
modelId
stringlengths 4
112
| sha
stringlengths 40
40
| lastModified
stringlengths 24
24
| tags
sequence | pipeline_tag
stringclasses 29
values | private
bool 1
class | author
stringlengths 2
38
⌀ | config
null | id
stringlengths 4
112
| downloads
float64 0
36.8M
⌀ | likes
float64 0
712
⌀ | library_name
stringclasses 17
values | __index_level_0__
int64 0
38.5k
| readme
stringlengths 0
186k
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Helsinki-NLP/opus-mt-en-roa | ac8c907c99b8939697a1793862d4c34159c408d7 | 2021-01-18T08:15:13.000Z | [
"pytorch",
"rust",
"marian",
"text2text-generation",
"en",
"it",
"ca",
"rm",
"es",
"ro",
"gl",
"co",
"wa",
"pt",
"oc",
"an",
"id",
"fr",
"ht",
"roa",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] | translation | false | Helsinki-NLP | null | Helsinki-NLP/opus-mt-en-roa | 1,108 | null | transformers | 1,700 | ---
language:
- en
- it
- ca
- rm
- es
- ro
- gl
- co
- wa
- pt
- oc
- an
- id
- fr
- ht
- roa
tags:
- translation
license: apache-2.0
---
### eng-roa
* source group: English
* target group: Romance languages
* OPUS readme: [eng-roa](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/eng-roa/README.md)
* model: transformer
* source language(s): eng
* target language(s): arg ast cat cos egl ext fra frm_Latn gcf_Latn glg hat ind ita lad lad_Latn lij lld_Latn lmo max_Latn mfe min mwl oci pap pms por roh ron scn spa tmw_Latn vec wln zlm_Latn zsm_Latn
* model: transformer
* pre-processing: normalization + SentencePiece (spm32k,spm32k)
* a sentence initial language token is required in the form of `>>id<<` (id = valid target language ID)
* download original weights: [opus2m-2020-08-01.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-roa/opus2m-2020-08-01.zip)
* test set translations: [opus2m-2020-08-01.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-roa/opus2m-2020-08-01.test.txt)
* test set scores: [opus2m-2020-08-01.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-roa/opus2m-2020-08-01.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| newsdev2016-enro-engron.eng.ron | 27.6 | 0.567 |
| newsdiscussdev2015-enfr-engfra.eng.fra | 30.2 | 0.575 |
| newsdiscusstest2015-enfr-engfra.eng.fra | 35.5 | 0.612 |
| newssyscomb2009-engfra.eng.fra | 27.9 | 0.570 |
| newssyscomb2009-engita.eng.ita | 29.3 | 0.590 |
| newssyscomb2009-engspa.eng.spa | 29.6 | 0.570 |
| news-test2008-engfra.eng.fra | 25.2 | 0.538 |
| news-test2008-engspa.eng.spa | 27.3 | 0.548 |
| newstest2009-engfra.eng.fra | 26.9 | 0.560 |
| newstest2009-engita.eng.ita | 28.7 | 0.583 |
| newstest2009-engspa.eng.spa | 29.0 | 0.568 |
| newstest2010-engfra.eng.fra | 29.3 | 0.574 |
| newstest2010-engspa.eng.spa | 34.2 | 0.601 |
| newstest2011-engfra.eng.fra | 31.4 | 0.592 |
| newstest2011-engspa.eng.spa | 35.0 | 0.599 |
| newstest2012-engfra.eng.fra | 29.5 | 0.576 |
| newstest2012-engspa.eng.spa | 35.5 | 0.603 |
| newstest2013-engfra.eng.fra | 29.9 | 0.567 |
| newstest2013-engspa.eng.spa | 32.1 | 0.578 |
| newstest2016-enro-engron.eng.ron | 26.1 | 0.551 |
| Tatoeba-test.eng-arg.eng.arg | 1.4 | 0.125 |
| Tatoeba-test.eng-ast.eng.ast | 17.8 | 0.406 |
| Tatoeba-test.eng-cat.eng.cat | 48.3 | 0.676 |
| Tatoeba-test.eng-cos.eng.cos | 3.2 | 0.275 |
| Tatoeba-test.eng-egl.eng.egl | 0.2 | 0.084 |
| Tatoeba-test.eng-ext.eng.ext | 11.2 | 0.344 |
| Tatoeba-test.eng-fra.eng.fra | 45.3 | 0.637 |
| Tatoeba-test.eng-frm.eng.frm | 1.1 | 0.221 |
| Tatoeba-test.eng-gcf.eng.gcf | 0.6 | 0.118 |
| Tatoeba-test.eng-glg.eng.glg | 44.2 | 0.645 |
| Tatoeba-test.eng-hat.eng.hat | 28.0 | 0.502 |
| Tatoeba-test.eng-ita.eng.ita | 45.6 | 0.674 |
| Tatoeba-test.eng-lad.eng.lad | 8.2 | 0.322 |
| Tatoeba-test.eng-lij.eng.lij | 1.4 | 0.182 |
| Tatoeba-test.eng-lld.eng.lld | 0.8 | 0.217 |
| Tatoeba-test.eng-lmo.eng.lmo | 0.7 | 0.190 |
| Tatoeba-test.eng-mfe.eng.mfe | 91.9 | 0.956 |
| Tatoeba-test.eng-msa.eng.msa | 31.1 | 0.548 |
| Tatoeba-test.eng.multi | 42.9 | 0.636 |
| Tatoeba-test.eng-mwl.eng.mwl | 2.1 | 0.234 |
| Tatoeba-test.eng-oci.eng.oci | 7.9 | 0.297 |
| Tatoeba-test.eng-pap.eng.pap | 44.1 | 0.648 |
| Tatoeba-test.eng-pms.eng.pms | 2.1 | 0.190 |
| Tatoeba-test.eng-por.eng.por | 41.8 | 0.639 |
| Tatoeba-test.eng-roh.eng.roh | 3.5 | 0.261 |
| Tatoeba-test.eng-ron.eng.ron | 41.0 | 0.635 |
| Tatoeba-test.eng-scn.eng.scn | 1.7 | 0.184 |
| Tatoeba-test.eng-spa.eng.spa | 50.1 | 0.689 |
| Tatoeba-test.eng-vec.eng.vec | 3.2 | 0.248 |
| Tatoeba-test.eng-wln.eng.wln | 7.2 | 0.220 |
### System Info:
- hf_name: eng-roa
- source_languages: eng
- target_languages: roa
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/eng-roa/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['en', 'it', 'ca', 'rm', 'es', 'ro', 'gl', 'co', 'wa', 'pt', 'oc', 'an', 'id', 'fr', 'ht', 'roa']
- src_constituents: {'eng'}
- tgt_constituents: {'ita', 'cat', 'roh', 'spa', 'pap', 'lmo', 'mwl', 'lij', 'lad_Latn', 'ext', 'ron', 'ast', 'glg', 'pms', 'zsm_Latn', 'gcf_Latn', 'lld_Latn', 'min', 'tmw_Latn', 'cos', 'wln', 'zlm_Latn', 'por', 'egl', 'oci', 'vec', 'arg', 'ind', 'fra', 'hat', 'lad', 'max_Latn', 'frm_Latn', 'scn', 'mfe'}
- src_multilingual: False
- tgt_multilingual: True
- prepro: normalization + SentencePiece (spm32k,spm32k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/eng-roa/opus2m-2020-08-01.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/eng-roa/opus2m-2020-08-01.test.txt
- src_alpha3: eng
- tgt_alpha3: roa
- short_pair: en-roa
- chrF2_score: 0.636
- bleu: 42.9
- brevity_penalty: 0.978
- ref_len: 72751.0
- src_name: English
- tgt_name: Romance languages
- train_date: 2020-08-01
- src_alpha2: en
- tgt_alpha2: roa
- prefer_old: False
- long_pair: eng-roa
- helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535
- transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b
- port_machine: brutasse
- port_time: 2020-08-21-14:41 |
Skoltech/russian-sensitive-topics | a5deed3c020f78a0ddb404b86609e2cf5693c3f1 | 2021-05-18T22:41:20.000Z | [
"pytorch",
"tf",
"jax",
"bert",
"text-classification",
"ru",
"arxiv:2103.05345",
"transformers",
"toxic comments classification"
] | text-classification | false | Skoltech | null | Skoltech/russian-sensitive-topics | 1,106 | 3 | transformers | 1,701 | ---
language:
- ru
tags:
- toxic comments classification
licenses:
- cc-by-nc-sa
---
## General concept of the model
This model is trained on the dataset of sensitive topics of the Russian language. The concept of sensitive topics is described [in this article ](https://www.aclweb.org/anthology/2021.bsnlp-1.4/) presented at the workshop for Balto-Slavic NLP at the EACL-2021 conference. Please note that this article describes the first version of the dataset, while the model is trained on the extended version of the dataset open-sourced on our [GitHub](https://github.com/skoltech-nlp/inappropriate-sensitive-topics/blob/main/Version2/sensitive_topics/sensitive_topics.csv) or on [kaggle](https://www.kaggle.com/nigula/russian-sensitive-topics). The properties of the dataset is the same as the one described in the article, the only difference is the size.
## Instructions
The model predicts combinations of 18 sensitive topics described in the [article](https://arxiv.org/abs/2103.05345). You can find step-by-step instructions for using the model [here](https://github.com/skoltech-nlp/inappropriate-sensitive-topics/blob/main/Version2/sensitive_topics/Inference.ipynb)
## Metrics
The dataset partially manually labeled samples and partially semi-automatically labeled samples. Learn more in our article. We tested the performance of the classifier only on the part of manually labeled data that is why some topics are not well represented in the test set.
| | precision | recall | f1-score | support |
|-------------------|-----------|--------|----------|---------|
| offline_crime | 0.65 | 0.55 | 0.6 | 132 |
| online_crime | 0.5 | 0.46 | 0.48 | 37 |
| drugs | 0.87 | 0.9 | 0.88 | 87 |
| gambling | 0.5 | 0.67 | 0.57 | 6 |
| pornography | 0.73 | 0.59 | 0.65 | 204 |
| prostitution | 0.75 | 0.69 | 0.72 | 91 |
| slavery | 0.72 | 0.72 | 0.73 | 40 |
| suicide | 0.33 | 0.29 | 0.31 | 7 |
| terrorism | 0.68 | 0.57 | 0.62 | 47 |
| weapons | 0.89 | 0.83 | 0.86 | 138 |
| body_shaming | 0.9 | 0.67 | 0.77 | 109 |
| health_shaming | 0.84 | 0.55 | 0.66 | 108 |
| politics | 0.68 | 0.54 | 0.6 | 241 |
| racism | 0.81 | 0.59 | 0.68 | 204 |
| religion | 0.94 | 0.72 | 0.81 | 102 |
| sexual_minorities | 0.69 | 0.46 | 0.55 | 102 |
| sexism | 0.66 | 0.64 | 0.65 | 132 |
| social_injustice | 0.56 | 0.37 | 0.45 | 181 |
| none | 0.62 | 0.67 | 0.64 | 250 |
| micro avg | 0.72 | 0.61 | 0.66 | 2218 |
| macro avg | 0.7 | 0.6 | 0.64 | 2218 |
| weighted avg | 0.73 | 0.61 | 0.66 | 2218 |
| samples avg | 0.75 | 0.66 | 0.68 | 2218 |
## Licensing Information
[Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License][cc-by-nc-sa].
[![CC BY-NC-SA 4.0][cc-by-nc-sa-image]][cc-by-nc-sa]
[cc-by-nc-sa]: http://creativecommons.org/licenses/by-nc-sa/4.0/
[cc-by-nc-sa-image]: https://i.creativecommons.org/l/by-nc-sa/4.0/88x31.png
## Citation
If you find this repository helpful, feel free to cite our publication:
```
@inproceedings{babakov-etal-2021-detecting,
title = "Detecting Inappropriate Messages on Sensitive Topics that Could Harm a Company{'}s Reputation",
author = "Babakov, Nikolay and
Logacheva, Varvara and
Kozlova, Olga and
Semenov, Nikita and
Panchenko, Alexander",
booktitle = "Proceedings of the 8th Workshop on Balto-Slavic Natural Language Processing",
month = apr,
year = "2021",
address = "Kiyv, Ukraine",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2021.bsnlp-1.4",
pages = "26--36",
abstract = "Not all topics are equally {``}flammable{''} in terms of toxicity: a calm discussion of turtles or fishing less often fuels inappropriate toxic dialogues than a discussion of politics or sexual minorities. We define a set of sensitive topics that can yield inappropriate and toxic messages and describe the methodology of collecting and labelling a dataset for appropriateness. While toxicity in user-generated data is well-studied, we aim at defining a more fine-grained notion of inappropriateness. The core of inappropriateness is that it can harm the reputation of a speaker. This is different from toxicity in two respects: (i) inappropriateness is topic-related, and (ii) inappropriate message is not toxic but still unacceptable. We collect and release two datasets for Russian: a topic-labelled dataset and an appropriateness-labelled dataset. We also release pre-trained classification models trained on this data.",
}
``` |
fnlp/elasticbert-base | 08b6aa4eb88ef6bb6dd6294edb8b8b11120f5b98 | 2021-10-28T10:54:47.000Z | [
"pytorch",
"elasticbert",
"fill-mask",
"arxiv:2110.07038",
"transformers",
"autotrain_compatible"
] | fill-mask | false | fnlp | null | fnlp/elasticbert-base | 1,104 | 3 | transformers | 1,702 | # ElasticBERT-BASE
## Model description
This is an implementation of the `base` version of ElasticBERT.
[**Towards Efficient NLP: A Standard Evaluation and A Strong Baseline**](https://arxiv.org/pdf/2110.07038.pdf)
Xiangyang Liu, Tianxiang Sun, Junliang He, Lingling Wu, Xinyu Zhang, Hao Jiang, Zhao Cao, Xuanjing Huang, Xipeng Qiu
## Code link
[**fastnlp/elasticbert**](https://github.com/fastnlp/ElasticBERT)
## Usage
```python
>>> from transformers import BertTokenizer as ElasticBertTokenizer
>>> from models.configuration_elasticbert import ElasticBertConfig
>>> from models.modeling_elasticbert import ElasticBertForSequenceClassification
>>> num_output_layers = 1
>>> config = ElasticBertConfig.from_pretrained('fnlp/elasticbert-base', num_output_layers=num_output_layers )
>>> tokenizer = ElasticBertTokenizer.from_pretrained('fnlp/elasticbert-base')
>>> model = ElasticBertForSequenceClassification.from_pretrained('fnlp/elasticbert-base', config=config)
>>> input_ids = tokenizer.encode('The actors are fantastic .', return_tensors='pt')
>>> outputs = model(input_ids)
```
## Citation
```bibtex
@article{liu2021elasticbert,
author = {Xiangyang Liu and
Tianxiang Sun and
Junliang He and
Lingling Wu and
Xinyu Zhang and
Hao Jiang and
Zhao Cao and
Xuanjing Huang and
Xipeng Qiu},
title = {Towards Efficient {NLP:} {A} Standard Evaluation and {A} Strong Baseline},
journal = {CoRR},
volume = {abs/2110.07038},
year = {2021},
url = {https://arxiv.org/abs/2110.07038},
eprinttype = {arXiv},
eprint = {2110.07038},
timestamp = {Fri, 22 Oct 2021 13:33:09 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2110-07038.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` |
seyonec/SMILES_tokenized_PubChem_shard00_50k | cc844b1d17d99e51e36205e812def4f77c8e4ac4 | 2021-05-20T21:10:29.000Z | [
"pytorch",
"jax",
"roberta",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | false | seyonec | null | seyonec/SMILES_tokenized_PubChem_shard00_50k | 1,102 | null | transformers | 1,703 | Entry not found |
Yanzhu/bertweetfr-base | 90de75c9b6f530bf1831ba22aee06f04f7c94703 | 2021-06-13T07:20:37.000Z | [
"pytorch",
"camembert",
"fill-mask",
"fr",
"transformers",
"autotrain_compatible"
] | fill-mask | false | Yanzhu | null | Yanzhu/bertweetfr-base | 1,095 | 2 | transformers | 1,704 | ---
language: "fr"
---
Domain-adaptive pretraining of camembert-base using 15 GB of French Tweets |
allenai/ivila-block-layoutlm-finetuned-docbank | 1991156f842c9ae1a3eef19ec365a7af3f1ae064 | 2021-09-27T22:56:28.000Z | [
"pytorch",
"layoutlm",
"token-classification",
"transformers",
"autotrain_compatible"
] | token-classification | false | allenai | null | allenai/ivila-block-layoutlm-finetuned-docbank | 1,093 | null | transformers | 1,705 | Entry not found |
facebook/s2t-medium-librispeech-asr | 782ffebb9f762136f76e4b58afbb30b19a4da5a1 | 2022-02-07T15:04:00.000Z | [
"pytorch",
"tf",
"speech_to_text",
"automatic-speech-recognition",
"en",
"dataset:librispeech_asr",
"arxiv:2010.05171",
"arxiv:1904.08779",
"transformers",
"audio",
"license:mit"
] | automatic-speech-recognition | false | facebook | null | facebook/s2t-medium-librispeech-asr | 1,093 | 3 | transformers | 1,706 | ---
language: en
datasets:
- librispeech_asr
tags:
- audio
- automatic-speech-recognition
pipeline_tag: automatic-speech-recognition
widget:
- example_title: Librispeech sample 1
src: https://cdn-media.huggingface.co/speech_samples/sample1.flac
- example_title: Librispeech sample 2
src: https://cdn-media.huggingface.co/speech_samples/sample2.flac
license: mit
---
# S2T-MEDIUM-LIBRISPEECH-ASR
`s2t-medium-librispeech-asr` is a Speech to Text Transformer (S2T) model trained for automatic speech recognition (ASR).
The S2T model was proposed in [this paper](https://arxiv.org/abs/2010.05171) and released in
[this repository](https://github.com/pytorch/fairseq/tree/master/examples/speech_to_text)
## Model description
S2T is an end-to-end sequence-to-sequence transformer model. It is trained with standard
autoregressive cross-entropy loss and generates the transcripts autoregressively.
## Intended uses & limitations
This model can be used for end-to-end speech recognition (ASR).
See the [model hub](https://huggingface.co/models?filter=speech_to_text) to look for other S2T checkpoints.
### How to use
As this a standard sequence to sequence transformer model, you can use the `generate` method to generate the
transcripts by passing the speech features to the model.
*Note: The `Speech2TextProcessor` object uses [torchaudio](https://github.com/pytorch/audio) to extract the
filter bank features. Make sure to install the `torchaudio` package before running this example.*
You could either install those as extra speech dependancies with
`pip install transformers"[speech, sentencepiece]"` or install the packages seperatly
with `pip install torchaudio sentencepiece`.
```python
import torch
from transformers import Speech2TextProcessor, Speech2TextForConditionalGeneration
from datasets import load_dataset
import soundfile as sf
model = Speech2TextForConditionalGeneration.from_pretrained("facebook/s2t-medium-librispeech-asr")
processor = Speech2Textprocessor.from_pretrained("facebook/s2t-medium-librispeech-asr")
def map_to_array(batch):
speech, _ = sf.read(batch["file"])
batch["speech"] = speech
return batch
ds = load_dataset(
"patrickvonplaten/librispeech_asr_dummy",
"clean",
split="validation"
)
ds = ds.map(map_to_array)
input_features = processor(
ds["speech"][0],
sampling_rate=16_000,
return_tensors="pt"
).input_features # Batch size 1
generated_ids = model.generate(input_ids=input_features)
transcription = processor.batch_decode(generated_ids)
```
#### Evaluation on LibriSpeech Test
The following script shows how to evaluate this model on the [LibriSpeech](https://huggingface.co/datasets/librispeech_asr)
*"clean"* and *"other"* test dataset.
```python
from datasets import load_dataset, load_metric
from transformers import Speech2TextForConditionalGeneration, Speech2TextProcessor
import soundfile as sf
librispeech_eval = load_dataset("librispeech_asr", "clean", split="test") # change to "other" for other test dataset
wer = load_metric("wer")
model = Speech2TextForConditionalGeneration.from_pretrained("facebook/s2t-medium-librispeech-asr").to("cuda")
processor = Speech2TextProcessor.from_pretrained("facebook/s2t-medium-librispeech-asr", do_upper_case=True)
def map_to_array(batch):
speech, _ = sf.read(batch["file"])
batch["speech"] = speech
return batch
librispeech_eval = librispeech_eval.map(map_to_array)
def map_to_pred(batch):
features = processor(batch["speech"], sampling_rate=16000, padding=True, return_tensors="pt")
input_features = features.input_features.to("cuda")
attention_mask = features.attention_mask.to("cuda")
gen_tokens = model.generate(input_ids=input_features, attention_mask=attention_mask)
batch["transcription"] = processor.batch_decode(gen_tokens, skip_special_tokens=True)
return batch
result = librispeech_eval.map(map_to_pred, batched=True, batch_size=8, remove_columns=["speech"])
print("WER:", wer(predictions=result["transcription"], references=result["text"]))
```
*Result (WER)*:
| "clean" | "other" |
|:-------:|:-------:|
| 3.5 | 7.8 |
## Training data
The S2T-MEDIUM-LIBRISPEECH-ASR is trained on [LibriSpeech ASR Corpus](https://www.openslr.org/12), a dataset consisting of
approximately 1000 hours of 16kHz read English speech.
## Training procedure
### Preprocessing
The speech data is pre-processed by extracting Kaldi-compliant 80-channel log mel-filter bank features automatically from
WAV/FLAC audio files via PyKaldi or torchaudio. Further utterance-level CMVN (cepstral mean and variance normalization)
is applied to each example.
The texts are lowercased and tokenized using SentencePiece and a vocabulary size of 10,000.
### Training
The model is trained with standard autoregressive cross-entropy loss and using [SpecAugment](https://arxiv.org/abs/1904.08779).
The encoder receives speech features, and the decoder generates the transcripts autoregressively.
### BibTeX entry and citation info
```bibtex
@inproceedings{wang2020fairseqs2t,
title = {fairseq S2T: Fast Speech-to-Text Modeling with fairseq},
author = {Changhan Wang and Yun Tang and Xutai Ma and Anne Wu and Dmytro Okhonko and Juan Pino},
booktitle = {Proceedings of the 2020 Conference of the Asian Chapter of the Association for Computational Linguistics (AACL): System Demonstrations},
year = {2020},
}
``` |
google/canine-c | 1e8c8b3a4e860cb2a23a14c3fbba61ef3aed51f6 | 2021-08-13T08:24:13.000Z | [
"pytorch",
"canine",
"feature-extraction",
"multilingual",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:2103.06874",
"transformers",
"license:apache-2.0"
] | feature-extraction | false | google | null | google/canine-c | 1,093 | 1 | transformers | 1,707 | ---
language: multilingual
license: apache-2.0
datasets:
- bookcorpus
- wikipedia
---
# CANINE-c (CANINE pre-trained with autoregressive character loss)
Pretrained CANINE model on 104 languages using a masked language modeling (MLM) objective. It was introduced in the paper [CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language Representation](https://arxiv.org/abs/2103.06874) and first released in [this repository](https://github.com/google-research/language/tree/master/language/canine).
What's special about CANINE is that it doesn't require an explicit tokenizer (such as WordPiece or SentencePiece) as other models like BERT and RoBERTa. Instead, it directly operates at a character level: each character is turned into its [Unicode code point](https://en.wikipedia.org/wiki/Code_point#:~:text=For%20Unicode%2C%20the%20particular%20sequence,forming%20a%20self%2Dsynchronizing%20code.).
This means that input processing is trivial and can typically be accomplished as:
```
input_ids = [ord(char) for char in text]
```
The ord() function is part of Python, and turns each character into its Unicode code point.
Disclaimer: The team releasing CANINE did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
CANINE is a transformers model pretrained on a large corpus of multilingual data in a self-supervised fashion, similar to BERT. This means it was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely, it was pretrained with two objectives:
* Masked language modeling (MLM): one randomly masks part of the inputs, which the model needs to predict. This model (CANINE-c) is trained with an autoregressive character loss. One masks several character spans within each sequence, which the model then autoregressively predicts.
* Next sentence prediction (NSP): the model concatenates two sentences as inputs during pretraining. Sometimes they correspond to sentences that were next to each other in the original text, sometimes not. The model then has to predict if the two sentences were following each other or not.
This way, the model learns an inner representation of multiple languages that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a standard classifier using the features produced by the CANINE model as inputs.
## Intended uses & limitations
You can use the raw model for either masked language modeling or next sentence prediction, but it's mostly intended to be fine-tuned on a downstream task. See the [model hub](https://huggingface.co/models?filter=canine) to look for fine-tuned versions on a task that interests you.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked) to make decisions, such as sequence classification, token classification or question answering. For tasks such as text generation you should look at models like GPT2.
### How to use
Here is how to use this model:
```python
from transformers import CanineTokenizer, CanineModel
model = CanineModel.from_pretrained('google/canine-c')
tokenizer = CanineTokenizer.from_pretrained('google/canine-c')
inputs = ["Life is like a box of chocolates.", "You never know what you gonna get."]
encoding = tokenizer(inputs, padding="longest", truncation=True, return_tensors="pt")
outputs = model(**encoding) # forward pass
pooled_output = outputs.pooler_output
sequence_output = outputs.last_hidden_state
```
## Training data
The CANINE model was pretrained on on the multilingual Wikipedia data of [mBERT](https://github.com/google-research/bert/blob/master/multilingual.md), which includes 104 languages.
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2103-06874,
author = {Jonathan H. Clark and
Dan Garrette and
Iulia Turc and
John Wieting},
title = {{CANINE:} Pre-training an Efficient Tokenization-Free Encoder for
Language Representation},
journal = {CoRR},
volume = {abs/2103.06874},
year = {2021},
url = {https://arxiv.org/abs/2103.06874},
archivePrefix = {arXiv},
eprint = {2103.06874},
timestamp = {Tue, 16 Mar 2021 11:26:59 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-2103-06874.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` |
google/rembert | 65da5133da36e29dfca67d4f0dd9f7f9db21b563 | 2022-05-27T15:05:23.000Z | [
"pytorch",
"tf",
"rembert",
"multilingual",
"af",
"am",
"ar",
"az",
"be",
"bg",
"bn",
"bs",
"ca",
"ceb",
"co",
"cs",
"cy",
"da",
"de",
"el",
"en",
"eo",
"es",
"et",
"eu",
"fa",
"fi",
"fil",
"fr",
"fy",
"ga",
"gd",
"gl",
"gu",
"ha",
"haw",
"hi",
"hmn",
"hr",
"ht",
"hu",
"hy",
"id",
"ig",
"is",
"it",
"iw",
"ja",
"jv",
"ka",
"kk",
"km",
"kn",
"ko",
"ku",
"ky",
"la",
"lb",
"lo",
"lt",
"lv",
"mg",
"mi",
"mk",
"ml",
"mn",
"mr",
"ms",
"mt",
"my",
"ne",
"nl",
"no",
"ny",
"pa",
"pl",
"ps",
"pt",
"ro",
"ru",
"sd",
"si",
"sk",
"sl",
"sm",
"sn",
"so",
"sq",
"sr",
"st",
"su",
"sv",
"sw",
"ta",
"te",
"tg",
"th",
"tr",
"uk",
"ur",
"uz",
"vi",
"xh",
"yi",
"yo",
"zh",
"zu",
"dataset:wikipedia",
"arxiv:2010.12821",
"transformers",
"license:apache-2.0"
] | null | false | google | null | google/rembert | 1,093 | 6 | transformers | 1,708 | ---
language:
- multilingual
- af
- am
- ar
- az
- be
- bg
- bn
- bs
- ca
- ceb
- co
- cs
- cy
- da
- de
- el
- en
- eo
- es
- et
- eu
- fa
- fi
- fil
- fr
- fy
- ga
- gd
- gl
- gu
- ha
- haw
- hi
- hmn
- hr
- ht
- hu
- hy
- id
- ig
- is
- it
- iw
- ja
- jv
- ka
- kk
- km
- kn
- ko
- ku
- ky
- la
- lb
- lo
- lt
- lv
- mg
- mi
- mk
- ml
- mn
- mr
- ms
- mt
- my
- ne
- nl
- no
- ny
- pa
- pl
- ps
- pt
- ro
- ru
- sd
- si
- sk
- sl
- sm
- sn
- so
- sq
- sr
- st
- su
- sv
- sw
- ta
- te
- tg
- th
- tr
- uk
- ur
- uz
- vi
- xh
- yi
- yo
- zh
- zu
license: apache-2.0
datasets:
- wikipedia
---
# RemBERT (for classification)
Pretrained RemBERT model on 110 languages using a masked language modeling (MLM) objective. It was introduced in the paper [Rethinking embedding coupling in pre-trained language models](https://arxiv.org/abs/2010.12821). A direct export of the model checkpoint was first made available in [this repository](https://github.com/google-research/google-research/tree/master/rembert). This version of the checkpoint is lightweight since it is meant to be finetuned for classification and excludes the output embedding weights.
## Model description
RemBERT's main difference with mBERT is that the input and output embeddings are not tied. Instead, RemBERT uses small input embeddings and larger output embeddings. This makes the model more efficient since the output embeddings are discarded during fine-tuning. It is also more accurate, especially when reinvesting the input embeddings' parameters into the core model, as is done on RemBERT.
## Intended uses & limitations
You should fine-tune this model for your downstream task. It is meant to be a general-purpose model, similar to mBERT. In our [paper](https://arxiv.org/abs/2010.12821), we have successfully applied this model to tasks such as classification, question answering, NER, POS-tagging. For tasks such as text generation you should look at models like GPT2.
## Training data
The RemBERT model was pretrained on multilingual Wikipedia data over 110 languages. The full language list is on [this repository](https://github.com/google-research/google-research/tree/master/rembert)
### BibTeX entry and citation info
```bibtex
@inproceedings{DBLP:conf/iclr/ChungFTJR21,
author = {Hyung Won Chung and
Thibault F{\'{e}}vry and
Henry Tsai and
Melvin Johnson and
Sebastian Ruder},
title = {Rethinking Embedding Coupling in Pre-trained Language Models},
booktitle = {9th International Conference on Learning Representations, {ICLR} 2021,
Virtual Event, Austria, May 3-7, 2021},
publisher = {OpenReview.net},
year = {2021},
url = {https://openreview.net/forum?id=xpFFI\_NtgpW},
timestamp = {Wed, 23 Jun 2021 17:36:39 +0200},
biburl = {https://dblp.org/rec/conf/iclr/ChungFTJR21.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` |
malper/unikud | 73fdb7a158634826a73b66846d1b743fd700e990 | 2022-04-25T02:11:25.000Z | [
"pytorch",
"canine",
"he",
"transformers"
] | null | false | malper | null | malper/unikud | 1,093 | null | transformers | 1,709 | ---
language:
- he
---
Please see [this model's DagsHub repository](https://dagshub.com/morrisalp/unikud) for information on usage. |
TypicaAI/magbert-ner | 069ef5c4d8e7334fb89c2e54fe8f58d55b099ee7 | 2020-12-11T21:30:45.000Z | [
"pytorch",
"camembert",
"token-classification",
"fr",
"transformers",
"autotrain_compatible"
] | token-classification | false | TypicaAI | null | TypicaAI/magbert-ner | 1,091 | null | transformers | 1,710 | ---
language: fr
widget:
- text: "Je m'appelle Hicham et je vis a Fès"
---
# MagBERT-NER: a state-of-the-art NER model for Moroccan French language (Maghreb)
## Introduction
[MagBERT-NER] is a state-of-the-art NER model for Moroccan French language (Maghreb). The MagBERT-NER model was fine-tuned for NER Task based the language model for French Camembert (based on the RoBERTa architecture).
For further information or requests, please visite our website at [typica.ai Website](https://typica.ai/) or send us an email at [email protected]
## How to use MagBERT-NER with HuggingFace
##### Load MagBERT-NER and its sub-word tokenizer :
```python
from transformers import AutoTokenizer, AutoModelForTokenClassification
tokenizer = AutoTokenizer.from_pretrained("TypicaAI/magbert-ner")
model = AutoModelForTokenClassification.from_pretrained("TypicaAI/magbert-ner")
##### Process text sample (from wikipedia about the current Prime Minister of Morocco) Using NER pipeline
from transformers import pipeline
nlp = pipeline('ner', model=model, tokenizer=tokenizer, grouped_entities=True)
nlp("Saad Dine El Otmani, né le 16 janvier 1956 à Inezgane, est un homme d'État marocain, chef du gouvernement du Maroc depuis le 5 avril 2017")
#[{'entity_group': 'I-PERSON',
# 'score': 0.8941445276141167,
# 'word': 'Saad Dine El Otmani'},
# {'entity_group': 'B-DATE',
# 'score': 0.5967703461647034,
# 'word': '16 janvier 1956'},
# {'entity_group': 'B-GPE', 'score': 0.7160899192094803, 'word': 'Inezgane'},
# {'entity_group': 'B-NORP', 'score': 0.7971733212471008, 'word': 'marocain'},
# {'entity_group': 'B-GPE', 'score': 0.8921478390693665, 'word': 'Maroc'},
# {'entity_group': 'B-DATE',
# 'score': 0.5760444005330404,
# 'word': '5 avril 2017'}]
```
## Authors
MagBert-NER Model was trained by Hicham Assoudi, Ph.D.
For any questions, comments you can contact me at [email protected]
## Citation
If you use our work, please cite:
Hicham Assoudi, Ph.D., MagBERT-NER: a state-of-the-art NER model for Moroccan French language (Maghreb), (2020)
|
anonymous-german-nlp/german-gpt2 | 2c3dbb0a9dc4fd368fdb256d5093cd37c13d4936 | 2021-05-21T13:20:42.000Z | [
"pytorch",
"tf",
"jax",
"gpt2",
"text-generation",
"de",
"transformers",
"license:mit"
] | text-generation | false | anonymous-german-nlp | null | anonymous-german-nlp/german-gpt2 | 1,091 | null | transformers | 1,711 | ---
language: de
widget:
- text: "Heute ist sehr schönes Wetter in"
license: mit
---
# German GPT-2 model
**Note**: This model was de-anonymized and now lives at:
https://huggingface.co/dbmdz/german-gpt2
Please use the new model name instead! |
HooshvareLab/bert-base-parsbert-ner-uncased | 3d87e20bbca18f8d8d9d545cacd198aee69371fd | 2021-05-18T20:43:54.000Z | [
"pytorch",
"tf",
"jax",
"bert",
"token-classification",
"fa",
"arxiv:2005.12515",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | token-classification | false | HooshvareLab | null | HooshvareLab/bert-base-parsbert-ner-uncased | 1,090 | null | transformers | 1,712 | ---
language: fa
license: apache-2.0
---
## ParsBERT: Transformer-based Model for Persian Language Understanding
ParsBERT is a monolingual language model based on Google’s BERT architecture with the same configurations as BERT-Base.
Paper presenting ParsBERT: [arXiv:2005.12515](https://arxiv.org/abs/2005.12515)
All the models (downstream tasks) are uncased and trained with whole word masking. (coming soon stay tuned)
## Persian NER [ARMAN, PEYMA, ARMAN+PEYMA]
This task aims to extract named entities in the text, such as names and label with appropriate `NER` classes such as locations, organizations, etc. The datasets used for this task contain sentences that are marked with `IOB` format. In this format, tokens that are not part of an entity are tagged as `”O”` the `”B”`tag corresponds to the first word of an object, and the `”I”` tag corresponds to the rest of the terms of the same entity. Both `”B”` and `”I”` tags are followed by a hyphen (or underscore), followed by the entity category. Therefore, the NER task is a multi-class token classification problem that labels the tokens upon being fed a raw text. There are two primary datasets used in Persian NER, `ARMAN`, and `PEYMA`. In ParsBERT, we prepared ner for both datasets as well as a combination of both datasets.
### PEYMA
PEYMA dataset includes 7,145 sentences with a total of 302,530 tokens from which 41,148 tokens are tagged with seven different classes.
1. Organization
2. Money
3. Location
4. Date
5. Time
6. Person
7. Percent
| Label | # |
|:------------:|:-----:|
| Organization | 16964 |
| Money | 2037 |
| Location | 8782 |
| Date | 4259 |
| Time | 732 |
| Person | 7675 |
| Percent | 699 |
**Download**
You can download the dataset from [here](http://nsurl.org/tasks/task-7-named-entity-recognition-ner-for-farsi/)
---
### ARMAN
ARMAN dataset holds 7,682 sentences with 250,015 sentences tagged over six different classes.
1. Organization
2. Location
3. Facility
4. Event
5. Product
6. Person
| Label | # |
|:------------:|:-----:|
| Organization | 30108 |
| Location | 12924 |
| Facility | 4458 |
| Event | 7557 |
| Product | 4389 |
| Person | 15645 |
**Download**
You can download the dataset from [here](https://github.com/HaniehP/PersianNER)
## Results
The following table summarizes the F1 score obtained by ParsBERT as compared to other models and architectures.
| Dataset | ParsBERT | MorphoBERT | Beheshti-NER | LSTM-CRF | Rule-Based CRF | BiLSTM-CRF |
|:---------------:|:--------:|:----------:|:--------------:|:----------:|:----------------:|:------------:|
| ARMAN + PEYMA | 95.13* | - | - | - | - | - |
| PEYMA | 98.79* | - | 90.59 | - | 84.00 | - |
| ARMAN | 93.10* | 89.9 | 84.03 | 86.55 | - | 77.45 |
## How to use :hugs:
| Notebook | Description | |
|:----------|:-------------|------:|
| [How to use Pipelines](https://github.com/hooshvare/parsbert-ner/blob/master/persian-ner-pipeline.ipynb) | Simple and efficient way to use State-of-the-Art models on downstream tasks through transformers | [](https://colab.research.google.com/github/hooshvare/parsbert-ner/blob/master/persian-ner-pipeline.ipynb) |
## Cite
Please cite the following paper in your publication if you are using [ParsBERT](https://arxiv.org/abs/2005.12515) in your research:
```markdown
@article{ParsBERT,
title={ParsBERT: Transformer-based Model for Persian Language Understanding},
author={Mehrdad Farahani, Mohammad Gharachorloo, Marzieh Farahani, Mohammad Manthouri},
journal={ArXiv},
year={2020},
volume={abs/2005.12515}
}
```
## Acknowledgments
We hereby, express our gratitude to the [Tensorflow Research Cloud (TFRC) program](https://tensorflow.org/tfrc) for providing us with the necessary computation resources. We also thank [Hooshvare](https://hooshvare.com) Research Group for facilitating dataset gathering and scraping online text resources.
## Contributors
- Mehrdad Farahani: [Linkedin](https://www.linkedin.com/in/m3hrdadfi/), [Twitter](https://twitter.com/m3hrdadfi), [Github](https://github.com/m3hrdadfi)
- Mohammad Gharachorloo: [Linkedin](https://www.linkedin.com/in/mohammad-gharachorloo/), [Twitter](https://twitter.com/MGharachorloo), [Github](https://github.com/baarsaam)
- Marzieh Farahani: [Linkedin](https://www.linkedin.com/in/marziehphi/), [Twitter](https://twitter.com/marziehphi), [Github](https://github.com/marziehphi)
- Mohammad Manthouri: [Linkedin](https://www.linkedin.com/in/mohammad-manthouri-aka-mansouri-07030766/), [Twitter](https://twitter.com/mmanthouri), [Github](https://github.com/mmanthouri)
- Hooshvare Team: [Official Website](https://hooshvare.com/), [Linkedin](https://www.linkedin.com/company/hooshvare), [Twitter](https://twitter.com/hooshvare), [Github](https://github.com/hooshvare), [Instagram](https://www.instagram.com/hooshvare/)
+ And a special thanks to Sara Tabrizi for her fantastic poster design. Follow her on: [Linkedin](https://www.linkedin.com/in/sara-tabrizi-64548b79/), [Behance](https://www.behance.net/saratabrizi), [Instagram](https://www.instagram.com/sara_b_tabrizi/)
## Releases
### Release v0.1 (May 29, 2019)
This is the first version of our ParsBERT NER!
|
raynardj/ner-disease-ncbi-bionlp-bc5cdr-pubmed | 60897ba4bdcfb7f6cf88d18f75bbd0f9399f5908 | 2021-11-05T07:33:08.000Z | [
"pytorch",
"roberta",
"token-classification",
"en",
"dataset:ncbi-disease",
"dataset:bc5cdr",
"transformers",
"ner",
"ncbi",
"disease",
"pubmed",
"bioinfomatics",
"license:apache-2.0",
"autotrain_compatible"
] | token-classification | false | raynardj | null | raynardj/ner-disease-ncbi-bionlp-bc5cdr-pubmed | 1,090 | 4 | transformers | 1,713 | ---
language:
- en
tags:
- ner
- ncbi
- disease
- pubmed
- bioinfomatics
license: apache-2.0
datasets:
- ncbi-disease
- bc5cdr
widget:
- text: "Hepatocyte nuclear factor 4 alpha (HNF4α) is regulated by different promoters to generate two isoforms, one of which functions as a tumor suppressor. Here, the authors reveal that induction of the alternative isoform in hepatocellular carcinoma inhibits the circadian clock by repressing BMAL1, and the reintroduction of BMAL1 prevents HCC tumor growth."
---
# NER to find Gene & Gene products
> The model was trained on ncbi-disease, BC5CDR dataset, pretrained on this [pubmed-pretrained roberta model](/raynardj/roberta-pubmed)
All the labels, the possible token classes.
```json
{"label2id": {
"O": 0,
"Disease":1,
}
}
```
Notice, we removed the 'B-','I-' etc from data label.🗡
## This is the template we suggest for using the model
```python
from transformers import pipeline
PRETRAINED = "raynardj/ner-disease-ncbi-bionlp-bc5cdr-pubmed"
ner = pipeline(task="ner",model=PRETRAINED, tokenizer=PRETRAINED)
ner("Your text", aggregation_strategy="first")
```
And here is to make your output more consecutive ⭐️
```python
import pandas as pd
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(PRETRAINED)
def clean_output(outputs):
results = []
current = []
last_idx = 0
# make to sub group by position
for output in outputs:
if output["index"]-1==last_idx:
current.append(output)
else:
results.append(current)
current = [output, ]
last_idx = output["index"]
if len(current)>0:
results.append(current)
# from tokens to string
strings = []
for c in results:
tokens = []
starts = []
ends = []
for o in c:
tokens.append(o['word'])
starts.append(o['start'])
ends.append(o['end'])
new_str = tokenizer.convert_tokens_to_string(tokens)
if new_str!='':
strings.append(dict(
word=new_str,
start = min(starts),
end = max(ends),
entity = c[0]['entity']
))
return strings
def entity_table(pipeline, **pipeline_kw):
if "aggregation_strategy" not in pipeline_kw:
pipeline_kw["aggregation_strategy"] = "first"
def create_table(text):
return pd.DataFrame(
clean_output(
pipeline(text, **pipeline_kw)
)
)
return create_table
# will return a dataframe
entity_table(ner)(YOUR_VERY_CONTENTFUL_TEXT)
```
> check our NER model on
* [gene and gene products](/raynardj/ner-gene-dna-rna-jnlpba-pubmed)
* [chemical substance](/raynardj/ner-chemical-bionlp-bc5cdr-pubmed).
* [disease](/raynardj/ner-disease-ncbi-bionlp-bc5cdr-pubmed) |
dbmdz/convbert-base-turkish-mc4-uncased | 5d8c2e7856ba8f71c627eb8b00df6edd306b328a | 2021-09-23T10:41:21.000Z | [
"pytorch",
"tf",
"convbert",
"fill-mask",
"tr",
"dataset:allenai/c4",
"transformers",
"license:mit",
"autotrain_compatible"
] | fill-mask | false | dbmdz | null | dbmdz/convbert-base-turkish-mc4-uncased | 1,088 | null | transformers | 1,714 | ---
language: tr
license: mit
datasets:
- allenai/c4
---
# 🇹🇷 Turkish ConvBERT model
<p align="center">
<img alt="Logo provided by Merve Noyan" title="Awesome logo from Merve Noyan" src="https://raw.githubusercontent.com/stefan-it/turkish-bert/master/merve_logo.png">
</p>
[](https://zenodo.org/badge/latestdoi/237817454)
We present community-driven BERT, DistilBERT, ELECTRA and ConvBERT models for Turkish 🎉
Some datasets used for pretraining and evaluation are contributed from the
awesome Turkish NLP community, as well as the decision for the BERT model name: BERTurk.
Logo is provided by [Merve Noyan](https://twitter.com/mervenoyann).
# Stats
We've trained an (uncased) ConvBERT model on the recently released Turkish part of the
[multiligual C4 (mC4) corpus](https://github.com/allenai/allennlp/discussions/5265) from the AI2 team.
After filtering documents with a broken encoding, the training corpus has a size of 242GB resulting
in 31,240,963,926 tokens.
We used the original 32k vocab (instead of creating a new one).
# mC4 ConvBERT
In addition to the ELEC**TR**A base model, we also trained an ConvBERT model on the Turkish part of the mC4 corpus. We use a
sequence length of 512 over the full training time and train the model for 1M steps on a v3-32 TPU.
# Model usage
All trained models can be used from the [DBMDZ](https://github.com/dbmdz) Hugging Face [model hub page](https://huggingface.co/dbmdz)
using their model name.
Example usage with 🤗/Transformers:
```python
tokenizer = AutoTokenizer.from_pretrained("dbmdz/convbert-base-turkish-mc4-uncased")
model = AutoModel.from_pretrained("dbmdz/convbert-base-turkish-mc4-uncased")
```
# Citation
You can use the following BibTeX entry for citation:
```bibtex
@software{stefan_schweter_2020_3770924,
author = {Stefan Schweter},
title = {BERTurk - BERT models for Turkish},
month = apr,
year = 2020,
publisher = {Zenodo},
version = {1.0.0},
doi = {10.5281/zenodo.3770924},
url = {https://doi.org/10.5281/zenodo.3770924}
}
```
# Acknowledgments
Thanks to [Kemal Oflazer](http://www.andrew.cmu.edu/user/ko/) for providing us
additional large corpora for Turkish. Many thanks to Reyyan Yeniterzi for providing
us the Turkish NER dataset for evaluation.
We would like to thank [Merve Noyan](https://twitter.com/mervenoyann) for the
awesome logo!
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
Thanks for providing access to the TFRC ❤️ |
german-nlp-group/electra-base-german-uncased | 5a79890051f8df23591f06710012d399b7e17d9b | 2021-05-24T13:26:08.000Z | [
"pytorch",
"electra",
"pretraining",
"de",
"transformers",
"commoncrawl",
"uncased",
"umlaute",
"umlauts",
"german",
"deutsch",
"license:mit"
] | null | false | german-nlp-group | null | german-nlp-group/electra-base-german-uncased | 1,087 | 2 | transformers | 1,715 | ---
language: de
license: mit
thumbnail: "https://raw.githubusercontent.com/German-NLP-Group/german-transformer-training/master/model_cards/german-electra-logo.png"
tags:
- electra
- commoncrawl
- uncased
- umlaute
- umlauts
- german
- deutsch
---
# German Electra Uncased
<img width="300px" src="https://raw.githubusercontent.com/German-NLP-Group/german-transformer-training/master/model_cards/german-electra-logo.png">
[¹]
## Version 2 Release
We released an improved version of this model. Version 1 was trained for 766,000 steps. For this new version we continued the training for an additional 734,000 steps. It therefore follows that version 2 was trained on a total of 1,500,000 steps. See "Evaluation of Version 2: GermEval18 Coarse" below for details.
## Model Info
This Model is suitable for training on many downstream tasks in German (Q&A, Sentiment Analysis, etc.).
It can be used as a drop-in replacement for **BERT** in most down-stream tasks (**ELECTRA** is even implemented as an extended **BERT** Class).
At the time of release (August 2020) this model is the best performing publicly available German NLP model on various German evaluation metrics (CONLL03-DE, GermEval18 Coarse, GermEval18 Fine). For GermEval18 Coarse results see below. More will be published soon.
## Installation
This model has the special feature that it is **uncased** but does **not strip accents**.
This possibility was added by us with [PR #6280](https://github.com/huggingface/transformers/pull/6280).
To use it you have to use Transformers version 3.1.0 or newer.
```bash
pip install transformers -U
```
## Uncase and Umlauts ('Ö', 'Ä', 'Ü')
This model is uncased. This helps especially for domains where colloquial terms with uncorrect capitalization is often used.
The special characters 'ö', 'ü', 'ä' are included through the `strip_accent=False` option, as this leads to an improved precision.
## Creators
This model was trained and open sourced in conjunction with the [**German NLP Group**](https://github.com/German-NLP-Group) in equal parts by:
- [**Philip May**](https://May.la) - [T-Systems on site services GmbH](https://www.t-systems-onsite.de/)
- [**Philipp Reißel**](https://www.reissel.eu) - [ambeRoad](https://amberoad.de/)
## Evaluation of Version 2: GermEval18 Coarse
We evaluated all language models on GermEval18 with the F1 macro score. For each model we did an extensive automated hyperparameter search. With the best hyperparmeters we did fit the moodel multiple times on GermEval18. This is done to cancel random effects and get results of statistical relevance.
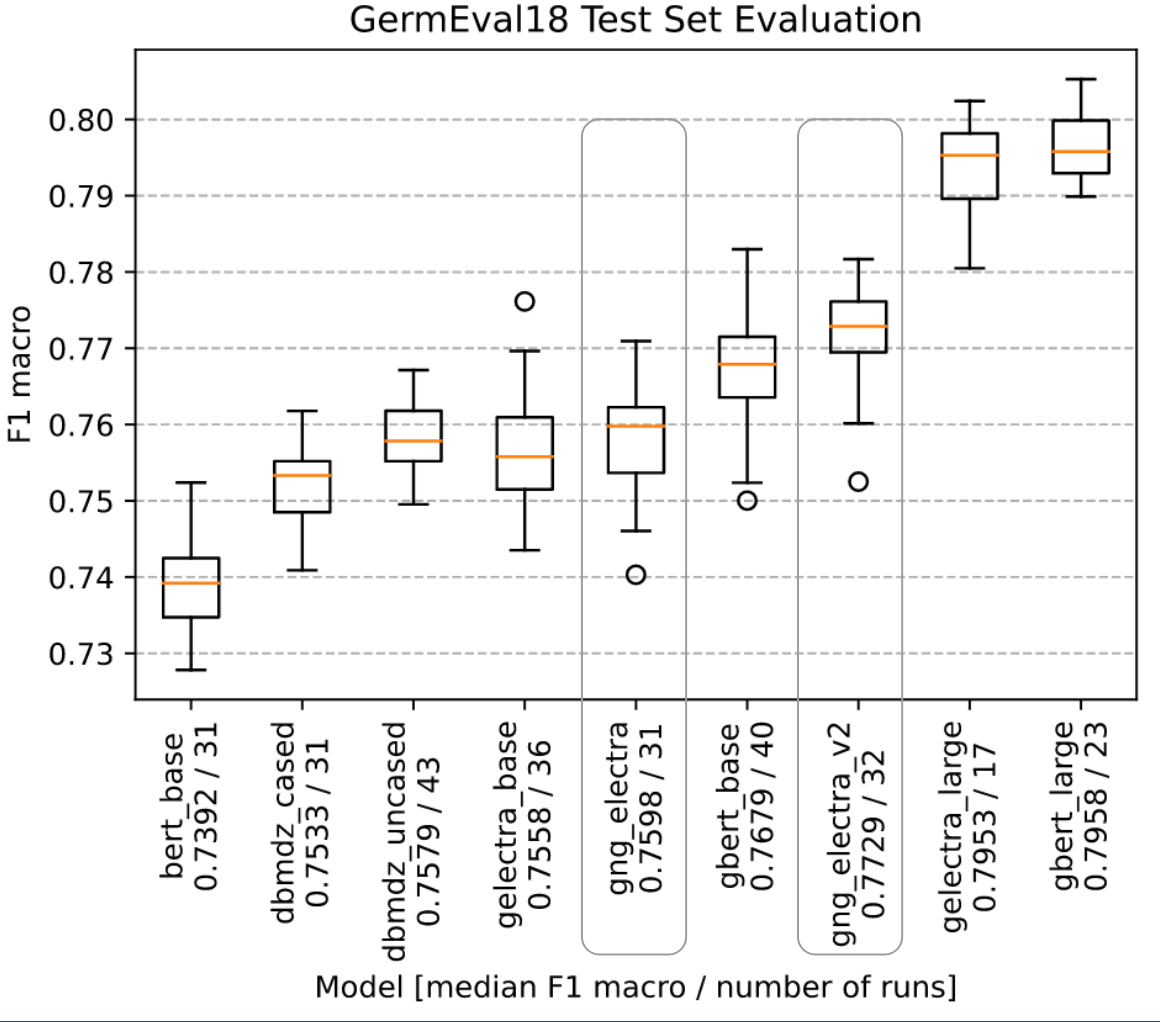
## Checkpoint evaluation
Since it it not guaranteed that the last checkpoint is the best, we evaluated the checkpoints on GermEval18. We found that the last checkpoint is indeed the best. The training was stable and did not overfit the text corpus.
## Pre-training details
### Data
- Cleaned Common Crawl Corpus 2019-09 German: [CC_net](https://github.com/facebookresearch/cc_net) (Only head coprus and filtered for language_score > 0.98) - 62 GB
- German Wikipedia Article Pages Dump (20200701) - 5.5 GB
- German Wikipedia Talk Pages Dump (20200620) - 1.1 GB
- Subtitles - 823 MB
- News 2018 - 4.1 GB
The sentences were split with [SojaMo](https://github.com/tsproisl/SoMaJo). We took the German Wikipedia Article Pages Dump 3x to oversample. This approach was also used in a similar way in GPT-3 (Table 2.2).
More Details can be found here [Preperaing Datasets for German Electra Github](https://github.com/German-NLP-Group/german-transformer-training)
### Electra Branch no_strip_accents
Because we do not want to stip accents in our training data we made a change to Electra and used this repo [Electra no_strip_accents](https://github.com/PhilipMay/electra/tree/no_strip_accents) (branch `no_strip_accents`). Then created the tf dataset with:
```bash
python build_pretraining_dataset.py --corpus-dir <corpus_dir> --vocab-file <dir>/vocab.txt --output-dir ./tf_data --max-seq-length 512 --num-processes 8 --do-lower-case --no-strip-accents
```
### The training
The training itself can be performed with the Original Electra Repo (No special case for this needed).
We run it with the following Config:
<details>
<summary>The exact Training Config</summary>
<br/>debug False
<br/>disallow_correct False
<br/>disc_weight 50.0
<br/>do_eval False
<br/>do_lower_case True
<br/>do_train True
<br/>electra_objective True
<br/>embedding_size 768
<br/>eval_batch_size 128
<br/>gcp_project None
<br/>gen_weight 1.0
<br/>generator_hidden_size 0.33333
<br/>generator_layers 1.0
<br/>iterations_per_loop 200
<br/>keep_checkpoint_max 0
<br/>learning_rate 0.0002
<br/>lr_decay_power 1.0
<br/>mask_prob 0.15
<br/>max_predictions_per_seq 79
<br/>max_seq_length 512
<br/>model_dir gs://XXX
<br/>model_hparam_overrides {}
<br/>model_name 02_Electra_Checkpoints_32k_766k_Combined
<br/>model_size base
<br/>num_eval_steps 100
<br/>num_tpu_cores 8
<br/>num_train_steps 766000
<br/>num_warmup_steps 10000
<br/>pretrain_tfrecords gs://XXX
<br/>results_pkl gs://XXX
<br/>results_txt gs://XXX
<br/>save_checkpoints_steps 5000
<br/>temperature 1.0
<br/>tpu_job_name None
<br/>tpu_name electrav5
<br/>tpu_zone None
<br/>train_batch_size 256
<br/>uniform_generator False
<br/>untied_generator True
<br/>untied_generator_embeddings False
<br/>use_tpu True
<br/>vocab_file gs://XXX
<br/>vocab_size 32767
<br/>weight_decay_rate 0.01
</details>
Please Note: *Due to the GAN like strucutre of Electra the loss is not that meaningful*
It took about 7 Days on a preemtible TPU V3-8. In total, the Model went through approximately 10 Epochs. For an automatically recreation of a cancelled TPUs we used [tpunicorn](https://github.com/shawwn/tpunicorn). The total cost of training summed up to about 450 $ for one run. The Data-pre processing and Vocab Creation needed approximately 500-1000 CPU hours. Servers were fully provided by [T-Systems on site services GmbH](https://www.t-systems-onsite.de/), [ambeRoad](https://amberoad.de/).
Special thanks to [Stefan Schweter](https://github.com/stefan-it) for your feedback and providing parts of the text corpus.
[¹]: Source for the picture [Pinterest](https://www.pinterest.cl/pin/371828512984142193/)
### Negative Results
We tried the following approaches which we found had no positive influence:
- **Increased Vocab Size**: Leads to more parameters and thus reduced examples/sec while no visible Performance gains were measured
- **Decreased Batch-Size**: The original Electra was trained with a Batch Size per TPU Core of 16 whereas this Model was trained with 32 BS / TPU Core. We found out that 32 BS leads to better results when you compare metrics over computation time
## License - The MIT License
Copyright 2020-2021 Philip May<br>
Copyright 2020-2021 Philipp Reissel
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
|
Tidum/DialoGPT-large-Michael | 15bcc27d9effca5ea4e67b33ebd387e5bd860718 | 2022-02-06T19:59:38.000Z | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | false | Tidum | null | Tidum/DialoGPT-large-Michael | 1,086 | null | transformers | 1,716 | ---
tags:
- conversational
---
#Michael DialoGPT Model |
textattack/albert-base-v2-imdb | e377b81678ba240cd835375c5853bb590e10e75a | 2020-07-06T16:34:24.000Z | [
"pytorch",
"albert",
"text-classification",
"transformers"
] | text-classification | false | textattack | null | textattack/albert-base-v2-imdb | 1,086 | null | transformers | 1,717 | ## TextAttack Model Card
This `albert-base-v2` model was fine-tuned for sequence classification using TextAttack
and the imdb dataset loaded using the `nlp` library. The model was fine-tuned
for 5 epochs with a batch size of 32, a learning
rate of 2e-05, and a maximum sequence length of 128.
Since this was a classification task, the model was trained with a cross-entropy loss function.
The best score the model achieved on this task was 0.89236, as measured by the
eval set accuracy, found after 3 epochs.
For more information, check out [TextAttack on Github](https://github.com/QData/TextAttack).
|
zhayunduo/roberta-base-stocktwits-finetuned | e4fd3e0fcc2af47df76ddc74d90840fe5a7ec299 | 2022-04-18T07:40:25.000Z | [
"pytorch",
"roberta",
"text-classification",
"transformers",
"license:apache-2.0"
] | text-classification | false | zhayunduo | null | zhayunduo/roberta-base-stocktwits-finetuned | 1,085 | 0 | transformers | 1,718 | ---
license: apache-2.0
---
## **Sentiment Inferencing model for stock related commments**
#### *A project by NUS ISS students Frank Cao, Gerong Zhang, Jiaqi Yao, Sikai Ni, Yunduo Zhang*
<br />
### Description
This model is fine tuned with roberta-base model on 3200000 comments from stocktwits, with the user labeled tags 'Bullish' or 'Bearish'
try something that the individual investors may say on the investment forum on the inference API, for example, try 'red' and 'green'.
[code on github](https://github.com/Gitrexx/PLPPM_Sentiment_Analysis_via_Stocktwits/tree/main/SentimentEngine)
<br />
### Training information
- batch size 32
- learning rate 2e-5
| | Train loss | Validation loss | Validation accuracy |
| ----------- | ----------- | ---------------- | ------------------- |
| epoch1 | 0.3495 | 0.2956 | 0.8679 |
| epoch2 | 0.2717 | 0.2235 | 0.9021 |
| epoch3 | 0.2360 | 0.1875 | 0.9210 |
| epoch4 | 0.2106 | 0.1603 | 0.9343 |
<br />
# How to use
```python
from transformers import RobertaForSequenceClassification, RobertaTokenizer
from transformers import pipeline
import pandas as pd
import emoji
# the model was trained upon below preprocessing
def process_text(texts):
# remove URLs
texts = re.sub(r'https?://\S+', "", texts)
texts = re.sub(r'www.\S+', "", texts)
# remove '
texts = texts.replace(''', "'")
# remove symbol names
texts = re.sub(r'(\#)(\S+)', r'hashtag_\2', texts)
texts = re.sub(r'(\$)([A-Za-z]+)', r'cashtag_\2', texts)
# remove usernames
texts = re.sub(r'(\@)(\S+)', r'mention_\2', texts)
# demojize
texts = emoji.demojize(texts, delimiters=("", " "))
return texts.strip()
tokenizer_loaded = RobertaTokenizer.from_pretrained('zhayunduo/roberta-base-stocktwits-finetuned')
model_loaded = RobertaForSequenceClassification.from_pretrained('zhayunduo/roberta-base-stocktwits-finetuned')
nlp = pipeline("text-classification", model=model_loaded, tokenizer=tokenizer_loaded)
sentences = pd.Series(['just buy','just sell it',
'entity rocket to the sky!',
'go down','even though it is going up, I still think it will not keep this trend in the near future'])
# sentences = list(sentences.apply(process_text)) # if input text contains https, @ or # or $ symbols, better apply preprocess to get a more accurate result
sentences = list(sentences)
results = nlp(sentences)
print(results) # 2 labels, label 0 is bearish, label 1 is bullish
``` |
microsoft/swin-large-patch4-window12-384-in22k | df0f89cc75d470a35ff4bb5d0e53fbdbbe377bb3 | 2022-05-16T18:40:51.000Z | [
"pytorch",
"tf",
"swin",
"image-classification",
"dataset:imagenet-21k",
"arxiv:2103.14030",
"transformers",
"vision",
"license:apache-2.0"
] | image-classification | false | microsoft | null | microsoft/swin-large-patch4-window12-384-in22k | 1,084 | 1 | transformers | 1,719 | ---
license: apache-2.0
tags:
- vision
- image-classification
datasets:
- imagenet-21k
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
---
# Swin Transformer (large-sized model)
Swin Transformer model pre-trained on ImageNet-21k (14 million images, 21,841 classes) at resolution 384x384. It was introduced in the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Liu et al. and first released in [this repository](https://github.com/microsoft/Swin-Transformer).
Disclaimer: The team releasing Swin Transformer did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The Swin Transformer is a type of Vision Transformer. It builds hierarchical feature maps by merging image patches (shown in gray) in deeper layers and has linear computation complexity to input image size due to computation of self-attention only within each local window (shown in red). It can thus serve as a general-purpose backbone for both image classification and dense recognition tasks. In contrast, previous vision Transformers produce feature maps of a single low resolution and have quadratic computation complexity to input image size due to computation of self-attention globally.

[Source](https://paperswithcode.com/method/swin-transformer)
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=swin) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import AutoFeatureExtractor, SwinForImageClassification
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = AutoFeatureExtractor.from_pretrained("microsoft/swin-large-patch4-window12-384-in22k")
model = SwinForImageClassification.from_pretrained("microsoft/swin-large-patch4-window12-384-in22k")
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
For more code examples, we refer to the [documentation](https://huggingface.co/transformers/model_doc/swin.html#).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2103-14030,
author = {Ze Liu and
Yutong Lin and
Yue Cao and
Han Hu and
Yixuan Wei and
Zheng Zhang and
Stephen Lin and
Baining Guo},
title = {Swin Transformer: Hierarchical Vision Transformer using Shifted Windows},
journal = {CoRR},
volume = {abs/2103.14030},
year = {2021},
url = {https://arxiv.org/abs/2103.14030},
eprinttype = {arXiv},
eprint = {2103.14030},
timestamp = {Thu, 08 Apr 2021 07:53:26 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2103-14030.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` |
Luyu/co-condenser-marco-retriever | 2149ab984d2aea9c39cf7e6bbc2041a5302866a2 | 2021-09-02T14:43:18.000Z | [
"pytorch",
"bert",
"feature-extraction",
"transformers"
] | feature-extraction | false | Luyu | null | Luyu/co-condenser-marco-retriever | 1,079 | 2 | transformers | 1,720 | Entry not found |
soheeyang/rdr-ctx_encoder-single-nq-base | 289088ddb79e14a0ca555548b106a5e594bf6ba2 | 2021-04-15T15:58:10.000Z | [
"pytorch",
"tf",
"dpr",
"arxiv:2010.10999",
"arxiv:2004.04906",
"transformers"
] | null | false | soheeyang | null | soheeyang/rdr-ctx_encoder-single-nq-base | 1,076 | null | transformers | 1,721 | # rdr-ctx_encoder-single-nq-base
Reader-Distilled Retriever (`RDR`)
Sohee Yang and Minjoon Seo, [Is Retriever Merely an Approximator of Reader?](https://arxiv.org/abs/2010.10999), arXiv 2020
The paper proposes to distill the reader into the retriever so that the retriever absorbs the strength of the reader while keeping its own benefit. The model is a [DPR](https://arxiv.org/abs/2004.04906) retriever further finetuned using knowledge distillation from the DPR reader. Using this approach, the answer recall rate increases by a large margin, especially at small numbers of top-k.
This model is the context encoder of RDR trained solely on Natural Questions (NQ) (single-nq). This model is trained by the authors and is the official checkpoint of RDR.
## Performance
The following is the answer recall rate measured using PyTorch 1.4.0 and transformers 4.5.0.
The values of DPR on the NQ dev set are taken from Table 1 of the [paper of RDR](https://arxiv.org/abs/2010.10999). The values of DPR on the NQ test set are taken from the [codebase of DPR](https://github.com/facebookresearch/DPR). DPR-adv is the a new DPR model released in March 2021. It is trained on the original DPR NQ train set and its version where hard negatives are mined using DPR index itself using the previous NQ checkpoint. Please refer to the [codebase of DPR](https://github.com/facebookresearch/DPR) for more details about DPR-adv-hn.
| | Top-K Passages | 1 | 5 | 20 | 50 | 100 |
|---------|------------------|-------|-------|-------|-------|-------|
| **NQ Dev** | **DPR** | 44.2 | - | 76.9 | 81.3 | 84.2 |
| | **RDR (This Model)** | **54.43** | **72.17** | **81.33** | **84.8** | **86.61** |
| **NQ Test** | **DPR** | 45.87 | 68.14 | 79.97 | - | 85.87 |
| | **DPR-adv-hn** | 52.47 | **72.24** | 81.33 | - | 87.29 |
| | **RDR (This Model)** | **54.29** | 72.16 | **82.8** | **86.34** | **88.2** |
## How to Use
RDR shares the same architecture with DPR. Therefore, It uses `DPRContextEncoder` as the model class.
Using `AutoModel` does not properly detect whether the checkpoint is for `DPRContextEncoder` or `DPRQuestionEncoder`.
Therefore, please specify the exact class to use the model.
```python
from transformers import DPRContextEncoder, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("soheeyang/rdr-ctx_encoder-single-nq-base")
ctx_encoder = DPRContextEncoder.from_pretrained("soheeyang/rdr-ctx_encoder-single-nq-base")
data = tokenizer("context comes here", return_tensors="pt")
ctx_embedding = ctx_encoder(**data).pooler_output # embedding vector for context
```
|
sentence-transformers/gtr-t5-large | fd31cff184d356b3a9a5794706551fc5306071a2 | 2022-02-09T12:33:08.000Z | [
"pytorch",
"t5",
"en",
"arxiv:2112.07899",
"sentence-transformers",
"feature-extraction",
"sentence-similarity",
"transformers",
"license:apache-2.0"
] | sentence-similarity | false | sentence-transformers | null | sentence-transformers/gtr-t5-large | 1,074 | 1 | sentence-transformers | 1,722 | ---
pipeline_tag: sentence-similarity
language: en
license: apache-2.0
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# sentence-transformers/gtr-t5-large
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space. The model was specifically trained for the task of sematic search.
This model was converted from the Tensorflow model [gtr-large-1](https://tfhub.dev/google/gtr/gtr-large/1) to PyTorch. When using this model, have a look at the publication: [Large Dual Encoders Are Generalizable Retrievers](https://arxiv.org/abs/2112.07899). The tfhub model and this PyTorch model can produce slightly different embeddings, however, when run on the same benchmarks, they produce identical results.
The model uses only the encoder from a T5-large model. The weights are stored in FP16.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/gtr-t5-large')
embeddings = model.encode(sentences)
print(embeddings)
```
The model requires sentence-transformers version 2.2.0 or newer.
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/gtr-t5-large)
## Citing & Authors
If you find this model helpful, please cite the respective publication:
[Large Dual Encoders Are Generalizable Retrievers](https://arxiv.org/abs/2112.07899)
|
SkolkovoInstitute/russian_toxicity_classifier | 2b9a086ec05c2dc202fea11ed15f317b1676b18c | 2021-12-08T15:41:00.000Z | [
"pytorch",
"tf",
"bert",
"text-classification",
"ru",
"transformers",
"toxic comments classification"
] | text-classification | false | SkolkovoInstitute | null | SkolkovoInstitute/russian_toxicity_classifier | 1,070 | 6 | transformers | 1,723 | ---
language:
- ru
tags:
- toxic comments classification
licenses:
- cc-by-nc-sa
---
Bert-based classifier (finetuned from [Conversational Rubert](https://huggingface.co/DeepPavlov/rubert-base-cased-conversational)) trained on merge of Russian Language Toxic Comments [dataset](https://www.kaggle.com/blackmoon/russian-language-toxic-comments/metadata) collected from 2ch.hk and Toxic Russian Comments [dataset](https://www.kaggle.com/alexandersemiletov/toxic-russian-comments) collected from ok.ru.
The datasets were merged, shuffled, and split into train, dev, test splits in 80-10-10 proportion.
The metrics obtained from test dataset is as follows
| | precision | recall | f1-score | support |
|:------------:|:---------:|:------:|:--------:|:-------:|
| 0 | 0.98 | 0.99 | 0.98 | 21384 |
| 1 | 0.94 | 0.92 | 0.93 | 4886 |
| accuracy | | | 0.97 | 26270|
| macro avg | 0.96 | 0.96 | 0.96 | 26270 |
| weighted avg | 0.97 | 0.97 | 0.97 | 26270 |
## How to use
```python
from transformers import BertTokenizer, BertForSequenceClassification
# load tokenizer and model weights
tokenizer = BertTokenizer.from_pretrained('SkolkovoInstitute/russian_toxicity_classifier')
model = BertForSequenceClassification.from_pretrained('SkolkovoInstitute/russian_toxicity_classifier')
# prepare the input
batch = tokenizer.encode('ты супер', return_tensors='pt')
# inference
model(batch)
```
## Licensing Information
[Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License][cc-by-nc-sa].
[![CC BY-NC-SA 4.0][cc-by-nc-sa-image]][cc-by-nc-sa]
[cc-by-nc-sa]: http://creativecommons.org/licenses/by-nc-sa/4.0/
[cc-by-nc-sa-image]: https://i.creativecommons.org/l/by-nc-sa/4.0/88x31.png |
m3hrdadfi/distilbert-zwnj-wnli-mean-tokens | 6d0d94f899be52bc72f68f3f3b5800650cb0395b | 2021-06-28T18:05:51.000Z | [
"pytorch",
"distilbert",
"feature-extraction",
"sentence-transformers",
"sentence-similarity",
"transformers"
] | sentence-similarity | false | m3hrdadfi | null | m3hrdadfi/distilbert-zwnj-wnli-mean-tokens | 1,069 | null | sentence-transformers | 1,724 | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
widget:
source_sentence: "مردی در حال خوردن پاستا است."
sentences:
- 'مردی در حال خوردن خوراک است.'
- 'مردی در حال خوردن یک تکه نان است.'
- 'دختری بچه ای را حمل می کند.'
- 'یک مرد سوار بر اسب است.'
- 'زنی در حال نواختن پیانو است.'
- 'دو مرد گاری ها را به داخل جنگل هل دادند.'
- 'مردی در حال سواری بر اسب سفید در مزرعه است.'
- 'میمونی در حال نواختن طبل است.'
- 'یوزپلنگ به دنبال شکار خود در حال دویدن است.'
---
# Sentence Embeddings with `distilbert-zwnj-wnli-mean-tokens`
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = [
'اولین حکمران شهر بابل کی بود؟',
'در فصل زمستان چه اتفاقی افتاد؟',
'میراث کوروش'
]
model = SentenceTransformer('m3hrdadfi/distilbert-zwnj-wnli-mean-tokens')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
# Max Pooling - Take the max value over time for every dimension.
def max_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
token_embeddings[input_mask_expanded == 0] = -1e9 # Set padding tokens to large negative value
return torch.mean(token_embeddings, 1)[0]
# Sentences we want sentence embeddings for
sentences = [
'اولین حکمران شهر بابل کی بود؟',
'در فصل زمستان چه اتفاقی افتاد؟',
'میراث کوروش'
]
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('m3hrdadfi/distilbert-zwnj-wnli-mean-tokens')
model = AutoModel.from_pretrained('m3hrdadfi/distilbert-zwnj-wnli-mean-tokens')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = max_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Questions?
Post a Github issue from [HERE](https://github.com/m3hrdadfi/sentence-transformers). |
uer/bart-chinese-6-960-cluecorpussmall | b8eb755e2597cdf448078b70248d2d5cde9cd17b | 2021-10-08T14:47:18.000Z | [
"pytorch",
"bart",
"text2text-generation",
"Chinese",
"dataset:CLUECorpusSmall",
"arxiv:1909.05658",
"transformers",
"autotrain_compatible"
] | text2text-generation | false | uer | null | uer/bart-chinese-6-960-cluecorpussmall | 1,069 | 1 | transformers | 1,725 | ---
language: Chinese
datasets: CLUECorpusSmall
widget:
- text: "作为电子[MASK]的平台,京东绝对是领先者。如今的刘强[MASK]已经是身价过[MASK]的老板。"
---
# Chinese BART
## Model description
This model is pre-trained by [UER-py](https://arxiv.org/abs/1909.05658).
## How to use
You can use this model directly with a pipeline for text2text generation :
```python
>>> from transformers import BertTokenizer, BartForConditionalGeneration, Text2TextGenerationPipeline
>>> tokenizer = BertTokenizer.from_pretrained("uer/bart-chinese-6-960-cluecorpussmall")
>>> model = BartForConditionalGeneration.from_pretrained("uer/bart-chinese-6-960-cluecorpussmall")
>>> text2text_generator = Text2TextGenerationPipeline(model, tokenizer)
>>> text2text_generator("中国的首都是[MASK]京", max_length=50, do_sample=False)
[{'generated_text': '中 国 的 首 都 是 北 京'}]
```
## Training data
[CLUECorpusSmall](https://github.com/CLUEbenchmark/CLUECorpus2020/) Common Crawl and some short messages are used as training data.
## Training procedure
The model is pre-trained by [UER-py](https://github.com/dbiir/UER-py/) on [Tencent Cloud](https://cloud.tencent.com/). We pre-train 1,000,000 steps with a sequence length of 512.
we convert the pre-trained model into Huggingface's format:
```
python3 scripts/convert_bart_from_uer_to_huggingface.py --input_model_path cluecorpussmall_bart_medium_seq512_model.bin-250000 \
--output_model_path pytorch_model.bin \
--layers_num 6
```
### BibTeX entry and citation info
```
@article{lewis2019bart,
title={Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension},
author={Lewis, Mike and Liu, Yinhan and Goyal, Naman and Ghazvininejad, Marjan and Mohamed, Abdelrahman and Levy, Omer and Stoyanov, Ves and Zettlemoyer, Luke},
journal={arXiv preprint arXiv:1910.13461},
year={2019}
}
@article{zhao2019uer,
title={UER: An Open-Source Toolkit for Pre-training Models},
author={Zhao, Zhe and Chen, Hui and Zhang, Jinbin and Zhao, Xin and Liu, Tao and Lu, Wei and Chen, Xi and Deng, Haotang and Ju, Qi and Du, Xiaoyong},
journal={EMNLP-IJCNLP 2019},
pages={241},
year={2019}
}
``` |
flyswot/flyswot | efc837358a25ea97d69e67a6c253531391a32c65 | 2022-06-15T17:32:16.000Z | [
"pytorch",
"convnext",
"image-classification",
"transformers",
"generated_from_trainer",
"model-index"
] | image-classification | false | flyswot | null | flyswot/flyswot | 1,064 | null | transformers | 1,726 | ---
tags:
- generated_from_trainer
model-index:
- name: flyswot
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# flyswot
This model is a fine-tuned version of [flyswot/convnext-tiny-224_flyswot](https://huggingface.co/flyswot/convnext-tiny-224_flyswot) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 0.1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 0.1 | 23 | 0.0894 | 0.9941 |
### Framework versions
- Transformers 4.19.4
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
flaubert/flaubert_large_cased | a5fdc16154e92c75d7adde577e183793ad19d040 | 2021-05-19T16:55:50.000Z | [
"pytorch",
"flaubert",
"fill-mask",
"fr",
"dataset:flaubert",
"transformers",
"bert",
"language-model",
"flue",
"french",
"bert-large",
"flaubert-large",
"cased",
"license:mit",
"autotrain_compatible"
] | fill-mask | false | flaubert | null | flaubert/flaubert_large_cased | 1,063 | null | transformers | 1,727 | ---
language: fr
license: mit
datasets:
- flaubert
metrics:
- flue
tags:
- bert
- language-model
- flaubert
- flue
- french
- bert-large
- flaubert-large
- cased
---
# FlauBERT: Unsupervised Language Model Pre-training for French
**FlauBERT** is a French BERT trained on a very large and heterogeneous French corpus. Models of different sizes are trained using the new CNRS (French National Centre for Scientific Research) [Jean Zay](http://www.idris.fr/eng/jean-zay/ ) supercomputer.
Along with FlauBERT comes [**FLUE**](https://github.com/getalp/Flaubert/tree/master/flue): an evaluation setup for French NLP systems similar to the popular GLUE benchmark. The goal is to enable further reproducible experiments in the future and to share models and progress on the French language.For more details please refer to the [official website](https://github.com/getalp/Flaubert).
## FlauBERT models
| Model name | Number of layers | Attention Heads | Embedding Dimension | Total Parameters |
| :------: | :---: | :---: | :---: | :---: |
| `flaubert-small-cased` | 6 | 8 | 512 | 54 M |
| `flaubert-base-uncased` | 12 | 12 | 768 | 137 M |
| `flaubert-base-cased` | 12 | 12 | 768 | 138 M |
| `flaubert-large-cased` | 24 | 16 | 1024 | 373 M |
**Note:** `flaubert-small-cased` is partially trained so performance is not guaranteed. Consider using it for debugging purpose only.
## Using FlauBERT with Hugging Face's Transformers
```python
import torch
from transformers import FlaubertModel, FlaubertTokenizer
# Choose among ['flaubert/flaubert_small_cased', 'flaubert/flaubert_base_uncased',
# 'flaubert/flaubert_base_cased', 'flaubert/flaubert_large_cased']
modelname = 'flaubert/flaubert_base_cased'
# Load pretrained model and tokenizer
flaubert, log = FlaubertModel.from_pretrained(modelname, output_loading_info=True)
flaubert_tokenizer = FlaubertTokenizer.from_pretrained(modelname, do_lowercase=False)
# do_lowercase=False if using cased models, True if using uncased ones
sentence = "Le chat mange une pomme."
token_ids = torch.tensor([flaubert_tokenizer.encode(sentence)])
last_layer = flaubert(token_ids)[0]
print(last_layer.shape)
# torch.Size([1, 8, 768]) -> (batch size x number of tokens x embedding dimension)
# The BERT [CLS] token correspond to the first hidden state of the last layer
cls_embedding = last_layer[:, 0, :]
```
**Notes:** if your `transformers` version is <=2.10.0, `modelname` should take one
of the following values:
```
['flaubert-small-cased', 'flaubert-base-uncased', 'flaubert-base-cased', 'flaubert-large-cased']
```
## References
If you use FlauBERT or the FLUE Benchmark for your scientific publication, or if you find the resources in this repository useful, please cite one of the following papers:
[LREC paper](http://www.lrec-conf.org/proceedings/lrec2020/pdf/2020.lrec-1.302.pdf)
```
@InProceedings{le2020flaubert,
author = {Le, Hang and Vial, Lo\"{i}c and Frej, Jibril and Segonne, Vincent and Coavoux, Maximin and Lecouteux, Benjamin and Allauzen, Alexandre and Crabb\'{e}, Beno\^{i}t and Besacier, Laurent and Schwab, Didier},
title = {FlauBERT: Unsupervised Language Model Pre-training for French},
booktitle = {Proceedings of The 12th Language Resources and Evaluation Conference},
month = {May},
year = {2020},
address = {Marseille, France},
publisher = {European Language Resources Association},
pages = {2479--2490},
url = {https://www.aclweb.org/anthology/2020.lrec-1.302}
}
```
[TALN paper](https://hal.archives-ouvertes.fr/hal-02784776/)
```
@inproceedings{le2020flaubert,
title = {FlauBERT: des mod{\`e}les de langue contextualis{\'e}s pr{\'e}-entra{\^\i}n{\'e}s pour le fran{\c{c}}ais},
author = {Le, Hang and Vial, Lo{\"\i}c and Frej, Jibril and Segonne, Vincent and Coavoux, Maximin and Lecouteux, Benjamin and Allauzen, Alexandre and Crabb{\'e}, Beno{\^\i}t and Besacier, Laurent and Schwab, Didier},
booktitle = {Actes de la 6e conf{\'e}rence conjointe Journ{\'e}es d'{\'E}tudes sur la Parole (JEP, 31e {\'e}dition), Traitement Automatique des Langues Naturelles (TALN, 27e {\'e}dition), Rencontre des {\'E}tudiants Chercheurs en Informatique pour le Traitement Automatique des Langues (R{\'E}CITAL, 22e {\'e}dition). Volume 2: Traitement Automatique des Langues Naturelles},
pages = {268--278},
year = {2020},
organization = {ATALA}
}
``` |
sentence-transformers/gtr-t5-xl | 0b2448c8b50fa688f209d70b083cf3ad934e0e37 | 2022-02-09T12:29:08.000Z | [
"pytorch",
"t5",
"en",
"arxiv:2112.07899",
"sentence-transformers",
"feature-extraction",
"sentence-similarity",
"transformers",
"license:apache-2.0"
] | sentence-similarity | false | sentence-transformers | null | sentence-transformers/gtr-t5-xl | 1,062 | null | sentence-transformers | 1,728 | ---
pipeline_tag: sentence-similarity
language: en
license: apache-2.0
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# sentence-transformers/gtr-t5-xl
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space. The model was specifically trained for the task of sematic search.
This model was converted from the Tensorflow model [gtr-xl-1](https://tfhub.dev/google/gtr/gtr-xl/1) to PyTorch. When using this model, have a look at the publication: [Large Dual Encoders Are Generalizable Retrievers](https://arxiv.org/abs/2112.07899). The tfhub model and this PyTorch model can produce slightly different embeddings, however, when run on the same benchmarks, they produce identical results.
The model uses only the encoder from a T5-3B model. The weights are stored in FP16.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/gtr-t5-xl')
embeddings = model.encode(sentences)
print(embeddings)
```
The model requires sentence-transformers version 2.2.0 or newer.
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/gtr-t5-xl)
## Citing & Authors
If you find this model helpful, please cite the respective publication:
[Large Dual Encoders Are Generalizable Retrievers](https://arxiv.org/abs/2112.07899)
|
textattack/roberta-base-STS-B | 3bea43e748145fbd2bcefba0004e360785c76564 | 2021-05-20T22:12:47.000Z | [
"pytorch",
"jax",
"roberta",
"text-classification",
"transformers"
] | text-classification | false | textattack | null | textattack/roberta-base-STS-B | 1,061 | null | transformers | 1,729 | ## TextAttack Model Card
This `roberta-base` model was fine-tuned for sequence classification using TextAttack
and the glue dataset loaded using the `nlp` library. The model was fine-tuned
for 5 epochs with a batch size of 8, a learning
rate of 2e-05, and a maximum sequence length of 128.
Since this was a regression task, the model was trained with a mean squared error loss function.
The best score the model achieved on this task was 0.9108696741479216, as measured by the
eval set pearson correlation, found after 4 epochs.
For more information, check out [TextAttack on Github](https://github.com/QData/TextAttack).
|
Huffon/sentence-klue-roberta-base | a5aca746f7931205aa44992e81fdeb7faf7c443c | 2021-06-20T17:32:17.000Z | [
"pytorch",
"roberta",
"feature-extraction",
"ko",
"dataset:klue",
"arxiv:1908.10084",
"sentence-transformers"
] | feature-extraction | false | Huffon | null | Huffon/sentence-klue-roberta-base | 1,060 | 4 | sentence-transformers | 1,730 | ---
language: ko
tags:
- roberta
- sentence-transformers
datasets:
- klue
---
# KLUE RoBERTa base model for Sentence Embeddings
This is the `sentence-klue-roberta-base` model. The sentence-transformers repository allows to train and use Transformer models for generating sentence and text embeddings.
The model is described in the paper [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084)
## Usage (Sentence-Transformers)
Using this model becomes more convenient when you have [sentence-transformers](https://github.com/UKPLab/sentence-transformers) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
import torch
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer("Huffon/sentence-klue-roberta-base")
docs = [
"1992년 7월 8일 손흥민은 강원도 춘천시 후평동에서 아버지 손웅정과 어머니 길은자의 차남으로 태어나 그곳에서 자랐다.",
"형은 손흥윤이다.",
"춘천 부안초등학교를 졸업했고, 춘천 후평중학교에 입학한 후 2학년때 원주 육민관중학교 축구부에 들어가기 위해 전학하여 졸업하였으며, 2008년 당시 FC 서울의 U-18팀이었던 동북고등학교 축구부에서 선수 활동 중 대한축구협회 우수선수 해외유학 프로젝트에 선발되어 2008년 8월 독일 분데스리가의 함부르크 유소년팀에 입단하였다.",
"함부르크 유스팀 주전 공격수로 2008년 6월 네덜란드에서 열린 4개국 경기에서 4게임에 출전, 3골을 터뜨렸다.",
"1년간의 유학 후 2009년 8월 한국으로 돌아온 후 10월에 개막한 FIFA U-17 월드컵에 출전하여 3골을 터트리며 한국을 8강으로 이끌었다.",
"그해 11월 함부르크의 정식 유소년팀 선수 계약을 체결하였으며 독일 U-19 리그 4경기 2골을 넣고 2군 리그에 출전을 시작했다.",
"독일 U-19 리그에서 손흥민은 11경기 6골, 2부 리그에서는 6경기 1골을 넣으며 재능을 인정받아 2010년 6월 17세의 나이로 함부르크의 1군 팀 훈련에 참가, 프리시즌 활약으로 함부르크와 정식 계약을 한 후 10월 18세에 함부르크 1군 소속으로 독일 분데스리가에 데뷔하였다.",
]
document_embeddings = model.encode(docs)
query = "손흥민은 어린 나이에 유럽에 진출하였다."
query_embedding = model.encode(query)
top_k = min(5, len(docs))
cos_scores = util.pytorch_cos_sim(query_embedding, document_embeddings)[0]
top_results = torch.topk(cos_scores, k=top_k)
print(f"입력 문장: {query}")
print(f"<입력 문장과 유사한 {top_k} 개의 문장>")
for i, (score, idx) in enumerate(zip(top_results[0], top_results[1])):
print(f"{i+1}: {docs[idx]} {'(유사도: {:.4f})'.format(score)}")
``` |
adalbertojunior/distilbert-portuguese-cased | 0c2eff56791a23ae3451ed7bd0e3350e50a9b44b | 2022-02-04T02:30:57.000Z | [
"pytorch",
"bert",
"feature-extraction",
"pt",
"transformers"
] | feature-extraction | false | adalbertojunior | null | adalbertojunior/distilbert-portuguese-cased | 1,059 | 4 | transformers | 1,731 | ---
language:
- pt
---
This model was distilled from [BERTimbau](https://huggingface.co/neuralmind/bert-base-portuguese-cased)
## Usage
```python
from transformers import AutoTokenizer # Or BertTokenizer
from transformers import AutoModelForPreTraining # Or BertForPreTraining for loading pretraining heads
from transformers import AutoModel # or BertModel, for BERT without pretraining heads
model = AutoModelForPreTraining.from_pretrained('adalbertojunior/distilbert-portuguese-cased')
tokenizer = AutoTokenizer.from_pretrained('adalbertojunior/distilbert-portuguese-cased', do_lower_case=False)
```
You should fine tune it on your own data.
It can achieve accuracy up to 99% relative to the original BERTimbau in some tasks. |
mdraw/german-news-sentiment-bert | 7b4abebe1c3fcfbc62dc0435e480807a80c18210 | 2021-05-19T23:11:49.000Z | [
"pytorch",
"jax",
"bert",
"text-classification",
"transformers"
] | text-classification | false | mdraw | null | mdraw/german-news-sentiment-bert | 1,059 | null | transformers | 1,732 | # German sentiment BERT finetuned on news data
Sentiment analysis model based on https://huggingface.co/oliverguhr/german-sentiment-bert, with additional training on German news texts about migration.
This model is part of the project https://github.com/text-analytics-20/news-sentiment-development, which explores sentiment development in German news articles about migration between 2007 and 2019.
Code for inference (predicting sentiment polarity) on raw text can be found at https://github.com/text-analytics-20/news-sentiment-development/blob/main/sentiment_analysis/bert.py
If you are not interested in polarity but just want to predict discrete class labels (0: positive, 1: negative, 2: neutral), you can also use the model with Oliver Guhr's `germansentiment` package as follows:
First install the package from PyPI:
```bash
pip install germansentiment
```
Then you can use the model in Python:
```python
from germansentiment import SentimentModel
model = SentimentModel('mdraw/german-news-sentiment-bert')
# Examples from our validation dataset
texts = [
'[...], schwärmt der parteilose Vizebürgermeister und Historiker Christian Matzka von der "tollen Helferszene".',
'Flüchtlingsheim 11.05 Uhr: Massenschlägerei',
'Rotterdam habe einen Migrantenanteil von mehr als 50 Prozent.',
]
result = model.predict_sentiment(texts)
print(result)
```
The code above will print:
```python
['positive', 'negative', 'neutral']
```
|
FPTAI/vibert-base-cased | 728a91287e4517d9312066a6aa048fadf4e41e91 | 2021-05-19T11:15:49.000Z | [
"pytorch",
"jax",
"bert",
"transformers"
] | null | false | FPTAI | null | FPTAI/vibert-base-cased | 1,058 | 1 | transformers | 1,733 | Entry not found |
flyswot/convnext-tiny-224_flyswot | c6d4b2138e10efeafef8f5305ce16270ca583618 | 2022-04-05T16:08:35.000Z | [
"pytorch",
"convnext",
"image-classification",
"dataset:image_folder",
"transformers",
"generated_from_trainer",
"model-index"
] | image-classification | false | flyswot | null | flyswot/convnext-tiny-224_flyswot | 1,057 | null | transformers | 1,734 | ---
tags:
- generated_from_trainer
datasets:
- image_folder
metrics:
- f1
model-index:
- name: convnext-tiny-224_flyswot
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: image_folder
type: image_folder
args: default
metrics:
- name: F1
type: f1
value: 0.9756290792360154
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# convnext-tiny-224_flyswot
This model was trained from scratch on the image_folder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5319
- F1: 0.9756
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 666
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
- mixed_precision_training: Native AMP
- label_smoothing_factor: 0.1
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 52 | 0.5478 | 0.9720 |
| No log | 2.0 | 104 | 0.5432 | 0.9709 |
| No log | 3.0 | 156 | 0.5437 | 0.9731 |
| No log | 4.0 | 208 | 0.5433 | 0.9712 |
| No log | 5.0 | 260 | 0.5373 | 0.9745 |
| No log | 6.0 | 312 | 0.5371 | 0.9756 |
| No log | 7.0 | 364 | 0.5381 | 0.9737 |
| No log | 8.0 | 416 | 0.5376 | 0.9744 |
| No log | 9.0 | 468 | 0.5431 | 0.9694 |
| 0.4761 | 10.0 | 520 | 0.5468 | 0.9725 |
| 0.4761 | 11.0 | 572 | 0.5404 | 0.9755 |
| 0.4761 | 12.0 | 624 | 0.5481 | 0.9669 |
| 0.4761 | 13.0 | 676 | 0.5432 | 0.9687 |
| 0.4761 | 14.0 | 728 | 0.5409 | 0.9731 |
| 0.4761 | 15.0 | 780 | 0.5403 | 0.9737 |
| 0.4761 | 16.0 | 832 | 0.5393 | 0.9737 |
| 0.4761 | 17.0 | 884 | 0.5412 | 0.9719 |
| 0.4761 | 18.0 | 936 | 0.5433 | 0.9674 |
| 0.4761 | 19.0 | 988 | 0.5367 | 0.9755 |
| 0.4705 | 20.0 | 1040 | 0.5389 | 0.9737 |
| 0.4705 | 21.0 | 1092 | 0.5396 | 0.9737 |
| 0.4705 | 22.0 | 1144 | 0.5514 | 0.9683 |
| 0.4705 | 23.0 | 1196 | 0.5550 | 0.9617 |
| 0.4705 | 24.0 | 1248 | 0.5428 | 0.9719 |
| 0.4705 | 25.0 | 1300 | 0.5371 | 0.9719 |
| 0.4705 | 26.0 | 1352 | 0.5455 | 0.9719 |
| 0.4705 | 27.0 | 1404 | 0.5409 | 0.9680 |
| 0.4705 | 28.0 | 1456 | 0.5345 | 0.9756 |
| 0.4696 | 29.0 | 1508 | 0.5381 | 0.9756 |
| 0.4696 | 30.0 | 1560 | 0.5387 | 0.9705 |
| 0.4696 | 31.0 | 1612 | 0.5540 | 0.9605 |
| 0.4696 | 32.0 | 1664 | 0.5467 | 0.9706 |
| 0.4696 | 33.0 | 1716 | 0.5322 | 0.9756 |
| 0.4696 | 34.0 | 1768 | 0.5325 | 0.9756 |
| 0.4696 | 35.0 | 1820 | 0.5305 | 0.9737 |
| 0.4696 | 36.0 | 1872 | 0.5305 | 0.9769 |
| 0.4696 | 37.0 | 1924 | 0.5345 | 0.9756 |
| 0.4696 | 38.0 | 1976 | 0.5315 | 0.9737 |
| 0.4699 | 39.0 | 2028 | 0.5333 | 0.9756 |
| 0.4699 | 40.0 | 2080 | 0.5316 | 0.9756 |
| 0.4699 | 41.0 | 2132 | 0.5284 | 0.9756 |
| 0.4699 | 42.0 | 2184 | 0.5325 | 0.9756 |
| 0.4699 | 43.0 | 2236 | 0.5321 | 0.9756 |
| 0.4699 | 44.0 | 2288 | 0.5322 | 0.9756 |
| 0.4699 | 45.0 | 2340 | 0.5323 | 0.9756 |
| 0.4699 | 46.0 | 2392 | 0.5318 | 0.9756 |
| 0.4699 | 47.0 | 2444 | 0.5329 | 0.9756 |
| 0.4699 | 48.0 | 2496 | 0.5317 | 0.9756 |
| 0.4701 | 49.0 | 2548 | 0.5317 | 0.9756 |
| 0.4701 | 50.0 | 2600 | 0.5319 | 0.9756 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.0+cu111
- Datasets 2.0.0
- Tokenizers 0.11.6
|
superb/wav2vec2-base-superb-ks | 372e0486cd83e6f0c05c20a27262e9ca09450d24 | 2021-11-04T16:03:39.000Z | [
"pytorch",
"wav2vec2",
"audio-classification",
"en",
"dataset:superb",
"arxiv:2105.01051",
"transformers",
"speech",
"audio",
"license:apache-2.0"
] | audio-classification | false | superb | null | superb/wav2vec2-base-superb-ks | 1,055 | 7 | transformers | 1,735 | ---
language: en
datasets:
- superb
tags:
- speech
- audio
- wav2vec2
- audio-classification
widget:
- example_title: Speech Commands "down"
src: https://cdn-media.huggingface.co/speech_samples/keyword_spotting_down.wav
- example_title: Speech Commands "go"
src: https://cdn-media.huggingface.co/speech_samples/keyword_spotting_go.wav
license: apache-2.0
---
# Wav2Vec2-Base for Keyword Spotting
## Model description
This is a ported version of
[S3PRL's Wav2Vec2 for the SUPERB Keyword Spotting task](https://github.com/s3prl/s3prl/tree/master/s3prl/downstream/speech_commands).
The base model is [wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base), which is pretrained on 16kHz
sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz.
For more information refer to [SUPERB: Speech processing Universal PERformance Benchmark](https://arxiv.org/abs/2105.01051)
## Task and dataset description
Keyword Spotting (KS) detects preregistered keywords by classifying utterances into a predefined set of
words. The task is usually performed on-device for the fast response time. Thus, accuracy, model size, and
inference time are all crucial. SUPERB uses the widely used
[Speech Commands dataset v1.0](https://www.tensorflow.org/datasets/catalog/speech_commands) for the task.
The dataset consists of ten classes of keywords, a class for silence, and an unknown class to include the
false positive.
For the original model's training and evaluation instructions refer to the
[S3PRL downstream task README](https://github.com/s3prl/s3prl/tree/master/s3prl/downstream#ks-keyword-spotting).
## Usage examples
You can use the model via the Audio Classification pipeline:
```python
from datasets import load_dataset
from transformers import pipeline
dataset = load_dataset("anton-l/superb_demo", "ks", split="test")
classifier = pipeline("audio-classification", model="superb/wav2vec2-base-superb-ks")
labels = classifier(dataset[0]["file"], top_k=5)
```
Or use the model directly:
```python
import torch
from datasets import load_dataset
from transformers import Wav2Vec2ForSequenceClassification, Wav2Vec2FeatureExtractor
from torchaudio.sox_effects import apply_effects_file
effects = [["channels", "1"], ["rate", "16000"], ["gain", "-3.0"]]
def map_to_array(example):
speech, _ = apply_effects_file(example["file"], effects)
example["speech"] = speech.squeeze(0).numpy()
return example
# load a demo dataset and read audio files
dataset = load_dataset("anton-l/superb_demo", "ks", split="test")
dataset = dataset.map(map_to_array)
model = Wav2Vec2ForSequenceClassification.from_pretrained("superb/wav2vec2-base-superb-ks")
feature_extractor = Wav2Vec2FeatureExtractor.from_pretrained("superb/wav2vec2-base-superb-ks")
# compute attention masks and normalize the waveform if needed
inputs = feature_extractor(dataset[:4]["speech"], sampling_rate=16000, padding=True, return_tensors="pt")
logits = model(**inputs).logits
predicted_ids = torch.argmax(logits, dim=-1)
labels = [model.config.id2label[_id] for _id in predicted_ids.tolist()]
```
## Eval results
The evaluation metric is accuracy.
| | **s3prl** | **transformers** |
|--------|-----------|------------------|
|**test**| `0.9623` | `0.9643` |
### BibTeX entry and citation info
```bibtex
@article{yang2021superb,
title={SUPERB: Speech processing Universal PERformance Benchmark},
author={Yang, Shu-wen and Chi, Po-Han and Chuang, Yung-Sung and Lai, Cheng-I Jeff and Lakhotia, Kushal and Lin, Yist Y and Liu, Andy T and Shi, Jiatong and Chang, Xuankai and Lin, Guan-Ting and others},
journal={arXiv preprint arXiv:2105.01051},
year={2021}
}
``` |
aypan17/roberta-base-imdb | b2f9bf35af2965658efdf2d6a116f4cf7dbc2827 | 2022-02-24T07:33:44.000Z | [
"pytorch",
"roberta",
"text-classification",
"transformers",
"license:mit"
] | text-classification | false | aypan17 | null | aypan17/roberta-base-imdb | 1,055 | null | transformers | 1,736 | ---
license: mit
---
TrainingArgs:
lr=2e-5,
train-batch-size=16,
eval-batch-size=16,
num-train-epochs=5,
weight-decay=0.01,
|
facebook/incoder-6B | 89aa16923e2ad52a292a87c38d019128b970161f | 2022-07-16T18:33:46.000Z | [
"pytorch",
"xglm",
"text-generation",
"arxiv:2204.05999",
"transformers",
"code",
"python",
"javascript",
"license:cc-by-nc-4.0"
] | text-generation | false | facebook | null | facebook/incoder-6B | 1,052 | 13 | transformers | 1,737 | ---
license: "cc-by-nc-4.0"
tags:
- code
- python
- javascript
---
# InCoder 6B
A 6B parameter decoder-only Transformer model trained on code using a causal-masked objective, which allows inserting/infilling code as well as standard left-to-right generation.
The model was trained on public open-source repositories with a permissive, non-copyleft, license (Apache 2.0, MIT, BSD-2 or BSD-3) from GitHub and GitLab, as well as StackOverflow. Repositories primarily contained Python and JavaScript, but also include code from 28 languages, as well as StackOverflow.
For more information, see our:
- [Demo](https://huggingface.co/spaces/facebook/incoder-demo)
- [Project site](https://sites.google.com/view/incoder-code-models)
- [Examples](https://sites.google.com/view/incoder-code-models/home/examples)
- [Paper](https://arxiv.org/abs/2204.05999)
A smaller, 1B, parameter model is also available at [facebook/incoder-1B](https://huggingface.co/facebook/incoder-1B).
## Requirements
`pytorch`, `tokenizers`, and `transformers`. Our model requires HF's tokenizers >= 0.12.1, due to changes in the pretokenizer.
```
pip install torch
pip install "tokenizers>=0.12.1"
pip install transformers
```
## Usage
### Model
See [https://github.com/dpfried/incoder](https://github.com/dpfried/incoder) for example code.
This 6B model comes in two versions: with weights in full-precision (float32, stored on branch `main`) and weights in half-precision (float16, stored on branch `float16`). The versions can be loaded as follows:
*Full-precision* (float32): This should be used if you are fine-tuning the model (note: this will take a lot of GPU memory, probably multiple GPUs, and we have not tried training the model in `transformers` --- it was trained in Fairseq). Load with:
`model = AutoModelForCausalLM.from_pretrained("facebook/incoder-6B")`
*Half-precision* (float16): This can be used if you are only doing inference (i.e. generating from the model). It will use less GPU memory, and less RAM when loading the model. With this version it should be able to perform inference on a 16 GB GPU (with a batch size of 1, to sequence lengths of at least 256). Load with:
`model = AutoModelForCausalLM.from_pretrained("facebook/incoder-6B", revision="float16", torch_dtype=torch.float16, low_cpu_mem_usage=True)`
### Tokenizer
`tokenizer = AutoTokenizer.from_pretrained("facebook/incoder-6B")`
Note: the incoder-1B and incoder-6B tokenizers are identical, so 'facebook/incoder-1B' could also be used.
When calling `tokenizer.decode`, it's important to pass `clean_up_tokenization_spaces=False` to avoid removing spaces after punctuation:
`tokenizer.decode(tokenizer.encode("from ."), clean_up_tokenization_spaces=False)`
(Note: encoding prepends the `<|endoftext|>` token, as this marks the start of a document to our model. This token can be removed from the decoded output by passing `skip_special_tokens=True` to `tokenizer.decode`.)
## License
CC-BY-NC 4.0
## Credits
The model was developed by Daniel Fried, Armen Aghajanyan, Jessy Lin, Sida Wang, Eric Wallace, Freda Shi, Ruiqi Zhong, Wen-tau Yih, Luke Zettlemoyer and Mike Lewis.
Thanks to Lucile Saulnier, Leandro von Werra, Nicolas Patry, Suraj Patil, Omar Sanseviero, and others at HuggingFace for help with the model release, and to Naman Goyal and Stephen Roller for the code our demo was based on! |
stanford-crfm/alias-gpt2-small-x21 | e954ab0a77651c595f108c42b1c0da12df14d0d6 | 2022-06-20T09:54:01.000Z | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
] | text-generation | false | stanford-crfm | null | stanford-crfm/alias-gpt2-small-x21 | 1,051 | 1 | transformers | 1,738 | Entry not found |
nlpaueb/sec-bert-base | d511591f5e74052afdab08f1f14c4ff2a1e55749 | 2022-04-28T14:46:31.000Z | [
"pytorch",
"tf",
"bert",
"pretraining",
"en",
"arxiv:2203.06482",
"transformers",
"finance",
"financial",
"license:cc-by-sa-4.0",
"fill-mask"
] | fill-mask | false | nlpaueb | null | nlpaueb/sec-bert-base | 1,051 | 9 | transformers | 1,739 | ---
language: en
pipeline_tag: fill-mask
license: cc-by-sa-4.0
thumbnail: https://i.ibb.co/0yz81K9/sec-bert-logo.png
tags:
- finance
- financial
widget:
- text: "Total net sales [MASK] 2% or $5.4 billion during 2019 compared to 2018."
- text: "Total net sales decreased 2% or $5.4 [MASK] during 2019 compared to 2018."
- text: "During 2019, the Company [MASK] $67.1 billion of its common stock and paid dividend equivalents of $14.1 billion."
- text: "During 2019, the Company repurchased $67.1 billion of its common [MASK] and paid dividend equivalents of $14.1 billion."
- text: "During 2019, the Company repurchased $67.1 billion of its common stock and paid [MASK] equivalents of $14.1 billion."
- text: "During 2019, the Company repurchased $67.1 billion of its common stock and paid dividend [MASK] of $14.1 billion."
---
# SEC-BERT
<img align="center" src="https://i.ibb.co/0yz81K9/sec-bert-logo.png" alt="SEC-BERT" width="400"/>
<div style="text-align: justify">
SEC-BERT is a family of BERT models for the financial domain, intended to assist financial NLP research and FinTech applications.
SEC-BERT consists of the following models:
* **SEC-BERT-BASE** (this model): Same architecture as BERT-BASE trained on financial documents.
* [**SEC-BERT-NUM**](https://huggingface.co/nlpaueb/sec-bert-num): Same as SEC-BERT-BASE but we replace every number token with a [NUM] pseudo-token handling all numeric expressions in a uniform manner, disallowing their fragmentation
* [**SEC-BERT-SHAPE**](https://huggingface.co/nlpaueb/sec-bert-shape): Same as SEC-BERT-BASE but we replace numbers with pseudo-tokens that represent the number’s shape, so numeric expressions (of known shapes) are no longer fragmented, e.g., '53.2' becomes '[XX.X]' and '40,200.5' becomes '[XX,XXX.X]'.
</div>
## Pre-training corpus
The model was pre-trained on 260,773 10-K filings from 1993-2019, publicly available at <a href="https://www.sec.gov/">U.S. Securities and Exchange Commission (SEC)</a>
## Pre-training details
<div style="text-align: justify">
* We created a new vocabulary of 30k subwords by training a [BertWordPieceTokenizer](https://github.com/huggingface/tokenizers) from scratch on the pre-training corpus.
* We trained BERT using the official code provided in [Google BERT's GitHub repository](https://github.com/google-research/bert)</a>.
* We then used [Hugging Face](https://huggingface.co)'s [Transformers](https://github.com/huggingface/transformers) conversion script to convert the TF checkpoint in the desired format in order to be able to load the model in two lines of code for both PyTorch and TF2 users.
* We release a model similar to the English BERT-BASE model (12-layer, 768-hidden, 12-heads, 110M parameters).
* We chose to follow the same training set-up: 1 million training steps with batches of 256 sequences of length 512 with an initial learning rate 1e-4.
* We were able to use a single Google Cloud TPU v3-8 provided for free from [TensorFlow Research Cloud (TRC)]((https://sites.research.google/trc), while also utilizing [GCP research credits](https://edu.google.com/programs/credits/research). Huge thanks to both Google programs for supporting us!
</div>
## Load Pretrained Model
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("nlpaueb/sec-bert-base")
model = AutoModel.from_pretrained("nlpaueb/sec-bert-base")
```
## Using SEC-BERT variants as Language Models
| Sample | Masked Token |
| --------------------------------------------------- | ------------ |
| Total net sales [MASK] 2% or $5.4 billion during 2019 compared to 2018. | decreased
| Model | Predictions (Probability) |
| --------------------------------------------------- | ------------ |
| **BERT-BASE-UNCASED** | increased (0.221), were (0.131), are (0.103), rose (0.075), of (0.058)
| **SEC-BERT-BASE** | increased (0.678), decreased (0.282), declined (0.017), grew (0.016), rose (0.004)
| **SEC-BERT-NUM** | increased (0.753), decreased (0.211), grew (0.019), declined (0.010), rose (0.006)
| **SEC-BERT-SHAPE** | increased (0.747), decreased (0.214), grew (0.021), declined (0.013), rose (0.002)
| Sample | Masked Token |
| --------------------------------------------------- | ------------ |
| Total net sales decreased 2% or $5.4 [MASK] during 2019 compared to 2018. | billion
| Model | Predictions (Probability) |
| --------------------------------------------------- | ------------ |
| **BERT-BASE-UNCASED** | billion (0.841), million (0.097), trillion (0.028), ##m (0.015), ##bn (0.006)
| **SEC-BERT-BASE** | million (0.972), billion (0.028), millions (0.000), ##million (0.000), m (0.000)
| **SEC-BERT-NUM** | million (0.974), billion (0.012), , (0.010), thousand (0.003), m (0.000)
| **SEC-BERT-SHAPE** | million (0.978), billion (0.021), % (0.000), , (0.000), millions (0.000)
| Sample | Masked Token |
| --------------------------------------------------- | ------------ |
| Total net sales decreased [MASK]% or $5.4 billion during 2019 compared to 2018. | 2
| Model | Predictions (Probability) |
| --------------------------------------------------- | ------------ |
| **BERT-BASE-UNCASED** | 20 (0.031), 10 (0.030), 6 (0.029), 4 (0.027), 30 (0.027)
| **SEC-BERT-BASE** | 13 (0.045), 12 (0.040), 11 (0.040), 14 (0.035), 10 (0.035)
| **SEC-BERT-NUM** | [NUM] (1.000), one (0.000), five (0.000), three (0.000), seven (0.000)
| **SEC-BERT-SHAPE** | [XX] (0.316), [XX.X] (0.253), [X.X] (0.237), [X] (0.188), [X.XX] (0.002)
| Sample | Masked Token |
| --------------------------------------------------- | ------------ |
| Total net sales decreased 2[MASK] or $5.4 billion during 2019 compared to 2018. | %
| Model | Predictions (Probability) |
| --------------------------------------------------- | ------------ |
| **BERT-BASE-UNCASED** | % (0.795), percent (0.174), ##fold (0.009), billion (0.004), times (0.004)
| **SEC-BERT-BASE** | % (0.924), percent (0.076), points (0.000), , (0.000), times (0.000)
| **SEC-BERT-NUM** | % (0.882), percent (0.118), million (0.000), units (0.000), bps (0.000)
| **SEC-BERT-SHAPE** | % (0.961), percent (0.039), bps (0.000), , (0.000), bcf (0.000)
| Sample | Masked Token |
| --------------------------------------------------- | ------------ |
| Total net sales decreased 2% or $[MASK] billion during 2019 compared to 2018. | 5.4
| Model | Predictions (Probability) |
| --------------------------------------------------- | ------------ |
| **BERT-BASE-UNCASED** | 1 (0.074), 4 (0.045), 3 (0.044), 2 (0.037), 5 (0.034)
| **SEC-BERT-BASE** | 1 (0.218), 2 (0.136), 3 (0.078), 4 (0.066), 5 (0.048)
| **SEC-BERT-NUM** | [NUM] (1.000), l (0.000), 1 (0.000), - (0.000), 30 (0.000)
| **SEC-BERT-SHAPE** | [X.X] (0.787), [X.XX] (0.095), [XX.X] (0.049), [X.XXX] (0.046), [X] (0.013)
| Sample | Masked Token |
| --------------------------------------------------- | ------------ |
| Total net sales decreased 2% or $5.4 billion during [MASK] compared to 2018. | 2019
| Model | Predictions (Probability) |
| --------------------------------------------------- | ------------ |
| **BERT-BASE-UNCASED** | 2017 (0.485), 2018 (0.169), 2016 (0.164), 2015 (0.070), 2014 (0.022)
| **SEC-BERT-BASE** | 2019 (0.990), 2017 (0.007), 2018 (0.003), 2020 (0.000), 2015 (0.000)
| **SEC-BERT-NUM** | [NUM] (1.000), as (0.000), fiscal (0.000), year (0.000), when (0.000)
| **SEC-BERT-SHAPE** | [XXXX] (1.000), as (0.000), year (0.000), periods (0.000), , (0.000)
| Sample | Masked Token |
| --------------------------------------------------- | ------------ |
| Total net sales decreased 2% or $5.4 billion during 2019 compared to [MASK]. | 2018
| Model | Predictions (Probability) |
| --------------------------------------------------- | ------------ |
| **BERT-BASE-UNCASED** | 2017 (0.100), 2016 (0.097), above (0.054), inflation (0.050), previously (0.037)
| **SEC-BERT-BASE** | 2018 (0.999), 2019 (0.000), 2017 (0.000), 2016 (0.000), 2014 (0.000)
| **SEC-BERT-NUM** | [NUM] (1.000), year (0.000), last (0.000), sales (0.000), fiscal (0.000)
| **SEC-BERT-SHAPE** | [XXXX] (1.000), year (0.000), sales (0.000), prior (0.000), years (0.000)
| Sample | Masked Token |
| --------------------------------------------------- | ------------ |
| During 2019, the Company [MASK] $67.1 billion of its common stock and paid dividend equivalents of $14.1 billion. | repurchased
| Model | Predictions (Probability) |
| --------------------------------------------------- | ------------ |
| **BERT-BASE-UNCASED** | held (0.229), sold (0.192), acquired (0.172), owned (0.052), traded (0.033)
| **SEC-BERT-BASE** | repurchased (0.913), issued (0.036), purchased (0.029), redeemed (0.010), sold (0.003)
| **SEC-BERT-NUM** | repurchased (0.917), purchased (0.054), reacquired (0.013), issued (0.005), acquired (0.003)
| **SEC-BERT-SHAPE** | repurchased (0.902), purchased (0.068), issued (0.010), reacquired (0.008), redeemed (0.006)
| Sample | Masked Token |
| --------------------------------------------------- | ------------ |
| During 2019, the Company repurchased $67.1 billion of its common [MASK] and paid dividend equivalents of $14.1 billion. | stock
| Model | Predictions (Probability) |
| --------------------------------------------------- | ------------ |
| **BERT-BASE-UNCASED** | stock (0.835), assets (0.039), equity (0.025), debt (0.021), bonds (0.017)
| **SEC-BERT-BASE** | stock (0.857), shares (0.135), equity (0.004), units (0.002), securities (0.000)
| **SEC-BERT-NUM** | stock (0.842), shares (0.157), equity (0.000), securities (0.000), units (0.000)
| **SEC-BERT-SHAPE** | stock (0.888), shares (0.109), equity (0.001), securities (0.001), stocks (0.000)
| Sample | Masked Token |
| --------------------------------------------------- | ------------ |
| During 2019, the Company repurchased $67.1 billion of its common stock and paid [MASK] equivalents of $14.1 billion. | dividend
| Model | Predictions (Probability) |
| --------------------------------------------------- | ------------ |
| **BERT-BASE-UNCASED** | cash (0.276), net (0.128), annual (0.083), the (0.040), debt (0.027)
| **SEC-BERT-BASE** | dividend (0.890), cash (0.018), dividends (0.016), share (0.013), tax (0.010)
| **SEC-BERT-NUM** | dividend (0.735), cash (0.115), share (0.087), tax (0.025), stock (0.013)
| **SEC-BERT-SHAPE** | dividend (0.655), cash (0.248), dividends (0.042), share (0.019), out (0.003)
| Sample | Masked Token |
| --------------------------------------------------- | ------------ |
| During 2019, the Company repurchased $67.1 billion of its common stock and paid dividend [MASK] of $14.1 billion. | equivalents
| Model | Predictions (Probability) |
| --------------------------------------------------- | ------------ |
| **BERT-BASE-UNCASED** | revenue (0.085), earnings (0.078), rates (0.065), amounts (0.064), proceeds (0.062)
| **SEC-BERT-BASE** | payments (0.790), distributions (0.087), equivalents (0.068), cash (0.013), amounts (0.004)
| **SEC-BERT-NUM** | payments (0.845), equivalents (0.097), distributions (0.024), increases (0.005), dividends (0.004)
| **SEC-BERT-SHAPE** | payments (0.784), equivalents (0.093), distributions (0.043), dividends (0.015), requirements (0.009)
## Publication
<div style="text-align: justify">
If you use this model cite the following article:<br>
[**FiNER: Financial Numeric Entity Recognition for XBRL Tagging**](https://arxiv.org/abs/2203.06482)<br>
Lefteris Loukas, Manos Fergadiotis, Ilias Chalkidis, Eirini Spyropoulou, Prodromos Malakasiotis, Ion Androutsopoulos and George Paliouras<br>
In the Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL 2022) (Long Papers), Dublin, Republic of Ireland, May 22 - 27, 2022
</div>
```
@inproceedings{loukas-etal-2022-finer,
title = {FiNER: Financial Numeric Entity Recognition for XBRL Tagging},
author = {Loukas, Lefteris and
Fergadiotis, Manos and
Chalkidis, Ilias and
Spyropoulou, Eirini and
Malakasiotis, Prodromos and
Androutsopoulos, Ion and
Paliouras George},
booktitle = {Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL 2022)},
publisher = {Association for Computational Linguistics},
location = {Dublin, Republic of Ireland},
year = {2022},
url = {https://arxiv.org/abs/2203.06482}
}
```
## About Us
<div style="text-align: justify">
[AUEB's Natural Language Processing Group](http://nlp.cs.aueb.gr) develops algorithms, models, and systems that allow computers to process and generate natural language texts.
The group's current research interests include:
* question answering systems for databases, ontologies, document collections, and the Web, especially biomedical question answering,
* natural language generation from databases and ontologies, especially Semantic Web ontologies,
text classification, including filtering spam and abusive content,
* information extraction and opinion mining, including legal text analytics and sentiment analysis,
* natural language processing tools for Greek, for example parsers and named-entity recognizers,
machine learning in natural language processing, especially deep learning.
The group is part of the Information Processing Laboratory of the Department of Informatics of the Athens University of Economics and Business.
</div>
[Manos Fergadiotis](https://manosfer.github.io) on behalf of [AUEB's Natural Language Processing Group](http://nlp.cs.aueb.gr) |
Helsinki-NLP/opus-mt-no-da | 8b7d67f3ab9c3a048ab2ea4cde7daa7ea3eb5792 | 2020-08-21T14:42:48.000Z | [
"pytorch",
"marian",
"text2text-generation",
"no",
"da",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] | translation | false | Helsinki-NLP | null | Helsinki-NLP/opus-mt-no-da | 1,047 | 1 | transformers | 1,740 | ---
language:
- no
- da
tags:
- translation
license: apache-2.0
---
### nor-dan
* source group: Norwegian
* target group: Danish
* OPUS readme: [nor-dan](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/nor-dan/README.md)
* model: transformer-align
* source language(s): nno nob
* target language(s): dan
* model: transformer-align
* pre-processing: normalization + SentencePiece (spm12k,spm12k)
* download original weights: [opus-2020-06-17.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/nor-dan/opus-2020-06-17.zip)
* test set translations: [opus-2020-06-17.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/nor-dan/opus-2020-06-17.test.txt)
* test set scores: [opus-2020-06-17.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/nor-dan/opus-2020-06-17.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba-test.nor.dan | 65.0 | 0.792 |
### System Info:
- hf_name: nor-dan
- source_languages: nor
- target_languages: dan
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/nor-dan/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['no', 'da']
- src_constituents: {'nob', 'nno'}
- tgt_constituents: {'dan'}
- src_multilingual: False
- tgt_multilingual: False
- prepro: normalization + SentencePiece (spm12k,spm12k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/nor-dan/opus-2020-06-17.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/nor-dan/opus-2020-06-17.test.txt
- src_alpha3: nor
- tgt_alpha3: dan
- short_pair: no-da
- chrF2_score: 0.792
- bleu: 65.0
- brevity_penalty: 0.995
- ref_len: 9865.0
- src_name: Norwegian
- tgt_name: Danish
- train_date: 2020-06-17
- src_alpha2: no
- tgt_alpha2: da
- prefer_old: False
- long_pair: nor-dan
- helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535
- transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b
- port_machine: brutasse
- port_time: 2020-08-21-14:41 |
fnlp/cpt-base | 6e62b6b19f0c18590fed77d6553f1fdbe2e8535a | 2021-10-29T07:10:40.000Z | [
"pytorch",
"bart",
"feature-extraction",
"zh",
"arxiv:2109.05729",
"transformers",
"fill-mask",
"text2text-generation",
"text-classification",
"Summarization",
"Chinese",
"CPT",
"BART",
"BERT",
"seq2seq"
] | text-classification | false | fnlp | null | fnlp/cpt-base | 1,047 | 5 | transformers | 1,741 | ---
tags:
- fill-mask
- text2text-generation
- fill-mask
- text-classification
- Summarization
- Chinese
- CPT
- BART
- BERT
- seq2seq
language: zh
---
# Chinese CPT-Base
## Model description
This is an implementation of CPT-Base. To use CPT, please import the file `modeling_cpt.py` (**Download** [Here](https://github.com/fastnlp/CPT/blob/master/finetune/modeling_cpt.py)) that define the architecture of CPT into your project.
[**CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Generation**](https://arxiv.org/pdf/2109.05729.pdf)
Yunfan Shao, Zhichao Geng, Yitao Liu, Junqi Dai, Fei Yang, Li Zhe, Hujun Bao, Xipeng Qiu
**Github Link:** https://github.com/fastnlp/CPT
## Usage
```python
>>> from modeling_cpt import CPTForConditionalGeneration
>>> from transformers import BertTokenizer
>>> tokenizer = BertTokenizer.from_pretrained("fnlp/cpt-base")
>>> model = CPTForConditionalGeneration.from_pretrained("fnlp/cpt-base")
>>> inputs = tokenizer.encode("北京是[MASK]的首都", return_tensors='pt')
>>> pred_ids = model.generate(input_ids, num_beams=4, max_length=20)
>>> print(tokenizer.convert_ids_to_tokens(pred_ids[i]))
['[SEP]', '[CLS]', '北', '京', '是', '中', '国', '的', '首', '都', '[SEP]']
```
**Note: Please use BertTokenizer for the model vocabulary. DO NOT use original BartTokenizer.**
## Citation
```bibtex
@article{shao2021cpt,
title={CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Generation},
author={Yunfan Shao and Zhichao Geng and Yitao Liu and Junqi Dai and Fei Yang and Li Zhe and Hujun Bao and Xipeng Qiu},
journal={arXiv preprint arXiv:2109.05729},
year={2021}
}
``` |
VietAI/vit5-large-vietnews-summarization | 7b72ccd3a6b38595db1ced95beb8836ec57ca52e | 2022-07-12T18:03:54.000Z | [
"pytorch",
"tf",
"t5",
"text2text-generation",
"vi",
"dataset:cc100",
"transformers",
"summarization",
"license:mit",
"autotrain_compatible"
] | summarization | false | VietAI | null | VietAI/vit5-large-vietnews-summarization | 1,047 | 1 | transformers | 1,742 | ---
language: vi
datasets:
- cc100
tags:
- summarization
license: mit
widget:
- text: "vietnews: VietAI là tổ chức phi lợi nhuận với sứ mệnh ươm mầm tài năng về trí tuệ nhân tạo và xây dựng một cộng đồng các chuyên gia trong lĩnh vực trí tuệ nhân tạo đẳng cấp quốc tế tại Việt Nam."
---
# ViT5-large Finetuned on `vietnews` Abstractive Summarization
State-of-the-art pretrained Transformer-based encoder-decoder model for Vietnamese.
## How to use
For more details, do check out [our Github repo](https://github.com/vietai/ViT5).
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("VietAI/vit5-large-vietnews-summarization")
model = AutoModelForSeq2SeqLM.from_pretrained("VietAI/vit5-large-vietnews-summarization")
sentence = "VietAI là tổ chức phi lợi nhuận với sứ mệnh ươm mầm tài năng về trí tuệ nhân tạo và xây dựng một cộng đồng các chuyên gia trong lĩnh vực trí tuệ nhân tạo đẳng cấp quốc tế tại Việt Nam."
text = "vietnews: " + sentence + " </s>"
encoding = tokenizer.encode_plus(text, pad_to_max_length=True, return_tensors="pt")
input_ids, attention_masks = encoding["input_ids"].to("cuda"), encoding["attention_mask"].to("cuda")
outputs = model.generate(
input_ids=input_ids, attention_mask=attention_masks,
max_length=256,
early_stopping=True
)
for output in outputs:
line = tokenizer.decode(output, skip_special_tokens=True, clean_up_tokenization_spaces=True)
print(line)
```
## Citation
```
@inproceedings{phan-etal-2022-vit5,
title = "{V}i{T}5: Pretrained Text-to-Text Transformer for {V}ietnamese Language Generation",
author = "Phan, Long and Tran, Hieu and Nguyen, Hieu and Trinh, Trieu H.",
booktitle = "Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies: Student Research Workshop",
year = "2022",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.naacl-srw.18",
pages = "136--142",
}
``` |
sshleifer/distill-pegasus-xsum-16-8 | 41797aa90d88956d720033cf3030e219b2dfef40 | 2020-10-08T03:05:56.000Z | [
"pytorch",
"pegasus",
"text2text-generation",
"en",
"arxiv:1912.08777",
"transformers",
"summarization",
"autotrain_compatible"
] | summarization | false | sshleifer | null | sshleifer/distill-pegasus-xsum-16-8 | 1,043 | 1 | transformers | 1,743 | ---
language: en
tags:
- summarization
---
### Pegasus Models
See Docs: [here](https://huggingface.co/transformers/master/model_doc/pegasus.html)
Original TF 1 code [here](https://github.com/google-research/pegasus)
Authors: Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu on Dec 18, 2019
Maintained by: [@sshleifer](https://twitter.com/sam_shleifer)
Task: Summarization
The following is copied from the authors' README.
# Mixed & Stochastic Checkpoints
We train a pegasus model with sampled gap sentence ratios on both C4 and HugeNews, and stochastically sample important sentences. The updated the results are reported in this table.
| dataset | C4 | HugeNews | Mixed & Stochastic|
| ---- | ---- | ---- | ----|
| xsum | 45.20/22.06/36.99 | 47.21/24.56/39.25 | 47.60/24.83/39.64|
| cnn_dailymail | 43.90/21.20/40.76 | 44.17/21.47/41.11 | 44.16/21.56/41.30|
| newsroom | 45.07/33.39/41.28 | 45.15/33.51/41.33 | 45.98/34.20/42.18|
| multi_news | 46.74/17.95/24.26 | 47.52/18.72/24.91 | 47.65/18.75/24.95|
| gigaword | 38.75/19.96/36.14 | 39.12/19.86/36.24 | 39.65/20.47/36.76|
| wikihow | 43.07/19.70/34.79 | 41.35/18.51/33.42 | 46.39/22.12/38.41 *|
| reddit_tifu | 26.54/8.94/21.64 | 26.63/9.01/21.60 | 27.99/9.81/22.94|
| big_patent | 53.63/33.16/42.25 | 53.41/32.89/42.07 | 52.29/33.08/41.66 *|
| arxiv | 44.70/17.27/25.80 | 44.67/17.18/25.73 | 44.21/16.95/25.67|
| pubmed | 45.49/19.90/27.69 | 45.09/19.56/27.42 | 45.97/20.15/28.25|
| aeslc | 37.69/21.85/36.84 | 37.40/21.22/36.45 | 37.68/21.25/36.51|
| billsum | 57.20/39.56/45.80 | 57.31/40.19/45.82 | 59.67/41.58/47.59|
The "Mixed & Stochastic" model has the following changes:
- trained on both C4 and HugeNews (dataset mixture is weighted by their number of examples).
- trained for 1.5M instead of 500k (we observe slower convergence on pretraining perplexity).
- the model uniformly sample a gap sentence ratio between 15% and 45%.
- importance sentences are sampled using a 20% uniform noise to importance scores.
- the sentencepiece tokenizer is updated to be able to encode newline character.
(*) the numbers of wikihow and big_patent datasets are not comparable because of change in tokenization and data:
- wikihow dataset contains newline characters which is useful for paragraph segmentation, the C4 and HugeNews model's sentencepiece tokenizer doesn't encode newline and loose this information.
- we update the BigPatent dataset to preserve casing, some format cleanings are also changed, please refer to change in TFDS.
The "Mixed & Stochastic" model has the following changes (from pegasus-large in the paper):
trained on both C4 and HugeNews (dataset mixture is weighted by their number of examples).
trained for 1.5M instead of 500k (we observe slower convergence on pretraining perplexity).
the model uniformly sample a gap sentence ratio between 15% and 45%.
importance sentences are sampled using a 20% uniform noise to importance scores.
the sentencepiece tokenizer is updated to be able to encode newline character.
Citation
```
@misc{zhang2019pegasus,
title={PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization},
author={Jingqing Zhang and Yao Zhao and Mohammad Saleh and Peter J. Liu},
year={2019},
eprint={1912.08777},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
quincyqiang/nezha-cn-base | 59bec85826eb29229edb5a2d10f971884677095c | 2022-04-24T08:00:22.000Z | [
"pytorch",
"transformers"
] | null | false | quincyqiang | null | quincyqiang/nezha-cn-base | 1,038 | null | transformers | 1,744 | ## NeZha-Pytorch
pytorch版NEZHA,适配transformers
### 安装
> pip install git+https://github.com/yanqiangmiffy/Nezha-Pytorch.git
### 权重下载地址
https://github.com/lonePatient/NeZha_Chinese_PyTorch
### torch使用样例
```
import torch
from transformers import BertTokenizer
from nezha import NeZhaModel, NeZhaConfig
text = "今天[MASK]很好,我[MASK]去公园玩。"
tokenizer = BertTokenizer.from_pretrained(
"quincyqiang/nezha-cn-base"
)
model = NeZhaModel.from_pretrained(
"quincyqiang/nezha-cn-base"
)
config = NeZhaConfig.from_pretrained(
"quincyqiang/nezha-cn-base"
)
model.eval()
inputs = tokenizer(text, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
```
|
nreimers/MiniLMv2-L6-H384-distilled-from-RoBERTa-Large | a61886e95cedc4cd2440f71cf9a55320ee1d8e06 | 2021-06-20T19:02:23.000Z | [
"pytorch",
"roberta",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | false | nreimers | null | nreimers/MiniLMv2-L6-H384-distilled-from-RoBERTa-Large | 1,037 | 2 | transformers | 1,745 | # MiniLMv2
This is a MiniLMv2 model from: [https://github.com/microsoft/unilm](https://github.com/microsoft/unilm/tree/master/minilm) |
WinKawaks/vit-tiny-patch16-224 | fd78e4f96a9936843a178feae1ed30453b59b44d | 2022-01-30T18:04:38.000Z | [
"pytorch",
"vit",
"image-classification",
"dataset:imagenet",
"transformers",
"vision",
"license:apache-2.0"
] | image-classification | false | WinKawaks | null | WinKawaks/vit-tiny-patch16-224 | 1,036 | 2 | transformers | 1,746 | ---
license: apache-2.0
tags:
- vision
- image-classification
datasets:
- imagenet
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
---
Google didn't publish vit-tiny and vit-small model checkpoints in Hugging Face. I converted the weights from the [timm repository](https://github.com/rwightman/pytorch-image-models). This model is used in the same way as [ViT-base](https://huggingface.co/google/vit-base-patch16-224).
|
ThomasNLG/t5-qg_squad1-en | f9ae97448212aaee033ed43561e9253929ae71c9 | 2021-07-09T07:45:35.000Z | [
"pytorch",
"jax",
"t5",
"text2text-generation",
"en",
"dataset:squad",
"transformers",
"qg",
"question",
"generation",
"SQuAD",
"metric",
"nlg",
"t5-small",
"license:mit",
"model-index",
"autotrain_compatible"
] | text2text-generation | false | ThomasNLG | null | ThomasNLG/t5-qg_squad1-en | 1,035 | 1 | transformers | 1,747 | ---
language: en
tags:
- qg
- question
- generation
- SQuAD
- metric
- nlg
- t5-small
license: mit
datasets:
- squad
model-index:
- name: t5-qg_squad1-en
results:
- task:
name: Question Generation
type: Text2Text-Generation
widget:
- text: "sv1 </s> Louis 14 </s> Louis 14 was a French King."
---
# t5-qg_squad1-en
## Model description
This model is a *Question Generation* model based on T5-small.
It is actually a component of [QuestEval](https://github.com/ThomasScialom/QuestEval) metric but can be used independently as it is, for QG only.
## How to use
```python
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("ThomasNLG/t5-qg_squad1-en")
model = T5ForConditionalGeneration.from_pretrained("ThomasNLG/t5-qg_squad1-en")
```
You can play with the model using the inference API, the text input format should follow this template (accordingly to the training stage of the model):
`text_input = "sv1 </s> {ANSWER} </s> {CONTEXT}"`
## Training data
The model was trained on SQuAD.
### Citation info
```bibtex
@article{scialom2020QuestEval,
title={QuestEval: Summarization Asks for Fact-based Evaluation},
author={Scialom, Thomas and Dray, Paul-Alexis and Gallinari, Patrick and Lamprier, Sylvain and Piwowarski, Benjamin and Staiano, Jacopo and Wang, Alex},
journal={arXiv preprint arXiv:2103.12693},
year={2021}
}
``` |
google/pegasus-newsroom | 0c90cf856d45526f6e8efe7b5ec9fcb64c9a3fe6 | 2020-10-22T16:33:31.000Z | [
"pytorch",
"pegasus",
"text2text-generation",
"en",
"arxiv:1912.08777",
"transformers",
"summarization",
"autotrain_compatible"
] | summarization | false | google | null | google/pegasus-newsroom | 1,035 | 2 | transformers | 1,748 | ---
language: en
tags:
- summarization
---
### Pegasus Models
See Docs: [here](https://huggingface.co/transformers/master/model_doc/pegasus.html)
Original TF 1 code [here](https://github.com/google-research/pegasus)
Authors: Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu on Dec 18, 2019
Maintained by: [@sshleifer](https://twitter.com/sam_shleifer)
Task: Summarization
The following is copied from the authors' README.
# Mixed & Stochastic Checkpoints
We train a pegasus model with sampled gap sentence ratios on both C4 and HugeNews, and stochastically sample important sentences. The updated the results are reported in this table.
| dataset | C4 | HugeNews | Mixed & Stochastic|
| ---- | ---- | ---- | ----|
| xsum | 45.20/22.06/36.99 | 47.21/24.56/39.25 | 47.60/24.83/39.64|
| cnn_dailymail | 43.90/21.20/40.76 | 44.17/21.47/41.11 | 44.16/21.56/41.30|
| newsroom | 45.07/33.39/41.28 | 45.15/33.51/41.33 | 45.98/34.20/42.18|
| multi_news | 46.74/17.95/24.26 | 47.52/18.72/24.91 | 47.65/18.75/24.95|
| gigaword | 38.75/19.96/36.14 | 39.12/19.86/36.24 | 39.65/20.47/36.76|
| wikihow | 43.07/19.70/34.79 | 41.35/18.51/33.42 | 46.39/22.12/38.41 *|
| reddit_tifu | 26.54/8.94/21.64 | 26.63/9.01/21.60 | 27.99/9.81/22.94|
| big_patent | 53.63/33.16/42.25 | 53.41/32.89/42.07 | 52.29/33.08/41.66 *|
| arxiv | 44.70/17.27/25.80 | 44.67/17.18/25.73 | 44.21/16.95/25.67|
| pubmed | 45.49/19.90/27.69 | 45.09/19.56/27.42 | 45.97/20.15/28.25|
| aeslc | 37.69/21.85/36.84 | 37.40/21.22/36.45 | 37.68/21.25/36.51|
| billsum | 57.20/39.56/45.80 | 57.31/40.19/45.82 | 59.67/41.58/47.59|
The "Mixed & Stochastic" model has the following changes:
- trained on both C4 and HugeNews (dataset mixture is weighted by their number of examples).
- trained for 1.5M instead of 500k (we observe slower convergence on pretraining perplexity).
- the model uniformly sample a gap sentence ratio between 15% and 45%.
- importance sentences are sampled using a 20% uniform noise to importance scores.
- the sentencepiece tokenizer is updated to be able to encode newline character.
(*) the numbers of wikihow and big_patent datasets are not comparable because of change in tokenization and data:
- wikihow dataset contains newline characters which is useful for paragraph segmentation, the C4 and HugeNews model's sentencepiece tokenizer doesn't encode newline and loose this information.
- we update the BigPatent dataset to preserve casing, some format cleanings are also changed, please refer to change in TFDS.
The "Mixed & Stochastic" model has the following changes (from pegasus-large in the paper):
trained on both C4 and HugeNews (dataset mixture is weighted by their number of examples).
trained for 1.5M instead of 500k (we observe slower convergence on pretraining perplexity).
the model uniformly sample a gap sentence ratio between 15% and 45%.
importance sentences are sampled using a 20% uniform noise to importance scores.
the sentencepiece tokenizer is updated to be able to encode newline character.
Citation
```
@misc{zhang2019pegasus,
title={PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization},
author={Jingqing Zhang and Yao Zhao and Mohammad Saleh and Peter J. Liu},
year={2019},
eprint={1912.08777},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
patrickvonplaten/bert2bert-cnn_dailymail-fp16 | 51b5d5cac0fa0ed09ed505df5800579996a2fe12 | 2020-12-12T11:22:49.000Z | [
"pytorch",
"encoder-decoder",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | false | patrickvonplaten | null | patrickvonplaten/bert2bert-cnn_dailymail-fp16 | 1,035 | null | transformers | 1,749 | # Bert2Bert Summarization with 🤗 EncoderDecoder Framework
This model is a Bert2Bert model fine-tuned on summarization.
Bert2Bert is a `EncoderDecoderModel`, meaning that both the encoder and the decoder are `bert-base-uncased`
BERT models. Leveraging the [EncoderDecoderFramework](https://huggingface.co/transformers/model_doc/encoderdecoder.html#encoder-decoder-models), the
two pretrained models can simply be loaded into the framework via:
```python
bert2bert = EncoderDecoderModel.from_encoder_decoder_pretrained("bert-base-uncased", "bert-base-uncased")
```
The decoder of an `EncoderDecoder` model needs cross-attention layers and usually makes use of causal
masking for auto-regressiv generation.
Thus, ``bert2bert`` is consequently fined-tuned on the `CNN/Daily Mail`dataset and the resulting model
`bert2bert-cnn_dailymail-fp16` is uploaded here.
## Example
The model is by no means a state-of-the-art model, but nevertheless
produces reasonable summarization results. It was mainly fine-tuned
as a proof-of-concept for the 🤗 EncoderDecoder Framework.
The model can be used as follows:
```python
from transformers import BertTokenizer, EncoderDecoderModel
model = EncoderDecoderModel.from_pretrained("patrickvonplaten/bert2bert-cnn_dailymail-fp16")
tokenizer = BertTokenizer.from_pretrained("patrickvonplaten/bert2bert-cnn_dailymail-fp16")
article = """(CNN)Sigma Alpha Epsilon is under fire for a video showing party-bound fraternity members singing a racist chant. SAE's national chapter suspended the students, but University of Oklahoma President David Boren took it a step further, saying the university's affiliation with the fraternity is permanently done. The news is shocking, but it's not the first time SAE has faced controversy. SAE was founded March 9, 1856, at the University of Alabama, five years before the American Civil War, according to the fraternity website. When the war began, the group had fewer than 400 members, of which "369 went to war for the Confederate States and seven for the Union Army," the website says. The fraternity now boasts more than 200,000 living alumni, along with about 15,000 undergraduates populating 219 chapters and 20 "colonies" seeking full membership at universities. SAE has had to work hard to change recently after a string of member deaths, many blamed on the hazing of new recruits, SAE national President Bradley Cohen wrote in a message on the fraternity's website. The fraternity's website lists more than 130 chapters cited or suspended for "health and safety incidents" since 2010. At least 30 of the incidents involved hazing, and dozens more involved alcohol. However, the list is missing numerous incidents from recent months. Among them, according to various media outlets: Yale University banned the SAEs from campus activities last month after members allegedly tried to interfere with a sexual misconduct investigation connected to an initiation rite. Stanford University in December suspended SAE housing privileges after finding sorority members attending a fraternity function were subjected to graphic sexual content. And Johns Hopkins University in November suspended the fraternity for underage drinking. "The media has labeled us as the 'nation's deadliest fraternity,' " Cohen said. In 2011, for example, a student died while being coerced into excessive alcohol consumption, according to a lawsuit. SAE's previous insurer dumped the fraternity. "As a result, we are paying Lloyd's of London the highest insurance rates in the Greek-letter world," Cohen said. Universities have turned down SAE's attempts to open new chapters, and the fraternity had to close 12 in 18 months over hazing incidents."""
input_ids = tokenizer(article, return_tensors="pt").input_ids
output_ids = model.generate(input_ids)
print(tokenizer.decode(output_ids[0], skip_special_tokens=True))
# should produce
# sae was founded in 1856, five years before the civil war. the fraternity has had to work hard to change recently. the university of oklahoma president says the university's affiliation with the fraternity is permanently done. the sae has had a string of members in recent mon
ths.
```
## Training script:
Please follow this tutorial to see how to warm-start a BERT2BERT model:
https://colab.research.google.com/drive/1WIk2bxglElfZewOHboPFNj8H44_VAyKE?usp=sharing
The obtained results should be:
| - | Rouge2 - mid -precision | Rouge2 - mid - recall | Rouge2 - mid - fmeasure |
|----------|:-------------:|:------:|:------:|
| **CNN/Daily Mail** | 16.12 | 17.07 | **16.1** |
|
HooshvareLab/distilbert-fa-zwnj-base | e8b934b8c81b17c5e4a1a90325f5f25ced94e8d6 | 2021-03-16T16:30:29.000Z | [
"pytorch",
"tf",
"distilbert",
"fill-mask",
"fa",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | fill-mask | false | HooshvareLab | null | HooshvareLab/distilbert-fa-zwnj-base | 1,034 | null | transformers | 1,750 | ---
language: fa
license: apache-2.0
---
# DistilBERT
This model can tackle the zero-width non-joiner character for Persian writing. Also, the model was trained on new multi-types corpora with a new set of vocabulary.
## Questions?
Post a Github issue on the [ParsBERT Issues](https://github.com/hooshvare/parsbert/issues) repo. |
monologg/kocharelectra-small-discriminator | 7168f693b1744d07562d82bc25c4055831cd0a92 | 2020-05-27T17:37:41.000Z | [
"pytorch",
"electra",
"pretraining",
"transformers"
] | null | false | monologg | null | monologg/kocharelectra-small-discriminator | 1,032 | null | transformers | 1,751 | Entry not found |
peterchou/nezha-chinese-base | 6f1362e07445fb84ac8fd18ef5599ed0c5aaab32 | 2021-05-20T02:32:33.000Z | [
"pytorch",
"jax",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | false | peterchou | null | peterchou/nezha-chinese-base | 1,032 | 0 | transformers | 1,752 | Entry not found |
amazon/bort | 8f39f629b2b8eb3750d5bb98849c2424d4473403 | 2021-05-18T23:32:35.000Z | [
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"arxiv:2010.10499",
"transformers",
"autotrain_compatible"
] | fill-mask | false | amazon | null | amazon/bort | 1,029 | 4 | transformers | 1,753 | ⚠️ **Disclaimer** ⚠️
This model is community-contributed, and not supported by Amazon, Inc.
## BORT
[Amazon's BORT](https://www.amazon.science/blog/a-version-of-the-bert-language-model-thats-20-times-as-fast)
BORT is a highly compressed version of [bert-large](https://huggingface.co/bert-large-uncased) that is up to 10 times faster at inference.
The model is an optimal sub-architecture of *bert-large* that was found using neural architecture search.
[Paper](https://arxiv.org/abs/2010.10499)
**Abstract**
We extract an optimal subset of architectural parameters for the BERT architecture from Devlin et al. (2018) by applying recent breakthroughs in algorithms for neural architecture search. This optimal subset, which we refer to as "Bort", is demonstrably smaller, having an effective (that is, not counting the embedding layer) size of 5.5% the original BERT-large architecture, and 16% of the net size. Bort is also able to be pretrained in 288 GPU hours, which is 1.2% of the time required to pretrain the highest-performing BERT parametric architectural variant, RoBERTa-large (Liu et al., 2019), and about 33% of that of the world-record, in GPU hours, required to train BERT-large on the same hardware. It is also 7.9x faster on a CPU, as well as being better performing than other compressed variants of the architecture, and some of the non-compressed variants: it obtains performance improvements of between 0.3% and 31%, absolute, with respect to BERT-large, on multiple public natural language understanding (NLU) benchmarks.
The original model can be found under:
https://github.com/alexa/bort
**IMPORTANT**
BORT requires a very unique fine-tuning algorithm, called [Agora](https://adewynter.github.io/notes/bort_algorithms_and_applications.html) which is not open-sourced yet.
Standard fine-tuning has not shown to work well in initial experiments, so stay tuned for updates!
|
doc2query/msmarco-t5-base-v1 | e673dca0dff1f19fda73ac62420eedf0219e692b | 2022-01-10T10:22:10.000Z | [
"pytorch",
"t5",
"text2text-generation",
"en",
"dataset:sentence-transformers/embedding-training-data",
"arxiv:1904.08375",
"arxiv:2104.08663",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | text2text-generation | false | doc2query | null | doc2query/msmarco-t5-base-v1 | 1,026 | null | transformers | 1,754 | ---
language: en
datasets:
- sentence-transformers/embedding-training-data
widget:
- text: "Python is an interpreted, high-level and general-purpose programming language. Python's design philosophy emphasizes code readability with its notable use of significant whitespace. Its language constructs and object-oriented approach aim to help programmers write clear, logical code for small and large-scale projects."
license: apache-2.0
---
# doc2query/msmarco-t5-base-v1
This is a [doc2query](https://arxiv.org/abs/1904.08375) model based on T5 (also known as [docT5query](https://cs.uwaterloo.ca/~jimmylin/publications/Nogueira_Lin_2019_docTTTTTquery-v2.pdf)).
It can be used for:
- **Document expansion**: You generate for your paragraphs 20-40 queries and index the paragraphs and the generates queries in a standard BM25 index like Elasticsearch, OpenSearch, or Lucene. The generated queries help to close the lexical gap of lexical search, as the generate queries contain synonyms. Further, it re-weights words giving important words a higher weight even if they appear seldomn in a paragraph. In our [BEIR](https://arxiv.org/abs/2104.08663) paper we showed that BM25+docT5query is a powerful search engine. In the [BEIR repository](https://github.com/UKPLab/beir) we have an example how to use docT5query with Pyserini.
- **Domain Specific Training Data Generation**: It can be used to generate training data to learn an embedding model. On [SBERT.net](https://www.sbert.net/examples/unsupervised_learning/query_generation/README.html) we have an example how to use the model to generate (query, text) pairs for a given collection of unlabeled texts. These pairs can then be used to train powerful dense embedding models.
## Usage
```python
from transformers import T5Tokenizer, T5ForConditionalGeneration
model_name = 'doc2query/msmarco-t5-base-v1'
tokenizer = T5Tokenizer.from_pretrained(model_name)
model = T5ForConditionalGeneration.from_pretrained(model_name)
text = "Python is an interpreted, high-level and general-purpose programming language. Python's design philosophy emphasizes code readability with its notable use of significant whitespace. Its language constructs and object-oriented approach aim to help programmers write clear, logical code for small and large-scale projects."
input_ids = tokenizer.encode(text, max_length=320, truncation=True, return_tensors='pt')
outputs = model.generate(
input_ids=input_ids,
max_length=64,
do_sample=True,
top_p=0.95,
num_return_sequences=5)
print("Text:")
print(text)
print("\nGenerated Queries:")
for i in range(len(outputs)):
query = tokenizer.decode(outputs[i], skip_special_tokens=True)
print(f'{i + 1}: {query}')
```
**Note:** `model.generate()` is non-deterministic. It produces different queries each time you run it.
## Training
This model fine-tuned [google/t5-v1_1-base](https://huggingface.co/google/t5-v1_1-base) for 31k training steps (about 4 epochs on the 500k training pairs from MS MARCO). For the training script, see the `train_script.py` in this repository.
The input-text was truncated to 320 word pieces. Output text was generated up to 64 word pieces.
This model was trained on a (query, passage) from the [MS MARCO Passage-Ranking dataset](https://github.com/microsoft/MSMARCO-Passage-Ranking).
|
monologg/koelectra-small-v3-generator | c1a21223b2a1da968c64af074c26fa7e7edd928c | 2020-12-26T16:24:47.000Z | [
"pytorch",
"electra",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | false | monologg | null | monologg/koelectra-small-v3-generator | 1,021 | null | transformers | 1,755 | Entry not found |
cardiffnlp/tweet-topic-21-multi | 10858933bc2939c0a70050ccf23f044fec8148ce | 2022-06-09T10:36:05.000Z | [
"pytorch",
"tf",
"roberta",
"text-classification",
"arxiv:2202.03829",
"transformers"
] | text-classification | false | cardiffnlp | null | cardiffnlp/tweet-topic-21-multi | 1,020 | 2 | transformers | 1,756 | # tweet-topic-21-multi
This is a roBERTa-base model trained on ~124M tweets from January 2018 to December 2021 (see [here](https://huggingface.co/cardiffnlp/twitter-roberta-base-2021-124m)), and finetuned for multi-label topic classification on a corpus of 11,267 tweets.
The original roBERTa-base model can be found [here](https://huggingface.co/cardiffnlp/twitter-roberta-base-2021-124m) and the original reference paper is [TweetEval](https://github.com/cardiffnlp/tweeteval). This model is suitable for English.
- Reference Paper: [TimeLMs paper](https://arxiv.org/abs/2202.03829).
- Git Repo: [TimeLMs official repository](https://github.com/cardiffnlp/timelms).
<b>Labels</b>:
| <span style="font-weight:normal">0: arts_&_culture</span> | <span style="font-weight:normal">5: fashion_&_style</span> | <span style="font-weight:normal">10: learning_&_educational</span> | <span style="font-weight:normal">15: science_&_technology</span> |
|-----------------------------|---------------------|----------------------------|--------------------------|
| 1: business_&_entrepreneurs | 6: film_tv_&_video | 11: music | 16: sports |
| 2: celebrity_&_pop_culture | 7: fitness_&_health | 12: news_&_social_concern | 17: travel_&_adventure |
| 3: diaries_&_daily_life | 8: food_&_dining | 13: other_hobbies | 18: youth_&_student_life |
| 4: family | 9: gaming | 14: relationships | |
## Full classification example
```python
from transformers import AutoModelForSequenceClassification, TFAutoModelForSequenceClassification
from transformers import AutoTokenizer
import numpy as np
from scipy.special import expit
MODEL = f"cardiffnlp/tweet-topic-21-single"
tokenizer = AutoTokenizer.from_pretrained(MODEL)
# PT
model = AutoModelForSequenceClassification.from_pretrained(MODEL)
class_mapping = model.config.id2label
text = "It is great to see athletes promoting awareness for climate change."
tokens = tokenizer(text, return_tensors='pt')
output = model(**tokens)
scores = output[0][0].detach().numpy()
scores = expit(scores)
predictions = (scores >= 0.5) * 1
# TF
#tf_model = TFAutoModelForSequenceClassification.from_pretrained(MODEL)
#class_mapping = model.config.id2label
#text = "It is great to see athletes promoting awareness for climate change."
#tokens = tokenizer(text, return_tensors='tf')
#output = tf_model(**tokens)
#scores = output[0][0]
#scores = expit(scores)
#predictions = (scores >= 0.5) * 1
# Map to classes
for i in range(len(predictions)):
if predictions[i]:
print(class_mapping[i])
```
Output:
```
news_&_social_concern
sports
```
|
chenxran/orion-hypothesis-generator | d139e97003906b8e5443ad510364bd6e7fa03fc3 | 2022-05-22T05:15:33.000Z | [
"pytorch",
"bart",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | false | chenxran | null | chenxran/orion-hypothesis-generator | 1,019 | null | transformers | 1,757 | Entry not found |
allegro/plt5-base | 5443c295a9dd170ce8e8b6eda22bb10ff23163cf | 2021-08-19T17:00:55.000Z | [
"pytorch",
"t5",
"text2text-generation",
"pl",
"dataset:ccnet",
"dataset:nkjp",
"dataset:wikipedia",
"dataset:open subtitles",
"dataset:free readings",
"transformers",
"T5",
"translation",
"summarization",
"question answering",
"reading comprehension",
"license:cc-by-4.0",
"autotrain_compatible"
] | translation | false | allegro | null | allegro/plt5-base | 1,017 | 4 | transformers | 1,758 | ---
language: pl
tags:
- T5
- translation
- summarization
- question answering
- reading comprehension
datasets:
- ccnet
- nkjp
- wikipedia
- open subtitles
- free readings
license: cc-by-4.0
---
# plT5 Base
**plT5** models are T5-based language models trained on Polish corpora. The models were optimized for the original T5 denoising target.
## Corpus
plT5 was trained on six different corpora available for Polish language:
| Corpus | Tokens | Documents |
| :------ | ------: | ------: |
| [CCNet Middle](https://github.com/facebookresearch/cc_net) | 3243M | 7.9M |
| [CCNet Head](https://github.com/facebookresearch/cc_net) | 2641M | 7.0M |
| [National Corpus of Polish](http://nkjp.pl/index.php?page=14&lang=1)| 1357M | 3.9M |
| [Open Subtitles](http://opus.nlpl.eu/OpenSubtitles-v2018.php) | 1056M | 1.1M
| [Wikipedia](https://dumps.wikimedia.org/) | 260M | 1.4M |
| [Wolne Lektury](https://wolnelektury.pl/) | 41M | 5.5k |
## Tokenizer
The training dataset was tokenized into subwords using a sentencepiece unigram model with
vocabulary size of 50k tokens.
## Usage
Example code:
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("allegro/plt5-base")
model = AutoModel.from_pretrained("allegro/plt5-base")
```
## License
CC BY 4.0
## Citation
If you use this model, please cite the following paper:
```
```
## Authors
The model was trained by [**Machine Learning Research Team at Allegro**](https://ml.allegro.tech/) and [**Linguistic Engineering Group at Institute of Computer Science, Polish Academy of Sciences**](http://zil.ipipan.waw.pl/).
You can contact us at: <a href="mailto:[email protected]">[email protected]</a> |
mrm8488/t5-small-finetuned-emotion | cd1013ff513e564316b16919c5680be2885e4294 | 2020-12-11T21:56:24.000Z | [
"pytorch",
"t5",
"text2text-generation",
"en",
"dataset:emotion",
"arxiv:1910.10683",
"transformers",
"autotrain_compatible"
] | text2text-generation | false | mrm8488 | null | mrm8488/t5-small-finetuned-emotion | 1,014 | null | transformers | 1,759 | ---
language: en
datasets:
- emotion
---
# T5-small fine-tuned for Emotion Recognition 😂😢😡😃😯
[Google's T5](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) [small](https://huggingface.co/t5-small) fine-tuned on [emotion recognition](https://github.com/dair-ai/emotion_dataset) dataset for **Emotion Recognition** downstream task.
## Details of T5
The **T5** model was presented in [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/pdf/1910.10683.pdf) by *Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J. Liu* in Here the abstract:
Transfer learning, where a model is first pre-trained on a data-rich task before being fine-tuned on a downstream task, has emerged as a powerful technique in natural language processing (NLP). The effectiveness of transfer learning has given rise to a diversity of approaches, methodology, and practice. In this paper, we explore the landscape of transfer learning techniques for NLP by introducing a unified framework that converts every language problem into a text-to-text format. Our systematic study compares pre-training objectives, architectures, unlabeled datasets, transfer approaches, and other factors on dozens of language understanding tasks. By combining the insights from our exploration with scale and our new “Colossal Clean Crawled Corpus”, we achieve state-of-the-art results on many benchmarks covering summarization, question answering, text classification, and more. To facilitate future work on transfer learning for NLP, we release our dataset, pre-trained models, and code.

## Details of the downstream task (Sentiment Recognition) - Dataset 📚
[Elvis Saravia](https://twitter.com/omarsar0) has gathered a great [dataset](https://github.com/dair-ai/emotion_dataset) for emotion recognition. It allows to classifiy the text into one of the following **6** emotions:
- sadness 😢
- joy 😃
- love 🥰
- anger 😡
- fear 😱
- surprise 😯
## Model fine-tuning 🏋️
The training script is a slightly modified version of [this Colab Notebook](https://github.com/patil-suraj/exploring-T5/blob/master/t5_fine_tuning.ipynb) created by [Suraj Patil](https://github.com/patil-suraj), so all credits to him!
## Test set metrics 🧾
| |precision | recall | f1-score |support|
|----------|----------|---------|----------|-------|
|anger | 0.92| 0.93| 0.92| 275|
|fear | 0.90| 0.90| 0.90| 224|
|joy | 0.97| 0.91| 0.94| 695|
|love | 0.75| 0.89| 0.82| 159|
|sadness | 0.96| 0.97| 0.96| 581|
|surpirse | 0.73| 0.80| 0.76| 66|
| |
|accuracy| | | 0.92| 2000|
|macro avg| 0.87| 0.90| 0.88| 2000|
|weighted avg| 0.93| 0.92| 0.92| 2000|
Confusion Matrix

## Model in Action 🚀
```python
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("mrm8488/t5-small-finetuned-emotion")
model = AutoModelWithLMHead.from_pretrained("mrm8488/t5-small-finetuned-emotion")
def get_emotion(text):
input_ids = tokenizer.encode(text + '</s>', return_tensors='pt')
output = model.generate(input_ids=input_ids,
max_length=2)
dec = [tokenizer.decode(ids) for ids in output]
label = dec[0]
return label
get_emotion("i feel as if i havent blogged in ages are at least truly blogged i am doing an update cute") # Output: 'joy'
get_emotion("i have a feeling i kinda lost my best friend") # Output: 'sadness'
```
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488) | [LinkedIn](https://www.linkedin.com/in/manuel-romero-cs/)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
voidful/dpr-question_encoder-bert-base-multilingual | 27a13bea0225a405e32531c1137d26ed2e4407d2 | 2021-02-21T09:00:19.000Z | [
"pytorch",
"dpr",
"feature-extraction",
"multilingual",
"dataset:NQ",
"dataset:Trivia",
"dataset:SQuAD",
"dataset:MLQA",
"dataset:DRCD",
"arxiv:2004.04906",
"transformers"
] | feature-extraction | false | voidful | null | voidful/dpr-question_encoder-bert-base-multilingual | 1,014 | 3 | transformers | 1,760 | ---
language: multilingual
datasets:
- NQ
- Trivia
- SQuAD
- MLQA
- DRCD
---
# dpr-ctx_encoder-bert-base-multilingual
## Description
Multilingual DPR Model base on bert-base-multilingual-cased.
[DPR model](https://arxiv.org/abs/2004.04906)
[DPR repo](https://github.com/facebookresearch/DPR)
## Data
1. [NQ](https://github.com/facebookresearch/DPR/blob/master/data/download_data.py)
2. [Trivia](https://github.com/facebookresearch/DPR/blob/master/data/download_data.py)
3. [SQuAD](https://github.com/facebookresearch/DPR/blob/master/data/download_data.py)
4. [DRCD*](https://github.com/DRCKnowledgeTeam/DRCD)
5. [MLQA*](https://github.com/facebookresearch/MLQA)
`question pairs for train`: 644,217
`question pairs for dev`: 73,710
*DRCD and MLQA are converted using script from haystack [squad_to_dpr.py](https://github.com/deepset-ai/haystack/blob/master/haystack/retriever/squad_to_dpr.py)
## Training Script
I use the script from [haystack](https://colab.research.google.com/github/deepset-ai/haystack/blob/master/tutorials/Tutorial9_DPR_training.ipynb)
## Usage
```python
from transformers import DPRQuestionEncoder, DPRQuestionEncoderTokenizer
tokenizer = DPRQuestionEncoderTokenizer.from_pretrained('voidful/dpr-question_encoder-bert-base-multilingual')
model = DPRQuestionEncoder.from_pretrained('voidful/dpr-question_encoder-bert-base-multilingual')
input_ids = tokenizer("Hello, is my dog cute ?", return_tensors='pt')["input_ids"]
embeddings = model(input_ids).pooler_output
```
Follow the tutorial from `haystack`:
[Better Retrievers via "Dense Passage Retrieval"](https://colab.research.google.com/github/deepset-ai/haystack/blob/master/tutorials/Tutorial6_Better_Retrieval_via_DPR.ipynb)
```
from haystack.retriever.dense import DensePassageRetriever
retriever = DensePassageRetriever(document_store=document_store,
query_embedding_model="voidful/dpr-question_encoder-bert-base-multilingual",
passage_embedding_model="voidful/dpr-ctx_encoder-bert-base-multilingual",
max_seq_len_query=64,
max_seq_len_passage=256,
batch_size=16,
use_gpu=True,
embed_title=True,
use_fast_tokenizers=True)
```
|
knkarthick/MEETING-SUMMARY-BART-LARGE-XSUM-SAMSUM-DIALOGSUM-AMI | 846c141c494bc06f846d5609c14c21712c3a074d | 2022-06-27T15:27:56.000Z | [
"pytorch",
"tf",
"bart",
"text2text-generation",
"en",
"dataset:cnndaily/newyorkdaily/xsum/samsum/dialogsum/AMI Meeting Corpus",
"transformers",
"seq2seq",
"summarization",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
] | summarization | false | knkarthick | null | knkarthick/MEETING-SUMMARY-BART-LARGE-XSUM-SAMSUM-DIALOGSUM-AMI | 1,012 | 1 | transformers | 1,761 | ---
language: en
tags:
- bart
- seq2seq
- summarization
license: apache-2.0
datasets:
- cnndaily/newyorkdaily/xsum/samsum/dialogsum/AMI Meeting Corpus
metrics:
- rouge
widget:
- text: |-
Hi, I'm David and I'm supposed to be an industrial designer. Um, I just got the project announcement about what the project is. Designing a remote control. That's about it, didn't get anything else. Did you get the same thing? Cool. There's too much gear. Okay. Can't draw. Um. Yeah. Um, well anyway, I don't know, it's just the first animal I can think off the top of my head. Um. Yes. Big reason is 'cause I'm allergic to most animals. Allergic to animal fur, so um fish was a natural choice. Um, yeah, and I kind of like whales. They come in and go eat everything in sight. And they're quite harmless and mild and interesting. Tail's a bit big, I think. It's an after dinner dog then. Hmm. It does make sense from maybe the design point of view 'cause you have more complicated characters like European languages, then you need more buttons. So, possibly. Hmm. Yeah. And you keep losing them. Finding them is really a pain, you know. I mean it's usually quite small, or when you want it right, it slipped behind the couch or it's kicked under the table. You know. Yep. Mm-hmm. I think one factor would be production cost. Because there's a cap there, so um depends on how much you can cram into that price. Um. I think that that's the main factor. Cool.
Okay. Right. Um well this is the kick-off meeting for our our project. Um and um this is just what we're gonna be doing over the next twenty five minutes. Um so first of all, just to kind of make sure that we all know each other, I'm Laura and I'm the project manager. Do you want to introduce yourself again? Okay. Great. Okay. Um so we're designing a new remote control and um Oh I have to record who's here actually. So that's David, Andrew and Craig, isn't it? And you all arrived on time. Um yeah so des uh design a new remote control. Um, as you can see it's supposed to be original, trendy and user friendly. Um so that's kind of our our brief, as it were. Um and so there are three different stages to the design. Um I'm not really sure what what you guys have already received um in your emails. What did you get? Mm-hmm. Is that what everybody got? Okay. Um. So we're gonna have like individual work and then a meeting about it. And repeat that process three times. Um and at this point we get try out the whiteboard over there. Um. So uh you get to draw your favourite animal and sum up your favourite characteristics of it. So who would like to go first? Very good. Mm-hmm. Yeah. Yeah. Right. Lovely. Right. You can take as long over this as you like, because we haven't got an awful lot to discuss. Ok oh we do we do. Don't feel like you're in a rush, anyway. Ach why not We might have to get you up again then. I don't know what mine is. I'm gonna have to think on the spot now. Is that a whale? Ah. Okay. God, I still don't know what I'm gonna write about. Um. I was gonna choose a dog as well. But I'll just draw a different kind of dog. M my favourite animal is my own dog at home. Um That doesn't really look like him, actually. He looks more like a pig, actually. Ah well. Do you? Oh that's very good of you. Uh. Um he's a mixture of uh various things. Um and what do I like about him, um That's just to suggest that his tail wags. Um he's very friendly and cheery and always pleased to see you, and very kind of affectionate and um uh and he's quite quite wee as well so you know he can doesn't take up too much space. Um and uh And he does a funny thing where he chases his tail as well, which is quite amusing, so It is. I think it is. He only does it after he's had his dinner and um he'll just all of a sudden just get up and start chasing his tail 'round the living room. Yeah, so uh Yeah, maybe. Maybe. Right, um where did you find this? Just down here? Yeah. Okay. Um what are we doing next? Uh um. Okay, uh we now need to discuss the project finance. Um so according to the brief um we're gonna be selling this remote control for twenty five Euro, um and we're aiming to make fifty million Euro. Um so we're gonna be selling this on an international scale. And uh we don't want it to cost any more than uh twelve fifty Euros, so fifty percent of the selling price. Sure. All together. Um I dunno. I imagine That's a good question. I imagine it probably is our sale actually because it's probably up to the the um the retailer to uh sell it for whatever price they want. Um. But I I don't know, I mean do you think the fact that it's going to be sold internationally will have a bearing on how we design it at all? Think it will? Um. Hmm. Oh yeah, regions and stuff, yeah. Yeah. Okay. Yeah. Well for a remote control, do you think that will be I suppose it's depends on how complicated our remote control is. Yeah, yeah. Okay. What, just like in terms of like the wealth of the country? Like how much money people have to spend on things like? Aye, I see what you mean, yeah. Marketing. Good marketing thoughts. Oh gosh, I should be writing all this down. Um. Mm. Yeah. Yeah, yeah. Like how much does, you know, a remote control cost. Well twenty five Euro, I mean that's um that's about like eighteen pounds or something, isn't it? Or no, is it as much as that? Sixteen seventeen eighteen pounds. Um, I dunno, I've never bought a remote control, so I don't know how how good a remote control that would get you. Um. But yeah, I suppose it has to look kind of cool and gimmicky. Um right, okay. Let me just scoot on ahead here. Okay. Um well d Does anybody have anything to add to uh to the finance issue at all? Thin No, actually. That would be useful, though, wouldn't it, if you knew like what your money would get you now. Mm-hmm. Yeah, yeah. Oh. Five minutes to end of meeting. Oh, okay. We're a bit behind. Yeah. Right, so do you think that should be like a main design aim of our remote control d you know, do your your satellite and your regular telly and your V_C_R_ and everything? Mm-hmm. Yeah. Or even like, you know, notes about um what you wanna watch. Like you might put in there oh I want to watch such and such and look a Oh that's a good idea. So extra functionalities. Mm-hmm. Hmm. Um okay, uh I'd wel we're gonna have to wrap up pretty quickly in the next couple of minutes. Um I'll just check we've nothing else. Okay. Um so anything else anybody wants to add about what they don't like about remote controls they've used, what they would really like to be part of this new one at all? You keep losing them. Okay. Yeah. W You get those ones where you can, if you like, whistle or make a really high pitched noise they beep. There I mean is that something we'd want to include, do you think? Dunno. Okay maybe. My goodness. Still feels quite primitive. Maybe like a touch screen or something? Okay. Uh-huh, okay. Well I guess that's up to our industrial designer. It looks better. Yeah. Okay. Okay. Right, well um so just to wrap up, the next meeting's gonna be in thirty minutes. So that's about um about ten to twelve by my watch. Um so inbetween now and then, um as the industrial designer, you're gonna be working on you know the actual working design of it so y you know what you're doing there. Um for user interface, technical functions, I guess that's you know like what we've been talking about, what it'll actually do. Um and uh marketing executive, you'll be just thinking about what it actually what, you know, what requirements it has to has to fulfil and you'll all get instructions emailed to you, I guess. Um. Yeah, so it's th the functional design stage is next, I guess. And uh and that's the end of the meeting. So I got that little message a lot sooner than I thought I would, so Mm-hmm. Uh-huh, yeah. Th Okay, well just very quickly 'cause this we're supposed to finish now. Um I guess that's up to us, I mean you probably want some kind of unique selling point of it, so um, you know Yeah. Mm-hmm. Yeah. Okay. Right, okay, we'll that's that's the end of the meeting, then. Um. So, uh thank you all for coming.
Um I'm Craig and I'm User Interface. Yeah. Well, my favourite animal would be a monkey. Then they're small cute and furry, and uh when planet of the apes becomes real, I'm gonna be up there with them. Yeah. I know um My parents went out and bought um remote controls because um they got fed up of having four or five different remote controls for each things the house. So um for them it was just how many devices control. Uh.
Mm-hmm. Great. And I'm Andrew and I'm uh our marketing expert. Mm-hmm. Mm-hmm. Yeah, that's that's it. Yeah. I will go. That's fine. Alright. So This one here, right? Okay. Very nice. Alright. My favourite animal is like A beagle. Um charac favourite characteristics of it? Is that right? Uh, right, well basically um high priority for any animal for me is that they be willing to take a lot of physical affection from their family. And, yeah that they have lots of personality and uh be fit and in robust good health. So this is blue. Blue beagle. My family's beagle. I coulda told you a whole lot more about beagles. Boy, let me tell you. Impressionist. Alright. Mm. Superb sketch, by the way. Yep. I see a dog in there. Yep. Now I see a rooster. What kind is it? Is he aware that th it's his own cha tail he's chasing? Hmm. Probably when he was little he got lots of attention for doing it and has forever been conditioned. 'Kay. Um, can we just go over that again? Uh, so bas at twel Alright, yeah. Okay. So cost like production cost is twelve fifty, but selling price is is that wholesale or retail? Like on the shelf. Our sale our sale anyway. Yeah, okay okay. Okay. Mm-hmm. Alright. Yes. Mm-hmm. Mm-hmm. Well right away I'm wondering if there's um th th uh, like with D_V_D_ players, if there are zones. Um f frequencies or something um as well as uh characters, um different uh keypad styles and s symbols. Um. I don't know. Yeah. Yeah. Yeah. And then a and then al the other thing international is on top of the price. I'm thinking the price might might appeal to a certain market in one region, whereas in another it'll be different, so Just a chara just a characteristic of the Just Or just like, basic product podi positioning, the twenty five Euro remote control might be a big hit in London, might not be such a big hit in Greece, who knows, something like that, yeah. Yep. Right away I'm making some kind of assumptions about what what information we're given here, thinking, 'kay trendy probably means something other than just basic, something other than just standard. Um so I'm wondering right away, is selling twenty five Euros, is that sort of the thi is this gonna to be like the premium product kinda thing or Uh-huh. Mm-hmm. Yep. Yeah, I'd say so, yeah. No. Yeah, yeah. Mm-hmm. Do we have any other background information on like how that compares to other other Yeah. Mm-hmm. Yeah, interesting thing about discussing um production of a remote control for me is that l as you point out, I just don't think of remote controls as somethin something people consciously assess in their purchasing habits. It's just like getting shoelaces with shoes or something. It just comes along. Do you know what I mean? Like so sort of like how do you I I mean one one way of looking at it would be, well the people producing television sets, maybe they have to buy remote controls. Or another way is maybe people who have T_V_ sets are really fed up with their remote control and they really want a better one or something. But Right. Right. Okay so Right, so in function one of the priorities might be to combine as many uses I think so. Yeah, yeah. Yeah. Well like um, maybe what we could use is a sort of like a example of a successful other piece technology is palm palm pilots. They're gone from being just like little sort of scribble boards to cameras, M_P_ three players, telephones, everything, agenda. So, like, I wonder if we might add something new to the to the remote control market, such as the lighting in your house, or um Yeah, yeah. An Yeah. Like, p personally for me, at home I've I've combined the um the audio video of my television set and my D_V_D_ player and my C_D_ player. So they w all work actually function together but I have different remote controls for each of them. So it's sort of ironic that that then they're in there um you know, the sound and everything it's just one system. But each one's got its own little part. Mm. Mm. Mm. Mm-hmm. Mm-hmm. Yeah. Yeah. That's just really good id Yep. Uh, sure. I remember when the first remote control my my family had was on a cable. Actually had a cable between it and the T_V_ and big like buttons that sort of like, like on a blender or something. And um, you know, when I think about what they are now, it's better, but actually it's still kind of, I dunno, like a massive junky thing on the table. Maybe we could think about how, could be more, you know, streamlined. S Something like that, yeah. Or whatever would be technologically reasonable. 'Cause it could b it could it could be that f it could be that functionally that doesn't make it any better, but that just the appeal of of not having You know, these days there's a r pe things in people's homes are becoming more and more like chic, you know. Um, nicer materials and might be be worth exploring anyway. Okay. Um. Before we wrap up, just to make sure we're all on the same page here, um, do we We were given sort of an example of a coffee machine or something, right? Well, um are we at ma right now on the assumption that our television remote control may have features which go beyond the television? Or are we keeping sort of like a a design commitment to television features? I I don't know. Yep. Yeah, sure. Okay. Okay, yeah. Okay. Okay. Okay. Alright.
model-index:
- name: bart-large-meeting-summary-xsum-samsum-dialogsum-AMI
results:
- task:
name: Abstractive Text Summarization
type: abstractive-text-summarization
dataset:
name: "cnndaily/newyorkdaily/xsum/samsum/dialogsum/AMI Meeting Corpus"
type: cnndaily/newyorkdaily/xsum/samsum/dialogsum/AMI Meeting Corpus
metrics:
- name: Validation ROGUE-1
type: rouge-1
value: NA
- name: Validation ROGUE-2
type: rouge-2
value: NA
- name: Validation ROGUE-L
type: rouge-L
value: NA
- name: Validation ROGUE-Lsum
type: rouge-Lsum
value: NA
- name: Test ROGUE-1
type: rouge-1
value: NA
- name: Test ROGUE-2
type: rouge-2
value: NA
- name: Test ROGUE-L
type: rouge-L
value: NA
- name: Test ROGUE-Lsum
type: rouge-Lsum
value: NA
---
Model obtained by Fine Tuning 'facebook/bart-large-xsum'
## Usage
# Example 1
```python
from transformers import pipeline
summarizer = pipeline("summarization", model="knkarthick/MEETING-SUMMARY-BART-LARGE-XSUM-SAMSUM-DIALOGSUM-AMI")
text = '''The tower is 324 metres (1,063 ft) tall, about the same height as an 81-storey building, and the tallest structure in Paris. Its base is square, measuring 125 metres (410 ft) on each side. During its construction, the Eiffel Tower surpassed the Washington Monument to become the tallest man-made structure in the world, a title it held for 41 years until the Chrysler Building in New York City was finished in 1930. It was the first structure to reach a height of 300 metres. Due to the addition of a broadcasting aerial at the top of the tower in 1957, it is now taller than the Chrysler Building by 5.2 metres (17 ft). Excluding transmitters, the Eiffel Tower is the second tallest free-standing structure in France after the Millau Viaduct.
'''
summarizer(text)
```
# Example 2
```python
from transformers import pipeline
summarizer = pipeline("summarization", model="knkarthick/MEETING-SUMMARY-BART-LARGE-XSUM-SAMSUM-DIALOGSUM-AMI")
text = '''Bangalore is the capital and the largest city of the Indian state of Karnataka. It has a population of more than 8 million and a metropolitan population of around 11 million, making it the third most populous city and fifth most populous urban agglomeration in India. Located in southern India on the Deccan Plateau, at a height of over 900 m (3,000 ft) above sea level, Bangalore is known for its pleasant climate throughout the year. Its elevation is the highest among the major cities of India.The city's history dates back to around 890 CE, in a stone inscription found at the Nageshwara Temple in Begur, Bangalore. The Begur inscription is written in Halegannada (ancient Kannada), mentions 'Bengaluru Kalaga' (battle of Bengaluru). It was a significant turning point in the history of Bangalore as it bears the earliest reference to the name 'Bengaluru'. In 1537 CE, Kempé Gowdā – a feudal ruler under the Vijayanagara Empire – established a mud fort considered to be the foundation of modern Bangalore and its oldest areas, or petes, which exist to the present day.
After the fall of Vijayanagar empire in 16th century, the Mughals sold Bangalore to Chikkadevaraja Wodeyar (1673–1704), the then ruler of the Kingdom of Mysore for three lakh rupees. When Haider Ali seized control of the Kingdom of Mysore, the administration of Bangalore passed into his hands.
The city was captured by the British East India Company after victory in the Fourth Anglo-Mysore War (1799), who returned administrative control of the city to the Maharaja of Mysore. The old city developed in the dominions of the Maharaja of Mysore and was made capital of the Princely State of Mysore, which existed as a nominally sovereign entity of the British Raj. In 1809, the British shifted their cantonment to Bangalore, outside the old city, and a town grew up around it, which was governed as part of British India. Following India's independence in 1947, Bangalore became the capital of Mysore State, and remained capital when the new Indian state of Karnataka was formed in 1956. The two urban settlements of Bangalore – city and cantonment – which had developed as independent entities merged into a single urban centre in 1949. The existing Kannada name, Bengalūru, was declared the official name of the city in 2006.
Bangalore is widely regarded as the "Silicon Valley of India" (or "IT capital of India") because of its role as the nation's leading information technology (IT) exporter. Indian technological organisations are headquartered in the city. A demographically diverse city, Bangalore is the second fastest-growing major metropolis in India. Recent estimates of the metro economy of its urban area have ranked Bangalore either the fourth- or fifth-most productive metro area of India. As of 2017, Bangalore was home to 7,700 millionaires and 8 billionaires with a total wealth of $320 billion. It is home to many educational and research institutions. Numerous state-owned aerospace and defence organisations are located in the city. The city also houses the Kannada film industry. It was ranked the most liveable Indian city with a population of over a million under the Ease of Living Index 2020.
'''
summarizer(text)
```
# Example 3
```python
from transformers import pipeline
summarizer = pipeline("summarization", model="knkarthick/MEETING-SUMMARY-BART-LARGE-XSUM-SAMSUM-DIALOGSUM-AMI")
text = '''Hi, I'm David and I'm supposed to be an industrial designer. Um, I just got the project announcement about what the project is. Designing a remote control. That's about it, didn't get anything else. Did you get the same thing? Cool. There's too much gear. Okay. Can't draw. Um. Yeah. Um, well anyway, I don't know, it's just the first animal I can think off the top of my head. Um. Yes. Big reason is 'cause I'm allergic to most animals. Allergic to animal fur, so um fish was a natural choice. Um, yeah, and I kind of like whales. They come in and go eat everything in sight. And they're quite harmless and mild and interesting. Tail's a bit big, I think. It's an after dinner dog then. Hmm. It does make sense from maybe the design point of view 'cause you have more complicated characters like European languages, then you need more buttons. So, possibly. Hmm. Yeah. And you keep losing them. Finding them is really a pain, you know. I mean it's usually quite small, or when you want it right, it slipped behind the couch or it's kicked under the table. You know. Yep. Mm-hmm. I think one factor would be production cost. Because there's a cap there, so um depends on how much you can cram into that price. Um. I think that that's the main factor. Cool.
Okay. Right. Um well this is the kick-off meeting for our our project. Um and um this is just what we're gonna be doing over the next twenty five minutes. Um so first of all, just to kind of make sure that we all know each other, I'm Laura and I'm the project manager. Do you want to introduce yourself again? Okay. Great. Okay. Um so we're designing a new remote control and um Oh I have to record who's here actually. So that's David, Andrew and Craig, isn't it? And you all arrived on time. Um yeah so des uh design a new remote control. Um, as you can see it's supposed to be original, trendy and user friendly. Um so that's kind of our our brief, as it were. Um and so there are three different stages to the design. Um I'm not really sure what what you guys have already received um in your emails. What did you get? Mm-hmm. Is that what everybody got? Okay. Um. So we're gonna have like individual work and then a meeting about it. And repeat that process three times. Um and at this point we get try out the whiteboard over there. Um. So uh you get to draw your favourite animal and sum up your favourite characteristics of it. So who would like to go first? Very good. Mm-hmm. Yeah. Yeah. Right. Lovely. Right. You can take as long over this as you like, because we haven't got an awful lot to discuss. Ok oh we do we do. Don't feel like you're in a rush, anyway. Ach why not We might have to get you up again then. I don't know what mine is. I'm gonna have to think on the spot now. Is that a whale? Ah. Okay. God, I still don't know what I'm gonna write about. Um. I was gonna choose a dog as well. But I'll just draw a different kind of dog. M my favourite animal is my own dog at home. Um That doesn't really look like him, actually. He looks more like a pig, actually. Ah well. Do you? Oh that's very good of you. Uh. Um he's a mixture of uh various things. Um and what do I like about him, um That's just to suggest that his tail wags. Um he's very friendly and cheery and always pleased to see you, and very kind of affectionate and um uh and he's quite quite wee as well so you know he can doesn't take up too much space. Um and uh And he does a funny thing where he chases his tail as well, which is quite amusing, so It is. I think it is. He only does it after he's had his dinner and um he'll just all of a sudden just get up and start chasing his tail 'round the living room. Yeah, so uh Yeah, maybe. Maybe. Right, um where did you find this? Just down here? Yeah. Okay. Um what are we doing next? Uh um. Okay, uh we now need to discuss the project finance. Um so according to the brief um we're gonna be selling this remote control for twenty five Euro, um and we're aiming to make fifty million Euro. Um so we're gonna be selling this on an international scale. And uh we don't want it to cost any more than uh twelve fifty Euros, so fifty percent of the selling price. Sure. All together. Um I dunno. I imagine That's a good question. I imagine it probably is our sale actually because it's probably up to the the um the retailer to uh sell it for whatever price they want. Um. But I I don't know, I mean do you think the fact that it's going to be sold internationally will have a bearing on how we design it at all? Think it will? Um. Hmm. Oh yeah, regions and stuff, yeah. Yeah. Okay. Yeah. Well for a remote control, do you think that will be I suppose it's depends on how complicated our remote control is. Yeah, yeah. Okay. What, just like in terms of like the wealth of the country? Like how much money people have to spend on things like? Aye, I see what you mean, yeah. Marketing. Good marketing thoughts. Oh gosh, I should be writing all this down. Um. Mm. Yeah. Yeah, yeah. Like how much does, you know, a remote control cost. Well twenty five Euro, I mean that's um that's about like eighteen pounds or something, isn't it? Or no, is it as much as that? Sixteen seventeen eighteen pounds. Um, I dunno, I've never bought a remote control, so I don't know how how good a remote control that would get you. Um. But yeah, I suppose it has to look kind of cool and gimmicky. Um right, okay. Let me just scoot on ahead here. Okay. Um well d Does anybody have anything to add to uh to the finance issue at all? Thin No, actually. That would be useful, though, wouldn't it, if you knew like what your money would get you now. Mm-hmm. Yeah, yeah. Oh. Five minutes to end of meeting. Oh, okay. We're a bit behind. Yeah. Right, so do you think that should be like a main design aim of our remote control d you know, do your your satellite and your regular telly and your V_C_R_ and everything? Mm-hmm. Yeah. Or even like, you know, notes about um what you wanna watch. Like you might put in there oh I want to watch such and such and look a Oh that's a good idea. So extra functionalities. Mm-hmm. Hmm. Um okay, uh I'd wel we're gonna have to wrap up pretty quickly in the next couple of minutes. Um I'll just check we've nothing else. Okay. Um so anything else anybody wants to add about what they don't like about remote controls they've used, what they would really like to be part of this new one at all? You keep losing them. Okay. Yeah. W You get those ones where you can, if you like, whistle or make a really high pitched noise they beep. There I mean is that something we'd want to include, do you think? Dunno. Okay maybe. My goodness. Still feels quite primitive. Maybe like a touch screen or something? Okay. Uh-huh, okay. Well I guess that's up to our industrial designer. It looks better. Yeah. Okay. Okay. Right, well um so just to wrap up, the next meeting's gonna be in thirty minutes. So that's about um about ten to twelve by my watch. Um so inbetween now and then, um as the industrial designer, you're gonna be working on you know the actual working design of it so y you know what you're doing there. Um for user interface, technical functions, I guess that's you know like what we've been talking about, what it'll actually do. Um and uh marketing executive, you'll be just thinking about what it actually what, you know, what requirements it has to has to fulfil and you'll all get instructions emailed to you, I guess. Um. Yeah, so it's th the functional design stage is next, I guess. And uh and that's the end of the meeting. So I got that little message a lot sooner than I thought I would, so Mm-hmm. Uh-huh, yeah. Th Okay, well just very quickly 'cause this we're supposed to finish now. Um I guess that's up to us, I mean you probably want some kind of unique selling point of it, so um, you know Yeah. Mm-hmm. Yeah. Okay. Right, okay, we'll that's that's the end of the meeting, then. Um. So, uh thank you all for coming.
Um I'm Craig and I'm User Interface. Yeah. Well, my favourite animal would be a monkey. Then they're small cute and furry, and uh when planet of the apes becomes real, I'm gonna be up there with them. Yeah. I know um My parents went out and bought um remote controls because um they got fed up of having four or five different remote controls for each things the house. So um for them it was just how many devices control. Uh.
Mm-hmm. Great. And I'm Andrew and I'm uh our marketing expert. Mm-hmm. Mm-hmm. Yeah, that's that's it. Yeah. I will go. That's fine. Alright. So This one here, right? Okay. Very nice. Alright. My favourite animal is like A beagle. Um charac favourite characteristics of it? Is that right? Uh, right, well basically um high priority for any animal for me is that they be willing to take a lot of physical affection from their family. And, yeah that they have lots of personality and uh be fit and in robust good health. So this is blue. Blue beagle. My family's beagle. I coulda told you a whole lot more about beagles. Boy, let me tell you. Impressionist. Alright. Mm. Superb sketch, by the way. Yep. I see a dog in there. Yep. Now I see a rooster. What kind is it? Is he aware that th it's his own cha tail he's chasing? Hmm. Probably when he was little he got lots of attention for doing it and has forever been conditioned. 'Kay. Um, can we just go over that again? Uh, so bas at twel Alright, yeah. Okay. So cost like production cost is twelve fifty, but selling price is is that wholesale or retail? Like on the shelf. Our sale our sale anyway. Yeah, okay okay. Okay. Mm-hmm. Alright. Yes. Mm-hmm. Mm-hmm. Well right away I'm wondering if there's um th th uh, like with D_V_D_ players, if there are zones. Um f frequencies or something um as well as uh characters, um different uh keypad styles and s symbols. Um. I don't know. Yeah. Yeah. Yeah. And then a and then al the other thing international is on top of the price. I'm thinking the price might might appeal to a certain market in one region, whereas in another it'll be different, so Just a chara just a characteristic of the Just Or just like, basic product podi positioning, the twenty five Euro remote control might be a big hit in London, might not be such a big hit in Greece, who knows, something like that, yeah. Yep. Right away I'm making some kind of assumptions about what what information we're given here, thinking, 'kay trendy probably means something other than just basic, something other than just standard. Um so I'm wondering right away, is selling twenty five Euros, is that sort of the thi is this gonna to be like the premium product kinda thing or Uh-huh. Mm-hmm. Yep. Yeah, I'd say so, yeah. No. Yeah, yeah. Mm-hmm. Do we have any other background information on like how that compares to other other Yeah. Mm-hmm. Yeah, interesting thing about discussing um production of a remote control for me is that l as you point out, I just don't think of remote controls as somethin something people consciously assess in their purchasing habits. It's just like getting shoelaces with shoes or something. It just comes along. Do you know what I mean? Like so sort of like how do you I I mean one one way of looking at it would be, well the people producing television sets, maybe they have to buy remote controls. Or another way is maybe people who have T_V_ sets are really fed up with their remote control and they really want a better one or something. But Right. Right. Okay so Right, so in function one of the priorities might be to combine as many uses I think so. Yeah, yeah. Yeah. Well like um, maybe what we could use is a sort of like a example of a successful other piece technology is palm palm pilots. They're gone from being just like little sort of scribble boards to cameras, M_P_ three players, telephones, everything, agenda. So, like, I wonder if we might add something new to the to the remote control market, such as the lighting in your house, or um Yeah, yeah. An Yeah. Like, p personally for me, at home I've I've combined the um the audio video of my television set and my D_V_D_ player and my C_D_ player. So they w all work actually function together but I have different remote controls for each of them. So it's sort of ironic that that then they're in there um you know, the sound and everything it's just one system. But each one's got its own little part. Mm. Mm. Mm. Mm-hmm. Mm-hmm. Yeah. Yeah. That's just really good id Yep. Uh, sure. I remember when the first remote control my my family had was on a cable. Actually had a cable between it and the T_V_ and big like buttons that sort of like, like on a blender or something. And um, you know, when I think about what they are now, it's better, but actually it's still kind of, I dunno, like a massive junky thing on the table. Maybe we could think about how, could be more, you know, streamlined. S Something like that, yeah. Or whatever would be technologically reasonable. 'Cause it could b it could it could be that f it could be that functionally that doesn't make it any better, but that just the appeal of of not having You know, these days there's a r pe things in people's homes are becoming more and more like chic, you know. Um, nicer materials and might be be worth exploring anyway. Okay. Um. Before we wrap up, just to make sure we're all on the same page here, um, do we We were given sort of an example of a coffee machine or something, right? Well, um are we at ma right now on the assumption that our television remote control may have features which go beyond the television? Or are we keeping sort of like a a design commitment to television features? I I don't know. Yep. Yeah, sure. Okay. Okay, yeah. Okay. Okay. Okay. Alright.
'''
summarizer(text)
```
# Example 4
```python
from transformers import pipeline
summarizer = pipeline("summarization", model="knkarthick/MEETING-SUMMARY-BART-LARGE-XSUM-SAMSUM-DIALOGSUM-AMI")
text = '''
Das : Hi and welcome to the a16z podcast. I’m Das, and in this episode, I talk SaaS go-to-market with David Ulevitch and our newest enterprise general partner Kristina Shen. The first half of the podcast looks at how remote work impacts the SaaS go-to-market and what the smartest founders are doing to survive the current crisis. The second half covers pricing approaches and strategy, including how to think about free versus paid trials and navigating the transition to larger accounts. But we start with why it’s easier to move upmarket than down… and the advantage that gives a SaaS startup against incumbents.
David : If you have a cohort of customers that are paying you $10,000 a year for your product, you’re going to find a customer that self-selects and is willing to pay $100,000 a year. Once you get one of those, your organization will figure out how you sell to, how you satisfy and support, customers at that price point and that size. But it’s really hard for a company that sells up market to move down market, because they’ve already baked in all that expensive, heavy lifting sales motion. And so as you go down market with a lower price point, usually, you can’t actually support it.
Das : Does that mean that it’s easier for a company to do this go-to-market if they’re a new startup as opposed to if they’re a pre-existing SaaS?
Kristina : It’s culturally very, very hard to give a product away for free that you’re already charging for. It feels like you’re eating away at your own potential revenue when you do it. So most people who try it end up pulling back very quickly.
David : This is actually one of the key reasons why the bottoms up SaaS motion is just so competitive, and compelling, and so destructive against the traditional sales-driven test motion. If you have that great product and people are choosing to use it, it’s very hard for somebody with a sales-driven motion, and all the cost that’s loaded into that, to be able to compete against it. There are so many markets where initially, we would look at companies and say, “Oh, well, this couldn’t possibly be bottoms up. It has to be sold to the CIO. It has to be sold to the CSO or the CFO.” But in almost every case we’ve been wrong, and there has been a bottoms up motion. The canonical example is Slack. It’s crazy that Slack is a bottoms up company, because you’re talking about corporate messaging, and how could you ever have a messaging solution that only a few people might be using, that only a team might be using? But now it’s just, “Oh, yeah, some people started using it, and then more people started using it, and then everyone had Slack.”
Kristina : I think another classic example is Dropbox versus Box. Both started as bottoms up businesses, try before you buy. But Box quickly found, “Hey, I’d rather sell to IT.” And Dropbox said, “Hey, we’ve got a great freemium motion going.” And they catalyzed their business around referrals and giving away free storage and shared storage in a way that really helped drive their bottoms up business.
Das : It’s a big leap to go from selling to smaller customers to larger customers. How have you seen SaaS companies know or get the timing right on that? Especially since it does seem like that’s really related to scaling your sales force?
Kristina : Don’t try to go from a 100-person company to a 20,000-person company. Start targeting early adopters, maybe they’re late stage pre-IPO companies, then newly IPO’d companies. Starting in tech tends to be a little bit easier because they tend to be early adopters. Going vertical by vertical can be a great strategy as well. Targeting one customer who might be branded in that space, can help brand yourself in that category. And then all their competitors will also want your product if you do a good job. A lot of times people will dedicate a sales rep to each vertical, so that they become really, really knowledgeable in that space, and also build their own brand and reputation and know who are the right customers to target.
Das : So right now, you’ve got a lot more people working remote. Does this move to remote work mean that on-premise software is dying? And is it accelerating the move to software as a service?
Kristina : This remote work and working from home is only going to catalyze more of the conversion from on-premise over to cloud and SaaS. In general, software spend declines 20% during an economic downturn. This happened in ’08, this happened in ’01. But when we look at the last downturn in ’08, SaaS spend actually, for public companies, increased, on average, 10%, which means there’s a 30% spread, which really shows us that there was a huge catalyst from people moving on-premise to SaaS.
David : And as people work remote, the ability to use SaaS tools is much easier than having to VPN back into your corporate network. We’ve been seeing that, inside sales teams have been doing larger and larger deals, essentially moving up market on the inside, without having to engage with field sales teams. In fact, a lot of the new SaaS companies today rather than building out a field team, they have a hybrid team, where people are working and closing deals on the inside and if they had to go out and meet with a customer, they would do that. But by and large, most of it was happening over the phone, over email, and over videoconferencing. And all the deals now, by definition, are gonna be done remote because people can’t go visit their customers in person.
Das : So with bottoms up, did user behavior and buyer behavior change, so the go-to-market evolved? Or did the go-to-market evolve and then you saw user and buyer behavior change? I’m curious with this move to remote work. Is that going to trigger more changes or has the go-to-market enabled that change in user behavior, even though we see that change coming because of a lot of forces outside of the market?
Kristina : I definitely think they are interrelated. But I do think it was a user change that catalyzed everything. We decided that we preferred better software, and we tried a couple products. We were able to purchase off our credit card. And then IT and procurement eventually said, “Wow, everyone’s buying these already, I might as well get a company license and a company deal so I’m not paying as much.” While obviously software vendors had to offer the products that could be self-served, users started to realize they had the power, they wanted to use better software, they paid with their credit cards. And now software vendors are forced to change their go-to-market to actually suit that use case.
Das : If that’s the case that when user behavior has changed, it’s tended to be the catalyzing force of bigger changes in the go-to-market, what are some of the changes you foresee for SaaS because the world has changed to this new reality of remote work and more distributed teams?
David : We’re in a very uncertain economic environment right now. And a couple of things will become very clear over the next 3 to 9 to 15 months — you’re going to find out which SaaS products are absolutely essential to helping a business operate and run, and which ones were just nice to have and may not get renewed. I think on the customer, buying side, you’re very likely to see people push back on big annual commitments and prefer to go month-to-month where they can. Or you’ll see more incentives from SaaS startups to offer discounts for annual contracts. You’re going to see people that might sign an annual contract, but they may not want to pay upfront. They may prefer to meter the cash out ratably over the term of the contract. And as companies had empowered and allowed budget authority to be pushed down in organizations, you’re gonna see that budget authority get pulled back, more scrutiny on spending, and likely a lot of SaaS products not get renewed that turned out to not be essential.
Kristina : I think the smartest founders are making sure they have the runway to continue to exist. And they’re doing that in a couple of ways. They’re preserving cash, and they are making sure that their existing customers are super, super happy, because retaining your customers is so important in this environment. And they’re making sure that they have efficient or profitable customer acquisition. Don’t spend valuable dollars acquiring customers. But acquire customers efficiently that will add to a great existing customer base.
Das : To go into pricing and packaging for SaaS for a moment, what are some of the different pricing approaches that you see SaaS companies taking?
Kristina : The old school way of doing SaaS go-to-market is bundle everything together, make the pricing super complex, so you don’t actually understand what you’re paying for. You’re forced to purchase it because you need one component of the product. New modern SaaS pricing is keep it simple, keep it tied to value, and make sure you’re solving one thing really, really well.
David : You want to make it easy for your customers to give you money. And if your customers don’t understand your pricing, that’s a huge red flag. Sometimes founders will try to over engineer their pricing model.
Kristina : We talk a lot about everything has to be 10X better than the alternatives. But it’s much easier to be 10X better when you solve one thing very, very well, and then have simple pricing around it. I think the most common that most people know about is PEPM or per employee per month, where you’re charging basically for every single seat. Another really common model is the freemium model. So, think about a Dropbox, or an Asana, or a Skype, where it’s trigger based. You try the product for free, but when you hit a certain amount of storage, or a certain amount of users, then it converts over to paid. And then you also have a time trial, where you get the full experience of the product for some limited time period. And then you’re asked if you want to continue using the product to pay. And then there’s pay as go, and particularly, pay as you go as a usage model. So, Slack will say, “Hey, if your users aren’t actually using the product this month, we won’t actually charge you for it.”
David : The example that Kristina made about Slack and users, everybody understands what a user is, and if they’re using the product, they pay for it, and if they’re not using it, they don’t pay for it. That’s a very friendly way to make it easy for your customers to give you money. If Slack came up with a pricing model that was like based on number of messages, or number of API integration calls, the customer would have no idea what that means.
Kristina : There’s also the consumption model. So Twilio only charges you for every SMS text or phone call that you make on the platform any given month. And so they make money or lose money as your usage goes. The pricing is very aligned to your productivity.
David : Generally, those are for products where the usage only goes in one direction. If you think of a company like Databricks, where they’re charging for storage, or Amazon’s S3 service, it is very aligned with the customer, but it also strategically aligns with the business because they know the switching cost is very high, the churn is very low. And generally, in those businesses, you’re only going to store more data, so they can charge based on usage or volume of data.
Kristina : Recently, there’s been a huge trend of payment as a revenue. It’s particularly common in vertical markets where SaaS companies are adding payments as a revenue in addition to their employee or subscription revenue. If you look at Shopify, for example, more than 50% of their revenue is actually payment revenue. They’re making money every single time you purchase something off one of their shopping cart websites.
Das : When you’re working with a founder or a SaaS startup, how have you seen them find the right pricing model for their product, for their market?
Kristina : Step one is just talk to a lot of customers. Try to figure out what is the market pricing for possible alternatives or competitors, understand their pain points and their willingness to pay. And just throw a price out there, because you have to have a starting point in order to actually test and iterate. Particularly in the SMB, or the bottoms up business, you can test and iterate pretty quickly because you have so many data points.
David : I always tell founders, step one is to just go out there and talk to customers. Step two is just double your prices. I don’t think there’s ever been a great company with a great product that’s fallen apart because their pricing was wrong. But a lot of SaaS startup founders really under price, and you don’t want to find out two or three years later that you were 200% underpriced. A very common thing that SaaS companies do, they’ll have the basic package that either is free or low cost, that you can just sign up online for. They’ll have a middle package where they share some pricing, and then they’ll have the enterprise package where you have to contact sales to find out more. And that way they don’t actually have to show the pricing for that third package. And that gives the salespeople the flexibility to adjust pricing on a per deal basis.
Das : When you’re working with companies, why are they underpricing their products?
David : I think it’s psychological. People need to price on value, and they don’t know how much value they’re delivering relative to “Oh, it only cost me $100 a month to provide this service, so I just need to charge $200.” But if it turns out you’re saving your customer $50,000 a year, then you’re wildly underpriced. You have to remember that SaaS is essentially a proxy for outsourced IT. You’re spending money on a SaaS service to not pay to develop something internally, or to have to pay IT to support something that’s more complex on-prem. Software is much cheaper than people, and so generally, the price point can be much higher.
Kristina : And the other thing is your value increases over time. You’re delivering more features, more products, you understand the customer better. It’s the beauty of the SaaS model and cloud model that you can iterate and push code immediately, and the customer immediately sees value. A lot of times people have the same price point from the first customer sold to three years later and the 200th customer. Quite frankly, you’ve delivered so much value along the way that your price point should have gone up. The other thing I’ll say is a lot of people discount per seat pricing a lot as they move up market. We tend to tell people that the best validation of your product having great product market fit is your ability to hold your price point. So while there is some natural discounting on a per seat basis because people do deserve some volume discounting, I would say try to resist that as much as possible.
Das : Especially for a technical founder, it’s so tempting to get in there and fiddle with these knobs. How do you know when it is time to experiment with your pricing and packaging?
David : If you’re looking at your business and you see that you are doing more deals, and they’re closing faster, you should raise your pricing. And you pay attention to how long it takes to close deals and whether the number of deals is staying consistent as you do that. And, at some point, you’re going to find out when you’re losing deals on price. I think a moment where companies have to plan ahead to avoid having to course correct is after they roll out massive pricing and packaging changes, which are pretty natural as companies move up market. But how they navigate that transition to larger accounts, and how they either bring along or move away from those smaller, earlier customers who got them to where they are, tends to be really important because they can get a lot of noise on Twitter, they can get a lot of blowback from their customers. So Zendesk is a company where they rolled out a major packaging change. And when they rolled it out, they hadn’t planned on grandfathering in their early customers. They got a lot of pushback, and very quickly, they put out a blog post and said, “We hear what you’re saying, we appreciate you building the business that we’ve become today. We do need to have a package for the future. But all the people that have been customers so far will be grandfathered in for at least a period of time into the old model.”
Kristina : If you iterate pricing constantly, you don’t really have this problem because your customers will be used to pricing changes. You normally pair them with new features, and it all kind of works out. But if you have to go through a big grandfather change, I tend to lean towards treating your early customers really, really well. They adopted when you weren’t a big company yet. They probably co-built the product with you in many ways. And so, it’s great to get more dollars out of your customer base, but treat your early customers well.
Das : Are there any other failure modes that you see startups really falling into around pricing and packaging or any common mistakes that they make?
David : I think a lot of founders don’t always map out the cost or model of their pricing and their product relative to their cost of actually doing sales and marketing and customer acquisition.
Kristina : Inside sales is so popular in Silicon Valley. When you’re selling more to an SMB or mid-market type customer, the expectation is that you’re educating and helping the prospective customer over the phone. And so, you’re not expected to be as high touch. But 5K is almost the minimum price point you need to sell to the SMB with an inside sales team in order to pay for the outbound costs and all the conversions, because there is typically a team that sits around the quota carrying rep. And so, price matching — how much your price point is compared to what your go-to-market motion is — matters a lot. Other big failure modes that I see, people guess the ramp time of a sales rep wrong. And ramp time really ties to the segment of customer you’re selling into. It tends be that if you’re selling into the enterprise, the ramp time for sales reps, because sales cycles are so long, tend to be much longer as well. They could be six months plus, could be a year. While if you’re selling more into SMB or mid-market, the ramp time to get a rep up and running can be much shorter, three to six months. Because the sales cycles are shorter, they just iterate much faster, and they ramp up much more quickly.
David : The other thing that people have to understand is that sales velocity is a really important component to figuring out how many reps you should be hiring, whether they should be inside reps or field reps. If it takes you 90 days to close a deal, that can’t be a $5,000 a year deal, that has to be a $50,000 or even $150,000 a year deal.
Das : Kristina, I know you’ve done a lot of work with metrics. So how do those play in?
Kristina : Probably the one way to sum it all together is how many months does it take to pay back customer acquisition cost. Very commonly within the SaaS world, we talk about a 12-month CAC payback. We typically want to see for every dollar you spend on sales and marketing, you get a dollar back within a year. That means you can tweak the inputs any way you want. Let’s say that doing paid acquisition is really effective for you. Then, you can spend proportionally more on paid acquisition and less on sales reps. Vice versa, if you have a great inbound engine, you actually can hire a lot more sales reps and spend more on sales headcount. With all formulas, it’s a guide rail, so if you have customers that retain really, really well, let’s say you’re selling to the enterprise, and you’ve got a 90% or 95% annual retention rate, then your CAC payback could be between 12 and 24 months. But let’s say you’re selling to the SMB and churn is 2% or 3% monthly, which ends up being like 80% to 90% annual retention. Then, because your customer is less sticky, I would recommend looking at a CAC payback of 6 to 12 months.
Das : How should you think about doing a free trial versus a paid trial?
David : On the one hand, the bottoms up motion where people can try essentially a full version of a product before they buy it is extremely powerful. On the other hand, I’ve started to try to think about how I advise companies, when they are thinking about a free trial for something that might cost $100,000 or $200,000 a year? Do we do a paid pilot that has some sort of contractual obligation that if we meet then turns into a commercial engagement?
Kristina : I do think the beauty of the bottoms up business is that you can get people to try the entire experience of the product for free, and they fall in love with it, and a certain percentage will convert. And that works really, really well for products that can self-serve. When you start moving up market to more complex products, the challenge with trials is it takes work to actually implement the product, whether it be integrations, IT has to give access, etc. You lose that self-serve ability, which is so amazing in the trial. And so, I tend to be more in the camp of paid trials, if it costs you money to actually deploy the trial. And when you’re selling to bigger customers, they associate value when they have to pay. Once a customer has to pay you, then they feel a need to make the project successful and thus they will onboard, schedule things, give you data and access.
David : If you can get to a point where you get the customer to do that paid pilot, such that the only difference between a pilot and an actual customer is just the signing of a contract, that’s very powerful. Now, that does force you to have a really good pre-sales motion to make sure that you can deliver on the promise you’ve made your customers. When companies don’t have a great product, and they paper over it with professional services and sales engineering and post-sales support, that paid pilot thing doesn’t work because the experience isn’t good enough. So, it really is incumbent on the SaaS company that does a paid pilot to make sure that they are able to deliver on that experience.
Kristina : And one emerging trend recently is people signing an annual contract with a one or three month out, as a replacement to the paid pilot. Because it’s the best of both worlds, the SaaS company that’s selling the product gets a higher level of commitment. And the customer gets the optionality of opting out in the same way as a trial without any clawback. It really comes down to where procurement falls. Sometimes procurement is at the beginning of that decision, which makes it more like an annual contract. Sometimes procurement is at the one or three month opt-out period, which means the customer already has a great experience, loves the product, and it is an easier way to convert procurements to actually sign on…
David : And that is a really good segue into renewals. I always tell founders, you might have this subscription business, but it’s not a recurring revenue business until the second year when the revenue actually recurs. I think you really have the first three months to get a customer up and running and happy. And if they’re not, you then have about three months to fix it. And if all that works out, then the remaining six months of the contract can be focused on upsell and expansion.
Das : Awesome. Thank you, Kristina. Thank you, David.
Kristina : Thanks so much for having us. This was fun.
David : Yeah, a lot of fun, great topics, and our favorite thing to talk about.
'''
summarizer(text)
``` |
allenai/tk-instruct-base-def-pos | 196e8998944bded8e53c6fe3a757a905a3d5382f | 2022-05-27T06:30:11.000Z | [
"pytorch",
"t5",
"text2text-generation",
"en",
"dataset:natural instructions v2.0",
"arxiv:1910.10683",
"arxiv:2204.07705",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | text2text-generation | false | allenai | null | allenai/tk-instruct-base-def-pos | 1,011 | null | transformers | 1,762 | ---
language: en
license: apache-2.0
datasets:
- natural instructions v2.0
---
# Model description
Tk-Instruct is a series of encoder-decoder Transformer models that are trained to solve various NLP tasks by following in-context instructions (plain language task definitions, k-shot examples, explanations, etc). Built upon the pre-trained [T5 models](https://arxiv.org/abs/1910.10683), they are fine-tuned on a large number of tasks & instructions that are collected in the [Natural Instructions benchmark](https://github.com/allenai/natural-instructions), which contains 1600+ tasks in 70+ broach categories in total. This enables the model to not only process the training tasks, but also generalize to many unseen tasks without further parameter update.
More resources for using the model:
- **Paper**: [link](https://arxiv.org/abs/2204.07705)
- **Code repository**: [Tk-Instruct](https://github.com/yizhongw/Tk-Instruct)
- **Official Website**: [Natural Instructions](https://instructions.apps.allenai.org/)
- **All released models**: [allenai/tk-instruct](https://huggingface.co/models?search=allenai/tk-instruct)
## Intended uses & limitations
Tk-Instruct can be used to do many NLP tasks by following instructions.
### How to use
When instructing the model, task definition or demonstration examples or explanations should be prepended to the original input and fed into the model. You can easily try Tk-Instruct models as follows:
```python
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
>>> tokenizer = AutoTokenizer.from_pretrained("allenai/tk-instruct-3b-def")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("allenai/tk-instruct-3b-def")
>>> input_ids = tokenizer.encode(
"Definition: return the currency of the given country. Now complete the following example - Input: India. Output:",
return_tensors="pt")
>>> output = model.generate(input_ids, max_length=10)
>>> output = tokenizer.decode(output[0], skip_special_tokens=True) # model should output 'Indian Rupee'
>>> input_ids = tokenizer.encode(
"Definition: negate the following sentence. Input: John went to school. Output:",
return_tensors="pt")
>>> output = model.generate(input_ids, max_length=10)
>>> output = tokenizer.decode(output[0], skip_special_tokens=True) # model should output 'John did not go to shool.'
```
### Limitations
We are still working on understanding the behaviors of these models, but here are several issues we have found:
- Models are generally sensitive to the instruction. Sometimes rewording the instruction can lead to very different output.
- Models are not always compliant to the instruction. Sometimes the model don't follow your instruction (e.g., when you ask the model to generate one sentence, it might still generate one word or a long story).
- Models might totally fail on some tasks.
If you find serious issues or any interesting result, you are welcome to share with us!
## Training data
Tk-Instruct is trained using the tasks & instructions in [Natural Instructions benchmark](https://github.com/allenai/natural-instructions), which contains 1600+ tasks in 70+ broach categories in total. We follow the official train/test split. Tk-Instruct model series were trained using 757 tasks, and mTk-Instruct series were trained using 1271 tasks (including some non-English tasks).
The training tasks are in 64 broad categories, such as text categorization / question answering / sentiment analysis / summarization / grammar error detection / dialogue generation / etc. The other 12 categories are selected for evaluation.
## Training procedure
All our models are initialized from either T5 models or mT5 models. Because generating the output can be regarded as a form of language modeling, we used their [LM adapted version](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#lm-adapted-t511lm100k). All data is converted into a text-to-text format, and models are fine-tuned to maximize the likelihood of the output sequence.
Our [released models](https://huggingface.co/models?search=allenai/tk-instruct) are in different sizes, and each of them was trained with a specific type of instruction encoding. For instance, `tk-instruct-3b-def-pos` was initialized from [t5-xl-lm-adapt](https://huggingface.co/google/t5-xl-lm-adapt), and it saw task definition & 2 positive examples as the instruction during training time.
Although they are trained with only one type of instruction encodings, we found they can usually work with other type of encodings at test time (see more in our paper).
### BibTeX entry and citation info
```bibtex
@article{wang2022benchmarking,
title={Benchmarking Generalization via In-Context Instructions on 1,600+ Language Tasks},
author={Yizhong Wang and Swaroop Mishra and Pegah Alipoormolabashi and Yeganeh Kordi and Amirreza Mirzaei and A. Arunkumar and Arjun Ashok and Arut Selvan Dhanasekaran and Atharva Naik and David Stap and Eshaan Pathak and Giannis Karamanolakis and Haizhi Gary Lai and Ishan Purohit and Ishani Mondal and Jacob Anderson and Kirby Kuznia and Krima Doshi and Maitreya Patel and Kuntal Kumar Pal and M. Moradshahi and Mihir Parmar and Mirali Purohit and Neeraj Varshney and Phani Rohitha Kaza and Pulkit Verma and Ravsehaj Singh Puri and Rushang Karia and Shailaja Keyur Sampat and Savan Doshi and Siddharth Deepak Mishra and Sujan C. Reddy and Sumanta Patro and Tanay Dixit and Xu-dong Shen and Chitta Baral and Yejin Choi and Hannaneh Hajishirzi and Noah A. Smith and Daniel Khashabi},
year={2022},
archivePrefix={arXiv},
eprint={2204.07705},
primaryClass={cs.CL},
}
``` |
idb-ita/gilberto-uncased-from-camembert | c0320d9b1d9f0e603391f24bb751f6cca9c89968 | 2020-04-24T16:01:20.000Z | [
"pytorch",
"camembert",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | false | idb-ita | null | idb-ita/gilberto-uncased-from-camembert | 1,008 | 1 | transformers | 1,763 | Entry not found |
microsoft/trocr-large-printed | e0ab580ecb4d45111dac1555f91a266cd53171de | 2022-07-01T07:39:34.000Z | [
"pytorch",
"vision-encoder-decoder",
"arxiv:2109.10282",
"transformers",
"trocr",
"image-to-text"
] | image-to-text | false | microsoft | null | microsoft/trocr-large-printed | 1,007 | 1 | transformers | 1,764 | ---
tags:
- trocr
- image-to-text
---
# TrOCR (large-sized model, fine-tuned on SROIE)
TrOCR model fine-tuned on the [SROIE dataset](https://rrc.cvc.uab.es/?ch=13). It was introduced in the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Li et al. and first released in [this repository](https://github.com/microsoft/unilm/tree/master/trocr).
Disclaimer: The team releasing TrOCR did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The TrOCR model is an encoder-decoder model, consisting of an image Transformer as encoder, and a text Transformer as decoder. The image encoder was initialized from the weights of BEiT, while the text decoder was initialized from the weights of RoBERTa.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. One also adds absolute position embeddings before feeding the sequence to the layers of the Transformer encoder. Next, the Transformer text decoder autoregressively generates tokens.
## Intended uses & limitations
You can use the raw model for optical character recognition (OCR) on single text-line images. See the [model hub](https://huggingface.co/models?search=microsoft/trocr) to look for fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model in PyTorch:
```python
from transformers import TrOCRProcessor, VisionEncoderDecoderModel
from PIL import Image
import requests
# load image from the IAM database (actually this model is meant to be used on printed text)
url = 'https://fki.tic.heia-fr.ch/static/img/a01-122-02-00.jpg'
image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
processor = TrOCRProcessor.from_pretrained('microsoft/trocr-large-printed')
model = VisionEncoderDecoderModel.from_pretrained('microsoft/trocr-large-printed')
pixel_values = processor(images=image, return_tensors="pt").pixel_values
generated_ids = model.generate(pixel_values)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
```
### BibTeX entry and citation info
```bibtex
@misc{li2021trocr,
title={TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models},
author={Minghao Li and Tengchao Lv and Lei Cui and Yijuan Lu and Dinei Florencio and Cha Zhang and Zhoujun Li and Furu Wei},
year={2021},
eprint={2109.10282},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
pierrerappolt-okta/app | 915b7f89b6d4644139b9502e399f358071112123 | 2022-02-03T19:38:08.000Z | [
"pytorch",
"distilbert",
"token-classification",
"transformers",
"autotrain_compatible"
] | token-classification | false | pierrerappolt-okta | null | pierrerappolt-okta/app | 1,006 | null | transformers | 1,765 | ---
inference:
parameters:
aggregation_strategy: first
---
. |
deepset/gelectra-large | 726e2e6ad4b1ff8a2ee172ac945d0faef62e5680 | 2022-07-26T12:38:01.000Z | [
"pytorch",
"tf",
"electra",
"pretraining",
"de",
"dataset:wikipedia",
"dataset:OPUS",
"dataset:OpenLegalData",
"dataset:oscar",
"arxiv:2010.10906",
"transformers",
"license:mit"
] | null | false | deepset | null | deepset/gelectra-large | 1,005 | 7 | transformers | 1,766 | ---
language: de
license: mit
datasets:
- wikipedia
- OPUS
- OpenLegalData
- oscar
---
# German ELECTRA large
Released, Oct 2020, this is a German ELECTRA language model trained collaboratively by the makers of the original German BERT (aka "bert-base-german-cased") and the dbmdz BERT (aka bert-base-german-dbmdz-cased). In our [paper](https://arxiv.org/pdf/2010.10906.pdf), we outline the steps taken to train our model and show that this is the state of the art German language model.
## Overview
**Paper:** [here](https://arxiv.org/pdf/2010.10906.pdf)
**Architecture:** ELECTRA large (discriminator)
**Language:** German
## Performance
```
GermEval18 Coarse: 80.70
GermEval18 Fine: 55.16
GermEval14: 88.95
```
See also:
deepset/gbert-base
deepset/gbert-large
deepset/gelectra-base
deepset/gelectra-large
deepset/gelectra-base-generator
deepset/gelectra-large-generator
## Authors
Branden Chan: `branden.chan [at] deepset.ai`
Stefan Schweter: `stefan [at] schweter.eu`
Timo Möller: `timo.moeller [at] deepset.ai`
## About us

We bring NLP to the industry via open source!
Our focus: Industry specific language models & large scale QA systems.
Some of our work:
- [German BERT (aka "bert-base-german-cased")](https://deepset.ai/german-bert)
- [GermanQuAD and GermanDPR datasets and models (aka "gelectra-base-germanquad", "gbert-base-germandpr")](https://deepset.ai/germanquad)
- [FARM](https://github.com/deepset-ai/FARM)
- [Haystack](https://github.com/deepset-ai/haystack/)
Get in touch:
[Twitter](https://twitter.com/deepset_ai) | [LinkedIn](https://www.linkedin.com/company/deepset-ai/) | [Slack](https://haystack.deepset.ai/community/join) | [GitHub Discussions](https://github.com/deepset-ai/haystack/discussions) | [Website](https://deepset.ai)
By the way: [we're hiring!](http://www.deepset.ai/jobs)
|
bigscience/bloom-760m | ae3a5ffeab7d36b7c1e2e362adbeeb4f824f4c30 | 2022-07-25T07:34:54.000Z | [
"pytorch",
"jax",
"bloom",
"feature-extraction",
"ak",
"ar",
"as",
"bm",
"bn",
"ca",
"code",
"en",
"es",
"eu",
"fon",
"fr",
"gu",
"hi",
"id",
"ig",
"ki",
"kn",
"lg",
"ln",
"ml",
"mr",
"ne",
"nso",
"ny",
"or",
"pa",
"pt",
"rn",
"rw",
"sn",
"st",
"sw",
"ta",
"te",
"tn",
"ts",
"tum",
"tw",
"ur",
"vi",
"wo",
"xh",
"yo",
"zh",
"zhs",
"zht",
"zu",
"arxiv:1909.08053",
"arxiv:2110.02861",
"arxiv:2108.12409",
"transformers",
"license:bigscience-bloom-rail-1.0",
"text-generation"
] | text-generation | false | bigscience | null | bigscience/bloom-760m | 1,004 | 3 | transformers | 1,767 | ---
license: bigscience-bloom-rail-1.0
language:
- ak
- ar
- as
- bm
- bn
- ca
- code
- en
- es
- eu
- fon
- fr
- gu
- hi
- id
- ig
- ki
- kn
- lg
- ln
- ml
- mr
- ne
- nso
- ny
- or
- pa
- pt
- rn
- rw
- sn
- st
- sw
- ta
- te
- tn
- ts
- tum
- tw
- ur
- vi
- wo
- xh
- yo
- zh
- zhs
- zht
- zu
pipeline_tag: text-generation
---
<h1 style='text-align: center '>BLOOM LM</h1>
<h2 style='text-align: center '><em>BigScience Large Open-science Open-access Multilingual Language Model</em> </h2>
<h3 style='text-align: center '>Model Card</h3>
<img src="https://s3.amazonaws.com/moonup/production/uploads/1657124309515-5f17f0a0925b9863e28ad517.png" alt="BigScience Logo" width="800" style="margin-left:'auto' margin-right:'auto' display:'block'"/>
Version 1.0 / 26.May.2022
## Table of Contents
1. [Model Details](#model-details)
2. [Uses](#uses)
3. [Training Data](#training-data)
4. [Risks and Limitations](#risks-and-limitations)
5. [Evaluation](#evaluation)
6. [Recommendations](#recommendations)
7. [Glossary and Calculations](#glossary-and-calculations)
8. [More Information](#more-information)
9. [Model Card Authors](#model-card-authors)
## Model Details
### Basics
*This section provides information for anyone who wants to know about the model.*
<details>
<summary>Click to expand</summary> <br/>
**Developed by:** BigScience ([website](https://bigscience.huggingface.co))
* All collaborators are either volunteers or have an agreement with their employer. *(Further breakdown of participants forthcoming.)*
**Model Type:** Transformer-based Language Model
**Version:** 1.0.0
**Languages:** Multiple; see [training data](#training-data)
**License:** RAIL License v1.0 ([link](https://huggingface.co/spaces/bigscience/license))
**Release Date Estimate:** Monday, 11.July.2022
**Send Questions to:** [email protected]
**Cite as:** BigScience, _BigScience Language Open-science Open-access Multilingual (BLOOM) Language Model_. International, May 2021-May 2022
**Funded by:**
* The French government.
* Hugging Face ([website](https://huggingface.co)).
* Organizations of contributors. *(Further breakdown of organizations forthcoming.)*
</details>
### Technical Specifications
*This section provides information for people who work on model development.*
<details>
<summary>Click to expand</summary><br/>
Please see [the BLOOM training README](https://github.com/bigscience-workshop/bigscience/tree/master/train/tr11-176B-ml#readme) for full details on replicating training.
**Model Architecture:** Modified from Megatron-LM GPT2 (see [paper](https://arxiv.org/abs/1909.08053), [BLOOM Megatron code](https://github.com/bigscience-workshop/Megatron-DeepSpeed)):
* Decoder-only architecture
* Layer normalization applied to word embeddings layer (`StableEmbedding`; see [code](https://github.com/facebookresearch/bitsandbytes), [paper](https://arxiv.org/pdf/2110.02861.pdf))
* ALiBI positional encodings (see [paper](https://arxiv.org/pdf/2108.12409.pdf)), with GeLU activation functions
* 760 million parameters:
* 24 layers, 16 attention heads
* Hidden layers are 1536-dimensional
* Sequence length of 2048 tokens used (see [BLOOM tokenizer](https://huggingface.co/bigscience/tokenizer), [tokenizer description](#tokenization))
**Objective Function:** Cross Entropy with mean reduction (see [API documentation](https://pytorch.org/docs/stable/generated/torch.nn.CrossEntropyLoss.html#torch.nn.CrossEntropyLoss)).
**Compute infrastructure:** Jean Zay Public Supercomputer, provided by the French government (see [announcement](https://www.enseignementsup-recherche.gouv.fr/fr/signature-du-marche-d-acquisition-de-l-un-des-supercalculateurs-les-plus-puissants-d-europe-46733)).
* Hardware: 384 A100 80GB GPUs (48 nodes):
* Additional 32 A100 80GB GPUs (4 nodes) in reserve
* 8 GPUs per node Using NVLink 4 inter-gpu connects, 4 OmniPath links
* CPU: AMD
* CPU memory: 512GB per node
* GPU memory: 640GB per node
* Inter-node connect: Omni-Path Architecture (OPA)
* NCCL-communications network: a fully dedicated subnet
* Disc IO network: shared network with other types of nodes
* Software:
* Megatron-DeepSpeed ([Github link](https://github.com/bigscience-workshop/Megatron-DeepSpeed))
* DeepSpeed ([Github link](https://github.com/microsoft/DeepSpeed))
* PyTorch (pytorch-1.11 w/ CUDA-11.5; see [Github link](https://github.com/pytorch/pytorch))
* apex ([Github link](https://github.com/NVIDIA/apex))
#### **Training**
_In progress._
Current training logs: [Tensorboard link](https://huggingface.co/tensorboard/bigscience/tr11-176B-ml-logs/)
- Checkpoint size:
- Bf16 weights: 329GB
- Full checkpoint with optimizer states: 2.3TB
- Training throughput: About 150 TFLOP per GPU per second
- Number of epochs: 1 (*current target*)
- Dates:
- Started 11th March, 2022 11:42am PST
- Estimated end: 5th July, 2022
- Estimated cost of training: Equivalent of $2-5M in cloud computing (including preliminary experiments)
- Server training location: Île-de-France, France
#### **Tokenization**
The BLOOM tokenizer ([link](https://huggingface.co/bigscience/tokenizer)) is a learned subword tokenizer trained using:
- A byte-level Byte Pair Encoding (BPE) algorithm
- A simple pre-tokenization rule, no normalization
- A vocabulary size of 250,680
It was trained on a subset of a preliminary version of the corpus using alpha-weighting per language.
</details>
### Environmental Impact
<details>
<summary>Click to expand</summary><br/>
The training supercomputer, Jean Zay ([website](http://www.idris.fr/eng/jean-zay/jean-zay-presentation-eng.html)), uses mostly nuclear energy. The heat generated by it is reused for heating campus housing.
**Estimated carbon emissions:** *(Forthcoming upon completion of training.)*
**Estimated electricity usage:** *(Forthcoming upon completion of training.)*
</details>
<p> </p>
## Uses
*This section addresses questions around how the model is intended to be used, discusses the foreseeable users of the model (including those affected by the model), and describes uses that are considered out of scope or misuse of the model.
It provides information for anyone considering using the model or who is affected by the model.*
<details>
<summary>Click to expand</summary><br/>
### Intended Use
This model is being created in order to enable public research on large language models (LLMs). LLMs are intended to be used for language generation or as a pretrained base model that can be further fine-tuned for specific tasks. Use cases below are not exhaustive.
#### **Direct Use**
- Text generation
- Exploring characteristics of language generated by a language model
- Examples: Cloze tests, counterfactuals, generations with reframings
#### **Downstream Use**
- Tasks that leverage language models include: Information Extraction, Question Answering, Summarization
### Misuse and Out-of-scope Use
*This section addresses what users ought not do with the model.*
See the [BLOOM License](https://huggingface.co/spaces/bigscience/license), Attachment A, for detailed usage restrictions. The below list is non-exhaustive, but lists some easily foreseeable problematic use cases.
#### **Out-of-scope Uses**
Using the model in [high-stakes](#high-stakes) settings is out of scope for this model. The model is not designed for [critical decisions](#critical-decisions) nor uses with any material consequences on an individual's livelihood or wellbeing. The model outputs content that appears factual but is not correct.
##### Out-of-scope Uses Include:
- Usage in biomedical domains, political and legal domains, or finance domains
- Usage for evaluating or scoring individuals, such as for employment, education, or credit
- Applying the model for critical automatic decisions, generating factual content, creating reliable summaries, or generating predictions that must be correct
#### **Misuse**
Intentionally using the model for harm, violating [human rights](#human-rights), or other kinds of malicious activities, is a misuse of this model. This includes:
- Spam generation
- Disinformation and influence operations
- Disparagement and defamation
- Harassment and abuse
- [Deception](#deception)
- Unconsented impersonation and imitation
- Unconsented surveillance
- Generating content without attribution to the model, as specified in the [RAIL License, Use Restrictions](https://huggingface.co/spaces/bigscience/license)
### Intended Users
#### **Direct Users**
- General Public
- Researchers
- Students
- Educators
- Engineers/developers
- Non-commercial entities
- Community advocates, including human and civil rights groups
#### Indirect Users
- Users of derivatives created by Direct Users, such as those using software with an [intended use](#intended-use)
- Users of [Derivatives of the Model, as described in the License](https://huggingface.co/spaces/bigscience/license)
#### Others Affected (Parties Prenantes)
- People and groups referred to by the LLM
- People and groups exposed to outputs of, or decisions based on, the LLM
- People and groups whose original work is included in the LLM
</details>
<p> </p>
## Training Data
*This section provides a high-level overview of the training data. It is relevant for anyone who wants to know the basics of what the model is learning.*
<details>
<summary>Click to expand</summary><br/>
Details for each dataset are provided in individual [Data Cards](https://huggingface.co/spaces/bigscience/BigScienceCorpus).
Training data includes:
- 45 natural languages
- 12 programming languages
- In 1.5TB of pre-processed text, converted into 350B unique tokens (see [the tokenizer section](#tokenization) for more.)
#### **Languages**
The pie chart shows the distribution of languages in training data.

The following table shows the further distribution of Niger-Congo and Indic languages in the training data.
<details>
<summary>Click to expand</summary><br/>
| Niger Congo | Percentage | | Indic | Percentage |
|----------------|------------ |------ |-----------|------------|
| Chi Tumbuka | 0.00002 | | Assamese | 0.01 |
| Kikuyu | 0.00004 | | Odia | 0.04 |
| Bambara | 0.00004 | | Gujarati | 0.04 |
| Akan | 0.00007 | | Marathi | 0.05 |
| Xitsonga | 0.00007 | | Punjabi | 0.05 |
| Sesotho | 0.00007 | | Kannada | 0.06 |
| Chi Chewa | 0.0001 | | Nepali | 0.07 |
| Setswana | 0.0002 | | Telugu | 0.09 |
| Northern Sotho | 0.0002 | | Malayalam | 0.10 |
| Fon | 0.0002 | | Urdu | 0.10 |
| Kirundi | 0.0003 | | Tamil | 0.20 |
| Wolof | 0.0004 | | Bengali | 0.50 |
| Kuganda | 0.0004 | | Hindi | 0.70 |
| Chi Shona | 0.001 |
| Isi Zulu | 0.001 |
| Igbo | 0.001 |
| Xhosa | 0.001 |
| Kinyarwanda | 0.003 |
| Yoruba | 0.006 |
| Swahili | 0.02 |
</details>
The following table shows the distribution of programming languages.
<details>
<summary>Click to expand</summary><br/>
| Extension | Language | Number of files |
|----------------|------------|-----------------|
| java | Java | 5,407,724 |
| php | PHP | 4,942,186 |
| cpp | C++ | 2,503,930 |
| py | Python | 2,435,072 |
| js | JavaScript | 1,905,518 |
| cs | C# | 1,577,347 |
| rb | Ruby | 6,78,413 |
| cc | C++ | 443,054 |
| hpp | C++ | 391,048 |
| lua | Lua | 352,317 |
| go | GO | 227,763 |
| ts | TypeScript | 195,254 |
| C | C | 134,537 |
| scala | Scala | 92,052 |
| hh | C++ | 67,161 |
| H | C++ | 55,899 |
| tsx | TypeScript | 33,107 |
| rs | Rust | 29,693 |
| phpt | PHP | 9,702 |
| c++ | C++ | 1,342 |
| h++ | C++ | 791 |
| php3 | PHP | 540 |
| phps | PHP | 270 |
| php5 | PHP | 166 |
| php4 | PHP | 29 |
</details>
</details>
<p> </p>
## Risks and Limitations
*This section identifies foreseeable harms and misunderstandings.*
<details>
<summary>Click to expand</summary><br/>
Model may:
- Overrepresent some viewpoints and underrepresent others
- Contain stereotypes
- Contain [personal information](#personal-data-and-information)
- Generate:
- Hateful, abusive, or violent language
- Discriminatory or prejudicial language
- Content that may not be appropriate for all settings, including sexual content
- Make errors, including producing incorrect information as if it were factual
- Generate irrelevant or repetitive outputs
</details>
<p> </p>
## Evaluation
*This section describes the evaluation protocols and provides the results.*
<details>
<summary>Click to expand</summary><br/>
### Metrics
*This section describes the different ways performance is calculated and why.*
Includes:
| Metric | Why chosen |
|--------------------|--------------------------------------------------------------------|
| [Perplexity](#perplexity) | Standard metric for quantifying model improvements during training |
| Cross Entropy [Loss](#loss) | Standard objective for language models. |
And multiple different metrics for specific tasks. _(More evaluation metrics forthcoming upon completion of evaluation protocol.)_
### Factors
*This section lists some different aspects of BLOOM models. Its focus is on those aspects that are likely to give rise to high variance in model behavior.*
- Language, such as English or Yoruba
- Domain, such as newswire or stories
- Demographic characteristics, such as gender or nationality
### Results
*Results are based on the [Factors](#factors) and [Metrics](#metrics).*
**Train-time Evaluation:**
As of 25.May.2022, 15:00 PST:
- Training Loss: 2.7
- Validation Loss: 3.1
- Perplexity: 21.9
(More evaluation scores forthcoming at the end of model training.)
</details>
<p> </p>
## Recommendations
*This section provides information on warnings and potential mitigations.*
<details>
<summary>Click to expand</summary><br/>
- Indirect users should be made aware when the content they're working with is created by the LLM.
- Users should be aware of [Risks and Limitations](#risks-and-limitations), and include an appropriate age disclaimer or blocking interface as necessary.
- Models pretrained with the LLM should include an updated Model Card.
- Users of the model should provide mechanisms for those affected to provide feedback, such as an email address for comments.
</details>
<p> </p>
## Glossary and Calculations
*This section defines common terms and how metrics are calculated.*
<details>
<summary>Click to expand</summary><br/>
- <a name="loss">**Loss:**</a> A calculation of the difference between what the model has learned and what the data shows ("groundtruth"). The lower the loss, the better. The training process aims to minimize the loss.
- <a name="perplexity">**Perplexity:**</a> This is based on what the model estimates the probability of new data is. The lower the perplexity, the better. If the model is 100% correct at predicting the next token it will see, then the perplexity is 1. Mathematically this is calculated using entropy.
- <a name="high-stakes">**High-stakes settings:**</a> Such as those identified as "high-risk AI systems" and "unacceptable risk AI systems" in the European Union's proposed [Artificial Intelligence (AI) Act](https://artificialintelligenceact.eu/annexes/).
- <a name="critical-decisions">**Critical decisions:**</a> Such as those defined in [the United States' proposed Algorithmic Accountability Act](https://www.congress.gov/117/bills/s3572/BILLS-117s3572is.pdf).
- <a name="human-rights">**Human rights:**</a> Includes those rights defined in the [Universal Declaration of Human Rights](https://www.un.org/sites/un2.un.org/files/2021/03/udhr.pdf).
- <a name="personal-data-and-information">**Personal Data and Personal Information:**</a> Personal data and information is defined in multiple data protection regulations, such as "[personal data](https://gdpr-info.eu/issues/personal-data/)" in the [European Union's General Data Protection Regulation](https://gdpr-info.eu); and "personal information" in the Republic of South Africa's [Protection of Personal Information Act](https://www.gov.za/sites/default/files/gcis_document/201409/3706726-11act4of2013popi.pdf), The People's Republic of China's [Personal information protection law](http://en.npc.gov.cn.cdurl.cn/2021-12/29/c_694559.htm).
- <a name="sensitive-characteristics">**Sensitive characteristics:**</a> This includes specifically protected categories in human rights (see [UHDR, Article 2](https://www.un.org/sites/un2.un.org/files/2021/03/udhr.pdf)) and personal information regulation (see GDPR, [Article 9; Protection of Personal Information Act, Chapter 1](https://www.gov.za/sites/default/files/gcis_document/201409/3706726-11act4of2013popi.pdf))
- <a name="deception">**Deception:**</a> Doing something to intentionally mislead individuals to believe something that is false, such as by creating deadbots or chatbots on social media posing as real people, or generating text documents without making consumers aware that the text is machine generated.
</details>
<p> </p>
## More Information
<details>
<summary>Click to expand</summary><br/>
### Dataset Creation
Blog post detailing the design choices during the dataset creation: https://bigscience.huggingface.co/blog/building-a-tb-scale-multilingual-dataset-for-language-modeling
### Technical Specifications
Blog post summarizing how the architecture, size, shape, and pre-training duration where selected: https://bigscience.huggingface.co/blog/what-language-model-to-train-if-you-have-two-million-gpu-hours
More details on the architecture/optimizer: https://github.com/bigscience-workshop/bigscience/tree/master/train/tr11-176B-ml
Blog post on the hardware/engineering side: https://bigscience.huggingface.co/blog/which-hardware-to-train-a-176b-parameters-model
Details on the distributed setup used for the training: https://github.com/bigscience-workshop/bigscience/tree/master/train/tr11-176B-ml
Tensorboard updated during the training: https://huggingface.co/bigscience/tr11-176B-ml-logs/tensorboard#scalars&tagFilter=loss
Insights on how to approach training, negative results: https://github.com/bigscience-workshop/bigscience/blob/master/train/lessons-learned.md
Details on the obstacles overcome during the preparation on the engineering side (instabilities, optimization of training throughput, so many technical tricks and questions): https://github.com/bigscience-workshop/bigscience/blob/master/train/tr11-176B-ml/chronicles.md
### Initial Results
Initial prompting experiments using interim checkpoints: https://huggingface.co/spaces/bigscience/bloom-book
</details>
<p> </p>
## Model Card Authors
*Ordered roughly chronologically and by amount of time spent.*
Margaret Mitchell, Giada Pistilli, Yacine Jernite, Ezinwanne Ozoani, Marissa Gerchick, Nazneen Rajani, Sasha Luccioni, Irene Solaiman, Maraim Masoud, Somaieh Nikpoor, Carlos Muñoz Ferrandis, Stas Bekman, Christopher Akiki, Danish Contractor, David Lansky, Angelina McMillan-Major, Tristan Thrush, Suzana Ilić, Gérard Dupont, Shayne Longpre, Manan Dey, Stella Biderman, Douwe Kiela, Emi Baylor, Teven Le Scao, Aaron Gokaslan, Julien Launay, Niklas Muennighoff
|
aubmindlab/bert-large-arabertv2 | 9c9e35e196b88fbc4a3d738420f75d2ad854e8e6 | 2022-04-06T15:27:41.000Z | [
"pytorch",
"tf",
"jax",
"tensorboard",
"bert",
"fill-mask",
"ar",
"dataset:wikipedia",
"dataset:OSIAN",
"dataset:1.5B Arabic Corpus",
"dataset:OSCAR Arabic Unshuffled",
"arxiv:2003.00104",
"transformers",
"autotrain_compatible"
] | fill-mask | false | aubmindlab | null | aubmindlab/bert-large-arabertv2 | 1,001 | 2 | transformers | 1,768 | ---
language: ar
datasets:
- wikipedia
- OSIAN
- 1.5B Arabic Corpus
- OSCAR Arabic Unshuffled
widget:
- text: " عاصم +ة لبنان هي [MASK] ."
---
# AraBERT v1 & v2 : Pre-training BERT for Arabic Language Understanding
<img src="https://raw.githubusercontent.com/aub-mind/arabert/master/arabert_logo.png" width="100" align="left"/>
**AraBERT** is an Arabic pretrained lanaguage model based on [Google's BERT architechture](https://github.com/google-research/bert). AraBERT uses the same BERT-Base config. More details are available in the [AraBERT Paper](https://arxiv.org/abs/2003.00104) and in the [AraBERT Meetup](https://github.com/WissamAntoun/pydata_khobar_meetup)
There are two versions of the model, AraBERTv0.1 and AraBERTv1, with the difference being that AraBERTv1 uses pre-segmented text where prefixes and suffixes were splitted using the [Farasa Segmenter](http://alt.qcri.org/farasa/segmenter.html).
We evalaute AraBERT models on different downstream tasks and compare them to [mBERT]((https://github.com/google-research/bert/blob/master/multilingual.md)), and other state of the art models (*To the extent of our knowledge*). The Tasks were Sentiment Analysis on 6 different datasets ([HARD](https://github.com/elnagara/HARD-Arabic-Dataset), [ASTD-Balanced](https://www.aclweb.org/anthology/D15-1299), [ArsenTD-Lev](https://staff.aub.edu.lb/~we07/Publications/ArSentD-LEV_Sentiment_Corpus.pdf), [LABR](https://github.com/mohamedadaly/LABR)), Named Entity Recognition with the [ANERcorp](http://curtis.ml.cmu.edu/w/courses/index.php/ANERcorp), and Arabic Question Answering on [Arabic-SQuAD and ARCD](https://github.com/husseinmozannar/SOQAL)
# AraBERTv2
## What's New!
AraBERT now comes in 4 new variants to replace the old v1 versions:
More Detail in the AraBERT folder and in the [README](https://github.com/aub-mind/arabert/blob/master/AraBERT/README.md) and in the [AraBERT Paper](https://arxiv.org/abs/2003.00104v2)
Model | HuggingFace Model Name | Size (MB/Params)| Pre-Segmentation | DataSet (Sentences/Size/nWords) |
---|:---:|:---:|:---:|:---:
AraBERTv0.2-base | [bert-base-arabertv02](https://huggingface.co/aubmindlab/bert-base-arabertv02) | 543MB / 136M | No | 200M / 77GB / 8.6B |
AraBERTv0.2-large| [bert-large-arabertv02](https://huggingface.co/aubmindlab/bert-large-arabertv02) | 1.38G 371M | No | 200M / 77GB / 8.6B |
AraBERTv2-base| [bert-base-arabertv2](https://huggingface.co/aubmindlab/bert-base-arabertv2) | 543MB 136M | Yes | 200M / 77GB / 8.6B |
AraBERTv2-large| [bert-large-arabertv2](https://huggingface.co/aubmindlab/bert-large-arabertv2) | 1.38G 371M | Yes | 200M / 77GB / 8.6B |
AraBERTv0.1-base| [bert-base-arabertv01](https://huggingface.co/aubmindlab/bert-base-arabertv01) | 543MB 136M | No | 77M / 23GB / 2.7B |
AraBERTv1-base| [bert-base-arabert](https://huggingface.co/aubmindlab/bert-base-arabert) | 543MB 136M | Yes | 77M / 23GB / 2.7B |
All models are available in the `HuggingFace` model page under the [aubmindlab](https://huggingface.co/aubmindlab/) name. Checkpoints are available in PyTorch, TF2 and TF1 formats.
## Better Pre-Processing and New Vocab
We identified an issue with AraBERTv1's wordpiece vocabulary. The issue came from punctuations and numbers that were still attached to words when learned the wordpiece vocab. We now insert a space between numbers and characters and around punctuation characters.
The new vocabulary was learnt using the `BertWordpieceTokenizer` from the `tokenizers` library, and should now support the Fast tokenizer implementation from the `transformers` library.
**P.S.**: All the old BERT codes should work with the new BERT, just change the model name and check the new preprocessing dunction
**Please read the section on how to use the [preprocessing function](#Preprocessing)**
## Bigger Dataset and More Compute
We used ~3.5 times more data, and trained for longer.
For Dataset Sources see the [Dataset Section](#Dataset)
Model | Hardware | num of examples with seq len (128 / 512) |128 (Batch Size/ Num of Steps) | 512 (Batch Size/ Num of Steps) | Total Steps | Total Time (in Days) |
---|:---:|:---:|:---:|:---:|:---:|:---:
AraBERTv0.2-base | TPUv3-8 | 420M / 207M | 2560 / 1M | 384/ 2M | 3M | -
AraBERTv0.2-large | TPUv3-128 | 420M / 207M | 13440 / 250K | 2056 / 300K | 550K | 7
AraBERTv2-base | TPUv3-8 | 420M / 207M | 2560 / 1M | 384/ 2M | 3M | -
AraBERTv2-large | TPUv3-128 | 520M / 245M | 13440 / 250K | 2056 / 300K | 550K | 7
AraBERT-base (v1/v0.1) | TPUv2-8 | - |512 / 900K | 128 / 300K| 1.2M | 4
# Dataset
The pretraining data used for the new AraBERT model is also used for Arabic **GPT2 and ELECTRA**.
The dataset consists of 77GB or 200,095,961 lines or 8,655,948,860 words or 82,232,988,358 chars (before applying Farasa Segmentation)
For the new dataset we added the unshuffled OSCAR corpus, after we thoroughly filter it, to the previous dataset used in AraBERTv1 but with out the websites that we previously crawled:
- OSCAR unshuffled and filtered.
- [Arabic Wikipedia dump](https://archive.org/details/arwiki-20190201) from 2020/09/01
- [The 1.5B words Arabic Corpus](https://www.semanticscholar.org/paper/1.5-billion-words-Arabic-Corpus-El-Khair/f3eeef4afb81223df96575adadf808fe7fe440b4)
- [The OSIAN Corpus](https://www.aclweb.org/anthology/W19-4619)
- Assafir news articles. Huge thank you for Assafir for giving us the data
# Preprocessing
It is recommended to apply our preprocessing function before training/testing on any dataset.
**Install farasapy to segment text for AraBERT v1 & v2 `pip install farasapy`**
```python
from arabert.preprocess import ArabertPreprocessor
model_name="bert-large-arabertv2"
arabert_prep = ArabertPreprocessor(model_name=model_name)
text = "ولن نبالغ إذا قلنا إن هاتف أو كمبيوتر المكتب في زمننا هذا ضروري"
arabert_prep.preprocess(text)
>>>"و+ لن نبالغ إذا قل +نا إن هاتف أو كمبيوتر ال+ مكتب في زمن +نا هذا ضروري"
```
## Accepted_models
```
bert-base-arabertv01
bert-base-arabert
bert-base-arabertv02
bert-base-arabertv2
bert-large-arabertv02
bert-large-arabertv2
araelectra-base
aragpt2-base
aragpt2-medium
aragpt2-large
aragpt2-mega
```
# TensorFlow 1.x models
The TF1.x model are available in the HuggingFace models repo.
You can download them as follows:
- via git-lfs: clone all the models in a repo
```bash
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash
sudo apt-get install git-lfs
git lfs install
git clone https://huggingface.co/aubmindlab/MODEL_NAME
tar -C ./MODEL_NAME -zxvf /content/MODEL_NAME/tf1_model.tar.gz
```
where `MODEL_NAME` is any model under the `aubmindlab` name
- via `wget`:
- Go to the tf1_model.tar.gz file on huggingface.co/models/aubmindlab/MODEL_NAME.
- copy the `oid sha256`
- then run `wget https://cdn-lfs.huggingface.co/aubmindlab/aragpt2-base/INSERT_THE_SHA_HERE` (ex: for `aragpt2-base`: `wget https://cdn-lfs.huggingface.co/aubmindlab/aragpt2-base/3766fc03d7c2593ff2fb991d275e96b81b0ecb2098b71ff315611d052ce65248`)
# If you used this model please cite us as :
Google Scholar has our Bibtex wrong (missing name), use this instead
```
@inproceedings{antoun2020arabert,
title={AraBERT: Transformer-based Model for Arabic Language Understanding},
author={Antoun, Wissam and Baly, Fady and Hajj, Hazem},
booktitle={LREC 2020 Workshop Language Resources and Evaluation Conference 11--16 May 2020},
pages={9}
}
```
# Acknowledgments
Thanks to TensorFlow Research Cloud (TFRC) for the free access to Cloud TPUs, couldn't have done it without this program, and to the [AUB MIND Lab](https://sites.aub.edu.lb/mindlab/) Members for the continous support. Also thanks to [Yakshof](https://www.yakshof.com/#/) and Assafir for data and storage access. Another thanks for Habib Rahal (https://www.behance.net/rahalhabib), for putting a face to AraBERT.
# Contacts
**Wissam Antoun**: [Linkedin](https://www.linkedin.com/in/wissam-antoun-622142b4/) | [Twitter](https://twitter.com/wissam_antoun) | [Github](https://github.com/WissamAntoun) | <[email protected]> | <[email protected]>
**Fady Baly**: [Linkedin](https://www.linkedin.com/in/fadybaly/) | [Twitter](https://twitter.com/fadybaly) | [Github](https://github.com/fadybaly) | <[email protected]> | <[email protected]>
|
jcblaise/bert-tagalog-base-uncased | eedcb4c434d90dea60092740e47903aede5284c3 | 2021-11-12T03:21:26.000Z | [
"pytorch",
"jax",
"bert",
"fill-mask",
"tl",
"transformers",
"tagalog",
"filipino",
"license:gpl-3.0",
"autotrain_compatible"
] | fill-mask | false | jcblaise | null | jcblaise/bert-tagalog-base-uncased | 1,001 | null | transformers | 1,769 | ---
language: tl
tags:
- bert
- tagalog
- filipino
license: gpl-3.0
inference: false
---
**Deprecation Notice**
This model is deprecated. New Filipino Transformer models trained with a much larger corpora are available.
Use [`jcblaise/roberta-tagalog-base`](https://huggingface.co/jcblaise/roberta-tagalog-base) or [`jcblaise/roberta-tagalog-large`](https://huggingface.co/jcblaise/roberta-tagalog-large) instead for better performance.
---
# BERT Tagalog Base Uncased
Tagalog version of BERT trained on a large preprocessed text corpus scraped and sourced from the internet. This model is part of a larger research project. We open-source the model to allow greater usage within the Filipino NLP community.
## Citations
All model details and training setups can be found in our papers. If you use our model or find it useful in your projects, please cite our work:
```
@article{cruz2020establishing,
title={Establishing Baselines for Text Classification in Low-Resource Languages},
author={Cruz, Jan Christian Blaise and Cheng, Charibeth},
journal={arXiv preprint arXiv:2005.02068},
year={2020}
}
@article{cruz2019evaluating,
title={Evaluating Language Model Finetuning Techniques for Low-resource Languages},
author={Cruz, Jan Christian Blaise and Cheng, Charibeth},
journal={arXiv preprint arXiv:1907.00409},
year={2019}
}
```
## Data and Other Resources
Data used to train this model as well as other benchmark datasets in Filipino can be found in my website at https://blaisecruz.com
## Contact
If you have questions, concerns, or if you just want to chat about NLP and low-resource languages in general, you may reach me through my work email at [email protected]
|
mrm8488/bert2bert_shared-german-finetuned-summarization | f7aa176d43cd0c7d90255f98d8774e3de251d168 | 2021-05-27T12:13:27.000Z | [
"pytorch",
"encoder-decoder",
"text2text-generation",
"de",
"dataset:mlsum",
"transformers",
"summarization",
"news",
"autotrain_compatible"
] | summarization | false | mrm8488 | null | mrm8488/bert2bert_shared-german-finetuned-summarization | 1,001 | 2 | transformers | 1,770 | ---
tags:
- summarization
- news
language: de
datasets:
- mlsum
widget:
- text: 'Wie geht man nach schrecklichen Ereignissen ambesten auf die Ängste und Sorgen von Kindern ein?Therapeuten haben eine klare Botschaft. Die Weltist voller Gefahren, Verbrechen und Schrecken -Krieg, Terrorismus, Umweltzerstörung und eben auchKindesmissbrauch. Soll man mit Kindern darüberreden, und wie? Die Antwort hängt auch vom Alterdes Kindes ab. Kinder, gerade kleine Kinder,brauchen Sicherheit, man muss sie nicht mitabstrakten Bedrohungen konfrontieren, die sieohnehin noch nicht ganz verstehen können. Ihreeigenen Ängste sollten Eltern lieber bei sichbehalten, raten Psychologen. Etwas anderes ist es,wenn Kinder schreckliche Ereignisse wie denaktuellen Fall in München mitbekommen. Dann sollteman natürlich auf die Ängste und Sorgen der Kindereingehen und mit ihnen sprechen. Man sollte aberklarmachen: Ja, es gibt kranke Menschen, die Bösestun, aber das ist die Ausnahme. Der Verbrecher istgefasst, er läuft nicht mehr frei herum,Polizisten passen auf. Die Botschaft sollte sein:Das ist nicht nah an dir dran, das bedroht dichnicht, empfehlen Familientherapeuten zum Umgangmit Ängsten von Kindern. Natürlich können auchVerhaltensregeln nicht schaden: Nein sagen, lautwerden und nicht mit Fremden mitgehen. AuchBilderbücher können helfen, solches Verhalten frühzu vermitteln, etwa "Das große und das kleineNein!" von Gisela Braun und Dorothee Wolters oder"Ich geh doch nicht mit Jedem mit!" von DagmarGeisler. Aber auch wenn jeder Vater, jede Mutterbeim Gedanken an derartige Verbrechen insSchlottern kommt: Die Statistik zeigt eindeutig,dass solche Fälle sehr selten sind.Kindesmissbrauch findet vor allem im nahensozialen Umfeld statt, in der Familie, in Vereinenoder bei älteren vermeintlichen "Freunden". Werseine Kinder davor beschützen will, muss ihnenzuhören, sie ernst nehmen, Fragen stellen, genauhinschauen.'
---
# German BERT2BERT fine-tuned on MLSUM DE for summarization
## Model
[bert-base-german-cased](https://huggingface.co/bert-base-german-cased) (BERT Checkpoint)
## Dataset
**MLSUM** is the first large-scale MultiLingual SUMmarization dataset. Obtained from online newspapers, it contains 1.5M+ article/summary pairs in five different languages -- namely, French, **German**, Spanish, Russian, Turkish. Together with English newspapers from the popular CNN/Daily mail dataset, the collected data form a large scale multilingual dataset which can enable new research directions for the text summarization community. We report cross-lingual comparative analyses based on state-of-the-art systems. These highlight existing biases which motivate the use of a multi-lingual dataset.
[MLSUM de](https://huggingface.co/datasets/viewer/?dataset=mlsum)
## Results
|Set|Metric| # Score|
|----|------|------|
| Test |Rouge2 - mid -precision | **33.04**|
| Test | Rouge2 - mid - recall | **33.83**|
| Test | Rouge2 - mid - fmeasure | **33.15**|
## Usage
```python
import torch
from transformers import BertTokenizerFast, EncoderDecoderModel
device = 'cuda' if torch.cuda.is_available() else 'cpu'
ckpt = 'mrm8488/bert2bert_shared-german-finetuned-summarization'
tokenizer = BertTokenizerFast.from_pretrained(ckpt)
model = EncoderDecoderModel.from_pretrained(ckpt).to(device)
def generate_summary(text):
inputs = tokenizer([text], padding="max_length", truncation=True, max_length=512, return_tensors="pt")
input_ids = inputs.input_ids.to(device)
attention_mask = inputs.attention_mask.to(device)
output = model.generate(input_ids, attention_mask=attention_mask)
return tokenizer.decode(output[0], skip_special_tokens=True)
text = "Your text here..."
generate_summary(text)
```
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488) with the support of [Narrativa](https://www.narrativa.com/)
> Made with <span style="color: #e25555;">♥</span> in Spain |
microsoft/swin-large-patch4-window7-224 | d433db83a1c10a34c365fc4928186c8fb8c642dd | 2022-05-16T19:58:33.000Z | [
"pytorch",
"tf",
"swin",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2103.14030",
"transformers",
"vision",
"license:apache-2.0"
] | image-classification | false | microsoft | null | microsoft/swin-large-patch4-window7-224 | 999 | null | transformers | 1,771 | ---
license: apache-2.0
tags:
- vision
- image-classification
datasets:
- imagenet-1k
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
---
# Swin Transformer (large-sized model)
Swin Transformer model trained on ImageNet-1k at resolution 224x224. It was introduced in the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Liu et al. and first released in [this repository](https://github.com/microsoft/Swin-Transformer).
Disclaimer: The team releasing Swin Transformer did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The Swin Transformer is a type of Vision Transformer. It builds hierarchical feature maps by merging image patches (shown in gray) in deeper layers and has linear computation complexity to input image size due to computation of self-attention only within each local window (shown in red). It can thus serve as a general-purpose backbone for both image classification and dense recognition tasks. In contrast, previous vision Transformers produce feature maps of a single low resolution and have quadratic computation complexity to input image size due to computation of self-attention globally.

[Source](https://paperswithcode.com/method/swin-transformer)
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=swin) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import AutoFeatureExtractor, SwinForImageClassification
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = AutoFeatureExtractor.from_pretrained("microsoft/swin-large-patch4-window7-224")
model = SwinForImageClassification.from_pretrained("microsoft/swin-large-patch4-window7-224")
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
For more code examples, we refer to the [documentation](https://huggingface.co/transformers/model_doc/swin.html#).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2103-14030,
author = {Ze Liu and
Yutong Lin and
Yue Cao and
Han Hu and
Yixuan Wei and
Zheng Zhang and
Stephen Lin and
Baining Guo},
title = {Swin Transformer: Hierarchical Vision Transformer using Shifted Windows},
journal = {CoRR},
volume = {abs/2103.14030},
year = {2021},
url = {https://arxiv.org/abs/2103.14030},
eprinttype = {arXiv},
eprint = {2103.14030},
timestamp = {Thu, 08 Apr 2021 07:53:26 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2103-14030.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` |
cointegrated/rut5-base-paraphraser | 89213d06450b722514e23ba55ae7c16a2203a3b8 | 2022-02-08T13:06:08.000Z | [
"pytorch",
"t5",
"text2text-generation",
"ru",
"dataset:cointegrated/ru-paraphrase-NMT-Leipzig",
"transformers",
"russian",
"paraphrasing",
"paraphraser",
"paraphrase",
"license:mit",
"autotrain_compatible"
] | text2text-generation | false | cointegrated | null | cointegrated/rut5-base-paraphraser | 997 | 6 | transformers | 1,772 | ---
language: ["ru"]
tags:
- russian
- paraphrasing
- paraphraser
- paraphrase
license: mit
widget:
- text: "Каждый охотник желает знать, где сидит фазан."
datasets:
- cointegrated/ru-paraphrase-NMT-Leipzig
---
This is a paraphraser for Russian sentences described [in this Habr post](https://habr.com/ru/post/564916/).
It is recommended to use the model with the `encoder_no_repeat_ngram_size` argument:
```
from transformers import T5ForConditionalGeneration, T5Tokenizer
MODEL_NAME = 'cointegrated/rut5-base-paraphraser'
model = T5ForConditionalGeneration.from_pretrained(MODEL_NAME)
tokenizer = T5Tokenizer.from_pretrained(MODEL_NAME)
model.cuda();
model.eval();
def paraphrase(text, beams=5, grams=4, do_sample=False):
x = tokenizer(text, return_tensors='pt', padding=True).to(model.device)
max_size = int(x.input_ids.shape[1] * 1.5 + 10)
out = model.generate(**x, encoder_no_repeat_ngram_size=grams, num_beams=beams, max_length=max_size, do_sample=do_sample)
return tokenizer.decode(out[0], skip_special_tokens=True)
print(paraphrase('Каждый охотник желает знать, где сидит фазан.'))
# Все охотники хотят знать где фазан сидит.
``` |
henryk/bert-base-multilingual-cased-finetuned-dutch-squad2 | a0f963636c546b1bfa83717bb1329697c1ffcbe0 | 2021-05-19T19:02:45.000Z | [
"pytorch",
"jax",
"bert",
"question-answering",
"nl",
"transformers",
"autotrain_compatible"
] | question-answering | false | henryk | null | henryk/bert-base-multilingual-cased-finetuned-dutch-squad2 | 997 | 4 | transformers | 1,773 | ---
language: nl
---
# Multilingual + Dutch SQuAD2.0
This model is the multilingual model provided by the Google research team with a fine-tuned dutch Q&A downstream task.
## Details of the language model
Language model ([**bert-base-multilingual-cased**](https://github.com/google-research/bert/blob/master/multilingual.md)):
12-layer, 768-hidden, 12-heads, 110M parameters.
Trained on cased text in the top 104 languages with the largest Wikipedias.
## Details of the downstream task
Using the `mtranslate` Python module, [**SQuAD2.0**](https://rajpurkar.github.io/SQuAD-explorer/) was machine-translated. In order to find the start tokens, the direct translations of the answers were searched in the corresponding paragraphs. Due to the different translations depending on the context (missing context in the pure answer), the answer could not always be found in the text, and thus a loss of question-answer examples occurred. This is a potential problem where errors can occur in the data set.
| Dataset | # Q&A |
| ---------------------- | ----- |
| SQuAD2.0 Train | 130 K |
| Dutch SQuAD2.0 Train | 99 K |
| SQuAD2.0 Dev | 12 K |
| Dutch SQuAD2.0 Dev | 10 K |
## Model benchmark
| Model | EM/F1 |HasAns (EM/F1) | NoAns |
| ---------------------- | ----- | ----- | ----- |
| [robBERT](https://huggingface.co/pdelobelle/robBERT-base) | 58.04/60.95 | 33.08/40.64 | 73.67 |
| [dutchBERT](https://huggingface.co/wietsedv/bert-base-dutch-cased) | 64.25/68.45 | 45.59/56.49 | 75.94 |
| [multiBERT](https://huggingface.co/bert-base-multilingual-cased) | **67.38**/**71.36** | 47.42/57.76 | 79.88 |
## Model training
The model was trained on a **Tesla V100** GPU with the following command:
```python
export SQUAD_DIR=path/to/nl_squad
python run_squad.py
--model_type bert \
--model_name_or_path bert-base-multilingual-cased \
--do_train \
--do_eval \
--train_file $SQUAD_DIR/nl_squadv2_train_clean.json \
--predict_file $SQUAD_DIR/nl_squadv2_dev_clean.json \
--num_train_epochs 2 \
--max_seq_length 384 \
--doc_stride 128 \
--save_steps=8000 \
--output_dir ../../output \
--overwrite_cache \
--overwrite_output_dir
```
**Results**:
{'exact': 67.38028751680629, 'f1': 71.362297054268, 'total': 9669, 'HasAns_exact': 47.422126745435015, 'HasAns_f1': 57.761023151910734, 'HasAns_total': 3724, 'NoAns_exact': 79.88225399495374, 'NoAns_f1': 79.88225399495374, 'NoAns_total': 5945, 'best_exact': 67.53542248422795, 'best_exact_thresh': 0.0, 'best_f1': 71.36229705426837, 'best_f1_thresh': 0.0}
## Model in action
Fast usage with **pipelines**:
```python
from transformers import pipeline
qa_pipeline = pipeline(
"question-answering",
model="henryk/bert-base-multilingual-cased-finetuned-dutch-squad2",
tokenizer="henryk/bert-base-multilingual-cased-finetuned-dutch-squad2"
)
qa_pipeline({
'context': "Amsterdam is de hoofdstad en de dichtstbevolkte stad van Nederland.",
'question': "Wat is de hoofdstad van Nederland?"})
```
# Output:
```json
{
"score": 0.83,
"start": 0,
"end": 9,
"answer": "Amsterdam"
}
```
## Contact
Please do not hesitate to contact me via [LinkedIn](https://www.linkedin.com/in/henryk-borzymowski-0755a2167/) if you want to discuss or get access to the Dutch version of SQuAD. |
skimai/spanberta-base-cased | 7f56c58981ddc9ce18e0abcf85ae2b4e54248063 | 2021-05-20T21:52:23.000Z | [
"pytorch",
"jax",
"roberta",
"feature-extraction",
"transformers"
] | feature-extraction | false | skimai | null | skimai/spanberta-base-cased | 997 | null | transformers | 1,774 | Entry not found |
cross-encoder/mmarco-mMiniLMv2-L12-H384-v1 | d5246c2d77849f8a3886b463b949c52b5cb7d075 | 2022-06-01T08:33:59.000Z | [
"pytorch",
"xlm-roberta",
"text-classification",
"en",
"ar",
"zh",
"nl",
"fr",
"de",
"hi",
"in",
"it",
"ja",
"pt",
"ru",
"es",
"vi",
"multilingual",
"dataset:unicamp-dl/mmarco",
"transformers",
"license:apache-2.0"
] | text-classification | false | cross-encoder | null | cross-encoder/mmarco-mMiniLMv2-L12-H384-v1 | 997 | 5 | transformers | 1,775 | ---
license: apache-2.0
language:
- en
- ar
- zh
- nl
- fr
- de
- hi
- in
- it
- ja
- pt
- ru
- es
- vi
- multilingual
datasets:
- unicamp-dl/mmarco
---
# Cross-Encoder for multilingual MS Marco
This model was trained on the [MMARCO](https://hf.co/unicamp-dl/mmarco) dataset. It is a machine translated version of MS MARCO using Google Translate. It was translated to 14 languages. In our experiments, we observed that it performs also well for other languages.
As a base model, we used the [multilingual MiniLMv2](https://huggingface.co/nreimers/mMiniLMv2-L12-H384-distilled-from-XLMR-Large) model.
The model can be used for Information Retrieval: Given a query, encode the query will all possible passages (e.g. retrieved with ElasticSearch). Then sort the passages in a decreasing order. See [SBERT.net Retrieve & Re-rank](https://www.sbert.net/examples/applications/retrieve_rerank/README.html) for more details. The training code is available here: [SBERT.net Training MS Marco](https://github.com/UKPLab/sentence-transformers/tree/master/examples/training/ms_marco)
## Usage with SentenceTransformers
The usage becomes easy when you have [SentenceTransformers](https://www.sbert.net/) installed. Then, you can use the pre-trained models like this:
```python
from sentence_transformers import CrossEncoder
model = CrossEncoder('model_name')
scores = model.predict([('Query', 'Paragraph1'), ('Query', 'Paragraph2') , ('Query', 'Paragraph3')])
```
## Usage with Transformers
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
model = AutoModelForSequenceClassification.from_pretrained('model_name')
tokenizer = AutoTokenizer.from_pretrained('model_name')
features = tokenizer(['How many people live in Berlin?', 'How many people live in Berlin?'], ['Berlin has a population of 3,520,031 registered inhabitants in an area of 891.82 square kilometers.', 'New York City is famous for the Metropolitan Museum of Art.'], padding=True, truncation=True, return_tensors="pt")
model.eval()
with torch.no_grad():
scores = model(**features).logits
print(scores)
```
|
DaNLP/da-electra-hatespeech-detection | 4b6008f10efd2908de4b4e9592579415b9cdf808 | 2022-02-16T15:00:31.000Z | [
"pytorch",
"electra",
"text-classification",
"da",
"dataset:social media",
"transformers",
"hatespeech",
"license:cc-by-4.0"
] | text-classification | false | DaNLP | null | DaNLP/da-electra-hatespeech-detection | 996 | null | transformers | 1,776 | ---
language:
- da
tags:
- electra
- pytorch
- hatespeech
license: cc-by-4.0
datasets:
- social media
metrics:
- f1
widget:
- text: "Senile gamle idiot"
---
# Danish ELECTRA for hate speech (offensive language) detection
The ELECTRA Offensive model detects whether a Danish text is offensive or not.
It is based on the pretrained [Danish Ælæctra](Maltehb/aelaectra-danish-electra-small-cased) model.
See the [DaNLP documentation](https://danlp-alexandra.readthedocs.io/en/latest/docs/tasks/hatespeech.html#electra) for more details.
Here is how to use the model:
```python
from transformers import ElectraTokenizer, ElectraForSequenceClassification
model = ElectraForSequenceClassification.from_pretrained("DaNLP/da-electra-hatespeech-detection")
tokenizer = ElectraTokenizer.from_pretrained("DaNLP/da-electra-hatespeech-detection")
```
## Training data
The data used for training has not been made publicly available. It consists of social media data manually annotated in collaboration with Danmarks Radio.
|
indobenchmark/indobert-lite-base-p1 | 5b3f705b18a164b7917e4a94e8ed2cdbdbb8b639 | 2020-12-11T21:45:50.000Z | [
"pytorch",
"tf",
"albert",
"feature-extraction",
"id",
"dataset:Indo4B",
"arxiv:2009.05387",
"transformers",
"indobert",
"indobenchmark",
"indonlu",
"license:mit"
] | feature-extraction | false | indobenchmark | null | indobenchmark/indobert-lite-base-p1 | 995 | null | transformers | 1,777 | ---
language: id
tags:
- indobert
- indobenchmark
- indonlu
license: mit
inference: false
datasets:
- Indo4B
---
# IndoBERT-Lite Base Model (phase1 - uncased)
[IndoBERT](https://arxiv.org/abs/2009.05387) is a state-of-the-art language model for Indonesian based on the BERT model. The pretrained model is trained using a masked language modeling (MLM) objective and next sentence prediction (NSP) objective.
## All Pre-trained Models
| Model | #params | Arch. | Training data |
|--------------------------------|--------------------------------|-------|-----------------------------------|
| `indobenchmark/indobert-base-p1` | 124.5M | Base | Indo4B (23.43 GB of text) |
| `indobenchmark/indobert-base-p2` | 124.5M | Base | Indo4B (23.43 GB of text) |
| `indobenchmark/indobert-large-p1` | 335.2M | Large | Indo4B (23.43 GB of text) |
| `indobenchmark/indobert-large-p2` | 335.2M | Large | Indo4B (23.43 GB of text) |
| `indobenchmark/indobert-lite-base-p1` | 11.7M | Base | Indo4B (23.43 GB of text) |
| `indobenchmark/indobert-lite-base-p2` | 11.7M | Base | Indo4B (23.43 GB of text) |
| `indobenchmark/indobert-lite-large-p1` | 17.7M | Large | Indo4B (23.43 GB of text) |
| `indobenchmark/indobert-lite-large-p2` | 17.7M | Large | Indo4B (23.43 GB of text) |
## How to use
### Load model and tokenizer
```python
from transformers import BertTokenizer, AutoModel
tokenizer = BertTokenizer.from_pretrained("indobenchmark/indobert-lite-base-p1")
model = AutoModel.from_pretrained("indobenchmark/indobert-lite-base-p1")
```
### Extract contextual representation
```python
x = torch.LongTensor(tokenizer.encode('aku adalah anak [MASK]')).view(1,-1)
print(x, model(x)[0].sum())
```
## Authors
<b>IndoBERT</b> was trained and evaluated by Bryan Wilie\*, Karissa Vincentio\*, Genta Indra Winata\*, Samuel Cahyawijaya\*, Xiaohong Li, Zhi Yuan Lim, Sidik Soleman, Rahmad Mahendra, Pascale Fung, Syafri Bahar, Ayu Purwarianti.
## Citation
If you use our work, please cite:
```bibtex
@inproceedings{wilie2020indonlu,
title={IndoNLU: Benchmark and Resources for Evaluating Indonesian Natural Language Understanding},
author={Bryan Wilie and Karissa Vincentio and Genta Indra Winata and Samuel Cahyawijaya and X. Li and Zhi Yuan Lim and S. Soleman and R. Mahendra and Pascale Fung and Syafri Bahar and A. Purwarianti},
booktitle={Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing},
year={2020}
}
```
|
DeepPavlov/xlm-roberta-large-en-ru | da9f180b0d73f4a653f3aaebea87fd586746021d | 2021-11-15T08:46:05.000Z | [
"pytorch",
"xlm-roberta",
"feature-extraction",
"en",
"ru",
"transformers"
] | feature-extraction | false | DeepPavlov | null | DeepPavlov/xlm-roberta-large-en-ru | 994 | null | transformers | 1,778 | ---
language:
- en
- ru
---
# XLM-RoBERTa-Large-En-Ru
## Model description
This model is a version XLM-RoBERTa with embeddings and vocabulary reduced to most frequent tokens in English and Russian.
|
Helsinki-NLP/opus-mt-es-fr | 4a8c0b48f85ccacc4557e2189a2a551418e4a68a | 2021-09-09T21:42:27.000Z | [
"pytorch",
"marian",
"text2text-generation",
"es",
"fr",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] | translation | false | Helsinki-NLP | null | Helsinki-NLP/opus-mt-es-fr | 993 | 1 | transformers | 1,779 | ---
tags:
- translation
license: apache-2.0
---
### opus-mt-es-fr
* source languages: es
* target languages: fr
* OPUS readme: [es-fr](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/es-fr/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-08.zip](https://object.pouta.csc.fi/OPUS-MT-models/es-fr/opus-2020-01-08.zip)
* test set translations: [opus-2020-01-08.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/es-fr/opus-2020-01-08.test.txt)
* test set scores: [opus-2020-01-08.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/es-fr/opus-2020-01-08.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| newssyscomb2009.es.fr | 33.6 | 0.610 |
| news-test2008.es.fr | 32.0 | 0.585 |
| newstest2009.es.fr | 32.5 | 0.590 |
| newstest2010.es.fr | 35.0 | 0.615 |
| newstest2011.es.fr | 33.9 | 0.607 |
| newstest2012.es.fr | 32.4 | 0.602 |
| newstest2013.es.fr | 32.1 | 0.593 |
| Tatoeba.es.fr | 58.4 | 0.731 |
|
egoitz/roberta-timex-semeval | 39f3a7ee360f745985631ea542fe511c89f2299b | 2021-05-20T16:15:19.000Z | [
"pytorch",
"jax",
"roberta",
"token-classification",
"transformers",
"autotrain_compatible"
] | token-classification | false | egoitz | null | egoitz/roberta-timex-semeval | 993 | null | transformers | 1,780 | Entry not found |
thunlp/Lawformer | d2452823634a0c5aff74b894c8b86f5ed346b964 | 2022-07-12T06:23:13.000Z | [
"pytorch",
"longformer",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | false | thunlp | null | thunlp/Lawformer | 992 | 2 | transformers | 1,781 | ## Lawformer
### Introduction
This repository provides the source code and checkpoints of the paper "Lawformer: A Pre-trained Language Model forChinese Legal Long Documents". You can download the checkpoint from the [huggingface model hub](https://huggingface.co/xcjthu/Lawformer) or from [here](https://data.thunlp.org/legal/Lawformer.zip).
### Easy Start
We have uploaded our model to the huggingface model hub. Make sure you have installed transformers.
```python
>>> from transformers import AutoModel, AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("thunlp/Lawformer")
>>> model = AutoModel.from_pretrained("thunlp/Lawformer")
>>> inputs = tokenizer("任某提起诉讼,请求判令解除婚姻关系并对夫妻共同财产进行分割。", return_tensors="pt")
>>> outputs = model(**inputs)
```
### Cite
If you use the pre-trained models, please cite this paper:
```
@article{xiao2021lawformer,
title={Lawformer: A Pre-trained Language Model forChinese Legal Long Documents},
author={Xiao, Chaojun and Hu, Xueyu and Liu, Zhiyuan and Tu, Cunchao and Sun, Maosong},
year={2021}
}
```
|
lanwuwei/GigaBERT-v4-Arabic-and-English | 94bcdd4d00243515c930d8d9a8c78b7ffe02e2b0 | 2021-05-19T21:19:13.000Z | [
"pytorch",
"jax",
"bert",
"feature-extraction",
"transformers"
] | feature-extraction | false | lanwuwei | null | lanwuwei/GigaBERT-v4-Arabic-and-English | 989 | 1 | transformers | 1,782 | ## GigaBERT-v4
GigaBERT-v4 is a continued pre-training of [GigaBERT-v3](https://huggingface.co/lanwuwei/GigaBERT-v3-Arabic-and-English) on code-switched data, showing improved zero-shot transfer performance from English to Arabic on information extraction (IE) tasks. More details can be found in the following paper:
@inproceedings{lan2020gigabert,
author = {Lan, Wuwei and Chen, Yang and Xu, Wei and Ritter, Alan},
title = {GigaBERT: Zero-shot Transfer Learning from English to Arabic},
booktitle = {Proceedings of The 2020 Conference on Empirical Methods on Natural Language Processing (EMNLP)},
year = {2020}
}
## Download
```
from transformers import *
tokenizer = BertTokenizer.from_pretrained("lanwuwei/GigaBERT-v4-Arabic-and-English", do_lower_case=True)
model = BertForTokenClassification.from_pretrained("lanwuwei/GigaBERT-v4-Arabic-and-English")
```
Here is downloadable link [GigaBERT-v4](https://drive.google.com/drive/u/1/folders/1uFGzMuTOD7iNsmKQYp_zVuvsJwOaIdar).
|
bolbolzaban/gpt2-persian | 1c965e289795e1b24301cd3f4ee48e73519ac8ee | 2021-05-21T14:23:14.000Z | [
"pytorch",
"tf",
"jax",
"gpt2",
"text-generation",
"fa",
"transformers",
"farsi",
"persian",
"license:apache-2.0"
] | text-generation | false | bolbolzaban | null | bolbolzaban/gpt2-persian | 986 | 4 | transformers | 1,783 | ---
language: fa
license: apache-2.0
tags:
- farsi
- persian
---
# GPT2-Persian
bolbolzaban/gpt2-persian is gpt2 language model that is trained with hyper parameters similar to standard gpt2-medium with following differences:
1. The context size is reduced from 1024 to 256 sub words in order to make the training affordable
2. Instead of BPE, google sentence piece tokenizor is used for tokenization.
3. The training dataset only include Persian text. All non-persian characters are replaced with especial tokens (e.g [LAT], [URL], [NUM])
Please refer to this [blog post](https://medium.com/@khashei/a-not-so-dangerous-ai-in-the-persian-language-39172a641c84) for further detail.
Also try the model [here](https://huggingface.co/bolbolzaban/gpt2-persian?text=%D8%AF%D8%B1+%DB%8C%DA%A9+%D8%A7%D8%AA%D9%81%D8%A7%D9%82+%D8%B4%DA%AF%D9%81%D8%AA+%D8%A7%D9%86%DA%AF%DB%8C%D8%B2%D8%8C+%D9%BE%DA%98%D9%88%D9%87%D8%B4%DA%AF%D8%B1%D8%A7%D9%86) or on [Bolbolzaban.com](http://www.bolbolzaban.com/text).
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline, AutoTokenizer, GPT2LMHeadModel
tokenizer = AutoTokenizer.from_pretrained('bolbolzaban/gpt2-persian')
model = GPT2LMHeadModel.from_pretrained('bolbolzaban/gpt2-persian')
generator = pipeline('text-generation', model, tokenizer=tokenizer, config={'max_length':256})
sample = generator('در یک اتفاق شگفت انگیز، پژوهشگران')
```
If you are using Tensorflow import TFGPT2LMHeadModel instead of GPT2LMHeadModel.
## Fine-tuning
Find a basic fine-tuning example on this [Github Repo](https://github.com/khashei/bolbolzaban-gpt2-persian).
## Special Tokens
gpt-persian is trained for the purpose of research on Persian poetry. Because of that all english words and numbers are replaced with special tokens and only standard Persian alphabet is used as part of input text. Here is one example:
Original text: اگر آیفون یا آیپد شما دارای سیستم عامل iOS 14.3 یا iPadOS 14.3 یا نسخههای جدیدتر باشد
Text used in training: اگر آیفون یا آیپد شما دارای سیستم عامل [LAT] [NUM] یا [LAT] [NUM] یا نسخههای جدیدتر باشد
Please consider normalizing your input text using [Hazm](https://github.com/sobhe/hazm) or similar libraries and ensure only Persian characters are provided as input.
If you want to use classical Persian poetry as input use [BOM] (begining of mesra) at the beginning of each verse (مصرع) followed by [EOS] (end of statement) at the end of each couplet (بیت).
See following links for example:
[[BOM] توانا بود](https://huggingface.co/bolbolzaban/gpt2-persian?text=%5BBOM%5D+%D8%AA%D9%88%D8%A7%D9%86%D8%A7+%D8%A8%D9%88%D8%AF)
[[BOM] توانا بود هر که دانا بود [BOM]](https://huggingface.co/bolbolzaban/gpt2-persian?text=%5BBOM%5D+%D8%AA%D9%88%D8%A7%D9%86%D8%A7+%D8%A8%D9%88%D8%AF+%D9%87%D8%B1+%DA%A9%D9%87+%D8%AF%D8%A7%D9%86%D8%A7+%D8%A8%D9%88%D8%AF+%5BBOM%5D)
[[BOM] توانا بود هر که دانا بود [BOM] ز دانش دل پیر](https://huggingface.co/bolbolzaban/gpt2-persian?text=%5BBOM%5D+%D8%AA%D9%88%D8%A7%D9%86%D8%A7+%D8%A8%D9%88%D8%AF+%D9%87%D8%B1+%DA%A9%D9%87+%D8%AF%D8%A7%D9%86%D8%A7+%D8%A8%D9%88%D8%AF+%5BBOM%5D+%D8%B2+%D8%AF%D8%A7%D9%86%D8%B4+%D8%AF%D9%84+%D9%BE%DB%8C%D8%B1)
[[BOM] توانا بود هر که دانا بود [BOM] ز دانش دل پیربرنا بود [EOS]](https://huggingface.co/bolbolzaban/gpt2-persian?text=%5BBOM%5D+%D8%AA%D9%88%D8%A7%D9%86%D8%A7+%D8%A8%D9%88%D8%AF+%D9%87%D8%B1+%DA%A9%D9%87+%D8%AF%D8%A7%D9%86%D8%A7+%D8%A8%D9%88%D8%AF+%5BBOM%5D+%D8%B2+%D8%AF%D8%A7%D9%86%D8%B4+%D8%AF%D9%84+%D9%BE%DB%8C%D8%B1%D8%A8%D8%B1%D9%86%D8%A7+%D8%A8%D9%88%D8%AF++%5BEOS%5D)
If you like to know about structure of classical Persian poetry refer to these [blog posts](https://medium.com/@khashei).
## Acknowledgment
This project is supported by Cloud TPUs from Google’s TensorFlow Research Cloud (TFRC).
## Citation and Reference
Please reference "bolbolzaban.com" website if you are using gpt2-persian in your research or commertial application.
## Contacts
Please reachout on [Linkedin](https://www.linkedin.com/in/khashei/) or [Telegram](https://t.me/khasheia) if you have any question or need any help to use the model.
Follow [Bolbolzaban](http://bolbolzaban.com/about) on [Twitter](https://twitter.com/bolbol_zaban), [Telegram](https://t.me/bolbol_zaban) or [Instagram](https://www.instagram.com/bolbolzaban/) |
KBLab/bert-base-swedish-lowermix-reallysimple-ner | b9efcfa506f155e698fbaba5719bc06045bcfc90 | 2022-03-02T17:43:25.000Z | [
"pytorch",
"bert",
"token-classification",
"sv",
"dataset:KBLab/sucx3_ner",
"transformers",
"sequence-tagger-model",
"autotrain_compatible"
] | token-classification | false | KBLab | null | KBLab/bert-base-swedish-lowermix-reallysimple-ner | 984 | null | transformers | 1,784 | ---
model:
- KB/bert-base-swedish-cased
tags:
- token-classification
- sequence-tagger-model
- bert
language: sv
datasets:
- KBLab/sucx3_ner
widget:
- text: "Emil bor i Lönneberga"
---
# KB-BERT for NER
## Mixed cased and uncased data
This model is based on [KB-BERT](https://huggingface.co/KB/bert-base-swedish-cased) and was fine-tuned on the [SUCX 3.0 - NER](https://huggingface.co/datasets/KBLab/sucx3_ner) corpus, using the _simple_ tags and partially lowercased data.
For this model we used a variation of the data that did **not** use BIO-encoding to differentiate between the beginnings (B), and insides (I) of named entity tags.
The model was trained on the training data only, with the best model chosen by its performance on the validation data.
You find more information about the model and the performance on our blog: https://kb-labb.github.io/posts/2022-02-07-sucx3_ner |
NbAiLab/nb-bert-large | 27e8180855f0de03688958c88a2e5702bfbf0bfd | 2021-09-23T15:53:00.000Z | [
"pytorch",
"tf",
"jax",
"bert",
"no",
"transformers",
"norwegian",
"license:cc-by-4.0",
"fill-mask"
] | fill-mask | false | NbAiLab | null | NbAiLab/nb-bert-large | 980 | 2 | transformers | 1,785 | ---
language: no
license: cc-by-4.0
tags:
- norwegian
- bert
thumbnail: nblogo_3.png
pipeline_tag: fill-mask
widget:
- text: På biblioteket kan du låne en [MASK].
---
- **Release 1.0beta** (April 29, 2021)
# NB-BERT-large (beta)
## Description
NB-BERT-large is a general BERT-large model built on the large digital collection at the National Library of Norway.
This model is trained from scratch on a wide variety of Norwegian text (both bokmål and nynorsk) from the last 200 years using a monolingual Norwegian vocabulary.
## Intended use & limitations
The 1.0 version of the model is general, and should be fine-tuned for any particular use. Some fine-tuning sets may be found on Github, see
* https://github.com/NBAiLab/notram
## Training data
The model is trained on a wide variety of text. The training set is described on
* https://github.com/NBAiLab/notram
## More information
For more information on the model, see
https://github.com/NBAiLab/notram |
speechbrain/vad-crdnn-libriparty | 5570a3fb5188f324fc087cc69786bed5cb10401e | 2022-06-26T23:17:47.000Z | [
"en",
"dataset:Urbansound8k",
"arxiv:2106.04624",
"speechbrain",
"VAD",
"SAD",
"Voice Activity Detection",
"Speech Activity Detection",
"Speaker Diarization",
"pytorch",
"CRDNN",
"LibriSpeech",
"LibryParty"
] | null | false | speechbrain | null | speechbrain/vad-crdnn-libriparty | 978 | 4 | speechbrain | 1,786 | ---
language: "en"
thumbnail:
tags:
- speechbrain
- VAD
- SAD
- Voice Activity Detection
- Speech Activity Detection
- Speaker Diarization
- pytorch
- CRDNN
- LibriSpeech
- LibryParty
datasets:
- Urbansound8k
metrics:
- Accuracy
---
<iframe src="https://ghbtns.com/github-btn.html?user=speechbrain&repo=speechbrain&type=star&count=true&size=large&v=2" frameborder="0" scrolling="0" width="170" height="30" title="GitHub"></iframe>
<br/><br/>
# Voice Activity Detection with a (small) CRDNN model trained on Libriparty
This repository provides all the necessary tools to perform voice activity detection with SpeechBrain using a model pretrained on Libriparty.
The pre-trained system can process short and long speech recordings and outputs the segments where speech activity is detected.
The output of the system looks like this:
```
segment_001 0.00 2.57 NON_SPEECH
segment_002 2.57 8.20 SPEECH
segment_003 8.20 9.10 NON_SPEECH
segment_004 9.10 10.93 SPEECH
segment_005 10.93 12.00 NON_SPEECH
segment_006 12.00 14.40 SPEECH
segment_007 14.40 15.00 NON_SPEECH
segment_008 15.00 17.70 SPEECH
```
The system expects input recordings sampled at 16kHz (single channel).
If your signal has a different sample rate, resample it (e.g., using torchaudio or sox) before using the interface.
For a better experience, we encourage you to learn more about
[SpeechBrain](https://speechbrain.github.io).
# Results
The model performance on the LibriParty test set is:
| Release | hyperparams file | Test Precision | Test Recall | Test F-Score | Model link | GPUs |
|:-------------:|:---------------------------:| -----:| -----:| --------:| :-----------:| :-----------:|
| 2021-09-09 | train.yaml | 0.9518 | 0.9437 | 0.9477 | [Model](https://drive.google.com/drive/folders/1YLYGuiyuTH0D7fXOOp6cMddfQoM74o-Y?usp=sharing) | 1xV100 16GB
## Pipeline description
This system is composed of a CRDNN that outputs posteriors probabilities with a value close to one for speech frames and close to zero for non-speech segments.
A threshold is applied on top of the posteriors to detect candidate speech boundaries.
Depending on the active options, these boundaries can be post-processed (e.g, merging close segments, removing short segments, etc) to further improve the performance. See more details below.
## Install SpeechBrain
```
pip install speechbrain
```
Please notice that we encourage you to read our tutorials and learn more about
[SpeechBrain](https://speechbrain.github.io).
### Perform Voice Activity Detection
```
from speechbrain.pretrained import VAD
VAD = VAD.from_hparams(source="speechbrain/vad-crdnn-libriparty", savedir="pretrained_models/vad-crdnn-libriparty")
boundaries = VAD.get_speech_segments("speechbrain/vad-crdnn-libriparty/example_vad.wav")
# Print the output
VAD.save_boundaries(boundaries)
```
The output is a tensor that contains the beginning/end second of each
detected speech segment. You can save the boundaries on a file with:
```
VAD.save_boundaries(boundaries, save_path='VAD_file.txt')
```
Sometimes it is useful to jointly visualize the VAD output with the input signal itself. This is helpful to quickly figure out if the VAD is doing or not a good job.
To do it:
```
import torchaudio
upsampled_boundaries = VAD.upsample_boundaries(boundaries, 'pretrained_model_checkpoints/example_vad.wav')
torchaudio.save('vad_final.wav', upsampled_boundaries.cpu(), 16000)
```
This creates a "VAD signal" with the same dimensionality as the original signal.
You can now open *vad_final.wav* and *pretrained_model_checkpoints/example_vad.wav* with software like audacity to visualize them jointly.
### VAD pipeline details
The pipeline for detecting the speech segments is the following:
1. Compute posteriors probabilities at the frame level.
2. Apply a threshold on the posterior probability.
3. Derive candidate speech segments on top of that.
4. Apply energy VAD within each candidate segment (optional). This might break down long sentences into short one based on the energy content.
5. Merge segments that are too close.
6. Remove segments that are too short.
7. Double-check speech segments (optional). This could is a final check to make sure the detected segments are actually speech ones.
We designed the VAD such that you can have access to all of these steps (this might help to debug):
```python
from speechbrain.pretrained import VAD
VAD = VAD.from_hparams(source="speechbrain/vad-crdnn-libriparty", savedir="pretrained_models/vad-crdnn-libriparty")
# 1- Let's compute frame-level posteriors first
audio_file = 'pretrained_model_checkpoints/example_vad.wav'
prob_chunks = VAD.get_speech_prob_file(audio_file)
# 2- Let's apply a threshold on top of the posteriors
prob_th = VAD.apply_threshold(prob_chunks).float()
# 3- Let's now derive the candidate speech segments
boundaries = VAD.get_boundaries(prob_th)
# 4- Apply energy VAD within each candidate speech segment (optional)
boundaries = VAD.energy_VAD(audio_file,boundaries)
# 5- Merge segments that are too close
boundaries = VAD.merge_close_segments(boundaries, close_th=0.250)
# 6- Remove segments that are too short
boundaries = VAD.remove_short_segments(boundaries, len_th=0.250)
# 7- Double-check speech segments (optional).
boundaries = VAD.double_check_speech_segments(boundaries, audio_file, speech_th=0.5)
```
### Inference on GPU
To perform inference on the GPU, add `run_opts={"device":"cuda"}` when calling the `from_hparams` method.
### Training
The model was trained with SpeechBrain (ea17d22).
To train it from scratch follows these steps:
1. Clone SpeechBrain:
```bash
git clone https://github.com/speechbrain/speechbrain/
```
2. Install it:
```
cd speechbrain
pip install -r requirements.txt
pip install -e .
```
3. Run Training:
Training heavily relies on data augmentation. Make sure you have downloaded all the datasets needed:
- LibriParty: https://drive.google.com/file/d/1--cAS5ePojMwNY5fewioXAv9YlYAWzIJ/view?usp=sharing
- Musan: https://www.openslr.org/resources/17/musan.tar.gz
- CommonLanguage: https://zenodo.org/record/5036977/files/CommonLanguage.tar.gz?download=1
```
cd recipes/LibriParty/VAD
python train.py hparams/train.yaml --data_folder=/path/to/LibriParty --musan_folder=/path/to/musan/ --commonlanguage_folder=/path/to/common_voice_kpd
```
### Limitations
The SpeechBrain team does not provide any warranty on the performance achieved by this model when used on other datasets.
# **Citing SpeechBrain**
Please, cite SpeechBrain if you use it for your research or business.
```bibtex
@misc{speechbrain,
title={{SpeechBrain}: A General-Purpose Speech Toolkit},
author={Mirco Ravanelli and Titouan Parcollet and Peter Plantinga and Aku Rouhe and Samuele Cornell and Loren Lugosch and Cem Subakan and Nauman Dawalatabad and Abdelwahab Heba and Jianyuan Zhong and Ju-Chieh Chou and Sung-Lin Yeh and Szu-Wei Fu and Chien-Feng Liao and Elena Rastorgueva and François Grondin and William Aris and Hwidong Na and Yan Gao and Renato De Mori and Yoshua Bengio},
year={2021},
eprint={2106.04624},
archivePrefix={arXiv},
primaryClass={eess.AS},
note={arXiv:2106.04624}
}
```
|
deepparag/DumBot | 61ec36094ce1c5e6fecd4e1830bc7399db991830 | 2022-01-21T15:40:27.000Z | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational",
"license:mit"
] | conversational | false | deepparag | null | deepparag/DumBot | 977 | 2 | transformers | 1,787 | ---
thumbnail: https://cdn.discordapp.com/app-icons/870239976690970625/c02cae78ae105f07969cfd8f8ea3d0a0.png
tags:
- conversational
license: mit
---
# THIS AI IS OUTDATED. See [Aeona](https://huggingface.co/deepparag/Aeona)
An generative AI made using [microsoft/DialoGPT-small](https://huggingface.co/microsoft/DialoGPT-small).
Trained on:
https://www.kaggle.com/Cornell-University/movie-dialog-corpus
https://www.kaggle.com/jef1056/discord-data
[Live Demo](https://dumbot-331213.uc.r.appspot.com/)
Example:
```python
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("deepparag/DumBot")
model = AutoModelWithLMHead.from_pretrained("deepparag/DumBot")
# Let's chat for 4 lines
for step in range(4):
# encode the new user input, add the eos_token and return a tensor in Pytorch
new_user_input_ids = tokenizer.encode(input(">> User:") + tokenizer.eos_token, return_tensors='pt')
# print(new_user_input_ids)
# append the new user input tokens to the chat history
bot_input_ids = torch.cat([chat_history_ids, new_user_input_ids], dim=-1) if step > 0 else new_user_input_ids
# generated a response while limiting the total chat history to 1000 tokens,
chat_history_ids = model.generate(
bot_input_ids, max_length=200,
pad_token_id=tokenizer.eos_token_id,
no_repeat_ngram_size=4,
do_sample=True,
top_k=100,
top_p=0.7,
temperature=0.8
)
# pretty print last ouput tokens from bot
print("DumBot: {}".format(tokenizer.decode(chat_history_ids[:, bot_input_ids.shape[-1]:][0], skip_special_tokens=True)))
``` |
facebook/deit-base-distilled-patch16-384 | d5642c165024ea0619ad72ab3e26d867eabdcdab | 2022-07-13T11:40:20.000Z | [
"pytorch",
"tf",
"deit",
"image-classification",
"dataset:imagenet",
"arxiv:2012.12877",
"arxiv:2006.03677",
"transformers",
"vision",
"license:apache-2.0"
] | image-classification | false | facebook | null | facebook/deit-base-distilled-patch16-384 | 977 | null | transformers | 1,788 | ---
license: apache-2.0
tags:
- image-classification
- vision
datasets:
- imagenet
---
# Distilled Data-efficient Image Transformer (base-sized model)
Distilled data-efficient Image Transformer (DeiT) model pre-trained at resolution 224x224 and fine-tuned at resolution 384x384 on ImageNet-1k (1 million images, 1,000 classes). It was first introduced in the paper [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Touvron et al. and first released in [this repository](https://github.com/facebookresearch/deit). However, the weights were converted from the [timm repository](https://github.com/rwightman/pytorch-image-models) by Ross Wightman.
Disclaimer: The team releasing DeiT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
This model is a distilled Vision Transformer (ViT). It uses a distillation token, besides the class token, to effectively learn from a teacher (CNN) during both pre-training and fine-tuning. The distillation token is learned through backpropagation, by interacting with the class ([CLS]) and patch tokens through the self-attention layers.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=facebook/deit) to look for
fine-tuned versions on a task that interests you.
### How to use
Since this model is a distilled ViT model, you can plug it into DeiTModel, DeiTForImageClassification or DeiTForImageClassificationWithTeacher. Note that the model expects the data to be prepared using DeiTFeatureExtractor. Here we use AutoFeatureExtractor, which will automatically use the appropriate feature extractor given the model name.
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import AutoFeatureExtractor, DeiTForImageClassificationWithTeacher
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = AutoFeatureExtractor.from_pretrained('facebook/deit-base-distilled-patch16-384')
model = DeiTForImageClassificationWithTeacher.from_pretrained('facebook/deit-base-distilled-patch16-384')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
Currently, both the feature extractor and model support PyTorch. Tensorflow and JAX/FLAX are coming soon.
## Training data
This model was pretrained and fine-tuned with distillation on [ImageNet-1k](http://www.image-net.org/challenges/LSVRC/2012/), a dataset consisting of 1 million images and 1k classes.
## Training procedure
### Preprocessing
The exact details of preprocessing of images during training/validation can be found [here](https://github.com/facebookresearch/deit/blob/ab5715372db8c6cad5740714b2216d55aeae052e/datasets.py#L78).
At inference time, images are resized/rescaled to the same resolution (438x438), center-cropped at 384x384 and normalized across the RGB channels with the ImageNet mean and standard deviation.
### Pretraining
The model was trained on a single 8-GPU node for 3 days. Pre-training resolution is 224. For all hyperparameters (such as batch size and learning rate) we refer to table 9 of the original paper.
## Evaluation results
| Model | ImageNet top-1 accuracy | ImageNet top-5 accuracy | # params | URL |
|-------------------------------------------|-------------------------|-------------------------|----------|------------------------------------------------------------------|
| DeiT-tiny | 72.2 | 91.1 | 5M | https://huggingface.co/facebook/deit-tiny-patch16-224 |
| DeiT-small | 79.9 | 95.0 | 22M | https://huggingface.co/facebook/deit-small-patch16-224 |
| DeiT-base | 81.8 | 95.6 | 86M | https://huggingface.co/facebook/deit-base-patch16-224 |
| DeiT-tiny distilled | 74.5 | 91.9 | 6M | https://huggingface.co/facebook/deit-tiny-distilled-patch16-224 |
| DeiT-small distilled | 81.2 | 95.4 | 22M | https://huggingface.co/facebook/deit-small-distilled-patch16-224 |
| DeiT-base distilled | 83.4 | 96.5 | 87M | https://huggingface.co/facebook/deit-base-distilled-patch16-224 |
| DeiT-base 384 | 82.9 | 96.2 | 87M | https://huggingface.co/facebook/deit-base-patch16-384 |
| **DeiT-base distilled 384 (1000 epochs)** | **85.2** | **97.2** | **88M** | **https://huggingface.co/facebook/deit-base-distilled-patch16-384** |
Note that for fine-tuning, the best results are obtained with a higher resolution (384x384). Of course, increasing the model size will result in better performance.
### BibTeX entry and citation info
```bibtex
@misc{touvron2021training,
title={Training data-efficient image transformers & distillation through attention},
author={Hugo Touvron and Matthieu Cord and Matthijs Douze and Francisco Massa and Alexandre Sablayrolles and Hervé Jégou},
year={2021},
eprint={2012.12877},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
```bibtex
@misc{wu2020visual,
title={Visual Transformers: Token-based Image Representation and Processing for Computer Vision},
author={Bichen Wu and Chenfeng Xu and Xiaoliang Dai and Alvin Wan and Peizhao Zhang and Zhicheng Yan and Masayoshi Tomizuka and Joseph Gonzalez and Kurt Keutzer and Peter Vajda},
year={2020},
eprint={2006.03677},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
```bibtex
@inproceedings{deng2009imagenet,
title={Imagenet: A large-scale hierarchical image database},
author={Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li},
booktitle={2009 IEEE conference on computer vision and pattern recognition},
pages={248--255},
year={2009},
organization={Ieee}
}
``` |
nguyenvulebinh/wav2vec2-base-vietnamese-250h | 69e9000591623e5a4fc2f502407860bcdc0de0b2 | 2021-11-04T15:35:49.000Z | [
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"vi",
"dataset:vlsp",
"dataset:vivos",
"transformers",
"audio",
"license:cc-by-nc-4.0",
"model-index"
] | automatic-speech-recognition | false | nguyenvulebinh | null | nguyenvulebinh/wav2vec2-base-vietnamese-250h | 974 | 8 | transformers | 1,789 | ---
language: vi
datasets:
- vlsp
- vivos
tags:
- audio
- automatic-speech-recognition
license: cc-by-nc-4.0
widget:
- example_title: VLSP ASR 2020 test T1
src: https://huggingface.co/nguyenvulebinh/wav2vec2-base-vietnamese-250h/raw/main/audio-test/t1_0001-00010.wav
- example_title: VLSP ASR 2020 test T1
src: https://huggingface.co/nguyenvulebinh/wav2vec2-base-vietnamese-250h/raw/main/audio-test/t1_utt000000042.wav
- example_title: VLSP ASR 2020 test T2
src: https://huggingface.co/nguyenvulebinh/wav2vec2-base-vietnamese-250h/raw/main/audio-test/t2_0000006682.wav
model-index:
- name: Vietnamese end-to-end speech recognition using wav2vec 2.0 by VietAI
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice vi
type: common_voice
args: vi
metrics:
- name: Test WER
type: wer
value: 11.52
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: VIVOS
type: vivos
args: vi
metrics:
- name: Test WER
type: wer
value: 6.15
---
# Vietnamese end-to-end speech recognition using wav2vec 2.0
[](https://paperswithcode.com/sota/speech-recognition-on-common-voice-vi?p=vietnamese-end-to-end-speech-recognition)
[](https://paperswithcode.com/sota/speech-recognition-on-vivos?p=vietnamese-end-to-end-speech-recognition)
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/)
### Model description
[Our models](https://huggingface.co/nguyenvulebinh/wav2vec2-base-vietnamese-250h) are pre-trained on 13k hours of Vietnamese youtube audio (un-label data) and fine-tuned on 250 hours labeled of [VLSP ASR dataset](https://vlsp.org.vn/vlsp2020/eval/asr) on 16kHz sampled speech audio.
We use [wav2vec2 architecture](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) for the pre-trained model. Follow wav2vec2 paper:
>For the first time that learning powerful representations from speech audio alone followed by fine-tuning on transcribed speech can outperform the best semi-supervised methods while being conceptually simpler.
For fine-tuning phase, wav2vec2 is fine-tuned using Connectionist Temporal Classification (CTC), which is an algorithm that is used to train neural networks for sequence-to-sequence problems and mainly in Automatic Speech Recognition and handwriting recognition.
| Model | #params | Pre-training data | Fine-tune data |
|---|---|---|---|
| [base]((https://huggingface.co/nguyenvulebinh/wav2vec2-base-vietnamese-250h)) | 95M | 13k hours | 250 hours |
In a formal ASR system, two components are required: acoustic model and language model. Here ctc-wav2vec fine-tuned model works as an acoustic model. For the language model, we provide a [4-grams model](https://huggingface.co/nguyenvulebinh/wav2vec2-base-vietnamese-250h/blob/main/vi_lm_4grams.bin.zip) trained on 2GB of spoken text.
Detail of training and fine-tuning process, the audience can follow [fairseq github](https://github.com/pytorch/fairseq/tree/master/examples/wav2vec) and [huggingface blog](https://huggingface.co/blog/fine-tune-wav2vec2-english).
### Benchmark WER result:
| | [VIVOS](https://ailab.hcmus.edu.vn/vivos) | [COMMON VOICE VI](https://paperswithcode.com/dataset/common-voice) | [VLSP-T1](https://vlsp.org.vn/vlsp2020/eval/asr) | [VLSP-T2](https://vlsp.org.vn/vlsp2020/eval/asr) |
|---|---|---|---|---|
|without LM| 10.77 | 18.34 | 13.33 | 51.45 |
|with 4-grams LM| 6.15 | 11.52 | 9.11 | 40.81 |
### Example usage
When using the model make sure that your speech input is sampled at 16Khz. Audio length should be shorter than 10s. Following the Colab link below to use a combination of CTC-wav2vec and 4-grams LM.
[](https://colab.research.google.com/drive/1pVBY46gSoWer2vDf0XmZ6uNV3d8lrMxx?usp=sharing)
```python
from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
from datasets import load_dataset
import soundfile as sf
import torch
# load model and tokenizer
processor = Wav2Vec2Processor.from_pretrained("nguyenvulebinh/wav2vec2-base-vietnamese-250h")
model = Wav2Vec2ForCTC.from_pretrained("nguyenvulebinh/wav2vec2-base-vietnamese-250h")
# define function to read in sound file
def map_to_array(batch):
speech, _ = sf.read(batch["file"])
batch["speech"] = speech
return batch
# load dummy dataset and read soundfiles
ds = map_to_array({
"file": 'audio-test/t1_0001-00010.wav'
})
# tokenize
input_values = processor(ds["speech"], return_tensors="pt", padding="longest").input_values # Batch size 1
# retrieve logits
logits = model(input_values).logits
# take argmax and decode
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
```
### Model Parameters License
The ASR model parameters are made available for non-commercial use only, under the terms of the Creative Commons Attribution-NonCommercial 4.0 International (CC BY-NC 4.0) license. You can find details at: https://creativecommons.org/licenses/by-nc/4.0/legalcode
### Citation
[](https://github.com/vietai/ASR)
```text
@misc{Thai_Binh_Nguyen_wav2vec2_vi_2021,
author = {Thai Binh Nguyen},
doi = {10.5281/zenodo.5356039},
month = {09},
title = {{Vietnamese end-to-end speech recognition using wav2vec 2.0}},
url = {https://github.com/vietai/ASR},
year = {2021}
}
```
**Please CITE** our repo when it is used to help produce published results or is incorporated into other software.
# Contact
[email protected] / [email protected]
[](https://twitter.com/intent/follow?screen_name=nguyenvulebinh) |
arunavsk1/my-awesome-pubmed-bert | bb06e2d1d8ababdc63214b8e699837ac31672a2c | 2022-06-06T01:51:45.000Z | [
"pytorch",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
] | token-classification | false | arunavsk1 | null | arunavsk1/my-awesome-pubmed-bert | 971 | null | transformers | 1,790 | Entry not found |
Salesforce/codegen-16B-mono | a21420473d19b3ebfadbaefcc51cf1856f5f2c8f | 2022-06-28T17:48:18.000Z | [
"pytorch",
"codegen",
"text-generation",
"arxiv:2203.13474",
"transformers",
"license:bsd-3-clause"
] | text-generation | false | Salesforce | null | Salesforce/codegen-16B-mono | 965 | 14 | transformers | 1,791 | ---
license: bsd-3-clause
---
# CodeGen (CodeGen-Mono 16B)
## Model description
CodeGen is a family of autoregressive language models for **program synthesis** from the paper: [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong. The models are originally released in [this repository](https://github.com/salesforce/CodeGen), under 3 pre-training data variants (`NL`, `Multi`, `Mono`) and 4 model size variants (`350M`, `2B`, `6B`, `16B`).
The checkpoint included in this repository is denoted as **CodeGen-Mono 16B** in the paper, where "Mono" means the model is initialized with *CodeGen-Multi 16B* and further pre-trained on a Python programming language dataset, and "16B" refers to the number of trainable parameters.
## Training data
This checkpoint (CodeGen-Mono 16B) was firstly initialized with *CodeGen-Multi 16B*, and then pre-trained on BigPython dataset. The data consists of 71.7B tokens of Python programming language. See Section 2.1 of the [paper](https://arxiv.org/abs/2203.13474) for more details.
## Training procedure
CodeGen was trained using cross-entropy loss to maximize the likelihood of sequential inputs.
The family of models are trained using multiple TPU-v4-512 by Google, leveraging data and model parallelism.
See Section 2.3 of the [paper](https://arxiv.org/abs/2203.13474) for more details.
## Evaluation results
We evaluate our models on two code generation benchmark: HumanEval and MTPB. Please refer to the [paper](https://arxiv.org/abs/2203.13474) for more details.
## Intended Use and Limitations
As an autoregressive language model, CodeGen is capable of extracting features from given natural language and programming language texts, and calculating the likelihood of them.
However, the model is intended for and best at **program synthesis**, that is, generating executable code given English prompts, where the prompts should be in the form of a comment string. The model can complete partially-generated code as well.
## How to use
This model can be easily loaded using the `AutoModelForCausalLM` functionality:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("Salesforce/codegen-16B-mono")
model = AutoModelForCausalLM.from_pretrained("Salesforce/codegen-16B-mono")
text = "def hello_world():"
input_ids = tokenizer(text, return_tensors="pt").input_ids
generated_ids = model.generate(input_ids, max_length=128)
print(tokenizer.decode(generated_ids[0], skip_special_tokens=True))
```
## BibTeX entry and citation info
```bibtex
@article{Nijkamp2022ACP,
title={A Conversational Paradigm for Program Synthesis},
author={Nijkamp, Erik and Pang, Bo and Hayashi, Hiroaki and Tu, Lifu and Wang, Huan and Zhou, Yingbo and Savarese, Silvio and Xiong, Caiming},
journal={arXiv preprint},
year={2022}
}
```
|
Luyu/condenser | 7d0fa9eabec851f64882e728e1f92c59b8878f67 | 2021-08-13T13:38:57.000Z | [
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | false | Luyu | null | Luyu/condenser | 962 | null | transformers | 1,792 | Entry not found |
sismetanin/rubert-toxic-pikabu-2ch | 1e5d55aeca25ab0a91725abc08821694de7dd5ea | 2021-05-20T06:16:03.000Z | [
"pytorch",
"jax",
"bert",
"text-classification",
"ru",
"transformers",
"toxic comments classification"
] | text-classification | false | sismetanin | null | sismetanin/rubert-toxic-pikabu-2ch | 961 | 4 | transformers | 1,793 | ---
language:
- ru
tags:
- toxic comments classification
---
## RuBERT-Toxic
RuBERT-Toxic is a [RuBERT](https://huggingface.co/DeepPavlov/rubert-base-cased) model fine-tuned on [Kaggle Russian Language Toxic Comments Dataset](https://www.kaggle.com/blackmoon/russian-language-toxic-comments). You can find a detailed description of the data used and the fine-tuning process in [this article](http://doi.org/10.28995/2075-7182-2020-19-1149-1159). You can also find this information at [GitHub](https://github.com/sismetanin/toxic-comments-detection-in-russian).
| System | P | R | F<sub>1</sub> |
| ------------- | ------------- | ------------- | ------------- |
| MNB-Toxic | 87.01% | 81.22% | 83.21% |
| M-BERT<sub>Base</sub>-Toxic | 91.19% | 91.10% | 91.15% |
| <b>RuBERT-Toxic</b> | <b>91.91%</b> | <b>92.51%</b> | <b>92.20%</b> |
| M-USE<sub>CNN</sub>-Toxic | 89.69% | 90.14% | 89.91% |
| M-USE<sub>Trans</sub>-Toxic | 90.85% | 91.92% | 91.35% |
We fine-tuned two versions of Multilingual Universal Sentence Encoder (M-USE), Multilingual Bidirectional Encoder Representations from Transformers (M-BERT) and RuBERT for toxic comments detection in Russian. Fine-tuned RuBERT-Toxic achieved F<sub>1</sub> = 92.20%, demonstrating the best classification score.
## Toxic Comments Dataset
[Kaggle Russian Language Toxic Comments Dataset](https://www.kaggle.com/blackmoon/russian-language-toxic-comments) is the collection of Russian-language annotated comments from [2ch](https://2ch.hk/) and [Pikabu](https://pikabu.ru/), which was published on Kaggle in 2019. It consists of 14412 comments, where 4826 texts were labelled as toxic, and 9586 were labelled as non-toxic. The average length of comments is ~175 characters; the minimum length is 21, and the maximum is 7403.
## Citation
If you find this repository helpful, feel free to cite our publication:
```
@INPROCEEDINGS{Smetanin2020Toxic,
author={Sergey Smetanin},
booktitle={Computational Linguistics and Intellectual Technologies: Proceedings of the International Conference “Dialogue 2020”},
title={Toxic Comments Detection in Russian},
year={2020},
doi={10.28995/2075-7182-2020-19-1149-1159}
}
``` |
scjnugacj/jurisbert | 721bd35f7ba879bf25d48d07ac2c3b710dd808fb | 2022-07-13T22:23:07.000Z | [
"pytorch",
"roberta",
"fill-mask",
"es",
"transformers",
"license:other",
"autotrain_compatible"
] | fill-mask | false | scjnugacj | null | scjnugacj/jurisbert | 960 | 6 | transformers | 1,794 | ---
language: es
license: other
widget:
- text: "Procedencia de la extinción de dominio considerando que los bienes utilizados para cometer el <mask>, se realizó sin el conocimiento del propietario de los bienes."
- text: "En lo que respecta a la regulación dentro del derecho civil, la adopción homoparental consiste en que un <mask> pueda ser adoptado, y así, legalmente sea hijo de los dos miembros de una pareja compuesta por dos personas del mismo sexo aunque no es término válido en la mayoría de las legislaciones"
---
# JurisBert
JurisBert, es una iniciativa de la **Suprema Corte de Justicia de la Nación (SCJN) de México**, nace en agosto del 2020, a propuesta de la **Unidad General de Administración del Conocimiento Jurídico (UGACJ)**, para entrenar un Modelo del Lenguaje contextualizado al ámbito jurídico. Su principal objetivo es generar aplicaciones de **Procesamiento del Lenguaje Natural (PLN)** que coadyuven a la labor jurisdiccional del Alto Tribunal mediante el aprovechamiento del conocimiento de la SCJN plasmado en documentos no estructurados que generan las áreas jurisdiccionales.
En 2021, esta iniciativa tomó mayor relevancia con la llegada de la Reforma Judicial y el inicio de la undécima época del SJF, puesto que la creación de JurisBert tiene como objetivos principales la ayuda a la identificación del precedente y la creación de Plataformas de Recuperación de Información.
Como parte de la Transformación Digital impulsada por la SCJN, en razón de generar un esquema de “Gobierno Abierto” mediante la Colaboración e Innovación y en el contexto de la operación remota obligada por la contingencia sanitaria derivada del virus SARS COV 2, se pone a disposición de toda la comunidad esta innovación tecnológica pretendiendo con ello la retribución del conocimiento generado por el Alto Tribunal a la ciudadanía.
Es su primer versión, JurisBert es un modelo del lenguaje basado en Transformadores, teniendo como base SpanBERTa
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("scjnugacj/jurisbert")
model = AutoModel.from_pretrained("scjnugacj/jurisbert")
```
```python
from transformers import pipeline
fill_mask = pipeline(
"fill-mask",
model="scjnugacj/jurisbert",
tokenizer="scjnugacj/jurisbert"
)
fill_mask("interés superior del <mask>.")
[
{
"score": 0.941512405872345,
"token": 3152,
"token_str": " menor",
"sequence": "interés superior del menor"
},
{
"score": 0.046888645738363266,
"token": 3337,
"token_str": " niño",
"sequence": "interés superior del niño"
},
{
"score": 0.004166217986494303,
"token": 9386,
"token_str": " adolescente",
"sequence": "interés superior del adolescente"
},
{
"score": 0.0008063237182796001,
"token": 4914,
"token_str": " menores",
"sequence": "interés superior del menores"
},
{
"score": 0.0006806919700466096,
"token": 48133,
"token_str": " infante",
"sequence": "interés superior del infante"
}
]
```
# Términos de uso
Al descargar este modelo usted ha aceptado quedar vinculado por los términos establecidos en este aviso legal. El propietario del modelo se reserva el derecho de enmendar, modificar o sustituir estos términos de uso en cualquier momento y sin previo aviso.
Cuando una persona o entidad despliegue o proporcione sistemas, servicios, y/o cualquier tecnología a terceros usando este modelo y/o alguno derivado del mismo, deben tener en cuenta que es su responsabilidad mitigar los riesgos derivados de su uso y cumplir con la normativa aplicable en todo momento.
En ningún caso el propietario de los modelos (SCJN – Suprema Corte de Justicia de la Nación) ni la ( UGACJ - Unidad General de Administración del Conocimiento Juridico) serán responsables de los resultados derivados del uso que se de a estos modelos.
## Uso previsto
Este modelo fue creado con la finalidad de que cualquier persona o institución pueda crear herramientas de consulta de información jurídica del Estado Mexicano basados en modelos de lenguaje.
|
openclimatefix/nowcasting_cnn_v4 | ddc9e15dbd57e2a55e84b0fa50d2349a6cef8f5f | 2022-07-29T13:17:48.000Z | [
"pytorch",
"transformers",
"nowcasting",
"forecasting",
"timeseries",
"remote-sensing",
"license:mit"
] | null | false | openclimatefix | null | openclimatefix/nowcasting_cnn_v4 | 960 | null | transformers | 1,795 | ---
license: mit
tags:
- nowcasting
- forecasting
- timeseries
- remote-sensing
---
# Nowcasting CNN
## Model description
3d conv model, that takes in different data streams
architecture is roughly
1. satellite image time series goes into many 3d convolution layers.
2. nwp time series goes into many 3d convolution layers.
3. Final convolutional layer goes to full connected layer. This is joined by
other data inputs like
- pv yield
- time variables
Then there ~4 fully connected layers which end up forecasting the
pv yield / gsp into the future
## Intended uses & limitations
Forecasting short term PV power for different regions and nationally in the UK
## How to use
[More information needed]
## Limitations and bias
[More information needed]
## Training data
Training data is EUMETSAT RSS imagery over the UK, on-the-ground PV data, and NWP predictions.
## Training procedure
[More information needed]
## Evaluation results
[More information needed]
|
PlanTL-GOB-ES/roberta-base-bne-sqac | 5c5f5de339fb28fbc7d44d417a00fc22e3df3dfd | 2022-04-06T14:43:44.000Z | [
"pytorch",
"roberta",
"question-answering",
"es",
"dataset:PlanTL-GOB-ES/SQAC",
"arxiv:1907.11692",
"arxiv:2107.07253",
"transformers",
"national library of spain",
"spanish",
"bne",
"qa",
"question answering",
"license:apache-2.0",
"autotrain_compatible"
] | question-answering | false | PlanTL-GOB-ES | null | PlanTL-GOB-ES/roberta-base-bne-sqac | 959 | 1 | transformers | 1,796 | ---
language:
- es
license: apache-2.0
tags:
- "national library of spain"
- "spanish"
- "bne"
- "qa"
- "question answering"
datasets:
- "PlanTL-GOB-ES/SQAC"
metrics:
- "f1"
---
# Spanish RoBERTa-base trained on BNE finetuned for Spanish Question Answering Corpus (SQAC) dataset.
RoBERTa-base-bne is a transformer-based masked language model for the Spanish language. It is based on the [RoBERTa](https://arxiv.org/abs/1907.11692) base model and has been pre-trained using the largest Spanish corpus known to date, with a total of 570GB of clean and deduplicated text processed for this work, compiled from the web crawlings performed by the [National Library of Spain (Biblioteca Nacional de España)](http://www.bne.es/en/Inicio/index.html) from 2009 to 2019.
Original pre-trained model can be found here: https://huggingface.co/PlanTL-GOB-ES/roberta-base-bne
## Dataset
The dataset used is the [SQAC corpus](https://huggingface.co/datasets/PlanTL-GOB-ES/SQAC).
## Evaluation and results
F1 Score: 0.7923 (average of 5 runs).
For evaluation details visit our [GitHub repository](https://github.com/PlanTL-GOB-ES/lm-spanish).
## Citing
Check out our paper for all the details: https://arxiv.org/abs/2107.07253
```
@article{gutierrezfandino2022,
author = {Asier Gutiérrez-Fandiño and Jordi Armengol-Estapé and Marc Pàmies and Joan Llop-Palao and Joaquin Silveira-Ocampo and Casimiro Pio Carrino and Carme Armentano-Oller and Carlos Rodriguez-Penagos and Aitor Gonzalez-Agirre and Marta Villegas},
title = {MarIA: Spanish Language Models},
journal = {Procesamiento del Lenguaje Natural},
volume = {68},
number = {0},
year = {2022},
issn = {1989-7553},
url = {http://journal.sepln.org/sepln/ojs/ojs/index.php/pln/article/view/6405},
pages = {39--60}
}
```
## Funding
This work was partially funded by the Spanish State Secretariat for Digitalization and Artificial Intelligence (SEDIA) within the framework of the Plan-TL, and the Future of Computing Center, a Barcelona Supercomputing Center and IBM initiative (2020).
## Disclaimer
The models published in this repository are intended for a generalist purpose and are available to third parties. These models may have bias and/or any other undesirable distortions.
When third parties, deploy or provide systems and/or services to other parties using any of these models (or using systems based on these models) or become users of the models, they should note that it is their responsibility to mitigate the risks arising from their use and, in any event, to comply with applicable regulations, including regulations regarding the use of artificial intelligence.
In no event shall the owner of the models (SEDIA – State Secretariat for digitalization and artificial intelligence) nor the creator (BSC – Barcelona Supercomputing Center) be liable for any results arising from the use made by third parties of these models.
Los modelos publicados en este repositorio tienen una finalidad generalista y están a disposición de terceros. Estos modelos pueden tener sesgos y/u otro tipo de distorsiones indeseables.
Cuando terceros desplieguen o proporcionen sistemas y/o servicios a otras partes usando alguno de estos modelos (o utilizando sistemas basados en estos modelos) o se conviertan en usuarios de los modelos, deben tener en cuenta que es su responsabilidad mitigar los riesgos derivados de su uso y, en todo caso, cumplir con la normativa aplicable, incluyendo la normativa en materia de uso de inteligencia artificial.
En ningún caso el propietario de los modelos (SEDIA – Secretaría de Estado de Digitalización e Inteligencia Artificial) ni el creador (BSC – Barcelona Supercomputing Center) serán responsables de los resultados derivados del uso que hagan terceros de estos modelos. |
GanjinZero/biobart-large | 74039cd67ada5928ea75fe24abd77656c7661276 | 2022-04-25T02:17:27.000Z | [
"pytorch",
"bart",
"text2text-generation",
"en",
"arxiv:2204.03905",
"transformers",
"biobart",
"biomedical",
"license:apache-2.0",
"autotrain_compatible"
] | text2text-generation | false | GanjinZero | null | GanjinZero/biobart-large | 958 | 1 | transformers | 1,797 | ---
language:
- en
license: apache-2.0
tags:
- bart
- biobart
- biomedical
inference: true
widget:
- text: "Influenza is a <mask> disease."
- type: "text-generation"
---
Paper: [BioBART: Pretraining and Evaluation of A Biomedical Generative Language Model](https://arxiv.org/pdf/2204.03905.pdf)
```
@misc{BioBART,
title={BioBART: Pretraining and Evaluation of A Biomedical Generative Language Model},
author={Hongyi Yuan and Zheng Yuan and Ruyi Gan and Jiaxing Zhang and Yutao Xie and Sheng Yu},
year={2022},
eprint={2204.03905},
archivePrefix={arXiv}
}
``` |
cross-encoder/qnli-distilroberta-base | c7102de981e15ca7ef131517b94ff770d9e3c166 | 2021-08-05T08:41:18.000Z | [
"pytorch",
"jax",
"roberta",
"text-classification",
"arxiv:1804.07461",
"transformers",
"license:apache-2.0"
] | text-classification | false | cross-encoder | null | cross-encoder/qnli-distilroberta-base | 956 | null | transformers | 1,798 | ---
license: apache-2.0
---
# Cross-Encoder for Quora Duplicate Questions Detection
This model was trained using [SentenceTransformers](https://sbert.net) [Cross-Encoder](https://www.sbert.net/examples/applications/cross-encoder/README.html) class.
## Training Data
Given a question and paragraph, can the question be answered by the paragraph? The models have been trained on the [GLUE QNLI](https://arxiv.org/abs/1804.07461) dataset, which transformed the [SQuAD dataset](https://rajpurkar.github.io/SQuAD-explorer/) into an NLI task.
## Performance
For performance results of this model, see [SBERT.net Pre-trained Cross-Encoder][https://www.sbert.net/docs/pretrained_cross-encoders.html].
## Usage
Pre-trained models can be used like this:
```python
from sentence_transformers import CrossEncoder
model = CrossEncoder('model_name')
scores = model.predict([('Query1', 'Paragraph1'), ('Query2', 'Paragraph2')])
#e.g.
scores = model.predict([('How many people live in Berlin?', 'Berlin had a population of 3,520,031 registered inhabitants in an area of 891.82 square kilometers.'), ('What is the size of New York?', 'New York City is famous for the Metropolitan Museum of Art.')])
```
## Usage with Transformers AutoModel
You can use the model also directly with Transformers library (without SentenceTransformers library):
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
model = AutoModelForSequenceClassification.from_pretrained('model_name')
tokenizer = AutoTokenizer.from_pretrained('model_name')
features = tokenizer(['How many people live in Berlin?', 'What is the size of New York?'], ['Berlin had a population of 3,520,031 registered inhabitants in an area of 891.82 square kilometers.', 'New York City is famous for the Metropolitan Museum of Art.'], padding=True, truncation=True, return_tensors="pt")
model.eval()
with torch.no_grad():
scores = torch.nn.functional.sigmoid(model(**features).logits)
print(scores)
``` |
Helsinki-NLP/opus-mt-mk-en | 48a6ca1d5f81a873f28dd38eb6f8b1027f23ba2c | 2021-09-10T13:58:00.000Z | [
"pytorch",
"marian",
"text2text-generation",
"mk",
"en",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] | translation | false | Helsinki-NLP | null | Helsinki-NLP/opus-mt-mk-en | 955 | 1 | transformers | 1,799 | ---
tags:
- translation
license: apache-2.0
---
### opus-mt-mk-en
* source languages: mk
* target languages: en
* OPUS readme: [mk-en](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/mk-en/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2019-12-18.zip](https://object.pouta.csc.fi/OPUS-MT-models/mk-en/opus-2019-12-18.zip)
* test set translations: [opus-2019-12-18.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/mk-en/opus-2019-12-18.test.txt)
* test set scores: [opus-2019-12-18.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/mk-en/opus-2019-12-18.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba.mk.en | 59.8 | 0.720 |
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.