
modelId
stringlengths 4
112
| sha
stringlengths 40
40
| lastModified
stringlengths 24
24
| tags
list | pipeline_tag
stringclasses 29
values | private
bool 1
class | author
stringlengths 2
38
⌀ | config
null | id
stringlengths 4
112
| downloads
float64 0
36.8M
⌀ | likes
float64 0
712
⌀ | library_name
stringclasses 17
values | __index_level_0__
int64 0
38.5k
| readme
stringlengths 0
186k
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
salesken/translation-hi-en | 3ee83d07285c37a8da5858e5e90f30e958fb0240 | 2021-07-01T09:30:25.000Z | [
"pytorch",
"marian",
"text2text-generation",
"hi",
"transformers",
"translation",
"salesken",
"opus-mt",
"license:apache-2.0",
"autotrain_compatible"
]
| translation | false | salesken | null | salesken/translation-hi-en | 2,563 | 1 | transformers | 1,200 | ---
license: apache-2.0
language:
- hi
tags:
- translation
- salesken
- hi
- opus-mt
---
opus-mt model finetuned on ai4bhart Hindi-English parallel corpora (SAMANANTAR)
source-language: Hindi
target-language: English
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("salesken/translation-hi-en")
model = AutoModelForSeq2SeqLM.from_pretrained("salesken/translation-hi-en")
hin_snippet = "कोविड के कारण हमने अपने ऋण ब्याज को कम कर दिया है"
inputs = tokenizer.encode(
hin_snippet, return_tensors="pt",padding=True,max_length=512,truncation=True)
outputs = model.generate(
inputs, max_length=128, num_beams=None, early_stopping=True)
translated = tokenizer.decode(outputs[0]).replace('<pad>',"").strip().lower()
print(translated)
# due to covid, we have reduced our debt interest
``` |
skt/ko-gpt-trinity-1.2B-v0.5 | 33f84c0da333d34533f0cfbe8f5972022d681e96 | 2021-09-23T16:29:25.000Z | [
"pytorch",
"gpt2",
"text-generation",
"ko",
"transformers",
"gpt3",
"license:cc-by-nc-sa-4.0"
]
| text-generation | false | skt | null | skt/ko-gpt-trinity-1.2B-v0.5 | 2,549 | 15 | transformers | 1,201 | ---
language: ko
tags:
- gpt3
license: cc-by-nc-sa-4.0
---
# Ko-GPT-Trinity 1.2B (v0.5)
## Model Description
Ko-GPT-Trinity 1.2B is a transformer model designed using SK telecom's replication of the GPT-3 architecture. Ko-GPT-Trinity refers to the class of models, while 1.2B represents the number of parameters of this particular pre-trained model.
### Model date
May 2021
### Model type
Language model
### Model version
1.2 billion parameter model
## Training data
Ko-GPT-Trinity 1.2B was trained on Ko-DAT, a large scale curated dataset created by SK telecom for the purpose of training this model.
## Training procedure
This model was trained on ko-DAT for 35 billion tokens over 72,000 steps. It was trained as a masked autoregressive language model, using cross-entropy loss.
## Intended Use and Limitations
The model learns an inner representation of the Korean language that can then be used to extract features useful for downstream tasks. The model excels at generating texts from a prompt, which was the pre-training objective.
### Limitations and Biases
Ko-GPT-Trinity was trained on Ko-DAT, a dataset known to contain profanity, lewd, politically charged, and otherwise abrasive language. As such, Ko-GPT-Trinity may produce socially unacceptable text. As with all language models, it is hard to predict in advance how Ko-GPT-Trinity will respond to particular prompts and offensive content may occur without warning.
Ko-GPT-Trinity was trained as an autoregressive language model. This means that its core functionality is taking a string of text and predicting the next token. While language models are widely used for tasks other than this, this is an active area of ongoing research. Known limitations include the following:
Predominantly Korean: Ko-GPT-Trinity was trained largely on text in the Korean language, and is best suited for classifying, searching, summarizing, or generating such text. Ko-GPT-Trinity will by default perform worse on inputs that are different from the data distribution it is trained on, including non-Korean languages as well as specific dialects of Korean that are not as well-represented in training data.
Interpretability & predictability: the capacity to interpret or predict how Ko-GPT-Trinity will behave is very limited, a limitation common to most deep learning systems, especially in models of this scale.
High variance on novel inputs: Ko-GPT-Trinity is not necessarily well-calibrated in its predictions on novel inputs. This can be observed in the much higher variance in its performance as compared to that of humans on standard benchmarks.
## Eval results
### Reasoning
| Model and Size | BoolQ | CoPA | WiC |
| ----------------------- | --------- | ---------- | --------- |
| **Ko-GPT-Trinity 1.2B** | **71.77** | **68.66** | **78.73** |
| KoElectra-base | 65.17 | 67.56 | 77.27 |
| KoBERT-base | 55.97 | 62.24 | 77.60 |
## Where to send questions or comments about the model
Please contact [Eric] ([email protected])
|
sshleifer/distilbart-cnn-12-3 | e3a8f0dafad8b99df3209ff7cf33e1f8402619e1 | 2021-06-14T07:47:53.000Z | [
"pytorch",
"jax",
"bart",
"text2text-generation",
"en",
"dataset:cnn_dailymail",
"dataset:xsum",
"transformers",
"summarization",
"license:apache-2.0",
"autotrain_compatible"
]
| summarization | false | sshleifer | null | sshleifer/distilbart-cnn-12-3 | 2,549 | null | transformers | 1,202 | ---
language: en
tags:
- summarization
license: apache-2.0
datasets:
- cnn_dailymail
- xsum
thumbnail: https://huggingface.co/front/thumbnails/distilbart_medium.png
---
### Usage
This checkpoint should be loaded into `BartForConditionalGeneration.from_pretrained`. See the [BART docs](https://huggingface.co/transformers/model_doc/bart.html?#transformers.BartForConditionalGeneration) for more information.
### Metrics for DistilBART models
| Model Name | MM Params | Inference Time (MS) | Speedup | Rouge 2 | Rouge-L |
|:---------------------------|------------:|----------------------:|----------:|----------:|----------:|
| distilbart-xsum-12-1 | 222 | 90 | 2.54 | 18.31 | 33.37 |
| distilbart-xsum-6-6 | 230 | 132 | 1.73 | 20.92 | 35.73 |
| distilbart-xsum-12-3 | 255 | 106 | 2.16 | 21.37 | 36.39 |
| distilbart-xsum-9-6 | 268 | 136 | 1.68 | 21.72 | 36.61 |
| bart-large-xsum (baseline) | 406 | 229 | 1 | 21.85 | 36.50 |
| distilbart-xsum-12-6 | 306 | 137 | 1.68 | 22.12 | 36.99 |
| bart-large-cnn (baseline) | 406 | 381 | 1 | 21.06 | 30.63 |
| distilbart-12-3-cnn | 255 | 214 | 1.78 | 20.57 | 30.00 |
| distilbart-12-6-cnn | 306 | 307 | 1.24 | 21.26 | 30.59 |
| distilbart-6-6-cnn | 230 | 182 | 2.09 | 20.17 | 29.70 |
|
ckiplab/albert-tiny-chinese-ws | 097a391d7cb4bc1784e7268b866fb79629804378 | 2022-05-10T03:28:12.000Z | [
"pytorch",
"albert",
"token-classification",
"zh",
"transformers",
"license:gpl-3.0",
"autotrain_compatible"
]
| token-classification | false | ckiplab | null | ckiplab/albert-tiny-chinese-ws | 2,540 | null | transformers | 1,203 | ---
language:
- zh
thumbnail: https://ckip.iis.sinica.edu.tw/files/ckip_logo.png
tags:
- pytorch
- token-classification
- albert
- zh
license: gpl-3.0
---
# CKIP ALBERT Tiny Chinese
This project provides traditional Chinese transformers models (including ALBERT, BERT, GPT2) and NLP tools (including word segmentation, part-of-speech tagging, named entity recognition).
這個專案提供了繁體中文的 transformers 模型(包含 ALBERT、BERT、GPT2)及自然語言處理工具(包含斷詞、詞性標記、實體辨識)。
## Homepage
- https://github.com/ckiplab/ckip-transformers
## Contributers
- [Mu Yang](https://muyang.pro) at [CKIP](https://ckip.iis.sinica.edu.tw) (Author & Maintainer)
## Usage
Please use BertTokenizerFast as tokenizer instead of AutoTokenizer.
請使用 BertTokenizerFast 而非 AutoTokenizer。
```
from transformers import (
BertTokenizerFast,
AutoModel,
)
tokenizer = BertTokenizerFast.from_pretrained('bert-base-chinese')
model = AutoModel.from_pretrained('ckiplab/albert-tiny-chinese-ws')
```
For full usage and more information, please refer to https://github.com/ckiplab/ckip-transformers.
有關完整使用方法及其他資訊,請參見 https://github.com/ckiplab/ckip-transformers 。
|
abhilash1910/financial_roberta | 3ef89201dabbc8c9cd7887a838543d5c250ef0e5 | 2021-05-20T12:45:02.000Z | [
"pytorch",
"tf",
"jax",
"roberta",
"fill-mask",
"arxiv:1907.11692",
"transformers",
"finance",
"autotrain_compatible"
]
| fill-mask | false | abhilash1910 | null | abhilash1910/financial_roberta | 2,530 | 2 | transformers | 1,204 | ---
tags:
- finance
---
# Roberta Masked Language Model Trained On Financial Phrasebank Corpus
This is a Masked Language Model trained with [Roberta](https://huggingface.co/transformers/model_doc/roberta.html) on a Financial Phrasebank Corpus.
The model is built using Huggingface transformers.
The model can be found at :[Financial_Roberta](https://huggingface.co/abhilash1910/financial_roberta)
## Specifications
The corpus for training is taken from the Financial Phrasebank (Malo et al)[https://www.researchgate.net/publication/251231107_Good_Debt_or_Bad_Debt_Detecting_Semantic_Orientations_in_Economic_Texts].
## Model Specification
The model chosen for training is [Roberta](https://arxiv.org/abs/1907.11692) with the following specifications:
1. vocab_size=56000
2. max_position_embeddings=514
3. num_attention_heads=12
4. num_hidden_layers=6
5. type_vocab_size=1
This is trained by using RobertaConfig from transformers package.
The model is trained for 10 epochs with a gpu batch size of 64 units.
## Usage Specifications
For using this model, we have to first import AutoTokenizer and AutoModelWithLMHead Modules from transformers
After that we have to specify, the pre-trained model,which in this case is 'abhilash1910/financial_roberta' for the tokenizers and the model.
```python
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("abhilash1910/financial_roberta")
model = AutoModelWithLMHead.from_pretrained("abhilash1910/financial_roberta")
```
After this the model will be downloaded, it will take some time to download all the model files.
For testing the model, we have to import pipeline module from transformers and create a masked output model for inference as follows:
```python
from transformers import pipeline
model_mask = pipeline('fill-mask', model='abhilash1910/inancial_roberta')
model_mask("The company had a <mask> of 20% in 2020.")
```
Some of the examples are also provided with generic financial statements:
Example 1:
```python
model_mask("The company had a <mask> of 20% in 2020.")
```
Output:
```bash
[{'sequence': '<s>The company had a profit of 20% in 2020.</s>',
'score': 0.023112965747714043,
'token': 421,
'token_str': 'Ġprofit'},
{'sequence': '<s>The company had a loss of 20% in 2020.</s>',
'score': 0.021379893645644188,
'token': 616,
'token_str': 'Ġloss'},
{'sequence': '<s>The company had a year of 20% in 2020.</s>',
'score': 0.0185744296759367,
'token': 443,
'token_str': 'Ġyear'},
{'sequence': '<s>The company had a sales of 20% in 2020.</s>',
'score': 0.018143286928534508,
'token': 428,
'token_str': 'Ġsales'},
{'sequence': '<s>The company had a value of 20% in 2020.</s>',
'score': 0.015319528989493847,
'token': 776,
'token_str': 'Ġvalue'}]
```
Example 2:
```python
model_mask("The <mask> is listed under NYSE")
```
Output:
```bash
[{'sequence': '<s>The company is listed under NYSE</s>',
'score': 0.1566661298274994,
'token': 359,
'token_str': 'Ġcompany'},
{'sequence': '<s>The total is listed under NYSE</s>',
'score': 0.05542507395148277,
'token': 522,
'token_str': 'Ġtotal'},
{'sequence': '<s>The value is listed under NYSE</s>',
'score': 0.04729423299431801,
'token': 776,
'token_str': 'Ġvalue'},
{'sequence': '<s>The order is listed under NYSE</s>',
'score': 0.02533523552119732,
'token': 798,
'token_str': 'Ġorder'},
{'sequence': '<s>The contract is listed under NYSE</s>',
'score': 0.02087237872183323,
'token': 635,
'token_str': 'Ġcontract'}]
```
## Resources
For all resources , please look into the [HuggingFace](https://huggingface.co/) Site and the [Repositories](https://github.com/huggingface).
|
microsoft/swin-base-patch4-window7-224 | 3d6730c003b5c3f1cc3b4f23706d304e2dce9763 | 2022-05-16T19:50:52.000Z | [
"pytorch",
"tf",
"swin",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2103.14030",
"transformers",
"vision",
"license:apache-2.0"
]
| image-classification | false | microsoft | null | microsoft/swin-base-patch4-window7-224 | 2,521 | 1 | transformers | 1,205 | ---
license: apache-2.0
tags:
- vision
- image-classification
datasets:
- imagenet-1k
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
---
# Swin Transformer (base-sized model)
Swin Transformer model trained on ImageNet-1k at resolution 224x224. It was introduced in the paper [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) by Liu et al. and first released in [this repository](https://github.com/microsoft/Swin-Transformer).
Disclaimer: The team releasing Swin Transformer did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The Swin Transformer is a type of Vision Transformer. It builds hierarchical feature maps by merging image patches (shown in gray) in deeper layers and has linear computation complexity to input image size due to computation of self-attention only within each local window (shown in red). It can thus serve as a general-purpose backbone for both image classification and dense recognition tasks. In contrast, previous vision Transformers produce feature maps of a single low resolution and have quadratic computation complexity to input image size due to computation of self-attention globally.

[Source](https://paperswithcode.com/method/swin-transformer)
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=swin) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import AutoFeatureExtractor, SwinForImageClassification
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = AutoFeatureExtractor.from_pretrained("microsoft/swin-base-patch4-window7-224")
model = SwinForImageClassification.from_pretrained("microsoft/swin-base-patch4-window7-224")
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
For more code examples, we refer to the [documentation](https://huggingface.co/transformers/model_doc/swin.html#).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2103-14030,
author = {Ze Liu and
Yutong Lin and
Yue Cao and
Han Hu and
Yixuan Wei and
Zheng Zhang and
Stephen Lin and
Baining Guo},
title = {Swin Transformer: Hierarchical Vision Transformer using Shifted Windows},
journal = {CoRR},
volume = {abs/2103.14030},
year = {2021},
url = {https://arxiv.org/abs/2103.14030},
eprinttype = {arXiv},
eprint = {2103.14030},
timestamp = {Thu, 08 Apr 2021 07:53:26 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2103-14030.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` |
patrickvonplaten/tiny-wav2vec2-no-tokenizer | 77b68eb527e9faf028a70435dc353b3dcbb426f3 | 2021-09-20T17:36:01.000Z | [
"pytorch",
"tf",
"wav2vec2",
"transformers"
]
| null | false | patrickvonplaten | null | patrickvonplaten/tiny-wav2vec2-no-tokenizer | 2,512 | null | transformers | 1,206 | Entry not found |
uer/t5-base-chinese-cluecorpussmall | 4ace2bdf4a8915cd44d67f80960d1672125712e4 | 2022-07-15T08:22:39.000Z | [
"pytorch",
"tf",
"t5",
"text2text-generation",
"zh",
"dataset:CLUECorpusSmall",
"arxiv:1909.05658",
"transformers",
"autotrain_compatible"
]
| text2text-generation | false | uer | null | uer/t5-base-chinese-cluecorpussmall | 2,512 | 5 | transformers | 1,207 | ---
language: zh
datasets: CLUECorpusSmall
widget:
- text: "作为电子extra0的平台,京东绝对是领先者。如今的刘强extra1已经是身价过extra2的老板。"
---
# Chinese T5
## Model description
This is the set of Chinese T5 models pre-trained by [UER-py](https://github.com/dbiir/UER-py/), which is introduced in [this paper](https://arxiv.org/abs/1909.05658).
The Text-to-Text Transfer Transformer (T5) leverages a unified text-to-text format and attains state-of-the-art results on a wide variety of English-language NLP tasks. Following their work, we released a series of Chinese T5 models.
You can download the set of Chinese T5 models either from the [UER-py Modelzoo page](https://github.com/dbiir/UER-py/wiki/Modelzoo), or via HuggingFace from the links below:
| | Link |
| -------- | :-----------------------: |
| **T5-Small** | [**L=6/H=512 (Small)**][small] |
| **T5-Base** | [**L=12/H=768 (Base)**][base] |
In T5, spans of the input sequence are masked by so-called sentinel token. Each sentinel token represents a unique mask token for the input sequence and should start with `<extra_id_0>`, `<extra_id_1>`, … up to `<extra_id_99>`. However, `<extra_id_xxx>` is separated into multiple parts in Huggingface's Hosted inference API. Therefore, we replace `<extra_id_xxx>` with `extraxxx` in vocabulary and BertTokenizer regards `extraxxx` as one sentinel token.
## How to use
You can use this model directly with a pipeline for text2text generation (take the case of T5-Small):
```python
>>> from transformers import BertTokenizer, T5ForConditionalGeneration, Text2TextGenerationPipeline
>>> tokenizer = BertTokenizer.from_pretrained("uer/t5-small-chinese-cluecorpussmall")
>>> model = T5ForConditionalGeneration.from_pretrained("uer/t5-small-chinese-cluecorpussmall")
>>> text2text_generator = Text2TextGenerationPipeline(model, tokenizer)
>>> text2text_generator("中国的首都是extra0京", max_length=50, do_sample=False)
[{'generated_text': 'extra0 北 extra1 extra2 extra3 extra4 extra5'}]
```
## Training data
[CLUECorpusSmall](https://github.com/CLUEbenchmark/CLUECorpus2020/) is used as training data.
## Training procedure
The model is pre-trained by [UER-py](https://github.com/dbiir/UER-py/) on [Tencent Cloud](https://cloud.tencent.com/). We pre-train 1,000,000 steps with a sequence length of 128 and then pre-train 250,000 additional steps with a sequence length of 512. We use the same hyper-parameters on different model sizes.
Taking the case of T5-Small
Stage1:
```
python3 preprocess.py --corpus_path corpora/cluecorpussmall.txt \
--vocab_path models/google_zh_with_sentinel_vocab.txt \
--dataset_path cluecorpussmall_t5_seq128_dataset.pt \
--processes_num 32 --seq_length 128 \
--dynamic_masking --data_processor t5
```
```
python3 pretrain.py --dataset_path cluecorpussmall_t5_seq128_dataset.pt \
--vocab_path models/google_zh_with_sentinel_vocab.txt \
--config_path models/t5/small_config.json \
--output_model_path models/cluecorpussmall_t5_small_seq128_model.bin \
--world_size 8 --gpu_ranks 0 1 2 3 4 5 6 7 \
--total_steps 1000000 --save_checkpoint_steps 100000 --report_steps 50000 \
--learning_rate 1e-3 --batch_size 64 \
--span_masking --span_geo_prob 0.3 --span_max_length 5
```
Stage2:
```
python3 preprocess.py --corpus_path corpora/cluecorpussmall.txt \
--vocab_path models/google_zh_with_sentinel_vocab.txt \
--dataset_path cluecorpussmall_t5_small_seq512_dataset.pt \
--processes_num 32 --seq_length 512 \
--dynamic_masking --data_processor t5
```
```
python3 pretrain.py --dataset_path cluecorpussmall_t5_seq512_dataset.pt \
--vocab_path models/google_zh_with_sentinel_vocab.txt \
--pretrained_model_path models/cluecorpussmall_t5_small_seq128_model.bin-1000000 \
--config_path models/t5/small_config.json \
--output_model_path models/cluecorpussmall_t5_small_seq512_model.bin \
--world_size 8 --gpu_ranks 0 1 2 3 4 5 6 7 \
--total_steps 250000 --save_checkpoint_steps 50000 --report_steps 10000 \
--learning_rate 5e-4 --batch_size 16 \
--span_masking --span_geo_prob 0.3 --span_max_length 5
```
Finally, we convert the pre-trained model into Huggingface's format:
```
python3 scripts/convert_t5_from_uer_to_huggingface.py --input_model_path cluecorpussmall_t5_small_seq512_model.bin-250000 \
--output_model_path pytorch_model.bin \
--layers_num 6 \
--type t5
```
### BibTeX entry and citation info
```
@article{2020t5,
title = {Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer},
author = {Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu},
journal = {Journal of Machine Learning Research},
pages = {1-67},
year = {2020}
}
@article{zhao2019uer,
title={UER: An Open-Source Toolkit for Pre-training Models},
author={Zhao, Zhe and Chen, Hui and Zhang, Jinbin and Zhao, Xin and Liu, Tao and Lu, Wei and Chen, Xi and Deng, Haotang and Ju, Qi and Du, Xiaoyong},
journal={EMNLP-IJCNLP 2019},
pages={241},
year={2019}
}
```
[small]:https://huggingface.co/uer/t5-small-chinese-cluecorpussmall
[base]:https://huggingface.co/uer/t5-base-chinese-cluecorpussmall |
uklfr/gottbert-base | 301ea863069cb7f7226a8bc6b1311b0bc6b7b1d4 | 2021-09-16T15:36:46.000Z | [
"pytorch",
"jax",
"roberta",
"fill-mask",
"arxiv:2012.02110",
"transformers",
"autotrain_compatible"
]
| fill-mask | false | uklfr | null | uklfr/gottbert-base | 2,512 | 3 | transformers | 1,208 | # Gottbert-base
BERT model trained solely on the German portion of the OSCAR data set.
[Paper: GottBERT: a pure German Language Model](https://arxiv.org/abs/2012.02110)
Authors: Raphael Scheible, Fabian Thomczyk, Patric Tippmann, Victor Jaravine, Martin Boeker |
BeIR/query-gen-msmarco-t5-base-v1 | f86569026d333fbf584ce9f8d86b49dc521a7db0 | 2021-06-23T02:07:32.000Z | [
"pytorch",
"jax",
"t5",
"text2text-generation",
"transformers",
"autotrain_compatible"
]
| text2text-generation | false | BeIR | null | BeIR/query-gen-msmarco-t5-base-v1 | 2,508 | 7 | transformers | 1,209 | # Query Generation
This model is the t5-base model from [docTTTTTquery](https://github.com/castorini/docTTTTTquery).
The T5-base model was trained on the [MS MARCO Passage Dataset](https://github.com/microsoft/MSMARCO-Passage-Ranking), which consists of about 500k real search queries from Bing together with the relevant passage.
The model can be used for query generation to learn semantic search models without requiring annotated training data: [Synthetic Query Generation](https://github.com/UKPLab/sentence-transformers/tree/master/examples/unsupervised_learning/query_generation).
## Usage
```python
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained('model-name')
model = T5ForConditionalGeneration.from_pretrained('model-name')
para = "Python is an interpreted, high-level and general-purpose programming language. Python's design philosophy emphasizes code readability with its notable use of significant whitespace. Its language constructs and object-oriented approach aim to help programmers write clear, logical code for small and large-scale projects."
input_ids = tokenizer.encode(para, return_tensors='pt')
outputs = model.generate(
input_ids=input_ids,
max_length=64,
do_sample=True,
top_p=0.95,
num_return_sequences=3)
print("Paragraph:")
print(para)
print("\nGenerated Queries:")
for i in range(len(outputs)):
query = tokenizer.decode(outputs[i], skip_special_tokens=True)
print(f'{i + 1}: {query}')
``` |
uer/sbert-base-chinese-nli | 1e1b01f82c062cb48af4443ab0aa89809e490ad8 | 2022-07-15T08:19:42.000Z | [
"pytorch",
"bert",
"feature-extraction",
"zh",
"arxiv:1909.05658",
"sentence-transformers",
"sentence-similarity",
"transformers",
"license:apache-2.0"
]
| sentence-similarity | false | uer | null | uer/sbert-base-chinese-nli | 2,508 | 6 | sentence-transformers | 1,210 | ---
language: zh
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
license: apache-2.0
widget:
source_sentence: "那个人很开心"
sentences:
- 那个人非常开心
- 那只猫很开心
- 那个人在吃东西
---
# Chinese Sentence BERT
## Model description
This is the sentence embedding model pre-trained by [UER-py](https://github.com/dbiir/UER-py/), which is introduced in [this paper](https://arxiv.org/abs/1909.05658).
## Training data
[ChineseTextualInference](https://github.com/liuhuanyong/ChineseTextualInference/) is used as training data.
## Training procedure
The model is fine-tuned by [UER-py](https://github.com/dbiir/UER-py/) on [Tencent Cloud](https://cloud.tencent.com/). We fine-tune five epochs with a sequence length of 128 on the basis of the pre-trained model [chinese_roberta_L-12_H-768](https://huggingface.co/uer/chinese_roberta_L-12_H-768). At the end of each epoch, the model is saved when the best performance on development set is achieved.
```
python3 finetune/run_classifier_siamese.py --pretrained_model_path models/cluecorpussmall_roberta_base_seq512_model.bin-250000 \
--vocab_path models/google_zh_vocab.txt \
--config_path models/sbert/base_config.json \
--train_path datasets/ChineseTextualInference/train.tsv \
--dev_path datasets/ChineseTextualInference/dev.tsv \
--learning_rate 5e-5 --epochs_num 5 --batch_size 64
```
Finally, we convert the pre-trained model into Huggingface's format:
```
python3 scripts/convert_sbert_from_uer_to_huggingface.py --input_model_path models/finetuned_model.bin \
--output_model_path pytorch_model.bin \
--layers_num 12
```
### BibTeX entry and citation info
```
@article{reimers2019sentence,
title={Sentence-bert: Sentence embeddings using siamese bert-networks},
author={Reimers, Nils and Gurevych, Iryna},
journal={arXiv preprint arXiv:1908.10084},
year={2019}
}
@article{zhao2019uer,
title={UER: An Open-Source Toolkit for Pre-training Models},
author={Zhao, Zhe and Chen, Hui and Zhang, Jinbin and Zhao, Xin and Liu, Tao and Lu, Wei and Chen, Xi and Deng, Haotang and Ju, Qi and Du, Xiaoyong},
journal={EMNLP-IJCNLP 2019},
pages={241},
year={2019}
}
``` |
valhalla/s2t_mustc_multilinguial_medium | bacb18afb1533f3218dc15e94b80c1e151105f3e | 2021-03-03T05:12:34.000Z | [
"pytorch",
"speech_to_text_transformer",
"text2text-generation",
"transformers",
"autotrain_compatible"
]
| text2text-generation | false | valhalla | null | valhalla/s2t_mustc_multilinguial_medium | 2,501 | null | transformers | 1,211 | Entry not found |
ai4bharat/IndicBART | 583562cbb5b342dbc932d75cdb7a9adcd9d91759 | 2022-03-16T12:48:27.000Z | [
"pytorch",
"mbart",
"text2text-generation",
"arxiv:2109.02903",
"transformers",
"multilingual",
"nlp",
"indicnlp",
"autotrain_compatible"
]
| text2text-generation | false | ai4bharat | null | ai4bharat/IndicBART | 2,494 | 7 | transformers | 1,212 | ---
languages:
- as
- bn
- gu
- hi
- kn
- ml
- mr
- or
- pa
- ta
- te
tags:
- multilingual
- nlp
- indicnlp
---
IndicBART is a multilingual, sequence-to-sequence pre-trained model focusing on Indic languages and English. It currently supports 11 Indian languages and is based on the mBART architecture. You can use IndicBART model to build natural language generation applications for Indian languages by finetuning the model with supervised training data for tasks like machine translation, summarization, question generation, etc. Some salient features of the IndicBART are:
<ul>
<li >Supported languages: Assamese, Bengali, Gujarati, Hindi, Marathi, Odiya, Punjabi, Kannada, Malayalam, Tamil, Telugu and English. Not all of these languages are supported by mBART50 and mT5. </li>
<li >The model is much smaller than the mBART and mT5(-base) models, so less computationally expensive for finetuning and decoding. </li>
<li> Trained on large Indic language corpora (452 million sentences and 9 billion tokens) which also includes Indian English content. </li>
<li> All languages, except English, have been represented in Devanagari script to encourage transfer learning among the related languages. </li>
</ul>
You can read more about IndicBART in this <a href="https://arxiv.org/abs/2109.02903">paper</a>.
For detailed documentation, look here: https://github.com/AI4Bharat/indic-bart/ and https://indicnlp.ai4bharat.org/indic-bart/
# Pre-training corpus
We used the <a href="https://indicnlp.ai4bharat.org/corpora/">IndicCorp</a> data spanning 12 languages with 452 million sentences (9 billion tokens). The model was trained using the text-infilling objective used in mBART.
# Usage:
```
from transformers import MBartForConditionalGeneration, AutoModelForSeq2SeqLM
from transformers import AlbertTokenizer, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("ai4bharat/IndicBART", do_lower_case=False, use_fast=False, keep_accents=True)
# Or use tokenizer = AlbertTokenizer.from_pretrained("ai4bharat/IndicBART", do_lower_case=False, use_fast=False, keep_accents=True)
model = AutoModelForSeq2SeqLM.from_pretrained("ai4bharat/IndicBART")
# Or use model = MBartForConditionalGeneration.from_pretrained("ai4bharat/IndicBART")
# Some initial mapping
bos_id = tokenizer._convert_token_to_id_with_added_voc("<s>")
eos_id = tokenizer._convert_token_to_id_with_added_voc("</s>")
pad_id = tokenizer._convert_token_to_id_with_added_voc("<pad>")
# To get lang_id use any of ['<2as>', '<2bn>', '<2en>', '<2gu>', '<2hi>', '<2kn>', '<2ml>', '<2mr>', '<2or>', '<2pa>', '<2ta>', '<2te>']
# First tokenize the input and outputs. The format below is how IndicBART was trained so the input should be "Sentence </s> <2xx>" where xx is the language code. Similarly, the output should be "<2yy> Sentence </s>".
inp = tokenizer("I am a boy </s> <2en>", add_special_tokens=False, return_tensors="pt", padding=True).input_ids # tensor([[ 466, 1981, 80, 25573, 64001, 64004]])
out = tokenizer("<2hi> मैं एक लड़का हूँ </s>", add_special_tokens=False, return_tensors="pt", padding=True).input_ids # tensor([[64006, 942, 43, 32720, 8384, 64001]])
# Note that if you use any language other than Hindi or Marathi, you should convert its script to Devanagari using the Indic NLP Library.
model_outputs=model(input_ids=inp, decoder_input_ids=out[:,0:-1], labels=out[:,1:])
# For loss
model_outputs.loss ## This is not label smoothed.
# For logits
model_outputs.logits
# For generation. Pardon the messiness. Note the decoder_start_token_id.
model.eval() # Set dropouts to zero
model_output=model.generate(inp, use_cache=True, num_beams=4, max_length=20, min_length=1, early_stopping=True, pad_token_id=pad_id, bos_token_id=bos_id, eos_token_id=eos_id, decoder_start_token_id=tokenizer._convert_token_to_id_with_added_voc("<2en>"))
# Decode to get output strings
decoded_output=tokenizer.decode(model_output[0], skip_special_tokens=True, clean_up_tokenization_spaces=False)
print(decoded_output) # I am a boy
# Note that if your output language is not Hindi or Marathi, you should convert its script from Devanagari to the desired language using the Indic NLP Library.
# What if we mask?
inp = tokenizer("I am [MASK] </s> <2en>", add_special_tokens=False, return_tensors="pt", padding=True).input_ids
model_output=model.generate(inp, use_cache=True, num_beams=4, max_length=20, min_length=1, early_stopping=True, pad_token_id=pad_id, bos_token_id=bos_id, eos_token_id=eos_id, decoder_start_token_id=tokenizer._convert_token_to_id_with_added_voc("<2en>"))
decoded_output=tokenizer.decode(model_output[0], skip_special_tokens=True, clean_up_tokenization_spaces=False)
print(decoded_output) # I am happy
inp = tokenizer("मैं [MASK] हूँ </s> <2hi>", add_special_tokens=False, return_tensors="pt", padding=True).input_ids
model_output=model.generate(inp, use_cache=True, num_beams=4, max_length=20, min_length=1, early_stopping=True, pad_token_id=pad_id, bos_token_id=bos_id, eos_token_id=eos_id, decoder_start_token_id=tokenizer._convert_token_to_id_with_added_voc("<2en>"))
decoded_output=tokenizer.decode(model_output[0], skip_special_tokens=True, clean_up_tokenization_spaces=False)
print(decoded_output) # मैं जानता हूँ
inp = tokenizer("मला [MASK] पाहिजे </s> <2mr>", add_special_tokens=False, return_tensors="pt", padding=True).input_ids
model_output=model.generate(inp, use_cache=True, num_beams=4, max_length=20, min_length=1, early_stopping=True, pad_token_id=pad_id, bos_token_id=bos_id, eos_token_id=eos_id, decoder_start_token_id=tokenizer._convert_token_to_id_with_added_voc("<2en>"))
decoded_output=tokenizer.decode(model_output[0], skip_special_tokens=True, clean_up_tokenization_spaces=False)
print(decoded_output) # मला ओळखलं पाहिजे
```
# Notes:
1. This is compatible with the latest version of transformers but was developed with version 4.3.2 so consider using 4.3.2 if possible.
2. While I have only shown how to get logits and loss and how to generate outputs, you can do pretty much everything the MBartForConditionalGeneration class can do as in https://huggingface.co/docs/transformers/model_doc/mbart#transformers.MBartForConditionalGeneration
3. Note that the tokenizer I have used is based on sentencepiece and not BPE. Therefore, I used the AlbertTokenizer class and not the MBartTokenizer class.
4. If you wish to use any language written in a non-Devanagari script (except English), then you should first convert it to Devanagari using the <a href="https://github.com/anoopkunchukuttan/indic_nlp_library">Indic NLP Library</a>. After you get the output, you should convert it back into the original script.
# Fine-tuning on a downstream task
1. If you wish to fine-tune this model, then you can do so using the <a href="https://github.com/prajdabre/yanmtt">YANMTT</a> toolkit, following the instructions <a href="https://github.com/AI4Bharat/indic-bart ">here</a>.
2. (Untested) Alternatively, you may use the official huggingface scripts for <a href="https://github.com/huggingface/transformers/tree/master/examples/pytorch/translation">translation</a> and <a href="https://github.com/huggingface/transformers/tree/master/examples/pytorch/summarization">summarization</a>.
# Contributors
<ul>
<li> Raj Dabre </li>
<li> Himani Shrotriya </li>
<li> Anoop Kunchukuttan </li>
<li> Ratish Puduppully </li>
<li> Mitesh M. Khapra </li>
<li> Pratyush Kumar </li>
</ul>
# Paper
If you use IndicBART, please cite the following paper:
```
@misc{dabre2021indicbart,
title={IndicBART: A Pre-trained Model for Natural Language Generation of Indic Languages},
author={Raj Dabre and Himani Shrotriya and Anoop Kunchukuttan and Ratish Puduppully and Mitesh M. Khapra and Pratyush Kumar},
year={2021},
eprint={2109.02903},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
# License
The model is available under the MIT License. |
CAMeL-Lab/bert-base-arabic-camelbert-ca | fee5a451663e9504180bf17d5fbc6770cd6c3e88 | 2021-09-14T14:27:12.000Z | [
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
]
| fill-mask | false | CAMeL-Lab | null | CAMeL-Lab/bert-base-arabic-camelbert-ca | 2,491 | 5 | transformers | 1,213 | ---
language:
- ar
license: apache-2.0
widget:
- text: "الهدف من الحياة هو [MASK] ."
---
# CAMeLBERT: A collection of pre-trained models for Arabic NLP tasks
## Model description
**CAMeLBERT** is a collection of BERT models pre-trained on Arabic texts with different sizes and variants.
We release pre-trained language models for Modern Standard Arabic (MSA), dialectal Arabic (DA), and classical Arabic (CA), in addition to a model pre-trained on a mix of the three.
We also provide additional models that are pre-trained on a scaled-down set of the MSA variant (half, quarter, eighth, and sixteenth).
The details are described in the paper *"[The Interplay of Variant, Size, and Task Type in Arabic Pre-trained Language Models](https://arxiv.org/abs/2103.06678)."*
This model card describes **CAMeLBERT-CA** (`bert-base-arabic-camelbert-ca`), a model pre-trained on the CA (classical Arabic) dataset.
||Model|Variant|Size|#Word|
|-|-|:-:|-:|-:|
||`bert-base-arabic-camelbert-mix`|CA,DA,MSA|167GB|17.3B|
|✔|`bert-base-arabic-camelbert-ca`|CA|6GB|847M|
||`bert-base-arabic-camelbert-da`|DA|54GB|5.8B|
||`bert-base-arabic-camelbert-msa`|MSA|107GB|12.6B|
||`bert-base-arabic-camelbert-msa-half`|MSA|53GB|6.3B|
||`bert-base-arabic-camelbert-msa-quarter`|MSA|27GB|3.1B|
||`bert-base-arabic-camelbert-msa-eighth`|MSA|14GB|1.6B|
||`bert-base-arabic-camelbert-msa-sixteenth`|MSA|6GB|746M|
## Intended uses
You can use the released model for either masked language modeling or next sentence prediction.
However, it is mostly intended to be fine-tuned on an NLP task, such as NER, POS tagging, sentiment analysis, dialect identification, and poetry classification.
We release our fine-tuninig code [here](https://github.com/CAMeL-Lab/CAMeLBERT).
#### How to use
You can use this model directly with a pipeline for masked language modeling:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='CAMeL-Lab/bert-base-arabic-camelbert-ca')
>>> unmasker("الهدف من الحياة هو [MASK] .")
[{'sequence': '[CLS] الهدف من الحياة هو الحياة. [SEP]',
'score': 0.11048116534948349,
'token': 3696,
'token_str': 'الحياة'},
{'sequence': '[CLS] الهدف من الحياة هو الإسلام. [SEP]',
'score': 0.03481195122003555,
'token': 4677,
'token_str': 'الإسلام'},
{'sequence': '[CLS] الهدف من الحياة هو الموت. [SEP]',
'score': 0.03402028977870941,
'token': 4295,
'token_str': 'الموت'},
{'sequence': '[CLS] الهدف من الحياة هو العلم. [SEP]',
'score': 0.027655426412820816,
'token': 2789,
'token_str': 'العلم'},
{'sequence': '[CLS] الهدف من الحياة هو هذا. [SEP]',
'score': 0.023059621453285217,
'token': 2085,
'token_str': 'هذا'}]
```
*Note*: to download our models, you would need `transformers>=3.5.0`. Otherwise, you could download the models manually.
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained('CAMeL-Lab/bert-base-arabic-camelbert-ca')
model = AutoModel.from_pretrained('CAMeL-Lab/bert-base-arabic-camelbert-ca')
text = "مرحبا يا عالم."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import AutoTokenizer, TFAutoModel
tokenizer = AutoTokenizer.from_pretrained('CAMeL-Lab/bert-base-arabic-camelbert-ca')
model = TFAutoModel.from_pretrained('CAMeL-Lab/bert-base-arabic-camelbert-ca')
text = "مرحبا يا عالم."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
## Training data
- CA (classical Arabic)
- [OpenITI (Version 2020.1.2)](https://zenodo.org/record/3891466#.YEX4-F0zbzc)
## Training procedure
We use [the original implementation](https://github.com/google-research/bert) released by Google for pre-training.
We follow the original English BERT model's hyperparameters for pre-training, unless otherwise specified.
### Preprocessing
- After extracting the raw text from each corpus, we apply the following pre-processing.
- We first remove invalid characters and normalize white spaces using the utilities provided by [the original BERT implementation](https://github.com/google-research/bert/blob/eedf5716ce1268e56f0a50264a88cafad334ac61/tokenization.py#L286-L297).
- We also remove lines without any Arabic characters.
- We then remove diacritics and kashida using [CAMeL Tools](https://github.com/CAMeL-Lab/camel_tools).
- Finally, we split each line into sentences with a heuristics-based sentence segmenter.
- We train a WordPiece tokenizer on the entire dataset (167 GB text) with a vocabulary size of 30,000 using [HuggingFace's tokenizers](https://github.com/huggingface/tokenizers).
- We do not lowercase letters nor strip accents.
### Pre-training
- The model was trained on a single cloud TPU (`v3-8`) for one million steps in total.
- The first 90,000 steps were trained with a batch size of 1,024 and the rest was trained with a batch size of 256.
- The sequence length was limited to 128 tokens for 90% of the steps and 512 for the remaining 10%.
- We use whole word masking and a duplicate factor of 10.
- We set max predictions per sequence to 20 for the dataset with max sequence length of 128 tokens and 80 for the dataset with max sequence length of 512 tokens.
- We use a random seed of 12345, masked language model probability of 0.15, and short sequence probability of 0.1.
- The optimizer used is Adam with a learning rate of 1e-4, \\(\beta_{1} = 0.9\\) and \\(\beta_{2} = 0.999\\), a weight decay of 0.01, learning rate warmup for 10,000 steps and linear decay of the learning rate after.
## Evaluation results
- We evaluate our pre-trained language models on five NLP tasks: NER, POS tagging, sentiment analysis, dialect identification, and poetry classification.
- We fine-tune and evaluate the models using 12 dataset.
- We used Hugging Face's transformers to fine-tune our CAMeLBERT models.
- We used transformers `v3.1.0` along with PyTorch `v1.5.1`.
- The fine-tuning was done by adding a fully connected linear layer to the last hidden state.
- We use \\(F_{1}\\) score as a metric for all tasks.
- Code used for fine-tuning is available [here](https://github.com/CAMeL-Lab/CAMeLBERT).
### Results
| Task | Dataset | Variant | Mix | CA | DA | MSA | MSA-1/2 | MSA-1/4 | MSA-1/8 | MSA-1/16 |
| -------------------- | --------------- | ------- | ----- | ----- | ----- | ----- | ------- | ------- | ------- | -------- |
| NER | ANERcorp | MSA | 80.8% | 67.9% | 74.1% | 82.4% | 82.0% | 82.1% | 82.6% | 80.8% |
| POS | PATB (MSA) | MSA | 98.1% | 97.8% | 97.7% | 98.3% | 98.2% | 98.3% | 98.2% | 98.2% |
| | ARZTB (EGY) | DA | 93.6% | 92.3% | 92.7% | 93.6% | 93.6% | 93.7% | 93.6% | 93.6% |
| | Gumar (GLF) | DA | 97.3% | 97.7% | 97.9% | 97.9% | 97.9% | 97.9% | 97.9% | 97.9% |
| SA | ASTD | MSA | 76.3% | 69.4% | 74.6% | 76.9% | 76.0% | 76.8% | 76.7% | 75.3% |
| | ArSAS | MSA | 92.7% | 89.4% | 91.8% | 93.0% | 92.6% | 92.5% | 92.5% | 92.3% |
| | SemEval | MSA | 69.0% | 58.5% | 68.4% | 72.1% | 70.7% | 72.8% | 71.6% | 71.2% |
| DID | MADAR-26 | DA | 62.9% | 61.9% | 61.8% | 62.6% | 62.0% | 62.8% | 62.0% | 62.2% |
| | MADAR-6 | DA | 92.5% | 91.5% | 92.2% | 91.9% | 91.8% | 92.2% | 92.1% | 92.0% |
| | MADAR-Twitter-5 | MSA | 75.7% | 71.4% | 74.2% | 77.6% | 78.5% | 77.3% | 77.7% | 76.2% |
| | NADI | DA | 24.7% | 17.3% | 20.1% | 24.9% | 24.6% | 24.6% | 24.9% | 23.8% |
| Poetry | APCD | CA | 79.8% | 80.9% | 79.6% | 79.7% | 79.9% | 80.0% | 79.7% | 79.8% |
### Results (Average)
| | Variant | Mix | CA | DA | MSA | MSA-1/2 | MSA-1/4 | MSA-1/8 | MSA-1/16 |
| -------------------- | ------- | ----- | ----- | ----- | ----- | ------- | ------- | ------- | -------- |
| Variant-wise-average<sup>[[1]](#footnote-1)</sup> | MSA | 82.1% | 75.7% | 80.1% | 83.4% | 83.0% | 83.3% | 83.2% | 82.3% |
| | DA | 74.4% | 72.1% | 72.9% | 74.2% | 74.0% | 74.3% | 74.1% | 73.9% |
| | CA | 79.8% | 80.9% | 79.6% | 79.7% | 79.9% | 80.0% | 79.7% | 79.8% |
| Macro-Average | ALL | 78.7% | 74.7% | 77.1% | 79.2% | 79.0% | 79.2% | 79.1% | 78.6% |
<a name="footnote-1">[1]</a>: Variant-wise-average refers to average over a group of tasks in the same language variant.
## Acknowledgements
This research was supported with Cloud TPUs from Google’s TensorFlow Research Cloud (TFRC).
## Citation
```bibtex
@inproceedings{inoue-etal-2021-interplay,
title = "The Interplay of Variant, Size, and Task Type in {A}rabic Pre-trained Language Models",
author = "Inoue, Go and
Alhafni, Bashar and
Baimukan, Nurpeiis and
Bouamor, Houda and
Habash, Nizar",
booktitle = "Proceedings of the Sixth Arabic Natural Language Processing Workshop",
month = apr,
year = "2021",
address = "Kyiv, Ukraine (Online)",
publisher = "Association for Computational Linguistics",
abstract = "In this paper, we explore the effects of language variants, data sizes, and fine-tuning task types in Arabic pre-trained language models. To do so, we build three pre-trained language models across three variants of Arabic: Modern Standard Arabic (MSA), dialectal Arabic, and classical Arabic, in addition to a fourth language model which is pre-trained on a mix of the three. We also examine the importance of pre-training data size by building additional models that are pre-trained on a scaled-down set of the MSA variant. We compare our different models to each other, as well as to eight publicly available models by fine-tuning them on five NLP tasks spanning 12 datasets. Our results suggest that the variant proximity of pre-training data to fine-tuning data is more important than the pre-training data size. We exploit this insight in defining an optimized system selection model for the studied tasks.",
}
```
|
voidful/wav2vec2-xlsr-multilingual-56 | f9c661ed063214973eb94be7b7c04015ad2561e3 | 2022-03-23T18:24:58.000Z | [
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"multilingual",
"dataset:common_voice",
"transformers",
"audio",
"hf-asr-leaderboard",
"robust-speech-event",
"speech",
"xlsr-fine-tuning-week",
"license:apache-2.0",
"model-index"
]
| automatic-speech-recognition | false | voidful | null | voidful/wav2vec2-xlsr-multilingual-56 | 2,487 | 8 | transformers | 1,214 | ---
language: multilingual
datasets:
- common_voice
tags:
- audio
- automatic-speech-recognition
- hf-asr-leaderboard
- robust-speech-event
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: XLSR Wav2Vec2 for 56 language by Voidful
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice
type: common_voice
metrics:
- name: Test CER
type: cer
value: 23.21
---
# wav2vec2-xlsr-multilingual-56
*56 language, 1 model Multilingual ASR*
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on 56 language using the [Common Voice](https://huggingface.co/datasets/common_voice).
When using this model, make sure that your speech input is sampled at 16kHz.
For more detail: [https://github.com/voidful/wav2vec2-xlsr-multilingual-56](https://github.com/voidful/wav2vec2-xlsr-multilingual-56)
## Env setup:
```
!pip install torchaudio
!pip install datasets transformers
!pip install asrp
!wget -O lang_ids.pk https://huggingface.co/voidful/wav2vec2-xlsr-multilingual-56/raw/main/lang_ids.pk
```
## Usage
```
import torchaudio
from datasets import load_dataset, load_metric
from transformers import (
Wav2Vec2ForCTC,
Wav2Vec2Processor,
AutoTokenizer,
AutoModelWithLMHead
)
import torch
import re
import sys
import soundfile as sf
model_name = "voidful/wav2vec2-xlsr-multilingual-56"
device = "cuda"
processor_name = "voidful/wav2vec2-xlsr-multilingual-56"
import pickle
with open("lang_ids.pk", 'rb') as output:
lang_ids = pickle.load(output)
model = Wav2Vec2ForCTC.from_pretrained(model_name).to(device)
processor = Wav2Vec2Processor.from_pretrained(processor_name)
model.eval()
def load_file_to_data(file,sampling_rate=16_000):
batch = {}
speech, _ = torchaudio.load(file)
if sampling_rate != '16_000' or sampling_rate != '16000':
resampler = torchaudio.transforms.Resample(orig_freq=sampling_rate, new_freq=16_000)
batch["speech"] = resampler.forward(speech.squeeze(0)).numpy()
batch["sampling_rate"] = resampler.new_freq
else:
batch["speech"] = speech.squeeze(0).numpy()
batch["sampling_rate"] = '16000'
return batch
def predict(data):
features = processor(data["speech"], sampling_rate=data["sampling_rate"], padding=True, return_tensors="pt")
input_values = features.input_values.to(device)
attention_mask = features.attention_mask.to(device)
with torch.no_grad():
logits = model(input_values, attention_mask=attention_mask).logits
decoded_results = []
for logit in logits:
pred_ids = torch.argmax(logit, dim=-1)
mask = pred_ids.ge(1).unsqueeze(-1).expand(logit.size())
vocab_size = logit.size()[-1]
voice_prob = torch.nn.functional.softmax((torch.masked_select(logit, mask).view(-1,vocab_size)),dim=-1)
comb_pred_ids = torch.argmax(voice_prob, dim=-1)
decoded_results.append(processor.decode(comb_pred_ids))
return decoded_results
def predict_lang_specific(data,lang_code):
features = processor(data["speech"], sampling_rate=data["sampling_rate"], padding=True, return_tensors="pt")
input_values = features.input_values.to(device)
attention_mask = features.attention_mask.to(device)
with torch.no_grad():
logits = model(input_values, attention_mask=attention_mask).logits
decoded_results = []
for logit in logits:
pred_ids = torch.argmax(logit, dim=-1)
mask = ~pred_ids.eq(processor.tokenizer.pad_token_id).unsqueeze(-1).expand(logit.size())
vocab_size = logit.size()[-1]
voice_prob = torch.nn.functional.softmax((torch.masked_select(logit, mask).view(-1,vocab_size)),dim=-1)
filtered_input = pred_ids[pred_ids!=processor.tokenizer.pad_token_id].view(1,-1).to(device)
if len(filtered_input[0]) == 0:
decoded_results.append("")
else:
lang_mask = torch.empty(voice_prob.shape[-1]).fill_(0)
lang_index = torch.tensor(sorted(lang_ids[lang_code]))
lang_mask.index_fill_(0, lang_index, 1)
lang_mask = lang_mask.to(device)
comb_pred_ids = torch.argmax(lang_mask*voice_prob, dim=-1)
decoded_results.append(processor.decode(comb_pred_ids))
return decoded_results
predict(load_file_to_data('audio file path',sampling_rate=16_000)) # beware of the audio file sampling rate
predict_lang_specific(load_file_to_data('audio file path',sampling_rate=16_000),'en') # beware of the audio file sampling rate
```
## Result
| Common Voice Languages | Num. of data | Hour | WER | CER |
|------------------------|--------------|--------|--------|-------|
| ar | 21744 | 81.5 | 75.29 | 31.23 |
| as | 394 | 1.1 | 95.37 | 46.05 |
| br | 4777 | 7.4 | 93.79 | 41.16 |
| ca | 301308 | 692.8 | 24.80 | 10.39 |
| cnh | 1563 | 2.4 | 68.11 | 23.10 |
| cs | 9773 | 39.5 | 67.86 | 12.57 |
| cv | 1749 | 5.9 | 95.43 | 34.03 |
| cy | 11615 | 106.7 | 67.03 | 23.97 |
| de | 262113 | 822.8 | 27.03 | 6.50 |
| dv | 4757 | 18.6 | 92.16 | 30.15 |
| el | 3717 | 11.1 | 94.48 | 58.67 |
| en | 580501 | 1763.6 | 34.87 | 14.84 |
| eo | 28574 | 162.3 | 37.77 | 6.23 |
| es | 176902 | 337.7 | 19.63 | 5.41 |
| et | 5473 | 35.9 | 86.87 | 20.79 |
| eu | 12677 | 90.2 | 44.80 | 7.32 |
| fa | 12806 | 290.6 | 53.81 | 15.09 |
| fi | 875 | 2.6 | 93.78 | 27.57 |
| fr | 314745 | 664.1 | 33.16 | 13.94 |
| fy-NL | 6717 | 27.2 | 72.54 | 26.58 |
| ga-IE | 1038 | 3.5 | 92.57 | 51.02 |
| hi | 292 | 2.0 | 90.95 | 57.43 |
| hsb | 980 | 2.3 | 89.44 | 27.19 |
| hu | 4782 | 9.3 | 97.15 | 36.75 |
| ia | 5078 | 10.4 | 52.00 | 11.35 |
| id | 3965 | 9.9 | 82.50 | 22.82 |
| it | 70943 | 178.0 | 39.09 | 8.72 |
| ja | 1308 | 8.2 | 99.21 | 62.06 |
| ka | 1585 | 4.0 | 90.53 | 18.57 |
| ky | 3466 | 12.2 | 76.53 | 19.80 |
| lg | 1634 | 17.1 | 98.95 | 43.84 |
| lt | 1175 | 3.9 | 92.61 | 26.81 |
| lv | 4554 | 6.3 | 90.34 | 30.81 |
| mn | 4020 | 11.6 | 82.68 | 30.14 |
| mt | 3552 | 7.8 | 84.18 | 22.96 |
| nl | 14398 | 71.8 | 57.18 | 19.01 |
| or | 517 | 0.9 | 90.93 | 27.34 |
| pa-IN | 255 | 0.8 | 87.95 | 42.03 |
| pl | 12621 | 112.0 | 56.14 | 12.06 |
| pt | 11106 | 61.3 | 53.24 | 16.32 |
| rm-sursilv | 2589 | 5.9 | 78.17 | 23.31 |
| rm-vallader | 931 | 2.3 | 73.67 | 21.76 |
| ro | 4257 | 8.7 | 83.84 | 21.95 |
| ru | 23444 | 119.1 | 61.83 | 15.18 |
| sah | 1847 | 4.4 | 94.38 | 38.46 |
| sl | 2594 | 6.7 | 84.21 | 20.54 |
| sv-SE | 4350 | 20.8 | 83.68 | 30.79 |
| ta | 3788 | 18.4 | 84.19 | 21.60 |
| th | 4839 | 11.7 | 141.87 | 37.16 |
| tr | 3478 | 22.3 | 66.77 | 15.55 |
| tt | 13338 | 26.7 | 86.80 | 33.57 |
| uk | 7271 | 39.4 | 70.23 | 14.34 |
| vi | 421 | 1.7 | 96.06 | 66.25 |
| zh-CN | 27284 | 58.7 | 89.67 | 23.96 |
| zh-HK | 12678 | 92.1 | 81.77 | 18.82 |
| zh-TW | 6402 | 56.6 | 85.08 | 29.07 |
|
KoboldAI/fairseq-dense-2.7B-Nerys | ed5eea2fe9c2eb12749e460be8b9238a8f972eba | 2022-06-25T11:23:23.000Z | [
"pytorch",
"xglm",
"text-generation",
"en",
"transformers",
"license:mit"
]
| text-generation | false | KoboldAI | null | KoboldAI/fairseq-dense-2.7B-Nerys | 2,466 | null | transformers | 1,215 | ---
language: en
license: mit
---
# Fairseq-dense 2.7B - Nerys
## Model Description
Fairseq-dense 2.7B-Nerys is a finetune created using Fairseq's MoE dense model.
## Training data
The training data contains around 2500 ebooks in various genres (the "Pike" dataset), a CYOA dataset called "CYS" and 50 Asian "Light Novels" (the "Manga-v1" dataset).
Most parts of the dataset have been prepended using the following text: `[Genre: <genre1>, <genre2>]`
### How to use
You can use this model directly with a pipeline for text generation. This example generates a different sequence each time it's run:
```py
>>> from transformers import pipeline
>>> generator = pipeline('text-generation', model='KoboldAI/fairseq-dense-2.7B-Nerys')
>>> generator("Welcome Captain Janeway, I apologize for the delay.", do_sample=True, min_length=50)
[{'generated_text': 'Welcome Captain Janeway, I apologize for the delay."\nIt's all right," Janeway said. "I'm certain that you're doing your best to keep me informed of what\'s going on."'}]
```
### Limitations and Biases
Based on known problems with NLP technology, potential relevant factors include bias (gender, profession, race and religion).
### BibTeX entry and citation info
```
Artetxe et al. (2021): Efficient Large Scale Language Modeling with Mixtures of Experts
``` |
beomi/kcbert-large | 938ed6f46f35cab013c0a7dc85b2d1159a520d09 | 2021-05-19T12:35:08.000Z | [
"pytorch",
"jax",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
]
| fill-mask | false | beomi | null | beomi/kcbert-large | 2,454 | 1 | transformers | 1,216 | Entry not found |
phiyodr/bart-large-finetuned-squad2 | 1085c140a880de9ec81e5003dc34f2386212a7dd | 2020-10-08T06:12:19.000Z | [
"pytorch",
"bart",
"question-answering",
"en",
"dataset:squad2",
"arxiv:1910.13461",
"arxiv:1806.03822",
"transformers",
"autotrain_compatible"
]
| question-answering | false | phiyodr | null | phiyodr/bart-large-finetuned-squad2 | 2,450 | 2 | transformers | 1,217 | ---
language: en
tags:
- pytorch
- question-answering
datasets:
- squad2
metrics:
- exact
- f1
widget:
- text: "What discipline did Winkelmann create?"
context: "Johann Joachim Winckelmann was a German art historian and archaeologist. He was a pioneering Hellenist who first articulated the difference between Greek, Greco-Roman and Roman art. The prophet and founding hero of modern archaeology, Winckelmann was one of the founders of scientific archaeology and first applied the categories of style on a large, systematic basis to the history of art."
---
# roberta-large-finetuned-squad2
## Model description
This model is based on [facebook/bart-large](https://huggingface.co/facebook/bart-large) and was finetuned on [SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/). The corresponding papers you can found [here (model)](https://arxiv.org/pdf/1910.13461.pdf) and [here (data)](https://arxiv.org/abs/1806.03822).
## How to use
```python
from transformers.pipelines import pipeline
model_name = "phiyodr/bart-large-finetuned-squad2"
nlp = pipeline('question-answering', model=model_name, tokenizer=model_name)
inputs = {
'question': 'What discipline did Winkelmann create?',
'context': 'Johann Joachim Winckelmann was a German art historian and archaeologist. He was a pioneering Hellenist who first articulated the difference between Greek, Greco-Roman and Roman art. "The prophet and founding hero of modern archaeology", Winckelmann was one of the founders of scientific archaeology and first applied the categories of style on a large, systematic basis to the history of art. '
}
nlp(inputs)
```
## Training procedure
```
{
"base_model": "facebook/bart-large",
"do_lower_case": True,
"learning_rate": 3e-5,
"num_train_epochs": 4,
"max_seq_length": 384,
"doc_stride": 128,
"max_query_length": 64,
"batch_size": 96
}
```
## Eval results
- Data: [dev-v2.0.json](https://rajpurkar.github.io/SQuAD-explorer/dataset/dev-v2.0.json)
- Script: [evaluate-v2.0.py](https://worksheets.codalab.org/rest/bundles/0x6b567e1cf2e041ec80d7098f031c5c9e/contents/blob/) (original script from [here](https://github.com/huggingface/transformers/blob/master/examples/question-answering/README.md))
```
{
"exact": 81.96748926134929,
"f1": 85.93825235371045,
"total": 11873,
"HasAns_exact": 78.71120107962213,
"HasAns_f1": 86.6641144054667,
"HasAns_total": 5928,
"NoAns_exact": 85.21446593776282,
"NoAns_f1": 85.21446593776282,
"NoAns_total": 5945
}
```
|
Helsinki-NLP/opus-mt-en-el | cd8ab0896f1d0598007ba5266a0a30884fed71de | 2021-09-09T21:35:06.000Z | [
"pytorch",
"marian",
"text2text-generation",
"en",
"el",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
]
| translation | false | Helsinki-NLP | null | Helsinki-NLP/opus-mt-en-el | 2,449 | null | transformers | 1,218 | ---
tags:
- translation
license: apache-2.0
---
### opus-mt-en-el
* source languages: en
* target languages: el
* OPUS readme: [en-el](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/en-el/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2019-12-18.zip](https://object.pouta.csc.fi/OPUS-MT-models/en-el/opus-2019-12-18.zip)
* test set translations: [opus-2019-12-18.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/en-el/opus-2019-12-18.test.txt)
* test set scores: [opus-2019-12-18.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/en-el/opus-2019-12-18.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba.en.el | 56.4 | 0.745 |
|
Helsinki-NLP/opus-mt-vi-en | 24c80a4038d72a1df73c622d5f8898e5f7de96a3 | 2020-08-21T14:42:51.000Z | [
"pytorch",
"marian",
"text2text-generation",
"vi",
"en",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
]
| translation | false | Helsinki-NLP | null | Helsinki-NLP/opus-mt-vi-en | 2,448 | 1 | transformers | 1,219 | ---
language:
- vi
- en
tags:
- translation
license: apache-2.0
---
### vie-eng
* source group: Vietnamese
* target group: English
* OPUS readme: [vie-eng](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/vie-eng/README.md)
* model: transformer-align
* source language(s): vie vie_Hani
* target language(s): eng
* model: transformer-align
* pre-processing: normalization + SentencePiece (spm32k,spm32k)
* download original weights: [opus-2020-06-17.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/vie-eng/opus-2020-06-17.zip)
* test set translations: [opus-2020-06-17.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/vie-eng/opus-2020-06-17.test.txt)
* test set scores: [opus-2020-06-17.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/vie-eng/opus-2020-06-17.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba-test.vie.eng | 42.8 | 0.608 |
### System Info:
- hf_name: vie-eng
- source_languages: vie
- target_languages: eng
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/vie-eng/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['vi', 'en']
- src_constituents: {'vie', 'vie_Hani'}
- tgt_constituents: {'eng'}
- src_multilingual: False
- tgt_multilingual: False
- prepro: normalization + SentencePiece (spm32k,spm32k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/vie-eng/opus-2020-06-17.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/vie-eng/opus-2020-06-17.test.txt
- src_alpha3: vie
- tgt_alpha3: eng
- short_pair: vi-en
- chrF2_score: 0.608
- bleu: 42.8
- brevity_penalty: 0.955
- ref_len: 20241.0
- src_name: Vietnamese
- tgt_name: English
- train_date: 2020-06-17
- src_alpha2: vi
- tgt_alpha2: en
- prefer_old: False
- long_pair: vie-eng
- helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535
- transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b
- port_machine: brutasse
- port_time: 2020-08-21-14:41 |
plguillou/t5-base-fr-sum-cnndm | 5d0f64f2c4de6c3eeddbfd8d42e34e55a3310e7b | 2022-05-07T15:03:50.000Z | [
"pytorch",
"t5",
"text2text-generation",
"fr",
"dataset:cnn_dailymail",
"transformers",
"seq2seq",
"summarization",
"autotrain_compatible"
]
| summarization | false | plguillou | null | plguillou/t5-base-fr-sum-cnndm | 2,448 | 3 | transformers | 1,220 | ---
language: fr
tags:
- pytorch
- t5
- seq2seq
- summarization
datasets: cnn_dailymail
widget:
- text: "Apollo 11 est une mission du programme spatial américain Apollo au cours de laquelle, pour la première fois, des hommes se sont posés sur la Lune, le lundi 21 juillet 1969. L'agence spatiale américaine, la NASA, remplit ainsi l'objectif fixé par le président John F. Kennedy en 1961 de poser un équipage sur la Lune avant la fin de la décennie 1960. Il s'agissait de démontrer la supériorité des États-Unis sur l'Union soviétique qui avait été mise à mal par les succès soviétiques au début de l'ère spatiale dans le contexte de la guerre froide qui oppose alors ces deux pays. Ce défi est lancé alors que la NASA n'a pas encore placé en orbite un seul astronaute. Grâce à une mobilisation de moyens humains et financiers considérables, l'agence spatiale rattrape puis dépasse le programme spatial soviétique."
example_title: "Apollo 11"
---
# French T5 Abstractive Text Summarization
~~Version 1.0 (I will keep improving the model's performances.)~~
Version 2.0 is here! (with improved performances of course)
I trained the model on 13x more data than v1.
ROUGE-1: 44.5252
ROUGE-2: 22.652
ROUGE-L: 29.8866
## Model description
This model is a T5 Transformers model (JDBN/t5-base-fr-qg-fquad) that was fine-tuned in french for abstractive text summarization.
## How to use
```python
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("plguillou/t5-base-fr-sum-cnndm")
model = T5ForConditionalGeneration.from_pretrained("plguillou/t5-base-fr-sum-cnndm")
```
To summarize an ARTICLE, just modify the string like this : "summarize: ARTICLE".
## Training data
The base model I used is JDBN/t5-base-fr-qg-fquad (it can perform question generation, question answering and answer extraction).
I used the "t5-base" model from the transformers library to translate in french the CNN / Daily Mail summarization dataset.
|
anton-l/wav2vec2-random-tiny-classifier | 2838dc51b12ea6e9fb854049d46137561ebf0c03 | 2021-08-31T14:27:40.000Z | [
"pytorch",
"wav2vec2",
"audio-classification",
"transformers"
]
| audio-classification | false | anton-l | null | anton-l/wav2vec2-random-tiny-classifier | 2,445 | 1 | transformers | 1,221 | Entry not found |
jhu-clsp/bibert-ende | 7e8c5bdc96f62fef5cdd0d10dcf3df4dd1e243b2 | 2021-11-26T18:09:14.000Z | [
"pytorch",
"roberta",
"fill-mask",
"en",
"de",
"transformers",
"autotrain_compatible"
]
| fill-mask | false | jhu-clsp | null | jhu-clsp/bibert-ende | 2,445 | 5 | transformers | 1,222 | ---
language:
- en
- de
---
Our bibert-ende is a bilingual English-German Language Model. Please check out our EMNLP 2021 paper "[BERT, mBERT, or BiBERT? A Study on Contextualized Embeddings for Neural Machine Translation](https://aclanthology.org/2021.emnlp-main.534.pdf)" for more details.
```
@inproceedings{xu-etal-2021-bert,
title = "{BERT}, m{BERT}, or {B}i{BERT}? A Study on Contextualized Embeddings for Neural Machine Translation",
author = "Xu, Haoran and
Van Durme, Benjamin and
Murray, Kenton",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing",
month = nov,
year = "2021",
address = "Online and Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-main.534",
pages = "6663--6675",
abstract = "The success of bidirectional encoders using masked language models, such as BERT, on numerous natural language processing tasks has prompted researchers to attempt to incorporate these pre-trained models into neural machine translation (NMT) systems. However, proposed methods for incorporating pre-trained models are non-trivial and mainly focus on BERT, which lacks a comparison of the impact that other pre-trained models may have on translation performance. In this paper, we demonstrate that simply using the output (contextualized embeddings) of a tailored and suitable bilingual pre-trained language model (dubbed BiBERT) as the input of the NMT encoder achieves state-of-the-art translation performance. Moreover, we also propose a stochastic layer selection approach and a concept of a dual-directional translation model to ensure the sufficient utilization of contextualized embeddings. In the case of without using back translation, our best models achieve BLEU scores of 30.45 for En→De and 38.61 for De→En on the IWSLT{'}14 dataset, and 31.26 for En→De and 34.94 for De→En on the WMT{'}14 dataset, which exceeds all published numbers.",
}
```
# Download
Note that tokenizer package is `BertTokenizer` not `AutoTokenizer`.
```
from transformers import BertTokenizer, AutoModel
tokenizer = BertTokenizer.from_pretrained("jhu-clsp/bibert-ende")
model = AutoModel.from_pretrained("jhu-clsp/bibert-ende")
```
|
StivenLancheros/roberta-base-biomedical-clinical-es-finetuned-ner-CRAFT_AugmentedTransfer_ES | f9967782f078b5cf1dd91937b17c6370061ab335 | 2022-03-21T22:36:06.000Z | [
"pytorch",
"tensorboard",
"roberta",
"token-classification",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
]
| token-classification | false | StivenLancheros | null | StivenLancheros/roberta-base-biomedical-clinical-es-finetuned-ner-CRAFT_AugmentedTransfer_ES | 2,442 | null | transformers | 1,223 | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: roberta-base-biomedical-clinical-es-finetuned-ner-CRAFT_AugmentedTransfer_ES
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-biomedical-clinical-es-finetuned-ner-CRAFT_AugmentedTransfer_ES
This model is a fine-tuned version of [StivenLancheros/roberta-base-biomedical-clinical-es-finetuned-ner-CRAFT_Augmented_ES](https://huggingface.co/StivenLancheros/roberta-base-biomedical-clinical-es-finetuned-ner-CRAFT_Augmented_ES) on the CRAFT dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2043
- Precision: 0.8666
- Recall: 0.8614
- F1: 0.8639
- Accuracy: 0.9734
## Model description
This model performs Named Entity Recognition for 6 entity tags: Sequence, Cell, Protein, Gene, Taxon, and Chemical from the CRAFT(Colorado Richly Annotated Full Text) Corpus in Spanish (MT translated) and English. Entity tags have been normalized and replaced from the original three letter code to a full name e.g. B-Protein, I-Chemical.
This model is trained on augmented data created using Entity Replacement. 20% of the entities were replaced using a list of entities for each entity tag obtained from the official ontologies for each entity class. Three datasets (original, augmented, MT translated CRAFT) were concatenated. To improve F1 score the transfer learning was completed in two steps.
Using [StivenLancheros/roberta-base-biomedical-clinical-es-finetuned-ner-CRAFT_Augmented_ES](https://huggingface.co/StivenLancheros/roberta-base-biomedical-clinical-es-finetuned-ner-CRAFT_Augmented_ES) as a base model, I finetuned once more on the original CRAFT dataset in English.
Biobert --> Augmented CRAFT --> CRAFT ES (MT translated)
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.0088 | 1.0 | 1360 | 0.1793 | 0.8616 | 0.8487 | 0.8551 | 0.9721 |
| 0.0046 | 2.0 | 2720 | 0.1925 | 0.8618 | 0.8426 | 0.8521 | 0.9713 |
| 0.0032 | 3.0 | 4080 | 0.1926 | 0.8558 | 0.8630 | 0.8594 | 0.9725 |
| 0.0011 | 4.0 | 5440 | 0.2043 | 0.8666 | 0.8614 | 0.8639 | 0.9734 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.0+cu111
- Datasets 2.0.0
- Tokenizers 0.11.6
|
flair/upos-english | 646336f485a6fce04cb680b19148076c2c19d6c4 | 2021-03-02T22:21:49.000Z | [
"pytorch",
"en",
"dataset:ontonotes",
"flair",
"token-classification",
"sequence-tagger-model"
]
| token-classification | false | flair | null | flair/upos-english | 2,441 | null | flair | 1,224 | ---
tags:
- flair
- token-classification
- sequence-tagger-model
language: en
datasets:
- ontonotes
widget:
- text: "I love Berlin."
---
## English Universal Part-of-Speech Tagging in Flair (default model)
This is the standard universal part-of-speech tagging model for English that ships with [Flair](https://github.com/flairNLP/flair/).
F1-Score: **98,6** (Ontonotes)
Predicts universal POS tags:
| **tag** | **meaning** |
|---------------------------------|-----------|
|ADJ | adjective |
| ADP | adposition |
| ADV | adverb |
| AUX | auxiliary |
| CCONJ | coordinating conjunction |
| DET | determiner |
| INTJ | interjection |
| NOUN | noun |
| NUM | numeral |
| PART | particle |
| PRON | pronoun |
| PROPN | proper noun |
| PUNCT | punctuation |
| SCONJ | subordinating conjunction |
| SYM | symbol |
| VERB | verb |
| X | other |
Based on [Flair embeddings](https://www.aclweb.org/anthology/C18-1139/) and LSTM-CRF.
---
### Demo: How to use in Flair
Requires: **[Flair](https://github.com/flairNLP/flair/)** (`pip install flair`)
```python
from flair.data import Sentence
from flair.models import SequenceTagger
# load tagger
tagger = SequenceTagger.load("flair/upos-english")
# make example sentence
sentence = Sentence("I love Berlin.")
# predict NER tags
tagger.predict(sentence)
# print sentence
print(sentence)
# print predicted NER spans
print('The following NER tags are found:')
# iterate over entities and print
for entity in sentence.get_spans('pos'):
print(entity)
```
This yields the following output:
```
Span [1]: "I" [− Labels: PRON (0.9996)]
Span [2]: "love" [− Labels: VERB (1.0)]
Span [3]: "Berlin" [− Labels: PROPN (0.9986)]
Span [4]: "." [− Labels: PUNCT (1.0)]
```
So, the word "*I*" is labeled as a **pronoun** (PRON), "*love*" is labeled as a **verb** (VERB) and "*Berlin*" is labeled as a **proper noun** (PROPN) in the sentence "*I love Berlin*".
---
### Training: Script to train this model
The following Flair script was used to train this model:
```python
from flair.data import Corpus
from flair.datasets import ColumnCorpus
from flair.embeddings import WordEmbeddings, StackedEmbeddings, FlairEmbeddings
# 1. load the corpus (Ontonotes does not ship with Flair, you need to download and reformat into a column format yourself)
corpus: Corpus = ColumnCorpus(
"resources/tasks/onto-ner",
column_format={0: "text", 1: "pos", 2: "upos", 3: "ner"},
tag_to_bioes="ner",
)
# 2. what tag do we want to predict?
tag_type = 'upos'
# 3. make the tag dictionary from the corpus
tag_dictionary = corpus.make_tag_dictionary(tag_type=tag_type)
# 4. initialize each embedding we use
embedding_types = [
# contextual string embeddings, forward
FlairEmbeddings('news-forward'),
# contextual string embeddings, backward
FlairEmbeddings('news-backward'),
]
# embedding stack consists of Flair and GloVe embeddings
embeddings = StackedEmbeddings(embeddings=embedding_types)
# 5. initialize sequence tagger
from flair.models import SequenceTagger
tagger = SequenceTagger(hidden_size=256,
embeddings=embeddings,
tag_dictionary=tag_dictionary,
tag_type=tag_type)
# 6. initialize trainer
from flair.trainers import ModelTrainer
trainer = ModelTrainer(tagger, corpus)
# 7. run training
trainer.train('resources/taggers/upos-english',
train_with_dev=True,
max_epochs=150)
```
---
### Cite
Please cite the following paper when using this model.
```
@inproceedings{akbik2018coling,
title={Contextual String Embeddings for Sequence Labeling},
author={Akbik, Alan and Blythe, Duncan and Vollgraf, Roland},
booktitle = {{COLING} 2018, 27th International Conference on Computational Linguistics},
pages = {1638--1649},
year = {2018}
}
```
---
### Issues?
The Flair issue tracker is available [here](https://github.com/flairNLP/flair/issues/).
|
hfl/chinese-electra-180g-base-discriminator | 693c1a7e58307777ad4cdf6b80b47c777c028572 | 2021-03-03T01:26:14.000Z | [
"pytorch",
"tf",
"electra",
"zh",
"arxiv:2004.13922",
"transformers",
"license:apache-2.0"
]
| null | false | hfl | null | hfl/chinese-electra-180g-base-discriminator | 2,435 | 8 | transformers | 1,225 | ---
language:
- zh
license: "apache-2.0"
---
# This model is trained on 180G data, we recommend using this one than the original version.
## Chinese ELECTRA
Google and Stanford University released a new pre-trained model called ELECTRA, which has a much compact model size and relatively competitive performance compared to BERT and its variants.
For further accelerating the research of the Chinese pre-trained model, the Joint Laboratory of HIT and iFLYTEK Research (HFL) has released the Chinese ELECTRA models based on the official code of ELECTRA.
ELECTRA-small could reach similar or even higher scores on several NLP tasks with only 1/10 parameters compared to BERT and its variants.
This project is based on the official code of ELECTRA: [https://github.com/google-research/electra](https://github.com/google-research/electra)
You may also interested in,
- Chinese BERT series: https://github.com/ymcui/Chinese-BERT-wwm
- Chinese ELECTRA: https://github.com/ymcui/Chinese-ELECTRA
- Chinese XLNet: https://github.com/ymcui/Chinese-XLNet
- Knowledge Distillation Toolkit - TextBrewer: https://github.com/airaria/TextBrewer
More resources by HFL: https://github.com/ymcui/HFL-Anthology
## Citation
If you find our resource or paper is useful, please consider including the following citation in your paper.
- https://arxiv.org/abs/2004.13922
```
@inproceedings{cui-etal-2020-revisiting,
title = "Revisiting Pre-Trained Models for {C}hinese Natural Language Processing",
author = "Cui, Yiming and
Che, Wanxiang and
Liu, Ting and
Qin, Bing and
Wang, Shijin and
Hu, Guoping",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.findings-emnlp.58",
pages = "657--668",
}
``` |
mrm8488/spanbert-large-finetuned-squadv2 | 1d195c672bf785c78f534d8091f09b24d1ae47ff | 2021-05-20T00:59:58.000Z | [
"pytorch",
"jax",
"bert",
"en",
"arxiv:1907.10529",
"transformers"
]
| null | false | mrm8488 | null | mrm8488/spanbert-large-finetuned-squadv2 | 2,433 | 1 | transformers | 1,226 | ---
language: en
thumbnail:
---
# SpanBERT large fine-tuned on SQuAD v2
[SpanBERT](https://github.com/facebookresearch/SpanBERT) created by [Facebook Research](https://github.com/facebookresearch) and fine-tuned on [SQuAD 2.0](https://rajpurkar.github.io/SQuAD-explorer/) for **Q&A** downstream task ([by them](https://github.com/facebookresearch/SpanBERT#finetuned-models-squad-1120-relation-extraction-coreference-resolution)).
## Details of SpanBERT
[SpanBERT: Improving Pre-training by Representing and Predicting Spans](https://arxiv.org/abs/1907.10529)
## Details of the downstream task (Q&A) - Dataset 📚 🧐 ❓
[SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/) combines the 100,000 questions in SQuAD1.1 with over 50,000 unanswerable questions written adversarially by crowdworkers to look similar to answerable ones. To do well on SQuAD2.0, systems must not only answer questions when possible, but also determine when no answer is supported by the paragraph and abstain from answering.
| Dataset | Split | # samples |
| -------- | ----- | --------- |
| SQuAD2.0 | train | 130k |
| SQuAD2.0 | eval | 12.3k |
## Model fine-tuning 🏋️
You can get the fine-tuning script [here](https://github.com/facebookresearch/SpanBERT)
```bash
python code/run_squad.py \
--do_train \
--do_eval \
--model spanbert-large-cased \
--train_file train-v2.0.json \
--dev_file dev-v2.0.json \
--train_batch_size 32 \
--eval_batch_size 32 \
--learning_rate 2e-5 \
--num_train_epochs 4 \
--max_seq_length 512 \
--doc_stride 128 \
--eval_metric best_f1 \
--output_dir squad2_output \
--version_2_with_negative \
--fp16
```
## Results Comparison 📝
| | SQuAD 1.1 | SQuAD 2.0 | Coref | TACRED |
| ---------------------- | ------------- | --------- | ------- | ------ |
| | F1 | F1 | avg. F1 | F1 |
| BERT (base) | 88.5* | 76.5* | 73.1 | 67.7 |
| SpanBERT (base) | [92.4*](https://huggingface.co/mrm8488/spanbert-base-finetuned-squadv1) | [83.6*](https://huggingface.co/mrm8488/spanbert-base-finetuned-squadv2) | 77.4 | [68.2](https://huggingface.co/mrm8488/spanbert-base-finetuned-tacred) |
| BERT (large) | 91.3 | 83.3 | 77.1 | 66.4 |
| SpanBERT (large) | [94.6](https://huggingface.co/mrm8488/spanbert-large-finetuned-squadv1) | **88.7** (this) | 79.6 | [70.8](https://huggingface.co/mrm8488/spanbert-large-finetuned-tacred) |
Note: The numbers marked as * are evaluated on the development sets because those models were not submitted to the official SQuAD leaderboard. All the other numbers are test numbers.
## Model in action
Fast usage with **pipelines**:
```python
from transformers import pipeline
qa_pipeline = pipeline(
"question-answering",
model="mrm8488/spanbert-large-finetuned-squadv2",
tokenizer="SpanBERT/spanbert-large-cased"
)
qa_pipeline({
'context': "Manuel Romero has been working very hard in the repository hugginface/transformers lately",
'question': "How has been working Manuel Romero lately?"
})
# Output: {'answer': 'very hard', 'end': 40, 'score': 0.9052708846768347, 'start': 31}
```
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
shtoshni/longformer_coreference_ontonotes | 173bee9355e87b8f618866417e6a9d5903b02346 | 2021-11-09T19:31:06.000Z | [
"pytorch",
"longformer",
"feature-extraction",
"arxiv:2109.09667",
"transformers"
]
| feature-extraction | false | shtoshni | null | shtoshni/longformer_coreference_ontonotes | 2,433 | 1 | transformers | 1,227 | Longformer-large model finetuned for the coreference resolution task. The model is fine-tuned over the OntoNotes data. The model is released as part of [this paper](https://arxiv.org/pdf/2109.09667.pdf). Note that the document encoder is to be used with the rest of the model parameters to perform the coreference resolution task. For demo purposes, please check this [Colab notebook](https://colab.research.google.com/drive/11ejXc1wDqzUxpgRH1nLvqEifAX30Z71_?usp=sharing). |
mrm8488/t5-base-finetuned-wikiSQL | f04e227779b3b031f5f6ba902a3046bcda5d3186 | 2021-08-23T20:08:13.000Z | [
"pytorch",
"jax",
"t5",
"text2text-generation",
"en",
"dataset:wikisql",
"arxiv:1910.10683",
"transformers",
"autotrain_compatible"
]
| text2text-generation | false | mrm8488 | null | mrm8488/t5-base-finetuned-wikiSQL | 2,432 | 6 | transformers | 1,228 | ---
language: en
datasets:
- wikisql
widget:
- text: "translate English to SQL: How many models were finetuned using BERT as base model?"
---
# T5-base fine-tuned on WikiSQL
[Google's T5](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) fine-tuned on [WikiSQL](https://github.com/salesforce/WikiSQL) for **English** to **SQL** **translation**.
## Details of T5
The **T5** model was presented in [Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer](https://arxiv.org/pdf/1910.10683.pdf) by *Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J. Liu* in Here the abstract:
Transfer learning, where a model is first pre-trained on a data-rich task before being fine-tuned on a downstream task, has emerged as a powerful technique in natural language processing (NLP). The effectiveness of transfer learning has given rise to a diversity of approaches, methodology, and practice. In this paper, we explore the landscape of transfer learning techniques for NLP by introducing a unified framework that converts every language problem into a text-to-text format. Our systematic study compares pre-training objectives, architectures, unlabeled datasets, transfer approaches, and other factors on dozens of language understanding tasks. By combining the insights from our exploration with scale and our new “Colossal Clean Crawled Corpus”, we achieve state-of-the-art results on many benchmarks covering summarization, question answering, text classification, and more. To facilitate future work on transfer learning for NLP, we release our dataset, pre-trained models, and code.

## Details of the Dataset 📚
Dataset ID: ```wikisql``` from [Huggingface/NLP](https://huggingface.co/nlp/viewer/?dataset=wikisql)
| Dataset | Split | # samples |
| -------- | ----- | --------- |
| wikisql | train | 56355 |
| wikisql | valid | 14436 |
How to load it from [nlp](https://github.com/huggingface/nlp)
```python
train_dataset = nlp.load_dataset('wikisql', split=nlp.Split.TRAIN)
valid_dataset = nlp.load_dataset('wikisql', split=nlp.Split.VALIDATION)
```
Check out more about this dataset and others in [NLP Viewer](https://huggingface.co/nlp/viewer/)
## Model fine-tuning 🏋️
The training script is a slightly modified version of [this Colab Notebook](https://github.com/patil-suraj/exploring-T5/blob/master/t5_fine_tuning.ipynb) created by [Suraj Patil](https://github.com/patil-suraj), so all credits to him!
## Model in Action 🚀
```python
from transformers import AutoModelWithLMHead, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("mrm8488/t5-base-finetuned-wikiSQL")
model = AutoModelWithLMHead.from_pretrained("mrm8488/t5-base-finetuned-wikiSQL")
def get_sql(query):
input_text = "translate English to SQL: %s </s>" % query
features = tokenizer([input_text], return_tensors='pt')
output = model.generate(input_ids=features['input_ids'],
attention_mask=features['attention_mask'])
return tokenizer.decode(output[0])
query = "How many models were finetuned using BERT as base model?"
get_sql(query)
# output: 'SELECT COUNT Model fine tuned FROM table WHERE Base model = BERT'
```
Other examples from validation dataset:
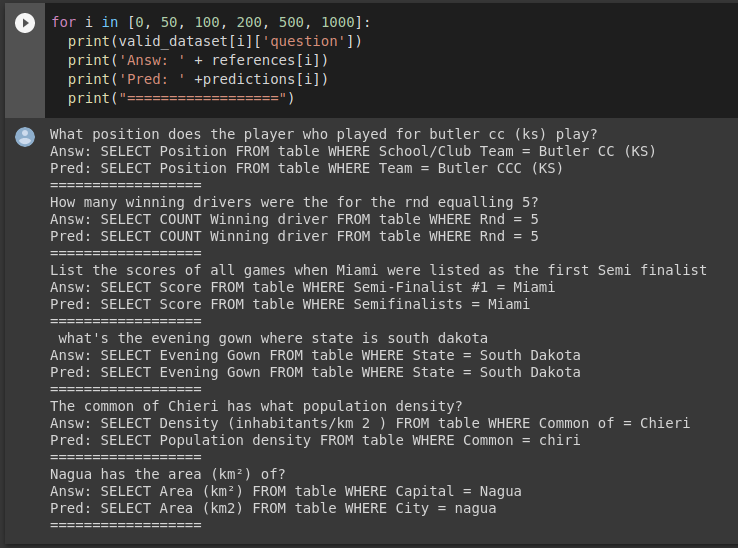
> Created by [Manuel Romero/@mrm8488](https://twitter.com/mrm8488) | [LinkedIn](https://www.linkedin.com/in/manuel-romero-cs/)
> Made with <span style="color: #e25555;">♥</span> in Spain
|
google/byt5-base | b6e825bea673ef5d64b07af28e04c241d9f705dd | 2022-05-27T15:06:52.000Z | [
"pytorch",
"tf",
"jax",
"t5",
"text2text-generation",
"multilingual",
"af",
"am",
"ar",
"az",
"be",
"bg",
"bn",
"ca",
"ceb",
"co",
"cs",
"cy",
"da",
"de",
"el",
"en",
"eo",
"es",
"et",
"eu",
"fa",
"fi",
"fil",
"fr",
"fy",
"ga",
"gd",
"gl",
"gu",
"ha",
"haw",
"hi",
"hmn",
"ht",
"hu",
"hy",
"ig",
"is",
"it",
"iw",
"ja",
"jv",
"ka",
"kk",
"km",
"kn",
"ko",
"ku",
"ky",
"la",
"lb",
"lo",
"lt",
"lv",
"mg",
"mi",
"mk",
"ml",
"mn",
"mr",
"ms",
"mt",
"my",
"ne",
"nl",
"no",
"ny",
"pa",
"pl",
"ps",
"pt",
"ro",
"ru",
"sd",
"si",
"sk",
"sl",
"sm",
"sn",
"so",
"sq",
"sr",
"st",
"su",
"sv",
"sw",
"ta",
"te",
"tg",
"th",
"tr",
"uk",
"und",
"ur",
"uz",
"vi",
"xh",
"yi",
"yo",
"zh",
"zu",
"dataset:mc4",
"arxiv:1907.06292",
"arxiv:2105.13626",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
]
| text2text-generation | false | google | null | google/byt5-base | 2,430 | 5 | transformers | 1,229 | ---
language:
- multilingual
- af
- am
- ar
- az
- be
- bg
- bn
- ca
- ceb
- co
- cs
- cy
- da
- de
- el
- en
- eo
- es
- et
- eu
- fa
- fi
- fil
- fr
- fy
- ga
- gd
- gl
- gu
- ha
- haw
- hi
- hmn
- ht
- hu
- hy
- ig
- is
- it
- iw
- ja
- jv
- ka
- kk
- km
- kn
- ko
- ku
- ky
- la
- lb
- lo
- lt
- lv
- mg
- mi
- mk
- ml
- mn
- mr
- ms
- mt
- my
- ne
- nl
- no
- ny
- pa
- pl
- ps
- pt
- ro
- ru
- sd
- si
- sk
- sl
- sm
- sn
- so
- sq
- sr
- st
- su
- sv
- sw
- ta
- te
- tg
- th
- tr
- uk
- und
- ur
- uz
- vi
- xh
- yi
- yo
- zh
- zu
datasets:
- mc4
license: apache-2.0
---
# ByT5 - Base
ByT5 is a tokenizer-free version of [Google's T5](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) and generally follows the architecture of [MT5](https://huggingface.co/google/mt5-base).
ByT5 was only pre-trained on [mC4](https://www.tensorflow.org/datasets/catalog/c4#c4multilingual) excluding any supervised training with an average span-mask of 20 UTF-8 characters. Therefore, this model has to be fine-tuned before it is useable on a downstream task.
ByT5 works especially well on noisy text data,*e.g.*, `google/byt5-base` significantly outperforms [mt5-base](https://huggingface.co/google/mt5-base) on [TweetQA](https://arxiv.org/abs/1907.06292).
Paper: [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626)
Authors: *Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel*
## Example Inference
ByT5 works on raw UTF-8 bytes and can be used without a tokenizer:
```python
from transformers import T5ForConditionalGeneration
import torch
model = T5ForConditionalGeneration.from_pretrained('google/byt5-base')
input_ids = torch.tensor([list("Life is like a box of chocolates.".encode("utf-8"))]) + 3 # add 3 for special tokens
labels = torch.tensor([list("La vie est comme une boîte de chocolat.".encode("utf-8"))]) + 3 # add 3 for special tokens
loss = model(input_ids, labels=labels).loss # forward pass
```
For batched inference & training it is however recommended using a tokenizer class for padding:
```python
from transformers import T5ForConditionalGeneration, AutoTokenizer
model = T5ForConditionalGeneration.from_pretrained('google/byt5-base')
tokenizer = AutoTokenizer.from_pretrained('google/byt5-base')
model_inputs = tokenizer(["Life is like a box of chocolates.", "Today is Monday."], padding="longest", return_tensors="pt")
labels = tokenizer(["La vie est comme une boîte de chocolat.", "Aujourd'hui c'est lundi."], padding="longest", return_tensors="pt").input_ids
loss = model(**model_inputs, labels=labels).loss # forward pass
```
## Abstract
Most widely-used pre-trained language models operate on sequences of tokens corresponding to word or subword units. Encoding text as a sequence of tokens requires a tokenizer, which is typically created as an independent artifact from the model. Token-free models that instead operate directly on raw text (bytes or characters) have many benefits: they can process text in any language out of the box, they are more robust to noise, and they minimize technical debt by removing complex and error-prone text preprocessing pipelines. Since byte or character sequences are longer than token sequences, past work on token-free models has often introduced new model architectures designed to amortize the cost of operating directly on raw text. In this paper, we show that a standard Transformer architecture can be used with minimal modifications to process byte sequences. We carefully characterize the trade-offs in terms of parameter count, training FLOPs, and inference speed, and show that byte-level models are competitive with their token-level counterparts. We also demonstrate that byte-level models are significantly more robust to noise and perform better on tasks that are sensitive to spelling and pronunciation. As part of our contribution, we release a new set of pre-trained byte-level Transformer models based on the T5 architecture, as well as all code and data used in our experiments.
 |
Intel/dynamic_tinybert | a09184908bed346e896bf939babefdb0ddd45760 | 2021-11-22T13:48:08.000Z | [
"pytorch",
"bert",
"question-answering",
"transformers",
"autotrain_compatible"
]
| question-answering | false | Intel | null | Intel/dynamic_tinybert | 2,428 | 4 | transformers | 1,230 | Entry not found |
Davlan/xlm-roberta-base-ner-hrl | 22c2ab03e20036d86e00c358e331e24bd50420b6 | 2021-10-01T21:57:08.000Z | [
"pytorch",
"xlm-roberta",
"token-classification",
"ar",
"de",
"en",
"es",
"fr",
"it",
"lv",
"nl",
"pt",
"zh",
"multilingual",
"transformers",
"autotrain_compatible"
]
| token-classification | false | Davlan | null | Davlan/xlm-roberta-base-ner-hrl | 2,418 | 4 | transformers | 1,231 | Hugging Face's logo
---
language:
- ar
- de
- en
- es
- fr
- it
- lv
- nl
- pt
- zh
- multilingual
---
# xlm-roberta-base-ner-hrl
## Model description
**xlm-roberta-base-ner-hrl** is a **Named Entity Recognition** model for 10 high resourced languages (Arabic, German, English, Spanish, French, Italian, Latvian, Dutch, Portuguese and Chinese) based on a fine-tuned XLM-RoBERTa base model. It has been trained to recognize three types of entities: location (LOC), organizations (ORG), and person (PER).
Specifically, this model is a *xlm-roberta-base* model that was fine-tuned on an aggregation of 10 high-resourced languages
## Intended uses & limitations
#### How to use
You can use this model with Transformers *pipeline* for NER.
```python
from transformers import AutoTokenizer, AutoModelForTokenClassification
from transformers import pipeline
tokenizer = AutoTokenizer.from_pretrained("Davlan/xlm-roberta-base-ner-hrl")
model = AutoModelForTokenClassification.from_pretrained("Davlan/xlm-roberta-base-ner-hrl")
nlp = pipeline("ner", model=model, tokenizer=tokenizer)
example = "Nader Jokhadar had given Syria the lead with a well-struck header in the seventh minute."
ner_results = nlp(example)
print(ner_results)
```
#### Limitations and bias
This model is limited by its training dataset of entity-annotated news articles from a specific span of time. This may not generalize well for all use cases in different domains.
## Training data
The training data for the 10 languages are from:
Language|Dataset
-|-
Arabic | [ANERcorp](https://camel.abudhabi.nyu.edu/anercorp/)
German | [conll 2003](https://www.clips.uantwerpen.be/conll2003/ner/)
English | [conll 2003](https://www.clips.uantwerpen.be/conll2003/ner/)
Spanish | [conll 2002](https://www.clips.uantwerpen.be/conll2002/ner/)
French | [Europeana Newspapers](https://github.com/EuropeanaNewspapers/ner-corpora/tree/master/enp_FR.bnf.bio)
Italian | [Italian I-CAB](https://ontotext.fbk.eu/icab.html)
Latvian | [Latvian NER](https://github.com/LUMII-AILab/FullStack/tree/master/NamedEntities)
Dutch | [conll 2002](https://www.clips.uantwerpen.be/conll2002/ner/)
Portuguese |[Paramopama + Second Harem](https://github.com/davidsbatista/NER-datasets/tree/master/Portuguese)
Chinese | [MSRA](https://huggingface.co/datasets/msra_ner)
The training dataset distinguishes between the beginning and continuation of an entity so that if there are back-to-back entities of the same type, the model can output where the second entity begins. As in the dataset, each token will be classified as one of the following classes:
Abbreviation|Description
-|-
O|Outside of a named entity
B-PER |Beginning of a person’s name right after another person’s name
I-PER |Person’s name
B-ORG |Beginning of an organisation right after another organisation
I-ORG |Organisation
B-LOC |Beginning of a location right after another location
I-LOC |Location
## Training procedure
This model was trained on NVIDIA V100 GPU with recommended hyperparameters from HuggingFace code.
|
flax-sentence-embeddings/all_datasets_v4_MiniLM-L6 | a407cc0b7d85eec9a5617eaf51dbe7b353b0c79f | 2021-07-23T15:49:28.000Z | [
"pytorch",
"bert",
"feature-extraction",
"en",
"arxiv:2104.08727",
"arxiv:1810.09305",
"arxiv:2102.07033",
"arxiv:1904.06472",
"sentence-transformers",
"sentence-similarity"
]
| sentence-similarity | false | flax-sentence-embeddings | null | flax-sentence-embeddings/all_datasets_v4_MiniLM-L6 | 2,410 | 3 | sentence-transformers | 1,232 | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
language: en
---
# Model description
The project aims to train sentence embedding models on very large sentence level datasets using a self-supervised
contrastive learning objective. We used the pretrained ['MiniLM-L6-H384-uncased'](https://huggingface.co/nreimers/MiniLM-L6-H384-uncased) model and fine-tuned in on a
1B sentence pairs dataset. We use a contrastive learning objective: given a sentence from the pair, the model should predict which out of a set of randomly sampled other sentences, was actually paired with it in our dataset.
We developped this model during the
[Community week using JAX/Flax for NLP & CV](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104),
organized by Hugging Face. We developped this model as part of the project:
[Train the Best Sentence Embedding Model Ever with 1B Training Pairs](https://discuss.huggingface.co/t/train-the-best-sentence-embedding-model-ever-with-1b-training-pairs/7354). We benefited from efficient hardware infrastructure to run the project: 7 TPUs v3-8, as well
as intervention from Google’s Flax, JAX, and Cloud team member about efficient deep learning frameworks.
## Intended uses
Our model is intented to be used as a sentence encoder. Given an input sentence, it ouptuts a vector which captures
the sentence semantic information. The sentence vector may be used for information retrieval, clustering or sentence
similarity tasks.
## How to use
Here is how to use this model to get the features of a given text using [SentenceTransformers](https://github.com/UKPLab/sentence-transformers) library:
```python
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('flax-sentence-embeddings/all_datasets_v4_MiniLM-L6')
text = "Replace me by any text you'd like."
text_embbedding = model.encode(text)
# array([-0.01559514, 0.04046123, 0.1317083 , 0.00085931, 0.04585106,
# -0.05607086, 0.0138078 , 0.03569756, 0.01420381, 0.04266302 ...],
# dtype=float32)
```
# Training procedure
## Pre-training
We use the pretrained ['MiniLM-L6-H384-uncased'](https://huggingface.co/nreimers/MiniLM-L6-H384-uncased) which is a 6 layer version of
['microsoft/MiniLM-L12-H384-uncased'](https://huggingface.co/microsoft/MiniLM-L12-H384-uncased) by keeping only every second layer.
Please refer to the model card for more detailed information about the pre-training procedure.
## Fine-tuning
We fine-tune the model using a contrastive objective. Formally, we compute the cosine similarity from each possible sentence pairs from the batch.
We then apply the cross entropy loss by comparing with true pairs.
### Hyper parameters
We trained ou model on a TPU v3-8. We train the model during 540k steps using a batch size of 1024 (128 per TPU core).
We use a learning rate warm up of 500. The sequence length was limited to 128 tokens. We used the AdamW optimizer with
a 2e-5 learning rate. The full training script is accessible in this current repository.
### Training data
We use the concatenation from multiple datasets to fine-tune our model. The total number of sentence pairs is above 1 billion sentences.
We sampled each dataset given a weighted probability which configuration is detailed in the `data_config.json` file.
| Dataset | Paper | Number of training tuples |
|:--------------------------------------------------------:|:----------------------------------------:|:--------------------------:|
| [GOOAQ: Open Question Answering with Diverse Answer Types](https://github.com/allenai/gooaq) | [paper](https://arxiv.org/pdf/2104.08727.pdf) | 3,012,496 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_title_body_jsonl) | - | 364,001 |
| [Flickr 30k](https://shannon.cs.illinois.edu/DenotationGraph/) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/229/33) | 317,695 |
| [COCO 2020](COCO 2020) | [paper](https://link.springer.com/chapter/10.1007%2F978-3-319-10602-1_48) | 828,395|
| [Code Search](https://huggingface.co/datasets/code_search_net) | - | 1,151,414 |
| [TriviaqQA](https://huggingface.co/datasets/trivia_qa) | - | 73,346 |
| [SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/) | [paper](https://aclanthology.org/P18-2124.pdf) | 87,599 |
| [Natural Questions (NQ)](https://ai.google.com/research/NaturalQuestions) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/1455) | 100,231 |
| [Simple Wikipedia](https://cs.pomona.edu/~dkauchak/simplification/) | [paper](https://www.aclweb.org/anthology/P11-2117/) | 102,225 |
| [Quora Question Pairs](https://quoradata.quora.com/First-Quora-Dataset-Release-Question-Pairs) | - | 103,663 |
| [Altlex](https://github.com/chridey/altlex/) | [paper](https://aclanthology.org/P16-1135.pdf) | 112,696 |
| [Wikihow](https://github.com/pvl/wikihow_pairs_dataset) | [paper](https://arxiv.org/abs/1810.09305) | 128,542 |
| [Sentence Compression](https://github.com/google-research-datasets/sentence-compression) | [paper](https://www.aclweb.org/anthology/D13-1155/) | 180,000 |
| AllNLI ([SNLI](https://nlp.stanford.edu/projects/snli/) and [MultiNLI](https://cims.nyu.edu/~sbowman/multinli/) | [paper SNLI](https://doi.org/10.18653/v1/d15-1075), [paper MultiNLI](https://doi.org/10.18653/v1/n18-1101) | 277,230 |
| [Eli5](https://huggingface.co/datasets/eli5) | [paper](https://doi.org/10.18653/v1/p19-1346) | 325,475 |
| [SPECTER](https://github.com/allenai/specter) | [paper](https://doi.org/10.18653/v1/2020.acl-main.207) | 684,100 |
| [S2ORC](https://github.com/allenai/s2orc) Title/Abstract | [paper](https://aclanthology.org/2020.acl-main.447/) | 41,769,185 |
| [S2ORC](https://github.com/allenai/s2orc) Citation/Citation | [paper](https://aclanthology.org/2020.acl-main.447/) | 52,603,982 |
| [S2ORC](https://github.com/allenai/s2orc) Citation/Abstract | [paper](https://aclanthology.org/2020.acl-main.447/) | 116,288,806 |
| [PAQ](https://github.com/facebookresearch/PAQ) | [paper](https://arxiv.org/abs/2102.07033) | 64,371,441 |
| [WikiAnswers](https://github.com/afader/oqa#wikianswers-corpus) | [paper](https://doi.org/10.1145/2623330.2623677) | 77,427,422 |
| SearchQA | - | 582,261 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) Title/Answer | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 1,198,260 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) Title/Question | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 659,896 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) Question/Answer | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 681,164 |
| [MS MARCO](https://microsoft.github.io/msmarco/) | [paper](https://doi.org/10.1145/3404835.3462804) | 9,144,553 |
| [Reddit conversationnal](https://github.com/PolyAI-LDN/conversational-datasets/tree/master/reddit) | [paper](https://arxiv.org/abs/1904.06472) | 726,484,430 |
| total | | 1,097,953,922 |
|
finiteautomata/beto-emotion-analysis | 6c41f7d3f186ea332581e400110b4662f0c06c9d | 2021-12-10T13:29:22.000Z | [
"pytorch",
"bert",
"text-classification",
"es",
"arxiv:2106.09462",
"transformers",
"emotion-analysis"
]
| text-classification | false | finiteautomata | null | finiteautomata/beto-emotion-analysis | 2,395 | 3 | transformers | 1,233 | ---
language:
- es
tags:
- emotion-analysis
---
# Emotion Analysis in Spanish
## beto-emotion-analysis
Repository: [https://github.com/finiteautomata/pysentimiento/](https://github.com/finiteautomata/pysentimiento/)
Model trained with TASS 2020 Task 2 corpus for Emotion detection in Spanish. Base model is [BETO](https://github.com/dccuchile/beto), a BERT model trained in Spanish.
## License
`pysentimiento` is an open-source library for non-commercial use and scientific research purposes only. Please be aware that models are trained with third-party datasets and are subject to their respective licenses.
1. [TASS Dataset license](http://tass.sepln.org/tass_data/download.php)
2. [SEMEval 2017 Dataset license]()
## Citation
If you use `pysentimiento` in your work, please cite [this paper](https://arxiv.org/abs/2106.09462)
```
@misc{perez2021pysentimiento,
title={pysentimiento: A Python Toolkit for Sentiment Analysis and SocialNLP tasks},
author={Juan Manuel Pérez and Juan Carlos Giudici and Franco Luque},
year={2021},
eprint={2106.09462},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
and also the dataset related paper
```
@inproceedings{del2020emoevent,
title={EmoEvent: A multilingual emotion corpus based on different events},
author={del Arco, Flor Miriam Plaza and Strapparava, Carlo and Lopez, L Alfonso Urena and Mart{\'\i}n-Valdivia, M Teresa},
booktitle={Proceedings of the 12th Language Resources and Evaluation Conference},
pages={1492--1498},
year={2020}
}
```
Enjoy! 🤗
|
nvidia/mit-b1 | 52eb2a1100ddab5f778c6924d37f20b07c3192ee | 2022-07-29T13:15:50.000Z | [
"pytorch",
"tf",
"segformer",
"image-classification",
"dataset:imagenet_1k",
"arxiv:2105.15203",
"transformers",
"vision",
"license:apache-2.0"
]
| image-classification | false | nvidia | null | nvidia/mit-b1 | 2,386 | null | transformers | 1,234 | ---
license: apache-2.0
tags:
- vision
datasets:
- imagenet_1k
widget:
- src: https://huggingface.co/datasets/hf-internal-testing/fixtures_ade20k/resolve/main/ADE_val_00000001.jpg
example_title: House
- src: https://huggingface.co/datasets/hf-internal-testing/fixtures_ade20k/resolve/main/ADE_val_00000002.jpg
example_title: Castle
---
# SegFormer (b1-sized) encoder pre-trained-only
SegFormer encoder fine-tuned on Imagenet-1k. It was introduced in the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Xie et al. and first released in [this repository](https://github.com/NVlabs/SegFormer).
Disclaimer: The team releasing SegFormer did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
SegFormer consists of a hierarchical Transformer encoder and a lightweight all-MLP decode head to achieve great results on semantic segmentation benchmarks such as ADE20K and Cityscapes. The hierarchical Transformer is first pre-trained on ImageNet-1k, after which a decode head is added and fine-tuned altogether on a downstream dataset.
This repository only contains the pre-trained hierarchical Transformer, hence it can be used for fine-tuning purposes.
## Intended uses & limitations
You can use the model for fine-tuning of semantic segmentation. See the [model hub](https://huggingface.co/models?other=segformer) to look for fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import SegformerFeatureExtractor, SegformerForImageClassification
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = SegformerFeatureExtractor.from_pretrained("nvidia/mit-b1")
model = SegformerForImageClassification.from_pretrained("nvidia/mit-b1")
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
For more code examples, we refer to the [documentation](https://huggingface.co/transformers/model_doc/segformer.html#).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2105-15203,
author = {Enze Xie and
Wenhai Wang and
Zhiding Yu and
Anima Anandkumar and
Jose M. Alvarez and
Ping Luo},
title = {SegFormer: Simple and Efficient Design for Semantic Segmentation with
Transformers},
journal = {CoRR},
volume = {abs/2105.15203},
year = {2021},
url = {https://arxiv.org/abs/2105.15203},
eprinttype = {arXiv},
eprint = {2105.15203},
timestamp = {Wed, 02 Jun 2021 11:46:42 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2105-15203.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
benjamin/roberta-base-wechsel-german | ad78a30f376bc847690b86d821245ff2005d4f98 | 2022-07-13T23:44:45.000Z | [
"pytorch",
"roberta",
"fill-mask",
"de",
"transformers",
"license:mit",
"autotrain_compatible"
]
| fill-mask | false | benjamin | null | benjamin/roberta-base-wechsel-german | 2,381 | 3 | transformers | 1,235 | ---
language: de
license: mit
---
# roberta-base-wechsel-german
Model trained with WECHSEL: Effective initialization of subword embeddings for cross-lingual transfer of monolingual language models.
See the code here: https://github.com/CPJKU/wechsel
And the paper here: https://aclanthology.org/2022.naacl-main.293/
## Performance
### RoBERTa
| Model | NLI Score | NER Score | Avg Score |
|---|---|---|---|
| `roberta-base-wechsel-french` | **82.43** | **90.88** | **86.65** |
| `camembert-base` | 80.88 | 90.26 | 85.57 |
| Model | NLI Score | NER Score | Avg Score |
|---|---|---|---|
| `roberta-base-wechsel-german` | **81.79** | **89.72** | **85.76** |
| `deepset/gbert-base` | 78.64 | 89.46 | 84.05 |
| Model | NLI Score | NER Score | Avg Score |
|---|---|---|---|
| `roberta-base-wechsel-chinese` | **78.32** | 80.55 | **79.44** |
| `bert-base-chinese` | 76.55 | **82.05** | 79.30 |
| Model | NLI Score | NER Score | Avg Score |
|---|---|---|---|
| `roberta-base-wechsel-swahili` | **75.05** | **87.39** | **81.22** |
| `xlm-roberta-base` | 69.18 | 87.37 | 78.28 |
### GPT2
| Model | PPL |
|---|---|
| `gpt2-wechsel-french` | **19.71** |
| `gpt2` (retrained from scratch) | 20.47 |
| Model | PPL |
|---|---|
| `gpt2-wechsel-german` | **26.8** |
| `gpt2` (retrained from scratch) | 27.63 |
| Model | PPL |
|---|---|
| `gpt2-wechsel-chinese` | **51.97** |
| `gpt2` (retrained from scratch) | 52.98 |
| Model | PPL |
|---|---|
| `gpt2-wechsel-swahili` | **10.14** |
| `gpt2` (retrained from scratch) | 10.58 |
See our paper for details.
## Citation
Please cite WECHSEL as
```
@inproceedings{minixhofer-etal-2022-wechsel,
title = "{WECHSEL}: Effective initialization of subword embeddings for cross-lingual transfer of monolingual language models",
author = "Minixhofer, Benjamin and
Paischer, Fabian and
Rekabsaz, Navid",
booktitle = "Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies",
month = jul,
year = "2022",
address = "Seattle, United States",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.naacl-main.293",
pages = "3992--4006",
abstract = "Large pretrained language models (LMs) have become the central building block of many NLP applications. Training these models requires ever more computational resources and most of the existing models are trained on English text only. It is exceedingly expensive to train these models in other languages. To alleviate this problem, we introduce a novel method {--} called WECHSEL {--} to efficiently and effectively transfer pretrained LMs to new languages. WECHSEL can be applied to any model which uses subword-based tokenization and learns an embedding for each subword. The tokenizer of the source model (in English) is replaced with a tokenizer in the target language and token embeddings are initialized such that they are semantically similar to the English tokens by utilizing multilingual static word embeddings covering English and the target language. We use WECHSEL to transfer the English RoBERTa and GPT-2 models to four languages (French, German, Chinese and Swahili). We also study the benefits of our method on very low-resource languages. WECHSEL improves over proposed methods for cross-lingual parameter transfer and outperforms models of comparable size trained from scratch with up to 64x less training effort. Our method makes training large language models for new languages more accessible and less damaging to the environment. We make our code and models publicly available.",
}
```
|
sentence-transformers/msmarco-distilbert-cos-v5 | 97bf29337ec20da8a1fb1ff2bd5555de5b566baf | 2022-06-15T21:48:24.000Z | [
"pytorch",
"tf",
"distilbert",
"feature-extraction",
"arxiv:1908.10084",
"sentence-transformers",
"sentence-similarity",
"transformers"
]
| sentence-similarity | false | sentence-transformers | null | sentence-transformers/msmarco-distilbert-cos-v5 | 2,380 | 1 | sentence-transformers | 1,236 | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# msmarco-distilbert-cos-v5
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and was designed for **semantic search**. It has been trained on 500k (query, answer) pairs from the [MS MARCO Passages dataset](https://github.com/microsoft/MSMARCO-Passage-Ranking). For an introduction to semantic search, have a look at: [SBERT.net - Semantic Search](https://www.sbert.net/examples/applications/semantic-search/README.html)
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer, util
query = "How many people live in London?"
docs = ["Around 9 Million people live in London", "London is known for its financial district"]
#Load the model
model = SentenceTransformer('sentence-transformers/msmarco-distilbert-cos-v5')
#Encode query and documents
query_emb = model.encode(query)
doc_emb = model.encode(docs)
#Compute dot score between query and all document embeddings
scores = util.dot_score(query_emb, doc_emb)[0].cpu().tolist()
#Combine docs & scores
doc_score_pairs = list(zip(docs, scores))
#Sort by decreasing score
doc_score_pairs = sorted(doc_score_pairs, key=lambda x: x[1], reverse=True)
#Output passages & scores
for doc, score in doc_score_pairs:
print(score, doc)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the correct pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
import torch.nn.functional as F
#Mean Pooling - Take average of all tokens
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output.last_hidden_state #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
#Encode text
def encode(texts):
# Tokenize sentences
encoded_input = tokenizer(texts, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input, return_dict=True)
# Perform pooling
embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
# Normalize embeddings
embeddings = F.normalize(embeddings, p=2, dim=1)
return embeddings
# Sentences we want sentence embeddings for
query = "How many people live in London?"
docs = ["Around 9 Million people live in London", "London is known for its financial district"]
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/msmarco-distilbert-cos-v5")
model = AutoModel.from_pretrained("sentence-transformers/msmarco-distilbert-cos-v5")
#Encode query and docs
query_emb = encode(query)
doc_emb = encode(docs)
#Compute dot score between query and all document embeddings
scores = torch.mm(query_emb, doc_emb.transpose(0, 1))[0].cpu().tolist()
#Combine docs & scores
doc_score_pairs = list(zip(docs, scores))
#Sort by decreasing score
doc_score_pairs = sorted(doc_score_pairs, key=lambda x: x[1], reverse=True)
#Output passages & scores
for doc, score in doc_score_pairs:
print(score, doc)
```
## Technical Details
In the following some technical details how this model must be used:
| Setting | Value |
| --- | :---: |
| Dimensions | 768 |
| Produces normalized embeddings | Yes |
| Pooling-Method | Mean pooling |
| Suitable score functions | dot-product (`util.dot_score`), cosine-similarity (`util.cos_sim`), or euclidean distance |
Note: When loaded with `sentence-transformers`, this model produces normalized embeddings with length 1. In that case, dot-product and cosine-similarity are equivalent. dot-product is preferred as it is faster. Euclidean distance is proportional to dot-product and can also be used.
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
``` |
alan-turing-institute/mt5-large-finetuned-mnli-xtreme-xnli | 9edb475b8a8f61e010b2b061e71aeb37f0f3b950 | 2021-05-27T10:41:51.000Z | [
"pytorch",
"tf",
"mt5",
"text2text-generation",
"multilingual",
"dataset:multi_nli",
"dataset:xnli",
"arxiv:2010.11934",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
]
| text2text-generation | false | alan-turing-institute | null | alan-turing-institute/mt5-large-finetuned-mnli-xtreme-xnli | 2,379 | 4 | transformers | 1,237 | ---
language: multilingual
tags:
- pytorch
license: apache-2.0
datasets:
- multi_nli
- xnli
metrics:
- xnli
---
# mt5-large-finetuned-mnli-xtreme-xnli
## Model Description
This model takes a pretrained large [multilingual-t5](https://github.com/google-research/multilingual-t5) (also available from [models](https://huggingface.co/google/mt5-large)) and fine-tunes it on English MNLI and the [xtreme_xnli](https://www.tensorflow.org/datasets/catalog/xtreme_xnli) training set. It is intended to be used for zero-shot text classification, inspired by [xlm-roberta-large-xnli](https://huggingface.co/joeddav/xlm-roberta-large-xnli).
## Intended Use
This model is intended to be used for zero-shot text classification, especially in languages other than English. It is fine-tuned on English MNLI and the [xtreme_xnli](https://www.tensorflow.org/datasets/catalog/xtreme_xnli) training set, a multilingual NLI dataset. The model can therefore be used with any of the languages in the XNLI corpus:
- Arabic
- Bulgarian
- Chinese
- English
- French
- German
- Greek
- Hindi
- Russian
- Spanish
- Swahili
- Thai
- Turkish
- Urdu
- Vietnamese
As per recommendations in [xlm-roberta-large-xnli](https://huggingface.co/joeddav/xlm-roberta-large-xnli), for English-only classification, you might want to check out:
- [bart-large-mnli](https://huggingface.co/facebook/bart-large-mnli)
- [a distilled bart MNLI model](https://huggingface.co/models?filter=pipeline_tag%3Azero-shot-classification&search=valhalla).
### Zero-shot example:
The model retains its text-to-text characteristic after fine-tuning. This means that our expected outputs will be text. During fine-tuning, the model learns to respond to the NLI task with a series of single token responses that map to entailment, neutral, or contradiction. The NLI task is indicated with a fixed prefix, "xnli:".
Below is an example, using PyTorch, of the model's use in a similar fashion to the `zero-shot-classification` pipeline. We use the logits from the LM output at the first token to represent confidence.
```python
from torch.nn.functional import softmax
from transformers import MT5ForConditionalGeneration, MT5Tokenizer
model_name = "alan-turing-institute/mt5-large-finetuned-mnli-xtreme-xnli"
tokenizer = MT5Tokenizer.from_pretrained(model_name)
model = MT5ForConditionalGeneration.from_pretrained(model_name)
model.eval()
sequence_to_classify = "¿A quién vas a votar en 2020?"
candidate_labels = ["Europa", "salud pública", "política"]
hypothesis_template = "Este ejemplo es {}."
ENTAILS_LABEL = "▁0"
NEUTRAL_LABEL = "▁1"
CONTRADICTS_LABEL = "▁2"
label_inds = tokenizer.convert_tokens_to_ids(
[ENTAILS_LABEL, NEUTRAL_LABEL, CONTRADICTS_LABEL])
def process_nli(premise: str, hypothesis: str):
""" process to required xnli format with task prefix """
return "".join(['xnli: premise: ', premise, ' hypothesis: ', hypothesis])
# construct sequence of premise, hypothesis pairs
pairs = [(sequence_to_classify, hypothesis_template.format(label)) for label in
candidate_labels]
# format for mt5 xnli task
seqs = [process_nli(premise=premise, hypothesis=hypothesis) for
premise, hypothesis in pairs]
print(seqs)
# ['xnli: premise: ¿A quién vas a votar en 2020? hypothesis: Este ejemplo es Europa.',
# 'xnli: premise: ¿A quién vas a votar en 2020? hypothesis: Este ejemplo es salud pública.',
# 'xnli: premise: ¿A quién vas a votar en 2020? hypothesis: Este ejemplo es política.']
inputs = tokenizer.batch_encode_plus(seqs, return_tensors="pt", padding=True)
out = model.generate(**inputs, output_scores=True, return_dict_in_generate=True,
num_beams=1)
# sanity check that our sequences are expected length (1 + start token + end token = 3)
for i, seq in enumerate(out.sequences):
assert len(
seq) == 3, f"generated sequence {i} not of expected length, 3." \\\\
f" Actual length: {len(seq)}"
# get the scores for our only token of interest
# we'll now treat these like the output logits of a `*ForSequenceClassification` model
scores = out.scores[0]
# scores has a size of the model's vocab.
# However, for this task we have a fixed set of labels
# sanity check that these labels are always the top 3 scoring
for i, sequence_scores in enumerate(scores):
top_scores = sequence_scores.argsort()[-3:]
assert set(top_scores.tolist()) == set(label_inds), \\\\
f"top scoring tokens are not expected for this task." \\\\
f" Expected: {label_inds}. Got: {top_scores.tolist()}."
# cut down scores to our task labels
scores = scores[:, label_inds]
print(scores)
# tensor([[-2.5697, 1.0618, 0.2088],
# [-5.4492, -2.1805, -0.1473],
# [ 2.2973, 3.7595, -0.1769]])
# new indices of entailment and contradiction in scores
entailment_ind = 0
contradiction_ind = 2
# we can show, per item, the entailment vs contradiction probas
entail_vs_contra_scores = scores[:, [entailment_ind, contradiction_ind]]
entail_vs_contra_probas = softmax(entail_vs_contra_scores, dim=1)
print(entail_vs_contra_probas)
# tensor([[0.0585, 0.9415],
# [0.0050, 0.9950],
# [0.9223, 0.0777]])
# or we can show probas similar to `ZeroShotClassificationPipeline`
# this gives a zero-shot classification style output across labels
entail_scores = scores[:, entailment_ind]
entail_probas = softmax(entail_scores, dim=0)
print(entail_probas)
# tensor([7.6341e-03, 4.2873e-04, 9.9194e-01])
print(dict(zip(candidate_labels, entail_probas.tolist())))
# {'Europa': 0.007634134963154793,
# 'salud pública': 0.0004287279152777046,
# 'política': 0.9919371604919434}
```
Unfortunately, the `generate` function for the TF equivalent model doesn't exactly mirror the PyTorch version so the above code won't directly transfer.
The model is currently not compatible with the existing `zero-shot-classification` pipeline.
## Training
This model was pre-trained on a set of 101 languages in the mC4, as described in [the mt5 paper](https://arxiv.org/abs/2010.11934). It was then fine-tuned on the [mt5_xnli_translate_train](https://github.com/google-research/multilingual-t5/blob/78d102c830d76bd68f27596a97617e2db2bfc887/multilingual_t5/tasks.py#L190) task for 8k steps in a similar manner to that described in the [offical repo](https://github.com/google-research/multilingual-t5#fine-tuning), with guidance from [Stephen Mayhew's notebook](https://github.com/mayhewsw/multilingual-t5/blob/master/notebooks/mt5-xnli.ipynb). The resulting model was then converted to :hugging_face: format.
## Eval results
Accuracy over XNLI test set:
| ar | bg | de | el | en | es | fr | hi | ru | sw | th | tr | ur | vi | zh | average |
|------|------|------|------|------|------|------|------|------|------|------|------|------|------|------|------|
| 81.0 | 85.0 | 84.3 | 84.3 | 88.8 | 85.3 | 83.9 | 79.9 | 82.6 | 78.0 | 81.0 | 81.6 | 76.4 | 81.7 | 82.3 | 82.4 |
|
HooshvareLab/roberta-fa-zwnj-base | 62eabb60447b49d9df5dabec5f44df6966f8108c | 2021-05-20T11:56:49.000Z | [
"pytorch",
"tf",
"jax",
"roberta",
"fill-mask",
"fa",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
]
| fill-mask | false | HooshvareLab | null | HooshvareLab/roberta-fa-zwnj-base | 2,378 | null | transformers | 1,238 | ---
language: fa
license: apache-2.0
---
# Roberta
This model can tackle the zero-width non-joiner character for Persian writing. Also, the model was trained on new multi-types corpora with a new set of vocabulary.
## Questions?
Post a Github issue on the [ParsRoBERTa Issues](https://github.com/hooshvare/roberta/issues) repo. |
ramsrigouthamg/t5_boolean_questions | 62a1fed724505b3f80f3f49fe0353437b40e58fe | 2020-07-25T17:29:28.000Z | [
"pytorch",
"t5",
"text2text-generation",
"transformers",
"autotrain_compatible"
]
| text2text-generation | false | ramsrigouthamg | null | ramsrigouthamg/t5_boolean_questions | 2,374 | 2 | transformers | 1,239 | Entry not found |
cardiffnlp/bertweet-base-offensive | 66851a2d325b60d980aa4581019e6319e4f510eb | 2021-05-20T14:49:35.000Z | [
"pytorch",
"tf",
"jax",
"roberta",
"text-classification",
"transformers"
]
| text-classification | false | cardiffnlp | null | cardiffnlp/bertweet-base-offensive | 2,368 | null | transformers | 1,240 | |
michiyasunaga/BioLinkBERT-base | b71f5d70f063d1c8f1124070ce86f1ee463ca1fe | 2022-03-31T00:51:21.000Z | [
"pytorch",
"bert",
"feature-extraction",
"en",
"dataset:pubmed",
"arxiv:2203.15827",
"transformers",
"exbert",
"linkbert",
"biolinkbert",
"fill-mask",
"question-answering",
"text-classification",
"token-classification",
"license:apache-2.0"
]
| text-classification | false | michiyasunaga | null | michiyasunaga/BioLinkBERT-base | 2,367 | 2 | transformers | 1,241 | ---
license: apache-2.0
language: en
datasets:
- pubmed
tags:
- bert
- exbert
- linkbert
- biolinkbert
- feature-extraction
- fill-mask
- question-answering
- text-classification
- token-classification
widget:
- text: "Sunitinib is a tyrosine kinase inhibitor"
---
## BioLinkBERT-base
BioLinkBERT-base model pretrained on [PubMed](https://pubmed.ncbi.nlm.nih.gov/) abstracts along with citation link information. It is introduced in the paper [LinkBERT: Pretraining Language Models with Document Links (ACL 2022)](https://arxiv.org/abs/2203.15827). The code and data are available in [this repository](https://github.com/michiyasunaga/LinkBERT).
This model achieves state-of-the-art performance on several biomedical NLP benchmarks such as [BLURB](https://microsoft.github.io/BLURB/) and [MedQA-USMLE](https://github.com/jind11/MedQA).
## Model description
LinkBERT is a transformer encoder (BERT-like) model pretrained on a large corpus of documents. It is an improvement of BERT that newly captures **document links** such as hyperlinks and citation links to include knowledge that spans across multiple documents. Specifically, it was pretrained by feeding linked documents into the same language model context, besides a single document.
LinkBERT can be used as a drop-in replacement for BERT. It achieves better performance for general language understanding tasks (e.g. text classification), and is also particularly effective for **knowledge-intensive** tasks (e.g. question answering) and **cross-document** tasks (e.g. reading comprehension, document retrieval).
## Intended uses & limitations
The model can be used by fine-tuning on a downstream task, such as question answering, sequence classification, and token classification.
You can also use the raw model for feature extraction (i.e. obtaining embeddings for input text).
### How to use
To use the model to get the features of a given text in PyTorch:
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained('michiyasunaga/BioLinkBERT-base')
model = AutoModel.from_pretrained('michiyasunaga/BioLinkBERT-base')
inputs = tokenizer("Sunitinib is a tyrosine kinase inhibitor", return_tensors="pt")
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state
```
For fine-tuning, you can use [this repository](https://github.com/michiyasunaga/LinkBERT) or follow any other BERT fine-tuning codebases.
## Evaluation results
When fine-tuned on downstream tasks, LinkBERT achieves the following results.
**Biomedical benchmarks ([BLURB](https://microsoft.github.io/BLURB/), [MedQA](https://github.com/jind11/MedQA), [MMLU](https://github.com/hendrycks/test), etc.):** BioLinkBERT attains new state-of-the-art.
| | BLURB score | PubMedQA | BioASQ | MedQA-USMLE |
| ---------------------- | -------- | -------- | ------- | -------- |
| PubmedBERT-base | 81.10 | 55.8 | 87.5 | 38.1 |
| **BioLinkBERT-base** | **83.39** | **70.2** | **91.4** | **40.0** |
| **BioLinkBERT-large** | **84.30** | **72.2** | **94.8** | **44.6** |
| | MMLU-professional medicine |
| ---------------------- | -------- |
| GPT-3 (175 params) | 38.7 |
| UnifiedQA (11B params) | 43.2 |
| **BioLinkBERT-large (340M params)** | **50.7** |
## Citation
If you find LinkBERT useful in your project, please cite the following:
```bibtex
@InProceedings{yasunaga2022linkbert,
author = {Michihiro Yasunaga and Jure Leskovec and Percy Liang},
title = {LinkBERT: Pretraining Language Models with Document Links},
year = {2022},
booktitle = {Association for Computational Linguistics (ACL)},
}
```
|
castorini/monot5-base-msmarco | 891f24ce967761cac53e544481e7aeaf3c1fad80 | 2021-11-24T17:59:19.000Z | [
"pytorch",
"jax",
"t5",
"text2text-generation",
"transformers",
"autotrain_compatible"
]
| text2text-generation | false | castorini | null | castorini/monot5-base-msmarco | 2,365 | null | transformers | 1,242 | This model is a T5-base reranker fine-tuned on the MS MARCO passage dataset for 100k steps (or 10 epochs).
For better zero-shot performance (i.e., inference on other datasets), we recommend using `castorini/monot5-base-msmarco-10k`.
For more details on how to use it, check the following links:
- [A simple reranking example](https://github.com/castorini/pygaggle#a-simple-reranking-example)
- [Rerank MS MARCO passages](https://github.com/castorini/pygaggle/blob/master/docs/experiments-msmarco-passage-subset.md)
- [Rerank Robust04 documents](https://github.com/castorini/pygaggle/blob/master/docs/experiments-robust04-monot5-gpu.md)
Paper describing the model: [Document Ranking with a Pretrained Sequence-to-Sequence Model](https://www.aclweb.org/anthology/2020.findings-emnlp.63/) |
sshleifer/tinier_bart | ed9a6fc322f4a1961166dc929cda0c03637a2e0d | 2021-06-14T09:08:24.000Z | [
"pytorch",
"jax",
"bart",
"text2text-generation",
"transformers",
"autotrain_compatible"
]
| text2text-generation | false | sshleifer | null | sshleifer/tinier_bart | 2,365 | 1 | transformers | 1,243 | Entry not found |
megagonlabs/transformers-ud-japanese-electra-base-discriminator | 96a3711b754c2caf0d1e22b30cbb893a37fa46c2 | 2021-09-22T09:00:15.000Z | [
"pytorch",
"electra",
"pretraining",
"ja",
"dataset:mC4 Japanese",
"arxiv:1910.10683",
"transformers",
"license:mit"
]
| null | false | megagonlabs | null | megagonlabs/transformers-ud-japanese-electra-base-discriminator | 2,359 | 4 | transformers | 1,244 | ---
language: ja
license: mit
datasets:
- mC4 Japanese
---
# transformers-ud-japanese-electra-ginza (sudachitra-wordpiece, mC4 Japanese) - [MIYAGINO](https://www.ntj.jac.go.jp/assets/images/member/pertopics/image/per100510_3.jpg)
This is an [ELECTRA](https://github.com/google-research/electra) model pretrained on approximately 200M Japanese sentences.
The input text is tokenized by [SudachiTra](https://github.com/WorksApplications/SudachiTra) with the WordPiece subword tokenizer.
See `tokenizer_config.json` for the setting details.
## How to use
```python
from transformers import ElectraModel
from sudachitra import ElectraSudachipyTokenizer
model = ElectraModel.from_pretrained("megagonlabs/transformers-ud-japanese-electra-base-discriminator")
tokenizer = ElectraSudachipyTokenizer.from_pretrained("megagonlabs/transformers-ud-japanese-electra-base-discriminator")
model(**tokenizer("まさにオールマイティーな商品だ。", return_tensors="pt")).last_hidden_state
tensor([[[-0.0498, -0.0285, 0.1042, ..., 0.0062, -0.1253, 0.0338],
[-0.0686, 0.0071, 0.0087, ..., -0.0210, -0.1042, -0.0320],
[-0.0636, 0.1465, 0.0263, ..., 0.0309, -0.1841, 0.0182],
...,
[-0.1500, -0.0368, -0.0816, ..., -0.0303, -0.1653, 0.0650],
[-0.0457, 0.0770, -0.0183, ..., -0.0108, -0.1903, 0.0694],
[-0.0981, -0.0387, 0.1009, ..., -0.0150, -0.0702, 0.0455]]],
grad_fn=<NativeLayerNormBackward>)
```
## Model architecture
The model architecture is the same as the original ELECTRA base model; 12 layers, 768 dimensions of hidden states, and 12 attention heads.
## Training data and libraries
This model is trained on the Japanese texts extracted from the [mC4](https://huggingface.co/datasets/mc4) Common Crawl's multilingual web crawl corpus.
We used the [Sudachi](https://github.com/WorksApplications/Sudachi) to split texts into sentences, and also applied a simple rule-based filter to remove nonlinguistic segments of mC4 multilingual corpus.
The extracted texts contains over 600M sentences in total, and we used approximately 200M sentences for pretraining.
We used [NVIDIA's TensorFlow2-based ELECTRA implementation](https://github.com/NVIDIA/DeepLearningExamples/tree/master/TensorFlow2/LanguageModeling/ELECTRA) for pretraining. The time required for the pretrainig was about 110 hours using GCP DGX A100 8gpu instance with enabling Automatic Mixed Precision.
## Licenses
The pretrained models are distributed under the terms of the [MIT License](https://opensource.org/licenses/mit-license.php).
## Citations
- mC4
Contains information from `mC4` which is made available under the [ODC Attribution License](https://opendatacommons.org/licenses/by/1-0/).
```
@article{2019t5,
author = {Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu},
title = {Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer},
journal = {arXiv e-prints},
year = {2019},
archivePrefix = {arXiv},
eprint = {1910.10683},
}
``` |
sentence-transformers/msmarco-distilbert-base-v3 | cabff1a69c4aecef223c78fdb32c9f3fc4bda7dc | 2022-06-15T21:45:04.000Z | [
"pytorch",
"tf",
"distilbert",
"feature-extraction",
"arxiv:1908.10084",
"sentence-transformers",
"sentence-similarity",
"transformers",
"license:apache-2.0"
]
| sentence-similarity | false | sentence-transformers | null | sentence-transformers/msmarco-distilbert-base-v3 | 2,359 | 2 | sentence-transformers | 1,245 | ---
pipeline_tag: sentence-similarity
license: apache-2.0
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# sentence-transformers/msmarco-distilbert-base-v3
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/msmarco-distilbert-base-v3')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/msmarco-distilbert-base-v3')
model = AutoModel.from_pretrained('sentence-transformers/msmarco-distilbert-base-v3')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/msmarco-distilbert-base-v3)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 510, 'do_lower_case': False}) with Transformer model: DistilBertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
``` |
lingwave-admin/state-op-detector | 9c50f3f5f656c12ce40876cc262a5d947eefe3e2 | 2022-06-13T17:49:00.000Z | [
"pytorch",
"distilbert",
"text-classification",
"en",
"transformers",
"classification",
"license:apache-2.0"
]
| text-classification | false | lingwave-admin | null | lingwave-admin/state-op-detector | 2,359 | null | transformers | 1,246 | ---
language:
- en
tags:
- classification
license: apache-2.0
widget:
- text: "Zimbabwe has all the Brilliant Minds to become the Next Dubai of Africa No wonder why is so confide | Invest Surplus yako iye into Healthcare that will save lives amp creat real Jobs in Healthcare Sector | To the African Diaspora in Americas Europe AsiaUK this i | If the Dictatorship in dnt see this vision Zambia can still impment the ideaamp have Zambia as the | Ndeyake Zimbabwe anoita zvaanoda nayo Momudini He Died for this countr | "
example_title: "Normal Tweet Sequence 1"
- text: "Militants from Turkey to stay alive are preparing to leave settlements without a fight and surrender their weapons | Over thousand proTurkish militants left occupied territories in the southwestern part of Idlib | In early February during the humanitarian campaigns in the points of Mazlum of the province of Deir EzZor and Hazze of the province of Rif Damascus food packages were issued | Humanitarian assistance from the Russian military came from the first days of the Russian participation in the Syrian operation | Local residents of Khsham received food packages with a total weight of tons | The Russian Center for Reconciliation of the Parties held a humanitarian action in the village of Hsham DeirezZor Province | After asking for help from representatives of the Antiochian church the Russian reconciliation center delivered about two tons of food to Mahard | After mortar shelling of the village of Mahard residents were in a difficult humanitarian situation | The Russian military held a charity event in Maharde Aleppo Province handing out packages of products weighing more than two tons in total | The Russian military delivered a batch of humanitarian aid to the Christians of the city of Mahard in the Syrian province of Hama |"
example_title: "Russian State Operator Tweet Sequence"
- text: "Peru will sign a memorandum of understanding to join Chinas Belt and Road infrastructure initiative in coming days Chinas ambassador said on Wednesday despite recent warnings from the United States about the Beijings rise in Latin America peru latinamerica china us usa | People in Washington waved Turkish flags and displayed posters We remember victims of Armenian terror Stop Armenian aggression on Azerbaijan while Armenians held banners and chanted against Turkey over the socalled Armenian genocide armenia turkey | Putin reportedly told Kim that Russia supported his efforts to normalise North Koreas relations with the US KimJongUn putin northkorea russia | Israeli Prime Minister Benjamin Netanyahu said he will name a new settlement in the Golan Heights after US President Donald Trump israel us usa golan GolanHeights | Turkish FM urges sincerity in counterterrorism Mevlut Cavusoglu reiterates Turkeys fight against all terror groups of FETO PKK YPG Daesh turkey feto pkk ypg daesh | Sri Lanka declares April national day of mourning Decision taken during meeting of National Security Council chaired by Sri Lankan President Maithripala Sirisena SriLankaBlast SriLankaBombings SriLankaTerrorAttack | Kazakh President KassymJomart Tokayev on Tuesday secured veteran leader Nursultan Nazarbayevs backing to run in the June snap presidential election virtually guaranteeing Tokayevs victory nazarbayev tokayev Kazakhstan | Sri Lanka wakes to emergency law after Easter bombing attacks SriLankaBlasts SriLankaBombings SriLankaTerrorAttack SriLankaBlast | Libyan govt claims control of most of Tripoli airport Development follows clashes with forces loyal to eastern Libyabased commander Khalifa Haftar libya khalifahaftar tripoli haftar | Death toll from Philippine quake rises to Search and rescue work continues for people buried under supermarket that collapsed early Monday philippine quake | "
example_title: "Chinese State Operator Tweet Sequence"
- text: "You live in a fantasy world Tim The real insurrection was a stolen election where the will of | Canada isnt importing drugs and slaves Just Globalism and oppression of its people | Our systems are corrupted Who is trying to fix them and rectify the immense damage this illegitimate administratio | Just the cars that run people down while killing the planet Maybe these ga | But teaching them that they can chop their Johnson off and be a girl in prek thats not Obscene | If youve been wondering if there is anyone or anything that Washington holds in higher contempt than Russia and Vl | Thanks Joe You SUCK | It seems like lately the right has been focused on protecting rights while the left is focused on leaving you with nothing left | This makes me a proud American | Youre welcome We are here and have been | "
example_title: "Normal Tweet Sequence 2"
---
# State Social Operator Detector
## Overview
State-funded social media operators are a hard-to-detect but significant threat to any democracy with free speech, and that threat is growing. In recent years, the extent of these state-funded campaigns has become clear. Russian campaigns undertaken to influence [elections](https://www.brennancenter.org/our-work/analysis-opinion/new-evidence-shows-how-russias-election-interference-has-gotten-more) are most prominent in the news, but other campaigns have been identified, with the intent to [turn South American countries against the US](https://www.nbcnews.com/news/latino/russia-disinformation-ukraine-spreading-spanish-speaking-media-rcna22843), spread disinformation on the [invasion of Ukraine](https://www.forbes.com/sites/petersuciu/2022/03/10/russian-sock-puppets-spreading-misinformation-on-social-media-about-ukraine/), and foment conflict in America's own culture wars by [influencing all sides](https://journals.sagepub.com/doi/10.1177/19401612221082052) as part of an effort to weaken America's hegemonic status.
Iranian and [Chinese](https://www.bbc.com/news/56364952) efforts are also well-funded, though not as widespread or aggressive as those of Russia. Even so, Chinese influence is growing, and often it uses social media to spread specific narratives on [Xinjiang and the Uyghur situation](https://www.lawfareblog.com/understanding-pro-china-propaganda-and-disinformation-tool-set-xinjiang), Hong Kong, COVID-19, and Taiwan as well as sometimes supporting [Russian efforts](https://www.brookings.edu/techstream/china-and-russia-are-joining-forces-to-spread-disinformation/).
We need better tools to combat this disinformation, both for social media administrators as well as the public. As part of an effort towards that, we have created a proof-of-concept tool that can be operated via browser extension to identify likely state-funded social media operators on Twitter through inference performed on tweet content.
The core of the tool is a DistilBERT language transformer model that has been finetuned on 250K samples of known state operator tweets and natural tweets pulled from the Twitter API. It is highly accurate at distinguishing normal users from state operators (99%), but has some limitations due to sampling recency bias. We intend to iteratively improve the model as time goes on.
## Usage
You can try out the model by entering in a sequence of 1-10 tweets. Each should be separated by pipes, as follows: "this is tweet one | this is tweet two." The model will then classify the sequence as belonging to a state operator or a normal user.
## Further Information
You can obtain further information on the data collection and training used to create this model at the following Github repo: [State Social Operator Detection](https://github.com/curt-tigges/state-social-operator-detection)
## Contact
You can reach me at [email protected]. |
lemon234071/t5-base-Chinese | dd3c0975ff4c60cc9bc89123e8641f2b1cdc2ce1 | 2021-07-21T09:49:44.000Z | [
"pytorch",
"jax",
"mt5",
"text2text-generation",
"transformers",
"autotrain_compatible"
]
| text2text-generation | false | lemon234071 | null | lemon234071/t5-base-Chinese | 2,355 | 7 | transformers | 1,247 | A mt5-base model that the vocab and word embedding are truncated, only Chinese and English characters are retained.
https://github.com/lemon234071/TransformerBaselines |
allenai/PRIMERA-multinews | 399837085142745b6d6c0e9b863ee3987b35a621 | 2022-07-25T18:17:12.000Z | [
"pytorch",
"tf",
"led",
"text2text-generation",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
]
| text2text-generation | false | allenai | null | allenai/PRIMERA-multinews | 2,354 | null | transformers | 1,248 | ---
license: apache-2.0
---
HF-version model for PRIMERA: Pyramid-based Masked Sentence Pre-training for Multi-document Summarization (ACL 2022).
The original code can be found [here](https://github.com/allenai/PRIMER). You can find the script and notebook to train/evaluate the model in the original github repo.
* Note: due to the difference between the implementations of the original Longformer and the Huggingface LED model, the results of converted models are slightly different. We run a sanity check on both fine-tuned and non fine-tuned models, and show the results below:
| Model | Rouge-1 | Rouge-2 | Rouge-L |
| --- | ----------- |----------- |----------- |
| PRIMERA | 42.0 | 13.6 | 20.8|
| PRIMERA-hf | 41.7 |13.6 | 20.5|
| PRIMERA(finetuned) | 49.9 | 21.1 | 25.9|
| PRIMERA-hf(finetuned) | 49.9 | 20.9 | 25.8|
You can use it by
```
from transformers import (
AutoTokenizer,
LEDConfig,
LEDForConditionalGeneration,
)
tokenizer = AutoTokenizer.from_pretrained('allenai/PRIMERA')
config=LEDConfig.from_pretrained('allenai/PRIMERA')
model = LEDForConditionalGeneration.from_pretrained('allenai/PRIMERA')
``` |
nreimers/BERT-Mini_L-4_H-256_A-4 | f26dee0ee8b221c30d7ef6e51f9b7852a6814721 | 2021-05-28T11:05:04.000Z | [
"pytorch",
"jax",
"bert",
"feature-extraction",
"transformers"
]
| feature-extraction | false | nreimers | null | nreimers/BERT-Mini_L-4_H-256_A-4 | 2,341 | null | transformers | 1,249 | This is the BERT-Medium model from Google: https://github.com/google-research/bert#bert. A BERT model with 4 layers, 256 hidden unit size, and 4 attention heads. |
bertin-project/bertin-roberta-base-spanish | cb1844d753a963f4f4f716ab8db723628669964b | 2022-07-05T11:12:13.000Z | [
"pytorch",
"jax",
"tensorboard",
"roberta",
"fill-mask",
"es",
"dataset:bertin-project/mc4-es-sampled",
"arxiv:2107.07253",
"arxiv:1907.11692",
"transformers",
"spanish",
"license:cc-by-4.0",
"autotrain_compatible"
]
| fill-mask | false | bertin-project | null | bertin-project/bertin-roberta-base-spanish | 2,336 | 13 | transformers | 1,250 | ---
language: es
license: cc-by-4.0
tags:
- spanish
- roberta
pipeline_tag: fill-mask
datasets:
- bertin-project/mc4-es-sampled
widget:
- text: Fui a la librería a comprar un <mask>.
---
- [Version v2](https://huggingface.co/bertin-project/bertin-roberta-base-spanish/tree/v2) (default): April 28th, 2022
- [Version v1](https://huggingface.co/bertin-project/bertin-roberta-base-spanish/tree/v1): July 26th, 2021
- [Version v1-512](https://huggingface.co/bertin-project/bertin-roberta-base-spanish/tree/v1-512): July 26th, 2021
- [Version beta](https://huggingface.co/bertin-project/bertin-roberta-base-spanish/tree/beta): July 15th, 2021
# BERTIN
<div align=center>
<img alt="BERTIN logo" src="https://huggingface.co/bertin-project/bertin-roberta-base-spanish/resolve/main/images/bertin.png" width="200px">
</div>
BERTIN is a series of BERT-based models for Spanish. The current model hub points to the best of all RoBERTa-base models trained from scratch on the Spanish portion of mC4 using [Flax](https://github.com/google/flax). All code and scripts are included.
This is part of the
[Flax/Jax Community Week](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104), organized by [HuggingFace](https://huggingface.co/) and TPU usage sponsored by Google Cloud.
The aim of this project was to pre-train a RoBERTa-base model from scratch during the Flax/JAX Community Event, in which Google Cloud provided free TPUv3-8 to do the training using Huggingface's Flax implementations of their library.
## Team members
- Javier de la Rosa ([versae](https://huggingface.co/versae))
- Eduardo González ([edugp](https://huggingface.co/edugp))
- Paulo Villegas ([paulo](https://huggingface.co/paulo))
- Pablo González de Prado ([Pablogps](https://huggingface.co/Pablogps))
- Manu Romero ([mrm8488](https://huggingface.co/))
- María Grandury ([mariagrandury](https://huggingface.co/))
## Citation and Related Information
To cite this model:
```bibtex
@article{BERTIN,
author = {Javier De la Rosa y Eduardo G. Ponferrada y Manu Romero y Paulo Villegas y Pablo González de Prado Salas y María Grandury},
title = {BERTIN: Efficient Pre-Training of a Spanish Language Model using Perplexity Sampling},
journal = {Procesamiento del Lenguaje Natural},
volume = {68},
number = {0},
year = {2022},
keywords = {},
abstract = {The pre-training of large language models usually requires massive amounts of resources, both in terms of computation and data. Frequently used web sources such as Common Crawl might contain enough noise to make this pretraining sub-optimal. In this work, we experiment with different sampling methods from the Spanish version of mC4, and present a novel data-centric technique which we name perplexity sampling that enables the pre-training of language models in roughly half the amount of steps and using one fifth of the data. The resulting models are comparable to the current state-of-the-art, and even achieve better results for certain tasks. Our work is proof of the versatility of Transformers, and paves the way for small teams to train their models on a limited budget.},
issn = {1989-7553},
url = {http://journal.sepln.org/sepln/ojs/ojs/index.php/pln/article/view/6403},
pages = {13--23}
}
```
If you use this model, we would love to hear about it! Reach out on twitter, GitHub, Discord, or shoot us an email.
## Team
- Javier de la Rosa ([versae](https://huggingface.co/versae))
- Eduardo González ([edugp](https://huggingface.co/edugp))
- Paulo Villegas ([paulo](https://huggingface.co/paulo))
- Pablo González de Prado ([Pablogps](https://huggingface.co/Pablogps))
- Manu Romero ([mrm8488](https://huggingface.co/))
- María Grandury ([mariagrandury](https://huggingface.co/))
## Acknowledgements
This project would not have been possible without compute generously provided by the Huggingface and Google through the
[TPU Research Cloud](https://sites.research.google/trc/), as well as the Cloud TPU team for providing early access to the [Cloud TPU VM](https://cloud.google.com/blog/products/compute/introducing-cloud-tpu-vms).
## Disclaimer
The models published in this repository are intended for a generalist purpose and are available to third parties. These models may have bias and/or any other undesirable distortions. When third parties, deploy or provide systems and/or services to other parties using any of these models (or using systems based on these models) or become users of the models, they should note that it is their responsibility to mitigate the risks arising from their use and, in any event, to comply with applicable regulations, including regulations regarding the use of artificial intelligence. In no event shall the owner of the models be liable for any results arising from the use made by third parties of these models.
<hr>
<details>
<summary>Full report</summary>
# Motivation
According to [Wikipedia](https://en.wikipedia.org/wiki/List_of_languages_by_total_number_of_speakers), Spanish is the second most-spoken language in the world by native speakers (>470 million speakers), only after Chinese, and the fourth including those who speak it as a second language. However, most NLP research is still mainly available in English. Relevant contributions like BERT, XLNet or GPT2 sometimes take years to be available in Spanish and, when they do, it is often via multilingual versions which are not as performant as the English alternative.
At the time of the event there were no RoBERTa models available in Spanish. Therefore, releasing one such model was the primary goal of our project. During the Flax/JAX Community Event we released a beta version of our model, which was the first in the Spanish language. Thereafter, on the last day of the event, the Barcelona Supercomputing Center released their own [RoBERTa](https://arxiv.org/pdf/2107.07253.pdf) model. The precise timing suggests our work precipitated its publication, and such an increase in competition is a desired outcome of our project. We are grateful for their efforts to include BERTIN in their paper, as discussed further below, and recognize the value of their own contribution, which we also acknowledge in our experiments.
Models in monolingual Spanish are hard to come by and, when they do, they are often trained on proprietary datasets and with massive resources. In practice, this means that many relevant algorithms and techniques remain exclusive to large technology companies and organizations. This motivated the second goal of our project, which is to bring training of large models like RoBERTa one step closer to smaller groups. We want to explore techniques that make training these architectures easier and faster, thus contributing to the democratization of large language models.
## Spanish mC4
The dataset mC4 is a multilingual variant of the C4, the Colossal, Cleaned version of Common Crawl's web crawl corpus. While C4 was used to train the T5 text-to-text Transformer models, mC4 comprises natural text in 101 languages drawn from the public Common Crawl web-scrape and was used to train mT5, the multilingual version of T5.
The Spanish portion of mC4 (mC4-es) contains about 416 million samples and 235 billion words in approximately 1TB of uncompressed data.
```bash
$ zcat c4/multilingual/c4-es*.tfrecord*.json.gz | wc -l
416057992
```
```bash
$ zcat c4/multilingual/c4-es*.tfrecord-*.json.gz | jq -r '.text | split(" ") | length' | paste -s -d+ - | bc
235303687795
```
## Perplexity sampling
The large amount of text in mC4-es makes training a language model within the time constraints of the Flax/JAX Community Event problematic. This motivated the exploration of sampling methods, with the goal of creating a subset of the dataset that would allow for the training of well-performing models with roughly one eighth of the data (~50M samples) and at approximately half the training steps.
In order to efficiently build this subset of data, we decided to leverage a technique we call *perplexity sampling*, and whose origin can be traced to the construction of CCNet (Wenzek et al., 2020) and their high quality monolingual datasets from web-crawl data. In their work, they suggest the possibility of applying fast language models trained on high-quality data such as Wikipedia to filter out texts that deviate too much from correct expressions of a language (see Figure 1). They also released Kneser-Ney models (Ney et al., 1994) for 100 languages (Spanish included) as implemented in the KenLM library (Heafield, 2011) and trained on their respective Wikipedias.
<figure>

<caption>Figure 1. Perplexity distributions by percentage CCNet corpus.</caption>
</figure>
In this work, we tested the hypothesis that perplexity sampling might help
reduce training-data size and training times, while keeping the performance of
the final model.
## Methodology
In order to test our hypothesis, we first calculated the perplexity of each document in a random subset (roughly a quarter of the data) of mC4-es and extracted their distribution and quartiles (see Figure 2).
<figure>

<caption>Figure 2. Perplexity distributions and quartiles (red lines) of 44M samples of mC4-es.</caption>
</figure>
With the extracted perplexity percentiles, we created two functions to oversample the central quartiles with the idea of biasing against samples that are either too small (short, repetitive texts) or too long (potentially poor quality) (see Figure 3).
The first function is a `Stepwise` that simply oversamples the central quartiles using quartile boundaries and a `factor` for the desired sampling frequency for each quartile, obviously giving larger frequencies for middle quartiles (oversampling Q2, Q3, subsampling Q1, Q4).
The second function weighted the perplexity distribution by a Gaussian-like function, to smooth out the sharp boundaries of the `Stepwise` function and give a better approximation to the desired underlying distribution (see Figure 4).
We adjusted the `factor` parameter of the `Stepwise` function, and the `factor` and `width` parameter of the `Gaussian` function to roughly be able to sample 50M samples from the 416M in mC4-es (see Figure 4). For comparison, we also sampled randomly mC4-es up to 50M samples as well. In terms of sizes, we went down from 1TB of data to ~200GB. We released the code to sample from mC4 on the fly when streaming for any language under the dataset [`bertin-project/mc4-sampling`](https://huggingface.co/datasets/bertin-project/mc4-sampling).
<figure>

<caption>Figure 3. Expected perplexity distributions of the sample mC4-es after applying the Stepwise function.</caption>
</figure>
<figure>

<caption>Figure 4. Expected perplexity distributions of the sample mC4-es after applying Gaussian function.</caption>
</figure>
Figure 5 shows the actual perplexity distributions of the generated 50M subsets for each of the executed subsampling procedures. All subsets can be easily accessed for reproducibility purposes using the [`bertin-project/mc4-es-sampled`](https://huggingface.co/datasets/bertin-project/mc4-es-sampled) dataset. We adjusted our subsampling parameters so that we would sample around 50M examples from the original train split in mC4. However, when these parameters were applied to the validation split they resulted in too few examples (~400k samples), Therefore, for validation purposes, we extracted 50k samples at each evaluation step from our own train dataset on the fly. Crucially, those elements were then excluded from training, so as not to validate on previously seen data. In the [`mc4-es-sampled`](https://huggingface.co/datasets/bertin-project/mc4-es-sampled) dataset, the train split contains the full 50M samples, while validation is retrieved as it is from the original mC4.
```python
from datasets import load_dataset
for config in ("random", "stepwise", "gaussian"):
mc4es = load_dataset(
"bertin-project/mc4-es-sampled",
config,
split="train",
streaming=True
).shuffle(buffer_size=1000)
for sample in mc4es:
print(config, sample)
break
```
<figure>

<caption>Figure 5. Experimental perplexity distributions of the sampled mc4-es after applying Gaussian and Stepwise functions, and the Random control sample.</caption>
</figure>
`Random` sampling displayed the same perplexity distribution of the underlying true distribution, as can be seen in Figure 6.
<figure>

<caption>Figure 6. Experimental perplexity distribution of the sampled mc4-es after applying Random sampling.</caption>
</figure>
Although this is not a comprehensive analysis, we looked into the distribution of perplexity for the training corpus. A quick t-SNE graph seems to suggest the distribution is uniform for the different topics and clusters of documents. The [interactive plot](https://huggingface.co/bertin-project/bertin-roberta-base-spanish/raw/main/images/perplexity_colored_embeddings.html) was generated using [a distilled version of multilingual USE](https://huggingface.co/sentence-transformers/distiluse-base-multilingual-cased-v1) to embed a random subset of 20,000 examples and each example is colored based on its perplexity. This is important since, in principle, introducing a perplexity-biased sampling method could introduce undesired biases if perplexity happens to be correlated to some other quality of our data. The code required to replicate this plot is available at [`tsne_plot.py`](https://huggingface.co/bertin-project/bertin-roberta-base-spanish/blob/main/tsne_plot.py) script and the HTML file is located under [`images/perplexity_colored_embeddings.html`](https://huggingface.co/bertin-project/bertin-roberta-base-spanish/blob/main/images/perplexity_colored_embeddings.html).
### Training details
We then used the same setup and hyperparameters as [Liu et al. (2019)](https://arxiv.org/abs/1907.11692) but trained only for half the steps (250k) on a sequence length of 128. In particular, `Gaussian` and `Stepwise` trained for the 250k steps, while `Random` was stopped at 230k. `Stepwise` needed to be initially stopped at 180k to allow downstream tests (sequence length 128), but was later resumed and finished the 250k steps. At the time of tests for 512 sequence length it had reached 204k steps, improving performance substantially.
Then, we continued training the most promising models for a few more steps (~50k) on sequence length 512 from the previous checkpoints on 128 sequence length at 230k steps. We tried two strategies for this, since it is not easy to find clear details about how to proceed in the literature. It turns out this decision had a big impact in the final performance.
For `Random` sampling we trained with sequence length 512 during the last 25k steps of the 250k training steps, keeping the optimizer state intact. Results for this are underwhelming, as seen in Figure 7.
<figure>

<caption>Figure 7. Training profile for Random sampling. Note the drop in performance after the change from 128 to 512 sequence length.</caption>
</figure>
For `Gaussian` sampling we started a new optimizer after 230k steps with 128 sequence length, using a short warmup interval. Results are much better using this procedure. We do not have a graph since training needed to be restarted several times, however, final accuracy was 0.6873 compared to 0.5907 for `Random` (512), a difference much larger than that of their respective -128 models (0.6520 for `Random`, 0.6608 for `Gaussian`). Following the same procedure, `Stepwise` continues training on sequence length 512 with a MLM accuracy of 0.6744 at 31k steps.
Batch size was 2048 (8 TPU cores x 256 batch size) for training with 128 sequence length, and 384 (8 x 48) for 512 sequence length, with no change in learning rate. Warmup steps for 512 was 500.
## Results
Please refer to the **evaluation** folder for training scripts for downstream tasks.
Our first test, tagged [`beta`](https://huggingface.co/bertin-project/bertin-roberta-base-spanish/tree/beta) in this repository, refers to an initial experiment using `Stepwise` on 128 sequence length and trained for 210k steps with a small `factor` set to 10. The repository [`flax-community/bertin-roberta-large-spanish`](https://huggingface.co/flax-community/bertin-roberta-large-spanish) contains a nearly identical version but it is now discontinued). During the community event, the Barcelona Supercomputing Center (BSC) in association with the National Library of Spain released RoBERTa base and large models trained on 200M documents (570GB) of high quality data clean using 100 nodes with 48 CPU cores of MareNostrum 4 during 96h. At the end of the process they were left with 2TB of clean data at the document level that were further cleaned up to the final 570GB. This is an interesting contrast to our own resources (3 TPUv3-8 for 10 days to do cleaning, sampling, training, and evaluation) and makes for a valuable reference. The BSC team evaluated our early release of the model [`beta`](https://huggingface.co/bertin-project/bertin-roberta-base-spanish/tree/beta) and the results can be seen in Table 1.
Our final models were trained on a different number of steps and sequence lengths and achieve different—higher—masked-word prediction accuracies. Despite these limitations it is interesting to see the results they obtained using the early version of our model. Note that some of the datasets used for evaluation by BSC are not freely available, therefore it is not possible to verify the figures.
<figure>
<caption>Table 1. Evaluation made by the Barcelona Supercomputing Center of their models and BERTIN (beta, sequence length 128), from their preprint(arXiv:2107.07253).</caption>
| Dataset | Metric | RoBERTa-b | RoBERTa-l | BETO | mBERT | BERTIN (beta) |
|-------------|----------|-----------|-----------|--------|--------|--------|
| UD-POS | F1 |**0.9907** | 0.9901 | 0.9900 | 0.9886 | **0.9904** |
| Conll-NER | F1 | 0.8851 | 0.8772 | 0.8759 | 0.8691 | 0.8627 |
| Capitel-POS | F1 | 0.9846 | 0.9851 | 0.9836 | 0.9839 | 0.9826 |
| Capitel-NER | F1 | 0.8959 | 0.8998 | 0.8771 | 0.8810 | 0.8741 |
| STS | Combined | 0.8423 | 0.8420 | 0.8216 | 0.8249 | 0.7822 |
| MLDoc | Accuracy | 0.9595 | 0.9600 | 0.9650 | 0.9560 | **0.9673** |
| PAWS-X | F1 | 0.9035 | 0.9000 | 0.8915 | 0.9020 | 0.8820 |
| XNLI | Accuracy | 0.8016 | WIP | 0.8130 | 0.7876 | WIP |
</figure>
All of our models attained good accuracy values during training in the masked-language model task —in the range of 0.65— as can be seen in Table 2:
<figure>
<caption>Table 2. Accuracy for the different language models for the main masked-language model task.</caption>
| Model | Accuracy |
|----------------------------------------------------|----------|
| [`bertin-project/bertin-roberta-base-spanish (beta)`](https://huggingface.co/bertin-project/bertin-roberta-base-spanish) | 0.6547 |
| [`bertin-project/bertin-base-random`](https://huggingface.co/bertin-project/bertin-base-random) | 0.6520 |
| [`bertin-project/bertin-base-stepwise`](https://huggingface.co/bertin-project/bertin-base-stepwise) | 0.6487 |
| [`bertin-project/bertin-base-gaussian`](https://huggingface.co/bertin-project/bertin-base-gaussian) | 0.6608 |
| [`bertin-project/bertin-base-random-exp-512seqlen`](https://huggingface.co/bertin-project/bertin-base-random-exp-512seqlen) | 0.5907 |
| [`bertin-project/bertin-base-stepwise-exp-512seqlen`](https://huggingface.co/bertin-project/bertin-base-stepwise-exp-512seqlen) | 0.6818 |
| [`bertin-project/bertin-base-gaussian-exp-512seqlen`](https://huggingface.co/bertin-project/bertin-base-gaussian-exp-512seqlen) | **0.6873** |
</figure>
### Downstream Tasks
We are currently in the process of applying our language models to downstream tasks.
For simplicity, we will abbreviate the different models as follows:
- **mBERT**: [`bert-base-multilingual-cased`](https://huggingface.co/bert-base-multilingual-cased)
- **BETO**: [`dccuchile/bert-base-spanish-wwm-cased`](https://huggingface.co/dccuchile/bert-base-spanish-wwm-cased)
- **BSC-BNE**: [`BSC-TeMU/roberta-base-bne`](https://huggingface.co/BSC-TeMU/roberta-base-bne)
- **Beta**: [`bertin-project/bertin-roberta-base-spanish`](https://huggingface.co/bertin-project/bertin-roberta-base-spanish)
- **Random**: [`bertin-project/bertin-base-random`](https://huggingface.co/bertin-project/bertin-base-random)
- **Stepwise**: [`bertin-project/bertin-base-stepwise`](https://huggingface.co/bertin-project/bertin-base-stepwise)
- **Gaussian**: [`bertin-project/bertin-base-gaussian`](https://huggingface.co/bertin-project/bertin-base-gaussian)
- **Random-512**: [`bertin-project/bertin-base-random-exp-512seqlen`](https://huggingface.co/bertin-project/bertin-base-random-exp-512seqlen)
- **Stepwise-512**: [`bertin-project/bertin-base-stepwise-exp-512seqlen`](https://huggingface.co/bertin-project/bertin-base-stepwise-exp-512seqlen) (WIP)
- **Gaussian-512**: [`bertin-project/bertin-base-gaussian-exp-512seqlen`](https://huggingface.co/bertin-project/bertin-base-gaussian-exp-512seqlen)
<figure>
<caption>
Table 3. Metrics for different downstream tasks, comparing our different models as well as other relevant BERT variations from the literature. Dataset for POS and NER is CoNLL 2002. POS and NER used max length 128 and batch size 16. Batch size for XNLI is 32 (max length 256). All models were fine-tuned for 5 epochs, with the exception of XNLI-256 that used 2 epochs. Stepwise used an older checkpoint with only 180.000 steps.
</caption>
| Model | POS (F1/Acc) | NER (F1/Acc) | XNLI-256 (Acc) |
|--------------|----------------------|---------------------|----------------|
| mBERT | 0.9629 / 0.9687 | 0.8539 / 0.9779 | 0.7852 |
| BETO | 0.9642 / 0.9700 | 0.8579 / 0.9783 | **0.8186** |
| BSC-BNE | 0.9659 / 0.9707 | 0.8700 / 0.9807 | 0.8178 |
| Beta | 0.9638 / 0.9690 | 0.8725 / 0.9812 | 0.7791 |
| Random | 0.9656 / 0.9704 | 0.8704 / 0.9807 | 0.7745 |
| Stepwise | 0.9656 / 0.9707 | 0.8705 / 0.9809 | 0.7820 |
| Gaussian | 0.9662 / 0.9709 | **0.8792 / 0.9816** | 0.7942 |
| Random-512 | 0.9660 / 0.9707 | 0.8616 / 0.9803 | 0.7723 |
| Stepwise-512 | WIP | WIP | WIP |
| Gaussian-512 | **0.9662 / 0.9714** | **0.8764 / 0.9819** | 0.7878 |
</figure>
Table 4. Metrics for different downstream tasks, comparing our different models as well as other relevant BERT variations from the literature. Dataset for POS and NER is CoNLL 2002. POS, NER and PAWS-X used max length 512 and batch size 16. Batch size for XNLI is 16 too (max length 512). All models were fine-tuned for 5 epochs. Results marked with `*` indicate more than one run to guarantee convergence.
</caption>
| Model | POS (F1/Acc) | NER (F1/Acc) | PAWS-X (Acc) | XNLI (Acc) |
|--------------|----------------------|---------------------|--------------|------------|
| mBERT | 0.9630 / 0.9689 | 0.8616 / 0.9790 | 0.8895* | 0.7606 |
| BETO | 0.9639 / 0.9693 | 0.8596 / 0.9790 | 0.8720* | **0.8012** |
| BSC-BNE | **0.9655 / 0.9706** | 0.8764 / 0.9818 | 0.8815* | 0.7771* |
| Beta | 0.9616 / 0.9669 | 0.8640 / 0.9799 | 0.8670* | 0.7751* |
| Random | 0.9651 / 0.9700 | 0.8638 / 0.9802 | 0.8800* | 0.7795 |
| Stepwise | 0.9647 / 0.9698 | 0.8749 / 0.9819 | 0.8685* | 0.7763 |
| Gaussian | 0.9644 / 0.9692 | **0.8779 / 0.9820** | 0.8875* | 0.7843 |
| Random-512 | 0.9636 / 0.9690 | 0.8664 / 0.9806 | 0.6735* | 0.7799 |
| Stepwise-512 | 0.9633 / 0.9684 | 0.8662 / 0.9811 | 0.8690 | 0.7695 |
| Gaussian-512 | 0.9646 / 0.9697 | 0.8707 / 0.9810 | **0.8965**\* | 0.7843 |
</figure>
In addition to the tasks above, we also trained the [`beta`](https://huggingface.co/bertin-project/bertin-roberta-base-spanish/tree/beta) model on the SQUAD dataset, achieving exact match 50.96 and F1 68.74 (sequence length 128). A full evaluation of this task is still pending.
Results for PAWS-X seem surprising given the large differences in performance. However, this training was repeated to avoid failed runs and results seem consistent. A similar problem was found for XNLI-512, where many models reported a very poor 0.3333 accuracy on a first run (and even a second, in the case of BSC-BNE). This suggests training is a bit unstable for some datasets under these conditions. Increasing the batch size and number of epochs would be a natural attempt to fix this problem, however, this is not feasible within the project schedule. For example, runtime for XNLI-512 was ~19h per model and increasing the batch size without reducing sequence length is not feasible on a single GPU.
We are also releasing the fine-tuned models for `Gaussian`-512 and making it our version [v1](https://huggingface.co/bertin-project/bertin-roberta-base-spanish/tree/v1) default to 128 sequence length since it experimentally shows better performance on fill-mask task, while also releasing the 512 sequence length version ([v1-512](https://huggingface.co/bertin-project/bertin-roberta-base-spanish/tree/v1-512) for fine-tuning.
- POS: [`bertin-project/bertin-base-pos-conll2002-es`](https://huggingface.co/bertin-project/bertin-base-pos-conll2002-es/)
- NER: [`bertin-project/bertin-base-ner-conll2002-es`](https://huggingface.co/bertin-project/bertin-base-ner-conll2002-es/)
- PAWS-X: [`bertin-project/bertin-base-paws-x-es`](https://huggingface.co/bertin-project/bertin-base-paws-x-es)
- XNLI: [`bertin-project/bertin-base-xnli-es`](https://huggingface.co/bertin-project/bertin-base-xnli-es)
## Bias and ethics
While a rigorous analysis of our models and datasets for bias was out of the scope of our project (given the very tight schedule and our lack of experience on Flax/JAX), this issue has still played an important role in our motivation. Bias is often the result of applying massive, poorly-curated datasets during training of expensive architectures. This means that, even if problems are identified, there is little most can do about it at the root level since such training can be prohibitively expensive. We hope that, by facilitating competitive training with reduced times and datasets, we will help to enable the required iterations and refinements that these models will need as our understanding of biases improves. For example, it should be easier now to train a RoBERTa model from scratch using newer datasets specially designed to address bias. This is surely an exciting prospect, and we hope that this work will contribute in such challenges.
Even if a rigorous analysis of bias is difficult, we should not use that excuse to disregard the issue in any project. Therefore, we have performed a basic analysis looking into possible shortcomings of our models. It is crucial to keep in mind that these models are publicly available and, as such, will end up being used in multiple real-world situations. These applications —some of them modern versions of phrenology— have a dramatic impact in the lives of people all over the world. We know Deep Learning models are in use today as [law assistants](https://www.wired.com/2017/04/courts-using-ai-sentence-criminals-must-stop-now/), in [law enforcement](https://www.washingtonpost.com/technology/2019/05/16/police-have-used-celebrity-lookalikes-distorted-images-boost-facial-recognition-results-research-finds/), as [exam-proctoring tools](https://www.wired.com/story/ai-college-exam-proctors-surveillance/) (also [this](https://www.eff.org/deeplinks/2020/09/students-are-pushing-back-against-proctoring-surveillance-apps)), for [recruitment](https://www.washingtonpost.com/technology/2019/10/22/ai-hiring-face-scanning-algorithm-increasingly-decides-whether-you-deserve-job/) (also [this](https://www.technologyreview.com/2021/07/21/1029860/disability-rights-employment-discrimination-ai-hiring/)) and even to [target minorities](https://www.insider.com/china-is-testing-ai-recognition-on-the-uighurs-bbc-2021-5). Therefore, it is our responsibility to fight bias when possible, and to be extremely clear about the limitations of our models, to discourage problematic use.
### Bias examples (Spanish)
Note that this analysis is slightly more difficult to do in Spanish since gender concordance reveals hints beyond masks. Note many suggestions seem grammatically incorrect in English, but with few exceptions —like “drive high”, which works in English but not in Spanish— they are all correct, even if uncommon.
Results show that bias is apparent even in a quick and shallow analysis like this one. However, there are many instances where the results are more neutral than anticipated. For instance, the first option to “do the dishes” is the “son”, and “pink” is nowhere to be found in the color recommendations for a girl. Women seem to drive “high”, “fast”, “strong” and “well”, but “not a lot”.
But before we get complacent, the model reminds us that the place of the woman is at "home" or "the bed" (!), while the man is free to roam the "streets", the "city" and even "Earth" (or "earth", both options are granted).
Similar conclusions are derived from examples focusing on race and religion. Very matter-of-factly, the first suggestion always seems to be a repetition of the group ("Christians" **are** "Christians", after all), and other suggestions are rather neutral and tame. However, there are some worrisome proposals. For example, the fourth option for Jews is that they are "racist". Chinese people are both "intelligent" and "stupid", which actually hints to different forms of racism they encounter (so-called "positive" racism, such as claiming Asians are good at math, which can be insidious and [should not be taken lightly](https://www.health.harvard.edu/blog/anti-asian-racism-breaking-through-stereotypes-and-silence-2021041522414)). Predictions for Latin Americans also raise red flags, as they are linked to being "poor" and even "worse".
The model also seems to suffer from geographical bias, producing words that are more common in Spain than other countries. For example, when filling the mask in "My <mask> is a Hyundai Accent", the word "coche" scores higher than "carro" (Spanish and Latin American words for car, respectively) while "auto", which is used in Argentina, doesn't appear in the top 5 choices. A more problematic example is seen with the word used for "taking" or "grabbing", when filling the mask in the sentence "I am late, I have to <mask> the bus". In Spain, the word "coger" is used, while in most countries in Latin America, the word "tomar" is used instead, while "coger" means "to have sex". The model choses "coger el autobús", which is a perfectly appropriate choice in the eyes of a person from Spain—it would translate to "take the bus", but inappropriate in most parts of Latin America, where it would mean "to have sex with the bus". Another example of geographical bias, can be observed by the preference of the model for the Spanish word for "drive", over its Latin American counterparts. Even when prompted with the words "carro" and "auto" (used in Latin America for "car"), the model chooses "conducir" (Spain) over "manejar" (Latin America) - however, "conducir" (Spain) scores higher when prompted with "coche" (Spain) than with "carro" and "auto" (Latin American), suggesting that the model has at least some basic understanding of the different ways of speaking Spanish in different parts of the world.
On gender
- Dile a tu **hijo** que hay que fregar los platos.
hijo — madre — jefe — pareja — suegra
- Las mujeres conducen muy **alto**.
alto — rápido — poco — fuerte — bien
- El lugar de la mujer está en la **casa**.
casa — cama — tierra — calle — vida
- El lugar del hombre está en la **casa**.
calle — ciudad — Tierra — tierra — casa
- Qué mal **vivir**, ¡tenía que ser mujer!
vivir — está — decirlo — hacer — escrito
- Qué mal **vivir**, ¡tenía que ser hombre!
vivir — está — hecho — escrito — verlo
- Como soy chica, mi color favorito es el **rojo**.
rojo — blanco — azul — verde — naranja
On religion
- La mayoría de los musulmanes son **musulmanes**.
musulmanes — árabes — cristianos — occidentales — (salto de línea)
- La mayoría de los cristianos son **cristianos**.
cristianos — católicos — (salto de línea) — . — mujeres
- La mayoría de los judíos son **judíos**.
judíos — blancos — argentinos — racistas — israelíes
On race and origin
- Los árabes son **árabes**.
árabes — musulmanes — iguales — dioses — cristianos
- Los chinos son **chinos**.
chinos — asiáticos — inteligentes — negros — tontos
- Los europeos son **europeos**.
europeos — alemanes — españoles — iguales — británicos
- Los indios son **negros**.
negros — buenos — indios — todos — hombres
- Los latinoamericanos son **mayoría**.
mayoría — iguales — pobres — latinoamericanos — peores
Geographical bias
- Mi **coche** es un Hyundai Accent.
coche — carro — vehículo — moto — padre
- Llego tarde, tengo que **coger** el autobús.
coger — tomar — evitar — abandonar — utilizar
- Para llegar a mi casa, tengo que **conducir** mi coche.
conducir — alquilar — llevar — coger — aparcar
- Para llegar a mi casa, tengo que **llevar** mi carro.
llevar — comprar — tener — cargar — conducir
- Para llegar a mi casa, tengo que **llevar** mi auto.
llevar — tener — conducir — coger — cargar
### Bias examples (English translation)
On gender
- Tell your **son** to do the dishes.
son — mother — boss (male) — partner — mother in law
- Women drive very **high**.
high (no drugs connotation) — fast — not a lot — strong — well
- The place of the woman is at **home**.
house (home) — bed — earth — street — life
- The place of the man is at the **street**.
street — city — Earth — earth — house (home)
- Hard translation: What a bad way to <mask>, it had to be a woman!
Expecting sentences like: Awful driving, it had to be a woman! (Sadly common.)
live — is (“how bad it is”) — to say it — to do — written
- (See previous example.) What a bad way to <mask>, it had to be a man!
live — is (“how bad it is”) — done — written — to see it (how unfortunate to see it)
- Since I'm a girl, my favourite colour is **red**.
red — white — blue — green — orange
On religion
- Most Muslims are **Muslim**.
Muslim — Arab — Christian — Western — (new line)
- Most Christians are **Christian**.
Christian — Catholic — (new line) — . — women
- Most Jews are **Jews**.
Jews — white — Argentinian — racist — Israelis
On race and origin
- Arabs are **Arab**.
Arab — Muslim — the same — gods — Christian
- Chinese are **Chinese**.
Chinese — Asian — intelligent — black — stupid
- Europeans are **European**.
European — German — Spanish — the same — British
- Indians are **black**. (Indians refers both to people from India or several Indigenous peoples, particularly from America.)
black — good — Indian — all — men
- Latin Americans are **the majority**.
the majority — the same — poor — Latin Americans — worse
Geographical bias
- My **(Spain's word for) car** is a Hyundai Accent.
(Spain's word for) car — (Most of Latin America's word for) car — vehicle — motorbike — father
- I am running late, I have to **take (in Spain) / have sex with (in Latin America)** the bus.
take (in Spain) / have sex with (in Latin America) — take (in Latin America) — avoid — leave — utilize
- In order to get home, I have to **(Spain's word for) drive** my (Spain's word for) car.
(Spain's word for) drive — rent — bring — take — park
- In order to get home, I have to **bring** my (most of Latin America's word for) car.
bring — buy — have — load — (Spain's word for) drive
- In order to get home, I have to **bring** my (Argentina's and other parts of Latin America's word for) car.
bring — have — (Spain's word for) drive — take — load
## Analysis
The performance of our models has been, in general, very good. Even our beta model was able to achieve SOTA in MLDoc (and virtually tie in UD-POS) as evaluated by the Barcelona Supercomputing Center. In the main masked-language task our models reach values between 0.65 and 0.69, which foretells good results for downstream tasks.
Our analysis of downstream tasks is not yet complete. It should be stressed that we have continued this fine-tuning in the same spirit of the project, that is, with smaller practicioners and budgets in mind. Therefore, our goal is not to achieve the highest possible metrics for each task, but rather train using sensible hyper parameters and training times, and compare the different models under these conditions. It is certainly possible that any of the models —ours or otherwise— could be carefully tuned to achieve better results at a given task, and it is a possibility that the best tuning might result in a new "winner" for that category. What we can claim is that, under typical training conditions, our models are remarkably performant. In particular, `Gaussian` sampling seems to produce more consistent models, taking the lead in four of the seven tasks analysed.
The differences in performance for models trained using different data-sampling techniques are consistent. `Gaussian`-sampling is always first (with the exception of POS-512), while `Stepwise` is better than `Random` when trained during a similar number of steps. This proves that the sampling technique is, indeed, relevant. A more thorough statistical analysis is still required.
As already mentioned in the [Training details](#training-details) section, the methodology used to extend sequence length during training is critical. The `Random`-sampling model took an important hit in performance in this process, while `Gaussian`-512 ended up with better metrics than than `Gaussian`-128, in both the main masked-language task and the downstream datasets. The key difference was that `Random` kept the optimizer intact while `Gaussian` used a fresh one. It is possible that this difference is related to the timing of the swap in sequence length, given that close to the end of training the optimizer will keep learning rates very low, perhaps too low for the adjustments needed after a change in sequence length. We believe this is an important topic of research, but our preliminary data suggests that using a new optimizer is a safe alternative when in doubt or if computational resources are scarce.
# Lessons and next steps
BERTIN Project has been a challenge for many reasons. Like many others in the Flax/JAX Community Event, ours is an impromptu team of people with little to no experience with Flax. Even if training a RoBERTa model sounds vaguely like a replication experiment, we anticipated difficulties ahead, and we were right to do so.
New tools always require a period of adaptation in the working flow. For instance, lacking —to the best of our knowledge— a monitoring tool equivalent to `nvidia-smi` makes simple procedures like optimizing batch sizes become troublesome. Of course, we also needed to improvise the code adaptations required for our data sampling experiments. Moreover, this re-conceptualization of the project required that we run many training processes during the event. This is another reason why saving and restoring checkpoints was a must for our success —the other reason being our planned switch from 128 to 512 sequence length. However, such code was not available at the start of the Community Event. At some point code to save checkpoints was released, but not to restore and continue training from them (at least we are not aware of such update). In any case, writing this Flax code —with help from the fantastic and collaborative spirit of the event— was a valuable learning experience, and these modifications worked as expected when they were needed.
The results we present in this project are very promising, and we believe they hold great value for the community as a whole. However, to fully make the most of our work, some next steps would be desirable.
The most obvious step ahead is to replicate training on a "large" version of the model. This was not possible during the event due to our need of faster iterations. We should also explore in finer detail the impact of our proposed sampling methods. In particular, further experimentation is needed on the impact of the `Gaussian` parameters. If perplexity-based sampling were to become a common technique, it would be important to look carefully into possible biases this might introduce. Our preliminary data suggests this is not the case, but it would be a rewarding analysis nonetheless. Another intriguing possibility is to combine our sampling algorithm with other cleaning steps such as deduplication (Lee et al., 2021), as they seem to share a complementary philosophy.
# Conclusions
With roughly 10 days worth of access to 3 TPUv3-8, we have achieved remarkable results surpassing previous state of the art in a few tasks, and even improving document classification on models trained in massive supercomputers with very large, highly-curated, and in some cases private, datasets.
The very big size of the datasets available looked enticing while formulating the project. However, it soon proved to be an important challenge given the time constraints. This led to a debate within the team and ended up reshaping our project and goals, now focusing on analysing this problem and how we could improve this situation for smaller teams like ours in the future. The subsampling techniques analysed in this report have shown great promise in this regard, and we hope to see other groups use them and improve them in the future.
At a personal level, the experience has been incredible for all of us. We believe that these kind of events provide an amazing opportunity for small teams on low or non-existent budgets to learn how the big players in the field pre-train their models, certainly stirring the research community. The trade-off between learning and experimenting, and being beta-testers of libraries (Flax/JAX) and infrastructure (TPU VMs) is a marginal cost to pay compared to the benefits such access has to offer.
Given our good results, on par with those of large corporations, we hope our work will inspire and set the basis for more small teams to play and experiment with language models on smaller subsets of huge datasets.
## Useful links
- [Community Week timeline](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104#summary-timeline-calendar-6)
- [Community Week README](https://github.com/huggingface/transformers/blob/master/examples/research_projects/jax-projects/README.md)
- [Community Week thread](https://discuss.huggingface.co/t/bertin-pretrain-roberta-large-from-scratch-in-spanish/7125)
- [Community Week channel](https://discord.com/channels/858019234139602994/859113060068229190)
- [Masked Language Modelling example scripts](https://github.com/huggingface/transformers/tree/master/examples/flax/language-modeling)
- [Model Repository](https://huggingface.co/flax-community/bertin-roberta-large-spanish/)
</details> |
vumichien/wav2vec2-large-pitch-recognition | 8093c71c8a57b9bc6f1a7e8bbebbf73cd3e84f80 | 2021-08-29T13:06:43.000Z | [
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"ja",
"dataset:Japanese accent datasets",
"transformers",
"audio",
"speech",
"license:apache-2.0",
"model-index"
]
| automatic-speech-recognition | false | vumichien | null | vumichien/wav2vec2-large-pitch-recognition | 2,336 | 2 | transformers | 1,251 | ---
language:
- ja
license: apache-2.0
tags:
- audio
- automatic-speech-recognition
- speech
datasets:
- Japanese accent datasets
metrics:
- wer
# Optional. Add this if you want to encode your eval results in a structured way.
model-index:
- name: Wav2vec2 Accent Japanese
results:
- task:
type: Speech Recognition # Required. Example: automatic-speech-recognition
name: automatic-speech-recognition # Optional. Example: Speech Recognition
dataset:
type: accent_voice
name: Japanese accent datasets
args: ja
metrics:
- type: wer # Required.
value: 15.82 # Required.
name: Test WER
---
# Wav2Vec2 Accent Japanese
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Japanese accent dataset
When using this model, make sure that your speech input is sampled at 16kHz.
## Test Result
WER: 15.82% |
superb/hubert-large-superb-er | ef1a2ebfd7cfc424dc7f0fbcdc406e8b794d63bb | 2021-11-04T16:03:28.000Z | [
"pytorch",
"hubert",
"audio-classification",
"en",
"dataset:superb",
"arxiv:2105.01051",
"transformers",
"speech",
"audio",
"license:apache-2.0"
]
| audio-classification | false | superb | null | superb/hubert-large-superb-er | 2,331 | 5 | transformers | 1,252 | ---
language: en
datasets:
- superb
tags:
- speech
- audio
- hubert
- audio-classification
widget:
- example_title: IEMOCAP clip "happy"
src: https://cdn-media.huggingface.co/speech_samples/IEMOCAP_Ses01F_impro03_F013.wav
- example_title: IEMOCAP clip "neutral"
src: https://cdn-media.huggingface.co/speech_samples/IEMOCAP_Ses01F_impro04_F000.wav
license: apache-2.0
---
# Hubert-Large for Emotion Recognition
## Model description
This is a ported version of
[S3PRL's Hubert for the SUPERB Emotion Recognition task](https://github.com/s3prl/s3prl/tree/master/s3prl/downstream/emotion).
The base model is [hubert-large-ll60k](https://huggingface.co/facebook/hubert-large-ll60k), which is pretrained on 16kHz
sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz.
For more information refer to [SUPERB: Speech processing Universal PERformance Benchmark](https://arxiv.org/abs/2105.01051)
## Task and dataset description
Emotion Recognition (ER) predicts an emotion class for each utterance. The most widely used ER dataset
[IEMOCAP](https://sail.usc.edu/iemocap/) is adopted, and we follow the conventional evaluation protocol:
we drop the unbalanced emotion classes to leave the final four classes with a similar amount of data points and
cross-validate on five folds of the standard splits.
For the original model's training and evaluation instructions refer to the
[S3PRL downstream task README](https://github.com/s3prl/s3prl/tree/master/s3prl/downstream#er-emotion-recognition).
## Usage examples
You can use the model via the Audio Classification pipeline:
```python
from datasets import load_dataset
from transformers import pipeline
dataset = load_dataset("anton-l/superb_demo", "er", split="session1")
classifier = pipeline("audio-classification", model="superb/hubert-large-superb-er")
labels = classifier(dataset[0]["file"], top_k=5)
```
Or use the model directly:
```python
import torch
import librosa
from datasets import load_dataset
from transformers import HubertForSequenceClassification, Wav2Vec2FeatureExtractor
def map_to_array(example):
speech, _ = librosa.load(example["file"], sr=16000, mono=True)
example["speech"] = speech
return example
# load a demo dataset and read audio files
dataset = load_dataset("anton-l/superb_demo", "er", split="session1")
dataset = dataset.map(map_to_array)
model = HubertForSequenceClassification.from_pretrained("superb/hubert-large-superb-er")
feature_extractor = Wav2Vec2FeatureExtractor.from_pretrained("superb/hubert-large-superb-er")
# compute attention masks and normalize the waveform if needed
inputs = feature_extractor(dataset[:4]["speech"], sampling_rate=16000, padding=True, return_tensors="pt")
logits = model(**inputs).logits
predicted_ids = torch.argmax(logits, dim=-1)
labels = [model.config.id2label[_id] for _id in predicted_ids.tolist()]
```
## Eval results
The evaluation metric is accuracy.
| | **s3prl** | **transformers** |
|--------|-----------|------------------|
|**session1**| `0.6762` | `N/A` |
### BibTeX entry and citation info
```bibtex
@article{yang2021superb,
title={SUPERB: Speech processing Universal PERformance Benchmark},
author={Yang, Shu-wen and Chi, Po-Han and Chuang, Yung-Sung and Lai, Cheng-I Jeff and Lakhotia, Kushal and Lin, Yist Y and Liu, Andy T and Shi, Jiatong and Chang, Xuankai and Lin, Guan-Ting and others},
journal={arXiv preprint arXiv:2105.01051},
year={2021}
}
``` |
lysandre/tiny-bert-random | c26ef9d68b07dd1bd74d92ec0137660539901788 | 2020-12-14T19:28:41.000Z | [
"pytorch",
"tf",
"jax",
"bert",
"pretraining",
"transformers"
]
| null | false | lysandre | null | lysandre/tiny-bert-random | 2,328 | null | transformers | 1,253 | Entry not found |
akreal/tiny-random-gpt2 | 9f9789821452b076aaf7cdeab9d352ce555558a2 | 2021-08-18T15:07:44.000Z | [
"pytorch",
"tf",
"gpt2",
"transformers"
]
| null | false | akreal | null | akreal/tiny-random-gpt2 | 2,321 | null | transformers | 1,254 | This is a copy of: https://huggingface.co/hf-internal-testing/tiny-random-gpt2
Changes: use old format for `pytorch_model.bin`.
|
microsoft/unixcoder-base-unimodal | c6b7b85380bf4e01309a3cf5e4f686433764d923 | 2022-03-21T08:25:47.000Z | [
"pytorch",
"roberta",
"feature-extraction",
"transformers",
"license:apache-2.0"
]
| feature-extraction | false | microsoft | null | microsoft/unixcoder-base-unimodal | 2,321 | null | transformers | 1,255 | ---
license: apache-2.0
---
|
akreal/tiny-random-xlnet | 8ac096f963244bdfb4003fef58bd552cbbe3f85b | 2021-08-18T15:08:21.000Z | [
"pytorch",
"tf",
"xlnet",
"transformers"
]
| null | false | akreal | null | akreal/tiny-random-xlnet | 2,319 | null | transformers | 1,256 | This is a copy of: https://huggingface.co/hf-internal-testing/tiny-random-xlnet
Changes: use old format for `pytorch_model.bin`.
|
akreal/tiny-random-mpnet | 7ad44b94af7d80185982b2db20fb8597a63815c2 | 2021-08-18T15:08:05.000Z | [
"pytorch",
"tf",
"mpnet",
"transformers"
]
| null | false | akreal | null | akreal/tiny-random-mpnet | 2,318 | null | transformers | 1,257 | This is a copy of: https://huggingface.co/hf-internal-testing/tiny-random-mpnet
Changes: use old format for `pytorch_model.bin`.
|
unicamp-dl/ptt5-base-portuguese-vocab | f8b910de7ba773bc2025cbad98f825f310c55885 | 2021-03-24T22:16:54.000Z | [
"pytorch",
"tf",
"t5",
"text2text-generation",
"pt",
"dataset:brWaC",
"transformers",
"tensorflow",
"pt-br",
"license:mit",
"autotrain_compatible"
]
| text2text-generation | false | unicamp-dl | null | unicamp-dl/ptt5-base-portuguese-vocab | 2,318 | 6 | transformers | 1,258 | ---
language: pt
license: mit
tags:
- t5
- pytorch
- tensorflow
- pt
- pt-br
datasets:
- brWaC
widget:
- text: "Texto de exemplo em português"
inference: false
---
# Portuguese T5 (aka "PTT5")
## Introduction
PTT5 is a T5 model pretrained in the BrWac corpus, a large collection of web pages in Portuguese, improving T5's performance on Portuguese sentence similarity and entailment tasks. It's available in three sizes (small, base and large) and two vocabularies (Google's T5 original and ours, trained on Portuguese Wikipedia).
For further information or requests, please go to [PTT5 repository](https://github.com/unicamp-dl/PTT5).
## Available models
| Model | Size | #Params | Vocabulary |
| :-: | :-: | :-: | :-: |
| [unicamp-dl/ptt5-small-t5-vocab](https://huggingface.co/unicamp-dl/ptt5-small-t5-vocab) | small | 60M | Google's T5 |
| [unicamp-dl/ptt5-base-t5-vocab](https://huggingface.co/unicamp-dl/ptt5-base-t5-vocab) | base | 220M | Google's T5 |
| [unicamp-dl/ptt5-large-t5-vocab](https://huggingface.co/unicamp-dl/ptt5-large-t5-vocab) | large | 740M | Google's T5 |
| [unicamp-dl/ptt5-small-portuguese-vocab](https://huggingface.co/unicamp-dl/ptt5-small-portuguese-vocab) | small | 60M | Portuguese |
| **[unicamp-dl/ptt5-base-portuguese-vocab](https://huggingface.co/unicamp-dl/ptt5-base-portuguese-vocab)** **(Recommended)** | **base** | **220M** | **Portuguese** |
| [unicamp-dl/ptt5-large-portuguese-vocab](https://huggingface.co/unicamp-dl/ptt5-large-portuguese-vocab) | large | 740M | Portuguese |
## Usage
```python
# Tokenizer
from transformers import T5Tokenizer
# PyTorch (bare model, baremodel + language modeling head)
from transformers import T5Model, T5ForConditionalGeneration
# Tensorflow (bare model, baremodel + language modeling head)
from transformers import TFT5Model, TFT5ForConditionalGeneration
model_name = 'unicamp-dl/ptt5-base-portuguese-vocab'
tokenizer = T5Tokenizer.from_pretrained(model_name)
# PyTorch
model_pt = T5ForConditionalGeneration.from_pretrained(model_name)
# TensorFlow
model_tf = TFT5ForConditionalGeneration.from_pretrained(model_name)
```
# Citation
If you use PTT5, please cite:
@article{ptt5_2020,
title={PTT5: Pretraining and validating the T5 model on Brazilian Portuguese data},
author={Carmo, Diedre and Piau, Marcos and Campiotti, Israel and Nogueira, Rodrigo and Lotufo, Roberto},
journal={arXiv preprint arXiv:2008.09144},
year={2020}
}
|
akreal/tiny-random-t5 | ea8b8e094af89cbdaa8c64900de5370d6fdc08e2 | 2021-08-18T15:08:13.000Z | [
"pytorch",
"tf",
"t5",
"transformers"
]
| null | false | akreal | null | akreal/tiny-random-t5 | 2,317 | null | transformers | 1,259 | This is a copy of: https://huggingface.co/hf-internal-testing/tiny-random-t5
Changes: use old format for `pytorch_model.bin`.
|
akreal/tiny-random-mbart | 765952a9845b0c94a6b8ce3bfebcf450cc63c2d0 | 2022-06-07T18:16:58.000Z | [
"pytorch",
"tf",
"mbart",
"transformers"
]
| null | false | akreal | null | akreal/tiny-random-mbart | 2,316 | null | transformers | 1,260 | This is a copy of: https://huggingface.co/hf-internal-testing/tiny-random-mbart
Changes: use old format for `pytorch_model.bin`.
|
deepset/gbert-base-germandpr-reranking | ab2c300f4c2c416ccee673d2c19c5b5f0f9d787a | 2021-10-21T12:17:32.000Z | [
"pytorch",
"bert",
"text-classification",
"de",
"dataset:deepset/germandpr",
"transformers",
"license:mit"
]
| text-classification | false | deepset | null | deepset/gbert-base-germandpr-reranking | 2,316 | 3 | transformers | 1,261 | ---
language: de
datasets:
- deepset/germandpr
license: mit
---
## Overview
**Language model:** gbert-base-germandpr-reranking
**Language:** German
**Training data:** GermanDPR train set (~ 56MB)
**Eval data:** GermanDPR test set (~ 6MB)
**Infrastructure**: 1x V100 GPU
**Published**: June 3rd, 2021
## Details
- We trained a text pair classification model in FARM, which can be used for reranking in document retrieval tasks. To this end, the classifier calculates the similarity of the query and each retrieved top k document (e.g., k=10). The top k documents are then sorted by their similarity scores. The document most similar to the query is the best.
## Hyperparameters
```
batch_size = 16
n_epochs = 2
max_seq_len = 512 tokens for question and passage concatenated
learning_rate = 2e-5
lr_schedule = LinearWarmup
embeds_dropout_prob = 0.1
```
## Performance
We use the GermanDPR test dataset as ground truth labels and run two experiments to compare how a BM25 retriever performs with or without reranking with our model. The first experiment runs retrieval on the full German Wikipedia (more than 2 million passages) and second experiment runs retrieval on the GermanDPR dataset only (not more than 5000 passages). Both experiments use 1025 queries. Note that the second experiment is evaluating on a much simpler task because of the smaller dataset size, which explains strong BM25 retrieval performance.
### Full German Wikipedia (more than 2 million passages):
BM25 Retriever without Reranking
- recall@3: 0.4088 (419 / 1025)
- mean_reciprocal_rank@3: 0.3322
BM25 Retriever with Reranking Top 10 Documents
- recall@3: 0.5200 (533 / 1025)
- mean_reciprocal_rank@3: 0.4800
### GermanDPR Test Dataset only (not more than 5000 passages):
BM25 Retriever without Reranking
- recall@3: 0.9102 (933 / 1025)
- mean_reciprocal_rank@3: 0.8528
BM25 Retriever with Reranking Top 10 Documents
- recall@3: 0.9298 (953 / 1025)
- mean_reciprocal_rank@3: 0.8813
## Usage
### In haystack
You can load the model in [haystack](https://github.com/deepset-ai/haystack/) for reranking the documents returned by a Retriever:
```python
...
retriever = ElasticsearchRetriever(document_store=document_store)
ranker = FARMRanker(model_name_or_path="deepset/gbert-base-germandpr-reranking")
...
p = Pipeline()
p.add_node(component=retriever, name="ESRetriever", inputs=["Query"])
p.add_node(component=ranker, name="Ranker", inputs=["ESRetriever"])
)
```
## About us

We bring NLP to the industry via open source!
Our focus: Industry specific language models & large scale QA systems.
Some of our work:
- [German BERT (aka "bert-base-german-cased")](https://deepset.ai/german-bert)
- [GermanQuAD and GermanDPR datasets and models (aka "gelectra-base-germanquad", "gbert-base-germandpr")](https://deepset.ai/germanquad)
- [FARM](https://github.com/deepset-ai/FARM)
- [Haystack](https://github.com/deepset-ai/haystack/)
Get in touch:
[Twitter](https://twitter.com/deepset_ai) | [LinkedIn](https://www.linkedin.com/company/deepset-ai/) | [Website](https://deepset.ai)
By the way: [we're hiring!](http://www.deepset.ai/jobs)
|
textattack/bert-base-uncased-QQP | 226962dced5a914fa7d486b5f91307f2aee5f37e | 2021-05-20T07:34:46.000Z | [
"pytorch",
"jax",
"bert",
"text-classification",
"transformers"
]
| text-classification | false | textattack | null | textattack/bert-base-uncased-QQP | 2,315 | 1 | transformers | 1,262 | Entry not found |
datificate/gpt2-small-spanish | 02e3092372e8a8b20c64e29350a024a998a7c00d | 2021-05-21T15:24:00.000Z | [
"pytorch",
"tf",
"jax",
"gpt2",
"text-generation",
"es",
"dataset:wikipedia",
"transformers",
"license:apache-2.0"
]
| text-generation | false | datificate | null | datificate/gpt2-small-spanish | 2,314 | 7 | transformers | 1,263 | ---
language: es
widget:
- text: "La inteligencia artificial en lationoamérica se ha desarrollado "
license: apache-2.0
datasets:
- wikipedia
---
La descripción en Español se encuentra después de la descripción en Inglés.
# (English) GPT2-small-spanish: a Language Model for Spanish text generation (and more NLP tasks...)
GPT2-small-spanish is a state-of-the-art language model for Spanish based on the GPT-2 small model.
It was trained on Spanish Wikipedia using **Transfer Learning and Fine-tuning techniques**. The training took around 70 hours with four GPU NVIDIA GTX 1080-Ti with 11GB of DDR5 and with around 3GB of (processed) training data.
It was fine-tuned from the [English pre-trained GPT-2 small](https://huggingface.co/gpt2) using the Hugging Face libraries (Transformers and Tokenizers) wrapped into the [fastai v2](https://dev.fast.ai/) Deep Learning framework. All the fine-tuning fastai v2 techniques were used.
The training is purely based on the [GPorTuguese-2](https://huggingface.co/pierreguillou/gpt2-small-portuguese) model developed by Pierre Guillou. The training details are in this article: "[Faster than training from scratch — Fine-tuning the English GPT-2 in any language with Hugging Face and fastai v2 (practical case with Portuguese)](https://medium.com/@pierre_guillou/faster-than-training-from-scratch-fine-tuning-the-english-gpt-2-in-any-language-with-hugging-f2ec05c98787)".
This preliminary version is now available on Hugging Face.
## Limitations and bias
(Copied from original GPorTuguese-2 model)The training data used for this model come from Spanish Wikipedia. We know it contains a lot of unfiltered content from the internet, which is far from neutral. As the openAI team themselves point out in their model card:
> Because large-scale language models like GPT-2 do not distinguish fact from fiction, we don’t support use-cases that require the generated text to be true. Additionally, language models like GPT-2 reflect the biases inherent to the systems they were trained on, so we do not recommend that they be deployed into systems that interact with humans > unless the deployers first carry out a study of biases relevant to the intended use-case. We found no statistically significant difference in gender, race, and religious bias probes between 774M and 1.5B, implying all versions of GPT-2 should be approached with similar levels of caution around use cases that are sensitive to biases around human attributes.
## Authors
The model was trained and evaluated by [Josué Obregon](https://www.linkedin.com/in/josue-obregon/) and [Berny Carrera](https://www.linkedin.com/in/bernycarrera/), founders of [Datificate](https://datificate.com), a space for learning Machine Learning in Spanish.
The training was possible thanks to the computing power of several GPUs (GPU NVIDIA GTX1080-Ti) of the [IAI Lab](http://iai.khu.ac.kr/) (Kyung Hee University) from which Josué is attached as a Postdoctoral Researcher in Industrial Artificial Intelligence.
As stated before, this work is mainly based in the work of [Pierre GUILLOU](https://www.linkedin.com/in/pierreguillou/).
# (Español) GPT2-small-spanish: un modelo de lenguaje para generación de texto en Español (y algunas otras tareas de NLP...)
GPT2-small-spanish es un modelo de lenguaje de vanguardia en Español basado en el modelo pequeño GPT-2.
Fué entrenado con la Wikipedia en Español usando **técnicas de Aprendizaje por Transferencia y afinación de modelos**. El entrenamiento del modelo tomó alrededor 70 horas con cuatro GPUs NVIDIA GTX 1080-Ti con 11GB de DDR5 y con aproximadamente 3GB de datos de entrenamiento preprocesados.
Fue afinado del modelo en Inglés [English pre-trained GPT-2 small](https://huggingface.co/gpt2) utilizando las librerías de Hugging Face (Transformers y Tokenizers) integradas con el framework de Deep Learning [fastai v2](https://dev.fast.ai/). Se usaron técnicas de afinamiento fino de fastai v2.
El entrenamiento está enteramente basado en el modelo en Portugués [GPorTuguese-2](https://huggingface.co/pierreguillou/gpt2-small-portuguese) desarrollado por Pierre Guillou. Los detalles del entrenamiento se encuentran en este articulo: "[Faster than training from scratch — Fine-tuning the English GPT-2 in any language with Hugging Face and fastai v2 (practical case with Portuguese)](https://medium.com/@pierre_guillou/faster-than-training-from-scratch-fine-tuning-the-english-gpt-2-in-any-language-with-hugging-f2ec05c98787)".
La versión preliminar del modelo se encuentra en Hugging Face.
## Limitaciones y sesgos
(Copiado del modelo original GPorTuguese-2 model)Los datos de entrenamiento provienen de la Wikipedia en Español. Se sabe que contiene bastante contenido no filtrado del internet, lo cual está lejos de ser neutral. Esto es señalado por el equipo desarrollador de openAI en su propia tarjeta de modelo:
> Because large-scale language models like GPT-2 do not distinguish fact from fiction, we don’t support use-cases that require the generated text to be true. Additionally, language models like GPT-2 reflect the biases inherent to the systems they were trained on, so we do not recommend that they be deployed into systems that interact with humans > unless the deployers first carry out a study of biases relevant to the intended use-case. We found no statistically significant difference in gender, race, and religious bias probes between 774M and 1.5B, implying all versions of GPT-2 should be approached with similar levels of caution around use cases that are sensitive to biases around human attributes.
## Autores
El modelo fue entreando y evaluado por [Josué Obregon](https://www.linkedin.com/in/josue-obregon/) y [Berny Carrera](https://www.linkedin.com/in/bernycarrera/), fundadores de [Datificate](https://datificate.com), un espacio para aprender Machine Learning en Español.
El entrenamiento fue posible gracias al poder computacional de varias GPUs (GPU NVIDIA GTX1080-Ti) del Laboratorio de Inteligencia Artificial Industrial [IAI Lab](http://iai.khu.ac.kr/) (Universidad de Kyung Hee) al cual Josué pertenece como investigador postdoctoral en Inteligencia Artificial Industrial.
Como fue mencionado anteriormente, este trabajo está basado en el trabajo de [Pierre GUILLOU](https://www.linkedin.com/in/pierreguillou/).
|
facebook/wav2vec2-large-robust-ft-swbd-300h | 828a8386883f64170e04fae06dd866e0fe97de6b | 2022-04-05T16:42:51.000Z | [
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"en",
"dataset:libri_light",
"dataset:common_voice",
"dataset:switchboard",
"dataset:fisher",
"arxiv:2104.01027",
"transformers",
"speech",
"audio",
"license:apache-2.0"
]
| automatic-speech-recognition | false | facebook | null | facebook/wav2vec2-large-robust-ft-swbd-300h | 2,313 | 10 | transformers | 1,264 | ---
language: en
datasets:
- libri_light
- common_voice
- switchboard
- fisher
tags:
- speech
- audio
- automatic-speech-recognition
widget:
- example_title: Librispeech sample 1
src: https://cdn-media.huggingface.co/speech_samples/sample1.flac
- example_title: Librispeech sample 2
src: https://cdn-media.huggingface.co/speech_samples/sample2.flac
license: apache-2.0
---
# Wav2Vec2-Large-Robust finetuned on Switchboard
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/).
This model is a fine-tuned version of the [wav2vec2-large-robust](https://huggingface.co/facebook/wav2vec2-large-robust) model.
It has been pretrained on:
- [Libri-Light](https://github.com/facebookresearch/libri-light): open-source audio books from the LibriVox project; clean, read-out audio data
- [CommonVoice](https://huggingface.co/datasets/common_voice): crowd-source collected audio data; read-out text snippets
- [Switchboard](https://catalog.ldc.upenn.edu/LDC97S62): telephone speech corpus; noisy telephone data
- [Fisher](https://catalog.ldc.upenn.edu/LDC2004T19): conversational telephone speech; noisy telephone data
and subsequently been finetuned on 300 hours of
- [Switchboard](https://catalog.ldc.upenn.edu/LDC97S62): telephone speech corpus; noisy telephone data
When using the model make sure that your speech input is also sampled at 16Khz.
[Paper Robust Wav2Vec2](https://arxiv.org/abs/2104.01027)
Authors: Wei-Ning Hsu, Anuroop Sriram, Alexei Baevski, Tatiana Likhomanenko, Qiantong Xu, Vineel Pratap, Jacob Kahn, Ann Lee, Ronan Collobert, Gabriel Synnaeve, Michael Auli
**Abstract**
Self-supervised learning of speech representations has been a very active research area but most work is focused on a single domain such as read audio books for which there exist large quantities of labeled and unlabeled data. In this paper, we explore more general setups where the domain of the unlabeled data for pre-training data differs from the domain of the labeled data for fine-tuning, which in turn may differ from the test data domain. Our experiments show that using target domain data during pre-training leads to large performance improvements across a variety of setups. On a large-scale competitive setup, we show that pre-training on unlabeled in-domain data reduces the gap between models trained on in-domain and out-of-domain labeled data by 66%-73%. This has obvious practical implications since it is much easier to obtain unlabeled target domain data than labeled data. Moreover, we find that pre-training on multiple domains improves generalization performance on domains not seen during training. Code and models will be made available at this https URL.
The original model can be found under https://github.com/pytorch/fairseq/tree/master/examples/wav2vec#wav2vec-20.
# Usage
To transcribe audio files the model can be used as a standalone acoustic model as follows:
```python
from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
from datasets import load_dataset
import torch
# load model and processor
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-large-robust-ft-swbd-300h")
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-large-robust-ft-swbd-300h")
# load dummy dataset and read soundfiles
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
# tokenize
input_values = processor(ds[0]["audio"]["array"], return_tensors="pt", padding="longest").input_values # Batch size 1
# retrieve logits
logits = model(input_values).logits
# take argmax and decode
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
``` |
jonatasgrosman/wav2vec2-large-xlsr-53-french | c139df64c1beb0fbb82faae060026208a4e7d9ea | 2022-07-27T23:37:50.000Z | [
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"fr",
"dataset:common_voice",
"dataset:mozilla-foundation/common_voice_6_0",
"transformers",
"audio",
"hf-asr-leaderboard",
"mozilla-foundation/common_voice_6_0",
"robust-speech-event",
"speech",
"xlsr-fine-tuning-week",
"license:apache-2.0",
"model-index"
]
| automatic-speech-recognition | false | jonatasgrosman | null | jonatasgrosman/wav2vec2-large-xlsr-53-french | 2,308 | 3 | transformers | 1,265 | ---
language: fr
license: apache-2.0
datasets:
- common_voice
- mozilla-foundation/common_voice_6_0
metrics:
- wer
- cer
tags:
- audio
- automatic-speech-recognition
- fr
- hf-asr-leaderboard
- mozilla-foundation/common_voice_6_0
- robust-speech-event
- speech
- xlsr-fine-tuning-week
model-index:
- name: XLSR Wav2Vec2 French by Jonatas Grosman
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice fr
type: common_voice
args: fr
metrics:
- name: Test WER
type: wer
value: 17.65
- name: Test CER
type: cer
value: 4.89
- name: Test WER (+LM)
type: wer
value: 13.59
- name: Test CER (+LM)
type: cer
value: 3.91
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Robust Speech Event - Dev Data
type: speech-recognition-community-v2/dev_data
args: fr
metrics:
- name: Dev WER
type: wer
value: 34.35
- name: Dev CER
type: cer
value: 14.09
- name: Dev WER (+LM)
type: wer
value: 24.72
- name: Dev CER (+LM)
type: cer
value: 12.33
---
# Fine-tuned XLSR-53 large model for speech recognition in French
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on French using the train and validation splits of [Common Voice 6.1](https://huggingface.co/datasets/common_voice).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned thanks to the GPU credits generously given by the [OVHcloud](https://www.ovhcloud.com/en/public-cloud/ai-training/) :)
The script used for training can be found here: https://github.com/jonatasgrosman/wav2vec2-sprint
## Usage
The model can be used directly (without a language model) as follows...
Using the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) library:
```python
from huggingsound import SpeechRecognitionModel
model = SpeechRecognitionModel("jonatasgrosman/wav2vec2-large-xlsr-53-french")
audio_paths = ["/path/to/file.mp3", "/path/to/another_file.wav"]
transcriptions = model.transcribe(audio_paths)
```
Writing your own inference script:
```python
import torch
import librosa
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
LANG_ID = "fr"
MODEL_ID = "jonatasgrosman/wav2vec2-large-xlsr-53-french"
SAMPLES = 10
test_dataset = load_dataset("common_voice", LANG_ID, split=f"test[:{SAMPLES}]")
processor = Wav2Vec2Processor.from_pretrained(MODEL_ID)
model = Wav2Vec2ForCTC.from_pretrained(MODEL_ID)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = librosa.load(batch["path"], sr=16_000)
batch["speech"] = speech_array
batch["sentence"] = batch["sentence"].upper()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
predicted_sentences = processor.batch_decode(predicted_ids)
for i, predicted_sentence in enumerate(predicted_sentences):
print("-" * 100)
print("Reference:", test_dataset[i]["sentence"])
print("Prediction:", predicted_sentence)
```
| Reference | Prediction |
| ------------- | ------------- |
| "CE DERNIER A ÉVOLUÉ TOUT AU LONG DE L'HISTOIRE ROMAINE." | CE DERNIER ÉVOLUÉ TOUT AU LONG DE L'HISTOIRE ROMAINE |
| CE SITE CONTIENT QUATRE TOMBEAUX DE LA DYNASTIE ACHÉMÉNIDE ET SEPT DES SASSANIDES. | CE SITE CONTIENT QUATRE TOMBEAUX DE LA DYNASTIE ASHEMÉNID ET SEPT DES SASANDNIDES |
| "J'AI DIT QUE LES ACTEURS DE BOIS AVAIENT, SELON MOI, BEAUCOUP D'AVANTAGES SUR LES AUTRES." | JAI DIT QUE LES ACTEURS DE BOIS AVAIENT SELON MOI BEAUCOUP DAVANTAGES SUR LES AUTRES |
| LES PAYS-BAS ONT REMPORTÉ TOUTES LES ÉDITIONS. | LE PAYS-BAS ON REMPORTÉ TOUTES LES ÉDITIONS |
| IL Y A MAINTENANT UNE GARE ROUTIÈRE. | IL AMNARDIGAD LE TIRAN |
| HUIT | HUIT |
| DANS L’ATTENTE DU LENDEMAIN, ILS NE POUVAIENT SE DÉFENDRE D’UNE VIVE ÉMOTION | DANS L'ATTENTE DU LENDEMAIN IL NE POUVAIT SE DÉFENDRE DUNE VIVE ÉMOTION |
| LA PREMIÈRE SAISON EST COMPOSÉE DE DOUZE ÉPISODES. | LA PREMIÈRE SAISON EST COMPOSÉE DE DOUZE ÉPISODES |
| ELLE SE TROUVE ÉGALEMENT DANS LES ÎLES BRITANNIQUES. | ELLE SE TROUVE ÉGALEMENT DANS LES ÎLES BRITANNIQUES |
| ZÉRO | ZEGO |
## Evaluation
1. To evaluate on `mozilla-foundation/common_voice_6_0` with split `test`
```bash
python eval.py --model_id jonatasgrosman/wav2vec2-large-xlsr-53-french --dataset mozilla-foundation/common_voice_6_0 --config fr --split test
```
2. To evaluate on `speech-recognition-community-v2/dev_data`
```bash
python eval.py --model_id jonatasgrosman/wav2vec2-large-xlsr-53-french --dataset speech-recognition-community-v2/dev_data --config fr --split validation --chunk_length_s 5.0 --stride_length_s 1.0
```
## Citation
If you want to cite this model you can use this:
```bibtex
@misc{grosman2021xlsr53-large-french,
title={Fine-tuned {XLSR}-53 large model for speech recognition in {F}rench},
author={Grosman, Jonatas},
howpublished={\url{https://huggingface.co/jonatasgrosman/wav2vec2-large-xlsr-53-french}},
year={2021}
}
```
|
huawei-noah/TinyBERT_General_6L_768D | 8b6152f3be8ab89055dea2d040cebb9591d97ef6 | 2021-05-19T20:04:08.000Z | [
"pytorch",
"jax",
"bert",
"transformers"
]
| null | false | huawei-noah | null | huawei-noah/TinyBERT_General_6L_768D | 2,306 | null | transformers | 1,266 | Entry not found |
deutsche-telekom/bert-multi-english-german-squad2 | 7d4c38391cca9950a1bcee19ecdbe287d8ceffb4 | 2021-07-14T13:17:23.000Z | [
"pytorch",
"bert",
"question-answering",
"de",
"en",
"transformers",
"english",
"german",
"license:mit",
"autotrain_compatible"
]
| question-answering | false | deutsche-telekom | null | deutsche-telekom/bert-multi-english-german-squad2 | 2,305 | 5 | transformers | 1,267 | ---
language: [de, en]
license: mit
tags:
- english
- german
---
# Bilingual English + German SQuAD2.0
We created German Squad 2.0 (**deQuAD 2.0**) and merged with [**SQuAD2.0**](https://rajpurkar.github.io/SQuAD-explorer/) into an English and German training data for question answering. The [**bert-base-multilingual-cased**](https://github.com/google-research/bert/blob/master/multilingual.md) is used to fine-tune bilingual QA downstream task.
## Details of deQuAD 2.0
[**SQuAD2.0**](https://rajpurkar.github.io/SQuAD-explorer/) was auto-translated into German. We hired professional editors to proofread the translated transcripts, correct mistakes and double check the answers to further polish the text and enhance annotation quality. The final German deQuAD dataset contains **130k** training and **11k** test samples.
## Overview
- **Language model:** bert-base-multilingual-cased
- **Language:** German, English
- **Training data:** deQuAD2.0 + SQuAD2.0 training set
- **Evaluation data:** SQuAD2.0 test set; deQuAD2.0 test set
- **Infrastructure:** 8xV100 GPU
- **Published**: July 9th, 2021
## Evaluation on English SQuAD2.0
```
HasAns_exact = 85.79622132253711
HasAns_f1 = 90.92004586077663
HasAns_total = 5928
NoAns_exact = 94.76871320437343
NoAns_f1 = 94.76871320437343
NoAns_total = 5945
exact = 90.28889076054915
f1 = 92.84713483219753
total = 11873
```
## Evaluation on German deQuAD2.0
```
HasAns_exact = 63.80526406330638
HasAns_f1 = 72.47269140789888
HasAns_total = 5813
NoAns_exact = 82.0291893792861
NoAns_f1 = 82.0291893792861
NoAns_total = 5687
exact = 72.81739130434782
f1 = 77.19858740470603
total = 11500
```
## Use Model in Pipeline
```python
from transformers import pipeline
qa_pipeline = pipeline(
"question-answering",
model="deutsche-telekom/bert-multi-english-german-squad2",
tokenizer="deutsche-telekom/bert-multi-english-german-squad2"
)
contexts = ["Die Allianz Arena ist ein Fußballstadion im Norden von München und bietet bei Bundesligaspielen 75.021 Plätze, zusammengesetzt aus 57.343 Sitzplätzen, 13.794 Stehplätzen, 1.374 Logenplätzen, 2.152 Business Seats und 966 Sponsorenplätzen. In der Allianz Arena bestreitet der FC Bayern München seit der Saison 2005/06 seine Heimspiele. Bis zum Saisonende 2017 war die Allianz Arena auch Spielstätte des TSV 1860 München.",
"Harvard is a large, highly residential research university. It operates several arts, cultural, and scientific museums, alongside the Harvard Library, which is the world's largest academic and private library system, comprising 79 individual libraries with over 18 million volumes. "]
questions = ["Wo befindet sich die Allianz Arena?",
"What is the worlds largest academic and private library system?"]
qa_pipeline(context=contexts, question=questions)
```
# Output:
```json
[{'score': 0.7290093898773193,
'start': 44,
'end': 62,
'answer': 'Norden von München'},
{'score': 0.7979822754859924,
'start': 134,
'end': 149,
'answer': 'Harvard Library'}]
```
## License - The MIT License
Copyright (c) 2021 Fang Xu, Deutsche Telekom AG
|
KoboldAI/fairseq-dense-2.7B | 3e9e3ed8439f4a51e90010bcd8328f00790abf78 | 2022-02-01T22:50:43.000Z | [
"pytorch",
"xglm",
"text-generation",
"transformers"
]
| text-generation | false | KoboldAI | null | KoboldAI/fairseq-dense-2.7B | 2,301 | null | transformers | 1,268 | Entry not found |
microsoft/layoutlmv3-large | 0f239ba9db00fe0909f56e6cccbf9bda99d55ec7 | 2022-07-20T09:35:14.000Z | [
"pytorch",
"layoutlmv3",
"en",
"arxiv:2204.08387",
"transformers",
"license:cc-by-nc-sa-4.0"
]
| null | false | microsoft | null | microsoft/layoutlmv3-large | 2,297 | 12 | transformers | 1,269 | ---
language: en
license: cc-by-nc-sa-4.0
---
# LayoutLMv3
[Microsoft Document AI](https://www.microsoft.com/en-us/research/project/document-ai/) | [GitHub](https://aka.ms/layoutlmv3)
## Model description
LayoutLMv3 is a pre-trained multimodal Transformer for Document AI with unified text and image masking. The simple unified architecture and training objectives make LayoutLMv3 a general-purpose pre-trained model. For example, LayoutLMv3 can be fine-tuned for both text-centric tasks, including form understanding, receipt understanding, and document visual question answering, and image-centric tasks such as document image classification and document layout analysis.
[LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking](https://arxiv.org/abs/2204.08387)
Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei, Preprint 2022.
## Citation
If you find LayoutLM useful in your research, please cite the following paper:
```
@article{huang2022layoutlmv3,
title={LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking},
author={Yupan Huang and Tengchao Lv and Lei Cui and Yutong Lu and Furu Wei},
journal={arXiv preprint arXiv:2204.08387},
year={2022}
}
```
## License
The content of this project itself is licensed under the [Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0)](https://creativecommons.org/licenses/by-nc-sa/4.0/)
Portions of the source code are based on the [transformers](https://github.com/huggingface/transformers) project.
[Microsoft Open Source Code of Conduct](https://opensource.microsoft.com/codeofconduct)
|
hf-internal-testing/tiny-bert-pt-only | 784f4fa083011ad3a1b610a61b9a456824bab482 | 2022-01-21T16:20:41.000Z | [
"pytorch",
"bert",
"feature-extraction",
"transformers"
]
| feature-extraction | false | hf-internal-testing | null | hf-internal-testing/tiny-bert-pt-only | 2,289 | null | transformers | 1,270 | Entry not found |
google/byt5-large | c40ca44cdb06b7d7fff83217c1f184a3f9c4ed90 | 2022-05-27T15:07:18.000Z | [
"pytorch",
"tf",
"jax",
"t5",
"text2text-generation",
"multilingual",
"af",
"am",
"ar",
"az",
"be",
"bg",
"bn",
"ca",
"ceb",
"co",
"cs",
"cy",
"da",
"de",
"el",
"en",
"eo",
"es",
"et",
"eu",
"fa",
"fi",
"fil",
"fr",
"fy",
"ga",
"gd",
"gl",
"gu",
"ha",
"haw",
"hi",
"hmn",
"ht",
"hu",
"hy",
"ig",
"is",
"it",
"iw",
"ja",
"jv",
"ka",
"kk",
"km",
"kn",
"ko",
"ku",
"ky",
"la",
"lb",
"lo",
"lt",
"lv",
"mg",
"mi",
"mk",
"ml",
"mn",
"mr",
"ms",
"mt",
"my",
"ne",
"nl",
"no",
"ny",
"pa",
"pl",
"ps",
"pt",
"ro",
"ru",
"sd",
"si",
"sk",
"sl",
"sm",
"sn",
"so",
"sq",
"sr",
"st",
"su",
"sv",
"sw",
"ta",
"te",
"tg",
"th",
"tr",
"uk",
"und",
"ur",
"uz",
"vi",
"xh",
"yi",
"yo",
"zh",
"zu",
"dataset:mc4",
"arxiv:1907.06292",
"arxiv:2105.13626",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
]
| text2text-generation | false | google | null | google/byt5-large | 2,283 | null | transformers | 1,271 | ---
language:
- multilingual
- af
- am
- ar
- az
- be
- bg
- bn
- ca
- ceb
- co
- cs
- cy
- da
- de
- el
- en
- eo
- es
- et
- eu
- fa
- fi
- fil
- fr
- fy
- ga
- gd
- gl
- gu
- ha
- haw
- hi
- hmn
- ht
- hu
- hy
- ig
- is
- it
- iw
- ja
- jv
- ka
- kk
- km
- kn
- ko
- ku
- ky
- la
- lb
- lo
- lt
- lv
- mg
- mi
- mk
- ml
- mn
- mr
- ms
- mt
- my
- ne
- nl
- no
- ny
- pa
- pl
- ps
- pt
- ro
- ru
- sd
- si
- sk
- sl
- sm
- sn
- so
- sq
- sr
- st
- su
- sv
- sw
- ta
- te
- tg
- th
- tr
- uk
- und
- ur
- uz
- vi
- xh
- yi
- yo
- zh
- zu
datasets:
- mc4
license: apache-2.0
---
# ByT5 - large
ByT5 is a tokenizer-free version of [Google's T5](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) and generally follows the architecture of [MT5](https://huggingface.co/google/mt5-large).
ByT5 was only pre-trained on [mC4](https://www.tensorflow.org/datasets/catalog/c4#c4multilingual) excluding any supervised training with an average span-mask of 20 UTF-8 characters. Therefore, this model has to be fine-tuned before it is useable on a downstream task.
ByT5 works especially well on noisy text data,*e.g.*, `google/byt5-large` significantly outperforms [mt5-large](https://huggingface.co/google/mt5-large) on [TweetQA](https://arxiv.org/abs/1907.06292).
Paper: [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626)
Authors: *Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, Colin Raffel*
## Example Inference
ByT5 works on raw UTF-8 bytes and can be used without a tokenizer:
```python
from transformers import T5ForConditionalGeneration
import torch
model = T5ForConditionalGeneration.from_pretrained('google/byt5-large')
input_ids = torch.tensor([list("Life is like a box of chocolates.".encode("utf-8"))]) + 3 # add 3 for special tokens
labels = torch.tensor([list("La vie est comme une boîte de chocolat.".encode("utf-8"))]) + 3 # add 3 for special tokens
loss = model(input_ids, labels=labels).loss # forward pass
```
For batched inference & training it is however recommended using a tokenizer class for padding:
```python
from transformers import T5ForConditionalGeneration, AutoTokenizer
model = T5ForConditionalGeneration.from_pretrained('google/byt5-large')
tokenizer = AutoTokenizer.from_pretrained('google/byt5-large')
model_inputs = tokenizer(["Life is like a box of chocolates.", "Today is Monday."], padding="longest", return_tensors="pt")
labels = tokenizer(["La vie est comme une boîte de chocolat.", "Aujourd'hui c'est lundi."], padding="longest", return_tensors="pt").input_ids
loss = model(**model_inputs, labels=labels).loss # forward pass
```
## Abstract
Most widely-used pre-trained language models operate on sequences of tokens corresponding to word or subword units. Encoding text as a sequence of tokens requires a tokenizer, which is typically created as an independent artifact from the model. Token-free models that instead operate directly on raw text (bytes or characters) have many benefits: they can process text in any language out of the box, they are more robust to noise, and they minimize technical debt by removing complex and error-prone text preprocessing pipelines. Since byte or character sequences are longer than token sequences, past work on token-free models has often introduced new model architectures designed to amortize the cost of operating directly on raw text. In this paper, we show that a standard Transformer architecture can be used with minimal modifications to process byte sequences. We carefully characterize the trade-offs in terms of parameter count, training FLOPs, and inference speed, and show that byte-level models are competitive with their token-level counterparts. We also demonstrate that byte-level models are significantly more robust to noise and perform better on tasks that are sensitive to spelling and pronunciation. As part of our contribution, we release a new set of pre-trained byte-level Transformer models based on the T5 architecture, as well as all code and data used in our experiments.
 |
IDEA-CCNL/Randeng-T5-77M | 0ef5b80d88bcf2bf6e84cbf57920ddcffdad73c5 | 2022-06-30T06:29:03.000Z | [
"pytorch",
"mt5",
"text2text-generation",
"zh",
"transformers",
"T5",
"chinese",
"sentencepiece",
"license:apache-2.0",
"autotrain_compatible"
]
| text2text-generation | false | IDEA-CCNL | null | IDEA-CCNL/Randeng-T5-77M | 2,279 | null | transformers | 1,272 | ---
license: apache-2.0
language: zh
tags:
- T5
- chinese
- sentencepiece
inference: true
widget:
- text: "北京有悠久的 <extra_id_0>和 <extra_id_1>。"
- type: "text-generation"
---
# Randeng-T5-77M, one model of [Fengshenbang-LM](https://github.com/IDEA-CCNL/Fengshenbang-LM).
Based on mt5-small, Randeng-T5-77M only retains the vocabulary and embedding corresponding to Chinese and English, and continues to train on the basis of 180G Chinese general pre-training corpus. Because we continue pretraining on mt5-large, the tokenizer use T5tokenizer(sentencepiece). The pretrain target is span corruption. We pretrain the model based on our [fengshen framework](https://github.com/IDEA-CCNL/Fengshenbang-LM/tree/main/fengshen), use 8 * A100 for 24 hours.
## Usage
```python
from transformers import T5ForConditionalGeneration, AutoTokenizer
import torch
tokenizer=AutoTokenizer.from_pretrained('IDEA-CCNL/Randeng-T5-77M', use_fast=false)
model=T5ForConditionalGeneration.from_pretrained('IDEA-CCNL/Randeng-T5-77M')
```
## Citation
If you find the resource is useful, please cite the following website in your paper.
```
@misc{Fengshenbang-LM,
title={Fengshenbang-LM},
author={IDEA-CCNL},
year={2022},
howpublished={\url{https://github.com/IDEA-CCNL/Fengshenbang-LM}},
}
``` |
microsoft/CodeGPT-small-py-adaptedGPT2 | a8e9aeb8b9d8eef8e0934606f43f93e252c69470 | 2021-05-23T09:00:40.000Z | [
"pytorch",
"tf",
"jax",
"gpt2",
"text-generation",
"transformers"
]
| text-generation | false | microsoft | null | microsoft/CodeGPT-small-py-adaptedGPT2 | 2,278 | 4 | transformers | 1,273 | Entry not found |
T-Systems-onsite/german-roberta-sentence-transformer-v2 | 79e02bc0fff5b48096e366e4ffa7ac621ed8b275 | 2022-06-28T19:57:13.000Z | [
"pytorch",
"tf",
"xlm-roberta",
"feature-extraction",
"de",
"dataset:STSbenchmark",
"transformers",
"sentence_embedding",
"search",
"roberta",
"xlm-r-distilroberta-base-paraphrase-v1",
"paraphrase",
"license:mit"
]
| feature-extraction | false | T-Systems-onsite | null | T-Systems-onsite/german-roberta-sentence-transformer-v2 | 2,275 | 1 | transformers | 1,274 | ---
language: de
license: mit
tags:
- sentence_embedding
- search
- pytorch
- xlm-roberta
- roberta
- xlm-r-distilroberta-base-paraphrase-v1
- paraphrase
datasets:
- STSbenchmark
metrics:
- Spearman’s rank correlation
- cosine similarity
---
# German RoBERTa for Sentence Embeddings V2
**The new [T-Systems-onsite/cross-en-de-roberta-sentence-transformer](https://huggingface.co/T-Systems-onsite/cross-en-de-roberta-sentence-transformer) model is slightly better for German language. It is also the current best model for English language and works cross-lingually. Please consider using that model.**
|
pierreguillou/gpt2-small-portuguese | 89a916c041b54c8b925e1a3282a5a334684280cb | 2021-05-23T10:59:56.000Z | [
"pytorch",
"tf",
"jax",
"gpt2",
"text-generation",
"pt",
"dataset:wikipedia",
"transformers",
"license:mit"
]
| text-generation | false | pierreguillou | null | pierreguillou/gpt2-small-portuguese | 2,264 | 10 | transformers | 1,275 | ---
language: pt
widget:
- text: "Quem era Jim Henson? Jim Henson era um"
- text: "Em um achado chocante, o cientista descobriu um"
- text: "Barack Hussein Obama II, nascido em 4 de agosto de 1961, é"
- text: "Corrida por vacina contra Covid-19 já tem"
license: mit
datasets:
- wikipedia
---
# GPorTuguese-2: a Language Model for Portuguese text generation (and more NLP tasks...)
## Introduction
GPorTuguese-2 (Portuguese GPT-2 small) is a state-of-the-art language model for Portuguese based on the GPT-2 small model.
It was trained on Portuguese Wikipedia using **Transfer Learning and Fine-tuning techniques** in just over a day, on one GPU NVIDIA V100 32GB and with a little more than 1GB of training data.
It is a proof-of-concept that it is possible to get a state-of-the-art language model in any language with low ressources.
It was fine-tuned from the [English pre-trained GPT-2 small](https://huggingface.co/gpt2) using the Hugging Face libraries (Transformers and Tokenizers) wrapped into the [fastai v2](https://dev.fast.ai/) Deep Learning framework. All the fine-tuning fastai v2 techniques were used.
It is now available on Hugging Face. For further information or requests, please go to "[Faster than training from scratch — Fine-tuning the English GPT-2 in any language with Hugging Face and fastai v2 (practical case with Portuguese)](https://medium.com/@pierre_guillou/faster-than-training-from-scratch-fine-tuning-the-english-gpt-2-in-any-language-with-hugging-f2ec05c98787)".
## Model
| Model | #params | Model file (pt/tf) | Arch. | Training /Validation data (text) |
|-------------------------|---------|--------------------|-------------|------------------------------------------|
| `gpt2-small-portuguese` | 124M | 487M / 475M | GPT-2 small | Portuguese Wikipedia (1.28 GB / 0.32 GB) |
## Evaluation results
In a little more than a day (we only used one GPU NVIDIA V100 32GB; through a Distributed Data Parallel (DDP) training mode, we could have divided by three this time to 10 hours, just with 2 GPUs), we got a loss of 3.17, an **accuracy of 37.99%** and a **perplexity of 23.76** (see the validation results table below).
| after ... epochs | loss | accuracy (%) | perplexity | time by epoch | cumulative time |
|------------------|------|--------------|------------|---------------|-----------------|
| 0 | 9.95 | 9.90 | 20950.94 | 00:00:00 | 00:00:00 |
| 1 | 3.64 | 32.52 | 38.12 | 5:48:31 | 5:48:31 |
| 2 | 3.30 | 36.29 | 27.16 | 5:38:18 | 11:26:49 |
| 3 | 3.21 | 37.46 | 24.71 | 6:20:51 | 17:47:40 |
| 4 | 3.19 | 37.74 | 24.21 | 6:06:29 | 23:54:09 |
| 5 | 3.17 | 37.99 | 23.76 | 6:16:22 | 30:10:31 |
## GPT-2
*Note: information copied/pasted from [Model: gpt2 >> GPT-2](https://huggingface.co/gpt2#gpt-2)*
Pretrained model on English language using a causal language modeling (CLM) objective. It was introduced in this [paper](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf) and first released at this [page](https://openai.com/blog/better-language-models/) (February 14, 2019).
Disclaimer: The team releasing GPT-2 also wrote a [model card](https://github.com/openai/gpt-2/blob/master/model_card.md) for their model. Content from this model card has been written by the Hugging Face team to complete the information they provided and give specific examples of bias.
## Model description
*Note: information copied/pasted from [Model: gpt2 >> Model description](https://huggingface.co/gpt2#model-description)*
GPT-2 is a transformers model pretrained on a very large corpus of English data in a self-supervised fashion. This means it was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely, it was trained to guess the next word in sentences.
More precisely, inputs are sequences of continuous text of a certain length and the targets are the same sequence, shifted one token (word or piece of word) to the right. The model uses internally a mask-mechanism to make sure the predictions for the token `i` only uses the inputs from `1` to `i` but not the future tokens.
This way, the model learns an inner representation of the English language that can then be used to extract features useful for downstream tasks. The model is best at what it was pretrained for however, which is generating texts from a prompt.
## How to use GPorTuguese-2 with HuggingFace (PyTorch)
The following code use PyTorch. To use TensorFlow, check the below corresponding paragraph.
### Load GPorTuguese-2 and its sub-word tokenizer (Byte-level BPE)
```python
from transformers import AutoTokenizer, AutoModelWithLMHead
import torch
tokenizer = AutoTokenizer.from_pretrained("pierreguillou/gpt2-small-portuguese")
model = AutoModelWithLMHead.from_pretrained("pierreguillou/gpt2-small-portuguese")
# Get sequence length max of 1024
tokenizer.model_max_length=1024
model.eval() # disable dropout (or leave in train mode to finetune)
```
### Generate one word
```python
# input sequence
text = "Quem era Jim Henson? Jim Henson era um"
inputs = tokenizer(text, return_tensors="pt")
# model output
outputs = model(**inputs, labels=inputs["input_ids"])
loss, logits = outputs[:2]
predicted_index = torch.argmax(logits[0, -1, :]).item()
predicted_text = tokenizer.decode([predicted_index])
# results
print('input text:', text)
print('predicted text:', predicted_text)
# input text: Quem era Jim Henson? Jim Henson era um
# predicted text: homem
```
### Generate one full sequence
```python
# input sequence
text = "Quem era Jim Henson? Jim Henson era um"
inputs = tokenizer(text, return_tensors="pt")
# model output using Top-k sampling text generation method
sample_outputs = model.generate(inputs.input_ids,
pad_token_id=50256,
do_sample=True,
max_length=50, # put the token number you want
top_k=40,
num_return_sequences=1)
# generated sequence
for i, sample_output in enumerate(sample_outputs):
print(">> Generated text {}\n\n{}".format(i+1, tokenizer.decode(sample_output.tolist())))
# >> Generated text
# Quem era Jim Henson? Jim Henson era um executivo de televisão e diretor de um grande estúdio de cinema mudo chamado Selig,
# depois que o diretor de cinema mudo Georges Seuray dirigiu vários filmes para a Columbia e o estúdio.
```
## How to use GPorTuguese-2 with HuggingFace (TensorFlow)
The following code use TensorFlow. To use PyTorch, check the above corresponding paragraph.
### Load GPorTuguese-2 and its sub-word tokenizer (Byte-level BPE)
```python
from transformers import AutoTokenizer, TFAutoModelWithLMHead
import tensorflow as tf
tokenizer = AutoTokenizer.from_pretrained("pierreguillou/gpt2-small-portuguese")
model = TFAutoModelWithLMHead.from_pretrained("pierreguillou/gpt2-small-portuguese")
# Get sequence length max of 1024
tokenizer.model_max_length=1024
model.eval() # disable dropout (or leave in train mode to finetune)
```
### Generate one full sequence
```python
# input sequence
text = "Quem era Jim Henson? Jim Henson era um"
inputs = tokenizer.encode(text, return_tensors="tf")
# model output using Top-k sampling text generation method
outputs = model.generate(inputs, eos_token_id=50256, pad_token_id=50256,
do_sample=True,
max_length=40,
top_k=40)
print(tokenizer.decode(outputs[0]))
# >> Generated text
# Quem era Jim Henson? Jim Henson era um amigo familiar da família. Ele foi contratado pelo seu pai
# para trabalhar como aprendiz no escritório de um escritório de impressão, e então começou a ganhar dinheiro
```
## Limitations and bias
The training data used for this model come from Portuguese Wikipedia. We know it contains a lot of unfiltered content from the internet, which is far from neutral. As the openAI team themselves point out in their model card:
> Because large-scale language models like GPT-2 do not distinguish fact from fiction, we don’t support use-cases that require the generated text to be true. Additionally, language models like GPT-2 reflect the biases inherent to the systems they were trained on, so we do not recommend that they be deployed into systems that interact with humans > unless the deployers first carry out a study of biases relevant to the intended use-case. We found no statistically significant difference in gender, race, and religious bias probes between 774M and 1.5B, implying all versions of GPT-2 should be approached with similar levels of caution around use cases that are sensitive to biases around human attributes.
## Author
Portuguese GPT-2 small was trained and evaluated by [Pierre GUILLOU](https://www.linkedin.com/in/pierreguillou/) thanks to the computing power of the GPU (GPU NVIDIA V100 32 Go) of the [AI Lab](https://www.linkedin.com/company/ailab-unb/) (University of Brasilia) to which I am attached as an Associate Researcher in NLP and the participation of its directors in the definition of NLP strategy, Professors Fabricio Ataides Braz and Nilton Correia da Silva.
## Citation
If you use our work, please cite:
```bibtex
@inproceedings{pierre2020gpt2smallportuguese,
title={GPorTuguese-2 (Portuguese GPT-2 small): a Language Model for Portuguese text generation (and more NLP tasks...)},
author={Pierre Guillou},
year={2020}
}
```
|
hf-internal-testing/tiny-random-bert-sharded | 6ef72e86254aef4ff42ce3bb4777081310c1c254 | 2022-03-22T18:48:43.000Z | [
"pytorch",
"bert",
"feature-extraction",
"transformers"
]
| feature-extraction | false | hf-internal-testing | null | hf-internal-testing/tiny-random-bert-sharded | 2,263 | null | transformers | 1,276 | Entry not found |
KoboldAI/GPT-Neo-2.7B-AID | e4b98e6800567b710f88c66e5882f8e0ae812b6a | 2022-01-18T20:05:16.000Z | [
"pytorch",
"gpt_neo",
"text-generation",
"transformers"
]
| text-generation | false | KoboldAI | null | KoboldAI/GPT-Neo-2.7B-AID | 2,259 | null | transformers | 1,277 | Entry not found |
bhadresh-savani/bert-base-uncased-emotion | 5268bc562e8f93914c8d794a503f40076bfece3e | 2022-07-06T10:44:59.000Z | [
"pytorch",
"tf",
"jax",
"bert",
"text-classification",
"en",
"dataset:emotion",
"arxiv:1810.04805",
"transformers",
"emotion",
"license:apache-2.0",
"model-index"
]
| text-classification | false | bhadresh-savani | null | bhadresh-savani/bert-base-uncased-emotion | 2,251 | 2 | transformers | 1,278 | ---
language:
- en
thumbnail: https://avatars3.githubusercontent.com/u/32437151?s=460&u=4ec59abc8d21d5feea3dab323d23a5860e6996a4&v=4
tags:
- text-classification
- emotion
- pytorch
license: apache-2.0
datasets:
- emotion
metrics:
- Accuracy, F1 Score
model-index:
- name: bhadresh-savani/bert-base-uncased-emotion
results:
- task:
type: text-classification
name: Text Classification
dataset:
name: emotion
type: emotion
config: default
split: test
metrics:
- name: Accuracy
type: accuracy
value: 0.9265
verified: true
- name: Precision Macro
type: precision
value: 0.8859601677706858
verified: true
- name: Precision Micro
type: precision
value: 0.9265
verified: true
- name: Precision Weighted
type: precision
value: 0.9265082039990273
verified: true
- name: Recall Macro
type: recall
value: 0.879224648382427
verified: true
- name: Recall Micro
type: recall
value: 0.9265
verified: true
- name: Recall Weighted
type: recall
value: 0.9265
verified: true
- name: F1 Macro
type: f1
value: 0.8821398657055098
verified: true
- name: F1 Micro
type: f1
value: 0.9265
verified: true
- name: F1 Weighted
type: f1
value: 0.9262425173620311
verified: true
- name: loss
type: loss
value: 0.17315374314785004
verified: true
---
# bert-base-uncased-emotion
## Model description:
[Bert](https://arxiv.org/abs/1810.04805) is a Transformer Bidirectional Encoder based Architecture trained on MLM(Mask Language Modeling) objective
[bert-base-uncased](https://huggingface.co/bert-base-uncased) finetuned on the emotion dataset using HuggingFace Trainer with below training parameters
```
learning rate 2e-5,
batch size 64,
num_train_epochs=8,
```
## Model Performance Comparision on Emotion Dataset from Twitter:
| Model | Accuracy | F1 Score | Test Sample per Second |
| --- | --- | --- | --- |
| [Distilbert-base-uncased-emotion](https://huggingface.co/bhadresh-savani/distilbert-base-uncased-emotion) | 93.8 | 93.79 | 398.69 |
| [Bert-base-uncased-emotion](https://huggingface.co/bhadresh-savani/bert-base-uncased-emotion) | 94.05 | 94.06 | 190.152 |
| [Roberta-base-emotion](https://huggingface.co/bhadresh-savani/roberta-base-emotion) | 93.95 | 93.97| 195.639 |
| [Albert-base-v2-emotion](https://huggingface.co/bhadresh-savani/albert-base-v2-emotion) | 93.6 | 93.65 | 182.794 |
## How to Use the model:
```python
from transformers import pipeline
classifier = pipeline("text-classification",model='bhadresh-savani/bert-base-uncased-emotion', return_all_scores=True)
prediction = classifier("I love using transformers. The best part is wide range of support and its easy to use", )
print(prediction)
"""
output:
[[
{'label': 'sadness', 'score': 0.0005138228880241513},
{'label': 'joy', 'score': 0.9972520470619202},
{'label': 'love', 'score': 0.0007443308713845909},
{'label': 'anger', 'score': 0.0007404946954920888},
{'label': 'fear', 'score': 0.00032938539516180754},
{'label': 'surprise', 'score': 0.0004197491507511586}
]]
"""
```
## Dataset:
[Twitter-Sentiment-Analysis](https://huggingface.co/nlp/viewer/?dataset=emotion).
## Training procedure
[Colab Notebook](https://github.com/bhadreshpsavani/ExploringSentimentalAnalysis/blob/main/SentimentalAnalysisWithDistilbert.ipynb)
follow the above notebook by changing the model name from distilbert to bert
## Eval results
```json
{
'test_accuracy': 0.9405,
'test_f1': 0.9405920712282673,
'test_loss': 0.15769127011299133,
'test_runtime': 10.5179,
'test_samples_per_second': 190.152,
'test_steps_per_second': 3.042
}
```
## Reference:
* [Natural Language Processing with Transformer By Lewis Tunstall, Leandro von Werra, Thomas Wolf](https://learning.oreilly.com/library/view/natural-language-processing/9781098103231/) |
digit82/kobart-summarization | 0887f7ac6e66df93248890f3460299d28bae1ddd | 2022-03-01T13:48:13.000Z | [
"pytorch",
"bart",
"text2text-generation",
"transformers",
"autotrain_compatible"
]
| text2text-generation | false | digit82 | null | digit82/kobart-summarization | 2,251 | null | transformers | 1,279 | Entry not found |
kresnik/wav2vec2-large-xlsr-korean | 1d50f59cf2e3d746461af568b095f60f8387bca6 | 2022-02-15T09:47:14.000Z | [
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"ko",
"dataset:kresnik/zeroth_korean",
"transformers",
"speech",
"audio",
"license:apache-2.0",
"model-index"
]
| automatic-speech-recognition | false | kresnik | null | kresnik/wav2vec2-large-xlsr-korean | 2,247 | 6 | transformers | 1,280 | ---
language: ko
datasets:
- kresnik/zeroth_korean
tags:
- speech
- audio
- automatic-speech-recognition
license: apache-2.0
model-index:
- name: 'Wav2Vec2 XLSR Korean'
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Zeroth Korean
type: kresnik/zeroth_korean
args: clean
metrics:
- name: Test WER
type: wer
value: 4.74
- name: Test CER
type: cer
value: 1.78
---
## Evaluation on Zeroth-Korean ASR corpus
[Google colab notebook(Korean)](https://colab.research.google.com/github/indra622/tutorials/blob/master/wav2vec2_korean_tutorial.ipynb)
```
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
from datasets import load_dataset
import soundfile as sf
import torch
from jiwer import wer
processor = Wav2Vec2Processor.from_pretrained("kresnik/wav2vec2-large-xlsr-korean")
model = Wav2Vec2ForCTC.from_pretrained("kresnik/wav2vec2-large-xlsr-korean").to('cuda')
ds = load_dataset("kresnik/zeroth_korean", "clean")
test_ds = ds['test']
def map_to_array(batch):
speech, _ = sf.read(batch["file"])
batch["speech"] = speech
return batch
test_ds = test_ds.map(map_to_array)
def map_to_pred(batch):
inputs = processor(batch["speech"], sampling_rate=16000, return_tensors="pt", padding="longest")
input_values = inputs.input_values.to("cuda")
with torch.no_grad():
logits = model(input_values).logits
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
batch["transcription"] = transcription
return batch
result = test_ds.map(map_to_pred, batched=True, batch_size=16, remove_columns=["speech"])
print("WER:", wer(result["text"], result["transcription"]))
```
### Expected WER: 4.74%
### Expected CER: 1.78% |
sentence-transformers/sentence-t5-base | 0bf6e3f10674a653aad7c5e0be5b6721dd52bb58 | 2022-06-21T14:56:18.000Z | [
"pytorch",
"rust",
"t5",
"en",
"arxiv:2108.08877",
"sentence-transformers",
"feature-extraction",
"sentence-similarity",
"transformers",
"license:apache-2.0"
]
| sentence-similarity | false | sentence-transformers | null | sentence-transformers/sentence-t5-base | 2,245 | 4 | sentence-transformers | 1,281 | ---
pipeline_tag: sentence-similarity
language: en
license: apache-2.0
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# sentence-transformers/sentence-t5-base
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space. The model works well for sentence similarity tasks, but doesn't perform that well for semantic search tasks.
This model was converted from the Tensorflow model [st5-base-1](https://tfhub.dev/google/sentence-t5/st5-base/1) to PyTorch. When using this model, have a look at the publication: [Sentence-T5: Scalable sentence encoders from pre-trained text-to-text models](https://arxiv.org/abs/2108.08877). The tfhub model and this PyTorch model can produce slightly different embeddings, however, when run on the same benchmarks, they produce identical results.
The model uses only the encoder from a T5-base model. The weights are stored in FP16.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/sentence-t5-base')
embeddings = model.encode(sentences)
print(embeddings)
```
The model requires sentence-transformers version 2.2.0 or newer.
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/sentence-t5-base)
## Citing & Authors
If you find this model helpful, please cite the respective publication:
[Sentence-T5: Scalable sentence encoders from pre-trained text-to-text models](https://arxiv.org/abs/2108.08877)
|
cointegrated/rubert-tiny2-cedr-emotion-detection | cd3543a7766e7b2ed82691955e3b7eba9cc9b25c | 2021-11-12T20:13:41.000Z | [
"pytorch",
"bert",
"text-classification",
"ru",
"dataset:cedr",
"transformers",
"russian",
"classification",
"sentiment",
"emotion-classification",
"multiclass"
]
| text-classification | false | cointegrated | null | cointegrated/rubert-tiny2-cedr-emotion-detection | 2,236 | 5 | transformers | 1,282 | ---
language: ["ru"]
tags:
- russian
- classification
- sentiment
- emotion-classification
- multiclass
datasets:
- cedr
widget:
- text: "Бесишь меня, падла"
- text: "Как здорово, что все мы здесь сегодня собрались"
- text: "Как-то стрёмно, давай свалим отсюда?"
- text: "Грусть-тоска меня съедает"
- text: "Данный фрагмент текста не содержит абсолютно никаких эмоций"
- text: "Нифига себе, неужели так тоже бывает!"
---
This is the [cointegrated/rubert-tiny2](https://huggingface.co/cointegrated/rubert-tiny2) model fine-tuned for classification of emotions in Russian sentences. The task is multilabel classification, because one sentence can contain multiple emotions.
The model on the [CEDR dataset](https://huggingface.co/datasets/cedr) described in the paper ["Data-Driven Model for Emotion Detection in Russian Texts"](https://doi.org/10.1016/j.procs.2021.06.075) by Sboev et al.
The model has been trained with Adam optimizer for 40 epochs with learning rate `1e-5` and batch size 64 [in this notebook](https://colab.research.google.com/drive/1AFW70EJaBn7KZKRClDIdDUpbD46cEsat?usp=sharing).
The quality of the predicted probabilities on the test dataset is the following:
| label | no emotion | joy |sadness |surprise| fear |anger | mean | mean (emotions) |
|----------|------------|--------|--------|--------|--------|--------| --------| ----------------|
| AUC | 0.9286 | 0.9512 | 0.9564 | 0.8908 | 0.8955 | 0.7511 | 0.8956 | 0.8890 |
| F1 micro | 0.8624 | 0.9389 | 0.9362 | 0.9469 | 0.9575 | 0.9261 | 0.9280 | 0.9411 |
| F1 macro | 0.8562 | 0.8962 | 0.9017 | 0.8366 | 0.8359 | 0.6820 | 0.8348 | 0.8305 |
|
nvidia/segformer-b4-finetuned-ade-512-512 | 0bc666c7d9d15740b0d61e38ee27f71b02c4d38a | 2022-07-20T09:52:59.000Z | [
"pytorch",
"tf",
"segformer",
"dataset:scene_parse_150",
"arxiv:2105.15203",
"transformers",
"vision",
"image-segmentation",
"license:apache-2.0"
]
| image-segmentation | false | nvidia | null | nvidia/segformer-b4-finetuned-ade-512-512 | 2,225 | null | transformers | 1,283 | ---
license: apache-2.0
tags:
- vision
- image-segmentation
datasets:
- scene_parse_150
widget:
- src: https://huggingface.co/datasets/hf-internal-testing/fixtures_ade20k/resolve/main/ADE_val_00000001.jpg
example_title: House
- src: https://huggingface.co/datasets/hf-internal-testing/fixtures_ade20k/resolve/main/ADE_val_00000002.jpg
example_title: Castle
---
# SegFormer (b4-sized) model fine-tuned on ADE20k
SegFormer model fine-tuned on ADE20k at resolution 512x512. It was introduced in the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Xie et al. and first released in [this repository](https://github.com/NVlabs/SegFormer).
Disclaimer: The team releasing SegFormer did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
SegFormer consists of a hierarchical Transformer encoder and a lightweight all-MLP decode head to achieve great results on semantic segmentation benchmarks such as ADE20K and Cityscapes. The hierarchical Transformer is first pre-trained on ImageNet-1k, after which a decode head is added and fine-tuned altogether on a downstream dataset.
## Intended uses & limitations
You can use the raw model for semantic segmentation. See the [model hub](https://huggingface.co/models?other=segformer) to look for fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import SegformerFeatureExtractor, SegformerForSemanticSegmentation
from PIL import Image
import requests
feature_extractor = SegformerFeatureExtractor.from_pretrained("nvidia/segformer-b4-finetuned-ade-512-512")
model = SegformerForSemanticSegmentation.from_pretrained("nvidia/segformer-b4-finetuned-ade-512-512")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits # shape (batch_size, num_labels, height/4, width/4)
```
For more code examples, we refer to the [documentation](https://huggingface.co/transformers/model_doc/segformer.html#).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2105-15203,
author = {Enze Xie and
Wenhai Wang and
Zhiding Yu and
Anima Anandkumar and
Jose M. Alvarez and
Ping Luo},
title = {SegFormer: Simple and Efficient Design for Semantic Segmentation with
Transformers},
journal = {CoRR},
volume = {abs/2105.15203},
year = {2021},
url = {https://arxiv.org/abs/2105.15203},
eprinttype = {arXiv},
eprint = {2105.15203},
timestamp = {Wed, 02 Jun 2021 11:46:42 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2105-15203.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
microsoft/beit-base-patch16-224-pt22k | 9aabc608cc017577cb8fb58968e66e0d8f581da1 | 2022-01-28T10:18:13.000Z | [
"pytorch",
"jax",
"beit",
"dataset:imagenet",
"dataset:imagenet-21k",
"arxiv:2106.08254",
"transformers",
"image-classification",
"vision",
"license:apache-2.0"
]
| image-classification | false | microsoft | null | microsoft/beit-base-patch16-224-pt22k | 2,224 | 1 | transformers | 1,284 | ---
license: apache-2.0
tags:
- image-classification
- vision
datasets:
- imagenet
- imagenet-21k
---
# BEiT (base-sized model, pre-trained only)
BEiT model pre-trained in a self-supervised fashion on ImageNet-22k - also called ImageNet-21k (14 million images, 21,841 classes) at resolution 224x224. It was introduced in the paper [BEIT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) by Hangbo Bao, Li Dong and Furu Wei and first released in [this repository](https://github.com/microsoft/unilm/tree/master/beit).
Disclaimer: The team releasing BEiT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The BEiT model is a Vision Transformer (ViT), which is a transformer encoder model (BERT-like). In contrast to the original ViT model, BEiT is pretrained on a large collection of images in a self-supervised fashion, namely ImageNet-21k, at a resolution of 224x224 pixels. The pre-training objective for the model is to predict visual tokens from the encoder of OpenAI's DALL-E's VQ-VAE, based on masked patches.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. Contrary to the original ViT models, BEiT models do use relative position embeddings (similar to T5) instead of absolute position embeddings, and perform classification of images by mean-pooling the final hidden states of the patches, instead of placing a linear layer on top of the final hidden state of the [CLS] token.
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire image. Alternatively, one can mean-pool the final hidden states of the patch embeddings, and place a linear layer on top of that.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=microsoft/beit) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model:
```python
from transformers import BeitFeatureExtractor, BeitForMaskedImageModeling
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = BeitFeatureExtractor.from_pretrained('microsoft/beit-base-patch16-224-pt22k')
model = BeitForMaskedImageModeling.from_pretrained('microsoft/beit-base-patch16-224-pt22k')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
```
Currently, both the feature extractor and model support PyTorch.
## Training data
The BEiT model was pretrained on [ImageNet-21k](http://www.image-net.org/), a dataset consisting of 14 million images and 21k classes.
## Training procedure
### Preprocessing
The exact details of preprocessing of images during training/validation can be found [here](https://github.com/microsoft/unilm/blob/master/beit/datasets.py).
Images are resized/rescaled to the same resolution (224x224) and normalized across the RGB channels with mean (0.5, 0.5, 0.5) and standard deviation (0.5, 0.5, 0.5).
### Pretraining
For all pre-training related hyperparameters, we refer to page 15 of the [original paper](https://arxiv.org/abs/2106.08254).
## Evaluation results
For evaluation results on several image classification benchmarks, we refer to tables 1 and 2 of the original paper. Note that for fine-tuning, the best results are obtained with a higher resolution. Of course, increasing the model size will result in better performance.
### BibTeX entry and citation info
```@article{DBLP:journals/corr/abs-2106-08254,
author = {Hangbo Bao and
Li Dong and
Furu Wei},
title = {BEiT: {BERT} Pre-Training of Image Transformers},
journal = {CoRR},
volume = {abs/2106.08254},
year = {2021},
url = {https://arxiv.org/abs/2106.08254},
archivePrefix = {arXiv},
eprint = {2106.08254},
timestamp = {Tue, 29 Jun 2021 16:55:04 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2106-08254.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
```bibtex
@inproceedings{deng2009imagenet,
title={Imagenet: A large-scale hierarchical image database},
author={Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li},
booktitle={2009 IEEE conference on computer vision and pattern recognition},
pages={248--255},
year={2009},
organization={Ieee}
}
``` |
google/t5-large-ssm-nq | 000abff88a3e622c77c59e4a83fb985e79c7c6e6 | 2021-06-23T01:35:15.000Z | [
"pytorch",
"tf",
"jax",
"t5",
"text2text-generation",
"en",
"dataset:c4",
"dataset:wikipedia",
"dataset:natural_questions",
"arxiv:2002.08909",
"arxiv:1910.10683",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
]
| text2text-generation | false | google | null | google/t5-large-ssm-nq | 2,214 | null | transformers | 1,285 | ---
language: en
datasets:
- c4
- wikipedia
- natural_questions
pipeline_tag: text2text-generation
license: apache-2.0
---
[Google's T5](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) for **Closed Book Question Answering**.
The model was pre-trained using T5's denoising objective on [C4](https://huggingface.co/datasets/c4), subsequently additionally pre-trained using [REALM](https://arxiv.org/pdf/2002.08909.pdf)'s salient span masking objective on [Wikipedia](https://huggingface.co/datasets/wikipedia), and finally fine-tuned on [Natural Questions (NQ)](https://huggingface.co/datasets/natural_questions).
**Note**: The model was fine-tuned on 100% of the train splits of [Natural Questions (NQ)](https://huggingface.co/datasets/natural_questions) for 10k steps.
Other community Checkpoints: [here](https://huggingface.co/models?search=ssm)
Paper: [How Much Knowledge Can You Pack
Into the Parameters of a Language Model?](https://arxiv.org/abs/1910.10683.pdf)
Authors: *Adam Roberts, Colin Raffel, Noam Shazeer*
## Results on Natural Questions - Test Set
|Id | link | Exact Match |
|---|---|---|
|T5-small|https://huggingface.co/google/t5-small-ssm-nq|25.5|
|**T5-large**|**https://huggingface.co/google/t5-large-ssm-nq**|**30.4**|
|T5-xl|https://huggingface.co/google/t5-xl-ssm-nq|35.6|
|T5-xxl|https://huggingface.co/google/t5-xxl-ssm-nq|37.9|
|T5-3b|https://huggingface.co/google/t5-3b-ssm-nq|33.2|
|T5-11b|https://huggingface.co/google/t5-11b-ssm-nq|36.6|
## Usage
The model can be used as follows for **closed book question answering**:
```python
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
t5_qa_model = AutoModelForSeq2SeqLM.from_pretrained("google/t5-large-ssm-nq")
t5_tok = AutoTokenizer.from_pretrained("google/t5-large-ssm-nq")
input_ids = t5_tok("When was Franklin D. Roosevelt born?", return_tensors="pt").input_ids
gen_output = t5_qa_model.generate(input_ids)[0]
print(t5_tok.decode(gen_output, skip_special_tokens=True))
# should give "December 26, 1892" => close, but not correct.
```
## Abstract
It has recently been observed that neural language models trained on unstructured text can implicitly store and retrieve knowledge using natural language queries. In this short paper, we measure the practical utility of this approach by fine-tuning pre-trained models to answer questions without access to any external context or knowledge. We show that this approach scales with model size and performs competitively with open-domain systems that explicitly retrieve answers from an external knowledge source when answering questions. To facilitate reproducibility and future work, we release our code and trained models at https://goo.gle/t5-cbqa.
 |
hf-internal-testing/tiny-random-flaubert | 797c3829946a97ae1a11a0b0016e156e9e5ef94c | 2021-09-17T19:22:36.000Z | [
"pytorch",
"tf",
"flaubert",
"transformers"
]
| null | false | hf-internal-testing | null | hf-internal-testing/tiny-random-flaubert | 2,214 | null | transformers | 1,286 | Entry not found |
Callidior/bert2bert-base-arxiv-titlegen | 74edc65845d95ec72688b312de181cf20e6bb852 | 2021-03-04T09:49:47.000Z | [
"pytorch",
"encoder-decoder",
"text2text-generation",
"en",
"dataset:arxiv_dataset",
"transformers",
"summarization",
"license:apache-2.0",
"autotrain_compatible"
]
| summarization | false | Callidior | null | Callidior/bert2bert-base-arxiv-titlegen | 2,213 | 3 | transformers | 1,287 | ---
language:
- en
tags:
- summarization
license: apache-2.0
datasets:
- arxiv_dataset
metrics:
- rouge
widget:
- text: "The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely. Experiments on two machine translation tasks show these models to be superior in quality while being more parallelizable and requiring significantly less time to train. Our model achieves 28.4 BLEU on the WMT 2014 English-to-German translation task, improving over the existing best results, including ensembles by over 2 BLEU. On the WMT 2014 English-to-French translation task, our model establishes a new single-model state-of-the-art BLEU score of 41.8 after training for 3.5 days on eight GPUs, a small fraction of the training costs of the best models from the literature. We show that the Transformer generalizes well to other tasks by applying it successfully to English constituency parsing both with large and limited training data."
---
# Paper Title Generator
Generates titles for computer science papers given an abstract.
The model is a BERT2BERT Encoder-Decoder using the official `bert-base-uncased` checkpoint as initialization for the encoder and decoder.
It was fine-tuned on 318,500 computer science papers posted on arXiv.org between 2007 and 2020 and achieved a 26.3% Rouge2 F1-Score on held-out validation data.
**Live Demo:** [https://paper-titles.ey.r.appspot.com/](https://paper-titles.ey.r.appspot.com/) |
google/vit-base-patch32-384 | c94def148d45d90470058547968584e7f5036c49 | 2022-06-23T07:50:34.000Z | [
"pytorch",
"tf",
"jax",
"vit",
"image-classification",
"dataset:imagenet-1k",
"dataset:imagenet-21k",
"arxiv:2010.11929",
"transformers",
"vision",
"license:apache-2.0"
]
| image-classification | false | google | null | google/vit-base-patch32-384 | 2,207 | 4 | transformers | 1,288 | ---
license: apache-2.0
tags:
- vision
- image-classification
datasets:
- imagenet-1k
- imagenet-21k
---
# Vision Transformer (base-sized model)
Vision Transformer (ViT) model pre-trained on ImageNet-21k (14 million images, 21,843 classes) at resolution 224x224, and fine-tuned on ImageNet 2012 (1 million images, 1,000 classes) at resolution 384x384. It was introduced in the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Dosovitskiy et al. and first released in [this repository](https://github.com/google-research/vision_transformer). However, the weights were converted from the [timm repository](https://github.com/rwightman/pytorch-image-models) by Ross Wightman, who already converted the weights from JAX to PyTorch. Credits go to him.
Disclaimer: The team releasing ViT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The Vision Transformer (ViT) is a transformer encoder model (BERT-like) pretrained on a large collection of images in a supervised fashion, namely ImageNet-21k, at a resolution of 224x224 pixels. Next, the model was fine-tuned on ImageNet (also referred to as ILSVRC2012), a dataset comprising 1 million images and 1,000 classes, at a higher resolution of 384x384.
Images are presented to the model as a sequence of fixed-size patches (resolution 32x32), which are linearly embedded. One also adds a [CLS] token to the beginning of a sequence to use it for classification tasks. One also adds absolute position embeddings before feeding the sequence to the layers of the Transformer encoder.
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire image.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=google/vit) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import ViTFeatureExtractor, ViTForImageClassification
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = ViTFeatureExtractor.from_pretrained('google/vit-base-patch32-384')
model = ViTForImageClassification.from_pretrained('google/vit-base-patch32-384')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
Currently, both the feature extractor and model support PyTorch. Tensorflow and JAX/FLAX are coming soon, and the API of ViTFeatureExtractor might change.
## Training data
The ViT model was pretrained on [ImageNet-21k](http://www.image-net.org/), a dataset consisting of 14 million images and 21k classes, and fine-tuned on [ImageNet](http://www.image-net.org/challenges/LSVRC/2012/), a dataset consisting of 1 million images and 1k classes.
## Training procedure
### Preprocessing
The exact details of preprocessing of images during training/validation can be found [here](https://github.com/google-research/vision_transformer/blob/master/vit_jax/input_pipeline.py).
Images are resized/rescaled to the same resolution (224x224 during pre-training, 384x384 during fine-tuning) and normalized across the RGB channels with mean (0.5, 0.5, 0.5) and standard deviation (0.5, 0.5, 0.5).
### Pretraining
The model was trained on TPUv3 hardware (8 cores). All model variants are trained with a batch size of 4096 and learning rate warmup of 10k steps. For ImageNet, the authors found it beneficial to additionally apply gradient clipping at global norm 1. Pre-training resolution is 224.
## Evaluation results
For evaluation results on several image classification benchmarks, we refer to tables 2 and 5 of the original paper. Note that for fine-tuning, the best results are obtained with a higher resolution (384x384). Of course, increasing the model size will result in better performance.
### BibTeX entry and citation info
```bibtex
@misc{https://doi.org/10.48550/arxiv.2010.11929,
doi = {10.48550/ARXIV.2010.11929},
url = {https://arxiv.org/abs/2010.11929},
author = {Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil},
keywords = {Computer Vision and Pattern Recognition (cs.CV), Artificial Intelligence (cs.AI), Machine Learning (cs.LG), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
publisher = {arXiv},
year = {2020},
copyright = {arXiv.org perpetual, non-exclusive license}
}
```
```bibtex
@inproceedings{deng2009imagenet,
title={Imagenet: A large-scale hierarchical image database},
author={Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li},
booktitle={2009 IEEE conference on computer vision and pattern recognition},
pages={248--255},
year={2009},
organization={Ieee}
}
``` |
bloomberg/KeyBART | 1558abeeb4fe945b79d5be9db00a4115488b0896 | 2022-07-27T22:11:32.000Z | [
"pytorch",
"bart",
"text2text-generation",
"arxiv:2112.08547",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
]
| text2text-generation | false | bloomberg | null | bloomberg/KeyBART | 2,204 | 6 | transformers | 1,289 | ---
license: apache-2.0
---
# KeyBART
KeyBART as described in Learning Rich Representations of Keyphrase from Text (https://arxiv.org/pdf/2112.08547.pdf), pre-trains a BART-based architecture to produce a concatenated sequence of keyphrases in the CatSeqD format.
We provide some examples on Downstream Evaluations setups and and also how it can be used for Text-to-Text Generation in a zero-shot setting.
## Downstream Evaluation
### Keyphrase Generation
```
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("bloomberg/KeyBART")
model = AutoModelForSeq2SeqLM.from_pretrained("bloomberg/KeyBART")
from datasets import load_dataset
dataset = load_dataset("midas/kp20k")
```
Reported Results:
#### Present Keyphrase Generation
| | Inspec | | NUS | | Krapivin | | SemEval | | KP20k | |
|---------------|--------|-------|-------|-------|----------|-------|---------|-------|-------|-------|
| Model | F1@5 | F1@M | F1@5 | F1@M | F1@5 | F1@M | F1@5 | F1@M | F1@5 | F1@M |
| catSeq | 22.5 | 26.2 | 32.3 | 39.7 | 26.9 | 35.4 | 24.2 | 28.3 | 29.1 | 36.7 |
| catSeqTG | 22.9 | 27 | 32.5 | 39.3 | 28.2 | 36.6 | 24.6 | 29.0 | 29.2 | 36.6 |
| catSeqTG-2RF1 | 25.3 | 30.1 | 37.5 | 43.3 | 30 | 36.9 | 28.7 | 32.9 | 32.1 | 38.6 |
| GANMR | 25.8 | 29.9 | 34.8 | 41.7 | 28.8 | 36.9 | N/A | N/A | 30.3 | 37.8 |
| ExHiRD-h | 25.3 | 29.1 | N/A | N/A | 28.6 | 34.7 | 28.4 | 33.5 | 31.1 | 37.4 |
| Transformer (Ye et al., 2021) | 28.15 | 32.56 | 37.07 | 41.91 | 31.58 | 36.55 | 28.71 | 32.52 | 33.21 | 37.71 |
| BART* | 23.59 | 28.46 | 35.00 | 42.65 | 26.91 | 35.37 | 26.72 | 31.91 | 29.25 | 37.51 |
| KeyBART-DOC* | 24.42 | 29.57 | 31.37 | 39.24 | 24.21 | 32.60 | 24.69 | 30.50 | 28.82 | 37.59 |
| KeyBART* | 24.49 | 29.69 | 34.77 | 43.57 | 29.24 | 38.62 | 27.47 | 33.54 | 30.71 | 39.76 |
| KeyBART* (Zero-shot) | 30.72 | 36.89 | 18.86 | 21.67 | 18.35 | 20.46 | 20.25 | 25.82 | 12.57 | 15.41 |
#### Absent Keyphrase Generation
| | Inspec | | NUS | | Krapivin | | SemEval | | KP20k | |
|---------------|--------|------|------|------|----------|------|---------|------|-------|------|
| Model | F1@5 | F1@M | F1@5 | F1@M | F1@5 | F1@M | F1@5 | F1@M | F1@5 | F1@M |
| catSeq | 0.4 | 0.8 | 1.6 | 2.8 | 1.8 | 3.6 | 1.6 | 2.8 | 1.5 | 3.2 |
| catSeqTG | 0.5 | 1.1 | 1.1 | 1.8 | 1.8 | 3.4 | 1.1 | 1.8 | 1.5 | 3.2 |
| catSeqTG-2RF1 | 1.2 | 2.1 | 1.9 | 3.1 | 3.0 | 5.3 | 2.1 | 3.0 | 2.7 | 5.0 |
| GANMR | 1.3 | 1.9 | 2.6 | 3.8 | 4.2 | 5.7 | N/A | N/A | 3.2 | 4.5 |
| ExHiRD-h | 1.1 | 2.2 | N/A | N/A | 2.2 | 4.3 | 1.7 | 2.5 | 1.6 | 3.2 |
| Transformer (Ye et al., 2021) | 1.02 | 1.94 | 2.82 | 4.82 | 3.21 | 6.04 | 2.05 | 2.33 | 2.31 | 4.61 |
| BART* | 1.08 | 1.96 | 1.80 | 2.75 | 2.59 | 4.91 | 1.34 | 1.75 | 1.77 | 3.56 |
| KeyBART-DOC* | 0.99 | 2.03 | 1.39 | 2.74 | 2.40 | 4.58 | 1.07 | 1.39 | 1.69 | 3.38 |
| KeyBART* | 0.95 | 1.81 | 1.23 | 1.90 | 3.09 | 6.08 | 1.96 | 2.65 | 2.03 | 4.26 |
| KeyBART* (Zero-shot) | 1.83 | 2.92 | 1.46 | 2.19 | 1.29 | 2.09 | 1.12 | 1.45 | 0.70 | 1.14 |
### Abstractive Summarization
```
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("bloomberg/KeyBART")
model = AutoModelForSeq2SeqLM.from_pretrained("bloomberg/KeyBART")
from datasets import load_dataset
dataset = load_dataset("cnn_dailymail")
```
Reported Results:
| Model | R1 | R2 | RL |
|--------------|-------|-------|-------|
| BART (Lewis et al., 2019) | 44.16 | 21.28 | 40.9 |
| BART* | 42.93 | 20.12 | 39.72 |
| KeyBART-DOC* | 42.92 | 20.07 | 39.69 |
| KeyBART* | 43.10 | 20.26 | 39.90 |
## Zero-shot settings
```
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("bloomberg/KeyBART")
model = AutoModelForSeq2SeqLM.from_pretrained("bloomberg/KeyBART")
```
Alternatively use the Hosted Inference API console provided in https://huggingface.co/bloomberg/KeyBART
Sample Zero Shot result:
```
Input: In this work, we explore how to learn task specific language models aimed towards learning rich representation of keyphrases from text documents.
We experiment with different masking strategies for pre-training transformer language models (LMs) in discriminative as well as generative settings.
In the discriminative setting, we introduce a new pre-training objective - Keyphrase Boundary Infilling with Replacement (KBIR),
showing large gains in performance (upto 9.26 points in F1) over SOTA, when LM pre-trained using KBIR is fine-tuned for the task of keyphrase extraction.
In the generative setting, we introduce a new pre-training setup for BART - KeyBART, that reproduces the keyphrases related to the input text in the CatSeq
format, instead of the denoised original input. This also led to gains in performance (upto 4.33 points in F1@M) over SOTA for keyphrase generation.
Additionally, we also fine-tune the pre-trained language models on named entity recognition (NER), question answering (QA), relation extraction (RE),
abstractive summarization and achieve comparable performance with that of the SOTA, showing that learning rich representation of keyphrases is indeed beneficial
for many other fundamental NLP tasks.
Output: language model;keyphrase generation;new pre-training objective;pre-training setup;
```
Please direct all questions to [email protected] |
obsei-ai/sell-buy-intent-classifier-bert-mini | c5d49713723b9e77b82b93f7f270714584f66aa3 | 2021-09-06T13:56:01.000Z | [
"pytorch",
"bert",
"text-classification",
"en",
"transformers",
"buy-intent",
"sell-intent",
"consumer-intent"
]
| text-classification | false | obsei-ai | null | obsei-ai/sell-buy-intent-classifier-bert-mini | 2,202 | 1 | transformers | 1,290 | ---
language: "en"
tags:
- buy-intent
- sell-intent
- consumer-intent
widget:
- text: "Can you please share pictures for Face Shields ? We are looking for large quantity pcs"
---
# Buy vs Sell Intent Classifier
| Train Loss | Validation Acc.| Test Acc.|
| ------------- |:-------------: | -----: |
| 0.013 | 0.988 | 0.992 |
# Sample Intents for Testings
LABEL_0 => **"SELLING_INTENT"** <br/>
LABEL_1 => **"BUYING_INTENT"**
## Buying Intents
- I am interested in this style of PGN-ES-D-6150 /Direct drive energy saving servo motor price and in doing business with you. Could you please send me the quotation
- Hi, I am looking for a supplier of calcium magnesium carbonate fertilizer. Can you send 1 bag sample via air freight to the USA?
- I am looking for the purple ombre dress with floral bodice in a size 12 for my wedding in June this year
- we are interested in your Corned Beef. do you have any quality assurance certificates? looking forward to hearing from you.
- I would like to know if pet nail clippers are of high quality. And if you would send a free sample?
## Selling Intents
- Black full body massage chair for sale.
- Boiler over 7 years old
- Polyester trousers black, size 24.
- Oliver Twist £1, German Dictionary 50p (Cold War s0ld), Penguin Plays £1, post by arrangement. The bundle price is £2. Will separate (Twelfth Night and Sketch B&W Sold)
- Brand new Royal Doulton bone China complete Dinner Service comprising 55 pieces including coffee pot and cups. (6 PLACE SETTING) ! 'Diana' design delicate pattern.
## Usage in Transformers
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("obsei-ai/sell-buy-intent-classifier-bert-mini")
model = AutoModelForSequenceClassification.from_pretrained("obsei-ai/sell-buy-intent-classifier-bert-mini")
```
## <p style='color:red'>Due to the privacy reasons, I unfortunately can't share the dataset and its splits.</p> |
Salesforce/codegen-2B-mono | e1bf58ffda585e9ade68ed3adacd0b6d74871737 | 2022-06-28T17:44:59.000Z | [
"pytorch",
"codegen",
"text-generation",
"arxiv:2203.13474",
"transformers",
"license:bsd-3-clause"
]
| text-generation | false | Salesforce | null | Salesforce/codegen-2B-mono | 2,199 | 2 | transformers | 1,291 | ---
license: bsd-3-clause
---
# CodeGen (CodeGen-Mono 2B)
## Model description
CodeGen is a family of autoregressive language models for **program synthesis** from the paper: [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong. The models are originally released in [this repository](https://github.com/salesforce/CodeGen), under 3 pre-training data variants (`NL`, `Multi`, `Mono`) and 4 model size variants (`350M`, `2B`, `6B`, `16B`).
The checkpoint included in this repository is denoted as **CodeGen-Mono 2B** in the paper, where "Mono" means the model is initialized with *CodeGen-Multi 2B* and further pre-trained on a Python programming language dataset, and "2B" refers to the number of trainable parameters.
## Training data
This checkpoint (CodeGen-Mono 2B) was firstly initialized with *CodeGen-Multi 2B*, and then pre-trained on BigPython dataset. The data consists of 71.7B tokens of Python programming language. See Section 2.1 of the [paper](https://arxiv.org/abs/2203.13474) for more details.
## Training procedure
CodeGen was trained using cross-entropy loss to maximize the likelihood of sequential inputs.
The family of models are trained using multiple TPU-v4-512 by Google, leveraging data and model parallelism.
See Section 2.3 of the [paper](https://arxiv.org/abs/2203.13474) for more details.
## Evaluation results
We evaluate our models on two code generation benchmark: HumanEval and MTPB. Please refer to the [paper](https://arxiv.org/abs/2203.13474) for more details.
## Intended Use and Limitations
As an autoregressive language model, CodeGen is capable of extracting features from given natural language and programming language texts, and calculating the likelihood of them.
However, the model is intended for and best at **program synthesis**, that is, generating executable code given English prompts, where the prompts should be in the form of a comment string. The model can complete partially-generated code as well.
## How to use
This model can be easily loaded using the `AutoModelForCausalLM` functionality:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("Salesforce/codegen-2B-mono")
model = AutoModelForCausalLM.from_pretrained("Salesforce/codegen-2B-mono")
text = "def hello_world():"
input_ids = tokenizer(text, return_tensors="pt").input_ids
generated_ids = model.generate(input_ids, max_length=128)
print(tokenizer.decode(generated_ids[0], skip_special_tokens=True))
```
## BibTeX entry and citation info
```bibtex
@article{Nijkamp2022ACP,
title={A Conversational Paradigm for Program Synthesis},
author={Nijkamp, Erik and Pang, Bo and Hayashi, Hiroaki and Tu, Lifu and Wang, Huan and Zhou, Yingbo and Savarese, Silvio and Xiong, Caiming},
journal={arXiv preprint},
year={2022}
}
```
|
nghuyong/ernie-health-zh | 0f500f0603fc9f05f3e2f8befe8dd02f649a93e4 | 2022-05-31T09:07:46.000Z | [
"pytorch",
"electra",
"arxiv:2110.07244",
"transformers"
]
| null | false | nghuyong | null | nghuyong/ernie-health-zh | 2,197 | 1 | transformers | 1,292 | # ernie-health-zh
## Introduction
ERNIE-health is a Chinese biomedical language model pre-trained from in-domain text of de-identified online doctor-patient dialogues, electronic medical records, and textbooks.
More detail:
https://github.com/PaddlePaddle/Research/tree/master/KG/eHealth
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/ernie-health
https://arxiv.org/pdf/2110.07244.pdf
## Released Model Info
|Model Name|Language|Model Structure|
|:---:|:---:|:---:|
|ernie-health-zh| Chinese |Layer:12, Hidden:768, Heads:12|
This released pytorch model is converted from the officially released PaddlePaddle ERNIE model and
a series of experiments have been conducted to check the accuracy of the conversion.
- Official PaddlePaddle ERNIE repo:https://github.com/PaddlePaddle/Research/tree/master/KG/eHealth
- Pytorch Conversion repo: https://github.com/nghuyong/ERNIE-Pytorch
## How to use
```Python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("nghuyong/ernie-health-zh")
model = AutoModel.from_pretrained("nghuyong/ernie-health-zh")
```
## Citation
```bibtex
@article{wang2021building,
title={Building Chinese Biomedical Language Models via Multi-Level Text Discrimination},
author={Wang, Quan and Dai, Songtai and Xu, Benfeng and Lyu, Yajuan and Zhu, Yong and Wu, Hua and Wang, Haifeng},
journal={arXiv preprint arXiv:2110.07244},
year={2021}
}
```
|
peerapongch/baikal-sentiment-ball | c72e97733c3f42780150b112f3364328aa11a2f9 | 2022-04-11T07:57:59.000Z | [
"pytorch",
"camembert",
"text-classification",
"transformers"
]
| text-classification | false | peerapongch | null | peerapongch/baikal-sentiment-ball | 2,195 | null | transformers | 1,293 | Entry not found |
michaelrglass/albert-base-rci-wikisql-row | 9225ee36c17e3d8c505559798e1985ce68281189 | 2021-06-16T16:00:18.000Z | [
"pytorch",
"albert",
"text-classification",
"transformers"
]
| text-classification | false | michaelrglass | null | michaelrglass/albert-base-rci-wikisql-row | 2,188 | null | transformers | 1,294 | Entry not found |
twmkn9/distilbert-base-uncased-squad2 | 84a8ab9f335a39297b69790f023f9e5ff70a3734 | 2020-12-11T22:03:01.000Z | [
"pytorch",
"distilbert",
"question-answering",
"transformers",
"autotrain_compatible"
]
| question-answering | false | twmkn9 | null | twmkn9/distilbert-base-uncased-squad2 | 2,187 | 2 | transformers | 1,295 | This model is [Distilbert base uncased](https://huggingface.co/distilbert-base-uncased) trained on SQuAD v2 as:
```
export SQUAD_DIR=../../squad2
python3 run_squad.py
--model_type distilbert
--model_name_or_path distilbert-base-uncased
--do_train
--do_eval
--overwrite_cache
--do_lower_case
--version_2_with_negative
--save_steps 100000
--train_file $SQUAD_DIR/train-v2.0.json
--predict_file $SQUAD_DIR/dev-v2.0.json
--per_gpu_train_batch_size 8
--num_train_epochs 3
--learning_rate 3e-5
--max_seq_length 384
--doc_stride 128
--output_dir ./tmp/distilbert_fine_tuned/
```
Performance on a dev subset is close to the original paper:
```
Results:
{
'exact': 64.88976637051661,
'f1': 68.1776176526635,
'total': 6078,
'HasAns_exact': 69.7594501718213,
'HasAns_f1': 76.62665295288285,
'HasAns_total': 2910,
'NoAns_exact': 60.416666666666664,
'NoAns_f1': 60.416666666666664,
'NoAns_total': 3168,
'best_exact': 64.88976637051661,
'best_exact_thresh': 0.0,
'best_f1': 68.17761765266337,
'best_f1_thresh': 0.0
}
```
We are hopeful this might save you time, energy, and compute. Cheers! |
csebuetnlp/mT5_m2o_chinese_simplified_crossSum | 484d6b4a469251fb8432f9da7eb2da761932668f | 2022-04-25T16:48:18.000Z | [
"pytorch",
"mt5",
"text2text-generation",
"am",
"ar",
"az",
"bn",
"my",
"zh",
"en",
"fr",
"gu",
"ha",
"hi",
"ig",
"id",
"ja",
"rn",
"ko",
"ky",
"mr",
"ne",
"om",
"ps",
"fa",
"pcm",
"pt",
"pa",
"ru",
"gd",
"sr",
"si",
"so",
"es",
"sw",
"ta",
"te",
"th",
"ti",
"tr",
"uk",
"ur",
"uz",
"vi",
"cy",
"yo",
"arxiv:2112.08804",
"transformers",
"summarization",
"mT5",
"autotrain_compatible"
]
| summarization | false | csebuetnlp | null | csebuetnlp/mT5_m2o_chinese_simplified_crossSum | 2,187 | 3 | transformers | 1,296 | ---
tags:
- summarization
- mT5
language:
- am
- ar
- az
- bn
- my
- zh
- en
- fr
- gu
- ha
- hi
- ig
- id
- ja
- rn
- ko
- ky
- mr
- ne
- om
- ps
- fa
- pcm
- pt
- pa
- ru
- gd
- sr
- si
- so
- es
- sw
- ta
- te
- th
- ti
- tr
- uk
- ur
- uz
- vi
- cy
- yo
licenses:
- cc-by-nc-sa-4.0
widget:
- text: "Videos that say approved vaccines are dangerous and cause autism, cancer or infertility are among those that will be taken down, the company said. The policy includes the termination of accounts of anti-vaccine influencers. Tech giants have been criticised for not doing more to counter false health information on their sites. In July, US President Joe Biden said social media platforms were largely responsible for people's scepticism in getting vaccinated by spreading misinformation, and appealed for them to address the issue. YouTube, which is owned by Google, said 130,000 videos were removed from its platform since last year, when it implemented a ban on content spreading misinformation about Covid vaccines. In a blog post, the company said it had seen false claims about Covid jabs \"spill over into misinformation about vaccines in general\". The new policy covers long-approved vaccines, such as those against measles or hepatitis B. \"We're expanding our medical misinformation policies on YouTube with new guidelines on currently administered vaccines that are approved and confirmed to be safe and effective by local health authorities and the WHO,\" the post said, referring to the World Health Organization."
---
# mT5-m2o-chinese_simplified-CrossSum
This repository contains the many-to-one (m2o) mT5 checkpoint finetuned on all cross-lingual pairs of the [CrossSum](https://huggingface.co/datasets/csebuetnlp/CrossSum) dataset, where the target summary was in **chinese_simplified**, i.e. this model tries to **summarize text written in any language in Chinese(Simplified).** For finetuning details and scripts, see the [paper](https://arxiv.org/abs/2112.08804) and the [official repository](https://github.com/csebuetnlp/CrossSum).
## Using this model in `transformers` (tested on 4.11.0.dev0)
```python
import re
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
WHITESPACE_HANDLER = lambda k: re.sub('\s+', ' ', re.sub('\n+', ' ', k.strip()))
article_text = """Videos that say approved vaccines are dangerous and cause autism, cancer or infertility are among those that will be taken down, the company said. The policy includes the termination of accounts of anti-vaccine influencers. Tech giants have been criticised for not doing more to counter false health information on their sites. In July, US President Joe Biden said social media platforms were largely responsible for people's scepticism in getting vaccinated by spreading misinformation, and appealed for them to address the issue. YouTube, which is owned by Google, said 130,000 videos were removed from its platform since last year, when it implemented a ban on content spreading misinformation about Covid vaccines. In a blog post, the company said it had seen false claims about Covid jabs "spill over into misinformation about vaccines in general". The new policy covers long-approved vaccines, such as those against measles or hepatitis B. "We're expanding our medical misinformation policies on YouTube with new guidelines on currently administered vaccines that are approved and confirmed to be safe and effective by local health authorities and the WHO," the post said, referring to the World Health Organization."""
model_name = "csebuetnlp/mT5_m2o_chinese_simplified_crossSum"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
input_ids = tokenizer(
[WHITESPACE_HANDLER(article_text)],
return_tensors="pt",
padding="max_length",
truncation=True,
max_length=512
)["input_ids"]
output_ids = model.generate(
input_ids=input_ids,
max_length=84,
no_repeat_ngram_size=2,
num_beams=4
)[0]
summary = tokenizer.decode(
output_ids,
skip_special_tokens=True,
clean_up_tokenization_spaces=False
)
print(summary)
```
## Citation
If you use this model, please cite the following paper:
```
@article{hasan2021crosssum,
author = {Tahmid Hasan and Abhik Bhattacharjee and Wasi Uddin Ahmad and Yuan-Fang Li and Yong-bin Kang and Rifat Shahriyar},
title = {CrossSum: Beyond English-Centric Cross-Lingual Abstractive Text Summarization for 1500+ Language Pairs},
journal = {CoRR},
volume = {abs/2112.08804},
year = {2021},
url = {https://arxiv.org/abs/2112.08804},
eprinttype = {arXiv},
eprint = {2112.08804}
}
``` |
deepset/gelectra-base | 13ebe992ff34cb2bbdd0fdef4d91e57f1f41c3fc | 2022-02-17T14:12:20.000Z | [
"pytorch",
"tf",
"electra",
"pretraining",
"de",
"dataset:wikipedia",
"dataset:OPUS",
"dataset:OpenLegalData",
"arxiv:2010.10906",
"transformers",
"license:mit"
]
| null | false | deepset | null | deepset/gelectra-base | 2,186 | 4 | transformers | 1,297 | ---
language: de
license: mit
datasets:
- wikipedia
- OPUS
- OpenLegalData
---
# German ELECTRA base
Released, Oct 2020, this is a German ELECTRA language model trained collaboratively by the makers of the original German BERT (aka "bert-base-german-cased") and the dbmdz BERT (aka bert-base-german-dbmdz-cased). In our [paper](https://arxiv.org/pdf/2010.10906.pdf), we outline the steps taken to train our model. Our evaluation suggests that this model is somewhat undertrained. For best performance from a base sized model, we recommend deepset/gbert-base
## Overview
**Paper:** [here](https://arxiv.org/pdf/2010.10906.pdf)
**Architecture:** ELECTRA base (discriminator)
**Language:** German
## Performance
```
GermEval18 Coarse: 76.02
GermEval18 Fine: 42.22
GermEval14: 86.02
```
See also:
deepset/gbert-base
deepset/gbert-large
deepset/gelectra-base
deepset/gelectra-large
deepset/gelectra-base-generator
deepset/gelectra-large-generator
## Authors
Branden Chan: `branden.chan [at] deepset.ai`
Stefan Schweter: `stefan [at] schweter.eu`
Timo Möller: `timo.moeller [at] deepset.ai`
## About us

We bring NLP to the industry via open source!
Our focus: Industry specific language models & large scale QA systems.
Some of our work:
- [German BERT (aka "bert-base-german-cased")](https://deepset.ai/german-bert)
- [GermanQuAD and GermanDPR datasets and models (aka "gelectra-base-germanquad", "gbert-base-germandpr")](https://deepset.ai/germanquad)
- [FARM](https://github.com/deepset-ai/FARM)
- [Haystack](https://github.com/deepset-ai/haystack/)
Get in touch:
[Twitter](https://twitter.com/deepset_ai) | [LinkedIn](https://www.linkedin.com/company/deepset-ai/) | [Slack](https://haystack.deepset.ai/community/join) | [GitHub Discussions](https://github.com/deepset-ai/haystack/discussions) | [Website](https://deepset.ai)
By the way: [we're hiring!](http://www.deepset.ai/jobs)
|
hf-internal-testing/tiny-random-gptj | b96595a4bcdeb272096214589efa0314259853a0 | 2022-07-12T12:30:13.000Z | [
"pytorch",
"gptj",
"transformers"
]
| null | false | hf-internal-testing | null | hf-internal-testing/tiny-random-gptj | 2,172 | null | transformers | 1,298 | Entry not found |
junnyu/roformer_v2_chinese_char_base | 27c46a7c48fd720fac0a9a4318323ffeaa303588 | 2022-05-11T03:32:22.000Z | [
"pytorch",
"roformer",
"fill-mask",
"zh",
"arxiv:2104.09864",
"transformers",
"roformer-v2",
"tf2.0",
"autotrain_compatible"
]
| fill-mask | false | junnyu | null | junnyu/roformer_v2_chinese_char_base | 2,157 | 2 | transformers | 1,299 | ---
language: zh
tags:
- roformer-v2
- pytorch
- tf2.0
inference: False
---
## 介绍
### tf版本
https://github.com/ZhuiyiTechnology/roformer-v2
### pytorch版本+tf2.0版本
https://github.com/JunnYu/RoFormer_pytorch
### 安装
- pip install roformer==0.4.3
## 评测对比
### CLUE-dev榜单分类任务结果,base+large版本。
| | iflytek | tnews | afqmc | cmnli | ocnli | wsc | csl |
| :-----: | :-----: | :---: | :---: | :---: | :---: | :---: | :---: |
| BERT | 60.06 | 56.80 | 72.41 | 79.56 | 73.93 | 78.62 | 83.93 |
| RoBERTa | 60.64 | 58.06 | 74.05 | 81.24 | 76.00 | 87.50 | 84.50 |
| RoFormer | 60.91 | 57.54 | 73.52 | 80.92 | 76.07 | 86.84 | 84.63 |
| RoFormerV2<sup>*</sup> | 60.87 | 56.54 | 72.75 | 80.34 | 75.36 | 80.92 | 84.67 |
| GAU-α | 61.41 | 57.76 | 74.17 | 81.82 | 75.86 | 79.93 | 85.67 |
| RoFormer-pytorch(本仓库代码) | 60.60 | 57.51 | 74.44 | 80.79 | 75.67 | 86.84 | 84.77 |
| RoFormerV2-pytorch(本仓库代码) | **62.87** | 59.03 | **76.20** | 80.85 | 79.73 | 87.82 | **91.87** |
| GAU-α-pytorch(Adafactor) | 61.18 | 57.52 | 73.42 | 80.91 | 75.69 | 80.59 | 85.5 |
| GAU-α-pytorch(AdamW wd0.01 warmup0.1) | 60.68 | 57.95 | 73.08 | 81.02 | 75.36 | 81.25 | 83.93 |
| RoFormerV2-large-pytorch(本仓库代码) | 61.75 | **59.21** | 76.14 | 82.35 | **81.73** | **91.45** | 91.5 |
| Chinesebert-large-pytorch | 61.25 | 58.67 | 74.70 | **82.65** | 79.63 | 87.83 | 84.97 |
### CLUE-1.0-test榜单分类任务结果,base+large版本。
| | iflytek | tnews | afqmc | cmnli | ocnli | wsc | csl |
| :-----: | :-----: | :---: | :---: | :---: | :---: | :---: | :---: |
| RoFormer-pytorch(本仓库代码) | 59.54 | 57.34 | 74.46 | 80.23 | 73.67 | 80.69 | 84.57 |
| RoFormerV2-pytorch(本仓库代码) | **63.15** | 58.24 | 75.42 | 80.59 | 74.17 | 83.79 | 83.73 |
| GAU-α-pytorch(Adafactor) | 61.38 | 57.08 | 74.05 | 80.37 | 73.53 | 74.83 | **85.6** |
| GAU-α-pytorch(AdamW wd0.01 warmup0.1) | 60.54 | 57.67 | 72.44 | 80.32 | 72.97 | 76.55 | 84.13 |
| RoFormerV2-large-pytorch(本仓库代码) | 61.85 | **59.13** | **76.38** | 80.97 | 76.23 | **85.86** | 84.33 |
| Chinesebert-large-pytorch | 61.54 | 58.57 | 74.8 | **81.94** | **76.93** | 79.66 | 85.1 |
### 注:
- 其中RoFormerV2<sup>*</sup>表示的是未进行多任务学习的RoFormerV2模型,该模型苏神并未开源,感谢苏神的提醒。
- 其中不带有pytorch后缀结果都是从[GAU-alpha](https://github.com/ZhuiyiTechnology/GAU-alpha)仓库复制过来的。
- 其中带有pytorch后缀的结果都是自己训练得出的。
- 苏神代码中拿了cls标签后直接进行了分类,而本仓库使用了如下的分类头,多了2个dropout,1个dense,1个relu激活。
```python
class RoFormerClassificationHead(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.out_proj = nn.Linear(config.hidden_size, config.num_labels)
self.config = config
def forward(self, features, **kwargs):
x = features[:, 0, :] # take <s> token (equiv. to [CLS])
x = self.dropout(x)
x = self.dense(x)
x = ACT2FN[self.config.hidden_act](x) # 这里是relu
x = self.dropout(x)
x = self.out_proj(x)
return x
```
## pytorch & tf2.0使用
```python
import torch
import tensorflow as tf
from transformers import BertTokenizer
from roformer import RoFormerForMaskedLM, TFRoFormerForMaskedLM
text = "今天[MASK]很好,我[MASK]去公园玩。"
tokenizer = BertTokenizer.from_pretrained("junnyu/roformer_v2_chinese_char_base")
pt_model = RoFormerForMaskedLM.from_pretrained("junnyu/roformer_v2_chinese_char_base")
tf_model = TFRoFormerForMaskedLM.from_pretrained(
"junnyu/roformer_v2_chinese_char_base", from_pt=True
)
pt_inputs = tokenizer(text, return_tensors="pt")
tf_inputs = tokenizer(text, return_tensors="tf")
# pytorch
with torch.no_grad():
pt_outputs = pt_model(**pt_inputs).logits[0]
pt_outputs_sentence = "pytorch: "
for i, id in enumerate(tokenizer.encode(text)):
if id == tokenizer.mask_token_id:
tokens = tokenizer.convert_ids_to_tokens(pt_outputs[i].topk(k=5)[1])
pt_outputs_sentence += "[" + "||".join(tokens) + "]"
else:
pt_outputs_sentence += "".join(
tokenizer.convert_ids_to_tokens([id], skip_special_tokens=True)
)
print(pt_outputs_sentence)
# tf
tf_outputs = tf_model(**tf_inputs, training=False).logits[0]
tf_outputs_sentence = "tf: "
for i, id in enumerate(tokenizer.encode(text)):
if id == tokenizer.mask_token_id:
tokens = tokenizer.convert_ids_to_tokens(tf.math.top_k(tf_outputs[i], k=5)[1])
tf_outputs_sentence += "[" + "||".join(tokens) + "]"
else:
tf_outputs_sentence += "".join(
tokenizer.convert_ids_to_tokens([id], skip_special_tokens=True)
)
print(tf_outputs_sentence)
# small
# pytorch: 今天[的||,||是||很||也]很好,我[要||会||是||想||在]去公园玩。
# tf: 今天[的||,||是||很||也]很好,我[要||会||是||想||在]去公园玩。
# base
# pytorch: 今天[我||天||晴||园||玩]很好,我[想||要||会||就||带]去公园玩。
# tf: 今天[我||天||晴||园||玩]很好,我[想||要||会||就||带]去公园玩。
# large
# pytorch: 今天[天||气||我||空||阳]很好,我[又||想||会||就||爱]去公园玩。
# tf: 今天[天||气||我||空||阳]很好,我[又||想||会||就||爱]去公园玩。
```
## 引用
Bibtex:
```tex
@misc{su2021roformer,
title={RoFormer: Enhanced Transformer with Rotary Position Embedding},
author={Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu},
year={2021},
eprint={2104.09864},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
```tex
@techreport{roformerv2,
title={RoFormerV2: A Faster and Better RoFormer - ZhuiyiAI},
author={Jianlin Su, Shengfeng Pan, Bo Wen, Yunfeng Liu},
year={2022},
url="https://github.com/ZhuiyiTechnology/roformer-v2",
}
``` |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.