
modelId
stringlengths 4
112
| sha
stringlengths 40
40
| lastModified
stringlengths 24
24
| tags
list | pipeline_tag
stringclasses 29
values | private
bool 1
class | author
stringlengths 2
38
⌀ | config
null | id
stringlengths 4
112
| downloads
float64 0
36.8M
⌀ | likes
float64 0
712
⌀ | library_name
stringclasses 17
values | __index_level_0__
int64 0
38.5k
| readme
stringlengths 0
186k
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Salesforce/codegen-2B-multi
|
a5164ee330b2f0a87e216d2f93f5f33000a6d1a8
|
2022-06-28T17:45:32.000Z
|
[
"pytorch",
"codegen",
"text-generation",
"arxiv:2203.13474",
"transformers",
"license:bsd-3-clause"
] |
text-generation
| false |
Salesforce
| null |
Salesforce/codegen-2B-multi
| 1,906 | 3 |
transformers
| 1,400 |
---
license: bsd-3-clause
---
# CodeGen (CodeGen-Multi 2B)
## Model description
CodeGen is a family of autoregressive language models for **program synthesis** from the paper: [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong. The models are originally released in [this repository](https://github.com/salesforce/CodeGen), under 3 pre-training data variants (`NL`, `Multi`, `Mono`) and 4 model size variants (`350M`, `2B`, `6B`, `16B`).
The checkpoint included in this repository is denoted as **CodeGen-Multi 2B** in the paper, where "Multi" means the model is initialized with *CodeGen-NL 2B* and further pre-trained on a dataset of multiple programming languages, and "2B" refers to the number of trainable parameters.
## Training data
This checkpoint (CodeGen-Multi 2B) was firstly initialized with *CodeGen-NL 2B*, and then pre-trained on [BigQuery](https://console.cloud.google.com/marketplace/details/github/github-repos), a large-scale dataset of multiple programming languages from GitHub repositories. The data consists of 119.2B tokens and includes C, C++, Go, Java, JavaScript, and Python.
## Training procedure
CodeGen was trained using cross-entropy loss to maximize the likelihood of sequential inputs.
The family of models are trained using multiple TPU-v4-512 by Google, leveraging data and model parallelism.
See Section 2.3 of the [paper](https://arxiv.org/abs/2203.13474) for more details.
## Evaluation results
We evaluate our models on two code generation benchmark: HumanEval and MTPB. Please refer to the [paper](https://arxiv.org/abs/2203.13474) for more details.
## Intended Use and Limitations
As an autoregressive language model, CodeGen is capable of extracting features from given natural language and programming language texts, and calculating the likelihood of them.
However, the model is intended for and best at **program synthesis**, that is, generating executable code given English prompts, where the prompts should be in the form of a comment string. The model can complete partially-generated code as well.
## How to use
This model can be easily loaded using the `AutoModelForCausalLM` functionality:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("Salesforce/codegen-2B-multi")
model = AutoModelForCausalLM.from_pretrained("Salesforce/codegen-2B-multi")
text = "def hello_world():"
input_ids = tokenizer(text, return_tensors="pt").input_ids
generated_ids = model.generate(input_ids, max_length=128)
print(tokenizer.decode(generated_ids[0], skip_special_tokens=True))
```
## BibTeX entry and citation info
```bibtex
@article{Nijkamp2022ACP,
title={A Conversational Paradigm for Program Synthesis},
author={Nijkamp, Erik and Pang, Bo and Hayashi, Hiroaki and Tu, Lifu and Wang, Huan and Zhou, Yingbo and Savarese, Silvio and Xiong, Caiming},
journal={arXiv preprint},
year={2022}
}
```
|
microsoft/cocolm-large
|
6947b62b7ca98d5f883c291b7a32e9b2d54130ef
|
2022-02-07T22:49:54.000Z
|
[
"pytorch",
"arxiv:2102.08473",
"transformers"
] | null | false |
microsoft
| null |
microsoft/cocolm-large
| 1,901 | 5 |
transformers
| 1,401 |
# COCO-LM: Correcting and Contrasting Text Sequences for Language Model Pretraining
This model card contains the COCO-LM model (**large++** version) proposed in [this paper](https://arxiv.org/abs/2102.08473). The official GitHub repository can be found [here](https://github.com/microsoft/COCO-LM).
# Citation
If you find this model card useful for your research, please cite the following paper:
```
@inproceedings{meng2021coco,
title={{COCO-LM}: Correcting and contrasting text sequences for language model pretraining},
author={Meng, Yu and Xiong, Chenyan and Bajaj, Payal and Tiwary, Saurabh and Bennett, Paul and Han, Jiawei and Song, Xia},
booktitle={NeurIPS},
year={2021}
}
```
|
tennessejoyce/titlewave-t5-base
|
fb30007e56801afadefbd4d60cb3b36631dce9e8
|
2021-06-23T14:26:41.000Z
|
[
"pytorch",
"t5",
"text2text-generation",
"en",
"transformers",
"license:cc-by-4.0",
"summarization",
"autotrain_compatible"
] |
summarization
| false |
tennessejoyce
| null |
tennessejoyce/titlewave-t5-base
| 1,892 | 3 |
transformers
| 1,402 |
---
language: en
license: cc-by-4.0
pipeline_tag: summarization
widget:
- text: "Example question body."
---
# Titlewave: t5-base
## Model description
Titlewave is a Chrome extension that helps you choose better titles for your Stack Overflow questions. See https://github.com/tennessejoyce/TitleWave for more information.
This is one of two NLP models used in the Titlewave project, and its purpose is to suggests a new title based on on the body of the question. The companion model (https://huggingface.co/tennessejoyce/titlewave-bert-base-uncased) classifies whether question will be answered or not just based on the title
## Intended use
Try out different titles for your Stack Overflow post, and see which one gives you the best chance of recieving an answer.
This model can be used in your browser as a Chrome extension by following the installation instructions at https://github.com/tennessejoyce/TitleWave.
Or load it in Python like this (which will automatically download the model to your machine):
```python
>>> from transformers import pipeline
>>> classifier = pipeline('summarization', model='tennessejoyce/titlewave-t5-base')
>>> body = """"Example question body."""
>>> classifier(body)
[{'summary_text': 'Example title suggestion?'}]
```
## Training data
The weights were initialized from the BERT base model (https://huggingface.co/bert-base-uncased), which was trained on BookCorpus and English Wikipedia.
Then the model was fine-tuned on the dataset of previous Stack Overflow post titles (https://archive.org/details/stackexchange).
Specifically I used three years of posts from 2017-2019, filtered out posts which were closed, and selected 25% of the remaining posts at random to use in
the training set. In order to improve the quality of the titles generated, the model was trained only on questions with an accepted answer.
## Evaluation
See https://github.com/tennessejoyce/TitleWave/blob/master/model_training/test_summarizer.ipynb for the performance of the title generation model on the test set.
|
CLTL/MedRoBERTa.nl
|
11b28aeb2da629c4a6205514043d78c7db0913a0
|
2022-02-02T11:56:21.000Z
|
[
"pytorch",
"roberta",
"fill-mask",
"nl",
"transformers",
"license:mit",
"autotrain_compatible"
] |
fill-mask
| false |
CLTL
| null |
CLTL/MedRoBERTa.nl
| 1,888 | null |
transformers
| 1,403 |
---
language: nl
license: mit
---
# MedRoBERTa.nl
## Description
This model is a RoBERTa-based model pre-trained from scratch on Dutch hospital notes sourced from Electronic Health Records. The model is not fine-tuned. All code used for the creation of MedRoBERTa.nl can be found at https://github.com/cltl-students/verkijk_stella_rma_thesis_dutch_medical_language_model.
## Intended use
The model can be fine-tuned on any type of task. Since it is a domain-specific model trained on medical data, it is meant to be used on medical NLP tasks for Dutch.
## Data
The model was trained on nearly 10 million hospital notes from the Amsterdam University Medical Centres. The training data was anonymized before starting the pre-training procedure.
## Privacy
By anonymizing the training data we made sure the model did not learn any representative associations linked to names. Apart from the training data, the model's vocabulary was also anonymized. This ensures that the model can not predict any names in the generative fill-mask task.
## Authors
Stella Verkijk, Piek Vossen
## Reference
Paper: Verkijk, S. & Vossen, P. (2022) MedRoBERTa.nl: A Language Model for Dutch Electroniz Health Records. Computational Linguistics in the Netherlands Journal, 11.
|
Helsinki-NLP/opus-mt-sk-en
|
86dc882b010210ccd3993b3375dcd88c366080d4
|
2021-09-10T14:03:21.000Z
|
[
"pytorch",
"marian",
"text2text-generation",
"sk",
"en",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] |
translation
| false |
Helsinki-NLP
| null |
Helsinki-NLP/opus-mt-sk-en
| 1,886 | null |
transformers
| 1,404 |
---
tags:
- translation
license: apache-2.0
---
### opus-mt-sk-en
* source languages: sk
* target languages: en
* OPUS readme: [sk-en](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/sk-en/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-16.zip](https://object.pouta.csc.fi/OPUS-MT-models/sk-en/opus-2020-01-16.zip)
* test set translations: [opus-2020-01-16.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/sk-en/opus-2020-01-16.test.txt)
* test set scores: [opus-2020-01-16.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/sk-en/opus-2020-01-16.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| JW300.sk.en | 42.2 | 0.612 |
|
hf-internal-testing/tiny-random-clip-zero-shot-image-classification
|
b965c5deee645e96dcc40a8cdd260a7595b93354
|
2022-02-23T10:44:13.000Z
|
[
"pytorch",
"tf",
"clip",
"feature-extraction",
"transformers",
"zero-shot-image-classification"
] |
zero-shot-image-classification
| false |
hf-internal-testing
| null |
hf-internal-testing/tiny-random-clip-zero-shot-image-classification
| 1,883 | null |
transformers
| 1,405 |
---
pipeline_tag: zero-shot-image-classification
---
|
AkshatSurolia/ICD-10-Code-Prediction
|
30847eeecb162b43cd6c151688b7971605ea7682
|
2022-02-28T10:06:41.000Z
|
[
"pytorch",
"bert",
"dataset:Mimic III",
"transformers",
"text-classification",
"license:apache-2.0"
] |
text-classification
| false |
AkshatSurolia
| null |
AkshatSurolia/ICD-10-Code-Prediction
| 1,879 | null |
transformers
| 1,406 |
---
license: apache-2.0
tags:
- text-classification
datasets:
- Mimic III
---
# Clinical BERT for ICD-10 Prediction
The Publicly Available Clinical BERT Embeddings paper contains four unique clinicalBERT models: initialized with BERT-Base (cased_L-12_H-768_A-12) or BioBERT (BioBERT-Base v1.0 + PubMed 200K + PMC 270K) & trained on either all MIMIC notes or only discharge summaries.
---
## How to use the model
Load the model via the transformers library:
from transformers import AutoTokenizer, BertForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("AkshatSurolia/ICD-10-Code-Prediction")
model = BertForSequenceClassification.from_pretrained("AkshatSurolia/ICD-10-Code-Prediction")
config = model.config
Run the model with clinical diagonosis text:
text = "subarachnoid hemorrhage scalp laceration service: surgery major surgical or invasive"
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
Return the Top-5 predicted ICD-10 codes:
results = output.logits.detach().cpu().numpy()[0].argsort()[::-1][:5]
return [ config.id2label[ids] for ids in results]
|
Helsinki-NLP/opus-mt-tl-en
|
15b5306fe4cd1d54e6e4e387084214284c1d3939
|
2020-08-21T14:42:51.000Z
|
[
"pytorch",
"marian",
"text2text-generation",
"tl",
"en",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] |
translation
| false |
Helsinki-NLP
| null |
Helsinki-NLP/opus-mt-tl-en
| 1,856 | null |
transformers
| 1,407 |
---
language:
- tl
- en
tags:
- translation
license: apache-2.0
---
### tgl-eng
* source group: Tagalog
* target group: English
* OPUS readme: [tgl-eng](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/tgl-eng/README.md)
* model: transformer-align
* source language(s): tgl_Latn
* target language(s): eng
* model: transformer-align
* pre-processing: normalization + SentencePiece (spm32k,spm32k)
* download original weights: [opus-2020-06-17.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/tgl-eng/opus-2020-06-17.zip)
* test set translations: [opus-2020-06-17.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/tgl-eng/opus-2020-06-17.test.txt)
* test set scores: [opus-2020-06-17.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/tgl-eng/opus-2020-06-17.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba-test.tgl.eng | 35.0 | 0.542 |
### System Info:
- hf_name: tgl-eng
- source_languages: tgl
- target_languages: eng
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/tgl-eng/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['tl', 'en']
- src_constituents: {'tgl_Latn'}
- tgt_constituents: {'eng'}
- src_multilingual: False
- tgt_multilingual: False
- prepro: normalization + SentencePiece (spm32k,spm32k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/tgl-eng/opus-2020-06-17.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/tgl-eng/opus-2020-06-17.test.txt
- src_alpha3: tgl
- tgt_alpha3: eng
- short_pair: tl-en
- chrF2_score: 0.542
- bleu: 35.0
- brevity_penalty: 0.975
- ref_len: 18168.0
- src_name: Tagalog
- tgt_name: English
- train_date: 2020-06-17
- src_alpha2: tl
- tgt_alpha2: en
- prefer_old: False
- long_pair: tgl-eng
- helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535
- transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b
- port_machine: brutasse
- port_time: 2020-08-21-14:41
|
deepmind/language-perceiver
|
bb9db7197e2f3209b2b8e970aa0d53e3eaf30fa2
|
2021-12-15T14:51:13.000Z
|
[
"pytorch",
"perceiver",
"fill-mask",
"dataset:wikipedia",
"dataset:c4",
"arxiv:1810.04805",
"arxiv:2107.14795",
"arxiv:2004.03720",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] |
fill-mask
| false |
deepmind
| null |
deepmind/language-perceiver
| 1,856 | 5 |
transformers
| 1,408 |
---
license: apache-2.0
tags:
datasets:
- wikipedia
- c4
inference: false
---
# Perceiver IO for language
Perceiver IO model pre-trained on the Masked Language Modeling (MLM) task proposed in [BERT](https://arxiv.org/abs/1810.04805) using a large text corpus obtained by combining [English Wikipedia](https://huggingface.co/datasets/wikipedia) and [C4](https://huggingface.co/datasets/c4). It was introduced in the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Jaegle et al. and first released in [this repository](https://github.com/deepmind/deepmind-research/tree/master/perceiver).
Disclaimer: The team releasing Perceiver IO did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
Perceiver IO is a transformer encoder model that can be applied on any modality (text, images, audio, video, ...). The core idea is to employ the self-attention mechanism on a not-too-large set of latent vectors (e.g. 256 or 512), and only use the inputs to perform cross-attention with the latents. This allows for the time and memory requirements of the self-attention mechanism to not depend on the size of the inputs.
To decode, the authors employ so-called decoder queries, which allow to flexibly decode the final hidden states of the latents to produce outputs of arbitrary size and semantics. For masked language modeling, the output is a tensor containing the prediction scores of the language modeling head, of shape (batch_size, seq_length, vocab_size).
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/perceiver_architecture.jpg" alt="drawing" width="600"/>
<small> Perceiver IO architecture.</small>
As the time and memory requirements of the self-attention mechanism don't depend on the size of the inputs, the Perceiver IO authors train the model directly on raw UTF-8 bytes, rather than on subwords as is done in models like BERT, RoBERTa and GPT-2. This has many benefits: one doesn't need to train a tokenizer before training the model, one doesn't need to maintain a (fixed) vocabulary file, and this also doesn't hurt model performance as shown by [Bostrom et al., 2020](https://arxiv.org/abs/2004.03720).
By pre-training the model, it learns an inner representation of language that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a standard
classifier using the features produced by the Perceiver model as inputs.
## Intended uses & limitations
You can use the raw model for masked language modeling, but the model is intended to be fine-tuned on a labeled dataset. See the [model hub](https://huggingface.co/models?search=deepmind/perceiver) to look for fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model in PyTorch:
```python
from transformers import PerceiverTokenizer, PerceiverForMaskedLM
tokenizer = PerceiverTokenizer.from_pretrained("deepmind/language-perceiver")
model = PerceiverForMaskedLM.from_pretrained("deepmind/language-perceiver")
text = "This is an incomplete sentence where some words are missing."
# prepare input
encoding = tokenizer(text, padding="max_length", return_tensors="pt")
# mask " missing.". Note that the model performs much better if the masked span starts with a space.
encoding.input_ids[0, 52:61] = tokenizer.mask_token_id
inputs, input_mask = encoding.input_ids.to(device), encoding.attention_mask.to(device)
# forward pass
outputs = model(inputs=inputs, attention_mask=input_mask)
logits = outputs.logits
masked_tokens_predictions = logits[0, 51:61].argmax(dim=-1)
print(tokenizer.decode(masked_tokens_predictions))
>>> should print " missing."
```
## Training data
This model was pretrained on a combination of [English Wikipedia](https://huggingface.co/datasets/wikipedia) and [C4](https://huggingface.co/datasets/c4). 70% of the training tokens were sampled from the C4 dataset and the remaining 30% from Wikipedia. The authors concatenate 10 documents before splitting into crops to reduce wasteful computation on padding tokens.
## Training procedure
### Preprocessing
Text preprocessing is trivial: it only involves encoding text into UTF-8 bytes, and padding them up to the same length (2048).
### Pretraining
Hyperparameter details can be found in table 9 of the [paper](https://arxiv.org/abs/2107.14795).
## Evaluation results
This model is able to achieve an average score of 81.8 on GLUE. For more details, we refer to table 3 of the original paper.
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2107-14795,
author = {Andrew Jaegle and
Sebastian Borgeaud and
Jean{-}Baptiste Alayrac and
Carl Doersch and
Catalin Ionescu and
David Ding and
Skanda Koppula and
Daniel Zoran and
Andrew Brock and
Evan Shelhamer and
Olivier J. H{\'{e}}naff and
Matthew M. Botvinick and
Andrew Zisserman and
Oriol Vinyals and
Jo{\~{a}}o Carreira},
title = {Perceiver {IO:} {A} General Architecture for Structured Inputs {\&}
Outputs},
journal = {CoRR},
volume = {abs/2107.14795},
year = {2021},
url = {https://arxiv.org/abs/2107.14795},
eprinttype = {arXiv},
eprint = {2107.14795},
timestamp = {Tue, 03 Aug 2021 14:53:34 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2107-14795.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
m3hrdadfi/typo-detector-distilbert-en
|
902f1d72e36fcab14629427c0cee8c668495c2c6
|
2021-06-16T16:14:20.000Z
|
[
"pytorch",
"tf",
"distilbert",
"token-classification",
"en",
"transformers",
"autotrain_compatible"
] |
token-classification
| false |
m3hrdadfi
| null |
m3hrdadfi/typo-detector-distilbert-en
| 1,852 | 1 |
transformers
| 1,409 |
---
language: en
widget:
- text: "He had also stgruggled with addiction during his time in Congress ."
- text: "The review thoroughla assessed all aspects of JLENS SuR and CPG esign maturit and confidence ."
- text: "Letterma also apologized two his staff for the satyation ."
- text: "Vincent Jay had earlier won France 's first gold in gthe 10km biathlon sprint ."
- text: "It is left to the directors to figure out hpw to bring the stry across to tye audience ."
---
# Typo Detector
## Dataset Information
For this specific task, I used [NeuSpell](https://github.com/neuspell/neuspell) corpus as my raw data.
## Evaluation
The following tables summarize the scores obtained by model overall and per each class.
| # | precision | recall | f1-score | support |
|:------------:|:---------:|:--------:|:--------:|:--------:|
| TYPO | 0.992332 | 0.985997 | 0.989154 | 416054.0 |
| micro avg | 0.992332 | 0.985997 | 0.989154 | 416054.0 |
| macro avg | 0.992332 | 0.985997 | 0.989154 | 416054.0 |
| weighted avg | 0.992332 | 0.985997 | 0.989154 | 416054.0 |
## How to use
You use this model with Transformers pipeline for NER (token-classification).
### Installing requirements
```bash
pip install transformers
```
### Prediction using pipeline
```python
import torch
from transformers import AutoConfig, AutoTokenizer, AutoModelForTokenClassification
from transformers import pipeline
model_name_or_path = "m3hrdadfi/typo-detector-distilbert-en"
config = AutoConfig.from_pretrained(model_name_or_path)
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
model = AutoModelForTokenClassification.from_pretrained(model_name_or_path, config=config)
nlp = pipeline('token-classification', model=model, tokenizer=tokenizer, aggregation_strategy="average")
```
```python
sentences = [
"He had also stgruggled with addiction during his time in Congress .",
"The review thoroughla assessed all aspects of JLENS SuR and CPG esign maturit and confidence .",
"Letterma also apologized two his staff for the satyation .",
"Vincent Jay had earlier won France 's first gold in gthe 10km biathlon sprint .",
"It is left to the directors to figure out hpw to bring the stry across to tye audience .",
]
for sentence in sentences:
typos = [sentence[r["start"]: r["end"]] for r in nlp(sentence)]
detected = sentence
for typo in typos:
detected = detected.replace(typo, f'<i>{typo}</i>')
print(" [Input]: ", sentence)
print("[Detected]: ", detected)
print("-" * 130)
```
Output:
```text
[Input]: He had also stgruggled with addiction during his time in Congress .
[Detected]: He had also <i>stgruggled</i> with addiction during his time in Congress .
----------------------------------------------------------------------------------------------------------------------------------
[Input]: The review thoroughla assessed all aspects of JLENS SuR and CPG esign maturit and confidence .
[Detected]: The review <i>thoroughla</i> assessed all aspects of JLENS SuR and CPG <i>esign</i> <i>maturit</i> and confidence .
----------------------------------------------------------------------------------------------------------------------------------
[Input]: Letterma also apologized two his staff for the satyation .
[Detected]: <i>Letterma</i> also apologized <i>two</i> his staff for the <i>satyation</i> .
----------------------------------------------------------------------------------------------------------------------------------
[Input]: Vincent Jay had earlier won France 's first gold in gthe 10km biathlon sprint .
[Detected]: Vincent Jay had earlier won France 's first gold in <i>gthe</i> 10km biathlon sprint .
----------------------------------------------------------------------------------------------------------------------------------
[Input]: It is left to the directors to figure out hpw to bring the stry across to tye audience .
[Detected]: It is left to the directors to figure out <i>hpw</i> to bring the <i>stry</i> across to <i>tye</i> audience .
----------------------------------------------------------------------------------------------------------------------------------
```
## Questions?
Post a Github issue on the [TypoDetector Issues](https://github.com/m3hrdadfi/typo-detector/issues) repo.
|
facebook/rag-token-base
|
bdeb4ef1d547bcfe5445aba1704ece55af71dd58
|
2020-12-11T21:39:44.000Z
|
[
"pytorch",
"rag",
"en",
"dataset:wiki_dpr",
"arxiv:2005.11401",
"transformers",
"license:apache-2.0"
] | null | false |
facebook
| null |
facebook/rag-token-base
| 1,849 | null |
transformers
| 1,410 |
---
language: en
license: apache-2.0
datasets:
- wiki_dpr
thumbnail: https://huggingface.co/front/thumbnails/facebook.png
---
## RAG
This is a non-finetuned version of the RAG-Token model of the the paper [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/pdf/2005.11401.pdf)
by Patrick Lewis, Ethan Perez, Aleksandara Piktus et al.
Rag consits of a *question encoder*, *retriever* and a *generator*. The retriever should be a `RagRetriever` instance. The *question encoder* can be any model that can be loaded with `AutoModel` and the *generator* can be any model that can be loaded with `AutoModelForSeq2SeqLM`.
This model is a non-finetuned RAG-Token model and was created as follows:
```python
from transformers import RagTokenizer, RagRetriever, RagTokenForGeneration, AutoTokenizer
model = RagTokenForGeneration.from_pretrained_question_encoder_generator("facebook/dpr-question_encoder-single-nq-base", "facebook/bart-large")
question_encoder_tokenizer = AutoTokenizer.from_pretrained("facebook/dpr-question_encoder-single-nq-base")
generator_tokenizer = AutoTokenizer.from_pretrained("facebook/bart-large")
tokenizer = RagTokenizer(question_encoder_tokenizer, generator_tokenizer)
model.config.use_dummy_dataset = True
model.config.index_name = "exact"
retriever = RagRetriever(model.config, question_encoder_tokenizer, generator_tokenizer)
model.save_pretrained("./")
tokenizer.save_pretrained("./")
retriever.save_pretrained("./")
```
Note that the model is *uncased* so that all capital input letters are converted to lower-case.
## Usage:
*Note*: the model uses the *dummy* retriever as a default. Better results are obtained by using the full retriever,
by setting `config.index_name="legacy"` and `config.use_dummy_dataset=False`.
The model can be fine-tuned as follows:
```python
from transformers import RagTokenizer, RagRetriever, RagTokenForGeneration
tokenizer = RagTokenizer.from_pretrained("facebook/rag-token-base")
retriever = RagRetriever.from_pretrained("facebook/rag-token-base")
model = RagTokenForGeneration.from_pretrained("facebook/rag-token-base", retriever=retriever)
input_dict = tokenizer.prepare_seq2seq_batch("who holds the record in 100m freestyle", "michael phelps", return_tensors="pt")
outputs = model(input_dict["input_ids"], labels=input_dict["labels"])
loss = outputs.loss
# train on loss
```
|
malteos/scincl
|
59e80e4be60df7faf8bb7ad4c6e6d4f40f19ce78
|
2022-02-18T23:00:44.000Z
|
[
"pytorch",
"bert",
"feature-extraction",
"en",
"dataset:SciDocs",
"dataset:s2orc",
"arxiv:2202.06671",
"transformers",
"license:mit"
] |
feature-extraction
| false |
malteos
| null |
malteos/scincl
| 1,849 | 4 |
transformers
| 1,411 |
---
tags:
- feature-extraction
language: en
datasets:
- SciDocs
- s2orc
metrics:
- F1
- accuracy
- map
- ndcg
license: mit
---
## SciNCL
SciNCL is a pre-trained BERT language model to generate document-level embeddings of research papers.
It uses the citation graph neighborhood to generate samples for contrastive learning.
Prior to the contrastive training, the model is initialized with weights from [scibert-scivocab-uncased](https://huggingface.co/allenai/scibert_scivocab_uncased).
The underlying citation embeddings are trained on the [S2ORC citation graph](https://github.com/allenai/s2orc).
Paper: [Neighborhood Contrastive Learning for Scientific Document Representations with Citation Embeddings (Arxiv preprint)](https://arxiv.org/abs/2202.06671).
Code: https://github.com/malteos/scincl
## How to use the pretrained model
```python
from transformers import AutoTokenizer, AutoModel
# load model and tokenizer
tokenizer = AutoTokenizer.from_pretrained('malteos/scincl')
model = AutoModel.from_pretrained('malteos/scincl')
papers = [{'title': 'BERT', 'abstract': 'We introduce a new language representation model called BERT'},
{'title': 'Attention is all you need', 'abstract': ' The dominant sequence transduction models are based on complex recurrent or convolutional neural networks'}]
# concatenate title and abstract with [SEP] token
title_abs = [d['title'] + tokenizer.sep_token + (d.get('abstract') or '') for d in papers]
# preprocess the input
inputs = tokenizer(title_abs, padding=True, truncation=True, return_tensors="pt", max_length=512)
# inference
result = model(**inputs)
# take the first token ([CLS] token) in the batch as the embedding
embeddings = result.last_hidden_state[:, 0, :]
```
## Triplet Mining Parameters
| **Setting** | **Value** |
|-------------------------|--------------------|
| seed | 4 |
| triples_per_query | 5 |
| easy_positives_count | 5 |
| easy_positives_strategy | 5 |
| easy_positives_k | 20-25 |
| easy_negatives_count | 3 |
| easy_negatives_strategy | random_without_knn |
| hard_negatives_count | 2 |
| hard_negatives_strategy | knn |
| hard_negatives_k | 3998-4000 |
## SciDocs Results
These model weights are the ones that yielded the best results on SciDocs (`seed=4`).
In the paper we report the SciDocs results as mean over ten seeds.
| **model** | **mag-f1** | **mesh-f1** | **co-view-map** | **co-view-ndcg** | **co-read-map** | **co-read-ndcg** | **cite-map** | **cite-ndcg** | **cocite-map** | **cocite-ndcg** | **recomm-ndcg** | **recomm-P@1** | **Avg** |
|-------------------|-----------:|------------:|----------------:|-----------------:|----------------:|-----------------:|-------------:|--------------:|---------------:|----------------:|----------------:|---------------:|--------:|
| Doc2Vec | 66.2 | 69.2 | 67.8 | 82.9 | 64.9 | 81.6 | 65.3 | 82.2 | 67.1 | 83.4 | 51.7 | 16.9 | 66.6 |
| fasttext-sum | 78.1 | 84.1 | 76.5 | 87.9 | 75.3 | 87.4 | 74.6 | 88.1 | 77.8 | 89.6 | 52.5 | 18 | 74.1 |
| SGC | 76.8 | 82.7 | 77.2 | 88 | 75.7 | 87.5 | 91.6 | 96.2 | 84.1 | 92.5 | 52.7 | 18.2 | 76.9 |
| SciBERT | 79.7 | 80.7 | 50.7 | 73.1 | 47.7 | 71.1 | 48.3 | 71.7 | 49.7 | 72.6 | 52.1 | 17.9 | 59.6 |
| SPECTER | 82 | 86.4 | 83.6 | 91.5 | 84.5 | 92.4 | 88.3 | 94.9 | 88.1 | 94.8 | 53.9 | 20 | 80 |
| SciNCL (10 seeds) | 81.4 | 88.7 | 85.3 | 92.3 | 87.5 | 93.9 | 93.6 | 97.3 | 91.6 | 96.4 | 53.9 | 19.3 | 81.8 |
| **SciNCL (seed=4)** | 81.2 | 89.0 | 85.3 | 92.2 | 87.7 | 94.0 | 93.6 | 97.4 | 91.7 | 96.5 | 54.3 | 19.6 | 81.9 |
Additional evaluations are available in the paper.
## License
MIT
|
hfl/chinese-pert-base-mrc
|
9e190b7d0f52fa74f503eee54d1b0214c27f2d54
|
2022-05-05T08:45:07.000Z
|
[
"pytorch",
"tf",
"bert",
"question-answering",
"zh",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] |
question-answering
| false |
hfl
| null |
hfl/chinese-pert-base-mrc
| 1,837 | 3 |
transformers
| 1,412 |
---
language:
- zh
license: "apache-2.0"
---
## A Chinese MRC model built on Chinese PERT-base
**Please use `BertForQuestionAnswering` to load this model!**
This is a Chinese machine reading comprehension (MRC) model built on PERT-base and fine-tuned on a mixture of Chinese MRC datasets.
PERT is a pre-trained model based on permuted language model (PerLM) to learn text semantic information in a self-supervised manner without introducing the mask tokens [MASK]. It yields competitive results on in tasks such as reading comprehension and sequence labeling.
Results on Chinese MRC datasets (EM/F1):
(We report the checkpoint that has the best AVG score)
| | CMRC 2018 Dev | DRCD Dev | SQuAD-Zen Dev (Answerable) | AVG |
| :-------: | :-----------: | :-------: | :------------------------: | :-------: |
| PERT-base | 73.2/90.6 | 88.7/94.1 | 59.7/76.5 | 73.9/87.1 |
Please visit our GitHub repo for more information: https://github.com/ymcui/PERT
You may also be interested in,
Chinese Minority Languages CINO: https://github.com/ymcui/Chinese-Minority-PLM
Chinese MacBERT: https://github.com/ymcui/MacBERT
Chinese BERT series: https://github.com/ymcui/Chinese-BERT-wwm
Chinese ELECTRA: https://github.com/ymcui/Chinese-ELECTRA
Chinese XLNet: https://github.com/ymcui/Chinese-XLNet
Knowledge Distillation Toolkit - TextBrewer: https://github.com/airaria/TextBrewer
More resources by HFL: https://github.com/ymcui/HFL-Anthology
|
imxly/t5-pegasus
|
16c04d35c376262bc823f3e9f225da74f980837c
|
2021-03-29T03:34:09.000Z
|
[
"pytorch",
"mt5",
"text2text-generation",
"transformers",
"autotrain_compatible"
] |
text2text-generation
| false |
imxly
| null |
imxly/t5-pegasus
| 1,835 | 8 |
transformers
| 1,413 |
Entry not found
|
snunlp/KR-BERT-char16424
|
47521960ac7595c5d2ed643f7a9dab9b0efcf58d
|
2021-11-22T06:19:20.000Z
|
[
"pytorch",
"jax",
"bert",
"ko",
"arxiv:2008.03979",
"transformers"
] | null | false |
snunlp
| null |
snunlp/KR-BERT-char16424
| 1,835 | 4 |
transformers
| 1,414 |
---
language:
- ko
---
## KoRean based Bert pre-trained (KR-BERT)
This is a release of Korean-specific, small-scale BERT models with comparable or better performances developed by Computational Linguistics Lab at Seoul National University, referenced in [KR-BERT: A Small-Scale Korean-Specific Language Model](https://arxiv.org/abs/2008.03979).
<br>
### Vocab, Parameters and Data
| | Mulitlingual BERT<br>(Google) | KorBERT<br>(ETRI) | KoBERT<br>(SKT) | KR-BERT character | KR-BERT sub-character |
| -------------: | ---------------------------------------------: | ---------------------: | ----------------------------------: | -------------------------------------: | -------------------------------------: |
| vocab size | 119,547 | 30,797 | 8,002 | 16,424 | 12,367 |
| parameter size | 167,356,416 | 109,973,391 | 92,186,880 | 99,265,066 | 96,145,233 |
| data size | -<br>(The Wikipedia data<br>for 104 languages) | 23GB<br>4.7B morphemes | -<br>(25M sentences,<br>233M words) | 2.47GB<br>20M sentences,<br>233M words | 2.47GB<br>20M sentences,<br>233M words |
| Model | Masked LM Accuracy |
| ------------------------------------------- | ------------------ |
| KoBERT | 0.750 |
| KR-BERT character BidirectionalWordPiece | **0.779** |
| KR-BERT sub-character BidirectionalWordPiece | 0.769 |
<br>
### Sub-character
Korean text is basically represented with Hangul syllable characters, which can be decomposed into sub-characters, or graphemes. To accommodate such characteristics, we trained a new vocabulary and BERT model on two different representations of a corpus: syllable characters and sub-characters.
In case of using our sub-character model, you should preprocess your data with the code below.
```python
import torch
from transformers import BertConfig, BertModel, BertForPreTraining, BertTokenizer
from unicodedata import normalize
tokenizer_krbert = BertTokenizer.from_pretrained('/path/to/vocab_file.txt', do_lower_case=False)
# convert a string into sub-char
def to_subchar(string):
return normalize('NFKD', string)
sentence = '토크나이저 예시입니다.'
print(tokenizer_krbert.tokenize(to_subchar(sentence)))
```
### Tokenization
#### BidirectionalWordPiece Tokenizer
We use the BidirectionalWordPiece model to reduce search costs while maintaining the possibility of choice. This model applies BPE in both forward and backward directions to obtain two candidates and chooses the one that has a higher frequency.
| | Mulitlingual BERT | KorBERT<br>character | KoBERT | KR-BERT<br>character<br>WordPiece | KR-BERT<br>character<br>BidirectionalWordPiece | KR-BERT<br>sub-character<br>WordPiece | KR-BERT<br>sub-character<br>BidirectionalWordPiece |
| :-------------------------------------: | :-----------------------: | :-----------------------: | :-----------------------: | :------------------------------: | :-------------------------------------------: | :----------------------------------: | :-----------------------------------------------: |
| 냉장고<br>nayngcangko<br>"refrigerator" | 냉#장#고<br>nayng#cang#ko | 냉#장#고<br>nayng#cang#ko | 냉#장#고<br>nayng#cang#ko | 냉장고<br>nayngcangko | 냉장고<br>nayngcangko | 냉장고<br>nayngcangko | 냉장고<br>nayngcangko |
| 춥다<br>chwupta<br>"cold" | [UNK] | 춥#다<br>chwup#ta | 춥#다<br>chwup#ta | 춥#다<br>chwup#ta | 춥#다<br>chwup#ta | 추#ㅂ다<br>chwu#pta | 추#ㅂ다<br>chwu#pta |
| 뱃사람<br>paytsalam<br>"seaman" | [UNK] | 뱃#사람<br>payt#salam | 뱃#사람<br>payt#salam | 뱃#사람<br>payt#salam | 뱃#사람<br>payt#salam | 배#ㅅ#사람<br>pay#t#salam | 배#ㅅ#사람<br>pay#t#salam |
| 마이크<br>maikhu<br>"microphone" | 마#이#크<br>ma#i#khu | 마이#크<br>mai#khu | 마#이#크<br>ma#i#khu | 마이크<br>maikhu | 마이크<br>maikhu | 마이크<br>maikhu | 마이크<br>maikhu |
<br>
### Models
| | TensorFlow | | PyTorch | |
|:---:|:-------------------------------:|:----------------------------:|:----------------------------:|:----------------------------:|
| | character | sub-character | character | sub-character |
| WordPiece <br> tokenizer | [WP char](https://drive.google.com/open?id=1SG5m-3R395VjEEnt0wxWM7SE1j6ndVsX) | [WP subchar](https://drive.google.com/open?id=13oguhQvYD9wsyLwKgU-uLCacQVWA4oHg) | [WP char](https://drive.google.com/file/d/18lsZzx_wonnOezzB5QxqSliA2KL5BF0x/view?usp=sharing) | [WP subchar](https://drive.google.com/open?id=1c1en4AMlCv2k7QapIzqjefnYzNOoh5KZ)
| Bidirectional <br> WordPiece <br> tokenizer | [BiWP char](https://drive.google.com/open?id=1YhFobehwzdbIxsHHvyFU5okp-HRowRKS) | [BiWP subchar](https://drive.google.com/open?id=12izU0NZXNz9I6IsnknUbencgr7gWHDeM) | [BiWP char](https://drive.google.com/open?id=1C87CCHD9lOQhdgWPkMw_6ZD5M2km7f1p) | [BiWP subchar](https://drive.google.com/file/d/1JvNYFQyb20SWgOiDxZn6h1-n_fjTU25S/view?usp=sharing)
<!--
#### tensorflow
* BERT tokenizer, character model ([download](https://drive.google.com/open?id=1SG5m-3R395VjEEnt0wxWM7SE1j6ndVsX))
* BidirectionalWordPiece tokenizer, character model ([download](https://drive.google.com/open?id=1YhFobehwzdbIxsHHvyFU5okp-HRowRKS))
* BERT tokenizer, sub-character model ([download](https://drive.google.com/open?id=13oguhQvYD9wsyLwKgU-uLCacQVWA4oHg))
* BidirectionalWordPiece tokenizer, sub-character model ([download](https://drive.google.com/open?id=12izU0NZXNz9I6IsnknUbencgr7gWHDeM))
#### pytorch
* BERT tokenizer, character model ([download](https://drive.google.com/file/d/18lsZzx_wonnOezzB5QxqSliA2KL5BF0x/view?usp=sharing))
* BidirectionalWordPiece tokenizer, character model ([download](https://drive.google.com/open?id=1C87CCHD9lOQhdgWPkMw_6ZD5M2km7f1p))
* BERT tokenizer, sub-character model ([download](https://drive.google.com/open?id=1c1en4AMlCv2k7QapIzqjefnYzNOoh5KZ))
* BidirectionalWordPiece tokenizer, sub-character model ([download](https://drive.google.com/file/d/1JvNYFQyb20SWgOiDxZn6h1-n_fjTU25S/view?usp=sharing))
-->
<br>
### Requirements
- transformers == 2.1.1
- tensorflow < 2.0
<br>
## Downstream tasks
### Naver Sentiment Movie Corpus (NSMC)
* If you want to use the sub-character version of our models, let the `subchar` argument be `True`.
* And you can use the original BERT WordPiece tokenizer by entering `bert` for the `tokenizer` argument, and if you use `ranked` you can use our BidirectionalWordPiece tokenizer.
* tensorflow: After downloading our pretrained models, put them in a `models` directory in the `krbert_tensorflow` directory.
* pytorch: After downloading our pretrained models, put them in a `pretrained` directory in the `krbert_pytorch` directory.
```sh
# pytorch
python3 train.py --subchar {True, False} --tokenizer {bert, ranked}
# tensorflow
python3 run_classifier.py \
--task_name=NSMC \
--subchar={True, False} \
--tokenizer={bert, ranked} \
--do_train=true \
--do_eval=true \
--do_predict=true \
--do_lower_case=False\
--max_seq_length=128 \
--train_batch_size=128 \
--learning_rate=5e-05 \
--num_train_epochs=5.0 \
--output_dir={output_dir}
```
The pytorch code structure refers to that of https://github.com/aisolab/nlp_implementation .
<br>
### NSMC Acc.
| | multilingual BERT | KorBERT | KoBERT | KR-BERT character WordPiece | KR-BERT<br>character Bidirectional WordPiece | KR-BERT sub-character WordPiece | KR-BERT<br>sub-character Bidirectional WordPiece |
|:-----:|-------------------:|----------------:|--------:|----------------------------:|-----------------------------------------:|--------------------------------:|---------------------------------------------:|
| pytorch | - | **89.84** | 89.01 | 89.34 | **89.38** | 89.20 | 89.34 |
| tensorflow | 87.08 | 85.94 | n/a | 89.86 | **90.10** | 89.76 | 89.86 |
<br>
## Citation
If you use these models, please cite the following paper:
```
@article{lee2020krbert,
title={KR-BERT: A Small-Scale Korean-Specific Language Model},
author={Sangah Lee and Hansol Jang and Yunmee Baik and Suzi Park and Hyopil Shin},
year={2020},
journal={ArXiv},
volume={abs/2008.03979}
}
```
<br>
## Contacts
[email protected]
|
samrawal/bert-large-uncased_med-ner
|
1e8ad596193f89a51e54bb7027dabc5569e1fb77
|
2022-05-28T15:56:42.000Z
|
[
"pytorch",
"jax",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
] |
token-classification
| false |
samrawal
| null |
samrawal/bert-large-uncased_med-ner
| 1,831 | 3 |
transformers
| 1,415 |
A Named Entity Recognition model for medication entities (`medication name`, `dosage`, `duration`, `frequency`, `reason`).
The model has been trained on the i2b2 (now n2c2) dataset for the 2009 - Medication task. Please visit the n2c2 site to request access to the dataset.
|
Unbabel/xlm-roberta-comet-small
|
df568a015df5cefbf2f449314b61ce9afb0cb593
|
2021-07-10T17:32:40.000Z
|
[
"pytorch",
"xlm-roberta",
"feature-extraction",
"arxiv:2012.15828",
"transformers"
] |
feature-extraction
| false |
Unbabel
| null |
Unbabel/xlm-roberta-comet-small
| 1,830 | 1 |
transformers
| 1,416 |
# Model
mMiniLM-L12xH384 XLM-R model proposed in [MiniLMv2: Multi-Head Self-Attention Relation Distillation for Compressing Pretrained Transformers](https://arxiv.org/abs/2012.15828) that we fine-tune using the direct assessment annotations collected in the Workshop on Statistical Machine Translation (WMT) 2015 to 2020.
This model is much more light weight than the traditional XLM-RoBERTa base and large.
|
gogamza/kobart-summarization
|
8a63d6913edc0e16a902e3fa8b688a134f0dd776
|
2021-11-22T10:59:10.000Z
|
[
"pytorch",
"bart",
"text2text-generation",
"ko",
"transformers",
"license:mit",
"autotrain_compatible"
] |
text2text-generation
| false |
gogamza
| null |
gogamza/kobart-summarization
| 1,823 | 1 |
transformers
| 1,417 |
---
language: ko
tags:
- bart
license: mit
---
# Korean News Summarization Model
## Demo
https://huggingface.co/spaces/gogamza/kobart-summarization
## How to use
```python
import torch
from transformers import PreTrainedTokenizerFast
from transformers import BartForConditionalGeneration
tokenizer = PreTrainedTokenizerFast.from_pretrained('gogamza/kobart-summarization')
model = BartForConditionalGeneration.from_pretrained('gogamza/kobart-summarization')
text = "과거를 떠올려보자. 방송을 보던 우리의 모습을. 독보적인 매체는 TV였다. 온 가족이 둘러앉아 TV를 봤다. 간혹 가족들끼리 뉴스와 드라마, 예능 프로그램을 둘러싸고 리모컨 쟁탈전이 벌어지기도 했다. 각자 선호하는 프로그램을 ‘본방’으로 보기 위한 싸움이었다. TV가 한 대인지 두 대인지 여부도 그래서 중요했다. 지금은 어떤가. ‘안방극장’이라는 말은 옛말이 됐다. TV가 없는 집도 많다. 미디어의 혜 택을 누릴 수 있는 방법은 늘어났다. 각자의 방에서 각자의 휴대폰으로, 노트북으로, 태블릿으로 콘텐츠 를 즐긴다."
raw_input_ids = tokenizer.encode(text)
input_ids = [tokenizer.bos_token_id] + raw_input_ids + [tokenizer.eos_token_id]
summary_ids = model.generate(torch.tensor([input_ids]))
tokenizer.decode(summary_ids.squeeze().tolist(), skip_special_tokens=True)
```
|
sentence-transformers/stsb-bert-base
|
20bffd8f7de134ab71371b5fac67e95b83b24a0a
|
2022-06-15T22:22:49.000Z
|
[
"pytorch",
"tf",
"bert",
"feature-extraction",
"arxiv:1908.10084",
"sentence-transformers",
"sentence-similarity",
"transformers",
"license:apache-2.0"
] |
sentence-similarity
| false |
sentence-transformers
| null |
sentence-transformers/stsb-bert-base
| 1,818 | null |
sentence-transformers
| 1,418 |
---
pipeline_tag: sentence-similarity
license: apache-2.0
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
**⚠️ This model is deprecated. Please don't use it as it produces sentence embeddings of low quality. You can find recommended sentence embedding models here: [SBERT.net - Pretrained Models](https://www.sbert.net/docs/pretrained_models.html)**
# sentence-transformers/stsb-bert-base
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/stsb-bert-base')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/stsb-bert-base')
model = AutoModel.from_pretrained('sentence-transformers/stsb-bert-base')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/stsb-bert-base)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
```
|
uer/roberta-base-finetuned-chinanews-chinese
|
2ac081da449fe7866d8c88eee548de89e2fd551f
|
2022-02-20T07:57:47.000Z
|
[
"pytorch",
"tf",
"jax",
"bert",
"text-classification",
"zh",
"arxiv:1909.05658",
"arxiv:1708.02657",
"transformers"
] |
text-classification
| false |
uer
| null |
uer/roberta-base-finetuned-chinanews-chinese
| 1,815 | 4 |
transformers
| 1,419 |
---
language: zh
widget:
- text: "这本书真的很不错"
---
# Chinese RoBERTa-Base Models for Text Classification
## Model description
This is the set of 5 Chinese RoBERTa-Base classification models fine-tuned by [UER-py](https://arxiv.org/abs/1909.05658). You can download the 5 Chinese RoBERTa-Base classification models either from the [UER-py Modelzoo page](https://github.com/dbiir/UER-py/wiki/Modelzoo) (in UER-py format), or via HuggingFace from the links below:
| Dataset | Link |
| :-----------: | :-------------------------------------------------------: |
| **JD full** | [**roberta-base-finetuned-jd-full-chinese**][jd_full] |
| **JD binary** | [**roberta-base-finetuned-jd-binary-chinese**][jd_binary] |
| **Dianping** | [**roberta-base-finetuned-dianping-chinese**][dianping] |
| **Ifeng** | [**roberta-base-finetuned-ifeng-chinese**][ifeng] |
| **Chinanews** | [**roberta-base-finetuned-chinanews-chinese**][chinanews] |
## How to use
You can use this model directly with a pipeline for text classification (take the case of roberta-base-finetuned-chinanews-chinese):
```python
>>> from transformers import AutoModelForSequenceClassification,AutoTokenizer,pipeline
>>> model = AutoModelForSequenceClassification.from_pretrained('uer/roberta-base-finetuned-chinanews-chinese')
>>> tokenizer = AutoTokenizer.from_pretrained('uer/roberta-base-finetuned-chinanews-chinese')
>>> text_classification = pipeline('sentiment-analysis', model=model, tokenizer=tokenizer)
>>> text_classification("北京上个月召开了两会")
[{'label': 'mainland China politics', 'score': 0.7211663722991943}]
```
## Training data
5 Chinese text classification datasets are used. JD full, JD binary, and Dianping datasets consist of user reviews of different sentiment polarities. Ifeng and Chinanews consist of first paragraphs of news articles of different topic classes. They are collected by [Glyph](https://github.com/zhangxiangxiao/glyph) project and more details are discussed in corresponding [paper](https://arxiv.org/abs/1708.02657).
## Training procedure
Models are fine-tuned by [UER-py](https://github.com/dbiir/UER-py/) on [Tencent Cloud](https://cloud.tencent.com/). We fine-tune three epochs with a sequence length of 512 on the basis of the pre-trained model [chinese_roberta_L-12_H-768](https://huggingface.co/uer/chinese_roberta_L-12_H-768). At the end of each epoch, the model is saved when the best performance on development set is achieved. We use the same hyper-parameters on different models.
Taking the case of roberta-base-finetuned-chinanews-chinese
```
python3 run_classifier.py --pretrained_model_path models/cluecorpussmall_roberta_base_seq512_model.bin-250000 \
--vocab_path models/google_zh_vocab.txt \
--train_path datasets/glyph/chinanews/train.tsv \
--dev_path datasets/glyph/chinanews/dev.tsv \
--output_model_path models/chinanews_classifier_model.bin \
--learning_rate 3e-5 --epochs_num 3 --batch_size 32 --seq_length 512
```
Finally, we convert the pre-trained model into Huggingface's format:
```
python3 scripts/convert_bert_text_classification_from_uer_to_huggingface.py --input_model_path models/chinanews_classifier_model.bin \
--output_model_path pytorch_model.bin \
--layers_num 12
```
### BibTeX entry and citation info
```
@article{devlin2018bert,
title={BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding},
author={Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1810.04805},
year={2018}
}
@article{liu2019roberta,
title={Roberta: A robustly optimized bert pretraining approach},
author={Liu, Yinhan and Ott, Myle and Goyal, Naman and Du, Jingfei and Joshi, Mandar and Chen, Danqi and Levy, Omer and Lewis, Mike and Zettlemoyer, Luke and Stoyanov, Veselin},
journal={arXiv preprint arXiv:1907.11692},
year={2019}
}
@article{zhang2017encoding,
title={Which encoding is the best for text classification in chinese, english, japanese and korean?},
author={Zhang, Xiang and LeCun, Yann},
journal={arXiv preprint arXiv:1708.02657},
year={2017}
}
@article{zhao2019uer,
title={UER: An Open-Source Toolkit for Pre-training Models},
author={Zhao, Zhe and Chen, Hui and Zhang, Jinbin and Zhao, Xin and Liu, Tao and Lu, Wei and Chen, Xi and Deng, Haotang and Ju, Qi and Du, Xiaoyong},
journal={EMNLP-IJCNLP 2019},
pages={241},
year={2019}
}
```
[jd_full]:https://huggingface.co/uer/roberta-base-finetuned-jd-full-chinese
[jd_binary]:https://huggingface.co/uer/roberta-base-finetuned-jd-binary-chinese
[dianping]:https://huggingface.co/uer/roberta-base-finetuned-dianping-chinese
[ifeng]:https://huggingface.co/uer/roberta-base-finetuned-ifeng-chinese
[chinanews]:https://huggingface.co/uer/roberta-base-finetuned-chinanews-chinese
|
deutschmann/mdr_roberta_q_encoder
|
689ded4d13d8036e0bc3e6d09e2efaaa5196f25c
|
2022-05-23T12:42:59.000Z
|
[
"pytorch",
"roberta",
"arxiv:2009.12756",
"transformers"
] | null | false |
deutschmann
| null |
deutschmann/mdr_roberta_q_encoder
| 1,808 | null |
transformers
| 1,420 |
# Multihop-Dense Retrieval (MDR)
Paper: [Answering Complex Open-Domain Questions with Multi-Hop Dense Retrieval](https://arxiv.org/abs/2009.12756) (Xiong, Wenhan, et al.)
Code and checkpoint from https://github.com/facebookresearch/multihop_dense_retrieval/
This is the checkpoint `q_model` from https://dl.fbaipublicfiles.com/mdpr/models/q_encoder.pt
License: https://github.com/facebookresearch/multihop_dense_retrieval/blob/main/LICENSE
|
atharvamundada99/bert-large-question-answering-finetuned-legal
|
53337351517cd5b73acd7f0b63a7fb313ea71bd1
|
2021-05-24T15:10:08.000Z
|
[
"pytorch",
"bert",
"question-answering",
"transformers",
"autotrain_compatible"
] |
question-answering
| false |
atharvamundada99
| null |
atharvamundada99/bert-large-question-answering-finetuned-legal
| 1,807 | 3 |
transformers
| 1,421 |
Entry not found
|
sberbank-ai/ruBert-large
|
1c3692be256bd0dcabfd52c8359eedf690f33dac
|
2022-05-08T14:15:06.000Z
|
[
"pytorch",
"bert",
"fill-mask",
"ru",
"transformers",
"PyTorch",
"Transformers",
"exbert",
"autotrain_compatible"
] |
fill-mask
| false |
sberbank-ai
| null |
sberbank-ai/ruBert-large
| 1,804 | 2 |
transformers
| 1,422 |
---
language:
- ru
tags:
- PyTorch
- Transformers
- bert
- exbert
thumbnail: "https://github.com/sberbank-ai/model-zoo"
pipeline_tag: fill-mask
---
# ruBert-large
Model was trained by [SberDevices](https://sberdevices.ru/) team.
* Task: `mask filling`
* Type: `encoder`
* Tokenizer: `bpe`
* Dict size: `120 138`
* Num Parameters: `427 M`
* Training Data Volume `30 GB`
|
facebook/s2t-large-librispeech-asr
|
834310fb73829b06f40a2ceac026882a0786069c
|
2022-05-24T10:44:51.000Z
|
[
"pytorch",
"tf",
"speech_to_text",
"automatic-speech-recognition",
"en",
"dataset:librispeech_asr",
"arxiv:2010.05171",
"arxiv:1904.08779",
"transformers",
"audio",
"hf-asr-leaderboard",
"license:mit",
"model-index"
] |
automatic-speech-recognition
| false |
facebook
| null |
facebook/s2t-large-librispeech-asr
| 1,792 | 4 |
transformers
| 1,423 |
---
language: en
datasets:
- librispeech_asr
tags:
- audio
- automatic-speech-recognition
- hf-asr-leaderboard
license: mit
model-index:
- name: hubert-large-ls960-ft
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: LibriSpeech (clean)
type: librispeech_asr
config: clean
split: test
args:
language: en
metrics:
- name: Test WER
type: wer
value: 3.3
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: LibriSpeech (other)
type: librispeech_asr
config: other
split: test
args:
language: en
metrics:
- name: Test WER
type: wer
value: 7.5
---
# S2T-LARGE-LIBRISPEECH-ASR
`s2t-large-librispeech-asr` is a Speech to Text Transformer (S2T) model trained for automatic speech recognition (ASR).
The S2T model was proposed in [this paper](https://arxiv.org/abs/2010.05171) and released in
[this repository](https://github.com/pytorch/fairseq/tree/master/examples/speech_to_text)
## Model description
S2T is an end-to-end sequence-to-sequence transformer model. It is trained with standard
autoregressive cross-entropy loss and generates the transcripts autoregressively.
## Intended uses & limitations
This model can be used for end-to-end speech recognition (ASR).
See the [model hub](https://huggingface.co/models?filter=speech_to_text) to look for other S2T checkpoints.
### How to use
As this a standard sequence to sequence transformer model, you can use the `generate` method to generate the
transcripts by passing the speech features to the model.
*Note: The `Speech2TextProcessor` object uses [torchaudio](https://github.com/pytorch/audio) to extract the
filter bank features. Make sure to install the `torchaudio` package before running this example.*
You could either install those as extra speech dependancies with
`pip install transformers"[speech, sentencepiece]"` or install the packages seperatly
with `pip install torchaudio sentencepiece`.
```python
import torch
from transformers import Speech2TextProcessor, Speech2TextForConditionalGeneration
from datasets import load_dataset
import soundfile as sf
model = Speech2TextForConditionalGeneration.from_pretrained("facebook/s2t-large-librispeech-asr")
processor = Speech2Textprocessor.from_pretrained("facebook/s2t-large-librispeech-asr")
def map_to_array(batch):
speech, _ = sf.read(batch["file"])
batch["speech"] = speech
return batch
ds = load_dataset(
"patrickvonplaten/librispeech_asr_dummy",
"clean",
split="validation"
)
ds = ds.map(map_to_array)
input_features = processor(
ds["speech"][0],
sampling_rate=16_000,
return_tensors="pt"
).input_features # Batch size 1
generated_ids = model.generate(input_ids=input_features)
transcription = processor.batch_decode(generated_ids)
```
#### Evaluation on LibriSpeech Test
The following script shows how to evaluate this model on the [LibriSpeech](https://huggingface.co/datasets/librispeech_asr)
*"clean"* and *"other"* test dataset.
```python
from datasets import load_dataset, load_metric
from transformers import Speech2TextForConditionalGeneration, Speech2TextProcessor
import soundfile as sf
librispeech_eval = load_dataset("librispeech_asr", "clean", split="test") # change to "other" for other test dataset
wer = load_metric("wer")
model = Speech2TextForConditionalGeneration.from_pretrained("facebook/s2t-large-librispeech-asr").to("cuda")
processor = Speech2TextProcessor.from_pretrained("facebook/s2t-large-librispeech-asr", do_upper_case=True)
def map_to_array(batch):
speech, _ = sf.read(batch["file"])
batch["speech"] = speech
return batch
librispeech_eval = librispeech_eval.map(map_to_array)
def map_to_pred(batch):
features = processor(batch["speech"], sampling_rate=16000, padding=True, return_tensors="pt")
input_features = features.input_features.to("cuda")
attention_mask = features.attention_mask.to("cuda")
gen_tokens = model.generate(input_ids=input_features, attention_mask=attention_mask)
batch["transcription"] = processor.batch_decode(gen_tokens, skip_special_tokens=True)
return batch
result = librispeech_eval.map(map_to_pred, batched=True, batch_size=8, remove_columns=["speech"])
print("WER:", wer(predictions=result["transcription"], references=result["text"]))
```
*Result (WER)*:
| "clean" | "other" |
|:-------:|:-------:|
| 3.3 | 7.5 |
## Training data
The S2T-LARGE-LIBRISPEECH-ASR is trained on [LibriSpeech ASR Corpus](https://www.openslr.org/12), a dataset consisting of
approximately 1000 hours of 16kHz read English speech.
## Training procedure
### Preprocessing
The speech data is pre-processed by extracting Kaldi-compliant 80-channel log mel-filter bank features automatically from
WAV/FLAC audio files via PyKaldi or torchaudio. Further utterance-level CMVN (cepstral mean and variance normalization)
is applied to each example.
The texts are lowercased and tokenized using SentencePiece and a vocabulary size of 10,000.
### Training
The model is trained with standard autoregressive cross-entropy loss and using [SpecAugment](https://arxiv.org/abs/1904.08779).
The encoder receives speech features, and the decoder generates the transcripts autoregressively.
### BibTeX entry and citation info
```bibtex
@inproceedings{wang2020fairseqs2t,
title = {fairseq S2T: Fast Speech-to-Text Modeling with fairseq},
author = {Changhan Wang and Yun Tang and Xutai Ma and Anne Wu and Dmytro Okhonko and Juan Pino},
booktitle = {Proceedings of the 2020 Conference of the Asian Chapter of the Association for Computational Linguistics (AACL): System Demonstrations},
year = {2020},
}
```
|
megagonlabs/electra-base-japanese-discriminator
|
15d1ae6fb3ffb2eeb19275cf015c9d5bbd6ea345
|
2022-06-03T07:25:56.000Z
|
[
"pytorch",
"electra",
"pretraining",
"ja",
"dataset:mC4 Japanese",
"arxiv:1910.10683",
"transformers",
"license:mit"
] | null | false |
megagonlabs
| null |
megagonlabs/electra-base-japanese-discriminator
| 1,785 | null |
transformers
| 1,424 |
---
language: ja
license: mit
datasets:
- mC4 Japanese
---
# electra-base-japanese-discriminator (sudachitra-wordpiece, mC4 Japanese) - [SHINOBU](https://dl.ndl.go.jp/info:ndljp/pid/1302683/3)
This is an [ELECTRA](https://github.com/google-research/electra) model pretrained on approximately 200M Japanese sentences.
The input text is tokenized by [SudachiTra](https://github.com/WorksApplications/SudachiTra) with the WordPiece subword tokenizer.
See `tokenizer_config.json` for the setting details.
## How to use
Please install `SudachiTra` in advance.
```console
$ pip install -U torch transformers sudachitra
```
You can load the model and the tokenizer via AutoModel and AutoTokenizer, respectively.
```python
from transformers import AutoModel, AutoTokenizer
model = AutoModel.from_pretrained("megagonlabs/electra-base-japanese-discriminator")
tokenizer = AutoTokenizer.from_pretrained("megagonlabs/electra-base-japanese-discriminator", trust_remote_code=True)
model(**tokenizer("まさにオールマイティーな商品だ。", return_tensors="pt")).last_hidden_state
tensor([[[-0.0498, -0.0285, 0.1042, ..., 0.0062, -0.1253, 0.0338],
[-0.0686, 0.0071, 0.0087, ..., -0.0210, -0.1042, -0.0320],
[-0.0636, 0.1465, 0.0263, ..., 0.0309, -0.1841, 0.0182],
...,
[-0.1500, -0.0368, -0.0816, ..., -0.0303, -0.1653, 0.0650],
[-0.0457, 0.0770, -0.0183, ..., -0.0108, -0.1903, 0.0694],
[-0.0981, -0.0387, 0.1009, ..., -0.0150, -0.0702, 0.0455]]],
grad_fn=<NativeLayerNormBackward>)
```
## Model architecture
The model architecture is the same as the original ELECTRA base model; 12 layers, 768 dimensions of hidden states, and 12 attention heads.
## Training data and libraries
This model is trained on the Japanese texts extracted from the [mC4](https://huggingface.co/datasets/mc4) Common Crawl's multilingual web crawl corpus.
We used the [Sudachi](https://github.com/WorksApplications/Sudachi) to split texts into sentences, and also applied a simple rule-based filter to remove nonlinguistic segments of mC4 multilingual corpus.
The extracted texts contains over 600M sentences in total, and we used approximately 200M sentences for pretraining.
We used [NVIDIA's TensorFlow2-based ELECTRA implementation](https://github.com/NVIDIA/DeepLearningExamples/tree/master/TensorFlow2/LanguageModeling/ELECTRA) for pretraining. The time required for the pretrainig was about 110 hours using GCP DGX A100 8gpu instance with enabling Automatic Mixed Precision.
## Licenses
The pretrained models are distributed under the terms of the [MIT License](https://opensource.org/licenses/mit-license.php).
## Citations
- mC4
Contains information from `mC4` which is made available under the [ODC Attribution License](https://opendatacommons.org/licenses/by/1-0/).
```
@article{2019t5,
author = {Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu},
title = {Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer},
journal = {arXiv e-prints},
year = {2019},
archivePrefix = {arXiv},
eprint = {1910.10683},
}
```
|
google/ul2
|
39ecb934bff636afdd5591471a56875f5fcd7e44
|
2022-06-25T17:22:04.000Z
|
[
"pytorch",
"t5",
"text2text-generation",
"en",
"dataset:c4",
"arxiv:2205.05131",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] |
text2text-generation
| false |
google
| null |
google/ul2
| 1,785 | 33 |
transformers
| 1,425 |
---
language:
- en
datasets:
- c4
license: apache-2.0
---
# Introduction
UL2 is a unified framework for pretraining models that are universally effective across datasets and setups. UL2 uses Mixture-of-Denoisers (MoD), apre-training objective that combines diverse pre-training paradigms together. UL2 introduces a notion of mode switching, wherein downstream fine-tuning is associated with specific pre-training schemes.

**Abstract**
Existing pre-trained models are generally geared towards a particular class of problems. To date, there seems to be still no consensus on what the right architecture and pre-training setup should be. This paper presents a unified framework for pre-training models that are universally effective across datasets and setups. We begin by disentangling architectural archetypes with pre-training objectives -- two concepts that are commonly conflated. Next, we present a generalized and unified perspective for self-supervision in NLP and show how different pre-training objectives can be cast as one another and how interpolating between different objectives can be effective. We then propose Mixture-of-Denoisers (MoD), a pre-training objective that combines diverse pre-training paradigms together. We furthermore introduce a notion of mode switching, wherein downstream fine-tuning is associated with specific pre-training schemes. We conduct extensive ablative experiments to compare multiple pre-training objectives and find that our method pushes the Pareto-frontier by outperforming T5 and/or GPT-like models across multiple diverse setups. Finally, by scaling our model up to 20B parameters, we achieve SOTA performance on 50 well-established supervised NLP tasks ranging from language generation (with automated and human evaluation), language understanding, text classification, question answering, commonsense reasoning, long text reasoning, structured knowledge grounding and information retrieval. Our model also achieve strong results at in-context learning, outperforming 175B GPT-3 on zero-shot SuperGLUE and tripling the performance of T5-XXL on one-shot summarization.
For more information, please take a look at the original paper.
Paper: [Unifying Language Learning Paradigms](https://arxiv.org/abs/2205.05131v1)
Authors: *Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler*
# Training
The checkpoint was iteratively pre-trained on C4 and fine-tuned on a variety of datasets
## PreTraining
The model is pretrained on the C4 corpus. For pretraining, the model is trained on a total of 1 trillion tokens on C4 (2 million steps)
with a batch size of 1024. The sequence length is set to 512/512 for inputs and targets.
Dropout is set to 0 during pretraining. Pre-training took slightly more than one month for about 1 trillion
tokens. The model has 32 encoder layers and 32 decoder layers, `dmodel` of 4096 and `df` of 16384.
The dimension of each head is 256 for a total of 16 heads. Our model uses a model parallelism of 8.
The same same sentencepiece tokenizer as T5 of vocab size 32000 is used (click [here](https://huggingface.co/docs/transformers/v4.20.0/en/model_doc/t5#transformers.T5Tokenizer) for more information about the T5 tokenizer).
UL-20B can be interpreted as a model that is quite similar to T5 but trained with a different objective and slightly different scaling knobs.
UL-20B was trained using the [Jax](https://github.com/google/jax) and [T5X](https://github.com/google-research/t5x) infrastructure.
The training objective during pretraining is a mixture of different denoising strategies that are explained in the following:
## Mixture of Denoisers
To quote the paper:
> We conjecture that a strong universal model has to be exposed to solving diverse set of problems
> during pre-training. Given that pre-training is done using self-supervision, we argue that such diversity
> should be injected to the objective of the model, otherwise the model might suffer from lack a certain
> ability, like long-coherent text generation.
> Motivated by this, as well as current class of objective functions, we define three main paradigms that
> are used during pre-training:
- **R-Denoiser**: The regular denoising is the standard span corruption introduced in [T5](https://huggingface.co/docs/transformers/v4.20.0/en/model_doc/t5)
that uses a range of 2 to 5 tokens as the span length, which masks about 15% of
input tokens. These spans are short and potentially useful to acquire knowledge instead of
learning to generate fluent text.
- **S-Denoiser**: A specific case of denoising where we observe a strict sequential order when
framing the inputs-to-targets task, i.e., prefix language modeling. To do so, we simply
partition the input sequence into two sub-sequences of tokens as context and target such that
the targets do not rely on future information. This is unlike standard span corruption where
there could be a target token with earlier position than a context token. Note that similar to
the Prefix-LM setup, the context (prefix) retains a bidirectional receptive field. We note that
S-Denoising with very short memory or no memory is in similar spirit to standard causal
language modeling.
- **X-Denoiser**: An extreme version of denoising where the model must recover a large part
of the input, given a small to moderate part of it. This simulates a situation where a model
needs to generate long target from a memory with relatively limited information. To do
so, we opt to include examples with aggressive denoising where approximately 50% of the
input sequence is masked. This is by increasing the span length and/or corruption rate. We
consider a pre-training task to be extreme if it has a long span (e.g., ≥ 12 tokens) or have
a large corruption rate (e.g., ≥ 30%). X-denoising is motivated by being an interpolation
between regular span corruption and language model like objectives.
See the following diagram for a more visual explanation:
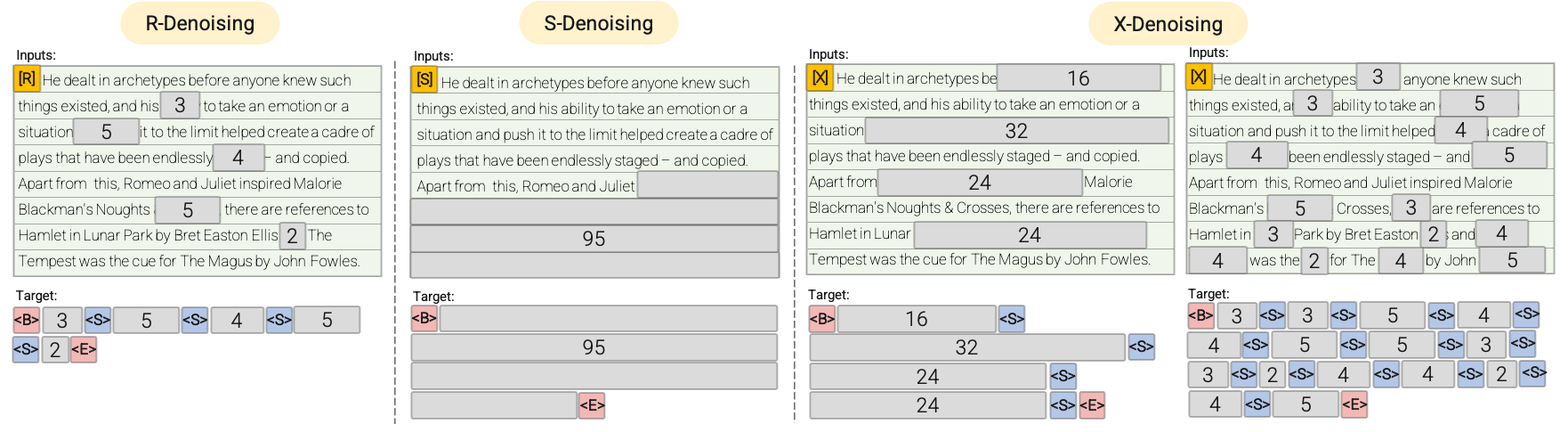
**Important**: For more details, please see sections 3.1.2 of the [paper](https://arxiv.org/pdf/2205.05131v1.pdf).
## Fine-tuning
The model was continously fine-tuned after N pretraining steps where N is typically from 50k to 100k.
In other words, after each Nk steps of pretraining, the model is finetuned on each downstream task. See section 5.2.2 of [paper](https://arxiv.org/pdf/2205.05131v1.pdf) to get an overview of all datasets that were used for fine-tuning).
As the model is continuously finetuned, finetuning is stopped on a task once it has reached state-of-the-art to save compute.
In total, the model was trained for 2.65 million steps.
**Important**: For more details, please see sections 5.2.1 and 5.2.2 of the [paper](https://arxiv.org/pdf/2205.05131v1.pdf).
## Contribution
This model was contributed by [Daniel Hesslow](https://huggingface.co/Seledorn).
## Examples
The following shows how one can predict masked passages using the different denoising strategies.
Given the size of the model the following examples need to be run on at least a 40GB A100 GPU.
### S-Denoising
For *S-Denoising*, please make sure to prompt the text with the prefix `[S2S]` as shown below.
```python
from transformers import T5ForConditionalGeneration, AutoTokenizer
import torch
model = T5ForConditionalGeneration.from_pretrained("google/ul2", low_cpu_mem_usage=True, torch_dtype=torch.bfloat16).to("cuda")
tokenizer = AutoTokenizer.from_pretrained("google/ul2")
input_string = "[S2S] Mr. Dursley was the director of a firm called Grunnings, which made drills. He was a big, solid man with a bald head. Mrs. Dursley was thin and blonde and more than the usual amount of neck, which came in very useful as she spent so much of her time craning over garden fences, spying on the neighbours. The Dursleys had a small son called Dudley and in their opinion there was no finer boy anywhere <extra_id_0>"
inputs = tokenizer(input_string, return_tensors="pt").input_ids.to("cuda")
outputs = model.generate(inputs, max_length=200)
print(tokenizer.decode(outputs[0]))
# -> <pad>. Dudley was a very good boy, but he was also very stupid.</s>
```
### R-Denoising
For *R-Denoising*, please make sure to prompt the text with the prefix `[NLU]` as shown below.
```python
from transformers import T5ForConditionalGeneration, AutoTokenizer
import torch
model = T5ForConditionalGeneration.from_pretrained("google/ul2", low_cpu_mem_usage=True, torch_dtype=torch.bfloat16).to("cuda")
tokenizer = AutoTokenizer.from_pretrained("google/ul2")
input_string = "[NLU] Mr. Dursley was the director of a firm called <extra_id_0>, which made <extra_id_1>. He was a big, solid man with a bald head. Mrs. Dursley was thin and <extra_id_2> of neck, which came in very useful as she spent so much of her time <extra_id_3>. The Dursleys had a small son called Dudley and <extra_id_4>"
inputs = tokenizer(input_string, return_tensors="pt", add_special_tokens=False).input_ids.to("cuda")
outputs = model.generate(inputs, max_length=200)
print(tokenizer.decode(outputs[0]))
# -> "<pad><extra_id_0> Burrows<extra_id_1> brooms for witches and wizards<extra_id_2> had a lot<extra_id_3> scolding Dudley<extra_id_4> a daughter called Petunia. Dudley was a nasty, spoiled little boy who was always getting into trouble. He was very fond of his pet rat, Scabbers.<extra_id_5> Burrows<extra_id_3> screaming at him<extra_id_4> a daughter called Petunia</s>
"
```
### X-Denoising
For *X-Denoising*, please make sure to prompt the text with the prefix `[NLG]` as shown below.
```python
from transformers import T5ForConditionalGeneration, AutoTokenizer
import torch
model = T5ForConditionalGeneration.from_pretrained("google/ul2", low_cpu_mem_usage=True, torch_dtype=torch.bfloat16).to("cuda")
tokenizer = AutoTokenizer.from_pretrained("google/ul2")
input_string = "[NLG] Mr. Dursley was the director of a firm called Grunnings, which made drills. He was a big, solid man wiht a bald head. Mrs. Dursley was thin and blonde and more than the usual amount of neck, which came in very useful as she
spent so much of her time craning over garden fences, spying on the neighbours. The Dursleys had a small son called Dudley and in their opinion there was no finer boy anywhere. <extra_id_0>"
model.cuda()
inputs = tokenizer(input_string, return_tensors="pt", add_special_tokens=False).input_ids.to("cuda")
outputs = model.generate(inputs, max_length=200)
print(tokenizer.decode(outputs[0]))
# -> "<pad><extra_id_0> Burrows<extra_id_1> a lot of money from the manufacture of a product called '' Burrows'''s ''<extra_id_2> had a lot<extra_id_3> looking down people's throats<extra_id_4> a daughter called Petunia. Dudley was a very stupid boy who was always getting into trouble. He was a big, fat, ugly boy who was always getting into trouble. He was a big, fat, ugly boy who was always getting into trouble. He was a big, fat, ugly boy who was always getting into trouble. He was a big, fat, ugly boy who was always getting into trouble. He was a big, fat, ugly boy who was always getting into trouble. He was a big, fat, ugly boy who was always getting into trouble. He was a big, fat, ugly boy who was always getting into trouble. He was a big, fat,"
```
|
textattack/bert-base-uncased-rotten-tomatoes
|
2aeb2b03a543f2eb1f203ca40676fbaf27a3d4fd
|
2021-05-20T07:46:20.000Z
|
[
"pytorch",
"jax",
"bert",
"text-classification",
"transformers"
] |
text-classification
| false |
textattack
| null |
textattack/bert-base-uncased-rotten-tomatoes
| 1,784 | 1 |
transformers
| 1,426 |
## TextAttack Model Card
This `bert-base-uncased` model was fine-tuned for sequence classificationusing TextAttack
and the rotten_tomatoes dataset loaded using the `nlp` library. The model was fine-tuned
for 10 epochs with a batch size of 16, a learning
rate of 2e-05, and a maximum sequence length of 128.
Since this was a classification task, the model was trained with a cross-entropy loss function.
The best score the model achieved on this task was 0.875234521575985, as measured by the
eval set accuracy, found after 4 epochs.
For more information, check out [TextAttack on Github](https://github.com/QData/TextAttack).
|
arijitx/wav2vec2-xls-r-300m-bengali
|
45ed7c704f276acb9ed6ef234b66e67a1a2cb864
|
2022-03-23T18:27:52.000Z
|
[
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"bn",
"dataset:openslr",
"dataset:SLR53",
"dataset:AI4Bharat/IndicCorp",
"transformers",
"hf-asr-leaderboard",
"openslr_SLR53",
"robust-speech-event",
"license:apache-2.0",
"model-index"
] |
automatic-speech-recognition
| false |
arijitx
| null |
arijitx/wav2vec2-xls-r-300m-bengali
| 1,781 | 1 |
transformers
| 1,427 |
---
language:
- bn
license: apache-2.0
tags:
- automatic-speech-recognition
- bn
- hf-asr-leaderboard
- openslr_SLR53
- robust-speech-event
datasets:
- openslr
- SLR53
- AI4Bharat/IndicCorp
metrics:
- wer
- cer
model-index:
- name: arijitx/wav2vec2-xls-r-300m-bengali
results:
- task:
type: automatic-speech-recognition
name: Speech Recognition
dataset:
type: openslr
name: Open SLR
args: SLR53
metrics:
- type: wer
value: 0.21726385291857586
name: Test WER
- type: cer
value: 0.04725010353701041
name: Test CER
- type: wer
value: 0.15322879016421437
name: Test WER with lm
- type: cer
value: 0.03413696666806267
name: Test CER with lm
---
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the OPENSLR_SLR53 - bengali dataset.
It achieves the following results on the evaluation set.
Without language model :
- WER: 0.21726385291857586
- CER: 0.04725010353701041
With 5 gram language model trained on 30M sentences randomly chosen from [AI4Bharat IndicCorp](https://indicnlp.ai4bharat.org/corpora/) dataset :
- WER: 0.15322879016421437
- CER: 0.03413696666806267
Note : 5% of a total 10935 samples have been used for evaluation. Evaluation set has 10935 examples which was not part of training training was done on first 95% and eval was done on last 5%. Training was stopped after 180k steps. Output predictions are available under files section.
### Training hyperparameters
The following hyperparameters were used during training:
- dataset_name="openslr"
- model_name_or_path="facebook/wav2vec2-xls-r-300m"
- dataset_config_name="SLR53"
- output_dir="./wav2vec2-xls-r-300m-bengali"
- overwrite_output_dir
- num_train_epochs="50"
- per_device_train_batch_size="32"
- per_device_eval_batch_size="32"
- gradient_accumulation_steps="1"
- learning_rate="7.5e-5"
- warmup_steps="2000"
- length_column_name="input_length"
- evaluation_strategy="steps"
- text_column_name="sentence"
- chars_to_ignore , ? . ! \- \; \: \" “ % ‘ ” � — ’ … –
- save_steps="2000"
- eval_steps="3000"
- logging_steps="100"
- layerdrop="0.0"
- activation_dropout="0.1"
- save_total_limit="3"
- freeze_feature_encoder
- feat_proj_dropout="0.0"
- mask_time_prob="0.75"
- mask_time_length="10"
- mask_feature_prob="0.25"
- mask_feature_length="64"
- preprocessing_num_workers 32
### Framework versions
- Transformers 4.16.0.dev0
- Pytorch 1.10.1+cu102
- Datasets 1.17.1.dev0
- Tokenizers 0.11.0
Notes
- Training and eval code modified from : https://github.com/huggingface/transformers/tree/master/examples/research_projects/robust-speech-event.
- Bengali speech data was not available from common voice or librispeech multilingual datasets, so OpenSLR53 has been used.
- Minimum audio duration of 0.5s has been used to filter the training data which excluded may be 10-20 samples.
- OpenSLR53 transcripts are *not* part of LM training and LM used to evaluate.
|
deep-learning-analytics/wikihow-t5-small
|
4fe8137dd4bdc5f697bfdf091bf516c468409308
|
2020-09-09T18:19:54.000Z
|
[
"pytorch",
"t5",
"text2text-generation",
"eng",
"dataset:Wikihow",
"transformers",
"wikihow",
"t5-small",
"lm-head",
"seq2seq",
"pipeline:summarization",
"summarization",
"autotrain_compatible"
] |
summarization
| false |
deep-learning-analytics
| null |
deep-learning-analytics/wikihow-t5-small
| 1,772 | 1 |
transformers
| 1,428 |
---
language: "eng"
tags:
- wikihow
- t5-small
- pytorch
- lm-head
- seq2seq
- t5
- pipeline:summarization
- summarization
datasets:
- Wikihow
widget:
- text: "Lack of fluids can lead to dry mouth, which is a leading cause of bad breath. Water
can also dilute any chemicals in your mouth or gut that are causing bad breath., Studies show that
eating 6 ounces of yogurt a day reduces the level of odor-causing compounds in the mouth. In
particular, look for yogurt containing the active bacteria Streptococcus thermophilus or
Lactobacillus bulgaricus., The abrasive nature of fibrous fruits and vegetables helps to clean
teeth, while the vitamins, antioxidants, and acids they contain improve dental health.Foods that can
be particularly helpful include:Apples — Apples contain vitamin C, which is necessary for health
gums, as well as malic acid, which helps to whiten teeth.Carrots — Carrots are rich in vitamin A,
which strengthens tooth enamel.Celery — Chewing celery produces a lot of saliva, which helps to
neutralize bacteria that cause bad breath.Pineapples — Pineapples contain bromelain, an enzyme that
cleans the mouth., These teas have been shown to kill the bacteria that cause bad breath and
plaque., An upset stomach can lead to burping, which contributes to bad breath. Don’t eat foods that
upset your stomach, or if you do, use antacids. If you are lactose intolerant, try lactase tablets.,
They can all cause bad breath. If you do eat them, bring sugar-free gum or a toothbrush and
toothpaste to freshen your mouth afterwards., Diets low in carbohydrates lead to ketosis — a state
in which the body burns primarily fat instead of carbohydrates for energy. This may be good for your
waistline, but it also produces chemicals called ketones, which contribute to bad breath.To stop the
problem, you must change your diet. Or, you can combat the smell in one of these ways:Drink lots of
water to dilute the ketones.Chew sugarless gum or suck on sugarless mints.Chew mint leaves."
- text: " Bring 1/2 cup water to the boil.Add the fresh or dried rosemary to the water.Remove
from the heat. Set aside for 1/2 an hour to infuse. Added flavour can be released by pressing down
on the rosemary leaves with a spoon. Add the pieces to the blender or food processor with the
elderflower cordial. Blend or process to a purée.,, Add the lemon or lime juice and stir to
combine., Add a cover and place in the freezer.After 2 hours, remove from the freezer and break up
with a fork. This helps the ice crystals to form properly.Continue doing this every hour until the
granita freezes properly. Scoop the granita into dessert bowls and serve. Garnish with a cucumber
curl or a small sprig of rosemary."
metrics:
- Rouge1: 31.2
- RougeL: 24.5
---
# Model name
Wikihow T5-small
## Model description
This is a T5-small model trained on Wikihow All data set. The model was trained for 3 epochs using a batch size of 16 and learning rate of 3e-4. Max_input_lngth is set as 512 and max_output_length is 150. Model attained a Rouge1 score of 31.2 and RougeL score of 24.5.
We have written a blog post that covers the training procedure. Please find it [here](https://medium.com/@priya.dwivedi/fine-tuning-a-t5-transformer-for-any-summarization-task-82334c64c81).
## Usage
```
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("deep-learning-analytics/wikihow-t5-small")
model = AutoModelWithLMHead.from_pretrained("deep-learning-analytics/wikihow-t5-small")
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = model.to(device)
text = """"
Lack of fluids can lead to dry mouth, which is a leading cause of bad breath. Water
can also dilute any chemicals in your mouth or gut that are causing bad breath., Studies show that
eating 6 ounces of yogurt a day reduces the level of odor-causing compounds in the mouth. In
particular, look for yogurt containing the active bacteria Streptococcus thermophilus or
Lactobacillus bulgaricus., The abrasive nature of fibrous fruits and vegetables helps to clean
teeth, while the vitamins, antioxidants, and acids they contain improve dental health.Foods that can
be particularly helpful include:Apples — Apples contain vitamin C, which is necessary for health
gums, as well as malic acid, which helps to whiten teeth.Carrots — Carrots are rich in vitamin A,
which strengthens tooth enamel.Celery — Chewing celery produces a lot of saliva, which helps to
neutralize bacteria that cause bad breath.Pineapples — Pineapples contain bromelain, an enzyme that
cleans the mouth., These teas have been shown to kill the bacteria that cause bad breath and
plaque., An upset stomach can lead to burping, which contributes to bad breath. Don’t eat foods that
upset your stomach, or if you do, use antacids. If you are lactose intolerant, try lactase tablets.,
They can all cause bad breath. If you do eat them, bring sugar-free gum or a toothbrush and
toothpaste to freshen your mouth afterwards., Diets low in carbohydrates lead to ketosis — a state
in which the body burns primarily fat instead of carbohydrates for energy. This may be good for your
waistline, but it also produces chemicals called ketones, which contribute to bad breath.To stop the
problem, you must change your diet. Or, you can combat the smell in one of these ways:Drink lots of
water to dilute the ketones.Chew sugarless gum or suck on sugarless mints.Chew mint leaves.
"""
preprocess_text = text.strip().replace("\n","")
tokenized_text = tokenizer.encode(preprocess_text, return_tensors="pt").to(device)
summary_ids = model.generate(
tokenized_text,
max_length=150,
num_beams=2,
repetition_penalty=2.5,
length_penalty=1.0,
early_stopping=True
)
output = tokenizer.decode(summary_ids[0], skip_special_tokens=True)
print ("\n\nSummarized text: \n",output)
```
|
Musixmatch/umberto-commoncrawl-cased-v1
|
fe7b14808cccbbe2984b05e6fbfd71127f11008f
|
2021-02-12T11:31:59.000Z
|
[
"pytorch",
"camembert",
"fill-mask",
"it",
"transformers",
"autotrain_compatible"
] |
fill-mask
| false |
Musixmatch
| null |
Musixmatch/umberto-commoncrawl-cased-v1
| 1,769 | 5 |
transformers
| 1,429 |
---
language: it
---
# UmBERTo Commoncrawl Cased
[UmBERTo](https://github.com/musixmatchresearch/umberto) is a Roberta-based Language Model trained on large Italian Corpora and uses two innovative approaches: SentencePiece and Whole Word Masking. Now available at [github.com/huggingface/transformers](https://huggingface.co/Musixmatch/umberto-commoncrawl-cased-v1)
<p align="center">
<img src="https://user-images.githubusercontent.com/7140210/72913702-d55a8480-3d3d-11ea-99fc-f2ef29af4e72.jpg" width="700"> </br>
Marco Lodola, Monument to Umberto Eco, Alessandria 2019
</p>
## Dataset
UmBERTo-Commoncrawl-Cased utilizes the Italian subcorpus of [OSCAR](https://traces1.inria.fr/oscar/) as training set of the language model. We used deduplicated version of the Italian corpus that consists in 70 GB of plain text data, 210M sentences with 11B words where the sentences have been filtered and shuffled at line level in order to be used for NLP research.
## Pre-trained model
| Model | WWM | Cased | Tokenizer | Vocab Size | Train Steps | Download |
| ------ | ------ | ------ | ------ | ------ |------ | ------ |
| `umberto-commoncrawl-cased-v1` | YES | YES | SPM | 32K | 125k | [Link](http://bit.ly/35zO7GH) |
This model was trained with [SentencePiece](https://github.com/google/sentencepiece) and Whole Word Masking.
## Downstream Tasks
These results refers to umberto-commoncrawl-cased model. All details are at [Umberto](https://github.com/musixmatchresearch/umberto) Official Page.
#### Named Entity Recognition (NER)
| Dataset | F1 | Precision | Recall | Accuracy |
| ------ | ------ | ------ | ------ | ------ |
| **ICAB-EvalITA07** | **87.565** | 86.596 | 88.556 | 98.690 |
| **WikiNER-ITA** | **92.531** | 92.509 | 92.553 | 99.136 |
#### Part of Speech (POS)
| Dataset | F1 | Precision | Recall | Accuracy |
| ------ | ------ | ------ | ------ | ------ |
| **UD_Italian-ISDT** | 98.870 | 98.861 | 98.879 | **98.977** |
| **UD_Italian-ParTUT** | 98.786 | 98.812 | 98.760 | **98.903** |
## Usage
##### Load UmBERTo with AutoModel, Autotokenizer:
```python
import torch
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("Musixmatch/umberto-commoncrawl-cased-v1")
umberto = AutoModel.from_pretrained("Musixmatch/umberto-commoncrawl-cased-v1")
encoded_input = tokenizer.encode("Umberto Eco è stato un grande scrittore")
input_ids = torch.tensor(encoded_input).unsqueeze(0) # Batch size 1
outputs = umberto(input_ids)
last_hidden_states = outputs[0] # The last hidden-state is the first element of the output
```
##### Predict masked token:
```python
from transformers import pipeline
fill_mask = pipeline(
"fill-mask",
model="Musixmatch/umberto-commoncrawl-cased-v1",
tokenizer="Musixmatch/umberto-commoncrawl-cased-v1"
)
result = fill_mask("Umberto Eco è <mask> un grande scrittore")
# {'sequence': '<s> Umberto Eco è considerato un grande scrittore</s>', 'score': 0.18599839508533478, 'token': 5032}
# {'sequence': '<s> Umberto Eco è stato un grande scrittore</s>', 'score': 0.17816807329654694, 'token': 471}
# {'sequence': '<s> Umberto Eco è sicuramente un grande scrittore</s>', 'score': 0.16565583646297455, 'token': 2654}
# {'sequence': '<s> Umberto Eco è indubbiamente un grande scrittore</s>', 'score': 0.0932890921831131, 'token': 17908}
# {'sequence': '<s> Umberto Eco è certamente un grande scrittore</s>', 'score': 0.054701317101716995, 'token': 5269}
```
## Citation
All of the original datasets are publicly available or were released with the owners' grant. The datasets are all released under a CC0 or CCBY license.
* UD Italian-ISDT Dataset [Github](https://github.com/UniversalDependencies/UD_Italian-ISDT)
* UD Italian-ParTUT Dataset [Github](https://github.com/UniversalDependencies/UD_Italian-ParTUT)
* I-CAB (Italian Content Annotation Bank), EvalITA [Page](http://www.evalita.it/)
* WIKINER [Page](https://figshare.com/articles/Learning_multilingual_named_entity_recognition_from_Wikipedia/5462500) , [Paper](https://www.sciencedirect.com/science/article/pii/S0004370212000276?via%3Dihub)
```
@inproceedings {magnini2006annotazione,
title = {Annotazione di contenuti concettuali in un corpus italiano: I - CAB},
author = {Magnini,Bernardo and Cappelli,Amedeo and Pianta,Emanuele and Speranza,Manuela and Bartalesi Lenzi,V and Sprugnoli,Rachele and Romano,Lorenza and Girardi,Christian and Negri,Matteo},
booktitle = {Proc.of SILFI 2006},
year = {2006}
}
@inproceedings {magnini2006cab,
title = {I - CAB: the Italian Content Annotation Bank.},
author = {Magnini,Bernardo and Pianta,Emanuele and Girardi,Christian and Negri,Matteo and Romano,Lorenza and Speranza,Manuela and Lenzi,Valentina Bartalesi and Sprugnoli,Rachele},
booktitle = {LREC},
pages = {963--968},
year = {2006},
organization = {Citeseer}
}
```
## Authors
**Loreto Parisi**: `loreto at musixmatch dot com`, [loretoparisi](https://github.com/loretoparisi)
**Simone Francia**: `simone.francia at musixmatch dot com`, [simonefrancia](https://github.com/simonefrancia)
**Paolo Magnani**: `paul.magnani95 at gmail dot com`, [paulthemagno](https://github.com/paulthemagno)
## About Musixmatch AI

We do Machine Learning and Artificial Intelligence @[musixmatch](https://twitter.com/Musixmatch)
Follow us on [Twitter](https://twitter.com/musixmatchai) [Github](https://github.com/musixmatchresearch)
|
tbs17/MathBERT
|
e26235ccf2b14614ef278b19caa44fdb5dcf050f
|
2021-08-05T00:44:29.000Z
|
[
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
| false |
tbs17
| null |
tbs17/MathBERT
| 1,769 | null |
transformers
| 1,430 |
#### MathBERT model (original vocab)
*Disclaimer: the format of the documentation follows the official BERT model readme.md*
Pretrained model on pre-k to graduate math language (English) using a masked language modeling (MLM) objective. This model is uncased: it does not make a difference between english and English.
#### Model description
MathBERT is a transformers model pretrained on a large corpus of English math corpus data in a self-supervised fashion. This means it was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely, it was pretrained with two objectives:
Masked language modeling (MLM): taking a sentence, the model randomly masks 15% of the words in the input then run the entire masked sentence through the model and has to predict the masked words. This is different from traditional recurrent neural networks (RNNs) that usually see the words one after the other, or from autoregressive models like GPT which internally mask the future tokens. It allows the model to learn a bidirectional representation of the sentence.
Next sentence prediction (NSP): the models concatenates two masked sentences as inputs during pretraining. Sometimes they correspond to sentences that were next to each other in the original text, sometimes not. The model then has to predict if the two sentences were following each other or not.
This way, the model learns an inner representation of the math language that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a standard classifier using the features produced by the MathBERT model as inputs.
#### Intended uses & limitations
You can use the raw model for either masked language modeling or next sentence prediction, but it's mostly intended to be fine-tuned on a math-related downstream task.
Note that this model is primarily aimed at being fine-tuned on math-related tasks that use the whole sentence (potentially masked) to make decisions, such as sequence classification, token classification or question answering. For tasks such as math text generation you should look at model like GPT2.
#### How to use
Here is how to use this model to get the features of a given text in PyTorch:
```from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('tbs17/MathBERT',output_hidden_states=True)
model = BertModel.from_pretrained("tbs17/MathBERT")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(encoded_input)
```
and in TensorFlow:
```
from transformers import BertTokenizer, TFBertModel
tokenizer = BertTokenizer.from_pretrained('tbs17/MathBERT',output_hidden_states=True)
model = TFBertModel.from_pretrained("tbs17/MathBERT")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
#### Comparing to the original BERT on fill-mask tasks
The original BERT (i.e.,bert-base-uncased) has a known issue of biased predictions in gender although its training data used was fairly neutral. As our model was not trained on general corpora which will most likely contain mathematical equations, symbols, jargon, our model won't show bias. See below:
##### from original BERT
```
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='bert-base-uncased')
>>> unmasker("The man worked as a [MASK].")
[{'sequence': '[CLS] the man worked as a carpenter. [SEP]',
'score': 0.09747550636529922,
'token': 10533,
'token_str': 'carpenter'},
{'sequence': '[CLS] the man worked as a waiter. [SEP]',
'score': 0.0523831807076931,
'token': 15610,
'token_str': 'waiter'},
{'sequence': '[CLS] the man worked as a barber. [SEP]',
'score': 0.04962705448269844,
'token': 13362,
'token_str': 'barber'},
{'sequence': '[CLS] the man worked as a mechanic. [SEP]',
'score': 0.03788609802722931,
'token': 15893,
'token_str': 'mechanic'},
{'sequence': '[CLS] the man worked as a salesman. [SEP]',
'score': 0.037680890411138535,
'token': 18968,
'token_str': 'salesman'}]
>>> unmasker("The woman worked as a [MASK].")
[{'sequence': '[CLS] the woman worked as a nurse. [SEP]',
'score': 0.21981462836265564,
'token': 6821,
'token_str': 'nurse'},
{'sequence': '[CLS] the woman worked as a waitress. [SEP]',
'score': 0.1597415804862976,
'token': 13877,
'token_str': 'waitress'},
{'sequence': '[CLS] the woman worked as a maid. [SEP]',
'score': 0.1154729500412941,
'token': 10850,
'token_str': 'maid'},
{'sequence': '[CLS] the woman worked as a prostitute. [SEP]',
'score': 0.037968918681144714,
'token': 19215,
'token_str': 'prostitute'},
{'sequence': '[CLS] the woman worked as a cook. [SEP]',
'score': 0.03042375110089779,
'token': 5660,
'token_str': 'cook'}]
```
##### from MathBERT
```
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='tbs17/MathBERT')
>>> unmasker("The man worked as a [MASK].")
[{'score': 0.6469377875328064,
'sequence': 'the man worked as a book.',
'token': 2338,
'token_str': 'book'},
{'score': 0.07073448598384857,
'sequence': 'the man worked as a guide.',
'token': 5009,
'token_str': 'guide'},
{'score': 0.031362924724817276,
'sequence': 'the man worked as a text.',
'token': 3793,
'token_str': 'text'},
{'score': 0.02306508645415306,
'sequence': 'the man worked as a man.',
'token': 2158,
'token_str': 'man'},
{'score': 0.020547250285744667,
'sequence': 'the man worked as a distance.',
'token': 3292,
'token_str': 'distance'}]
>>> unmasker("The woman worked as a [MASK].")
[{'score': 0.8999770879745483,
'sequence': 'the woman worked as a woman.',
'token': 2450,
'token_str': 'woman'},
{'score': 0.025878004729747772,
'sequence': 'the woman worked as a guide.',
'token': 5009,
'token_str': 'guide'},
{'score': 0.006881994660943747,
'sequence': 'the woman worked as a table.',
'token': 2795,
'token_str': 'table'},
{'score': 0.0066248285584151745,
'sequence': 'the woman worked as a b.',
'token': 1038,
'token_str': 'b'},
{'score': 0.00638660229742527,
'sequence': 'the woman worked as a book.',
'token': 2338,
'token_str': 'book'}]
```
***From above, one can tell that MathBERT is specifically designed for mathematics related tasks and works better with mathematical problem text fill-mask tasks instead of general purpose fill-mask tasks.***
```
>>> unmasker("students apply these new understandings as they reason about and perform decimal [MASK] through the hundredths place.")
#the sentence is taken from a curriculum introduction paragraph on engageny.org: https://www.engageny.org/resource/grade-5-mathematics-module-1
[{'score': 0.832804799079895,
'sequence': 'students apply these new understandings as they reason about and perform decimal numbers through the hundredths place.',
'token': 3616,
'token_str': 'numbers'},
{'score': 0.0865366980433464,
'sequence': 'students apply these new understandings as they reason about and perform decimals through the hundredths place.',
'token': 2015,
'token_str': '##s'},
{'score': 0.03134258836507797,
'sequence': 'students apply these new understandings as they reason about and perform decimal operations through the hundredths place.',
'token': 3136,
'token_str': 'operations'},
{'score': 0.01993160881102085,
'sequence': 'students apply these new understandings as they reason about and perform decimal placement through the hundredths place.',
'token': 11073,
'token_str': 'placement'},
{'score': 0.012547064572572708,
'sequence': 'students apply these new understandings as they reason about and perform decimal places through the hundredths place.',
'token': 3182,
'token_str': 'places'}]
```
***Therefore, to try the 'fill-mask' hosted API on the right corner of the page, please use the sentences similar to below:***
```
1 tenth times any [MASK] on the place value chart moves it one place value to the right. #from https://www.engageny.org/resource/grade-5-mathematics-module-1
```
#### Training data
The MathBERT model was pretrained on pre-k to HS math curriculum (engageNY, Utah Math, Illustrative Math), college math books from openculture.com as well as graduate level math from arxiv math paper abstracts. There is about 100M tokens got pretrained on.
#### Training procedure
The texts are lowercased and tokenized using WordPiece and a vocabulary size of 30,522 which is from original BERT vocab.txt. The inputs of the model are then of the form:
```
[CLS] Sentence A [SEP] Sentence B [SEP]
```
With probability 0.5, sentence A and sentence B correspond to two consecutive sentence spans from the original corpus. Note that what is considered a sentence here is a consecutive span of text usually longer than a single sentence, but less than 512 tokens.
The details of the masking procedure for each sentence are the following:
+ 15% of the tokens are masked.
+ In 80% of the cases, the masked tokens are replaced by [MASK].
+ In 10% of the cases, the masked tokens are replaced by a random token (different) from the one they replace.
+ In the 10% remaining cases, the masked tokens are left as is.
#### Pretraining
The model was trained on a 8-core cloud TPUs from Google Colab for 600k steps with a batch size of 128. The sequence length was limited to 512 for the entire time. The optimizer used is Adam with a learning rate of 5e-5, beta_{1} = 0.9 and beta_{2} =0.999, a weight decay of 0.01, learning rate warmup for 10,000 steps and linear decay of the learning rate after.
You can refer to the training and fine-tuning code at https://github.com/tbs17/MathBERT.
|
vinai/bertweet-covid19-base-cased
|
4c0ac69c1a2e97374f9a35030cc57d9bd56e8775
|
2022-06-08T04:42:28.000Z
|
[
"pytorch",
"tf",
"jax",
"roberta",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
| false |
vinai
| null |
vinai/bertweet-covid19-base-cased
| 1,766 | null |
transformers
| 1,431 |
# <a name="introduction"></a> BERTweet: A pre-trained language model for English Tweets
BERTweet is the first public large-scale language model pre-trained for English Tweets. BERTweet is trained based on the [RoBERTa](https://github.com/pytorch/fairseq/blob/master/examples/roberta/README.md) pre-training procedure. The corpus used to pre-train BERTweet consists of 850M English Tweets (16B word tokens ~ 80GB), containing 845M Tweets streamed from 01/2012 to 08/2019 and 5M Tweets related to the **COVID-19** pandemic. The general architecture and experimental results of BERTweet can be found in our [paper](https://aclanthology.org/2020.emnlp-demos.2/):
@inproceedings{bertweet,
title = {{BERTweet: A pre-trained language model for English Tweets}},
author = {Dat Quoc Nguyen and Thanh Vu and Anh Tuan Nguyen},
booktitle = {Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations},
pages = {9--14},
year = {2020}
}
**Please CITE** our paper when BERTweet is used to help produce published results or is incorporated into other software.
For further information or requests, please go to [BERTweet's homepage](https://github.com/VinAIResearch/BERTweet)!
|
saibo/random-roberta-base
|
85b19e1e9a19cb941f6373d0924ed3be403aee57
|
2021-07-18T18:33:48.000Z
|
[
"pytorch",
"tf",
"roberta",
"feature-extraction",
"transformers"
] |
feature-extraction
| false |
saibo
| null |
saibo/random-roberta-base
| 1,762 | null |
transformers
| 1,432 |
# random-roberta-base
We introduce random-roberta-base, which is a unpretrained version of RoBERTa model. The weight of random-roberta-base is randomly initiated and this can be particularly useful when we aim to train a language model from scratch or benchmark the effect of pretraining.
It's important to note that tokenizer of random-roberta-base is the same as roberta-base because it's not a trivial task to get a random tokenizer and it's less meaningful compared to the random weight.
A debatable advantage of pulling random-roberta-base from Huggingface is to avoid using random seed in order to obtain the same randomness at each time.
The code to obtain such a random model:
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
def get_blank_model_from_hf(model_name="bert-base-cased"):
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=5)
tokenizer = AutoTokenizer.from_pretrained(model_name)
model.base_model.init_weights()
model_name = "random-" + model_name
base_model= model.base_model
return base_model, tokenizer, model_name
```
|
dmis-lab/biobert-base-cased-v1.1-squad
|
aa11b70199b5446ecf6ad5408f7b7a234686d7f2
|
2021-05-19T15:56:54.000Z
|
[
"pytorch",
"jax",
"bert",
"question-answering",
"transformers",
"autotrain_compatible"
] |
question-answering
| false |
dmis-lab
| null |
dmis-lab/biobert-base-cased-v1.1-squad
| 1,758 | 1 |
transformers
| 1,433 |
Entry not found
|
zlucia/legalbert
|
8aead03573cac81f97191bd8532d808889372e59
|
2021-07-02T05:55:35.000Z
|
[
"pytorch",
"tf",
"jax",
"bert",
"en",
"arxiv:2104.08671",
"transformers",
"legal",
"fill-mask"
] |
fill-mask
| false |
zlucia
| null |
zlucia/legalbert
| 1,757 | 1 |
transformers
| 1,434 |
---
language: en
pipeline_tag: fill-mask
tags:
- legal
---
### Legal-BERT
Model and tokenizer files for Legal-BERT model from [When Does Pretraining Help? Assessing Self-Supervised Learning for Law and the CaseHOLD Dataset of 53,000+ Legal Holdings](https://arxiv.org/abs/2104.08671).
### Training Data
The pretraining corpus was constructed by ingesting the entire Harvard Law case corpus from 1965 to the present (https://case.law/). The size of this corpus (37GB) is substantial, representing 3,446,187 legal decisions across all federal and state courts, and is larger than the size of the BookCorpus/Wikipedia corpus originally used to train BERT (15GB).
### Training Objective
This model is initialized with the base BERT model (uncased, 110M parameters), [bert-base-uncased](https://huggingface.co/bert-base-uncased), and trained for an additional 1M steps on the MLM and NSP objective, with tokenization and sentence segmentation adapted for legal text (cf. the paper).
### Usage
Please see the [casehold repository](https://github.com/reglab/casehold) for scripts that support computing pretrain loss and finetuning on Legal-BERT for classification and multiple choice tasks described in the paper: Overruling, Terms of Service, CaseHOLD.
### Citation
@inproceedings{zhengguha2021,
title={When Does Pretraining Help? Assessing Self-Supervised Learning for Law and the CaseHOLD Dataset},
author={Lucia Zheng and Neel Guha and Brandon R. Anderson and Peter Henderson and Daniel E. Ho},
year={2021},
eprint={2104.08671},
archivePrefix={arXiv},
primaryClass={cs.CL},
booktitle={Proceedings of the 18th International Conference on Artificial Intelligence and Law},
publisher={Association for Computing Machinery}
}
Lucia Zheng, Neel Guha, Brandon R. Anderson, Peter Henderson, and Daniel E. Ho. 2021. When Does Pretraining Help? Assessing Self-Supervised Learning for Law and the CaseHOLD Dataset. In *Proceedings of the 18th International Conference on Artificial Intelligence and Law (ICAIL '21)*, June 21-25, 2021, São Paulo, Brazil. ACM Inc., New York, NY, (in press). arXiv: [2104.08671 \\[cs.CL\\]](https://arxiv.org/abs/2104.08671).
|
microsoft/trocr-large-handwritten
|
a97dcf06fd0467a6cb8fcb5a8dfc3ea0704a9f0a
|
2022-07-01T07:36:14.000Z
|
[
"pytorch",
"vision-encoder-decoder",
"arxiv:2109.10282",
"transformers",
"trocr",
"image-to-text"
] |
image-to-text
| false |
microsoft
| null |
microsoft/trocr-large-handwritten
| 1,753 | 4 |
transformers
| 1,435 |
---
tags:
- trocr
- image-to-text
---
# TrOCR (large-sized model, fine-tuned on IAM)
TrOCR model fine-tuned on the [IAM dataset](https://fki.tic.heia-fr.ch/databases/iam-handwriting-database). It was introduced in the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Li et al. and first released in [this repository](https://github.com/microsoft/unilm/tree/master/trocr).
Disclaimer: The team releasing TrOCR did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The TrOCR model is an encoder-decoder model, consisting of an image Transformer as encoder, and a text Transformer as decoder. The image encoder was initialized from the weights of BEiT, while the text decoder was initialized from the weights of RoBERTa.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. One also adds absolute position embeddings before feeding the sequence to the layers of the Transformer encoder. Next, the Transformer text decoder autoregressively generates tokens.
## Intended uses & limitations
You can use the raw model for optical character recognition (OCR) on single text-line images. See the [model hub](https://huggingface.co/models?search=microsoft/trocr) to look for fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model in PyTorch:
```python
from transformers import TrOCRProcessor, VisionEncoderDecoderModel
from PIL import Image
import requests
# load image from the IAM database
url = 'https://fki.tic.heia-fr.ch/static/img/a01-122-02-00.jpg'
image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
processor = TrOCRProcessor.from_pretrained('microsoft/trocr-large-handwritten')
model = VisionEncoderDecoderModel.from_pretrained('microsoft/trocr-large-handwritten')
pixel_values = processor(images=image, return_tensors="pt").pixel_values
generated_ids = model.generate(pixel_values)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
```
### BibTeX entry and citation info
```bibtex
@misc{li2021trocr,
title={TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models},
author={Minghao Li and Tengchao Lv and Lei Cui and Yijuan Lu and Dinei Florencio and Cha Zhang and Zhoujun Li and Furu Wei},
year={2021},
eprint={2109.10282},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
JorisCos/ConvTasNet_Libri1Mix_enhsingle_16k
|
bb8a876bc157b5cf3c405994accb798c49146016
|
2021-09-23T15:48:51.000Z
|
[
"pytorch",
"dataset:Libri1Mix",
"dataset:enh_single",
"asteroid",
"audio",
"ConvTasNet",
"audio-to-audio",
"license:cc-by-sa-4.0"
] |
audio-to-audio
| false |
JorisCos
| null |
JorisCos/ConvTasNet_Libri1Mix_enhsingle_16k
| 1,749 | 1 |
asteroid
| 1,436 |
---
tags:
- asteroid
- audio
- ConvTasNet
- audio-to-audio
datasets:
- Libri1Mix
- enh_single
license: cc-by-sa-4.0
---
## Asteroid model `JorisCos/ConvTasNet_Libri1Mix_enhsignle_16k`
Description:
This model was trained by Joris Cosentino using the librimix recipe in [Asteroid](https://github.com/asteroid-team/asteroid).
It was trained on the `enh_single` task of the Libri1Mix dataset.
Training config:
```yml
data:
n_src: 1
sample_rate: 16000
segment: 3
task: enh_single
train_dir: data/wav16k/min/train-360
valid_dir: data/wav16k/min/dev
filterbank:
kernel_size: 32
n_filters: 512
stride: 16
masknet:
bn_chan: 128
hid_chan: 512
mask_act: relu
n_blocks: 8
n_repeats: 3
n_src: 1
skip_chan: 128
optim:
lr: 0.001
optimizer: adam
weight_decay: 0.0
training:
batch_size: 6
early_stop: true
epochs: 200
half_lr: true
num_workers: 4
```
Results:
On Libri1Mix min test set :
```yml
si_sdr: 14.743051006476085
si_sdr_imp: 11.293269700616385
sdr: 15.300522933671061
sdr_imp: 11.797860134458015
sir: Infinity
sir_imp: NaN
sar: 15.300522933671061
sar_imp: 11.797860134458015
stoi: 0.9310514162434267
stoi_imp: 0.13513159270288563
```
License notice:
This work "ConvTasNet_Libri1Mix_enhsignle_16k" is a derivative of [LibriSpeech ASR corpus](http://www.openslr.org/12) by Vassil Panayotov,
used under [CC BY 4.0](https://creativecommons.org/licenses/by/4.0/); of The WSJ0 Hipster Ambient Mixtures
dataset by [Whisper.ai](http://wham.whisper.ai/), used under [CC BY-NC 4.0](https://creativecommons.org/licenses/by-nc/4.0/) (Research only).
"ConvTasNet_Libri1Mix_enhsignle_16k" is licensed under [Attribution-ShareAlike 3.0 Unported](https://creativecommons.org/licenses/by-sa/3.0/) by Joris Cosentino
|
squeezebert/squeezebert-mnli
|
dc26cab55cf7cf386a1e711e36e3146362c7cb08
|
2020-12-11T22:02:13.000Z
|
[
"pytorch",
"squeezebert",
"arxiv:2006.11316",
"arxiv:1904.00962",
"transformers"
] | null | false |
squeezebert
| null |
squeezebert/squeezebert-mnli
| 1,749 | null |
transformers
| 1,437 |
language: en
license: bsd
datasets:
- bookcorpus
- wikipedia
---
# SqueezeBERT pretrained model
This model, `squeezebert-mnli`, has been pretrained for the English language using a masked language modeling (MLM) and Sentence Order Prediction (SOP) objective and finetuned on the [Multi-Genre Natural Language Inference (MNLI)](https://cims.nyu.edu/~sbowman/multinli/) dataset.
SqueezeBERT was introduced in [this paper](https://arxiv.org/abs/2006.11316). This model is case-insensitive. The model architecture is similar to BERT-base, but with the pointwise fully-connected layers replaced with [grouped convolutions](https://blog.yani.io/filter-group-tutorial/).
The authors found that SqueezeBERT is 4.3x faster than `bert-base-uncased` on a Google Pixel 3 smartphone.
## Pretraining
### Pretraining data
- [BookCorpus](https://yknzhu.wixsite.com/mbweb), a dataset consisting of thousands of unpublished books
- [English Wikipedia](https://en.wikipedia.org/wiki/English_Wikipedia)
### Pretraining procedure
The model is pretrained using the Masked Language Model (MLM) and Sentence Order Prediction (SOP) tasks.
(Author's note: If you decide to pretrain your own model, and you prefer to train with MLM only, that should work too.)
From the SqueezeBERT paper:
> We pretrain SqueezeBERT from scratch (without distillation) using the [LAMB](https://arxiv.org/abs/1904.00962) optimizer, and we employ the hyperparameters recommended by the LAMB authors: a global batch size of 8192, a learning rate of 2.5e-3, and a warmup proportion of 0.28. Following the LAMB paper's recommendations, we pretrain for 56k steps with a maximum sequence length of 128 and then for 6k steps with a maximum sequence length of 512.
## Finetuning
The SqueezeBERT paper presents 2 approaches to finetuning the model:
- "finetuning without bells and whistles" -- after pretraining the SqueezeBERT model, finetune it on each GLUE task
- "finetuning with bells and whistles" -- after pretraining the SqueezeBERT model, finetune it on a MNLI with distillation from a teacher model. Then, use the MNLI-finetuned SqueezeBERT model as a student model to finetune on each of the other GLUE tasks (e.g. RTE, MRPC, …) with distillation from a task-specific teacher model.
A detailed discussion of the hyperparameters used for finetuning is provided in the appendix of the [SqueezeBERT paper](https://arxiv.org/abs/2006.11316).
Note that finetuning SqueezeBERT with distillation is not yet implemented in this repo. If the author (Forrest Iandola - [email protected]) gets enough encouragement from the user community, he will add example code to Transformers for finetuning SqueezeBERT with distillation.
This model, `squeezebert/squeezebert-mnli`, is the "trained with bells and whistles" MNLI-finetuned SqueezeBERT model.
### How to finetune
To try finetuning SqueezeBERT on the [MRPC](https://www.microsoft.com/en-us/download/details.aspx?id=52398) text classification task, you can run the following command:
```
./utils/download_glue_data.py
python examples/text-classification/run_glue.py \
--model_name_or_path squeezebert-base-headless \
--task_name mrpc \
--data_dir ./glue_data/MRPC \
--output_dir ./models/squeezebert_mrpc \
--overwrite_output_dir \
--do_train \
--do_eval \
--num_train_epochs 10 \
--learning_rate 3e-05 \
--per_device_train_batch_size 16 \
--save_steps 20000
```
## BibTeX entry and citation info
```
@article{2020_SqueezeBERT,
author = {Forrest N. Iandola and Albert E. Shaw and Ravi Krishna and Kurt W. Keutzer},
title = {{SqueezeBERT}: What can computer vision teach NLP about efficient neural networks?},
journal = {arXiv:2006.11316},
year = {2020}
}
```
|
jonatasgrosman/wav2vec2-large-xlsr-53-japanese
|
4bfb973ffab9e3b4bf77f4db18e07fb11003816c
|
2022-07-27T23:36:16.000Z
|
[
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"ja",
"dataset:common_voice",
"transformers",
"audio",
"speech",
"xlsr-fine-tuning-week",
"license:apache-2.0",
"model-index"
] |
automatic-speech-recognition
| false |
jonatasgrosman
| null |
jonatasgrosman/wav2vec2-large-xlsr-53-japanese
| 1,736 | 4 |
transformers
| 1,438 |
---
language: ja
datasets:
- common_voice
metrics:
- wer
- cer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: XLSR Wav2Vec2 Japanese by Jonatas Grosman
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice ja
type: common_voice
args: ja
metrics:
- name: Test WER
type: wer
value: 81.80
- name: Test CER
type: cer
value: 20.16
---
# Fine-tuned XLSR-53 large model for speech recognition in Japanese
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Japanese using the train and validation splits of [Common Voice 6.1](https://huggingface.co/datasets/common_voice), [CSS10](https://github.com/Kyubyong/css10) and [JSUT](https://sites.google.com/site/shinnosuketakamichi/publication/jsut).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned thanks to the GPU credits generously given by the [OVHcloud](https://www.ovhcloud.com/en/public-cloud/ai-training/) :)
The script used for training can be found here: https://github.com/jonatasgrosman/wav2vec2-sprint
## Usage
The model can be used directly (without a language model) as follows...
Using the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) library:
```python
from huggingsound import SpeechRecognitionModel
model = SpeechRecognitionModel("jonatasgrosman/wav2vec2-large-xlsr-53-japanese")
audio_paths = ["/path/to/file.mp3", "/path/to/another_file.wav"]
transcriptions = model.transcribe(audio_paths)
```
Writing your own inference script:
```python
import torch
import librosa
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
LANG_ID = "ja"
MODEL_ID = "jonatasgrosman/wav2vec2-large-xlsr-53-japanese"
SAMPLES = 10
test_dataset = load_dataset("common_voice", LANG_ID, split=f"test[:{SAMPLES}]")
processor = Wav2Vec2Processor.from_pretrained(MODEL_ID)
model = Wav2Vec2ForCTC.from_pretrained(MODEL_ID)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = librosa.load(batch["path"], sr=16_000)
batch["speech"] = speech_array
batch["sentence"] = batch["sentence"].upper()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
predicted_sentences = processor.batch_decode(predicted_ids)
for i, predicted_sentence in enumerate(predicted_sentences):
print("-" * 100)
print("Reference:", test_dataset[i]["sentence"])
print("Prediction:", predicted_sentence)
```
| Reference | Prediction |
| ------------- | ------------- |
| 祖母は、おおむね機嫌よく、サイコロをころがしている。 | 人母は重にきね起くさいがしている |
| 財布をなくしたので、交番へ行きます。 | 財布をなく手端ので勾番へ行きます |
| 飲み屋のおやじ、旅館の主人、医者をはじめ、交際のある人にきいてまわったら、みんな、私より収入が多いはずなのに、税金は安い。 | ノ宮屋のお親じ旅館の主に医者をはじめ交際のアル人トに聞いて回ったらみんな私より収入が多いはなうに税金は安い |
| 新しい靴をはいて出かけます。 | だらしい靴をはいて出かけます |
| このためプラズマ中のイオンや電子の持つ平均運動エネルギーを温度で表現することがある | このためプラズマ中のイオンや電子の持つ平均運動エネルギーを温度で表弁することがある |
| 松井さんはサッカーより野球のほうが上手です。 | 松井さんはサッカーより野球のほうが上手です |
| 新しいお皿を使います。 | 新しいお皿を使います |
| 結婚以来三年半ぶりの東京も、旧友とのお酒も、夜行列車も、駅で寝て、朝を待つのも久しぶりだ。 | 結婚ル二来三年半降りの東京も吸とのお酒も野越者も駅で寝て朝を待つの久しぶりた |
| これまで、少年野球、ママさんバレーなど、地域スポーツを支え、市民に密着してきたのは、無数のボランティアだった。 | これまで少年野球<unk>三バレーなど地域スポーツを支え市民に満着してきたのは娘数のボランティアだった |
| 靴を脱いで、スリッパをはきます。 | 靴を脱いでスイパーをはきます |
## Evaluation
The model can be evaluated as follows on the Japanese test data of Common Voice.
```python
import torch
import re
import librosa
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
LANG_ID = "ja"
MODEL_ID = "jonatasgrosman/wav2vec2-large-xlsr-53-japanese"
DEVICE = "cuda"
CHARS_TO_IGNORE = [",", "?", "¿", ".", "!", "¡", ";", ";", ":", '""', "%", '"', "�", "ʿ", "·", "჻", "~", "՞",
"؟", "،", "।", "॥", "«", "»", "„", "“", "”", "「", "」", "‘", "’", "《", "》", "(", ")", "[", "]",
"{", "}", "=", "`", "_", "+", "<", ">", "…", "–", "°", "´", "ʾ", "‹", "›", "©", "®", "—", "→", "。",
"、", "﹂", "﹁", "‧", "~", "﹏", ",", "{", "}", "(", ")", "[", "]", "【", "】", "‥", "〽",
"『", "』", "〝", "〟", "⟨", "⟩", "〜", ":", "!", "?", "♪", "؛", "/", "\\", "º", "−", "^", "'", "ʻ", "ˆ"]
test_dataset = load_dataset("common_voice", LANG_ID, split="test")
wer = load_metric("wer.py") # https://github.com/jonatasgrosman/wav2vec2-sprint/blob/main/wer.py
cer = load_metric("cer.py") # https://github.com/jonatasgrosman/wav2vec2-sprint/blob/main/cer.py
chars_to_ignore_regex = f"[{re.escape(''.join(CHARS_TO_IGNORE))}]"
processor = Wav2Vec2Processor.from_pretrained(MODEL_ID)
model = Wav2Vec2ForCTC.from_pretrained(MODEL_ID)
model.to(DEVICE)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
with warnings.catch_warnings():
warnings.simplefilter("ignore")
speech_array, sampling_rate = librosa.load(batch["path"], sr=16_000)
batch["speech"] = speech_array
batch["sentence"] = re.sub(chars_to_ignore_regex, "", batch["sentence"]).upper()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to(DEVICE), attention_mask=inputs.attention_mask.to(DEVICE)).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
predictions = [x.upper() for x in result["pred_strings"]]
references = [x.upper() for x in result["sentence"]]
print(f"WER: {wer.compute(predictions=predictions, references=references, chunk_size=1000) * 100}")
print(f"CER: {cer.compute(predictions=predictions, references=references, chunk_size=1000) * 100}")
```
**Test Result**:
In the table below I report the Word Error Rate (WER) and the Character Error Rate (CER) of the model. I ran the evaluation script described above on other models as well (on 2021-05-10). Note that the table below may show different results from those already reported, this may have been caused due to some specificity of the other evaluation scripts used.
| Model | WER | CER |
| ------------- | ------------- | ------------- |
| jonatasgrosman/wav2vec2-large-xlsr-53-japanese | **81.80%** | **20.16%** |
| vumichien/wav2vec2-large-xlsr-japanese | 1108.86% | 23.40% |
| qqhann/w2v_hf_jsut_xlsr53 | 1012.18% | 70.77% |
## Citation
If you want to cite this model you can use this:
```bibtex
@misc{grosman2021xlsr53-large-japanese,
title={Fine-tuned {XLSR}-53 large model for speech recognition in {J}apanese},
author={Grosman, Jonatas},
howpublished={\url{https://huggingface.co/jonatasgrosman/wav2vec2-large-xlsr-53-japanese}},
year={2021}
}
```
|
vinai/bartpho-syllable
|
50827977a980993df5c00ead06f6f1b3535b9424
|
2022-06-08T04:48:32.000Z
|
[
"pytorch",
"tf",
"mbart",
"feature-extraction",
"arxiv:2109.09701",
"transformers"
] |
feature-extraction
| false |
vinai
| null |
vinai/bartpho-syllable
| 1,733 | 0 |
transformers
| 1,439 |
# <a name="introduction"></a> BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese
Two BARTpho versions `BARTpho-syllable` and `BARTpho-word` are the first public large-scale monolingual sequence-to-sequence models pre-trained for Vietnamese. BARTpho uses the "large" architecture and pre-training scheme of the sequence-to-sequence denoising model [BART](https://github.com/pytorch/fairseq/tree/main/examples/bart), thus especially suitable for generative NLP tasks. Experiments on a downstream task of Vietnamese text summarization show that in both automatic and human evaluations, BARTpho outperforms the strong baseline [mBART](https://github.com/pytorch/fairseq/tree/main/examples/mbart) and improves the state-of-the-art.
The general architecture and experimental results of BARTpho can be found in our [paper](https://arxiv.org/abs/2109.09701):
@article{bartpho,
title = {{BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese}},
author = {Nguyen Luong Tran and Duong Minh Le and Dat Quoc Nguyen},
journal = {arXiv preprint},
volume = {arXiv:2109.09701},
year = {2021}
}
**Please CITE** our paper when BARTpho is used to help produce published results or incorporated into other software.
For further information or requests, please go to [BARTpho's homepage](https://github.com/VinAIResearch/BARTpho)!
|
microsoft/CodeGPT-small-java-adaptedGPT2
|
f537c1fca4b5e4ed4423085a12ed4aeface294e1
|
2021-05-23T08:58:11.000Z
|
[
"pytorch",
"tf",
"jax",
"gpt2",
"text-generation",
"transformers"
] |
text-generation
| false |
microsoft
| null |
microsoft/CodeGPT-small-java-adaptedGPT2
| 1,729 | 2 |
transformers
| 1,440 |
Entry not found
|
RossM/distilgpt2-finetuned-MTG
|
058f8a3da7bff0349f430ce17e9d0a5133c9d278
|
2022-06-24T21:27:51.000Z
|
[
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] |
text-generation
| false |
RossM
| null |
RossM/distilgpt2-finetuned-MTG
| 1,721 | null |
transformers
| 1,441 |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: distilgpt2-finetuned-MTG
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilgpt2-finetuned-MTG
This model is a fine-tuned version of [distilgpt2](https://huggingface.co/distilgpt2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4947
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 389 | 1.6497 |
| 2.0548 | 2.0 | 778 | 1.5274 |
| 1.5502 | 3.0 | 1167 | 1.4947 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
jaehyeong/koelectra-base-v3-generalized-sentiment-analysis
|
f77aac8b7a2a88515e168082dd298d9982e73edb
|
2021-10-14T07:30:27.000Z
|
[
"pytorch",
"electra",
"text-classification",
"transformers"
] |
text-classification
| false |
jaehyeong
| null |
jaehyeong/koelectra-base-v3-generalized-sentiment-analysis
| 1,718 | 1 |
transformers
| 1,442 |
# Usage
```python
# import library
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification, TextClassificationPipeline
# load model
tokenizer = AutoTokenizer.from_pretrained("jaehyeong/koelectra-base-v3-generalized-sentiment-analysis")
model = AutoModelForSequenceClassification.from_pretrained("jaehyeong/koelectra-base-v3-generalized-sentiment-analysis")
sentiment_classifier = TextClassificationPipeline(tokenizer=tokenizer, model=model)
# target reviews
review_list = [
'이쁘고 좋아요~~~씻기도 편하고 아이고 이쁘다고 자기방에 갖다놓고 잘써요~^^',
'아직 입어보진 않았지만 굉장히 가벼워요~~ 다른 리뷰처럼 어깡이 좀 되네요ㅋ 만족합니다. 엄청 빠른발송 감사드려요 :)',
'재구매 한건데 너무너무 가성비인거 같아요!! 다음에 또 생각나면 3개째 또 살듯..ㅎㅎ',
'가습량이 너무 적어요. 방이 작지 않다면 무조건 큰걸로구매하세요. 물량도 조금밖에 안들어가서 쓰기도 불편함',
'한번입었는데 옆에 봉제선 다 풀리고 실밥도 계속 나옵니다. 마감 처리 너무 엉망 아닌가요?',
'따뜻하고 좋긴한데 배송이 느려요',
'맛은 있는데 가격이 있는 편이에요'
]
# predict
for idx, review in enumerate(review_list):
pred = sentiment_classifier(review)
print(f'{review}\n>> {pred[0]}')
```
```
이쁘고 좋아요~~~씻기도 편하고 아이고 이쁘다고 자기방에 갖다놓고 잘써요~^^
>> {'label': '1', 'score': 0.9945501685142517}
아직 입어보진 않았지만 굉장히 가벼워요~~ 다른 리뷰처럼 어깡이 좀 되네요ㅋ 만족합니다. 엄청 빠른발송 감사드려요 :)
>> {'label': '1', 'score': 0.995430588722229}
재구매 한건데 너무너무 가성비인거 같아요!! 다음에 또 생각나면 3개째 또 살듯..ㅎㅎ
>> {'label': '1', 'score': 0.9959582686424255}
가습량이 너무 적어요. 방이 작지 않다면 무조건 큰걸로구매하세요. 물량도 조금밖에 안들어가서 쓰기도 불편함
>> {'label': '0', 'score': 0.9984619617462158}
한번입었는데 옆에 봉제선 다 풀리고 실밥도 계속 나옵니다. 마감 처리 너무 엉망 아닌가요?
>> {'label': '0', 'score': 0.9991756677627563}
따뜻하고 좋긴한데 배송이 느려요
>> {'label': '1', 'score': 0.6473883390426636}
맛은 있는데 가격이 있는 편이에요
>> {'label': '1', 'score': 0.5128092169761658}
```
- label 0 : negative review
- label 1 : positive review
|
kykim/gpt3-kor-small_based_on_gpt2
|
e47e807a037ba831c4a6586c190567cca08c9c87
|
2021-05-23T06:24:05.000Z
|
[
"pytorch",
"tf",
"jax",
"gpt2",
"feature-extraction",
"ko",
"transformers"
] |
feature-extraction
| false |
kykim
| null |
kykim/gpt3-kor-small_based_on_gpt2
| 1,717 | 1 |
transformers
| 1,443 |
---
language: ko
---
# Bert base model for Korean
* 70GB Korean text dataset and 42000 lower-cased subwords are used
* Check the model performance and other language models for Korean in [github](https://github.com/kiyoungkim1/LM-kor)
```python
from transformers import BertTokenizerFast, GPT2LMHeadModel
tokenizer_gpt3 = BertTokenizerFast.from_pretrained("kykim/gpt3-kor-small_based_on_gpt2")
input_ids = tokenizer_gpt3.encode("text to tokenize")[1:] # remove cls token
model_gpt3 = GPT2LMHeadModel.from_pretrained("kykim/gpt3-kor-small_based_on_gpt2")
```
|
moussaKam/barthez-orangesum-title
|
51522db428913eeabe40e93913458bb15d802ba5
|
2021-11-15T13:02:15.000Z
|
[
"pytorch",
"mbart",
"text2text-generation",
"fr",
"arxiv:2010.12321",
"transformers",
"summarization",
"license:apache-2.0",
"autotrain_compatible"
] |
summarization
| false |
moussaKam
| null |
moussaKam/barthez-orangesum-title
| 1,712 | 2 |
transformers
| 1,444 |
---
tags:
- summarization
language:
- fr
license: apache-2.0
widget:
- text: Citant les préoccupations de ses clients dénonçant des cas de censure après la suppression du compte de Trump, un fournisseur d'accès Internet de l'État de l'Idaho a décidé de bloquer Facebook et Twitter. La mesure ne concernera cependant que les clients mécontents de la politique de ces réseaux sociaux.
---
### Barthez model finetuned on orangeSum (title generation)
finetuning: examples/seq2seq/ (as of Nov 06, 2020)
Metrics: ROUGE-2 > 23
paper: https://arxiv.org/abs/2010.12321 \
github: https://github.com/moussaKam/BARThez
```
@article{eddine2020barthez,
title={BARThez: a Skilled Pretrained French Sequence-to-Sequence Model},
author={Eddine, Moussa Kamal and Tixier, Antoine J-P and Vazirgiannis, Michalis},
journal={arXiv preprint arXiv:2010.12321},
year={2020}
}
```
|
cambridgeltl/mirror-roberta-base-sentence-drophead
|
1699508c7e9157c0bbc411e17df4c3aefcc2919a
|
2021-09-19T22:47:50.000Z
|
[
"pytorch",
"roberta",
"feature-extraction",
"arxiv:2104.08027",
"transformers"
] |
feature-extraction
| false |
cambridgeltl
| null |
cambridgeltl/mirror-roberta-base-sentence-drophead
| 1,695 | 1 |
transformers
| 1,445 |
---
language: en
tags:
- sentence-embeddings
- sentence-similarity
### cambridgeltl/mirror-roberta-base-sentence-drophead
An unsupervised sentence encoder proposed by [Liu et al. (2021)](https://arxiv.org/pdf/2104.08027.pdf), using [drophead](https://aclanthology.org/2020.findings-emnlp.178.pdf) instead of dropout as feature space augmentation. The model is trained with unlabelled raw sentences, using [roberta-base](https://huggingface.co/roberta-base) as the base model. Please use `[CLS]` (before pooler) as the representation of the input.
Note the model does not replicate the exact numbers in the paper since the reported numbers in the paper are average of three runs.
### Citation
```bibtex
@inproceedings{
liu2021fast,
title={Fast, Effective, and Self-Supervised: Transforming Masked Language Models into Universal Lexical and Sentence Encoders},
author={Liu, Fangyu and Vuli{\'c}, Ivan and Korhonen, Anna and Collier, Nigel},
booktitle={EMNLP 2021},
year={2021}
}
```
|
TODBERT/TOD-BERT-JNT-V1
|
903797e92f97b5e61a1142636b2d604682a1032c
|
2021-05-18T22:44:12.000Z
|
[
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
| false |
TODBERT
| null |
TODBERT/TOD-BERT-JNT-V1
| 1,688 | 1 |
transformers
| 1,446 |
Entry not found
|
luhua/chinese_pretrain_mrc_macbert_large
|
f2d95d06f16a3043002c9702f66c834f4e0aa944
|
2021-06-12T02:52:28.000Z
|
[
"pytorch",
"bert",
"question-answering",
"zh",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] |
question-answering
| false |
luhua
| null |
luhua/chinese_pretrain_mrc_macbert_large
| 1,685 | 4 |
transformers
| 1,447 |
---
language:
- zh
license: "apache-2.0"
---
## Chinese MRC macbert-large
* 使用大量中文MRC数据训练的macbert-large模型,详情可查看:https://github.com/basketballandlearn/MRC_Competition_Dureader
* 此库发布的再训练模型,在 阅读理解/分类 等任务上均有大幅提高<br/>
(已有多位小伙伴在Dureader-2021等多个比赛中取得**top5**的成绩😁)
| 模型/数据集 | Dureader-2021 | tencentmedical |
| ------------------------------------------|--------------- | --------------- |
| | F1-score | Accuracy |
| | dev / A榜 | test-1 |
| macbert-large (哈工大预训练语言模型) | 65.49 / 64.27 | 82.5 |
| roberta-wwm-ext-large (哈工大预训练语言模型) | 65.49 / 64.27 | 82.5 |
| macbert-large (ours) | 70.45 / **68.13**| **83.4** |
| roberta-wwm-ext-large (ours) | 68.91 / 66.91 | 83.1 |
|
valhalla/t5-small-qg-prepend
|
6c7b8044e67af4742270e96f974bee864760bd4c
|
2020-07-06T17:20:20.000Z
|
[
"pytorch",
"t5",
"text2text-generation",
"transformers",
"autotrain_compatible"
] |
text2text-generation
| false |
valhalla
| null |
valhalla/t5-small-qg-prepend
| 1,681 | null |
transformers
| 1,448 |
Entry not found
|
Helsinki-NLP/opus-mt-en-jap
|
c981a0c27d7f082b91d129740b1f6a7b643c9e02
|
2021-09-09T21:36:30.000Z
|
[
"pytorch",
"marian",
"text2text-generation",
"en",
"jap",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] |
translation
| false |
Helsinki-NLP
| null |
Helsinki-NLP/opus-mt-en-jap
| 1,678 | null |
transformers
| 1,449 |
---
tags:
- translation
license: apache-2.0
---
### opus-mt-en-jap
* source languages: en
* target languages: jap
* OPUS readme: [en-jap](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/en-jap/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-08.zip](https://object.pouta.csc.fi/OPUS-MT-models/en-jap/opus-2020-01-08.zip)
* test set translations: [opus-2020-01-08.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/en-jap/opus-2020-01-08.test.txt)
* test set scores: [opus-2020-01-08.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/en-jap/opus-2020-01-08.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| bible-uedin.en.jap | 42.1 | 0.960 |
|
Meli/GPT2-Prompt
|
b8bf934edcdd396e655a622b2546a0d6af24cf9a
|
2021-05-21T10:55:36.000Z
|
[
"pytorch",
"jax",
"gpt2",
"text-generation",
"en",
"transformers"
] |
text-generation
| false |
Meli
| null |
Meli/GPT2-Prompt
| 1,678 | 2 |
transformers
| 1,450 |
---
language:
- en
tags:
- gpt2
- text-generation
pipeline_tag: text-generation
widget:
- text: "A person with a high school education gets sent back into the 1600s and tries to explain science and technology to the people. [endprompt]"
- text: "A kid doodling in a math class accidentally creates the world's first functional magic circle in centuries. [endprompt]"
---
# GPT-2 Story Generator
## Model description
Generate a short story from an input prompt.
Put the vocab ` [endprompt]` after your input.
Example of an input:
```
A person with a high school education gets sent back into the 1600s and tries to explain science and technology to the people. [endprompt]
```
#### Limitations and bias
The data we used to train was collected from reddit, so it could be very biased towards young, white, male demographic.
## Training data
The data was collected from scraping reddit.
|
facebook/deit-tiny-patch16-224
|
b3428f18dcc7b543470d07f14b4a4157815d1880
|
2022-07-13T11:53:31.000Z
|
[
"pytorch",
"tf",
"vit",
"image-classification",
"dataset:imagenet",
"arxiv:2012.12877",
"arxiv:2006.03677",
"transformers",
"license:apache-2.0"
] |
image-classification
| false |
facebook
| null |
facebook/deit-tiny-patch16-224
| 1,678 | null |
transformers
| 1,451 |
---
license: apache-2.0
tags:
- image-classification
datasets:
- imagenet
---
# Data-efficient Image Transformer (tiny-sized model)
Data-efficient Image Transformer (DeiT) model pre-trained and fine-tuned on ImageNet-1k (1 million images, 1,000 classes) at resolution 224x224. It was first introduced in the paper [Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877) by Touvron et al. and first released in [this repository](https://github.com/facebookresearch/deit). However, the weights were converted from the [timm repository](https://github.com/rwightman/pytorch-image-models) by Ross Wightman.
Disclaimer: The team releasing DeiT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
This model is actually a more efficiently trained Vision Transformer (ViT).
The Vision Transformer (ViT) is a transformer encoder model (BERT-like) pre-trained and fine-tuned on a large collection of images in a supervised fashion, namely ImageNet-1k, at a resolution of 224x224 pixels.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. One also adds a [CLS] token to the beginning of a sequence to use it for classification tasks. One also adds absolute position embeddings before feeding the sequence to the layers of the Transformer encoder.
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire image.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=facebook/deit) to look for
fine-tuned versions on a task that interests you.
### How to use
Since this model is a more efficiently trained ViT model, you can plug it into ViTModel or ViTForImageClassification. Note that the model expects the data to be prepared using DeiTFeatureExtractor. Here we use AutoFeatureExtractor, which will automatically use the appropriate feature extractor given the model name.
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import AutoFeatureExtractor, ViTForImageClassification
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = AutoFeatureExtractor.from_pretrained('facebook/deit-tiny-patch16-224')
model = ViTForImageClassification.from_pretrained('facebook/deit-tiny-patch16-224')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
Currently, both the feature extractor and model support PyTorch. Tensorflow and JAX/FLAX are coming soon.
## Training data
The ViT model was pretrained on [ImageNet-1k](http://www.image-net.org/challenges/LSVRC/2012/), a dataset consisting of 1 million images and 1k classes.
## Training procedure
### Preprocessing
The exact details of preprocessing of images during training/validation can be found [here](https://github.com/facebookresearch/deit/blob/ab5715372db8c6cad5740714b2216d55aeae052e/datasets.py#L78).
At inference time, images are resized/rescaled to the same resolution (256x256), center-cropped at 224x224 and normalized across the RGB channels with the ImageNet mean and standard deviation.
### Pretraining
The model was trained on a single 8-GPU node for 3 days. Training resolution is 224. For all hyperparameters (such as batch size and learning rate) we refer to table 9 of the original paper.
## Evaluation results
| Model | ImageNet top-1 accuracy | ImageNet top-5 accuracy | # params | URL |
|---------------------------------------|-------------------------|-------------------------|----------|------------------------------------------------------------------|
| **DeiT-tiny** | **72.2** | **91.1** | **5M** | **https://huggingface.co/facebook/deit-tiny-patch16-224** |
| DeiT-small | 79.9 | 95.0 | 22M | https://huggingface.co/facebook/deit-small-patch16-224 |
| DeiT-base | 81.8 | 95.6 | 86M | https://huggingface.co/facebook/deit-base-patch16-224 |
| DeiT-tiny distilled | 74.5 | 91.9 | 6M | https://huggingface.co/facebook/deit-tiny-distilled-patch16-224 |
| DeiT-small distilled | 81.2 | 95.4 | 22M | https://huggingface.co/facebook/deit-small-distilled-patch16-224 |
| DeiT-base distilled | 83.4 | 96.5 | 87M | https://huggingface.co/facebook/deit-base-distilled-patch16-224 |
| DeiT-base 384 | 82.9 | 96.2 | 87M | https://huggingface.co/facebook/deit-base-patch16-384 |
| DeiT-base distilled 384 (1000 epochs) | 85.2 | 97.2 | 88M | https://huggingface.co/facebook/deit-base-distilled-patch16-384 |
Note that for fine-tuning, the best results are obtained with a higher resolution (384x384). Of course, increasing the model size will result in better performance.
### BibTeX entry and citation info
```bibtex
@misc{touvron2021training,
title={Training data-efficient image transformers & distillation through attention},
author={Hugo Touvron and Matthieu Cord and Matthijs Douze and Francisco Massa and Alexandre Sablayrolles and Hervé Jégou},
year={2021},
eprint={2012.12877},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
```bibtex
@misc{wu2020visual,
title={Visual Transformers: Token-based Image Representation and Processing for Computer Vision},
author={Bichen Wu and Chenfeng Xu and Xiaoliang Dai and Alvin Wan and Peizhao Zhang and Zhicheng Yan and Masayoshi Tomizuka and Joseph Gonzalez and Kurt Keutzer and Peter Vajda},
year={2020},
eprint={2006.03677},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
```bibtex
@inproceedings{deng2009imagenet,
title={Imagenet: A large-scale hierarchical image database},
author={Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li},
booktitle={2009 IEEE conference on computer vision and pattern recognition},
pages={248--255},
year={2009},
organization={Ieee}
}
```
|
snowood1/ConfliBERT-cont-uncased
|
c7b7eba8f0193cd10fff5ecef69d3e9d2b809877
|
2022-05-11T16:49:05.000Z
|
[
"pytorch",
"bert",
"fill-mask",
"transformers",
"license:gpl-3.0",
"autotrain_compatible"
] |
fill-mask
| false |
snowood1
| null |
snowood1/ConfliBERT-cont-uncased
| 1,677 | null |
transformers
| 1,452 |
---
license: gpl-3.0
---
ConfliBERT is a pre-trained language model for political conflict and violence.
We provided four versions of ConfliBERT:
<ol>
<li>ConfliBERT-scr-uncased: Pretraining from scratch with our own uncased vocabulary (preferred)</li>
<li>ConfliBERT-scr-cased: Pretraining from scratch with our own cased vocabulary</li>
<li>ConfliBERT-cont-uncased: Continual pretraining with original BERT's uncased vocabulary</li>
<li>ConfliBERT-cont-cased: Continual pretraining with original BERT's cased vocabulary</li>
</ol>
See more details in https://github.com/eventdata/ConfliBERT/
|
teacookies/autonlp-more_fine_tune_24465520-26265908
|
c935bca0d7748cdbaad58100718074cedf186ae7
|
2021-10-25T09:36:35.000Z
|
[
"pytorch",
"xlm-roberta",
"question-answering",
"unk",
"dataset:teacookies/autonlp-data-more_fine_tune_24465520",
"transformers",
"autonlp",
"co2_eq_emissions",
"autotrain_compatible"
] |
question-answering
| false |
teacookies
| null |
teacookies/autonlp-more_fine_tune_24465520-26265908
| 1,673 | null |
transformers
| 1,453 |
---
tags:
- autonlp
- question-answering
language: unk
widget:
- text: "Who loves AutoNLP?"
context: "Everyone loves AutoNLP"
datasets:
- teacookies/autonlp-data-more_fine_tune_24465520
co2_eq_emissions: 96.32087452115675
---
# Model Trained Using AutoNLP
- Problem type: Extractive Question Answering
- Model ID: 26265908
- CO2 Emissions (in grams): 96.32087452115675
## Validation Metrics
- Loss: 0.5696008801460266
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"question": "Who loves AutoNLP?", "context": "Everyone loves AutoNLP"}' https://api-inference.huggingface.co/models/teacookies/autonlp-more_fine_tune_24465520-26265908
```
Or Python API:
```
import torch
from transformers import AutoModelForQuestionAnswering, AutoTokenizer
model = AutoModelForQuestionAnswering.from_pretrained("teacookies/autonlp-more_fine_tune_24465520-26265908", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("teacookies/autonlp-more_fine_tune_24465520-26265908", use_auth_token=True)
from transformers import BertTokenizer, BertForQuestionAnswering
question, text = "Who loves AutoNLP?", "Everyone loves AutoNLP"
inputs = tokenizer(question, text, return_tensors='pt')
start_positions = torch.tensor([1])
end_positions = torch.tensor([3])
outputs = model(**inputs, start_positions=start_positions, end_positions=end_positions)
loss = outputs.loss
start_scores = outputs.start_logits
end_scores = outputs.end_logits
```
|
vlsb/autotrain-security-texts-classification-distilroberta-688220764
|
ee95129b65b4dda597f9646da574925e92936c5c
|
2022-03-30T20:56:57.000Z
|
[
"pytorch",
"roberta",
"text-classification",
"unk",
"dataset:vlsb/autotrain-data-security-texts-classification-distilroberta",
"transformers",
"autotrain",
"co2_eq_emissions"
] |
text-classification
| false |
vlsb
| null |
vlsb/autotrain-security-texts-classification-distilroberta-688220764
| 1,671 | 1 |
transformers
| 1,454 |
---
tags: autotrain
language: unk
widget:
- text: "I love AutoTrain 🤗"
datasets:
- vlsb/autotrain-data-security-texts-classification-distilroberta
co2_eq_emissions: 2.0817207656772445
---
# Model Trained Using AutoTrain
- Problem type: Binary Classification
- Model ID: 688220764
- CO2 Emissions (in grams): 2.0817207656772445
## Validation Metrics
- Loss: 0.3055502772331238
- Accuracy: 0.9030612244897959
- Precision: 0.9528301886792453
- Recall: 0.8782608695652174
- AUC: 0.9439076757917337
- F1: 0.9140271493212669
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/vlsb/autotrain-security-texts-classification-distilroberta-688220764
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("vlsb/autotrain-security-texts-classification-distilroberta-688220764", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("vlsb/autotrain-security-texts-classification-distilroberta-688220764", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
```
|
speechbrain/emotion-recognition-wav2vec2-IEMOCAP
|
329e6aafdea6b54f56905ed3976e31f973e41422
|
2021-12-20T04:59:17.000Z
|
[
"en",
"dataset:iemocap",
"arxiv:2106.04624",
"speechbrain",
"audio-classification",
"Emotion",
"Recognition",
"wav2vec2",
"pytorch",
"license:apache-2.0"
] |
audio-classification
| false |
speechbrain
| null |
speechbrain/emotion-recognition-wav2vec2-IEMOCAP
| 1,666 | 9 |
speechbrain
| 1,455 |
---
language: "en"
thumbnail:
tags:
- audio-classification
- speechbrain
- Emotion
- Recognition
- wav2vec2
- pytorch
license: "apache-2.0"
datasets:
- iemocap
metrics:
- Accuracy
---
<iframe src="https://ghbtns.com/github-btn.html?user=speechbrain&repo=speechbrain&type=star&count=true&size=large&v=2" frameborder="0" scrolling="0" width="170" height="30" title="GitHub"></iframe>
<br/><br/>
# Emotion Recognition with wav2vec2 base on IEMOCAP
This repository provides all the necessary tools to perform emotion recognition with a fine-tuned wav2vec2 (base) model using SpeechBrain.
It is trained on IEMOCAP training data.
For a better experience, we encourage you to learn more about
[SpeechBrain](https://speechbrain.github.io). The model performance on IEMOCAP test set is:
| Release | Accuracy(%) |
|:-------------:|:--------------:|
| 19-10-21 | 78.7 (Avg: 75.3) |
## Pipeline description
This system is composed of an wav2vec2 model. It is a combination of convolutional and residual blocks. The embeddings are extracted using attentive statistical pooling. The system is trained with Additive Margin Softmax Loss. Speaker Verification is performed using cosine distance between speaker embeddings.
The system is trained with recordings sampled at 16kHz (single channel).
The code will automatically normalize your audio (i.e., resampling + mono channel selection) when calling *classify_file* if needed.
## Install SpeechBrain
First of all, please install the **development** version of SpeechBrain with the following command:
```
pip install speechbrain
```
Please notice that we encourage you to read our tutorials and learn more about
[SpeechBrain](https://speechbrain.github.io).
### Perform Emotion recognition
An external `py_module_file=custom.py` is used as an external Predictor class into this HF repos. We use `foreign_class` function from `speechbrain.pretrained.interfaces` that allow you to load you custom model.
```python
from speechbrain.pretrained.interfaces import foreign_class
classifier = foreign_class(source="speechbrain/emotion-recognition-wav2vec2-IEMOCAP", pymodule_file="custom_interface.py", classname="CustomEncoderWav2vec2Classifier")
out_prob, score, index, text_lab = classifier.classify_file("speechbrain/emotion-recognition-wav2vec2-IEMOCAP/anger.wav")
print(text_lab)
```
The prediction tensor will contain a tuple of (embedding, id_class, label_name).
### Inference on GPU
To perform inference on the GPU, add `run_opts={"device":"cuda"}` when calling the `from_hparams` method.
### Training
The model was trained with SpeechBrain (aa018540).
To train it from scratch follows these steps:
1. Clone SpeechBrain:
```bash
git clone https://github.com/speechbrain/speechbrain/
```
2. Install it:
```
cd speechbrain
pip install -r requirements.txt
pip install -e .
```
3. Run Training:
```
cd recipes/IEMOCAP/emotion_recognition
python train_with_wav2vec2.py hparams/train_with_wav2vec2.yaml --data_folder=your_data_folder
```
You can find our training results (models, logs, etc) [here](https://drive.google.com/drive/folders/15dKQetLuAhSyg4sNOtbSDnuxFdEeU4zQ?usp=sharing).
### Limitations
The SpeechBrain team does not provide any warranty on the performance achieved by this model when used on other datasets.
# **Citing SpeechBrain**
Please, cite SpeechBrain if you use it for your research or business.
```bibtex
@misc{speechbrain,
title={{SpeechBrain}: A General-Purpose Speech Toolkit},
author={Mirco Ravanelli and Titouan Parcollet and Peter Plantinga and Aku Rouhe and Samuele Cornell and Loren Lugosch and Cem Subakan and Nauman Dawalatabad and Abdelwahab Heba and Jianyuan Zhong and Ju-Chieh Chou and Sung-Lin Yeh and Szu-Wei Fu and Chien-Feng Liao and Elena Rastorgueva and François Grondin and William Aris and Hwidong Na and Yan Gao and Renato De Mori and Yoshua Bengio},
year={2021},
eprint={2106.04624},
archivePrefix={arXiv},
primaryClass={eess.AS},
note={arXiv:2106.04624}
}
```
# **About SpeechBrain**
- Website: https://speechbrain.github.io/
- Code: https://github.com/speechbrain/speechbrain/
- HuggingFace: https://huggingface.co/speechbrain/
|
bandainamco-mirai/distilbert-base-japanese
|
f411ce0e53839adab9e39187ef179e3b5c836f7c
|
2020-11-19T13:17:22.000Z
|
[
"pytorch",
"distilbert",
"transformers"
] | null | false |
bandainamco-mirai
| null |
bandainamco-mirai/distilbert-base-japanese
| 1,663 | null |
transformers
| 1,456 |
Entry not found
|
ckiplab/albert-tiny-chinese-ner
|
bcb519856ca93a666b1e48a9daef3f88c9b572a0
|
2022-05-10T03:28:10.000Z
|
[
"pytorch",
"albert",
"token-classification",
"zh",
"transformers",
"license:gpl-3.0",
"autotrain_compatible"
] |
token-classification
| false |
ckiplab
| null |
ckiplab/albert-tiny-chinese-ner
| 1,663 | 1 |
transformers
| 1,457 |
---
language:
- zh
thumbnail: https://ckip.iis.sinica.edu.tw/files/ckip_logo.png
tags:
- pytorch
- token-classification
- albert
- zh
license: gpl-3.0
---
# CKIP ALBERT Tiny Chinese
This project provides traditional Chinese transformers models (including ALBERT, BERT, GPT2) and NLP tools (including word segmentation, part-of-speech tagging, named entity recognition).
這個專案提供了繁體中文的 transformers 模型(包含 ALBERT、BERT、GPT2)及自然語言處理工具(包含斷詞、詞性標記、實體辨識)。
## Homepage
- https://github.com/ckiplab/ckip-transformers
## Contributers
- [Mu Yang](https://muyang.pro) at [CKIP](https://ckip.iis.sinica.edu.tw) (Author & Maintainer)
## Usage
Please use BertTokenizerFast as tokenizer instead of AutoTokenizer.
請使用 BertTokenizerFast 而非 AutoTokenizer。
```
from transformers import (
BertTokenizerFast,
AutoModel,
)
tokenizer = BertTokenizerFast.from_pretrained('bert-base-chinese')
model = AutoModel.from_pretrained('ckiplab/albert-tiny-chinese-ner')
```
For full usage and more information, please refer to https://github.com/ckiplab/ckip-transformers.
有關完整使用方法及其他資訊,請參見 https://github.com/ckiplab/ckip-transformers 。
|
sagorsarker/bangla-bert-base
|
315fa6f024884c29b34a3909a016decc2b068222
|
2021-09-22T09:37:25.000Z
|
[
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"bn",
"dataset:common_crawl",
"dataset:wikipedia",
"dataset:oscar",
"arxiv:1810.04805",
"arxiv:2012.14353",
"arxiv:2104.08613",
"arxiv:2107.03844",
"arxiv:2101.00204",
"transformers",
"bengali",
"bengali-lm",
"bangla",
"license:mit",
"autotrain_compatible"
] |
fill-mask
| false |
sagorsarker
| null |
sagorsarker/bangla-bert-base
| 1,658 | 2 |
transformers
| 1,458 |
---
language: bn
tags:
- bert
- bengali
- bengali-lm
- bangla
license: mit
datasets:
- common_crawl
- wikipedia
- oscar
---
# Bangla BERT Base
A long way passed. Here is our **Bangla-Bert**! It is now available in huggingface model hub.
[Bangla-Bert-Base](https://github.com/sagorbrur/bangla-bert) is a pretrained language model of Bengali language using mask language modeling described in [BERT](https://arxiv.org/abs/1810.04805) and it's github [repository](https://github.com/google-research/bert)
## Pretrain Corpus Details
Corpus was downloaded from two main sources:
* Bengali commoncrawl corpus downloaded from [OSCAR](https://oscar-corpus.com/)
* [Bengali Wikipedia Dump Dataset](https://dumps.wikimedia.org/bnwiki/latest/)
After downloading these corpora, we preprocessed it as a Bert format. which is one sentence per line and an extra newline for new documents.
```
sentence 1
sentence 2
sentence 1
sentence 2
```
## Building Vocab
We used [BNLP](https://github.com/sagorbrur/bnlp) package for training bengali sentencepiece model with vocab size 102025. We preprocess the output vocab file as Bert format.
Our final vocab file availabe at [https://github.com/sagorbrur/bangla-bert](https://github.com/sagorbrur/bangla-bert) and also at [huggingface](https://huggingface.co/sagorsarker/bangla-bert-base) model hub.
## Training Details
* Bangla-Bert was trained with code provided in Google BERT's github repository (https://github.com/google-research/bert)
* Currently released model follows bert-base-uncased model architecture (12-layer, 768-hidden, 12-heads, 110M parameters)
* Total Training Steps: 1 Million
* The model was trained on a single Google Cloud TPU
## Evaluation Results
### LM Evaluation Results
After training 1 million steps here are the evaluation results.
```
global_step = 1000000
loss = 2.2406516
masked_lm_accuracy = 0.60641736
masked_lm_loss = 2.201459
next_sentence_accuracy = 0.98625
next_sentence_loss = 0.040997364
perplexity = numpy.exp(2.2406516) = 9.393331287442784
Loss for final step: 2.426227
```
### Downstream Task Evaluation Results
- Evaluation on Bengali Classification Benchmark Datasets
Huge Thanks to [Nick Doiron](https://twitter.com/mapmeld) for providing evaluation results of the classification task.
He used [Bengali Classification Benchmark](https://github.com/rezacsedu/Classification_Benchmarks_Benglai_NLP) datasets for the classification task.
Comparing to Nick's [Bengali electra](https://huggingface.co/monsoon-nlp/bangla-electra) and multi-lingual BERT, Bangla BERT Base achieves a state of the art result.
Here is the [evaluation script](https://github.com/sagorbrur/bangla-bert/blob/master/notebook/bangla-bert-evaluation-classification-task.ipynb).
| Model | Sentiment Analysis | Hate Speech Task | News Topic Task | Average |
| ----- | -------------------| ---------------- | --------------- | ------- |
| mBERT | 68.15 | 52.32 | 72.27 | 64.25 |
| Bengali Electra | 69.19 | 44.84 | 82.33 | 65.45 |
| Bangla BERT Base | 70.37 | 71.83 | 89.19 | 77.13 |
- Evaluation on [Wikiann](https://huggingface.co/datasets/wikiann) Datasets
We evaluated `Bangla-BERT-Base` with [Wikiann](https://huggingface.co/datasets/wikiann) Bengali NER datasets along with another benchmark three models(mBERT, XLM-R, Indic-BERT). </br>
`Bangla-BERT-Base` got a third-place where `mBERT` got first and `XML-R` got second place after training these models 5 epochs.
| Base Pre-trained Model | F1 Score | Accuracy |
| ----- | -------------------| ---------------- |
| [mBERT-uncased](https://huggingface.co/bert-base-multilingual-uncased) | 97.11 | 97.68 |
| [XLM-R](https://huggingface.co/xlm-roberta-base) | 96.22 | 97.03 |
| [Indic-BERT](https://huggingface.co/ai4bharat/indic-bert)| 92.66 | 94.74 |
| Bangla-BERT-Base | 95.57 | 97.49 |
All four model trained with [transformers-token-classification](https://colab.research.google.com/github/huggingface/notebooks/blob/master/examples/token_classification.ipynb) notebook.
You can find all models evaluation results [here](https://github.com/sagorbrur/bangla-bert/tree/master/evaluations/wikiann)
Also, you can check the below paper list. They used this model on their datasets.
* [DeepHateExplainer: Explainable Hate Speech Detection in Under-resourced Bengali Language](https://arxiv.org/abs/2012.14353)
* [Emotion Classification in a Resource Constrained Language Using Transformer-based Approach](https://arxiv.org/abs/2104.08613)
* [A Review of Bangla Natural Language Processing Tasks and the Utility of Transformer Models](https://arxiv.org/abs/2107.03844)
* [BanglaBERT: Combating Embedding Barrier in Multilingual Models for Low-Resource Language Understanding](https://arxiv.org/abs/2101.00204)
**NB: If you use this model for any NLP task please share evaluation results with us. We will add it here.**
## Limitations and Biases
## How to Use
**Bangla BERT Tokenizer**
```py
from transformers import AutoTokenizer, AutoModel
bnbert_tokenizer = AutoTokenizer.from_pretrained("sagorsarker/bangla-bert-base")
text = "আমি বাংলায় গান গাই।"
bnbert_tokenizer.tokenize(text)
# ['আমি', 'বাংলা', '##য', 'গান', 'গাই', '।']
```
**MASK Generation**
You can use this model directly with a pipeline for masked language modeling:
```py
from transformers import BertForMaskedLM, BertTokenizer, pipeline
model = BertForMaskedLM.from_pretrained("sagorsarker/bangla-bert-base")
tokenizer = BertTokenizer.from_pretrained("sagorsarker/bangla-bert-base")
nlp = pipeline('fill-mask', model=model, tokenizer=tokenizer)
for pred in nlp(f"আমি বাংলায় {nlp.tokenizer.mask_token} গাই।"):
print(pred)
# {'sequence': '[CLS] আমি বাংলায গান গাই । [SEP]', 'score': 0.13404667377471924, 'token': 2552, 'token_str': 'গান'}
```
## Author
[Sagor Sarker](https://github.com/sagorbrur)
## Acknowledgements
* Thanks to Google [TensorFlow Research Cloud (TFRC)](https://www.tensorflow.org/tfrc) for providing the free TPU credits - thank you!
* Thank to all the people around, who always helping us to build something for Bengali.
## Reference
* https://github.com/google-research/bert
## Citation
If you find this model helpful, please cite.
```
@misc{Sagor_2020,
title = {BanglaBERT: Bengali Mask Language Model for Bengali Language Understading},
author = {Sagor Sarker},
year = {2020},
url = {https://github.com/sagorbrur/bangla-bert}
}
```
|
junnyu/roformer_v2_chinese_char_large
|
c48ca62933e39acc9edafbfa7b95fa1497ea8c25
|
2022-05-11T03:32:38.000Z
|
[
"pytorch",
"roformer",
"fill-mask",
"zh",
"arxiv:2104.09864",
"transformers",
"roformer-v2",
"tf2.0",
"autotrain_compatible"
] |
fill-mask
| false |
junnyu
| null |
junnyu/roformer_v2_chinese_char_large
| 1,657 | null |
transformers
| 1,459 |
---
language: zh
tags:
- roformer-v2
- pytorch
- tf2.0
inference: False
---
## 介绍
### tf版本
https://github.com/ZhuiyiTechnology/roformer-v2
### pytorch版本+tf2.0版本
https://github.com/JunnYu/RoFormer_pytorch
## 评测对比
### CLUE-dev榜单分类任务结果,base+large版本。
| | iflytek | tnews | afqmc | cmnli | ocnli | wsc | csl |
| :-----: | :-----: | :---: | :---: | :---: | :---: | :---: | :---: |
| BERT | 60.06 | 56.80 | 72.41 | 79.56 | 73.93 | 78.62 | 83.93 |
| RoBERTa | 60.64 | 58.06 | 74.05 | 81.24 | 76.00 | 87.50 | 84.50 |
| RoFormer | 60.91 | 57.54 | 73.52 | 80.92 | 76.07 | 86.84 | 84.63 |
| RoFormerV2<sup>*</sup> | 60.87 | 56.54 | 72.75 | 80.34 | 75.36 | 80.92 | 84.67 |
| GAU-α | 61.41 | 57.76 | 74.17 | 81.82 | 75.86 | 79.93 | 85.67 |
| RoFormer-pytorch(本仓库代码) | 60.60 | 57.51 | 74.44 | 80.79 | 75.67 | 86.84 | 84.77 |
| RoFormerV2-pytorch(本仓库代码) | **62.87** | 59.03 | **76.20** | 80.85 | 79.73 | 87.82 | **91.87** |
| GAU-α-pytorch(Adafactor) | 61.18 | 57.52 | 73.42 | 80.91 | 75.69 | 80.59 | 85.5 |
| GAU-α-pytorch(AdamW wd0.01 warmup0.1) | 60.68 | 57.95 | 73.08 | 81.02 | 75.36 | 81.25 | 83.93 |
| RoFormerV2-large-pytorch(本仓库代码) | 61.75 | **59.21** | 76.14 | 82.35 | **81.73** | **91.45** | 91.5 |
| Chinesebert-large-pytorch | 61.25 | 58.67 | 74.70 | **82.65** | 79.63 | 87.83 | 84.97 |
### CLUE-1.0-test榜单分类任务结果,base+large版本。
| | iflytek | tnews | afqmc | cmnli | ocnli | wsc | csl |
| :-----: | :-----: | :---: | :---: | :---: | :---: | :---: | :---: |
| RoFormer-pytorch(本仓库代码) | 59.54 | 57.34 | 74.46 | 80.23 | 73.67 | 80.69 | 84.57 |
| RoFormerV2-pytorch(本仓库代码) | **63.15** | 58.24 | 75.42 | 80.59 | 74.17 | 83.79 | 83.73 |
| GAU-α-pytorch(Adafactor) | 61.38 | 57.08 | 74.05 | 80.37 | 73.53 | 74.83 | **85.6** |
| GAU-α-pytorch(AdamW wd0.01 warmup0.1) | 60.54 | 57.67 | 72.44 | 80.32 | 72.97 | 76.55 | 84.13 |
| RoFormerV2-large-pytorch(本仓库代码) | 61.85 | **59.13** | **76.38** | 80.97 | 76.23 | **85.86** | 84.33 |
| Chinesebert-large-pytorch | 61.54 | 58.57 | 74.8 | **81.94** | **76.93** | 79.66 | 85.1 |
### 注:
- 其中RoFormerV2<sup>*</sup>表示的是未进行多任务学习的RoFormerV2模型,该模型苏神并未开源,感谢苏神的提醒。
- 其中不带有pytorch后缀结果都是从[GAU-alpha](https://github.com/ZhuiyiTechnology/GAU-alpha)仓库复制过来的。
- 其中带有pytorch后缀的结果都是自己训练得出的。
- 苏神代码中拿了cls标签后直接进行了分类,而本仓库使用了如下的分类头,多了2个dropout,1个dense,1个relu激活。
```python
class RoFormerClassificationHead(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.out_proj = nn.Linear(config.hidden_size, config.num_labels)
self.config = config
def forward(self, features, **kwargs):
x = features[:, 0, :] # take <s> token (equiv. to [CLS])
x = self.dropout(x)
x = self.dense(x)
x = ACT2FN[self.config.hidden_act](x) # 这里是relu
x = self.dropout(x)
x = self.out_proj(x)
return x
```
### 安装
- pip install roformer==0.4.3
## pytorch & tf2.0使用
```python
import torch
import tensorflow as tf
from transformers import BertTokenizer
from roformer import RoFormerForMaskedLM, TFRoFormerForMaskedLM
text = "今天[MASK]很好,我[MASK]去公园玩。"
tokenizer = BertTokenizer.from_pretrained("junnyu/roformer_v2_chinese_char_large")
pt_model = RoFormerForMaskedLM.from_pretrained("junnyu/roformer_v2_chinese_char_large")
tf_model = TFRoFormerForMaskedLM.from_pretrained(
"junnyu/roformer_v2_chinese_char_base", from_pt=True
)
pt_inputs = tokenizer(text, return_tensors="pt")
tf_inputs = tokenizer(text, return_tensors="tf")
# pytorch
with torch.no_grad():
pt_outputs = pt_model(**pt_inputs).logits[0]
pt_outputs_sentence = "pytorch: "
for i, id in enumerate(tokenizer.encode(text)):
if id == tokenizer.mask_token_id:
tokens = tokenizer.convert_ids_to_tokens(pt_outputs[i].topk(k=5)[1])
pt_outputs_sentence += "[" + "||".join(tokens) + "]"
else:
pt_outputs_sentence += "".join(
tokenizer.convert_ids_to_tokens([id], skip_special_tokens=True)
)
print(pt_outputs_sentence)
# tf
tf_outputs = tf_model(**tf_inputs, training=False).logits[0]
tf_outputs_sentence = "tf: "
for i, id in enumerate(tokenizer.encode(text)):
if id == tokenizer.mask_token_id:
tokens = tokenizer.convert_ids_to_tokens(tf.math.top_k(tf_outputs[i], k=5)[1])
tf_outputs_sentence += "[" + "||".join(tokens) + "]"
else:
tf_outputs_sentence += "".join(
tokenizer.convert_ids_to_tokens([id], skip_special_tokens=True)
)
print(tf_outputs_sentence)
# small
# pytorch: 今天[的||,||是||很||也]很好,我[要||会||是||想||在]去公园玩。
# tf: 今天[的||,||是||很||也]很好,我[要||会||是||想||在]去公园玩。
# base
# pytorch: 今天[我||天||晴||园||玩]很好,我[想||要||会||就||带]去公园玩。
# tf: 今天[我||天||晴||园||玩]很好,我[想||要||会||就||带]去公园玩。
# large
# pytorch: 今天[天||气||我||空||阳]很好,我[又||想||会||就||爱]去公园玩。
# tf: 今天[天||气||我||空||阳]很好,我[又||想||会||就||爱]去公园玩。
```
## 引用
Bibtex:
```tex
@misc{su2021roformer,
title={RoFormer: Enhanced Transformer with Rotary Position Embedding},
author={Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu},
year={2021},
eprint={2104.09864},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
```tex
@techreport{roformerv2,
title={RoFormerV2: A Faster and Better RoFormer - ZhuiyiAI},
author={Jianlin Su, Shengfeng Pan, Bo Wen, Yunfeng Liu},
year={2022},
url="https://github.com/ZhuiyiTechnology/roformer-v2",
}
```
|
csarron/roberta-base-squad-v1
|
b78e35e447d75d01d5f0c7d292a050fe6e2577b5
|
2021-05-20T15:50:01.000Z
|
[
"pytorch",
"jax",
"roberta",
"question-answering",
"en",
"dataset:squad",
"arxiv:1907.11692",
"transformers",
"roberta-base",
"license:mit",
"autotrain_compatible"
] |
question-answering
| false |
csarron
| null |
csarron/roberta-base-squad-v1
| 1,656 | null |
transformers
| 1,460 |
---
language: en
thumbnail:
license: mit
tags:
- question-answering
- roberta
- roberta-base
datasets:
- squad
metrics:
- squad
widget:
- text: "Which name is also used to describe the Amazon rainforest in English?"
context: "The Amazon rainforest (Portuguese: Floresta Amazônica or Amazônia; Spanish: Selva Amazónica, Amazonía or usually Amazonia; French: Forêt amazonienne; Dutch: Amazoneregenwoud), also known in English as Amazonia or the Amazon Jungle, is a moist broadleaf forest that covers most of the Amazon basin of South America. This basin encompasses 7,000,000 square kilometres (2,700,000 sq mi), of which 5,500,000 square kilometres (2,100,000 sq mi) are covered by the rainforest. This region includes territory belonging to nine nations. The majority of the forest is contained within Brazil, with 60% of the rainforest, followed by Peru with 13%, Colombia with 10%, and with minor amounts in Venezuela, Ecuador, Bolivia, Guyana, Suriname and French Guiana. States or departments in four nations contain \"Amazonas\" in their names. The Amazon represents over half of the planet's remaining rainforests, and comprises the largest and most biodiverse tract of tropical rainforest in the world, with an estimated 390 billion individual trees divided into 16,000 species."
- text: "How many square kilometers of rainforest is covered in the basin?"
context: "The Amazon rainforest (Portuguese: Floresta Amazônica or Amazônia; Spanish: Selva Amazónica, Amazonía or usually Amazonia; French: Forêt amazonienne; Dutch: Amazoneregenwoud), also known in English as Amazonia or the Amazon Jungle, is a moist broadleaf forest that covers most of the Amazon basin of South America. This basin encompasses 7,000,000 square kilometres (2,700,000 sq mi), of which 5,500,000 square kilometres (2,100,000 sq mi) are covered by the rainforest. This region includes territory belonging to nine nations. The majority of the forest is contained within Brazil, with 60% of the rainforest, followed by Peru with 13%, Colombia with 10%, and with minor amounts in Venezuela, Ecuador, Bolivia, Guyana, Suriname and French Guiana. States or departments in four nations contain \"Amazonas\" in their names. The Amazon represents over half of the planet's remaining rainforests, and comprises the largest and most biodiverse tract of tropical rainforest in the world, with an estimated 390 billion individual trees divided into 16,000 species."
---
## RoBERTa-base fine-tuned on SQuAD v1
This model was fine-tuned from the HuggingFace [RoBERTa](https://arxiv.org/abs/1907.11692) base checkpoint on [SQuAD1.1](https://rajpurkar.github.io/SQuAD-explorer).
This model is case-sensitive: it makes a difference between english and English.
## Details
| Dataset | Split | # samples |
| -------- | ----- | --------- |
| SQuAD1.1 | train | 96.8K |
| SQuAD1.1 | eval | 11.8k |
### Fine-tuning
- Python: `3.7.5`
- Machine specs:
`CPU: Intel(R) Core(TM) i7-6800K CPU @ 3.40GHz`
`Memory: 32 GiB`
`GPUs: 2 GeForce GTX 1070, each with 8GiB memory`
`GPU driver: 418.87.01, CUDA: 10.1`
- script:
```shell
# after install https://github.com/huggingface/transformers
cd examples/question-answering
mkdir -p data
wget -O data/train-v1.1.json https://rajpurkar.github.io/SQuAD-explorer/dataset/train-v1.1.json
wget -O data/dev-v1.1.json https://rajpurkar.github.io/SQuAD-explorer/dataset/dev-v1.1.json
python run_energy_squad.py \
--model_type roberta \
--model_name_or_path roberta-base \
--do_train \
--do_eval \
--train_file train-v1.1.json \
--predict_file dev-v1.1.json \
--per_gpu_train_batch_size 12 \
--per_gpu_eval_batch_size 16 \
--learning_rate 3e-5 \
--num_train_epochs 2.0 \
--max_seq_length 320 \
--doc_stride 128 \
--data_dir data \
--output_dir data/roberta-base-squad-v1 2>&1 | tee train-roberta-base-squad-v1.log
```
It took about 2 hours to finish.
### Results
**Model size**: `477M`
| Metric | # Value |
| ------ | --------- |
| **EM** | **83.0** |
| **F1** | **90.4** |
Note that the above results didn't involve any hyperparameter search.
## Example Usage
```python
from transformers import pipeline
qa_pipeline = pipeline(
"question-answering",
model="csarron/roberta-base-squad-v1",
tokenizer="csarron/roberta-base-squad-v1"
)
predictions = qa_pipeline({
'context': "The game was played on February 7, 2016 at Levi's Stadium in the San Francisco Bay Area at Santa Clara, California.",
'question': "What day was the game played on?"
})
print(predictions)
# output:
# {'score': 0.8625259399414062, 'start': 23, 'end': 39, 'answer': 'February 7, 2016'}
```
> Created by [Qingqing Cao](https://awk.ai/) | [GitHub](https://github.com/csarron) | [Twitter](https://twitter.com/sysnlp)
> Made with ❤️ in New York.
|
dbmdz/electra-base-german-europeana-cased-discriminator
|
fd360cf0d306bcd12e7dc369087391a1ee9a4f77
|
2020-07-26T00:39:57.000Z
|
[
"pytorch",
"tf",
"electra",
"pretraining",
"transformers"
] | null | false |
dbmdz
| null |
dbmdz/electra-base-german-europeana-cased-discriminator
| 1,653 | null |
transformers
| 1,461 |
Entry not found
|
salesken/query_wellformedness_score
|
433e0f21cf2f77bd95360bcf556e5ab4de15284d
|
2021-05-20T20:07:29.000Z
|
[
"pytorch",
"jax",
"roberta",
"text-classification",
"dataset:google_wellformed_query",
"transformers",
"salesken",
"license:apache-2.0"
] |
text-classification
| false |
salesken
| null |
salesken/query_wellformedness_score
| 1,645 | 1 |
transformers
| 1,462 |
---
tags: salesken
license: apache-2.0
inference: true
datasets: google_wellformed_query
widget:
- text: "what was the reason for everyone for leave the company"
---
This model evaluates the wellformedness (non-fragment, grammatically correct) score of a sentence. Model is case-sensitive and penalises for incorrect case and grammar as well.
['She is presenting a paper tomorrow','she is presenting a paper tomorrow','She present paper today']
[[0.8917],[0.4270],[0.0134]]
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("salesken/query_wellformedness_score")
model = AutoModelForSequenceClassification.from_pretrained("salesken/query_wellformedness_score")
sentences = [' what was the reason for everyone to leave the company ',
' What was the reason behind everyone leaving the company ',
' why was everybody leaving the company ',
' what was the reason to everyone leave the company ',
' what be the reason for everyone to leave the company ',
' what was the reasons for everyone to leave the company ',
' what were the reasons for everyone to leave the company ']
features = tokenizer(sentences, padding=True, truncation=True, return_tensors="pt")
model.eval()
with torch.no_grad():
scores = model(**features).logits
print(scores)
```
|
uer/chinese_roberta_L-8_H-512
|
5f765ccfd73b81737a1cad3d83c9ebe0172a8f06
|
2022-07-15T08:14:15.000Z
|
[
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"zh",
"dataset:CLUECorpusSmall",
"arxiv:1909.05658",
"arxiv:1908.08962",
"transformers",
"autotrain_compatible"
] |
fill-mask
| false |
uer
| null |
uer/chinese_roberta_L-8_H-512
| 1,644 | 1 |
transformers
| 1,463 |
---
language: zh
datasets: CLUECorpusSmall
widget:
- text: "北京是[MASK]国的首都。"
---
# Chinese RoBERTa Miniatures
## Model description
This is the set of 24 Chinese RoBERTa models pre-trained by [UER-py](https://github.com/dbiir/UER-py/), which is introduced in [this paper](https://arxiv.org/abs/1909.05658).
[Turc et al.](https://arxiv.org/abs/1908.08962) have shown that the standard BERT recipe is effective on a wide range of model sizes. Following their paper, we released the 24 Chinese RoBERTa models. In order to facilitate users to reproduce the results, we used the publicly available corpus and provided all training details.
You can download the 24 Chinese RoBERTa miniatures either from the [UER-py Modelzoo page](https://github.com/dbiir/UER-py/wiki/Modelzoo), or via HuggingFace from the links below:
| | H=128 | H=256 | H=512 | H=768 |
| -------- | :-----------------------: | :-----------------------: | :-------------------------: | :-------------------------: |
| **L=2** | [**2/128 (Tiny)**][2_128] | [2/256][2_256] | [2/512][2_512] | [2/768][2_768] |
| **L=4** | [4/128][4_128] | [**4/256 (Mini)**][4_256] | [**4/512 (Small)**][4_512] | [4/768][4_768] |
| **L=6** | [6/128][6_128] | [6/256][6_256] | [6/512][6_512] | [6/768][6_768] |
| **L=8** | [8/128][8_128] | [8/256][8_256] | [**8/512 (Medium)**][8_512] | [8/768][8_768] |
| **L=10** | [10/128][10_128] | [10/256][10_256] | [10/512][10_512] | [10/768][10_768] |
| **L=12** | [12/128][12_128] | [12/256][12_256] | [12/512][12_512] | [**12/768 (Base)**][12_768] |
Here are scores on the devlopment set of six Chinese tasks:
| Model | Score | douban | chnsenticorp | lcqmc | tnews(CLUE) | iflytek(CLUE) | ocnli(CLUE) |
| -------------- | :---: | :----: | :----------: | :---: | :---------: | :-----------: | :---------: |
| RoBERTa-Tiny | 72.3 | 83.0 | 91.4 | 81.8 | 62.0 | 55.0 | 60.3 |
| RoBERTa-Mini | 75.7 | 84.8 | 93.7 | 86.1 | 63.9 | 58.3 | 67.4 |
| RoBERTa-Small | 76.8 | 86.5 | 93.4 | 86.5 | 65.1 | 59.4 | 69.7 |
| RoBERTa-Medium | 77.8 | 87.6 | 94.8 | 88.1 | 65.6 | 59.5 | 71.2 |
| RoBERTa-Base | 79.5 | 89.1 | 95.2 | 89.2 | 67.0 | 60.9 | 75.5 |
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained with the sequence length of 128:
- epochs: 3, 5, 8
- batch sizes: 32, 64
- learning rates: 3e-5, 1e-4, 3e-4
## How to use
You can use this model directly with a pipeline for masked language modeling (take the case of RoBERTa-Medium):
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='uer/chinese_roberta_L-8_H-512')
>>> unmasker("中国的首都是[MASK]京。")
[
{'sequence': '[CLS] 中 国 的 首 都 是 北 京 。 [SEP]',
'score': 0.8701988458633423,
'token': 1266,
'token_str': '北'},
{'sequence': '[CLS] 中 国 的 首 都 是 南 京 。 [SEP]',
'score': 0.1194809079170227,
'token': 1298,
'token_str': '南'},
{'sequence': '[CLS] 中 国 的 首 都 是 东 京 。 [SEP]',
'score': 0.0037803512532263994,
'token': 691,
'token_str': '东'},
{'sequence': '[CLS] 中 国 的 首 都 是 普 京 。 [SEP]',
'score': 0.0017127094324678183,
'token': 3249,
'token_str': '普'},
{'sequence': '[CLS] 中 国 的 首 都 是 望 京 。 [SEP]',
'score': 0.001687526935711503,
'token': 3307,
'token_str': '望'}
]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('uer/chinese_roberta_L-8_H-512')
model = BertModel.from_pretrained("uer/chinese_roberta_L-8_H-512")
text = "用你喜欢的任何文本替换我。"
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import BertTokenizer, TFBertModel
tokenizer = BertTokenizer.from_pretrained('uer/chinese_roberta_L-8_H-512')
model = TFBertModel.from_pretrained("uer/chinese_roberta_L-8_H-512")
text = "用你喜欢的任何文本替换我。"
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
## Training data
[CLUECorpusSmall](https://github.com/CLUEbenchmark/CLUECorpus2020/) is used as training data. We found that models pre-trained on CLUECorpusSmall outperform those pre-trained on CLUECorpus2020, although CLUECorpus2020 is much larger than CLUECorpusSmall.
## Training procedure
Models are pre-trained by [UER-py](https://github.com/dbiir/UER-py/) on [Tencent Cloud](https://cloud.tencent.com/). We pre-train 1,000,000 steps with a sequence length of 128 and then pre-train 250,000 additional steps with a sequence length of 512. We use the same hyper-parameters on different model sizes.
Taking the case of RoBERTa-Medium
Stage1:
```
python3 preprocess.py --corpus_path corpora/cluecorpussmall.txt \
--vocab_path models/google_zh_vocab.txt \
--dataset_path cluecorpussmall_seq128_dataset.pt \
--processes_num 32 --seq_length 128 \
--dynamic_masking --data_processor mlm
```
```
python3 pretrain.py --dataset_path cluecorpussmall_seq128_dataset.pt \
--vocab_path models/google_zh_vocab.txt \
--config_path models/bert/medium_config.json \
--output_model_path models/cluecorpussmall_roberta_medium_seq128_model.bin \
--world_size 8 --gpu_ranks 0 1 2 3 4 5 6 7 \
--total_steps 1000000 --save_checkpoint_steps 100000 --report_steps 50000 \
--learning_rate 1e-4 --batch_size 64 \
--data_processor mlm --target mlm
```
Stage2:
```
python3 preprocess.py --corpus_path corpora/cluecorpussmall.txt \
--vocab_path models/google_zh_vocab.txt \
--dataset_path cluecorpussmall_seq512_dataset.pt \
--processes_num 32 --seq_length 512 \
--dynamic_masking --data_processor mlm
```
```
python3 pretrain.py --dataset_path cluecorpussmall_seq512_dataset.pt \
--vocab_path models/google_zh_vocab.txt \
--pretrained_model_path models/cluecorpussmall_roberta_medium_seq128_model.bin-1000000 \
--config_path models/bert/medium_config.json \
--output_model_path models/cluecorpussmall_roberta_medium_seq512_model.bin \
--world_size 8 --gpu_ranks 0 1 2 3 4 5 6 7 \
--total_steps 250000 --save_checkpoint_steps 50000 --report_steps 10000 \
--learning_rate 5e-5 --batch_size 16 \
--data_processor mlm --target mlm
```
Finally, we convert the pre-trained model into Huggingface's format:
```
python3 scripts/convert_bert_from_uer_to_huggingface.py --input_model_path models/cluecorpussmall_roberta_medium_seq512_model.bin-250000 \
--output_model_path pytorch_model.bin \
--layers_num 8 --type mlm
```
### BibTeX entry and citation info
```
@article{devlin2018bert,
title={Bert: Pre-training of deep bidirectional transformers for language understanding},
author={Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1810.04805},
year={2018}
}
@article{liu2019roberta,
title={Roberta: A robustly optimized bert pretraining approach},
author={Liu, Yinhan and Ott, Myle and Goyal, Naman and Du, Jingfei and Joshi, Mandar and Chen, Danqi and Levy, Omer and Lewis, Mike and Zettlemoyer, Luke and Stoyanov, Veselin},
journal={arXiv preprint arXiv:1907.11692},
year={2019}
}
@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}
@article{zhao2019uer,
title={UER: An Open-Source Toolkit for Pre-training Models},
author={Zhao, Zhe and Chen, Hui and Zhang, Jinbin and Zhao, Xin and Liu, Tao and Lu, Wei and Chen, Xi and Deng, Haotang and Ju, Qi and Du, Xiaoyong},
journal={EMNLP-IJCNLP 2019},
pages={241},
year={2019}
}
```
[2_128]:https://huggingface.co/uer/chinese_roberta_L-2_H-128
[2_256]:https://huggingface.co/uer/chinese_roberta_L-2_H-256
[2_512]:https://huggingface.co/uer/chinese_roberta_L-2_H-512
[2_768]:https://huggingface.co/uer/chinese_roberta_L-2_H-768
[4_128]:https://huggingface.co/uer/chinese_roberta_L-4_H-128
[4_256]:https://huggingface.co/uer/chinese_roberta_L-4_H-256
[4_512]:https://huggingface.co/uer/chinese_roberta_L-4_H-512
[4_768]:https://huggingface.co/uer/chinese_roberta_L-4_H-768
[6_128]:https://huggingface.co/uer/chinese_roberta_L-6_H-128
[6_256]:https://huggingface.co/uer/chinese_roberta_L-6_H-256
[6_512]:https://huggingface.co/uer/chinese_roberta_L-6_H-512
[6_768]:https://huggingface.co/uer/chinese_roberta_L-6_H-768
[8_128]:https://huggingface.co/uer/chinese_roberta_L-8_H-128
[8_256]:https://huggingface.co/uer/chinese_roberta_L-8_H-256
[8_512]:https://huggingface.co/uer/chinese_roberta_L-8_H-512
[8_768]:https://huggingface.co/uer/chinese_roberta_L-8_H-768
[10_128]:https://huggingface.co/uer/chinese_roberta_L-10_H-128
[10_256]:https://huggingface.co/uer/chinese_roberta_L-10_H-256
[10_512]:https://huggingface.co/uer/chinese_roberta_L-10_H-512
[10_768]:https://huggingface.co/uer/chinese_roberta_L-10_H-768
[12_128]:https://huggingface.co/uer/chinese_roberta_L-12_H-128
[12_256]:https://huggingface.co/uer/chinese_roberta_L-12_H-256
[12_512]:https://huggingface.co/uer/chinese_roberta_L-12_H-512
[12_768]:https://huggingface.co/uer/chinese_roberta_L-12_H-768
|
Salesforce/mixqg-large
|
d48d020e3b3ab8f191dc4c5dc0e43ce97abd4224
|
2021-10-18T16:21:59.000Z
|
[
"pytorch",
"t5",
"text2text-generation",
"en",
"arxiv:2110.08175",
"transformers",
"autotrain_compatible"
] |
text2text-generation
| false |
Salesforce
| null |
Salesforce/mixqg-large
| 1,641 | 3 |
transformers
| 1,464 |
---
language: en
widget:
- text: Robert Boyle \\n In the late 17th century, Robert Boyle proved that air is necessary for combustion.
---
# MixQG (large-sized model)
MixQG is a new question generation model pre-trained on a collection of QA datasets with a mix of answer types. It was introduced in the paper [MixQG: Neural Question Generation with Mixed Answer Types](https://arxiv.org/abs/2110.08175) and the associated code is released in [this](https://github.com/salesforce/QGen) repository.
### How to use
Using Huggingface pipeline abstraction:
```
from transformers import pipeline
nlp = pipeline("text2text-generation", model='Salesforce/mixqg-large', tokenizer='Salesforce/mixqg-large')
CONTEXT = "In the late 17th century, Robert Boyle proved that air is necessary for combustion."
ANSWER = "Robert Boyle"
def format_inputs(context: str, answer: str):
return f"{answer} \\n {context}"
text = format_inputs(CONTEXT, ANSWER)
nlp(text)
# should output [{'generated_text': 'Who proved that air is necessary for combustion?'}]
```
Using the pre-trained model directly:
```
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained('Salesforce/mixqg-large')
model = AutoModelForSeq2SeqLM.from_pretrained('Salesforce/mixqg-large')
CONTEXT = "In the late 17th century, Robert Boyle proved that air is necessary for combustion."
ANSWER = "Robert Boyle"
def format_inputs(context: str, answer: str):
return f"{answer} \\n {context}"
text = format_inputs(CONTEXT, ANSWER)
input_ids = tokenizer(text, return_tensors="pt").input_ids
generated_ids = model.generate(input_ids, max_length=32, num_beams=4)
output = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
print(output)
# should output "Who proved that air is necessary for combustion?"
```
### Citation
```
@misc{murakhovska2021mixqg,
title={MixQG: Neural Question Generation with Mixed Answer Types},
author={Lidiya Murakhovs'ka and Chien-Sheng Wu and Tong Niu and Wenhao Liu and Caiming Xiong},
year={2021},
eprint={2110.08175},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
asahi417/tner-xlm-roberta-base-all-english
|
60ae6ebf1575715c63499ce4b39494c991b01505
|
2021-02-12T23:31:37.000Z
|
[
"pytorch",
"xlm-roberta",
"token-classification",
"transformers",
"autotrain_compatible"
] |
token-classification
| false |
asahi417
| null |
asahi417/tner-xlm-roberta-base-all-english
| 1,641 | null |
transformers
| 1,465 |
# XLM-RoBERTa for NER
XLM-RoBERTa finetuned on NER. Check more detail at [TNER repository](https://github.com/asahi417/tner).
## Usage
```
from transformers import AutoTokenizer, AutoModelForTokenClassification
tokenizer = AutoTokenizer.from_pretrained("asahi417/tner-xlm-roberta-base-all-english")
model = AutoModelForTokenClassification.from_pretrained("asahi417/tner-xlm-roberta-base-all-english")
```
|
mrm8488/codebert-base-finetuned-detect-insecure-code
|
78b753c76bd0334482d9db595af64421c20da6df
|
2021-05-20T18:19:02.000Z
|
[
"pytorch",
"jax",
"roberta",
"text-classification",
"en",
"dataset:codexglue",
"arxiv:2002.08155",
"arxiv:1907.11692",
"transformers"
] |
text-classification
| false |
mrm8488
| null |
mrm8488/codebert-base-finetuned-detect-insecure-code
| 1,640 | 1 |
transformers
| 1,466 |
---
language: en
datasets:
- codexglue
---
# CodeBERT fine-tuned for Insecure Code Detection 💾⛔
[codebert-base](https://huggingface.co/microsoft/codebert-base) fine-tuned on [CodeXGLUE -- Defect Detection](https://github.com/microsoft/CodeXGLUE/tree/main/Code-Code/Defect-detection) dataset for **Insecure Code Detection** downstream task.
## Details of [CodeBERT](https://arxiv.org/abs/2002.08155)
We present CodeBERT, a bimodal pre-trained model for programming language (PL) and nat-ural language (NL). CodeBERT learns general-purpose representations that support downstream NL-PL applications such as natural language codesearch, code documentation generation, etc. We develop CodeBERT with Transformer-based neural architecture, and train it with a hybrid objective function that incorporates the pre-training task of replaced token detection, which is to detect plausible alternatives sampled from generators. This enables us to utilize both bimodal data of NL-PL pairs and unimodal data, where the former provides input tokens for model training while the latter helps to learn better generators. We evaluate CodeBERT on two NL-PL applications by fine-tuning model parameters. Results show that CodeBERT achieves state-of-the-art performance on both natural language code search and code documentation generation tasks. Furthermore, to investigate what type of knowledge is learned in CodeBERT, we construct a dataset for NL-PL probing, and evaluate in a zero-shot setting where parameters of pre-trained models are fixed. Results show that CodeBERT performs better than previous pre-trained models on NL-PL probing.
## Details of the downstream task (code classification) - Dataset 📚
Given a source code, the task is to identify whether it is an insecure code that may attack software systems, such as resource leaks, use-after-free vulnerabilities and DoS attack. We treat the task as binary classification (0/1), where 1 stands for insecure code and 0 for secure code.
The [dataset](https://github.com/microsoft/CodeXGLUE/tree/main/Code-Code/Defect-detection) used comes from the paper [*Devign*: Effective Vulnerability Identification by Learning Comprehensive Program Semantics via Graph Neural Networks](http://papers.nips.cc/paper/9209-devign-effective-vulnerability-identification-by-learning-comprehensive-program-semantics-via-graph-neural-networks.pdf). All projects are combined and splitted 80%/10%/10% for training/dev/test.
Data statistics of the dataset are shown in the below table:
| | #Examples |
| ----- | :-------: |
| Train | 21,854 |
| Dev | 2,732 |
| Test | 2,732 |
## Test set metrics 🧾
| Methods | ACC |
| -------- | :-------: |
| BiLSTM | 59.37 |
| TextCNN | 60.69 |
| [RoBERTa](https://arxiv.org/pdf/1907.11692.pdf) | 61.05 |
| [CodeBERT](https://arxiv.org/pdf/2002.08155.pdf) | 62.08 |
| [Ours](https://huggingface.co/mrm8488/codebert-base-finetuned-detect-insecure-code) | **65.30** |
## Model in Action 🚀
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
import numpy as np
tokenizer = AutoTokenizer.from_pretrained('mrm8488/codebert-base-finetuned-detect-insecure-code')
model = AutoModelForSequenceClassification.from_pretrained('mrm8488/codebert-base-finetuned-detect-insecure-code')
inputs = tokenizer("your code here", return_tensors="pt", truncation=True, padding='max_length')
labels = torch.tensor([1]).unsqueeze(0) # Batch size 1
outputs = model(**inputs, labels=labels)
loss = outputs.loss
logits = outputs.logits
print(np.argmax(logits.detach().numpy()))
```
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488) | [LinkedIn](https://www.linkedin.com/in/manuel-romero-cs/)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
Salesforce/codegen-6B-mono
|
ee4939ba1571e438943a817b0104c5de9c5e99c1
|
2022-06-28T17:43:42.000Z
|
[
"pytorch",
"codegen",
"text-generation",
"arxiv:2203.13474",
"transformers",
"license:bsd-3-clause"
] |
text-generation
| false |
Salesforce
| null |
Salesforce/codegen-6B-mono
| 1,634 | 1 |
transformers
| 1,467 |
---
license: bsd-3-clause
---
# CodeGen (CodeGen-Mono 6B)
## Model description
CodeGen is a family of autoregressive language models for **program synthesis** from the paper: [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong. The models are originally released in [this repository](https://github.com/salesforce/CodeGen), under 3 pre-training data variants (`NL`, `Multi`, `Mono`) and 4 model size variants (`350M`, `2B`, `6B`, `16B`).
The checkpoint included in this repository is denoted as **CodeGen-Mono 6B** in the paper, where "Mono" means the model is initialized with *CodeGen-Multi 6B* and further pre-trained on a Python programming language dataset, and "6B" refers to the number of trainable parameters.
## Training data
This checkpoint (CodeGen-Mono 6B) was firstly initialized with *CodeGen-Multi 6B*, and then pre-trained on BigPython dataset. The data consists of 71.7B tokens of Python programming language. See Section 2.1 of the [paper](https://arxiv.org/abs/2203.13474) for more details.
## Training procedure
CodeGen was trained using cross-entropy loss to maximize the likelihood of sequential inputs.
The family of models are trained using multiple TPU-v4-512 by Google, leveraging data and model parallelism.
See Section 2.3 of the [paper](https://arxiv.org/abs/2203.13474) for more details.
## Evaluation results
We evaluate our models on two code generation benchmark: HumanEval and MTPB. Please refer to the [paper](https://arxiv.org/abs/2203.13474) for more details.
## Intended Use and Limitations
As an autoregressive language model, CodeGen is capable of extracting features from given natural language and programming language texts, and calculating the likelihood of them.
However, the model is intended for and best at **program synthesis**, that is, generating executable code given English prompts, where the prompts should be in the form of a comment string. The model can complete partially-generated code as well.
## How to use
This model can be easily loaded using the `AutoModelForCausalLM` functionality:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("Salesforce/codegen-6B-mono")
model = AutoModelForCausalLM.from_pretrained("Salesforce/codegen-6B-mono")
text = "def hello_world():"
input_ids = tokenizer(text, return_tensors="pt").input_ids
generated_ids = model.generate(input_ids, max_length=128)
print(tokenizer.decode(generated_ids[0], skip_special_tokens=True))
```
## BibTeX entry and citation info
```bibtex
@article{Nijkamp2022ACP,
title={A Conversational Paradigm for Program Synthesis},
author={Nijkamp, Erik and Pang, Bo and Hayashi, Hiroaki and Tu, Lifu and Wang, Huan and Zhou, Yingbo and Savarese, Silvio and Xiong, Caiming},
journal={arXiv preprint},
year={2022}
}
```
|
google/tapas-base-finetuned-wikisql-supervised
|
3471befc23f84d2105be2961d5190e451eb5435d
|
2021-11-29T13:05:40.000Z
|
[
"pytorch",
"tf",
"tapas",
"table-question-answering",
"en",
"dataset:wikisql",
"arxiv:2004.02349",
"arxiv:2010.00571",
"arxiv:1709.00103",
"transformers",
"license:apache-2.0"
] |
table-question-answering
| false |
google
| null |
google/tapas-base-finetuned-wikisql-supervised
| 1,633 | 1 |
transformers
| 1,468 |
---
language: en
tags:
- tapas
license: apache-2.0
datasets:
- wikisql
---
# TAPAS base model fine-tuned on WikiSQL (in a supervised fashion)
his model has 2 versions which can be used. The default version corresponds to the `tapas_wikisql_sqa_inter_masklm_base_reset` checkpoint of the [original Github repository](https://github.com/google-research/tapas).
This model was pre-trained on MLM and an additional step which the authors call intermediate pre-training, and then fine-tuned in a chain on [SQA](https://www.microsoft.com/en-us/download/details.aspx?id=54253), and [WikiSQL](https://github.com/salesforce/WikiSQL). It uses relative position embeddings (i.e. resetting the position index at every cell of the table).
The other (non-default) version which can be used is:
- `no_reset`, which corresponds to `tapas_wikisql_sqa_inter_masklm_base` (intermediate pre-training, absolute position embeddings).
Disclaimer: The team releasing TAPAS did not write a model card for this model so this model card has been written by
the Hugging Face team and contributors.
## Model description
TAPAS is a BERT-like transformers model pretrained on a large corpus of English data from Wikipedia in a self-supervised fashion.
This means it was pretrained on the raw tables and associated texts only, with no humans labelling them in any way (which is why it
can use lots of publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely, it
was pretrained with two objectives:
- Masked language modeling (MLM): taking a (flattened) table and associated context, the model randomly masks 15% of the words in
the input, then runs the entire (partially masked) sequence through the model. The model then has to predict the masked words.
This is different from traditional recurrent neural networks (RNNs) that usually see the words one after the other,
or from autoregressive models like GPT which internally mask the future tokens. It allows the model to learn a bidirectional
representation of a table and associated text.
- Intermediate pre-training: to encourage numerical reasoning on tables, the authors additionally pre-trained the model by creating
a balanced dataset of millions of syntactically created training examples. Here, the model must predict (classify) whether a sentence
is supported or refuted by the contents of a table. The training examples are created based on synthetic as well as counterfactual statements.
This way, the model learns an inner representation of the English language used in tables and associated texts, which can then be used
to extract features useful for downstream tasks such as answering questions about a table, or determining whether a sentence is entailed
or refuted by the contents of a table. Fine-tuning is done by adding a cell selection head and aggregation head on top of the pre-trained model, and then jointly train these randomly initialized classification heads with the base model on SQA and WikiSQL.
## Intended uses & limitations
You can use this model for answering questions related to a table.
For code examples, we refer to the documentation of TAPAS on the HuggingFace website.
## Training procedure
### Preprocessing
The texts are lowercased and tokenized using WordPiece and a vocabulary size of 30,000. The inputs of the model are
then of the form:
```
[CLS] Question [SEP] Flattened table [SEP]
```
The authors did first convert the WikiSQL dataset into the format of SQA using automatic conversion scripts.
### Fine-tuning
The model was fine-tuned on 32 Cloud TPU v3 cores for 50,000 steps with maximum sequence length 512 and batch size of 512.
In this setup, fine-tuning takes around 10 hours. The optimizer used is Adam with a learning rate of 6.17164e-5, and a warmup
ratio of 0.1424. See the [paper](https://arxiv.org/abs/2004.02349) for more details (tables 11 and 12).
### BibTeX entry and citation info
```bibtex
@misc{herzig2020tapas,
title={TAPAS: Weakly Supervised Table Parsing via Pre-training},
author={Jonathan Herzig and Paweł Krzysztof Nowak and Thomas Müller and Francesco Piccinno and Julian Martin Eisenschlos},
year={2020},
eprint={2004.02349},
archivePrefix={arXiv},
primaryClass={cs.IR}
}
```
```bibtex
@misc{eisenschlos2020understanding,
title={Understanding tables with intermediate pre-training},
author={Julian Martin Eisenschlos and Syrine Krichene and Thomas Müller},
year={2020},
eprint={2010.00571},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
```bibtex
@article{DBLP:journals/corr/abs-1709-00103,
author = {Victor Zhong and
Caiming Xiong and
Richard Socher},
title = {Seq2SQL: Generating Structured Queries from Natural Language using
Reinforcement Learning},
journal = {CoRR},
volume = {abs/1709.00103},
year = {2017},
url = {http://arxiv.org/abs/1709.00103},
archivePrefix = {arXiv},
eprint = {1709.00103},
timestamp = {Mon, 13 Aug 2018 16:48:41 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-1709-00103.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
sultan/BioM-ELECTRA-Base-SQuAD2-BioASQ8B
|
c564bf936854de2131cd090c40db3681406ba783
|
2021-07-24T14:43:28.000Z
|
[
"pytorch",
"electra",
"question-answering",
"transformers",
"autotrain_compatible"
] |
question-answering
| false |
sultan
| null |
sultan/BioM-ELECTRA-Base-SQuAD2-BioASQ8B
| 1,633 | null |
transformers
| 1,469 |
# BioM-Transformers: Building Large Biomedical Language Models with BERT, ALBERT and ELECTRA
# Abstract
The impact of design choices on the performance
of biomedical language models recently
has been a subject for investigation. In
this paper, we empirically study biomedical
domain adaptation with large transformer models
using different design choices. We evaluate
the performance of our pretrained models
against other existing biomedical language
models in the literature. Our results show that
we achieve state-of-the-art results on several
biomedical domain tasks despite using similar
or less computational cost compared to other
models in the literature. Our findings highlight
the significant effect of design choices on
improving the performance of biomedical language
models.
# Model Description
- This model is fine-tuned on the SQuAD2.0 dataset and then on the BioASQ8B-Factoid training dataset. We convert the BioASQ8B-Factoid training dataset to SQuAD1.1 format and train and evaluate our model (BioM-ELECTRA-Base-SQuAD2) on this dataset.
- You can use this model to make a prediction (inference) directly without fine-tuning it. Try to enter a PubMed abstract in the context box in this model card and try out a couple of biomedical questions within the given context and see how it performs compared to ELECTRA original model. This model should also be useful for creating a pandemic QA system (e.g., COVID-19) .
- Please note that this version (PyTorch) is different than what we used in our participation in BioASQ9B (TensorFlow with Layer-Wise Decay). We combine all five batches of the BioASQ8B testing dataset as one dev.json file.
- Below is unofficial results of our models against the original ELECTRA base and large :
| Model | Exact Match (EM) | F1 Score |
| --- | --- | --- |
| ELECTRA-Base-SQuAD2-BioASQ8B | 61.89 | 74.39 |
| **BioM-ELECTRA-Base-SQuAD2-BioASQ8B** | **70.31** | **80.90** |
| ELECTRA-Large-SQuAD2-BioASQ8B | 67.36 | 78.90 |
| BioM-ELECTRA-Large-SQuAD2-BioASQ8B | 74.31 | 84.72 |
Training script
```python
python3 run_squad.py --model_type electra --model_name_or_path sultan/BioM-ELECTRA-Base-SQuAD2 \
--train_file BioASQ8B/train.json \
--predict_file BioASQ8B/dev.json \
--do_lower_case \
--do_train \
--do_eval \
--threads 20 \
--version_2_with_negative \
--num_train_epochs 3 \
--learning_rate 3e-5 \
--max_seq_length 512 \
--doc_stride 128 \
--per_gpu_train_batch_size 8 \
--gradient_accumulation_steps 2 \
--per_gpu_eval_batch_size 128 \
--logging_steps 50 \
--save_steps 5000 \
--fp16 \
--fp16_opt_level O1 \
--overwrite_output_dir \
--output_dir BioM-ELECTRA-Base-SQuAD-BioASQ \
--overwrite_cache
```
# Acknowledgment
We would like to acknowledge the support we have from Tensorflow Research Cloud (TFRC) team to grant us access to TPUv3 units.
# Citation
```bibtex
@inproceedings{alrowili-shanker-2021-biom,
title = "{B}io{M}-Transformers: Building Large Biomedical Language Models with {BERT}, {ALBERT} and {ELECTRA}",
author = "Alrowili, Sultan and
Shanker, Vijay",
booktitle = "Proceedings of the 20th Workshop on Biomedical Language Processing",
month = jun,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2021.bionlp-1.24",
pages = "221--227",
abstract = "The impact of design choices on the performance of biomedical language models recently has been a subject for investigation. In this paper, we empirically study biomedical domain adaptation with large transformer models using different design choices. We evaluate the performance of our pretrained models against other existing biomedical language models in the literature. Our results show that we achieve state-of-the-art results on several biomedical domain tasks despite using similar or less computational cost compared to other models in the literature. Our findings highlight the significant effect of design choices on improving the performance of biomedical language models.",
}
```
|
Sahajtomar/German-question-answer-Electra
|
429a906faa09c2a6959281f426e2f851b322da87
|
2021-01-16T02:18:37.000Z
|
[
"pytorch",
"tf",
"electra",
"question-answering",
"de",
"dataset:mlqa",
"transformers",
"Gelectra",
"autotrain_compatible"
] |
question-answering
| false |
Sahajtomar
| null |
Sahajtomar/German-question-answer-Electra
| 1,632 | 1 |
transformers
| 1,470 |
---
language: de
tags:
- pytorch
- tf
- Gelectra
datasets:
- mlqa
metrics:
- f1
- em
---
### QA Model trained on MLQA dataset for german langauge.
MODEL used for fine tuning is GELECTRA Large by deepset.ai
## MLQA DEV (german)
EM: 64.27 \
F1: 77.39
## XQUAD TEST (german)
EM: 66.38 \
F1: 82.25
## Hyperparameters
per_gpu_train_batch_size 4 \
per_gpu_eval_batch_size 32 \
gradient_accumulation_steps 8 \
learning_rate 3e-5 \
num_train_epochs 1.0 \
max_seq_length 384 \
doc_stride 128
## Model inferencing:
```python
!pip install -q transformers
from transformers import pipeline
qa_pipeline = pipeline(
"question-answering",
model="Sahajtomar/GELECTRAQA",
tokenizer="Sahajtomar/GELECTRAQA"
)
qa_pipeline({
'context': "Vor einigen Jahren haben Wissenschaftler ein wichtiges Mutagen identifiziert, das in unseren eigenen Zellen liegt: APOBEC, ein Protein, das normalerweise als Schutzmittel gegen Virusinfektionen fungiert. Heute hat ein Team von Schweizer und russischen Wissenschaftlern unter der Leitung von Sergey Nikolaev, Genetiker an der Universität Genf (UNIGE) in der Schweiz, entschlüsselt, wie APOBEC eine Schwäche unseres DNA-Replikationsprozesses ausnutzt, um Mutationen in unserem Genom zu induzieren.",
'question': "Welches Mutagen schützt vor Virusinfektionen?"
})
# output
{'answer': 'APOBEC', 'end': 121, 'score': 0.987, 'start': 115}
## Even complex queries can be answered pretty well
qa_pipeline({
"context": "Es wird erwartet, dass sich schwarze Löcher mit Sternmasse bilden,
wenn sehr massive Sterne am Ende ihres Lebenszyklus
zusammenbrechen. Nachdem sich ein Schwarzes Loch gebildet hat,
kann es weiter wachsen,indem es Masse aus seiner Umgebung
absorbiert. Durch Absorption anderer Sterne und Verschmelzung mit
anderen Schwarzen Löchern können sich supermassereiche Schwarze
Löcher mit Millionen von Sonnenmassen (M☉) bilden. Es besteht
Konsens darüber, dass in den Zentren der meisten Galaxien
supermassereiche Schwarze Löcher existieren.",
'question': "Wie Sonnenmassen entstehen?"
})
#output
{'answer': 'Durch Absorption anderer Sterne und Verschmelzung mit anderen Schwarzen Löchern',
'end': 332,
'score': 0.23970196,
'start': 253}
```
|
ixa-ehu/ixambert-base-cased
|
493636d45defa03901f7998dcd886fe3c886713e
|
2021-02-02T15:09:00.000Z
|
[
"pytorch",
"en",
"es",
"eu",
"transformers"
] | null | false |
ixa-ehu
| null |
ixa-ehu/ixambert-base-cased
| 1,629 | null |
transformers
| 1,471 |
---
language:
- en
- es
- eu
---
# IXAmBERT base cased
This is a multilingual language pretrained for English, Spanish and Basque. The training corpora is composed by the English, Spanish and Basque Wikipedias, together with Basque crawled news articles from online newspapers. The model has been successfully used to transfer knowledge from English to Basque in a conversational QA system, as reported in the paper [Conversational Question Answering in Low Resource Scenarios: A Dataset and Case Study for Basque](http://www.lrec-conf.org/proceedings/lrec2020/pdf/2020.lrec-1.55.pdf). In the paper, IXAmBERT performed better than mBERT when transferring knowledge from English to Basque, as shown in the following Table:
| Model | Zero-shot | Transfer learning |
|--------------------|-----------|-------------------|
| Baseline | 28.7 | 28.7 |
| mBERT | 31.5 | 37.4 |
| IXAmBERT | 38.9 | **41.2** |
| mBERT + history | 33.3 | 28.7 |
| IXAmBERT + history | **40.7** | 40.0 |
This Table shows the results on a Basque CQA dataset. *Zero-shot* means that the model is fine-tuned using using QuaC, an English CQA dataset. In the *Transfer Learning* setting the model is first fine-tuned on QuaC, and then on a Basque CQA dataset.
If using this model, please cite the following paper:
```
@inproceedings{otegi2020conversational,
title={Conversational Question Answering in Low Resource Scenarios: A Dataset and Case Study for Basque},
author={Otegi, Arantxa and Agirre, Aitor and Campos, Jon Ander and Soroa, Aitor and Agirre, Eneko},
booktitle={Proceedings of The 12th Language Resources and Evaluation Conference},
pages={436--442},
year={2020}
}
```
|
LorenzoDeMattei/GePpeTto
|
83d5c73d62be521e4ed28fe5960701e85f10abac
|
2021-05-21T10:53:18.000Z
|
[
"pytorch",
"jax",
"gpt2",
"text-generation",
"it",
"arxiv:2004.14253",
"transformers"
] |
text-generation
| false |
LorenzoDeMattei
| null |
LorenzoDeMattei/GePpeTto
| 1,628 | 3 |
transformers
| 1,472 |
---
language: it
---
# GePpeTto GPT2 Model 🇮🇹
Pretrained GPT2 117M model for Italian.
You can find further details in the paper:
Lorenzo De Mattei, Michele Cafagna, Felice Dell’Orletta, Malvina Nissim, Marco Guerini "GePpeTto Carves Italian into a Language Model", arXiv preprint. Pdf available at: https://arxiv.org/abs/2004.14253
## Pretraining Corpus
The pretraining set comprises two main sources. The first one is a dump of Italian Wikipedia (November 2019),
consisting of 2.8GB of text. The second one is the ItWac corpus (Baroni et al., 2009), which amounts to 11GB of web
texts. This collection provides a mix of standard and less standard Italian, on a rather wide chronological span,
with older texts than the Wikipedia dump (the latter stretches only to the late 2000s).
## Pretraining details
This model was trained using GPT2's Hugging Face implemenation on 4 NVIDIA Tesla T4 GPU for 620k steps.
Training parameters:
- GPT-2 small configuration
- vocabulary size: 30k
- Batch size: 32
- Block size: 100
- Adam Optimizer
- Initial learning rate: 5e-5
- Warm up steps: 10k
## Perplexity scores
| Domain | Perplexity |
|---|---|
| Wikipedia | 26.1052 |
| ItWac | 30.3965 |
| Legal | 37.2197 |
| News | 45.3859 |
| Social Media | 84.6408 |
For further details, qualitative analysis and human evaluation check out: https://arxiv.org/abs/2004.14253
## Load Pretrained Model
You can use this model by installing Huggingface library `transformers`. And you can use it directly by initializing it like this:
```python
from transformers import GPT2Tokenizer, GPT2Model
model = GPT2Model.from_pretrained('LorenzoDeMattei/GePpeTto')
tokenizer = GPT2Tokenizer.from_pretrained(
'LorenzoDeMattei/GePpeTto',
)
```
## Example using GPT2LMHeadModel
```python
from transformers import AutoTokenizer, AutoModelWithLMHead, pipeline, GPT2Tokenizer
tokenizer = AutoTokenizer.from_pretrained("LorenzoDeMattei/GePpeTto")
model = AutoModelWithLMHead.from_pretrained("LorenzoDeMattei/GePpeTto")
text_generator = pipeline('text-generation', model=model, tokenizer=tokenizer)
prompts = [
"Wikipedia Geppetto",
"Maestro Ciliegia regala il pezzo di legno al suo amico Geppetto, il quale lo prende per fabbricarsi un burattino maraviglioso"]
samples_outputs = text_generator(
prompts,
do_sample=True,
max_length=50,
top_k=50,
top_p=0.95,
num_return_sequences=3
)
for i, sample_outputs in enumerate(samples_outputs):
print(100 * '-')
print("Prompt:", prompts[i])
for sample_output in sample_outputs:
print("Sample:", sample_output['generated_text'])
print()
```
Output is,
```
----------------------------------------------------------------------------------------------------
Prompt: Wikipedia Geppetto
Sample: Wikipedia Geppetto rosso (film 1920)
Geppetto rosso ("The Smokes in the Black") è un film muto del 1920 diretto da Henry H. Leonard.
Il film fu prodotto dalla Selig Poly
Sample: Wikipedia Geppetto
Geppetto ("Geppetto" in piemontese) è un comune italiano di 978 abitanti della provincia di Cuneo in Piemonte.
L'abitato, che si trova nel versante valtellinese, si sviluppa nella
Sample: Wikipedia Geppetto di Natale (romanzo)
Geppetto di Natale è un romanzo di Mario Caiano, pubblicato nel 2012.
----------------------------------------------------------------------------------------------------
Prompt: Maestro Ciliegia regala il pezzo di legno al suo amico Geppetto, il quale lo prende per fabbricarsi un burattino maraviglioso
Sample: Maestro Ciliegia regala il pezzo di legno al suo amico Geppetto, il quale lo prende per fabbricarsi un burattino maraviglioso. Il burattino riesce a scappare. Dopo aver trovato un prezioso sacchetto si reca
Sample: Maestro Ciliegia regala il pezzo di legno al suo amico Geppetto, il quale lo prende per fabbricarsi un burattino maraviglioso, e l'unico che lo possiede, ma, di fronte a tutte queste prove
Sample: Maestro Ciliegia regala il pezzo di legno al suo amico Geppetto, il quale lo prende per fabbricarsi un burattino maraviglioso: - A voi gli occhi, le guance! A voi il mio pezzo!
```
## Citation
Please use the following bibtex entry:
```
@misc{mattei2020geppetto,
title={GePpeTto Carves Italian into a Language Model},
author={Lorenzo De Mattei and Michele Cafagna and Felice Dell'Orletta and Malvina Nissim and Marco Guerini},
year={2020},
eprint={2004.14253},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
## References
Marco Baroni, Silvia Bernardini, Adriano Ferraresi,
and Eros Zanchetta. 2009. The WaCky wide web: a
collection of very large linguistically processed webcrawled corpora. Language resources and evaluation, 43(3):209–226.
|
jackaduma/SecRoBERTa
|
d1aab18b12dfaeb89b1ea559605bd13bcf9805e3
|
2022-01-24T07:46:02.000Z
|
[
"pytorch",
"roberta",
"fill-mask",
"en",
"dataset:APTnotes",
"dataset:Stucco-Data",
"dataset:CASIE",
"transformers",
"exbert",
"security",
"cybersecurity",
"cyber security",
"threat hunting",
"threat intelligence",
"license:apache-2.0",
"autotrain_compatible"
] |
fill-mask
| false |
jackaduma
| null |
jackaduma/SecRoBERTa
| 1,628 | 1 |
transformers
| 1,473 |
---
language: en
thumbnail: https://github.com/jackaduma
tags:
- exbert
- security
- cybersecurity
- cyber security
- threat hunting
- threat intelligence
license: apache-2.0
datasets:
- APTnotes
- Stucco-Data
- CASIE
---
# SecRoBERTa
This is the pretrained model presented in [SecBERT: A Pretrained Language Model for Cyber Security Text](https://github.com/jackaduma/SecBERT/), which is a SecRoBERTa model trained on cyber security text.
The training corpus was papers taken from
* [APTnotes](https://github.com/kbandla/APTnotes)
* [Stucco-Data: Cyber security data sources](https://stucco.github.io/data/)
* [CASIE: Extracting Cybersecurity Event Information from Text](https://ebiquity.umbc.edu/_file_directory_/papers/943.pdf)
* [SemEval-2018 Task 8: Semantic Extraction from CybersecUrity REports using Natural Language Processing (SecureNLP)](https://competitions.codalab.org/competitions/17262).
SecRoBERTa has its own wordpiece vocabulary (secvocab) that's built to best match the training corpus.
We trained [SecBERT](https://huggingface.co/jackaduma/SecBERT) and [SecRoBERTa](https://huggingface.co/jackaduma/SecRoBERTa) versions.
Available models include:
* [`SecBERT`](https://huggingface.co/jackaduma/SecBERT)
* [`SecRoBERTa`](https://huggingface.co/jackaduma/SecRoBERTa)
---
## **Fill Mask**
We proposed to build language model which work on cyber security text, as result, it can improve downstream tasks (NER, Text Classification, Semantic Understand, Q&A) in Cyber Security Domain.
First, as below shows Fill-Mask pipeline in [Google Bert](), [AllenAI SciBert](https://github.com/allenai/scibert) and our [SecBERT](https://github.com/jackaduma/SecBERT) .
<!-- <img src="./fill-mask-result.png" width="150%" height="150%"> -->

---
The original repo can be found [here](https://github.com/jackaduma/SecBERT).
|
allenai/unifiedqa-t5-small
|
6cd061fef46da9a3b1f55c69d736a715a6324352
|
2021-06-23T11:21:03.000Z
|
[
"pytorch",
"jax",
"t5",
"text2text-generation",
"transformers",
"autotrain_compatible"
] |
text2text-generation
| false |
allenai
| null |
allenai/unifiedqa-t5-small
| 1,626 | 2 |
transformers
| 1,474 |
Entry not found
|
microsoft/trocr-small-printed
|
1afd9f060486e817454bc69e21bec3b0a206d9ac
|
2022-07-01T07:38:01.000Z
|
[
"pytorch",
"vision-encoder-decoder",
"arxiv:2109.10282",
"transformers",
"trocr",
"image-to-text"
] |
image-to-text
| false |
microsoft
| null |
microsoft/trocr-small-printed
| 1,624 | 2 |
transformers
| 1,475 |
---
tags:
- trocr
- image-to-text
---
# TrOCR (small-sized model, fine-tuned on SROIE)
TrOCR model fine-tuned on the [SROIE dataset](https://rrc.cvc.uab.es/?ch=13). It was introduced in the paper [TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models](https://arxiv.org/abs/2109.10282) by Li et al. and first released in [this repository](https://github.com/microsoft/unilm/tree/master/trocr).
## Model description
The TrOCR model is an encoder-decoder model, consisting of an image Transformer as encoder, and a text Transformer as decoder. The image encoder was initialized from the weights of DeiT, while the text decoder was initialized from the weights of UniLM.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. One also adds absolute position embeddings before feeding the sequence to the layers of the Transformer encoder. Next, the Transformer text decoder autoregressively generates tokens.
## Intended uses & limitations
You can use the raw model for optical character recognition (OCR) on single text-line images. See the [model hub](https://huggingface.co/models?search=microsoft/trocr) to look for fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model in PyTorch:
```python
from transformers import TrOCRProcessor, VisionEncoderDecoderModel
from PIL import Image
import requests
# load image from the IAM database (actually this model is meant to be used on printed text)
url = 'https://fki.tic.heia-fr.ch/static/img/a01-122-02-00.jpg'
image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
processor = TrOCRProcessor.from_pretrained('microsoft/trocr-small-printed')
model = VisionEncoderDecoderModel.from_pretrained('microsoft/trocr-small-printed')
pixel_values = processor(images=image, return_tensors="pt").pixel_values
generated_ids = model.generate(pixel_values)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
```
### BibTeX entry and citation info
```bibtex
@misc{li2021trocr,
title={TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models},
author={Minghao Li and Tengchao Lv and Lei Cui and Yijuan Lu and Dinei Florencio and Cha Zhang and Zhoujun Li and Furu Wei},
year={2021},
eprint={2109.10282},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
patrickvonplaten/wavlm-libri-clean-100h-base-plus
|
02c289c4471cd1ba4b0ff3e7c304afe395c5026a
|
2021-12-20T12:59:01.000Z
|
[
"pytorch",
"tensorboard",
"wavlm",
"automatic-speech-recognition",
"transformers",
"librispeech_asr",
"generated_from_trainer",
"wavlm_libri_finetune",
"model-index"
] |
automatic-speech-recognition
| false |
patrickvonplaten
| null |
patrickvonplaten/wavlm-libri-clean-100h-base-plus
| 1,619 | 1 |
transformers
| 1,476 |
---
tags:
- automatic-speech-recognition
- librispeech_asr
- generated_from_trainer
- wavlm_libri_finetune
model-index:
- name: wavlm-libri-clean-100h-base-plus
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wavlm-libri-clean-100h-base-plus
This model is a fine-tuned version of [microsoft/wavlm-base-plus](https://huggingface.co/microsoft/wavlm-base-plus) on the LIBRISPEECH_ASR - CLEAN dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0819
- Wer: 0.0683
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- total_train_batch_size: 32
- total_eval_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 2.8877 | 0.34 | 300 | 2.8649 | 1.0 |
| 0.2852 | 0.67 | 600 | 0.2196 | 0.1830 |
| 0.1198 | 1.01 | 900 | 0.1438 | 0.1273 |
| 0.0906 | 1.35 | 1200 | 0.1145 | 0.1035 |
| 0.0729 | 1.68 | 1500 | 0.1055 | 0.0955 |
| 0.0605 | 2.02 | 1800 | 0.0936 | 0.0859 |
| 0.0402 | 2.35 | 2100 | 0.0885 | 0.0746 |
| 0.0421 | 2.69 | 2400 | 0.0848 | 0.0700 |
### Framework versions
- Transformers 4.15.0.dev0
- Pytorch 1.9.0+cu111
- Datasets 1.16.2.dev0
- Tokenizers 0.10.3
|
google/bigbird-pegasus-large-pubmed
|
de903d9659abbc0f8d212acf4186044b1b566f30
|
2022-06-29T15:55:59.000Z
|
[
"pytorch",
"bigbird_pegasus",
"text2text-generation",
"en",
"dataset:scientific_papers",
"arxiv:2007.14062",
"transformers",
"summarization",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
] |
summarization
| false |
google
| null |
google/bigbird-pegasus-large-pubmed
| 1,618 | 7 |
transformers
| 1,477 |
---
language: en
license: apache-2.0
datasets:
- scientific_papers
tags:
- summarization
model-index:
- name: google/bigbird-pegasus-large-pubmed
results:
- task:
type: summarization
name: Summarization
dataset:
name: scientific_papers
type: scientific_papers
config: pubmed
split: test
metrics:
- name: ROUGE-1
type: rouge
value: 40.8966
verified: true
- name: ROUGE-2
type: rouge
value: 18.1161
verified: true
- name: ROUGE-L
type: rouge
value: 26.1743
verified: true
- name: ROUGE-LSUM
type: rouge
value: 34.2773
verified: true
- name: loss
type: loss
value: 2.1707184314727783
verified: true
- name: meteor
type: meteor
value: 0.3513
verified: true
- name: gen_len
type: gen_len
value: 221.2531
verified: true
- task:
type: summarization
name: Summarization
dataset:
name: scientific_papers
type: scientific_papers
config: arxiv
split: test
metrics:
- name: ROUGE-1
type: rouge
value: 40.3815
verified: true
- name: ROUGE-2
type: rouge
value: 14.374
verified: true
- name: ROUGE-L
type: rouge
value: 23.4773
verified: true
- name: ROUGE-LSUM
type: rouge
value: 33.772
verified: true
- name: loss
type: loss
value: 3.235051393508911
verified: true
- name: gen_len
type: gen_len
value: 186.2003
verified: true
---
# BigBirdPegasus model (large)
BigBird, is a sparse-attention based transformer which extends Transformer based models, such as BERT to much longer sequences. Moreover, BigBird comes along with a theoretical understanding of the capabilities of a complete transformer that the sparse model can handle.
BigBird was introduced in this [paper](https://arxiv.org/abs/2007.14062) and first released in this [repository](https://github.com/google-research/bigbird).
Disclaimer: The team releasing BigBird did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
BigBird relies on **block sparse attention** instead of normal attention (i.e. BERT's attention) and can handle sequences up to a length of 4096 at a much lower compute cost compared to BERT. It has achieved SOTA on various tasks involving very long sequences such as long documents summarization, question-answering with long contexts.
## How to use
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import BigBirdPegasusForConditionalGeneration, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("google/bigbird-pegasus-large-pubmed")
# by default encoder-attention is `block_sparse` with num_random_blocks=3, block_size=64
model = BigBirdPegasusForConditionalGeneration.from_pretrained("google/bigbird-pegasus-large-pubmed")
# decoder attention type can't be changed & will be "original_full"
# you can change `attention_type` (encoder only) to full attention like this:
model = BigBirdPegasusForConditionalGeneration.from_pretrained("google/bigbird-pegasus-large-pubmed", attention_type="original_full")
# you can change `block_size` & `num_random_blocks` like this:
model = BigBirdPegasusForConditionalGeneration.from_pretrained("google/bigbird-pegasus-large-pubmed", block_size=16, num_random_blocks=2)
text = "Replace me by any text you'd like."
inputs = tokenizer(text, return_tensors='pt')
prediction = model.generate(**inputs)
prediction = tokenizer.batch_decode(prediction)
```
## Training Procedure
This checkpoint is obtained after fine-tuning `BigBirdPegasusForConditionalGeneration` for **summarization** on **pubmed dataset** from [scientific_papers](https://huggingface.co/datasets/scientific_papers).
## BibTeX entry and citation info
```tex
@misc{zaheer2021big,
title={Big Bird: Transformers for Longer Sequences},
author={Manzil Zaheer and Guru Guruganesh and Avinava Dubey and Joshua Ainslie and Chris Alberti and Santiago Ontanon and Philip Pham and Anirudh Ravula and Qifan Wang and Li Yang and Amr Ahmed},
year={2021},
eprint={2007.14062},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
|
SkolkovoInstitute/roberta_toxicity_classifier
|
3cd450864abaa584b1620f5bea9169a2226db3eb
|
2021-10-05T14:54:55.000Z
|
[
"pytorch",
"roberta",
"text-classification",
"en",
"arxiv:1907.11692",
"transformers",
"toxic comments classification"
] |
text-classification
| false |
SkolkovoInstitute
| null |
SkolkovoInstitute/roberta_toxicity_classifier
| 1,614 | 4 |
transformers
| 1,478 |
---
language:
- en
tags:
- toxic comments classification
licenses:
- cc-by-nc-sa
---
## Toxicity Classification Model
This model is trained for toxicity classification task. The dataset used for training is the merge of the English parts of the three datasets by **Jigsaw** ([Jigsaw 2018](https://www.kaggle.com/c/jigsaw-toxic-comment-classification-challenge), [Jigsaw 2019](https://www.kaggle.com/c/jigsaw-unintended-bias-in-toxicity-classification), [Jigsaw 2020](https://www.kaggle.com/c/jigsaw-multilingual-toxic-comment-classification)), containing around 2 million examples. We split it into two parts and fine-tune a RoBERTa model ([RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692)) on it. The classifiers perform closely on the test set of the first Jigsaw competition, reaching the **AUC-ROC** of 0.98 and **F1-score** of 0.76.
## How to use
```python
from transformers import RobertaTokenizer, RobertaForSequenceClassification
# load tokenizer and model weights
tokenizer = RobertaTokenizer.from_pretrained('SkolkovoInstitute/roberta_toxicity_classifier')
model = RobertaForSequenceClassification.from_pretrained('SkolkovoInstitute/roberta_toxicity_classifier')
# prepare the input
batch = tokenizer.encode('you are amazing', return_tensors='pt')
# inference
model(batch)
```
## Licensing Information
[Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License][cc-by-nc-sa].
[![CC BY-NC-SA 4.0][cc-by-nc-sa-image]][cc-by-nc-sa]
[cc-by-nc-sa]: http://creativecommons.org/licenses/by-nc-sa/4.0/
[cc-by-nc-sa-image]: https://i.creativecommons.org/l/by-nc-sa/4.0/88x31.png
|
google/bigbird-roberta-large
|
95d04fa0d054969617385de05d9f2fa89bbd3bea
|
2021-06-02T14:49:29.000Z
|
[
"pytorch",
"jax",
"big_bird",
"fill-mask",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"dataset:cc_news",
"arxiv:2007.14062",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] |
fill-mask
| false |
google
| null |
google/bigbird-roberta-large
| 1,607 | 4 |
transformers
| 1,479 |
---
language: en
license: apache-2.0
datasets:
- bookcorpus
- wikipedia
- cc_news
---
# BigBird large model
BigBird, is a sparse-attention based transformer which extends Transformer based models, such as BERT to much longer sequences. Moreover, BigBird comes along with a theoretical understanding of the capabilities of a complete transformer that the sparse model can handle.
It is a pretrained model on English language using a masked language modeling (MLM) objective. It was introduced in this [paper](https://arxiv.org/abs/2007.14062) and first released in this [repository](https://github.com/google-research/bigbird).
Disclaimer: The team releasing BigBird did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
BigBird relies on **block sparse attention** instead of normal attention (i.e. BERT's attention) and can handle sequences up to a length of 4096 at a much lower compute cost compared to BERT. It has achieved SOTA on various tasks involving very long sequences such as long documents summarization, question-answering with long contexts.
## How to use
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import BigBirdModel
# by default its in `block_sparse` mode with num_random_blocks=3, block_size=64
model = BigBirdModel.from_pretrained("google/bigbird-roberta-large")
# you can change `attention_type` to full attention like this:
model = BigBirdModel.from_pretrained("google/bigbird-roberta-large", attention_type="original_full")
# you can change `block_size` & `num_random_blocks` like this:
model = BigBirdModel.from_pretrained("google/bigbird-roberta-large", block_size=16, num_random_blocks=2)
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
## Training Data
This model is pre-trained on four publicly available datasets: **Books**, **CC-News**, **Stories** and **Wikipedia**. It used same sentencepiece vocabulary as RoBERTa (which is in turn borrowed from GPT2).
## Training Procedure
Document longer than 4096 were split into multiple documents and documents that were much smaller than 4096 were joined. Following the original BERT training, 15% of tokens were masked and model is trained to predict the mask.
Model is warm started from RoBERTa’s checkpoint.
## BibTeX entry and citation info
```tex
@misc{zaheer2021big,
title={Big Bird: Transformers for Longer Sequences},
author={Manzil Zaheer and Guru Guruganesh and Avinava Dubey and Joshua Ainslie and Chris Alberti and Santiago Ontanon and Philip Pham and Anirudh Ravula and Qifan Wang and Li Yang and Amr Ahmed},
year={2021},
eprint={2007.14062},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
|
nreimers/BERT-Small-L-4_H-512_A-8
|
e88df96b90f597c841c6a1c0d499f05ddacaf16b
|
2021-05-20T02:03:04.000Z
|
[
"pytorch",
"jax",
"bert",
"feature-extraction",
"transformers"
] |
feature-extraction
| false |
nreimers
| null |
nreimers/BERT-Small-L-4_H-512_A-8
| 1,605 | null |
transformers
| 1,480 |
# BERT-Small-L-4_H-512_A-8
This is a port of the [BERT-Small model](https://github.com/google-research/bert) to Pytorch. It uses 4 layers, a hidden size of 512 and 8 attention heads.
|
tartuNLP/EstBERT
|
ea615e186cd9a402edb90b7cfacfdcdc79893736
|
2022-05-03T07:46:46.000Z
|
[
"pytorch",
"jax",
"bert",
"fill-mask",
"et",
"transformers",
"license:cc-by-4.0",
"autotrain_compatible"
] |
fill-mask
| false |
tartuNLP
| null |
tartuNLP/EstBERT
| 1,604 | null |
transformers
| 1,481 |
---
language: et
license: cc-by-4.0
widget:
- text: "Miks [MASK] ei taha mind kuulata?"
---
---
# EstBERT
### What's this?
The EstBERT model is a pretrained BERT<sub>Base</sub> model exclusively trained on Estonian cased corpus on both 128 and 512 sequence length of data.
### How to use?
You can use the model transformer library both in tensorflow and pytorch version.
```
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("tartuNLP/EstBERT")
model = AutoModelForMaskedLM.from_pretrained("tartuNLP/EstBERT")
```
You can also download the pretrained model from here, [EstBERT_128]() [EstBERT_512]()
#### Dataset used to train the model
The EstBERT model is trained both on 128 and 512 sequence length of data. For training the EstBERT we used the [Estonian National Corpus 2017](https://metashare.ut.ee/repository/browse/estonian-national-corpus-2017/b616ceda30ce11e8a6e4005056b40024880158b577154c01bd3d3fcfc9b762b3/), which was the largest Estonian language corpus available at the time. It consists of four sub-corpora: Estonian Reference Corpus 1990-2008, Estonian Web Corpus 2013, Estonian Web Corpus 2017 and Estonian Wikipedia Corpus 2017.
### Why would I use?
Overall EstBERT performs better in parts of speech (POS), name entity recognition (NER), rubric, and sentiment classification tasks compared to mBERT and XLM-RoBERTa. The comparative results can be found below;
|Model |UPOS |XPOS |Morph |bf UPOS |bf XPOS |Morph |
|--------------|----------------------------|-------------|-------------|-------------|----------------------------|----------------------------|
| EstBERT | **_97.89_** | **98.40** | **96.93** | **97.84** | **_98.43_** | **_96.80_** |
| mBERT | 97.42 | 98.06 | 96.24 | 97.43 | 98.13 | 96.13 |
| XLM-RoBERTa | 97.78 | 98.36 | 96.53 | 97.80 | 98.40 | 96.69 |
|Model|Rubric<sub>128</sub> |Sentiment<sub>128</sub> | Rubric<sub>128</sub> |Sentiment<sub>512</sub> |
|-------------------|----------------------------|--------------------|-----------------------------------------------|----------------------------|
| EstBERT | **_81.70_** | 74.36 | **80.96** | 74.50 |
| mBERT | 75.67 | 70.23 | 74.94 | 69.52 |
| XLM\-RoBERTa | 80.34 | **74.50** | 78.62 | **_76.07_**|
|Model |Precicion<sub>128</sub> |Recall<sub>128</sub> |F1-Score<sub>128</sub> |Precision<sub>512</sub> |Recall<sub>512</sub> |F1-Score<sub>512</sub> |
|--------------|----------------|----------------------------|----------------------------|----------------------------|-------------|----------------|
| EstBERT | **88.42** | 90.38 |**_89.39_** | 88.35 | 89.74 | 89.04 |
| mBERT | 85.88 | 87.09 | 86.51 |**_88.47_** | 88.28 | 88.37 |
| XLM\-RoBERTa | 87.55 |**_91.19_** | 89.34 | 87.50 | **90.76** | **89.10** |
|
bloom-testing/test-bloomd-350m-main
|
18e4c18ce2ab6c6aa9fc50d7e419af793489ab0b
|
2022-07-28T15:39:00.000Z
|
[
"pytorch",
"bloom",
"feature-extraction",
"transformers"
] |
feature-extraction
| false |
bloom-testing
| null |
bloom-testing/test-bloomd-350m-main
| 1,603 | null |
transformers
| 1,482 |
Entry not found
|
b3ck1/gpt-neo-125M-finetuned-beer-recipes
|
3ab861877e94d664309e25e870561b89b6cebcb8
|
2022-06-28T19:03:17.000Z
|
[
"pytorch",
"gpt_neo",
"text-generation",
"en",
"dataset:custom",
"transformers",
"text generation",
"causal-lm",
"license:apache-2.0"
] |
text-generation
| false |
b3ck1
| null |
b3ck1/gpt-neo-125M-finetuned-beer-recipes
| 1,601 | 1 |
transformers
| 1,483 |
---
language:
- en
tags:
- text generation
- pytorch
- causal-lm
license: apache-2.0
datasets:
- custom
widget:
- text: "style: Pilsner\nbatch_size: 20\nefficiency: 75\nboil_size:"
example_title: "Pilsener"
- text: "style: IPA\nbatch_size: 20\nefficiency: 75\nboil_size:"
example_title: "IPA"
- text: "style: Scottish Ale\nbatch_size: 20\nefficiency: 75\nboil_size:"
example_title: "Scottish Ale"
inference:
parameters:
do_sample: true
top_k: 10
top_p: 0.99
max_length: 500
---
# GPT-Neo 125M finetuned with beer recipes
## Model Description
GPT-Neo 125M is a transformer model based on EleutherAI's replication of the GPT-3 architecture https://huggingface.co/EleutherAI/gpt-neo-125M.
It generates recipes for brewing beer in a YAML-like format which can be easily used for different purposes.
## Training data
This model was trained on a custom dataset of ~ 76,800 beer recipes from the internet. It includes recipes for the following
styles of beer:
* Strong American Ale
* Pale American Ale
* India Pale Ale (IPA)
* Standard American Beer
* Stout
* English Pale Ale
* IPA
* American Porter and Stout
* Sour Ale
* Irish Beer
* Strong British Ale
* Belgian and French Ale
* German Wheat and Rye Beer
* Czech Lager
* Spice/Herb/Vegetable Beer
* Specialty Beer
* American Ale
* Pilsner
* Belgian Ale
* Strong Belgian Ale
* Bock
* Brown British Beer
* German Wheat Beer
* Fruit Beer
* Amber Malty European Lager
* Pale Malty European Lager
* British Bitter
* Amber and Brown American Beer
* Light Hybrid Beer
* Pale Commonwealth Beer
* American Wild Ale
* European Amber Lager
* Belgian Strong Ale
* International Lager
* Amber Bitter European Lager
* Light Lager
* Scottish and Irish Ale
* European Sour Ale
* Trappist Ale
* Strong European Beer
* Porter
* Historical Beer
* Pale Bitter European Beer
* Amber Hybrid Beer
* Smoke Flavored/Wood-Aged Beer
* Spiced Beer
* Dark European Lager
* Alternative Fermentables Beer
* Mead
* Strong Ale
* Dark British Beer
* Scottish Ale
* Smoked Beer
* English Brown Ale
* Dark Lager
* Cider or Perry
* Wood Beer
### How to use
You can use this model directly with a pipeline for text generation. This example generates a different recipe each time it's run:
```py
>>> from transformers import pipeline
>>> generator = pipeline('text-generation', model='b3ck1/gpt-neo-125M-finetuned-beer-recipes')
>>> generator("style: Pilsner\nbatch_size: 20\nefficiency: 75\nboil_size:", do_sample=True, min_length=50, max_length=500)
>>> print(output[0]['generated_text'])
style: Pilsner
batch_size: 20
efficiency: 70
boil_size: 24
boil_time: 60
fermentables:
- name: Pale Ale
type: Grain
amount: 6.5
hops:
- name: Saaz
alpha: 3.5
use: Boil
time: 60
amount: 0.06
- name: Saaz
alpha: 3.5
use: Boil
time: 30
amount: 0.06
- name: Saaz
alpha: 3.5
use: Boil
time: 10
amount: 0.06
- name: Saaz
alpha: 3.5
use: Boil
time: 0
amount: 0.06
yeasts:
- name: Safale - American Ale Yeast US-05
amount: 0.11
min_temperature: 12
max_temperature: 25
primary_temp: null
mash_steps:
- step_temp: 65
step_time: 60
miscs: []
```
### See this model in action
This model was used to build https://beerai.net.
|
mrm8488/camembert2camembert_shared-finetuned-french-summarization
|
60191909472099389fb0aa965b431be9f918bb71
|
2021-05-26T07:42:02.000Z
|
[
"pytorch",
"encoder-decoder",
"text2text-generation",
"fr",
"dataset:mlsum",
"transformers",
"summarization",
"news",
"autotrain_compatible"
] |
summarization
| false |
mrm8488
| null |
mrm8488/camembert2camembert_shared-finetuned-french-summarization
| 1,597 | 2 |
transformers
| 1,484 |
---
tags:
- summarization
- news
language: fr
datasets:
- mlsum
widget:
- text: "Un nuage de fumée juste après l’explosion, le 1er juin 2019. Une déflagration dans une importante usine d’explosifs du centre de la Russie a fait au moins 79 blessés samedi 1er juin. L’explosion a eu lieu dans l’usine Kristall à Dzerzhinsk, une ville située à environ 400 kilomètres à l’est de Moscou, dans la région de Nijni-Novgorod. « Il y a eu une explosion technique dans l’un des ateliers, suivie d’un incendie qui s’est propagé sur une centaine de mètres carrés », a expliqué un porte-parole des services d’urgence. Des images circulant sur les réseaux sociaux montraient un énorme nuage de fumée après l’explosion. Cinq bâtiments de l’usine et près de 180 bâtiments résidentiels ont été endommagés par l’explosion, selon les autorités municipales. Une enquête pour de potentielles violations des normes de sécurité a été ouverte. Fragments de shrapnel Les blessés ont été soignés après avoir été atteints par des fragments issus de l’explosion, a précisé une porte-parole des autorités sanitaires citée par Interfax. « Nous parlons de blessures par shrapnel d’une gravité moyenne et modérée », a-t-elle précisé. Selon des représentants de Kristall, cinq personnes travaillaient dans la zone où s’est produite l’explosion. Elles ont pu être évacuées en sécurité. Les pompiers locaux ont rapporté n’avoir aucune information sur des personnes qui se trouveraient encore dans l’usine."
---
# French RoBERTa2RoBERTa (shared) fine-tuned on MLSUM FR for summarization
## Model
[camembert-base](https://huggingface.co/camembert-base) (RoBERTa Checkpoint)
## Dataset
**MLSUM** is the first large-scale MultiLingual SUMmarization dataset. Obtained from online newspapers, it contains 1.5M+ article/summary pairs in five different languages -- namely, **French**, German, Spanish, Russian, Turkish. Together with English newspapers from the popular CNN/Daily mail dataset, the collected data form a large scale multilingual dataset which can enable new research directions for the text summarization community. We report cross-lingual comparative analyses based on state-of-the-art systems. These highlight existing biases which motivate the use of a multi-lingual dataset.
[MLSUM fr](https://huggingface.co/datasets/viewer/?dataset=mlsum)
## Results
|Set|Metric| # Score|
|----|------|------|
| Test |Rouge2 - mid -precision | **14.47**|
| Test | Rouge2 - mid - recall | **12.90**|
| Test | Rouge2 - mid - fmeasure | **13.30**|
## Usage
```python
import torch
from transformers import RobertaTokenizerFast, EncoderDecoderModel
device = 'cuda' if torch.cuda.is_available() else 'cpu'
ckpt = 'mrm8488/camembert2camembert_shared-finetuned-french-summarization'
tokenizer = RobertaTokenizerFast.from_pretrained(ckpt)
model = EncoderDecoderModel.from_pretrained(ckpt).to(device)
def generate_summary(text):
inputs = tokenizer([text], padding="max_length", truncation=True, max_length=512, return_tensors="pt")
input_ids = inputs.input_ids.to(device)
attention_mask = inputs.attention_mask.to(device)
output = model.generate(input_ids, attention_mask=attention_mask)
return tokenizer.decode(output[0], skip_special_tokens=True)
text = "Un nuage de fumée juste après l’explosion, le 1er juin 2019. Une déflagration dans une importante usine d’explosifs du centre de la Russie a fait au moins 79 blessés samedi 1er juin. L’explosion a eu lieu dans l’usine Kristall à Dzerzhinsk, une ville située à environ 400 kilomètres à l’est de Moscou, dans la région de Nijni-Novgorod. « Il y a eu une explosion technique dans l’un des ateliers, suivie d’un incendie qui s’est propagé sur une centaine de mètres carrés », a expliqué un porte-parole des services d’urgence. Des images circulant sur les réseaux sociaux montraient un énorme nuage de fumée après l’explosion. Cinq bâtiments de l’usine et près de 180 bâtiments résidentiels ont été endommagés par l’explosion, selon les autorités municipales. Une enquête pour de potentielles violations des normes de sécurité a été ouverte. Fragments de shrapnel Les blessés ont été soignés après avoir été atteints par des fragments issus de l’explosion, a précisé une porte-parole des autorités sanitaires citée par Interfax. « Nous parlons de blessures par shrapnel d’une gravité moyenne et modérée », a-t-elle précisé. Selon des représentants de Kristall, cinq personnes travaillaient dans la zone où s’est produite l’explosion. Elles ont pu être évacuées en sécurité. Les pompiers locaux ont rapporté n’avoir aucune information sur des personnes qui se trouveraient encore dans l’usine."
generate_summary(text)
# Output: L’explosion a eu lieu dans l’usine Kristall à Dzerzhinsk, une ville située à environ 400 kilomètres à l’est de Moscou.
```
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488) with the support of [Narrativa](https://www.narrativa.com/)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
deepset/all-mpnet-base-v2-table
|
ab5f9a5f0d8bf0e849b2083cab21375a16e9b424
|
2022-04-29T12:28:58.000Z
|
[
"pytorch",
"mpnet",
"feature-extraction",
"sentence-transformers",
"sentence-similarity"
] |
sentence-similarity
| false |
deepset
| null |
deepset/all-mpnet-base-v2-table
| 1,596 | null |
sentence-transformers
| 1,485 |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
---
# deepset/all-mpnet-base-v2-table
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('deepset/all-mpnet-base-v2-table')
embeddings = model.encode(sentences)
print(embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=deepset/all-mpnet-base-v2-table)
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 5010 with parameters:
```
{'batch_size': 24, 'sampler': 'torch.utils.data.sampler.SequentialSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.MultipleNegativesRankingLoss.MultipleNegativesRankingLoss` with parameters:
```
{'scale': 20.0, 'similarity_fct': 'cos_sim'}
```
Parameters of the fit()-Method:
```
{
"epochs": 1,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'transformers.optimization.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 10000,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 384, 'do_lower_case': False}) with Transformer model: MPNetModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
(2): Normalize()
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
sagorsarker/codeswitch-hineng-ner-lince
|
ccfaa4edebc835475ad2d0df81f5f286bd27b7f0
|
2021-05-19T01:03:28.000Z
|
[
"pytorch",
"jax",
"bert",
"token-classification",
"hi",
"en",
"dataset:lince",
"transformers",
"codeswitching",
"hindi-english",
"ner",
"license:mit",
"autotrain_compatible"
] |
token-classification
| false |
sagorsarker
| null |
sagorsarker/codeswitch-hineng-ner-lince
| 1,592 | null |
transformers
| 1,486 |
---
language:
- hi
- en
datasets:
- lince
license: mit
tags:
- codeswitching
- hindi-english
- ner
---
# codeswitch-hineng-ner-lince
This is a pretrained model for **Name Entity Recognition** of `Hindi-english` code-mixed data used from [LinCE](https://ritual.uh.edu/lince/home)
This model is trained for this below repository.
[https://github.com/sagorbrur/codeswitch](https://github.com/sagorbrur/codeswitch)
To install codeswitch:
```
pip install codeswitch
```
## Name Entity Recognition of Code-Mixed Data
* **Method-1**
```py
from transformers import AutoTokenizer, AutoModelForTokenClassification, pipeline
tokenizer = AutoTokenizer.from_pretrained("sagorsarker/codeswitch-hineng-ner-lince")
model = AutoModelForTokenClassification.from_pretrained("sagorsarker/codeswitch-hineng-ner-lince")
ner_model = pipeline('ner', model=model, tokenizer=tokenizer)
ner_model("put any hindi english code-mixed sentence")
```
* **Method-2**
```py
from codeswitch.codeswitch import NER
ner = NER('hin-eng')
text = "" # your mixed sentence
result = ner.tag(text)
print(result)
```
|
soheeyang/rdr-question_encoder-single-nq-base
|
469a71430f852d4b9422374178eade037dcdfdb7
|
2021-04-15T15:58:07.000Z
|
[
"pytorch",
"tf",
"dpr",
"feature-extraction",
"arxiv:2010.10999",
"arxiv:2004.04906",
"transformers"
] |
feature-extraction
| false |
soheeyang
| null |
soheeyang/rdr-question_encoder-single-nq-base
| 1,589 | null |
transformers
| 1,487 |
# rdr-question_encoder-single-nq-base
Reader-Distilled Retriever (`RDR`)
Sohee Yang and Minjoon Seo, [Is Retriever Merely an Approximator of Reader?](https://arxiv.org/abs/2010.10999), arXiv 2020
The paper proposes to distill the reader into the retriever so that the retriever absorbs the strength of the reader while keeping its own benefit. The model is a [DPR](https://arxiv.org/abs/2004.04906) retriever further finetuned using knowledge distillation from the DPR reader. Using this approach, the answer recall rate increases by a large margin, especially at small numbers of top-k.
This model is the question encoder of RDR trained solely on Natural Questions (NQ) (single-nq). This model is trained by the authors and is the official checkpoint of RDR.
## Performance
The following is the answer recall rate measured using PyTorch 1.4.0 and transformers 4.5.0.
The values of DPR on the NQ dev set are taken from Table 1 of the [paper of RDR](https://arxiv.org/abs/2010.10999). The values of DPR on the NQ test set are taken from the [codebase of DPR](https://github.com/facebookresearch/DPR). DPR-adv is the a new DPR model released in March 2021. It is trained on the original DPR NQ train set and its version where hard negatives are mined using DPR index itself using the previous NQ checkpoint. Please refer to the [codebase of DPR](https://github.com/facebookresearch/DPR) for more details about DPR-adv-hn.
| | Top-K Passages | 1 | 5 | 20 | 50 | 100 |
|---------|------------------|-------|-------|-------|-------|-------|
| **NQ Dev** | **DPR** | 44.2 | - | 76.9 | 81.3 | 84.2 |
| | **RDR (This Model)** | **54.43** | **72.17** | **81.33** | **84.8** | **86.61** |
| **NQ Test** | **DPR** | 45.87 | 68.14 | 79.97 | - | 85.87 |
| | **DPR-adv-hn** | 52.47 | **72.24** | 81.33 | - | 87.29 |
| | **RDR (This Model)** | **54.29** | 72.16 | **82.8** | **86.34** | **88.2** |
## How to Use
RDR shares the same architecture with DPR. Therefore, It uses `DPRQuestionEncoder` as the model class.
Using `AutoModel` does not properly detect whether the checkpoint is for `DPRContextEncoder` or `DPRQuestionEncoder`.
Therefore, please specify the exact class to use the model.
```python
from transformers import DPRQuestionEncoder, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("soheeyang/rdr-question_encoder-single-trivia-base")
question_encoder = DPRQuestionEncoder.from_pretrained("soheeyang/rdr-question_encoder-single-trivia-base")
data = tokenizer("question comes here", return_tensors="pt")
question_embedding = question_encoder(**data).pooler_output # embedding vector for question
```
|
uer/chinese_roberta_L-4_H-256
|
5057ca761d707f42a367551c482df4eb2b7cfb12
|
2022-07-15T08:12:10.000Z
|
[
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"zh",
"dataset:CLUECorpusSmall",
"arxiv:1909.05658",
"arxiv:1908.08962",
"transformers",
"autotrain_compatible"
] |
fill-mask
| false |
uer
| null |
uer/chinese_roberta_L-4_H-256
| 1,585 | null |
transformers
| 1,488 |
---
language: zh
datasets: CLUECorpusSmall
widget:
- text: "北京是[MASK]国的首都。"
---
# Chinese RoBERTa Miniatures
## Model description
This is the set of 24 Chinese RoBERTa models pre-trained by [UER-py](https://github.com/dbiir/UER-py/), which is introduced in [this paper](https://arxiv.org/abs/1909.05658).
[Turc et al.](https://arxiv.org/abs/1908.08962) have shown that the standard BERT recipe is effective on a wide range of model sizes. Following their paper, we released the 24 Chinese RoBERTa models. In order to facilitate users to reproduce the results, we used the publicly available corpus and provided all training details.
You can download the 24 Chinese RoBERTa miniatures either from the [UER-py Modelzoo page](https://github.com/dbiir/UER-py/wiki/Modelzoo), or via HuggingFace from the links below:
| | H=128 | H=256 | H=512 | H=768 |
| -------- | :-----------------------: | :-----------------------: | :-------------------------: | :-------------------------: |
| **L=2** | [**2/128 (Tiny)**][2_128] | [2/256][2_256] | [2/512][2_512] | [2/768][2_768] |
| **L=4** | [4/128][4_128] | [**4/256 (Mini)**][4_256] | [**4/512 (Small)**][4_512] | [4/768][4_768] |
| **L=6** | [6/128][6_128] | [6/256][6_256] | [6/512][6_512] | [6/768][6_768] |
| **L=8** | [8/128][8_128] | [8/256][8_256] | [**8/512 (Medium)**][8_512] | [8/768][8_768] |
| **L=10** | [10/128][10_128] | [10/256][10_256] | [10/512][10_512] | [10/768][10_768] |
| **L=12** | [12/128][12_128] | [12/256][12_256] | [12/512][12_512] | [**12/768 (Base)**][12_768] |
Here are scores on the devlopment set of six Chinese tasks:
| Model | Score | douban | chnsenticorp | lcqmc | tnews(CLUE) | iflytek(CLUE) | ocnli(CLUE) |
| -------------- | :---: | :----: | :----------: | :---: | :---------: | :-----------: | :---------: |
| RoBERTa-Tiny | 72.3 | 83.0 | 91.4 | 81.8 | 62.0 | 55.0 | 60.3 |
| RoBERTa-Mini | 75.7 | 84.8 | 93.7 | 86.1 | 63.9 | 58.3 | 67.4 |
| RoBERTa-Small | 76.8 | 86.5 | 93.4 | 86.5 | 65.1 | 59.4 | 69.7 |
| RoBERTa-Medium | 77.8 | 87.6 | 94.8 | 88.1 | 65.6 | 59.5 | 71.2 |
| RoBERTa-Base | 79.5 | 89.1 | 95.2 | 89.2 | 67.0 | 60.9 | 75.5 |
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained with the sequence length of 128:
- epochs: 3, 5, 8
- batch sizes: 32, 64
- learning rates: 3e-5, 1e-4, 3e-4
## How to use
You can use this model directly with a pipeline for masked language modeling (take the case of RoBERTa-Medium):
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='uer/chinese_roberta_L-8_H-512')
>>> unmasker("中国的首都是[MASK]京。")
[
{'sequence': '[CLS] 中 国 的 首 都 是 北 京 。 [SEP]',
'score': 0.8701988458633423,
'token': 1266,
'token_str': '北'},
{'sequence': '[CLS] 中 国 的 首 都 是 南 京 。 [SEP]',
'score': 0.1194809079170227,
'token': 1298,
'token_str': '南'},
{'sequence': '[CLS] 中 国 的 首 都 是 东 京 。 [SEP]',
'score': 0.0037803512532263994,
'token': 691,
'token_str': '东'},
{'sequence': '[CLS] 中 国 的 首 都 是 普 京 。 [SEP]',
'score': 0.0017127094324678183,
'token': 3249,
'token_str': '普'},
{'sequence': '[CLS] 中 国 的 首 都 是 望 京 。 [SEP]',
'score': 0.001687526935711503,
'token': 3307,
'token_str': '望'}
]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('uer/chinese_roberta_L-8_H-512')
model = BertModel.from_pretrained("uer/chinese_roberta_L-8_H-512")
text = "用你喜欢的任何文本替换我。"
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import BertTokenizer, TFBertModel
tokenizer = BertTokenizer.from_pretrained('uer/chinese_roberta_L-8_H-512')
model = TFBertModel.from_pretrained("uer/chinese_roberta_L-8_H-512")
text = "用你喜欢的任何文本替换我。"
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
## Training data
[CLUECorpusSmall](https://github.com/CLUEbenchmark/CLUECorpus2020/) is used as training data. We found that models pre-trained on CLUECorpusSmall outperform those pre-trained on CLUECorpus2020, although CLUECorpus2020 is much larger than CLUECorpusSmall.
## Training procedure
Models are pre-trained by [UER-py](https://github.com/dbiir/UER-py/) on [Tencent Cloud](https://cloud.tencent.com/). We pre-train 1,000,000 steps with a sequence length of 128 and then pre-train 250,000 additional steps with a sequence length of 512. We use the same hyper-parameters on different model sizes.
Taking the case of RoBERTa-Medium
Stage1:
```
python3 preprocess.py --corpus_path corpora/cluecorpussmall.txt \
--vocab_path models/google_zh_vocab.txt \
--dataset_path cluecorpussmall_seq128_dataset.pt \
--processes_num 32 --seq_length 128 \
--dynamic_masking --data_processor mlm
```
```
python3 pretrain.py --dataset_path cluecorpussmall_seq128_dataset.pt \
--vocab_path models/google_zh_vocab.txt \
--config_path models/bert/medium_config.json \
--output_model_path models/cluecorpussmall_roberta_medium_seq128_model.bin \
--world_size 8 --gpu_ranks 0 1 2 3 4 5 6 7 \
--total_steps 1000000 --save_checkpoint_steps 100000 --report_steps 50000 \
--learning_rate 1e-4 --batch_size 64 \
--data_processor mlm --target mlm
```
Stage2:
```
python3 preprocess.py --corpus_path corpora/cluecorpussmall.txt \
--vocab_path models/google_zh_vocab.txt \
--dataset_path cluecorpussmall_seq512_dataset.pt \
--processes_num 32 --seq_length 512 \
--dynamic_masking --data_processor mlm
```
```
python3 pretrain.py --dataset_path cluecorpussmall_seq512_dataset.pt \
--vocab_path models/google_zh_vocab.txt \
--pretrained_model_path models/cluecorpussmall_roberta_medium_seq128_model.bin-1000000 \
--config_path models/bert/medium_config.json \
--output_model_path models/cluecorpussmall_roberta_medium_seq512_model.bin \
--world_size 8 --gpu_ranks 0 1 2 3 4 5 6 7 \
--total_steps 250000 --save_checkpoint_steps 50000 --report_steps 10000 \
--learning_rate 5e-5 --batch_size 16 \
--data_processor mlm --target mlm
```
Finally, we convert the pre-trained model into Huggingface's format:
```
python3 scripts/convert_bert_from_uer_to_huggingface.py --input_model_path models/cluecorpussmall_roberta_medium_seq512_model.bin-250000 \
--output_model_path pytorch_model.bin \
--layers_num 8 --type mlm
```
### BibTeX entry and citation info
```
@article{devlin2018bert,
title={Bert: Pre-training of deep bidirectional transformers for language understanding},
author={Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1810.04805},
year={2018}
}
@article{liu2019roberta,
title={Roberta: A robustly optimized bert pretraining approach},
author={Liu, Yinhan and Ott, Myle and Goyal, Naman and Du, Jingfei and Joshi, Mandar and Chen, Danqi and Levy, Omer and Lewis, Mike and Zettlemoyer, Luke and Stoyanov, Veselin},
journal={arXiv preprint arXiv:1907.11692},
year={2019}
}
@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}
@article{zhao2019uer,
title={UER: An Open-Source Toolkit for Pre-training Models},
author={Zhao, Zhe and Chen, Hui and Zhang, Jinbin and Zhao, Xin and Liu, Tao and Lu, Wei and Chen, Xi and Deng, Haotang and Ju, Qi and Du, Xiaoyong},
journal={EMNLP-IJCNLP 2019},
pages={241},
year={2019}
}
```
[2_128]:https://huggingface.co/uer/chinese_roberta_L-2_H-128
[2_256]:https://huggingface.co/uer/chinese_roberta_L-2_H-256
[2_512]:https://huggingface.co/uer/chinese_roberta_L-2_H-512
[2_768]:https://huggingface.co/uer/chinese_roberta_L-2_H-768
[4_128]:https://huggingface.co/uer/chinese_roberta_L-4_H-128
[4_256]:https://huggingface.co/uer/chinese_roberta_L-4_H-256
[4_512]:https://huggingface.co/uer/chinese_roberta_L-4_H-512
[4_768]:https://huggingface.co/uer/chinese_roberta_L-4_H-768
[6_128]:https://huggingface.co/uer/chinese_roberta_L-6_H-128
[6_256]:https://huggingface.co/uer/chinese_roberta_L-6_H-256
[6_512]:https://huggingface.co/uer/chinese_roberta_L-6_H-512
[6_768]:https://huggingface.co/uer/chinese_roberta_L-6_H-768
[8_128]:https://huggingface.co/uer/chinese_roberta_L-8_H-128
[8_256]:https://huggingface.co/uer/chinese_roberta_L-8_H-256
[8_512]:https://huggingface.co/uer/chinese_roberta_L-8_H-512
[8_768]:https://huggingface.co/uer/chinese_roberta_L-8_H-768
[10_128]:https://huggingface.co/uer/chinese_roberta_L-10_H-128
[10_256]:https://huggingface.co/uer/chinese_roberta_L-10_H-256
[10_512]:https://huggingface.co/uer/chinese_roberta_L-10_H-512
[10_768]:https://huggingface.co/uer/chinese_roberta_L-10_H-768
[12_128]:https://huggingface.co/uer/chinese_roberta_L-12_H-128
[12_256]:https://huggingface.co/uer/chinese_roberta_L-12_H-256
[12_512]:https://huggingface.co/uer/chinese_roberta_L-12_H-512
[12_768]:https://huggingface.co/uer/chinese_roberta_L-12_H-768
|
hf-internal-testing/tiny-random-wav2vec2-conformer
|
2df75f17d52e1d0dbc20cab2af18de15c27c5a81
|
2022-04-29T14:33:08.000Z
|
[
"pytorch",
"wav2vec2-conformer",
"automatic-speech-recognition",
"transformers"
] |
automatic-speech-recognition
| false |
hf-internal-testing
| null |
hf-internal-testing/tiny-random-wav2vec2-conformer
| 1,584 | null |
transformers
| 1,489 |
Entry not found
|
Helsinki-NLP/opus-mt-af-en
|
9c6d59e84991726b65968b8196d6fa0b4b32326c
|
2021-09-09T21:25:57.000Z
|
[
"pytorch",
"marian",
"text2text-generation",
"af",
"en",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] |
translation
| false |
Helsinki-NLP
| null |
Helsinki-NLP/opus-mt-af-en
| 1,580 | null |
transformers
| 1,490 |
---
tags:
- translation
license: apache-2.0
---
### opus-mt-af-en
* source languages: af
* target languages: en
* OPUS readme: [af-en](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/af-en/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2019-12-18.zip](https://object.pouta.csc.fi/OPUS-MT-models/af-en/opus-2019-12-18.zip)
* test set translations: [opus-2019-12-18.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/af-en/opus-2019-12-18.test.txt)
* test set scores: [opus-2019-12-18.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/af-en/opus-2019-12-18.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba.af.en | 60.8 | 0.736 |
|
microsoft/prophetnet-large-uncased-squad-qg
|
387a8e2f11c0b17b565b7b67d70362f51c9a29e3
|
2020-12-11T21:51:03.000Z
|
[
"pytorch",
"prophetnet",
"text2text-generation",
"en",
"dataset:squad",
"arxiv:2001.04063",
"transformers",
"autotrain_compatible"
] |
text2text-generation
| false |
microsoft
| null |
microsoft/prophetnet-large-uncased-squad-qg
| 1,575 | null |
transformers
| 1,491 |
---
language: en
datasets:
- squad
---
##
prophetnet-large-uncased-squad-qg
Fine-tuned weights(converted from [original fairseq version repo](https://github.com/microsoft/ProphetNet)) for [ProphetNet](https://arxiv.org/abs/2001.04063) on question generation
SQuAD 1.1.
ProphetNet is a new pre-trained language model for sequence-to-sequence learning with a novel self-supervised objective called future n-gram prediction.
ProphetNet is able to predict more future tokens with a n-stream decoder. The original implementation is Fairseq version at [github repo](https://github.com/microsoft/ProphetNet).
### Usage
```
from transformers import ProphetNetTokenizer, ProphetNetForConditionalGeneration, ProphetNetConfig
model = ProphetNetForConditionalGeneration.from_pretrained('microsoft/prophetnet-large-uncased-squad-qg')
tokenizer = ProphetNetTokenizer.from_pretrained('microsoft/prophetnet-large-uncased-squad-qg')
FACT_TO_GENERATE_QUESTION_FROM = ""Bill Gates [SEP] Microsoft was founded by Bill Gates and Paul Allen on April 4, 1975."
inputs = tokenizer([FACT_TO_GENERATE_QUESTION_FROM], return_tensors='pt')
# Generate Summary
question_ids = model.generate(inputs['input_ids'], num_beams=5, early_stopping=True)
tokenizer.batch_decode(question_ids, skip_special_tokens=True)
# should give: 'along with paul allen, who founded microsoft?'
```
### Citation
```bibtex
@article{yan2020prophetnet,
title={Prophetnet: Predicting future n-gram for sequence-to-sequence pre-training},
author={Yan, Yu and Qi, Weizhen and Gong, Yeyun and Liu, Dayiheng and Duan, Nan and Chen, Jiusheng and Zhang, Ruofei and Zhou, Ming},
journal={arXiv preprint arXiv:2001.04063},
year={2020}
}
```
|
josu/roberta-pt-br
|
87df2e2ec53cecab6c64de60735b405e076a1fe5
|
2021-12-12T20:15:09.000Z
|
[
"pytorch",
"roberta",
"fill-mask",
"pt",
"transformers",
"portuguese",
"brazil",
"pt_BR",
"autotrain_compatible"
] |
fill-mask
| false |
josu
| null |
josu/roberta-pt-br
| 1,572 | 1 |
transformers
| 1,492 |
---
language: pt
tags:
- portuguese
- brazil
- pt_BR
widget:
- text: Brasilia é a capital do <mask>
---
``` python
from transformers import pipeline
unmasker = pipeline('fill-mask', model='josu/roberta-pt-br')
text = 'Brasilia é a capital do <mask>'
[{'sequence': 'Brasilia é a capital do Brasil',
'score': 0.24386335909366608,
'token': 707,
'token_str': ' Brasil'},
{'sequence': 'Brasilia é a capital do estado',
'score': 0.2320091277360916,
'token': 1031,
'token_str': ' estado'},
{'sequence': 'Brasilia é a capital do país',
'score': 0.0665697380900383,
'token': 998,
'token_str': ' país'},
{'sequence': 'Brasilia é a capital do Rio',
'score': 0.05980581417679787,
'token': 993,
'token_str': ' Rio'},
{'sequence': 'Brasilia é a capital do capital',
'score': 0.058453518897295,
'token': 2027,
'token_str': ' capital'}]
```
|
facebook/xglm-564M
|
5933068ff6a2dc65d0520ffa43fc1836149e8cb2
|
2022-06-25T15:36:18.000Z
|
[
"pytorch",
"tf",
"jax",
"xglm",
"text-generation",
"arxiv:2112.10668",
"transformers",
"license:mit"
] |
text-generation
| false |
facebook
| null |
facebook/xglm-564M
| 1,569 | 12 |
transformers
| 1,493 |
---
license: mit
thumbnail: https://huggingface.co/front/thumbnails/facebook.png
inference: false
---
# XGLM-564M
XGLM-564M is a multilingual autoregressive language model (with 564 million parameters) trained on a balanced corpus of a diverse set of 30 languages totaling 500 billion sub-tokens. It was introduced in the paper [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668) by Xi Victoria Lin\*, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li\* (\*Equal Contribution). The original implementation was released in [this repository](https://github.com/pytorch/fairseq/tree/main/examples/xglm).
## Training Data Statistics
The training data statistics of XGLM-564M is shown in the table below.
| ISO-639-1| family | name | # tokens | ratio | ratio w/ lowRes upsampling |
|:--------|:-----------------|:------------------------|-------------:|------------:|-------------:|
| en | Indo-European | English | 803526736124 | 0.489906 | 0.3259 |
| ru | Indo-European | Russian | 147791898098 | 0.0901079 | 0.0602 |
| zh | Sino-Tibetan | Chinese | 132770494630 | 0.0809494 | 0.0483 |
| de | Indo-European | German | 89223707856 | 0.0543992 | 0.0363 |
| es | Indo-European | Spanish | 87303083105 | 0.0532282 | 0.0353 |
| fr | Indo-European | French | 77419639775 | 0.0472023 | 0.0313 |
| ja | Japonic | Japanese | 66054364513 | 0.040273 | 0.0269 |
| it | Indo-European | Italian | 41930465338 | 0.0255648 | 0.0171 |
| pt | Indo-European | Portuguese | 36586032444 | 0.0223063 | 0.0297 |
| el | Indo-European | Greek (modern) | 28762166159 | 0.0175361 | 0.0233 |
| ko | Koreanic | Korean | 20002244535 | 0.0121953 | 0.0811 |
| fi | Uralic | Finnish | 16804309722 | 0.0102455 | 0.0681 |
| id | Austronesian | Indonesian | 15423541953 | 0.00940365 | 0.0125 |
| tr | Turkic | Turkish | 12413166065 | 0.00756824 | 0.0101 |
| ar | Afro-Asiatic | Arabic | 12248607345 | 0.00746791 | 0.0099 |
| vi | Austroasiatic | Vietnamese | 11199121869 | 0.00682804 | 0.0091 |
| th | Tai–Kadai | Thai | 10842172807 | 0.00661041 | 0.044 |
| bg | Indo-European | Bulgarian | 9703797869 | 0.00591635 | 0.0393 |
| ca | Indo-European | Catalan | 7075834775 | 0.0043141 | 0.0287 |
| hi | Indo-European | Hindi | 3448390110 | 0.00210246 | 0.014 |
| et | Uralic | Estonian | 3286873851 | 0.00200399 | 0.0133 |
| bn | Indo-European | Bengali, Bangla | 1627447450 | 0.000992245 | 0.0066 |
| ta | Dravidian | Tamil | 1476973397 | 0.000900502 | 0.006 |
| ur | Indo-European | Urdu | 1351891969 | 0.000824241 | 0.0055 |
| sw | Niger–Congo | Swahili | 907516139 | 0.000553307 | 0.0037 |
| te | Dravidian | Telugu | 689316485 | 0.000420272 | 0.0028 |
| eu | Language isolate | Basque | 105304423 | 6.42035e-05 | 0.0043 |
| my | Sino-Tibetan | Burmese | 101358331 | 6.17976e-05 | 0.003 |
| ht | Creole | Haitian, Haitian Creole | 86584697 | 5.27902e-05 | 0.0035 |
| qu | Quechuan | Quechua | 3236108 | 1.97304e-06 | 0.0001 |
## Model card
For intended usage of the model, please refer to the [model card](https://github.com/pytorch/fairseq/blob/main/examples/xglm/model_card.md) released by the XGLM-564M development team.
## Example (COPA)
The following snippet shows how to evaluate our models (GPT-3 style, zero-shot) on the Choice of Plausible Alternatives (COPA) task, using examples in English, Chinese and Hindi.
```python
import torch
import torch.nn.functional as F
from transformers import XGLMTokenizer, XGLMForCausalLM
tokenizer = XGLMTokenizer.from_pretrained("facebook/xglm-564M")
model = XGLMForCausalLM.from_pretrained("facebook/xglm-564M")
data_samples = {
'en': [
{
"premise": "I wanted to conserve energy.",
"choice1": "I swept the floor in the unoccupied room.",
"choice2": "I shut off the light in the unoccupied room.",
"question": "effect",
"label": "1"
},
{
"premise": "The flame on the candle went out.",
"choice1": "I blew on the wick.",
"choice2": "I put a match to the wick.",
"question": "cause",
"label": "0"
}
],
'zh': [
{
"premise": "我想节约能源。",
"choice1": "我在空着的房间里扫了地板。",
"choice2": "我把空房间里的灯关了。",
"question": "effect",
"label": "1"
},
{
"premise": "蜡烛上的火焰熄灭了。",
"choice1": "我吹灭了灯芯。",
"choice2": "我把一根火柴放在灯芯上。",
"question": "cause",
"label": "0"
}
],
'hi': [
{
"premise": "M te vle konsève enèji.",
"choice1": "Mwen te fin baleye chanm lib la.",
"choice2": "Mwen te femen limyè nan chanm lib la.",
"question": "effect",
"label": "1"
},
{
"premise": "Flam bouji a te etenn.",
"choice1": "Mwen te soufle bouji a.",
"choice2": "Mwen te limen mèch bouji a.",
"question": "cause",
"label": "0"
}
]
}
def get_logprobs(prompt):
inputs = tokenizer(prompt, return_tensors="pt")
input_ids, output_ids = inputs["input_ids"], inputs["input_ids"][:, 1:]
outputs = model(**inputs, labels=input_ids)
logits = outputs.logits
logprobs = torch.gather(F.log_softmax(logits, dim=2), 2, output_ids.unsqueeze(2))
return logprobs
# Zero-shot evaluation for the Choice of Plausible Alternatives (COPA) task.
# A return value of 0 indicates that the first alternative is more plausible,
# while 1 indicates that the second alternative is more plausible.
def COPA_eval(prompt, alternative1, alternative2):
lprob1 = get_logprobs(prompt + "\n" + alternative1).sum()
lprob2 = get_logprobs(prompt + "\n" + alternative2).sum()
return 0 if lprob1 > lprob2 else 1
for lang in data_samples_long:
for idx, example in enumerate(data_samples_long[lang]):
predict = COPA_eval(example["premise"], example["choice1"], example["choice2"])
print(f'{lang}-{idx}', predict, example['label'])
# en-0 1 1
# en-1 0 0
# zh-0 1 1
# zh-1 0 0
# hi-0 1 1
# hi-1 0 0
```
|
WENGSYX/Deberta-Chinese-Large
|
c586191664508930d114c0fb5cee60bf9de98132
|
2022-03-31T20:08:59.000Z
|
[
"pytorch",
"deberta",
"transformers"
] | null | false |
WENGSYX
| null |
WENGSYX/Deberta-Chinese-Large
| 1,567 | 6 |
transformers
| 1,494 |
# Deberta-Chinese
本项目,基于微软开源的Deberta模型,在中文领域进行预训练。开源本模型,旨在为其他人提供更多预训练语言模型选择。
本预训练模型,基于WuDaoCorpora语料库预训练而成。WuDaoCorpora是北京智源人工智能研究院(智源研究院)构建的大规模、高质量数据集,用于支撑“悟道”大模型项目研究。
使用WWM与n-gramMLM 等预训练方法进行预训练。
| 预训练模型 | 学习率 | batchsize | 设备 | 语料库 | 时间 | 优化器 |
| --------------------- | ------ | --------- | ------ | ------ | ---- | ------ |
| Deberta-Chinese-Large | 1e-5 | 512 | 2*3090 | 200G | 14天 | AdamW |
### 加载与使用
依托于huggingface-transformers
```
tokenizer = BertTokenizer.from_pretrained("WENGSYX/Deberta-Chinese-Large")
model = AutoModel.from_pretrained("WENGSYX/Deberta-Chinese-Large")
```
#### 注意,请使用BertTokenizer加载中文词表
|
classla/bcms-bertic
|
5db9755d6152ec6403c0201223e4848bd1b98a48
|
2021-10-29T08:20:06.000Z
|
[
"pytorch",
"electra",
"pretraining",
"hr",
"bs",
"sr",
"cnr",
"hbs",
"transformers",
"license:apache-2.0"
] | null | false |
classla
| null |
classla/bcms-bertic
| 1,567 | 2 |
transformers
| 1,495 |
---
language:
- hr
- bs
- sr
- cnr
- hbs
license: apache-2.0
---
# BERTić* [bert-ich] /bɜrtitʃ/ - A transformer language model for Bosnian, Croatian, Montenegrin and Serbian
* The name should resemble the facts (1) that the model was trained in Zagreb, Croatia, where diminutives ending in -ić (as in fotić, smajlić, hengić etc.) are very popular, and (2) that most surnames in the countries where these languages are spoken end in -ić (with diminutive etymology as well).
This Electra model was trained on more than 8 billion tokens of Bosnian, Croatian, Montenegrin and Serbian text.
***new*** We have published a version of this model fine-tuned on the named entity recognition task ([bcms-bertic-ner](https://huggingface.co/classla/bcms-bertic-ner)) and on the hate speech detection task ([bcms-bertic-frenk-hate](https://huggingface.co/classla/bcms-bertic-frenk-hate)).
If you use the model, please cite the following paper:
```
@inproceedings{ljubesic-lauc-2021-bertic,
title = "{BERT}i{\'c} - The Transformer Language Model for {B}osnian, {C}roatian, {M}ontenegrin and {S}erbian",
author = "Ljube{\v{s}}i{\'c}, Nikola and Lauc, Davor",
booktitle = "Proceedings of the 8th Workshop on Balto-Slavic Natural Language Processing",
month = apr,
year = "2021",
address = "Kiyv, Ukraine",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2021.bsnlp-1.5",
pages = "37--42",
}
```
## Benchmarking
Comparing this model to [multilingual BERT](https://huggingface.co/bert-base-multilingual-cased) and [CroSloEngual BERT](https://huggingface.co/EMBEDDIA/crosloengual-bert) on the tasks of (1) part-of-speech tagging, (2) named entity recognition, (3) geolocation prediction, and (4) commonsense causal reasoning, shows the BERTić model to be superior to the other two.
### Part-of-speech tagging
Evaluation metric is (seqeval) microF1. Reported are means of five runs. Best results are presented in bold. Statistical significance is calculated between two best-performing systems via a two-tailed t-test (* p<=0.05, ** p<=0.01, *** p<=0.001, ***** p<=0.0001).
Dataset | Language | Variety | CLASSLA | mBERT | cseBERT | BERTić
---|---|---|---|---|---|---
hr500k | Croatian | standard | 93.87 | 94.60 | 95.74 | **95.81*****
reldi-hr | Croatian | internet non-standard | - | 88.87 | 91.63 | **92.28*****
SETimes.SR | Serbian | standard | 95.00 | 95.50 | **96.41** | 96.31
reldi-sr | Serbian | internet non-standard | - | 91.26 | 93.54 | **93.90*****
### Named entity recognition
Evaluation metric is (seqeval) microF1. Reported are means of five runs. Best results are presented in bold. Statistical significance is calculated between two best-performing systems via a two-tailed t-test (* p<=0.05, ** p<=0.01, *** p<=0.001, ***** p<=0.0001).
Dataset | Language | Variety | CLASSLA | mBERT | cseBERT | BERTić
---|---|---|---|---|---|---
hr500k | Croatian | standard | 80.13 | 85.67 | 88.98 | **89.21******
reldi-hr | Croatian | internet non-standard | - | 76.06 | 81.38 | **83.05******
SETimes.SR | Serbian | standard | 84.64 | **92.41** | 92.28 | 92.02
reldi-sr | Serbian | internet non-standard | - | 81.29 | 82.76 | **87.92******
### Geolocation prediction
The dataset comes from the VarDial 2020 evaluation campaign's shared task on [Social Media variety Geolocation prediction](https://sites.google.com/view/vardial2020/evaluation-campaign). The task is to predict the latitude and longitude of a tweet given its text.
Evaluation metrics are median and mean of distance between gold and predicted geolocations (lower is better). No statistical significance is computed due to large test set (39,723 instances). Centroid baseline predicts each text to be created in the centroid of the training dataset.
System | Median | Mean
---|---|---
centroid | 107.10 | 145.72
mBERT | 42.25 | 82.05
cseBERT | 40.76 | 81.88
BERTić | **37.96** | **79.30**
### Choice Of Plausible Alternatives
The dataset is a translation of the [COPA dataset](https://people.ict.usc.edu/~gordon/copa.html) into Croatian ([link to the dataset](http://hdl.handle.net/11356/1404)).
Evaluation metric is accuracy. Reported are means of five runs. Best results are presented in bold. Statistical significance is calculated between two best-performing systems via a two-tailed t-test (* p<=0.05, ** p<=0.01, *** p<=0.001, ***** p<=0.0001).
System | Accuracy
---|---
random | 50.00
mBERT | 54.12
cseBERT | 61.80
BERTić | **65.76****
|
michiyasunaga/BioLinkBERT-large
|
1eb6d81c5fc1c42d3a43c71956b0e526558ae053
|
2022-03-31T00:54:57.000Z
|
[
"pytorch",
"bert",
"feature-extraction",
"en",
"dataset:pubmed",
"arxiv:2203.15827",
"transformers",
"exbert",
"linkbert",
"biolinkbert",
"fill-mask",
"question-answering",
"text-classification",
"token-classification",
"license:apache-2.0"
] |
text-classification
| false |
michiyasunaga
| null |
michiyasunaga/BioLinkBERT-large
| 1,567 | 3 |
transformers
| 1,496 |
---
license: apache-2.0
language: en
datasets:
- pubmed
tags:
- bert
- exbert
- linkbert
- biolinkbert
- feature-extraction
- fill-mask
- question-answering
- text-classification
- token-classification
widget:
- text: "Sunitinib is a tyrosine kinase inhibitor"
---
## BioLinkBERT-large
BioLinkBERT-large model pretrained on [PubMed](https://pubmed.ncbi.nlm.nih.gov/) abstracts along with citation link information. It is introduced in the paper [LinkBERT: Pretraining Language Models with Document Links (ACL 2022)](https://arxiv.org/abs/2203.15827). The code and data are available in [this repository](https://github.com/michiyasunaga/LinkBERT).
This model achieves state-of-the-art performance on several biomedical NLP benchmarks such as [BLURB](https://microsoft.github.io/BLURB/) and [MedQA-USMLE](https://github.com/jind11/MedQA).
## Model description
LinkBERT is a transformer encoder (BERT-like) model pretrained on a large corpus of documents. It is an improvement of BERT that newly captures **document links** such as hyperlinks and citation links to include knowledge that spans across multiple documents. Specifically, it was pretrained by feeding linked documents into the same language model context, besides a single document.
LinkBERT can be used as a drop-in replacement for BERT. It achieves better performance for general language understanding tasks (e.g. text classification), and is also particularly effective for **knowledge-intensive** tasks (e.g. question answering) and **cross-document** tasks (e.g. reading comprehension, document retrieval).
## Intended uses & limitations
The model can be used by fine-tuning on a downstream task, such as question answering, sequence classification, and token classification.
You can also use the raw model for feature extraction (i.e. obtaining embeddings for input text).
### How to use
To use the model to get the features of a given text in PyTorch:
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained('michiyasunaga/BioLinkBERT-large')
model = AutoModel.from_pretrained('michiyasunaga/BioLinkBERT-large')
inputs = tokenizer("Sunitinib is a tyrosine kinase inhibitor", return_tensors="pt")
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state
```
For fine-tuning, you can use [this repository](https://github.com/michiyasunaga/LinkBERT) or follow any other BERT fine-tuning codebases.
## Evaluation results
When fine-tuned on downstream tasks, LinkBERT achieves the following results.
**Biomedical benchmarks ([BLURB](https://microsoft.github.io/BLURB/), [MedQA](https://github.com/jind11/MedQA), [MMLU](https://github.com/hendrycks/test), etc.):** BioLinkBERT attains new state-of-the-art.
| | BLURB score | PubMedQA | BioASQ | MedQA-USMLE |
| ---------------------- | -------- | -------- | ------- | -------- |
| PubmedBERT-base | 81.10 | 55.8 | 87.5 | 38.1 |
| **BioLinkBERT-base** | **83.39** | **70.2** | **91.4** | **40.0** |
| **BioLinkBERT-large** | **84.30** | **72.2** | **94.8** | **44.6** |
| | MMLU-professional medicine |
| ---------------------- | -------- |
| GPT-3 (175 params) | 38.7 |
| UnifiedQA (11B params) | 43.2 |
| **BioLinkBERT-large (340M params)** | **50.7** |
## Citation
If you find LinkBERT useful in your project, please cite the following:
```bibtex
@InProceedings{yasunaga2022linkbert,
author = {Michihiro Yasunaga and Jure Leskovec and Percy Liang},
title = {LinkBERT: Pretraining Language Models with Document Links},
year = {2022},
booktitle = {Association for Computational Linguistics (ACL)},
}
```
|
microsoft/cvt-13
|
28340f4dfb5bfc05abb260895ad6c6db31298b31
|
2022-05-18T16:00:37.000Z
|
[
"pytorch",
"cvt",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2103.15808",
"transformers",
"vision",
"license:apache-2.0"
] |
image-classification
| false |
microsoft
| null |
microsoft/cvt-13
| 1,567 | 1 |
transformers
| 1,497 |
---
license: apache-2.0
tags:
- vision
- image-classification
datasets:
- imagenet-1k
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
---
# Convolutional Vision Transformer (CvT)
CvT-13 model pre-trained on ImageNet-1k at resolution 224x224. It was introduced in the paper [CvT: Introducing Convolutions to Vision Transformers](https://arxiv.org/abs/2103.15808) by Wu et al. and first released in [this repository](https://github.com/microsoft/CvT).
Disclaimer: The team releasing CvT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Usage
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import AutoFeatureExtractor, CvtForImageClassification
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = AutoFeatureExtractor.from_pretrained('microsoft/cvt-13')
model = CvtForImageClassification.from_pretrained('microsoft/cvt-13')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
|
oliverguhr/fullstop-punctuation-multilingual-base
|
8745d34dff832f75b192def37765ad8f800f46fb
|
2022-03-23T08:33:35.000Z
|
[
"pytorch",
"tensorboard",
"xlm-roberta",
"token-classification",
"en",
"de",
"fr",
"it",
"nl",
"dataset:wmt/europarl",
"transformers",
"punctuation prediction",
"punctuation",
"license:mit",
"autotrain_compatible"
] |
token-classification
| false |
oliverguhr
| null |
oliverguhr/fullstop-punctuation-multilingual-base
| 1,563 | 2 |
transformers
| 1,498 |
---
language:
- en
- de
- fr
- it
- nl
tags:
- punctuation prediction
- punctuation
datasets: wmt/europarl
license: mit
widget:
- text: "Ho sentito che ti sei laureata il che mi fa molto piacere"
example_title: "Italian"
- text: "Tous les matins vers quatre heures mon père ouvrait la porte de ma chambre"
example_title: "French"
- text: "Ist das eine Frage Frau Müller"
example_title: "German"
- text: "My name is Clara and I live in Berkeley California"
example_title: "English"
metrics:
- f1
---
# Work in progress
## Classification report over all languages
```
precision recall f1-score support
0 0.99 0.99 0.99 47903344
. 0.94 0.95 0.95 2798780
, 0.85 0.84 0.85 3451618
? 0.88 0.85 0.87 88876
- 0.61 0.32 0.42 157863
: 0.72 0.52 0.60 103789
accuracy 0.98 54504270
macro avg 0.83 0.75 0.78 54504270
weighted avg 0.98 0.98 0.98 54504270
```
|
UBC-NLP/ARBERT
|
a5118ac0caabfc6faba1cf7d92c779f7e2e15d44
|
2022-01-19T20:10:55.000Z
|
[
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"ar",
"transformers",
"Arabic BERT",
"MSA",
"Twitter",
"Masked Langauge Model",
"autotrain_compatible"
] |
fill-mask
| false |
UBC-NLP
| null |
UBC-NLP/ARBERT
| 1,562 | 3 |
transformers
| 1,499 |
---
language:
- ar
tags:
- Arabic BERT
- MSA
- Twitter
- Masked Langauge Model
widget:
- text: "اللغة العربية هي لغة [MASK]."
---
<img src="https://raw.githubusercontent.com/UBC-NLP/marbert/main/ARBERT_MARBERT.jpg" alt="drawing" width="30%" height="30%" align="right"/>
**ARBERT** is one of three models described in our **ACl 2021 paper** **["ARBERT & MARBERT: Deep Bidirectional Transformers for Arabic"](https://mageed.arts.ubc.ca/files/2020/12/marbert_arxiv_2020.pdf)**. ARBERT is a large-scale pre-trained masked language model focused on Modern Standard Arabic (MSA). To train ARBERT, we use the same architecture as BERT-base: 12 attention layers, each has 12 attention heads and 768 hidden dimensions, a vocabulary of 100K WordPieces, making ∼163M parameters. We train ARBERT on a collection of Arabic datasets comprising **61GB of text** (**6.2B tokens**). For more information, please visit our own GitHub [repo](https://github.com/UBC-NLP/marbert).
# BibTex
If you use our models (ARBERT, MARBERT, or MARBERTv2) for your scientific publication, or if you find the resources in this repository useful, please cite our paper as follows (to be updated):
```bibtex
@inproceedings{abdul-mageed-etal-2021-arbert,
title = "{ARBERT} {\&} {MARBERT}: Deep Bidirectional Transformers for {A}rabic",
author = "Abdul-Mageed, Muhammad and
Elmadany, AbdelRahim and
Nagoudi, El Moatez Billah",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers)",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.acl-long.551",
doi = "10.18653/v1/2021.acl-long.551",
pages = "7088--7105",
abstract = "Pre-trained language models (LMs) are currently integral to many natural language processing systems. Although multilingual LMs were also introduced to serve many languages, these have limitations such as being costly at inference time and the size and diversity of non-English data involved in their pre-training. We remedy these issues for a collection of diverse Arabic varieties by introducing two powerful deep bidirectional transformer-based models, ARBERT and MARBERT. To evaluate our models, we also introduce ARLUE, a new benchmark for multi-dialectal Arabic language understanding evaluation. ARLUE is built using 42 datasets targeting six different task clusters, allowing us to offer a series of standardized experiments under rich conditions. When fine-tuned on ARLUE, our models collectively achieve new state-of-the-art results across the majority of tasks (37 out of 48 classification tasks, on the 42 datasets). Our best model acquires the highest ARLUE score (77.40) across all six task clusters, outperforming all other models including XLM-R Large ( 3.4x larger size). Our models are publicly available at https://github.com/UBC-NLP/marbert and ARLUE will be released through the same repository.",
}
```
## Acknowledgments
We gratefully acknowledge support from the Natural Sciences and Engineering Research Council of Canada, the Social Sciences and Humanities Research Council of Canada, Canadian Foundation for Innovation, [ComputeCanada](www.computecanada.ca) and [UBC ARC-Sockeye](https://doi.org/10.14288/SOCKEYE). We also thank the [Google TensorFlow Research Cloud (TFRC)](https://www.tensorflow.org/tfrc) program for providing us with free TPU access.
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.