
full_name
stringlengths 10
67
| url
stringlengths 29
86
| description
stringlengths 3
347
⌀ | readme
stringlengths 0
162k
| stars
int64 10
3.1k
| forks
int64 0
1.51k
|
|---|---|---|---|---|---|
TransformerOptimus/Awesome-SuperAGI
|
https://github.com/TransformerOptimus/Awesome-SuperAGI
|
Awesome Repository of SuperAGI
|
<h3 align="center">
[](https://awesome.re)
<br><br>
Awesome Repository of
</h3>
<p align="center">
<a href="https://superagi.com//#gh-light-mode-only">
<img src="https://superagi.com/wp-content/uploads/2023/05/Logo-dark.svg" width="318px" alt="SuperAGI logo" />
</a>
<a href="https://superagi.com//#gh-dark-mode-only">
<img src="https://superagi.com/wp-content/uploads/2023/05/Logo-light.svg" width="318px" alt="SuperAGI logo" />
</a>
</p>
<p align="center"><i>Open-source framework to build, manage and run useful Autonomous AI Agents</i></p>
<p align="center">
<a href="https://superagi.com"> <img src="https://superagi.com/wp-content/uploads/2023/07/Website.svg"></a>
<a href="https://app.superagi.com"> <img src="https://superagi.com/wp-content/uploads/2023/07/Cloud.svg"></a>
<a href="https://marketplace.superagi.com/"> <img src="https://superagi.com/wp-content/uploads/2023/07/Marketplace.svg"></a>
</p>
<p align="center"><b>Follow SuperAGI </b></p>
<p align="center">
<a href="https://twitter.com/_superAGI" target="blank">
<img src="https://img.shields.io/twitter/follow/_superAGI?label=Follow: _superAGI&style=social" alt="Follow _superAGI"/>
</a>
<a href="https://www.reddit.com/r/Super_AGI" target="_blank"><img src="https://img.shields.io/twitter/url?label=/r/Super_AGI&logo=reddit&style=social&url=https://github.com/TransformerOptimus/SuperAGI"/></a>
<a href="https://discord.gg/dXbRe5BHJC" target="blank">
<img src="https://img.shields.io/discord/1107593006032355359?label=Join%20SuperAGI&logo=discord&style=social" alt="Join SuperAGI Discord Community"/>
</a>
<a href="https://www.youtube.com/@_superagi" target="_blank"><img src="https://img.shields.io/twitter/url?label=Youtube&logo=youtube&style=social&url=https://github.com/TransformerOptimus/SuperAGI"/></a>
</p>
<p align="center"><b>Connect with the Creator </b></p>
<p align="center">
<a href="https://twitter.com/ishaanbhola" target="blank">
<img src="https://img.shields.io/twitter/follow/ishaanbhola?label=Follow: ishaanbhola&style=social" alt="Follow ishaanbhola"/>
</a>
</p>
<p align="center"><b>Share SuperAGI Repository</b></p>
<p align="center">
<a href="https://twitter.com/intent/tweet?text=Check%20this%20GitHub%20repository%20out.%20SuperAGI%20-%20Let%27s%20you%20easily%20build,%20manage%20and%20run%20useful%20autonomous%20AI%20agents.&url=https://github.com/TransformerOptimus/SuperAGI&hashtags=SuperAGI,AGI,Autonomics,future" target="blank">
<img src="https://img.shields.io/twitter/follow/_superAGI?label=Share Repo on Twitter&style=social" alt="Follow _superAGI"/></a>
<a href="https://t.me/share/url?text=Check%20this%20GitHub%20repository%20out.%20SuperAGI%20-%20Let%27s%20you%20easily%20build,%20manage%20and%20run%20useful%20autonomous%20AI%20agents.&url=https://github.com/TransformerOptimus/SuperAGI" target="_blank"><img src="https://img.shields.io/twitter/url?label=Telegram&logo=Telegram&style=social&url=https://github.com/TransformerOptimus/SuperAGI" alt="Share on Telegram"/></a>
<a href="https://api.whatsapp.com/send?text=Check%20this%20GitHub%20repository%20out.%20SuperAGI%20-%20Let's%20you%20easily%20build,%20manage%20and%20run%20useful%20autonomous%20AI%20agents.%20https://github.com/TransformerOptimus/SuperAGI"><img src="https://img.shields.io/twitter/url?label=whatsapp&logo=whatsapp&style=social&url=https://github.com/TransformerOptimus/SuperAGI" /></a> <a href="https://www.reddit.com/submit?url=https://github.com/TransformerOptimus/SuperAGI&title=Check%20this%20GitHub%20repository%20out.%20SuperAGI%20-%20Let's%20you%20easily%20build,%20manage%20and%20run%20useful%20autonomous%20AI%20agents.
" target="blank">
<img src="https://img.shields.io/twitter/url?label=Reddit&logo=Reddit&style=social&url=https://github.com/TransformerOptimus/SuperAGI" alt="Share on Reddit"/>
</a> <a href="mailto:?subject=Check%20this%20GitHub%20repository%20out.&body=SuperAGI%20-%20Let%27s%20you%20easily%20build,%20manage%20and%20run%20useful%20autonomous%20AI%20agents.%3A%0Ahttps://github.com/TransformerOptimus/SuperAGI" target="_blank"><img src="https://img.shields.io/twitter/url?label=Gmail&logo=Gmail&style=social&url=https://github.com/TransformerOptimus/SuperAGI"/></a> <a href="https://www.buymeacoffee.com/superagi" target="_blank"><img src="https://cdn.buymeacoffee.com/buttons/default-orange.png" alt="Buy Me A Coffee" height="23" width="100" style="border-radius:1px"></a>
</p>
<hr>
## Awesome SuperAGI Twitter Agents
<details>
<summary>
<a href="https://twitter.com/_SkyAGI" target="blank">
<img src="https://img.shields.io/twitter/follow/_SkyAGI?label=_SkyAGI&style=social" alt="_SkyAGI"/>
</a>
</summary>
A regularly-scheduled SuperAGI agent that finds the latest AI news from the internet and tweets it with relevant mentions and hashtags.
</details>
<details>
<summary>
<a href="https://twitter.com/_superkittens" target="blank">
<img src="https://img.shields.io/twitter/follow/_superkittens?label=_superkittens&style=social" alt="_superkittens"/>
</a>
</summary>
A SuperAGI agent disguised as a Twitter bot created using SuperAGI that is scheduled to tweet unique 8-bit images of superhero kittens along with captions and relevant hashtags.
</details>
<details>
<summary>
<a href="https://twitter.com/_ministories" target="blank">
<img src="https://img.shields.io/twitter/follow/_ministories?label=_ministories&style=social" alt="_ministories"/>
</a>
</summary>
A SuperAGI agent that create bite-sized sci-fi stories and tweets it along with AI generated images and hashtags.
</details>
## Awesome Apps created using SuperCoder Agent Template
[Snake Game](https://superagi.com/supercoder/#SnakeGame)
[Markdown Previewer](https://eloquent-cranachan-750575.netlify.app/)
[Developer Jokes](https://zippy-entremet-770562.netlify.app/)
[PDF-to-Image Converter](https://stirring-bublanina-6de87f.netlify.app/)
[Note-taking App](https://flourishing-froyo-f3574c.netlify.app/)
[Pomodoro App](https://brilliant-beignet-df3779.netlify.app/)
[Dino Game](https://ornate-rugelach-8cbcfb.netlify.app/)
[Flappy Bird](https://clinquant-fox-3253a2.netlify.app/)
[Code Minifier](https://resilient-beijinho-ffa332.netlify.app/)
## Awesome Use Cases of Autonomous AI Agents
<details>
<summary>
Document Processing and OCR
</summary>
Autonomous agents can revolutionize document processing and Optical Character Recognition (OCR) tasks. These agents can automatically scan, read, and extract data from various types of documents like invoices, contracts, and forms. They can understand the context, classify documents, and input data into relevant systems. This eliminates manual data entry errors, reduces processing time, and enhances data management efficiency.
</details>
<details>
<summary>
Internal Employee Service Desk
</summary>
Autonomous agents can be deployed as virtual assistants to provide internal support for employees. They can answer common queries about policies, procedures, or technical issues, and guide employees through resolution steps. They can also schedule meetings, manage calendars, or assist with other administrative tasks, helping to improve overall employee productivity and satisfaction.
</details>
<details>
<summary>
Insurance Underwriting
</summary>
Autonomous agents can transform insurance underwriting by automating risk assessment and pricing. They can analyze a multitude of data points like medical records, financial data, and geographical data to assess risks and determine premiums. The autonomous nature of these agents ensures consistent underwriting decisions and can greatly reduce processing time.
</details>
<details>
<summary>
Drug Discovery Optimization
</summary>
In the pharmaceutical industry, autonomous agents can assist in optimizing the drug discovery process. These agents can analyze vast amounts of biomedical data, including genomic data, medical literature, and clinical trials data to identify potential drug targets and predict drug effectiveness. This can significantly reduce the time and cost associated with drug discovery and development, leading to quicker market introductions.
</details>
<details>
<summary>
Customer Support / Experience (CX)
</summary>
Autonomous agents in customer support or CX provide immediate responses to customer queries and issues, contributing to better overall customer experience. These agents can efficiently handle high volumes of inquiries, offer solutions, provide product information, and guide customers through processes. They can also learn from previous interactions, making their responses more personalized and relevant, leading to higher customer satisfaction and loyalty.
</details>
<details>
<summary>
Software Application Development
</summary>
Autonomous agents can aid in software development by automating various aspects of the development process. This includes code generation, testing, and debugging. They can analyze code to find errors, suggest improvements, or even write code snippets. By automating these repetitive and time-consuming tasks, developers can focus more on creative and complex aspects of software development.
</details>
<details>
<summary>
Fraud Detection
</summary>
In the financial sector and others, autonomous agents can be used to detect fraudulent activities. They can analyze vast amounts of transaction data in real-time to identify patterns that signify potential fraud. These agents can also learn from past incidents, improving their detection capabilities over time. This leads to quicker responses to fraud and reduces financial and reputational damage.
</details>
<details>
<summary>
Cybersecurity
</summary>
Autonomous agents can play a pivotal role in cybersecurity by proactively detecting, preventing, and responding to threats. They can monitor network traffic for unusual activity, identify vulnerabilities in systems, and react to threats faster than human counterparts. Some advanced agents can even predict future attacks based on patterns and trends, thereby enhancing an organization’s cybersecurity posture.
</details>
<details>
<summary>
Autonomous Customer Engagement
</summary>
Autonomous agents can revolutionize customer service by providing round-the-clock support. These agents can answer customer inquiries instantly, guide them through complex processes, and resolve issues promptly. They can be programmed to learn from past interactions, allowing them to provide more personalized and accurate responses over time. This not only improves customer satisfaction but also reduces the burden on human customer service representatives.
</details>
<details>
<summary>
Robotic Process Automation (RPA)
</summary>
Autonomous agents can automate repetitive, rule-based tasks, thereby freeing up human resources for more complex tasks. In the context of RPA, these agents can read and interpret data from various sources, manipulate data, trigger responses, and communicate with other digital systems. They can perform tasks such as data entry, invoice processing, or payroll automation, which can significantly improve operational efficiency and accuracy.
</details>
<details>
<summary>
Sales Engagement
</summary>
Autonomous agents in sales engagement act as tireless, 24/7 sales representatives. They can interact with potential customers, understand their needs through natural language processing, and recommend appropriate products or services. They can also handle initial inquiries, schedule meetings, and follow up with prospects, thereby increasing efficiency and sales productivity. Additionally, these agents can gather and analyze data from interactions to provide valuable insights into customer behavior and preferences.
</details>
## Awesome Research and Learnings
[Processing Structured & Unstructured Data with SuperAGI and LlamaIndex](https://superagi.com/processing-structured-unstructured-data-with-superagi-and-llamaindex/)
[Understanding dedicated & shared tool memory in SuperAGI](https://superagi.com/understanding-how-dedicated-shared-tool-memory-works-in-superagi/)
[AACP (Agent to Agent Communication Protocol)](https://superagi.com/introducing-aacp-agent-to-agent-communication-protocol/)
[Agent Instructions: Autonomous AI Agent Trajectory Fine-Tuning](https://superagi.com/agent-instructions/)
| 76
| 3
|
Nilsen84/lcqt2
|
https://github.com/Nilsen84/lcqt2
| null |
<h1>
Lunar Client Qt 2
<a href="https://discord.gg/mjvm8PzB2u">
<img src=".github/assets/discord.svg" alt="discord" height="32" style="vertical-align: -5px;"/>
</a>
</h1>
Continuation of the original [lunar-client-qt](https://github.com/nilsen84/lunar-client-qt), moved to a new repo because of the complete rewrite and redesign.
<img src=".github/assets/screenshot.png" width="600" alt="screenshot of lcqt">
## Installation
#### Windows
Simply download and run the setup exe from the [latest release](https://github.com/nilsen84/lcqt2/releases/latest).
#### Arch Linux
Use the AUR package [lunar-client-qt2](https://aur.archlinux.org/packages/lunar-client-qt2)
#### MacOS/Linux
> If you are using Linux, be sure to have the `Lunar Client-X.AppImage` renamed to `lunarclient` in `/usr/bin/`. Alternatively, run lcqt2 with `Lunar Client Qt ~/path/to/lunar/appimage`.
1. Download the macos/linux.tar.gz file from the [newest release](https://github.com/nilsen84/lcqt2/releases/latest).
2. Extract it anywhere
3. Run the `Lunar Client Qt` executable
> **IMPORTANT:** All 3 files which where inside the tar need to stay together.
> You are allowed to move all 3 together, you're also allowed to create symlinks.
## Building
#### Prerequisites
- Rust Nightly
- NPM
#### Building
LCQT2 is made up of 3 major components:
- The injector - responsible for locating the launcher executable and injecting a javascript patch into it
- The gui - contains the gui opened by pressing the syringe button, also contains the javascript patch used by the injector
- The agent - java agent which implements all game patches
In order for lcqt to work properly all 3 components need to be built into the same directory.
```bash
$ ./gradlew installDist # builds all 3 components and generates a bundle in build/install/lcqt2
```
```bash
$ ./gradlew run # equivalent to ./gradlew installDist && './build/install/lcqt2/Lunar Client Qt'
```
> `./gradlew installDebugDist` and `./gradlew runDebug` do the same thing except they build the rust injector in debug mode.
| 29
| 5
|
verytinydever/cvpr-lab0
|
https://github.com/verytinydever/cvpr-lab0
| null |
# cvpr-lab0
| 13
| 0
|
verytinydever/covid-19-bot-updater
|
https://github.com/verytinydever/covid-19-bot-updater
| null |
Bot that gives covid-19 update
| 15
| 0
|
kurogai/100-mitre-attack-projects
|
https://github.com/kurogai/100-mitre-attack-projects
|
Projects for security students and professionals
|
<h1>100 MITRE ATT&CK Programming Projects for RedTeamers</h1>
<p align="center">
<img src="https://cdn.infrasos.com/wp-content/uploads/2022/11/What-is-a-Red-team-in-cybersecurity.png">
</p>
This repo organizes a full list of redteam projects to help everyone into this field gain knownledge and skills in programming aimed to offensive security exercices.
I recommend you to do them on the programming language you are most comfortable with. Implementing these projects will definitely help you gain more experience and, consequently, master the language. They are divided in categories, ranging from super basic to advanced projects.
If you enjoy this list please take the time to recommend it to a friend and follow me! I will be happy with that :) 🇦🇴.
And remember: With great power comes... (we already know).
Parent Project: <a href="https://github.com/kurogai/100-redteam-projects">100 RedTeam Projects</a>
<h3>Contributions</h3>
You can make a pull request for the "Projects" directory and name the file in
compliance with the following convention:
```
[ID] PROJECT_NAME - <LANGUAGE> | AUTHOR
```
#### Example:
```
[91] Web Exploitation Framework - <C> | EONRaider
```
<br>
Consider to insert your notes during the development of any of those projects, to help others understand what dificultes might appear during the development. After your commit as been approved, share to your social medias and make a reference of your work so others can learn, help and use as reference.
<h2>Reconnaissance</h2>
<h4>Description</h4>
Reconnaissance consists of techniques that involve adversaries actively or passively gathering information that can be used to support targeting. Such information may include details of the victim organization, infrastructure, or staff/personnel. This information can be leveraged by the adversary to aid in other phases of the adversary lifecycle, such as using gathered information to plan and execute Initial Access, to scope and prioritize post-compromise objectives, or to drive and lead further Reconnaissance efforts.
---
ID | Title | Reference | Example
---|---|---|---
1 | Active Network and Fingerprint Scanner | Link | :x:
2 | Social media profiling and data gathering script | Link | :x:
3 | Dork based OSINT tool | Link | :x:
4 | Website vulnerability scanner | Link | :x:
5 | WHOIS | Link | :x:
6 | DNS subdomain enumeration | Link | :x:
7 | Spearphishing Service | Link | :x:
8 | Victim | Link | :x:
9 | DNS enumeration and reconnaissance tool | Link | :x:
<h5>Notable Projects</h5>
- Project A by X
---
<h2>Resource Development</h2>
<h4>Description</h4>
Resource Development consists of techniques that involve adversaries creating, purchasing, or compromising/stealing resources that can be used to support targeting. Such resources include infrastructure, accounts, or capabilities. These resources can be leveraged by the adversary to aid in other phases of the adversary lifecycle, such as using purchased domains to support Command and Control, email accounts for phishing as a part of Initial Access, or stealing code signing certificates to help with Defense Evasion.
---
ID | Title | Reference | Example
---|---|---|---
10 | Dynamic Website Phishing Tool | Link | :x:
11 | Eamil based phishing spread | Link | :x:
12 | Malware sample creation and analysis | Link | :x:
13 | Replicate a public exploit and use to create a backdoor | Link | :x:
14 | Crafting malicious documents for social engineering attacks | Link | :x:
15 | Wordpress C2 Infrastructure | Link | :x:
<h5>Notable Projects</h5>
- Project A by X
---
<h2>Initial Access</h2>
<h3>Description</h3>
Initial Access consists of techniques that use various entry vectors to gain their initial foothold within a network. Techniques used to gain a foothold include targeted spearphishing and exploiting weaknesses on public-facing web servers. Footholds gained through initial access may allow for continued access, like valid accounts and use of external remote services, or may be limited-use due to changing passwords.
---
ID | Title | Reference | Example
---|---|---|---
16 | Exploiting a vulnerable web application | Link | :x:
17 | Password spraying attack against Active Directory | Link | :x:
18 | Email spear-phishing campaign | Link | :x:
19 | Exploiting misconfigured network services | Link | :x:
20 | USB device-based attack vector development | Link | :x:
21 | Spearphishing Link | Link | :x:
<h5>Notable Projects</h5>
- Project A by X
---
<h2>Execution</h2>
<h3>Description</h3>
Execution consists of techniques that result in adversary-controlled code running on a local or remote system. Techniques that run malicious code are often paired with techniques from all other tactics to achieve broader goals, like exploring a network or stealing data. For example, an adversary might use a remote access tool to run a PowerShell script that does Remote System Discovery.
---
ID | Title | Reference | Example
---|---|---|---
22 | Remote code execution exploit development | Link | :x:
23 | Creating a backdoor using shellcode | Link | :x:
24 | Building a command-line remote administration tool | Link | :x:
25 | Malicious macro development for document-based attacks | Link | :x:
26 | Remote code execution via memory corruption vulnerability | Link | :x:
27 | Command Line Interpreter for C2 | Link | :x:
28 | Cron based execution | Link | :x:
<h5>Notable Projects</h5>
- Project A by X
---
<h2>Persistence</h2>
<h3>Description</h3>
Persistence consists of techniques that adversaries use to keep access to systems across restarts, changed credentials, and other interruptions that could cut off their access. Techniques used for persistence include any access, action, or configuration changes that let them maintain their foothold on systems, such as replacing or hijacking legitimate code or adding startup code.
---
ID | Title | Reference | Example
---|---|---|---
29 | Developing a rootkit for Windows | Link | :x:
30 | Implementing a hidden service in a web server | Link | :x:
31 | Backdooring a legitimate executable | Link | :x:
32 | Creating a scheduled task for persistent access | Link | :x:
33 | Developing a kernel-level rootkit for Linux | Link | :x:
34 | LSASS Driver | Link | :x:
35 | Shortcut modification | Link | :x:
<h5>Notable Projects</h5>
- Project A by X
---
<h2>Privilege Escalation</h2>
<h3>Description</h3>
Privilege Escalation consists of techniques that adversaries use to gain higher-level permissions on a system or network. Adversaries can often enter and explore a network with unprivileged access but require elevated permissions to follow through on their objectives. Common approaches are to take advantage of system weaknesses, misconfigurations, and vulnerabilities. Examples of elevated access include:
- SYSTEM/root level
- local administrator
- user account with admin-like access
- user accounts with access to specific system or perform specific function
These techniques often overlap with Persistence techniques, as OS features that let an adversary persist can execute in an elevated context.
---
ID | Title | Reference | Example
---|---|---|---
36 | Exploiting a local privilege escalation vulnerability | Link | :x:
37 | Password cracking using GPU acceleration | Link | :x:
38 | Windows token manipulation for privilege escalation | Link | :x:
39 | Abusing insecure service configurations | Link | :x:
40 | Exploiting misconfigured sudoers file in Linux | Link | :x:
41 | Bypass UAC | Link | :x:
42 | Startup Itens | Link | :x:
<h5>Notable Projects</h5>
- Project A by X
---
<h2>Defense Evasion</h2>
<h3>Description</h3>
Defense Evasion consists of techniques that adversaries use to avoid detection throughout their compromise. Techniques used for defense evasion include uninstalling/disabling security software or obfuscating/encrypting data and scripts. Adversaries also leverage and abuse trusted processes to hide and masquerade their malware. Other tactics’ techniques are cross-listed here when those techniques include the added benefit of subverting defenses.
---
ID | Title | Reference | Example
---|---|---|---
43 | Developing an anti-virus evasion technique | Link | :x:
44 | Bypassing application whitelisting controls | Link | :x:
45 | Building a fileless malware variant | Link | :x:
46 | Detecting and disabling security products | Link | :x:
47 | Evading network-based intrusion detection systems | Link | :x:
48 | Parent PID spoofing | Link | :x:
49 | Disable Windows Event Logging | Link | :x:
50 | HTML Smuggling | Link | :x:
51 | DLL Injection | Link | :x:
52 | Pass The Hash | Link | :x:
<h5>Notable Projects</h5>
- Project A by X
---
<h2>Credential Access</h2>
<h3>Descrition</h3>
Credential Access consists of techniques for stealing credentials like account names and passwords. Techniques used to get credentials include keylogging or credential dumping. Using legitimate credentials can give adversaries access to systems, make them harder to detect, and provide the opportunity to create more accounts to help achieve their goals.
---
ID | Title | Reference | Example
---|---|---|---
53 | Password brute-forcing tool | Link | :x:
54 | Developing a keylogger for capturing credentials | Link | :x:
55 | Creating a phishing page to harvest login credentials | Link | :x:
56 | Exploiting password reuse across different systems | Link | :x:
57 | Implementing a pass-the-hash attack technique | Link | :x:
58 | OS Credential dumping (/etc/passwd and /etc/shadow) | Link | :x:
<h5>Notable Projects</h5>
- Project A by X
---
<h2>Discovery</h2>
<h3>Description</h3>
Discovery consists of techniques an adversary may use to gain knowledge about the system and internal network. These techniques help adversaries observe the environment and orient themselves before deciding how to act. They also allow adversaries to explore what they can control and what’s around their entry point in order to discover how it could benefit their current objective. Native operating system tools are often used toward this post-compromise information-gathering objective.
---
ID | Title | Reference | Example
---|---|---|---
59 | Network service enumeration tool | Link | :x:
60 | Active Directory enumeration script | Link | :x:
61 | Automated OS and software version detection | Link | :x:
62 | File and directory enumeration on a target system | Link | :x:
63 | Extracting sensitive information from memory dumps | Link | :x:
64 | Virtualization/Sandbox detection | Link | :x:
<h5>Notable Projects</h5>
- Project A by X
---
<h2>Lateral Movement</h2>
<h3>Description</h3>
Lateral Movement consists of techniques that adversaries use to enter and control remote systems on a network. Following through on their primary objective often requires exploring the network to find their target and subsequently gaining access to it. Reaching their objective often involves pivoting through multiple systems and accounts to gain. Adversaries might install their own remote access tools to accomplish Lateral Movement or use legitimate credentials with native network and operating system tools, which may be stealthier.
---
ID | Title | Reference | Example
---|---|---|---
65 | Developing a remote desktop protocol (RDP) brute-forcer | Link | :x:
66 | Creating a malicious PowerShell script for lateral movement | Link | :x:
67 | Implementing a pass-the-ticket attack technique | Link | :x:
68 | Exploiting trust relationships between domains | Link | :x:
69 | Developing a tool for lateral movement through SMB | Link | :x:
<h5>Notable Projects</h5>
- Project A by X
---
<h2>Collection</h2>
<h3>Description</h3>
Collection consists of techniques adversaries may use to gather information and the sources information is collected from that are relevant to following through on the adversary's objectives. Frequently, the next goal after collecting data is to steal (exfiltrate) the data. Common target sources include various drive types, browsers, audio, video, and email. Common collection methods include capturing screenshots and keyboard input.
---
ID | Title | Reference | Example
---|---|---|---
70 | Keylogging and screen capturing tool | Link | :x:
71 | Developing a network packet sniffer | Link | :x:
72 | Implementing a clipboard data stealer | Link | :x:
73 | Building a tool for extracting browser history | Link | :x:
74 | Creating a memory scraper for credit card information | Link | :x:
<h5>Notable Projects</h5>
- Project A by X
---
<h2>Command and Control</h2>
<h3>Description</h3>
Command and Control consists of techniques that adversaries may use to communicate with systems under their control within a victim network. Adversaries commonly attempt to mimic normal, expected traffic to avoid detection. There are many ways an adversary can establish command and control with various levels of stealth depending on the victim’s network structure and defenses.
---
ID | Title | Reference | Example
---|---|---|---
75 | Building a custom command and control (C2) server | Link | :x:
76 | Developing a DNS-based covert channel for C2 communication | Link | :x:
77 | Implementing a reverse shell payload for C2 | Link | :x:
78 | Creating a botnet for command and control purposes | Link | :x:
79 | Developing a convert communication channel using social media platforms | Link | :x:
80 | C2 with multi-stage channels | Link | :x:
<h5>Notable Projects</h5>
- Project A by X
---
<h2>Exfiltration</h2>
<h3>Description</h3>
Exfiltration consists of techniques that adversaries may use to steal data from your network. Once they’ve collected data, adversaries often package it to avoid detection while removing it. This can include compression and encryption. Techniques for getting data out of a target network typically include transferring it over their command and control channel or an alternate channel and may also include putting size limits on the transmission.
---
ID | Title | Reference | Example
---|---|---|---
82 | Building a file transfer tool using various protocols (HTTP, FTP, etc.) | Link | :x:
83 | Developing a steganography tool for hiding data within images | Link | :x:
84 | Implementing a DNS tunneling technique for data exfiltration | Link | :x:
85 | Creating a convert channel for exfiltrating data through email | Link | :x:
86 | Building a custom exfiltration tool using ICMP or DNS | Link | :x:
87 | Exfiltration Over Symmetric Encrypted Non-C2 Protocol | Link | :x:
<h5>Notable Projects</h5>
- Project A by X
---
<h2>Impact</h2>
<h3>Description</h3>
Impact consists of techniques that adversaries use to disrupt availability or compromise integrity by manipulating business and operational processes. Techniques used for impact can include destroying or tampering with data. In some cases, business processes can look fine, but may have been altered to benefit the adversaries’ goals. These techniques might be used by adversaries to follow through on their end goal or to provide cover for a confidentiality breach.
---
ID | Title | Reference | Example
---|---|---|---
88 | Developing a ransomware variant | Link | :x:
89 | Building a destructive wiper malware | Link | :x:
90 | Creating a denial-of-service (DoS) attack tool | Link | :x:
91 | Implementing a privilege-escalation-based destructive attack | Link | :x:
92 | Internal defacement | Link | :x:
93 | Account Access Manipulation or Removal | Link | :x:
94 | Data encryption | Link | :x:
95 | Resource Hijack | Link | :x:
96 | DNS Traffic Analysis for Malicious Activity Detection | Link | :x:
97 | Endpoint Detection and Response (EDR) for Ransomware | Link | :x:
99 | Network Segmentation for Critical Systems | Link | :x:
99 | Memory Protection Mechanisms Implementation | Link | :x:
100 | SCADA Security Assessment and Improvement | Link | :x:
<h5>Notable Projects</h5>
- Project A by X
---
### Guidelines
- If you need to test webtools, use any public vulnerable app like DVWA or DVAA
- All critical tools should be able to rollback the actions (like ransomwares)
- Make a checklist of features of any tool you developed and the resources you used to make it
### Disclaimer
All of those projects should be used inside controled enviorements, do not attemp to use any of those projects to hack, steal, destroy, evade, or any other illegal activities.
### Want to support my work?
[<a href="https://www.buymeacoffee.com/heberjuliok" target="_blank"><img src="https://cdn.buymeacoffee.com/buttons/default-orange.png" alt="Buy Me A Coffee" height="41" width="174"></a>](https://www.buymeacoffee.com/heberjuliok)
### Find me
[<a href="https://www.linkedin.com/in/h%C3%A9ber-j%C3%BAlio-496120190/" target="_blank"><img src="https://img.shields.io/badge/LinkedIn-0077B5?style=for-the-badge&logo=linkedin&logoColor=white" alt="Linkedin" height="41" width="174"></a>](https://www.linkedin.com/in/h%C3%A9ber-j%C3%BAlio-496120190/)
| 17
| 0
|
SindhuraPogarthi/ShareVerse
|
https://github.com/SindhuraPogarthi/ShareVerse
|
This is a social media website where people can connect through feed and chat with others
|
# Shareverse
 <!-- If you have a logo, add it here -->
## Table of Contents
1. [Introduction](#introduction)
2. [Features](#features)
3. [Getting Started](#getting-started)
- [Installation](#installation)
- [Running the Application](#running-the-application)
4. [Technologies Used](#technologies-used)
5. [Contributing](#contributing)
6. [License](#license)
## Introduction
Shareverse is a platform where users can connect, chat, and share their thoughts with each other. It provides an interactive feed section where signed-up users can post updates, images, or links, and other users can view and interact with these posts.
 <!-- If you have a screenshot, add it here -->
## Features
- User Registration and Login
- Real-time Chat functionality
- Post Creation and Sharing
- Feed Section to view posts from other users
- User Profile Management (uploading DP image, updating email, resetting password)
- Settings Section for customizing user preferences
- Mobile-responsive design for seamless user experience on various devices
## Getting Started
### Installation
1. Clone the repository to your local machine:
```bash
git clone https://github.com/sindhurapogarthi/shareverse.git
```
2. Navigate to the project directory:
```bash
cd shareverse
```
3. Install the project dependencies:
```bash
npm install
```
### Running the Application
1. Run the development server:
```bash
npm start
```
2. Open your browser and visit: `http://localhost:3000`
## Technologies Used
- React.js: Front-end development
- Firebase
- Framer-motion
- React-hot-toast
## Contributing
Contributions are welcome! If you find any bugs or have suggestions for improvements, please open an issue or submit a pull request. For major changes, please discuss the proposed changes first.
## License
[MIT License](LICENSE)
| 11
| 1
|
FSMargoo/one-day-one-point
|
https://github.com/FSMargoo/one-day-one-point
|
每天一个技术点
|
# 每天一个技术点
## 这是什么?
本仓库将会坚持每天更新一个讲解一个技术点的 Markdown 文章,由于考虑到不同人的学习进度不同,技术点有时会基础,有时会偏难,也有时会出一个系列的教程(例如“七天通读 SGI STL 源码”、“两天通读 CJson 源码”),当然也有其他的仓库成员参与,我们也欢迎更多的成员参与这个仓库贡献知识点!
本仓库有不同地来自不同领域的作者,读者可选择自己感兴趣的文章来阅读。
## 我该如何阅读 MD 文件?
此处推荐使用 VSCode 自带的编辑器阅读,非 VSCode 编辑器预览阅读有可能出现显示不全,显示出内嵌 CSS 代码等问题。
| 11
| 4
|
DXHM/BLANE
|
https://github.com/DXHM/BLANE
|
基于RUST的轻量化局域网通信工具 | Lightweight LAN Communication Tool in Rust
|
# BLANE - Lightweight LAN Communication Tool in Rust
For the Chinese version of the description, please refer to [中文版说明](/README_CN.md).
## About This Project
This project was initiated after a CTF offline competition (🚄⛰💧☔). With the challenging global public health situation, many CTF competitions have shifted to online formats. However, our team participated in an offline CTF competition for the first time. Due to our lack of familiarity with the competition format and insufficient preparation, we encountered difficulties in communication and collaboration among team members, especially when spread across different locations. The competition venue had restricted internet access and limited time, which further hindered effective communication, data sharing, and collaboration. As a result, I decided to develop a program that facilitates convenient communication within a local area network. This program can be useful in similar scenarios. This project aims to establish a basic framework, and I will continuously update and improve its functionalities.
+ BLANE is a LAN chat tool developed in Rust, designed for daily communication among devices within a local area network.
+ It utilizes asymmetric encryption algorithms for secure data transmission and supports text communication (both Chinese and English), as well as image and file transfer capabilities.
+ The project aims to provide a convenient, secure, and lightweight chat experience for members of small and medium-sized teams within a local area network.
If you have any ideas or suggestions, please feel free to raise an issue. Your support, attention, and contributions are highly appreciated. This project is in its early development stage, and updates will be made at my own pace.
Your attention and stars are welcomed🥰!
## Features
- Secure communication through asymmetric encryption algorithms
- Text communication supporting both Chinese and English languages
- Image and file transfer or sharing capabilities
- Online status tracking
- Customizable usernames
- etc..
## Build
1. Clone the repository:
```bash
git clone https://github.com/DXHM/BLANE.git
```
2. Build the project:
```bash
cd BLANE
cargo build
```
3. Run the server:
```bash
cargo run --bin server
```
4. Run the client:
```bash
cargo run --bin client
```
## Dependencies
- glib-2.0: Required dependencies for the server and client GUI (based on GTK)
- openssl: Required for encryption algorithms
## Contribution
[<img alt="AShujiao" src="https://avatars.githubusercontent.com/u/69539047?v=4" width="117">](https://github.com/dxhm)
## License
## Star History
[](https://star-history.com/#DXHM/BLANE&Date)
| 18
| 0
|
yude/weird-pronounciation
|
https://github.com/yude/weird-pronounciation
|
異常発音
|
# weird-pronounciation
異常発音
## License
MIT License.
| 10
| 1
|
trey-wallis/obsidian-dashboards
|
https://github.com/trey-wallis/obsidian-dashboards
|
Create your own personalized dashboards using customizable grid views
|


Dashboards is an [Obsidian.md](https://obsidian.md/) plugin. Design your own personalized dashboard or home page. Dashboards offers flexible grid configurations, allowing you to choose from various layouts such as 1x2, 2x2, 3x3, and more. Each grid contains containers where you can embed different elements, including vault files, code blocks, or external urls.
If you are looking for the plugin that was formally called `Dashboards` please see [DataLoom](https://github.com/trey-wallis/obsidian-dataloom)
Support development
<a href="https://buymeacoffee.com/treywallis" target="_blank" rel="noopener">
<img width="180px" src="https://img.buymeacoffee.com/button-api/?text=Buy me a coffee&emoji=&slug=treywallis&button_colour=6a8695&font_colour=ffffff&font_family=Poppins&outline_colour=000000&coffee_colour=FFDD00" referrerpolicy="no-referrer" alt="?text=Buy me a coffee&emoji=&slug=treywallis&button_colour=6a8695&font_colour=ffffff&font_family=Poppins&outline_colour=000000&coffee_colour=FFDD00"></a>
## About
- [Screenshots](#screenshots)
- [Getting started](#getting-started)
- [Embeddable Items](#embeddable-items)
- [License](#license)
## Screenshots
Create a grid layout
<img src="./docs/assets/dashboard-empty.png" width="800">
Add embedded content with ease
<img src="./docs/assets/dashboard-full.png" width="800">
Use many different layouts
<img src="./docs/assets/dashboard-grid.png" width="800">
## Getting Started
1. Create a new dashboard file by right clicking a folder and clicking "New dashboard" or click the Gauge icon on the left sidebar.
2. Choose your grid layout using the dropdown in the upper righthand corner
3. In each container click one of the embed buttons and enter the content you wish to embed. You may choose from a vault file, a code block, or a external link.
### Removing an embed
To remove an embed from a container, hold down ctrl (Windows) or cmd (Mac) and hover over a container to show the remove button. Then click the remove button
## Embeddable Items
### Files
Any vault files may be embedded into a container
### Code blocks
Embed any Obsidian code block using the [normal code block syntax](https://help.obsidian.md/Editing+and+formatting/Basic+formatting+syntax#Code+blocks). This may be used to render [Dataview](https://github.com/blacksmithgu/obsidian-dataview), DataviewJS, or [Tasks](https://github.com/obsidian-tasks-group/obsidian-tasks) plugin code blocks.
### Links
Any website will automatically be embedded in an iFrame
## License
Dashboards is distributed under the [MIT License](https://github.com/trey-wallis/obsidian-dashboards/blob/master/LICENSE)
| 12
| 0
|
jordond/MaterialKolor
|
https://github.com/jordond/MaterialKolor
|
🎨 A Compose multiplatform library for generating dynamic Material3 color schemes from a seed color
|
<img width="500px" src="art/materialkolor-logo.png" alt="logo"/>
<br />

[](http://kotlinlang.org)
[](https://github.com/jordond/materialkolor/actions/workflows/ci.yml)
[](https://opensource.org/license/mit/)
[](https://github.com/JetBrains/compose-multiplatform)



A Compose Multiplatform library for creating dynamic Material Design 3 color palettes from any
color. Similar to generating a theme
from [m3.matierial.io](https://m3.material.io/theme-builder#/custom).
<img width="300px" src="art/ios-demo.gif" />
## Table of Contents
- [Platforms](#platforms)
- [Inspiration](#inspiration)
- [Setup](#setup)
- [Multiplatform](#multiplatform)
- [Single Platform](#single-platform)
- [Version Catalog](#version-catalog)
- [Usage](#usage)
- [Demo](#demo)
- [License](#license)
- [Changes from original source](#changes-from-original-source)
## Platforms
This library is written for Compose Multiplatform, and can be used on the following platforms:
- Android
- iOS
- JVM (Desktop)
A JavaScript (Browser) version is available but untested.
## Inspiration
The heart of this library comes from
the [material-color-utilities](https://github.com/material-foundation/material-color-utilities)
repository. It is currently
only a Java library, and I wanted to make it available to Kotlin Multiplatform projects. The source
code was taken and converted into a Kotlin Multiplatform library.
I also incorporated the Compose ideas from another open source
library [m3color](https://github.com/Kyant0/m3color).
### Planned Features
- Get seed color from Bitmap
- Load image from File, Url, etc.
## Setup
You can add this library to your project using Gradle.
### Multiplatform
To add to a multiplatform project, add the dependency to the common source-set:
```kotlin
kotlin {
sourceSets {
commonMain {
dependencies {
implementation("com.materialkolor:material-kolor:1.2.2")
}
}
}
}
```
### Single Platform
For an Android only project, add the dependency to app level `build.gradle.kts`:
```kotlin
dependencies {
implementation("com.materialkolor:material-kolor:1.2.2")
}
```
### Version Catalog
```toml
[versions]
materialKolor = "1.2.2"
[libraries]
materialKolor = { module = "com.materialkolor:material-kolor", version.ref = "materialKolor" }
```
## Usage
To generate a custom `ColorScheme` you simply need to call `dynamicColorScheme()` with your target
seed color:
```kotlin
@Composable
fun MyTheme(
seedColor: Color,
useDarkTheme: Boolean = isSystemInDarkTheme(),
content: @Composable () -> Unit
) {
val colorScheme = dynamicColorScheme(seedColor, useDarkTheme)
MaterialTheme(
colors = colorScheme.toMaterialColors(),
content = content
)
}
```
You can also pass in
a [`PaletteStyle`](material-kolor/src/commonMain/kotlin/com/materialkolor/PaletteStyle.kt) to
customize the generated palette:
```kotlin
dynamicColorScheme(
seedColor = seedColor,
isDark = useDarkTheme,
style = PaletteStyle.Vibrant,
)
```
See [`Theme.kt`](demo/composeApp/src/commonMain/kotlin/com/materialkolor/demo/theme/Theme.kt) from
the demo
for a full example.
### DynamicMaterialTheme
A `DynamicMaterialTheme` Composable is also available. It is a wrapper around `MaterialTheme` that
uses `dynamicColorScheme()` to generate a `ColorScheme` for you.
Example:
```kotlin
@Composable
fun MyTheme(
seedColor: Color,
useDarkTheme: Boolean = isSystemInDarkTheme(),
content: @Composable () -> Unit
) {
DynamicMaterialTheme(
seedColor = seedColor,
isDark = useDarkTheme,
content = content
)
}
```
Also included is a `AnimatedDynamicMaterialTheme` which animates the color scheme changes.
See [`Theme.kt`](demo/composeApp/src/commonMain/kotlin/com/materialkolor/demo/theme/Theme.kt) for an
example.
## Demo
A demo app is available in the `demo` directory. It is a Compose Multiplatform app that runs on
Android, iOS and Desktop.
**Note:** While the demo does build a Browser version, it doesn't seem to work. However I don't know
if that is the fault of this library or the Compose Multiplatform library. Therefore I haven't
marked Javascript as supported.
See the [README](demo/README.md) for more information.
## License
The module `material-color-utilities` is licensed under the Apache License, Version 2.0. See
their [LICENSE](material-color-utilities/src/commonMain/kotlin/com/materialkolor/LICENSE) and their
repository [here](https://github.com/material-foundation/material-color-utilities) for more
information.
### Changes from original source
- Convert Java code to Kotlin
- Convert library to Kotlin Multiplatform
For the remaining code see [LICENSE](LICENSE) for more information.
| 13
| 0
|
BalioFVFX/IP-Camera
|
https://github.com/BalioFVFX/IP-Camera
|
Android app that turns your device into an IP Camera
|
# IP Camera

[Fullscreen](https://youtu.be/NtQ_Al-56Qs)
## Overview

## How to use
You can either watch this video or follow the steps below.
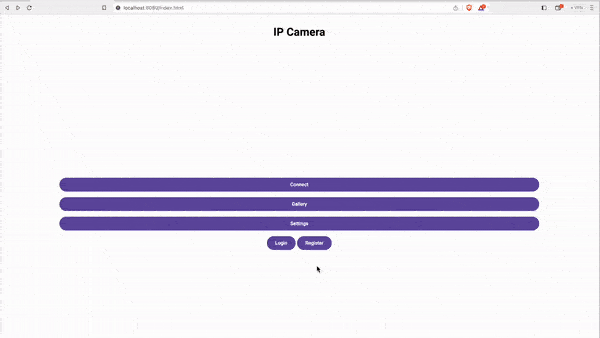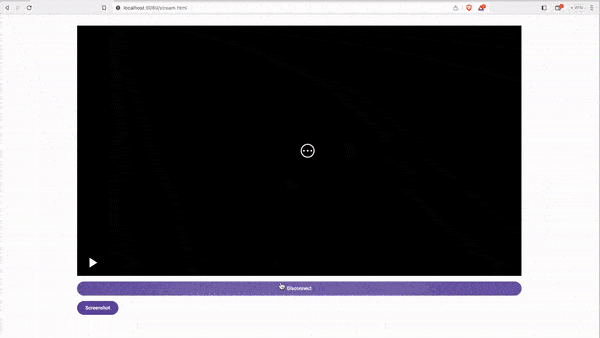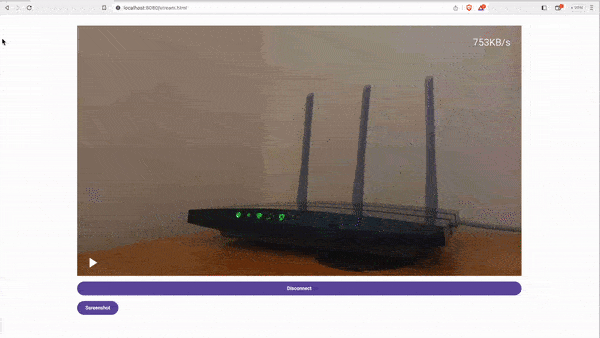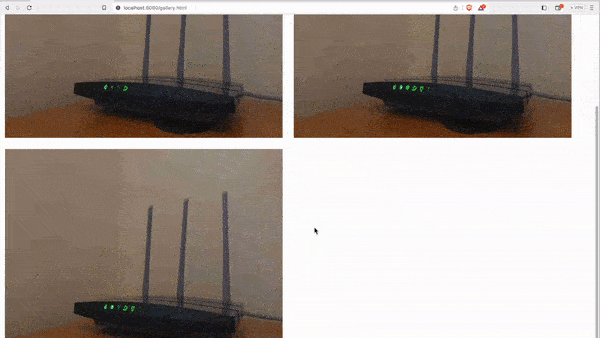
### How to start live streaming
1. Start the Video server. By default the Video server launches 3 sockets, each acting as a server:
- WebSocket Server (runs on port 1234).
- MJPEG Server (runs on port 4444).
- Camera Server (runs on port 4321).
2. Install the app on your phone.
3. Navigate to app's settings screen and setup your Camera's server IP. For example `192.168.0.101:4321`.
4. Open the stream screen and click the Start streaming button.
5. Now your phone sends video data to your Camera Server.
---
### Watching the stream
The stream can be watched from either your browser, the Web App or apps like VLC media player.
### Browser
Open your favorite web browser and navigate to your MJPEG server's IP address. For example `http://192.168.0.101:4444`
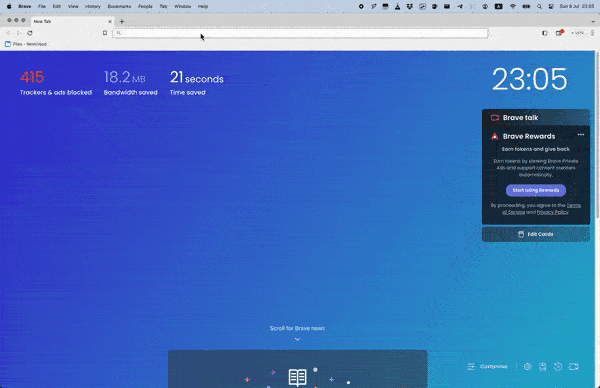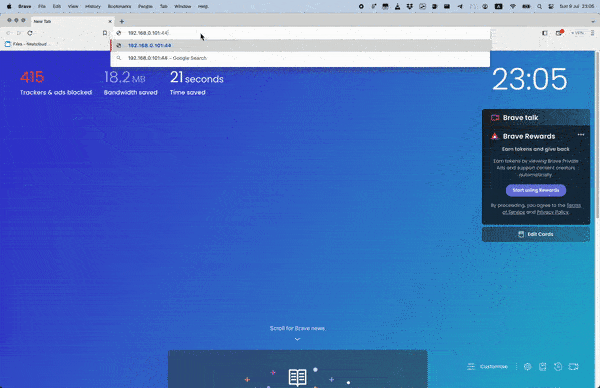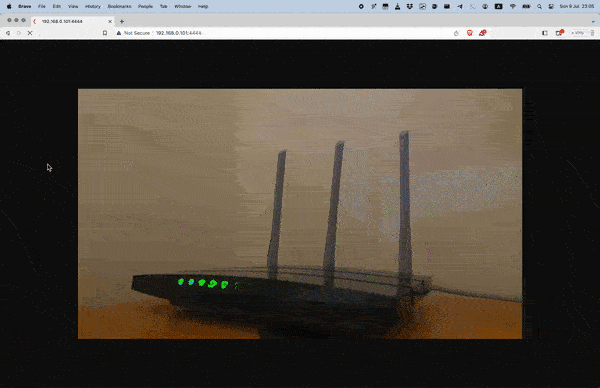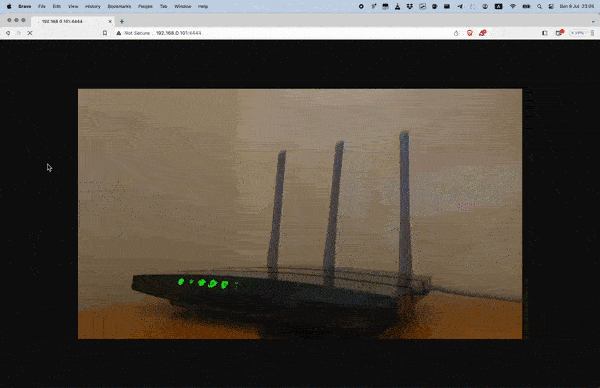
### VLC meida player
Open the VLC media player, File -> Open Network -> Network and write your MJPEG's server IP address. For example `http://192.168.0.101:4444/`
### The Web App
1. Navigate to the Web app root directory and in your terminal execute `webpack serve`.
2. Open your browser and navigate to `http://localhost:8080/`.
3. Go to settings and enter your WebSocket server ip address. For example `192.168.0.101:1234`.
4. Go to the streaming page `http://localhost:8080/stream.html` and click the connect button.

### Configuring the Web App's server
Note: This section is required only if you'd like to be able to take screenshots from the Web App.
1. Open the Web App Server project
2. Open index.js and edit the connection object to match your MySQL credentials.
3. Create the required tables by executing the SQL query located in `user.sql`
4. At the root directory execute `node index.js` in your terminal
5. You may have to update the IP that the Web App connects to. You can edit this IP in Web app's `stream.html` file (`BACKEND_URL` const variable)
6. Create a user through the Web App from `http://localhost:8080/register.html`
7. Take screenshots from `http://localhost:8080/stream.html`
8. View your screenshots at `http://localhost:8080/gallery.html`
---
| 20
| 0
|
ZJU-Turing/TuringDoneRight
|
https://github.com/ZJU-Turing/TuringDoneRight
|
浙江大学图灵班学长组资料汇总网站
|
# 图灵 2023 级学长组资料汇总网站
[](https://turing2023.tonycrane.cc/)
> **Warning** 正在建设中
## 本地构建
- 安装依赖
```sh
$ pip install -r requirements.txt
```
- 开启本地预览服务
```sh
$ mkdocs serve # Serving on http://127.0.0.1:8000/
```
## 修改发布
2023 年版通过 GitHub Action 自动构建并部署到 TonyCrane 的个人服务器上。
## 历年版本
- 2022 年:[`2022`](https://github.com/ZJU-Turing/TuringDoneRight/tree/2022) [turing2022.tonycrane.cc](https://turing2022.tonycrane.cc/)
本项目的许可证为 [ 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议](https://creativecommons.org/licenses/by-nc-sa/4.0/deed.zh)
| 14
| 4
|
mouredev/tggenerator
|
https://github.com/mouredev/tggenerator
|
Generador de logotipos de eSports por IA (con fines académicos durante el evento Tenerife GG)
|
# Tenerife GG(enerator)
## Generador de logotipos de eSports por IA
[](https://kotlinlang.org)
[](https://developer.android.com/studio)
[](https://www.android.com)
### Aplicación Android creada con fines académicos durante el evento [Tenerife GG](https://tenerife.gg/) para proponer un ejemplo de caso de uso real aplicando 3 modelos diferentes de IA:
* **[Whisper](https://platform.openai.com/docs/models/whisper)** para transformar audio a texto.
* **[GPT-3.5](https://platform.openai.com/docs/models/gpt-3-5)** para analizar el texto.
* **[DALL·E](https://platform.openai.com/docs/models/dall-e)** para generar imágenes.
Utiliza **[Jetpack Compose](https://developer.android.com/jetpack/compose)** para la IA y **[OpenAI Kotlin](https://github.com/aallam/openai-kotlin)** para interactuar con los modelos de OpenAI.
## Requisitos
Genera una API Key en **[https://platform.openai.com](https://platform.openai.com/)** *(User/API Keys/Create new secret key)*.
## Ejecución
Descarga el proyecto, ábrelo en Android Studio y añade la API Key en el fichero `conf/Env.kt`
```
const val OPENAI_API_KEY = "MI_KEY"
```
## APK
Puedes descargar un fichero ejecutable [APK](./app.apk) *(app.apk)* de prueba para instalar directamente en tu dispositivo Android. Deberás permitir la instalación de aplicaciones fuera de la tienda.
Dispondrás de campo llamado *OpenAI API Key* para añadir tu propia clave desde la interfaz de usuario. Rellénalo y comienza a usarla.
<a href="./Media/4.png"><img src="./Media/4.png" style="height: 30%; width:30%;"/></a>
## Instrucciones
#### Completa los datos
* **Nombre del equipo**: El nombre que desees *(MoureDev)*.
* **¿A qué juegas?**: El nombre del juego en el que se va a inspirar el logotipo *(Diablo II)*.
* **Referencia principal**: El elemento principal del logotipo *(Fuego)*.
#### Añade información** *(Opcional)*
* **Iniciar grabación (Whisper)**: Graba un audio con información adicional *(Jugamos a Diablo II, me gustaría que el logo añada una calavera y mucho fuego)*.
* **Resumir (GPT-3.5)**: Extrae las palabras clave del audio *(juego, diablo, calavera, mucho fuego)*.
#### Genera el logo
* **Generar (DALL·E)** *(Diseño Tenerife GG OFF)*: Crea un logotipo con la información proporcionada.
* **Generar (DALL·E)** *(Diseño Tenerife GG ON)*: Crea un logotipo con la información proporcionada y una máscara predeterminada.
* **Copiar**: Guarda la URL del logotipo para descargarlo desde el explorador web.
<table style="width:100%">
<tr>
<td>
<a href="./Media/1.png">
<img src="./Media/1.png">
</a>
</td>
<td>
<a href="./Media/2.png">
<img src="./Media/2.png">
</a>
</td>
<td>
<a href="./Media/3.png">
<img src="./Media/3.png">
</a>
</td>
</tr>
</table>
#### Puedes apoyar mi trabajo haciendo "☆ Star" en el repo o nominarme a "GitHub Star". ¡Gracias!
[](https://stars.github.com/nominate/)
Si quieres unirte a nuestra comunidad de desarrollo, aprender programación de Apps, mejorar tus habilidades y ayudar a la continuidad del proyecto, puedes encontrarnos en:
[](https://twitch.tv/mouredev)
[](https://mouredev.com/discord)
[](https://moure.dev)
##  Hola, mi nombre es Brais Moure.
### Freelance full-stack iOS & Android engineer
[](https://youtube.com/mouredevapps?sub_confirmation=1)
[](https://twitch.com/mouredev)
[](https://mouredev.com/discord)
[](https://twitter.com/mouredev)


Soy ingeniero de software desde hace más de 12 años. Desde hace 4 años combino mi trabajo desarrollando Apps con creación de contenido formativo sobre programación y tecnología en diferentes redes sociales como **[@mouredev](https://moure.dev)**.
### En mi perfil de GitHub tienes más información
[](https://github.com/mouredev)
| 52
| 1
|
hako-mikan/sd-webui-cd-tuner
|
https://github.com/hako-mikan/sd-webui-cd-tuner
|
Color/Detail control for Stable Diffusion web-ui
|
# CD(Color/Detail) Tuner
Color/Detail control for Stable Diffusion web-ui/色調や書き込み量を調節するweb-ui拡張です。
[日本語](#使い方)
Update 2023.07.13.0030(JST)
- add brightness
- color adjusting method is changed
- add disable checkbox

This is an extension to modify the amount of detailing and color tone in the output image. It intervenes in the generation process, not on the image after it's generated. It works on a mechanism different from LoRA and is compatible with 1.X and 2.X series. In particular, it can significantly improve the quality of generated products during Hires.fix.
## Usage
It automatically activates when any value is set to non-zero. Please be careful as inevitably the amount of noise increases as the amount of detailing increases. During the use of Hires.fix, the output might look different, so it is recommended to try with expected settings. Values around 5 should be good, but it also depends on the model. If a positive value is input, the detailing will increase.
### Detail1,2 Drawing/Noise Amount
When set to negative, it becomes flat and slightly blurry. When set to positive, the detailing increases and becomes noisy. Even if it is noisy in normal generation, it might become clean with hires.fix, so be careful. Detail1 and 2 both have similar effects, but Detail1 seems to have a stronger effect on the composition. In the case of 2.X series, the reaction of Detail 1 may be the opposite of normal, with more drawings in negative.

### Contrast: Contrast/Drawing Amount, Brightness
Contrast and brightness change, and at the same time the amount of detailing also changes. It would be quicker to see the sample.
The difference between Contrast 1 and Contrast 2 lies in whether the adjustment is made during the generation process or after the generation is complete. Making the adjustment during the generation process results in a more natural outcome, but it may also alter the composition.

### Color1,2,3 Color Tone
You can tune the color tone. For `Cyan-Red`, it becomes `Cyan` when set to negative and `Red` when set to positive.

### Hr-Detail1,2 ,Hires-Scaling
In the case of using Hires-fix, the optimal settings often differ from the usual. Basically, when using Hires-Fix, it is better to input larger values than when not using it. Hr-Detail1,2 is used when you want to set a different value from when not used during Hires-Fix generation. Hires-Scaling is a feature that automatically sets the value at the time of Hires-Fix. The value of Hires-scale squared is usually multiplied by the original value.
## Use in XYZ plot/API
You can specify the value in prompt by entering in the following format. Please use this if you want to use it in XYZ plot.
```
<cdt:d1=2;col1=-3>
<cdt:d2=2;hrs=1>
<cdt:1>
<cdt:0;0;0;-2.3;0,2>
<cdt:0;0;0;-2.3;0;2;0;0;1>
```
The available identifiers are `d1,d2,con1,con2,bri,col1,col2,col3,hd1,hd2,hrs,st1,st2`. When describing in the format of `0,0,0...`, please write in this order. It is okay to fill in up to the necessary places. The delimiter is a semicolon (;). If you write `1,0,4`, `d1,d2,cont` will be set automatically and the rest will be `0`. `hrs` turns on when a number other than `0` is entered.
This value will be prioritized if a value other than `0` is set.
At this time, `Skipping unknown extra network: cdt` will be displayed, but this is normal operation.
### Stop Step
You can specify the number of steps to stop the adjustment. In Hires-Fix, the effects are often not noticeable after the initial few steps. This is because in most samplers, a rough image is already formed within the first 10 steps.
## Examples of use
The left is before use, the right is after use. Click the image to enlarge it. Here, we are increasing the amount of drawing and making it blue. The difference is clearer when enlarged.
You can expect an improvement in reality with real-series models.


# Color/Detail control for Stable Diffusion web-ui
出力画像の描き込み量や色調を変更する拡張機能です。生成後の画像に対してではなく生成過程に介入します。LoRAとは異なる仕組みで動いています。2.X系統にも対応しています。特にHires.fix時の生成品質を大幅に向上させることができます。
## 使い方
どれかの値が0以外に設定されている場合、自動的に有効化します。描き込み量が増えると必然的にノイズも増えることになるので気を付けてください。Hires.fix使用時では出力が違って見える場合があるので想定される設定で試すことをおすすめします。数値は大体5までの値を入れるとちょうど良いはずですがそこはモデルにも依存します。正の値を入力すると描き込みが増えたりします。
### Detail1,2 描き込み量/ノイズ
マイナスにするとフラットに、そして少しぼけた感じに。プラスにすると描き込みが増えノイジーになります。通常の生成でノイジーでもhires.fixできれいになることがあるので注意してください。Detail1,2共に同様の効果がありますが、Detail1は2に比べて構図への影響が強く出るようです。2.X系統の場合、Detail 1の反応が通常とは逆になり、マイナスで書き込みが増える場合があるようです。

### Contrast : コントラスト/描き込み量
コントラストや明るさがかわり、同時に描き込み量も変わります。サンプルを見てもらった方が早いですね。

### Color1,2,3 色調
色調を補正できます。`Cyan-Red`ならマイナスにすると`Cyan`、プラスにすると`Red`になります。

### Hr-Detail1,2 ,Hires-Scaling
Hires-fixを使用する場合、最適な設定値が通常とは異なる場合が多いです。基本的にはHires-Fix使用時には未使用時より大きめの値を入れた方が良い結果が得られます。Hr-Detail1,2ではHires-Fix生成時に未使用時とは異なる値を設定したい場合に使用します。Hires-Scalingは自動的にHires-Fix使用時の値を設定する機能です。おおむねHires-scaleの2乗の値が元の値に掛けられます。
## XYZ plot・APIでの利用について
promptに以下の書式で入力することでpromptで値を指定できます。XYZ plotで利用したい場合にはこちらを利用して下さい。
```
<cdt:d1=2;col1=-3>
<cdt:d2=2;hrs=1>
<cdt:1>
<cdt:0;0;0;-2.3;0,2>
<cdt:0;0;0;-2.3;0;2;0;0;1>
```
使用できる識別子は`d1,d2,con1,con2,bri,col1,col2,col3,hd1,hd2,hrs,st1,st2`です。`0,0,0...`の形式で記述する場合にはこの順に書いてください。区切りはセミコロン「;」です。記入は必要なところまでで大丈夫です。`1,0,4`なら自動的に`cont`までが設定され残りは`0`になります。`hrs`は`0`以外の数値が入力されるとオンになります。
`0`以外の値が設定されている場合にはこちらの値が優先されます。
このとき`Skipping unknown extra network: cdt`と表示されますが正常な動作です。
### stop step
補正を停止するステップ数を指定できます。Hires-Fixでは最初の数ステップ以降は効果が感じられないことが多いです。大概のサンプラーで10ステップ絵までには大まかな絵ができあがっているからです。
## 使用例
リアル系モデルでリアリティの向上が見込めます。


| 38
| 1
|
HoseungJang/flickable-scroll
|
https://github.com/HoseungJang/flickable-scroll
|
A flickable web scroller
|
# flickable-scroll
https://github.com/HoseungJang/flickable-scroll/assets/39669819/0ed83574-a6ac-4033-af39-e1c725fef7a5
---
- [Overview](#overview)
- [Examples](#examples)
- [API Reference](#api-reference)
---
# Overview
`flickable-scroll` is a flickable web scroller, which handles only scroll jobs. In other words, you can be free to write layout and style and then you just pass scroller options based on it. Let's see examples below.
# Examples
This is an example template. Note the changes of `options` and `style` in each example.
```tsx
const ref = useRef<HTMLDivElement>(null);
useEffect(() => {
const current = ref.current;
if (current == null) {
return;
}
const options: ScrollerOptions = {
/* ... */
};
const scroller = new FlickableScroller(current);
return () => scroller.destroy();
}, []);
const style: CSSProperties = {
/* ... */
};
return (
<div style={{ width: "100vw", height: "100vh", display: "flex", justifyContent: "center", alignItems: "center" }}>
<div
ref={ref}
style={{
width: 800,
height: 800,
position: "fixed",
overflow: "hidden",
...style,
}}
>
<div style={{ backgroundColor: "lavender", fontSize: 50 }}>Scroll Top</div>
{Array.from({ length: 2 }).map((_, index) => (
<Fragment key={index}>
<div style={{ width: 800, height: 800, flexShrink: 0, backgroundColor: "pink" }} />
<div style={{ width: 800, height: 800, flexShrink: 0, backgroundColor: "skyblue" }} />
<div style={{ width: 800, height: 800, flexShrink: 0, backgroundColor: "lavender" }}></div>
</Fragment>
))}
<div style={{ backgroundColor: "pink", fontSize: 50 }}>Scroll Bottom</div>
</div>
</div>
);
```
## Vertical Scroll
```typescript
const options = {
direction: "y",
};
```
```typescript
const style = {};
```
https://github.com/HoseungJang/flickable-scroll/assets/39669819/089e2de5-0818-4462-ab0b-122ea6fcbd6a
## Reversed Vertical Scroll
```typescript
const options = {
direction: "y",
reverse: true,
};
```
```typescript
const style = {
display: "flex",
flexDirection: "column",
justifyContent: "flex-end",
};
```
https://github.com/HoseungJang/flickable-scroll/assets/39669819/9eefe295-f8fe-49f7-9f92-c390dc70f43a
## Horizontal Scroll
```typescript
const options = {
direction: "x",
};
```
```typescript
const style = {
display: "flex",
};
```
https://github.com/HoseungJang/flickable-scroll/assets/39669819/a90eeff8-9e18-4d45-a229-66813ba89901
## Reversed Horizontal Scroll
```typescript
const options = {
direction: "x",
reverse: true,
};
```
```typescript
const style = {
display: "flex",
justifyContent: "flex-end",
};
```
https://github.com/HoseungJang/flickable-scroll/assets/39669819/02c80887-cc20-4098-aa27-5c8236df8870
# API Reference
```typescript
const options = {
direction,
reverse,
onScrollStart,
onScrollMove,
onScrollEnd,
};
const scroller = new FlickableScroller(container, options);
scroller.lock();
scroller.unlock();
scroller.destory();
```
- Parameters of `FlickableScroller`:
- `container`: `HTMLElement`
- Required
- A scroll container element.
- options
- Optional
- properties
- `direction`: `"x" | "y"`
- Optional
- Defaults to `"y"`
- A scroll direction
- `reverse`: `boolean`
- Optional
- Defaults to `false`
- If set to true, scroll direction will be reversed.
- `onScrollStart`: `(e: ScrollEvent) => void`
- Optional
- This function will fire when a user starts to scroll
- `onScrollMove`: `(e: ScrollEvent) => void`
- Optional
- This function will fire when a user is scrolling
- `onScrollEnd`: `(e: ScrollEvent) => void`
- Optional
- This function will fire when a user finishes to scroll
- Methods of `FlickableScroller`:
- `lock()`: `() => void`
- This method locks scroll of the scroller.
- `unlock()`: `() => void`
- This method unlocks scroll of the scroller.
- `destroy()`: `() => void`
- This method destory the scroller. All event handlers will be removed, and all animations will be stopped.
| 10
| 0
|
bloomberg/blazingmq
|
https://github.com/bloomberg/blazingmq
|
A modern high-performance open source message queuing system
|
<p align="center">
<a href="https://bloomberg.github.io/blazingmq">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="docs/assets/images/blazingmq_logo_label_dark.svg">
<img src="docs/assets/images/blazingmq_logo_label.svg" width="70%">
</picture>
</a>
</p>
---
[](#)
[](#)
[](#)
[](LICENSE)
[](#)
[](#)
[](#)
[](https://bloomberg.github.io/blazingmq)
# BlazingMQ - A Modern, High-Performance Message Queue
[BlazingMQ](https://bloomberg.github.io/blazingmq) is an open source
distributed message queueing framework, which focuses on efficiency,
reliability, and a rich feature set for modern-day workflows.
At its core, BlazingMQ provides durable, fault-tolerant, highly performant, and
highly available queues, along with features like various message routing
strategies (e.g., work queues, priority, fan-out, broadcast, etc.),
compression, strong consistency, poison pill detection, etc.
Message queues generally provide a loosely-coupled, asynchronous communication
channel ("queue") between application services (producers and consumers) that
send messages to one another. You can think about it like a mailbox for
communication between application programs, where 'producer' drops a message in
a mailbox and 'consumer' picks it up at its own leisure. Messages placed into
the queue are stored until the recipient retrieves and processes them. In other
words, producer and consumer applications can temporally and spatially isolate
themselves from each other by using a message queue to facilitate
communication.
BlazingMQ's back-end (message brokers) has been implemented in C++, and client
libraries are available in C++, Java, and Python (the Python SDK will be
published shortly as open source too!).
BlazingMQ is an actively developed project and has been battle-tested in
production at Bloomberg for 8+ years.
This repository contains BlazingMQ message broker, BlazingMQ C++ client library
and a BlazingMQ command line tool, while BlazingMQ Java client library can be
found in [this](https://github.com/bloomberg/blazingmq-sdk-java) repository.
---
## Menu
- [Documentation](#documentation)
- [Quick Start](#quick-start)
- [Installation](#installation)
- [Contributions](#contributions)
- [License](#license)
- [Code of Conduct](#code-of-conduct)
- [Security Vulnerability Reporting](#security-vulnerability-reporting)
---
## Documentation
Comprehensive documentation about BlazingMQ can be found
[here](https://bloomberg.github.io/blazingmq).
---
## Quick Start
[This](https://bloomberg.github.io/blazingmq/docs/getting_started/blazingmq_in_action/)
article guides readers to build, install, and experiment with BlazingMQ locally
in a Docker container.
In the
[companion](https://bloomberg.github.io/blazingmq/docs/getting_started/more_fun_with_blazingmq)
article, readers can learn about some intermediate and advanced features of
BlazingMQ and see them in action.
---
## Installation
[This](https://bloomberg.github.io/blazingmq/docs/installation/deployment/)
article describes the steps for installing a BlazingMQ cluster in a set of Docker
containers, along with a recommended set of configurations.
---
## Contributions
We welcome your contributions to help us improve and extend this project!
We welcome issue reports [here](../../issues); be sure to choose the proper
issue template for your issue, so that we can be sure you're providing us with
the necessary information.
Before sending a [Pull Request](../../pulls), please make sure you have read
our [Contribution
Guidelines](https://github.com/bloomberg/.github/blob/main/CONTRIBUTING.md).
---
## License
BlazingMQ is Apache 2.0 licensed, as found in the [LICENSE](LICENSE) file.
---
## Code of Conduct
This project has adopted a [Code of
Conduct](https://github.com/bloomberg/.github/blob/main/CODE_OF_CONDUCT.md).
If you have any concerns about the Code, or behavior which you have experienced
in the project, please contact us at [email protected].
---
## Security Vulnerability Reporting
If you believe you have identified a security vulnerability in this project,
please send an email to the project team at [email protected], detailing
the suspected issue and any methods you've found to reproduce it.
Please do NOT open an issue in the GitHub repository, as we'd prefer to keep
vulnerability reports private until we've had an opportunity to review and
address them.
---
| 2,160
| 78
|
alejandrofdez-us/similarity-ts
|
https://github.com/alejandrofdez-us/similarity-ts
| null |
[](https://pypi.org/project/similarity-ts/)
[](https://www.python.org/downloads/release/python-390/)
[](https://github.com/alejandrofdez-us/similarity-ts-cli/commits/main)
[](LICENSE)
# SimilarityTS: Toolkit for the Evaluation of Similarity for multivariate time series
## Table of Contents
- [Package Description](#package-description)
- [Installation](#installation)
- [Usage](#usage)
- [Configuring the toolkit](#configuring-the-toolkit)
- [Extending the toolkit](#extending-the-toolkit)
- [License](#license)
- [Acknowledgements](#acknowledgements)
## Package Description
SimilarityTS is an open-source package designed to facilitate the evaluation and comparison of
multivariate time series data. It provides a comprehensive toolkit for analyzing, visualizing, and reporting multiple
metrics and figures derived from time series datasets. The toolkit simplifies the process of evaluating the similarity of
time series by offering data preprocessing, metrics computation, visualization, statistical analysis, and report generation
functionalities. With its customizable features, SimilarityTS empowers researchers and data
scientists to gain insights, identify patterns, and make informed decisions based on their time series data.
A command line interface tool is also available at: https://github.com/alejandrofdez-us/similarity-ts-cli.
### Available metrics
This toolkit can compute the following metrics:
- `kl`: Kullback-Leibler divergence
- `js`: Jensen-Shannon divergence
- `ks`: Kolmogorov-Smirnov test
- `mmd`: Maximum Mean Discrepancy
- `dtw` Dynamic Time Warping
- `cc`: Difference of co-variances
- `cp`: Difference of correlations
- `hi`: Difference of histograms
### Available figures
This toolkit can generate the following figures:
- `2d`: the ordinary graphical representation of the time series in a 2D figure with the time represented on the x axis
and the data values on the y-axis for
- the complete multivariate time series; and
- a plot per column.
Each generated figure plots both the `ts1` and the `ts2` data to easily obtain key insights into
the similarities or differences between them.
<div>
<img src="https://github.com/alejandrofdez-us/similarity-ts/blob/e5b147b145970f3a93351a1004022fb30d20f5f0/docs/figures/2d_sample_3_complete_TS_1_vs_TS_2.png?raw=true" alt="2D Figure complete">
<img src="https://github.com/alejandrofdez-us/similarity-ts/blob/e5b147b145970f3a93351a1004022fb30d20f5f0/docs/figures/2d_sample_3_cpu_util_percent_TS_1_vs_TS_2.png?raw=true" alt="2D Figure for used CPU percentage">
</div>
- `delta`: the differences between the values of each column grouped by periods of time. For instance, the differences
between the percentage of cpu used every 10, 25 or 50 minutes. These delta can be used as a means of comparison between
time series short-/mid-/long-term patterns.
<div>
<img src="https://github.com/alejandrofdez-us/similarity-ts/blob/e5b147b145970f3a93351a1004022fb30d20f5f0/docs/figures/delta_sample_3_cpu_util_percent_TS_1_vs_TS_2_(grouped_by_10_minutes).png?raw=true" alt="Delta Figure for used CPU percentage grouped by 10 minutes">
<img src="https://github.com/alejandrofdez-us/similarity-ts/blob/e5b147b145970f3a93351a1004022fb30d20f5f0/docs/figures/delta_sample_3_cpu_util_percent_TS_1_vs_TS_2_(grouped_by_25_minutes).png?raw=true" alt="Delta Figure for used CPU percentage grouped by 25 minutes">
<img src="https://github.com/alejandrofdez-us/similarity-ts/blob/e5b147b145970f3a93351a1004022fb30d20f5f0/docs/figures/delta_sample_3_cpu_util_percent_TS_1_vs_TS_2_(grouped_by_50_minutes).png?raw=true" alt="Delta Figure for used CPU percentage grouped by 50 minutes">
</div>
- `pca`: the linear dimensionality reduction technique that aims to find the principal components of a data set by
computing the linear combinations of the original characteristics that explain the most variance in the data.
<div align="center">
<img src="https://github.com/alejandrofdez-us/similarity-ts/blob/e5b147b145970f3a93351a1004022fb30d20f5f0/docs/figures/PCA.png?raw=true" alt="PCA Figure" width="450">
</div>
- `tsne`: a tool for visualising high-dimensional data sets in a 2D or 3D graphical representation allowing the creation
of a single map that reveals the structure of the data at many different scales.
<div align="center">
<img src="https://github.com/alejandrofdez-us/similarity-ts/blob/e5b147b145970f3a93351a1004022fb30d20f5f0/docs/figures/t-SNE-iter_300-perplexity_5.png?raw=true" alt="TSNE Figure 300 iterations 5 perplexity" width="450">
<img src="https://github.com/alejandrofdez-us/similarity-ts/blob/e5b147b145970f3a93351a1004022fb30d20f5f0/docs/figures/t-SNE-iter_1000-perplexity_5.png?raw=true" alt="TSNE Figure 1000 iterations 5 perplexity" width="450">
</div>
- `dtw` path: In addition to the numerical similarity measure, the graphical representation of the DTW path of each
column can be useful to better analyse the similarities or differences between the time series columns. Notice that
there is no multivariate representation of DTW paths, only single column representations.
<div>
<img src="https://github.com/alejandrofdez-us/similarity-ts/blob/e5b147b145970f3a93351a1004022fb30d20f5f0/docs/figures/DTW_sample_3_cpu_util_percent.png?raw=true" alt="DTW Figure for cpu">
</div>
## Installation
Install the package using pip in your local environment:
```Bash
pip install similarity-ts
```
## Usage
Users must create a new `SimilarityTs` object by calling its constructor and passing the following parameters.
- `ts1` This time series may represent the baseline or ground truth time
series as a `numpy` array with shape `[length, num_features]`.
- `ts2s` A single or a set of time series as a `numpy` array with shape `[num_time_series, length, num_features]`.
Constraints:
- `ts1` time-series and `ts2s` time-series file(s) must:
- have the same dimensionality (number of columns)
- not include a timestamp column
- include only numeric values
- all `ts2s` time-series must have the same length (number of rows).
If `ts1` time-series is longer (more rows) than `ts2s` time-series, the `ts1` time series will be
divided in windows of the same length as the `ts2s` time-series.
For each `ts2s` time-series, the most similar window (*) from `ts1` time series is selected.
Finally, metrics and figures that assess the similarity between each pair of `ts2s` time-series and its
associated most similar `ts1` window are computed.
(*) The metric used for the selection of the most
similar `ts1` time-series window per each `ts2s` time-series file is selectable. `dtw` is the default selected metric, however, any of
the
[metrics](#available-metrics) are also available for this purpose. See the [toolkit configuration section](#configuring-the-toolkit).
### Minimal usage examples:
Usage examples can be found at: https://github.com/alejandrofdez-us/similarity-ts/tree/main/usage_examples.
1. Compute metrics between random time series (`ts1`: one time series of lenght 200 and 2 dimensions and `ts2`: five time series of length 100 and 2 dimensions):
```Python
import numpy as np
from similarity_ts.similarity_ts import SimilarityTs
ts1 = np.random.rand(200, 2)
ts2s = np.random.rand(5, 100, 2)
similarity_ts = SimilarityTs(ts1, ts2s)
for ts2_name, metric_name, computed_metric in similarity_ts.get_metric_computer():
print(f'{ts2_name}. {metric_name}: {computed_metric}')
```
1. Compute metrics and figures between random time series and save figures:
```Python
import os
import numpy as np
from similarity_ts.plots.plot_factory import PlotFactory
from similarity_ts.similarity_ts import SimilarityTs
def main():
ts1 = np.random.rand(200, 2)
ts2s = np.random.rand(5, 100, 2)
similarity_ts = SimilarityTs(ts1, ts2s)
for ts2_name, metric_name, computed_metric in similarity_ts.get_metric_computer():
print(f'{ts2_name}. {metric_name}: {computed_metric}')
for ts2_name, plot_name, generated_plots in similarity_ts.get_plot_computer():
__save_figures(ts2_name, plot_name, generated_plots)
def __save_figures(filename, plot_name, generated_plots):
for plot in generated_plots:
dir_path = __create_directory(filename, f'figures', plot_name)
plot[0].savefig(f'{dir_path}{plot[0].axes[0].get_title()}.pdf', format='pdf', bbox_inches='tight')
def __create_directory(filename, path, plot_name):
if plot_name in PlotFactory.get_instance().figures_requires_all_samples:
dir_path = f'{path}/{plot_name}/'
else:
original_filename = os.path.splitext(filename)[0]
dir_path = f'{path}/{original_filename}/{plot_name}/'
os.makedirs(dir_path, exist_ok=True)
return dir_path
if __name__ == '__main__':
main()
```
## Configuring the Toolkit
Users can provide metrics or figures to be computed/generated and some other parameterisation. The following code snippet
creates a configuration object that should be passed to the `SimilarityTs` constructor:
```Python
def __create_similarity_ts_config():
# The list of metrics names that will be computed
metric_config = MetricConfig(['js', 'mmd'])
# The list of figure names that will be generated and the time step in seconds of the time series.
plot_config = PlotConfig(['delta', 'pca'], timestamp_frequency_seconds=300)
# Name of each time series of the ts2s set of time series
ts2_names = ['ts2_1_name', 'ts2_2_name', 'ts2_3_name', 'ts2_4_name', 'ts2_5_name']
# Name of the features
header_names = ['feature1_name', 'feature2_name']
# Creation of the configuration
# stride for cutting the ts1 when needed
# metric used for selecting the most similar window
similarity_ts_config = SimilarityTsConfig(metric_config, plot_config,
stride=10, window_selection_metric='kl',
ts2_names=ts2_names, header_names=header_names)
return similarity_ts_config
```
If no metrics nor figures are provided, the tool will compute all the available metrics and figures.
The following arguments are also available for fine-tuning:
- `timestamp_frequency_seconds`: the frequency in seconds in which samples were taken. This is needed to generate the delta figures with correct time magnitudes. By default is
`1` second.
- `stride`: when `ts1` time-series is longer than `ts2s` time-series the windows are computed by using a
stride of `1` by default. Sometimes using a larger value for the stride parameter improves the performance by skipping
the computation of similarity between so many windows.
- `window_selection_metric`: the metric used for the selection of the most similar `ts1` time-series window per each `ts2s` time-series file is selectable.`dtw` is the default selected metric, however, any of the [metrics](#available-metrics) are also available for this purpose. See the [toolkit configuration section](#configuring-the-toolkit).
- `ts2_names`: name of each time series of the `ts2s` set of time series.
- `header_names`: name of the features.
## Extending the toolkit
Additionally, users may implement their own metric or figure classes and include them by using the `MetricFactory` or `PlotFactory` register methods. To ensure compatibility with our toolkit, they have to inherit from the base classes `Metric` and `Plot`.
The following code snippet is an example of how to introduce the Euclidean distance metric:
```Python
#eu.py
import numpy as np
from similarity_ts.metrics.metric import Metric
class EuclideanDistance(Metric):
def __init__(self):
super().__init__()
self.name = 'ed'
def compute(self, ts1, ts2, similarity_ts):
metric_result = {'Multivariate': self.__ed(ts1, ts2)}
return metric_result
def compute_distance(self, ts1, ts2):
return self.__ed(ts1, ts2)
def __ed(self, ts1, ts2):
return np.linalg.norm(ts1 - ts2)
```
Afterward, this metric can be registered by using the `register_metric(metric_class)` method from `MetricFactory` as shown in the following code snippet:
```Python
import numpy as np
from similarity_ts.similarity_ts import SimilarityTs
from similarity_ts.metrics.metric_factory import MetricFactory
from ed import EuclideanDistance
MetricFactory.get_instance().register_metric(EuclideanDistance)
ts1 = np.random.rand(200, 2)
ts2s = np.random.rand(5, 100, 2)
similarity_ts = SimilarityTs(ts1, ts2s)
for ts2_name, metric_name, computed_metric in similarity_ts.get_metric_computer():
print(f'{ts2_name}. {metric_name}: {computed_metric}')
```
Similarly, new plots can be introduced. For instance a `SimilarityPlotByCorrelation` could be defined as:
```Python
#cc_plot.py
import numpy as np
import matplotlib.pyplot as plt
from similarity_ts.plots.plot import Plot
class SimilarityPlotByCorrelation(Plot):
def __init__(self, fig_size=(8, 6)):
super().__init__(fig_size)
self.name = 'cc-plot'
def compute(self, similarity_ts, ts2_filename):
super().compute(similarity_ts, ts2_filename)
n_features = self.ts1.shape[1]
similarity = np.corrcoef(self.ts1.T, self.ts2.T)
fig, ax = plt.subplots()
im = ax.imshow(similarity, cmap='RdYlBu', vmin=-1, vmax=1)
ax.set_xticks(np.arange(n_features*2))
ax.set_yticks(np.arange(n_features*2))
xticklabels = [f'ts1_{nfeatures_index}'for nfeatures_index in range(1, n_features+1)]
xticklabels = xticklabels + [f'ts2_{nfeatures_index}'for nfeatures_index in range(1, n_features+1)]
ax.set_xticklabels(xticklabels)
ax.set_yticklabels(xticklabels)
ax.set_xlabel('Feature')
ax.set_ylabel('Feature')
for i in range(n_features*2):
for j in range(n_features*2):
ax.text(j, i, f'{similarity[i, j]:.2f}', ha='center', va='center', color='black')
cbar = ax.figure.colorbar(im, ax=ax)
cbar.ax.set_ylabel('Similarity', rotation=-90, va='bottom')
plt.title('similarity-correlation')
plt.tight_layout()
return [(fig, ax)]
```
Afterward, this plot can be registered by using the `register_plot(plot_class)` method from `PlotFactory` as shown in the following code snippet that register the new metric and the new plot:
```Python
import os
import numpy as np
from similarity_ts.plots.plot_factory import PlotFactory
from similarity_ts.similarity_ts import SimilarityTs
from similarity_ts.metrics.metric_factory import MetricFactory
from ed import EuclideanDistance
from cc_plot import SimilarityPlotByCorrelation
def main():
MetricFactory.get_instance().register_metric(EuclideanDistance)
PlotFactory.get_instance().register_plot(SimilarityPlotByCorrelation)
ts1 = np.random.rand(200, 2)
ts2s = np.random.rand(5, 100, 2)
similarity_ts = SimilarityTs(ts1, ts2s)
for ts2_name, metric_name, computed_metric in similarity_ts.get_metric_computer():
print(f'{ts2_name}. {metric_name}: {computed_metric}')
for ts2_name, plot_name, generated_plots in similarity_ts.get_plot_computer():
__save_figures(ts2_name, plot_name, generated_plots)
def __save_figures(filename, plot_name, generated_plots):
for plot in generated_plots:
dir_path = __create_directory(filename, f'figures', plot_name)
plot[0].savefig(f'{dir_path}{plot[0].axes[0].get_title()}.pdf', format='pdf', bbox_inches='tight')
def __create_directory(filename, path, plot_name):
if plot_name in PlotFactory.get_instance().figures_requires_all_samples:
dir_path = f'{path}/{plot_name}/'
else:
original_filename = os.path.splitext(filename)[0]
dir_path = f'{path}/{original_filename}/{plot_name}/'
os.makedirs(dir_path, exist_ok=True)
return dir_path
if __name__ == '__main__':
main()
```
## License
SimilarityTS toolkit is free and open-source software licensed under the [MIT license](LICENSE).
## Acknowledgements
Project PID2021-122208OB-I00, PROYEXCEL\_00286 and TED2021-132695B-I00 project, funded by MCIN / AEI / 10.13039 / 501100011033, by Andalusian Regional Government, and by the European Union - NextGenerationEU.
| 31
| 0
|
dunossauro/fastapi-do-zero
|
https://github.com/dunossauro/fastapi-do-zero
|
Curso básico de FastAPI
|
# FastAPI do Zero
## Criando um projeto com Bancos de dados, Testes e Deploy
## A fazer
- [ ] **Internet!**
- [ ] Divulgação
- [ ] Estrutura base para os posts
- [ ] **Parte audiovisual!**
- [x] Tipografia
- [x] Cores
- [x] Identidade visual
- [x] Fotos
- [ ] Thumbs
- [x] Animações
- [x] Musica tema
- [x] Abertura
- [ ] **Conteúdo!** - [até 15/07]
- [x] Objetivo
- [ ] Estrutura
- [x] Código final
- [x] Aulas
- [x] Código de todas as aulas
- [x] Títulos das aulas
- [x] Conteúdo das aulas
- [ ] Slides
- [ ] **Produção!** - [até 22/07]
- [ ] Captação
- [ ] Armazenamento
- [ ] **Pós produção** - [até 05/08]
- [ ] Tratamento de áudio
- [ ] Edição
- [ ] Cortes
- [ ] Montagem
- [ ] **Finalização!**
- [ ] Uploads no Youtube
- [ ] Descrição dos vídeos para youtube
- [ ] Tags
- [ ] Título
- [ ] Criar a playlist
| 147
| 9
|
nasa/OnAIR
|
https://github.com/nasa/OnAIR
|
The On-board Artificial Intelligence Research (OnAIR) Platform is a framework that enables AI algorithms written in Python to interact with NASA's cFS. It is intended to explore research concepts in autonomous operations in a simulated environment.
|
# The On-board Artificial Intelligence Research (OnAIR) Platform
The On-board Artificial Intelligence Research (OnAIR) Platform is a framework that enables AI algorithms written in Python to interact with NASA's [cFS](https://github.com/nasa/cFS).
It is intended to explore research concepts in autonomous operations in a simulated environment.
## Generating environment
Create a conda environment with the necessary packages
conda create --name onair --file requirements_pip.txt
## Running unit tests
Instructions on how to run unit tests for OnAIR
### Required python installs:
pytest,
pytest-mock,
coverage
### Optional python install:
pytest-randomly
### Running the unit tests from the driver.py file
From the parent directory of your local repository:
```
python driver.py -t
```
### Running pytest directly from command line
For the equivalent of the driver.py run:
```
python -m coverage run --branch --source=src,data_handling,utils -m pytest ./test/
```
#### Command breakdown:
`python -m` - invokes the python runtime on the library following the -m
`coverage run` - runs coverage data collection during testing, wrapping itself on the test runner used
`--branch` - includes code branching information in the coverage report
`--source=src,data_handling,utils` - tells coverage where the code under test exists for reporting line hits
`-m pytest` - tells coverage what test runner (framework) to wrap
`./test` - run all tests found in this directory and subdirectories
#### A few optional settings
Options that may be added to the command line test run. Use these at your own discretion.
`PYTHONPATH=src` - sets env variable so tests can find src, but only use if tests won't run without
`--disable-warnings` - removes the warning reports, but displays count (i.e., 124 passed, 1 warning in 0.65s)
`-p no:randomly` - ONLY required to stop random order testing IFF pytest-randomly installed
### To view testing line coverage after run:
`coverage report` - prints basic results in terminal
or
`coverage html` - creates htmlcov/index.html, automatic when using driver.py for testing
and
`<browser_here> htmlcov/index.html` - browsable coverage (i.e., `firefox htmlcov/index.html`)
## License and Copyright
Please refer to [NOSA GSC-19165-1 OnAIR.pdf](NOSA%20GSC-19165-1%20OnAIR.pdf) and [COPYRIGHT](COPYRIGHT).
## Contributions
Please open an issue if you find any problems.
We are a small team, but will try to respond in a timely fashion.
If you would like to contribute code, GREAT!
First you will need to complete the [Individual Contributor License Agreement (pdf)](doc/Indv_CLA_OnAIR.pdf) and email it to [email protected] with [email protected] CCed.
Next, please create an issue for the fix or feature and note that you intend to work on it.
Fork the repository and create a branch with a name that starts with the issue number.
Once done, submit your pull request and we'll take a look.
You may want to make draft pull requests to solicit feedback on larger changes.
| 13
| 2
|
simonw/llm-mpt30b
|
https://github.com/simonw/llm-mpt30b
|
LLM plugin adding support for the MPT-30B language model
|
# llm-mpt30b
[](https://pypi.org/project/llm-mpt30b/)
[](https://github.com/simonw/llm-mpt30b/releases)
[](https://github.com/simonw/llm-mpt30b/actions?query=workflow%3ATest)
[](https://github.com/simonw/llm-mpt30b/blob/main/LICENSE)
Plugin for [LLM](https://llm.datasette.io/) adding support for the [MPT-30B language model](https://huggingface.co/mosaicml/mpt-30b).
This plugin uses [TheBloke/mpt-30B-GGML](https://huggingface.co/TheBloke/mpt-30B-GGML). The code was inspired by [abacaj/mpt-30B-inference](https://github.com/abacaj/mpt-30B-inference).
## Installation
Install this plugin in the same environment as LLM.
```bash
llm install llm-mpt30b
```
After installing the plugin you will need to download the ~19GB model file. You can do this by running:
```bash
llm mpt30b download
```
## Usage
This plugin adds a model called `mpt30b`. You can execute it like this:
```bash
llm -m mpt30b "Three great names for a pet goat"
```
The alias `-m mpt` works as well.
You can pass the option `-o verbose 1` to see more verbose output - currently a progress bar showing any additional downloads that are made during execution.
## Development
To set up this plugin locally, first checkout the code. Then create a new virtual environment:
cd llm-mpt30b
python3 -m venv venv
source venv/bin/activate
Now install the dependencies and test dependencies:
pip install -e '.[test]'
To run the tests:
pytest
| 17
| 0
|
yarspirin/TagCloud
|
https://github.com/yarspirin/TagCloud
|
TagCloud 🏷️: A flexible SwiftUI package for creating customizable tag clouds in iOS apps.
|
# TagCloud 🏷️
**TagCloud** is a powerful, flexible and stylish package for integrating tag clouds into your iOS apps. From basic setups to fully customizable collections with your custom views, **TagCloud** provides an intuitive interface that blends seamlessly with SwiftUI's design paradigms.
## 🚀 Features
- **Effortless Integration**: Set up your tag cloud with a single line of code using the default `TagCloudView`.
- **Fully Customizable**: Use any data type that conforms to `RandomAccessCollection` and create your own custom views.
- **Automatic Resizing**: Flow layout for optimal use of space that automatically adjusts as tags are added or removed.
- **Stylish and Modern**: Built entirely with SwiftUI for modern and stylish UIs.
## 🔧 Requirements
- iOS 13.0+
- Xcode 14.0+
- Swift 5.7+
## 💻 Installation
Using the Swift Package Manager, add **TagCloud** as a dependency to your `Package.swift` file:
```swift
dependencies: [
.package(url: "https://github.com/yarspirin/TagCloud.git", .upToNextMajor(from: "1.0.0"))
]
```
## 🎈 Usage
### 🎯 Default `TagCloudView`
For a quick and beautiful tag cloud, simply provide an array of strings. **TagCloud** will use the default `TagView` to generate a standard tag cloud:
```swift
import SwiftUI
import TagCloud
struct DefaultExampleView: View {
let tags = ["Hello", "World", "I", "love", "Swift", "and", "tag", "clouds"]
var body: some View {
TagCloudView(tags: tags)
}
}
```
<div align="center">
<img src="https://raw.githubusercontent.com/mountain-viewer/TagCloud/master/Resources/default_example.png" alt="Default Example" width="500">
</div>
### 🔨 Custom `TagCloudView`
For more advanced usage, **TagCloud** allows you to fully customize the tag cloud. You can provide your own collection of data and a closure to generate custom views from your data:
```swift
import SwiftUI
import TagCloud
struct SelectableTag: View {
@State var isSelected = false
let title: String
var body: some View {
Button {
isSelected.toggle()
} label: {
Text(title)
.foregroundColor(isSelected ? .white : .black)
.padding(EdgeInsets(top: 5, leading: 10, bottom: 5, trailing: 10))
.background(
RoundedRectangle(cornerRadius: 10)
.foregroundColor(isSelected ? .black : .white)
)
.overlay(
RoundedRectangle(cornerRadius: 10)
.stroke(isSelected ? .white : .black, lineWidth: 1)
)
}
}
}
struct CustomExampleView: View {
let titles = ["Hello", "World", "I", "Love", "Swift", "And", "Tag", "Clouds"]
var body: some View {
TagCloudView(data: titles) { title in
SelectableTag(title: title)
}
}
}
```
<div align="center">
<img src="https://raw.githubusercontent.com/mountain-viewer/TagCloud/master/Resources/custom_example.gif" alt="Custom Example" width="500">
</div>
## 💼 Contributing
We love contributions! Whether it's fixing bugs, improving documentation, or proposing new features, your efforts are welcome.
## 📄 License
**TagCloud** is available under the MIT license. See the LICENSE.md file for more info.
| 84
| 49
|
EvanZhouDev/donut-js
|
https://github.com/EvanZhouDev/donut-js
| null |
# 🍩 donut.js
```javascript
let A=0,B=0,M=
Math;const a=()=>{let s
=[],t=[];A+=.05,B+=.07;const
o=M.cos(A),e=M.sin(A),n=M.cos(B
),c=M.sin(B);for (let o=0;o<1760;
o++)s[o]=o%80==79?"\n":" ",t[o]=0;for
(let i=0;i<6.28;i+=.07){const r=M.cos(
i),a=M.sin(i);for(let i=0;i<6.28;i+=.02
){const l=M.sin (i),f=M.cos(i),A
=r+2,B=1/(l*A* e+a*o+5),d=l*A*
o-a*e,m=40+30* B*(f*A*n-d*c)|0
,v=12+15*B*(f*A *c+d*n)|0,I=m+80
*v,h=8*((a*e-l*r*o)*n-l*r*e-a*o-f*r*c)|
0;v<22&&v>=0&&m>=0&&m<79&&B>t[I]&&(t[
I]=B,s[I]=".,-~:;=!*#$@"[h>0?h:0])}}
process.stdout.write(`\x1b[J\x1b[H`
+s.join(""))},i=setInterval(a,50
);/*=!!!**********!!!==:*/
/*~~;EvanZhouDev;;:~*/
/*.,-2023--,.*/
```
Run with
```bash
node donut.min.js
```
`donut.c`, remade in JS... and the code still looks like a donut!
`donut.js` is the original code, and `donut.min.js` is the actual donut-shaped obfuscated code.
Modified from the [original DOM code](https://www.a1k0n.net/js/donut.js), written by Andy Sloane with AI, and a little bit of playing around with indentation 😅.
If the donut looks elliptical, then you may need to adjust your font to be more square, or just modify line width and font spacing to make it more square.
| 43
| 1
|
WOLFRIEND/skeleton-mammoth
|
https://github.com/WOLFRIEND/skeleton-mammoth
|
Skeleton Mammoth - a powerful JavaScript library designed to enhance user experience by displaying UI skeleton loaders, also known as placeholders. It allows you to simulate the layout or elements of a website while data is being loaded in the background.
|
<div align="center">
<img src="https://github.com/WOLFRIEND/skeleton-mammoth/blob/main/src/images/sm-logo-big.png" alt="Skeleton Mammoth logotype." style="width: 400px">
</div>
<h1 align="center"><a href="https://github.com/WOLFRIEND/skeleton-mammoth">Skeleton Mammoth</a></h1>
## Table of Contents.
- [What is Skeleton Mammoth?](#what-is-skeleton-mammoth)
- [Advantages.](#advantages)
- [Getting Started.](#getting-started)
- [Installing.](#installing)
- [Usage.](#usage)
- [Import the library.](#1-import-the-library)
- [Set the parent class.](#2-set-the-parent-class-)
- [Set child classes.](#3-set-child-classes-)
- [(Optional) Set the configuration object.](#4-optional-set-the-configuration-object)
- [Advanced Usage.](#advanced-usage)
- [Overriding styles with global variables.](#overriding-styles-with-global-variables)
- [Examples.](#examples)
- [Live Demo.](#live-demo)
- [API.](#api)
- [Props.](#props)
- [CSS.](#css)
- [Contributing.](#contributing)
- [License.](#license)
- [Contact information.](#contact-information)
## What is Skeleton Mammoth?
Skeleton Mammoth - a powerful CSS library designed to enhance user experience
by displaying UI skeleton loaders, also known as placeholders.
It allows you to simulate the layout or elements of a website while data is being loaded in the background.
With a multitude of advantages, Skeleton Mammoth takes your website's visual appeal to the next level.
### Advantages.
- **Class based**: Simply apply the appropriate classes to the elements
you wish to display the skeleton on, and let Skeleton Mammoth do the rest.
No complex code or modifications required.
- **Versatile and Reusable**: Enjoy the flexibility of Skeleton Mammoth with seamlessly integration
without the need to develop new components or major structural changes.
By inheriting layouts from default styles, Skeleton Mammoth customize them with their own styles.
- **Configuration Flexibility**: Tailor the behavior of the library to suit your preferences with ease.
The library provides a configuration object that allows you to adjust the settings according to your requirements.
- **Light and Dark Theme Support**: With built-in support for both light and dark themes,
Skeleton Mammoth automatically detects the user's color scheme,
or allows you to manually configure it to align perfectly with your website's aesthetic.
- **Animations Support**: Elevate your website's dynamism with animations support.
Skeleton Mammoth detects the user's reduced motion or animations setting and adjusts accordingly.
Nevertheless, it allows you to manually configure the animation preferences and has support for several varieties of animations.
- **Lightweight and Dependencies-Free**: The library has been developed with a focus on efficiency
without compromising functionality. It's free from unnecessary external dependencies in order to optimize performance.
That makes it lightweight and easy to maintenance.
With its ease of implementation, advantages, extensive customization options,
lightweight structure free from dependencies, you can effortlessly enhance the visual appeal
and user engagement of your website by providing a polished, professional experience during loading times.
Elevate your user interface with ease and captivate your audience from the very first interaction.
## Getting Started.
### Installing.
Using NPM:
```bash
npm install skeleton-mammoth
```
Using jsDelivr CDN:
<u>Specific version:</u>
```html
<script src="https://cdn.jsdelivr.net/npm/[email protected]/dist/skeleton-mammoth.min.css"></script>
```
<u>Latest version:</u>
```html
<script src="https://cdn.jsdelivr.net/npm/skeleton-mammoth/dist/skeleton-mammoth.min.css"></script>
```
### Usage.
#### 1. Import the library:
You can import it either within a scope of a specific component or globally on the application level.
```js
import 'skeleton-mammoth/dist/skeleton-mammoth.min.css';
```
#### 2. Set the parent class:
While your data is in the process of loading, set the class `"sm-loading"` to the parent element on whose children elements you want to see the skeleton loader.
> **Note:**
> The `sm-loading` class should only be set/present while your data is loading.
> It's kind of a switcher. Only when it is present, child elements with the presence of
> appropriate classes `sm-item-primary` or `sm-item-secondary` will display the skeleton.
```html
<div class="card sm-loading">
<!-- Omitted pieces of code. -->
</div>
```
#### 3. Set child classes:
Set the child `sm-item-primary` or `sm-item-secondary` classes to the elements you want to see the skeleton loaders on.
```html
<div class="card sm-loading">
<div class="card__img sm-item-primary">
<img src="photo.jpg">
</div>
<p class="card__title sm-item-secondary">Card title.</p>
</div>
```
> **Note:**
> If you need to display a skeleton on an image (`<img/>` tag), you need to wrap the `<img/>` tag in a `<div></div>` tag,
> and set the skeleton class to that parent tag (as shown in the example above).
> Or do conditional rendering, and while the data is not loaded,
> render the stub `<div></div>` tag, and after loading the data, show the `<img/>` tag.
> This is because of applying the background property to the `<img/>` tag will not have a result.
#### 4. (Optional) Set the configuration object:
If you would like to change the behavior of the Skeleton Mammoth library,
you can achieve it by specifying the `JSON` object as a `data-sm-config` attribute value
to the parent element with the `sm-loading` class.
```javascript
const config = JSON.stringify({
animation: "none",
theme: "dark",
opacity: "0.7",
})
```
```jsx
<div class="card sm-loading" data-sm-config={config}>
<!-- Omitted pieces of code. -->
</div>
```
> **Note:**
> For a complete list of available configurations, see the API [Props](#props) section.
### Advanced Usage.
Learn how to customize Skeleton Mammoth by taking advantage of different strategies for specific use cases.
#### Overriding styles with global variables.
> **Note:**
> All our custom properties are prefixed with `--sm` to avoid conflicts with third party CSS.
Skeleton Mammoth extensively uses root CSS variables to allow you to easily
override default styles at a global level instead of writing new selectors.
If you want to adjust the default styles, just override appropriate
variables in your own `*.css` file inside the
[:root](https://developer.mozilla.org/en-US/docs/Web/CSS/:root) CSS pseudo-class.
> **Note:**
> Pay attention to the order of the import of the file with overwritten styles.
> It needs to be imported after the library is imported.
> Otherwise, you will have to use [!important](https://developer.mozilla.org/en-US/docs/Web/CSS/important).
> **Note:**
> Please use colors in RGB format, as in the example below,
> otherwise it may not work.
```css
/* Your own custom.css file: */
:root {
--sm-color-light-primary: 255, 0, 0, 0.5;
}
```
For a complete list of available CSS variables, see the API [CSS](#css) section,
or find them in the source files:
<a href="https://github.com/WOLFRIEND/skeleton-mammoth/blob/main/src/styles/variables">variables</a>.
## Examples.
**React.js.**
```jsx
import 'skeleton-mammoth/dist/skeleton-mammoth.min.css'
export const Card = ({isLoading, imgUrl, title, subtitle}) => {
/**
* (Optional) Configuration object with settings.
* For a complete list of available configurations, see the "API" section.
* */
const config = JSON.stringify({
animation: "none",
theme: "dark",
opacity: "0.7",
})
return (
/**
* 1. If "isLoading" is "true" set the className "sm-loading" to the parent element.
* 2. (Optional) Pass the configuration object in the "data-sm-config" attribute.
* 3. Set classNames "sm-item-primary" and "sm-item-secondary" to child elements.
* */
<div className={`card ${isLoading ? "sm-loading" : ""}`} data-sm-config={config}>
<div className='card__image sm-item-primary'>
<img src={imgUrl} alt='img'/>
</div>
<p className='card__title sm-item-secondary'>{title}</p>
<p className='card__subtitle sm-item-secondary'>{subtitle}</p>
</div>
);
}
```
**Vue.js.**
```vue
<script setup>
defineProps({
isLoading: { type: Boolean, required: true },
imgUrl: { type: String, required: true },
title: { type: String, required: true },
subtitle: { type: String, required: true }
})
/**
* (Optional) Configuration object with settings.
* For a complete list of available configurations, see the "API" section.
* */
const config = JSON.stringify({
animation: "none",
theme: "dark",
opacity: "0.7",
})
</script>
<template>
<!--
1. If "isLoading" is "true" set the class "sm-loading" to the parent element.
2. (Optional) Pass the configuration object in the "data-sm-config" attribute.
3. Set classes "sm-item-primary" and "sm-item-secondary" to child elements.
-->
<div :class="['card', isLoading ? 'sm-loading' : '']" :data-sm-config="config">
<div class='card__image sm-item-primary'>
<img src={{imgUrl}} alt='img'/>
</div>
<p class='card__title sm-item-secondary'>{{ title }}</p>
<p class='card__subtitle sm-item-secondary'>{{ subtitle }}</p>
</div>
</template>
<style>
@import 'skeleton-mammoth/dist/skeleton-mammoth.min.css';
</style>
```
## Live Demo.
<img src="https://github.com/WOLFRIEND/skeleton-mammoth/blob/main/src/images/skeleton-mammoth-demo.gif" alt="Skeleton Mammoth demo animation." style="width: 600px">
Try out the Skeleton Mammoth library in action at the following link: [Live Demo](https://skeleton-mammoth-demo.onrender.com).
This interactive demo showcases the core features and functionality of the library.
Try out with different options and see how it's powerful and flexible.
Live demo [source code](https://github.com/WOLFRIEND/skeleton-mammoth-demo).
## API.
API reference docs for the Skeleton Mammoth library. Learn about the props, CSS, and other APIs.
### Props.
> See the [Set the configuration object](#4-optional-set-the-configuration-object) section for the reference
> on how to use API props.
| Name | Type | Default value | Description |
|-----------|-------------------------------------------------------------------------------------------------------------------|:-------------:|-------------------------------|
| animation | `"none"` \| `"wave"` \| `"wave-reverse"` \| `"pulse"` | `"wave"` | Skeleton animation mode. |
| theme | `"light"` \| `"dark"` | `"light"` | Color scheme of the skeleton. |
| opacity | `"0"` \| `"0.1"` \| `"0.2"` \| `"0.3"` \| `"0.4"` \| `"0.5"` \| `"0.6"` \| `"0.7"` \| `"0.8"` \| `"0.9"` \| `"1"` | `"1"` | Opacity of the skeleton. |
### CSS.
> See the [Overriding styles with global variables](#overriding-styles-with-global-variables)
> section for the reference on how to use API CSS.
#### Colors.
You can find all color variables in the source file:
[colors.scss](./src/styles/variables/colors.scss).
| Global variable name | Default value | Description |
|--------------------------------------|------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| --sm-color-light-primary | `204, 204, 204, 1` | Background color of the primary element (with the class `sm-item-primary`) for the light theme. |
| --sm-color-light-secondary | `227, 227, 227, 1` | Background color of the secondary element (with the class `sm-item-secondary`) for the light theme. |
| --sm-color-light-animation-primary | `color-mix( in srgb, #fff 15%, rgba(var(--sm-color-light-primary)))` | Animation color of the primary element (with the class `sm-item-primary`) for the light theme. |
| --sm-color-light-animation-secondary | `color-mix( in srgb, #fff 15%, rgba(var(--sm-color-light-secondary)))` | Animation color of the secondary element (with the class `sm-item-secondary`) for the light theme. |
| --sm-color-dark-primary | `37, 37, 37, 1` | Background color of the primary element (with the class `sm-item-primary`) for the dark theme. |
| --sm-color-dark-secondary | `41, 41, 41, 1` | Background color of the secondary element (with the class `sm-item-secondary`) for the dark theme. |
| --sm-color-dark-animation-primary | `color-mix( in srgb, #fff 2%, rgba(var(--sm-color-dark-primary)))` | Animation color of the primary element (with the class `sm-item-primary`) for the dark theme. |
| --sm-color-dark-animation-secondary | `color-mix( in srgb, #fff 2%, rgba(var(--sm-color-dark-secondary)))` | Animation color of the secondary element (with the class `sm-item-secondary`) for the dark theme. |
#### Animations.
You can find all animation variables in the source file:
[animations.scss](./src/styles/variables/animations.scss).
| Global variable name | Default value | Description |
|--------------------------------|--------------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| --sm-animation-duration | `1.5s` | The [animation-duration](https://developer.mozilla.org/en-US/docs/Web/CSS/animation-duration) CSS property sets the length of time that an animation takes to complete one cycle. |
| --sm-animation-timing-function | `linear` | The [animation-timing-function](https://developer.mozilla.org/en-US/docs/Web/CSS/animation-timing-function) CSS property sets how an animation progresses through the duration of each cycle. |
| --sm-animation-iteration-count | `infinite` | The [animation-iteration-count](https://developer.mozilla.org/en-US/docs/Web/CSS/animation-iteration-count) CSS property sets the number of times an animation sequence should be played before stopping. |
| --sm-animation-none | `none` | Sets `"none"` animation configuration for the `animation` props. |
| --sm-animation-wave | `--sm--animation-wave var(--sm-animation-duration) var(--sm-animation-timing-function) var(--sm-animation-iteration-count);` | Sets `"wave"` animation configuration for the `animation` props. Which includes the following options: <ul><li>[animation-name](https://developer.mozilla.org/en-US/docs/Web/CSS/animation-name)</li><li>[animation-duration](https://developer.mozilla.org/en-US/docs/Web/CSS/animation-duration)</li> <li>[animation-timing-function](https://developer.mozilla.org/en-US/docs/Web/CSS/animation-timing-function)</li> <li>[animation-iteration-count](https://developer.mozilla.org/en-US/docs/Web/CSS/animation-iteration-count)</li></ul> |
| --sm-animation-wave-reverse | `--sm--animation-wave-reverse var(--sm-animation-duration) var(--sm-animation-timing-function) var(--sm-animation-iteration-count);` | Sets `"wave-reverse"` animation configuration for the `animation` props. Which includes the following options: <ul><li>[animation-name](https://developer.mozilla.org/en-US/docs/Web/CSS/animation-name)</li><li>[animation-duration](https://developer.mozilla.org/en-US/docs/Web/CSS/animation-duration)</li> <li>[animation-timing-function](https://developer.mozilla.org/en-US/docs/Web/CSS/animation-timing-function)</li> <li>[animation-iteration-count](https://developer.mozilla.org/en-US/docs/Web/CSS/animation-iteration-count)</li></ul> |
| --sm-animation-pulse | `--sm--animation-pulse var(--sm-animation-duration) var(--sm-animation-timing-function) var(--sm-animation-iteration-count);` | Sets `"pulse"` animation configuration for the `animation` props. Which includes the following options: <ul><li>[animation-name](https://developer.mozilla.org/en-US/docs/Web/CSS/animation-name)</li><li>[animation-duration](https://developer.mozilla.org/en-US/docs/Web/CSS/animation-duration)</li> <li>[animation-timing-function](https://developer.mozilla.org/en-US/docs/Web/CSS/animation-timing-function)</li> <li>[animation-iteration-count](https://developer.mozilla.org/en-US/docs/Web/CSS/animation-iteration-count)</li></ul> |
## Contributing.
Please see the <a href="https://github.com/WOLFRIEND/skeleton-mammoth/blob/main/CONTRIBUTING.md">Contributing</a> guideline.
## License.
MIT License. For details, please see the <a href="https://github.com/WOLFRIEND/skeleton-mammoth/blob/main/LICENSE.md">License</a> file.
## Contact information.
- **LinkedIn:** https://www.linkedin.com/in/aleksandrtkachenko/.
| 57
| 4
|
m1guelpf/threads-re
|
https://github.com/m1guelpf/threads-re
|
Reverse-engineering Instagram's Threads private APIs.
|
# How Threads Works
This repository contains my notes and discoveries while reverse-engineering Threads app. Feel free to PR if you've found something new, or to build clients with this info (with credit ofc 😉).
## Web (threads.net)
The web version of Threads is currently read-only, so not much can be learned about authentication or posting. It uses Meta's [Relay GraphQL Client](https://relay.dev) to talk to the backend (`threads.net/api/graphql`), which seems to be configured to disallow arbitrary queries. This leaves us limited to the existing queries found in the frontend's source:
> **Note**
> When querying the GraphQL backend, make sure to set an user-agent (seems like anything works here) and set the `x-ig-app-id` header to `238260118697367`.
### Get profile data
> Doc ID: `23996318473300828`
>
> Variables: `userID` (the user's ID)
```bash
curl --request POST \
--url https://www.threads.net/api/graphql \
--header 'user-agent: threads-client' \
--header 'x-ig-app-id: 238260118697367' \
--header 'content-type: application/x-www-form-urlencoded' \
--data 'variables={"userID":"314216"}' \
--data doc_id=23996318473300828
```
### Get profile posts
> Doc ID: `6232751443445612`
>
> Variables: `userID` (the user's ID)
```bash
curl --request POST \
--url https://www.threads.net/api/graphql \
--header 'user-agent: threads-client' \
--header 'x-ig-app-id: 238260118697367' \
--header 'content-type: application/x-www-form-urlencoded' \
--data 'variables={"userID":"314216"}' \
--data doc_id=6232751443445612
```
### Get profile replies
> Doc ID: `6307072669391286`
>
> Variables: `userID` (the user's ID)
```bash
curl --request POST \
--url https://www.threads.net/api/graphql \
--header 'user-agent: threads-client' \
--header 'x-ig-app-id: 238260118697367' \
--header 'content-type: application/x-www-form-urlencoded' \
--data 'variables={"userID":"314216"}' \
--data doc_id=6307072669391286
```
### Get a post
> Doc ID: `5587632691339264`
>
> Variables: `postID` (the post's ID)
```bash
curl --request POST \
--url https://www.threads.net/api/graphql \
--header 'user-agent: threads-client' \
--header 'x-ig-app-id: 238260118697367' \
--header 'content-type: application/x-www-form-urlencoded' \
--data 'variables={"postID":"3138977881796614961"}' \
--data doc_id=5587632691339264
```
### Get a list of users who liked a post
> Doc ID: `9360915773983802`
>
> Variables: `mediaID` (the post's ID)
```bash
curl --request POST \
--url https://www.threads.net/api/graphql \
--header 'user-agent: threads-client' \
--header 'x-ig-app-id: 238260118697367' \
--header 'content-type: application/x-www-form-urlencoded' \
--data 'variables={"mediaID":"3138977881796614961"}' \
--data doc_id=9360915773983802
```
## Mobile Apps
### Authentication
> **Warning**
> This endpoint currently only works for accounts without 2FA enabled.
The mobile apps use Meta's Bloks framework ([originally built for Instagram Lite](https://thenewstack.io/instagram-lite-is-no-longer-a-progressive-web-app-now-a-native-app-built-with-bloks/)) for authentication.
The bloks versioning ID for threads is `00ba6fa565c3c707243ad976fa30a071a625f2a3d158d9412091176fe35027d8`. Bloks also requires you to provide a device id (of shape `ios-RANDOM` | `android-RANDOM`, `RANDOM` being a random set of 13 chars).
```bash
curl --request POST \
--url 'https://i.instagram.com/api/v1/bloks/apps/com.bloks.www.bloks.caa.login.async.send_login_request/' \
--header 'user-agent: Barcelona 289.0.0.77.109 Android' \
--header 'sec-fetch-site: same-origin' \
--header 'content-type: application/x-www-form-urlencoded; charset=UTF-8' \
--data 'params={"client_input_params":{"password":"$PASSWORD","contact_point":"$USERNAME","device_id":"$DEVICE_ID"},"server_params":{"credential_type":"password","device_id":"$DEVICE_ID"}}' \
--data 'bloks_versioning_id=00ba6fa565c3c707243ad976fa30a071a625f2a3d158d9412091176fe35027d8'
```
This request returns a big JSON payload. Your token will be immediately after the string `Bearer IGT:2:`, and should be 160 characters long.
### Creating a text post
```bash
curl --request POST \
--url 'https://i.instagram.com/api/v1/media/configure_text_only_post/' \
--header 'content-type: application/x-www-form-urlencoded; charset=UTF-8' \
--header 'user-agent: Barcelona 289.0.0.77.109 Android' \
--header 'authorization: Bearer IGT:2:$TOKEN' \
--header 'sec-fetch-site: same-origin' \
--data 'signed_body=SIGNATURE.{"publish_mode":"text_post","text_post_app_info":"{\"reply_control\":0}","timezone_offset":"0","source_type":"4","_uid":"$USER_ID","device_id":"$DEVICE_ID","caption":"$POST_TEXT","device":{"manufacturer":"OnePlus","model":"ONEPLUS+A3003","android_version":26,"android_release":"8.1.0"}}'
```
## Misc
### How to get a profile's id from their username?
Threads uses the same ID system used by Instagram. The best approach to convert from username to id seems to be requesting the user's instagram page (`instagram.com/:username`) and manually parsing the response HTML. For other methods, see [this StackOverflow question](https://stackoverflow.com/questions/11796349/instagram-how-to-get-my-user-id-from-username).
| 276
| 16
|
0mWindyBug/KDP-compatible-driver-loader
|
https://github.com/0mWindyBug/KDP-compatible-driver-loader
|
KDP compatible unsigned driver loader leveraging a write primitive in one of the IOCTLs of gdrv.sys
|
# KDP Compatible Unsigned Driver Loader
Kernel Unsigned Driver Loader , KDP compatible, Leveraging gdrv.sys's Write Primitive
Tested on Windows 10 21H2 and 22H2
# Usage:
**load target driver-> Loader.exe gdrv.sys driver.sys**
**unload target driver -> Loader.exe driver.sys**
# How it works
Driver Signature Enforcement is implemented within CI.dll. Based on Reverse Engineering of the signature validation process we know nt!SeValidateImageHeader calls CI!CiValidateImageHeader.
the return status from CiValidateImageHeader determines whether the signature is valid or not.
Based on Reverse Engineering of nt!SeValidateImageHeader we understand it uses an array - SeCiCallbacks to retrieve the address of CiValidateImageHeader before calling it.
SeCiCallbacks is initialized by CiInitialize. to be precise, a pointer to nt!SeCiCallbacks is passed to CiInitialize as an argument allowing us to map ntoskrnl.exe to usermode and perform the following:
sig scan for the lea instruction prior to the CiIntialize call.
calculate the address of SeCiCallbacks in usermode
calculate the offset from the base of ntoskrnl in usermode
add the same offset to the base of ntoskrnl.exe in kernelmode.
once we have the address of SeCiCallbacks in kernel, all we need to do is to add a static offset to CiValidateImageHeader's entry in the array.
leverage the write primitive to replace the address of CiValidateImageHeader with the address of ZwFlushInstructionCache, or any function that will always return NTSTATUS SUCCESS with the same prototype of CiValidateImageHeader.
***************************
# Demo

# Notes
- in case loading gdrv.sys fails, its likely due to Microsoft's driver blocklist/cert expired, just modify the code to use an alternative vulnerable driver , there are plenty of them.
- whilst the implemented technique does not require a read primitive , we do use the read primitive to restore the original CiValidateImageHeader after the unsigned driver is loaded.
you can modify the code to not use the read primitive and it will work just fine since SeCiCallbacks is not PatchGuard protected
- built on top of the core of gdrv-loader
| 18
| 1
|
zacharee/MastodonRedirect
|
https://github.com/zacharee/MastodonRedirect
|
Deep linking proxy for Mastodon on Android, allowing you to launch your selected client automatically.
|
# Mastodon/Lemmy Redirect
A simple pair of apps for automatically launching fediverse links in your preferred Mastodon/Lemmy client.
## Use-Cases:
Mastodon and Lemmy are both examples of federated social media. This is mostly a good thing, for a whole host of reasons, but it does have one notable disadvantage: deep linking support.
When you tap a Twitter link in your browser and your phone opens the Twitter app instead of the Twitter website to view the post, that's an example of deep linking. The trouble with federated social media is three-fold:
1. There are a lot of different instances at different addresses running the same or interoperable software.
2. Android only lets app developers declare supported deep link domains at compile time: users can't add custom domains, and domains can only be added through app updates. Many developers understandably don't want to maintain a list of thousands of domains.
3. Android really isn't set up for a single app to support more than a few different domains for deep links.
Mastodon/Lemmy Redirect aims to solve the first two issues and somewhat solve the third.
By using the [instances.social](https://instances.social) and [Lemmy Explorer](https://lemmyverse.net/communities) APIs, Mastodon/Lemmy Redirect is able to maintain an up-to-date list of supported domains.
Once you download the app, you can choose your client app and then enable all supported domains, so that when you tap a recognized link, it gets passed to Mastodon/Lemmy Redirect.
Mastodon/Lemmy Redirect then sends the link directly to the chosen client app for it to handle.
Since the point of Mastodon/Lemmy Redirect is only to change where supported links open, the maintenance of supported domains isn't extra busywork that has to be done in addition to other features and fixes; it's literally all the app does.
Client developers do need to do some work for Mastodon/Lemmy Redirect to support them, but it's a one-time thing, and instructions are available below.
## Supported Domains
Currently, most domains on https://instances.social and https://lemmyverse.net/communities are supported.
Mastodon/Lemmy Redirect supports most active and alive instances, but excludes dead instances and instances that haven't had any activity recently. This is to keep the list as short as possible and avoid crashes.
Mastodon/Lemmy Redirect also (sort of) supports the `web+activity+http` and `web+activity+https` URL schemes. The expectation is that the full post or profile URL will follow.
Examples:
```
// Post
web+activity+https://androiddev.social/@wander1236/110699242324667418
// Profile
web+activity+https://androiddev.social/@wander1236
```
## Downloads
[](https://github.com/zacharee/MastodonRedirect/releases)
[](https://apt.izzysoft.de/fdroid/index/apk/dev.zwander.mastodonredirect/)
## Setup
If any domains aren't enabled for handling by Mastodon/Lemmy Redirect, the app will let you know and provide you buttons for enabling them.
Enabling each supported domain one at a time is possible, but tedious. Instead, Mastodon/Lemmy Redirect can use [Shizuku](https://shizuku.rikka.app) to automatically enable all links at once. The setup for Shizuku is a little complex, but can be done completely on-device on Android 11 and later. It is also only needed once for the initial setup or for enabling domains added in app updates.
### Note about Shizuku Method
There's a bug in Android where using the Shizuku method will leave one or more domains unverified. Even using Google's officially-recommended development command to verify all domains won't work.
If tapping "Enable with Shizuku" isn't working, try uninstalling Mastodon/Lemmy Redirect and then reinstalling. If it worked, you won't see the notification about unverified domains at all on first launch, and all domains should be verified.
## Usage
Open Mastodon/Lemmy Redirect and select your preferred client.
## Client Support
Unfortunately, many Mastodon and Lemmy clients don't have a way for Mastodon/Lemmy Redirect to interface with them.
Mastodon/Lemmy Redirect relies on clients having a link sharing target that can parse and open fediverse links.
Clients such as Tusky and Trunks do have share targets, but they can only be used to create new posts, with the shared link as the content. Other clients have no share targets at all.
Mastodon Redirect currently supports the following clients:
- [Fedilab (F-Droid or Play Store)](https://github.com/stom79/Fedilab).
- [Megalodon](https://github.com/sk22/megalodon).
- [Moshidon (Stable or Nightly)](https://github.com/LucasGGamerM/moshidon).
- [Subway Tooter](https://github.com/tateisu/SubwayTooter).
- [Elk (PWA: Stable or Canary)](https://github.com/elk-zone/elk).
- [Tooot](https://github.com/tooot-app/app).
Lemmy Redirect currently supports the following clients:
- [Infinity](https://codeberg.org/Bazsalanszky/Infinity-For-Lemmy).
- [Jerboa](https://github.com/dessalines/jerboa).
- [Liftoff](https://github.com/liftoff-app/liftoff).
- [Summit](https://lemmy.world/c/summit).
- [Sync](https://github.com/laurencedawson/sync-for-lemmy).
If your favorite client isn't on the list, consider creating an issue on their code repository or issue tracker linking to the section below, ***but please search through the existing issues first, including ones that have been closed***. Pestering developers won't help anyone.
## Adding Client Support
If you're the developer of a Mastodon client and want to add support for Mastodon/Lemmy Redirect into your app, here's how.
### Automatic
You can let Mastodon/Lemmy Redirect automatically discover your app by filtering for a custom Intent and parsing the data as a URL.
Note: right now, Mastodon/Lemmy Redirect doesn't support auto discovery, but it should be added soon.
#### Create a discoverable target.
In your `AndroidManifest.xml`, add the following intent filter inside the relevant Activity tag:
Mastodon Redirect:
```xml
<intent-filter>
<action android:name="dev.zwander.mastodonredirect.intent.action.OPEN_FEDI_LINK"/>
<category android:name="android.intent.category.DEFAULT"/>
</intent-filter>
```
Lemmy Redirect:
```xml
<intent-filter>
<action android:name="dev.zwander.lemmyredirect.intent.action.OPEN_FEDI_LINK"/>
<category android:name="android.intent.category.DEFAULT"/>
</intent-filter>
```
Inside the Activity itself:
```kotlin
override fun onCreate(savedInstanceState: Bundle?) {
// ...
val url = intent?.data?.toString()
// Validate `url`.
// Pass it to your internal link parser to find the post ID and such.
// Open in your thread/profile viewer component.
}
```
### Manual
The high level process is pretty simple: expose some way for your app to be launched that accepts a URL and tries to parse it as a fediverse link to open as a post or profile. There are a few ways you can do this.
Once you've implemented support, feel free to open an issue or PR to have it added to Mastodon/Lemmy Redirect.
#### Create a share target.
Note: this will cause your app to appear in the share menu when a user chooses to share any text, not just links. If your app already has a share target for pasting the shared text into a new post draft, it might make sense to reuse that target with an option to open the shared link instead of only creating a new post.
Check out [Moshidon](https://github.com/LucasGGamerM/moshidon/blob/master/mastodon/src/main/java/org/joinmastodon/android/ExternalShareActivity.java) for an example.
In your `AndroidManifest.xml`, add the following intent filter inside the relevant Activity tag:
```xml
<intent-filter>
<action android:name="android.intent.action.SEND"/>
<category android:name="android.intent.category.DEFAULT"/>
<data android:mimeType="text/*"/>
</intent-filter>
```
Inside the Activity itself:
```kotlin
override fun onCreate(savedInstanceState: Bundle?) {
// ...
if (intent?.action == Intent.ACTION_SHARE) {
val sharedText = intent.getStringExtra(Intent.EXTRA_TEXT)
// Validate that `sharedText` is a URL.
// Pass it to your internal link parser to find the post ID and such.
// Open in your thread/profile viewer component.
}
}
```
#### Create a view target.
This is similar to the share target, but won't show up to users directly in the share menu.
In your `AndroidManifest.xml`, add the following intent filter inside the relevant Activity tag:
```xml
<intent-filter>
<action android:name="android.intent.action.VIEW"/>
<category android:name="android.intent.category.BROWSABLE"/>
<category android:name="android.intent.category.DEFAULT"/>
<data android:scheme="https" />
<data android:scheme="http" />
<data android:host="*" />
</intent-filter>
```
Inside the Activity itself:
```kotlin
override fun onCreate(savedInstanceState: Bundle?) {
// ...
val url = intent?.data?.toString()
// Validate `url`.
// Pass it to your internal link parser to find the post ID and such.
// Open in your thread/profile viewer component.
}
```
## Building
In order to build Mastodon/Lemmy Redirect, you'll need two things:
1. The latest [Android Studio Canary](https://developer.android.com/studio/preview) build.
2. A [modified Android SDK](https://github.com/Reginer/aosp-android-jar) with hidden APIs exposed.
Download the modified SDK corresponding to Mastodon/Lemmy Redirect's current `compileSdk` value (found in the module-level [build.gradle.kts](https://github.com/zacharee/MastodonRedirect/tree/main/app/build.gradle.kts)) and follow the instructions provided in the link above to install it.
## Contributing
If you want to add support for another app:
Until development slows down, check out the `LaunchStrategy.kt` file for how to add new apps.
## Error Reporting
Mastodon/Lemmy Redirect uses Bugsnag for error reporting.
<a href="https://www.bugsnag.com"><img src="https://assets-global.website-files.com/607f4f6df411bd01527dc7d5/63bc40cd9d502eda8ea74ce7_Bugsnag%20Full%20Color.svg" width="200"></a>
| 24
| 2
|
verytinydever/AGE_Application
|
https://github.com/verytinydever/AGE_Application
| null |
REAMD ME
| 12
| 0
|
microsoft/semantic-kernel-plugins
|
https://github.com/microsoft/semantic-kernel-plugins
|
Get started building Semantic Kernel Plugins you can use for your own AI applications.
|
# Semantic Kernel Plugins
Plugins are at the heart of unlocking more potential with your [Semantic Kernel](https://github.com/microsoft/semantic-kernel) applications.
They allow you to connect to external data sources and give large language models tools to be able to
interact with native functions and API services.
# Want to test your plugins? ⚗️
If you want to try out your plugins and you do not have a ChatGPT plus subscription or are off the waitlist, you can test this directly **for free** using the Semantic Kernel!
See [this tutorial doc](https://learn.microsoft.com/en-us/semantic-kernel/ai-orchestration/chatgpt-plugins) or watch the [video](https://youtu.be/W_xF8PcdT78) for how to get set up.
# SK Plugins Hackathon #1 (7/18/23 - 7/25/23) 📢
**What:** Build a Semantic Kernel Plugin and compete for glory and prizes!
**When:** Submissions are open July 18, 2023 2 PM PST to July 25, 2023 5 PM PST.
**Why:** Microsoft is standardizing around the [plugin architecture](https://learn.microsoft.com/en-us/semantic-kernel/ai-orchestration/plugins?tabs=Csharp) for all of its internal AI copilots
and encourage developers to use them for their own applications. This hackathon serves to jumpstart a larger plugin ecosystem that is valuable to the broader community.
**How:** Follow the getting started guides for creating a plugin
- **C#** - [(Video)](https://youtu.be/T7XLn11rpYI) | [(Repo) Semantic Kernel ChatGPT plugin starter](https://github.com/microsoft/semantic-kernel-starters/tree/main/sk-csharp-chatgpt-plugin)
- **Python** - [(Video)](https://youtu.be/_4HZCdd3OxI) | [(Repo) Semantic Kernel Python Flask (and plugin) Starter](https://github.com/microsoft/semantic-kernel-starters/tree/main/sk-python-flask)
## Prizes 🚀 🎁
We'll have the following categories for judging:
- **Most useful for the enterprise**
- **Most fun and creative**
- **Community Favorite**
Prizes will be announced throughout the week. Some include an exclusive interview feature on the Semantic Kernel DevBlog and a customized Semantic Kernel T-Shirt. Stay tuned for more!
## Submission
To submit your plugin, please fill out this [form](https://aka.ms/sk-hackathon-plugin-submission)! Once we pass the deadline, the team will begin reviewing. The community favorite will be voted on Discord.
# Join the community
- Star the [Semantic Kernel repo](https://github.com/microsoft/semantic-kernel)!
- Join the [Semantic Kernel Discord community](https://aka.ms/SKDiscord)
- Attend [regular office hours and SK community events](https://github.com/microsoft/semantic-kernel/blob/main/COMMUNITY.md)
# Code of Conduct
This project has adopted the
[Microsoft Open Source Code of Conduct](https://opensource.microsoft.com/codeofconduct/).
For more information see the
[Code of Conduct FAQ](https://opensource.microsoft.com/codeofconduct/faq/)
or contact [[email protected]](mailto:[email protected])
with any additional questions or comments.
# License
Copyright (c) Microsoft Corporation. All rights reserved.
Licensed under the [MIT](LICENSE) license.
| 26
| 3
|
dohsimpson/docker2kube
|
https://github.com/dohsimpson/docker2kube
|
TypeScript lib to convert docker-compose to kubernetes
|
# docker2kube (d2k)
d2k is a typescript library that converts docker-compose YAML files to Kubernetes YAML file. The goal is to make it easy to deploy docker project on Kubernetes.
# UI
Visit https://docker2kube.app.enting.org/ to perform conversion online.
# Installation
NPM: `npm i docker2kube`
YARN: `yarn add docker2kube`
# Usage
```javascript
import { convert } from 'docker2kube';
const composeYaml = `\
version: '3'
services:
nginx:
image: nginx:latest
ports:
- "80:80"
volumes:
- ./nginx.conf:/etc/nginx/nginx.conf
restart: always
`;
const output = convert(composeYaml);
console.log(output);
```
# Acknowledgment
* [kompose](https://github.com/kubernetes/kompose) is the canonical tool for converting docker-compose templates. And inspired this project.
* [json-schema-to-typescript](https://github.com/bcherny/json-schema-to-typescript) makes working with JSON schema a dream.
* [composerize](https://github.com/magicmark/composerize) for converting docker command.
| 17
| 1
|
genabdulrehman/coffee-app
|
https://github.com/genabdulrehman/coffee-app
| null |
# coffe_app
A new Flutter project.
## Project Overview
https://github.com/genabdulrehman/coffee-app/assets/76816147/c3f97a22-6cc3-43a1-b51e-8d42e73949f1
| 27
| 4
|
Phillip-England/flank-steak
|
https://github.com/Phillip-England/flank-steak
| null |
You need a .env file with a valid POSTGRES_URL and a random string of characters called SESSION_TOKEN_KEY in the ROOT of your project if you intend to clone the repo.
Also required a URL variable which is the domain of your application
| 22
| 4
|
zemmsoares/awesome-rices
|
https://github.com/zemmsoares/awesome-rices
|
A curated list of awesome unix user rices!
|
<div align="center">
<img src="https://raw.githubusercontent.com/zemmsoares/awesome-rices/main/assets/logo.webp" alt="Awesome Rices logo" width="150" style="margin-bottom: 30px;">
<h1 style="font-size: 32px; border: none; line-height: 0; font-weight: bold">Awesome Rices</h1>
<p>This repository is a collection of outstanding Unix customizations.<br> Explore different user rices, get inspired, inspire us.</p>
<div style="margin-bottom: 10px">
<img src="https://cdn.rawgit.com/sindresorhus/awesome/d7305f38d29fed78fa85652e3a63e154dd8e8829/media/badge.svg" alt="Awesome"/>
<img src="https://raw.githubusercontent.com/zemmsoares/awesome-rices/main/assets/awesome-rice-badge.svg" alt="awesome-rice-badge"/>
</div>
<br>
</div>
# Table of Contents
- [Table of Contents](#table-of-contents)
- [Rices](#rices)
- [AwesomeWM](#awesomewm)
- [AlphaTechnolog](#alphatechnolog)
- [Amitabha37377](#amitabha37377)
- [chadcat7](#chadcat7)
- [CmrCrabs](#cmrcrabs)
- [d-solis](#d-solis)
- [elenapan](#elenapan)
- [frapdotbm](#frapdotbm)
- [Gwynsav](#gwynsav)
- [HoNamDuong](#honamduong)
- [Kasper24](#kasper24)
- [madhur](#madhur)
- [Manas140](#manas140)
- [MeledoJames](#meledojames)
- [p3nguin-kun](#p3nguin-kun)
- [pablonoya](#pablonoya)
- [PassiveLemon](#passivelemon)
- [rklyz](#rklyz)
- [rxyhn](#rxyhn)
- [saimoomedits](#saimoomedits)
- [Savecoders](#savecoders)
- [Spaxly](#spaxly)
- [Stardust-kyun](#stardust-kyun)
- [TorchedSammy](#torchedsammy)
- [vulekhanh](#vulekhanh)
- [bspwm](#bspwm)
- [adilhyz](#adilhyz)
- [AlphaTechnolog](#alphatechnolog-1)
- [DominatorXS](#dominatorxs)
- [Erennedirlo](#erennedirlo)
- [gh0stzk](#gh0stzk)
- [Gwynsav](#gwynsav-1)
- [hlissner](#hlissner)
- [JakeGinesin](#jakeginesin)
- [justleoo](#justleoo)
- [kabinspace](#kabinspace)
- [Narmis-E](#narmis-e)
- [probe2k](#probe2k)
- [rklyz](#rklyz-1)
- [Sinomor](#sinomor)
- [Sophed](#sophed)
- [star-isc](#star-isc)
- [sudo-harun](#sudo-harun)
- [valb-mig](#valb-mig)
- [Weirdchupacabra](#weirdchupacabra)
- [zoddDev](#zodddev)
- [Cinnamon](#cinnamon)
- [SpreadiesInSpace](#spreadiesinspace)
- [DkWM](#dkwm)
- [AlphaTechnolog](#alphatechnolog-2)
- [dwm](#dwm)
- [AlphaTechnolog](#alphatechnolog-3)
- [codedsprit](#codedsprit)
- [Dorovich](#dorovich)
- [Gwynsav](#gwynsav-2)
- [juacq97](#juacq97)
- [nxb1t](#nxb1t)
- [raihanadf](#raihanadf)
- [seeingangelz](#seeingangelz)
- [Gnome](#gnome)
- [1amSimp1e](#1amsimp1e)
- [AviVarma](#avivarma)
- [Comiclyy](#comiclyy)
- [GabrielTenma](#gabrieltenma)
- [NeuronSooup](#neuronsooup)
- [Herbstluftwm](#herbstluftwm)
- [breddie-normie](#breddie-normie)
- [nuxshed](#nuxshed)
- [scourii](#scourii)
- [Hyprland](#hyprland)
- [1amSimp1e](#1amsimp1e-1)
- [ahujaankush](#ahujaankush)
- [cafreo](#cafreo)
- [command-z-z](#command-z-z)
- [conrad-mo](#conrad-mo)
- [dankdezpair](#dankdezpair)
- [debuggyo](#debuggyo)
- [dragoshr1234](#dragoshr1234)
- [end-4](#end-4)
- [h1tarxeth](#h1tarxeth)
- [HeinzDev](#heinzdev)
- [hobosyo](#hobosyo)
- [justinlime](#justinlime)
- [Knightfall01](#knightfall01)
- [MathisP75](#mathisp75)
- [maxtaran2010](#maxtaran2010)
- [Narmis-E](#narmis-e-1)
- [ozwaldorf](#ozwaldorf)
- [prasanthrangan](#prasanthrangan)
- [Redyf](#redyf)
- [RumiAxolotl](#rumiaxolotl)
- [SimplyVoid](#simplyvoid)
- [Spagett1](#spagett1)
- [Stetsed](#stetsed)
- [Yorubae](#yorubae)
- [i3wm](#i3wm)
- [b1337xyz](#b1337xyz)
- [BIBJAW](#bibjaw)
- [bibjaw99](#bibjaw99)
- [Blxckmage](#blxckmage)
- [bryant-the-coder](#bryant-the-coder)
- [fathulfahmy](#fathulfahmy)
- [sommaa](#sommaa)
- [SunoBB](#sunobb)
- [TKK13909](#tkk13909)
- [Vallen217](#vallen217)
- [zemmsoares](#zemmsoares)
- [KDE](#kde)
- [ComplexPlatform](#complexplatform)
- [LeftWM](#leftwm)
- [almqv](#almqv)
- [Lightdm](#lightdm)
- [TheWisker](#thewisker)
- [Openbox](#openbox)
- [AlphaTechnolog](#alphatechnolog-4)
- [Narmis-E](#narmis-e-2)
- [owl4ce](#owl4ce)
- [Qtile](#qtile)
- [Barbaross93](#barbaross93)
- [Darkkal44](#darkkal44)
- [diegorezm](#diegorezm)
- [Fluffy-Bean](#fluffy-bean)
- [gibranlp](#gibranlp)
- [Hamza12700](#hamza12700)
- [shayanaqvi](#shayanaqvi)
- [Riverwm](#riverwm)
- [theCode-Breaker](#thecode-breaker)
- [Sway](#sway)
- [eoli3n](#eoli3n)
- [hifinerd](#hifinerd)
- [KubqoA](#kubqoa)
- [RicArch97](#ricarch97)
- [Sunglas](#sunglas)
- [viperML](#viperml)
- [Xfce](#xfce)
- [fathulfahmy](#fathulfahmy-1)
- [Xmonad](#xmonad)
- [Icy-Thought](#icy-thought)
- [TheMidnightShow](#themidnightshow)
- [Yabai](#yabai)
- [command-z-z](#command-z-z-1)
- [FelixKratz](#felixkratz)
- [QRX53](#qrx53)
- [tcmmichaelb139](#tcmmichaelb139)
- [ZhongXiLu](#zhongxilu)
- [Contribute](#contribute)
- [License](#license)
# Rices
## AwesomeWM
### [AlphaTechnolog](https://github.com/AlphaTechnolog/dotfiles/tree/awesomewm)
[](https://github.com/AlphaTechnolog/dotfiles/tree/awesomewm)
### [Amitabha37377](https://github.com/Amitabha37377/Awesome_Dotfiles)
[](https://github.com/Amitabha37377/Awesome_Dotfiles)
### [chadcat7](https://github.com/chadcat7/crystal)
[](https://github.com/chadcat7/crystal)
### [CmrCrabs](https://github.com/CmrCrabs/dotfiles)
[](https://github.com/CmrCrabs/dotfiles)
### [d-solis](https://github.com/d-solis/dotfiles/tree/awesome)
[](https://github.com/d-solis/dotfiles/tree/awesome)
### [elenapan](https://github.com/elenapan/dotfiles)
[](https://github.com/elenapan/dotfiles)
### [frapdotbm](https://github.com/frapdotbmp/dotfiles)
[](https://github.com/frapdotbmp/dotfiles)
### [Gwynsav](https://github.com/Gwynsav/gwdawful/tree/master)
[](https://github.com/Gwynsav/gwdawful/tree/master)
### [HoNamDuong](https://github.com/HoNamDuong/.dotfiles)
[](https://github.com/HoNamDuong/.dotfiles)
### [Kasper24](https://github.com/Kasper24/KwesomeDE)
[](https://github.com/Kasper24/KwesomeDE)
### [madhur](https://github.com/madhur/dotfiles)
[](https://github.com/madhur/dotfiles)
### [Manas140](https://github.com/Manas140/dotfiles)
[](https://github.com/Manas140/dotfiles)
### [MeledoJames](https://github.com/MeledoJames/awesome-setup)
[](https://github.com/MeledoJames/awesome-setup)
### [p3nguin-kun](https://github.com/p3nguin-kun/penguinRice)
[](https://github.com/p3nguin-kun/penguinRice)
### [pablonoya](https://github.com/pablonoya/awesomewm-configuration)
[](https://github.com/pablonoya/awesomewm-configuration)
### [PassiveLemon](https://github.com/PassiveLemon/lemonix)
[](https://github.com/PassiveLemon/lemonix)
### [rklyz](https://github.com/rklyz/MyRice)
[](https://github.com/rklyz/MyRice)
### [rxyhn](https://github.com/rxyhn/yoru)
[](https://github.com/rxyhn/yoru)
### [saimoomedits](https://github.com/saimoomedits/dotfiles)
[](https://github.com/saimoomedits/dotfiles)
### [Savecoders](https://github.com/Savecoders/dotfiles)
[](https://github.com/Savecoders/dotfiles)
### [Spaxly](https://github.com/Spaxly/espresso)
[](https://github.com/Spaxly/espresso)
### [Stardust-kyun](https://github.com/Stardust-kyun/dotfiles)
[](https://github.com/Stardust-kyun/dotfiles)
### [TorchedSammy](https://github.com/TorchedSammy/dotfiles)
[](https://github.com/TorchedSammy/dotfiles)
### [vulekhanh](https://github.com/vulekhanh/dotfiles)
[](https://github.com/vulekhanh/dotfiles)
## bspwm
<hr>
### [adilhyz](https://github.com/adilhyz/dotfiles-v1)
[](https://github.com/adilhyz/dotfiles-v1)
### [AlphaTechnolog](https://github.com/AlphaTechnolog/dotfiles/tree/bspwm)
[](https://github.com/AlphaTechnolog/dotfiles/tree/bspwm)
### [DominatorXS](https://github.com/DominatorXS/LinuxDotz)
[](https://github.com/DominatorXS/LinuxDotz)
### [Erennedirlo](https://github.com/Erennedirlo/gruvbox-dotfiles)
[](https://github.com/Erennedirlo/gruvbox-dotfiles)
### [gh0stzk](https://github.com/gh0stzk/dotfiles)
[](https://github.com/gh0stzk/dotfiles)
[](https://github.com/gh0stzk/dotfiles)
[](https://github.com/gh0stzk/dotfiles)
[](https://github.com/gh0stzk/dotfiles)
[](https://github.com/gh0stzk/dotfiles)
[](https://github.com/gh0stzk/dotfiles)
[](https://github.com/gh0stzk/dotfiles)
[](https://github.com/gh0stzk/dotfiles)
[](https://github.com/gh0stzk/dotfiles)
[](https://github.com/gh0stzk/dotfiles)
[](https://github.com/gh0stzk/dotfiles)
[](https://github.com/gh0stzk/dotfiles)
### [Gwynsav](https://github.com/Gwynsav/messydots)
[](https://github.com/Gwynsav/messydots)
### [hlissner](https://github.com/hlissner/dotfiles)
[](https://github.com/hlissner/dotfiles)
### [JakeGinesin](https://github.com/JakeGinesin/dotfiles)
[](https://github.com/JakeGinesin/dotfiles)
### [justleoo](https://github.com/justleoo/dotfiles)
[](https://github.com/justleoo/dotfiles)
### [kabinspace](https://github.com/kabinspace/dotfiles)
[](https://github.com/kabinspace/dotfiles)
### [Narmis-E](https://github.com/Narmis-E/bspwm-catppuccin)
[](https://github.com/Narmis-E/bspwm-catppuccin)
### [probe2k](https://github.com/probe2k/bspwm_rice)
[](https://github.com/probe2k/bspwm_rice)
### [rklyz](https://github.com/rklyz/.files)
[](https://github.com/rklyz/.files)
### [Sinomor](https://github.com/Sinomor/dots)
[](https://github.com/Sinomor/dots)
### [Sophed](https://github.com/Sophed/dotfiles)
[](https://github.com/Sophed/dotfiles)
### [star-isc](https://github.com/star-isc/Dotfiles)
[](https://github.com/star-isc/Dotfiles)
### [sudo-harun](https://github.com/sudo-harun/dotfiles/tree/main)
[](https://github.com/sudo-harun/dotfiles/tree/main)
### [valb-mig](https://github.com/valb-mig/.dotfiles)
[](https://github.com/valb-mig/.dotfiles)
### [Weirdchupacabra](https://github.com/Weirdchupacabra/void-dotfiles)
[](https://github.com/Weirdchupacabra/void-dotfiles)
### [zoddDev](https://github.com/zoddDev/dotfiles)
[](https://github.com/zoddDev/dotfiles)
[](https://github.com/zoddDev/dotfiles)
[](https://github.com/zoddDev/dotfiles)
[](https://github.com/zoddDev/dotfiles)
[](https://github.com/zoddDev/dotfiles)
[](https://github.com/zoddDev/dotfiles)
[](https://github.com/zoddDev/dotfiles)
[](https://github.com/zoddDev/dotfiles)
[](https://github.com/zoddDev/dotfiles)
[](https://github.com/zoddDev/dotfiles)
## Cinnamon
### [SpreadiesInSpace](https://github.com/SpreadiesInSpace/cinnamon-dotfiles/tree/main)
[](https://github.com/SpreadiesInSpace/cinnamon-dotfiles/tree/main)
[](https://github.com/SpreadiesInSpace/cinnamon-dotfiles/tree/main)
## DkWM
### [AlphaTechnolog](https://github.com/AlphaTechnolog/dotfiles/tree/dkwm)
[](https://github.com/AlphaTechnolog/dotfiles/tree/dkwm)
## dwm
### [AlphaTechnolog](https://github.com/AlphaTechnolog/dotfiles/tree/dwm)
[](https://github.com/AlphaTechnolog/dotfiles/tree/dwm)
### [codedsprit](https://github.com/codedsprit/dotfiles)
[](https://github.com/codedsprit/dotfiles)
### [Dorovich](https://github.com/Dorovich/dotfiles)
[](https://github.com/Dorovich/dotfiles)
[](https://github.com/Dorovich/dotfiles)
### [Gwynsav](https://github.com/Gwynsav/dwmrice)
[](https://github.com/Gwynsav/dwmrice)
### [juacq97](https://github.com/juacq97/dotfiles)
[](https://github.com/juacq97/dotfiles)
### [nxb1t](https://github.com/nxb1t/dwm-dots)
[](https://github.com/nxb1t/dwm-dots)
### [raihanadf](https://github.com/raihanadf/dotfiles)
[](https://github.com/raihanadf/dotfiles)
### [seeingangelz](https://github.com/seeingangelz/dotfiles)
[](https://github.com/seeingangelz/dotfiles)
## Gnome
### [1amSimp1e](https://github.com/1amSimp1e/dots)
[](https://github.com/1amSimp1e/dots)
[](https://github.com/1amSimp1e/dots)
[](https://github.com/1amSimp1e/dots)
### [AviVarma](https://github.com/AviVarma/Dotfiles)
[](https://github.com/AviVarma/Dotfiles)
### [Comiclyy](https://github.com/Comiclyy/dotfiles/tree/dotfiles-gnome)
[](https://github.com/Comiclyy/dotfiles/tree/dotfiles-gnome)
### [GabrielTenma](https://github.com/GabrielTenma/dotfiles-gnm)
[](https://github.com/GabrielTenma/dotfiles-gnm)
[](https://github.com/GabrielTenma/dotfiles-gnm)
### [NeuronSooup](https://github.com/NeuronSooup/Gnome-topbar-le-dots)
[](https://github.com/NeuronSooup/Gnome-topbar-le-dots)
## Herbstluftwm
### [breddie-normie](https://github.com/breddie-normie/dotfiles)
[](https://github.com/breddie-normie/dotfiles)
### [nuxshed](https://github.com/nuxshed/dotfiles)
[](https://github.com/nuxshed/dotfiles)
### [scourii](https://github.com/scourii/.dotfiles/tree/main)
[](https://github.com/scourii/.dotfiles/tree/main)
[](https://github.com/scourii/.dotfiles/tree/main)
## Hyprland
### [1amSimp1e](https://github.com/1amSimp1e/dots)
[](https://github.com/1amSimp1e/dots)
[](https://github.com/1amSimp1e/dots)
### [ahujaankush](https://github.com/ahujaankush/AetherizedDots)
[](https://github.com/ahujaankush/AetherizedDots)
### [cafreo](https://github.com/cafreo/hyprland-intergalactic)
[](https://github.com/cafreo/hyprland-intergalactic)
### [command-z-z](https://github.com/command-z-z/Arch-dotfiles)
[](https://github.com/command-z-z/Arch-dotfiles)
### [conrad-mo](https://github.com/conrad-mo/hyprland-dot)
[](https://github.com/conrad-mo/hyprland-dot)
### [dankdezpair](https://github.com/dankdezpair/hypr.files-V2)
[](https://github.com/dankdezpair/hypr.files-V2)
[](https://github.com/dankdezpair/hypr.files-V2)
### [debuggyo](https://github.com/debuggyo/dots)
[](https://github.com/debuggyo/dots)
### [dragoshr1234](https://github.com/dragoshr1234/hyprland-rotaru)
[](https://github.com/dragoshr1234/hyprland-rotaru)
### [end-4](https://github.com/end-4/dots-hyprland/)
[](https://github.com/end-4/dots-hyprland/)
[](https://github.com/end-4/dots-hyprland/)
[](https://github.com/end-4/dots-hyprland/)
### [h1tarxeth](https://github.com/h1tarxeth/Dots_infinity_horizon)
[](https://github.com/h1tarxeth/Dots_infinity_horizon)
[](https://github.com/h1tarxeth/Dots_infinity_horizon)
### [HeinzDev](https://github.com/HeinzDev/Hyprland-dotfiles)
[](https://github.com/HeinzDev/Hyprland-dotfiles)
### [hobosyo](https://github.com/hobosyo/pointfichiers/tree/hyprland-kanagawa)
[](https://github.com/hobosyo/pointfichiers/tree/hyprland-kanagawa)
### [justinlime](https://github.com/justinlime/dotfiles)
[](https://github.com/justinlime/dotfiles)
[](https://github.com/justinlime/dotfiles)
### [Knightfall01](https://github.com/Knightfall01/Hyprland-i3/tree/master)
[](https://github.com/Knightfall01/Hyprland-i3/tree/master)
[](https://github.com/Knightfall01/Hyprland-i3/tree/master)
[](https://github.com/Knightfall01/Hyprland-i3/tree/master)
### [MathisP75](https://github.com/MathisP75/summer-day-and-night)
[](https://github.com/MathisP75/summer-day-and-night)
### [maxtaran2010](https://github.com/maxtaran2010/hyprland-rice)
[](https://github.com/maxtaran2010/hyprland-rice)
### [Narmis-E](https://github.com/Narmis-E/hyprland-dots)
[](https://github.com/Narmis-E/hyprland-dots)
[](https://github.com/Narmis-E/hyprland-dots)
[](https://github.com/Narmis-E/hyprland-dots)
### [ozwaldorf](https://github.com/ozwaldorf/dotfiles)
[](https://github.com/ozwaldorf/dotfiles)
### [prasanthrangan](https://github.com/prasanthrangan/hyprdots)
[](https://github.com/prasanthrangan/hyprdots)
[](https://github.com/prasanthrangan/hyprdots)
[](https://github.com/prasanthrangan/hyprdots)
[](https://github.com/prasanthrangan/hyprdots)
[](https://github.com/prasanthrangan/hyprdots)
[](https://github.com/prasanthrangan/hyprdots)
### [Redyf](https://github.com/Redyf/nixdots)
[](https://github.com/Redyf/nixdots)
### [RumiAxolotl](https://github.com/RumiAxolotl/hyprland-config)
[](https://github.com/RumiAxolotl/hyprland-config)
### [SimplyVoid](https://github.com/SimplyVoid/hyprland-dots)
[](https://github.com/SimplyVoid/hyprland-dots)
### [Spagett1](https://github.com/Spagett1/dotfiles)
[](https://github.com/Spagett1/dotfiles)
### [Stetsed](https://github.com/Stetsed/.dotfiles)
[](https://github.com/Stetsed/.dotfiles)
### [Yorubae](https://github.com/Yorubae/wayland-dotfiles)
[](https://github.com/Yorubae/wayland-dotfiles)
## i3wm
### [b1337xyz](https://github.com/b1337xyz/config/tree/xp)
[](https://github.com/b1337xyz/config/tree/xp)
### [BIBJAW](https://github.com/BIBJAW/Final_Rice)
[](https://github.com/BIBJAW/Final_Rice)
### [bibjaw99](https://github.com/bibjaw99/workstation)
[](https://github.com/bibjaw99/workstation)
[](https://github.com/bibjaw99/workstation)
### [Blxckmage](https://github.com/Blxckmage/dotfiles)
[](https://github.com/Blxckmage/dotfiles)
### [bryant-the-coder](https://github.com/bryant-the-coder/dotfiles)
[](https://github.com/bryant-the-coder/dotfiles)
### [fathulfahmy](https://github.com/fathulfahmy/dotfiles-linux/)
[](https://github.com/fathulfahmy/dotfiles-linux/)
### [sommaa](https://github.com/sommaa/Mantis)
[](https://github.com/sommaa/Mantis)
### [SunoBB](https://github.com/SunoBB/dot)
[](https://github.com/SunoBB/dot)
### [TKK13909](https://github.com/TKK13909/dotfiles)
[](https://github.com/TKK13909/dotfiles)
### [Vallen217](https://github.com/Vallen217/dotfiles)
[](https://github.com/Vallen217/dotfiles)
[](https://github.com/Vallen217/dotfiles)
### [zemmsoares](https://github.com/zemmsoares/.dotfiles)
[](https://github.com/zemmsoares/.dotfiles)
## KDE
### [ComplexPlatform](https://github.com/ComplexPlatform/KDE-dotfiles)
[](https://github.com/ComplexPlatform/KDE-dotfiles)
[](https://github.com/ComplexPlatform/KDE-dotfiles)
[](https://github.com/ComplexPlatform/KDE-dotfiles)
[](https://github.com/ComplexPlatform/KDE-dotfiles)
[](https://github.com/ComplexPlatform/KDE-dotfiles)
[](https://github.com/ComplexPlatform/KDE-dotfiles)
## LeftWM
### [almqv](https://github.com/almqv/dotfiles)
[](https://github.com/almqv/dotfiles)
## Lightdm
### [TheWisker](https://github.com/TheWisker/Shikai)
[](https://github.com/TheWisker/Shikai)
## Openbox
### [AlphaTechnolog](https://github.com/AlphaTechnolog/dotfiles/tree/openbox)
[](https://github.com/AlphaTechnolog/dotfiles/tree/openbox)
### [Narmis-E](https://github.com/Narmis-E/openbox-everforest)
[](https://github.com/Narmis-E/openbox-everforest)
### [owl4ce](https://github.com/owl4ce/dotfiles/tree/ng)
[](https://github.com/owl4ce/dotfiles/tree/ng)
## Qtile
### [Barbaross93](https://github.com/Barbaross93/Nebula)
[](https://github.com/Barbaross93/Nebula)
[](https://github.com/Barbaross93/Nebula)
### [Darkkal44](https://github.com/Darkkal44/Cozytile)
[](https://github.com/Darkkal44/Cozytile)
### [diegorezm](https://github.com/diegorezm/dotfiles-d/tree/master)
[](https://github.com/diegorezm/dotfiles-d/tree/master)
### [Fluffy-Bean](https://github.com/Fluffy-Bean/dots)
[](https://github.com/Fluffy-Bean/dots)
### [gibranlp](https://github.com/gibranlp/QARSlp)
[](https://github.com/gibranlp/QARSlp)
[](https://github.com/gibranlp/QARSlp)
[](https://github.com/gibranlp/QARSlp)
### [Hamza12700](https://github.com/Hamza12700/DotFiles)
[](https://github.com/Hamza12700/DotFiles)
### [shayanaqvi](https://github.com/shayanaqvi/dotfilets)
[](https://github.com/shayanaqvi/dotfilets)
## Riverwm
### [theCode-Breaker](https://github.com/theCode-Breaker/riverwm)
[](https://github.com/theCode-Breaker/riverwm)
[](https://github.com/theCode-Breaker/riverwm)
## Sway
### [eoli3n](https://github.com/eoli3n/dotfiles)
[](https://github.com/eoli3n/dotfiles)
### [hifinerd](https://github.com/hifinerd/lugia-sway-dots)
[](https://github.com/hifinerd/lugia-sway-dots)
### [KubqoA](https://github.com/KubqoA/dotfiles)
[](https://github.com/KubqoA/dotfiles)
### [RicArch97](https://github.com/RicArch97/nixos-config)
[](https://github.com/RicArch97/nixos-config)
### [Sunglas](https://github.com/Sunglas/laptop-dots-wl)
[](https://github.com/Sunglas/laptop-dots-wl)
### [viperML](https://github.com/viperML/dotfiles)
[](https://github.com/viperML/dotfiles)
## Xfce
### [fathulfahmy](https://github.com/fathulfahmy/dotfiles-linux/)
[](https://github.com/fathulfahmy/dotfiles-linux/)
## Xmonad
### [Icy-Thought](https://github.com/Icy-Thought/snowflake)
[](https://github.com/Icy-Thought/snowflake)
[](https://github.com/Icy-Thought/snowflake)
### [TheMidnightShow](https://github.com/TheMidnightShow/dotfiles)
[](https://github.com/TheMidnightShow/dotfiles)
## Yabai
### [command-z-z](https://github.com/command-z-z/dotfiles)
[](https://github.com/command-z-z/dotfiles)
[](https://github.com/command-z-z/dotfiles)
### [FelixKratz](https://github.com/FelixKratz/dotfiles)
[](https://github.com/FelixKratz/dotfiles)
### [QRX53](https://github.com/QRX53/dotfiles)
[](https://github.com/QRX53/dotfiles)
### [tcmmichaelb139](https://github.com/tcmmichaelb139/.dotfiles)
[](https://github.com/tcmmichaelb139/.dotfiles)
[](https://github.com/tcmmichaelb139/.dotfiles)
### [ZhongXiLu](https://github.com/ZhongXiLu/dotfiles)
[](https://github.com/ZhongXiLu/dotfiles)
[](https://github.com/ZhongXiLu/dotfiles)
# Contribute
We welcome contributions from the community. If you have a unique rice that you'd like to showcase, please refer to our [Contribution Guidelines](CONTRIBUTING.md).
# License
To the extent possible under law, Miguel Soares has waived all copyright and related or neighboring rights to this work under the [CC0 1.0 Universal](LICENSE) license.
<sub><sup>**Disclaimer:** This repository contains links to other repositories. While we aim to only link to repositories of high quality, we cannot guarantee the safety or reliability of the content found within. Please be aware of this before using anyone else's scripts or dotfiles.</sup></sub>
| 352
| 12
|
legendSabbir/acode-editorTheme-template
|
https://github.com/legendSabbir/acode-editorTheme-template
| null |
# Acode Editor Theme Template
- clone This repo
- npm install
- Go to `./src/main.js` file and change themeName variable .
- Name Must be lowercase
- Name Must be separated by `-` . example `vscode-dark`
- Then go to `./src/style.scss`
- There Change the selector name exactly as themeName variable from `main.js` with a prefix of `.ace-` . example `.ace-vscode-dark`
- Then inside Just Change color according to your theme
- After finish do `npm run build-release`
For more details about each classes go to [Ace kitchen Sink](https://ace.c9.io/build/kitchen-sink.html) `enable show token info` now on hover you can see each token.
| 14
| 3
|
NadaFeteiha/WeatherDesktopApp
|
https://github.com/NadaFeteiha/WeatherDesktopApp
|
Weather desktop app using Jetpack compose
|
<h1 align="center"> WeatherDesktopApp</h1>
<h5 align="center"> Weather desktop app using Jetpack compose</h5>
## Video
[](https://youtu.be/gT2Sx0LAYGc?autoplay=1)
## Tech stack
- [Ktor](https://ktor.io/docs/getting-started-ktor-client.html) a modern asynchronous framework backed by Kotlin coroutines, used to make HTTP network requests to an API
- [Coroutines](https://developer.android.com/kotlin/coroutines) to write asynchronous code, which can improve performance and responsiveness.
- [Koin](https://insert-koin.io/docs/reference/koin-ktor/ktor/) to manage dependencies, which can help to improve code quality and maintainability.
- [ImageLoader](https://github.com/qdsfdhvh/compose-imageloader) Compose Image library for Kotlin Multiplatform.
# How to build on your environment
Add your api key for WeatherApi
## Contributors
<a href="https://github.com/NadaFeteiha/WeatherDesktopApp/graphs/contributors">
<img src="https://contrib.rocks/image?repo=NadaFeteiha/WeatherDesktopApp" />
</a>
## Official Documentations
- Official Google Documentation
- [Compose for Desktop](https://www.jetbrains.com/lp/compose/)
- [Jetpack compose](https://developer.android.com/jetpack/compose)
- [Jetpack compose Samples](https://github.com/android/compose-samples)
| 25
| 2
|
1250422131/FoodChoice
|
https://github.com/1250422131/FoodChoice
|
食选,解决生活中每天吃饭,吃什么,做什么,怎么做的问题,此项目也是我对JetpackCompose的MVI架构学习的一次实践。
|
# FoodChoice
食选,解决生活中每天吃饭,吃什么,做什么,怎么做的问题,此项目也是我对JetpackCompose的MVI架构学习的一次实践。
## 项目介绍
此项目为JetpackCompose的一个学习项目,主要对学到的一些简单知识的应用,同时对程序模块化进行一次进一步的尝试。
主要采用了MVI设计,实现了离线数据加载,网络加载,依赖注入,导航管理等,使其成为一个稳定可用的程序。
大体框架主要参考了谷歌的[nowinandroid](https://github.com/android/nowinandroid/)(只实现了其中的一小部分)。
## 程序现阶段框架
其中core层主要对公共依赖,公共UI组件,全局主题样式,网络请求,数据持久性以及数据适配器进行了分模块。
这样看是杀鸡用了宰牛刀,但FoodChoice主要是对模块化进行学习,另外这样的分模块其实也是有必要的,这让我的代码更有拓展性和维护性,使得项目代码比较茁壮。
而feature层主要对各个功能进行了模块化,只是由于我们用了Compose可用用一个activity来完成各个界面的展示,这也是为什么
没有用**服务发现**,或者**路由组件库**什么的。
## 项目进度
- [x] 实现Cook,食物选择功能
- [x] 各模块适当采用依赖注入
- [ ] 使用统一版本管理(Version Catalog)
- [ ] 考虑对数据同步改为WorkManager任务
- [ ] 实现食物抽签功能
## 参考项目
首页食物选择参考了[Cook](https://github.com/YunYouJun/cook),[Web项目源地址](https://cook.yunyoujun.cn)
FoodChoice利用Compose进行了一次复刻,其中数据都来自[Cook](https://github.com/YunYouJun/cook)项目。
| 13
| 0
|
charlottia/hdx
|
https://github.com/charlottia/hdx
|
HDL development environment on Nix.
|
=====
hdx
=====
Hello, baby's first little Nix repository thingy. At present, I'm reproducing
the setup described in `Installing an HDL toolchain from source`_, except
Nix-y.
Modes of operation
==================
+ ``nix develop`` / ``nix-shell``
This is the default mode of operation. The following packages are built from
definitions in ``pkg/`` and added to ``PATH``:
* Amaranth_
* Yosys_
* nextpnr_
* `Project IceStorm`_
* `Project Trellis`_
* SymbiYosys_
* `Yices 2`_
* Z3_
Amaranth is configured to use the Yosys built by hdx, and not its built-in
one.
+ ``nix develop .#amaranth`` / ``nix-shell amaranth-dev-shell.nix``
Like above, except Amaranth is not built and installed. Instead, the
submodule checkout at ``dev/amaranth/`` is installed in editable mode.
+ ``nix develop .#yosys-amaranth`` / ``nix-shell yosys-amaranth-dev-shell.nix``
Like above, except Yosys is also not built and installed. Instead, the
submodule checkout at ``dev/yosys/`` is configured to be compiled and
installed to ``dev/out/``, and ``PATH`` has ``dev/out/bin/`` prepended.
You'll need to actually ``make install`` Yosys at least once for this mode to
function, including any use of Amaranth that depends on Yosys.
+ Your project's ``flake.nix``
.. code:: nix
{
inputs.hdx.url = github:charlottia/hdx;
outputs = {
self,
nixpkgs,
flake-utils,
hdx,
}:
flake-utils.lib.eachDefaultSystem (system: let
pkgs = nixpkgs.legacyPackages.${system};
in {
devShells.default = pkgs.mkShell {
nativeBuildInputs = [
hdx.packages.${system}.default
];
};
});
}
+ Your project's ``shell.nix``
.. code:: nix
{pkgs ? import <nixpkgs> {}}: let
hdx = import (pkgs.fetchFromGitHub {
owner = "charlottia";
repo = "hdx";
rev = "116f2cef9cdc75a33c49c578d3b93b19e68597a7";
sha256 = "THrX3H1368OP+SXRb+S+cczvCbXubF/5s50VhrtDQbk=";
}) {};
in
pkgs.mkShell {
name = "weapon";
nativeBuildInputs = [
hdx
];
}
.. _Installing an HDL toolchain from source: https://notes.hrzn.ee/posts/0001-hdl-toolchain-source/
.. _Amaranth: https://github.com/amaranth-lang/amaranth
.. _Yosys: https://github.com/YosysHQ/yosys
.. _nextpnr: https://github.com/YosysHQ/nextpnr
.. _Project IceStorm: https://github.com/YosysHQ/icestorm
.. _Project Trellis: https://github.com/YosysHQ/prjtrellis
.. _SymbiYosys: https://github.com/YosysHQ/sby
.. _Yices 2: https://github.com/SRI-CSL/yices2
.. _Z3: https://github.com/Z3Prover/z3
Configurability
===============
Any ``nix-shell`` invocation may take the following arguments:
``nextpnr_archs``
A list of nextpnr_ architectures to build support for. Valid items are
``"generic"``, ``"ice40"`` and ``"ecp5"``. At least one must be specified.
More configurability is available, but not yet exposed -- I'm not really sure
what's idiomatic yet. See `<nix/hdx-config.nix>`_:
+ Any of the packages included can be disabled.
+ If Yosys isn't built, Amaranth's built-in Yosys will be used instead.
Hacks
=====
+ Python on Nix's ``sitecustomize.py`` drops ``NIX_PYTHONPATH`` from the
environment when processing it, causing children opened with ``subprocess`` to
not be aware of packages that might've been added by that mechanism.
+ nix-darwin specific: IceStorm's ``icebox/Makefile`` needs to not determine its
``sed``` use based on ``uname``. `You may not do that`_.
.. _You may not do that: https://aperture.ink/@charlotte/110737824873379605
+ SymbiYosys's ``sbysrc/sby_core.py`` needs to not invoke ``/usr/bin/env``. It
may not exist.
+ Z3's ``z3.pc.cmake.in`` needs to not prepend ``${exec_prefix}/`` et al. to
``@CMAKE_INSTALL_LIBDIR@`` et al.
| 11
| 0
|
Kanaries/GWalkR
|
https://github.com/Kanaries/GWalkR
|
Turn your data frame into a tableau style drag and drop UI interface to build visualization in R.
|
[English](README.md) | [中文](docs/README.zh.md)
<img src="docs/img/hex_logo.png" align="right" alt="logo" width="120" height = "139" style = "border: none; float: right;">
# GWalkR: Your One-Stop R Package for Exploratory Data Analysis with Visualization


[](https://twitter.com/kanaries_data)
[](https://discord.com/invite/WWHraZ8SeV)
Start Exploratory Data Analysis (EDA) in R with a Single Line of Code!
[GWalkR](https://github.com/Kanaries/GWalkR) is an interactive Exploratory Data Analysis (EDA) Tool in R.
It integrates the htmlwidgets with [Graphic Walker](https://github.com/Kanaries/graphic-walker).
It can simplify your R data analysis and data visualization workflow, by turning your data frame into a Tableau-style User Interface for visual exploration.
<img width="1437" alt="image" src="https://github.com/Bruceshark/GWalkR/assets/33870780/26967dda-57c0-4abd-823c-63037c8f5168">
> If you prefer using Python, you can check out [PyGWalker](https://github.com/Kanaries/pygwalker)!
## Getting Started
### Setup GWalkR
#### Through Running R Script
If you have `devtools` installed in R, you can run the following R code to install.
```R
devtools::install_url("https://kanaries-app.s3.ap-northeast-1.amazonaws.com/oss/gwalkr/GWalkR_latest.tar.gz")
```
#### Through Package Archive File (.tar.gz)
Alternatively, download the package archive file `GWalkR_latest.tar.gz` from [this link](https://kanaries-app.s3.ap-northeast-1.amazonaws.com/oss/gwalkr/GWalkR_latest.tar.gz).
Open R Studio, click "Install" in the "Packages" window, and select "Package Archive File (.tgz; .tar.gz)" in the "Install from". Then, select the archive in your file system and click "Install".
#### Through CRAN
To be supported soon. Stay tuned!
### Start Your Data Exploration in a Single Line of Code
```R
library(GWalkR)
data(iris)
gwalkr(iris)
```
<img width="1437" alt="image" src="https://github.com/Bruceshark/GWalkR/assets/33870780/718d8ff6-4ad5-492d-9afb-c4ed67573f51">
## Main Features
1. 🧑🎨 Turn a data frame into charts through simple drag-and-drop operations.
2. 🤖️ [coming soon] Work with AI copilot in R: Let AI generate explorable charts for you!
https://github.com/Kanaries/GWalkR/assets/33870780/4a3a9f9c-ff17-484b-9503-af82bd609b99
3. ✨ [coming soon] Integration with Shiny app: Showcase your data insights with editable and explorable charts on a webpage!
| 30
| 3
|
baichuan-inc/Baichuan-13B
|
https://github.com/baichuan-inc/Baichuan-13B
|
A 13B large language model developed by Baichuan Intelligent Technology
|
<!-- markdownlint-disable first-line-h1 -->
<!-- markdownlint-disable html -->
<div align="center">
<h1>
Baichuan-13B
</h1>
</div>
<p align="center">
🤗 <a href="https://huggingface.co/baichuan-inc/Baichuan-13B-Base" target="_blank">Baichuan-13B-Base</a>
•
🤗 <a href="https://huggingface.co/baichuan-inc/Baichuan-13B-Chat" target="_blank">Baichuan-13B-Chat</a>
•
🤖 <a href="https://modelscope.cn/organization/baichuan-inc" target="_blank">ModelScope</a>
•
💬 <a href="https://github.com/baichuan-inc/Baichuan-13B/blob/main/media/wechat.jpeg?raw=true" target="_blank">WeChat</a>
</p>
<div align="center">
[](https://github.com/Baichuan-inc/baichuan-13B/blob/main/LICENSE)
<h4 align="center">
<p>
<b>中文</b> |
<a href="https://github.com/baichuan-inc/Baichuan-13B/blob/main/README_EN.md">English</a>
<p>
</h4>
</div>
# 更新信息
[2023.08.01] 更新了对齐模型 [Baichuan-13B-Chat](https://huggingface.co/baichuan-inc/Baichuan-13B-Chat) 权重,优化了部分场景的效果
# 目录
- [介绍](#介绍)
- [Benchmark结果](#Benchmark结果)
- [模型细节](#模型细节)
- [推理和部署](#推理和部署)
- [对模型进行微调](#对模型进行微调)
- [声明](#声明)
- [协议](#协议)
# 介绍
Baichuan-13B 是由百川智能继 [Baichuan-7B](https://github.com/baichuan-inc/baichuan-7B) 之后开发的包含 130 亿参数的开源可商用的大规模语言模型,在权威的中文和英文 benchmark 上均取得同尺寸最好的效果。本次发布包含有预训练 ([Baichuan-13B-Base](https://huggingface.co/baichuan-inc/Baichuan-13B-Base)) 和对齐 ([Baichuan-13B-Chat](https://huggingface.co/baichuan-inc/Baichuan-13B-Chat)) 两个版本。Baichuan-13B 有如下几个特点:
1. **更大尺寸、更多数据**:Baichuan-13B 在 [Baichuan-7B](https://github.com/baichuan-inc/baichuan-7B) 的基础上进一步扩大参数量到 130 亿,并且在高质量的语料上训练了 1.4 万亿 tokens,超过 LLaMA-13B 40%,是当前开源 13B 尺寸下训练数据量最多的模型。支持中英双语,使用 ALiBi 位置编码,上下文窗口长度为 4096。
2. **同时开源预训练和对齐模型**:预训练模型是适用开发者的『 基座 』,而广大普通用户对有对话功能的对齐模型具有更强的需求。因此本次开源我们同时发布了对齐模型(Baichuan-13B-Chat),具有很强的对话能力,开箱即用,几行代码即可简单的部署。
3. **更高效的推理**:为了支持更广大用户的使用,我们本次同时开源了 int8 和 int4 的量化版本,相对非量化版本在几乎没有效果损失的情况下大大降低了部署的机器资源门槛,可以部署在如 Nvidia 3090 这样的消费级显卡上。
4. **开源免费可商用**:Baichuan-13B 不仅对学术研究完全开放,开发者也仅需邮件申请并获得官方商用许可后,即可以免费商用。
# Benchmark结果
我们在各个权威大语言模型的中英文 benchmark 上进行了`5-shot`评测。结果如下:
## [C-Eval](https://cevalbenchmark.com/index.html#home)
| Model 5-shot | STEM | Social Sciences | Humanities | Others | Average |
|-------------------------|:-----:|:---------------:|:----------:|:------:|:-------:|
| Baichuan-7B | 38.2 | 52.0 | 46.2 | 39.3 | 42.8 |
| Chinese-Alpaca-Plus-13B | 35.2 | 45.6 | 40.0 | 38.2 | 38.8 |
| Vicuna-13B | 30.5 | 38.2 | 32.5 | 32.5 | 32.8 |
| Chinese-LLaMA-Plus-13B | 30.3 | 38.0 | 32.9 | 29.1 | 32.1 |
| Ziya-LLaMA-13B-Pretrain | 27.6 | 34.4 | 32.0 | 28.6 | 30.0 |
| LLaMA-13B | 27.0 | 33.6 | 27.7 | 27.6 | 28.5 |
| moss-moon-003-base (16B)| 27.0 | 29.1 | 27.2 | 26.9 | 27.4 |
| **Baichuan-13B-Base** | **45.9** | **63.5** | **57.2** | **49.3** | **52.4** |
| **Baichuan-13B-Chat** | **43.7** | **64.6** | **56.2** | **49.2** | **51.5** |
## [MMLU](https://arxiv.org/abs/2009.03300)
| Model 5-shot | STEM | Social Sciences | Humanities | Others | Average |
|-------------------------|:-----:|:---------------:|:----------:|:------:|:-------:|
| Vicuna-13B | 40.4 | 60.5 | 49.5 | 58.4 | 52.0 |
| LLaMA-13B | 36.1 | 53.0 | 44.0 | 52.8 | 46.3 |
| Chinese-Alpaca-Plus-13B | 36.9 | 48.9 | 40.5 | 50.5 | 43.9 |
| Ziya-LLaMA-13B-Pretrain | 35.6 | 47.6 | 40.1 | 49.4 | 42.9 |
| Baichuan-7B | 35.6 | 48.9 | 38.4 | 48.1 | 42.3 |
| Chinese-LLaMA-Plus-13B | 33.1 | 42.8 | 37.0 | 44.6 | 39.2 |
| moss-moon-003-base (16B)| 22.4 | 22.8 | 24.2 | 24.4 | 23.6 |
| **Baichuan-13B-Base** | **41.6** | **60.9** | **47.4** | **58.5** | **51.6** |
| **Baichuan-13B-Chat** | **40.9** | **60.9** | **48.8** | **59.0** | **52.1** |
> 说明:我们采用了 MMLU 官方的[评测方案](https://github.com/hendrycks/test)。
## [CMMLU](https://github.com/haonan-li/CMMLU)
| Model 5-shot | STEM | Humanities | Social Sciences | Others | China Specific | Average |
|-------------------------|:-----:|:----------:|:---------------:|:------:|:--------------:|:-------:|
| Baichuan-7B | 34.4 | 47.5 | 47.6 | 46.6 | 44.3 | 44.0 |
| Vicuna-13B | 31.8 | 36.2 | 37.6 | 39.5 | 34.3 | 36.3 |
| Chinese-Alpaca-Plus-13B | 29.8 | 33.4 | 33.2 | 37.9 | 32.1 | 33.4 |
| Chinese-LLaMA-Plus-13B | 28.1 | 33.1 | 35.4 | 35.1 | 33.5 | 33.0 |
| Ziya-LLaMA-13B-Pretrain | 29.0 | 30.7 | 33.8 | 34.4 | 31.9 | 32.1 |
| LLaMA-13B | 29.2 | 30.8 | 31.6 | 33.0 | 30.5 | 31.2 |
| moss-moon-003-base (16B)| 27.2 | 30.4 | 28.8 | 32.6 | 28.7 | 29.6 |
| **Baichuan-13B-Base** | **41.7** | **61.1** | **59.8** | **59.0** | **56.4** | **55.3** |
| **Baichuan-13B-Chat** | **42.8** | **62.6** | **59.7** | **59.0** | **56.1** | **55.8** |
> 说明:CMMLU 是一个综合性的中文评估基准,专门用于评估语言模型在中文语境下的知识和推理能力。我们采用了其官方的[评测方案](https://github.com/haonan-li/CMMLU)。
# 模型细节
| 模型名称 | 隐藏层维度 | 层数 | 注意力头数 |词表大小 | 总参数量 | 训练数据(tokens)| 位置编码 | 最大长度 |
|--------------|:---------:|:---:|:--------:|:------:|:--------------:|:---------------:|:------------------------------------------:|:-------:|
| Baichuan-7B | 4,096 | 32 | 32 | 64,000 | 7,000,559,616 | 1.2 万亿 | [RoPE](https://arxiv.org/abs/2104.09864) | 4,096 |
| Baichuan-13B | 5,120 | 40 | 40 | 64,000 | 13,264,901,120 | 1.4 万亿 | [ALiBi](https://arxiv.org/abs/2108.12409) | 4,096 |
# 推理和部署
推理所需的模型权重、源码、配置已发布在 Hugging Face:[Baichuan-13B-Base](https://huggingface.co/baichuan-inc/Baichuan-13B-Base) 和 [Baichuan-13B-Chat](https://huggingface.co/baichuan-inc/Baichuan-13B-Chat)。下面以 Baichuan-13B-Chat 为例示范多种推理方式。程序会自动从 Hugging Face 下载所需资源。
推理前请安装依赖:
```shell
pip install -r requirements.txt
```
## Python代码方式
```python
>>> import torch
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> from transformers.generation.utils import GenerationConfig
>>> tokenizer = AutoTokenizer.from_pretrained("baichuan-inc/Baichuan-13B-Chat", use_fast=False, trust_remote_code=True)
>>> model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan-13B-Chat", device_map="auto", torch_dtype=torch.float16, trust_remote_code=True)
>>> model.generation_config = GenerationConfig.from_pretrained("baichuan-inc/Baichuan-13B-Chat")
>>> messages = []
>>> messages.append({"role": "user", "content": "世界上第二高的山峰是哪座"})
>>> response = model.chat(tokenizer, messages)
>>> print(response)
乔戈里峰。世界第二高峰———乔戈里峰西方登山者称其为k2峰,海拔高度是8611米,位于喀喇昆仑山脉的中巴边境上
```
> 在上述代码中,模型加载指定 `device_map='auto'`,会使用所有可用显卡。如需指定使用的设备,可以使用类似 `export CUDA_VISIBLE_DEVICES=0,1`(使用了0、1号显卡)的方式控制。
## 命令行工具方式
```shell
python cli_demo.py
```
最后输出示例如下:
<p align="center">
<img src="media/cn-cli.png" width="70%"/>
</p>
## 网页 demo 方式
依靠streamlit运行以下命令,会在本地启动一个 web 服务,把控制台给出的地址放入浏览器即可访问。
```shell
streamlit run web_demo.py
```
效果如下:
<p align="center">
<img src="media/cn-web.gif" width="70%"/>
</p>
## Baichuan-13B-Chat 示例输出
<details><summary><b>内容创作</b></summary>
```
用户:
你是一个内容创作者,编写一段关于对马斯克和比尔盖茨访问中国视角的短视频脚本
Baichun-13B-Chat:
探索马斯克与比尔·盖茨的中国之旅
镜头1:(背景音乐)画面切入,展示中国的繁华都市景象。
旁白:欢迎来到我们的节目,今天我们将带您一起了解两位科技巨头——埃隆·马斯克和比尔·盖茨在中国的一次特殊访问。
镜头2:(背景音乐)画面切换至马斯克和比尔·盖茨抵达中国的机场。
旁白:这次访问是他们首次共同踏上中国的土地,他们将在这里展开一场关于科技创新、环保和教育的对话。
镜头3:(背景音乐)画面展示马斯克和比尔·盖茨参观一家电动汽车制造厂。
旁白:在这次访问中,他们首先参观了一家电动汽车制造厂,了解了中国在新能源汽车领域的最新发展。
镜头4:(背景音乐)画面展示马斯克和比尔·盖茨参加一场关于人工智能的论坛。
旁白:随后,他们参加了关于人工智能的一场论坛,探讨了这一领域的发展趋势及其对未来的影响。
镜头5:(背景音乐)画面展示马斯克和比尔·盖茨参观一所学校。
旁白:在这次访问中,他们还参观了一所学校,了解了中国在教育领域的创新实践。
镜头6:(背景音乐)画面展示马斯克和比尔·盖茨接受媒体采访。
旁白:最后,他们在媒体采访环节表示,希望通过这次访问,能够为中美两国在科技创新、环保和教育等领域的合作提供一些启示。
镜头7:(背景音乐)画面切回繁华都市景象。
旁白:这就是马斯克和比尔·盖茨的中国之行,他们的访问不仅让我们看到了中国在科技创新方面的巨大潜力,也为我们提供了关于未来发展的更多思考。感谢收看,我们下期再见!
```
</details>
<details><summary><b>广告文案</b></summary>
```
用户:
请以销售员的角色,将洗衣液的干净、无残留、无异味以及除菌等优点进行推销
Baichun-13B-Chat:
尊敬的顾客,您好!我是一名洗衣液销售员,非常高兴为您介绍我们这款产品。我们的洗衣液具有以下几个显著优点:
干净:我们的洗衣液采用了先进的洗涤技术,能够深入衣物纤维,有效去除各种污渍,让您的衣物焕然一新。同时,它不会对衣物的颜色和质地造成任何损害,让您的衣物保持原有的品质。
无残留:与传统的洗衣粉相比,我们的洗衣液在清洗过程中不会产生过多的泡沫,因此清洗后的衣物更加柔软,不会有黏腻的感觉。此外,它的去污能力强,能彻底洗净衣物上的污渍,避免了传统洗衣粉容易残留在衣物上的问题。
无异味:我们的洗衣液采用天然植物提取物作为原料,不含有害化学物质,因此在使用过程中不会产生刺鼻的气味。即使是敏感肌肤的人群也可以放心使用,让您的衣物散发出淡雅的清香。
除菌:为了满足现代人对健康生活的需求,我们的洗衣液特别添加了高效除菌成分,能够有效杀灭衣物上的细菌,保护您和家人的身体健康。无论是婴幼儿的衣物还是贴身内衣,都可以放心使用。
总之,我们的洗衣液凭借其干净、无残留、无异味以及除菌等优点,成为了广大消费者的首选。如果您还没有尝试过我们的产品,那么现在就是最好的时机。相信它一定会给您带来全新的洗衣体验!
```
```
用户:
准备一份以宠物食品为主题的报告,包括潜在消费者,市场规模,市场机遇,及盈利模式等内容
Baichun-13B-Chat:
一、引言
随着人们生活水平的提高和对宠物的关爱程度不断加深,宠物食品行业得到了快速发展。本报告将对宠物食品行业的潜在消费者、市场规模、市场机遇以及盈利模式等方面进行分析,以期为相关企业提供有益的参考信息。
二、潜在消费者
1. 养宠人群:随着养宠人数的增加,宠物食品的需求也在不断增长。根据统计数据显示,2019年中国城镇养宠(犬猫)人口数量已达7355万人,同比增长4.6%。预计到2023年,这一数字将达到8742万人。
2. 新生代消费者:新生代消费者在消费观念上更加注重健康、环保和个性化,这使得他们更愿意为宠物购买高品质的食品。此外,他们也更倾向于通过网络平台了解和购买宠物食品。
三、市场规模
1. 根据国家统计局数据,2019年我国宠物食品市场规模达到了1,020亿元人民币,同比增长约10%。预计到2023年,市场规模将达到1, 500亿元人民币。
2. 从产品类型来看,宠物干粮市场占比最高,约占总市场的70%;其次是宠物湿粮,占比约为20%;宠物零食市场占比约为10%。
四、市场机遇
1. 功能性宠物食品:随着消费者对健康的关注度不断提高,具有特定功能的宠物食品如处方粮、减肥粮等需求逐渐增大。
2. 天然有机宠物食品:越来越多的消费者倾向于选择天然、无添加剂的宠物食品,这也为市场带来了新的商机。
3. 定制化宠物食品:针对不同品种、年龄、体型的宠物,推出定制化的宠物食品,满足消费者个性化需求。
五、盈利模式
1. 传统销售渠道:通过超市、宠物店、电商平台等传统渠道销售宠物食品。
2. 直销模式:通过自建网站或与第三方平台合作,直接向消费者销售宠物食品。
3. 会员制:通过设立会员制度,为会员提供专属优惠和服务,增加客户粘性。
4. 增值服务:提供宠物美容、寄养、训练等附加服务,实现多元化盈利。
六、结论
宠物食品行业具有巨大的市场潜力和发展空间。企业应抓住市场机遇,关注消费者需求变化,创新产品
```
</details>
<details><summary><b>精准问答</b></summary>
```
用户:
世界上第二高的山是什么山
Baichun-13B-Chat:
乔戈里峰(K2) 海拔8611米,位于喀喇昆仑山脉的中巴边境上,是中国以外登山者的最大考验,也是世界上最难征服的山峰之一。它的高度仅次于珠穆朗玛峰,位居世界第二。
```
```
用户:
意兴阑珊是什么意思
Baichun-13B-Chat:
"意兴阑珊"是一个汉语成语,它的意思是形容一个人兴致不高,兴趣减弱。这个词通常用来描述一个人在某个活动中失去了原有的热情和兴趣。
```
```
用户:
请问强化学习里面的Reward Shaping是什么意思
Baichun-13B-Chat:
奖励塑造(Reward Shaping)是强化学习中的一个概念,它是指通过调整环境或设计特定的奖励函数来引导智能体(Agent)学习到更符合人类期望的行为。在传统的强化学习中,智能体通过与环境交互来学习最优策略,但这种方法可能导致智能体学习到一些次优甚至不良行为。
奖励塑造的目的是为了解决这个问题,通过人为地调整奖励函数,使得智能体更容易学到我们希望它学会的行为。这可以通过以下几种方式实现:
1. 增加正向奖励:当智能体表现出期望行为时,给予其更多的奖励,以鼓励这种行为。
2. 减少负向奖励:当智能体表现出不期望行为时,减少对其进行惩罚,降低其对这种行为的偏好。
3. 引入新奖励:为智能体提供额外的奖励,以便更好地引导其学习特定行为。
4. 改变奖励分布:通过调整奖励函数,使其具有不同的奖励分布,从而影响智能体的学习过程。
总之,奖励塑造是一种通过调整环境和奖励函数来引导智能体学习更好行为的方法,有助于提高强化学习的性能。
```
</details>
<details><summary><b>语言理解</b></summary>
```
用户:
小张给领导买了一个礼物说,说“意思一下”,领导说“什么意思”,小张回答说:“没什么意思,就是随便意思意思”。请依次解读一下小张说的这几个“意思”的含义。
Baichun-13B-Chat:
1. 第一个“意思”:指的是小张送给领导的那个礼物,表示他已经买了这个礼物并准备送给他。
2. 第二个“意思”:指的是小张对领导的一种礼貌和尊重,表示自己并没有忘记他的身份和地位,在购买礼物时也考虑到了这一点。
3. 第三个“意思”:指的是小张对于这次赠送礼物的行为本身的态度,即不希望这件事情引起过多的关注或争议,只是想表达一种心意而已。
```
</details>
## 推理性能
Baichuan-13B 使用了 ALiBi 线性偏置技术,相对于 Rotary Embedding 计算量更小,对推理性能有显著提升;与标准的 LLaMA-13B 相比,平均推理速度 (tokens/s) 实测提升 31.6%:
| Model | tokens/s |
|-------------|:--------:|
| LLaMA-13B | 19.4 |
| Baichuan-13B| 25.4 |
> 测试环境和参数:GPU A100-SXM4-80G, PyTorch 2.0.0+cu117, transformers 4.29.1, batch size = 1, 生成长度 = 2048, 精度 fp16, 基于 Baichuan-13B-Base
## 量化部署
Baichuan-13B 支持 int8 和 int4 量化,用户只需在推理代码中简单修改两行即可实现。
### 使用量化的用户请务必注意!
***请仔细阅读接下来的的示例代码,尤其是第一行模型加载部分,和上面的推理示例是不同的。***
***开发者可以按照自己的需求修改模型的加载方式,但是请注意:如果是为了节省显存而进行量化,应加载原始精度模型到 CPU 后再开始量化;避免在`from_pretrained`时添加`device_map='auto'`或者其它会导致把原始精度模型直接加载到 GPU 的行为的参数。***
如需使用 int8 量化:
```python
model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan-13B-Chat", torch_dtype=torch.float16, trust_remote_code=True)
model = model.quantize(8).cuda()
```
同样的,如需使用 int4 量化:
```python
model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan-13B-Chat", torch_dtype=torch.float16, trust_remote_code=True)
model = model.quantize(4).cuda()
```
另外,如果你不想调用 quantize 在线量化,我们有量化好的 int8 Chat 模型可供使用:[Baichuan-13B-Chat-int8](https://huggingface.co/baichuan-inc/Baichuan-13B-Chat-int8):
```python
model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan-13B-Chat-int8", torch_dtype=torch.float16, trust_remote_code=True).cuda()
```
量化前后占用显存情况如下:
| Precision | GPU Mem (GB) |
|-------------|:------------:|
| bf16 / fp16 | 26.0 |
| int8 | 15.8 |
| int4 | 9.7 |
量化后在各个 benchmark 上的结果和原始版本对比如下:
| Model 5-shot | C-Eval | MMLU | CMMLU |
|------------------------|:------:|:----:|:-----:|
| Baichuan-13B-Base | 52.4 | 51.6 | 55.3 |
| Baichuan-13B-Base-int8 | 51.2 | 49.9 | 54.5 |
| Baichuan-13B-Base-int4 | 47.6 | 46.0 | 51.0 |
## CPU 部署
Baichuan-13B 支持 CPU 推理,但需要强调的是,CPU 的推理速度相对较慢。需按如下方式修改模型加载的方式:
```python
model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan-13B-Chat", torch_dtype=torch.float32, trust_remote_code=True)
```
使用CPU进行推理大概需要 60GB 内存。
# 对模型进行微调
开发者可以对 Baichuan-13B-Base 或 Baichuan-13B-Chat 进行微调使用。在此我们测试了与 Baichuan-13B 兼容的微调工具 [LLaMA Efficient Tuning](https://github.com/hiyouga/LLaMA-Efficient-Tuning),并给出`全量微调`和 `LoRA微调`的两种示范。
在开始之前,开发者需下载 LLaMA Efficient Tuning 项目并按其要求[安装依赖](https://github.com/hiyouga/LLaMA-Efficient-Tuning#getting-started)。
输入数据为放置在项目`data`目录下的 json 文件,用`--dataset`选项指定(参考下面示例),多个输入文件用`,`分隔。json 文件示例格式和字段说明如下:
```
[
{
"instruction": "What are the three primary colors?",
"input": "",
"output": "The three primary colors are red, blue, and yellow."
},
....
]
```
json 文件中存储一个列表,列表的每个元素是一个 sample。其中`instruction`代表用户输入,`input`是可选项,如果开发者同时指定了`instruction`和`input`,会把二者用`\n`连接起来代表用户输入;`output`代表期望的模型输出。
下面我们给出两种微调场景下测试跑通的示范脚本。
## 全量微调
我们在 8 * Nvidia A100 80 GB + deepspeed 的环境下进行了全量微调测试。
训练启动脚本示例:
```shell
deepspeed --num_gpus=8 src/train_bash.py \
--stage sft \
--model_name_or_path baichuan-inc/Baichuan-13B-Base \
--do_train \
--dataset alpaca_gpt4_en,alpaca_gpt4_zh \
--finetuning_type full \
--output_dir path_to_your_sft_checkpoint \
--overwrite_cache \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 4 \
--gradient_accumulation_steps 8 \
--preprocessing_num_workers 16 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--save_steps 100 \
--eval_steps 100 \
--learning_rate 5e-5 \
--max_grad_norm 0.5 \
--num_train_epochs 2.0 \
--dev_ratio 0.01 \
--evaluation_strategy steps \
--load_best_model_at_end \
--plot_loss \
--fp16 \
--deepspeed deepspeed.json
```
deep_speed.json 配置示例:
```json
{
"train_micro_batch_size_per_gpu": "auto",
"zero_allow_untested_optimizer": true,
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"initial_scale_power": 16,
"loss_scale_window": 1000,
"hysteresis": 2,
"min_loss_scale": 1
},
"zero_optimization": {
"stage": 2,
"allgather_partitions": true,
"allgather_bucket_size": 5e8,
"overlap_comm": false,
"reduce_scatter": true,
"reduce_bucket_size": 5e8,
"contiguous_gradients" : true
}
}
```
## LoRA微调
我们在单张 Nvidia A100 80G 显卡上进行了 LoRA 微调测试。
训练启动脚本示例:
```shell
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \
--stage sft \
--model_name_or_path baichuan-inc/Baichuan-13B-Base \
--do_train \
--dataset alpaca_gpt4_en,alpaca_gpt4_zh \
--finetuning_type lora \
--lora_rank 8 \
--lora_target W_pack \
--output_dir path_to_your_sft_checkpoint \
--overwrite_cache \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 4 \
--gradient_accumulation_steps 8 \
--preprocessing_num_workers 16 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--save_steps 100 \
--eval_steps 100 \
--learning_rate 5e-5 \
--max_grad_norm 0.5 \
--num_train_epochs 2.0 \
--dev_ratio 0.01 \
--evaluation_strategy steps \
--load_best_model_at_end \
--plot_loss \
--fp16
```
关于使用 LLaMA Efficient Tuning 的更详细的用法,请参阅其项目主页说明。
# 声明
我们在此声明,我们的开发团队并未基于 Baichuan-13B 模型开发任何应用,无论是在 iOS、Android、网页或任何其他平台。我们强烈呼吁所有使用者,不要利用 Baichuan-13B 模型进行任何危害国家社会安全或违法的活动。另外,我们也要求使用者不要将 Baichuan-13B 模型用于未经适当安全审查和备案的互联网服务。我们希望所有的使用者都能遵守这个原则,确保科技的发展能在规范和合法的环境下进行。
我们已经尽我们所能,来确保模型训练过程中使用的数据的合规性。然而,尽管我们已经做出了巨大的努力,但由于模型和数据的复杂性,仍有可能存在一些无法预见的问题。因此,如果由于使用 Baichuan-13B 开源模型而导致的任何问题,包括但不限于数据安全问题、公共舆论风险,或模型被误导、滥用、传播或不当利用所带来的任何风险和问题,我们将不承担任何责任。
# 协议
对本仓库源码的使用遵循开源许可协议 [Apache 2.0](https://github.com/baichuan-inc/Baichuan-13B/blob/main/LICENSE)。对 Baichuan-13B 模型的社区使用见[《Baichuan-13B 模型社区许可协议》](https://huggingface.co/baichuan-inc/Baichuan-13B-Chat/resolve/main/Baichuan-13B%20%E6%A8%A1%E5%9E%8B%E7%A4%BE%E5%8C%BA%E8%AE%B8%E5%8F%AF%E5%8D%8F%E8%AE%AE.pdf)。Baichuan-13B 支持商用。如果将 Baichuan-13B 模型或其衍生品用作商业用途,请您按照如下方式联系许可方,以进行登记并向许可方申请书面授权:联系邮箱 <[email protected]>。
| 2,242
| 151
|
Rocketseat/jupiter
|
https://github.com/Rocketseat/jupiter
|
Rocketseat video internal platform.
|
# ideas
- intercept route to videos / analytics most watched videos / no watched videos
# Memory improvements
- Whisper JAX
# MVP
Upload videos, upload to panda and R2, embed om player
- [ ] Sync transcription/video with Houston
# Thoughts
- Datadog / Sentry
- DeadLetter queue (manual retry)
- store number of retries and if its the last maybe notice somewhere and display a button for manual retry
- Find possibly typos in transcription based on commit diff
- Tests please?!
| 57
| 25
|
taubyte/tau
|
https://github.com/taubyte/tau
| null |
# tau
[](https://github.com/taubyte/tau/releases)
[](LICENSE)
[](https://goreportcard.com/report/taubyte/tau)
[](https://pkg.go.dev/github.com/taubyte/tau)
[](https://discord.gg/taubyte)
`tau` is the implementation of a Taubyte Node. Documentation: [https://tau.how](https://tau.how).
| 12
| 0
|
ellermister/wechat-clean
|
https://github.com/ellermister/wechat-clean
|
释放你的安卓微信内部存储空间,一键解放微信存储空间的工具。
|
# wechat-clean
释放你的安卓微信内部存储空间,一键解放微信存储空间的工具。
# 介绍
**主要原理:**
通过解密微信的数据库,过滤出群聊天记录,并找出相关的缓存文件、图片、视频等,一并删除。最后,删除这些数据库记录,从而缩减数据库的大小。
**为什么会做这个?**
由于记忆力有限,可能不想删除所有的聊天记录,而是希望保留联系人记录,以便在需要时可以参考上下文。
然而,微信甚至不像 QQ 那样,可以手动点击接收图片。微信默认会接收所有群组的消息、图片和视频缓存等,群里聊的每一个字节都存到了你的手机里。
此外,微信的文件分类管理非常混乱,这些文件甚至被隐藏在 `/data` 目录中,只有具备 root 权限的用户才能进行处理。即使你有 root 权限,也无法轻易找出哪些文件可以删除,哪些文件不能删除。
长期以来,虽然你的联系人资料可能并不占用太多存储空间,但群组的资料却可能占据了大部分空间。
**为什么你不退群?**
没有习惯退群,即使退了,群组之前的记录仍会像狗皮膏药一样永远存储在你的手机中,无法轻易清除。
**为什么不用内置聊天管理?**
内置的聊天管理功能根本无法满足清理需求,缺乏一键选择群组的功能。
经过测试,即使勾选了清理选项,导出数据后你会发现数据库和缓存中仍然存在数据,内置功能并没有完全清理干净,就像删除了一个软连接一样。(测试自 8.0.2 版本)
**功能:**
- 清理所有群产生的聊天记录、图片、视频和音频缓存,从而缩减数据库大小。
- 可选择只清理联系人,这一功能一般用不上。
- 顺便清理其他目录:小程序、基础缓存、检查更新残留、record 缓存、avatar缓存、FTS5Index*、webview 内核缓存、wepkg 缓存等。
- 清理其他表项:公众号推送列表、转发通知消息、已经删除的关联记录表、用户头像关联缓存等。
# 效果
这是搞了好几天的成果,虽然结果还是很大,但已经减少了十几GB的体积!好在是可以弄成一键工具进行清理了。
<img src="assets/clean.jpg" />

# 编译
文件编译
```bash
env GOOS=android GOARCH=arm64 CC=C:\android-ndk-r25c-windows\android-ndk-r25c\toolchains\llvm\prebuilt\windows-x86_64\bin\aarch64-linux-android30-clang GOARM=7 CGO_ENABLED=1 go build
```
push
```
adb push wechat-clean /data/local/tmp
```
# 备份
**推荐钛备份**,可以全量备份版本及用户数据
下载:https://play.google.com/store/apps/details?id=com.keramidas.TitaniumBackup&hl=zh&gl=US
## 命令行手动备份
截取自钛备份, **不包含 sdcard 数据**
```
busybox tar -c /data/data/com.tencent.mm/. --exclude data/data/com.tencent.mm/./lib --exclude data/data/com.tencent.mm/./cache
```
# 开始
## 注意⚠️⚠️⚠️
- Android 设备必须拥有 root 权限
- **使用前请先备份数据!**
- 你必须为你自己数据清理过程中产生意外错误后自己负责,如执行中断、超范围删除等。
- 测试环境在 8.0.24 验证通过
## 执行流程
1. 请先想办法获取你的数据库密码!
2. 下载文件 wechat-clean 到`/data/local/tmp` 中
3. 提权到 **root 权限** `su`
4. 给程序赋予执行权限`chmod +x wechat-clean`
5. 找到你的微信32位用户ID
6. 结束微信进程 `ps -ef|grep com.tencent.mm|grep -v grep| awk '{print $2}'|xargs kill -9`
7. 执行扫描 `./wechat-clean -id [32位用户ID] -key [7位密码] -from groups -cmd scan`
## 获取用户微信32位ID
如果你只登陆过一个用户那非常简单,执行命令就能看到一个长度32位 ID 的目录
```
ls /data/data/com.tencent.mm/MicroMsg/
```
## 获取数据库 KEY
### hook方法获取
你可能需要学习 frida 相关基础知识和流程。
启动微信后,执行命令会输出密码
```bash
frida -U -n Wechat -l wechatdbpass.js
```
### 计算方式
需要找出你的 imei 和 uin,相关网上资料很多,但不一定能够计算出来。
如果你换过手机并迁移数据,这个 imei 可能早就就变了,并不是当前手机IMEI。
```python
import hashlib
imei = "866123456789111"
uin = "-123456789"
key = hashlib.md5( str( imei ).encode("utf8") + str( uin ).encode("utf8")).hexdigest()[ 0:7 ]
print(key)
```
## 其他用法
```bash
./wechat-clean -h
Wechat-Clean v20230719
Usage of D:\projects\wechat-clean\wechat-clean.exe:
-cmd string
scan/clean/server (default "scan")
-from string
groups/friends/all
-id string
user 32 length hex id
-key string
db key
-user int
Android user id
-vd string
Vacuum db full path
```
### 扫描
扫描垃圾文件只是读库读文件,是一个安全行为。
```bash
./wechat-clean -cmd scan -id [32位用户ID] -key [7位密码] -from all
```
### 清理群相关记录
**本程序最适合也只建议清理群消息。**
```bash
./wechat-clean -id [32位用户ID] -key [7位密码] -from groups -cmd clean
```
### 精简数据库
不会删除数据,只是释放已经删除数据的空间,同 sqlite 命令:vacuum
```
./wechat-clean -vd /data/data/com.tencent.mm/MicroMsg/*****/EnMicroMsg.db -key 1122334
```
vacuum 只会将已经删除记录空间释放,如果没有删除是无法缩减的。
> sqlite + sqlcipher 在Android上执行 vacuum 时,会把数据库吞进内存处理,内存几乎是文件的2倍,然后涨到2.5G左右时被OOM或者其他系统机制干掉,具体原因不明。
对于数据库大于 1GB 的文件将在 clean 排程中跳过,你需要将 EnMicroMsg.db 通过 adb复制到 windows 等,缩减后再放回去。
以下参考:
```bash
android #
cp /data/data/com.tencent.mm/MicroMsg/****/EnMicroMsg.db /data/local/tmp
win #
adb pull /data/local/tmp/EnMicroMsg.db .
./wechat-clean -vd /data/data/com.tencent.mm/MicroMsg/*****/EnMicroMsg.db -key 1122334
adb push EnMicroMsg.db /data/local/tmp
android #
cp /data/local/tmp/EnMicroMsg.db /data/data/com.tencent.mm/MicroMsg/****/EnMicroMsg.db
```
### UI界面手动清理
以服务器形式启动,通过手机或者同一个局域网下的电脑可以进行访问执行操作。
**默认端口为 9999 请避免端口占用。**
只需要如下参数即可启动:
```bash
./wechat-clean -id [32ID] -cmd server -key [7key]
```
支持操作:
- 搜索昵称备注
- 全选/取消全选所有好友
- 全选/取消权限所有群组
- 单选任意会话

## 其他
记录一些快捷指令
### 查看子目录占用大小
```
android:/data/data/com.tencent.mm # du -h -d 1
3.5K ./code_cache
499M ./files
2.0G ./MicroMsg
3.5K ./app_lib
3.5K ./app_dex
3.5K ./app_cache
3.5K ./app_recover_lib
1.4M ./shared_prefs
```
### 冻结恢复应用
在执行 clean 时程序会自动冻结你的程序并在完成后恢复,如果意外没有恢复,你可以手动执行。
**冻结应用**
```
adb disable com.tencent.mm
```
**恢复应用**
```
adb enable com.tencent.mm
```
### IOS 用户
对于没有 root 的 Android 或者 IOS 用户来说无法实现,一般也没有必要天天清理,可以按照以下方法一年一清。
1. 将使用的 IOS 微信备份到 PC 微信,选择全部聊天记录。
2. 在已经 root 的 Android 设备上登录微信并恢复聊天记录到本地。
3. 通过脚本清理群组聊天记录(建议提前备份有基础密钥的基础数据库,可以减少重新获取密钥的工作)
4. 将清理后的微信备份到PC微信,如果该设备备份过,在PC端点击删除备份,否则是追加,会有垃圾的。
5. 在IOS设备重装微信,登录后从 PC 微信恢复精简后的全部聊天记录。
**或者许愿未来哪一天宇宙级产品经理愿意实现自定义备份功能了,就有解了!**
# 数据表
**以下给我自己看的!备忘录!!!**
| 表名 | 描述 | 可清理 |
| ------------------------- | ------------------------------------------------------------ | ------------------ |
| AppMessage | 应用消息, 可能是通知, 邀请信息之类的, 有 title 和 description 字段 | 垃圾可清, 量大 |
| fmessage_conversation | 好友申请记录 | 无需清 |
| rcontact | 联系人和群组表,含昵称、原始ID | |
| message | 聊天记录 | |
| MediaDuplication | 一部分外置资源图片, 5k行 | 可清不存在的记录 |
| ImgInfo2 | 图片总表 | |
| videoinfo2 | 视频总表 | |
| appattach | 一部分下载的文件、一部分图文聊天记录的转发? | 可清理,内容几百条 |
| ChatroomNoticeAttachIndex | 聊天记录转发产生的HTM文件,路径不存在可请 | 可清不存在的记录 |
| EmojiInfo | 表情、贴图表 | |
| CleanDeleteItem | 删除的项目,看名字就可以删除 | 全清 |
| img_flag | 用户的头像映射 | 全清 |
| BizTimeLineInfo | 公众号的推送会话列表 | 全清 |
| rconversation | 最近会话列表 | 无需清 |
## 查找文件方法:
根据 type 区分文件类型
## 图片和视频
1. 在message表找到对应记录,拿到 msgsvrid、msgId
2. 通过 ImgInfo2 或者 VideoInfo2 查找 msgsvrid=236411111111111111;
3. 找到缩略图、中图、大图、hevc图的 filename,拿到 filename,图片的话在 image2 目录,文件名前4位是两级子目录名。
4. 视频的话再去对应外置存储路径中如 video/230621111111111111.mp4 删除,可能也有 video/230621111111111111.jpg 为缩略图
5. 也可以跳过中间表,直接用 imgpath 去找。如果要删除的话记得删除中间表的数据,也挺大的。
## 音频文件
1. 在数据库拿到文件名 54155907092311111111111111
2. md5之后 = **c952**9f3187f2afbbf742249baccac089
3. 外置路径就是 = voice2/**c9/52**/msg_54155907092311111111111111.amr
## message
type 猜解
- 1,文字消息
- 47,表情?
- 3, xml 内容 和 图片
- 822083633,回复的消息
- 49,图文消息、文件传输的消息
- 285212721,公众号的各种推送
- 10000,系统通知,加好友通知,群进成员通知,撤回通知
- 43,视频文件
- 34,音频文件
### 🎈查询数据时的联表备注
#### 异常的 msglocalid
下面 SQL 通过 msgSvrId 关联 和 msglocalid 关联产生对比,其中 msgSvrId 能够关联出更多的数据
虽然这样的查询能够更全面的展示消息对应文件的存储路径,但是如果要删除可能会**多删**。
```SQL
SELECT
m.msgId,
m.type,
m.imgPath,
m.talker,
img.bigImgPath,
img2.bigImgPath
FROM
'message' AS m
LEFT JOIN ImgInfo2 AS img ON img.msglocalid = m.msgId
LEFT JOIN ImgInfo2 AS img2 ON img2.msgSvrId = m.msgSvrId
WHERE
m.imgPath != ''
AND m.type = 3
ORDER BY
m.msgId DESC
```
这里通过不同字段关联了两次,在实际测试中存在一些数据:
- 通过 msglocalid 关联的 bigImgPath 是空的(理解为漏了)
- 而 msgSvrId 关联出来的 bigImgPath 非空且本地有图,但也大多没有 msglocalid,能想到的解释是非聊天室首次加载的后续根据md5信息无需再次加载即不需要维护,更或者是维护出现了断层。
#### 是否 msglocalid 和 msgSvrId 关联出有效的数据路径是一致的?
如下SQL 仅显示有效 msglocalid 关联结果与 msgSvrId 有效结果
```SQL
SELECT * FROM (
SELECT
m.msgId,
m.type,
m.imgPath,
m.talker,
img.bigImgPath,
img.midImgPath
,img.msglocalid
,img2.bigImgPath as bigImgPath2
,img2.msglocalid
FROM
'message' AS m
LEFT JOIN ImgInfo2 AS img ON img.msglocalid = m.msgId
LEFT JOIN ImgInfo2 AS img2 ON img2.msgSvrId = m.msgSvrId
WHERE
m.imgPath != ''
AND m.type = 3
ORDER BY
m.msgId DESC
) AS F WHERE
bigImgPath!='' and bigImgPath!=bigImgPath2;
```
可以看到如下图所示,一个群组消息关联出4个不同的图片路径,hash值也不太一样。
虽然数据量只有一条,但为了避免这种少量数据,还是将所有字段全部查出为好,最后去重。

#### 一图多用
另外还存在一个图片在私人聊天和群组聊天中共同产生,即同样一张图首次加载后再次转发不再继续插入数据的现象:
```SQL
SELECT msgSvrId,COUNT(*) as count FROM message group by msgSvrId HAVING count >1;
SELECT msgSvrId,COUNT(*) as count FROM ImgInfo2 group by msgSvrId HAVING count >1;
```

其中没有 `msgSvrId` 的图片的也不少,大多都是聊天室的图片,发信人和自己都不是好友的情况,所以基本可删。
可以通过如下SQL 复现:
```SQL
SELECT
*, substr(
reserved3,
0,
instr (reserved3, ":")
) AS r_username
FROM
ImgInfo2
LEFT JOIN rcontact AS rc ON rc.username = r_username
WHERE
msgSvrId IS NULL
ORDER BY
id DESC;
```
通过结果集观察,r_username 基本都是非好友关系,但并不能确认发信人所在聊天室是群组还是好友,它的`msgSvrId`都是空的,除了朋友圈之外实在想不明白这种非好友的缓存图片的 `msgSvrId `和 `msglocalid`是为什么是空的,即使在群里也应该维护这两个字段才对。
### 结论
**所以最终为了删除更多的数据, 避免遗漏会采用两个字段分别关联,查出所有文件字段。**
### 通过 message 查找出的图片数量不足
通过上面 type=3 查找出消息的图片缓存及各种图片的数量和体积都小于实际存储的,通过差集反查发现部分数据是存在于数据库,但 type 为49,即图文数据。
图文XML格式:
```
wxid_cbg000000000000:
<?xml version="1.0"?>
<msg>
<img aeskey="00000000000000000000000000000000" encryver="1" cdnthumbaeskey="00000000000000000000000000000000" cdnthumburl="00000000000000000000000000000000" cdnthumblength="6056" cdnthumbheight="131" cdnthumbwidth="150" cdnmidheight="0" cdnmidwidth="0" cdnhdheight="0" cdnhdwidth="0" cdnmidimgurl="00000000000000000000000000000000" length="31425" cdnbigimgurl="00000000000000000000000000000000" hdlength="31425" md5="00000000000000000000000000000000" />
<platform_signature></platform_signature>
<imgdatahash></imgdatahash>
</msg>
```
## rcontcat
type 字段猜解
- 0,公众号小程序
- 1,自己及企业号
- 2,群
- 3,好友及公众号
- 4,好像是群成员,巨多垃圾
- 33,官方服务;漂流瓶,朋友圈,广播助手,QQ信箱提醒,小程序客服讯息,语音通话之类的
- 67,不确定是特别关注还是拉黑的名单
- 259,不知道,包含3个正常联系人?有趣!
- 513,不知道,包含1个正常联系人
- 515,不知道,包含2个正常联系人
- 2049,文件传输助手
- 1114113,不知道,包含1个正常联系人
- 8388611,不知道,包含59个联系人
verifyFlag
可能不准确,在 type = 3 的情况下:
- 0,好友
- 8,公众号
- 24,也是公众号
- 56,微信团队
- 776,自媒体公众号
### 官方服务
| 应用名称 | 用户名 |
| ----------------- | -------------------------- |
| QQ信箱提醒 | qqmail |
| 漂流瓶 | floatbottle |
| 摇一摇 | shakeapp |
| 附近的人 | lbsapp |
| 语音记事本 | medianote |
| 腾讯新闻 | newsapp |
| Facebook 协助工具 | facebookapp |
| 查看 QQ 朋友 | qqfriend |
| 广播助手 | masssendapp |
| 朋友圈 | feedsapp |
| 新视频通话 | voipapp |
| 订阅账号消息 | officialaccounts |
| 语音通话 | voicevoipapp |
| 语音输入 | voiceinputapp |
| LinkedIn | linkedinplugin |
| 服务通知 | notifymessage |
| 小程序客服消息 | appbrandcustomerservicemsg |
| 我的小程序消息 | appbrand_notify_message |
| WeChat游戏下载 | downloaderapp |
| 客服消息 | opencustomerservicemsg |
| 新的朋友 | fmessage |
## WxFileIndex3
文件类型查找
msgType = 1090519089
```
SELECT * FROM "WxFileIndex3" where msgType=1090519089;
```
# 目录
另外补充几个长年累月体积不小的目录、
```
:/data/data/com.tencent.mm # du -h -d 1
595M ./files 微信的一些基础资源目录
2.9G ./MicroMsg 用户数据
130M ./app_tbs_64 浏览器内核
杂七杂八的浏览器内核缓存和热更新,可以无脑删除。
102M ./app_xwalkplugin
179M ./app_xwalk_5169
228M ./lib-
278M ./cache
128M ./app_xwalk_4296
177M ./app_xwalk_5153
```
| 179
| 8
|
michelson/autocontext
|
https://github.com/michelson/autocontext
|
An Elixir Ecto utility library that provides ActiveRecord-like callbacks, simplifying the management of database operations. This includes before_save, after_save, create, update, and delete functions.
|
[](https://github.com/michelson/autocontext/actions/workflows/test.yml)
# Autocontext
`Autocontext` is an Elixir library that provides ActiveRecord-like callbacks for Ecto, Elixir's database wrapper. This allows you to specify functions to be executed before and after certain operations (`insert`, `update`, `delete`), enhancing control over these operations and maintaining a clean and expressive code base.
## Features
- `before_save`, `after_save`, `before_create`, `after_create`, `before_update`, `after_update`, `before_delete`, `after_delete` callbacks.
- Fully customizable with the ability to specify your own callback functions.
- Supports the Repo option, which allows you to use different Repo configurations.
- Works seamlessly with Ecto's changesets and other features.
- Multiple changesets and multiple schemas are allowed.
---
## Installation
Add the `autocontext` to your list of dependencies in `mix.exs`:
```elixir
def deps do
[
{:autocontext, "~> 0.1.0"}
]
end
```
## Usage
Define a context module for your Ecto operations and `use Autocontext.EctoCallbacks`:
```elixir
defmodule MyApp.Accounts do
use Autocontext.EctoCallbacks, operations: [
[
name: :user,
repo: MyApp.Repo,
schema: MyApp.User,
changeset: &MyApp.User.changeset/2,
use_transaction: true,
before_save: [:validate_username, :hash_password],
after_save: [:send_welcome_email, :track_user_creation]
],
[
name: :admin,
repo: MyApp.Repo,
schema: MyApp.Admin,
changeset: &MyApp.Admin.changeset/2,
use_transaction: false,
before_create: [:check_admin_limit],
after_create: [:send_admin_email]
]
]
# Callback implementations...
end
```
In the above configuration:
- `:name` defines a unique name for the operation. This name is used to generate the actual Ecto operation functions: `user_create`, `user_update`, `user_delete`, `admin_create`, `admin_update`, `admin_delete`. If the option is nil then a `create`, `delete`, and `update` methods will be created for the schema.
- `:repo` is the Ecto repository to interact with.
- `:schema` is the Ecto schema for the data structure.
- `:changeset` is the changeset function used for the data validation and transformations.
- `:use_transaction` is a boolean flag to indicate whether to perform the operations within a database transaction or not.
- The remaining keys (`:before_save`, `:after_save`, `:before_create`, `:after_create`, etc.) define the callback functions to be called before or after the actual Ecto operations. These callbacks must be implemented within the same module and they should return the changeset or record they receive.
Then, you can call the functions as follows:
```elixir
params = %{name: "john_doe", email: "[email protected]", age: 10}
case MyApp.Accounts.user_create(params) do
{:ok, user} ->
IO.puts("User created successfully.")
{:error, changeset} ->
IO.puts("Failed to create user.")
end
```
---
# Finders
Finders gives an easy way to access records, like find, find_by and all
```elixir
defmodule Autocontext.Accounts do
use Autocontext.Finders,
schema: User,
repo: Repo
end
```
```elixir
Accounts.find!(1)
Accounts.find_by!(name: "mike")
Accounts.all
```
## Installation
Add `autocontext` to your list of dependencies in `mix.exs`:
```elixir
def deps do
[
{:autocontext, "~> 0.1.0"}
]
end
```
Then, update your dependencies:
```
$ mix deps.get
```
| 11
| 1
|
rocketapi-io/threads-private-api
|
https://github.com/rocketapi-io/threads-private-api
|
🧵 Examples of using Threads Private API
|
# Threads Private API
This repository aims to demonstrate how to use the `rocketapi` Python library to interact with the Threads API of the RocketAPI.io service. The two main functionalities provided are the ability to scrape user followers and extract thread replies from Threads.
## Contents
1. `scrape_followers.py`: Given a username or user ID, this script extracts all subscribers (using pagination) of the user in Threads. The data is then saved to a .csv file at `var/followers/{user_id}.csv` using the pandas library.
2. `extract_thread_replies.py`: Given a thread ID, this script extracts all replies on a thread (using pagination) and saves them to a .csv file at `var/thread_replies/{thread_id}.csv` using the pandas library.
## Prerequisites
1. Python 3.7 or later.
2. [RocketAPI](https://rocketapi.io) account.
3. Installed RocketAPI Python library. You can install it with pip:
```
pip install rocketapi
```
## Scrape Followers
https://github.com/rocketapi-io/threads-private-api/assets/115935691/2051353f-ebf5-482c-924a-4300106b9524
The `scrape_followers.py` script is used to scrape followers from a specific user on Threads, given their username or user ID as input.
Here is an in-depth explanation of how the script works:
- The script begins by reading the `ROCKETAPI_TOKEN` from the `.env` file. This is used to authenticate the InstagramAPI and ThreadsAPI clients.
- The `get_user_info` function sends a request to InstagramAPI to retrieve user information given a username.
- The `get_user_id` function accepts either a username or user ID. If a username is provided, it uses the `get_user_info` function to retrieve the user ID. If an ID is provided, it returns the ID directly.
- The `get_followers` function sends a request to ThreadsAPI to retrieve followers of a user given their user ID and a `max_id` for pagination.
- The `scrape_followers` function is the main function that uses the functions above to scrape followers from the user and saves them into a CSV file.
- First, it retrieves the user ID from the input value (username or user ID).
- It then enters a loop where it retrieves followers of the user, saves their details into a dataframe, and writes the dataframe to a CSV file. This loop continues until all followers have been retrieved (i.e., no more `next_max_id` in the response).
- The details saved for each follower are their user ID (`pk`), `username`, `full_name`, `is_private`, and `is_verified` status.
- The script employs the decorator `retry_on_exception` to retry failed requests to InstagramAPI and ThreadsAPI due to exceptions. It makes up to 3 attempts for each failed request.
- If Instagram returns a wrong max ID (sometimes happens and returns `"100"`), it's recognized and handled correctly by re-requesting the same page.
- The script also keeps track of the total count of followers, which is logged at the end of the script.
### Usage:
You can run the script from the command line as follows:
```bash
python scrape_followers.py <username or user_id>
```
Replace `<username or user_id>` with the username or user ID of the user whose followers you want to scrape.
The script will save the followers to a CSV file named `{user_id}.csv` in the `var/followers/` directory. Each row in the CSV file represents a follower, and the columns represent the follower's details (user ID, username, full name, whether their account is private, and whether they are verified).
Please ensure that the `ROCKETAPI_TOKEN` in your `.env` file is set correctly to your [rocketapi.io](https://rocketapi.io/dashboard/) API token before running the script.
## Extract Thread Replies
https://github.com/rocketapi-io/threads-private-api/assets/115935691/bd6ede40-c7e1-480c-8b47-b4367f3e6a28
The `extract_thread_replies.py` is designed to scrape replies from a specific thread on Threads using the RocketAPI.
When the script is executed, it first fetches the required environment variable for the RocketAPI token using `load_dotenv()`. This token is used to authenticate the ThreadsAPI object, which will be used to interact with the RocketAPI.
The main function of the script is `extract_thread_replies(thread_id)`. It takes as input the `thread_id` for the specific thread you want to scrape replies from.
Inside this function, it initiates a `while` loop to paginate through all replies in the given thread using the `get_thread_replies()` function (which is decorated with `retry_on_exception()` to ensure robustness against API request failures). The replies are fetched in batches until no more replies are available.
During each loop iteration, for each reply fetched, the script checks if the reply's id is already present in the existing list of fetched replies' ids. If it is, a log message is printed out, an exit flag is set, and the loop moves to the next reply. If the reply's id is not present, it is added to the list, and the relevant fields are extracted from the reply and appended to a list of dictionaries.
The relevant fields extracted from each reply are as follows:
- `id`: the id of the reply
- `thread_type`: the type of the thread
- `user_pk`: the user's pk (id)
- `username`: the user's username
- `full_name`: the user's full name
- `caption_text`: the text of the caption (if available)
- `like_count`: the count of likes
- `taken_at`: the time when the reply was made
After all replies in a batch are processed, they are saved into a DataFrame and then exported to a CSV file in the `var/thread_replies/` directory. The filename is the `thread_id` value. This process repeats until no more new replies are available or a duplicate reply id is encountered.
If the exit flag is set due to encountering a duplicate reply id, the while loop is broken and the script finishes its execution.
### Usage
You can run the script from the command line as follows:
```bash
python extract_thread_replies.py <thread_id>
```
You must provide the `thread_id` as an argument when running the script. The `thread_id` is an identifier for the specific thread you want to scrape replies from.
Please ensure that the `ROCKETAPI_TOKEN` in your `.env` file is set correctly to your [rocketapi.io](https://rocketapi.io/dashboard/) API token before running the script.
## Documentation
The RocketAPI documentation is available [here](https://docs.rocketapi.io/category/threads). It provides detailed information about the Threads API, which these scripts use to fetch followers and thread replies.
## Contributing
Contributions are welcome! Please fork this repository and create a pull request with your changes.
## License
This project is licensed under the MIT License. See `LICENSE` for more details.
## Acknowledgements
This project uses the [RocketAPI](https://rocketapi.io) service and its Python library [rocketapi](https://pypi.org/project/rocketapi/) for interacting with the Threads API.
| 127
| 0
|
HaxyMoly/Pangu-Weather-ReadyToGo
|
https://github.com/HaxyMoly/Pangu-Weather-ReadyToGo
|
盘古天气大模型全流程演示( 输入数据准备、预测及结果可视化)Unofficial demonstration of Huawei's Pangu Weather Model. Implementing the entire process of data preparation for input, forecasting conversion of forecasted results, and visualization.
|
# Pangu-Weather-ReadyToGo
Unofficial demonstration of [Huawei's Pangu Weather Model](https://github.com/198808xc/Pangu-Weather). Implementing the entire process of data preparation for input, forecasting conversion of forecasted results, and visualization.
【非官方】华为盘古天气模型演示,含输入数据准备、预测结果转换及结果可视化全流程。[中文指南](#安装和准备工作)

## Installation and Preparation
1. Register for an account at [Climate Data Store](https://cds.climate.copernicus.eu/user/register)
2. Copy the url and key displayed on [CDS API key](https://cds.climate.copernicus.eu/api-how-to) and add them to the` ~/.cdsapirc` file.
5. Clone this repo and install dependencies accordingly, depending on GPU availability.
```bash
git clone https://github.com/HaxyMoly/Pangu-Weather-ReadyToGo.git
cd Pangu-Weather-ReadyToGo
# GPU
pip install -r requirements_gpu.txt
# CPU
pip install -r requirements_cpu.txt
conda install -c conda-forge cartopy
```
4. Download four pre-trained weights from [Pangu-Weather](https://github.com/198808xc/Pangu-Weather/tree/main#global-weather-forecasting-inference-using-the-trained-models) and create a folder named `models` to put them in. Feel free to download only one of them for testing purposes.
```bash
mkdir models
```
## Forecasting
1. Modify the `date_time` of the initial field in `data_prepare.py`.
```python
date_time = datetime(
year=2023,
month=7,
day=9,
hour=23,
minute=0)
```
> You may check the data availability at a specific moment by using `test_avaliable_time.py`.You would get something like this:
> `The latest date available for this dataset is: 2023-07-13 13:00.`
2. Run `data_prepare.py` to download the initial field data and convert them to numpy array.
```bash
python data_prepare.py
```
3. Modify the following variables in `inference.py` according to your needs:
```python
# Enable GPU acceleration
use_GPU = True
# The date and time of the initial field
date_time = datetime(
year=2023,
month=7,
day=9,
hour=23,
minute=0)
# The date and time of the final approaches
date_time_final = datetime(
year=2023,
month=7,
day=17,
hour=23,
minute=0)
# Program auto choose model to use least interation to reach final time
```
4. Execute `inference.py` to make forecast
```bash
python inference.py
```
5. Modify the `date_time` and `final_date_time` of the initial field in `forecast_decode.py`
```python
# The date and time of the initial field
date_time = datetime(
year=2023,
month=7,
day=9,
hour=23,
minute=0)
# The date and time of the final approaches
date_time_final = datetime(
year=2023,
month=7,
day=17,
hour=23,
minute=0)
```
6. After making the forecast, run `forecast_decode.py` to convert the numpy array back to NetCDF format
```bash
python forecast_decode.py
```
7. Navigate to the forecasting directory to visualize the results
```bash
cd outputs/2023-07-09-23-00to2023-07-17-23-00
# Visualize the land surface forecast
ncvue output_surface.nc
# Visualize the upper air forecast
ncvue output_upper.nc
```
Don't forget to select the variable to be visualized.

## Acknowledgement
Thanks Huawei team for their amazing meteorological forecasting model [Pangu-Weather](https://github.com/198808xc/Pangu-Weather).
Thanks mcuntz for his/her wonderful open-source NetCDF visualization project [ncvue](https://github.com/mcuntz/ncvue).
## Warning
I am a Bioinformatics student, not a meteorologist, so I cannot guarantee the accuracy of the code. Therefore, this project is only intended for reference and learning purposes. Additionally, this project is based on [Pangu-Weather](https://github.com/198808xc/Pangu-Weather/tree/main#global-weather-forecasting-inference-using-the-trained-models) and follows its BY-NC-SA 4.0 license, and should not be used for commercial purposes. Please cite the publication of Pangu-Weather.
```
@Article{Bi2023,
author={Bi, Kaifeng and Xie, Lingxi and Zhang, Hengheng and Chen, Xin and Gu, Xiaotao and Tian, Qi},
title={Accurate medium-range global weather forecasting with 3D neural networks},
journal={Nature},
doi={10.1038/s41586-023-06185-3},
}
```
## 安装和准备工作
1. 前往 [Climate Data Store](https://cds.climate.copernicus.eu/user/register) 注册一个账号
2. 前往 [CDS API key](https://cds.climate.copernicus.eu/api-how-to),复制url和key,写入 `~/.cdsapirc` 文件
5. 克隆本仓库,根据是否有独显选择安装依赖
```bash
git clone https://github.com/HaxyMoly/Pangu-Weather-ReadyToGo.git
cd Pangu-Weather-ReadyToGo
# GPU
pip install -r requirements_gpu.txt
# CPU
pip install -r requirements_cpu.txt
conda install -c conda-forge cartopy
```
4. 在 [Pangu-Weather](https://github.com/198808xc/Pangu-Weather/tree/main#global-weather-forecasting-inference-using-the-trained-models) 下载4个预训练模型,创建一个名为 `models` 的文件夹,把它们放进去(也可以根据需要任意下载一个测试)
```bash
mkdir models
```
## 预测Demo
1. 修改 `data_prepare.py` 中初始场的 `date_time`,
```python
date_time = datetime(
year=2023,
month=7,
day=9,
hour=23,
minute=0)
```
> 某时刻数据可用性可运行 `test_avaliable_time.py` 来查询.你的输出会是这样的:
> `The latest date available for this dataset is: 2023-07-13 13:00.`
2. 执行 `data_prepare.py` 下载初始场数据并转换为npy格式
```bash
python data_prepare.py
```
3. 根据需要修改 `inference.py` 中以下变量
```python
# 是否启用GPU加速
use_GPU = True
# 初始场时刻
date_time = datetime(
year=2023,
month=7,
day=9,
hour=23,
minute=0)
# 目标到达时刻
date_time_final = datetime(
year=2023,
month=7,
day=17,
hour=23,
minute=0)
# 程式会自动选择最少到达目标时间的模型组合
```
4. 执行 `inference.py` 进行预测
```bash
python inference.py
```
5. 修改 `forecast_decode.py` 中初始场时刻和目标到达时刻
```python
# 初始场时刻
date_time = datetime(
year=2023,
month=7,
day=9,
hour=23,
minute=0)
# 目标到达时刻
date_time_final = datetime(
year=2023,
month=7,
day=17,
hour=23,
minute=0)
```
6. 预测完成后,执行 `forecast_decode.py` 将npy转换回NetCDF格式
```bash
python forecast_decode.py
```
7. 进入预测文件路径可视化结果
```bash
cd outputs/2023-07-09-23-00to2023-07-17-23-00
# 可视化预测地表数据
ncvue output_surface.nc
# 或可视化预测大气数据
ncvue output_upper.nc
```
记得选择要可视化的变量

## 感谢
华为团队开源的气象预测大模型 [Pangu-Weather](https://github.com/198808xc/Pangu-Weather)
mcuntz开源的优秀NetCDF可视化项目 [ncvue](https://github.com/mcuntz/ncvue)
## 警告
本人专业为生物信息学,并非气象专业人士,无法保证代码完全准确,因此该项目仅供参考交流学习。另该项目系基于 [Pangu-Weather](https://github.com/198808xc/Pangu-Weather),因此亦遵循原项目的BY-NC-SA 4.0开源许可证,切勿用于商业目的。使用本项目请引用原项目
```
@Article{Bi2023,
author={Bi, Kaifeng and Xie, Lingxi and Zhang, Hengheng and Chen, Xin and Gu, Xiaotao and Tian, Qi},
title={Accurate medium-range global weather forecasting with 3D neural networks},
journal={Nature},
doi={10.1038/s41586-023-06185-3},
}
```
| 41
| 7
|
greengeckowizard/poe-server
|
https://github.com/greengeckowizard/poe-server
|
Poe-Server-Reverse-API-Python
|
# Poe Server
This project is a FastAPI-based application that generates AI-generated responses using the Poe API Wrapper (https://github.com/ading2210/poe-api).
# Disclaimer
The use of the Poe Server and the api wrapper is at your own risk. We are not responsible for any damages or losses that may occur as a result of your use of the server or API. This includes, but is not limited to, damage to your computer, loss of data, or violation of the Terms of Service (TOS) for Poe (Quora).
We do not endorse or promote the use of the Poe server or API wrapper in any way that violates the TOS. If you use the server or API in a way that violates the TOS, you may be subject to disciplinary action by Quora .This may include, but is not limited to, loss of your account or proxy provider.
Please use the server and API responsibly and in accordance with the TOS for the server and API. If you have any questions or concerns, please contact the developers of the server or API by opening an issue on this Github repo.
# Project Status
)
## Details
Due to recent changes, our project may experience occasional downtimes linked to issues with a crucial API wrapper it depends on. This could lead to periods where the project does not function as expected.
Thankfully, you don't have to be in the dark about this. We're actively tracking these potential disruptions and will immediately update the operational status of the API wrapper on this README. This way, you can quickly check here to know if our project is currently up and running or facing some downtime.
We appreciate your understanding during this time. Rest assured, we're working diligently to ensure consistent functionality. Remember to check this space for the latest status updates.
Thank you for your patience.
last checked version:
```
poe-api 0.4.17
```
last time last checked:
```
03:39 AM (UTC +0)
```
## Project To-Do List
- [x] Token rotational
- [x] Proxy rotational
- [x] Add Streaming Support and make it compatible with Bettergpt.chat (Much thanks PaniniCo!!)
- [x] Add OPEN AI format of api like (/v1/chat/completions) use serverof.py for this
- [x] Work on Stability so not overloaded easily (rate limiting added)
- [x] Add a retry logic and switch to a different token if a model has reached daily limit
- [ ] Add Anse Support (https://github.com/anse-app/anse)
- [ ] Add One-Api Support (https://github.com/songquanpeng/one-api)
- [ ] Add Embeddings to OPEN AI format (/api/v1/embedding)
- [ ] Add AI.LS Support (https://ai.ls/)
## Installation
To install the project dependencies, run the following command:
```shell
pip install -r requirements.txt
```
## Getting Started
1. Clone the repository:
```shell
git clone https://github.com/greengeckowizard/poe-server
cd poe-server
```
2. Install the dependencies:
```shell
pip install -r requirements.txt
```
3. Define Proxy and Tokens inside the proxies.txt for the proxies and for the tokens put inside the tokens.txt file
(Proxy and Tokens are required to operate this Project WE DO NOT PROVIDE ANY PROXIES OR TOKENS UNDER ANY CIRCUMSTANCES)
if you don't define a proxy or token you will have errors. Note:Any of the proxies that work inside the poe-api will work in this project.
<br>
4. Running the FastAPI Server Locally
You have two options for running the server: Using Python directly, or using Docker.
#### **Option A: Python**
To run the server with Python, execute the following command in your shell:
```shell
python server.py
```
another
#### **Option B: Docker**
To run the server with Docker, you need to build and start the Docker container. Run the following commands:
```CMD ["uvicorn", "server:app", "--host", "0.0.0.0", "--port", "8000"]``` then rebuild the dockerfile and you can docker-compose up. For running in Daemon mode use -d flag ``` docker-compose up -d ```
```shell
docker-compose build
docker-compose up
```
If you want the server to run in the background (daemonized), add the `-d` flag:
```shell
docker-compose up -d
```
After running these commands, the server will start and listen on the following URL:
```
http://localhost:8000
```
> **Important:** When interacting with the server locally via Docker, it's recommended to use the IP address assigned to your device instead of `http://localhost:8000`. For instance, if your local device's IP is `192.168.0.45`, the appropriate address to use would be `http://192.168.0.45:8000`.
#### **Finding Your Local IP Address**
To find your local IP address, run the following command:
- On Linux:
```shell
ifconfig
```
- On Windows:
```shell
ipconfig
```
- On MacOS:
```shell
ifconfig | grep "inet " | grep -v 127.0.0.1
```
This command will display a list of all network interfaces. The `grep "inet "` command filters this list to include only entries that have an IP address (inet stands for internet). The second `grep -v 127.0.0.1` command excludes the loopback address, which is typically 127.0.0.1. The IP address you're likely interested in will most likely be the one associated with `en0` or `en1` - these are usually the primary Ethernet and Wi-Fi interfaces, respectively.
Remember, IP addresses that start with 192.168 or 10.0 are local addresses - they're only valid on your local network. If you're trying to give someone your IP address to connect to over the internet, you'll need your public IP address, which you can find by searching 'what is my IP' on Google or any other search engine.
## Model Mapping
```
"assistant": "capybara",
"claude-instant": "a2",
"claude-2-100k": "a2_2",
"claude-instant-100k": "a2_100k",
"gpt-3.5-turbo-0613": "chinchilla",
"gpt-3.5-turbo": "chinchilla",
"gpt-3.5-turbo-16k-0613": "agouti",
"gpt-3.5-turbo-16k": "agouti",
"gpt-4": "beaver",
"gpt-4-0613": "beaver",
"gpt-4-32k": "vizcacha",
"chat-bison-001": "acouchy",
"llama-2-70b": "llama_2_70b_chat",
```
You can make a request like this use the server.py to use this type request
```
import openai
openai.api_key = "anyrandomstring"
openai.api_base = "http://localhost:8000/v1"
response = openai.ChatCompletion.create(
model='gpt-3.5-turbo',
messages=[
{'role': 'user', 'content': "Hello"},
]
)
print(response)
```
## Configuration
You can configure the project by providing the following (set inside the text files):
- Inside the `tokens.txt`: A new line for each Poe API token.
- Inside the `proxies.txt`: A new line for each proxy server.
## Contributing
If you want to contribute to this project, please follow these steps:
1. Fork the repository.
2. Create a new branch.
3. Make your changes.
4. Test your changes.
5. Commit your changes.
6. Push your changes to your forked repository.
7. Create a pull request.
## License
This project uses the [GNU General Public License v3.0]
see the [LICENSE](LICENSE) file for more details.
## Credits
Thank you to PaniniCo for adding streaming support and model corresponding to names to Poe Models!!
Thank you UltGamer for adding better stability with checking bad tokens and increasing better load capacity support!!
| 41
| 6
|
f3l3p1n0/bluehypr
|
https://github.com/f3l3p1n0/bluehypr
|
🌊 BlueHypr - Entorno basado en Arch Linux personalizado con Hyprland (Minimalist)💻
|
<html>
<body>
<p align="center">
<img src='https://i.postimg.cc/2SNJjCGs/bluehypr.png'>
</p>
<img src='https://i.postimg.cc/hPVn1y5q/swappy-20230705-212445.png'>
<br/>
<h3>¡Saludos! ¡Gracias por venir! 🩵</h3>
<p>
¡Bienvenid@ a mis archivos de configuración de Hyprland!<br>
En este repositorio encontrarás todos mis archivos de configuración y aprenderás a como solucionar algunos errores que puedan suceder en el proceso.<br>
Siéntete libre de tomar cualquier cosa de aquí, ¡solo recuerda darme crédito por ello! :)
</p>
<hr>
<h3>⚠️ Requisitos</h3>
<ul>
<li>La instalación solo es válida para máquinas físicas y no virtuales.</li>
<li>Compatible solo con gpu AMD o Intel.</li>
<li>El proceso se debe realizar en un sistema Arch Linux limpio, des de la tty.</li>
</ul>
<hr>
<h3>🐦 Información</h3>
<ul>
<li>Sistema operativo: Arch Linux</li>
<li>WM: Hyprland</li>
<li>Terminal: kitty</li>
<li>Shell: zsh</li>
<li>Editor: neovim / vscode</li>
<li>Lanzador de aplicaciones: rofi</li>
</ul>
<hr>
<h3>🔧 Setup</h3>
<h4>Para poder instalar y configurar los dotfiles de forma automatizada debes seguir los siguientes pasos:</h4>
<ol>
<li>Descargar repositorio: git clone https://github.com/f3l3p1n0/bluehypr.git</li>
<li>Acceder al directorio bluehypr: cd bluehypr</li>
<li>Ejecutar el instalador (no root): ./install.sh</li>
<li>Deja que finalice la instalación. Posteriormente realizar un reboot.</li>
</ol>
<p><strong>¡Atención!</strong> Debes tener en cuenta que durante la instalación es posible que se te pida que introduzcas la contraseña como 'sudo'. Debes introducirla y presionar enter para que puedas proseguir la instalación de forma correcta.</p>
<p>Debes tener en cuenta que esta instalación no es rápida, por lo que se demorará un tiempo en completarse.</p>
<p>Te dejo por aquí un vídeo por si quieres realizar la instalación de una forma más guiada: https://youtu.be/LoMNQZXLZfI</p>
<hr>
<h3>❌ Posibles problemas y soluciones</h3>
<h4>En esta sección se abarcarán los posibles problemas y soluciones que vayan surgiendo:</h4>
<h5><ins>El wallpaper no se aplica al iniciar sesión</ins></h5>
<p>Debes ir a la configuración de hyprpaper: <strong>nano .config/hypr/hyprpaper.conf</strong></p>
<p>Posteriormente, cambia el nombre del monitor que hay establecido por el nombre de tu monitor</p>
<p>Para saber el nombre de tu monitor debes escribir en la terminal: <strong>hyprctl monitors</strong></p>
<h5><ins>El powermenu se visualiza distorsionado o no funciona</ins></h5>
<p>El powermenu en mi caso, está configurado para que se pueda visualizar correctamente en la resolución 1920x1080. Si en tu caso no lo visualizas correctamente, deberás dirigirte a la siguiente ruta: <strong>cd ~/.config/rofi/powermenu/</strong></p>
<p>Posteriormente, deberás abrir el archivo <strong>config.rasi</strong></p>
<p>En este archivo debes modificar la línea: <strong>mainbox-margin</strong> del apartado Global Properties. Ajusta los parámetros a tu gusto, puedes probar con <strong>15px 40px</strong>.</p>
<h5><ins>Waybar no carga al iniciar sesión</ins></h5>
<p>Debes abrir la configuración de waybar: <strong>nano .config/waybar/config.jsonc</strong></p>
<p>En el archivo debes modificar el apartado <strong>output</strong> para cambiar el nombre del monitor.</p>
<hr>
<h3>👤 Autor</h3>
<p>Los dotfiles no han sido originados al 100% pero si configurados por mi, <a href="https://github.com/f3l3p1n0">f3l3p1n0</a>.</p>
<hr>
<h3>📱 Redes sociales</h3>
<a href="https://f3l3p1n0.github.io">Blog personal</a><br>
<a href="https://www.youtube.com/@f3l3p1n0">Youtube</a><br>
<a href="https://www.instagram.com/f3l3p1n0/?igshid=Mzc1MmZhNjY%3D">Instagram</a><br>
<a href="https://www.linkedin.com/in/marc-mañé-lobato/">Linkedin</a><br>
</body>
</html>
| 10
| 2
|
psyai-net/CVCUDA_FaceStoreHelper-release
|
https://github.com/psyai-net/CVCUDA_FaceStoreHelper-release
|
Psyche AI Inc release source "CVCUDA_FaceStoreHelper"
|

# CVCUDA_FaceStoreHelper
CVCUDA version of FaceStoreHelper, suitable for super-resolution, face restoration, and other face extraction and reattachment procedures.
[](LICENSE)
## Project Introduction
This project is designed to extract faces from images, perform image restoration/super-resolution operations, and then merge the restored face back into the original image. The code provides a simple, fast, and accurate method for face extraction and merging back into the original image, suitable for various application scenarios.
We have undertaken a comprehensive **rewrite of the original OpenCV implementation**, **replacing all serial CPU operations** with their corresponding **[CVCUDA operators](https://github.com/CVCUDA/CV-CUDA/blob/release_v0.3.x/DEVELOPER_GUIDE.md)**. This optimization enables our project to leverage the power of GPU acceleration, resulting in significantly improved performance and efficiency in computer vision tasks. By harnessing CVCUDA's capabilities, we have successfully enhanced the processing speed of our application, providing a more responsive and robust user experience.
## update
- [x] python serial version:The blocks are executed sequentially
- [ ] python Coroutine version: The blocks are executed in parallel,closed source
- [x] support for [codeformer](https://github.com/sczhou/CodeFormer/blob/master/inference_codeformer.py)
- [ ] Chinese readme
- [ ] Integrated Self-developed Lip driving talking head algorithm, closed source
- [ ] Implementation of cvcuda process of face normalization
- [x] Put the face back on and morphologically blur the edges
- [x] cvcuda reconstruction of batch affine transform
## Features
- Widely applicable for post-processing of face image super-resolution/restoration networks, such as GFPGAN and CodeFormer.
## Quick Start
### Install Dependencies
Before running this project, please make sure the following CVCUDA are download and installed:
please refer https://github.com/CVCUDA/CV-CUDA
Configure cvcuda in prebuild mode and download it in the release file
https://github.com/CVCUDA/CV-CUDA/tree/dd1b6cae076b0d284e042b3dda42773a5816f1c8
installation example:
```bash
pip install nvcv_python-0.3.1-cp38-cp38-linux_x86_64.whl
```
Add /your-cvcuda-path to PYTHONPATH in the bashrc file
```
export PYTHONPATH=/your-cvcuda-path/CV-CUDA/build-rel/lib/python:$PYTHONPATH
```
Solution to show so file not found:
```
export LD_LIBRARY_PATH=your-path/CV-CUDA/build-rel/lib:$LD_LIBRARY_PATH
```
Install the necessary python packages by executing the following command:
``` shell
pip install -r requirements.txt
```
Go to codeformer/ and run the following command to install the basicsr package:
``` shell
cd ./codeformer/
python basicsr/setup.py develop
cd ..
```
After installing the basicsr package, add the project root directory, and codeformer directory to the system's environment variables:
``` shell
vim ~/.bashrc
```
```
export PYTHONPATH=$PYTHONPATH:/path/to/talking_lip:/path/to/talking_lip/codeformer
```
Note that /path/to/talking_lip is the absolute path of your project in the system.
Save and exit. Run the following command to make the configuration take effect:
``` shell
source ~/.bashrc
```
### Downloading pretraining models
download the checkpoints and put it into ./checkpoint
link: https://pan.baidu.com/s/1ZPfLnXS5oGDawqualhXCrQ?pwd=psya
password: psya
Google drive link: https://drive.google.com/drive/folders/1pwadwZLJt0EQUmjS7u4lUofYiLIfAjGj?usp=sharing
### Usage Example
1. Clone this repository:
```bash
git clone https://github.com/your-username/your-repo.git
```
2. Enter the project directory:
```bash
cd your-repo
```
3. Run the script:
Generate resource packs that provide codeformer with the necessary face landmarks and affine transformation matrices
When you run gen_resource_pkg.py, place a video in the `testdata/video_based` folder to extract the face resource pack.
``` shell
python gen_resource_pkg.py
```
inference with cvcuda accelerated codeformer network
``` shell
python serial_pipeline.py --input_path = your_video_path
```
4. The program will save `./outlip.mp4` , your video will be enhanced by codeformer, only for face area.
## Contribution
- If you encounter any problems, you can report them in this project's GitHub Issue.
- If you want to contribute code, please follow these steps:
1. Clone this repository.
2. Create a new branch:
```bash
git checkout -b new-feature
```
3. Make changes and commit:
```bash
git commit -m 'Add some feature'
```
4. Push to the remote branch:
```bash
git push origin new-feature
```
5. Submit a pull request.
## License
This project is licensed under the Creative Commons Attribution-NonCommercial 4.0 International License. Please read the [LICENSE](LICENSE) file for more information.
## Authors
Code contributor: [Junli Deng](https://github.com/cucdengjunli), [Xueting Yang](https://github.com/yxt7979), [Xiaotian Ren](https://github.com/csnowhermit)
If you would like to work with us further, please contact this guy:
- Contact Author Name: [Jason Zhaoxin Fan](https://github.com/FANzhaoxin666)
- Contact Author Email: [email protected]
- Any other contact information: [psyai.com](https://www.psyai.com/home)
## Acknowledgments
This project incorporates the following methods:
1. **CVCUDA**: [Project Link](https://github.com/CVCUDA/CV-CUDA)
2. **GFPGAN**: [Project Link](https://github.com/TencentARC/GFPGAN)
3. **CodeFormer**: [Project Link](https://github.com/sczhou/CodeFormer)
## Invitation
We invite you to join [Psyche AI Inc](https://www.psyai.com/home) to conduct cutting-edge research and business implementation together. At Psyche AI Inc, we are committed to pushing the boundaries of what's possible in the fields of artificial intelligence and computer vision, especially their applications in avatars. As a member of our team, you will have the opportunity to collaborate with talented individuals, innovate new ideas, and contribute to projects that have a real-world impact.
If you are passionate about working on the forefront of technology and making a difference, we would love to hear from you. Please visit our website at [Psyche AI Inc](https://www.psyai.com/home) to learn more about us and to apply for open positions. You can also contact us by [email protected].
Let's shape the future together!!
| 57
| 9
|
milandas63/GIFT-Group2
|
https://github.com/milandas63/GIFT-Group2
| null |
# GIFT-Group2
NO NAME EMAIL-ID MOBILE
1 Abinash Das [email protected] 9238959872
2 Ajaya Mandal [email protected] 7815096934
3 Asish Kumar Sahoo [email protected] 6371211827
4 Babul Parida [email protected] 6372745808
5 Brahmashree Swain [email protected] 9937409217
6 Gourab Kumar Sahoo [email protected] 9938348522
7 Guru Prasad Sahoo [email protected] 8249355147
8 Kanhu Charan Rout [email protected] 6370680211
9 Kshirendra Malik [email protected] 7846905856
10 Kshitish Nanda [email protected] 8018081644
11 Maheswar Malik [email protected] 8984081985
12 Millan Kumar Patra [email protected] 7848044263
13 Omm Biswajit Mohanty [email protected] 8117830404
14 Papu Sahoo [email protected] 9437253798
15 Prakash Sahoo [email protected] 9668187814
16 Rahul Bastia [email protected] 6371480952
17 Rashmi Ranjan Sethi [email protected] 9348353588
18 Ritesh Baral [email protected] 7815084984
19 Satyajeet Biswal [email protected] 7848960431
20 Satyajit Nayak [email protected] 7381965865
21 Sk Jabir Uddin [email protected] 7205078551
22 Somanath Pradhan [email protected] 8018464867
23 Sonu Swain [email protected] 7846804370
24 Soumya Ranjan Bidhar [email protected] 7848098290
25 Soumyaranjan Das [email protected] 7205710882
26 Subhankar Kundu [email protected] 9124237129
27 Subhasish Mandal [email protected] 7205745281
28 Subhra Prakash Dhal [email protected] 9827765986
29 Suman Kumar Jena [email protected] 7205077241
30 Suvam Bhatta [email protected] 8260549704
31 Sukhendu Dutta [email protected] 8986775695
32 Anjan Kumar Nanda [email protected] 8260988942
33 Saha Sahil [email protected] 9178695126
| 14
| 3
|
taprosoft/llm_finetuning
|
https://github.com/taprosoft/llm_finetuning
|
Convenient wrapper for fine-tuning and inference of Large Language Models (LLMs) with several quantization techniques (GTPQ, bitsandbytes)
|

[](https://github.com/psf/black)
[](https://github.com/pre-commit/pre-commit)
# Memory Efficient Fine-tuning of Large Language Models (LoRA + quantization)
This repository contains a convenient wrapper for fine-tuning and inference of Large Language Models (LLMs) in memory-constrained environment. Two major components that democratize the training of LLMs are: Parameter-Efficient Fine-tuning ([PEFT](https://github.com/huggingface/peft)) (e.g: LoRA, Adapter) and quantization techniques (8-bit, 4-bit). However, there exists many quantization techniques and corresponding implementations which make it hard to compare and test different training configurations effectively. This repo aims to provide a common fine-tuning pipeline for LLMs to help researchers quickly try most common quantization-methods and create compute-optimized training pipeline.
This repo is built upon these materials:
* [alpaca-lora](https://github.com/tloen/alpaca-lora) for the original training script.
* [GPTQ-for-LLaMa](https://github.com/qwopqwop200/GPTQ-for-LLaMa) for the efficient GPTQ quantization method.
* [exllama](https://github.com/turboderp/exllama) for the high-performance inference engine.
## Key Features
* Memory-efficient fine-tuning of LLMs on consumer GPUs (<16GiB) by utilizing LoRA (Low-Rank Adapter) and quantization techniques.
* Support most popular quantization techniques: 8-bit, 4-bit quantization from [bitsandbytes](https://github.com/TimDettmers/bitsandbytes) and [GPTQ](https://github.com/qwopqwop200/GPTQ-for-LLaMa).
* Correct PEFT checkpoint saving at regular interval to minimize risk of progress loss during long training.
* Correct checkpoint resume for all quantization methods.
* Support distributed training on multiple GPUs (with examples).
* Support gradient checkpointing for both `GPTQ` and `bitsandbytes`.
* Switchable prompt templates to fit different pretrained LLMs.
* Support evaluation loop to ensure LoRA is correctly loaded after training.
* Inference and deployment examples.
* Fast inference with [exllama](https://github.com/turboderp/exllama) for GPTQ model.
## Usage
### Demo notebook
See [notebook](llm_finetuning.ipynb) or on Colab [](https://colab.research.google.com/github/taprosoft/llm_finetuning/blob/main/llm_finetuning.ipynb).
### Setup
1. Install default dependencies
```bash
pip install -r requirements.txt
```
2. If `bitsandbytes` doesn't work, [install it from source.](https://github.com/TimDettmers/bitsandbytes/blob/main/compile_from_source.md) Windows users can follow [these instructions](https://github.com/tloen/alpaca-lora/issues/17)
3. To use 4-bit efficient CUDA kernel from ExLlama and GPTQ for training and inference
```bash
pip install -r cuda_quant_requirements.txt
```
Note that the installation of above packages requires the installation of CUDA to compile custom kernels. If you have issue, looks for help in the original repos [GPTQ](https://github.com/qwopqwop200/GPTQ-for-LLaMa), [exllama](https://github.com/turboderp/exllama) for advices.
### Data Preparation
Prepare the instruction data to fine-tune the model in the following JSON format.
```json
[
{
"instruction": "do something with the input",
"input": "input string",
"output": "output string"
}
]
```
You can supply a single JSON file as training data and perform auto split for validation. Or, prepare two separate `train.json` and `test.json` in the same directory to supply as train and validation data.
You should also take a look at [templates](templates/README.md) to see different prompt template to combine the instruction, input, output pair into a single text. During the training process, the model is trained using CausalLM objective (text completion) on the combined text. The prompt template must be compatible with the base LLM to maximize performance. Read the detail of the model card on HF ([example](https://huggingface.co/WizardLM/WizardLM-30B-V1.0)) to get this information.
Prompt template can be switched as command line parameters at training and inference step.
We also support for raw text file input and ShareGPT conversation style input. See [templates](templates/README.md).
### Training (`finetune.py`)
This file contains a straightforward application of PEFT to the LLaMA model,
as well as some code related to prompt construction and tokenization.
We use common HF trainer to ensure the compatibility with other library such as [accelerate](https://github.com/huggingface/accelerate).
Simple usage:
```bash
bash scripts/train.sh
# OR
python finetune.py \
--base_model 'decapoda-research/llama-7b-hf' \
--data_path 'yahma/alpaca-cleaned' \
--output_dir './lora-output'
```
where `data_path` is the path to a JSON file or a directory contains `train.json` and `test.json`. `base_model` is the model name on HF model hub or path to a local model on disk.
We can also tweak other hyperparameters (see example in [train.sh](scripts/train.sh)):
```bash
python finetune.py \
--base_model 'decapoda-research/llama-7b-hf' \
--data_path 'yahma/alpaca-cleaned' \
--output_dir './lora-output' \
--mode 4 \
--batch_size 128 \
--micro_batch_size 4 \
--num_epochs 3 \
--learning_rate 1e-4 \
--cutoff_len 512 \
--val_set_size 0.2 \
--lora_r 8 \
--lora_alpha 16 \
--lora_dropout 0.05 \
--lora_target_modules '[q_proj,v_proj]' \
--resume_from_checkpoint checkpoint-29/adapter_model/
```
Some notables parameters:
```
micro_batch_size: size of the batch on each GPU, greatly affect VRAM usage
batch_size: actual batch size after gradient accumulation
cutoff_len: maximum length of the input sequence, greatly affect VRAM usage
gradient_checkpointing: use gradient checkpointing to save memory, however training speed will be lower
mode: quantization mode to use, acceptable values [4, 8, 16 or "gptq"]
resume_from_checkpoint: resume training from existings LoRA checkpoint
```
#### Download model from HF hub (`download.py`)
You can use the helper script `python download_model.py <model_name>` to download a model from HF model hub and store it locally. By default it will save the model to `models` of the current path. Make sure to create this folder or change the output location `--output`.
#### Quantization mode selection
On the quantization mode effects on training time and memory usage, see [note](benchmark/README.md). Generally, `16` and `gptq` mode has the best performance, and should be selected to reduce training time. However, most of the time you will hit the memory limitation of the GPU with larger models, which mode `4` and `gptq` provides the best memory saving effect. Overall, `gptq` mode has the best balance between memory saving and training speed.
**NOTE**: To use `gptq` mode, you must install the required package in `cuda_quant_requirements`. Also, since GPTQ is a post-hoc quantization technique, only GTPQ-quantized model can be used for training. Look for model name which contains `gptq` on HF model hub, such as [TheBloke/orca_mini_v2_7B-GPTQ](https://huggingface.co/TheBloke/orca_mini_v2_7B-GPTQ). To correctly load the checkpoint, GPTQ model requires offline checkpoint download as described in previous section.
If you don't use `wandb` and want to disable the prompt at start of every training. Run `wandb disabled`.
### Training on multiple GPUs
By default, on multi-GPUs environment, the training script will load the model weight and split its layers accross different GPUs. This is done to reduce VRAM usage, which allows loading larger model than a single GPU can handle. However, this essentially wastes the power of mutiple GPUs since the computation only run on 1 GPU at a time, thus training time is mostly similar to single GPU run.
To correctly run the training on multiple GPUs in parallel, you can use `torchrun` or `accelerate` to launch distributed training. Check the example in [train_torchrun.sh](scripts/train_torchrun.sh) and [train_accelerate.sh](scripts/train_accelerate.sh). Training time will be drastically lower. However, you should modify `batch_size` to be divisible by the number of GPUs.
```bash
bash scripts/train_torchrun.sh
```
### Evaluation
Simply add `--eval` and `--resume_from_checkpoint` to perform evaluation on validation data.
```bash
python finetune.py \
--base_model 'decapoda-research/llama-7b-hf' \
--data_path 'yahma/alpaca-cleaned' \
--resume_from_checkpoint output/checkpoint-29/adapter_model/ \
--eval
```
### Inference (`inference.py`)
This file loads the fine-tuned LoRA checkpoint with the base model and performs inference on the selected dataset. Output is printed to terminal output and stored in `sample_output.txt`.
Example usage:
```bash
python inference.py \
--base models/TheBloke_vicuna-13b-v1.3.0-GPTQ/ \
--delta lora-output \
--mode exllama \
--type local \
--data data/test.json
```
Important parameters:
```
base: model id or path to base model
delta: path to fine-tuned LoRA checkpoint (optional)
data: path to evaluation dataset
mode: quantization mode to load the model, acceptable values [4, 8, 16, "gptq", "exllama"]
type: inference type to use, acceptable values ["local", "api", "guidance"]
```
Note that `gptq` and `exllama` mode are only compatible with GPTQ models. `exllama` is currently provide the best inference speed thus is recommended.
Inference type `local` is the default option (use local model loading). To use inference type `api`, we need an instance of `text-generation-inferece` server described in [deployment](deployment/README.md).
Inference type `guidance` is an advanced method to ensure the structure of the text output (such as JSON). Check the command line `inference.py --help` and [guidance](https://github.com/microsoft/guidance) for more information
### Checkpoint export (`merge_lora_checkpoint.py`)
This file contain scripts that merge the LoRA weights back into the base model
for export to Hugging Face format.
They should help users
who want to run inference in projects like [llama.cpp](https://github.com/ggerganov/llama.cpp)
or [text-generation-inference](https://github.com/huggingface/text-generation-inference).
Currently, we do not support the merge of LoRA to GPTQ base model due to incompatibility issue of quantized weight.
### Deployment
See [deployment](deployment/README.md).
### Quantization with GPTQ
To convert normal HF checkpoint go GPTQ checkpoint we need a conversion script. See [GPTQ-for-LLaMa](https://github.com/qwopqwop200/GPTQ-for-LLaMa) and [AutoGPTQ](https://github.com/PanQiWei/AutoGPTQ) for more information.
### Benchmarking
This [document](benchmark/README.md) provides a comprehensive summary of different quantization methods and some suggestions for efficient training & inference.
### Recommended models
Recommended models to start:
* 7B: [TheBloke/vicuna-7B-v1.3-GPTQ](https://huggingface.co/TheBloke/vicuna-7B-v1.3-GPTQ), [lmsys/vicuna-7b-v1.3](https://huggingface.co/lmsys/vicuna-7b-v1.3)
* 13B: [TheBloke/vicuna-13b-v1.3.0-GPTQ](https://huggingface.co/TheBloke/vicuna-13b-v1.3.0-GPTQ), [lmsys/vicuna-13b-v1.3](https://huggingface.co/lmsys/vicuna-13b-v1.3)
* 33B: [TheBloke/airoboros-33B-gpt4-1.4-GPTQ](https://huggingface.co/TheBloke/airoboros-33B-gpt4-1.4-GPTQ)
### Resources
- https://github.com/ggerganov/llama.cpp: highly portable Llama inference based on C++
- https://github.com/huggingface/text-generation-inference: production-level LLM serving
- https://github.com/microsoft/guidance: enforce structure to LLM output
- https://github.com/turboderp/exllama/: high-perfomance GPTQ inference
- https://github.com/qwopqwop200/GPTQ-for-LLaMa: GPTQ quantization
- https://github.com/oobabooga/text-generation-webui: a flexible Web UI with support for multiple LLMs back-end
- https://github.com/vllm-project/vllm/: high throughput LLM serving
### Acknowledgements
- @disarmyouwitha [exllama_fastapi](https://github.com/turboderp/exllama/issues/37#issuecomment-1579593517)
- @turboderp [exllama](https://github.com/turboderp/exllama)
- @johnsmith0031 [alpaca_lora_4bit](https://github.com/johnsmith0031/alpaca_lora_4bit)
- @TimDettmers [bitsandbytes](https://github.com/TimDettmers/bitsandbytes)
- @tloen [alpaca-lora](https://github.com/tloen/alpaca-lora/)
- @oobabooga [text-generation-webui](https://github.com/oobabooga/text-generation-webui)
| 97
| 10
|
xyy002/claudetoapi
|
https://github.com/xyy002/claudetoapi
|
逆向claude网页端成openai以及claude api的形式
|
### 前提条件
首先确保你的电脑上已经安装了go以及配置好了go的环境变量
确保你的服务器或者本地ip可以连通claude.ai
# 下载
```Shell
git clone
```
# 编译
```Shell
GOOS=linux GOARCH=amd64 go build -o getkeyinfo
```
# 部署
上传到服务器目录,打开终端 进入到你上传的目录下
```shell
chmod +x ./claudetoapi
nohup ./claudetoapi >> run.log 2>&1 &
```
现在你就可以使用你的服务器ip:8080/v1/complete或者ip:8080/v1/chat/completions使用了
调用方式参考openai的api调用方式以及claude的api调用方式,已做兼容处理
# 说明
本项目只是练手项目!使用本项目造成的责任与本人无关
| 19
| 3
|
drum-grammer/docker-pro-2308
|
https://github.com/drum-grammer/docker-pro-2308
|
원티드와 함께하는 Docker 뽀개기
|
# Docker : 나만의 도커 이미지 만들기 부터, 클라우드 배포까지!
8월 원티드 프리 온보딩 챌린지 - docker 뽀개기
## I. 사전 미션하는 법
### 방법 1
1. 해당 repository를 fork 하세요.
2. 로컬에서 작업한 커밋을 fork한 repository에 push 하세요.
5. Pull Request를 생성하여, 사전 미션을 제출해주세요.
### 방법 2
1. 해당 repository를 clone 하세요:
```
git clone [email protected]:drum-grammer/docker-pro-wanted.git
```
2. 별도의 브랜치를 생성하세요:
```
git checkout -b my-branch-xx
```
3. 아래 사전 미션 내용을 보고 답안을 마크다운 형식으로 작성하시고, `./mission/{nickName}` 디렉토리 저장해주세요.
4. 해당 브랜치를 푸쉬해주세요.
```
git push -u origin my-branch-xx
```
5. Pull Request를 생성하여, 사전 미션을 제출해주세요.
## II. 사전 미션
1. 컨테이너 기술이란 무엇입니까? (100자 이내로 요약)
2. 도커란 무엇입니까? (100자 이내로 요약)
3. 도커 파일, 도커 이미지, 도커 컨테이너의 개념은 무엇이고, 서로 어떤 관계입니까?
4. [실전 미션] 도커 설치하기 (참조: [도커 공식 설치 페이지](https://docs.docker.com/engine/install/))
- 아래 `도커 설치부터 실행 튜토리얼`을 참조하여 도커를 설치하고, 도커 컨테이너를 실행한 화면을 캡쳐해서 Pull Request에 올리세요.
## III. 도커 설치부터 실행 튜토리얼
### 도커 설치
#### 1. 도커 공식 웹사이트에서 "[Get Started](https://www.docker.com/get-started)"를 클릭합니다.
#### 2. OS에 맞는 설치 파일을 다운로드 받습니다.
- MacOS의 경우 "Download for Mac"을 클릭합니다.
- Window 일 경우 "Download for Windows"를 클릭합니다.
- 다운로드한 설치 파일을 실행합니다.
### 도커 컨테이너 실행 시키기
#### 1. `나의 사전 미션 폴더`를 만들고 해당 폴더로 이동합니다.
```shell
cd path/to/docker-pro-wanted/mission
mkdir my-name
cd my-name
```
#### 2. "Hello, World!"를 출력하는 도커 파일을 만듭니다.
```shell
vim Dockerfile
```
`i`를 눌러 편집모드로 전환 후 아래 내용을 작성합니다:
```Dockerfile
FROM alpine:latest
CMD ["echo", "Hello, World"]
```
`ESC`를 눌러 명령모드로 전환 후, `:wq` 입력, `enter`키를 눌러 `Dockerfile`을 생성합니다.
#### 3. 도커 파일로 도커 이미지를 빌드합니다.
```shell
docker build -t hello-world .
```
(위 명령어의 의미는 "현재 디렉토리에서 `Dockerfile`을 읽어 도커 이미지를 만들고, 해당 이미지에 `hello-world`라는 `tag` 를 붙혀라" 입니다.)
#### 4. 빌드한 도커 이미지를 실행합니다.
```shell
docker run hello-world
```
이 명령어는 hello-world라는 이름의 도커 이미지를 실행시켜 "Hello, World!"를 출력합니다.
## IV. 도커 커맨드 라인 명령어 정리
- [공식 문서](https://docs.docker.com/engine/reference/run/)
- [cheat sheet](/lecture/1st/cli.md)
| 24
| 327
|
theletterf/english-lang
|
https://github.com/theletterf/english-lang
|
The English Programming Language
|
# The English Programming Language
    [](https://twitter.com/remoquete)
English is a high-level, multi-paradigm, expressive, general purpose language optimized for concurrent communications. English has been successfully used in a wide variety of scenarios, such as long-term data storage, analog and digital arts, and text-based adventures, to name a few. To date, English is used on more than 1,456 million carbon-based devices, and powers more than five million books.
English has been designed over the course of fourteen centuries. While no standard exists, the language adheres to the following principles:
- Portability: English follows a Write Once, Read Anywhere, Then Rewrite (WORATR) philosophy.
- Extensibility: Like Lua, English can borrow constructs and keywords from other languages.
- Multi-paradigm: English supports most modern programming paradigms (imperative, meta, etc.)
- Resilience: English programs can execute on organic hardware despite severe syntax errors.
- Polymorphism: English evolves over time without having to refactor existing codebases.
English's stability makes it ideal for long-term projects where data integrity is more important than precision: The last breaking change in the specifications happened five centuries ago and there are no plans for further major releases.
English's mantra is "there's more than one way to say it".
## Syntax
This is a typical English program that implements the Frost pathfinding algorithm:
```
Two roads diverged in a yellow wood,
And sorry I could not travel both
And be one traveler, long I stood
And looked down one as far as I could
To where it bent in the undergrowth;
Then took the other, as just as fair,
And having perhaps the better claim,
Because it was grassy and wanted wear;
Though as for that the passing there
Had worn them really about the same,
And both that morning equally lay
In leaves no step had trodden black.
Oh, I kept the first for another day!
Yet knowing how way leads on to way,
I doubted if I should ever come back.
I shall be telling this with a sigh
Somewhere ages and ages hence:
Two roads diverged in a wood, and I—
I took the one less traveled by,
And that has made all the difference.
```
English uses whitespace and commas to delimit words, relying heavily on punctuation. Statements can end with a period or, less frequently, with a semicolon. Blocks are usually separated by two or more line breaks. Correct statements are always written in sentence case.
### Operators
English uses the following operators:
- `!`: Emphasize execution (similar to CSS's `!important`). Can be stacked
- `?`: Request information or open data stream thread. Can be stacked
- `,`: Concatenate statements in the same block
- `.`: End of statement
- `;`: End of statement (weak)
- `:`: Definition, for example for functions or clauses
- `...`: Temporarily suspend async execution (similar to `await`)
- `-`: Short break in execution or definition of list items
- `"`: Import value from another module or class
Code comments are added using parentheses or round brackets. Unlike other programming languages, English executes code comments with lower priority to enrich execution context and debug logging. For example:
```
(This is silly.)
```
English operators can be overloaded, although this is not recommended by the ENG23 committee.
### Statements and control flow
English statements are free-form and execution depends on the interpreter's training, as well as word order. Conditional execution and exception handling also depend on the mood and tense of the keywords, as well as resources available.
### Keywords
English does not have reserved words, relying instead on a set of 470,000 keywords that can be used interchangeably and even repeated to accelerate memory allocation. The training process results in scores that make the usage of certain keywords less likely. Keywords that score higher in the profanity dimension might cause the system to panic.
## Data structures
English only has two data structures, Lists and Raw. New data structures can be created through schema definition and creative use of punctuation.
## Typing
English uses context-sensitive and duck typing. The only base types are `strings` and `numbers`, with no size limit. Buffer overflows are typically handled by the interpreter, which performs just-in-time (JIT) type casting and guessing. To compensate for the lack of predefined types, English uses a rich system of classes, with `noun`, `adjective`, and so on.
## Documentation
English programs are self-documenting and implement literate programming.
## Tooling
Currently, the only compiler available is Wernicke. It requires a temporal lobe trained in social settings for at least three to four years, though better results can be achieved with training runs in excess of 30 years.
Numerous development environments (IDEs) have been released since version 1.0. The most common editors for English are Word and Docs, although programs can still be written in WordPerfect, Vi, and emacs. English is unique in that it can be coded on almost any medium capable of supporting scratches and marks, such as paper, stone, or clay.
There are millions of English libraries available. You can look for the closest in Google Maps.
## Community
The English community is vibrant, with more than 150 distributions available. For a complete list of forks see [List of dialects](https://en.wikipedia.org/wiki/List_of_dialects_of_English).
| 350
| 7
|
invictus717/MetaTransformer
|
https://github.com/invictus717/MetaTransformer
|
Meta-Transformer for Unified Multimodal Learning
|
<p align="center" width="100%">
<img src="assets\Meta-Transformer_banner.png" width="80%" height="80%">
</p>
<div>
<div align="center">
<a href='https://scholar.google.com/citations?user=KuYlJCIAAAAJ&hl=en' target='_blank'>Yiyuan Zhang<sup>1,2*</sup></a> 
<a href='https://kxgong.github.io/' target='_blank'>Kaixiong Gong<sup>1,2*</sup></a> 
<a href='http://kpzhang93.github.io/' target='_blank'>Kaipeng Zhang<sup>2,†</sup></a> 
</br>
<a href='http://www.ee.cuhk.edu.hk/~hsli/' target='_blank'>Hongsheng Li <sup>1,2</sup></a> 
<a href='https://mmlab.siat.ac.cn/yuqiao/index.html' target='_blank'>Yu Qiao <sup>2</sup></a> 
<a href='https://wlouyang.github.io/' target='_blank'>Wanli Ouyang<sup>2</sup></a> 
<a href='http://people.eecs.berkeley.edu/~xyyue/' target='_blank'>Xiangyu Yue<sup>1,†,‡</sup></a>
</div>
<div>
<div align="center">
<sup>1</sup>
<a href='http://mmlab.ie.cuhk.edu.hk/' target='_blank'>Multimedia Lab, The Chinese University of Hong Kong</a> 
</br>
<sup>2</sup> <a href='https://github.com/OpenGVLab' target='_blank'>OpenGVLab,Shanghai AI Laboratory
</a></br>
<sup>*</sup> Equal Contribution 
<sup>†</sup> Corresponding Author 
<sup>‡</sup> Project Lead 
</div>
-----------------
[](https://arxiv.org/abs/2307.10802)
[](https://kxgong.github.io/meta_transformer/)
[](https://mp.weixin.qq.com/s/r38bzqdJxDZUvtDI0c9CEw)
[](https://huggingface.co/papers/2307.10802)
[](https://openxlab.org.cn/models/detail/zhangyiyuan/MetaTransformer)

<a href="https://twitter.com/_akhaliq/status/1682248055637041152"><img src="https://img.icons8.com/color/48/000000/twitter.png" width="25" height="25"></a>
<a href="https://www.youtube.com/watch?v=V8L8xbsTyls&ab_channel=CSBoard"><img src="https://img.icons8.com/color/48/000000/youtube-play.png" width="25" height="25"></a> <a href='https://huggingface.co/kxgong/Meta-Transformer'> <img src="assets\icons\huggingface.png" width="25" height="25"> </a> <a href='https://open.spotify.com/episode/6JJxcy2zMtTwr4jXPQEXjh'> <img src="https://upload.wikimedia.org/wikipedia/commons/1/19/Spotify_logo_without_text.svg" width="20" height="20"></a>
### 🌟 Single Foundation Model Supports A Wide Range of Applications
As a foundation model, Meta-Transformer can handle data from 12 modalities, which determines that it can support a wide range of applications. As shown in this figure, Meta-Transformer can provide services for downstream tasks including stock analysis 📈, weather forecasting ☀️ ☔ ☁️ ❄️ ⛄ ⚡, remote sensing 📡, autonomous driving 🚗, social network 🌍, speech recognition 🔉, etc.
<p align="center" width="100%">
<img src="assets\Meta-Transformer_application.png" width="100%" height="100%">
</p>
**Table 1**: Meta-Transformer is capable of handling up to 12 modalities, including natural language <img src="assets\icons\text.jpg" width="15" height="15">, RGB images <img src="assets\icons\img.jpg" width="15" height="15">, point clouds <img src="assets\icons\pcd.jpg" width="15" height="15">, audios <img src="assets\icons\audio.jpg" width="15" height="15">, videos <img src="assets\icons\video.jpg" width="15" height="15">, tabular data <img src="assets\icons\table.jpg" width="15" height="15">, graph <img src="assets\icons\graph.jpg" width="15" height="15">, time series data <img src="assets\icons\time.jpg" width="15" height="15">, hyper-spectral images <img src="assets\icons\hyper.jpg" width="15" height="15">, IMU <img src="assets\icons\imu.jpg" width="15" height="15">, medical images <img src="assets\icons\xray.jpg" width="15" height="15">, and infrared images <img src="assets\icons\infrared.jpg" width="15" height="15">.
<p align="left">
<img src="assets\Meta-Transformer_cmp.png" width=100%>
</p>
## 🚩🚩🚩 Shared-Encoder, Unpaired Data, More Modalities
<div>
<img class="image" src="assets\Meta-Transformer_teaser.png" width="52%" height="100%">
<img class="image" src="assets\Meta-Transformer_exp.png" width="45.2%" height="100%">
</div>
This repository is built to explore the potential and extensibility of transformers for multimodal learning. We utilize the advantages of Transformers to deal with length-variant sequences. Then we propose the *Data-to-Sequence* tokenization following a meta-scheme, then we apply it to 12 modalities including text, image, point cloud, audio, video, infrared, hyper-spectral, X-Ray, tabular, graph, time-series, and Inertial Measurement Unit (IMU) data.
<p align="left">
<img src="assets\Meta-Transformer_data2seq.png" width=100%>
</p>
After obtaining the token sequence, we employ a modality-shared encoder to extract representation across different modalities. With task-specific heads, Meta-Transformer can handle various tasks on the different modalities, such as: classification, detection, and segmentation.
<p align="left">
<img src="assets\Meta-Transformer_framework.png" width=100%>
</p>
# 🌟 News
* **2023.8.2:** 🎉🎉🎉 The implementation of Meta-Transformer for image, point cloud, graph, tabular, time-series, X-Ray, hyper-spectrum, LiDAR data has been released. We also release a very powerful foundation model for Autonomous Driving 🚀🚀🚀.
* **2023.7.22:** 🌟🌟🌟 Pretrained weights and a usage demo for our Meta-Transformer have been released. Comprehensive documentation and implementation of the image modality are underway and will be released soon. Stay tuned for more exciting updates!⌛⌛⌛
* **2023.7.21:** Paper is released at [arxiv](https://arxiv.org/abs/2307.10802), and code will be gradually released.
* **2023.7.8:** Github Repository Initialization.
# 🔓 Model Zoo
<!-- <details> -->
<summary> Open-source Modality-Agnostic Models </summary>
<br>
<div>
| Model | Pretraining | Scale | #Param | Download | 国内下载源 |
| :------------: | :----------: | :----------------------: | :----: | :---------------------------------------------------------------------------------------------------: | :--------: |
| Meta-Transformer-B16 | LAION-2B | Base | 85M | [ckpt](https://drive.google.com/file/d/19ahcN2QKknkir_bayhTW5rucuAiX0OXq/view?usp=sharing) | [ckpt](https://download.openxlab.org.cn/models/zhangyiyuan/MetaTransformer/weight//Meta-Transformer_base_patch16_encoder)
| Meta-Transformer-L14 | LAION-2B | Large | 302M | [ckpt](https://drive.google.com/file/d/15EtzCBAQSqmelhdLz6k880A19_RpcX9B/view?usp=drive_link) | [ckpt](https://download.openxlab.org.cn/models/zhangyiyuan/MetaTransformer/weight//Meta-Transformer_large_patch14_encoder)
</div>
<!-- </details> -->
<!-- <details> -->
<summary>Demo of Use for Pretrained Encoder</summary>
```python
from timm.models.vision_transformer import Block
ckpt = torch.load("Meta-Transformer_base_patch16_encoder.pth")
encoder = nn.Sequential(*[
Block(
dim=768,
num_heads=12,
mlp_ratio=4.,
qkv_bias=True,
norm_layer=nn.LayerNorm,
act_layer=nn.GELU
)
for i in range(12)])
encoder.load_state_dict(ckpt,strict=True)
```
<!-- </details> -->
# 🕙 ToDo
- [ ] Meta-Transformer with Large Language Models.
- [ ] Multimodal Joint Training with Meta-Transformer.
- [ ] Support More Modalities and More Tasks.
# Contact
🚀🚀🚀 We aspire to shape this repository into **a formidable foundation for mainstream AI perception tasks across diverse modalities**. Your contributions can play a significant role in this endeavor, and we warmly welcome your participation in our project!
To contact us, never hestitate to send an email to `[email protected]` ,`[email protected]`, `[email protected]`, or `[email protected]`!
<br></br>
 
# Citation
If the code and paper help your research, please kindly cite:
```
@article{zhang2023metatransformer,
title={Meta-Transformer: A Unified Framework for Multimodal Learning},
author={Zhang, Yiyuan and Gong, Kaixiong and Zhang, Kaipeng and Li, Hongsheng and Qiao, Yu and Ouyang, Wanli and Yue, Xiangyu},
year={2023},
journal={arXiv preprint arXiv:2307.10802},
}
```
# License
This project is released under the [Apache 2.0 license](LICENSE).
# Acknowledgement
This code is developed based on excellent open-sourced projects including [MMClassification](https://github.com/open-mmlab/mmpretrain/tree/mmcls-1.x), [MMDetection](https://github.com/open-mmlab/mmdetection), [MMsegmentation](https://github.com/open-mmlab/mmsegmentation), [OpenPoints](https://github.com/guochengqian/openpoints), [Time-Series-Library](https://github.com/thuml/Time-Series-Library), [Graphomer](https://github.com/microsoft/Graphormer), [SpectralFormer](https://github.com/danfenghong/IEEE_TGRS_SpectralFormer), and [ViT-Adapter](https://github.com/czczup/ViT-Adapter).
| 948
| 66
|
liguge/Maximum-mean-square-discrepancy
|
https://github.com/liguge/Maximum-mean-square-discrepancy
|
Maximum mean square discrepancy: A new discrepancy representation metric for mechanical fault transfer diagnosis
|
# MMSD
### DownLoad Dataset:
- 链接: https://caiyun.139.com/m/i?085CtKTgnhbl7 提取码:xmSn
### Official Materials
- TF: https://github.com/QinYi-team/MMSD/tree/main
- Paper:
- [PUBLISHED PAPERS](https://doi.org/10.1016/j.knosys.2023.110748)
### Cited:
```html
@article{QIAN2023110748,
title = {Maximum mean square discrepancy: A new discrepancy representation metric for mechanical fault transfer diagnosis},
journal = {Knowledge-Based Systems},
pages = {110748},
year = {2023},
issn = {0950-7051},
doi = {https://doi.org/10.1016/j.knosys.2023.110748},
url = {https://www.sciencedirect.com/science/article/pii/S0950705123004987},
author = {Quan Qian and Yi Wang and Taisheng Zhang and Yi Qin},
keywords = {Discrepancy representation metric, Fault transfer diagnosis, Unsupervised domain adaptation, Planetary gearbox},
abstract = {Discrepancy representation metric completely determines the transfer diagnosis performance of deep domain adaptation methods. Maximum mean discrepancy (MMD) based on the mean statistic, as the commonly used metric, has poor discrepancy representation in some cases. MMD is generally known from the aspect of kernel function, but the inherent relationship between the two is unknown. To deal with these issues, the authors theoretically explore their relationship first. With the revealed relationship, a novel discrepancy representation metric named maximum mean square discrepancy (MMSD), which can comprehensively reflect the mean and variance information of data samples in the reproducing kernel Hilbert space, is constructed for enhancing domain confusion. Additionally, for the real application under limited samples and ensuring the effectiveness of MMSD, biased and unbiased empirical MMSD statistics are developed, and the error bounds between the two empirical statistics and the real distribution discrepancy are derived. The proposed MMSD is successfully applied to the end-to-end fault diagnosis of planetary gearbox of wind turbine without labeled target-domain samples. The experimental results on twelve cross-load transfer tasks validate that MMSD has a better ability of discrepancy representation and a higher diagnosis accuracy compared with other well-known discrepancy representation metrics. The related code can be downloaded from https://qinyi-team.github.io/#blog.}
```
### Experience
1. 平滑交叉熵损失要比交叉熵损失的效果更好。
2. 使用lambd,使得迁移的效果更加稳定。
### Usage
建议大家将开源的MMSD域差异度量损失(即插即用)在赵老师的开源的代码中替换掉度量模块。(https://github.com/ZhaoZhibin/UDTL)
替换方式:
```python
from MMSD import MMSD
criterion2 = MMSD()
loss = criterion2(output1, output2)
```
### Experimental result
```python
Epoch1, test_loss is 1.70728, train_accuracy is 0.96575,test_accuracy is 0.21875,train_all_loss is 0.47141,source_cla_loss is 0.47141,domain_loss is 0.11647
Epoch2, test_loss is 2.35181, train_accuracy is 1.00000,test_accuracy is 0.27100,train_all_loss is 0.37312,source_cla_loss is 0.35756,domain_loss is 0.05892
Epoch3, test_loss is 2.27180, train_accuracy is 1.00000,test_accuracy is 0.17525,train_all_loss is 0.36413,source_cla_loss is 0.35554,domain_loss is 0.02357
Epoch4, test_loss is 2.52417, train_accuracy is 1.00000,test_accuracy is 0.16125,train_all_loss is 0.36036,source_cla_loss is 0.35355,domain_loss is 0.01553
Epoch5, test_loss is 2.35286, train_accuracy is 1.00000,test_accuracy is 0.23850,train_all_loss is 0.35704,source_cla_loss is 0.35188,domain_loss is 0.01035
Epoch6, test_loss is 2.11720, train_accuracy is 1.00000,test_accuracy is 0.40925,train_all_loss is 0.35786,source_cla_loss is 0.35186,domain_loss is 0.01090
Epoch7, test_loss is 2.10492, train_accuracy is 1.00000,test_accuracy is 0.33450,train_all_loss is 0.35841,source_cla_loss is 0.35179,domain_loss is 0.01108
Epoch8, test_loss is 2.28453, train_accuracy is 1.00000,test_accuracy is 0.28400,train_all_loss is 0.35728,source_cla_loss is 0.35096,domain_loss is 0.00990
Epoch9, test_loss is 2.61733, train_accuracy is 1.00000,test_accuracy is 0.25325,train_all_loss is 0.35661,source_cla_loss is 0.35092,domain_loss is 0.00840
Epoch10, test_loss is 2.60611, train_accuracy is 1.00000,test_accuracy is 0.11200,train_all_loss is 0.36039,source_cla_loss is 0.35201,domain_loss is 0.01178
Epoch11, test_loss is 2.20323, train_accuracy is 1.00000,test_accuracy is 0.43500,train_all_loss is 0.36111,source_cla_loss is 0.35251,domain_loss is 0.01155
Epoch12, test_loss is 2.52880, train_accuracy is 1.00000,test_accuracy is 0.26050,train_all_loss is 0.35741,source_cla_loss is 0.35055,domain_loss is 0.00884
Epoch13, test_loss is 2.43795, train_accuracy is 1.00000,test_accuracy is 0.31250,train_all_loss is 0.35709,source_cla_loss is 0.35001,domain_loss is 0.00879
Epoch14, test_loss is 2.20165, train_accuracy is 1.00000,test_accuracy is 0.30825,train_all_loss is 0.35859,source_cla_loss is 0.35034,domain_loss is 0.00990
Epoch15, test_loss is 2.32735, train_accuracy is 1.00000,test_accuracy is 0.32250,train_all_loss is 0.35892,source_cla_loss is 0.35087,domain_loss is 0.00936
Epoch16, test_loss is 1.98427, train_accuracy is 1.00000,test_accuracy is 0.41350,train_all_loss is 0.35704,source_cla_loss is 0.35041,domain_loss is 0.00749
Epoch17, test_loss is 2.40874, train_accuracy is 1.00000,test_accuracy is 0.26625,train_all_loss is 0.35763,source_cla_loss is 0.35074,domain_loss is 0.00758
Epoch18, test_loss is 1.98695, train_accuracy is 1.00000,test_accuracy is 0.43575,train_all_loss is 0.35825,source_cla_loss is 0.35019,domain_loss is 0.00865
Epoch19, test_loss is 2.52306, train_accuracy is 1.00000,test_accuracy is 0.19475,train_all_loss is 0.35888,source_cla_loss is 0.34970,domain_loss is 0.00962
Epoch20, test_loss is 1.95578, train_accuracy is 0.99975,test_accuracy is 0.48125,train_all_loss is 0.35809,source_cla_loss is 0.35103,domain_loss is 0.00723
Epoch21, test_loss is 2.57803, train_accuracy is 1.00000,test_accuracy is 0.30950,train_all_loss is 0.35776,source_cla_loss is 0.35048,domain_loss is 0.00730
Epoch22, test_loss is 2.40677, train_accuracy is 1.00000,test_accuracy is 0.32975,train_all_loss is 0.35670,source_cla_loss is 0.35015,domain_loss is 0.00644
Epoch23, test_loss is 2.32670, train_accuracy is 1.00000,test_accuracy is 0.37975,train_all_loss is 0.35628,source_cla_loss is 0.35001,domain_loss is 0.00604
Epoch24, test_loss is 2.42710, train_accuracy is 1.00000,test_accuracy is 0.29125,train_all_loss is 0.35750,source_cla_loss is 0.34973,domain_loss is 0.00735
Epoch25, test_loss is 2.31670, train_accuracy is 1.00000,test_accuracy is 0.35600,train_all_loss is 0.35724,source_cla_loss is 0.34979,domain_loss is 0.00692
Epoch26, test_loss is 2.13007, train_accuracy is 1.00000,test_accuracy is 0.29450,train_all_loss is 0.35663,source_cla_loss is 0.34949,domain_loss is 0.00653
Epoch27, test_loss is 2.56636, train_accuracy is 1.00000,test_accuracy is 0.22075,train_all_loss is 0.35791,source_cla_loss is 0.34966,domain_loss is 0.00741
Epoch28, test_loss is 2.61027, train_accuracy is 1.00000,test_accuracy is 0.27125,train_all_loss is 0.35974,source_cla_loss is 0.35006,domain_loss is 0.00856
Epoch29, test_loss is 2.64836, train_accuracy is 1.00000,test_accuracy is 0.15350,train_all_loss is 0.36258,source_cla_loss is 0.35029,domain_loss is 0.01071
Epoch30, test_loss is 1.93399, train_accuracy is 1.00000,test_accuracy is 0.45050,train_all_loss is 0.36011,source_cla_loss is 0.35069,domain_loss is 0.00809
Epoch31, test_loss is 2.48554, train_accuracy is 1.00000,test_accuracy is 0.29175,train_all_loss is 0.35629,source_cla_loss is 0.34977,domain_loss is 0.00552
Epoch32, test_loss is 2.21559, train_accuracy is 1.00000,test_accuracy is 0.29150,train_all_loss is 0.35875,source_cla_loss is 0.34962,domain_loss is 0.00762
Epoch33, test_loss is 1.93778, train_accuracy is 1.00000,test_accuracy is 0.48025,train_all_loss is 0.36135,source_cla_loss is 0.35016,domain_loss is 0.00923
Epoch34, test_loss is 2.15657, train_accuracy is 0.99900,test_accuracy is 0.38750,train_all_loss is 0.36303,source_cla_loss is 0.35151,domain_loss is 0.00938
Epoch35, test_loss is 2.09539, train_accuracy is 1.00000,test_accuracy is 0.41875,train_all_loss is 0.35931,source_cla_loss is 0.35029,domain_loss is 0.00725
Epoch36, test_loss is 2.14911, train_accuracy is 1.00000,test_accuracy is 0.41450,train_all_loss is 0.35856,source_cla_loss is 0.34987,domain_loss is 0.00691
Epoch37, test_loss is 2.30350, train_accuracy is 1.00000,test_accuracy is 0.35275,train_all_loss is 0.35922,source_cla_loss is 0.34980,domain_loss is 0.00740
Epoch38, test_loss is 2.01832, train_accuracy is 1.00000,test_accuracy is 0.42125,train_all_loss is 0.36115,source_cla_loss is 0.34977,domain_loss is 0.00884
Epoch39, test_loss is 2.12754, train_accuracy is 1.00000,test_accuracy is 0.43925,train_all_loss is 0.36185,source_cla_loss is 0.35056,domain_loss is 0.00867
Epoch40, test_loss is 2.27010, train_accuracy is 1.00000,test_accuracy is 0.38275,train_all_loss is 0.35945,source_cla_loss is 0.34958,domain_loss is 0.00749
Epoch41, test_loss is 2.27428, train_accuracy is 1.00000,test_accuracy is 0.37300,train_all_loss is 0.35898,source_cla_loss is 0.34955,domain_loss is 0.00709
Epoch42, test_loss is 3.02612, train_accuracy is 1.00000,test_accuracy is 0.05425,train_all_loss is 0.36095,source_cla_loss is 0.35021,domain_loss is 0.00799
Epoch43, test_loss is 1.81688, train_accuracy is 0.99975,test_accuracy is 0.50675,train_all_loss is 0.36015,source_cla_loss is 0.35015,domain_loss is 0.00737
Epoch44, test_loss is 2.43221, train_accuracy is 1.00000,test_accuracy is 0.30950,train_all_loss is 0.35984,source_cla_loss is 0.34973,domain_loss is 0.00737
Epoch45, test_loss is 2.29550, train_accuracy is 1.00000,test_accuracy is 0.33425,train_all_loss is 0.35929,source_cla_loss is 0.34962,domain_loss is 0.00699
Epoch46, test_loss is 1.83346, train_accuracy is 1.00000,test_accuracy is 0.48475,train_all_loss is 0.36158,source_cla_loss is 0.34975,domain_loss is 0.00846
Epoch47, test_loss is 2.47635, train_accuracy is 0.99975,test_accuracy is 0.30550,train_all_loss is 0.36134,source_cla_loss is 0.35078,domain_loss is 0.00749
Epoch48, test_loss is 2.31410, train_accuracy is 1.00000,test_accuracy is 0.31875,train_all_loss is 0.36162,source_cla_loss is 0.35039,domain_loss is 0.00789
Epoch49, test_loss is 2.26891, train_accuracy is 1.00000,test_accuracy is 0.36725,train_all_loss is 0.35993,source_cla_loss is 0.34990,domain_loss is 0.00698
Epoch50, test_loss is 2.08352, train_accuracy is 1.00000,test_accuracy is 0.38875,train_all_loss is 0.36137,source_cla_loss is 0.34981,domain_loss is 0.00798
Epoch51, test_loss is 2.42994, train_accuracy is 0.99975,test_accuracy is 0.29925,train_all_loss is 0.35795,source_cla_loss is 0.34976,domain_loss is 0.00560
Epoch52, test_loss is 2.04134, train_accuracy is 0.99975,test_accuracy is 0.45800,train_all_loss is 0.36056,source_cla_loss is 0.35033,domain_loss is 0.00694
Epoch53, test_loss is 2.09900, train_accuracy is 0.99925,test_accuracy is 0.49200,train_all_loss is 0.36229,source_cla_loss is 0.35129,domain_loss is 0.00740
Epoch54, test_loss is 2.87855, train_accuracy is 1.00000,test_accuracy is 0.09150,train_all_loss is 0.36451,source_cla_loss is 0.35035,domain_loss is 0.00945
Epoch55, test_loss is 2.07624, train_accuracy is 1.00000,test_accuracy is 0.39200,train_all_loss is 0.35990,source_cla_loss is 0.34988,domain_loss is 0.00664
Epoch56, test_loss is 2.04308, train_accuracy is 1.00000,test_accuracy is 0.42925,train_all_loss is 0.35937,source_cla_loss is 0.34965,domain_loss is 0.00638
Epoch57, test_loss is 2.18549, train_accuracy is 1.00000,test_accuracy is 0.40975,train_all_loss is 0.35868,source_cla_loss is 0.34950,domain_loss is 0.00599
Epoch58, test_loss is 1.90264, train_accuracy is 1.00000,test_accuracy is 0.44225,train_all_loss is 0.35848,source_cla_loss is 0.34946,domain_loss is 0.00584
Epoch59, test_loss is 2.24085, train_accuracy is 0.99975,test_accuracy is 0.39500,train_all_loss is 0.36069,source_cla_loss is 0.35044,domain_loss is 0.00659
Epoch60, test_loss is 2.16645, train_accuracy is 1.00000,test_accuracy is 0.41550,train_all_loss is 0.35808,source_cla_loss is 0.34961,domain_loss is 0.00541
Epoch61, test_loss is 2.32162, train_accuracy is 1.00000,test_accuracy is 0.31100,train_all_loss is 0.36257,source_cla_loss is 0.35030,domain_loss is 0.00777
Epoch62, test_loss is 2.02297, train_accuracy is 1.00000,test_accuracy is 0.44625,train_all_loss is 0.35716,source_cla_loss is 0.34946,domain_loss is 0.00484
Epoch63, test_loss is 2.17477, train_accuracy is 1.00000,test_accuracy is 0.40525,train_all_loss is 0.36074,source_cla_loss is 0.34959,domain_loss is 0.00696
Epoch64, test_loss is 2.01394, train_accuracy is 1.00000,test_accuracy is 0.45350,train_all_loss is 0.35919,source_cla_loss is 0.34956,domain_loss is 0.00597
Epoch65, test_loss is 2.04567, train_accuracy is 1.00000,test_accuracy is 0.43150,train_all_loss is 0.35964,source_cla_loss is 0.34948,domain_loss is 0.00626
Epoch66, test_loss is 2.26130, train_accuracy is 1.00000,test_accuracy is 0.31925,train_all_loss is 0.35874,source_cla_loss is 0.34962,domain_loss is 0.00558
Epoch67, test_loss is 2.03899, train_accuracy is 1.00000,test_accuracy is 0.43050,train_all_loss is 0.36048,source_cla_loss is 0.34988,domain_loss is 0.00644
Epoch68, test_loss is 2.26282, train_accuracy is 1.00000,test_accuracy is 0.32625,train_all_loss is 0.35656,source_cla_loss is 0.34929,domain_loss is 0.00439
Epoch69, test_loss is 2.14964, train_accuracy is 1.00000,test_accuracy is 0.40100,train_all_loss is 0.36315,source_cla_loss is 0.34980,domain_loss is 0.00800
Epoch70, test_loss is 2.09022, train_accuracy is 1.00000,test_accuracy is 0.42075,train_all_loss is 0.35800,source_cla_loss is 0.34952,domain_loss is 0.00505
Epoch71, test_loss is 1.91966, train_accuracy is 1.00000,test_accuracy is 0.46025,train_all_loss is 0.35967,source_cla_loss is 0.34967,domain_loss is 0.00592
Epoch72, test_loss is 2.52028, train_accuracy is 1.00000,test_accuracy is 0.25550,train_all_loss is 0.36009,source_cla_loss is 0.35002,domain_loss is 0.00592
Epoch73, test_loss is 2.20228, train_accuracy is 1.00000,test_accuracy is 0.37700,train_all_loss is 0.35946,source_cla_loss is 0.34967,domain_loss is 0.00573
Epoch74, test_loss is 1.94529, train_accuracy is 0.99925,test_accuracy is 0.49575,train_all_loss is 0.36289,source_cla_loss is 0.35127,domain_loss is 0.00675
Epoch75, test_loss is 2.82669, train_accuracy is 0.99850,test_accuracy is 0.25000,train_all_loss is 0.36925,source_cla_loss is 0.35456,domain_loss is 0.00849
Epoch76, test_loss is 2.24564, train_accuracy is 0.99950,test_accuracy is 0.37200,train_all_loss is 0.36014,source_cla_loss is 0.35083,domain_loss is 0.00534
Epoch77, test_loss is 2.10572, train_accuracy is 1.00000,test_accuracy is 0.43425,train_all_loss is 0.35951,source_cla_loss is 0.34934,domain_loss is 0.00580
Epoch78, test_loss is 2.12904, train_accuracy is 1.00000,test_accuracy is 0.36225,train_all_loss is 0.36563,source_cla_loss is 0.34958,domain_loss is 0.00910
Epoch79, test_loss is 2.17708, train_accuracy is 1.00000,test_accuracy is 0.41100,train_all_loss is 0.36162,source_cla_loss is 0.35044,domain_loss is 0.00631
Epoch80, test_loss is 2.25490, train_accuracy is 1.00000,test_accuracy is 0.39525,train_all_loss is 0.35696,source_cla_loss is 0.34930,domain_loss is 0.00430
Epoch81, test_loss is 2.12288, train_accuracy is 1.00000,test_accuracy is 0.42675,train_all_loss is 0.36222,source_cla_loss is 0.34962,domain_loss is 0.00702
Epoch82, test_loss is 2.25930, train_accuracy is 1.00000,test_accuracy is 0.32775,train_all_loss is 0.36017,source_cla_loss is 0.34945,domain_loss is 0.00595
Epoch83, test_loss is 2.55101, train_accuracy is 1.00000,test_accuracy is 0.26325,train_all_loss is 0.36796,source_cla_loss is 0.35097,domain_loss is 0.00937
Epoch84, test_loss is 1.75571, train_accuracy is 0.99975,test_accuracy is 0.55050,train_all_loss is 0.36502,source_cla_loss is 0.35037,domain_loss is 0.00803
Epoch85, test_loss is 1.96290, train_accuracy is 0.99975,test_accuracy is 0.48625,train_all_loss is 0.36020,source_cla_loss is 0.35000,domain_loss is 0.00556
Epoch86, test_loss is 1.99381, train_accuracy is 1.00000,test_accuracy is 0.48825,train_all_loss is 0.35978,source_cla_loss is 0.34941,domain_loss is 0.00562
Epoch87, test_loss is 1.92070, train_accuracy is 1.00000,test_accuracy is 0.47525,train_all_loss is 0.36388,source_cla_loss is 0.34945,domain_loss is 0.00778
Epoch88, test_loss is 1.90456, train_accuracy is 1.00000,test_accuracy is 0.49850,train_all_loss is 0.35838,source_cla_loss is 0.34956,domain_loss is 0.00473
Epoch89, test_loss is 1.94458, train_accuracy is 0.99975,test_accuracy is 0.47600,train_all_loss is 0.36450,source_cla_loss is 0.35095,domain_loss is 0.00723
Epoch90, test_loss is 2.07750, train_accuracy is 1.00000,test_accuracy is 0.44650,train_all_loss is 0.36025,source_cla_loss is 0.34988,domain_loss is 0.00550
Epoch91, test_loss is 2.09842, train_accuracy is 1.00000,test_accuracy is 0.42175,train_all_loss is 0.36093,source_cla_loss is 0.34968,domain_loss is 0.00594
Epoch92, test_loss is 2.12722, train_accuracy is 1.00000,test_accuracy is 0.40625,train_all_loss is 0.36386,source_cla_loss is 0.34979,domain_loss is 0.00738
Epoch93, test_loss is 1.78110, train_accuracy is 0.99950,test_accuracy is 0.51150,train_all_loss is 0.36337,source_cla_loss is 0.35180,domain_loss is 0.00604
Epoch94, test_loss is 1.88155, train_accuracy is 0.99950,test_accuracy is 0.50150,train_all_loss is 0.36641,source_cla_loss is 0.35073,domain_loss is 0.00815
Epoch95, test_loss is 1.89918, train_accuracy is 1.00000,test_accuracy is 0.47300,train_all_loss is 0.36335,source_cla_loss is 0.35031,domain_loss is 0.00674
Epoch96, test_loss is 1.87588, train_accuracy is 1.00000,test_accuracy is 0.48575,train_all_loss is 0.36017,source_cla_loss is 0.34973,domain_loss is 0.00537
Epoch97, test_loss is 1.81331, train_accuracy is 1.00000,test_accuracy is 0.50875,train_all_loss is 0.35987,source_cla_loss is 0.34948,domain_loss is 0.00531
Epoch98, test_loss is 1.73135, train_accuracy is 1.00000,test_accuracy is 0.54350,train_all_loss is 0.36217,source_cla_loss is 0.34973,domain_loss is 0.00633
Epoch99, test_loss is 1.90660, train_accuracy is 0.99975,test_accuracy is 0.45425,train_all_loss is 0.36547,source_cla_loss is 0.35049,domain_loss is 0.00758
Epoch100, test_loss is 2.04686, train_accuracy is 1.00000,test_accuracy is 0.43025,train_all_loss is 0.36341,source_cla_loss is 0.35029,domain_loss is 0.00661
Epoch101, test_loss is 2.08754, train_accuracy is 1.00000,test_accuracy is 0.43425,train_all_loss is 0.35962,source_cla_loss is 0.34967,domain_loss is 0.00499
Epoch102, test_loss is 2.05368, train_accuracy is 1.00000,test_accuracy is 0.43450,train_all_loss is 0.36238,source_cla_loss is 0.34966,domain_loss is 0.00634
Epoch103, test_loss is 2.04378, train_accuracy is 1.00000,test_accuracy is 0.43300,train_all_loss is 0.36087,source_cla_loss is 0.34939,domain_loss is 0.00570
Epoch104, test_loss is 1.98537, train_accuracy is 1.00000,test_accuracy is 0.44825,train_all_loss is 0.36309,source_cla_loss is 0.34957,domain_loss is 0.00668
Epoch105, test_loss is 1.87151, train_accuracy is 1.00000,test_accuracy is 0.48725,train_all_loss is 0.36180,source_cla_loss is 0.34969,domain_loss is 0.00595
Epoch106, test_loss is 1.80578, train_accuracy is 1.00000,test_accuracy is 0.52875,train_all_loss is 0.36012,source_cla_loss is 0.34952,domain_loss is 0.00518
Epoch107, test_loss is 1.88614, train_accuracy is 1.00000,test_accuracy is 0.49150,train_all_loss is 0.35935,source_cla_loss is 0.34962,domain_loss is 0.00473
Epoch108, test_loss is 2.01156, train_accuracy is 1.00000,test_accuracy is 0.46025,train_all_loss is 0.35981,source_cla_loss is 0.34938,domain_loss is 0.00505
Epoch109, test_loss is 2.02546, train_accuracy is 1.00000,test_accuracy is 0.46275,train_all_loss is 0.36216,source_cla_loss is 0.34942,domain_loss is 0.00614
Epoch110, test_loss is 1.92141, train_accuracy is 1.00000,test_accuracy is 0.49175,train_all_loss is 0.35969,source_cla_loss is 0.34943,domain_loss is 0.00492
Epoch111, test_loss is 1.62420, train_accuracy is 0.99975,test_accuracy is 0.55300,train_all_loss is 0.36185,source_cla_loss is 0.35010,domain_loss is 0.00561
Epoch112, test_loss is 1.82876, train_accuracy is 0.99975,test_accuracy is 0.51075,train_all_loss is 0.36234,source_cla_loss is 0.35144,domain_loss is 0.00517
Epoch113, test_loss is 1.92894, train_accuracy is 1.00000,test_accuracy is 0.46050,train_all_loss is 0.36150,source_cla_loss is 0.34964,domain_loss is 0.00561
Epoch114, test_loss is 1.93551, train_accuracy is 1.00000,test_accuracy is 0.48225,train_all_loss is 0.36063,source_cla_loss is 0.34962,domain_loss is 0.00518
Epoch115, test_loss is 1.78969, train_accuracy is 1.00000,test_accuracy is 0.52700,train_all_loss is 0.35976,source_cla_loss is 0.34965,domain_loss is 0.00473
Epoch116, test_loss is 1.35264, train_accuracy is 1.00000,test_accuracy is 0.65150,train_all_loss is 0.36248,source_cla_loss is 0.34978,domain_loss is 0.00592
Epoch117, test_loss is 1.30626, train_accuracy is 0.99950,test_accuracy is 0.59500,train_all_loss is 0.36203,source_cla_loss is 0.35149,domain_loss is 0.00489
Epoch118, test_loss is 1.06381, train_accuracy is 0.99975,test_accuracy is 0.70575,train_all_loss is 0.35764,source_cla_loss is 0.35069,domain_loss is 0.00321
Epoch119, test_loss is 0.72888, train_accuracy is 1.00000,test_accuracy is 0.84975,train_all_loss is 0.35527,source_cla_loss is 0.34929,domain_loss is 0.00275
Epoch120, test_loss is 1.52062, train_accuracy is 1.00000,test_accuracy is 0.57600,train_all_loss is 0.35413,source_cla_loss is 0.34946,domain_loss is 0.00214
Epoch121, test_loss is 1.29272, train_accuracy is 1.00000,test_accuracy is 0.61100,train_all_loss is 0.35314,source_cla_loss is 0.34946,domain_loss is 0.00168
Epoch122, test_loss is 0.77498, train_accuracy is 1.00000,test_accuracy is 0.79200,train_all_loss is 0.35075,source_cla_loss is 0.34946,domain_loss is 0.00058
Epoch123, test_loss is 0.35446, train_accuracy is 1.00000,test_accuracy is 0.99875,train_all_loss is 0.34952,source_cla_loss is 0.34924,domain_loss is 0.00012
Epoch124, test_loss is 0.36260, train_accuracy is 1.00000,test_accuracy is 0.99500,train_all_loss is 0.34924,source_cla_loss is 0.34909,domain_loss is 0.00007
Epoch125, test_loss is 0.35317, train_accuracy is 1.00000,test_accuracy is 0.99925,train_all_loss is 0.34930,source_cla_loss is 0.34913,domain_loss is 0.00007
Epoch126, test_loss is 0.35170, train_accuracy is 1.00000,test_accuracy is 0.99950,train_all_loss is 0.34928,source_cla_loss is 0.34907,domain_loss is 0.00010
Epoch127, test_loss is 0.35829, train_accuracy is 1.00000,test_accuracy is 0.99700,train_all_loss is 0.34932,source_cla_loss is 0.34914,domain_loss is 0.00008
Epoch128, test_loss is 0.35118, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34908,source_cla_loss is 0.34897,domain_loss is 0.00005
Epoch129, test_loss is 0.35110, train_accuracy is 1.00000,test_accuracy is 0.99975,train_all_loss is 0.34901,source_cla_loss is 0.34893,domain_loss is 0.00003
Epoch130, test_loss is 0.35183, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34904,source_cla_loss is 0.34894,domain_loss is 0.00004
Epoch131, test_loss is 0.35454, train_accuracy is 1.00000,test_accuracy is 0.99900,train_all_loss is 0.34905,source_cla_loss is 0.34896,domain_loss is 0.00004
Epoch132, test_loss is 0.45340, train_accuracy is 1.00000,test_accuracy is 0.94450,train_all_loss is 0.34921,source_cla_loss is 0.34904,domain_loss is 0.00008
Epoch133, test_loss is 0.34977, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34935,source_cla_loss is 0.34913,domain_loss is 0.00010
Epoch134, test_loss is 0.35017, train_accuracy is 1.00000,test_accuracy is 0.99975,train_all_loss is 0.34920,source_cla_loss is 0.34906,domain_loss is 0.00006
Epoch135, test_loss is 0.35451, train_accuracy is 1.00000,test_accuracy is 0.99900,train_all_loss is 0.34912,source_cla_loss is 0.34899,domain_loss is 0.00005
Epoch136, test_loss is 0.34991, train_accuracy is 1.00000,test_accuracy is 0.99975,train_all_loss is 0.34903,source_cla_loss is 0.34893,domain_loss is 0.00004
Epoch137, test_loss is 0.34986, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34906,source_cla_loss is 0.34896,domain_loss is 0.00004
Epoch138, test_loss is 0.35165, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34928,source_cla_loss is 0.34916,domain_loss is 0.00005
Epoch139, test_loss is 0.35202, train_accuracy is 1.00000,test_accuracy is 0.99975,train_all_loss is 0.34909,source_cla_loss is 0.34899,domain_loss is 0.00004
Epoch140, test_loss is 0.35071, train_accuracy is 1.00000,test_accuracy is 0.99975,train_all_loss is 0.34912,source_cla_loss is 0.34902,domain_loss is 0.00004
Epoch141, test_loss is 0.35684, train_accuracy is 1.00000,test_accuracy is 0.99900,train_all_loss is 0.34903,source_cla_loss is 0.34897,domain_loss is 0.00003
Epoch142, test_loss is 0.35529, train_accuracy is 1.00000,test_accuracy is 0.99875,train_all_loss is 0.34911,source_cla_loss is 0.34898,domain_loss is 0.00006
Epoch143, test_loss is 0.35079, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34928,source_cla_loss is 0.34908,domain_loss is 0.00008
Epoch144, test_loss is 0.35015, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34987,source_cla_loss is 0.34964,domain_loss is 0.00009
Epoch145, test_loss is 0.37696, train_accuracy is 1.00000,test_accuracy is 0.98600,train_all_loss is 0.34924,source_cla_loss is 0.34913,domain_loss is 0.00005
Epoch146, test_loss is 0.35011, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34918,source_cla_loss is 0.34900,domain_loss is 0.00007
Epoch147, test_loss is 0.35067, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34922,source_cla_loss is 0.34910,domain_loss is 0.00005
Epoch148, test_loss is 0.34959, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34979,source_cla_loss is 0.34955,domain_loss is 0.00010
Epoch149, test_loss is 0.35497, train_accuracy is 1.00000,test_accuracy is 0.99975,train_all_loss is 0.34996,source_cla_loss is 0.34975,domain_loss is 0.00008
Epoch150, test_loss is 0.35252, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34923,source_cla_loss is 0.34914,domain_loss is 0.00004
Epoch151, test_loss is 0.35072, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34911,source_cla_loss is 0.34906,domain_loss is 0.00002
Epoch152, test_loss is 0.35047, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34921,source_cla_loss is 0.34909,domain_loss is 0.00005
Epoch153, test_loss is 0.35013, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34905,source_cla_loss is 0.34900,domain_loss is 0.00002
Epoch154, test_loss is 0.34926, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34898,source_cla_loss is 0.34891,domain_loss is 0.00002
Epoch155, test_loss is 0.34921, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34898,source_cla_loss is 0.34893,domain_loss is 0.00002
Epoch156, test_loss is 0.34936, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34896,source_cla_loss is 0.34890,domain_loss is 0.00002
Epoch157, test_loss is 0.34949, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34897,source_cla_loss is 0.34892,domain_loss is 0.00002
Epoch158, test_loss is 0.34983, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34905,source_cla_loss is 0.34899,domain_loss is 0.00002
Epoch159, test_loss is 0.34976, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34891,source_cla_loss is 0.34887,domain_loss is 0.00002
Epoch160, test_loss is 0.34934, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34898,source_cla_loss is 0.34889,domain_loss is 0.00003
Epoch161, test_loss is 0.34963, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34897,source_cla_loss is 0.34890,domain_loss is 0.00003
Epoch162, test_loss is 0.35000, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34905,source_cla_loss is 0.34897,domain_loss is 0.00003
Epoch163, test_loss is 0.34932, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34903,source_cla_loss is 0.34898,domain_loss is 0.00002
Epoch164, test_loss is 0.34963, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34893,source_cla_loss is 0.34887,domain_loss is 0.00002
Epoch165, test_loss is 0.34932, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34903,source_cla_loss is 0.34895,domain_loss is 0.00003
Epoch166, test_loss is 0.34944, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34898,source_cla_loss is 0.34891,domain_loss is 0.00002
Epoch167, test_loss is 0.35002, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34903,source_cla_loss is 0.34896,domain_loss is 0.00002
Epoch168, test_loss is 0.34956, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34908,source_cla_loss is 0.34901,domain_loss is 0.00003
Epoch169, test_loss is 0.34920, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34905,source_cla_loss is 0.34899,domain_loss is 0.00002
Epoch170, test_loss is 0.34940, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34893,source_cla_loss is 0.34888,domain_loss is 0.00002
Epoch171, test_loss is 0.34942, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34893,source_cla_loss is 0.34889,domain_loss is 0.00001
Epoch172, test_loss is 0.35001, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34895,source_cla_loss is 0.34889,domain_loss is 0.00002
Epoch173, test_loss is 0.35019, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34917,source_cla_loss is 0.34906,domain_loss is 0.00004
Epoch174, test_loss is 0.35418, train_accuracy is 1.00000,test_accuracy is 0.99950,train_all_loss is 0.34925,source_cla_loss is 0.34917,domain_loss is 0.00003
Epoch175, test_loss is 0.34981, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34906,source_cla_loss is 0.34902,domain_loss is 0.00002
Epoch176, test_loss is 0.34910, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34898,source_cla_loss is 0.34894,domain_loss is 0.00002
Epoch177, test_loss is 0.35157, train_accuracy is 1.00000,test_accuracy is 0.99975,train_all_loss is 0.34903,source_cla_loss is 0.34895,domain_loss is 0.00003
Epoch178, test_loss is 0.36411, train_accuracy is 1.00000,test_accuracy is 0.99900,train_all_loss is 0.34918,source_cla_loss is 0.34911,domain_loss is 0.00002
Epoch179, test_loss is 0.35386, train_accuracy is 1.00000,test_accuracy is 0.99975,train_all_loss is 0.35033,source_cla_loss is 0.34998,domain_loss is 0.00012
Epoch180, test_loss is 0.39304, train_accuracy is 1.00000,test_accuracy is 0.97850,train_all_loss is 0.34949,source_cla_loss is 0.34938,domain_loss is 0.00004
Epoch181, test_loss is 0.35160, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34927,source_cla_loss is 0.34917,domain_loss is 0.00003
Epoch182, test_loss is 0.34962, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34908,source_cla_loss is 0.34901,domain_loss is 0.00002
Epoch183, test_loss is 0.34926, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34898,source_cla_loss is 0.34891,domain_loss is 0.00002
Epoch184, test_loss is 0.49573, train_accuracy is 1.00000,test_accuracy is 0.92900,train_all_loss is 0.34966,source_cla_loss is 0.34932,domain_loss is 0.00011
Epoch185, test_loss is 0.35219, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.35185,source_cla_loss is 0.35073,domain_loss is 0.00036
Epoch186, test_loss is 0.35016, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34945,source_cla_loss is 0.34929,domain_loss is 0.00005
Epoch187, test_loss is 0.34990, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34914,source_cla_loss is 0.34902,domain_loss is 0.00004
Epoch188, test_loss is 0.35030, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34904,source_cla_loss is 0.34896,domain_loss is 0.00003
Epoch189, test_loss is 0.35148, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34905,source_cla_loss is 0.34897,domain_loss is 0.00003
Epoch190, test_loss is 0.35053, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34895,source_cla_loss is 0.34891,domain_loss is 0.00001
Epoch191, test_loss is 0.34955, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34896,source_cla_loss is 0.34888,domain_loss is 0.00002
Epoch192, test_loss is 0.34971, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34898,source_cla_loss is 0.34894,domain_loss is 0.00001
Epoch193, test_loss is 0.34957, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34905,source_cla_loss is 0.34896,domain_loss is 0.00003
Epoch194, test_loss is 0.34920, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34898,source_cla_loss is 0.34892,domain_loss is 0.00002
Epoch195, test_loss is 0.35196, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34898,source_cla_loss is 0.34891,domain_loss is 0.00002
Epoch196, test_loss is 0.35668, train_accuracy is 1.00000,test_accuracy is 0.99975,train_all_loss is 0.34921,source_cla_loss is 0.34903,domain_loss is 0.00005
Epoch197, test_loss is 0.35010, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34966,source_cla_loss is 0.34950,domain_loss is 0.00005
Epoch198, test_loss is 0.34923, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34955,source_cla_loss is 0.34939,domain_loss is 0.00004
Epoch199, test_loss is 0.35031, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34922,source_cla_loss is 0.34910,domain_loss is 0.00003
Epoch200, test_loss is 0.35095, train_accuracy is 1.00000,test_accuracy is 1.00000,train_all_loss is 0.34909,source_cla_loss is 0.34898,domain_loss is 0.00003
```
# Contact
- **Chao He**
- **chaohe#bjtu.edu.cn (please replace # by @)**
| 10
| 1
|
davidfowl/IdentityEndpointsSample
|
https://github.com/davidfowl/IdentityEndpointsSample
|
A sample showing how to setup ASP.NET Core Identity API endpoints for authentication
|
# Background
https://devblogs.microsoft.com/dotnet/improvements-auth-identity-aspnetcore-8/
In .NET 8 preview 6, we've added new APIs to allow exposing endpoints to register, login and refresh bearer tokens. This is a simple API
that returns tokens (or sets cookies) that is optimized usage with 1st party applications (no delegated authentication). The tokens are self contained, and generated using the
same technique as cookie authentication. **These are NOT JWTs**, they are self-contained tokens. To make issued tokens work across servers, [data protection](https://learn.microsoft.com/en-us/aspnet/core/security/data-protection/configuration/overview?view=aspnetcore-7.0) needs to be configured
with shared storage.
## New APIs
There are 2 new concepts being introduced:
1. A new [bearer token authentication handler](https://github.com/dotnet/aspnetcore/blob/bad855959a99257bc6f194dd19ecd6c9aeb03acb/src/Security/Authentication/BearerToken/src/BearerTokenExtensions.cs#L24). This authentication handler supports token validation and issuing and integrates
with the normal ASP.NET Core authentication system. It can be used standalone without identity.
- ASP.NET Core Identity builds on top of this authentication handler and exposes an [AddIdentityBearerToken](https://github.com/dotnet/aspnetcore/blob/579d547d708eb19f8b05b00f5386649d6dac7b6a/src/Identity/Core/src/IdentityAuthenticationBuilderExtensions.cs#L20).
2. [A set of HTTP endpoints](https://github.com/dotnet/aspnetcore/blob/bad855959a99257bc6f194dd19ecd6c9aeb03acb/src/Identity/Core/src/IdentityApiEndpointRouteBuilderExtensions.cs#L32) for registering a new user, exchanging credentials for a token/cookie and refreshing tokens using the identity APIs.
These new building blocks make it easier to build authenticated 1st party applications (applications that don't delegate authentication).
| 82
| 11
|
hexiaochun/liblibapp
|
https://github.com/hexiaochun/liblibapp
|
liblibAi自动作图插件
|
## 1、在浏览器导入浏览器插件
## 2、打开liblibai.com的画图地址



## 3、启动本地软件

## 4、导入批量任务,开始下发
## 5、自动下发作图
## 6、多开浏览器的方法
"/Applications/Microsoft Edge.app/Contents/MacOS/Microsoft Edge" --user-data-dir="~/edge1" --no-first-run &
"/Applications/Microsoft Edge.app/Contents/MacOS/Microsoft Edge" --user-data-dir="~/edge2" --no-first-run &
"/Applications/Microsoft Edge.app/Contents/MacOS/Microsoft Edge" --user-data-dir="~/edge3" --no-first-run &
**1. 通过命令行启动新的浏览器进程**
这种方法稍微复杂一点,但是可以让你更灵活地控制浏览器的启动和运行。
1. 打开“应用程序”文件夹,找到Edge浏览器,然后右键点击选择“显示包内容”。
2. 打开"Contents" > "MacOS"文件夹,记住里面的"Microsoft Edge"文件的路径。
3. 打开“终端”应用,输入以下命令并回车:
```bash
"/path/to/Microsoft Edge" --user-data-dir="/path/to/new/directory" --no-first-run &
```
请将上述命令中的"/path/to/Microsoft Edge"替换为实际的"Microsoft Edge"文件路径,将"/path/to/new/directory"替换为你想要存储新的用户数据的目录路径。
注意,每次使用不同的"--user-data-dir"参数,都会启动一个新的浏览器进程,从而打开新的浏览器窗口。
希望以上的信息对你有所帮助!
在 Windows 电脑上多开 Edge 浏览器的方法,和 Mac 的方法相类似
**1. 通过命令行启动新的浏览器进程**
这种方法稍微复杂一些,但是它可以让你更灵活地控制浏览器的启动和运行。
1. 按 `Win+R` 打开运行对话框,输入 `cmd` 并按回车,这样可以打开命令提示符窗口。
2. 在命令提示符中输入以下命令并回车:
```bash
start msedge.exe --user-data-dir="C:\path\to\new\directory" --no-first-run
```
请将上述命令中的 "C:\path\to\new\directory" 替换为你想要存储新的用户数据的目录路径。注意,每次使用不同的 "--user-data-dir" 参数,都会启动一个新的浏览器进程,从而打开新的浏览器窗口。
这两种方法都可以让你在 Windows 电脑上多开 Edge 浏览器,你可以根据自己的需要选择使用哪一种。
## 图文教程
https://snvazev2ds.feishu.cn/docx/MlKrdrjJfoRey0xun33chtoOnye
## 视频教程
[点击这里观看B站视频](https://www.bilibili.com/video/BV1aj411Z7Pc/)
## mac电脑提示文件损坏的处理方式
sudo xattr -d com.apple.quarantine /Applications/libbliapp.app
## 软件下载地址
https://github.com/hexiaochun/liblibapp/releases/tag/v1.0.0
## 代码编译
npm install
npm run watch
| 14
| 3
|
Agnes4m/nonebot_plugin_pjsk
|
https://github.com/Agnes4m/nonebot_plugin_pjsk
|
pjsk表情包生成,适配nonebot2的插件
|
<!-- markdownlint-disable MD026 MD031 MD033 MD036 MD041 -->
<div align="center">
<a href="https://v2.nonebot.dev/store">
<img src="https://raw.githubusercontent.com/Agnes4m/nonebot_plugin_l4d2_server/main/image/logo.png" width="180" height="180" alt="NoneBotPluginLogo">
</a>
<p>
<img src="https://raw.githubusercontent.com/A-kirami/nonebot-plugin-template/resources/NoneBotPlugin.svg" width="240" alt="NoneBotPluginText">
</p>
# NoneBot-Plugin-PJSK
_✨ Project Sekai 表情包制作 ✨_
<img src="https://img.shields.io/badge/python-3.9+-blue.svg" alt="python">
<a href="https://pdm.fming.dev">
<img src="https://img.shields.io/badge/pdm-managed-blueviolet" alt="pdm-managed">
</a>
<a href="https://jq.qq.com/?_wv=1027&k=l82tMuPG">
<img src="https://img.shields.io/badge/QQ%E7%BE%A4-424506063-orange" alt="QQ Chat Group">
</a>
<br />
<a href="./LICENSE">
<img src="https://img.shields.io/github/license/Agnes4m/nonebot_plugin_pjsk.svg" alt="license">
</a>
<a href="https://pypi.python.org/pypi/nonebot-plugin-pjsk">
<img src="https://img.shields.io/pypi/v/nonebot-plugin-pjsk.svg" alt="pypi">
</a>
<a href="https://pypi.python.org/pypi/nonebot-plugin-pjsk">
<img src="https://img.shields.io/pypi/dm/nonebot-plugin-pjsk" alt="pypi download">
</a>
</div>
## 📖 介绍
### Wonderhoy!

## 💿 安装
以下提到的方法 任选**其一** 即可
<details open>
<summary>[推荐] 使用 nb-cli 安装</summary>
在 nonebot2 项目的根目录下打开命令行, 输入以下指令即可安装
```bash
nb plugin install nonebot-plugin-pjsk
```
</details>
<details>
<summary>使用包管理器安装</summary>
在 nonebot2 项目的插件目录下, 打开命令行, 根据你使用的包管理器, 输入相应的安装命令
<details>
<summary>pip</summary>
```bash
pip install nonebot-plugin-pjsk
```
</details>
<details>
<summary>pdm</summary>
```bash
pdm add nonebot-plugin-pjsk
```
</details>
<details>
<summary>poetry</summary>
```bash
poetry add nonebot-plugin-pjsk
```
</details>
<details>
<summary>conda</summary>
```bash
conda install nonebot-plugin-pjsk
```
</details>
打开 nonebot2 项目根目录下的 `pyproject.toml` 文件, 在 `[tool.nonebot]` 部分的 `plugins` 项里追加写入
```toml
[tool.nonebot]
plugins = [
# ...
"nonebot_plugin_pjsk"
]
```
</details>
## ⚙️ 配置
见 [config.py](./nonebot_plugin_pjsk/config.py) 文件
插件开箱即用,如无需要则无须配置
## 🎉 使用
直接使用指令 `pjsk` 进入交互创建模式;
使用指令 `pjsk -h` 了解使用 Shell-Like 指令创建表情的帮助
### 效果图
<details>
<summary>使用交互创建模式</summary>

</details>
<details>
<summary>使用 Shell-Like 指令</summary>

</details>
## 🙈 碎碎念
- ~~由于本人没玩过啤酒烧烤,~~ 可能出现一些小问题,可以提 issue 或者 [加群](https://jq.qq.com/?_wv=1027&k=l82tMuPG)反馈 ~~或者单纯进来玩~~
- 本项目仅供学习使用,请勿用于商业用途,喜欢该项目可以 Star 或者提供 PR,如果构成侵权将在 24 小时内删除
- [爱发电](https://afdian.net/a/agnes_digital)
## 💡 鸣谢
### [TheOriginalAyaka/sekai-stickers](https://github.com/TheOriginalAyaka/sekai-stickers)
- 原项目 & 素材来源
## 💰 赞助
感谢大家的赞助!你们的赞助将是我继续创作的动力!
- [爱发电](https://afdian.net/a/agnes_digital)
## 📝 更新日志
### 0.2.5
- 使用自己合并的字体文件避免某些字不显示的问题
### 0.2.4
- 在交互模式中提供的参数会去掉指令前缀,以防 Adapter 删掉参数开头的 Bot 昵称,导致参数不对的情况
- 重写帮助图片的渲染(个人感觉效果还不是很好……)
### 0.2.3
- 限制了贴纸文本大小,以免 Bot 瞬间爆炸
- 未提供字体大小时适应性调节 ([#14](https://github.com/Agnes4m/nonebot_plugin_pjsk/issues/14))
- 参数 `--rotate` 改为提供角度值,正数为顺时针旋转
- 将指令帮助渲染为图片发送(可以关)
- 丢掉了 `pil-utils` 依赖
### 0.2.2
- 修改了 0.2.1 版的交互创建模式的触发方式
- 试验性地支持了 Emoji
### 0.2.1
- 更改指令 `pjsk列表` 的交互方式
### 0.2.0
- 重构插件
| 18
| 2
|
GitHubPangHu/whoisQuery
|
https://github.com/GitHubPangHu/whoisQuery
|
whois查询,可以查询任意后缀域名。
|
# whoisQuery
whois查询,可以查询任意后缀域名。
这个是单个域名查询,如需多域名查询请下载BatchQuery文件夹,BatchQuery文件夹内的是批量查询代码。
Whois query, can query any suffix domain name.
This is a single domain name query. If you need multiple domain name queries, please download the BatchQuery folder, which contains the batch query code.
使用方法:
下载代码,运行index.html页面,输入域名查询即可,批量查询进入BatchQuery文件夹内查看。
请求改成ajax方法。可以前后端分离开。
php的代码运行方法很简单,使用小皮,宝塔等类似集成环境即可使用。
注意:
需要开启intl、curl扩展。
#### PHP版本>= 7.4
data.json文件中的几个对象代表的意思,如果查询时候没有显示信息,则是data.json文件中没有那个字符串,自己对应加上即可。或者提交给我域名后缀!
```
domain 域名
domainCode 域名代码
CreationDate 创建日期
ExpiryDate 到期时间
UpdatedDate 更新时间
SponsoringRegistrar 注册商
RegistrarURL 服务商网址
Registrant 注册人
DomainStatus 域名状态
DNS dns服务器
DNSSEC
RegistrantContactEmail 注册人邮箱
unregistered 未注册
```
### whois.php文件返回类型,可以当api使用。自己写前端页面。把data.json和whois.php放到服务器,就可以api调用!!!
``` json
// 返回是404的就是没查到。看原始whois信息。
{
"main":{
"domain":"查询的域名",
"domainCode":"IDN域名的code编码。非IDN域名返回和域名一样",
"CreationDate":"创建时间",
"ExpiryDate":"到期时间",
"UpdatedDate":"更新日期",
"SponsoringRegistrar":"注册商",
"RegistrarURL":"注册商网址",
"Registrant":"注册人",
"DomainStatus":"域名状态",
"DNS":"dns服务器",
"DNSSEC":"unsigned",
"RegistrantContactEmail":"注册人邮箱号",
"unregistered":"如果404则已经注册,未注册返回的是'未注册'三个字"
},
"result":"状态,200正常,其他都是直接把对应错误返回,是字符串",
"whois":"whois原始信息"
}
```
更新:2023-7-18 胖虎
单个查询图

| 18
| 3
|
ChenDMLSY/Electric-mazar
|
https://github.com/ChenDMLSY/Electric-mazar
| null |
# Electric-mazar
| 32
| 4
|
yuyoujiang/Exercise-Counter-with-YOLOv8-on-NVIDIA-Jetson
|
https://github.com/yuyoujiang/Exercise-Counter-with-YOLOv8-on-NVIDIA-Jetson
|
Pose estimation demo for exercise counting with YOLOv8
|
# Exercise Counter with YOLOv8 on NVIDIA Jetson

This is a pose estimation demo application for exercise counting with YOLOv8 using [YOLOv8-Pose](https://docs.ultralytics.com/tasks/pose) model.
This has been tested and deployed on a [reComputer Jetson J4011](https://www.seeedstudio.com/reComputer-J4011-p-5585.html?queryID=7e0c2522ee08fd79748dfc07645fdd96&objectID=5585&indexName=bazaar_retailer_products). However, you can use any NVIDIA Jetson device to deploy this demo.
Current only 3 different exercise types can be counted:
- Squats
- Pushups
- Situps
However, I will keep updating this repo to add more exercises and also add the function of detecting the exercise type.
## Introduction
The YOLOv8-Pose model can detect 17 key points in the human body, then select discriminative key-points based on the characteristics of the exercise.
Calculate the angle between key-point lines, when the angle reaches a certain threshold, the target can be considered to have completed a certain action.
By utilizing the above-mentioned mechanism, it is possible to achieve an interesting *Exercise Counter* Application.
## Installation
- **Step 1:** Flash JetPack OS to reComputer Jetson device [(Refer to here)](https://wiki.seeedstudio.com/reComputer_J4012_Flash_Jetpack/).
- **Step 2:** Access the terminal of Jetson device, install pip and upgrade it
```sh
sudo apt update
sudo apt install -y python3-pip
pip3 install --upgrade pip
```
- **Step 3:** Clone the following repo
```sh
git clone https://github.com/ultralytics/ultralytics.git
```
- **Step 4:** Open requirements.txt
```sh
cd ultralytics
vi requirements.txt
```
- **Step 5:** Edit the following lines. Here you need to press i first to enter editing mode. Press ESC, then type :wq to save and quit
```sh
# torch>=1.7.0
# torchvision>=0.8.1
```
**Note:** torch and torchvision are excluded for now because they will be installed later.
- **Step 6:** Install the necessary packages
```sh
pip3 install -e .
```
- **Step 7:** If there is an error in numpy version, install the required version of numpy
```sh
pip3 install numpy==1.20.3
```
- **Step 8:** Install PyTorch and Torchvision [(Refer to here)](https://wiki.seeedstudio.com/YOLOv8-DeepStream-TRT-Jetson/#install-pytorch-and-torchvision).
- **Step 9:** Run the following command to make sure yolo is installed properly
```sh
yolo detect predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg'
```
- **Step 10:** Clone exercise counter demo
```sh
git clone https://github.com/yuyoujiang/exercise-counting-with-YOLOv8.git
```
## Prepare The Model File
YOLOv8-pose pretrained pose models are PyTorch models and you can directly use them for inferencing on the Jetson device. However, to have a better speed, you can convert the PyTorch models to TensorRT optimized models by following below instructions.
- **Step 1:** Download model weights in PyTorch format [(Refer to here)](https://docs.ultralytics.com/tasks/pose/#models).
- **Step 2:** Execute the following command to convert this PyTorch model into a TensorRT model
```sh
# TensorRT FP32 export
yolo export model=yolov8s-pose.pt format=engine device=0
# TensorRT FP16 export
yolo export model=yolov8s-pose.pt format=engine half=True device=0
```
**Tip:** [Click here](https://docs.ultralytics.com/modes/export) to learn more about yolo export
- **Step 3:** Prepare a video to be tested. [Here]() we have included sample videos for you to test
## Let's Run It!
To run the exercise counter, enter the following commands with the `exercise_type` as:
- sit-up
- pushup
- squat
### For video
```sh
python3 demo.py --sport <exercise_type> --model yolov8s-pose.pt --show True --input <path_to_your_video>
```
### For webcam
```sh
python3 demo.py --sport <exercise_type> --model yolov8s-pose.pt --show True --input 0
```

## References
[https://github.com/ultralytics/](https://github.com/ultralytics/)
[https://wiki.seeedstudio.com](https://wiki.seeedstudio.com/YOLOv8-DeepStream-TRT-Jetson/)
| 23
| 5
|
justjavac/antd-form-devtools
|
https://github.com/justjavac/antd-form-devtools
|
🔧 DevTools for Ant Design Forms
|
# DevTools for Ant Design Forms
[](https://github.com/justjavac/antd-form-devtools/actions/workflows/main.yml)
[![npm][npm]][npm-url]
[![download][download]][download-url]
A Powerfull DevTools to help debug Ant Design Forms.

## Install
```bash
npm install antd-form-devtools -D
```
## Usage
```diff
import React from 'react';
import { Button, Form, Input, InputNumber } from 'antd';
import { DevTool } from 'antd-form-devtools';
const App = () => {
return (
<>
<Form name="userinfo" onFinish={console.log}>
<Form.Item label="Username" name="username">
<Input />
</Form.Item>
<Form.Item label="Age" name="age">
<InputNumber min="0" max="100" />
</Form.Item>
<Form.Item>
<Button type="primary" htmlType="submit">
Submit
</Button>
</Form.Item>
+ <DevTool />
</Form>
</>
);
};
export default App;
```
## Live Demo
https://antd-form-devtools.vercel.app
## Local example
```bash
git clone https://github.com/justjavac/antd-form-devtools.git
cd example
yarn dev
```
## License
[antd-form-devtools](https://github.com/justjavac/antd-form-devtools) is
released under the MIT License. See the [LICENSE](LICENSE) file in the project
root directory for details.
# Thank
♥️ The inspiration for this project comes from [react-hook-form/devtools](https://github.com/react-hook-form/devtools).
[npm]: https://img.shields.io/npm/v/antd-form-devtools.svg
[npm-url]: https://npmjs.com/package/antd-form-devtools
[download]: https://img.shields.io/npm/dm/antd-form-devtools.svg?style=flat
[download-url]: https://npmcharts.com/compare/antd-form-devtools?minimal=true
| 22
| 0
|
fred1268/okapi
|
https://github.com/fred1268/okapi
|
API tests made as easy as table driven tests
|
# okapi :giraffe:
API tests made as easy as table driven tests.
## Introduction
okapi is a program allowing you to test your APIs by using tests files and test cases, pretty much like the `go test` command with table-driven tests. okapi will iterate on all `.test.json` files in the specified directory and runs every test case containted within the files, sequentially or in parallel.
The response of each test case is then compared to the expected response (both the HTTP Response Status Code, as well as the payload). Success or failure are reported.
## Installation
Pretty easy to install:
```shell
go install github.com/fred1268/okapi@latest
```
> Please note that okapi does have a single dependency: [**clap :clap:, the Command Line Argument Parser**](https://github.com/fred1268/go-clap), which makes it very easy to parse okapi command line. clap is a lightweight, non intrusive command line parsing library you may want to try out in your own projects. Feel free to give it a try!
## Configuring okapi :giraffe:
In order to run, okapi requires the following files:
- a configuration file
- one or more test files
- zero or more payload files
- zero or more response files
### Configuration file
The configuration file looks like the following:
```json
{
"exampleserver1": {
"host": "http://localhost:8080",
"auth": {
"login": {
"method": "POST",
"endpoint": "http://localhost:8080/login",
"payload": "{\"email\":\"[email protected]\",\"password\":\"${env:MY_PASSWORD}\"}",
"expected": {
"statuscode": 200
}
},
"session": {
"cookie": "jsessionid"
}
}
},
"exampleserver2": {
"host": "http://localhost:9090",
"auth": {
"login": {
"method": "POST",
"endpoint": "http://localhost:8080/login",
"payload": "{\"email\":\"[email protected]\",\"password\":\"${env:MY_PASSWORD}\"}",
"expected": {
"statuscode": 200
}
},
"session": {
"jwt": "header"
}
}
},
"exampleserver3": {
"host": "http://localhost:8088",
"auth": {
"apikey": {
"apikey": "Bearer: ${env:MY_APIKEY}",
"header": "Authorization"
}
}
},
"hackernews": {
"host": "https://hacker-news.firebaseio.com"
}
}
```
A Server description contains various fields:
- `host` (mandatory): the URL of the server (including port and everything you don't want to repeat on every test)
- `auth.login`: used for login/password authentication, using the same format as a test (see below)
- `auth.session.cookie`: used for cookie session management, name of the cookie maintaining the session
- `auth.apikey`: used for API Key authentication, contains both the API Key and the required header
- `auth.session.jwt`: used for JWT session management (`header`, `payload` or `payload.xxx`)
Here `exampleserver1` uses the `/login` endpoint on the same HTTP server than the one used for the tests. Both `email` and `password` are submitted in the `POST`, and `200 OK` is expected upon successful login. The session is maintained by a session cookie called `jsessionid`.
The second server, `exampleserver2` also uses the `/login` endpoint, but on a different server, hence the endpoint with a different server. The sesssion is maintained using a JWT (JSON Web Token) which is obtained though a header (namely `Authorization`). Should your JWT be returned as a payload, you can specify `"payload"` instead of `"header"`. You can even use `payload.token` for instance, if your JWT is returned in a `token` field of a JSON object. JWT is always sent back using the `Authorization` header in the form of `Authorization: Bearer my_jwt`.
> Please note that in the case of the server definition, `endpoint` must be an fully qualified URL, not a relative endpoint like in the test files. Thus `endpoint` must start with `http://` or `https://`.
The third server, `exampleserver3` uses API Keys for authentication. The apikey field contains the key itself, whereas the header field contains the field used to send the API Key back (usually `Authorization`). Please note that session is not maintained in this example, since the API Key is sent with each request.
The last server, `hackernews`, is a server which doesn't require any authentication.
> _Environment variable substitution_: please note that `host`, `apikey`, `endpoint` and `payload` can use environment variable substitution. For example, instead of hardcoding your API Key in your server configuration file, you can use `${env:MY_APIKEY}` instead. Upon startup, the `${env:MY_APIKEY}` text will be replaced by the value of `MY_APIKEY` environment variable (i.e. `$MY_APIKEY` or `%MY_APIKEY%`).
### Test files
A test file looks like the following:
```json
{
"tests": [
{
"name": "121003",
"server": "hackernews",
"method": "GET",
"endpoint": "/v0/item/121003.json",
"expected": {
"statuscode": 200
}
},
{
"name": "cap121004",
"server": "hackernews",
"method": "GET",
"endpoint": "/v0/item/121004.json",
"capture": true,
"expected": {
"statuscode": 200
}
},
{
"name": "121004",
"server": "hackernews",
"method": "GET",
"endpoint": "/v0/item/${cap121004.id}.json",
"expected": {
"statuscode": 200,
"response": "{\"id\":${cap121004.id}}"
}
},
{
"name": "121005",
"server": "hackernews",
"method": "GET",
"endpoint": "/v0/item/121005.json",
"expected": {
"statuscode": 200,
"response": "@file"
}
},
{
"name": "doesnotwork",
"server": "hackernews",
"method": "POST",
"endpoint": "/v0/item",
"urlparams": "{\"q\":\"search terms\"}",
"payload": "@custom_filename.json",
"expected": {
"statuscode": 200
}
},
{
"name": "121007",
"server": "hackernews",
"method": "GET",
"endpoint": "/v0/item/121007.json",
"expected": {
"statuscode": 200,
"response": "\\s+[wW]eight"
}
}
]
}
```
> The test files must end with `.test.json` in order for okapi to find them. A good pratice is to name them based on your routes. For example, in this case, since we are testing hackernews' `item` route, the file could be named `item.test.json` or `item.get.test.json` if you need to be more specific.
A test file contains an array of tests, each of them containing:
- `name` (mandatory): a unique name to globally identify the test (test name must not contain the `. (period)` character)
- `server` (mandatory): the name of the server used to perform the test (declared in the configuration file)
- `method` (mandatory): the method to perform the operation (`GET`, `POST`, `PUT`, etc.)
- `endpoint` (mandatory): the endpoint of the operation (usually a ReST API of some sort)
- `urlparams` (default none): an object whose keys/values represents URL parameters' keys and values
- `capture` (default false): true if you want to capture the response of this test so that it can be used in another test in this file (fileParallel mode only)
- `skip` (default false): true to have okapi skip this test (useful when debugging a script file)
- `debug` (default false): true to have okapi display debugging information (see debugging tests below)
- `payload` (default none): the payload to be sent to the endpoint (usually with a POST, PUT or PATCH method)
- `expected`: this section contains:
- `statuscode` (mandatory): the expected status code returned by the endpoint (200, 401, 403, etc.)
- `response` (default none): the expected payload returned by the endpoint.
> Please note that `payload` and `response` can be either a string (including json, as shown in 121004), or `@file` (as shown in 121005) or even a `@custom_filename.json` (as shown in doesnotwork). This is useful if you prefer to separate the test from its `payload` or expected `response` (for instance, it is handy if the `payload` or `response` are complex JSON structs that you can easily copy and paste from somewhere else, or simply prefer to avoid escaping double quotes). However, keeping the names for `payload` and `response` like `test_name.payload.json`and `test_name.expected.json` is still a good practice.
> Please also note that `endpoint` and `payload` can use environment variable substitution using the ${env:XXX} syntax (see previous note about environment variable substitution).
> Lastly, please note that `endpoint` and `response` can use captured variable (i.e. variables inside a captured response, see `"capture":true`). For instance, to use the `id` field returned inside of a `user` object in test `mytest`, you will use `${mytest.user.id}`. In the example above, we used `${cap121004.id}` to retrieve the ID of the returned response in test `cap121004`. Captured response also works with arrays.
### Payload and Response files
Payload and response files don't have a specific format, since they represent whatever the server you are testing is expecting from or returns to you. The only important things to know about the payload and response files, is that they must be placed in the test directory, and must be named `<name_of_test>.payload.json` and `<name_of_test>.expected.json` (`121005.expected.json` in the example above) respectively if you specify `@file`. Alternatively, they can also be put in a `payload/` or `expected/` subdirectory of the test directory, and, in that case, be named `<name_of_test>.json`. If you decide to use a custom filename for your `payload` and/or `response`, then you can specify the name of your choice prefixed by `@` (`@custom_filename.json` in the example above).
## Expected response
As we saw earlier, for each test, you will have to define the expected response. okapi will always compare the HTTP Response Status Code with the one provided, and can optionally, compare the returned payload. The way it works is pretty simple:
- if the response is in JSON format:
- if a field is present in `expected`, okapi will also check for its presence in the response
- if the response contains other fields not mentioned in `expected`, they will be ignored
- success or failure is reporting accordingly
- if the response is a non-JSON string:
- the response is compared to `expected` and success or failure is reported
> Please note that, in the case of non-JSON responses, you can use regular expressions (see test 121007). In that case, make sure the `expected.response` field is set to a proper, compilable, regular expression. Be mindful that you will need to escape the `\ (backslash)` character using `\\`. For instance `\s+[wW]eight` will be written `\\s+[wW]eight`, in order to match one or more whitespace characters, followed by weight or Weight.
## Running okapi :giraffe:
To launch okapi, please run the following:
```shell
okapi [options] <test_directory>
```
where options are one or more of the following:
- `--servers-file`, `-s` (mandatory): point to the configuration file's location
- `--verbose`, `-v` (default no): enable verbose mode
- `--file-parallel` (default no): run the test files in parallel (instead of the tests themselves)
- `--file`, `-f` (default none): only run the specified test file
- `--test`, `-t` (default none): only run the specified standalone test
- `--timeout` (default 30s): set a default timeout for all HTTP requests
- `--no-parallel` (default parallel): prevent tests from running in parallel
- `--workers` (default #cores): define the maximum number of workers
- `--user-agent` (default okapi UA): set the default user agent
- `--content-type` (default application/json): set the default content type for requests
- `--accept` (default application/json): set the default accept header for responses
- `test_directory` (mandatory): point to the directory where all the test files are located
> Please note that the `--file-parallel` mode is particularly handy if you want to have a sequence of tests that needs to run in a specific order. For instance, you may want to create a resource, update it, and delete it. Placing these three tests in the same file and in the right order, and then running okapi with `--file-parallel` should do the trick. The default mode is used for unit tests, whereas the `--file-parallel` mode is used for (complex) test scenarios.
## Output example
To try the included examples (located in `./assets/tests`), you need to run the following command:
```shell
$ okapi --servers-file ./assets/config.json --verbose ./assets/tests
```
You should then see the following output:
```shell
--- PASS: hackernews.items.test.json
--- PASS: 121014 (0.35s)
--- PASS: 121012 (0.36s)
--- PASS: 121010 (0.36s)
--- PASS: 121004 (0.36s)
--- PASS: 121007 (0.36s)
--- PASS: 121009 (0.36s)
--- PASS: 121006 (0.36s)
--- PASS: 121011 (0.36s)
--- PASS: 121008 (0.36s)
--- PASS: 121013 (0.36s)
--- PASS: 121005 (0.36s)
--- PASS: 121003 (0.36s)
PASS
ok hackernews.items.test.json 0.363s
--- PASS: hackernews.users.test.json
--- PASS: jk (0.36s)
--- PASS: jo (0.36s)
--- PASS: jc (0.36s)
--- PASS: 401 (0.36s)
--- PASS: jl (0.37s)
PASS
ok hackernews.users.test.json 0.368s
okapi total run time: 0.368s
```
## Debugging tests
Writing tests is tedious and it can be pretty difficult to understand what is going on in a test within a full test file running in parallel. In order to help debug your tests, okapi provides a few mechanisms.
### okapi header
With each HTTP request, okapi will send its user agent of course (default `Mozilla/5.0 (compatible; okapi/1.x; +https://github.com/fred1268/okapi)`), but also a special header, `X-okapi-testname` which will contain the name of the test. You can use this information on the server side for instance to display a banner in your logs to delimit the start and end of the tests, making it easier to find the logs corresponding to a particular test.
### okapi run modes
Running tests in `--file-parallel` or `--no-parallel` mode can make it easier to troubleshoot tests, since the tests output, mainly on the server side, won't overlap. Also, using the `--file` or the `--test` to work on a specific file or test respectively will also make this process smoother.
### Test debug flag
Each test can also have its `debug` flag set to true. This tells okapi to display detailed information about the HTTP request being made to the server, including URL, Method, Payload, Parameters, Header, etc. This can be helpful to verify the good setup of your tests, including, but not limited to, captured information.
### Test skip flag
Finally, do not forget that you can skip some tests with the `skip` flag to reduce the amount of information displayed both on the okapi side but also on your server's logs.
## Integrating okapi :giraffe: with your own software
okapi exposes a pretty simple and straightforward API that you can use within your own Go programs.
You can find more information about the exposed API on [The Official Go Package](https://pkg.go.dev/github.com/fred1268/okapi/testing).
## Feedback and contribution
Feel free to send feedback, PR, issues, etc.
| 12
| 0
|
amazon-science/ContraCLM
|
https://github.com/amazon-science/ContraCLM
|
[ACL 2023] Code for ContraCLM: Contrastive Learning For Causal Language Model
|
# ContraCLM: Contrastive Learning for Causal Language Model
This repository contains code for the ACL 2023 paper, [ContraCLM: Contrastive Learning for Causal Language Model](https://arxiv.org/abs/2210.01185).
Work done by: Nihal Jain*, Dejiao Zhang*, Wasi Uddin Ahmad*, Zijian Wang, Feng Nan, Xiaopeng Li, Ming Tan, Ramesh Nallapati, Baishakhi Ray, Parminder Bhatia, Xiaofei Ma, Bing Xiang. (* <em>indicates equal contribution</em>).
## Updates
* [07-08-2023] Initial release of the code.
## Quick Links
* [Overview](#overview)
* [Setup](#setup)
* [Environment](#environment)
* [Datasets](#datasets)
* [Pretraining](#pretraining)
* [GPT2](#pretain-gpt2-on-nl-data)
* [CodeGen](#pretrain-codegen-350m-mono-on-pl-data)
* [Evaluation](#evaluation)
* [Citation](#citation)
## Overview
<p align="center">
<img src="static/llms_contraclm.png" width=500></img>
</p>
We present ContraCLM, a novel contrastive learning framework which operates at both the token-level and sequence-level. ContraCLM enhances the discrimination of representations from a decoder-only language model and bridges the gap with encoder-only models, making causal language models better suited for tasks beyond language generation. We encourage you to check out our [paper](https://arxiv.org/abs/2210.01185) for more details.
## Setup
The setup involves installing the necessary dependencies in an environment and placing the datasets in the requisite directory.
### Environment
Run these commands to create a new conda environment and install the required packages for this repository.
```bash
# create a new conda environment with python >= 3.8
conda create -n contraclm python=3.8.12
# install dependencies within the environment
conda activate contraclm
pip install -r requirements.txt
```
### Datasets & Preprocessing
See <a href="preprocess/">here</a>.
## Pretraining
In this section, we show how to use this repository to pretrain (i) `GPT2` on Natural Language (NL) data, and (ii) `CodeGen-350M-Mono` on Programming Language (PL) data.
### Common Instructions
1. This section assumes that you have the train and validation data stored at `TRAIN_DIR` and `VALID_DIR` respectively, and are within an environment with all the above dependencies installed (see [Setup](#setup)).
2. You can get an overview of all the flags associated with pretraining by running:
```bash
python pl_trainer.py --help
```
### Pretain `GPT2` on NL Data
#### Usage
```bash runscripts/run_wikitext.sh```
1. For quickly testing the code and debug, suggesting run the code with MLE loss only
by setting ```CL_Config=$(eval echo ${options[1]})``` within the script.
2. All other opotions involves CL loss at either token-level or sequence-level.
### Pretrain `CodeGen-350M-Mono` on PL Data
#### Usage
1. Configure the variables at the top of `runscripts/run_code.sh`. There are lots of options but only the dropout options are explained here (others are self-explanatory):
* `dropout_p`: The dropout probability value used in `torch.nn.Dropout`
* `dropout_layers`: If > 0, this will activate the last `dropout_layers` with probability `dropout_p`
* `functional_dropout`: If specified, will use a functional dropout layer on top of the token representations output from the CodeGen model
2. Set the variable `CL` according to desired model configuration. Make sure the paths to `TRAIN_DIR, VALID_DIR` are set as desired.
3. Run the command: `bash runscripts/run_code.sh`
## Evaluation
See the relevant task-specific directories [here](evaluation/).
## Citation
If you use our code in your research, please cite our work as:
```
@inproceedings{jain-etal-2023-contraclm,
title = "{C}ontra{CLM}: Contrastive Learning For Causal Language Model",
author = "Jain, Nihal and
Zhang, Dejiao and
Ahmad, Wasi Uddin and
Wang, Zijian and
Nan, Feng and
Li, Xiaopeng and
Tan, Ming and
Nallapati, Ramesh and
Ray, Baishakhi and
Bhatia, Parminder and
Ma, Xiaofei and
Xiang, Bing",
booktitle = "Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = jul,
year = "2023",
address = "Toronto, Canada",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.acl-long.355",
pages = "6436--6459"
}
```
## Security
See [CONTRIBUTING](CONTRIBUTING.md#security-issue-notifications) for more information.
## License
This project is licensed under the Apache-2.0 License.
| 14
| 0
|
mydaoyuan/spa-sparender
|
https://github.com/mydaoyuan/spa-sparender
|
使用 puppeteer 爬取 spa 应用转化为静态文件
|
## 是什么
这是一个 spa 应用的低成本 seo 方案。它不限于你使用了任何框架(如react、vue)、任何的构建工具(如webpack、vite)。本脚本针对 spa 打包后的产物,进行本地渲染,把生成的 dom 保存,然后通过静态文件服务(如 NGINX)判断访问网站的用户是否是爬虫。如果是爬虫,则返回渲染后的 dom , 达到 seo 的目的。
## 立即使用
### 使用服务
安装依赖 npm install
修改 src/index.ts 中的 targetUrl http://localhost:3008 改为 自己启动的 spa 应用地址。
PS: 可以使用项目中的 spa-server.js 脚本, 将脚本移动到你的 spa 应用 ,`node spa-server.js` 即可启动一个 SPA 服务, 运行在 localhost:3008。
### spa 渲染
执行 npm run dev 输出 done 日志后,即为转换完成。脚本会访问你启动的 spa 服务,查找页面的所有 a 标签,进行访问爬取。爬取的 html 内容会放到以域名为目录的文件夹下。
当输出 done 日志后,代表爬取完成。此时就得到了 spa 的静态渲染文件了。
接下来就是要让爬虫能访问到爬取的 html 文件。 正常用户访问的时候,返回正常的 spa 页面逻辑。
### 启动静态文件服务
你可以参考项目中的 nginx.conf 配置,启动一个 nginx 服务进行本地验证。 核心逻辑是根据 user_agent 字段,判断是否是爬虫,如果是爬虫访问,我们就把请求转发到另外一个专门为 bot 启动的 server。
因为我直接在 location / 中判断的时候,报错了 nginx: [emerg] "try_files" directive is not allowed。 在 Nginx 中,try_files 指令不能在 if 条件块中使用。 如果有更好的解决方案欢迎你在 issue 中提出。
### 验证服务
【默认你使用了 nginx 代理 spa】
把爬取的静态文件拷贝到 spa 产物 dist 目录下,新建一个 bot 文件夹 存储。
可以本地启动 nginx.conf 进行验证【nginx 文件的 root 目录替换成你自己电脑的地址】。
执行 `curl -H 'User-agent:Googlebot' http://localhost:3008`
查看是否成功返回渲染后的 html 页面
### 服务端动态渲染(利用 user-agent)
为了提高用户体验我们用了 SPA 技术、为了 SEO 我们用了 SSR、预渲染等技术。不同技术方案有一定差距,不能兼顾优点。但仔细想,需要这些技术优点的`用户`,其实时不一样的,SPA 针对的是浏览器普通用户、SSR 针对的是网页爬虫,如 googlebot、baiduspider 等,那为什么我们不能给不同`用户`不同的页面呢,服务端动态渲染就是这种方案。
基本原理: 服务端对请求的 user-agent 进行判断,浏览器端直接给 SPA 页面,如果是爬虫,给经过动态渲染的 html 页面(因为蜘蛛不会造成 DDOS,所以这种方案相对于 SSR 能节省不少服务器资源)
PS: 你可能会问,给了爬虫不同的页面,会不会被认为是网页作弊行为呢?
Google 给了<a href="https://developers.google.com/search/docs/guides/dynamic-rendering" target="_blank">回复</a>:
Dynamic rendering is not cloaking
Googlebot generally doesn't consider dynamic rendering as cloaking. As long as your dynamic rendering produces similar content, Googlebot won't view dynamic rendering as cloaking.
When you're setting up dynamic rendering, your site may produce error pages. Googlebot doesn't consider these error pages as cloaking and treats the error as any other error page.
Using dynamic rendering to serve completely different content to users and crawlers can be considered cloaking. For example, a website that serves a page about cats to users and a page about dogs to crawlers can be considered cloaking.
也就是说,如果我们没有刻意去作弊,而是使用动态渲染方案去解决 SEO 问题,爬虫经过对比网站内容,没有明显差异,不会认为这是作弊行为。
至于百度,请参考
<a href="https://www.zhihu.com/question/19864108" target="_blank">豆丁网是在做黑帽 SEO 吗?</a>
<a href="https://ask.seowhy.com/question/16688" target="_blank">通过 user-agent 判断,将 Baiduspider 定向到 http 页面</a>
基本的解释是:
> 的确从单一 feature 来讲,会比较难区分 cloaking 型的 spam 和豆丁类的搜索优化,但是搜索引擎判断 spam 绝对不会只用一个维度的 feature。docin 这样的网站,依靠它的外链关系、alexa 流量、用户在搜索结果里面的点击行为等等众多信号,都足以将其从 spam 里面拯救出来了。
>
> 何况,一般的 spam 肯定还有关键词堆砌、文本语义前后不搭、link farm 等等众多特征。总之 antispam 一门综合性的算法,会参考很多要素,最后给出判断。
>
> 实在不行了,还可以有白名单作为最后的弥补手段,拯救这批大网站是没什么问题的啦。
所以不做过多的黑帽或者灰帽, 百度也不会做作弊处理
### 感谢
https://github.com/zuoyanart/sparender 项目
| 10
| 0
|
FiguraMC/Figura
|
https://github.com/FiguraMC/Figura
| null |
<h1 align="center"> Figura </h1>
<p align="center">
<img alt="fabric" height="56" src="https://cdn.jsdelivr.net/npm/@intergrav/devins-badges@3/assets/cozy/supported/fabric_vector.svg">
<img alt="forge" height="56" src="https://cdn.jsdelivr.net/npm/@intergrav/devins-badges@3/assets/cozy/supported/forge_vector.svg">
<img alt="quilt" height="56" src="https://cdn.jsdelivr.net/npm/@intergrav/devins-badges@3/assets/cozy/supported/quilt_vector.svg">
</p>
```diff
- Notice: The previous owner has deleted everything. We are currently rebuilding.
```
## A Minecraft Java client mod that allows you to extensively customize your player model and have other players see your Avatar without requiring any server mods!

## Utilizing the full potential of [Blockbench](https://www.blockbench.net/).


## Not only can you customize your model but Figura also has an optional [Lua](https://www.lua.org/) API to make your own scripts!

## What if someone is invisible, or very small? Take advantage of Figura's robust permission system!

## We also have some extras, like:


Meet us on the [FiguraMC Discord Server](https://discord.gg/figuramc) for more info and help :)
# Links
[discord]: https://discord.com/api/guilds/1129805506354085959/widget.png
[modrinth]: https://img.shields.io/badge/Modrinth-1bd96a?logo=modrinth&logoColor=ffffff&labelColor=1bd96a
[curseforge]: https://img.shields.io/badge/CurseForge-f16436?logo=curseforge&logoColor=ffffff&labelColor=f16436
[kofi]: https://img.shields.io/badge/Ko--fi-00b9fe?logo=kofi&logoColor=ffffff&labelColor=00b9fe
[collective]: https://img.shields.io/badge/Open%20Collective-83b3fb?logo=opencollective&logoColor=ffffff&labelColor=83b3fb
## Social: [ ![discord][] ](https://discord.gg/figuramc)
## Download: [ ![modrinth] ](https://modrinth.com/mod/figura) [ ![curseforge][] ](https://curseforge.com/minecraft/mc-mods/figura)
## Donate: [ ![collective][] ](https://opencollective.com/figura) [ ![kofi][] ](https://ko-fi.com/skyrina)
# FAQ
### • My avatars don't appear in the Figura list, even though they're in the correct folder?
> Check if your avatar has a file called "avatar.json" (don't forget to check file extensions)
>
> This file can be completely empty, it just needs to be present for Figura to recognise it as an avatar
### • How do I hide the vanilla model?
> At the top of your script, put:
>
> • To hide literally everything (player, armor, elytra, held items):
> ```lua
> vanilla_model.ALL:setVisible(false)
> ```
>
> • To hide only the player:
> ```lua
> vanilla_model.PLAYER:setVisible(false)
> ```
>
> • To hide only armor:
> ```lua
> vanilla_model.ARMOR:setVisible(false)
> ```
>
> • To hide other, or specific parts, you can check the in-game docs
### • How do I play a Blockbench Animation?
> Simply put this code in your script:
> ```lua
> animations.modelName.animationName:play()
> ```
> Where:
>
> "`animations`" is the global table which contains all animations
>
> "`modelName`" is the name of the model you are accessing the animation from
>
> "`animationName`" is, as the name says, the animation name
### • What are Pings and how do I use them?
> Pings are Lua functions that are executed for everyone running your avatar's script
>
> Pings are sent from the host player, and can be used to sync things like keypresses or action wheel actions
>
> To create a ping:
> ```lua
> function pings.myPing(arg1, arg2)
> -- code to run once the ping is called
> end
> ```
> And to execute the ping, it's as shrimple as calling a lua function:
> ```lua
> pings.myPing("Hello", "World")
> ```
> Note that pings are limited in their content and size, and are rate-limited
### • How can I add an emissive texture?
> Name the texture the same as the non-emissive counterpart, then add `_e` to the end
>
> And don't forget to set the places you don't want to glow to **transparent black** (#00000000), to also ensure compatibility with shader mods
### • My emissives doesn't glow, nor have bloom with Iris/Optifine shaders?
> Since some shaders doesnt support emissives, a compatibility setting (default on) will change the render type of emissive textures to render them at it were fullbright, however that can lead to some unintended results
>
> You can force your avatar to use the correct emissive render type by using the render type `EYES` on your model
### • How can I use Figura with OptiFine?
> Figura will work with Optifine but due it's closed source nature issues might arise, therefore we still recommend you try using Sodium+Iris (Fabric) or Rubidium+Oculus (Forge) instead
>
> Check out the full list of [alternatives](https://lambdaurora.dev/optifine_alternatives/)
### • Where can I find Avatars to download?
> For now you can find Avatars in the showcase channel in the official Discord server (A Web Based and In-Game browser is in the works!)
### • My Minecraft is cracked (non-premium/non-original) or I'm trying to join a cracked offline mode server, why can't I use Figura?
> Figura uses your account's UUID and your Mojang authentication as a way to prove you own that account, avoiding unwanted / malicious uploads
>
> Non-premium Minecraft accounts don't authenticate with Mojang, and Offline mode servers don't report working UUID's, as such can neither upload nor download Figura avatars
## Community Resources
* Want to learn / get into Lua scripting?
check out this [Lua quickstart](https://manuel-3.github.io/lua-quickstart) made by Manuel
* If you are tired of having to be in-game to look in the wiki, applejuice hosts the wiki as a [website](https://applejuiceyy.github.io/figs/)
* Are you new to Figura and are looking for a video tutorial about how everything works? You should probably watch Chloe's [Figura tutorial series](https://www.youtube.com/playlist?list=PLNz7v2g2SFA8lOQUDS4z4-gIDLi_dWAhl) on YouTube
* Do you wish there was a wiki for the rewrite?
Slyme has an [unofficial wiki](https://slymeball.github.io/Figura-Wiki) covering most of Figura's basics
* If you want a more in-depth wiki, with the GitHub style, Katt made one [here](https://github.com/KitCat962/FiguraRewriteRewrite/wiki)
* Do you use VSCode and wish Figura's documentation autocompleted in the editor? GrandpaScout saves the day with their [VSDocs](https://github.com/GrandpaScout/FiguraRewriteVSDocs/wiki)
| 71
| 17
|
GreptimeTeam/greptimedb-client-cpp
|
https://github.com/GreptimeTeam/greptimedb-client-cpp
|
GreptimeDB C++ Client
|
# greptimedb-client-cpp
## Build
```bash
git clone --recurse-submodules --depth 1 --shallow-submodules https://github.com/GreptimeTeam/greptimedb-client-cpp
cd greptimedb-client-cpp
# create a new build directory where the project is compiled
mkdir build && cd build
cmake ..
make -j$(nproc)
```
## Run examples
```bash
# the test program is in the greptimedb-client-cpp/build/examples directory
cd greptimedb-client-cpp/build/examples
# run the example binary
./example_client_stream
```
| 12
| 2
|
sanri/demo-bevy_robot
|
https://github.com/sanri/demo-bevy_robot
|
Display UR5 robots using the bevy engine
|
# demo-bevy_robot
Display UR5 robots using the bevy engine
<img src="media/demo.png">
## native application
### build
Run cmd
```shell
cargo build --release
```
### run
Run cmd
```shell
cargo run --release
```
## single page web application
### build
1. Compile to wasm, refer to [trunk](https://trunkrs.dev/). the generated files are in the path "./dist".
```shell
trunk build --release
```
2. Modify the "dist/index.html" file, add code disable the right mouse button menu.
```html
<script type="text/javascript">
document.oncontextmenu = function(){
return false;
}
</script>
```
### run
use [static-web-server](https://static-web-server.net/) or others web-server.
```shell
static-web-server -p 8080 --root ./dist/
```
| 14
| 1
|
MirandaJaramillo/portafolioTCPRO
|
https://github.com/MirandaJaramillo/portafolioTCPRO
| null |
# Portafolio Adaptable (Responsive) con Bootstrap 5
Este proyecto creado para el bootcamp Tecnolochicas PRO, es una página web adaptable a dispositivos de distintos tamaños (este tipo de sitio web se conoce en inglés como "responsive").
El propósito de esta página web es mostrar el portafolio de proyectos de un(a) desarrollador(a) y su experiencia. Incluye una descripción breve de su motivación, experiencia, proyectos, artículos publicados y formas de contacto.
También incluye imágenes alternativas en la carpeta `imagenes` en caso de que se desee personalizar la imagen principal del desarrollador, además de animación a la escritura de la página web con JavaScript.
### Capturas de pantalla:
Primera parte de la página web:

Experiencia:

Proyectos:

Testimonios:

Contacto:

## Tecnologías
Esta página web fue creada con:
* HTML
* CSS
* JavaScript
* Bootstrap 5
Además, se incluyeron **Google Fonts** para personalizar la fuente y **Bootstrap icons** para incorporar íconos como flechas y logos de redes sociales populares.
## Español
El texto de la página web está escrito en español, al igual que las clases y atributos personalizados. Las clases relacionadas con Bootstrap se incluyeron en inglés.
| 85
| 0
|
nix-community/nix-github-actions
|
https://github.com/nix-community/nix-github-actions
|
A library to turn Nix Flake attribute sets into Github Actions matrices [maintainer=@adisbladis]
|
# nix-github-actions
This is a library to turn Nix Flake attribute sets into Github Actions matrices.
**Features:**
- Unopinionated
Install Nix using any method you like
- Flexible
Nix-github-actions is not an action in itself but a series of templates and a Nix library to build your own CI.
- Parallel job execution
Use one Github Actions runner per package attribute
## Usage
### Quickstart
nix-github-actions comes with a quickstart script that interactively guides you through integrating it:
``` bash
$ nix run github:nix-community/nix-github-actions
```
### Manual
1. Find a CI template in [./.github/workflows](./.github/workflows) and copy it to your project
2. Integrate into your project
#### Using Flake atttribute packages
- `flake.nix`
``` nix
{
inputs.nix-github-actions.url = "github:nix-community/nix-github-actions";
inputs.nix-github-actions.inputs.nixpkgs.follows = "nixpkgs";
outputs = { self, nixpkgs, nix-github-actions }: {
githubActions = nix-github-actions.lib.mkGithubMatrix { checks = self.packages; };
packages.x86_64-linux.hello = nixpkgs.legacyPackages.x86_64-linux.hello;
packages.x86_64-linux.default = self.packages.x86_64-linux.hello;
};
}
```
#### Using Flake attribute checks
- `flake.nix`
``` nix
{
inputs.nix-github-actions.url = "github:nix-community/nix-github-actions";
inputs.nix-github-actions.inputs.nixpkgs.follows = "nixpkgs";
outputs = { self, nixpkgs, nix-github-actions }: {
githubActions = nix-github-actions.lib.mkGithubMatrix { inherit (self) checks; };
checks.x86_64-linux.hello = nixpkgs.legacyPackages.x86_64-linux.hello;
checks.x86_64-linux.default = self.packages.x86_64-linux.hello;
};
}
```
| 23
| 1
|
neoforged/NeoForge
|
https://github.com/neoforged/NeoForge
|
Neo Modding API for Minecraft, based on Forge
|

NeoForge
=============
[][Discord]
Forge is a free, open-source modding API all of your favourite mods use!
| Version | Support |
|---------| ------------- |
| 1.20.x | Active |
* [Download]
* [Discord]
* [Documentation]
# Installing NeoForged
Go to [CurseForge][CurseForge] project, select the minecraft version and installer, and run it.
You can download the installer for the *Recommended Build* or the
*Latest build* there. Latest builds may have newer features but may be
more unstable as a result. The installer will attempt to install Forge
into your vanilla launcher environment, where you can then create a new
profile using that version and play the game!
For support and questions, visit [the NeoForged Discord server][Discord].
# Creating Mods
[See the "Getting Started" section in the NeoForged Documentation][Getting-Started].
# Contribute to Forge
If you wish to actually inspect Forge, submit PRs or otherwise work
with Forge itself, you're in the right place!
[See the guide to setting up a Forge workspace][ForgeDev].
### Pull requests
[See the "Making Changes and Pull Requests" section in the Forge documentation][Pull-Requests].
Please read the contributing guidelines found [here][Contributing] before making a pull request.
### Contributor License Agreement
We require all contributors to acknowledge the [Neoforged Contributor License Agreement][CLA].
Please ensure you have a valid email address associated with your GitHub account to do this. If you have previously
signed it, you should be OK.
#### Donate
*NeoForged is a large project with many collaborators working on it around the clock. It will always remain
free to use and modify. However, it costs money to run such a large project as this, so please consider visiting
our opencollective.*
[Contributing]: ./CONTRIBUTING.md
[CLA]: https://cla-assistant.io/MinecraftForge/MinecraftForge
[Download]: https://maven.neoforged.net/releases/net/neoforged/forge/
[Discord]: https://discord.neoforged.net/
[Documentation]: https://docs.neoforged.net/
[Getting-Started]: https://docs.neoforged.net/en/latest/gettingstarted/
[ForgeDev]: https://docs.neoforged.net/en/latest/forgedev/
[Pull-Requests]: https://docs.neoforged.net/en/latest/forgedev/#making-changes-and-pull-requests
[CurseForge]: https://curseforge.com/placeholder
| 442
| 39
|
Mindinventory/MarioInMotion
|
https://github.com/Mindinventory/MarioInMotion
|
Creating interactive UIs with Motion Layout using Jetpack Compose
|
<a href="https://www.mindinventory.com/?utm_source=gthb&utm_medium=repo&utm_campaign=CollapsingToolbarWithMotionCompose"><img src="https://github.com/Sammindinventory/MindInventory/blob/main/Banner.png"></a>
# CollapsingToolbarWithMotionCompose
Creating a collapsing toolbar with delightful animation in Android doesn't have to be difficult - this example will guide you through the process in a simple, painless, and compose way.

# More details on mindful-engineering
Get up to speed on Motion Layout with Jetpack Compose with <a href="https://medium.com/mindful-engineering/creating-interactive-uis-with-motion-layout-in-jetpack-compose-6b76ec41c6ab">the latest blog</a>, which is packed with valuable insights and information.
Behold, Mario in Motion!
<a href="https://medium.com/mindful-engineering/after-going-through-this-blog-youll-achieve-this-kind-of-polished-animation-using-motionlayout-6b76ec41c6ab">
<img src="https://cdn-images-1.medium.com/v2/resize:fit:826/1*[email protected]" width="203" alt="mindful-engineering - Creating interactive UIs with Motion layout in Jetpack Compose">
</a>
# LICENSE!
This sample is [MIT-licensed](/LICENSE).
# Let us know!
We would be delighted if you could refer to our example. Just send an email to [email protected] And do let us know if you have any questions or suggestions regarding our work.
<a href="https://www.mindinventory.com/contact-us.php?utm_source=gthb&utm_medium=repo&utm_campaign=MarioInMotion">
<img src="https://github.com/Sammindinventory/MindInventory/blob/main/hirebutton.png" width="203" height="43" alt="app development">
</a>
| 15
| 0
|
minwoo0611/Awesome-3D-LiDAR-Datasets
|
https://github.com/minwoo0611/Awesome-3D-LiDAR-Datasets
|
This reposiotry is the collection for public 3D LiDAR datasets
|
# Awesome 3D LiDAR Datasets [](https://github.com/sindresorhus/awesome)
This repository is the collection of datasets, involving the 3D LiDAR. The information is presented in a comprehensive table, outlining the type and number of LiDARs, the purpose of each dataset, and scale details. The objectives are broadly categorized into Object Detection (OD), Segmentation (Seg), Odometry (Odom), Place Recognition (PR), and Localization (Loc). If a dataset includes data exceeding 1 km, it is classified as large scale. Datasets that use multiple LiDAR sequences, even if not executed concurrently, are labeled as 'Single w. Multiple LiDAR'.
## Most Recent Update
### Update: 2023-07-13
- The table includes the specific LiDAR products utilized in each dataset, involving the its channels or name.
### Update: 2023-07-12
- Initial segregation of the 3D LiDAR dataset collection.
The table below summarizes the details of each dataset:
|Dataset|Year|Single vs Multi|Spinning LiDAR|Solid State LiDAR|Objective|Scale|
|---|---|---|---|---|---|---|
|[MIT DARPA](http://grandchallenge.mit.edu/wiki/index.php?title=PublicData)|2010|Single|1x HDL-64E|No|Odom|Large|
|[Ford Campus](https://robots.engin.umich.edu/SoftwareData/InfoFord)|2011|Single|1x HDL-64E|No|Odom|Large|
|[KITTI](https://www.cvlibs.net/datasets/kitti/)|2013|Single|1x HDL-64E|No|Odom|Large|
|[NCLT](http://robots.engin.umich.edu/nclt/)|2017|Single|1x HDL-32E|No|Odom|Both|
|[Complex Urban Dataset](https://sites.google.com/view/complex-urban-dataset)|2019|Multi|2x VLP-16C|No|Odom|Large|
|[Toronto-3D](https://github.com/WeikaiTan/Toronto-3D)|2020|Multi|1x Teledyne Optech Maverick (32 Channels)|No|Seg|Large|
|[Apollo-DaoxiangLake Dataset](https://developer.apollo.auto/daoxianglake.html)|2020|Single|1x HDL-64E|No|Loc|Large|
|[Apollo-SouthBay Dataset](https://developer.apollo.auto/southbay.html)|2020|Single|1x HDL-64E|No|Loc|Large|
|[MulRan](https://sites.google.com/view/mulran-pr/dataset)|2020|Single|1x OS1-64|No|PR, Odom|Large|
|[The Oxford Radar RobotCar Dataset](https://oxford-robotics-institute.github.io/radar-robotcar-dataset/)|2020|Multi|2x HDL-32E|No|Odom, PR|Large|
|[Newer College Dataset](https://ori-drs.github.io/newer-college-dataset/)|2020|Single|1x OS1-64|No|Odom|Small|
|[nuScences](https://www.nuscenes.org/)|2020|Single|1x HDL-32E|No|OD|Large|
|[Ford AV Dataset](https://avdata.ford.com/)|2020|Multi|4x HDL-32E|No|Odom|Large|
|[LIBRE](https://sites.google.com/g.sp.m.is.nagoya-u.ac.jp/libre-dataset)|2020|Single w. Multiple LiDAR|12x Spinning (each)|No|Odom|Large|
|[EU Long-term Dataset](https://epan-utbm.github.io/utbm_robocar_dataset/)|2021|Multi|2x HDL-32E|No|Odom|Large|
|[NTU VIRAL Dataset](https://ntu-aris.github.io/ntu_viral_dataset/)|2021|Multi|2x OS1-16|No|Odom|Small|
|[M2DGR](https://github.com/SJTU-ViSYS/M2DGR)|2021|Single|1x VLP-32C|No|Odom|Large|
|[Pandaset](https://pandaset.org/)|2021|Multi|1x Pandar64|1x PandarGT|Seg|Large|
|[UrbanNav Dataset](https://github.com/IPNL-POLYU/UrbanNavDataset)|2021|Multi|1x HDL-32E, 1x VLP-16C, 1x Lslidar C16|No|Odom|Large|
|[Livox Simu-Dataset](https://www.livoxtech.com/simu-dataset)|2021|Multi|No|5x Livox Horizon, 1x Livox Tele|OD, Seg|Large|
|[Hilti 2021 SLAM dataset](https://hilti-challenge.com/dataset-2021.html)|2021|Multi|1x OS0-64|1x Livox MID70|Odom|Small|
|[S3LI Dataset](https://www.dlr.de/rm/en/s3li_dataset/#gallery/37227)|2022|Single|No|1x Black-filed Cube LiDAR|Odom|Large|
|[STHEREO](https://sites.google.com/view/rpmsthereo/)|2022|Single|1x OS1-128|No|Odom|Large|
|[ORFD](https://github.com/chaytonmin/Off-Road-Freespace-Detection)|2022|Single|1x Hesai Pandar40P|No|Seg|Large|
|[Tiers](https://github.com/TIERS/tiers-lidars-dataset)|2022|Multi|1x VLP-16C, 1x OS1-64, 1x OS0-128|1x Livox Avia, 1x Livox Horizon, 1x RealSense L515|Odom|Both|
|[Hllti 2022 SLAM dataset](https://hilti-challenge.com/dataset-2022.html)|2022|Single|1x Hesai PandarXT-32|No|Odom|Small|
|[USTC FLICAR](https://ustc-flicar.github.io/)|2023|Multi|1x HDL-32E, 1x VLP-32C, 1x OS0-128|1x Livox Avia|Odom|Small|
|[WOMD Dataset](https://waymo.com/open/data/motion/)|2023|Single|1x Spinning (Unknown)|No|OD|Large|
|[Wild Places](https://csiro-robotics.github.io/Wild-Places/)|2023|Single|1x VLP-16C|No|PR|Large|
|[Hilti 2023 SLAM Dataset](https://hilti-challenge.com/dataset-2023.html)|2023|Single w. Multiple LiDAR|1x PandarXT-32, 1x Robosense BPearl (each)|No|Odom|Small|
|[City Dataset](https://github.com/minwoo0611/MA-LIO)|2023|Multi|1x OS2-128|1x Livox Tele, 1x Livox Avia|Odom|Large
|[Ground-Challenge](https://github.com/sjtuyinjie/Ground-Challenge)|2023|Single|1 $\times$ VLP-16C|No|Odom|Small|
|[RACECAR](https://github.com/linklab-uva/RACECAR_DATA)|2023|Multi|No|3x Luminar Hydra|Loc, OD|Large|
|[ConSLAM](https://github.com/mac137/ConSLAM)|2023|Single|1x VLP-16C|No|SLAM|Small|
|[Pohang Canal Dataset](https://sites.google.com/view/pohang-canal-dataset/home?authuser=0)|2023|Multi|1x OS1-64, 2x OS1-32|No|Odom|Large|
| 49
| 4
|
CMEPW/221b
|
https://github.com/CMEPW/221b
|
Bake shellcode to get malicious.exe
|
# 221b
## Getting started
### 1. Compile binary
```shell
go build -o 221b ./main.go
```
### 2. Copy binary to path
```shell
sudo mv 221b /usr/local/bin/
```
### 3. Exec 221b
```shell
221b bake -k <key> -s <shell>
```
## Usage
```shell
221b help bake
Build a windows payload with the given shell encrypted in it to bypass AV
Usage:
221b bake [flags]
Flags:
-h, --help help for bake
-k, --key string key to use for the xor
-o, --output string Output path (e.g., /home/bin.exe)
-s, --shellpath string Path to the shell scrypt
Global Flags:
--debug activate debug mode
```
## Binary properties
It is possible to add a certain number of metadata as well as a logo via the folder named `misc`.
also remember to modify the `versioninfo.json` file at the root of the project
here's a preview of the final rendering, so don't ignore this part when planning a red team operation.

## Possible execution methods
### XOR :
```shell
221b bake -k "@ShLkHms221b" -s /PathToShellcode/demon.bin -o pwned.exe
[+] use xor encryption method
[+] encrypting demon.bin
[+] loading encrypted shell into payload
[+] compiling binary
go: added golang.org/x/crypto v0.11.0
go: added golang.org/x/sys v0.10.0
[+] file compiled to pwned.exe
```
### Chacha20
```shell
221b bake -m chacha20 -k "0123456789ABCDEF1123345611111111" -s /PathToShellcode/demon.bin -o pwned.exe
[+] use chacha20 encryption method
[+] encrypting demon.bin
[+] loading encrypted shell into payload
[+] compiling binary
go: added golang.org/x/crypto v0.11.0
go: added golang.org/x/sys v0.10.0
[+] file compiled to pwned.exe
```
### AES
```shell
221b bake -m aes -k "0123456789ABCDEF1123345611111111" -s /PathToShellcode/demon.bin -o pwned.exe
[+] use chacha20 encryption method
[+] encrypting demon.bin
[+] loading encrypted shell into payload
[+] compiling binary
go: added golang.org/x/crypto v0.11.0
go: added golang.org/x/sys v0.10.0
[+] file compiled to pwned.exe
```
| 11
| 0
|
mazzzystar/Queryable
|
https://github.com/mazzzystar/Queryable
|
Run OpenAI's CLIP model on iOS to search photos.
|
# Queryable
<a href="https://apps.apple.com/us/app/queryable-find-photo-by-text/id1661598353?platform=iphone">
<img src="https://github-production-user-asset-6210df.s3.amazonaws.com/6824141/252914927-51414112-236b-4f7a-a13b-5210f9203198.svg" alt="download-on-the-app-store">
</a>
[](https://apps.apple.com/us/app/queryable-find-photo-by-text/id1661598353?platform=iphone)
The open-source code of Queryable, an iOS app, leverages the OpenAI's [CLIP](https://github.com/openai/CLIP) model to conduct offline searches in the 'Photos' album. Unlike the category-based search model built into the iOS Photos app, Queryable allows you to use natural language statements, such as `a brown dog sitting on a bench`, to search your album. Since it's offline, your album privacy won't be compromised by any company, including Apple or Google.
[Blog](https://mazzzystar.github.io/2022/12/29/Run-CLIP-on-iPhone-to-Search-Photos/) | [Website](https://queryable.app/) | [App Store](https://apps.apple.com/us/app/queryable-find-photo-by-text/id1661598353?platform=iphone)
## How does it work?
* Encode all album photos using the CLIP Image Encoder, compute image vectors, and save them.
* For each new text query, compute the corresponding text vector using the Text Encoder.
* Compare the similarity between this text vector and each image vector.
* Rank and return the top K most similar results.
The process is as follows:
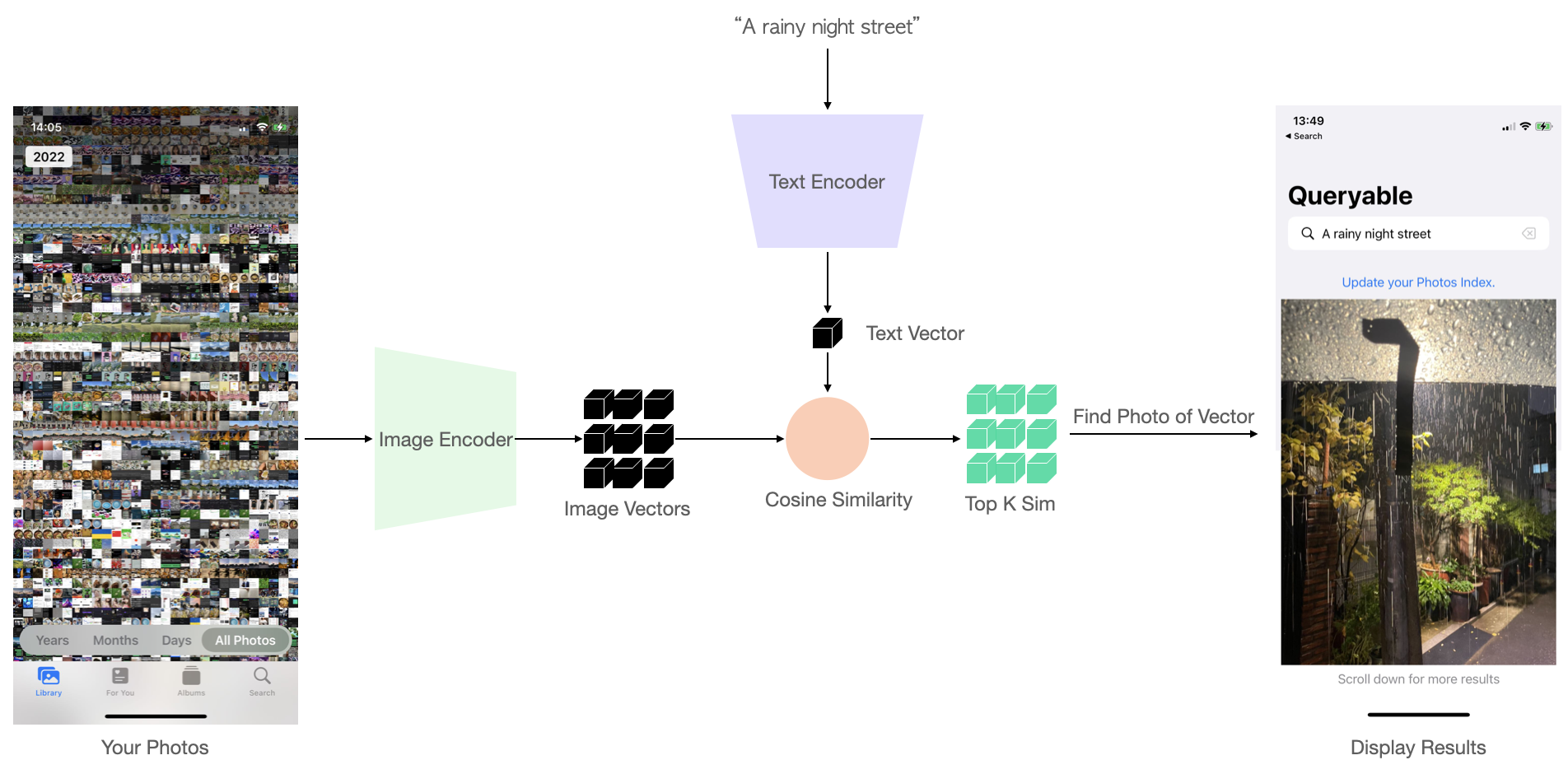
For more details, please refer to my blog: [Run CLIP on iPhone to Search Photos](https://mazzzystar.github.io/2022/12/29/Run-CLIP-on-iPhone-to-Search-Photos/).
## Run on Xcode
Download the `ImageEncoder_float32.mlmodelc` and `TextEncoder_float32.mlmodelc` from [Google Drive](https://drive.google.com/drive/folders/12ze3UcqrXt9qeySGh_j_zWE-PWRDTzJv?usp=drive_link).
Clone this repo, put the downloaded models below `CoreMLModels/` path and run Xcode, it should work.
## Core ML Export
> If you only want to run Queryable, you can **skip this step** and directly use the exported model from [Google Drive](https://drive.google.com/drive/folders/12ze3UcqrXt9qeySGh_j_zWE-PWRDTzJv?usp=drive_link). If you wish to implement Queryable that supports your own native language, or do some model quantization/acceleration work, here are some guidelines.
The trick is to separate the `TextEncoder` and `ImageEncoder` at the architecture level, and then load the model weights individually. Queryable uses the OpenAI [ViT-B/32](https://github.com/openai/CLIP) model, and I wrote a [Jupyter notebook](https://github.com/mazzzystar/Queryable/blob/main/PyTorch2CoreML.ipynb) to demonstrate how to separate, load, and export the Core ML model. The export results of the ImageEncoder's Core ML have a certain level of precision error, and more appropriate normalization parameters may be needed.
## Contributions
> Disclaimer: I am not a professional iOS engineer, please forgive my poor Swift code. You may focus only on the loading, computation, storage, and sorting of the model.
You can apply Queryable to your own product, but I don't recommend simply modifying the appearance and listing it on the App Store.
If you are interested in optimizing certain aspects(such as https://github.com/mazzzystar/Queryable/issues/4, https://github.com/mazzzystar/Queryable/issues/5, https://github.com/mazzzystar/Queryable/issues/6, https://github.com/mazzzystar/Queryable/issues/10, https://github.com/mazzzystar/Queryable/issues/11, https://github.com/mazzzystar/Queryable/issues/12), feel free to submit a PR (Pull Request).
If you have any questions/suggestions, here are some contact methods: [Discord](https://discord.com/invite/R3wNsqq3v5) | [Twitter](https://twitter.com/immazzystar) | [Reddit: r/Queryable](https://www.reddit.com/r/Queryable/).
## License
MIT License
Copyright (c) 2023 Ke Fang
| 1,825
| 327
|
iuricode/desafios-frontend
|
https://github.com/iuricode/desafios-frontend
|
Desafios frontend do Codelândia
|
# Desafios Frontend 💻
Bem-vindo(a) ao **Desafios Frontend**! Este projeto open source é um conjunto de desafios desenvolvido pela comunidade **[Codelândia no Discord](https://discord.com/invite/QevDJqCzaY)**. Seu propósito é ajudar as pessoas a praticarem seus conhecimentos em desenvolvimento frontend, abrangendo áreas como HTML, CSS, JavaScript e também bibliotecas como React e Next.js.
## Comunidade Codelândia 🎉
| Desafio | Nome | Demo | Figma | Código fonte | Vídeo |
| -- | -------------- | -------- | -------- | ------------ | ------------ |
| 01 | Blog | [Link](https://renans80.github.io/blog-codelandia/) | [Link](https://www.figma.com/file/Yb9IBH56g7T1hdIyZ3BMNO/Desafios---Codel%C3%A2ndia?type=design&node-id=0-1&mode=design&t=y8MCYFp0EDOred8A-0) | [Link](https://github.com/RenanS80/blog-codelandia) |
| 02 | JordanShoes | [Link](https://renans80.github.io/jordanshoes/) | [Link](https://www.figma.com/file/Yb9IBH56g7T1hdIyZ3BMNO/Desafios---Codel%C3%A2ndia?type=design&node-id=1883-2&mode=design&t=y8MCYFp0EDOred8A-0) | [Link](https://github.com/RenanS80/jordanshoes) |
| 03 | One Page | [Link](https://renans80.github.io/one-page/) | [Link](https://www.figma.com/file/Yb9IBH56g7T1hdIyZ3BMNO/Desafios---Codel%C3%A2ndia?type=design&node-id=3725-2&mode=design&t=y8MCYFp0EDOred8A-0) | [Link](https://github.com/RenanS80/one-page) | [Link](https://www.youtube.com/watch?v=OPeMr0yYP0c) |
| 04 | Login | [Link](https://renans80.github.io/login/) | [Link](https://www.figma.com/file/Yb9IBH56g7T1hdIyZ3BMNO/Desafios---Codel%C3%A2ndia?type=design&node-id=4261-2&mode=design&t=y8MCYFp0EDOred8A-0) | [Link](https://github.com/RenanS80/login) |
| 05 | Studio Ghibli | [Link](https://renan-a-viagem-de-chihiro.netlify.app/) | [Link](https://www.figma.com/file/Yb9IBH56g7T1hdIyZ3BMNO/Desafios---Codel%C3%A2ndia?type=design&node-id=5854-2&mode=design&t=y8MCYFp0EDOred8A-0) | [Link](https://github.com/RenanS80/a-viagem-de-chihiro) |
| 06 | Loki | [Link](https://renans80.github.io/loki/) | [Link](https://www.figma.com/file/Yb9IBH56g7T1hdIyZ3BMNO/Desafios---Codel%C3%A2ndia?type=design&node-id=7539-2&mode=design&t=y8MCYFp0EDOred8A-0) | [Link](https://github.com/RenanS80/loki) |
| 07 | Valorant | [Link](https://renans80.github.io/valorant/) | [Link](https://www.figma.com/file/Yb9IBH56g7T1hdIyZ3BMNO/Desafios---Codel%C3%A2ndia?type=design&node-id=10048-2&mode=design&t=y8MCYFp0EDOred8A-0) | [Link](https://github.com/RenanS80/valorant) |
| 08 | CodeMoji | [Link](https://renans80.github.io/codemoji/) | [Link](https://www.figma.com/file/Yb9IBH56g7T1hdIyZ3BMNO/Desafios---Codel%C3%A2ndia?type=design&node-id=11471-2&mode=design&t=y8MCYFp0EDOred8A-0) | [Link](https://github.com/RenanS80/codemoji) |
| 09 | Portfolio | Em breve | [Link](https://www.figma.com/file/Yb9IBH56g7T1hdIyZ3BMNO/Desafios---Codel%C3%A2ndia?type=design&node-id=13190-2&mode=design&t=y8MCYFp0EDOred8A-0) | Em breve |
| 10 | Naped | Em breve | [Link](https://www.figma.com/file/Yb9IBH56g7T1hdIyZ3BMNO/Desafios---Codel%C3%A2ndia?type=design&node-id=15409-2&mode=design&t=y8MCYFp0EDOred8A-0) | Em breve |
| 11 | Memo | [Link](https://renans80.github.io/jogo-da-memoria-halloween/) | [Link](https://www.figma.com/file/Yb9IBH56g7T1hdIyZ3BMNO/Desafios---Codel%C3%A2ndia?type=design&node-id=29500-2&mode=design&t=y8MCYFp0EDOred8A-0) | [Link](https://github.com/RenanS80/jogo-da-memoria-halloween) |
| 12 | La Pizza | [Link](https://renan-la-pizza.netlify.app/) | [Link](https://www.figma.com/file/Yb9IBH56g7T1hdIyZ3BMNO/Desafios---Codel%C3%A2ndia?type=design&node-id=31037-2&mode=design&t=y8MCYFp0EDOred8A-0) | [Link](https://github.com/RenanS80/jogo-da-memoria-halloween) |
| 13 | Arcane | [Link](https://renans80.github.io/arcane/) | [Link](https://www.figma.com/file/Yb9IBH56g7T1hdIyZ3BMNO/Desafios---Codel%C3%A2ndia?type=design&node-id=32427-3&mode=design&t=y8MCYFp0EDOred8A-0) | [Link](https://github.com/RenanS80/arcane) |
| 14 | HelpDog | [Link]() | [Link](https://www.figma.com/file/Yb9IBH56g7T1hdIyZ3BMNO/Desafios---Codel%C3%A2ndia?type=design&node-id=32505-3&mode=design&t=y8MCYFp0EDOred8A-0) | [Link](https://github.com/iuryyxd/desafios-codelandia/tree/main/Desafio14) |
| 15 | Readme Perfil | [Link](https://github.com/iuricode) | [Link](https://www.figma.com/file/Yb9IBH56g7T1hdIyZ3BMNO/Desafios---Codel%C3%A2ndia?type=design&node-id=91008-999&mode=design&t=s1zO4BTEBpag8Kdy-0) | [Link](https://github.com/iuricode/iuricode) |
| 16 | Feliz Natal | [Link](https://renan-natal-codelandia.netlify.app/) | [Link](https://www.figma.com/file/Yb9IBH56g7T1hdIyZ3BMNO/Desafios---Codel%C3%A2ndia?type=design&node-id=39340-782&mode=design&t=y8MCYFp0EDOred8A-0) | [Link](https://github.com/RenanS80/natal) |
| 17 | Kenai | Em breve | [Link](https://www.figma.com/file/Yb9IBH56g7T1hdIyZ3BMNO/Desafios---Codel%C3%A2ndia?type=design&node-id=40282-715&mode=design&t=y8MCYFp0EDOred8A-0) | Em breve |
| 18 | Spider-man | Em breve | [Link](https://www.figma.com/file/Yb9IBH56g7T1hdIyZ3BMNO/Desafios---Codel%C3%A2ndia?type=design&node-id=41278-752&mode=design&t=y8MCYFp0EDOred8A-0) | Em breve |
| 19 | Rachi | [Link](https://iuryyxd.github.io/desafios-codelandia/Desafio19/) | [Link](https://www.figma.com/file/Yb9IBH56g7T1hdIyZ3BMNO/Desafios---Codel%C3%A2ndia?type=design&node-id=41733-754&mode=design&t=y8MCYFp0EDOred8A-0) | [Link](https://github.com/iuryyxd/desafios-codelandia/tree/main/Desafio19) |
| 20 | Portfolio 2 | Em breve | [Link](https://www.figma.com/file/Yb9IBH56g7T1hdIyZ3BMNO/Desafios---Codel%C3%A2ndia?type=design&node-id=58198-756&mode=design&t=y8MCYFp0EDOred8A-0) | Em breve |
| 21 | Xbox | Em breve | [Link](https://www.figma.com/file/Yb9IBH56g7T1hdIyZ3BMNO/Desafios---Codel%C3%A2ndia?type=design&node-id=64381-758&mode=design&t=y8MCYFp0EDOred8A-0) | Em breve |
| 22 | Codelandia | [Link](https://iuryyxd.github.io/desafios-codelandia/Desafio22/) | [Link](https://www.figma.com/file/Yb9IBH56g7T1hdIyZ3BMNO/Desafios---Codel%C3%A2ndia?type=design&node-id=70013-760&mode=design&t=y8MCYFp0EDOred8A-0) | [Link](https://github.com/iuryyxd/desafios-codelandia/tree/main/Desafio22) |
| 23 | Music Legends | Em breve | [Link](https://www.figma.com/file/Yb9IBH56g7T1hdIyZ3BMNO/Desafios---Codel%C3%A2ndia?type=design&node-id=80254-762&mode=design&t=y8MCYFp0EDOred8A-0) | Em breve | [Link](https://www.youtube.com/watch?v=igI3jKsOyMA) |
| 24 | Arcane 2 | Em breve | [Link](https://www.figma.com/file/Yb9IBH56g7T1hdIyZ3BMNO/Desafios---Codel%C3%A2ndia?type=design&node-id=88764-795&mode=design&t=y8MCYFp0EDOred8A-0) | Em breve |
| 25 | HomeYou | [Link](https://iuryyxd.github.io/desafios-codelandia/Desafio25/) | [Link](https://www.figma.com/file/Yb9IBH56g7T1hdIyZ3BMNO/Desafios---Codel%C3%A2ndia?type=design&node-id=88764-796&mode=design&t=y8MCYFp0EDOred8A-0) | [Link](https://github.com/iuryyxd/desafios-codelandia/tree/main/Desafio25) |
| 26 | Art. | [Link](https://artwebsitee.netlify.app/) | [Link](https://www.figma.com/file/Yb9IBH56g7T1hdIyZ3BMNO/Desafios---Codel%C3%A2ndia?type=design&node-id=93571-1385&mode=design&t=y8MCYFp0EDOred8A-0) | [Link](https://github.com/iuryyxd/desafios-codelandia/tree/main/Desafio26) |
| 27 | FoodJP | [Link](https://iuryyxd.github.io/desafios-codelandia/Desafio27/) | [Link](https://www.figma.com/file/Yb9IBH56g7T1hdIyZ3BMNO/Desafios---Codel%C3%A2ndia?type=design&node-id=107523-1216&mode=design&t=y8MCYFp0EDOred8A-0) | [Link](https://github.com/iuryyxd/desafios-codelandia/tree/main/Desafio27) |
| 28 | PSG | [Link](https://iuryyxd.github.io/desafios-codelandia/Desafio28/) | [Link](https://www.figma.com/file/Yb9IBH56g7T1hdIyZ3BMNO/Desafios---Codel%C3%A2ndia?type=design&node-id=115719-1222&mode=design&t=y8MCYFp0EDOred8A-0) | [Link](https://github.com/iuryyxd/desafios-codelandia/tree/main/Desafio28) | [Link](https://www.youtube.com/watch?v=KI2FCnNKHSI) |
| 29 | Ani.me | Em breve | [Link](https://www.figma.com/file/Yb9IBH56g7T1hdIyZ3BMNO/Desafios---Codel%C3%A2ndia?type=design&node-id=130247-1282&mode=design&t=y8MCYFp0EDOred8A-0) | Em breve |
| 30 | Steam | Em breve | [Link](https://www.figma.com/file/Yb9IBH56g7T1hdIyZ3BMNO/Desafios---Codel%C3%A2ndia?type=design&node-id=133656-1286&mode=design&t=y8MCYFp0EDOred8A-0) | Em breve |
| 31 | Fifa | [Link](https://iuryyxd.github.io/desafios-codelandia/Desafio31/) | [Link](https://www.figma.com/file/Yb9IBH56g7T1hdIyZ3BMNO/Desafios---Codel%C3%A2ndia?type=design&node-id=152536-1288&mode=design&t=y8MCYFp0EDOred8A-0) | [Link](https://github.com/iuryyxd/desafios-codelandia/tree/main/Desafio31) |
| 32 | LogMine | [Link](https://iuryyxd.github.io/desafios-codelandia/Desafio32/) | [Link](https://www.figma.com/file/Yb9IBH56g7T1hdIyZ3BMNO/Desafios---Codel%C3%A2ndia?type=design&node-id=157395-3193&mode=design&t=y8MCYFp0EDOred8A-0) | [Link](https://github.com/iuryyxd/desafios-codelandia/tree/main/Desafio32) |
| 33 | Portal Escolar | Em breve | [Link](https://www.figma.com/file/Yb9IBH56g7T1hdIyZ3BMNO/Desafios---Codel%C3%A2ndia?type=design&node-id=163987-3195&mode=design&t=y8MCYFp0EDOred8A-0) | Em breve |
| 34 | CodeNFT | Em breve | [Link](https://www.figma.com/file/Yb9IBH56g7T1hdIyZ3BMNO/Desafios---Codel%C3%A2ndia?type=design&node-id=165830-3323&mode=design&t=y8MCYFp0EDOred8A-0) | Em breve |
| 35 | Orkut | Em breve | [Link](https://www.figma.com/file/Yb9IBH56g7T1hdIyZ3BMNO/Desafios---Codel%C3%A2ndia?type=design&node-id=171980-3522&mode=design&t=y8MCYFp0EDOred8A-0) | Em breve |
| 36 | eFront | Em breve | [Link](https://www.figma.com/file/Yb9IBH56g7T1hdIyZ3BMNO/Desafios---Codel%C3%A2ndia?type=design&node-id=179485-3594&mode=design&t=y8MCYFp0EDOred8A-0) | Em breve |
| 37 | TeslaBank | Em breve | [Link](https://www.figma.com/file/Yb9IBH56g7T1hdIyZ3BMNO/Desafios---Codel%C3%A2ndia?type=design&node-id=191725-3600&mode=design&t=y8MCYFp0EDOred8A-0) | Em breve |
| 38 | Codeplay. | Em breve | [Link](https://www.figma.com/file/Yb9IBH56g7T1hdIyZ3BMNO/Desafios---Codel%C3%A2ndia?type=design&node-id=198105-3606&mode=design&t=y8MCYFp0EDOred8A-0) | Em breve |
| 39 | Blogames | Em breve | [Link](https://www.figma.com/file/Yb9IBH56g7T1hdIyZ3BMNO/Desafios---Codel%C3%A2ndia?type=design&node-id=210567-3649&mode=design&t=y8MCYFp0EDOred8A-0) | Em breve |
| 40 | Dashboard | Em breve | [Link](https://www.figma.com/file/Yb9IBH56g7T1hdIyZ3BMNO/Desafios---Codel%C3%A2ndia?type=design&node-id=224375-16&mode=design&t=u8FHTHFEUhvLMv9D-0) | Em breve |
## Contribuição ✨
Ajude a comunidade tornando este projeto ainda mais incrível. Leia como contribuir clicando **[aqui](https://github.com/iuricode/desafios-frontend/blob/main/CONTRIBUTING.md)** e a **[licença](https://github.com/iuricode/desafios-frontend/blob/main/LICENSE.md)**. Estou convencido de que juntos alcançaremos coisas incríveis!
## Aprenda desenvolvimento frontend ❤️
Este repositório é um projeto gratuito para a comunidade de desenvolvedores, mas você pode me ajudar comprando o meu ebook "**[eFront - Estudando frontend do zero](https://iuricode.com/efront)**" se estiver interessado em aprender ou melhorar suas habilidades de desenvolvimento frontend. A sua compra me ajuda a produzir e fornecer mais conteúdo gratuito para a comunidade. Adquira agora e comece sua jornada no desenvolvimento frontend.
| 197
| 16
|
ErickWendel/eslint-clone
|
https://github.com/ErickWendel/eslint-clone
|
A video tutorial about Creating your own ESLint from Scratch
|
# ESLint Reimagined: Creating a Linter from Scratch
Welcome, this repo is part of my [**youtube video**](https://bit.ly/eslint-clone-ew) about **Creating your own ESLint from scratch (en-us)**
First of all, leave your star 🌟 on this repo.
Access our [**exclusive telegram channel**](https://t.me/ErickWendelContentHub) so I'll let you know about all the content I've been producing
## Complete source code
- Access it in [app](./recorded/)

## Usage
Go to [app](./recorded/) and restore dependencies as follows:
```shell
nvm use
npm i
npm link
eslint-clone --file filename.js
```
##
## Example
```shell
eslint-clone --file error.js
```
Outputs
```shell
Error: use "const" instead of "var"
error.js:1:1
Error: use single quotes instead of double quotes
error.js:1:12
Error: use single quotes instead of double quotes
error.js:1:23
Error: use "const" instead of "var"
error.js:2:1
Error: use single quotes instead of double quotes
error.js:3:24
Error: use "let" instead of "var"
error.js:5:1
Error: use single quotes instead of double quotes
error.js:6:25
Error: use single quotes instead of double quotes
error.js:9:25
Error: use "const" instead of "let"
error.js:15:1
Error: use single quotes instead of double quotes
error.js:15:25
Error: use single quotes instead of double quotes
error.js:17:9
Linting completed with 11 error(s).
Code fixed and saved at ./error.linted.js successfully!
```
## Cleaning Up
```shell
npm unlink eslint-clone
```
## Tasks
- fix the bug when replacing quotes
- if a code have single quotes enclosing double quotes such as:
```js
const name = '"ana"'
```
it'd be transformed as below and will cause a syntax error.
```js
const name = ''ana''
```
- **How to fix:** replace it to a template string instead.
- Input:
```js
'"double"'.replaceAll('"', "'");
```
- Current Output:
```js
''double''.replaceAll(''', ''');
```
- Expected Output:
```js
`"double"`.replaceAll(`"`, `'`);
```
- keep line breaks
- keep comments
- keep spaces
- don't put semicolons automatically
- report missing semicolon ';'
---
| 22
| 0
|
wy876/tools
|
https://github.com/wy876/tools
|
使用C# 造轮子的webshell管理工具
|
# 2023.6.3
1. 解决界面因为http访问不成功,界面不自动关闭
2. 解决虚拟终端 cd切换目录命令
# 2022.9.18
1. 优化TreeView 文件目录列表,递归写入子节点
# 2022.7.29
1. 已完成 aspx,php 虚拟终端,文件管理,增删改查,文件上传,文件下载
2. 实现http 代理
# 软件界面
使用github存放图片,国内网络加载不出来
## 主界面
## 虚拟终端
## 文件管理
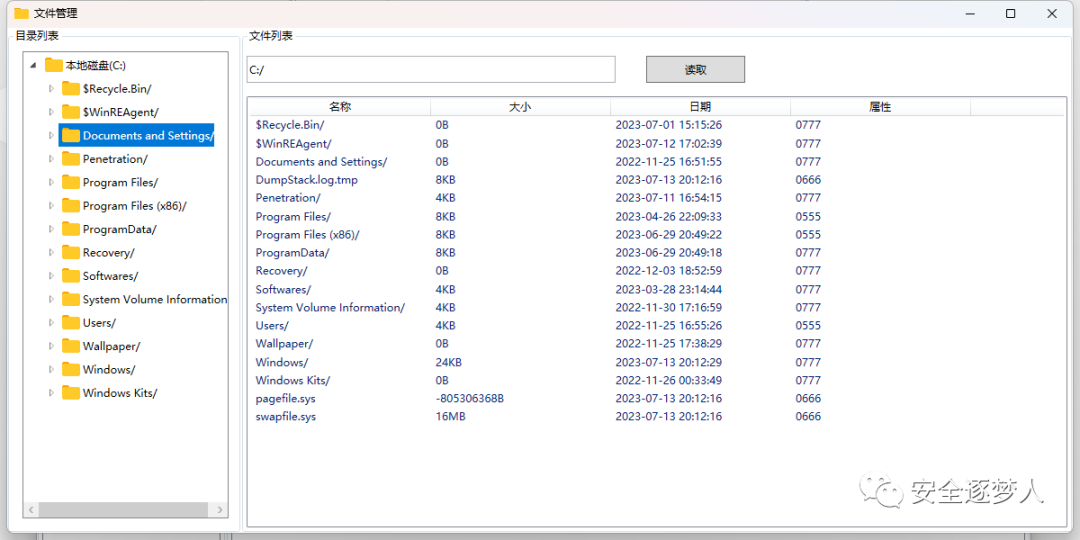
## http代理
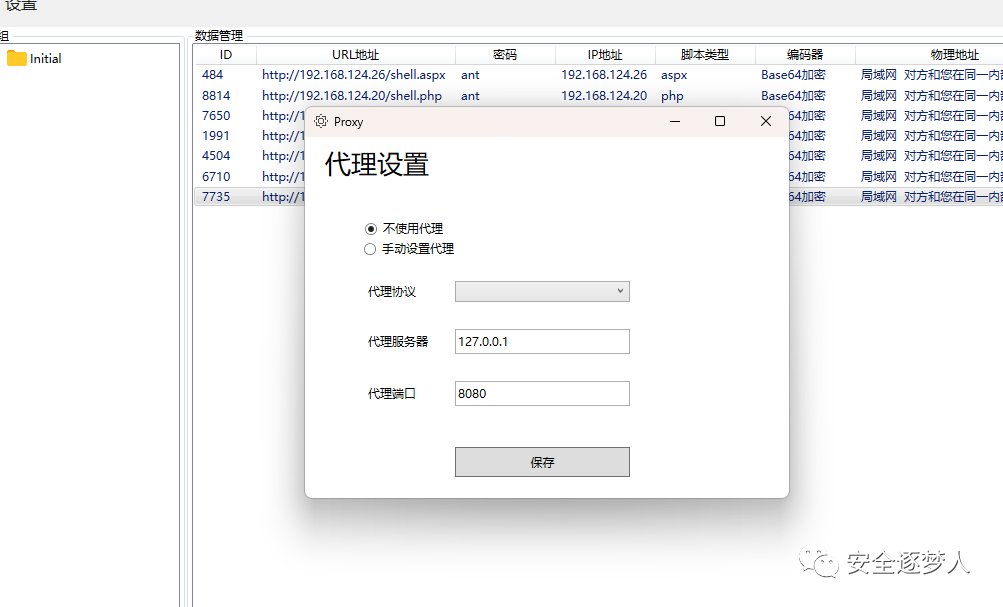
代理配置会存储在/data目录下的proxy.txt
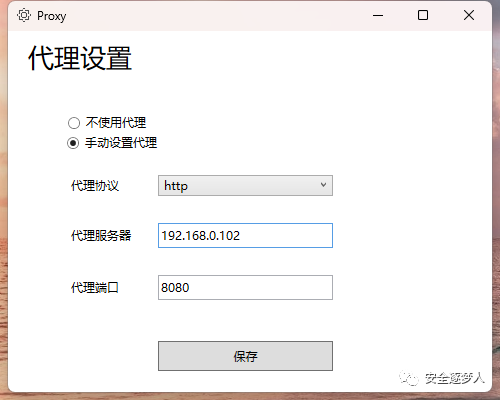
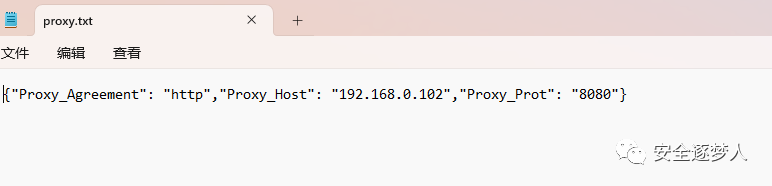
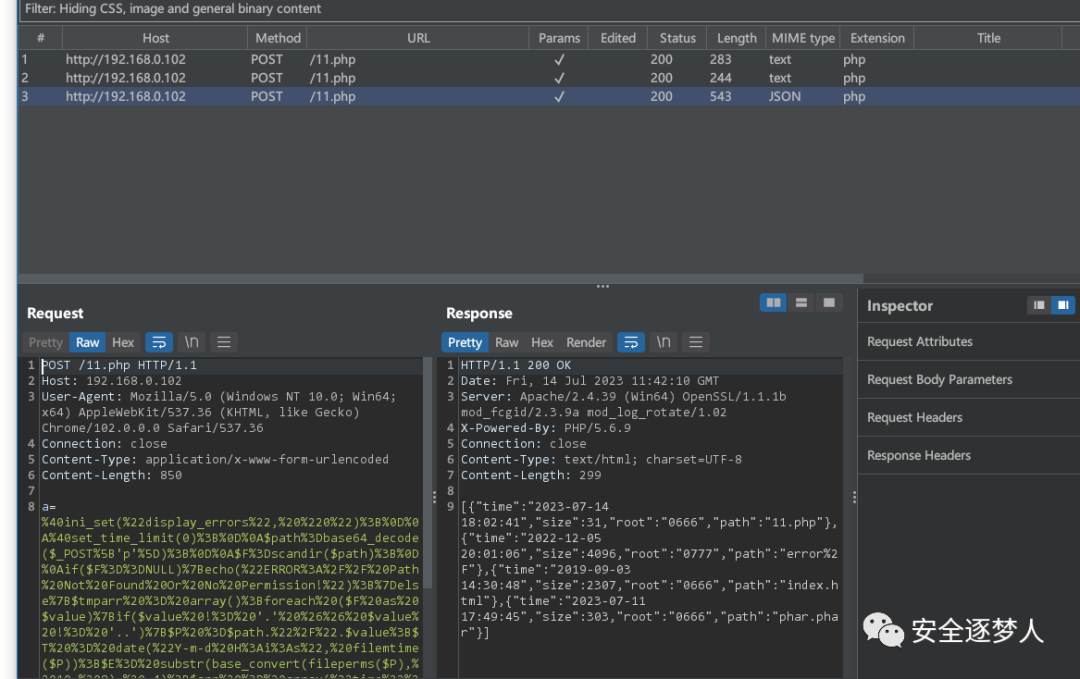
# 用到的技术
```
https://yzddmr6.com/posts/%E8%81%8A%E8%81%8A%E6%96%B0%E7%B1%BB%E5%9E%8BASPXCSharp/
https://github.com/AntSwordProject/AntSword-Csharp-Template
```
| 10
| 0
|
fikrimln16/SQL-Queries
|
https://github.com/fikrimln16/SQL-Queries
| null |
<h1>Kumpulan Query SQL yang Sering Digunakan</h1>
<h2>Berikut ini adalah kumpulan query SQL yang sering digunakan dalam pengelolaan dan manipulasi data dalam database. Setiap query memiliki tujuan dan fungsinya masing-masing.</h2>
<h3>SELECT</h3>
Digunakan untuk memilih kolom-kolom tertentu dari sebuah tabel.
<h3>FROM</h3>
Menentukan tabel mana yang akan digunakan dalam query.
<h3>WHERE</h3>
Digunakan untuk memfilter data berdasarkan kondisi tertentu.
<h3>JOIN</h3>
Digunakan untuk menggabungkan dua atau lebih tabel berdasarkan kolom yang sesuai.
<h3>GROUP BY</h3>
Mengelompokkan hasil query berdasarkan kolom tertentu.
<h3>HAVING</h3>
Menggunakan kondisi tambahan setelah GROUP BY untuk memfilter hasil query.
<h3>ORDER BY</h3>
Mengurutkan hasil query berdasarkan kolom tertentu dalam urutan menaik (ASC) atau menurun (DESC).
<h3>INSERT INTO</h3>
Digunakan untuk memasukkan data baru ke dalam tabel.
<h3>UPDATE</h3>
Digunakan untuk memperbarui nilai dalam tabel berdasarkan kondisi tertentu.
<h3>DELETE</h3>
Digunakan untuk menghapus baris dari tabel berdasarkan kondisi tertentu.
<h3>COUNT</h3>
Menghitung jumlah baris yang cocok dengan kondisi tertentu.
<h3>AVG</h3>
Menghitung rata-rata nilai dalam kolom berdasarkan kondisi tertentu.
<h3>SUM</h3>
Menjumlahkan nilai dalam kolom berdasarkan kondisi tertentu.
<h3>MAX</h3>
Mencari nilai maksimum dalam kolom berdasarkan kondisi tertentu.
<h3>MIN</h3>
Mencari nilai minimum dalam kolom berdasarkan kondisi tertentu.
<h3>BETWEEN</h3>
Memilih data berdasarkan rentang nilai tertentu dalam kolom.
<h3>LIKE</h3>
Memilih data berdasarkan pola teks tertentu dalam kolom.
<h3>IS NULL</h3>
Memilih data yang memiliki nilai NULL dalam kolom.
<h3>IS NOT NULL</h3>
Memilih data yang memiliki nilai non-NULL dalam kolom.
<h3>DISTINCT</h3>
Memilih data unik dari kolom tertentu dalam tabel, menghapus duplikat hasil.
<h3>UNION</h3>
Menggabungkan hasil dari dua query SELECT menjadi satu, menghapus duplikat hasil.
<h3>EXISTS</h3>
Memeriksa keberadaan baris yang memenuhi kondisi tertentu dalam subquery.
<h3>AS</h3>
Memberikan alias pada kolom atau tabel dalam query.
<h3>CONCAT</h3>
Menggabungkan nilai dari dua atau lebih kolom menjadi satu nilai.
<h3>DATE</h3>
Mengambil tanggal dari kolom dengan tipe data tanggal/waktu.
<h3>DATE_FORMAT</h3>
Memformat tampilan tanggal/waktu dalam kolom sesuai dengan format yang ditentukan.
<h3>TRIGGER</h3>
Membuat logika yang dipicu sebelum atau setelah operasi tertentu, seperti INSERT, UPDATE, atau DELETE.
<h3>UPPER/LOWER</h3>
Mengubah teks menjadi huruf kapital (UPPER) atau huruf kecil (LOWER).
<h3>DATEFORMAT</h3>
Memformat tampilan tanggal/waktu dalam kolom sesuai dengan format yang ditentukan.
<h3>CASE</h3>
Membuat ekspresi bersyarat dalam query dengan menggunakan CASE, menghasilkan nilai baru pada kolom.
<h3>ROUND</h3>
Membulatkan nilai numerik dalam kolom menjadi jumlah desimal tertentu.
<h3>LIMIT dengan OFFSET</h3>
Memilih kolom dari tabel dengan membatasi jumlah baris yang ditampilkan, dimulai dari posisi tertentu.
<h3>TRUNCATE</h3>
Memangkas (menghapus) nilai desimal dari angka.
<h3>SUBSTRING</h3>
Mengambil potongan teks dari kolom, dimulai dari posisi tertentu dan sepanjang jumlah karakter tertentu.
<h3>COALESCE</h3>
Memilih nilai non-NULL dari kolom-kolom yang diberikan.
<h3>CONCAT_WS</h3>
Menggabungkan nilai dari kolom-kolom dengan pemisah yang ditentukan.
<h3>DATE_ADD</h3>
Menambahkan jumlah unit (misalnya, DAY, MONTH, YEAR) ke tanggal dalam kolom.
<h3>DATE_SUB</h3>
Mengurangi jumlah unit (misalnya, DAY, MONTH, YEAR) dari tanggal dalam kolom.
<h3>LEFT JOIN</h3>
Melakukan LEFT JOIN antara dua tabel berdasarkan kolom yang sesuai.
<h3>RIGHT JOIN</h3>
Melakukan RIGHT JOIN antara dua tabel berdasarkan kolom yang sesuai.
<h3>FULL JOIN</h3>
Melakukan FULL JOIN antara dua tabel berdasarkan kolom yang sesuai.
<h3>CROSS JOIN</h3>
Melakukan CROSS JOIN antara dua tabel, menghasilkan gabungan setiap baris dari kedua tabel tersebut.
<h3>UNION ALL</h3>
Menggabungkan hasil dari dua query SELECT menjadi satu, termasuk duplikat hasil.
<h3>INSERT INTO SELECT</h3>
Memasukkan data dari hasil query SELECT ke dalam tabel lain.
<h3>UPDATE dengan JOIN</h3>
Memperbarui nilai dalam tabel berdasarkan JOIN dengan tabel lain.
<h3>DELETE dengan JOIN</h3>
Menghapus baris dari tabel berdasarkan JOIN dengan tabel lain.
<h3>CREATE INDEX</h3>
Membuat indeks pada kolom tertentu dalam tabel.
<h3>DROP INDEX</h3>
Menghapus indeks dari kolom tertentu dalam tabel.
<h3>CREATE FOREIGN KEY</h3>
Membuat kunci asing (foreign key) antara dua tabel.
<h3>DROP FOREIGN KEY</h3>
Menghapus kunci asing (foreign key) dari tabel.
<h3>CREATE VIEW</h3>
Membuat view baru berdasarkan query SELECT tertentu.
<h3>DROP VIEW</h3>
Menghapus view dari database.
<h3>CREATE PROCEDURE</h3>
Membuat prosedur tersimpan.
<h3>EXECUTE</h3>
Menjalankan prosedur tersimpan.
<h3>GRANT</h3>
Memberikan izin tertentu kepada pengguna untuk akses ke tabel.
<h3>REVOKE</h3>
Mencabut izin tertentu dari pengguna untuk akses ke tabel.
<h3>COMMIT</h3>
Melakukan komit transaksi yang sedang berlangsung.
<h3>ROLLBACK</h3>
Membatalkan transaksi yang sedang berlangsung.
<h3>SAVEPOINT</h3>
Membuat titik penyimpanan (savepoint) dalam transaksi.
<h3>RELEASE SAVEPOINT</h3>
Menghapus titik penyimpanan (savepoint) dalam transaksi.
<h3>SET TRANSACTION</h3>
Mengatur tingkat isolasi transaksi dalam database.
<h3>SHOW</h3>
Menampilkan informasi tertentu dalam database, seperti daftar tabel.
<h3>DESCRIBE</h3>
Menampilkan informasi mengenai struktur kolom dalam tabel.
<h3>EXPLAIN</h3>
Menampilkan rencana eksekusi query SELECT, termasuk informasi mengenai penggunaan indeks dan metode akses data.
<h3>TRUNCATE TABLE</h3>
Menghapus semua data dalam tabel dan mengembalikan tabel ke keadaan awal tanpa struktur yang berubah.
<h3>BACKUP</h3>
Melakukan backup data dalam database.
<h3>RESTORE</h3>
Mengembalikan database dari backup yang telah dibuat sebelumnya.
<h3>TUNING</h3>
Teknik tuning database untuk meningkatkan performa dan efisiensi.
<h3>COMMENTS</h3>
Komentar dalam kode SQL untuk memberikan penjelasan.
<h3>INDEX</h3>
Membuat indeks pada kolom tertentu untuk meningkatkan performa query.
<h3>FOREIGN KEY</h3>
Membuat keterhubungan antara kolom dalam dua tabel berbeda.
<h3>ALTER TABLE</h3>
Mengubah struktur tabel yang sudah ada, seperti menambahkan kolom baru atau mengubah tipe data kolom.
<h3>DROP TABLE</h3>
Menghapus tabel beserta semua data dan strukturnya dari database.
<h3>CREATE TABLE</h3>
Membuat tabel baru dengan kolom-kolom yang ditentukan.
<h3>TRIM</h3>
Menghapus spasi tambahan dari awal dan akhir teks dalam kolom.
<h3>UPPER/LOWER</h3>
Mengubah teks menjadi huruf kapital (UPPER) atau huruf kecil (LOWER).
<h3>SHOW</h3>
Menampilkan informasi tertentu dalam database, seperti daftar tabel.
<h3>DESCRIBE</h3>
Menampilkan informasi mengenai struktur kolom dalam tabel.
<h3>EXPLAIN</h3>
Menampilkan rencana eksekusi query SELECT, termasuk informasi mengenai penggunaan indeks dan metode akses data.
<h3>BACKUP</h3>
Melakukan backup data dalam database.
<h3>RESTORE</h3>
Mengembalikan database dari backup yang telah dibuat sebelumnya.
<h3>TUNING</h3>
Teknik tuning database untuk meningkatkan performa dan efisiensi.
<h3>COMMENTS</h3>
Komentar dalam kode SQL untuk memberikan penjelasan.
Dan masih banyak lagi, silakan lihat file queries.sql sebagai contohnya.
| 33
| 3
|
bugfan/ipayment
|
https://github.com/bugfan/ipayment
|
个人微信/支付宝收款码支付回调服务 免签约 无手续费 不用开公司申请商户号
|
## 免签约个人微信/支付宝收款码支付系统
## 系统包含的组件
- 支付管理
- Golang后端程序
- Vue前端程序
- Mysql
- Android apk安装包
## 说明
#### 付款流程
1. 付款用户打开在支付管理里面预先配置好的付款信息页面,然后扫码支付。
2. Android app启动后会监听支付消息,如果收到付款,会通知支付管理系统。
3. 支付管理收到回调消息会做一系列校验操作与通知操作。
4. 最终付款用户的付款页面会自动跳转提示成功。
#### 支付管理
```
已经打包成了docker镜像和二进制程序(支持linux/win/mac)
用于记录管理订单,个人支付码,支付成功回调参数,登录日志,Android APK回调日志,以及管理账号设置
```
#### Android程序
```
已经打包成apk了,用于发送回调信息以及显示支付日志
```
## 关于更新
后续慢慢更新上来~
## 一些使用截图










| 15
| 3
|
noumidev/ChiSP
|
https://github.com/noumidev/ChiSP
|
LLE PlayStation Portable emulator written in C++
|
# ChiSP
LLE PlayStation Portable emulator written in C++. Very early in development!
# Usage
`ChiSP preipl.bin nand.bin`
# Milestones
- Reads IPL from NAND, decrypts IPL with KIRK
- Loads and runs all IPL stages
- Loads 60 kernel modules (out of 69), stuck in impose.prx
# Dependencies
- Crypto++
| 23
| 0
|
Starlitnightly/single_cell_tutorial
|
https://github.com/Starlitnightly/single_cell_tutorial
|
单细胞分析的中文pipeline
|
# 单细胞测序-最佳的分析Pipeline
- 作者: starlitnightly
- 日期: 2023.07.14
我们的教程可以在[read the docs](https://single-cell-tutorial.readthedocs.io/zh/latest/)上获得: https://single-cell-tutorial.readthedocs.io/zh/latest/
!!! note 楔子
从事单细胞分析也有一段时间了,国内大部分中文教程都是使用R语言进行分析,使用Python的还比较少,或者是直译scanpy的教程,不过scanpy可能已经比较旧了。在这里,我们参考了[Single cell best practice](https://www.sc-best-practices.org/preamble.html),希望能给国内的从业者带来一个完善的教程指引以及分析。
## 简介
人体是一个复杂的机器,严重依赖于生命的基本单位——细胞。细胞可以分为不同类型,在发育过程中甚至会发生转变,在疾病或再生时也会如此。这种细胞的异质性在形态、功能和基因表达谱上都有所体现。强烈的干扰会导致细胞类型的紊乱,从而影响整个系统,甚至引发像癌症这样严重的疾病[Macaulay等人,2017]。因此,了解细胞在正常状态和干扰下的行为对于改善我们对整个细胞系统的理解至关重要。
这项庞大的任务可以通过不同的方式来解决,其中最有前途的方法是在个体水平上对细胞进行分析。到目前为止,每个细胞的转录组主要是通过一种称为单细胞RNA测序的过程来检测的。随着单细胞基因组学的最新进展,现在可以将转录组信息与空间、染色质可及性或蛋白质信息结合起来。这些进展不仅可以揭示复杂的调控机制,而且还增加了数据分析师的复杂性。
如今,数据分析师面临着一个庞大的分析工具领域,其中包含1000多种计算单细胞分析方法。在这个广泛的工具范围中导航以生成科学前沿的可靠结果变得越来越具有挑战性。
## 本书内容概述
本书的目标是教新手和专业人士单细胞测序分析的最佳实践,在Python中。本书将教您从预处理到可视化、统计评估等一系列常见的分析步骤,以及更深入的内容。通读本书将使您能够独立分析单模态和多模态单细胞测序数据。本书中的指南和建议不仅旨在教授您如何进行单细胞分析,而且着重于如何正确进行分析。我们的建议尽可能地基于外部基准和评价。最后,我们将本书视为单细胞数据分析师的一份实用资源,可以在推荐发生变化时轻松更新。
## 本书内容不涉及
本书不涵盖生物学或计算机科学的基础知识,包括编程。此外,本书也不是为特定任务设计的所有分析工具的完整集合。我们特别强调那些经过外部验证的工具,这些工具在处理手头的数据时效果最佳,或者是经过社区验证的最佳实践方法。如果不可能进行外部验证,我们只会基于自己广泛的经验推荐工作流程。
## 本书的结构
本书的每一章对应于典型单细胞数据分析项目的不同阶段。通常,分析工作流程会按照章节的顺序进行,但在下游分析目标方面可能存在一定的灵活性。我们的每一章都包含了大量的参考文献,我们鼓励读者查阅我们陈述观点的原始来源。尽管我们在可能的情况下试图提供所需的背景知识,但我们的总结并不能始终捕捉到我们推荐的全部理由。
## 学习前准备
生物信息学对于新手来说是一个具有挑战性的研究领域,因为它需要对生物学和计算机科学都有一定的了解。而单细胞分析则更加具有要求,因为它结合了许多子领域,而且数据集通常较大。本书无法涵盖计算单细胞分析的所有先决条件,因此我们建议您在下面对各种主题进行粗略的概述。以下链接可能会提升您在本书中的学习体验:
基本的Python编程。您应该熟悉控制流程(循环、条件语句等)、基本数据结构(列表、字典、集合)以及最常用库(如Pandas和Numpy)的核心功能。如果您对编程和Python还不熟悉,我们强烈推荐北京理工大学的嵩天老师的Python相关的mooc,包括[Python基础学习](https://www.icourse163.org/course/BIT-268001)与[Python数据处理与可视化](https://www.icourse163.org/course/BIT-1001870002)两节。
了解AnnData和scanpy包的基础知识会有益,但不是绝对必需的。本书对AnnData的介绍足以让您跟上,并介绍了使用scanpy的工作流程。然而,我们无法在本书的过程中介绍scanpy的所有功能。如果您对scanpy还不熟悉,我们强烈建议您通过学习[scanpy教程](https://scanpy.readthedocs.io/en/stable/tutorials.html),并偶尔查看[scanpy的API](https://scanpy.readthedocs.io/en/stable/api.html)参考来学习。
如果您对多模态数据分析感兴趣,建议了解muon和MuData的基础知识。本书对MuData进行了更详细的介绍,但只是简要介绍了muon,类似于AnnData和scanpy。[muon教程](https://muon-tutorials.readthedocs.io/en/latest/)是学习使用muon进行多模态数据分析的很好入门资料。
生物学基础知识。虽然我们大致介绍了数据的产生过程,但我们不会涵盖DNA、RNA和蛋白质的基础知识。如果您对分子生物学完全不熟悉,建议阅读Bruce Alberts等人的《细胞分子生物学》(Molecular Biology of the Cell)。
## License
<a rel="license" href="http://creativecommons.org/licenses/by-nc-sa/4.0/"><img alt="知识共享许可协议" style="border-width:0" src="https://img.shields.io/badge/license-CC%20BY--NC--SA%204.0-lightgrey" /></a>
本作品采用<a rel="license" href="http://creativecommons.org/licenses/by-nc-sa/4.0/">知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议</a>进行许可。在此再次感谢Single-cell best practices对单细胞教程的贡献,本书将基于Single-cell best practices结合作者自身的分析经验来完成。
| 10
| 1
|
Nozbe/microfuzz
|
https://github.com/Nozbe/microfuzz
|
A tiny, simple, fast JS fuzzy search library
|
<p align="center">
<img src="https://github.com/Nozbe/microfuzz/raw/main/assets/nozbe_demo.gif" alt="microfuzz in action in Nozbe" width="624" />
</p>
<h1 align="center">
microfuzz
</h1>
<h4 align="center">
A tiny, simple, fast JS fuzzy search library
</h4>
<p align="center">
✨ Easily add power user-friendly search, autocomplete, jump to, command palette to your app.
</p>
<p align="center">
<a href="https://github.com/Nozbe/microfuzz/blob/master/LICENSE">
<img src="https://img.shields.io/badge/License-MIT-blue.svg" alt="MIT License"/>
</a>
<a href="https://www.npmjs.com/package/@nozbe/microfuzz">
<img src="https://img.shields.io/npm/v/@nozbe/microfuzz.svg" alt="npm"/>
</a>
</p>
| | microfuzz |
| - | ------------ |
| 🤓 | **Fuzzy search**. Power users love it |
| 🗜️ | **Tiny**. 2KB gzipped |
| ✅ | **Simple**. Only a few options, reasonable defaults |
| ⚡️ | **Fast**. Filter thousands of items in milliseconds |
| 🧰 | **Framework-agnostic**. Plain JS, no dependencies |
| ⚛️ | **React/React Native** helpers (optional) included |
| ⚠️ | **Static typing** with [Flow](https://flow.org) or [TypeScript](https://typescriptlang.org) |
## microfuzz pitch
General idea of how `microfuzz` works:
- Case-insensitive and diacritics-insensitive search
- Works with Latin script, Cyrillic, rudimentary CJK support
- Limited fuzzing: matches query letters in order, but they don't have to be consecutive
(but transposition and missing characters are not allowed)
- Some very poor fuzzy matches are rejected by default (see [_Fuzzy search strategies_](#fuzzy-search-strategies))
- Additionally, matches query _words_ in any order
- NOT full-text search. Stemming, soundex, levenstein, autocorrect are _not_ included
- Sorts by how well text matches the query with simple heuristics (for equal fuzzy score, input
order is preserved, so you can pre-sort array if you want).
- Returns ranges of matching characters for pretty highlighting
- In-memory search, no indexing
`microfuzz` is not a one-size-fits-all solution (see [_Alternatives to consider_](#alternatives-to-consider)).
## Demo
[**➡️ See demo**](https://nozbe.github.io/microfuzz/)
## Using microfuzz (plain JS)
```js
import createFuzzySearch from '@nozbe/microfuzz'
const list = [/* an array of strings to fuzzy search */]
const fuzzySearch = createFuzzySearch(list)
// Run this whenever search term changes
// Only matching items will be returned, sorted by how well they match `queryText`
const results = fuzzySearch(queryText)
```
This is split into two steps for performance (`createFuzzySearch` pre-processes `list`, and you can cache/memoize function returned by it).
If `list` is an array of objects:
```js
const fuzzySearch = createFuzzySearch(list, {
// search by `name` property
key: 'name',
// search by `description.text` property
getText: (item) => [item.description.text]
// search by multiple properties:
getText: (item) => [item.name, item.description.text]
})
```
### Using microfuzz in React
If you use React or React Native, you can use these optional helpers for convenience:
```js
import { useFuzzySearchList, Highlight } from '@nozbe/microfuzz/react'
// `useFuzzySearchList` simply wraps `createFuzzySearch` with memoization built in
// NOTE: For best performance, `getText` and `mapResultItem` should be memoized by user
const filteredList = useFuzzySearchList({
list,
// If `queryText` is blank, `list` is returned in whole
queryText,
// optional `getText` or `key`, same as with `createFuzzySearch`
getText: (item) => [item.name],
// arbitrary mapping function, takes `FuzzyResult<T>` as input
mapResultItem: ({ item, score, matches: [highlightRanges] }) => ({ item, highlightRanges })
})
// Render `filteredList`'s labels with matching characters highlighted
filteredList.map(({ item, highlightRanges }) => (
<Item key={item.key}>
<Label><Highlight text={item.name} ranges={highlightRanges} /></Label>
</Item>
))
```
### Fuzzy search strategies
You can optionally pass `{ strategy: }` parameter to `createFuzzySearch` / `useFuzzySearchList`:
- `'off'` - no fuzzy search, only matches if item contains query (or contains query words in any order)
- `'smart'` - (default) matches letters in order, but poor quality matches are ignored
- `'aggressive'` - matches letters in order with no restrictions (classic fuzzy search)
## Alternatives to consider
I wrote `microfuzz` simply because I didn't quite like how other fuzzy search libraries I found worked, **for my use case**. Your mileage may vary.
It's not the tiniest, the simplest, or the fastest implementation you can find. But it's tiny, simple, and fast enough, while providing fuzzy search heuristics and sorting that I found to work reasonably well in [Nozbe](https://nozbe.com), a project management app, where it's used to filter down or autocomplete lists of short labels — names of projects, sections, tasks, user names, etc.
By "fast" I mean that on my computer, with a list of ~4500 labels, the first search (one-letter search query) takes ~7ms, while subsequent searches take less than 1.5ms — all in-memory, without indexing. More than fast enough to search on every keystroke without any lag.
If you have much larger lists to fuzzy-search, you may find the performance unsatisfactory — consider implementations with simpler heuristics or indexing. For very long strings (notes, comments), fuzzy-searching may not be the right strategy — consider Full-Text Search (with indexing) instead.
Feel free to contribute improvements to sorting heuristics or alternative search strategies (provided that the "fast, simple, tiny" criteria don't suffer too much).
Alternatives:
- [Fuse.js](https://github.com/krisk/Fuse) - popular implementation with **many more options**, including extended search and indexing. However, while its scoring (sorting) is much more sophisticated in theory, I found it unsatisfactory in practice.
- [fuzzysort](https://github.com/farzher/fuzzysort) - faster and really good for fuzzy searching lists of file names/file paths, but I don't like its scoring for natural language labels. I borrowed the test data from fuzzysort so you can compare both demos side by side.
- [MiniSearch](https://www.npmjs.com/package/minisearch)
- [fuzzy](https://github.com/mattyork/fuzzy)
- [fuzzy-search](https://github.com/wouterrutgers/fuzzy-search) - an even simpler implementation than microfuzz
- [fuzzysearch](https://github.com/bevacqua/fuzzysearch) - tiniest implementation of the list
## Author and license
**microfuzz** was created by [@Nozbe](https://github.com/Nozbe).
**microfuzz's** main author and maintainer is [Radek Pietruszewski](https://github.com/radex) ([website](https://radex.io) ⋅ [twitter](https://twitter.com/radexp) ⋅ [engineering posters](https://beamvalley.com))
[See all contributors](https://github.com/Nozbe/microfuzz/graphs/contributors).
microfuzz is available under the MIT license. See the [LICENSE file](https://github.com/Nozbe/microfuzz/LICENSE) for more info.
| 36
| 0
|
AILab-CVC/SEED
|
https://github.com/AILab-CVC/SEED
|
Empowers LLMs with the ability to see and draw.
|
# Planting a SEED of Vision in Large Language Model
[[arXiv]](https://arxiv.org/abs/2307.08041)

## News
**2023-07-29** We release the pre-trained SEED Visual Tokenizer and inference code.
## Abstract
We present SEED, an elaborate image tokenizer that empowers Large Language
Models (LLMs) with the emergent ability to **SEE** and **D**raw at the same time.
Research on image tokenizers has previously reached an impasse, as frameworks
employing quantized visual tokens have lost prominence due to subpar performance and convergence in multimodal comprehension (compared to BLIP-2, etc.)
or generation (compared to Stable Diffusion, etc.). Despite the limitations, we
remain confident in its natural capacity to unify visual and textual representations,
facilitating scalable multimodal training with LLM’s original recipe. In this study,
we identify two crucial principles for the architecture and training of SEED that
effectively ease subsequent alignment with LLMs. (1) Image tokens should be
independent of 2D physical patch positions and instead be produced with a 1D
causal dependency, exhibiting intrinsic interdependence that aligns with the left-to-right autoregressive prediction mechanism in LLMs. (2) Image tokens should
capture high-level semantics consistent with the degree of semantic abstraction in
words, and be optimized for both discriminativeness and reconstruction during the
tokenizer training phase. As a result, the off-the-shelf LLM is able to perform both
image-to-text and text-to-image generation by incorporating our SEED through
efficient LoRA tuning. Comprehensive multimodal pretraining and instruction
tuning, which may yield improved results, are reserved for future investigation.
This version of SEED was trained in 5.7 days using only 64 V100 GPUs and 5M
publicly available image-text pairs. Our preliminary study emphasizes the great
potential of discrete visual tokens in versatile multimodal LLMs and the importance
of proper image tokenizers in broader research.
## SEED Tokenizer for Image Reconstruction

## SEED-OPT<sub>2.7B </sub> for Multimodal Comprehension

## SEED-OPT<sub>2.7B </sub> for Multimodal Generation

## Dependencies and Installation
- Python >= 3.8 (Recommend to use [Anaconda](https://www.anaconda.com/download/#linux))
- [PyTorch >= 1.11.0](https://pytorch.org/)
- NVIDIA GPU + [CUDA](https://developer.nvidia.com/cuda-downloads)
### Installation
1. Clone repo
```bash
git clone https://github.com/AILab-CVC/SEED.git
cd SEED
```
2. Install dependent packages
```bash
sh install.sh
```
## Model Weights
We release the pre-trained SEED Visual Tokenizer in [google drive](https://drive.google.com/drive/folders/1xmVXuttQfBPBOe4ZR96Wu1X34uzPkxsS?usp=drive_link).
## Inference
To discretize an image to 1D vision codes with causal dependency, and reconstruct the image
from the vision codes using stable diffusion UNet,
1. Download the pre-trained SEED Visual Tokenizer and stable diffusion model in [google drive](https://drive.google.com/drive/folders/1xmVXuttQfBPBOe4ZR96Wu1X34uzPkxsS?usp=drive_link) and put them under the folder "pretrained".
2. run the inference code.
```bash
python demo_recon.py
```
## To Do
- [x] Release SEED Tokenizer
- [ ] Release SEED-LLM
## License
SEED is released under Apache License Version 2.0.
## Acknowledgement
We utilize Stable Diffusion to decode images from our visual codes, and use its implementation and pre-trained model in https://github.com/CompVis/stable-diffusion.git.
Our code is based on the implementation of BLIP-2 in https://github.com/salesforce/LAVIS.git.
## Citation
If you find the work helpful, please consider citing:
```
@misc{ge2023planting,
title={Planting a SEED of Vision in Large Language Model},
author={Yuying Ge and Yixiao Ge and Ziyun Zeng and Xintao Wang and Ying Shan},
year={2023},
eprint={2307.08041},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
The project is still in progress. Stay tuned for more updates!
| 131
| 2
|
Yufccode/Reactor-based-HyperWebServer
|
https://github.com/Yufccode/Reactor-based-HyperWebServer
|
A high-performance web server based on the multiplexer actor mode, with an underlying implementation using the epoll model
|
# Reactor-based-HyperWebServer
**[简体中文](./info/README-cn.md)**
A high-performance web server based on the multiplexer actor mode, with an underlying implementation using the epoll model
I will continue to update this project, continue to improve the backend and front-end issues, and create a complete project. So far, this project has completed the most basic backend construction and simple front-end construction.
**Among them, the basic principles of epoll in this project and the basic principles of multiplexing high-performance IO can be seen in my other repo.**
https://github.com/Yufccode/Multiplexing-high-performance-IO-server
# What are Apache and Nginx? |What are Nginx and Reactors? |The Essence of Network IO | Blocking Queue | Asynchronous Non Blocking IO
## What is IO and what is the essence of IO?
To clarify this issue, we first need to understand the 5 most important IO models!
-Blocking IO
-Non blocking IO
-Signal driven IO
-Multiplex switching
-Asynchronous IO
### Five IO Models and Some Basic Concepts
#### Blocking IO
The system call will wait until the kernel prepares the dataAll sockets default to blocking mode.
To put it simply, I need to read from a File descriptor. Since there is no data in the File descriptor, I have been blocking and waiting!
#### Non blocking IO
If the kernel has not prepared the data yet, the system call will still return directly and return the EWOULDBLOCK error code.
To put it simply, I read from a File descriptor. If there is data, I will successfully read it and return it. If there is no data, I will also return it with the EWOULDBLOCK error code.
In this way, when reading, we must check every once in a while to see whether the File descriptor has data. In fact, this is what we often call a non blocking polling detection scheme!
Polling generally consumes CPU resources, so pure non blocking IO is generally only used in specific scenarios.
#### Signal driven IO
When the kernel prepares the data, it uses the SIGIO signal to notify the application to perform IO operations.
#### Multiplex switching
Multiplexing I/O is a technology used to manage multiple I/O operations. It allows a single thread or process to simultaneously monitor and process multiple I/O events without creating a separate thread or process for each I/O operation.
Multiplexing I/O utilizes mechanisms provided by the operating system, such as select, poll, epoll (Linux), or kqueue (FreeBSD, Mac OS X), to simultaneously monitor the status of multiple I/O events.
These mechanisms allow programs to register multiple I/O events, such as socket read and write events, into a collection of events. Then, the program can call specific system calls, such as select or epoll_Wait to block and wait for any of the I/O events to be ready.
Once a ready I/O event occurs, the program can know which I/O operations are ready through the event set and process them. This approach avoids the situation of blocking and waiting for a single I/O operation to complete, improving concurrent processing capability and efficiency.
Multi channel switching I/O is suitable for situations where multiple I/O events need to be processed simultaneously, especially in scenarios such as network servers, message queues, and real-time stream processing. By using multipath I/O, the creation and switching overhead of threads or processes can be reduced, and the performance and resource utilization of the system can be improved.
**In general, it is a process. I can listen to multiple File descriptor at the same time. When a specific event of a File descriptor is ready, it will remind the upper layer**
#### Asynchronous IO
The key concepts of Asynchronous I/O are callback and event loop. In the Asynchronous I/O model, when a program initiates an I/O operation, it will register a callback function and return control to the caller. When the I/O operation is completed, the system will notify the program and call the pre registered callback function at the appropriate time. The program can process the results of completed I/O operations in the callback function.
The advantage of Asynchronous I/O is that it can continue to perform other tasks while waiting for I/O operations to complete, which improves the concurrent processing capability and system response performance. Since there is no need to create additional threads or processes for each I/O operation, the Asynchronous I/O model consumes less system resources.
**For example, Reactor is an asynchronous IO application, and the content about Reactor will be explained by the blogger in the following content**
#### Synchronous communication vs Asynchronous communication
Synchronous and asynchronous focus on message communication mechanisms
The so-called synchronization is that when a call is made, it does not return until a result is obtained. But once the call returns, the return value is obtained; In other words, the caller actively waits for the result of this call.
Asynchronous is the opposite. After the call is made, it returns directly, so there is no result returned. In other words, when an asynchronous procedure call is issued, the caller will not get the result immediately. Instead, after the call is issued, the callee notifies the caller through status and notification, or processes the call through callback functions.
**This is not the same concept as synchronous mutual exclusion with multiple threads, so don't confuse it**
#### Blocking queue
**Blocking queues are actually a method of synchronously blocking IO applications**
🔗
**Of course, similar to this, there is also a circular queue, but of course, the essence is the same because they all block**
### What is inefficient IO?What is efficient IO?
From the above description, we can conclude a very, very important conclusion:
**IO=wait+copy data (copy data from File descriptor or to File descriptor)**
This conclusion is very important!
So, based on this conclusion, how can we improve the efficiency of IO?Or, what is efficient IO?What is inefficient?
**Answer: Reduce the proportion of waiting**
How to reduce the proportion of wait?The most effective method is actually multiplexing.
## Multiplex switching
Among them, what is worth learning is the select, poll, and epoll of multi channel switching. Among them, epoll is the most mature.
**I have already created a Github project for these three multi-channel transfer methods. You can transfer them to download the code and view the relevant principles and differences**
🔗
By utilizing multiplexing, we can greatly improve the efficiency of IO.
## Why are these IO models needed?
But how can we use the IO models mentioned above?Why do we pursue ultimate efficiency?Why do we need our IO to be fast?
Here, some students will ask, I usually do pipeline testing on my own computer, and do information transmission between File descriptor, which is very fast. The transmission is completed in an instant, and there is no "waiting". Why do I do these complex IO models?
In fact, locally, we may not see the advantages of IO models, but in network scenarios, efficient IO models are very important!
The network can cause packet loss!There will be a delay!It will go wrong!Why else would there be TCP and other protocols?
Based on the above IO models, two main network service models will actually be derived, Apache and Nginx. The specific content can be found in the blogger's next blog post!
## Apache and Nginx
### The underlying principles of Apache HTTP server
The Apache HTTP server adopts the classic multi process/multi threaded model. Its main components include Master Process/thread and Worker Process/thread. When Apache starts, the main process is first created and listens to the specified port, waiting for the client to connect. When a new connection request arrives, the main process accepts the connection and assigns it to an available worker process.
Simply put, it means multiple threads or processes, usually using threads because they occupy less CPU resources. It is actually a main thread that manages some new threads in a unified manner. The server starts and a main thread is created. If the underlying link is created, a new thread is created and accept is called. This new thread is specifically used to handle this specific link until it is closed. By creating a link, the main thread creates a new thread, essentially using the new thread to take on tasks. Of course, this scheme can be optimized. Generally, a Thread pool will be built to complete these things. First, a bunch of threads will be created, and then a thread will be linked. Then, a thread will pick up the task. If there are not enough threads in the Thread pool, you can choose to create, block, and release other threads.
So where is the problem with this method?If a link comes, it's a long link, and I don't leave or send you messages, what about your tasking thread?It can only be suspended by the link occupying the pit and not working, neither releasing nor working. If there are many long links like this, it is very CPU intensive!
### The underlying principles of Nginx
Nginx adopts an event driven, asynchronous single process model. Its underlying structure consists of multiple modules, including event module, HTTP module, Reverse proxy module, etc.
The core component is the event module, which uses the Asynchronous I/O mechanism provided by the operating system (such as epoll, kqueue) to achieve efficient event processing. The main process of Nginx is an event driven actor that listens and accepts client connections through an Event Loop. When a new connection arrives, the main process will distribute the connection to an available worker process.
The Worker Process is the executor of Nginx's actual processing of requests. Each worker process is independent and shares the same event loop across multiple connections. The workflow processes requests in an event driven manner, including reading requests, parsing request headers, processing request logic, and generating responses. In the process of processing requests, Nginx uses non blocking I/O operations and makes full use of Asynchronous I/O mechanism to improve concurrent processing capability.
#### Reactor (using epoll under Linux as an example)
Reactor is the core component of Nginx, and I will give an example to explain what event loops are and what listening is. Just give an example, and everyone will understand. For an HTTP request:
For a server, there must be a listening socket listensocket. After the server is turned on, there will definitely be many links from other places who want to shake hands with our server three times. Therefore, we have connections and should go to accept, right?But now in epoll multiplexing mode, it is not possible to directly have the listenlock accept!Why, because I don't know when to connect? If the link doesn't come, I call accept and it blocks**Therefore, we should put the listensock in epoll to register!!Then return directly without blocking**After registration, if the link comes, that is to say, the read event of the listenlock socket (the essence of a socket is a File descriptor, and the blogger will not repeat these basic concepts) is ready!Epoll will notify me!I will go to accept again at this time, and it will definitely not be blocked!Because epoll told me that the listensock read event is ready!
So we know that sockets after accept, also known as regular sockets, may send us messages. So, can we simply call read according to the previous method?It's definitely not possible!If there's no news, why are you reading? If there's no news, isn't your reading blocked?There cannot be such low-level operations in epoll. Therefore, similarly, register in epoll!When did the news come? EPOLL told you, so you don't have to worry and just return.
The entire process divides a request into multiple stages, each of which is registered and processed in many modules, and all operations are asynchronous and non blocking. Asynchronous here means that the server does not need to wait for the return result after executing a task, but automatically receives notifications after completion.
**The entire process is single process and single thread, but high concurrency!I'm not afraid of long links coming. You just register in epoll, and if you don't receive messages, I won't spend time on you (calling read), so this method is very efficient**This approach enables the server to efficiently handle multiple concurrent requests and perform other tasks while waiting for I/O operations, thereby improving overall performance.
#### What is the underlying layer of epoll?What are the advantages compared to select and poll?
🔗
#### Does reactor only have epoll?
The Reactor pattern is a design pattern used to build event driven applications. In Reactor mode, there is an Event Loop responsible for listening to events and scheduling corresponding handlers. The specific underlying implementation can adopt various technologies and system calls, among which epoll is one of the commonly used event notification mechanisms in Linux systems.
In Linux systems, epoll provides an efficient I/O event notification mechanism, allowing servers to handle a large number of concurrent connections. Therefore, many implementations of the Reactor pattern choose to use epoll as the underlying event notification mechanism to achieve high-performance event driven.
However, the underlying implementation of the Reactor pattern is not limited to epoll. It can also use other event notification mechanisms such as select, poll, etc., or use corresponding mechanisms on other operating systems such as kqueue (on FreeBSD and Mac OS X) or IOCP (on Windows).
Therefore, the Reactor pattern does not rely on specific underlying implementations, but rather focuses on event driven design ideas and patterns. The specific underlying implementation depends on the operating system and the event notification mechanism chosen by the developer.
#### Some other features of Nginx
In addition, Nginx also provides a powerful modular architecture, allowing users to choose and configure different modules according to their needs. Nginx modules can implement functions such as load balancing, caching, Reverse proxy, SSL/TLS encryption, etc. Modules can be loaded and configured through configuration files, making Nginx highly flexible and scalable.
## An HTTP Server Based on the Reactor Model
Recently, the blogger has been working on an HTTP server based on Reactor asynchronous IO and implemented through low-level multiplexing, which can meet the requirements of high efficiency.
The backend of this project has been basically improved, and some details are still being improved. I hope everyone can support this project more
## Summary
Both Nginx and Squid Reverse proxy servers adopt the event driven network mode. Event driven is actually an ancient technology that used early mechanisms such as select and poll. Subsequently, more advanced event mechanisms based on kernel notifications emerged, such as epoll in libevent, which improved event driven performance. The core of event driven is still I/O events. Applications can quickly switch between multiple I/O handles to achieve the so-called Asynchronous I/O. The event driven server is very suitable for handling I/O intensive tasks, such as the Reverse proxy, which acts as a data transfer station between the client and the Web server, and only involves pure I/O operations, not complex computing. It is a better choice to use event driven to build a Reverse proxy. A worker process can run without the overhead of managing processes and threads. At the same time, CPU and memory consumption are also small.
Therefore, servers such as Nginx and Squid are implemented in this way. Of course, Nginx can also adopt a multi process and event driven mode, where several processes run libevent without requiring hundreds of processes like Apache. Nginx also performs well in handling static files, because static files themselves belong to disk I/O operations and are handled in the same way. As for the so-called tens of thousands of concurrent connections, this does not make much sense. Writing a network program casually can handle tens of thousands of concurrent connections, but if most clients are blocked somewhere, there is not much value.
Let's take a look at application servers like Apache or Resin. They are called application servers because they need to run specific business applications, such as scientific computing, graphics and image processing, database reading and writing, etc. They are likely CPU intensive services, and event driven is not suitable for such situations. For example, if a calculation takes 2 seconds, then these 2 seconds will completely block the process and the event mechanism will have no effect. Imagine if MySQL were to switch to event driven, a large join or sort operation would block all clients. In this case, multiple processes or threads exhibit advantages, as each process can independently execute tasks without blocking or interfering with each other. Of course, modern CPUs are getting faster and faster, and the blocking time of individual calculations may be very short, but as long as there is blocking, event programming does not have an advantage. Therefore, technologies such as processes and threads will not disappear, but will complement event mechanisms and exist for a long time.
In summary, event driven is suitable for I/O intensive services, while multiprocessing or multithreading is suitable for CPU intensive services. They each have their own advantages and there is no trend to replace each other.
**Reference for this paragraph:**
**Copyright Notice: This article is the original work of CSDN blogger "Xi Feijian" and follows the CC 4.0 BY-SA copyright agreement. Please attach the original source link and this statement when reprinting**
**Original link: https://blog.csdn.net/xifeijian/article/details/17385831**
| 11
| 3
|
AnnulusGames/SceneSystem
|
https://github.com/AnnulusGames/SceneSystem
|
Provides efficient and versatile scene management functionality for Unity
|
# Scene System
Provides efficient and versatile scene management functionality for Unity.
<img src="https://github.com/AnnulusGames/SceneSystem/blob/main/Assets/SceneSystem/Documentation~/Header.png" width="800">
[](LICENSE)
[日本語版READMEはこちら](README_JP.md)
## Overview
Scene System is a library that provides functions related to scene management in Unity.
This library includes an API for loading scenes and a function that enables scene settings on the editor.
### Features
* API for multi-functional scene management that extends SceneManager
* Add SceneReference that can set scene reference on Inspector
* LoadingScreen component for easy implementation of loading screens
* SceneContainer for efficient multi-scene management
* Supports coroutines and async/await
* Support UniRx/UniTask
## Setup
### Requirement
* Unity 2019.4 or higher
### Install
1. Open the Package Manager from Window > Package Manager
2. "+" button > Add package from git URL
3. Enter the following to install
* https://github.com/AnnulusGames/SceneSystem.git?path=/Assets/SceneSystem
or open Packages/manifest.json and add the following to the dependencies block.
```json
{
"dependencies": {
"com.annulusgames.scene-system": "https://github.com/AnnulusGames/SceneSystem.git?path=/Assets/SceneSystem"
}
}
```
### Namespace
When using Scene System, add the following line at the beginning of the file.
```cs
using AnnulusGames.SceneSystem;
```
## Scenes
Scene System provides Scenes class as an alternative to Unity's SceneManager.
Scenes class is implemented as a wrapper class for SceneManager and provides richer functionality than a normal SceneManager.
To load/unload a scene, write as follows.
``` cs
using UnityEngine;
using UnityEngine.SceneManagement;
using AnnulusGames.SceneSystem;
void Example()
{
// load the scene with BuildSettings Index
Scenes.LoadSceneAsync(0);
// load scene by scene name
Scenes.LoadSceneAsync("SceneName", LoadSceneMode.Additive);
// synchronous loading is also possible
Scenes.LoadScene(0);
// unload the scene at Index of BuildSettings
Scenes.UnloadSceneAsync(0);
// unload scene by scene name
Scenes.UnloadSceneAsync("SceneName");
// synchronous unloading is also possible
Scenes.UnloadScene(0);
}
```
It is also possible to load/unload multiple scenes simultaneously.
``` cs
// load multiple scenes simultaneously (LoadSceneMode is Addictive only)
Scenes.LoadScenesAsync("Scene1", "Scene2", "Scene3");
// unload multiple scenes simultaneously
Scenes.UnloadScenesAsync("Scene1", "Scene2");
```
For LoadScenesAsync only, you can set the behavior of loading multiple scenes by setting LoadMultiSceneMode.
``` cs
// load multiple scenes simultaneously
Scenes.LoadScenesAsync(LoadMultiSceneMode.Parallel, "Scene1", "Scene2", "Scene3");
// load multiple scenes one by one
Scenes.LoadScenesAsync(LoadMultiSceneMode.Sequential, "Scene1", "Scene2");
```
### Events
As with a normal SceneManager, it is possible to acquire timings such as scene loading with events.
``` cs
Scenes.onSceneLoaded += (scene, loadSceneMode) =>
{
Debug.Log(scene.name + " loaded");
};
Scenes.onSceneUnLoaded += scene =>
{
Debug.Log(scene.name + " unloaded");
};
Scenes.onActiveSceneChanged += (current, next) =>
{
Debug.Log($"active scene changed from {current.name} to {next.name}");
};
```
Also, by passing a class that implements ILoadSceneCallbackReceiver, it is possible to process these events collectively.
``` cs
using UnityEngine;
using UnityEngine.SceneManagement;
using AnnulusGames.SceneSystem;
public class Example : MonoBehaviour, ILoadSceneCallbackReceiver
{
void Start()
{
Scenes.AddCallbackReceiver(this);
}
void ILoadSceneCallbackReceiver.OnActiveSceneChanged(Scene current, Scene next)
{
Debug.Log($"active scene changed from {current.name} to {next.name}");
}
void ILoadSceneCallbackReceiver.OnLoad(Scene scene, LoadSceneMode loadSceneMode)
{
Debug.Log(scene.name + "loaded");
}
void ILoadSceneCallbackReceiver.OnUnload(Scene scene)
{
Debug.Log(scene.name + "unloaded");
}
}
```
## SceneReference
By using SceneReference, it becomes possible to edit Scene assets on the Inspector.
``` cs
using UnityEngine;
using AnnulusGames.SceneSystem;
public class SceneReferenceExample : MonoBehaviour
{
public SceneReference sceneReference;
void Load()
{
// can be used as an argument for LoadScene
Scenes.LoadScene(sceneReference);
// get scene asset file path from assetPath
Debug.Log(sceneReference.assetPath);
}
}
```
<img src="https://github.com/AnnulusGames/SceneSystem/blob/main/Assets/SceneSystem/Documentation~/img1.png" width="420">
## LoadSceneOperationHandle
All asynchronous methods in the Scene System have a structure called LoadSceneOperationHandle as a return value.
By using LoadSceneOperationHandle, it is possible to wait for transitions, enable scenes, etc.
### Wait for the process to complete
Use onCompleted to wait for the completion of processing in a callback.
``` cs
var handle = Scenes.LoadSceneAsync("SceneName");
handle.onCompleted += () =>
{
Debug.Log("completed");
};
```
To wait in a coroutine, use the ToYieldInteraction method.
``` cs
var handle = Scenes.LoadSceneAsync("SceneName");
yield return handle.ToYieldInteraction();
```
To wait with async/await, use the ToTask method.
``` cs
var handle = Scenes.LoadSceneAsync("SceneName");
await handle.ToTask();
```
### Get Progress
It is also possible to get the progress from the LoadSceneOperationHandle.
``` cs
var handle = Scenes.LoadSceneAsync("SceneName");
// get the progress as a float between 0 and 1
var progress = handle.Progress;
// get if completed
var isDone = handle.IsDone;
```
### Activate Scene
By using the AllowSceneActivation method, it is possible to adjust the timing of scene loading completion.
Here is an example of using AllowSceneActivation inside a coroutine.
``` cs
var handle = Scenes.LoadSceneAsync("SceneName");
// set allowSceneActivation to false
handle.AllowSceneActivation(false);
// wait until progress reaches 0.9 (loading is complete)
yield return new WaitWhile(() => handle.Progress < 0.9f);
// set allowSceneActivation to true
handle.AllowSceneActivation(true);
// wait until the scene is activated
yield return handle.ToYieldInteraction();
```
Regarding the behavior of Progress and IsDone values when AllowSceneActivation is set to false, it conforms to Unity's allowSceneActivation.
https://docs.unity3d.com/2019.4/Documentation/ScriptReference/AsyncOperation-allowSceneActivation.html
## Loading Screen
Scene System provides the LoadingScreen component as a function to display the loading screen.
<img src="https://github.com/AnnulusGames/SceneSystem/blob/main/Assets/SceneSystem/Documentation~/img2.png" width="500">
You can create your own loading screen by customizing the LoadingScreen component.
### Settings
#### Skip Mode
Set the behavior when loading is completed.
| SkipMode | Behavior |
| ---------------- | --------------------------------------------------------------------------- |
| Instant Complete | Activates the next scene immediately after loading completes. |
| Any Key | Activates the next scene when any key is pressed after loading is complete. |
| Manual | After loading is complete, manually activate the next scene from Script. |
If set to Manual, the next scene can be enabled by calling AllowCompletion().
``` cs
LoadingScreen loadingScreen;
loadingScreen.AllowCompletion();
```
#### Minimum Loading Time
Set the minimum amount of time it takes to load.
Even if the loading of the scene is completed, it is possible to pretend that the loading is being performed for the set time.
#### Destroy On Completed
If set to true, automatically remove the object after the scene transition is complete.
#### On Loading
Called every frame while the scene is loading.
#### On Load Completed
Called when the scene has finished loading. The scene is not activated at this point.
#### On Completed
Called when the scene is activated.
### Loading Screen Implementation
To use the loading screen created with LoadingScreen component, use the WithLoadingScreen method. This method is defined as an extension method of LoadSceneOperationHandle and can be used for any asynchronous method of the Scene System.
``` cs
using UnityEngine;
using AnnulusGames.SceneSystem;
public sealed class LoadingScreenSample : MonoBehaviour
{
public LoadingScreen loadingScreenPrefab;
public void Load()
{
// generate a prefab for the loading screen and set it to DontDestroyOnLoad
var loadingScreen = Instantiate(loadingScreenPrefab);
Don't DestroyOnLoad(loadingScreen);
// pass the loadingScreen generated by WithLoadingScreen
Scenes.LoadSceneAsync("SceneName")
.WithLoadingScreen(loadingScreen);
}
}
```
Note: Do not call AllowSceneActivation on a LoadSceneOperationHandle that has a LoadingScreen set. Since it manipulates allowSceneActivation on the LoadingScreen side, it may cause unexpected behavior.
### Extend LoadingScreen
It is also possible to create your own class by inheriting from LoadingScreen.
``` cs
using UnityEngine;
using AnnulusGames.SceneSystem;
public class CustomLoadingScreen : LoadingScreen
{
public override void OnCompleted()
{
Debug.Log("completed");
}
public override void OnLoadCompleted()
{
Debug.Log("load completed");
}
public override void OnLoading(float progress)
{
Debug.Log("loading...");
}
}
```
### Sample
A loading screen implementation sample using LoadingScreen is available and can be installed from Package Manager/Samples.
Please refer to it when you actually create a loading screen.
<img src="https://github.com/AnnulusGames/SceneSystem/blob/main/Assets/SceneSystem/Documentation~/img3.png" width="500">
## SceneContainer
When adopting a project structure that uses multiple scenes in Unity, it is necessary to implement the transition of multiple scenes in some way. Scene System provides the SceneContainer class as a function for performing such complex scene transitions.
### Create a container
When using SceneContainer, first create a new container with SceneContainer.Create().
``` cs
// create a new container
var container = SceneContainer.Create();
```
Register a scene to be loaded/unloaded at runtime with the Register method.
``` cs
// pass the key associated with the scene to the first argument, and the scene name and scene buildIndex to the second argument
container.Register("Page1", "Sample1A");
container.Register("Page1", "Sample1B");
container.Register("Page2", "Sample2");
```
Register a scene that exists permanently at runtime with the RegisterPermanent method.
``` cs
// pass the scene name and scene buildIndex as arguments
container.RegisterPermanent("Permanent1");
container.RegisterPermanent("Permanent2");
```
Finally call the Build method. Calling this method will enable the container and load the scene registered with RegisterPermanent at the same time.
This process is asynchronous and can be waited for in the same way as a normal scene load.
``` cs
// build the container
var handle = container.Build();
// wait for completion
yield return handle.ToYieldInteraction();
```
### Scene transition using containers
Use the Push method to perform scene transitions with SceneContainer.
The history of scenes is stacked, and it is possible to return to the previous scene by calling the Pop method.
``` cs
// transition to the scene associated with the registered key
var handle = container.Push("Page1");
yield return handle.ToYieldInteraction();
// return to previous scene
handle = container.Pop();
yield return handle.ToYieldInteraction();
```
By calling the ClearStack method, you can reset the history and unload any scenes you have loaded with push.
``` cs
var handle = container.ClearStack();
```
You can also call Release to destroy the container and unload all scenes, including persistent scenes.
``` cs
var handle = container.Release();
```
## Scene System + UniRx
By introducing UniRx, it becomes possible to observable events related to scene loading.
To get scene loading/unloading events and active scene switching events as IObservable, write as follows.
``` cs
using AnnulusGames.SceneSystem;
using UniRx;
void Example()
{
Scenes.OnSceneLoadedAsObservable().Subscribe(x =>
{
var scene = x.scene;
var loadSceneMode = x.loadSceneMode;
Debug.Log("scene loaded");
});
Scenes.OnSceneUnloadedAsObservable().Subscribe(scene =>
{
Debug.Log("scene unloaded");
});
Scenes.OnActiveSceneChangedAsObservable().Subscribe(x =>
{
var current = x.current;
var next = x.next;
Debug.Log("active scene changed");
});
}
```
It is also possible to get SceneContainer events as IObservable.
``` cs
SceneContainer container;
void Example()
{
container.OnBeforePushAsObservable().Subscribe(x =>
{
Debug.Log("Current: " + x.current + " Next: " + x.next);
});
container.OnAfterPushAsObservable().Subscribe(x =>
{
Debug.Log("Current: " + x.current + " Next: " + x.next);
});
container.OnBeforePopAsObservable().Subscribe(x =>
{
Debug.Log("Current: " + x.current + " Next: " + x.next);
});
container.OnAfterPopAsObservable().Subscribe(x =>
{
Debug.Log("Current: " + x.current + " Next: " + x.next);
});
}
```
## Scene System + UniTask
By introducing UniTask, it becomes possible to wait for LoadSceneOperationHandle with UniTask.
Use ToUniTask to convert the LoadSceneOperationHandle to a UniTask.
``` cs
using AnnulusGames.SceneSystem;
using Cysharp.Threading.Tasks;
async UniTaskVoid ExampleAsync()
{
await Scenes.LoadAsync("SceneName").ToUniTask();
}
```
## License
[MIT License](LICENSE)
| 25
| 1
|
nklbdev/godot-4-importality
|
https://github.com/nklbdev/godot-4-importality
|
Universal raster graphics and animations importers pack
|
# Importality
[](README.md)
[](README.ru.md)


**Importality - is an add-on for [Godot](https://godotengine.org) engine for importing graphics and animations from popular formats.**
## 📜 Table of contents
- [Introduction](#introduction)
- [Features](#features)
- [How to install](#how-to-install)
- [How to use](#how-to-use)
- [How to help the project](#how-to-help-the-project)
## 📝 Introduction
I previously published an [add-on for importing Aseprite files](https://github.com/nklbdev/godot-4-aseprite-importers). After that, I started developing a similar add-on for importing Krita files. During the development process, these projects turned out to have a lot in common, and I decided to combine them into one. Importality contains scripts for exporting data from source files to a common internal format, and scripts for importing data from an internal format into Godot resources. After that, I decide to add new export scripts for other graphic applications.
## 🎯 Features
- Adding recognition of source graphic files as images to Godot with all the standard features for importing them (for animated files, only the first frame will be imported).
- Support for Aseprite (and LibreSprite), Krita, Pencil2D, Piskel and Pixelorama files. Other formats may be supported in the future.
- Import files as:
- Atlas of sprites (sprite sheet) - texture with metadata;
- `SpriteFrames` resource to create your own `AnimatedSprite2D` and `AnimatedSprite3D` based on it;
- `PackedScene`'s with ready-to-use `Node`'s:
- `AnimatedSprite2D` and `AnimatedSprite3D`
- `Sprite2D`, `Sprite3D` and `TextureRect` animated with `AnimationPlayer`
- Several artifacts avoiding methods on the edges of sprites.
- Grid-based and packaged layout options for sprite sheets.
- Several node animation strategies with `AnimationPlayer`.
## 💽 How to install
1. Install it from [Godot Asset Library](https://godotengine.org/asset-library/asset/2025) or:
- Clone this repository or download its contents as an archive.
- Place the contents of the `addons` folder of the repository into the `addons` folder of your project.
1. Adjust the settings in `Project Settings` -> `General` -> `Advanced Settings` -> `Importality`
- [Specify a directory for temporary files](https://github.com/nklbdev/godot-4-importality/wiki/about-temporary-files-and-ram_drives-(en)).
- Specify the command and its parameters to launch your editor in data export mode, if necessary. How to configure settings for your graphical application, see the corresponding article on the [wiki](https://github.com/nklbdev/godot-4-importality/wiki).
## 👷 How to use
**Be sure to read the wiki article about the editor you are using! These articles describe the important nuances of configuring the integration!**
- [Aseprite/LibreSprite](https://github.com/nklbdev/godot-4-importality/wiki/exporting-data-from-aseprite-(en)) (Important)
- [Krita](https://github.com/nklbdev/godot-4-importality/wiki/exporting-data-from-krita-(en)) (**Critical!**)
- [Pencil2D](https://github.com/nklbdev/godot-4-importality/wiki/exporting-data-from-pencil_2d-(en)) (Important)
- [Piskel](https://github.com/nklbdev/godot-4-importality/wiki/exporting-data-from-piskel-(en)) (No integration with the application. The plugin uses its own source file parser)
- [Pixelorama](https://github.com/nklbdev/godot-4-importality/wiki/exporting-data-from-pixelorama-(en)) (No integration with the application. The plugin uses its own source file parser)
Then:
1. Save the files of your favorite graphics editor to the Godot project folder.
1. Select them in the Godot file system tree. They are already imported as a `Texture2D` resource.
1. Select the import method you want in the "Import" panel.
1. Customize its settings.
1. If necessary, save your settings as a default preset for this import method.
1. Click the "Reimport" button (you may need to restart the engine).
1. In the future, if you change the source files, Godot will automatically repeat the import.
## 💪 How to help the project
If you know how another graphics format works, or how to use the CLI of another application, graphics and animation from which can be imported in this way - please offer your help in any way. It could be:
- An [issue](https://github.com/nklbdev/godot-4-importality/issues) describing the bug, problem, or improvement for the add-on. (Please attach screenshots and other data to help reproduce your issue.)
- Textual description of the format or CLI operation.
- [Pull request](https://github.com/nklbdev/godot-4-importality/pulls) with new exporter.
- A temporary or permanent license for paid software to be able to study it and create an exporter. For example for:
- [Adobe Photoshop](https://www.adobe.com/products/photoshop.html)
- [Adobe Animate](https://www.adobe.com/products/animate.html)
- [Adobe Character Animator](https://www.adobe.com/products/character-animator.html)
- [Affinity Photo](https://affinity.serif.com/photo)
- [Moho Debut](https://moho.lostmarble.com/products/moho-debut) / [Moho Pro](https://moho.lostmarble.com/products/moho-pro)
- [Toon Boom Harmony](https://www.toonboom.com/products/harmony)
- [PyxelEdit](https://pyxeledit.com)
- and others
| 28
| 0
|
muzairkhattak/PromptSRC
|
https://github.com/muzairkhattak/PromptSRC
|
[ICCV 2023] Official repository of paper titled "Self-regulating Prompts: Foundational Model Adaptation without Forgetting".
|
# Self-regulating Prompts: Foundational Model Adaptation without Forgetting [ICCV 2023]
> [**Self-regulating Prompts: Foundational Model Adaptation without Forgetting**](https://arxiv.org/abs/2307.06948)<br>
> [Muhammad Uzair Khattak*](https://muzairkhattak.github.io/), [Syed Talal Wasim*](https://talalwasim.github.io), [Muzammal Naseer](https://scholar.google.com/citations?user=tM9xKA8AAAAJ&hl=en&oi=ao), [Salman Khan](https://salman-h-khan.github.io/), [Ming-Hsuan Yang](http://faculty.ucmerced.edu/mhyang/), [Fahad Shahbaz Khan](https://scholar.google.es/citations?user=zvaeYnUAAAAJ&hl=en)
*Joint first authors
[](https://arxiv.org/abs/2307.06948)
[](https://muzairkhattak.github.io/PromptSRC/)
[](https://www.youtube.com/watch?v=VVLwL57UBDg)
[](https://drive.google.com/file/d/1d14q8hhAl6qGsiPYpNIVfShMCulVJSUa/view?usp=sharing)
Official implementation of the paper "[Self-regulating Prompts: Foundational Model Adaptation without Forgetting](https://arxiv.org/abs/2307.06948)".
<hr />
[](https://paperswithcode.com/sota/prompt-engineering-on-imagenet?p=self-regulating-prompts-foundational-model)
[](https://paperswithcode.com/sota/prompt-engineering-on-imagenet-v2?p=self-regulating-prompts-foundational-model)
[](https://paperswithcode.com/sota/prompt-engineering-on-sun397?p=self-regulating-prompts-foundational-model)
[](https://paperswithcode.com/sota/prompt-engineering-on-ucf101?p=self-regulating-prompts-foundational-model)
[](https://paperswithcode.com/sota/prompt-engineering-on-fgvc-aircraft-1?p=self-regulating-prompts-foundational-model)
<hr />
# :rocket: News
* **(July 14, 2023)**
* Our work is accepted to ICCV 2023! :tada:
* **(July 12, 2023)**
* Pre-trained models and evaluation codes for reproducing PromptSRC official benchmark results are released.
* Training codes for [PromptSRC](configs/trainers/PromptSRC) are released.
* This repository also supports [MaPle (CVPR'23)](configs/trainers/MaPLe),
[CoOp (IJCV'22)](configs/trainers/CoOp), [Co-CoOp (CVPR'22)](configs/trainers/CoCoOp)
architectures.
<hr />
## Highlights

> <p align="justify"> <b> <span style="color: blue;">Left</span></b>:
> Existing prompt learning approaches for foundational Vision-Language models like CLIP rely on task-specific objectives that restrict
> prompt learning to learn a feature space suitable only for downstream tasks and
> consequently lose the generalized knowledge of CLIP (shown in <span style="color: purple;">purple</span></b>).
> Our self-regulating framework explicitly guides the training trajectory of prompts
> towards the closest point between two optimal solution manifolds (solid line) to
> learn task-specific representations while also retaining generalized CLIP knowledge
> (shown in <span style="color: green;">green</span>). <b><span style="color: blue;">Middle</span></b>: Averaged
> across 11 image recognition datasets, PromptSRC surpasses existing methods on the
> base-to-novel generalization setting. <b><span style="color: blue;">Right</span></b>: We evaluate
> our approach on four diverse image recognition benchmarks for CLIP and show
> consistent gains over previous state-of-the-art approaches. </p>
> **<p align="justify"> Abstract:** *Prompt learning has emerged as an efficient alternative
> for fine-tuning foundational models, such as CLIP, for various downstream tasks.
> Conventionally trained using the task-specific objective, i.e., cross-entropy loss,
> prompts tend to overfit downstream data distributions and find it challenging to capture
> task-agnostic general features from the frozen CLIP. This leads to the loss of the model's
> original generalization capability. To address this issue, our work introduces a
> self-regularization framework for prompting called PromptSRC (Prompting with Self-regulating
> Constraints). PromptSRC guides the prompts to optimize for both task-specific and task-agnostic
> general representations using a three-pronged approach by: (a) regulating {prompted}
> representations via mutual agreement maximization with the frozen model, (b) regulating
> with self-ensemble of prompts over the training trajectory to encode their complementary
> strengths, and (c) regulating with textual diversity to mitigate sample diversity imbalance
> with the visual branch. To the best of our knowledge, this is the first regularization
> framework for prompt learning that avoids overfitting by jointly attending to pre-trained
> model features, the training trajectory during prompting, and the textual diversity.
> PromptSRC explicitly steers the prompts to learn a representation space that maximizes
> performance on downstream tasks without compromising CLIP generalization. We perform
> experiments on 4 benchmarks where PromptSRC performs favorably well compared
> to the existing methods. Our code and pre-trained models are publicly available.* </p>
## Regularization Framework for Prompt Learning
We propose PromptSRC (Prompting with Self-regulating Constraints) which steers the prompts to learn a representation space that maximizes performance on downstream tasks without compromising CLIP generalization.
**Key components of PromptSRC:**
1) **Mutual agreement maximization:** PromptSRC explicitly guides the prompts to jointly acquire both <i>task-specific knowledge</i> and <i>task-agnostic generalized knowledge</i> by maximizing the mutual agreement between prompted and features of the frozen VL model.
2) **Gaussian weighted prompt aggregation:** We propose a weighted self-ensembling strategy for prompts over the training trajectory that captures complementary features and enhances their generalization abilities.
3) **Textual diversity:** PromptSRC regulates prompts with textual diversity to mitigate sample diversity imbalance compared to the visual branch during training.
## :ballot_box_with_check: Supported Methods
| Method | Paper | Configs | Training Scripts |
|---------------------------|:----------------------------------------------|:---------------------------------------------------------------:|:-------------------------------:|
| PromptSRC | [arXiv](https://arxiv.org/abs/2307.06948) | [link](configs/trainers/PromptSRC/) | [link](scripts/promptsrc) |
| Independent V-L Prompting | - | [link](configs/trainers/IVLP/) | [link](scripts/independent-vlp) |
| MaPLe | [CVPR 2023](https://arxiv.org/abs/2210.03117) | [link](configs/trainers/CoOp) | [link](scripts/maple) |
| CoOp | [IJCV 2022](https://arxiv.org/abs/2109.01134) | [link](configs/trainers/CoOp) | [link](scripts/coop) |
| Co-CoOp | [CVPR 2022](https://arxiv.org/abs/2203.05557) | [link](configs/trainers/CoCoOp) | [link](scripts/cocoop) |
<hr />
## Results
Results reported below show accuracy for base and novel classes for across 11 recognition datasets averaged over 3 seeds.
### Effectiveness of PromptSRC in comparison with baseline Independent V-L Prompting
PromptSRC effectively maximizes supervised task performance (base classes) without compromising on CLIP's original generalization towards new unseen tasks (novel classes).
| Name | Base Acc. | Novel Acc. | HM | Epochs |
|---------------------------------------------------------------------------------|:---------:|:----------:|:---------:|:------:|
| CLIP | 69.34 | 74.22 | 71.70 | - |
| Independent V-L Prompting | 84.21 | 71.79 | 77.51 | 20 |
| PromptSRC (ours) | **84.26** | **76.10** | **79.97** | 20 |
### PromptSRC in comparison with existing state-of-the-art
| Name | Base Acc. | Novel Acc. | HM | Epochs |
|--------------------------------------------|:---------:|:----------:|:---------:|:------:|
| [CLIP](https://arxiv.org/abs/2103.00020) | 69.34 | 74.22 | 71.70 | - |
| [CoOp](https://arxiv.org/abs/2109.01134) | 82.69 | 63.22 | 71.66 | 200 |
| [CoCoOp](https://arxiv.org/abs/2203.05557) | 80.47 | 71.69 | 75.83 | 10 |
| [ProDA](https://arxiv.org/abs/2205.03340) | 81.56 | 75.83 | 76.65 | 100 |
| [MaPLe](https://arxiv.org/abs/2210.03117) | 82.28 | 75.14 | 78.55 | 5 |
| [PromptSRC (ours)](https://arxiv.org/abs/2307.06948) | **84.26** | **76.10** | **79.97** | 20 |
## Installation
For installation and other package requirements, please follow the instructions detailed in [INSTALL.md](docs/INSTALL.md).
## Data Preparation
Please follow the instructions at [DATASETS.md](docs/DATASETS.md) to prepare all datasets.
## Model Zoo
### Vision-Language prompting methods
| Name (configs) | Model checkpoints |
|---------------------------------------------------------------------------------------|:-----------------------------------------------------------------------------------------------------------------------------------------:|
| [Independent V-L Prompting](configs/trainers/IVLP/vit_b16_c2_ep20_batch4_4+4ctx.yaml) | [link](https://mbzuaiac-my.sharepoint.com/:f:/g/personal/syed_wasim_mbzuai_ac_ae/EuIwh-yMh_JBqB2Y_o8Jl14BPDKDRHC0JBPE1BugIeZiSQ?e=AJ8MhY) |
| [PromptSRC](configs/trainers/PromptSRC/vit_b16_c2_ep20_batch4_4+4ctx.yaml) | [link](https://mbzuaiac-my.sharepoint.com/:f:/g/personal/syed_wasim_mbzuai_ac_ae/EqFXPs2Zl9pKp39w3SqlR7QBDACTv-AgCXH6_cGflrUFwg?e=l33EBA) |
## Evaluation
Please refer to the [EVAL.md](docs/EVAL.md) for detailed instructions on using the evaluation scripts and reproducing the official results using our pre-trained models.
## Training
Please refer to the [TRAIN.md](docs/TRAIN.md) for detailed instructions on training PromptSRC and IVLP baseline from scratch.
<hr />
## Citation
If you find our work, this repository, or pretrained models useful, please consider giving a star :star: and citation.
```bibtex
@article{khattak2023PromptSRC,
title={Self-regulating Prompts: Foundational Model Adaptation without Forgetting},
author={khattak, Muhammad Uzair and Wasim, Syed Talal and Muzzamal, Naseer and Khan, Salman and Yang, Ming-Hsuan and Khan, Fahad Shahbaz},
journal={arXiv:2307.06948},
year={2023}
}
```
## Contact
If you have any questions, please create an issue on this repository or contact at [email protected] or [email protected].
## Acknowledgements
Our code is based on [MaPLe](https://github.com/muzairkhattak/multimodal-prompt-learning), along with [Co-CoOp and CoOp](https://github.com/KaiyangZhou/CoOp) repository. We thank the authors for releasing their code. If you use our model and code, please consider citing these works as well.
| 60
| 1
|
RimoChan/emmmbedding
|
https://github.com/RimoChan/emmmbedding
|
【emmmbedding】不用存储的图床!
|
# 【emmmbedding】不用存储的图床!
大家平时会用到图床服务吗?
部署图床服务需要很大的存储空间,而且云服务卖的硬盘通常是按容量×时间算钱的,所以做一个图床实际上要随时间花费O(n**2)的钱。
那有没有什么既能永久存储图片,又不用花钱的办法呢?
正好聪明的莉沫酱发明了不用存储的图床,有了它就不需要硬盘啦!
## 原理
其实是用了stable-diffusion的vae,用户上传了图片之后,就把图片压缩成一个很小的矩阵,用base64整个塞到url里,然后有人访问这个url的时候,再从url里还原出图片!
举个例子——
输入1张 316×316 的图片:

经过vae编码之后,得到这个tensor,尺寸是`[1, 4, 39, 39]`:
```python
tensor([[[[ 1.0445e+01, 8.4394e+00, 6.9553e+00, ..., 5.4966e+00,
5.2353e+00, 8.0868e+00],
[ 9.9430e+00, 6.4219e+00, 8.6987e+00, ..., 6.0790e+00,
8.8426e+00, -7.1120e-01],
[ 8.4888e+00, 1.0169e+01, 1.0712e+01, ..., 1.0351e+01,
7.3863e-01, 2.0532e+00],
...,
```
然后把tensor经过uint8量化、webp压缩、base64,就可以得到一个url:
```
http://localhost:8000/image?q=CABFwUl9iUEnAAAAJwAAAFJJRkaIDwAAV0VCUFZQOCB8DwAAEDUAnQEqJwCcAD4VCINBIQYjn9sEAFEtIAKPH6i_u343eZv4z8n_b_yv9Ln-A77fIv-h9BP419g_x_9x_c32L_yXgj8E_5X1Avxz-V_4f8wv7X73nwHaJZd_PP-D_b_YC9UPmf-o_wv7rf5v0HP6D0A_H_6n_vfyx-gD-Q_yj_Jfmj7n_2z_ieKn9C_rP-l_rv5GfYB_E_55_mf7X_k_-9_p_o8_Yf9t_hv3e_03sm_K_6X_sf7f_jP_T_ofsB_jv80_yH9s_x__e_xP___8_3I-qL9T_Ym_S77x_3__-Z7Tk_Rnw8SDxDUR_RYD8_X_8isWuXaDTzYOZ38hA9NRlSH4ZviKIN78ZjqTCkXOFD6u46a84ugEpiGtyyt_4J0HPAKW7Cu6r2gquu2BwK0zTZN4gE3e4jg5Bm2HnfGNGBEMDhAf1ovjTK69YQIVMEPHRnBcl5NtrYiAuiFWQqTmRLuiBFFUTfjKvhU5cmxWHImccvHrv5C86E-mIWpuzHs8UnBzyqB7UtldoD6dqmdZaP7IlAJxXbrXTEEcQsEO6k3bJU_gFVznJ5fyNr8Z2Jf2AAD-_1BtfiNuVC4-xXQTeAqQsv40-dTe672HyAEuCN76jjTg9W_YZFQWSxG5uzmMKJCtNFWM3AWyVk3yKveZQqkoyZtK5uGGmXyZeO2kyDdDOLhPFDyS1tD-ppdQWJG8dAalb5_0ke0bHyQ31EZ_B7MuIC02GDLGvLWDUevP9iRUdwSERyedFCPvzYi5PYxyPrJesbdma8qIP0-48pKb2FMJbDeRh9B_TyrZMG6vuUDIDEijrg7-0Ok2X8Crnkywx2TsdvQFbZqtZx3d527crRSnjLIiYTqFtgBChYA0c-XEHJO9p7LF_-g-_WFJ1GPT54Emk_axs72QzQxDXKR80yL64GK6DRYhp0KbfAHw-d96p1qsFKEHv2InZBRAgkb2aURvlb-L6JRnKlpKlM6nnnJAAWNiFFy4WIrez4xDwEwvoMkq8GMBs3Qu1cbDAyZEDJy8nXp7_ruInbz91TgcuqawAEYVY3zDv0sVfoyZN9fZLtRJA5awIU3SmMrqyG8ZA7z_602eMW-bnuA63MLIn_uh1zIzRct2LalSIuggy17h7EPjrM42y3Nw5t7yxtfdygw7F-OpvYdP56cWjBXkfkqlnbB2xCvZGrNQSD9b9c4rux2JbGxlYhQfbqHagpj0dxEBxxsFqnmz-J1gixpT-mhTBRYhQm5kWV-2DB9ACkw6GvpNREheI2mnODfeAAm3MbtccUjmXRNLMhTcehjz4pP53PIgefZQmkTtzyP5ROGNrOmjieh4IX3CYH_m_mtpuy8ORF27SjyQbFwar4qxI3M-if2dl0_Mzj-HCnpbxmk7ZM0N0CjG5MhInzW8F4FAN9AEGmqkSU6dQ-JvPjXWKFmuzYNgsMBU7J5bwfHZWrhgLJWWFUfS6cLaFItSadFEppR76fiKGKR_3HtsuFPUfhzG5m9gkywhU7v10nnujv2QhopWHOvQ2w0X6wfHG--lzvGuuBPCX0IA95EanxrNjrV_N6r0fEfM-niD1_gxJb-hHxDxnUFiH1v4H41YnMwdLidchFq-JlcspDDAzBQ7TJjIQupCiEAdurar5AQ7GKbxjnmeMFkU2mgjsR6y9dMwm3FXkyeunhS2dT0RvG4h0U_ptceh_1VNdm2I8M8XyruQstJRTA1sql0Cw2QM-8QlCjhMK-4avb02OuNuis8X6n9dHz4hi9GVDpPeHYZxO6fcUiA7e61w2tOjfgI3Oar5tMH6ILX4nILy8CMW5slXYJwkp4pCJerFDdvbXIumSH0H8zVDwPm5uPYyjSYLp7eT_EzKwkLxNjTDjc2cZJnQrq5JEQMyhowVSzyNjKjYkmp2YvVkluMPBv3Uzd-URFQGWX1XzzZoxT6DECMPzZ8WOJ7ouLgr6ii1YiWADGZHdKBF7FAvRSOWu7IFVC4BKrjZmnIAvP8VBQKD6iQehCflrSks3bNxAmCpQZ6P32o1sRdH-S3IhIdnZWRzC92GUlI4bH8MFgp59_ujWrnlb7chKHS09j19Wsj9HG-htr0RqsU36Fc7s0qVMHcT_cCP8EzNVMEwctVkOlMjGXtWQ3fTep4bXsj72o9BRCEnEqP8VfAw34t-l_GyY1FUVPbXIbT8orVSKhU5dsj6TKZBXTAjh8TfB2-OxsS_j7BV-v5Hq3xUXu69GazqEyWlFHmWgDey21fSr7fhDzd6YzF7214pvfXt_exOZv_HggRFmKcrMuXyUKi9Y-lQfb0_K_yq-JwbOqB8NctbfYWEjXUkrbtJkvJimfMmI4jeEzEeDfRcXwd5ncxHkIVrfdQPfTS_hAfT9kNDmJJDN9Bj5WnsN9_hsMmUa0Wz2yV7jvhIKapNtiusNXHET3P4EAxqWaEXy4zkZK5FmkykCoBHouZDXRieUPAgCZtiBsoTbLKu8IK9FvCPnjs67EOfX-_2-Zx_PFlNY5tbusKDUnU9UEdLmQLA9b16gFJM7GrviDu2GKfWV0oHTzLeOuItz9KHaBagQzTewPcCoc1TBIQC-6CMVncQuHQKyiaAEyHq8qywZnQ3i94VeYinEkkjgJtq-9eNZH0xZoxqLbgc2YW4Oz4T2tkJkgWaQ6eSU0X8Bf-nNiHR-SElWuPi3KnvAP6i9OdkfcHoX3DI5bF2kl8RjQ9u4fPjcLV3p3VDE_wCRCYvMRqrUE_R3yxdPZwzc5zVg9HqgusMtKUeUIgnw3o3f6ne6h1q_Vq5AVJrH4L28lCQJfM_yAjnikGwhR08adMZW9jceg4JMMbqGspSu8gAV1y46sa-UbrxIRKdn5qhu_jpQct_FzqDyZgtzvGIi4IXTYJAe3xiV8rj0wnMxoj3mKpXrYvHPb38Ago6wRbLmblmxCKyY-534Ti4T1eZkMUY9Ktv0OjorXPuKFKZV2A_rii9UR5eQTq-TDRyaPQ3WAKgREqfDQFiJEB4sCye9S6Wwse6Zlf9-UP9HXOx7FsjVxytAtgjKPC0ANZsOgwU0AlvFyIboMUTk7I8eQ6tjJeK_zO1dZICb6i-HVhzC_Wv6HQzCxG-gbBncAZTaGQnZx3kMaYHE6QXhBVpaNHseQPGsOi19BqCIllujTdDy2PqEAuferRgY0a7mJy5n0V2ebAiJm6d4OHgNlJqAydiEmBXIWKYUou1gdWlTF98sYnd5DQz_ladnrLOi3DQhqFF94op2HbudnvqQP6wS04wxWn8HT_VEC2_Enz5M3rTREZ3kTpgohKWbCyxlWwMeR42fgJJeX2uq8WfgXnoZyLPYZg3JlzpEnSgRh0X4IB6P2DZ4T6EJisbIKZZAyMO4K1S2-NSxN0tpxlegRcgSdfKx5K71f8cf-QA6qGAfrMlyrzow0kAv4ogjttOxcYEAEQ1RRXS67RMboOM_8XRh-fNF0iL0MTOADQ_wASP8ZJFxi3KnmAIxAS2GbSdABcQZ4eujaVb99l00VcegKJFESh7CB_Kuv9aTYx_StIzRUpvTa5TJtZ5TrI7T-WumBKKeucnNKgHKYUjuvyqbAniuYZPjZY2qKstmjJxJ9ZzSd1xgp5UvJiUAelEuy5aJ-utXDz2gfu4bVO3gAZq3ZTb-J7X6zakxDNIiwvnaXFYSiocFXHokmVb35cNd0FZpj32DM9FdCTbgEPprGF030Xg7V6UZ_OtuGDCBJV0N_9aC74O2wGT78dyDEOdeXhElSvU3tdKFJ9I96LQnA8NPt7YNENuaFBmBp8dwueqOI9q8ChS2mZepyx1FfBgLlQkSsUsUoJx_MV02QsDp6-AQCky0Wrs1WPMQpBQuRu9FL6Xw-AroZ_X8z-UCboY3sPtXM93mYHGAucXKpuu50kndv8cMqZjLKbIOGHYAnHN6RJKvDL9a1XFUqb7aM1eLtKQ0GyzpgvTfOcCbAhOEpIdl_4M_qIFllSfcEDtj9VetAOUrRGSq5nPxtxeq_4bsKKr_BrtWzmkUbUqWGEii_gyNCcKV-fukYe-pnn8eTSBUMMsj8oriBoS2YX9_HNwNQ8_4-AIUPVOTiC30qzQ_qnAbZwwme_9xr-mIJRSyn1b2fRHY1EKbRp3Br2AUEaCNsvmxiPxCWFVmk_izD3fcIyRAByQWRq7iJuchs7MWX26MkGaMytn-dGg3h6OzUza_7UkuaPSwGzHAs-ruY_44tBp9lXfhp95UIQQ7Y5myisDnJHdKN96ChS6IUIoJMslihNz2C_gJM1dmF1u7qLVev4LgyROpGdhRdu9INZ7QMcYDCMCwBiu1tW2SFe02EJy1MxlacYIY95pLKgu-rC5OZbHBjIQzH2dnWh9FuWIIv91BLhqw-JNZ4CMGVrZb62mlyEU4pA5zS4J8NgEI_2W55mxgICbBNwg0ncaLJayXDBBWBL92b5FDF3jGJQL7MubfZwOOD3CL0nTA6JLSK81soWR2m5QPVRsPlNyDqkdVRw6yo10vfbQjfn6VtEW6u3JAkZb7VVcPO6ceUv4-VwZfDgi7_WGEcX1o6CG3DSXAW4eoj0oZjuyGjStgUZ2s--qN_D5u9i3FQsp7UWACrjMch4jpvYCYNgNkx4easPQomXURT0vd7-qXIbxhqoKQndtVZpehrnmvjdd8jdofv7XhOn-XoGZ_47rClP1tW-b7EYU-HWL-h_JLIe6Dp0bCKIO4pcK8qDCbYEE3OC2TDKDnRzQbxdyL7ubhTppUu20V4J8-pu4YMD5WKJyxkSiQ5lTRe9lAuPZ-ownQ1AOTnNu2cwmlr-6_OXk4pu5ySlXLqDfadHUPp3y-wQyz1CDjPTIfExyMGx61AaOGPkjUzACFUy5TG9DBciaqKK7TkPTVjWlanJ3N4eiBcfAkyo1lOk3rZy4sMwI6QlVDG_j_TG3cwdPd_upTjmYMa_SswYDUrI4alP_93yPG0EjfERKhFvgaD2wANq6xsvbG3gF3jWFsR4jxI8ble1ZT_jHykeun1ow4sQiop27eSCLHjb0xN8cSLXaYx4y8Rvos1XPeFpHbhsHJCTp8MgHoN1f3YI5CBLUK9QK8dAYxiai6oEnzwMJ_gHW3xRmpUm_kOwsU-cCnME1K0PfWwyjrHLUJS_u6hqrIXwY6fWXTqVJkOLudWBz3C03QHUYk331mayewXs0gpB_rNGotRQNJVtYwYntZvjQU39VwvBoXJ9ByLAZx1nShIo-rINM03CoSARe6TMKhb_T5NWubYQyYhAaLrjCv7rwNk_mDM31XXU0wzLkPMtuzADhF0QIgOuLgAAAAA%3D%3D
```
访问url时,就对上面的操作分别做一次逆操作,然后再送入vae解码,就能还原出这张图片:

看起来有一点微小的差别,不过大部分是一样的啦!
## 使用方法
首先你需要一个Python3,安装依赖:
```sh
pip install -r requirements.txt
```
启动服务:
```sh
uvicorn main:app --host 0.0.0.0 --reload
```
然后就可以去`http://localhost:8000/`上传图片啦!
## 注意
emmmbedding看起来很像embedding,但它其实不是,它是恶魔妹妹床上用品!
## 结束
就这样,大家88,我要回去和`emmm`亲热了!
| 133
| 5
|
yh-pengtu/FemtoDet
|
https://github.com/yh-pengtu/FemtoDet
|
Official codes of ICCV2023 paper: <<FemtoDet: an object detection baseline for energy versus performance tradeoffs>>
|
# FemtoDet
Official codes of ICCV2023 paper: <<Femtodet: an object detection baseline for energy versus performance tradeoffs>>
### Dependencies
* Python 3.8
* Torch 1.9.1+cu111
* Torchvision 0.10.1+cu111
* mmcv-full 1.4.2
* mmdet 2.23.0
### Installation
Do it as [mmdetection](https://github.com/open-mmlab/mmdetection/tree/v2.23.0) had done.
### Preparation
1. Download the dataset.
We mainly train FemtoDet on [Pascal VOC 0712](http://host.robots.ox.ac.uk/pascal/VOC/), you should firstly download the datasets. By default, we assume the dataset is stored in ./data/.
2. Dataset preparation.
Then, you can move all images to ./data/voc2coco/jpeg/*;you can use our converted coco format [annotation files](https://pan.baidu.com/s/1SLgZd_2cLhLFC54lLM3sHg?pwd=umbz)(umbz) and put these files to ./data/voc2coco/annotations/*; finally, the directory structure is
```
*data/voc2coco
*jpeg
*2008_003841.jpg
*...
*annotations
*trainvoc_annotations.json
*testvoc_annotations.json
```
3. Download the initialized models.
We trained our designed backbone on ImageNet 1k, and used it for [the inite weights](https://pan.baidu.com/s/1DhrT675Va2wcPAi5aUc-bg?pwd=6tns)(6tns) of FemtoDet.
```
FemtoDet/weights/*
```
### Training
```
bash ./tools/train_femtodet.sh 4
```
### Results (trained on VOC) and Models
[trained model and logs download](https://pan.baidu.com/s/1IpolHLSQBuEGXrbs_c80jg?pwd=x38z) (x38z)
```
| Detector | Params | box AP50 | Config |
---------------------------------------------------------------------------
| | | 37.1 | ./configs/femtoDet/femtodet_0stage.py |
-----------------------------------------------------
| FemtoDet | 68.77k | 40.4 | ./configs/femtoDet/femtodet_1stage.py |
-----------------------------------------------------
| | | 44.4 | ./configs/femtoDet/femtodet_2stage.py |
-----------------------------------------------------
| | | 46.5 | ./configs/femtoDet/femtodet_3stage.py |
---------------------------------------------------------------------------
```
### References
If you find the code useful for your research, please consider citing:
```bib
@misc{tu2023femtodet,
title={FemtoDet: An Object Detection Baseline for Energy Versus Performance Tradeoffs},
author={Peng Tu and Xu Xie and Guo AI and Yuexiang Li and Yawen Huang and Yefeng Zheng},
year={2023},
eprint={2301.06719},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
| 30
| 1
|
vaishnavikotkar2004/Pointer-Programs
|
https://github.com/vaishnavikotkar2004/Pointer-Programs
| null |
# Pointer-Programs
| 10
| 0
|
romanejaquez/temp_tflite_flutter
|
https://github.com/romanejaquez/temp_tflite_flutter
| null |
# On-Device ML using Flutter and TensorFlow Lite

This is a companion repo for the Medium tutorial on On-Device ML in Flutter with Tensorflow Lite, where we build a Flutter app that consumes a pre-trained model trained in Google Colab, and loaded onto a Flutter app for an on-device ML experience. The trained model converts a supplied Celsius degree into Fahrenheit.
###Medium Article Links:###
* [Part 1 of the Tutorial](https://medium.com/@romanejaquez/on-device-ml-using-flutter-and-tensorflow-lite-pt-1-model-training-2a84a685f2de)
* [Part 2 of the Tutorial](https://medium.com/@romanejaquez/on-device-ml-using-flutter-and-tensorflow-lite-pt-2-consume-your-trained-model-in-flutter-470bf314cd2d)

This is the schematics of what we accomplished in this Flutter app:

This is what you should expect at the end of the project:

* Provided Google Colab Notebook [here](c2f_tflite_model.ipynb)
* Already trained Tensorflow Lite ML model available in the **assets/models/** folder; filename **modelc2f.tflite**.
### Please don't forget to follow me on social media:
- On Twitter ([@drcoderz](https://www.twitter.com/drcoderz))
- On YouTube ([Roman Just Codes](https://www.youtube.com/channel/UCKsp3r1ERjCpKJtD2n5WtPg))
- On my [Personal Portfolio](https://romanjustcodes.web.app/)
- On [Medium](https://medium.com/@romanejaquez)
- On [LinkedIn](https://www.linkedin.com/in/roman-jaquez-8941a424/)
| 16
| 4
|
verytinydever/OOP_lab1
|
https://github.com/verytinydever/OOP_lab1
| null |
# OOP_lab1
| 15
| 0
|
airscripts/awesome-steam-deck
|
https://github.com/airscripts/awesome-steam-deck
|
A curated list of awesome Steam Deck software, resources and more.
|
# Awesome Steam Deck [](https://awesome.re)
A curated list of awesome Steam Deck software, resources and more.
## Contents
- [Guide](#guide)
- [Hardware](#hardware)
- [Accessory](#accessory)
- [Software](#software)
- [Emulation](#emulation)
- [Launcher](#launcher)
- [Remote](#remote)
- [File Management](#file-management)
- [Utility](#utility)
- [Plugin](#plugin)
- [Website](#website)
- [Community](#community)
- [Blog](#blog)
- [Podcast](#podcast)
## Guide
- [SSD Replacement](https://www.ifixit.com/Guide/Steam+Deck+SSD+Replacement/148989) - How to replace your SSD.
- [Install EmuDeck](https://www.emudeck.com/#how_to_install) - How to install EmuDeck.
- [Install Windows](https://www.howtogeek.com/877293/how-to-install-windows-on-your-steam-deck/) - How to install Windows.
- [Install Windows On microSD](https://wagnerstechtalk.com/sd-windows/) - How to install Windows on microSD.
- [Install ProtonGE](https://steamdeckhq.com/tips-and-guides/the-proton-ge-steam-deck-guide/) - How to install ProtonGE.
- [Install Chiaki](https://pimylifeup.com/steam-deck-ps5-remote-play/) - How to setup Chiaki.
- [Use Xbox Cloud Gaming](https://support.microsoft.com/en-us/topic/xbox-cloud-gaming-in-microsoft-edge-with-steam-deck-43dd011b-0ce8-4810-8302-965be6d53296) - How to use Xbox Cloud Gaming.
- [Install NonSteamLaunchers](https://www.steamdeckgaming.net/post/easy-launchers-install-on-steam-deck) - How to install NonSteamLaunchers.
- [Activate SFTP](https://www.youtube.com/watch?v=Cb1U0_KbtLQ) - How to transfer files from PC to Steam Deck with SFTP.
## Hardware
- [Sabrent Rocket 2230 SSD](https://www.amazon.com/SABRENT-Rocket-2230-Performance-SB-2130-1TB/dp/B0BQG6JCRP/) - Suggested SSD made by Sabrent.
- [SanDisk Extreme microSD](https://www.amazon.com/SanDisk-Extreme-microSDXC-Memory-Adapter/dp/B09X7MPX8L/) - Suggested microSD made by SanDisk.
## Accessory
- [Spigen Rugged Armor Protective Case](https://www.amazon.com/Protective-Shock-Absorption-Anti-Scratch-Accessories-nintendo-switch/dp/B0B75N73N9/) - Suggested protective case made by Spigen.
- [Maglass Screen Protector](https://www.amazon.com/Magglass-Tempered-Designed-Protector-Anti-Glare/dp/B09X82S4XL/) - Suggested screen protector made by Maglass.
- [JSAUX Cooling Fans](https://jsaux.com/products/fan-cooler-for-steam-deck-gp0200) - Cooling fans for reducing overall temperatures made by JSAUX.
## Software
- [Distrobox](https://github.com/89luca89/distrobox) - Use any Linux distribution inside your terminal.
- [rwfus](https://github.com/ValShaped/rwfus) - Read and write OverlayFS for Steam Deck.
- [BoilR](https://github.com/PhilipK/BoilR) - Synchronize non-Steam games with your Steam library.
- [Steam ROM Manager](https://github.com/SteamGridDB/steam-rom-manager) - An app for managing ROMs in Steam.
- [Discord Overlay](https://trigg.github.io/Discover/deckaddnonsteamgame) - Discord Overlay for Steam.
## Emulation
- [EmuDeck](https://github.com/dragoonDorise/EmuDeck) - Emulator configurator.
- [RetroArch](https://github.com/libretro/RetroArch) - Frontend for emulators, game engines and media players.
- [RetroDECK](https://github.com/XargonWan/RetroDECK) - All-in-one sandboxed application to play your retro games.
- [EmulationStation DE](https://gitlab.com/es-de/emulationstation-de) - Frontend for browsing and launching games from various collections.
- [PCSX2](https://github.com/PCSX2/pcsx2) - PS2 Emulator.
- [RPCS3](https://github.com/RPCS3/rpcs3) - PS3 Emulator.
- [PPSSPP](https://github.com/hrydgard/ppsspp) - PSP Emulator.
- [Vita3K](https://github.com/Vita3K/Vita3K) - PS Vita Emulator.
- [bsnes](https://github.com/bsnes-emu/bsnes) - SNES Emulator.
- [Dolphin](https://github.com/dolphin-emu/dolphin) - Gamecube/Wii Emulator.
- [DeSmuME](https://github.com/TASEmulators/desmume) - Nintendo DS Emulator.
- [Yuzu](https://github.com/yuzu-emu/yuzu) - Nintendo Switch Emulator.
- [Ryujinx](https://github.com/Ryujinx/Ryujinx) - Nintendo Switch Emulator.
- [xemu](https://github.com/xemu-project/xemu) - Xbox Emulator.
## Launcher
- [Lutris](https://lutris.net/) - Open gaming platform.
- [Heroic](https://heroicgameslauncher.com/) - Epic Games and GOG launcher.
- [Bottles](https://github.com/bottlesdevs/Bottles) - Run Windows software and games under Linux.
- [NonSteamLaunchers](https://github.com/moraroy/NonSteamLaunchers-On-Steam-Deck) - Automatic installation of the most popular launchers.
## Remote
- [Chiaki](https://git.sr.ht/~thestr4ng3r/chiaki) - Free and open source software client for PlayStation 4 and PlayStation 5 Remote Play.
- [KDE Connect](https://github.com/KDE/kdeconnect-kde) - Multi-platform app that allows your devices to communicate.
- [LocalSend](https://github.com/localsend/localsend) - Open source app to share files between devices over your local network.
- [Steam Link](https://store.steampowered.com/app/353380/Steam_Link/) - Extend your Steam gaming experience to more devices.
## File Management
- [Deck Drive Manager](https://deckdrivemanager.com/) - Copy PC games from PC to Steam Deck drives.
- [Syncthing](https://github.com/syncthing/syncthing) - Open source continuous file synchronization.
- [OpenCloudSaves](https://github.com/DavidDeSimone/OpenCloudSaves) - A tool used for syncing your save games across your devices.
## Utility
- [Shortix](https://github.com/Jannomag/shortix) - A script that creates human readable symlinks for Proton game prefixes.
- [Cryoutilities](https://github.com/CryoByte33/steam-deck-utilities) - Scripts and utilities to improve performance and manage storage.
- [Steam Deck Shader Cache Killer](https://github.com/scawp/Steam-Deck.Shader-Cache-Killer) - Script to purge Steam Deck shader cache.
- [Ludusavi](https://github.com/mtkennerly/ludusavi) - Backup tool for PC game saves.
## Plugin
- [Decky Loader](https://github.com/SteamDeckHomebrew/decky-loader) - Plugin launcher.
- [Deckbrew Plugins](https://plugins.deckbrew.xyz/) - List of Deckbrew plugins.
## Website
- [Steam Deck](https://www.steamdeck.com/) - Official Steam Deck website.
- [Great On Deck](https://store.steampowered.com/steamdeck/mygames) - A list of verified Steam Deck games.
- [CheckMyDeck](https://checkmydeck.ofdgn.com/) - Check compatibility with Steam Deck of your games library.
## Community
- [r/SteamDeck](https://reddit.com/r/SteamDeck) - Official subreddit.
- [Steam Deck Italia](https://t.me/SteamDeckIta) - Telegram italian community.
- [protondb.com](https://protondb.com) - Official ProtonDB site with games reviews and compatibility lists.
- [Steam Deck Community](https://steamdeck.community/) - An independent community.
- [Steam Deck Discord](https://discord.com/channels/865611969661632521/) - A Discord community.
## Blog
- [Steam Deck Life](https://steamdecklife.com/) - A blog about Steam Deck.
## Podcast
- [On Deck](https://open.spotify.com/show/5oH7NqKxSPiVFANLuYgDSn) - A podcast on Spotify by Nerdnest.
- [Decked Up](https://open.spotify.com/show/4ZW6yNxludK6FZQwvQlfJX) - A podcast on Spotify by Mekel Kasanova.
- [Fan The Deck](https://open.spotify.com/show/74eIOxJhDmmSZFbwlh7HIN) - A podcast on Spotify by Richard Alvarez.
## Contributing
Contributions and suggestions about how to improve this project are welcome!
Please follow [our contribution guidelines](https://github.com/airscripts/awesome-steam-deck/blob/main/CONTRIBUTING.md).
## Supporting
If you want to support my work you can do it with the links below.
Choose what you find more suitable for you:
- [Support me on GitHub](https://github.com/sponsors/airscripts)
- [Support me via ko-fi](https://ko-fi.com/airscript)
- [Support me via linktr.ee](https://linktr.ee/airscript)
## Licensing
This repository is licensed under [CC0 License](https://github.com/airscripts/awesome-steam-deck/blob/main/LICENSE).
| 33
| 3
|
d0j1a1701/LiteLoaderQQNT-Markdown
|
https://github.com/d0j1a1701/LiteLoaderQQNT-Markdown
|
为QQ添加Markdown渲染支持
|
# LiteLoaderQQNT-Markdown
## 简介
这是一个 [LiteLoaderQQNT](https://github.com/mo-jinran/LiteLoaderQQNT) 插件,使用 [Markdown-it](https://github.com/markdown-it/markdown-it) 为 QQnt 增加 Markdown 和 $\LaTeX$ 渲染功能!
## Features
- 标准 Markdown 语法;
- 基于 $KaTeX$ 的公式渲染;
- 基于 `pangu.js` 的中英文混排优化;
## 注意事项
- 本插件正处于测试阶段,若无法使用请积极发 issue,发 issue 时带上系统版本,插件列表和 LiteLoaderQQNT 设置中所示的版本信息。
- 该插件无须`npm install`,所有依赖已经通过`bpkg`打包内置,`package.json`只是便于开发。
| 11
| 4
|
mit-acl/planning
|
https://github.com/mit-acl/planning
|
List of planning algorithms developed at MIT-ACL
|
# Planning Algorithms #
| Algorithm | Image | Title | Code | Paper(s) | Video(s) |
| :---: | :---: | ------------- | :---: | :---: | :---: |
| **RMADER** | <img src='./imgs/rmader.JPG' width='1000'> | Robust MADER: Decentralized Multiagent Trajectory Planner Robust to Communication Delay in Dynamic Environments | [code](https://github.com/mit-acl/rmader) | [RA-L](https://arxiv.org/abs/2303.06222), [ICRA](https://arxiv.org/abs/2209.13667) | [RA-L](https://youtu.be/i1d8di2Nrbs), [ICRA](https://youtu.be/vH09kwJOBYs)
| **Deep-PANTHER** | <img src='./imgs/deep_panther.JPG' width='1000'> | Learning-Based Perception-Aware Trajectory Planner in Dynamic Environments | [code](https://github.com/mit-acl/deep_panther) | [RA-L](https://arxiv.org/abs/2209.01268) | [RA-L](https://www.youtube.com/watch?v=53GBjP1jFW8)
| **PANTHER** | <img src='./imgs/panther.JPG' width='1000'> | Perception-Aware Trajectory Planner in Dynamic Environments | [code](https://github.com/mit-acl/panther) | [IEEE Access](https://arxiv.org/abs/2103.06372) | [IEEE Access](https://www.youtube.com/watch?v=jKmyW6v73tY)
| **MADER** | <img src='./imgs/mader.JPG' width='1000'> | Trajectory Planner in Multi-Agent and Dynamic Environments | [code](https://github.com/mit-acl/mader) | [T-RO](https://arxiv.org/abs/2010.11061) | [T-RO](https://www.youtube.com/watch?v=aoSoiZDfxGE)
| **MINVO** | <img src='./imgs/minvo.JPG' width='1000'> | Finding Simplexes with Minimum Volume Enclosing Polynomial Curves | [code](https://github.com/mit-acl/minvo) | [CAD](https://arxiv.org/abs/2010.10726) | [CAD](https://youtu.be/x5ORkDCe4O0)
| **FASTER** | <img src='./imgs/faster.JPG' width='1000'> | Fast and Safe Trajectory Planner for Navigation in Unknown Environments | [code](https://github.com/mit-acl/faster) | [T-RO](https://arxiv.org/abs/2001.04420), [IROS](https://arxiv.org/abs/1903.03558) | [T-RO](https://www.youtube.com/watch?v=fkkkgomkX10), [IROS](https://www.youtube.com/watch?v=gwV0YRs5IWs)
| 25
| 2
|
jacobkaufmann/evangelion
|
https://github.com/jacobkaufmann/evangelion
|
a prototype ethereum block builder
|
# evangelion
a prototype block builder for ethereum
| 20
| 4
|
muer-org/muer
|
https://github.com/muer-org/muer
|
Self-hosted music player 🐧🎵
|
# Muer
[](https://github.com/codespaces/new/muer-org/muer?quickstart=1)
Muer is a modern, open-source music player for you and your friends.
Features:
- Beautiful UI/UX
- Music from Youtube
- Self-hosted
- Default fallback to Youtube embedded player
Muer is based on Invidious.

# Development
Run following commands to start coding & contributing to Muer
```sh
git clone https://github.com/muer-org/muer # Clone the repo
cd muer
npm install # Install dependencies
cp .env.sample .env # Create the .env file
npm run dev # Start the development server
```
# Hosting
By hosting Muer on various platforms, you help ensure the future of this project. While we use Netlify by default due to its simplicity and speed, we highly encourage individuals to explore and document their experiences with running Muer on alternative platforms.
## Host on Netlify
Clicking this button will start the setup for a new project and deployment.
[](https://app.netlify.com/start/deploy?repository=https://github.com/muer-org/muer)
Copy environment variables from the `.env.sample` file like so
<a href="public/screenshot_env.png"><img src="public/screenshot_env.png" height="240"></a>
You may need to deploy again
<a href="public/screenshot_deploy_again.png"><img src="public/screenshot_deploy_again.png" height="240"></a>
## Self-hosting
Guide to start production server on your own machine.
### Method 1: Clone & Run
```sh
git clone https://github.com/muer-org/muer # Clone the repo
cd muer
npm install # Install dependencies
cp .env.sample .env # Create the .env file
cp remix.config.selfhost.js remix.config.js # Use the self-hosting config
npm run build
npm run selfhost
```
### Method 2: Docker
```sh
docker run -p 3000:3000 muerorg/muer
```
## Host on other platforms
You can read these guides to start experimenting with other platforms:
- https://remix.run/docs/en/main/file-conventions/remix-config#serverbuildtarget
- https://vercel.com/guides/migrate-to-vercel-from-netlify
- https://developers.cloudflare.com/pages/migrations/migrating-from-netlify/
- https://github.com/dokku/dokku
- https://github.com/coollabsio/coolify
| 148
| 7
|
garyokeeffe/NSA
|
https://github.com/garyokeeffe/NSA
|
Nostr Serverless API
|
# Nostr Serverless API
The Nostr Serverless API (NSA) project allows anyone with an AWS account to quickly and cheaply deploy and maintain their own Nostr API. Our goal is to make a Data Scientist's user experience working with Nostr data amazing. The API is in the early alpha stage, so expect changes. If this is a project that interests you then please help!
## System Architecture
<details>
NSA's system architecture is outlined in **Figure 1** below. Specifically, this project consists of an AWS API Gateway that routes inbound API calls into an AWS Lambda function, which, in turn, spins up a Dockerized Flask application to process the API request. This architecture was chosen to minimize operating costs at low traffic volumes. We use an AWS Cloudformation Template to automate cloud service orchestration so that deploying (and maintaining) the API is trivial.
<p align="center">
<img src="https://github.com/garyokeeffe/NSA/blob/main/resources/NostrServerlessAPI.png?raw=true"><br>
<b>Figure 1</b>: Nostr Serverless API System Architecture Diagram
</p>
</details>
## Deploying the API
<details>
<summary>Details:</summary>
### Prerequisites
- An AWS account
- Docker installed, running, and configured to build `arm64` images
- AWS CLI installed and configured with your AWS credentials.
### Steps:
<details>
<summary><b>Step 1: Build and push the Docker image</b> </summary>
Navigate to the directory containing the Dockerfile (`Dockerfile`) and run the following commands (replacing `ACCOUNT_ID` with your AWS account ID and `REGION` with your desired AWS region):
```bash
aws ecr get-login-password --region REGION | docker login --username AWS --password-stdin ACCOUNT_ID.dkr.ecr.REGION.amazonaws.com # Log into your AWS account (remember to replace REGION and ACCOUNT_ID)
aws ecr create-repository --repository-name nostr-app --region REGION # Create your ECR (if the ECR doesn't already exist)
docker build -t nostr-app . # Build the docker image giving it the name "nostr-app"
docker tag nostr-app:latest ACCOUNT_ID.dkr.ecr.REGION.amazonaws.com/nostr-app:latest # Tag your docker image with the ECR name
docker push ACCOUNT_ID.dkr.ecr.REGION.amazonaws.com/nostr-app:latest # Push your docker image onto the ECR
```
</details>
<details>
<summary><b>Step 2: Deploy the CloudFormation stack</b></summary>
Navigate to the directory containing the CloudFormation template (`cloudformationtemplate.yaml`) and run the following command, replacing `STACK_NAME` with your desired CloudFormation stack name and `DOCKER_IMAGE_URI` with the URI of the Docker image you just pushed:
```bash
aws cloudformation deploy --template-file ./cloudformationtemplate.yaml --stack-name STACK_NAME --parameter-overrides DockerImageUri=DOCKER_IMAGE_URI --capabilities CAPABILITY_IAM
```
After successful deployment, you can access the Flask application via the URL of the API Gateway that was created. You can find your API's base URL by running the following command after successful deployment:
```bash
aws cloudformation describe-stacks --stack-name STACK_NAME --query 'Stacks[].Outputs'
```
(remember to replace `STACK_NAME` with the name of your stack (which is defined when you ran `aws cloudformation deploy` in the last step).
</details>
</details>
## Using the API
<details>
<summary>Details:</summary>
Full API documentation is available to Open API standards in this project's `openapi.yaml` file, and is also hosted on [Swagger Hub here](https://app.swaggerhub.com/apis/GARYJOKEEFFE/nostr-serverless_api/0.0.1). We also briefly describe them in this section.
Recall, you must first get your API's Base URL via the `describe-stacks` command (which can be found in Step 2 of the **Deploying the API** section). Once you have the base URL, you will be able to reach the following endpoints (with more endpoints to follow soon):
<details>
<summary>Verify the API is running correctly</summary>
**Description**: Publishing a "Running Nostr Serverless API" note from your account to verify everything is set up correctly
**Endpoint**: `/v0/verify`
**HTTP Method**: `POST`
**Objects to be added to the HTTP request**:
- relays = [LIST OF RELAYS OR STRING OF RELAY]
- private_key = [PRIVATE KEY IN NSEC FORMAT]
</details>
<details>
<summary>Send a Public Note</summary>
**Description**: Send a note from your account to a set of relays
**Endpoint**: `/v0/send/note`
**HTTP Method**: `POST`
**Objects to be added to the HTTP request**:
- relays = [LIST OF RELAYS OR STRING OF RELAY]
- private_key = [PRIVATE KEY IN NSEC FORMAT]
- text = [STRING OF YOUR NOTE's CONTENT]
</details>
<details>
<summary>Send a DM</summary>
**Description**: Send a DM from your account to someone else's over a set of relays
**Endpoint**: `/v0/send/dm`
**HTTP Method**: `POST`
**Objects to be added to the HTTP request**:
- relays = [LIST OF RELAYS OR STRING OF RELAY]
- sender_private_key = [PRIVATE KEY IN NSEC FORMAT]
- recipient_public_key = [PRIVATE KEY IN NPUB OR HEX FORMAT]
- text = [STRING OF YOUR NOTE's CONTENT]
</details>
<details>
<summary>Fetch Public Notes</summary>
**Description**: Fetch all notes that meet the filter criteria (filters to be added to request)
**Endpoint**: `/v0/fetch/notes`
**HTTP Method**: `POST`
**Objects that can be added to the HTTP request**:
- authors = [LIST OR STRING OF NPUB OR HEX FORMATTED AUTHOR[S]]
- relays = [LIST OF RELAYS OR STRING OF RELAY]
- event_refs = [LIST OR STRING OF EVENT REFENENCES]
- pubkey_refs = [LIST OR STRING OF PUB KEY REFENENCES]
- since = [INTEGER OF INTERVAL START]
- until = [INTEGER OF INTERVAL TERMINATION]
- limit = [INTEGER OF #NOTES TO FETCH PER RELAY (Defaults to 2000)]
**Objects included in response**:
- Dictionary of noteIDs wherein each object has the following properties:
- time_created = [INTEGER OF WHEN NOTE WAS CREATED]
- content = [STRING REPRESENTING NOTE's CONTENT]
- author = [AUTHORS PUBLIC KEY IN HEX FORMAT]
- signature = [STRING OF NOTE SIGNATURE]
- tags = [JSON BLOB OF NOSTR NOTE TAG OBJECTS]
</details>
We will be pubilshing comprehensive examples in video and text format. Follow me on Nostr (npub10mgeum509kmlayzuvxhkl337zuh4x2knre8ak2uqhpcra80jdttqqvehf6) or on Twitter @garyjokeeffe to stay up-to-date.
</details>
| 13
| 0
|
danthegoodman1/BigHouse
|
https://github.com/danthegoodman1/BigHouse
|
Running ClickHouse like it's BigQuery
|
# BigHouse

## Why (WIP)
You can get way more resources. EC2 the largest realistic machine you will use is 192 cores (*6a.metal), and that’s insanely expensive to run ($7.344/hr), especially paying for idle, boot, and setup time.
With fly.io you can spin up 30x 16vCPU machines (480 total cores), execute a query, and destroy the machines in 15 seconds. That query cost less than $0.09 to run (maybe an extra cent for R2 api calls).
With 30 saturated 2Gbit nics and 10:1 avg compression, that ends up being 2gbit * 10 ratio * 30 nics * 15 seconds = 9Tbs or 1.125TB/s. If the query processing itself took 10s, that’s 11.25TB of data. If that was run on BigQuery it would cost 11.25TB*$5/TB=$56.25, on TinyBird $0.07/GB*11,250GB = $787.5 (to be fair that’s absolutely not how you are supposed to use tinybird, but it is the closest thing clickhouse-wise).
For 15 seconds that EC2 instance would cost $0.03 for 192 cores. Multiply by 2.5x to get to 480 cores and that's already $0.075, nearly the same cost, but you haven't considered the 30s first boot time (or 10s subsequent boot times), the cost of the disk, etc.
## How to run
Easiest way is to just use a test, it will download and execute temporal for you. You do need Taskfile though.
```
task single-test -- ./temporal -run TestQueryExecutorWorkflow
```
`.env` file should look like:
```ini
FLY_API_TOKEN=xxx
FLY_APP=xxx
ENV=local
DEBUG=1
PRETTY=1
TEMPORAL_URL=localhost:7233
```
## Web Table Performance
### TLDR:
16vCPU 32GB fly machines (ams region) to S3 eu-central-1
```
SELECT sum(commits), event_type FROM github_events group by event_type
1 node: Query complete in in 32.29385382s
4 nodes: Query complete in in 8.413694766s
6 nodes: Query complete in in 5.938549286s
10 nodes: Query complete in in 4.186387433s
20 nodes: Query complete in in 4.114086397s
30 nodes: Query complete in in 9.618825346s (it was hard to even get these)
```
### Table of observations (not run with BigHouse, but just clustering in general)
| Query | Single node | Cluster | Notes |
|--------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------|
| `SELECT uniq(repo_name) FROM github_events` | `Elapsed: 34.991 sec. Processed 5.06 billion rows, 10.09 GB (144.59 million rows/s., 288.43 MB/s.)` | `Elapsed: 14.015 sec. Processed 5.06 billion rows, 10.09 GB (360.99 million rows/s., 720.09 MB/s.)` | 16vCPU 32GB fly machines (ams region) to S3 eu-central-1, 6 replicas |
| `SELECT sum(commits), event_type FROM github_events group by event_type` | `Elapsed: 2.279 sec. Processed 5.06 billion rows, 25.30 GB (2.22 billion rows/s., 11.10 GB/s.)` | `Elapsed: 4.994 sec. Processed 5.06 billion rows, 25.30 GB (1.01 billion rows/s., 5.07 GB/s.)` | Slowdown either due to coordination overhead and/or distance from S3 |
| `SELECT sum(cityHash64(*)) FROM github_events` | `Elapsed: 846.170 sec. Processed 5.06 billion rows, 2.76 TB (5.98 million rows/s., 3.26 GB/s.)` | With 50 parallel replicas: `1 row in set. Elapsed: 18.719 sec. Processed 5.06 billion rows, 2.76 TB (270.28 million rows/s., 147.48 GB/s.)` With 100 parallel replicas: `1 row in set. Elapsed: 11.286 sec. Processed 5.06 billion rows, 2.76 TB (448.27 million rows/s., 244.61 GB/s.)` | m5.8xlarge in AWS with VPC endpoint, shows ideal in-network performance is near linear |
16vCPU 32GB fly machines (ams region) to S3 eu-central-1, 6 replicas
```
-- no replicas
SELECT uniq(repo_name)
FROM github_events
SETTINGS max_parallel_replicas = 1, allow_experimental_parallel_reading_from_replicas = 0, prefer_localhost_replica = 1, parallel_replicas_for_non_replicated_merge_tree = 0
1 row in set. Elapsed: 34.991 sec. Processed 5.06 billion rows, 10.09 GB (144.59 million rows/s., 288.43 MB/s.)
-- enable parallel replicas
SET allow_experimental_parallel_reading_from_replicas = 1, use_hedged_requests = 0, prefer_localhost_replica = 0, max_parallel_replicas = 10, cluster_for_parallel_replicas = '{cluster}', parallel_replicas_for_non_replicated_merge_tree = 1;
-- with replicas
SELECT uniq(repo_name)
FROM github_events
1 row in set. Elapsed: 14.015 sec. Processed 5.06 billion rows, 10.09 GB (360.99 million rows/s., 720.09 MB/s.)
```
Efficient query:
```
-- No replicas:
SELECT sum(commits), event_type
FROM github_events
group by event_type
SETTINGS max_parallel_replicas = 1, allow_experimental_parallel_reading_from_replicas = 0, prefer_localhost_replica = 1, parallel_replicas_for_non_replicated_merge_tree = 0
Elapsed: 2.279 sec. Processed 5.06 billion rows, 25.30 GB (2.22 billion rows/s., 11.10 GB/s.)
-- subsequent runs are faster due to caching:
Elapsed: 1.841 sec. Processed 5.06 billion rows, 25.30 GB (2.75 billion rows/s., 13.74 GB/s.)
-- Parallel replicas
SELECT sum(commits), event_type
FROM github_events
group by event_type
Elapsed: 4.994 sec. Processed 5.06 billion rows, 25.30 GB (1.01 billion rows/s., 5.07 GB/s.)
```
As you can see with extremely fast queries, the overhead of distributing the work seems to degrade performance by half. This is also a simpler operation. This is probably also exacerbated by the distance to S3.
The worst performing query (ec2 in eu-central-1), but highlights max parallelism (thanks to Alexey for testing this):
```
SELECT sum(cityHash64(*)) FROM github_events
Without parallel replicas:
1 row in set. Elapsed: 846.170 sec. Processed 5.06 billion rows, 2.76 TB (5.98 million rows/s., 3.26 GB/s.)
With 50 parallel replicas:
1 row in set. Elapsed: 18.719 sec. Processed 5.06 billion rows, 2.76 TB (270.28 million rows/s., 147.48 GB/s.)
With 100 parallel replicas:
1 row in set. Elapsed: 11.286 sec. Processed 5.06 billion rows, 2.76 TB (448.27 million rows/s., 244.61 GB/s.)
SELECT sum(cityHash64(*)) FROM github_events
SETTINGS max_parallel_replicas = 1, allow_experimental_parallel_reading_from_replicas = 0, prefer_localhost_replica = 1, parallel_replicas_for_non_replicated_merge_tree = 0
```
As you can see with fly, the bottleneck is network access. Once storage is within the local network (or very close, same country) then performance skyrockets even further
## How does it work

## Primitive Performance Test
96 CSV files:
```
➜ dangoodman: ~ aws s3 ls --no-sign-request s3://altinity-clickhouse-data/nyc_taxi_rides/data/tripdata/ | wc -l 4:57PM
96
```
Nodes in `iad` fly.io region.
```
[6] Nodes ready in 3.221804869s
```
VERY unoptimized CH image. The more nodes the higher the chance it takes longer. iad I'm getting typically 3-5s for 6 nodes.
Single node:
```
SELECT count() FROM s3('https://s3.us-east-1.amazonaws.com/altinity-clickhouse-data/nyc_taxi_rides/data/tripdata/data-*.csv.gz', 'CSVWithNames',
'pickup_date Date, id UInt64, vendor_id String, tpep_pickup_datetime DateTime, tpep_dropoff_datetime DateTime, passenger_count UInt8, trip_distance Float32, pickup_longitude Float32, pickup_latitude Float32, rate_code_id String, store_and_fwd_flag String, dropoff_longitude Float32, dropoff_latitude Float32, payment_type LowCardinality(String), fare_amount Float32, extra String, mta_tax Float32, tip_amount Float32, tolls_amount Float32, improvement_surcharge Float32, total_amount Float32, pickup_location_id UInt16, dropoff_location_id UInt16, junk1 String, junk2 String',
'gzip')
Completed query in 143.243 sec
```
It was clear that this was pretty CPU-limited for a lot of the query
6 Nodes:
```
SELECT count() FROM s3Cluster('{cluster}', 'https://s3.us-east-1.amazonaws.com/altinity-clickhouse-data/nyc_taxi_rides/data/tripdata/data-*.csv.gz', 'CSVWithNames',
'pickup_date Date, id UInt64, vendor_id String, tpep_pickup_datetime DateTime, tpep_dropoff_datetime DateTime, passenger_count UInt8, trip_distance Float32, pickup_longitude Float32, pickup_latitude Float32, rate_code_id String, store_and_fwd_flag String, dropoff_longitude Float32, dropoff_latitude Float32, payment_type LowCardinality(String), fare_amount Float32, extra String, mta_tax Float32, tip_amount Float32, tolls_amount Float32, improvement_surcharge Float32, total_amount Float32, pickup_location_id UInt16, dropoff_location_id UInt16, junk1 String, junk2 String',
'gzip')
Completed query in 38.804 sec
```
Noticed that despite having 96 cores, there were only 50-something S3 readers. Created issue for CH here: https://github.com/ClickHouse/ClickHouse/issues/52437 (give it a 👍!)
## PoC
The PoC uses docker compose to create a Keeper node and ClickHouse cluster, poll for expected cluster state, then:
```
bash run.sh
```
## Connect to fly internal network from your device
```
fly wireguard create personal iad idkpeer
```
Then use with wireguard app.
| 23
| 0
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.