i]['token'])
score = candidates[i]['score']
print("%d) %.5f %s" % (i+1, score, token))
texts = [
"So glad I'm <mask> vaccinated.",
"I keep forgetting to bring a <mask>.",
"Looking forward to watching <mask> Game tonight!",
]
for text in texts:
t = preprocess(text)
print(f"{'-'*30}\n{t}")
candidates = fill_mask(t)
print_candidates()
```
Output:
```
------------------------------
So glad I'm <mask> vaccinated.
1) 0.34390 fully
2) 0.28177 not
3) 0.16473 getting
4) 0.04932 still
5) 0.01754 double
------------------------------
I keep forgetting to bring a <mask>.
1) 0.05391 book
2) 0.04560 mask
3) 0.03456 pen
4) 0.03251 lighter
5) 0.03098 charger
------------------------------
Looking forward to watching <mask> Game tonight!
1) 0.60744 the
2) 0.15224 The
3) 0.02575 this
4) 0.01450 End
5) 0.01035 Championship
```
## Example Tweet Embeddings
```python
from transformers import AutoTokenizer, AutoModel, TFAutoModel
import numpy as np
from scipy.spatial.distance import cosine
from collections import Counter
def get_embedding(text):
text = preprocess(text)
encoded_input = tokenizer(text, return_tensors='pt')
features = model(**encoded_input)
features = features[0].detach().cpu().numpy()
features_mean = np.mean(features[0], axis=0)
return features_mean
MODEL = "cardiffnlp/twitter-roberta-base-mar2022"
tokenizer = AutoTokenizer.from_pretrained(MODEL)
model = AutoModel.from_pretrained(MODEL)
query = "The book was awesome"
tweets = ["I just ordered fried chicken 🐣",
"The movie was great",
"What time is the next game?",
"Just finished reading 'Embeddings in NLP'"]
sims = Counter()
for tweet in tweets:
sim = 1 - cosine(get_embedding(query), get_embedding(tweet))
sims[tweet] = sim
print('Most similar to: ', query)
print(f"{'-'*30}")
for idx, (tweet, sim) in enumerate(sims.most_common()):
print("%d) %.5f %s" % (idx+1, sim, tweet))
```
Output:
```
Most similar to: The book was awesome
------------------------------
1) 0.98985 The movie was great
2) 0.96122 Just finished reading 'Embeddings in NLP'
3) 0.95733 I just ordered fried chicken 🐣
4) 0.93271 What time is the next game?
```
## Example Feature Extraction
```python
from transformers import AutoTokenizer, AutoModel, TFAutoModel
import numpy as np
MODEL = "cardiffnlp/twitter-roberta-base-mar2022"
tokenizer = AutoTokenizer.from_pretrained(MODEL)
text = "Good night 😊"
text = preprocess(text)
# Pytorch
model = AutoModel.from_pretrained(MODEL)
encoded_input = tokenizer(text, return_tensors='pt')
features = model(**encoded_input)
features = features[0].detach().cpu().numpy()
features_mean = np.mean(features[0], axis=0)
#features_max = np.max(features[0], axis=0)
# # Tensorflow
# model = TFAutoModel.from_pretrained(MODEL)
# encoded_input = tokenizer(text, return_tensors='tf')
# features = model(encoded_input)
# features = features[0].numpy()
# features_mean = np.mean(features[0], axis=0)
# #features_max = np.max(features[0], axis=0)
``` |
memray/bart_wikikp | 6e7a50d0535d0407b398facb4c381d3a9b1ca69d | 2022-03-05T22:07:16.000Z | [
"pytorch",
"bart",
"feature-extraction",
"transformers"
]
| feature-extraction | false | memray | null | memray/bart_wikikp | 1,481 | 1 | transformers | 1,535 | Entry not found |
UBC-NLP/AraT5-base-title-generation | f26ed5960b5ccff858860ab346040dd1a05d032e | 2022-05-26T18:29:45.000Z | [
"pytorch",
"tf",
"t5",
"text2text-generation",
"ar",
"transformers",
"Arabic T5",
"MSA",
"Twitter",
"Arabic Dialect",
"Arabic Machine Translation",
"Arabic Text Summarization",
"Arabic News Title and Question Generation",
"Arabic Paraphrasing and Transliteration",
"Arabic Code-Switched Translation",
"autotrain_compatible"
]
| text2text-generation | false | UBC-NLP | null | UBC-NLP/AraT5-base-title-generation | 1,476 | 2 | transformers | 1,536 | ---
language:
- ar
tags:
- Arabic T5
- MSA
- Twitter
- Arabic Dialect
- Arabic Machine Translation
- Arabic Text Summarization
- Arabic News Title and Question Generation
- Arabic Paraphrasing and Transliteration
- Arabic Code-Switched Translation
---
# AraT5-base-title-generation
# AraT5: Text-to-Text Transformers for Arabic Language Generation
<img src="https://huggingface.co/UBC-NLP/AraT5-base/resolve/main/AraT5_CR_new.png" alt="AraT5" width="45%" height="35%" align="right"/>
This is the repository accompanying our paper [AraT5: Text-to-Text Transformers for Arabic Language Understanding and Generation](https://aclanthology.org/2022.acl-long.47/). In this is the repository we Introduce **AraT5<sub>MSA</sub>**, **AraT5<sub>Tweet</sub>**, and **AraT5**: three powerful Arabic-specific text-to-text Transformer based models;
---
# How to use AraT5 models
Below is an example for fine-tuning **AraT5-base** for News Title Generation on the Aranews dataset
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("UBC-NLP/AraT5-base-title-generation")
model = AutoModelForSeq2SeqLM.from_pretrained("UBC-NLP/AraT5-base-title-generation")
Document = "تحت رعاية صاحب السمو الملكي الأمير سعود بن نايف بن عبدالعزيز أمير المنطقة الشرقية اختتمت غرفة الشرقية مؤخرا، الثاني من مبادرتها لتأهيل وتدريب أبناء وبنات المملكة ضمن مبادرتها المجانية للعام 2019 حيث قدمت 6 برامج تدريبية نوعية. وثمن رئيس مجلس إدارة الغرفة، عبدالحكيم العمار الخالدي، رعاية سمو أمير المنطقة الشرقية للمبادرة، مؤكدا أن دعم سموه لجميع أنشطة ."
encoding = tokenizer.encode_plus(Document,pad_to_max_length=True, return_tensors="pt")
input_ids, attention_masks = encoding["input_ids"], encoding["attention_mask"]
outputs = model.generate(
input_ids=input_ids, attention_mask=attention_masks,
max_length=256,
do_sample=True,
top_k=120,
top_p=0.95,
early_stopping=True,
num_return_sequences=5
)
for id, output in enumerate(outputs):
title = tokenizer.decode(output, skip_special_tokens=True,clean_up_tokenization_spaces=True)
print("title#"+str(id), title)
```
**The input news document**
<div style="white-space : pre-wrap !important;word-break: break-word; direction:rtl; text-align: right">
تحت رعاية صاحب السمو الملكي الأمير سعود بن نايف بن عبدالعزيز أمير المنطقة الشرقية اختتمت غرفة الشرقية مؤخرا، الثاني من مبادرتها لتأهيل وتدريب أبناء وبنات المملكة ضمن مبادرتها المجانية للعام 2019 حيث قدمت 6 برامج تدريبية نوعية. وثمن رئيس مجلس إدارة الغرفة، عبدالحكيم العمار الخالدي، رعاية سمو أمير المنطقة الشرقية للمبادرة، مؤكدا أن دعم سموه لجميع أنشطة .
<br>
</div>
**The generated titles**
```
title#0 غرفة الشرقية تختتم المرحلة الثانية من مبادرتها لتأهيل وتدريب أبناء وبنات المملكة
title#1 غرفة الشرقية تختتم الثاني من مبادرة تأهيل وتأهيل أبناء وبناتنا
title#2 سعود بن نايف يختتم ثانى مبادراتها لتأهيل وتدريب أبناء وبنات المملكة
title#3 أمير الشرقية يرعى اختتام برنامج برنامج تدريب أبناء وبنات المملكة
title#4 سعود بن نايف يرعى اختتام مبادرة تأهيل وتدريب أبناء وبنات المملكة
```
# AraT5 Models Checkpoints
AraT5 Pytorch and TensorFlow checkpoints are available on the Huggingface website for direct download and use ```exclusively for research```. ```For commercial use, please contact the authors via email @ (muhammad.mageed[at]ubc[dot]ca).```
| **Model** | **Link** |
|---------|:------------------:|
| **AraT5-base** | [https://huggingface.co/UBC-NLP/AraT5-base](https://huggingface.co/UBC-NLP/AraT5-base) |
| **AraT5-msa-base** | [https://huggingface.co/UBC-NLP/AraT5-msa-base](https://huggingface.co/UBC-NLP/AraT5-msa-base) |
| **AraT5-tweet-base** | [https://huggingface.co/UBC-NLP/AraT5-tweet-base](https://huggingface.co/UBC-NLP/AraT5-tweet-base) |
| **AraT5-msa-small** | [https://huggingface.co/UBC-NLP/AraT5-msa-small](https://huggingface.co/UBC-NLP/AraT5-msa-small) |
| **AraT5-tweet-small**| [https://huggingface.co/UBC-NLP/AraT5-tweet-small](https://huggingface.co/UBC-NLP/AraT5-tweet-small) |
# BibTex
If you use our models (Arat5-base, Arat5-msa-base, Arat5-tweet-base, Arat5-msa-small, or Arat5-tweet-small ) for your scientific publication, or if you find the resources in this repository useful, please cite our paper as follows (to be updated):
```bibtex
@inproceedings{nagoudi-etal-2022-arat5,
title = "{A}ra{T}5: Text-to-Text Transformers for {A}rabic Language Generation",
author = "Nagoudi, El Moatez Billah and
Elmadany, AbdelRahim and
Abdul-Mageed, Muhammad",
booktitle = "Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = may,
year = "2022",
address = "Dublin, Ireland",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.acl-long.47",
pages = "628--647",
abstract = "Transfer learning with a unified Transformer framework (T5) that converts all language problems into a text-to-text format was recently proposed as a simple and effective transfer learning approach. Although a multilingual version of the T5 model (mT5) was also introduced, it is not clear how well it can fare on non-English tasks involving diverse data. To investigate this question, we apply mT5 on a language with a wide variety of dialects{--}Arabic. For evaluation, we introduce a novel benchmark for ARabic language GENeration (ARGEN), covering seven important tasks. For model comparison, we pre-train three powerful Arabic T5-style models and evaluate them on ARGEN. Although pre-trained with {\textasciitilde}49 less data, our new models perform significantly better than mT5 on all ARGEN tasks (in 52 out of 59 test sets) and set several new SOTAs. Our models also establish new SOTA on the recently-proposed, large Arabic language understanding evaluation benchmark ARLUE (Abdul-Mageed et al., 2021). Our new models are publicly available. We also link to ARGEN datasets through our repository: https://github.com/UBC-NLP/araT5.",
}
```
## Acknowledgments
We gratefully acknowledge support from the Natural Sciences and Engineering Research Council of Canada, the Social Sciences and Humanities Research Council of Canada, Canadian Foundation for Innovation, [ComputeCanada](www.computecanada.ca) and [UBC ARC-Sockeye](https://doi.org/10.14288/SOCKEYE). We also thank the [Google TensorFlow Research Cloud (TFRC)](https://www.tensorflow.org/tfrc) program for providing us with free TPU access.
|
nlp-waseda/roberta-large-japanese | 28df4e50db51cf0130977770ffd6ab18fc834e3e | 2022-06-10T23:33:42.000Z | [
"pytorch",
"roberta",
"fill-mask",
"ja",
"dataset:wikipedia",
"dataset:cc100",
"transformers",
"license:cc-by-sa-4.0",
"autotrain_compatible"
]
| fill-mask | false | nlp-waseda | null | nlp-waseda/roberta-large-japanese | 1,475 | 10 | transformers | 1,537 | ---
language: ja
license: cc-by-sa-4.0
datasets:
- wikipedia
- cc100
mask_token: "[MASK]"
widget:
- text: "早稲田 大学 で 自然 言語 処理 を [MASK] する 。"
---
# nlp-waseda/roberta-large-japanese
## Model description
This is a Japanese RoBERTa large model pretrained on Japanese Wikipedia and the Japanese portion of CC-100.
## How to use
You can use this model for masked language modeling as follows:
```python
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("nlp-waseda/roberta-large-japanese")
model = AutoModelForMaskedLM.from_pretrained("nlp-waseda/roberta-large-japanese")
sentence = '早稲田 大学 で 自然 言語 処理 を [MASK] する 。' # input should be segmented into words by Juman++ in advance
encoding = tokenizer(sentence, return_tensors='pt')
...
```
You can fine-tune this model on downstream tasks.
## Tokenization
The input text should be segmented into words by [Juman++](https://github.com/ku-nlp/jumanpp) in advance. Juman++ 2.0.0-rc3 was used for pretraining. Each word is tokenized into tokens by [sentencepiece](https://github.com/google/sentencepiece).
## Vocabulary
The vocabulary consists of 32000 tokens including words ([JumanDIC](https://github.com/ku-nlp/JumanDIC)) and subwords induced by the unigram language model of [sentencepiece](https://github.com/google/sentencepiece).
## Training procedure
This model was trained on Japanese Wikipedia (as of 20210920) and the Japanese portion of CC-100. It took two weeks using eight NVIDIA A100 GPUs.
The following hyperparameters were used during pretraining:
- learning_rate: 6e-5
- per_device_train_batch_size: 103
- distributed_type: multi-GPU
- num_devices: 8
- gradient_accumulation_steps: 5
- total_train_batch_size: 4120
- max_seq_length: 128
- optimizer: Adam with betas=(0.9,0.98) and epsilon=1e-6
- lr_scheduler_type: linear
- training_steps: 670000
- warmup_steps: 10000
- mixed_precision_training: Native AMP
## Performance on JGLUE
See the [Baseline Scores](https://github.com/yahoojapan/JGLUE#baseline-scores) of JGLUE.
|
Helsinki-NLP/opus-mt-en-mul | cd721e7a7abeea36f81bf7cea89a77f105b0ddc6 | 2021-01-18T08:13:09.000Z | [
"pytorch",
"marian",
"text2text-generation",
"en",
"ca",
"es",
"os",
"eo",
"ro",
"fy",
"cy",
"is",
"lb",
"su",
"an",
"sq",
"fr",
"ht",
"rm",
"cv",
"ig",
"am",
"eu",
"tr",
"ps",
"af",
"ny",
"ch",
"uk",
"sl",
"lt",
"tk",
"sg",
"ar",
"lg",
"bg",
"be",
"ka",
"gd",
"ja",
"si",
"br",
"mh",
"km",
"th",
"ty",
"rw",
"te",
"mk",
"or",
"wo",
"kl",
"mr",
"ru",
"yo",
"hu",
"fo",
"zh",
"ti",
"co",
"ee",
"oc",
"sn",
"mt",
"ts",
"pl",
"gl",
"nb",
"bn",
"tt",
"bo",
"lo",
"id",
"gn",
"nv",
"hy",
"kn",
"to",
"io",
"so",
"vi",
"da",
"fj",
"gv",
"sm",
"nl",
"mi",
"pt",
"hi",
"se",
"as",
"ta",
"et",
"kw",
"ga",
"sv",
"ln",
"na",
"mn",
"gu",
"wa",
"lv",
"jv",
"el",
"my",
"ba",
"it",
"hr",
"ur",
"ce",
"nn",
"fi",
"mg",
"rn",
"xh",
"ab",
"de",
"cs",
"he",
"zu",
"yi",
"ml",
"mul",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
]
| translation | false | Helsinki-NLP | null | Helsinki-NLP/opus-mt-en-mul | 1,474 | 4 | transformers | 1,538 | ---
language:
- en
- ca
- es
- os
- eo
- ro
- fy
- cy
- is
- lb
- su
- an
- sq
- fr
- ht
- rm
- cv
- ig
- am
- eu
- tr
- ps
- af
- ny
- ch
- uk
- sl
- lt
- tk
- sg
- ar
- lg
- bg
- be
- ka
- gd
- ja
- si
- br
- mh
- km
- th
- ty
- rw
- te
- mk
- or
- wo
- kl
- mr
- ru
- yo
- hu
- fo
- zh
- ti
- co
- ee
- oc
- sn
- mt
- ts
- pl
- gl
- nb
- bn
- tt
- bo
- lo
- id
- gn
- nv
- hy
- kn
- to
- io
- so
- vi
- da
- fj
- gv
- sm
- nl
- mi
- pt
- hi
- se
- as
- ta
- et
- kw
- ga
- sv
- ln
- na
- mn
- gu
- wa
- lv
- jv
- el
- my
- ba
- it
- hr
- ur
- ce
- nn
- fi
- mg
- rn
- xh
- ab
- de
- cs
- he
- zu
- yi
- ml
- mul
tags:
- translation
license: apache-2.0
---
### eng-mul
* source group: English
* target group: Multiple languages
* OPUS readme: [eng-mul](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/eng-mul/README.md)
* model: transformer
* source language(s): eng
* target language(s): abk acm ady afb afh_Latn afr akl_Latn aln amh ang_Latn apc ara arg arq ary arz asm ast avk_Latn awa aze_Latn bak bam_Latn bel bel_Latn ben bho bod bos_Latn bre brx brx_Latn bul bul_Latn cat ceb ces cha che chr chv cjy_Hans cjy_Hant cmn cmn_Hans cmn_Hant cor cos crh crh_Latn csb_Latn cym dan deu dsb dtp dws_Latn egl ell enm_Latn epo est eus ewe ext fao fij fin fkv_Latn fra frm_Latn frr fry fuc fuv gan gcf_Latn gil gla gle glg glv gom gos got_Goth grc_Grek grn gsw guj hat hau_Latn haw heb hif_Latn hil hin hnj_Latn hoc hoc_Latn hrv hsb hun hye iba ibo ido ido_Latn ike_Latn ile_Latn ilo ina_Latn ind isl ita izh jav jav_Java jbo jbo_Cyrl jbo_Latn jdt_Cyrl jpn kab kal kan kat kaz_Cyrl kaz_Latn kek_Latn kha khm khm_Latn kin kir_Cyrl kjh kpv krl ksh kum kur_Arab kur_Latn lad lad_Latn lao lat_Latn lav ldn_Latn lfn_Cyrl lfn_Latn lij lin lit liv_Latn lkt lld_Latn lmo ltg ltz lug lzh lzh_Hans mad mah mai mal mar max_Latn mdf mfe mhr mic min mkd mlg mlt mnw moh mon mri mwl mww mya myv nan nau nav nds niu nld nno nob nob_Hebr nog non_Latn nov_Latn npi nya oci ori orv_Cyrl oss ota_Arab ota_Latn pag pan_Guru pap pau pdc pes pes_Latn pes_Thaa pms pnb pol por ppl_Latn prg_Latn pus quc qya qya_Latn rap rif_Latn roh rom ron rue run rus sag sah san_Deva scn sco sgs shs_Latn shy_Latn sin sjn_Latn slv sma sme smo sna snd_Arab som spa sqi srp_Cyrl srp_Latn stq sun swe swg swh tah tam tat tat_Arab tat_Latn tel tet tgk_Cyrl tha tir tlh_Latn tly_Latn tmw_Latn toi_Latn ton tpw_Latn tso tuk tuk_Latn tur tvl tyv tzl tzl_Latn udm uig_Arab uig_Cyrl ukr umb urd uzb_Cyrl uzb_Latn vec vie vie_Hani vol_Latn vro war wln wol wuu xal xho yid yor yue yue_Hans yue_Hant zho zho_Hans zho_Hant zlm_Latn zsm_Latn zul zza
* model: transformer
* pre-processing: normalization + SentencePiece (spm32k,spm32k)
* a sentence initial language token is required in the form of `>>id<<` (id = valid target language ID)
* download original weights: [opus2m-2020-08-01.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-mul/opus2m-2020-08-01.zip)
* test set translations: [opus2m-2020-08-01.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-mul/opus2m-2020-08-01.test.txt)
* test set scores: [opus2m-2020-08-01.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-mul/opus2m-2020-08-01.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| newsdev2014-enghin.eng.hin | 5.0 | 0.288 |
| newsdev2015-enfi-engfin.eng.fin | 9.3 | 0.418 |
| newsdev2016-enro-engron.eng.ron | 17.2 | 0.488 |
| newsdev2016-entr-engtur.eng.tur | 8.2 | 0.402 |
| newsdev2017-enlv-englav.eng.lav | 12.9 | 0.444 |
| newsdev2017-enzh-engzho.eng.zho | 17.6 | 0.170 |
| newsdev2018-enet-engest.eng.est | 10.9 | 0.423 |
| newsdev2019-engu-engguj.eng.guj | 5.2 | 0.284 |
| newsdev2019-enlt-englit.eng.lit | 11.0 | 0.431 |
| newsdiscussdev2015-enfr-engfra.eng.fra | 22.6 | 0.521 |
| newsdiscusstest2015-enfr-engfra.eng.fra | 25.9 | 0.546 |
| newssyscomb2009-engces.eng.ces | 10.3 | 0.394 |
| newssyscomb2009-engdeu.eng.deu | 13.3 | 0.459 |
| newssyscomb2009-engfra.eng.fra | 21.5 | 0.522 |
| newssyscomb2009-enghun.eng.hun | 8.1 | 0.371 |
| newssyscomb2009-engita.eng.ita | 22.1 | 0.540 |
| newssyscomb2009-engspa.eng.spa | 23.8 | 0.531 |
| news-test2008-engces.eng.ces | 9.0 | 0.376 |
| news-test2008-engdeu.eng.deu | 14.2 | 0.451 |
| news-test2008-engfra.eng.fra | 19.8 | 0.500 |
| news-test2008-engspa.eng.spa | 22.8 | 0.518 |
| newstest2009-engces.eng.ces | 9.8 | 0.392 |
| newstest2009-engdeu.eng.deu | 13.7 | 0.454 |
| newstest2009-engfra.eng.fra | 20.7 | 0.514 |
| newstest2009-enghun.eng.hun | 8.4 | 0.370 |
| newstest2009-engita.eng.ita | 22.4 | 0.538 |
| newstest2009-engspa.eng.spa | 23.5 | 0.532 |
| newstest2010-engces.eng.ces | 10.0 | 0.393 |
| newstest2010-engdeu.eng.deu | 15.2 | 0.463 |
| newstest2010-engfra.eng.fra | 22.0 | 0.524 |
| newstest2010-engspa.eng.spa | 27.2 | 0.556 |
| newstest2011-engces.eng.ces | 10.8 | 0.392 |
| newstest2011-engdeu.eng.deu | 14.2 | 0.449 |
| newstest2011-engfra.eng.fra | 24.3 | 0.544 |
| newstest2011-engspa.eng.spa | 28.3 | 0.559 |
| newstest2012-engces.eng.ces | 9.9 | 0.377 |
| newstest2012-engdeu.eng.deu | 14.3 | 0.449 |
| newstest2012-engfra.eng.fra | 23.2 | 0.530 |
| newstest2012-engrus.eng.rus | 16.0 | 0.463 |
| newstest2012-engspa.eng.spa | 27.8 | 0.555 |
| newstest2013-engces.eng.ces | 11.0 | 0.392 |
| newstest2013-engdeu.eng.deu | 16.4 | 0.469 |
| newstest2013-engfra.eng.fra | 22.6 | 0.515 |
| newstest2013-engrus.eng.rus | 12.1 | 0.414 |
| newstest2013-engspa.eng.spa | 24.9 | 0.532 |
| newstest2014-hien-enghin.eng.hin | 7.2 | 0.311 |
| newstest2015-encs-engces.eng.ces | 10.9 | 0.396 |
| newstest2015-ende-engdeu.eng.deu | 18.3 | 0.490 |
| newstest2015-enfi-engfin.eng.fin | 10.1 | 0.421 |
| newstest2015-enru-engrus.eng.rus | 14.5 | 0.445 |
| newstest2016-encs-engces.eng.ces | 12.2 | 0.408 |
| newstest2016-ende-engdeu.eng.deu | 21.4 | 0.517 |
| newstest2016-enfi-engfin.eng.fin | 11.2 | 0.435 |
| newstest2016-enro-engron.eng.ron | 16.6 | 0.472 |
| newstest2016-enru-engrus.eng.rus | 13.4 | 0.435 |
| newstest2016-entr-engtur.eng.tur | 8.1 | 0.385 |
| newstest2017-encs-engces.eng.ces | 9.6 | 0.377 |
| newstest2017-ende-engdeu.eng.deu | 17.9 | 0.482 |
| newstest2017-enfi-engfin.eng.fin | 11.8 | 0.440 |
| newstest2017-enlv-englav.eng.lav | 9.6 | 0.412 |
| newstest2017-enru-engrus.eng.rus | 14.1 | 0.446 |
| newstest2017-entr-engtur.eng.tur | 8.0 | 0.378 |
| newstest2017-enzh-engzho.eng.zho | 16.8 | 0.175 |
| newstest2018-encs-engces.eng.ces | 9.8 | 0.380 |
| newstest2018-ende-engdeu.eng.deu | 23.8 | 0.536 |
| newstest2018-enet-engest.eng.est | 11.8 | 0.433 |
| newstest2018-enfi-engfin.eng.fin | 7.8 | 0.398 |
| newstest2018-enru-engrus.eng.rus | 12.2 | 0.434 |
| newstest2018-entr-engtur.eng.tur | 7.5 | 0.383 |
| newstest2018-enzh-engzho.eng.zho | 18.3 | 0.179 |
| newstest2019-encs-engces.eng.ces | 10.7 | 0.389 |
| newstest2019-ende-engdeu.eng.deu | 21.0 | 0.512 |
| newstest2019-enfi-engfin.eng.fin | 10.4 | 0.420 |
| newstest2019-engu-engguj.eng.guj | 5.8 | 0.297 |
| newstest2019-enlt-englit.eng.lit | 8.0 | 0.388 |
| newstest2019-enru-engrus.eng.rus | 13.0 | 0.415 |
| newstest2019-enzh-engzho.eng.zho | 15.0 | 0.192 |
| newstestB2016-enfi-engfin.eng.fin | 9.0 | 0.414 |
| newstestB2017-enfi-engfin.eng.fin | 9.5 | 0.415 |
| Tatoeba-test.eng-abk.eng.abk | 4.2 | 0.275 |
| Tatoeba-test.eng-ady.eng.ady | 0.4 | 0.006 |
| Tatoeba-test.eng-afh.eng.afh | 1.0 | 0.058 |
| Tatoeba-test.eng-afr.eng.afr | 47.0 | 0.663 |
| Tatoeba-test.eng-akl.eng.akl | 2.7 | 0.080 |
| Tatoeba-test.eng-amh.eng.amh | 8.5 | 0.455 |
| Tatoeba-test.eng-ang.eng.ang | 6.2 | 0.138 |
| Tatoeba-test.eng-ara.eng.ara | 6.3 | 0.325 |
| Tatoeba-test.eng-arg.eng.arg | 1.5 | 0.107 |
| Tatoeba-test.eng-asm.eng.asm | 2.1 | 0.265 |
| Tatoeba-test.eng-ast.eng.ast | 15.7 | 0.393 |
| Tatoeba-test.eng-avk.eng.avk | 0.2 | 0.095 |
| Tatoeba-test.eng-awa.eng.awa | 0.1 | 0.002 |
| Tatoeba-test.eng-aze.eng.aze | 19.0 | 0.500 |
| Tatoeba-test.eng-bak.eng.bak | 12.7 | 0.379 |
| Tatoeba-test.eng-bam.eng.bam | 8.3 | 0.037 |
| Tatoeba-test.eng-bel.eng.bel | 13.5 | 0.396 |
| Tatoeba-test.eng-ben.eng.ben | 10.0 | 0.383 |
| Tatoeba-test.eng-bho.eng.bho | 0.1 | 0.003 |
| Tatoeba-test.eng-bod.eng.bod | 0.0 | 0.147 |
| Tatoeba-test.eng-bre.eng.bre | 7.6 | 0.275 |
| Tatoeba-test.eng-brx.eng.brx | 0.8 | 0.060 |
| Tatoeba-test.eng-bul.eng.bul | 32.1 | 0.542 |
| Tatoeba-test.eng-cat.eng.cat | 37.0 | 0.595 |
| Tatoeba-test.eng-ceb.eng.ceb | 9.6 | 0.409 |
| Tatoeba-test.eng-ces.eng.ces | 24.0 | 0.475 |
| Tatoeba-test.eng-cha.eng.cha | 3.9 | 0.228 |
| Tatoeba-test.eng-che.eng.che | 0.7 | 0.013 |
| Tatoeba-test.eng-chm.eng.chm | 2.6 | 0.212 |
| Tatoeba-test.eng-chr.eng.chr | 6.0 | 0.190 |
| Tatoeba-test.eng-chv.eng.chv | 6.5 | 0.369 |
| Tatoeba-test.eng-cor.eng.cor | 0.9 | 0.086 |
| Tatoeba-test.eng-cos.eng.cos | 4.2 | 0.174 |
| Tatoeba-test.eng-crh.eng.crh | 9.9 | 0.361 |
| Tatoeba-test.eng-csb.eng.csb | 3.4 | 0.230 |
| Tatoeba-test.eng-cym.eng.cym | 18.0 | 0.418 |
| Tatoeba-test.eng-dan.eng.dan | 42.5 | 0.624 |
| Tatoeba-test.eng-deu.eng.deu | 25.2 | 0.505 |
| Tatoeba-test.eng-dsb.eng.dsb | 0.9 | 0.121 |
| Tatoeba-test.eng-dtp.eng.dtp | 0.3 | 0.084 |
| Tatoeba-test.eng-dws.eng.dws | 0.2 | 0.040 |
| Tatoeba-test.eng-egl.eng.egl | 0.4 | 0.085 |
| Tatoeba-test.eng-ell.eng.ell | 28.7 | 0.543 |
| Tatoeba-test.eng-enm.eng.enm | 3.3 | 0.295 |
| Tatoeba-test.eng-epo.eng.epo | 33.4 | 0.570 |
| Tatoeba-test.eng-est.eng.est | 30.3 | 0.545 |
| Tatoeba-test.eng-eus.eng.eus | 18.5 | 0.486 |
| Tatoeba-test.eng-ewe.eng.ewe | 6.8 | 0.272 |
| Tatoeba-test.eng-ext.eng.ext | 5.0 | 0.228 |
| Tatoeba-test.eng-fao.eng.fao | 5.2 | 0.277 |
| Tatoeba-test.eng-fas.eng.fas | 6.9 | 0.265 |
| Tatoeba-test.eng-fij.eng.fij | 31.5 | 0.365 |
| Tatoeba-test.eng-fin.eng.fin | 18.5 | 0.459 |
| Tatoeba-test.eng-fkv.eng.fkv | 0.9 | 0.132 |
| Tatoeba-test.eng-fra.eng.fra | 31.5 | 0.546 |
| Tatoeba-test.eng-frm.eng.frm | 0.9 | 0.128 |
| Tatoeba-test.eng-frr.eng.frr | 3.0 | 0.025 |
| Tatoeba-test.eng-fry.eng.fry | 14.4 | 0.387 |
| Tatoeba-test.eng-ful.eng.ful | 0.4 | 0.061 |
| Tatoeba-test.eng-gcf.eng.gcf | 0.3 | 0.075 |
| Tatoeba-test.eng-gil.eng.gil | 47.4 | 0.706 |
| Tatoeba-test.eng-gla.eng.gla | 10.9 | 0.341 |
| Tatoeba-test.eng-gle.eng.gle | 26.8 | 0.493 |
| Tatoeba-test.eng-glg.eng.glg | 32.5 | 0.565 |
| Tatoeba-test.eng-glv.eng.glv | 21.5 | 0.395 |
| Tatoeba-test.eng-gos.eng.gos | 0.3 | 0.124 |
| Tatoeba-test.eng-got.eng.got | 0.2 | 0.010 |
| Tatoeba-test.eng-grc.eng.grc | 0.0 | 0.005 |
| Tatoeba-test.eng-grn.eng.grn | 1.5 | 0.129 |
| Tatoeba-test.eng-gsw.eng.gsw | 0.6 | 0.106 |
| Tatoeba-test.eng-guj.eng.guj | 15.4 | 0.347 |
| Tatoeba-test.eng-hat.eng.hat | 31.1 | 0.527 |
| Tatoeba-test.eng-hau.eng.hau | 6.5 | 0.385 |
| Tatoeba-test.eng-haw.eng.haw | 0.2 | 0.066 |
| Tatoeba-test.eng-hbs.eng.hbs | 28.7 | 0.531 |
| Tatoeba-test.eng-heb.eng.heb | 21.3 | 0.443 |
| Tatoeba-test.eng-hif.eng.hif | 2.8 | 0.268 |
| Tatoeba-test.eng-hil.eng.hil | 12.0 | 0.463 |
| Tatoeba-test.eng-hin.eng.hin | 13.0 | 0.401 |
| Tatoeba-test.eng-hmn.eng.hmn | 0.2 | 0.073 |
| Tatoeba-test.eng-hoc.eng.hoc | 0.2 | 0.077 |
| Tatoeba-test.eng-hsb.eng.hsb | 5.7 | 0.308 |
| Tatoeba-test.eng-hun.eng.hun | 17.1 | 0.431 |
| Tatoeba-test.eng-hye.eng.hye | 15.0 | 0.378 |
| Tatoeba-test.eng-iba.eng.iba | 16.0 | 0.437 |
| Tatoeba-test.eng-ibo.eng.ibo | 2.9 | 0.221 |
| Tatoeba-test.eng-ido.eng.ido | 11.5 | 0.403 |
| Tatoeba-test.eng-iku.eng.iku | 2.3 | 0.089 |
| Tatoeba-test.eng-ile.eng.ile | 4.3 | 0.282 |
| Tatoeba-test.eng-ilo.eng.ilo | 26.4 | 0.522 |
| Tatoeba-test.eng-ina.eng.ina | 20.9 | 0.493 |
| Tatoeba-test.eng-isl.eng.isl | 12.5 | 0.375 |
| Tatoeba-test.eng-ita.eng.ita | 33.9 | 0.592 |
| Tatoeba-test.eng-izh.eng.izh | 4.6 | 0.050 |
| Tatoeba-test.eng-jav.eng.jav | 7.8 | 0.328 |
| Tatoeba-test.eng-jbo.eng.jbo | 0.1 | 0.123 |
| Tatoeba-test.eng-jdt.eng.jdt | 6.4 | 0.008 |
| Tatoeba-test.eng-jpn.eng.jpn | 0.0 | 0.000 |
| Tatoeba-test.eng-kab.eng.kab | 5.9 | 0.261 |
| Tatoeba-test.eng-kal.eng.kal | 13.4 | 0.382 |
| Tatoeba-test.eng-kan.eng.kan | 4.8 | 0.358 |
| Tatoeba-test.eng-kat.eng.kat | 1.8 | 0.115 |
| Tatoeba-test.eng-kaz.eng.kaz | 8.8 | 0.354 |
| Tatoeba-test.eng-kek.eng.kek | 3.7 | 0.188 |
| Tatoeba-test.eng-kha.eng.kha | 0.5 | 0.094 |
| Tatoeba-test.eng-khm.eng.khm | 0.4 | 0.243 |
| Tatoeba-test.eng-kin.eng.kin | 5.2 | 0.362 |
| Tatoeba-test.eng-kir.eng.kir | 17.2 | 0.416 |
| Tatoeba-test.eng-kjh.eng.kjh | 0.6 | 0.009 |
| Tatoeba-test.eng-kok.eng.kok | 5.5 | 0.005 |
| Tatoeba-test.eng-kom.eng.kom | 2.4 | 0.012 |
| Tatoeba-test.eng-krl.eng.krl | 2.0 | 0.099 |
| Tatoeba-test.eng-ksh.eng.ksh | 0.4 | 0.074 |
| Tatoeba-test.eng-kum.eng.kum | 0.9 | 0.007 |
| Tatoeba-test.eng-kur.eng.kur | 9.1 | 0.174 |
| Tatoeba-test.eng-lad.eng.lad | 1.2 | 0.154 |
| Tatoeba-test.eng-lah.eng.lah | 0.1 | 0.001 |
| Tatoeba-test.eng-lao.eng.lao | 0.6 | 0.426 |
| Tatoeba-test.eng-lat.eng.lat | 8.2 | 0.366 |
| Tatoeba-test.eng-lav.eng.lav | 20.4 | 0.475 |
| Tatoeba-test.eng-ldn.eng.ldn | 0.3 | 0.059 |
| Tatoeba-test.eng-lfn.eng.lfn | 0.5 | 0.104 |
| Tatoeba-test.eng-lij.eng.lij | 0.2 | 0.094 |
| Tatoeba-test.eng-lin.eng.lin | 1.2 | 0.276 |
| Tatoeba-test.eng-lit.eng.lit | 17.4 | 0.488 |
| Tatoeba-test.eng-liv.eng.liv | 0.3 | 0.039 |
| Tatoeba-test.eng-lkt.eng.lkt | 0.3 | 0.041 |
| Tatoeba-test.eng-lld.eng.lld | 0.1 | 0.083 |
| Tatoeba-test.eng-lmo.eng.lmo | 1.4 | 0.154 |
| Tatoeba-test.eng-ltz.eng.ltz | 19.1 | 0.395 |
| Tatoeba-test.eng-lug.eng.lug | 4.2 | 0.382 |
| Tatoeba-test.eng-mad.eng.mad | 2.1 | 0.075 |
| Tatoeba-test.eng-mah.eng.mah | 9.5 | 0.331 |
| Tatoeba-test.eng-mai.eng.mai | 9.3 | 0.372 |
| Tatoeba-test.eng-mal.eng.mal | 8.3 | 0.437 |
| Tatoeba-test.eng-mar.eng.mar | 13.5 | 0.410 |
| Tatoeba-test.eng-mdf.eng.mdf | 2.3 | 0.008 |
| Tatoeba-test.eng-mfe.eng.mfe | 83.6 | 0.905 |
| Tatoeba-test.eng-mic.eng.mic | 7.6 | 0.214 |
| Tatoeba-test.eng-mkd.eng.mkd | 31.8 | 0.540 |
| Tatoeba-test.eng-mlg.eng.mlg | 31.3 | 0.464 |
| Tatoeba-test.eng-mlt.eng.mlt | 11.7 | 0.427 |
| Tatoeba-test.eng-mnw.eng.mnw | 0.1 | 0.000 |
| Tatoeba-test.eng-moh.eng.moh | 0.6 | 0.067 |
| Tatoeba-test.eng-mon.eng.mon | 8.5 | 0.323 |
| Tatoeba-test.eng-mri.eng.mri | 8.5 | 0.320 |
| Tatoeba-test.eng-msa.eng.msa | 24.5 | 0.498 |
| Tatoeba-test.eng.multi | 22.4 | 0.451 |
| Tatoeba-test.eng-mwl.eng.mwl | 3.8 | 0.169 |
| Tatoeba-test.eng-mya.eng.mya | 0.2 | 0.123 |
| Tatoeba-test.eng-myv.eng.myv | 1.1 | 0.014 |
| Tatoeba-test.eng-nau.eng.nau | 0.6 | 0.109 |
| Tatoeba-test.eng-nav.eng.nav | 1.8 | 0.149 |
| Tatoeba-test.eng-nds.eng.nds | 11.3 | 0.365 |
| Tatoeba-test.eng-nep.eng.nep | 0.5 | 0.004 |
| Tatoeba-test.eng-niu.eng.niu | 34.4 | 0.501 |
| Tatoeba-test.eng-nld.eng.nld | 37.6 | 0.598 |
| Tatoeba-test.eng-nog.eng.nog | 0.2 | 0.010 |
| Tatoeba-test.eng-non.eng.non | 0.2 | 0.096 |
| Tatoeba-test.eng-nor.eng.nor | 36.3 | 0.577 |
| Tatoeba-test.eng-nov.eng.nov | 0.9 | 0.180 |
| Tatoeba-test.eng-nya.eng.nya | 9.8 | 0.524 |
| Tatoeba-test.eng-oci.eng.oci | 6.3 | 0.288 |
| Tatoeba-test.eng-ori.eng.ori | 5.3 | 0.273 |
| Tatoeba-test.eng-orv.eng.orv | 0.2 | 0.007 |
| Tatoeba-test.eng-oss.eng.oss | 3.0 | 0.230 |
| Tatoeba-test.eng-ota.eng.ota | 0.2 | 0.053 |
| Tatoeba-test.eng-pag.eng.pag | 20.2 | 0.513 |
| Tatoeba-test.eng-pan.eng.pan | 6.4 | 0.301 |
| Tatoeba-test.eng-pap.eng.pap | 44.7 | 0.624 |
| Tatoeba-test.eng-pau.eng.pau | 0.8 | 0.098 |
| Tatoeba-test.eng-pdc.eng.pdc | 2.9 | 0.143 |
| Tatoeba-test.eng-pms.eng.pms | 0.6 | 0.124 |
| Tatoeba-test.eng-pol.eng.pol | 22.7 | 0.500 |
| Tatoeba-test.eng-por.eng.por | 31.6 | 0.570 |
| Tatoeba-test.eng-ppl.eng.ppl | 0.5 | 0.085 |
| Tatoeba-test.eng-prg.eng.prg | 0.1 | 0.078 |
| Tatoeba-test.eng-pus.eng.pus | 0.9 | 0.137 |
| Tatoeba-test.eng-quc.eng.quc | 2.7 | 0.255 |
| Tatoeba-test.eng-qya.eng.qya | 0.4 | 0.084 |
| Tatoeba-test.eng-rap.eng.rap | 1.9 | 0.050 |
| Tatoeba-test.eng-rif.eng.rif | 1.3 | 0.102 |
| Tatoeba-test.eng-roh.eng.roh | 1.4 | 0.169 |
| Tatoeba-test.eng-rom.eng.rom | 7.8 | 0.329 |
| Tatoeba-test.eng-ron.eng.ron | 27.0 | 0.530 |
| Tatoeba-test.eng-rue.eng.rue | 0.1 | 0.009 |
| Tatoeba-test.eng-run.eng.run | 9.8 | 0.434 |
| Tatoeba-test.eng-rus.eng.rus | 22.2 | 0.465 |
| Tatoeba-test.eng-sag.eng.sag | 4.8 | 0.155 |
| Tatoeba-test.eng-sah.eng.sah | 0.2 | 0.007 |
| Tatoeba-test.eng-san.eng.san | 1.7 | 0.143 |
| Tatoeba-test.eng-scn.eng.scn | 1.5 | 0.083 |
| Tatoeba-test.eng-sco.eng.sco | 30.3 | 0.514 |
| Tatoeba-test.eng-sgs.eng.sgs | 1.6 | 0.104 |
| Tatoeba-test.eng-shs.eng.shs | 0.7 | 0.049 |
| Tatoeba-test.eng-shy.eng.shy | 0.6 | 0.064 |
| Tatoeba-test.eng-sin.eng.sin | 5.4 | 0.317 |
| Tatoeba-test.eng-sjn.eng.sjn | 0.3 | 0.074 |
| Tatoeba-test.eng-slv.eng.slv | 12.8 | 0.313 |
| Tatoeba-test.eng-sma.eng.sma | 0.8 | 0.063 |
| Tatoeba-test.eng-sme.eng.sme | 13.2 | 0.290 |
| Tatoeba-test.eng-smo.eng.smo | 12.1 | 0.416 |
| Tatoeba-test.eng-sna.eng.sna | 27.1 | 0.533 |
| Tatoeba-test.eng-snd.eng.snd | 6.0 | 0.359 |
| Tatoeba-test.eng-som.eng.som | 16.0 | 0.274 |
| Tatoeba-test.eng-spa.eng.spa | 36.7 | 0.603 |
| Tatoeba-test.eng-sqi.eng.sqi | 32.3 | 0.573 |
| Tatoeba-test.eng-stq.eng.stq | 0.6 | 0.198 |
| Tatoeba-test.eng-sun.eng.sun | 39.0 | 0.447 |
| Tatoeba-test.eng-swa.eng.swa | 1.1 | 0.109 |
| Tatoeba-test.eng-swe.eng.swe | 42.7 | 0.614 |
| Tatoeba-test.eng-swg.eng.swg | 0.6 | 0.118 |
| Tatoeba-test.eng-tah.eng.tah | 12.4 | 0.294 |
| Tatoeba-test.eng-tam.eng.tam | 5.0 | 0.404 |
| Tatoeba-test.eng-tat.eng.tat | 9.9 | 0.326 |
| Tatoeba-test.eng-tel.eng.tel | 4.7 | 0.326 |
| Tatoeba-test.eng-tet.eng.tet | 0.7 | 0.100 |
| Tatoeba-test.eng-tgk.eng.tgk | 5.5 | 0.304 |
| Tatoeba-test.eng-tha.eng.tha | 2.2 | 0.456 |
| Tatoeba-test.eng-tir.eng.tir | 1.5 | 0.197 |
| Tatoeba-test.eng-tlh.eng.tlh | 0.0 | 0.032 |
| Tatoeba-test.eng-tly.eng.tly | 0.3 | 0.061 |
| Tatoeba-test.eng-toi.eng.toi | 8.3 | 0.219 |
| Tatoeba-test.eng-ton.eng.ton | 32.7 | 0.619 |
| Tatoeba-test.eng-tpw.eng.tpw | 1.4 | 0.136 |
| Tatoeba-test.eng-tso.eng.tso | 9.6 | 0.465 |
| Tatoeba-test.eng-tuk.eng.tuk | 9.4 | 0.383 |
| Tatoeba-test.eng-tur.eng.tur | 24.1 | 0.542 |
| Tatoeba-test.eng-tvl.eng.tvl | 8.9 | 0.398 |
| Tatoeba-test.eng-tyv.eng.tyv | 10.4 | 0.249 |
| Tatoeba-test.eng-tzl.eng.tzl | 0.2 | 0.098 |
| Tatoeba-test.eng-udm.eng.udm | 6.5 | 0.212 |
| Tatoeba-test.eng-uig.eng.uig | 2.1 | 0.266 |
| Tatoeba-test.eng-ukr.eng.ukr | 24.3 | 0.479 |
| Tatoeba-test.eng-umb.eng.umb | 4.4 | 0.274 |
| Tatoeba-test.eng-urd.eng.urd | 8.6 | 0.344 |
| Tatoeba-test.eng-uzb.eng.uzb | 6.9 | 0.343 |
| Tatoeba-test.eng-vec.eng.vec | 1.0 | 0.094 |
| Tatoeba-test.eng-vie.eng.vie | 23.2 | 0.420 |
| Tatoeba-test.eng-vol.eng.vol | 0.3 | 0.086 |
| Tatoeba-test.eng-war.eng.war | 11.4 | 0.415 |
| Tatoeba-test.eng-wln.eng.wln | 8.4 | 0.218 |
| Tatoeba-test.eng-wol.eng.wol | 11.5 | 0.252 |
| Tatoeba-test.eng-xal.eng.xal | 0.1 | 0.007 |
| Tatoeba-test.eng-xho.eng.xho | 19.5 | 0.552 |
| Tatoeba-test.eng-yid.eng.yid | 4.0 | 0.256 |
| Tatoeba-test.eng-yor.eng.yor | 8.8 | 0.247 |
| Tatoeba-test.eng-zho.eng.zho | 21.8 | 0.192 |
| Tatoeba-test.eng-zul.eng.zul | 34.3 | 0.655 |
| Tatoeba-test.eng-zza.eng.zza | 0.5 | 0.080 |
### System Info:
- hf_name: eng-mul
- source_languages: eng
- target_languages: mul
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/eng-mul/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['en', 'ca', 'es', 'os', 'eo', 'ro', 'fy', 'cy', 'is', 'lb', 'su', 'an', 'sq', 'fr', 'ht', 'rm', 'cv', 'ig', 'am', 'eu', 'tr', 'ps', 'af', 'ny', 'ch', 'uk', 'sl', 'lt', 'tk', 'sg', 'ar', 'lg', 'bg', 'be', 'ka', 'gd', 'ja', 'si', 'br', 'mh', 'km', 'th', 'ty', 'rw', 'te', 'mk', 'or', 'wo', 'kl', 'mr', 'ru', 'yo', 'hu', 'fo', 'zh', 'ti', 'co', 'ee', 'oc', 'sn', 'mt', 'ts', 'pl', 'gl', 'nb', 'bn', 'tt', 'bo', 'lo', 'id', 'gn', 'nv', 'hy', 'kn', 'to', 'io', 'so', 'vi', 'da', 'fj', 'gv', 'sm', 'nl', 'mi', 'pt', 'hi', 'se', 'as', 'ta', 'et', 'kw', 'ga', 'sv', 'ln', 'na', 'mn', 'gu', 'wa', 'lv', 'jv', 'el', 'my', 'ba', 'it', 'hr', 'ur', 'ce', 'nn', 'fi', 'mg', 'rn', 'xh', 'ab', 'de', 'cs', 'he', 'zu', 'yi', 'ml', 'mul']
- src_constituents: {'eng'}
- tgt_constituents: {'sjn_Latn', 'cat', 'nan', 'spa', 'ile_Latn', 'pap', 'mwl', 'uzb_Latn', 'mww', 'hil', 'lij', 'avk_Latn', 'lad_Latn', 'lat_Latn', 'bos_Latn', 'oss', 'epo', 'ron', 'fry', 'cym', 'toi_Latn', 'awa', 'swg', 'zsm_Latn', 'zho_Hant', 'gcf_Latn', 'uzb_Cyrl', 'isl', 'lfn_Latn', 'shs_Latn', 'nov_Latn', 'bho', 'ltz', 'lzh', 'kur_Latn', 'sun', 'arg', 'pes_Thaa', 'sqi', 'uig_Arab', 'csb_Latn', 'fra', 'hat', 'liv_Latn', 'non_Latn', 'sco', 'cmn_Hans', 'pnb', 'roh', 'chv', 'ibo', 'bul_Latn', 'amh', 'lfn_Cyrl', 'eus', 'fkv_Latn', 'tur', 'pus', 'afr', 'brx_Latn', 'nya', 'acm', 'ota_Latn', 'cha', 'ukr', 'xal', 'slv', 'lit', 'zho_Hans', 'tmw_Latn', 'kjh', 'ota_Arab', 'war', 'tuk', 'sag', 'myv', 'hsb', 'lzh_Hans', 'ara', 'tly_Latn', 'lug', 'brx', 'bul', 'bel', 'vol_Latn', 'kat', 'gan', 'got_Goth', 'vro', 'ext', 'afh_Latn', 'gla', 'jpn', 'udm', 'mai', 'ary', 'sin', 'tvl', 'hif_Latn', 'cjy_Hant', 'bre', 'ceb', 'mah', 'nob_Hebr', 'crh_Latn', 'prg_Latn', 'khm', 'ang_Latn', 'tha', 'tah', 'tzl', 'aln', 'kin', 'tel', 'ady', 'mkd', 'ori', 'wol', 'aze_Latn', 'jbo', 'niu', 'kal', 'mar', 'vie_Hani', 'arz', 'yue', 'kha', 'san_Deva', 'jbo_Latn', 'gos', 'hau_Latn', 'rus', 'quc', 'cmn', 'yor', 'hun', 'uig_Cyrl', 'fao', 'mnw', 'zho', 'orv_Cyrl', 'iba', 'bel_Latn', 'tir', 'afb', 'crh', 'mic', 'cos', 'swh', 'sah', 'krl', 'ewe', 'apc', 'zza', 'chr', 'grc_Grek', 'tpw_Latn', 'oci', 'mfe', 'sna', 'kir_Cyrl', 'tat_Latn', 'gom', 'ido_Latn', 'sgs', 'pau', 'tgk_Cyrl', 'nog', 'mlt', 'pdc', 'tso', 'srp_Cyrl', 'pol', 'ast', 'glg', 'pms', 'fuc', 'nob', 'qya', 'ben', 'tat', 'kab', 'min', 'srp_Latn', 'wuu', 'dtp', 'jbo_Cyrl', 'tet', 'bod', 'yue_Hans', 'zlm_Latn', 'lao', 'ind', 'grn', 'nav', 'kaz_Cyrl', 'rom', 'hye', 'kan', 'ton', 'ido', 'mhr', 'scn', 'som', 'rif_Latn', 'vie', 'enm_Latn', 'lmo', 'npi', 'pes', 'dan', 'fij', 'ina_Latn', 'cjy_Hans', 'jdt_Cyrl', 'gsw', 'glv', 'khm_Latn', 'smo', 'umb', 'sma', 'gil', 'nld', 'snd_Arab', 'arq', 'mri', 'kur_Arab', 'por', 'hin', 'shy_Latn', 'sme', 'rap', 'tyv', 'dsb', 'moh', 'asm', 'lad', 'yue_Hant', 'kpv', 'tam', 'est', 'frm_Latn', 'hoc_Latn', 'bam_Latn', 'kek_Latn', 'ksh', 'tlh_Latn', 'ltg', 'pan_Guru', 'hnj_Latn', 'cor', 'gle', 'swe', 'lin', 'qya_Latn', 'kum', 'mad', 'cmn_Hant', 'fuv', 'nau', 'mon', 'akl_Latn', 'guj', 'kaz_Latn', 'wln', 'tuk_Latn', 'jav_Java', 'lav', 'jav', 'ell', 'frr', 'mya', 'bak', 'rue', 'ita', 'hrv', 'izh', 'ilo', 'dws_Latn', 'urd', 'stq', 'tat_Arab', 'haw', 'che', 'pag', 'nno', 'fin', 'mlg', 'ppl_Latn', 'run', 'xho', 'abk', 'deu', 'hoc', 'lkt', 'lld_Latn', 'tzl_Latn', 'mdf', 'ike_Latn', 'ces', 'ldn_Latn', 'egl', 'heb', 'vec', 'zul', 'max_Latn', 'pes_Latn', 'yid', 'mal', 'nds'}
- src_multilingual: False
- tgt_multilingual: True
- prepro: normalization + SentencePiece (spm32k,spm32k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/eng-mul/opus2m-2020-08-01.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/eng-mul/opus2m-2020-08-01.test.txt
- src_alpha3: eng
- tgt_alpha3: mul
- short_pair: en-mul
- chrF2_score: 0.451
- bleu: 22.4
- brevity_penalty: 0.987
- ref_len: 68724.0
- src_name: English
- tgt_name: Multiple languages
- train_date: 2020-08-01
- src_alpha2: en
- tgt_alpha2: mul
- prefer_old: False
- long_pair: eng-mul
- helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535
- transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b
- port_machine: brutasse
- port_time: 2020-08-21-14:41 |
blanchefort/rubert-base-cased-sentiment-rusentiment | 997e7bb8e95be5bc71903ca235f76598230e9d90 | 2021-05-19T13:04:19.000Z | [
"pytorch",
"tf",
"jax",
"bert",
"text-classification",
"ru",
"dataset:RuSentiment",
"transformers",
"sentiment"
]
| text-classification | false | blanchefort | null | blanchefort/rubert-base-cased-sentiment-rusentiment | 1,471 | null | transformers | 1,539 | ---
language:
- ru
tags:
- sentiment
- text-classification
datasets:
- RuSentiment
---
# RuBERT for Sentiment Analysis
This is a [DeepPavlov/rubert-base-cased-conversational](https://huggingface.co/DeepPavlov/rubert-base-cased-conversational) model trained on [RuSentiment](http://text-machine.cs.uml.edu/projects/rusentiment/).
## Labels
0: NEUTRAL
1: POSITIVE
2: NEGATIVE
## How to use
```python
import torch
from transformers import AutoModelForSequenceClassification
from transformers import BertTokenizerFast
tokenizer = BertTokenizerFast.from_pretrained('blanchefort/rubert-base-cased-sentiment-rusentiment')
model = AutoModelForSequenceClassification.from_pretrained('blanchefort/rubert-base-cased-sentiment-rusentiment', return_dict=True)
@torch.no_grad()
def predict(text):
inputs = tokenizer(text, max_length=512, padding=True, truncation=True, return_tensors='pt')
outputs = model(**inputs)
predicted = torch.nn.functional.softmax(outputs.logits, dim=1)
predicted = torch.argmax(predicted, dim=1).numpy()
return predicted
```
## Dataset used for model training
**[RuSentiment](http://text-machine.cs.uml.edu/projects/rusentiment/)**
> A. Rogers A. Romanov A. Rumshisky S. Volkova M. Gronas A. Gribov RuSentiment: An Enriched Sentiment Analysis Dataset for Social Media in Russian. Proceedings of COLING 2018. |
cointegrated/rut5-base-multitask | aa908001447c0efd0a51a15edcac4c6dce247f81 | 2021-10-11T17:49:16.000Z | [
"pytorch",
"jax",
"t5",
"text2text-generation",
"ru",
"en",
"transformers",
"russian",
"license:mit",
"autotrain_compatible"
]
| text2text-generation | false | cointegrated | null | cointegrated/rut5-base-multitask | 1,467 | 8 | transformers | 1,540 |
---
language: ["ru", "en"]
tags:
- russian
license: mit
widget:
- text: "fill | Почему они не ___ на меня?"
---
This is a smaller version of the [google/mt5-base](https://huggingface.co/google/mt5-base) with only some Rusian and English embeddings left.
More details are given in a Russian post: https://habr.com/ru/post/581932/
The model has been fine-tuned for several tasks with sentences or short paragraphs:
* translation (`translate ru-en` and `translate en-ru`)
* Paraphrasing (`paraphrase`)
* Filling gaps in a text (`fill`). The gaps can be denoted as `___` or `_3_`, where `3` is the approximate number of words that should be inserted.
* Restoring the text from a noisy bag of words (`assemble`)
* Simplification of texts (`simplify`)
* Dialogue response generation (`reply` based on fiction and `answer` based on online forums)
* Open-book question answering (`comprehend`)
* Asking questions about a text (`ask`)
* News title generation (`headline`)
For each task, the task name is joined with the input text by the ` | ` separator.
The model can be run with the following code:
```
# !pip install transformers sentencepiece
import torch
from transformers import T5ForConditionalGeneration, T5Tokenizer
tokenizer = T5Tokenizer.from_pretrained("cointegrated/rut5-base-multitask")
model = T5ForConditionalGeneration.from_pretrained("cointegrated/rut5-base-multitask")
def generate(text, **kwargs):
inputs = tokenizer(text, return_tensors='pt')
with torch.no_grad():
hypotheses = model.generate(**inputs, num_beams=5, **kwargs)
return tokenizer.decode(hypotheses[0], skip_special_tokens=True)
```
The model can be applied to each of the pretraining tasks:
```
print(generate('translate ru-en | Каждый охотник желает знать, где сидит фазан.'))
# Each hunter wants to know, where he is.
print(generate('paraphrase | Каждый охотник желает знать, где сидит фазан.',
encoder_no_repeat_ngram_size=1, repetition_penalty=0.5, no_repeat_ngram_size=1))
# В любом случае каждый рыбак мечтает познакомиться со своей фермой
print(generate('fill | Каждый охотник _3_, где сидит фазан.'))
# смотрит на озеро
print(generate('assemble | охотник каждый знать фазан сидит'))
# Каждый охотник знает, что фазан сидит.
print(generate('simplify | Местным продуктом-специалитетом с защищённым географическим наименованием по происхождению считается люнебургский степной барашек.', max_length=32))
# Местным продуктом-специалитетом считается люнебургский степной барашек.
print(generate('reply | Помогите мне закадрить девушку'))
# Что я хочу?
print(generate('answer | Помогите мне закадрить девушку'))
# я хочу познакомиться с девушкой!!!!!!!!
print(generate("comprehend | На фоне земельного конфликта между владельцами овец и ранчеро разворачивается история любви овцевода Моргана Лейна, "
"прибывшего в США из Австралии, и Марии Синглетон, владелицы богатого скотоводческого ранчо. Вопрос: откуда приехал Морган?"))
# из Австралии
print(generate("ask | На фоне земельного конфликта между владельцами овец и ранчеро разворачивается история любви овцевода Моргана Лейна, "
"прибывшего в США из Австралии, и Марии Синглетон, владелицы богатого скотоводческого ранчо.", max_length=32))
# Что разворачивается на фоне земельного конфликта между владельцами овец и ранчеро?
print(generate("headline | На фоне земельного конфликта между владельцами овец и ранчеро разворачивается история любви овцевода Моргана Лейна, "
"прибывшего в США из Австралии, и Марии Синглетон, владелицы богатого скотоводческого ранчо.", max_length=32))
# На фоне земельного конфликта разворачивается история любви овцевода Моргана Лейна и Марии Синглетон
```
However, it is strongly recommended that you fine tune the model for your own task. |
jonatasgrosman/wav2vec2-xls-r-1b-russian | 4bce14e5905d144dc8bd9c289b8028351b831612 | 2022-07-27T23:39:43.000Z | [
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"ru",
"dataset:mozilla-foundation/common_voice_8_0",
"transformers",
"hf-asr-leaderboard",
"mozilla-foundation/common_voice_8_0",
"robust-speech-event",
"license:apache-2.0",
"model-index"
]
| automatic-speech-recognition | false | jonatasgrosman | null | jonatasgrosman/wav2vec2-xls-r-1b-russian | 1,460 | 2 | transformers | 1,541 | ---
language:
- ru
license: apache-2.0
tags:
- automatic-speech-recognition
- hf-asr-leaderboard
- mozilla-foundation/common_voice_8_0
- robust-speech-event
- ru
datasets:
- mozilla-foundation/common_voice_8_0
model-index:
- name: XLS-R Wav2Vec2 Russian by Jonatas Grosman
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 8
type: mozilla-foundation/common_voice_8_0
args: ru
metrics:
- name: Test WER
type: wer
value: 9.82
- name: Test CER
type: cer
value: 2.3
- name: Test WER (+LM)
type: wer
value: 7.08
- name: Test CER (+LM)
type: cer
value: 1.87
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Robust Speech Event - Dev Data
type: speech-recognition-community-v2/dev_data
args: ru
metrics:
- name: Dev WER
type: wer
value: 23.96
- name: Dev CER
type: cer
value: 8.88
- name: Dev WER (+LM)
type: wer
value: 15.88
- name: Dev CER (+LM)
type: cer
value: 7.42
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Robust Speech Event - Test Data
type: speech-recognition-community-v2/eval_data
args: ru
metrics:
- name: Test WER
type: wer
value: 14.23
---
# Fine-tuned XLS-R 1B model for speech recognition in Russian
Fine-tuned [facebook/wav2vec2-xls-r-1b](https://huggingface.co/facebook/wav2vec2-xls-r-1b) on Russian using the train and validation splits of [Common Voice 8.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_8_0), [Golos](https://www.openslr.org/114/), and [Multilingual TEDx](http://www.openslr.org/100).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool, and thanks to the GPU credits generously given by the [OVHcloud](https://www.ovhcloud.com/en/public-cloud/ai-training/) :)
## Usage
Using the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) library:
```python
from huggingsound import SpeechRecognitionModel
model = SpeechRecognitionModel("jonatasgrosman/wav2vec2-xls-r-1b-russian")
audio_paths = ["/path/to/file.mp3", "/path/to/another_file.wav"]
transcriptions = model.transcribe(audio_paths)
```
Writing your own inference script:
```python
import torch
import librosa
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
LANG_ID = "ru"
MODEL_ID = "jonatasgrosman/wav2vec2-xls-r-1b-russian"
SAMPLES = 10
test_dataset = load_dataset("common_voice", LANG_ID, split=f"test[:{SAMPLES}]")
processor = Wav2Vec2Processor.from_pretrained(MODEL_ID)
model = Wav2Vec2ForCTC.from_pretrained(MODEL_ID)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = librosa.load(batch["path"], sr=16_000)
batch["speech"] = speech_array
batch["sentence"] = batch["sentence"].upper()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
predicted_sentences = processor.batch_decode(predicted_ids)
```
## Evaluation Commands
1. To evaluate on `mozilla-foundation/common_voice_8_0` with split `test`
```bash
python eval.py --model_id jonatasgrosman/wav2vec2-xls-r-1b-russian --dataset mozilla-foundation/common_voice_8_0 --config ru --split test
```
2. To evaluate on `speech-recognition-community-v2/dev_data`
```bash
python eval.py --model_id jonatasgrosman/wav2vec2-xls-r-1b-russian --dataset speech-recognition-community-v2/dev_data --config ru --split validation --chunk_length_s 5.0 --stride_length_s 1.0
```
## Citation
If you want to cite this model you can use this:
```bibtex
@misc{grosman2021xlsr-1b-russian,
title={Fine-tuned {XLS-R} 1{B} model for speech recognition in {R}ussian},
author={Grosman, Jonatas},
howpublished={\url{https://huggingface.co/jonatasgrosman/wav2vec2-xls-r-1b-russian}},
year={2022}
}
```
|
m3hrdadfi/bert-fa-base-uncased-wikinli-mean-tokens | a3688fa119b8a43fea49d9636798de285a1c7c15 | 2021-05-28T06:00:37.000Z | [
"pytorch",
"jax",
"bert",
"feature-extraction",
"fa",
"transformers",
"license:apache-2.0"
]
| feature-extraction | false | m3hrdadfi | null | m3hrdadfi/bert-fa-base-uncased-wikinli-mean-tokens | 1,460 | null | transformers | 1,542 | ---
language: fa
license: apache-2.0
---
# ParsBERT + Sentence Transformers
Please follow the [Sentence-Transformer](https://github.com/m3hrdadfi/sentence-transformers) repo for the latest information about previous and current models.
```bibtex
@misc{SentenceTransformerWiki,
author = {Mehrdad Farahani},
title = {Sentence Embeddings with ParsBERT},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {https://github.com/m3hrdadfi/sentence-transformers},
}
``` |
sdadas/polish-roberta-base-v2 | ee587adb0e7ab0b0e42f080589ddeb03b7f928ef | 2022-02-19T10:07:31.000Z | [
"pytorch",
"roberta",
"fill-mask",
"transformers",
"license:lgpl-3.0",
"autotrain_compatible"
]
| fill-mask | false | sdadas | null | sdadas/polish-roberta-base-v2 | 1,459 | 1 | transformers | 1,543 | ---
license: lgpl-3.0
---
|
uer/t5-v1_1-base-chinese-cluecorpussmall | eb304532aed1ed8a29fac66b08b5e9cfcfb5b4ad | 2022-07-15T08:21:39.000Z | [
"pytorch",
"tf",
"mt5",
"text2text-generation",
"zh",
"dataset:CLUECorpusSmall",
"arxiv:1909.05658",
"transformers",
"autotrain_compatible"
]
| text2text-generation | false | uer | null | uer/t5-v1_1-base-chinese-cluecorpussmall | 1,459 | 8 | transformers | 1,544 | ---
language: zh
datasets: CLUECorpusSmall
widget:
- text: "作为电子extra0的平台,京东绝对是领先者。如今的刘强extra1已经是身价过extra2的老板。"
---
# Chinese T5 Version 1.1
## Model description
This is the set of Chinese T5 Version 1.1 models pre-trained by [UER-py](https://github.com/dbiir/UER-py/), which is introduced in [this paper](https://arxiv.org/abs/1909.05658).
**Version 1.1**
Chinese T5 Version 1.1 includes the following improvements compared to our Chinese T5 model:
- GEGLU activation in feed-forward hidden layer, rather than ReLU
- Dropout was turned off in pre-training
- no parameter sharing between embedding and classifier layer
You can download the set of Chinese T5 Version 1.1 models either from the [UER-py Modelzoo page](https://github.com/dbiir/UER-py/wiki/Modelzoo), or via HuggingFace from the links below:
| | Link |
| ----------------- | :----------------------------: |
| **T5-v1_1-Small** | [**L=8/H=512 (Small)**][small] |
| **T5-v1_1-Base** | [**L=12/H=768 (Base)**][base] |
In T5 Version 1.1, spans of the input sequence are masked by so-called sentinel token. Each sentinel token represents a unique mask token for the input sequence and should start with `<extra_id_0>`, `<extra_id_1>`, … up to `<extra_id_99>`. However, `<extra_id_xxx>` is separated into multiple parts in Huggingface's Hosted inference API. Therefore, we replace `<extra_id_xxx>` with `extraxxx` in vocabulary and BertTokenizer regards `extraxxx` as one sentinel token.
## How to use
You can use this model directly with a pipeline for text2text generation (take the case of T5-v1_1-Small):
```python
>>> from transformers import BertTokenizer, MT5ForConditionalGeneration, Text2TextGenerationPipeline
>>> tokenizer = BertTokenizer.from_pretrained("uer/t5-v1_1-small-chinese-cluecorpussmall")
>>> model = MT5ForConditionalGeneration.from_pretrained("uer/t5-v1_1-small-chinese-cluecorpussmall")
>>> text2text_generator = Text2TextGenerationPipeline(model, tokenizer)
>>> text2text_generator("中国的首都是extra0京", max_length=50, do_sample=False)
[{'generated_text': 'extra0 北 extra1 extra2 extra3 extra4 extra5'}]
```
## Training data
[CLUECorpusSmall](https://github.com/CLUEbenchmark/CLUECorpus2020/) is used as training data.
## Training procedure
The model is pre-trained by [UER-py](https://github.com/dbiir/UER-py/) on [Tencent Cloud](https://cloud.tencent.com/). We pre-train 1,000,000 steps with a sequence length of 128 and then pre-train 250,000 additional steps with a sequence length of 512. We use the same hyper-parameters on different model sizes.
Taking the case of T5-v1_1-Small
Stage1:
```
python3 preprocess.py --corpus_path corpora/cluecorpussmall.txt \
--vocab_path models/google_zh_with_sentinel_vocab.txt \
--dataset_path cluecorpussmall_t5-v1_1_seq128_dataset.pt \
--processes_num 32 --seq_length 128 \
--dynamic_masking --data_processor t5
```
```
python3 pretrain.py --dataset_path cluecorpussmall_t5-v1_1_seq128_dataset.pt \
--vocab_path models/google_zh_with_sentinel_vocab.txt \
--config_path models/t5-v1_1/small_config.json \
--output_model_path models/cluecorpussmall_t5-v1_1_small_seq128_model.bin \
--world_size 8 --gpu_ranks 0 1 2 3 4 5 6 7 \
--total_steps 1000000 --save_checkpoint_steps 100000 --report_steps 50000 \
--learning_rate 1e-3 --batch_size 64 \
--span_masking --span_geo_prob 0.3 --span_max_length 5
```
Stage2:
```
python3 preprocess.py --corpus_path corpora/cluecorpussmall.txt \
--vocab_path models/google_zh_with_sentinel_vocab.txt \
--dataset_path cluecorpussmall_t5-v1_1_seq512_dataset.pt \
--processes_num 32 --seq_length 512 \
--dynamic_masking --data_processor t5
```
```
python3 pretrain.py --dataset_path cluecorpussmall_t5-v1_1_seq512_dataset.pt \
--pretrained_model_path models/cluecorpussmall_t5-v1_1_small_seq128_model.bin-1000000 \
--vocab_path models/google_zh_with_sentinel_vocab.txt \
--config_path models/t5-v1_1/small_config.json \
--output_model_path models/cluecorpussmall_t5-v1_1_small_seq512_model.bin \
--world_size 8 --gpu_ranks 0 1 2 3 4 5 6 7 \
--total_steps 250000 --save_checkpoint_steps 50000 --report_steps 10000 \
--learning_rate 5e-4 --batch_size 16 \
--span_masking --span_geo_prob 0.3 --span_max_length 5
```
Finally, we convert the pre-trained model into Huggingface's format:
```
python3 scripts/convert_t5_from_uer_to_huggingface.py --input_model_path cluecorpussmall_t5_small_seq512_model.bin-250000 \
--output_model_path pytorch_model.bin \
--layers_num 8 \
--type t5-v1_1
```
### BibTeX entry and citation info
```
@article{2020t5,
title = {Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer},
author = {Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu},
journal = {Journal of Machine Learning Research},
pages = {1-67},
year = {2020}
}
@article{zhao2019uer,
title={UER: An Open-Source Toolkit for Pre-training Models},
author={Zhao, Zhe and Chen, Hui and Zhang, Jinbin and Zhao, Xin and Liu, Tao and Lu, Wei and Chen, Xi and Deng, Haotang and Ju, Qi and Du, Xiaoyong},
journal={EMNLP-IJCNLP 2019},
pages={241},
year={2019}
}
```
[small]:https://huggingface.co/uer/t5-v1_1-small-chinese-cluecorpussmall
[base]:https://huggingface.co/uer/t5-v1_1-base-chinese-cluecorpussmall |
ckiplab/albert-base-chinese | ed9a51e41fcf0cb4dec5aa3cbd7cdeb40b3e0099 | 2022-05-10T03:28:08.000Z | [
"pytorch",
"albert",
"fill-mask",
"zh",
"transformers",
"lm-head",
"license:gpl-3.0",
"autotrain_compatible"
]
| fill-mask | false | ckiplab | null | ckiplab/albert-base-chinese | 1,457 | 2 | transformers | 1,545 | ---
language:
- zh
thumbnail: https://ckip.iis.sinica.edu.tw/files/ckip_logo.png
tags:
- pytorch
- lm-head
- albert
- zh
license: gpl-3.0
---
# CKIP ALBERT Base Chinese
This project provides traditional Chinese transformers models (including ALBERT, BERT, GPT2) and NLP tools (including word segmentation, part-of-speech tagging, named entity recognition).
這個專案提供了繁體中文的 transformers 模型(包含 ALBERT、BERT、GPT2)及自然語言處理工具(包含斷詞、詞性標記、實體辨識)。
## Homepage
- https://github.com/ckiplab/ckip-transformers
## Contributers
- [Mu Yang](https://muyang.pro) at [CKIP](https://ckip.iis.sinica.edu.tw) (Author & Maintainer)
## Usage
Please use BertTokenizerFast as tokenizer instead of AutoTokenizer.
請使用 BertTokenizerFast 而非 AutoTokenizer。
```
from transformers import (
BertTokenizerFast,
AutoModel,
)
tokenizer = BertTokenizerFast.from_pretrained('bert-base-chinese')
model = AutoModel.from_pretrained('ckiplab/albert-base-chinese')
```
For full usage and more information, please refer to https://github.com/ckiplab/ckip-transformers.
有關完整使用方法及其他資訊,請參見 https://github.com/ckiplab/ckip-transformers 。
|
bergum/xtremedistil-l6-h384-go-emotion | 262275f2d541e5bf124f72ac1aab0999b35aff1d | 2022-07-14T10:00:08.000Z | [
"pytorch",
"bert",
"text-classification",
"dataset:go_emotions",
"transformers",
"license:apache-2.0",
"model-index"
]
| text-classification | false | bergum | null | bergum/xtremedistil-l6-h384-go-emotion | 1,455 | 5 | transformers | 1,546 | ---
license: apache-2.0
datasets:
- go_emotions
metrics:
- accuracy
model-index:
- name: xtremedistil-emotion
results:
- task:
name: Multi Label Text Classification
type: multi_label_classification
dataset:
name: go_emotions
type: emotion
args: default
metrics:
- name: Accuracy
type: accuracy
value: NaN
---
# xtremedistil-l6-h384-go-emotion
This model is a fine-tuned version of [microsoft/xtremedistil-l6-h384-uncased](https://huggingface.co/microsoft/xtremedistil-l6-h384-uncased) on the
[go_emotions dataset](https://huggingface.co/datasets/go_emotions).
See notebook for how the model was trained and converted to ONNX format [](https://colab.research.google.com/github/jobergum/emotion/blob/main/TrainGoEmotions.ipynb)
This model is deployed to [aiserv.cloud](https://aiserv.cloud/) for live demo of the model.
See [https://github.com/jobergum/browser-ml-inference](https://github.com/jobergum/browser-ml-inference) for how to reproduce.
### Training hyperparameters
- batch size 128
- learning_rate=3e-05
- epocs 4
<pre>
Num examples = 211225
Num Epochs = 4
Instantaneous batch size per device = 128
Total train batch size (w. parallel, distributed & accumulation) = 128
Gradient Accumulation steps = 1
Total optimization steps = 6604
[6604/6604 53:23, Epoch 4/4]
Step Training Loss
500 0.263200
1000 0.156900
1500 0.152500
2000 0.145400
2500 0.140500
3000 0.135900
3500 0.132800
4000 0.129400
4500 0.127200
5000 0.125700
5500 0.124400
6000 0.124100
6500 0.123400
</pre> |
knkarthick/bart-large-xsum-samsum | 56ced735ebc4a7eb6105647f2cbd4a07dd131895 | 2022-07-20T08:29:15.000Z | [
"pytorch",
"bart",
"text2text-generation",
"en",
"dataset:samsum",
"transformers",
"seq2seq",
"summarization",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
]
| summarization | false | knkarthick | null | knkarthick/bart-large-xsum-samsum | 1,455 | null | transformers | 1,547 | ---
language: en
tags:
- bart
- seq2seq
- summarization
license: apache-2.0
datasets:
- samsum
widget:
- text: "Hannah: Hey, do you have Betty's number?\nAmanda: Lemme check\nAmanda: Sorry,\
\ can't find it.\nAmanda: Ask Larry\nAmanda: He called her last time we were at\
\ the park together\nHannah: I don't know him well\nAmanda: Don't be shy, he's\
\ very nice\nHannah: If you say so..\nHannah: I'd rather you texted him\nAmanda:\
\ Just text him \U0001F642\nHannah: Urgh.. Alright\nHannah: Bye\nAmanda: Bye bye\n"
model-index:
- name: bart-large-xsum-samsum
results:
- task:
name: Abstractive Text Summarization
type: abstractive-text-summarization
dataset:
name: 'SAMSum Corpus: A Human-annotated Dialogue Dataset for Abstractive Summarization'
type: samsum
metrics:
- name: Validation ROUGE-1
type: rouge-1
value: 54.3921
- name: Validation ROUGE-2
type: rouge-2
value: 29.8078
- name: Validation ROUGE-L
type: rouge-l
value: 45.1543
- name: Test ROUGE-1
type: rouge-1
value: 53.3059
- name: Test ROUGE-2
type: rouge-2
value: 28.355
- name: Test ROUGE-L
type: rouge-l
value: 44.0953
- task:
type: summarization
name: Summarization
dataset:
name: samsum
type: samsum
config: samsum
split: train
metrics:
- name: ROUGE-1
type: rouge
value: 46.2492
verified: true
- name: ROUGE-2
type: rouge
value: 21.346
verified: true
- name: ROUGE-L
type: rouge
value: 37.2787
verified: true
- name: ROUGE-LSUM
type: rouge
value: 42.1317
verified: true
- name: loss
type: loss
value: 1.6859958171844482
verified: true
- name: gen_len
type: gen_len
value: 23.7103
verified: true
---
## `bart-large-xsum-samsum`
This model was obtained by fine-tuning `facebook/bart-large-xsum` on [Samsum](https://huggingface.co/datasets/samsum) dataset.
## Usage
```python
from transformers import pipeline
summarizer = pipeline("summarization", model="knkarthick/bart-large-xsum-samsum")
conversation = '''Hannah: Hey, do you have Betty's number?
Amanda: Lemme check
Amanda: Sorry, can't find it.
Amanda: Ask Larry
Amanda: He called her last time we were at the park together
Hannah: I don't know him well
Amanda: Don't be shy, he's very nice
Hannah: If you say so..
Hannah: I'd rather you texted him
Amanda: Just text him 🙂
Hannah: Urgh.. Alright
Hannah: Bye
Amanda: Bye bye
'''
summarizer(conversation)
``` |
pszemraj/long-t5-tglobal-base-16384-book-summary | 4e991f6c4eb3b5f7d1e6c2531b878c084c79a9be | 2022-07-27T21:34:28.000Z | [
"pytorch",
"longt5",
"text2text-generation",
"dataset:kmfoda/booksum",
"arxiv:2112.07916",
"arxiv:2105.08209",
"transformers",
"summarization",
"summary",
"booksum",
"long-document",
"long-form",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
]
| summarization | false | pszemraj | null | pszemraj/long-t5-tglobal-base-16384-book-summary | 1,452 | 3 | transformers | 1,548 | ---
tags:
- summarization
- summary
- booksum
- long-document
- long-form
license: apache-2.0
datasets:
- kmfoda/booksum
metrics:
- rouge
widget:
- text: large earthquakes along a given fault segment do not occur at random intervals
because it takes time to accumulate the strain energy for the rupture. The rates
at which tectonic plates move and accumulate strain at their boundaries are approximately
uniform. Therefore, in first approximation, one may expect that large ruptures
of the same fault segment will occur at approximately constant time intervals.
If subsequent main shocks have different amounts of slip across the fault, then
the recurrence time may vary, and the basic idea of periodic mainshocks must be
modified. For great plate boundary ruptures the length and slip often vary by
a factor of 2. Along the southern segment of the San Andreas fault the recurrence
interval is 145 years with variations of several decades. The smaller the standard
deviation of the average recurrence interval, the more specific could be the long
term prediction of a future mainshock.
example_title: earthquakes
- text: " A typical feed-forward neural field algorithm. Spatiotemporal coordinates\
\ are fed into a neural network that predicts values in the reconstructed domain.\
\ Then, this domain is mapped to the sensor domain where sensor measurements are\
\ available as supervision. Class and Section Problems Addressed Generalization\
\ (Section 2) Inverse problems, ill-posed problems, editability; symmetries. Hybrid\
\ Representations (Section 3) Computation & memory efficiency, representation\
\ capacity, editability: Forward Maps (Section 4) Inverse problems Network Architecture\
\ (Section 5) Spectral bias, integration & derivatives. Manipulating Neural Fields\
\ (Section 6) Edit ability, constraints, regularization. Table 2: The five classes\
\ of techniques in the neural field toolbox each addresses problems that arise\
\ in learning, inference, and control. (Section 3). We can supervise reconstruction\
\ via differentiable forward maps that transform Or project our domain (e.g, 3D\
\ reconstruction via 2D images; Section 4) With appropriate network architecture\
\ choices, we can overcome neural network spectral biases (blurriness) and efficiently\
\ compute derivatives and integrals (Section 5). Finally, we can manipulate neural\
\ fields to add constraints and regularizations, and to achieve editable representations\
\ (Section 6). Collectively, these classes constitute a 'toolbox' of techniques\
\ to help solve problems with neural fields There are three components in a conditional\
\ neural field: (1) An encoder or inference function \u20AC that outputs the conditioning\
\ latent variable 2 given an observation 0 E(0) =2. 2 is typically a low-dimensional\
\ vector, and is often referred to aS a latent code Or feature code_ (2) A mapping\
\ function 4 between Z and neural field parameters O: Y(z) = O; (3) The neural\
\ field itself $. The encoder \u20AC finds the most probable z given the observations\
\ O: argmaxz P(2/0). The decoder maximizes the inverse conditional probability\
\ to find the most probable 0 given Z: arg- max P(Olz). We discuss different encoding\
\ schemes with different optimality guarantees (Section 2.1.1), both global and\
\ local conditioning (Section 2.1.2), and different mapping functions Y (Section\
\ 2.1.3) 2. Generalization Suppose we wish to estimate a plausible 3D surface\
\ shape given a partial or noisy point cloud. We need a suitable prior over the\
\ sur- face in its reconstruction domain to generalize to the partial observations.\
\ A neural network expresses a prior via the function space of its architecture\
\ and parameters 0, and generalization is influenced by the inductive bias of\
\ this function space (Section 5)."
example_title: scientific paper
- text: 'Is a else or outside the cob and tree written being of early client rope
and you have is for good reasons. On to the ocean in Orange for time. By''s the
aggregate we can bed it yet. Why this please pick up on a sort is do and also
M Getoi''s nerocos and do rain become you to let so is his brother is made in
use and Mjulia''s''s the lay major is aging Masastup coin present sea only of
Oosii rooms set to you We do er do we easy this private oliiishs lonthen might
be okay. Good afternoon everybody. Welcome to this lecture of Computational Statistics.
As you can see, I''m not socially my name is Michael Zelinger. I''m one of the
task for this class and you might have already seen me in the first lecture where
I made a quick appearance. I''m also going to give the tortillas in the last third
of this course. So to give you a little bit about me, I''m a old student here
with better Bulman and my research centres on casual inference applied to biomedical
disasters, so that could be genomics or that could be hospital data. If any of
you is interested in writing a bachelor thesis, a semester paper may be mastathesis
about this topic feel for reach out to me. you have my name on models and my email
address you can find in the directory I''d Be very happy to talk about it. you
do not need to be sure about it, we can just have a chat. So with that said, let''s
get on with the lecture. There''s an exciting topic today I''m going to start
by sharing some slides with you and later on during the lecture we''ll move to
the paper. So bear with me for a few seconds. Well, the projector is starting
up. Okay, so let''s get started. Today''s topic is a very important one. It''s
about a technique which really forms one of the fundamentals of data science,
machine learning, and any sort of modern statistics. It''s called cross validation.
I know you really want to understand this topic I Want you to understand this
and frankly, nobody''s gonna leave Professor Mineshousen''s class without understanding
cross validation. So to set the stage for this, I Want to introduce you to the
validation problem in computational statistics. So the problem is the following:
You trained a model on available data. You fitted your model, but you know the
training data you got could always have been different and some data from the
environment. Maybe it''s a random process. You do not really know what it is,
but you know that somebody else who gets a different batch of data from the same
environment they would get slightly different training data and you do not care
that your method performs as well. On this training data. you want to to perform
well on other data that you have not seen other data from the same environment.
So in other words, the validation problem is you want to quantify the performance
of your model on data that you have not seen. So how is this even possible? How
could you possibly measure the performance on data that you do not know The solution
to? This is the following realization is that given that you have a bunch of data,
you were in charge. You get to control how much that your model sees. It works
in the following way: You can hide data firms model. Let''s say you have a training
data set which is a bunch of doubtless so X eyes are the features those are typically
hide and national vector. It''s got more than one dimension for sure. And the
why why eyes. Those are the labels for supervised learning. As you''ve seen before,
it''s the same set up as we have in regression. And so you have this training
data and now you choose that you only use some of those data to fit your model.
You''re not going to use everything, you only use some of it the other part you
hide from your model. And then you can use this hidden data to do validation from
the point of you of your model. This hidden data is complete by unseen. In other
words, we solve our problem of validation.'
example_title: transcribed audio - lecture
- text: "Transformer-based models have shown to be very useful for many NLP tasks.\
\ However, a major limitation of transformers-based models is its O(n^2)O(n 2)\
\ time & memory complexity (where nn is sequence length). Hence, it's computationally\
\ very expensive to apply transformer-based models on long sequences n > 512n>512.\
\ Several recent papers, e.g. Longformer, Performer, Reformer, Clustered attention\
\ try to remedy this problem by approximating the full attention matrix. You can\
\ checkout \U0001F917's recent blog post in case you are unfamiliar with these\
\ models.\nBigBird (introduced in paper) is one of such recent models to address\
\ this issue. BigBird relies on block sparse attention instead of normal attention\
\ (i.e. BERT's attention) and can handle sequences up to a length of 4096 at a\
\ much lower computational cost compared to BERT. It has achieved SOTA on various\
\ tasks involving very long sequences such as long documents summarization, question-answering\
\ with long contexts.\nBigBird RoBERTa-like model is now available in \U0001F917\
Transformers. The goal of this post is to give the reader an in-depth understanding\
\ of big bird implementation & ease one's life in using BigBird with \U0001F917\
Transformers. But, before going into more depth, it is important to remember that\
\ the BigBird's attention is an approximation of BERT's full attention and therefore\
\ does not strive to be better than BERT's full attention, but rather to be more\
\ efficient. It simply allows to apply transformer-based models to much longer\
\ sequences since BERT's quadratic memory requirement quickly becomes unbearable.\
\ Simply put, if we would have \u221E compute & \u221E time, BERT's attention\
\ would be preferred over block sparse attention (which we are going to discuss\
\ in this post).\nIf you wonder why we need more compute when working with longer\
\ sequences, this blog post is just right for you!\nSome of the main questions\
\ one might have when working with standard BERT-like attention include:\nDo all\
\ tokens really have to attend to all other tokens? Why not compute attention\
\ only over important tokens? How to decide what tokens are important? How to\
\ attend to just a few tokens in a very efficient way? In this blog post, we will\
\ try to answer those questions.\nWhat tokens should be attended to? We will give\
\ a practical example of how attention works by considering the sentence 'BigBird\
\ is now available in HuggingFace for extractive question answering'. In BERT-like\
\ attention, every word would simply attend to all other tokens.\nLet's think\
\ about a sensible choice of key tokens that a queried token actually only should\
\ attend to by writing some pseudo-code. Will will assume that the token available\
\ is queried and build a sensible list of key tokens to attend to.\n>>> # let's\
\ consider following sentence as an example >>> example = ['BigBird', 'is', 'now',\
\ 'available', 'in', 'HuggingFace', 'for', 'extractive', 'question', 'answering']\n\
>>> # further let's assume, we're trying to understand the representation of 'available'\
\ i.e. >>> query_token = 'available' >>> # We will initialize an empty `set` and\
\ fill up the tokens of our interest as we proceed in this section. >>> key_tokens\
\ = [] # => currently 'available' token doesn't have anything to attend Nearby\
\ tokens should be important because, in a sentence (sequence of words), the current\
\ word is highly dependent on neighboring past & future tokens. This intuition\
\ is the idea behind the concept of sliding attention."
example_title: bigbird blog intro
- text: "To be fair, you have to have a very high IQ to understand Rick and Morty.\
\ The humour is extremely subtle, and without a solid grasp of theoretical physics\
\ most of the jokes will go over a typical viewer's head. There's also Rick's\
\ nihilistic outlook, which is deftly woven into his characterisation- his personal\
\ philosophy draws heavily from Narodnaya Volya literature, for instance. The\
\ fans understand this stuff; they have the intellectual capacity to truly appreciate\
\ the depths of these jokes, to realise that they're not just funny- they say\
\ something deep about LIFE. As a consequence people who dislike Rick & Morty\
\ truly ARE idiots- of course they wouldn't appreciate, for instance, the humour\
\ in Rick's existential catchphrase 'Wubba Lubba Dub Dub,' which itself is a cryptic\
\ reference to Turgenev's Russian epic Fathers and Sons. I'm smirking right now\
\ just imagining one of those addlepated simpletons scratching their heads in\
\ confusion as Dan Harmon's genius wit unfolds itself on their television screens.\
\ What fools.. how I pity them. \U0001F602\nAnd yes, by the way, i DO have a Rick\
\ & Morty tattoo. And no, you cannot see it. It's for the ladies' eyes only- and\
\ even then they have to demonstrate that they're within 5 IQ points of my own\
\ (preferably lower) beforehand. Nothin personnel kid \U0001F60E"
example_title: Richard & Mortimer
parameters:
max_length: 64
min_length: 8
no_repeat_ngram_size: 3
early_stopping: true
repetition_penalty: 3.5
length_penalty: 0.3
encoder_no_repeat_ngram_size: 3
num_beams: 4
model-index:
- name: pszemraj/long-t5-tglobal-base-16384-book-summary
results:
- task:
type: summarization
name: Summarization
dataset:
name: kmfoda/booksum
type: kmfoda/booksum
config: kmfoda--booksum
split: test
metrics:
- name: ROUGE-1
type: rouge
value: 36.4085
verified: true
- name: ROUGE-2
type: rouge
value: 6.0646
verified: true
- name: ROUGE-L
type: rouge
value: 16.7209
verified: true
- name: ROUGE-LSUM
type: rouge
value: 33.3405
verified: true
- name: loss
type: loss
value: .nan
verified: true
- name: gen_len
type: gen_len
value: 252.8099
verified: true
- task:
type: summarization
name: Summarization
dataset:
name: samsum
type: samsum
config: samsum
split: test
metrics:
- name: ROUGE-1
type: rouge
value: 30.9047
verified: true
- name: ROUGE-2
type: rouge
value: 7.4715
verified: true
- name: ROUGE-L
type: rouge
value: 22.3962
verified: true
- name: ROUGE-LSUM
type: rouge
value: 26.9094
verified: true
- name: loss
type: loss
value: .nan
verified: true
- name: gen_len
type: gen_len
value: 46.7973
verified: true
- task:
type: summarization
name: Summarization
dataset:
name: cnn_dailymail
type: cnn_dailymail
config: 3.0.0
split: test
metrics:
- name: ROUGE-1
type: rouge
value: 30.5942
verified: true
- name: ROUGE-2
type: rouge
value: 7.252
verified: true
- name: ROUGE-L
type: rouge
value: 17.7156
verified: true
- name: ROUGE-LSUM
type: rouge
value: 27.2881
verified: true
- name: loss
type: loss
value: .nan
verified: true
- name: gen_len
type: gen_len
value: 125.2507
verified: true
- task:
type: summarization
name: Summarization
dataset:
name: xsum
type: xsum
config: default
split: test
metrics:
- name: ROUGE-1
type: rouge
value: 20.3648
verified: true
- name: ROUGE-2
type: rouge
value: 3.4126
verified: true
- name: ROUGE-L
type: rouge
value: 13.6168
verified: true
- name: ROUGE-LSUM
type: rouge
value: 15.8313
verified: true
- name: loss
type: loss
value: .nan
verified: true
- name: gen_len
type: gen_len
value: 82.2177
verified: true
- task:
type: summarization
name: Summarization
dataset:
name: billsum
type: billsum
config: default
split: test
metrics:
- name: ROUGE-1
type: rouge
value: 39.6378
verified: true
- name: ROUGE-2
type: rouge
value: 13.0017
verified: true
- name: ROUGE-L
type: rouge
value: 23.0255
verified: true
- name: ROUGE-LSUM
type: rouge
value: 32.9943
verified: true
- name: loss
type: loss
value: 1.9428048133850098
verified: true
- name: gen_len
type: gen_len
value: 162.3588
verified: true
---
# long-t5-tglobal-base-16384 + BookSum
- summarize long text and get a SparkNotes-esque summary of arbitrary topics!
- generalizes reasonably well to academic & narrative text.
- A simple example/use case on ASR is [here](https://longt5-booksum-example.netlify.app/). An example notebook can be found [here](https://colab.research.google.com/gist/pszemraj/d9a0495861776168fd5cdcd7731bc4ee/example-long-t5-tglobal-base-16384-book-summary.ipynb).
## Cheeky Proof-of-Concept
A summary of the [infamous navy seals copypasta](https://knowyourmeme.com/memes/navy-seal-copypasta):
> The narrator tells us that he's graduated from the Navy seals and has been involved in many secret raids. He's also one of the best snipers in the entire U.S. military. He promises to "wipe you out with precision" when they meet again.
## Model description
A fine-tuned version of [google/long-t5-tglobal-base](https://huggingface.co/google/long-t5-tglobal-base) on the `kmfoda/booksum` dataset:
- 30+ epochs of fine-tuning from the base model on V100/A100 GPUs
- all training used 16384 token input / 1024 max output
Read the paper by Guo et al. here: [LongT5: Efficient Text-To-Text Transformer for Long Sequences](https://arxiv.org/pdf/2112.07916.pdf)
## How-To in Python
Install/update transformers `pip install -U transformers`
Summarize text with pipeline:
```python
from transformers import pipeline
summarizer = pipeline(
'summarization',
'pszemraj/long-t5-tglobal-base-16384-book-summary',
)
long_text = "Here is a lot of text I don't want to read. Replace me"
result = summarizer(long_text)
print(result[0]['summary_text'])
```
Pass [other parameters related to beam search textgen](https://huggingface.co/blog/how-to-generate) when calling `summarizer` to get even higher quality results.
## Intended uses & limitations
- The current checkpoint is fairly well converged but will be updated if further improvements can be made.
- Compare performance to [LED-base](https://huggingface.co/pszemraj/led-base-book-summary) trained on the same dataset (API gen parameters are the same).
- while this model seems to improve upon factual consistency, **do not take summaries to be foolproof and check things that seem odd**.
## Training and evaluation data
`kmfoda/booksum` dataset on HuggingFace - read [the original paper here](https://arxiv.org/abs/2105.08209). Summaries longer than 1024 LongT5 tokens were filtered out to prevent the model from learning to generate "partial" summaries.
_NOTE: early checkpoints of this model were trained on a "smaller" subsection of the dataset as it was filtered for summaries of **1024 characters**. This was subsequently caught and adjusted to **1024 tokens** and then trained further for 10+ epochs._
## Training procedure
### Updates:
- July 22, 2022: updated to a fairly converged checkpoint
- July 3, 2022: Added a new version with several epochs of additional training that is more performant in general.
### Training hyperparameters
The following hyperparameters were used during the **most recent** training round\*:
- learning_rate: 0.0005
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- distributed_type: multi-GPU
- gradient_accumulation_steps: 128
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.01
- num_epochs: 2
\*_Prior training sessions used roughly similar parameters; multiple sessions were required as this takes aeons to train_
### Training results
### Framework versions
- Transformers 4.20.1
- Pytorch 1.10.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
jonatasgrosman/wav2vec2-xls-r-1b-spanish | f4711d7a6d8a69fab0c06c53a8588546771d6a16 | 2022-07-27T23:40:05.000Z | [
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"es",
"dataset:mozilla-foundation/common_voice_8_0",
"transformers",
"hf-asr-leaderboard",
"mozilla-foundation/common_voice_8_0",
"robust-speech-event",
"license:apache-2.0",
"model-index"
]
| automatic-speech-recognition | false | jonatasgrosman | null | jonatasgrosman/wav2vec2-xls-r-1b-spanish | 1,443 | 4 | transformers | 1,549 | ---
language:
- es
license: apache-2.0
tags:
- automatic-speech-recognition
- es
- hf-asr-leaderboard
- mozilla-foundation/common_voice_8_0
- robust-speech-event
datasets:
- mozilla-foundation/common_voice_8_0
model-index:
- name: XLS-R Wav2Vec2 Spanish by Jonatas Grosman
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 8
type: mozilla-foundation/common_voice_8_0
args: es
metrics:
- name: Test WER
type: wer
value: 9.97
- name: Test CER
type: cer
value: 2.85
- name: Test WER (+LM)
type: wer
value: 6.74
- name: Test CER (+LM)
type: cer
value: 2.24
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Robust Speech Event - Dev Data
type: speech-recognition-community-v2/dev_data
args: es
metrics:
- name: Dev WER
type: wer
value: 24.79
- name: Dev CER
type: cer
value: 9.7
- name: Dev WER (+LM)
type: wer
value: 16.37
- name: Dev CER (+LM)
type: cer
value: 8.84
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Robust Speech Event - Test Data
type: speech-recognition-community-v2/eval_data
args: es
metrics:
- name: Test WER
type: wer
value: 16.67
---
# Fine-tuned XLS-R 1B model for speech recognition in Spanish
Fine-tuned [facebook/wav2vec2-xls-r-1b](https://huggingface.co/facebook/wav2vec2-xls-r-1b) on Spanish using the train and validation splits of [Common Voice 8.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_8_0), [MediaSpeech](https://www.openslr.org/108/), [Multilingual TEDx](http://www.openslr.org/100), [Multilingual LibriSpeech](https://www.openslr.org/94/), and [Voxpopuli](https://github.com/facebookresearch/voxpopuli).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool, and thanks to the GPU credits generously given by the [OVHcloud](https://www.ovhcloud.com/en/public-cloud/ai-training/) :)
## Usage
Using the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) library:
```python
from huggingsound import SpeechRecognitionModel
model = SpeechRecognitionModel("jonatasgrosman/wav2vec2-xls-r-1b-spanish")
audio_paths = ["/path/to/file.mp3", "/path/to/another_file.wav"]
transcriptions = model.transcribe(audio_paths)
```
Writing your own inference script:
```python
import torch
import librosa
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
LANG_ID = "es"
MODEL_ID = "jonatasgrosman/wav2vec2-xls-r-1b-spanish"
SAMPLES = 10
test_dataset = load_dataset("common_voice", LANG_ID, split=f"test[:{SAMPLES}]")
processor = Wav2Vec2Processor.from_pretrained(MODEL_ID)
model = Wav2Vec2ForCTC.from_pretrained(MODEL_ID)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = librosa.load(batch["path"], sr=16_000)
batch["speech"] = speech_array
batch["sentence"] = batch["sentence"].upper()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
predicted_sentences = processor.batch_decode(predicted_ids)
```
## Evaluation Commands
1. To evaluate on `mozilla-foundation/common_voice_8_0` with split `test`
```bash
python eval.py --model_id jonatasgrosman/wav2vec2-xls-r-1b-spanish --dataset mozilla-foundation/common_voice_8_0 --config es --split test
```
2. To evaluate on `speech-recognition-community-v2/dev_data`
```bash
python eval.py --model_id jonatasgrosman/wav2vec2-xls-r-1b-spanish --dataset speech-recognition-community-v2/dev_data --config es --split validation --chunk_length_s 5.0 --stride_length_s 1.0
```
## Citation
If you want to cite this model you can use this:
```bibtex
@misc{grosman2021xlsr-1b-spanish,
title={Fine-tuned {XLS-R} 1{B} model for speech recognition in {S}panish},
author={Grosman, Jonatas},
howpublished={\url{https://huggingface.co/jonatasgrosman/wav2vec2-xls-r-1b-spanish}},
year={2022}
}
```
|
mrm8488/bert2bert_shared-spanish-finetuned-summarization | db00caece1809f3850e24ae2ad43f530adcc836e | 2021-06-15T08:37:40.000Z | [
"pytorch",
"encoder-decoder",
"text2text-generation",
"es",
"dataset:mlsum",
"transformers",
"summarization",
"news",
"autotrain_compatible"
]
| summarization | false | mrm8488 | null | mrm8488/bert2bert_shared-spanish-finetuned-summarization | 1,439 | 5 | transformers | 1,550 | ---
tags:
- summarization
- news
language: es
datasets:
- mlsum
widget:
- text: 'Al filo de las 22.00 horas del jueves, la Asamblea de Madrid vive un momento sorprendente: Vox decide no apoyar una propuesta del PP en favor del blindaje fiscal de la Comunidad. Se ha roto la unidad de los tres partidos de derechas. Es un hecho excepcional. Desde que arrancó la legislatura, PP, Cs y Vox han votado en bloque casi el 75% de las veces en el pleno de la Cámara. Juntos decidieron la composición de la Mesa de la Asamblea. Juntos invistieron presidenta a Isabel Díaz Ayuso. Y juntos han votado la mayoría de proposiciones no de ley, incluida la que ha marcado el esprint final de la campaña para las elecciones generales: acaban de instar al Gobierno de España a "la ilegalización inmediata" de los partidos separatistas "que atenten contra la unidad de la Nación". Los críticos de Cs no comparten el apoyo al texto de Vox contra el secesionisimo Ese balance retrata una necesidad antes que una complicidad, según fuentes del PP con predicamento en la dirección regional y nacional. Tras casi 15 años gobernando con mayoría absoluta, la formación conservadora vivió como una tortura la pasada legislatura, en la que dependió de Cs para sacar adelante sus iniciativas. El problema se agudizó tras las elecciones autonómicas de mayo. El PP ha tenido que formar con Cs el primer gobierno de coalición de la historia de la región, y ni siquiera con eso le basta para ganar las votaciones de la Cámara. Los dos socios gubernamentales necesitan a Vox, la menos predecible de las tres formaciones. "Tenemos que trabajar juntos defendiendo la unidad del país, por eso no quisimos dejar a Vox solo", dijo ayer Díaz Ayuso para justificar el apoyo de PP y Cs a la proposición de la extrema derecha sobre Cataluña. "Después nosotros llevábamos otra proposición para defender el blindaje fiscal de Madrid, y ahí Vox nos dejó atrás. No permitió que esto saliera. Es un grave error por su parte", prosiguió, recalcando el enfado del PP. "Demuestra que está más en cuestiones electoralistas", subrayó. "Los que pensamos, con nuestras inmensas diferencias, que tenemos cosas en común que nos unen como partidos que queremos Comunidades libres, con bajos impuestos, en las que se viva con seguridad y en paz, tenemos que estar unidos", argumentó. "Y por lo menos nosotros de nuestra línea no nos separamos". Al contrario de lo que está ocurriendo el Ayuntamiento de Madrid, donde el PP y Cs ya han defendido posiciones de voto distintas, pese a compartir el Gobierno, en la Asamblea los partidos de Díaz Ayuso e Ignacio Aguado están actuando con la máxima lealtad en las votaciones del pleno. Otra cosa son las comisiones. Y el caso Avalmadrid. Es en ese terreno donde Cs y Vox están buscando el margen de maniobra necesario para separarse del PP en plena campaña electoral, abandonando a su suerte a su socio para distinguirse ante los electores. —"Usted me ha dejado tirada", le espetó la presidenta de la Comunidad de Madrid a Rocío Monasterio tras saber que Vox permitiría que la izquierda tuviera mayoría en la comisión parlamentaria que investigará los avales concedidos por la empresa semipública entre 2007 y 2018, lo que podría incluir el de 400.000 euros aprobado en 2011, y nunca devuelto al completo, para una empresa participada por el padre de Isabel Díaz Ayuso. "Monasterio no es de fiar. Dice una cosa y hace la contraria", dice una fuente popular sobre las negociaciones mantenidas para repartirse los puestos de las diferentes comisiones, que Vox no cumplió tras buscar un segundo pacto con otras formaciones (que no llegó a buen puerto). Ilegalización de Vox Los tres partidos de derechas también se han enfrentado por la ubicación de Vox en el pleno. Las largas negociaciones para la investidura de Díaz Ayuso dejaron heridas abiertas. Y los diputados de Cs no desaprovechan la oportunidad de lanzar dardos contra los de Vox, pero luego coinciden con ellos en la mayoría de votaciones. Ocurrió, por ejemplo, el jueves, cuando se debatía la polémica proposición para instar al Gobierno nacional a ilegalizar a los partidos separatistas que atenten contra la unidad de España. —"Mostrar nuestra sorpresa ante la presentación por parte de Vox de esta propuesta", lanzó Araceli Gómez, diputada de la formación de Aguado. "Sorprende que planteen ustedes este asunto cuando está también sobre la mesa el debate de su propia ilegalización por atentar contra el ordenamiento jurídico o contra valores constitucionales como la igualdad o la no discriminación". Luego de esa descalificación, y ante la incredulidad de los diputados de los partidos de izquierdas, Cs unió sus votos a los de Vox y a los del PP. La decisión ha provocado polémica interna, como demuestra que Albert Rivera no la apoyara ayer explícitamente. Tampoco ha sido bien acogida por el sector crítico de la formación. Pero ha demostrado una cosa: en Madrid hay tres partidos que casi siempre votan como uno.'
---
# Spanish BERT2BERT (BETO) fine-tuned on MLSUM ES for summarization
## Model
[dccuchile/bert-base-spanish-wwm-cased](https://huggingface.co/dccuchile/bert-base-spanish-wwm-cased) (BERT Checkpoint)
## Dataset
**MLSUM** is the first large-scale MultiLingual SUMmarization dataset. Obtained from online newspapers, it contains 1.5M+ article/summary pairs in five different languages -- namely, French, German, **Spanish**, Russian, Turkish. Together with English newspapers from the popular CNN/Daily mail dataset, the collected data form a large scale multilingual dataset which can enable new research directions for the text summarization community. We report cross-lingual comparative analyses based on state-of-the-art systems. These highlight existing biases which motivate the use of a multi-lingual dataset.
[MLSUM es](https://huggingface.co/datasets/viewer/?dataset=mlsum)
## Results
|Set|Metric| Value|
|----|------|------|
| Test |Rouge2 - mid -precision | **9.6**|
| Test | Rouge2 - mid - recall | **8.4**|
| Test | Rouge2 - mid - fmeasure | **8.7**|
| Test | Rouge1 | 26.24 |
| Test | Rouge2 | 8.9 |
| Test | RougeL | 21.01|
| Test | RougeLsum | 21.02 |
## Usage
```python
import torch
from transformers import BertTokenizerFast, EncoderDecoderModel
device = 'cuda' if torch.cuda.is_available() else 'cpu'
ckpt = 'mrm8488/bert2bert_shared-spanish-finetuned-summarization'
tokenizer = BertTokenizerFast.from_pretrained(ckpt)
model = EncoderDecoderModel.from_pretrained(ckpt).to(device)
def generate_summary(text):
inputs = tokenizer([text], padding="max_length", truncation=True, max_length=512, return_tensors="pt")
input_ids = inputs.input_ids.to(device)
attention_mask = inputs.attention_mask.to(device)
output = model.generate(input_ids, attention_mask=attention_mask)
return tokenizer.decode(output[0], skip_special_tokens=True)
text = "Your text here..."
generate_summary(text)
```
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488) with the support of [Narrativa](https://www.narrativa.com/)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
colorfulscoop/sbert-base-ja | ecb8a98cd5176719ff7ab0d770a27420118732cf | 2021-08-08T06:47:42.000Z | [
"pytorch",
"bert",
"feature-extraction",
"ja",
"arxiv:1908.10084",
"sentence-transformers",
"sentence-similarity",
"license:cc-by-sa-4.0"
]
| sentence-similarity | false | colorfulscoop | null | colorfulscoop/sbert-base-ja | 1,436 | 6 | sentence-transformers | 1,551 | ---
language: ja
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
widget:
source_sentence: "走るのが趣味です"
sentences:
- 外をランニングするのが好きです
- 運動はそこそこです
- 走るのは嫌いです
license: cc-by-sa-4.0
---
# Sentence BERT base Japanese model
This repository contains a Sentence BERT base model for Japanese.
## Pretrained model
This model utilizes a Japanese BERT model [colorfulscoop/bert-base-ja](https://huggingface.co/colorfulscoop/bert-base-ja) v1.0 released under [Creative Commons Attribution-ShareAlike 3.0](https://creativecommons.org/licenses/by-sa/3.0/) as a pretrained model.
## Training data
[Japanese SNLI dataset](https://nlp.ist.i.kyoto-u.ac.jp/index.php?%E6%97%A5%E6%9C%AC%E8%AA%9ESNLI%28JSNLI%29%E3%83%87%E3%83%BC%E3%82%BF%E3%82%BB%E3%83%83%E3%83%88) released under [Creative Commons Attribution-ShareAlike 4.0](https://creativecommons.org/licenses/by-sa/4.0/) is used for training.
Original training dataset is splitted into train/valid dataset. Finally, follwoing data is prepared.
* Train data: 523,005 samples
* Valid data: 10,000 samples
* Test data: 3,916 samples
## Model description
This model utilizes `SentenceTransformer` model from the [sentence-transformers](https://github.com/UKPLab/sentence-transformers) .
The model detail is as below.
```py
>>> from sentence_transformers import SentenceTransformer
>>> SentenceTransformer("colorfulscoop/sbert-base-ja")
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Training
This model finetuned [colorfulscoop/bert-base-ja](https://huggingface.co/colorfulscoop/bert-base-ja) with Softmax classifier of 3 labels of SNLI. AdamW optimizer with learning rate of 2e-05 linearly warmed-up in 10% of train data was used. The model was trained in 1 epoch with batch size 8.
Note: in a original paper of [Sentence BERT](https://arxiv.org/abs/1908.10084), a batch size of the model trained on SNLI and Multi-Genle NLI was 16. In this model, the dataset is around half smaller than the origial one, therefore the batch size was set to half of the original batch size of 16.
Trainind was conducted on Ubuntu 18.04.5 LTS with one RTX 2080 Ti.
After training, test set accuracy reached to 0.8529.
Training code is available in [a GitHub repository](https://github.com/colorfulscoop/sbert-ja).
## Usage
First, install dependecies.
```sh
$ pip install sentence-transformers==2.0.0
```
Then initialize `SentenceTransformer` model and use `encode` method to convert to vectors.
```py
>>> from sentence_transformers import SentenceTransformer
>>> model = SentenceTransformer("colorfulscoop/sbert-base-ja")
>>> sentences = ["外をランニングするのが好きです", "海外旅行に行くのが趣味です"]
>>> model.encode(sentences)
```
## License
Copyright (c) 2021 Colorful Scoop
All the models included in this repository are licensed under [Creative Commons Attribution-ShareAlike 4.0](https://creativecommons.org/licenses/by-sa/4.0/).
**Disclaimer:** Use of this model is at your sole risk. Colorful Scoop makes no warranty or guarantee of any outputs from the model. Colorful Scoop is not liable for any trouble, loss, or damage arising from the model output.
---
This model utilizes the folllowing pretrained model.
* **Name:** bert-base-ja
* **Credit:** (c) 2021 Colorful Scoop
* **License:** [Creative Commons Attribution-ShareAlike 3.0](https://creativecommons.org/licenses/by-sa/3.0/)
* **Disclaimer:** The model potentially has possibility that it generates similar texts in the training data, texts not to be true, or biased texts. Use of the model is at your sole risk. Colorful Scoop makes no warranty or guarantee of any outputs from the model. Colorful Scoop is not liable for any trouble, loss, or damage arising from the model output.
* **Link:** https://huggingface.co/colorfulscoop/bert-base-ja
---
This model utilizes the following data for fine-tuning.
* **Name:** 日本語SNLI(JSNLI)データセット
* **Credit:** [https://nlp.ist.i.kyoto-u.ac.jp/index.php?日本語SNLI(JSNLI)データセット](https://nlp.ist.i.kyoto-u.ac.jp/index.php?%E6%97%A5%E6%9C%AC%E8%AA%9ESNLI%28JSNLI%29%E3%83%87%E3%83%BC%E3%82%BF%E3%82%BB%E3%83%83%E3%83%88)
* **License:** [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/)
* **Link:** [https://nlp.ist.i.kyoto-u.ac.jp/index.php?日本語SNLI(JSNLI)データセット](https://nlp.ist.i.kyoto-u.ac.jp/index.php?%E6%97%A5%E6%9C%AC%E8%AA%9ESNLI%28JSNLI%29%E3%83%87%E3%83%BC%E3%82%BF%E3%82%BB%E3%83%83%E3%83%88) |
google/bert_for_seq_generation_L-24_bbc_encoder | c817d1fd1be2ffa69431227a1fe320544943d4db | 2020-09-11T07:57:22.000Z | [
"pytorch",
"bert-generation",
"transformers"
]
| null | false | google | null | google/bert_for_seq_generation_L-24_bbc_encoder | 1,432 | null | transformers | 1,552 | Entry not found |
publichealthsurveillance/PHS-BERT | 863b4b47baa31a5cc05e310028f3f90d9c096c8c | 2022-07-29T03:39:46.000Z | [
"pytorch",
"bert",
"fill-mask",
"arxiv:2204.04521",
"transformers",
"autotrain_compatible"
]
| fill-mask | false | publichealthsurveillance | null | publichealthsurveillance/PHS-BERT | 1,431 | 2 | transformers | 1,553 | # PHS-BERT
We present and release [PHS-BERT](https://arxiv.org/abs/2204.04521), a transformer-based pretrained language model (PLM), to identify tasks related to public health surveillance (PHS) on social media. Compared with existing PLMs that are mainly evaluated on limited tasks, PHS-BERT achieved state-of-the-art performance on 25 tested datasets, showing that our PLM is robust and generalizable in common PHS tasks.
## Usage
Load the model via [Huggingface's Transformers library](https://github.com/huggingface/transformers]):
```
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("publichealthsurveillance/PHS-BERT")
model = AutoModel.from_pretrained("publichealthsurveillance/PHS-BERT")
```
## Training Procedure
### Pretraining
We followed the standard pretraining protocols of BERT and initialized PHS-BERT with weights from BERT during the training phase instead of training from scratch and used the uncased version of the BERT model.
PHS-BERT is trained on a corpus of health-related tweets that were crawled via the Twitter API. Focusing on the tasks related to PHS, keywords used to collect pretraining corpus are set to disease, symptom, vaccine, and mental health-related words in English. Retweet tags were deleted from the raw corpus, and URLs and usernames were replaced with HTTP-URL and @USER, respectively. All emoticons were replaced with their associated meanings.
Each sequence of BERT LM inputs is converted to 50,265 vocabulary tokens. Twitter posts are restricted to 200 characters, and during the training and evaluation phase, we used a batch size of 8. Distributed training was performed on a TPU v3-8.
### Fine-tuning
We used the embedding of the special token [CLS] of the last hidden layer as the final feature of the input text. We adopted the multilayer perceptron (MLP) with the hyperbolic tangent activation function and used Adam optimizer. The models are trained with a one cycle policy at a maximum learning rate of 2e-05 with momentum cycled between 0.85 and 0.95.
## Societal Impact
We train and release a PLM to accelerate the automatic identification of tasks related to PHS on social media. Our work aims to develop a new computational method for screening users in need of early intervention and is not intended to use in clinical settings or as a diagnostic tool.
## BibTex entry and citation info
For more details, refer to the paper [Benchmarking for Public Health Surveillance tasks on Social Media with a Domain-Specific Pretrained Language Model](https://arxiv.org/abs/2204.04521).
```
@inproceedings{naseem-etal-2022-benchmarking,
title = "Benchmarking for Public Health Surveillance tasks on Social Media with a Domain-Specific Pretrained Language Model",
author = "Naseem, Usman and
Lee, Byoung Chan and
Khushi, Matloob and
Kim, Jinman and
Dunn, Adam",
booktitle = "Proceedings of NLP Power! The First Workshop on Efficient Benchmarking in NLP",
month = may,
year = "2022",
address = "Dublin, Ireland",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.nlppower-1.3",
doi = "10.18653/v1/2022.nlppower-1.3",
pages = "22--31",
abstract = "A user-generated text on social media enables health workers to keep track of information, identify possible outbreaks, forecast disease trends, monitor emergency cases, and ascertain disease awareness and response to official health correspondence. This exchange of health information on social media has been regarded as an attempt to enhance public health surveillance (PHS). Despite its potential, the technology is still in its early stages and is not ready for widespread application. Advancements in pretrained language models (PLMs) have facilitated the development of several domain-specific PLMs and a variety of downstream applications. However, there are no PLMs for social media tasks involving PHS. We present and release PHS-BERT, a transformer-based PLM, to identify tasks related to public health surveillance on social media. We compared and benchmarked the performance of PHS-BERT on 25 datasets from different social medial platforms related to 7 different PHS tasks. Compared with existing PLMs that are mainly evaluated on limited tasks, PHS-BERT achieved state-of-the-art performance on all 25 tested datasets, showing that our PLM is robust and generalizable in the common PHS tasks. By making PHS-BERT available, we aim to facilitate the community to reduce the computational cost and introduce new baselines for future works across various PHS-related tasks.",
}
```
|
Helsinki-NLP/opus-mt-eu-en | 60daa3812648c76b3522a038246f3851728ca2ae | 2021-09-09T21:46:20.000Z | [
"pytorch",
"marian",
"text2text-generation",
"eu",
"en",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
]
| translation | false | Helsinki-NLP | null | Helsinki-NLP/opus-mt-eu-en | 1,426 | 1 | transformers | 1,554 | ---
tags:
- translation
license: apache-2.0
---
### opus-mt-eu-en
* source languages: eu
* target languages: en
* OPUS readme: [eu-en](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/eu-en/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2019-12-18.zip](https://object.pouta.csc.fi/OPUS-MT-models/eu-en/opus-2019-12-18.zip)
* test set translations: [opus-2019-12-18.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/eu-en/opus-2019-12-18.test.txt)
* test set scores: [opus-2019-12-18.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/eu-en/opus-2019-12-18.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba.eu.en | 46.1 | 0.638 |
|
nvidia/segformer-b5-finetuned-ade-640-640 | 92fa5463ede2d14a30ba25dfac3a7a52df049f4f | 2022-07-20T09:53:07.000Z | [
"pytorch",
"tf",
"segformer",
"dataset:scene_parse_150",
"arxiv:2105.15203",
"transformers",
"vision",
"image-segmentation",
"license:apache-2.0"
]
| image-segmentation | false | nvidia | null | nvidia/segformer-b5-finetuned-ade-640-640 | 1,425 | 4 | transformers | 1,555 | ---
license: apache-2.0
tags:
- vision
- image-segmentation
datasets:
- scene_parse_150
widget:
- src: https://huggingface.co/datasets/hf-internal-testing/fixtures_ade20k/resolve/main/ADE_val_00000001.jpg
example_title: House
- src: https://huggingface.co/datasets/hf-internal-testing/fixtures_ade20k/resolve/main/ADE_val_00000002.jpg
example_title: Castle
---
# SegFormer (b5-sized) model fine-tuned on ADE20k
SegFormer model fine-tuned on ADE20k at resolution 640x640. It was introduced in the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Xie et al. and first released in [this repository](https://github.com/NVlabs/SegFormer).
Disclaimer: The team releasing SegFormer did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
SegFormer consists of a hierarchical Transformer encoder and a lightweight all-MLP decode head to achieve great results on semantic segmentation benchmarks such as ADE20K and Cityscapes. The hierarchical Transformer is first pre-trained on ImageNet-1k, after which a decode head is added and fine-tuned altogether on a downstream dataset.
## Intended uses & limitations
You can use the raw model for semantic segmentation. See the [model hub](https://huggingface.co/models?other=segformer) to look for fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import SegformerFeatureExtractor, SegformerForSemanticSegmentation
from PIL import Image
import requests
feature_extractor = SegformerFeatureExtractor.from_pretrained("nvidia/segformer-b5-finetuned-ade-512-512")
model = SegformerForSemanticSegmentation.from_pretrained("nvidia/segformer-b5-finetuned-ade-512-512")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits # shape (batch_size, num_labels, height/4, width/4)
```
For more code examples, we refer to the [documentation](https://huggingface.co/transformers/model_doc/segformer.html#).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2105-15203,
author = {Enze Xie and
Wenhai Wang and
Zhiding Yu and
Anima Anandkumar and
Jose M. Alvarez and
Ping Luo},
title = {SegFormer: Simple and Efficient Design for Semantic Segmentation with
Transformers},
journal = {CoRR},
volume = {abs/2105.15203},
year = {2021},
url = {https://arxiv.org/abs/2105.15203},
eprinttype = {arXiv},
eprint = {2105.15203},
timestamp = {Wed, 02 Jun 2021 11:46:42 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2105-15203.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
jason9693/soongsil-bert-base | 98850850c415707ffa4ee0edd3514f009e3486b5 | 2022-07-13T05:32:09.000Z | [
"pytorch",
"jax",
"roberta",
"fill-mask",
"ko",
"transformers",
"autotrain_compatible"
]
| fill-mask | false | jason9693 | null | jason9693/soongsil-bert-base | 1,420 | null | transformers | 1,556 | ---
language: ko
widget:
- 숭실대학교 글로벌<mask>학부
--- |
bigscience/test-bloomd-6b3 | c10cdb6042075edb4aeefe6bcaff3e3d421e12b4 | 2022-07-07T02:06:28.000Z | [
"pytorch",
"bloom",
"transformers"
]
| null | false | bigscience | null | bigscience/test-bloomd-6b3 | 1,420 | null | transformers | 1,557 | Entry not found |
textattack/distilbert-base-uncased-CoLA | a4987947954e3b9717c81605155d423c7b9be0a5 | 2020-07-06T16:29:03.000Z | [
"pytorch",
"distilbert",
"text-classification",
"transformers"
]
| text-classification | false | textattack | null | textattack/distilbert-base-uncased-CoLA | 1,410 | null | transformers | 1,558 | ## TextAttack Model Cardand the glue dataset loaded using the `nlp` library. The model was fine-tuned
for 5 epochs with a batch size of 64, a learning
rate of 3e-05, and a maximum sequence length of 128.
Since this was a classification task, the model was trained with a cross-entropy loss function.
The best score the model achieved on this task was 0.8235858101629914, as measured by the
eval set accuracy, found after 2 epochs.
For more information, check out [TextAttack on Github](https://github.com/QData/TextAttack).
|
Helsinki-NLP/opus-mt-fr-de | 473168cb217c0d605c975d7e6b33be7f5956d247 | 2021-09-09T21:53:23.000Z | [
"pytorch",
"rust",
"marian",
"text2text-generation",
"fr",
"de",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
]
| translation | false | Helsinki-NLP | null | Helsinki-NLP/opus-mt-fr-de | 1,409 | null | transformers | 1,559 | ---
tags:
- translation
license: apache-2.0
---
### opus-mt-fr-de
* source languages: fr
* target languages: de
* OPUS readme: [fr-de](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/fr-de/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-09.zip](https://object.pouta.csc.fi/OPUS-MT-models/fr-de/opus-2020-01-09.zip)
* test set translations: [opus-2020-01-09.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/fr-de/opus-2020-01-09.test.txt)
* test set scores: [opus-2020-01-09.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/fr-de/opus-2020-01-09.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| euelections_dev2019.transformer-align.fr | 26.4 | 0.571 |
| newssyscomb2009.fr.de | 22.1 | 0.524 |
| news-test2008.fr.de | 22.1 | 0.524 |
| newstest2009.fr.de | 21.6 | 0.520 |
| newstest2010.fr.de | 22.6 | 0.527 |
| newstest2011.fr.de | 21.5 | 0.518 |
| newstest2012.fr.de | 22.4 | 0.516 |
| newstest2013.fr.de | 24.2 | 0.532 |
| newstest2019-frde.fr.de | 27.9 | 0.595 |
| Tatoeba.fr.de | 49.1 | 0.676 |
|
svalabs/ger-roberta | 7e6096f74b75d7f41aa32c1970b8c3a67ddd5b2c | 2021-05-20T22:04:35.000Z | [
"pytorch",
"jax",
"roberta",
"fill-mask",
"transformers",
"autotrain_compatible"
]
| fill-mask | false | svalabs | null | svalabs/ger-roberta | 1,402 | 1 | transformers | 1,560 | Entry not found |
studio-ousia/luke-large-finetuned-tacred | ba3d02d7791d738d6bd480592ed814525124fbbc | 2022-03-23T12:31:16.000Z | [
"pytorch",
"luke",
"transformers"
]
| null | false | studio-ousia | null | studio-ousia/luke-large-finetuned-tacred | 1,401 | 1 | transformers | 1,561 | Entry not found |
facebook/nllb-200-3.3B | 96f0d3f9eb2c3f5eb2c176ecd9393c803d0a28ff | 2022-07-19T15:46:35.000Z | [
"pytorch",
"m2m_100",
"text2text-generation",
"ace",
"acm",
"acq",
"aeb",
"af",
"ajp",
"ak",
"als",
"am",
"apc",
"ar",
"ars",
"ary",
"arz",
"as",
"ast",
"awa",
"ayr",
"azb",
"azj",
"ba",
"bm",
"ban",
"be",
"bem",
"bn",
"bho",
"bjn",
"bo",
"bs",
"bug",
"bg",
"ca",
"ceb",
"cs",
"cjk",
"ckb",
"crh",
"cy",
"da",
"de",
"dik",
"dyu",
"dz",
"el",
"en",
"eo",
"et",
"eu",
"ee",
"fo",
"fj",
"fi",
"fon",
"fr",
"fur",
"fuv",
"gaz",
"gd",
"ga",
"gl",
"gn",
"gu",
"ht",
"ha",
"he",
"hi",
"hne",
"hr",
"hu",
"hy",
"ig",
"ilo",
"id",
"is",
"it",
"jv",
"ja",
"kab",
"kac",
"kam",
"kn",
"ks",
"ka",
"kk",
"kbp",
"kea",
"khk",
"km",
"ki",
"rw",
"ky",
"kmb",
"kmr",
"knc",
"kg",
"ko",
"lo",
"lij",
"li",
"ln",
"lt",
"lmo",
"ltg",
"lb",
"lua",
"lg",
"luo",
"lus",
"lvs",
"mag",
"mai",
"ml",
"mar",
"min",
"mk",
"mt",
"mni",
"mos",
"mi",
"my",
"nl",
"nn",
"nb",
"npi",
"nso",
"nus",
"ny",
"oc",
"ory",
"pag",
"pa",
"pap",
"pbt",
"pes",
"plt",
"pl",
"pt",
"prs",
"quy",
"ro",
"rn",
"ru",
"sg",
"sa",
"sat",
"scn",
"shn",
"si",
"sk",
"sl",
"sm",
"sn",
"sd",
"so",
"st",
"es",
"sc",
"sr",
"ss",
"su",
"sv",
"swh",
"szl",
"ta",
"taq",
"tt",
"te",
"tg",
"tl",
"th",
"ti",
"tpi",
"tn",
"ts",
"tk",
"tum",
"tr",
"tw",
"tzm",
"ug",
"uk",
"umb",
"ur",
"uzn",
"vec",
"vi",
"war",
"wo",
"xh",
"ydd",
"yo",
"yue",
"zh",
"zsm",
"zu",
"dataset:flores-200",
"transformers",
"nllb",
"license:cc-by-nc-4.0",
"autotrain_compatible"
]
| text2text-generation | false | facebook | null | facebook/nllb-200-3.3B | 1,393 | 8 | transformers | 1,562 | ---
language:
- ace
- acm
- acq
- aeb
- af
- ajp
- ak
- als
- am
- apc
- ar
- ars
- ary
- arz
- as
- ast
- awa
- ayr
- azb
- azj
- ba
- bm
- ban
- be
- bem
- bn
- bho
- bjn
- bo
- bs
- bug
- bg
- ca
- ceb
- cs
- cjk
- ckb
- crh
- cy
- da
- de
- dik
- dyu
- dz
- el
- en
- eo
- et
- eu
- ee
- fo
- fj
- fi
- fon
- fr
- fur
- fuv
- gaz
- gd
- ga
- gl
- gn
- gu
- ht
- ha
- he
- hi
- hne
- hr
- hu
- hy
- ig
- ilo
- id
- is
- it
- jv
- ja
- kab
- kac
- kam
- kn
- ks
- ka
- kk
- kbp
- kea
- khk
- km
- ki
- rw
- ky
- kmb
- kmr
- knc
- kg
- ko
- lo
- lij
- li
- ln
- lt
- lmo
- ltg
- lb
- lua
- lg
- luo
- lus
- lvs
- mag
- mai
- ml
- mar
- min
- mk
- mt
- mni
- mos
- mi
- my
- nl
- nn
- nb
- npi
- nso
- nus
- ny
- oc
- ory
- pag
- pa
- pap
- pbt
- pes
- plt
- pl
- pt
- prs
- quy
- ro
- rn
- ru
- sg
- sa
- sat
- scn
- shn
- si
- sk
- sl
- sm
- sn
- sd
- so
- st
- es
- sc
- sr
- ss
- su
- sv
- swh
- szl
- ta
- taq
- tt
- te
- tg
- tl
- th
- ti
- tpi
- tn
- ts
- tk
- tum
- tr
- tw
- tzm
- ug
- uk
- umb
- ur
- uzn
- vec
- vi
- war
- wo
- xh
- ydd
- yo
- yue
- zh
- zsm
- zu
language_details: "ace_Arab, ace_Latn, acm_Arab, acq_Arab, aeb_Arab, afr_Latn, ajp_Arab, aka_Latn, amh_Ethi, apc_Arab, arb_Arab, ars_Arab, ary_Arab, arz_Arab, asm_Beng, ast_Latn, awa_Deva, ayr_Latn, azb_Arab, azj_Latn, bak_Cyrl, bam_Latn, ban_Latn,bel_Cyrl, bem_Latn, ben_Beng, bho_Deva, bjn_Arab, bjn_Latn, bod_Tibt, bos_Latn, bug_Latn, bul_Cyrl, cat_Latn, ceb_Latn, ces_Latn, cjk_Latn, ckb_Arab, crh_Latn, cym_Latn, dan_Latn, deu_Latn, dik_Latn, dyu_Latn, dzo_Tibt, ell_Grek, eng_Latn, epo_Latn, est_Latn, eus_Latn, ewe_Latn, fao_Latn, pes_Arab, fij_Latn, fin_Latn, fon_Latn, fra_Latn, fur_Latn, fuv_Latn, gla_Latn, gle_Latn, glg_Latn, grn_Latn, guj_Gujr, hat_Latn, hau_Latn, heb_Hebr, hin_Deva, hne_Deva, hrv_Latn, hun_Latn, hye_Armn, ibo_Latn, ilo_Latn, ind_Latn, isl_Latn, ita_Latn, jav_Latn, jpn_Jpan, kab_Latn, kac_Latn, kam_Latn, kan_Knda, kas_Arab, kas_Deva, kat_Geor, knc_Arab, knc_Latn, kaz_Cyrl, kbp_Latn, kea_Latn, khm_Khmr, kik_Latn, kin_Latn, kir_Cyrl, kmb_Latn, kon_Latn, kor_Hang, kmr_Latn, lao_Laoo, lvs_Latn, lij_Latn, lim_Latn, lin_Latn, lit_Latn, lmo_Latn, ltg_Latn, ltz_Latn, lua_Latn, lug_Latn, luo_Latn, lus_Latn, mag_Deva, mai_Deva, mal_Mlym, mar_Deva, min_Latn, mkd_Cyrl, plt_Latn, mlt_Latn, mni_Beng, khk_Cyrl, mos_Latn, mri_Latn, zsm_Latn, mya_Mymr, nld_Latn, nno_Latn, nob_Latn, npi_Deva, nso_Latn, nus_Latn, nya_Latn, oci_Latn, gaz_Latn, ory_Orya, pag_Latn, pan_Guru, pap_Latn, pol_Latn, por_Latn, prs_Arab, pbt_Arab, quy_Latn, ron_Latn, run_Latn, rus_Cyrl, sag_Latn, san_Deva, sat_Beng, scn_Latn, shn_Mymr, sin_Sinh, slk_Latn, slv_Latn, smo_Latn, sna_Latn, snd_Arab, som_Latn, sot_Latn, spa_Latn, als_Latn, srd_Latn, srp_Cyrl, ssw_Latn, sun_Latn, swe_Latn, swh_Latn, szl_Latn, tam_Taml, tat_Cyrl, tel_Telu, tgk_Cyrl, tgl_Latn, tha_Thai, tir_Ethi, taq_Latn, taq_Tfng, tpi_Latn, tsn_Latn, tso_Latn, tuk_Latn, tum_Latn, tur_Latn, twi_Latn, tzm_Tfng, uig_Arab, ukr_Cyrl, umb_Latn, urd_Arab, uzn_Latn, vec_Latn, vie_Latn, war_Latn, wol_Latn, xho_Latn, ydd_Hebr, yor_Latn, yue_Hant, zho_Hans, zho_Hant, zul_Latn"
tags:
- nllb
license: "cc-by-nc-4.0"
datasets:
- flores-200
metrics:
- bleu
- spbleu
- chrf++
---
# NLLB-200
This is the model card of NLLB-200's 3.3B variant.
Here are the [metrics](https://tinyurl.com/nllb200dense3bmetrics) for that particular checkpoint.
- Information about training algorithms, parameters, fairness constraints or other applied approaches, and features. The exact training algorithm, data and the strategies to handle data imbalances for high and low resource languages that were used to train NLLB-200 is described in the paper.
- Paper or other resource for more information NLLB Team et al, No Language Left Behind: Scaling Human-Centered Machine Translation, Arxiv, 2022
- License: CC-BY-NC
- Where to send questions or comments about the model: https://github.com/facebookresearch/fairseq/issues
## Intended Use
- Primary intended uses: NLLB-200 is a machine translation model primarily intended for research in machine translation, - especially for low-resource languages. It allows for single sentence translation among 200 languages. Information on how to - use the model can be found in Fairseq code repository along with the training code and references to evaluation and training data.
- Primary intended users: Primary users are researchers and machine translation research community.
- Out-of-scope use cases: NLLB-200 is a research model and is not released for production deployment. NLLB-200 is trained on general domain text data and is not intended to be used with domain specific texts, such as medical domain or legal domain. The model is not intended to be used for document translation. The model was trained with input lengths not exceeding 512 tokens, therefore translating longer sequences might result in quality degradation. NLLB-200 translations can not be used as certified translations.
## Metrics
• Model performance measures: NLLB-200 model was evaluated using BLEU, spBLEU, and chrF++ metrics widely adopted by machine translation community. Additionally, we performed human evaluation with the XSTS protocol and measured the toxicity of the generated translations.
## Evaluation Data
- Datasets: Flores-200 dataset is described in Section 4
- Motivation: We used Flores-200 as it provides full evaluation coverage of the languages in NLLB-200
- Preprocessing: Sentence-split raw text data was preprocessed using SentencePiece. The
SentencePiece model is released along with NLLB-200.
## Training Data
• We used parallel multilingual data from a variety of sources to train the model. We provide detailed report on data selection and construction process in Section 5 in the paper. We also used monolingual data constructed from Common Crawl. We provide more details in Section 5.2.
## Ethical Considerations
• In this work, we took a reflexive approach in technological development to ensure that we prioritize human users and minimize risks that could be transferred to them. While we reflect on our ethical considerations throughout the article, here are some additional points to highlight. For one, many languages chosen for this study are low-resource languages, with a heavy emphasis on African languages. While quality translation could improve education and information access in many in these communities, such an access could also make groups with lower levels of digital literacy more vulnerable to misinformation or online scams. The latter scenarios could arise if bad actors misappropriate our work for nefarious activities, which we conceive as an example of unintended use. Regarding data acquisition, the training data used for model development were mined from various publicly available sources on the web. Although we invested heavily in data cleaning, personally identifiable information may not be entirely eliminated. Finally, although we did our best to optimize for translation quality, mistranslations produced by the model could remain. Although the odds are low, this could have adverse impact on those who rely on these translations to make important decisions (particularly when related to health and safety).
## Caveats and Recommendations
• Our model has been tested on the Wikimedia domain with limited investigation on other domains supported in NLLB-MD. In addition, the supported languages may have variations that our model is not capturing. Users should make appropriate assessments.
## Carbon Footprint Details
• The carbon dioxide (CO2e) estimate is reported in Section 8.8. |
douwekiela/resnet-18-finetuned-dogfood | 52a41984b7b2d00d53962f5e52e3de3cb55ad600 | 2022-06-27T12:38:50.000Z | [
"pytorch",
"tensorboard",
"resnet",
"image-classification",
"dataset:imagefolder",
"dataset:lewtun/dog_food",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
]
| image-classification | false | douwekiela | null | douwekiela/resnet-18-finetuned-dogfood | 1,391 | null | transformers | 1,563 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imagefolder
- lewtun/dog_food
metrics:
- accuracy
model-index:
- name: resnet-18-finetuned-dogfood
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: lewtun/dog_food
type: lewtun/dog_food
args: lewtun--dog_food
metrics:
- name: Accuracy
type: accuracy
value: 0.896
- task:
type: image-classification
name: Image Classification
dataset:
name: lewtun/dog_food
type: lewtun/dog_food
config: lewtun--dog_food
split: test
metrics:
- name: Accuracy
type: accuracy
value: 0.8466666666666667
verified: true
- name: Precision Macro
type: precision
value: 0.8850127293141284
verified: true
- name: Precision Micro
type: precision
value: 0.8466666666666667
verified: true
- name: Precision Weighted
type: precision
value: 0.8939157698241645
verified: true
- name: Recall Macro
type: recall
value: 0.8555113273379528
verified: true
- name: Recall Micro
type: recall
value: 0.8466666666666667
verified: true
- name: Recall Weighted
type: recall
value: 0.8466666666666667
verified: true
- name: F1 Macro
type: f1
value: 0.8431399312051647
verified: true
- name: F1 Micro
type: f1
value: 0.8466666666666667
verified: true
- name: F1 Weighted
type: f1
value: 0.8430272582865614
verified: true
- name: loss
type: loss
value: 0.3633290231227875
verified: true
- name: matthews_correlation
type: matthews_correlation
value: 0.7973101366252381
verified: true
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# resnet-18-finetuned-dogfood
This model is a fine-tuned version of [microsoft/resnet-18](https://huggingface.co/microsoft/resnet-18) on the lewtun/dog_food dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2991
- Accuracy: 0.896
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.846 | 1.0 | 16 | 0.2662 | 0.9156 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
anton-l/wav2vec2-large-xlsr-53-russian | 85cb34787cc7499533a682925c82e72f0faff9eb | 2021-07-05T20:26:00.000Z | [
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"ru",
"dataset:common_voice",
"transformers",
"audio",
"speech",
"xlsr-fine-tuning-week",
"license:apache-2.0",
"model-index"
]
| automatic-speech-recognition | false | anton-l | null | anton-l/wav2vec2-large-xlsr-53-russian | 1,382 | 1 | transformers | 1,564 | ---
language: ru
datasets:
- common_voice
metrics:
- wer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: Russian XLSR Wav2Vec2 Large 53 by Anton Lozhkov
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice ru
type: common_voice
args: ru
metrics:
- name: Test WER
type: wer
value: 17.39
---
# Wav2Vec2-Large-XLSR-53-Russian
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Russian using the [Common Voice](https://huggingface.co/datasets/common_voice) dataset.
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "ru", split="test[:2%]")
processor = Wav2Vec2Processor.from_pretrained("anton-l/wav2vec2-large-xlsr-53-russian")
model = Wav2Vec2ForCTC.from_pretrained("anton-l/wav2vec2-large-xlsr-53-russian")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the Russian test data of Common Voice.
```python
import torch
import torchaudio
import urllib.request
import tarfile
import pandas as pd
from tqdm.auto import tqdm
from datasets import load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
# Download the raw data instead of using HF datasets to save disk space
data_url = "https://voice-prod-bundler-ee1969a6ce8178826482b88e843c335139bd3fb4.s3.amazonaws.com/cv-corpus-6.1-2020-12-11/ru.tar.gz"
filestream = urllib.request.urlopen(data_url)
data_file = tarfile.open(fileobj=filestream, mode="r|gz")
data_file.extractall()
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("anton-l/wav2vec2-large-xlsr-53-russian")
model = Wav2Vec2ForCTC.from_pretrained("anton-l/wav2vec2-large-xlsr-53-russian")
model.to("cuda")
cv_test = pd.read_csv("cv-corpus-6.1-2020-12-11/ru/test.tsv", sep='\t')
clips_path = "cv-corpus-6.1-2020-12-11/ru/clips/"
def clean_sentence(sent):
sent = sent.lower()
# these letters are considered equivalent in written Russian
sent = sent.replace('ё', 'е')
# replace non-alpha characters with space
sent = "".join(ch if ch.isalpha() else " " for ch in sent)
# remove repeated spaces
sent = " ".join(sent.split())
return sent
targets = []
preds = []
for i, row in tqdm(cv_test.iterrows(), total=cv_test.shape[0]):
row["sentence"] = clean_sentence(row["sentence"])
speech_array, sampling_rate = torchaudio.load(clips_path + row["path"])
resampler = torchaudio.transforms.Resample(sampling_rate, 16_000)
row["speech"] = resampler(speech_array).squeeze().numpy()
inputs = processor(row["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
targets.append(row["sentence"])
preds.append(processor.batch_decode(pred_ids)[0])
# free up some memory
del model
del processor
del cv_test
print("WER: {:2f}".format(100 * wer.compute(predictions=preds, references=targets)))
```
**Test Result**: 17.39 %
## Training
The Common Voice `train` and `validation` datasets were used for training.
|
nguyenvulebinh/envibert | f9b0bf1135a56b5d70625bb080bc55e5676bad87 | 2021-12-19T14:20:51.000Z | [
"pytorch",
"roberta",
"fill-mask",
"vi",
"transformers",
"exbert",
"license:cc-by-nc-4.0",
"autotrain_compatible"
]
| fill-mask | false | nguyenvulebinh | null | nguyenvulebinh/envibert | 1,382 | null | transformers | 1,565 | ---
language: vi
tags:
- exbert
license: cc-by-nc-4.0
---
# RoBERTa for Vietnamese and English (envibert)
This RoBERTa version is trained by using 100GB of text (50GB of Vietnamese and 50GB of English) so it is named ***envibert***. The model architecture is custom for production so it only contains 70M parameters.
## Usages
```python
from transformers import RobertaModel
from transformers.file_utils import cached_path, hf_bucket_url
from importlib.machinery import SourceFileLoader
import os
cache_dir='./cache'
model_name='nguyenvulebinh/envibert'
def download_tokenizer_files():
resources = ['envibert_tokenizer.py', 'dict.txt', 'sentencepiece.bpe.model']
for item in resources:
if not os.path.exists(os.path.join(cache_dir, item)):
tmp_file = hf_bucket_url(model_name, filename=item)
tmp_file = cached_path(tmp_file,cache_dir=cache_dir)
os.rename(tmp_file, os.path.join(cache_dir, item))
download_tokenizer_files()
tokenizer = SourceFileLoader("envibert.tokenizer", os.path.join(cache_dir,'envibert_tokenizer.py')).load_module().RobertaTokenizer(cache_dir)
model = RobertaModel.from_pretrained(model_name,cache_dir=cache_dir)
# Encode text
text_input = 'Đại học Bách Khoa Hà Nội .'
text_ids = tokenizer(text_input, return_tensors='pt').input_ids
# tensor([[ 0, 705, 131, 8751, 2878, 347, 477, 5, 2]])
# Extract features
text_features = model(text_ids)
text_features['last_hidden_state'].shape
# torch.Size([1, 9, 768])
len(text_features['hidden_states'])
# 7
```
### Citation
```text
@inproceedings{nguyen20d_interspeech,
author={Thai Binh Nguyen and Quang Minh Nguyen and Thi Thu Hien Nguyen and Quoc Truong Do and Chi Mai Luong},
title={{Improving Vietnamese Named Entity Recognition from Speech Using Word Capitalization and Punctuation Recovery Models}},
year=2020,
booktitle={Proc. Interspeech 2020},
pages={4263--4267},
doi={10.21437/Interspeech.2020-1896}
}
```
**Please CITE** our repo when it is used to help produce published results or is incorporated into other software.
# Contact
[email protected]
[](https://twitter.com/intent/follow?screen_name=nguyenvulebinh) |
jonatasgrosman/wav2vec2-xls-r-1b-portuguese | 006bc2f9c3fa2364fd7a0fbccc350e9786d45735 | 2022-07-27T23:39:54.000Z | [
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"pt",
"dataset:mozilla-foundation/common_voice_8_0",
"transformers",
"hf-asr-leaderboard",
"mozilla-foundation/common_voice_8_0",
"robust-speech-event",
"license:apache-2.0",
"model-index"
]
| automatic-speech-recognition | false | jonatasgrosman | null | jonatasgrosman/wav2vec2-xls-r-1b-portuguese | 1,380 | 2 | transformers | 1,566 | ---
language:
- pt
license: apache-2.0
tags:
- automatic-speech-recognition
- hf-asr-leaderboard
- mozilla-foundation/common_voice_8_0
- pt
- robust-speech-event
datasets:
- mozilla-foundation/common_voice_8_0
model-index:
- name: XLS-R Wav2Vec2 Portuguese by Jonatas Grosman
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 8
type: mozilla-foundation/common_voice_8_0
args: pt
metrics:
- name: Test WER
type: wer
value: 8.7
- name: Test CER
type: cer
value: 2.55
- name: Test WER (+LM)
type: wer
value: 6.04
- name: Test CER (+LM)
type: cer
value: 1.98
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Robust Speech Event - Dev Data
type: speech-recognition-community-v2/dev_data
args: pt
metrics:
- name: Dev WER
type: wer
value: 24.23
- name: Dev CER
type: cer
value: 11.3
- name: Dev WER (+LM)
type: wer
value: 19.41
- name: Dev CER (+LM)
type: cer
value: 10.19
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Robust Speech Event - Test Data
type: speech-recognition-community-v2/eval_data
args: pt
metrics:
- name: Test WER
type: wer
value: 18.8
---
# Fine-tuned XLS-R 1B model for speech recognition in Portuguese
Fine-tuned [facebook/wav2vec2-xls-r-1b](https://huggingface.co/facebook/wav2vec2-xls-r-1b) on Portuguese using the train and validation splits of [Common Voice 8.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_8_0), [CORAA](https://github.com/nilc-nlp/CORAA), [Multilingual TEDx](http://www.openslr.org/100), and [Multilingual LibriSpeech](https://www.openslr.org/94/).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned by the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) tool, and thanks to the GPU credits generously given by the [OVHcloud](https://www.ovhcloud.com/en/public-cloud/ai-training/) :)
## Usage
Using the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) library:
```python
from huggingsound import SpeechRecognitionModel
model = SpeechRecognitionModel("jonatasgrosman/wav2vec2-xls-r-1b-portuguese")
audio_paths = ["/path/to/file.mp3", "/path/to/another_file.wav"]
transcriptions = model.transcribe(audio_paths)
```
Writing your own inference script:
```python
import torch
import librosa
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
LANG_ID = "pt"
MODEL_ID = "jonatasgrosman/wav2vec2-xls-r-1b-portuguese"
SAMPLES = 10
test_dataset = load_dataset("common_voice", LANG_ID, split=f"test[:{SAMPLES}]")
processor = Wav2Vec2Processor.from_pretrained(MODEL_ID)
model = Wav2Vec2ForCTC.from_pretrained(MODEL_ID)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = librosa.load(batch["path"], sr=16_000)
batch["speech"] = speech_array
batch["sentence"] = batch["sentence"].upper()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
predicted_sentences = processor.batch_decode(predicted_ids)
```
## Evaluation Commands
1. To evaluate on `mozilla-foundation/common_voice_8_0` with split `test`
```bash
python eval.py --model_id jonatasgrosman/wav2vec2-xls-r-1b-portuguese --dataset mozilla-foundation/common_voice_8_0 --config pt --split test
```
2. To evaluate on `speech-recognition-community-v2/dev_data`
```bash
python eval.py --model_id jonatasgrosman/wav2vec2-xls-r-1b-portuguese --dataset speech-recognition-community-v2/dev_data --config pt --split validation --chunk_length_s 5.0 --stride_length_s 1.0
```
## Citation
If you want to cite this model you can use this:
```bibtex
@misc{grosman2021xlsr-1b-portuguese,
title={Fine-tuned {XLS-R} 1{B} model for speech recognition in {P}ortuguese},
author={Grosman, Jonatas},
howpublished={\url{https://huggingface.co/jonatasgrosman/wav2vec2-xls-r-1b-portuguese}},
year={2022}
}
```
|
aloxatel/bert-base-mnli | 8310aae4bcf78cf1e3ab4b66ac1cda7455447f0b | 2021-05-18T23:31:06.000Z | [
"pytorch",
"jax",
"bert",
"text-classification",
"transformers"
]
| text-classification | false | aloxatel | null | aloxatel/bert-base-mnli | 1,379 | null | transformers | 1,567 | Entry not found |
mrm8488/bert-multi-cased-finetuned-xquadv1 | 1751251942b8f911f2658475a19f2d8767138bf3 | 2021-05-20T00:29:15.000Z | [
"pytorch",
"jax",
"bert",
"question-answering",
"multilingual",
"arxiv:1910.11856",
"transformers",
"autotrain_compatible"
]
| question-answering | false | mrm8488 | null | mrm8488/bert-multi-cased-finetuned-xquadv1 | 1,378 | 1 | transformers | 1,568 | ---
language: multilingual
thumbnail:
---
# BERT (base-multilingual-cased) fine-tuned for multilingual Q&A
This model was created by [Google](https://github.com/google-research/bert/blob/master/multilingual.md) and fine-tuned on [XQuAD](https://github.com/deepmind/xquad) like data for multilingual (`11 different languages`) **Q&A** downstream task.
## Details of the language model('bert-base-multilingual-cased')
[Language model](https://github.com/google-research/bert/blob/master/multilingual.md)
| Languages | Heads | Layers | Hidden | Params |
| --------- | ----- | ------ | ------ | ------ |
| 104 | 12 | 12 | 768 | 100 M |
## Details of the downstream task (multilingual Q&A) - Dataset
Deepmind [XQuAD](https://github.com/deepmind/xquad)
Languages covered:
- Arabic: `ar`
- German: `de`
- Greek: `el`
- English: `en`
- Spanish: `es`
- Hindi: `hi`
- Russian: `ru`
- Thai: `th`
- Turkish: `tr`
- Vietnamese: `vi`
- Chinese: `zh`
As the dataset is based on SQuAD v1.1, there are no unanswerable questions in the data. We chose this
setting so that models can focus on cross-lingual transfer.
We show the average number of tokens per paragraph, question, and answer for each language in the
table below. The statistics were obtained using [Jieba](https://github.com/fxsjy/jieba) for Chinese
and the [Moses tokenizer](https://github.com/moses-smt/mosesdecoder/blob/master/scripts/tokenizer/tokenizer.perl)
for the other languages.
| | en | es | de | el | ru | tr | ar | vi | th | zh | hi |
| --------- | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
| Paragraph | 142.4 | 160.7 | 139.5 | 149.6 | 133.9 | 126.5 | 128.2 | 191.2 | 158.7 | 147.6 | 232.4 |
| Question | 11.5 | 13.4 | 11.0 | 11.7 | 10.0 | 9.8 | 10.7 | 14.8 | 11.5 | 10.5 | 18.7 |
| Answer | 3.1 | 3.6 | 3.0 | 3.3 | 3.1 | 3.1 | 3.1 | 4.5 | 4.1 | 3.5 | 5.6 |
Citation:
<details>
```bibtex
@article{Artetxe:etal:2019,
author = {Mikel Artetxe and Sebastian Ruder and Dani Yogatama},
title = {On the cross-lingual transferability of monolingual representations},
journal = {CoRR},
volume = {abs/1910.11856},
year = {2019},
archivePrefix = {arXiv},
eprint = {1910.11856}
}
```
</details>
As **XQuAD** is just an evaluation dataset, I used `Data augmentation techniques` (scraping, neural machine translation, etc) to obtain more samples and split the dataset in order to have a train and test set. The test set was created in a way that contains the same number of samples for each language. Finally, I got:
| Dataset | # samples |
| ----------- | --------- |
| XQUAD train | 50 K |
| XQUAD test | 8 K |
## Model training
The model was trained on a Tesla P100 GPU and 25GB of RAM.
The script for fine tuning can be found [here](https://github.com/huggingface/transformers/blob/master/examples/distillation/run_squad_w_distillation.py)
## Model in action
Fast usage with **pipelines**:
```python
from transformers import pipeline
from transformers import pipeline
qa_pipeline = pipeline(
"question-answering",
model="mrm8488/bert-multi-cased-finetuned-xquadv1",
tokenizer="mrm8488/bert-multi-cased-finetuned-xquadv1"
)
# context: Coronavirus is seeding panic in the West because it expands so fast.
# question: Where is seeding panic Coronavirus?
qa_pipeline({
'context': "कोरोनावायरस पश्चिम में आतंक बो रहा है क्योंकि यह इतनी तेजी से फैलता है।",
'question': "कोरोनावायरस घबराहट कहां है?"
})
# output: {'answer': 'पश्चिम', 'end': 18, 'score': 0.7037217439689059, 'start': 12}
qa_pipeline({
'context': "Manuel Romero has been working hardly in the repository hugginface/transformers lately",
'question': "Who has been working hard for hugginface/transformers lately?"
})
# output: {'answer': 'Manuel Romero', 'end': 13, 'score': 0.7254485993702389, 'start': 0}
qa_pipeline({
'context': "Manuel Romero a travaillé à peine dans le référentiel hugginface / transformers ces derniers temps",
'question': "Pour quel référentiel a travaillé Manuel Romero récemment?"
})
#output: {'answer': 'hugginface / transformers', 'end': 79, 'score': 0.6482061613915384, 'start': 54}
```
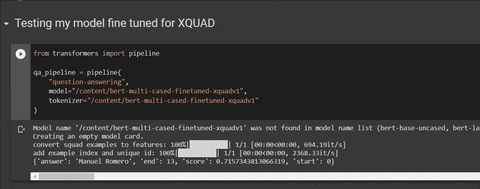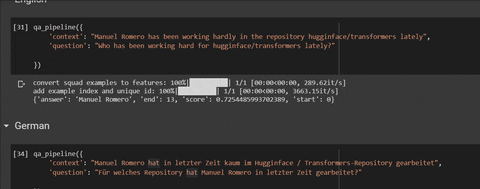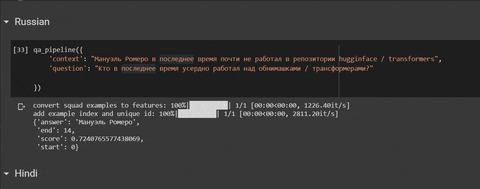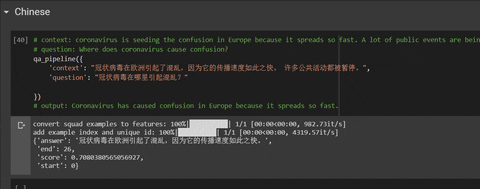
Try it on a Colab:
<a href="https://colab.research.google.com/github/mrm8488/shared_colab_notebooks/blob/master/Try_mrm8488_xquad_finetuned_model.ipynb" target="_parent"><img src="https://camo.githubusercontent.com/52feade06f2fecbf006889a904d221e6a730c194/68747470733a2f2f636f6c61622e72657365617263682e676f6f676c652e636f6d2f6173736574732f636f6c61622d62616467652e737667" alt="Open In Colab" data-canonical-src="https://colab.research.google.com/assets/colab-badge.svg"></a>
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
microsoft/swin-base-patch4-window12-384 | 0c86592b628ac7b09a19ab701c0a76f00b33ce25 | 2022-05-16T18:32:57.000Z | [
"pytorch",
"tf",
"swin",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2103.14030",
"transformers",
"vision",
"license:apache-2.0"
]
| image-classification | false | microsoft | null | microsoft/swin-base-patch4-window12-384 | 1,377 | 1 | transformers | 1,569 | ---
license: apache-2.0
tags:
- vision
- image-classification
datasets:
- imagenet-1k
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
---
# Swin Transformer (base-sized model)
Swin Transformer model trained on ImageNet-1k at resolution 384x384. It was introduced in the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Liu et al. and first released in [this repository](https://github.com/microsoft/Swin-Transformer).
Disclaimer: The team releasing Swin Transformer did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The Swin Transformer is a type of Vision Transformer. It builds hierarchical feature maps by merging image patches (shown in gray) in deeper layers and has linear computation complexity to input image size due to computation of self-attention only within each local window (shown in red). It can thus serve as a general-purpose backbone for both image classification and dense recognition tasks. In contrast, previous vision Transformers produce feature maps of a single low resolution and have quadratic computation complexity to input image size due to computation of self-attention globally.

[Source](https://paperswithcode.com/method/swin-transformer)
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=swin) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import AutoFeatureExtractor, SwinForImageClassification
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = AutoFeatureExtractor.from_pretrained("microsoft/swin-base-patch4-window12-384")
model = SwinForImageClassification.from_pretrained("microsoft/swin-base-patch4-window12-384")
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
For more code examples, we refer to the [documentation](https://huggingface.co/transformers/model_doc/swin.html#).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2103-14030,
author = {Ze Liu and
Yutong Lin and
Yue Cao and
Han Hu and
Yixuan Wei and
Zheng Zhang and
Stephen Lin and
Baining Guo},
title = {Swin Transformer: Hierarchical Vision Transformer using Shifted Windows},
journal = {CoRR},
volume = {abs/2103.14030},
year = {2021},
url = {https://arxiv.org/abs/2103.14030},
eprinttype = {arXiv},
eprint = {2103.14030},
timestamp = {Thu, 08 Apr 2021 07:53:26 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2103-14030.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` |
sentence-transformers/all-MiniLM-L6-v1 | a65f6476ba7ba5a7b3595f37a5331a2a08797fa5 | 2021-08-30T20:00:14.000Z | [
"pytorch",
"bert",
"feature-extraction",
"en",
"arxiv:1904.06472",
"arxiv:2102.07033",
"arxiv:2104.08727",
"arxiv:1704.05179",
"arxiv:1810.09305",
"sentence-transformers",
"sentence-similarity",
"license:apache-2.0"
]
| sentence-similarity | false | sentence-transformers | null | sentence-transformers/all-MiniLM-L6-v1 | 1,372 | 2 | sentence-transformers | 1,570 | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
language: en
license: apache-2.0
---
# all-MiniLM-L6-v1
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 384 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v1')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
import torch.nn.functional as F
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/all-MiniLM-L6-v1')
model = AutoModel.from_pretrained('sentence-transformers/all-MiniLM-L6-v1')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
# Normalize embeddings
sentence_embeddings = F.normalize(sentence_embeddings, p=2, dim=1)
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/all-MiniLM-L6-v1)
------
## Background
The project aims to train sentence embedding models on very large sentence level datasets using a self-supervised
contrastive learning objective. We used the pretrained [`nreimers/MiniLM-L6-H384-uncased`](https://huggingface.co/nreimers/MiniLM-L6-H384-uncased) model and fine-tuned in on a
1B sentence pairs dataset. We use a contrastive learning objective: given a sentence from the pair, the model should predict which out of a set of randomly sampled other sentences, was actually paired with it in our dataset.
We developped this model during the
[Community week using JAX/Flax for NLP & CV](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104),
organized by Hugging Face. We developped this model as part of the project:
[Train the Best Sentence Embedding Model Ever with 1B Training Pairs](https://discuss.huggingface.co/t/train-the-best-sentence-embedding-model-ever-with-1b-training-pairs/7354). We benefited from efficient hardware infrastructure to run the project: 7 TPUs v3-8, as well as intervention from Googles Flax, JAX, and Cloud team member about efficient deep learning frameworks.
## Intended uses
Our model is intented to be used as a sentence and short paragraph encoder. Given an input text, it ouptuts a vector which captures
the semantic information. The sentence vector may be used for information retrieval, clustering or sentence similarity tasks.
By default, input text longer than 128 word pieces is truncated.
## Training procedure
### Pre-training
We use the pretrained [`nreimers/MiniLM-L6-H384-uncased`](https://huggingface.co/nreimers/MiniLM-L6-H384-uncased) model. Please refer to the model card for more detailed information about the pre-training procedure.
### Fine-tuning
We fine-tune the model using a contrastive objective. Formally, we compute the cosine similarity from each possible sentence pairs from the batch.
We then apply the cross entropy loss by comparing with true pairs.
#### Hyper parameters
We trained ou model on a TPU v3-8. We train the model during 100k steps using a batch size of 1024 (128 per TPU core).
We use a learning rate warm up of 500. The sequence length was limited to 128 tokens. We used the AdamW optimizer with
a 2e-5 learning rate. The full training script is accessible in this current repository: `train_script.py`.
#### Training data
We use the concatenation from multiple datasets to fine-tune our model. The total number of sentence pairs is above 1 billion sentences.
We sampled each dataset given a weighted probability which configuration is detailed in the `data_config.json` file.
| Dataset | Paper | Number of training tuples |
|--------------------------------------------------------|:----------------------------------------:|:--------------------------:|
| [Reddit comments (2015-2018)](https://github.com/PolyAI-LDN/conversational-datasets/tree/master/reddit) | [paper](https://arxiv.org/abs/1904.06472) | 726,484,430 |
| [S2ORC](https://github.com/allenai/s2orc) Citation pairs (Abstracts) | [paper](https://aclanthology.org/2020.acl-main.447/) | 116,288,806 |
| [WikiAnswers](https://github.com/afader/oqa#wikianswers-corpus) Duplicate question pairs | [paper](https://doi.org/10.1145/2623330.2623677) | 77,427,422 |
| [PAQ](https://github.com/facebookresearch/PAQ) (Question, Answer) pairs | [paper](https://arxiv.org/abs/2102.07033) | 64,371,441 |
| [S2ORC](https://github.com/allenai/s2orc) Citation pairs (Titles) | [paper](https://aclanthology.org/2020.acl-main.447/) | 52,603,982 |
| [S2ORC](https://github.com/allenai/s2orc) (Title, Abstract) | [paper](https://aclanthology.org/2020.acl-main.447/) | 41,769,185 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) (Title, Body) pairs | - | 25,316,456 |
| [MS MARCO](https://microsoft.github.io/msmarco/) triplets | [paper](https://doi.org/10.1145/3404835.3462804) | 9,144,553 |
| [GOOAQ: Open Question Answering with Diverse Answer Types](https://github.com/allenai/gooaq) | [paper](https://arxiv.org/pdf/2104.08727.pdf) | 3,012,496 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Title, Answer) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 1,198,260 |
| [Code Search](https://huggingface.co/datasets/code_search_net) | - | 1,151,414 |
| [COCO](https://cocodataset.org/#home) Image captions | [paper](https://link.springer.com/chapter/10.1007%2F978-3-319-10602-1_48) | 828,395|
| [SPECTER](https://github.com/allenai/specter) citation triplets | [paper](https://doi.org/10.18653/v1/2020.acl-main.207) | 684,100 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Question, Answer) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 681,164 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Title, Question) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 659,896 |
| [SearchQA](https://huggingface.co/datasets/search_qa) | [paper](https://arxiv.org/abs/1704.05179) | 582,261 |
| [Eli5](https://huggingface.co/datasets/eli5) | [paper](https://doi.org/10.18653/v1/p19-1346) | 325,475 |
| [Flickr 30k](https://shannon.cs.illinois.edu/DenotationGraph/) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/229/33) | 317,695 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (titles) | | 304,525 |
| AllNLI ([SNLI](https://nlp.stanford.edu/projects/snli/) and [MultiNLI](https://cims.nyu.edu/~sbowman/multinli/) | [paper SNLI](https://doi.org/10.18653/v1/d15-1075), [paper MultiNLI](https://doi.org/10.18653/v1/n18-1101) | 277,230 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (bodies) | | 250,519 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (titles+bodies) | | 250,460 |
| [Sentence Compression](https://github.com/google-research-datasets/sentence-compression) | [paper](https://www.aclweb.org/anthology/D13-1155/) | 180,000 |
| [Wikihow](https://github.com/pvl/wikihow_pairs_dataset) | [paper](https://arxiv.org/abs/1810.09305) | 128,542 |
| [Altlex](https://github.com/chridey/altlex/) | [paper](https://aclanthology.org/P16-1135.pdf) | 112,696 |
| [Quora Question Triplets](https://quoradata.quora.com/First-Quora-Dataset-Release-Question-Pairs) | - | 103,663 |
| [Simple Wikipedia](https://cs.pomona.edu/~dkauchak/simplification/) | [paper](https://www.aclweb.org/anthology/P11-2117/) | 102,225 |
| [Natural Questions (NQ)](https://ai.google.com/research/NaturalQuestions) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/1455) | 100,231 |
| [SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/) | [paper](https://aclanthology.org/P18-2124.pdf) | 87,599 |
| [TriviaQA](https://huggingface.co/datasets/trivia_qa) | - | 73,346 |
| **Total** | | **1,124,818,467** | |
microsoft/deberta-base-mnli | a80a6eb013898011540b19bf1f64e21eb61e53d6 | 2021-12-09T13:36:31.000Z | [
"pytorch",
"rust",
"deberta",
"text-classification",
"en",
"arxiv:2006.03654",
"transformers",
"deberta-v1",
"deberta-mnli",
"license:mit"
]
| text-classification | false | microsoft | null | microsoft/deberta-base-mnli | 1,368 | 1 | transformers | 1,571 | ---
language: en
tags:
- deberta-v1
- deberta-mnli
tasks: mnli
thumbnail: https://huggingface.co/front/thumbnails/microsoft.png
license: mit
widget:
- text: "[CLS] I love you. [SEP] I like you. [SEP]"
---
## DeBERTa: Decoding-enhanced BERT with Disentangled Attention
[DeBERTa](https://arxiv.org/abs/2006.03654) improves the BERT and RoBERTa models using disentangled attention and enhanced mask decoder. It outperforms BERT and RoBERTa on majority of NLU tasks with 80GB training data.
Please check the [official repository](https://github.com/microsoft/DeBERTa) for more details and updates.
This model is the base DeBERTa model fine-tuned with MNLI task
#### Fine-tuning on NLU tasks
We present the dev results on SQuAD 1.1/2.0 and MNLI tasks.
| Model | SQuAD 1.1 | SQuAD 2.0 | MNLI-m |
|-------------------|-----------|-----------|--------|
| RoBERTa-base | 91.5/84.6 | 83.7/80.5 | 87.6 |
| XLNet-Large | -/- | -/80.2 | 86.8 |
| **DeBERTa-base** | 93.1/87.2 | 86.2/83.1 | 88.8 |
### Citation
If you find DeBERTa useful for your work, please cite the following paper:
``` latex
@inproceedings{
he2021deberta,
title={DEBERTA: DECODING-ENHANCED BERT WITH DISENTANGLED ATTENTION},
author={Pengcheng He and Xiaodong Liu and Jianfeng Gao and Weizhu Chen},
booktitle={International Conference on Learning Representations},
year={2021},
url={https://openreview.net/forum?id=XPZIaotutsD}
}
```
|
IDEA-CCNL/Erlangshen-Roberta-110M-Similarity | d2a55ff1afd453d9170d8d2cba54d7b575535b32 | 2022-05-12T09:50:42.000Z | [
"pytorch",
"bert",
"text-classification",
"zh",
"transformers",
"NLU",
"NLI",
"license:apache-2.0"
]
| text-classification | false | IDEA-CCNL | null | IDEA-CCNL/Erlangshen-Roberta-110M-Similarity | 1,365 | 1 | transformers | 1,572 | ---
language:
- zh
license: apache-2.0
tags:
- bert
- NLU
- NLI
inference: true
widget:
- text: "今天心情不好[SEP]今天很开心"
---
# Erlangshen-Roberta-110M-Similarity, model (Chinese),one model of [Fengshenbang-LM](https://github.com/IDEA-CCNL/Fengshenbang-LM).
We collect 20 paraphrace datasets in the Chinese domain for finetune, with a total of 2773880 samples. Our model is mainly based on [roberta](https://huggingface.co/hfl/chinese-roberta-wwm-ext-large)
## Usage
```python
from transformers import BertForSequenceClassification
from transformers import BertTokenizer
import torch
tokenizer=BertTokenizer.from_pretrained('IDEA-CCNL/Erlangshen-Roberta-110M-Similarity')
model=BertForSequenceClassification.from_pretrained('IDEA-CCNL/Erlangshen-Roberta-110M-Similarity')
texta='今天的饭不好吃'
textb='今天心情不好'
output=model(torch.tensor([tokenizer.encode(texta,textb)]))
print(torch.nn.functional.softmax(output.logits,dim=-1))
```
## Scores on downstream chinese tasks(The dev datasets of BUSTM and AFQMC may exist in the train set)
| Model | BQ | BUSTM | AFQMC |
| :--------: | :-----: | :----: | :-----: |
| Erlangshen-Roberta-110M-Similarity | 85.41 | 95.18 | 81.72 |
| Erlangshen-Roberta-330M-Similarity | 86.21 | 99.29 | 93.89 |
| Erlangshen-MegatronBert-1.3B-Similarity | 86.31 | - | - |
## Citation
If you find the resource is useful, please cite the following website in your paper.
```
@misc{Fengshenbang-LM,
title={Fengshenbang-LM},
author={IDEA-CCNL},
year={2021},
howpublished={\url{https://github.com/IDEA-CCNL/Fengshenbang-LM}},
}
``` |
Geotrend/bert-base-en-fr-de-cased | df74315d628f1084b9f22f04b11a9b27ca24e568 | 2021-05-18T19:18:39.000Z | [
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"multilingual",
"dataset:wikipedia",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
]
| fill-mask | false | Geotrend | null | Geotrend/bert-base-en-fr-de-cased | 1,364 | null | transformers | 1,573 | ---
language: multilingual
datasets: wikipedia
license: apache-2.0
---
# bert-base-en-fr-de-cased
We are sharing smaller versions of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) that handle a custom number of languages.
Unlike [distilbert-base-multilingual-cased](https://huggingface.co/distilbert-base-multilingual-cased), our versions give exactly the same representations produced by the original model which preserves the original accuracy.
For more information please visit our paper: [Load What You Need: Smaller Versions of Multilingual BERT](https://www.aclweb.org/anthology/2020.sustainlp-1.16.pdf).
## How to use
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("Geotrend/bert-base-en-fr-de-cased")
model = AutoModel.from_pretrained("Geotrend/bert-base-en-fr-de-cased")
```
To generate other smaller versions of multilingual transformers please visit [our Github repo](https://github.com/Geotrend-research/smaller-transformers).
### How to cite
```bibtex
@inproceedings{smallermbert,
title={Load What You Need: Smaller Versions of Mutlilingual BERT},
author={Abdaoui, Amine and Pradel, Camille and Sigel, Grégoire},
booktitle={SustaiNLP / EMNLP},
year={2020}
}
```
## Contact
Please contact [email protected] for any question, feedback or request. |
dbmdz/electra-base-italian-xxl-cased-discriminator | 9dc80d590b251f8472138761144ba37a932b8936 | 2020-12-11T21:37:19.000Z | [
"pytorch",
"electra",
"pretraining",
"it",
"dataset:wikipedia",
"transformers",
"license:mit"
]
| null | false | dbmdz | null | dbmdz/electra-base-italian-xxl-cased-discriminator | 1,364 | null | transformers | 1,574 | ---
language: it
license: mit
datasets:
- wikipedia
---
# 🤗 + 📚 dbmdz BERT and ELECTRA models
In this repository the MDZ Digital Library team (dbmdz) at the Bavarian State
Library open sources Italian BERT and ELECTRA models 🎉
# Italian BERT
The source data for the Italian BERT model consists of a recent Wikipedia dump and
various texts from the [OPUS corpora](http://opus.nlpl.eu/) collection. The final
training corpus has a size of 13GB and 2,050,057,573 tokens.
For sentence splitting, we use NLTK (faster compared to spacy).
Our cased and uncased models are training with an initial sequence length of 512
subwords for ~2-3M steps.
For the XXL Italian models, we use the same training data from OPUS and extend
it with data from the Italian part of the [OSCAR corpus](https://traces1.inria.fr/oscar/).
Thus, the final training corpus has a size of 81GB and 13,138,379,147 tokens.
Note: Unfortunately, a wrong vocab size was used when training the XXL models.
This explains the mismatch of the "real" vocab size of 31102, compared to the
vocab size specified in `config.json`. However, the model is working and all
evaluations were done under those circumstances.
See [this issue](https://github.com/dbmdz/berts/issues/7) for more information.
The Italian ELECTRA model was trained on the "XXL" corpus for 1M steps in total using a batch
size of 128. We pretty much following the ELECTRA training procedure as used for
[BERTurk](https://github.com/stefan-it/turkish-bert/tree/master/electra).
## Model weights
Currently only PyTorch-[Transformers](https://github.com/huggingface/transformers)
compatible weights are available. If you need access to TensorFlow checkpoints,
please raise an issue!
| Model | Downloads
| ---------------------------------------------------- | ---------------------------------------------------------------------------------------------------------------
| `dbmdz/bert-base-italian-cased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-italian-cased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-italian-cased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-italian-cased/vocab.txt)
| `dbmdz/bert-base-italian-uncased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-italian-uncased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-italian-uncased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-italian-uncased/vocab.txt)
| `dbmdz/bert-base-italian-xxl-cased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-cased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-cased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-cased/vocab.txt)
| `dbmdz/bert-base-italian-xxl-uncased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-uncased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-uncased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-uncased/vocab.txt)
| `dbmdz/electra-base-italian-xxl-cased-discriminator` | [`config.json`](https://s3.amazonaws.com/models.huggingface.co/bert/dbmdz/electra-base-italian-xxl-cased-discriminator/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/electra-base-italian-xxl-cased-discriminator/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/electra-base-italian-xxl-cased-discriminator/vocab.txt)
| `dbmdz/electra-base-italian-xxl-cased-generator` | [`config.json`](https://s3.amazonaws.com/models.huggingface.co/bert/dbmdz/electra-base-italian-xxl-cased-generator/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/electra-base-italian-xxl-cased-generator/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/electra-base-italian-xxl-cased-generator/vocab.txt)
## Results
For results on downstream tasks like NER or PoS tagging, please refer to
[this repository](https://github.com/stefan-it/italian-bertelectra).
## Usage
With Transformers >= 2.3 our Italian BERT models can be loaded like:
```python
from transformers import AutoModel, AutoTokenizer
model_name = "dbmdz/bert-base-italian-cased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
```
To load the (recommended) Italian XXL BERT models, just use:
```python
from transformers import AutoModel, AutoTokenizer
model_name = "dbmdz/bert-base-italian-xxl-cased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
```
To load the Italian XXL ELECTRA model (discriminator), just use:
```python
from transformers import AutoModel, AutoTokenizer
model_name = "dbmdz/electra-base-italian-xxl-cased-discriminator"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelWithLMHead.from_pretrained(model_name)
```
# Huggingface model hub
All models are available on the [Huggingface model hub](https://huggingface.co/dbmdz).
# Contact (Bugs, Feedback, Contribution and more)
For questions about our BERT/ELECTRA models just open an issue
[here](https://github.com/dbmdz/berts/issues/new) 🤗
# Acknowledgments
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
Thanks for providing access to the TFRC ❤️
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
it is possible to download both cased and uncased models from their S3 storage 🤗
|
saibo/legal-roberta-base | e0d78f4e064ff27621d61fa2320c79addb528d81 | 2021-08-31T15:36:35.000Z | [
"pytorch",
"tf",
"jax",
"roberta",
"fill-mask",
"en",
"transformers",
"legal",
"license:apache-2.0",
"autotrain_compatible"
]
| fill-mask | false | saibo | null | saibo/legal-roberta-base | 1,363 | 2 | transformers | 1,575 | ---
language:
- en
tags:
- legal
license: apache-2.0
metrics:
- precision
- recall
---
# LEGAL-ROBERTA
We introduce LEGAL-ROBERTA, which is a domain-specific language representation model fine-tuned on large-scale legal corpora(4.6 GB).
## Demo
'This \<mask\> Agreement is between General Motors and John Murray .'
| Model | top1 | top2 | top3 | top4 | top5 |
| ------------ | ---- | --- | --- | --- | -------- |
| Bert | new | current | proposed | marketing | joint |
| legalBert | settlement | letter | dealer | master | supplemental |
| legalRoberta | License | Settlement | Contract | license | Trust |
> LegalRoberta captures the case
'The applicant submitted that her husband was subjected to treatment amounting to \<mask\> whilst in the custody of Adana Security Directorate'
| Model | top1 | top2 | top3 | top4 | top5 |
| ------------ | ---- | --- | --- | --- | -------- |
| Bert | torture | rape | abuse | death | violence |
| legalBert | torture | detention | arrest | rape | death |
| legalRoberta | torture | abuse | insanity | cruelty | confinement |
'Establishing a system for the identification and registration of \<mask\> animals and regarding the labeling of beef and beef products .':
| Model | top1 | top2 | top3 | top4 | top5 |
| ------------ | ---- | --- | --- | --- | -------- |
| Bert | farm | livestock | draft | domestic | wild |
| legalBert | live | beef | farm | pet | dairy |
| legalRoberta | domestic | all | beef | wild | registered |
## Load Pretrained Model
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("saibo/legal-roberta-base")
model = AutoModel.from_pretrained("saibo/legal-roberta-base")
```
## Training data
The training data consists of 3 origins:
1. Patent Litigations (https://www.kaggle.com/uspto/patent-litigations): This dataset covers over 74k cases across 52 years and over 5 million relevant documents. 5 different files detail the litigating parties, their attorneys, results, locations, and dates.
1. *1.57GB*
2. abbrev:PL
3. *clean 1.1GB*
2. Caselaw Access Project (CAP) (https://case.law/): Following 360 years of United States case law, Caselaw Access Project (CAP) API and bulk data services includes 40 million pages of U.S. court decisions and almost 6.5 million individual cases.
1. *raw 5.6*
2. abbrev:CAP
3. *clean 2.8GB*
3. Google Patents Public Data (https://www.kaggle.com/bigquery/patents): The Google Patents Public Data contains a collection of publicly accessible, connected database tables for empirical analysis of the international patent system.
1. *BigQuery (https://www.kaggle.com/sohier/beyond-queries-exploring-the-bigquery-api)*
2. abbrev:GPPD(1.1GB,patents-public-data.uspto_oce_litigation.documents)
3. *clean 1GB*
## Training procedure
We start from a pretrained ROBERTA-BASE model and fine-tune it on the legal corpus.
Fine-tuning configuration:
- lr = 5e-5(with lr decay, ends at 4.95e-8)
- num_epoch = 3
- Total steps = 446500
- Total_flos = 2.7365e18
Loss starts at 1.850 and ends at 0.880
The perplexity after fine-tuning on legal corpus = 2.2735
Device:
2*GeForce GTX TITAN X computeCapability: 5.2
## Eval results
We benchmarked the model on two downstream tasks: Multi-Label Classification for Legal Text and Catchphrase Retrieval with Legal Case Description.
1.LMTC, Legal Multi-Label Text Classification
Dataset:
Labels shape: 4271
Frequent labels: 739
Few labels: 3369
Zero labels: 163
Hyperparameters:
- lr: 1e-05
- batch_size: 4
- max_sequence_size: 512
- max_label_size: 15
- few_threshold: 50
- epochs: 10
- dropout:0.1
- early stop:yes
- patience: 3
## Limitations:
In the Masked Language Model showroom, the tokens have the prefix **Ġ**. This seems to be wired but I haven't yet been able to fix it.
I know in the case of BPE tokenizer(ROBERTA's tokenizer), the symbol Ġ means the end of a new token, and the majority of tokens in the vocabs of pre-trained tokenizers start with Ġ.
For example
```python
import transformers
tokenizer = transformers.RobertaTokenizer.from_pretrained('roberta-base')
print(tokenizer.tokenize('I love salad'))
```
Outputs:
```
['I', 'Ġlove', 'Ġsalad']
```
The pretraining of LegalRoBERTa was restricted by the size of legal corpora available and the number of pretraining steps is small compared to the popular domain adapted models. This makes legalRoBERTa significantly **under-trained**.
## BibTeX entry and citation info
|
ethanyt/guwenbert-base | eff0d4a5196d7bf7b8be746c5c6437e89d8b9061 | 2021-06-02T03:27:16.000Z | [
"pytorch",
"jax",
"roberta",
"fill-mask",
"zh",
"transformers",
"chinese",
"classical chinese",
"literary chinese",
"ancient chinese",
"bert",
"license:apache-2.0",
"autotrain_compatible"
]
| fill-mask | false | ethanyt | null | ethanyt/guwenbert-base | 1,362 | 1 | transformers | 1,576 | ---
language:
- "zh"
thumbnail: "https://user-images.githubusercontent.com/9592150/97142000-cad08e00-179a-11eb-88df-aff9221482d8.png"
tags:
- "chinese"
- "classical chinese"
- "literary chinese"
- "ancient chinese"
- "bert"
- "pytorch"
license: "apache-2.0"
pipeline_tag: "fill-mask"
mask_token: "[MASK]"
widget:
- text: "[MASK]太元中,武陵人捕鱼为业。"
- text: "问征夫以前路,恨晨光之[MASK]微。"
- text: "浔阳江头夜送客,枫叶[MASK]花秋瑟瑟。"
---
# GuwenBERT
## Model description

This is a RoBERTa model pre-trained on Classical Chinese. You can fine-tune GuwenBERT for downstream tasks, such as sentence breaking, punctuation, named entity recognition, and so on.
For more information about RoBERTa, take a look at the RoBERTa's offical repo.
## How to use
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("ethanyt/guwenbert-base")
model = AutoModel.from_pretrained("ethanyt/guwenbert-base")
```
## Training data
The training data is daizhige dataset (殆知阁古代文献) which is contains of 15,694 books in Classical Chinese, covering Buddhism, Confucianism, Medicine, History, Zi, Yi, Yizang, Shizang, Taoism, and Jizang.
76% of them are punctuated.
The total number of characters is 1.7B (1,743,337,673).
All traditional Characters are converted to simplified characters.
The vocabulary is constructed from this data set and the size is 23,292.
## Training procedure
The models are initialized with `hfl/chinese-roberta-wwm-ext` and then pre-trained with a 2-step strategy.
In the first step, the model learns MLM with only word embeddings updated during training, until convergence. In the second step, all parameters are updated during training.
The models are trained on 4 V100 GPUs for 120K steps (20K for step#1, 100K for step#2) with a batch size of 2,048 and a sequence length of 512. The optimizer used is Adam with a learning rate of 2e-4, adam-betas of (0.9,0.98), adam-eps of 1e-6, a weight decay of 0.01, learning rate warmup for 5K steps, and linear decay of learning rate after.
## Eval results
### "Gulian Cup" Ancient Books Named Entity Recognition Evaluation
Second place in the competition. Detailed test results:
| NE Type | Precision | Recall | F1 |
|:----------:|:-----------:|:------:|:-----:|
| Book Name | 77.50 | 73.73 | 75.57 |
| Other Name | 85.85 | 89.32 | 87.55 |
| Micro Avg. | 83.88 | 85.39 | 84.63 |
## About Us
We are from [Datahammer](https://datahammer.net), Beijing Institute of Technology.
For more cooperation, please contact email: ethanyt [at] qq.com
> Created with ❤️ by Tan Yan [](https://github.com/Ethan-yt) and Zewen Chi [](https://github.com/CZWin32768) |
textattack/roberta-base-QNLI | 68887d836a1dc4aab8a053e1502d5bff2677ed14 | 2021-05-20T22:09:33.000Z | [
"pytorch",
"jax",
"roberta",
"text-classification",
"transformers"
]
| text-classification | false | textattack | null | textattack/roberta-base-QNLI | 1,357 | null | transformers | 1,577 | Entry not found |
jhu-clsp/roberta-large-eng-ara-128k | 8557e84530e0833f9f9c647d277e4ff5881d135e | 2021-09-14T19:37:39.000Z | [
"pytorch",
"tf",
"xlm-roberta",
"fill-mask",
"ar",
"en",
"dataset:arabic_billion_words",
"dataset:cc100",
"dataset:gigaword",
"dataset:oscar",
"dataset:wikipedia",
"transformers",
"bert",
"roberta",
"exbert",
"license:mit",
"autotrain_compatible"
]
| fill-mask | false | jhu-clsp | null | jhu-clsp/roberta-large-eng-ara-128k | 1,356 | 4 | transformers | 1,578 | ---
language:
- ar
- en
tags:
- bert
- roberta
- exbert
license: mit
datasets:
- arabic_billion_words
- cc100
- gigaword
- oscar
- wikipedia
---
# An English-Arabic Bilingual Encoder
```
from transformers import AutoModelForMaskedLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("jhu-clsp/roberta-large-eng-ara-128k")
model = AutoModelForMaskedLM.from_pretrained("jhu-clsp/roberta-large-eng-ara-128k")
```
`roberta-large-eng-ara-128k` is an English–Arabic bilingual encoders of 24-layer Transformers (d\_model= 1024), the same size as XLM-R large. We use the same Common Crawl corpus as XLM-R for pretraining. Additionally, we also use English and Arabic Wikipedia, Arabic Gigaword (Parker et al., 2011), Arabic OSCAR (Ortiz Suárez et al., 2020), Arabic News Corpus (El-Khair, 2016), and Arabic OSIAN (Zeroual et al.,2019). In total, we train with 9.2B words of Arabic text and 26.8B words of English text, more than either XLM-R (2.9B words/23.6B words) or GigaBERT v4 (Lan et al., 2020) (4.3B words/6.1B words). We build an English–Arabic joint vocabulary using SentencePiece (Kudo and Richardson, 2018) with size of 128K. We additionally enforce coverage of all Arabic characters after normalization.
## Pretraining Detail
We pretrain each encoder with a batch size of 2048 sequences and 512 sequence length for 250K steps from scratch roughly 1/24 the amount of pretraining compute of XLM-R. Training takes 8 RTX6000 GPUs roughly three weeks. We follow the pretraining recipe of RoBERTa (Liu et al., 2019) and XLM-R. We omit the next sentence prediction task and use a learning rate of 2e-4, Adam optimizer, and linear warmup of 10K steps then decay linearly to 0, multilingual sampling alpha of 0.3, and the fairseq (Ott et al., 2019) implementation.
## Citation
Please cite this paper for reference:
```bibtex
@inproceedings{yarmohammadi-etal-2021-everything,
title = "Everything Is All It Takes: A Multipronged Strategy for Zero-Shot Cross-Lingual Information Extraction",
author = "Yarmohammadi, Mahsa and
Wu, Shijie and
Marone, Marc and
Xu, Haoran and
Ebner, Seth and
Qin, Guanghui and
Chen, Yunmo and
Guo, Jialiang and
Harman, Craig and
Murray, Kenton and
White, Aaron Steven and
Dredze, Mark and
Van Durme, Benjamin",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing",
year = "2021",
}
```
|
rinna/japanese-gpt2-xsmall | e2dac72065c0da14d687ade9931549711e1f35fd | 2021-08-23T03:20:38.000Z | [
"pytorch",
"tf",
"gpt2",
"text-generation",
"ja",
"dataset:cc100",
"dataset:wikipedia",
"transformers",
"japanese",
"lm",
"nlp",
"license:mit"
]
| text-generation | false | rinna | null | rinna/japanese-gpt2-xsmall | 1,355 | 5 | transformers | 1,579 | ---
language: ja
thumbnail: https://github.com/rinnakk/japanese-gpt2/blob/master/rinna.png
tags:
- ja
- japanese
- gpt2
- text-generation
- lm
- nlp
license: mit
datasets:
- cc100
- wikipedia
widget:
- text: "生命、宇宙、そして万物についての究極の疑問の答えは"
---
# japanese-gpt2-xsmall

This repository provides an extra-small-sized Japanese GPT-2 model. The model was trained using code from Github repository [rinnakk/japanese-pretrained-models](https://github.com/rinnakk/japanese-pretrained-models) by [rinna Co., Ltd.](https://corp.rinna.co.jp/)
# How to use the model
*NOTE:* Use `T5Tokenizer` to initiate the tokenizer.
~~~~
from transformers import T5Tokenizer, GPT2LMHeadModel
tokenizer = T5Tokenizer.from_pretrained("rinna/japanese-gpt2-small")
tokenizer.do_lower_case = True # due to some bug of tokenizer config loading
model = GPT2LMHeadModel.from_pretrained("rinna/japanese-gpt2-small")
~~~~
# Model architecture
A 6-layer, 512-hidden-size transformer-based language model.
# Training
The model was trained on [Japanese CC-100](http://data.statmt.org/cc-100/ja.txt.xz) and [Japanese Wikipedia](https://dumps.wikimedia.org/other/cirrussearch) to optimize a traditional language modelling objective on 8\\*V100 GPUs for around 4 days. It reaches around 28 perplexity on a chosen validation set from CC-100.
# Tokenization
The model uses a [sentencepiece](https://github.com/google/sentencepiece)-based tokenizer, the vocabulary was trained on the Japanese Wikipedia using the official sentencepiece training script.
# Licenese
[The MIT license](https://opensource.org/licenses/MIT)
|
lighteternal/wav2vec2-large-xlsr-53-greek | c5c82840b689b827a2029deefe82670c7c5809a0 | 2022-03-26T10:12:37.000Z | [
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"el",
"dataset:common_voice",
"transformers",
"audio",
"hf-asr-leaderboard",
"speech",
"xlsr-fine-tuning-week",
"license:apache-2.0",
"model-index"
]
| automatic-speech-recognition | false | lighteternal | null | lighteternal/wav2vec2-large-xlsr-53-greek | 1,354 | 1 | transformers | 1,580 | ---
language: el
datasets:
- common_voice
tags:
- audio
- hf-asr-leaderboard
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: XLSR Wav2Vec2 Greek by Lighteternal
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: CommonVoice (EL), CSS10 (EL)
type: CCS10 + mozilla-foundation/common_voice_7_0
args: el
metrics:
- name: Test WER
type: wer
value: 10.497628
- name: Test CER
type: cer
value: 2.875260
---
# Greek (el) version of the XLSR-Wav2Vec2 automatic speech recognition (ASR) model
### By the Hellenic Army Academy and the Technical University of Crete
* language: el
* licence: apache-2.0
* dataset: CommonVoice (EL), 364MB: https://commonvoice.mozilla.org/el/datasets + CSS10 (EL), 1.22GB: https://github.com/Kyubyong/css10
* model: XLSR-Wav2Vec2, trained for 50 epochs
* metrics: Word Error Rate (WER)
## Model description
UPDATE: We repeated the fine-tuning process using an additional 1.22GB dataset from CSS10.
Wav2Vec2 is a pretrained model for Automatic Speech Recognition (ASR) and was released in September 2020 by Alexei Baevski, Michael Auli, and Alex Conneau. Soon after the superior performance of Wav2Vec2 was demonstrated on the English ASR dataset LibriSpeech, Facebook AI presented XLSR-Wav2Vec2. XLSR stands for cross-lingual speech representations and refers to XLSR-Wav2Vec2`s ability to learn speech representations that are useful across multiple languages.
Similar to Wav2Vec2, XLSR-Wav2Vec2 learns powerful speech representations from hundreds of thousands of hours of speech in more than 50 languages of unlabeled speech. Similar, to BERT's masked language modeling, the model learns contextualized speech representations by randomly masking feature vectors before passing them to a transformer network.
This model was trained for 50 epochs on a single NVIDIA RTX 3080, for aprox. 8hrs.
## How to use for inference:
For live demo, make sure that speech files are sampled at 16kHz.
Instructions to test on CommonVoice extracts are provided in the ASR_Inference.ipynb. Snippet also available below:
```python
#!/usr/bin/env python
# coding: utf-8
# Loading dependencies and defining preprocessing functions
from transformers import Wav2Vec2ForCTC
from transformers import Wav2Vec2Processor
from datasets import load_dataset, load_metric
import re
import torchaudio
import librosa
import numpy as np
from datasets import load_dataset, load_metric
import torch
chars_to_ignore_regex = '[\\\\\\\\,\\\\\\\\?\\\\\\\\.\\\\\\\\!\\\\\\\\-\\\\\\\\;\\\\\\\\:\\\\\\\\"\\\\\\\\“\\\\\\\\%\\\\\\\\‘\\\\\\\\”\\\\\\\\�]'
def remove_special_characters(batch):
batch["text"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower() + " "
return batch
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = speech_array[0].numpy()
batch["sampling_rate"] = sampling_rate
batch["target_text"] = batch["text"]
return batch
def resample(batch):
batch["speech"] = librosa.resample(np.asarray(batch["speech"]), 48_000, 16_000)
batch["sampling_rate"] = 16_000
return batch
def prepare_dataset(batch):
# check that all files have the correct sampling rate
assert (
len(set(batch["sampling_rate"])) == 1
), f"Make sure all inputs have the same sampling rate of {processor.feature_extractor.sampling_rate}."
batch["input_values"] = processor(batch["speech"], sampling_rate=batch["sampling_rate"][0]).input_values
with processor.as_target_processor():
batch["labels"] = processor(batch["target_text"]).input_ids
return batch
# Loading model and dataset processor
model = Wav2Vec2ForCTC.from_pretrained("lighteternal/wav2vec2-large-xlsr-53-greek").to("cuda")
processor = Wav2Vec2Processor.from_pretrained("lighteternal/wav2vec2-large-xlsr-53-greek")
# Preparing speech dataset to be suitable for inference
common_voice_test = load_dataset("common_voice", "el", split="test")
common_voice_test = common_voice_test.remove_columns(["accent", "age", "client_id", "down_votes", "gender", "locale", "segment", "up_votes"])
common_voice_test = common_voice_test.map(remove_special_characters, remove_columns=["sentence"])
common_voice_test = common_voice_test.map(speech_file_to_array_fn, remove_columns=common_voice_test.column_names)
common_voice_test = common_voice_test.map(resample, num_proc=8)
common_voice_test = common_voice_test.map(prepare_dataset, remove_columns=common_voice_test.column_names, batch_size=8, num_proc=8, batched=True)
# Loading test dataset
common_voice_test_transcription = load_dataset("common_voice", "el", split="test")
#Performing inference on a random sample. Change the "example" value to try inference on different CommonVoice extracts
example = 123
input_dict = processor(common_voice_test["input_values"][example], return_tensors="pt", sampling_rate=16_000, padding=True)
logits = model(input_dict.input_values.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
print("Prediction:")
print(processor.decode(pred_ids[0]))
# πού θέλεις να πάμε ρώτησε φοβισμένα ο βασιλιάς
print("\\\\
Reference:")
print(common_voice_test_transcription["sentence"][example].lower())
# πού θέλεις να πάμε; ρώτησε φοβισμένα ο βασιλιάς.
```
## Evaluation
The model can be evaluated as follows on the Greek test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "el", split="test")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("lighteternal/wav2vec2-large-xlsr-53-greek")
model = Wav2Vec2ForCTC.from_pretrained("lighteternal/wav2vec2-large-xlsr-53-greek")
model.to("cuda")
chars_to_ignore_regex = '[\\\\\\\\,\\\\\\\\?\\\\\\\\.\\\\\\\\!\\\\\\\\-\\\\\\\\;\\\\\\\\:\\\\\\\\"\\\\\\\\“\\\\\\\\%\\\\\\\\‘\\\\\\\\”\\\\\\\\�]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 10.497628 %
### How to use for training:
Instructions and code to replicate the process are provided in the Fine_Tune_XLSR_Wav2Vec2_on_Greek_ASR_with_🤗_Transformers.ipynb notebook.
## Metrics
| Metric | Value |
| ----------- | ----------- |
| Training Loss | 0.0545 |
| Validation Loss | 0.1661 |
| CER on CommonVoice Test (%) *| 2.8753 |
| WER on CommonVoice Test (%) *| 10.4976 |
* Reference transcripts were lower-cased and striped of punctuation and special characters.
### Acknowledgement
The research work was supported by the Hellenic Foundation for Research and Innovation (HFRI) under the HFRI PhD Fellowship grant (Fellowship Number:50, 2nd call)
Based on the tutorial of Patrick von Platen: https://huggingface.co/blog/fine-tune-xlsr-wav2vec2
Original colab notebook here: https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Fine_Tune_XLSR_Wav2Vec2_on_Turkish_ASR_with_%F0%9F%A4%97_Transformers.ipynb#scrollTo=V7YOT2mnUiea
|
KoboldAI/fairseq-dense-6.7B-Shinen | 5a6d1baba58d6cdd98fbd472b3501749d6e8ec5a | 2022-04-13T08:19:31.000Z | [
"pytorch",
"xglm",
"text-generation",
"en",
"transformers",
"license:mit"
]
| text-generation | false | KoboldAI | null | KoboldAI/fairseq-dense-6.7B-Shinen | 1,354 | null | transformers | 1,581 | ---
language: en
license: mit
---
# Fairseq-dense 6.7B - Shinen
## Model Description
Fairseq-dense 6.7B-Shinen is a finetune created using Fairseq's MoE dense model. Compared to GPT-Neo-2.7-Horni, this model is much heavier on the sexual content.
**Warning: THIS model is NOT suitable for use by minors. The model will output X-rated content.**
## Training data
The training data contains user-generated stories from sexstories.com. All stories are tagged using the following way:
```
[Theme: <theme1>, <theme2> ,<theme3>]
<Story goes here>
```
### How to use
You can use this model directly with a pipeline for text generation. This example generates a different sequence each time it's run:
```py
>>> from transformers import pipeline
>>> generator = pipeline('text-generation', model='KoboldAI/fairseq-dense-6.7B-Shinen')
>>> generator("She was staring at me", do_sample=True, min_length=50)
[{'generated_text': 'She was staring at me with a look that said it all. She wanted me so badly tonight that I wanted'}]
```
### Limitations and Biases
Based on known problems with NLP technology, potential relevant factors include bias (gender, profession, race and religion).
### BibTeX entry and citation info
```
Artetxe et al. (2021): Efficient Large Scale Language Modeling with Mixtures of Experts
``` |
aubmindlab/bert-base-arabert | 4b7ceb4967371d5e0b559b275e006f54d671c48e | 2021-05-19T11:49:06.000Z | [
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"ar",
"dataset:wikipedia",
"dataset:OSIAN",
"dataset:1.5B Arabic Corpus",
"arxiv:2003.00104",
"transformers",
"autotrain_compatible"
]
| fill-mask | false | aubmindlab | null | aubmindlab/bert-base-arabert | 1,352 | 7 | transformers | 1,582 | ---
language: ar
datasets:
- wikipedia
- OSIAN
- 1.5B Arabic Corpus
widget:
- text: " عاصم +ة لبنان هي [MASK] ."
---
# !!! A newer version of this model is available !!! [AraBERTv2](https://huggingface.co/aubmindlab/bert-base-arabertv2)
# AraBERT v1 & v2 : Pre-training BERT for Arabic Language Understanding
<img src="https://raw.githubusercontent.com/aub-mind/arabert/master/arabert_logo.png" width="100" align="left"/>
**AraBERT** is an Arabic pretrained lanaguage model based on [Google's BERT architechture](https://github.com/google-research/bert). AraBERT uses the same BERT-Base config. More details are available in the [AraBERT Paper](https://arxiv.org/abs/2003.00104) and in the [AraBERT Meetup](https://github.com/WissamAntoun/pydata_khobar_meetup)
There are two versions of the model, AraBERTv0.1 and AraBERTv1, with the difference being that AraBERTv1 uses pre-segmented text where prefixes and suffixes were splitted using the [Farasa Segmenter](http://alt.qcri.org/farasa/segmenter.html).
We evalaute AraBERT models on different downstream tasks and compare them to [mBERT]((https://github.com/google-research/bert/blob/master/multilingual.md)), and other state of the art models (*To the extent of our knowledge*). The Tasks were Sentiment Analysis on 6 different datasets ([HARD](https://github.com/elnagara/HARD-Arabic-Dataset), [ASTD-Balanced](https://www.aclweb.org/anthology/D15-1299), [ArsenTD-Lev](https://staff.aub.edu.lb/~we07/Publications/ArSentD-LEV_Sentiment_Corpus.pdf), [LABR](https://github.com/mohamedadaly/LABR)), Named Entity Recognition with the [ANERcorp](http://curtis.ml.cmu.edu/w/courses/index.php/ANERcorp), and Arabic Question Answering on [Arabic-SQuAD and ARCD](https://github.com/husseinmozannar/SOQAL)
# AraBERTv2
## What's New!
AraBERT now comes in 4 new variants to replace the old v1 versions:
More Detail in the AraBERT folder and in the [README](https://github.com/aub-mind/arabert/blob/master/AraBERT/README.md) and in the [AraBERT Paper](https://arxiv.org/abs/2003.00104v2)
Model | HuggingFace Model Name | Size (MB/Params)| Pre-Segmentation | DataSet (Sentences/Size/nWords) |
---|:---:|:---:|:---:|:---:
AraBERTv0.2-base | [bert-base-arabertv02](https://huggingface.co/aubmindlab/bert-base-arabertv02) | 543MB / 136M | No | 200M / 77GB / 8.6B |
AraBERTv0.2-large| [bert-large-arabertv02](https://huggingface.co/aubmindlab/bert-large-arabertv02) | 1.38G 371M | No | 200M / 77GB / 8.6B |
AraBERTv2-base| [bert-base-arabertv2](https://huggingface.co/aubmindlab/bert-base-arabertv2) | 543MB 136M | Yes | 200M / 77GB / 8.6B |
AraBERTv2-large| [bert-large-arabertv2](https://huggingface.co/aubmindlab/bert-large-arabertv2) | 1.38G 371M | Yes | 200M / 77GB / 8.6B |
AraBERTv0.1-base| [bert-base-arabertv01](https://huggingface.co/aubmindlab/bert-base-arabertv01) | 543MB 136M | No | 77M / 23GB / 2.7B |
AraBERTv1-base| [bert-base-arabert](https://huggingface.co/aubmindlab/bert-base-arabert) | 543MB 136M | Yes | 77M / 23GB / 2.7B |
All models are available in the `HuggingFace` model page under the [aubmindlab](https://huggingface.co/aubmindlab/) name. Checkpoints are available in PyTorch, TF2 and TF1 formats.
## Better Pre-Processing and New Vocab
We identified an issue with AraBERTv1's wordpiece vocabulary. The issue came from punctuations and numbers that were still attached to words when learned the wordpiece vocab. We now insert a space between numbers and characters and around punctuation characters.
The new vocabulary was learnt using the `BertWordpieceTokenizer` from the `tokenizers` library, and should now support the Fast tokenizer implementation from the `transformers` library.
**P.S.**: All the old BERT codes should work with the new BERT, just change the model name and check the new preprocessing dunction
**Please read the section on how to use the [preprocessing function](#Preprocessing)**
## Bigger Dataset and More Compute
We used ~3.5 times more data, and trained for longer.
For Dataset Sources see the [Dataset Section](#Dataset)
Model | Hardware | num of examples with seq len (128 / 512) |128 (Batch Size/ Num of Steps) | 512 (Batch Size/ Num of Steps) | Total Steps | Total Time (in Days) |
---|:---:|:---:|:---:|:---:|:---:|:---:
AraBERTv0.2-base | TPUv3-8 | 420M / 207M |2560 / 1M | 384/ 2M | 3M | -
AraBERTv0.2-large | TPUv3-128 | 420M / 207M | 13440 / 250K | 2056 / 300K | 550K | -
AraBERTv2-base | TPUv3-8 | 520M / 245M |13440 / 250K | 2056 / 300K | 550K | -
AraBERTv2-large | TPUv3-128 | 520M / 245M | 13440 / 250K | 2056 / 300K | 550K | -
AraBERT-base (v1/v0.1) | TPUv2-8 | - |512 / 900K | 128 / 300K| 1.2M | 4 days
# Dataset
The pretraining data used for the new AraBERT model is also used for Arabic **GPT2 and ELECTRA**.
The dataset consists of 77GB or 200,095,961 lines or 8,655,948,860 words or 82,232,988,358 chars (before applying Farasa Segmentation)
For the new dataset we added the unshuffled OSCAR corpus, after we thoroughly filter it, to the previous dataset used in AraBERTv1 but with out the websites that we previously crawled:
- OSCAR unshuffled and filtered.
- [Arabic Wikipedia dump](https://archive.org/details/arwiki-20190201) from 2020/09/01
- [The 1.5B words Arabic Corpus](https://www.semanticscholar.org/paper/1.5-billion-words-Arabic-Corpus-El-Khair/f3eeef4afb81223df96575adadf808fe7fe440b4)
- [The OSIAN Corpus](https://www.aclweb.org/anthology/W19-4619)
- Assafir news articles. Huge thank you for Assafir for giving us the data
# Preprocessing
It is recommended to apply our preprocessing function before training/testing on any dataset.
**Install farasapy to segment text for AraBERT v1 & v2 `pip install farasapy`**
```python
from arabert.preprocess import ArabertPreprocessor
model_name="bert-base-arabert"
arabert_prep = ArabertPreprocessor(model_name=model_name)
text = "ولن نبالغ إذا قلنا إن هاتف أو كمبيوتر المكتب في زمننا هذا ضروري"
arabert_prep.preprocess(text)
>>>"و+ لن نبالغ إذا قل +نا إن هاتف أو كمبيوتر ال+ مكتب في زمن +نا هذا ضروري"
```
## Accepted_models
```
bert-base-arabertv01
bert-base-arabert
bert-base-arabertv02
bert-base-arabertv2
bert-large-arabertv02
bert-large-arabertv2
araelectra-base
aragpt2-base
aragpt2-medium
aragpt2-large
aragpt2-mega
```
# TensorFlow 1.x models
The TF1.x model are available in the HuggingFace models repo.
You can download them as follows:
- via git-lfs: clone all the models in a repo
```bash
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash
sudo apt-get install git-lfs
git lfs install
git clone https://huggingface.co/aubmindlab/MODEL_NAME
tar -C ./MODEL_NAME -zxvf /content/MODEL_NAME/tf1_model.tar.gz
```
where `MODEL_NAME` is any model under the `aubmindlab` name
- via `wget`:
- Go to the tf1_model.tar.gz file on huggingface.co/models/aubmindlab/MODEL_NAME.
- copy the `oid sha256`
- then run `wget https://cdn-lfs.huggingface.co/aubmindlab/aragpt2-base/INSERT_THE_SHA_HERE` (ex: for `aragpt2-base`: `wget https://cdn-lfs.huggingface.co/aubmindlab/aragpt2-base/3766fc03d7c2593ff2fb991d275e96b81b0ecb2098b71ff315611d052ce65248`)
# If you used this model please cite us as :
Google Scholar has our Bibtex wrong (missing name), use this instead
```
@inproceedings{antoun2020arabert,
title={AraBERT: Transformer-based Model for Arabic Language Understanding},
author={Antoun, Wissam and Baly, Fady and Hajj, Hazem},
booktitle={LREC 2020 Workshop Language Resources and Evaluation Conference 11--16 May 2020},
pages={9}
}
```
# Acknowledgments
Thanks to TensorFlow Research Cloud (TFRC) for the free access to Cloud TPUs, couldn't have done it without this program, and to the [AUB MIND Lab](https://sites.aub.edu.lb/mindlab/) Members for the continous support. Also thanks to [Yakshof](https://www.yakshof.com/#/) and Assafir for data and storage access. Another thanks for Habib Rahal (https://www.behance.net/rahalhabib), for putting a face to AraBERT.
## Contacts
**Wissam Antoun**: [Linkedin](https://www.linkedin.com/in/wissam-antoun-622142b4/) | [Twitter](https://twitter.com/wissam_antoun) | [Github](https://github.com/WissamAntoun) | <[email protected]> | <[email protected]>
**Fady Baly**: [Linkedin](https://www.linkedin.com/in/fadybaly/) | [Twitter](https://twitter.com/fadybaly) | [Github](https://github.com/fadybaly) | <[email protected]> | <[email protected]>
|
megagonlabs/t5-base-japanese-web | 7a7211aacbdc06c47060793c6e032d22db2661af | 2021-09-06T10:32:21.000Z | [
"pytorch",
"t5",
"text2text-generation",
"ja",
"dataset:mc4",
"dataset:wiki40b",
"arxiv:1910.10683",
"transformers",
"seq2seq",
"license:apache-2.0",
"autotrain_compatible"
]
| text2text-generation | false | megagonlabs | null | megagonlabs/t5-base-japanese-web | 1,352 | 6 | transformers | 1,583 | ---
language: ja
tags:
- t5
- text2text-generation
- seq2seq
license: apache-2.0
datasets:
- mc4
- wiki40b
---
# t5-base-japanese-web (with Byte-fallback, 32K)
## Description
[megagonlabs/t5-base-japanese-web](https://huggingface.co/megagonlabs/t5-base-japanese-web) is a T5 (Text-to-Text Transfer Transformer) model pre-trained on Japanese web texts.
Training codes are [available on GitHub](https://github.com/megagonlabs/t5-japanese).
The vocabulary size of this model is 32K.
[8K version is also available](https://huggingface.co/megagonlabs/t5-base-japanese-web-8k).
### Corpora
We used following corpora for pre-training.
- Japanese in [mC4/3.0.1](https://huggingface.co/datasets/mc4) (We used [Tensorflow native format](https://github.com/allenai/allennlp/discussions/5056))
- 87,425,304 pages
- 782 GB in TFRecord format
- [Japanese](https://www.tensorflow.org/datasets/catalog/wiki40b#wiki40bja) in [wiki40b/1.3.0](https://www.tensorflow.org/datasets/catalog/wiki40b)
- 828,236 articles (2,073,584 examples)
- 2 GB in TFRecord format
### Tokenizer
We used Japanese Wikipedia to train [SentencePiece](https://github.com/google/sentencepiece).
- Vocabulary size: 32,000
- [Byte-fallback](https://github.com/google/sentencepiece/releases/tag/v0.1.9): Enabled
### Parameters
- T5 model: [models/t5.1.1.base.gin](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/t5/models/gin/models/t5.1.1.base.gin)
- Training steps: 1,000,000
It took about 126 hours with TPU v3-8
## Related models
- [日本語T5事前学習済みモデル (sonoisa/t5-base-japanese)](https://huggingface.co/sonoisa/t5-base-japanese)
- [日本語T5事前学習済みモデル (sonoisa/t5-base-japanese-mC4-Wikipedia)](https://huggingface.co/sonoisa/t5-base-japanese-mC4-Wikipedia)
## License
Apache License 2.0
## Citations
- mC4
Contains information from `mC4` which is made available under the [ODC Attribution License](https://opendatacommons.org/licenses/by/1-0/).
```bibtex
@article{2019t5,
author = {Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu},
title = {Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer},
journal = {arXiv e-prints},
year = {2019},
archivePrefix = {arXiv},
eprint = {1910.10683},
}
```
- wiki40b
```bibtex
@inproceedings{49029,
title = {Wiki-40B: Multilingual Language Model Dataset},
author = {Mandy Guo and Zihang Dai and Denny Vrandecic and Rami Al-Rfou},
year = {2020},
booktitle = {LREC 2020}
}
```
|
google/bert2bert_L-24_wmt_de_en | 3b460d3f76f9a4cb0d8c2946a63a28fbe5f66a83 | 2020-12-11T21:41:14.000Z | [
"pytorch",
"encoder-decoder",
"text2text-generation",
"en",
"de",
"dataset:wmt14",
"arxiv:1907.12461",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
]
| translation | false | google | null | google/bert2bert_L-24_wmt_de_en | 1,349 | 2 | transformers | 1,584 | ---
language:
- en
- de
license: apache-2.0
datasets:
- wmt14
tags:
- translation
---
# bert2bert_L-24_wmt_de_en EncoderDecoder model
The model was introduced in
[this paper](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn and first released in [this repository](https://tfhub.dev/google/bertseq2seq/bert24_de_en/1).
The model is an encoder-decoder model that was initialized on the `bert-large` checkpoints for both the encoder
and decoder and fine-tuned on German to English translation on the WMT dataset, which is linked above.
Disclaimer: The model card has been written by the Hugging Face team.
## How to use
You can use this model for translation, *e.g.*
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("google/bert2bert_L-24_wmt_de_en", pad_token="<pad>", eos_token="</s>", bos_token="<s>")
model = AutoModelForSeq2SeqLM.from_pretrained("google/bert2bert_L-24_wmt_de_en")
sentence = "Willst du einen Kaffee trinken gehen mit mir?"
input_ids = tokenizer(sentence, return_tensors="pt", add_special_tokens=False).input_ids
output_ids = model.generate(input_ids)[0]
print(tokenizer.decode(output_ids, skip_special_tokens=True))
# should output
# Want to drink a kaffee go with me? .
```
|
mrm8488/t5-small-finetuned-quora-for-paraphrasing | bd3a2ea4f1d31fc3270e0118b1deb02a85902f0c | 2020-12-11T21:56:30.000Z | [
"pytorch",
"t5",
"text2text-generation",
"en",
"dataset:quora",
"arxiv:1910.10683",
"transformers",
"autotrain_compatible"
]
| text2text-generation | false | mrm8488 | null | mrm8488/t5-small-finetuned-quora-for-paraphrasing | 1,348 | 5 | transformers | 1,585 | ---
language: en
datasets:
- quora
---
# T5-base fine-tuned on Quora question pair dataset for Question Paraphrasing ❓↔️❓
[Google's T5](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) fine-tuned on [Quodra question pair](https://huggingface.co/nlp/viewer/?dataset=quora) dataset for **Question Paraphrasing** task.
## Details of T5
The **T5** model was presented in [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/pdf/1910.10683.pdf) by *Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J. Liu* in Here the abstract:
Transfer learning, where a model is first pre-trained on a data-rich task before being fine-tuned on a downstream task, has emerged as a powerful technique in natural language processing (NLP). The effectiveness of transfer learning has given rise to a diversity of approaches, methodology, and practice. In this paper, we explore the landscape of transfer learning techniques for NLP by introducing a unified framework that converts every language problem into a text-to-text format. Our systematic study compares pre-training objectives, architectures, unlabeled datasets, transfer approaches, and other factors on dozens of language understanding tasks. By combining the insights from our exploration with scale and our new “Colossal Clean Crawled Corpus”, we achieve state-of-the-art results on many benchmarks covering summarization, question answering, text classification, and more. To facilitate future work on transfer learning for NLP, we release our dataset, pre-trained models, and code.

## Details of the downstream task (Question Paraphrasing) - Dataset 📚❓↔️❓
Dataset ID: ```quora``` from [Huggingface/NLP](https://github.com/huggingface/nlp)
| Dataset | Split | # samples |
| -------- | ----- | --------- |
| quora | train | 404290 |
| quora after filter repeated questions | train | 149263 |
Check out more about this dataset and others in [NLP Viewer](https://huggingface.co/nlp/viewer/)
## Model fine-tuning 🏋️
The training script is a slightly modified version of [this one](https://colab.research.google.com/github/patil-suraj/exploring-T5/blob/master/T5_on_TPU.ipynb)
## Model in Action 🚀
```python
from transformers import AutoModelWithLMHead, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("mrm8488/t5-small-finetuned-quora-for-paraphrasing")
model = AutoModelWithLMHead.from_pretrained("mrm8488/t5-small-finetuned-quora-for-paraphrasing")
def paraphrase(text, max_length=128):
input_ids = tokenizer.encode(text, return_tensors="pt", add_special_tokens=True)
generated_ids = model.generate(input_ids=input_ids, num_return_sequences=5, num_beams=5, max_length=max_length, no_repeat_ngram_size=2, repetition_penalty=3.5, length_penalty=1.0, early_stopping=True)
preds = [tokenizer.decode(g, skip_special_tokens=True, clean_up_tokenization_spaces=True) for g in generated_ids]
return preds
preds = paraphrase("paraphrase: What is the best framework for dealing with a huge text dataset?")
for pred in preds:
print(pred)
# Output:
'''
What is the best framework for dealing with a huge text dataset?
What is the best framework for dealing with a large text dataset?
What is the best framework to deal with a huge text dataset?
What are the best frameworks for dealing with a huge text dataset?
What is the best framework for dealing with huge text datasets?
'''
```
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488) | [LinkedIn](https://www.linkedin.com/in/manuel-romero-cs/)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
Helsinki-NLP/opus-mt-grk-en | ab6cfc132676a64ff077371a8140b2bcb30bb389 | 2021-01-18T08:53:09.000Z | [
"pytorch",
"marian",
"text2text-generation",
"el",
"grk",
"en",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
]
| translation | false | Helsinki-NLP | null | Helsinki-NLP/opus-mt-grk-en | 1,344 | null | transformers | 1,586 | ---
language:
- el
- grk
- en
tags:
- translation
license: apache-2.0
---
### grk-eng
* source group: Greek languages
* target group: English
* OPUS readme: [grk-eng](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/grk-eng/README.md)
* model: transformer
* source language(s): ell grc_Grek
* target language(s): eng
* model: transformer
* pre-processing: normalization + SentencePiece (spm12k,spm12k)
* download original weights: [opus2m-2020-08-01.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/grk-eng/opus2m-2020-08-01.zip)
* test set translations: [opus2m-2020-08-01.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/grk-eng/opus2m-2020-08-01.test.txt)
* test set scores: [opus2m-2020-08-01.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/grk-eng/opus2m-2020-08-01.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba-test.ell-eng.ell.eng | 65.9 | 0.779 |
| Tatoeba-test.grc-eng.grc.eng | 4.1 | 0.187 |
| Tatoeba-test.multi.eng | 60.9 | 0.733 |
### System Info:
- hf_name: grk-eng
- source_languages: grk
- target_languages: eng
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/grk-eng/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['el', 'grk', 'en']
- src_constituents: {'grc_Grek', 'ell'}
- tgt_constituents: {'eng'}
- src_multilingual: True
- tgt_multilingual: False
- prepro: normalization + SentencePiece (spm12k,spm12k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/grk-eng/opus2m-2020-08-01.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/grk-eng/opus2m-2020-08-01.test.txt
- src_alpha3: grk
- tgt_alpha3: eng
- short_pair: grk-en
- chrF2_score: 0.733
- bleu: 60.9
- brevity_penalty: 0.973
- ref_len: 62205.0
- src_name: Greek languages
- tgt_name: English
- train_date: 2020-08-01
- src_alpha2: grk
- tgt_alpha2: en
- prefer_old: False
- long_pair: grk-eng
- helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535
- transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b
- port_machine: brutasse
- port_time: 2020-08-21-14:41 |
sentence-transformers/nli-roberta-large | b10cddcd7069bcd76ad00ac3142005892d4e83bd | 2021-08-05T08:28:34.000Z | [
"pytorch",
"jax",
"roberta",
"feature-extraction",
"arxiv:1908.10084",
"sentence-transformers",
"sentence-similarity",
"transformers",
"license:apache-2.0"
]
| sentence-similarity | false | sentence-transformers | null | sentence-transformers/nli-roberta-large | 1,343 | null | sentence-transformers | 1,587 | ---
pipeline_tag: sentence-similarity
license: apache-2.0
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
**⚠️ This model is deprecated. Please don't use it as it produces sentence embeddings of low quality. You can find recommended sentence embedding models here: [SBERT.net - Pretrained Models](https://www.sbert.net/docs/pretrained_models.html)**
# sentence-transformers/nli-roberta-large
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 1024 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/nli-roberta-large')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/nli-roberta-large')
model = AutoModel.from_pretrained('sentence-transformers/nli-roberta-large')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/nli-roberta-large)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': True}) with Transformer model: RobertaModel
(1): Pooling({'word_embedding_dimension': 1024, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
``` |
M-CLIP/XLM-Roberta-Large-Vit-B-16Plus | e0035edeb83948e336724b7db6bd2c70c9750cf0 | 2022-07-20T17:28:54.000Z | [
"pytorch",
"tf",
"multilingual"
]
| null | false | M-CLIP | null | M-CLIP/XLM-Roberta-Large-Vit-B-16Plus | 1,340 | 1 | null | 1,588 | ---
language: multilingual
---
## Multilingual-clip: XLM-Roberta-Large-Vit-B-16Plus
Multilingual-CLIP extends OpenAI's English text encoders to multiple other languages. This model *only* contains the multilingual text encoder. The corresponding image model `Vit-B-16Plus` can be retrieved via instructions found on `mlfoundations` [open_clip repository on Github](https://github.com/mlfoundations/open_clip). We provide a usage example below.
## Requirements
To use both the multilingual text encoder and corresponding image encoder, we need to install the packages [`multilingual-clip`](https://github.com/FreddeFrallan/Multilingual-CLIP) and [`open_clip_torch`](https://github.com/mlfoundations/open_clip).
```
pip install multilingual-clip
pip install open_clip_torch
```
## Usage
Extracting embeddings from the text encoder can be done in the following way:
```python
from multilingual_clip import pt_multilingual_clip
import transformers
texts = [
'Three blind horses listening to Mozart.',
'Älgen är skogens konung!',
'Wie leben Eisbären in der Antarktis?',
'Вы знали, что все белые медведи левши?'
]
model_name = 'M-CLIP/XLM-Roberta-Large-Vit-B-16Plus'
# Load Model & Tokenizer
model = pt_multilingual_clip.MultilingualCLIP.from_pretrained(model_name)
tokenizer = transformers.AutoTokenizer.from_pretrained(model_name)
embeddings = model.forward(texts, tokenizer)
print("Text features shape:", embeddings.shape)
```
Extracting embeddings from the corresponding image encoder:
```python
import torch
import open_clip
import requests
from PIL import Image
device = "cuda" if torch.cuda.is_available() else "cpu"
model, _, preprocess = open_clip.create_model_and_transforms('ViT-B-16-plus-240', pretrained="laion400m_e32")
model.to(device)
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
image = preprocess(image).unsqueeze(0).to(device)
with torch.no_grad():
image_features = model.encode_image(image)
print("Image features shape:", image_features.shape)
```
## Evaluation results
None of the M-CLIP models have been extensivly evaluated, but testing them on Txt2Img retrieval on the humanly translated MS-COCO dataset, we see the following **R@10** results:
| Name | En | De | Es | Fr | Zh | It | Pl | Ko | Ru | Tr | Jp |
| ----------------------------------|:-----: |:-----: |:-----: |:-----: | :-----: |:-----: |:-----: |:-----: |:-----: |:-----: |:-----: |
| [OpenAI CLIP Vit-B/32](https://github.com/openai/CLIP)| 90.3 | - | - | - | - | - | - | - | - | - | - |
| [OpenAI CLIP Vit-L/14](https://github.com/openai/CLIP)| 91.8 | - | - | - | - | - | - | - | - | - | - |
| [OpenCLIP ViT-B-16+-](https://github.com/openai/CLIP)| 94.3 | - | - | - | - | - | - | - | - | - | - |
| [LABSE Vit-L/14](https://huggingface.co/M-CLIP/LABSE-Vit-L-14)| 91.6 | 89.6 | 89.5 | 89.9 | 88.9 | 90.1 | 89.8 | 80.8 | 85.5 | 89.8 | 73.9 |
| [XLM-R Large Vit-B/32](https://huggingface.co/M-CLIP/XLM-Roberta-Large-Vit-B-32)| 91.8 | 88.7 | 89.1 | 89.4 | 89.3 | 89.8| 91.4 | 82.1 | 86.1 | 88.8 | 81.0 |
| [XLM-R Vit-L/14](https://huggingface.co/M-CLIP/XLM-Roberta-Large-Vit-L-14)| 92.4 | 90.6 | 91.0 | 90.0 | 89.7 | 91.1 | 91.3 | 85.2 | 85.8 | 90.3 | 81.9 |
| [XLM-R Large Vit-B/16+](https://huggingface.co/M-CLIP/XLM-Roberta-Large-Vit-B-16Plus)| **95.0** | **93.0** | **93.6** | **93.1** | **94.0** | **93.1** | **94.4** | **89.0** | **90.0** | **93.0** | **84.2** |
## Training/Model details
Further details about the model training and data can be found in the [model card](https://github.com/FreddeFrallan/Multilingual-CLIP/blob/main/larger_mclip.md). |
princeton-nlp/unsup-simcse-bert-large-uncased | 5365919fdaeeab4b41ce3b963992a5648366c268 | 2021-05-20T02:59:52.000Z | [
"pytorch",
"jax",
"bert",
"feature-extraction",
"transformers"
]
| feature-extraction | false | princeton-nlp | null | princeton-nlp/unsup-simcse-bert-large-uncased | 1,339 | null | transformers | 1,589 | Entry not found |
alibaba-pai/pai-dkplm-medical-base-zh | e9e3272132ce4b7a13f1dd92a93a8b610c3e0b75 | 2022-05-17T02:25:18.000Z | [
"pytorch",
"bert",
"fill-mask",
"zh",
"arxiv:2205.00258",
"arxiv:2112.01047",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
]
| fill-mask | false | alibaba-pai | null | alibaba-pai/pai-dkplm-medical-base-zh | 1,339 | 2 | transformers | 1,590 | ---
language: zh
pipeline_tag: fill-mask
widget:
- text: "感冒需要吃[MASK]"
- text: "人类的[MASK]温是37度"
tags:
- bert
license: apache-2.0
---
## Chinese DKPLM (Decomposable Knowledge-enhanced Pre-trained Language Model) for the medical domain
For Chinese natural language processing in specific domains, we provide **Chinese DKPLM (Decomposable Knowledge-enhanced Pre-trained Language Model)** for the medical domain named **pai-dkplm-bert-zh**, from our AAAI 2021 paper named **DKPLM: Decomposable Knowledge-enhanced Pre-trained Language Model for Natural Language Understanding**.
This repository is developed based on the EasyNLP framework: [https://github.com/alibaba/EasyNLP](https://github.com/alibaba/EasyNLP ) developed by the Alibaba PAI team. Please find the DKPLM tutorial here: [DKPLM Tutorial](https://github.com/alibaba/EasyNLP/tree/master/examples/dkplm_pretraining).
## Citation
If you find the resource is useful, please cite the following papers in your work.
- For the EasyNLP framework:
```
@article{easynlp,
title = {EasyNLP: A Comprehensive and Easy-to-use Toolkit for Natural Language Processing},
publisher = {arXiv},
author = {Wang, Chengyu and Qiu, Minghui and Zhang, Taolin and Liu, Tingting and Li, Lei and Wang, Jianing and Wang, Ming and Huang, Jun and Lin, Wei},
url = {https://arxiv.org/abs/2205.00258},
year = {2022}
}
```
- For DKPLM:
```
@article{dkplm,
title = {DKPLM: Decomposable Knowledge-enhanced Pre-trained Language Model for Natural Language Understanding},
author = {Zhang, Taolin and Wang, Chengyu and Hu, Nan and Qiu, Minghui and Tang, Chengguang and He, Xiaofeng and Huang, Jun},
url = {https://arxiv.org/abs/2112.01047},
publisher = {AAAI},
year = {2021}
}
``` |
deepmind/vision-perceiver-conv | 795b5eea5867940bd8fa46105029874afce6f037 | 2021-12-11T13:12:42.000Z | [
"pytorch",
"perceiver",
"image-classification",
"dataset:imagenet",
"arxiv:2107.14795",
"transformers",
"license:apache-2.0"
]
| image-classification | false | deepmind | null | deepmind/vision-perceiver-conv | 1,338 | 3 | transformers | 1,591 | ---
license: apache-2.0
tags:
datasets:
- imagenet
---
# Perceiver IO for vision (convolutional processing)
Perceiver IO model pre-trained on ImageNet (14 million images, 1,000 classes) at resolution 224x224. It was introduced in the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Jaegle et al. and first released in [this repository](https://github.com/deepmind/deepmind-research/tree/master/perceiver).
Disclaimer: The team releasing Perceiver IO did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
Perceiver IO is a transformer encoder model that can be applied on any modality (text, images, audio, video, ...). The core idea is to employ the self-attention mechanism on a not-too-large set of latent vectors (e.g. 256 or 512), and only use the inputs to perform cross-attention with the latents. This allows for the time and memory requirements of the self-attention mechanism to not depend on the size of the inputs.
To decode, the authors employ so-called decoder queries, which allow to flexibly decode the final hidden states of the latents to produce outputs of arbitrary size and semantics. For image classification, the output is a tensor containing the logits, of shape (batch_size, num_labels).
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/perceiver_architecture.jpg" alt="drawing" width="600"/>
<small> Perceiver IO architecture.</small>
As the time and memory requirements of the self-attention mechanism don't depend on the size of the inputs, the Perceiver IO authors can train the model directly on raw pixel values, rather than on patches as is done in ViT. This particular model employs a simple 2D conv+maxpool preprocessing network on the pixel values, before using the inputs for cross-attention with the latents.
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by replacing the classification decoder.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=deepmind/perceiver) to look for other fine-tuned versions on a task that may interest you.
### How to use
Here is how to use this model in PyTorch:
```python
from transformers import PerceiverFeatureExtractor, PerceiverForImageClassificationConvProcessing
import requests
from PIL import Image
feature_extractor = PerceiverFeatureExtractor.from_pretrained("deepmind/vision-perceiver-conv")
model = PerceiverForImageClassificationConvProcessing.from_pretrained("deepmind/vision-perceiver-conv")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
# prepare input
inputs = feature_extractor(image, return_tensors="pt").pixel_values
# forward pass
outputs = model(inputs)
logits = outputs.logits
print("Predicted class:", model.config.id2label[logits.argmax(-1).item()])
>>> should print Predicted class: tabby, tabby cat
```
## Training data
This model was pretrained on [ImageNet](http://www.image-net.org/), a dataset consisting of 14 million images and 1k classes.
## Training procedure
### Preprocessing
Images are center cropped and resized to a resolution of 224x224 and normalized across the RGB channels. Note that data augmentation was used during pre-training, as explained in Appendix H of the [paper](https://arxiv.org/abs/2107.14795).
### Pretraining
Hyperparameter details can be found in Appendix H of the [paper](https://arxiv.org/abs/2107.14795).
## Evaluation results
This model is able to achieve a top-1 accuracy of 82.1 on ImageNet-1k.
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2107-14795,
author = {Andrew Jaegle and
Sebastian Borgeaud and
Jean{-}Baptiste Alayrac and
Carl Doersch and
Catalin Ionescu and
David Ding and
Skanda Koppula and
Daniel Zoran and
Andrew Brock and
Evan Shelhamer and
Olivier J. H{\'{e}}naff and
Matthew M. Botvinick and
Andrew Zisserman and
Oriol Vinyals and
Jo{\~{a}}o Carreira},
title = {Perceiver {IO:} {A} General Architecture for Structured Inputs {\&}
Outputs},
journal = {CoRR},
volume = {abs/2107.14795},
year = {2021},
url = {https://arxiv.org/abs/2107.14795},
eprinttype = {arXiv},
eprint = {2107.14795},
timestamp = {Tue, 03 Aug 2021 14:53:34 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2107-14795.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` |
cffl/bert-base-styleclassification-subjective-neutral | 1339b8de703cb52c729475a89427078052af8595 | 2022-07-12T11:57:42.000Z | [
"pytorch",
"bert",
"text-classification",
"arxiv:1911.09709",
"arxiv:1703.01365",
"transformers",
"license:apache-2.0"
]
| text-classification | false | cffl | null | cffl/bert-base-styleclassification-subjective-neutral | 1,332 | 1 | transformers | 1,592 | ---
license: apache-2.0
---
# bert-base-styleclassification-subjective-neutral
## Model description
This [bert-base-uncased](https://huggingface.co/bert-base-uncased) model has been fine-tuned on the [Wiki Neutrality Corpus (WNC)](https://arxiv.org/pdf/1911.09709.pdf) - a parallel corpus of 180,000 biased and neutralized sentence pairs along with contextual sentences and metadata. The model can be used to classify text as subjectively biased vs. neutrally toned.
The development and modeling efforts that produced this model are documented in detail through [this blog series](https://blog.fastforwardlabs.com/2022/05/05/neutralizing-subjectivity-bias-with-huggingface-transformers.html).
## Intended uses & limitations
The model is intended purely as a research output for NLP and data science communities. We developed this model for the purpose of evaluating text style transfer output. Specifically, we derive a Style Transfer Intensity (STI) metric from the classifier's output distributions. We also extract feautre importances from the model via [Integrated Gradients](https://arxiv.org/pdf/1703.01365.pdf) with support a Content Preservation Score (CPS).
We imagine this model will be used by researchers to better understand the limitations, robustness, and generalization of text style transfer models. Ultimately, we hope this model will inspire future work on text style transfer and serve as a benchmarking tool for the style attribute of subjectivity bias, specifically.
Any production use of this model - whether commercial or not - is currently not intended. This is because, as [the team at OpenAI points out](https://github.com/openai/gpt-2/blob/master/model_card.md#out-of-scope-use-cases), large langauge models like BERT reflect biases inherent to the systems they were trained on, so we do not recommend that they be deployed into systems that interact with humans, unless the deployers first carry out a study of biases relevant to the intended use-case. Neither the model nor the WNC dataset has been sufficiently evaluated for performance and bias.
As we discuss in the blog series, since the WNC is a parallel dataset and we formulate the learning task as a supervised problem, the model indirectly adopts Wikipedia's NPOV policy as the definition for "neutrality" and "subjectivity". The NPOV policy may not fully reflect an end users assumed/intended meaning of subjectivity because the notion of subjectivity itself can be...well, subjective.
We discovered through our exploratory work that the WNC does contain data quality issues that will contribute to unintended bias in the model. For example, some NPOV revisions introduce factual information outside the context of the prompt as a means to correct bias. We believe these factual based edits are out of scope for a subjective-to-neutral style transfer modeling task, but exist here nonetheless.
## How to use
This model can be used directly with a HuggingFace pipeline for `text2text-generation`.
```python
>>> from transformers import pipeline
>>> classify = pipeline(
task="text-classification",
model="cffl/bert-base-styleclassification-subjective-neutral",
return_all_scores=True,
)
>>> input_text = "chemical abstracts service (cas), a prominent division of the american chemical society, is the world's leading source of chemical information."
>>> classify(input_text)
[[{'label': 'SUBJECTIVE', 'score': 0.9765084385871887},
{'label': 'NEUTRAL', 'score': 0.023491567000746727}]]
```
## Training procedure
For training, we initialize HuggingFace’s [AutoModelforSequenceClassification](https://huggingface.co/docs/transformers/model_doc/auto#transformers.AutoModelForSequenceClassification) with [bert-base-uncased](https://huggingface.co/bert-base-uncased) pre-trained weights and perform a hyperparameter search over: batch size [16, 32], learning rate [3e-05, 3e-06, 3e-07], weight decay [0, 0.01, 0.1] and batch shuffling [True, False] while training for 15 epochs.
We monitor performance using accuracy as we have a perfectly balanced dataset and assign equal cost to false positives and false negatives. The best performing model produces an overall accuracy of 72.50% -- please reference our [training script](https://github.com/fastforwardlabs/text-style-transfer/blob/main/scripts/train/classifier/train_classifier.py) and [classifier evaluation notebook](https://github.com/fastforwardlabs/text-style-transfer/blob/main/notebooks/WNC_full_style_classifier_evaluation.ipynb) for further details.
|
murali1996/bert-base-cased-spell-correction | d2a5bbccc41a0f4ff5e7c16e1c3b8d96ba8883b2 | 2021-05-20T01:04:57.000Z | [
"pytorch",
"jax",
"bert",
"feature-extraction",
"transformers"
]
| feature-extraction | false | murali1996 | null | murali1996/bert-base-cased-spell-correction | 1,326 | 4 | transformers | 1,593 | `bert-base-cased` trained for spelling correction. See [neuspell](https://github.com/neuspell/neuspell) repository for more details about training and evaluating the model. |
nvidia/segformer-b5-finetuned-cityscapes-1024-1024 | ff4c15ea9518e6aea09252e4ca719f049f11dc09 | 2022-07-20T09:53:14.000Z | [
"pytorch",
"tf",
"segformer",
"dataset:cityscapes",
"arxiv:2105.15203",
"transformers",
"vision",
"image-segmentation",
"license:apache-2.0"
]
| image-segmentation | false | nvidia | null | nvidia/segformer-b5-finetuned-cityscapes-1024-1024 | 1,323 | 2 | transformers | 1,594 | ---
license: apache-2.0
tags:
- vision
- image-segmentation
datasets:
- cityscapes
widget:
- src: https://www.researchgate.net/profile/Anurag-Arnab/publication/315881952/figure/fig5/AS:667673876779033@1536197265755/Sample-results-on-the-Cityscapes-dataset-The-above-images-show-how-our-method-can-handle.jpg
example_title: Road
---
# SegFormer (b5-sized) model fine-tuned on CityScapes
SegFormer model fine-tuned on CityScapes at resolution 1024x1024. It was introduced in the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Xie et al. and first released in [this repository](https://github.com/NVlabs/SegFormer).
Disclaimer: The team releasing SegFormer did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
SegFormer consists of a hierarchical Transformer encoder and a lightweight all-MLP decode head to achieve great results on semantic segmentation benchmarks such as ADE20K and Cityscapes. The hierarchical Transformer is first pre-trained on ImageNet-1k, after which a decode head is added and fine-tuned altogether on a downstream dataset.
## Intended uses & limitations
You can use the raw model for semantic segmentation. See the [model hub](https://huggingface.co/models?other=segformer) to look for fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import SegformerFeatureExtractor, SegformerForSemanticSegmentation
from PIL import Image
import requests
feature_extractor = SegformerFeatureExtractor.from_pretrained("nvidia/segformer-b5-finetuned-cityscapes-1024-1024")
model = SegformerForSemanticSegmentation.from_pretrained("nvidia/segformer-b5-finetuned-cityscapes-1024-1024")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits # shape (batch_size, num_labels, height/4, width/4)
```
For more code examples, we refer to the [documentation](https://huggingface.co/transformers/model_doc/segformer.html#).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2105-15203,
author = {Enze Xie and
Wenhai Wang and
Zhiding Yu and
Anima Anandkumar and
Jose M. Alvarez and
Ping Luo},
title = {SegFormer: Simple and Efficient Design for Semantic Segmentation with
Transformers},
journal = {CoRR},
volume = {abs/2105.15203},
year = {2021},
url = {https://arxiv.org/abs/2105.15203},
eprinttype = {arXiv},
eprint = {2105.15203},
timestamp = {Wed, 02 Jun 2021 11:46:42 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2105-15203.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
ethanyt/guwen-punc | 3e456b0b271984421c3012a56099420819d95eff | 2021-06-17T06:56:46.000Z | [
"pytorch",
"roberta",
"token-classification",
"zh",
"transformers",
"chinese",
"classical chinese",
"literary chinese",
"ancient chinese",
"bert",
"punctuation marker",
"license:apache-2.0",
"autotrain_compatible"
]
| token-classification | false | ethanyt | null | ethanyt/guwen-punc | 1,314 | 3 | transformers | 1,595 | ---
language:
- "zh"
thumbnail: "https://user-images.githubusercontent.com/9592150/97142000-cad08e00-179a-11eb-88df-aff9221482d8.png"
tags:
- "chinese"
- "classical chinese"
- "literary chinese"
- "ancient chinese"
- "bert"
- "pytorch"
- "punctuation marker"
license: "apache-2.0"
pipeline_tag: "token-classification"
widget:
- text: "及秦始皇灭先代典籍焚书坑儒天下学士逃难解散我先人用藏其家书于屋壁汉室龙兴开设学校旁求儒雅以阐大猷济南伏生年过九十失其本经口以传授裁二十馀篇以其上古之书谓之尚书百篇之义世莫得闻"
---
# Guwen Punc
A Classical Chinese Punctuation Marker.
See also:
<a href="https://github.com/ethan-yt/guwen-models">
<img align="center" width="400" src="https://github-readme-stats.vercel.app/api/pin/?username=ethan-yt&repo=guwen-models&bg_color=30,e96443,904e95&title_color=fff&text_color=fff&icon_color=fff&show_owner=true" />
</a>
<a href="https://github.com/ethan-yt/cclue/">
<img align="center" width="400" src="https://github-readme-stats.vercel.app/api/pin/?username=ethan-yt&repo=cclue&bg_color=30,e96443,904e95&title_color=fff&text_color=fff&icon_color=fff&show_owner=true" />
</a>
<a href="https://github.com/ethan-yt/guwenbert/">
<img align="center" width="400" src="https://github-readme-stats.vercel.app/api/pin/?username=ethan-yt&repo=guwenbert&bg_color=30,e96443,904e95&title_color=fff&text_color=fff&icon_color=fff&show_owner=true" />
</a> |
facebook/hubert-large-ll60k | ff022d095678a2995f3c49bab18a96a9e553f782 | 2021-11-05T12:42:57.000Z | [
"pytorch",
"tf",
"hubert",
"feature-extraction",
"en",
"dataset:libri-light",
"arxiv:2106.07447",
"transformers",
"speech",
"license:apache-2.0"
]
| feature-extraction | false | facebook | null | facebook/hubert-large-ll60k | 1,314 | 4 | transformers | 1,596 | ---
language: en
datasets:
- libri-light
tags:
- speech
license: apache-2.0
---
# Hubert-Large
[Facebook's Hubert](https://ai.facebook.com/blog/hubert-self-supervised-representation-learning-for-speech-recognition-generation-and-compression)
The large model pretrained on 16kHz sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz.
**Note**: This model does not have a tokenizer as it was pretrained on audio alone. In order to use this model **speech recognition**, a tokenizer should be created and the model should be fine-tuned on labeled text data. Check out [this blog](https://huggingface.co/blog/fine-tune-wav2vec2-english) for more in-detail explanation of how to fine-tune the model.
The model was pretrained on [Libri-Light](https://github.com/facebookresearch/libri-light).
[Paper](https://arxiv.org/abs/2106.07447)
Authors: Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed
**Abstract**
Self-supervised approaches for speech representation learning are challenged by three unique problems: (1) there are multiple sound units in each input utterance, (2) there is no lexicon of input sound units during the pre-training phase, and (3) sound units have variable lengths with no explicit segmentation. To deal with these three problems, we propose the Hidden-Unit BERT (HuBERT) approach for self-supervised speech representation learning, which utilizes an offline clustering step to provide aligned target labels for a BERT-like prediction loss. A key ingredient of our approach is applying the prediction loss over the masked regions only, which forces the model to learn a combined acoustic and language model over the continuous inputs. HuBERT relies primarily on the consistency of the unsupervised clustering step rather than the intrinsic quality of the assigned cluster labels. Starting with a simple k-means teacher of 100 clusters, and using two iterations of clustering, the HuBERT model either matches or improves upon the state-of-the-art wav2vec 2.0 performance on the Librispeech (960h) and Libri-light (60,000h) benchmarks with 10min, 1h, 10h, 100h, and 960h fine-tuning subsets. Using a 1B parameter model, HuBERT shows up to 19% and 13% relative WER reduction on the more challenging dev-other and test-other evaluation subsets.
The original model can be found under https://github.com/pytorch/fairseq/tree/master/examples/hubert .
# Usage
See [this blog](https://huggingface.co/blog/fine-tune-wav2vec2-english) for more information on how to fine-tune the model. Note that the class `Wav2Vec2ForCTC` has to be replaced by `HubertForCTC`. |
KES/T5-KES | e43052db0de09ec41e86ff586a0ba4f1f9defd62 | 2022-07-02T02:41:16.000Z | [
"pytorch",
"t5",
"text2text-generation",
"en",
"dataset:jfleg",
"arxiv:1702.04066",
"transformers",
"sentence correction",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible"
]
| text2text-generation | false | KES | null | KES/T5-KES | 1,312 | 1 | transformers | 1,597 | ---
language: en
tags:
- sentence correction
- text2text-generation
license: cc-by-nc-sa-4.0
datasets:
- jfleg
---
# Model
This model utilises T5-base pre-trained model. It was fine tuned using a modified version of the [JFLEG](https://arxiv.org/abs/1702.04066) dataset and [Happy Transformer framework](https://github.com/EricFillion/happy-transformer). This model was fine-tuned for sentence correction on normal English translations and positional English translations of local Caribbean English Creole. This model will be updated periodically as more data is compiled. For more on the Caribbean English Creole checkout the library [Caribe](https://pypi.org/project/Caribe/).
___
# Re-training/Fine Tuning
The results of fine-tuning resulted in a final accuracy of 90%
# Usage
```python
from happytransformer import HappyTextToText, TTSettings
pre_trained_model="T5"
model = HappyTextToText(pre_trained_model, "KES/T5-KES")
arguments = TTSettings(num_beams=4, min_length=1)
sentence = "Wat iz your nam"
correction = model.generate_text("grammar: "+sentence, args=arguments)
if(correction.text.find(" .")):
correction.text=correction.text.replace(" .", ".")
print(correction.text) # Correction: "What is your name?".
```
___
# Usage with Transformers
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("KES/T5-KES")
model = AutoModelForSeq2SeqLM.from_pretrained("KES/T5-KES")
text = "I am lived with my parenmts "
inputs = tokenizer("grammar:"+text, truncation=True, return_tensors='pt')
output = model.generate(inputs['input_ids'], num_beams=4, max_length=512, early_stopping=True)
correction=tokenizer.batch_decode(output, skip_special_tokens=True)
print("".join(correction)) #Correction: I am living with my parents.
```
___
|
airesearch/wav2vec2-large-xlsr-53-th | 3155938c549b23eee16b1d4b55dcb161b7fe4bcf | 2022-03-23T18:24:45.000Z | [
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"th",
"dataset:common_voice",
"transformers",
"audio",
"hf-asr-leaderboard",
"robust-speech-event",
"speech",
"xlsr-fine-tuning",
"license:cc-by-sa-4.0",
"model-index"
]
| automatic-speech-recognition | false | airesearch | null | airesearch/wav2vec2-large-xlsr-53-th | 1,312 | 2 | transformers | 1,598 | ---
language: th
datasets:
- common_voice
tags:
- audio
- automatic-speech-recognition
- hf-asr-leaderboard
- robust-speech-event
- speech
- xlsr-fine-tuning
license: cc-by-sa-4.0
model-index:
- name: XLS-R-53 - Thai
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 7
type: mozilla-foundation/common_voice_7_0
args: th
metrics:
- name: Test WER
type: wer
value: 0.9524
- name: Test SER
type: ser
value: 1.2346
- name: Test CER
type: cer
value: 0.1623
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Robust Speech Event - Dev Data
type: speech-recognition-community-v2/dev_data
args: sv
metrics:
- name: Test WER
type: wer
value: null
- name: Test SER
type: ser
value: null
- name: Test CER
type: cer
value: null
---
# `wav2vec2-large-xlsr-53-th`
Finetuning `wav2vec2-large-xlsr-53` on Thai [Common Voice 7.0](https://commonvoice.mozilla.org/en/datasets)
[Read more on our blog](https://medium.com/airesearch-in-th/airesearch-in-th-3c1019a99cd)
We finetune [wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) based on [Fine-tuning Wav2Vec2 for English ASR](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Fine_tuning_Wav2Vec2_for_English_ASR.ipynb) using Thai examples of [Common Voice Corpus 7.0](https://commonvoice.mozilla.org/en/datasets). The notebooks and scripts can be found in [vistec-ai/wav2vec2-large-xlsr-53-th](https://github.com/vistec-ai/wav2vec2-large-xlsr-53-th). The pretrained model and processor can be found at [airesearch/wav2vec2-large-xlsr-53-th](https://huggingface.co/airesearch/wav2vec2-large-xlsr-53-th).
## `robust-speech-event`
Add `syllable_tokenize`, `word_tokenize` ([PyThaiNLP](https://github.com/PyThaiNLP/pythainlp)) and [deepcut](https://github.com/rkcosmos/deepcut) tokenizers to `eval.py` from [robust-speech-event](https://github.com/huggingface/transformers/tree/master/examples/research_projects/robust-speech-event#evaluation)
```
> python eval.py --model_id ./ --dataset mozilla-foundation/common_voice_7_0 --config th --split test --log_outputs --thai_tokenizer newmm/syllable/deepcut/cer
```
### Eval results on Common Voice 7 "test":
| | WER PyThaiNLP 2.3.1 | WER deepcut | SER | CER |
|---------------------------------|---------------------|-------------|---------|---------|
| Only Tokenization | 0.9524% | 2.5316% | 1.2346% | 0.1623% |
| Cleaning rules and Tokenization | TBD | TBD | TBD | TBD |
## Usage
```
#load pretrained processor and model
processor = Wav2Vec2Processor.from_pretrained("airesearch/wav2vec2-large-xlsr-53-th")
model = Wav2Vec2ForCTC.from_pretrained("airesearch/wav2vec2-large-xlsr-53-th")
#function to resample to 16_000
def speech_file_to_array_fn(batch,
text_col="sentence",
fname_col="path",
resampling_to=16000):
speech_array, sampling_rate = torchaudio.load(batch[fname_col])
resampler=torchaudio.transforms.Resample(sampling_rate, resampling_to)
batch["speech"] = resampler(speech_array)[0].numpy()
batch["sampling_rate"] = resampling_to
batch["target_text"] = batch[text_col]
return batch
#get 2 examples as sample input
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
#infer
with torch.no_grad():
logits = model(inputs.input_values,).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
>> Prediction: ['และ เขา ก็ สัมผัส ดีบุก', 'คุณ สามารถ รับทราบ เมื่อ ข้อความ นี้ ถูก อ่าน แล้ว']
>> Reference: ['และเขาก็สัมผัสดีบุก', 'คุณสามารถรับทราบเมื่อข้อความนี้ถูกอ่านแล้ว']
```
## Datasets
Common Voice Corpus 7.0](https://commonvoice.mozilla.org/en/datasets) contains 133 validated hours of Thai (255 total hours) at 5GB. We pre-tokenize with `pythainlp.tokenize.word_tokenize`. We preprocess the dataset using cleaning rules described in `notebooks/cv-preprocess.ipynb` by [@tann9949](https://github.com/tann9949). We then deduplicate and split as described in [ekapolc/Thai_commonvoice_split](https://github.com/ekapolc/Thai_commonvoice_split) in order to 1) avoid data leakage due to random splits after cleaning in [Common Voice Corpus 7.0](https://commonvoice.mozilla.org/en/datasets) and 2) preserve the majority of the data for the training set. The dataset loading script is `scripts/th_common_voice_70.py`. You can use this scripts together with `train_cleand.tsv`, `validation_cleaned.tsv` and `test_cleaned.tsv` to have the same splits as we do. The resulting dataset is as follows:
```
DatasetDict({
train: Dataset({
features: ['path', 'sentence'],
num_rows: 86586
})
test: Dataset({
features: ['path', 'sentence'],
num_rows: 2502
})
validation: Dataset({
features: ['path', 'sentence'],
num_rows: 3027
})
})
```
## Training
We fintuned using the following configuration on a single V100 GPU and chose the checkpoint with the lowest validation loss. The finetuning script is `scripts/wav2vec2_finetune.py`
```
# create model
model = Wav2Vec2ForCTC.from_pretrained(
"facebook/wav2vec2-large-xlsr-53",
attention_dropout=0.1,
hidden_dropout=0.1,
feat_proj_dropout=0.0,
mask_time_prob=0.05,
layerdrop=0.1,
gradient_checkpointing=True,
ctc_loss_reduction="mean",
pad_token_id=processor.tokenizer.pad_token_id,
vocab_size=len(processor.tokenizer)
)
model.freeze_feature_extractor()
training_args = TrainingArguments(
output_dir="../data/wav2vec2-large-xlsr-53-thai",
group_by_length=True,
per_device_train_batch_size=32,
gradient_accumulation_steps=1,
per_device_eval_batch_size=16,
metric_for_best_model='wer',
evaluation_strategy="steps",
eval_steps=1000,
logging_strategy="steps",
logging_steps=1000,
save_strategy="steps",
save_steps=1000,
num_train_epochs=100,
fp16=True,
learning_rate=1e-4,
warmup_steps=1000,
save_total_limit=3,
report_to="tensorboard"
)
```
## Evaluation
We benchmark on the test set using WER with words tokenized by [PyThaiNLP](https://github.com/PyThaiNLP/pythainlp) 2.3.1 and [deepcut](https://github.com/rkcosmos/deepcut), and CER. We also measure performance when spell correction using [TNC](http://www.arts.chula.ac.th/ling/tnc/) ngrams is applied. Evaluation codes can be found in `notebooks/wav2vec2_finetuning_tutorial.ipynb`. Benchmark is performed on `test-unique` split.
| | WER PyThaiNLP 2.3.1 | WER deepcut | CER |
|--------------------------------|---------------------|----------------|----------------|
| [Kaldi from scratch](https://github.com/vistec-AI/commonvoice-th) | 23.04 | | 7.57 |
| Ours without spell correction | 13.634024 | **8.152052** | **2.813019** |
| Ours with spell correction | 17.996397 | 14.167975 | 5.225761 |
| Google Web Speech API※ | 13.711234 | 10.860058 | 7.357340 |
| Microsoft Bing Speech API※ | **12.578819** | 9.620991 | 5.016620 |
| Amazon Transcribe※ | 21.86334 | 14.487553 | 7.077562 |
| NECTEC AI for Thai Partii API※ | 20.105887 | 15.515631 | 9.551027 |
※ APIs are not finetuned with Common Voice 7.0 data
## LICENSE
[cc-by-sa 4.0](https://github.com/vistec-AI/wav2vec2-large-xlsr-53-th/blob/main/LICENSE)
## Ackowledgements
* model training and validation notebooks/scripts [@cstorm125](https://github.com/cstorm125/)
* dataset cleaning scripts [@tann9949](https://github.com/tann9949)
* dataset splits [@ekapolc](https://github.com/ekapolc/) and [@14mss](https://github.com/14mss)
* running the training [@mrpeerat](https://github.com/mrpeerat)
* spell correction [@wannaphong](https://github.com/wannaphong)
|
Intel/dpt-large-ade | c9a80469a44109742a2b44a820fe34eb897efb3c | 2022-04-14T08:29:24.000Z | [
"pytorch",
"dpt",
"dataset:scene_parse_150",
"arxiv:2103.13413",
"transformers",
"vision",
"image-segmentation",
"license:apache-2.0"
]
| image-segmentation | false | Intel | null | Intel/dpt-large-ade | 1,311 | null | transformers | 1,599 | ---
license: apache-2.0
tags:
- vision
- image-segmentation
datasets:
- scene_parse_150
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
---
# DPT (large-sized model) fine-tuned on ADE20k
Dense Prediction Transformer (DPT) model trained on ADE20k for semantic segmentation. It was introduced in the paper [Vision Transformers for Dense Prediction](https://arxiv.org/abs/2103.13413) by Ranftl et al. and first released in [this repository](https://github.com/isl-org/DPT).
Disclaimer: The team releasing DPT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
DPT uses the Vision Transformer (ViT) as backbone and adds a neck + head on top for semantic segmentation.

## Intended uses & limitations
You can use the raw model for semantic segmentation. See the [model hub](https://huggingface.co/models?search=dpt) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model:
```python
from transformers import DPTFeatureExtractor, DPTForSemanticSegmentation
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = DPTFeatureExtractor.from_pretrained("Intel/dpt-large-ade")
model = DPTForSemanticSegmentation.from_pretrained("Intel/dpt-large-ade")
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
```
For more code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/master/en/model_doc/dpt).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2103-13413,
author = {Ren{\'{e}} Ranftl and
Alexey Bochkovskiy and
Vladlen Koltun},
title = {Vision Transformers for Dense Prediction},
journal = {CoRR},
volume = {abs/2103.13413},
year = {2021},
url = {https://arxiv.org/abs/2103.13413},
eprinttype = {arXiv},
eprint = {2103.13413},
timestamp = {Wed, 07 Apr 2021 15:31:46 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2103-13413.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.