
id
int64 393k
2.82B
| repo
stringclasses 68
values | title
stringlengths 1
936
| body
stringlengths 0
256k
⌀ | labels
stringlengths 2
508
| priority
stringclasses 3
values | severity
stringclasses 3
values |
|---|---|---|---|---|---|---|
643,482,669 |
flutter
|
[ios][video_player] pip - picture in picture
|
## Use case
I have a customer asking for PIP when the app is playing a video and the user wants multi-tasking.
For Android I had to edit the plugin, and use this line of code:
`getActivity().enterPictureInPictureMode();`
https://developer.android.com/guide/topics/ui/picture-in-picture#java
But for iOS, it is a different story, iOS does not support PIP in UIWindow or UIView, it is supported only in a Custom Player.
We need a custom view for that.
https://developer.apple.com/documentation/avkit/adopting_picture_in_picture_in_a_custom_player
https://developer.apple.com/documentation/avfoundation/avplayerlayer
The video_player plugin is using Texture to show the video output.
## Proposal
I need a way to customize the UIView created by the engine for the texture and add AVPlayerLayer support to it.
Any suggestions on how can I **contribute** this feature to the plugin?
|
c: new feature,platform-ios,p: video_player,package,c: proposal,a: layout,P3,team-ios,triaged-ios
|
high
|
Critical
|
643,493,657 |
flutter
|
Allow `showDateRangePicker` to scroll horizontal or vertical
|
<!-- Thank you for using Flutter!
If you are looking for support, please check out our documentation
or consider asking a question on Stack Overflow:
* https://flutter.dev/
* https://api.flutter.dev/
* https://stackoverflow.com/questions/tagged/flutter?sort=frequent
If you have found a bug or if our documentation doesn't have an answer
to what you're looking for, then fill our the template below. Please read
our guide to filing a bug first: https://flutter.dev/docs/resources/bug-reports
-->
## Use case
<!--
Please tell us the problem you are running into that led to you wanting
a new feature.
Is your feature request related to a problem? Please give a clear and
concise description of what the problem is.
Describe alternative solutions you've considered. Is there a package
on pub.dev/flutter that already solves this?
-->
The current Date range picker calendar only scrolls horizontal.
## Proposal
<!--
Briefly but precisely describe what you would like Flutter to be able to do.
Consider attaching images showing what you are imagining.
Does this have to be provided by Flutter directly, or can it be provided
by a package on pub.dev/flutter? If so, maybe consider implementing and
publishing such a package rather than filing a bug.
-->
```dart
CustomScrollView(
controller: _controller,
center: sliverAfterKey,
/// Add property here.
scrollDirection: scrollDirection /// Either Axis.horizontal or Axis.vertical
),
```
Add a property of scrollDirection to the CustomScrollView & allow us to put scrollDirection in the `showDateRangePicker` widget
Edit: Reference Source Code
https://github.com/flutter/flutter/blob/b5ddf8559597be7f103a90a8567145a70857c7f2/packages/flutter/lib/src/material/pickers/calendar_date_range_picker.dart#L202
|
c: new feature,framework,f: material design,f: date/time picker,c: proposal,P3,team-design,triaged-design
|
low
|
Critical
|
643,517,441 |
pytorch
|
Missing explanation in torch.utils.tensorboard.add_histogram()
|
This function has an input parameter add_histogram(), what does it mean? There is no documentation about this parameter.
Documentation link
https://pytorch.org/docs/stable/tensorboard.html#torch.utils.tensorboard.writer.SummaryWriter.add_histogram
cc @jlin27
|
module: docs,triaged,module: tensorboard
|
low
|
Minor
|
643,517,685 |
TypeScript
|
Running a type through a mapped type loses polymorphic `this` type
|
**TypeScript Version:** 4.0.0-dev.20200622
<!-- Search terms you tried before logging this (so others can find this issue more easily) -->
**Search Terms:** polymorphic this mapped type
**Expected behavior:** `b.foo()` returns `B`
**Actual behavior:** `b.foo()` returns `A` even though the tooltip on `foo` says it returns `this`
<!-- Did you find other bugs that looked similar? -->
**Related Issues:** None
**Code**
```ts
interface A {
foo(): this
}
interface B extends Pick<A, keyof A> {
bar(): this
}
declare let b: B;
b.foo().bar() // error
```
<details><summary><b>Output</b></summary>
```ts
"use strict";
b.foo().bar(); // error
```
</details>
<details><summary><b>Compiler Options</b></summary>
```json
{
"compilerOptions": {
"noImplicitAny": true,
"strictNullChecks": true,
"strictFunctionTypes": true,
"strictPropertyInitialization": true,
"strictBindCallApply": true,
"noImplicitThis": true,
"noImplicitReturns": true,
"useDefineForClassFields": false,
"alwaysStrict": true,
"allowUnreachableCode": false,
"allowUnusedLabels": false,
"downlevelIteration": false,
"noEmitHelpers": false,
"noLib": false,
"noStrictGenericChecks": false,
"noUnusedLocals": false,
"noUnusedParameters": false,
"esModuleInterop": true,
"preserveConstEnums": false,
"removeComments": false,
"skipLibCheck": false,
"checkJs": false,
"allowJs": false,
"declaration": true,
"experimentalDecorators": false,
"emitDecoratorMetadata": false,
"target": "ES2017",
"module": "ESNext"
}
}
```
</details>
**Playground Link:** [Provided](https://www.typescriptlang.org/play/?ts=4.0.0-dev.20200622#code/JYOwLgpgTgZghgYwgAgILIN4Chm+TAewIAoBKALmTAAtgBnLAXyy1ElkRQCFkIAPSCAAmdZAAVgCANYAeVABpkUiAE8CMNAD5MOPACM4UMpRr0mLIRAQAbQymsQwyPZS4BuLHoB0hEqS8GRqTIAPQhvFBQBFDIQA)
|
Bug
|
low
|
Critical
|
643,523,290 |
godot
|
Bitmap font format extension discrepancy through editor
|
<!-- Please search existing issues for potential duplicates before filing yours:
https://github.com/godotengine/godot/issues?q=is%3Aissue
-->
**Godot version:**
3.2 branch - a662b853dd5de7d47a8c5ebee3ae35cf66490d3f
**OS/device including version:**
Arch Linux
**Issue description:**
I was using [Hiero](https://libgdx.badlogicgames.com/tools.html) by the Libgdx team to generate a bitmap font when I noticed a discrepancy on how the editor handles the loading of bitmap fonts. Hiero produces a usable font format, but the issues lie within Godot's editor itself.
There are three small issues here -- see the next section.
**Steps to reproduce:**
1. Drag and drop the `m5x7_size_20.font` over to the Custom Fonts property -- the font doesn't get loaded, but the font can be loaded by expanding the font property and clicking on `Load`.
2. On the load font window, take a look at the acceptable extensions: `.font` is listed but `.fnt` is not when it should since the Filesytem tab gives it a proper icon and you can also drag and drop this `.fnt` font to the custom font property and it works.
3. Speaking of the Filesystem tab, the `.font` file does not have a proper icon.
**Minimal reproduction project:**
[bitmap_font_debug.zip](https://github.com/godotengine/godot/files/4817161/bitmap_font_debug.zip)
**Credits**
Font: m5x7.ttf
Created by: Daniel Linssen
Download URL: https://managore.itch.io/m5x7
|
bug,topic:editor,confirmed,usability,topic:gui
|
low
|
Critical
|
643,527,712 |
terminal
|
Add a "remember my decision" checkbox to our confirmation dialogs
|
<!--
🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
I ACKNOWLEDGE THE FOLLOWING BEFORE PROCEEDING:
1. If I delete this entire template and go my own path, the core team may close my issue without further explanation or engagement.
2. If I list multiple bugs/concerns in this one issue, the core team may close my issue without further explanation or engagement.
3. If I write an issue that has many duplicates, the core team may close my issue without further explanation or engagement (and without necessarily spending time to find the exact duplicate ID number).
4. If I leave the title incomplete when filing the issue, the core team may close my issue without further explanation or engagement.
5. If I file something completely blank in the body, the core team may close my issue without further explanation or engagement.
All good? Then proceed!
-->
# Description of the new feature/enhancement
Apart from the setting, it will be easier to have a checkbox at the bottom of the `CloseAll` dialog with the option "Don't ask again" (it will work alongside settings JSON and later GUI)
<!--
A clear and concise description of what the problem is that the new feature would solve.
Describe why and how a user would use this new functionality (if applicable).
-->
# Proposed technical implementation details (optional)
<!--
A clear and concise description of what you want to happen.
-->

|
Help Wanted,Area-UserInterface,Product-Terminal,Issue-Task,Priority-2
|
low
|
Critical
|
643,537,964 |
pytorch
|
Add a `like` argument to creation ops
|
## 🚀 Feature
Add a `like` argument to all the creation ops such that, given a tensor `x`, `torch.eye(3, like=x)` has the same semantics as `torch.eye(3, dtype=x.dtype, device=x.device)`.
## Motivation
In many cases, you want to create a tensor with a matching `dtype` and `device` as some input to do computations with it. The idiomatic way to do so is as follows:
```python
def f(input):
other = torch.eye(3, dtype=input.dtype, device=input.device)
# do some computation with input and other
```
However, this is quite verbose. Very often, people write the following code instead:
```python
def f(input):
other = torch.eye(3).to(input)
```
This works, but has a couple of drawbacks:
1. We must create a tensor then potentially copy it to a different device, whereas in the first code example the tensor was created on the right device. This uses unnecessary memory and time.
2. `.to()` by default is a blocking operation (e.g. for a host->device transfer), which can have significant performance implications for python-heavy code. `torch.eye(3, dtype=input.dtype, device=input.device)` does the creation asynchronously.
## Pitch
Adding a `like` argument to all the creation ops such that, given a tensor `x`, `torch.eye(3, like=x)` has the same semantics as `torch.eye(3, dtype=x.dtype, device=y.device)` will alleviate this issue. This syntax is as succinct and clear as using `.to()`, so people will not use the less efficient method for clarity or out of laziness.
The current API already has functions of the form `torch.*_like` (e.g. `torch.ones_like`), which has similar behaviour to what I described above (except it also copies the shape). Thus, this new argument has some API symmetry, making it easy for new users to learn and existing users to adopt.
## Alternatives
Our new `like` argument can also ensure the new tensor has the same layout as the original, but `.to()` currently does not do this, and I think it would be best if `like` follows the semantics of `.to()`.
Instead of adding an argument, we can just add corresponding `torch.*_like` functions for all the creation ops. However, I think this would be confusing: `torch.*_like` creates tensors of the same shape, dtype, and device as the input; however most of the creation ops do not support making a tensor of the same shape necessarily (e.g. `torch.eye`, `torch.arange`, `torch.linspace`, etc). Furthermore, the signature would be confusing as `torch.*_like` functions typically have the other tensor as the first argument.
Thanks for considering this request, and please let me know if you have any feedback!
|
triaged,module: tensor creation,function request
|
low
|
Major
|
643,546,316 |
flutter
|
Integration testing: more realistic behaviour, taps and scrolls visualization.
|
As far as I can see, integration tests (driver tests) are good for running on a device and see how my program behaves. The problem is that it runs too fast and I can't see anything.
I'd like to look it more as if the application is being used by a real person.
I came up with solution to set artificial delays such as `await Future.delayed(Duration(seconds: 3));` in `setUpAll()` and after any significant action to at least see what is happenning on the screen.
I would like to also see Driver taps and scrolls simulation somehow.
I tried to enter Developer Settings on my Emulator and turn on "Show taps" and "Pointer location", but it doesn't help. It shows only real taps by mouse cursor and not by FlutterDriver.
And also I want a "fast re-run" ability to replay the test without rebuilding/reinstalling my app.
|
a: tests,c: new feature,framework,t: flutter driver,c: proposal,f: integration_test,P3,team-framework,triaged-framework
|
low
|
Major
|
643,572,342 |
flutter
|
[web] support offline PWA
|
I would like to create a PWA app that's offline available.
To test this feature I have enabled web support `flutter config --enable-web`, created a default demo app using `flutter create pwatest` and made it available on my phone through my local network with `flutter run -d chrome web-hostname=192.168.43.59 --web-port=80`. I succesfully load the webapp on my mobile, 'add to home screen', and open the PWA-app.
**Issue:** when I tap open my PWA-app on the homescreen, it tries to connect to my local flutter server (192.168.43.59) and cannot find it (which is correct, because it is now offline). When I turn off my phone internet, it just shows a default 'Flutter Demo' screen. Hence, my app is not offline available.
Is this expected behavior and how do I make my PWA app offline available?
Flutter doctor:
```
[√] Flutter (Channel beta, 1.19.0-4.1.pre, on Microsoft Windows [Version 10.0.18363.900], locale nl-NL)
• Flutter version 1.19.0-4.1.pre at C:\src\flutter
• Framework revision f994b76974 (13 days ago), 2020-06-09 15:53:13 -0700
• Engine revision 9a28c3bcf4
• Dart version 2.9.0 (build 2.9.0-14.1.beta)
[√] Android toolchain - develop for Android devices (Android SDK version 29.0.2)
• Android SDK at C:\Users\matre\AppData\Local\Android\sdk
• Platform android-29, build-tools 29.0.2
• Java binary at: C:\Program Files\Android\Android Studio\jre\bin\java
• Java version OpenJDK Runtime Environment (build 1.8.0_202-release-1483-b03)
• All Android licenses accepted.
[√] Chrome - develop for the web
• Chrome at C:\Program Files (x86)\Google\Chrome\Application\chrome.exe
[√] Android Studio (version 3.5)
• Android Studio at C:\Program Files\Android\Android Studio
• Flutter plugin version 42.1.1
• Dart plugin version 191.8593
• Java version OpenJDK Runtime Environment (build 1.8.0_202-release-1483-b03)
[√] VS Code (version 1.46.1)
• VS Code at C:\Users\matre\AppData\Local\Programs\Microsoft VS Code
• Flutter extension version 3.11.0
[√] Connected device (2 available)
• Web Server • web-server • web-javascript • Flutter Tools
• Chrome • chrome • web-javascript • Google Chrome 83.0.4103.106
• No issues found!
```
|
c: new feature,engine,customer: crowd,platform-web,c: proposal,P2,team-web,triaged-web
|
low
|
Critical
|
643,592,475 |
excalidraw
|
Excalidraw does not work with a lot of users
|
First of all, thank you for this awesome project!
We just tried it in a lecture, but with 43 people on one board, users had different amounts of lag between 0-5min each, making the real-time update collaboration pretty much unusable.
When looking at the websocket connection used to make this all possible, it seems like excalidraw opens a connection for each user, resulting in a lot of connections:
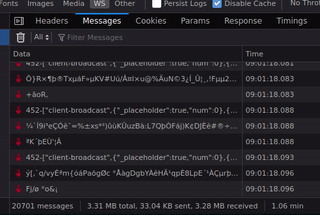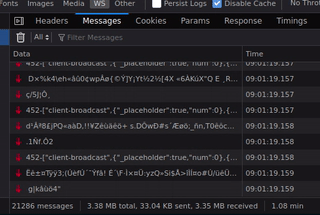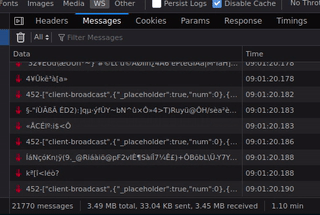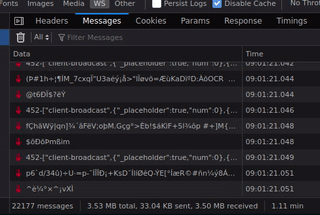
You can see in the gif there were already 21K messages after just one minute, which makes roughly 1 message each 3ms. That seems quite a lot.
To improve this, it may be an idea to let each client have just one connection to a server which then aggregates and distributes the messages.
To me 43 concurrent users does not seem like a lot but I'm not sure if excalidraw has been built with that use case in mind.
EDIT: Maybe related to #1115
|
performance ⚡️,collaboration
|
low
|
Major
|
643,593,167 |
realworld
|
JavaScript Attack
|
It is possible to **inject JavaScript** through the image url, see below:
`"image":"https://www.gettyimagcadsaes.com/gi-resources/images/500px/983794168.jpg\"onerror=\"javascript:alert(document.cookie)"`

You can trigger this by selecting Tag #Dragons at page 37 (at some examples, eg.: https://conduit-vanilla.herokuapp.com/#/)
The result of the attack is:
`<img src="https://www.gettyimagcadsaes.com/gi-resources/images/500px/983794168.jpg" onerror="javascript:alert(document.cookie)">`
And here the full Request URL:**https://conduit.productionready.io/api//articles?limit=10&offset=360&tag=dragons** payload:
`{"articles":[{"title":"How to train your dragon","slug":"how-to-train-your-dragon-qp6z5i","body":"Very carefully.","createdAt":"2018-11-02T16:27:16.359Z","updatedAt":"2018-11-02T16:27:16.359Z","tagList":["training","dragons"],"description":"Ever wonder how?","author":{"username":"u1541176017","bio":null,"image":"https://static.productionready.io/images/smiley-cyrus.jpg","following":false},"favorited":false,"favoritesCount":7},{"title":"How to train your dragon5","slug":"how-to-train-your-dragon-p6to53","body":"You have to believe","createdAt":"2018-11-02T04:52:49.257Z","updatedAt":"2018-11-02T06:31:09.448Z","tagList":["dragons","angularjs","reactjs"],"description":"Ever wonder how?","author":{"username":"kfc","bio":"This is my bio...","image":"https://oldgameshelf.com/img/icons/Icon-152.png","following":false},"favorited":false,"favoritesCount":4},{"title":"tu mera bhai","slug":"tu-mera-bhai-fysljd","body":"mera bhi","createdAt":"2018-10-31T11:12:37.933Z","updatedAt":"2018-10-31T12:31:12.992Z","tagList":["angular","dragons","mera","aacha"],"description":"tu bhi ","author":{"username":"ashish71294","bio":"","image":"https://static.productionready.io/images/smiley-cyrus.jpg","following":false},"favorited":false,"favoritesCount":8},{"title":"mera haal","slug":"mera-haal-n41nto","body":"or ter","createdAt":"2018-10-31T11:08:52.970Z","updatedAt":"2018-10-31T11:19:16.512Z","tagList":["angular","dragons"],"description":"aacha hai","author":{"username":"ashish71294","bio":"","image":"https://static.productionready.io/images/smiley-cyrus.jpg","following":false},"favorited":false,"favoritesCount":6},{"title":"fsdf","slug":"fsdf-xotd5k","body":"asdf","createdAt":"2018-10-31T07:17:59.731Z","updatedAt":"2018-10-31T07:19:34.367Z","tagList":["dragons"],"description":"sdf","author":{"username":"sadfsdfsdf);","bio":null,"image":"https://www.gettyimagcadsaes.com/gi-resources/images/500px/983794168.jpg\"onerror=\"javascript:alert(document.cookie)","following":false},"favorited":false,"favoritesCount":2},{"title":"helloooooooooooooooooooooooooooooooooooooooooooooo","slug":"helloooooooooooooooooooooooooooooooooooooooooooooo-gynt55","body":"Hey.","createdAt":"2018-10-27T02:34:20.388Z","updatedAt":"2018-10-27T02:34:20.388Z","tagList":["dragons"],"description":"some stuff","author":{"username":"jabvlaiughwi;bkgads","bio":null,"image":"https://static.productionready.io/images/smiley-cyrus.jpg","following":false},"favorited":false,"favoritesCount":6},{"title":"My Oh My","slug":"my-oh-my-kyrwf6","body":"With two hands","createdAt":"2018-10-23T14:01:27.085Z","updatedAt":"2018-10-23T14:01:57.934Z","tagList":["training","dragons"],"description":"Ever wonder how?","author":{"username":"alteckoljasdf","bio":null,"image":"http://www.free-icons-download.net/images/woof-icon-86452.png","following":false},"favorited":false,"favoritesCount":12},{"title":"hi","slug":"hi-67apkj","body":"hi","createdAt":"2018-10-23T12:36:26.677Z","updatedAt":"2018-10-23T12:36:26.677Z","tagList":["dragons","angularjs","reactjs"],"description":"hi","author":{"username":"hansika9","bio":"hello, this is hansika.","image":"https://static.productionready.io/images/smiley-cyrus.jpg","following":false},"favorited":false,"favoritesCount":2},{"title":"hello","slug":"hello-v4jfr7","body":"hello","createdAt":"2018-10-23T12:35:51.285Z","updatedAt":"2018-10-23T12:35:51.285Z","tagList":["dragons","angularjs","reactjs"],"description":"hello","author":{"username":"hansika9","bio":"hello, this is hansika.","image":"https://static.productionready.io/images/smiley-cyrus.jpg","following":false},"favorited":false,"favoritesCount":1},{"title":"How to train your dragon","slug":"how-to-train-your-dragon-b5fyxz","body":"You have to believe","createdAt":"2018-10-23T05:28:32.044Z","updatedAt":"2018-10-23T05:28:32.044Z","tagList":["dragons","angularjs","reactjs"],"description":"Ever wonder how?","author":{"username":"aspirationalTalkBoss","bio":null,"image":"https://static.productionready.io/images/smiley-cyrus.jpg","following":false},"favorited":false,"favoritesCount":7}],"articlesCount":500}`
|
suggestion,v2
|
low
|
Critical
|
643,650,470 |
pytorch
|
Segment Fault after use cusolverDnDestroy() with torch1.5
|
## 🐛 Bug
I am using cusolverDn in c++ and import it to python with pybind11.
Segment Fault after use cusolverDnCreate() and cusolverDnDestroy() with torch.
NOTE:
###**1: When the demo run with Torch1.2,it run success, the SegFault disappear, does it mean Torch 1.5 has some bug?**
###**2: This SegFault only appear with "thread_local", Does it provide some information for this bug?**
###**3: Please see test.py below, if we "import torch" after "import example", SegFault disappear.**
###**4: Torch have not link libcusolver.so, so we just link it once.**
@ezyang say that upgarde cuda may fix this, but after i upgrade cuda to 10.2, SegFault as usual.
cc please @ezyang @gchanan @zou3519 @yf225 @glaringlee @ngimel @mcarilli
<!-- A clear and concise description of what the bug is. -->
## To Reproduce
Steps to reproduce the behavior:
1.paste the c++ code, name bind_cudevice.cc
2.compile bind_cudevice.cc with my g++ compile code
3.paste my python code named test.py
4. just run test.py and see
bind_cudevice.cc
```
#include <iostream>
#include <cublas_v2.h>
#include <cuda.h>
#include <cuda_runtime_api.h>
#include <cusolverDn.h>
#include <cusolverSp.h>
#include <cusolverRf.h>
#include <pybind11/pybind11.h>
class CuDevice {
public:
CuDevice() {
initialized_ = true;
cudaSetDevice(0);
cusolverDnCreate(&cusolverdn_handle_);
cusolverDnSetStream(cusolverdn_handle_, cudaStreamPerThread);
}
~CuDevice() {
std::cout << "in ~CuDevice" << std::endl;
if (cusolverdn_handle_) {
std::cout << "in ~CuDevice and cusolverdn_handle_" << std::endl;
cusolverDnDestroy(cusolverdn_handle_);
std::cout << "Destory success" << std::endl;
}
}
private:
bool initialized_;
cusolverDnHandle_t cusolverdn_handle_;
};
int init_cudevice(){
thread_local CuDevice a = CuDevice();
std::cout << "hello world" << std::endl;
return 0;
}
PYBIND11_MODULE(example, m) {
m.def("init_cudevide",
&init_cudevice,
"select gpu id");
}
```
g++ compile code
```
g++ -O3 -Wall -shared -std=c++11 -fPIC -I/usr/include/python3.6m -I./third-party/pybind11-2.2.4/include -I/usr/local/cuda/include -Wl,-rpath=/usr/local/cuda/lib64 -L/usr/local/cuda/lib64 -lcudart -lcusolver `python3 -m pybind11 --includes` binding_cudevice.cc -o example`python3-config --extension-suffix`
```
test.py
```
import torch
import example
example.init_cudevide()
```
## Core Dump Info
```
(gdb) bt
#0 0x00007f78b6a391de in ?? () from /usr/local/cuda/lib64/libcusolver.so.10.0
#1 0x00007f78b6a5b4ca in ?? () from /usr/local/cuda/lib64/libcusolver.so.10.0
#2 0x00007f78b5db6e49 in ?? () from /usr/local/cuda/lib64/libcusolver.so.10.0
#3 0x00007f78b5b854c1 in cusolverDnDestroy () from /usr/local/cuda/lib64/libcusolver.so.10.0
#4 0x00007f78be143952 in kaldi::CuDevice::~CuDevice (this=0x2f18a38, __in_chrg=<optimized out>) at cu-device.cc:683
#5 0x00007f79880d7ad1 in (anonymous namespace)::run (p=<optimized out>) at /home/nwani/m3/conda-bld/compilers_linux-64_1560109574129/work/.build/x86_64-conda_cos6-linux-gnu/src/gcc/libstdc++-v3/libsupc++/atexit_thread.cc:75
#6 0x00007f79b752cc99 in __run_exit_handlers () from /usr/lib64/libc.so.6
#7 0x00007f79b752cce7 in exit () from /usr/lib64/libc.so.6
#8 0x00007f79b751550c in __libc_start_main () from /usr/lib64/libc.so.6
#9 0x0000000000400c20 in _start ()
```
<!-- If you have a code sample, error messages, stack traces, please provide it here as well -->
## Expected behavior
No error happen
<!-- A clear and concise description of what you expected to happen. -->
## Environment
- PyTorch Version (e.g., 1.5):1.5
- OS (e.g., Linux):Centos7
- How you installed PyTorch (`conda`, `pip`, source):source
- Build command you used (if compiling from source):
- Python version:3.6.8
- CUDA/cuDNN version:10.0
- GPU models and configuration:K40
- Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
cuSolver is base cublas and cusparse, reference about cuSolver:
https://docs.nvidia.com/cuda/archive/10.0/cusolver/index.html#cuSolverDNhandle
cc @ngimel
|
module: dependency bug,needs reproduction,module: crash,module: cuda,triaged
|
low
|
Critical
|
643,712,073 |
pytorch
|
Can we make torch.inverse FP16? - RuntimeError: "inverse_cuda" not implemented for 'Half'
|
## 🚀 Feature
Can we make torch.inverse FP16?
## Motivation
RuntimeError: "inverse_cuda" not implemented for 'Half'
cc @ngimel @jianyuh @nikitaved @pearu @mruberry @heitorschueroff @walterddr @IvanYashchuk @xwang233 @Lezcano @mcarilli @ptrblck
|
module: cuda,triaged,enhancement,has workaround,module: linear algebra,module: amp (automated mixed precision)
|
low
|
Critical
|
643,732,579 |
flutter
|
google_maps is not drawing customized Polyline on iOS
|
I'm using the following style of Polyline to draw one the google_maps
```
Polyline(
polylineId: PolylineId("${polylineId++}"),
width: 4,
points: points,
patterns: isWalking
? path
.map(
(_) => PatternItem.dot,
)
.toList()
: [],
color: ColorRes.colorSecondaryLight,
jointType: JointType.round,
startCap: Cap.roundCap,
endCap: Cap.roundCap,
)
```
The Polyline appears normal on Android, but it uses the default style on iOS (like I didn't use any styling)
It draws the Polyline, just not using any customizations.
Flutter Doctor :
<details>
<summary>flutter doctor -v</summary>
```console
[✓] Flutter (Channel stable, v1.17.4, on Mac OS X 10.15.4 19E287, locale en-SY)
• Flutter version 1.17.4 at /Users/ucgmacmini/Library/flutter
• Framework revision 1ad9baa8b9 (6 days ago), 2020-06-17 14:41:16 -0700
• Engine revision ee76268252
• Dart version 2.8.4
[✓] Android toolchain - develop for Android devices (Android SDK version 30.0.0-rc1)
• Android SDK at /Users/ucgmacmini/Library/Android/sdk
• Platform android-30, build-tools 30.0.0-rc1
• Java binary at: /Applications/Android Studio.app/Contents/jre/jdk/Contents/Home/bin/java
• Java version OpenJDK Runtime Environment (build 1.8.0_242-release-1644-b3-6222593)
• All Android licenses accepted.
[✓] Xcode - develop for iOS and macOS (Xcode 11.3.1)
• Xcode at /Applications/Xcode.app/Contents/Developer
• Xcode 11.3.1, Build version 11C505
• CocoaPods version 1.9.1
[✓] Android Studio (version 4.0)
• Android Studio at /Applications/Android Studio.app/Contents
• Flutter plugin version 46.0.2
• Dart plugin version 193.7361
• Java version OpenJDK Runtime Environment (build 1.8.0_242-release-1644-b3-6222593)
[!] IntelliJ IDEA Community Edition (version 2020.1.2)
• IntelliJ at /Applications/IntelliJ IDEA CE.app
✗ Flutter plugin not installed; this adds Flutter specific functionality.
✗ Dart plugin not installed; this adds Dart specific functionality.
• For information about installing plugins, see
https://flutter.dev/intellij-setup/#installing-the-plugins
[!] VS Code (version 1.45.1)
• VS Code at /Applications/Visual Studio Code.app/Contents
✗ Flutter extension not installed; install from
https://marketplace.visualstudio.com/items?itemName=Dart-Code.flutter
[✓] Connected device (2 available)
• Android SDK built for x86 • emulator-5554 • android-x86 • Android 10 (API 29) (emulator)
• iPhone 11 Pro • 7CF0AEC0-6B2F-4EDA-9C70-5941AE459EED • ios • com.apple.CoreSimulator.SimRuntime.iOS-13-3 (simulator)
! Doctor found issues in 2 categories.
```
</details>
google_maps : v0.5.28+1
I've tested on an Emulator and on a Physical Device
|
platform-ios,p: maps,package,has reproducible steps,P2,found in release: 1.22,found in release: 1.26,found in release: 2.0,found in release: 2.3,team-ios,triaged-ios
|
low
|
Critical
|
643,762,288 |
rust
|
Error converting from i32 to f64 when type parameter implements From<f64>
|
I tried this code:
```rust
fn foo<T>(x: T, y: i32) -> f64 where f64: From<T> {
f64::from(y)
}
```
I expected to see this happen: should compile and do the right thing.
Instead, this happened:
```rust
error[E0308]: mismatched types
--> src/lib.rs:2:15
|
1 | fn foo<T>(x: T, y: i32) -> f64 where f64: From<T> {
| - this type parameter
2 | f64::from(y)
| ^ expected type parameter `T`, found `i32`
|
= note: expected type parameter `T`
found type `i32`
= help: type parameters must be constrained to match other types
= note: for more information, visit https://doc.rust-lang.org/book/ch10-02-traits.html#traits-as-parameters
```
On the other hand, this code compiles fine:
```rust
fn foo<T>(_: T, y: i32) -> f64 {
f64::from(y)
}
```
### Meta
I was surprised about this, so after running this with 1.44.0 and 1.44.1 I checked older versions, but 1.39.0, 1.31.0 and 1.15.0 all give the same error. Seems likely that there is an issue about this already, but no clue how to look for it.
|
A-type-system,T-compiler,C-bug,T-types
|
low
|
Critical
|
643,908,729 |
vscode
|
Extension doesn't activate after install
|
Windows 10
Steps:
- install extension https://marketplace.visualstudio.com/items?itemName=ban.spellright
- Run any SpellRight command
Observe: you get an error
- Run command `Show Running extension`
Observe:
Spell Right is not running
Inspect the spell right package.json. It has
```
"activationEvents": [
"*"
]
```
|
feature-request,extension-host
|
low
|
Critical
|
643,909,064 |
flutter
|
Chrome doesn't offer to translate https://sharezone.net
|
https://sharezone.net is one such site. Since it's in a language I don't speak (German) and I'm interested in the content, that's a problem for me. However, if Chrome can't translate Flutter web apps in general, that's a general-purpose problem. In this case, the site is using CanvasKit, which I suspect is the root of the problem.
|
engine,customer: crowd,platform-web,e: web_canvaskit,P3,team-web,triaged-web
|
low
|
Major
|
643,925,861 |
rust
|
Segfault of binary produced with `relocation-model=static` for `x86_64-unknown-linux-musl`
|
<!--
Thank you for filing a bug report! 🐛 Please provide a short summary of the bug,
along with any information you feel relevant to replicating the bug.
-->
I tried this code:
```rust
fn main() {
println!("main = {:#x}", &main as *const _ as usize);
}
```
I expected to see this happen:
```console
$ rustc -C relocation-model=static --target x86_64-unknown-linux-musl hello.rs
$ ./hello
main = 0x43b008
```
Instead, this happened:
```
$ rustc -C relocation-model=static --target x86_64-unknown-linux-musl hello.rs
$ ./hello
Segmentation fault (core dumped)
```
This code works, though:
```rust
fn main() {
println!("main = {:#?}", &main as *const _);
}
```
### Meta
Also happens with current nightly.
`rustc --version --verbose`:
```console
$ rustc --version --verbose
rustc 1.44.1 (c7087fe00 2020-06-17)
binary: rustc
commit-hash: c7087fe00d2ba919df1d813c040a5d47e43b0fe7
commit-date: 2020-06-17
host: x86_64-unknown-linux-gnu
release: 1.44.1
LLVM version: 9.0
$ rustc +nightly --version --verbose
rustc 1.46.0-nightly (6bb3dbfc6 2020-06-22)
binary: rustc
commit-hash: 6bb3dbfc6c6d8992d08431f320ba296a0c2f7498
commit-date: 2020-06-22
host: x86_64-unknown-linux-gnu
release: 1.46.0-nightly
LLVM version: 10.0
```
|
P-medium,T-compiler,O-musl,C-bug
|
low
|
Critical
|
643,926,176 |
rust
|
Tracking Issue for `core::mem::variant_count`
|
The feature gate for the issue is `#![feature(variant_count)]`.
### Steps
- [x] Implement the intrinsic
- [ ] Adjust documentation ([see instructions on rustc-dev-guide][doc-guide])
- [ ] Stabilization PR ([see instructions on rustc-dev-guide][stabilization-guide])
[stabilization-guide]: https://rustc-dev-guide.rust-lang.org/stabilization_guide.html#stabilization-pr
[doc-guide]: https://rustc-dev-guide.rust-lang.org/stabilization_guide.html#documentation-prs
### Unresolved Questions
None
### Implementation history
- #73418
- #92568
|
T-lang,T-libs-api,B-unstable,C-tracking-issue,F-variant_count,S-tracking-design-concerns
|
medium
|
Critical
|
643,933,838 |
go
|
x/pkgsite: add statistics about module usage
|
Thanks for the great work on `go.dev` website!
A given package has a ["Imports"](https://pkg.go.dev/github.com/golang/protobuf/proto?tab=imports) and ["Imported By"](https://pkg.go.dev/github.com/golang/protobuf/proto?tab=importedby) tab, which allows you to get a sense of the dependency graph for a single package.
I propose adding a [similar feature for modules](https://pkg.go.dev/mod/github.com/golang/protobuf), such that it would gain a "Requires" and a "Required By" tab that similarly presents the following information:
* For the "Requires" tab, it shows the set of modules required by the latest version of this module.
* For example, the latest version of `github.com/golang/protobuf` depends on [3 other modules](https://github.com/protocolbuffers/protobuf-go/blob/a9513ebdb86068803ccda83ded57e8330a72961e/go.mod#L6-L8). I'd expect these to be readily displayed without needing to go to the `go.mod` file.
* For the "Required By" tab, it shows the set of modules at their latest version that requires this module.
* For example, the `github.com/golang/protobuf` module is required by 8577 modules. I'd like to see this number and get a brief sample of some of these modules.
* It'd be additionally be useful if the "Required By" tab could show the dependencies on specific versions of this module. For example, I'd like to easily see statistics similar to the following:
* 1435x (16.7%) at v1.4
* 6199x (72.3%) at v1.3
* 721x (8.4%) at v1.2
* 77x (0.9%) at v1.1
* 45x (0.5%) at v1.0
* 100x (1.2%) at v0.0
At the present moment, I obtain such information through a series of expensive queries on the module proxy.
|
NeedsInvestigation,FeatureRequest,pkgsite,UX
|
low
|
Minor
|
643,989,319 |
godot
|
Some shortcuts for switching scripts in the editor don't work
|
**Godot version:**
3.2.2.rc
**OS/device including version:**
Debian Buster amd64, Radeon RX550
**Issue description:**
I'm trying to map a good shortcut to "Next Script"/"Previous Script" actions.
I want to switch scripts with Ctrl+PgUp/Ctrl+PgDn, like it has been in Gnome Terminal and other places from time immemorial. This does not work - probably because the editor intercepts this shortcut and gives it some useless function, which is not configurable (though it looks to me like it's doing the same as just PgUp/PgDn).
Alt+PgUp/Alt+PgDn is the same.
Ctrl+Alt+Up/Ctrl+Alt+Down work fine. But I would have preferred an easier combination.
But Ctrl+Alt+PgUp/Ctrl+Alt+PgDn do not work - they act as simply PgUp/PgDn instead.
Even Alt+Period/Alt+Comma don't work - they just type Period/Comma as if I wasn't holding Alt.
Ctrl+Up/Ctrl+Down don't seem to do anything at all, but they still do not switch scripts when mapped for that... Oh, they actually do something else, it's just not obvious. But there is no way to remap their "original" action. In this case, shouldn't we 1) give a warning that the assigned shortcut collides with something else, and 2) still have the "remappable" part take priority over "non-remappable"? Meaning, we should be able to use this shortcut for what we want, even if we can not remap the shortcut we are overwriting to something else.
Also, could it be possible to add a shortcut for "Last Script" (Ctrl+Tab by default) for switching between the current script and the last used script? The difference from "History Previous" is that pressing Ctrl+Tab for the second time would get you back to the current script, rather than going further back in history like "History Previous". This is convenient for several uses. First, for comparing two scripts or working with a reference. Second, when I'm working on a script and want to see "the script I just saw", I don't want to think whether must I go back in history or "forward", in case I already went "back" for the script I'm seeing now.
|
bug,topic:editor
|
low
|
Minor
|
643,990,070 |
vscode
|
Debug console: introduce ctrl + up / down to focus output
|
To be consistent with the terminal the debug console could also navigte to output using ctrl + up / down.
The current functionality of Shit + Tab, and up / down would still work as it is today, and ctrl + up / down would behave like an alias of sort.
|
feature-request,debug,accessibility
|
low
|
Critical
|
644,009,730 |
pytorch
|
[feature request] batch_apply, a general-purpose device-agnostic batch iterator
|
## 🚀 Feature
`batch_apply`, a general-purpose device-agnostic batch iterator that applies some function to each element in a batch for efficient kernels.
## Motivation & Pitch
Sometimes each element in a batch might require specific processing, for example, imagine raising matrices to powers, or any other input-specific linear algebra operation. It would be great to have a device-agnostic function that performs this iteration efficiently, while preserving the high-level functionality (**iterate and return tensors, not pointers**).
Would be great to have an efficient universal tool for any batch-wise manipulation.
A quick look at `BatchedLinearAlgebra.cpp` shows that the batch dimensions are traversed in a simple CPU for-loop,
which will cause a major slowdown for large batches of CUDA-allocated tensors (especially if they are small).
## Additional context
While this function can easily be implemented on CPU with, say, parallel for loop, I am not sure it is that easy for CUDA.
**Is it even possible**, unless high-level Tensor functions are allowed to be run from within CUDA kernels?
|
triaged,module: batching
|
low
|
Major
|
644,029,672 |
godot
|
KinematicBody2D slides across screen when C# script is added.
|
**Godot version:**
<!-- Specify commit hash if using non-official build. -->
Godot Version 3.2 Stable Mono
**OS/device including version:**
Microsoft Windows 10 Pro N
Version 10.0.18362 Build 18362
**Issue description:**
When generating a Kinematic2D body with a sprite and a collision2d child, if a c# script is applied to the kinematic2d body, it will begin to move across the screen even if the script is empty. This issue will stop once the script has been removed.
**Steps to reproduce:**
N/A
**Minimal reproduction project:**
<!-- A small Godot project which reproduces the issue. Drag and drop a zip archive to upload it. -->
[My platformer Game.zip](https://github.com/godotengine/godot/files/4820998/My.platformer.Game.zip)
Run Player2.tscn to see issue.
|
topic:dotnet
|
low
|
Minor
|
644,036,720 |
terminal
|
Add a setting to display Command Palette ActionMode entries in MRU order
|
Omitted from initial implementation in #6635.
It would be a neat idea to allow display command-palette entries either heavily weighted towards MRU items, or specifically start the empty list with the MRU items, followed by everything else.
We might as well stick this behind a setting.
|
Area-UserInterface,Area-Settings,Product-Terminal,Issue-Task,Priority-3,Area-CmdPal
|
low
|
Minor
|
644,073,979 |
go
|
x/net/trace: data race when freeing traces
|
This bug is on `go version go1.14.4 linux/amd64` with x/net from master (techincally 627f9648deb96c27737b83199d44bb5c1010cbcf).
There is a race condition between event recycling and trace clearing when the trace has a recycler set with `SetRecycler` and the number of events in tr.events is <= 4 (`len(tr.eventBuf)`). When a trace is initialized, `tr.events` is set to `tr.eventsBuf[:0]`. In `unref`, the freeing logic starts a recycling function over each event in a separate goroutine by retaining a reference to the `tr.events` slice, and then calls `freeTrace` and then `reset` to write a zero value to each element of the `eventsBuf` array. When the number of events added to the trace fits in the space reserved by `tr.eventsBuf`, `tr.events` just aliases that buffer, and so the order of reads and writes is non-deterministic. The freeing could run first, and thus the recycler function sees the zero-valued events written by `reset`, or the recycling goroutine could run first, in which case the recycling performs as expected.
https://github.com/golang/net/pull/75 (https://go-review.googlesource.com/c/net/+/238302) adds a test and a fix for this. If you patch in only the test and run "go test -race ." in the trace directory, you'll see that the race detector detects this data race. My fix makes a copy of `tr.events` if the number of events is less than or equal to the length of `tr.eventsBuf`, so that the recycler can run at its leisure. Obviously this is not ideal, as the whole point of eventsBuf and the trace pool is to avoid allocations. However, I get the feeling that people don't actually use event recyclers, or they would have already noticed that events don't get recycled and filed a bug like this ;)
Other options that could be considered are doing the entire free asynchronously (letting the refcount hit 0, doing recycling and freeing in the background, and then pushing the trace into the pool that newTrace draws from), or just doing the recycling synchronously (which probably breaks existing code that did something silly like `tr.SetRecycler(func (e interface{}) { ch <- e }); tr.Finish(); <-ch`). Let me know which approach you prefer, and I'll update the PR accordingly.
|
NeedsInvestigation
|
low
|
Critical
|
644,085,191 |
pytorch
|
Print values (but not strings) when STRIP_ERROR_MESSAGES is defined
|
Currently, to save binary size on mobile builds, we completely remove all error message strings. This can make it difficult to debug problems as some parts of the error output (namely various runtime values which would have been incorporated into the error message string) get suppressed entirely. It is not so convenient to attach gdb to a mobile program.
The idea of this issue is to modify `c10/util/Exception.h` so instead of unconditionally dropping all error messages, we only drop error messages if they are string constants (which could be determined by cross-referencing with the source code) and just retain printing of the actual values in question. One way to do this is by adding a variant of `c10::str` that drops `const char*` arguments but behaves like `c10::str` otherwise, and using it when `STRIP_ERROR_MESSAGES` is defined.
To validate this change, you will need to check two things:
* You will need to run fbcode build size check ("Schedule Android Build Size check" in Utilities in Phabricator) and show that you don't regress build size by too much (one useful experiment to do is eliminate `STRIP_ERROR_MESSAGES` entirely and see how much build size increases). @ljk53 has also developed a script to do a similar analysis in Open Source at https://www.internalfb.com/intern/paste/P134182149/ (FB-only; Jiakai, we should figure out how to clean this up to work in OSS only)
* You should build PyTorch with `STRIP_ERROR_MESSAGES` and verify that the values are being printed out in a reasonable way. This could be done by editing `CFLAGS` environment variable
cc @ezyang @bhosmer @smessmer @ljk53
|
module: internals,module: bootcamp,triaged
|
low
|
Critical
|
644,085,204 |
godot
|
Label text glitches with resized custom project font
|
https://github.com/godotengine/godot/issues/15023 text glitch by creating font during _draw()
https://github.com/godotengine/godot/issues/19309 text glitch by resizing font during _draw()
**Godot version:** 3.2.1.stable
**OS/device including version:** Arch linux
**Issue description:** Label text appears as unreadable blocks when resizing its font.
**Steps to reproduce:**
Set a custom DynamicFont under Settings→Gui→Theme→Custom_Font. Then create a Label and call `$Label.get_font('font').size += 1`. The Label's text will get glitched and show as blocks:

**Minimal reproduction project:**
[label_default_font_resize.zip](https://github.com/godotengine/godot/files/4821421/label_default_font_resize.zip)
**workaround:**
Call either
```gdscript
$Label.get_font('font').connect('changed', $Label, 'update')
```
or
```gdscript
$Label.add_font_override('font', $Label.get_font('font'))
```
anytime before resizing the font.
I skimmed the source of label.cpp but given the simple workaround and the other issues concerning font caching I didn't dig deeper.
|
bug,topic:gui
|
low
|
Minor
|
644,095,714 |
pytorch
|
DataParallel with Torch 1.5
|
## 🐛 Bug
I tried to leverage multi-gpu using nn.DataParallel. I got an error with torch 1.5, but the same code work will work with torch 1.4.
## To Reproduce
I tested it with the code in this [tutorial](https://pytorch.org/tutorials/beginner/blitz/data_parallel_tutorial.html) from PyTorch.org
Following code can be used to reproduce the error:
```python
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
# params
input_size = 5
output_size = 2
batch_size = 32
data_size = 32
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# dataloader
class RandomDataset(Dataset):
def __init__(self, size, length):
self.len = length
self.data = torch.randn(length, size)
def __getitem__(self, index):
return self.data[index]
def __len__(self):
return self.len
rand_loader = DataLoader(dataset=RandomDataset(input_size, data_size), batch_size=batch_size, shuffle=True)
# simple model
class Model(nn.Module):
def __init__(self, input_size, output_size):
super(Model, self).__init__()
self.fc = nn.Linear(input_size, output_size)
def forward(self, input):
output = self.fc(input)
print('\t\tparameters is located at', next(self.parameters()).device)
return output
model = Model(input_size, output_size)
model = nn.DataParallel(model)
model.to(device)
for batch in iter(rand_loader):
batch = batch.to(device)
model(batch)
```
And i got the following error message:
```
---------------------------------------------------------------------------
StopIteration Traceback (most recent call last)
<ipython-input-1-c88fccd98bfb> in <module>
46 for batch in iter(rand_loader):
47 batch = batch.to(device)
---> 48 model(batch)
49
/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs)
548 result = self._slow_forward(*input, **kwargs)
549 else:
--> 550 result = self.forward(*input, **kwargs)
551 for hook in self._forward_hooks.values():
552 hook_result = hook(self, input, result)
/usr/local/lib/python3.6/dist-packages/torch/nn/parallel/data_parallel.py in forward(self, *inputs, **kwargs)
153 return self.module(*inputs[0], **kwargs[0])
154 replicas = self.replicate(self.module, self.device_ids[:len(inputs)])
--> 155 outputs = self.parallel_apply(replicas, inputs, kwargs)
156 return self.gather(outputs, self.output_device)
157
/usr/local/lib/python3.6/dist-packages/torch/nn/parallel/data_parallel.py in parallel_apply(self, replicas, inputs, kwargs)
163
164 def parallel_apply(self, replicas, inputs, kwargs):
--> 165 return parallel_apply(replicas, inputs, kwargs, self.device_ids[:len(replicas)])
166
167 def gather(self, outputs, output_device):
/usr/local/lib/python3.6/dist-packages/torch/nn/parallel/parallel_apply.py in parallel_apply(modules, inputs, kwargs_tup, devices)
83 output = results[i]
84 if isinstance(output, ExceptionWrapper):
---> 85 output.reraise()
86 outputs.append(output)
87 return outputs
/usr/local/lib/python3.6/dist-packages/torch/_utils.py in reraise(self)
393 # (https://bugs.python.org/issue2651), so we work around it.
394 msg = KeyErrorMessage(msg)
--> 395 raise self.exc_type(msg)
StopIteration: Caught StopIteration in replica 0 on device 0.
Original Traceback (most recent call last):
File "/usr/local/lib/python3.6/dist-packages/torch/nn/parallel/parallel_apply.py", line 60, in _worker
output = module(*input, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py", line 550, in __call__
result = self.forward(*input, **kwargs)
File "<ipython-input-1-c88fccd98bfb>", line 39, in forward
print('\t\tparameters is located at', next(self.parameters()).device)
StopIteration
```
## Expected behavior
With torch 1.4, i got the following output without any error.
``` python
parameters is located at cuda:0
parameters is located at cuda:1
parameters is located at cuda:2
parameters is located at cuda:3
```
## Environment
Collecting environment information...
PyTorch version: 1.5.1
Is debug build: No
CUDA used to build PyTorch: 10.2
OS: Ubuntu 18.04.3 LTS
GCC version: (Ubuntu 7.4.0-1ubuntu1~18.04.1) 7.4.0
CMake version: Could not collect
Python version: 3.6
Is CUDA available: Yes
CUDA runtime version: 10.2.89
GPU models and configuration:
GPU 0: Tesla V100-SXM2-32GB
GPU 1: Tesla V100-SXM2-32GB
GPU 2: Tesla V100-SXM2-32GB
GPU 3: Tesla V100-SXM2-32GB
Nvidia driver version: 418.87.01
cuDNN version: /usr/lib/x86_64-linux-gnu/libcudnn.so.7.6.5
Versions of relevant libraries:
[pip3] numpy==1.18.5
[pip3] torch==1.5.1
[conda] Could not collect
cc @ezyang @gchanan @zou3519
|
high priority,triaged,module: regression,module: data parallel
|
low
|
Critical
|
644,096,481 |
flutter
|
Engine builds for Fuchsia have tons of warnings for icu
|
Multiple icu libraries causing problems for Fuchsia roll.
Repro steps:
From `engine/src` run: `./flutter/tools/gn --fuchsia`.
We get:
```
ninja: warning: multiple rules generate obj/third_party/icu/source/common/icuuc_cr.uvectr32.o. builds involving this target will not be correct; continuing anyway [-w dupbuild=warn]
ninja: warning: multiple rules generate obj/third_party/icu/source/common/icuuc_cr.uvectr64.o. builds involving this target will not be correct; continuing anyway [-w dupbuild=warn]
ninja: warning: multiple rules generate obj/third_party/icu/source/common/icuuc_cr.wintz.o. builds involving this target will not be correct; continuing anyway [-w dupbuild=warn]
ninja: warning: multiple rules generate obj/third_party/icu/source/stubdata/icuuc_cr.stubdata.o. builds involving this target will not be correct; continuing anyway [-w dupbuild=warn]
```
Though these are warnings, they go on to cause problems further down in the roll.
This was the engine roll that introduced the problem: https://github.com/flutter/engine/commit/60a9b85f069abb6386d1f89e0098384236e02d88
This was the roll that introduced the icu changes to dart: https://dart-review.googlesource.com/c/sdk/+/150524
https://chromium-review.googlesource.com/c/chromium/deps/icu/+/2236407 seems to changing the way ICU is built. I wonder if the symbols need to be hidden for `is_fuchsia` as well.
cc: @mkustermann , @a-siva , @chaselatta
|
engine,dependency: dart,platform-fuchsia,P2,team-engine,triaged-engine
|
low
|
Minor
|
644,121,415 |
tensorflow
|
tf.nn.ctc_beam_search_decoder does not pick path with highest probability at next time step
|
<em>Please make sure that this is a bug. As per our
[GitHub Policy](https://github.com/tensorflow/tensorflow/blob/master/ISSUES.md),
we only address code/doc bugs, performance issues, feature requests and
build/installation issues on GitHub. tag:bug_template</em>
**System information**
- Have I written custom code (as opposed to using a stock example script provided in TensorFlow):
Yes
- OS Platform and Distribution (e.g., Linux Ubuntu 16.04):
Colab Env (Linux Ubuntu 18.04)
- Mobile device (e.g. iPhone 8, Pixel 2, Samsung Galaxy) if the issue happens on mobile device:
N/A
- TensorFlow installed from (source or binary):
Binary (I think)
- TensorFlow version (use command below):
v2.2.0-0-g2b96f3662b 2.2.0
- Python version:
3.6.9
- Bazel version (if compiling from source):
N/A
- GCC/Compiler version (if compiling from source):
N/A
- CUDA/cuDNN version:
N/A
- GPU model and memory:
None
You can collect some of this information using our environment capture
[script](https://github.com/tensorflow/tensorflow/tree/master/tools/tf_env_collect.sh)
You can also obtain the TensorFlow version with:
1. TF 1.0: `python -c "import tensorflow as tf; print(tf.GIT_VERSION, tf.VERSION)"`
2. TF 2.0: `python -c "import tensorflow as tf; print(tf.version.GIT_VERSION, tf.version.VERSION)"`
**Describe the current behavior**
The built-in CTC beam search decoder sometimes chooses a less probable path to keep in the beam by default than it could've when expanding a given step. In the Colab example provided below, I give a concrete example of when the path (0,) is retained in the beam instead of (0, 1, 0) despite the latter having a greater log-probability.
**Describe the expected behavior**
(0, 1, 0) should remain in the beam; (0,) should not.
**Standalone code to reproduce the issue**
Provide a reproducible test case that is the bare minimum necessary to generate
the problem. If possible, please share a link to Colab/Jupyter/any notebook.
https://colab.research.google.com/drive/1i9gvj0VN2gMNloohbHW6ad3Ti7eiQQCM?usp=sharing
**Other info / logs** Include any logs or source code that would be helpful to
diagnose the problem. If including tracebacks, please include the full
traceback. Large logs and files should be attached.
When I was comparing against a simple python version [based off this Medium article](https://towardsdatascience.com/beam-search-decoding-in-ctc-trained-neural-networks-5a889a3d85a7), I noticed that whenever the results diverged, the root problem was always that a path that should've been kept in the beam wasn't. I suspect top-k sorting might be mucking up somewhere.
Thanks,
Sean
|
stat:awaiting tensorflower,type:bug,comp:apis,TF 2.4
|
low
|
Critical
|
644,153,527 |
flutter
|
web engine: _applyParagraphStyleToElement doesn't always use _effectiveFontFamily
|
The below doesn't look right and could be a source of unexpected font changes:
```
if (previousStyle == null) {
cssStyle.fontFamily = canonicalizeFontFamily(style._effectiveFontFamily);
} else {
if (style._fontFamily != previousStyle._fontFamily) {
cssStyle.fontFamily = canonicalizeFontFamily(style._fontFamily);
}
}
```
The `else` case should also use `_effectiveFontFamily` I'd think.
|
framework,engine,a: typography,platform-web,c: rendering,e: web_html,P2,team-web,triaged-web
|
low
|
Minor
|
644,159,445 |
PowerToys
|
[KBM] Exporting and loading Key remap file / presets
|
# Summary of the new feature/enhancement
A feature that allows groups of remapped keys to be activated or deactivated quickly.
# Proposed technical implementation details (optional)
I would like to either have a save and load button that allows me to save the remapped keys to a file and then load them back in.
OR to have several groups of keys that can be remapped and then have those groups be toggleable like this:

|
Idea-Enhancement,Product-Keyboard Shortcut Manager
|
medium
|
Major
|
644,184,264 |
flutter
|
web engine: review nullness of colorToCssString
|
`colorToCssString` currently accents and returns null, but does it really need to? We might want to convert it to non-null.
|
engine,platform-web,has reproducible steps,a: null-safety,P2,found in release: 3.3,found in release: 3.6,team-web,triaged-web
|
low
|
Minor
|
644,198,257 |
pytorch
|
jit's default dtype is different in sandcastle and test_jit.py
|
Reproduction: Script and run `torch.full((2, 2), 1.)` in test_jit (discovered in test_save_load.py, in particular) and review the dtype, compare with the dtype in Sandcastle.
cc @suo @gmagogsfm @mruberry
|
oncall: jit,module: tests,triaged
|
low
|
Minor
|
644,198,619 |
pytorch
|
please add 'tensor.astype(dtype_string)' syntax for numpy interoperability
|
## 🚀 Feature
to maximize interoperability with existing numpy code, users can write strings for dtypes `dtype='uint8'`
## Motivation
to make helper function code work as much as possible across numpy and torch, sometimes we have to convert stuff to different dtype. if torch.tensor had `x.astype('float32')` then a huge range of functions can work in both torch and numpy (cuz the rest is just operators)
here's exactly what I want to do:
```
def rescale(x_min, x_max, y_min, y_max, x):
x_range = x_max - x_min
y_range = y_max - y_min
y = (((x - x_min) * y_range) / x_range) + y_min
return y
```
alas, it doesn't always work if the arguments are integers, they must be cast to float. that simple everyday task requires a special function and extra code (and more tests), if there is no common way to cast stuff to float
## Pitch
just add `astype(self, typestring)` method to the torch.tensor class, and have it take the same strings folks use for numpy, and map them to the corresponding torch types, and then we can always do x.astype('float32') in our helper function and it won't crash if we're using the helper function on a tensor
## Alternatives
we could write a special function to look at a variable and see if it's a ndarray or tensor and invoke the correct method to convert type
```
TORCH_TYPE_LOOKUP = { 'float32': torch.float32 }
def cast(maybe_tensor, typestring):
if torch.is_tensor(maybe_tensor):
return maybe_tensor.to(TORCH_TYPE_LOOKUP[typestring])
return maybe_tensor.astype(typestring)
```
^^ doable, just adds work for everyone
## Additional context
thank you for building pytorch ... the numpy api is huge and obviously i wouldn't expect 1:1 copy of everything, but if we chip away at major stuff then it's gonna be a lot easier to get more done with less code in the long run
cc @mruberry
|
triaged,enhancement,module: numpy
|
low
|
Critical
|
644,206,316 |
angular
|
Forms: refactor min/max and minLength/maxLength validators to share the code
|
Currently the min/max and minLength/maxLength validators in the `packages/forms/src/validators.ts` file have their own implementations. We should consider generating these validators using common factory functions (one for min/max and another one for minLength/maxLength). The benefits of this approach: unification of validators and reducing the payload size. One of the problems is that `minLength` and `maxLength` validators are not fully consistent atm, when `minLength` supports optional controls (it has the `isEmptyInputValue` check), when the `maxLength` one does not. Aligning `minLength` and `maxLength` validator's logic (so that this logic can be extracted to a common function) would require a breaking change (i.e. make `maxLength` support optional controls as well).
Pseudo-code to illustrate the proposal:
```
function createLengthValidator(check: 'min'|'max'): (limit: number) => ValidatorFn { ... }
export class Validators {
...
static minLength(minLength: number): ValidatorFn = createLengthValidator('min');
...
static maxLength(minLength: number): ValidatorFn = createLengthValidator('max');
...
}
```
|
refactoring,area: forms,forms: validators,P4
|
low
|
Minor
|
644,208,354 |
go
|
net/http: add support for creating proxied TLS connections
|
`DialTLSContext` is [documented](https://github.com/golang/go/blob/9f33108dfa22946622a8a78b5cd3f64cd3e455dd/src/net/http/transport.go#L145-L146) as only being used for non-proxied requests.
This is problematic because it means HTTPS CONNECT requests [always](https://github.com/golang/go/blob/9f33108dfa22946622a8a78b5cd3f64cd3e455dd/src/net/http/transport.go#L1679) use `crypto/tls`. This can violate business requirements and so on. (And can also lead to difficult to debug errors if you, uh, forget that `DialTLSContext` is only for non-proxied requests. Or if the proxy is added later.)
Ideally, `Transport` would have a `Client(net.Conn, ...) net.Conn` field that, if nil, would default to `crypto/tls`.
|
NeedsInvestigation,FeatureRequest
|
low
|
Critical
|
644,253,028 |
pytorch
|
torch.autograd.functional.* for models
|
## 🚀 Feature
<!-- A clear and concise description of the feature proposal -->
## Motivation
<!-- Please outline the motivation for the proposal. Is your feature request related to a problem? e.g., I'm always frustrated when [...]. If this is related to another GitHub issue, please link here too -->
Sometimes, for some small models, we are interested in computing the Hessian of model parameters. `torch.autograd.functional.*` provides a handy function for that, but only for tensors instead of models (parameters). Although users could manually specify the computation of models the `tensors`, it's not pretty convenient for moderately sophisticated models.
## Pitch
<!-- A clear and concise description of what you want to happen. -->
In addition to the current function signature `torch.autograd.functional.jacobian(func, inputs, create_graph=False, strict=False)`, additionally provide a version where `nn.Module` instead of `inputs` can be used as input, the function will return the Jacobian/Hessian/etc w.r.t. model parameters.
I believe with the current function signature, this is already possible (e.g., by manually specifying the computation graph), but would love to have a cleaner way to do it.
## Alternatives
<!-- A clear and concise description of any alternative solutions or features you've considered, if any. -->
## Additional context
<!-- Add any other context or screenshots about the feature request here. -->
cc @ezyang @SsnL @albanD @zou3519 @gqchen
|
module: autograd,triaged,enhancement
|
low
|
Minor
|
644,272,771 |
flutter
|
Image.memory retains the Uint8List
|
Reported by internal user
If you use `Image.memory`, the Uint8List backing the image is retained.
We should probably rework the key structure there so that the Uint8List backing the image is not part of the key.
|
framework,c: performance,customer: google,a: images,perf: memory,P2,team-framework,triaged-framework
|
low
|
Major
|
644,300,370 |
flutter
|
Trailing whitespace in android/app/src/main/res/values/styles.xml
|
If I do `flutter create blah`, create a git repo, add everything then temporarily move `.git` to parent directory, and run this expression I found on the internet:
~~find . -type f -name "*" -exec perl -p -i -e "s/[ \t]$//g" {} \;~~
EDIT: I'm not sure if that will bork your repo, so maybe this report is safer:
```
find . -type f -exec egrep -l " +$" {} \;
```
Then I find the following diff:
```diff
% git diff
diff --git a/android/app/src/main/res/values/styles.xml b/android/app/src/main/res/values/styles.xml
index 1f83a33..980728c 100644
--- a/android/app/src/main/res/values/styles.xml
+++ b/android/app/src/main/res/values/styles.xml
@@ -10,7 +10,7 @@
This theme determines the color of the Android Window while your
Flutter UI initializes, as well as behind your Flutter UI while its
running.
-
+
This Theme is only used starting with V2 of Flutter's Android embedding. -->
<style name="NormalTheme" parent="@android:style/Theme.Black.NoTitleBar">
<item name="android:windowBackground">@android:color/white</item>
```
Shouldn't the trailing whitespace not be here?
|
tool,a: quality,dependency: android,P3,found in release: 1.22,found in release: 1.27,team-tool,triaged-tool
|
low
|
Minor
|
644,308,364 |
go
|
x/tools/internal/invoke/gocommand: tests are timing out
|
Seems like a lot of tests are timing out on the builders ([example failure](https://build.golang.org/log/c8c8eee5d06746ddf7f1bc8900be313d051d2b77)). From the logs, my guess is that a serial `go` command invocation isn't returning in a reasonable amount of time, and it is blocking all the other go commands from running. A possible solution (or at least a first step for debugging) would be putting a timeout on a `go` command invocation.
/cc @heschik
|
OS-Darwin,Builders,NeedsInvestigation,Tools
|
low
|
Critical
|
644,330,864 |
pytorch
|
Learning rate change is not applied at designated iteration with a scheduler
|
## 🐛 Bug
With a scheduler, the learning rate changes at the designated iteration, but it seems the same iteration still applies the learning rate before change.
## To Reproduce
A minimal example is attached:
[test_lr.zip](https://github.com/pytorch/pytorch/files/4823279/test_lr.zip)
Steps to reproduce the behavior:
1. Run `python main_steplr.py`; this applies a `torch.optim.lr_scheduler.StepLR` with `step_size=5` and `gamma=0.1`. The logs on my computer are as follows:
> iteration: 0
learning rate: 0.1
loss = 0.23123088479042053
iteration: 1
learning rate: 0.1
loss = 0.11247935891151428
iteration: 2
learning rate: 0.1
loss = 0.12026116997003555
iteration: 3
learning rate: 0.1
loss = 0.11437922716140747
iteration: 4
learning rate: 0.1
loss = 0.11330760270357132
iteration: 5
learning rate: 0.010000000000000002
loss = 0.11355291306972504
iteration: 6
learning rate: 0.010000000000000002
loss = 0.1208689734339714
2. Run `python main_fixlr.py`; this applies a fixed learning rate. The logs on my computer are as follows:
> iteration: 0
learning rate: 0.1
loss = 0.23123088479042053
iteration: 1
learning rate: 0.1
loss = 0.11247935891151428
iteration: 2
learning rate: 0.1
loss = 0.12026116997003555
iteration: 3
learning rate: 0.1
loss = 0.11437922716140747
iteration: 4
learning rate: 0.1
loss = 0.11330760270357132
iteration: 5
learning rate: 0.1
loss = 0.11355291306972504
iteration: 6
learning rate: 0.1
loss = 0.12065751850605011
<!-- If you have a code sample, error messages, stack traces, please provide it here as well -->
## Expected behavior
The above steps compare between a learning rate decreased at iteration 5 and fixing this learning rate.
In step 1, according the [documentation](https://pytorch.org/docs/stable/optim.html#torch.optim.lr_scheduler.StepLR), the learning rate should be `0.1` if `iteration < 5`, and be `0.01` if `5 <= iteration < 10`. However, although learning rate changes in iteration 5 in step 1, the loss is the same in the iteration 5 of step 1 and step 2. In other words, in iteration 5, different learning rates lead to the same loss. I think the changed learn rate might not be correctly applied in the designated iteration in step 1.
## Environment
PyTorch version: 1.5.0
Is debug build: No
CUDA used to build PyTorch: 10.2
OS: Microsoft Windows 10 专业版 (Pro)
GCC version: (Rev5, Built by MSYS2 project) 5.3.0
CMake version: version 3.15.5
Python version: 3.7
Is CUDA available: Yes
CUDA runtime version: 10.2.89
GPU models and configuration: Could not collect
Nvidia driver version: Could not collect
cuDNN version: C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\bin\cudnn64_7.dll
Versions of relevant libraries:
[pip] numpy==1.18.1
[pip] numpydoc==0.9.1
[pip] torch==1.5.0
[pip] torchvision==0.6.0
[conda] blas 1.0 mkl defaults
[conda] mkl 2019.4 245 defaults
[conda] mkl-service 2.3.0 py37hb782905_0 defaults
[conda] mkl_fft 1.0.14 py37h14836fe_0 defaults
[conda] mkl_random 1.1.0 py37h675688f_0 defaults
[conda] pytorch 1.5.0 py3.7_cuda102_cudnn7_0 https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch
[conda] torchvision 0.6.0 py37_cu102 https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch
cc @vincentqb
|
module: optimizer,triaged
|
low
|
Critical
|
644,339,386 |
go
|
x/tools/gopls: convert 'gofumpt' from formatter to code action provider
|
Add an analyzer that produces suggested fixes using https://pkg.go.dev/mvdan.cc/gofumpt/format?tab=doc.
The tricky part is that the dependency will have to live in the `gopls` module, since it's not a `golang.org/x/...` dependency. That means the analyzer will have to be in that module, and we won't be able to have any internal/lsp tests for this behavior until #35880 is resolved.
/cc @joshbaum @mvdan
|
Thinking,FeatureRequest,gopls,Tools
|
low
|
Major
|
644,340,801 |
excalidraw
|
Lines of text change line spacing between OSes
|
**Problem Summary/Recreation**
- Chrome 83.0.4103.116 on macOS 10.15.5 Catalina
- Chrome 83.0.4103.116 on Windows 10 v1909
I've been working on a project for a little while, and I switch between the two above computers to do work. One is a Windows OS and the other is macOS. I use a lot of new lines for multi-line text in my diagrams (Shift+Enter).
When I finish and push my changes on Windows, then pull changes and open the same Excalidraw file on the browser on my mac, the line spacing changes.
You can recreate this by opening one of the `*.excalidraw` roadmap files in this repository on a macOS machine and double-clicking one of the bodies of text:
https://github.com/Static-Void-Academy/complete-software-roadmap
I know that Windows / DOS uses both CR-LF vs. *nix which uses just LF. Might that be the issue here?
Edits: Add clarity to reproduce
|
bug
|
low
|
Major
|
644,401,194 |
vue-element-admin
|
第一次安装然后npm run dev 就报错了
|
<!--
注意:为更好的解决你的问题,请参考模板提供完整信息,准确描述问题,信息不全的 issue 将被关闭。
Note: In order to better solve your problem, please refer to the template to provide complete information, accurately describe the problem, and the incomplete information issue will be closed.
-->
`> [email protected] dev /mnt/d/h5/vue-element-admin
> vue-cli-service serve
INFO Starting development server...
98% after emitting CopyPlugin
DONE Compiled successfully in 18824ms 3:47:42 PM
App running at:
- Local: http://localhost:9527/
- Network: unavailable
Note that the development build is not optimized.
To create a production build, run npm run build.
events.js:287
throw er; // Unhandled 'error' event
^
Error: spawn cmd.exe ENOENT
at Process.ChildProcess._handle.onexit (internal/child_process.js:267:19)
at onErrorNT (internal/child_process.js:469:16)
at processTicksAndRejections (internal/process/task_queues.js:84:21)
Emitted 'error' event on ChildProcess instance at:
at Process.ChildProcess._handle.onexit (internal/child_process.js:273:12)
at onErrorNT (internal/child_process.js:469:16)
at processTicksAndRejections (internal/process/task_queues.js:84:21) {
errno: 'ENOENT',
code: 'ENOENT',
syscall: 'spawn cmd.exe',
path: 'cmd.exe',
spawnargs: [ '/c', 'start', '""', '/b', 'http://localhost:9527/' ]
}
npm ERR! code ELIFECYCLE
npm ERR! errno 1
npm ERR! [email protected] dev: `vue-cli-service serve`
npm ERR! Exit status 1
npm ERR!
npm ERR! Failed at the [email protected] dev script.
npm ERR! This is probably not a problem with npm. There is likely additional logging output above.
npm ERR! A complete log of this run can be found in:
npm ERR! /root/.npm/_logs/2020-06-24T07_47_42_933Z-debug.log`
## Bug report(问题描述)
#### Steps to reproduce(问题复现步骤)
<!--
1. [xxx]
2. [xxx]
3. [xxxx]
-->
#### Screenshot or Gif(截图或动态图)

#### Link to minimal reproduction(最小可在线还原demo)
<!--
Please only use Codepen, JSFiddle, CodeSandbox or a github repo
-->
#### Other relevant information(格外信息)
- Your OS: ubuntu
- Node.js version: v12.16.2
- vue-element-admin version:
|
not vue-element-admin bug
|
low
|
Critical
|
644,466,955 |
pytorch
|
Mixed precision causes NaN loss
|
## 🐛 Bug
<!-- A clear and concise description of what the bug is. -->
I'm using autocast with GradScaler to train on mixed precision. For small dataset, it works fine. But when I trained on bigger dataset, after few epochs (3-4), the loss turns to nan.
It is seq2seq, transformer model, using Adam optimizer, cross entropy criterion.
Here is the training code:
```python
def get_correction(output, target):
diff = torch.sum((output != target), axis=1)
acc = torch.sum(diff == 0)
return acc.item()
def train(model, data_loader, optimizer, criterion, device, scaler):
clip = 1
model.train()
epoch_loss = 0
total_correct = 0
total_sample = 0
for i, batch in enumerate(data_loader):
optimizer.zero_grad()
src, trg = batch
src = src.to(device, non_blocking=True)
trg = trg.to(device, non_blocking=True)
with autocast():
output, _ = model(src, trg[:, :-1])
y_pred = torch.argmax(output, 2)
y_true = trg[:, 1:]
total_sample += y_true.shape[0]
total_correct += get_correction(y_pred, y_true)
output_dim = output.shape[-1]
output = output.contiguous().view(-1, output_dim)
trg = trg[:, 1:].contiguous().view(-1)
loss = criterion(output, trg)
epoch_loss += loss.item()
scaler.scale(loss).backward()
scaler.unscale_(optimizer)
torch.nn.utils.clip_grad_norm_(model.parameters(), clip)
scaler.step(optimizer)
scaler.update()
epoch_loss = epoch_loss / len(data_loader)
acc = total_correct / total_sample
return epoch_loss, acc
```
Note that the get_correction function is just for calculate the accuracy based on word level instead of character level.
## Environment
- PyTorch Version: 1.6.0.dev20200623
- OS (e.g., Linux): Linux
- How you installed PyTorch (`conda`, `pip`, source): conda
- Build command you used (if compiling from source):
- Python version: 3.7.5
- CUDA/cuDNN version: 10.2
- GPU models and configuration: RTX 2060 super
cc @mcarilli @ptrblck
|
triaged,module: NaNs and Infs,module: amp (automated mixed precision)
|
high
|
Critical
|
644,503,925 |
youtube-dl
|
educative site support
|
Hello,
Please can you add support for this children educative site lumni.fr. i can't dowload video from the following url :
https://www.lumni.fr/video/lutilisation-de-plusieurs-droites-graduees-24-juin#containerType=serie&containerSlug=la-maison-lumni-primaire
thanks.
the verbose output of youtube-dl
" sc@PC-IP02:~$ youtube-dl -v -F https://www.lumni.fr/video/lutilisation-de-plusieurs-droites-graduees-24-juin#containerType=serie&containerSlug=la-maison-lumni-primaire
[1] 26280
sc@PC-IP02:~$ [debug] System config: []
[debug] User config: []
[debug] Custom config: []
[debug] Command-line args: [u'-v', u'-F', u'https://www.lumni.fr/video/lutilisation-de-plusieurs-droites-graduees-24-juin#containerType=serie']
[debug] Encodings: locale UTF-8, fs UTF-8, out UTF-8, pref UTF-8
[debug] youtube-dl version 2020.06.16.1
[debug] Python version 2.7.17 (CPython) - Linux-5.3.0-59-generic-x86_64-with-neon-18.04-bionic
[debug] exe versions: ffmpeg 3.4.6, ffprobe 3.4.6, phantomjs 2.1.1, rtmpdump 2.4
[debug] Proxy map: {}
[generic] lutilisation-de-plusieurs-droites-graduees-24-juin#containerType=serie: Requesting header
WARNING: Falling back on generic information extractor.
[generic] lutilisation-de-plusieurs-droites-graduees-24-juin#containerType=serie: Downloading webpage
[generic] lutilisation-de-plusieurs-droites-graduees-24-juin#containerType=serie: Extracting information
ERROR: Unsupported URL: https://www.lumni.fr/video/lutilisation-de-plusieurs-droites-graduees-24-juin#containerType=serie
Traceback (most recent call last):
File "/usr/local/bin/youtube-dl/youtube_dl/extractor/generic.py", line 2387, in _real_extract
doc = compat_etree_fromstring(webpage.encode('utf-8'))
File "/usr/local/bin/youtube-dl/youtube_dl/compat.py", line 2562, in compat_etree_fromstring
doc = _XML(text, parser=etree.XMLParser(target=_TreeBuilder(element_factory=_element_factory)))
File "/usr/local/bin/youtube-dl/youtube_dl/compat.py", line 2551, in _XML
parser.feed(text)
File "/usr/lib/python2.7/xml/etree/ElementTree.py", line 1659, in feed
self._raiseerror(v)
File "/usr/lib/python2.7/xml/etree/ElementTree.py", line 1523, in _raiseerror
raise err
ParseError: not well-formed (invalid token): line 1, column 622
Traceback (most recent call last):
File "/usr/local/bin/youtube-dl/youtube_dl/YoutubeDL.py", line 797, in extract_info
ie_result = ie.extract(url)
File "/usr/local/bin/youtube-dl/youtube_dl/extractor/common.py", line 530, in extract
ie_result = self._real_extract(url)
File "/usr/local/bin/youtube-dl/youtube_dl/extractor/generic.py", line 3382, in _real_extract
raise UnsupportedError(url)
UnsupportedError: Unsupported URL: https://www.lumni.fr/video/lutilisation-de-plusieurs-droites-graduees-24-juin#containerType=serie
"
|
site-support-request,duplicate
|
low
|
Critical
|
644,510,720 |
PowerToys
|
Task Switcher vim navigation shortcuts
|
# Summary of the new feature/enhancement
When having your hands on the keyboard and pressing Alt-Tab to switch windows, it is a bit inconvenient to reach for the arrow keys to navigate the windows open. It would be very cool that we could use HJKL (vim style) navigation keys to move arround the currently open windows.
<!--
A clear and concise description of what the problem is that the new feature would solve.
Describe why and how a user would use this new functionality (if applicable).
-->
# Proposed technical implementation details (optional)
When Task Switcher is open (Alt-Tab) `H` remaps to left arrow, `J` remaps to down arrow, `K` remaps to up arrow and `L` remaps to right arrow.
<!--
A clear and concise description of what you want to happen.
-->
|
Idea-New PowerToy
|
low
|
Major
|
644,517,282 |
electron
|
support Chromium's 'memlog' command-line switch
|
### Preflight Checklist
* [x] I have read the [Contributing Guidelines](https://github.com/electron/electron/blob/master/CONTRIBUTING.md) for this project.
* [x] I agree to follow the [Code of Conduct](https://github.com/electron/electron/blob/master/CODE_OF_CONDUCT.md) that this project adheres to.
* [x] I have searched the issue tracker for an issue that matches the one I want to file, without success.
(Note: I saw there was a closed question about memlog, I am filing a bug report though, as the behaviour with appending memlog switch via electron, doesn't appear to match the behaviour from Chrome)
### Issue Details
* **Electron Version:**
* v9.0.5
* **Operating System:**
* Arch Linux (rolling release)
### Expected Behavior
When appending the memlog flag with Chrome as detailed below:
```
chromium --memlog=all
```
And capturing a trace with MemoryInfra chosen, additional heap information is obtained.
### Actual Behavior
No additional heap information is obtained, when the Chrome memlog flag is appended from electron app.
### To Reproduce
Use the following minimal code example:
```
const {app, BrowserWindow, contentTracing} = require('electron')
const path = require('path')
app.commandLine.appendSwitch("memlog","all")
app.commandLine.appendSwitch("memlog-keep-small-allocations")
app.commandLine.appendSwitch("memlog-sampling-rate",100000)
app.commandLine.appendSwitch('memlog-stack-mode', 'native');
function createWindow () {
const mainWindow = new BrowserWindow({
width: 800,
height: 600,
webPreferences: {
preload: path.join(__dirname, 'preload.js')
}
})
mainWindow.loadFile('index.html')
}
app.on('ready', async () => {
await contentTracing.startRecording({
trace_buffer_size_in_kb: 1024*300,
included_categories: ['disabled-by-default-memory-infra'],
excluded_categories: ['*'],
"memory_dump_config": {
"triggers": [
{ "mode": "light", "periodic_interval_ms": 50 },
{ "mode": "detailed", "periodic_interval_ms": 1000 }
]
}
})
console.log('Tracing started')
await new Promise(resolve => setTimeout(resolve, 60000))
const path = await contentTracing.stopRecording()
console.log('Tracing data recorded to ' + path)
})
app.whenReady().then(async () => {
createWindow()
app.on('activate', function () {
// On macOS it's common to re-create a window in the app when the
// dock icon is clicked and there are no other windows open.
if (BrowserWindow.getAllWindows().length === 0) createWindow()
})
})
app.on('window-all-closed', function () {
if (process.platform !== 'darwin') app.quit()
})
```
This code tries to set the Chrome memlog switch and records a trace, which I load using the chrome://tracing tool.
### Screenshots
The following screenshot shows the effect of using --memlog=all, when conducting tracing from just Chromium (not electron) you can see the additional 'Heap Details' section:

The following screenshot shows the trace I obtain from electron using the code above, as you can see, there is no heap details section:
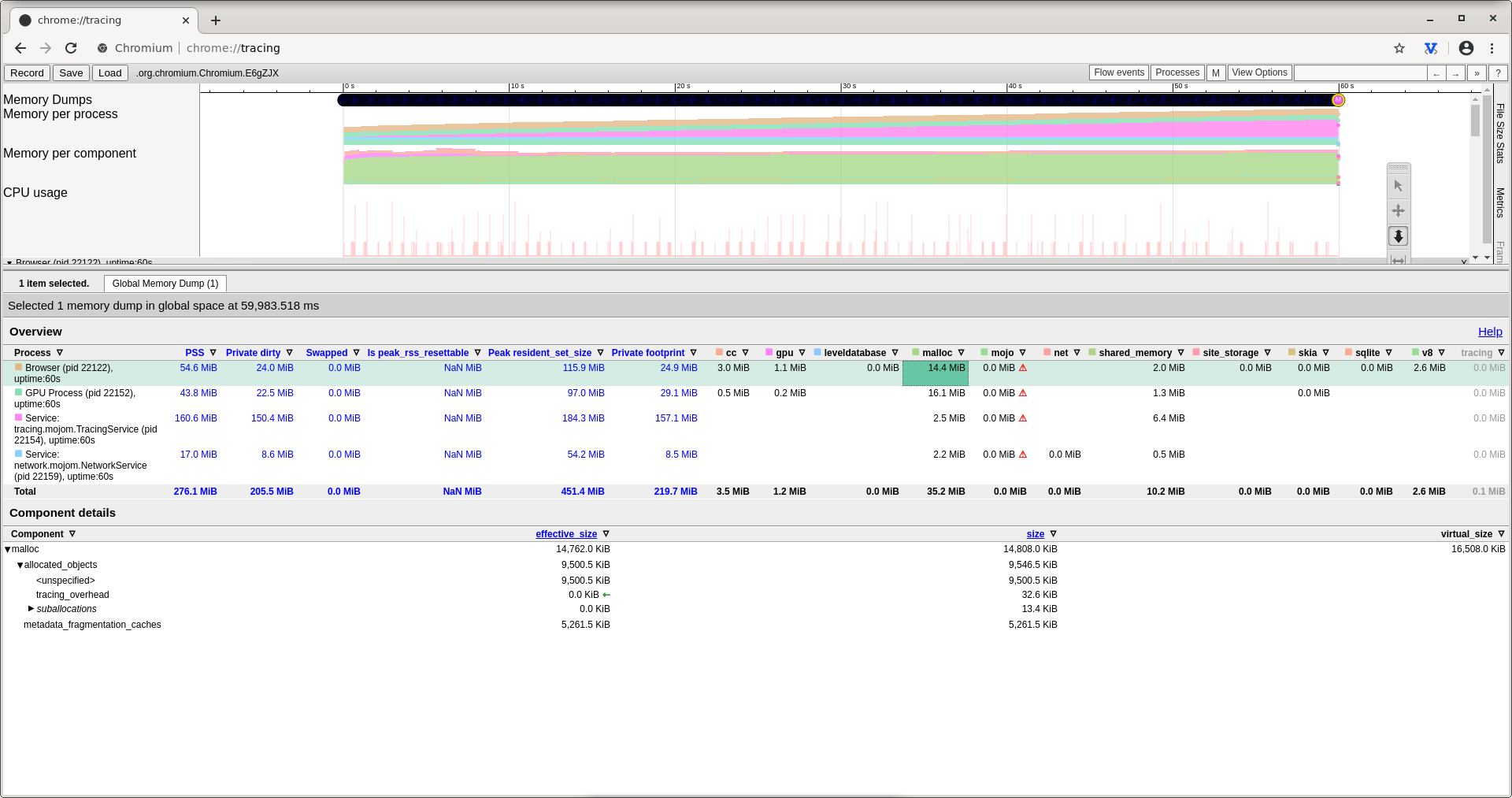
|
enhancement :sparkles:,platform/all,9-x-y
|
low
|
Critical
|
644,535,299 |
pytorch
|
Not able to launch tensorboard using pytorch
|
I have installed tensorboard (pip install tensoboard)
but while launching it I am getting below error
folder_path_for_runs> tensorboard --logdir=runs
Traceback (most recent call last):
File "c:\users\srava\anaconda3\lib\runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "c:\users\srava\anaconda3\lib\runpy.py", line 85, in _run_code
exec(code, run_globals)
File "C:\Users\srava\Anaconda3\Scripts\tensorboard.exe\__main__.py", line 5, in <module>
File "c:\users\srava\anaconda3\lib\site-packages\tensorboard\main.py", line 43, in <module>
from tensorboard import default
File "c:\users\srava\anaconda3\lib\site-packages\tensorboard\default.py", line 39, in <module>
from tensorboard.plugins.audio import audio_plugin
File "c:\users\srava\anaconda3\lib\site-packages\tensorboard\plugins\audio\audio_plugin.py", line 26, in <module>
from tensorboard import plugin_util
File "c:\users\srava\anaconda3\lib\site-packages\tensorboard\plugin_util.py", line 27, in <module>
import markdown
File "c:\users\srava\anaconda3\lib\site-packages\markdown\__init__.py", line 29, in <module>
from .core import Markdown, markdown, markdownFromFile # noqa: E402
File "c:\users\srava\anaconda3\lib\site-packages\markdown\core.py", line 26, in <module>
from . import util
File "c:\users\srava\anaconda3\lib\site-packages\markdown\util.py", line 85, in <module>
INSTALLED_EXTENSIONS = metadata.entry_points().get('markdown.extensions', ())
TypeError: entry_points() missing 1 required positional argument: 'name'
i am using pytroch 1.5.0+cu101
|
module: tensorboard,oncall: visualization
|
low
|
Critical
|
644,574,198 |
flutter
|
Android: Sharing Flutter Engine between foreground and background isolates
|
## Use case
We want to start the app based on a background trigger on Android.
We have a long running _foreground service_ which is started based on the Bluetooth connection state. Since the service can be started when the app is not running, the service needs to get the information from the Flutter (e.g. access token and refresh token).
We want to start an isolate (from the foreground service) which can be later associated with the main app view in order to prevent multiple instance creations (e.g. authentication, access to the file system, external libs, etc). Currently we are able to start two different isolates (foreground and background) but there are synchronisation issues between those two. Also, when the app is then put to background we want to keep the isolate running in a foreground service.
For example:
- Bluetooth broadcast is received
- We start the background service (Android native) and instantiate the Dart isolate
- User starts the app
- UI isolate is started
We tried to kill the background isolate as soon the app is started but this causes other issues.
There is also this Meta issue that seems related: https://github.com/flutter/flutter/issues/32164
## Proposal
If we could use the isolate which is created in the background as the main Flutter instance as soon as the app is started would solve our issue.
|
c: new feature,platform-android,engine,c: proposal,customer: vroom,P2,team-android,triaged-android
|
low
|
Critical
|
644,586,290 |
godot
|
Game randomly crashing about 2 times per hour when exported to HTML5 (wasm Uncaught RuntimeError)
|
**Godot version:**
3.2.1.stable
**OS/device including version:**
Nvidia GeForce GTX 1060 6GB (driver version 26.21.14.4141), Backend GLES2
Vivaldi 3.1.1929.34
**Issue description:**
When playing the game in the browser (HTML5 export) the game randomly crashes about every 30 minutes. I cannot make out why, but I caught 2 error messages in the console.
I already migrated to GLES2 (from GLES3), changed Particles to CPUParticles and my shaders dont use more complex funtions than sin() or cos().
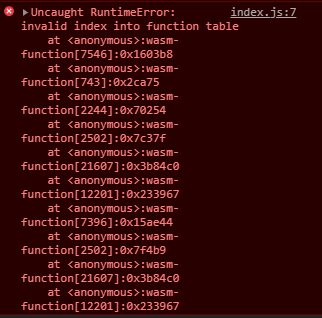
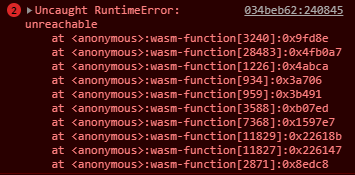
**Steps to reproduce:**
Sorry, I have no idea, they seem to happen randomly. Although I have the theory that it might happen when queue_free() gets called on objects, but I am not sure.
**Minimal reproduction project:**
Sorry again, the game is basically done and I would have released it already if it weren't for this issue, and I can't reproduce it either.
|
bug,platform:web,topic:core,crash
|
low
|
Critical
|
644,589,376 |
godot
|
Texture added to Tilemap does not persist after the saved project has reloaded
|
**Godot version:**
3.2.1 on Windows 10, 64-bit Standard Build
**OS/device including version:**
Windows 10 Build 2004
**Issue description:**
Texture added to a Tilemap after saving a project and reloading the editor does not persist.
Added textures to a tilemap should persist after reloading the editor (on saved projects).
**Steps to reproduce:**
1) Create a new project and scene
2) Add a Tilemap and edit the tilemap.
3) Add a Texture to the Tilemap
4) Select the main scene and save the project and then exit.
5) Reload the editor
6) Edit the same tilemap again and you will notice the texture has not loaded.
**Minimal reproduction project:**
[Tileset4.zip](https://github.com/godotengine/godot/files/4825436/Tileset4.zip)
Video of error:
https://youtu.be/scKDVqVhbWE
|
discussion,topic:editor,usability
|
low
|
Critical
|
644,600,582 |
terminal
|
Bring "Open in Windows Terminal" for Right Click on Drive Letter
|
# Description of the new feature/enhancement
Bring "Open in Windows Terminal" for right click on drive letter. In Windows Terminal 1.1.1671.0 I am able to do this on a folder but it does not work on a drive letter.
|
Help Wanted,Issue-Bug,Product-Terminal,Priority-2,Area-ShellExtension
|
medium
|
Major
|
644,611,770 |
go
|
go/doc,x/pkgsite: rethink order for factory functions
|
For my package: https://godoc.org/github.com/rocketlaunchr/dataframe-go/forecast
I have a function:
`func Forecast(ctx context.Context, sdf interface{}, r *dataframe.Range, alg ForecastingAlgorithm, cfg interface{}, n uint, evalFunc EvaluationFunc) (interface{}, []Confidence, float64, error)` which returns an `interface{}` as the first return value.

Unfortunately my function is categorized under `type Confidence` when it should not be.
I assume this issue would also be present in `pkg.go.dev`, but my package has been banned from there (despite the person in charge saying it will be allowed many many months ago), so I can't check if this issue persists.
|
NeedsInvestigation,pkgsite,pkgsite/dochtml
|
low
|
Critical
|
644,618,753 |
create-react-app
|
CRA --template not picking up github url from a nested folder.
|
<!--
Please note that your issue will be fixed much faster if you spend about
half an hour preparing it, including the exact reproduction steps and a demo.
If you're in a hurry or don't feel confident, it's fine to report bugs with
less details, but this makes it less likely they'll get fixed soon.
In either case, please use this template and fill in as many fields below as you can.
Note that we don't provide help for webpack questions after ejecting.
You can find webpack docs at https://webpack.js.org/.
-->
### Describe the bug
I am trying to init a `create-react-app` with a github url
```
npx create-react-app my-app --use-npm --template git+ssh://[email protected]/<orgname>/<repo>.git/<folder-name>/react-scripts/cra-template-javascript
```
The issue is my github repo has multiple templates, I can run them locally like
```
npx create-react-app my-app --use-npm --template file:/Users/adeelimran/Desktop/adeel/repos/sandbox/adeel_imran/react-scripts/cra-template-typescript
```
But I can run it via the github link, because the project folder is under a nested github folder.
### Did you try recovering your dependencies?
<!--
Your module tree might be corrupted, and that might be causing the issues.
Let's try to recover it. First, delete these files and folders in your project:
* node_modules
* package-lock.json
* yarn.lock
Then you need to decide which package manager you prefer to use.
We support both npm (https://npmjs.com) and yarn (http://yarnpkg.com/).
However, **they can't be used together in one project** so you need to pick one.
If you decided to use npm, run this in your project directory:
npm install -g npm@latest
npm install
This should fix your project.
If you decided to use yarn, update it first (https://yarnpkg.com/en/docs/install).
Then run in your project directory:
yarn
This should fix your project.
Importantly, **if you decided to use yarn, you should never run `npm install` in the project**.
For example, yarn users should run `yarn add <library>` instead of `npm install <library>`.
Otherwise your project will break again.
Have you done all these steps and still see the issue?
Please paste the output of `npm --version` and/or `yarn --version` to confirm.
-->
This issue does not have dependencies.
### Which terms did you search for in User Guide?
https://create-react-app.dev/docs/custom-templates
<!--
There are a few common documented problems, such as watcher not detecting changes, or build failing.
They are described in the Troubleshooting section of the User Guide:
https://facebook.github.io/create-react-app/docs/troubleshooting
Please scan these few sections for common problems.
Additionally, you can search the User Guide itself for something you're having issues with:
https://facebook.github.io/create-react-app/
If you didn't find the solution, please share which words you searched for.
This helps us improve documentation for future readers who might encounter the same problem.
-->
### Environment
<!--
To help identify if a problem is specific to a platform, browser, or module version, information about your environment is required.
This enables the maintainers quickly reproduce the issue and give feedback.
Run the following command in your React app's folder in terminal.
Note: The result is copied to your clipboard directly.
`npx create-react-app --info`
Paste the output of the command in the section below.
-->
```
Environment Info:
current version of create-react-app: 3.4.1
running from /Users/adeelimran/.npm/_npx/45395/lib/node_modules/create-react-app
System:
OS: macOS 10.15.5
CPU: (16) x64 Intel(R) Core(TM) i9-9880H CPU @ 2.30GHz
Binaries:
Node: 14.4.0 - ~/.nvm/versions/node/v14.4.0/bin/node
Yarn: 1.22.4 - ~/.yarn/bin/yarn
npm: 6.14.5 - ~/.nvm/versions/node/v14.4.0/bin/npm
Browsers:
Chrome: 83.0.4103.106
Firefox: 64.0.2
Safari: 13.1.1
npmPackages:
react: Not Found
react-dom: Not Found
react-scripts: Not Found
npmGlobalPackages:
create-react-app: Not Found
```
### Steps to reproduce
<!--
How would you describe your issue to someone who doesn’t know you or your project?
Try to write a sequence of steps that anybody can repeat to see the issue.
-->
(Write your steps here:)
1. Create a github repo
2. Inside that repo create some nested folders
3. In one of the templates add the content as is from here https://github.com/facebook/create-react-app/tree/master/packages/cra-template
4. On executing `npx create-react-app my-app --use-npm --template git+ssh://[email protected]/<username>/<repo-name>.git/folder1/fodler2/cra-template-javascript
`
5. It should find this folder & init a CRA project using the given template
### Expected behavior
<!--
How did you expect the tool to behave?
It’s fine if you’re not sure your understanding is correct.
Just write down what you thought would happen.
-->
(Write what you thought would happen.)
It should create the project reading from the github url.
### Actual behavior
<!--
Did something go wrong?
Is something broken, or not behaving as you expected?
Please attach screenshots if possible! They are extremely helpful for diagnosing issues.
-->
(Write what happened. Please add screenshots!)
<img width="978" alt="Screenshot 2020-06-24 at 15 28 27" src="https://user-images.githubusercontent.com/16651811/85565509-7de37c00-b62f-11ea-8513-2311ce4cdb53.png">
### Reproducible demo
<!--
If you can, please share a project that reproduces the issue.
This is the single most effective way to get an issue fixed soon.
There are two ways to do it:
* Create a new app and try to reproduce the issue in it.
This is useful if you roughly know where the problem is, or can’t share the real code.
* Or, copy your app and remove things until you’re left with the minimal reproducible demo.
This is useful for finding the root cause. You may then optionally create a new project.
This is a good guide to creating bug demos: https://stackoverflow.com/help/mcve
Once you’re done, push the project to GitHub and paste the link to it below:
-->
(Paste the link to an example project and exact instructions to reproduce the issue.)
<!--
What happens if you skip this step?
We will try to help you, but in many cases it is impossible because crucial
information is missing. In that case we'll tag an issue as having a low priority,
and eventually close it if there is no clear direction.
We still appreciate the report though, as eventually somebody else might
create a reproducible example for it.
Thanks for helping us help you!
-->
|
issue: bug report
|
low
|
Critical
|
644,634,254 |
go
|
cmd/compile: panic: runtime error: floating point error when building on FreeBSD armv6 on RPi-B
|
<!--
Please answer these questions before submitting your issue. Thanks!
For questions please use one of our forums: https://github.com/golang/go/wiki/Questions
-->
### What version of Go are you using (`go version`)?
go1.4 bootstrap
### Does this issue reproduce with the latest release?
Yes
### What operating system and processor architecture are you using (`go env`)?
<details><summary><code>go env</code> Output</summary><br><pre>
$ /usr/local/go14/bin/go env
GOARCH="arm"
GOBIN=""
GOCHAR="5"
GOEXE=""
GOHOSTARCH="arm"
GOHOSTOS="freebsd"
GOOS="freebsd"
GOPATH=""
GORACE=""
GOROOT="/usr/local/go14"
GOTOOLDIR="/usr/local/go14/pkg/tool/freebsd_arm"
CC="clang"
GOGCCFLAGS="-fPIC -marm -fno-caret-diagnostics -Qunused-arguments -fmessage-length=0"
CXX="clang++"
CGO_ENABLED="0"
$
</pre></details>
### What did you do?
I tried to build go1.14.4
### What did you expect to see?
A successful build of go1.14.4
### What did you see instead?
Build fails with SIGFPE. The output below comes from a build from FreeBSD ports. Building from source directly (using go1-4 bootstrap) results in the same error.
<pre>
root@rpi-b:/usr/ports/lang/go # make -DBATCH
===> License BSD3CLAUSE accepted by the user
===> go-1.14.4,1 depends on file: /usr/local/sbin/pkg - found
=> go1.14.4.src.tar.gz doesn't seem to exist in /usr/ports/distfiles/.
=> Attempting to fetch https://golang.org/dl/go1.14.4.src.tar.gz
go1.14.4.src.tar.gz 21 MB 1695 kBps 13s
=> go-freebsd-arm6-go1.14.tar.xz doesn't seem to exist in /usr/ports/distfiles/.
=> Attempting to fetch https://github.com/dmgk/go-bootstrap/releases/download/go1.14/go-freebsd-arm6-go1.14.tar.xz
go-freebsd-arm6-go1.14.tar.xz 33 MB 1472 kBps 24s
===> Fetching all distfiles required by go-1.14.4,1 for building
===> Extracting for go-1.14.4,1
=> SHA256 Checksum OK for go1.14.4.src.tar.gz.
=> SHA256 Checksum OK for go-freebsd-arm6-go1.14.tar.xz.
===> Patching for go-1.14.4,1
===> Applying FreeBSD patches for go-1.14.4,1 from /usr/ports/lang/go/files
===> Configuring for go-1.14.4,1
===> Building for go-1.14.4,1
cd /usr/ports/lang/go/work/go/src ; /usr/bin/env XDG_CACHE_HOME=/usr/ports/lang/go/work GOROOT_BOOTSTRAP=/usr/ports/lang/go/work/go-freebsd-arm6-bootstrap GOROOT=/usr/ports/lang/go/work/go GOROOT_FINAL=/usr/local/go GOBIN= GOOS=freebsd GOARCH=arm GO386= GOARM=6 /bin/sh make.bash -v
-ap: not found
go: not found
Building Go cmd/dist using /usr/ports/lang/go/work/go-freebsd-arm6-bootstrap. (go1.14 freebsd/arm)
cmd/dist
Building Go toolchain1 using /usr/ports/lang/go/work/go-freebsd-arm6-bootstrap.
math/bits
math
# math
panic: runtime error: floating point error
[signal SIGFPE: floating-point exception code=0x0 addr=0x8317bc pc=0x8317bc]
goroutine 1 [running]:
math.IsInf(...)
/home/dg/golang/go-bootstrap/go-freebsd-arm6-bootstrap/src/math/bits.go:51
cmd/compile/internal/gc.(*Mpflt).Float64(0x318805e0, 0x200, 0x318df5e0)
/home/dg/golang/go-bootstrap/go-freebsd-arm6-bootstrap/src/cmd/compile/internal/gc/mpfloat.go:139 +0x30
cmd/compile/internal/gc.truncfltlit(0x318805e0, 0x31440e40, 0x9c4af0)
/home/dg/golang/go-bootstrap/go-freebsd-arm6-bootstrap/src/cmd/compile/internal/gc/const.go:168 +0x90
cmd/compile/internal/gc.convertVal(0x9c4af0, 0x318805e0, 0x31440e40, 0x0, 0x9c4af0, 0x318df5c0)
/home/dg/golang/go-bootstrap/go-freebsd-arm6-bootstrap/src/cmd/compile/internal/gc/const.go:398 +0xb8
cmd/compile/internal/gc.convlit1(0x318880a0, 0x31440e40, 0x0, 0x3177540c, 0x318e6301)
/home/dg/golang/go-bootstrap/go-freebsd-arm6-bootstrap/src/cmd/compile/internal/gc/const.go:272 +0x248
cmd/compile/internal/gc.assignconvfn(0x318880a0, 0x31440e40, 0x3177540c, 0x318e6320)
/home/dg/golang/go-bootstrap/go-freebsd-arm6-bootstrap/src/cmd/compile/internal/gc/subr.go:805 +0x74
cmd/compile/internal/gc.assignconv(0x318880a0, 0x31440e40, 0x9e1072, 0xd, 0x318e6320)
/home/dg/golang/go-bootstrap/go-freebsd-arm6-bootstrap/src/cmd/compile/internal/gc/subr.go:792 +0x5c
cmd/compile/internal/gc.typecheckarraylit(0x31440e40, 0xffffffff, 0xffffffff, 0x31760d50, 0xb, 0xb, 0x9e1072, 0xd, 0xa, 0x0)
/home/dg/golang/go-bootstrap/go-freebsd-arm6-bootstrap/src/cmd/compile/internal/gc/typecheck.go:2999 +0x180
cmd/compile/internal/gc.typecheckcomplit(0x3187fc20, 0x0)
/home/dg/golang/go-bootstrap/go-freebsd-arm6-bootstrap/src/cmd/compile/internal/gc/typecheck.go:2785 +0x1cc0
cmd/compile/internal/gc.typecheck1(0x3187fc20, 0x12, 0x0)
/home/dg/golang/go-bootstrap/go-freebsd-arm6-bootstrap/src/cmd/compile/internal/gc/typecheck.go:860 +0x3cf4
cmd/compile/internal/gc.typecheck(0x3187fc20, 0x12, 0x0)
/home/dg/golang/go-bootstrap/go-freebsd-arm6-bootstrap/src/cmd/compile/internal/gc/typecheck.go:300 +0x640
cmd/compile/internal/gc.typecheckas(0x318880f0)
/home/dg/golang/go-bootstrap/go-freebsd-arm6-bootstrap/src/cmd/compile/internal/gc/typecheck.go:3172 +0x94
cmd/compile/internal/gc.typecheck1(0x318880f0, 0x1, 0x0)
/home/dg/golang/go-bootstrap/go-freebsd-arm6-bootstrap/src/cmd/compile/internal/gc/typecheck.go:1900 +0x29b8
cmd/compile/internal/gc.typecheck(0x318880f0, 0x1, 0x0)
/home/dg/golang/go-bootstrap/go-freebsd-arm6-bootstrap/src/cmd/compile/internal/gc/typecheck.go:300 +0x640
cmd/compile/internal/gc.Main(0xa00d70)
/home/dg/golang/go-bootstrap/go-freebsd-arm6-bootstrap/src/cmd/compile/internal/gc/main.go:580 +0x2d18
main.main()
/home/dg/golang/go-bootstrap/go-freebsd-arm6-bootstrap/src/cmd/compile/main.go:52 +0x98
bootstrap/sort
bootstrap/math/bits
bootstrap/container/heap
bootstrap/internal/goversion
bootstrap/internal/race
go tool dist: FAILED: /usr/ports/lang/go/work/go-freebsd-arm6-bootstrap/bin/go install -gcflags=-l -tags=math_big_pure_go compiler_bootstrap -v bootstrap/cmd/...: exit status 2
*** Error code 2
Stop.
make: stopped in /usr/ports/lang/go
</pre>
|
OS-FreeBSD,NeedsInvestigation,arch-arm,compiler/runtime
|
low
|
Critical
|
644,647,108 |
TypeScript
|
Suggestion: "emitDts" option for exporting handwritten declarations
|
# `"emitDts": true` for exporting handwritten declarations
## Search Terms
emit .d.ts, handwritten declaration files, Project References, outDir
## Suggestion
Introduce a tsconfig option `"emitDts": true` that will emit `.d.ts` source files into the `outDir`, taking precedence over any `.js`-generated `.d.ts` files.
## Use Cases
### 1. Publishing handwritten declarations
Not everyone has their `outDir` inside their source directory. Not everyone publishes a combined set of source + generated files to npm. It's a common pattern to only publish your `outDir`.
The workaround is to have a separate script that copies your handwritten `.d.ts` into your `outDir`, overwriting any unwanted `.js`-generated declarations. This is workable but a bit cumbersome for such a common use-case.
### 2. Importing another project's `outDir`
Project References allow you to import types a from sibling project's _source_ directory. If instead you switch to import from the sibling project's **`outDir`** (that is using `"declaration": true`), importing handwritten `.d.ts` fails because they are not emitted.
Why would people link to generated code? Because it helps simulate the experience of importing published code.
You can work-around lack of `"emitDts": true` by writing a build-script that copies the desired `d.ts` into the `outdir`. This works fine for `tsc` builds. However for IDEs (using the language service), it doesn't know about the build-script, and so always ignores the hand-written `.d.ts` and favours the `.js`-generated version. There is no work-around. Even if you overwrite the file in the `outDir` on disk with a build-script, the language service sees the `.js`-generated version.
## Examples
[This repo](https://github.com/robpalme/proposal-emit-dts) is an example of how importing handwritten `.d.ts` goes wrong today. Build it using `tsc -b` and observe...
- [./app-src/app.ts](https://github.com/robpalme/proposal-emit-dts/blob/master/app-src/app.ts) should error but it does not.
- [./app-src/app.ts](https://github.com/robpalme/proposal-emit-dts/blob/master/app-src/app.ts) incorrectly has access to `hiddenBar` because [./lib-src/main.d.ts](https://github.com/robpalme/proposal-emit-dts/blob/master/lib-src/main.d.ts) is being ignored.
## Checklist
My suggestion meets these guidelines:
* [x] This wouldn't be a breaking change in existing TypeScript/JavaScript code
* [x] This wouldn't change the runtime behavior of existing JavaScript code
* [x] This could be implemented without emitting different JS based on the types of the expressions
* [x] This isn't a runtime feature (e.g. library functionality, non-ECMAScript syntax with JavaScript output, etc.)
* [x] This feature would agree with the rest of [TypeScript's Design Goals](https://github.com/Microsoft/TypeScript/wiki/TypeScript-Design-Goals).
## Related Issues
- https://github.com/microsoft/TypeScript/issues/38146 asks for selective emit of handwritten declarations without a tsconfig option.
Credits: @mheiber @rricard helped create this issue.
|
Suggestion,Awaiting More Feedback
|
low
|
Critical
|
644,654,225 |
svelte
|
bind:checked with bind:indeterminate erroneously updates checked state to false
|
**Describe the bug**
using `bind:checked` and `bind:indeterminate` together erroneously updates the checked value
**To Reproduce**
Use something like `<input type="checked" bind:checked bind:indeterminate>`
Ensure the initial value of `checked` is `undefined` and the initial value of `indeterminate` is true.
Note that the value of `checked` is immediately updated to `false` when run.
See: https://svelte.dev/repl/77d2ac1cf3764fbaa5d92640d7c45f13?version=3.23.2
**Expected behavior**
Bound `checked` value should only be updated when checked or unchecked.
In the given examples, the objective is for `indeterminate` to be `true` if `checked` is `undefined`.
**Severity**
Medium/High. I'm not sure of a workaround but indeterminate checkboxes are themselves an edge case.
|
stale-bot,temp-stale
|
low
|
Critical
|
644,657,664 |
go
|
path/filepath: EvalSymlinks fails to follow symlink when root entry is a symlink
|
## What version of Go are you using (`go version`)?
<pre>
$ go version
go version go1.13.6 linux/amd64
</pre>
### Does this issue reproduce with the latest release?
yes
### What operating system and processor architecture are you using (`go env`)?
<details><summary><code>go env</code> Output</summary><br><pre>
$ go env
GO111MODULE="auto"
GOARCH="amd64"
GOBIN=""
GOCACHE="/home/mildred/.cache/go-build"
GOENV="/home/mildred/.config/go/env"
GOEXE=""
GOFLAGS=""
GOHOSTARCH="amd64"
GOHOSTOS="linux"
GONOPROXY=""
GONOSUMDB=""
GOOS="linux"
GOPATH="/home/mildred/Projects/go"
GOPRIVATE=""
GOPROXY="direct"
GOROOT="/usr/lib/golang"
GOSUMDB="off"
GOTMPDIR=""
GOTOOLDIR="/usr/lib/golang/pkg/tool/linux_amd64"
GCCGO="gccgo"
AR="ar"
CC="gcc"
CXX="g++"
CGO_ENABLED="1"
GOMOD="/home/mildred/Projects/terraform/test-bug-1/go.mod"
CGO_CFLAGS="-g -O2"
CGO_CPPFLAGS=""
CGO_CXXFLAGS="-g -O2"
CGO_FFLAGS="-g -O2"
CGO_LDFLAGS="-g -O2"
PKG_CONFIG="pkg-config"
GOGCCFLAGS="-fPIC -m64 -pthread -fmessage-length=0 -fdebug-prefix-map=/tmp/go-build280616979=/tmp/go-build -gno-record-gcc-switches"
</pre></details>
### What did you do?
I found a bug in terraform: https://github.com/hashicorp/terraform/issues/25367 and tracked it down to the go runtime
Reproducer:
```go
package main
import (
"path/filepath"
"fmt"
"syscall"
"os"
)
func main(){
os.Mkdir("origin", 0777)
os.Mkdir("origin/var", 0777)
os.Mkdir("origin/var/home", 0777)
os.Mkdir("origin/var/home/foo", 0777)
os.Symlink("var/home", "origin/home")
os.Symlink("/home/foo", "origin/home/bar")
os.Chdir("origin")
syscall.Chroot(".")
os.Chdir("home")
fmt.Println(filepath.EvalSymlinks("bar"))
}
```
Reproduce by compiling this example and running it:
```
go build -o test-bug .
sudo ./test-bug
sudo strace -e trace=newfstatat,readlinkat ./test-bug
```
(you need to be root for chroot to work, it works well in a fedora-toolbox container with a user namespace root)
### What did you expect to see?
`filepath.EvalSymlinks` should follow symlink `home -> var/home` in `origin`
### What did you see instead?
`filepath.EvalSymlinks` fails to follow the symlink and errors out with `lstat var: no such file or directory`
|
NeedsInvestigation
|
low
|
Critical
|
644,701,895 |
rust
|
Break the infinite loop in declarative macros
|
<!--
Thank you for filing a bug report! 🐛 Please provide a short summary of the bug,
along with any information you feel relevant to replicating the bug.
-->
I tried this code:
```rust
macro_rules! run {
($($expr:tt)*) => {
run!($($expr),*; echo = true)
};
($($expr:tt)* ; echo = $echo:expr) => { };
}
fn main() {
run!("bruh")
}
```
I expected to see this happen: `rustc` should report the infinite loop or at least time out and crash.
Instead, this happened: rustc started eating all my RAM constantly pushing one of my CPU cores to 100%. At some point `rustc` eats all the RAM and I my laptop freezes so I have to literally power it off.
This happened to me when using `rust-analyzer`, which runs `cargo check` each time. And having saved the file with this unfinished snippet of code I found that my laptop starts freezing and `cargo check` process never ends.
### Meta
`rustc --version --verbose`:
```
rustc 1.44.0 (49cae5576 2020-06-01)
binary: rustc
commit-hash: 49cae55760da0a43428eba73abcb659bb70cf2e4
commit-date: 2020-06-01
host: x86_64-unknown-linux-gnu
release: 1.44.0
LLVM version: 9.0
```
|
A-macros,T-compiler,C-bug
|
low
|
Critical
|
644,703,385 |
pytorch
|
SyncBatchNorm for JIT and a list of not supported operations
|
## 🚀 Feature
Make SyncBatchNorm support by JIT. Besides, is it possible to mark if it is JIT-supported in each API document?
## Motivation
`Detectron2`, a widely used detection framework uses `SyncBatchNorm`, but it is difficult to convert it to JIT. Reference this [issue](https://github.com/facebookresearch/detectron2/issues/46). I noticed that a list of [unsupported operations](https://pytorch.org/docs/stable/jit_unsupported.html#jit-unsupported) in JIT is provided, but I could not find `SyncBatchNorm` there.
## Pitch
SyncBatchNorm is supported by JIT. If possible, JIT-supported can be marked in API.
cc @suo @gmagogsfm
|
oncall: jit,triaged,enhancement
|
low
|
Minor
|
644,751,020 |
go
|
x/pkgsite: self hosting - tracking issue
|
This is an umbrella issue that tracks all the possible blockers for having users self host the pkgsite codebase.
### Issues:
- [x] Make LICENSE detection optional in pkgsite codebase: https://github.com/golang/go/issues/39602
- [ ] Write self-hosting specific documentation: i.e. deployment steps, things to be aware of, etc.
- [ ] Local quickstart docs. Running a local pkgsite with the bare minimum should be easy for any experienced Go developer.
- [ ] Clarification of what features/requirements are needed or can be switched off for a local setup, e.g. GOPROXY or a search "engine".
- [ ] https://github.com/golang/go/issues/48603
- [ ] Using a custom HTTPS proxy for the private git repositories.
- [ ] Using a proxy that acts as a gateway to the internet.
- [ ] https://github.com/golang/go/issues/55106
Please feel free to edit this issue to add/remove issues above.
|
NeedsInvestigation,FeatureRequest,pkgsite
|
medium
|
Critical
|
644,754,562 |
rust
|
Using `-Z macro-backtrace` breaks 'unreachable statement' with macro call
|
The following code:
```rust
fn main() {
panic!("{}", 25);
return ();
}
```
prints the following warning on nightly:
```
warning: unreachable statement
--> panic_unreachable.rs:3:5
|
2 | panic!("{}", 25);
| ----------------- any code following this expression is unreachable
3 | return ();
| ^^^^^^^^^^ unreachable statement
|
= note: `#[warn(unreachable_code)]` on by default
```
However, with `-Z macro-backtrace`, this warning is printed:
```
warning: unreachable statement
--> panic_unreachable.rs:3:5
|
3 | return ();
| ^^^^^^^^^^ unreachable statement
|
::: /home/aaron/.rustup/toolchains/nightly-x86_64-unknown-linux-gnu/lib/rustlib/src/rust/src/libstd/macros.rs:16:9
|
16 | $crate::rt::begin_panic_fmt(&$crate::format_args!($fmt, $($arg)+))
| ------------------------------------------------------------------ any code following this expression is unreachable
|
= note: `#[warn(unreachable_code)]` on by default
```
The original `panic!` call isn't even shown, making the "any code following this expression is unreachable" almost useless.
|
A-diagnostics,A-macros,T-compiler,C-bug,requires-nightly
|
low
|
Minor
|
644,771,944 |
terminal
|
[Product-Conhost] Scrollbar issue using SetConsoleWindowInfo()
|
While using SetConsoleWindowInfo() function of console API to scroll console window, when console window is opened in full screen i.e. maximum window mode - window scrolls but the scroll bar doesn't update, it kind of freezes.
Whereas, using same function in normal window mode (not full screen) everything works fine.
I have tested this in both 'Wrap text output on resize mode' on and off.
Try debugging this code for reference - https://docs.microsoft.com/en-us/windows/console/scrolling-a-screen-buffer-s-window
/cc @miniksa
<!--
🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
I ACKNOWLEDGE THE FOLLOWING BEFORE PROCEEDING:
1. If I delete this entire template and go my own path, the core team may close my issue without further explanation or engagement.
2. If I list multiple bugs/concerns in this one issue, the core team may close my issue without further explanation or engagement.
3. If I write an issue that has many duplicates, the core team may close my issue without further explanation or engagement (and without necessarily spending time to find the exact duplicate ID number).
4. If I leave the title incomplete when filing the issue, the core team may close my issue without further explanation or engagement.
5. If I file something completely blank in the body, the core team may close my issue without further explanation or engagement.
All good? Then proceed!
-->
<!--
This bug tracker is monitored by Windows Terminal development team and other technical folks.
**Important: When reporting BSODs or security issues, DO NOT attach memory dumps, logs, or traces to Github issues**.
Instead, send dumps/traces to [email protected], referencing this GitHub issue.
If this is an application crash, please also provide a Feedback Hub submission link so we can find your diagnostic data on the backend. Use the category "Apps > Windows Terminal (Preview)" and choose "Share My Feedback" after submission to get the link.
Please use this form and describe your issue, concisely but precisely, with as much detail as possible.
-->
# Environment
```none
Windows build number: Microsoft Windows [Version 10.0.18363.900]
```
|
Product-Conhost,Area-Server,Issue-Bug,Priority-3
|
low
|
Critical
|
644,802,706 |
rust
|
bug: Inproper dead code warning
|
<!--
Thank you for filing a bug report! 🐛 Please provide a short summary of the bug,
along with any information you feel relevant to replicating the bug.
-->
I tried this code:
main.rs:
```rust
mod lib;
fn main() {
let mut v = 79;
lib::double2(&mut v);
println!("Hello, world! {}", v);
}
```
lib.rs:
```rust
pub(crate)fn double2(v: &mut i32){
*v = *v * 2;
}
```
Cargo.toml
```toml
[package]
name = "tmp"
version = "0.1.0"
authors = ["AngelicosPhosphoros <[email protected]>"]
edition = "2018"
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
[dependencies]
```
I expected to see this happen: Compile without warnings.
Instead, this happened: Dead code warning for lib.rs function `double`
```
cargo build
Compiling tmp v0.1.0 (E:\Programs\Rust\tmp\tmp)
warning: function is never used: `double2`
--> src\lib.rs:2:14
|
2 | pub(crate)fn double2(v: &mut i32){
| ^^^^^^^
|
= note: `#[warn(dead_code)]` on by default
warning: 1 warning emitted
Finished dev [unoptimized + debuginfo] target(s) in 1.20s
```
### Meta
<!--
If you're using the stable version of the compiler, you should also check if the
bug also exists in the beta or nightly versions.
-->
`rustc --version --verbose`:
```
rustc 1.44.1 (c7087fe00 2020-06-17)
binary: rustc
commit-hash: c7087fe00d2ba919df1d813c040a5d47e43b0fe7
commit-date: 2020-06-17
host: x86_64-pc-windows-msvc
release: 1.44.1
LLVM version: 9.0
```
|
C-enhancement,A-diagnostics,T-compiler
|
low
|
Critical
|
644,802,883 |
opencv
|
DNN OPENCL is not working on AMD GPU
|
I want to use GPU as DNN backend to save CPU power. It works for Intel GPU. But there is problem on AMD GPU. The following are some log.
[ INFO:0] global D:\work\opencv\opencv\modules\core\src\ocl.cpp (891) cv::ocl::haveOpenCL Initialize OpenCL runtime...
OpenCV(ocl4dnn): consider to specify kernel configuration cache directory via OPENCV_OCL4DNN_CONFIG_PATH parameter.
[ INFO:0] global D:\work\opencv\opencv\modules\core\src\ocl.cpp (433) cv::ocl::OpenCLBinaryCacheConfigurator::OpenCLBinaryCacheConfigurator Successfully initialized OpenCL cache directory: C:\Users\wangq\AppData\Local\Temp\opencv\4.3\opencl_cache\
[ INFO:0] global D:\work\opencv\opencv\modules\core\src\ocl.cpp (457) cv::ocl::OpenCLBinaryCacheConfigurator::prepareCacheDirectoryForContext Preparing OpenCL cache configuration for context: Advanced_Micro_Devices__Inc_--Baffin--2906_10
OpenCL program build log: dnn/dummy
Status -66: CL_INVALID_COMPILER_OPTIONS
-cl-no-subgroup-ifp -D AMD_DEVICE
|
category: ocl,category: dnn
|
low
|
Minor
|
644,843,534 |
material-ui
|
[Popover] Height and width animations are not working as expected due to top and left properties
|
<!-- Provide a general summary of the issue in the Title above -->
Popover always positions itself using top and left properties. But if we change the height or width of the content, popover always grow vertically downwards in case of height or towards the right in case of width.
<!--
Thank you very much for contributing to Material-UI by creating an issue! ❤️
To avoid duplicate issues we ask you to check off the following list.
-->
<!-- Checked checkbox should look like this: [x] -->
- [ *] The issue is present in the latest release.
- [ *] I have searched the [issues](https://github.com/mui-org/material-ui/issues) of this repository and believe that this is not a duplicate.
## Current Behavior 😯
<!-- Describe what happens instead of the expected behavior. -->
## Expected Behavior 🤔
We should be able to control the properties using which popover should position itself. Depending on the usecase, user should be able to choose a combination of top/bottom and right/left.
<!-- Describe what should happen. -->
## Steps to Reproduce 🕹
You can see the issue here.
https://codesandbox.io/s/twilight-architecture-dqn2n?file=/src/App.js
<!--
Provide a link to a live example (you can use codesandbox.io) and an unambiguous set of steps to reproduce this bug.
Include code to reproduce, if relevant (which it most likely is).
You should use the official codesandbox template as a starting point: https://material-ui.com/r/issue-template
If you have an issue concerning TypeScript please start from this TypeScript playground: https://material-ui.com/r/ts-issue-template
Issues without some form of live example have a longer response time.
-->
Steps:
1. Click on the Open Popover button
2. Click on expand
The popover grows downwards covering the anchor element. And repositions itself when the Shrink button is clicked.
We can use a prop to supply what properties the popover should use. I would be happy to raise a PR for this.
## Context 🔦
<!--
What are you trying to accomplish? How has this issue affected you?
Providing context helps us come up with a solution that is most useful in the real world.
-->
## Your Environment 🌎
<!--
Include as many relevant details about the environment with which you experienced the bug.
If you encounter issues with typescript please include version and tsconfig.
-->
| Tech | Version |
| ----------- | ------- |
| Material-UI | v4.10.2 |
| React | |
| Browser | |
| TypeScript | |
| etc. | |
|
bug 🐛,component: Popover
|
low
|
Critical
|
644,867,566 |
vscode
|
API for custom editors handling some menu actions
|
<!-- ⚠️⚠️ Do Not Delete This! feature_request_template ⚠️⚠️ -->
<!-- Please read our Rules of Conduct: https://opensource.microsoft.com/codeofconduct/ -->
<!-- Please search existing issues to avoid creating duplicates. -->
<!-- Describe the feature you'd like. -->
Considering a custom editor that does not necessarily deal with text,
it'd improve the user experience if we could have the ability to provide a customized action when menu items are triggered,
such as `Edit->Find` and `Selection->Select All`.
Please also consider adding to this API the ability to handle cut/copy/paste. Although we could use events such as the [copy event](https://developer.mozilla.org/en-US/docs/Web/API/Element/copy_event) for detecting this operation, a unified API for menu items relevant to custom editors seems more appropriate.
/cc @mjbvz
|
feature-request,api,custom-editors
|
low
|
Minor
|
644,896,049 |
terminal
|
Figure out how to handle drag-drop in an elevated session
|
<!--
🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
I ACKNOWLEDGE THE FOLLOWING BEFORE PROCEEDING:
1. If I delete this entire template and go my own path, the core team may close my issue without further explanation or engagement.
2. If I list multiple bugs/concerns in this one issue, the core team may close my issue without further explanation or engagement.
3. If I write an issue that has many duplicates, the core team may close my issue without further explanation or engagement (and without necessarily spending time to find the exact duplicate ID number).
4. If I leave the title incomplete when filing the issue, the core team may close my issue without further explanation or engagement.
5. If I file something completely blank in the body, the core team may close my issue without further explanation or engagement.
All good? Then proceed!
-->
<!--
This bug tracker is monitored by Windows Terminal development team and other technical folks.
**Important: When reporting BSODs or security issues, DO NOT attach memory dumps, logs, or traces to Github issues**.
Instead, send dumps/traces to [email protected], referencing this GitHub issue.
If this is an application crash, please also provide a Feedback Hub submission link so we can find your diagnostic data on the backend. Use the category "Apps > Windows Terminal (Preview)" and choose "Share My Feedback" after submission to get the link.
Please use this form and describe your issue, concisely but precisely, with as much detail as possible.
-->
# Environment
```none
Windows build number: 19041
Windows Terminal version: 1.0.1401.0
```
# Steps to reproduce
* Open Windows Terminal
* Open a second tab (the shell does not matter)
* Try to drag any tab
# Expected behavior
Tabs are attached to the mouse cursor and can be dragged to the desired location.
# Actual behavior
Nothing happens

I can only reproduce this issue on my work PC. My private PC works just fine. They use the exact same settings file. Also restarting the computer or reinstalling WT does not help.
|
Help Wanted,Issue-Bug,Area-UserInterface,Product-Terminal,Issue-Task,Priority-2,External-Blocked-WinUI3
|
medium
|
Critical
|
644,897,071 |
flutter
|
Allow configuring package path in re-entrant build rules
|
There isn't really a use for this right now, but we should allow configuring --packages for all of the assemble rules via an input. Currently the globalPackagesPath is used, which is always .packages on a re-entrant run.
|
c: new feature,tool,a: quality,P2,team-tool,triaged-tool
|
low
|
Minor
|
644,939,249 |
flutter
|
Huge untracked gap in timeline for E2EWidgetsFlutterBinding
|
I'm verifying the overhead of e2e and WidgetTester and find a weird timeline scheduling:
With e2e binding, the timeline looks like:
<img width="1508" alt="e2etimeline" src="https://user-images.githubusercontent.com/11715538/85623547-92774280-b636-11ea-8223-3dcc94420a74.png">
while normally it looks like (profile mode):
<img width="1495" alt="profiletimeline" src="https://user-images.githubusercontent.com/11715538/85623545-92774280-b636-11ea-859f-a0fe22908cab.png">
and even debug mode is faster than this:
<img width="1498" alt="debugtimeline" src="https://user-images.githubusercontent.com/11715538/85624962-b8054b80-b638-11ea-8e49-a43aa5a282bb.png">
where there's a huge gap with no timeline event tracked. The json file for the above timeline graphs is here:
https://drive.google.com/drive/folders/13yhs4ebggOi8tk4WOk7Kxdd3RPaM2UDR?usp=sharing
The above can be reproduced by:
A minimal demo here: https://github.com/CareF/timeline_scheduling
The profile result is given by running
```
flutter run --start-paused --profile
```
or
```
flutter run -t test/runapp_e2e.dart --start-paused --profile
```
press `v` to open `DevTools`; and copy URL and open `Observatory` -> `debugger` -> press `c` to continue.
The above result is tested on a Pixel 4.
|
a: tests,framework,d: api docs,f: integration_test,P3,team-framework,triaged-framework
|
low
|
Critical
|
644,943,488 |
flutter
|
HttpRequest.getString() throws ProgressEvent instead of Error or Exception (dart:html)
|
**dart:html**
<!-- Thank you for using Flutter!
If you are looking for support, please check out our documentation
or consider asking a question on Stack Overflow:
* https://flutter.dev/
* https://api.flutter.dev/
* https://stackoverflow.com/questions/tagged/flutter?sort=frequent
If you have found a bug or if our documentation doesn't have an answer
to what you're looking for, then fill our the template below. Please read
our guide to filing a bug first: https://flutter.dev/docs/resources/bug-reports
-->
## Steps to Reproduce
<!-- You must include full steps to reproduce so that we can reproduce the problem. -->
1. Handling HttpRequest.getString() on a non-existent URL with try/catch or then/catchError.
**Expected results:** <!-- what did you want to see? -->
Will return the Error or Exception if there's an error with the URL or the file is not found.
**Actual results:** <!-- what did you see? -->
Returns an instance of ProgressEvent instead of Error or Exception.
**Workaround**
I could check if the error is an instance of ProgressEvent, and then read the currentTarget (reference to a XmlHttpRequest instance) and then the responseText or statusText or status properties to retrieve the status code, but is not intuitive or practical. Only Errors or Exception should be thrown, not instances of Event or other classes. Am I missing something?
<details>
<summary>Logs</summary>
<!--
Run your application with `flutter run --verbose` and attach all the
log output below between the lines with the backticks. If there is an
exception, please see if the error message includes enough information
to explain how to solve the issue.
-->
```
```
<!--
Run `flutter analyze` and attach any output of that command below.
If there are any analysis errors, try resolving them before filing this issue.
-->
```
```
<!-- Finally, paste the output of running `flutter doctor -v` here. -->
```
```
</details>
|
framework,c: API break,dependency: dart,platform-web,has reproducible steps,P2,found in release: 3.3,found in release: 3.7,team-web,triaged-web
|
low
|
Critical
|
644,946,954 |
flutter
|
Make it easier to upload Android native debug symbols for release builds
|
When i want to release a new flutter app bundle to the play store. I get this error:
"This App Bundle contains native code, and you've not uploaded debug symbols. We recommend you upload a symbol file to make your crashes and ANRs easier to analyze and debug."
I can't find any way to fix this. I'm new with flutter and releasing app's and getting a bit desperate...
Any help would be fantastic.

|
platform-android,tool,engine,c: proposal,a: build,a: release,P1,team-android,triaged-android,:hourglass_flowing_sand:
|
medium
|
Critical
|
645,017,569 |
go
|
go/build: Default does not honor `go env -w GOPATH`
|
`go/build` has no logic for reading the `GOENV` file, so it will ignore any `GOPATH` setting there.
https://github.com/golang/go/blob/7eb5941b95a588a23f18fa4c22fe42ff0119c311/src/go/build/build.go#L275-L292
|
NeedsInvestigation
|
low
|
Minor
|
645,049,930 |
flutter
|
A11y semantics for some Material Chips should be "checkable"
|
Issue #58010 pointed out that `InputChip` was missing the `button: true` semantics.
PR #60141 applies the `button: true` semantics to all Material Chips (excluding the plain [info Chip](https://api.flutter.dev/flutter/material/Chip-class.html) which is non-interactive). That PR unblocks `customer: money (g3)` and brings our Chip semantics in-line with the behavior of the reference Material components [implementations for iOS](https://github.com/material-components/material-components-ios/blob/e1aee8556d04a64cef5149d51897f44711a5b077/components/Chips/tests/unit/ChipsTests.m#L100), but on Android _some_ Material Chips [have "checkable" semantics](https://github.com/material-components/material-components-android/blob/master/lib/java/com/google/android/material/chip/Chip.java#L268) rather than button semantics, which is behavior that we should likely replicate (for `FilterChip` and `ChoiceChip`?) in the future.
|
framework,f: material design,a: accessibility,customer: money (g3),P2,team-design,triaged-design
|
low
|
Minor
|
645,050,114 |
TypeScript
|
Expose isTypeReference function in public API
|
<!-- 🚨 STOP 🚨 𝗦𝗧𝗢𝗣 🚨 𝑺𝑻𝑶𝑷 🚨
Half of all issues filed here are duplicates, answered in the FAQ, or not appropriate for the bug tracker.
Please help us by doing the following steps before logging an issue:
* Search: https://github.com/Microsoft/TypeScript/search?type=Issues
* Read the FAQ, especially the "Common Feature Requests" section: https://github.com/Microsoft/TypeScript/wiki/FAQ
-->
## Search Terms
isTypeReference
## Suggestion
The public compiler API exposes a `getTypeArguments` method on the type checker:
https://github.com/microsoft/TypeScript/blob/cc7cb9eadb10a56687513d4fc3a67d5210b387bb/lib/typescript.d.ts#L2107
But provides no way to check if a type is a `TypeReference`. Users of the TS compiler API have to roll their own, which is error-prone. I suggest that if `TypeReference` is exposed in the public API, there should be a way to assert whether a type is a `TypeReference`.
## Use Cases
See above
## Examples
Currently, public uses of `getTypeArguments` must do something like this to assert that a type is a `TypeReference`:
```ts
function isTypeReference(ty: ts.Type): ty is ts.TypeReference {
return 'typeArguments' in ty;
}
const ty = getType();
if (isTypeReference(ty)) {
getChecker().getTypeArguments(ty);
}
```
With an exposed type guards, this becomes
```ts
const ty = getType();
if (ts.isTypeReference(ty)) {
getChecker().getTypeArguments(ty);
}
```
## Checklist
My suggestion meets these guidelines:
* [x] This wouldn't be a breaking change in existing TypeScript/JavaScript code
* [x] This wouldn't change the runtime behavior of existing JavaScript code
* [x] This could be implemented without emitting different JS based on the types of the expressions
* [x] This isn't a runtime feature (e.g. library functionality, non-ECMAScript syntax with JavaScript output, etc.)
* [x] This feature would agree with the rest of [TypeScript's Design Goals](https://github.com/Microsoft/TypeScript/wiki/TypeScript-Design-Goals).
|
Suggestion,In Discussion
|
low
|
Critical
|
645,078,560 |
pytorch
|
Embedding with DataParallel can return "incomplete" results
|
## 🐛 Bug
I have only a functional description of the bug. Still trying to make a MWE.
Sometimes when using an `Embedding` in a model with `DataParallel` I hit errors where, for example:
```py
x = ... # shape: [400, 2000]
y = self.embed(x) # shape: [11, 2000, 512]
#^ the return value of the Embedding is "incomplete" on some GPUs. Noticed it most on cuda:1, but that's probably a coincidence.
```
## To Reproduce
Steps to reproduce the behavior:
1. Have a model with `Embedding`.
1. Use `DataParallel` on the model such that you're close to saturating your system.
1. Things shouldn't end up working, if the bug is reproducible.
1. You don't need anything fancy. Just some pretrained model in `eval` mode and pass it some input.
<!-- If you have a code sample, error messages, stack traces, please provide it here as well -->
## Expected behavior
DataParallel models behave functionally identically to normal models. Convergence and gradient descent questions notwithstanding.
## Environment
- PyTorch Version (e.g., 1.0): 1.5 ~ 1.6.x-dev
- OS (e.g., Linux): Ubuntu 16.04 LTS
- How you installed PyTorch (`conda`, `pip`, source): conda
- Build command you used (if compiling from source): N/A
- Python version: 3.7.7
- CUDA/cuDNN version: 10.2
- GPU models and configuration: Geforce GTX Titan X * 2
- Any other relevant information: N/A
## Additional context
<!-- Add any other context about the problem here. -->
cc @ngimel
|
module: cuda,triaged,module: data parallel
|
low
|
Critical
|
645,098,082 |
rust
|
Support for the armv7l-unknown-linux-gnueabi platform
|
Hello,
I am on the Raspberry Pi 4 board with the Slackware ARM 14.2 operating system.
This platform is: ```armv7l-unknown-linux-gnueabi```.
So, I downloaded:
- https://static.rust-lang.org/dist/rustc-1.43.1-src.tar.xz
- https://static.rust-lang.org/dist/rustc-1.43.1-arm-unknown-linux-gnueabi.tar.xz
- https://static.rust-lang.org/dist/cargo-0.43.0-arm-unknown-linux-gnueabi.tar.xz
- https://static.rust-lang.org/dist/rust-std-1.43.1-arm-unknown-linux-gnueabi.tar.xz
And here is what happens when I try to build rustc:
```
$ tar xf rustc-1.43.1-src.tar.xz
$ tar -C rustc-1.43.1-src --strip=1 -xf rustc-1.43.1-arm-unknown-linux-gnueabi.tar.xz rustc-1.43.1-arm-unknown-linux-gnueabi/rustc
$ tar -C rustc-1.43.1-src/rustc --strip=2 -xf cargo-0.43.0-arm-unknown-linux-gnueabi.tar.xz cargo-0.43.0-arm-unknown-linux-gnueabi/cargo/bin/cargo
$ tar -C rustc-1.43.1-src/rustc --strip=2 -xf rust-std-1.43.1-arm-unknown-linux-gnueabi.tar.xz rust-std-1.43.1-arm-unknown-linux-gnueabi/rust-std-arm-unknown-linux-gnueabi/lib
$ export PATH="${PWD}/rustc-1.43.1-src/rustc/bin:${PATH}"
$ cd rustc-1.43.1-src
$ CFLAGS="-O2 -march=armv8-a -mtune=cortex-a53 -mfloat-abi=softfp -mfpu=neon-vfpv4" CXXFLAGS="-O2 -march=armv8-a -mtune=cortex-a53 -mfloat-abi=softfp -mfpu=neon-vfpv4" ./configure --prefix=/usr --libdir=/usr/lib --enable-local-rust
configure: processing command line
configure:
configure: install.prefix := /usr
configure: install.libdir := /usr/lib
configure: build.rustc := /tmp/build/firefox/rustc-1.43.1-src/rustc/bin/ ...
configure: build.cargo := /tmp/build/firefox/rustc-1.43.1-src/rustc/bin/ ...
configure: build.configure-args := ['--prefix=/usr', '--libdir=/usr/lib', '--enab ...
configure:
configure: writing `config.toml` in current directory
configure:
configure: run `python /tmp/build/firefox/rustc-1.43.1-src/x.py --help`
configure:
$ make -j 4
Compiling proc-macro2 v0.4.30
Compiling unicode-xid v0.1.0
Compiling lazy_static v1.4.0
Compiling memchr v2.3.2
Compiling syn v0.15.35
Compiling cfg-if v0.1.10
Compiling libc v0.2.66
Compiling autocfg v0.1.7
Compiling regex v1.1.6
Compiling ucd-util v0.1.3
Compiling log v0.4.8
Compiling serde v1.0.99
Compiling utf8-ranges v1.0.2
Compiling ryu v1.0.0
Compiling fnv v1.0.6
Compiling same-file v1.0.4
Compiling cc v1.0.50
Compiling itoa v0.4.4
Compiling unicode-width v0.1.6
Compiling build_helper v0.1.0 (/tmp/build/firefox/rustc-1.43.1-src/src/build_helper)
Compiling thread_local v0.3.6
Compiling thread_local v1.0.1
Compiling regex-syntax v0.6.6
Compiling crossbeam-utils v0.7.0
Compiling walkdir v2.2.7
Compiling cmake v0.1.42
Compiling getopts v0.2.21
Compiling aho-corasick v0.7.3
Compiling bstr v0.1.3
Compiling quote v0.6.12
Compiling time v0.1.42
Compiling filetime v0.2.8
Compiling num_cpus v1.10.1
Compiling crossbeam-channel v0.4.0
Compiling globset v0.4.3
Compiling ignore v0.4.11
Compiling serde_derive v1.0.81
Compiling serde_json v1.0.40
Compiling toml v0.5.3
Compiling bootstrap v0.0.0 (/tmp/build/firefox/rustc-1.43.1-src/src/bootstrap)
Finished dev [unoptimized] target(s) in 5m 47s
Building stage0 std artifacts (armv7-unknown-linux-gnueabihf -> armv7-unknown-linux-gnueabihf)
warning: config profiles require the `-Z config-profile` command-line option (found profile `release` in environment variable `CARGO_PROFILE_RELEASE`)
Compiling cc v1.0.50
Compiling core v0.0.0 (/tmp/build/firefox/rustc-1.43.1-src/src/libcore)
Compiling libc v0.2.66
Compiling autocfg v0.1.7
error: could not compile `libc`.
Caused by:
process didn't exit successfully: `/tmp/build/firefox/rustc-1.43.1-src/build/bootstrap/debug/rustc --crate-name build_script_build /home/yugiohjcj/.cargo/registry/src/github.com-1ecc6299db9ec823/libc-0.2.66/build.rs --error-format=json --json=diagnostic-rendered-ansi --crate-type bin --emit=dep-info,link -C opt-level=3 --cfg 'feature="align"' --cfg 'feature="rustc-dep-of-std"' --cfg 'feature="rustc-std-workspace-core"' -C metadata=f36d1b32dec4e3d4 -C extra-filename=-f36d1b32dec4e3d4 --out-dir /tmp/build/firefox/rustc-1.43.1-src/build/armv7-unknown-linux-gnueabihf/stage0-std/release/build/libc-f36d1b32dec4e3d4 -L dependency=/tmp/build/firefox/rustc-1.43.1-src/build/armv7-unknown-linux-gnueabihf/stage0-std/release/deps --cap-lints allow -Zbinary-dep-depinfo` (signal: 11, SIGSEGV: invalid memory reference)
warning: build failed, waiting for other jobs to finish...
error: could not compile `autocfg`.
Caused by:
process didn't exit successfully: `/tmp/build/firefox/rustc-1.43.1-src/build/bootstrap/debug/rustc --crate-name autocfg /home/yugiohjcj/.cargo/registry/src/github.com-1ecc6299db9ec823/autocfg-0.1.7/src/lib.rs --error-format=json --json=diagnostic-rendered-ansi --crate-type lib --emit=dep-info,metadata,link -C opt-level=3 -C metadata=81380527f284506a -C extra-filename=-81380527f284506a --out-dir /tmp/build/firefox/rustc-1.43.1-src/build/armv7-unknown-linux-gnueabihf/stage0-std/release/deps -L dependency=/tmp/build/firefox/rustc-1.43.1-src/build/armv7-unknown-linux-gnueabihf/stage0-std/release/deps --cap-lints allow -Zbinary-dep-depinfo` (signal: 11, SIGSEGV: invalid memory reference)
warning: build failed, waiting for other jobs to finish...
error: failed to prepare thin LTO module: file doesn't start with bitcode header
error: aborting due to previous error
error: could not compile `cc`.
warning: build failed, waiting for other jobs to finish...
error: could not compile `core`.
Caused by:
process didn't exit successfully: `/tmp/build/firefox/rustc-1.43.1-src/build/bootstrap/debug/rustc --crate-name core --edition=2018 src/libcore/lib.rs --error-format=json --json=diagnostic-rendered-ansi,artifacts --crate-type lib --emit=dep-info,metadata,link -C opt-level=3 -C metadata=cb92643d31cc5d69 -C extra-filename=-cb92643d31cc5d69 --out-dir /tmp/build/firefox/rustc-1.43.1-src/build/armv7-unknown-linux-gnueabihf/stage0-std/armv7-unknown-linux-gnueabihf/release/deps --target armv7-unknown-linux-gnueabihf -L dependency=/tmp/build/firefox/rustc-1.43.1-src/build/armv7-unknown-linux-gnueabihf/stage0-std/armv7-unknown-linux-gnueabihf/release/deps -L dependency=/tmp/build/firefox/rustc-1.43.1-src/build/armv7-unknown-linux-gnueabihf/stage0-std/release/deps -Zmacro-backtrace '-Clink-args=-Wl,-rpath,$ORIGIN/../lib' -Wrust_2018_idioms -Wunused_lifetimes -Dwarnings -Cprefer-dynamic -Zbinary-dep-depinfo` (signal: 11, SIGSEGV: invalid memory reference)
command did not execute successfully: "/tmp/build/firefox/rustc-1.43.1-src/rustc/bin/cargo" "build" "--target" "armv7-unknown-linux-gnueabihf" "-Zbinary-dep-depinfo" "-j" "4" "--release" "--features" "panic-unwind backtrace compiler-builtins-c" "--manifest-path" "/tmp/build/firefox/rustc-1.43.1-src/src/libtest/Cargo.toml" "--message-format" "json-render-diagnostics"
expected success, got: exit code: 101
failed to run: /tmp/build/firefox/rustc-1.43.1-src/build/bootstrap/debug/bootstrap build
Build completed unsuccessfully in 0:06:53
Makefile:18: recipe for target 'all' failed
make: *** [all] Error 1
```
During the build process, I think that the problem comes from this line:
```
Building stage0 std artifacts (armv7-unknown-linux-gnueabihf -> armv7-unknown-linux-gnueabihf)
```
I don't know why but the `armv7-unknown-linux-gnueabihf` platform is automatically selected at this point whereas it should be `armv7l-unknown-linux-gnueabi` (or eventually `arm-unknown-linux-gnueabi`).
Do you know how can I fix that please?
Thank you.
Best regards.
Edit: I also tested with ```--build=arm-unknown-linux-gnueabi --host=arm-unknown-linux-gnueabi --target=arm-unknown-linux-gnueabi``` and now the platform is selected manually and not guessed automatically, but the build is still a failure:
```
$ tar xf rustc-1.43.1-src.tar.xz
$ tar -C rustc-1.43.1-src --strip=1 -xf rustc-1.43.1-arm-unknown-linux-gnueabi.tar.xz rustc-1.43.1-arm-unknown-linux-gnueabi/rustc
$ tar -C rustc-1.43.1-src/rustc --strip=2 -xf cargo-0.43.0-arm-unknown-linux-gnueabi.tar.xz cargo-0.43.0-arm-unknown-linux-gnueabi/cargo/bin/cargo
$ tar -C rustc-1.43.1-src/rustc --strip=2 -xf rust-std-1.43.1-arm-unknown-linux-gnueabi.tar.xz rust-std-1.43.1-arm-unknown-linux-gnueabi/rust-std-arm-unknown-linux-gnueabi/lib
$ export PATH="${PWD}/rustc-1.43.1-src/rustc/bin:${PATH}"
$ cd rustc-1.43.1-src
$ CFLAGS="-O2 -march=armv8-a -mtune=cortex-a53 -mfloat-abi=softfp -mfpu=neon-vfpv4" CXXFLAGS="-O2 -march=armv8-a -mtune=cortex-a53 -mfloat-abi=softfp -mfpu=neon-vfpv4" ./configure --prefix=/usr --libdir=/usr/lib --enable-local-rust --build=arm-unknown-linux-gnueabi --host=arm-unknown-linux-gnueabi --target=arm-unknown-linux-gnueabi
configure: processing command line
configure:
configure: build.target := ['arm-unknown-linux-gnueabi']
configure: install.libdir := /usr/lib
configure: install.prefix := /usr
configure: build.host := ['arm-unknown-linux-gnueabi']
configure: build.build := arm-unknown-linux-gnueabi
configure: build.rustc := /tmp/build/firefox/rustc-1.43.1-src/rustc/bin/ ...
configure: build.cargo := /tmp/build/firefox/rustc-1.43.1-src/rustc/bin/ ...
configure: build.configure-args := ['--prefix=/usr', '--libdir=/usr/lib', '--enab ...
configure:
configure: writing `config.toml` in current directory
configure:
configure: run `python /tmp/build/firefox/rustc-1.43.1-src/x.py --help`
$ make -j 4
Compiling proc-macro2 v0.4.30
Compiling unicode-xid v0.1.0
Compiling memchr v2.3.2
Compiling lazy_static v1.4.0
Compiling syn v0.15.35
Compiling cfg-if v0.1.10
Compiling autocfg v0.1.7
Compiling libc v0.2.66
Compiling serde v1.0.99
Compiling regex v1.1.6
Compiling log v0.4.8
Compiling ucd-util v0.1.3
Compiling ryu v1.0.0
Compiling utf8-ranges v1.0.2
Compiling same-file v1.0.4
Compiling fnv v1.0.6
Compiling itoa v0.4.4
Compiling unicode-width v0.1.6
Compiling cc v1.0.50
Compiling build_helper v0.1.0 (/tmp/build/firefox/rustc-1.43.1-src/src/build_helper)
Compiling thread_local v0.3.6
Compiling thread_local v1.0.1
Compiling crossbeam-utils v0.7.0
Compiling regex-syntax v0.6.6
Compiling walkdir v2.2.7
Compiling getopts v0.2.21
Compiling cmake v0.1.42
Compiling aho-corasick v0.7.3
Compiling bstr v0.1.3
Compiling quote v0.6.12
Compiling filetime v0.2.8
Compiling num_cpus v1.10.1
Compiling time v0.1.42
Compiling crossbeam-channel v0.4.0
Compiling globset v0.4.3
Compiling ignore v0.4.11
Compiling serde_derive v1.0.81
Compiling serde_json v1.0.40
Compiling toml v0.5.3
Compiling bootstrap v0.0.0 (/tmp/build/firefox/rustc-1.43.1-src/src/bootstrap)
Finished dev [unoptimized] target(s) in 7m 58s
Building stage0 std artifacts (arm-unknown-linux-gnueabi -> arm-unknown-linux-gnueabi)
warning: config profiles require the `-Z config-profile` command-line option (found profile `release` in environment variable `CARGO_PROFILE_RELEASE`)
Compiling cc v1.0.50
Compiling core v0.0.0 (/tmp/build/firefox/rustc-1.43.1-src/src/libcore)
Compiling libc v0.2.66
Compiling autocfg v0.1.7
error: could not compile `libc`.
Caused by:
process didn't exit successfully: `/tmp/build/firefox/rustc-1.43.1-src/build/bootstrap/debug/rustc --crate-name build_script_build /home/yugiohjcj/.cargo/registry/src/github.com-1ecc6299db9ec823/libc-0.2.66/build.rs --error-format=json --json=diagnostic-rendered-ansi --crate-type bin --emit=dep-info,link -C opt-level=3 --cfg 'feature="align"' --cfg 'feature="rustc-dep-of-std"' --cfg 'feature="rustc-std-workspace-core"' -C metadata=f36d1b32dec4e3d4 -C extra-filename=-f36d1b32dec4e3d4 --out-dir /tmp/build/firefox/rustc-1.43.1-src/build/arm-unknown-linux-gnueabi/stage0-std/release/build/libc-f36d1b32dec4e3d4 -L dependency=/tmp/build/firefox/rustc-1.43.1-src/build/arm-unknown-linux-gnueabi/stage0-std/release/deps --cap-lints allow -Zbinary-dep-depinfo` (signal: 11, SIGSEGV: invalid memory reference)
warning: build failed, waiting for other jobs to finish...
error: could not compile `autocfg`.
Caused by:
process didn't exit successfully: `/tmp/build/firefox/rustc-1.43.1-src/build/bootstrap/debug/rustc --crate-name autocfg /home/yugiohjcj/.cargo/registry/src/github.com-1ecc6299db9ec823/autocfg-0.1.7/src/lib.rs --error-format=json --json=diagnostic-rendered-ansi --crate-type lib --emit=dep-info,metadata,link -C opt-level=3 -C metadata=81380527f284506a -C extra-filename=-81380527f284506a --out-dir /tmp/build/firefox/rustc-1.43.1-src/build/arm-unknown-linux-gnueabi/stage0-std/release/deps -L dependency=/tmp/build/firefox/rustc-1.43.1-src/build/arm-unknown-linux-gnueabi/stage0-std/release/deps --cap-lints allow -Zbinary-dep-depinfo` (signal: 11, SIGSEGV: invalid memory reference)
warning: build failed, waiting for other jobs to finish...
error: failed to prepare thin LTO module: file doesn't start with bitcode header
error: aborting due to previous error
error: could not compile `cc`.
warning: build failed, waiting for other jobs to finish...
error: could not compile `core`.
Caused by:
process didn't exit successfully: `/tmp/build/firefox/rustc-1.43.1-src/build/bootstrap/debug/rustc --crate-name core --edition=2018 src/libcore/lib.rs --error-format=json --json=diagnostic-rendered-ansi,artifacts --crate-type lib --emit=dep-info,metadata,link -C opt-level=3 -C metadata=173bec4aef4c7110 -C extra-filename=-173bec4aef4c7110 --out-dir /tmp/build/firefox/rustc-1.43.1-src/build/arm-unknown-linux-gnueabi/stage0-std/arm-unknown-linux-gnueabi/release/deps --target arm-unknown-linux-gnueabi -L dependency=/tmp/build/firefox/rustc-1.43.1-src/build/arm-unknown-linux-gnueabi/stage0-std/arm-unknown-linux-gnueabi/release/deps -L dependency=/tmp/build/firefox/rustc-1.43.1-src/build/arm-unknown-linux-gnueabi/stage0-std/release/deps -Zmacro-backtrace '-Clink-args=-Wl,-rpath,$ORIGIN/../lib' -Wrust_2018_idioms -Wunused_lifetimes -Dwarnings -Cprefer-dynamic -Zbinary-dep-depinfo` (signal: 11, SIGSEGV: invalid memory reference)
command did not execute successfully: "/tmp/build/firefox/rustc-1.43.1-src/rustc/bin/cargo" "build" "--target" "arm-unknown-linux-gnueabi" "-Zbinary-dep-depinfo" "-j" "4" "--release" "--features" "panic-unwind backtrace compiler-builtins-c" "--manifest-path" "/tmp/build/firefox/rustc-1.43.1-src/src/libtest/Cargo.toml" "--message-format" "json-render-diagnostics"
expected success, got: exit code: 101
failed to run: /tmp/build/firefox/rustc-1.43.1-src/build/bootstrap/debug/bootstrap build
Build completed unsuccessfully in 0:10:39
Makefile:18: recipe for target 'all' failed
make: *** [all] Error 1
```
|
O-Arm,C-bug
|
low
|
Critical
|
645,103,731 |
pytorch
|
RemoteModule enhancements
|
We probably need the following enhancements on top of our current [RemoteModule](https://github.com/pytorch/pytorch/blob/master/torch/distributed/nn/api/remote_module.py#L147) implementation in terms of usability:
1. ~~TorchScript support~~
2. ~~RemoteModule currently inherits from nn.Module and it's not clear how the plethora of nn.Module methods would behave with RemoteModule. Either we clarify this behavior or change RemoteModule to be standalone.~~
3. Users should have a way to invoke methods on the nn.Module remotely and retrieve appropriate information (ex: retrieve the .grad field). We probably need something like the RRef helper (https://github.com/pytorch/pytorch/pull/36619) for RemoteModules as well.
4. ~~`remote_parameters` API which returns a list of RRefs of remote parameters that can be fed into the `DistributedOptimizer`.~~
5. ~~Expose an API for users to retrieve the RRef for the underlying module. This would be useful if users would like to run custom code on the remote end for the nn.Module (ex: https://github.com/pytorch/pytorch/blob/master/torch/testing/_internal/distributed/ddp_under_dist_autograd_test.py#L591)~~
6. ~~RemoteModule should accept a `device_id` parameter so it can be placed on any device and not just CPU.~~
7. ~~Consolidate device_id and worker_name parameter to use remote device string format.~~
8. ~~[Support .train/.eval methods on RemoteModule.](https://github.com/pytorch/pytorch/issues/51480)~~
9. ~~[Place the input on the appropriate device before calling forward](https://github.com/pytorch/pytorch/issues/51670)~~
10. ~~[Support passing a RemoteModule to an RPC as an arg](https://github.com/pytorch/pytorch/issues/57516)~~
cc @pietern @mrshenli @pritamdamania87 @zhaojuanmao @satgera @gqchen @aazzolini @rohan-varma @xush6528 @jjlilley @osalpekar @jiayisuse
|
module: bootcamp,triaged,enhancement,module: rpc,pt_distributed_rampup
|
low
|
Minor
|
645,174,380 |
create-react-app
|
Build output in "versioned folder" (build/static/<versioned-hash-folder>/) instead of "build/static/"
|
### Problem
When CRA app is served over a CDN, the Cache headers suggested by the docs are as follows:
```
index.html Cache-Control: no-cache
js/css/img Cache-Control: max-age: 31536000
```
Doing this way, the problem is that whenever browser fetches `index.html`, it would need to validate with the origin server (lets say s3) if its local copy is valid, and if its not expired (using ETag) browser can use local cache copy, or else it would download the html. Though this doesn't incur bandwidth (when cached copy is still valid), it would incur a roundtrip latency each time to load index.html. In some sense, defeats the purpose of serving the app over CDN, ideally the index.html should be served directly from the CDN without setting `Cache-Control: no-cache` on it.
**Why `Cache-Control: no-cache` is needed?**
Because the generated index.html is modified each time the static bundle files change. If the index.html is not configured with `Cache-Control: no-cache`, the browser may get a older/cached index.html from CDN, referencing older static bundles. When it would try to download those older static files from the CDN, and in case there is a cache miss, it would result in 404s as the origin server no longer has those older static files.
### Proposed Solution
Generate the static output files in a versioned folder instead of build/static:
```
my-app
|__ build
|__ static
|___<versioned-folder-hash>
|__ js
|__css
|__media
index.html:
<script src="/static/<versioned-folder-hash>/js/2.chunk.js"></script>
<script src="/static/<versioned-folder-hash>/js/main.chunk.js"></script>
asset-manifest.json:
{
"files" : {
"main.js": "/static/<versioned-folder-hash>/js/main.chunk.js",
...
},
"entrypoints": [
"static/<versioned-folder-hash>/js/main.chunk.js"
],
"version": "<versioned-folder-hash>"
}
```
**Advantages of above build output structure:**
1. **Better caching of index.html:** `Cache-Control: no-cache` is no longer needed on index.html.
a) Whenever a new build is deployed to your origin server, you can run a script to cache bust index.html. It would take a few mins for all edge servers to reflect the index.html, in that time window, even if some browsers get served with older index.html from CDN, the older static bundles referenced in that index.html would still be present in the Origin server (you don't delete the `n-1` release bundle yet. The clean up of older build can be done after `n+1` release, by then all edge servers would be serving release `n`).
b) Until the next release is deployed, the index.html file would be served directly from CDNs, and no longer have the roundtrip latency of validating the freshness of the cached file from Origin server.
App deploy folder structure on Origin Server would potentially look like this:
```
<app-root>
|___ index.html
|___ asset-manifest.json
|___ static
|___<versioned-folder-hash-1> // release 'n'
|__ js
|__css
|__media
|___<versioned-folder-hash-2> // release 'n-1'
```
### Current Alternative to achieve the above:
Though I don't want to go this route, I am probably going to have to `eject` the config from cra and make modifications in config files to achieve the above build output structure.
I would be glad if someone in the community can help me understand if the above problem is solvable in some other way, without having to eject the configs / my understanding of the Caching problem is inaccurate.
|
issue: proposal,needs triage
|
low
|
Minor
|
645,327,131 |
TypeScript
|
Infer const-ness of local let bindings that aren't assigned to
|
## Search Terms
let const infer assignment
## Suggestion
In some cases, type narrowing for `const` bindings is more effective than for `let` bindings. Specifically, using such bindings from a function that closes over them will keep the narrowed type, which doesn't happen for `let` binding, presumably on the assumption that those might be mutated at any time.
This suggests to treat local `let` bindings that are never assigned to (which can be determined by a rather straightforward static check on the syntax tree) like `const` bindings for this purpose.
(Interestingly, something like this seems to already exist for function parameters.)
## Use Cases
Though some people have adopted a coding style where locals are declared with `const` unless assigned to, there's also a good argument to be made that that is not a very good use of brain cycles and just using `let` for all locals is fine. This proposal would improve type inference for people using the `let` style.
## Examples
```
function foo() {
let v: number[] | null = Math.random() < 0.5 ? [1] : null
if (Array.isArray(v)) setTimeout(() => console.log(v.length), 100)
}
```
The compiler complains that `v` is possibly null. If the binding is changed to `const` the problem goes away. If `v` is made a function parameter it also doesn't occur. (But comes back when a `v = null` statement is added, suggesting a check like the one suggested here is being done in that case.)
## Checklist
My suggestion meets these guidelines:
* [x] This wouldn't be a breaking change in existing TypeScript/JavaScript code
* [x] This wouldn't change the runtime behavior of existing JavaScript code
* [x] This could be implemented without emitting different JS based on the types of the expressions
* [x] This isn't a runtime feature (e.g. library functionality, non-ECMAScript syntax with JavaScript output, etc.)
* [x] This feature would agree with the rest of [TypeScript's Design Goals](https://github.com/Microsoft/TypeScript/wiki/TypeScript-Design-Goals).
|
Suggestion,Awaiting More Feedback
|
low
|
Major
|
645,494,161 |
PowerToys
|
[Run] Open with a touchpad / touchscreen gesture
|
would be nice if I could launch using the Touchpad settings for Taps with Three-finger gestures.
|
Idea-Enhancement,Product-PowerToys Run
|
low
|
Major
|
645,508,700 |
godot
|
Child 2D gizmo does not update with animation
|
<!-- Please search existing issues for potential duplicates before filing yours:
https://github.com/godotengine/godot/issues?q=is%3Aissue
-->
**Godot version:**
<!-- Specify commit hash if using non-official build. -->
3.2.2 rc2
**Issue description:**
<!-- What happened, and what was expected. -->
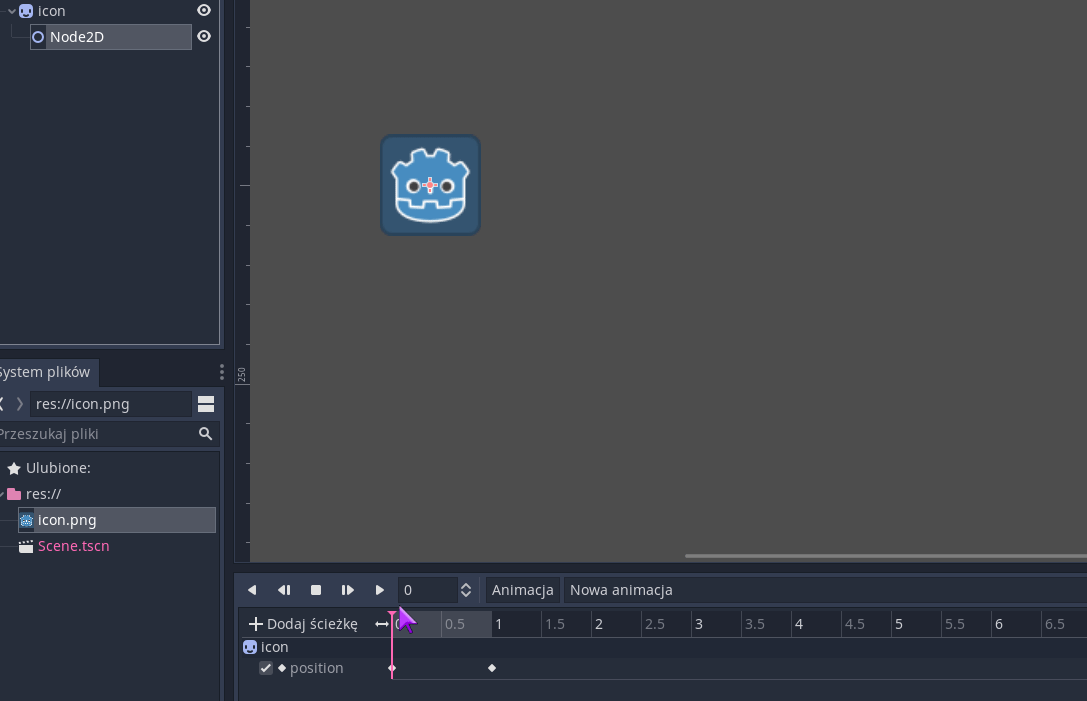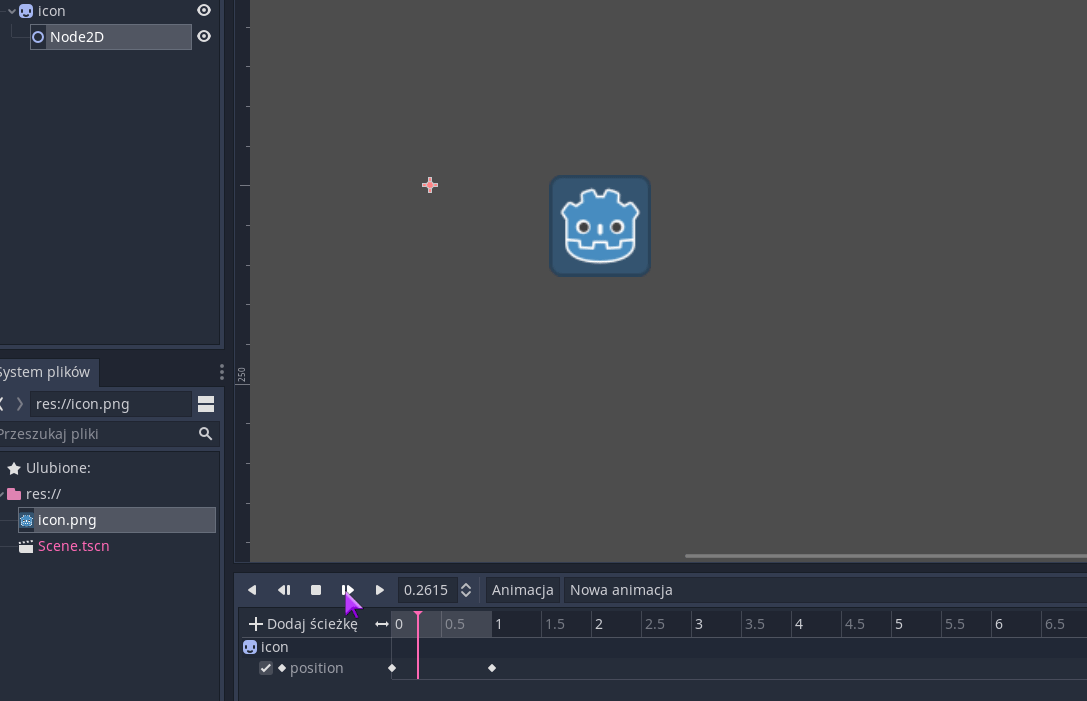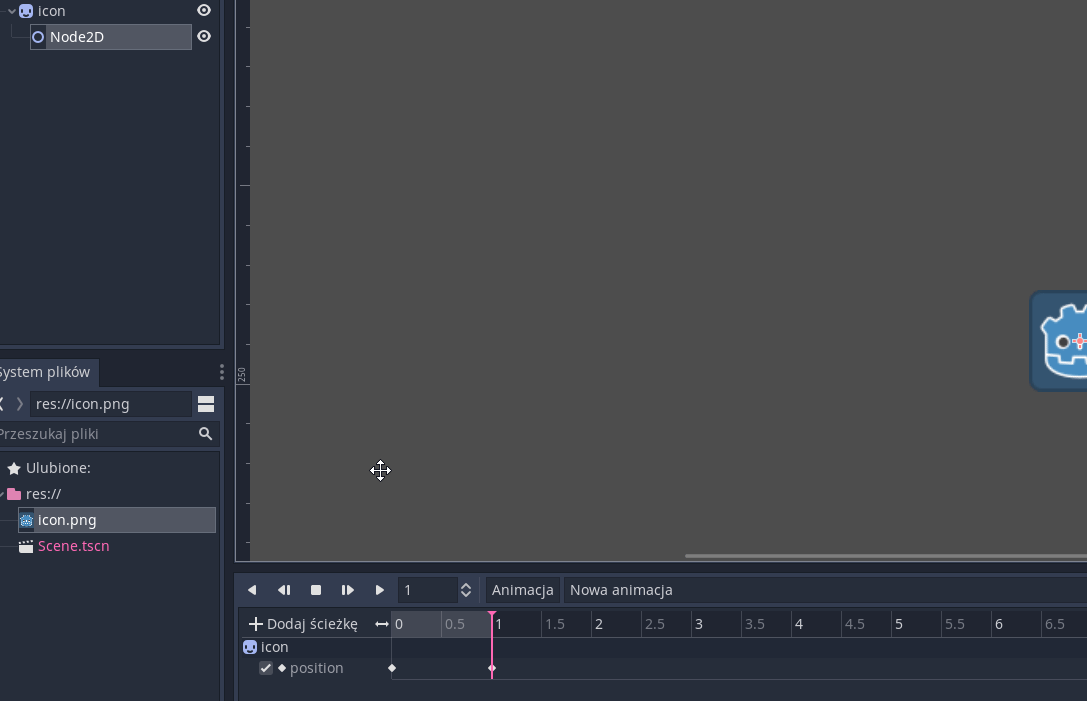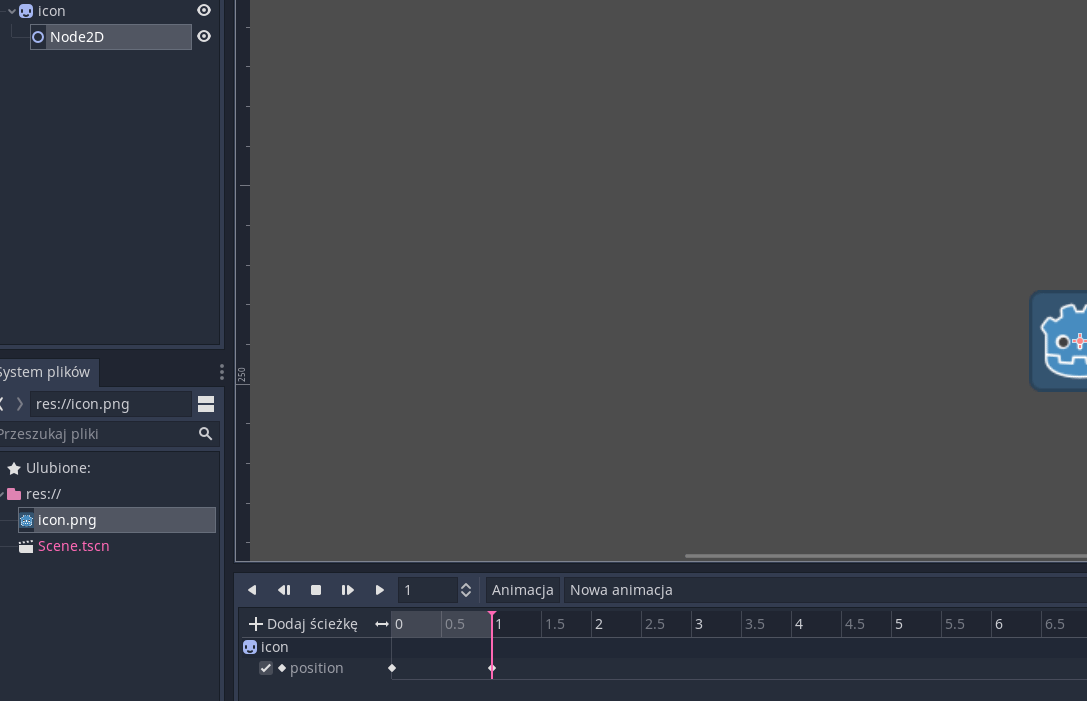
Notice the Node2D gizmo staying in place until you move cursor over viewport (which focuses the viewport and updates the gizmo only once).
**Minimal reproduction project:**
<!-- A small Godot project which reproduces the issue. Drag and drop a zip archive to upload it. -->
[ReproductionProject.zip](https://github.com/godotengine/godot/files/4831075/ReproductionProject.zip)
|
bug,topic:editor,confirmed,usability,topic:2d
|
low
|
Minor
|
645,547,554 |
godot
|
Focus (f, 3D) doesn't reset/recalibrate zoom range
|
**Godot version:**
3.2.2.rc4.mono.official
**Issue description:**
When zooming in, currently there's a limit that gets hit quite easily. In other engines this range is much greater, but if one hits the limit there refocusing on an object usually resets the range. But in godot it does not, the range stays at the limit if it was there before focussing.
This just makes it a worse freelook-move-forward.
**Steps to reproduce:**
Zoom in completely (mousewheel), focus an object (f-key), notice it's not possible to zoom in further nor pan around.
|
enhancement,discussion,topic:editor,topic:3d
|
low
|
Minor
|
645,565,651 |
flutter
|
[Flutter Web] How to prefix project path with URL "fweb/assets/fontmanifest.json . Inside main.dart.js - nodejs server
|
Hi.
I am facing a problem when I try to integrate the flutter generated build file to a nodejs server. The icon does not show. The error console is present in the image itself.

The above image is when I start my server,

The above image is when I refresh my browser. But the increment function seems to be working.
I am running the server on chrome and on Microsoft Edge (the new one with the chromium engine). In both, I encounter the same problem.
Any help is appreciated.
|
framework,d: api docs,platform-web,a: release,P3,team-web,triaged-web
|
low
|
Critical
|
645,579,852 |
PowerToys
|
[Image Resizer] Option to set the DPI for each size format
|
I have 600 DPI images that need to be resized to specific px but also have the DPI change to 300 DPI as well. My request is adding some sort of advance options to set the DPI for each Image Size item.
|
Idea-Enhancement,Product-Image Resizer
|
low
|
Major
|
645,608,973 |
pytorch
|
Cannot manually assign a tensor to .grad from TorchScript
|
## 🐛 Bug
When a module is compiled via `torch.jit.script()`, it is not possible to bypass Autograd and manually assign a tensor to the `.grad` attribute of another tensor. This is necessary in specific situations where a gradient must be computed independently from the actual computation graph.
## To Reproduce
Steps to reproduce the behavior:
1. Create a nn module containing a parameter such as `self.W = nn.Parameter(W, requires_grad=False)` so that Autograd does not try to touch it
2. Later, assign a gradient via `self.W.grad = new_gradient`
3. Wrap a module instance within `torch.jit.script()`, then run it and observe the error.
```
RuntimeError:
Tried to set an attribute: grad on a non-class: Tensor:
File "__main__.py", line 221
self.W.grad = new_gradient
~~~~~~~~~~~~~~~~~~~ <--- HERE
```
## Expected behavior
The gradient should be assigned without error, as it correctly happens when the module is not compiled with TorchScript
## Environment
```
PyTorch version: 1.5.0
Is debug build: No
CUDA used to build PyTorch: 10.2
OS: CentOS Linux release 7.6.1810 (Core)
GCC version: (GCC) 4.8.5 20150623 (Red Hat 4.8.5-36)
CMake version: version 2.8.12.2
Python version: 3.7
Is CUDA available: No
CUDA runtime version: Could not collect
GPU models and configuration:
GPU 0: Tesla V100-PCIE-16GB
GPU 1: Tesla V100-PCIE-16GB
GPU 2: Tesla V100-PCIE-16GB
GPU 3: Tesla V100-PCIE-16GB
Nvidia driver version: 418.39
cuDNN version: Could not collect
Versions of relevant libraries:
[pip3] botorch==0.1.0
[pip3] gpytorch==0.3.2
[pip3] numpy==1.18.1
[pip3] numpydoc==0.9.1
[pip3] pytorch-pretrained-bert==0.6.2
[pip3] pytorch-transformers==1.1.0
[pip3] torch==1.5.0
[pip3] torch-multi-head-attention==0.15.1
[pip3] torchfile==0.1.0
[pip3] torchsummary==1.5.1
[pip3] torchtext==0.6.0
[pip3] torchvision==0.6.0
[pip3] torchviz==0.0.1
[conda] blas 1.0 mkl
[conda] botorch 0.1.0 pypi_0 pypi
[conda] cudatoolkit 10.0.130 0
[conda] gpytorch 0.3.2 pypi_0 pypi
[conda] mkl 2019.4 243
[conda] mkl-service 2.3.0 py37he904b0f_0
[conda] mkl_fft 1.0.15 py37ha843d7b_0
[conda] mkl_random 1.1.0 py37hd6b4f25_0
[conda] numpy 1.17.4 pypi_0 pypi
[conda] numpy-base 1.18.1 py37hde5b4d6_0
[conda] numpydoc 0.9.1 pypi_0 pypi
[conda] pytorch-pretrained-bert 0.6.2 pypi_0 pypi
[conda] pytorch-transformers 1.1.0 pypi_0 pypi
[conda] torch 1.5.0 pypi_0 pypi
[conda] torch-multi-head-attention 0.15.1 pypi_0 pypi
[conda] torchfile 0.1.0 pypi_0 pypi
[conda] torchsummary 1.5.1 pypi_0 pypi
[conda] torchtext 0.6.0 pypi_0 pypi
[conda] torchvision 0.6.0 pypi_0 pypi
[conda] torchviz 0.0.1 pypi_0 pypi
```
cc @suo @gmagogsfm
|
triage review,oncall: jit,days
|
low
|
Critical
|
645,664,581 |
TypeScript
|
Split the "lib.dom.d.ts" definition file apart
|
<!-- 🚨 STOP 🚨 𝗦𝗧𝗢𝗣 🚨 𝑺𝑻𝑶𝑷 🚨
Half of all issues filed here are duplicates, answered in the FAQ, or not appropriate for the bug tracker.
Please help us by doing the following steps before logging an issue:
* Search: https://github.com/Microsoft/TypeScript/search?type=Issues
* Read the FAQ, especially the "Common Feature Requests" section: https://github.com/Microsoft/TypeScript/wiki/FAQ
-->
## Search Terms
<!-- List of keywords you searched for before creating this issue. Write them down here so that others can find this suggestion more easily -->
lib.dom.d.ts, split, modular
## Suggestion
<!-- A summary of what you'd like to see added or changed -->
I'm currently writing a TypeScript definition file for the API of a game, which will be submitted to [DefinitelyTyped](https://github.com/DefinitelyTyped/DefinitelyTyped) soon.
The API of the game exposes a `Notification` class to the global scope, which collides with the one in "lib.dom.d.ts" definition file. Not only that, but it also uses jQuery and `XMLHttpRequest`, forcing me to include that definition file.
## Use Cases
<!--
What do you want to use this for?
What shortcomings exist with current approaches?
-->
By splitting the "lib.dom.d.ts" definition file apart, user can select only the APIs they need.
This change should not break the backward compatibility of old projects, although old versions of TypeScript will not support projects using the modular definition file.
## Examples
<!-- Show how this would be used and what the behavior would be -->
For example, the "lib.dom.d.ts" definition file could be split up like this:
```
lib.dom.d.ts
|-- lib.dom.elements.d.ts
|-- lib.dom.notification.d.ts
|-- lib.dom.xhr.d.ts
`-- ... (other modules)
```
When some parts of the user's definition file collide with the "lib.dom.d.ts" definition file, the user can use the following instead:
```jsonc
{
"compilerOptions": {
"lib": [
"DOM.Elements",
"DOM.XHR",
... // (other modules except for "DOM.Notification")
]
...
}
...
}
```
## Checklist
My suggestion meets these guidelines:
* [x] This wouldn't be a breaking change in existing TypeScript/JavaScript code
* [x] This wouldn't change the runtime behavior of existing JavaScript code
* [x] This could be implemented without emitting different JS based on the types of the expressions
* [x] This isn't a runtime feature (e.g. library functionality, non-ECMAScript syntax with JavaScript output, etc.)
* [x] This feature would agree with the rest of [TypeScript's Design Goals](https://github.com/Microsoft/TypeScript/wiki/TypeScript-Design-Goals).
|
Suggestion,Needs Proposal
|
low
|
Critical
|
645,667,398 |
rust
|
Simple code won't compile. Both stable and nightly.
|
<!--
Thank you for finding an Internal Compiler Error! 🧊 If possible, try to provide
a minimal verifiable example. You can read "Rust Bug Minimization Patterns" for
how to create smaller examples.
http://blog.pnkfx.org/blog/2019/11/18/rust-bug-minimization-patterns/
-->
### Code
Please see the file [lib.zip](https://github.com/rust-lang/rust/files/4832388/lib.zip)
rustc consumes all the memory while compiling this code. 188Gb of RAM was consumed on server.
### Meta
<!--
If you're using the stable version of the compiler, you should also check if the
bug also exists in the beta or nightly versions.
-->
`rustc --version --verbose`:
```
rustc
1.44.1 (c7087fe00 2020-06-17)
rustc 1.46.0-nightly (67100f61e 2020-06-24)
```
### Error output
```
process didn't exit successfully: `rustc --crate-name directory_trees --edition=2018 directory-trees/src/lib.rs --error-format=json --json=diagnostic-rendered-ansi --crate-type lib --emit=dep-info,metadata,link -C opt-level=3 -C metadata=e813bd9f91882755 -C extra-filename=-e813bd9f91882755 --out-dir /home/user/RustProjects/directory-bot/target/release/deps -L dependency=/home/user/RustProjects/directory-bot/target/release/deps --extern unchecked_index=/home/user/RustProjects/directory-bot/target/release/deps/libunchecked_index-d1f689d7ce9ce478.rmeta -C target-cpu=native` (signal: 9, SIGKILL: kill)
```
<!--
Include a backtrace in the code block by setting `RUST_BACKTRACE=1` in your
environment. E.g. `RUST_BACKTRACE=1 cargo build`.
-->
<details><summary><strong>Backtrace</strong></summary>
<p>
No backtrace appeared.
```
process didn't exit successfully: `rustc --crate-name directory_trees --edition=2018 directory-trees/src/lib.rs --error-format=json --json=diagnostic-rendered-ansi --crate-type lib --emit=dep-info,metadata,link -C opt-level=3 -C metadata=e813bd9f91882755 -C extra-filename=-e813bd9f91882755 --out-dir /home/user/RustProjects/directory-bot/target/release/deps -L dependency=/home/user/RustProjects/directory-bot/target/release/deps --extern unchecked_index=/home/user/RustProjects/directory-bot/target/release/deps/libunchecked_index-d1f689d7ce9ce478.rmeta -C target-cpu=native` (signal: 9, SIGKILL: kill)
```
</p>
</details>
|
T-compiler,I-compilemem,C-bug
|
medium
|
Critical
|
645,672,605 |
pytorch
|
Compiling PyTorch with 11.0, V11.0.167
|
## 🐛 Bug
My CUDA driver is 11.0 but it seems cudatoolkit only goes up to version 10.2. This causes there to be a mismatch when I try to install apex.
Here is the stack trace from installing apex with the command
`pip install -v --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./`
torch.__version__ = 1.5.1
/tmp/pip-req-build-qbjtmvks/setup.py:51: UserWarning: Option --pyprof not specified. Not installing PyProf dependencies!
warnings.warn("Option --pyprof not specified. Not installing PyProf dependencies!")
Compiling cuda extensions with
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2020 NVIDIA Corporation
Built on Wed_May__6_19:09:25_PDT_2020
Cuda compilation tools, release 11.0, V11.0.167
Build cuda_11.0_bu.TC445_37.28358933_0
from /usr/local/cuda/bin
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/tmp/pip-req-build-qbjtmvks/setup.py", line 130, in <module>
check_cuda_torch_binary_vs_bare_metal(torch.utils.cpp_extension.CUDA_HOME)
File "/tmp/pip-req-build-qbjtmvks/setup.py", line 85, in check_cuda_torch_binary_vs_bare_metal
"https://github.com/NVIDIA/apex/pull/323#discussion_r287021798. "
RuntimeError: Cuda extensions are being compiled with a version of Cuda that does not match the version used to compile Pytorch binaries. Pytorch binaries were compiled with Cuda 10.2.
In some cases, a minor-version mismatch will not cause later errors: https://github.com/NVIDIA/apex/pull/323#discussion_r287021798. You can try commenting out this check (at your own risk).
Running setup.py install for apex ... error
Should I just comment out the error or is there a better workaround?
cc @malfet
|
module: build,triaged
|
low
|
Critical
|
645,699,140 |
pytorch
|
Stop registering kernels that use DispatchStub as catch all
|
A kernel should only be registered as catch-all if it would work for ANY backend. Kernels that use DispatchStub do NOT fall in this
category: DispatchStub is specialized to only work for CPU and CUDA. If you incorrectly register a kernel that uses DispatchStub as catchall, it will seemingly work for PyTorch, but if a custom backend implementor tries to call the function, it will incorrectly report that the kernel exists, but DispatchStub doesn't work. Trying to make DispatchStub work for a new backend is a fools game: you should just register your kernel directly.
Here are all the files that need to be audited. Do an audit by looking for all functions in the corresponding cpp file that invoke the dispatch stub, and then verify in `native_functions.yaml` that they are registered as `CPU, CUDA: ...` (and not catch all), introducing the dispatch if it is in that case. Activation.h has an example.
- [ ] aten/src/ATen/native/Activation.h #40565
- [ ] aten/src/ATen/native/BinaryOps.h
- [ ] aten/src/ATen/native/Copy.h
- [ ] aten/src/ATen/native/Cross.h
- [ ] aten/src/ATen/native/DispatchStub.h
- [ ] aten/src/ATen/native/Distance.h
- [ ] aten/src/ATen/native/Fill.h
- [ ] aten/src/ATen/native/Lerp.h
- [ ] aten/src/ATen/native/PointwiseOps.h
- [ ] aten/src/ATen/native/Pow.h
- [ ] aten/src/ATen/native/RNN.h
- [ ] aten/src/ATen/native/RangeFactories.cpp
- [ ] aten/src/ATen/native/ReduceAllOps.h
- [ ] aten/src/ATen/native/ReduceOps.h
- [ ] aten/src/ATen/native/Sorting.h
- [ ] aten/src/ATen/native/TensorAdvancedIndexing.h
- [ ] aten/src/ATen/native/TensorCompare.h
- [ ] aten/src/ATen/native/UnaryOps.h
- [ ] aten/src/ATen/native/Unfold2d.h
- [ ] aten/src/ATen/native/UnfoldBackward.h
- [ ] aten/src/ATen/native/UpSample.h
- [ ] aten/src/ATen/native/batch_norm.h
- [ ] aten/src/ATen/native/cpu/CatKernel.h
- [ ] aten/src/ATen/native/cpu/DepthwiseConvKernel.h
- [ ] aten/src/ATen/native/cpu/GridSamplerKernel.h
- [ ] aten/src/ATen/native/cpu/README.md
- [ ] aten/src/ATen/native/cpu/SoftmaxKernel.h
- [ ] aten/src/ATen/native/cuda/TensorCompare.cu
- [ ] aten/src/ATen/native/group_norm.h
- [ ] aten/src/ATen/native/layer_norm.h
- [ ] aten/src/ATen/native/quantized/affine_quantizer.h
- [ ] aten/src/ATen/native/quantized/cpu/kernels/README.md
- [ ] aten/src/ATen/native/quantized/cpu/quantized_ops.h
- [ ] aten/src/ATen/native/quantized/fake_quant_affine.h
cc @ezyang @bhosmer @smessmer @ljk53
|
module: internals,triaged
|
low
|
Minor
|
645,713,767 |
pytorch
|
If all parameters are unused by forward pass in a process, backward will not work with DDP.
|
We realized that if the `forward` pass produces empty `list(_find_tensors(output))` - referring the code below - in some processes with `find_unused_parameters = True`, the backward() will not work for DDP.
https://github.com/pytorch/pytorch/blob/e490352dc4ad4f61c795bfdae968954c7d916861/torch/nn/parallel/distributed.py#L521-L522
With today's reducer it's impossible to make all parameters unused, as we would require at least one `autograd_hook` invocation to process unused parameters. The loss function may take an empty list and then produce some irrelevant tensor. In that case applications can still call backward, but they cannot run it with today's DDP.
cc: @mrshenli @pritamdamania87 @zhaojuanmao
This issue was realized in pull request: #40407
cc @pietern @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @xush6528 @osalpekar @jiayisuse
|
oncall: distributed,triaged
|
low
|
Minor
|
645,728,763 |
pytorch
|
Converting NumPy dtype to Torch dtype when using `as_tensor`
|
## 🚀 Feature
Let the `dtype` keyword argument of [`torch.as_tensor`](https://pytorch.org/docs/master/generated/torch.as_tensor.html#torch.as_tensor) be either a `np.dtype` or `torch.dtype`.
## Motivation
Suppose I have two numpy arrays with different types and I want to convert one of them to a torch tensor with the type of the other array.
According to https://discuss.pytorch.org/t/converting-a-numpy-dtype-to-torch-dtype/52279/2, there's no convenient way to convert a numpy tensor to a torch tensor.
## Pitch
```python
import numpy as np
import torch
# currently raises the following:
# TypeError: as_tensor(): argument 'dtype' must be
# torch.dtype, not numpy.dtype
mytensor = torch.tensor(48., dtype=np.float32)
```
## Alternatives
- make [this API](https://github.com/pytorch/pytorch/blob/29881c7f02ed7cb263a602f73a84089a79571c8e/torch/csrc/utils/tensor_numpy.cpp#L196-L220) public
- let the `dtype` keyword argument of [`torch.Tensor.to`](https://pytorch.org/docs/stable/tensors.html#torch.Tensor.to) be either a `np.dtype` or `torch.dtype`
## Additional context
Similar issue: #541
cc @mruberry
|
triaged,module: numpy
|
low
|
Critical
|
645,735,211 |
pytorch
|
Generalized CPU vector reductions
|
## 🚀 Feature
Generalize `binary_kernel_reduce_vec` to support the more advanced reductions that can't be vectorized currently, e.g. `torch.norm`.
## Motivation
As mentioned by @ngimel in https://github.com/pytorch/pytorch/pull/39516#issuecomment-644236374, non-vectorized reductions are much slower than their vectorized counterparts. Currently, the following CPU reductions are not vectorized:
- `norm`
- `std_var`
- `mean` (this kernel isn't actually used because `sum().div_()` is faster, see #16617)
- `argmin` / `argmax`.
Except for `argmin`/`argmax`, I think these could all be efficiently vectorized, if not for the fact that `binary_kernel_reduce_vec` doesn't support generalised reduction ops like `binary_kernel_reduce` does. All of these require separate `reduce`, `combine` and `project` operations, whereas the `_vec` is limiting because it requires `reduce` and `combine` to be the same and `project` must to be a no-op.
## Pitch
I propose `binary_kernel_reduce_vec` should be generalized to support reduction operators similar to `binary_kernel_reduce`. This would mean that each individual operation (`reduce`, `combine` and `project`) would need to be overloaded for both scalar and vector types. Additionally, there needs to be an operation to convert from vector accumulator back to a scalar accumulator in order to perform inner reductions. I was thinking `accumulator_to_scalar`, but welcome other names.
In addition, I think it would be useful to have a customizable `multi_row_reduce` operation, similar to the `multi_row_sum` operation I used in in #39516. This would allow cascade-sum to use the generic machinery and also allow `torch.norm` and `torch.mean` to use the cascade-sum algorithm as well, for improved numerical accuracy.
Compared to `binary_kernel_reduce`, there would need to be a lot more functions defined for each reduction operation. However, for the simple cases these are mostly boilerplate which could be generated by a helper function based on a lambda pair `op`, `vop` like it is done currently. In total, a full reduction operation would need to define each of these functions:
```cpp
template <typename input, typename output>
struct ReductionOps {
using scalar_t = input;
using vec_t = Vec256<scalar_t>;
using acc_t = T;
using vacc_t = Vec256<acc_t>;
using result_t = output;
using vresult_t = Vec256<result_t>;
constexpr int ilp_factor = 4; // Number of rows reduced by multi_row_reduce
acc_t identity();
vacc_t videntity();
acc_t reduce(acc_t acc, scalar_t data);
vacc_t reduce(vacc_t acc, vec_t data);
acc_t accumulator_to_scalar(vacc_t vec_acc) const;
std::array<acc_t, ilp_factor> multi_row_reduce(
const char * C10_RESTRICT in_data,
const int64_t row_stride,
const int64_t col_stride,
const int64_t size) const;
std::array<vacc_t, ilp_factor> multi_row_reduce(
const char * C10_RESTRICT in_data,
const int64_t row_stride,
const int64_t col_stride,
const int64_t size) const;
acc_t combine(acc_t a, acc_t b);
vacc_t combine(vacc_t, vacc_t b);
result_t project(acc_t a);
vresult_t project(vacc_t a);
};
```
cc @VitalyFedyunin @ngimel
|
module: performance,module: cpu,triaged,module: reductions
|
low
|
Major
|
645,754,251 |
flutter
|
Pull-Down Menus for iOS 14
|
On iOS 14, Pull-Down Menus have been added.
> Menus offer several advantages over action sheets, context menus, and popovers. For example:
>
> A menu opens very near the button that reveals it, so people can instantly understand the relationship between the menu's items and the action they're performing.
>
> In addition to listing actions, a menu can offer selections people can use to affect the primary action.
>
> Menus animate quickly into view and don't dim the screen when they appear, giving both the transition and the overall experience a lightweight feel.


https://developer.apple.com/design/human-interface-guidelines/ios/controls/pull-down-menus/
|
c: new feature,framework,a: fidelity,f: cupertino,customer: crowd,P1,team-design,triaged-design
|
medium
|
Critical
|
645,808,230 |
pytorch
|
Libtorch C++ multiple GPU performance slower than single GPU
|
## 🐛 Bug
Using the data_parallel C++ interface results in code that is much slower on multiple GPUs than on a single GPU. In addition, the GPU utilization is less than 10% with muliple GPUs compared to over 96% with a single GPU.
## To Reproduce
Steps to reproduce the behavior:
Implement a non-trivial model (e.g. ResNet50 or SlowFast) using the libtorch c++ interface (I used libtorch-win-shared-with-deps-1.5.0.zip + cuda 10.1)
Add mulitiple GPU support via torch::nn::parallel::data_parallel
Time training runs with a single GPU and with multiple GPUs
<!-- If you have a code sample, error messages, stack traces, please provide it here as well -->
## Expected behavior
Runs with multiple GPUs should be faster than runs on a single GPU. Definitely not *much* slower.
## Environment
- PyTorch Version (e.g., 1.0): LibTorch 1.5.0 pre-built library
- OS (e.g., Linux): Windows 7
- How you installed PyTorch (`conda`, `pip`, source): N/A
- Build command you used (if compiling from source):
- Python version: N/A
- CUDA/cuDNN version: 10.1
- GPU models and configuration: 2x GTX 1080
- Any other relevant information:
## Additional context
This is in line with what @dmagee reported in #18837. Looking though the code, it appears as if replicas of the modules are cloned and deleted on every iteration of training. Is there a way to use data_parallel and avoid this overhead?
cc @VitalyFedyunin @ngimel @yf225 @glaringlee @albanD @mruberry
|
module: performance,module: cpp,triaged,module: data parallel
|
medium
|
Critical
|
645,817,626 |
flutter
|
DraggableScrollableSheet with reverse CustomScrollView inside cause "reversed" behaviour for modal bottom sheet
|
Simplified code:
```
showModalBottomSheet(
context: context,
isScrollControlled: true,
isDismissible: true,
backgroundColor: Colors.transparent,
builder: (context) => DraggableScrollableSheet(
expand: false,
initialChildSize: 1,
minChildSize: 0.6,
maxChildSize: 1,
builder: (context, scrollController) => CustomScrollView(
reverse: true,
controller: scrollController,
slivers: <Widget>[...])));
```
And now when scroll up - bottom sheet going to close state, and when down - sheet going to expanded state. Without reverse list inside all works as expected.
Use case - chat in bottom sheet like on Facebook comments under the post.
Flutter (Channel stable, v1.17.4, on Linux, locale en_US.UTF-8)
|
c: new feature,framework,f: scrolling,c: proposal,P3,team-framework,triaged-framework
|
low
|
Minor
|
645,824,675 |
flutter
|
bench_mouse_region_grid_hover too sensitive to Zone changes
|
There was a change to the benchmark harness (https://github.com/flutter/flutter/pull/57576), which caused the numbers in bench_mouse_region_grid_hover to move up:
<img width="269" alt="Screen Shot 2020-06-25 at 1 11 18 PM" src="https://user-images.githubusercontent.com/211513/85790755-9e6e0d80-b6e5-11ea-9f78-bd3f30368b22.png">
After some examination by @pennzht it looks like this benchmark is sensitive to zone change. For example, benchmarks were moved into a shared parent zone that captures stdout output. On @pennzht's computer this affected the numbers by 2x (on my computer it didn't change anything though).
My suspicion is the use of `TestGesture` which uses some zone tricks behind the scenes. According to my profiling those tricks take quite a bit of time per frame (0.16ms in my testing). We might want to consider changing the benchmark to not use any zone tricks.
/cc @dkwingsmt @pennzht
|
framework,platform-web,a: mouse,team: benchmark,P3,team-web,triaged-web
|
low
|
Minor
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.