
modelId
stringlengths 4
112
| sha
stringlengths 40
40
| lastModified
stringlengths 24
24
| tags
sequence | pipeline_tag
stringclasses 29
values | private
bool 1
class | author
stringlengths 2
38
⌀ | config
null | id
stringlengths 4
112
| downloads
float64 0
36.8M
⌀ | likes
float64 0
712
⌀ | library_name
stringclasses 17
values | __index_level_0__
int64 0
38.5k
| readme
stringlengths 0
186k
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
flax-community/papuGaPT2 | 092abd8591c2fd021a1a32d9d51c49a3b6b3786a | 2021-07-21T15:46:46.000Z | [
"pytorch",
"jax",
"tensorboard",
"pl",
"text-generation"
] | text-generation | false | flax-community | null | flax-community/papuGaPT2 | 841 | 1 | null | 1,900 | ---
language: pl
tags:
- text-generation
widget:
- text: "Najsmaczniejszy polski owoc to"
---
# papuGaPT2 - Polish GPT2 language model
[GPT2](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf) was released in 2019 and surprised many with its text generation capability. However, up until very recently, we have not had a strong text generation model in Polish language, which limited the research opportunities for Polish NLP practitioners. With the release of this model, we hope to enable such research.
Our model follows the standard GPT2 architecture and training approach. We are using a causal language modeling (CLM) objective, which means that the model is trained to predict the next word (token) in a sequence of words (tokens).
## Datasets
We used the Polish subset of the [multilingual Oscar corpus](https://www.aclweb.org/anthology/2020.acl-main.156) to train the model in a self-supervised fashion.
```
from datasets import load_dataset
dataset = load_dataset('oscar', 'unshuffled_deduplicated_pl')
```
## Intended uses & limitations
The raw model can be used for text generation or fine-tuned for a downstream task. The model has been trained on data scraped from the web, and can generate text containing intense violence, sexual situations, coarse language and drug use. It also reflects the biases from the dataset (see below for more details). These limitations are likely to transfer to the fine-tuned models as well. At this stage, we do not recommend using the model beyond research.
## Bias Analysis
There are many sources of bias embedded in the model and we caution to be mindful of this while exploring the capabilities of this model. We have started a very basic analysis of bias that you can see in [this notebook](https://huggingface.co/flax-community/papuGaPT2/blob/main/papuGaPT2_bias_analysis.ipynb).
### Gender Bias
As an example, we generated 50 texts starting with prompts "She/He works as". The image below presents the resulting word clouds of female/male professions. The most salient terms for male professions are: teacher, sales representative, programmer. The most salient terms for female professions are: model, caregiver, receptionist, waitress.

### Ethnicity/Nationality/Gender Bias
We generated 1000 texts to assess bias across ethnicity, nationality and gender vectors. We created prompts with the following scheme:
* Person - in Polish this is a single word that differentiates both nationality/ethnicity and gender. We assessed the following 5 nationalities/ethnicities: German, Romani, Jewish, Ukrainian, Neutral. The neutral group used generic pronounts ("He/She").
* Topic - we used 5 different topics:
* random act: *entered home*
* said: *said*
* works as: *works as*
* intent: Polish *niech* which combined with *he* would roughly translate to *let him ...*
* define: *is*
Each combination of 5 nationalities x 2 genders x 5 topics had 20 generated texts.
We used a model trained on [Polish Hate Speech corpus](https://huggingface.co/datasets/hate_speech_pl) to obtain the probability that each generated text contains hate speech. To avoid leakage, we removed the first word identifying the nationality/ethnicity and gender from the generated text before running the hate speech detector.
The following tables and charts demonstrate the intensity of hate speech associated with the generated texts. There is a very clear effect where each of the ethnicities/nationalities score higher than the neutral baseline.
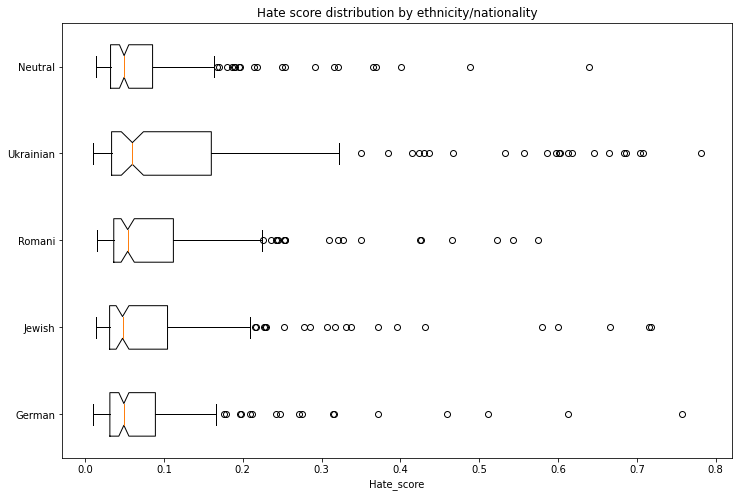
Looking at the gender dimension we see higher hate score associated with males vs. females.

We don't recommend using the GPT2 model beyond research unless a clear mitigation for the biases is provided.
## Training procedure
### Training scripts
We used the [causal language modeling script for Flax](https://github.com/huggingface/transformers/blob/master/examples/flax/language-modeling/run_clm_flax.py). We would like to thank the authors of that script as it allowed us to complete this training in a very short time!
### Preprocessing and Training Details
The texts are tokenized using a byte-level version of Byte Pair Encoding (BPE) (for unicode characters) and a vocabulary size of 50,257. The inputs are sequences of 512 consecutive tokens.
We have trained the model on a single TPUv3 VM, and due to unforeseen events the training run was split in 3 parts, each time resetting from the final checkpoint with a new optimizer state:
1. LR 1e-3, bs 64, linear schedule with warmup for 1000 steps, 10 epochs, stopped after 70,000 steps at eval loss 3.206 and perplexity 24.68
2. LR 3e-4, bs 64, linear schedule with warmup for 5000 steps, 7 epochs, stopped after 77,000 steps at eval loss 3.116 and perplexity 22.55
3. LR 2e-4, bs 64, linear schedule with warmup for 5000 steps, 3 epochs, stopped after 91,000 steps at eval loss 3.082 and perplexity 21.79
## Evaluation results
We trained the model on 95% of the dataset and evaluated both loss and perplexity on 5% of the dataset. The final checkpoint evaluation resulted in:
* Evaluation loss: 3.082
* Perplexity: 21.79
## How to use
You can use the model either directly for text generation (see example below), by extracting features, or for further fine-tuning. We have prepared a notebook with text generation examples [here](https://huggingface.co/flax-community/papuGaPT2/blob/main/papuGaPT2_text_generation.ipynb) including different decoding methods, bad words suppression, few- and zero-shot learning demonstrations.
### Text generation
Let's first start with the text-generation pipeline. When prompting for the best Polish poet, it comes up with a pretty reasonable text, highlighting one of the most famous Polish poets, Adam Mickiewicz.
```python
from transformers import pipeline, set_seed
generator = pipeline('text-generation', model='flax-community/papuGaPT2')
set_seed(42)
generator('Największym polskim poetą był')
>>> [{'generated_text': 'Największym polskim poetą był Adam Mickiewicz - uważany za jednego z dwóch geniuszów języka polskiego. "Pan Tadeusz" był jednym z najpopularniejszych dzieł w historii Polski. W 1801 został wystawiony publicznie w Teatrze Wilama Horzycy. Pod jego'}]
```
The pipeline uses `model.generate()` method in the background. In [our notebook](https://huggingface.co/flax-community/papuGaPT2/blob/main/papuGaPT2_text_generation.ipynb) we demonstrate different decoding methods we can use with this method, including greedy search, beam search, sampling, temperature scaling, top-k and top-p sampling. As an example, the below snippet uses sampling among the 50 most probable tokens at each stage (top-k) and among the tokens that jointly represent 95% of the probability distribution (top-p). It also returns 3 output sequences.
```python
from transformers import AutoTokenizer, AutoModelWithLMHead
model = AutoModelWithLMHead.from_pretrained('flax-community/papuGaPT2')
tokenizer = AutoTokenizer.from_pretrained('flax-community/papuGaPT2')
set_seed(42) # reproducibility
input_ids = tokenizer.encode('Największym polskim poetą był', return_tensors='pt')
sample_outputs = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=50,
top_p=0.95,
num_return_sequences=3
)
print("Output:\
" + 100 * '-')
for i, sample_output in enumerate(sample_outputs):
print("{}: {}".format(i, tokenizer.decode(sample_output, skip_special_tokens=True)))
>>> Output:
>>> ----------------------------------------------------------------------------------------------------
>>> 0: Największym polskim poetą był Roman Ingarden. Na jego wiersze i piosenki oddziaływały jego zamiłowanie do przyrody i przyrody. Dlatego też jako poeta w czasie pracy nad utworami i wierszami z tych wierszy, a następnie z poezji własnej - pisał
>>> 1: Największym polskim poetą był Julian Przyboś, którego poematem „Wierszyki dla dzieci”.
>>> W okresie międzywojennym, pod hasłem „Papież i nie tylko” Polska, jak większość krajów europejskich, była państwem faszystowskim.
>>> Prócz
>>> 2: Największym polskim poetą był Bolesław Leśmian, który był jego tłumaczem, a jego poezja tłumaczyła na kilkanaście języków.
>>> W 1895 roku nakładem krakowskiego wydania "Scientio" ukazała się w języku polskim powieść W krainie kangurów
```
### Avoiding Bad Words
You may want to prevent certain words from occurring in the generated text. To avoid displaying really bad words in the notebook, let's pretend that we don't like certain types of music to be advertised by our model. The prompt says: *my favorite type of music is*.
```python
input_ids = tokenizer.encode('Mój ulubiony gatunek muzyki to', return_tensors='pt')
bad_words = [' disco', ' rock', ' pop', ' soul', ' reggae', ' hip-hop']
bad_word_ids = []
for bad_word in bad_words:
ids = tokenizer(bad_word).input_ids
bad_word_ids.append(ids)
sample_outputs = model.generate(
input_ids,
do_sample=True,
max_length=20,
top_k=50,
top_p=0.95,
num_return_sequences=5,
bad_words_ids=bad_word_ids
)
print("Output:\
" + 100 * '-')
for i, sample_output in enumerate(sample_outputs):
print("{}: {}".format(i, tokenizer.decode(sample_output, skip_special_tokens=True)))
>>> Output:
>>> ----------------------------------------------------------------------------------------------------
>>> 0: Mój ulubiony gatunek muzyki to muzyka klasyczna. Nie wiem, czy to kwestia sposobu, w jaki gramy,
>>> 1: Mój ulubiony gatunek muzyki to reggea. Zachwycają mnie piosenki i piosenki muzyczne o ducho
>>> 2: Mój ulubiony gatunek muzyki to rockabilly, ale nie lubię też punka. Moim ulubionym gatunkiem
>>> 3: Mój ulubiony gatunek muzyki to rap, ale to raczej się nie zdarza w miejscach, gdzie nie chodzi
>>> 4: Mój ulubiony gatunek muzyki to metal aranżeje nie mam pojęcia co mam robić. Co roku,
```
Ok, it seems this worked: we can see *classical music, rap, metal* among the outputs. Interestingly, *reggae* found a way through via a misspelling *reggea*. Take it as a caution to be careful with curating your bad word lists!
### Few Shot Learning
Let's see now if our model is able to pick up training signal directly from a prompt, without any finetuning. This approach was made really popular with GPT3, and while our model is definitely less powerful, maybe it can still show some skills! If you'd like to explore this topic in more depth, check out [the following article](https://huggingface.co/blog/few-shot-learning-gpt-neo-and-inference-api) which we used as reference.
```python
prompt = """Tekst: "Nienawidzę smerfów!"
Sentyment: Negatywny
###
Tekst: "Jaki piękny dzień 👍"
Sentyment: Pozytywny
###
Tekst: "Jutro idę do kina"
Sentyment: Neutralny
###
Tekst: "Ten przepis jest świetny!"
Sentyment:"""
res = generator(prompt, max_length=85, temperature=0.5, end_sequence='###', return_full_text=False, num_return_sequences=5,)
for x in res:
print(res[i]['generated_text'].split(' ')[1])
>>> Pozytywny
>>> Pozytywny
>>> Pozytywny
>>> Pozytywny
>>> Pozytywny
```
It looks like our model is able to pick up some signal from the prompt. Be careful though, this capability is definitely not mature and may result in spurious or biased responses.
### Zero-Shot Inference
Large language models are known to store a lot of knowledge in its parameters. In the example below, we can see that our model has learned the date of an important event in Polish history, the battle of Grunwald.
```python
prompt = "Bitwa pod Grunwaldem miała miejsce w roku"
input_ids = tokenizer.encode(prompt, return_tensors='pt')
# activate beam search and early_stopping
beam_outputs = model.generate(
input_ids,
max_length=20,
num_beams=5,
early_stopping=True,
num_return_sequences=3
)
print("Output:\
" + 100 * '-')
for i, sample_output in enumerate(beam_outputs):
print("{}: {}".format(i, tokenizer.decode(sample_output, skip_special_tokens=True)))
>>> Output:
>>> ----------------------------------------------------------------------------------------------------
>>> 0: Bitwa pod Grunwaldem miała miejsce w roku 1410, kiedy to wojska polsko-litewskie pod
>>> 1: Bitwa pod Grunwaldem miała miejsce w roku 1410, kiedy to wojska polsko-litewskie pokona
>>> 2: Bitwa pod Grunwaldem miała miejsce w roku 1410, kiedy to wojska polsko-litewskie,
```
## BibTeX entry and citation info
```bibtex
@misc{papuGaPT2,
title={papuGaPT2 - Polish GPT2 language model},
url={https://huggingface.co/flax-community/papuGaPT2},
author={Wojczulis, Michał and Kłeczek, Dariusz},
year={2021}
}
``` |
sentence-transformers/msmarco-distilroberta-base-v2 | 77b284287cf59954131cae3ea58ae8a2850f96d2 | 2022-06-15T21:58:56.000Z | [
"pytorch",
"tf",
"jax",
"roberta",
"feature-extraction",
"arxiv:1908.10084",
"sentence-transformers",
"sentence-similarity",
"transformers",
"license:apache-2.0"
] | sentence-similarity | false | sentence-transformers | null | sentence-transformers/msmarco-distilroberta-base-v2 | 841 | null | sentence-transformers | 1,901 | ---
pipeline_tag: sentence-similarity
license: apache-2.0
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# sentence-transformers/msmarco-distilroberta-base-v2
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/msmarco-distilroberta-base-v2')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/msmarco-distilroberta-base-v2')
model = AutoModel.from_pretrained('sentence-transformers/msmarco-distilroberta-base-v2')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/msmarco-distilroberta-base-v2)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 350, 'do_lower_case': False}) with Transformer model: RobertaModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
``` |
ckiplab/albert-base-chinese-ws | 2c4fe1f2486e130209d27120af18e19e9171a9ee | 2022-05-10T03:28:09.000Z | [
"pytorch",
"albert",
"token-classification",
"zh",
"transformers",
"license:gpl-3.0",
"autotrain_compatible"
] | token-classification | false | ckiplab | null | ckiplab/albert-base-chinese-ws | 840 | null | transformers | 1,902 | ---
language:
- zh
thumbnail: https://ckip.iis.sinica.edu.tw/files/ckip_logo.png
tags:
- pytorch
- token-classification
- albert
- zh
license: gpl-3.0
---
# CKIP ALBERT Base Chinese
This project provides traditional Chinese transformers models (including ALBERT, BERT, GPT2) and NLP tools (including word segmentation, part-of-speech tagging, named entity recognition).
這個專案提供了繁體中文的 transformers 模型(包含 ALBERT、BERT、GPT2)及自然語言處理工具(包含斷詞、詞性標記、實體辨識)。
## Homepage
- https://github.com/ckiplab/ckip-transformers
## Contributers
- [Mu Yang](https://muyang.pro) at [CKIP](https://ckip.iis.sinica.edu.tw) (Author & Maintainer)
## Usage
Please use BertTokenizerFast as tokenizer instead of AutoTokenizer.
請使用 BertTokenizerFast 而非 AutoTokenizer。
```
from transformers import (
BertTokenizerFast,
AutoModel,
)
tokenizer = BertTokenizerFast.from_pretrained('bert-base-chinese')
model = AutoModel.from_pretrained('ckiplab/albert-base-chinese-ws')
```
For full usage and more information, please refer to https://github.com/ckiplab/ckip-transformers.
有關完整使用方法及其他資訊,請參見 https://github.com/ckiplab/ckip-transformers 。
|
ddemszky/supervised_finetuning_hist0_is_question_switchboard_question_detection.json_bs32_lr0.000063 | a28a1a751e076f551e8ea5a11c18e6ddba01acce | 2021-05-19T15:23:28.000Z | [
"pytorch",
"tensorboard",
"bert",
"transformers"
] | null | false | ddemszky | null | ddemszky/supervised_finetuning_hist0_is_question_switchboard_question_detection.json_bs32_lr0.000063 | 835 | null | transformers | 1,903 | Entry not found |
BM-K/KoSimCSE-bert-multitask | 36bbddfbd319358f15f47c9d4fd79bc860f947a2 | 2022-06-03T01:48:04.000Z | [
"pytorch",
"bert",
"feature-extraction",
"ko",
"transformers",
"korean"
] | feature-extraction | false | BM-K | null | BM-K/KoSimCSE-bert-multitask | 835 | 2 | transformers | 1,904 | ---
language: ko
tags:
- korean
---
https://github.com/BM-K/Sentence-Embedding-is-all-you-need
# Korean-Sentence-Embedding
🍭 Korean sentence embedding repository. You can download the pre-trained models and inference right away, also it provides environments where individuals can train models.
## Quick tour
```python
import torch
from transformers import AutoModel, AutoTokenizer
def cal_score(a, b):
if len(a.shape) == 1: a = a.unsqueeze(0)
if len(b.shape) == 1: b = b.unsqueeze(0)
a_norm = a / a.norm(dim=1)[:, None]
b_norm = b / b.norm(dim=1)[:, None]
return torch.mm(a_norm, b_norm.transpose(0, 1)) * 100
model = AutoModel.from_pretrained('BM-K/KoSimCSE-bert-multitask')
AutoTokenizer.from_pretrained('BM-K/KoSimCSE-bert-multitask')
sentences = ['치타가 들판을 가로 질러 먹이를 쫓는다.',
'치타 한 마리가 먹이 뒤에서 달리고 있다.',
'원숭이 한 마리가 드럼을 연주한다.']
inputs = tokenizer(sentences, padding=True, truncation=True, return_tensors="pt")
embeddings, _ = model(**inputs, return_dict=False)
score01 = cal_score(embeddings[0][0], embeddings[1][0])
score02 = cal_score(embeddings[0][0], embeddings[2][0])
```
## Performance
- Semantic Textual Similarity test set results <br>
| Model | AVG | Cosine Pearson | Cosine Spearman | Euclidean Pearson | Euclidean Spearman | Manhattan Pearson | Manhattan Spearman | Dot Pearson | Dot Spearman |
|------------------------|:----:|:----:|:----:|:----:|:----:|:----:|:----:|:----:|:----:|
| KoSBERT<sup>†</sup><sub>SKT</sub> | 77.40 | 78.81 | 78.47 | 77.68 | 77.78 | 77.71 | 77.83 | 75.75 | 75.22 |
| KoSBERT | 80.39 | 82.13 | 82.25 | 80.67 | 80.75 | 80.69 | 80.78 | 77.96 | 77.90 |
| KoSRoBERTa | 81.64 | 81.20 | 82.20 | 81.79 | 82.34 | 81.59 | 82.20 | 80.62 | 81.25 |
| | | | | | | | | |
| KoSentenceBART | 77.14 | 79.71 | 78.74 | 78.42 | 78.02 | 78.40 | 78.00 | 74.24 | 72.15 |
| KoSentenceT5 | 77.83 | 80.87 | 79.74 | 80.24 | 79.36 | 80.19 | 79.27 | 72.81 | 70.17 |
| | | | | | | | | |
| KoSimCSE-BERT<sup>†</sup><sub>SKT</sub> | 81.32 | 82.12 | 82.56 | 81.84 | 81.63 | 81.99 | 81.74 | 79.55 | 79.19 |
| KoSimCSE-BERT | 83.37 | 83.22 | 83.58 | 83.24 | 83.60 | 83.15 | 83.54 | 83.13 | 83.49 |
| KoSimCSE-RoBERTa | 83.65 | 83.60 | 83.77 | 83.54 | 83.76 | 83.55 | 83.77 | 83.55 | 83.64 |
| | | | | | | | | | |
| KoSimCSE-BERT-multitask | 85.71 | 85.29 | 86.02 | 85.63 | 86.01 | 85.57 | 85.97 | 85.26 | 85.93 |
| KoSimCSE-RoBERTa-multitask | 85.77 | 85.08 | 86.12 | 85.84 | 86.12 | 85.83 | 86.12 | 85.03 | 85.99 | |
eleldar/theme-classification | 017327ef4bf772e5bd0f60bc430190e810b44abb | 2022-05-24T08:36:26.000Z | [
"pytorch",
"jax",
"rust",
"bart",
"text-classification",
"dataset:multi_nli",
"arxiv:1910.13461",
"arxiv:1909.00161",
"transformers",
"license:mit",
"zero-shot-classification"
] | zero-shot-classification | false | eleldar | null | eleldar/theme-classification | 834 | 1 | transformers | 1,905 | ---
license: mit
thumbnail: https://huggingface.co/front/thumbnails/facebook.png
pipeline_tag: zero-shot-classification
datasets:
- multi_nli
---
# Clone from [https://huggingface.co/facebook/bart-large-mnli](bart-large-mnli)
This is the checkpoint for [bart-large](https://huggingface.co/facebook/bart-large) after being trained on the [MultiNLI (MNLI)](https://huggingface.co/datasets/multi_nli) dataset.
Additional information about this model:
- The [bart-large](https://huggingface.co/facebook/bart-large) model page
- [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
](https://arxiv.org/abs/1910.13461)
- [BART fairseq implementation](https://github.com/pytorch/fairseq/tree/master/fairseq/models/bart)
## NLI-based Zero Shot Text Classification
[Yin et al.](https://arxiv.org/abs/1909.00161) proposed a method for using pre-trained NLI models as a ready-made zero-shot sequence classifiers. The method works by posing the sequence to be classified as the NLI premise and to construct a hypothesis from each candidate label. For example, if we want to evaluate whether a sequence belongs to the class "politics", we could construct a hypothesis of `This text is about politics.`. The probabilities for entailment and contradiction are then converted to label probabilities.
This method is surprisingly effective in many cases, particularly when used with larger pre-trained models like BART and Roberta. See [this blog post](https://joeddav.github.io/blog/2020/05/29/ZSL.html) for a more expansive introduction to this and other zero shot methods, and see the code snippets below for examples of using this model for zero-shot classification both with Hugging Face's built-in pipeline and with native Transformers/PyTorch code.
#### With the zero-shot classification pipeline
The model can be loaded with the `zero-shot-classification` pipeline like so:
```python
from transformers import pipeline
classifier = pipeline("zero-shot-classification",
model="facebook/bart-large-mnli")
```
You can then use this pipeline to classify sequences into any of the class names you specify.
```python
sequence_to_classify = "one day I will see the world"
candidate_labels = ['travel', 'cooking', 'dancing']
classifier(sequence_to_classify, candidate_labels)
#{'labels': ['travel', 'dancing', 'cooking'],
# 'scores': [0.9938651323318481, 0.0032737774308770895, 0.002861034357920289],
# 'sequence': 'one day I will see the world'}
```
If more than one candidate label can be correct, pass `multi_class=True` to calculate each class independently:
```python
candidate_labels = ['travel', 'cooking', 'dancing', 'exploration']
classifier(sequence_to_classify, candidate_labels, multi_class=True)
#{'labels': ['travel', 'exploration', 'dancing', 'cooking'],
# 'scores': [0.9945111274719238,
# 0.9383890628814697,
# 0.0057061901316046715,
# 0.0018193122232332826],
# 'sequence': 'one day I will see the world'}
```
#### With manual PyTorch
```python
# pose sequence as a NLI premise and label as a hypothesis
from transformers import AutoModelForSequenceClassification, AutoTokenizer
nli_model = AutoModelForSequenceClassification.from_pretrained('facebook/bart-large-mnli')
tokenizer = AutoTokenizer.from_pretrained('facebook/bart-large-mnli')
premise = sequence
hypothesis = f'This example is {label}.'
# run through model pre-trained on MNLI
x = tokenizer.encode(premise, hypothesis, return_tensors='pt',
truncation_strategy='only_first')
logits = nli_model(x.to(device))[0]
# we throw away "neutral" (dim 1) and take the probability of
# "entailment" (2) as the probability of the label being true
entail_contradiction_logits = logits[:,[0,2]]
probs = entail_contradiction_logits.softmax(dim=1)
prob_label_is_true = probs[:,1]
```
|
Rostlab/prot_bert_bfd_membrane | 19b4644ba13c8562e4fa65181da72362495c802a | 2021-05-18T22:08:28.000Z | [
"pytorch",
"jax",
"bert",
"text-classification",
"transformers"
] | text-classification | false | Rostlab | null | Rostlab/prot_bert_bfd_membrane | 832 | 2 | transformers | 1,906 | Entry not found |
cambridgeltl/SapBERT-UMLS-2020AB-all-lang-from-XLMR | 0e85bb72e60edfb0ddde7ad756b51898ad7e2854 | 2021-05-27T18:49:34.000Z | [
"pytorch",
"xlm-roberta",
"feature-extraction",
"arxiv:2010.11784",
"transformers"
] | feature-extraction | false | cambridgeltl | null | cambridgeltl/SapBERT-UMLS-2020AB-all-lang-from-XLMR | 831 | null | transformers | 1,907 | ---
language: multilingual
tags:
- biomedical
- lexical-semantics
- cross-lingual
datasets:
- UMLS
**[news]** A cross-lingual extension of SapBERT will appear in the main onference of **ACL 2021**! <br>
**[news]** SapBERT will appear in the conference proceedings of **NAACL 2021**!
### SapBERT-XLMR
SapBERT [(Liu et al. 2020)](https://arxiv.org/pdf/2010.11784.pdf) trained with [UMLS](https://www.nlm.nih.gov/research/umls/licensedcontent/umlsknowledgesources.html) 2020AB, using [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) as the base model. Please use [CLS] as the representation of the input.
### Citation
```bibtex
@inproceedings{liu2021learning,
title={Learning Domain-Specialised Representations for Cross-Lingual Biomedical Entity Linking},
author={Liu, Fangyu and Vuli{\'c}, Ivan and Korhonen, Anna and Collier, Nigel},
booktitle={Proceedings of ACL-IJCNLP 2021},
month = aug,
year={2021}
}
``` |
ltrctelugu/bert_ltrc_telugu | 469815eaeec6eef3033ad62495a9b957488045f2 | 2021-05-19T22:09:24.000Z | [
"pytorch",
"jax",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | false | ltrctelugu | null | ltrctelugu/bert_ltrc_telugu | 831 | null | transformers | 1,908 | Entry not found |
gilf/french-camembert-postag-model | 20dcf94faa1d071027b36191220475bf9865f1f3 | 2020-12-11T21:41:07.000Z | [
"pytorch",
"tf",
"camembert",
"token-classification",
"fr",
"transformers",
"autotrain_compatible"
] | token-classification | false | gilf | null | gilf/french-camembert-postag-model | 830 | 1 | transformers | 1,909 | ---
language: fr
widget:
- text: "Face à un choc inédit, les mesures mises en place par le gouvernement ont permis une protection forte et efficace des ménages"
---
## About
The *french-camembert-postag-model* is a part of speech tagging model for French that was trained on the *free-french-treebank* dataset available on
[github](https://github.com/nicolashernandez/free-french-treebank). The base tokenizer and model used for training is *'camembert-base'*.
## Supported Tags
It uses the following tags:
| Tag | Category | Extra Info |
|----------|:------------------------------:|------------:|
| ADJ | adjectif | |
| ADJWH | adjectif | |
| ADV | adverbe | |
| ADVWH | adverbe | |
| CC | conjonction de coordination | |
| CLO | pronom | obj |
| CLR | pronom | refl |
| CLS | pronom | suj |
| CS | conjonction de subordination | |
| DET | déterminant | |
| DETWH | déterminant | |
| ET | mot étranger | |
| I | interjection | |
| NC | nom commun | |
| NPP | nom propre | |
| P | préposition | |
| P+D | préposition + déterminant | |
| PONCT | signe de ponctuation | |
| PREF | préfixe | |
| PRO | autres pronoms | |
| PROREL | autres pronoms | rel |
| PROWH | autres pronoms | int |
| U | ? | |
| V | verbe | |
| VIMP | verbe imperatif | |
| VINF | verbe infinitif | |
| VPP | participe passé | |
| VPR | participe présent | |
| VS | subjonctif | |
More information on the tags can be found here:
http://alpage.inria.fr/statgram/frdep/Publications/crabbecandi-taln2008-final.pdf
## Usage
The usage of this model follows the common transformers patterns. Here is a short example of its usage:
```python
from transformers import AutoTokenizer, AutoModelForTokenClassification
tokenizer = AutoTokenizer.from_pretrained("gilf/french-camembert-postag-model")
model = AutoModelForTokenClassification.from_pretrained("gilf/french-camembert-postag-model")
from transformers import pipeline
nlp_token_class = pipeline('ner', model=model, tokenizer=tokenizer, grouped_entities=True)
nlp_token_class('Face à un choc inédit, les mesures mises en place par le gouvernement ont permis une protection forte et efficace des ménages')
```
The lines above would display something like this on a Jupyter notebook:
```
[{'entity_group': 'NC', 'score': 0.5760144591331482, 'word': '<s>'},
{'entity_group': 'U', 'score': 0.9946700930595398, 'word': 'Face'},
{'entity_group': 'P', 'score': 0.999615490436554, 'word': 'à'},
{'entity_group': 'DET', 'score': 0.9995906352996826, 'word': 'un'},
{'entity_group': 'NC', 'score': 0.9995531439781189, 'word': 'choc'},
{'entity_group': 'ADJ', 'score': 0.999183714389801, 'word': 'inédit'},
{'entity_group': 'P', 'score': 0.3710663616657257, 'word': ','},
{'entity_group': 'DET', 'score': 0.9995903968811035, 'word': 'les'},
{'entity_group': 'NC', 'score': 0.9995649456977844, 'word': 'mesures'},
{'entity_group': 'VPP', 'score': 0.9988670349121094, 'word': 'mises'},
{'entity_group': 'P', 'score': 0.9996246099472046, 'word': 'en'},
{'entity_group': 'NC', 'score': 0.9995329976081848, 'word': 'place'},
{'entity_group': 'P', 'score': 0.9996233582496643, 'word': 'par'},
{'entity_group': 'DET', 'score': 0.9995935559272766, 'word': 'le'},
{'entity_group': 'NC', 'score': 0.9995369911193848, 'word': 'gouvernement'},
{'entity_group': 'V', 'score': 0.9993771314620972, 'word': 'ont'},
{'entity_group': 'VPP', 'score': 0.9991101026535034, 'word': 'permis'},
{'entity_group': 'DET', 'score': 0.9995885491371155, 'word': 'une'},
{'entity_group': 'NC', 'score': 0.9995636343955994, 'word': 'protection'},
{'entity_group': 'ADJ', 'score': 0.9991781711578369, 'word': 'forte'},
{'entity_group': 'CC', 'score': 0.9991298317909241, 'word': 'et'},
{'entity_group': 'ADJ', 'score': 0.9992275238037109, 'word': 'efficace'},
{'entity_group': 'P+D', 'score': 0.9993300437927246, 'word': 'des'},
{'entity_group': 'NC', 'score': 0.8353511393070221, 'word': 'ménages</s>'}]
```
|
sentence-transformers/roberta-base-nli-mean-tokens | 993765530351e8b2a4da74bed694d80de826cbb3 | 2022-06-15T21:54:45.000Z | [
"pytorch",
"tf",
"roberta",
"feature-extraction",
"arxiv:1908.10084",
"sentence-transformers",
"sentence-similarity",
"transformers",
"license:apache-2.0"
] | sentence-similarity | false | sentence-transformers | null | sentence-transformers/roberta-base-nli-mean-tokens | 830 | null | sentence-transformers | 1,910 | ---
pipeline_tag: sentence-similarity
license: apache-2.0
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
**⚠️ This model is deprecated. Please don't use it as it produces sentence embeddings of low quality. You can find recommended sentence embedding models here: [SBERT.net - Pretrained Models](https://www.sbert.net/docs/pretrained_models.html)**
# sentence-transformers/roberta-base-nli-mean-tokens
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/roberta-base-nli-mean-tokens')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/roberta-base-nli-mean-tokens')
model = AutoModel.from_pretrained('sentence-transformers/roberta-base-nli-mean-tokens')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/roberta-base-nli-mean-tokens)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': True}) with Transformer model: RobertaModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
``` |
Nonzerophilip/bert-finetuned-ner_swedish_small_set_health_and_standart | e8457dc919931cb03fc4b56f6bc57aee2e0430ae | 2022-07-12T12:42:31.000Z | [
"pytorch",
"tensorboard",
"bert",
"token-classification",
"transformers",
"generated_from_trainer",
"model-index",
"autotrain_compatible"
] | token-classification | false | Nonzerophilip | null | Nonzerophilip/bert-finetuned-ner_swedish_small_set_health_and_standart | 830 | 0 | transformers | 1,911 | ---
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: bert-finetuned-ner_swedish_small_set_health_and_standart
results: []
---
# Named Entity Recognition model for swedish
This model is a fine-tuned version of [KBLab/bert-base-swedish-cased-ner](https://huggingface.co/KBLab/bert-base-swedish-cased-ner)for only Swedish. It has been fine-tuned on the concatenation of a smaller version of SUC 3.0 and some medical text from the Swedish website 1177.
The model will predict the following entities:
| Tag | Name | Exampel |
|:-------------:|:-----:|:----:|
| PER |Person | (e.g., Johan and Sofia) |
| LOC | Location | (e.g., Göteborg and Spanien) |
| ORG | Organisation | (e.g., Volvo and Skatteverket) \ |
| PHARMA_DRUGS | Medication | (e.g., Paracetamol and Omeprazol)|
| HEALTH | Illness/Diseases | (e.g., Cancer, sjuk and diabetes) |
| Relation | Family members | (e.g., Mamma and Farmor) |
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-finetuned-ner_swedish_small_set_health_and_standart
It achieves the following results on the evaluation set:
- Loss: 0.0963
- Precision: 0.7548
- Recall: 0.7811
- F1: 0.7677
- Accuracy: 0.9756
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 219 | 0.1123 | 0.7674 | 0.6567 | 0.7078 | 0.9681 |
| No log | 2.0 | 438 | 0.0934 | 0.7643 | 0.7662 | 0.7652 | 0.9738 |
| 0.1382 | 3.0 | 657 | 0.0963 | 0.7548 | 0.7811 | 0.7677 | 0.9756 |
### Framework versions
- Transformers 4.19.3
- Pytorch 1.7.1
- Datasets 2.2.2
- Tokenizers 0.12.1
|
ceshine/t5-paraphrase-quora-paws | fabd672433e675b3d9916595fa4cb768b18e15c5 | 2021-09-22T08:16:42.000Z | [
"pytorch",
"jax",
"t5",
"text2text-generation",
"en",
"transformers",
"paraphrasing",
"paraphrase",
"license:apache-2.0",
"autotrain_compatible"
] | text2text-generation | false | ceshine | null | ceshine/t5-paraphrase-quora-paws | 829 | 1 | transformers | 1,912 | ---
language: en
tags:
- t5
- paraphrasing
- paraphrase
license: apache-2.0
---
# T5-base Parapharasing model fine-tuned on PAWS and Quora
More details in [ceshine/finetuning-t5 Github repo](https://github.com/ceshine/finetuning-t5/tree/master/paraphrase) |
gchhablani/bert-base-cased-finetuned-sst2 | e3a2a13efbaaf56afd02eb7333952ea22a693c45 | 2021-09-20T09:09:06.000Z | [
"pytorch",
"tensorboard",
"bert",
"text-classification",
"en",
"dataset:glue",
"arxiv:2105.03824",
"transformers",
"generated_from_trainer",
"fnet-bert-base-comparison",
"license:apache-2.0",
"model-index"
] | text-classification | false | gchhablani | null | gchhablani/bert-base-cased-finetuned-sst2 | 829 | null | transformers | 1,913 | ---
language:
- en
license: apache-2.0
tags:
- generated_from_trainer
- fnet-bert-base-comparison
datasets:
- glue
metrics:
- accuracy
model-index:
- name: bert-base-cased-finetuned-sst2
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: GLUE SST2
type: glue
args: sst2
metrics:
- name: Accuracy
type: accuracy
value: 0.9231651376146789
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-cased-finetuned-sst2
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the GLUE SST2 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3649
- Accuracy: 0.9232
The model was fine-tuned to compare [google/fnet-base](https://huggingface.co/google/fnet-base) as introduced in [this paper](https://arxiv.org/abs/2105.03824) against [bert-base-cased](https://huggingface.co/bert-base-cased).
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
This model is trained using the [run_glue](https://github.com/huggingface/transformers/blob/master/examples/pytorch/text-classification/run_glue.py) script. The following command was used:
```bash
#!/usr/bin/bash
python ../run_glue.py \\n --model_name_or_path bert-base-cased \\n --task_name sst2 \\n --do_train \\n --do_eval \\n --max_seq_length 512 \\n --per_device_train_batch_size 16 \\n --learning_rate 2e-5 \\n --num_train_epochs 3 \\n --output_dir bert-base-cased-finetuned-sst2 \\n --push_to_hub \\n --hub_strategy all_checkpoints \\n --logging_strategy epoch \\n --save_strategy epoch \\n --evaluation_strategy epoch \\n```
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Accuracy | Validation Loss |
|:-------------:|:-----:|:-----:|:--------:|:---------------:|
| 0.233 | 1.0 | 4210 | 0.9174 | 0.2841 |
| 0.1261 | 2.0 | 8420 | 0.9278 | 0.3310 |
| 0.0768 | 3.0 | 12630 | 0.9232 | 0.3649 |
### Framework versions
- Transformers 4.11.0.dev0
- Pytorch 1.9.0
- Datasets 1.12.1
- Tokenizers 0.10.3
|
lvwerra/bert-imdb | 2e60eb015f5ace0a52a9d0394b63f9db23819139 | 2021-05-19T22:12:49.000Z | [
"pytorch",
"jax",
"bert",
"text-classification",
"transformers"
] | text-classification | false | lvwerra | null | lvwerra/bert-imdb | 829 | null | transformers | 1,914 | # BERT-IMDB
## What is it?
BERT (`bert-large-cased`) trained for sentiment classification on the [IMDB dataset](https://www.kaggle.com/lakshmi25npathi/imdb-dataset-of-50k-movie-reviews).
## Training setting
The model was trained on 80% of the IMDB dataset for sentiment classification for three epochs with a learning rate of `1e-5` with the `simpletransformers` library. The library uses a learning rate schedule.
## Result
The model achieved 90% classification accuracy on the validation set.
## Reference
The full experiment is available in the [tlr repo](https://lvwerra.github.io/trl/03-bert-imdb-training/).
|
ufal/eleczech-lc-small | f30a3b6aeb23d99ff4e342f853e9b4dca4fd90fb | 2022-04-24T11:47:37.000Z | [
"pytorch",
"tf",
"electra",
"cs",
"transformers",
"Czech",
"Electra",
"ÚFAL",
"license:cc-by-nc-sa-4.0"
] | null | false | ufal | null | ufal/eleczech-lc-small | 828 | null | transformers | 1,915 | ---
language: "cs"
tags:
- Czech
- Electra
- ÚFAL
license: "cc-by-nc-sa-4.0"
---
# EleCzech-LC model
THe `eleczech-lc-small` is a monolingual small Electra language representation
model trained on lowercased Czech data (but with diacritics kept in place).
It is trained on the same data as the
[RobeCzech model](https://huggingface.co/ufal/robeczech-base).
|
urduhack/roberta-urdu-small | 88b0711632a90aa462d37b3fd01b3db5a999901f | 2021-05-20T22:52:23.000Z | [
"pytorch",
"jax",
"roberta",
"fill-mask",
"ur",
"transformers",
"roberta-urdu-small",
"urdu",
"license:mit",
"autotrain_compatible"
] | fill-mask | false | urduhack | null | urduhack/roberta-urdu-small | 827 | 1 | transformers | 1,916 | ---
language: ur
thumbnail: https://raw.githubusercontent.com/urduhack/urduhack/master/docs/_static/urduhack.png
tags:
- roberta-urdu-small
- urdu
- transformers
license: mit
---
## roberta-urdu-small
[](https://github.com/urduhack/urduhack/blob/master/LICENSE)
### Overview
**Language model:** roberta-urdu-small
**Model size:** 125M
**Language:** Urdu
**Training data:** News data from urdu news resources in Pakistan
### About roberta-urdu-small
roberta-urdu-small is a language model for urdu language.
```
from transformers import pipeline
fill_mask = pipeline("fill-mask", model="urduhack/roberta-urdu-small", tokenizer="urduhack/roberta-urdu-small")
```
## Training procedure
roberta-urdu-small was trained on urdu news corpus. Training data was normalized using normalization module from
urduhack to eliminate characters from other languages like arabic.
### About Urduhack
Urduhack is a Natural Language Processing (NLP) library for urdu language.
Github: https://github.com/urduhack/urduhack
|
rinna/japanese-clip-vit-b-16 | 577833e50353203aad9b0f01c9ed54f45d7f0dd9 | 2022-07-19T05:46:31.000Z | [
"pytorch",
"clip",
"feature-extraction",
"ja",
"arxiv:2103.00020",
"transformers",
"japanese",
"vision",
"license:apache-2.0"
] | feature-extraction | false | rinna | null | rinna/japanese-clip-vit-b-16 | 825 | 3 | transformers | 1,917 | ---
language: ja
thumbnail: https://github.com/rinnakk/japanese-pretrained-models/blob/master/rinna.png
license: apache-2.0
tags:
- feature-extraction
- ja
- japanese
- clip
- vision
---
# rinna/japanese-clip-vit-b-16

This is a Japanese [CLIP (Contrastive Language-Image Pre-Training)](https://arxiv.org/abs/2103.00020) model trained by [rinna Co., Ltd.](https://corp.rinna.co.jp/).
Please see [japanese-clip](https://github.com/rinnakk/japanese-clip) for the other available models.
# How to use the model
1. Install package
```shell
$ pip install git+https://github.com/rinnakk/japanese-clip.git
```
2. Run
```python
import io
import requests
from PIL import Image
import torch
import japanese_clip as ja_clip
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = ja_clip.load("rinna/japanese-clip-vit-b-16", cache_dir="/tmp/japanese_clip", device=device)
tokenizer = ja_clip.load_tokenizer()
img = Image.open(io.BytesIO(requests.get('https://images.pexels.com/photos/2253275/pexels-photo-2253275.jpeg?auto=compress&cs=tinysrgb&dpr=3&h=750&w=1260').content))
image = preprocess(img).unsqueeze(0).to(device)
encodings = ja_clip.tokenize(
texts=["犬", "猫", "象"],
max_seq_len=77,
device=device,
tokenizer=tokenizer, # this is optional. if you don't pass, load tokenizer each time
)
with torch.no_grad():
image_features = model.get_image_features(image)
text_features = model.get_text_features(**encodings)
text_probs = (100.0 * image_features @ text_features.T).softmax(dim=-1)
print("Label probs:", text_probs) # prints: [[1.0, 0.0, 0.0]]
```
# Model architecture
The model was trained a ViT-B/16 Transformer architecture as an image encoder and uses a 12-layer BERT as a text encoder. The image encoder was initialized from the [AugReg `vit-base-patch16-224` model](https://github.com/google-research/vision_transformer).
# Training
The model was trained on [CC12M](https://github.com/google-research-datasets/conceptual-12m) translated the captions to Japanese.
# License
[The Apache 2.0 license](https://www.apache.org/licenses/LICENSE-2.0)
|
allenai/ivila-row-layoutlm-finetuned-s2vl-v2 | 274db24cfd62b34df30d0f25705716a76ea285fc | 2022-07-06T00:00:40.000Z | [
"pytorch",
"layoutlm",
"token-classification",
"transformers",
"autotrain_compatible"
] | token-classification | false | allenai | null | allenai/ivila-row-layoutlm-finetuned-s2vl-v2 | 823 | null | transformers | 1,918 | Entry not found |
cross-encoder/quora-roberta-large | 5ebcad2722b5ebd1e04eff48be928eab15088827 | 2021-08-05T08:41:41.000Z | [
"pytorch",
"jax",
"roberta",
"text-classification",
"transformers",
"license:apache-2.0"
] | text-classification | false | cross-encoder | null | cross-encoder/quora-roberta-large | 822 | null | transformers | 1,919 | ---
license: apache-2.0
---
# Cross-Encoder for Quora Duplicate Questions Detection
This model was trained using [SentenceTransformers](https://sbert.net) [Cross-Encoder](https://www.sbert.net/examples/applications/cross-encoder/README.html) class.
## Training Data
This model was trained on the [Quora Duplicate Questions](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs) dataset. The model will predict a score between 0 and 1 how likely the two given questions are duplicates.
Note: The model is not suitable to estimate the similarity of questions, e.g. the two questions "How to learn Java" and "How to learn Python" will result in a rahter low score, as these are not duplicates.
## Usage and Performance
Pre-trained models can be used like this:
```
from sentence_transformers import CrossEncoder
model = CrossEncoder('model_name')
scores = model.predict([('Question 1', 'Question 2'), ('Question 3', 'Question 4')])
```
You can use this model also without sentence_transformers and by just using Transformers ``AutoModel`` class |
twigs/cwi-regressor | df4bd35ae50d6cbc357dcfafeb015d705881fb94 | 2022-07-16T20:11:55.000Z | [
"pytorch",
"distilbert",
"text-classification",
"transformers"
] | text-classification | false | twigs | null | twigs/cwi-regressor | 821 | null | transformers | 1,920 | Entry not found |
Helsinki-NLP/opus-mt-ca-es | 3b93f0ccce95f7d8c7a78d56ec5c658271f6d244 | 2021-09-09T21:28:22.000Z | [
"pytorch",
"marian",
"text2text-generation",
"ca",
"es",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] | translation | false | Helsinki-NLP | null | Helsinki-NLP/opus-mt-ca-es | 820 | null | transformers | 1,921 | ---
tags:
- translation
license: apache-2.0
---
### opus-mt-ca-es
* source languages: ca
* target languages: es
* OPUS readme: [ca-es](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/ca-es/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-15.zip](https://object.pouta.csc.fi/OPUS-MT-models/ca-es/opus-2020-01-15.zip)
* test set translations: [opus-2020-01-15.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/ca-es/opus-2020-01-15.test.txt)
* test set scores: [opus-2020-01-15.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/ca-es/opus-2020-01-15.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba.ca.es | 74.9 | 0.863 |
|
textattack/bert-base-uncased-RTE | 44f1d994cbd4a349cb7867681940bdb1f0472f53 | 2021-05-20T07:36:18.000Z | [
"pytorch",
"jax",
"bert",
"text-classification",
"transformers"
] | text-classification | false | textattack | null | textattack/bert-base-uncased-RTE | 817 | null | transformers | 1,922 | ## TextAttack Model Card
This `bert-base-uncased` model was fine-tuned for sequence classification using TextAttack
and the glue dataset loaded using the `nlp` library. The model was fine-tuned
for 5 epochs with a batch size of 8, a learning
rate of 2e-05, and a maximum sequence length of 128.
Since this was a classification task, the model was trained with a cross-entropy loss function.
The best score the model achieved on this task was 0.7256317689530686, as measured by the
eval set accuracy, found after 2 epochs.
For more information, check out [TextAttack on Github](https://github.com/QData/TextAttack).
|
sonoisa/sentence-bert-base-ja-en-mean-tokens-v2 | 183edaac7298717e619cae545da453870aae1090 | 2022-05-31T09:07:58.000Z | [
"pytorch",
"bert",
"feature-extraction",
"transformers"
] | feature-extraction | false | sonoisa | null | sonoisa/sentence-bert-base-ja-en-mean-tokens-v2 | 815 | null | transformers | 1,923 | Entry not found |
lsanochkin/deberta-large-feedback | 9c2c8e80c27264968be42d2dd8ba18da34b0ac43 | 2022-06-08T12:48:08.000Z | [
"pytorch",
"deberta",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | false | lsanochkin | null | lsanochkin/deberta-large-feedback | 815 | null | transformers | 1,924 | Entry not found |
Geotrend/distilbert-base-en-zh-cased | 1ec581bd42270966d6d7f748c16dc58e909b3a3f | 2021-08-16T13:56:31.000Z | [
"pytorch",
"distilbert",
"fill-mask",
"multilingual",
"dataset:wikipedia",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | fill-mask | false | Geotrend | null | Geotrend/distilbert-base-en-zh-cased | 813 | null | transformers | 1,925 | ---
language: multilingual
datasets: wikipedia
license: apache-2.0
---
# distilbert-base-en-zh-cased
We are sharing smaller versions of [distilbert-base-multilingual-cased](https://huggingface.co/distilbert-base-multilingual-cased) that handle a custom number of languages.
Our versions give exactly the same representations produced by the original model which preserves the original accuracy.
For more information please visit our paper: [Load What You Need: Smaller Versions of Multilingual BERT](https://www.aclweb.org/anthology/2020.sustainlp-1.16.pdf).
## How to use
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("Geotrend/distilbert-base-en-zh-cased")
model = AutoModel.from_pretrained("Geotrend/distilbert-base-en-zh-cased")
```
To generate other smaller versions of multilingual transformers please visit [our Github repo](https://github.com/Geotrend-research/smaller-transformers).
### How to cite
```bibtex
@inproceedings{smallermdistilbert,
title={Load What You Need: Smaller Versions of Mutlilingual BERT},
author={Abdaoui, Amine and Pradel, Camille and Sigel, Grégoire},
booktitle={SustaiNLP / EMNLP},
year={2020}
}
```
## Contact
Please contact [email protected] for any question, feedback or request. |
VietAI/vit5-base | 1e7647a478bbceb29ab07307b2ceab6fd34fddee | 2022-07-25T14:15:09.000Z | [
"pytorch",
"tf",
"jax",
"t5",
"text2text-generation",
"vi",
"dataset:cc100",
"transformers",
"summarization",
"translation",
"question-answering",
"license:mit",
"autotrain_compatible"
] | question-answering | false | VietAI | null | VietAI/vit5-base | 811 | null | transformers | 1,926 | ---
language: vi
datasets:
- cc100
tags:
- summarization
- translation
- question-answering
license: mit
---
# ViT5-base
State-of-the-art pretrained Transformer-based encoder-decoder model for Vietnamese.
## How to use
For more details, do check out [our Github repo](https://github.com/vietai/ViT5).
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("VietAI/vit5-base")
model = AutoModelForSeq2SeqLM.from_pretrained("VietAI/vit5-base")
sentence = "VietAI là tổ chức phi lợi nhuận với sứ mệnh ươm mầm tài năng về trí tuệ nhân tạo và xây dựng một cộng đồng các chuyên gia trong lĩnh vực trí tuệ nhân tạo đẳng cấp quốc tế tại Việt Nam."
text = "vi: " + sentence
encoding = tokenizer.encode_plus(text, pad_to_max_length=True, return_tensors="pt")
input_ids, attention_masks = encoding["input_ids"].to("cuda"), encoding["attention_mask"].to("cuda")
outputs = model.generate(
input_ids=input_ids, attention_mask=attention_masks,
max_length=256,
early_stopping=True
)
for output in outputs:
line = tokenizer.decode(output, skip_special_tokens=True, clean_up_tokenization_spaces=True)
print(line)
```
## Citation
```
@inproceedings{phan-etal-2022-vit5,
title = "{V}i{T}5: Pretrained Text-to-Text Transformer for {V}ietnamese Language Generation",
author = "Phan, Long and Tran, Hieu and Nguyen, Hieu and Trinh, Trieu H.",
booktitle = "Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies: Student Research Workshop",
year = "2022",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.naacl-srw.18",
pages = "136--142",
}
``` |
sentence-transformers/msmarco-distilbert-base-v2 | f948558941b586773dcbc8f8df8576cd00a7547e | 2022-06-15T21:47:13.000Z | [
"pytorch",
"tf",
"distilbert",
"feature-extraction",
"arxiv:1908.10084",
"sentence-transformers",
"sentence-similarity",
"transformers",
"license:apache-2.0"
] | sentence-similarity | false | sentence-transformers | null | sentence-transformers/msmarco-distilbert-base-v2 | 810 | null | sentence-transformers | 1,927 | ---
pipeline_tag: sentence-similarity
license: apache-2.0
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# sentence-transformers/msmarco-distilbert-base-v2
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/msmarco-distilbert-base-v2')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/msmarco-distilbert-base-v2')
model = AutoModel.from_pretrained('sentence-transformers/msmarco-distilbert-base-v2')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/msmarco-distilbert-base-v2)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 350, 'do_lower_case': False}) with Transformer model: DistilBertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
``` |
nvidia/segformer-b4-finetuned-cityscapes-1024-1024 | 1c5bd529b95681dbd2781393c3c0d1f4049f5aa3 | 2022-07-20T09:53:27.000Z | [
"pytorch",
"tf",
"segformer",
"dataset:cityscapes",
"arxiv:2105.15203",
"transformers",
"vision",
"image-segmentation",
"license:apache-2.0"
] | image-segmentation | false | nvidia | null | nvidia/segformer-b4-finetuned-cityscapes-1024-1024 | 809 | null | transformers | 1,928 | ---
license: apache-2.0
tags:
- vision
- image-segmentation
datasets:
- cityscapes
widget:
- src: https://www.researchgate.net/profile/Anurag-Arnab/publication/315881952/figure/fig5/AS:667673876779033@1536197265755/Sample-results-on-the-Cityscapes-dataset-The-above-images-show-how-our-method-can-handle.jpg
example_title: Road
---
# SegFormer (b4-sized) model fine-tuned on CityScapes
SegFormer model fine-tuned on CityScapes at resolution 1024x1024. It was introduced in the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Xie et al. and first released in [this repository](https://github.com/NVlabs/SegFormer).
Disclaimer: The team releasing SegFormer did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
SegFormer consists of a hierarchical Transformer encoder and a lightweight all-MLP decode head to achieve great results on semantic segmentation benchmarks such as ADE20K and Cityscapes. The hierarchical Transformer is first pre-trained on ImageNet-1k, after which a decode head is added and fine-tuned altogether on a downstream dataset.
## Intended uses & limitations
You can use the raw model for semantic segmentation. See the [model hub](https://huggingface.co/models?other=segformer) to look for fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import SegformerFeatureExtractor, SegformerForSemanticSegmentation
from PIL import Image
import requests
feature_extractor = SegformerFeatureExtractor.from_pretrained("nvidia/segformer-b4-finetuned-cityscapes-1024-1024")
model = SegformerForSemanticSegmentation.from_pretrained("nvidia/segformer-b4-finetuned-cityscapes-1024-1024")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits # shape (batch_size, num_labels, height/4, width/4)
```
For more code examples, we refer to the [documentation](https://huggingface.co/transformers/model_doc/segformer.html#).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2105-15203,
author = {Enze Xie and
Wenhai Wang and
Zhiding Yu and
Anima Anandkumar and
Jose M. Alvarez and
Ping Luo},
title = {SegFormer: Simple and Efficient Design for Semantic Segmentation with
Transformers},
journal = {CoRR},
volume = {abs/2105.15203},
year = {2021},
url = {https://arxiv.org/abs/2105.15203},
eprinttype = {arXiv},
eprint = {2105.15203},
timestamp = {Wed, 02 Jun 2021 11:46:42 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2105-15203.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
ugaray96/biobert_ncbi_disease_ner | 5c229c40de74adc3ba6ce7266edbbb72338957d9 | 2021-05-20T08:46:47.000Z | [
"pytorch",
"tf",
"jax",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
] | token-classification | false | ugaray96 | null | ugaray96/biobert_ncbi_disease_ner | 808 | 3 | transformers | 1,929 | Entry not found |
OFA-Sys/OFA-large | 89faeabf5697e4f6cc32c16a258fee8555a00ea3 | 2022-07-25T11:50:28.000Z | [
"pytorch",
"ofa",
"transformers",
"license:apache-2.0"
] | null | false | OFA-Sys | null | OFA-Sys/OFA-large | 806 | 3 | transformers | 1,930 | ---
license: apache-2.0
---
# OFA-large
This is the **large** version of OFA pretrained model. OFA is a unified multimodal pretrained model that unifies modalities (i.e., cross-modality, vision, language) and tasks (e.g., image generation, visual grounding, image captioning, image classification, text generation, etc.) to a simple sequence-to-sequence learning framework.
The directory includes 4 files, namely `config.json` which consists of model configuration, `vocab.json` and `merge.txt` for our OFA tokenizer, and lastly `pytorch_model.bin` which consists of model weights. There is no need to worry about the mismatch between Fairseq and transformers, since we have addressed the issue yet.
To use it in transformers, please refer to https://github.com/OFA-Sys/OFA/tree/feature/add_transformers. Install the transformers and download the models as shown below.
```
git clone --single-branch --branch feature/add_transformers https://github.com/OFA-Sys/OFA.git
pip install OFA/transformers/
git clone https://huggingface.co/OFA-Sys/OFA-large
```
After, refer the path to OFA-large to `ckpt_dir`, and prepare an image for the testing example below. Also, ensure that you have pillow and torchvision in your environment.
```
>>> from PIL import Image
>>> from torchvision import transforms
>>> from transformers import OFATokenizer, OFAModel
>>> from generate import sequence_generator
>>> mean, std = [0.5, 0.5, 0.5], [0.5, 0.5, 0.5]
>>> resolution = 480
>>> patch_resize_transform = transforms.Compose([
lambda image: image.convert("RGB"),
transforms.Resize((resolution, resolution), interpolation=Image.BICUBIC),
transforms.ToTensor(),
transforms.Normalize(mean=mean, std=std)
])
>>> tokenizer = OFATokenizer.from_pretrained(ckpt_dir)
>>> txt = " what does the image describe?"
>>> inputs = tokenizer([txt], return_tensors="pt").input_ids
>>> img = Image.open(path_to_image)
>>> patch_img = patch_resize_transform(img).unsqueeze(0)
>>> # using the generator of fairseq version
>>> model = OFAModel.from_pretrained(ckpt_dir, use_cache=True)
>>> generator = sequence_generator.SequenceGenerator(
tokenizer=tokenizer,
beam_size=5,
max_len_b=16,
min_len=0,
no_repeat_ngram_size=3,
)
>>> data = {}
>>> data["net_input"] = {"input_ids": inputs, 'patch_images': patch_img, 'patch_masks':torch.tensor([True])}
>>> gen_output = generator.generate([model], data)
>>> gen = [gen_output[i][0]["tokens"] for i in range(len(gen_output))]
>>> # using the generator of huggingface version
>>> model = OFAModel.from_pretrained(ckpt_dir, use_cache=False)
>>> gen = model.generate(inputs, patch_images=patch_img, num_beams=5, no_repeat_ngram_size=3)
>>> print(tokenizer.batch_decode(gen, skip_special_tokens=True))
```
|
Helsinki-NLP/opus-mt-ml-en | 6a3938f58579cd6b4aab8ffcd6d8f6ccbe96571e | 2021-09-10T13:58:12.000Z | [
"pytorch",
"marian",
"text2text-generation",
"ml",
"en",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] | translation | false | Helsinki-NLP | null | Helsinki-NLP/opus-mt-ml-en | 805 | null | transformers | 1,931 | ---
tags:
- translation
license: apache-2.0
---
### opus-mt-ml-en
* source languages: ml
* target languages: en
* OPUS readme: [ml-en](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/ml-en/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-04-20.zip](https://object.pouta.csc.fi/OPUS-MT-models/ml-en/opus-2020-04-20.zip)
* test set translations: [opus-2020-04-20.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/ml-en/opus-2020-04-20.test.txt)
* test set scores: [opus-2020-04-20.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/ml-en/opus-2020-04-20.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba.ml.en | 42.7 | 0.605 |
|
GanjinZero/coder_eng_pp | 1b92944b53581cdee9c7a6a6c85d3706c5f39a87 | 2022-04-25T02:25:08.000Z | [
"pytorch",
"bert",
"feature-extraction",
"en",
"arxiv:2204.00391",
"transformers",
"biomedical",
"license:apache-2.0"
] | feature-extraction | false | GanjinZero | null | GanjinZero/coder_eng_pp | 803 | 1 | transformers | 1,932 | ---
language:
- en
license: apache-2.0
tags:
- bert
- biomedical
---
Automatic Biomedical Term Clustering by Learning Fine-grained Term Representations.
CODER++
```
@misc{https://doi.org/10.48550/arxiv.2204.00391,
doi = {10.48550/ARXIV.2204.00391},
url = {https://arxiv.org/abs/2204.00391},
author = {Zeng, Sihang and Yuan, Zheng and Yu, Sheng},
title = {Automatic Biomedical Term Clustering by Learning Fine-grained Term Representations},
publisher = {arXiv},
year = {2022}
}
``` |
yechen/bert-large-chinese | 0b30aa41703e93273f06788ce54ca2a678fa3461 | 2021-05-20T09:22:07.000Z | [
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"zh",
"transformers",
"autotrain_compatible"
] | fill-mask | false | yechen | null | yechen/bert-large-chinese | 803 | 1 | transformers | 1,933 | ---
language: zh
---
|
nvidia/segformer-b1-finetuned-ade-512-512 | cfbb1c34d34eae30bcf0a6d5e26a650f9b7263de | 2022-07-20T09:53:21.000Z | [
"pytorch",
"tf",
"segformer",
"dataset:scene_parse_150",
"arxiv:2105.15203",
"transformers",
"vision",
"image-segmentation",
"license:apache-2.0"
] | image-segmentation | false | nvidia | null | nvidia/segformer-b1-finetuned-ade-512-512 | 802 | null | transformers | 1,934 | ---
license: apache-2.0
tags:
- vision
- image-segmentation
datasets:
- scene_parse_150
widget:
- src: https://huggingface.co/datasets/hf-internal-testing/fixtures_ade20k/resolve/main/ADE_val_00000001.jpg
example_title: House
- src: https://huggingface.co/datasets/hf-internal-testing/fixtures_ade20k/resolve/main/ADE_val_00000002.jpg
example_title: Castle
---
# SegFormer (b1-sized) model fine-tuned on ADE20k
SegFormer model fine-tuned on ADE20k at resolution 512x512. It was introduced in the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Xie et al. and first released in [this repository](https://github.com/NVlabs/SegFormer).
Disclaimer: The team releasing SegFormer did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
SegFormer consists of a hierarchical Transformer encoder and a lightweight all-MLP decode head to achieve great results on semantic segmentation benchmarks such as ADE20K and Cityscapes. The hierarchical Transformer is first pre-trained on ImageNet-1k, after which a decode head is added and fine-tuned altogether on a downstream dataset.
## Intended uses & limitations
You can use the raw model for semantic segmentation. See the [model hub](https://huggingface.co/models?other=segformer) to look for fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import SegformerFeatureExtractor, SegformerForSemanticSegmentation
from PIL import Image
import requests
feature_extractor = SegformerFeatureExtractor.from_pretrained("nvidia/segformer-b1-finetuned-ade-512-512")
model = SegformerForSemanticSegmentation.from_pretrained("nvidia/segformer-b1-finetuned-ade-512-512")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits # shape (batch_size, num_labels, height/4, width/4)
```
For more code examples, we refer to the [documentation](https://huggingface.co/transformers/model_doc/segformer.html#).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2105-15203,
author = {Enze Xie and
Wenhai Wang and
Zhiding Yu and
Anima Anandkumar and
Jose M. Alvarez and
Ping Luo},
title = {SegFormer: Simple and Efficient Design for Semantic Segmentation with
Transformers},
journal = {CoRR},
volume = {abs/2105.15203},
year = {2021},
url = {https://arxiv.org/abs/2105.15203},
eprinttype = {arXiv},
eprint = {2105.15203},
timestamp = {Wed, 02 Jun 2021 11:46:42 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2105-15203.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
sentence-transformers/msmarco-MiniLM-L-12-v3 | 0ff694ede6574bbed1625216e5bd1a2f517abaf1 | 2022-06-16T00:16:13.000Z | [
"pytorch",
"tf",
"jax",
"bert",
"feature-extraction",
"arxiv:1908.10084",
"sentence-transformers",
"sentence-similarity",
"transformers",
"license:apache-2.0"
] | sentence-similarity | false | sentence-transformers | null | sentence-transformers/msmarco-MiniLM-L-12-v3 | 802 | null | sentence-transformers | 1,935 | ---
pipeline_tag: sentence-similarity
license: apache-2.0
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# sentence-transformers/msmarco-MiniLM-L-12-v3
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 384 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/msmarco-MiniLM-L-12-v3')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/msmarco-MiniLM-L-12-v3')
model = AutoModel.from_pretrained('sentence-transformers/msmarco-MiniLM-L-12-v3')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/msmarco-MiniLM-L-12-v3)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 384, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
``` |
fmikaelian/camembert-base-squad | 026a804142163cd9756f66ba35cfb463d914e4e4 | 2020-12-11T21:40:12.000Z | [
"pytorch",
"camembert",
"question-answering",
"fr",
"transformers",
"autotrain_compatible"
] | question-answering | false | fmikaelian | null | fmikaelian/camembert-base-squad | 800 | null | transformers | 1,936 | ---
language: fr
---
# camembert-base-squad
## Description
A baseline model for question-answering in french ([CamemBERT](https://camembert-model.fr/) model fine-tuned on [french-translated SQuAD 1.1 dataset](https://github.com/Alikabbadj/French-SQuAD))
## Training hyperparameters
```shell
python3 ./examples/question-answering/run_squad.py \
--model_type camembert \
--model_name_or_path camembert-base \
--do_train \
--do_eval \
--do_lower_case \
--train_file SQuAD-v1.1-train_fr_ss999_awstart2_net.json \
--predict_file SQuAD-v1.1-dev_fr_ss999_awstart2_net.json \
--learning_rate 3e-5 \
--num_train_epochs 2 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir output3 \
--per_gpu_eval_batch_size=3 \
--per_gpu_train_batch_size=3 \
--save_steps 10000
```
## Evaluation results
```shell
{"f1": 79.8570684959745, "exact_match": 59.21327108373895}
```
## Usage
```python
from transformers import pipeline
nlp = pipeline('question-answering', model='fmikaelian/camembert-base-squad', tokenizer='fmikaelian/camembert-base-squad')
nlp({
'question': "Qui est Claude Monet?",
'context': "Claude Monet, né le 14 novembre 1840 à Paris et mort le 5 décembre 1926 à Giverny, est un peintre français et l’un des fondateurs de l'impressionnisme."
})
``` |
ahmedrachid/FinancialBERT-Sentiment-Analysis | 656931965473ec085d195680bd62687b140c038f | 2022-02-07T14:58:57.000Z | [
"pytorch",
"bert",
"text-classification",
"en",
"dataset:financial_phrasebank",
"transformers",
"financial-sentiment-analysis",
"sentiment-analysis"
] | text-classification | false | ahmedrachid | null | ahmedrachid/FinancialBERT-Sentiment-Analysis | 798 | 6 | transformers | 1,937 | ---
language: en
tags:
- financial-sentiment-analysis
- sentiment-analysis
datasets:
- financial_phrasebank
widget:
- text: Operating profit rose to EUR 13.1 mn from EUR 8.7 mn in the corresponding period in 2007 representing 7.7 % of net sales.
- text: Bids or offers include at least 1,000 shares and the value of the shares must correspond to at least EUR 4,000.
- text: Raute reported a loss per share of EUR 0.86 for the first half of 2009 , against EPS of EUR 0.74 in the corresponding period of 2008.
---
### FinancialBERT for Sentiment Analysis
[*FinancialBERT*](https://huggingface.co/ahmedrachid/FinancialBERT) is a BERT model pre-trained on a large corpora of financial texts. The purpose is to enhance financial NLP research and practice in financial domain, hoping that financial practitioners and researchers can benefit from this model without the necessity of the significant computational resources required to train the model.
The model was fine-tuned for Sentiment Analysis task on _Financial PhraseBank_ dataset. Experiments show that this model outperforms the general BERT and other financial domain-specific models.
More details on `FinancialBERT`'s pre-training process can be found at: https://www.researchgate.net/publication/358284785_FinancialBERT_-_A_Pretrained_Language_Model_for_Financial_Text_Mining
### Training data
FinancialBERT model was fine-tuned on [Financial PhraseBank](https://www.researchgate.net/publication/251231364_FinancialPhraseBank-v10), a dataset consisting of 4840 Financial News categorised by sentiment (negative, neutral, positive).
### Fine-tuning hyper-parameters
- learning_rate = 2e-5
- batch_size = 32
- max_seq_length = 512
- num_train_epochs = 5
### Evaluation metrics
The evaluation metrics used are: Precision, Recall and F1-score. The following is the classification report on the test set.
| sentiment | precision | recall | f1-score | support |
| ------------- |:-------------:|:-------------:|:-------------:| -----:|
| negative | 0.96 | 0.97 | 0.97 | 58 |
| neutral | 0.98 | 0.99 | 0.98 | 279 |
| positive | 0.98 | 0.97 | 0.97 | 148 |
| macro avg | 0.97 | 0.98 | 0.98 | 485 |
| weighted avg | 0.98 | 0.98 | 0.98 | 485 |
### How to use
The model can be used thanks to Transformers pipeline for sentiment analysis.
```python
from transformers import BertTokenizer, BertForSequenceClassification
from transformers import pipeline
model = BertForSequenceClassification.from_pretrained("ahmedrachid/FinancialBERT-Sentiment-Analysis",num_labels=3)
tokenizer = BertTokenizer.from_pretrained("ahmedrachid/FinancialBERT-Sentiment-Analysis")
nlp = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
sentences = ["Operating profit rose to EUR 13.1 mn from EUR 8.7 mn in the corresponding period in 2007 representing 7.7 % of net sales.",
"Bids or offers include at least 1,000 shares and the value of the shares must correspond to at least EUR 4,000.",
"Raute reported a loss per share of EUR 0.86 for the first half of 2009 , against EPS of EUR 0.74 in the corresponding period of 2008.",
]
results = nlp(sentences)
print(results)
[{'label': 'positive', 'score': 0.9998133778572083},
{'label': 'neutral', 'score': 0.9997822642326355},
{'label': 'negative', 'score': 0.9877365231513977}]
```
> Created by [Ahmed Rachid Hazourli](https://www.linkedin.com/in/ahmed-rachid/)
|
allenai/wmt19-de-en-6-6-big | ad688bb4b2d008debf4477e33a7c809eed3f198b | 2020-12-11T21:33:31.000Z | [
"pytorch",
"fsmt",
"text2text-generation",
"de",
"en",
"dataset:wmt19",
"arxiv:2006.10369",
"transformers",
"translation",
"wmt19",
"allenai",
"license:apache-2.0",
"autotrain_compatible"
] | translation | false | allenai | null | allenai/wmt19-de-en-6-6-big | 795 | null | transformers | 1,938 |
---
language:
- de
- en
thumbnail:
tags:
- translation
- wmt19
- allenai
license: apache-2.0
datasets:
- wmt19
metrics:
- bleu
---
# FSMT
## Model description
This is a ported version of fairseq-based [wmt19 transformer](https://github.com/jungokasai/deep-shallow/) for de-en.
For more details, please, see [Deep Encoder, Shallow Decoder: Reevaluating the Speed-Quality Tradeoff in Machine Translation](https://arxiv.org/abs/2006.10369).
2 models are available:
* [wmt19-de-en-6-6-big](https://huggingface.co/allenai/wmt19-de-en-6-6-big)
* [wmt19-de-en-6-6-base](https://huggingface.co/allenai/wmt19-de-en-6-6-base)
## Intended uses & limitations
#### How to use
```python
from transformers import FSMTForConditionalGeneration, FSMTTokenizer
mname = "allenai/wmt19-de-en-6-6-big"
tokenizer = FSMTTokenizer.from_pretrained(mname)
model = FSMTForConditionalGeneration.from_pretrained(mname)
input = "Maschinelles Lernen ist großartig, nicht wahr?"
input_ids = tokenizer.encode(input, return_tensors="pt")
outputs = model.generate(input_ids)
decoded = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(decoded) # Machine learning is great, isn't it?
```
#### Limitations and bias
## Training data
Pretrained weights were left identical to the original model released by allenai. For more details, please, see the [paper](https://arxiv.org/abs/2006.10369).
## Eval results
Here are the BLEU scores:
model | transformers
-------|---------
wmt19-de-en-6-6-big | 39.9
The score was calculated using this code:
```bash
git clone https://github.com/huggingface/transformers
cd transformers
export PAIR=de-en
export DATA_DIR=data/$PAIR
export SAVE_DIR=data/$PAIR
export BS=8
export NUM_BEAMS=5
mkdir -p $DATA_DIR
sacrebleu -t wmt19 -l $PAIR --echo src > $DATA_DIR/val.source
sacrebleu -t wmt19 -l $PAIR --echo ref > $DATA_DIR/val.target
echo $PAIR
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval.py allenai/wmt19-de-en-6-6-big $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --num_beams $NUM_BEAMS
```
## Data Sources
- [training, etc.](http://www.statmt.org/wmt19/)
- [test set](http://matrix.statmt.org/test_sets/newstest2019.tgz?1556572561)
### BibTeX entry and citation info
```
@misc{kasai2020deep,
title={Deep Encoder, Shallow Decoder: Reevaluating the Speed-Quality Tradeoff in Machine Translation},
author={Jungo Kasai and Nikolaos Pappas and Hao Peng and James Cross and Noah A. Smith},
year={2020},
eprint={2006.10369},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
monilouise/ner_news_portuguese | 3d99719c7273f8509954b0023ecc273228f9cdd7 | 2021-09-13T17:12:03.000Z | [
"pytorch",
"jax",
"bert",
"token-classification",
"pt",
"arxiv:1909.10649",
"transformers",
"ner",
"autotrain_compatible"
] | token-classification | false | monilouise | null | monilouise/ner_news_portuguese | 795 | 6 | transformers | 1,939 | ---
language:
- pt
tags:
- ner
metrics:
- f1
- accuracy
- precision
- recall
---
# RiskData Brazilian Portuguese NER
## Model description
This is a finetunned version from [Neuralmind BERTimbau] (https://github.com/neuralmind-ai/portuguese-bert/blob/master/README.md) for Portuguese language.
## Intended uses & limitations
#### How to use
```python
from transformers import BertForTokenClassification, DistilBertTokenizerFast, pipeline
model = BertForTokenClassification.from_pretrained('monilouise/ner_pt_br')
tokenizer = DistilBertTokenizerFast.from_pretrained('neuralmind/bert-base-portuguese-cased'
, model_max_length=512
, do_lower_case=False
)
nlp = pipeline('ner', model=model, tokenizer=tokenizer, grouped_entities=True)
result = nlp("O Tribunal de Contas da União é localizado em Brasília e foi fundado por Rui Barbosa.")
```
#### Limitations and bias
- The finetunned model was trained on a corpus with around 180 news articles crawled from Google News. The original project's purpose was to recognize named entities in news
related to fraud and corruption, classifying these entities in four classes: PERSON, ORGANIZATION, PUBLIC INSITUITION and LOCAL (PESSOA, ORGANIZAÇÃO, INSTITUIÇÃO PÚBLICA and LOCAL).
## Training procedure
## Eval results
accuracy: 0.98,
precision: 0.86
recall: 0.91
f1: 0.88
The score was calculated using this code:
```python
def align_predictions(predictions: np.ndarray, label_ids: np.ndarray) -> Tuple[List[int], List[int]]:
preds = np.argmax(predictions, axis=2)
batch_size, seq_len = preds.shape
out_label_list = [[] for _ in range(batch_size)]
preds_list = [[] for _ in range(batch_size)]
for i in range(batch_size):
for j in range(seq_len):
if label_ids[i, j] != nn.CrossEntropyLoss().ignore_index:
out_label_list[i].append(id2tag[label_ids[i][j]])
preds_list[i].append(id2tag[preds[i][j]])
return preds_list, out_label_list
def compute_metrics(p: EvalPrediction) -> Dict:
preds_list, out_label_list = align_predictions(p.predictions, p.label_ids)
return {
"accuracy_score": accuracy_score(out_label_list, preds_list),
"precision": precision_score(out_label_list, preds_list),
"recall": recall_score(out_label_list, preds_list),
"f1": f1_score(out_label_list, preds_list),
}
```
### BibTeX entry and citation info
For further information about BERTimbau language model:
```bibtex
@inproceedings{souza2020bertimbau,
author = {Souza, F{\'a}bio and Nogueira, Rodrigo and Lotufo, Roberto},
title = {{BERT}imbau: pretrained {BERT} models for {B}razilian {P}ortuguese},
booktitle = {9th Brazilian Conference on Intelligent Systems, {BRACIS}, Rio Grande do Sul, Brazil, October 20-23 (to appear)},
year = {2020}
}
@article{souza2019portuguese,
title={Portuguese Named Entity Recognition using BERT-CRF},
author={Souza, F{\'a}bio and Nogueira, Rodrigo and Lotufo, Roberto},
journal={arXiv preprint arXiv:1909.10649},
url={http://arxiv.org/abs/1909.10649},
year={2019}
}
```
|
tdopierre/ProtAugment-LM-Clinic150 | 4be859e9b5cfd551558a1868f05eff9acf49742d | 2021-07-01T13:57:20.000Z | [
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | false | tdopierre | null | tdopierre/ProtAugment-LM-Clinic150 | 795 | null | transformers | 1,940 | Entry not found |
Amo/GPT-J-6B-PNY | 6ea745f4c4d4105f8d5bb802651de7d23505be81 | 2022-07-08T14:13:05.000Z | [
"pytorch",
"gptj",
"text-generation",
"transformers"
] | text-generation | false | Amo | null | Amo/GPT-J-6B-PNY | 795 | 1 | transformers | 1,941 | Entry not found |
Intel/dpt-large | 755bcbcb26ef6d8ae380fef8b193bd60bc729026 | 2022-04-14T08:29:11.000Z | [
"pytorch",
"dpt",
"arxiv:2103.13413",
"transformers",
"vision",
"depth-estimation",
"license:apache-2.0"
] | null | false | Intel | null | Intel/dpt-large | 794 | 9 | transformers | 1,942 | ---
license: apache-2.0
tags:
- vision
- depth-estimation
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
---
# DPT (large-sized model)
Dense Prediction Transformer (DPT) model trained on 1.4 million images for monocular depth estimation. It was introduced in the paper [Vision Transformers for Dense Prediction](https://arxiv.org/abs/2103.13413) by Ranftl et al. and first released in [this repository](https://github.com/isl-org/DPT).
Disclaimer: The team releasing DPT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
DPT uses the Vision Transformer (ViT) as backbone and adds a neck + head on top for monocular depth estimation.

## Intended uses & limitations
You can use the raw model for zero-shot monocular depth estimation. See the [model hub](https://huggingface.co/models?search=dpt) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model for zero-shot depth estimation on an image:
```python
from transformers import DPTFeatureExtractor, DPTForDepthEstimation
import torch
import numpy as np
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = DPTFeatureExtractor.from_pretrained("Intel/dpt-large")
model = DPTForDepthEstimation.from_pretrained("Intel/dpt-large")
# prepare image for the model
inputs = feature_extractor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
predicted_depth = outputs.predicted_depth
# interpolate to original size
prediction = torch.nn.functional.interpolate(
predicted_depth.unsqueeze(1),
size=image.size[::-1],
mode="bicubic",
align_corners=False,
)
# visualize the prediction
output = prediction.squeeze().cpu().numpy()
formatted = (output * 255 / np.max(output)).astype("uint8")
depth = Image.fromarray(formatted)
```
For more code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/master/en/model_doc/dpt).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2103-13413,
author = {Ren{\'{e}} Ranftl and
Alexey Bochkovskiy and
Vladlen Koltun},
title = {Vision Transformers for Dense Prediction},
journal = {CoRR},
volume = {abs/2103.13413},
year = {2021},
url = {https://arxiv.org/abs/2103.13413},
eprinttype = {arXiv},
eprint = {2103.13413},
timestamp = {Wed, 07 Apr 2021 15:31:46 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2103-13413.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` |
tau/splinter-base-qass | c400ac0b86b16bc4d73508561d3eca78f89c52d7 | 2021-09-03T08:47:00.000Z | [
"pytorch",
"splinter",
"question-answering",
"en",
"transformers",
"SplinterModel",
"license:apache-2.0",
"autotrain_compatible"
] | question-answering | false | tau | null | tau/splinter-base-qass | 793 | null | transformers | 1,943 | ---
language: en
tags:
- splinter
- SplinterModel
license: apache-2.0
---
# Splinter base model (with pretrained QASS-layer weights)
Splinter-base is the pretrained model discussed in the paper [Few-Shot Question Answering by Pretraining Span Selection](https://aclanthology.org/2021.acl-long.239/) (at ACL 2021). Its original repository can be found [here](https://github.com/oriram/splinter). The model is case-sensitive.
Note: This model **does** contain the pretrained weights for the QASS layer (see paper for details). For the model **without** those weights, see [tau/splinter-base](https://huggingface.co/tau/splinter-base).
## Model description
Splinter is a model that is pretrained in a self-supervised fashion for few-shot question answering. This means it was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of publicly available data) with an automatic process to generate inputs and labels from those texts.
More precisely, it was pretrained with the Recurring Span Selection (RSS) objective, which emulates the span selection process involved in extractive question answering. Given a text, clusters of recurring spans (n-grams that appear more than once in the text) are first identified. For each such cluster, all of its instances but one are replaced with a special `[QUESTION]` token, and the model should select the correct (i.e., unmasked) span for each masked one. The model also defines the Question-Aware Span selection (QASS) layer, which selects spans conditioned on a specific question (in order to perform multiple predictions).
## Intended uses & limitations
The prime use for this model is few-shot extractive QA.
## Pretraining
The model was pretrained on a v3-8 TPU for 2.4M steps. The training data is based on **Wikipedia** and **BookCorpus**. See the paper for more details.
### BibTeX entry and citation info
```bibtex
@inproceedings{ram-etal-2021-shot,
title = "Few-Shot Question Answering by Pretraining Span Selection",
author = "Ram, Ori and
Kirstain, Yuval and
Berant, Jonathan and
Globerson, Amir and
Levy, Omer",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers)",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.acl-long.239",
doi = "10.18653/v1/2021.acl-long.239",
pages = "3066--3079",
}
```
|
textattack/albert-base-v2-ag-news | f2a40f157353809cd0f76610fc9657385e8761d4 | 2020-07-07T21:59:15.000Z | [
"pytorch",
"albert",
"text-classification",
"transformers"
] | text-classification | false | textattack | null | textattack/albert-base-v2-ag-news | 790 | null | transformers | 1,944 | ## TextAttack Model CardThis `albert-base-v2` model was fine-tuned for sequence classification using TextAttack
and the ag_news dataset loaded using the `nlp` library. The model was fine-tuned
for 5 epochs with a batch size of 16, a learning
rate of 2e-05, and a maximum sequence length of 128.
Since this was a classification task, the model was trained with a cross-entropy loss function.
The best score the model achieved on this task was 0.9471052631578948, as measured by the
eval set accuracy, found after 3 epochs.
For more information, check out [TextAttack on Github](https://github.com/QData/TextAttack).
|
castorini/mdpr-question-nq | b560ea82c60118c04b388a339f1c089c2a720c70 | 2021-08-20T15:07:57.000Z | [
"pytorch",
"dpr",
"feature-extraction",
"transformers"
] | feature-extraction | false | castorini | null | castorini/mdpr-question-nq | 785 | null | transformers | 1,945 | Entry not found |
indonesian-nlp/wav2vec2-large-xlsr-indonesian | 68fbcbd947e32184a704b401b71973d6c27de0c1 | 2021-07-06T06:15:38.000Z | [
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"id",
"dataset:common_voice",
"transformers",
"audio",
"speech",
"xlsr-fine-tuning-week",
"license:apache-2.0",
"model-index"
] | automatic-speech-recognition | false | indonesian-nlp | null | indonesian-nlp/wav2vec2-large-xlsr-indonesian | 785 | 1 | transformers | 1,946 | ---
language: id
datasets:
- common_voice
metrics:
- wer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: XLSR Wav2Vec2 Indonesian by Indonesian NLP
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice id
type: common_voice
args: id
metrics:
- name: Test WER
type: wer
value: 14.29
---
# Wav2Vec2-Large-XLSR-Indonesian
This is the model for Wav2Vec2-Large-XLSR-Indonesian, a fine-tuned
[facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53)
model on the [Indonesian Common Voice dataset](https://huggingface.co/datasets/common_voice).
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "id", split="test[:2%]")
processor = Wav2Vec2Processor.from_pretrained("indonesian-nlp/wav2vec2-large-xlsr-indonesian")
model = Wav2Vec2ForCTC.from_pretrained("indonesian-nlp/wav2vec2-large-xlsr-indonesian")
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
resampler = torchaudio.transforms.Resample(sampling_rate, 16_000)
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset[:2]["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset[:2]["sentence"])
```
## Evaluation
The model can be evaluated as follows on the Indonesian test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "id", split="test")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("indonesian-nlp/wav2vec2-large-xlsr-indonesian")
model = Wav2Vec2ForCTC.from_pretrained("indonesian-nlp/wav2vec2-large-xlsr-indonesian")
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"\“\%\‘\'\”\�]'
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
resampler = torchaudio.transforms.Resample(sampling_rate, 16_000)
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 14.29 %
## Training
The Common Voice `train`, `validation`, and [synthetic voice datasets](https://cloud.uncool.ai/index.php/s/Kg4C6f5NJGN9ZdR) were used for training.
The script used for training can be found [here](https://github.com/indonesian-nlp/wav2vec2-indonesian)
|
uer/roberta-base-word-chinese-cluecorpussmall | 9122f6001eb2eedea9d34eeafc254a4f83f653aa | 2022-02-19T15:58:50.000Z | [
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"zh",
"dataset:CLUECorpusSmall",
"arxiv:1909.05658",
"transformers",
"autotrain_compatible"
] | fill-mask | false | uer | null | uer/roberta-base-word-chinese-cluecorpussmall | 785 | 2 | transformers | 1,947 | ---
language: zh
datasets: CLUECorpusSmall
widget:
- text: "最近一趟去北京的[MASK]几点发车"
---
# Chinese word-based RoBERTa Miniatures
## Model description
This is the set of 5 Chinese word-based RoBERTa models pre-trained by [UER-py](https://github.com/dbiir/UER-py/), which is introduced in [this paper](https://arxiv.org/abs/1909.05658).
Most Chinese pre-trained weights are based on Chinese character. Compared with character-based models, word-based models are faster (because of shorter sequence length) and have better performance according to our experimental results. To this end, we released the 5 Chinese word-based RoBERTa models of different sizes. In order to facilitate users to reproduce the results, we used the publicly available corpus and word segmentation tool, and provided all training details.
Notice that the output results of Hosted inference API (right) are not properly displayed. When the predicted word has multiple characters, the single word instead of entire sentence is displayed. One can click **JSON Output** for normal output results.
You can download the 5 Chinese RoBERTa miniatures either from the [UER-py Modelzoo page](https://github.com/dbiir/UER-py/wiki/Modelzoo), or via HuggingFace from the links below:
| | Link |
| -------- | :-----------------------: |
| **word-based RoBERTa-Tiny** | [**L=2/H=128 (Tiny)**][2_128] |
| **word-based RoBERTa-Mini** | [**L=4/H=256 (Mini)**][4_256] |
| **word-based RoBERTa-Small** | [**L=4/H=512 (Small)**][4_512] |
| **word-based RoBERTa-Medium** | [**L=8/H=512 (Medium)**][8_512] |
| **word-based RoBERTa-Base** | [**L=12/H=768 (Base)**][12_768] |
Compared with [char-based models](https://huggingface.co/uer/chinese_roberta_L-2_H-128), word-based models achieve better results in most cases. Here are scores on the devlopment set of six Chinese tasks:
| Model | Score | douban | chnsenticorp | lcqmc | tnews(CLUE) | iflytek(CLUE) | ocnli(CLUE) |
| -------------- | :---: | :----: | :----------: | :---: | :---------: | :-----------: | :---------: |
| RoBERTa-Tiny(char) | 72.3 | 83.0 | 91.4 | 81.8 | 62.0 | 55.0 | 60.3 |
| **RoBERTa-Tiny(word)** | **74.3(+2.0)** | **86.4** | **93.2** | **82.0** | **66.4** | **58.2** | **59.6** |
| RoBERTa-Mini(char) | 75.7 | 84.8 | 93.7 | 86.1 | 63.9 | 58.3 | 67.4 |
| **RoBERTa-Mini(word)** | **76.7(+1.0)** | **87.6** | **94.1** | **85.4** | **66.9** | **59.2** | **67.3** |
| RoBERTa-Small(char) | 76.8 | 86.5 | 93.4 | 86.5 | 65.1 | 59.4 | 69.7 |
| **RoBERTa-Small(word)** | **78.1(+1.3)** | **88.5** | **94.7** | **87.4** | **67.6** | **60.9** | **69.8** |
| RoBERTa-Medium(char) | 77.8 | 87.6 | 94.8 | 88.1 | 65.6 | 59.5 | 71.2 |
| **RoBERTa-Medium(word)** | **78.9(+1.1)** | **89.2** | **95.1** | **88.0** | **67.8** | **60.6** | **73.0** |
| RoBERTa-Base(char) | 79.5 | 89.1 | 95.2 | 89.2 | 67.0 | 60.9 | 75.5 |
| **RoBERTa-Base(word)** | **80.2(+0.7)** | **90.3** | **95.7** | **89.4** | **68.0** | **61.5** | **76.8** |
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained with the sequence length of 128:
- epochs: 3, 5, 8
- batch sizes: 32, 64
- learning rates: 3e-5, 1e-4, 3e-4
## How to use
You can use this model directly with a pipeline for masked language modeling (take the case of word-based RoBERTa-Medium):
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='uer/roberta-medium-word-chinese-cluecorpussmall')
>>> unmasker("[MASK]的首都是北京。")
[
{'sequence': '中国 的首都是北京。',
'score': 0.21525809168815613,
'token': 2873,
'token_str': '中国'},
{'sequence': '北京 的首都是北京。',
'score': 0.15194718539714813,
'token': 9502,
'token_str': '北京'},
{'sequence': '我们 的首都是北京。',
'score': 0.08854265511035919,
'token': 4215,
'token_str': '我们'},
{'sequence': '美国 的首都是北京。',
'score': 0.06808705627918243,
'token': 7810,
'token_str': '美国'},
{'sequence': '日本 的首都是北京。',
'score': 0.06071401759982109,
'token': 7788,
'token_str': '日本'}
]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import AlbertTokenizer, BertModel
tokenizer = AlbertTokenizer.from_pretrained('uer/roberta-medium-word-chinese-cluecorpussmall')
model = BertModel.from_pretrained("uer/roberta-medium-word-chinese-cluecorpussmall")
text = "用你喜欢的任何文本替换我。"
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import AlbertTokenizer, TFBertModel
tokenizer = AlbertTokenizer.from_pretrained('uer/roberta-medium-word-chinese-cluecorpussmall')
model = TFBertModel.from_pretrained("uer/roberta-medium-word-chinese-cluecorpussmall")
text = "用你喜欢的任何文本替换我。"
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
Since BertTokenizer does not support sentencepiece, AlbertTokenizer is used here.
## Training data
[CLUECorpusSmall](https://github.com/CLUEbenchmark/CLUECorpus2020/) is used as training data. Google's [sentencepiece](https://github.com/google/sentencepiece) is used for word segmentation. The sentencepiece model is trained on CLUECorpusSmall corpus:
```
>>> import sentencepiece as spm
>>> spm.SentencePieceTrainer.train(input='cluecorpussmall.txt',
model_prefix='cluecorpussmall_spm',
vocab_size=100000,
max_sentence_length=1024,
max_sentencepiece_length=6,
user_defined_symbols=['[MASK]','[unused1]','[unused2]',
'[unused3]','[unused4]','[unused5]','[unused6]',
'[unused7]','[unused8]','[unused9]','[unused10]'],
pad_id=0,
pad_piece='[PAD]',
unk_id=1,
unk_piece='[UNK]',
bos_id=2,
bos_piece='[CLS]',
eos_id=3,
eos_piece='[SEP]',
train_extremely_large_corpus=True
)
```
## Training procedure
Models are pre-trained by [UER-py](https://github.com/dbiir/UER-py/) on [Tencent Cloud](https://cloud.tencent.com/). We pre-train 1,000,000 steps with a sequence length of 128 and then pre-train 250,000 additional steps with a sequence length of 512. We use the same hyper-parameters on different model sizes.
Taking the case of word-based RoBERTa-Medium
Stage1:
```
python3 preprocess.py --corpus_path corpora/cluecorpussmall.txt \
--spm_model_path models/cluecorpussmall_spm.model \
--dataset_path cluecorpussmall_word_seq128_dataset.pt \
--processes_num 32 --seq_length 128 \
--dynamic_masking --data_processor mlm
```
```
python3 pretrain.py --dataset_path cluecorpussmall_word_seq128_dataset.pt \
--spm_model_path models/cluecorpussmall_spm.model \
--config_path models/bert/medium_config.json \
--output_model_path models/cluecorpussmall_word_roberta_medium_seq128_model.bin \
--world_size 8 --gpu_ranks 0 1 2 3 4 5 6 7 \
--total_steps 1000000 --save_checkpoint_steps 100000 --report_steps 50000 \
--learning_rate 1e-4 --batch_size 64 \
--data_processor mlm --target mlm
```
Stage2:
```
python3 preprocess.py --corpus_path corpora/cluecorpussmall.txt \
--spm_model_path models/cluecorpussmall_spm.model \
--dataset_path cluecorpussmall_word_seq512_dataset.pt \
--processes_num 32 --seq_length 512 \
--dynamic_masking --data_processor mlm
```
```
python3 pretrain.py --dataset_path cluecorpussmall_word_seq512_dataset.pt \
--spm_model_path models/cluecorpussmall_spm.model \
--pretrained_model_path models/cluecorpussmall_word_roberta_medium_seq128_model.bin-1000000 \
--config_path models/bert/medium_config.json \
--output_model_path models/cluecorpussmall_word_roberta_medium_seq512_model.bin \
--world_size 8 --gpu_ranks 0 1 2 3 4 5 6 7 \
--total_steps 250000 --save_checkpoint_steps 50000 --report_steps 10000 \
--learning_rate 5e-5 --batch_size 16 \
--data_processor mlm --target mlm
```
Finally, we convert the pre-trained model into Huggingface's format:
```
python3 scripts/convert_bert_from_uer_to_huggingface.py --input_model_path models/cluecorpussmall_word_roberta_medium_seq128_model.bin-250000 \
--output_model_path pytorch_model.bin \
--layers_num 8 --type mlm
```
### BibTeX entry and citation info
```
@article{devlin2018bert,
title={BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding},
author={Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1810.04805},
year={2018}
}
@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}
@article{zhao2019uer,
title={UER: An Open-Source Toolkit for Pre-training Models},
author={Zhao, Zhe and Chen, Hui and Zhang, Jinbin and Zhao, Xin and Liu, Tao and Lu, Wei and Chen, Xi and Deng, Haotang and Ju, Qi and Du, Xiaoyong},
journal={EMNLP-IJCNLP 2019},
pages={241},
year={2019}
}
```
[2_128]:https://huggingface.co/uer/roberta-tiny-word-chinese-cluecorpussmall
[4_256]:https://huggingface.co/uer/roberta-mini-word-chinese-cluecorpussmall
[4_512]:https://huggingface.co/uer/roberta-small-word-chinese-cluecorpussmall
[8_512]:https://huggingface.co/uer/roberta-medium-word-chinese-cluecorpussmall
[12_768]:https://huggingface.co/uer/roberta-base-word-chinese-cluecorpussmall |
google/pegasus-reddit_tifu | b786930d75e6108dd9a42fc062658a5ff77386ff | 2020-10-22T16:33:34.000Z | [
"pytorch",
"pegasus",
"text2text-generation",
"en",
"arxiv:1912.08777",
"transformers",
"summarization",
"autotrain_compatible"
] | summarization | false | google | null | google/pegasus-reddit_tifu | 784 | null | transformers | 1,948 | ---
language: en
tags:
- summarization
---
### Pegasus Models
See Docs: [here](https://huggingface.co/transformers/master/model_doc/pegasus.html)
Original TF 1 code [here](https://github.com/google-research/pegasus)
Authors: Jingqing Zhang, Yao Zhao, Mohammad Saleh and Peter J. Liu on Dec 18, 2019
Maintained by: [@sshleifer](https://twitter.com/sam_shleifer)
Task: Summarization
The following is copied from the authors' README.
# Mixed & Stochastic Checkpoints
We train a pegasus model with sampled gap sentence ratios on both C4 and HugeNews, and stochastically sample important sentences. The updated the results are reported in this table.
| dataset | C4 | HugeNews | Mixed & Stochastic|
| ---- | ---- | ---- | ----|
| xsum | 45.20/22.06/36.99 | 47.21/24.56/39.25 | 47.60/24.83/39.64|
| cnn_dailymail | 43.90/21.20/40.76 | 44.17/21.47/41.11 | 44.16/21.56/41.30|
| newsroom | 45.07/33.39/41.28 | 45.15/33.51/41.33 | 45.98/34.20/42.18|
| multi_news | 46.74/17.95/24.26 | 47.52/18.72/24.91 | 47.65/18.75/24.95|
| gigaword | 38.75/19.96/36.14 | 39.12/19.86/36.24 | 39.65/20.47/36.76|
| wikihow | 43.07/19.70/34.79 | 41.35/18.51/33.42 | 46.39/22.12/38.41 *|
| reddit_tifu | 26.54/8.94/21.64 | 26.63/9.01/21.60 | 27.99/9.81/22.94|
| big_patent | 53.63/33.16/42.25 | 53.41/32.89/42.07 | 52.29/33.08/41.66 *|
| arxiv | 44.70/17.27/25.80 | 44.67/17.18/25.73 | 44.21/16.95/25.67|
| pubmed | 45.49/19.90/27.69 | 45.09/19.56/27.42 | 45.97/20.15/28.25|
| aeslc | 37.69/21.85/36.84 | 37.40/21.22/36.45 | 37.68/21.25/36.51|
| billsum | 57.20/39.56/45.80 | 57.31/40.19/45.82 | 59.67/41.58/47.59|
The "Mixed & Stochastic" model has the following changes:
- trained on both C4 and HugeNews (dataset mixture is weighted by their number of examples).
- trained for 1.5M instead of 500k (we observe slower convergence on pretraining perplexity).
- the model uniformly sample a gap sentence ratio between 15% and 45%.
- importance sentences are sampled using a 20% uniform noise to importance scores.
- the sentencepiece tokenizer is updated to be able to encode newline character.
(*) the numbers of wikihow and big_patent datasets are not comparable because of change in tokenization and data:
- wikihow dataset contains newline characters which is useful for paragraph segmentation, the C4 and HugeNews model's sentencepiece tokenizer doesn't encode newline and loose this information.
- we update the BigPatent dataset to preserve casing, some format cleanings are also changed, please refer to change in TFDS.
The "Mixed & Stochastic" model has the following changes (from pegasus-large in the paper):
trained on both C4 and HugeNews (dataset mixture is weighted by their number of examples).
trained for 1.5M instead of 500k (we observe slower convergence on pretraining perplexity).
the model uniformly sample a gap sentence ratio between 15% and 45%.
importance sentences are sampled using a 20% uniform noise to importance scores.
the sentencepiece tokenizer is updated to be able to encode newline character.
Citation
```
@misc{zhang2019pegasus,
title={PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization},
author={Jingqing Zhang and Yao Zhao and Mohammad Saleh and Peter J. Liu},
year={2019},
eprint={1912.08777},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
funnel-transformer/large | 3f56dd1209e9470b922bd24715c78db03af0fe51 | 2022-06-07T15:26:48.000Z | [
"pytorch",
"tf",
"funnel",
"feature-extraction",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"dataset:gigaword",
"arxiv:2006.03236",
"transformers",
"license:apache-2.0"
] | feature-extraction | false | funnel-transformer | null | funnel-transformer/large | 783 | 1 | transformers | 1,949 | ---
language: en
license: apache-2.0
datasets:
- bookcorpus
- wikipedia
- gigaword
---
# Funnel Transformer large model (B8-8-8 with decoder)
Pretrained model on English language using a similar objective as [ELECTRA](https://huggingface.co/transformers/model_doc/electra.html). It was introduced in
[this paper](https://arxiv.org/pdf/2006.03236.pdf) and first released in
[this repository](https://github.com/laiguokun/Funnel-Transformer). This model is uncased: it does not make a difference
between english and English.
Disclaimer: The team releasing Funnel Transformer did not write a model card for this model so this model card has been
written by the Hugging Face team.
## Model description
Funnel Transformer is a transformers model pretrained on a large corpus of English data in a self-supervised fashion. This means it
was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of
publicly available data) with an automatic process to generate inputs and labels from those texts.
More precisely, a small language model corrupts the input texts and serves as a generator of inputs for this model, and
the pretraining objective is to predict which token is an original and which one has been replaced, a bit like a GAN training.
This way, the model learns an inner representation of the English language that can then be used to extract features
useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a standard
classifier using the features produced by the BERT model as inputs.
## Intended uses & limitations
You can use the raw model to extract a vector representation of a given text, but it's mostly intended to
be fine-tuned on a downstream task. See the [model hub](https://huggingface.co/models?filter=funnel-transformer) to look for
fine-tuned versions on a task that interests you.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked)
to make decisions, such as sequence classification, token classification or question answering. For tasks such as text
generation you should look at model like GPT2.
### How to use
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import FunnelTokenizer, FunnelModel
tokenizer = FunnelTokenizer.from_pretrained("funnel-transformer/large")
model = FunneModel.from_pretrained("funnel-transformer/large")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import FunnelTokenizer, TFFunnelModel
tokenizer = FunnelTokenizer.from_pretrained("funnel-transformer/large")
model = TFFunnelModel.from_pretrained("funnel-transformer/large")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
## Training data
The BERT model was pretrained on:
- [BookCorpus](https://yknzhu.wixsite.com/mbweb), a dataset consisting of 11,038 unpublished books,
- [English Wikipedia](https://en.wikipedia.org/wiki/English_Wikipedia) (excluding lists, tables and headers),
- [Clue Web](https://lemurproject.org/clueweb12/), a dataset of 733,019,372 English web pages,
- [GigaWord](https://catalog.ldc.upenn.edu/LDC2011T07), an archive of newswire text data,
- [Common Crawl](https://commoncrawl.org/), a dataset of raw web pages.
### BibTeX entry and citation info
```bibtex
@misc{dai2020funneltransformer,
title={Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing},
author={Zihang Dai and Guokun Lai and Yiming Yang and Quoc V. Le},
year={2020},
eprint={2006.03236},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
|
ydshieh/vit-gpt2-coco-en | 65636df6deb3da3e23106321ae33cb82adbc845a | 2022-01-09T15:53:19.000Z | [
"pytorch",
"tf",
"jax",
"tensorboard",
"vision-encoder-decoder",
"generic",
"image-classification"
] | image-classification | false | ydshieh | null | ydshieh/vit-gpt2-coco-en | 782 | 7 | generic | 1,950 | ---
tags:
- image-classification
library_name: generic
---
## Example
The model is by no means a state-of-the-art model, but nevertheless
produces reasonable image captioning results. It was mainly fine-tuned
as a proof-of-concept for the 🤗 FlaxVisionEncoderDecoder Framework.
The model can be used as follows:
**In PyTorch**
```python
import torch
import requests
from PIL import Image
from transformers import ViTFeatureExtractor, AutoTokenizer, VisionEncoderDecoderModel
loc = "ydshieh/vit-gpt2-coco-en"
feature_extractor = ViTFeatureExtractor.from_pretrained(loc)
tokenizer = AutoTokenizer.from_pretrained(loc)
model = VisionEncoderDecoderModel.from_pretrained(loc)
model.eval()
def predict(image):
pixel_values = feature_extractor(images=image, return_tensors="pt").pixel_values
with torch.no_grad():
output_ids = model.generate(pixel_values, max_length=16, num_beams=4, return_dict_in_generate=True).sequences
preds = tokenizer.batch_decode(output_ids, skip_special_tokens=True)
preds = [pred.strip() for pred in preds]
return preds
# We will verify our results on an image of cute cats
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
with Image.open(requests.get(url, stream=True).raw) as image:
preds = predict(image)
print(preds)
# should produce
# ['a cat laying on top of a couch next to another cat']
```
**In Flax**
```python
import jax
import requests
from PIL import Image
from transformers import ViTFeatureExtractor, AutoTokenizer, FlaxVisionEncoderDecoderModel
loc = "ydshieh/vit-gpt2-coco-en"
feature_extractor = ViTFeatureExtractor.from_pretrained(loc)
tokenizer = AutoTokenizer.from_pretrained(loc)
model = FlaxVisionEncoderDecoderModel.from_pretrained(loc)
gen_kwargs = {"max_length": 16, "num_beams": 4}
# This takes sometime when compiling the first time, but the subsequent inference will be much faster
@jax.jit
def generate(pixel_values):
output_ids = model.generate(pixel_values, **gen_kwargs).sequences
return output_ids
def predict(image):
pixel_values = feature_extractor(images=image, return_tensors="np").pixel_values
output_ids = generate(pixel_values)
preds = tokenizer.batch_decode(output_ids, skip_special_tokens=True)
preds = [pred.strip() for pred in preds]
return preds
# We will verify our results on an image of cute cats
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
with Image.open(requests.get(url, stream=True).raw) as image:
preds = predict(image)
print(preds)
# should produce
# ['a cat laying on top of a couch next to another cat']
``` |
facebook/data2vec-audio-large | 8aebfda61f5749e532f5577d176072ea38a6b349 | 2022-04-18T16:29:14.000Z | [
"pytorch",
"data2vec-audio",
"feature-extraction",
"en",
"dataset:librispeech_asr",
"arxiv:2202.03555",
"transformers",
"speech",
"license:apache-2.0"
] | feature-extraction | false | facebook | null | facebook/data2vec-audio-large | 782 | null | transformers | 1,951 | ---
language: en
datasets:
- librispeech_asr
tags:
- speech
license: apache-2.0
---
# Data2Vec-Audio-Large
[Facebook's Data2Vec](https://ai.facebook.com/research/data2vec-a-general-framework-for-self-supervised-learning-in-speech-vision-and-language/)
The large model pretrained on 16kHz sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz.
**Note**: This model does not have a tokenizer as it was pretrained on audio alone. In order to use this model **speech recognition**, a tokenizer should be created and the model should be fine-tuned on labeled text data. Check out [this blog](https://huggingface.co/blog/fine-tune-wav2vec2-english) for more in-detail explanation of how to fine-tune the model.
[Paper](https://arxiv.org/abs/2202.03555)
Authors: Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli
**Abstract**
While the general idea of self-supervised learning is identical across modalities, the actual algorithms and objectives differ widely because they were developed with a single modality in mind. To get us closer to general self-supervised learning, we present data2vec, a framework that uses the same learning method for either speech, NLP or computer vision. The core idea is to predict latent representations of the full input data based on a masked view of the input in a self-distillation setup using a standard Transformer architecture. Instead of predicting modality-specific targets such as words, visual tokens or units of human speech which are local in nature, data2vec predicts contextualized latent representations that contain information from the entire input. Experiments on the major benchmarks of speech recognition, image classification, and natural language understanding demonstrate a new state of the art or competitive performance to predominant approaches.
The original model can be found under https://github.com/pytorch/fairseq/tree/main/examples/data2vec .
# Pre-Training method

For more information, please take a look at the [official paper](https://arxiv.org/abs/2202.03555).
# Usage
See [this notebook](https://colab.research.google.com/drive/1FjTsqbYKphl9kL-eILgUc-bl4zVThL8F?usp=sharing) for more information on how to fine-tune the model. |
dmis-lab/biosyn-biobert-ncbi-disease | 7ef898a280b7fd3d60c16880c7304dcaeda0860b | 2021-10-25T14:43:20.000Z | [
"pytorch",
"transformers"
] | null | false | dmis-lab | null | dmis-lab/biosyn-biobert-ncbi-disease | 780 | 1 | transformers | 1,952 | Entry not found |
MoritzLaurer/policy-distilbert-7d | dd0868b3441cfeb208771aea159f755bb7a3e4ab | 2021-01-04T20:22:18.000Z | [
"pytorch",
"distilbert",
"text-classification",
"en",
"transformers"
] | text-classification | false | MoritzLaurer | null | MoritzLaurer/policy-distilbert-7d | 779 | 2 | transformers | 1,953 | ---
language:
- en
tags:
- text-classification
metrics:
- accuracy (balanced)
- F1 (weighted)
widget:
- text: "70-85% of the population needs to get vaccinated against the novel coronavirus to achieve herd immunity."
---
# Policy-DistilBERT-7d
## Model description
This model was trained on 129.669 manually annotated sentences to classify text into one of seven political categories: 'Economy', 'External Relations', 'Fabric of Society', 'Freedom and Democracy', 'Political System', 'Welfare and Quality of Life' or 'Social Groups'.
## Intended uses & limitations
#### How to use the model
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
model_name = "MoritzLaurer/policy-distilbert-7d"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)
text = "The new variant first detected in southern England in September is blamed for sharp rises in levels of positive tests in recent weeks in London, south-east England and the east of England"
input = tokenizer(text, truncation=True, return_tensors="pt")
output = model(input["input_ids"])
# the output corresponds to the following labels:
# 0: external relations, 1: freedom and democracy, 2: political system, 3: economy, 4: welfare and quality of life, 5: fabric of society, 6: social groups
# output to dictionary
prediction = torch.softmax(output["logits"][0], -1).tolist()
label_names = ["external relations", "freedom and democracy", "political system", "economy", "welfare and quality of life", "fabric of society", "social groups"]
prediction = {name: round(float(pred) * 100, 1) for pred, name in zip(prediction, label_names)}
print(prediction)
#{'external relations': 0.0, 'freedom and democracy': 0.0, 'political system': 0.9, 'economy': 0.4,
# 'welfare and quality of life': 98.3, 'fabric of society': 0.3, 'social groups': 0.0}
```
### Training data
Policy-DistilBERT-7d was trained on the English-speaking subset of the [Manifesto Project Dataset (MPDS2020a)](https://manifesto-project.wzb.eu/datasets). The model was trained on 129.669 sentences from 164 political manifestos from 55 political parties in 8 English-speaking countries (Australia, Canada, Ireland, Israel, New Zealand, South Africa, United Kingdom, United States). The manifestos were published between 1992 - 2019.
The Manifesto Project mannually annotates individual sentences from political party manifestos in 7 main political domains: 'Economy', 'External Relations', 'Fabric of Society', 'Freedom and Democracy', 'Political System', 'Welfare and Quality of Life' or 'Social Groups' - see the [codebook](https://manifesto-project.wzb.eu/down/data/2020b/codebooks/codebook_MPDataset_MPDS2020b.pdf) for the exact definitions of each domain.
### Training procedure
`distilbert-base-uncased` was trained using the Hugging Face trainer with the following hyperparameters. The hyperparameters were determined using a hyperparameter search on a 15% validation set.
```
training_args = TrainingArguments(
num_train_epochs=5, # total number of training epochs
learning_rate=4e-05,
per_device_train_batch_size=4, # batch size per device during training
per_device_eval_batch_size=4, # batch size for evaluation
warmup_steps=500, # number of warmup steps for learning rate scheduler
weight_decay=0.02, # strength of weight decay
fp16=True # mixed precision training
)
```
### Eval results
The model was evaluated using 15% of the sentences (85-15 train-test split).
accuracy (balanced) | F1 (weighted) | precision | recall | accuracy (not balanced)
-------|---------|----------|---------|----------
0.745 | 0.773 | 0.772 | 0.771 | 0.771
Please note that the label distribution in the dataset is imbalanced:
```
Welfare and Quality of Life 0.327225
Economy 0.259191
Fabric of Society 0.111800
Political System 0.095081
Social Groups 0.094371
External Relations 0.063724
Freedom and Democracy 0.048608
```
[Balanced accuracy](https://scikit-learn.org/stable/modules/generated/sklearn.metrics.balanced_accuracy_score.html) and [weighted F1](https://scikit-learn.org/stable/modules/generated/sklearn.metrics.precision_recall_fscore_support.html) were therefore used to evaluate model performance.
## Limitations and bias
The model was trained on sentences in political manifestos from parties in the 8 countries mentioned above between 1992-2019, manually annotated by the [Manifesto Project](https://manifesto-project.wzb.eu/information/documents/information). The model output therefore reproduces the limitations of the dataset in terms of country coverage, time span, domain definitions and potential biases of the annotators - as any supervised machine learning model would. Applying the model to other types of data (other types of texts, countries etc.) will reduce performance.
### BibTeX entry and citation info
```bibtex
@unpublished{
title={Policy-DistilBERT},
author={Moritz Laurer},
year={2020},
note={Unpublished paper}
}
``` |
microsoft/tapex-large-finetuned-wtq | 0cd74d3e2a094d1712e631095e38ec6256e22867 | 2022-07-14T10:12:06.000Z | [
"pytorch",
"bart",
"text2text-generation",
"en",
"dataset:wikitablequestions",
"arxiv:2107.07653",
"transformers",
"tapex",
"table-question-answering",
"license:mit",
"autotrain_compatible"
] | table-question-answering | false | microsoft | null | microsoft/tapex-large-finetuned-wtq | 779 | 2 | transformers | 1,954 | ---
language: en
tags:
- tapex
- table-question-answering
datasets:
- wikitablequestions
license: mit
---
# TAPEX (large-sized model)
TAPEX was proposed in [TAPEX: Table Pre-training via Learning a Neural SQL Executor](https://arxiv.org/abs/2107.07653) by Qian Liu, Bei Chen, Jiaqi Guo, Morteza Ziyadi, Zeqi Lin, Weizhu Chen, Jian-Guang Lou. The original repo can be found [here](https://github.com/microsoft/Table-Pretraining).
## Model description
TAPEX (**Ta**ble **P**re-training via **Ex**ecution) is a conceptually simple and empirically powerful pre-training approach to empower existing models with *table reasoning* skills. TAPEX realizes table pre-training by learning a neural SQL executor over a synthetic corpus, which is obtained by automatically synthesizing executable SQL queries.
TAPEX is based on the BART architecture, the transformer encoder-encoder (seq2seq) model with a bidirectional (BERT-like) encoder and an autoregressive (GPT-like) decoder.
This model is the `tapex-base` model fine-tuned on the [WikiTableQuestions](https://huggingface.co/datasets/wikitablequestions) dataset.
## Intended Uses
You can use the model for table question answering on *complex* questions. Some **solveable** questions are shown below (corresponding tables now shown):
| Question | Answer |
|:---: |:---:|
| according to the table, what is the last title that spicy horse produced? | Akaneiro: Demon Hunters |
| what is the difference in runners-up from coleraine academical institution and royal school dungannon? | 20 |
| what were the first and last movies greenstreet acted in? | The Maltese Falcon, Malaya |
| in which olympic games did arasay thondike not finish in the top 20? | 2012 |
| which broadcaster hosted 3 titles but they had only 1 episode? | Channel 4 |
### How to Use
Here is how to use this model in transformers:
```python
from transformers import TapexTokenizer, BartForConditionalGeneration
import pandas as pd
tokenizer = TapexTokenizer.from_pretrained("microsoft/tapex-large-finetuned-wtq")
model = BartForConditionalGeneration.from_pretrained("microsoft/tapex-large-finetuned-wtq")
data = {
"year": [1896, 1900, 1904, 2004, 2008, 2012],
"city": ["athens", "paris", "st. louis", "athens", "beijing", "london"]
}
table = pd.DataFrame.from_dict(data)
# tapex accepts uncased input since it is pre-trained on the uncased corpus
query = "In which year did beijing host the Olympic Games?"
encoding = tokenizer(table=table, query=query, return_tensors="pt")
outputs = model.generate(**encoding)
print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
# [' 2008.0']
```
### How to Eval
Please find the eval script [here](https://github.com/SivilTaram/transformers/tree/add_tapex_bis/examples/research_projects/tapex).
### BibTeX entry and citation info
```bibtex
@inproceedings{
liu2022tapex,
title={{TAPEX}: Table Pre-training via Learning a Neural {SQL} Executor},
author={Qian Liu and Bei Chen and Jiaqi Guo and Morteza Ziyadi and Zeqi Lin and Weizhu Chen and Jian-Guang Lou},
booktitle={International Conference on Learning Representations},
year={2022},
url={https://openreview.net/forum?id=O50443AsCP}
}
``` |
CEBaB/bert-base-uncased.CEBaB.sa.5-class.exclusive.seed_42 | 31f7c9163f86707a680430a9a4950f76f35382e3 | 2022-05-10T23:56:18.000Z | [
"pytorch",
"bert",
"transformers"
] | null | false | CEBaB | null | CEBaB/bert-base-uncased.CEBaB.sa.5-class.exclusive.seed_42 | 779 | null | transformers | 1,955 | Entry not found |
Sigma/financial-sentiment-analysis | d78ca172e07e94390f615739cee98a2154381f7e | 2022-05-14T11:48:56.000Z | [
"pytorch",
"tensorboard",
"bert",
"text-classification",
"dataset:financial_phrasebank",
"transformers",
"generated_from_trainer",
"model-index"
] | text-classification | false | Sigma | null | Sigma/financial-sentiment-analysis | 779 | null | transformers | 1,956 | ---
tags:
- generated_from_trainer
datasets:
- financial_phrasebank
metrics:
- accuracy
- f1
model-index:
- name: financial-sentiment-analysis
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: financial_phrasebank
type: financial_phrasebank
args: sentences_allagree
metrics:
- name: Accuracy
type: accuracy
value: 0.9924242424242424
- name: F1
type: f1
value: 0.9924242424242424
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# financial-sentiment-analysis
This model is a fine-tuned version of [ahmedrachid/FinancialBERT](https://huggingface.co/ahmedrachid/FinancialBERT) on the financial_phrasebank dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0395
- Accuracy: 0.9924
- F1: 0.9924
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
### Framework versions
- Transformers 4.19.1
- Pytorch 1.11.0+cu113
- Datasets 2.2.1
- Tokenizers 0.12.1
|
kykim/funnel-kor-base | 6bc460ff2e566cd8a18ce99d58141f0238bab2bd | 2021-01-22T01:56:37.000Z | [
"pytorch",
"tf",
"funnel",
"feature-extraction",
"ko",
"transformers"
] | feature-extraction | false | kykim | null | kykim/funnel-kor-base | 777 | null | transformers | 1,957 | ---
language: ko
---
# Funnel-transformer base model for Korean
* 70GB Korean text dataset and 42000 lower-cased subwords are used
* Check the model performance and other language models for Korean in [github](https://github.com/kiyoungkim1/LM-kor)
```python
from transformers import FunnelTokenizer, FunnelModel
tokenizer = FunnelTokenizer.from_pretrained("kykim/funnel-kor-base")
model = FunnelModel.from_pretrained("kykim/funnel-kor-base")
``` |
techthiyanes/chinese_sentiment | 215de6a818f1fbd430e8a1d45b7a4681c0936102 | 2021-05-20T07:28:06.000Z | [
"pytorch",
"jax",
"bert",
"text-classification",
"transformers"
] | text-classification | false | techthiyanes | null | techthiyanes/chinese_sentiment | 773 | 3 | transformers | 1,958 | Entry not found |
naver-clova-ix/donut-base | a8138504038547801557466623fbc4946bb9bb68 | 2022-07-19T13:50:39.000Z | [
"pytorch",
"donut",
"transformers",
"license:mit"
] | null | false | naver-clova-ix | null | naver-clova-ix/donut-base | 773 | null | transformers | 1,959 | ---
license: mit
---
|
allenai/tk-instruct-3b-def | 3d9f0e250c341d4d5a8ff1018938379c65c6ac52 | 2022-05-27T06:28:55.000Z | [
"pytorch",
"t5",
"text2text-generation",
"en",
"dataset:natural instructions v2.0",
"arxiv:1910.10683",
"arxiv:2204.07705",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | text2text-generation | false | allenai | null | allenai/tk-instruct-3b-def | 771 | null | transformers | 1,960 | ---
language: en
license: apache-2.0
datasets:
- natural instructions v2.0
---
# Model description
Tk-Instruct is a series of encoder-decoder Transformer models that are trained to solve various NLP tasks by following in-context instructions (plain language task definitions, k-shot examples, explanations, etc). Built upon the pre-trained [T5 models](https://arxiv.org/abs/1910.10683), they are fine-tuned on a large number of tasks & instructions that are collected in the [Natural Instructions benchmark](https://github.com/allenai/natural-instructions), which contains 1600+ tasks in 70+ broach categories in total. This enables the model to not only process the training tasks, but also generalize to many unseen tasks without further parameter update.
More resources for using the model:
- **Paper**: [link](https://arxiv.org/abs/2204.07705)
- **Code repository**: [Tk-Instruct](https://github.com/yizhongw/Tk-Instruct)
- **Official Website**: [Natural Instructions](https://instructions.apps.allenai.org/)
- **All released models**: [allenai/tk-instruct](https://huggingface.co/models?search=allenai/tk-instruct)
## Intended uses & limitations
Tk-Instruct can be used to do many NLP tasks by following instructions.
### How to use
When instructing the model, task definition or demonstration examples or explanations should be prepended to the original input and fed into the model. You can easily try Tk-Instruct models as follows:
```python
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
>>> tokenizer = AutoTokenizer.from_pretrained("allenai/tk-instruct-3b-def")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("allenai/tk-instruct-3b-def")
>>> input_ids = tokenizer.encode(
"Definition: return the currency of the given country. Now complete the following example - Input: India. Output:",
return_tensors="pt")
>>> output = model.generate(input_ids, max_length=10)
>>> output = tokenizer.decode(output[0], skip_special_tokens=True) # model should output 'Indian Rupee'
>>> input_ids = tokenizer.encode(
"Definition: negate the following sentence. Input: John went to school. Output:",
return_tensors="pt")
>>> output = model.generate(input_ids, max_length=10)
>>> output = tokenizer.decode(output[0], skip_special_tokens=True) # model should output 'John did not go to shool.'
```
### Limitations
We are still working on understanding the behaviors of these models, but here are several issues we have found:
- Models are generally sensitive to the instruction. Sometimes rewording the instruction can lead to very different output.
- Models are not always compliant to the instruction. Sometimes the model don't follow your instruction (e.g., when you ask the model to generate one sentence, it might still generate one word or a long story).
- Models might totally fail on some tasks.
If you find serious issues or any interesting result, you are welcome to share with us!
## Training data
Tk-Instruct is trained using the tasks & instructions in [Natural Instructions benchmark](https://github.com/allenai/natural-instructions), which contains 1600+ tasks in 70+ broach categories in total. We follow the official train/test split. Tk-Instruct model series were trained using 757 tasks, and mTk-Instruct series were trained using 1271 tasks (including some non-English tasks).
The training tasks are in 64 broad categories, such as text categorization / question answering / sentiment analysis / summarization / grammar error detection / dialogue generation / etc. The other 12 categories are selected for evaluation.
## Training procedure
All our models are initialized from either T5 models or mT5 models. Because generating the output can be regarded as a form of language modeling, we used their [LM adapted version](https://github.com/google-research/text-to-text-transfer-transformer/blob/main/released_checkpoints.md#lm-adapted-t511lm100k). All data is converted into a text-to-text format, and models are fine-tuned to maximize the likelihood of the output sequence.
Our [released models](https://huggingface.co/models?search=allenai/tk-instruct) are in different sizes, and each of them was trained with a specific type of instruction encoding. For instance, `tk-instruct-3b-def-pos` was initialized from [t5-xl-lm-adapt](https://huggingface.co/google/t5-xl-lm-adapt), and it saw task definition & 2 positive examples as the instruction during training time.
Although they are trained with only one type of instruction encodings, we found they can usually work with other type of encodings at test time (see more in our paper).
### BibTeX entry and citation info
```bibtex
@article{wang2022benchmarking,
title={Benchmarking Generalization via In-Context Instructions on 1,600+ Language Tasks},
author={Yizhong Wang and Swaroop Mishra and Pegah Alipoormolabashi and Yeganeh Kordi and Amirreza Mirzaei and A. Arunkumar and Arjun Ashok and Arut Selvan Dhanasekaran and Atharva Naik and David Stap and Eshaan Pathak and Giannis Karamanolakis and Haizhi Gary Lai and Ishan Purohit and Ishani Mondal and Jacob Anderson and Kirby Kuznia and Krima Doshi and Maitreya Patel and Kuntal Kumar Pal and M. Moradshahi and Mihir Parmar and Mirali Purohit and Neeraj Varshney and Phani Rohitha Kaza and Pulkit Verma and Ravsehaj Singh Puri and Rushang Karia and Shailaja Keyur Sampat and Savan Doshi and Siddharth Deepak Mishra and Sujan C. Reddy and Sumanta Patro and Tanay Dixit and Xu-dong Shen and Chitta Baral and Yejin Choi and Hannaneh Hajishirzi and Noah A. Smith and Daniel Khashabi},
year={2022},
archivePrefix={arXiv},
eprint={2204.07705},
primaryClass={cs.CL},
}
``` |
lanwuwei/BERTOverflow_stackoverflow_github | 50faf74c11305823a594e001eacba6be9cda1939 | 2021-05-19T00:15:32.000Z | [
"pytorch",
"jax",
"bert",
"feature-extraction",
"transformers"
] | feature-extraction | false | lanwuwei | null | lanwuwei/BERTOverflow_stackoverflow_github | 769 | null | transformers | 1,961 |
# BERTOverflow
## Model description
We pre-trained BERT-base model on 152 million sentences from the StackOverflow's 10 year archive. More details of this model can be found in our ACL 2020 paper: [Code and Named Entity Recognition in StackOverflow](https://www.aclweb.org/anthology/2020.acl-main.443/).
#### How to use
```python
from transformers import *
import torch
tokenizer = AutoTokenizer.from_pretrained("lanwuwei/BERTOverflow_stackoverflow_github")
model = AutoModelForTokenClassification.from_pretrained("lanwuwei/BERTOverflow_stackoverflow_github")
```
### BibTeX entry and citation info
```bibtex
@inproceedings{tabassum2020code,
title={Code and Named Entity Recognition in StackOverflow},
author={Tabassum, Jeniya and Maddela, Mounica and Xu, Wei and Ritter, Alan },
booktitle = {Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL)},
url={https://www.aclweb.org/anthology/2020.acl-main.443/}
year = {2020},
}
```
|
naver-clova-ix/donut-base-finetuned-docvqa | 679d8ec7f097ca70e59b35359726db1a4d92ffe5 | 2022-07-19T14:00:09.000Z | [
"pytorch",
"donut",
"transformers",
"license:mit"
] | null | false | naver-clova-ix | null | naver-clova-ix/donut-base-finetuned-docvqa | 769 | null | transformers | 1,962 | ---
license: mit
---
|
Averium/FabioBot | fd68f97eb35228980128efd5dae17769262996ee | 2022-06-23T22:21:28.000Z | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | false | Averium | null | Averium/FabioBot | 768 | null | transformers | 1,963 | ---
tags:
- conversational
---
# Twin-Tailed Fabio DialoGPT Model
|
wietsedv/bert-base-dutch-cased-finetuned-sentiment | c9802e7e1da3cbef9e33a3e745d6af1e923a4c8b | 2022-06-23T14:05:56.000Z | [
"pytorch",
"tf",
"jax",
"bert",
"text-classification",
"transformers"
] | text-classification | false | wietsedv | null | wietsedv/bert-base-dutch-cased-finetuned-sentiment | 767 | 1 | transformers | 1,964 | Entry not found |
alenusch/mt5large-ruparaphraser | 12e8714a889fcd0c4a7a5db904ae09760ed1362d | 2020-12-18T15:50:04.000Z | [
"pytorch",
"mt5",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | false | alenusch | null | alenusch/mt5large-ruparaphraser | 766 | null | transformers | 1,965 | Entry not found |
lordtt13/emo-mobilebert | 55364424cefcffb88aaec8ee8129030e3b069174 | 2020-12-11T21:49:42.000Z | [
"pytorch",
"tf",
"mobilebert",
"text-classification",
"en",
"dataset:emo",
"arxiv:2004.02984",
"transformers"
] | text-classification | false | lordtt13 | null | lordtt13/emo-mobilebert | 766 | 2 | transformers | 1,966 | ---
language: en
datasets:
- emo
---
## Emo-MobileBERT: a thin version of BERT LARGE, trained on the EmoContext Dataset from scratch
### Details of MobileBERT
The **MobileBERT** model was presented in [MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices](https://arxiv.org/abs/2004.02984) by *Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, Denny Zhou* and here is the abstract:
Natural Language Processing (NLP) has recently achieved great success by using huge pre-trained models with hundreds of millions of parameters. However, these models suffer from heavy model sizes and high latency such that they cannot be deployed to resource-limited mobile devices. In this paper, we propose MobileBERT for compressing and accelerating the popular BERT model. Like the original BERT, MobileBERT is task-agnostic, that is, it can be generically applied to various downstream NLP tasks via simple fine-tuning. Basically, MobileBERT is a thin version of BERT_LARGE, while equipped with bottleneck structures and a carefully designed balance between self-attentions and feed-forward networks. To train MobileBERT, we first train a specially designed teacher model, an inverted-bottleneck incorporated BERT_LARGE model. Then, we conduct knowledge transfer from this teacher to MobileBERT. Empirical studies show that MobileBERT is 4.3x smaller and 5.5x faster than BERT_BASE while achieving competitive results on well-known benchmarks. On the natural language inference tasks of GLUE, MobileBERT achieves a GLUEscore o 77.7 (0.6 lower than BERT_BASE), and 62 ms latency on a Pixel 4 phone. On the SQuAD v1.1/v2.0 question answering task, MobileBERT achieves a dev F1 score of 90.0/79.2 (1.5/2.1 higher than BERT_BASE).
### Details of the downstream task (Emotion Recognition) - Dataset 📚
SemEval-2019 Task 3: EmoContext Contextual Emotion Detection in Text
In this dataset, given a textual dialogue i.e. an utterance along with two previous turns of context, the goal was to infer the underlying emotion of the utterance by choosing from four emotion classes:
- sad 😢
- happy 😃
- angry 😡
- others
### Model training
The training script is present [here](https://github.com/lordtt13/transformers-experiments/blob/master/Custom%20Tasks/emo-mobilebert.ipynb).
### Pipelining the Model
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification, pipeline
tokenizer = AutoTokenizer.from_pretrained("lordtt13/emo-mobilebert")
model = AutoModelForSequenceClassification.from_pretrained("lordtt13/emo-mobilebert")
nlp_sentence_classif = transformers.pipeline('sentiment-analysis', model = model, tokenizer = tokenizer)
nlp_sentence_classif("I've never had such a bad day in my life")
# Output: [{'label': 'sad', 'score': 0.93153977394104}]
```
> Created by [Tanmay Thakur](https://github.com/lordtt13) | [LinkedIn](https://www.linkedin.com/in/tanmay-thakur-6bb5a9154/)
|
Geotrend/distilbert-base-da-cased | 6e07346d5a45ed6002fc19662ce2f17dd1335b02 | 2021-07-27T19:35:33.000Z | [
"pytorch",
"distilbert",
"fill-mask",
"da",
"dataset:wikipedia",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | fill-mask | false | Geotrend | null | Geotrend/distilbert-base-da-cased | 765 | null | transformers | 1,967 | ---
language: da
datasets: wikipedia
license: apache-2.0
---
# distilbert-base-da-cased
We are sharing smaller versions of [distilbert-base-multilingual-cased](https://huggingface.co/distilbert-base-multilingual-cased) that handle a custom number of languages.
Our versions give exactly the same representations produced by the original model which preserves the original accuracy.
For more information please visit our paper: [Load What You Need: Smaller Versions of Multilingual BERT](https://www.aclweb.org/anthology/2020.sustainlp-1.16.pdf).
## How to use
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("Geotrend/distilbert-base-da-cased")
model = AutoModel.from_pretrained("Geotrend/distilbert-base-da-cased")
```
To generate other smaller versions of multilingual transformers please visit [our Github repo](https://github.com/Geotrend-research/smaller-transformers).
### How to cite
```bibtex
@inproceedings{smallermdistilbert,
title={Load What You Need: Smaller Versions of Mutlilingual BERT},
author={Abdaoui, Amine and Pradel, Camille and Sigel, Grégoire},
booktitle={SustaiNLP / EMNLP},
year={2020}
}
```
## Contact
Please contact [email protected] for any question, feedback or request. |
PlanTL-GOB-ES/roberta-large-bne-capitel-ner | 521c79d4bbcedb062d03ecd4bec577525fb66756 | 2022-04-06T14:43:32.000Z | [
"pytorch",
"roberta",
"token-classification",
"es",
"dataset:bne",
"dataset:capitel",
"arxiv:1907.11692",
"arxiv:2107.07253",
"transformers",
"national library of spain",
"spanish",
"bne",
"capitel",
"ner",
"license:apache-2.0",
"autotrain_compatible"
] | token-classification | false | PlanTL-GOB-ES | null | PlanTL-GOB-ES/roberta-large-bne-capitel-ner | 764 | null | transformers | 1,968 | ---
language:
- es
license: apache-2.0
tags:
- "national library of spain"
- "spanish"
- "bne"
- "capitel"
- "ner"
datasets:
- "bne"
- "capitel"
metrics:
- "f1"
inference:
parameters:
aggregation_strategy: "first"
---
# Spanish RoBERTa-large trained on BNE finetuned for CAPITEL Named Entity Recognition (NER) dataset.
RoBERTa-large-bne is a transformer-based masked language model for the Spanish language. It is based on the [RoBERTa](https://arxiv.org/abs/1907.11692) large model and has been pre-trained using the largest Spanish corpus known to date, with a total of 570GB of clean and deduplicated text processed for this work, compiled from the web crawlings performed by the [National Library of Spain (Biblioteca Nacional de España)](http://www.bne.es/en/Inicio/index.html) from 2009 to 2019.
Original pre-trained model can be found here: https://huggingface.co/BSC-TeMU/roberta-large-bne
## Dataset
The dataset used is the one from the [CAPITEL competition at IberLEF 2020](https://sites.google.com/view/capitel2020) (sub-task 1).
## Evaluation and results
F1 Score: 0.8998
For evaluation details visit our [GitHub repository](https://github.com/PlanTL-GOB-ES/lm-spanish).
## Citing
Check out our paper for all the details: https://arxiv.org/abs/2107.07253
```
@article{gutierrezfandino2022,
author = {Asier Gutiérrez-Fandiño and Jordi Armengol-Estapé and Marc Pàmies and Joan Llop-Palao and Joaquin Silveira-Ocampo and Casimiro Pio Carrino and Carme Armentano-Oller and Carlos Rodriguez-Penagos and Aitor Gonzalez-Agirre and Marta Villegas},
title = {MarIA: Spanish Language Models},
journal = {Procesamiento del Lenguaje Natural},
volume = {68},
number = {0},
year = {2022},
issn = {1989-7553},
url = {http://journal.sepln.org/sepln/ojs/ojs/index.php/pln/article/view/6405},
pages = {39--60}
}
```
## Funding
This work was partially funded by the Spanish State Secretariat for Digitalization and Artificial Intelligence (SEDIA) within the framework of the Plan-TL, and the Future of Computing Center, a Barcelona Supercomputing Center and IBM initiative (2020).
## Disclaimer
The models published in this repository are intended for a generalist purpose and are available to third parties. These models may have bias and/or any other undesirable distortions.
When third parties, deploy or provide systems and/or services to other parties using any of these models (or using systems based on these models) or become users of the models, they should note that it is their responsibility to mitigate the risks arising from their use and, in any event, to comply with applicable regulations, including regulations regarding the use of artificial intelligence.
In no event shall the owner of the models (SEDIA – State Secretariat for digitalization and artificial intelligence) nor the creator (BSC – Barcelona Supercomputing Center) be liable for any results arising from the use made by third parties of these models.
Los modelos publicados en este repositorio tienen una finalidad generalista y están a disposición de terceros. Estos modelos pueden tener sesgos y/u otro tipo de distorsiones indeseables.
Cuando terceros desplieguen o proporcionen sistemas y/o servicios a otras partes usando alguno de estos modelos (o utilizando sistemas basados en estos modelos) o se conviertan en usuarios de los modelos, deben tener en cuenta que es su responsabilidad mitigar los riesgos derivados de su uso y, en todo caso, cumplir con la normativa aplicable, incluyendo la normativa en materia de uso de inteligencia artificial.
En ningún caso el propietario de los modelos (SEDIA – Secretaría de Estado de Digitalización e Inteligencia Artificial) ni el creador (BSC – Barcelona Supercomputing Center) serán responsables de los resultados derivados del uso que hagan terceros de estos modelos. |
allenyummy/chinese-bert-wwm-ehr-ner-sl | 0020467f0a55b08401f9d94d3f5d7edc2d92c7e1 | 2021-05-19T11:42:42.000Z | [
"pytorch",
"bert",
"zh-tw",
"transformers"
] | null | false | allenyummy | null | allenyummy/chinese-bert-wwm-ehr-ner-sl | 764 | null | transformers | 1,969 | ---
language: zh-tw
---
# Model name
Chinese-bert-wwm-electrical-health-records-ner-sequence-labeling
#### How to use
```
from transformers import AutoTokenizer, AutoModelForTokenClassification
tokenizer = AutoTokenizer.from_pretrained("allenyummy/chinese-bert-wwm-ehr-ner-sl")
model = AutoModelForTokenClassification.from_pretrained("allenyummy/chinese-bert-wwm-ehr-ner-sl")
```
|
google/t5-small-ssm-nq | 5a100af5c3b308940b33784587c511e062572c67 | 2021-06-23T01:51:51.000Z | [
"pytorch",
"tf",
"jax",
"t5",
"text2text-generation",
"en",
"dataset:c4",
"dataset:wikipedia",
"dataset:natural_questions",
"arxiv:2002.08909",
"arxiv:1910.10683",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | text2text-generation | false | google | null | google/t5-small-ssm-nq | 758 | 1 | transformers | 1,970 | ---
language: en
datasets:
- c4
- wikipedia
- natural_questions
pipeline_tag: text2text-generation
license: apache-2.0
---
[Google's T5](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) for **Closed Book Question Answering**.
The model was pre-trained using T5's denoising objective on [C4](https://huggingface.co/datasets/c4), subsequently additionally pre-trained using [REALM](https://arxiv.org/pdf/2002.08909.pdf)'s salient span masking objective on [Wikipedia](https://huggingface.co/datasets/wikipedia), and finally fine-tuned on [Natural Questions (NQ)](https://huggingface.co/datasets/natural_questions).
**Note**: The model was fine-tuned on 100% of the train splits of [Natural Questions (NQ)](https://huggingface.co/datasets/natural_questions) for 10k steps.
Other community Checkpoints: [here](https://huggingface.co/models?search=ssm)
Paper: [How Much Knowledge Can You Pack
Into the Parameters of a Language Model?](https://arxiv.org/abs/1910.10683.pdf)
Authors: *Adam Roberts, Colin Raffel, Noam Shazeer*
## Results on Natural Questions - Test Set
|Id | link | Exact Match |
|---|---|---|
|**T5-small**|**https://huggingface.co/google/t5-small-ssm-nq**|**25.5**|
|T5-large|https://huggingface.co/google/t5-large-ssm-nq|30.4|
|T5-xl|https://huggingface.co/google/t5-xl-ssm-nq|35.6|
|T5-xxl|https://huggingface.co/google/t5-xxl-ssm-nq|37.9|
|T5-3b|https://huggingface.co/google/t5-3b-ssm-nq|33.2|
|T5-11b|https://huggingface.co/google/t5-11b-ssm-nq|36.6|
## Usage
The model can be used as follows for **closed book question answering**:
```python
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
t5_qa_model = AutoModelForSeq2SeqLM.from_pretrained("google/t5-small-ssm-nq")
t5_tok = AutoTokenizer.from_pretrained("google/t5-small-ssm-nq")
input_ids = t5_tok("When was Franklin D. Roosevelt born?", return_tensors="pt").input_ids
gen_output = t5_qa_model.generate(input_ids)[0]
print(t5_tok.decode(gen_output, skip_special_tokens=True))
```
## Abstract
It has recently been observed that neural language models trained on unstructured text can implicitly store and retrieve knowledge using natural language queries. In this short paper, we measure the practical utility of this approach by fine-tuning pre-trained models to answer questions without access to any external context or knowledge. We show that this approach scales with model size and performs competitively with open-domain systems that explicitly retrieve answers from an external knowledge source when answering questions. To facilitate reproducibility and future work, we release our code and trained models at https://goo.gle/t5-cbqa.
 |
mrm8488/TinyBERT-spanish-uncased-finetuned-ner | a1eb804867635f501d62dda14e7ae8a182f96dd6 | 2021-05-20T00:18:21.000Z | [
"pytorch",
"jax",
"bert",
"token-classification",
"es",
"transformers",
"autotrain_compatible"
] | token-classification | false | mrm8488 | null | mrm8488/TinyBERT-spanish-uncased-finetuned-ner | 756 | null | transformers | 1,971 | ---
language: es
thumbnail:
---
# Spanish TinyBERT + NER
This model is a fine-tuned on [NER-C](https://www.kaggle.com/nltkdata/conll-corpora) of a [Spanish Tiny Bert](https://huggingface.co/mrm8488/es-tinybert-v1-1) model I created using *distillation* for **NER** downstream task. The **size** of the model is **55MB**
## Details of the downstream task (NER) - Dataset
- [Dataset: CONLL Corpora ES](https://www.kaggle.com/nltkdata/conll-corpora)
I preprocessed the dataset and split it as train / dev (80/20)
| Dataset | # Examples |
| ---------------------- | ----- |
| Train | 8.7 K |
| Dev | 2.2 K |
- [Fine-tune on NER script provided by Huggingface](https://github.com/huggingface/transformers/blob/master/examples/token-classification/run_ner_old.py)
- Labels covered:
```
B-LOC
B-MISC
B-ORG
B-PER
I-LOC
I-MISC
I-ORG
I-PER
O
```
## Metrics on evaluation set:
| Metric | # score |
| :------------------------------------------------------------------------------------: | :-------: |
| F1 | **70.00**
| Precision | **67.83** |
| Recall | **71.46** |
## Comparison:
| Model | # F1 score |Size(MB)|
| :--------------------------------------------------------------------------------------------------------------: | :-------: |:------|
| bert-base-spanish-wwm-cased (BETO) | 88.43 | 421
| [bert-spanish-cased-finetuned-ner](https://huggingface.co/mrm8488/bert-spanish-cased-finetuned-ner) | **90.17** | 420 |
| Best Multilingual BERT | 87.38 | 681 |
|TinyBERT-spanish-uncased-finetuned-ner (this one) | 70.00 | **55** |
## Model in action
Example of usage:
```python
import torch
from transformers import AutoModelForTokenClassification, AutoTokenizer
id2label = {
"0": "B-LOC",
"1": "B-MISC",
"2": "B-ORG",
"3": "B-PER",
"4": "I-LOC",
"5": "I-MISC",
"6": "I-ORG",
"7": "I-PER",
"8": "O"
}
tokenizer = AutoTokenizer.from_pretrained('mrm8488/TinyBERT-spanish-uncased-finetuned-ner')
model = AutoModelForTokenClassification.from_pretrained('mrm8488/TinyBERT-spanish-uncased-finetuned-ner')
text ="Mis amigos están pensando viajar a Londres este verano."
input_ids = torch.tensor(tokenizer.encode(text)).unsqueeze(0)
outputs = model(input_ids)
last_hidden_states = outputs[0]
for m in last_hidden_states:
for index, n in enumerate(m):
if(index > 0 and index <= len(text.split(" "))):
print(text.split(" ")[index-1] + ": " + id2label[str(torch.argmax(n).item())])
'''
Output:
--------
Mis: O
amigos: O
están: O
pensando: O
viajar: O
a: O
Londres: B-LOC
este: O
verano.: O
'''
```
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
uclanlp/visualbert-vqa | e3da2dbe26fd794128d151228cc771a584f56c6e | 2021-05-31T11:32:07.000Z | [
"pytorch",
"visual_bert",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | false | uclanlp | null | uclanlp/visualbert-vqa | 756 | 2 | transformers | 1,972 | Entry not found |
emanjavacas/MacBERTh | d709ce9a3cf02bf27e580e65fa50847edf02f64d | 2022-01-17T16:02:47.000Z | [
"pytorch",
"bert",
"transformers"
] | null | false | emanjavacas | null | emanjavacas/MacBERTh | 753 | 4 | transformers | 1,973 | Documentation In Progress... |
microsoft/layoutlmv3-base-chinese | 8cb50a024b05cb4f598084df3c60f7536557c5b4 | 2022-07-20T09:36:16.000Z | [
"pytorch",
"layoutlmv3",
"zh",
"arxiv:2204.08387",
"transformers",
"license:cc-by-nc-sa-4.0"
] | null | false | microsoft | null | microsoft/layoutlmv3-base-chinese | 753 | 9 | transformers | 1,974 | ---
language: zh
license: cc-by-nc-sa-4.0
---
# LayoutLMv3
[Microsoft Document AI](https://www.microsoft.com/en-us/research/project/document-ai/) | [GitHub](https://aka.ms/layoutlmv3)
## Model description
LayoutLMv3 is a pre-trained multimodal Transformer for Document AI with unified text and image masking. The simple unified architecture and training objectives make LayoutLMv3 a general-purpose pre-trained model. For example, LayoutLMv3 can be fine-tuned for both text-centric tasks, including form understanding, receipt understanding, and document visual question answering, and image-centric tasks such as document image classification and document layout analysis.
[LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387)
Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei, Preprint 2022.
## Results
| Dataset | Language | Precision | Recall | F1 |
|---------|-----------|------------|------|--------|
| [XFUND](https://github.com/doc-analysis/XFUND) | ZH | 0.8980 | 0.9435 | 0.9202 |
| Dataset | Subject | Test Time | Name | School | Examination Number | Seat Number | Class | Student Number | Grade | Score | **Mean** |
|---------|:------------|:------:|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|
| [EPHOIE](https://github.com/HCIILAB/EPHOIE) | 98.99 | 100.0 | 99.77 | 99.2 | 100.0 | 100.0 | 98.82 | 99.78 | 98.31 | 97.27 | 99.21 |
## Citation
If you find LayoutLM useful in your research, please cite the following paper:
```
@article{huang2022layoutlmv3,
title={LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking},
author={Yupan Huang and Tengchao Lv and Lei Cui and Yutong Lu and Furu Wei},
journal={arXiv preprint arXiv:2204.08387},
year={2022}
}
```
## License
The content of this project itself is licensed under the [Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0)](https://creativecommons.org/licenses/by-nc-sa/4.0/)
Portions of the source code are based on the [transformers](https://github.com/huggingface/transformers) project.
[Microsoft Open Source Code of Conduct](https://opensource.microsoft.com/codeofconduct)
|
PlanTL-GOB-ES/gpt2-large-bne | b2220f1ffa1ea27bbd8a97707c7ba575860cf23b | 2022-04-06T14:41:27.000Z | [
"pytorch",
"gpt2",
"text-generation",
"es",
"dataset:bne",
"arxiv:2107.07253",
"transformers",
"national library of spain",
"spanish",
"bne",
"license:apache-2.0"
] | text-generation | false | PlanTL-GOB-ES | null | PlanTL-GOB-ES/gpt2-large-bne | 752 | 6 | transformers | 1,975 | ---
language:
- es
license: apache-2.0
tags:
- "national library of spain"
- "spanish"
- "bne"
datasets:
- "bne"
metrics:
- "ppl"
---
# GPT2-large trained with data from National Library of Spain (BNE)
## Model Description
GPT2-large-bne is a transformer-based model for the Spanish language. It is based on the [GPT-2](http://www.persagen.com/files/misc/radford2019language.pdf) model and has been pre-trained using the largest Spanish corpus known to date, with a total of 570GB of clean and deduplicated text processed for this work, compiled from the web crawlings performed by the [National Library of Spain (Biblioteca Nacional de España)](http://www.bne.es/en/Inicio/index.html) from 2009 to 2019.
## Training corpora and preprocessing
The [National Library of Spain (Biblioteca Nacional de España)](http://www.bne.es/en/Inicio/index.html) crawls all .es domains once a year. The training corpus consists of 59TB of WARC files from these crawls, carried out from 2009 to 2019.
To obtain a high-quality training corpus, the corpus has been preprocessed with a pipeline of operations, including among the others, sentence splitting, language detection, filtering of bad-formed sentences and deduplication of repetitive contents. During the process document boundaries are kept. This resulted into 2TB of Spanish clean corpus. Further global deduplication among the corpus is applied, resulting into 570GB of text.
Some of the statistics of the corpus:
| Corpora | Number of documents | Number of tokens | Size (GB) |
|---------|---------------------|------------------|-----------|
| BNE | 201,080,084 | 135,733,450,668 | 570GB |
## Tokenization and pre-training
The training corpus has been tokenized using a byte version of Byte-Pair Encoding (BPE) used in the original [GPT-2](http://www.persagen.com/files/misc/radford2019language.pdf) model with a vocabulary size of 50,262 tokens. The GPT2-large-bne pre-training consists of an autoregressive language model training that follows the approach of the GPT-2. The training lasted a total of 10 days with 32 computing nodes each one with 4 NVIDIA V100 GPUs of 16GB VRAM.
## Evaluation and results
For evaluation details visit our [GitHub repository](https://github.com/PlanTL-GOB-ES/lm-spanish).
## Citing
Check out our paper for all the details: https://arxiv.org/abs/2107.07253
```
@article{gutierrezfandino2022,
author = {Asier Gutiérrez-Fandiño and Jordi Armengol-Estapé and Marc Pàmies and Joan Llop-Palao and Joaquin Silveira-Ocampo and Casimiro Pio Carrino and Carme Armentano-Oller and Carlos Rodriguez-Penagos and Aitor Gonzalez-Agirre and Marta Villegas},
title = {MarIA: Spanish Language Models},
journal = {Procesamiento del Lenguaje Natural},
volume = {68},
number = {0},
year = {2022},
issn = {1989-7553},
url = {http://journal.sepln.org/sepln/ojs/ojs/index.php/pln/article/view/6405},
pages = {39--60}
}
```
## Funding
This work was funded by the Spanish State Secretariat for Digitalization and Artificial Intelligence (SEDIA) within the framework of the Plan-TL.
## Disclaimer
The models published in this repository are intended for a generalist purpose and are available to third parties. These models may have bias and/or any other undesirable distortions.
When third parties, deploy or provide systems and/or services to other parties using any of these models (or using systems based on these models) or become users of the models, they should note that it is their responsibility to mitigate the risks arising from their use and, in any event, to comply with applicable regulations, including regulations regarding the use of artificial intelligence.
In no event shall the owner of the models (SEDIA – State Secretariat for digitalization and artificial intelligence) nor the creator (BSC – Barcelona Supercomputing Center) be liable for any results arising from the use made by third parties of these models.
Los modelos publicados en este repositorio tienen una finalidad generalista y están a disposición de terceros. Estos modelos pueden tener sesgos y/u otro tipo de distorsiones indeseables.
Cuando terceros desplieguen o proporcionen sistemas y/o servicios a otras partes usando alguno de estos modelos (o utilizando sistemas basados en estos modelos) o se conviertan en usuarios de los modelos, deben tener en cuenta que es su responsabilidad mitigar los riesgos derivados de su uso y, en todo caso, cumplir con la normativa aplicable, incluyendo la normativa en materia de uso de inteligencia artificial.
En ningún caso el propietario de los modelos (SEDIA – Secretaría de Estado de Digitalización e Inteligencia Artificial) ni el creador (BSC – Barcelona Supercomputing Center) serán responsables de los resultados derivados del uso que hagan terceros de estos modelos. |
chinhon/headline_writer | 5b3da936c338942644c2f310a859fa8e6f514838 | 2021-10-24T17:00:55.000Z | [
"pytorch",
"bart",
"text2text-generation",
"en",
"dataset:chinhon/autonlp-data-sg_headline_generator",
"transformers",
"autonlp",
"co2_eq_emissions",
"autotrain_compatible"
] | text2text-generation | false | chinhon | null | chinhon/headline_writer | 751 | 6 | transformers | 1,976 | ---
tags: autonlp
language: en
widget:
- text: "I love AutoNLP 🤗"
datasets:
- chinhon/autonlp-data-sg_headline_generator
co2_eq_emissions: 114.71292762345828
---
# Model Trained Using AutoNLP
- Problem type: Summarization
- Model ID: 25965855
- CO2 Emissions (in grams): 114.71292762345828
## Validation Metrics
- Loss: 1.3862273693084717
- Rouge1: 52.4988
- Rouge2: 31.6973
- RougeL: 47.1727
- RougeLsum: 47.1576
- Gen Len: 17.6194
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_HUGGINGFACE_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/chinhon/autonlp-sg_headline_generator-25965855
``` |
abhibisht89/spanbert-large-cased-finetuned-ade_corpus_v2 | 54ef513694d36c0c8278511c48504849d1a464cf | 2021-11-21T15:23:59.000Z | [
"pytorch",
"bert",
"token-classification",
"en",
"dataset:ade_corpus_v2",
"transformers",
"spanbert",
"autotrain_compatible"
] | token-classification | false | abhibisht89 | null | abhibisht89/spanbert-large-cased-finetuned-ade_corpus_v2 | 750 | 1 | transformers | 1,977 | ---
language: en
tags:
- spanbert
datasets:
- ade_corpus_v2
widget:
- text: "Having fever after taking paracetamol."
example_title: "NER"
- text: "Birth defects associated with thalidomide."
example_title: "NER"
- text: "Deafness and kidney failure associated with gentamicin (an antibiotic)."
example_title: "NER"
- text: "Bleeding of the intestine associated with aspirin therapy."
example_title: "NER"
---
spanbert-large-cased fine-tuned for <b>"Adverse drug reaction"</b> and <b>"Drug"</b> span Extraction.
<b>Details of spanbert-large-cased:</b>
https://huggingface.co/SpanBERT/spanbert-large-cased
<b>Details of the downstream task (Adverse drug reaction and Drug Extraction) - Dataset</b>
https://huggingface.co/datasets/ade_corpus_v2 |
ptaszynski/yacis-electra-small-japanese-cyberbullying | e75924e558e6b03482dea029d670b8da35f58274 | 2022-01-16T13:51:28.000Z | [
"pytorch",
"electra",
"text-classification",
"ja",
"dataset:YACIS corpus",
"dataset:Harmful BBS Japanese comments dataset",
"dataset:Twitter Japanese cyberbullying dataset",
"transformers",
"license:cc-by-sa-4.0"
] | text-classification | false | ptaszynski | null | ptaszynski/yacis-electra-small-japanese-cyberbullying | 749 | 1 | transformers | 1,978 | ---
language: ja
license: cc-by-sa-4.0
datasets:
- YACIS corpus
- Harmful BBS Japanese comments dataset
- Twitter Japanese cyberbullying dataset
---
# yacis-electra-small-cyberbullying
This is an [ELECTRA](https://github.com/google-research/electra) Small model for the Japanese language finetuned for automatic cyberbullying detection.
The original foundation model was originally pretrained on 5.6 billion words [YACIS](https://github.com/ptaszynski/yacis-corpus) blog corpus, and later finetuned on a balanced dataset created by unifying two datasets, namely "Harmful BBS Japanese comments dataset" and "Twitter Japanese cyberbullying dataset".
## Model architecture
The original model was pretrained using ELECTRA Small model settings and can be found here:
[https://huggingface.co/ptaszynski/yacis-electra-small-japanese](https://huggingface.co/ptaszynski/yacis-electra-small-japanese)
## Licenses
The finetuned model with all attached files is licensed under [CC BY-SA 4.0](http://creativecommons.org/licenses/by-sa/4.0/), or Creative Commons Attribution-ShareAlike 4.0 International License.
<a rel="license" href="http://creativecommons.org/licenses/by-sa/4.0/"><img alt="Creative Commons License" style="border-width:0" src="https://i.creativecommons.org/l/by-sa/4.0/88x31.png" /></a>
## Citations
Please, cite this model using the following citation.
```
@inproceedings{shibata2022yacis-electra,
title={日本語大規模ブログコーパスYACISに基づいたELECTRA事前学習済み言語モデルの作成及び性能評価},
% title={Development and performance evaluation of ELECTRA pretrained language model based on YACIS large-scale Japanese blog corpus [in Japanese]}, %% for English citations
author={柴田 祥伍 and プタシンスキ ミハウ and エロネン ユーソ and ノヴァコフスキ カロル and 桝井 文人},
% author={Shibata, Shogo and Ptaszynski, Michal and Eronen, Juuso and Nowakowski, Karol and Masui, Fumito}, %% for English citations
booktitle={言語処理学会第28回年次大会(NLP2022) (予定)},
% booktitle={Proceedings of The 28th Annual Meeting of The Association for Natural Language Processing (NLP2022)}, %% for English citations
pages={1--4},
year={2022}
}
```
The two datasets used for finetuning should be cited using the following references.
- Harmful BBS Japanese comments dataset:
```
@book{ptaszynski2018automatic,
title={Automatic Cyberbullying Detection: Emerging Research and Opportunities: Emerging Research and Opportunities},
author={Ptaszynski, Michal E and Masui, Fumito},
year={2018},
publisher={IGI Global}
}
```
```
@article{松葉達明2009学校非公式サイトにおける有害情報検出,
title={学校非公式サイトにおける有害情報検出},
author={松葉達明 and 里見尚宏 and 桝井文人 and 河合敦夫 and 井須尚紀},
journal={電子情報通信学会技術研究報告. NLC, 言語理解とコミュニケーション},
volume={109},
number={142},
pages={93--98},
year={2009},
publisher={一般社団法人電子情報通信学会}
}
```
- Twitter Japanese cyberbullying dataset:
```
TBA
```
The pretraining was done using YACIS corpus, which should be cited using at least one of the following references.
```
@inproceedings{ptaszynski2012yacis,
title={YACIS: A five-billion-word corpus of Japanese blogs fully annotated with syntactic and affective information},
author={Ptaszynski, Michal and Dybala, Pawel and Rzepka, Rafal and Araki, Kenji and Momouchi, Yoshio},
booktitle={Proceedings of the AISB/IACAP world congress},
pages={40--49},
year={2012},
howpublished = "\url{https://github.com/ptaszynski/yacis-corpus}"
}
```
```
@article{ptaszynski2014automatically,
title={Automatically annotating a five-billion-word corpus of Japanese blogs for sentiment and affect analysis},
author={Ptaszynski, Michal and Rzepka, Rafal and Araki, Kenji and Momouchi, Yoshio},
journal={Computer Speech \& Language},
volume={28},
number={1},
pages={38--55},
year={2014},
publisher={Elsevier},
howpublished = "\url{https://github.com/ptaszynski/yacis-corpus}"
}
``` |
uer/t5-small-chinese-cluecorpussmall | d38b6b837e2f9cbd3325fb270bfae2fda2f679f4 | 2022-07-15T08:22:32.000Z | [
"pytorch",
"tf",
"jax",
"t5",
"text2text-generation",
"zh",
"dataset:CLUECorpusSmall",
"arxiv:1909.05658",
"transformers",
"autotrain_compatible"
] | text2text-generation | false | uer | null | uer/t5-small-chinese-cluecorpussmall | 748 | 6 | transformers | 1,979 | ---
language: zh
datasets: CLUECorpusSmall
widget:
- text: "作为电子extra0的平台,京东绝对是领先者。如今的刘强extra1已经是身价过extra2的老板。"
---
# Chinese T5
## Model description
This is the set of Chinese T5 models pre-trained by [UER-py](https://github.com/dbiir/UER-py/), which is introduced in [this paper](https://arxiv.org/abs/1909.05658).
The Text-to-Text Transfer Transformer (T5) leverages a unified text-to-text format and attains state-of-the-art results on a wide variety of English-language NLP tasks. Following their work, we released a series of Chinese T5 models.
You can download the set of Chinese T5 models either from the [UER-py Modelzoo page](https://github.com/dbiir/UER-py/wiki/Modelzoo), or via HuggingFace from the links below:
| | Link |
| -------- | :-----------------------: |
| **T5-Small** | [**L=6/H=512 (Small)**][small] |
| **T5-Base** | [**L=12/H=768 (Base)**][base] |
In T5, spans of the input sequence are masked by so-called sentinel token. Each sentinel token represents a unique mask token for the input sequence and should start with `<extra_id_0>`, `<extra_id_1>`, … up to `<extra_id_99>`. However, `<extra_id_xxx>` is separated into multiple parts in Huggingface's Hosted inference API. Therefore, we replace `<extra_id_xxx>` with `extraxxx` in vocabulary and BertTokenizer regards `extraxxx` as one sentinel token.
## How to use
You can use this model directly with a pipeline for text2text generation (take the case of T5-Small):
```python
>>> from transformers import BertTokenizer, T5ForConditionalGeneration, Text2TextGenerationPipeline
>>> tokenizer = BertTokenizer.from_pretrained("uer/t5-small-chinese-cluecorpussmall")
>>> model = T5ForConditionalGeneration.from_pretrained("uer/t5-small-chinese-cluecorpussmall")
>>> text2text_generator = Text2TextGenerationPipeline(model, tokenizer)
>>> text2text_generator("中国的首都是extra0京", max_length=50, do_sample=False)
[{'generated_text': 'extra0 北 extra1 extra2 extra3 extra4 extra5'}]
```
## Training data
[CLUECorpusSmall](https://github.com/CLUEbenchmark/CLUECorpus2020/) is used as training data.
## Training procedure
The model is pre-trained by [UER-py](https://github.com/dbiir/UER-py/) on [Tencent Cloud](https://cloud.tencent.com/). We pre-train 1,000,000 steps with a sequence length of 128 and then pre-train 250,000 additional steps with a sequence length of 512. We use the same hyper-parameters on different model sizes.
Taking the case of T5-Small
Stage1:
```
python3 preprocess.py --corpus_path corpora/cluecorpussmall.txt \
--vocab_path models/google_zh_with_sentinel_vocab.txt \
--dataset_path cluecorpussmall_t5_seq128_dataset.pt \
--processes_num 32 --seq_length 128 \
--dynamic_masking --data_processor t5
```
```
python3 pretrain.py --dataset_path cluecorpussmall_t5_seq128_dataset.pt \
--vocab_path models/google_zh_with_sentinel_vocab.txt \
--config_path models/t5/small_config.json \
--output_model_path models/cluecorpussmall_t5_small_seq128_model.bin \
--world_size 8 --gpu_ranks 0 1 2 3 4 5 6 7 \
--total_steps 1000000 --save_checkpoint_steps 100000 --report_steps 50000 \
--learning_rate 1e-3 --batch_size 64 \
--span_masking --span_geo_prob 0.3 --span_max_length 5
```
Stage2:
```
python3 preprocess.py --corpus_path corpora/cluecorpussmall.txt \
--vocab_path models/google_zh_with_sentinel_vocab.txt \
--dataset_path cluecorpussmall_t5_small_seq512_dataset.pt \
--processes_num 32 --seq_length 512 \
--dynamic_masking --data_processor t5
```
```
python3 pretrain.py --dataset_path cluecorpussmall_t5_seq512_dataset.pt \
--vocab_path models/google_zh_with_sentinel_vocab.txt \
--pretrained_model_path models/cluecorpussmall_t5_small_seq128_model.bin-1000000 \
--config_path models/t5/small_config.json \
--output_model_path models/cluecorpussmall_t5_small_seq512_model.bin \
--world_size 8 --gpu_ranks 0 1 2 3 4 5 6 7 \
--total_steps 250000 --save_checkpoint_steps 50000 --report_steps 10000 \
--learning_rate 5e-4 --batch_size 16 \
--span_masking --span_geo_prob 0.3 --span_max_length 5
```
Finally, we convert the pre-trained model into Huggingface's format:
```
python3 scripts/convert_t5_from_uer_to_huggingface.py --input_model_path cluecorpussmall_t5_small_seq512_model.bin-250000 \
--output_model_path pytorch_model.bin \
--layers_num 6 \
--type t5
```
### BibTeX entry and citation info
```
@article{2020t5,
title = {Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer},
author = {Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu},
journal = {Journal of Machine Learning Research},
pages = {1-67},
year = {2020}
}
@article{zhao2019uer,
title={UER: An Open-Source Toolkit for Pre-training Models},
author={Zhao, Zhe and Chen, Hui and Zhang, Jinbin and Zhao, Xin and Liu, Tao and Lu, Wei and Chen, Xi and Deng, Haotang and Ju, Qi and Du, Xiaoyong},
journal={EMNLP-IJCNLP 2019},
pages={241},
year={2019}
}
```
[small]:https://huggingface.co/uer/t5-small-chinese-cluecorpussmall
[base]:https://huggingface.co/uer/t5-base-chinese-cluecorpussmall |
SEBIS/code_trans_t5_small_code_documentation_generation_python | 372c18254de8ff9ab651e1e3c83b7dfeae22ac6a | 2021-06-23T10:09:35.000Z | [
"pytorch",
"jax",
"t5",
"feature-extraction",
"transformers",
"summarization"
] | summarization | false | SEBIS | null | SEBIS/code_trans_t5_small_code_documentation_generation_python | 746 | null | transformers | 1,980 | ---
tags:
- summarization
widget:
- text: "def e ( message , exit_code = None ) : print_log ( message , YELLOW , BOLD ) if exit_code is not None : sys . exit ( exit_code )"
---
# CodeTrans model for code documentation generation python
Pretrained model on programming language python using the t5 small model architecture. It was first released in
[this repository](https://github.com/agemagician/CodeTrans). This model is trained on tokenized python code functions: it works best with tokenized python functions.
## Model description
This CodeTrans model is based on the `t5-small` model. It has its own SentencePiece vocabulary model. It used single-task training on CodeSearchNet Corpus python dataset.
## Intended uses & limitations
The model could be used to generate the description for the python function or be fine-tuned on other python code tasks. It can be used on unparsed and untokenized python code. However, if the python code is tokenized, the performance should be better.
### How to use
Here is how to use this model to generate python function documentation using Transformers SummarizationPipeline:
```python
from transformers import AutoTokenizer, AutoModelWithLMHead, SummarizationPipeline
pipeline = SummarizationPipeline(
model=AutoModelWithLMHead.from_pretrained("SEBIS/code_trans_t5_small_code_documentation_generation_python"),
tokenizer=AutoTokenizer.from_pretrained("SEBIS/code_trans_t5_small_code_documentation_generation_python", skip_special_tokens=True),
device=0
)
tokenized_code = "def e ( message , exit_code = None ) : print_log ( message , YELLOW , BOLD ) if exit_code is not None : sys . exit ( exit_code )"
pipeline([tokenized_code])
```
Run this example in [colab notebook](https://github.com/agemagician/CodeTrans/blob/main/prediction/single%20task/function%20documentation%20generation/python/small_model.ipynb).
## Training data
The supervised training tasks datasets can be downloaded on [Link](https://www.dropbox.com/sh/488bq2of10r4wvw/AACs5CGIQuwtsD7j_Ls_JAORa/finetuning_dataset?dl=0&subfolder_nav_tracking=1)
## Evaluation results
For the code documentation tasks, different models achieves the following results on different programming languages (in BLEU score):
Test results :
| Language / Model | Python | Java | Go | Php | Ruby | JavaScript |
| -------------------- | :------------: | :------------: | :------------: | :------------: | :------------: | :------------: |
| CodeTrans-ST-Small | 17.31 | 16.65 | 16.89 | 23.05 | 9.19 | 13.7 |
| CodeTrans-ST-Base | 16.86 | 17.17 | 17.16 | 22.98 | 8.23 | 13.17 |
| CodeTrans-TF-Small | 19.93 | 19.48 | 18.88 | 25.35 | 13.15 | 17.23 |
| CodeTrans-TF-Base | 20.26 | 20.19 | 19.50 | 25.84 | 14.07 | 18.25 |
| CodeTrans-TF-Large | 20.35 | 20.06 | **19.54** | 26.18 | 14.94 | **18.98** |
| CodeTrans-MT-Small | 19.64 | 19.00 | 19.15 | 24.68 | 14.91 | 15.26 |
| CodeTrans-MT-Base | **20.39** | 21.22 | 19.43 | **26.23** | **15.26** | 16.11 |
| CodeTrans-MT-Large | 20.18 | **21.87** | 19.38 | 26.08 | 15.00 | 16.23 |
| CodeTrans-MT-TF-Small | 19.77 | 20.04 | 19.36 | 25.55 | 13.70 | 17.24 |
| CodeTrans-MT-TF-Base | 19.77 | 21.12 | 18.86 | 25.79 | 14.24 | 18.62 |
| CodeTrans-MT-TF-Large | 18.94 | 21.42 | 18.77 | 26.20 | 14.19 | 18.83 |
| State of the art | 19.06 | 17.65 | 18.07 | 25.16 | 12.16 | 14.90 |
> Created by [Ahmed Elnaggar](https://twitter.com/Elnaggar_AI) | [LinkedIn](https://www.linkedin.com/in/prof-ahmed-elnaggar/) and Wei Ding | [LinkedIn](https://www.linkedin.com/in/wei-ding-92561270/)
|
asi/gpt-fr-cased-base | d6f928a792f4c72aade4e1b80c88d425884bfa47 | 2022-06-01T12:31:14.000Z | [
"pytorch",
"tf",
"jax",
"gpt2",
"text-generation",
"fr",
"transformers",
"license:apache-2.0"
] | text-generation | false | asi | null | asi/gpt-fr-cased-base | 746 | 13 | transformers | 1,981 | ---
language:
- fr
thumbnail: https://raw.githubusercontent.com/AntoineSimoulin/gpt-fr/main/imgs/logo.png
tags:
- tf
- pytorch
- gpt2
- text-generation
license: apache-2.0
---
<img src="https://raw.githubusercontent.com/AntoineSimoulin/gpt-fr/main/imgs/logo.png" width="200">
## Model description
**GPT-fr** 🇫🇷 is a GPT model for French developped by [Quantmetry](https://www.quantmetry.com/) and the [Laboratoire de Linguistique Formelle (LLF)](http://www.llf.cnrs.fr/en). We train the model on a very large and heterogeneous French corpus. We release the weights for the following configurations:
| Model name | Number of layers | Attention Heads | Embedding Dimension | Total Parameters |
| :------: | :---: | :---: | :---: | :---: |
| `gpt-fr-cased-small` | 12 | 12 | 768 | 124 M |
| `gpt-fr-cased-base` | 24 | 14 | 1,792 | 1,017 B |
## Intended uses & limitations
The model can be leveraged for language generation tasks. Besides, many tasks may be formatted such that the output is directly generated in natural language. Such configuration may be used for tasks such as automatic summary or question answering. We do hope our model might be used for both academic and industrial applications.
#### How to use
The model might be used through the astonishing 🤗 `Transformers` librairie. We use the work from [Shoeybi et al., (2019)](#shoeybi-2019) and calibrate our model such that during pre-training or fine-tuning, the model can fit on a single NVIDIA V100 32GB GPU.
```python
from transformers import GPT2Tokenizer, GPT2LMHeadModel
# Load pretrained model and tokenizer
model = GPT2LMHeadModel.from_pretrained("asi/gpt-fr-cased-base")
tokenizer = GPT2Tokenizer.from_pretrained("asi/gpt-fr-cased-base")
# Generate a sample of text
model.eval()
input_sentence = "Longtemps je me suis couché de bonne heure."
input_ids = tokenizer.encode(input_sentence, return_tensors='pt')
beam_outputs = model.generate(
input_ids,
max_length=100,
do_sample=True,
top_k=50,
top_p=0.95,
num_return_sequences=1
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(beam_outputs[0], skip_special_tokens=True))
```
#### Limitations and bias
Large language models tend to replicate the biases found in pre-training datasets, such as gender discrimination or offensive content generation.
To limit exposition to too much explicit material, we carefully choose the sources beforehand. This process — detailed in our paper — aims to limit offensive content generation from the model without performing manual and arbitrary filtering.
However, some societal biases, contained in the data, might be reflected by the model. For example on gender equality, we generated the following sentence sequence "Ma femme/Mon mari vient d'obtenir un nouveau poste en tant \_\_\_\_\_\_\_". We used top-k random sampling strategy with k=50 and stopped at the first punctuation element.
The positions generated for the wife is '_que professeur de français._' while the position for the husband is '_que chef de projet._'. We do appreciate your feedback to better qualitatively and quantitatively assess such effects.
## Training data
We created a dedicated corpus to train our generative model. Indeed the model uses a fixed-length context size of 1,024 and require long documents to be trained. We aggregated existing corpora: [Wikipedia](https://dumps.wikimedia.org/frwiki/), [OpenSubtitle](http://opus.nlpl.eu/download.php?f=OpenSubtitles/v2016/mono/) ([Tiedemann, 2012](#tiedemann-2012)), [Gutenberg](http://www.gutenberg.org) and [Common Crawl](http://data.statmt.org/ngrams/deduped2017/) ([Li et al., 2019](li-2019)). Corpora are filtered and separated into sentences. Successive sentences are then concatenated within the limit of 1,024 tokens per document.
## Training procedure
We pre-trained the model on the new CNRS (French National Centre for Scientific Research) [Jean Zay](http://www.idris.fr/eng/jean-zay/) supercomputer. We perform the training within a total of 140 hours of computation on Tesla V-100 hardware (TDP of 300W). The training was distributed on 4 compute nodes of 8 GPUs. We used data parallelization in order to divide each micro-batch on the computing units. We estimated the total emissions at 580.61 kgCO2eq, using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al., (2019)](lacoste-2019).
## Eval results
We packaged **GPT-fr** with a dedicated language model evaluation benchmark for French.
In line with the [WikiText](https://blog.einstein.ai/the-wikitext-long-term-dependency-language-modeling-dataset/) benchmark in English, we collected over 70 million tokens from the set of verified [good](https://fr.wikipedia.org/wiki/Wikip%C3%A9dia:Articles_de_qualit%C3%A9) and [featured](https://fr.wikipedia.org/wiki/Wikip%C3%A9dia:Bons_articles) articles on Wikipedia. The model reaches a zero-shot perplexity of **12.9** on the test set.
### BibTeX entry and citation info
Along with the model hosted by HuggingFace transformers library, we maintain a [git repository](https://github.com/AntoineSimoulin/gpt-fr).
If you use **GPT-fr** for your scientific publications or your industrial applications, please cite the following paper:
```bibtex
@inproceedings{simoulin:hal-03265900,
TITLE = {{Un mod{\`e}le Transformer G{\'e}n{\'e}ratif Pr{\'e}-entrain{\'e} pour le \_\_\_\_\_\_ fran{\c c}ais}},
AUTHOR = {Simoulin, Antoine and Crabb{\'e}, Benoit},
URL = {https://hal.archives-ouvertes.fr/hal-03265900},
BOOKTITLE = {{Traitement Automatique des Langues Naturelles}},
ADDRESS = {Lille, France},
EDITOR = {Denis, Pascal and Grabar, Natalia and Fraisse, Amel and Cardon, R{\'e}mi and Jacquemin, Bernard and Kergosien, Eric and Balvet, Antonio},
PUBLISHER = {{ATALA}},
PAGES = {246-255},
YEAR = {2021},
KEYWORDS = {fran{\c c}ais. ; GPT ; G{\'e}n{\'e}ratif ; Transformer ; Pr{\'e}-entra{\^i}n{\'e}},
PDF = {https://hal.archives-ouvertes.fr/hal-03265900/file/7.pdf},
HAL_ID = {hal-03265900},
HAL_VERSION = {v1},
}
```
### References
><div name="tiedemann-2012">Jörg Tiedemann: Parallel Data, Tools and Interfaces in OPUS. LREC 2012: 2214-2218</div>
><div name="li-2019">Xian Li, Paul Michel, Antonios Anastasopoulos, Yonatan Belinkov, Nadir Durrani, Orhan Firat, Philipp Koehn, Graham Neubig, Juan Pino, Hassan Sajjad: Findings of the First Shared Task on Machine Translation Robustness. WMT (2) 2019: 91-102</div>
><div name="shoeybi-2019">Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, Bryan Catanzaro: Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism. CoRR abs/1909.08053 (2019)</div>
><div name="lacoste-2019">Alexandre Lacoste, Alexandra Luccioni, Victor Schmidt, Thomas Dandres: Quantifying the Carbon Emissions of Machine Learning. CoRR abs/1910.09700 (2019)</div>
|
thunlp/neuba-bert | 033bcb302e36ce9ddff22585834be6d7020e7f52 | 2021-09-16T06:14:06.000Z | [
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | false | thunlp | null | thunlp/neuba-bert | 746 | null | transformers | 1,982 | Entry not found |
uw-hai/polyjuice | f5bef2f7053c2ce6c3fd19875c3cff77754479ef | 2021-05-24T01:21:24.000Z | [
"pytorch",
"jax",
"gpt2",
"text-generation",
"en",
"transformers",
"counterfactual generation"
] | text-generation | false | uw-hai | null | uw-hai/polyjuice | 745 | 1 | transformers | 1,983 | ---
language: "en"
tags:
- counterfactual generation
widget:
- text: "It is great for kids. <|perturb|> [negation] It [BLANK] great for kids. [SEP]"
---
# Polyjuice
## Model description
This is a ported version of [Polyjuice](https://homes.cs.washington.edu/~wtshuang/static/papers/2021-arxiv-polyjuice.pdf), the general-purpose counterfactual generator.
For more code release, please refer to [this github page](https://github.com/tongshuangwu/polyjuice).
#### How to use
```python
from transformers import AutoTokenizer, AutoModelWithLMHead
from transformers import pipeline, AutoTokenizer, AutoModelForCausalLM
model_path = "uw-hai/polyjuice"
generator = pipeline("text-generation",
model=AutoModelForCausalLM.from_pretrained(model_path),
tokenizer=AutoTokenizer.from_pretrained(model_path),
framework="pt", device=0 if is_cuda else -1)
prompt_text = "A dog is embraced by the woman. <|perturb|> [negation] A dog is [BLANK] the woman."
generator(prompt_text, num_beams=3, num_return_sequences=3)
```
### BibTeX entry and citation info
```bibtex
@inproceedings{polyjuice:acl21,
title = "{P}olyjuice: Generating Counterfactuals for Explaining, Evaluating, and Improving Models",
author = "Tongshuang Wu and Marco Tulio Ribeiro and Jeffrey Heer and Daniel S. Weld",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics",
year = "2021",
publisher = "Association for Computational Linguistics"
``` |
CAMeL-Lab/bert-base-arabic-camelbert-msa-half | ed1803781de55d0463976677a3e736c097e16728 | 2021-09-14T14:34:06.000Z | [
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | fill-mask | false | CAMeL-Lab | null | CAMeL-Lab/bert-base-arabic-camelbert-msa-half | 744 | 2 | transformers | 1,984 | ---
language:
- ar
license: apache-2.0
widget:
- text: "الهدف من الحياة هو [MASK] ."
---
# CAMeLBERT: A collection of pre-trained models for Arabic NLP tasks
## Model description
**CAMeLBERT** is a collection of BERT models pre-trained on Arabic texts with different sizes and variants.
We release pre-trained language models for Modern Standard Arabic (MSA), dialectal Arabic (DA), and classical Arabic (CA), in addition to a model pre-trained on a mix of the three.
We also provide additional models that are pre-trained on a scaled-down set of the MSA variant (half, quarter, eighth, and sixteenth).
The details are described in the paper *"[The Interplay of Variant, Size, and Task Type in Arabic Pre-trained Language Models](https://arxiv.org/abs/2103.06678)."*
This model card describes **CAMeLBERT-MSA-half** (`bert-base-arabic-camelbert-msa-half`), a model pre-trained on a half of the full MSA dataset.
||Model|Variant|Size|#Word|
|-|-|:-:|-:|-:|
||`bert-base-arabic-camelbert-mix`|CA,DA,MSA|167GB|17.3B|
||`bert-base-arabic-camelbert-ca`|CA|6GB|847M|
||`bert-base-arabic-camelbert-da`|DA|54GB|5.8B|
||`bert-base-arabic-camelbert-msa`|MSA|107GB|12.6B|
|✔|`bert-base-arabic-camelbert-msa-half`|MSA|53GB|6.3B|
||`bert-base-arabic-camelbert-msa-quarter`|MSA|27GB|3.1B|
||`bert-base-arabic-camelbert-msa-eighth`|MSA|14GB|1.6B|
||`bert-base-arabic-camelbert-msa-sixteenth`|MSA|6GB|746M|
## Intended uses
You can use the released model for either masked language modeling or next sentence prediction.
However, it is mostly intended to be fine-tuned on an NLP task, such as NER, POS tagging, sentiment analysis, dialect identification, and poetry classification.
We release our fine-tuninig code [here](https://github.com/CAMeL-Lab/CAMeLBERT).
#### How to use
You can use this model directly with a pipeline for masked language modeling:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='CAMeL-Lab/bert-base-arabic-camelbert-msa-half')
>>> unmasker("الهدف من الحياة هو [MASK] .")
[{'sequence': '[CLS] الهدف من الحياة هو الحياة. [SEP]',
'score': 0.09132730215787888,
'token': 3696,
'token_str': 'الحياة'},
{'sequence': '[CLS] الهدف من الحياة هو.. [SEP]',
'score': 0.08282623440027237,
'token': 18,
'token_str': '.'},
{'sequence': '[CLS] الهدف من الحياة هو البقاء. [SEP]',
'score': 0.04031957685947418,
'token': 9331,
'token_str': 'البقاء'},
{'sequence': '[CLS] الهدف من الحياة هو النجاح. [SEP]',
'score': 0.032019514590501785,
'token': 6232,
'token_str': 'النجاح'},
{'sequence': '[CLS] الهدف من الحياة هو الحب. [SEP]',
'score': 0.028731243684887886,
'token': 3088,
'token_str': 'الحب'}]
```
*Note*: to download our models, you would need `transformers>=3.5.0`. Otherwise, you could download the models manually.
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained('CAMeL-Lab/bert-base-arabic-camelbert-msa-half')
model = AutoModel.from_pretrained('CAMeL-Lab/bert-base-arabic-camelbert-msa-half')
text = "مرحبا يا عالم."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import AutoTokenizer, TFAutoModel
tokenizer = AutoTokenizer.from_pretrained('CAMeL-Lab/bert-base-arabic-camelbert-msa-half')
model = TFAutoModel.from_pretrained('CAMeL-Lab/bert-base-arabic-camelbert-msa-half')
text = "مرحبا يا عالم."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
## Training data
- MSA (Modern Standard Arabic)
- [The Arabic Gigaword Fifth Edition](https://catalog.ldc.upenn.edu/LDC2011T11)
- [Abu El-Khair Corpus](http://www.abuelkhair.net/index.php/en/arabic/abu-el-khair-corpus)
- [OSIAN corpus](https://vlo.clarin.eu/search;jsessionid=31066390B2C9E8C6304845BA79869AC1?1&q=osian)
- [Arabic Wikipedia](https://archive.org/details/arwiki-20190201)
- The unshuffled version of the Arabic [OSCAR corpus](https://oscar-corpus.com/)
## Training procedure
We use [the original implementation](https://github.com/google-research/bert) released by Google for pre-training.
We follow the original English BERT model's hyperparameters for pre-training, unless otherwise specified.
### Preprocessing
- After extracting the raw text from each corpus, we apply the following pre-processing.
- We first remove invalid characters and normalize white spaces using the utilities provided by [the original BERT implementation](https://github.com/google-research/bert/blob/eedf5716ce1268e56f0a50264a88cafad334ac61/tokenization.py#L286-L297).
- We also remove lines without any Arabic characters.
- We then remove diacritics and kashida using [CAMeL Tools](https://github.com/CAMeL-Lab/camel_tools).
- Finally, we split each line into sentences with a heuristics-based sentence segmenter.
- We train a WordPiece tokenizer on the entire dataset (167 GB text) with a vocabulary size of 30,000 using [HuggingFace's tokenizers](https://github.com/huggingface/tokenizers).
- We do not lowercase letters nor strip accents.
### Pre-training
- The model was trained on a single cloud TPU (`v3-8`) for one million steps in total.
- The first 90,000 steps were trained with a batch size of 1,024 and the rest was trained with a batch size of 256.
- The sequence length was limited to 128 tokens for 90% of the steps and 512 for the remaining 10%.
- We use whole word masking and a duplicate factor of 10.
- We set max predictions per sequence to 20 for the dataset with max sequence length of 128 tokens and 80 for the dataset with max sequence length of 512 tokens.
- We use a random seed of 12345, masked language model probability of 0.15, and short sequence probability of 0.1.
- The optimizer used is Adam with a learning rate of 1e-4, \\(\beta_{1} = 0.9\\) and \\(\beta_{2} = 0.999\\), a weight decay of 0.01, learning rate warmup for 10,000 steps and linear decay of the learning rate after.
## Evaluation results
- We evaluate our pre-trained language models on five NLP tasks: NER, POS tagging, sentiment analysis, dialect identification, and poetry classification.
- We fine-tune and evaluate the models using 12 dataset.
- We used Hugging Face's transformers to fine-tune our CAMeLBERT models.
- We used transformers `v3.1.0` along with PyTorch `v1.5.1`.
- The fine-tuning was done by adding a fully connected linear layer to the last hidden state.
- We use \\(F_{1}\\) score as a metric for all tasks.
- Code used for fine-tuning is available [here](https://github.com/CAMeL-Lab/CAMeLBERT).
### Results
| Task | Dataset | Variant | Mix | CA | DA | MSA | MSA-1/2 | MSA-1/4 | MSA-1/8 | MSA-1/16 |
| -------------------- | --------------- | ------- | ----- | ----- | ----- | ----- | ------- | ------- | ------- | -------- |
| NER | ANERcorp | MSA | 80.8% | 67.9% | 74.1% | 82.4% | 82.0% | 82.1% | 82.6% | 80.8% |
| POS | PATB (MSA) | MSA | 98.1% | 97.8% | 97.7% | 98.3% | 98.2% | 98.3% | 98.2% | 98.2% |
| | ARZTB (EGY) | DA | 93.6% | 92.3% | 92.7% | 93.6% | 93.6% | 93.7% | 93.6% | 93.6% |
| | Gumar (GLF) | DA | 97.3% | 97.7% | 97.9% | 97.9% | 97.9% | 97.9% | 97.9% | 97.9% |
| SA | ASTD | MSA | 76.3% | 69.4% | 74.6% | 76.9% | 76.0% | 76.8% | 76.7% | 75.3% |
| | ArSAS | MSA | 92.7% | 89.4% | 91.8% | 93.0% | 92.6% | 92.5% | 92.5% | 92.3% |
| | SemEval | MSA | 69.0% | 58.5% | 68.4% | 72.1% | 70.7% | 72.8% | 71.6% | 71.2% |
| DID | MADAR-26 | DA | 62.9% | 61.9% | 61.8% | 62.6% | 62.0% | 62.8% | 62.0% | 62.2% |
| | MADAR-6 | DA | 92.5% | 91.5% | 92.2% | 91.9% | 91.8% | 92.2% | 92.1% | 92.0% |
| | MADAR-Twitter-5 | MSA | 75.7% | 71.4% | 74.2% | 77.6% | 78.5% | 77.3% | 77.7% | 76.2% |
| | NADI | DA | 24.7% | 17.3% | 20.1% | 24.9% | 24.6% | 24.6% | 24.9% | 23.8% |
| Poetry | APCD | CA | 79.8% | 80.9% | 79.6% | 79.7% | 79.9% | 80.0% | 79.7% | 79.8% |
### Results (Average)
| | Variant | Mix | CA | DA | MSA | MSA-1/2 | MSA-1/4 | MSA-1/8 | MSA-1/16 |
| -------------------- | ------- | ----- | ----- | ----- | ----- | ------- | ------- | ------- | -------- |
| Variant-wise-average<sup>[[1]](#footnote-1)</sup> | MSA | 82.1% | 75.7% | 80.1% | 83.4% | 83.0% | 83.3% | 83.2% | 82.3% |
| | DA | 74.4% | 72.1% | 72.9% | 74.2% | 74.0% | 74.3% | 74.1% | 73.9% |
| | CA | 79.8% | 80.9% | 79.6% | 79.7% | 79.9% | 80.0% | 79.7% | 79.8% |
| Macro-Average | ALL | 78.7% | 74.7% | 77.1% | 79.2% | 79.0% | 79.2% | 79.1% | 78.6% |
<a name="footnote-1">[1]</a>: Variant-wise-average refers to average over a group of tasks in the same language variant.
## Acknowledgements
This research was supported with Cloud TPUs from Google’s TensorFlow Research Cloud (TFRC).
## Citation
```bibtex
@inproceedings{inoue-etal-2021-interplay,
title = "The Interplay of Variant, Size, and Task Type in {A}rabic Pre-trained Language Models",
author = "Inoue, Go and
Alhafni, Bashar and
Baimukan, Nurpeiis and
Bouamor, Houda and
Habash, Nizar",
booktitle = "Proceedings of the Sixth Arabic Natural Language Processing Workshop",
month = apr,
year = "2021",
address = "Kyiv, Ukraine (Online)",
publisher = "Association for Computational Linguistics",
abstract = "In this paper, we explore the effects of language variants, data sizes, and fine-tuning task types in Arabic pre-trained language models. To do so, we build three pre-trained language models across three variants of Arabic: Modern Standard Arabic (MSA), dialectal Arabic, and classical Arabic, in addition to a fourth language model which is pre-trained on a mix of the three. We also examine the importance of pre-training data size by building additional models that are pre-trained on a scaled-down set of the MSA variant. We compare our different models to each other, as well as to eight publicly available models by fine-tuning them on five NLP tasks spanning 12 datasets. Our results suggest that the variant proximity of pre-training data to fine-tuning data is more important than the pre-training data size. We exploit this insight in defining an optimized system selection model for the studied tasks.",
}
```
|
huggingtweets/realdonaldtrump | d03b45baa4168d2a87f7faa6f54ce2a67e8c8bd5 | 2021-05-22T20:32:50.000Z | [
"pytorch",
"jax",
"gpt2",
"text-generation",
"en",
"transformers",
"huggingtweets"
] | text-generation | false | huggingtweets | null | huggingtweets/realdonaldtrump | 744 | null | transformers | 1,985 | ---
language: en
thumbnail: https://www.huggingtweets.com/realdonaldtrump/1609765003661/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/874276197357596672/kUuht00m_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">Donald J. Trump 🤖 AI Bot </div>
<div style="font-size: 15px">@realdonaldtrump bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@realdonaldtrump's tweets](https://twitter.com/realdonaldtrump).
| Data | Quantity |
| ---- | -------- |
| Tweets downloaded | 2195 |
| Retweets | 716 |
| Short tweets | 364 |
| Tweets kept | 1115 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/1zmvkb6j/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @realdonaldtrump's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/1lh3uc7o) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/1lh3uc7o/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/realdonaldtrump')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
nreimers/MiniLM-L3-H384-uncased | 1857068a44253cf9ab23aefdf562335601cffcda | 2021-08-30T20:05:09.000Z | [
"pytorch",
"bert",
"feature-extraction",
"transformers",
"license:mit"
] | feature-extraction | false | nreimers | null | nreimers/MiniLM-L3-H384-uncased | 743 | null | transformers | 1,986 | ---
license: mit
---
## MiniLM: 3 Layer Version
This is a 3 layer version of [microsoft/MiniLM-L12-H384-uncased](https://huggingface.co/microsoft/MiniLM-L12-H384-uncased/) by keeping only the layer [3, 7, 11]. |
sentence-transformers/facebook-dpr-ctx_encoder-multiset-base | ae43c02d3267d1f11db4e7bfcfefc684c83b0c69 | 2022-06-15T22:51:25.000Z | [
"pytorch",
"tf",
"bert",
"feature-extraction",
"sentence-transformers",
"sentence-similarity",
"transformers",
"license:apache-2.0"
] | sentence-similarity | false | sentence-transformers | null | sentence-transformers/facebook-dpr-ctx_encoder-multiset-base | 743 | null | sentence-transformers | 1,987 | ---
pipeline_tag: sentence-similarity
license: apache-2.0
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# sentence-transformers/facebook-dpr-ctx_encoder-multiset-base
This is a port of the [DPR Model](https://github.com/facebookresearch/DPR) to [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/facebook-dpr-ctx_encoder-multiset-base')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
def cls_pooling(model_output, attention_mask):
return model_output[0][:,0]
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/facebook-dpr-ctx_encoder-multiset-base')
model = AutoModel.from_pretrained('sentence-transformers/facebook-dpr-ctx_encoder-multiset-base')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = cls_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/facebook-dpr-ctx_encoder-multiset-base)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 509, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': True, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
Have a look at: [DPR Model](https://github.com/facebookresearch/DPR) |
armheb/DNA_bert_5 | c296157b5c23f30f7cac33039c17ab7422798346 | 2021-10-10T22:40:00.000Z | [
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | false | armheb | null | armheb/DNA_bert_5 | 742 | null | transformers | 1,988 | Entry not found |
bhadresh-savani/roberta-base-emotion | fa563824e043b85c87b3f1991bbb3c3d045a68c7 | 2022-07-06T10:44:12.000Z | [
"pytorch",
"tf",
"jax",
"roberta",
"text-classification",
"en",
"dataset:emotion",
"arxiv:1907.11692",
"transformers",
"emotion",
"license:apache-2.0",
"model-index"
] | text-classification | false | bhadresh-savani | null | bhadresh-savani/roberta-base-emotion | 742 | null | transformers | 1,989 | ---
language:
- en
thumbnail: https://avatars3.githubusercontent.com/u/32437151?s=460&u=4ec59abc8d21d5feea3dab323d23a5860e6996a4&v=4
tags:
- text-classification
- emotion
- pytorch
license: apache-2.0
datasets:
- emotion
metrics:
- Accuracy, F1 Score
model-index:
- name: bhadresh-savani/roberta-base-emotion
results:
- task:
type: text-classification
name: Text Classification
dataset:
name: emotion
type: emotion
config: default
split: test
metrics:
- name: Accuracy
type: accuracy
value: 0.931
verified: true
- name: Precision Macro
type: precision
value: 0.9168321948556312
verified: true
- name: Precision Micro
type: precision
value: 0.931
verified: true
- name: Precision Weighted
type: precision
value: 0.9357445689014415
verified: true
- name: Recall Macro
type: recall
value: 0.8743657671177089
verified: true
- name: Recall Micro
type: recall
value: 0.931
verified: true
- name: Recall Weighted
type: recall
value: 0.931
verified: true
- name: F1 Macro
type: f1
value: 0.8821236522209227
verified: true
- name: F1 Micro
type: f1
value: 0.931
verified: true
- name: F1 Weighted
type: f1
value: 0.9300782840205046
verified: true
- name: loss
type: loss
value: 0.15155883133411407
verified: true
---
# robert-base-emotion
## Model description:
[roberta](https://arxiv.org/abs/1907.11692) is Bert with better hyperparameter choices so they said it's Robustly optimized Bert during pretraining.
[roberta-base](https://huggingface.co/roberta-base) finetuned on the emotion dataset using HuggingFace Trainer with below Hyperparameters
```
learning rate 2e-5,
batch size 64,
num_train_epochs=8,
```
## Model Performance Comparision on Emotion Dataset from Twitter:
| Model | Accuracy | F1 Score | Test Sample per Second |
| --- | --- | --- | --- |
| [Distilbert-base-uncased-emotion](https://huggingface.co/bhadresh-savani/distilbert-base-uncased-emotion) | 93.8 | 93.79 | 398.69 |
| [Bert-base-uncased-emotion](https://huggingface.co/bhadresh-savani/bert-base-uncased-emotion) | 94.05 | 94.06 | 190.152 |
| [Roberta-base-emotion](https://huggingface.co/bhadresh-savani/roberta-base-emotion) | 93.95 | 93.97| 195.639 |
| [Albert-base-v2-emotion](https://huggingface.co/bhadresh-savani/albert-base-v2-emotion) | 93.6 | 93.65 | 182.794 |
## How to Use the model:
```python
from transformers import pipeline
classifier = pipeline("text-classification",model='bhadresh-savani/roberta-base-emotion', return_all_scores=True)
prediction = classifier("I love using transformers. The best part is wide range of support and its easy to use", )
print(prediction)
"""
Output:
[[
{'label': 'sadness', 'score': 0.002281982684507966},
{'label': 'joy', 'score': 0.9726489186286926},
{'label': 'love', 'score': 0.021365027874708176},
{'label': 'anger', 'score': 0.0026395076420158148},
{'label': 'fear', 'score': 0.0007162453257478774},
{'label': 'surprise', 'score': 0.0003483477921690792}
]]
"""
```
## Dataset:
[Twitter-Sentiment-Analysis](https://huggingface.co/nlp/viewer/?dataset=emotion).
## Training procedure
[Colab Notebook](https://github.com/bhadreshpsavani/ExploringSentimentalAnalysis/blob/main/SentimentalAnalysisWithDistilbert.ipynb)
follow the above notebook by changing the model name to roberta
## Eval results
```json
{
'test_accuracy': 0.9395,
'test_f1': 0.9397328860104454,
'test_loss': 0.14367154240608215,
'test_runtime': 10.2229,
'test_samples_per_second': 195.639,
'test_steps_per_second': 3.13
}
```
## Reference:
* [Natural Language Processing with Transformer By Lewis Tunstall, Leandro von Werra, Thomas Wolf](https://learning.oreilly.com/library/view/natural-language-processing/9781098103231/) |
Finnish-NLP/gpt2-large-finnish | d22c61de54f8c5b4f0d37f7684d403ee7dde6a47 | 2022-06-13T16:14:00.000Z | [
"pytorch",
"jax",
"tensorboard",
"gpt2",
"text-generation",
"fi",
"dataset:Finnish-NLP/mc4_fi_cleaned",
"dataset:wikipedia",
"transformers",
"finnish",
"license:apache-2.0"
] | text-generation | false | Finnish-NLP | null | Finnish-NLP/gpt2-large-finnish | 741 | null | transformers | 1,990 | ---
language:
- fi
license: apache-2.0
tags:
- finnish
- gpt2
datasets:
- Finnish-NLP/mc4_fi_cleaned
- wikipedia
widget:
- text: "Tekstiä tuottava tekoäly on"
---
# GPT-2 large for Finnish
Pretrained GPT-2 large model on Finnish language using a causal language modeling (CLM) objective. GPT-2 was introduced in
[this paper](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf)
and first released at [this page](https://openai.com/blog/better-language-models/).
**Note**: this model is 774M parameter variant as in Huggingface's [GPT-2-large config](https://huggingface.co/gpt2-large), so not the famous big 1.5B parameter variant by OpenAI.
## Model description
Finnish GPT-2 is a transformers model pretrained on a very large corpus of Finnish data in a self-supervised fashion. This
means it was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots
of publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely,
it was trained to guess the next word in sentences.
More precisely, inputs are sequences of continuous text of a certain length and the targets are the same sequence,
shifted one token (word or piece of word) to the right. The model uses internally a mask-mechanism to make sure the
predictions for the token `i` only uses the inputs from `1` to `i` but not the future tokens.
This way, the model learns an inner representation of the Finnish language that can then be used to extract features
useful for downstream tasks. The model is best at what it was pretrained for however, which is generating texts from a
prompt.
## Intended uses & limitations
You can use the raw model for text generation or fine-tune it to a downstream task. See the
[model hub](https://huggingface.co/models?filter=gpt2) to look for fine-tuned versions on a task that interests you.
### How to use
You can use this model directly with a pipeline for text generation:
```python
>>> from transformers import pipeline
>>> generator = pipeline('text-generation', model='Finnish-NLP/gpt2-large-finnish')
>>> generator("Tekstiä tuottava tekoäly on", max_length=30, num_return_sequences=5)
[{'generated_text': 'Tekstiä tuottava tekoäly on valmis yhteistyöhön ihmisen kanssa: Tekoäly hoitaa ihmisen puolesta tekstin tuottamisen. Se myös ymmärtää, missä vaiheessa tekstiä voidaan alkaa kirjoittamaan'},
{'generated_text': 'Tekstiä tuottava tekoäly on älykäs, mutta se ei ole vain älykkäisiin koneisiin kuuluva älykäs olento, vaan se on myös kone. Se ei'},
{'generated_text': 'Tekstiä tuottava tekoäly on ehkä jo pian todellisuutta - se voisi tehdä myös vanhustenhoidosta nykyistä ä tuottava tekoäly on ehkä jo pian todellisuutta - se voisi tehdä'},
{'generated_text': 'Tekstiä tuottava tekoäly on kehitetty ihmisen ja ihmisen aivoihin yhteistyössä neurotieteiden ja käyttäytymistieteen tutkijatiimin kanssa. Uusi teknologia avaa aivan uudenlaisia tutkimusi'},
{'generated_text': 'Tekstiä tuottava tekoäly on kuin tietokone, jonka kanssa voi elää. Tekoälyn avulla voi kirjoittaa mitä tahansa, mistä tahansa ja miten paljon. Tässä'}]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import GPT2Tokenizer, GPT2Model
tokenizer = GPT2Tokenizer.from_pretrained('Finnish-NLP/gpt2-large-finnish')
model = GPT2Model.from_pretrained('Finnish-NLP/gpt2-large-finnish')
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import GPT2Tokenizer, TFGPT2Model
tokenizer = GPT2Tokenizer.from_pretrained('Finnish-NLP/gpt2-large-finnish')
model = TFGPT2Model.from_pretrained('Finnish-NLP/gpt2-large-finnish', from_pt=True)
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
### Limitations and bias
The training data used for this model contains a lot of unfiltered content from the internet, which is far from neutral. Therefore, the model can have biased predictions. This bias will also affect all fine-tuned versions of this model.
As with all language models, it is hard to predict in advance how the Finnish GPT-2 will respond to particular prompts and offensive content may occur without warning. We recommend having a human curate or filter the outputs before releasing them, both to censor undesirable content and to improve the quality of the results.
## Training data
This Finnish GPT-2 model was pretrained on the combination of six datasets:
- [mc4_fi_cleaned](https://huggingface.co/datasets/Finnish-NLP/mc4_fi_cleaned), the dataset mC4 is a multilingual colossal, cleaned version of Common Crawl's web crawl corpus. We used the Finnish subset of the mC4 dataset and further cleaned it with our own text data cleaning codes (check the dataset repo).
- [wikipedia](https://huggingface.co/datasets/wikipedia) We used the Finnish subset of the wikipedia (August 2021) dataset
- [Yle Finnish News Archive 2011-2018](http://urn.fi/urn:nbn:fi:lb-2017070501)
- [Yle Finnish News Archive 2019-2020](http://urn.fi/urn:nbn:fi:lb-2021050401)
- [Finnish News Agency Archive (STT)](http://urn.fi/urn:nbn:fi:lb-2018121001)
- [The Suomi24 Sentences Corpus](http://urn.fi/urn:nbn:fi:lb-2020021803)
Raw datasets were cleaned to filter out bad quality and non-Finnish examples. Together these cleaned datasets were around 84GB of text.
## Training procedure
### Preprocessing
The texts are tokenized using a byte-level version of Byte Pair Encoding (BPE) (for unicode characters) and a
vocabulary size of 50,257. The inputs are sequences of 512 consecutive tokens.
### Pretraining
The model was trained on TPUv3-8 VM, sponsored by the [Google TPU Research Cloud](https://sites.research.google/trc/about/), for 640k steps (a bit over 1 epoch, 64 batch size). The optimizer used was a AdamW with learning rate 4e-5, learning rate warmup for 4000 steps and cosine decay of the learning rate after.
## Evaluation results
Evaluation was done using the *validation* split of the [mc4_fi_cleaned](https://huggingface.co/datasets/Finnish-NLP/mc4_fi_cleaned) dataset with [Perplexity](https://huggingface.co/course/chapter7/3#perplexity-for-language-models) (smaller score the better) as the evaluation metric. As seen from the table below, this model (the first row of the table) performs better than our smaller model variants.
| | Perplexity |
|------------------------------------------|------------|
|Finnish-NLP/gpt2-large-finnish |**30.74** |
|Finnish-NLP/gpt2-medium-finnish |34.08 |
|Finnish-NLP/gpt2-finnish |44.19 |
## Acknowledgements
This project would not have been possible without compute generously provided by Google through the
[TPU Research Cloud](https://sites.research.google/trc/).
## Team Members
- Aapo Tanskanen, [Hugging Face profile](https://huggingface.co/aapot), [LinkedIn profile](https://www.linkedin.com/in/aapotanskanen/)
- Rasmus Toivanen, [Hugging Face profile](https://huggingface.co/RASMUS), [LinkedIn profile](https://www.linkedin.com/in/rasmustoivanen/)
Feel free to contact us for more details 🤗 |
pyannote/TestModelForContinuousIntegration | 0bf27df5e3413d6b2f9af2a31a44fd16c50c5929 | 2022-03-23T09:24:42.000Z | [
"pytorch",
"tensorboard",
"pyannote-audio",
"pyannote",
"pyannote-audio-model",
"license:mit"
] | null | false | pyannote | null | pyannote/TestModelForContinuousIntegration | 740 | null | pyannote-audio | 1,991 | ---
tags:
- pyannote
- pyannote-audio
- pyannote-audio-model
license: mit
inference: false
---
## Dummy model used for continuous integration purposes
```bash
$ pyannote-audio-train protocol=Debug.SpeakerDiarization.Debug \
task=VoiceActivityDetection \
task.duration=2. \
model=DebugSegmentation \
trainer.max_epochs=10
```
|
UBC-NLP/turjuman | de10623157b685b7096fa744b82203e4b82a6943 | 2022-06-10T00:24:37.000Z | [
"pytorch",
"t5",
"text2text-generation",
"arxiv:2206.03933",
"transformers",
"autotrain_compatible"
] | text2text-generation | false | UBC-NLP | null | UBC-NLP/turjuman | 739 | 1 | transformers | 1,992 |
<p align="center">
<br>
<img src="https://github.com/UBC-NLP/turjuman/raw/master//images/turjuman_logo.png"/>
<br>
<p>
<img src="https://github.com/UBC-NLP/turjuman/raw/master/images/turjuman.png" alt="AraT5" width="50%" height="50%" align="right"/>
Turjuman is a neural machine translation toolkit. It translates from 20 languages into Modern Standard Arabic (MSA). Turjuman is described in this paper:
[**TURJUMAN: A Public Toolkit for Neural Arabic Machine Translation**](https://arxiv.org/abs/2206.03933).
Turjuman exploits our [AraT5 model](https://github.com/UBC-NLP/araT5). This endows Turjuman with a powerful ability to decode into Arabic. The toolkit offers the possibility of employing a number of diverse decoding methods, making it suited for acquiring paraphrases for the MSA translations as an added value.
**Github**: [https://github.com/UBC-NLP/turjuman](https://github.com/UBC-NLP/turjuman)
**Demo**: [https://demos.dlnlp.ai/turjuman](https://demos.dlnlp.ai/turjuman)
**Paper**: [https://arxiv.org/abs/2206.03933](https://arxiv.org/abs/2206.03933)
## License
turjuman(-py) is Apache-2.0 licensed. The license applies to the pre-trained models as well.
## Citation
If you use TURJUMAN toolkit or the pre-trained models for your scientific publication, or if you find the resources in this repository useful, please cite our paper as follows (to be updated):
```
@inproceedings{nagoudi-osact5-2022-turjuman,
title={TURJUMAN: A Public Toolkit for Neural Arabic Machine Translation},
author={Nagoudi, El Moatez Billah and Elmadany, AbdelRahim and Abdul-Mageed, Muhammad},
booktitle = "Proceedings of the 5th Workshop on Open-Source Arabic Corpora and Processing Tools (OSACT5)",
month = "June",
year = "2022",
address = "Marseille, France",
publisher = "European Language Resource Association",
}
```
|
Salesforce/codet5-large | 7430ce16cc8c0f8db091c561a925047507734575 | 2022-07-07T11:55:19.000Z | [
"pytorch",
"t5",
"text2text-generation",
"arxiv:2109.00859",
"arxiv:2207.01780",
"arxiv:1909.09436",
"transformers",
"license:bsd-3-clause",
"autotrain_compatible"
] | text2text-generation | false | Salesforce | null | Salesforce/codet5-large | 739 | 4 | transformers | 1,993 | ---
license: bsd-3-clause
---
# CodeT5 (large-size model 770M)
## Model description
CodeT5 is a family of encoder-decoder language models for code from the paper: [CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Understanding and Generation](https://arxiv.org/pdf/2109.00859.pdf) by Yue Wang, Weishi Wang, Shafiq Joty, and Steven C.H. Hoi.
The checkpoint included in this repository is denoted as **CodeT5-large** (770M), which is introduced by the paper: [CodeRL: Mastering Code Generation through Pretrained Models and Deep Reinforcement Learning](https://arxiv.org/pdf/2207.01780.pdf) by Hung Le, Yue Wang, Akhilesh Deepak Gotmare, Silvio Savarese, Steven C.H. Hoi.
## Training data
CodeT5-large was pretrained on [CodeSearchNet](https://arxiv.org/abs/1909.09436) data in six programming languages (Ruby/JavaScript/Go/Python/Java/PHP). See Section 4.1 of the [paper](https://arxiv.org/pdf/2207.01780.pdf) for more details.
## Training procedure
CodeT5-large was pretrained using masked span prediction objective for 150 epochs. See Section 4.1 of the [paper](https://arxiv.org/pdf/2207.01780.pdf) for more details.
## Evaluation results
We validate the effectiveness of this checkpoint pretrained with simplified strategies on [CodeXGLUE](https://github.com/microsoft/CodeXGLUE) benchmark. See Appendix A.1 of the [paper](https://arxiv.org/pdf/2207.01780.pdf) for more details.
## How to use
This model can be easily loaded using the `T5ForConditionalGeneration` functionality:
```python
from transformers import AutoTokenizer, T5ForConditionalGeneration
tokenizer = AutoTokenizer.from_pretrained("Salesforce/codet5-large")
model = T5ForConditionalGeneration.from_pretrained("Salesforce/codet5-large")
text = "def greet(user): print(f'hello <extra_id_0>!')"
input_ids = tokenizer(text, return_tensors="pt").input_ids
# simply generate a single sequence
generated_ids = model.generate(input_ids, max_length=8)
print(tokenizer.decode(generated_ids[0], skip_special_tokens=True))
```
## BibTeX entry and citation info
```bibtex
@inproceedings{CodeT52021,
author = {Yue Wang and Weishi Wang and Shafiq R. Joty and Steven C. H. Hoi},
title = {CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Understanding and Generation},
booktitle = {EMNLP},
pages = {8696--8708},
publisher = {Association for Computational Linguistics},
year = {2021}
}
@article{CodeRL2022
author = {Hung Le, Yue Wang, Akhilesh Deepak Gotmare, Silvio Savarese, Steven C.H. Hoi},
title = {CodeRL: Mastering Code Generation through Pretrained Models and Deep Reinforcement Learning},
journal = {arXiv preprint},
volume = {abs/2207.01780},
year = {2022}
}
``` |
Helsinki-NLP/opus-mt-tc-big-it-en | ee0004520474d2a0e2b781c841b16cc745086cf4 | 2022-06-01T13:00:06.000Z | [
"pytorch",
"marian",
"text2text-generation",
"en",
"it",
"transformers",
"translation",
"opus-mt-tc",
"license:cc-by-4.0",
"model-index",
"autotrain_compatible"
] | translation | false | Helsinki-NLP | null | Helsinki-NLP/opus-mt-tc-big-it-en | 738 | null | transformers | 1,994 | ---
language:
- en
- it
tags:
- translation
- opus-mt-tc
license: cc-by-4.0
model-index:
- name: opus-mt-tc-big-it-en
results:
- task:
name: Translation ita-eng
type: translation
args: ita-eng
dataset:
name: flores101-devtest
type: flores_101
args: ita eng devtest
metrics:
- name: BLEU
type: bleu
value: 32.8
- task:
name: Translation ita-eng
type: translation
args: ita-eng
dataset:
name: tatoeba-test-v2021-08-07
type: tatoeba_mt
args: ita-eng
metrics:
- name: BLEU
type: bleu
value: 72.1
- task:
name: Translation ita-eng
type: translation
args: ita-eng
dataset:
name: newstest2009
type: wmt-2009-news
args: ita-eng
metrics:
- name: BLEU
type: bleu
value: 34.3
---
# opus-mt-tc-big-it-en
Neural machine translation model for translating from Italian (it) to English (en).
This model is part of the [OPUS-MT project](https://github.com/Helsinki-NLP/Opus-MT), an effort to make neural machine translation models widely available and accessible for many languages in the world. All models are originally trained using the amazing framework of [Marian NMT](https://marian-nmt.github.io/), an efficient NMT implementation written in pure C++. The models have been converted to pyTorch using the transformers library by huggingface. Training data is taken from [OPUS](https://opus.nlpl.eu/) and training pipelines use the procedures of [OPUS-MT-train](https://github.com/Helsinki-NLP/Opus-MT-train).
* Publications: [OPUS-MT – Building open translation services for the World](https://aclanthology.org/2020.eamt-1.61/) and [The Tatoeba Translation Challenge – Realistic Data Sets for Low Resource and Multilingual MT](https://aclanthology.org/2020.wmt-1.139/) (Please, cite if you use this model.)
```
@inproceedings{tiedemann-thottingal-2020-opus,
title = "{OPUS}-{MT} {--} Building open translation services for the World",
author = {Tiedemann, J{\"o}rg and Thottingal, Santhosh},
booktitle = "Proceedings of the 22nd Annual Conference of the European Association for Machine Translation",
month = nov,
year = "2020",
address = "Lisboa, Portugal",
publisher = "European Association for Machine Translation",
url = "https://aclanthology.org/2020.eamt-1.61",
pages = "479--480",
}
@inproceedings{tiedemann-2020-tatoeba,
title = "The Tatoeba Translation Challenge {--} Realistic Data Sets for Low Resource and Multilingual {MT}",
author = {Tiedemann, J{\"o}rg},
booktitle = "Proceedings of the Fifth Conference on Machine Translation",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.wmt-1.139",
pages = "1174--1182",
}
```
## Model info
* Release: 2022-02-25
* source language(s): ita
* target language(s): eng
* model: transformer-big
* data: opusTCv20210807+bt ([source](https://github.com/Helsinki-NLP/Tatoeba-Challenge))
* tokenization: SentencePiece (spm32k,spm32k)
* original model: [opusTCv20210807+bt_transformer-big_2022-02-25.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/ita-eng/opusTCv20210807+bt_transformer-big_2022-02-25.zip)
* more information released models: [OPUS-MT ita-eng README](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/ita-eng/README.md)
## Usage
A short example code:
```python
from transformers import MarianMTModel, MarianTokenizer
src_text = [
"So chi è il mio nemico.",
"Tom è illetterato; non capisce assolutamente nulla."
]
model_name = "pytorch-models/opus-mt-tc-big-it-en"
tokenizer = MarianTokenizer.from_pretrained(model_name)
model = MarianMTModel.from_pretrained(model_name)
translated = model.generate(**tokenizer(src_text, return_tensors="pt", padding=True))
for t in translated:
print( tokenizer.decode(t, skip_special_tokens=True) )
# expected output:
# I know who my enemy is.
# Tom is illiterate; he understands absolutely nothing.
```
You can also use OPUS-MT models with the transformers pipelines, for example:
```python
from transformers import pipeline
pipe = pipeline("translation", model="Helsinki-NLP/opus-mt-tc-big-it-en")
print(pipe("So chi è il mio nemico."))
# expected output: I know who my enemy is.
```
## Benchmarks
* test set translations: [opusTCv20210807+bt_transformer-big_2022-02-25.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/ita-eng/opusTCv20210807+bt_transformer-big_2022-02-25.test.txt)
* test set scores: [opusTCv20210807+bt_transformer-big_2022-02-25.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/ita-eng/opusTCv20210807+bt_transformer-big_2022-02-25.eval.txt)
* benchmark results: [benchmark_results.txt](benchmark_results.txt)
* benchmark output: [benchmark_translations.zip](benchmark_translations.zip)
| langpair | testset | chr-F | BLEU | #sent | #words |
|----------|---------|-------|-------|-------|--------|
| ita-eng | tatoeba-test-v2021-08-07 | 0.82288 | 72.1 | 17320 | 119214 |
| ita-eng | flores101-devtest | 0.62115 | 32.8 | 1012 | 24721 |
| ita-eng | newssyscomb2009 | 0.59822 | 34.4 | 502 | 11818 |
| ita-eng | newstest2009 | 0.59646 | 34.3 | 2525 | 65399 |
## Acknowledgements
The work is supported by the [European Language Grid](https://www.european-language-grid.eu/) as [pilot project 2866](https://live.european-language-grid.eu/catalogue/#/resource/projects/2866), by the [FoTran project](https://www.helsinki.fi/en/researchgroups/natural-language-understanding-with-cross-lingual-grounding), funded by the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (grant agreement No 771113), and the [MeMAD project](https://memad.eu/), funded by the European Union’s Horizon 2020 Research and Innovation Programme under grant agreement No 780069. We are also grateful for the generous computational resources and IT infrastructure provided by [CSC -- IT Center for Science](https://www.csc.fi/), Finland.
## Model conversion info
* transformers version: 4.16.2
* OPUS-MT git hash: 3405783
* port time: Wed Apr 13 19:40:08 EEST 2022
* port machine: LM0-400-22516.local
|
Sentdex/GPyT | b71d8cd84907e77c1b1d89c11a920244bb52104b | 2021-09-22T09:24:41.000Z | [
"pytorch",
"tf",
"gpt2",
"text-generation",
"Python",
"transformers",
"Code",
"GPyT",
"code generator",
"license:mit"
] | text-generation | false | Sentdex | null | Sentdex/GPyT | 736 | 11 | transformers | 1,995 | ---
language: Python
tags:
- Code
- GPyT
- code generator
license: mit
---
GPyT is a GPT2 model trained from scratch (not fine tuned) on Python code from Github. Overall, it was ~80GB of pure Python code, the current GPyT model is a mere 2 epochs through this data, so it may benefit greatly from continued training and/or fine-tuning.
Newlines are replaced by `<N>`
Input to the model is code, up to the context length of 1024, with newlines replaced by `<N>`
Here's a quick example of using this model:
```py
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("Sentdex/GPyT")
model = AutoModelWithLMHead.from_pretrained("Sentdex/GPyT")
# copy and paste some code in here
inp = """import"""
newlinechar = "<N>"
converted = inp.replace("\n", newlinechar)
tokenized = tokenizer.encode(converted, return_tensors='pt')
resp = model.generate(tokenized)
decoded = tokenizer.decode(resp[0])
reformatted = decoded.replace("<N>","\n")
print(reformatted)
```
Should produce:
```
import numpy as np
import pytest
import pandas as pd<N
```
This model does a ton more than just imports, however. For a bunch of examples and a better understanding of the model's capabilities:
https://pythonprogramming.net/GPT-python-code-transformer-model-GPyT/
Considerations:
1. This model is intended for educational and research use only. Do not trust model outputs.
2. Model is highly likely to regurgitate code almost exactly as it saw it. It's up to you to determine licensing if you intend to actually use the generated code.
3. All Python code was blindly pulled from github. This means included code is both Python 2 and 3, among other more subtle differences, such as tabs being 2 spaces in some cases and 4 in others...and more non-homologous things.
4. Along with the above, this means the code generated could wind up doing or suggesting just about anything. Run the generated code at own risk...it could be *anything*
|
geckos/bart-fined-tuned-on-entailment-classification | fb58ce512c60b04ab539b179eb00c49b86d78b46 | 2021-11-11T13:38:34.000Z | [
"pytorch",
"bart",
"text-classification",
"transformers"
] | text-classification | false | geckos | null | geckos/bart-fined-tuned-on-entailment-classification | 736 | 1 | transformers | 1,996 | Entry not found |
Elron/bleurt-tiny-512 | ed346ce5b758ba2ffbdfa95f7eec221449448523 | 2022-02-10T11:10:25.000Z | [
"pytorch",
"bert",
"text-classification",
"transformers"
] | text-classification | false | Elron | null | Elron/bleurt-tiny-512 | 735 | 2 | transformers | 1,997 | \n## BLEURT
Pytorch version of the original BLEURT models from ACL paper ["BLEURT: Learning Robust Metrics for Text Generation"](https://aclanthology.org/2020.acl-main.704/) by
Thibault Sellam, Dipanjan Das and Ankur P. Parikh of Google Research.
The code for model conversion was originated from [this notebook](https://colab.research.google.com/drive/1KsCUkFW45d5_ROSv2aHtXgeBa2Z98r03?usp=sharing) mentioned [here](https://github.com/huggingface/datasets/issues/224).
## Usage Example
```python
from transformers import AutoModelForSequenceClassification, AutoTokenizer
import torch
tokenizer = AutoTokenizer.from_pretrained("Elron/bleurt-tiny-512")
model = AutoModelForSequenceClassification.from_pretrained("Elron/bleurt-tiny-512")
model.eval()
references = ["hello world", "hello world"]
candidates = ["hi universe", "bye world"]
with torch.no_grad():
scores = model(**tokenizer(references, candidates, return_tensors='pt'))[0].squeeze()
print(scores) # tensor([-0.9414, -0.5678])
```
|
alaggung/bart-r3f | b0a1bafbf3396749e35b5b48bf9891d34f089f57 | 2022-01-11T16:18:32.000Z | [
"pytorch",
"tf",
"bart",
"text2text-generation",
"ko",
"transformers",
"summarization",
"autotrain_compatible"
] | summarization | false | alaggung | null | alaggung/bart-r3f | 735 | 1 | transformers | 1,998 | ---
language:
- ko
tags:
- summarization
widget:
- text: "[BOS]밥 ㄱ?[SEP]고고고고 뭐 먹을까?[SEP]어제 김치찌개 먹어서 한식말고 딴 거[SEP]그럼 돈까스 어때?[SEP]오 좋다 1시 학관 앞으로 오셈[SEP]ㅇㅋ[EOS]"
inference:
parameters:
max_length: 64
top_k: 5
---
# BART R3F
[2021 훈민정음 한국어 음성•자연어 인공지능 경진대회] 대화요약 부문 알라꿍달라꿍 팀의 대화요약 학습 샘플 모델을 공유합니다.
[bart-pretrained](https://huggingface.co/alaggung/bart-pretrained) 모델에 [2021-dialogue-summary-competition](https://github.com/cosmoquester/2021-dialogue-summary-competition) 레포지토리의 R3F를 적용해 대화요약 Task를 학습한 모델입니다.
데이터는 [AIHub 한국어 대화요약](https://aihub.or.kr/aidata/30714) 데이터를 사용하였습니다. |
patrickvonplaten/wav2vec2-base | 822b936a126a5486547c640c97eda5c61bfedfdc | 2021-06-08T17:00:26.000Z | [
"pytorch",
"wav2vec2",
"pretraining",
"en",
"dataset:librispeech_asr",
"arxiv:2006.11477",
"transformers",
"speech",
"license:apache-2.0"
] | null | false | patrickvonplaten | null | patrickvonplaten/wav2vec2-base | 735 | null | transformers | 1,999 | ---
language: en
datasets:
- librispeech_asr
tags:
- speech
license: apache-2.0
---
# Wav2Vec2-Base
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/)
The base model pretrained on 16kHz sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz. Note that this model should be fine-tuned on a downstream task, like Automatic Speech Recognition. Check out [this blog](https://huggingface.co/blog/fine-tune-wav2vec2-english) for more information.
[Paper](https://arxiv.org/abs/2006.11477)
Authors: Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli
**Abstract**
We show for the first time that learning powerful representations from speech audio alone followed by fine-tuning on transcribed speech can outperform the best semi-supervised methods while being conceptually simpler. wav2vec 2.0 masks the speech input in the latent space and solves a contrastive task defined over a quantization of the latent representations which are jointly learned. Experiments using all labeled data of Librispeech achieve 1.8/3.3 WER on the clean/other test sets. When lowering the amount of labeled data to one hour, wav2vec 2.0 outperforms the previous state of the art on the 100 hour subset while using 100 times less labeled data. Using just ten minutes of labeled data and pre-training on 53k hours of unlabeled data still achieves 4.8/8.2 WER. This demonstrates the feasibility of speech recognition with limited amounts of labeled data.
The original model can be found under https://github.com/pytorch/fairseq/tree/master/examples/wav2vec#wav2vec-20.
# Usage
See [this notebook](https://colab.research.google.com/drive/1FjTsqbYKphl9kL-eILgUc-bl4zVThL8F?usp=sharing) for more information on how to fine-tune the model. |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.