
code
stringlengths 30
403k
| size
int64 31
406k
| license
stringclasses 10
values |
|---|---|---|
##Union Find
###Basic Java Model
优化前合并与查找时间复杂度都是O(n)
Compressed path优化后 都是O(1)
union find不支持删除操作
###Implementation
```java
class UnionFind{
/*
用数组或者hashmap都可以
*/
HashMap<Integer, Integer> hashmap = new HashMap<Integer, Integer>();
UnionFind(HashSet<Integer> hashSet){
for(Integer now : hashSet) {
hashmap.put(now, now);
}
}
int find(int x){
/*
当没找到自己是根节点的时候,就继续深度遍历进入曾祖父找,直到找到最后的根节点
*/
int parent = hashmap.get(x);
while(parent!=hashmap.get(parent)) {
parent = hashmap.get(parent);
}
return parent;
}
int compressed_find(int x){
int parent = hashmap.get(x);
while(parent!=hashmap.get(parent)) {
parent = hashmap.get(parent);
}
int temp = -1;
int fa = hashmap.get(x);
while(fa!=hashmap.get(fa)) {
temp = hashmap.get(fa);
hashmap.put(fa, parent) ;
fa = temp;
}
return parent;
}
void union(int x, int y){
int root_x = find(x);
int root_y = find(y);
if(root_x != root_y) {
hashmap.put(root_x, root_y);
}
}
}
```
###题目参考
- Find the Weak Connected Component in the Directed Graph
###课件参考


###Better Solution
#### just change the root of p to q, not every element to q

###Still two ways to better to improve
#### 1: Weighted quick-union


#### 2: Path Compression


####Summary
 | 1,770 | MIT |
次に、登録を試みる前にユーザーが認証されるように、プッシュ通知を登録する方法を変更する必要があります。
1. Visual Studio のソリューション エクスプローラーで、**Application\_Launching** イベント ハンドラー内の app.xaml.cs プロジェクト ファイルを開き、**AcquirePushChannel** メソッドの呼び出しをコメントアウトまたは削除します。
2. **AcquirePushChannel** メソッドへのアクセス制限を `private` から `public` に変更し、`static` 修飾子を追加します。
3. MainPage.xaml.cs プロジェクト ファイルを開き、**OnNavigatedTo** メソッドのオーバーライドを次のコードに置き換えます。
protected override async void OnNavigatedTo(NavigationEventArgs e)
{
await AuthenticateAsync();
App.AcquirePushChannel();
RefreshTodoItems();
}
<!---HONumber=Oct15_HO3--> | 619 | CC-BY-3.0 |
---
title: 教程:创建使用 Microsoft 标识平台进行身份验证的 Android 应用 | Azure
titleSuffix: Microsoft identity platform
description: 在本教程中,我们生成一个使用 Microsoft 标识平台登录用户的 Android 应用,并获取访问令牌以代表用户调用 Microsoft Graph API。
services: active-directory
author: mmacy
manager: CelesteDG
ms.service: active-directory
ms.subservice: develop
ms.topic: tutorial
ms.workload: identity
ms.date: 11/26/2019
ms.author: hahamil
ms.reviewer: brandwe
ms.custom: aaddev, identityplatformtop40
ms.openlocfilehash: 7d297d96ba764c812a3d4db6d9383122c73cfe31
ms.sourcegitcommit: 126ee1e8e8f2cb5dc35465b23d23a4e3f747949c
ms.translationtype: HT
ms.contentlocale: zh-CN
ms.lasthandoff: 02/10/2021
ms.locfileid: "100103135"
---
# <a name="tutorial-sign-in-users-and-call-the-microsoft-graph-api-from-an-android-application"></a>教程:从 Android 应用程序登录用户并调用 Microsoft Graph API
在本教程中,你要构建一个与 Microsoft 标识平台集成的 Android 应用,用户可登录该应用并获取访问令牌以调用 Microsoft Graph API。
完成本教程后,应用程序将接受个人 Microsoft 帐户(包括 outlook.com、live.com 和其他帐户)进行登录,还能够接受使用 Azure Active Directory 的任何公司或组织的工作或学校帐户进行登录。
在本教程中:
> [!div class="checklist"]
> * 在 Android Studio 中创建 Android 应用项目
> * 在 Azure 门户中注册应用
> * 添加代码以支持用户登录和注销
> * 添加代码以调用 Microsoft Graph API
> * 测试应用程序
## <a name="prerequisites"></a>先决条件
* Android Studio 3.5+
## <a name="how-this-tutorial-works"></a>本教程工作原理

本教程中的应用会将用户登录并代表他们获取数据。 该数据可通过一个受保护的 API (Microsoft 图形 API) 进行访问,该 API 需要授权并且受 Microsoft 标识平台保护。
更具体说来:
* 你的应用将通过浏览器或 Microsoft Authenticator 和 Intune 公司门户登录用户。
* 最终用户将接受应用程序请求的权限。
* 将为你的应用颁发 Microsoft Graph API 的一个访问令牌。
* 该访问令牌将包括在对 Web API 的 HTTP 请求中。
* 处理 Microsoft Graph 响应。
该示例使用适用于 Android 的 Microsoft 身份验证库 (MSAL) 来实现身份验证:[com.microsoft.identity.client](https://javadoc.io/doc/com.microsoft.identity.client/msal)。
MSAL 将自动续订令牌,在设备上的其他应用之间提供单一登录 (SSO),并管理帐户。
本教程演示简化的示例,介绍如何使用适用于 Android 的 MSAL。 为简单起见,本教程仅使用“单帐户模式”。 若要探索更复杂的场景,请参阅 GitHub 上已完成的[工作代码示例](https://github.com/Azure-Samples/ms-identity-android-java/)。
## <a name="create-a-project"></a>创建一个项目
如果你还没有 Android 应用程序,请按照以下步骤设置新项目。
1. 打开 Android Studio,然后选择“启动新的 Android Studio 项目” 。
2. 选择“基本活动”,再选择“下一步” 。
3. 命名应用程序。
4. 保存包名称。 以后需将它输入 Azure 门户中。
5. 将语言从“Kotlin” 更改为“Java” 。
6. 将“最低 API 级别” 设置为 **API 19** 或更高,然后单击“完成”。
7. 在项目视图的下拉列表中选择“项目” ,以便显示源和非源的项目文件,然后打开 **app/build.gradle**,将 `targetSdkVersion` 设置为 `28`。
## <a name="integrate-with-the-microsoft-authentication-library"></a>与 Microsoft 身份验证库集成
### <a name="register-your-application"></a>注册应用程序
1. 登录 <a href="https://portal.azure.com/" target="_blank">Azure 门户</a>。
1. 如果有权访问多个租户,请使用顶部菜单中的“目录 + 订阅”筛选器:::image type="icon" source="./media/common/portal-directory-subscription-filter.png" border="false":::,选择要在其中注册应用程序的租户。
1. 搜索并选择“Azure Active Directory” 。
1. 在“管理”下,选择“应用注册” > “新建注册” 。
1. 输入应用程序的 **名称**。 应用的用户可能会看到此名称,你稍后可对其进行更改。
1. 选择“注册” 。
1. 在“管理”下,选择“身份验证” > “添加平台” > “Android” 。
1. 输入项目的包名称。 如果下载了代码,则该值为 `com.azuresamples.msalandroidapp`。
1. 在“配置 Android 应用”页的“签名哈希”部分,选择“生成开发签名哈希”。 然后复制用于平台的 KeyTool 命令。
安装 KeyTool.exe,使其作为 Java 开发工具包 (JDK) 的一部分。 还必须安装 OpenSSL 工具才能执行 KeyTool 命令。 有关详细信息,请参阅[有关如何生成密钥的 Android 文档](https://developer.android.com/studio/publish/app-signing#generate-key)。
1. 生成由 KeyTool 生成的 **签名哈希**。
1. 选择“配置”并保存出现在“Android 配置”页中的“MSAL 配置”,以便在稍后配置应用时输入它 。
1. 选择“完成”。
### <a name="configure-your-application"></a>配置应用程序
1. 在 Android Studio 的项目窗格中,导航到 **app\src\main\res**。
1. 右键单击“res” ,选择“新建” > “目录”。 输入 `raw` 作为新目录名称,然后单击“确定”。
1. 在 **app** > **src** > **main** > **res** > **raw** 中,新建名为 `auth_config_single_account.json` 的 JSON 文件,然后粘贴以前保存的 MSAL 配置。
在“重定向 URI”下方,粘贴:
```json
"account_mode" : "SINGLE",
```
配置文件应与如下示例类似:
```json
{
"client_id" : "0984a7b6-bc13-4141-8b0d-8f767e136bb7",
"authorization_user_agent" : "DEFAULT",
"redirect_uri" : "msauth://com.azuresamples.msalandroidapp/1wIqXSqBj7w%2Bh11ZifsnqwgyKrY%3D",
"broker_redirect_uri_registered" : true,
"account_mode" : "SINGLE",
"authorities" : [
{
"type": "AAD",
"audience": {
"type": "AzureADandPersonalMicrosoftAccount",
"tenant_id": "common"
}
}
]
}
```
本教程仅演示如何在单帐户模式下配置应用。 查看文档,详细了解[单帐户模式与多帐户模式](./single-multi-account.md)以及[配置应用](./msal-configuration.md)
4. 在 **app** > **src** > **main** > **AndroidManifest.xml** 中,将以下 `BrowserTabActivity` 活动添加到应用程序主体。 该条目允许 Microsoft 在完成身份验证后回调应用程序:
```xml
<!--Intent filter to capture System Browser or Authenticator calling back to our app after sign-in-->
<activity
android:name="com.microsoft.identity.client.BrowserTabActivity">
<intent-filter>
<action android:name="android.intent.action.VIEW" />
<category android:name="android.intent.category.DEFAULT" />
<category android:name="android.intent.category.BROWSABLE" />
<data android:scheme="msauth"
android:host="Enter_the_Package_Name"
android:path="/Enter_the_Signature_Hash" />
</intent-filter>
</activity>
```
将 `android:host=` 值替换为在 Azure 门户中注册的包名称。
将 `android:path=` 值替换为在 Azure 门户中注册的密钥哈希。 签名哈希不应进行 URL 编码 。 确保签名哈希的开头有前导 `/`。
将用来替换 `android:host` 值的“包名称”应类似于:“com.azuresamples.msalandroidapp”。
将用来替换 `android:path` 值的“签名哈希”应类似于:“/1wIqXSqBj7w+h11ZifsnqwgyKrY=”。
还可以在应用注册的“身份验证”边栏选项卡中找到这些值。 请注意,重定向 URI 将如下所示:“msauth://com.azuresamples.msalandroidapp/1wIqXSqBj7w%2Bh11ZifsnqwgyKrY%3D”。 尽管签名哈希会在此值末尾进行 URL 编码,但签名哈希不应在 `android:path` 值中进行 URL 编码 。
## <a name="use-msal"></a>使用 MSAL
### <a name="add-msal-to-your-project"></a>将 MSAL 添加到项目
1. 在 Android Studio 项目窗口中,导航到 app > src > build.gradle,然后添加以下内容 :
```gradle
repositories{
jcenter()
}
dependencies{
implementation 'com.microsoft.identity.client:msal:2.+'
implementation 'com.microsoft.graph:microsoft-graph:1.5.+'
}
packagingOptions{
exclude("META-INF/jersey-module-version")
}
```
[有关 Microsoft Graph SDK 的详细信息](https://github.com/microsoftgraph/msgraph-sdk-java/)
### <a name="required-imports"></a>要求的导入
将以下内容添加到 app > src > main> java > com.example(yourapp) > MainActivity.java 的顶部
```java
import android.os.Bundle;
import android.util.Log;
import android.view.View;
import android.widget.Button;
import android.widget.TextView;
import android.widget.Toast;
import androidx.annotation.NonNull;
import androidx.annotation.Nullable;
import androidx.appcompat.app.AppCompatActivity;
import com.google.gson.JsonObject;
import com.microsoft.graph.authentication.IAuthenticationProvider; //Imports the Graph sdk Auth interface
import com.microsoft.graph.concurrency.ICallback;
import com.microsoft.graph.core.ClientException;
import com.microsoft.graph.http.IHttpRequest;
import com.microsoft.graph.models.extensions.*;
import com.microsoft.graph.requests.extensions.GraphServiceClient;
import com.microsoft.identity.client.AuthenticationCallback; // Imports MSAL auth methods
import com.microsoft.identity.client.*;
import com.microsoft.identity.client.exception.*;
```
## <a name="instantiate-publicclientapplication"></a>实例化 PublicClientApplication
#### <a name="initialize-variables"></a>初始化变量
```java
private final static String[] SCOPES = {"Files.Read"};
/* Azure AD v2 Configs */
final static String AUTHORITY = "https://login.microsoftonline.com/common";
private ISingleAccountPublicClientApplication mSingleAccountApp;
private static final String TAG = MainActivity.class.getSimpleName();
/* UI & Debugging Variables */
Button signInButton;
Button signOutButton;
Button callGraphApiInteractiveButton;
Button callGraphApiSilentButton;
TextView logTextView;
TextView currentUserTextView;
```
### <a name="oncreate"></a>onCreate
在 `MainActivity` 类中,参阅下方的 onCreate() 方法以使用 `SingleAccountPublicClientApplication` 实例化 MSAL。
```java
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
initializeUI();
PublicClientApplication.createSingleAccountPublicClientApplication(getApplicationContext(),
R.raw.auth_config_single_account, new IPublicClientApplication.ISingleAccountApplicationCreatedListener() {
@Override
public void onCreated(ISingleAccountPublicClientApplication application) {
mSingleAccountApp = application;
loadAccount();
}
@Override
public void onError(MsalException exception) {
displayError(exception);
}
});
}
```
### <a name="loadaccount"></a>loadAccount
```java
//When app comes to the foreground, load existing account to determine if user is signed in
private void loadAccount() {
if (mSingleAccountApp == null) {
return;
}
mSingleAccountApp.getCurrentAccountAsync(new ISingleAccountPublicClientApplication.CurrentAccountCallback() {
@Override
public void onAccountLoaded(@Nullable IAccount activeAccount) {
// You can use the account data to update your UI or your app database.
updateUI(activeAccount);
}
@Override
public void onAccountChanged(@Nullable IAccount priorAccount, @Nullable IAccount currentAccount) {
if (currentAccount == null) {
// Perform a cleanup task as the signed-in account changed.
performOperationOnSignOut();
}
}
@Override
public void onError(@NonNull MsalException exception) {
displayError(exception);
}
});
}
```
### <a name="initializeui"></a>initializeUI
侦听按钮并相应地调用方法或日志错误。
```java
private void initializeUI(){
signInButton = findViewById(R.id.signIn);
callGraphApiSilentButton = findViewById(R.id.callGraphSilent);
callGraphApiInteractiveButton = findViewById(R.id.callGraphInteractive);
signOutButton = findViewById(R.id.clearCache);
logTextView = findViewById(R.id.txt_log);
currentUserTextView = findViewById(R.id.current_user);
//Sign in user
signInButton.setOnClickListener(new View.OnClickListener(){
public void onClick(View v) {
if (mSingleAccountApp == null) {
return;
}
mSingleAccountApp.signIn(MainActivity.this, null, SCOPES, getAuthInteractiveCallback());
}
});
//Sign out user
signOutButton.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
if (mSingleAccountApp == null){
return;
}
mSingleAccountApp.signOut(new ISingleAccountPublicClientApplication.SignOutCallback() {
@Override
public void onSignOut() {
updateUI(null);
performOperationOnSignOut();
}
@Override
public void onError(@NonNull MsalException exception){
displayError(exception);
}
});
}
});
//Interactive
callGraphApiInteractiveButton.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
if (mSingleAccountApp == null) {
return;
}
mSingleAccountApp.acquireToken(MainActivity.this, SCOPES, getAuthInteractiveCallback());
}
});
//Silent
callGraphApiSilentButton.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
if (mSingleAccountApp == null){
return;
}
mSingleAccountApp.acquireTokenSilentAsync(SCOPES, AUTHORITY, getAuthSilentCallback());
}
});
}
```
> [!Important]
> 使用 MSAL 注销会从应用程序中删除有关用户的所有已知信息,但是用户的设备上仍然有一个活动会话。 如果用户尝试再次登录,则可能会看到登录 UI,但由于设备会话仍处于活动状态,可能无需重新输入其凭据。
### <a name="getauthinteractivecallback"></a>getAuthInteractiveCallback
用于交互式请求的回调。
```java
private AuthenticationCallback getAuthInteractiveCallback() {
return new AuthenticationCallback() {
@Override
public void onSuccess(IAuthenticationResult authenticationResult) {
/* Successfully got a token, use it to call a protected resource - MSGraph */
Log.d(TAG, "Successfully authenticated");
/* Update UI */
updateUI(authenticationResult.getAccount());
/* call graph */
callGraphAPI(authenticationResult);
}
@Override
public void onError(MsalException exception) {
/* Failed to acquireToken */
Log.d(TAG, "Authentication failed: " + exception.toString());
displayError(exception);
}
@Override
public void onCancel() {
/* User canceled the authentication */
Log.d(TAG, "User cancelled login.");
}
};
}
```
### <a name="getauthsilentcallback"></a>getAuthSilentCallback
用于无提示请求的回调
```java
private SilentAuthenticationCallback getAuthSilentCallback() {
return new SilentAuthenticationCallback() {
@Override
public void onSuccess(IAuthenticationResult authenticationResult) {
Log.d(TAG, "Successfully authenticated");
callGraphAPI(authenticationResult);
}
@Override
public void onError(MsalException exception) {
Log.d(TAG, "Authentication failed: " + exception.toString());
displayError(exception);
}
};
}
```
## <a name="call-microsoft-graph-api"></a>调用 Microsoft Graph API
以下代码演示如何使用 Graph SDK 调用 GraphAPI。
### <a name="callgraphapi"></a>callGraphAPI
```java
private void callGraphAPI(IAuthenticationResult authenticationResult) {
final String accessToken = authenticationResult.getAccessToken();
IGraphServiceClient graphClient =
GraphServiceClient
.builder()
.authenticationProvider(new IAuthenticationProvider() {
@Override
public void authenticateRequest(IHttpRequest request) {
Log.d(TAG, "Authenticating request," + request.getRequestUrl());
request.addHeader("Authorization", "Bearer " + accessToken);
}
})
.buildClient();
graphClient
.me()
.drive()
.buildRequest()
.get(new ICallback<Drive>() {
@Override
public void success(final Drive drive) {
Log.d(TAG, "Found Drive " + drive.id);
displayGraphResult(drive.getRawObject());
}
@Override
public void failure(ClientException ex) {
displayError(ex);
}
});
}
```
## <a name="add-ui"></a>添加 UI
### <a name="activity"></a>活动
如果要根据本教程为 UI 建模,则以下方法可提供有关更新文本和侦听按钮的指导。
#### <a name="updateui"></a>updateUI
根据登录状态启用/禁用按钮,并设置文本。
```java
private void updateUI(@Nullable final IAccount account) {
if (account != null) {
signInButton.setEnabled(false);
signOutButton.setEnabled(true);
callGraphApiInteractiveButton.setEnabled(true);
callGraphApiSilentButton.setEnabled(true);
currentUserTextView.setText(account.getUsername());
} else {
signInButton.setEnabled(true);
signOutButton.setEnabled(false);
callGraphApiInteractiveButton.setEnabled(false);
callGraphApiSilentButton.setEnabled(false);
currentUserTextView.setText("");
logTextView.setText("");
}
}
```
#### <a name="displayerror"></a>displayError
```java
private void displayError(@NonNull final Exception exception) {
logTextView.setText(exception.toString());
}
```
#### <a name="displaygraphresult"></a>displayGraphResult
```java
private void displayGraphResult(@NonNull final JsonObject graphResponse) {
logTextView.setText(graphResponse.toString());
}
```
#### <a name="performoperationonsignout"></a>performOperationOnSignOut
在 UI 中更新文本以表示注销的方法。
```java
private void performOperationOnSignOut() {
final String signOutText = "Signed Out.";
currentUserTextView.setText("");
Toast.makeText(getApplicationContext(), signOutText, Toast.LENGTH_SHORT)
.show();
}
```
### <a name="layout"></a>布局
示例 `activity_main.xml` 文件,显示按钮和文本框。
```xml
<?xml version="1.0" encoding="utf-8"?>
<LinearLayout xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:tools="http://schemas.android.com/tools"
android:id="@+id/activity_main"
android:layout_width="match_parent"
android:layout_height="match_parent"
android:background="#FFFFFF"
android:orientation="vertical"
tools:context=".MainActivity">
<LinearLayout
android:layout_width="match_parent"
android:layout_height="wrap_content"
android:orientation="horizontal"
android:paddingTop="5dp"
android:paddingBottom="5dp"
android:weightSum="10">
<Button
android:id="@+id/signIn"
android:layout_width="0dp"
android:layout_height="wrap_content"
android:layout_weight="5"
android:gravity="center"
android:text="Sign In"/>
<Button
android:id="@+id/clearCache"
android:layout_width="0dp"
android:layout_height="wrap_content"
android:layout_weight="5"
android:gravity="center"
android:text="Sign Out"
android:enabled="false"/>
</LinearLayout>
<LinearLayout
android:layout_width="match_parent"
android:layout_height="wrap_content"
android:gravity="center"
android:orientation="horizontal">
<Button
android:id="@+id/callGraphInteractive"
android:layout_width="0dp"
android:layout_height="wrap_content"
android:layout_weight="5"
android:text="Get Graph Data Interactively"
android:enabled="false"/>
<Button
android:id="@+id/callGraphSilent"
android:layout_width="0dp"
android:layout_height="wrap_content"
android:layout_weight="5"
android:text="Get Graph Data Silently"
android:enabled="false"/>
</LinearLayout>
<TextView
android:text="Getting Graph Data..."
android:textColor="#3f3f3f"
android:layout_width="match_parent"
android:layout_height="wrap_content"
android:layout_marginLeft="5dp"
android:id="@+id/graphData"
android:visibility="invisible"/>
<TextView
android:id="@+id/current_user"
android:layout_width="match_parent"
android:layout_height="0dp"
android:layout_marginTop="20dp"
android:layout_weight="0.8"
android:text="Account info goes here..." />
<TextView
android:id="@+id/txt_log"
android:layout_width="match_parent"
android:layout_height="0dp"
android:layout_marginTop="20dp"
android:layout_weight="0.8"
android:text="Output goes here..." />
</LinearLayout>
```
## <a name="test-your-app"></a>测试应用
### <a name="run-locally"></a>在本地运行
构建应用并将其部署到测试设备或模拟器。 你应能够登录并获取 Azure AD 或个人 Microsoft 帐户的令牌。
你登录后,此应用将显示从 Microsoft Graph `/me` 终结点返回的数据。
PR 4
### <a name="consent"></a>同意
任何用户首次登录你的应用时,Microsoft 标识都将提示他们同意所请求的权限。 某些 Azure AD 租户已禁用用户同意功能,这要求管理员代表所有用户同意。 若要支持此场景,需创建自己的租户或获得管理员的同意。
## <a name="clean-up-resources"></a>清理资源
如果不再需要,请删除[注册应用程序](#register-your-application) 步骤中创建的应用对象。
[!INCLUDE [Help and support](../../../includes/active-directory-develop-help-support-include.md)]
## <a name="next-steps"></a>后续步骤
在我们的多部分场景系列中,详细了解如何构建可调用受保护 Web API 的移动应用。
> [!div class="nextstepaction"]
> [方案:用于调用 Web API 的移动应用程序](scenario-mobile-overview.md) | 20,333 | CC-BY-4.0 |
---
id: 2855
title: 免费PDF虚拟打印机
date: 2014-04-22T18:29:44+08:00
author: chonghua
layout: post
guid: http://hechonghua.com/?p=2855
permalink: /free-pdf-creator/
categories:
- 软件资源
tags:
- pdf
---
一般来说,要与其他用户分享文档的最佳方法就是将文档转换成PDF格式,因为PDF格式不存在平台的问题,几乎有人用的平台就能支持PDF,而且PDF体积小巧、排版一致,成为事实上的标准。通常我们一般使用Adobe Acrobat系列软件来生成PDF文档,但是,Adobe Acrobat体积巨大,售价不菲,不是每个人都用得起的。其它的像是Openoffice,Word等软件,虽然可以输出为PDF格式,当有很大的局限性,只能生成所支持格式的PDF。所以通用的做法就是安装一个PDF虚拟打印机。
<!--more-->
<a href="http://download.cnet.com/PrimoPDF/3000-2016_4-10264577.html" target="_blank">PrimoPDF</a>
PrimoPDF是一个免费、使用简单的 PDF 转文件软件,这套PrimoPDF可以”伪装”自己是一台打印机,然后把所有可以打印的文件都用PDF格式输出,所以不论是Word、html、 Excel、jpg文件等等,只要是可以打印的文件,全部都可以转成PDF格式。而且输出的文件无水印,没有有效期。PrimoPDF号称是世界上最好的免费PDF虚拟打印机,在Download下载站排名第一,名符其实,值得一试。并且PrimoPDF还是开放源代码的。

#### [PDFCreator](http://www.pdfforge.org/pdfcreator)
除了安装成为打印驱动外, PDFCreator 还可以与.ps文件关联,这样可以手动将PostScript文件转换为 PDF 格式。
OpenCD 项目已经选择 PDFCreator 做为 自由开源软件(FOSS) 计划中Windows下制作 PDF 文件的最佳软件。
<img src="http://chonghua-1251666171.cos.ap-shanghai.myqcloud.com/PDFCreator.png" width="600" height="589" alt="免费PDF虚拟打印机" />
#### <a href="http://www.dopdf.com/cn/" target="_blank">doPDF</a>
doPDF 是一个免费的PDF转换器,可同时运用于商业和个人,它把自己安装为一个打印机驱动,允许从任意一个有打印输出的Windows程序中打印,还包含缩放,质量定义和页面大小定义。不需要第三方软件,像是 GhostScript 或是 .NET Framework 就可以建立 PDF 文件,这使得 doPDF 程序的文件大小,要比其它免费 PDF 打印机小非常多。官方原生多语言。
#### <a href="http://www.cutepdf.com/Products/CutePDF/writer.asp" target="_blank">CutePDF Writer</a>
CutePDF家族包括多种软件,其中此款免费,可以满足基本的打印生成PDF的需求。它也是基于GS,因此,请先从CutePDF网站下载并安装 [<a href="http://www.cutepdf.com/download/converter.exe" target="_blank">GPL Ghostscript转换程序</a>],然后再装CutePDF Writer。
它只有打印生成PDF的基本功能。如果需要页面多合一、删加页、旋转、页面大小、文件信息更改、加密等功能,可以使用下文介绍的相关工具。也可以下载 [CutePDF Writer Companion],与Writer无缝集成,实现更多功能。注意Companion内有一广告插件,可选择安装。
<img src="http://chonghua-1251666171.cos.ap-shanghai.myqcloud.com/cutepdf.png" width="600" height="540" alt="免费PDF虚拟打印机" />
#### <a href="http://www.tinypdf.com/" target="_blank">TinyPDF</a>
TinyPDF是一款小巧免费的PDF虚拟打印机程序,几乎可以把任何可打印的文档创建成专业品质的 PDF 文件。 。它不依赖Acrobat、GhostScript等程序,可以生成高质量的PDF文档。
本文为翻译文章,原文:<a title="http://dailytechpost.com/2014/04/12/free-pdf-creator/" href="http://dailytechpost.com/2014/04/12/free-pdf-creator/" target="_blank">http://dailytechpost.com/2014/04/12/free-pdf-creator/</a> | 2,566 | MIT |
---
layout: post
category: "DS"
title: "关于test数据的省时省力的方法"
---
* content
{:toc}
# 引入
关于测试数据,本来不应该给予过多的关注,但是,很多时候我们在调试数据上面浪费
了很多的时间,下面,这篇文章我将持续的更新,介绍自己方法。
# 打印
首先,写出一个头文件:
```c
#include<stdlib.h>
/*
*
* 使用方法,只需在主函数中声明i,j;
* Right now, i dont have realize extern from "header.h",
* Only to use "cat macro.h >> filename" ;
* 2016-03-11
*
*/
#define print_maritx_int(n,a) \
for (i = 0; i < n ;i++) \
{ \
printf("\n"); \
for (j = 0; j < n; j++) \
printf("%d\t",a[i][j]); \
}
```
目前我还没有实现导入外部头文件的方法使用这个宏,我的本意是是在需要的源文件
插入:
> extern print_maritx_int(n,a);
可惜,不给力,每次给我报错误,不知道是哪里的问题。
现在的解决方案很简单,就是这个头文件放在手头上,暂时将需要的宏用命令插进去。 | 639 | MIT |
---
author: alkohli
ms.service: storsimple
ms.topic: include
ms.date: 10/26/2018
ms.author: alkohli
ms.openlocfilehash: 350dbc286c060ad10c21ebe1e8715b910871f837
ms.sourcegitcommit: 48592dd2827c6f6f05455c56e8f600882adb80dc
ms.translationtype: HT
ms.contentlocale: ja-JP
ms.lasthandoff: 10/26/2018
ms.locfileid: "50165583"
---
<!--author=alkohli last changed: 11/02/17 -->
#### <a name="to-install-updates-via-the-azure-portal"></a>Azure Portal を使用して更新プログラムをインストールするには
1. StorSimple デバイス マネージャーに移動し、**[デバイス]** を選択します。 サービスに接続されているデバイスの一覧から、更新するデバイスを選択してクリックします。

2. **[設定]** ブレードで **[デバイスの更新プログラム]** をクリックします。

3. ソフトウェアの更新プログラムが利用可能な場合は、メッセージが表示されます。 更新プログラムを確認するには、**[スキャン]** をクリックします。 実行しているソフトウェアのバージョンをメモしておきます。

スキャンが開始され、正常に完了すると、その旨が通知されます。

4. 更新プログラムのスキャンが完了したら、**[更新プログラムのダウンロード]** をクリックします。

5. **[新しい更新プログラム]** ブレードで、リリース ノートを確認します。 更新プログラムをダウンロードしたら、インストールを確認する必要があることにもご注意ください。 Click **OK**.

6. アップロードが開始され、正常に完了すると、その旨が通知されます。

5. **[デバイスの更新プログラム]** ブレードで **[インストール]** をクリックします。

6. **[新しい更新プログラム]** ブレードで、更新には中断が伴うという警告が表示されます。 仮想アレイが単一ノード デバイスであるため、更新された後にデバイスが再起動されます。 これにより、進行中の IO が中断されます。 **[OK]** をクリックして、更新プログラムをインストールします。

7. インストール ジョブの開始されると、その旨が通知されます。

8. インストール ジョブが正常に完了したら、**[デバイスの更新プログラム]** ブレードの **[ジョブの表示]** リンクをクリックして、インストールを監視します。

**[更新プログラムのインストール]** ブレードに移動します。 ここでは、ジョブの詳細情報を確認できます。

9. 更新プログラム 0.6 (10.0.10293.0) のソフトウェア バージョンを実行している仮想アレイで開始した場合は、この時点で更新プログラム 1 が実行されており、アップデートは完了となります。 残りの手順を省略できます。 更新プログラム 0.6 (10.0.10293.0) より前のソフトウェア バージョンを実行している仮想アレイで開始した場合、この時点で更新プログラム 0.6 に更新されます。 更新プログラムが利用できることを示すメッセージがまた表示されます。 手順 4 - 8 を繰り返して更新プログラム 1 をインストールします。
 | 2,971 | BSD-Source-Code |
# 2021-11-25
共 212 条
<!-- BEGIN ZHIHUQUESTIONS -->
<!-- 最后更新时间 Thu Nov 25 2021 23:00:55 GMT+0800 (China Standard Time) -->
1. [陕西潼关肉夹馍协会官网疑似被黑客攻击,黑底绿字「无良协会」飘屏,具体情况如何?反映了哪些问题?](https://www.zhihu.com/question/501213997)
1. [11 月 25 日上海市新增 3 例本土确诊病例,目前当地情况如何?](https://www.zhihu.com/question/501530186)
1. [土耳其总统反向操作,坚持降息对抗通胀,近期里拉大贬值,一周暴跌 20%,苹果暂停该地区销售,你怎么看?](https://www.zhihu.com/question/501178367)
1. [如何看待上海宣布生育假从 30 天增加到 60 天?此举对促进生育将产生怎样的影响?](https://www.zhihu.com/question/501477980)
1. [学生因被困酒店厕所 16 小时错过专升本考试索赔 13 万,此次事件中酒店该承担哪些责任?](https://www.zhihu.com/question/500837857)
1. [《梦想改造家》建筑师陶磊住房被指违建,镇城管称「已前往测绘」,如果情况属实他会面临哪些责任?](https://www.zhihu.com/question/500878603)
1. [00 后上班太懒散,领导「发火」骂了滚,年轻人「发火」叫记者,两人谁该「发火」?](https://www.zhihu.com/question/489482590)
1. [如何看待甘肃白银当地居民认为,陶磊在《梦想改造家》中花费 132 万的改造房不如自家 5 万的房子?](https://www.zhihu.com/question/501407445)
1. [高校打印店张贴欠费 0.75 元学生照片,该处理方式是否妥当?如果你是打印店老板会怎么做?](https://www.zhihu.com/question/500904587)
1. [11 月 25 日杭州新增两例新冠肺炎无症状感染者,其中一人为浙大教职工,还有哪些信息值得关注?](https://www.zhihu.com/question/501588574)
1. [如何看待淄博一中学被曝要求高一学完高中全部课程,劝成绩好的学生「学习艺术,冲击清华美术学院」?](https://www.zhihu.com/question/501520341)
1. [我爸因为樊登说牛肉致痴不让我吃牛肉了,我该怎么办?](https://www.zhihu.com/question/499979556)
1. [如何看待中科大 5 名学生凌晨两点半发现实验室漏水,处置后被奖励 12 万元?科研人经常熬夜工作吗?](https://www.zhihu.com/question/501465611)
1. [如何看待腾讯手游《火影忍者》川剧自来也要 2000 元以上引争议后,官方迅速退费,忍者免费的处理?](https://www.zhihu.com/question/501092943)
1. [英国威廉王子称「由于人口增长,非洲野生动物面临的压力越来越大」,如何看待其言论?](https://www.zhihu.com/question/501356246)
1. [梦想改造家陶磊设计的西北红砖房怎么补救才能挽回节目口碑?](https://www.zhihu.com/question/501141628)
1. [字节跳动旗下大力教育将彻底放弃中小学业务,被裁员工获赔 n+2,被裁的两千名员工将何去何从?](https://www.zhihu.com/question/501362474)
1. [为什么川渝地区吃火锅时喜欢蘸油碟,而北方地区更喜欢麻酱呢?](https://www.zhihu.com/question/333401552)
1. [水浒里,西门庆为什么不给武大郎一笔钱,买下潘金莲做长久夫妻,而要害了武大性命?](https://www.zhihu.com/question/492755627)
1. [《英雄联盟》退役选手良小伞发声寻求试训机会,你有什么想说的?](https://www.zhihu.com/question/501340027)
1. [媒体称 BLACKPINK 成员 LISA 接种疫苗后确诊感染新冠,目前情况如何?](https://www.zhihu.com/question/501326049)
1. [上百商户被「库尔勒香梨协会」起诉,近期此类「地名+产品」模式起诉多发,这些协会是否合理使用商标专利法?](https://www.zhihu.com/question/501510540)
1. [杨幂现在的状态还适合演少女吗?](https://www.zhihu.com/question/499576882)
1. [面对一个长期不工作的老公,怎么办?](https://www.zhihu.com/question/403831716)
1. [如果你现在月薪过万,存款六位数,想花一万块买个相机过分吗?](https://www.zhihu.com/question/500982491)
1. [德国又一州将尝试完全使用 Linux 和 LibreOffice,对此你有哪些看法?](https://www.zhihu.com/question/500653831)
1. [如何评价杨紫在电视剧《女心理师》中的表现?](https://www.zhihu.com/question/500930603)
1. [心理咨询师是如何看待《女心理师》这部剧的?](https://www.zhihu.com/question/500981544)
1. [假如你写御兽流小说,御使什么才是最离谱又合理的?](https://www.zhihu.com/question/497887574)
1. [你的研究生导师是什么样的?](https://www.zhihu.com/question/298181420)
1. [初高中生年轻人应该追逐梦想,还是提高学历?](https://www.zhihu.com/question/500783038)
1. [因为intp一直不回消息,我生气之后被她冷处理,现在应该怎么办?](https://www.zhihu.com/question/494482491)
1. [如何看待郑州一女子辞职前骗走同事们 200 万后消失,她可能承担那些责任?同事间借款需要注意哪些事宜?](https://www.zhihu.com/question/501135400)
1. [离开互联网算法岗,切入最近大行其道的AI生物医药研发靠谱吗?](https://www.zhihu.com/question/488346668)
1. [我是个高三美术生,今天上了色彩课,然后发现了自己是个色盲,红绿不分,我该怎么办?](https://www.zhihu.com/question/421975708)
1. [多方消息指向 Uzi 将于 2021 转会期复出,他现在的实力状态还能适应职业的强度吗?](https://www.zhihu.com/question/501083156)
1. [如何评价《令人心动的 offer》第三季第三期(下)?](https://www.zhihu.com/question/501344261)
1. [动画《新秦时明月》开播,你感觉如何?](https://www.zhihu.com/question/501068047)
1. [花呗启动品牌隔离,将成为蚂蚁消金专属消费信贷品牌,与之前有哪些不同?会带来怎样的影响?](https://www.zhihu.com/question/501248601)
1. [如何看待宝可梦 DP 游戏《精灵宝可梦:晶灿钻石/明亮珍珠》复刻版?](https://www.zhihu.com/question/446607805)
1. [今年冬天计划滑雪旅行,国内有哪些推荐的雪场?](https://www.zhihu.com/question/499977639)
1. [是什么让你抛弃了 Windows 而转向 Mac?](https://www.zhihu.com/question/20585523)
1. [《黑客帝国:矩阵重生》确认引进,将于全国影院上映,时隔 20 年你觉得这部的票房和口碑还能爆吗?](https://www.zhihu.com/question/501056268)
1. [有什么适合冬天喝的甜甜的咖啡?](https://www.zhihu.com/question/499058418)
1. [科幻走向现实!NASA今天发射「飞镖」探测器拟将小行星撞离原轨道以保护地球,你如何看待这次科技探索?](https://www.zhihu.com/question/501257766)
1. [有没有舍不得换掉的全面屏手机壁纸?](https://www.zhihu.com/question/420662927)
1. [如何看待大疆与长光辰芯联合推出国产 8K 全画幅传感器?](https://www.zhihu.com/question/500958484)
1. [《甄嬛传》中的果郡王为什么不讨喜呢?换演员会好点吗?](https://www.zhihu.com/question/499278485)
1. [有哪些你一直坚持的好习惯?](https://www.zhihu.com/question/329310508)
1. [《复仇者联盟 4》之后的漫威电影质量是不是不如以前了?](https://www.zhihu.com/question/499936712)
1. [如何看待央视新闻 AI 手语主播正式亮相,将从冬奥会开始全年无休提供手语服务?](https://www.zhihu.com/question/501336223)
1. [什么事情是你当了老板才知道的?](https://www.zhihu.com/question/364147974)
1. [你有哪些「后悔没早读」的书籍?](https://www.zhihu.com/question/483988438)
1. [如何看待《中共中央、国务院关于加强新时代老龄工作的意见》鼓励成年子女与老年父母就近居住或共同生活?](https://www.zhihu.com/question/501345877)
1. [如何看待衡水居民拨打政务热线遭工作人员辱骂「打 12345 的人基本上都是废了」?暴露出什么问题?](https://www.zhihu.com/question/501356830)
1. [高三复读,做什么都是独来独往,自己感觉也挺好的,可能别人就觉得我挺孤独的,独来独往好吗?](https://www.zhihu.com/question/501219417)
1. [歼-15 舰载机着舰首飞成功 9 周年,你对国产舰载机有哪些期待?](https://www.zhihu.com/question/500989797)
1. [NBA 21-22 赛季 76 人 96:116 勇士,库里 25+10 带队逆转,如何评价这场比赛?](https://www.zhihu.com/question/501453709)
1. [对于中年人来说,哪些渠道比较好找工作?](https://www.zhihu.com/question/501060050)
1. [都说读博选导师大于学校排名,可是这个事情的界限在哪?](https://www.zhihu.com/question/500366814)
1. [云南哀牢山究竟有多凶险?](https://www.zhihu.com/question/500806226)
1. [NBA 21-22 赛季湖人加时 124:116 步行者,詹姆斯复出砍 39 分,如何评价这场比赛?](https://www.zhihu.com/question/501395527)
1. [二战法国你是贝当,你会投降吗?](https://www.zhihu.com/question/495356179)
1. [网传四川苍溪一网红被丈夫杀害,警方回应正在调查,事件具体情况如何?](https://www.zhihu.com/question/501279542)
1. [如何看待《原神》竞速榜榜首玩家 SanaQwQ 直播融号?《原神》圣遗物机制是否存在不合理?](https://www.zhihu.com/question/501360404)
1. [如何跟孩子解释「为什么方便面是卷曲的而不是直的」?](https://www.zhihu.com/question/499991484)
1. [当孩子问「鱼儿用什么呼吸」该如何回答?](https://www.zhihu.com/question/498110403)
1. [21-22 赛季欧冠曼城 2:1 巴黎圣日耳曼,如何评价这场比赛?](https://www.zhihu.com/question/501391765)
1. [恋爱之后让你明白了什么?](https://www.zhihu.com/question/36951304)
1. [如何以「我亲手杀了他,却世世守着他轮回」为开头写一个故事?](https://www.zhihu.com/question/493667312)
1. [目前预算不足,是选择廉价 CPU 和较好的 GPU,还是选择较好的 CPU 再整个亮机卡?](https://www.zhihu.com/question/500896127)
1. [11 月 25 日是国际反家暴日,应如何预防、处理家暴?有哪些行之有效的措施?](https://www.zhihu.com/question/501434696)
1. [如何看待 FPX 前员工对 Doinb 的评价?](https://www.zhihu.com/question/500876559)
1. [如何看待小米高管表示「小米第三季度市场占有率下降」主要与 iPhone 13 表现强势有关?](https://www.zhihu.com/question/501311080)
1. [如何看待游戏《FIFA Online 4》成为杭州亚运会正式项目?](https://www.zhihu.com/question/500782086)
1. [进入二次元世界,一千万或者考入 985 学校,你会选择哪一个?](https://www.zhihu.com/question/498766373)
1. [电影《教父》中有哪些易被忽略却令人深思的小细节?](https://www.zhihu.com/question/22920209)
1. [国内新造车企业势头很猛,它们是昙花一现还是有核心科技?](https://www.zhihu.com/question/501320667)
1. [有哪些物品,很适合小厨房的收纳整理?](https://www.zhihu.com/question/447760903)
1. [文科生和理科生看书角度是否真的不同?](https://www.zhihu.com/question/499811733)
1. [有哪些发朋友圈的沙雕文案?](https://www.zhihu.com/question/486583833)
1. [《知否》没如兰出身好,也没墨兰受宠,吴大娘子为何只看中明兰?](https://www.zhihu.com/question/402223494)
1. [2021 世乒赛周启豪负波尔成国乒出局第 1 人,张本 3:4 遭逆转淘汰, 男单战况很意外?](https://www.zhihu.com/question/501400188)
1. [大学四年时间,物理学能学到什么水平?](https://www.zhihu.com/question/496319121)
1. [写小说的时候,如何才能让相爱的两个人物变得对立?](https://www.zhihu.com/question/487057977)
1. [国内的哪个游戏质量可以超过《原神》?](https://www.zhihu.com/question/497894517)
1. [看完杨紫的新剧 《女心理师》你最大的感受是什么?](https://www.zhihu.com/question/501089687)
1. [如何评价美剧《鹰眼》第一集和第二集?](https://www.zhihu.com/question/501227929)
1. [普通人有没有必要打灭活新冠疫苗第三针?](https://www.zhihu.com/question/501376193)
1. [华为最新发布的新款二合一笔记本 MateBook E 的性价比如何,是否值得入手?](https://www.zhihu.com/question/499657277)
1. [巴巴多斯不再承认英女王为国家元首,英媒急呼「巴巴多斯成了小中国」,如何看待这种联想?](https://www.zhihu.com/question/500722409)
1. [没有玩过战地风云系列、想入手《战地2042》,要做什么准备吗?](https://www.zhihu.com/question/500579949)
1. [有没有什么又甜又虐的小说推荐?](https://www.zhihu.com/question/364002744)
1. [如何评价虚拟偶像 A-SOUL 对部分高校大学生的吸引力如此之大?](https://www.zhihu.com/question/500900104)
1. [如何看待电影《永恒族》导演赵婷力排众议,在片中保留了「黑人对广岛核爆痛哭反思」的剧情?](https://www.zhihu.com/question/501419451)
1. [如何评价2021年APMCM亚太地区大学生数学建模竞赛(2021亚太赛)?](https://www.zhihu.com/question/431888513)
1. [如何看待生活中经常出现「人工智能翻车」的情况,目前人工智能技术究竟发展到什么程度了?](https://www.zhihu.com/question/501007277)
1. [当孩子问「世界上最小的鱼是什么」该如何回答?](https://www.zhihu.com/question/499988560)
1. [大数据显示互联网大厂诉讼原告胜诉率高,判决结果与「主客场」无关,透露了什么信息?](https://www.zhihu.com/question/501073126)
1. [网传云南哀牢山遇难地质人员仅配备一次性塑料雨衣,或与其失温有关,是真的吗?为何会出现这种情况?](https://www.zhihu.com/question/501150344)
1. [可以推荐一些好吃的零食吗?](https://www.zhihu.com/question/488750070)
1. [动画《英雄联盟双城之战》中,希尔科为什么这么想杀蔚而不是收留蔚?](https://www.zhihu.com/question/499278184)
1. [为什么三大民工漫(死神,火影,海贼)没有龙珠呢?](https://www.zhihu.com/question/500713159)
1. [为什么公司永远都问不到员工离职的真实原因?](https://www.zhihu.com/question/493844417)
1. [用奖学金买 iPhone 13 会不会对不起父母?](https://www.zhihu.com/question/499188066)
1. [钱少但清闲的工作要继续吗?](https://www.zhihu.com/question/499243830)
1. [美国地铁被非裔暴徒殴打的华裔女性,被曝为「黑命贵」运动支持者,如何看待亚裔被反向歧视?](https://www.zhihu.com/question/501138781)
1. [瓜迪奥拉究竟是一个什么样的人?](https://www.zhihu.com/question/23158804)
1. [用极端落后技术(至少落后两代)造先进武器会造出什么奇葩来?](https://www.zhihu.com/question/478170187)
1. [如何看待四川开展超时加班专项执法检查,会带来哪些影响?](https://www.zhihu.com/question/501035523)
1. [如何评价华为调侃美国「黑五」,所有美国在售手机享 100% 折扣,随后又表示他们不能在美国卖任何东西?](https://www.zhihu.com/question/500998306)
1. [如何跟孩子解释「为什么要说‘上’厕所,‘下’厨房呢」?](https://www.zhihu.com/question/501106093)
1. [夏天的脚臭,冬天还会有味儿吗?](https://www.zhihu.com/question/500361037)
1. [如何看待山东两服务员调包 18 瓶茅台无人喝出异常,这两位服务员需要承担什么法律责任?](https://www.zhihu.com/question/500892506)
1. [下身胖怎么穿衣服显得好看?](https://www.zhihu.com/question/499186668)
1. [如何评价原神2.3版本北斗邀约任务?](https://www.zhihu.com/question/501265316)
1. [被要过微信的女生是因为长的好看吗?](https://www.zhihu.com/question/500613155)
1. [2021 年感恩节有哪些文案呢?](https://www.zhihu.com/question/497964014)
1. [如何看待菲律宾总统候选人登中业岛「宣誓主权」,收到短信「欢迎来到中国」?](https://www.zhihu.com/question/501177599)
1. [有哪些年轻人喜欢用,市面上比较热销的家电?](https://www.zhihu.com/question/500930342)
1. [如何评价《令人心动的 offer》第三季第三期(上)?](https://www.zhihu.com/question/501087282)
1. [动画《英雄联盟双城之战》希尔科和蔚到底谁更爱爆爆/金克丝?](https://www.zhihu.com/question/500576254)
1. [2021 KPL 秋季赛LGD大鹅 3:1 成都AG,如何评价这场比赛?](https://www.zhihu.com/question/501344594)
1. [无忧无虑且家里有钱漂亮的女生是什么样的?](https://www.zhihu.com/question/369021998)
1. [当面试官问「你能加班吗」是想问什么?怎么回答能加分?](https://www.zhihu.com/question/499229089)
1. [iPhone 15 概念设计图曝光,15 可能做出哪些升级和改变?](https://www.zhihu.com/question/501241765)
1. [天坑专业能考研吗?应该及时跑路转专业吗?](https://www.zhihu.com/question/499498038)
1. [如何评价人生一串第三季第二期?](https://www.zhihu.com/question/501347707)
1. [如何评价游戏《钢铁雄心》新 DLC 绝不后退(No Step Back)?](https://www.zhihu.com/question/501129988)
1. [阿斯伯格综合征的手写字体都是什么样的?](https://www.zhihu.com/question/427380255)
1. [如何看待 2021 转会期 Doinb 加入 LNG 战队?](https://www.zhihu.com/question/500652422)
1. [公司没有签劳动合同,员工申请仲裁,公司一定会输吗?](https://www.zhihu.com/question/500865462)
1. [11 月 25 日是感恩节,你有哪些感谢的话想对「旅行路上帮助过你的陌生人」说?](https://www.zhihu.com/question/494873539)
1. [杭州上调新房限价,个别板块涨了 2000 元/平方米。此政策有何影响?](https://www.zhihu.com/question/500937937)
1. [如何看待卖肉夹馍商户因「潼关」两个字被告?此事与逍遥镇胡辣汤是否有相同性质?](https://www.zhihu.com/question/501098535)
1. [网传腾讯旗下 App 不得新上架或版本更新,腾讯回应正配合监管部门进行合规检测,还有哪些信息值得关注?](https://www.zhihu.com/question/501292908)
1. [如何看待张艺兴作为艺人代表在 2021 中国网络媒体论坛上发表的演讲?](https://www.zhihu.com/question/501301934)
1. [上班第一天就听到同事吐槽公司,我该怎么办?](https://www.zhihu.com/question/491853906)
1. [《长津湖》票房超《战狼2》登顶中国影史票房第一,具有哪些意义?](https://www.zhihu.com/question/500714490)
1. [拉夏贝尔被申请破产清算,或将告别 A 股,曾经的「国民女装」为何会走向衰落?](https://www.zhihu.com/question/501088802)
1. [健身小白刚办了健身卡,在不请私教的情况下该如何训练?](https://www.zhihu.com/question/315892465)
1. [如何评价 A-Soul 的嘉然?](https://www.zhihu.com/question/443450817)
1. [媒体爆料称汪小菲已有新欢,大 S 和经纪人暂未回应, 如何评价两人的婚姻?](https://www.zhihu.com/question/500948534)
1. [如何看待继逍遥镇胡辣汤事件后,陕西潼关肉夹馍协会起诉数百家小吃店,近期有 210 个开庭公告?](https://www.zhihu.com/question/501235190)
1. [如何看待各大博物馆都在推出「考古式」盲盒?盲盒经济还会持续多久?](https://www.zhihu.com/question/501058715)
1. [客观评价一下白百何的演技?](https://www.zhihu.com/question/58843765)
1. [如果果郡王当初喜欢的是安陵容会怎么样呢?](https://www.zhihu.com/question/488825490)
1. [有哪些性价比高的粉底液值得推荐?](https://www.zhihu.com/question/314574738)
1. [为什么很多人说喜剧是最难演绎的?](https://www.zhihu.com/question/264359919)
1. [NBA 21-22 赛季湖人 100:106 尼克斯,威少 31+13+10,如何评价这场比赛?](https://www.zhihu.com/question/501138591)
1. [如何评价游戏扳机 Game Trigger 这家投资机构?](https://www.zhihu.com/question/407985683)
1. [新手该如何提高写作能力?](https://www.zhihu.com/question/500781048)
1. [21-22 赛季欧冠切尔西 4:0 尤文图斯,如何评价这场比赛?](https://www.zhihu.com/question/501133461)
1. [有没有特别委屈的文案?](https://www.zhihu.com/question/440934709)
1. [编程那么难,为什么不弄一个大众一学就会的计算机语言呢?](https://www.zhihu.com/question/500406718)
1. [为什么自己总是一个人?](https://www.zhihu.com/question/495160153)
1. [看了动画《英雄联盟双城之战》,符文大陆会不会成为下一个漫威宇宙?](https://www.zhihu.com/question/499364068)
1. [我们读书的意义是什么呢?](https://www.zhihu.com/question/499129635)
1. [如何向孩子解释「为什么飞机能飞上天」?](https://www.zhihu.com/question/500256610)
1. [适合在北方冬季穿的厚外套有哪些推荐?](https://www.zhihu.com/question/493413782)
1. [过生日,男朋友送了一条金项链,该收吗?](https://www.zhihu.com/question/500064501)
1. [可以分享一下伤感文案吗?](https://www.zhihu.com/question/479988450)
1. [如何跟 5 岁的小孩子解释宇宙飞船和飞机有什么不一样?](https://www.zhihu.com/question/447361031)
1. [11 月 23 日北京中关村地库一比亚迪电动汽车起火,事故原因可能是什么?目前情况如何?](https://www.zhihu.com/question/500960060)
1. [哪种食物有利于美白皮肤?](https://www.zhihu.com/question/468527303)
1. [在你生命中,对你最重要的是什么?](https://www.zhihu.com/question/499281115)
1. [你感觉能力跟学历哪个更重要?](https://www.zhihu.com/question/497552777)
1. [衣服被同学弄丢了,该怎么解决?](https://www.zhihu.com/question/498942241)
1. [在你熟悉的领域里,有哪些创新在悄悄改变生活?](https://www.zhihu.com/question/500695607)
1. [广东一老人洗虾手指遭刺被迫截肢保命,被海鲜扎伤为什么伤害这么大?日常处理食材有没有什么技巧?](https://www.zhihu.com/question/500889984)
1. [如果人类是反刍动物,胃病患者数量是否会大幅度减少?](https://www.zhihu.com/question/496418756)
1. [快三十了,干了快九年的工作在一线城市月入 4~6k 还要继续吗?](https://www.zhihu.com/question/500698069)
1. [你觉得打工好还是创业好呢?](https://www.zhihu.com/question/492063575)
1. [安全工程出来之后找工作怎么样,工资多少?](https://www.zhihu.com/question/495287420)
1. [国台办称「大陆正规划两岸交通建设,福建完成与金门、马祖通桥初步方案」,这对两岸经济发展有哪些积极意义?](https://www.zhihu.com/question/501194267)
1. [我们辛苦地工作就只是为了生活上的享受吗?](https://www.zhihu.com/question/500228773)
1. [当孩子问「地球上的水是从哪里来的」该如何回答?](https://www.zhihu.com/question/499988775)
1. [当孩子问「鱼类是否会飞翔」该如何回答?](https://www.zhihu.com/question/498110417)
1. [如何看待《令人心动的 offer 》中提到的医生职业成长期的「熬」,好医生都是熬出来的么?](https://www.zhihu.com/question/500764689)
1. [电影《沙丘》其实换个中世纪魔幻背景也毫无问题吧?](https://www.zhihu.com/question/500488287)
1. [公务员考试是本科毕业就考好,还是考研后再考?](https://www.zhihu.com/question/499679435)
1. [云南 4 名地质队员遇难,搜救队员称「或因罗盘失灵,失温所致」,失温有多可怕?哪些装备能更好保护他们?](https://www.zhihu.com/question/500928729)
1. [孩子情绪崩溃,母亲不理解孩子的心理,作为父亲怎么做合适?](https://www.zhihu.com/question/495643871)
1. [研一新生,写了一篇较差的论文发给导师,感觉要被批评,怎么办?](https://www.zhihu.com/question/491096343)
1. [你住过最贵的酒店是哪家?](https://www.zhihu.com/question/35236983)
1. [郑州 8 元爱心面馆老板疑被同行威胁,涉事者将承担怎样的责任?该如何解决爱心与同行竞争间的矛盾?](https://www.zhihu.com/question/500812179)
1. [做独立游戏制作人真的很难吗?](https://www.zhihu.com/question/431681557)
1. [语文作文里面有什么高级词汇能替换众所周知的词语?](https://www.zhihu.com/question/318964543)
1. [女生写起点男频小说,有哪些难度?](https://www.zhihu.com/question/501183300)
1. [生活好浮躁,有哪些反焦虑的句子?](https://www.zhihu.com/question/489496108)
1. [《女心理师》有哪些戳中你的细节?](https://www.zhihu.com/question/500980783)
1. [武汉警方已受理「女子以死对抗遛狗人」案,称该案为「重大疑难案件」,如何从法律角度分析其立案难点?](https://www.zhihu.com/question/501171913)
1. [隐晦表达爱意的文案有哪些?](https://www.zhihu.com/question/489364707)
1. [有什么类似《国王排名》这样好看的动漫?](https://www.zhihu.com/question/497075886)
1. [有哪些描写雪的很美的诗词?](https://www.zhihu.com/question/302508179)
1. [当今最前沿的理论物理学家都在干什么?是否还有一场物理学革命在前方等着我们?](https://www.zhihu.com/question/499914286)
1. [如何评价动画《英雄联盟:双城之战》中的角色「梅尔」?](https://www.zhihu.com/question/499027801)
1. [如何看待网易云音乐将于 12 月 2 日挂牌上市?这对在线音乐市场有什么影响?](https://www.zhihu.com/question/500928888)
1. [怎样看待年轻人「辞职式养生」?反映了哪些问题?](https://www.zhihu.com/question/496961304)
1. [如何看待公司同工不同酬的现象?](https://www.zhihu.com/question/388136268)
1. [男女朋友存在的意义是什么,谈恋爱的意义何在?](https://www.zhihu.com/question/61467321)
1. [湖南一女主播喝药自杀,骨灰被殡葬从业者掉包配阴婚,涉案人员将面临什么处罚?起到了什么警示作用?](https://www.zhihu.com/question/501012306)
1. [如果高铁上有一节车厢承包给电影院搞成观影车厢是不是个好主意?](https://www.zhihu.com/question/499915495)
1. [建筑师和设计师怎么看待《梦想改造家》第三季第八期陶磊的作品?](https://www.zhihu.com/question/500723840)
1. [下雪天为什么这么浪漫?](https://www.zhihu.com/question/266462404)
1. [中演协将吴亦凡、郑爽、张哲瀚等 88 人列入警示名单,你有什么想说的?还有哪些信息值得关注?](https://www.zhihu.com/question/501054451)
1. [东部战区回应美舰过航台湾海峡称「将采取一切必要措施,坚决反制一切威胁挑衅」,释放了什么信号?](https://www.zhihu.com/question/501017271)
1. [11 月 22 日俄前司令「库尔斯克号核潜艇沉没原因为与北约潜艇相撞」,发生此次事故的原因有哪些?](https://www.zhihu.com/question/500818710)
1. [调查报告显示「超九成大学生认为直播行业有发展前景」,反映了哪些问题?该行业发展现状如何?](https://www.zhihu.com/question/500697906)
1. [程序员周报写不出来怎么办?](https://www.zhihu.com/question/495754023)
1. [动物是住在动物园好,还是住在野外好?](https://www.zhihu.com/question/500225337)
1. [天冷的时候,家中的哪些地方特别有「温暖的治愈感」?](https://www.zhihu.com/question/496406610)
<!-- END ZHIHUQUESTIONS --> | 16,530 | MIT |
---
layout: article
title: "三天打鱼两天晒网"
date: 2022-02-05
mode: immersive
header:
theme: dark
article_header:
type: overlay
theme: dark
background_color: '#203028'
background_image:
gradient: 'linear-gradient(135deg, rgba(34, 139, 87 , .4), rgba(139, 34, 139, .4))'
src: assets/images/cover.jpg
modify_date: 2022-02-05
author: "Bedoom"
mathjax_autoNumber: false
show_tags: true
tags:
- 考研心得
---
考研虽然不如高考,但也是千军万马过独木桥。于我而言,考试向来不是难事,8 门科目,1 周时间,就足以不会挂科。但,如果这样,我能考研吗?
<!--more-->

考研人中有比我努力的,有比我聪明的,有比我能熬的,那这样的我想来结果并不是很好。因此我寻求改变。
往常,早上我总是在GitHub中寻找有意思、有趣的项目,加以实现。这一个月里,因为选课太肝,因此学习爬虫基础,以减轻选课压力;因为在bilibili上看到一个qq机器人,因此接触nonebot;因为过年抢红包,因此看了看Hamibot的编写脚本方式,但由于JavaScript没有学,我又去学了一下JavaScript。而现在我又在看机器学习相关内容。

今年,我要考研,但我却没有办法权衡二者的时间,有时我会一天都在弄脚本,所以高数忘了学。最近心情有些急躁,因为没有退路,但我并不喜欢被动,我想要主动权,但是没有办法得到。ε=(´ο`*)))唉,这是我最后一个项目了吧,往后,要考研啦!
计算机行业不存在大器晚成,年轻就应该多闯闯,看遍大千世界,经历人间百态。毕竟 35 岁危机并不会消失,所以程序员也是一个青春饭?不管怎样,选择的路,就算是爬也要到达终点。加油,奥利给
 | 1,215 | MIT |
---
toc : true
title : "JMS实现参数的集中式管理"
description : "JMS实现参数的集中式管理"
zhuan : true
tags : [
"JMS",
"UCM"
]
date : "2017-09-05 17:12:36"
categories : [
"JMS",
"技术"
]
menu : "main"
---
# 点评
虽然现在开源的UCM套件很多,UCM统一配置管理(百度的disconf、阿里的diamond、点评的lion,等很多开源的)。但是很多人是知其然不知其所以然,刚好发现下面这篇文章可以作为原理的教程文章,使用JMS、Redis、Zookeeper简单的实现UCM基本功能,作为学习交流还是很不错的。
文章转自:https://my.oschina.net/OutOfMemory/blog/1510101
作者:@ksfzhaohui
## 前言
JMS的发布订阅机制也能实现类似的功能,集群节点通过订阅指定的节点,同时使用JMS对消息的过滤器功能,实现对指定参数的更新,本文将介绍通过JMS实现简单的参数集中式管理。
## Maven引入
Spring相关的jar引入参考上一篇文章
```xml
<dependency>
<groupId>javax.jms</groupId>
<artifactId>jms</artifactId>
<version>1.1</version>
</dependency>
<dependency>
<groupId>org.apache.activemq</groupId>
<artifactId>activemq-all</artifactId>
<version>5.10.0</version>
</dependency>
```
## 目标
1. 可以同时配置监听多个节点如/app1,/app2;
2. 希望只需要配置如/app1,就能够监听其子节点如/app1/modual1以及子节点的子节点如/app1/modual1/xxx/…;
3. 服务器启动能获取当前指定父节点下的所有子节点数据;
4. 在添加节点或者在更新节点数据的时候能够动态通知,这样代码中就能够实时获取最新的数据;
5. spring配置中可以从Zookeeper中读取参数进行初始化。
虽然在实现的方式上有点区别,但是最终达成的目标是一致的,同样列出了这5条目标
## 实现
MQWatcher主要用来和JMS建立连接,同时订阅指定节点,建立点对点连接,过滤出需要监听的数据,更新数据,初始化数据,存储数据等
InitConfServer主要作为点对点连接的服务器端用来初始化数据
1.同时配置监听多个节点
提供一个字符串数组给用户用来添加需要监听的节点:
```java
private String[] keyPatterns;
```
2.能够监听其子节点以及子节点的子节点
使用了一种和Zookeeper不一样的方式,JMS的方式是将所有的数据变更都发送到订阅者,然后订阅者通过过滤出需要的数据进行更新
```java
/** MQ的过滤器 **/
private StringBuffer keyFilter = new StringBuffer();
private final String TOPIC = "dynamicConfTopic";
private void watcherPaths() throws JMSException {
Topic topic = session.createTopic(TOPIC);
MessageConsumer consumer = session.createConsumer(topic, keyFilter.toString());
consumer.setMessageListener(new MessageListener() {
@Override
public void onMessage(Message message) {
try {
String key = message.getStringProperty(IDENTIFIER);
TextMessage tm = (TextMessage) message;
keyValueMap.put(key, tm.getText());
LOGGER.info("key = " + key + ",value = " + tm.getText());
} catch (JMSException e) {
LOGGER.error("onMessage error", e);
}
}
});
}
```
对TOPIC进行了订阅,并且指定了过滤器keyFilter,keyFilter正是基于keyPatterns组装而成的
```java
private final String IDENTIFIER = "confKey";
/**
* 生成接受过滤器
*/
private void generateKeyFilter() {
for (int i = 0; i < keyPatterns.length; i++) {
keyFilter.append(IDENTIFIER + " LIKE '" + keyPatterns[i] + "%'");
if (i < keyPatterns.length - 1) {
keyFilter.append(" OR ");
}
}
LOGGER.info("keyFilter : " + keyFilter.toString());
}
```
对指定的属性IDENTIFIER,通过LIKE和OR关键字进行过滤
3.服务器启动初始化节点数据
通过点对点的方式,在服务器启动时通过请求响应模式来获取初始化数据
```java
private final String QUEUE = "dynamicConfQueue";
/**
* 初始化key-value值
*
* @throws JMSException
*/
private void initKeyValues() throws JMSException {
TemporaryQueue responseQueue = null;
MessageProducer producer = null;
MessageConsumer consumer = null;
Queue queue = queueSession.createQueue(QUEUE);
TextMessage requestMessage = queueSession.createTextMessage();
requestMessage.setText(generateKeyString());
responseQueue = queueSession.createTemporaryQueue();
producer = queueSession.createProducer(queue);
consumer = queueSession.createConsumer(responseQueue);
requestMessage.setJMSReplyTo(responseQueue);
producer.send(requestMessage);
MapMessage receiveMap = (MapMessage) consumer.receive();
@SuppressWarnings("unchecked")
Enumeration<String> mapNames = receiveMap.getPropertyNames();
while (mapNames.hasMoreElements()) {
String key = mapNames.nextElement();
String value = receiveMap.getStringProperty(key);
keyValueMap.put(key, value);
LOGGER.info("init key = " + key + ",value = " + value);
}
}
```
通过对指定QUEUE请求,同时建立一个临时的响应QUEUE,然后接受一个MapMessage,用来初始化keyValueMap
4.监听节点数据的变更
通过发布订阅模式,接受所有数据,然后进行过滤,目标2中已经有相关实现
5.spring配置中可以从Zookeeper中读取参数进行初始化
```java
public class MQPropPlaceholderConfigurer extends PropertyPlaceholderConfigurer {
private MQWatcher mqwatcher;
@Override
protected Properties mergeProperties() throws IOException {
return loadPropFromMQ(super.mergeProperties());
}
/**
* 从MQ中加载配置的常量
*
* @param result
* @return
*/
private Properties loadPropFromMQ(Properties result) {
mqwatcher.watcherKeys();
mqwatcher.fillProperties(result);
return result;
}
}
```
通过以上的处理,可以使用如下简单的配置来达到目标:
```xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-3.0.xsd
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.0.xsd
http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-3.0.xsd">
<bean id="person" class="zh.maven.DynamicConf.Person">
<property name="name">
<value>${/a2/m1}</value>
</property>
<property name="address">
<value>${/a3/m1/v2}</value>
</property>
<property name="company">
<value>${/a3/m1/v2/t2}</value>
</property>
</bean>
<bean id="mqwatcher" class="zh.maven.DynamicConf.mq.MQWatcher">
<property name="keyPatterns" value="/a2,/a3" />
</bean>
<bean id="propertyConfigurer" class="zh.maven.DynamicConf.mq.MQPropPlaceholderConfigurer">
<property name="mqwatcher" ref="mqwatcher"></property>
</bean>
</beans>
```
## 测试
1.启动ActiveMQ
```
activemq.bat
```
2.InitConfServer启动
用来监听集群节点的初始化请求,获取到集群节点发送来的keyPatterns,然后将符合其模式的数据封装成MapMessage发送给集群节点
```java
@Override
public void onMessage(Message message) {
try {
TextMessage receiveMessage = (TextMessage) message;
String keys = receiveMessage.getText();
LOGGER.info("keys = " + keys);
MapMessage returnMess = session.createMapMessage();
returnMess.setStringProperty("/a2/m1", "zhaohui");
returnMess.setStringProperty("/a3/m1/v2", "nanjing");
returnMess.setStringProperty("/a3/m1/v2/t2", "zhaohui");
QueueSender sender = session.createSender((Queue) message.getJMSReplyTo());
sender.send(returnMess);
} catch (Exception e) {
LOGGER.error("onMessage error", e);
}
}
```
以上代码只是进行了简单的模拟,提供了一个思路
3.启动Main类
```java
public class Main {
public static void main(String[] args) throws Exception {
ApplicationContext context = new ClassPathXmlApplicationContext(new String[] { "spring-config.xml" });
Person person = (Person) context.getBean("person");
System.out.println(person.toString());
}
}
```
4.启动TopicPublisher
定时发布数据,同时查看集群节点的Main类日志输出
```java
public class TopicPublisher {
private static final String TOPIC = "dynamicConfTopic";
private static final String IDENTIFIER = "confKey";
public static void main(String[] args) throws JMSException {
ActiveMQConnectionFactory factory = new ActiveMQConnectionFactory("tcp://localhost:61616");
Connection connection = factory.createConnection();
connection.start();
Session session = connection.createSession(false, Session.AUTO_ACKNOWLEDGE);
Topic topic = session.createTopic(TOPIC);
MessageProducer producer = session.createProducer(topic);
producer.setDeliveryMode(DeliveryMode.NON_PERSISTENT);
int i=1;
while (true) {
TextMessage message = session.createTextMessage();
message.setStringProperty(IDENTIFIER, "/a2/"+i);
message.setText("message_" + System.currentTimeMillis());
producer.send(message);
System.out.println("Sent message: " + message.getText());
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
i++;
}
}
}
```
日志输出如下:
```log
2017-08-14 21:52:23 - keyFilter : confKey LIKE '/a2%' OR confKey LIKE '/a3%'
2017-08-14 21:52:24 - init key = /a3/m1/v2/t2,value = zhaohui
2017-08-14 21:52:24 - init key = /a3/m1/v2,value = nanjing
2017-08-14 21:52:24 - init key = /a2/m1,value = zhaohui
2017-08-14 21:52:24 - Pre-instantiating singletons in org.springframework.beans.factory.support.DefaultListableBeanFactory@223dd567: defining beans [person,mqwatcher,propertyConfigurer]; root of factory hierarchy
name = zhaohui,address = nanjing,company = zhaohui
2017-08-14 21:52:33 - key = /a2/1,value = message_1502718753819
2017-08-14 21:52:35 - key = /a2/2,value = message_1502718755832
2017-08-14 21:52:37 - key = /a2/3,value = message_1502718757846
2017-08-14 21:52:39 - key = /a2/4,value = message_1502718759860
2017-08-14 21:52:41 - key = /a2/5,value = message_1502718761876
```
## 总结
通过JMS实现了一个简单的参数化平台系统,当然想在生产中使用还有很多需要优化的地方,本文在于提供一个思路;后续有时间准备对DynamicConf提供更加完善的方案。 | 9,205 | MIT |
<!--
* @Author: your name
* @Date: 2021-01-27 14:31:52
* @LastEditTime: 2021-02-22 17:31:07
* @LastEditors: Please set LastEditors
* @Description: In User Settings Edit
* @FilePath: \electron-serialport-start\README.md
-->
## electron 和 serialport 项目整合(编译打包成安装包全流程)
项目地址: 项目地址: https://github.com/han-guang-xue/electronSerialport
下载项目
```shell
cnpm|npm install #安装包依赖
npm run rebuild #编译serialport文件
npm run builder #打包并发布
```
## 使用 electron-builder 打包碰见的问题
碰见的问题:
1. 在使用 electron-rebuild 重新编译之后开发环境中是正常使用,但是 electron-build 打包之后,串口连接返回错误状态码(electron 版本是 9.0.5)
解决方案: 替换 electron 版本为 11.1.0
2. 替换 electron 版本为 11.1.0 之后, 直接使用 electron-builder 编译打包, 串口接口使用报错; 报错信息:
```java
TypeError: Third argument must be a function
at internal/util.js:297:30
at new Promise (<anonymous>)
at open (internal/util.js:296:12)
at WindowsBinding.open (C:\Program Files\client\resources\app\node_modules\serialport\node_modules\@serialport\bindings\lib\win32.js:56:22)
at processTicksAndRejections (internal/process/task_queues.js:97:5)
```
解决方案: 在 package.json 中的 build 中配置 `"buildDependenciesFromSource":true,`
```json
"build": {
"directories": {"output":"E:\\YCXGIT\\building\\build17"},
"asar":false,
"buildDependenciesFromSource":true,
"appId": "com.vasen.serialport",
"mac": {
"target": [
"dmg"
]
},
"win": {
"target": [
"nsis"
]
},
"nsis": {
"oneClick": false,
"perMachine": true,
"allowElevation": true,
"allowToChangeInstallationDirectory": true
}
},
```
## electron 实现单例程序
该方式只针对 electron@3 以上的
```JavaScript
const getTheLock = app.requestSingleInstanceLock()
if (!getTheLock) {
app.quit()
return
} else {
app.on('second-instance', (event, commandLine, workingDirectory) => {
//isMinimized 判断窗口是否最小化
if (loginWin) {
if (loginWin.isMinimized()) loginWin.restore()
loginWin.focus() //聚焦
}
if (mainWin) {
if (mainWin.isMinimized()) mainWin.restore()
mainWin.focus()
}
})
app.on('ready', createLoginWin)
}
```
## electron 中如何使用 jquery, 去除 require 导入模块引起的冲突
在创建窗体的时候添加属性 `nodeIntegration: false`
```JavaScript
webPreferences: {
nodeIntegration: false
}
``` | 2,260 | CC0-1.0 |
---
layout: post
title: "设计模式:观察者模式"
subtitle: "观察者模式"
date: 2016--08-21 15:20:00
author: "Lushun"
header-img: "img/post-bg-2015.jpg"
catalog: true
tags:
- 设计模式
---
## 设计原则
为了交互对象的松耦合设计而努力。
## 定义
定义了对象之间的一对多依赖,这样一来,当一个对象改变状态时,它的所有依赖者都会收到通知并自动更新。
## 类图

## 代码
{% highlight ruby %}
public interface Subject {
void addObserver(Observer observer);
void removeObserver(Observer observer);
void notifyObservers();
}
public class WeatherSubject implements Subject {
private double temprature;
private double humidity;
private double pressure;
/*
* 增加heat属性,只需要修改这个WeatherSubject类,和Test测试类,不需要修改观察者类。
*/
private double heat;
private List<Observer> observers = new ArrayList<>();
public WeatherSubject() {
super();
}
public WeatherSubject(double temprature, double humidity, double pressure,double heat) {
super();
this.temprature = temprature;
this.humidity = humidity;
this.pressure = pressure;
this.heat = heat;
}
@Override
public void addObserver(Observer observer) {
observers.add(observer);
}
@Override
public void removeObserver(Observer observer) {
int index = observers.indexOf(observer);
if(index>=0)
observers.remove(index);
}
@Override
public void notifyObservers() {
for(Observer observer : observers)
observer.update();
}
public void measurementsChanged(){
notifyObservers();
}
@Override
public String toString() {
return "WeatherSubject [temprature=" + temprature + ", humidity="
+ humidity + ", pressure=" + pressure + ", heat=" + heat + "]";
}
}
public interface Observer {
public void update();
public void unregitst(Subject subject);
public void regist(Subject subject);
}
public interface Displayable {
public void display();
}
public class ConcurrentConditionObserver implements Observer, Displayable {
private Subject subject;
public ConcurrentConditionObserver(Subject subject) {
super();
this.subject = subject;
this.subject.addObserver(this);
}
public Subject getSubject() {
return subject;
}
public void setSubject(Subject subject) {
this.subject = subject;
}
@Override
public void display() {
System.out.println(subject.toString());
}
@Override
public void update() {
System.out.println("更新当前天气板:"+subject);
display();
}
@Override
public void unregitst(Subject subject) {
this.subject.removeObserver(this);
}
@Override
public void regist(Subject subject) {
setSubject(subject);
subject.addObserver(this);
}
}
public class ForecastObserver implements Observer, Displayable {
private Subject subject;
public ForecastObserver(Subject subject) {
super();
this.subject = subject;
this.subject.addObserver(this);
}
public Subject getSubject() {
return subject;
}
public void setSubject(Subject subject) {
this.subject = subject;
}
@Override
public void display() {
System.out.println(subject.toString());
}
@Override
public void update() {
System.out.println("更新了天气预告板:"+subject.getClass());
display();
}
@Override
public void unregitst(Subject subject) {
this.subject.removeObserver(this);
}
@Override
public void regist(Subject subject) {
setSubject(subject);
subject.addObserver(this);
}
}
{% endhighlight %} | 3,585 | Apache-2.0 |
### # 文本<a id="文本"></a>
> 数据绑定最常见的形式就是使用“Mustache”语法 (双大括号) 的文本插值:
`<span>{{message}}</span>`
`v-once指令`数据只会在页面创建的时候插入一次,update时不再改变
```html
<!--
Vue 会`响应式`刷新
每当数据更新,Mustache中的变量都会更新。
可以通过v-once指令,实现只插入一次。
-->
<span v-once>{{message}}</span>
```
### # HTML<a id="文本"></a>
> 默认情况下Mustache会将HTML渲染成文本,为了渲染真的HTML,需要使用`v-html指令`
```html
<p>Using mustaches: {{ rawHtml }}</p>
<p>Using v-html directive: <span v-html="rawHtml"></span></p>
```
> <div id="app-1">
<p>Using mustaches: {{ rawHtml }}</p>
<p>Using v-html directive: <span v-html="rawHtml"></span></p>
</div>
### # Attribute<a id="Attribute"></a>
Mustache 语法不能作用在 HTML attribute 上,遇到这种情况应该使用 `v-bind` 指令:
> 即不能这么使用:
`<span id="{{id}}"></span>`
> 遇到这种情况要使用指令
> `<span v-bind:id="id"></span>`
对于布尔 attribute (它们只要存在就意味着值为 `true`),`v-bind` 工作起来略有不同,在这个例子中:
`<button v-bind:disabled="isButtonDisabled"></button>`
> <div id="app-2">
<button v-bind:disabled="isButtonDisabled1">不能使用</button>
<button v-bind:disabled="isButtonDisabled2">可以使用</button>
</div>
### # 使用JavaScript表达式<a id="使用JavaScript表达式"></a>
> `JavaScript`原生的一些方法
例如:
```html
{{number + 1}}
{{ok ? 'yes' : 'no'}}
{{message.split('').reverse.join('')}}
<div v-bind:id="'list-' + id"></div>
```
> <div id="app-3">
<p>number: {{number}}</p>
<p>number + 1: {{number + 1}}</p>
<p>ok: {{ok}}</p>
<p>ok: {{ok ? 'yes' : 'no'}}</p>
<p>message: {{message}}</p>
<p>message reverse: {{message.split('').reverse().join('')}}</p>
</div>
每个绑定的表达式必须是单个表达式,所以一些不会被解析。
```html
<!-- 这是语句,不是表达式 -->
{{ var a = 1 }}
<!-- 流控制也不会生效,请使用三元表达式 -->
{{ if (ok) { return message } }}
```
<script>
new Vue({
el: '#app-1',
data: {
rawHtml: '<span>测试插入原生HTML</span>'
}
});
new Vue({
el: '#app-2',
data: {
isButtonDisabled1: true,
isButtonDisabled2: false,
}
});
new Vue({
el: '#app-3',
data: {
number: 2,
ok: true,
message: 'this is some text!!!',
}
});
</script> | 2,008 | MIT |
# Typeh<img src="../images/title-logo.png" align="top" width="24px">le
为所有运行时可序列化的值自动生成 Typescript 类型和接口
[English](../README.md) | [简体中文](#)
Typehole 是 Visual Studio Code 的 TypeScript 开发工具,它通过将运行时的值从 Node.js 或浏览器应用程序中桥接到代码编辑器来自动创建静态类型。当您需要 API 响应的类型或想要得到来自 JS 模块值的类型时,它是非常有用的。
<br/>
<br/>

## 安装
安装 [Visual Studio Code - extension](https://marketplace.visualstudio.com/items?itemName=rikurouvila.typehole) 即可,不需要额外的构建工具或编译器插件。
## 它是如何工作的?
1. 从一个接口中获得 `any` / `unknown` 类型的值的类型。
```typescript
const response = await axios.get("https://reddit.com/r/typescript.json");
const data /* any */ = response.data;
```
2. 通过选择表达式并按 ⌘ + 打开 **Quick Fix** 菜单,将值放置在 typeholes 中。 (macOS) 或 ctrl + . (Windows) 并选择 **Add a typehole**。
```typescript
type RedditResponse = any; // 由扩展插入的类型占位符
const response = await axios.get("https://reddit.com/r/typescript.json");
const data: RedditResponse = typehole.t(response.data);
```
3. 在浏览器或 Node.js 中运行您的代码。 Typehole 会在运行时捕获该值并将其发送回您的代码编辑器。VSCode 扩展会记录捕获的值,将来自该 typehole 的所有值转换为一个 interface 并将其插入到同一个模块中。
```typescript
interface RedditResponse {
/* ✨ 实际的字段和类型是自动生成的 ✨ */
}
const response = await axios.get("https://reddit.com/r/typescript.json");
const data: RedditResponse = typehole.t(response.data);
```
4. 移除 typehole,就完成了所有的操作。 Typeholes 仅用于开发阶段,所以您不应该提交它们。 Typehole 为您提供了 2 个 [命令](#命令) 来轻松移除 typehole
```typescript
interface RedditResponse {
/* ✨ 实际的字段和类型是自动生成的 ✨ */
}
const response = await axios.get("https://reddit.com/r/typescript.json");
const data: RedditResponse = response.data;
```
这个插件任然是实验性质的,如有问题请反馈 issues
## 特性
- 从运行中的值生成 Typescript 类型
- 使用不同的值多次运行代码,从而增加您的类型<br/><br/><img width="500" src="../images/samples.gif" />
- 使用代码操作将值自动包装到 typeholes<br/><br/><img width="500" src="../images/code-action.png" />
### 值能够自动的被转换为类型
所有原始值和 JSON 可序列化的值。
- Booleans
- Numbers
- Strings
- Arrays
- Objects
- null
因此,您可以其作为 HTTP 请求有效负载,接收的所有值都可以转换为 interface。
从 1.4.0 开始,支持 Promise。所有其他值(函数等)将被输入为 `any`。
## 命令

- 默认情况下不需要手动启动和停止服务器。 添加第一个 typehole 后,服务器将启动。
## 扩展设置
| 设置 | 类型 | 默认值 | 描述 |
| ------------------------------- | ----------------- | --------- | ------------------------------------------------ |
| typehole.runtime.autoInstall | boolean | true | 添加第一个 typehole 时自动安装 Typehole 运行时包 |
| typehole.runtime.projectPath | string | | 安装 Typehole 运行时的项目目录 |
| typehole.runtime.packageManager | npm \| yarn | npm | 安装运行时使用的包管理器 |
| typehole.runtime.extensionPort | number | 17341 | 监听传入示例的 HTTP 扩展的 HTTP 端口 |
| typehole.typeOrInterface | interface \| type | interface | 生成类型的关键字 |
## 运行时
Typehole 运行时的工作是捕获代码中的值,并将它们以序列化格式发送给扩展。
```typescript
import typehole from "typehole";
// -> POST http://extension/samples {"id": "t", "sample": "value"}
typehole.t("value");
// -> POST http://extension/samples {"id": "t1", "sample": 23423.432}
typehole.t1(23423.432);
// -> POST http://extension/samples {"id": "t2", "sample": {"some": "value"}}
typehole.t2({ some: "value" });
```
typehole 是通过您的 typehole 调用的方法名来识别的。 调用 `.t2()` 的时候会给这个 hole 一个 id "t2".因为 ids 的存在, 所以扩展知道值来自代码中的什么地方。
大部分情况下, 你应该为所有的 holes 使用唯一的 id. 然而, 如果您希望将许多 holes 中的值记录到同一类型中,您可以使用相同的 id。
有时候, 扩展可能与您的代码不在同一台主机上运行, 你想配置运行时发送值的地址。 在 Docker 容器内运行的 Node.js 应用程序就是这样一种情况。但是,在大多数情况下,您不需要配置任何内容。
```typescript
import typehole, { configure } from "typehole";
configure({
extensionHost: "http://host.docker.internal:17341",
});
```
### 可用的运行时设置
| 设置 | 类型 | 默认值 | 描述 |
| ------------- | ------ | ---------------------- | -------------------------- |
| extensionHost | string | http://localhost:17341 | 扩展 HTTP 监听器的运行地址 |
## 已知问题
- Typehole 服务器不能在 2 个 VSCode 编辑器中同时运行,因为服务器端口硬编码为 17341
## 发行说明
## [1.7.0] - 2021-07-08
### Added
- 新选项”typehole.typeOrInterface"添加用于使用' type '关键字而不是' interface '。 这一切都归功于 @akafaneh 🎉
## [1.6.3] - 2021-06-20
### Fixed
- 修复代码格式生成损坏/重复的代码
## [1.6.2] - 2021-05-22
### Fixed
- 修复了将字段标记为可选的空值。 `[{"foo": null}, {"foo": 2}]` 现在生成一个 type `{foo: null | number}[]` 而不是像以前一样生成 `{foo?: number}[]`. 应该被修复 [#14](https://github.com/rikukissa/typehole/issues/14)
## [1.6.1] - 2021-05-22
### Fixed
- 修复插入了类型的文件的自动格式化
## [1.6.0] - 2021-05-20
### Added
- 用于配置扩展服务器端口和运行时主机地址的选项。 地址 [#13](https://github.com/rikukissa/typehole/issues/13)
## [1.5.1] - 2021-05-18
### Fixed
- 多个 typeholes 可以使用同一个 id。 它们的每一次更新都会更新附加到孔上的所有类型。 例如,当您希望有多个 typeholes 更新相同的类型时,这很有用。
- 当生成的顶层类型是一个 `ParenthesizedType` 的时候,不会再有重复的 interfaces。
- 当 interface 和 typehole 不在同一个文件的时候,interface 不会更新。
- 当编辑器中聚焦其他文件时,类型不会更新。
- `typehole.tNaN` [issue](https://github.com/rikukissa/typehole/issues/7) 当有非`t<number>`格式的 typeholes 的时候
## [1.5.0] - 2021-05-15
### Added
- 支持推断 Promises 👀
### Fixed
- 如果你的代码中有 typehole,那么 runtime 也会在启动时安装
- AutoDiscoveredN 类型不再重复
## [1.4.1] - 2021-05-09
### Fixed
- 非序列化的诊断现在每个 typehole 只显示一次。 以前,工具提示可能有多次相同的警告。
- 删除所有的 typeholes 后,服务器会停止。重新启动服务器现在也可以工作。
### Added
## [1.4.0] - 2021-05-09
### Added
- 样本收集。 为一个 typehole 提供多个不同的值,生成的类型将基于这些值进行优化。
## [1.3.0] - 2021-05-08
### Added
- 项目路径、包管理器和是否应该自动安装运行时的配置选项
## [1.1.0] - 2021-05-08
### Added
- 所有生成的接口和类型别名的自动 PascalCase 转换
---
**尽情畅享!** | 5,431 | MIT |
---
layout: post # 使用的布局(不需要改)
title: Lychee自建图床配置教程 # 标题
subtitle: 基于Apache2+PHP+MariaDB #副标题
date: 2020-01-21 # 时间
author: zhaiyunfan # 作者
header-img: img/post-cover-Lychee.jpg #这篇文章标题背景图片
catalog: true # 是否归档
tags: #标签
- 教程
- Apache2
- PHP
- MariaDB
- Ubuntu
- Lychee
---
## 前言
对于一个*blog*来说,图文并茂是最基本的要求。*GitHub Page*没办法把做到把repo中的图片插入并显示到正文中 ~~也不应该,因为很不优雅~~ 所以一个可以上传图片并提供外链的图床就成了必需品。
免费的图床稳定性堪忧,付费服务对于学生来说性价比又有一点低,于是在*GitHub*上找了很久之后,锁定了[*Lychee*](https://github.com/LycheeOrg/Lychee)这套开源图床
于是也就理所应当的在阿里云用上了学生特惠的低价服务器 ~~感谢马云爸爸~~ 。配置的过程本来以为很简单,但在因为不熟悉*Linux*系统和整套*PHP*+*Nginx*+*MySQL*体系的缘故,前前后后踩了好几天的坑
为了方便后来人,这里提供一套已经在*Ubuntu16.04*环境下完整测试保证正常的配置流程,其中,弃用了原本性能更强的*Nginx*框架改用了*PHP*下配置更友好的*Apache2* *web*服务器,你只需要跟着整个安装步骤走,就一定可以正确的配置好属于你的个人图床
>注意:[*Lychee*](https://github.com/LycheeOrg/Lychee)现在有更新的[*Lychee-Laravel*](https://github.com/LycheeOrg/Lychee-Laravel),下文中所有提及*Lychee*处所指均为*Lychee-Laravel*,所配置的网站亦基于后者,如果你遇到意料之外的错误,既可以在评论区与我沟通,也可以在[*Lychee-Laravel*](https://github.com/LycheeOrg/Lychee-Laravel)处查阅*LycheeOrg*提供的*wiki*,如果这依然没有解决你的问题,你可以访问[他们的讨论组](https://gitter.im/LycheeOrg/Lobby)来求教,社区中的维护者们都非常nice! ~~没有嫌弃我糟糕的散装英语~~
那么,让我们开始吧!
## 预备工作
>这里以阿里云上标准的*ECH*服务器为例,预装环境为*Ubuntu16.04*,由于各人可能使用不同的云服务 ~~如腾讯云~~ 这里不再赘述服务器的申请过程。同时由于现在各家云服务的控制台操作已经基本傻瓜化,我们假定你已经使用SSH连接上了你的服务器
在利用*SSH*远程连接到你的服务器上之后,会自动启动一个终端
由于整个服务器刚刚初始化,在配置网站环境前需要先更新一下你的本地包索引,保证可以获取最新的软件
先后应用以下两个命令
apt-get update
apt-get upgrade
>关于这两个命令的意义和区别,总的来说,*apt-get update*就是访问服务器,更新可获取软件及其版本信息,但仅仅给出一个可更新的list,具体更新需要使用*apt-get upgrade*,此命令可以执行你已安装的全部软件的更新操作
如果没有报错则是更新成功,可以进行环境的配置工作
## 安装工作
### 安装*Apache2*
>*Apache2 HTTP*服务器是世界上使用最广泛的*Web*服务器。它提供了许多强大的功能,包括动态加载模块,强大的媒体支持,以及与其他流行软件的广泛集成。在这个项目的部署中我们使用*Apache2*而非性能更强的*Nginx*的原因是前者配置时更友好
使用*apt-get*命令可以很方便的安装*Apache2*,更新完本地包索引后直接使用命令:
apt-get install apache2
确认安装后,*apt-get*将安装*Apache2*和所有必需的依赖项。
如果没有报错则是安装成功,使用命令:
service apache2 status
确认一下*Apache2*的运行状态,如果返回类似于:
● apache2.service - LSB: Apache2 web server
Loaded: loaded (/etc/init.d/apache2; bad; vendor preset: enabled)
Drop-In: /lib/systemd/system/apache2.service.d
└─apache2-systemd.conf
Active: active (running) since Tue 2020-01-21 13:38:25 CST; 44min ago
Docs: man:systemd-sysv-generator(8)
CGroup: /system.slice/apache2.service
├─3298 /usr/sbin/apache2 -k start
├─3301 /usr/sbin/apache2 -k start
└─3302 /usr/sbin/apache2 -k start
则证明运行正常,此时可以直接在浏览器地址栏直接输入你服务器的**ip地址**,如果显示了*Apache2*的默认欢迎界面,则证明配置成功;如果访问失败,则需要更改你云端服务器防火墙的安全策略,这块的步骤将在后文讲述*MariaDB*的配置方法时介绍,如果需要你可以先直接跳到后面那节来先配置好
### 安装*PHP*
运行以下命令:
apt-get install software-properties-common
apt-get install python-software-properties
add-apt-repository ppa:ondrej/php && sudo apt-get update
>上面这三步是在安装必要的依赖项。由于我使用的阿里云镜像默认最高只能安装*PHP7.0*,而Lychee最低需要*PHP7.1*才能正常运行,所以这里添加了*PHP*官方的*ppa*软件源以直接获取目标版本的*PHP*
apt install libapache2-mod-php7.3
>这一步安装了*Apache2*的*PHP7.3*模块本体,安装完成之后可以使用命令:
php -v
来确认*PHP*的安装情况,如果显示类似于:
PHP 7.3.13-1+ubuntu16.04.1+deb.sury.org+1 (cli) (built: Dec 18 2019 14:48:32) ( NTS )
Copyright (c) 1997-2018 The PHP Group
Zend Engine v3.3.13, Copyright (c) 1998-2018 Zend Technologies
with Zend OPcache v7.3.13-1+ubuntu16.04.1+deb.sury.org+1, Copyright (c) 1999-2018, by Zend Technologies
的结果则证明安装成功,上文结果显示已安装了*PHP7.3*,这是*Lychee*官方推荐的版本
然后安装之后从*GitHub*拉取*Lychee*必备的*Git*模块
apt install git
安装完成后开始安装Lychee必备的几个*PHP*模块,分别是:
apt install php7.3-mysql
apt install php7.3-imagick
apt install php7.3-mbstring
apt install php7.3-json
apt install php7.3-gd
apt install php7.3-xml
apt install php7.3-zip
这里安装完后可以使用:
php -m
命令显示全部已安装模块,来确认一下是否安装了全部必需的模块,这里包括:
session exif mbstring gd mysqli json zip imagick
全部安装完成后顺便安装一下*Lychee*展开安装时必备的软件,其中最重要的就是*Composer*
>*Composer*是*PHP*的一个依赖管理工具。我们可以在项目中声明所依赖的外部工具库,*Composer*会帮你安装这些依赖的库文件,有了它,我们就可以很轻松的使用一个命令将其他人的优秀代码引用到我们的项目中来。
为了安装*Composer*,我们一般会直接使用:
apt-get install composer
但是对于阿里云这里有一些问题:阿里云默认的镜像中,即使执行了命令:
apt-get update
apt-get upgrade
*apt*能自动安装的*Composer*的最新版本仍为*1.0.0(beta)*,而且无法更新!而当极低版本的*Composer*搭配高版本的*PHP*如*PHP7*时,由于在版本更迭中*PHP*的语法已发生了一些变化,*Composer*完全处于无法使用的状态,不论你执行什么命令,都会跳出*ERROR*:
[ErrorException]
"continue" targeting switch is equivalent to "break". Did you mean to use "continue 2"?
所以为了从源头上规避这一问题,我们使用**阿里云提供的全量镜像**进行手动安装
首先使用此命令进行下载:
curl -O https://mirrors.aliyun.com/composer/composer.phar
从阿里云下载*Composer*本体完成后,使用此命令重命名:
mv composer.phar composer
接着添加可执行权限:
chmod +x composer
最后将该文件放到/usr/local/bin下:
mv composer /usr/local/bin
这样就安装完成了,可以直接使用composer命令,在终端输入:
composer
如果正常显示了*Composer*的欢迎界面,即表明功能正常
而对于国内用户来说,在*Composer*的使用过程中官方源的下载速度实在令人难以恭维,所以可以使用国内的镜像,这里以阿里云镜像为例,推荐进行全局配置(所有项目都会使用该镜像地址):
composer config -g repo.packagist composer https://mirrors.aliyun.com/composer/
没有*ERROR*则为安装正常
注:此处可能提醒:
Do not run Composer as root/super user! See https://getcomposer.org/root for details
这是一个安全性提醒,你输入的命令仍会被正常执行,但使用*root*用户使用*Composer*
确实是不安全的,这里推荐读者访问[该界面](https://getcomposer.org/root)进行进一步的了解
接着安装一下unzip模块
apt-get install unzip
以备后用
至此*PHP*的基础安装就完成了,稍后还需进一步配置
### 安装Mariadb
>MariaDB数据库管理系统是*MySQL*的一个分支,主要由开源社区在维护,采用*GPL*授权许可*。MariaDB*的目的是完全兼容*MySQL*,包括API和命令行,使之能轻松成为*MySQL*的代替品。
在本项目中我们使用*MariaDB*替代标准*MySQL*,来提供数据库支持。若想安装*MariaDB*,运行命令:
apt install mariadb-server
即可直接通过*apt*安装*MariaDB*
## 配置工作
安装完毕后我们仍需对环境进行进一步配置才能拉取*Lychee*
### 配置*PHP*
在[*Lychee-Laravel*](https://github.com/LycheeOrg/Lychee-Laravel)的*GitHub*主页上,推荐修改*PHP*的配置文件以保证上传图片时文件大小上限得到合理配置,如下文:
To use Lychee without restrictions, we recommend to increase the values of the following properties in php.ini. If you are processing large photos or videos, you may need to increase them further.
max_execution_time = 200
post_max_size = 100M
upload_max_filesize = 20M
memory_limit = 256M
使用以下命令,按上文修改你的*PHP*配置:
vim /etc/php/7.3/cli/php.ini
>准确来说这里应当修改你自己服务器上的、正在使用中的版本的*PHP*的*php.ini*文件,所以你需要修改的文件所在路径可能会与我给出的不同。这里假定你完全按照我描述的步骤操作,那么你的安装路径理应和我相同,则按我的命令修改指定文件理应也不会出错
### 配置*MariaDB*
在这一步中,我们预先在*MariaDB*中为*Lychee*创建一个数据库,并为之创建权限足够的用户
使用命令访问*MariaDB*:
mysql
如果显示类似以下字样:
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MariaDB connection id is 42
Server version: 10.0.38-MariaDB-0ubuntu0.16.04.1 Ubuntu 16.04
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
则你已经正常安装MariaDB并且已进入了其控制台,接下来创建Lychee的*Database*和*user*,先后使用以下命令:
create database lychee;
CREATE USER lychee@localhost IDENTIFIED BY 'password';
GRANT ALL ON *.* TO lychee@localhost WITH GRANT OPTION;
FLUSH PRIVILEGES;
其中*password*填你自己准备设置的密码
>以上四条语句的含义分别是:1.创建一个名为*lychee*的*database* 2.创建一个名为*lychee*的*user*,并将其密码设置为你自定义的*password* 3.给*user*:*lychee*全部权限 4.刷新缓存,确认修改
操作完成后可以使用命令:
show databases;
来显示所有*Database*,以确认是否创建成功,如果一切成功,使用命令:
exit;
可以退出*MariaDB*系统,返回终端
### 配置防火墙规则
>安全起见你的云服务供应商一般默认会关闭很多*高危端口*,而这里我们需要用其中的3306端口来远程访问*MySQL*,这里以阿里云为例
为了保证服务器的安全,阿里云的默认安全组会关闭*MySQL*和*MariaDB*远程连接时必需端口的入向访问(默认一般使用3306端口),为了允许客户机远程访问服务器数据库,需要修改安全组规则,按以下步骤操作
1. 进入阿里云服务器的控制台
2. 进入本实例安全组标签
3. 在安全组列表中找到本实例,点击配置规则
4. 选择快速创建规则
5. 在自定义端口处选择*TCP*,端口填3306
6. 授权对象填 *0.0.0.0/0*
7. 描述可以填*MySQL*以备忘
8. 确认修改
同理可以开放80、443以及一切你工程中需要开放的端口,不再赘述。使用*Navicat*等软件可以确认你的MariaDB数据库的访问情况,如果一切正常,至此,前期的所有预备环境的安装都已完成了
## 安装配置*Lychee*
准备好了一切必须的环境条件,现在安装并配置*Lychee*
首先从*GitHub*上*clone*整个*repo*,切换到目标路径后使用*Git*即可达成这一目标:
cd /var/www/html
git clone --recurse-submodules https://github.com/LycheeOrg/Lychee-Laravel.git
等待*clone*完成后,按照以下步骤:
首先切换到刚刚拉取下来的目录里,重命名*env*文件:
cd Lychee-Laravel
cp .env.example .env
# edit .env to match the parameters
然后使用vim编辑刚刚重命名的文件
vim .env
找到类似于下文的行:
DB_CONNECTION=mysql
DB_HOST=[你的数据库地址]
DB_PORT=[端口(3306)]
DB_DATABASE=[数据库]
DB_USERNAME=[用户名]
DB_PASSWORD=[密码]
然后按照配置MariaDB时创建的的数据库名、用户名、密码填写,之后保存退出即可
>*Vim*是从*Vi*发展出来的一个文本编辑器。代码补完、编译及错误跳转等方便编程的功能特别丰富,在程序员中被广泛使用。即使它于图形界面截然不同的操作习惯并不好上手,但它仍在*Linux*下被广为使用,尤其当你使用*SSH*远程连接服务器时,它几乎是你唯一的选择,欲学习如何使用*Vim*,可以花几分钟阅读一下[这个网站](https://www.runoob.com/linux/linux-vim.html),并在修改这段文本时随用随读,以熟悉它的命令模式和快捷键,之后会多次用到 ~~要不然连保存退出都做不到~~
接着使用刚才安装的*Composer*安装*PHP*的依赖项:
# install php libraries.
composer install --no-dev
接着进行一些进一步的初始化配置:
设置上传储存权限
chmod -R 775 storage/* app/* public/uploads public/sym public/dist
sudo chown -R www-data:www-data storage/* app/* public/uploads public/sym public/dist
chmod -R 777 public
生成密钥以确保*cookies*无法解密:
# generate the key (to make sure that cookies cannot be decrypted etc)
./artisan key:generate
迁移数据库:
# migrate the database
./artisan migrate
接着重启*Apache2*服务以应用配置:
service apache2 restart
而后启用*rewrite*模块
a2enmod rewrite
接着再次重启*Apache2*服务:
service apache2 restart
再次使用*Vim*,编辑*Apache2*配置文件:
vim /etc/apache2/apache2.conf
向其中添加以下代码:
<Directory /var/www/html/Lychee-Laravel>
Options Indexes FollowSymLinks
AllowOverride All
Require all granted
</Directory>
切换到*Apache2*的网站配置目录下:
cd /etc/apache2/sites-available
接着再次使用*Vim*,新建配置文件
vim example.com.conf
在其中写入以下代码,来配置*Apache2*的虚拟服务器,监听80端口。其中*example.com*替换为你**自己的域名** ~~如果有的话,比如我就没有,因为穷和懒~~ :
<VirtualHost *:80>
ServerName example.com
DocumentRoot /var/www/html/Lychee-Laravel/public
ErrorLog ${APACHE_LOG_DIR}/error.log
CustomLog ${APACHE_LOG_DIR}/access.log combined
</VirtualHost>
>如果你像我一样打算暂时不为域名花钱,而打算直接用你服务器的*公网IP*地址来访问你的*Lychee*的话,可以把*ServerName*直接填成你的***公网IP地址***,这样你在这个文件中创建的虚拟主机就会监听你***公网IP地址的80端口***的访问,这里涉及到一点关于**域名、DNS、和IP地址**的知识,如果你明白当你在浏览器中输入你想访问的域名之后会发生什么,并对*Apache2*服务器的结构有一些了解的话,我想你会很快理解这样写的意义
启用新建的网页:
a2ensite `example.com`
重启*Apache2*服务:
service apache2 reload
如果你在前文认真做好了每一步,那么以上这几步应该是一切正常的,现在你的*Lychee*服务已经被配置好了
你可以在浏览器中通过以下任一一种方式访问你的图床,你第一次登录时设定的账号密码是你的管理员账户
http://你服务器的ip地址/Lychee-Laravel/public/
http://example.com
至此,整个网站配置完成!
---
## 尽情享受吧
*Lychee*的操作界面优美而友好,你可以自己尽情探索它的各项功能!Enjoy youself!
---
## 后记
这篇博文的长度可能不长,但是我从申请服务器到最终配置完成整整用了三四天时间。
项目*wiki*上提供的安装说明并不详尽,而网络上的中文资源也漏洞百出 ~~似乎都是同一个大兄弟写的~~ 即使是*Google*上找到的英文讨论也不一定能提供帮助。再加上由于很多知识——尤其是*Linux*系统相关的背景知识——的缺失,我在配置和编辑过程中遇到的种种坎坷可能是我入门以来遇到的最复杂而难解的 ~~愿天堂没有这沙雕*PHP*~~
踩了无数次雷,这篇教程甚至可以说是**遗传算法**撞南墙生撞出来的 ~~不行就卸了重来呗~~ 为了调试到底哪个模块出了问题甚至重置了一次云盘 ~~我好难~~ 。放弃过,*Nginx*实在配不明白,考虑过干脆就用[**七牛**](https://www.qiniu.com/)算了;最终也还是坚持下来了,打开*Lychee*主页,上传第一张图片的那一刻,很难描述自己的心情。是如释重负,还是欣喜若狂,实在未可说也
值得一提的是,在调试的过程中,我得到了**LycheeOrg**开源社区里的维护者@ildyria的无私帮助,他顶着我的散装英语耐心的提供了尽可能多的建议,他的洞察力帮我少走了很多弯路 ~~PHP和Composer必死就完事了~~ 大概是从收到他的回复的那一刹那,只是惊鸿一瞥,便初尝到了**开源精神**这两个字的甘露。对于这种精神,我的理解浅薄,但不论如何不是国内常见的仅仅把代码push到*GitHub*上就甩手完事而已
这确实不是一个很难的任务,但我得到的感悟和收获实在太多 ~~熬夜掉的头发也很多~~ 作为这个博客的第一篇干货博文,这400行*Markdown*代表着太多了
>zhaiyunfan 2020-01-21 23:45 | 11,143 | MIT |
# Model-Based Deep Reinforcement Learning
## Q-Planning and Dyna
### Q-Planning
1. 从经验数据学习一个(环境)模型 $p(s', r|s,a)$
2. 从模型中采样以训练模型
Q-Planning同样产生一个四元组 $(s,a,r,s')$,但是其中 $s,a$ 是和真实环境交互的真实(历史)数据、$r,s'$ 是学习到的模型生成的虚假数据
```js
s = sample_state()
a = sample_action(s)
r, s_ = model(s, a)
/* One-step Q-function update */
```
### Dyna-Q
## Shooting Methods
1. “凭空产生”一组长度为 $T$ 的行动 $[a_0,\dots,a_T]$ ($a_0$是初始状态)
2. 用该行动序列和环境交互,得到一组轨迹 $[s_0,a_0,\hat{r}_0,\hat{s}_1,a_1,\hat{r}_0,\dots,\hat{s}_T,a_T,\hat{r}_T]$
3. 选择预期价值最高的动作序列 $\pi(s) = \arg\max_a \hat{Q}(s,a)$
### Random Shooting
- 纯随机采样动作序列
- 优势
- 实现简单
- 计算开销小
- 问题
- 高方差
- 可能采不到高回报的动作序列
### Cross Entropy Method CEM
- 根据已知的会产生较高回报的动作序列
- 在新采样时使用接近该高回报序列的分布
### Probabilistic Ensembles with Trajectory Sampling PETS
$$ loss_P(\theta) = -\sum_{n=1}^N \log\tilde{f}_{\theta}(s_{n+1}|s_n,a_n) $$
$$ \tilde{f} = P(s_{t+1}|s_t,a_t) = \mathcal{N}(\mu_\theta(s_t,a_t), \Sigma_\theta(s_t,a_t)) $$
- 假设 $P(s'|s,a)$ 是一个高斯过程,且使用神经网络拟合该过程
- 集成多个拟合的模型
## Branched Rollout Method
### Branched Rollout
- 从历史数据中,根据状态的分布采样一个历史起点
- 从历史起点跑 $k$ 步模拟
- Dyna算法可以看作 $k=1$ 的 Rollout
### Model-Based Policy Optimization MBPO
## BMPO and AMPO
### Bidirectional Model BMPO
- 除了向后推演外,双向模型同时向前推演(TENET.jpg)
- 在同样长度的情况下,Compouding Error更小
- 但是需要额外的后向模型
- 后向模型 $q_\theta'(s|s',a)$
- 后向策略 $\tilde{\pi}_\phi(a|s')$
### AMPO
#### Distribution Mismatch in MBRL
- 环境的真实数据和模型模拟的数据之间的分布存在误差
- 这是 Compounding Model Error 的来源
##### Alleviations
- 学习过程中
- 设计不同的损失函数和模型架构
- 让rollout更拟真
- 使用模型时
- 设计比较合理的rollout情景
- 在误差造成问题之前停止rollout
- 但是问题仍然存在 | 1,596 | MIT |
* 不能使用类似 #116 的递归解法,因为递归并不是依次对每层节点来执行的。层次序遍历二叉树,将每层节点连接起来即可
```cpp
/*
// Definition for a Node.
class Node {
public:
int val;
Node* left;
Node* right;
Node* next;
Node() : val(0), left(NULL), right(NULL), next(NULL) {}
Node(int _val) : val(_val), left(NULL), right(NULL), next(NULL) {}
Node(int _val, Node* _left, Node* _right, Node* _next)
: val(_val), left(_left), right(_right), next(_next) {}
};
*/
class Solution {
public:
Node* connect(Node* root) {
if (!root) {
return nullptr;
}
queue<Node*> q;
q.emplace(root);
while (!empty(q)) {
int n = size(q);
Node* pre = nullptr;
while (n--) {
Node* cur = q.front();
q.pop();
if (!pre) {
pre = cur;
} else {
pre->next = cur;
pre = cur;
}
if (cur->left) {
q.emplace(cur->left);
}
if (cur->right) {
q.emplace(cur->right);
}
}
}
return root;
}
};
``` | 1,022 | MIT |
## Luffy SDK package
### Import and constructor
```JavaScript
const Luffy3 = require('luffy3-sdk');
const luffy3 = new Luffy3(email, password, baseUrl);
```
### Methods
#### 1. 获取token
```JavaScript
/**
* @return {string}
*/
luffy3.updateToken();
```
#### 2. 获取项目下的服务列表
```JavaScript
/**
* @param {String} projectId project id
* @return {}
*/
luffy3.listService(projectId);
```
#### 3.获取服务的详细信息
```JavaScript
/**
* @param {String} projectId project id
* @param {String} appId 服务名
* @return {object}
*/
luffy3.getService(projectId, appId);
```
#### 4.获取容器服务实例列表
```JavaScript
/**
* @param {String} projectId project id
* @param {String} appId 服务名
* @return {object}
*/
luffy3.listPods(projectId, appId)
```
#### 5.创建服务统一入口
```JavaScript
/**
* @param {String} projectId project id
* @param {Object} options body参数
* @return {}
*/
luffy3.createService(projectId, options);
```
#### 6.重启指定服务
```JavaScript
/**
* @param {String} projectId project id
* @param {String} appId 服务名
* @return {object}
*/
luffy3.restartService(projectId, appId);
```
#### 7.删除服务
```JavaScript
/**
* @param {String} projectId project id
* @param {String} appId 服务名
* @return {object}
*/
luffy3.destroyService(projectId, appId);
```
...
### 单元测试
```cmd
npm test
``` | 1,368 | MIT |
```c++
/*
* 给定一个有相同值的二叉搜索树(BST),找出 BST 中的所有众数(出现频率最高的元素)。
* 假定 BST 有如下定义:
* 结点左子树中所含结点的值小于等于当前结点的值
* 结点右子树中所含结点的值大于等于当前结点的值
* 左子树和右子树都是二叉搜索树
*/
// curr=当前众数,count=当前数的出现次数,maxCount=众数次数
int curr, count, maxCount;
vector<int> ans;
// 中序遍历,所有元素都会连续重复出现
// update更新当前众数及次数
void update(int x) {
if (curr == x)
++count;
else {
count = 1;
curr = x;
}
if (count == maxCount) {
ans.push_back(x);
}
else if (count > maxCount) {
maxCount = count;
ans = {x};
}
}
vector<int> findMode(TreeNode* root) {
TreeNode* now = root;
// 中序遍历
if (!now)
return ans;
if (now->left)
findMode(now->left);
update(now->val);
if (now->right)
findMode(now->right);
return ans;
}
``` | 788 | Apache-2.0 |
## gulp API 文档
<a name="gulp.src"></a>
### gulp.src(globs[, options])
分发(emit)匹配 glob(模式匹配) 或 glob 数组的文件。
返回一个 [Vinyl files](https://github.com/wearefractal/vinyl-fs) 类型的 [stream](http://nodejs.org/api/stream.html),可以通过 [管道(pipe)](http://nodejs.org/api/stream.html#stream_readable_pipe_destination_options) 传递给插件。
```javascript
gulp.src('client/templates/*.jade')
.pipe(jade())
.pipe(minify())
.pipe(gulp.dest('build/minified_templates'));
```
`glob` 可以是 [node-glob 语法](https://github.com/isaacs/node-glob) 或者也可以直接就是一个路径。
<a name="gulp.src-globs"></a>
#### globs
类型:`String` 或者 `Array`
单个 glob 或者 glob 数组。
<a name="gulp.src-options"></a>
#### options
类型:`Object`
通过 [glob-stream] 传送到 [node-glob] 的参数对象。
gulp 除了支持 [node-glob 支持的参数] [node-glob documentation] 和 [glob-stream] 支持的参数外,还额外增加了一些参数:
<a name="gulp.src-options.buffer"></a>
#### options.buffer
类型:`Boolean`
默认值:`true`
当把这属性设置成 `false` 时,返回的 `file.contents` 将是一个数据流而不是缓冲文件。当在文件非常大时,这个属性非常有用。**注意:** 某些插件可能没有实现对数据流的支持。
<a name="gulp.src-options.read"></a>
#### options.read
Type: `Boolean`
Default: `true`
当把这个属性设置成 `false` 时,`file.contents` 返回的将是 null 并且根本不去读取文件。
<a name="gulp.src-options.base"></a>
#### options.base
Type: `String`
默认值:glob 模式匹配串之前的所有内容(见 [glob2base])
例如,`client/js/somedir` 目录中的 `somefile.js` :
```js
gulp.src('client/js/**/*.js') // 匹配 'client/js/somedir/somefile.js' ,并且将 `base` 设置为 `client/js/`
.pipe(minify())
.pipe(gulp.dest('build')); // 写入文件 'build/somedir/somefile.js'
gulp.src('client/js/**/*.js', { base: 'client' })
.pipe(minify())
.pipe(gulp.dest('build')); // 写入文件 'build/js/somedir/somefile.js'
```
<a name="gulp.dest"></a>
### gulp.dest(path[, options])
可以作为管道(pipe)传输或者写入生成。将传输进来的数据重新发出(emit)出去就可以通过管道(pipe)输出到多个文件夹。不存在的文件夹会被创建。
```js
gulp.src('./client/templates/*.jade')
.pipe(jade())
.pipe(gulp.dest('./build/templates'))
.pipe(minify())
.pipe(gulp.dest('./build/minified_templates'));
```
文件路径是将给定的目标目录和文件相对路径合并后计出的新路径。相对路径是在文件的基础路径的基础上计算得到的。查看上面的 `gulp.src` 以获取更多信息。
<a name="gulp.dest-path"></a>
#### path
类型:`String` 或者 `Function`
输出文件的目标路径(或目录)。或者是一个 function 返回的路径,function 将接收一个 [vinyl 文件实例](https://github.com/wearefractal/vinyl) 作为参数。
<a name="gulp.dest-options"></a>
#### options
Type: `Object`
<a name="gulp.dest-options.cwd"></a>
#### options.cwd
Type: `String`
Default: `process.cwd()`
`cwd` 用于计算输出目录的,只有提供的输出目录是相对路径时此参数才有用。
<a name="gulp.dest-options.mode"></a>
#### options.mode
Type: `String`
Default: `0777`
8进制数字组成的字符串,用于为创建的输出目录指定权限。
<a name="gulp.task"></a>
### gulp.task(name[, deps], fn)
定义一个使用 [Orchestrator] 的任务。
```js
gulp.task('somename', function() {
// Do stuff
});
```
<a name="gulp.task-name"></a>
#### name
任务的名字。从命令行运行任务时,任务名的中间不能存在空格。
<a name="gulp.task-deps"></a>
#### deps
类型:`Array`
此数组中列出的所有从属任务将在你的任务执行前执行并执行完毕。
```js
gulp.task('mytask', ['array', 'of', 'task', 'names'], function() {
// Do stuff
});
```
**注意:** 在从属任务完整前,你的任务是否提前执行完毕了?请确保你所依赖的任务是否正确的实现了异步:接收一个回调函数或者返回一个 promise 对象或者事件流(event stream)。
<a name="gulp.task-fn"></a>
#### fn
此函数用于执行任务。一般形式是 `gulp.src().pipe(someplugin())`。
#### 对异步任务的支持
如果 `fn` 函数是以下形式中的一种,那么此任务可以被设置成异步的:
##### 接收一个回调函数
```js
// run a command in a shell
var exec = require('child_process').exec;
gulp.task('jekyll', function(cb) {
// build Jekyll
exec('jekyll build', function(err) {
if (err) return cb(err); // return error
cb(); // finished task
});
});
```
##### 返回一个数据流(stream)
```js
gulp.task('somename', function() {
var stream = gulp.src('client/**/*.js')
.pipe(minify())
.pipe(gulp.dest('build'));
return stream;
});
```
##### 返回一个 promise 对象
```js
var Q = require('q');
gulp.task('somename', function() {
var deferred = Q.defer();
// do async stuff
setTimeout(function() {
deferred.resolve();
}, 1);
return deferred.promise;
});
```
**注意:** 默认情况下,任务将被最大限度的并发执行 -- 例如,所有任务同时被启动执行并且不做任何等待。如果你想让任务按照一个特定的顺序执行,你需要做以下两件事:
- 当任务完成时给 gulp 一个提示。
- 给 gulp 一个提示告诉 gulp 这个任务是依赖于另外一个任务的。
举个例子,我们假定你有两个任务,"one" 和 "two",你希望他们按照以下的顺序执行:
1. 在任务 "one" 中添加一个提示告诉 gulp 此任务何时完成。可以选择接收一个回调函数并在任务执行完毕后调用此回调函数;也可以返回一个 promise 对象或者一个数据流(stream),然后由 gulp 等待 promise 被处理(resolve)或者数据流(stream)结束。
2. 为任务 "two" 添加一个提示,告诉 gulp 该任务须在第一个任务执行完毕后才能执行。
上述实例实现代码如下:
```js
var gulp = require('gulp');
// takes in a callback so the engine knows when it'll be done
gulp.task('one', function(cb) {
// do stuff -- async or otherwise
cb(err); // if err is not null and not undefined, the run will stop, and note that it failed
});
// identifies a dependent task must be complete before this one begins
gulp.task('two', ['one'], function() {
// task 'one' is done now
});
gulp.task('default', ['one', 'two']);
```
<a name="gulp.watch-or-gulp.watch"></a>
### gulp.watch(glob [, opts], tasks) 或者 gulp.watch(glob [, opts, cb])
如果被监视的文件发生了改变就执行某些动作。此方法永远返回一个可以发出 `change` 事件的 EventEmitter 对象。
<a name="gulp.watch1"></a>
### gulp.watch(glob[, opts], tasks)
<a name="gulp.watch1-glob"></a>
#### glob
类型:`String` 或 `Array`
单个 glob 或 一组 glob,用于匹配需要监视的文件。
<a name="gulp.watch1-opts"></a>
#### opts
类型:`Object`
此参数将被传递给 [`gaze`](https://github.com/shama/gaze)。
<a name="gulp.watch1-tasks"></a>
#### tasks
类型:`Array`
当文件改变时所需要运行的任务的名称(可以是多个任务),通过 `gulp.task()` 添加。
```js
var watcher = gulp.watch('js/**/*.js', ['uglify','reload']);
watcher.on('change', function(event) {
console.log('File ' + event.path + ' was ' + event.type + ', running tasks...');
});
```
<a name="gulp.watch2"></a>
### gulp.watch(glob[, opts, cb])
<a name="gulp.watch2-glob"></a>
#### glob
类型:`String` 或 `Array`
单个 glob 或 一组 glob,用于匹配需要监视的文件。
<a name="gulp.watch2-opts"></a>
#### opts
类型:`Object`
此参数将被传递给 [`gaze`](https://github.com/shama/gaze)。
<a name="gulp.watch2-cb"></a>
#### cb(event)
类型:`Function`
当文件每次变化时都会调用此回调函数。
```js
gulp.watch('js/**/*.js', function(event) {
console.log('File ' + event.path + ' was ' + event.type + ', running tasks...');
});
```
此回调函数接收一个对象类型的参数 -- `event`,它包含了此次文件改变所对应的信息:
<a name="gulp.watch2-cb-event.type"></a>
##### event.type
类型:string
已经发生的改变所对应的类型,可以是 `added`、`changed` 或 `deleted`。
<a name="gulp.watch2-cb-event.path"></a>
##### event.path
类型:`String`
此路径指向触发事件的文件。
[node-glob documentation]:https://github.com/isaacs/node-glob#options
[node-glob]:https://github.com/isaacs/node-glob
[glob-stream]:https://github.com/wearefractal/glob-stream
[gulp-if]: https://github.com/robrich/gulp-if
[Orchestrator]:https://github.com/robrich/orchestrator
[glob2base]:https://github.com/wearefractal/glob2base | 6,513 | MIT |
# iwaSync3
## Overview
iwaSyncVideoPlayer の SDK3(Udon) 対応版です。
更新に伴い、マスターのみ操作可能にする機能やシーク機能が追加されています。
また他の SDK3 対応プレイヤーに比べて動作が軽量なのが特徴です。
使用していない時は完全に動作を停止するためほぼ負荷がかかりません。
今後のアップデートでプレイリストなどの対応も予定しています。
追加機能の要望などは作者 Twitter までどうぞ。
### 追加予定の機能
- 割込みや順次再生・シャッフルなどができるプレイリスト
- 小さい画面を見やすい場所に移動できるミニプレイヤー
- どこでもURLを入力できる機能
## Usage
1. VRCSDK3-WORLD, UdonSharp をインポート
2. iwaSync3 プレハブをシーンに設置、位置調整
## Dependencies
- [VRCSDK3-UDON](https://files.vrchat.cloud/sdk/VRCSDK3-WORLD-2020.12.09.04.44_Public.unitypackage) v2020.12.09.04.44
- [UdonSharp](https://github.com/Merlin-san/UdonSharp) v0.19.0
## Author
<!-- markdownlint-disable -->
<!-- markdownlint-disable -->
<table>
<tr>
<td align="center">
<img src="https://avatars.githubusercontent.com/u/8447771?v=3" width="100px;" alt=""/><br />
<sub><b>ikuko</b></sub><br />
<sub><a href="https://twitter.com/magi_ikuko" title="Twitter">Twitter</a></sub>
<sub><a href="https://github.com/ikuko" title="GitHub">GitHub</a></sub>
</td>
</tr>
</table>
<!-- markdownlint-enable -->
<!-- markdownlint-enable -->
## License
"iwaSync3" is under [MIT license](https://en.wikipedia.org/wiki/MIT_License). | 1,204 | MIT |
<!-- START doctoc generated TOC please keep comment here to allow auto update -->
<!-- DON'T EDIT THIS SECTION, INSTEAD RE-RUN doctoc TO UPDATE -->
**Table of Contents** *generated with [DocToc](https://github.com/thlorenz/doctoc)*
- [PostCSS配置指北](#postcss%E9%85%8D%E7%BD%AE%E6%8C%87%E5%8C%97)
- [Use with webpack](#use-with-webpack)
- [基本配置](#%E5%9F%BA%E6%9C%AC%E9%85%8D%E7%BD%AE)
- [使用插件](#%E4%BD%BF%E7%94%A8%E6%8F%92%E4%BB%B6)
- [兼容性CSS的自动补全](#%E5%85%BC%E5%AE%B9%E6%80%A7css%E7%9A%84%E8%87%AA%E5%8A%A8%E8%A1%A5%E5%85%A8)
- [Use stylelint](#use-stylelint)
- [在webpack内单独使用stylelint](#%E5%9C%A8webpack%E5%86%85%E5%8D%95%E7%8B%AC%E4%BD%BF%E7%94%A8stylelint)
- [在PostCSS内使用(荐)](#%E5%9C%A8postcss%E5%86%85%E4%BD%BF%E7%94%A8%E8%8D%90)
- [1. 基础使用方式](#1-%E5%9F%BA%E7%A1%80%E4%BD%BF%E7%94%A8%E6%96%B9%E5%BC%8F)
- [2. 增加配置文件](#2-%E5%A2%9E%E5%8A%A0%E9%85%8D%E7%BD%AE%E6%96%87%E4%BB%B6)
- [`.stylelintignore`](#stylelintignore)
- [`stylelint.config.js`](#stylelintconfigjs)
- [3. StyleLintPlugin的配置参数](#3-stylelintplugin%E7%9A%84%E9%85%8D%E7%BD%AE%E5%8F%82%E6%95%B0)
- [资源](#%E8%B5%84%E6%BA%90)
- [postcss & loader](#postcss--loader)
- [autoprefixer & cssnext](#autoprefixer--cssnext)
- [stylelint](#stylelint)
<!-- END doctoc generated TOC please keep comment here to allow auto update -->
## [PostCSS](https://github.com/postcss/postcss)配置指北

> `PostCSS`并不是一门语言,而是一个类似于`webpack`的工具,它支持很多插件,来达到便捷的编译效果,组成一个CSS编译/lint/autoprefixer的生态圈。它的作者是[Euil Martians](https://evilmartians.com/),一家致力于技术研究与网站外包开发的公司。其后端技术栈偏重于Ruby,而前端从React到Node都有涉猎。
`PostCSS`的一大特点是,具体的编译插件甚至是CSS书写风格,可以根据自己的需要进行安装,选择自己需要的特性:嵌套,函数,变量。自动补全,CSS新特性等等,而不是像`less`或者`scss`一样的大型全家桶。因此,不需要再专门去学习`less`或者`scss`的语法,只要选择自己喜欢的特性,可以只写CSS文件,但依旧可以写嵌套或者函数,然后选择合适的插件编译它就行了。
### Use with webpack
鉴于现在`webpack`也越来越火,所以之后的配置主要是借助于`postcss-loader`,将`PostCSS`的生态圈依托在`webpack`之下。
```bash
# 安装webpack postcss loader
$ npm install postcss-loader --save-dev
```
#### 基本配置
```javascript
// 配置webpack.config.js
// ...
module: {
loaders: [
{
test: /\.css$/,
// 如果使用了 ExtractTextPlugin
loader: ExtractTextPlugin.extract('style', 'css!postcss')
// 否则
// loader: "style-loader!css-loader!postcss-loader"
}
]
},
postcss: function () {
return [ // 里面是我们要用的插件
];
}
```
#### 使用插件
> 快速配置一览
```bash
# cssnext可以让你写CSS4的语言,并能配合autoprefixer进行浏览器兼容的不全,而且还支持嵌套语法
$ npm install postcss-cssnext --save-dev
# 浏览器兼容补全
$ npm install autoprefixer --save-dev
# 类似scss的语法,实际上如果只是想用嵌套的话有cssnext就够了
$ npm install precss --save-dev
# 在@import css文件的时候让webpack监听并编译
$ npm install postcss-import --save-dev
```
```javascript
// 配置webpack.config.js
const postcssImport = require('postcss-import');
const cssnext = require('postcss-cssnext');
// ...
postcss: function () {
return [
postcssImport({ addDependencyTo: webpack }),
cssnext({autoprefixer: {browsers: "ie >= 10, ..."}})
];
}
```
### [兼容性CSS的自动补全](https://github.com/postcss/autoprefixer)
```bash
$ npm install autoprefixer --save-dev
```
- `autoprefixer`也可以单独配置使用
```javascript
// webpack.config.js
const autoprefixer = require('autoprefixer');
// ...
postcss: function(){
return [autoprefixer({ browsers: ['last 2 versions'] })]
}
```
- 或者与[postcss-cssnext](https://github.com/MoOx/postcss-cssnext)一起使用,但`autoprefixer`都要进行安装
```javascript
const cssnext = require('postcss-cssnext');
postcss: function(){
// 通过配置browsers,可以指定将CSS语法兼容到什么程度
return [cssnext({autoprefixer: {browsers: "ie >= 10, ..."}})]
}
```
- [`autoprefixer`的配置](https://github.com/postcss/autoprefixer#options)
### Use stylelint
[Stylelint](https://github.com/stylelint/stylelint)插件可以让你在编译的时候就知道自己CSS文件里的错误
#### 在webpack内单独使用stylelint
用到如下插件:
- [stylelint-webpack-plugin](https://github.com/vieron/stylelint-webpack-plugin)
- [stylelint-config-standard](https://github.com/stylelint/stylelint-config-standard)
```bash
$ npm install stylelint-webpack-plugin --save-dev
# stylelint语法,使用标准语法
$ npm install stylelint-config-standard --save-dev
```
```javascript
// webpack.config.js
const StyleLintPlugin = require('stylelint-webpack-plugin');
// ...
plugins: [
new StyleLintPlugin({
config: {
// 你的lint扩展自刚刚安装的stylelint-config-standard
"extends": "stylelint-config-standard"
},
// 正则匹配想要lint监测的文件
files: 'frontend/stylesheet/**/*.l?(e|c)ss'
}),
],
```
#### 在PostCSS内使用(荐)
会用到如下插件:
- [stylelint](https://github.com/stylelint/stylelint)
- [postcss-reporter](https://github.com/postcss/postcss-reporter)
- [stylelint-config-standard](https://github.com/stylelint/stylelint-config-standard)
#### 1. [基础使用方式](https://github.com/stylelint/stylelint/blob/master/docs/user-guide/postcss-plugin.md)
```bash
# 安装stylelint
$ npm install stylelint --save-dev
```
```javascript
// webpack.config.js
const stylelint = require('stylelint');
// ...
module: {
loaders: [
{ test: /\.css$/, loader: ExtractTextPlugin.extract('style', 'css!postcss') }
]
}
postcss: function() {
return [
postcssImport({ addDependencyTo: webpack }),
stylelint({
failOnError: true
})
]
}
```
这就是最基本的配置了。因为有`postcss-loader`的存在,所以在webpack解析css的时候,都会调用postcss里返回的插件,因此就会使用`stylelint`对代码进行检查。
但这样的配置有一个很严重的缺点:如果你在js中引用了node_module里的css文件,或者引用了其他不想进行编译的文件,PostCSS会对其一视同仁的调用插件编译/检查。此时就需要我们来配置`.stylelintignore`以及`stylelint.config.js`进行更精确的编译/检查。
#### 2. 增加配置文件
- [stylelint配置说明](https://github.com/stylelint/stylelint/blob/master/docs/user-guide/configuration.md)
- [stylelint with postcss配置说明](https://github.com/stylelint/stylelint/blob/master/docs/user-guide/postcss-plugin.md)
##### `.stylelintignore`
在项目根目录下添加`.stylelintignore`文件,并在内部写下不想通过PostCSS编译的文件路径:
```text
node_modules/
frontend/vendor/
```
之后,在没有指明`ignorePath`的情况下,stylelint会自动寻找根目录下的`.stylelintignore`文件。
##### `stylelint.config.js`
安装`stylelint-config-standard`
```bash
$ npm install stylelint-config-standard --save-dev
```
在配置文件中指明我们的检测语法扩展自该插件:
- [User guide](https://github.com/stylelint/stylelint/blob/master/docs/user-guide.md)
- [配置规则](https://github.com/stylelint/stylelint/blob/master/docs/user-guide/rules.md)
```javascript
// 常用配置
module.exports = {
extends: "stylelint-config-standard",
// 各rules的具体作用见上面链接
rules: {
"block-no-empty": null,
"color-no-invalid-hex": true,
"comment-empty-line-before": [ "always", {
"ignore": ["stylelint-commands", "between-comments"],
} ],
"declaration-colon-space-after": "always",
"max-empty-lines": 2,
"rule-nested-empty-line-before": [ "always", {
"except": ["first-nested"],
"ignore": ["after-comment"],
} ],
// 允许的单位
"unit-whitelist": ["em", "rem", "%", "s", "ms", "px"]
}
};
```
然后指明PostCSS的配置文件:
```javascript
postcss: function() {
return [
postcssImport({ addDependencyTo: webpack }),
stylelint({
config: require('../../stylelint.config.js'),
failOnError: true
})
]
}
```
此时运行webpack,有问题的CSS文件输出大概是这样的:
```bash
WARNING in ./~/css-loader!./~/postcss-loader!./frontend/stylesheet/layout/test_post_css.css
stylelint: /Users/ecmadao1/Dev/Python/where_to_go/frontend/stylesheet/layout/test_post_css.css:17:1: Expected indentation of 2 spaces (indentation)
```
很难看清楚吧!因此接下来安装`postcss-reporter`来美化输出:
```bash
$ npm install postcss-reporter --save-dev
```
webpack配置:
```javascript
postcss: function() {
return [
postcssImport({ addDependencyTo: webpack }),
stylelint({
config: require('../../stylelint.config.js'),
failOnError: true
}),
postcssReporter({ clearMessages: true })
]
}
```
之后的输出会是这样的:
```bash
frontend/stylesheet/layout/test_post_css.css
17:1 ⚠ Expected indentation of 2 spaces (indentation) [stylelint]
```
吊吊哒!
#### 3. [StyleLintPlugin的配置参数](https://github.com/vieron/stylelint-webpack-plugin#options)
[stylelint options](http://stylelint.io/user-guide/node-api/#options)里面的配置也可以在plugin里使用。介绍几个常用的配置:
- config:lint基础配置。没有的话则会去寻找`.stylelintrc`
- configFile:lint配置文件。可以被config的配置替代。默认为`.stylelintrc`文件
- context:上下文环境。默认使用webpack的context
- files:要匹配的文件。默认为`['**/*.s?(a|c)ss']`
- failOnError:错误时是否停止编译。默认`false`
- quiet:在console中不打印错误信息。默认`false`
### 资源
#### postcss & loader
- [postcss](https://github.com/postcss/postcss)
- [postcss-loader](https://github.com/postcss/postcss-loader)
- [postcss-import](https://github.com/postcss/postcss-import)
#### autoprefixer & cssnext
- [cssnext](http://cssnext.io/)
- [autoprefixer](https://github.com/postcss/autoprefixer)
- [browserslist](https://github.com/ai/browserslist)
#### stylelint
- [stylelint](https://github.com/stylelint/stylelint)
- [stylelint-webpack-plugin](https://github.com/vieron/stylelint-webpack-plugin)
- [stylelint-config-standard](https://github.com/stylelint/stylelint-config-standard)
- [postcss-reporter](https://github.com/postcss/postcss-reporter) | 8,869 | Apache-2.0 |
title: PHP 学习资料
date: 2016-12-14 2:26 PM
categories:
tags: php
---
简单记录下 PHP 学习资料备忘。
<!--more-->
## 资料
### 视频
* [网易哈佛公开课](http://open.163.com/special/opencourse/buildingdynamicwebsites.html)
* Laracast/Laravel
### 文字&书籍
* [PHP 手册](http://php.net/manual/zh/)
* [Psysh](http://psysh.org/)可以随时试验代码
* [packagist 流行的包](https://packagist.org/explore/popular)
* 书籍 《 Modern PHP》 | 376 | MIT |
---
layout: post
title: CentOS 6 vps上搭建Wordpress开源博客平台
---
用LNMP的一键安装包,安装Nginx、MySQL、PHP、phpMyAdmin。然后安装WordPress
### 首先安装LNMP
#### 先安装scrrent
```
yum install screen
安装完成之后在终端下运行如下命令
screen -S lnmp (这个命令能保证过程中ssh不会断线)
```
#### 然后安装lnmp
lnmp是linu下的(Nginx、MySQL、PHP、phpMyAdmin)一键安装Shell脚本
wget -c http://soft.vpser.net/lnmp/lnmp1.1-full.tar.gz && tar zxf lnmp1.1-full.tar.gz && cd lnmp1.1-full && ./centos.sh
在终端运行上面的命令之后开始安装lnmp,等待安装完成即可(具体安装完成时间视你的网速以及服务器硬件配置)
详细的LNMP安装教程可以去[lnmp官网](http://lnmp.org/install.html)查看.
安装完成之后在浏览器里面输入你的IP地址即可打开默认的lnmp界面啦;
```
1.设置MySQL的root密码,直接回车会默认密码root
2.需要确认是否启用MySQL InnoDB,如果不确定是否启用可以输入 y ,这个可以单独在MySQL文件里关闭,输入 y 表示启用,输入 n 表示不启用。输入 y 或 n 后回车进入下一步
3.选择php版本,可以选择 PHP 5.3.28 或 PHP 5.2.17,如果需要安装PHP 5.3.28的话输入 y ,如果需要安装PHP 5.2.17 输入 n,(一般选高版本的这里按y)
4.选择MySQL 版本 5.1.73、5.5.37或MariaDB 5.5.37,如果需要安装MySQL 5.5.37的话输入 y ,如果需要安装MySQL 5.1.73 输入n,如果需要安装MariaDB 5.5.37的话输入 md,输入完成后回车,完成选择。(这里我选的y)
5.输入完成后回车,完成选择。
提示"Press any key to start...",按回车键确认开始安装。
LNMP脚本就会自动安装编译Nginx、MySQL、PHP、phpMyAdmin、Zend Optimizer这几个软件。
安装时间可能会几十分钟到几个小时不等,主要是机器的配置网速等原因会造成影响
```
安装完成
如果显示如下界面:
Nginx、MySQL、PHP都是running,80和3306端口都存在,说明已经安装成功。
接下来按添加虚拟主机教程,添加虚拟主机,通过sftp或ftp服务器上传网站,将域名解析到VPS或服务器的IP上,解析生效即可使用。
如果显示 则失败了
### 添加虚主机
添加虚主机也就是在VPS上给你的wordpress添加一下文件目录,设置一下域名什么的;
#### 运行vhost.sh
cd /root
./ vhost.sh
在终端里面执行上面的命令,即可开始添加虚拟主机;
#### 域名设置
=========================================================================
Add Virtual Host for LNMP V1.0 , Written by Licess
=========================================================================
LNMP is a tool to auto-compile & install Nginx+MySQL+PHP on Linux
This script is a tool to add virtual host for nginx
For more information please visit http://www.lnmp.org/
=========================================================================
Please input domain:
(Default domain: www.lnmp.org):www.w-zh.ml w-zh.ml
===========================
我这里输入了2个域名;
www.w-zh.ml和w-zh.ml是2个不同的域名
#### 是否还要添加域名
domain=www.w-zh.ml w-zh.ml
===========================
Do you want to add more domain name? (y/n)
如果需要就添加,不需要就直接输入n即可
#### 接下来设置网站目录
Please input the directory for the domain:www.w-zh.ml w-zh.ml :
(Default directory: /home/wwwroot/www.w-zh.ml w-zh.ml):
一般默认直接回车即可,要修改也可以,需要绝对路径。
#### 是否开启伪静态
===========================
Allow Rewrite rule? (y/n)
===========================
一般都是要的,所以输入y后回车
#### 下面选择伪静态类型
Please input the rewrite of programme :
wordpress,discuz,typecho,sablog,dabr rewrite was exist.
(Default rewrite: other):wordpress
默认有discuz、discuzx、wordpress、sablog、emlog、dabr、phpwind、wp2(二级目录wp伪静态)、dedecms、drupal、ecshop、shopex可选,主机输入即可。
#### 是否开启log功能
===========================
Allow access_log? (y/n)
===========================
这个一般没啥用输入n后回车
#### 开始安装
Press any key to start create virtul host...
出现按任意键提示后敲回车开始安装,等待安装完成。
### 安装WordPress
先切换到网站目录下
cd /home/wwwroot/
然后看看你的'www.w-zh.ml'文件夹是否存在.
#### 下载WorPress
wget https://cn.wordpress.org/wordpress-4.1-zh_CN.zip
运行wget下载最版本的WordPress
#### 运行unzip解压
unzip wordpress-4.1-zh_CN.zip
#### 拷贝Wordpress到你的网站目录下
cp -R wordpress/* /home/wwwroot/www.w-zh.ml/
将wordpress目录下的所有文件拷贝到www.w-zh.ml中
#### 设置目录权限
由于wordpress在安装的时候以及在安装插件主题和自升级的需要可写权限。所以我要对特定目录设权限。
```
chmod -R 777 wp-admin/
chmod -R 777 wp-content/
chmod -R 777 wp-includes/
chmod -R 777 wp-config-sample.php
chmod -R 777 readme.html
```
#### 创建数据库
在安装lnmp之后我们就已经可以通过pvs主机IP打开默认网站,通过上面的phpmyadmin这个连接
用户名是root
密码是之前设置的mysql数据库密码
完事后可以进入图形界面的数据库管理程序,phpmyadmin
点击数据库标签
创建一个名字叫wordpress的数据库(只要创建这样一个空的数据库就行了)
#### 关于域名解析
1.去自己的域名商那里修改dns为dnspod的(我的用国内的dnspod解析)
2.去dnspod面板添加需要解析的w-zh.ml 添加a记录(里面填写自己的vps主机的ip地址)
#### 安装wordpress
现在直接打开w-zh.ml就可开始安装了,按照提示输数据库名,账号密码之后即可开始安装。
到此在VPS上用lnmp搭wordpress就完成了。
### 注意事项
#### 1,安装主题需要FTP账号密码
修改网站目录下的wp-config.php文件,添加如下内容
define("FS_METHOD","direct");
define("FS_CHMOD_DIR",0777);
define("FS_CHMOD_FILE",0777);
保存之后,在wordpress刷新即可。
#### 2,wordpress后台主题不显示,仅显示默认使用的主题(还有一直显示刷新翻译都使用下面的解决方式)
这是由于lnmp默认禁用了一些php的函数导致的,
修改/usr/local/php/etc/php.ini
查找disable_functions下删除scandir
然后重启php-fpm即可
service php-fpm restart
问题及解决
绑定域名后,在浏览器中输入域名,无法解析到主机目录。
解决方法 :绑定域名后需要重启lnmp , 执行命令 /root/lnmp restart 重启lnmp服务重新登录后成功
#### 3.重启后只能用代理访问的问题
没错,你的防火墙iptables的问题。80端口没开................
```
sudo iptables -A INPUT -p tcp --dport 80 -j ACCEPT
或是
#/sbin/iptables -I INPUT -p tcp --dport 80 -j ACCEPT
然后保存:
#/etc/init.d/iptables save
查看打开的端口:
# /etc/init.d/iptables status
``` | 4,674 | MIT |
# MyBatis-Plus 代码生成器
## Current Version
3.3.2
## 概述
代码生成器,又被叫做逆向工程,MyBatis官方为了推广,自己也写了一个,我之前也使用这个,功能也是非常强大,强大以为支持自定义配置,那么问题来了,我该怎么配置才合理呢,所以,有人把所有的配置项都弄成中文的,还有人开发了生成插件,这些在我以往的博文中都看看到。MyBatis-Plus的代码生成器到底怎么样,这我就不评判了,我就这样说,用用看吧。
**功能列表:**
* [x] 自动生成model类
* [x] 自动生成dao接口
* [x] 自动生成xml文件
* [x] 自动生成service接口
* [x] 自动生成service实现类
* [x] model支持Builder模式
* [x] 支持swagger2
* [x] 支持生成数据库字段常量
* [x] 支持生成Kotlin代码
* [x] ……more……
## 目录结构
```
.
├── README.md
├── pom.xml
└── src
├── main
│ └── java
│ └── com
│ └── fengwenyi
│ └── code_generator
│ ├── Config.java // 自定义配置
│ ├── MySQL8CodeGenerator.java // MySQL代码生成器
│ ├── OracleCodeGenerator.java // Oracle代码生成器
│ └── util
│ └── CommonUtils.java
└── test
└── java
└── com
└── fengwenyi
└── code_generator
└── CodeGeneratorTests // 代码生成器测试
```
## 支持的数据库
* [x] MySQL
* [x] Oracle
## 快速开始
你只需要三步,就能生成代码
#### 第一步:Git克隆
```
git clone [email protected]:fengwenyi/mybatis-plus-code-generator.git
```
#### 第二步:IDE导入
#### 第三步:简单且必应的配置即可运行
`MySQL`:MySQL8CodeGenerator
`Oracle`:OracleCodeGenerator
## 简单且必要的配置
```
String dbUrl = "jdbc:mysql://localhost:3306/dbName";
String username = "dbUsername";
String password = "dbPassword";
String driver = "com.mysql.cj.jdbc.Driver";
// 表前缀,生成的实体类,不含前缀
String [] tablePrefixes = {};
// 表名,为空,生成所有的表
String [] tableNames = {};
// 字段前缀
String [] fieldPrefixes = {};
// 基础包名
String packageName = "com.example.module.db";
```
## 更多配置
```java
package com.fengwenyi.code_generator;
/**
* @author Erwin Feng
* @since 2019-04-17 12:04
*/
public class Config {
/** 包名:controller */
public static final String PACKAGE_NAME_CONTROLLER = "controller";
/** 包名:service */
public static final String PACKAGE_NAME_SERVICE = "service";
/** 包名:service.impl */
public static final String PACKAGE_NAME_SERVICE_IMPL = "service.impl";
/** 包名:model */
public static final String PACKAGE_NAME_MODEL = "model";
/** 包名:dao */
public static final String PACKAGE_NAME_DAO = "dao";
/** 包名:xml */
public static final String PACKAGE_NAME_XML = "mapper";
/** 文件名后缀:Model */
public static final String FILE_NAME_MODEL = "%sModel";
/** 文件名后缀:Dao */
public static final String FILE_NAME_DAO = "%sDao";
/** 文件名后缀:Mapper */
public static final String FILE_NAME_XML = "%sMapper";
/** MP开头,Service结尾 */
public static final String FILE_NAME_SERVICE = "MP%sService";
/** 文件名后缀:ServiceImpl */
public static final String FILE_NAME_SERVICE_IMPL = "%sServiceImpl";
/** 文件名后缀:Controller */
public static final String FILE_NAME_CONTROLLER = "%sController";
/** 作者 */
public static final String AUTHOR = "Erwin Feng";
/** 生成文件的输出目录 */
public static String projectPath = System.getProperty("user.dir");
/** 输出目录 */
// public static final String outputDir = projectPath + "/src/main/java";
public static final String outputDir = "/Users/code-generator";
}
```
## 注意事项
1、关于指定生成的表名
```
// 表名,为空,生成所有的表
String [] tableNames = {};
// 表名,具体表名
String [] tableNames = {"table"};
// 表名,多张表
String [] tableNames = {"table1", "table1"};
// 注意:生成多张表时,不能写成
String [] tableNames = {""};
```
2、包名
```
// 基础包名
// 这是基础包名,会在后面加dao/model/service等包名
String packageName = "com.example.module.db";
```
3、数据库操作服务接口默认以 `MP` 为前缀,如:`MPUserService`
4、报错 `Error java: 错误;不支持发行版5`
解决办法:
将 `Java Compiler` 下 `module` 对应的 `java` 版本改成 `8+` | 3,716 | MIT |
# OximeterSDK
OximeterSDK是一个用于快速与蓝牙BLE交互的工具包,仅提供给我们合作的客户下载使用,方便提升客户的开发效率。
README: [中文](https://github.com/OximeterSDK/android/edit/master/README.md)
## 必要条件
* API>19&&BLE 4.0
* [jar](https://github.com/OximeterSDK/android/tree/master/oximeter_1.0.0)
## 如何使用
### 1. 配置 build.gradle
compile files('libs/ximeter_x.x.x.jar')
compile files('libs/vpbluetooth_x.x.x.jar')
compile files('libs/gson-x.x.x.jar') 或者 compile 'com.google.code.gson:gson:x.x.x'
### 2. 配置 Androidmanifest.xml
<uses-permission android:name="android.permission.BLUETOOTH" />
<uses-permission android:name="android.permission.BLUETOOTH_ADMIN" />
<uses-permission android:name="android.permission.ACCESS_FINE_LOCATION" />
<uses-permission android:name="android.permission.ACCESS_COARSE_LOCATION" />
<uses-permission android:name="android.permission.INTERNET" />
<uses-permission android:name="android.permission.ACCESS_NETWORK_STATE" />
<!--Activity&Service-->
<service android:name="com.inuker.bluetooth.library.BluetoothService" />
### 3. 蓝牙通信连接
操作说明:所有的操作都只是通过OxiOprateManager;
3.1 获取OxiOprateManager实例: OxiOprateManager.getMangerInstance()
3.2 扫描蓝牙设备: startScanDevice();
3.3 连接蓝牙设备: connectDevice();
3.4 设置连接设备的连接状态监听:registerConnectStatusListener(); //这个方法最好是在连接成功后设置
3.5 设置系统蓝牙的开关状态监听:registerBluetoothStateListener(); //这个方法可以在任何状态下设置
3.6 其他数据交互操作
备注1:
为了避免内存泄漏的情况,请谨慎使用context,推荐使用getApplicationContext();
如:获取OxiOprateManager实例:OxiOprateManager.getMangerInstance(getApplicationContext());
备注2:
如调用扫描设备:OxiOprateManager.getMangerInstance().startScanDevice();
以上统一简写为:startScanDevice();
备注3:
设备不支持异步操作,当多个耗时操作同时进行时,可能会导致数据异常;因此在与设备进行交互时,尽可能避免多个操作同时进行
### 4. 蓝牙数据交互说明
SDK在蓝牙数据的下发的设计是只需要调用方法,传入设置参数以及监听接口,当数据有返回时,接口会触发回调,以confirmDevicePwd为例
//调用方法,匿名内部类用于回调监听
OxiOprateManager.getMangerInstance(mContext).readBatterInfo(writeResponse, new OnBatteryDataListener () {
@Override
public void onDataChange(BatteryData batteryData) {
//触发回调
String message = "batteryData:\n" + batteryData.toString();
Logger.t(TAG).i(message);
}
});
### 5. 固件升级说明
## 鸣谢
* [BluetoothKit](https://github.com/dingjikerbo/BluetoothKit)
* [Gson](https://github.com/google/gson)
## 许可协议
[Apache Version 2.0](http://www.apache.org/licenses/LICENSE-2.0.html)
Copyright (C) 2010 Michael Pardo
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. | 3,132 | Apache-2.0 |
# 2021-05-28
## 1. [滑动窗口最大值](https://leetcode-cn.com/problems/sliding-window-maximum/)
题号:#239
### 我的解法
```js
/**
* @param {number[]} nums
* @param {number} k
* @return {number[]}
* 入参:
* - 整数数组 nums
* - 滑动窗口大小 k
* 入参条件:
* - 1 <= nums.length <= 105
* - -104 <= nums[i] <= 104
* - 1 <= k <= nums.length
* 出参:
* 滑动窗口的最大值
* 出参条件:
* - 对于[0, k-2]的部分无需返回
* 思路:
* - 思路1:循环比较
* - 思路2:单调队列
*/
class MonotonicQueue {
constructor() {
this.queue = [];
}
// 添加时,将小于当前数的数全部移除
push(n) {
let queue = this.queue;
while (queue.length && queue[queue.length - 1] < n) {
queue.pop();
}
queue.push(n);
}
// 最大值
max(){
return this.queue[0];
}
// 删除对头元素
pop(n) {
if(n == this.queue[0]){
this.queue.shift();
}
}
}
var maxSlidingWindow = function (nums, k) {
let window = new MonotonicQueue();
let res = [];
for(let i=0; i<nums.length; i++){
if(i<k-1){
window.push(nums[i]);
}else{
window.push(nums[i]);
// 加入新数字
// console.log("window.max()", window.max());
res.push(window.max());
// 移出旧数字
window.pop(nums[i-k+1]);
}
}
return res;
};
```
执行用时:928 ms, 在所有 JavaScript 提交中击败了47.70%的用户
内存消耗:73.5 MB, 在所有 JavaScript 提交中击败了28.53%的用户
### 最小执行用时
```js
/**
* @param {number[]} nums
* @param {number} k
* @return {number[]}
*/
var maxSlidingWindow = function(nums, k) {
const n = nums.length
if (n < 2 || k === 1) return nums
const ans = new Array(n - k + 1)
const q = []
for (let i = 0; i < n; i++) {
// 保证从大到小 如果前面数小则需要依次弹出,直至满足要求
while (q.length && nums[q[q.length - 1]] <= nums[i]) {
q.pop()
}
q.push(i) // 添加当前值对应的数组下标
if (q[0] <= i - k) {
q.shift()
}
if (i + 1 >= k) {
ans[i + 1 - k] = nums[q[0]]
}
}
return ans
};
```
### 最少消耗内存
```js
/**
* @param {number[]} nums
* @param {number} k
* @return {number[]}
*/
var maxSlidingWindow = function(nums, k) {
let n = nums.length, p = new Int16Array(n), s = new Int16Array(n), r = new Int16Array(n - k + 1), i = n, j = -1
while (i--) {
p[++j] = j % k ? Math.max(p[j - 1], nums[j]) : nums[j]
s[i] = i % k ? Math.max(s[i + 1], nums[i]) : nums[i]
}
while (i++ < n - k) r[i] = Math.max(s[i], p[i + k - 1])
return r
};
``` | 2,358 | MIT |
# 向后台服务发送任务请求
> 编写:[kesenhoo](https://github.com/kesenhoo) - 原文:<http://developer.android.com/training/run-background-service/send-request.html>
前一篇文章演示了如何创建一个IntentService类。这次会演示如何通过发送一个Intent来触发IntentService执行任务。这个Intent可以传递一些数据给IntentService。我们可以在Activity或者Fragment的任何时间点发送这个Intent。
## 创建任务请求并发送到IntentService
为了创建一个任务请求并发送到IntentService。需要先创建一个显式Intent,并将请求数据添加到intent中,然后通过调用
`startService()` 方法把任务请求数据发送到IntentService。
下面的是代码示例:
* 创建一个新的显式Intent用来启动IntentService。
```java
/*
* Creates a new Intent to start the RSSPullService
* IntentService. Passes a URI in the
* Intent's "data" field.
*/
mServiceIntent = new Intent(getActivity(), RSSPullService.class);
mServiceIntent.setData(Uri.parse(dataUrl));
```
<!-- More -->
* 执行`startService()`
```java
// Starts the IntentService
getActivity().startService(mServiceIntent);
```
注意可以在Activity或者Fragment的任何位置发送任务请求。例如,如果你先获取用户输入,您可以从响应按钮单击或类似手势的回调方法里面发送任务请求。
一旦执行了startService(),IntentService在自己本身的`onHandleIntent()`方法里面开始执行这个任务,任务结束之后,会自动停止这个Service。
下一步是如何把工作任务的执行结果返回给发送任务的Activity或者Fragment。下节课会演示如何使用[BroadcastReceiver](http://developer.android.com/reference/android/content/BroadcastReceiver.html)来完成这个任务。 | 1,179 | Apache-2.0 |
[教程]: ./doc/教程.md
[API接口文档]: ./doc/API.md
[GitHub仓库]: https://github.com/GuoBinyong/storage-data
[发行地址]: https://github.com/GuoBinyong/storage-data/releases
[issues]: https://github.com/GuoBinyong/storage-data/issues
[码云仓库]: https://gitee.com/guobinyong/storage-data
目录
=========
<!-- TOC -->
- [1. 背景](#1-背景)
- [2. 简介](#2-简介)
- [3. 安装方式](#3-安装方式)
- [3.1. 方式1:通过 npm 安装](#31-方式1通过-npm-安装)
- [3.2. 方式2:直接下载原代码](#32-方式2直接下载原代码)
- [3.3. 方式3:通过`<script>`标签引入](#33-方式3通过script标签引入)
- [4. 教程](#4-教程)
- [5. API接口文档](#5-api接口文档)
<!-- /TOC -->
内容
=====
# 1. 背景
项目中,经常有持久化(存储)数据的需要,在前端中,常用的方案就是 Storage(如:localStorage、sessionStorage) 和 cookie;然后它们各有优缺点,如:
**Storage**(相对 cookie 而言)
+ 优点:
- 易保存 和 获取;
- 存储容量大;
+ 缺点:
- 不支持设置有效期
**cookie**(相对 Storage 而言)
+ 缺点:
- 保存 和 获取的操作太麻烦;
- 存储容量小;
+ 优点:
- 支持设置有效期;
为了前端世界不再那么令人纠结,于是 **StorageData** 诞生了!!!
# 2. 简介
StorageData 是一个用于自动存储数据,并且可以指定数据有效期的工具;它更像是 cookie 和 Storage(如:localStorage、sessionStorage)的结合;
**具有以下特性:**
- 在程序中以普通对像的方式操作数据;_(易操作)_
- 数据被修改后,会自动存储到指定的 Storage(如:localStorage、sessionStorage)中;_(存储容量大)_
- 可以给数据指定有效期,如:指定多长时间后失效 或 指定到某一具体日期后失效;_(支持有效期)_
- 可对保存做节流设置;
- 可以监听数据更改;
- 可以拦截数据变更;
- 可以监听存储操作;
- 可以拦截存储操作;
- 兼容 浏览器 与 node;
**详情请看:**
- 主页:<https://github.com/GuoBinyong/storage-data>
- [GitHub仓库][]
- [码云仓库][]
- [教程][]
- [API接口文档][]
**如果您在使用的过程中遇到了问题,或者有好的建议和想法,您都可以通过以下方式联系我,期待与您的交流:**
- 给该仓库提交 [issues][]
- 给我 Pull requests
- 邮箱:<[email protected]>
- QQ:[email protected]
- 微信:keyanzhe
# 3. 安装方式
目前,安装方式有以下几种:
## 3.1. 方式1:通过 npm 安装
```
npm install --save-prod storage-data
```
## 3.2. 方式2:直接下载原代码
您可直接从项目的 [发行地址][] 下载 源码 或 构建后包文件;
您可以直接把 源码 或 构建后 的包拷贝到您的项目中去;然后使用如下代码在您的项目中引入 `StorageData`:
```
import { createStorageData } from "path/to/package/storage-data";
```
或者
```
import createStorageData from "path/to/package/storage-data";
```
## 3.3. 方式3:通过`<script>`标签引入
您可直接从项目的 [发行地址][] 中下载以 `.iife.js` 作为缀的文件,然后使用如下代码引用 和 使用 storage-data:
1. 引用 storage-data
```
<script src="path/to/package/storage-data.iife.js"></script>
```
2. 使用全局的 `createStorageData()`
```
<script>
// 使用全局的 StorageData
const sd = StorageData.createStorageData(localStorage,"logInfo");
</script>
```
# 4. 教程
详情跳转至[教程][]
# 5. API接口文档
详情跳转至[API接口文档][]
--------------------
> 有您的支持,我会在开源的道路上,越走越远
 | 2,393 | MIT |
# Dubbo教程
* dubbo的调用返回关注对象的值,不关注调用对象的方法
* 消费端类加载器加载不到类接口的类,会使用map去装结果集
* 在 Provider 端配置后,Consumer 端不配置则会使用 Provider 端的配置,即 Provider 端的配置可以作为 Consumer 的缺省值
* 否则,Consumer 会使用 Consumer 端的全局设置,这对于 Provider 是不可控的
## 协议
* Hessian 二进制序列化
* 单包建议小于100K
* dubbo最大可以传输2G的数据,dubbo没有对报文压缩,如果传输大报文,造成网络传输数据量过大,可能会造成网络拥塞;默认消费端发送请求数据后等待服务端返回,大数据包造成网络传输时间长,消费端长时间等待;dubbo最大只能传输2G的数据,过大的包,dubbo无法处理;dubbo是为在微服务环境下快速响应请求的场景设计的,传输大数据包与此设计相违背
### 协议头
* [](https://imgchr.com/i/rLOsRf)
* header总包含了16个字节的数据
| magic(2) | requstflag/serializationId(1) | responseCode(1) | requestid(8) | dataLength(4) |
| ---- | ---- | ---- | ---- | ---- |
| 魔数 | 请求和序列化标记的组合结果 | 响应的结果码 | 请求id | body内容大小,单位是byte |
* 范例
```
0000: DA BB C2 00 00 00 00 00 00 00 00 00 00 00 00 E8 ................
0010: 05 32 2E 30 2E 32 03 31 32 33 05 30 2E 30 2E 30 .2.0.2.123.0.0.0
0020: 07 24 69 6E 76 6F 6B 65 30 38 4C 6A 61 76 61 2F .$invoke08Ljava/
0030: 6C 61 6E 67 2F 53 74 72 69 6E 67 3B 5B 4C 6A 61 lang/String;[Lja
0040: 76 61 2F 6C 61 6E 67 2F 53 74 72 69 6E 67 3B 5B va/lang/String;[
0050: 4C 6A 61 76 61 2F 6C 61 6E 67 2F 4F 62 6A 65 63 Ljava/lang/Objec
0060: 74 3B 0B 67 65 74 55 73 65 72 49 6E 66 6F 72 07 t;.getUserInfor.
0070: 5B 73 74 72 69 6E 67 11 6A 61 76 61 2E 6C 61 6E [string.java.lan
0080: 67 2E 49 6E 74 65 67 65 72 10 6A 61 76 61 2E 6C g.Integer.java.l
0090: 61 6E 67 2E 53 74 72 69 6E 67 72 07 5B 6F 62 6A ang.Stringr.[obj
00A0: 65 63 74 91 08 67 75 6F 78 69 2E 6C 69 48 04 70 ect..guoxi.liH.p
00B0: 61 74 68 03 31 32 33 12 72 65 6D 6F 74 65 2E 61 ath.123.remote.a
00C0: 70 70 6C 69 63 61 74 69 6F 6E 03 79 79 79 09 69 pplication.yyy.i
00D0: 6E 74 65 72 66 61 63 65 03 31 32 33 07 76 65 72 nterface.123.ver
00E0: 73 69 6F 6E 05 30 2E 30 2E 30 07 67 65 6E 65 72 sion.0.0.0.gener
00F0: 69 63 04 74 72 75 65 5A
//计算 0x00 0x00 0x00 0xE8 =232
```
#### 组合结果requstflag|serializationId
* 高四位标示请求的requstflag
```
protected static final byte FLAG_REQUEST = (byte) 0x80;//1000
protected static final byte FLAG_TWOWAY = (byte) 0x40;//0100
protected static final byte FLAG_EVENT = (byte) 0x20;//0010
```
* 低四位标示序列化方式serializationId:
```
DubboSerialization:0001
FastJsonSerialization:0110
Hessian2Serialization:0010
JavaSerialization:0011
```
#### 响应的结果码
* 请求报文里面不设置,用来标示响应的结果码
```
/**
* ok.
*/
public static final byte OK = 20;
```
```
/**
* clien side timeout.
*/
public static final byte CLIENT_TIMEOUT = 30;
```
```
/**
* server side timeout.
*/
public static final byte SERVER_TIMEOUT = 31;
```
```
/**
* request format error.
*/
public static final byte BAD_REQUEST = 40;
```
```
/**
* response format error.
*/
public static final byte BAD_RESPONSE = 50;
```
```
/**
* service not found.
*/
public static final byte SERVICE_NOT_FOUND = 60;
```
```
/**
* service error.
*/
public static final byte SERVICE_ERROR = 70;
```
```
/**
* internal server error.
*/
public static final byte SERVER_ERROR = 80;
```
```
/**
* internal server error.
*/
public static final byte CLIENT_ERROR = 90;
```
```
/**
* server side threadpool exhausted and quick return.
*/
public static final byte SERVER_THREADPOOL_EXHAUSTED_ERROR = 100;
```
### 协议体
* 请求包 ( Req/Res = 1),则每个部分依次为:
```
Dubbo version,dubbo协议版本号,比如在2.7.5版本里面,dubbo version是2.0.2
Service name,服务接口名
Service version,服务的group值
Method name,方法名
Method parameter types,参数类型
Method arguments,参数值
Attachments,附录
```
* 范例(反序列化出的对象)
```
public int sayHi(int i,String s,Long l,Double d,int i2);
class java.lang.String--->2.0.2
class java.lang.String--->com.config.dubbo.producer.ViewInter
class java.lang.String--->0.0.0
class java.lang.String--->sayHi
class java.lang.String--->ILjava/lang/String;Ljava/lang/Long;Ljava/lang/Double;I
class java.lang.Integer--->123777
class java.lang.String--->sss
class java.lang.Long--->5
class java.lang.Double--->5.0
class java.lang.Integer--->888
class java.util.HashMap--->{path=com.config.dubbo.producer.ViewInter, remote.application=yyy, interface=com.config.dubbo.producer.ViewInter, version=0.0.0}
```
* 如果是响应包(Req/Res = 0),则每个部分依次为:
```
返回值类型(byte),标识从服务器端返回的值类型:
异常:RESPONSE_WITH_EXCEPTION=0
正常响应值: RESPONSE_VALUE=1
返回空值:RESPONSE_NULL_VALUE=2
带附录的异常返回值:RESPONSE_WITH_EXCEPTION_WITH_ATTACHMENTS=3
带附录的正常响应值:RESPONSE_VALUE_WITH_ATTACHMENTS=4
带附录的空值:RESPONSE_NULL_VALUE_WITH_ATTACHMENTS=5
返回值:从服务端返回的响应bytes,如果返回值类型是2或者5,该字段是空
Attachments:当返回值类型是3、4、5时,则在响应包里面添加附录信息,在2.7.5版本里面,附录值只有dubbo协议的版本号,也就是2.0.2。
```
* 范例(反序列化出的对象)
```
class java.lang.Integer-->4
class java.lang.Integer-->123
class java.util.HashMap-->{dubbo=2.0.2}
```
## Url Key值
```
dubbo://192.168.31.5:889/123?anyhost=true&
application=hello_dubbo&
bind.ip=192.168.31.5&
bind.port=889&
deprecated=false&
dubbo=2.0.2&
dynamic=true&
generic=true&
group=g_20201230&
interface=123&
methods=*&
pid=21496&
release=2.7.8&
side=provider&
timestamp=1609308397514&
version=v_20201230
```
* method在使用泛化时候会是*否则用逗号隔开
```
methods=sayHi2,sayHi3,sayHi
```
* version,group 不设置默认是没有的
* 端口没有绑定会用默认的20880
```
public class DubboProtocol extends AbstractProtocol {
public int getDefaultPort() {
return 20880;
}
```
## 消费者直连
```
reference.setUrl("dubbo://localhost:889");
```
## Dubbo范例
### 依赖
```
<dependency>
<groupId>org.apache.dubbo</groupId>
<artifactId>dubbo</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>4.2.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.curator/curator-recipes -->
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>4.2.0</version>
</dependency>
```
### 配置
* 接口
```
public interface JobInterface {
public String doJob();
}
```
* 实现
```
public class JobImpl implements JobInterface {
@Override
public String doJob() {
System.out.println("do job");
return UUID.randomUUID().toString();
}
}
```
* 生产者
```
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:dubbo="http://dubbo.apache.org/schema/dubbo"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-4.3.xsd http://dubbo.apache.org/schema/dubbo http://dubbo.apache.org/schema/dubbo/dubbo.xsd">
<!-- 提供方应用信息,用于计算依赖关系 -->
<dubbo:application name="hello-world-app" />
<!-- 使用multicast广播注册中心暴露服务地址 -->
<!-- <dubbo:registry address="multicast://224.2.2.2:1234?unicast=false" />-->
<dubbo:registry address="zookeeper://127.0.0.1:2181"/>
<!-- 用dubbo协议在20880端口暴露服务 -->
<dubbo:protocol name="dubbo" port="20880" />
<!-- 声明需要暴露的服务接口 -->
<dubbo:service interface="dubbo.JobInterface" ref="demoService" version="1.0"/>
<!-- 和本地bean一样实现服务 -->
<bean id="demoService" class="dubbo.JobImpl" />
</beans>
```
* 消费者
```
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:dubbo="http://dubbo.apache.org/schema/dubbo"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-4.3.xsd http://dubbo.apache.org/schema/dubbo http://dubbo.apache.org/schema/dubbo/dubbo.xsd">
<!-- 消费方应用名,用于计算依赖关系,不是匹配条件,不要与提供方一样 -->
<dubbo:application name="consumer-of-helloworld-app" />
<!-- 使用multicast广播注册中心暴露发现服务地址 -->
<!-- <dubbo:registry address="multicast://224.2.2.2:1234?unicast=false" />-->
<dubbo:registry address="zookeeper://127.0.0.1:2181"/>
<!-- 生成远程服务代理,可以和本地bean一样使用demoService -->
<dubbo:reference id="demoService" interface="dubbo.JobInterface" version="1.0" check="false"/>
</beans>
```
## 泛化
### 通过一个字符串绑定GenericService接口实现
* provider
```
@Bean
public ServiceConfig getServiceConfig(){
GenericService xxxService = new GenericServiceImpl();
ServiceConfig<GenericService> service = new ServiceConfig<>();
service.setApplication(getApplicationConfig());
service.setRegistry(getRegistryConfig()); // 多个注册中心可以用setRegistries()
service.setProtocol(getProtocolConfig()); // 多个协议可以用setProtocols()
service.setInterface("com.xxx.XxxService");//泛化的话调用类全部指向这个,是个虚类
service.setRef(xxxService );//实际指向类引用
service.setVersion("1");//版本
service.export();
return service;
}
```
```
public class GenericServiceImpl implements GenericService {
@Override
public Object $invoke(String s, String[] strings, Object[] objects) throws GenericException {
System.out.println("method"+s);
System.out.println(Arrays.toString(strings));
System.out.println(Arrays.toString(objects));
return "welcome";
}
}
```
* consumer
```
// 普通编码配置方式
ApplicationConfig application = new ApplicationConfig();
application.setName("generic-consumer");
// 连接注册中心配置
RegistryConfig registry = new RegistryConfig();
registry.setAddress("zookeeper://127.0.0.1:2181");
ReferenceConfig<GenericService> reference = new ReferenceConfig<GenericService>();
reference.setApplication(application);
reference.setRegistry(registry);
reference.setVersion("1");//版本也要一样
reference.setInterface("com.xxx.XxxService");//要与提供者名字一样
reference.setGeneric(true); // 声明为泛化接口
ReferenceConfigCache cache = ReferenceConfigCache.getCache();
GenericService genericService = cache.get(reference);
// 基本类型以及Date,List,Map等不需要转换,直接调用
Object resultObj = genericService.$invoke("getUserInfo", new String[] {"java.lang.Integer", "java.lang.String"},
new Object[] {1, "guoxi.li"});
removeClassFeild(resultObj);
System.out.println(resultObj);
```
## 踩坑
* 使用apache的包,不然会有奇奇怪怪的问题
* 暴露的接口和实现中如果申明为public 的方法,那么就不能是void,否则会报compile error: getPropertyValue (Ljava/lang/Object;Ljava/lang/String;)
## 依赖
* 不要引成alibaba的,可能造成异步返回失败
```
<dependencies>
<!-- https://mvnrepository.com/artifact/org.springframework/spring-context -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>5.1.8.RELEASE</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.alibaba/dubbo -->
<dependency>
<groupId>org.apache.dubbo</groupId>
<artifactId>dubbo</artifactId>
<version>2.7.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/io.netty/netty-all -->
<dependency>
<groupId>io.netty</groupId>
<artifactId>netty-all</artifactId>
<version>4.1.37.Final</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.curator/curator-framework -->
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>4.2.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.curator/curator-recipes -->
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>4.2.0</version>
</dependency>
</dependencies>
```
# --------------------------------------旧笔记分割线----------------------------------
## Xml配置
[xml参考手册](http://dubbo.apache.org/zh-cn/docs/user/references/xml/introduction.html)
### produce范例
```
<beans xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:dubbo="http://dubbo.apache.org/schema/dubbo"
xmlns="http://www.springframework.org/schema/beans"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://dubbo.apache.org/schema/dubbo http://dubbo.apache.org/schema/dubbo/dubbo.xsd">
<dubbo:application name="demo-provider"/>
<dubbo:registry address="zookeeper://127.0.0.1:2181"/>
<dubbo:protocol name="dubbo" port="20890"/>
<bean id="demoService" class="org.apache.dubbo.samples.basic.impl.DemoServiceImpl"/>
<dubbo:service interface="org.apache.dubbo.samples.basic.api.DemoService" ref="demoService"/>
</beans>
```
### consumer范例
```
<beans xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:dubbo="http://dubbo.apache.org/schema/dubbo"
xmlns="http://www.springframework.org/schema/beans"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://dubbo.apache.org/schema/dubbo http://dubbo.apache.org/schema/dubbo/dubbo.xsd">
<dubbo:application name="demo-consumer"/>
<dubbo:registry group="aaa" address="zookeeper://127.0.0.1:2181"/>
<dubbo:reference id="demoService" check="false" interface="org.apache.dubbo.samples.basic.api.DemoService"/>
</beans>
```
### dubbo:service(生产端)
* 服务提供者暴露服务配置,对应的配置类:org.apache.dubbo.config.ServiceConfig
### dubbo:reference(消费端)
* 服务消费者引用服务配置。对应的配置类: org.apache.dubbo.config.ReferenceConfig
### dubbo:protocol
* 服务提供者协议配置。对应的配置类:org.apache.dubbo.config.ProtocolConfig。
* 同时,如果需要支持多协议,可以声明多个 <dubbo:protocol> 标签,并在 <dubbo:service> 中通过 protocol 属性指定使用的协议。
### dubbo:registry
* 注册中心配置。对应的配置类:org.apache.dubbo.config.RegistryConfig。
* 同时如果有多个不同的注册中心,可以声明多个 <dubbo:registry> 标签,并在 <dubbo:service> 或 <dubbo:reference> 的 registry 属性指定使用的注册中心。
### dubbo:monitor
* 监控中心配置。对应的配置类: org.apache.dubbo.config.MonitorConfig
### dubbo:application
* 应用信息配置。对应的配置类:org.apache.dubbo.config.ApplicationConfig
### dubbo:module
* 模块信息配置。对应的配置类 org.apache.dubbo.config.ModuleConfig
### dubbo:provider
* 服务提供者缺省值配置。对应的配置类: org.apache.dubbo.config.ProviderConfig。
* 同时该标签为 <dubbo:service> 和 <dubbo:protocol> 标签的缺省值设置。
### dubbo:consumer
* 服务消费者缺省值配置。配置类: org.apache.dubbo.config.ConsumerConfig 。
* 同时该标签为 <dubbo:reference> 标签的缺省值设置。
### dubbo:method
* 方法级配置。对应的配置类: org.apache.dubbo.config.MethodConfig。
* 同时该标签为 <dubbo:service> 或 <dubbo:reference> 的子标签,用于控制到方法级。
### dubbo:argument
* 方法参数配置。对应的配置类: org.apache.dubbo.config.ArgumentConfig。
* 该标签为 <dubbo:method> 的子标签,用于方法参数的特征描述,比如:
```xml
<dubbo:method name="findXxx" timeout="3000" retries="2">
<dubbo:argument index="0" callback="true" />
</dubbo:method>
```
### dubbo:parameter
* 选项参数配置。对应的配置类:java.util.Map。
* 同时该标签为```<dubbo:protocol>```或```<dubbo:service>```或```<dubbo:provider>```或```<dubbo:reference>```或```<dubbo:consumer>```的子标签,用于配置自定义参数,该配置项将作为扩展点设置自定义参数使用
### dubbo:config-center
* 配置中心。对应的配置类:org.apache.dubbo.config.ConfigCenterConfig
## Api配置
* 配置类
```
org.apache.dubbo.config.ServiceConfig
org.apache.dubbo.config.ReferenceConfig
org.apache.dubbo.config.ProtocolConfig
org.apache.dubbo.config.RegistryConfig
org.apache.dubbo.config.MonitorConfig
org.apache.dubbo.config.ApplicationConfig
org.apache.dubbo.config.ModuleConfig
org.apache.dubbo.config.ProviderConfig
org.apache.dubbo.config.ConsumerConfig
org.apache.dubbo.config.MethodConfig
org.apache.dubbo.config.ArgumentConfig
```
### producer配置
```
package config;
import org.apache.dubbo.config.*;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import service.AppService;
import service.AppServiceImpl;
import java.util.Arrays;
@Configuration
public class DubboConfig {
@Bean
public ApplicationConfig getApplicationConfig(){
ApplicationConfig applicationConfig=new ApplicationConfig();
applicationConfig.setName("dubboProducer");
return applicationConfig;
}
@Bean
public RegistryConfig getRegistryConfig(){
RegistryConfig registryConfig=new RegistryConfig();
registryConfig.setAddress("zookeeper://127.0.0.1:2181");
return registryConfig;
}
@Bean
public ProtocolConfig getProtocolConfig(){
ProtocolConfig protocolConfig=new ProtocolConfig();
protocolConfig.setName("dubbo");
protocolConfig.setPort(-1);
return protocolConfig;
}
@Bean
public ServiceConfig getServiceConfig(){
ServiceConfig serviceConfig=new ServiceConfig();
serviceConfig.setApplication(getApplicationConfig());
serviceConfig.setRegistry(getRegistryConfig()); // 多个注册中心可以用setRegistries()
serviceConfig.setProtocol(getProtocolConfig()); // 多个协议可以用setProtocols()
serviceConfig.setInterface(AppService.class);//接口
serviceConfig.setRef(getAppServiceImpl());//实现
serviceConfig.export();//暴露接口
/* serviceConfig.setAsync(true);*/ //这个不知道怎么影响异步
return serviceConfig;
}
@Bean
AppServiceImpl getAppServiceImpl(){
return new AppServiceImpl();
}
}
```
### consumer配置
```
package config;
import org.apache.dubbo.config.ApplicationConfig;
import org.apache.dubbo.config.MethodConfig;
import org.apache.dubbo.config.ReferenceConfig;
import org.apache.dubbo.config.RegistryConfig;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import service.AppService;
import java.util.Arrays;
@Configuration
public class DubboConfig {
@Bean
public ApplicationConfig getApplicationConfig() {
ApplicationConfig applicationConfig = new ApplicationConfig();
applicationConfig.setName("dubboConsumer");
return applicationConfig;
}
@Bean
public RegistryConfig getRegistryConfig() {
RegistryConfig registryConfig = new RegistryConfig();
registryConfig.setAddress("zookeeper://127.0.0.1:2181");
return registryConfig;
}
@Bean
public ReferenceConfig getReferenceConfig() {
ReferenceConfig referenceConfig = new ReferenceConfig();
referenceConfig.setInterface(AppService.class);//设置接口
referenceConfig.setApplication(getApplicationConfig());//设置应用
referenceConfig.setRegistry(getRegistryConfig());//设置注册中心
/* referenceConfig.setAsync(true);*/ //这个也不知道怎么影响到异步的
referenceConfig.setTimeout(10000);
/* MethodConfig methodConfig=new MethodConfig();
methodConfig.setAsync(true);
methodConfig.setName("sayHello");
referenceConfig.setTimeout(10000);
referenceConfig.setMethods(Arrays.asList(methodConfig));*/
return referenceConfig;
}
@Bean
public AppService getAppService(){
return (AppService) getReferenceConfig().get();
}
}
```
## 集群容错
### Failover Cluster
* 没有验证成功
* 失败自动切换,当出现失败,重试其它服务器 [1]。通常用于读操作,但重试会带来更长延迟。可通过 retries="2" 来设置重试次数(不含第一次)。
### Failfast Cluster
* 没有验证
* 快速失败,只发起一次调用,失败立即报错。通常用于非幂等性的写操作,比如新增记录。
### Failsafe Cluster
* 失败安全,出现异常时,直接忽略。通常用于写入审计日志等操作。
### Failback Cluster
* 失败自动恢复,后台记录失败请求,定时重发。通常用于消息通知操作。
### Forking Cluster
* 并行调用多个服务器,只要一个成功即返回。通常用于实时性要求较高的读操作,但需要浪费更多服务资源。可通过 forks="2" 来设置最大并行数。
### Broadcast Cluster
* 广播调用所有提供者,逐个调用,任意一台报错则报错。通常用于通知所有提供者更新缓存或日志等本地资源信息。
## 负载均衡策略
### Random LoadBalance
* 随机,按权重设置随机概率。
在一个截面上碰撞的概率高,但调用量越大分布越均匀,而且按概率使用权重后也比较均匀,有利于动态调整提供者权重。
### RoundRobin LoadBalance
* 轮询,按公约后的权重设置轮询比率。
存在慢的提供者累积请求的问题,比如:第二台机器很慢,但没挂,当请求调到第二台时就卡在那,久而久之,所有请求都卡在调到第二台上。
### LeastActive LoadBalance
* 最少活跃调用数,相同活跃数的随机,活跃数指调用前后计数差。
使慢的提供者收到更少请求,因为越慢的提供者的调用前后计数差会越大。
### ConsistentHash LoadBalance
* 一致性 Hash,相同参数的请求总是发到同一提供者。
当某一台提供者挂时,原本发往该提供者的请求,基于虚拟节点,平摊到其它提供者,不会引起剧烈变动。
算法参见:http://en.wikipedia.org/wiki/Consistent_hashing
缺省只对第一个参数 Hash,如果要修改,请配置 <dubbo:parameter key="hash.arguments" value="0,1" />
缺省用 160 份虚拟节点,如果要修改,请配置 <dubbo:parameter key="hash.nodes" value="320" />
## 服务分组
* 两组服务互不干扰,独自调用
服务,api配置直接申明两个service
```
<dubbo:service group="feedback" interface="com.xxx.IndexService" />
<dubbo:service group="member" interface="com.xxx.IndexService" />
```
消费,api配置直接申明两个reference
```
<dubbo:reference id="feedbackIndexService" group="feedback" interface="com.xxx.IndexService" />
<dubbo:reference id="memberIndexService" group="member" interface="com.xxx.IndexService" />
```
任意组 [1]:
```
<dubbo:reference id="barService" interface="com.foo.BarService" group="*" />
```
## 多版本
* 当一个接口实现,出现不兼容升级时,可以用版本号过渡,版本号不同的服务相互间不引用。
* 可以按照以下的步骤进行版本迁移:
1. 在低压力时间段,先升级一半提供者为新版本
2. 再将所有消费者升级为新版本
3. 然后将剩下的一半提供者升级为新版本
老版本服务提供者配置:
```
<dubbo:service interface="com.foo.BarService" version="1.0.0" />
```
新版本服务提供者配置:
```
<dubbo:service interface="com.foo.BarService" version="2.0.0" />
```
老版本服务消费者配置:
```
<dubbo:reference id="barService" interface="com.foo.BarService" version="1.0.0" />
```
新版本服务消费者配置:
```
<dubbo:reference id="barService" interface="com.foo.BarService" version="2.0.0" />
```
如果不需要区分版本,可以按照以下的方式配置 [1]:
```
<dubbo:reference id="barService" interface="com.foo.BarService" version="*" />
```
## 异步调用
* 接口申明,CompletableFuture返回值
```
package service;
import java.util.concurrent.CompletableFuture;
public interface AppService {
CompletableFuture<String> sayHello(String name);
}
```
### 生产者实现
* Provider端异步执行,将阻塞的业务从Dubbo内部线程池切换到业务自定义线程,避免Dubbo线程池的过度占用,有助于避免不同服务间的互相影响。
* 异步执行无益于节省资源或提升RPC响应性能,因为如果业务执行需要阻塞,则始终还是要有线程来负责执行
* 注意:Provider端异步执行和Consumer端异步调用是相互独立的,你可以任意正交组合两端配置
```
Consumer同步 - Provider同步
Consumer异步 - Provider同步
Consumer同步 - Provider异步
Consumer异步 - Provider异步
```
* 类实现代码,通过return CompletableFuture.supplyAsync(),业务执行已从Dubbo线程切换到业务线程,避免了对Dubbo线程池的阻塞。
```
@Override
public CompletableFuture<String> sayHello(String name) {
// 建议为supplyAsync提供自定义线程池,避免使用JDK公用线程池
CompletableFuture<String> stringCompletableFuture = CompletableFuture.supplyAsync(() -> {
try {
Thread.sleep(5 * 1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("发送响应");
return "你好啊," + name + "等了很久吧";
});
RpcContext savedContext = RpcContext.getContext();
return stringCompletableFuture;
}
```
### 消费者调用
* 从v2.7.0开始,Dubbo的所有异步编程接口开始以CompletableFuture为基础
* 基于 NIO 的非阻塞实现并行调用,客户端不需要启动多线程即可完成并行调用多个远程服务,相对多线程开销较小
* 设置允许超时等待
```
referenceConfig.setTimeout(10000);
```
* 调用
```
CompletableFuture<String> stringCompletableFuture = bean.sayHello("大头");
CountDownLatch latch = new CountDownLatch(1);
stringCompletableFuture.whenComplete((x, y) -> {
String x1 = x;
Throwable y1 = y;
if (y1 == null) {
System.out.println("获取响应:" + x1);
latch.countDown();
DebugUtils.stopTheTimer(1);
} else {
System.out.println("程序出错:" + y1);
}
});
DebugUtils.startTheTimer(1);
latch.await();
```
## 本地调用
* 本地调用使用了 injvm 协议,是一个伪协议,它不开启端口,不发起远程调用,只在 JVM 内直接关联,但执行 Dubbo 的 Filter 链。
## 参数回调
* Dubbo 将基于长连接生成反向代理,这样就可以从服务器端调用客户端逻辑
* 即服务器去调用客户端
### 服务端暴露接口
```
void addListener(String key, CallbackListener listener);
```
```
package service;
public interface CallbackListener {
void changed(String msg);
}
```
### 服务端接口实现
```
@Override
public void addListener(String key, CallbackListener listener) {
getAddress();
listeners.put(key, listener);
CompletableFuture.runAsync(()->{
while (true){
DebugUtils.sleep(1);
listener.changed(getChanged(key));//服务器去主动调用消费者
}
});// 发送变更通知
}
```
### 消费端调用
* 接口也是要相同的定义
```
AppService bean = classPathXmlApplicationContext.getBean(AppService.class);
bean.addListener("view",(x)->{
System.out.println("run back:"+x);
});
DebugUtils.bock();
```
## 事件通知(未尝试)
* 在调用之前、调用之后、出现异常时,会触发 oninvoke、onreturn、onthrow 三个事件,可以配置当事件发生时,通知哪个类的哪个方法
* 服务消费者 Callback 接口
```
interface Notify {
public void onreturn(Person msg, Integer id);
public void onthrow(Throwable ex, Integer id);
}
```
* 服务消费者 Callback 实现
```
class NotifyImpl implements Notify {
public Map<Integer, Person> ret = new HashMap<Integer, Person>();
public Map<Integer, Throwable> errors = new HashMap<Integer, Throwable>();
public void onreturn(Person msg, Integer id) {
System.out.println("onreturn:" + msg);
ret.put(id, msg);
}
public void onthrow(Throwable ex, Integer id) {
errors.put(id, ex);
}
}
```
* 服务消费者 Callback 配置
```xml
<bean id ="demoCallback" class = "org.apache.dubbo.callback.implicit.NofifyImpl" />
<dubbo:reference id="demoService"interface="org.apache.dubbo.callback.implicit.IDemoService"version="1.0.0" group="cn" >
<dubbo:method name="get" async="true" onreturn = "demoCallback.onreturn"onthrow="demoCallback.onthrow" />
</dubbo:reference>
callback 与 async 功能正交分解,async=true 表示结果是否马上返回,onreturn 表示是否需要回调。
```
* 两者叠加存在以下几种组合情况:
```
异步回调模式:async=true onreturn="xxx"
同步回调模式:async=false onreturn="xxx"
异步无回调 :async=true
同步无回调 :async=false
```
## 本地伪装
* 本地伪装通常用于服务降级,比如某验权服务,当服务提供方全部挂掉后,客户端不抛出异常,而是通过 Mock 数据返回授权失败
* 仅force通过了
```
<dubbo:reference id="demoService" check="false" interface="com.foo.BarService">
<dubbo:parameter key="sayHello.mock" value="force:return fake"/>
</dubbo:reference>
```
## 并发控制
* 限制 com.foo.BarService 的每个方法,服务器端并发执行(或占用线程池线程数)不能超过 10 个:
```
<dubbo:service interface="com.foo.BarService" executes="10" />
```
## 连接控制
### 服务端连接控制
* 限制服务器端接受的连接不能超过 10 个 [1]:
```
<dubbo:provider protocol="dubbo" accepts="10" />
```
或
```
<dubbo:protocol name="dubbo" accepts="10" />
```
### 客户端连接控制
* 限制客户端服务使用连接不能超过 10 个 [2]:
```
<dubbo:reference interface="com.foo.BarService" connections="10" />
```
## 延迟连接
延迟连接用于减少长连接数。当有调用发起时,再创建长连接。[1]
```
<dubbo:protocol name="dubbo" lazy="true" />
```
## 令牌验证
* 通过令牌验证在注册中心控制权限,以决定要不要下发令牌给消费者,可以防止消费者绕过注册中心访问提供者,另外通过注册中心可灵活改变授权方式,而不需修改或升级提供者
### 可以全局设置开启令牌验证:
```
<!--随机token令牌,使用UUID生成-->
<dubbo:provider interface="com.foo.BarService" token="true" />
```
或
```
<!--固定token令牌,相当于密码-->
<dubbo:provider interface="com.foo.BarService" token="123456" />
```
### 也可在服务级别设置:
```
<!--随机token令牌,使用UUID生成-->
<dubbo:service interface="com.foo.BarService" token="true" />
```
或
```
<!--固定token令牌,相当于密码-->
<dubbo:service interface="com.foo.BarService" token="123456" />
```
## 在 Provider 端尽量多配置 Consumer 端属性
原因如下:
* 作服务的提供方,比服务消费方更清楚服务的性能参数,如调用的超时时间、合理的重试次数等
* 在 Provider 端配置后,Consumer 端不配置则会使用 Provider 端的配置,即 Provider 端的配置可以作为 Consumer 的缺省值 [1]。否则,Consumer 会使用 Consumer 端的全局设置,这对于 Provider 是不可控的,并且往往是不合理的
* Provider 端尽量多配置 Consumer 端的属性,让 Provider 的实现者一开始就思考 Provider 端的服务特点和服务质量等问题。
示例:
```
<dubbo:service interface="com.alibaba.hello.api.HelloService" version="1.0.0" ref="helloService"
timeout="300" retry="2" loadbalance="random" actives="0" />
<dubbo:service interface="com.alibaba.hello.api.WorldService" version="1.0.0" ref="helloService"
timeout="300" retry="2" loadbalance="random" actives="0" >
<dubbo:method name="findAllPerson" timeout="10000" retries="9" loadbalance="leastactive" actives="5" />
<dubbo:service/>
```
* 建议在 Provider 端配置的 Consumer 端属性有:
1. timeout:方法调用的超时时间
2. retries:失败重试次数,缺省是 2 [2]
3. loadbalance:负载均衡算法 [3],缺省是随机 random。还可以配置轮询 roundrobin、最不活跃优先 [4] leastactive 和一致性哈希 consistenthash 等
4. actives:消费者端的最大并发调用限制,即当 Consumer 对一个服务的并发调用到上限后,新调用会阻塞直到超时,在方法上配置 dubbo:method 则针对该方法进行并发限制,在接口上配置 dubbo:service,则针对该服务进行并发限制
## 在 Provider 端配置合理的 Provider 端属性
```
<dubbo:protocol threads="200" />
<dubbo:service interface="com.alibaba.hello.api.HelloService" version="1.0.0" ref="helloService"
executes="200" >
<dubbo:method name="findAllPerson" executes="50" />
</dubbo:service>
```
* 建议在 Provider 端配置的 Provider 端属性有:
1. threads:服务线程池大小
2. executes:一个服务提供者并行执行请求上限,即当 Provider 对一个服务的并发调用达到上限后,新调用会阻塞,此时 Consumer 可能会超时。在方法上配置 dubbo:method 则针对该方法进行并发限制,在接口上配置 dubbo:service,则针对该服务进行并发限制
## 配置 Dubbo 缓存文件
提供者列表缓存文件:
```
<dubbo:registry file=”${user.home}/output/dubbo.cache” />
```
注意:
可以根据需要调整缓存文件的路径,保证这个文件不会在发布过程中被清除;
如果有多个应用进程,请注意不要使用同一个文件,避免内容被覆盖;
该文件会缓存注册中心列表和服务提供者列表。配置缓存文件后,应用重启过程中,若注册中心不可用,应用会从该缓存文件读取服务提供者列表,进一步保证应用可靠性。
## 新版本 telnet 命令使用说明
* dubbo 2.5.8 新版本增加了 QOS 模块,提供了新的 telnet 命令支持。
### 端口
* 新版本的 telnet 端口 与 dubbo 协议的端口是不同的端口,默认为 22222,可通过配置文件dubbo.properties 修改:
```
dubbo.application.qos.port=33333
```
* 默认情况下,dubbo 接收任何主机发起的命令,可通过配置文件dubbo.properties 修改:
```
dubbo.application.qos.accept.foreign.ip=false
```
### 支持的命令
* ls 列出消费者和提供者
* Online 上线服务命令
* Offline 下线服务命令
* help 命令 | 28,723 | Apache-2.0 |
---
title: Great Teacher Onizuka
date: 2008-06-03 16:00:03 +0800
layout: post
permalink: /blog/2008/06/gto-great-teacher-onizuka.html
categories:
- 景彡 | Vision
tags:
- Comic
- TV
- 动画片
- 反町隆史
- 漫画
- 电视剧
- 鬼塚英吉
---
初次使用<a title="Windows Live Writer" href="http://writer.live.com" target="_blank" rel="bookmark">Live Writer</a> 写日志,不知道是否能完美支持<a title="WordPress" href="http://wordpress.org/" target="_blank" rel="bookmark">WordPress</a>。周末儿童节,终于看完了GTO,看到他牛X的跑到美国载着金发姐姐一脸YD,然后冲入某*California High School*,一帮金毛孩成了Great Teacher Onizuka 即简称GTO的22岁单身教师鬼塚 英吉, *Onizuka Eikichi*的学生,而天真可爱的冬月 あずさ, *Fuyutsuki Azusa*还在武藏野圣林学苑苦等着他。
<a href="/blog/upload/GTO.jpg" target="_blank"><img title="GTO" height="200" alt="GTO" src="http://junnie.3322.org/images/zhu8.net/GTO.jpg" width="260" class="alignleft" /></a>个人比较喜欢动画版(43集),因为电视剧和电影版的无法表现那么夸张,很多东西电视剧表现不了,比如,鬼塚那种猥琐的神情,十个反町隆史都不能刻画一二。而且对原著不忠实,很多地方看得人二楞二楞的……。感谢伟大的<a href="http://www.emule.org.cn" target="_blank">骡子</a>,包罗万象,我可以把GTO的<a href="http://lib.verycd.com/2007/12/25/0000175166.html" target="_blank">《麻辣教师》(G.T.O.)[R2Jraw+外挂字幕][43更新][wmv][DVDRip]</a>、[原声大碟 -《麻辣教师 1》(Great.Teacher.Onizuka OST 1)[MP3!]][1]、[原声大碟 -《麻辣教师 2》(Great Teacher Onizuka Ost 2)[MP3!]][2]、[《麻辣教师》(Great.Teacher.Onizuka)DVD转制蓝色字幕版(1-12集全)[RMVB]][3]全部下齐了,然后慢慢看,刻到我一块三一张的紫光 16X DVD+R 里面去。对了,wmv版的动画片字幕不对,万能的电骡告诉我还有这个字幕[GTO.Lesson.01-43[R3DVDSUB].rar][4]可以下载。
<!--more-->
<a href="/blog/upload/GTO-comic.jpg" target="_blank"><img title="GTO-comic" alt="GTO-comic" src="http://junnie.3322.org/images/zhu8.net/gto-comic.jpg" width="180" height="260" class="alignright" /></a>不过很惭愧啊,原版漫画到现在还没看过,但还是要拜谢藤沢とおる *Fujisawa Tooru*先师(GTO漫画原版作者),以及阿部 記之 (formerly 阿部 紀之), *Abe Noriyuki*师(GTO动画版导演)。在Verycd倒是找到:<a href="http://lib.verycd.com/2004/03/31/0000008077.html" target="_blank">[漫画]《麻辣教师》(G.T.O)</a>,<a title="VeryCD.com 分享互联网社区-《麻辣教师》(GTO)PDF格式东立版" href="http://board.verycd.com/t334956.html" target="_blank"> 《麻辣教师》(GTO)PDF格式东立版</a>两个版本,都在下。不知道什么时候能下完,源很少,但每天上班开着总会有下完的时候的,哈哈!又得说到我支持eMule而不用BT那种短命的有违P2P最基本原则的东西。(下比赛录像等有时效性的东西除外,当然是刚放出来没多久的时候,种子多,种越多越好。)如果下下来看不行就得到淘宝上去淘一套来就得了。不知道以后会不会再找来《湘南純愛組!, *Shōnan Jun’ai Gumi*》看看。
在我以前的旧日志:***短長書***里,我就记录过GTO了。
> 编号:**148**|[GTO麻辣教师有的看了][5]
>
> 时间:**2005-11-12 14:57**|评论:**1**|浏览:**1776**
当年在学校的时候,和HSF一起把电视剧和动画版全部下了下来,在**网吧**哦!花费了不少时间和精力,嘻嘻哈哈的看完,昨日通电话的时候还提起当年的时光,如今已经过去应该差不多4、5年了罢。
怀念GTO,怀念从内测就开始玩大海战时候的鬼塚英吉-我以及弹间龙二-HSF,怀念当年与几个哥们的狗脸岁月。
[1]: http://lib.verycd.com/2005/09/05/0000063934.html
[2]: http://lib.verycd.com/2005/09/05/0000063936.html
[3]: http://lib.verycd.com/2005/11/08/0000073685.html
[4]: http://www.verycd.com/files/a680106dea1a3fdaee2bae8bec97cc11479318
[5]: /old/post/GTO.html | 2,683 | MIT |
---
title: 手順 5 DirectAccess 接続をテスト クラスターと、インターネットから
description: このトピックは一部のテスト ラボ ガイド - Windows Server 2016 で Windows NLB を使用するクラスターでの DirectAccess のデモンストレーション
manager: brianlic
ms.custom: na
ms.prod: windows-server-threshold
ms.reviewer: na
ms.suite: na
ms.technology: networking-da
ms.tgt_pltfrm: na
ms.topic: article
ms.assetid: 8399bdfa-809a-45e4-9963-f9b6a631007f
ms.author: pashort
author: shortpatti
ms.openlocfilehash: 23aed915edb827fd0cd61e6778167108647269ea
ms.sourcegitcommit: afb0602767de64a76aaf9ce6a60d2f0e78efb78b
ms.translationtype: MT
ms.contentlocale: ja-JP
ms.lasthandoff: 06/20/2019
ms.locfileid: "67283342"
---
# <a name="step-5-test-directaccess-connectivity-from-the-internet-and-through-the-cluster"></a>手順 5 DirectAccess 接続をテスト クラスターと、インターネットから
>適用先:Windows Server 2016 の Windows Server (半期チャネル)
CLIENT1 は、DirectAccess のテストの準備ができました。
- インターネットからの DirectAccess の接続をテストします。 CLIENT1 は、シミュレートされたインターネットに接続します。 シミュレートされたインターネットに接続しているときに、クライアントには、パブリック IPv4 アドレスが割り当てられます。 DirectAccess クライアントには、パブリック IPv4 アドレスが割り当てられますが、IPv6 移行テクノロジを使用して、リモート アクセス サーバーへの接続を確立しようとします。
- クラスターによって、DirectAccess クライアント接続をテストします。 クラスターの機能をテストします。 テストを開始する前に、EDGE1 と EDGE2 の両方を少なくとも 5 分間シャットすることをお勧めします。 多くの ARP キャッシュ タイムアウトおよび NLB に関連する変更が含まれますが、この理由があります。 テスト ラボでの NLB の構成を検証するときに患者に構成の変更はすぐに反映されませんまで接続で、一定期間が経過した後にする必要があります。 これは、次のタスクを実行する場合に注意してください。
> [!TIP]
> この手順を実行する前に、Internet Explorer のキャッシュをクリアし、接続のテストと web ページをキャッシュから取得しないいるかどうかを確認する別のリモート アクセス サーバー経由の接続をテストするたびにすることをお勧めします。
## <a name="test-directaccess-connectivity-from-the-internet"></a>インターネットから DirectAccess 接続をテストします。
1. 企業ネットワーク スイッチから CLIENT1 を外し、インターネット スイッチに接続します。 30 秒間待機します。
2. 管理者特権で Windows PowerShell ウィンドウで、次のように入力します。 **ipconfig/flushdns** ENTER キーを押します。 これにより、クライアント コンピューターが、企業ネットワークに接続されているときにまだクライアント DNS キャッシュに存在する名前解決エントリがフラッシュします。
3. Windows PowerShell ウィンドウで、入力**Get-dnsclientnrptpolicy** ENTER キーを押します。
出力には、名前解決ポリシー テーブル (NRPT) の現在の設定が表示されます。 これらの設定を指定するすべての接続。 corp.contoso.com を IPv6 アドレスの 2001:db8:1::2、リモート アクセス DNS サーバーで解決できる必要があります。 また、nls.corp.contoso.com という名前が除外されることを示す NRPT エントリがあります。除外リストの名前は、リモート アクセス DNS サーバーから応答されません。 リモート アクセス サーバーへの接続を確認するリモート アクセス DNS サーバーの IP アドレスに ping を実行します。たとえば、2001:db8:1::2 の ping を実行することができます。
4. Windows PowerShell ウィンドウで、入力**ping app1** ENTER キーを押します。 IPv6 アドレスからの応答は、2001:db8:1::3 この例では、APP1 に表示されます。
5. Windows PowerShell ウィンドウで、入力**ping app2** ENTER キーを押します。 EDGE1 から割り当てられた NAT64 アドレスから APP2 (この例では fdc9:9f4e:eb1b:7777::a00:4) に返信があります。
APP2 の ping を実行する機能は、成功した場合は、APP2 が IPv4 唯一のリソースは、NAT64 と DNS64 を使用して接続を確立することができたことを示しているため、重要です。
6. Windows PowerShell ウィンドウは、次の手順を開いたままにしておきます。
7. Internet Explorer のアドレス バーに Internet Explorer を開き、入力 **https://app1/** ENTER キーを押します。 APP1 の既定の IIS Web サイトが表示されます。
8. Internet Explorer のアドレス バーに次のように入力します。 **https://app2/** ENTER キーを押します。 APP2 の既定の Web サイトが表示されます。
9. **開始**画面で「<strong>\\\App2\Files</strong>し、ENTER キーを押します。 [新しいテキスト ドキュメント] ファイルをダブルクリックします。
これは、SMB を使用して、リソース ドメイン内のリソースを取得する IPv4 のみのサーバーに接続することができたことを示します。
10. **開始**画面で「**wf.msc**、し、ENTER キーを押します。
11. **セキュリティが強化された Windows ファイアウォール**コンソールで、だけであることを確認、**プライベート**または**パブリック プロファイル**がアクティブになっています。 正常に動作する DirectAccess には、Windows ファイアウォールを有効にする必要があります。 Windows ファイアウォールを無効にすると、DirectAccess の接続は機能しません。
12. コンソールの左側のウィンドウで、展開、**監視**ノード、およびクリック、**接続セキュリティ規則**ノード。 アクティブな接続のセキュリティ規則が表示されます。**DirectAccess ポリシー-ClientToCorp**、 **DirectAccess ポリシー-ClientToDNS64NAT64PrefixExemption**、 **DirectAccess ポリシー-ClientToInfra**、および**DirectAccessポリシー ClientToNlaExempt**します。 右を表示するのには、中央のウィンドウのスクロール、 **1 番目の認証方法**と**2 番目の認証方法**列。 最初のルール (ClientToCorp) では、Kerberos V5 を使用して、イントラネット トンネルを確立するために 3 番目の規則 (ClientToInfra) は、インフラストラクチャ トンネルを確立するために NTLMv2 を使用していることを確認します。
13. コンソールの左側のウィンドウで、展開、**セキュリティ アソシエーション**ノード、およびクリック、**メイン モード**ノード。 NTLMv2 を使用して、インフラストラクチャ トンネルのセキュリティ アソシエーションと Kerberos V5 を使用して、イントラネット トンネルのセキュリティ アソシエーションに注意してください。 表示するエントリを右クリックして**ユーザー (Kerberos V5)** として、 **2 番目の認証方法** をクリック**プロパティ**します。 **全般** タブに注意してください、 **2 番目の認証のローカル ID**は**corp \user1**User1 を使用して CORP ドメインに正常に認証できるようにしたことを示すKerberos。
## <a name="test-directaccess-client-connectivity-through-the-cluster"></a>クラスターでの DirectAccess クライアント接続をテストします。
1. EDGE2 では、正常なシャット ダウンを実行します。
ネットワーク負荷分散マネージャーを使用して、これらのテストを実行するときに、サーバーの状態を表示することができます。
2. Client1 で Windows PowerShell ウィンドウで、次のように入力します。 **ipconfig/flushdns** ENTER キーを押します。 これにより、まだクライアント DNS キャッシュに残っている名前解決エントリがフラッシュします。
3. Windows PowerShell ウィンドウで、APP1 および APP2 に対して ping を実行します。 これらのリソースの両方から応答を受信する必要があります。
4. **開始**画面で「<strong>\\\app2\files</strong>します。 APP2 コンピューター上の共有フォルダーが表示されます。 APP2 のファイル共有を開くことができますでは、ユーザーの Kerberos 認証を必要とする 2 番目のトンネルが正しく動作していることを示します。
5. Internet Explorer を開き、web サイトを開きます https://app1/ と https://app2/ します。 両方の web サイトを開くことができますを確認する最初と 2 つ目の両方のトンネルが機能しているとします。 Internet Explorer を閉じます。
6. EDGE2 コンピューターを起動します。
7. EDGE1 では、正常なシャット ダウンを実行します。
8. 5 分間待機し、CLIENT1 に戻ります。 手順 2. ~ 5. を実行します。 CLIENT1 が透過的にフェールオーバーする EDGE2 EDGE1 は使用できなくなった後できたことを確認します。 | 5,137 | CC-BY-4.0 |
---
title: 'Visual Studio Code简介'
tags: deepin solution ide
---
<section>
<div class="before">
<div class="other">
</div>
</div>
<div class="new-box">
<div id="mw-content-text" lang="zh-CN" dir="ltr" class="mw-content-ltr"><div id="toc" class="toc"><div id="toctitle"><h3>目录</h3></div>
</div>
<h3><span class="mw-headline" id=".E7.AE.80.E4.BB.8B">简介</span></h3>
<p>Visual Studio Code是一款轻量级代码编辑器,它具有语法高亮、可定制的热键绑定、括号匹配、代码片段收集、代码调试、自定义语言和主题、支持扩展/插件等功能。</p>
<h3><span class="mw-headline" id=".E5.AE.89.E8.A3.85">安装</span></h3>
<p><code>sudo apt-get install vscode</code></p>
<h3><span class="mw-headline" id=".E5.8D.B8.E8.BD.BD">卸载</span></h3>
<p><code>sudo apt-get remove vscode</code></p>
<h3><span class="mw-headline" id=".E4.BB.93.E5.BA.93.E5.9C.B0.E5.9D.80">仓库地址</span></h3>
<p><a rel="nofollow" class="external text" href="http://packages.deepin.com/deepin/pool/main/v/vscode/"></a><a href="http://packages.deepin.com/deepin/pool/main/v/vscode/">http://packages.deepin.com/deepin/pool/main/v/vscode/</a><a rel="nofollow" class="external text" href="http://packages.deepin.com/deepin/pool/main/v/vscode/"></a></p>
<h3><span class="mw-headline" id=".E5.B8.B8.E8.A7.81.E9.97.AE.E9.A2.98">常见问题</span></h3>
<h3><span class="mw-headline" id=".E7.9B.B8.E5.85.B3.E9.93.BE.E6.8E.A5">相关链接</span></h3>
<p>维基百科:</p>
<!--
NewPP limit report
Cached time: 20190903044709
Cache expiry: 86400
Dynamic content: false
CPU time usage: 0.008 seconds
Real time usage: 0.006 seconds
Preprocessor visited node count: 1/1000000
Preprocessor generated node count: 4/1000000
Post‐expand include size: 0/2097152 bytes
Template argument size: 0/2097152 bytes
Highest expansion depth: 1/40
Expensive parser function count: 0/100
-->
<!--
Transclusion expansion time report (%,ms,calls,template)
100.00% 0.000 1 - -total
-->
<!-- Saved in parser cache with key mediawiki:pcache:idhash:224-0!*!*!!zh-cn!*!* and timestamp 20190903044709 and revision id 428
-->
</div> </div>
</section> | 2,107 | Apache-2.0 |
# 摆动排序 II
> 难度:中等
>
> https://leetcode-cn.com/problems/wiggle-sort-ii/
## 题目
给你一个整数数组`nums`,将它重新排列成`nums[0] < nums[1] > nums[2] < nums[3]...`的顺序。
你可以假设所有输入数组都可以得到满足题目要求的结果。
### 示例
#### 示例 1:
```
输入:nums = [1,5,1,1,6,4]
输出:[1,6,1,5,1,4]
解释:[1,4,1,5,1,6] 同样是符合题目要求的结果,可以被判题程序接受。
```
#### 示例 2:
```
输入:nums = [1,3,2,2,3,1]
输出:[2,3,1,3,1,2]
```
## 解题
### 排序
```ts
/**
* 排序
* @desc 时间复杂度 O(NlogN) 空间复杂度 O(N)
* @param nums
*/
export function wiggleSort(nums: number[]): void {
const sorted = nums.sort((a, b) => a - b).slice()
let i = nums.length - 1
let j = i >> 1
let k = 0
while (k < sorted.length) {
nums[k] = (k & 1) ? sorted[i--] : sorted[j--]
k++
}
}
```
### 快速排序 + 中位数
```ts
/**
* 快速排序 + 中位数
* @desc 时间复杂度 O(N) 空间复杂度 O(N)
* @param nums
*/
export function wiggleSort2(nums: number[]): void {
const len = nums.length
const mid = getMedian(0, 0, nums) // 中位数
const leftArr: number[] = []
const rightArr: number[] = []
let count = 0 // 记录与中位数相等的数量
for (const num of nums) {
if (num > mid)
rightArr.push(num)
else if (num < mid)
leftArr.push(num)
else
count++
}
// 将mid放入数组中,保证leftArr和rightArr长度相差不超过1
const diff = leftArr.length - rightArr.length
if (diff === 0) {
leftArr.splice(0, 0, ...new Array(Math.ceil(count / 2)).fill(mid))
rightArr.push(...new Array(count >> 1).fill(mid))
}
else if (diff > 0) {
count -= diff
leftArr.splice(0, 0, ...new Array(Math.ceil(count / 2)).fill(mid))
rightArr.push(...new Array((count >> 1) + diff).fill(mid))
}
else {
count += diff
leftArr.splice(0, 0, ...new Array(Math.ceil(count / 2) - diff).fill(mid))
rightArr.push(...new Array(count >> 1).fill(mid))
}
for (let i = 0; i < len; i++) {
if (i % 2)
nums[i] = rightArr.shift()!
else
nums[i] = leftArr.shift()!
}
/**
* 使用快排获取中位数
* @param left
* @param right
* @param nums
* @returns
*/
function getMedian(left: number, right: number, nums: number[]): number {
const len = nums.length
const mid = nums[len >> 1]
const leftArr: number[] = []
const rightArr: number[] = []
// 记录与 mid 相等的数量
let count = 0
for (const num of nums) {
if (num > mid)
rightArr.push(num)
else if (num < mid)
leftArr.push(num)
else
count++
}
if (Math.abs(left + leftArr.length - right - rightArr.length) <= count)
return mid
if (left + leftArr.length > right + rightArr.length)
return getMedian(left, right + rightArr.length + count, leftArr)
else
return getMedian(left + leftArr.length + count, right, rightArr)
}
}
``` | 2,675 | MIT |
---
title: 子资源-Azure 资源管理器模板
description: 介绍如何在 Azure 资源管理器模板中设置子资源的名称和类型。
author: tfitzmac
ms.service: azure-resource-manager
ms.topic: conceptual
ms.date: 08/26/2019
ms.author: tomfitz
ms.openlocfilehash: 3a90b2155b11d4c12bc1f571af3f15fdbceb12b9
ms.sourcegitcommit: 6eecb9a71f8d69851bc962e2751971fccf29557f
ms.translationtype: MT
ms.contentlocale: zh-CN
ms.lasthandoff: 10/17/2019
ms.locfileid: "72532301"
---
# <a name="set-name-and-type-for-child-resources"></a>设置子资源的名称和类型
子资源是仅存在于另一资源的上下文中的资源。 例如,在没有[虚拟机](/azure/templates/microsoft.compute/2019-03-01/virtualmachines)的情况下,[虚拟机扩展](/azure/templates/microsoft.compute/2019-03-01/virtualmachines/extensions)不存在。 扩展资源是虚拟机的子资源。
在资源管理器模板中,可以在父资源内或父资源之外指定子资源。 下面的示例演示了父资源的资源属性中包含的子资源。
```json
"resources": [
{
<parent-resource>
"resources": [
<child-resource>
]
}
]
```
下一个示例演示父资源之外的子资源。 如果父资源未部署在同一个模板中,或者如果要使用[copy](resource-group-create-multiple.md)来创建多个子资源,则可以使用此方法。
```json
"resources": [
{
<parent-resource>
},
{
<child-resource>
}
]
```
你为资源名称和类型提供的值根据子资源是在父资源内部还是外部定义的而有所不同。
## <a name="within-parent-resource"></a>父资源内
在父资源类型中定义时,可以将类型和名称值的格式设置为一个不带斜杠的单词。
```json
"type": "{child-resource-type}",
"name": "{child-resource-name}",
```
以下示例显示了一个虚拟网络和一个子网。 请注意,子网包含在虚拟网络的资源阵列中。 名称设置为**Subnet1** ,类型设置为**子网**。 子资源被标记为依赖于父资源,因为父资源必须存在,然后才能部署子资源。
```json
"resources": [
{
"apiVersion": "2018-10-01",
"type": "Microsoft.Network/virtualNetworks",
"name": "VNet1",
"location": "[parameters('location')]",
"properties": {
"addressSpace": {
"addressPrefixes": [
"10.0.0.0/16"
]
}
},
"resources": [
{
"apiVersion": "2018-10-01",
"type": "subnets",
"location": "[parameters('location')]",
"name": "Subnet1",
"dependsOn": [
"VNet1"
],
"properties": {
"addressPrefix": "10.0.0.0/24"
}
}
]
}
]
```
完整资源类型仍为 " **virtualNetworks/子网**"。 不提供**virtualNetworks/** ,因为它是从父资源类型中假定的。
子资源名称设置为**Subnet1** ,但完整名称包括父名称。 不提供**VNet1** ,因为它是从父资源中假定的。
## <a name="outside-parent-resource"></a>父资源外
在父资源外定义时,可以将类型和带斜杠的格式设置为包含父类型和名称。
```json
"type": "{resource-provider-namespace}/{parent-resource-type}/{child-resource-type}",
"name": "{parent-resource-name}/{child-resource-name}",
```
以下示例显示了在根级别定义的虚拟网络和子网。 请注意,此子网不包含在虚拟网络的资源阵列中。 名称设置为**VNet1/Subnet1** ,类型设置为 " **virtualNetworks/子网**"。 子资源被标记为依赖于父资源,因为父资源必须存在,然后才能部署子资源。
```json
"resources": [
{
"apiVersion": "2018-10-01",
"type": "Microsoft.Network/virtualNetworks",
"name": "VNet1",
"location": "[parameters('location')]",
"properties": {
"addressSpace": {
"addressPrefixes": [
"10.0.0.0/16"
]
}
}
},
{
"apiVersion": "2018-10-01",
"type": "Microsoft.Network/virtualNetworks/subnets",
"location": "[parameters('location')]",
"name": "VNet1/Subnet1",
"dependsOn": [
"VNet1"
],
"properties": {
"addressPrefix": "10.0.0.0/24"
}
}
]
```
## <a name="next-steps"></a>后续步骤
* 若要了解有关创建 Azure 资源管理器模板的信息,请参阅[创作模板](resource-group-authoring-templates.md)。
* 若要了解引用资源时资源名称的格式,请参阅[reference 函数](resource-group-template-functions-resource.md#reference)。 | 3,264 | CC-BY-4.0 |
---
ms.openlocfilehash: 265fc5bea97bf85bcb9cc8111f915e14297d9957
ms.sourcegitcommit: 55f438d4d00a34b9aca9eedaac3f85590bb11565
ms.translationtype: HT
ms.contentlocale: ja-JP
ms.lasthandoff: 09/23/2019
ms.locfileid: "71181825"
---
### <a name="switchsystemwindowsformsdonotloadlatestricheditcontrol-compatibility-switch-not-supported"></a>Switch.System.Windows.Forms.DoNotLoadLatestRichEditControl 互換性スイッチはサポートされていません
.NET Framework 4.7.1 で導入された `Switch.System.Windows.Forms.UseLegacyImages` 互換スイッチは、.NET Core 3.0 上の Windows フォームではサポートされていません。
#### <a name="change-description"></a>変更の説明
.NET Framework 4.6.2 とそれ以前のバージョンでは、<xref:System.Windows.Forms.RichTextBox> コントロールによって Win32 RichEdit コントロール v3.0 がインスタンス化され、.NET Framework 4.7.1 をターゲットとするアプリケーションの場合、<xref:System.Windows.Forms.RichTextBox> コントロールによって RichEdit v4.1 (*msftedit.dll*) がインスタンス化されます。 `Switch.System.Windows.Forms.DoNotLoadLatestRichEditControl` 互換性スイッチは、.NET Framework 4.7.1 以降のバージョンをターゲットとするアプリケーションが新しい RichEdit v4.1 コントロールをオプトアウトし、代わりに古い RichEdit v3 コントロールを使用できるようにするために導入されました。
.NET Core では、`Switch.System.Windows.Forms.DoNotLoadLatestRichEditControl` スイッチはサポートされていません。 <xref:System.Windows.Forms.RichTextBox> コントロールの新しいバージョンのみがサポートされています。
#### <a name="version-introduced"></a>導入されたバージョン
3.0 Preview 9
#### <a name="recommended-action"></a>推奨される操作
スイッチを削除します。 スイッチはサポートされておらず、代替機能は使用できません。
#### <a name="category"></a>カテゴリ
Windows フォーム
#### <a name="affected-apis"></a>影響を受ける API
- <xref:System.Windows.Forms.RichTextBox?displayProperty=nameWithType>
<!--
### Affected APIs
- `T:System.Windows.Forms.RichTextBox`
--> | 1,605 | CC-BY-4.0 |
---
layout: post
title: "[redis 源码走读] 字典(dict)"
categories: redis
tags: redis dict
author: wenfh2020
---
redis 是 key-value 的 NoSQL 数据库,dict 是基础数据结构,dict 总体来说是一个`哈希表`,哈希表 O(1) 的时间复杂度,能高效进行数据读取。
dict 还有动态扩容/缩容功能,能灵活高效地使用机器内存。
因为 redis 是单进程服务,所以当数据量很大时,扩容/缩容这些内存操作,涉及到新内存重新分配,数据拷贝,必然会影响服务质量。redis 作者采用了渐进方式,将一次性操作,分散到 dict 对应的各个增删改查操作里,每个操作触发有限的数据迁移。所以 dict 会有两个哈希表(`dictht ht[2];`),相应的 `rehashidx` 迁移位置,方便数据迁移。
* content
{:toc}
---
## 1. 数据结构
{: data-action="zoom"}
> 设计图来源:《[redis dict 字典数据结构](https://www.processon.com/view/5e1deaa3e4b0a55fbb5dcc8e)》
```c
//字典
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx;/* rehashing not in progress if rehashidx == -1 */
int iterators; /* number of iterators currently running */
} dict;
// 哈希表
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
// 链表数据结点
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
// 数据类型,不同应用实现是不同的,所以用指针函数抽象出通用的接口,方便调用。
typedef struct dictType {
unsigned int (*hashFunction)(const void *key);
void *(*keyDup)(void *privdata, const void *key);
void *(*valDup)(void *privdata, const void *obj);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
} dictType;
```
---
## 2. 时间复杂度(读数据)
查找数据,哈希表 O(1) 时间复杂度,但是哈希表也会存在碰撞问题,所以哈希索引指向的列表长度也会影响效率。
```c
#define dictHashKey(d, key) (d)->type->hashFunction(key)
dictEntry *dictFind(dict *d, const void *key) {
dictEntry *he;
uint64_t h, idx, table;
if (d->ht[0].used + d->ht[1].used == 0) return NULL; /* dict is empty */
if (dictIsRehashing(d)) _dictRehashStep(d);
h = dictHashKey(d, key);
for (table = 0; table <= 1; table++) {
idx = h & d->ht[table].sizemask;
he = d->ht[table].table[idx];
while(he) {
// 如果 key 已经存在则返回对应的数据结构。
if (key==he->key || dictCompareKeys(d, key, he->key))
return he;
he = he->next;
}
// 如果数据正在迁移,从第二张表上查找。
if (!dictIsRehashing(d)) return NULL;
}
return NULL;
}
```
---
## 3. 工作流程
* 堆栈调用流程,下面会通过这个堆栈函数调用时序,看以下写操作的源码流程:
> 调试方法,可以参考视频:
>
> * bilibili: [Debug Redis in VsCode with Gdb](https://www.bilibili.com/video/av83070640)
>
> * youtube: [Debug Redis in VsCode with Gdb](https://youtu.be/QltK3vV5Slw)
```shell
#0 dictAdd (d=0x100529310, key=0x1018000b1, val=0x101800090) at dict.c:324
#1 0x000000010002bb9c in dbAdd (db=0x101005800, key=0x101800070, val=0x101800090) at db.c:159
#2 0x000000010002bd5c in setKey (db=0x101005800, key=0x101800070, val=0x101800090) at db.c:186
#3 0x000000010003abad in setGenericCommand (c=0x101015400, flags=0, key=0x101800070, val=0x101800090, expire=0x0, unit=0, ok_reply=0x0, abort_reply=0x0) at t_string.c:86
#4 0x000000010003afdd in setCommand (c=0x101015400) at t_string.c:139
#5 0x000000010001052d in call (c=0x101015400, flags=15) at server.c:2252
#6 0x00000001000112ac in processCommand (c=0x101015400) at server.c:2531
#7 0x0000000100025619 in processInputBuffer (c=0x101015400) at networking.c:1299
#8 0x0000000100021cb8 in readQueryFromClient (el=0x100528ba0, fd=5, privdata=0x101015400, mask=1) at networking.c:1363
#9 0x000000010000583c in aeProcessEvents (eventLoop=0x100528ba0, flags=3) at ae.c:412
#10 0x0000000100005ede in aeMain (eventLoop=0x100528ba0) at ae.c:455
#11 0x00000001000159d7 in main (argc=2, argv=0x7ffeefbff8c8) at server.c:4114
```
---
## 4. 写数据
### 4.1. 保存数据
数据库保存数据时,先检查这个键是否已经存在,从而分开添加,删除逻辑。
```c
/* High level Set operation. This function can be used in order to set
* a key, whatever it was existing or not, to a new object.
*
* 1) The ref count of the value object is incremented.
* 2) clients WATCHing for the destination key notified.
* 3) The expire time of the key is reset (the key is made persistent). */
void setKey(redisDb *db, robj *key, robj *val) {
if (lookupKeyWrite(db,key) == NULL) {
dbAdd(db,key,val);
} else {
dbOverwrite(db,key,val);
}
incrRefCount(val);
removeExpire(db,key);
signalModifiedKey(db,key);
}
```
---
### 4.2. 添加数据
要添加一个元素,首先需要申请一个空间,申请空间涉及到是否需要扩容,key 是否已经存在了。
```c
/* Add an element to the target hash table */
int dictAdd(dict *d, void *key, void *val) {
dictEntry *entry = dictAddRaw(d,key);
if (!entry) return DICT_ERR;
dictSetVal(d, entry, val);
return DICT_OK;
}
```
---
### 4.3. 增加数据结点
```c
/* Low level add. This function adds the entry but instead of setting
* a value returns the dictEntry structure to the user, that will make
* sure to fill the value field as he wishes.
*
* This function is also directly exposed to the user API to be called
* mainly in order to store non-pointers inside the hash value, example:
*
* entry = dictAddRaw(dict,mykey);
* if (entry != NULL) dictSetSignedIntegerVal(entry,1000);
*
* Return values:
*
* If key already exists NULL is returned.
* If key was added, the hash entry is returned to be manipulated by the caller.
*/
dictEntry *dictAddRaw(dict *d, void *key) {
int index;
dictEntry *entry;
dictht *ht;
if (dictIsRehashing(d)) _dictRehashStep(d);
/* Get the index of the new element, or -1 if
* the element already exists. */
// 检查 key 是否存在,避免重复添加。
if ((index = _dictKeyIndex(d, key)) == -1)
return NULL;
/* Allocate the memory and store the new entry.
* Insert the element in top, with the assumption that in a database
* system it is more likely that recently added entries are accessed
* more frequently. */
// 如果哈希表正在迁移数据,操作哈希表2.
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0];
entry = zmalloc(sizeof(*entry));
entry->next = ht->table[index];
ht->table[index] = entry;
ht->used++;
/* Set the hash entry fields. */
dictSetKey(d, entry, key);
return entry;
}
```
---
### 4.4. 哈希索引
检查哈希键是否已经被占用,被占用了就返回 -1,否则返回 key 对应的哈希索引。
```c
/* Returns the index of a free slot that can be populated with
* a hash entry for the given 'key'.
* If the key already exists, -1 is returned.
*
* Note that if we are in the process of rehashing the hash table, the
* index is always returned in the context of the second (new) hash table. */
static int _dictKeyIndex(dict *d, const void *key) {
unsigned int h, idx, table;
dictEntry *he;
/* Expand the hash table if needed */
if (_dictExpandIfNeeded(d) == DICT_ERR)
return -1;
/* Compute the key hash value */
h = dictHashKey(d, key);
for (table = 0; table <= 1; table++) {
idx = h & d->ht[table].sizemask;
/* Search if this slot does not already contain the given key */
he = d->ht[table].table[idx];
while(he) {
// 如果 key 已经存在则返回 -1。
if (key==he->key || dictCompareKeys(d, key, he->key))
return -1;
he = he->next;
}
// 如果哈希表处在数据迁移状态,从第二张表上查找。
if (!dictIsRehashing(d)) break;
}
return idx;
}
```
---
## 5. 数据迁移
### 5.1. 哈希表数据迁移
避免数据量大,一次性迁移需要耗费大量资源,每次只迁移部分数据。
```c
/* This function performs just a step of rehashing, and only if there are
* no safe iterators bound to our hash table. When we have iterators in the
* middle of a rehashing we can't mess with the two hash tables otherwise
* some element can be missed or duplicated.
*
* This function is called by common lookup or update operations in the
* dictionary so that the hash table automatically migrates from H1 to H2
* while it is actively used. */
static void _dictRehashStep(dict *d) {
if (d->iterators == 0) dictRehash(d,1);
}
/* Performs N steps of incremental rehashing. Returns 1 if there are still
* keys to move from the old to the new hash table, otherwise 0 is returned.
*
* Note that a rehashing step consists in moving a bucket (that may have more
* than one key as we use chaining) from the old to the new hash table, however
* since part of the hash table may be composed of empty spaces, it is not
* guaranteed that this function will rehash even a single bucket, since it
* will visit at max N*10 empty buckets in total, otherwise the amount of
* work it does would be unbound and the function may block for a long time. */
int dictRehash(dict *d, int n) {
// empty_visits 记录哈希表最大遍历空桶个数。
int empty_visits = n*10; /* Max number of empty buckets to visit. */
if (!dictIsRehashing(d)) return 0;
// 从 ht[0] rehashidx 位置开始遍历 n 个桶进行数据迁移。
while(n-- && d->ht[0].used != 0) {
dictEntry *de, *nextde;
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
assert(d->ht[0].size > (unsigned long)d->rehashidx);
while(d->ht[0].table[d->rehashidx] == NULL) {
d->rehashidx++;
// 当遍历限制的空桶数量后,返回。
if (--empty_visits == 0) return 1;
}
// 获取桶上的数据链表
de = d->ht[0].table[d->rehashidx];
/* Move all the keys in this bucket from the old to the new hash HT */
while(de) {
unsigned int h;
nextde = de->next;
/* Get the index in the new hash table */
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
// 旧的数据链表插入新的数据链表前面。
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
d->ht[0].used--;
d->ht[1].used++;
de = nextde;
}
d->ht[0].table[d->rehashidx] = NULL;
d->rehashidx++;
}
// 数据迁移完毕,重置哈希表两个 table。
/* Check if we already rehashed the whole table... */
if (d->ht[0].used == 0) {
zfree(d->ht[0].table);
d->ht[0] = d->ht[1];
_dictReset(&d->ht[1]);
d->rehashidx = -1;
return 0;
}
/* More to rehash... */
return 1;
}
```
---
### 5.2. 定时执行任务
```c
/* Rehash for an amount of time between ms milliseconds and ms+1 milliseconds */
int dictRehashMilliseconds(dict *d, int ms) {
long long start = timeInMilliseconds();
int rehashes = 0;
while(dictRehash(d,100)) {
rehashes += 100;
if (timeInMilliseconds()-start > ms) break;
}
return rehashes;
}
```
---
## 6. 扩容缩容
`dict` 是 redis 基础数据之一,该数据结构有动态扩容和缩容功能。
### 6.1. 是否需要扩容
```c
/* Expand the hash table if needed */
static int _dictExpandIfNeeded(dict *d) {
/* Incremental rehashing already in progress. Return. */
if (dictIsRehashing(d)) return DICT_OK;
/* If the hash table is empty expand it to the initial size. */
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);
/* If we reached the 1:1 ratio, and we are allowed to resize the hash
* table (global setting) or we should avoid it but the ratio between
* elements/buckets is over the "safe" threshold, we resize doubling
* the number of buckets. */
// 当使用的数据大于哈希表大小就可以扩展了。当`dict_can_resize` 不允许扩展时,数据的使用与哈希表的大小对比,超出一个比率强制扩展内存。
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio)) {
// 使用数据大小的两倍增长
return dictExpand(d, d->ht[0].used*2);
}
return DICT_OK;
}
```
---
### 6.2. 扩容容量大小
```c
/* Our hash table capability is a power of two */
static unsigned long _dictNextPower(unsigned long size) {
unsigned long i = DICT_HT_INITIAL_SIZE;
// 新容量大小是 2 的 n 次方,并且这个数值是第一个大于 2 * 原长度 的值。
if (size >= LONG_MAX) return LONG_MAX;
while(1) {
if (i >= size)
return i;
i *= 2;
}
}
```
---
### 6.3. 扩容
```c
/* Expand or create the hash table */
int dictExpand(dict *d, unsigned long size) {
dictht n; /* the new hash table */
unsigned long realsize = _dictNextPower(size);
/* the size is invalid if it is smaller than the number of
* elements already inside the hash table */
if (dictIsRehashing(d) || d->ht[0].used > size)
return DICT_ERR;
/* Rehashing to the same table size is not useful. */
if (realsize == d->ht[0].size) return DICT_ERR;
/* Allocate the new hash table and initialize all pointers to NULL */
n.size = realsize;
n.sizemask = realsize-1;
n.table = zcalloc(realsize*sizeof(dictEntry*));
n.used = 0;
/* Is this the first initialization? If so it's not really a rehashing
* we just set the first hash table so that it can accept keys. */
// 如果哈希表还是空的,给表1分配空间,否则空间分配给表2
if (d->ht[0].table == NULL) {
d->ht[0] = n;
return DICT_OK;
}
/* Prepare a second hash table for incremental rehashing */
d->ht[1] = n;
d->rehashidx = 0;
return DICT_OK;
}
```
---
### 6.4. 缩容
* 缩容,部分删除操作,会触发重新分配内存进行存储。
```c
#define HASHTABLE_MIN_FILL 10 /* Minimal hash table fill 10% */
int zsetDel(robj *zobj, sds ele) {
...
if (htNeedsResize(zs->dict)) dictResize(zs->dict);
...
}
int htNeedsResize(dict *dict) {
long long size, used;
size = dictSlots(dict);
used = dictSize(dict);
return (size > DICT_HT_INITIAL_SIZE &&
(used*100/size < HASHTABLE_MIN_FILL));
}
/* Resize the table to the minimal size that contains all the elements,
* but with the invariant of a USED/BUCKETS ratio near to <= 1 */
int dictResize(dict *d) {
int minimal;
if (!dict_can_resize || dictIsRehashing(d)) return DICT_ERR;
minimal = d->ht[0].used;
if (minimal < DICT_HT_INITIAL_SIZE)
minimal = DICT_HT_INITIAL_SIZE;
return dictExpand(d, minimal);
}
```
---
## 7. 随机键
随机键是配合一些算法使用的,例如 `maxmemory` 的淘汰策略,需要对数据进行采样,如果要随机取多个数据,`dictGetSomeKeys` 速度要比 `dictGetRandomKey` 快,但是随机分布效果没有`dictGetRandomKey` 好。
### 7.1. 随机取多个
字典随机连续采样。不保证能采样满足 count 个数。采集到指定数量样本,或者样本不够,但是查找次数到达上限,会退出。
```c
unsigned int dictGetSomeKeys(dict *d, dictEntry **des, unsigned int count) {
unsigned long j; /* internal hash table id, 0 or 1. */
unsigned long tables; /* 1 or 2 tables? */
unsigned long stored = 0, maxsizemask;
unsigned long maxsteps;
if (dictSize(d) < count) count = dictSize(d);
maxsteps = count*10;
// 如果字典正在数据迁移,多迁移几个数据,然后再进行逻辑。
for (j = 0; j < count; j++) {
if (dictIsRehashing(d))
_dictRehashStep(d);
else
break;
}
tables = dictIsRehashing(d) ? 2 : 1;
maxsizemask = d->ht[0].sizemask;
if (tables > 1 && maxsizemask < d->ht[1].sizemask)
maxsizemask = d->ht[1].sizemask;
unsigned long i = random() & maxsizemask;
unsigned long emptylen = 0;
// 两个条件,采集到指定数量样本,或者样本不够,但是查找次数到达上限。
while(stored < count && maxsteps--) {
for (j = 0; j < tables; j++) {
if (tables == 2 && j == 0 && i < (unsigned long) d->rehashidx) {
/* 哈希表正在数据迁移,我们在表 1 上采样,如果 i < d->rehashidx,
* 说明 i 下标指向的数据已经迁移到表 2 中去了,那么我们到表 2 中进行采样。
* 如果 i 下标大于表 2 的大小,那么在表2 中索引将会越界,那么继续在表 1 中
* 没有迁移的数据段( > rehashidx)中查找。*/
if (i >= d->ht[1].size)
i = d->rehashidx;
else
continue;
}
// 如果下标已经超出了当前表大小,继续遍历下一张表。
if (i >= d->ht[j].size) continue;
dictEntry *he = d->ht[j].table[i];
// 如果连续几个桶都是空的,再随机位置进行采样。
if (he == NULL) {
emptylen++;
if (emptylen >= 5 && emptylen > count) {
i = random() & maxsizemask;
emptylen = 0;
}
} else {
emptylen = 0;
while (he) {
*des = he;
des++;
he = he->next;
stored++;
if (stored == count) return stored;
}
}
}
i = (i+1) & maxsizemask;
}
return stored;
}
```
---
### 7.2. 随机取一个
先找一个随机非空桶,再在桶里随机找一个元素。
```c
/* Return a random entry from the hash table. Useful to
* implement randomized algorithms */
dictEntry *dictGetRandomKey(dict *d) {
dictEntry *he, *orighe;
unsigned long h;
int listlen, listele;
if (dictSize(d) == 0) return NULL;
if (dictIsRehashing(d)) _dictRehashStep(d);
if (dictIsRehashing(d)) {
do {
// 哈希表正在进行数据迁移,
// 从 表 1 的 rehashidx 到 d->ht[0].size 和 表 2 上随机抽取数据。
// 但是当哈希表正在扩容时,表2的大小至少是表 1 的两倍,而随机值落在表 2 的几率会更
//大。这个时候表2 的数据还没怎么进行填充,所以数据采集就会失败。失败几率会比较高。
h = d->rehashidx + (random() % (d->ht[0].size +
d->ht[1].size -
d->rehashidx));
he = (h >= d->ht[0].size) ? d->ht[1].table[h - d->ht[0].size] :
d->ht[0].table[h];
} while(he == NULL);
} else {
do {
h = random() & d->ht[0].sizemask;
he = d->ht[0].table[h];
} while(he == NULL);
}
listlen = 0;
orighe = he;
while(he) {
he = he->next;
listlen++;
}
listele = random() % listlen;
he = orighe;
while(listele--) he = he->next;
return he;
}
```
---
## 8. 参考
* [Redis源码剖析和注释(三)--- Redis 字典结构](https://blog.csdn.net/men_wen/article/details/69787532)
* 《redis 设计与实现》
* [Redis源码学习简记(三)dict哈希原理与个人理解](https://blog.csdn.net/qq_30085733/article/details/79843175)
* [Redis源码剖析和注释](https://blog.csdn.net/men_wen/article/details/69787532)
* [Redis Scan迭代器遍历操作原理(二)–dictScan反向二进制迭代器](http://chenzhenianqing.com/articles/1101.html) | 17,721 | MIT |
---
layout: post
title: "中原大地世纪回眸:论文化大革命之二(1/2)"
date: 2010-09-14T11:20:19.000Z
author: 明居正
from: https://www.youtube.com/watch?v=IN2uFiHsDAE
tags: [ 明居正 ]
categories: [ 明居正 ]
---
<!--1284463219000-->
[中原大地世纪回眸:论文化大革命之二(1/2)](https://www.youtube.com/watch?v=IN2uFiHsDAE)
------
<div>
論文化大革命(二):文革的原因,"鬥爭走資派"的合理與不合理之處。個人崇拜的過程
</div> | 333 | MIT |
# decimaltool
**基础核心四则运算**
/**
* 提供(相对)精确的除法运算,当发生除不尽的情况时,精确到
* 小数点以后10位,以后的数字四舍五入。
*
* @param v1 被除数
* @param v2 除数
* @param scale 保留scale位小数
* @return 两个参数的商
*/
decimalCore.div(double v1, double v2, Integer scale)
scale参数默认保留两位小数(可不传)。
/**
* 提供精确的加法运算。
*
* @param v1 被加数
* @param v2 加数
* @return 两个参数的和
*/
decimalCore.add(double v1, double v2)
/**
* 提供精确的减法运算。
*
* @param v1 被减数
* @param v2 减数
* @return 两个参数的差
*/
decimalCore.sub(double v1, double v2)
/**
* 提供精确的乘法运算。
*
* @param v1 被乘数
* @param v2 乘数
* @return 两个参数的积
*/
decimalCore.mul(double v1, double v2) | 725 | Apache-2.0 |
---
title: "Logic Apps に Office 365 ユーザー コネクタを追加する | Microsoft Docs"
description: "Office 365 Users コネクタと REST API パラメーターの概要"
services:
documentationcenter:
author: msftman
manager: erikre
editor:
tags: connectors
ms.assetid: b2146481-9105-4f56-b4c2-7ae340cb922f
ms.service: multiple
ms.devlang: na
ms.topic: article
ms.tgt_pltfrm: na
ms.workload: integration
ms.date: 08/18/2016
ms.author: deonhe
translationtype: Human Translation
ms.sourcegitcommit: b92f954680603891ced503a1134791312b5214f0
ms.openlocfilehash: 2e4af1c9369a97d518d027dc4679b9f01ca53d4c
---
# <a name="get-started-with-the-office-365-users-connector"></a>Office 365 Users コネクタの使用
Office 365 ユーザーに接続して、プロファイルの取得、ユーザーの検索などを行います。
> [!NOTE]
> 本記事は、ロジック アプリの 2015-08-01-preview スキーマ バージョンを対象としています。
>
>
Office 365 ユーザーは、次のことを行えます。
* Office 365 ユーザーから取得したデータに基づいてビジネス フローを構築できます。
* 直属の部下の取得、上司のユーザーのプロファイルの取得などのアクションを使用できます。 また、これらのアクションで応答を取得すると、他のアクションから出力を使用できます。 たとえば、ユーザーの直属の部下を取得し、この情報を利用して、SQL Azure Database を更新します。
ロジック アプリに操作を追加する方法については、「 [ロジック アプリの作成](../logic-apps/logic-apps-create-a-logic-app.md)」を参照してください。
## <a name="triggers-and-actions"></a>トリガーとアクション
Office 365 Users コネクタでは、次のアクションを使用できます。 トリガーはありません。
| トリガー | アクション |
| --- | --- |
| なし |<ul><li>上司の取得</li><li>自分のプロファイルを取得</li><li>直接の部下を取得</li><li>ユーザー プロファイルの取得</li><li>ユーザーの検索</li></ul> |
すべてのコネクタは、JSON および XML 形式のデータに対応します。
## <a name="create-a-connection-to-office-365-users"></a>Office 365 Users への接続を作成します
このコネクタをロジック アプリに追加する場合は、Office 365 ユーザー アカウントにサインインして、ロジック アプリでアカウントに接続できるようにする必要があります。
> [!INCLUDE [Steps to create a connection to Office 365 Users](../../includes/connectors-create-api-office365users.md)]
>
>
接続を作成したら、ユーザー ID など、Office 365 ユーザー プロパティを入力します。 これらのプロパティについては、このトピックの **REST API リファレンス** を参照してください。
> [!TIP]
> 他のロジック アプリでも、前述の Office 365 ユーザー接続を使用できます。
>
>
## <a name="office-365-users-rest-api-reference"></a>Office 365 Users REST API リファレンス
適用されるバージョン: 1.0。
### <a name="get-my-profile"></a>自分のプロファイルを取得
現在のユーザーのプロファイルを取得します。
```GET: /users/me```
この呼び出しには、パラメーターはありません。
#### <a name="response"></a>Response
| 名前 | 説明 |
| --- | --- |
| 200 |操作に成功しました |
| 202 |操作に成功しました |
| 400 |BadRequest |
| 401 |権限がありません |
| 403 |許可されていません |
| 500 |内部サーバー エラー |
| default |操作に失敗しました。 |
### <a name="get-user-profile"></a>ユーザー プロファイルの取得
特定のユーザー プロファイルを取得します。
```GET: /users/{userId}```
| 名前 | データ型 | 必須 | 場所 | 既定値 | 説明 |
| --- | --- | --- | --- | --- | --- |
| userId |string |あり |path |なし |ユーザー プリンシパル名または電子メール ID |
#### <a name="response"></a>Response
| 名前 | 説明 |
| --- | --- |
| 200 |操作に成功しました |
| 202 |操作に成功しました |
| 400 |BadRequest |
| 401 |権限がありません |
| 403 |許可されていません |
| 500 |内部サーバー エラー |
| default |操作に失敗しました。 |
### <a name="get-manager"></a>上司の取得
指定されたユーザーの上司のユーザー プロファイルを取得します。
```GET: /users/{userId}/manager```
| 名前 | データ型 | 必須 | 場所 | 既定値 | 説明 |
| --- | --- | --- | --- | --- | --- |
| userId |string |あり |path |なし |ユーザー プリンシパル名または電子メール ID |
#### <a name="response"></a>Response
| 名前 | 説明 |
| --- | --- |
| 200 |操作に成功しました |
| 202 |操作に成功しました |
| 400 |BadRequest |
| 401 |権限がありません |
| 403 |許可されていません |
| 500 |内部サーバー エラー |
| default |操作に失敗しました。 |
### <a name="get-direct-reports"></a>直接の部下を取得
直接の部下を取得します。
```GET: /users/{userId}/directReports```
| 名前 | データ型 | 必須 | 場所 | 既定値 | 説明 |
| --- | --- | --- | --- | --- | --- |
| userId |string |あり |path |なし |ユーザー プリンシパル名または電子メール ID |
#### <a name="response"></a>Response
| 名前 | 説明 |
| --- | --- |
| 200 |操作に成功しました |
| 202 |操作に成功しました |
| 400 |BadRequest |
| 401 |権限がありません |
| 403 |許可されていません |
| 500 |内部サーバー エラー |
| default |操作に失敗しました。 |
### <a name="search-for-users"></a>ユーザーの検索
ユーザー プロファイルの検索結果を取得します。
```GET: /users```
| 名前 | データ型 | 必須 | 場所 | 既定値 | 説明 |
| --- | --- | --- | --- | --- | --- |
| searchTerm |string |× |query |なし |検索文字列 (以下に適用されます: 表示名、姓を含まない名前、姓、電子メール、メールのニックネーム、ユーザー プリンシパル名) |
#### <a name="response"></a>Response
| 名前 | 説明 |
| --- | --- |
| 200 |操作に成功しました |
| 202 |操作に成功しました |
| 400 |BadRequest |
| 401 |権限がありません |
| 403 |許可されていません |
| 500 |内部サーバー エラー |
| default |操作に失敗しました。 |
## <a name="object-definitions"></a>オブジェクト定義
#### <a name="user-user-model-class"></a>ユーザー: ユーザー モデル クラス
| プロパティ名 | データ型 | 必須 |
| --- | --- | --- |
| DisplayName |string |× |
| GivenName |string |× |
| Surname |string |× |
| Mail |string |× |
| MailNickname |string |× |
| TelephoneNumber |string |× |
| AccountEnabled |ブール値 |× |
| ID |string |○ |
| UserPrincipalName |string |× |
| 学科 |string |× |
| JobTitle |string |× |
| MobilePhone |string |× |
## <a name="next-steps"></a>次のステップ
[ロジック アプリを作成](../logic-apps/logic-apps-create-a-logic-app.md)します。
[API リスト](apis-list.md)に戻ります。
<!--References-->
[5]: https://portal.azure.com
[7]: ./media/connectors-create-api-office365-users/aad-tenant-applications.PNG
[8]: ./media/connectors-create-api-office365-users/aad-tenant-applications-add-appinfo.PNG
[9]: ./media/connectors-create-api-office365-users/aad-tenant-applications-add-app-properties.PNG
[10]: ./media/connectors-create-api-office365-users/contoso-aad-app.PNG
[11]: ./media/connectors-create-api-office365-users/contoso-aad-app-configure.PNG
<!--HONumber=Jan17_HO3--> | 5,168 | CC-BY-3.0 |
---
layout: post
title: "redis数据删除策略"
date: 2021-09-06 11:03:28
categories: [数据库, redis]
excerpt_separator: <!--more-->
---
redis数据删除策略
<!--more-->
## 1. 概述
当redis的键值设置过期时间后,redis会按照策略进行删除
## 2. 策略
被动删除:当读/写一个已经过期的key时,会触发惰性删除策略,直接删除掉这个过期key
主动删除:由于惰性删除策略无法保证冷数据被及时删掉,所以Redis会定期主动淘汰一批已过期的key
主动清理:当前已用内存超过maxmemory限定时,触发主动清理策略 | 330 | MIT |
---
title: CountDown 倒计时
description: 用于实时展示倒计时数值。
spline: data
isComponent: true
---
## 引入
全局引入,在 miniprogram 根目录下的`app.json`中配置,局部引入,在需要引入的页面或组件的`index.json`中配置。
```json
"usingComponents": {
"t-count-down": "tdesign-miniprogram/count-down/count-down"
}
```
## 代码演示
### 基础倒计时
动态倒计时间主要有时间数字和时分秒分割组成,尺寸可通过 class 进行控制
<img src="https://tdesign.gtimg.com/miniprogram/readme/countdown.png" width="375px" height="50%">
```html
<!-- 时分秒毫秒 -->
<t-count-down time="{{96 * 60 * 1000}}" />
<!-- 带毫秒 -->
<t-count-down format="HH:mm:ss:SSS" time="{{96 * 60 * 1000}}" millisecond />
<!-- 带方形底 -->
<t-count-down content="default" time="{{96 * 60 * 1000}}" theme="square" />
<!-- Large 带方形底 -->
<t-count-down content="default" time="{{96 * 60 * 1000}}" theme="square" size="large" />
<!-- 自定义内容 -->
<t-count-down
t-class="custom-theme"
content="slot"
time="{{96 * 60 * 1000}}"
bind:change="onChange"
>
<text class="item">{{timeData.hours}}</text>
<text class="item-dot">:</text>
<text class="item">{{timeData.minutes}}</text>
<text class="item-dot">:</text>
<text class="item">{{timeData.seconds}}</text>
</t-count-down>
```
```js
onChange(e) {
this.setData({
timeData: e.detail,
});
},
```
## API
### CountDown Props
名称 | 类型 | 默认值 | 说明 | 必传
-- | -- | -- | -- | --
auto-start | Boolean | true | 是否自动开始倒计时 | N
content | String / Slot | 'default' | 最终倒计时的展示内容,值为'default'时使用默认的格式,否则使用自定义样式插槽 | N
format | String | HH:mm:ss | 时间格式,DD-日,HH-时,mm-分,ss-秒,SSS-毫秒 | N
millisecond | Boolean | false | 是否开启毫秒级渲染 | N
size | String | 'small' | 倒计时尺寸。可选项:small/medium/large `v0.5.1` | N
split-with-unit | Boolean | false | 使用时间单位分割 `v0.5.1` | N
theme | String | 'default' | 倒计时风格。可选项:default/round/square `v0.5.1` | N
time | Number | - | 必需。倒计时时长,单位毫秒 | Y
### CountDown Events
名称 | 参数 | 描述
-- | -- | --
change | `(time: TimeData)` | 时间变化时触发。[详细类型定义](https://github.com/Tencent/tdesign-miniprogram/tree/develop/src/count-down/type.ts)。<br/>`interface TimeData { days: number; hours: number; minutes: number; seconds: number; milliseconds: number }`<br/>
finish | - | 倒计时结束时触发 | 2,092 | MIT |
<properties
pageTitle="SQL Server 資料庫移轉至 SQL Database | Microsoft Azure"
description="了解將內部部署 SQL Server 資料庫移轉至雲端 Azure SQL Database 的相關做法。請先使用資料庫移轉工具測試相容性再進行資料庫移轉。"
keywords="database migration,sql server database migration,database migration tools,migrate database,migrate sql database,資料庫移轉,sql server 資料庫移轉,資料庫移轉工具,移轉資料庫,移轉 sql database"
services="sql-database"
documentationCenter=""
authors="carlrabeler"
manager="jeffreyg"
editor=""/>
<tags
ms.service="sql-database"
ms.devlang="NA"
ms.topic="article"
ms.tgt_pltfrm="NA"
ms.workload="data-management"
ms.date="01/05/2016"
ms.author="carlrab"/>
# SQL Server 資料庫移轉至雲端 SQL Database
在本文中,您將學習如何將內部部署 SQL Server 2005 或更新版的資料庫移轉到 Azure SQL Database。在此資料庫移轉過程中,您會將您的結構描述和資料從目前環境中的 SQL Server 資料庫移轉到 SQL Database,但前提是現有的資料庫通過相容性測試。使用 [SQL Database V12](sql-database-v12-whats-new.md),除了伺服器層級和跨資料庫作業以外,剩餘的相容性問題很少。依賴[部分或未支援功能](sql-database-transact-sql-information.md)的資料庫和應用程式會需要一些再造來[修正這些不相容情況](sql-database-cloud-migrate-fix-compatibility-issues.md),然後才能移轉 SQL Server 資料。
> [AZURE.NOTE] 若要將非 SQL Server 資料庫 (包括 Microsoft Access、Sybase、MySQL Oracle 和 DB2) 移轉到 Azure SQL Database,請參閱 [SQL Server 移轉小幫手](http://blogs.msdn.com/b/ssma/)。
## 資料庫移轉工具會測試 SQL Server 資料庫與 SQL Database 的相容性
> [AZURE.SELECTOR]
- [SqlPackage](sql-database-cloud-migrate-determine-compatibility-sqlpackage.md)
- [SQL Server Management Studio](sql-database-cloud-migrate-determine-compatibility-ssms.md)
若要在開始資料庫移轉程序之前,測試 SQL Database 相容性問題,請使用下列其中一種方法:
- [使用 SqlPackage](sql-database-cloud-migrate-determine-compatibility-sqlpackage.md):SqlPackage 是一個命令提示字元公用程式,將會測試相容性問題並在發現時產生包含偵測到的相容性問題的報表。
- [使用 SQL Server Management Studio](sql-database-cloud-migrate-determine-compatibility-ssms.md):SQL Server Management Studio 中的「匯出資料層應用程式精靈」將會在螢幕上顯示偵測到的錯誤。
## 修正資料庫移轉相容性問題
如果偵測到相容性問題,您必須先修正這些相容性問題,再繼續進行 SQL Server 資料庫移轉。使用下列資料庫移轉工具:
- 使用 [SQL Azure 移轉精靈](sql-database-cloud-migrate-fix-compatibility-issues.md)
- 使用 [Visual Studio 適用的 SQL Server Data Tools ](sql-database-cloud-migrate-fix-compatibility-issues-ssdt.md)
- 使用 [SQL Server Management Studio](sql-database-cloud-migrate-fix-compatibility-issues-ssms.md)
## 將相容 SQL Server 資料庫移轉到 SQL Database
若要移轉相容的 SQL Server 資料庫,Microsoft 會為各種案例提供數種移轉方法。您選擇的方法取決於您允許的停機時間、SQL Server 資料庫的大小和複雜度,以及您連線到 Microsoft Azure 雲端的能力。
> [AZURE.SELECTOR]
- [SSMS Migration Wizard](sql-database-cloud-migrate-compatible-using-ssms-migration-wizard.md)
- [Export to BACPAC File](sql-database-cloud-migrate-compatible-export-bacpac-ssms.md)
- [Import from BACPAC File](sql-database-cloud-migrate-compatible-import-bacpac-ssms.md)
- [Transactional Replication](sql-database-cloud-migrate-compatible-using-transactional-replication.md)
若要選擇移轉方法,要提問的第一個問題是您是否經得起在移轉期間將資料庫移出生產環境。在發生作用中交易時移轉資料庫,可能會導致資料庫不一致且資料庫可能損毀。有許多方法可以停止資料庫,從停用用戶端連接性到建立[資料庫快照集](https://msdn.microsoft.com/library/ms175876.aspx)。
若要在停機時間最短的情況下移轉,如果您的資料庫符合交易複寫的需求,請使用 [SQL Server 交易複寫](sql-database-cloud-migrate-compatible-using-transactional-replication.md)。如果您可以經得起一些停機時間,或者您在執行生產資料庫的測試移轉,以便稍後進行移轉,請考慮下列三種方法之一:
- [SSMS 移轉精靈](sql-database-cloud-migrate-compatible-using-ssms-migration-wizard.md):針對小型到中型資料庫,移轉相容的 SQL Server 2005 或更新版本資料庫的步驟跟在 SQL Server Management Studio 中執行[將資料庫部署到 Microsoft Azure Database 精靈](sql-database-cloud-migrate-compatible-using-ssms-migration-wizard.md)一樣簡單。
- [匯出到 BACPAC 檔案](sql-database-cloud-migrate-compatible-export-bacpac-ssms.md),然後 [從 BACPAC 檔案匯入](sql-database-cloud-migrate-compatible-import-bacpac-ssms.md):如果您有連線挑戰 (沒有連線能力、低頻寬或逾時問題),對於中大型資料庫,請使用 [BACPAC](https://msdn.microsoft.com/library/ee210546.aspx#Anchor_4) 檔案。使用此方法,將 SQL Server 結構描述和資料匯出至 BACPAC 檔案,然後使用 SQL Server Management Studio 中的 [匯出資料層應用程式精靈] 或 [SqlPackage](https://msdn.microsoft.com/library/hh550080.aspx) 命令提示字元公用程式,將 BACPAC 檔案匯入 SQL 資料庫中。
- 同時使用 BACPAC 和 BCP:對更大型的資料庫使用 [BACPAC](https://msdn.microsoft.com/library/ee210546.aspx#Anchor_4) 檔案和 [BCP](https://msdn.microsoft.com/library/ms162802.aspx),以達到規模更大的平行處理來增加效能 (儘管複雜性更高)。使用此方法,分開移轉結構描述和資料。
- [將結構描述只匯出至 BACPAC 檔案](sql-database-cloud-migrate-compatible-export-bacpac-ssms.md)。
- [只從 BACPAC 檔案匯入結構描述](sql-database-cloud-migrate-compatible-import-bacpac-ssms.md)到 SQL Database。
- 使用 [BCP](https://msdn.microsoft.com/library/ms162802.aspx) 將資料擷取至一般檔案,然後將這些檔案[平行載入](https://technet.microsoft.com/library/dd425070.aspx)至 Azure SQL Database。

<!---HONumber=AcomDC_0128_2016--> | 4,519 | CC-BY-3.0 |
---
title: 載入資料
description: 您可以使用 Integration Services、bcp 公用程式、dwloader 或 SQL INSERT 語句,將資料載入或插入 SQL Server 平行處理資料倉儲(PDW)。
author: mzaman1
ms.prod: sql
ms.technology: data-warehouse
ms.topic: conceptual
ms.date: 04/17/2018
ms.author: murshedz
ms.reviewer: martinle
ms.custom: seo-dt-2019
ms.openlocfilehash: fd161820fd53d45642848697bce9589a98dec4ca
ms.sourcegitcommit: b87d36c46b39af8b929ad94ec707dee8800950f5
ms.translationtype: MT
ms.contentlocale: zh-TW
ms.lasthandoff: 02/08/2020
ms.locfileid: "74401042"
---
# <a name="loading-data-into-parallel-data-warehouse"></a>將資料載入平行處理資料倉儲
您可以使用 Integration Services、 [Bcp 公用程式](../tools/bcp-utility.md)、 **Dwloader**命令列載入器或 SQL insert 語句,將資料載入或插入 SQL Server 平行處理資料倉儲(PDW)。
## <a name="loading-environment"></a>正在載入環境
若要載入資料,您需要一或多個載入伺服器。 您可以使用您自己現有的 ETL 或其他伺服器,也可以購買新的伺服器。 如需詳細資訊,請參閱[取得和設定載入伺服器](acquire-and-configure-loading-server.md)。 這些指示包括 [[載入伺服器容量規劃] 工作表](loading-server-capacity-planning-worksheet.md),可協助您規劃適當的載入解決方案。
## <a name="load-with-dwloader"></a>使用 dwloader 載入
使用[Dwloader 命令列載入](dwloader.md)器是將資料載入 PDW 的最快方式。

dwloader 會將資料直接載入計算節點,而不需透過控制節點傳遞資料。 為了載入資料,dwloader 會先與控制節點進行通訊,以取得計算節點的連絡人資訊。 dwloader 會設定每個計算節點的通道,然後以迴圈配置資源方式將256個區塊的資料傳送至計算節點。
在每個計算節點上,資料移動服務(DMS)會接收和處理資料區塊。 處理資料時,會將每個資料列轉換成 SQL Server 原生格式,以及計算散發雜湊來判斷每個資料列所屬的計算節點。
處理資料列之後,DMS 會使用隨機移動來將每個資料列傳輸到正確的計算節點和 SQL Server 的實例。 當 SQL Server 收到資料列時,它會根據 dwloader 中所設定的 **-b**批次大小參數來批次處理它們,然後大量載入批次。
## <a name="load-with-prepared-statements"></a>具有備妥語句的載入
您可以使用備妥的語句,將資料載入分散式和複寫的資料表。 當輸入資料不符合目標資料類型時,會執行隱含轉換。 PDW 備妥語句支援的隱含轉換是 SQL Server 支援的轉換子集。 也就是說,只支援子集的轉換,但支援的轉換會符合 SQL Server 隱含轉換。 不論要載入的目標資料表是否定義為分散式或複寫資料表,都會將隱含轉換套用(如有需要)到存在於目標資料表中的所有資料行。
<!-- MISSING LINK
For more information, see [Prepared statements](prepared-statements.md).
-->
## <a name="related-tasks"></a>相關工作
|Task|描述|
|--------|---------------|
|建立臨時資料庫。|[建立臨時資料庫](staging-database.md)|
|使用 Integration Services 載入。|[使用 Integration Services 載入](load-with-ssis.md)|
|瞭解 dwloader 的類型轉換。|[dwloader 的資料類型轉換規則](dwloader-data-type-conversion-rules.md)|
|使用 dwloader 載入資料。|[dwloader 命令列載入器](dwloader.md)|
|瞭解 INSERT 的類型轉換。|[使用 INSERT 載入資料](load-with-insert.md)|
<!-- MISSING LINKS
## See Also
[Grant permissions to load data](grant-permissions-to-load-data.md)
[Common metadata query examles](metadata-query-examples.md)
--> | 2,425 | CC-BY-4.0 |
---
title: [NAME] {{text}}
preview: https://didi.github.io/mand-mobile/examples/#/{{name}}
---
[此处填写组件简介xxx]
### 引入
```javascript
import { SingleComponent } from 'mand-mobile'
Vue.component(SingleComponent.name, SingleComponent)
```
### 使用指南
[此处填写组件使用特殊说明,如使用其他依赖或项目配置,如无可缺省(如缺省删去标题)]
### 代码演示
<!-- DEMO -->
### API
#### [Component] Props
|属性 | 说明 | 类型 | 默认值 | 备注 |
|----|-----|------|------|------|
|xxx|xxx|String|xxx|xxx|
|xxx|xxx|Number|xxx|xxx|
|xxx|xxx|Boolean|xxx|xxx|
|xxx|xxx|Array<{a, b, c}>|xxx|xxx|
|xxx|xxx|Object:{a, b, c}|xxx|xxx|
|xxx|xxx|Function(a: String): void|xxx|xxx|
#### [Component] Methods
方法说明
|参数 | 说明 | 类型 | 默认值 |
|----|-----|------|------|
|xxx|xxx|xxx|xxx|
返回(如有)
|属性 | 说明 | 类型 |
|----|-----|------|
|xxx|xxx|xxx|
#### [Component] Events
事件说明
|属性 | 说明 | 类型 |
|----|-----|------|
|xxx|xxx|xxx| | 842 | Apache-2.0 |
```text
hexo clean && hexo g && gulp && hexo d
```
## 删除子模块
有时子模块的项目维护地址发生了变化,或者需要替换子模块,就需要删除原有的子模块。
删除子模块较复杂,步骤如下:
- rm -rf 子模块目录 删除子模块目录及源码
- vi .gitmodules 删除项目目录下.gitmodules文件中子模块相关条目
- vi .git/config 删除配置项中子模块相关条目
- rm .git/module/* 删除模块下的子模块目录,每个子模块对应一个目录,注意只删除对应的子模块目录即可
```git
git rm --cached 子模块名称
``` | 320 | MIT |
title: CMake后置-如何读懂复杂的文档
date: 2019-12-09 00:00:00
categories: Tutorial
tags: [CMake]
---
## 如何读懂复杂的文档
CMake的官方文档一直都以晦涩著称,学习曲线比较陡峭,仅有指令的手册没有完善的入门指导
这里补充一些入门提示,帮助新手理解
```
file(GLOB <variable>
[LIST_DIRECTORIES true|false] [RELATIVE <path>] [CONFIGURE_DEPENDS]
[<globbing-expressions>...])
```
### 符号的含义
| 符号 | 含义 | 示例 |
| :------------ | :------------ | :------------ |
| Plain Text | 命令本身,不能修改和自定义 | file、GLOB |
| Brackets () | 函数的参数 | 和所有类C语言一样 |
| Angle Brackets <> | 必选参数 | \<variable> |
| Square Brackets [] | 可选参数 | [CONFIGURE_DEPENDS] |
| Oring \| | 多选一的可选项 | true\|false |
| Variable | 用户自定义变量 | variable |
| Ellipsis ... | 变长参数 | [\<>...] |
这些符号规则和Shell的说明文档十分类似,如果有Linux相关经验的人应该不难理解
### 解析举例
根据符号分析,我们可以拆分解析指令
1. file是指令本身
2. 第一个固定参数 GLOB 代表Action
3. 第二个参数代表传入一个变量用于储存结果
4. 第三、四个参数一起作为可选输入参数,参数名 LIST_DIRECTORIES 参数值 true 或 false
5. 第五、六个参数一起作为可选输入参数,但是如果第四个存在,则第五个必须存在,参数名 RELATIVE 参数值为一个路径
6. 第七个参数参数为可选参数,本身不附带输入,为标记位,参数名 CONFIGURE_DEPENDS
7. 其八个参数为可选参数,该参数为变长参数,且必须使用 globbing-expressions
```SH
# file : 固定命令
# GLOB : 固定一个参数
# CPP_FILES : 第二个参数
# 3 - 7 个参数均被省略
# ..../*.cpp : 第八个参数
file(GLOB CPP_FILES ${CMAKE_CURRENT_LIST_DIR}/source/*.cpp)
``` | 1,196 | MIT |
---
title: 原始檔控制
description: 瞭解如何在 Azure Data Factory 中設定原始檔控制
services: data-factory
ms.service: data-factory
ms.workload: data-services
author: djpmsft
ms.author: daperlov
manager: anandsub
ms.reviewer: ''
ms.topic: conceptual
ms.custom: seo-lt-2019
ms.date: 04/30/2020
ms.openlocfilehash: f327844be57d7f8e177f3bf72b1e3b56c5147e00
ms.sourcegitcommit: 1895459d1c8a592f03326fcb037007b86e2fd22f
ms.translationtype: MT
ms.contentlocale: zh-TW
ms.lasthandoff: 05/01/2020
ms.locfileid: "82629315"
---
# <a name="source-control-in-azure-data-factory"></a>Azure Data Factory 中的原始檔控制
[!INCLUDE[appliesto-adf-xxx-md](includes/appliesto-adf-xxx-md.md)]
根據預設,會直接對 Data Factory 服務 Azure Data Factory 使用者介面體驗(UX)作者。 這項體驗有下列限制:
- Data Factory 服務未包含存放庫,此存放庫會用於儲存變更的 JSON 實體。 儲存變更的唯一方式是透過 [**全部發佈**] 按鈕,所有變更都會直接發佈至 data factory 服務。
- Data Factory 服務未針對共同作業和版本控制進行優化。
為了提供更好的撰寫經驗,Azure Data Factory 可讓您使用 Azure Repos 或 GitHub 來設定 Git 存放庫。 Git 是一種版本控制系統,可讓您更輕鬆地進行變更追蹤和共同作業。 本教學課程將概述如何在 git 存放庫中進行設定和工作,以及反白顯示最佳做法和疑難排解指南。
> [!NOTE]
> Azure data factory git 整合無法在 Azure Government 雲端中使用。
## <a name="advantages-of-git-integration"></a>Git 整合的優點
以下是 git 整合提供給撰寫經驗的一些優點清單:
- **原始檔控制:** 當您的資料處理站工作負載變得很重要時,您會想要整合您的處理站與 Git,以運用數個來源控制優點,如下所示:
- 追蹤/稽核變更的能力。
- 還原造成錯誤 (Bug) 之變更的能力。
- **部分儲存:** 針對 data factory 服務撰寫時,您無法將變更儲存為草稿,而且所有發行都必須通過 data factory 驗證。 不論您的管線是否未完成,或您只是不想在電腦損毀時遺失變更,git 整合允許資料處理站資源的累加式變更,而不論其狀態為何。 設定 git 存放庫可讓您儲存變更,讓您只在測試過您對滿意度的變更時才發行。
- 共同作業**與控制:** 如果您有多個小組成員參與同一個工廠,您可能會想要讓您的團隊能夠透過程式碼審核程式彼此共同作業。 您也可以設定 factory,使其不是每個參與者都具有相同的許可權。 某些小組成員可能只允許透過 Git 進行變更,而小組中的特定人員只允許將變更發佈至 factory。
- **更好的 CI/CD:** 如果您要使用[持續傳遞](continuous-integration-deployment.md)程式部署至多個環境,git 整合可以讓某些動作更容易。 其中一些動作包括:
- 將發行管線設定為在對「dev」 factory 進行任何變更時自動觸發。
- 在您的 factory 中自訂可做為 Resource Manager 範本中參數的屬性。 只保留必要屬性集做為參數並將其他項目以硬式編碼方式撰寫非常實用。
- **較佳的效能:** 具有 git 整合的平均處理站,會比對 data factory 服務所進行的一次撰寫快載入10倍。 這種效能改進是因為資源是透過 Git 下載。
> [!NOTE]
> 設定 Git 儲存機制時,會在 Azure Data Factory UX 中停用直接使用 Data Factory 服務的撰寫。 您可以透過 PowerShell 或 SDK 直接對服務進行變更。
## <a name="author-with-azure-repos-git-integration"></a>使用 Azure Repos Git 整合來進行撰寫
使用 Azure Repos Git 整合來進行視覺化撰寫時,可針對您資料處理站管線上的工作支援原始檔控制和共同作業。 您可以將資料處理站與 Azure Repos Git 組織存放庫建立關聯,以進行原始檔控制、共同作業及版本設定等。 一個 Azure Repos Git 組織可以有多個存放庫,但一個 Azure Repos Git 存放庫只能與一個資料處理站建立關聯。 如果您沒有 Azure Repos 組織或存放庫,請依照[這些指示](https://docs.microsoft.com/azure/devops/organizations/accounts/create-organization-msa-or-work-student)來建立您的資源。
> [!NOTE]
> 您可以將指令碼和資料檔案儲存在 Azure Repos Git 存放庫中。 不過,您必須手動將檔案上載至 Azure 儲存體。 Data Factory 管線不會自動將儲存在 Azure Repos Git 存放庫中的指令碼或資料檔案上傳至「Azure 儲存體」。
### <a name="configure-an-azure-repos-git-repository-with-azure-data-factory"></a>設定搭配 Azure Data Factory 的 Azure Repos Git 存放庫
您可以透過兩種方法設定搭配資料處理站的 Azure Repos Git 存放庫。
#### <a name="configuration-method-1-azure-data-factory-home-page"></a>設定方法1: Azure Data Factory 首頁
在 [Azure Data Factory] 首頁上,選取 [**設定程式碼存放庫**]。

#### <a name="configuration-method-2-ux-authoring-canvas"></a>設定方法 2:UX 撰寫畫布
在 [Azure Data Factory UX 撰寫畫布] 中,選取 [ **Data Factory** ] 下拉式功能表,然後選取 [**設定程式碼存放庫**]。

這兩種方法都會開啟 [存放庫設定] 設定窗格。

[設定] 窗格會顯示下列 Azure Repos 程式碼存放庫設定:
| 設定 | 描述 | 值 |
|:--- |:--- |:--- |
| **存放庫類型** | Azure Repos 程式碼存放庫的類型。<br/> | Azure DevOps Git 或 GitHub |
| **Azure Active Directory** | 您的 Azure AD 租用戶名稱。 | `<your tenant name>` |
| **Azure Repos 組織** | 您的 Azure Repos 組織名稱。 您可以在 `https://{organization name}.visualstudio.com` 找到您的 Azure Repos 組織名稱。 您可以[登入您的 Azure Repos 組織](https://www.visualstudio.com/team-services/git/),以存取 Visual Studio 設定檔和查看您的存放庫與專案。 | `<your organization name>` |
| **ProjectName** | 您的 Azure Repos 專案名稱。 您可以在 `https://{organization name}.visualstudio.com/{project name}` 找到您的 Azure Repos 專案名稱。 | `<your Azure Repos project name>` |
| **Event.pushnotification.repositoryname** | 您的 Azure Repos 程式碼存放庫名稱。 Azure Repos 專案包含 Git 存放庫,可隨著您的專案成長管理原始程式碼。 您可以建立新的存放庫,或使用專案中既有的存放庫。 | `<your Azure Repos code repository name>` |
| **共同作業分支** | 用於進行發佈的 Azure Repos 共同作業分支。 根據預設,其`master`為。 如果您想要從其他分支發行資源,請變更此設定。 | `<your collaboration branch name>` |
| **根資料夾** | 在您 Azure Repos 共同作業分支中的根資料夾。 | `<your root folder name>` |
| **將現有的 Data Factory 資源匯入存放庫** | 指定是否要從 UX **撰寫畫布**將現有的資料處理站資源匯入到 Azure Repos Git 存放庫。 選取此方塊可將您的資料處理站資源以 JSON 格式匯入到相關聯的 Git 存放庫。 此動作會將每個資源個別匯出 (亦即,已連結的服務和資料集會匯出至個別的 JSON)。 若未選取此方塊,則不會匯入現有資源。 | 已選取 (預設值) |
| **要匯入資源的分支** | 指定要匯入資料處理站資源 (管線、資料集、連結服務等等) 的分支。 您可以將資源匯入下列其中一個分支:a. 共同作業 b. 新建 c. 使用現有的 | |
> [!NOTE]
> 如果您使用 Microsoft Edge,但在 Azure DevOps 帳戶] 下拉式清單中看不到任何值,請將 HTTPs://* visualstudio 新增至信任的網站清單。
### <a name="use-a-different-azure-active-directory-tenant"></a>使用不同的 Azure Active Directory 租用戶
Azure Repos Git 存放庫可以位於不同的 Azure Active Directory 租使用者中。 若要指定不同的 Azure AD 租用戶,您必須擁有所用 Azure 訂用帳戶的系統管理員權限。
### <a name="use-your-personal-microsoft-account"></a>使用您的個人 Microsoft 帳戶
若要使用個人 Microsoft 帳戶進行 Git 整合,您可以將個人的 Azure Repos 連結至貴組織的 Active Directory。
1. 以來賓身分將您的個人 Microsoft 帳戶新增到貴組織的 Active Directory。 如需詳細資訊,請參閱[在 Azure 入口網站中新增 Azure Active Directory B2B 共同作業使用者](../active-directory/b2b/add-users-administrator.md)。
2. 使用您的個人 Microsoft 帳戶登入 Azure 入口網站。 然後切換到貴組織的 Active Directory。
3. 移至 [Azure DevOps] 區段,您現在會在其中看到您的個人存放庫。 選取存放庫並與 Active Directory 連線。
在這些設定步驟之後,當您在 Data Factory UI 中設定 Git 整合時,可以使用您的個人存放庫。
如需將 Azure Repos 連線至貴組織 Active Directory 的詳細資訊,請參閱[將您的 Azure DevOps 組織連線至 Azure Active Directory](/azure/devops/organizations/accounts/connect-organization-to-azure-ad)。
## <a name="author-with-github-integration"></a>使用 GitHub 整合進行撰寫
使用 GitHub 整合所進行的視覺化撰寫,會對資料處理站管線上的工作支援原始檔控制和共同作業功能。 您可以將資料處理站與 GitHub 帳戶存放庫建立關聯,以進行原始檔控制、共同作業及版本設定。 一個 GitHub 帳戶可以有多個存放庫,但一個 GitHub 存放庫只能與一個資料處理站建立關聯。 如果您沒有 GitHub 帳戶或存放庫,請遵循[這些指示](https://github.com/join)來建立您的資源。
GitHub 與 Data Factory 整合同時支援公用 GitHub (也就是[https://github.com](https://github.com))和 GitHub Enterprise。 只要您具備 GitHub 中存放庫的讀取和寫入權限,就能搭配 Data Factory 使用公用和私人 GitHub 存放庫。
若要設定 GitHub 存放庫,您必須具有您所使用之 Azure 訂用帳戶的系統管理員許可權。
如需此功能的 9 分鐘簡介與示範,請觀看下列影片:
> [!VIDEO https://channel9.msdn.com/shows/azure-friday/Azure-Data-Factory-visual-tools-now-integrated-with-GitHub/player]
### <a name="configure-a-github-repository-with-azure-data-factory"></a>使用 Azure Data Factory 設定 GitHub 存放庫
您可以透過兩種方法設定搭配資料處理站的 GitHub 存放庫。
#### <a name="configuration-method-1-azure-data-factory-home-page"></a>設定方法1: Azure Data Factory 首頁
在 [Azure Data Factory] 首頁上,選取 [**設定程式碼存放庫**]。

#### <a name="configuration-method-2-ux-authoring-canvas"></a>設定方法 2:UX 撰寫畫布
在 [Azure Data Factory UX 撰寫畫布] 中,選取 [ **Data Factory** ] 下拉式功能表,然後選取 [**設定程式碼存放庫**]。

這兩種方法都會開啟 [存放庫設定] 設定窗格。

[設定] 窗格會顯示下列 GitHub 存放庫設定:
| **設定** | **說明** | **ReplTest1** |
|:--- |:--- |:--- |
| **存放庫類型** | Azure Repos 程式碼存放庫的類型。 | GitHub |
| **使用 GitHub Enterprise** | 選取 GitHub Enterprise 的核取方塊 | 未選取(預設值) |
| **GitHub Enterprise URL** | GitHub Enterprise 根 URL (必須是本機 GitHub Enterprise 伺服器的 HTTPS)。 例如: `https://github.mydomain.com` 。 只有在選取 [**使用 GitHub Enterprise**時才需要 | `<your GitHub enterprise url>` |
| **GitHub 帳戶** | 您的 GitHub 帳戶名稱。 您可以從 HTTPs:\//github.com/{account name}/{repository name} 找到此名稱。 瀏覽到此頁面時,系統會提示您輸入 GitHub 帳戶的 GitHub OAuth 認證。 | `<your GitHub account name>` |
| **存放庫名稱** | 您的 GitHub 程式碼存放庫名稱。 GitHub 帳戶包含 Git 存放庫,可用來管理原始程式碼。 您可以建立新的存放庫,或使用帳戶中既有的存放庫。 | `<your repository name>` |
| **共同作業分支** | 用於發行的 GitHub 共同作業分支。 預設為主要。 如果您想要從其他分支發行資源,請變更此設定。 | `<your collaboration branch>` |
| **根資料夾** | 在您 GitHub 共同作業分支中的根資料夾。 |`<your root folder name>` |
| **將現有的 Data Factory 資源匯入存放庫** | 指定是否要從 UX 撰寫畫布將現有的 data factory 資源匯入到 GitHub 存放庫。 選取此方塊可將您的資料處理站資源以 JSON 格式匯入到相關聯的 Git 存放庫。 此動作會將每個資源個別匯出 (亦即,已連結的服務和資料集會匯出至個別的 JSON)。 若未選取此方塊,則不會匯入現有資源。 | 已選取 (預設值) |
| **要匯入資源的分支** | 指定要匯入資料處理站資源 (管線、資料集、連結服務等等) 的分支。 您可以將資源匯入下列其中一個分支:a. 共同作業 b. 新建 c. 使用現有的 | |
### <a name="known-github-limitations"></a>已知的 GitHub 限制
- 您可以將指令碼和資料檔案儲存在 GitHub 存放庫。 不過,您必須手動將檔案上載至 Azure 儲存體。 Data Factory 管線不會自動將 GitHub 存放庫中儲存的指令碼或資料檔案上傳至 Azure 儲存體。
- 早於 2.14.0 的 GitHub Enterprise 版本不適用於 Microsoft Edge 瀏覽器。
- GitHub 與 Data Factory 的視覺效果撰寫工具整合僅適用于 Data Factory 的正式運作版本。
- 針對每個資源類型(例如管線和資料集),最多可以從單一 GitHub 分支提取1000個實體。 若達到此限制,建議您將資源分割成不同的工廠。 Azure DevOps Git 沒有這項限制。
## <a name="version-control"></a>版本控制
版本控制系統 (也稱為_原始檔控制_) 可讓開發人員在程式碼上共同作業,並追蹤對程式碼基底所進行的變更。 來源控制是多開發人員專案的必要工具。
### <a name="creating-feature-branches"></a>建立功能分支
與資料處理站相關聯的每個 Azure Repos Git 存放庫都有共同作業分支。 (`master` 是預設的共同作業分支)。 使用者也可以按一下 [分支] 下拉式清單中的 [ **+ 新增分支**] 來建立功能分支。 [新增分支] 窗格出現之後,請輸入功能分支的名稱。

當您準備好要將功能分支中的變更合併到共同作業分支時,請按一下 [分支] 下拉式清單,然後選取 [**建立提取要求**]。 此動作會將您帶往 Azure Repos Git,您可以在其中發出提取要求、執行程式碼檢閱,以及將變更合併到您的共同作業分支。 (`master` 是預設值)。 您只被允許從您的共同作業分支發佈到 Data Factory 服務。

### <a name="configure-publishing-settings"></a>設定發佈設定
根據預設,data factory 會產生已發佈處理站的 Resource Manager 範本,並將它們儲存到`adf_public`名為的分支中。 若要設定自訂發行分支,請`publish_config.json`將檔案新增至共同作業分支中的根資料夾。 發佈時,ADF 會讀取此檔案、尋找欄位`publishBranch`,並將所有 Resource Manager 範本儲存到指定的位置。 如果該分支不存在,data factory 會自動加以建立。 以下是此檔案的樣子範例:
```json
{
"publishBranch": "factory/adf_publish"
}
```
Azure Data Factory 一次只能有一個發佈分支。 當您指定新的發佈分支時,Data Factory 並不會刪除先前的發佈分支。 如果您想要移除先前的發佈分支,請以手動方式刪除它。
> [!NOTE]
> Data Factory 只有在載入處理站時才會讀取 `publish_config.json` 檔案。 如果您已經在入口網站中載入處理站,請重新整理瀏覽器以讓變更生效。
### <a name="publish-code-changes"></a>發佈程式碼變更
將變更合併到共同作業分支之後(`master`是預設值),請按一下 [**發佈**],以手動方式將主要分支中的程式碼變更發佈至 Data Factory 服務。

側邊窗格隨即開啟,您可以在其中確認發佈分支和暫止變更是否正確。 驗證變更後,按一下 **[確定]** 確認發佈。

> [!IMPORTANT]
> 主要分支不代表在 Data Factory 服務中部署的內容。 「必須」** 以手動方式將主要分支主發佈至 Data Factory 服務。
## <a name="best-practices-for-git-integration"></a>Git 整合的最佳做法
### <a name="permissions"></a>權限
通常您不會希望每個小組成員都擁有更新處理站的許可權。 建議使用下列許可權設定:
* 所有小組成員都應該有資料處理站的唯讀權限。
* 只應允許一組選取的人員發佈至 factory。 若要這麼做,他們必須擁有 Factory 所在資源群組的「 **Data Factory 參與者**」角色。 如需許可權的詳細資訊,請參閱[Azure Data Factory 的角色和許可權](concepts-roles-permissions.md)。
建議您不要允許直接簽入共同作業分支。 這項限制可協助防止錯誤,因為每個簽入都將經歷[建立功能分支](source-control.md#creating-feature-branches)中所述的提取要求審核程式。
### <a name="using-passwords-from-azure-key-vault"></a>使用 Azure Key Vault 的密碼
建議使用 Azure Key Vault 來儲存 Data Factory 連結服務的任何連接字串或密碼或受控識別驗證。 基於安全性理由,data factory 不會在 Git 中儲存秘密。 包含秘密(例如密碼)之連結服務的任何變更都會立即發佈到 Azure Data Factory 服務。
使用 Key Vault 或 MSI 驗證也可以讓持續整合和部署更輕鬆,因為您不需要在 Resource Manager 範本部署期間提供這些秘密。
## <a name="troubleshooting-git-integration"></a>針對 Git 整合進行疑難排解
### <a name="stale-publish-branch"></a>過時的發行分支
如果發行分支與 master 分支不同步,而且即使最近發佈也包含過期的資源,請嘗試執行下列步驟:
1. 移除目前的 Git 存放庫
1. 以相同的設定重新設定 Git,但請確定已選取 [**將現有的 Data Factory 資源匯入到存放庫**],然後選擇 [**新增分支**]
1. 建立提取要求以將變更合併到共同作業分支
以下是一些可能會導致過時發佈分支的情況範例:
- 使用者有多個分支。 在一個功能分支中,他們會刪除未 AKV 關聯的連結服務(非 AKV 連結服務會立即發行,不論它們是否在 Git 中),而且永遠不會將功能分支合併到共同作業分支。
- 使用者使用 SDK 或 PowerShell 修改過 data factory
- 使用者已將所有資源移到新的分支,並嘗試第一次發行。 匯入資源時,應該手動建立連結服務。
- 使用者以手動方式上傳非 AKV 連結服務或 Integration Runtime JSON。 它們會從另一個資源(例如資料集、連結的服務或管線)參考該資源。 透過 UX 建立的非 AKV 連結服務會立即發佈,因為認證需要加密。 如果您上傳參考該連結服務的資料集並嘗試發佈,UX 會允許它,因為它存在於 git 環境中。 它會在發行時遭到拒絕,因為它不存在於 data factory 服務中。
## <a name="switch-to-a-different-git-repository"></a>切換至不同的 Git 存放庫
若要切換至不同的 Git 存放庫,請按一下 Data Factory [總覽] 頁面右上角的 [Git 儲存機制**設定**] 圖示。 如果您看不到此圖示,請清除您的本機瀏覽器快取。 選取適當圖示以移除與目前存放庫的關聯。

出現 [存放庫設定] 窗格之後,請選取 [**移除 Git**]。 輸入您的資料處理站名稱,然後按一下 [**確認**] 以移除與您的 data factory 相關聯的 Git 存放庫。

移除與目前存放庫的關聯之後,您可以將 Git 設定設定為使用不同的存放庫,然後將現有的 Data Factory 資源匯入到新的存放庫。
> [!IMPORTANT]
> 從資料處理站移除 Git 設定並不會從存放庫中刪除任何專案。 Factory 會包含所有已發佈的資源。 您可以繼續直接針對服務編輯工廠。
## <a name="next-steps"></a>後續步驟
* 若要深入了解如何監視和管理管線,請參閱[以程式設計方式監視和管理管線](monitor-programmatically.md)。
* 若要執行持續整合和部署,請參閱[Azure Data Factory 中的持續整合與傳遞(CI/CD)](continuous-integration-deployment.md)。 | 12,317 | CC-BY-4.0 |
date : 2016-12-06 19:50:20
title : jsonrpc4j初步使用(Quick Start For Jsonrpc4j)
categories : 2016-12
tags :
- Programming
- Java
- Rpc
- jsonrpc4j
---
## 概述
目前有个项目需要向外提供服务:
1. 不打算用spring相对来说比较重的框架
2. 后来考虑过jersey+jetty的restful框架,但是restful本身的应用场景,或者说是抽象较为局限,主要是编者水平有限
3. 再之后又看了thrift的使用,稍微上手,认为操作还是较为繁杂.
4. json-rpc以前并没有接触过,json相对来说又有传输占用带宽较小等广为人知的优点,便以此篇为个契机学习一下.
jsonrpc4j是briandilley开发,项目的地址是[github](https://github.com/briandilley/jsonrpc4j)
jsonrpc4j 服从json-rpc的规范,[规范链接在此](http://www.jsonrpc.org/)
其主要支持下面这4类客户端:
Streaming server (InputStream \ OutputStream)
HTTP Server (HttpServletRequest \ HttpServletResponse)
Portlet Server (ResourceRequest \ ResourceResponse)
Socket Server (StreamServer)
这次主要使用的是HTTP Server
## Maven
jsonrpc项目通过Maven构建,首先需要在pom.xm中加入对jsonrpc4j的依赖,如下面所示:
```
<!-- jsonrpc4j -->
<dependency>
<groupId>com.github.briandilley.jsonrpc4j</groupId>
<artifactId>jsonrpc4j</artifactId>
<version>1.4.6</version>
</dependency>
```
但是仅仅加入上面的依赖还不够,完整的pom.xml如下所示:
```
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.littleji</groupId>
<artifactId>jsonrpc-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>com.github.briandilley.jsonrpc4j</groupId>
<artifactId>jsonrpc4j</artifactId>
<version>1.4.6</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-annotations</artifactId>
<version>2.7.2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.fasterxml.jackson.core/jackson-databind -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.9</version>
</dependency>
<!-- https://mvnrepository.com/artifact/javax.servlet/javax.servlet-api -->
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>javax.servlet-api</artifactId>
<version>3.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpcore-nio</artifactId>
<version>4.4.4</version>
</dependency>
<dependency>
<groupId>commons-codec</groupId>
<artifactId>commons-codec</artifactId>
<version>1.10</version>
</dependency>
<!-- https://mvnrepository.com/artifact/javax.portlet/portlet-api -->
<dependency>
<groupId>javax.portlet</groupId>
<artifactId>portlet-api</artifactId>
<version>2.0</version>
</dependency>
<dependency>
<groupId>net.iharder</groupId>
<artifactId>base64</artifactId>
<version>2.3.9</version>
</dependency>
</dependencies>
</project>
```
## 配置测试用的model,service
### model
```
package com.littleji.jsonrpc.demo;
import java.io.Serializable;
public class DemoBean implements Serializable{
private static final long serialVersionUID = -5141784935371524L;
private int code;
private String msg;
public int getCode() {
return code;
}
public void setCode(int code) {
this.code = code;
}
public String getMsg() {
return msg;
}
public void setMsg(String msg) {
this.msg = msg;
}
}
```
### Service和其Implement
```
package com.littleji.jsonrpc.demo;
/**
* Created by Jimmy on 2016/12/6.
*/
public interface DemoService {
public DemoBean getDemo(String code, String msg);
public Integer getInt(Integer code);
public String getString(String msg);
public void doSomething();
}
```
```
public class DemoServiceImply implements DemoService {
public DemoBean getDemo(String code, String msg) {
DemoBean bean1 = new DemoBean();
bean1.setCode(Integer.parseInt(code));
bean1.setMsg(msg);
return bean1;
}
public Integer getInt(Integer code) {
return code;
}
public String getString(String msg) {
return "{"+msg+"}";
}
public void doSomething() {
System.out.println("do something");
}
}
```
## 配置server端
```
package com.littleji.jsonrpc.demo;
/**
* Created by Jimmy on 2016/12/6.
*/
import java.io.IOException;
import javax.servlet.ServletConfig;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import com.googlecode.jsonrpc4j.JsonRpcServer;
import com.googlecode.jsonrpc4j.ProxyUtil;
public class RpcServer extends HttpServlet {
private static final long serialVersionUID = 12341234345L;
private JsonRpcServer rpcServer = null;
private DemoService demoService = null;
@Override
public void init(ServletConfig config) throws ServletException {
super.init(config);
demoService = new DemoServiceImply();
Object compositeService = ProxyUtil.createCompositeServiceProxy(
this.getClass().getClassLoader(),
new Object[] { demoService},
new Class<?>[] { DemoService.class},
true);
rpcServer = new JsonRpcServer(compositeService);
}
@Override
protected void service(HttpServletRequest request,
HttpServletResponse response) throws ServletException, IOException {
rpcServer.handle(request, response);
}
}
```
## Servlet的web.xml
```
<!DOCTYPE web-app PUBLIC
"-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN"
"http://java.sun.com/dtd/web-app_2_3.dtd" >
<web-app>
<display-name>Archetype Created Web Application</display-name>
<servlet>
<servlet-name>RpcServer</servlet-name>
<display-name>RpcServer</display-name>
<description></description>
<servlet-class>com.littleji.jsonrpc.demo.RpcServer</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>RpcServer</servlet-name>
<url-pattern>/rpc</url-pattern>
</servlet-mapping>
</web-app>
```
## 测试类
```
package com.littleji.jsonrpc.test;
import com.googlecode.jsonrpc4j.JsonRpcHttpClient;
import com.googlecode.jsonrpc4j.ProxyUtil;
import com.littleji.jsonrpc.demo.DemoService;
import java.net.URL;
/**
* Created by Jimmy on 2016/12/7.
*/
public class jsonrpctest2 {
public static void main(String [] args) throws Throwable {
try {
JsonRpcHttpClient client = new JsonRpcHttpClient(
new URL("http://127.0.0.1:8080/rpc"));
DemoService userService = ProxyUtil.createClientProxy(
client.getClass().getClassLoader(),
DemoService.class,
client);
//两种调用方式
System.out.println(userService.getString("aa"));
System.out.println( client.invoke("getString", new String[] { "haha" }, String.class));
System.out.println( client.invoke("getInt", new Integer[] { 2 }, Integer.class));
}
catch (Exception e) {
e.printStackTrace();
}
}
}
```
## Streaming server and client
jsonrpc4j 主要是通过流服务器和客户端来处理应用(不仅仅是HTTP)的请求,而`JsonRpcClient`和`JsonRpcServer`有一些简单的方法来获得输入和输出流,且在库中附带着一个JsonRpcHttpClient,用来扩展JsonRpcClient对于HTTP的支持
## Without the Spring Framework
jsonrpc4j可以不使用spring框架,事实上二者均可运行于Android环境中
## 对测试的解释
其实测试类就是一个客户端的简单使用
下面是一个客户端使用JSON-RPC服务的例子,具体如下:
```
JsonRpcHttpClient client = new JsonRpcHttpClient(
new URL("http://example.com/UserService.json"));
User user = client.invoke("createUser", new Object[] { "bob", "the builder" }, User.class);
```
或者使用ProxyUtil类结合接口,来创建一个动态的代理,如下所示:
```
JsonRpcHttpClient client = new JsonRpcHttpClient(
new URL("http://example.com/UserService.json"));
UserService userService = ProxyUtil.createClientProxy(
getClass().getClassLoader(),
UserService.class,
client);
User user = userService.createUser("bob", "the builder");
```
## 参考
[jsonrpc4j](https://github.com/briandilley/jsonrpc4j)
[JSON-RPC(jsonrpc4j)使用demo](http://blog.csdn.net/hjcenry/article/details/52440925) | 9,082 | MIT |
---
layout: post
title: "反射调用Kotlin类里的Companion函数"
subtitle: "支持重载、检查可空类型"
date: 2018-11-20 16:00
author: "Vove"
header-img: "img/title-bg/post-bg-18-8-25.jpg"
tags:
- kotlin
- reflection
---
> 支持重载、检查可空类型
此时有个类`C`
```kotlin
class C {
companion object {
fun a() {
println("a")
}
fun b(s: String?) {
println("b string $s")
}
fun b(a: Int) {
println("b int $a")
}
fun c(): String {
return "c 12345"
}
fun e(a: Int, b: Int, c: String?): String {
return "$c $a + $b = ${a + b}"
}
}
}
```
现在反射C类中的`companion`函数
```kotlin
@Test
fun kotlinReflectTest() {
val cls = Class.forName("cn.vassistant.repluginapi.C")
KotlinReflectHelper.invokeCompanionMethod(cls, "a")//无参数函数
KotlinReflectHelper.invokeCompanionMethod(cls, "b", "sss")//可空参数函数
KotlinReflectHelper.invokeCompanionMethod(cls, "b", null)//可空参数函数
KotlinReflectHelper.invokeCompanionMethod(cls, "b", 1)//重载函数
val s = KotlinReflectHelper.invokeCompanionMethod(cls, "c")//返回值函数
println(s)
var r = KotlinReflectHelper.invokeCompanionMethod(cls, "e", 1, 2, "求和")//多参数函数
println(r)
r = KotlinReflectHelper.invokeCompanionMethod(cls, "e", 1, 2, null)//多参数函数
println(r)
}
```
输出结果:
```
a
b string sss
b string null
b int 1
c 12345
求和 1 + 2 = 3
null 1 + 2 = 3
```
其中`KotlinReflectHelper`类:
```kotlin
object KotlinReflectHelper {
/**
* 反射调用Kotlin类里的Companion函数
* 支持函数重载调用
* 注:参数位置严格匹配
*
* Companion函数的第一个参数为[Companion]
* @param cls Class<*> javaClass
* @param name String 函数名
* @param args Array<out Any?> 参数
* @return Any? 返回值
*/
@Throws
fun invokeCompanionMethod(cls: Class<*>, name: String, vararg args: Any?): Any? {
val k = Reflection.createKotlinClass(cls)
k.companionObject?.declaredFunctions?.forEach eachFun@{ f ->
val ps = f.parameters
if (f.name == name && ps.size == args.size + 1) {//函数名相同, 参数数量相同
//匹配函数参数
ps.subList(1, ps.size).withIndex().forEach {
val paramType = it.value.type
val userParam = args[it.index]
val canNullAndNull = paramType.isMarkedNullable && userParam == null //isMarkedNullable参数类型是否可空
if (!canNullAndNull) {
val typeMatch = when {//判断类型匹配
paramType.isMarkedNullable -> //参数可空 userParam不空 转不可空类型比较
paramType.withNullability(false).isSubtypeOf(userParam!!::class.defaultType)
userParam != null -> // 参数不可空 且用户参数不空
paramType.isSubtypeOf(userParam::class.defaultType)//类型匹配
else -> return@eachFun//参数不可空 用户参数空 不符合
}
if (!typeMatch) return@eachFun //匹配下一个函数
}
//else 参数可空 给定参数空 过
}
val argsWithInstance = arrayOf(k.companionObjectInstance, *args)
return f.call(*argsWithInstance)
}
}
throw Exception("no companion method named : $name")
}
}
```
1. 添加依赖`implementation "org.jetbrains.kotlin:kotlin-reflect:$kotlin_version"
`或下载`kotlin-reflect.jar`包
#### 另一种方式
指定参数类型
```kotlin
/**
*
* @param cls Class<*> 类 可通过Class.forName(..) 获取
* @param name String 函数名
* @param argPairs Array<out Pair<Class<*>, Any?>> first: 值类型, second: 值
* @return Any? 函数返回值
*/
@Throws
fun invokeCompanion(cls: Class<*>, name: String, vararg argPairs: Pair<Class<*>, Any?>): Any? {
// println("调用函数: ----> $name(${Arrays.toString(argPairs)})")
val types = arrayOfNulls<KClass<*>>(argPairs.size)
val args = arrayOfNulls<Any>(argPairs.size)
var i = 0
argPairs.forEach {
types[i] = Reflection.createKotlinClass(it.first)
args[i++] = it.second
}
val k = Reflection.createKotlinClass(cls)
k.companionObject?.declaredFunctions?.forEach eachFun@{ f ->
// println("invokeCompanionMethod 匹配函数 ----> ${f.name}()")
val ps = f.parameters
if (f.name == name && ps.size == argPairs.size + 1) {//函数名相同, 参数数量相同
//匹配函数参数
ps.subList(1, ps.size).withIndex().forEach {
val paramType = it.value.type
val userType = types[it.index]!!.defaultType
val typeMatch = paramType.withNullability(false).isSubtypeOf(userType)
if (!typeMatch) {
// println("invokeCompanionMethod ----> 参数类型不匹配")
return@eachFun //匹配下一个函数
}
//else 参数可空 给定参数空 过
}
val argsWithInstance = arrayOf(k.companionObjectInstance, *args)
return f.call(*argsWithInstance)
} else {
// println("invokeCompanionMethod ----> 名称or参数数量不同")
}
}
throw Exception("no companion method named : $name")
}
```
测试:
```kotlin
@Test
fun kotlinReflectTest2() {
val cls = Class.forName("cn.vassistant.repluginapi.C")
KotlinReflectHelper.invokeCompanion(cls, "a")//无参数函数
KotlinReflectHelper.invokeCompanion(cls, "b", Pair(String::class.java, "sss"))//可空参数函数
KotlinReflectHelper.invokeCompanion(cls, "b", Pair(Int::class.java, null))//可空参数函数
KotlinReflectHelper.invokeCompanion(cls, "b", Pair(Int::class.java, 1))//重载函数
val s = KotlinReflectHelper.invokeCompanion(cls, "c")//返回值函数
println(s)
var r = KotlinReflectHelper.invokeCompanion(cls, "e", Pair(Int::class.java, 1),
Pair(Int::class.java, 2), Pair(String::class.java, "求和"))//多参数函数
println(r)
r = KotlinReflectHelper.invokeCompanion(cls, "e", Pair(Int::class.java, 1),
Pair(Int::class.java, 2), Pair(String::class.java, null))//多参数函数
println(r)
}
``` | 6,102 | Apache-2.0 |
# Fuseサンプル - AMQ Brokerへ(AMQP)メッセージ送受信
<!-- @import "[TOC]" {cmd="toc" depthFrom=2 depthTo=6 orderedList=false} -->
<!-- code_chunk_output -->
- [前提条件](#前提条件)
- [本サンプルについて](#本サンプルについて)
- [Camel Routeの処理概要](#camel-routeの処理概要)
- [1. amqp-producer](#1-amqp-producer)
- [2. amqp-consumer](#2-amqp-consumer)
- [本サンプルの実行方法](#本サンプルの実行方法)
- [1. ローカルPCで実行する場合](#1-ローカルpcで実行する場合)
- [2. Openshift環境へデプロイして実行する場合](#2-openshift環境へデプロイして実行する場合)
- [ゼロから作成の手順](#ゼロから作成の手順)
<!-- /code_chunk_output -->
## 前提条件
- AMQ Broker 7.x (ローカル、またはOpenshift上)
- Fuse 7.x (ローカル、またはOpenshift上)
## 本サンプルについて
本サンプルでは、[camel-amqpコンポーネント][1]を使って、AMQ Broker 7.xのキューへ送受信の実装方法を示します。
[camel-amqp][1]のオプションが非常に多いですが、今回は初心者向けのため、最低限のAMQP接続設定だけ行っています。詳細なオプションはリンク先の製品ドキュメントをご参照ください。
[1]: https://access.redhat.com/documentation/en-us/red_hat_fuse/7.5/html/apache_camel_component_reference/amqp-component
## Camel Routeの処理概要
### 1. amqp-producer
このCamel Routeは、2秒間隔で3桁の乱数を生成します。生成された乱数がAMQPメッセージのボディとなり、AMQPプロトコルを利用してAMQ-Broker上の`demoQueue`へ送信します。送信が成功すると、以下のログ出力します。
`INFO amqp-producer - SEND AMQP request. 779`
### 2. amqp-consumer
このCamel Routeは、AMQ-Broker上の`demoQueue`をリスニングします。キューに到達したメッセージをトリガーに、取得したメッセージのボデイをログに出力します。
`INFO amqp-consumer - GOT AMQP request. 779`
## 本サンプルの実行方法
### 1. ローカルPCで実行する場合
前提条件:
- AMQ Broker 7.5 がローカルPCで構築済み、起動していること
- Maven 3.x がローカルPCでインストール済みであること
- Maven Remote Repositoryがアクセスできること
実行手順:
1. AMQP接続情報を設定します。
`application.properties` へ以下の内容を追加してください。
```properties
# AMQP connectivity
amqp.uri=amqp://localhost:5672
amqp.username=admin
amqp.password=admin
```
※ *usernameとpasswordは自分のAMQ設定に合わせて変更すること*
2. コマンドプロンプトにて実行します。
`mvn spring-boot:run`
3. コマンドプロンプトで2秒間隔に以下のような出力を確認してください。
```
... INFO amqp-producer - SEND AMQP request. 779
... INFO amqp-consumer - GOT AMQP request. 779
```
### 2. Openshift環境へデプロイして実行する場合
前提条件:
- AMQ Broker 7.5 がOpenshiftで構築済み、起動していること
- Maven 3.x がローカルPCでインストール済みであること
- Maven Remote Repositoryがアクセスできること
- [oc(openshift client)][2]がローカルPCでインストール済みであること
[2]: https://docs.openshift.com/container-platform/3.11/cli_reference/get_started_cli.html
実行手順:
1. AMQP接続情報を設定します。
`application.properties` へ以下の内容を追加してください。
```properties
# AMQP connectivity
amqp.uri=amqp://broker-amq-amqp.amq-demo-non-ssl.svc.cluster.local:5672
amqp.username=admin
amqp.password=admin
```
※ *上記usernameとpasswordはOpenshift上のAMQ設定に合わせて変更すること*
※ *上記ampq.url内の"amq-demo-non-ssl"は、Openshift上のAMQプロジェクト名に置き換えてください*
2. [oc][2]コマンドでOpenshiftへログインして、AMQ Brokerプロジェクトに切り替えします。
```sh
oc login https://openshift-server:port
oc project amq-demo-non-ssl
```
※ *上記の"amq-demo-non-ssl"は、Openshift上のAMQプロジェクト名に置き換えてください*
3. コマンドプロンプトにて実行します。
このコマンドでは、ローカルPCのocコマンドでログインしたOpenshiftプロジェクト(AMQ Brokerのプロジェクト)にFuseアプリをデプロイします。
`mvn fabric8:deploy -Popenshift`
4. コマンドプロンプトで以下のような出力を確認してください。
```
[INFO] F8: Pushing image docker-registry.default.
...
[INFO] F8: Build fuse-amq-demo-s2i-4 in status Complete
...
[INFO] Updated DeploymentConfig: target/fabric8/applyJson/amq-demo-non-ssl/deploymentconfig-fuse-amq-demo-3.json
...
------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 47.076 s
[INFO] Finished at: 2020-02-14T14:13:18+09:00
[INFO] ------------------------------------------------------------------------
```
## ゼロから作成の手順
以下は本サンプルをゼロから作成する場合の手順を説明します。
※ 本手順の実施には、インターネット接続が必要。
1. Maven archetypeより、Fuseアプリの雛形を生成します。
```sh
# Config archetype to use
archetypeVersion=2.2.0.fuse-sb2-750011-redhat-00006
archetypeCatalog=https://maven.repository.redhat.com/ga/io/fabric8/archetypes/archetypes-catalog/${archetypeVersion}/archetypes-catalog-${archetypeVersion}-archetype-catalog.xml
# Config Fuse project name to generate
MY_PROJECT=fuse-amq-demo
# Generate from archetype, which is SpringBoot2 based Camel Application using XML DSL
mvn org.apache.maven.plugins:maven-archetype-plugin:2.4:generate -B \
-DarchetypeCatalog=${archetypeCatalog} \
-DarchetypeGroupId=org.jboss.fuse.fis.archetypes \
-DarchetypeVersion=${archetypeVersion} \
-DarchetypeArtifactId=spring-boot-camel-xml-archetype \
-DgroupId=com.sample \
-DartifactId=${MY_PROJECT} \
-DoutputDirectory=${MY_PROJECT}
```
2. `pom.xml` へ依存ライブラリcamel-amqpを追加
```xml
<dependency>
<groupId>org.apache.camel</groupId>
<artifactId>camel-amqp</artifactId>
</dependency>
```
3. `src/main/resources/spring/camel-context.xml` へ`<camelContext>`の前に、bean定義を追加
```xml
<!-- AMQP connectivity -->
<bean id="jmsConnectionFactory"
class="org.apache.qpid.jms.JmsConnectionFactory"
primary="true">
<property name="remoteURI" value="${amqp.uri}" />
<property name="username" value="${amqp.username}" />
<property name="password" value="${amqp.password}" />
</bean>
<bean id="jmsCachingConnectionFactory"
class="org.springframework.jms.connection.CachingConnectionFactory">
<property name="targetConnectionFactory" ref="jmsConnectionFactory" />
</bean>
<bean id="jmsConfig"
class="org.apache.camel.component.jms.JmsConfiguration" >
<constructor-arg ref="jmsCachingConnectionFactory" />
<property name="cacheLevelName" value="CACHE_CONSUMER" />
</bean>
<bean id="amqp"
class="org.apache.camel.component.amqp.AMQPComponent">
<property name="configuration" ref="jmsConfig" />
</bean>
```
4. `src/main/resources/spring/camel-context.xml` `<camelContext>`内のCamel Routeをすべて削除して、以下の2つRouteを追加
```xml
<route id="amqp-producer">
<from id="route-timer" uri="timer:foo?period=2000"/>
<transform id="route-transform">
<method ref="myTransformer"/>
</transform>
<to uri="amqp:queue:demoQueue"/>
<log id="route-log" message="SEND AMQP request. ${body}"/>
</route>
<route id="amqp-consumer">
<from uri="amqp:queue:demoQueue"/>
<log message="GOT AMQP request. ${body}"/>
</route>
```
5. `src/main/resources/application.properties` へAMQP接続情報を追加
```properties
# AMQP connectivity
amqp.uri=amqp://localhost:5672
amqp.username=admin
amqp.password=admin
``` | 6,482 | Apache-2.0 |
# Hu-Template-Minifier
该类库将使用了 [模板字符串 - 标签 ( Template literals )](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Template_literals#Tagged_templates) 功能实现模板定义的类库中的 HTML 代码进行压缩.
<br>
<br>
## Overview
```js
html`
<div title=${ 'title' } class="a ${ b } c ${ d }">
<div>...</div>
${
html`
<div>
<span>Something ...</span>
</div>
`
}
<div>...</div>
</div>
`
// ↓↓↓
html`<div title=${ 'title' } class="a ${ b } c ${ d }"> <div>...</div> ${
html`<div> <span>Something ...</span> </div>`
} <div>...</div> </div>`
```
## Installation
```bash
npm install @moomfe/hu-template-minifier
```
## Usage
```js
// 使用 minifier 的 rollup 插件
const minifier = require('@moomfe/hu-template-minifier/rollup');
rollup({
plugins: [
minifier(/* options */)
]
});
```
### Plugin Options
``` js
{
// 需要进行压缩的文件后缀
extensions: [ '.js' ], // 默认值
// 可包含多个
extensions: [ '.js', '.ts' ],
// 需要包含的文件
include: undefined, // 默认值 ( 包含全部 )
// 普通匹配
include: 'index.js',
// 使用 minimatch 格式进行匹配
include: 'components/*/index.js',
include: 'components/**/index.js',
// 使用正则进行匹配
include: /api\.js/,
// 使用支持的格式组成数组进行匹配
include: [
'components/*/index.js',
/api\.js/
],
// 需要从已包含的文件中排除的文件
// 使用的格式与 include 选项一致, 不再进行举例
exclude: undefined, // 默认值
// 保留一个空格
conservativeCollapse: true,
// 移除注释
removeComments: false
}
```
## Supports
- [Hu](https://github.com/MoomFE/Hu)
- [lit-html](https://github.com/Polymer/lit-html)
- [hyperHTML](https://github.com/WebReflection/hyperhtml)
- [lighterhtml](https://github.com/WebReflection/lighterhtml)
## Transplant From
- [parse-literals](https://github.com/asyncLiz/parse-literals) - [LICENSE](https://github.com/asyncLiz/parse-literals/blob/master/LICENSE.md)
- [minify-html-literals](https://github.com/asyncLiz/minify-html-literals) - [LICENSE](https://github.com/asyncLiz/minify-html-literals/blob/master/README.md)
## License
Hu-Template-Minifier is licensed under a [MIT License](./LICENSE). | 2,119 | MIT |
---
title: Microsoft 标识平台 Windows 桌面入门 | Microsoft Docs
description: 了解 Windows 桌面 .NET (XAML) 应用程序如何获取访问令牌并调用受 Microsoft 标识平台保护的 API。
services: active-directory
documentationcenter: dev-center-name
author: jmprieur
manager: CelesteDG
editor: ''
ms.service: active-directory
ms.subservice: develop
ms.devlang: na
ms.topic: tutorial
ms.tgt_pltfrm: na
ms.workload: identity
origin.date: 04/10/2019
ms.date: 08/23/2019
ms.author: v-junlch
ms.custom: aaddev, identityplatformtop40
ms.collection: M365-identity-device-management
ms.openlocfilehash: cd3cc931b99fa138d53e0155901cce12275310ca
ms.sourcegitcommit: 599d651afb83026938d1cfe828e9679a9a0fb69f
ms.translationtype: HT
ms.contentlocale: zh-CN
ms.lasthandoff: 08/23/2019
ms.locfileid: "69993363"
---
# <a name="call-the-microsoft-graph-api-from-a-windows-desktop-app"></a>从 Windows 桌面应用调用 Microsoft Graph API
本指南演示了本机 Windows 桌面 .NET (XAML) 应用程序如何使用访问令牌来调用 Microsoft Graph API。 该应用还可以访问其他 API,这些 API 需要来自面向开发人员的 Microsoft 标识平台 v2.0 终结点的访问令牌。 此平台以前名为 Azure AD。
> [!NOTE]
> 本指南需要 Visual Studio 2015 Update 3、Visual Studio 2017 或 Visual Studio 2019。 没有这些版本? [免费下载 Visual Studio 2019](https://www.visualstudio.com/downloads/)。
## <a name="how-the-sample-app-generated-by-this-guide-works"></a>本指南生成的示例应用的工作原理

本指南创建的示例应用程序使 Windows 桌面应用程序能够查询接受 Microsoft 标识平台终结点令牌的 Microsoft Graph API 或 Web API。 对于此方案,通过 Authorization 标头将令牌添加到 HTTP 请求。 Microsoft 身份验证库 (MSAL) 处理令牌获取和续订。
## <a name="handling-token-acquisition-for-accessing-protected-web-apis"></a>负责获得用于访问受保护 Web API 的令牌
对用户进行身份验证后,示例应用程序会收到一个令牌,该令牌可用于查询受面向开发人员的 Microsoft 标识平台保护的 Microsoft Graph API 或 Web API。
API(如 Microsoft Graph)需要令牌以允许访问特定资源。 例如,需要使用令牌读取用户的配置文件、访问用户的日历或发送电子邮件。 应用程序可通过指定 API 作用域来使用 MSAL 请求访问令牌,从而访问这些资源。 然后对于针对受保护资源发出的每个调用,将此访问令牌添加到 HTTP 授权标头。
MSAL 负责管理缓存和刷新访问令牌,因此应用程序无需执行这些任务。
## <a name="nuget-packages"></a>NuGet 包
本指南使用以下 NuGet 包:
|库|说明|
|---|---|
|[Microsoft.Identity.Client](https://www.nuget.org/packages/Microsoft.Identity.Client)|Microsoft 身份验证库 (MSAL.NET)|
## <a name="set-up-your-project"></a>设置项目
本部分将创建新项目,用于演示如何将 Windows 桌面 .NET 应用程序 (XAML) 与“使用 Microsoft 登录”集成,使该应用程序能查询需要令牌的 Web API 。
使用本指南创建的应用程序将显示一个用于调用图的按钮、一个用于在屏幕上显示结果的区域和一个注销按钮。
> [!NOTE]
> 想要改为下载此示例的 Visual Studio 项目? [下载一个项目](https://github.com/Azure-Samples/active-directory-dotnet-desktop-msgraph-v2/archive/msal3x.zip),并且在执行该项目之前跳到[配置步骤](#register-your-application)来配置代码示例。
>
若要创建应用程序,请执行以下操作:
1. 在 Visual Studio 中,选择“文件” > “新建” > “项目” 。
2. 在“模板”下,选择“Visual C#” 。
3. 选择“WPF 应用(.NET Framework)” ,具体取决于所使用的 Visual Studio 版本。
## <a name="add-msal-to-your-project"></a>将 MSAL 添加到项目
1. 在 Visual Studio 中,选择“工具” > “NuGet 包管理器”> “包管理器控制台” 。
2. 在“包管理器控制台”窗口中,粘贴以下 Azure PowerShell 命令:
```powershell
Install-Package Microsoft.Identity.Client -Pre
```
> [!NOTE]
> 此命令将安装 Microsoft 身份验证库。 MSAL 负责获取、缓存和刷新用于访问受 Azure Active Directory v2.0 保护的 API 的用户令牌
>
## <a name="register-your-application"></a>注册应用程序
可以通过以下两种方式之一注册应用程序。
### <a name="option-1-express-mode"></a>选项 1:快速模式
可以通过执行以下操作快速注册应用程序:
1. 访问 [Azure 门户 - 应用程序注册](https://portal.azure.cn/#blade/Microsoft_AAD_RegisteredApps/applicationsListBlade/quickStartType/WinDesktopQuickstartPage/sourceType/docs)。
1. 输入应用程序的名称并选择“注册” 。
1. 遵照说明下载内容,并只需单击一下自动配置新应用程序。
### <a name="option-2-advanced-mode"></a>选项 2:高级模式
若要注册应用程序并将应用程序注册信息添加到解决方案,请执行以下操作:
1. 使用工作或学校帐户登录到 [Azure 门户](https://portal.azure.cn)。
1. 如果你的帐户有权访问多个租户,请在右上角选择该帐户,并将门户会话设置为所需的 Azure AD 租户。
1. 导航到面向开发人员的 Microsoft 标识平台的[应用注册](https://portal.azure.cn/#blade/Microsoft_AAD_IAM/ActiveDirectoryMenuBlade/RegisteredAppsPreview)页。
1. 选择“新注册”。
- 在“名称” 部分输入一个会显示给应用用户的有意义的应用程序名称,例如 `Win-App-calling-MsGraph`。
- 在“支持的帐户类型”部分,选择“任何组织目录中的帐户”。
- 选择“注册” 以创建应用程序。
1. 在应用的页面列表中,选择“身份验证”。
1. 在“重定向 URI” 部分的重定向 URI 列表中:
1. 在“类型” 列中选择“公共客户端(移动和桌面)” 。
1. 在“重定向 URI”列中输入 `urn:ietf:wg:oauth:2.0:oob`
1. 选择“保存” 。
1. 转到 Visual Studio,打开 App.xaml.cs 文件,然后将下面代码片段中的 `Enter_the_Application_Id_here` 替换为刚注册并复制的应用程序 ID。
```csharp
private static string ClientId = "Enter_the_Application_Id_here";
```
## <a name="add-the-code-to-initialize-msal"></a>添加代码以初始化 MSAL
此步骤将创建用于处理与 MSAL 的交互(例如令牌处理)的类。
1. 打开 *App.xaml.cs* 文件,将 MSAL 的引用添加到类:
```csharp
using Microsoft.Identity.Client;
```
<!-- Workaround for Docs conversion bug -->
2. 将 App 类更新为:
```csharp
public partial class App : Application
{
static App()
{
_clientApp = PublicClientApplicationBuilder.Create(ClientId)
.WithAuthority(AzureCloudInstance.AzureChina, Tenant)
.Build();
}
// Below are the clientId (Application Id) of your app registration and the tenant information.
// You have to replace:
// - the content of ClientID with the Application Id for your app registration
// - the content of Tenant by the information about the accounts allowed to sign-in in your application:
// - For Work or School account in your org, use your tenant ID, or domain
// - for any Work or School accounts, use `organizations` or `common`
private static string ClientId = "0b8b0665-bc13-4fdc-bd72-e0227b9fc011";
private static string Tenant = "common";
private static IPublicClientApplication _clientApp ;
public static IPublicClientApplication PublicClientApp { get { return _clientApp; } }
}
```
## <a name="create-the-application-ui"></a>创建应用程序 UI
本部分说明应用程序如何查询受保护的后端服务器,例如 Microsoft Graph。
项目模板中应自动创建了 *MainWindow.xaml* 文件。 打开此文件,然后将应用程序的 *\<Grid>* 节点替换为以下代码:
```xml
<Grid>
<StackPanel Background="Azure">
<StackPanel Orientation="Horizontal" HorizontalAlignment="Right">
<Button x:Name="CallGraphButton" Content="Call Microsoft Graph API" HorizontalAlignment="Right" Padding="5" Click="CallGraphButton_Click" Margin="5" FontFamily="Segoe Ui"/>
<Button x:Name="SignOutButton" Content="Sign-Out" HorizontalAlignment="Right" Padding="5" Click="SignOutButton_Click" Margin="5" Visibility="Collapsed" FontFamily="Segoe Ui"/>
</StackPanel>
<Label Content="API Call Results" Margin="0,0,0,-5" FontFamily="Segoe Ui" />
<TextBox x:Name="ResultText" TextWrapping="Wrap" MinHeight="120" Margin="5" FontFamily="Segoe Ui"/>
<Label Content="Token Info" Margin="0,0,0,-5" FontFamily="Segoe Ui" />
<TextBox x:Name="TokenInfoText" TextWrapping="Wrap" MinHeight="70" Margin="5" FontFamily="Segoe Ui"/>
</StackPanel>
</Grid>
```
## <a name="use-msal-to-get-a-token-for-the-microsoft-graph-api"></a>使用 MSAL 获取 Microsoft Graph API 的令牌
本部分使用 MSAL 获取 Microsoft Graph API 的令牌。
1. 在 *MainWindow.xaml.cs* 文件中,将 MSAL 的引用添加到类:
```csharp
using Microsoft.Identity.Client;
```
2. 将 `MainWindow` 类代码替换为以下内容:
```csharp
public partial class MainWindow : Window
{
//Set the API Endpoint to Graph 'me' endpoint
string graphAPIEndpoint = "https://microsoftgraph.chinacloudapi.cn/v1.0/me";
//Set the scope for API call to https://microsoftgraph.chinacloudapi.cn/user.read
string[] scopes = new string[] { "https://microsoftgraph.chinacloudapi.cn/user.read" };
public MainWindow()
{
InitializeComponent();
}
/// <summary>
/// Call AcquireToken - to acquire a token requiring user to sign-in
/// </summary>
private async void CallGraphButton_Click(object sender, RoutedEventArgs e)
{
AuthenticationResult authResult = null;
var app = App.PublicClientApp;
ResultText.Text = string.Empty;
TokenInfoText.Text = string.Empty;
var accounts = await app.GetAccountsAsync();
var firstAccount = accounts.FirstOrDefault();
try
{
authResult = await app.AcquireTokenSilent(scopes, firstAccount)
.ExecuteAsync();
}
catch (MsalUiRequiredException ex)
{
// A MsalUiRequiredException happened on AcquireTokenSilent.
// This indicates you need to call AcquireTokenInteractive to acquire a token
System.Diagnostics.Debug.WriteLine($"MsalUiRequiredException: {ex.Message}");
try
{
authResult = await app.AcquireTokenInteractive(scopes)
.WithAccount(accounts.FirstOrDefault())
.WithPrompt(Prompt.SelectAccount)
.ExecuteAsync();
}
catch (MsalException msalex)
{
ResultText.Text = $"Error Acquiring Token:{System.Environment.NewLine}{msalex}";
}
}
catch (Exception ex)
{
ResultText.Text = $"Error Acquiring Token Silently:{System.Environment.NewLine}{ex}";
return;
}
if (authResult != null)
{
ResultText.Text = await GetHttpContentWithToken(graphAPIEndpoint, authResult.AccessToken);
DisplayBasicTokenInfo(authResult);
this.SignOutButton.Visibility = Visibility.Visible;
}
}
```
<!--start-collapse-->
### <a name="more-information"></a>详细信息
#### <a name="get-a-user-token-interactively"></a>以交互方式获取用户令牌
调用 `AcquireTokenInteractive` 方法将出现提示用户登录的窗口。 当用户首次需要访问受保护的资源时,应用程序通常会要求用户进行交互式登录。 当用于获取令牌的无提示操作失败时(例如,当用户的密码过期时),用户也可能需要登录。
#### <a name="get-a-user-token-silently"></a>以无提示方式获取用户令牌
`AcquireTokenSilent` 方法处理令牌获取和续订,无需进行任何用户交互。 首次执行 `AcquireTokenInteractive` 后,通常使用 `AcquireTokenSilent` 方法获得用于访问受保护资源的令牌,以便进行后续调用,因为调用请求或续订令牌都以无提示方式进行。
最终,`AcquireTokenSilent` 方法会失败。 失败可能是因为用户已注销,或者在另一设备上更改了密码。 MSAL 检测到可以通过请求交互式操作解决问题时,它将引发 `MsalUiRequiredException` 异常。 应用程序可以通过两种方式处理此异常:
* 它可以立即调用 `AcquireTokenInteractive`。 此调用会导致系统提示用户进行登录。 此模式通常用于联机应用程序,这类应用程序中没有可供用户使用的脱机内容。 此指导式设置生成的示例遵循此模式,第一次执行示例时可以看到其正在运行。
* 由于没有用户使用过该应用程序,因此 `PublicClientApp.Users.FirstOrDefault()` 包含一个 null 值,并且引发 `MsalUiRequiredException` 异常。
* 此示例中的代码随后处理此异常,方法是通过调用 `AcquireTokenInteractive` 使其显示用户登录提示。
* 它可以改为向用户呈现视觉指示,要求用户进行交互式登录,以便他们可以选择适当的时间进行登录。 也可以让应用程序稍后重试 `AcquireTokenSilent`。 当用户可以使用其他应用程序功能而不导致中断时(例如,当脱机内容在应用程序中可用时),会频繁使用此模式。 在这种情况下,用户可以决定何时需要登录来访问受保护的资源或刷新过期信息。 也可让应用程序决定在网络临时不可用又还原后,是否重试 `AcquireTokenSilent`。
<!--end-collapse-->
## <a name="call-the-microsoft-graph-api-by-using-the-token-you-just-obtained"></a>使用刚获得的令牌调用 Microsoft Graph API
将以下新方法添加到 `MainWindow.xaml.cs`。 该方法用于通过 Authorize 标头对图形 API 执行 `GET` 请求:
```csharp
/// <summary>
/// Perform an HTTP GET request to a URL using an HTTP Authorization header
/// </summary>
/// <param name="url">The URL</param>
/// <param name="token">The token</param>
/// <returns>String containing the results of the GET operation</returns>
public async Task<string> GetHttpContentWithToken(string url, string token)
{
var httpClient = new System.Net.Http.HttpClient();
System.Net.Http.HttpResponseMessage response;
try
{
var request = new System.Net.Http.HttpRequestMessage(System.Net.Http.HttpMethod.Get, url);
//Add the token in Authorization header
request.Headers.Authorization = new System.Net.Http.Headers.AuthenticationHeaderValue("Bearer", token);
response = await httpClient.SendAsync(request);
var content = await response.Content.ReadAsStringAsync();
return content;
}
catch (Exception ex)
{
return ex.ToString();
}
}
```
<!--start-collapse-->
### <a name="more-information-about-making-a-rest-call-against-a-protected-api"></a>对受保护 API 进行 REST 调用的详细信息
在此示例应用程序中,请使用 `GetHttpContentWithToken` 方法对需要令牌的受保护资源发出 HTTP `GET` 请求,然后将内容返回给调用方。 此方法可在 HTTP 授权标头中添加获取的令牌。 此示例中的资源是 Microsoft Graph API me 终结点,可显示用户个人资料信息 。
<!--end-collapse-->
## <a name="add-a-method-to-sign-out-a-user"></a>添加注销用户的方法
将以下方法添加到 `MainWindow.xaml.cs` 文件可注销用户:
```csharp
/// <summary>
/// Sign out the current user
/// </summary>
private async void SignOutButton_Click(object sender, RoutedEventArgs e)
{
var accounts = await App.PublicClientApp.GetAccountsAsync();
if (accounts.Any())
{
try
{
await App.PublicClientApp.RemoveAsync(accounts.FirstOrDefault());
this.ResultText.Text = "User has signed-out";
this.CallGraphButton.Visibility = Visibility.Visible;
this.SignOutButton.Visibility = Visibility.Collapsed;
}
catch (MsalException ex)
{
ResultText.Text = $"Error signing-out user: {ex.Message}";
}
}
}
```
<!--start-collapse-->
### <a name="more-information-about-user-sign-out"></a>有关用户注销的详细信息
`SignOutButton_Click` 方法删除 MSAL 用户缓存中的用户,这样可有效地告知 MSAL 忘记当前用户,使将来获取令牌的请求只能在交互模式下取得成功。
此示例中的应用程序支持单个用户,但 MSAL 也支持同时注册多个帐户的情况。 例如,用户可在电子邮件应用程序中使用多个帐户。
<!--end-collapse-->
## <a name="display-basic-token-information"></a>显示基本令牌信息
若要显示有关令牌的基本信息,请将以下方法添加到 *MainWindow.xaml.cs* 文件:
```csharp
/// <summary>
/// Display basic information contained in the token
/// </summary>
private void DisplayBasicTokenInfo(AuthenticationResult authResult)
{
TokenInfoText.Text = "";
if (authResult != null)
{
TokenInfoText.Text += $"Username: {authResult.Account.Username}" + Environment.NewLine;
TokenInfoText.Text += $"Token Expires: {authResult.ExpiresOn.ToLocalTime()}" + Environment.NewLine;
}
}
```
<!--start-collapse-->
### <a name="more-information"></a>详细信息
除了用于调用 Microsoft Graph API 的访问令牌,MSAL 还可以在用户登录后获取 ID 令牌。 此令牌包含一小部分与用户相关的信息。 `DisplayBasicTokenInfo` 方法显示包含在令牌中的基本信息。 例如,它显示用户的显示名称和 ID,以及令牌到期日期和表示访问令牌本身的字符串。 多次选择“调用 Microsoft Graph API”按钮,便会发现后续请求使用了同一令牌。 而且还会注意到,在 MSAL 决定续订令牌时,到期日期也延长了。
<!--end-collapse-->
[!INCLUDE [5. Test and Validate](../../../includes/active-directory-develop-guidedsetup-windesktop-test.md)] | 14,009 | CC-BY-4.0 |
---
layout: post
title: CoreCLR源码探索(二) new是什么
tag: CoreCLR源码探索
---
前一篇我们看到了CoreCLR中对Object的定义,这一篇我们将会看CoreCLR中对new的定义和处理
new对于.Net程序员们来说同样是耳熟能详的关键词,我们每天都会用到new,然而new究竟是什么?
因为篇幅限制和避免难度跳的太高,这一篇将不会详细讲解以下的内容,请耐心等待后续的文章
- GC如何分配内存
- JIT如何解析IL
- JIT如何生成机器码
### 使用到的名词和缩写
以下的内容将会使用到一些名词和缩写,如果碰到看不懂的可以到这里来对照
```plain
BasicBlock: 在同一个分支(Branch)的一群指令,使用双向链表连接
GenTree: 语句树,节点类型以GT开头
Importation: 从BasicBlock生成GenTree的过程
Lowering: 具体化语句树,让语句树的各个节点可以明确的转换到机器码
SSA: Static Single Assignment
R2R: Ready To Run
Phases: JIT编译IL到机器码经过的各个阶段
JIT: Just In Time
CEE: CLR Execute Engine
ee: Execute Engine
EH: Exception Handling
Cor: CoreCLR
comp: Compiler
fg: FlowGraph
imp: Import
LDLOCA: Load Local Variable
gt: Generate
hlp: Help
Ftn: Function
MP: Multi Process
CER: Constrained Execution Regions
TLS: Thread Local Storage
```
### .Net中的三种new
请看图中的代码和生成的IL,我们可以看到尽管同样是new,却生成了三种不同的IL代码


- 对class的new,IL指令是newobj
- 对array的new,IL指令是newarr
- 对struct的new,因为myStruct已经在本地变量里面了,new的时候仅仅是调用ldloca加载然后调用构造函数
我们先来看newobj和newarr这两个指令在coreclr中是怎么定义的
源代码: https://github.com/dotnet/coreclr/blob/release/1.1.0/src/inc/opcode.def#L153
``` c++
OPDEF(CEE_NEWOBJ, "newobj", VarPop, PushRef, InlineMethod, IObjModel, 1, 0xFF, 0x73, CALL)
OPDEF(CEE_NEWARR, "newarr", PopI, PushRef, InlineType, IObjModel, 1, 0xFF, 0x8D, NEXT)
```
我们可以看到这两个指令的定义,名称分别是CEE_NEWOBJ和CEE_NEWARR,请记住这两个名称
### 第一种new(对class的new)生成了什么机器码
接下来我们将看看coreclr是如何把CEE_NEWOBJ指令变为机器码的
在讲解之前请先大概了解JIT的工作流程,JIT编译按函数为单位,当调用函数时会自动触发JIT编译
- 把函数的IL转换为BasicBlock(基本代码块)
- 从BasicBlock(基本代码块)生成GenTree(语句树)
- 对GenTree(语句树)进行Morph(变形)
- 对GenTree(语句树)进行Lowering(具体化)
- 根据GenTree(语句树)生成机器码
下面的代码虽然进过努力的提取,但仍然比较长,请耐心阅读
我们从JIT的入口函数开始看,这个函数会被EE(运行引擎)调用
源代码: https://github.com/dotnet/coreclr/blob/release/1.1.0/src/inc/corjit.h#L350
源代码: https://github.com/dotnet/coreclr/blob/release/1.1.0/src/jit/ee_il_dll.cpp#L279
注: 按微软文档中说CILJit是32位上的实现,PreJit是64位上的实现,但实际我找不到PreJit在哪里
``` c++
CorJitResult CILJit::compileMethod(
ICorJitInfo* compHnd, CORINFO_METHOD_INFO* methodInfo, unsigned flags, BYTE** entryAddress, ULONG* nativeSizeOfCode)
{
// 省略部分代码......
assert(methodInfo->ILCode);
result = jitNativeCode(methodHandle, methodInfo->scope, compHnd, methodInfo, &methodCodePtr, nativeSizeOfCode,
&jitFlags, nullptr);
// 省略部分代码......
return CorJitResult(result);
}
```
jitNativeCode是一个负责使用JIT编译单个函数的静态函数,会在内部为编译的函数创建单独的Compiler实例
源代码: https://github.com/dotnet/coreclr/blob/release/1.1.0/src/jit/compiler.cpp#L6075
``` c++
int jitNativeCode(CORINFO_METHOD_HANDLE methodHnd,
CORINFO_MODULE_HANDLE classPtr,
COMP_HANDLE compHnd,
CORINFO_METHOD_INFO* methodInfo,
void** methodCodePtr,
ULONG* methodCodeSize,
JitFlags* compileFlags,
void* inlineInfoPtr)
{
// 省略部分代码......
pParam->pComp->compInit(pParam->pAlloc, pParam->inlineInfo);
pParam->pComp->jitFallbackCompile = pParam->jitFallbackCompile;
// Now generate the code
pParam->result =
pParam->pComp->compCompile(pParam->methodHnd, pParam->classPtr, pParam->compHnd, pParam->methodInfo,
pParam->methodCodePtr, pParam->methodCodeSize, pParam->compileFlags);
// 省略部分代码......
return result;
}
```
Compiler::compCompile是Compiler类提供的入口函数,作用同样是编译函数
注意这个函数有7个参数,等一会还会有一个同名但只有3个参数的函数
这个函数主要调用了Compiler::compCompileHelper函数
源代码: https://github.com/dotnet/coreclr/blob/release/1.1.0/src/jit/compiler.cpp#L4693
``` c++
int Compiler::compCompile(CORINFO_METHOD_HANDLE methodHnd,
CORINFO_MODULE_HANDLE classPtr,
COMP_HANDLE compHnd,
CORINFO_METHOD_INFO* methodInfo,
void** methodCodePtr,
ULONG* methodCodeSize,
JitFlags* compileFlags)
{
// 省略部分代码......
pParam->result = pParam->pThis->compCompileHelper(pParam->classPtr, pParam->compHnd, pParam->methodInfo,
pParam->methodCodePtr, pParam->methodCodeSize,
pParam->compileFlags, pParam->instVerInfo);
// 省略部分代码......
return param.result;
}
```
让我们继续看Compiler::compCompileHelper
源代码: https://github.com/dotnet/coreclr/blob/release/1.1.0/src/jit/compiler.cpp#L5294
``` c++
int Compiler::compCompileHelper(CORINFO_MODULE_HANDLE classPtr,
COMP_HANDLE compHnd,
CORINFO_METHOD_INFO* methodInfo,
void** methodCodePtr,
ULONG* methodCodeSize,
JitFlags* compileFlags,
CorInfoInstantiationVerification instVerInfo)
{
// 省略部分代码......
// 初始化本地变量表
lvaInitTypeRef();
// 省略部分代码......
// 查找所有BasicBlock
fgFindBasicBlocks();
// 省略部分代码......
// 调用3个参数的compCompile函数,注意不是7个函数的compCompile函数
compCompile(methodCodePtr, methodCodeSize, compileFlags);
// 省略部分代码......
return CORJIT_OK;
}
```
现在到了3个参数的compCompile,这个函数被微软认为是JIT最被感兴趣的入口函数
你可以额外阅读一下微软的[JIT介绍文档](https://github.com/dotnet/coreclr/blob/master/Documentation/botr/ryujit-overview.md)
源代码: https://github.com/dotnet/coreclr/blob/release/1.1.0/src/jit/compiler.cpp#L4078
``` c++
//*********************************************************************************************
// #Phases
//
// This is the most interesting 'toplevel' function in the JIT. It goes through the operations of
// importing, morphing, optimizations and code generation. This is called from the EE through the
// code:CILJit::compileMethod function.
//
// For an overview of the structure of the JIT, see:
// https://github.com/dotnet/coreclr/blob/master/Documentation/botr/ryujit-overview.md
//
void Compiler::compCompile(void** methodCodePtr, ULONG* methodCodeSize, JitFlags* compileFlags)
{
// 省略部分代码......
// 转换BasicBlock(基本代码块)到GenTree(语句树)
fgImport();
// 省略部分代码......
// 这里会进行各个处理步骤(Phases),如Inline和优化等
// 省略部分代码......
// 转换GT_ALLOCOBJ节点到GT_CALL节点(分配内存=调用帮助函数)
ObjectAllocator objectAllocator(this);
objectAllocator.Run();
// 省略部分代码......
// 创建本地变量表和计算各个变量的引用计数
lvaMarkLocalVars();
// 省略部分代码......
// 具体化语句树
Lowering lower(this, m_pLinearScan); // PHASE_LOWERING
lower.Run();
// 省略部分代码......
// 生成机器码
codeGen->genGenerateCode(methodCodePtr, methodCodeSize);
}
```
到这里你应该大概知道JIT在总体上做了什么事情
接下来我们来看Compiler::fgImport函数,这个函数负责把BasicBlock(基本代码块)转换到GenTree(语句树)
源代码: https://github.com/dotnet/coreclr/blob/release/1.1.0/src/jit/flowgraph.cpp#L6663
``` c++
void Compiler::fgImport()
{
// 省略部分代码......
impImport(fgFirstBB);
// 省略部分代码......
}
```
再看Compiler::impImport
源代码: https://github.com/dotnet/coreclr/blob/release/1.1.0/src/jit/importer.cpp#L9207
``` c++
void Compiler::impImport(BasicBlock* method)
{
// 省略部分代码......
/* Import blocks in the worker-list until there are no more */
while (impPendingList)
{
PendingDsc* dsc = impPendingList;
impPendingList = impPendingList->pdNext;
// 省略部分代码......
/* Now import the block */
impImportBlock(dsc->pdBB);
}
}
```
再看Compiler::impImportBlock
源代码: https://github.com/dotnet/coreclr/blob/release/1.1.0/src/jit/importer.cpp#L15321
``` c++
//***************************************************************
// Import the instructions for the given basic block. Perform
// verification, throwing an exception on failure. Push any successor blocks that are enabled for the first
// time, or whose verification pre-state is changed.
void Compiler::impImportBlock(BasicBlock* block)
{
// 省略部分代码......
pParam->pThis->impImportBlockCode(pParam->block);
}
```
在接下来的Compiler::impImportBlockCode函数里面我们终于可以看到对CEE_NEWOBJ指令的处理了
这个函数有5000多行,推荐直接搜索case CEE_NEWOBJ来看以下的部分
源代码: https://github.com/dotnet/coreclr/blob/release/1.1.0/src/jit/importer.cpp#L9207
``` c++
/*****************************************************************************
* Import the instr for the given basic block
*/
void Compiler::impImportBlockCode(BasicBlock* block)
{
// 省略部分代码......
// 处理CEE_NEWOBJ指令
case CEE_NEWOBJ:
// 在这里微软给出了有三种情况
// 一种是对象是array,一种是对象有活动的长度(例如string),一种是普通的class
// 在这里我们只分析第三种情况
// There are three different cases for new
// Object size is variable (depends on arguments)
// 1) Object is an array (arrays treated specially by the EE)
// 2) Object is some other variable sized object (e.g. String)
// 3) Class Size can be determined beforehand (normal case)
// In the first case, we need to call a NEWOBJ helper (multinewarray)
// in the second case we call the constructor with a '0' this pointer
// In the third case we alloc the memory, then call the constuctor
// 省略部分代码......
// 创建一个GT_ALLOCOBJ类型的GenTree(语句树)节点,用于分配内存
op1 = gtNewAllocObjNode(info.compCompHnd->getNewHelper(&resolvedToken, info.compMethodHnd),
resolvedToken.hClass, TYP_REF, op1);
// 省略部分代码......
// 因为GT_ALLOCOBJ仅负责分配内存,我们还需要调用构造函数
// 这里复用了CEE_CALL指令的处理
goto CALL;
// 省略部分代码......
CALL: // memberRef should be set.
// 省略部分代码......
// 创建一个GT_CALL类型的GenTree(语句树)节点,用于调用构造函数
callTyp = impImportCall(opcode, &resolvedToken, constraintCall ? &constrainedResolvedToken : nullptr,
newObjThisPtr, prefixFlags, &callInfo, opcodeOffs);
```
请记住上面代码中新建的两个GenTree(语句树)节点
- 节点GT_ALLOCOBJ用于分配内存
- 节点GT_CALL用于调用构造函数
在上面的代码我们可以看到在生成GT_ALLOCOBJ类型的节点时还传入了一个newHelper参数,这个newHelper正是分配内存函数的一个标识(索引值)
在CoreCLR中有很多HelperFunc(帮助函数)供JIT生成的代码调用
源代码: https://github.com/dotnet/coreclr/blob/release/1.1.0/src/vm/jitinterface.cpp#L5894
``` c++
CorInfoHelpFunc CEEInfo::getNewHelper(CORINFO_RESOLVED_TOKEN * pResolvedToken, CORINFO_METHOD_HANDLE callerHandle)
{
// 省略部分代码......
MethodTable* pMT = VMClsHnd.AsMethodTable();
// 省略部分代码......
result = getNewHelperStatic(pMT);
// 省略部分代码......
return result;
}
```
看CEEInfo::getNewHelperStatic
源代码: https://github.com/dotnet/coreclr/blob/release/1.1.0/src/vm/jitinterface.cpp#L5941
``` c++
CorInfoHelpFunc CEEInfo::getNewHelperStatic(MethodTable * pMT)
{
// 省略部分代码......
// 这里有很多判断,例如是否是Com对象或拥有析构函数,默认会返回CORINFO_HELP_NEWFAST
// Slow helper is the default
CorInfoHelpFunc helper = CORINFO_HELP_NEWFAST;
// 省略部分代码......
return helper;
}
```
到这里,我们可以知道新建的两个节点带有以下的信息
- GT_ALLOCOBJ节点
- 分配内存的帮助函数标识,默认是CORINFO_HELP_NEWFAST
- GT_CALL节点
- 构造函数的句柄
在使用fgImport生成了GenTree(语句树)以后,还不能直接用这个树来生成机器代码,需要经过很多步的变换
其中的一步变换会把GT_ALLOCOBJ节点转换为GT_CALL节点,因为分配内存实际上是一个对JIT专用的帮助函数的调用
这个变换在ObjectAllocator中实现,ObjectAllocator是JIT编译过程中的一个阶段(Phase)
源代码: https://github.com/dotnet/coreclr/blob/release/1.1.0/src/jit/objectalloc.cpp#L27
``` c++
void ObjectAllocator::DoPhase()
{
// 省略部分代码......
MorphAllocObjNodes();
}
```
MorphAllocObjNodes用于查找所有节点,如果是GT_ALLOCOBJ则进行转换
源代码: https://github.com/dotnet/coreclr/blob/release/1.1.0/src/jit/objectalloc.cpp#L63
``` c++
void ObjectAllocator::MorphAllocObjNodes()
{
// 省略部分代码......
for (GenTreeStmt* stmt = block->firstStmt(); stmt; stmt = stmt->gtNextStmt)
{
// 省略部分代码......
bool canonicalAllocObjFound = false;
// 省略部分代码......
if (op2->OperGet() == GT_ALLOCOBJ)
canonicalAllocObjFound = true;
// 省略部分代码......
if (canonicalAllocObjFound)
{
// 省略部分代码......
op2 = MorphAllocObjNodeIntoHelperCall(asAllocObj);
}
}
}
```
MorphAllocObjNodeIntoHelperCall的定义
源代码: https://github.com/dotnet/coreclr/blob/release/1.1.0/src/jit/objectalloc.cpp#L152
``` c++
// MorphAllocObjNodeIntoHelperCall: Morph a GT_ALLOCOBJ node into an
// allocation helper call.
GenTreePtr ObjectAllocator::MorphAllocObjNodeIntoHelperCall(GenTreeAllocObj* allocObj)
{
// 省略部分代码......
GenTreePtr helperCall = comp->fgMorphIntoHelperCall(allocObj, allocObj->gtNewHelper, comp->gtNewArgList(op1));
return helperCall;
}
```
fgMorphIntoHelperCall的定义
这个函数转换GT_ALLOCOBJ节点到GT_CALL节点,并且获取指向分配内存的函数的指针
源代码: https://github.com/dotnet/coreclr/blob/release/1.1.0/src/jit/morph.cpp#L61
``` c++
GenTreePtr Compiler::fgMorphIntoHelperCall(GenTreePtr tree, int helper, GenTreeArgList* args)
{
tree->ChangeOper(GT_CALL);
tree->gtFlags |= GTF_CALL;
// 省略部分代码......
// 如果GT_ALLOCOBJ中帮助函数的标识是CORINFO_HELP_NEWFAST,这里就是eeFindHelper(CORINFO_HELP_NEWFAST)
// eeFindHelper会把帮助函数的表示转换为帮助函数的句柄
tree->gtCall.gtCallType = CT_HELPER;
tree->gtCall.gtCallMethHnd = eeFindHelper(helper);
// 省略部分代码......
tree = fgMorphArgs(tree->AsCall());
return tree;
}
```
到这里,我们可以知道新建的两个节点变成了这样
- GT_CALL节点 (调用帮助函数)
- 分配内存的帮助函数的句柄
- GT_CALL节点 (调用Managed函数)
- 构造函数的句柄
接下来JIT还会对GenTree(语句树)做出大量处理,这里省略说明,接下来我们来看机器码的生成
函数CodeGen::genCallInstruction负责把GT_CALL节点转换为汇编
源代码: https://github.com/dotnet/coreclr/blob/release/1.1.0/src/jit/codegenxarch.cpp#L5934
``` c++
// Produce code for a GT_CALL node
void CodeGen::genCallInstruction(GenTreePtr node)
{
// 省略部分代码......
if (callType == CT_HELPER)
{
// 把句柄转换为帮助函数的句柄,默认是CORINFO_HELP_NEWFAST
helperNum = compiler->eeGetHelperNum(methHnd);
// 获取指向帮助函数的指针
// 这里等于调用compiler->compGetHelperFtn(CORINFO_HELP_NEWFAST, ...)
addr = compiler->compGetHelperFtn(helperNum, (void**)&pAddr);
}
else
{
// 调用普通函数
// Direct call to a non-virtual user function.
addr = call->gtDirectCallAddress;
}
}
```
我们来看下compGetHelperFtn究竟把CORINFO_HELP_NEWFAST转换到了什么函数
compGetHelperFtn的定义
源代码: https://github.com/dotnet/coreclr/blob/release/1.1.0/src/jit/compiler.hpp#L1907
``` c++
void* Compiler::compGetHelperFtn(CorInfoHelpFunc ftnNum, /* IN */
void** ppIndirection) /* OUT */
{
// 省略部分代码......
addr = info.compCompHnd->getHelperFtn(ftnNum, ppIndirection);
return addr;
}
```
getHelperFtn的定义
这里我们可以看到获取了hlpDynamicFuncTable这个函数表中的函数
源代码: https://github.com/dotnet/coreclr/blob/release/1.1.0/src/vm/jitinterface.cpp#L10369
``` c++
void* CEEJitInfo::getHelperFtn(CorInfoHelpFunc ftnNum, /* IN */
void ** ppIndirection) /* OUT */
{
// 省略部分代码......
pfnHelper = hlpDynamicFuncTable[dynamicFtnNum].pfnHelper;
// 省略部分代码......
result = (LPVOID)GetEEFuncEntryPoint(pfnHelper);
return result;
}
```
hlpDynamicFuncTable函数表使用了jithelpers.h中的定义,其中CORINFO_HELP_NEWFAST对应的函数如下
源代码: https://github.com/dotnet/coreclr/blob/release/1.1.0/src/inc/jithelpers.h#L78
``` c++
JITHELPER(CORINFO_HELP_NEWFAST, JIT_New, CORINFO_HELP_SIG_REG_ONLY)
```
可以看到对应了JIT_New,这个就是JIT生成的代码调用分配内存的函数了,JIT_New的定义如下
需要注意的是函数表中的JIT_New在满足一定条件时会被替换为更快的实现,但作用和JIT_New是一样的,这一块将在后面提及
源代码: https://github.com/dotnet/coreclr/blob/release/1.1.0/src/vm/jithelpers.cpp#L2908
``` c++
HCIMPL1(Object*, JIT_New, CORINFO_CLASS_HANDLE typeHnd_)
{
// 省略部分代码......
MethodTable *pMT = typeHnd.AsMethodTable();
// 省略部分代码......
// AllocateObject是分配内存的函数,这个函数供CoreCLR的内部代码或非托管代码调用
// JIT_New是对这个函数的一个包装,仅供JIT生成的代码调用
newobj = AllocateObject(pMT);
// 省略部分代码......
return(OBJECTREFToObject(newobj));
}
HCIMPLEND
```
**总结:**
JIT从CEE_NEWOBJ生成了两段代码,一段是调用JIT_New函数分配内存的代码,一段是调用构造函数的代码
### 第二种new(对array的new)生成了什么机器码
我们来看一下CEE_NEWARR指令是怎样处理的,因为前面已经花了很大篇幅介绍对CEE_NEWOBJ的处理,这里仅列出不同的部分
源代码: https://github.com/dotnet/coreclr/blob/release/1.1.0/src/jit/importer.cpp#L13334
``` c++
/*****************************************************************************
* Import the instr for the given basic block
*/
void Compiler::impImportBlockCode(BasicBlock* block)
{
// 省略部分代码......
// 处理CEE_NEWARR指令
case CEE_NEWARR:
// 省略部分代码......
args = gtNewArgList(op1, op2);
// 生成GT_CALL类型的节点调用帮助函数
/* Create a call to 'new' */
// Note that this only works for shared generic code because the same helper is used for all
// reference array types
op1 = gtNewHelperCallNode(info.compCompHnd->getNewArrHelper(resolvedToken.hClass), TYP_REF, 0, args);
}
```
我们可以看到CEE_NEWARR直接生成了GT_CALL节点,不像CEE_NEWOBJ需要进一步的转换
getNewArrHelper返回了调用的帮助函数,我们来看一下getNewArrHelper
源代码: https://github.com/dotnet/coreclr/blob/release/1.1.0/src/vm/jitinterface.cpp#L6035
``` c++
/***********************************************************************/
// <REVIEW> this only works for shared generic code because all the
// helpers are actually the same. If they were different then things might
// break because the same helper would end up getting used for different but
// representation-compatible arrays (e.g. one with a default constructor
// and one without) </REVIEW>
CorInfoHelpFunc CEEInfo::getNewArrHelper (CORINFO_CLASS_HANDLE arrayClsHnd)
{
// 省略部分代码......
TypeHandle arrayType(arrayClsHnd);
result = getNewArrHelperStatic(arrayType);
// 省略部分代码......
return result;
}
```
再看getNewArrHelperStatic,我们可以看到一般情况下会返回CORINFO_HELP_NEWARR_1_OBJ
源代码: https://github.com/dotnet/coreclr/blob/release/1.1.0/src/vm/jitinterface.cpp#L6060
``` c++
CorInfoHelpFunc CEEInfo::getNewArrHelperStatic(TypeHandle clsHnd)
{
// 省略部分代码......
if (CorTypeInfo::IsGenericVariable(elemType))
{
result = CORINFO_HELP_NEWARR_1_OBJ;
}
else if (CorTypeInfo::IsObjRef(elemType))
{
// It is an array of object refs
result = CORINFO_HELP_NEWARR_1_OBJ;
}
else
{
// These cases always must use the slow helper
// 省略部分代码......
}
return result;
{
```
CORINFO_HELP_NEWARR_1_OBJ对应的函数如下
源代码: https://github.com/dotnet/coreclr/blob/release/1.1.0/src/inc/jithelpers.h#L86
``` c++
DYNAMICJITHELPER(CORINFO_HELP_NEWARR_1_OBJ, JIT_NewArr1,CORINFO_HELP_SIG_REG_ONLY)
```
可以看到对应了JIT_NewArr1这个包装给JIT调用的帮助函数
和JIT_New一样,在满足一定条件时会被替换为更快的实现
源代码: https://github.com/dotnet/coreclr/blob/release/1.1.0/src/vm/jithelpers.cpp#L3303
``` c++
HCIMPL2(Object*, JIT_NewArr1, CORINFO_CLASS_HANDLE arrayTypeHnd_, INT_PTR size)
{
// 省略部分代码......
CorElementType elemType = pArrayClassRef->GetArrayElementTypeHandle().GetSignatureCorElementType();
if (CorTypeInfo::IsPrimitiveType(elemType)
{
// 省略部分代码......
// 如果类型是基元类型(int, double等)则使用更快的FastAllocatePrimitiveArray函数
newArray = FastAllocatePrimitiveArray(pArrayClassRef->GetMethodTable(), static_cast<DWORD>(size), bAllocateInLargeHeap);
}
else
{
// 省略部分代码......
// 默认使用AllocateArrayEx函数
INT32 size32 = (INT32)size;
newArray = AllocateArrayEx(typeHnd, &size32, 1);
}
// 省略部分代码......
return(OBJECTREFToObject(newArray));
}
HCIMPLEND
```
**总结:**
JIT从CEE_NEWARR只生成了一段代码,就是调用JIT_NewArr1函数的代码
### 第三种new(对struct的new)生成了什么机器码
这种new会在栈(stack)分配内存,所以不需要调用任何分配内存的函数
在一开始的例子中,myStruct在编译时就已经定义为一个本地变量,对本地变量的需要的内存会在函数刚进入的时候一并分配
这里我们先来看本地变量所需要的内存是怎么计算的
先看Compiler::lvaAssignVirtualFrameOffsetsToLocals
源代码: https://github.com/dotnet/coreclr/blob/release/1.1.0/src/jit/lclvars.cpp#L4863
``` c++
/*****************************************************************************
* lvaAssignVirtualFrameOffsetsToLocals() : Assign virtual stack offsets to
* locals, temps, and anything else. These will all be negative offsets
* (stack grows down) relative to the virtual '0'/return address
*/
void Compiler::lvaAssignVirtualFrameOffsetsToLocals()
{
// 省略部分代码......
for (cur = 0; alloc_order[cur]; cur++)
{
// 省略部分代码......
for (lclNum = 0, varDsc = lvaTable; lclNum < lvaCount; lclNum++, varDsc++)
{
// 省略部分代码......
// Reserve the stack space for this variable
stkOffs = lvaAllocLocalAndSetVirtualOffset(lclNum, lvaLclSize(lclNum), stkOffs);
}
}
}
```
再看Compiler::lvaAllocLocalAndSetVirtualOffset
源代码: https://github.com/dotnet/coreclr/blob/release/1.1.0/src/jit/lclvars.cpp#L5537
``` c++
int Compiler::lvaAllocLocalAndSetVirtualOffset(unsigned lclNum, unsigned size, int stkOffs)
{
// 省略部分代码......
/* Reserve space on the stack by bumping the frame size */
lvaIncrementFrameSize(size);
stkOffs -= size;
lvaTable[lclNum].lvStkOffs = stkOffs;
// 省略部分代码......
return stkOffs;
}
```
再看Compiler::lvaIncrementFrameSize
我们可以看到最终会加到compLclFrameSize这个变量中,这个变量就是当前函数总共需要在栈(Stack)分配的内存大小
源代码: https://github.com/dotnet/coreclr/blob/release/1.1.0/src/jit/lclvars.cpp#L3528
``` c++
inline void Compiler::lvaIncrementFrameSize(unsigned size)
{
if (size > MAX_FrameSize || compLclFrameSize + size > MAX_FrameSize)
{
BADCODE("Frame size overflow");
}
compLclFrameSize += size;
}
```
现在来看生成机器码的代码,在栈分配内存的代码会在CodeGen::genFnProlog生成
源代码: https://github.com/dotnet/coreclr/blob/release/1.1.0/src/jit/codegencommon.cpp#L8140
``` c++
void CodeGen::genFnProlog()
{
// 省略部分代码......
// ARM64和其他平台的调用时机不一样,但是参数一样
genAllocLclFrame(compiler->compLclFrameSize, initReg, &initRegZeroed, intRegState.rsCalleeRegArgMaskLiveIn);
}
```
再看CodeGen::genAllocLclFrame,这里就是分配栈内存的代码了,简单的rsp(esp)减去了frameSize
源代码: https://github.com/dotnet/coreclr/blob/release/1.1.0/src/jit/codegencommon.cpp#L5846
``` c++
/*-----------------------------------------------------------------------------
*
* Probe the stack and allocate the local stack frame: subtract from SP.
* On ARM64, this only does the probing; allocating the frame is done when callee-saved registers are saved.
*/
void CodeGen::genAllocLclFrame(unsigned frameSize, regNumber initReg, bool* pInitRegZeroed, regMaskTP maskArgRegsLiveIn)
{
// 省略部分代码......
// sub esp, frameSize 6
inst_RV_IV(INS_sub, REG_SPBASE, frameSize, EA_PTRSIZE);
}
```
**总结:**
JIT对struct的new会生成统一在栈分配内存的代码,所以你在IL中看不到new struct的指令
调用构造函数的代码会从后面的call指令生成
### 第一种new(对class的new)做了什么
从上面的分析我们可以知道第一种new先调用JIT_New分配内存,然后调用构造函数
在上面JIT_New的源代码中可以看到,JIT_New内部调用了AllocateObject
先看AllocateObject函数
源代码: https://github.com/dotnet/coreclr/blob/release/1.1.0/src/vm/gchelpers.cpp#L931
``` c++
// AllocateObject will throw OutOfMemoryException so don't need to check
// for NULL return value from it.
OBJECTREF AllocateObject(MethodTable *pMT
#ifdef FEATURE_COMINTEROP
, bool fHandleCom
#endif
)
{
// 省略部分代码......
Object *orObject = NULL;
// 如果类型有重要的析构函数,预编译所有相关的函数(详细可以搜索CER)
// 同一个类型只会处理一次
if (pMT->HasCriticalFinalizer())
PrepareCriticalFinalizerObject(pMT);
// 省略部分代码......
DWORD baseSize = pMT->GetBaseSize();
// 调用gc的帮助函数分配内存,如果需要向8对齐则调用AllocAlign8,否则调用Alloc
if (pMT->RequiresAlign8())
{
// 省略部分代码......
orObject = (Object *) AllocAlign8(baseSize,
pMT->HasFinalizer(),
pMT->ContainsPointers(),
pMT->IsValueType());
}
else
{
orObject = (Object *) Alloc(baseSize,
pMT->HasFinalizer(),
pMT->ContainsPointers());
}
// 检查同步块索引(SyncBlock)是否为0
// verify zero'd memory (at least for sync block)
_ASSERTE( orObject->HasEmptySyncBlockInfo() );
// 设置类型信息(MethodTable)
if ((baseSize >= LARGE_OBJECT_SIZE))
{
orObject->SetMethodTableForLargeObject(pMT);
GCHeap::GetGCHeap()->PublishObject((BYTE*)orObject);
}
else
{
orObject->SetMethodTable(pMT);
}
// 省略部分代码......
return UNCHECKED_OBJECTREF_TO_OBJECTREF(oref);
}
```
再看Alloc函数
源代码:
``` c++
// There are only three ways to get into allocate an object.
// * Call optimized helpers that were generated on the fly. This is how JIT compiled code does most
// allocations, however they fall back code:Alloc, when for all but the most common code paths. These
// helpers are NOT used if profiler has asked to track GC allocation (see code:TrackAllocations)
// * Call code:Alloc - When the jit helpers fall back, or we do allocations within the runtime code
// itself, we ultimately call here.
// * Call code:AllocLHeap - Used very rarely to force allocation to be on the large object heap.
//
// While this is a choke point into allocating an object, it is primitive (it does not want to know about
// MethodTable and thus does not initialize that poitner. It also does not know if the object is finalizable
// or contains pointers. Thus we quickly wrap this function in more user-friendly ones that know about
// MethodTables etc. (see code:FastAllocatePrimitiveArray code:AllocateArrayEx code:AllocateObject)
//
// You can get an exhaustive list of code sites that allocate GC objects by finding all calls to
// code:ProfilerObjectAllocatedCallback (since the profiler has to hook them all).
inline Object* Alloc(size_t size, BOOL bFinalize, BOOL bContainsPointers )
{
// 省略部分代码......
// We don't want to throw an SO during the GC, so make sure we have plenty
// of stack before calling in.
INTERIOR_STACK_PROBE_FOR(GetThread(), static_cast<unsigned>(DEFAULT_ENTRY_PROBE_AMOUNT * 1.5));
if (GCHeapUtilities::UseAllocationContexts())
retVal = GCHeapUtilities::GetGCHeap()->Alloc(GetThreadAllocContext(), size, flags);
else
retVal = GCHeapUtilities::GetGCHeap()->Alloc(size, flags);
if (!retVal)
{
ThrowOutOfMemory();
}
END_INTERIOR_STACK_PROBE;
return retVal;
}
```
**总结:**
第一种new做的事情主要有
- 调用JIT_New
- 从GCHeap中申请一块内存
- 设置类型信息(MethodTable)
- 同步块索引默认为0,不需要设置
- 调用构造函数
### 第二种new(对array的new)做了什么
第二种new只调用了JIT_NewArr1,从上面JIT_NewArr1的源代码可以看到
如果元素的类型是基元类型(int, double等)则会调用FastAllocatePrimitiveArray,否则会调用AllocateArrayEx
先看FastAllocatePrimitiveArray函数
源代码: https://github.com/dotnet/coreclr/blob/release/1.1.0/src/vm/gchelpers.cpp#L563
``` c++
/*
* Allocates a single dimensional array of primitive types.
*/
OBJECTREF FastAllocatePrimitiveArray(MethodTable* pMT, DWORD cElements, BOOL bAllocateInLargeHeap)
{
// 省略部分代码......
// 检查元素数量不能大于一个硬性限制
SIZE_T componentSize = pMT->GetComponentSize();
if (cElements > MaxArrayLength(componentSize))
ThrowOutOfMemory();
// 检查总大小不能溢出
S_SIZE_T safeTotalSize = S_SIZE_T(cElements) * S_SIZE_T(componentSize) + S_SIZE_T(pMT->GetBaseSize());
if (safeTotalSize.IsOverflow())
ThrowOutOfMemory();
size_t totalSize = safeTotalSize.Value();
// 省略部分代码......
// 调用gc的帮助函数分配内存
ArrayBase* orObject;
if (bAllocateInLargeHeap)
{
orObject = (ArrayBase*) AllocLHeap(totalSize, FALSE, FALSE);
}
else
{
ArrayTypeDesc *pArrayR8TypeDesc = g_pPredefinedArrayTypes[ELEMENT_TYPE_R8];
if (DATA_ALIGNMENT < sizeof(double) && pArrayR8TypeDesc != NULL && pMT == pArrayR8TypeDesc->GetMethodTable() && totalSize < LARGE_OBJECT_SIZE - MIN_OBJECT_SIZE)
{
// Creation of an array of doubles, not in the large object heap.
// We want to align the doubles to 8 byte boundaries, but the GC gives us pointers aligned
// to 4 bytes only (on 32 bit platforms). To align, we ask for 12 bytes more to fill with a
// dummy object.
// If the GC gives us a 8 byte aligned address, we use it for the array and place the dummy
// object after the array, otherwise we put the dummy object first, shifting the base of
// the array to an 8 byte aligned address.
// Note: on 64 bit platforms, the GC always returns 8 byte aligned addresses, and we don't
// execute this code because DATA_ALIGNMENT < sizeof(double) is false.
_ASSERTE(DATA_ALIGNMENT == sizeof(double)/2);
_ASSERTE((MIN_OBJECT_SIZE % sizeof(double)) == DATA_ALIGNMENT); // used to change alignment
_ASSERTE(pMT->GetComponentSize() == sizeof(double));
_ASSERTE(g_pObjectClass->GetBaseSize() == MIN_OBJECT_SIZE);
_ASSERTE(totalSize < totalSize + MIN_OBJECT_SIZE);
orObject = (ArrayBase*) Alloc(totalSize + MIN_OBJECT_SIZE, FALSE, FALSE);
Object *orDummyObject;
if((size_t)orObject % sizeof(double))
{
orDummyObject = orObject;
orObject = (ArrayBase*) ((size_t)orObject + MIN_OBJECT_SIZE);
}
else
{
orDummyObject = (Object*) ((size_t)orObject + totalSize);
}
_ASSERTE(((size_t)orObject % sizeof(double)) == 0);
orDummyObject->SetMethodTable(g_pObjectClass);
}
else
{
orObject = (ArrayBase*) Alloc(totalSize, FALSE, FALSE);
bPublish = (totalSize >= LARGE_OBJECT_SIZE);
}
}
// 设置类型信息(MethodTable)
// Initialize Object
orObject->SetMethodTable( pMT );
_ASSERTE(orObject->GetMethodTable() != NULL);
// 设置数组长度
orObject->m_NumComponents = cElements;
// 省略部分代码......
return( ObjectToOBJECTREF((Object*)orObject) );
}
```
再看AllocateArrayEx函数,这个函数比起上面的函数多出了对多维数组的处理
JIT_NewArr1调用AllocateArrayEx时传了3个参数,剩下2个参数是可选参数
源代码: https://github.com/dotnet/coreclr/blob/release/1.1.0/src/vm/gchelpers.cpp#L282
``` c++
// Handles arrays of arbitrary dimensions
//
// If dwNumArgs is set to greater than 1 for a SZARRAY this function will recursively
// allocate sub-arrays and fill them in.
//
// For arrays with lower bounds, pBounds is <lower bound 1>, <count 1>, <lower bound 2>, ...
OBJECTREF AllocateArrayEx(TypeHandle arrayType, INT32 *pArgs, DWORD dwNumArgs, BOOL bAllocateInLargeHeap
DEBUG_ARG(BOOL bDontSetAppDomain))
{
// 省略部分代码......
ArrayBase * orArray = NULL;
// 省略部分代码......
// 调用gc的帮助函数分配内存
if (bAllocateInLargeHeap)
{
orArray = (ArrayBase *) AllocLHeap(totalSize, FALSE, pArrayMT->ContainsPointers());
// 设置类型信息(MethodTable)
orArray->SetMethodTableForLargeObject(pArrayMT);
}
else
{
#ifdef FEATURE_64BIT_ALIGNMENT
MethodTable *pElementMT = arrayDesc->GetTypeParam().GetMethodTable();
if (pElementMT->RequiresAlign8() && pElementMT->IsValueType())
{
// This platform requires that certain fields are 8-byte aligned (and the runtime doesn't provide
// this guarantee implicitly, e.g. on 32-bit platforms). Since it's the array payload, not the
// header that requires alignment we need to be careful. However it just so happens that all the
// cases we care about (single and multi-dim arrays of value types) have an even number of DWORDs
// in their headers so the alignment requirements for the header and the payload are the same.
_ASSERTE(((pArrayMT->GetBaseSize() - SIZEOF_OBJHEADER) & 7) == 0);
orArray = (ArrayBase *) AllocAlign8(totalSize, FALSE, pArrayMT->ContainsPointers(), FALSE);
}
else
#endif
{
orArray = (ArrayBase *) Alloc(totalSize, FALSE, pArrayMT->ContainsPointers());
}
// 设置类型信息(MethodTable)
orArray->SetMethodTable(pArrayMT);
}
// 设置数组长度
// Initialize Object
orArray->m_NumComponents = cElements;
// 省略部分代码......
return ObjectToOBJECTREF((Object *) orArray);
}
```
**总结:**
第二种new做的事情主要有
- 调用JIT_NewArr1
- 从GCHeap中申请一块内存
- 设置类型信息(MethodTable)
- 设置数组长度(m_NumComponents)
- 不会调用构造函数,所以所有内容都会为0(所有成员都会为默认值)
### 第三种new(对struct的new)做了什么
对struct的new不会从GCHeap申请内存,也不会设置类型信息(MethodTable),所以可以直接进入总结
**总结:**
第三种new做的事情主要有
- 在进入函数时统一从栈(Stack)分配内存
- 分配的内存不会包含同步块索引(SyncBlock)和类型信息(MethodTable)
- 调用构造函数
### 验证第一种new(对class的new)
打开VS反汇编和内存窗口,让我们来看看第一种new实际做了什么事情

第一种new的反汇编结果如下,一共有两个call
``` asm
00007FF919570B53 mov rcx,7FF9194161A0h // 设置第一个参数(指向MethodTable的指针)
00007FF919570B5D call 00007FF97905E350 // 调用分配内存的函数,默认是JIT_New
00007FF919570B62 mov qword ptr [rbp+38h],rax // 把地址设置到临时变量(rbp+38)
00007FF919570B66 mov r8,37BFC73068h
00007FF919570B70 mov r8,qword ptr [r8] // 设置第三个参数("hello")
00007FF919570B73 mov rcx,qword ptr [rbp+38h] // 设置第一个参数(this)
00007FF919570B77 mov edx,12345678h // 设置第二个参数(0x12345678)
00007FF919570B7C call 00007FF9195700B8 // 调用构造函数
00007FF919570B81 mov rcx,qword ptr [rbp+38h]
00007FF919570B85 mov qword ptr [rbp+50h],rcx // 把临时变量复制到myClass变量中
```
第一个call是分配内存使用的帮助函数,默认调用JIT_New
但是这里实际调用的不是JIT_New而是JIT_TrialAllocSFastMP_InlineGetThread函数,这是一个优化版本允许分配上下文中快速分配内存
我们来看一下JIT_TrialAllocSFastMP_InlineGetThread函数的定义

源代码: https://github.com/dotnet/coreclr/blob/release/1.1.0/src/vm/amd64/JitHelpers_InlineGetThread.asm#L59
``` asm
; IN: rcx: MethodTable*
; OUT: rax: new object
LEAF_ENTRY JIT_TrialAllocSFastMP_InlineGetThread, _TEXT
mov edx, [rcx + OFFSET__MethodTable__m_BaseSize] // 从MethodTable获取需要分配的内存大小,放到edx
; m_BaseSize is guaranteed to be a multiple of 8.
PATCHABLE_INLINE_GETTHREAD r11, JIT_TrialAllocSFastMP_InlineGetThread__PatchTLSOffset
mov r10, [r11 + OFFSET__Thread__m_alloc_context__alloc_limit] // 获取分配上下文的限制地址,放到r10
mov rax, [r11 + OFFSET__Thread__m_alloc_context__alloc_ptr] // 获取分配上下文的当前地址,放到rax
add rdx, rax // 地址 + 需要分配的内存大小,放到rdx
cmp rdx, r10 // 判断是否可以从分配上下文分配内存
ja AllocFailed // if (rdx > r10)
mov [r11 + OFFSET__Thread__m_alloc_context__alloc_ptr], rdx // 设置新的当前地址
mov [rax], rcx // 给刚刚分配到的内存设置MethodTable
ifdef _DEBUG
call DEBUG_TrialAllocSetAppDomain_NoScratchArea
endif ; _DEBUG
ret // 分配成功,返回
AllocFailed:
jmp JIT_NEW // 分配失败,调用默认的JIT_New函数
LEAF_END JIT_TrialAllocSFastMP_InlineGetThread, _TEXT
```
可以当分配上下文未用完时会从分配上下文中分配,但用完时会调用JIT_New做更多的处理
第二个call调用构造函数,call的地址和下面的地址不一致可能是因为中间有一层包装,目前还未解明包装中的处理

最后一个call调用的是JIT_WriteBarrier
### 验证第二种new(对array的new)
反汇编可以看到第二种new只有一个call

``` asm
00007FF919570B93 mov rcx,7FF9195B4CFAh // 设置第一个参数(指向MethodTable的指针)
00007FF919570B9D mov edx,378h // 设置第二个参数(数组的大小)
00007FF919570BA2 call 00007FF97905E440 // 调用分配内存的函数,默认是JIT_NewArr1
00007FF919570BA7 mov qword ptr [rbp+30h],rax // 设置到临时变量(rbp+30)
00007FF919570BAB mov rcx,qword ptr [rbp+30h]
00007FF919570BAF mov qword ptr [rbp+48h],rcx // 把临时变量复制到myArray变量中
```
call实际调用的是JIT_NewArr1VC_MP_InlineGetThread这个函数
和JIT_TrialAllocSFastMP_InlineGetThread一样,同样是从分配上下文中快速分配内存的函数
源代码: https://github.com/dotnet/coreclr/blob/release/1.1.0/src/vm/amd64/JitHelpers_InlineGetThread.asm#L207
具体代码这里就不再分析,有兴趣的可以去阅读上面的源代码
### 验证第三种new(对struct的new)
对struct的new会在函数进入的时候从栈分配内存,这里是减少rsp寄存器(栈顶)的值

```
00007FF919570B22 push rsi // 保存原rsi
00007FF919570B23 sub rsp,60h // 从栈分配内存
00007FF919570B27 mov rbp,rsp // 复制值到rbp
00007FF919570B2A mov rsi,rcx // 保存原rcx到rsi
00007FF919570B2D lea rdi,[rbp+28h] // rdi = rbp+28,有28个字节需要清零
00007FF919570B31 mov ecx,0Eh // rcx = 14 (计数)
00007FF919570B36 xor eax,eax // eax = 0
00007FF919570B38 rep stos dword ptr [rdi] // 把eax的值(short)设置到rdi直到rcx为0,总共清空14*2=28个字节
00007FF919570B3A mov rcx,rsi // 恢复原rcx
```
因为分配的内存已经在栈里面,后面只需要直接调构造函数

```
00007FF919570BBD lea rcx,[rbp+40h] // 第一个参数 (this)
00007FF919570BC1 mov edx,55667788h // 第二个参数 (0x55667788)
00007FF919570BC6 call 00007FF9195700A0 // 调用构造函数
```
构造函数的反编译

中间有一个call 00007FF97942E260调用的是JIT_DbgIsJustMyCode
在函数结束时会自动释放从栈分配的内存,在最后会让rsp = rbp + 0x60,这样rsp就恢复原值了

### 参考
http://stackoverflow.com/questions/1255803/does-the-net-clr-jit-compile-every-method-every-time
https://github.com/dotnet/coreclr/blob/release/1.1.0/src/vm/gchelpers.h
https://github.com/dotnet/coreclr/blob/release/1.1.0/src/vm/gchelpers.cpp#L986
https://github.com/dotnet/coreclr/blob/release/1.1.0/src/vm/jithelpers.cpp#L2908
https://github.com/dotnet/coreclr/blob/release/1.1.0/src/vm/jitinterface.cpp
https://github.com/dotnet/coreclr/blob/release/1.1.0/src/vm/jitinterfacegen.cpp
https://github.com/dotnet/coreclr/blob/release/1.1.0/src/vm/amd64/JitHelpers_InlineGetThread.asm
https://github.com/dotnet/coreclr/blob/release/1.1.0/src/gc/gcinterface.h#L230
https://github.com/dotnet/coreclr/blob/release/1.1.0/src/gc/gc.h
https://github.com/dotnet/coreclr/blob/release/1.1.0/src/gc/gc.cpp
https://github.com/dotnet/coreclr/blob/release/1.1.0/src/inc/opcode.def#L153
https://github.com/dotnet/coreclr/blob/release/1.1.0/src/inc/readytorunhelpers.h#L46
https://github.com/dotnet/coreclr/blob/release/1.1.0/src/inc/readytorun.h#L236
https://github.com/dotnet/coreclr/blob/release/1.1.0/src/inc/corinfo.h##L1147
https://github.com/dotnet/coreclr/blob/release/1.1.0/src/inc/corjit.h#L350
https://github.com/dotnet/coreclr/blob/release/1.1.0/src/jit/ee_il_dll.cpp#L279
https://github.com/dotnet/coreclr/blob/release/1.1.0/src/inc/jithelpers.h
https://github.com/dotnet/coreclr/blob/release/1.1.0/src/jit/compiler.hpp
https://github.com/dotnet/coreclr/blob/release/1.1.0/src/jit/compiler.h
https://github.com/dotnet/coreclr/blob/release/1.1.0/src/jit/compiler.cpp
https://github.com/dotnet/coreclr/blob/release/1.1.0/src/jit/flowgraph.cpp
https://github.com/dotnet/coreclr/blob/release/1.1.0/src/jit/importer.cpp
https://github.com/dotnet/coreclr/blob/release/1.1.0/src/jit/gentree.cpp
https://github.com/dotnet/coreclr/blob/release/1.1.0/src/jit/objectalloc.cpp
https://github.com/dotnet/coreclr/blob/release/1.1.0/src/jit/morph.cpp
https://github.com/dotnet/coreclr/blob/release/1.1.0/src/jit/codegenxarch.cpp#L8404
https://github.com/dotnet/coreclr/blob/release/1.1.0/Documentation/botr/ryujit-overview.md
https://github.com/dotnet/coreclr/blob/master/Documentation/building/viewing-jit-dumps.md
https://github.com/dotnet/coreclr/blob/master/Documentation/building/linux-instructions.md
https://en.wikipedia.org/wiki/Basic_block
https://en.wikipedia.org/wiki/Control_flow_graph
https://en.wikipedia.org/wiki/Static_single_assignment_form
https://msdn.microsoft.com/en-us/library/windows/hardware/ff561499(v=vs.85).aspx
https://msdn.microsoft.com/en-us/library/ms228973(v=vs.110).aspx
https://msdn.microsoft.com/en-us/library/system.runtime.constrainedexecution.criticalfinalizerobject(v=vs.110).aspx
https://msdn.microsoft.com/en-us/library/system.runtime.interopservices.safehandle(v=vs.110).aspx
https://msdn.microsoft.com/en-us/library/system.runtime.interopservices.criticalhandle(v=vs.110).aspx
https://dotnet.myget.org/feed/dotnet-core/package/nuget/runtime.win7-x64.Microsoft.NETCore.Runtime.CoreCLR
http://www.codemachine.com/article_x64deepdive.html
这一篇相对前一篇多了很多c++和汇编代码,也在表面上涉及到了JIT,你们可能会说看不懂
这是正常的,我也不是完全看懂这篇提到的所有处理
欢迎大神们勘误,也欢迎小白们提问
接下来我会重点分析GC分配内存的算法,敬请期待 | 39,779 | MIT |
---
title: "博客装修啦 - 从 Jekyll 到 Hugo"
date: 2020-12-28T17:54:42+11:00
draft: false
tags: ["Blog"]
---
过去几年这个博客一直用的 [Jekyll](https://jekyllrb.com/) 来生成。
最近我决定把它迁移到 [Hugo](https://gohugo.io/) 上,把评论系统也换成了 [Valine](https://valine.js.org/)。
<!--more-->
## 原因
1. Hugo 使用 Golang 写的,生成速度比 Jekyll 快很多。这决定了编辑的时候多久能在本地看到效果。
1. 老版本上一些插件很久没有更新,变得很难维护。
## 我的主题选择 - LoveIt
官网上有[很多主题](https://www.gohugo.org/theme/)可以选择。
[LoveIt](https://github.com/dillonzq/LoveIt/blob/master/README.zh-cn.md) 支持很多好用的工具和功能。整个主题也很容易自定义。快看看吧 :+1:
## Valine + Valine Admin
每篇文章下面的评论系统换成了 [Valine](https://valine.js.org/)。
放弃 [Disqus](https://disqus.com/) 的原因主要是有些地方对它的限制。
Valine 基于 LeanCloud, 按照官网的[快速开始](https://valine.js.org/quickstart.html)只需要几步就能轻松部署。
Valine 并没有内置的评论管理系统。这就需要在 LeanCloud 上部署另一个服务—— [Valine-Admin](https://github.com/DesertsP/Valine-Admin)。它支持
- 新评论邮件提醒
- 评论管理
- 垃圾评论过滤(通过 [Akismet](https://akismet.com/))
{{< admonition tip "LeanCloud 上出现因为流控原因唤醒失败">}}
使用 [cron-job](https://cron-job.org/en/) 或其他第三方服务。
{{< /admonition >}}
## 使用 GitHub Actions 进行部署
Hugo 的[官网](https://gohugo.io/hosting-and-deployment/hosting-on-github/)上有关于如何在 GitHub 上进行通过脚本进行部署的例子。
我更喜欢用 CI,比如 GitHub Actions 来部署。每次在 `main` 分支上有改动就能自动部署到 `gh-pages` 分支上。下面这个 yaml 文件描述了部署过程。
```yaml
name: deploy
on:
push:
branches:
- main # Set a branch to deploy
jobs:
deploy:
runs-on: ubuntu-18.04
steps:
- uses: actions/checkout@v2
with:
submodules: true # Fetch Hugo themes (true OR recursive)
fetch-depth: 0 # Fetch all history for .GitInfo and .Lastmod
- name: Setup Hugo
uses: peaceiris/actions-hugo@v2
with:
hugo-version: 'latest'
extended: true
- uses: actions/cache@v2
with:
path: /tmp/hugo_cache
key: ${{ runner.os }}-hugomod-${{ hashFiles('**/go.sum') }}
restore-keys: |
${{ runner.os }}-hugomod-
- name: Build
run: hugo --minify
- name: Deploy
uses: peaceiris/actions-gh-pages@v3
with:
github_token: ${{ secrets.GITHUB_TOKEN }}
publish_dir: ./public
cname: example.com # CHANGE THIS
```
## 一些经验和踩过的坑
* 在从 Jekyll 迁移到 Hugo 的时候,文章可以使用一些[自动化工具](https://gohugo.io/tools/migrations/)。
* 之前在 Disqus 的评论可以通过 [disqus-to-valine](https://taosky.github.io/disqus-to-valine/) 来迁移。
* 模板(layouts)和样式(css、scss)的查找顺序是先查看根目录,再查看 `themes` 下的目录。所以如果想对主题有什么更改,可以在根目录下创建相似的路径,然后自定义。
* 对于标签(tags)的多语言支持有点奇怪。你需要在 `/content/tags/` 目录下对于每一个标签创建一个文件夹,在文件夹下创建对应语言的 `.md` 文件,里面写上翻译。
希望新博客的样式和内容你们能够喜欢 :heart: :heart: :heart: | 2,593 | MIT |
---
title: 内存泄漏排查
date: 2021.08.10 18:48
updated: 2021.08.10 18:48
categories:
- vue
tags:
- vue
- memory
---
### 前言
目前web端在浏览器中操作时,会存在明显的卡顿,而且会越用越卡,初步怀疑是内存泄漏导致。
<!-- more -->
### 问题排查
#### 1. 不断重复打开、关闭页面,发现内存一直在增加;
初始内存占用:
一顿操作之后:
排查占用内存较大的数据点:
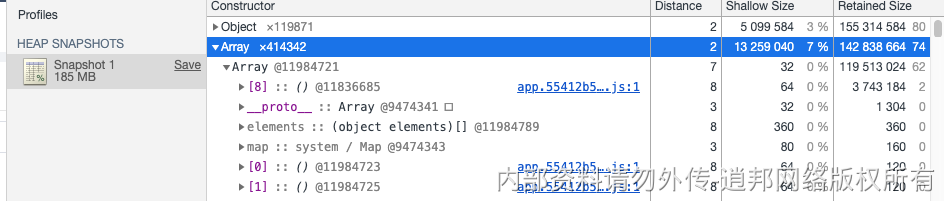
#### 2.图表中心来回切换不同图表,会有内存增加情况
可能原因:
1. 页面中有添加自定义的监听事件,但是销毁时没有移除事件
2. echarts在组件销毁的时候可能没有清除引用,组件销毁时需要调用dispose销毁实例
关于内存泄漏的排查方法可参考下面的文章:
1. https://zhuanlan.zhihu.com/p/26269860
2. https://zhuanlan.zhihu.com/p/67843006
3. https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Memory_Management | 915 | MIT |
<div class="mp-cu-doc-view">
<div class="mp-cu-doc">
# 输入框 ui-input
由于input等相关组件的参数太多,涉及的组件也多,封装的时候,考虑到各种场景和业务逻辑,所以,目前的输入框,并不是完整封装的,只是封装了个form的容器,提供一些样式,仅此而已,后期看情况再决定是否重新完整封装。
```json
"usingComponents": {
"ui-form" : "/mp-cu/colorUI/components/ui-form/ui-form",
"ui-form-group" : "/mp-cu/colorUI/components/ui-form-group/ui-form-group",
"ui-input-box" : "/mp-cu/colorUI/components/ui-input-box/ui-input-box"
}
```
## 基础用法
```html
<ui-form-group title="文本">
<ui-input-box>
<input class="ui-input-wrapper" placeholder="请输入文本"/>
</ui-input-box>
</ui-form-group>
```
## 自定义类型
```html
<ui-form ui="ui-BG">
<!-- 输入任意文本 -->
<ui-form-group title="文本">
<ui-input-box>
<input class="ui-input-wrapper" placeholder="请输入文本"/>
</ui-input-box>
</ui-form-group>
<!-- 带小数点的数字键盘 -->
<ui-form-group title="整数">
<ui-input-box>
<input class="ui-input-wrapper" type="digit" placeholder="请输入整数"/>
</ui-input-box>
</ui-form-group>
<!-- 数字输入键盘 -->
<ui-form-group title="数字">
<ui-input-box>
<input class="ui-input-wrapper" type="number" placeholder="请输入数字"/>
</ui-input-box>
</ui-form-group>
<!-- 输入密码 -->
<ui-form-group title="密码">
<ui-input-box isType="password">
<input class="ui-input-wrapper" type="password" placeholder="请输入密码"/>
</ui-input-box>
</ui-form-group>
</ui-form>
```
## 禁用输入框
```html
<ui-form ui="ui-BG">
<ui-form-group title="文本" disabled>
<ui-input-box isDisabled>
<input class="ui-input-wrapper" disabled placeholder="请输入文本"/>
</ui-input-box>
</ui-form-group>
</ui-form>
```
## 显示图标
```html
<ui-form ui="ui-BG">
<ui-form-group title="图标" icon="cicon-safe-check">
<ui-input-box>
<input class="ui-input-wrapper" placeholder="请输入文本"/>
</ui-input-box>
</ui-form-group>
<ui-form-group icon="cicon-safe-check">
<ui-input-box>
<input class="ui-input-wrapper" placeholder="请输入文本"/>
</ui-input-box>
</ui-form-group>
<ui-form-group title="图标" isAction>
<ui-input-box>
<input class="ui-input-wrapper" placeholder="请输入文本"/>
</ui-input-box>
<block slot="action">
<text class="cicon-place icon-xl"/>
</block>
</ui-form-group>
</ui-form>
```
## 必填项
```html
<ui-form ui="ui-BG">
<ui-form-group required icon="cicon-mobile" type="phone">
<ui-input-box>
<input class="ui-input-wrapper" placeholder="请输入手机号"/>
</ui-input-box>
</ui-form-group>
</ui-form>
```
## 插槽
```html
<ui-form ui="ui-BG">
<ui-form-group title="短信验证" isAction>
<ui-input-box>
<input class="ui-input-wrapper" placeholder="请输入短信验证码"/>
</ui-input-box>
<view slot="action">
<button class="ui-btn bg-blue-gradient sm">发送验证码</button>
</view>
</ui-form-group>
</ui-form>
```
## 文本域
```html
<ui-form ui="ui-BG mt-4">
<ui-form-group title="高度自适应" titleTop>
<ui-input-box isType="textarea">
<textarea class="ui-textarea-wrapper" placeholder="请输入用户名" maxlength="140" auto-height/>
</ui-input-box>
</ui-form-group>
</ui-form>
```
## 显示字数统计
```html
<ui-form ui="ui-BG mt-4">
<ui-form-group title="显示字数统计" titleTop>
<ui-input-box isType="textarea" showTag>
<textarea class="ui-textarea-wrapper" placeholder="请输入用户名" maxlength="50" auto-height/>
</ui-input-box>
</ui-form-group>
</ui-form>
```
## 内容对齐
```html
<ui-form-group title="右对齐">
<ui-input-box ui="text-right">
<input class="ui-input-wrapper" placeholder="输入框内容右对齐"/>
</ui-input-box>
</ui-form-group>
<ui-form-group title="居中">
<ui-input-box ui="text-center">
<input class="ui-input-wrapper" placeholder="输入框内容居中"/>
</ui-input-box>
</ui-form-group>
```
## 组
```html
<ui-form ui="ui-BG mt-4">
<ui-form-group icon="cicon-avatar">
<ui-input-box>
<input class="ui-input-wrapper" placeholder="请输入用户名"/>
</ui-input-box>
</ui-form-group>
<ui-form-group icon="cicon-mobile" required>
<ui-input-box>
<input class="ui-input-wrapper" type="number" placeholder="请输入手机号"/>
</ui-input-box>
</ui-form-group>
<ui-form-group icon="cicon-lock" required>
<ui-input-box isType="password">
<input class="ui-input-wrapper" type="password" placeholder="请输入密码" name="password"/>
</ui-input-box>
</ui-form-group>
<ui-form-group icon="cicon-numcode" isAction>
<ui-input-box>
<input class="ui-input-wrapper" placeholder="请输入验证码"/>
</ui-input-box>
<view slot="action">
<button class="ui-btn bg-blue-gradient sm">发送验证码</button>
</view>
</ui-form-group>
</ui-form>
```
## 参数
### ui-form
| 参数 | 类型 | 可选值 | 默认值 | 说明 |
|----------|----------|----------|----------|----------|
| ui | String | - | - | 其它class样式 |
### ui-form-group
| 参数 | 类型 | 可选值 | 默认值 | 说明 |
|----------|----------|----------|----------|----------|
| ui | String | - | - | 其它class样式 |
| contentui | String | - | - | 内容区自定义class |
| icon | String | - | - | 图标class |
| disabled | Boolean | - | false | 禁用 |
| required | Boolean | - | false | 必填项 |
| titleTop | Boolean | - | false | 高度自适应 |
| title | String | - | - | 标题 |
| isAction | Boolean | - | false | 右边插槽 |
### ui-input-box
| 参数 | 类型 | 可选值 | 默认值 | 说明 |
|----------|----------|----------|----------|----------|
| ui | String | - | - | 其它class样式 |
| isType | String | text/textarea/password | text | 类型 |
| value | String/Number | - | - | 内容 |
| showTag | Boolean | - | false | 显示统计,textarea下有效 |
| maxlength | Number/String | - | 140 | 字数 |
| clear | Boolean | - | false | 可否清空 |
| isDisabled | Boolean | - | false | 禁用 |
| bind:clear | Event | - | - | 清空事件 |
| bind:visible | Event | true,false | - | 显示/隐藏事件 |
## 插槽
### ui-form-group
| 参数 | 说明 |
|----------|----------|
| 默认 | 默认插槽 |
| action | 右边插槽 |
</div>
<div class="mp-cu-doc-image" style="max-height: inherit;">

</div>
</div> | 6,278 | MIT |
### 检查清单
🚨 在提交 PR 之前请先阅读 [贡献指南](.github/CONTRIBUTING.md)。
### 这个 PR 是否包涵一个不兼容变更? (单选)
- [ ] Yes
- [ ] No
<!-- If yes, please describe the impact and migration path for existing applications: -->
<!-- 如果是, 请描述对现有应用程序的影响以及迁移方法: -->
### 这个 PR 的性质? (单选)
- [ ] Bugfix
- [ ] Feature
- [ ] Docs Update
- [ ] Code Style Update
- [ ] Refactor
- [ ] Performance Improvements
- [ ] Build-related changes
- [ ] Other, please describe:
### 请求合并前的自查清单
- [ ] 确保你的 PR 请求是由 **feature/bugfix** 分支 (右侧). 发起的 **_而不是 master_!**
- [ ] 确保你的 PR 请求是以 **main** 分支 (左侧) 为目标的.
- [ ] 确保你的 commit messages 符合我们的[规范](https://docs.edge.lianhe.art/styleguide/git-guide.html#commit-message-%E7%9A%84%E6%A0%BC%E5%BC%8F)要求
- [ ] 确保所有的变更已经通过 CI 测试
### 描述
Please describe your pull request.
❤️ Thank you! | 783 | Apache-2.0 |
---
layout: wiki
title: Markdown
categories: Markdown
description: Markdown 常用语法示例
keywords: Markdown
---
外部参考: [MD简明教程](https://ouweiya.gitbooks.io/markdown/index.html)
-------------------------------------------
<!-- TOC depthFrom:1 depthTo:6 withLinks:1 updateOnSave:1 orderedList:0 -->
- [常用篇](#常用篇)
- [分级标题](#分级标题)
- [文字修饰(斜体/加粗)](#文字修饰斜体加粗)
- [无序列表](#无序列表)
- [有序列表](#有序列表)
- [链接](#链接)
- [内嵌图片](#内嵌图片)
- [引用块](#引用块)
- [代码](#代码)
<!-- /TOC -->
------------------------------------
# 常用篇
## 分级标题
> #\~###### h1\~h6
> 注:标题只有6个等级,#后面有空格
> 示例:
>
> # h1
> ## h2
> ### h3
> #### h4
> ##### h5
> ###### h6
> ####### h7(错误代码)
## 文字修饰(斜体/加粗)
> 使用 \* 和 \*\* 表示斜体和加粗。
> 示例:
> 这是*斜体*, 这是**加粗**。
> 使用<u\></u\> 处理下划线
> 示例:
> 这是<u>下划线</u>测试
## 无序列表
> 使用 \* + -表示无序列表
> 示例:
>
> * 无序表项一
> * 无序表项二
> * 无序表项三
> ## 有序列表
> 使用数组和点表示
> 示例:
>
> 1. 有序表项一
> 2. 有序表项二
> 3. 有序表项三
## 链接
> 内链式:
> 使用 \[描述\]\(链接地址\) 为文字增加外链接。链接到同样主机的资源,可以使用相对路径\[about\]\(about.md\).
> 示例:
> [baidu](https://www.baidu.com)
> [baidu2](3)
[3]:https://www.baidu.com
## 内嵌图片
> 使用 \!\[描述\]\(图片链接地址\) 插入图像。
> 示例:
> 
## 引用块
> 使用 \> 符号 表示引用,\>\> 表示多层嵌套
> 示例:
>
> > > > 一行
> > > > 两行(多行时,可以省略引用符号)
>
> > > 多层嵌套
## 代码
> * 单行标记
> 使用 \` 标记单行代码块
> 示例: 这是`hello world`
> 使用 \`\`\` 标记多行代码块
> 多行代码块示例:
```c
var num = 0;
for (var i = 0; i < 5; i++) {
num+=i;
}
console.log(num);
```
## TODO列表
使用带有- [ ] 或 - [x] (未完成或已完成)项的列表语法撰写一个待办事宜列表.
示例:
- [ ] todo1
- [x] todo2
## 表格
* 居左:“:---”
* 居中:“:---:”
* 居右:“---:”
| 姓名 | 性别 | 年龄 |
|:---:|:---:|---|
| li | boy |24 | | 1,579 | MIT |
---
title: 对数据排序 (C#)
ms.date: 07/20/2015
ms.assetid: d93fa055-2f19-46d2-9898-e2aed628f1c9
ms.openlocfilehash: bceb599d9e8eb3c51c07526b9ad22d3d4206efdd
ms.sourcegitcommit: 16aefeb2d265e69c0d80967580365fabf0c5d39a
ms.translationtype: HT
ms.contentlocale: zh-CN
ms.lasthandoff: 03/18/2019
ms.locfileid: "58125715"
---
# <a name="sorting-data-c"></a>对数据排序 (C#)
排序操作基于一个或多个属性对序列的元素进行排序。 第一个排序条件对元素执行主要排序。 通过指定第二个排序条件,您可以对每个主要排序组内的元素进行排序。
下图展示了对一系列字符执行按字母顺序排序操作的结果。

下节列出了对数据进行排序的标准查询运算符方法。
## <a name="methods"></a>方法
|方法名|说明|C# 查询表达式语法|详细信息|
|-----------------|-----------------|---------------------------------|----------------------|
|OrderBy|按升序对值排序。|`orderby`|<xref:System.Linq.Enumerable.OrderBy%2A?displayProperty=nameWithType><br /><br /> <xref:System.Linq.Queryable.OrderBy%2A?displayProperty=nameWithType>|
|OrderByDescending|按降序对值排序。|`orderby … descending`|<xref:System.Linq.Enumerable.OrderByDescending%2A?displayProperty=nameWithType><br /><br /> <xref:System.Linq.Queryable.OrderByDescending%2A?displayProperty=nameWithType>|
|ThenBy|按升序执行次要排序。|`orderby …, …`|<xref:System.Linq.Enumerable.ThenBy%2A?displayProperty=nameWithType><br /><br /> <xref:System.Linq.Queryable.ThenBy%2A?displayProperty=nameWithType>|
|ThenByDescending|按降序执行次要排序。|`orderby …, … descending`|<xref:System.Linq.Enumerable.ThenByDescending%2A?displayProperty=nameWithType><br /><br /> <xref:System.Linq.Queryable.ThenByDescending%2A?displayProperty=nameWithType>|
|Reverse|反转集合中元素的顺序。|不适用。|<xref:System.Linq.Enumerable.Reverse%2A?displayProperty=nameWithType><br /><br /> <xref:System.Linq.Queryable.Reverse%2A?displayProperty=nameWithType>|
## <a name="query-expression-syntax-examples"></a>查询表达式语法示例
### <a name="primary-sort-examples"></a>主要排序示例
#### <a name="primary-ascending-sort"></a>主要升序排序
下面的示例演示如何在 LINQ 查询中使用 `orderby` 子句按字符串长度对数组中的字符串进行升序排序。
```csharp
string[] words = { "the", "quick", "brown", "fox", "jumps" };
IEnumerable<string> query = from word in words
orderby word.Length
select word;
foreach (string str in query)
Console.WriteLine(str);
/* This code produces the following output:
the
fox
quick
brown
jumps
*/
```
#### <a name="primary-descending-sort"></a>主要降序排序
下面的示例演示如何在 LINQ 查询中使用 `orderby descending` 子句按字符串的第一个字母对字符串进行降序排序。
```csharp
string[] words = { "the", "quick", "brown", "fox", "jumps" };
IEnumerable<string> query = from word in words
orderby word.Substring(0, 1) descending
select word;
foreach (string str in query)
Console.WriteLine(str);
/* This code produces the following output:
the
quick
jumps
fox
brown
*/
```
### <a name="secondary-sort-examples"></a>次要排序示例
#### <a name="secondary-ascending-sort"></a>次要升序排序
下面的示例演示如何在 LINQ 查询中使用 `orderby` 子句对数组中的字符串执行主要和次要排序。 首先按字符串长度,其次按字符串的第一个字母,对字符串进行升序排序。
```csharp
string[] words = { "the", "quick", "brown", "fox", "jumps" };
IEnumerable<string> query = from word in words
orderby word.Length, word.Substring(0, 1)
select word;
foreach (string str in query)
Console.WriteLine(str);
/* This code produces the following output:
fox
the
brown
jumps
quick
*/
```
#### <a name="secondary-descending-sort"></a>次要降序排序
下面的示例演示如何在 LINQ 查询中使用 `orderby descending` 子句按升序执行主要排序,按降序执行次要排序。 首先按字符串长度,其次按字符串的第一个字母,对字符串进行排序。
```csharp
string[] words = { "the", "quick", "brown", "fox", "jumps" };
IEnumerable<string> query = from word in words
orderby word.Length, word.Substring(0, 1) descending
select word;
foreach (string str in query)
Console.WriteLine(str);
/* This code produces the following output:
the
fox
quick
jumps
brown
*/
```
## <a name="see-also"></a>请参阅
- <xref:System.Linq>
- [标准查询运算符概述 (C#)](../../../../csharp/programming-guide/concepts/linq/standard-query-operators-overview.md)
- [orderby 子句](../../../../csharp/language-reference/keywords/orderby-clause.md)
- [如何:对 join 子句的结果进行排序](../../../../csharp/programming-guide/linq-query-expressions/how-to-order-the-results-of-a-join-clause.md)
- [如何:按任意词或字段对文本数据进行排序或筛选 (LINQ) (C#)](../../../../csharp/programming-guide/concepts/linq/how-to-sort-or-filter-text-data-by-any-word-or-field-linq.md) | 4,682 | CC-BY-4.0 |
---
title: 表单 input 绑定
type: guide
order: 10
---
## 基础用法
可以通过使用 `v-model` 指令,在表单 input, textarea 和 select 元素上创建双向数据绑定。`v-model` 指令可以根据 input 的 type 类型,自动地以正确的方式更新元素。虽然略显神奇,然而本质上 `v-model` 不过是「通过监听用户的 input 事件来更新数据」的语法糖,以及对一些边界情况做特殊处理。
<p class="tip">`v-model` 会忽略所有表单元素中 `value`, `checked` 或 `selected` 属性上初始设置的值,而总是将 Vue 实例中的 data 作为真实数据来源。因此你应该在 JavaScript 端的组件 `data` 选项中声明这些初始值,而不是 HTML 端。</p>
<p class="tip" id="vmodel-ime-tip">对于需要使用[输入法](https://zh.wikipedia.org/wiki/%E8%BE%93%E5%85%A5%E6%B3%95)的语言(中文、日文、韩文等),你会发现,在输入法字母组合窗口输入时,`v-model` 并不会触发数据更新。如果你想在此输入过程中,满足更新数据的需求,请使用 `input` 事件。</p>
### 单行文本(text)
``` html
<input v-model="message" placeholder="编辑">
<p>message 是:{{ message }}</p>
```
{% raw %}
<div id="example-1" class="demo">
<input v-model="message" placeholder="编辑">
<p>message 是:{{ message }}</p>
</div>
<script>
new Vue({
el: '#example-1',
data: {
message: ''
}
})
</script>
{% endraw %}
### 多行文本(multiple text)
``` html
<span>多行 message 是:</span>
<p style="white-space: pre-line;">{{ message }}</p>
<br>
<textarea v-model="message" placeholder="添加多行"></textarea>
```
{% raw %}
<div id="example-textarea" class="demo">
<span>多行 message 是:</span>
<p style="white-space: pre-line;">{{ message }}</p>
<br>
<textarea v-model="message" placeholder="添加多行"></textarea>
</div>
<script>
new Vue({
el: '#example-textarea',
data: {
message: ''
}
})
</script>
{% endraw %}
{% raw %}
<p class="tip">在 textarea 中插值(<code><textarea>{{text}}</textarea></code>)并不会生效。使用 <code>v-model</code> 来替代。</p>
{% endraw %}
### checkbox
单选 checkbox,绑定到布尔值:
``` html
<input type="checkbox" id="checkbox" v-model="checked">
<label for="checkbox">{{ checked }}</label>
```
{% raw %}
<div id="example-2" class="demo">
<input type="checkbox" id="checkbox" v-model="checked">
<label for="checkbox">{{ checked }}</label>
</div>
<script>
new Vue({
el: '#example-2',
data: {
checked: false
}
})
</script>
{% endraw %}
多选 checkbox,绑定到同一个数组:
``` html
<div id='example-3'>
<input type="checkbox" id="jack" value="Jack" v-model="checkedNames">
<label for="jack">Jack</label>
<input type="checkbox" id="john" value="John" v-model="checkedNames">
<label for="john">John</label>
<input type="checkbox" id="mike" value="Mike" v-model="checkedNames">
<label for="mike">Mike</label>
<br>
<span>勾选的名字是:{{ checkedNames }}</span>
</div>
```
``` js
new Vue({
el: '#example-3',
data: {
checkedNames: []
}
})
```
{% raw %}
<div id="example-3" class="demo">
<input type="checkbox" id="jack" value="Jack" v-model="checkedNames">
<label for="jack">Jack</label>
<input type="checkbox" id="john" value="John" v-model="checkedNames">
<label for="john">John</label>
<input type="checkbox" id="mike" value="Mike" v-model="checkedNames">
<label for="mike">Mike</label>
<br>
<span>勾选的名字是:{{ checkedNames }}</span>
</div>
<script>
new Vue({
el: '#example-3',
data: {
checkedNames: []
}
})
</script>
{% endraw %}
### radio
``` html
<input type="radio" id="one" value="One" v-model="picked">
<label for="one">One</label>
<br>
<input type="radio" id="two" value="Two" v-model="picked">
<label for="two">Two</label>
<br>
<span>选中的是:{{ picked }}</span>
```
{% raw %}
<div id="example-4" class="demo">
<input type="radio" id="one" value="One" v-model="picked">
<label for="one">One</label>
<br>
<input type="radio" id="two" value="Two" v-model="picked">
<label for="two">Two</label>
<br>
<span>选中的是:{{ picked }}</span>
</div>
<script>
new Vue({
el: '#example-4',
data: {
picked: ''
}
})
</script>
{% endraw %}
### select
单选 select:
``` html
<select v-model="selected">
<option disabled value="">请选择其中一项</option>
<option>A</option>
<option>B</option>
<option>C</option>
</select>
<span>选中的是:{{ selected }}</span>
```
``` js
new Vue({
el: '...',
data: {
selected: ''
}
})
```
{% raw %}
<div id="example-5" class="demo">
<select v-model="selected">
<option disabled value="">请选择其中一项</option>
<option>A</option>
<option>B</option>
<option>C</option>
</select>
<span>选中的是:{{ selected }}</span>
</div>
<script>
new Vue({
el: '#example-5',
data: {
selected: ''
}
})
</script>
{% endraw %}
<p class="tip">如果 `v-model` 表达式的初始值,不能与任何 option 选项匹配,`<select>` 元素将会渲染为“未选中”状态。在 iOS 中,这会导致用户无法选中第一项,因为在这种“未选中”状态的情况下,iOS 不会触发 change 事件。因此,推荐按照上面的示例,预先提供一个 value 为空字符串的禁用状态的 option 选项。</p>
多选 select(绑定到一个数组):
``` html
<select v-model="selected" multiple>
<option>A</option>
<option>B</option>
<option>C</option>
</select>
<br>
<span>选中的是:{{ selected }}</span>
```
{% raw %}
<div id="example-6" class="demo">
<select v-model="selected" multiple style="width: 50px;">
<option>A</option>
<option>B</option>
<option>C</option>
</select>
<br>
<span>选中的是:{{ selected }}</span>
</div>
<script>
new Vue({
el: '#example-6',
data: {
selected: []
}
})
</script>
{% endraw %}
使用 `v-for` 渲染动态的 option:
``` html
<select v-model="selected">
<option v-for="option in options" v-bind:value="option.value">
{{ option.text }}
</option>
</select>
<span>选中的是:{{ selected }}</span>
```
``` js
new Vue({
el: '...',
data: {
selected: 'A',
options: [
{ text: 'One', value: 'A' },
{ text: 'Two', value: 'B' },
{ text: 'Three', value: 'C' }
]
}
})
```
{% raw %}
<div id="example-7" class="demo">
<select v-model="selected">
<option v-for="option in options" v-bind:value="option.value">
{{ option.text }}
</option>
</select>
<span>选中的是:{{ selected }}</span>
</div>
<script>
new Vue({
el: '#example-7',
data: {
selected: 'A',
options: [
{ text: 'One', value: 'A' },
{ text: 'Two', value: 'B' },
{ text: 'Three', value: 'C' }
]
}
})
</script>
{% endraw %}
## 与 value 属性绑定
对于 radio, checkbox 和 select 的 option 选项,通常可以将 `v-model` 与值是静态字符串的 value 属性关联在一起(或者,在 checkbox 中,绑定到布尔值):
``` html
<!-- 当选中时,`picked` 的值是字符串 "a"(译者注:如果没有 value 属性,选中时值是 null) -->
<input type="radio" v-model="picked" value="a">
<!-- `toggle` 的值是 true 或 false -->
<input type="checkbox" v-model="toggle">
<!-- 当选中第一个选项时,`selected` 的值是字符串 "abc"(译者注:如果没有 value 属性,选中时 selected 值是 option 元素内的文本) -->
<select v-model="selected">
<option value="abc">ABC</option>
</select>
```
然而,有时可能需要把 value 与 Vue 实例上的一个动态属性绑定在一起。这时我们可以通过 `v-bind` 来实现。`v-bind` 还允许我们将 input 元素的值绑定到非字符串值。
### checkbox
``` html
<input
type="checkbox"
v-model="toggle"
true-value="yes"
false-value="no"
>
```
``` js
// 选中时:
vm.toggle === 'yes'
// 没有选中时:
vm.toggle === 'no'
```
<p class="tip">`true-value` 和 `false-value` 属性不会影响到 input 元素的 `value` 属性,这是因为浏览器在提交表单时,并不会包含未被选中的 checkbox 的值。如果要确保表单中,这两个值的一个能够被提交(例如 "yes" 或 "no"),请换用类型是 radio 的 input 元素。</p>
### radio
``` html
<input type="radio" v-model="pick" v-bind:value="a">
```
``` js
// 选中时
vm.pick === vm.a
```
### select 选项
``` html
<select v-model="selected">
<!-- 内联对象字面量 -->
<option v-bind:value="{ number: 123 }">123</option>
</select>
```
``` js
// 选中时:
typeof vm.selected // => 'object'
vm.selected.number // => 123
```
## 修饰符(modifiers)
### `.lazy`
默认情况下,`v-model` 会在每次 `input` 事件触发之后,将数据同步至 input 元素中(除了[上述](#vmodel-ime-tip)提到的输入法组合文字时不会)。可以添加 `lazy` 修饰符,从而转为在触发 `change` 事件后同步:
``` html
<!-- 在触发 "change" 事件后同步,而不是在触发 "input" 事件后更新 -->
<input v-model.lazy="msg" >
```
### `.number`
如果想要将用户的输入,自动转换为 Number 类型(译注:如果转换结果为 NaN 则返回字符串类型的输入值),可以在 `v-model` 之后添加一个 `number` 修饰符,来处理输入值:
``` html
<input v-model.number="age" type="number">
```
这通常很有用,因为即使是在 `type="number"` 时,HTML 中 input 元素也总是返回一个字符串类型的值。
### `.trim`
如果想要将用户的输入,自动过滤掉首尾空格,可以在 `v-model` 之后添加一个 `trim` 修饰符,来处理输入值:
```html
<input v-model.trim="msg">
```
## 在组件上使用 `v-model`
> 如果你还不熟悉 Vue 组件,现在先跳过此处。
HTML 内置的几种 input 类型有时并不总能满足需求。幸运的是,使用 Vue 可以创建出可复用的输入框组件,并且能够完全自定义组件的行为。这些输入框组件甚至可以使用 `v-model`!想要了解更多信息,请阅读组件指南中 [自定义输入框](components.html#在组件中使用-v-model)。 | 7,909 | CC-BY-4.0 |
---
title: include 文件
description: include 文件
services: service-bus-messaging
author: spelluru
ms.service: service-bus-messaging
ms.topic: include
ms.date: 02/20/2019
ms.author: spelluru
ms.custom: include file
ms.openlocfilehash: dc80141d796b66dd7e610342166f7b88df58f530
ms.sourcegitcommit: 849bb1729b89d075eed579aa36395bf4d29f3bd9
ms.translationtype: HT
ms.contentlocale: zh-CN
ms.lasthandoff: 04/28/2020
ms.locfileid: "75928229"
---
## <a name="create-a-namespace-in-the-azure-portal"></a>在 Azure 门户中创建命名空间
若要开始在 Azure 中使用服务总线消息实体,必须先使用在 Azure 中唯一的名称创建一个命名空间。 命名空间提供了用于对应用程序中的 Service Bus 资源进行寻址的范围容器。
创建命名空间:
1. 登录到 [Azure 门户](https://portal.azure.com)
2. 在门户的左侧导航窗格中,依次选择“+ 创建资源”、“集成”、“服务总线” 。

3. 在“创建命名空间”对话框中执行以下步骤 :
1. 输入**命名空间的名称**。 系统会立即检查该名称是否可用。 若需用于对命名空间进行命名的规则的列表,请参阅[创建命名空间 REST API](/rest/api/servicebus/create-namespace)。
2. 选择命名空间的定价层(“基本”、“标准”或“高级”)。 若要使用[主题和订阅](../articles/service-bus-messaging/service-bus-queues-topics-subscriptions.md#topics-and-subscriptions),请选择“标准”或“高级”。 基本定价层中不支持主题/订阅。
3. 如果选择了“高级”定价层,请执行以下步骤:
1. 指定**消息传送单元**的数目。 高级层在 CPU 和内存级别提供资源隔离,使每个工作负荷在隔离的环境中运行。 此资源容器称为消息传送单元。 高级命名空间至少具有一个消息传送单元。 可为每个服务总线高级命名空间选择 1、2 或 4 个消息传送单元。 有关详细信息,请参阅[服务总线高级消息传送](../articles/service-bus-messaging/service-bus-premium-messaging.md)。
2. 指定是否要将命名空间设为**区域冗余**。 区域冗余通过在一个区域中的所有可用性区域之间分散副本来提供增强的可用性。 有关详细信息,请参阅 [Azure 中的可用性区域](../articles/availability-zones/az-overview.md)。
4. 对于“订阅”,请选择要在其中创建命名空间的 Azure 订阅。
5. 对于“资源组”,请选择该命名空间驻留到的现有资源组,或创建一个新资源组。
6. 对于“位置”,请选择托管该命名空间的区域。
7. 选择“创建” 。 系统现已创建命名空间并已将其启用。 可能需要等待几分钟,因为系统将为帐户配置资源。

4. 确认是否已成功部署服务总线命名空间。 若要查看通知,请在工具栏上选择**钟形图标(警报)** 。 如下图所示,在通知中选择**资源组的名称**。 将会看到包含服务总线命名空间的资源组。

5. 在资源组的“资源组”页上,选择你的**服务总线命名空间**。

6. 将会看到服务总线命名空间的主页。

## <a name="get-the-connection-string"></a>获取连接字符串
创建新的命名空间时,会自动生成一项初始的共享访问签名 (SAS) 规则,将一对主密钥和辅助密钥关联到一起,向每个密钥授予对命名空间的所有资产的完全控制权限。 请参阅[服务总线身份验证和授权](../articles/service-bus-messaging/service-bus-authentication-and-authorization.md),了解如何创建规则来对普通发送者和接收者的权限进行更多限制。 若要复制命名空间的主要密钥和辅助密钥,请执行以下步骤:
1. 单击“所有资源”,然后单击新创建的命名空间名称。
2. 在命名空间窗口中,单击“共享访问策略” 。
3. 在“共享访问策略” 屏幕中,单击“RootManageSharedAccessKey” 。

4. 在“策略: RootManageSharedAccessKey”窗口中,单击“主连接字符串”旁边的复制按钮,将连接字符串复制到剪贴板供稍后使用 。 将此值粘贴到记事本或其他某个临时位置。

5. 重复上述步骤,将**主键**的值复制和粘贴到临时位置,以供将来使用。
<!--Image references--> | 3,006 | CC-BY-4.0 |
<!-- title: 服务; order: 10 -->
# 基本概念
`Service` 类是 **SFN** 框架中的基本类,其他类如 `HttpController`、
`WebSocketController` 都继承自它。它提供了一些有用的特性,如 `i18n`、`logger`、
`cache` 等,能够让你用来做真正的事情。
## 如何使用?
`Service` 类,继承自 `EventEmitter`,用法也相同,你可以定义一个新的类来扩展服务,
或者直接使用它。为了方便,你应该将你的服务文件存储在 `src/service/` 目录下。
### 示例
#### 直接使用 Service
```typescript
import { Service } from "sfn";
import { User } from "modelar";
var srv = new Service;
(async (id: number) => {
try {
let user = <User>await User.use(srv.db).get(id);
srv.logger.log(`Getting user (id: ${id}, name: ${user.name}) succeed.`);
// ...
} catch (e) {
srv.logger.error(`Getting user (id: ${id}) failed: ${e.message}.`);
}
})(1);
```
#### 定义一个新的服务类
你可以定义一个新的服务类来存储一些常用功能的执行过程。
```typescript
import { Service } from "sfn";
import { User } from "modelar";
export class MyService extends Service {
async getUser(id: number): User {
let user: User = null;
try {
let data = this.cache.get(`user[${id}]`);
if (data) {
user = (new User).assign(data);
} else {
user = <User>await User.use(this.db).get(id);
this.cache.set(`user.${id}`, user.data);
}
this.logger.log(`Getting user (id: ${id}, name: ${user.name}) succeed.`);
} catch (err) {
this.logger.error(`Getting user (id: ${id}) failed: ${err.message}.`);
}
return user;
}
}
let srv = new MyService;
(async () => {
let user = await srv.getUser(1);
// ...
})();
``` | 1,578 | MIT |
---
title: 使用门户创建 Azure 共享映像库
description: 了解如何使用 Azure 门户创建和共享虚拟机映像。
ms.service: virtual-machines-windows
ms.subservice: imaging
ms.topic: how-to
ms.workload: infrastructure
author: rockboyfor
ms.date: 11/02/2020
ms.testscope: yes
ms.testdate: 11/02/2020
ms.author: v-yeche
ms.openlocfilehash: 66040baf93c27e3274cad0e8cd463d2511bd8552
ms.sourcegitcommit: 93309cd649b17b3312b3b52cd9ad1de6f3542beb
ms.translationtype: HT
ms.contentlocale: zh-CN
ms.lasthandoff: 10/30/2020
ms.locfileid: "93103600"
---
# <a name="create-an-azure-shared-image-gallery-using-the-portal"></a>使用门户创建 Azure 共享映像库
[共享映像库](shared-image-galleries.md)大大简化了整个组织中的自定义映像共享。 自定义映像类似于市场映像,不同的是自定义映像的创建者是自己。 自定义映像可用于启动部署任务,例如预加载应用程序、应用程序配置和其他 OS 配置。
使用共享映像库,你可以在 AAD 租户内在同一区域或跨区域与组织中的其他用户共享自定义 VM 映像。 选择要共享哪些映像,要在哪些区域中共享,以及希望与谁共享它们。 你可以创建多个库,以便可以按逻辑方式对共享映像进行分组。
库是顶级资源,它提供完全基于角色的访问控制 (RBAC)。 你可以控制映像的版本,并且可以选择将每个映像版本复制到一组不同的 Azure 区域。 库仅适用于托管映像。
共享映像库功能具有多种资源类型。 我们将在本文中使用或生成这些资源类型:
[!INCLUDE [virtual-machines-shared-image-gallery-resources](../../../includes/virtual-machines-shared-image-gallery-resources.md)]
<br />
通过本文进行操作时,请根据需要替换资源组和 VM 名称。
[!INCLUDE [virtual-machines-common-shared-images-portal](../../../includes/virtual-machines-common-shared-images-portal.md)]
## <a name="create-vms"></a>创建 VM
现在,可以创建一个或多个新的 VM。 本示例在“中国东部”数据中心的 *myResourceGroup* 中创建名为 *myVM* 的 VM。
1. 转到映像定义。 可以使用资源筛选器显示所有可用的映像定义。
1. 在映像定义的页面顶部,从菜单中选择“创建 VM”。
1. 对于“资源组”,请选择“新建”并键入
1. 在“虚拟机名称”中键入
1. 对于“区域”,请选择“中国东部”。
1. 对于“可用性选项”,请保留默认设置“无需基础结构冗余”。
1. 如果你是从映像定义的页面开始操作的,系统会自动使用 `latest` 映像版本填充“映像”的值。
1. 对于“大小”,请从可用大小列表中选择一种 VM 大小,然后选择“选择”。
1. 在“管理员帐户” 下,如果映像已通用化,则需提供用户名(例如 *azureuser* )和密码。 密码必须至少 12 个字符长,且符合[定义的复杂性要求](faq.md#what-are-the-password-requirements-when-creating-a-vm)。 如果映像已专用化,则用户名和密码字段会灰显,因为使用的是源 VM 的用户名和密码。
1. 若要允许远程访问 VM,请在“公共入站端口”下选择“允许所选端口”,然后从下拉列表中选择“RDP (3389)”。 如果你不希望允许远程访问 VM,请为“公共入站端口”保留选择“无”。
1. 完成后,选择页面底部的“查看 + 创建”按钮。
1. VM 通过验证后,选择页面底部的“创建”以开始部署。
## <a name="clean-up-resources"></a>清理资源
当不再需要时,可以删除资源组、虚拟机和所有相关资源。 为此,请选择虚拟机的资源组,选择“删除”,然后确认要删除的资源组的名称。
若要删除单个资源,需要按相反的顺序删除。 例如,若要删除某个映像定义,需要先删除基于该映像创建的所有映像版本。
## <a name="next-steps"></a>后续步骤
此外可以使用模板创建共享映像库资源。 提供多个 Azure 快速入门模板:
- [创建共享映像库](https://azure.microsoft.com/resources/templates/101-sig-create/)
- [在共享的映像库中创建映像定义](https://azure.microsoft.com/resources/templates/101-sig-image-definition-create/)
- [在共享映像库中创建映像版本](https://azure.microsoft.com/resources/templates/101-sig-image-version-create/)
- [根据映像版本创建 VM](https://azure.microsoft.com/resources/templates/101-vm-from-sig/)
有关共享映像库的详细信息,请参阅[概述](shared-image-galleries.md)。 如果遇到问题,请参阅[排查共享映像库问题](../troubleshooting-shared-images.md)。
<!-- Update_Description: update meta properties, wording update, update link --> | 2,749 | CC-BY-4.0 |
# 实现频道删除
## 实现删除频道的功能
::: tip 目标
这一小节,我们的目标是实现删除频道的功能
:::
::: warning 步骤
1. 在 `Home`组件的`data` 节点下声明布尔值 `isDel`,来控制当前是否处于删除的状态
2. 点击编辑按钮的时候,切换 `isDel` 的状态
3. 根据 `isDel` 的状态,动态渲染按钮的文本和提示的文本
4. 在 `Home` 组件中,在用户的频道中渲染删除的小图标
5. 使用 `v-if` 控制图标的显示与隐藏
6. 为用户的频道 `Item` 项绑定点击事件处理函数,命名为 `onUserChannelClick`
7. 在 `methods` 中声明 `onUserChannelClick` 方法
8. 实现删除频道的功能
:::
::: info 体验
* **Step.1:在 `Home`组件的`data` 节点下声明布尔值 `isDel`,来控制当前是否处于删除的状态**
```js
data() {
return {
// 其它的数据节点...
// 频道数据是否处于删除的状态
isDel: false
}
}
```
* **Step.2:点击编辑按钮的时候,切换 `isDel` 的状态**
```html
<span class="btn-edit" @click="isDel = !isDel">编辑</span>
```
* **Step.3:根据 `isDel` 的状态,动态渲染按钮的文本和提示的文本**
```html
<div class="channel-title">
<div>
<span class="title-bold">已添加频道:</span>
<!-- 提示的文本 -->
<span class="title-gray">{{ isDel ? '点击移除频道' : '点击进入频道' }}</span>
</div>
<!-- 按钮的文本 -->
<span class="btn-edit" @click="isDel = !isDel">{{ isDel ? '完成' : '编辑' }}</span>
</div>
```
* **Step.4:在 `Home` 组件中,在用户的频道中渲染删除的小图标**
```html
<!-- 我的频道列表 -->
<van-row type="flex">
<van-col span="6" v-for="item in userChannel" :key="item.id">
<!-- 用户的频道 Item 项 -->
<div class="channel-item van-hairline--surround">
{{item.name}}
<!-- 删除的图标 -->
<van-badge color="transparent" class="cross-badge">
<template #content>
<van-icon name="cross" class="badge-icon" color="#cfcfcf" size="12" />
</template>
</van-badge>
</div>
</van-col>
</van-row>
```
* **Step.5:使用 `v-if` 控制图标的显示与隐藏**
```html
<!-- 删除的图标 -->
<van-badge color="transparent" class="cross-badge" v-if="isDel">
<!-- 省略其它代码... -->
</van-badge>
```
* **Step.6:为用户的频道 `Item` 项绑定点击事件处理函数,命名为 `onUserChannelClick`**
```html
<!-- 用户的频道 Item 项 -->
<div class="channel-item van-hairline--surround" @click="onUserChannelClick(item)"></div>
```
* **Step.7:在 `methods` 中声明 `onUserChannelClick` 方法**
```js
methods: {
// 从用户频道列表中,移除指定 id 的频道
onUserChannelClick(channel) {
if (this.isDel) {
// 处于删除状态
// TODO1:从 userChannel 中移除指定的频道
// TODO2:将更改过后的用户频道数据,提交到服务器保存
} else {
// 不处于删除状态
}
}
}
```
* **Step.8:实现删除频道的功能**
```js
methods: {
// 从用户频道列表中,移除指定 id 的频道
onUserChannelClick(channel) {
if (this.isDel) {
// 处于删除状态
// TODO1:从 userChannel 中移除指定的频道
this.userChannel = this.userChannel.filter(item => item.id !== channel.id)
// TODO2:将更改过后的用户频道数据,提交到服务器保存
this.updateChannel()
} else {
// 不处于删除状态
}
}
}
```
:::
::: danger 总结
* 【重点】
* 【难点】
* 【注意点】
:::
## 优化删除频道的功能
::: tip 目标
这一小节,我们的目标是优化删除频道
:::
::: warning 步骤
1. 如果频道的名字是“推荐”,则不渲染删除的小图标
2. 如果频道的名字是“推荐”,则点击频道的时候不执行删除的操作
3. 如果`userChannel`数组中仅剩下两个频道,则不渲染删除的小图标
4. 如果`userChannel`数组中仅剩下两个频道,则点击频道的时候不执行删除的操作
:::
::: info 体验
* **Step.1:如果频道的名字是“推荐”,则不渲染删除的小图标**
```html
<!-- 删除的图标 -->
<van-badge color="transparent" class="cross-badge" v-if="isDel && item.name !== '推荐'">
</van-badge>
```
* **Step.2:如果频道的名字是“推荐”,则点击频道的时候不执行删除的操作**
```js
// 从用户频道列表中,移除指定 id 的频道
removeChannel(channel) {
if (this.isDel) {
// 处于删除状态
// 判断用户点击的是否为“推荐”
if (channel.name === '推荐') return
// 移除频道
this.userChannel = this.userChannel.filter(item => item.id !== channel.id)
this.updateChannel()
} else {
// 不处于删除状态
}
}
```
* **Step.3:如果`userChannel`数组中仅剩下两个频道,则不渲染删除的小图标**
```html
<!-- 删除的图标 -->
<van-badge color="transparent" class="cross-badge" v-if="isDel && item.name !== '推荐' && userChannel.length > 2"></van-badge>
```
* **Step.4:如果`userChannel`数组中仅剩下两个频道,则点击频道的时候不执行删除的操作**
```js
// 从用户频道列表中,移除指定 id 的频道
removeChannel(channel) {
if (this.isDel) {
// 处于删除状态
// 判断用户点击的是否为“推荐” 或 仅剩下两个频道
if (channel.name === '推荐' || this.userChannel.length === 2) return
// 移除频道
this.userChannel = this.userChannel.filter(item => item.id !== channel.id)
this.updateChannel()
} else {
// 不处于删除状态
}
}
```
:::
::: danger 总结
* 【重点】
* 【难点】
* 【注意点】
::: | 3,953 | Apache-2.0 |
---
layout: post
title: 多线程-Join
date: 2017-07-15 19:15:10
categories: Java
tags: Java并发
keywords:
description:
---
Thread类中的join方法的主要作用就是同步,它可以使得线程之间的并行执行变为串行执行。具体看代码:
```
public class JoinTest {
public static void main(String [] args) throws InterruptedException {
ThreadJoinTest t1 = new ThreadJoinTest("A");
ThreadJoinTest t2 = new ThreadJoinTest("B");
t1.start();
/**join的意思是使得放弃当前线程的执行,并返回对应的线程,例如下面代码的意思就是:
程序在main线程中调用t1线程的join方法,则main线程放弃cpu控制权,并返回t1线程继续执行直到线程t1执行完毕
所以结果是t1线程执行完后,才到主线程执行,相当于在main线程中同步t1线程,t1执行完了,main线程才有执行的机会
*/
t1.join();
t2.start();
}
}
class ThreadJoinTest extends Thread{
public ThreadJoinTest(String name){
super(name);
}
@Override
public void run(){
for(int i=0;i<1000;i++){
System.out.println(this.getName() + ":" + i);
}
}
}
```
上面程序结果是先打印完A线程,在打印B线程;
上面注释也大概说明了join方法的作用:在A线程中调用了B线程的join()方法时,表示只有当B线程执行完毕时,A线程才能继续执行。注意,这里调用的join方法是没有传参的,join方法其实也可以传递一个参数给它的,具体看下面的简单例子:
```
public class JoinTest {
public static void main(String [] args) throws InterruptedException {
ThreadJoinTest t1 = new ThreadJoinTest("A");
ThreadJoinTest t2 = new ThreadJoinTest("B");
t1.start();
/**join方法可以传递参数,join(10)表示main线程会等待t1线程10毫秒,10毫秒过去后,
* main线程和t1线程之间执行顺序由串行执行变为普通的并行执行
*/
t1.join(10);
t2.start();
}
}
class ThreadJoinTest extends Thread{
public ThreadJoinTest(String name){
super(name);
}
@Override
public void run(){
for(int i=0;i<1000;i++){
System.out.println(this.getName() + ":" + i);
}
}
}
```
上面代码结果是:程序执行前面10毫秒内打印的都是A线程,10毫秒后,A和B程序交替打印。
所以,join方法中如果传入参数,则表示这样的意思:如果A线程中掉用B线程的join(10),则表示A线程会等待B线程执行10毫秒,10毫秒过后,A、B线程并行执行。需要注意的是,jdk规定,join(0)的意思不是A线程等待B线程0秒,而是A线程等待B线程无限时间,直到B线程执行完毕,即join(0)等价于join()。 | 1,925 | MIT |
---
title: 在 Azure 安全中心中添加 Web 应用程序防火墙 | Azure Docs
description: 本文档演示如何实现 Azure 安全中心建议“添加 web 应用程序防火墙” 和完成应用程序保护” 。
services: security-center
documentationcenter: na
author: lingliw
manager: digimobile
editor: ''
ms.assetid: 8f56139a-4466-48ac-90fb-86d002cf8242
ms.service: security-center
ms.devlang: na
ms.topic: conceptual
ms.tgt_pltfrm: na
ms.workload: na
ms.date: 5/22/2019
ms.author: v-lingwu
ms.openlocfilehash: 40cae869719d4911174545064c4077f3d9638174
ms.sourcegitcommit: 5191c30e72cbbfc65a27af7b6251f7e076ba9c88
ms.translationtype: HT
ms.contentlocale: zh-CN
ms.lasthandoff: 07/05/2019
ms.locfileid: "67569591"
---
# <a name="add-a-web-application-firewall-in-azure-security-center"></a>在 Azure 安全中心中添加 web 应用程序防火墙
为保护 web 应用程序,Azure 安全中心可能会建议从 Azure 合作伙伴添加 web 应用程序防火墙 (WAF)。 本文档将举例说明如何应用此建议。
为任何面向公众的 IP(实例级 IP 或负载均衡 IP)显示 WAF 建议,该 IP 具有与开放入站 Web 端口 (80,443) 关联的网络安全组。
安全中心建议预配 WAF,以帮助防范针对虚拟机和在[独立](https://www.azure.cn/pricing/details/app-service)服务计划下部署的外部应用服务环境 (ASE) 上 Web 应用程序的攻击。 独立计划在私有专用 Azure 环境中托管应用,对于需要与本地网络或其他性能和规模安全连接的应用而言,这是理想选择。 除应用需要处于独立环境,应用还需要有外部 IP 地址负载均衡器。
> [!NOTE]
> 本文档将使用示例部署介绍该服务。 本文档不是一份分步指南。
>
>
## <a name="implement-the-recommendation"></a>实现该建议
1. 在“建议” 下,选择“使用 web 应用程序防火墙保护 web 应用程序” 。
![保护 web 应用程序][1]
2. 在“使用 web 应用程序防火墙保护 web 应用程序” 下,选择一个 web 应用程序。 此时会打开“添加 Web 应用程序防火墙”
![添加 Web 应用程序防火墙][2]
3. 可选择使用现有的 web 应用程序防火墙(如果可用)或创建新的防火墙。 此示例中没有任何现有可用的 WAF,因此需要创建 WAF。
4. 若要创建 WAF,请从集成合作伙伴列表中选择一个解决方案。 在此示例中,选择“Barracuda Web 应用程序防火墙” 。
5. “Barracuda Web 应用程序防火墙” 会打开,提供有关该合作伙伴解决方案的信息。 选择“创建” 。
![防火墙信息边栏选项卡][3]
6. 会打开“Web 应用程序防火墙” ,可在其中执行“VM 配置” 步骤和提供“WAF 信息” 。 选择“VM 配置” 。
7. 在“VM 配置” 下输入启动要运行此 WAF 的虚拟机所需的信息。
![VM 配置][4]
8. 返回到“ Web 应用程序防火墙” ,并选择“WAF 信息” 。 在“WAF 信息” 下可对此 WAF 本身进行配置。 通过步骤 7 可对要在其上运行 WAF 的虚拟机进行配置,通过步骤 8 可对此 WAF 本身进行预配。
## <a name="finalize-application-protection"></a>完成应用程序保护
1. 返回到“建议” 。 创建此 WAF 后,会生成一个名为“完成应用程序保护” 的新条目。 通过此条目,可知道需要完成将此 WAF 连接在 Azure 虚拟网络内的过程才可使其保护此应用程序。
![完成应用程序保护][5]
2. 选择“完成应用程序保护” 。 此时会打开一个新的边栏选项卡。 可看到有一个 web 应用程序需要路由其流量。
3. 选择此 web 应用程序。 会打开一个边栏选项卡,提供完成此 web 应用程序防火墙设置的步骤。 完成这些步骤,并选择“限制” 。 然后,安全中心会进行连接。
![限制流量][6]
> [!NOTE]
> 可以通过将应用程序添加到现有的 WAF 部署来保护安全中心中的多个 web 应用程序。
>
>
此 WAF 的日志现已完整集成。 安全中心可开始自动收集和分析这些日志,以便显示重要的安全警报。
## <a name="next-steps"></a>后续步骤
本文档演示了如何实现安全中心建议“添加 web 应用程序”。 若要了解有关配置 web 应用程序防火墙的详细信息,请参阅以下内容:
若要了解有关安全中心的详细信息,请参阅以下文章:
* [在 Azure 安全中心中设置安全策略](tutorial-security-policy.md) - 了解如何配置 Azure 订阅和资源组的安全策略。
* [在 Azure 安全中心中管理安全建议](security-center-recommendations.md) -- 了解建议如何帮助保护 Azure 资源。
* [Azure 安全中心常见问题](security-center-faq.md) - 查找有关使用服务的常见问题。
* [Azure 安全性博客](https://blogs.msdn.com/b/azuresecurity/) - 查找关于 Azure 安全性及合规性的博客文章。
<!--Image references-->
[1]: ./media/security-center-add-web-application-firewall/secure-web-application.png
[2]:./media/security-center-add-web-application-firewall/add-a-waf.png
[3]: ./media/security-center-add-web-application-firewall/info-blade.png
[4]: ./media/security-center-add-web-application-firewall/select-vm-config.png
[5]: ./media/security-center-add-web-application-firewall/finalize-waf.png
[6]: ./media/security-center-add-web-application-firewall/restrict-traffic.png | 3,193 | CC-BY-4.0 |
---
layout: post
title: "216. 组合总和 III"
categories: 算法
tags: leetcode 数组
---
* content
{:toc}
<!--more-->
找出所有相加之和为 n 的 k 个数的组合。组合中只允许含有 1 - 9 的正整数,并且每种组合中不存在重复的数字。
说明:
所有数字都是正整数。
解集不能包含重复的组合。
示例 1:
```
输入: k = 3, n = 7
输出: [[1,2,4]]
```
示例 2:
```
输入: k = 3, n = 9
输出: [[1,2,6], [1,3,5], [2,3,4]]
```
解:很简单,标准回溯法
```
public List<List<Integer>> combinationSum3(int k, int n) {
int nums[] = {1, 2, 3, 4, 5, 6, 7, 8, 9};
List<List<Integer>> result = new ArrayList<>();
List<Integer> tmp = new ArrayList<>();
dfs(result, tmp, nums, 0, k, n);
return result;
}
private void dfs(List<List<Integer>> result, List<Integer> tmp, int[] nums, int start, int k, int n) {
if (tmp.size() == k && summ(tmp) == n) {
result.add(new ArrayList<Integer>(tmp));
}
for (int i = start; i < nums.length; i++) {
tmp.add(nums[i]);
dfs(result, tmp, nums, i + 1, k, n);
tmp.remove(tmp.size() - 1);
}
}
private int summ(List<Integer> tmp) {
if (tmp == null || tmp.size() == 0) {
return 0;
}
int sum = 0;
for (Integer i : tmp) {
sum = sum + i;
}
return sum;
}
``` | 1,259 | MIT |
---
layout: post
title: "中國採取更多人民幣國際化行動;中美貿易協議陷入困境"
date: 2020-05-15T02:06:36+08:00
author: 透視中國
from: https://tw.sinoinsider.com/2020/05/%e4%b8%ad%e5%9c%8b%e6%8e%a1%e5%8f%96%e6%9b%b4%e5%a4%9a%e4%ba%ba%e6%b0%91%e5%b9%a3%e5%9c%8b%e9%9a%9b%e5%8c%96%e8%a1%8c%e5%8b%95%ef%bc%9b%e4%b8%ad%e7%be%8e%e8%b2%bf%e6%98%93%e5%8d%94%e8%ad%b0%e9%99%b7/
tags: [ 透視中國 ]
categories: [ 透視中國 ]
---
<article class="post-9000 post type-post status-publish format-standard has-post-thumbnail hentry category-subscription category-weekly-plus" id="post-9000" itemscope="" itemtype="https://schema.org/CreativeWork">
<div class="inside-article">
<div class="featured-image page-header-image-single">
<img alt="" class="attachment-full size-full" height="82" itemprop="image" sizes="(max-width: 800px) 100vw, 800px" src="https://tw.sinoinsider.com/wp-content/uploads/sites/2/2019/09/Weekly-Plus-bar-cn.jpg" srcset="https://tw.sinoinsider.com/wp-content/uploads/sites/2/2019/09/Weekly-Plus-bar-cn.jpg 800w, https://tw.sinoinsider.com/wp-content/uploads/sites/2/2019/09/Weekly-Plus-bar-cn-450x46.jpg 450w, https://tw.sinoinsider.com/wp-content/uploads/sites/2/2019/09/Weekly-Plus-bar-cn-768x79.jpg 768w, https://tw.sinoinsider.com/wp-content/uploads/sites/2/2019/09/Weekly-Plus-bar-cn-300x31.jpg 300w, https://tw.sinoinsider.com/wp-content/uploads/sites/2/2019/09/Weekly-Plus-bar-cn-600x62.jpg 600w" width="800"/>
</div>
<header class="entry-header">
<h1 class="entry-title" itemprop="headline">
中國採取更多人民幣國際化行動;中美貿易協議陷入困境
</h1>
<div class="entry-meta">
<span class="posted-on">
<a href="https://tw.sinoinsider.com/2020/05/%e4%b8%ad%e5%9c%8b%e6%8e%a1%e5%8f%96%e6%9b%b4%e5%a4%9a%e4%ba%ba%e6%b0%91%e5%b9%a3%e5%9c%8b%e9%9a%9b%e5%8c%96%e8%a1%8c%e5%8b%95%ef%bc%9b%e4%b8%ad%e7%be%8e%e8%b2%bf%e6%98%93%e5%8d%94%e8%ad%b0%e9%99%b7/" rel="bookmark" title="02:06">
<time class="updated" datetime="2020-05-25T02:08:16+08:00" itemprop="dateModified">
2020-05-25
</time>
<time class="entry-date published" datetime="2020-05-15T02:06:36+08:00" itemprop="datePublished">
2020-05-15
</time>
</a>
</span>
</div>
<!-- .entry-meta -->
</header>
<!-- .entry-header -->
<div class="entry-content" itemprop="text">
<p>
透視中國視角 1 5月11日,中國最大的國有鋼鐵集團中國寶武宣佈,最近,與澳大利亞力拓集團完成了首單利用區 …
</p>
<p class="read-more-container">
<a class="read-more button" href="https://tw.sinoinsider.com/2020/05/%e4%b8%ad%e5%9c%8b%e6%8e%a1%e5%8f%96%e6%9b%b4%e5%a4%9a%e4%ba%ba%e6%b0%91%e5%b9%a3%e5%9c%8b%e9%9a%9b%e5%8c%96%e8%a1%8c%e5%8b%95%ef%bc%9b%e4%b8%ad%e7%be%8e%e8%b2%bf%e6%98%93%e5%8d%94%e8%ad%b0%e9%99%b7/#more-9000" title="中國採取更多人民幣國際化行動;中美貿易協議陷入困境">
全文閱讀
<span class="screen-reader-text">
中國採取更多人民幣國際化行動;中美貿易協議陷入困境
</span>
</a>
</p>
<div class="woocommerce">
<div class="woocommerce-info wc-memberships-restriction-message wc-memberships-message wc-memberships-content-restricted-message">
會員區文章,請
<a href="https://tw.sinoinsider.com/%e6%88%91%e7%9a%84%e5%b8%b3%e8%99%9f/">
<u>
登入
</u>
</a>
。
</div>
</div>
</div>
<!-- .entry-content -->
<footer class="entry-meta">
<span class="cat-links">
<span class="screen-reader-text">
分類
</span>
<a href="https://tw.sinoinsider.com/category/subscription/" rel="category tag">
會員
</a>
,
<a href="https://tw.sinoinsider.com/category/weekly-plus/" rel="category tag">
高級時事週報
</a>
</span>
<nav class="post-navigation" id="nav-below">
<span class="screen-reader-text">
文章導覽
</span>
</nav>
<!-- #nav-below -->
</footer>
<!-- .entry-meta -->
</div>
<!-- .inside-article -->
</article> | 3,719 | MIT |
# Xamarin.iOS App Center ハンズオン テキスト #
# はじめに #
App Center で Xamarin.iOS アプリの自動ビルド、UIテストが試せる ハンズオンです。
Cognitive Services の Translator Text API を利用して、入力した日本語を英語に翻訳してくれるサンプルアプリを題材としています。

# 必要環境 #
- Visual Studio for Mac 最新版のインストール
- Xcode 最新版のインストール
- 有効な Github のアカウント
- 有効な Azure のアカウント
- 有効な App Center のアカウント(テストの無料試用が終了している場合、11,088円を Microsoft に支払う必要があります)
- 有効な Apple のディベロッパー登録
- iOS11 以上のインストールされた iPhone の実機
# アプリの準備 #
## Cognitive Services の Translator Text API 作成 ##
Azure ポータルにログインし、「新規」 -> 「translate」 で検索します。

Translator Text API を選択します。

「作成」をクリックします。

項目を入力して「作成」をクリックします。
価格レベルは必ず「F0」(無料)にしてください!

作成した Translator Text API を開いて Key をコピーし保管しておいて下さい。

## リポジトリを Fork ##
https://github.com/TomohiroSuzuki128/XamAppCenterSample2018/
にアクセスしてリポジトリを Fork してください。
## ソリューションを開きます。 ##
/src/StartShort/XamAppCenterSample2018.sln を開いてください。
## iOS の バンドル識別子 の設定 ##
iOS プロジェクトの `Info.plist` を開き、iOS のアプリの バンドル識別子 を御自身の固有のものに変更して下さい。
- アプリケーション名 は `XamAppCenterSample2018` にして下さい。
- バンドル識別子の Organization Identifier の部分(hiro127777)は全世界で固有となるような文字列にして下さい。

## Visual Studio App Center に App を作成する ##
App Center にログインし、右上の「add new」から「add new app」を選択
App Name, OS, Platform を入力、選択し、「Add new app」をクリック

## App Center で Android のビルドの設定 ##
「Build」を選択し、ソースコードをホストしたサービスを選択します。

「XamAppCenterSample2018」を選択します。

自動ビルドしたいブランチの設定アイコンを選択します。

ビルド設定を選択し、入力し、「Save & Build」を選択。

ビルドが始まるのでしばらく待ち、成功すれば完了です。

# App Center で、API Key をビルド時にインサートする #
自動ビルドするときに API へのアクセスキーなどの秘匿情報などは、リポジトリにプッシュしてはいけません。でもそうすると、自動ビルド後のテストなどで、API にアクセスできないので自動テストで困ってしまいます。よって、ビルドサーバがリポジトリから Clone した後か、ビルド前に秘匿情報をインサートする方法が便利です。
今回は、ビルドサーバがリポジトリから Clone した後に API Key が自動インサートされるように設定します。
## Visual Studio App Center のビルド設定に秘匿情報を環境変数として登録する ##
Visual Studio App Center のビルド設定を開きます。

`Environment variables` に環境変数名とキーの値を登録します。

## ソリューションを開きます。 ##
/src/StartShort/XamAppCenterSample2018.sln を開いてください。
## ソースコード上に置き換え用の目印となる文字列を準備します。 ##
/src/StartShort/XamAppCenterSample2018/Variables.cs を確認してください。
**/src/StartShort/XamAppCenterSample2018/Variables.cs**
```csharp
using System;
namespace XamAppCenterSample2018
{
public static class Variables
{
// NOTE: Replace this example key with a valid subscription key.
public static readonly string ApiKey = "[ENTER YOUR API KEY]";
}
}
```
上記の`[ENTER YOUR API KEY]`のように置き換えの目印になる文字列を設定しておきます。
## clone 後に自動実行されるシェルスクリプトを準備します。 ##
App Center には ビルドする`cspoj`と同じ階層に、`appcenter-post-clone.sh`という名前でシェルスクリプトを配置しておくと、自動認識し clone 後に自動実行してくれる機能があります。
よって、`appcenter-post-clone.sh`に`[ENTER YOUR API KEY]`を本物のキーに置き換えを行う処理を書きます。
**/src/StartShort/iOS/appcenter-post-clone.sh**
```sh
#!/usr/bin/env bash
# Insert App Center Secret into Variables.cs file in my common project
# Exit immediately if a command exits with a non-zero status (failure)
set -e
##################################################
# variables
# (1) The target file
MyWorkingDir=$(cd $(dirname $0); pwd)
DirName=$(dirname ${MyWorkingDir})
filename="$DirName/XamAppCenterSample2018/Variables.cs"
# (2) The text that will be replaced
stringToFind="\[ENTER YOUR API KEY\]"
# (3) The secret it will be replaced with
AppCenterSecret=$API_Key # this is set up in the App Center build config
##################################################
echo ""
echo "##################################################################################################"
echo "Post clone script"
echo " *Insert App Center Secret"
echo "##################################################################################################"
echo " Working directory:" $DirName
echo "Secret from env variables:" $AppCenterSecret
echo " Target file:" $filename
echo " Text to replace:" $stringToFind
echo "##################################################################################################"
echo ""
# Check if file exists first
if [ -e $filename ]; then
echo "Target file found"
else
echo "Target file($filename) not found. Exiting."
exit 1 # exit with unspecified error code. Should be obvious why we can't continue the script
fi
# Load the file
echo "Load file: $filename"
apiKeysFile=$(<$filename)
# Seach for replacement text in file
matchFound=false # flag to indicate we found a match
while IFS= read -r line; do
if [[ $line == *$stringToFind* ]]
then
# echo "Line found:" $line
echo "Line found"
matchFound=true
# Edit the file and replace the found text with the Secret text
# sed: stream editior
# -i: in-place edit
# -e: the following string is an instruction or set of instructions
# s: substitute pattern2 ($AppCenterSecret) for first instance of pattern1 ($stringToFind) in a line
cat $filename | sed -i -e "s/$stringToFind/$AppCenterSecret/" $filename
echo "App secret inserted"
break # found the line, so break out of loop
fi
done< "$filename"
# Show error if match not found
if [ $matchFound == false ]
then
echo "Unable to find match for:" $stringToFind
exit 1 # exit with unspecified error code.
fi
echo ""
echo "##################################################################################################"
echo "Post clone script completed"
echo "##################################################################################################"
```
このスクリプトがやっていることは、
- キーを置き換えるファイルを探す。
- ファイルの中から置き換え用の目印となる文字列を探し、本物のキーに置き換える。
それだけです。
このスクリプトを含んだリポジトリをプッシュすると、以下のように、App Center 側で認識されます。

## ビルドを実行し、ログを確認してシェルスクリプトが正しく実行されていることを確認。 ##
正しく実行されていれば、以下のようにログで確認できます。

以上で、Visual Studio App Center で、秘匿情報をビルド時にインサートする手順は完了です。
# Visual Studio App Center で、自動ビルド後に iOS の自動実機UIテストを実行する #
次は、いよいよ自動ビルド後に iOS の自動実機UIテストを実行する設定を進めていきます。
## Visual Studio App Center のテスト設定に実機UIテストを走らせるデバイスの組み合わせのセットを登録します ##
Visual Studio App Center では、1回のテストで、複数の実機の自動UIテストを走らせることができますので、テストを走らせる実機を選択して登録しておきます。
Visual Studio App Center のテスト設定のデバイスセット設定を開きます。

`Set name` を設定し、テストを実行するデバイスにチェックを入れ `New device set` で保存します。

Device set が登録されていることを確認します。

## Visual Studio App Center にログインするキーを準備します。 ##
自動実行されるシェルスクリプトが自動テストを実行するときに、事前に取得しておいたキーを使って App Center にログインします。そのキーをスクリプトから利用できるように環境変数に登録しておきます。
「Account settings」を開きます。

「New API token」を開きます。

APIの利用目的の説明とアクセス権を設定し保存します。

キーが表示されるのでコピーしメモ(保管)しておきます。キーは画面を閉じると2度と表示されないのでご注意ください。

キーが登録されていることを確認します。

次にビルド設定を開きます。

環境変数にキーを設定して、保存します。

## 証明書と Provisioning Profile を準備します。 ##
App Center で iOS 実機での自動UIテストを行うには、証明書と Provisioning Profile が必要になりますので準備します。
Apple Developer Program のサイトで証明書(.cer)、Provisioning Profile(.mobileprovision) を作成し、ローカルの Mac の キーチェーンアクセス で 証明書(.p12) を作成します。
この方法についてはWeb上に情報がたくさんあるので、以下のセクションのリンクのWebの情報を参考に行なってください。
### 証明書を準備します。 ###
[証明書作成方法](https://i-app-tec.com/ios/app-release.html#1)
### Provisioning Profile を準備します。 ###
[Provisioning Profile作成方法](https://i-app-tec.com/ios/app-release.html#2)
作成した Provisioning Profile(.mobileprovision)、証明書(.p12)を保管しておきます。
## 作成した Provisioning Profile(.mobileprovision)、証明書(.p12)を App Center にアップロードします ##
ビルド設定を開きます。

`Build type` を `Device build` に変更します。

作成した Provisioning Profile(.mobileprovision)、証明書(.p12)を アップロードし、保存します。

## build 後に自動実行されるシェルスクリプトを準備します。 ##
Visual Studio App Center には ビルドする`cspoj`と同じ階層に、`appcenter-post-build.sh`という名前でシェルスクリプトを配置しておくと、自動認識し build 後に自動実行してくれる機能があります。
よって、`appcenter-post-build.sh`に、自動実機UIテストを実行する処理を書きます。
ファイルはすでに準備されていますので、設定値を書き換えてください。
**/src/StartShort/iOS/appcenter-post-build.sh**
```sh
#!/usr/bin/env bash
# Post Build Script
# Exit immediately if a command exits with a non-zero status (failure)
set -e
##################################################
# variables
appCenterLoginApiToken=$AppCenterLoginToken # this comes from the build environment variables
appName="TomohiroSuzuki128/XamAppCenterSample2018iOS" # 自分のアプリ名に書き換える
deviceSetName="TomohiroSuzuki128/my-devices" # 自分のデバイスセット名に書き換える
publishedAppFileName="XamAppCenterSample2018.iOS.ipa"
sourceFileRootDir="$APPCENTER_SOURCE_DIRECTORY/src/StartShort"
uiTestProjectName="UITests"
testSeriesName="all-tests"
##################################################
echo "##################################################################################################"
echo "Post Build Script"
echo "##################################################################################################"
echo "Starting Xamarin.UITest"
echo " App Name: $appName"
echo " Device Set: $deviceSetName"
echo "Test Series: $testSeriesName"
echo "##################################################################################################"
echo ""
echo "> Build UI test projects"
find $sourceFileRootDir -regex '.*Test.*\.csproj' -exec msbuild {} \;
echo "> Run UI test command"
# Note: must put a space after each parameter/value pair
appcenter test run uitest --app $appName --devices $deviceSetName --app-path $APPCENTER_OUTPUT_DIRECTORY/$publishedAppFileName --test-series $testSeriesName --locale "ja_JP" --build-dir $sourceFileRootDir/$uiTestProjectName/bin/Debug --uitest-tools-dir $sourceFileRootDir/packages/Xamarin.UITest.*/tools --token $appCenterLoginApiToken
echo ""
echo "##################################################################################################"
echo "Post Build Script complete"
echo "##################################################################################################"
```
このスクリプトがやっていることは、
- UIテストプロジェクトをビルドする。
- App Center に、自動UIテストのコマンドを発行し、実行させる。
の2つです。
このスクリプトを含んだリポジトリをプッシュすると、以下のように、App Center 側で認識されます。

## スクリプトのデバッグ方法 ##
このようなスクリプトを自作するときに一番困るのが、
- 「指定したファイルが見つからない」エラーが発生すること
- 環境変数の中身がよくわからないこと
です。
よってスクリプトを自作するときには、下記のように環境変数やディレクトリの中身をコンソールに表示させながらスクリプトを書くことで効率よくデバッグできます。
```sh
# for test
echo $APPCENTER_SOURCE_DIRECTORY
echo ""
files="$APPCENTER_SOURCE_DIRECTORY/src/StartShort/UITests/*"
for filepath in $files
do
echo $filepath
done
```
## ビルドを実行し、テスト結果を確認してテストが正しく実行されていることを確認します。 ##
正しく実行されていれば、以下のようにテスト結果が確認できます。

また、テストコード内に以下のように、`app.Screenshot("<スクリーンショット名>")`と記述することで、スクーンショットが自動で保存されます。
```csharp
[Test]
public async void SucceedTranslate()
{
await Task.Delay(2000);
app.Screenshot("App launched");
await Task.Delay(2000);
app.Tap(c => c.Marked("inputText"));
await Task.Delay(2000);
app.EnterText("私は毎日電車に乗って会社に行きます。");
await Task.Delay(2000);
app.Screenshot("Japanese text entered");
await Task.Delay(2000);
app.DismissKeyboard();
await Task.Delay(2000);
app.Tap(c => c.Button("translateButton"));
await Task.Delay(4000);
var elements = app.Query(c => c.Marked("translatedText"));
await Task.Delay(2000);
app.Screenshot("Japanese text translated");
await Task.Delay(2000);
Assert.AreEqual("I go to the office by train every day.", elements.FirstOrDefault().Text);
}
```
保存されたスクリンショットは以下の手順で確認できます。



これで、リポジトリにプッシュすると自動ビルドが走り、自動実機UIテストが実行されるようになりました!!
お疲れ様でした。これでハンズオンは終了です。 | 15,621 | MIT |
# SWARM
Swarm is a distributed scheduled job framework, based on Quartz.
## DESGIN
```
+------------------+ +------------+ +------------------+ +------------+
| Swarm Server 1 +------> | | Swarm Server 3 +------> |
+------------------+ | | +------------------+ | |
| Quartz | | Quartz |
+------------------+ | Scheduler 1| +------------------+ | Scheduler 2|
| Swarm Server 2 +------> | | Swarm Server 4 +------> |
+------------------+ +------------+ +------------------+ +------------+
+----------------------------------+
| Swarm DB |
+----------------------------------+
--------------------------------------SHARDING MODULE---------------------------------------
|
HTTP, WebSocket
|
+-------------------+---------+---------+-------------------+
| | | |
+-------v--------+ +-------v--------+ +-------v--------+ +-------v--------+
| Swarm Client 1 | | Swarm Client 2 | | Swarm Client 3 | | Swarm Client 4 |
+----------------+ +----------------+ +----------------+ +----------------+
```
##### SWARM SHARDING NODE
+ 2 or more Swarm Server as a quartz cluster node to make sure triggers will be performed.
+ Via ISharding to choose a Scheduler to create/update/delete job
##### EXECUTE JOB TYPE
+ Process: Client receive message from Swarm server, then start a process to execute the job
+ Reflection: Swarm client load all DLLs from job directory, create a job instance and invoke the Task Handler(JobContext context) method
##### TRIGGER TYPE
+ Cron,
+ Simple,
+ DailyTimeInterval,
+ CalendarInterval
##### PERFOM TYPE
+ WebSocket
+ HTTP
+ Kafka
+ Other
## WHY SWARM?
Quartz is a great scheduler framework, but if we have millions or more jobs or trigger very frequent, one database can't load this scenario. So we want to implement a distributed scheduler system can scheudler millions jobs, millions clients
## LET'S MAKE A BRAIN STORM
#### Quartz 定时系统的基本原理
```
触发规划表
| job1, 2018-11-01 17:36:00 |
|----------------------------|
| job2, 2018-11-01 18:36:00 |
|----------------------------|
| job3, 2018-11-01 18:37:00 |
|----------------------------|
| job4, 2018-11-01 19:30:00 |
+----------------------------+
循环查询规划表以SQL SERVER举例:
1. 取得原子锁
2. 查询需要触发的 Trigger: SELECT TOP {maxCount} FROM TRIGGERS WHERE NextFireTime <=noLaterThan AND NextFireTime >= @noEarlierThan AND State = StateWaiting , 其中 noLaterThan 是当前时间 和 noEarlierThan 是当前时间加扫描频率, 在 Quartz中可以配置
3. 计算每一个 Trigger 的下一次触发时间, 更新 State 和下一次触发时间到数据库
4. 释放原子锁
5. 触发所有任务
```
那么其实这一类任务触发系统的问题也就很明显了, 在单位扫描时间内如果不能处理完所有的任务, 就会造成 miss fire. 其中 {maxCount} 的值很关键, 默认是 1, 可以根据需求调整可以大大提高性能.
#### Quartz 集群解决了什么问题?
Quartz 的集群模式是通过 SchedulerName 来标识同一组集群, 即在上面的第二步查找时添加 SchedulerName= @SchedulerName 这样的限制条件, 同时分布式锁的实现也是针对 SchedulerName 来做的, 下图是 Quartz 的 LOCKS 表
SCHED_NAME | LOCK_NAME |
-----------| ----------------|
SCHEDULER1 | TRIGGER_ACCESS |
可以知道 Quartz 的集群是侧重任务端,把任务触发到不同的 Quartz 实例, 保证任务的执行是它的目的。 因此, Quartz 的默认集群模式并不能解决如果任务量过多、锁的竞争导致的 miss fire 问题
#### 是否真的需要考虑触发性能?
我不知道在真实场景中触发时间的分布, 假设我们的性能指标是每天调度100万次,触发时间是平均的则每秒要触发约 12 个任务, 这个数据量即便是使用了分布式锁相信也是能够轻轻松松负荷的. 如果要做到如阿里云 SchedulerX 所说的每天调度10亿次, 每秒要查询和更新11000+行, 这个量级我觉得高性能硬件数据库也不是不能完成. 但是这样并没有压榨掉数据库的极限性能, 毕竟是依靠一个原子锁
#### 解决思路
1. 直接依赖 Quartz 默认支持的多个 Scheduler, 如对一个数据库默认分配多个 Scheduler:
```
Scheduler1, Scheduler2, Scheduler3, Scheduler4, Scheduler5, ...
```
2. 每个 Scheduler 由 2 个以上的实例来保证稳定性, 组成一个 Swarm Sharding Node, SSN 通过 SignalR 组成集群, 每个 SSN 启动后把信息添加到数据库, 并定时更新心跳. 每个 SSN 定时扫描注册表, 如果发现掉线的节点(分布式锁)则触发迁移
3. 每触发一个任务在数据库中给对应的 Scheduler 增加 1 次计数
4. SSN 还可以创建、删除、修改、触发, 同时也是对外的连接中心, 管理分布式客户端的触发, 创建任务的时候, 查询各 Scheduler 的触发计数, 取最小的一个 Scheduler 调用其Quartz数据库接口添加任务(负载算法可调整)
5. 当 SSN 触发一个任务时, 通过任务信息归属和分片信息等分发到对应的客户端
6. 当某个 SSN 只有一个实例时, 提示警告信息, 当 SSN 节点完全当掉时, 集群中的其它 SSN 应该把此节点的所有任务迁移到其它节点或者备用节点
+----------------------+ +-----------------------+ +----------------------+
| JOBS | | NODES | | CLIENTS |
+----------------------+ +-----------------------+ +----------------------+
| TriggerType | | SchedInstanceId | | Name |
| PermformerType | | SchedName | | Group |
| LastModificationTime| | Provider | | ConnectionId |
| Name | | TriggerTimes | | Ip |
| Group | | LastModificationTime | | Os |
| CreationTime | | CreationTime | | CoreCount |
| Description | | ConnectString | | Memory |
| Owner | +-----------------------+ | CreationTime |
| Load | | LastModificationTime|
| Sharding | | IsConnected |
| ShardingParameters | | SchedName |
| StartAt | | SchedInstanceId |
| EndAt | | IsConnected |
| AllowConcurrent | +----------------------+
| SchedInstanceId |
| SchedName |
+----------------------+
| ExecutorType |
| Cron |
| CallbackHost |
| App |
| AppArguments |
+----------------------+
+----------------------+ +----------------------+ +----------------------+
| CLIENT_JOBS | | CLIENT_PROCESSES | | LOG |
+----------------------+ +----------------------+ +----------------------+
| Name | | Name | | ClientName |
| Group | | Group | | ClientGroup |
| ClassName | | ProcessId | | TraceId |
| CreationTime | | JobId | | JobId |
+----------------------+ | App | | Sharding |
| AppArguments | | Msg |
| LastModificationTime| | CreationTime |
| CreationTime | +----------------------+
| Sharding |
| Msg |
| TraceId |
| State |
+----------------------+
实际上以上设计已经完全不关心SSN是同一个数据库还是不同的数据库了
Module | Feature | Interface | Description |Compelete | Unit Tests |
-------|-------|-------|-------|-------| -------|
SSN | Heartbeat | ISwarmCluster| 从配置文件读取信息: SchedName, NodeId, 以此为条件更新心跳时间到数据库. 如果更新影响行数为 0, 则插入一条新的记录, 初始 TriggerTimes 为 0. 循环执行 | ☑ | ☐ |
SSN | Sharding | ISharding | 从数据库中取出负载最小的节点| ☑ | ☐ |
SSN | Health Check | ISwarmCluster | 每隔一定时间查询心跳超时节点, 发现警告信息或邮件给管理员, 严重的自动迁移数据, 需要分布式锁| ☐ | ☐ |
SSN | Client Process Timeout Check | ISwarmCluster | 每隔一定时间查询客户端进程表, 发现超时的标识为超时| ☐ | ☐ |
SSN | Create Job | IJobService | 参数验证 -> 判断任务是否存在 -> 通过分片接查询节点 -> 创建 Sched -> 添加任务到节点 ->任务更新节点编号, 保存任务到 Swarm数据库, 保存失败需要从节点中删除 | ☑ | ☐ |
SSN | Delete Job | IJobService | 参数验证 -> 判断任务是否存在 -> 通过任务中的节点编号查询节点 -> 创建节点对应的 Sched ->删除任务, 删除触发器 ->从 Swarm 数据库中删除任务信息 | ☑ | ☐ |
SSN | Update Job | IJobService | 参数验证 -> 判断任务是否存在 -> ... | ☐ | ☐ |
SSN | Trigger Job | IJobService | 参数验证 -> 判断任务是否存在 -> 通过任务中的节点编号查询节点 -> 创建节点对应的 Sched ->触发任务 | ☑ | ☐ |
SSN | Exit All | IJobService | 参数验证 -> 判断任务是否存在 -> 通知所有节点根据任务编号退出此任务所有进程(Http触发任务无法退出) | ☑ | ☐ |
SSN | Exit | IJobService | 参数验证 -> 判断任务是否存在 -> 根据任务编号, 批次, 分片查询客户端连接信息, 通知对应节点退出对应任务 | ☐ | ☐ |
Client | Loop Connect | IClient | 配置重试次数, 如果连接失败或者连接被断开则重试| ☑ | ☐ |
Client | Register Jobs | IClient | 递归扫描/{base}/jobs/下所有 DLLs, 扫描得到继承 ISwarmJob 的类型, 并注册到SSN中| ☐ | ☐ |
Client | ExecutorFactory | IExecutorFactory | 通过名字创建对应的任务执行器| ☑ | ☐ |
Client | Process Executor | IExecutor | 启动一个新进程, 执行配置好的任务| ☑ | ☐ |
Client | Reflection Executor | IExecutor | 反射任务类型, 执行配置好的任务| ☑ | ☐ |
Client | Process Storage | IProcessStorage | 存储正在执行的任务, 一旦客户端崩溃重启依据本地存储信息检测还在跑的进程有哪些和SSN同步状态, 执行存储操作前先同步到 SSN| ☐ | ☐ |
Client | Log Filter | ILogFilter | 筛选用户需要的日志上传到 SSN, 默认是全部上传| ☐ | ☐ |
## INSTALLATION
1. open a command prompt/terminal
2. install Swarm.Node
dotnet tool install --global Swarm.Node
3. install Swarm.ConsoleClient vi execute
dotnet tool install --global Swarm.ConsoleClient
4. create a swarm node configuration
mkdir /etc/swarm
vi /etc/swarm/appsettings.json
paste below configs and change sqlserver connectionstring or other settings
{
"Swarm": {
"ConnectionString": "Data Source=.;Initial Catalog=Swarm;User Id=sa;Password='1qazZAQ!'",
"AccessTokens": [
"%wTAd6IgcnQZauJKDTGdkmxyJgFxffXe"
],
"SchedName": "SwarmCluster",
"SchedInstanceId": "Swarm001",
"Provider": "SqlServer",
"QuartzConnectionString": "Data Source=.;Initial Catalog=Swarm001;User Id=sa;Password='1qazZAQ!'"
},
"AllowedHosts": "*",
"urls": "http://*:8000"
}
5. create a systemctl config
vi /etc/systemd/system/swarm.service
paste below codes
[Unit]
Description = Swarm Node
[Service]
ExecStart = /root/.dotnet/tools/Swarm.Node /ect/swarm/appsettings.json
Restart = always
RestartSec = 10
SyslogIdentifier = swarm
6. start swarm service
systemctl start swarm
7. create a swarm console client configuraiton
vi /etc/swarm/client.ini
paste below codes and change it as you wish, the host should be swarm node's url
[client]
name = inhouse001
group = DEFAULT
host = http://localhost:8000
accessToken= %wTAd6IgcnQZauJKDTGdkmxyJgFxffXe
retryTimes = 7200
heartbeatInterval = 5000
ip = 192.168.10.147
8. create a systemctl config
vi /etc/systemd/system/swarmclient.service
paste below codes
[Unit]
Description = Swarm Client
[Service]
ExecStart = /root/.dotnet/tools/Swarm.ConsoleClient /etc/swarm/client.ini
Restart = always
RestartSec = 10
SyslogIdentifier = swarmclient
9. start client
systemctl start swarmclient
10. let try a cron process job: http://[host]/job/cronProc
input Name: testEcho
input ShardingParameters: boy;girl
update Sharding: 2
input Application: echo
input Arguemnts: i am %csp%
then submit
11. back to http://[host]/job/cron and press Log to see the execute logs
+------------+-----------+----------------------------------+-----------+-----------+--------------------+
| Name | Group | TraceId | Sharding | Msg | Time |
|------------|-----------|----------------------------------|-----------|-----------|---------------------|
| inhouse001 | DEFAULT | 889bb3b8a6004975b8a1b2ed5d017112 | 2 | i am girl | 2018-11-10 00:40:59 |
| inhouse001 | DEFAULT | 889bb3b8a6004975b8a1b2ed5d017112 | 1 | i am boy | 2018-11-10 00:40:59 |
## UI




## CONSIDERATION
+ Client can't connect to Swarm server, but processes of jobs are still running, when the server restart, server should know those information and update job's state to database?
+ Client down, all processes it opened still alive? may be we should store process<-> job info to help rescue client.
## CONTRIBUTION
1. Fork the project
2. Create Feat_xxx branch
3. Commit your code
4. Create Pull Request | 13,266 | MIT |
<br/>
```html
<!-- html -->
<m-table :options="options"></m-table>
```
<br/>
```javascript
/*js*/
<script setup>
import { reactive } from 'vue'
const state = reactive({
options:{
fileds:[
{field:'id',title:'ID',align:'center'},
{field:'name',title:'姓名',align:'center'},
{field:'job',title:'职业',align:'center'},
{field:'address',title:'地址',align:'center'},
{field:'from',title:'籍贯',align:'center'}
],
datas:[
{id:10,name:'王小二',job:'放羊娃',address:'在那遥远的小山村',from:"民间流传故事"},
{id:13,name:'猪八戒',job:'徒弟',address:'高老庄',from:"西游记神话故事"},
{id:2,name:'刘老四',job:'农民',address:'可能在中国',from:"想象出来的"},
{id:11,name:'白骨精',job:'妖精',address:'西游记',from:"西游记神话故事"},
]
}
})
const {options} = state
</script>
```
<br/> | 808 | MIT |
#### 单选框
本例实现NeoUI组件radio的数据绑定。
[试一试](http://tinper.org/webide/#/demos/kero/radio)
**注意**:
1、datasource对应的对象需要在数据模型viewModel中定义。
2、radio选中的真实值会绑定到dataTable对应的字段上
#### API
#### u-meta 属性
* type:`u-radio`
* datasource
* 类型: Array
* 说明:设置单选框的数据源,具体数组内容需要在viewmodel中定义,数组中的每个对象需要有value,name字段。其中name为单选框的显示值,value为单选框的真实值。
* 用法:
```
radiodata:[{value:'01',name:'男'},{value:'02',name:'女'}]
```
* hasOther
* 类型:Boolean
* 说明:是否含有其他单选框,当hasOther为true时,单选框会自动多一个显示值为“其他”的单选框和一个输入框,输入框默认是不可输入的,当单选框选中时,输入框可输入,存放该单选框的真实值。默认为false。
#### radioAdapter对象
* 类型:`Object`
* 说明: 获取radioAdapter对象,可以通过此对象的一些方法来改变单选框的效果状态。下面方法均是在此对象基础上调用的。
* 用法:`app.getComp('控件id值');`
```
<div u-meta='{"id":"r1","type":"u-radio","data":"dt1","field":"f1","datasource":"radiodata","hasOther":true}'>
<label class="u-radio" >
<input type="radio" class="u-radio-button" name="options">
<span class="u-radio-label"></span>
</label>
</div>
var radioAObject = app.getComp('r1');//r1为在u-meta中定义的id值
```
#### setEnable对象
* 类型: `Function`
* 说明: 设置单选框是否可用。
* 参数:{Boolean} isEnable,isEnable=true时可用,isEnable=false时不可用
* 用法:
```
radioAObject.setEnable(true);//设置可用
```
相关内容:
[基础单选框](http://docs.tinper.org/neoui/plugin.html#单选框)
[单选框在grid中使用](http://tinper.org/webide/#/demos/grids/edit)
实现效果如下:
``` html
<!--
HTML
u-meta:框架特有标记,框架通过识别此标记创建对应UI组件,以及进行数据绑定
id,type.data,field为必选项
id:创建组件唯一标识
type:创建组件对应的类型,单选框对应的type为u-radio
data:指定数据模型中的数据集
field:绑定数据集中对应的字段
datasource:绑定数据
-->
<div u-meta='{"id":"r1","type":"u-radio","data":"dt1","field":"f1","datasource":"radiodata"}'>
<label class="u-radio" >
<input type="radio" class="u-radio-button" name="options">
<span class="u-radio-label"></span>
</label>
</div>
```
``` js
// JS
/**
* viewModel 创建数据模型
* dt1 创建的数据集
* f1 创建数据集中的字段
* type:指定数据对应的类型
* radiodata:自定义单选框数据,用于绑定数据
*/
var app,viewModel;
viewModel = {
dt1: new u.DataTable({
meta:{
f1:{},
f2:{}
}
}),
radiodata:[{value:'01',name:'男'},{value:'02',name:'女'}]
};
/**
* app 创建框架服务
* el 指定服务对应的顶层DOM
* model 指定服务对应的数据模型
*/
app = u.createApp({
el:'body',
model:viewModel
});
// 创建空行,绑定默认值
var r = viewModel.dt1.createEmptyRow();
r.setValue('f1',"01");
viewModel.dt1.setRowSelect(0);
``` | 2,318 | MIT |
### Circle
使用纯CSS制作一个圆球。
#### HTML
```html
<div class="circle"></div>
```
#### CSS
```css
.circle {
border-radius: 50%;
width: 2rem;
height: 2rem;
background: #333;
}
```
#### Demo
<div class="snippet-demo">
<div class="snippet-demo__circle"></div>
</div>
<style>
.snippet-demo__circle {
border-radius: 50%;
width: 2rem;
height: 2rem;
background: #333;
}
</style>
#### 解释
`border-radius: 50%` 改变节点边框的圆角来创建一个圆。
因为一个圆要在给定的点中半径相同,所以 `width` 和 `height` 必须相同。 两个值不同会创建一个椭圆。
#### 浏览器兼容性
<span class="snippet__support-note">✅ 没啥警告.</span>
* https://caniuse.com/#feat=border-radius
<!-- tags: visual --> | 629 | CC0-1.0 |
#### 仮想デバイスを作成するには
1. Azure ポータルで **StorSimple Manager** サービスに移動します。
2. **[デバイス]** ページに移動します。**[デバイス]** ページ下部の **[仮想デバイスの作成]** をクリックします。
3. **[仮想デバイスの作成]** ダイアログ ボックスで、次のように詳細を指定します。

1. **[名前]** – 仮想デバイスの一意の名前。
2. **[モデル]** - 仮想デバイスのモデルを選択します。このフィールドは、Update 2 以降を実行している場合のみ表示されます。8010 デバイス モデルは 30 TB (テラバイト) の Standard Storage を提供し、8020 は 64 TB の Premium Storage を提供します。バックアップから項目レベルの取得を行うシナリオをデプロイする場合は、8010 を
3. 指定します。パフォーマンスが高く、待機時間が短いワークロードをデプロイするか、災害復旧のためのセカンダリ デバイスとして使用する場合は、8020 を選択します。
4. **[バージョン]** -仮想デバイスのバージョンを選択します。8020 デバイス モデルを選択した場合、バージョン フィールドはユーザーには表示されません。このサービスに登録されたすべての物理デバイスが Update 1 (またはそれ以降) で実行されている場合、このオプションは表示されません。このフィールドは、Update 1 を適用する前の物理デバイスと Update 1 が適用された物理デバイスが、同じサービスに同時に登録されている場合のみ表示されます。フェールオーバーまたは複製元として有効な物理デバイスは仮想デバイスのバージョンによって決まるので、適切なバージョンの仮想デバイスを作成することが重要です。選択肢:
- バージョン Update 0.3。Update 0.3 以前を実行中の物理デバイスからフェールオーバーまたは DR を行う場合。-
- バージョン Update 1。Update 1 以降を実行中の物理デバイスからフェールオーバーまたは複製を行う場合。
5. **Virtual Network** – この仮想デバイスで使用する仮想ネットワークを指定します。Premium Storage (Update 2 以降) を使用する場合は、Premium Storage アカウントでサポートされている仮想ネットワークを選択する必要があります。サポートされていない仮想ネットワークは、ドロップダウン リストに淡色表示され、選択できません。サポートされていない仮想ネットワークを選択すると、警告が表示されます。
5. **仮想デバイスの作成に使用するストレージ アカウント** – プロビジョニング中に仮想デバイスのイメージを保持するストレージ アカウントを選択します。このストレージ アカウントは、仮想デバイスおよび仮想ネットワークと同じリージョンに存在する必要があります。物理デバイスまたは仮想デバイスのデータ保管にこのストレージ アカウントを使用することは避けてください。既定では、この目的に使用する新しいストレージ アカウントが作成されます。ただし、この用途に適したストレージ アカウントが既にあることがわかっている場合は、一覧からそのアカウントを選択してください。Premium 仮想デバイスを作成する場合、ドロップダウン リストには Premium Storage アカウントだけが表示されます。
>[AZURE.NOTE]仮想デバイスは Azure ストレージ アカウントでのみ使用できます。Amazon、HP、OpenStack などの他のクラウド サービス プロバイダーは StorSimple 仮想デバイスではサポートされません (物理デバイスではサポートされます)。
1. 仮想デバイスに格納するデータがマイクロソフトのデータセンターでホストされることに同意する旨のチェック ボックスをオンにします。物理デバイスのみを使用する場合は、暗号化キーがご利用のデバイスに保管されるため、マイクロソフトが暗号化を解除することはできません。
仮想デバイスを使用する場合、暗号化キーと復号化キーの両方が Microsoft Azure に保管されます。詳細については、「[仮想デバイスを使用するためのセキュリティに関する考慮事項](storsimple-security/#storsimple-virtual-device-security)」を参照してください。
2. チェック アイコンをクリックして仮想デバイスを作成します。デバイスは、プロビジョニングされるまで約 30 分かかることがあります。

<!---HONumber=AcomDC_1217_2015--> | 2,329 | CC-BY-3.0 |
# Terway 主机网络栈路由
## 背景
- 在 Terway IPVLAN 模式中,使用 Terway 网络的 Pod 网络流量会被转发至主机网络中 IPVLAN 接口,通过其 `tc egress filter` 策略转发流量。
- 默认情况下,`tc egress` 仅会将 `ServiceCIDR` 的流量转发至主机网络栈,交由 IPVS 等策略进行处理。如果希望将部分网段额外路由至主机网络栈,您可以参考本文进行设置。
- 常见场景:DNS 缓存方案 `node-local-dns` 中,Local DNS 缓存作为 DaemonSet 部署在每个集群节点上,通过 Link-Local Address 暴露缓存服务。如需在 IPVLAN 模式下使用本地
DNS 缓存,可以将 Link-Local Address 设置到主机网络栈路由中。
- 在 Terway ENIONLY 模式中,使用 Terway 网络的 Pod 中会默认添加 `ServiceCIDR` 路由至主机,通过设置主机网络栈,可以将指定网络同样路由至主机,配置方式同下。

## 操作流程
1. 执行以下命令,打开 Terway 配置文件修改
```bash
kubectl -n kube-system edit cm eni-config -o yaml
```
2. 可以看到默认的配置包含以下内容,如需增加主机网络栈路由,请添加 `host_stack_cidrs` 字段,并填入需要转发的网段,保存退出
```json
10-terway.conf: |
{
"cniVersion": "0.3.1",
"name": "terway",
"eniip_virtual_type": "IPVlan",
"host_stack_cidrs": ["169.254.0.0/16"], // 此处为您希望添加的主机网络栈路由
"type": "terway"
}
```
3. 执行以下命令,过滤出当前 Terway 的所有 DaemonSet 容器组
```bash
kubectl -n kube-system get pod | grep terway-eniip
terway-eniip-7d56l 2/2 Running 0 30m
terway-eniip-s7m2t 2/2 Running 0 30m
```
4. 执行以下命令,触发 Terway 容器组重建
```bash
kubectl -n kube-system delete pod terway-eniip-7d56l terway-eniip-s7m2t
```
5. 登录任意集群节点,执行以下命令,查看 Terway 配置文件,如果包含添加的网段,则说明变更成功
```bash
cat /etc/cni/net.d/*
{
"cniVersion": "0.3.1",
"name": "terway-chainer",
"plugins": [
{
"eniip_virtual_type": "IPVlan",
"host_stack_cidrs": [ // 此处为新增的主机网络栈路由
"169.254.0.0/16",
],
"type": "terway"
},
{
"type": "cilium-cni"
}
]
}
```
6. 重建任意一个使用 Terway 网络的 Pod 后,Pod 所在节点即可在容器中访问该新网段。 | 1,823 | Apache-2.0 |
最理想的拆分后又组合的方式是“粘贴”到一起。就像你把一块砖,劈开了。拼装回去就是把两半又放一起。也就是我们可以有一个通用的函数 integrate(comp1, comp2, .. compN)。很多组件化系统都是这么吹捧自己的,比如说父类与子类,最终拼装出结果,这个拼装就是继承规则。比如说 OSGi,一堆 bundle,不用管他们是什么,都可以用同样的方式拼装起来。然而,我们都知道业务逻辑拆分出 git 仓库之后,往往是没有办法用通用的函数组合回去的。
比如说我们需要描述两个模块提供的按钮,哪个在哪个的左边。比如说我们要拼装两条促销规则,要说明哪个用了之后哪个就不能用了。这些业务上的空间组合,时间组合是必不可少的。
任何向你推销通用的组合式组件系统的人,最终都会搞出一个配置文件给你写“装配逻辑”。这样的模块装配文件就是没事找事,本来可以用大家都懂的 javascript 解决的问题,要变成用 XML 换了花来写。
# 文件做“集成”
业务逻辑会拆分成
* 文件
* 文件夹
* Git 仓库
Git 仓库负责了拆分。文件的作用就是“集成”。比如最最常用的方式
```ts
function functionA() {
funcitonB();
functionC();
}
```
我们把 functionA 放在 A 中,functionB 和 functionC 放在 B/C 中。这就是最常用的“编排”集成方式。通过把它们放在一个文件中,我们声明了 functionB 要发生在 functionC 之前,说明了时间上的顺序规则。
如果我们用的是 React 写界面,可以声明
```ts
function functionA() {
return <ul><li><functionB/></li><li><functionC/></li></ul>
}
```
这个就说明了在界面上,functionB 要放在 functionC 的上一行。通过一个文件,说明了空间上的顺序规则。
这也说明了文件的主要意义,它是用来把逻辑**在时间和空间上做集成**的。
说明在空间上,多个Git仓库是如何组合的,哪个在左哪个在右。
说明在时间上,多个Git仓库是互相交互的,哪个在前哪个在后。
如果两行代码,写在同一个文件,和写两个文件里,没有啥区别。
那说明这两行代码没有必要强行塞到同一个文件里。比如你写了一个 User.ts,有用户可以发招租的界面样式代码,也有用户买外卖的处理过程代码。
这些没有强烈时空上集成规则的两个东西都强行塞到 User.ts 里,实际上就没有利用好“文件”的特殊性质,是对稀缺注意力资源的浪费。
我们如果拆出了 B 和 C 这两个 Git 仓库。理论上只有两种把 B 和 C 集成起来的办法。
# 顶层编排
引入一个 A 仓库,它依赖了 B 和 C。

集成"文件"定义在依赖的最顶层里。
# 依赖倒置
引入一个 A 仓库,提供接口。由 B 和 C 实现这个接口,插入到 A 上。就像主板和显卡那样,A 就是主板,B 和 C 就是显卡。

在 B 和 C 上面还需要一个仓库 D 把大家都包括进去,但是这个仓库里可以没有业务逻辑了。
集成"文件"定义在依赖的最底层。
与顶层编排的区别在于,编排的方式里,A 是可以依赖任意 B 和 C 的实现细节的,没有必要声明哪些是接口,哪些是实现。
在依赖倒置的模式下,如果 A 没有声明接口让 B 和 C 实现,B 和 C 就没有办法通过 A 把它们俩集成到一起去。
依赖倒置在传统的思维里是为了让代码更“可复用”。如果明显是一次性的业务,是不是一定不需要依赖倒置。
或者说依赖倒置了,一定是追求复用呢?
我觉得,依赖倒置主要的目的是让做集成的Git仓库依赖最少。依赖越多,能力就强大,就越难抵制被“往里面加代码的诱惑”。
顶层编排的做法里,编排处于依赖关系的最顶层,能力最强大,从而也最容易变成大杂烩。
在拆分 Git 仓库的前提下,集成代码变动越频繁,需要付出的沟通成本就越大。
Autonomy 的核心关键就是负责集成Git仓库的接口尽量稳定,少修改。
一方面是选择更模糊信息量少的接口,例如能用UI集成的,就不要用数据集成。
另外一方面就是最小化接口部分的代码量,能用两个参数搞定的,就不要用三个参数。
依赖倒置是一种“抑制剂”,它使得集成代码的修改更困难,更不方便,从而去迫使开发者会更慎重地去设计接口。
# 如何实现依赖倒置?
要实现依赖倒置有运行时和编译时两大类做法,无数种具体实现。这里列举几种代表性的。
## 运行时:组合函数
以 TypeScript 示例。
我们可以在 A 中写这样的一个接口
```ts
function functionA(b: () => void, c: () => void) {
b();
c();
}
```
然后在 B 和 C 中写两个函数
```ts
function functionB() {
console.log('b');
}
```
```ts
function functionC() {
console.log('c');
}
```
然后在 D 中组装,添加 A,B,C 三个 Git 仓库做为依赖,并调用 functionA:
```ts
const functionA = require('A');
const functionB = require('B');
const functionC = require('C');
function functionD() {
functionA(functionB, functionC);
}
```
## 运行时:组合对象
以 TypeScript 示例。
我们可以在 A 中写这样的一个接口
```ts
function functionA(b: { doSomething(): void; }, c: { doSomething(): void; }) {
b.doSomething();
c.doSomething();
}
```
然后在 B 和 C 中写两个对象
```ts
const b = {
doSomething: function() {
console.log('b');
}
}
```
```ts
const c = {
doSomething: function() {
console.log('c');
}
}
```
然后在 D 中组装,添加 A,B,C 三个 Git 仓库做为依赖,并调用 functionA:
```ts
const functionA = require('A');
const b = require('B');
const c = require('C');
function functionD() {
functionA(b, c);
}
```
## 编译时:模板
以 C++ 为例。
我们可以在 A 中写这样的一个接口
```c++
template<typename TB, typename TC>
void functionA() {
TB::doSomething();
TC::doSomething();
}
```
然后在 B 和 C 中写两个类
```c++
#include <iostream>
class ClassB {
public:
static void doSomething() {
std::cout << 'b' << std::endl;
}
};
```
```c++
#include <iostream>
class ClassC {
public:
static void doSomething() {
std::cout << 'c' << std::endl;
}
};
```
然后在 D 中组装,添加 A,B,C 三个 Git 仓库做为依赖,并调用 functionA:
```ts
#include "A.hpp"
#include "B.hpp"
#include "C.hpp"
void functionD() {
functionA<ClassB, ClassC>();
}
```
## 编译时:函数替换
以 TypeScript 为例
我们可以在 A 中写这样的一个接口
```ts
class A {
public a() {
this.b();
this.c();
}
public b() {
throw new Error('not implemented');
}
public c() {
throw new Error('not implemented');
}
}
```
然后在 B 和 C 的 Git 仓库中“覆盖” ClassA 的实现
```ts
// 在同样的文件夹和文件名中定义
class A {
@override
public b() {
console.log('b');
}
}
```
```ts
// 在同样的文件夹和文件名中定义
class A {
@override
public c() {
console.log('c');
}
}
```
然后在 D 中组装,添加 A,B,C 三个 Git 仓库做为依赖:
```json
{
"name": "@someOrg/D",
"version": "0.0.1",
"dependencies": {
"@someOrg/A": "0.0.1",
"@someOrg/B": "0.0.1",
"@someOrg/C": "0.0.1"
}
}
```
然后需要用编译工具,在编译 D 的时候,因为 B/C 中的 ClassA 与 A中的 ClassA 同文件夹且同文件名,替换 ClassA 中的函数。
这样就达到了和 C++ 模板类似的效果。
## 运行时:Vue 插槽
Vue 的插槽和 TypeScript 函数组合是类似的。
我们可以在 A 中写这样的一个接口
```html
<!-- A.vue -->
<div class="container">
<header>
<slot name="header"></slot>
</header>
<footer>
<slot name="footer"></slot>
</footer>
</div>
```
然后在 B 和 C 中写两个组件
```html
<!-- B.vue -->
<div>b</div>
```
```html
<!-- C.vue -->
<div>c</div>
```
然后在 D 中组装,添加 A,B,C 三个 Git 仓库做为依赖,调用 A 组件:
```html
<A>
<template #header>
<B/>
</template>
<template #header>
<C/>
</template>
</A>
```
## 编译时:页面模板替换
和函数替换一样,也可以对页面模板做替换。
我们可以在 A 中写这样的一个接口
```html
<!-- A.tm -->
<template #default>
<div class="container">
<header>
<B/>
</header>
<footer>
<C/>
</footer>
</div>
</template>
<template #B>
</template>
<template #C>
</template>
```
然后在 B 和 C 中覆盖 A.tm 页面模板中的子模板
```html
<!-- 在同样的文件夹和文件名中定义 -->
<override #B>
<div>b</div>
</override>
```
```html
<!-- 在同样的文件夹和文件名中定义 -->
<override #C>
<div>c</div>
</override>
```
然后在 D 中组装,添加 A,B,C 三个 Git 仓库做为依赖:
```json
{
"name": "@someOrg/D",
"version": "0.0.1",
"dependencies": {
"@someOrg/A": "0.0.1",
"@someOrg/B": "0.0.1",
"@someOrg/C": "0.0.1"
}
}
```
然后需要用编译工具,在编译 D 的时候,因为 B/C 中的 A.tm 与 A中的 A.tm 同文件夹且同文件名,替换 A.tm 中的子模板。
这样就达到了和 C++ 模板类似的效果。
# 显式组合与隐式组合
显式组合需要在代码中定义新的函数或者类,由新定义的函数或者类来组装原有的东西。例如
```ts
const functionA = require('A');
const functionB = require('B');
const functionC = require('C');
function functionD() {
functionA(functionB, functionC);
}
```
优点是组装非常灵活,可以表达任意复杂的逻辑。缺点是组装非常灵活,导致实际运行时的装配关系很难阅读代码得知。
隐式组合是指:
```json
{
"name": "@someOrg/D",
"version": "0.0.1",
"dependencies": {
"@someOrg/A": "0.0.1",
"@someOrg/B": "0.0.1",
"@someOrg/C": "0.0.1"
}
}
```
仅仅声明 Git 仓库之间的依赖关系。由编译工具,根据同文件夹,同文件名做函数和模板替换。这样的隐式组合缺点是依赖特殊编译工具链,好处是搞不出花样,仅仅实现了依赖倒置的目的,而不具有二次动态装配的能力(以及随之而来的理解成本)。
# 主板 + 插件
前面我们看了5种需求模式,在各种需求下用依赖倒置来把集成代码放到底层Git仓库里。
使用隐式组合的方式来做依赖倒置,顶层的Git仓库里就没代码了,可以保证除了依赖最底层被倒置的那个模块,其他地方都写不了集成代码。

这两点就实现了“主板+插件”的业务拆分方式。用编译器保证了,容易写出幺蛾子的代码都是集中在一个(主板)Git仓库里的。
在做 Code Review 的时候,只需要重点观照倒置到底层的集成Git仓库是否合理。
所谓合理,就是能不改就不改。除非不开槽,不开扩展点,需求在插件中无法实现了。
“主板+插件”不仅仅可以写 Visual Studio Code 这样的 IDE,对于各种类型的业务系统都是同样适用的。
只是 VsCode 可能一个插件点上可以有多个插件,而业务系统上一般不会有那么多彼此可替换的插件,更多是一个萝卜一个坑的搞法。
主板部分一定要尽可能的小,要不然就会变成所有的需求都要堆到主板里去实现了。
那我们只要一个主板吗?并不是这样的,主板的需求来自于 UI 界面的耦合,以及混合流程的耦合。
如果两个业务需求都有完全独立的界面,流程上可以拆分为事件驱动的,那完全可以写两个主板,彼此独立的发展。
比如说我们有一个主板承载了商城订单的界面和流程,来了一个淘宝商品搬家的需求。
这个淘宝商品搬家有独立的UI,只需要商城开个写入商品的接口就可以完成需求。
类似这样的需求就没有必要写成插件,插到商城主板上,而是独立有一个“商品搬家”的主板。
这种写法和面向对象设计中的依赖注入等理念是不是一回事?从倒置的角度是一回事。但是这里有两个关键词:
* 依赖:是指 Git 仓库之间的依赖关系
* 倒置:把集成代码放在依赖关系的底层
过去我们在做设计的时候只做到了倒置,但是并没有关注Git仓库的依赖关系。

这两个禁止才是关键。
* 禁止主板Git仓库反向依赖插件Git仓库
* 禁止插件Git仓库之间互相依赖
* 根据5种需求模式设计尽可能黑盒的接口,使得主板不用那么频繁的修改
听起来很难。但是比泛泛而谈的“高内聚/低耦合”要好操作多了。
# 中台?集成!
中国企业喜欢包办一个客户的所有需求,这和国外崇尚专业化的做法是非常不同的。这就导致了中国式的 App 从需求上就包括
* 所有的功能都要挤到同一个App的同一个界面的同一个流程里去实现。特别是要往主业务里挤,这样才能分到流量。
* 业务与业务之间有网状的互联互通需求。比如 Uber 就不会分专车,快车,优享。但是国内的业务就会分得很细,彼此之间又要倒流升舱一键呼叫。
中台的出现,不是为了复用,减少新业务的软件开发成本。软件开发能有多少成本,或者说能省多少成本。
不是因为我们认为需求都差不多,可以归纳出可复用的预制件,然后沉淀到中台去。
中台的本质是为了让上面这样的深度整合的需求因为集中到一个部门能做得更快一些。这种类型的需求也许是有中国特色的。
与传统企业财务集中那样的离线整合不同,这里的集成需求需要是在线,深入参与客户交互体验过程之中的。
如果让主界面被任意一个业务所全部独占,其他业务与其合作就阻力会更大一些。
“收口”到中台可以方便业务之间实现稀缺资源的共享(分配,撕逼),也方便业务之间的互联互通,减少适配成本。
中台的本质是“中间的台”,是因为其位置在中间,把各种业务各种功能整合集成到了一起。
过去某种特定的实现中台的技术方案可能会过时,会消失。
但是只要中国式的 App 风格不变化,对中台的需求是不会消失的。
最大化客户 LTV 在获客成本高企的今天有其合理性。
技术是为业务成功服务的。如果业务需要高复杂度的逻辑整合,那么技术写得出来得写,写不出来也得写。
希望前面提过的几种业务逻辑拆分模式可以让我们对于中台该做什么,不该做什么,有一个不同的视角的认识。
以这个[虚构故事](https://zhuanlan.zhihu.com/p/82586450)自省:
```
中台部门自称自己是 Software Product Line,提供了一堆预制件以及装配用的 DSL,能加速新业务的快速上线与试错。
CTO 希望中台是 Central Platform 削平内部的山头,打通数据和权限的利器。
实际不小心落地成了 Middle Office(Middle 衙门),只要从此过,留下买路财的官僚机构。
```
当我们拆分出了一堆Git仓库之后,
对于某些集成的需求(并不是所有的集成需求都是如此)使用星型的集成比点对点的集成更经济。
这个负责集成的Git仓库需不需要一个专职的团队,是不是一定要是独立的进程,是不是要创建一个名为中台的组织?
与财务,法务,市场,营销,人力资源等职能不同,这些职能是有自己的专职工作内容的,对技能的要求是有专业性的。
有 HRBP,那需要中台 BP 吗?
业务逻辑拆分模式只探讨到Git仓库的拆分,关于Git仓库如何与组织架构对应起来,留给读者自行寻找答案。 | 8,583 | CC0-1.0 |
---
layout: post
title: "Chrome扩展推荐:可在线编辑图片的 QuickSearch"
date: 2010-03-31 17:12
author: Eyon
comments: true
tags: [Chrome, Chrome扩展, QuickSearch, 中国人]
---
感谢 [Chrome迷](http://www.chromi.org/)读者 [王祥](http://searchforchrome.googlecode.com/) 的投递
国内第一款拖拽图片直接编辑的扩展
<p style="text-align: center;"><a href="http://pic002.cnblogs.com/img/wangxiang/201003/2010033014231684.png"></a>
最新版的QuickSearch(v1.10)支持在线编辑和保存网页图片了。
<a href="http://pic002.cnblogs.com/img/wangxiang/201003/2010033014233741.png"></a>
在选项里,还能设置更多的操作。
<!--more-->
<a href="http://pic002.cnblogs.com/img/wangxiang/201003/2010033014235311.png"></a>
点击链接下载安装此扩展: [http://searchforchrome.googlecode.com/files/quicksearch-1.10.0.crx](http://searchforchrome.googlecode.com/files/quicksearch-1.10.0.crx) | 1,063 | Apache-2.0 |
---
title: 快速开始
order: 0
---
`markdown:docs/common/style.md`
地图行政区划组件,支持世界地图,中国地图省市县三级,支持中国地图省市县上钻下取。
## 使用
**using modules**
```javascript
import { WorldLayer } from '@antv/l7-district';
```
**CDN 版本引用**
CDN 引用所有的方法都在 L7.District 命名空间下。
```html
<head>
<! --引入最新版的L7-District -->
<script src="https://unpkg.com/@antv/l7-district"></script>
</head>
```
```javascript
import { WorldLayer } from '@antv/l7-district';
/**
* L7.District.WorldLayer()// CDN 引用
* */
new WorldLayer(scene, {
data: [],
fill: {
color: {
field: 'NAME_CHN',
values: [
'#feedde',
'#fdd0a2',
'#fdae6b',
'#fd8d3c',
'#e6550d',
'#a63603',
],
},
},
stroke: '#ccc',
label: {
enable: true,
textAllowOverlap: false,
field: 'Short_Name_ZH',
},
popup: {
enable: false,
Html: (props) => {
return `<span>${props.Short_Name_ZH}</span>`;
},
},
});
```
## 简介
District 支持下面几种图
- WorldLayer 世界地图
- CountryLayer 国家地图,目前只支持中国
- ProvinceLayer 省级地图
- CityLayer 市级地图
- CountyLayer 县级地图
- DrillDownLayer 上钻下取地图
## 构造函数
参数:
- scene L7 scene 对象
- option 行政区划配置项
- zIndex 图层绘制顺序
- data `Array` 属性数据用于可视化渲染
- joinBy 数据关联,属性数据如何内部空间数据关联绑定 目前支持 NAME_CHN,adcode 字段连接
对照表 `Array [string, string]` 第一个值为空间数据字段,第二个为传入数据字段名
- depth 数据显示层级 0:国家级,1:省级,2: 市级,3:县级
- label 标注配置项 支持常量,不支持数据映射
- enable `boolean` 是否显示标注
- color 标注字体颜色 常量
- field 标注字段 常量
- size 标注大小 常量
- stroke 文字描边颜色
- strokeWidth 文字描边宽度
- textAllowOverlap 是否允许文字压盖
- opacity 标注透明度
- fill 填充配置项 支持数据映射
- color 图层填充颜色,支持常量和数据映射
常量:统一设置成一样的颜色
数据映射
- field 填充映射字段
- values 映射值,同 color 方法第二个参数数组,回调函数
- style 同 polygonLayer 的 style 方法
- activeColor 鼠标滑过高亮颜色
- bubble 气泡图
- enable `boolean` 是否显示气泡 default false
- color 气泡颜色 支持常量、数据映射
- size 气泡大小 支持常量、数据映射
- shape 气泡形状 支持常量、数据映射
- style 气泡图样式 同 PointLayer
- stroke 填充描边颜色
- strokeWidth 填充描边宽度
- autoFit 是否自动缩放到图层范围 `boolean`
- popup 信息窗口
- enable 是否开启 `boolean`
- triggerEvent 触发事件 例如 'mousemove' | 'click';
- Html popup html 字符串,支持回调函数 (properties: any) => string;
- chinaNationalStroke 中国国界线颜色
- chinaNationalWidth 中国国界线宽度
- coastlineStroke 海岸线颜色
- coastlineWidth 海岸线宽度 `WorldLayer` `CountryLayer`
- nationalWidth 国界线 `WorldLayer` `CountryLayer`
- nationalStroke 国界线 `WorldLayer` `CountryLayer`
- provinceStroke 省界颜色 `CountryLayer`
- provinceStrokeWidth 省界宽度 `CountryLayer`
- cityStroke 市级边界颜色 `CountryLayer`
- cityStrokeWidth 市级边界宽度 `CountryLayer`
- countyStroke 县级边界颜色 `CountryLayer`
- countyStrokeWidth 县级边界宽度 `CountryLayer`
### 数据
District 提供 polygon 数据需要跟用户的属性数据,通过关系字段进行连接
- [国家名称对照表](https://gw.alipayobjects.com/os/bmw-prod/b6fcd072-72a7-4875-8e05-9652ffc977d9.csv)
- [省级行政名称*adcode*对照表.csv](https://gw.alipayobjects.com/os/bmw-prod/2aa6fb7b-3694-4df3-b601-6f6f9adac496.csv)
- [市级行政区划及编码](https://gw.alipayobjects.com/os/bmw-prod/d2aefd78-f5df-486f-9310-7449cc7f5569.csv)
- [县级行政区名称级编码](https://gw.alipayobjects.com/os/bmw-prod/fafd299e-0e1e-4fa2-a8ac-10a984c6e983.csv)
### 属性
行政区划组件每个图层有多个子图层组成,如标注层,国界线、省界线等等,
#### fillLayer
### 方法
#### updateData(data, joinBy)
更新显示数据,
参数:
- data 需要更新的数据
- joinBy 关联字段 可选,如果不设置保持和初始化一致。
#### show
显示图层
#### hide
图层隐藏不显示
#### destroy
移除并销毁图层 | 3,345 | MIT |
---
title: "雲端商務持續性 - 資料庫復原 - SQL Database | Microsoft Docs"
description: "了解 Azure SQL Database 如何支援雲端商務持續性和資料庫復原,以及如何協助維持任務關鍵性雲端應用程式持續執行。"
keywords: "business continuity,cloud business continuity,database disaster recovery,database recovery,商務持續性,雲端商務持續性,資料庫災害復原,資料庫復原"
services: sql-database
documentationcenter:
author: anosov1960
manager: jhubbard
editor:
ms.assetid: 18e5d3f1-bfe5-4089-b6fd-76988ab29822
ms.service: sql-database
ms.custom: business continuity
ms.devlang: NA
ms.topic: get-started-article
ms.tgt_pltfrm: NA
ms.workload: NA
ms.date: 10/13/2016
ms.author: carlrab;sashan
translationtype: Human Translation
ms.sourcegitcommit: 2ea002938d69ad34aff421fa0eb753e449724a8f
ms.openlocfilehash: b2653afe1aeb920ef7e14f3e15501c8541c43219
---
# <a name="overview-of-business-continuity-with-azure-sql-database"></a>使用 Azure SQL Database 的商務持續性概觀
本概觀說明 Azure SQL Database 針對商務持續性和災害復原所提供的功能。 它提供從可能導致資料遺失或造成資料庫和應用程式無法使用的干擾性事件復原的選項、建議和教學課程。 討論包含當使用者或應用程式錯誤影響資料完整性、Azure 區域中斷,或您的應用程式需要維護時該如何處理。
## <a name="sql-database-features-that-you-can-use-to-provide-business-continuity"></a>您可用來提供商務持續性的 SQL Database 功能
SQL Database 提供幾種商務持續性功能,包括自動備份和選用的資料庫複寫。 每個功能對於預估的復原時間 (ERT) 都有不同的特性,最近的交易都有可能遺失資料。 一旦您了解這些選項,就可以在其中選擇,而在大部分情況下,可以針對不同情況一起搭配使用。 當您開發商務持續性方案時,您必須了解應用程式在干擾性事件之後完全復原的最大可接受時間 - 這是您的復原時間目標 (RTO)。 您也必須了解在干擾性事件之後復原時,應用程式可忍受遺失的最近資料更新 (時間間隔) 最大數量 - 復原點目標 (RPO)。
下表針對三種最常見的案例提供 ERT 與 RPO 的比較。
| 功能 | 基本層 | 標準層 | 高階層 |
| --- | --- | --- | --- |
| 從備份進行時間點還原 |7 天內的任何還原點 |35 天內的任何還原點 |35 天內的任何還原點 |
| 從異地複寫備份進行異地還原 |ERT < 12 小時,RPO < 1 小時 |ERT < 12 小時,RPO < 1 小時 |ERT < 12 小時,RPO < 1 小時 |
| 從 Azure 備份保存庫還原 |ERT < 12 小時,RPO < 1 週 |ERT < 12 小時,RPO < 1 週 |ERT < 12 小時,RPO < 1 週 |
| 主動式異地複寫 |ERT < 30 秒,RPO < 5 秒 |ERT < 30 秒,RPO < 5 秒 |ERT < 30 秒,RPO < 5 秒 |
### <a name="use-database-backups-to-recover-a-database"></a>使用資料庫備份來復原資料庫
SQL Database 會每週自動執行完整資料庫備份、每小時自動執行差異資料庫備份,以及每 5 分鐘自動執行交易記錄備份,透過這樣的備份組合來防止您的企業遺失資料。 針對「標準」和「進階」服務層中的資料庫,這些備份會在本地備援儲存體中儲存達 35 天,如果是「基本」服務層中的資料庫,則儲存天數為 7 天 - 如需有關服務層的更多詳細資料,請參閱 [服務層](sql-database-service-tiers.md) 。 如果服務層的保留期間不符合您的企業需求,您可以 [變更服務層](sql-database-scale-up.md)來增長保留期間。 完整和差異資料庫備份也會複寫到[配對的資料中心](../best-practices-availability-paired-regions.md),以防止發生資料中心中斷的情況。 如需更多詳細資料,請參閱[自動資料庫備份](sql-database-automated-backups.md)。
如果您的應用程式內建保留期間不足,可以藉由針對資料庫設定長期保留期原則來擴充。 如需詳細資訊,請參閱[長期保存](sql-database-long-term-retention.md)。
您可以使用這些自動資料庫備份,將資料庫從各種干擾性事件復原,不論是在您的資料中心內復原,還是復原到另一個資料中心,都可以。 使用自動資料庫備份時,預估的復原時間取決於數個因素,包括在相同區域中同時進行復原的資料庫總數、資料庫大小、交易記錄大小,以及網路頻寬。 大部分情況下,復原時間會小於 12 小時。 復原到另一個資料區域時,每小時差異資料庫備份的異地備援儲存體就限制為可能遺失 1 小時的資料。
> [!IMPORTANT]
> 若要使用自動備份來進行復原,您必須是「SQL Server 參與者」角色的成員或訂用帳戶擁有者 - 請參閱 [RBAC︰內建角色](../active-directory/role-based-access-built-in-roles.md)。 您可以使用 Azure 入口網站、PowerShell 或 REST API 來進行復原。 您無法使用 Transact-SQL。
>
>
如果您的應用程式有下列狀況,可以使用自動備份做為您的商務持續性和復原機制︰
* 非關鍵性應用程式。
* 沒有繫結 SLA,因此停機 24 小時或更長的時間不會衍生財務責任。
* 資料變更率低 (每小時的交易次數低),並且最多可接受遺失一小時的資料變更。
* 成本有限。
如果您需要更快速的復原,請使用 [主動式異地複寫](sql-database-geo-replication-overview.md) (接下來將討論)。 如果您需要能夠復原 35 天前的資料,請考慮將您的資料庫定期封存成 BACPAC 檔案 (一種包含您資料庫結構描述和相關資料的壓縮檔案),並儲存在 Azure Blob 儲存體或您所選擇的另一個位置中。 如需有關如何建立交易一致資料庫封存的詳細資訊,請參閱[建立資料庫複本](sql-database-copy.md)和[匯出資料庫複本](sql-database-export.md)。
### <a name="use-active-geo-replication-to-reduce-recovery-time-and-limit-data-loss-associated-with-a-recovery"></a>使用主動式異地複寫減少復原時間,並限制與復原相關聯的資料遺失
除了在發生業務中斷時使用資料庫備份來進行資料庫復原之外,您還可以使用 [主動式異地複寫](sql-database-geo-replication-overview.md) 來設定資料庫,在您選擇的區域中最多可擁有 4 個可讀取的次要資料庫。 這些次要資料庫會使用非同步複寫機制與主要資料庫保持同步。 此功能可用來防範資料中心中斷或應用程式升級期間的業務中斷。 「主動式異地複寫」也可用來為地理位置分散的使用者,就唯讀查詢方面提供較佳的查詢效能。
如果主要資料庫意外離線,或者您需要離線進行維護活動,可以快速將次要升級成主要 (也稱為容錯移轉),並且設定應用程式連線到新升級的主要資料庫。 使用計劃性容錯移轉時,不會有任何資料遺失。 使用非計劃性容錯移轉時,則由於非同步複寫的性質緣故,可能會有一些少量的資料遺失。 容錯移轉之後,無論是根據計畫或當資料中心再次上線時,就可以容錯回復。 在所有情況下,使用者都會經歷短暫的停機時間,而需要重新連線。
> [!IMPORTANT]
> 若要使用主動式異地複寫,您必須是訂用帳戶擁有者,或是在 SQL Server 中擁有系統管理權限。 您可以使用 Azure 入口網站、PowerShell 或 REST API,透過訂用帳戶的權限,或使用 Transact-SQL 透過 SQL Server 中的權限,來設定和容錯移轉。
>
>
如果您的應用程式符合下列任何準則,就使用主動式異地複寫:
* 是關鍵性應用程式。
* 具有服務等級協定 (SLA),不允許 24 小時以上的停機時間。
* 停機時間會衍生財務責任。
* 具有很高的資料變更率,而且不接受遺失一個小時的資料。
* 與潛在的財務責任和相關企業損失相較下,使用主動式異地複寫的額外成本較低。
## <a name="recover-a-database-after-a-user-or-application-error"></a>在使用者或應用程式錯誤之後復原資料庫
* 沒有人是完美的! 使用者可能會不小心刪除某些資料、不小心卸除重要的資料表,或甚至是卸除整個資料庫。 或者,應用程式可能會因為應用程式缺陷,而意外以不正確的資料覆寫正確的資料。
在此案例中,以下是您的復原選項。
### <a name="perform-a-point-in-time-restore"></a>執行還原時間點
您可以使用自動備份,將資料庫的複本復原到已知是在資料庫保留期限內的時間點。 資料庫還原之後,您可以將原始資料庫取代為還原的資料庫,或從還原的資料將所需的資料複製到原始資料庫。 如果資料庫使用主動式異地複寫,我們建議從還原的複本將所需的資料複製到原始資料庫。 如果您將原始資料庫取代為還原的資料庫,則必須重新設定並重新同步處理主動式異地複寫 (大型資料庫可能要花費很久的時間)。
如需詳細資訊以及使用 Azure 入口網站或 PowerShell 將資料庫還原至某個時間點的詳細步驟,請參閱 [還原時間點](sql-database-recovery-using-backups.md#point-in-time-restore)。 您無法使用 Transact-SQL 進行復原。
### <a name="restore-a-deleted-database"></a>還原已刪除的資料庫
如果資料庫已刪除,但邏輯伺服器尚未刪除,您可以將已刪除的資料庫還原到它被刪除時的時間點。 這會將資料庫備份還原到資料庫被刪除的相同邏輯 SQL 伺服器。 您可以使用原始名稱還原,或是為還原的資料庫提供新的名稱。
如需詳細資訊以及使用 Azure 入口網站或 PowerShell 來還原已刪除資料庫的詳細步驟,請參閱 [還原已刪除的資料庫](sql-database-recovery-using-backups.md#deleted-database-restore)。 您無法使用 Transact-SQL 進行還原。
> [!IMPORTANT]
> 如果邏輯伺服器已刪除,您就無法復原已刪除的資料庫。
>
>
### <a name="restore-from-azure-backup-vault"></a>從 Azure 備份保存庫還原
如果在自動備份的目前保留期間外發生資料遺失,且您的資料庫設定為長期保留,則您可以從 Azure 備份保存庫的每週備份還原至新的資料庫。 目前,您可以將原始資料庫取代為還原的資料庫,或從還原的資料庫將所需的資料複製到原始資料庫。 如果您需要在主要應用程式升級之前擷取舊版資料庫,請滿足稽核員或合法順序的要求,您可以使用 Azure 備份保存庫中儲存的完整備份來建立新的資料庫。 如需詳細資訊,請參閱[長期保存](sql-database-long-term-retention.md)。
## <a name="recover-a-database-to-another-region-from-an-azure-regional-data-center-outage"></a>將資料庫從 Azure 區域資料中心中斷復原到另一個區域
<!-- Explain this scenario -->
雖然很罕見,但 Azure 資料中心也可能會有中斷的時候。 發生中斷時,可能只會讓業務中斷幾分鐘,也可能會持續幾小時。
* 其中一個選項是在資料中心中斷結束時等待您的資料庫重新上線。 這適用於可以容忍資料庫離線的應用程式。 例如,您不需要不斷處理的開發專案或免費試用版。 當資料中心中斷時,您不會知道中斷會持續多久,因此這個選項僅適用於您可以一段時間暫時不需要資料庫。
* 另一個選項是容錯移轉到另一個資料區域 (如果您使用主動式異地複寫) 或使用異地備援資料庫備份進行復原 (異地還原)。 容錯移轉只需要幾秒鐘的時間,而從備份復原則需要幾個小時。
當您採取行動時,復原所需的時間,以及資料中心中斷而導致多少資料遺失,取決於您如何決定在應用程式中使用上述討論的商務持續性功能。 事實上,您可以根據應用程式需求,選擇使用資料庫備份和主動式異地複寫的組合。 若要探討使用這些商務持續性功能針對獨立資料庫和彈性集區進行應用程式設計時的考量,請參閱[設計雲端災害復原應用程式](sql-database-designing-cloud-solutions-for-disaster-recovery.md)和[彈性集區災害復原策略](sql-database-disaster-recovery-strategies-for-applications-with-elastic-pool.md)。
下列各節概述使用資料庫備份或主動式異地複寫來進行復原的步驟。 如需包括規劃需求的詳細步驟、復原後步驟,以及有關如何模擬中斷以執行災害復原演練的資訊,請參閱 [從中斷復原 SQL Database](sql-database-disaster-recovery.md)。
### <a name="prepare-for-an-outage"></a>準備中斷
無論您要使用何種商務持續性功能,您都必須︰
* 識別並準備目標伺服器,包括伺服器層級防火牆規則、登入和 master 資料庫層級權限。
* 決定如何將用戶端和用戶端應用程式重新導向到新的伺服器
* 記錄其他相依性,例如稽核設定和警示
如果您沒有適當地規劃和準備,在容錯移轉或復原後讓應用程式上線將會多花費時間,而且也可能需要在有壓力的情況下進行疑難排解 - 這是不良的情況組合。
### <a name="failover-to-a-geo-replicated-secondary-database"></a>容錯移轉至異地複寫的次要資料庫
如果您使用「主動式異地複寫」作為復原機制,請 [強制容錯移轉至異地複寫的次要資料庫](sql-database-disaster-recovery.md#failover-to-geo-replicated-secondary-database)。 在幾秒鐘內,次要資料庫就會升級成為新的主要資料庫,而且準備好記錄新的交易,並回應任何查詢 - 只會遺失幾秒尚未複寫的資料。 如需有關將容錯移轉程序自動化的資訊,請參閱 [設計雲端災害復原應用程式](sql-database-designing-cloud-solutions-for-disaster-recovery.md)。
> [!NOTE]
> 當資料中心再次上線時,您就可以選擇容錯回復到原始的主要資料庫。
>
>
### <a name="perform-a-geo-restore"></a>執行異地還原
如果您使用自動備份搭配異地備援儲存體複寫作為復原機制,請 [使用異地還原起始資料庫復原](sql-database-disaster-recovery.md#recover-using-geo-restore)。 復原通常會在 12 小時內進行 - 視最後一次每小時差異備份的執行和複寫時間而定,最多可能遺失 1 小時的資料。 在復原完成之前,資料庫無法記錄任何交易或回應任何查詢。
> [!NOTE]
> 如果資料中心在您的應用程式切換到復原的資料庫之前就再次上線,您只要取消復原即可。
>
>
### <a name="perform-post-failover-recovery-tasks"></a>執行容錯移轉後/復原後工作
從其中任何一種復原機制復原之後,您都必須執行下列額外的工作,您的使用者和應用程式才能回復正常執行狀態︰
* 重新導向用戶端與用戶端應用程式到新的伺服器與還原的資料庫
* 確定有適當的伺服器層級防火牆規則供使用者連線 (或使用 [資料庫層級防火牆](sql-database-firewall-configure.md#creating-database-level-firewall-rules))
* 確定有適當的登入和 master 資料庫層級權限 (或使用 [自主的使用者](https://msdn.microsoft.com/library/ff929188.aspx))
* 依適當情況設定稽核
* 依適當情況設定警示
## <a name="upgrade-an-application-with-minimal-downtime"></a>在最少停機時間的情況下升級應用程式
有時,應用程式會因為計劃性維護 (例如應用程式升級) 而必須離線。 [管理應用程式升級](sql-database-manage-application-rolling-upgrade.md) 說明如何使用「主動式異地複寫」來輪流升級雲端應用程式,以將升級時的停機時間縮到最短,並提供萬一發生錯誤時的復原路徑。 本文將探討兩種不同的升級程序協調方法,並討論每個選項的優缺點。
## <a name="next-steps"></a>後續步驟
如需獨立資料庫和彈性集區的應用程式設計考量探討,請參閱[設計雲端災害復原應用程式](sql-database-designing-cloud-solutions-for-disaster-recovery.md)和[彈性集區災害復原策略](sql-database-disaster-recovery-strategies-for-applications-with-elastic-pool.md)。
<!--HONumber=Nov16_HO3--> | 8,196 | CC-BY-3.0 |
---
layout: post
title: "锵锵老嘉宾 格子讲书|入心之作《天真的人类学家》"
date: 2021-06-17T12:15:06.000Z
author: 百香果文化放映空间
from: https://www.youtube.com/watch?v=x3S0w-8Gzeo
tags: [ 百香果文化放映空间 ]
categories: [ 百香果文化放映空间 ]
---
<!--1623932106000-->
[锵锵老嘉宾 格子讲书|入心之作《天真的人类学家》](https://www.youtube.com/watch?v=x3S0w-8Gzeo)
------
<div>
锵锵老嘉宾 格子讲书|入心之作《天真的人类学家》
</div> | 339 | MIT |
---
title: 如何从备份还原 Azure Cosmos DB 数据
description: 本文介绍如何从备份还原 Azure Cosmos DB 数据,如何联系 Azure 支持人员还原数据,以及数据恢复后要执行的步骤。
author: rockboyfor
ms.service: cosmos-db
ms.topic: how-to
origin.date: 09/01/2019
ms.date: 08/17/2020
ms.testscope: no
ms.testdate: ''
ms.author: v-yeche
ms.reviewer: sngun
ms.openlocfilehash: da380bb96f108588b1757451c984a6ed35544bcb
ms.sourcegitcommit: 84606cd16dd026fd66c1ac4afbc89906de0709ad
ms.translationtype: HT
ms.contentlocale: zh-CN
ms.lasthandoff: 08/14/2020
ms.locfileid: "88222710"
---
# <a name="restore-data-from-a-backup-in-azure-cosmos-db"></a>如何在 Azure Cosmos DB 中从备份还原数据
如果意外删除了数据库或容器,可以[提交支持票证]( https://support.azure.cn/support/support-azure/)或[联系 Azure 支持]( https://www.azure.cn/support/contact/),以便从自动联机备份中还原数据。 Azure 支持仅适用于选定计划(例如**标准**计划、**开发人员**计划以及更高级别的计划)。 不适用于基本计划 。 若要了解不同的支持方案,请参阅 [Azure 支持计划](https://www.azure.cn/support/plans/)页。
若要还原备份的特定快照,Azure Cosmos DB 要求在该快照的备份周期的持续时间内可用。
## <a name="request-a-restore"></a>请求还原
在请求还原之前,应该了解以下详细信息:
* 准备好订阅 ID。
* 应根据数据被意外删除或修改的方式,准备好提供其他信息。 建议提前准备可用的信息,从而尽量减少可能在某些有时效的情况下造成不良影响的来回传输。
* 如果删除了整个 Azure Cosmos DB 帐户,则需要提供删除的帐户的名称。 如果创建了同名的另一个帐户,请与支持团队共享该帐户,因为这有助于确定要选择的正确帐户。 建议为删除的每个帐户提交不同的支持票证,因为这可以最大限度地减少还原状态的混乱。
* 如果删除了一个或多个数据库,应提供 Azure Cosmos 帐户及 Azure Cosmos 数据库名,并指定是否存在同名的新数据库。
* 如果删除了一个或多个容器,应提供 Azure Cosmos 帐户名、数据库名和容器名。 并指定是否存在同名容器。
* 如果意外删除或损坏了数据,则应在 8 小时内联系 [Azure 支持](https://support.azure.cn/support/contact/),以便 Azure Cosmos DB 团队帮助你从备份中还原数据。
* 如果意外删除了数据库或容器,请提交一个严重性级别为 B 或 C 的 Azure 支持案例。
* 如果意外删除或损坏了容器中的某些文档,请提交一个严重性级别为 A 的支持案例。
发生数据损坏时,如果容器中的文档遭到修改或删除,请尽快删除容器 。 这样就可以避免 Azure Cosmos DB 覆盖备份。 如果因某种原因而无法删除,应尽快提交票证。 除了 Azure Cosmos 帐户名、数据库名、容器名以外,还应指定数据可以还原到的时间点。 务必尽量精确,因为这有助于我们确定当时可用的最佳备份。 指定 UTC 时间也很重要。
<!--MOONCAKE CUSTOMIZE on SUPPORT REQUEST-->
下面的屏幕截图说明如何为容器(集合/图/表)创建通过 Azure 门户还原数据的支持请求。 提供其他详细信息(例如数据类型、还原目的、删除数据的时间),以帮助我们设置请求的优先级。
:::image type="content" source="./media/how-to-backup-and-restore/backup-support-request-portal.png" alt-text="使用 Azure 门户创建备份支持请求":::
<!--MOONCAKE CUSTOMIZE on SUPPORT REQUEST-->
## <a name="post-restore-actions"></a>还原后的操作
还原数据后,你会收到有关新帐户名(通常采用 `<original-name>-restored1` 格式)和帐户要还原到的时间的通知。 还原的帐户与原始帐户具有相同的预配吞吐量、索引策略,并且二者位于同一区域。 角色为订阅管理员或共同管理员的用户可以看到还原的帐户。
还原数据后,应检查并验证还原的帐户中的数据,确保其中包含你需要的版本。 如果一切正常,应该使用 [Azure Cosmos DB 更改源](change-feed.md)或 [Azure 数据工厂](../data-factory/connector-azure-cosmos-db.md)将数据迁移回原始帐户。
<!-- Not Available on [Azure Data Factory](../data-factory/connector-azure-cosmos-db.md)-->
建议在迁移数据之后立即删除容器或数据库。 如果不删除已还原的数据库或容器,它们将在请求单位、存储和流出量方面产生成本。
## <a name="next-steps"></a>后续步骤
接下来,可以通过以下文章学习如何将数据迁移回原始帐户:
* 若要提出还原请求,请联系 Azure 支持,并[从 Azure 门户提交票证](https://support.azure.cn/support/support-azure/)
* [使用 Cosmos DB 更改源](change-feed.md)将数据移动到 Azure Cosmos DB。
* [使用 Azure 数据工厂](../data-factory/connector-azure-cosmos-db.md)将数据移动到 Azure Cosmos DB。
<!-- Update_Description: update meta properties, wording update, update link --> | 2,939 | CC-BY-4.0 |
---
title: '[新しいユーザー ロール] (Management Studio) | Microsoft Docs'
ms.custom: ''
ms.date: 06/13/2017
ms.prod: sql-server-2014
ms.reviewer: ''
ms.technology: reporting-services-native
ms.topic: conceptual
f1_keywords:
- sql12.swb.reportserver.newrole.f1
ms.assetid: 9f76a235-0b58-479c-8e5b-50588091b71c
author: maggiesMSFT
ms.author: maggies
manager: kfile
ms.openlocfilehash: 4b40fa294cb682746fe1b69a5fb03bf841d8e334
ms.sourcegitcommit: b87d36c46b39af8b929ad94ec707dee8800950f5
ms.translationtype: MT
ms.contentlocale: ja-JP
ms.lasthandoff: 02/08/2020
ms.locfileid: "66100132"
---
# <a name="new-user-role-management-studio"></a>[新しいユーザー ロール]\(Management Studio)
このページを使用すると、アイテムレベルのロールの定義を作成できます。 アイテムレベルのロールの定義とは、レポート サーバーによって管理されるフォルダー、レポート、モデル、リソース、および共有データ ソースに関連してユーザーが実行できるタスクを列挙する、名前付きの一連のタスクです。 アイテムレベルのロールの定義の一例として、事前定義された閲覧者ロールがあります。閲覧者ロールは、レポートのエンド ユーザーがフォルダー間の移動やレポートの表示に必要とする操作の種類を識別します。
ロールの定義の数は、それほど多くありません。 ほとんどの組織では、少数のロールの定義しか必要としません。 ただし、事前定義されたロールの定義が不十分な場合は、既存のロールの定義を変更したり、新しいロールの定義を作成したりできます。
> [!NOTE]
> ロールの定義は、ネイティブ モードで実行されているレポート サーバーでのみ使用されます。 レポート サーバーが SharePoint 統合モード用に構成されている場合、このページは使用できません。
## <a name="options"></a>オプション
**名前**
ロールの定義名を入力します。 ロールの定義名は、レポート サーバーの名前空間内で一意である必要があります。 名前には、少なくとも 1 つの英数字が含まれている必要があります。 また、スペースおよびいくつかの記号を含めることもできます。 名前を指定するときに使用できない記号は次のとおりです。
; ? : \@ & = +、$/*\< >
" /
**説明**
ロールの使用方法やロールがサポートする内容を列挙する説明を入力します。
**タスク**
このロールで実行できるタスクを選択します。 新しいタスクを作成したり、 [!INCLUDE[ssRSnoversion](../../includes/ssrsnoversion-md.md)]によってサポートされている既存のタスクを変更したりすることはできません。 アイテムレベルのロールの定義には、アイテムレベルのタスクのみを使用できます。
**タスクの説明**
タスクでサポートされる操作または権限を列挙する、タスクの説明を表示します。
## <a name="see-also"></a>参照
[Management Studio のレポート サーバーの F1 ヘルプ](report-server-in-management-studio-f1-help.md)
[ロールの定義](../security/role-definitions.md) | 1,853 | CC-BY-4.0 |
# 2021-10-29
共50条
<!-- BEGIN -->
1. [如何看待上海一餐馆声明免费添饭,环卫工连吃 7 碗饭后饭店老板翻脸怼人,老板回应「他们要打包带走」?](https://www.zhihu.com/question/495059975)
1. [网传沈阳师范大学图书馆考研资料被扔一地,备考学子当场崩溃,如何看待在图书馆用资料占位的行为?](https://www.zhihu.com/question/495198247)
1. [Netflix 剧版《三体》官宣 12 位主演,书迷怎么看这次的演员阵容?你看好这部剧的表现吗?](https://www.zhihu.com/question/495214844)
1. [为什么人类天天吃同样的东西很快会腻,但是动物比如说牛天天吃草却从不会腻?](https://www.zhihu.com/question/492888437)
1. [20 万集装箱积压在港口,美国供应链紧张,商品短缺物价上涨,你认为有哪些原因?](https://www.zhihu.com/question/494685861)
1. [一早教中心 3 岁女童被老师用胶带捆绑裹被子午休,母亲希望开除老师,该早教中心和老师面临什么法律责任?](https://www.zhihu.com/question/495000512)
1. [穷人突然有钱后能挥霍到什么程度?](https://www.zhihu.com/question/494101013)
1. [宠物狗被吊死在小区健身器材,监控显示系遛狗老人所为,警方已介入,事情将如何处置?](https://www.zhihu.com/question/495213851)
1. [杨天真签约小牛杨等 5 位大码女性,在目前审美背景下能够被接受吗?能够对这种审美造成冲击吗?](https://www.zhihu.com/question/495136577)
1. [NBA 乔丹要是放在当今联盟,还能封神吗?](https://www.zhihu.com/question/494003731)
1. [腾讯视频回应买会员后还得看广告,称「不在会员免广告特权范围」,从法律角度看,腾讯的做法是否合理?](https://www.zhihu.com/question/494785308)
1. [曲婉婷之母张明杰案关键同案人回国投案,是否将推动该案取得进展?还有哪些值得关注的细节?](https://www.zhihu.com/question/495239751)
1. [美国取消中国电信运营牌照,商务部称已向美方提出严正交涉,这释放了哪些信号?](https://www.zhihu.com/question/495095756)
1. [如何看待某平台宣布「半年内购房就报销双十一账单」,会有人参加这类高门槛活动吗?](https://www.zhihu.com/question/494883659)
1. [如何看待小米 MIX4 在双十一叠加 88VIP 再降 300,仅 3699 元起?](https://www.zhihu.com/question/495006942)
1. [如何看待 10 月 27 日开始,新加坡新增确诊新冠病例突破 5000+ 人?](https://www.zhihu.com/question/494966445)
1. [如何看待游戏《战神 4》上架 Steam 不支持简体中文?](https://www.zhihu.com/question/493926965)
1. [中年男性除了沉迷游戏外还有别的爱好吗?](https://www.zhihu.com/question/459226864)
1. [美国取消中国和欧洲等地旅行禁令,此举意味着什么?你会去美国旅游吗?](https://www.zhihu.com/question/494653257)
1. [今年冬季将形成拉尼娜事件,形成的原因是什么?部分北方城市开始提前供暖,会涉及哪些方面的工作?](https://www.zhihu.com/question/495017310)
1. [安徽一学校发现弃婴被从楼上摔下,刑警队表示遗弃者系学生,具体情况如何?遗弃者需承担怎样的法律责任?](https://www.zhihu.com/question/494638624)
1. [西北大学 23 岁研三生校内坠亡,家属称「多次遭导师辱骂,压力非常大」,还有哪些值得关注的信息?](https://www.zhihu.com/question/495105171)
1. [卢俊义在家练武成了天下第一,合理吗?](https://www.zhihu.com/question/494715870)
1. [如何看待 2021 年 Q3 国内智能手机市场份额变化,vivo 第一,荣耀超过小米排名第三?](https://www.zhihu.com/question/495117699)
1. [《长津湖》续作《水门桥》官宣,你期望影片还原哪些真实的历史细节?](https://www.zhihu.com/question/495132702)
1. [为什么越来越多的男生不喜欢穿皮鞋了?](https://www.zhihu.com/question/277260124)
1. [为什么感觉现在玩《英雄联盟》很累?](https://www.zhihu.com/question/447453640)
1. [长期吃超市里面卖的「熟食肉」好吗?喜欢吃咸味重的肉,会对身体有什么影响吗?](https://www.zhihu.com/question/492526714)
1. [如何评价 10 月新番动画《国王排名》第三集?](https://www.zhihu.com/question/495039670)
1. [为什么有的人不愿意买滚筒洗衣机?](https://www.zhihu.com/question/393287010)
1. [如何看待 HM 因销售劣质产品被罚 9 万,累计被行政处罚 30 次,屡教不改?还有哪些信息值得关注?](https://www.zhihu.com/question/495044569)
1. [有什么电影适合情侣晚上在家看?](https://www.zhihu.com/question/358887778)
1. [10 月 28 日发布的游戏《帝国时代 4》体验如何?](https://www.zhihu.com/question/494972702)
1. [如何看待「听障店主开设线上手语翻译店,月售三单仍坚持6年」,残障人士还有哪些网购需求值得被关注?](https://www.zhihu.com/question/495158426)
1. [同样是写爱情故事,为什么张爱玲和琼瑶的文学地位不一样?](https://www.zhihu.com/question/25156692)
1. [大家在计算机学习路上,都看过哪些神一般的书?](https://www.zhihu.com/question/58905568)
1. [为什么说程序员是一个极度劳累的工作?](https://www.zhihu.com/question/461572685)
1. [大特所处的时空为什么对生化人这么绝望?](https://www.zhihu.com/question/410056426)
1. [冯绍峰、文淇、范丞丞主演的电视剧《致命愿望》定档 11 月 3 日,对此你有哪些期待?](https://www.zhihu.com/question/495228653)
1. [新消费品牌盛行,盛行的是什么?](https://www.zhihu.com/question/493693161)
1. [2021年双十一有什么值得买的汽车用品?](https://www.zhihu.com/question/491731781)
1. [如果父母不同意的爱情,还要坚持吗?](https://www.zhihu.com/question/494386923)
1. [情绪低落推荐看什么书?](https://www.zhihu.com/question/491919718)
1. [你在辩论赛赛场上听到最惊艳的话是什么?](https://www.zhihu.com/question/442060907)
1. [领克09正式发布了,大家如何看待这辆车?](https://www.zhihu.com/question/493574709)
1. [有哪些适合学生党的面霜推荐?](https://www.zhihu.com/question/408588806)
1. [只用烤箱可以做出什么逆天的菜?](https://www.zhihu.com/question/20642227)
1. [高一选科已经选了化学,但是家长和我说高二化学会很难,生物会比较好学,心里很忐忑,怎么办呀?](https://www.zhihu.com/question/416822698)
1. [如何评价《DOTA2》新英雄「玛西」的技能设定?](https://www.zhihu.com/question/495210396)
1. [NBA 21-22 赛季灰熊加时 104:101 送勇士赛季首败,库里 36 分,如何评价这场比赛?](https://www.zhihu.com/question/495217119)
<!-- END --> | 4,039 | MIT |
---
title: "Learning ELF"
date: 2019-10-14
draft: false
---
In computing, the **Executable and Linkable Format** (**ELF**, formerly called **Extensible Linking Format**) is a common standard file format for executables, object code, shared libraries, and core dumps.
Unlike many proprietary executable file formats, ELF is very flexible and extensible, and it is not bound to any particular processor or Instruction set architecture|architecture. This has allowed it to be adopted by many different operating systems on many different platforms.
### ELF file layout
Each ELF file is made up of one **ELF header**, followed by file data. The file data can include:
- **Program header table**, describing zero or more **segments**
- **Section header table**, describing zero or more **sections**
- Data referred to by entries in the program header table, or the section header table
The **segments** contain information that is necessary for **runtime execution of the file**, while **sections** contain important data for **linking and relocation**. Each byte in the entire file is taken by **no more than one section at a time**, but there can be orphan bytes, which are not covered by a section. In the normal case of a Unix executable **one or more sections are enclosed in one segment**.
{{< figure src="/doc-img/elf/layout.png" alt="layout" class="img-md">}}
### ELF Header
文件开始处是一个 ELF 头部(ELF Header), 用来描述整个文件的组织, 除了 ELF 头部表以外, 其他节区和段都没有规定的顺序.
```bash
readelf -h vmlinux
```
```c
typedef struct elfhdr {
unsigned char e_ident[EI_NIDENT]; /* ELF Identification */
Elf32_Half e_type; /* object file type */
Elf32_Half e_machine; /* machine */
Elf32_Word e_version; /* object file version */
Elf32_Addr e_entry; /* virtual entry point */
Elf32_Off e_phoff; /* program header table offset */
Elf32_Off e_shoff; /* section header table offset */
Elf32_Word e_flags; /* processor-specific flags */
Elf32_Half e_ehsize; /* ELF header size */
Elf32_Half e_phentsize; /* program header entry size */
Elf32_Half e_phnum; /* number of program header entries */
Elf32_Half e_shentsize; /* section header entry size */
Elf32_Half e_shnum; /* number of section header entries */
Elf32_Half e_shstrndx; /* section header table's "section
header string table" entry offset */
} Elf32_Ehdr;
typedef struct {
unsigned char e_ident[EI_NIDENT]; /* Id bytes */
Elf64_Quarter e_type; /* file type */
Elf64_Quarter e_machine; /* machine type */
Elf64_Half e_version; /* version number */
Elf64_Addr e_entry; /* entry point */
Elf64_Off e_phoff; /* Program hdr offset */
Elf64_Off e_shoff; /* Section hdr offset */
Elf64_Half e_flags; /* Processor flags */
Elf64_Quarter e_ehsize; /* sizeof ehdr */
Elf64_Quarter e_phentsize; /* Program header entry size */
Elf64_Quarter e_phnum; /* Number of program headers */
Elf64_Quarter e_shentsize; /* Section header entry size */
Elf64_Quarter e_shnum; /* Number of section headers */
Elf64_Quarter e_shstrndx; /* String table index */
} Elf64_Ehdr;
```
{{< figure src="/doc-img/elf/header.png" alt="elf-header" class="img-lg">}}
>Magic number of ELF: 7f 45 4c 46
>Class: 02 -> ELF64
>Data: 01 -> 2's complement; little endian
>**Entry point address: [e_entry]** 0x8000 0000
>**Start of program headers, Size of program headers, Number of program headers:
> [e_phoff, e_phentsize, e_phnum]**
>**Start of section headers, Size of section headers, Number of section headers:
> [e_shoff, e_shentsize, e_shnum]**
>**Section header string table index: [e_shstrndx]** Index of string table in section table
### Program Header Table
可执行文件或者共享目标文件的程序头部是一个结构数组, 每个结构描述了一个段或者系统准备程序执行所必需的其它信息. 目标文件的“段”包含一个或者多个“节区”, 也就是“段内容(Segment Contents)”.
**程序头部仅对于可执行文件和共享目标文件有意义**
```bash
readelf -l vmlinux
```
```c
/* Program Header */
typedef struct {
Elf32_Word p_type; /* segment type */
Elf32_Off p_offset; /* segment offset */
Elf32_Addr p_vaddr; /* virtual address of segment */
Elf32_Addr p_paddr; /* physical address - ignored? */
Elf32_Word p_filesz; /* number of bytes in file for seg. */
Elf32_Word p_memsz; /* number of bytes in mem. for seg. */
Elf32_Word p_flags; /* flags */
Elf32_Word p_align; /* memory alignment */
} Elf32_Phdr;
typedef struct {
Elf64_Half p_type; /* entry type */
Elf64_Half p_flags; /* flags */
Elf64_Off p_offset; /* offset */
Elf64_Addr p_vaddr; /* virtual address */
Elf64_Addr p_paddr; /* physical address */
Elf64_Xword p_filesz; /* file size */
Elf64_Xword p_memsz; /* memory size */
Elf64_Xword p_align; /* memory & file alignment */
} Elf64_Phdr;
```
{{< figure src="/doc-img/elf/pheader.png" alt="program-header" class="img-lg">}}
> - p_type 此数组元素描述的段的类型,或者如何解释此数组元素的信息。具体如下图。
> - p_offset 此成员给出从文件头到该段第一个字节的偏移。
> - p_vaddr 此成员给出段的第一个字节将被放到内存中的虚拟地址。
> - p_paddr 此成员仅用于与物理地址相关的系统中。因为 System V 忽略所有应用程序的物理地址信息,此字段对与可执行文件和共享目标文件而言具体内容是指定的。
> - p_filesz 此成员给出段在文件映像中所占的字节数。可以为 0。
> - p_memsz 此成员给出段在内存映像中占用的字节数。可以为 0。
> - p_flags 此成员给出与段相关的标志。
> - p_align 可加载的进程段的 p_vaddr 和 p_offset 取值必须合适,相对于对页面大小的取模而言。此成员给出段在文件中和内存中如何 对齐。数值 0 和 1 表示不需要对齐。否则 p_align 应该是个正整数,并且是 2 的幂次数,p_vaddr 和 p_offset 对 p_align 取模后应该相等。
### Section Header Table
节区中包含目标文件中除了ELF 头部, 程序/节区头部表格外的所有信息, 满足以下条件:
1. 目标文件中的每个节区都有对应的节区头部描述它, 但有节区头部不意味着有节区;
2. 每个节区占用文件中一个连续字节区域(这个区域可能长度为 0);
3. 文件中的节区不能重叠, 不允许一个字节存在于两个节区中;
4. 目标文件中可能包含非活动空间(INACTIVE SPACE), 这些区域不属于任何头部和节区.
```bash
readelf -S vmlinux
```
```c
/* Section Header */
typedef struct {
Elf32_Word sh_name; /* name - index into section header string table section */
Elf32_Word sh_type; /* type */
Elf32_Word sh_flags; /* flags */
Elf32_Addr sh_addr; /* address */
Elf32_Off sh_offset; /* file offset */
Elf32_Word sh_size; /* section size */
Elf32_Word sh_link; /* section header table index link */
Elf32_Word sh_info; /* extra information */
Elf32_Word sh_addralign; /* address alignment */
Elf32_Word sh_entsize; /* section entry size */
} Elf32_Shdr;
typedef struct {
Elf64_Half sh_name; /* section name */
Elf64_Half sh_type; /* section type */
Elf64_Xword sh_flags; /* section flags */
Elf64_Addr sh_addr; /* virtual address */
Elf64_Off sh_offset; /* file offset */
Elf64_Xword sh_size; /* section size */
Elf64_Half sh_link; /* link to another */
Elf64_Half sh_info; /* misc info */
Elf64_Xword sh_addralign; /* memory alignment */
Elf64_Xword sh_entsize; /* table entry size */
} Elf64_Shdr;
```
{{< figure src="/doc-img/elf/sheader.png" alt="section-header" class="img-lg">}}
> * sh_name: 给出节区的名称, 是字符串表节区的索引;
>
> * sh_type: 为节区的内容和语义进行分类;
>
> * SHT_NULL: 非活动
>
> * SHT_PROGBITS: 包含程序定义的信息
>
> * SHT_NOBITS: 此部分不占用程序空间
>
> * SHT_SYMTAB: 符号表
>
> * SHT_STRTAB: 字符串表
>
> ......
>
> * sh_flags: 定义节区中内容是否可以修改, 执行等信息
>
> * SHF_WRITE: 节区包含进程执行过程中将可写的数据;
> * SHF_ALLOC: 此节区在进程执行过程中占用内存;
> * SHF_EXECINSTR: 节区包含可执行的机器指令;
>
> * sh_link & sh_info
#### 特殊节区
- 以“.”开头的节区名称是系统保留的, 应用程序可以使用没有前缀的节区名称, 以避 免与系统节区冲突。
- 目标文件格式允许人们定义非保留的节区
- 目标文件中也可以包含多个名字相同的节区
- 保留给处理器体系结构的节区名称一般构成为:处理器体系结构名称简写 + 节区
名称

#### Reference
[ELF文件格式分析](https://segmentfault.com/a/1190000007103522) | 7,796 | MIT |
## shared_ptr
#### 理解
share_ptr,这种智能指针思想是共享所有权,即多个指针共享一个对象,通过引用计数,当最后一个指针离开作用域时;
内存才会自动释放
#### 创建
```cpp
void main( )
{
shared_ptr<int> sptr1( new int );
}
```
使用make_shared宏来加速创建的过程。因为shared_ptr主动分配内存并且保存引用计数(reference count),make_shared 以一种更有效率的方法来实现创建工作。
```cpp
void main( )
{
shared_ptr<int> sptr1 = make_shared<int>(100);
}
```
上面的代码创建了一个shared_ptr,指向一块内存,该内存包含一个整数100,以及引用计数1.如果通过sptr1再创建一个shared_ptr,引用计数就会变成2. 该计数被称为强引用(strong reference),除此之外,shared_ptr还有另外一种引用计数叫做弱引用(weak reference),后面将介绍。
通过调用use_count()可以得到引用计数, 据此你能找到shared_ptr的数量。当debug的时候,可以通过观察shared_ptr中strong_ref的值得到引用计数。
#### 析构
shared_ptr默认调用delete释放关联的资源。如果用户采用一个不一样的析构策略时,他可以自由指定构造这个shared_ptr的策略。下面的例子是一个由于采用默认析构策略导致的问题:
```cpp
class Test
{
public:
Test(int a = 0 ) : m_a(a)
{
}
~Test( )
{
cout<<"Calling destructor"<<endl;
}
public:
int m_a;
};
void main( )
{
shared_ptr<Test> sptr1( new Test[5] );
}
```
在此场景下,shared_ptr指向一组对象,但是当离开作用域时,默认的析构函数调用delete释放资源。实际上,我们应该调用delete[]来销毁这个数组。用户可以通过调用一个函数,例如一个lamda表达式,来指定一个通用的释放步骤。
```cpp
void main( )
{
shared_ptr<Test> sptr1( new Test[5],
[ ](Test* p) { delete[ ] p; } );
}
```
通过指定delete[]来析构,上面的代码可以完美运行。
#### 问题
##### 从裸指针创建share_ptr导致crash
- 良好的写法
```cpp
void main( )
{
shared_ptr<int> sptr1( new int );
shared_ptr<int> sptr2 = sptr1;
shared_ptr<int> sptr3;
sptr3 =sptr1
```

如上图,所有的shared_ptrs拥有相同的引用计数,属于相同的组。上述代码工作良好,让我们看另外一组例子
- 错误的使用
```cpp
void main( )
{
int* p = new int;
shared_ptr<int> sptr1( p);
shared_ptr<int> sptr2( p );
}
```
上述代码会产生一个错误,因为两个来自不同组的shared_ptr指向同一个资源。下表给你关于错误原因的图景:

避免这个问题,尽量不要从一个裸指针(naked pointer)创建shared_ptr.
##### 循环引用--导致内存泄漏
```cpp
class B;
class A
{
public:
A( ) : m_sptrB(nullptr) { };
~A( )
{
cout<<" A is destroyed"<<endl;
}
shared_ptr<B> m_sptrB;
};
class B
{
public:
B( ) : m_sptrA(nullptr) { };
~B( )
{
cout<<" B is destroyed"<<endl;
}
shared_ptr<A> m_sptrA;
};
//***********************************************************
void main( )
{
shared_ptr<B> sptrB( new B );
shared_ptr<A> sptrA( new A );
sptrB->m_sptrA = sptrA;
sptrA->m_sptrB = sptrB;
}
```
上面的代码产生了一个循环引用.A对B有一个shared_ptr, B对A也有一个shared_ptr,与sptrA和sptrB关联的资源都没有被释放,参考下表:

当sptrA和sptrB离开作用域时,它们的引用计数都只减少到1,所以它们指向的资源并没有释放!!!!!
#### 注意点
1.如果几个shared_ptrs指向的内存块属于不同组,将产生错误。
2. 如果从一个普通指针创建一个shared_ptr还会引发另外一个问题。在上面的代码中,考虑到只有一个shared_ptr是由p创建的,代码可以好好工作。万一程序员在智能指针作用域结束之前删除了普通指针p。天啦噜!!!又是一个crash。
3. 循环引用:如果共享智能指针卷入了循环引用,资源都不会正常释放。
为了解决循环引用,C++提供了另外一种智能指针:weak_ptr
### unique_ptr
独享指针所有权,不能进行赋值,
#### 理解
unique_ptr也是对auto_ptr的替换。unique_ptr遵循着独占语义。在任何时间点,资源只能唯一地被一个unique_ptr占有。当unique_ptr离开作用域,所包含的资源被释放。如果资源被其它资源重写了,之前拥有的资源将被释放。所以它保证了他所关联的资源总是能被释放。
#### 使用
##### 创建
1. 创建非数组类型
与shared_ptr一样
```cpp
unique_ptr<int> uptr( new int );
```
2. 创建数组类型
unique_ptr提供了创建数组对象的特殊方法,当指针离开作用域时,调用delete[]代替delete。当创建unique_ptr时,这一组对象被视作模板参数的部分。这样,程序员就不需要再提供一个指定的析构方法,如下:
```cpp
unique_ptr<int[ ]> uptr( new int[5] );
```
当把unique_ptr赋给另外一个对象时,资源的所有权就会被转移。
**记住unique_ptr不提供复制语义(拷贝赋值和拷贝构造都不可以),只支持移动语义(move semantics).**s
在上面的例子里,如果upt3和upt5已经拥有了资源,只有当拥有新资源时,之前的资源才会释放。
```cpp
unique_ptr<int> ap(new int(88 ));
unique_ptr<int> one (ap) ; // 会出错
unique_ptr<int> two = one; //会出错
```
#### 接口
unique_ptr提供的接口和传统指针差不多,但是不支持指针运算。
unique_ptr提供一个release()的方法,释放所有权。release和reset的区别在于,release仅仅释放所有权但不释放资源,reset也释放资源。 | 3,419 | MIT |
---
title: Kubernetes on Azure のチュートリアル - アプリケーションの更新
description: この Azure Kubernetes Service (AKS) チュートリアルでは、AKS にデプロイされている既存のアプリケーションを新しいバージョンのアプリケーション コードで更新する方法について説明します。
services: container-service
author: mlearned
ms.service: container-service
ms.topic: tutorial
ms.date: 12/19/2018
ms.author: mlearned
ms.custom: mvc
ms.openlocfilehash: b645fc9f67229d087a5d1655f733e2f3e50d4471
ms.sourcegitcommit: 6a42dd4b746f3e6de69f7ad0107cc7ad654e39ae
ms.translationtype: HT
ms.contentlocale: ja-JP
ms.lasthandoff: 07/07/2019
ms.locfileid: "67614373"
---
# <a name="tutorial-update-an-application-in-azure-kubernetes-service-aks"></a>チュートリアル:Azure Kubernetes Service (AKS) でのアプリケーションの更新
Kubernetes でアプリケーションをデプロイした後で、新しいコンテナー イメージまたはイメージ バージョンを指定することによってアプリケーションを更新できます。 更新は、デプロイの全体が一度に更新されないように、段階的に行われます。 この段階的な更新プログラムを使用すると、アプリケーションの更新中も引き続きアプリケーションを実行することができます。 デプロイ エラーが発生した場合のロールバック メカニズムも提供されています。
この 7 部構成の 6 番目のチュートリアルでは、サンプルの Azure Vote アプリを更新します。 学習内容は次のとおりです。
> [!div class="checklist"]
> * フロントエンド アプリケーションのコードを更新する
> * 更新後のコンテナー イメージを作成する
> * Azure Container Registry にコンテナー イメージをプッシュする
> * 更新したコンテナー イメージをデプロイする
## <a name="before-you-begin"></a>開始する前に
これまでのチュートリアルでは、アプリケーションをコンテナー イメージにパッケージ化しました。 このイメージを Azure Container Registry にアップロードし、AKS クラスターを作成しました。 その後、AKS クラスターにアプリケーションをデプロイしました。
アプリケーション リポジトリも複製しましたが、それにはアプリケーションのソース コードと、このチュートリアルで使用する事前作成された Docker Compose ファイルが含まれています。 リポジトリの複製を作成したこと、およびディレクトリを複製ディレクトリに変更したことを確認します。 これらの手順を行っておらず、順番に進めたい場合は、[チュートリアル 1 – コンテナー イメージを作成する][aks-tutorial-prepare-app]に関するページから始めてください。
このチュートリアルでは、Azure CLI バージョン 2.0.53 以降を実行している必要があります。 バージョンを確認するには、`az --version` を実行します。 インストールまたはアップグレードする必要がある場合は、[Azure CLI のインストール][azure-cli-install]に関するページを参照してください。
## <a name="update-an-application"></a>アプリケーションを更新する
サンプル アプリケーションに変更を加えたうえで、AKS クラスターにデプロイ済みのバージョンを更新してみましょう。 複製された *azure-voting-app-redis* ディレクトリにいることを確認します。 その場合、サンプル アプリケーションのソース コードは、*azure-vote* ディレクトリ内にあります。 `vi` などのエディターで *config_file.cfg* ファイルを開きます。
```console
vi azure-vote/azure-vote/config_file.cfg
```
*VOTE1VALUE* と *VOTE2VALUE* の値を、色などの別の値に変更します。 次の例は、更新後の値を示しています。
```
# UI Configurations
TITLE = 'Azure Voting App'
VOTE1VALUE = 'Blue'
VOTE2VALUE = 'Purple'
SHOWHOST = 'false'
```
ファイルを保存して閉じます。 `vi` で `:wq` を使用します。
## <a name="update-the-container-image"></a>コンテナー イメージを更新する
フロントエンド イメージを再作成し、更新したアプリケーションをテストするには、[docker-compose][docker-compose] を使用します。 引数 `--build` は、Docker Compose にアプリケーション イメージの再作成を指示するために使用されます。
```console
docker-compose up --build -d
```
## <a name="test-the-application-locally"></a>ローカルでアプリケーションをテストする
更新後のコンテナー イメージに変更内容が反映されていることを確認するために、ローカル Web ブラウザーで `http://localhost:8080` を開きます。

実行中のアプリケーションに、*config_file.cfg* ファイルで指定した更新後の値が表示されます。
## <a name="tag-and-push-the-image"></a>イメージにタグを付けてプッシュする
更新したイメージを正しく使用するために、*azure-vote-front* イメージに ACR レジストリのログイン サーバー名のタグを付けます。 [az acr list](/cli/azure/acr) コマンドを使用して、ログイン サーバー名を取得します。
```azurecli
az acr list --resource-group myResourceGroup --query "[].{acrLoginServer:loginServer}" --output table
```
[docker tag][docker-tag] を使用してイメージにタグを付けます。 `<acrLoginServer>` を実際の ACR ログイン サーバー名またはパブリック レジストリのホスト名に置き換え、イメージのバージョンを次のように *:v2* に更新します。
```console
docker tag azure-vote-front <acrLoginServer>/azure-vote-front:v2
```
次に、[docker push][docker-push] を使用してご利用のレジストリにイメージをアップロードします。 `<acrLoginServer>` は、実際の ACR ログイン サーバー名に置き換えてください。
> [!NOTE]
> ACR レジストリにプッシュする際に問題が発生する場合は、まだログインしていることを確認してください。 「[Azure Container Registry を作成する](tutorial-kubernetes-prepare-acr.md#create-an-azure-container-registry)」手順で作成した Azure Container Registry の名前を使用して [az acr login][az-acr-login] コマンドを実行します。 たとえば、「 `az acr login --name <azure container registry name>` 」のように入力します。
```console
docker push <acrLoginServer>/azure-vote-front:v2
```
## <a name="deploy-the-updated-application"></a>更新したアプリケーションをデプロイする
最大限のアップタイムを提供するには、アプリケーション ポッドの複数のインスタンスを実行する必要があります。 実行中のフロントエンド インスタンスの数を [kubectl get pods][kubectl-get] コマンドを使用して確認します。
```
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
azure-vote-back-217588096-5w632 1/1 Running 0 10m
azure-vote-front-233282510-b5pkz 1/1 Running 0 10m
azure-vote-front-233282510-dhrtr 1/1 Running 0 10m
azure-vote-front-233282510-pqbfk 1/1 Running 0 10m
```
複数のフロントエンド ポッドがない場合は、次のように *azure-vote-front* デプロイをスケーリングします。
```console
kubectl scale --replicas=3 deployment/azure-vote-front
```
アプリケーションを更新するには、[kubectl set][kubectl-set] コマンドを使用します。 実際のコンテナー レジストリのログイン サーバー名またはホスト名で `<acrLoginServer>` を更新し、アプリケーション バージョンとして *v2* を指定します。
```console
kubectl set image deployment azure-vote-front azure-vote-front=<acrLoginServer>/azure-vote-front:v2
```
デプロイを監視するには、[kubectl get pod][kubectl-get] コマンドを使います。 更新されたアプリケーションがデプロイされると、ポッドが終了されて、新しいコンテナー イメージで再作成されます。
```console
kubectl get pods
```
次の出力例には、デプロイの進行状況として、終了状態のポッドと実行状態の新しいインスタンスが示されています。
```
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
azure-vote-back-2978095810-gq9g0 1/1 Running 0 5m
azure-vote-front-1297194256-tpjlg 1/1 Running 0 1m
azure-vote-front-1297194256-tptnx 1/1 Running 0 5m
azure-vote-front-1297194256-zktw9 1/1 Terminating 0 1m
```
## <a name="test-the-updated-application"></a>更新したアプリケーションをテストする
更新したアプリケーションを表示するには、まず、`azure-vote-front` サービスの外部 IP アドレスを取得します。
```console
kubectl get service azure-vote-front
```
次に、ローカル Web ブラウザーを開き、サービスの IP アドレスに移動します。

## <a name="next-steps"></a>次の手順
このチュートリアルでは、アプリケーションを更新し、この更新を AKS クラスターにロールアウトしました。 以下の方法について学習しました。
> [!div class="checklist"]
> * フロントエンド アプリケーションのコードを更新する
> * 更新後のコンテナー イメージを作成する
> * Azure Container Registry にコンテナー イメージをプッシュする
> * 更新したコンテナー イメージをデプロイする
次のチュートリアルに進んで、AKS クラスターを新しいバージョンの Kubernetes にアップグレードする方法を学習してください。
> [!div class="nextstepaction"]
> [Kubernetes のアップグレード][aks-tutorial-upgrade]
<!-- LINKS - external -->
[docker-compose]: https://docs.docker.com/compose/
[docker-push]: https://docs.docker.com/engine/reference/commandline/push/
[docker-tag]: https://docs.docker.com/engine/reference/commandline/tag/
[kubectl-get]: https://kubernetes.io/docs/reference/generated/kubectl/kubectl-commands#get
[kubectl-set]: https://kubernetes.io/docs/reference/generated/kubectl/kubectl-commands#set
<!-- LINKS - internal -->
[aks-tutorial-prepare-app]: ./tutorial-kubernetes-prepare-app.md
[aks-tutorial-upgrade]: ./tutorial-kubernetes-upgrade-cluster.md
[az-acr-login]: /cli/azure/acr
[azure-cli-install]: /cli/azure/install-azure-cli | 6,811 | CC-BY-4.0 |
## Evaluators of EvalCSU
> 贡献者样例:
>
> ```
> ### <your id>
> - 竞赛:...
> - 绩点:...
> - 科研:...
> - 就业:...
> ```
> <!-- 奖学金属于`绩点`类 -->
### jzndd
- 竞赛:一项国奖、两项省奖
- 绩点:国家级奖学金、特等奖学金
- 排名:专业前2%
### Jacob953
- 竞赛:一项国奖、三项省奖
- 科研:一篇一作论文
### typedrandomly
- 竞赛:ICPC金牌
### the-fall-moon
- 排名:专业前10
- 绩点:一等奖学金 | 314 | Apache-2.0 |
# 2022-01-25
共 0 条
<!-- BEGIN WEIBO -->
<!-- 最后更新时间 Tue Jan 25 2022 23:21:18 GMT+0800 (China Standard Time) -->
<!-- END WEIBO --> | 134 | MIT |
首发于:https://studygolang.com/articles/34004
# GoLang AST 简介
## 写在前面
当你对 GoLang AST 感兴趣时,你会参考什么?文档还是源代码?
虽然阅读文档可以帮助你抽象地理解它,但你无法看到 API 之间的关系等等。
如果是阅读整个源代码,你会完全看懂,但你想看完整个代码我觉得您应该会很累。
因此,本着高效学习的原则,我写了此文,希望对您能有所帮助。
让我们轻松一点,通过 AST 来了解我们平时写的 Go 代码在内部是如何表示的。
本文不深入探讨如何解析源代码,先从 AST 建立后的描述开始。
> 如果您对代码如何转换为 AST 很好奇,请浏览[深入挖掘分析 Go 代码](https://nakabonne.dev/posts/digging-deeper-into-the-analysis-of-go-code/)。
让我们开始吧!
## 接口(Interfaces)
首先,让我简单介绍一下代表 AST 每个节点的接口。
所有的 AST 节点都实现了 `ast.Node` 接口,它只是返回 AST 中的一个位置。
另外,还有 3 个主要接口实现了 `ast.Node`。
- ast.Expr - 代表表达式和类型的节点
- ast.Stmt - 代表报表节点
- ast.Decl - 代表声明节点

从定义中你可以看到,每个 Node 都满足了 `ast.Node` 的接口。
[ast/ast.go](https://github.com/golang/go/blob/0b7c202e98949b530f7f4011efd454164356ba69/src/go/ast/ast.go#L32-L54)
```go
// All node types implement the Node interface.
type Node interface {
Pos() token.Pos // position of first character belonging to the node
End() token.Pos // position of first character immediately after the node
}
// All expression nodes implement the Expr interface.
type Expr interface {
Node
exprNode()
}
// All statement nodes implement the Stmt interface.
type Stmt interface {
Node
stmtNode()
}
// All declaration nodes implement the Decl interface.
type Decl interface {
Node
declNode()
}
```
## 具体实践
下面我们将使用到如下代码:
```go
package hello
import "fmt"
func greet() {
fmt.Println("Hello World!")
}
```
首先,我们尝试[生成上述这段简单的代码 AST](https://golang.org/src/go/ast/example_test.go):
```go
package main
import (
"go/ast"
"go/parser"
"go/token"
)
func main() {
src := `
package hello
import "fmt"
func greet() {
fmt.Println("Hello World!")
}
`
// Create the AST by parsing src.
fset := token.NewFileSet() // positions are relative to fset
f, err := parser.ParseFile(fset, "", src, 0)
if err != nil {
panic(err)
}
// Print the AST.
ast.Print(fset, f)
}
```
执行命令:
```bash
F:\hello>go run main.go
```
上述命令的输出 ast.File 内容如下:
```bash
0 *ast.File {
1 . Package: 2:1
2 . Name: *ast.Ident {
3 . . NamePos: 2:9
4 . . Name: "hello"
5 . }
6 . Decls: []ast.Decl (len = 2) {
7 . . 0: *ast.GenDecl {
8 . . . TokPos: 4:1
9 . . . Tok: import
10 . . . Lparen: -
11 . . . Specs: []ast.Spec (len = 1) {
12 . . . . 0: *ast.ImportSpec {
13 . . . . . Path: *ast.BasicLit {
14 . . . . . . ValuePos: 4:8
15 . . . . . . Kind: STRING
16 . . . . . . Value: "\"fmt\""
17 . . . . . }
18 . . . . . EndPos: -
19 . . . . }
20 . . . }
21 . . . Rparen: -
22 . . }
23 . . 1: *ast.FuncDecl {
24 . . . Name: *ast.Ident {
25 . . . . NamePos: 6:6
26 . . . . Name: "greet"
27 . . . . Obj: *ast.Object {
28 . . . . . Kind: func
29 . . . . . Name: "greet"
30 . . . . . Decl: *(obj @ 23)
31 . . . . }
32 . . . }
33 . . . Type: *ast.FuncType {
34 . . . . Func: 6:1
35 . . . . Params: *ast.FieldList {
36 . . . . . Opening: 6:11
37 . . . . . Closing: 6:12
38 . . . . }
39 . . . }
40 . . . Body: *ast.BlockStmt {
41 . . . . Lbrace: 6:14
42 . . . . List: []ast.Stmt (len = 1) {
43 . . . . . 0: *ast.ExprStmt {
44 . . . . . . X: *ast.CallExpr {
45 . . . . . . . Fun: *ast.SelectorExpr {
46 . . . . . . . . X: *ast.Ident {
47 . . . . . . . . . NamePos: 7:2
48 . . . . . . . . . Name: "fmt"
49 . . . . . . . . }
50 . . . . . . . . Sel: *ast.Ident {
51 . . . . . . . . . NamePos: 7:6
52 . . . . . . . . . Name: "Println"
53 . . . . . . . . }
54 . . . . . . . }
55 . . . . . . . Lparen: 7:13
56 . . . . . . . Args: []ast.Expr (len = 1) {
57 . . . . . . . . 0: *ast.BasicLit {
58 . . . . . . . . . ValuePos: 7:14
59 . . . . . . . . . Kind: STRING
60 . . . . . . . . . Value: "\"Hello World!\""
61 . . . . . . . . }
62 . . . . . . . }
63 . . . . . . . Ellipsis: -
64 . . . . . . . Rparen: 7:28
65 . . . . . . }
66 . . . . . }
67 . . . . }
68 . . . . Rbrace: 8:1
69 . . . }
70 . . }
71 . }
72 . Scope: *ast.Scope {
73 . . Objects: map[string]*ast.Object (len = 1) {
74 . . . "greet": *(obj @ 27)
75 . . }
76 . }
77 . Imports: []*ast.ImportSpec (len = 1) {
78 . . 0: *(obj @ 12)
79 . }
80 . Unresolved: []*ast.Ident (len = 1) {
81 . . 0: *(obj @ 46)
82 . }
83 }
```
### 如何分析
我们要做的就是按照深度优先的顺序遍历这个 AST 节点,通过递归调用 `ast.Inspect()` 来逐一打印每个节点。
如果直接打印 AST,那么我们通常会看到一些无法被人类阅读的东西。
为了防止这种情况的发生,我们将使用 `ast.Print`(一个强大的 API)来实现对 AST 的人工读取。
代码如下:
```go
package main
import (
"fmt"
"go/ast"
"go/parser"
"go/token"
)
func main() {
fset := token.NewFileSet()
f, _ := parser.ParseFile(fset, "dummy.go", src, parser.ParseComments)
ast.Inspect(f, func(n ast.Node) bool {
// Called recursively.
ast.Print(fset, n)
return true
})
}
var src = `package hello
import "fmt"
func greet() {
fmt.Println("Hello, World")
}
`
```
**ast.File**
第一个要访问的节点是 `*ast.File`,它是所有 AST 节点的根。它只实现了 `ast.Node` 接口。

`ast.File` 有引用 ` 包名 `、` 导入声明 ` 和 ` 函数声明 ` 作为子节点。
> 准确地说,它还有 `Comments` 等,但为了简单起见,我省略了它们。
让我们从包名开始。
> 注意,带 nil 值的字段会被省略。每个节点类型的完整字段列表请参见文档。
### 包名
**ast.Indent**
```bash
*ast.Ident {
. NamePos: dummy.go:1:9
. Name: "hello"
}
```
一个包名可以用 AST 节点类型 `*ast.Ident` 来表示,它实现了 `ast.Expr` 接口。
所有的标识符都由这个结构来表示,它主要包含了它的名称和在文件集中的源位置。
从上述所示的代码中,我们可以看到包名是 `hello`,并且是在 `dummy.go` 的第一行声明的。
> 对于这个节点我们不会再深入研究了,让我们再回到 `*ast.File.Go` 中。
### 导入声明
**ast.GenDecl**
```bash
*ast.GenDecl {
. TokPos: dummy.go:3:1
. Tok: import
. Lparen: -
. Specs: []ast.Spec (len = 1) {
. . 0: *ast.ImportSpec {/* Omission */}
. }
. Rparen: -
}
```
`ast.GenDecl` 代表除函数以外的所有声明,即 `import`、`const`、`var` 和 `type`。
`Tok` 代表一个词性标记--它指定了声明的内容(import 或 const 或 type 或 var)。
这个 AST 节点告诉我们,`import` 声明在 dummy.go 的第 3 行。
让我们从上到下深入地看一下 `ast.GenDecl` 的下一个节点 `*ast.ImportSpec`。
**ast.ImportSpec**
```bash
*ast.ImportSpec {
. Path: *ast.BasicLit {/* Omission */}
. EndPos: -
}
```
一个 `ast.ImportSpec` 节点对应一个导入声明。它实现了 `ast.Spec` 接口,访问路径可以让导入路径更有意义。
**ast.BasicLit**
```bash
*ast.BasicLit {
. ValuePos: dummy.go:3:8
. Kind: STRING
. Value: "\"fmt\""
}
```
一个 `ast.BasicLit` 节点表示一个基本类型的文字,它实现了 `ast.Expr` 接口。
它包含一个 token 类型,可以使用 token.INT、token.FLOAT、token.IMAG、token.CHAR 或 token.STRING。
从 `ast.ImportSpec` 和 `ast.BasicLit` 中,我们可以看到它导入了名为 `"fmt "` 的包。
我们不再深究了,让我们再回到顶层。
### 函数声明
**ast.FuncDecl**
```bash
*ast.FuncDecl {
. Name: *ast.Ident {/* Omission */}
. Type: *ast.FuncType {/* Omission */}
. Body: *ast.BlockStmt {/* Omission */}
}
```
一个 `ast.FuncDecl` 节点代表一个函数声明,但它只实现了 `ast.Node` 接口。我们从代表函数名的 `Name` 开始,依次看一下。
**ast.Ident**
```go
*ast.Ident {
. NamePos: dummy.go:5:6
. Name: "greet"
. Obj: *ast.Object {
. . Kind: func
. . Name: "greet"
. . Decl: *(obj @ 0)
. }
}
```
第二次出现这种情况,我就不做基本解释了。
值得注意的是 `*ast.Object`,它代表了标识符所指的对象,但为什么需要这个呢?
大家知道,GoLang 有一个 `scope` 的概念,就是源文本的 `scope`,其中标识符表示指定的常量、类型、变量、函数、标签或包。
`Decl 字` 段表示标识符被声明的位置,这样就确定了标识符的 `scope`。指向相同对象的标识符共享相同的 `*ast.Object.Label`。
**ast.FuncType**
```bash
*ast.FuncType {
. Func: dummy.go:5:1
. Params: *ast.FieldList {/* Omission */}
}
```
一个 `ast.FuncType` 包含一个函数签名,包括参数、结果和 "func "关键字的位置。
**ast.FieldList**
```bash
*ast.FieldList {
. Opening: dummy.go:5:11
. List: nil
. Closing: dummy.go:5:12
}
```
`ast.FieldList` 节点表示一个 Field 的列表,用括号或大括号括起来。如果定义了函数参数,这里会显示,但这次没有,所以没有信息。
列表字段是 `*ast.Field` 的一个切片,包含一对标识符和类型。它的用途很广,用于各种 Nodes,包括 `*ast.StructType`、`*ast.InterfaceType` 和本文中使用示例。
也就是说,当把一个类型映射到一个标识符时,需要用到它(如以下的代码):
```bash
foot int
bar string
```
让我们再次回到 `*ast.FuncDecl`,再深入了解一下最后一个字段 `Body`。
**ast.BlockStmt**
```bash
*ast.BlockStmt {
. Lbrace: dummy.go:5:14
. List: []ast.Stmt (len = 1) {
. . 0: *ast.ExprStmt {/* Omission */}
. }
. Rbrace: dummy.go:7:1
}
```
一个 `ast.BlockStmt` 节点表示一个括号内的语句列表,它实现了 `ast.Stmt` 接口。
**ast.ExprStmt**
```bash
*ast.ExprStmt {
. X: *ast.CallExpr {/* Omission */}
}
```
`ast.ExprStmt` 在语句列表中表示一个表达式,它实现了 `ast.Stmt` 接口,并包含一个 `ast.Expr`。
**ast.CallExpr**
```bash
*ast.CallExpr {
. Fun: *ast.SelectorExpr {/* Omission */}
. Lparen: dummy.go:6:13
. Args: []ast.Expr (len = 1) {
. . 0: *ast.BasicLit {/* Omission */}
. }
. Ellipsis: -
. Rparen: dummy.go:6:28
}
```
`ast.CallExpr` 表示一个调用函数的表达式,要查看的字段是:
- Fun
- 要调用的函数和 Args
- 要传递给它的参数列表
**ast.SelectorExpr**
```bash
*ast.SelectorExpr {
. X: *ast.Ident {
. . NamePos: dummy.go:6:2
. . Name: "fmt"
. }
. Sel: *ast.Ident {
. . NamePos: dummy.go:6:6
. . Name: "Println"
. }
}
```
`ast.SelectorExpr` 表示一个带有选择器的表达式。简单地说,它的意思是 `fmt.Println`。
**ast.BasicLit**
```bash
*ast.BasicLit {
. ValuePos: dummy.go:6:14
. Kind: STRING
. Value: "\"Hello, World\""
}
```
这个就不需要多解释了,就是简单的"Hello, World。
## 小结
需要注意的是,在介绍的节点类型时,节点类型中的一些字段及很多其它的节点类型都被我省略了。
尽管如此,我还是想说,即使有点粗糙,但实际操作一下还是很有意义的,而且最重要的是,它是相当有趣的。
复制并粘贴本文第一节中所示的代码,在你的电脑上试着实操一下吧。
---
via: https://nakabonne.dev/posts/take-a-walk-the-go-ast/
作者:[nakabonne](https://github.com/nakabonne)
译者:[double12gzh](https://github.com/double12gzh)
校对:[polaris1119](https://github.com/polaris1119)
本文由 [GCTT](https://github.com/studygolang/GCTT) 原创编译,[Go 中文网](https://studygolang.com/) 荣誉推出 | 10,294 | Apache-2.0 |
# webpack 工作流程
## 调试 webpack
### 生成调试文件
vscode 可以新增调试文件入口 `.vscode\launch.json`,然后点击调试按钮。
vscode 里的路径有问题,所以 entry 使用绝对路径 path.resolve 一下,然后再 cli.js 里 debugger 即可。
```
{
"version": "0.2.0",
"configurations": [
{
"type": "node",
"request": "launch",
"name": "调试 webpack",
"cwd": "${workspaceFolder}",
"skipFiles": [
"<node_internals>/**" // 跳过 node 内部模块
],
"program": "${workspaceFolder}/node_modules/webpack-cli/bin/cli.js"
}
]
}
```
### debugger.js
新建 debugger.js 文件,然后点击调试 -> 选择 node.js -> 选择 Run Current File。

```js
const webpack = require("webpack");
const config = require("./webpack.config");
const compiler = webpack(config);
debugger;
compiler.run((err, stats) => {
console.log(
stats.toJson({ assets: true, chunks: true, modules: true, entries: true })
);
});
```
## tapable.js
- tapable 类似 nodejs 里的 EventEmitter 库,但是更专注自定义事件的触发和处理。
- webpack 里使用 tapable 将实现与流程解耦,实现是通过插件的形式存在。
```js
// const { SyncHook } = require('tapable')
class SyncHook {
constructor() {
this.taps = [];
}
tap(name, fn) {
this.taps.push(fn);
}
call() {
this.taps.forEach((tap) => tap());
}
}
// 这里的参数无意义,只是标识一下接收几个参数
// tapable 内部会将后续的参数 [].slice.call(arguments, 0, arr.length)
const hook = new SyncHook(["name"]);
hook.tap("aa", () => console.log("你好"));
// 插件的原理: webpack 内部会调用插件的 apply 方法
class Plugin {
apply() {
hook.tap("Plugin", () => console.log("插件调用"));
}
}
new Plugin().apply();
hook.call();
// 你好
// 插件调用
```
## webpack 编译流程
1. 初始化参数:从配置文件和 Shell 语句中读取合并参数,得到最终配置
2. 用配置实例化 compiler: new Compiler(config)
3. 用配置里的 plugins 挂载所有的插件
4. 执行 compiler 对象的 run 方法开始编译
5. 根据配置中的 entry 得到入口文件的绝对路径 | 1,741 | MIT |
---
title: 新機能のお知らせ
titleSuffix: Azure Cognitive Search
description: Azure Cognitive Search への Azure Search のサービス名の変更を含む、新機能や拡張機能についてのお知らせです。
manager: nitinme
author: HeidiSteen
ms.author: heidist
ms.service: cognitive-search
ms.topic: conceptual
ms.date: 11/04/2019
ms.openlocfilehash: b1df328f151a4085ec0aadd1b880048f81483a51
ms.sourcegitcommit: 375b70d5f12fffbe7b6422512de445bad380fe1e
ms.translationtype: HT
ms.contentlocale: ja-JP
ms.lasthandoff: 12/06/2019
ms.locfileid: "74901323"
---
# <a name="whats-new-in-azure-cognitive-search"></a>Azure Cognitive Search の新機能
サービス内の新機能について説明します。 このページをブックマークして、常にサービスの最新情報を確認してください。
<a name="new-service-name"></a>
## <a name="new-service-name-for-azure-search"></a>Azure Search の新しいサービス名
コア操作での認識スキルと AI 処理の拡張された使用を反映するため、Azure Search の名前が **Azure Cognitive Search** に変更されました。 認知スキルによって新機能が追加されますが、AI の使用は厳密には省略可能です。 AI を使用せずに Azure Cognitive Search を引き続き使用して、クラウドで作成および管理するインデックスにある非公開で、異種の、テキストベースのコンテンツに対して、リッチな、フル テキスト検索ソリューションを構築することができます。
API バージョン、Nuget パッケージ、名前空間、およびエンドポイントは変更されません。 既存の検索ソリューションは、サービス名の変更の影響を受けません。
## <a name="feature-announcements"></a>機能のお知らせ
### <a name="december-2019"></a>2019 年 12 月
+ [アプリの作成 (プレビュー)](search-create-app-portal.md) はポータルの新しいウィザードです。これを使ってダウンロード可能な HTML ファイルを生成できます。 このファイルには、検索サービスのインデックスにバインドされた、操作可能な "localhost" スタイルの Web アプリをレンダリングする埋め込みスクリプトが付属しています。 ページはウィザードで構成できます。また、検索バー、結果領域、サイドバー ナビゲーション、および先行入力クエリのサポートを含めることができます。 HTML をオフラインに変更して、ワークフローや外観を拡張したりカスタマイズしたりすることができます。
### <a name="november-2019---ignite-conference"></a>2019 年 11 月 - Ignite Conference
+ [増分インデックス (プレビュー)](cognitive-search-incremental-indexing-conceptual.md) は、エンリッチメント パイプラインに変更を加えるときに、再処理の手順を選択できるようにします。 増分インデックスは、以前に分析したイメージ コンテンツがある場合に特に便利です。 コストのかかる分析の出力が保存され、追加のインデックス作成またはエンリッチメントの基礎として使用されます。
<!--
+ Custom Entity Lookup is a cognitive skill used during indexing that allows you to provide a list of custom entities (such as part numbers, diseases, or names of locations you care about) that should be found within the text. It supports fuzzy matching, case-insensitive matching, and entity synonyms. -->
+ [ドキュメント抽出 (プレビュー)](cognitive-search-skill-document-extraction.md) は、インデックスの作成中に使用されるコグニティブ スキルであり、スキルセット内からファイルのコンテンツを抽出できます。 ドキュメント解析は、これまでスキルセットの実行前にのみ行われていました。 このスキルを追加することで、スキルセットの実行内でこの操作を実行することもできます。
+ [テキスト翻訳 (プレビュー)](cognitive-search-skill-text-translation.md) は、インデックスの作成中に使用されるコグニティブ スキルであり、テキストを評価し、各レコードについて、指定したターゲット言語に翻訳されたテキストを返します。
+ [Power BI テンプレート](https://github.com/Azure-Samples/cognitive-search-templates/blob/master/README.md)は、Power BI デスクトップのナレッジ ストアで、強化されたコンテンツの視覚化と分析をすぐに開始することができます。 このテンプレートは、[データのインポート ウィザード](knowledge-store-create-portal.md)を使用して作成された Azure テーブルのプロジェクション向けに設計されています。
+ インデクサーで [Azure Data Lake Storage Gen2 (プレビュー)](search-howto-index-azure-data-lake-storage.md)、[Cosmos DB Gremlin API (プレビュー)](search-howto-index-cosmosdb.md)、[Cosmos DB Cassandra API (プレビュー)](search-howto-index-cosmosdb.md) のサポートを開始しました。 [こちらのフォーム](https://aka.ms/azure-cognitive-search/indexer-preview)を使ってサインアップできます。 プレビュー プログラムへの参加が承認されると、確認メールが届きます。
### <a name="july-2019"></a>2019 年 7 月
+ [Azure Government クラウド](../azure-government/documentation-government-services-webandmobile.md#azure-cognitive-search)で一般提供されています。
## <a name="service-updates"></a>サービスの更新情報
Azure Cognitive Search の[サービス更新のお知らせ](https://azure.microsoft.com/updates/?product=search&status=all)に関する情報については、Azure の Web サイトで参照できます。 | 3,434 | CC-BY-4.0 |
<div class="panel panel-default">
<div class="panel-body">
# 目次
```
@[toc]
```
@[toc]
</div>
</div>
# :pencil: Block Elements
## Headers 見出し
先頭に`#`をレベルの数だけ記述します。
```
# 見出し1
## 見出し2
### 見出し3
#### 見出し4
##### 見出し5
###### 見出し6
```
### 見出し3
#### 見出し4
##### 見出し5
###### 見出し6
## Block 段落
空白行を挟むことで段落となります。aaaa
```
段落1
(空行)
段落2
```
段落1
段落2
## Br 改行
改行の前に半角スペース` `を2つ記述します。
***この挙動は、オプションで変更可能です***
```
hoge
fuga(スペース2つ)
piyo
```
hoge
fuga
piyo
## Blockquotes 引用
先頭に`>`を記述します。ネストは`>`を多重に記述します。
```
> 引用
> 引用
>> 多重引用
```
> 引用
> 引用
>> 多重引用
## Code コード
`` `バッククオート` `` 3つ、あるいはチルダ`~`3つで囲みます。
```
print 'hoge'
```
### シンタックスハイライトとファイル名
- [highlight.js Demo](https://highlightjs.org/static/demo/) の common カテゴリ内の言語に対応しています
~~~
```javascript:mersenne-twister.js
function MersenneTwister(seed) {
if (arguments.length == 0) {
seed = new Date().getTime();
}
this._mt = new Array(624);
this.setSeed(seed);
}
```
~~~
```javascript:mersenne-twister.js
function MersenneTwister(seed) {
if (arguments.length == 0) {
seed = new Date().getTime();
}
this._mt = new Array(624);
this.setSeed(seed);
}
```
### インラインコード
`` `バッククオート` `` で単語を囲むとインラインコードになります。
```
これは `インラインコード`です。
```
これは `インラインコード`です。
## pre 整形済みテキスト
半角スペース4個もしくはタブで、コードブロックをpre表示できます
```
class Hoge
def hoge
print 'hoge'
end
end
```
class Hoge
def hoge
print 'hoge'
end
end
## Hr 水平線
アンダースコア`_` 、アスタリスク`*`を3つ以上連続して記述します。
```
***
___
---
```
***
___
---
# :pencil: Typography
## 強調
### em
アスタリスク`*`もしくはアンダースコア`_`1個で文字列を囲みます。
```
これは *イタリック* です
これは _イタリック_ です
```
これは *イタリック* です
これは _イタリック_ です
### strong
アスタリスク`*`もしくはアンダースコア`_`2個で文字列を囲みます。
```
これは **ボールド** です
これは __ボールド__ です
```
これは **ボールド** です
これは __ボールド__ です
### em + strong
アスタリスク`*`もしくはアンダースコア`_`3個で文字列を囲みます。
```
これは ***イタリック&ボールド*** です
これは ___イタリック&ボールド___ です
```
これは ***イタリック&ボールド*** です
これは ___イタリック&ボールド___ です
# :pencil: Images
`` で`<img>`タグを挿入できます。
```markdown


```


画像の大きさなどの指定をする場合はimgタグを使用します。
```html
<img src="https://octodex.github.com/images/dojocat.jpg" width="200px">
```
<img src="https://octodex.github.com/images/dojocat.jpg" width="200px">
# :pencil: Link
## Markdown 標準
`[表示テキスト](URL)`でリンクに変換されます。
```
[Google](https://www.google.co.jp/)
```
[Google](https://www.google.co.jp/)
## Crowi 互換
```
[/Sandbox]
</user/admin1>
```
[/Sandbox]
</user/admin1>
## Pukiwiki like linker
(available by [weseek/growi-plugin-pukiwiki-like-linker
](https://github.com/weseek/growi-plugin-pukiwiki-like-linker) )
最も柔軟な Linker です。
記述中のページを基点とした相対リンクと、表示テキストに対するリンクを同時に実現できます。
```
[[./Bootstrap3]]
Bootstrap3のExampleは[[こちら>./Bootstrap3]]
```
[[../user]]
Bootstrap3のExampleは[[こちら>./Bootstrap3]]
# :pencil: Lists
## Ul 箇条書きリスト
ハイフン`-`、プラス`+`、アスタリスク`*`のいずれかを先頭に記述します。
ネストはタブで表現します。
```
- リスト1
- リスト1_1
- リスト1_1_1
- リスト1_1_2
- リスト1_2
- リスト2
- リスト3
```
- リスト1
- リスト1_1
- リスト1_1_1
- リスト1_1_2
- リスト1_2
- リスト2
- リスト3
## Ol 番号付きリスト
`番号.`を先頭に記述します。ネストはタブで表現します。
番号は自動的に採番されるため、すべての行を1.と記述するのがお勧めです。
```
1. 番号付きリスト1
1. 番号付きリスト1-1
1. 番号付きリスト1-2
1. 番号付きリスト2
1. 番号付きリスト3
```
1. 番号付きリスト1
1. 番号付きリスト1-1
1. 番号付きリスト1-2
1. 番号付きリスト2
1. 番号付きリスト3
## タスクリスト
```
- [ ] タスク 1
- [x] タスク 1.1
- [ ] タスク 1.2
- [x] タスク2
```
- [ ] タスク 1
- [x] タスク 1.1
- [ ] タスク 1.2
- [x] タスク2
# :pencil: Table
## Markdown 標準
```markdown
| Left align | Right align | Center align |
|:-----------|------------:|:------------:|
| This | This | This |
| column | column | column |
| will | will | will |
| be | be | be |
| left | right | center |
| aligned | aligned | aligned |
OR
Left align | Right align | Center align
:--|--:|:-:
This | This | This
column | column | column
will | will | will
be | be | be
left | right | center
aligned | aligned | aligned
```
| Left align | Right align | Center align |
|:-----------|------------:|:------------:|
| This | This | This |
| column | column | column |
| will | will | will |
| be | be | be |
| left | right | center |
| aligned | aligned | aligned |
## TSV (crowi-plus 独自記法)
```
::: tsv
Content Cell Content Cell
Content Cell Content Cell
:::
```
::: tsv
Content Cell Content Cell
Content Cell Content Cell
:::
## TSV ヘッダ付き (crowi-plus 独自記法)
```
::: tsv-h
First Header Second Header
Content Cell Content Cell
Content Cell Content Cell
:::
```
::: tsv-h
First Header Second Header
Content Cell Content Cell
Content Cell Content Cell
:::
## CSV (crowi-plus 独自記法)
```
::: csv
Content Cell,Content Cell
Content Cell,Content Cell
:::
```
::: csv
Content Cell,Content Cell
Content Cell,Content Cell
:::
## CSV ヘッダ付き (crowi-plus 独自記法)
```
::: csv-h
First Header,Second Header
Content Cell,Content Cell
Content Cell,Content Cell
:::
```
::: csv-h
First Header,Second Header
Content Cell,Content Cell
Content Cell,Content Cell
:::
# :pencil: Footnote
脚注への参照[^1]を書くことができます。また、インラインの脚注^[インラインで記述できる脚注です]を入れる事も出来ます。
長い脚注は[^longnote]のように書くことができます。
[^1]: 1つめの脚注への参照です。
[^longnote]: 脚注を複数ブロックで書く例です。
後続の段落はインデントされて、前の脚注に属します。
# :pencil: Emoji
See [emojione](https://www.emojione.com/)
:smiley: :smile: :laughing: :innocent: :drooling_face:
:family: :family_man_boy: :family_man_girl: :family_man_girl_girl: :family_woman_girl_girl:
:thumbsup: :thumbsdown: :open_hands: :raised_hands: :point_right:
:apple: :green_apple: :strawberry: :cake: :hamburger:
:basketball: :football: :baseball: :volleyball: :8ball:
:hearts: :broken_heart: :heartbeat: :heartpulse: :heart_decoration:
:watch: :gear: :gem: :wrench: :envelope:
# :pencil: Math
See [MathJax](https://www.mathjax.org/).
## Inline Formula
When $a \ne 0$, there are two solutions to \(ax^2 + bx + c = 0\) and they are
$$x = {-b \pm \sqrt{b^2-4ac} \over 2a}.$$
## The Lorenz Equations
$$
\begin{align}
\dot{x} & = \sigma(y-x) \\
\dot{y} & = \rho x - y - xz \\
\dot{z} & = -\beta z + xy
\end{align}
$$
## The Cauchy-Schwarz Inequality
$$
\left( \sum_{k=1}^n a_k b_k \right)^{\!\!2} \leq
\left( \sum_{k=1}^n a_k^2 \right) \left( \sum_{k=1}^n b_k^2 \right)
$$
## A Cross Product Formula
$$
\mathbf{V}_1 \times \mathbf{V}_2 =
\begin{vmatrix}
\mathbf{i} & \mathbf{j} & \mathbf{k} \\
\frac{\partial X}{\partial u} & \frac{\partial Y}{\partial u} & 0 \\
\frac{\partial X}{\partial v} & \frac{\partial Y}{\partial v} & 0 \\
\end{vmatrix}
$$
## The probability of getting $\left(k\right)$ heads when flipping $\left(n\right)$ coins is:
$$
P(E) = {n \choose k} p^k (1-p)^{ n-k}
$$
## An Identity of Ramanujan
$$
\frac{1}{(\sqrt{\phi \sqrt{5}}-\phi) e^{\frac25 \pi}} =
1+\frac{e^{-2\pi}} {1+\frac{e^{-4\pi}} {1+\frac{e^{-6\pi}}
{1+\frac{e^{-8\pi}} {1+\ldots} } } }
$$
## A Rogers-Ramanujan Identity
$$
1 + \frac{q^2}{(1-q)}+\frac{q^6}{(1-q)(1-q^2)}+\cdots =
\prod_{j=0}^{\infty}\frac{1}{(1-q^{5j+2})(1-q^{5j+3})},
\quad\quad \text{for $|q|<1$}.
$$
## Maxwell's Equations
$$
\begin{align}
\nabla \times \vec{\mathbf{B}} -\, \frac1c\, \frac{\partial\vec{\mathbf{E}}}{\partial t} & = \frac{4\pi}{c}\vec{\mathbf{j}} \\
\nabla \cdot \vec{\mathbf{E}} & = 4 \pi \rho \\
\nabla \times \vec{\mathbf{E}}\, +\, \frac1c\, \frac{\partial\vec{\mathbf{B}}}{\partial t} & = \vec{\mathbf{0}} \\
\nabla \cdot \vec{\mathbf{B}} & = 0
\end{align}
$$
<!-- Reset MathJax -->
<div class="clearfix"></div>
# :pencil: UML Diagrams
See [PlantUML](http://plantuml.com/).
## シーケンス図
@startuml
skinparam sequenceArrowThickness 2
skinparam roundcorner 20
skinparam maxmessagesize 60
skinparam sequenceParticipant underline
actor User
participant "First Class" as A
participant "Second Class" as B
participant "Last Class" as C
User -> A: DoWork
activate A
A -> B: Create Request
activate B
B -> C: DoWork
activate C
C --> B: WorkDone
destroy C
B --> A: Request Created
deactivate B
A --> User: Done
deactivate A
@enduml
<!-- Reset PlantUML -->
<div class="clearfix"></div>
## クラス図
@startuml
class BaseClass
namespace net.dummy #DDDDDD {
.BaseClass <|-- Person
Meeting o-- Person
.BaseClass <|- Meeting
}
namespace net.foo {
net.dummy.Person <|- Person
.BaseClass <|-- Person
net.dummy.Meeting o-- Person
}
BaseClass <|-- net.unused.Person
@enduml
<!-- Reset PlantUML -->
<div class="clearfix"></div>
## コンポーネント図
@startuml
package "Some Group" {
HTTP - [First Component]
[Another Component]
}
node "Other Groups" {
FTP - [Second Component]
[First Component] --> FTP
}
cloud {
[Example 1]
}
database "MySql" {
folder "This is my folder" {
[Folder 3]
}
frame "Foo" {
[Frame 4]
}
}
[Another Component] --> [Example 1]
[Example 1] --> [Folder 3]
[Folder 3] --> [Frame 4]
@enduml
<!-- Reset PlantUML -->
<div class="clearfix"></div>
## ステート図
@startuml
scale 600 width
[*] -> State1
State1 --> State2 : Succeeded
State1 --> [*] : Aborted
State2 --> State3 : Succeeded
State2 --> [*] : Aborted
state State3 {
state "Accumulate Enough Data\nLong State Name" as long1
long1 : Just a test
[*] --> long1
long1 --> long1 : New Data
long1 --> ProcessData : Enough Data
}
State3 --> State3 : Failed
State3 --> [*] : Succeeded / Save Result
State3 --> [*] : Aborted
@enduml
<!-- Reset PlantUML -->
<div class="clearfix"></div>
# :pencil: blockdiag
See [blockdiag](http://blockdiag.com/).
## blockdiag
<!-- Resize blockdiag -->
<div style="max-width: 600px">
::: blockdiag
blockdiag {
A -> B -> C -> D;
A -> E -> F -> G;
}
:::
</div>
## seqdiag
<!-- Resize blockdiag -->
<div style="max-width: 600px">
::: seqdiag
seqdiag {
browser -> webserver [label = "GET /index.html"];
browser <-- webserver;
browser -> webserver [label = "POST /blog/comment"];
webserver -> database [label = "INSERT comment"];
webserver <-- database;
browser <-- webserver;
}
:::
</div>
## actdiag
<!-- Resize blockdiag -->
<div style="max-width: 600px">
::: actdiag
actdiag {
write -> convert -> image
lane user {
label = "User"
write [label = "Writing reST"];
image [label = "Get diagram IMAGE"];
}
lane actdiag {
convert [label = "Convert reST to Image"];
}
}
:::
</div>
## nwdiag
<!-- Resize blockdiag -->
<div style="max-width: 600px">
::: nwdiag
nwdiag {
network dmz {
address = "210.x.x.x/24"
web01 [address = "210.x.x.1"];
web02 [address = "210.x.x.2"];
}
network internal {
address = "172.x.x.x/24";
web01 [address = "172.x.x.1"];
web02 [address = "172.x.x.2"];
db01;
db02;
}
}
:::
</div>
## rackdiag
<!-- Resize blockdiag -->
<div style="max-width: 600px">
::: rackdiag
rackdiag {
// define height of rack
8U;
// define rack items
1: UPS [2U];
3: DB Server
4: Web Server
5: Web Server
6: Web Server
7: Load Balancer
8: L3 Switch
}
:::
</div>
## packetdiag
<!-- Resize blockdiag -->
<div style="max-width: 600px">
::: packetdiag
packetdiag {
colwidth = 32
node_height = 72
0-15: Source Port
16-31: Destination Port
32-63: Sequence Number
64-95: Acknowledgment Number
96-99: Data Offset
100-105: Reserved
106: URG [rotate = 270]
107: ACK [rotate = 270]
108: PSH [rotate = 270]
109: RST [rotate = 270]
110: SYN [rotate = 270]
111: FIN [rotate = 270]
112-127: Window
128-143: Checksum
144-159: Urgent Pointer
160-191: (Options and Padding)
192-223: data [colheight = 3]
}
:::
</div> | 12,035 | MIT |
---
title: "Promise设计思维——底层原理"
subtitle: "「ES6」- 浅谈Promise设计思维 —— 源码"
header-img: "img/post-bg-js-version.jpg"
header-mask: 0.2
layout: post
author: "wendy"
tags:
- ES6
- JavaScript
- Promise
---
- 什么是Promise
- 传统异步解决方案
- 认识Promise
- 实现一个Promise
> JavaScript作为单线程语言,其特点也是其缺陷,特点是不用处理多线程引发的占用资源、冲突等,缺陷就是同一时间,只能做一件事情。因此会存在一个问题,网络传输是有延迟的。比如A发一条信息给B, B还没返回信息给A, 那么A就会一直等待接受信息,会造成页面卡顿等问题。于是出现了异步。
什么是Promise
----------------------
> Promise是一个容器,保存着一个异步操作的结果。Promise是一个对象,从它可以获取异步操作的消息。Promise提供了统一的api, 各种异步操作都可以用同样的方法进行处理。
传统异步解决方案
----------------------
#### 一、callback回调
通过参数闯入回调,未来调用回调时让函数的调用者判断发生了什么?回调函数被认为是一种高级函数,一种被作为参数传递给另一个函数(在这称作"otherFunction")的高级函数
```js
<img src='../a.jpg'></img>
<img src='../b.jpg'></img>
<img src='../c.jpg'></img>
$("img").attr("title",function(index,attr){
console.log(index) // 依次返回0 1 2
});
```
- 优点:简单、容易理解和部署
- 缺点:不利于代码的阅读和维护,程序流程混乱,每个任务只能指定一个回调函数
```coq
目录结构:
- iamswr
- A.txt
- B.txt
- C.txt
其中
A.txt文件里的内容为字符串B.txt
B.txt文件里的内容为字符串C.txt
C.txt文件里的内容为字符串'hello swr'
那么当我们想获取到'hello swr',会遇到什么问题呢?请看下面的代码
let fs = require('fs')
fs.readFile('A.txt','utf8',function(err,data){ // 此时回调函数data值为'B.txt'
fs.readFile(data,'utf8',function(err,data){ // 此时回调函数data值为'C.txt'
fs.readFile(data,'utf8',function(err,data){
console.log(data) // 'hello swr'
})
})
})
```
#### 二、事件发布/订阅模式
回调函数的事件化,任务的执行不取决于代码的顺序,而取决于某个事件是否发生
- 优点:容易理解,可以绑定多个事件,每个事件可以指定多个回调函数
- 缺点:整个程序变成了事件驱动型,运行流程会变得很不清晰
#### 三、Deferred延迟函数
通过deferred对象给异步操作进行状态绑定,deferred对象提供统一的api, 对各种异步操作状态进行操作(成功、失败、进行中)
- 优点:避免了层层嵌套的回调函数deferred对象提供统一的接口,控制异步操作更容易;
- 缺点:状态不可逆,从待定状态切换到任何一个确定状态后,再次调用resole和reject对愿状态将不起任何作用;
认识Promise
----------------------
> 思考: 用同步化的方法来书写异步代码
异步操作的状态管理:成功\失败\进行中,每一个状态管理一个容器(3个),即成功之后的事情(找到对应的callback)、失败之后的事情(找到对应的callback)、进行中之后的事情(找到对应的callback)
- `成功` resolve()
- `失败` reject()
- `进行中`
知识普及:
> 闭包最大用处: 一个可以读取函数内部的变量,另一个就是让这些变量值保持在内存中;
> 思考:封闭作用域,保存作用域,作用域链条, 不污染全局变量、块级作用域
Promise的一些特性
- promise是有兼容性问题的,node环境下默认支持,还可以下载相应插件来解决兼容性问题
- promise是有三种状态的,等待态pending / 成功态resolved / 失败态rejected
- promise的状态是可以转换的,可以从pending -> resolved 或 pending -> rejected,但是resolved不能转换为rejected/pending,rejected不能转换为resolved/pending,简而言之即状态只会更改一次
```js
// Promise构造函数的第一个参数为executor
let promise = new Promise(function(resolve,reject){
console.log('我是会被立即执行的哟')
})
// promise的实例都有then方法
promise.then(()=>{ // 成功的回调
},()=>{ // 失败的回调
})
```
- executor默认在new的时候会自动执行
- 每个promise的实例都有then方法
- then方法中,有两个参数,分别是成功的回调函数和失败的回调函数
```js
// 默认时为pending态,既不会走成功的回调也不会走失败的回调
promise.then(()=>{
console.log('success1')
},()=>{
console.log('error1')
})
console.log('2')
// 在这段代码中,只会打印出'2',因为promise一直处于pending态,不会走then后的回调函数
```
```js
let promise = new Promise(function(resolve,reject){
console.log('1')
resolve() // 更改pending状态为resolved
})
promise.then(()=>{
console.log('success1')
},()=>{
console.log('error1')
})
console.log('2')
// 此时输出顺序为'1' -> '2' -> 'success1'
```
then方法是异步的,属于微任务,从上面的例子可以看出,先执行完同步代码,再执行异步代码
```js
let promise = new Promise(function(resolve,reject){
console.log('1')
setTimeout(()=>{ // 异步行为
resolve() // 更改状态为成功
},1000)
})
promise.then(()=>{
console.log("success1")
})
promise.then(()=>{
console.log('success2')
})
console.log("2")
// 此时输出顺序为'1' -> '2' -> 'success1' -> 'success2'
```
- 同一个promise的实例可以then多次,成功时会调用所有的成功方法,失败时会调用所有的失败方法
- new Promise中可以支持异步行为
- 如果发现错误,就会进入失败态
```js
let promise = new Promise(function(resolve,reject){
throw new Error('出错了') // 抛出错误
})
promise.then(()=>{
console.log('success1')
},()=>{
console.log('error1')
})
// 此时输出为 'error1'
```
实现一个Promise
----------------------
###### 基础结构
下面代码部分和源码实现部分要结合来看
```js
// ----- 代码部分
// 1.executor默认在new的时候会自动执行
// 成功和失败的视乎可以传递参数
let promise = new Promise((resolve,reject)=>{ // 6.resolve、reject函数对应源码实现部分的resolve、reject函数
resolve('hello swr') // 11.执行resolve
})
// 7.Promise的实例都有then方法
promise.then((data)=>{ // 8.成功的回调函数
},(err)=>{ // 9.失败的回调函数
})
```
```js
// ----- 源码实现部分
// 2.声明一个Promise构造函数
function Promise(executor){
let self = this
self.value = undefined
self.reason = undefined // 12.因为value和reason值需要在Promise实例方法then中使用,所以把这两个值,赋给new出来的实例
function resolve(value){ // 3.声明一个resolve函数
if(self.status === 'pending'){ // 2.此时新增一个状态判断,当状态为pending的时候才能执行
self.value = value // 13.当调用了resolve并且传参数时,则把这value值赋予self.value
self.status = 'resolved' // 2.当调用了resolve时,更改状态为resolved
}
}
function reject(reason){ // 4.声明一个reject函数
if(self.status === 'pending'){ // 2.此时新增一个状态判断,当状态为pending的时候才能执行
self.reason = reason // 13.当调用了reject并且传参数时,则把这reason值赋予self.reason
self.status = 'rejected' // 2.当调用了reject时,更改状态为rejected
}
}
// 5.当我们在执行executor时,内部抛出错误的时候,可以利用try catch来处理这个问题
try{
executor(resolve,reject)
}catch(error){
reject(error)
}
}
}
// 因为Promise的实例都有then方法,那么意味着then方法是在Promise的原型对象中的方法
// 10.对应上面成功的回调函数onFulfilled以及失败的回调函数onRejected
Promise.prototype.then = function(onFulfilled,onRejected){
let self = this
// 3.当我们在then中,执行了成功或者失败的回调函数时,首先要判断目前处于什么状态
if(self.status === 'resolved'){
onFulfilled(self.value) // 4.当调用了resolve函数后,会执行成功的回调函数,并且把resolve中传递的值,传递给成功的回调函数
}
if(self.status === 'rejected'){
onRejected(self.reason) // 4.当调用了reject函数后,会执行成功的回调函数,并且把reject中传递的值,传递给失败的回调函数
}
}
module.exports = Promise // 把Promise暴露出去
```
> 思考:如果此时resolve或者reject是处于setTimeout(()=>{resolve()},3000)中,即处于异步中,当我们new一个Promise时,不会马上执行异步代码,而是直接执行了promise.then这个函数,而此时因为self.status的状态依然是处于pending,所以不会执行resolve或者reject,当同步代码执行完毕后,执行异步代码时,更改了状态为resolved或者rejected时,此时then方法已经执行完毕了,不会再次执行then的方法,那么此时我们该如何处理?
```js
// ----- 源码实现部分
function Promise(executor){
let self = this
self.value = undefined
self.reason = undefined
self.status = 'pending'
self.onResolvedCallbacks = [] // 2.可能new Promise中会有异步的操作,此时我们把异步操作时,执行的then函数的成功回调,统一保存在该数组中
self.onRejectedCallbacks = [] // 2.可能new Promise中会有异步的操作,此时我们把异步操作时,执行的then函数的失败回调,统一保存在该数组中
function resolve(value){
if(self.status === 'pending'){
self.value = value
self.status = 'resolved'
// 4.当调用resolve时,把该数组中存放的成功回调都执行一遍,如果是异步,则会把成功的回调都存到该数组里了,如果是异步,则没存到。
self.onResolvedCallbacks.forEach(fn=>fn())
}
}
function reject(reason){
if(self.status === 'pending'){
self.reason = reason
self.status = 'rejected'
// 4.当调用reject时,把该数组中存放的失败回调都执行一遍,如果是异步,则会把成功的回调都存到该数组里了,如果是异步,则没存到。
self.onRejectedCallbacks.forEach(fn=>fn())
}
}
try{
executor(resolve,reject)
}catch(error){
reject(error)
}
}
Promise.prototype.then = function(onFulfilled,onRejected){
let self = this
if(self.status === 'resolved'){
onFulfilled(self.value)
}
if(self.status === 'rejected'){
onRejected(self.reason)
}
// 3.当new Promise中有resolve、reject处于异步中,执行then的时候,状态为pending,
if(self.status === 'pending'){
self.onResolvedCallbacks.push(()=>{
onFulfilled(self.value)
}) // 3. 把成功的回调函数,存到该数组中,这样写的好处,就是把参数传进去,不需要将来遍历onResolvedCallbacks时,再传参
self.onRejectedCallbacks.push(()=>{
onRejected(self.reason)
}) // 3. 把失败的回调函数,存到该数组中,这样写的好处,就是把参数传进去,不需要将来遍历onRejectedCallbacks时,再传参
}
}
module.exports = Promise
```
> 思考:同一个promise的实例可以then多次,成功时会调用所有的成功方法,失败时会调用所有的失败方法,那这个又该如何处理呢?
###### Promise的链式调用
其实Promise的核心在于链式调用,Promise主要是解决2个问题:
- 回调地狱
- 并发异步io操作,同一时间内把这个结果拿到,即比如有两个异步io操作,当这2个获取完毕后,才执行相应的代码,比如前面所说的after函数,发布订阅、Promise.all等。
用Promise方式可以得出结论:
- 1.如果一个promise执行完后,返回的还是一个promise,会把这个promise的执行结果会传递给下一次then中
- 2.如果在then中返回的不是一个promise,而是一个普通值,会将这个普通值作为下次then的成功的结果
- 3.如果当前then中失败了,会走下一个then的失败回调
- 4.如果在then中不返回值,虽然没有显式返回,但是默认是返回undefined,是属于普通值,依然会把这个普通值传到下一个then的成功回调中
- 5.catch是错误没有处理的情况下才会执行
- 6.then中可以不写东西
```js
Promise.prototype.then = function(onFulfilled,onRejected){
let self = this
let promise2 // 3.上面讲promise链式调用时,已经说了返回的是一个新的promise对象,那么我们声明一个新的promise
// 4.那么我们new一个新的promise,并且把以下代码放到promise中
let promise2 = new Promise((resolve,reject)=>{
if(self.status === 'resolved'){
// 7.当执行成功回调的时候,可能会出现异常,那么就把这个异常作为promise2的错误的结果
try{
let x = onFulfilled(self.value) // 6.这里的x,就是上面then中执行完返回的结果,我们在这里声明一个x用来接收
// 8.根据promiseA+规范,我们应该提供一个函数来处理promise2
// 我个人的理解是,then中不管是成功回调还是失败回调,其返回
// 值,有可能是promise,也有可能是普通值,也有可能是抛出错误
// 那么我们就需要一个函数来处理这几种不同的情况
// 这个函数我们声明为resolvePromise吧
resolvePromise(promise2,x,resolve,reject)
// 9. 这里的promise2就是当前的promise2,x则是执行then中成功回调后返回的结果,如果是成功则调promise2的resolve,失败则调reject
}catch(e){
reject(e) // 注意:这里的reject是这个promise2的reject
}
}
if(self.status === 'rejected'){
// 同6-7步
try{
let x = onRejected(self.reason)
// 同8-9
resolvePromise(promise2,x,resolve,reject)
}catch(e){
reject(e)
}
}
if(self.status === 'pending'){
self.onResolvedCallbacks.push(()=>{
// 同6-7步
try{
let x = onFulfilled(self.value)
// 同8-9
resolvePromise(promise2,x,resolve,reject)
}catch(e){
reject(e)
}
})
self.onRejectedCallbacks.push(()=>{
// 同6-7步
try{
let x = onRejected(self.reason)
// 同8-9
resolvePromise(promise2,x,resolve,reject)
}catch(e){
reject(e)
}
})
}
})
return promise2 // 5.在jquery中是return this,但是在promise中,则是返回一个新的promise对象
}
```
###### 写一个resolvePromise函数
接下来我们写一下resolvePromise这个函数,整个Promise最核心的部分就是在这里
```js
// 1.声明一个resolvePromise函数
// 这个函数非常核心,所有的promise都遵循这个规范,所有的promise可以通用,
/**
*
* @param {*} promise2 then的返回值,返回新的promise
* @param {*} x then中成功函数或者失败函数的返回值
* @param {*} resolve promise2的resolve
* @param {*} reject promise2的reject
*/
function resolvePromise(promise2,x,resolve,reject){
// 3.从2中我们可以得出,自己不能等于自己
// 当promise2和x是同一个对象的时候,则走reject
if(promise2 === x){
return reject(new TypeError('Chaining cycle detected for promise'))
}
// 4.因为then中的返回值可以为promise,当x为对象或者函数,才有可能返回的是promise
let called
if(x !== null && (typeof x === 'object' || typeof x === 'function')){
// 8.从第7步,可以看出为什么会存在抛出异常的可能,所以使用try catch处理
try{
// 6.因为当x为promise的话,是存在then方法的
// 但是我们取一个对象上的属性,也有可能出现异常,我们可以看一下第7步
let then = x.then
// 9.我们为什么在这里用call呢?解决了什么问题呢?可以看上面的第10步
// x可能还是个promise,那么就让这个promise执行
// 但是还是存在一个恶作剧的情况,就是{then:{}}
// 此时需要新增一个判断then是否函数
if(typeof === 'function'){
then.call(x,(y)=>{ // y是返回promise后的成功结果
// 一开始我们在这里写的是resolve(y),但是考虑到一点
// 这个y,有可能还是一个promise,
// 也就是说resolve(new Promise(...))
// 所以涉及到递归,我们把resolve(y)改成以下
// 12.限制既调resolve,也调reject
if(called) return
called = true
resolvePromise(promise2,y,resolve,reject)
// 这样的话,代码会一直递归,取到最后一层promise
// 11.这里有一种情况,就是不能既调成功也调失败,只能挑一次,
// 但是我们前面不是处理过这个情况了吗?
// 理论上是这样的,但是我们前面也说了,resolvePromise这个函数
// 是所有promise通用的,也可以是别人写的promise,如果别人
// 的promise可能既会调resolve也会调reject,那么就会出问题了,所以我们接下来要
// 做一下限制,这个我们写在第12步
},(err)=>{ // err是返回promise后的失败结果
if(called) return
called = true
reject(err)
})
}else{
resolve(x) // 如果then不是函数的话,那么则是普通对象,直接走resolve成功
}
}catch(e){ // 当出现异常则直接走reject失败
if(called) return
called = true
reject(e)
}
}else{ // 5.x为一个常量,则是走resolve成功
resolve(x)
}
}
```
###### 完整代码 也顺便带大家理顺一下
```js
function Promise(executor){
let self = this;
self.value = undefined; // 成功的值
self.reason = undefined; // 失败的值
self.status = "pending"; // 目前promise的状态为pending,还有resolved、rejected
self.onResolvedCallbacks = []; // 可能new promise的时候存在异步操作,把成功和失败回调保存起来
self.onRejectedCallbacks = [];
// 把状态更改为成功
function resolve(value){
// 只有pending状态才能转为成功状态
if(self.status === 'pending'){
self.value = value;
self.status = "resolved";
self.onResolvedCallbacks.forEach(fn => fn());
}
}
function reject(reason){
if(self.status === 'pending'){
self.status = "rejected"
self.reason = reason;
self.onRejectedCallbacks.forEach(fn => fn());
}
}
try {
executor(resolve, reject);
} catch(error) {
reject(error);
}
}
/**
* 所有的promise都遵循这个规范,所有的promise可以通用
* @param {*} promise2 then的返回值,返回新的promise
* @param {*} x then中成功函数或失败函数的返回值
* @param {*} resolve promise2的resolve
* @param {*} reject promise2的reject
*/
function resolvePromise(promise2, x, resolve, reject){
// promise2和x是同一个对象,reject
if(promise2 === x){
return reject(new TypeError('Chaining cycle detected for promise'));
}
let called;
// then的返回值是promise,当x为对象或者函数,才可能是promise
if(x!==null && (typeof x === 'object' || typeof x === 'function')){
try{
let then = x.then;
// x可以还是个promise,排除{then:{}}
if(typeof then === 'function'){
then.call(x, (y)=>{
// y是返回promise后成功结果
// 如果别人的promise可能既会调resolve也会调reject,那么就会出问题了,所以我们接下来要限制
if(called) return;
called = true;
// 代码会一直递归,取到最后一层promis
resolvePromise(promise2, y, resolve, reject);
},(err)=>{
// 返回promise失败结果
if(called) return;
called = true;
reject(err);
});
}else{
resolve(x) // 如果then不是函数的话,那么则是普通对象,直接走resolve成功
}
}catch(e){
if(called) return;
called = true;
reject(e);
}
}else{
// x为一个常量,则是走resolve成功
resolve(x);
}
}
Promise.prototype.then = function(onFullfilled, onRejected){
let self = this;
// 那么我们new一个新的promise,并且把以下代码放到promise中
let promise2 = new Promise((resolve, reject)=>{
if(self.status === 'resolved'){
try {
// 这里的x, 上一层then执行返回的结果
let x = onFullfilled(self.value);
// 提供一个resolvePromise函数处理promise2, then不管是成功回调、失败回调,返回值可能为promise/普通值/抛出错误值
resolvePromise(promise2, x, resolve, reject);
} catch(e){
reject(e);
}
}
if(self.status === 'rejected'){
try {
let x = onRejected(self.reason);
resolvePromise(promise2, x, resolve, reject);
} catch(e){
reject(e);
}
}
if(self.status === 'pending'){
// 把成功回调函数,存到改数组中,把参数传进去,不需要将来遍历onResolvedCallbacks时,再传参
self.onResolvedCallbacks.push(()=> {
try {
let x = onFullfilled(self.value);
resolvePromise(promise2, x, resolve, reject);
} catch(e){
reject(e);
}
});
self.onRejectedCallbacks.push(() => {
try {
let x = onRejected(self.reason);
resolvePromise(promise2, x, resolve, reject);
} catch(e){
reject(e);
}
});
}
});
return promise2;
}
// 是否为模块引入,健壮性判断
if (typeof module !== 'undefined' && typeof module.exports !== 'undefined') {
module.exports = Promise;
} else {
if (typeof define === 'function' && define.amd) {
define([], function() {
return Promise;
});
} else {
window.Promise = Promise;
}
}
```
###### 常用的promise方法
接下来,我们完善一下这个promise,写一下常用的promise方法
- Promise.reject
- Promise.resolve
- catch
- Promise.all
- Promise.race
```js
// 简化的promise, 语法糖可以简化一些操作
Promise.defer = Promise.deferred = function(){
let dfd = {};
dfd.promise = new Promise((resolve, reject)=>{
dfd.resolve =resolve;
dfd.reject =reject;
});
return dfd;
}
// 原生的Promise.resolve使用
Promise.resolve = function(value){
return new Promise((resolve, reject)=>{
resolve(value);
});
}
Promise.reject = function(reason){
return new Promise((resolve, reject)=>{
reject(reason);
});
}
Promise.prototype.catch = function(onRejected){
return this.then(null, onRejected);
}
Promise.all = function(promises){
return new Promise((resolve, reject)=>{
let arr = [];
let i = 0;
function processData(index, data){
arr[index] = data;
// 所有结束时候
if(++i === promises.length){
resolve(arr);
}
}
for(let i = 0; i < promises.length; i++){
promises[i].then((data)=> processData(i, data), reject);
}
});
}
Promise.race = function(promises){
return new Promise((resolve, reject)=>{
for(let i = 0; i < promises.length; i++){
promises[i].then(resolve, reject);
}
});
}
```
结尾:希望对大家有所帮助,promise的源码实现,我最大的收获并不是怎么实现promise,而是编程思维,大家可以多多往深里想一想,也希望大家可以和我进行交流,共同进步 | 17,522 | Apache-2.0 |
---
ms.openlocfilehash: a9b6af31b68c25ab58c52757f48ed23cca3f5a35
ms.sourcegitcommit: 79a2d6a07ba4ed08979819666a0ee6927bbf1b01
ms.translationtype: HT
ms.contentlocale: zh-CN
ms.lasthandoff: 11/28/2019
ms.locfileid: "74568007"
---
### <a name="better-argument-validation-in-the-pkcs8privatekeyinfo-constructor"></a>Pkcs8PrivateKeyInfo 构造函数中更好的参数验证
从 .NET Core 3.0 预览版 9 开始,`Pkcs8PrivateKeyInfo` 构造函数将 `algorithmParameters` 参数作为单一 BER 编码值进行验证。
#### <a name="change-description"></a>更改描述
在 .NET Core 3.0 预览版 9 之前,[`Pkcs8PrivateKeyInfo` 构造函数](xref:System.Security.Cryptography.Pkcs.Pkcs8PrivateKeyInfo.%23ctor(System.Security.Cryptography.Oid,System.Nullable%7BSystem.ReadOnlyMemory%7BSystem.Byte%7D%7D,System.ReadOnlyMemory%7BSystem.Byte%7D,System.Boolean))不验证 `algorithmParameters` 参数。 如果此参数表示的值无效,构造函数仍会成功,但对任何 <xref:System.Security.Cryptography.Pkcs.Pkcs8PrivateKeyInfo.Encode>、<xref:System.Security.Cryptography.Pkcs.Pkcs8PrivateKeyInfo.TryEncode%2A>、<xref:System.Security.Cryptography.Pkcs.Pkcs8PrivateKeyInfo.Encrypt%2A> 或 <xref:System.Security.Cryptography.Pkcs.Pkcs8PrivateKeyInfo.TryEncrypt%2A> 方法的调用将引发 <xref:System.ArgumentException>(对于其不接受的参数)(`preEncodedValue`) 或 <xref:System.Security.Cryptography.CryptographicException>。
如果运行 .NET Core 3.0 预览版 9 之前的版本,则以下代码仅在调用 <xref:System.Security.Cryptography.Pkcs.Pkcs8PrivateKeyInfo.Encode> 方法时引发异常:
```csharp
byte[] algorithmParameters = { 0x05, 0x00, 0x05, 0x00 };
var info = new Pkcs8PrivateKeyInfo(algorithmId, algorithmParameters, privateKey);
// This line throws an ArgumentException for `preEncodedValue`:
byte[] encoded = info.Encode();
```
从 .NET Core 3.0 预览版 9 开始,参数在构造函数中进行验证,无效值导致方法引发 <xref:System.Security.Cryptography.CryptographicException>。 此更改使异常更接近数据错误源。 例如:
```csharp
byte[] algorithmParameters = { 0x05, 0x00, 0x05, 0x00 };
// This line throws a CryptographicException
var info = new Pkcs8PrivateKeyInfo(algorithmId, algorithmParameters, privateKey);
```
#### <a name="version-introduced"></a>引入的版本
3.0 预览版 9
#### <a name="recommended-action"></a>建议的操作
请确保只提供有效的 `algorithmParameters` 值,否则对 `Pkcs8PrivateKeyInfo` 构造函数的调用既测试 <xref:System.ArgumentException> 也测试 <xref:System.Security.Cryptography.CryptographicException>(如果需要异常处理)。
### <a name="category"></a>类别
密码
### <a name="affected-apis"></a>受影响的 API
- [Pkcs8PrivateKeyInfo 构造函数](xref:System.Security.Cryptography.Pkcs.Pkcs8PrivateKeyInfo.%23ctor(System.Security.Cryptography.Oid,System.Nullable%7BSystem.ReadOnlyMemory%7BSystem.Byte%7D%7D,System.ReadOnlyMemory%7BSystem.Byte%7D,System.Boolean))
<!--
### Affected APIs
- `M:System.Security.Cryptography.Pkcs.Pkcs8PrivateKeyInfo.#ctor(System.Security.Cryptography.Oid,System.Nullable{System.ReadOnlyMemory{System.Byte}},System.ReadOnlyMemory{System.Byte},System.Boolean))
--> | 2,771 | CC-BY-4.0 |
---
title: 将服务主体添加到 Azure Analysis Services 管理员角色 | Azure
description: 了解如何将自动化服务主体添加到 Azure Analysis Services 服务器管理员角色
author: rockboyfor
ms.service: azure-analysis-services
ms.topic: conceptual
origin.date: 10/29/2019
ms.date: 03/23/2020
ms.author: v-yeche
ms.reviewer: minewiskan
ms.custom: fasttrack-edit
ms.openlocfilehash: 0c8dba45f8481fa46835f18d96c92a067c990636
ms.sourcegitcommit: 1436f1851342ca5631eb25342eed954adb707af0
ms.translationtype: HT
ms.contentlocale: zh-CN
ms.lasthandoff: 03/19/2020
ms.locfileid: "79543791"
---
# <a name="add-a-service-principal-to-the-server-administrator-role"></a>将服务主体添加到服务器管理员角色
若要自动执行无人参与的 PowerShell 任务,服务主体在托管的 Analysis Services 服务器上必须具备“服务器管理员”权限 。 本文介绍如何将服务主体添加到 Azure AS 服务器上的服务器管理员角色。 可以使用 SQL Server Management Studio 或资源管理器模板来执行此操作。
## <a name="before-you-begin"></a>准备阶段
在完成此项任务之前,必须有一个在 Azure Active Directory 中注册的服务主体。
[创建服务主体 - Azure 门户](../active-directory/develop/howto-create-service-principal-portal.md)
[创建服务主体 - PowerShell](../active-directory/develop/howto-authenticate-service-principal-powershell.md)
## <a name="using-sql-server-management-studio"></a>使用 SQL Server Management Studio
可以使用 SQL Server Management Studio (SSMS) 配置服务器管理员。 若要完成此项任务,在 Azure AS 服务器上必须具备[服务器管理员](analysis-services-server-admins.md)权限。
1. 在 SSMS 中连接至 Azure AS 服务器。
2. 在“服务器属性” > “安全性”中,单击“添加” 。
3. 在“选择用户或组”中,按名称搜索注册的应用,选中以后单击“添加” 。

4. 验证服务主体帐户 ID,然后单击“确定” 。

## <a name="using-a-resource-manager-template"></a>使用资源管理器模板
还可以通过使用 Azure 资源管理器模板部署 Analysis Services 服务器来配置服务器管理员。 运行部署的身份必须在 [Azure 基于角色的访问控制 (RBAC)](../role-based-access-control/overview.md) 中属于资源的“参与者” 角色。
> [!IMPORTANT]
> 必须使用格式 `app:{service-principal-client-id}@{azure-ad-tenant-id}` 来添加服务主体。
以下资源管理器模板使用已添加到 Analysis Services 管理员角色中的指定服务主体部署 Analysis Services 服务器:
```json
{
"$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"analysisServicesServerName": {
"type": "string"
},
"location": {
"type": "string"
},
"analysisServicesSkuName": {
"type": "string"
},
"analysisServicesCapacity": {
"type": "int"
},
"servicePrincipalClientId": {
"type": "string"
},
"servicePrincipalTenantId": {
"type": "string"
}
},
"resources": [
{
"name": "[parameters('analysisServicesServerName')]",
"type": "Microsoft.AnalysisServices/servers",
"apiVersion": "2017-08-01",
"location": "[parameters('location')]",
"sku": {
"name": "[parameters('analysisServicesSkuName')]",
"capacity": "[parameters('analysisServicesCapacity')]"
},
"properties": {
"asAdministrators": {
"members": [
"[concat('app:', parameters('servicePrincipalClientId'), '@', parameters('servicePrincipalTenantId'))]"
]
}
}
}
]
}
```
## <a name="using-managed-identities"></a>使用托管标识
还可以将托管标识添加到 Analysis Services 管理员列表。
<!--Not Available on [Logic App with a system-assigned managed identity](../logic-apps/create-managed-service-identity.md)-->
在 Azure 门户和 API 的大多数部分中,托管标识是使用其服务主体对象 ID 标识的。 但是,Analysis Services 要求使用其客户端 ID 进行标识。 若要获取服务主体的客户端 ID,可以使用 Azure CLI:
```bash
az ad sp show --id <ManagedIdentityServicePrincipalObjectId> --query appId -o tsv
```
也可以使用 PowerShell:
```powershell
(Get-AzureADServicePrincipal -ObjectId <ManagedIdentityServicePrincipalObjectId>).AppId
```
然后,可以将此客户端 ID 与租户 ID 结合使用,以将托管标识添加到 Analysis Services 管理员列表中,如上所述。
## <a name="related-information"></a>相关信息
* [下载 SQL Server PowerShell 模块](https://docs.microsoft.com/sql/ssms/download-sql-server-ps-module)
* [下载 SSMS](https://docs.microsoft.com/sql/ssms/download-sql-server-management-studio-ssms)
<!-- Update_Description: update meta properties, wording update, update link --> | 4,262 | CC-BY-4.0 |
# MarkDown 通关任务
环境准备:
- 在 C: 盘根目录创建 MarkDown 文件夹,此文件夹用于创建通关任务的 md 文件;
- 在 MarkDown 文件夹下创建 images 文件夹,此文件夹用于放置通关任务需要的图片;
- 在 C:\MarkDown 文件夹下执行 git init 初始化成 Git 仓库;
- 在自己的 Github 个人主页创建 MarkDown 空白仓库;
- 将本地的 MarkDown 仓库与自己的 Github 上的 MarkDown 仓库关联上;
## 任务一:了解 MarkDown
要求:
- 阅读[维基百科的 MarkDown 词条];
- 阅读[百度百科的 MarkDown 词条];
- 浏览[课程资料页面];
- 浏览 [Github 2016 年度报告]中前十位开源项目中的**文档型项目**并收藏;
## 任务二:安装 HBuilder 工具
要求:
- 百度搜索 HBuilder;
- 从 DCloud 官网下载 HBuilder 安装包;
- 安装 HBuilder;
- 注册 HBuilder 账户;
- 安装 GFM Viewer 插件(可选);
- 安装 HBuilder 主题(可选);
- 导入 HBuilder 配置文件(可选);
## 任务三:练习 MarkDown 语法(一)
要求:
- 新建 README.md 文件(注意文件名大小写);
- 在 README.md 中对 MarkDown 仓库内容做一个简单描述;
- 新建 demo1.md 文件
- 在 demo1.md 文件中把课程视频中讲到**段落**、**标题**、**强调**和**列表**这些 MarkDown 语法练习一下;
- MarkDown 实战一:多级列表实战
- 创建 list.md
- 内容是 wangding/selenium-ide-doc 仓库的 [README.md]
- 只需要完成多级列表,不需要添加超链接
- 多级列表的样式,需要跟 wangding/selenium-ide-doc 仓库的 [README.md] 文件中的样式保持一致
- 将本次任务创建的所有文件 push 推到自己的 Github MarkDown 远程仓库
- 在 Github 网站上查看上传的文件,检查样式是否正确,如果不正确请在本地修改,重新上传
## 任务四:练习 MarkDown 语法(二)
要求:
- 新建 demo2.md 文件
- 在 demo2.md 文件中把课程视频中讲到**链接**、**图片**、**引用**和**代码块**这些 MarkDown 语法练习一下;
- MarkDown 实战二
- 图片实战
- 创建 open.md
- 内容是 wangding/selenium-ide-doc 仓库的 [Open.md]
- 链接实战
- 从 wangding/selenium-ide-doc 仓库下载 [Features.md] 以及该文档引用的所有图片,放到自己的 MarkDown 目录下;
- 把任务三中的 list.md 中的 “IDE 的功能”列表项及其子列表项与本地 Features.md 的相关内容关联起来;
- 代码块实战
- 创建 TestSuit.md 文件
- 内容是 wangding/selenium-ide-doc 仓库的 [TestSuit.md],注意代码块要求设置语法高亮
- 将本次任务创建的所有文件 push 推到自己的 Github MarkDown 远程仓库
- 在 Github 网站上查看上传的文件,检查样式是否正确,如果不正确请在本地修改,重新上传
## 任务五:练习 MarkDown 语法(三)
要求:
- 新建 demo3.md 文件
- 在 demo3.md 文件中把课程视频中讲到**表格**、**水平分隔线**、**HTML语法**和**GFM** 这些 MarkDown 语法练习一下;
- MarkDown 实战三
- 表格实战
- 创建 JavaScript.md
- 内容是 Selenium IDEDoc 仓库的 [JavaScript.md]
- 将本次任务创建的所有文件 push 推到自己的 Github MarkDown 远程仓库
- 在 Github 网站上查看上传的文件,检查样式是否正确,如果不正确请在本地修改,重新上传
## 任务六:开始写 MarkDown 文档
要求:
- 完成[在线通关任务];
- 打通 [how-to-markdown] 12 关;
- 根据自己的实际需要,自由选择下面一个或多个任务;
- 在 Github 上创建 log 仓库,用 MarkDown 记录自己每天的工作和学习经历;
- 在 Github 上创建 study 仓库,用 MarkDown 记录自己平时学习中收藏的学习资料;
- 其他用途,请自由发挥自己的想象力和创造力;
<!-- 下面是文中的链接 -->
[维基百科的 MarkDown 词条]: https://en.wikipedia.org/wiki/Markdown
[百度百科的 MarkDown 词条]: http://baike.baidu.com/link?url=TEREhJsIPUnfMdpMVsSJv0RVWPsHxUqmv_gF8zn9lkM6zaRmgGIb7PE0SbXX1F96oRGJ54ykjIqcHkfUUlf59DAnbFiwaFg_YCwKyBLRBZ_
[课程资料页面]: README.md
[Github 2016 年度报告]: https://octoverse.github.com/
[README.md]: https://github.com/wangding/selenium-ide-doc/blob/master/SUMMARY.md
[Open.md]: https://github.com/wangding/selenium-ide-doc/blob/master/Open.md
[Features.md]: https://github.com/wangding/selenium-ide-doc/blob/master/Features.md
[TestSuit.md]: https://github.com/wangding/selenium-ide-doc/blob/master/TestSuite.md
[JavaScript.md]: https://github.com/wangding/selenium-ide-doc/blob/master/JavaScript.md
[在线通关任务]: http://www.markdowntutorial.com/lesson/1/
[how-to-markdown]: https://github.com/workshopper/how-to-markdown/ | 3,080 | MIT |
# block-closing-brace-newline-before
要求在块的闭大括号之前必须有换行符或不能有空白符。
```css
a { color: pink;
}
/** ↑
* 这个大括号之前的换行符 */
```
[命令行](../../../docs/user-guide/cli.md#自动修复错误)中的 `--fix` 选项可以自动修复此规则报告的所有问题。
## 选项
`string`: `"always"|"always-multi-line"|"never-multi-line"`
### `"always"`
在闭大括号之前*必须*有一个换行符。
以下模式被视为违规:
```css
a { color: pink;}
```
以下模式*不*被视为违规:
```css
a { color: pink;
}
```
```css
a {
color: pink;
}
```
### `"always-multi-line"`
在多行块的闭大括号之前*必须*有一个换行符。
以下模式被视为违规:
```css
a {
color: pink;}
```
以下模式*不*被视为违规:
```css
a { color: pink; }
```
```css
a { color: pink;
}
```
### `"never-multi-line"`
在多行块的闭大括号之前*不能*有空白符。
以下模式被视为违规:
```css
a {
color: pink; }
```
以下模式*不*被视为违规:
```css
a { color: pink; }
```
```css
a {
color: pink;}
``` | 764 | MIT |
---
layout: post
title: CSS3 Gradients
date: 2014-11-02
categories: jekyll update
---
## 定义
CSS3 定义了两种类型的渐变(gradients):
* 线性渐变(Linear Gradients)- 向下/向上/向左/向右/对角方向
* 径向渐变(Radial Gradients)- 由它们的中心定义
兼容前缀;-webkit-、-moz- 或 -o-
### CSS3 线性渐变
语法 :`background: linear-gradient(direction, color-stop1, color-stop2, ...);`
为了创建一个线性渐变,您必须至少定义两种颜色结点。颜色结点即您想要呈现平稳过渡的颜色。同时,您也可以设置一个起点和一个方向(或一个角度)。
* 线性渐变 - 从上到下(默认情况下)
``
#grad {
background: -webkit-linear-gradient(red, blue); /* Safari 5.1 - 6.0 */
background: -o-linear-gradient(red, blue); /* Opera 11.1 - 12.0 */
background: -moz-linear-gradient(red, blue); /* Firefox 3.6 - 15 */
background: linear-gradient(red, blue); /* 标准的语法 */
}
``
* 线性渐变 - 从左到右
``
#grad {
background: -webkit-linear-gradient(left, red , blue); /* Safari 5.1 - 6.0 */
background: -o-linear-gradient(right, red, blue); /* Opera 11.1 - 12.0 */
background: -moz-linear-gradient(right, red, blue); /* Firefox 3.6 - 15 */
background: linear-gradient(to right, red , blue); /* 标准的语法 */
}
``
* 线性渐变 - 对角
``
#grad {
background: -webkit-linear-gradient(left top, red , blue); /* Safari 5.1 - 6.0 */
background: -o-linear-gradient(bottom right, red, blue); /* Opera 11.1 - 12.0 */
background: -moz-linear-gradient(bottom right, red, blue); /* Firefox 3.6 - 15 */
background: linear-gradient(to bottom right, red , blue); /* 标准的语法 */
}
``
#### 使用角度
如果您想要在渐变的方向上做更多的控制,您可以定义一个角度,而不用预定义方向(to bottom、to top、to right、to left、to bottom right,等等)。
角度是指水平线和渐变线之间的角度,逆时针方向计算
#### 使用多个颜色结点
#### 使用透明度(Transparency)
rgba() 函数来定义颜色结点
#### 重复的线性渐变
repeating-linear-gradient() 函数用于重复线性渐变:
---
## CSS3 径向渐变
径向渐变由它的中心定义。
为了创建一个径向渐变,您也必须至少定义两种颜色结点。颜色结点即您想要呈现平稳过渡的颜色。同时,您也可以指定渐变的中心、形状(原型或椭圆形)、大小。默认情况下,渐变的中心是 center(表示在中心点),渐变的形状是 ellipse(表示椭圆形),渐变的大小是 farthest-corner(表示到最远的角落)。
语法:'background: radial-gradient(center, shape size, start-color, ..., last-color);'
* 径向渐变 - 颜色结点均匀分布(默认情况下)
``
#grad {
background: -webkit-radial-gradient(red, green, blue); /* Safari 5.1 - 6.0 */
background: -o-radial-gradient(red, green, blue); /* Opera 11.6 - 12.0 */
background: -moz-radial-gradient(red, green, blue); /* Firefox 3.6 - 15 */
background: radial-gradient(red, green, blue); /* 标准的语法 */
}
``
* 径向渐变 - 颜色结点不均匀分布
``
#grad {
background: -webkit-radial-gradient(red 5%, green 15%, blue 60%); /* Safari 5.1 - 6.0 */
background: -o-radial-gradient(red 5%, green 15%, blue 60%); /* Opera 11.6 - 12.0 */
background: -moz-radial-gradient(red 5%, green 15%, blue 60%); /* Firefox 3.6 - 15 */
background: radial-gradient(red 5%, green 15%, blue 60%); /* 标准的语法 */
}
``
#### 设置形状
shape 参数定义了形状。它可以是值 circle 或 ellipse。其中,circle 表示圆形,ellipse 表示椭圆形。默认值是 ellipse。
#### 不同尺寸大小关键字的使用
size 参数定义了渐变的大小。它可以是以下四个值:
* closest-side
* farthest-side
* closest-corner
* farthest-corner
#### 重复的径向渐变
repeating-radial-gradient() 函数用于重复径向渐变:
## 参考
1. [W3C: CSS3 Gradients](http://www.w3schools.com/css/css3_gradients.asp) 或 [CSS3 渐变](http://www.w3cschool.cc/css3/css3-gradients.html)
2. [CSS3 Gradients](http://gaoli.github.io/css3-gradients.html)
3. [Cross browser, imageless linear gradients](http://lea.verou.me/2009/03/cross-browser-imageless-linear-gradients/)
4. [CSS3 Patterns, Explained](http://24ways.org/2011/css3-patterns-explained/) | 3,312 | MIT |
---
title: Apache反向代理Discuz地址有问题的解决方法
tags:
- apache
categories:
- nginx
author: Lison
img: ''
top: false
cover: false
coverImg: ''
toc: false
mathjax: false
summary: ''
date: 2014-11-6 17:14:04
desc:
keywords: Apache反向代理,Apache Discuz反向代理,您的请求来路不正确解决办法
---
机器A拥有外网ip,机器B处于内网。
机器A运行apache,本地程序,开放80端口,并且作为代理服务器处理外部泛解析域名,例如bbs.lison.com。并且解析到机器B的端口8090。
机器B运行nginx,处理8090端口的web服务。
<!--more-->
部署成功后,出现的问题是:访问bbs.lison.com之后,页面能打开,但是样式无法加载,查看源代码发现<base href=”http://机器B:8090″ />,依然是机器B的内网地址端口号。
这个问题困扰了我好几天,直到今天看到大神的文章:
Apache反向代理Discuz出现“您的请求来路不正确”解决办法
http://rayyn.net/2010/06/37.html | 595 | Apache-2.0 |
---
title : Mac OS X ABI Mach-O File Format Reference
categories: iOS
---
# Overview
This document describes the structure of the Mach-O (Mach object) file format, which is the standard
used to store programs and libraries on disk in the Mac OS X application binary interface (ABI). To
understand how the Xcode tools work with Mach-O files, and to perform low-level debugging tasks,
you need to understand this information.
本文档描述了Mach- o (Mach object)文件格式的结构,这是Mac OS X应用程序二进制接口(ABI)中用于在磁盘上存储程序和库的标准格式。要理解Xcode工具如何处理Mach-O文件,并执行 low-level 调试任务,您需要理解这些信息。
The Mach-O file format provides both intermediate (during the build process) and final (after linking
the final product) storage of machine code and data. It was designed as a flexible replacement for the
BSD a.out format, to be used by the compiler and the static linker and to contain statically linked
executable code at runtime. Features for dynamic linking were added as the goals of Mac OS X evolved,
resulting in a single file format for both statically linked and dynamically linked code.
Mach-O文件格式提供了机器代码和数据的中间(在构建过程中)和最终(在链接最终产品之后)存储。它被设计为一个灵活的替代BSD `a.out`输出格式,由编译器和静态链接器使用,并在运行时包含静态链接的可执行代码。随着Mac OS X目标的发展,动态链接的特性也被添加进来,从而为静态链接和动态链接代码提供了一种单一的文件格式。
## Basic Structure
A Mach-O file contains three major regions (as shown in Figure 1):
一个Mach-O文件包含三个主要区域(如图1所示):
- At the beginning of every Mach-O file is a **header structure** that identifies the file as a Mach-O file. The header also contains other basic file type information, indicates the target architecture, and contains flags specifying options that affect the interpretation of the rest of the file.
在每个Mach-O文件的开头都有一个头结构,它将文件标识为一个Mach-O文件。头文件还包含其他基本文件类型信息,指示目标体系结构,并包含指定影响文件其余部分解释的选项的标志。
- Directly following the header are a series of variable-size **load commands** that specify the layout and linkage characteristics of the file. Among other information, the load commands can specify:
头文件后面是一系列大小可变的**load commands**,它们指定文件的布局和链接特性。在其他信息中,load commands可以指定:
- The initial layout of the file in virtual memory
文件在虚拟内存中的初始布局
- The location of the symbol table (used for dynamic linking)
符号表的位置(用于动态链接)
- The initial execution state of the main thread of the program
程序主线程的初始执行状态
- The names of shared libraries that contain definitions for the main executable’s imported
symbols
包含主可执行文件导入符号定义的共享库的名称
- Following the load commands, all Mach-O files contain the data of one or more segments. Each **segment** contains zero or more sections. Each **section** of a segment contains code or data of some particular type. Each segment defines a region of virtual memory that the dynamic linker maps into the address space of the process. The exact number and layout of segments and sections is specified by the load commands and the file type.
按照load commands, Mach-O文件都包含一个或多个**segment**的数据。每个段包含零个或多个**sections**。段的每个**section**都包含某种特定类型的代码或数据。每个**segment**定义一个虚拟内存区域,动态链接器将该区域映射到进程的地址空间。**segment**和**sections**的确切数量和布局由`load commands`和文件类型指定。
- In user-level fully linked Mach-O files, the last segment is the **link edit** segment. This segment contains the tables of link edit information, such as the symbol table, string table, and so forth, used by the dynamic loader to link an executable file or Mach-O bundle to its dependent libraries.
在用户级完全链接的Mach-O文件中,最后一个段是链接编辑段。此段包含链接编辑信息的表,如符号表、字符串表等,动态加载程序使用这些表将可执行文件或Mach-O包链接到其依赖库。
**Figure 1** Mach-O file format basic structure
Various tables within a Mach-O file refer to sections by number. Section numbering begins at 1 (not
0) and continues across segment boundaries. Thus, the first segment in a file may contain sections 1
and 2 and the second segment may contain sections 3 and 4.
Mach-O文件中的各种表都是按编号引用节的。节编号从1(不是0)开始,并跨越段边界。因此,文件中的第一个段可以包含第1节和第2节,第二个段可以包含第3节和第4节。
When using the Stabs debugging format, the symbol table also holds debugging information. When
using DWARF, debugging information is stored in the image’s corresponding dSYM file, specified
by the uuid_command (page 20) structure
当使用Stabs调试格式时,符号表还包含调试信息。使用DWARF时,调试信息存储在image对应的dSYM文件中,该文件由uuid_command 结构指定
## Header Structure and Load Commands
A Mach-O file contains code and data for one architecture. The header structure of a Mach-O file
specifies the target architecture, which allows the kernel to ensure that, for example, code intended
for PowerPC-based Macintosh computers is not executed on Intel-based Macintosh computers.
一个Mach-O文件包含一个架构的代码和数据。Mach-O文件的头结构指定了目标体系结构,这允许内核确保,例如,针对基于powerpc的Macintosh计算机的代码不会在基于intel的Macintosh计算机上执行。
You can group multiple Mach-O files (one for each architecture you want to support) in one binary
using the format described in “Universal Binaries and 32-bit/64-bit PowerPC Binaries” (page 55).
您可以使用“Universal Binaries and 32-bit/64-bit PowerPC Binaries”中描述的格式将多个Mach-O文件(每个体系结构一个)分组到一个二进制文件中。
> **Note:** Binaries that contain object files for more than one architecture are not Mach-O files. They
> archive one or more Mach-O files.
>
> 注意:包含多个体系结构的目标文件的二进制文件不是Mach-O文件。他们存档一个或多个Mach-O文件。
Segments and sections are normally accessed by name. Segments, by convention, are named using
all uppercase letters preceded by two underscores (for example, _TEXT); sections should be named
using all lowercase letters preceded by two underscores (for example, __text). This naming convention is standard, although not required for the tools to operate correctly.
`Segments`和`sections`通常按名称访问。按照惯例,`Segments`的命名使用所有大写字母加上两个下划线(例如,__ TEXT); `sections`的命名应该使用所有小写字母加上两个下划线(例如,__ text)。这只是一个规范的命名约定,不强制要求必须这样做
## Segments
A segment defines a range of bytes in a Mach-O file and the addresses and memory protection
attributes at which those bytes are mapped into virtual memory when the dynamic linker loads the
application. As such, segments are always virtual memory page aligned. A segment contains zero or
more sections.
`segment`在Mach-O文件中定义一个字节范围,以及地址和内存保护属性,当动态链接器加载应用程序时,这些字节被映射到虚拟内存中。因此,`segments`始终是虚拟内存页面对齐的。一个`segment`包含零个或多个`sections`。
Segments that require more memory at runtime than they do at build time can specify a larger
in-memory size than they actually have on disk. For example, the __PAGEZERO segment generated by
the linker for PowerPC executable files has a virtual memory size of one page but an on-disk size of 0.
Because __PAGEZERO contains no data, there is no need for it to occupy any space in the executable
file.
运行时比构建时需要更多内存的段可以指定比它们在磁盘上实际拥有的更大的内存大小。例如,链接器为PowerPC可执行文件生成的__ PAGEZERO段的虚拟内存大小为一页,而磁盘大小为0。由于__ PAGEZERO不包含数据,因此不需要占用可执行文件中的任何空间。
> **Note:** Sections that are to be filled with zeros must always be placed at the end of the segment.
> Otherwise, the standard tools will not be able to successfully manipulate the Mach-O file.
>
> 注意:要用零填充的部分必须始终放在段的末尾。否则,标准工具将无法成功地操作Mach-O文件。
For compactness, an intermediate object file contains only one segment. This segment has no name;
it contains all the sections destined ultimately for different segments in the final object file. The data
structure that defines a section (page 23) contains the name of the segment the section is intended
for, and the static linker places each section in the final object file accordingly.
为了紧凑性,中间对象文件只包含一个`segment`。这个`segment`没有名字;它包含为最终目标文件中的不同`segment`指定的所有`sections`。定义`section`的数据结构(第23页)包含节的目标段的名称,静态链接器将每个节相应地放在最终目标文件中。
For best performance, segments should be aligned on virtual memory page boundaries—4096 bytes
for PowerPC and x86 processors. To calculate the size of a segment, add up the size of each section,
then round up the sum to the next virtual memory page boundary (4096 bytes, or 4 kilobytes). Using
this algorithm, the minimum size of a segment is 4 kilobytes, and thereafter it is sized at 4 kilobyte
increments.
为了获得最佳性能,段应该对齐到虚拟内存页边界上—PowerPC和x86处理器的4096字节。要计算段的大小,请将每个段的大小相加,然后将总和四舍五入到下一个虚拟内存页边界(4096字节,或4 kb)。使用这种算法,一个段的最小大小是4 kb,然后以4 kb的增量进行调整。
The header and load commands are considered part of the first segment of the file for paging purposes.
In an executable file, this generally means that the headers and load commands live at the start of the __ TEXT segment because that is the first segment that contains data. The __PAGEZERO segment contains no data on disk, so it’s ignored for this purpose.
出于分页的目的,`header`和`load commands`被认为是文件第一`segment`的一部分。在一个可执行文件中,这通常意味着`headers`和`load commands`位于`__ TEXT` `segment`的开头,因为这是包含数据的第一个`segment`。由于`__PAGEZERO` `segment`没有包含任何数据,因此忽略了它。
These are the segments the standard Mac OS X development tools (contained in the Xcode Tools CD)
may include in a Mac OS X executable:
以下是标准Mac OS X开发工具(包含在Xcode tools CD中)可能包含在Mac OS X可执行文件中的部分:
- The static linker creates a __ PAGEZERO segment as the first segment of an executable file. This
segment is located at virtual memory location 0 and has no protection rights assigned, the
combination of which causes accesses to NULL, a common C programming error, to immediately
crash. The __ PAGEZERO segment is the size of one full VM page for the current architecture (for
Intel-based and PowerPC-based Macintosh computers, this is 4096 bytes or 0x1000 in hexadecimal).
Because there is no data in the __PAGEZERO segment, it occupies no space in the file (the file size
in the segment command is 0).
静态链接器创建一个__PAGEZERO `segment` 作为可执行文件的第一个`segment`。这个`segment`位于虚拟内存位置0,没有分配任何保护权限,两者的组合会导致对NULL的访问立即崩溃,这是一个常见的C编程错误。对于当前的体系结构(对于基于intel和基于powerpc的Macintosh计算机,这是4096字节,或者十六进制是0x1000), _ PAGEZERO`segment`的大小相当于一个完整的VM页面。因为在PAGEZERO段中没有数据,所以它在文件中不占空间(segment命令中的文件大小为0)。
- The __ TEXT segment contains executable code and other read-only data. To allow the kernel to map it directly from the executable into sharable memory, the static linker sets this segment’s virtual memory permissions to disallow writing. When the segment is mapped into memory, it can be shared among all processes interested in its contents. (This is primarily used with frameworks, bundles, and shared libraries, but it is possible to run multiple copies of the same executable in Mac OS X, and this applies in that case as well.) The read-only attribute also means that the pages that make up the __ TEXT segment never need to be written back to disk. When the kernel needs to free up physical memory, it can simply discard one or more __TEXT pages and re-read them from disk when they are next needed.
TEXT `segment`包含可执行代码和其他只读数据。为了允许内核将它直接从可执行文件映射到可共享内存,静态链接器将这个段的虚拟内存权限设置为不允许写入。当段被映射到内存中时,它可以在对其内容感兴趣的所有进程之间共享。(这主要用于框架、捆绑包和共享库,但也可以在Mac OS X中运行同一可执行文件的多个副本,在这种情况下也是适用的。)只读属性还意味着组成TEXT段的页面永远不需要写回磁盘。当内核需要释放物理内存时,它可以简单地丢弃一个或多个TEXT页面,然后在下次需要时从磁盘重新读取它们。
- The __ DATA segment contains writable data. The static linker sets the virtual memory permissions of this segment to allow both reading and writing. Because it is writable, the __ DATA segment of a framework or other shared library is logically copied for each process linking with the library. When memory pages such as those making up the __DATA segment are readable and writable, the kernel marks them copy-on-write; therefore when a process writes to one of these pages, that process receives its own private copy of the page.
DATA段包含可写数据。静态链接器设置此段的虚拟内存权限为允许读写。因为它是可写的,所以framework或其他共享库的DATA segment在逻辑上被复制到与库链接的每个进程。当组成DATA段的内存页可读可写时,内核将它们标记为copy-on-write; 因此,当一个进程写到其中一个页面时,该进程将收到该页面的私有副本。
- The __OBJC segment contains data used by the Objective-C language runtime support library.
__OBJC段包含OC运行时支持库使用的数据。
- The __IMPORT segment contains symbol stubs and non-lazy pointers to symbols not defined in
the executable. This segment is generated only for executables targeted for the IA-32 architecture.
__IMPORT段含符号存根和指向可执行文件中未定义的符号的非懒加载指针。此段只在IA-32架构下的可执行文件中生成
- The __LINKEDIT segment contains raw data used by the dynamic linker, such as symbol, string, and relocation table entries.
__LINKEDIT段包含动态链接器使用的原始数据,例如符号、字符串和重定位表条目。
## Sections
The __ TEXT and __ DATA segments may contain a number of standard sections, listed in Table 1, Table 2 (page 11), and Table 3 (page 11). The __OBJC segment contains a number of sections that are private to the Objective-C compiler. Note that the static linker and file analysis tools use the section type and attributes (instead of the section name) to determine how they should treat the section. The section name, type and attributes are explained further in the description of the section (page 23) data type.
TEXT和DATA `segments`可以包含许多标准`sections`,如表1、表2和表3中列出。__OBJC段包含许多对Objective-C编译器私有的部分。注意,静态链接器和文件分析工具使用`section`类型和属性(而不是section name)来确定它们应该如何处理这个`section`。`section`名称、类型和属性将在section数据类型描述中进一步解释。
**Table 1** The sections of a __TEXT segment
| Segment and section name | Contents |
| ------------------------- | ------------------------------------------------------------ |
| __ TEXT, __text | Executable machine code. The compiler generally places only executable<br/>code in this section, no tables or data of any sort.<br>可执行的机器代码。编译器通常只将可执行代码放在这一节中,没有任何类型的表或数据。 |
| __ TEXT, __cstring | Constant C strings. A C string is a sequence of non-null bytes that ends<br/>with a null byte ('\0'). The static linker coalesces constant C string values,<br/>removing duplicates, when building the final product.<br>常数C字符串。C字符串是一个以空字节('\0')结尾的非空字节序列。静态链接器在构建最终产品时合并常量C字符串值,删除重复项。 |
| __ TEXT, __picsymbol_stub | Position-independent indirect symbol stubs. See “Dynamic Code<br/>Generation” in *Mach-O Programming Topics* for more information.<br>位置无关的间接符号存根。有关更多信息,请参阅Mach-O编程主题中的“动态代码生成”。 |
| __ TEXT, __symbol_stub | Indirect symbol stubs. See “Dynamic Code Generation” in *Mach-O<br/>Programming Topics* for more information.<br>间接的象征存根。有关更多信息,请参阅Mach-O编程主题中的“动态代码生成”。 |
| __ TEXT, __const | Initialized constant variables. The compiler places all nonrelocatable data<br/>declared const in this section. (The compiler typically places uninitialized constant variables in a zero-filled section.)<br>初始化常数变量。编译器将在本节中放置所有声明的const的不可重定位数据。(编译器通常将未初始化的常量变量放在一个零填充的部分。) |
| __ TEXT, __literal4 | 4-byte literal values. The compiler places single-precision floating point<br/>constants in this section. The static linker coalesces these values, removing<br/>duplicates, when building the final product. With some architectures,<br/>it’s more efficient for the compiler to use immediate load instructions<br/>rather than adding to this section.<br>4字节的文本值。编译器在本节中放置单精度浮点常量。静态链接器在构建最终产品时合并这些值,删除重复项。对于某些架构,编译器使用立即加载指令比添加到本节更有效。 |
| __ TEXT, __literal8 | 8-byte literal values. The compiler places double-precision floating point<br/>constants in this section. The static linker coalesces these values, removing<br/>duplicates, when building the final product. With some architectures,<br/>it’s more efficient for the compiler to use immediate load instructions<br/>rather than adding to this section.<br>8字节文字值。编译器在本节中放置双精度浮点常量。静态链接器在构建最终产品时合并这些值,删除重复项。对于某些架构,编译器使用立即加载指令比添加到本节更有效。 |
**Table 2** The sections of a __DATA segment
| Segment and section name | Contents |
| ------------------------ | ------------------------------------------------------------ |
| __ DATA, __data | Initialized mutable variables, such as writable C strings and data arrays.<br>初始化可变变量,如可写C字符串和数据数组。 |
| __ DATA, __la_symbol_ptr | Lazy symbol pointers, which are indirect references to functions<br/>imported from a different file. See “Dynamic Code Generation” in<br/>*Mach-O Programming Topics* for more information.<br>懒加载符号指针,是对从不同文件导入的函数的间接引用。有关更多信息,请参阅Mach-O编程主题中的“动态代码生成”。 |
| __ DATA, __nl_symbol_ptr | Non-lazy symbol pointers, which are indirect references to data items imported from a different file. See “Dynamic Code Generation” in Mach-O Programming Topics for more information.<br>非懒加载符号指针,是对从其他文件导入的函数的间接引用。有关详细信息,请参阅[Mach-O Programming Topics](https://developer.apple.com/library/archive/documentation/DeveloperTools/Conceptual/MachOTopics/0-Introduction/introduction.html#//apple_ref/doc/uid/TP40001827-SW1)中的“Dynamic Code Generatio”。 |
| __ DATA, __dyld | Placeholder section used by the dynamic linker.<br>动态链接器使用的占位section |
| __ DATA, __const | Initialized relocatable constant variables.<br>初始化可重定位常量变量。 |
| __ DATA, __mod_init_func | Module initialization functions. The C++ compiler places static<br/>constructors here.<br>模块初始化方法,c++的静态构造函数在这里放 |
| __ DATA, __mod_term_func | Module termination functions.<br>退出方法,类似析构函数 |
| __ DATA, __bss | Data for uninitialized static variables (for example, static int i;).<br>未初始化静态变量的数据(例如,static int i;) |
| __ DATA, __common | Uninitialized imported symbol definitions (for example, int i;)<br/>located in the global scope (outside of a function declaration).<br>位于全局范围(函数声明之外)中的未初始化全局符号的定义(例如,int i;) |
**Table 3** The sections of a __IMPORT segment
| Segment and section name | Contents |
| ------------------------ | ------------------------------------------------------------ |
| __ IMPORT, __jump_table | Stubs for calls to functions in a dynamic library.<br>动态库中函数调用的存根。 |
| __ IMPORT, __pointers | Non-lazy symbol pointers, which are direct references to functions<br/>imported from a different file.<br>非懒加载符号指针,它们直接引用从其他文件导入的函数 |
> Note: Compilers or any tools that create Mach-O files are free to define additional section names. These additional names do not appear in Table
>
> 注意:编译器或任何创建mach-o文件的工具都可以自由定义附加的节名。这些附加名称不出现在表中
# Data Types
This reference describes the data types that compose a Mach-O file. Values for integer types in all Mach-O data structures are written using the host CPU’s byte ordering scheme, except for `fat_header` (page 56) and `fat_arch` (page 56), which are written in big-endian byte order.
此参考描述组成mach-o文件的数据类型。所有mach-o数据结构中的整数类型的值都是使用主机cpu的字节顺序方案编写的,除了`fat_header`(第56页)和`fat_arch`(第56页)之外,它们都是以大端字节顺序编写的。
## Header Data Structure
### mach_header
Specifies the general attributes of a file. Appears at the beginning of object files targeted to 32-bit architectures. Declared in /usr/include/mach-o/loader.h. See also mach_header_64 (page 14).
```c
/*
* The 32-bit mach header appears at the very beginning of the object file for
* 32-bit architectures.
*/
struct mach_header {
uint32_t magic; /* mach magic number identifier */
cpu_type_t cputype; /* cpu specifier */
cpu_subtype_t cpusubtype; /* machine specifier */
uint32_t filetype; /* type of file */
uint32_t ncmds; /* number of load commands */
uint32_t sizeofcmds; /* the size of all the load commands */
uint32_t flags; /* flags */
};
/* Constant for the magic field of the mach_header (32-bit architectures) */
#define MH_MAGIC 0xfeedface /* the mach magic number */
#define MH_CIGAM 0xcefaedfe /* NXSwapInt(MH_MAGIC) */
```
- **magic**
An integer containing a value identifying this file as a 32-bit Mach-O file. Use the constant MH_MAGIC if the file is intended for use on a CPU with the same endianness as the computer on which the compiler is running. The constant MH_CIGAM can be used when the byte ordering scheme of the target machine is the reverse of the host CPU.
一个整数将文件标识为32位Mach-O文件。如果文件要在与运行编译器的计算机具有相同端点的CPU上使用,请使用常量MH_MAGIC。当目标机器的字节排序方案与主机cpu相反时,可以使用常数MH_CIGAM。(大小端值不相同)
- **cputype**
An integer indicating the architecture you intend to use the file on. Appropriate values include:
一个整数,指示要在其上使用文件的体系结构。适当的值包括:
```c
#include <mach/machine.h>
/*
* Machine types known by all.
*/
#define CPU_TYPE_ANY ((cpu_type_t) -1)
#define CPU_TYPE_VAX ((cpu_type_t) 1)
/* skip ((cpu_type_t) 2) */
/* skip ((cpu_type_t) 3) */
/* skip ((cpu_type_t) 4) */
/* skip ((cpu_type_t) 5) */
#define CPU_TYPE_MC680x0 ((cpu_type_t) 6)
#define CPU_TYPE_X86 ((cpu_type_t) 7)
#define CPU_TYPE_I386 CPU_TYPE_X86 /* compatibility */
#define CPU_TYPE_X86_64 (CPU_TYPE_X86 | CPU_ARCH_ABI64)
/* skip CPU_TYPE_MIPS ((cpu_type_t) 8) */
/* skip ((cpu_type_t) 9) */
#define CPU_TYPE_MC98000 ((cpu_type_t) 10)
#define CPU_TYPE_HPPA ((cpu_type_t) 11)
#define CPU_TYPE_ARM ((cpu_type_t) 12)
#define CPU_TYPE_ARM64 (CPU_TYPE_ARM | CPU_ARCH_ABI64)
#define CPU_TYPE_MC88000 ((cpu_type_t) 13)
#define CPU_TYPE_SPARC ((cpu_type_t) 14)
#define CPU_TYPE_I860 ((cpu_type_t) 15)
/* skip CPU_TYPE_ALPHA ((cpu_type_t) 16) */
/* skip ((cpu_type_t) 17) */
#define CPU_TYPE_POWERPC ((cpu_type_t) 18)
#define CPU_TYPE_POWERPC64 (CPU_TYPE_POWERPC | CPU_ARCH_ABI64)
```
- **cpusubtype**
An integer specifying the exact model of the CPU. To run on all PowerPC or x86 processors supported by the Mac OS X kernel, this should be set to CPU_SUBTYPE_POWERPC_ALL or CPU_SUBTYPE_I386_ALL.
一个整数,指定CPU的确切型号。要在Mac OS X内核支持的所有PowerPC或x86处理器上运行,应将其设置为CPU_Subtype_PowerPC_All或CPU_Subtype_i386_All。
```c
#define CPU_SUBTYPE_ARM_ALL ((cpu_subtype_t) 0)
#define CPU_SUBTYPE_X86_ALL ((cpu_subtype_t)3)
```
- **filetype**
An integer indicating the usage and alignment of the file. Valid values for this field include:
```c
/*
* A core file is in MH_CORE format and can be any in an arbritray legal
* Mach-O file.
*
* Constants for the filetype field of the mach_header
*/
#define MH_OBJECT 0x1 /* relocatable object file */
#define MH_EXECUTE 0x2 /* demand paged executable file */
#define MH_FVMLIB 0x3 /* fixed VM shared library file */
#define MH_CORE 0x4 /* core file */
#define MH_PRELOAD 0x5 /* preloaded executable file */
#define MH_DYLIB 0x6 /* dynamically bound shared library */
#define MH_DYLINKER 0x7 /* dynamic link editor */
#define MH_BUNDLE 0x8 /* dynamically bound bundle file */
#define MH_DYLIB_STUB 0x9 /* shared library stub for static */
/* linking only, no section contents */
#define MH_DSYM 0xa /* companion file with only debug */
/* sections */
#define MH_KEXT_BUNDLE 0xb /* x86_64 kexts */
```
- The `MH_OBJECT` file type is the format used for intermediate object files. It is a very compact format containing all its sections in one segment. The compiler and assembler usually create one `MH_OBJECT` file for each source code file. By convention, the file name extension for this format is .o.
`MH_OBJECT`文件类型是用于中间对象文件的格式。它是一种非常紧凑的格式,将其所有部分都包含在一个段中。编译器和汇编程序通常为每个源代码文件创建一个`MH_OBJECT`文件。按照惯例,此格式的文件扩展名为.o。
- The `MH_EXECUTE` file type is the format used by standard executable programs.
`MH_EXECUTE` file type是标准可执行程序使用的格式。
- The `MH_BUNDLE` file type is the type typically used by code that you load at runtime (typically called bundles or plug-ins). By convention, the file name extension for this format is .bundle.
`MH_BUNDLE`文件类型是运行时加载的代码通常使用的类型(通常称为bundle或插件)。按照惯例,此格式的文件扩展名为.bundle。
- The `MH_DYLIB` file type is for dynamic shared libraries. It contains some additional tables to support multiple modules. By convention, the file name extension for this format is .dylib, except for the main shared library of a framework, which does not usually have a file name extension.
`MH_DYLIB`文件类型用于动态共享库。它包含一些额外的表来支持多个模块。按照惯例,此格式的文件扩展名为.dylib,但框架的主共享库除外,它通常没有文件扩展名。
- The `MH_PRELOAD` file type is an executable format used for special-purpose programs that are not loaded by the Mac OS X kernel, such as programs burned into programmable ROM chips. Do not confuse this file type with the `MH_PREBOUND` flag, which is a flag that the static linker sets in the header structure to mark a prebound image.
`MH_PRELOAD`文件类型是一种可执行格式,用于mac os x内核未加载的特殊用途程序,例如烧录到可编程ROM芯片中的程序。不要将此文件类型与`MH_PREBOUND`标志混淆,`MH_PREBOUND`标志是静态链接器在头结构中设置的用于标记预绑定图像的标志。
- The `MH_CORE` file type is used to store core files, which are traditionally created when a program crashes. Core files store the entire address space of a process at the time it crashed. You can later run gdb on the core file to figure out why the crash occurred.
`MH_CORE`文件类型用于存储核心文件,这些文件通常在程序崩溃时创建。核心文件存储进程崩溃时的整个地址空间。您可以稍后在核心文件上运行gdb来找出崩溃的原因。
- The `MH_DYLINKER` file type is the type of a dynamic linker shared library. This is the type of the dyld file.
`MH_DYLINKER`文件类型是动态链接器共享库的类型。这是dyld文件的类型。
- The `MH_DSYM` file type designates files that store symbol information for a corresponding binary file.
`MH_DSYM`文件类型指定存储相应二进制文件的符号信息的文件。
- **ncmds**
An integer indicating the number of load commands following the header structure.
指定架构load commands的个数
- **sizeofcmds**
An integer indicating the number of bytes occupied by the load commands following the header structure. 所有load commands的size
- **flags**
An integer containing a set of bit flags that indicate the state of certain optional features of the
Mach-O file format. These are the masks you can use to manipulate this field:
一个整数,包含一组位标志,指示mach-o文件格式某些可选功能的状态。以下是可用于操作此字段的掩码:
```c
/* Constants for the flags field of the mach_header */
#define MH_NOUNDEFS 0x1 /* the object file has no undefined
references */
#define MH_INCRLINK 0x2 /* the object file is the output of an
incremental link against a base file
and can't be link edited again */
#define MH_DYLDLINK 0x4 /* the object file is input for the
dynamic linker and can't be staticly
link edited again */
#define MH_BINDATLOAD 0x8 /* the object file's undefined
references are bound by the dynamic
linker when loaded. */
#define MH_PREBOUND 0x10 /* the file has its dynamic undefined
references prebound. */
#define MH_SPLIT_SEGS 0x20 /* the file has its read-only and
read-write segments split */
#define MH_LAZY_INIT 0x40 /* the shared library init routine is
to be run lazily via catching memory
faults to its writeable segments
(obsolete) */
#define MH_TWOLEVEL 0x80 /* the image is using two-level name
space bindings */
#define MH_FORCE_FLAT 0x100 /* the executable is forcing all images
to use flat name space bindings */
#define MH_NOMULTIDEFS 0x200 /* this umbrella guarantees no multiple
defintions of symbols in its
sub-images so the two-level namespace
hints can always be used. */
#define MH_NOFIXPREBINDING 0x400 /* do not have dyld notify the
prebinding agent about this
executable */
#define MH_PREBINDABLE 0x800 /* the binary is not prebound but can
have its prebinding redone. only used
when MH_PREBOUND is not set. */
#define MH_ALLMODSBOUND 0x1000 /* indicates that this binary binds to
all two-level namespace modules of
its dependent libraries. only used
when MH_PREBINDABLE and MH_TWOLEVEL
are both set. */
#define MH_SUBSECTIONS_VIA_SYMBOLS 0x2000/* safe to divide up the sections into
sub-sections via symbols for dead
code stripping */
#define MH_CANONICAL 0x4000 /* the binary has been canonicalized
via the unprebind operation */
#define MH_WEAK_DEFINES 0x8000 /* the final linked image contains
external weak symbols */
#define MH_BINDS_TO_WEAK 0x10000 /* the final linked image uses
weak symbols */
#define MH_ALLOW_STACK_EXECUTION 0x20000/* When this bit is set, all stacks
in the task will be given stack
execution privilege. Only used in
MH_EXECUTE filetypes. */
#define MH_ROOT_SAFE 0x40000 /* When this bit is set, the binary
declares it is safe for use in
processes with uid zero */
#define MH_SETUID_SAFE 0x80000 /* When this bit is set, the binary
declares it is safe for use in
processes when issetugid() is true */
#define MH_NO_REEXPORTED_DYLIBS 0x100000 /* When this bit is set on a dylib,
the static linker does not need to
examine dependent dylibs to see
if any are re-exported */
#define MH_PIE 0x200000 /* When this bit is set, the OS will
load the main executable at a
random address. Only used in
MH_EXECUTE filetypes. */
#define MH_DEAD_STRIPPABLE_DYLIB 0x400000 /* Only for use on dylibs. When
linking against a dylib that
has this bit set, the static linker
will automatically not create a
LC_LOAD_DYLIB load command to the
dylib if no symbols are being
referenced from the dylib. */
#define MH_HAS_TLV_DESCRIPTORS 0x800000 /* Contains a section of type
S_THREAD_LOCAL_VARIABLES */
#define MH_NO_HEAP_EXECUTION 0x1000000 /* When this bit is set, the OS will
run the main executable with
a non-executable heap even on
platforms (e.g. i386) that don't
require it. Only used in MH_EXECUTE
filetypes. */
#define MH_APP_EXTENSION_SAFE 0x02000000 /* The code was linked for use in an
application extension. */
#define MH_NLIST_OUTOFSYNC_WITH_DYLDINFO 0x04000000 /* The external symbols
listed in the nlist symbol table do
not include all the symbols listed in
the dyld info. */
#define MH_SIM_SUPPORT 0x08000000 /* Allow LC_MIN_VERSION_MACOS and
LC_BUILD_VERSION load commands with
the platforms macOS, macCatalyst,
iOSSimulator, tvOSSimulator and
watchOSSimulator. */
#define MH_DYLIB_IN_CACHE 0x80000000 /* Only for use on dylibs. When this bit
is set, the dylib is part of the dyld
shared cache, rather than loose in
the filesystem. */
```
- `MH_NOUNDEFS`—The object file contained no undefined references when it was built.
对象文件在生成时不包含未定义的引用
- `MH_INCRLINK` The object file is the output of an incremental link against a base file and
cannot be linked again
对象文件是对基本文件的增量链接的输出,并且无法再次链接
- `MH_DYLDLINK`
- The file is input for the dynamic linker and cannot be statically linked again.
该文件是动态链接器的输入,不能再次静态链接。
- `MH_TWOLEVEL`
- The image is using two-level namespace bindings
Image正在使用两级命名空间绑定
- `MH_BINDATLOAD `
- The dynamic linker should bind the undefined references when the file
is loaded.
动态链接器应该在文件加载时绑定未定义的引用
- `MH_PREBOUND `
- The file’s undefined references are prebound.
文件的未定义引用是预先绑定的。
- `MH_PREBINDABLE `
- This file is not prebound but can have its prebinding redone. Used only when MH_PREBEOUND is not set
- 此文件不是预绑定的,但可以重新进行预绑定。仅在未设置MH_PREBEOUND时使用
- `MH_NOFIXPREBINDING`
- The dynamic linker doesn’t notify the prebinding agent about this executable.
动态链接器不会将此可执行文件通知预绑定代理。
- `MH_ALLMODSBOUND`
- Indicates that this binary binds to all two-level namespace modules of its dependent libraries. Used only when MH_PREBINDABLE and MH_TWOLEVEL are set.
- 指示此二进制文件绑定到其依赖库的所有两级命名空间模块。仅当设置了MH_PREBINDABLE和MH_TWOLEVEL时使用。
- `MH_CANONICAL`
- This file has been canonicalized by unprebinding—clearing prebinding information from the file. See the redo_prebinding man page for details
- 此文件已通过取消绑定从文件中清除预绑定信息来规范化。有关详细信息,请参阅重做预绑定手册页
- `MH_SPLIT_SEGS`
- The file has its read-only and read-write segments split.
- 文件的只读段和读写段被拆分。
- `MH_FORCE_FLAT`
- The executable is forcing all images to use flat namespace bindings.
- 可执行文件正在强制所有映像使用平面命名空间绑定。
- `MH_SUBSECTIONS_VIA_SYMBOLS`
- The sections of the object file can be divided into individual blocks. These blocks are dead-stripped if they are not used by other code. See “Linking” in Xcode User Guide for details.
- 对象文件的各个部分可以划分为单独的块。如果其他代码不使用这些块,则它们将被完全剥离。有关详细信息,请参阅Xcode用户指南中的“链接”。
- `MH_NOMULTIDEFS`
- This umbrella guarantees there are no multiple definitions of symbols in its subimages. As a result, the two-level namespace hints can always be used.
- 这把伞保证了它的子图像中没有符号的多重定义。因此,始终可以使用两级命名空间提示。
- `MH_PIE`
- When this bit is set, the OS will load the main executable at a random address. Only used in `MH_EXECUTE` filetypes
- 随机地址分布,ASLR 用于MH_EXECUTE filetype
- **Special Considerations**
For all file types, except `MH_OBJECT`, segments must be aligned on page boundaries for the given CPU
architecture: 4096 bytes for PowerPC and x86 processors. This allows the kernel to page virtual memory
directly from the segment into the address space of the process. The header and load commands must
be aligned as part of the data of the first segment stored on disk (which would be the __TEXT segment,
in the file types described in filetype).
对于除MH_OBJECT以外的所有文件类型,对于给定的cpu体系结构,段必须在页面边界上对齐:对于powerpc和x86处理器,为4096字节。这允许内核将虚拟内存直接从段分页到进程的地址空间。`header`和`load commands`存储在磁盘上的第一个段的数据的一部分对齐(在filetype中描述的文件类型中,第一个段是__TEXT段)
## Load Command Data Structures
The load command structures are located directly after the header of the object file, and they specify
both the logical structure of the file and the layout of the file in virtual memory. Each load command
begins with fields that specify the command type and the size of the command data.
加载命令结构直接位于对象文件头的后面,它们指定文件的逻辑结构和虚拟内存中文件的布局。每个加载命令都以指定命令类型和命令数据大小的字段开头。
### load_command
Contains fields that are common to all load commands.
包含所有加载命令通用的字段。
```c
struct load_command {
uint32_t cmd; /* type of load command */
uint32_t cmdsize; /* total size of command in bytes */
};
```
**Fields**
- `cmd`
An integer indicating the type of load command. Table 4 lists the valid load command types.
- `cmdsize`
An integer specifying the total size in bytes of the load command data structure. Each load
command structure contains a different set of data, depending on the load command type, so
each might have a different size. In 32-bit architectures, the size must always be a multiple of
4; in 64-bit architectures, the size must always be a multiple of 8. If the load command data
does not divide evenly by 4 or 8 (depending on whether the target architecture is 32-bit or
64-bit, respectively), add bytes containing zeros to the end until it does.
一个整数,指定加载命令数据结构的总大小(字节)。每个加载命令结构都包含不同的数据集,具体取决于加载命令类型,因此每个数据集的大小可能不同。在32位体系结构中,大小必须始终是4的倍数;在64位体系结构中,大小必须始终是8的倍数。如果加载命令数据没有被4或8等分(分别取决于目标体系结构是32位还是64位),请在末尾添加包含零的字节,直到它等分为止。
**Discussion**
Table 4 lists the valid load command types, with links to the full data structures for each type.
表4列出了有效的加载命令类型,每种类型都有指向完整数据结构的链接。
**Table 4** Mach-O load commands
| Commands | Data Structures | Purpose |
| ----------------------- | ---------------------- | ------------------------------------------------------------ |
| LC_UUID | uuid_command | Specifies the 128-bit UUID for an image <br>or its corresponding dSYM file.<br>为image或其相应的dSYM文件指定128位uuid |
| LC_SEGMENT | segment_command | Defines a segment of this file to be<br/>mapped into the address space of the<br/>process that loads this file. It also includes<br/>all the sections contained by the segment.<br>定义要映射到加载此文件的进程的地址空间中的此文件段。它还包括该段所包含的所有部分。 |
| LC_SEGMENT_64 | segment_command_64 | Defines a 64-bit segment of this file to be<br/>mapped into the address space of the<br/>process that loads this file. It also includes<br/>all the sections contained by the segment. |
| LC_SYMTAB | symtab_command | Specifies the symbol table for this file.<br/>This information is used by both static<br/>and dynamic linkers when linking the<br/>file, and also by debuggers to map<br/>symbols to the original source code files<br/>from which the symbols were generated.<br>指定此文件的符号表。静态和动态链接器在链接文件时都会使用此信息,调试器也会使用此信息将符号映射到生成符号的原始源代码文件。 |
| LC_DYSYMTAB | dysymtab_command | Specifies additional symbol table<br/>information used by the dynamic linker.<br>指定动态链接器使用的其他符号表信息。 |
| LC_THREAD LC_UNIXTHREAD | thread_command | For an executable file, the LC_UNIXTHREAD<br/>command defines the initial thread state<br/>of the main thread of the process.<br/>LC_THREAD is similar to LC_UNIXTHREAD<br/>but does not cause the kernel to allocate<br/>a stack.<br>对于可执行文件,LC_UNIXTHREAD命令定义进程主线程的初始线程状态。LC_THREAD类似于LC_UNIXTHREAD,但不会导致内核分配堆栈。 |
| LC_LOAD_DYLIB | dylib_command | Defines the name of a dynamic shared<br/>library that this file links against.<br>定义此文件链接所针对的动态共享库的名称。 |
| LC_ID_DYLIB | dylib_command | Specifies the install name of a dynamic<br/>shared library.<br>指定动态共享库的安装名称。 |
| LC_PREBOUND_DYLIB | prebound_dylib_command | For a shared library that this executable<br/>is linked prebound against, specifies the<br/>modules in the shared library that are<br/>used.<br>对于此可执行文件链接到的共享库,请指定共享库中使用的模块。 |
| LC_LOAD_DYLINKER | dylinker_command | Specifies the dynamic linker that the<br/>kernel executes to load this file.<br>指定内核执行以加载此文件的动态链接器。 |
| LC_ID_DYLINKER | dylinker_command | Identifies this file as a dynamic linker.<br>将此文件标识为动态链接器。 |
| LC_ROUTINES | routines_command | Contains the address of the shared library<br/>initialization routine (specified by the<br/>linker’s -init option).<br>包含共享库初始化例程的地址(由链接器的-init选项指定)。 |
| LC_ROUTINES_64 | routines_command_64 | Contains the address of the shared library<br/>64-bit initialization routine (specified by<br/>the linker’s -init option). |
| LC_TWOLEVEL_HINTS | twolevel_hints_command | Contains the two-level namespace lookup<br/>hint table.<br>包含两级命名空间查找提示表。 |
| LC_SUB_FRAMEWORK | sub_framework_command | Identifies this file as the implementation<br/>of a subframework of an umbrella<br/>framework. The name of the umbrella<br/>framework is stored in the string<br/>parameter.<br>将此文件标识为伞形框架的子框架的实现。伞形框架的名称存储在字符串参数中。 |
| LC_SUB_UMBRELLA | sub_umbrella_command | Specifies a file that is a subumbrella of<br/>this umbrella framework.<br>指定作为此伞形框架的子伞形结构的文件。 |
| LC_SUB_LIBRARY | sub_library_command | Identifies this file as the implementation<br/>of a sublibrary of an umbrella framework.<br/>The name of the umbrella framework is<br/>stored in the string parameter. Note that<br/>Apple has not defined a supported<br/>location for sublibraries.<br>将此文件标识为伞形框架的子库的实现。伞形框架的名称存储在字符串参数中。请注意,Apple尚未为子库定义支持的位置。 |
| LC_SUB_CLIENT | sub_client_command | A subframework can explicitly allow<br/>another framework or bundle to link<br/>against it by including an LC_SUB_CLIENT<br/>load command containing the name of<br/>the framework or a client name for a<br/>bundle.<br>子框架可以通过包含lc_sub_client load命令显式地允许另一个框架或捆绑包与之链接,该命令包含框架的名称或捆绑包的客户端名称。 |
- **uuid_command**
Specifies the 128-bit universally unique identifier (UUID) for an image or for its corresponding dSYM file.
为image或其相应的dSYM文件指定128位uuid
```c
/*
* The uuid load command contains a single 128-bit unique random number that
* identifies an object produced by the static link editor.
*/
struct uuid_command {
uint32_t cmd; /* LC_UUID */
uint32_t cmdsize; /* sizeof(struct uuid_command) */
uint8_t uuid[16]; /* the 128-bit uuid */
};
```
**Fields**
- `cmd`
Set to LC_UUID for this structure.
- `cmdsize`
Set to sizeof(uuid_command).
- `uuid `
128-bit unique identifier
**Declared In**
/usr/include/mach-o/loader.h
- **segment_command**
Specifies the range of bytes in a 32-bit Mach-O file that make up a segment. Those bytes are mapped by the loader into the address space of a program. Declared in /usr/include/mach-o/loader.h.
指定组成段的32位mach-o文件中的字节范围。这些字节由加载程序映射到程序的地址空间中
```c
struct segment_command { /* for 32-bit architectures */
uint32_t cmd; /* LC_SEGMENT */
uint32_t cmdsize; /* includes sizeof section structs */
char segname[16]; /* segment name */
uint32_t vmaddr; /* memory address of this segment */
uint32_t vmsize; /* memory size of this segment */
uint32_t fileoff; /* file offset of this segment */
uint32_t filesize; /* amount to map from the file */
vm_prot_t maxprot; /* maximum VM protection */
vm_prot_t initprot; /* initial VM protection */
uint32_t nsects; /* number of sections in segment */
uint32_t flags; /* flags */
};
/*
* The 64-bit segment load command indicates that a part of this file is to be
* mapped into a 64-bit task's address space. If the 64-bit segment has
* sections then section_64 structures directly follow the 64-bit segment
* command and their size is reflected in cmdsize.
*/
struct segment_command_64 { /* for 64-bit architectures */
uint32_t cmd; /* LC_SEGMENT_64 */
uint32_t cmdsize; /* includes sizeof section_64 structs */
char segname[16]; /* segment name */
uint64_t vmaddr; /* memory address of this segment */
uint64_t vmsize; /* memory size of this segment */
uint64_t fileoff; /* file offset of this segment */
uint64_t filesize; /* amount to map from the file */
vm_prot_t maxprot; /* maximum VM protection */
vm_prot_t initprot; /* initial VM protection */
uint32_t nsects; /* number of sections in segment */
uint32_t flags; /* flags */
};
```
**Fields**
- `cmd`
Common to all load command structures. Set to LC_SEGMENT for this structure.
- `cmdsize`
Common to all load command structures. For this structure, set this field to
sizeof(segment_command) plus the size of all the section data structures that follow
(sizeof(segment_command + (sizeof(section) * segment->nsect))).
- `segname`
A C string specifying the name of the segment. The value of this field can be any sequence of
ASCII characters, although segment names defined by Apple begin with two underscores and
consist of capital letters (as in ___TEXT and ___DATA). This field is fixed at 16 bytes in length.
指定段名称的C字符串。此字段的值可以是任意一个ASCII字符序列,尽管Apple定义的段名称以两个下划线开头,并由大写字母组成(如在“_______TEXT”和"_____DATA"中)。此字段的长度固定为16字节。
- `vmaddr`
Indicates the starting virtual memory address of this segment.
指示此段的起始虚拟内存地址。
- `vmsize`
Indicates the number of bytes of virtual memory occupied by this segment. See also the
description of filesize, below.
指示此段占用的虚拟内存字节数。另请参见下面的文件大小说明。
- `fileoff`
Indicates the offset in this file of the data to be mapped at vmaddr.
指示此文件中要在vmaddr映射的数据的偏移量。
- `filesize`
Indicates the number of bytes occupied by this segment on disk. For segments that require
more memory at runtime than they do at build time, vmsize can be larger than filesize. For
example, the __ PAGEZERO segment generated by the linker for MH_EXECUTABLE files has a
vmsize of 0x1000 but a filesize of 0. Because _ PAGEZERO contains no data, there is no need
for it to occupy any space until runtime. Also, the static linker often allocates uninitialized data
at the end of the __DATA segment; in this case, the vmsize is larger than the filesize. The
loader guarantees that any memory of this sort is initialized with zeros.
指示磁盘上此段占用的字节数。对于运行时比构建时需要更多内存的段,vmsize可以大于filesize。例如,链接器为MH_EXECUTABLE文件生成的u pagezero段的vmsize为0x1000,而filesize为0。因为pagezero不包含任何数据,所以在运行之前不需要占用任何空间。此外,静态链接器通常在数据段末尾分配未初始化的数据;在这种情况下,vmsize大于filesize。加载程序保证这类内存都是用零初始化的。
- `maxprot`
Specifies the maximum permitted virtual memory protections of this segment.
指定此段允许的最大虚拟内存保护。
- `initprot`
Specifies the initial virtual memory protections of this segment.
指定此段的初始虚拟内存保护。
- `nsects`
Indicates the number of section data structures following this load command.
指示此load commands命令下的section数量
- `flags`
Defines a set of flags that affect the loading of this segment:
- SG_HIGHVM—The file contents for this segment are for the high part of the virtual memory space; the low part is zero filled (for stacks in core files).
- SG_NORELOC—This segment has nothing that was relocated in it and nothing relocated to it. It may be safely replaced without relocation.
- 定义一组影响此段加载的标志:
SG_HIGHVM—此段的文件内容用于虚拟内存空间的高部分;低部分为零填充(用于核心文件中的堆栈)。
SG_NORELOC-该段没有重新安置的任何东西,也没有重新安置的任何东西。可安全更换,无需重新安置。
- **section**
Defines the elements used by a 32-bit section. Directly following a segment_command data structure
is an array of section data structures, with the exact count determined by the nsects field of the
segment_command (page 20) structure. Declared in /usr/include/mach-o/loader.h.
定义32位节使用的元素。段命令数据结构的正后方是一个段数据结构数组,其精确计数由段命令(第20页)结构的nsects字段确定。在/usr/include/mach-o/loader.h中声明。
```c
struct section { /* for 32-bit architectures */
char sectname[16]; /* name of this section */
char segname[16]; /* segment this section goes in */
uint32_t addr; /* memory address of this section */
uint32_t size; /* size in bytes of this section */
uint32_t offset; /* file offset of this section */
uint32_t align; /* section alignment (power of 2) */
uint32_t reloff; /* file offset of relocation entries */
uint32_t nreloc; /* number of relocation entries */
uint32_t flags; /* flags (section type and attributes)*/
uint32_t reserved1; /* reserved (for offset or index) */
uint32_t reserved2; /* reserved (for count or sizeof) */
};
struct section_64 { /* for 64-bit architectures */
char sectname[16]; /* name of this section */
char segname[16]; /* segment this section goes in */
uint64_t addr; /* memory address of this section */
uint64_t size; /* size in bytes of this section */
uint32_t offset; /* file offset of this section */
uint32_t align; /* section alignment (power of 2) */
uint32_t reloff; /* file offset of relocation entries */
uint32_t nreloc; /* number of relocation entries */
uint32_t flags; /* flags (section type and attributes)*/
uint32_t reserved1; /* reserved (for offset or index) */
uint32_t reserved2; /* reserved (for count or sizeof) */
uint32_t reserved3; /* reserved */
};
```
**Fields**
- `sectname`
A string specifying the name of this section. The value of this field can be any sequence of
ASCII characters, although section names defined by Apple begin with two underscores and
consist of lowercase letters (as in __text and __data). This field is fixed at 16 bytes in length.
指定此节名称的字符串。此字段的值可以是任意一个ASCII字符序列,尽管Apple定义的节名称以两个下划线开头,并且由小写字母组成(如文本和数据)。此字段的长度固定为16字节。
- `segname`
A string specifying the name of the segment that should eventually contain this section. For
compactness, intermediate object files—files of type MH_OBJECT—contain only one segment,
in which all sections are placed. The static linker places each section in the named segment
when building the final product (any file that is not of type MH_OBJECT).
指定最终应包含此节的段的名称的字符串。对于紧凑性,MH_OBJECT类型的中间对象文件只包含一个段,其中放置了所有的段。静态链接器在生成最终产品(任何不属于MH_OBJECT类型的文件)时将每个部分放置在命名段中。
- `addr`
An integer specifying the virtual memory address of this section.
指定此节的虚拟内存地址的整数。
- `size`
An integer specifying the size in bytes of the virtual memory occupied by this section.
一个整数,指定此节占用的虚拟内存的字节大小。
- `offset`
An integer specifying the offset to this section in the file.
一个整数,指定文件中此节的偏移量。
- `align`
An integer specifying the section’s byte alignment. Specify this as a power of two; for example,
a section with 8-byte alignment would have an align value of 3 (2 to the 3rd power equals 8).
指定节字节对齐方式的整数。将其指定为2的幂;例如,具有8字节对齐的节的对齐值为3(2到3的幂等于8)。
- `reloff`
An integer specifying the file offset of the first relocation entry for this section.
一个整数,指定此节的第一个重定位项的文件偏移量。
- `nreloc`
An integer specifying the number of relocation entries located at reloff for this section.
一个整数,指定位于此节的reloff处的重定位条目数。
- `flags`
An integer divided into two parts. The least significant 8 bits contain the section type, while
the most significant 24 bits contain a set of flags that specify other attributes of the section.
These types and flags are primarily used by the static linker and file analysis tools, such as
otool, to determine how to modify or display the section. These are the possible types:
分成两部分的整数。最低有效8位包含节类型,而最高有效24位包含指定节的其他属性的标志集。这些类型和标志主要由静态链接器和文件分析工具(如otool)使用,以确定如何修改或显示节。以下是可能的类型:
- `S_REGULAR`
This section has no particular type. The standard tools create a __TEXT,__text section of this type.
此节没有特定类型。标准工具会创建此类型的文本节。
- `S_ZEROFILL`
Zero-fill-on-demand section—when this section is first read from or written to, each page within is automatically filled with bytes containing zero.
零按需填充节第一次读取或写入此节时,其中的每一页都会自动填充包含零的字节。
- `S_CSTRING_LITERALS`
This section contains only constant C strings. The standard tools create a __TEXT,__cstring section of this type.
这个section仅包含C常量字符串。标准工具在此type下创建了__TEXT, __string
- `S_4BYTE_LITERALS`
This section contains only constant values that are 4 bytes long. The standard tools create a __TEXT,__literal4 section of this type.
- `S_8BYTE_LITERALS `
This section contains only constant values that are 8 bytes long. The standard tools create a __TEXT,__literal8 section of this type.
- `S_LITERAL_POINTERS `
This section contains only pointers to constant values.
本节仅包含指向常量值的指针。
- `S_NON_LAZY_SYMBOL_POINTERS`
This section contains only non-lazy pointers to symbols.
The standard tools create a section of the __DATA,__nl_symbol_ptrs section of this type.
此部分仅包含指向符号的非懒加载指针。
- `S_LAZY_SYMBOL_POINTERS`
This section contains only lazy pointers to symbols. The
standard tools create a __DATA,__la_symbol_ptrs section of this type.
此部分仅包含指向符号的懒加载指针。
- `S_SYMBOL_STUBS`
This section contains symbol stubs. The standard tools create __TEXT,__symbol_stub and __TEXT,__picsymbol_stub sections of this type. See “Dynamic Code Generation” in *Mach-O Programming Topics* for more information.
本节包含符号存根
- `S_MOD_INIT_FUNC_POINTERS`
This section contains pointers to module initialization functions. The standard tools create __DATA,__mod_init_func sections of this type.
包含模块初始化方法的指针
- `S_MOD_TERM_FUNC_POINTERS `
This section contains pointers to module termination functions. The standard tools create __DATA,__mod_term_func sections of this type.
包含模块结束方法的指针
- `S_COALESCED`
This section contains symbols that are coalesced by the static linker and possibly the dynamic linker. More than one file may contain coalesced definitions of the same symbol without causing multiple-defined-symbol errors.
此部分包含由静态链接器(可能还有动态链接器)合并的符号。多个文件可能包含同一符号的合并定义,但不会导致多个定义的符号错误。
- `S_GB_ZEROFILL `
This is a zero-filled on-demand section. It can be larger than 4 GB. This section must be placed in a segment containing only zero-filled sections. If you place a zero-filled section in a segment with non–zero-filled sections, you may cause those sections to be unreachable with a 31-bit offset. That outcome stems from the fact that the size of a zero-filled section can be larger than 4 GB (in a 32-bit address space). As a result of this, the static linker would be unable to build the output file. See segment_command (page 20) for more information.
这是一个零填充的按需部分。它可以大于4 GB。此节必须放在只包含零填充节的段中。如果将零填充部分放在具有非零填充部分的段中,则可能会导致以31位偏移量无法访问这些部分。这一结果源于这样一个事实:零填充部分的大小可以大于4GB(在32位地址空间中)。因此,静态链接器将无法生成输出文件。有关更多信息,请参阅StEngSub命令(第20页)。
The following are the possible attributes of a section:
- `S_ATTR_PURE_INSTRUCTIONS`
This section contains only executable machine instructions. The standard tools set this flag for the sections __TEXT,__text, __TEXT,__symbol_stub, and __TEXT,__picsymbol_stub.
本节仅包含可执行的机器指令。
- `S_ATTR_SOME_INSTRUCTIONS `
This section contains executable machine instructions.
- `S_ATTR_NO_TOC`
This section contains coalesced symbols that must not be placed in the
table of contents (SYMDEF member) of a static archive library.
- `S_ATTR_EXT_RELOC`
This section contains references that must be relocated. These references refer to data that exists in other files (undefined symbols). To support external relocation, the maximum virtual memory protections of the segment that contains this section must allow both reading and writing.
本节包含必须重新定位的引用。这些引用引用其他文件中存在的数据(未定义的符号)。为了支持外部重定位,包含此节的段的最大虚拟内存保护必须允许读写。
- `S_ATTR_LOC_RELOC`
This section contains references that must be relocated. These references refer to data within this file.
本节包含必须重新定位的引用。这些引用引用此文件中的数据。
- `S_ATTR_STRIP_STATIC_SYMS `
The static symbols in this section can be stripped if the MH_DYLDLINK flag of the image’s mach_header (page 12) header structure is set.
- `S_ATTR_NO_DEAD_STRIP `
This section must not be dead-stripped. See “Linking” in *Xcode User Guide* for details.
- `S_ATTR_LIVE_SUPPORT `
This section must not be dead-stripped if they reference code that is live, but the reference is undetectable.
- `reserved1`
An integer reserved for use with certain section types. For symbol pointer sections and symbol stubs sections that refer to indirect symbol table entries, this is the index into the indirect table for this section’s entries. The number of entries is based on the section size divided by the size of the symbol pointer or stub. Otherwise, this field is set to 0.
保留用于某些节类型的整数。对于引用间接符号表项的符号指针节和符号存根节,这是指向该节项的间接表的索引。条目的数目基于节大小除以符号指针或存根的大小。否则,此字段设置为0。
- `reserved2`
For sections of type S_SYMBOL_STUBS, an integer specifying the size (in bytes) of the symbol
stub entries contained in the section. Otherwise, this field is reserved for future use and should be set to 0.
对于S_SYMBOL_STUBS类型的section,使用整数指定符号的大小(以字节为单位)
section中包含的stub条目。否则,此字段将保留以供将来使用,并应设置为0。
**Discussion**
Each section in a Mach-O file has both a type and a set of attribute flags. In intermediate object files, the type and attributes determine how the static linker copies the sections into the final product. Object file analysis tools (such as otool) use the type and attributes to determine how to read and display the sections. Some section types and attributes are used by the dynamic linker.
These are important static-linking variants of the symbol type and attributes:
mach-o文件中的每个部分都有一个类型和一组属性标志。在中间对象文件中,类型和属性决定静态链接器如何将节复制到最终产品中。对象文件分析工具(如otool)使用类型和属性来确定如何读取和显示节。动态链接器使用某些节类型和属性。
这些是符号类型和属性的重要静态链接变体:
- **Regular sections**. In a regular section, only one definition of an external symbol may exist in intermediate object files. The static linker returns an error if it finds any duplicate external symbol definitions.
在常规部分中,中间对象文件中只能存在外部符号的一个定义。如果发现任何重复的外部符号定义,静态链接器将返回错误。
- **Coalesced sections**. In the final product, the static linker retains only one instance of each symbol defined in coalesced sections. To support complex language features (such as C++ vtables and RTTI) the compiler may create a definition of a particular symbol in every intermediate object file. The static linker and the dynamic linker would then reduce the duplicate definitions to the single definition used by the program.
在最终产品中,静态链接器只保留合并部分中定义的每个符号的一个实例。为了支持复杂的语言特性(如C++ VTABLE和RTTI),编译器可以在每个中间对象文件中创建一个特定符号的定义。静态链接器和动态链接器将把重复的定义减少到程序使用的单个定义。
- **Coalesced sections with weak definitions** Weak symbol definitions may appear only in coalesced sections. When the static linker finds duplicate definitions for a symbol, it discards any coalesced symbol definition that has the weak definition attribute set (see nlist (page 39)). If there are no non-weak definitions, the first weak definition is used instead. This feature is designed to support C++ templates; it allows explicit template instantiations to override implicit ones. The C++ compiler places explicit definitions in a regular section, and it places implicit definitions in a coalesced section, marked as weak definitions. Intermediate object files (and thus static archive libraries) built with weak definitions can be used only with the static linker in Mac OS X v10.2 and later. Final products (applications and shared libraries) should not contain weak definitions if they are expected to be used on earlier versions of Mac OS X.
弱符号定义只能出现在合并部分中。当静态链接器发现符号的重复定义时,它将丢弃任何具有弱定义属性集的合并符号定义(请参阅nlist(第39页))。如果没有非弱定义,则使用第一个弱定义。该特性被设计为支持C++模板;它允许显式模板实例化来重写隐式模板。C++编译器将显式定义放在一个常规的部分中,它将隐含的定义放在一个合并的区段中,标记为弱定义。使用弱定义构建的中间对象文件(以及静态存档库)只能与Mac OS X v10.2及更高版本中的静态链接器一起使用。如果最终产品(应用程序和共享库)预期在早期版本的MacOSX上使用,则不应包含弱定义。
- **twolevel_hints_command**
Defines the attributes of a LC_TWOLEVEL_HINTS load command
```c
/*
* The twolevel_hints_command contains the offset and number of hints in the
* two-level namespace lookup hints table.
*/
struct twolevel_hints_command {
uint32_t cmd; /* LC_TWOLEVEL_HINTS */
uint32_t cmdsize; /* sizeof(struct twolevel_hints_command) */
uint32_t offset; /* offset to the hint table */
uint32_t nhints; /* number of hints in the hint table */
};
```
**Fields**
- `cmd`
Common to all load command structures. Set to LC_TWOLEVEL_HINTS for this structure.
- `cmdsize`
Common to all load command structures. For this structure, set to
sizeof(twolevel_hints_command).
- `offset`
An integer specifying the byte offset from the start of this file to an array of
twolevel_hint (page 30) data structures, known as the two-level namespace hint table.
在文件内的offset
- `nhints`
The number of twolevel_hint data structures located at offset.
位于偏移量的二级提示数据结构的数目。
**Discussion**
The static linker adds the LC_TWOLEVEL_HINTS load command and the two-level namespace hint table to the output file when building a two-level namespace image.
讨论
静态链接器在生成两级命名空间映像时将lc_twowlevel_hints load命令和两级命名空间提示表添加到输出文件中。
**Special Considerations**
By default, ld does not include the LC_TWOLEVEL_HINTS command or the two-level namespace hint table in an MH_BUNDLE file because the presence of this load command causes the version of the dynamic linker shipped with Mac OS X v10.0 to crash. If you know the code will run only on Mac OS X v10.1 and later, you should explicitly enable the two-level namespace hint table. See -twolevel_namespace_hints in the ld man page for more information.
特殊注意事项
默认情况下,ld不会在MH_BUNDLE文件中包含lc_twolevel_hint命令或两级名称空间提示表,因为这个load命令的存在会导致Mac OS X v10.0附带的动态链接器版本崩溃。如果您知道代码只在Mac OS X v10.1及更高版本上运行,那么应该显式启用两级名称空间提示表。有关更多信息,请参见ld手册页中的- twolevel_namespace_tips。
- **twolevel_hint**
Specifies an entry in the two-level namespace hint table. Declared in /usr/include/mach-o/loader.h.
```c
struct twolevel_hint {
uint32_t
isub_image:8, /* index into the sub images */
itoc:24; /* index into the table of contents */
};
```
**Fields**
- `isub_image`
The subimage in which the symbol is defined. It is an index into the list of images that make
up the umbrella image. If this field is 0, the symbol is in the umbrella image itself. If the image is not an umbrella framework or library, this field is 0.
定义符号的subimage。它是组成雨伞图像的图像列表的索引。如果此字段为0,则符号在伞图像本身中。如果图像不是伞形框架或库,则此字段为0。
- `itoc`
The symbol index into the table of contents of the image specified by the isub_image field.
由isub_image字段指定的图像目录中的符号索引。
**Discussion**
The two-level namespace hint table provides the dynamic linker with suggested positions to start searching for symbols in the libraries the current image is linked against.
Every undefined symbol (that is, every symbol of type N_UNDF or N_PBUD) in a two-level namespace image has a corresponding entry in the two-level hint table, at the same index.
The static linker adds the LC_TWOLEVEL_HINTS load command and the two-level namespace hint table to the output file when building a two-level namespace image.
By default, the linker does not include the LC_TWOLEVEL_HINTS command or the two-level namespace hint table in an MH_BUNDLE file, because the presence of this load command causes the version of the dynamic linker shipped with Mac OS X v10.0 to crash. If you know the code will run only on Mac OS X v10.1 and later, you should explicitly enable the two-level namespace hints. See the linker documentation for more information.
两级命名空间提示表为动态链接器提供建议的位置,以便开始在当前图像所链接的库中搜索符号。
两级命名空间映像中的每个未定义符号(即,类型为n_undf或n_pbud的每个符号)在两级提示表中的同一索引处都有相应的项。
静态链接器在生成两级命名空间映像时将lc_twowlevel_hints load命令和两级命名空间提示表添加到输出文件中。
默认情况下,链接器不包括mh_捆绑包文件中的lc_two level_hints命令或两级命名空间提示表,因为此加载命令的存在会导致mac os x v10.0附带的动态链接器版本崩溃。如果您知道代码将只在macosxv10.1及更高版本上运行,那么应该显式地启用两级命名空间提示。有关详细信息,请参阅链接器文档。
- **lc_str**
Defines a variable-length string. Declared in /usr/include/mach-o/loader.h.
```c
union lc_str {
uint32_t offset; /* offset to the string */
#ifndef __LP64__
char *ptr; /* pointer to the string */
#endif
};
```
**Fields**
- `offset`
A long integer. A byte offset from the start of the load command that contains this string to
the start of the string data.
一个长整数。从包含此字符串的加载命令开始到字符串数据开始的字节偏移量。
- `ptr`
A pointer to an array of bytes. At runtime, this pointer contains the virtual memory address
of the string data. The ptr field is not used in Mach-O files.
指向字节数组的指针。在运行时,此指针包含字符串数据的虚拟内存地址。在mach-o文件中不使用ptr字段。
**Discussion**
Load commands store variable-length data such as library names using the lc_str data structure. Unless otherwise specified, the data consists of a C string.
The data pointed to is stored just after the load command, and the size is added to the size of the load command. The string should be null terminated; any extra bytes to round up the size should be null. You can also determine the size of the string by subtracting the size of the load command data structure from the cmdsize field of the load command data structure.
`Load Commands`使用`lc_str`数据结构存储可变长度的数据,例如库名称。除非另有说明,否则数据由C字符串组成。
指向的数据存储在`load command`之后,大小将添加到`load command`的大小中。字符串应以空结尾;要舍入大小的任何额外字节都应为空。还可以通过从加载命令数据结构的cmdSize字段中减去加载命令数据结构的大小来确定字符串的大小。
- **dylib**
Defines the data used by the dynamic linker to match a shared library against the files that have linked to it. Used exclusively in the dylib_command (page 32) data structure. Declared in
/usr/include/mach-o/loader.h.
定义动态链接器用于将共享库与链接到该库的文件匹配的数据
```c
/*
* Dynamicly linked shared libraries are identified by two things. The
* pathname (the name of the library as found for execution), and the
* compatibility version number. The pathname must match and the compatibility
* number in the user of the library must be greater than or equal to the
* library being used. The time stamp is used to record the time a library was
* built and copied into user so it can be use to determined if the library used
* at runtime is exactly the same as used to built the program.
*/
struct dylib {
union lc_str name; /* library's path name */
uint32_t timestamp; /* library's build time stamp */
uint32_t current_version; /* library's current version number */
uint32_t compatibility_version; /* library's compatibility vers number*/
};
```
**Fields**
- `name`
A data structure of type lc_str (page 31). Specifies the name of the shared library.
指定共享库的名称 是一个lc_str的结构类型
- `timestamp`
The date and time when the shared library was built.
创建共享库的日期和时间。
- `current_version`
The current version of the shared library.
共享库的当前版本
- `compatibility_version`
The compatibility version of the shared library.
共享库的兼容版本
- **dylib_command**
Defines the attributes of the `LC_LOAD_DYLIB` and `LC_ID_DYLIB` load commands. Declared in
/usr/include/mach-o/loader.h.
```c
/*
* A dynamically linked shared library (filetype == MH_DYLIB in the mach header)
* contains a dylib_command (cmd == LC_ID_DYLIB) to identify the library.
* An object that uses a dynamically linked shared library also contains a
* dylib_command (cmd == LC_LOAD_DYLIB, LC_LOAD_WEAK_DYLIB, or
* LC_REEXPORT_DYLIB) for each library it uses.
*/
struct dylib_command {
uint32_t cmd; /* LC_ID_DYLIB, LC_LOAD_{,WEAK_}DYLIB,
LC_REEXPORT_DYLIB */
uint32_t cmdsize; /* includes pathname string */
struct dylib dylib; /* the library identification */
};
```
**Fields**
- `cmd`
Common to all load command structures. For this structure, set to either` LC_LOAD_DYLIB`,
`LC_LOAD_WEAK_DYLIB`, or `LC_ID_DYLIB`.
- `cmdsize`
Common to all load command structures. For this structure, set to sizeof(dylib_command)
plus the size of the data pointed to by the name field of the dylib field.
- `dylib`
A data structure of type dylib (page 31). Specifies the attributes of the shared library.
dylib类型的数据结构。指定共享库的属性。
**Discussion**
For each shared library that a file links against, the static linker creates an LC_LOAD_DYLIB command and sets its dylib field to the value of the dylib field of the LC_ID_DYLD load command of the target library. All the LC_LOAD_DYLIB commands together form a list that is ordered according to location in the file, earliest LC_LOAD_DYLIB command first. For two-level namespace files, undefined symbol entries in the symbol table refer to their parent shared libraries by index into this list. The index is called a *library ordinal*, and it is stored in the n_desc field of the nlist (page 39) data structure.
对于文件链接所针对的每个共享库,静态链接器创建一个LC_LOAD_DYLIB命令,并将其dylib字段设置为目标库的LC_ID_DYLD load commands的dylib字段的值。所有LC_LOAD_DYLIB命令一起形成一个列表,该列表根据文件中的位置进行排序,首先是最早的LC_LOAD_DYLIB命令。对于两级命名空间文件,符号表中未定义的符号项通过索引指向该列表中的父共享库。索引称为库序号,它存储在nlist数据结构的n_desc字段中。
At runtime, the dynamic linker uses the name in the dyld field of the LC_LOAD_DYLIB command to locate the shared library. If it finds the library, the dynamic linker compares the version information of the LC_LOAD_DYLIB load command against the library’s version. For the dynamic linker to successfully link the shared library, the compatibility version of the shared library must be less than or equal to the compatibility version in the LC_LOAD_DYLIB command.
在运行时,动态链接器使用LC_LOAD_DYLIB命令的dyld字段中的名称来定位共享库。如果找到库,动态链接器将LC_LOAD_DYLIB `load commands`的版本信息与库的版本进行比较。要使动态链接器成功链接共享库,共享库的兼容版本必须小于或等于LC_LOAD_DYLIB命令中的兼容版本。
The dynamic linker uses the timestamp to determine whether it can use the prebinding information.
The current version is returned by the function NSVersionOfRunTimeLibrary to allow you to determine the version of the library your program is using.
动态链接器使用时间戳来确定是否可以使用预绑定信息。函数NSVersionOfRunTimeLibrary返回当前版本,允许您确定程序正在使用的库的版本。
- **dylinker_command**
Defines the attributes of the `LC_LOAD_DYLINKER` and `LC_ID_DYLINKER` load commands. Declared in
/usr/include/mach-o/loader.h.
```c
/*
* A program that uses a dynamic linker contains a dylinker_command to identify
* the name of the dynamic linker (LC_LOAD_DYLINKER). And a dynamic linker
* contains a dylinker_command to identify the dynamic linker (LC_ID_DYLINKER).
* A file can have at most one of these.
* This struct is also used for the LC_DYLD_ENVIRONMENT load command and
* contains string for dyld to treat like environment variable.
*/
struct dylinker_command {
uint32_t cmd; /* LC_ID_DYLINKER, LC_LOAD_DYLINKER or
LC_DYLD_ENVIRONMENT */
uint32_t cmdsize; /* includes pathname string */
union lc_str name; /* dynamic linker's path name */
};
```
**Fields**
- `cmd`
Common to all load command structures. For this structure, set to either `LC_ID_DYLINKER` or
`LC_LOAD_DYLINKER`.
- `cmdsize`
Common to all load command structures. For this structure, set to sizeof(dylinker_command),
plus the size of the data pointed to by the name field.
- `name`
A data structure of type lc_str (page 31). Specifies the name of the dynamic linker
**Discussion**
Every executable file that is dynamically linked contains a LC_LOAD_DYLINKER command that specifies the name of the dynamic linker that the kernel must load in order to execute the file. The dynamic linker itself specifies its name using the LC_ID_DYLINKER load command.
每个动态链接的可执行文件都包含一个LC_LOAD_DYLINKER命令,该命令指定内核为了执行文件必须加载的动态链接器的名称。动态链接器本身使用LC_ID_DYLINKER load command指定其名称。
- **prebound_dylib_command**
Defines the attributes of the `LC_PREBOUND_DYLIB` load command. For every library that a prebound executable file links to, the static linker adds one LC_PREBOUND_DYLIB command. Declared in
/usr/include/mach-o/loader.h.
```c
/*
* A program (filetype == MH_EXECUTE) that is
* prebound to its dynamic libraries has one of these for each library that
* the static linker used in prebinding. It contains a bit vector for the
* modules in the library. The bits indicate which modules are bound (1) and
* which are not (0) from the library. The bit for module 0 is the low bit
* of the first byte. So the bit for the Nth module is:
* (linked_modules[N/8] >> N%8) & 1
*/
struct prebound_dylib_command {
uint32_t cmd; /* LC_PREBOUND_DYLIB */
uint32_t cmdsize; /* includes strings */
union lc_str name; /* library's path name */
uint32_t nmodules; /* number of modules in library */
union lc_str linked_modules; /* bit vector of linked modules */
};
```
**Fields**
- `cmd`
Common to all load command structures. For this structure, set to LC_PREBOUND_DYLIB.
- `cmdsize`
Common to all load command structures. For this structure, set to
sizeof(prebound_dylib_command) plus the size of the data pointed to by the name and
linked_modules fields.
- `name`
A data structure of type lc_str (page 31). Specifies the name of the prebound shared library.
预绑定共享库的名称
- `nmodules`
An integer. Specifies the number of modules the prebound shared library contains. The size
of the linked_modules string is (nmodules / 8) + (nmodules % 8).
一个整数。指定预绑定共享库包含的模块数。链接的模块字符串的大小为(nmodules/8)+(nmodules%8)
- `linked_modules`
A data structure of type lc_str (page 31). Usually, this data structure defines the offset of a
C string; in this usage, it is a variable-length bitset, containing one bit for each module. Each
bit represents whether the corresponding module is linked to a module in the current file, 1
for yes, 0 for no. The bit for the first module is the low bit of the first byte
lc_str类型的数据结构(第31页)。通常,此数据结构定义C字符串的偏移量;在这种用法中,它是一个可变长度的位集,每个模块包含一个位。每个位表示对应的模块是否链接到当前文件中的模块,1表示是,0表示否。第一个模块的位是第一个字节的低位
- **thread_command**
Defines the attributes of the` LC_THREAD` and `LC_UNIXTHREAD` load commands. The data of this command is specific to each architecture and appears in thread_status.h, located in the architecture’s directory in /usr/include/mach. Declared in /usr/include/mach-o/loader.h.
```c
struct thread_command {
uint32_t cmd; /* LC_THREAD or LC_UNIXTHREAD */
uint32_t cmdsize; /* total size of this command */
/* uint32_t flavor flavor of thread state */
/* uint32_t count count of uint32_t's in thread state */
/* struct XXX_thread_state state thread state for this flavor */
/* ... */
};
```
**Fields**
- `cmd`
Common to all load command structures. For this structure, set to `LC_THREAD` or `LC_UNIXTHREAD`.
- `cmdsize`
Common to all load command structures. For this structure, set to sizeof(thread_command)
plus the size of the flavor and count fields plus the size of the CPU-specific thread state data structure.
- `flavor`
Integer specifying the particular flavor of the thread state data structure. See the thread_status.h file for your target architecture.
整数,指定线程状态数据结构的特殊类型。请参阅目标体系结构的thread_status.h文件。
- `count`
Size of the thread state data, in number of 32-bit integers. The thread state data structure must be fully padded to 32-bit alignment.
线程状态数据的大小,以32位整数为单位。线程状态数据结构必须完全填充为32位对齐。
- **routines_command**
Defines the attributes of the `LC_ROUTINES` load command, used in 32-bit architectures. Describes the location of the shared library initialization function, which is a function that the dynamic linker calls before allowing any of the routines in the library to be called. Declared in
/usr/include/mach-o/loader.h. See also routines_command_64
定义32位体系结构中使用的LC_ROUTINES load commands的属性。描述共享库初始化函数的位置,该函数是动态链接器在允许调用库中的任何例程之前调用的函数。在/usr/include/mach-o/loader.h中声明。另请参见例程命令(第36页)。
```c
/*
* The routines command contains the address of the dynamic shared library
* initialization routine and an index into the module table for the module
* that defines the routine. Before any modules are used from the library the
* dynamic linker fully binds the module that defines the initialization routine
* and then calls it. This gets called before any module initialization
* routines (used for C++ static constructors) in the library.
*/
struct routines_command { /* for 32-bit architectures */
uint32_t cmd; /* LC_ROUTINES */
uint32_t cmdsize; /* total size of this command */
uint32_t init_address; /* address of initialization routine */
uint32_t init_module; /* index into the module table that */
/* the init routine is defined in */
uint32_t reserved1;
uint32_t reserved2;
uint32_t reserved3;
uint32_t reserved4;
uint32_t reserved5;
uint32_t reserved6;
};
/*
* The 64-bit routines command. Same use as above.
*/
struct routines_command_64 { /* for 64-bit architectures */
uint32_t cmd; /* LC_ROUTINES_64 */
uint32_t cmdsize; /* total size of this command */
uint64_t init_address; /* address of initialization routine */
uint64_t init_module; /* index into the module table that */
/* the init routine is defined in */
uint64_t reserved1;
uint64_t reserved2;
uint64_t reserved3;
uint64_t reserved4;
uint64_t reserved5;
uint64_t reserved6;
};
```
**Fields**
- `cmd`
Common to all load command structures. For this structure, set to LC_ROUTINES.
- `cmdsize`
Common to all load command structures. For this structure, set to sizeof(routines_command).
- `init_address`
An integer specifying the virtual memory address of the initialization function.
指定初始化函数的虚拟内存地址的整数。
- `init_module`
An integer specifying the index into the module table of the module containing the initialization function.
一个整数,指定包含初始化函数的模块的模块表中的索引。
- `reserved1`
Reserved for future use. Set this field to 0.
保留以备将来使用。将此字段设置为0
- `reserved2`
Reserved for future use. Set this field to 0.
- `reserved3`
Reserved for future use. Set this field to 0.
- `reserved4`
Reserved for future use. Set this field to 0.
- `reserved5`
Reserved for future use. Set this field to 0.
- `reserved6`
Reserved for future use. Set this field to 0.
**Discussion**
The static linker adds an LC_ROUTINES command when you specify a shared library initialization function using the -init option (see the ld man page for more information).
使用-init选项指定共享库初始化函数时,静态链接器会添加LC_ROUTINES命令(有关详细信息,请参阅ld手册页)。
- **sub_framework_command**
Defines the attributes of the LC_SUB_FRAMEWORK load command. Identifies the umbrella framework of which this file is a subframework. Declared in /usr/include/mach-o/loader.h.
```c
/*
* A dynamically linked shared library may be a subframework of an umbrella
* framework. If so it will be linked with "-umbrella umbrella_name" where
* Where "umbrella_name" is the name of the umbrella framework. A subframework
* can only be linked against by its umbrella framework or other subframeworks
* that are part of the same umbrella framework. Otherwise the static link
* editor produces an error and states to link against the umbrella framework.
* The name of the umbrella framework for subframeworks is recorded in the
* following structure.
*/
struct sub_framework_command {
uint32_t cmd; /* LC_SUB_FRAMEWORK */
uint32_t cmdsize; /* includes umbrella string */
union lc_str umbrella; /* the umbrella framework name */
};
```
**Fields**
- `cmd`
- `cmdsize`
- `umbrella`
A data structure of type lc_str (page 31). Specifies the name of the umbrella framework of
which this file is a member.
- **sub_umbrella_command**
Defines the attributes of the LC_SUB_UMBRELLA load command. Identifies the named framework as a subumbrella of this framework. Unlike a subframework, any client may link to a subumbrella. Declared
in /usr/include/mach-o/loader.h.
```c
/*
* A dynamically linked shared library may be a sub_umbrella of an umbrella
* framework. If so it will be linked with "-sub_umbrella umbrella_name" where
* Where "umbrella_name" is the name of the sub_umbrella framework. When
* staticly linking when -twolevel_namespace is in effect a twolevel namespace
* umbrella framework will only cause its subframeworks and those frameworks
* listed as sub_umbrella frameworks to be implicited linked in. Any other
* dependent dynamic libraries will not be linked it when -twolevel_namespace
* is in effect. The primary library recorded by the static linker when
* resolving a symbol in these libraries will be the umbrella framework.
* Zero or more sub_umbrella frameworks may be use by an umbrella framework.
* The name of a sub_umbrella framework is recorded in the following structure.
*/
struct sub_umbrella_command {
uint32_t cmd; /* LC_SUB_UMBRELLA */
uint32_t cmdsize; /* includes sub_umbrella string */
union lc_str sub_umbrella; /* the sub_umbrella framework name */
};
```
**Fields**
- `cmd`
- `cmdsize`
- `sub_umbrella`
A data structure of type lc_str (page 31). Specifies the name of the umbrella framework of
which this file is a member.
- **sub_library_command**
Defines the attributes of the LC_SUB_LIBRARY load command. Identifies a sublibrary of this framework and marks this framework as an umbrella framework. Unlike a subframework, any client may link to a sublibrary. Declared in /usr/include/mach-o/loader.h.
```c
/*
* A dynamically linked shared library may be a sub_library of another shared
* library. If so it will be linked with "-sub_library library_name" where
* Where "library_name" is the name of the sub_library shared library. When
* staticly linking when -twolevel_namespace is in effect a twolevel namespace
* shared library will only cause its subframeworks and those frameworks
* listed as sub_umbrella frameworks and libraries listed as sub_libraries to
* be implicited linked in. Any other dependent dynamic libraries will not be
* linked it when -twolevel_namespace is in effect. The primary library
* recorded by the static linker when resolving a symbol in these libraries
* will be the umbrella framework (or dynamic library). Zero or more sub_library
* shared libraries may be use by an umbrella framework or (or dynamic library).
* The name of a sub_library framework is recorded in the following structure.
* For example /usr/lib/libobjc_profile.A.dylib would be recorded as "libobjc".
*/
struct sub_library_command {
uint32_t cmd; /* LC_SUB_LIBRARY */
uint32_t cmdsize; /* includes sub_library string */
union lc_str sub_library; /* the sub_library name */
};
```
- **sub_client_command**
Defines the attributes of the LC_SUB_CLIENT load command. Specifies the name of a file that is allowed to link to this subframework. This file would otherwise be required to link to the umbrella framework of which this file is a component. Declared in /usr/include/mach-o/loader.h.
```c
/*
* For dynamically linked shared libraries that are subframework of an umbrella
* framework they can allow clients other than the umbrella framework or other
* subframeworks in the same umbrella framework. To do this the subframework
* is built with "-allowable_client client_name" and an LC_SUB_CLIENT load
* command is created for each -allowable_client flag. The client_name is
* usually a framework name. It can also be a name used for bundles clients
* where the bundle is built with "-client_name client_name".
*/
struct sub_client_command {
uint32_t cmd; /* LC_SUB_CLIENT */
uint32_t cmdsize; /* includes client string */
union lc_str client; /* the client name */
};
```
**Special Considerations**
The ld tool generates a sub_client_command load command in the built product if you pass the option -allowable_client <name>, where <name> is the install name of a framework or the client name of a bundle. See the ld man page, specifically about the options -allowable_client and -client_name, for more information.
如果传递选项-allowable_client<name>,其中<name>是框架的安装名称或捆绑包的客户端名称,则ld工具会在生成的产品中生成一个sub_client_command load commands。有关详细信息,请参阅ld手册页,特别是关于选项-允许的客户机和-客户机名称。
## Symbol Table and Related Data Structures
Two load commands, LC_SYMTAB and LC_DYSYMTAB, describe the size and location of the symbol
tables, along with additional metadata. The other data structures listed in this section represent the
symbol tables themselves.
两个加载命令`LC_SYMTAB`和`LC_DYSYMTAB`描述了符号表的大小和位置以及其他元数据。本节中列出的其他数据结构表示符号表本身。
- **symtab_command**
Defines the attributes of the` LC_SYMTAB` load command. Describes the size and location of the symbol table data structures. Declared in /usr/include/mach-o/loader.h.
定义lc_symtab load commands的属性。描述符号表数据结构的大小和位置。在/usr/include/mach-o/loader.h中声明。
```c
/*
* The symtab_command contains the offsets and sizes of the link-edit 4.3BSD
* "stab" style symbol table information as described in the header files
* <nlist.h> and <stab.h>.
*/
struct symtab_command {
uint32_t cmd; /* LC_SYMTAB */
uint32_t cmdsize; /* sizeof(struct symtab_command) */
uint32_t symoff; /* symbol table offset */
uint32_t nsyms; /* number of symbol table entries */
uint32_t stroff; /* string table offset */
uint32_t strsize; /* string table size in bytes */
};
```
**Fields**
- `cmd`
- `cmdsize`
- `symoff`
An integer containing the byte offset from the start of the file to the location of the symbol table entries. The symbol table is an array of nlist (page 39) data structures.
包含从文件开始到符号表项位置的字节偏移量的整数。符号表是一个由nlist(第39页)数据结构组成的数组。
- `nsyms`
An integer indicating the number of entries in the symbol table.
符号表中条目数
- `stroff`
An integer containing the byte offset from the start of the image to the location of the string
table.
包含从图像开始到字符串表位置的字节偏移量。
- `strsize`
An integer indicating the size (in bytes) of the string table.
表示字符串表的大小(字节)。
**Discussion**
LC_SYMTAB should exist in both statically linked and dynamically linked file types.
`LC_SYMTAB`应该同时存在于静态链接和动态链接的文件类型中。
- **nlist**
Describes an entry in the symbol table for 32-bit architectures. Declared in
/usr/include/mach-o/nlist.h. See also nlist_64
```c
struct nlist {
union {
#ifndef __LP64__
char *n_name; /* for use when in-core */
#endif
uint32_t n_strx; /* index into the string table */
} n_un;
uint8_t n_type; /* type flag, see below */
uint8_t n_sect; /* section number or NO_SECT */
int16_t n_desc; /* see <mach-o/stab.h> */
uint32_t n_value; /* value of this symbol (or stab offset) */
};
/*
* This is the symbol table entry structure for 64-bit architectures.
*/
struct nlist_64 {
union {
uint32_t n_strx; /* index into the string table */
} n_un;
uint8_t n_type; /* type flag, see below */
uint8_t n_sect; /* section number or NO_SECT */
uint16_t n_desc; /* see <mach-o/stab.h> */
uint64_t n_value; /* value of this symbol (or stab offset) */
};
```
**Fields**
- `n_un`
A union that holds an index into the string table, n_strx. To specify an empty string (""), set
this value to 0. The n_name field is not used in Mach-O files.
共用体保存着在string table中的index,n_strx。若要指定空字符串(“”),请将此值设置为0。mach-o文件中不使用n_name字段。
- `n_type`
A byte value consisting of data accessed using four bit masks:
一个字节值,由使用四位掩码访问的数据组成:
```c
/*
* The n_type field really contains four fields:
* unsigned char N_STAB:3,
* N_PEXT:1,
* N_TYPE:3,
* N_EXT:1;
* which are used via the following masks.
*/
#define N_STAB 0xe0 /* if any of these bits set, a symbolic debugging entry */
#define N_PEXT 0x10 /* private external symbol bit */
#define N_TYPE 0x0e /* mask for the type bits */
#define N_EXT 0x01 /* external symbol bit, set for external symbols */
/*
* Only symbolic debugging entries have some of the N_STAB bits set and if any
* of these bits are set then it is a symbolic debugging entry (a stab). In
* which case then the values of the n_type field (the entire field) are given
* in <mach-o/stab.h>
*/
/*
* Values for N_TYPE bits of the n_type field.
*/
#define N_UNDF 0x0 /* undefined, n_sect == NO_SECT */
#define N_ABS 0x2 /* absolute, n_sect == NO_SECT */
#define N_SECT 0xe /* defined in section number n_sect */
#define N_PBUD 0xc /* prebound undefined (defined in a dylib) */
#define N_INDR 0xa /* indirect */
```
- `N_STAB (0xe0)`—If any of these 3 bits are set, the symbol is a symbolic debugging table (stab) entry. In that case, the entire n_type field is interpreted as a stab value. See /usr/include/mach-o/stab.h for valid stab values.
如果设置了这3位中的任何一位,则符号是符号调试表(stab)项。在这种情况下,整个n_type字段被解释为stab值。有关有效的stab值,请参见/usr/include/mach-o/stab.h。
- `N_PEXT (0x10)`—If this bit is on, this symbol is marked as having limited global scope. When the file is fed to the static linker, it clears the N_EXT bit for each symbol with the N_PEXT bit set. (The ld option -keep_private_externs turns off this behavior.) With Mac OS X GCC, you can use the __private_extern__ function attribute to set this bit.
如果该位为开,则该符号被标记为具有有限的全局范围。当文件被馈送到静态链接器时,它会为每个设置了n_-pext位的符号清除n_-ext位。(ld选项-keep_private_externs关闭此行为)使用mac os x gcc,可以使用u private_u extern_uu函数属性设置此位。
- `N_TYPE (0x0e)`—These bits define the type of the symbol.
定义符号的类型
- `N_EXT (0x01)`—If this bit is on, this symbol is an external symbol, a symbol that is either defined outside this file or that is defined in this file but can be referenced by other files.
如果该位为开,则该符号为外部符号,即在此文件外部定义的,或在此文件中定义但可以被其他文件引用的。
Values for the `N_TYPE` field include:
- `N_UNDF (0x0)`—The symbol is undefined. Undefined symbols are symbols referenced in this module but defined in a different module. The n_sect field is set to NO_SECT.
符号未定义。未定义符号是指在此模块中引用但在其他模块中定义的符号。n_sect字段设置为NO_SECT。
- `N_ABS (0x2)`—The symbol is absolute. The linker does not change the value of an absolute symbol. The n_sect field is set to NO_SECT.
符号是绝对的。链接器不会更改绝对符号的值。n_sect字段设置为NO_SECT。
- `N_SECT (0xe)`—The symbol is defined in the section number given in n_sect.
- `N_PBUD (0xc)`—The symbol is undefined and the image is using a prebound value for the symbol. The n_sect field is set to NO_SECT.
- `N_INDR ( 0xa)`—The symbol is defined to be the same as another symbol. The n_value field is an index into the string table specifying the name of the other symbol. When that symbol is linked, both this and the other symbol have the same defined type and value.
该符号被定义为与另一个符号相同。n_value字段是字符串表的索引,用于指定另一个符号的名称。链接该符号时,此符号和其他符号都具有相同的定义类型和值。
- `n_sect`
An integer specifying the number of the section that this symbol can be found in, or NO_SECT
if the symbol is not to be found in any section of this image. The sections are contiguously numbered across segments, starting from 1, according to the order they appear in the LC_SEGMENT load commands.
一个整数,指定可以在其中找到该符号的节的数目,或NO_SECT
如果在图像的任何部分都找不到符号。根据它们在LC_SEGMENT load commands中出现的顺序,分段在分段之间连续编号,从1开始。
- `n_desc`
A 16-bit value providing additional information about the nature of this symbol for non-stab
symbols. The reference flags can be accessed using the REFERENCE_TYPE mask (0xF) and are
defined as follows:
一个16位值,为非stab符号提供关于此符号性质的附加信息。可以使用REFERENCE_TYPE掩码(0xF)访问引用标志,定义如下:
- `n_value`
An integer that contains the value of the symbol. The format of this value is different for each type of symbol table entry (as specified by the n_type field). For the N_SECT symbol type, n_value is the address of the symbol. See the description of the n_type field for information on other possible values.
包含符号值的整数。对于每种类型的符号表条目(由n_type字段指定),此值的格式是不同的。对于N_SECT符号类型,n_value是符号的地址。有关其他可能值的信息,请参见n_type字段的描述。
**Discussion**
Common symbols must be of type N_UNDF and must have the N_EXT bit set. The n_value for a common symbol is the size (in bytes) of the data of the symbol. In C, a common symbol is a variable that is declared but not initialized in this file. Common symbols can appear only in MH_OBJECT Mach-O files.
公共符号必须是N_UNDF类型的,并且必须设置N_EXT位。公共符号的n_value是符号数据的大小(以字节为单位)。在C语言中,公共符号是在该文件中声明但未初始化的变量。通用符号只能出现在MH_OBJECT Mach-O文件中。
- **dysymtab_command**
The data structure for the `LC_DYSYMTAB` load command. It describes the sizes and locations of the parts of the symbol table used for dynamic linking. Declared in /usr/include/mach-o/loader.h.
```c
struct dysymtab_command {
uint32_t cmd; /* LC_DYSYMTAB */
uint32_t cmdsize; /* sizeof(struct dysymtab_command) */
/*
* The symbols indicated by symoff and nsyms of the LC_SYMTAB load command
* are grouped into the following three groups:
* local symbols (further grouped by the module they are from)
* defined external symbols (further grouped by the module they are from)
* undefined symbols
*
* The local symbols are used only for debugging. The dynamic binding
* process may have to use them to indicate to the debugger the local
* symbols for a module that is being bound.
*
* The last two groups are used by the dynamic binding process to do the
* binding (indirectly through the module table and the reference symbol
* table when this is a dynamically linked shared library file).
*/
uint32_t ilocalsym; /* index to local symbols */
uint32_t nlocalsym; /* number of local symbols */
uint32_t iextdefsym;/* index to externally defined symbols */
uint32_t nextdefsym;/* number of externally defined symbols */
uint32_t iundefsym; /* index to undefined symbols */
uint32_t nundefsym; /* number of undefined symbols */
/*
* For the for the dynamic binding process to find which module a symbol
* is defined in the table of contents is used (analogous to the ranlib
* structure in an archive) which maps defined external symbols to modules
* they are defined in. This exists only in a dynamically linked shared
* library file. For executable and object modules the defined external
* symbols are sorted by name and is use as the table of contents.
*/
uint32_t tocoff; /* file offset to table of contents */
uint32_t ntoc; /* number of entries in table of contents */
/*
* To support dynamic binding of "modules" (whole object files) the symbol
* table must reflect the modules that the file was created from. This is
* done by having a module table that has indexes and counts into the merged
* tables for each module. The module structure that these two entries
* refer to is described below. This exists only in a dynamically linked
* shared library file. For executable and object modules the file only
* contains one module so everything in the file belongs to the module.
*/
uint32_t modtaboff; /* file offset to module table */
uint32_t nmodtab; /* number of module table entries */
/*
* To support dynamic module binding the module structure for each module
* indicates the external references (defined and undefined) each module
* makes. For each module there is an offset and a count into the
* reference symbol table for the symbols that the module references.
* This exists only in a dynamically linked shared library file. For
* executable and object modules the defined external symbols and the
* undefined external symbols indicates the external references.
*/
uint32_t extrefsymoff; /* offset to referenced symbol table */
uint32_t nextrefsyms; /* number of referenced symbol table entries */
/*
* The sections that contain "symbol pointers" and "routine stubs" have
* indexes and (implied counts based on the size of the section and fixed
* size of the entry) into the "indirect symbol" table for each pointer
* and stub. For every section of these two types the index into the
* indirect symbol table is stored in the section header in the field
* reserved1. An indirect symbol table entry is simply a 32bit index into
* the symbol table to the symbol that the pointer or stub is referring to.
* The indirect symbol table is ordered to match the entries in the section.
*/
uint32_t indirectsymoff; /* file offset to the indirect symbol table */
uint32_t nindirectsyms; /* number of indirect symbol table entries */
/*
* To support relocating an individual module in a library file quickly the
* external relocation entries for each module in the library need to be
* accessed efficiently. Since the relocation entries can't be accessed
* through the section headers for a library file they are separated into
* groups of local and external entries further grouped by module. In this
* case the presents of this load command who's extreloff, nextrel,
* locreloff and nlocrel fields are non-zero indicates that the relocation
* entries of non-merged sections are not referenced through the section
* structures (and the reloff and nreloc fields in the section headers are
* set to zero).
*
* Since the relocation entries are not accessed through the section headers
* this requires the r_address field to be something other than a section
* offset to identify the item to be relocated. In this case r_address is
* set to the offset from the vmaddr of the first LC_SEGMENT command.
* For MH_SPLIT_SEGS images r_address is set to the the offset from the
* vmaddr of the first read-write LC_SEGMENT command.
*
* The relocation entries are grouped by module and the module table
* entries have indexes and counts into them for the group of external
* relocation entries for that the module.
*
* For sections that are merged across modules there must not be any
* remaining external relocation entries for them (for merged sections
* remaining relocation entries must be local).
*/
uint32_t extreloff; /* offset to external relocation entries */
uint32_t nextrel; /* number of external relocation entries */
/*
* All the local relocation entries are grouped together (they are not
* grouped by their module since they are only used if the object is moved
* from it staticly link edited address).
*/
uint32_t locreloff; /* offset to local relocation entries */
uint32_t nlocrel; /* number of local relocation entries */
};
```
**Fields**
- `cmd`
Common to all load command structures. For this structure, set to LC_DYSYMTAB.
- `cmdsize`
Common to all load command structures. For this structure, set to sizeof(dysymtab_command).
- `ilocalsym`
An integer indicating the index of the first symbol in the group of local symbols.
一个整数,表示本地符号组中第一个符号的索引
- `nlocalsym`
An integer indicating the total number of symbols in the group of local symbols.
表示本地符号组中符号总数
- `iextdefsym`
An integer indicating the index of the first symbol in the group of defined external symbols.
一个整数,表示定义的外部符号组中第一个符号的索引。
- `nextdefsym`
An integer indicating the total number of symbols in the group of defined external symbols.
一个整数,表示定义的外部符号组中的符号总数。
- `iundefsym`
An integer indicating the index of the first symbol in the group of undefined external symbols.
一个整数,表示未定义外部符号组中第一个符号的索引。
- `nundefsym`
An integer indicating the total number of symbols in the group of undefined external symbols
表示未定义外部符号组中符号总数
- `tocoff`
An integer indicating the byte offset from the start of the file to the table of contents data.
一个整数,表示从文件开始到目录数据的字节偏移量。
- `ntoc`
An integer indicating the number of entries in the table of contents.
表示目录中条目数的整数。
- `modtaboff`
An integer indicating the byte offset from the start of the file to the module table data.
一个整数,表示从文件开始到模块表数据的字节偏移量。
- `nmodtab`
An integer indicating the number of entries in the module table.
表示模块表中条目数的整数。
- `extrefsymoff`
An integer indicating the byte offset from the start of the file to the external reference table
data.
一个整数,表示从文件开始到外部引用表数据的字节偏移量。
- `nextrefsyms`
An integer indicating the number of entries in the external reference table.
表示外部引用表中条目数的整数。
- `indirectsymoff`
An integer indicating the byte offset from the start of the file to the indirect symbol table data.
一个整数,表示从文件开头到间接符号表数据的字节偏移量。
- `nindirectsyms`
An integer indicating the number of entries in the indirect symbol table.
指示间接符号表中条目数的整数。
- `extreloff`
An integer indicating the byte offset from the start of the file to the external relocation table data.
一个整数,表示从文件开始到外部重定位表数据的字节偏移量
- `nextrel`
An integer indicating the number of entries in the external relocation table.
一个整数,指示外部重新定位表中的条目数
- `locreloff`
An integer indicating the byte offset from the start of the file to the local relocation table data.
一个整数,表示从文件开始到本地重定位表数据的字节偏移量
- `nlocrel`
An integer indicating the number of entries in the local relocation table.
一个整数,指示本地重新定位表中的条目数
**Discussion**
The LC_DYSYMTAB load command contains a set of indexes into the symbol table and a set of file offsets that define the location of several other tables. Fields for tables not used in the file should be set to 0. These tables are described in “Dynamic Code Generation” in *Mach-O Programming Topics*.
LC_DYSYMTAB load command包含符号表中的一组索引和一组文件偏移量,它们定义了其他几个表的位置。文件中未使用的表的字段应设置为0。这些表在*Mach-O Programming Topics*.中的“Dynamic Code Generation”中进行了描述。
- **dylib_table_of_contents**
Describes an entry in the table of contents of a dynamic shared library. Declared in
/usr/include/mach-o/loader.h.
```c
/* a table of contents entry */
struct dylib_table_of_contents {
uint32_t symbol_index; /* the defined external symbol
(index into the symbol table) */
uint32_t module_index; /* index into the module table this symbol
is defined in */
};
```
**Fields**
- `symbol_index`
An index into the symbol table indicating the defined external symbol to which this entry
refers.
符号表中的索引,指示此项所引用的已定义外部符号。
- `module_index`
An index into the module table indicating the module in which this defined external symbol
is defined.
模块表中的索引,指示在其中定义此定义的外部符号的模块。
- **dylib_module**
Describes a module table entry for a dynamic shared library for 32-bit architectures. Declared in
/usr/include/mach-o/loader.h.
```c
/* a module table entry */
struct dylib_module {
uint32_t module_name; /* the module name (index into string table) */
uint32_t iextdefsym; /* index into externally defined symbols */
uint32_t nextdefsym; /* number of externally defined symbols */
uint32_t irefsym; /* index into reference symbol table */
uint32_t nrefsym; /* number of reference symbol table entries */
uint32_t ilocalsym; /* index into symbols for local symbols */
uint32_t nlocalsym; /* number of local symbols */
uint32_t iextrel; /* index into external relocation entries */
uint32_t nextrel; /* number of external relocation entries */
uint32_t iinit_iterm; /* low 16 bits are the index into the init
section, high 16 bits are the index into
the term section */
uint32_t ninit_nterm; /* low 16 bits are the number of init section
entries, high 16 bits are the number of
term section entries */
uint32_t /* for this module address of the start of */
objc_module_info_addr; /* the (__OBJC,__module_info) section */
uint32_t /* for this module size of */
objc_module_info_size; /* the (__OBJC,__module_info) section */
};
/* a 64-bit module table entry */
struct dylib_module_64 {
uint32_t module_name; /* the module name (index into string table) */
uint32_t iextdefsym; /* index into externally defined symbols */
uint32_t nextdefsym; /* number of externally defined symbols */
uint32_t irefsym; /* index into reference symbol table */
uint32_t nrefsym; /* number of reference symbol table entries */
uint32_t ilocalsym; /* index into symbols for local symbols */
uint32_t nlocalsym; /* number of local symbols */
uint32_t iextrel; /* index into external relocation entries */
uint32_t nextrel; /* number of external relocation entries */
uint32_t iinit_iterm; /* low 16 bits are the index into the init
section, high 16 bits are the index into
the term section */
uint32_t ninit_nterm; /* low 16 bits are the number of init section
entries, high 16 bits are the number of
term section entries */
uint32_t /* for this module size of */
objc_module_info_size; /* the (__OBJC,__module_info) section */
uint64_t /* for this module address of the start of */
objc_module_info_addr; /* the (__OBJC,__module_info) section */
};
```
**Fields**
- `module_name`
An index to an entry in the string table indicating the name of the module.
指向字符串表中指示模块名称的项的索引。
- `iextdefsym`
The index into the symbol table of the first defined external symbol provided by this module.
此模块提供的第一个定义的外部符号的符号表索引。
- `nextdefsym`
The number of defined external symbols provided by this module.
此模块提供的已定义外部符号的数目
- `irefsym`
The index into the external reference table of the first entry provided by this module.
此模块提供的第一个条目的外部引用表的索引
- `nrefsym`
The number of external reference entries provided by this module.
此模块提供的外部引用条目数。
- `ilocalsym`
The index into the symbol table of the first local symbol provided by this module.
此模块提供的第一个本地符号的符号表索引。
- `nlocalsym`
The number of local symbols provided by this module.
此模块提供的本地符号数。
- `iextrel`
The index into the external relocation table of the first entry provided by this module.
此模块提供的第一个条目的外部重新定位表的索引
- `nextrel`
The number of entries in the external relocation table that are provided by this module.
此模块提供的外部重新定位表中的条目数。
- `iinit_iterm`
Contains both the index into the module initialization section (the low 16 bits) and the index into the module termination section (the high 16 bits) to the pointers for this module.
包含指向模块初始化部分(低16位)的索引和指向此模块指针的模块终止部分(高16位)的索引。
- `ninit_nterm`
Contains both the number of pointers in the module initialization (the low 16 bits) and the
number of pointers in the module termination section (the high 16 bits) for this module.
包含模块初始化中的指针数(低16位)和此模块的模块终止部分中的指针数(高16位)。
- `objc_module_info_addr`
The statically linked address of the start of the data for this module in the __module_info section in the __OBJC segment.
在objc段中的模块信息部分中,此模块的数据起始的静态链接地址。
- `objc_module_info_size`
The number of bytes of data for this module that are used in the __module_info section in the __OBJC segment.
此模块在objc段中的模块信息部分中使用的数据字节数。
- **dylib_reference**
Defines the attributes of an external reference table entry for the external reference entries provided by a module in a shared library. Declared in /usr/include/mach-o/loader.h.
```c
/*
* The entries in the reference symbol table are used when loading the module
* (both by the static and dynamic link editors) and if the module is unloaded
* or replaced. Therefore all external symbols (defined and undefined) are
* listed in the module's reference table. The flags describe the type of
* reference that is being made. The constants for the flags are defined in
* <mach-o/nlist.h> as they are also used for symbol table entries.
*/
struct dylib_reference {
uint32_t isym:24, /* index into the symbol table */
flags:8; /* flags to indicate the type of reference */
};
```
**Fields**
- `isym`
An index into the symbol table for the symbol being referenced
符号表中被引用符号的索引
- `flags`
A constant for the type of reference being made. Use the same REFERENCE_FLAG constants as described in the nlist (page 39) structure description.
引用类型的常量。使用与nlist(第39页)结构描述中描述的相同的REFERENCE_FLAG常量。
## Relocation Data Structures
**Relocation** is the process of moving symbols to a different address. When the static linker moves a
symbol (a function or an item of data) to a different address, it needs to change all the references to
that symbol to use the new address. The **relocation entries** in a Mach-O file contain offsets in the file
to addresses that need to be relocated when the contents of the file are relocated. The addresses stored
in CPU instructions can be absolute or relative. Each relocation entry specifies the exact format of the
address. When creating the intermediate object file, the compiler generates one or more relocation
entries for every instruction that contains an address. Because relocation to symbols at fixed addresses,
and to relative addresses for position independent references, does not occur at runtime, the static
linker typically removes some or all the relocation entries when building the final product.
重定位是将符号移动到另一个地址的过程。当静态链接器将符号(函数或数据项)移动到另一个地址时,需要更改对该符号的所有引用,以使用新地址。Mach-O文件中的重定位条目包含文件中的偏移量,这些偏移量指向当文件内容重定位时需要重定位的地址。CPU指令中存储的地址可以是绝对地址,也可以是相对地址。每个重定位条目指定地址的确切格式。在创建中间对象文件时,编译器为包含地址的每条指令生成一个或多个重定位项。由于在运行时不会对固定地址的符号和位置独立引用的相对地址进行重定位,因此静态链接器通常会在构建最终产品时删除部分或所有重定位项。
> Note: In the Mac OS X x86-64 environment scattered relocations are not used. Compiler-generated code uses mostly external relocations, in which the r_extern bit is set to 1 and the r_symbolnum field contains the symbol-table index of the target label.
>
> 注意:在Mac OS X x86-64环境中不使用分散重定位。编译器生成的代码主要使用外部重定位,其中r_extern位设置为1,r_symbolnum字段包含目标标签的符号表索引。
- **relocation_info**
Describes an item in the file that uses an address that needs to be updated when the address is changed.
Declared in /usr/include/mach-o/reloc.h.
描述文件中使用地址的项,该地址在地址更改时需要更新。在/usr/include/mach-o/reloc.h中声明。
```c
/*
* Format of a relocation entry of a Mach-O file. Modified from the 4.3BSD
* format. The modifications from the original format were changing the value
* of the r_symbolnum field for "local" (r_extern == 0) relocation entries.
* This modification is required to support symbols in an arbitrary number of
* sections not just the three sections (text, data and bss) in a 4.3BSD file.
* Also the last 4 bits have had the r_type tag added to them.
*/
struct relocation_info {
int32_t r_address; /* offset in the section to what is being
relocated */
uint32_t r_symbolnum:24, /* symbol index if r_extern == 1 or section
ordinal if r_extern == 0 */
r_pcrel:1, /* was relocated pc relative already */
r_length:2, /* 0=byte, 1=word, 2=long, 3=quad */
r_extern:1, /* does not include value of sym referenced */
r_type:4; /* if not 0, machine specific relocation type */
};
```
**Fields**
- `r_address`
In MH_OBJECT files, this is an offset from the start of the section to the item containing the address requiring relocation. If the high bit of this field is set (which you can check using the R_SCATTERED bit mask), the relocation_info structure is actually a scattered_relocation_info (page 52) structure.
In images used by the dynamic linker, this is an offset from the virtual memory address of the data of the first segment_command (page 20) that appears in the file (not necessarily the one with the lowest address). For images with the MH_SPLIT_SEGS flag set, this is an offset from the virtual memory address of data of the first read/write segment_command (page 20).
在MH_OBJECT文件中,这是从节的开始到包含需要重新定位的地址的项的偏移量。如果设置了该字段的高位(可以使用r_scatter位掩码检查),则relocation_info结构实际上是scattered_relocation_info(第52页)结构。
在动态链接器使用的图像中,这是与文件中出现的第一个segment_command(第20页)的数据的虚拟内存地址的偏移量(不一定是地址最低的那个)。对于设置了MH_SPLIT_SEGS标志的图像,这是第一个读/写段_command(第20页)数据的虚拟内存地址的偏移量。
- `r_symbolnum`
Indicates either an index into the symbol table (when the r_extern field is set to 1) or a section
number (when the r_extern field is set to 0). As previously mentioned, sections are ordered
from 1 to 255 in the order in which they appear in the LC_SEGMENT load commands. This field
is set to R_ABS for relocation entries for absolute symbols, which need no relocation.
表示符号表中的索引(当r_extern字段设置为1时)或节号(当r_extern字段设置为0时)。这个字段被设置为R_ABS,用于绝对符号的重新定位条目,绝对符号不需要重新定位。
- `r_pcrel`
Indicates whether the item containing the address to be relocated is part of a CPU instruction that uses PC-relative addressing.
For addresses contained in PC-relative instructions, the CPU adds the address of the instruction to the address contained in the instruction.
指示包含要重新定位的地址的项是否属于使用pc相对寻址的CPU指令的一部分。
对于pc相关指令中包含的地址,CPU将指令的地址添加到指令中包含的地址中。
- `r_length`
Indicates the length of the item containing the address to be relocated. The following table lists
r_length values and the corresponding address length.
指示包含要重新定位的地址的项的长度。下表列出了r_length值和相应的地址长度。
| Value | Address length |
| ----- | ------------------------------------------------------------ |
| 0 | 1 byte |
| 1 | 2 bytes |
| 2 | 4 bytes |
| 3 | 4 bytes. See description for the PPC_RELOC_BR14 r_type in<br/>scattered_relocation_info (page 52). |
- `r_extern`
Indicates whether the r_symbolnum field is an index into the symbol table (1) or a section
number (0).
指示r_symbolnum字段是符号表(1)的索引还是节号(0)的索引。
- `r_type`
- **scattered_relocation_info**
Describes an item in the file—using a nonzero constant in its relocatable expression or two addresses in its relocatable expression—that needs to be updated if the addresses that it uses are changed. This information is needed to reconstruct the addresses that make up the relocatable expression’s value in order to change the addresses independently of each other. Declared in /usr/include/mach-o/reloc.h.
在可重定位表达式中使用非零常量或在可重定位表达式中使用两个地址来描述文件中的项——如果使用的地址发生更改,则需要更新这些常量。需要此信息来重构构成可重定位表达式值的地址,以便独立地更改地址。中声明/usr/include/mach-o/reloc.h.
```c
struct scattered_relocation_info {
#ifdef __BIG_ENDIAN__
uint32_t r_scattered:1, /* 1=scattered, 0=non-scattered (see above) */
r_pcrel:1, /* was relocated pc relative already */
r_length:2, /* 0=byte, 1=word, 2=long, 3=quad */
r_type:4, /* if not 0, machine specific relocation type */
r_address:24; /* offset in the section to what is being
relocated */
int32_t r_value; /* the value the item to be relocated is
refering to (without any offset added) */
#endif /* __BIG_ENDIAN__ */
#ifdef __LITTLE_ENDIAN__
uint32_t
r_address:24, /* offset in the section to what is being
relocated */
r_type:4, /* if not 0, machine specific relocation type */
r_length:2, /* 0=byte, 1=word, 2=long, 3=quad */
r_pcrel:1, /* was relocated pc relative already */
r_scattered:1; /* 1=scattered, 0=non-scattered (see above) */
int32_t r_value; /* the value the item to be relocated is
refering to (without any offset added) */
#endif /* __LITTLE_ENDIAN__ */
};
```
**Fields**
- `r_scattered`
If this bit is 0, this structure is actually a relocation_info (page 49) structure.
如果这个位是0,那么这个结构实际上是一个relocation_info(第49页)结构。
- `r_address`
In MH_OBJECT files, this is an offset from the start of the section to the item containing the address requiring relocation. If the high bit of this field is clear (which you can check using the R_SCATTERED bit mask), this structure is actually a relocation_info (page 49) structure.
In images used by the dynamic linker, this is an offset from the virtual memory address of the data of the first segment_command (page 20) that appears in the file (not necessarily the one with the lowest address). For images with the MH_SPLIT_SEGS flag set, this is an offset from the virtual memory address of data of the first read/write segment_command (page 20).
Since this field is only 24 bits long, the offset in this field can never be larger than 0x00FFFFFF, thus limiting the size of the relocatable contents of this image to 16 megabytes.
在MH_OBJECT文件中,这是从节的开始到包含需要重新定位的地址的项的偏移量。如果这个字段的高位是清除的(可以使用r_scatter位掩码检查),那么这个结构实际上是一个relocation_info(第49页)结构。
在动态链接器使用的图像中,这是与文件中出现的第一个segment_command(第20页)的数据的虚拟内存地址的偏移量(不一定是地址最低的那个)。对于设置了MH_SPLIT_SEGS标志的图像,这是第一个读/写段_command(第20页)数据的虚拟内存地址的偏移量。
由于该字段只有24位长,因此该字段中的偏移量永远不能大于0x00FFFFFF,从而将此图像的可重定位内容的大小限制为16 mb。
- `r_pcrel`
Indicates whether the item containing the address to be relocated is part of a CPU instruction that uses PC-relative addressing.
For addresses contained in PC-relative instructions, the CPU adds the address of the instruction to the address contained in the instruction.
指示包含要重新定位的地址的项是否属于使用pc相对寻址的CPU指令的一部分。
对于pc相关指令中包含的地址,CPU将指令的地址添加到指令中包含的地址中。
- `r_length`
Indicates the length of the item containing the address to be relocated. A value of 0 indicates
a single byte; a value of 1 indicates a 2-byte address, and a value of 2 indicates a 4-byte address.
指示包含要重新定位的地址的项的长度。值为0表示单个字节;值1表示2字节地址,值2表示4字节地址。
- `r_type`
Indicates the type of relocation to be performed. Possible values for this field are shared between
this structure and the relocation_info data structure; see the description of the r_type field
in the relocation_info (page 49) data structure for more details.
指示要执行的重定位类型。这个字段的可能值在这个结构和relocation_info数据结构之间共享;有关详细信息,请参阅relocation_info(第49页)数据结构中r_type字段的描述。
- `r_value`
The address of the relocatable expression for the item in the file that needs to be updated if the
address is changed. For relocatable expressions with the difference of two section addresses,
the address from which to subtract (in mathematical terms, the minuend) is contained in the
first relocation entry and the address to subtract (the subtrahend) is contained in the second
relocation entry.
如果地址更改,则需要更新文件中项的可重定位表达式的地址。对于两个节地址不同的可重定位表达式,要减去的地址(数学术语为被减数)包含在第一个重定位项中,要减去的地址(减数)包含在第二个重定位项中。
**Discussion**
Mach-O relocation data structures support two types of relocatable expressions in machine code and data:
Mach-O重定位数据结构支持两种类型的可重定位表达式:
- **Symbol address + constant**. The most typical form of relocation is referencing a symbol’s address with no constant added. In this case, the value of the constant expression is 0.
最典型的重定位形式是引用没有添加常量的符号地址。在本例中,常量表达式的值为0。
- **Address of section y** **–** **address of section x + constant**. The section difference form of relocation. This form of relocation supports position-independent code.
节差形式的移位。这种形式的重新定位支持与位置无关的代码。
## Static Archive Libraries
This section describes the file format used for static archive libraries. Mac OS X uses a format derived from the original BSD static archive library format, with a few minor additions. See the discussion for the ranlib data structure for more information.
本节描述用于静态存档库的文件格式。Mac OS X使用的格式是从原始的BSD静态存档库格式派生出来的,只添加了一些小功能。有关更多信息,请参阅ranlib数据结构的讨论。
- **ranlib**
Defines the attributes of a static archive library symbol table entry. Declared in /usr/include/mach-o/ranlib.h.
```c
/*
* Structure of the __.SYMDEF table of contents for an archive.
* __.SYMDEF begins with a uint32_t giving the size in bytes of the ranlib
* structures which immediately follow, and then continues with a string
* table consisting of a uint32_t giving the number of bytes of strings which
* follow and then the strings themselves. The ran_strx fields index the
* string table whose first byte is numbered 0.
*/
struct ranlib {
union {
uint32_t ran_strx; /* string table index of */
#ifndef __LP64__
char *ran_name; /* symbol defined by */
#endif
} ran_un;
uint32_t ran_off; /* library member at this offset */
};
```
**Fields**
- `ran_strx`
The index number (zero-based) of the string in the string table that follows the array of ranlib data structures.
在ranlib数据结构数组后面的字符串表中字符串的索引号(从零开始)。
- `ran_name`
The byte offset, from the start of the file, at which the symbol name can be found. This field is not used in Mach-O files.
从文件开始的字节偏移量,在该偏移量处可以找到符号名。此字段在Mach-O文件中不使用。
- `ran_off`
The byte offset, from the start of the file, at which the header line for the member containing this symbol can be found.
从文件开始的字节偏移量,在此位置可以找到包含此符号的成员的头行。
**Discussion**
A static archive library begins with the file identifier string !<arch>, followed by a newline character (ASCII value 0x0A). The file identifier string is followed by a series of member files. Each member consists of a fixed-length header line followed by the file data. The header line is 60 bytes long and is divided into five fixed-length fields, as shown in this example header line:
静态存档库以文件标识符字符串!<arch>开始,后跟一个换行符(ASCII值0x0A)。文件标识符字符串后面跟着一系列成员文件。每个成员由一个固定长度的头行和文件数据组成。头行为60字节长,分为5个固定长度的字段,如下例头行所示:
```shell
grapple.c 999514211 501 20 100644 167 `
```
The last 2 bytes of the header line are a grave accent (`) character (ASCII value 0x60) and a newline
character. All header fields are defined in ASCII and padded with spaces to the full length of the field.
All fields are defined in decimal notation, except for the file mode field, which is defined in octal.
These are the descriptions for each field:
头行最后两个字节是一个重重音(')字符(ASCII值0x60)和一个换行字符。所有头字段都是用ASCII定义的,并用空格填充到字段的完整长度。所有字段都是用十进制记数法定义的,文件模式字段除外,它是用八进制定义的。以下是每个领域的描述:
- The name field (16 bytes) contains the name of the file. If the name is either longer than 16 bytes or contains a space character, the actual name should be written directly after the header line and the name field should contain the string #1/ followed by the length. To keep the archive entries aligned to 8 byte boundaries, the length of the name that follows the #1/ is rounded to 8 bytes and the name that follows the header is padded with null bytes.
name字段(16字节)包含文件的名称。如果名称大于16字节或包含空格字符,则实际名称应该直接写在标题行之后,name字段应该包含字符串#1/后跟长度。为了使归档条目对齐到8个字节的边界,#1/后面的名称的长度四舍五入为8个字节,头部后面的名称用空字节填充。
- The modified date field (12 bytes) is taken from the st_time field returned by the stat system call.
修改后的日期字段(12字节)取自stat系统调用返回的st_time字段。
- The user ID field (6 bytes) is taken from the st_uid field returned by the stat system call.
用户ID字段(6字节)取自stat系统调用返回的st_uid字段。
- The group ID field (6 bytes) is taken from the st_gid field returned by the stat system call.
组ID字段(6字节)取自stat系统调用返回的st_gid字段。
- The file mode field (8 bytes) is taken from the st_mode field returned by the stat system call. This field is written in octal notation.
文件模式字段(8字节)取自stat系统调用返回的st_mode字段。这个字段用八进制符号表示。
- The file size field (8 bytes) is taken from the st_size field returned by the stat system call.
文件大小字段(8字节)取自stat系统调用返回的st_size字段。
The first member in a static archive library is always the symbol table describing the contents of the rest of the member files. This member is always called either __.SYMDEF or __.SYMDEF SORTED (note the two leading underscores and the period). The name used depends on the sort order of the symbol table. The older variant—__.SYMDEF—contains entries in the same order that they appear in the object files. The newer variant—__.SYMDEF SORTED— contains entries in alphabetical order, which allows the static linker to load the symbols faster.
静态存档库中的第一个成员总是描述其余成员文件内容的符号表。这个成员总是被称为__。SYMDEF或__。SYMDEF排序(注意两个前导下划线和句号)。使用的名称取决于符号表的排序顺序。__年长的变体。symdef -包含与它们在目标文件中出现的顺序相同的条目。__新的变体。按字母顺序包含条目,这允许静态链接器更快地加载符号。
The __.SYMDEF and .__SORTED SYMDEF archive members contain an array of ranlib data structures preceded by the length in bytes (a long integer, 4 bytes) of the number of items in the array. The array is followed by a string table of null-terminated strings, which are preceded by the length in bytes of the entire string table (again, a 4-byte long integer).
__。已排序的SYMDEF archive成员包含一个ranlib数据结构数组,前面是数组中项数的字节长度(一个长整数,4个字节)。数组后面是一个以null结尾的字符串字符串表,它的前面是整个字符串表的字节长度(同样是一个4字节长的整数)。
The string table is an array of C strings, each terminated by a null byte.
The ranlib declarations can be found in /usr/include/mach-o/ranlib.h.
**Special Considerations**
Prior to the advent of libtool, a tool called ranlib was used to generate the symbol table. ranlib has since been integrated into libtool. See the man page for libtool for more information.
在libtool出现之前,使用了一个名为ranlib的工具来生成符号表。ranlib已经集成到libtool中。有关更多信息,请参见libtool的手册页。
## Universal Binaries 32-bit/64-bit PowerPC Binaries
The standard development tools accept as parameters two kinds of binaries:
标准开发工具接受两种二进制文件作为参数:
- Object files targeted at one architecture. These include Mach-O files, static libraries, and dynamic libraries.
目标文件针对一个体系结构。其中包括Mach-O文件、静态库和动态库。
- Binaries targeted at more than one architecture. These binaries contain compiled code and data for one of these system types:
针对多个体系结构的二进制文件。这些二进制文件包含以下系统类型的编译代码和数据:
- PowerPC-based (32-bit and 64-bit) Macintosh computers. Binaries that contain code for both
32-bit and 64-bit PowerPC-based Macintosh computers are are known as **PPC/PPC64 binaries**.
基于powerpc(32位和64位)的Macintosh计算机。包含两者代码的二进制文件
基于32位和64位powerpc的Macintosh计算机被称为**PPC/PPC64二进制文件**。
- Intel-based and PowerPC-based (32-bit, 64-bit, or both) Macintosh computers. Binaries that
contain code for both Intel-based and PowerPC-based Macintosh computers are known as
**universal binaries**.
基于intel和基于powerpc(32位、64位或两者都有)的Macintosh计算机。二进制文件
包含基于intel和基于powerpc的Macintosh计算机的代码 通用二进制文件
Each object file is stored as a continuous set of bytes at an offset from the beginning of the binary.
They use a simple archive format to store the two object files with a special header at the beginning
of the file to allow the various runtime tools to quickly find the code appropriate for the current
architecture.
每个目标文件都存储为一组连续的字节,以二进制文件开头的偏移量为单位。它们使用一种简单的归档格式来存储这两个目标文件,并在文件的开头使用一个特殊的头,以允许各种运行时工具快速找到适合当前体系结构的代码。
A binary that contains code for more than one architecture always begins with a fat_header (page
56) data structure, followed by two fat_arch (page 56) data structures and the actual data for the
architectures contained in the file. All data in these data structures is stored in big-endian byte order.
包含多个体系结构代码的二进制文件总是以fat_header(第56页)数据结构开始,然后是两个fat_arch(第56页)数据结构和文件中包含的体系结构的实际数据。这些数据结构中的所有数据都以大端字节顺序存储。
- **fat_header**
Defines the layout of a binary that contains code for more than one architecture. Declared in the
header /usr/include/mach-o/fat.h.
```c
#define FAT_MAGIC 0xcafebabe
#define FAT_CIGAM 0xbebafeca /* NXSwapLong(FAT_MAGIC) */
struct fat_header {
uint32_t magic; /* FAT_MAGIC or FAT_MAGIC_64 */
uint32_t nfat_arch; /* number of structs that follow */
};
```
**Fields**
- `magic`
An integer containing the value 0xCAFEBABE in big-endian byte order format. On a big-endian
host CPU, this can be validated using the constant FAT_MAGIC; on a little-endian host CPU, it
can be validated using the constant FAT_CIGAM.
包含值0xCAFEBABE的整数,采用大端字节顺序格式。在大端主机CPU上,可以使用常量FAT_MAGIC验证这一点;在little-endian主机CPU上,可以使用常量FAT_CIGAM验证它。
- `nfat_arch`
An integer specifying the number of fat_arch (page 56) data structures that follow. This is
the number of architectures contained in this binary.
一个整数,指定后面的fat_arch(第56页)数据结构的数量。这是这个二进制文件中包含的体系结构的数量。
**Discussion**
The fat_header data structure is placed at the start of a binary that contains code for multiple architectures. Directly following the fat_header data structure is a set of fat_arch (page 56) data structures, one for each architecture included in the binary.
Regardless of the content this data structure describes, all its fields are stored in big-endian byte order.
fat_header数据结构位于包含多个体系结构代码的二进制文件的开头。直接跟随fat_header数据结构的是一组fat_arch(第56页)数据结构,每个结构都包含在二进制文件中。
不管这个数据结构描述的内容是什么,它的所有字段都以大端字节顺序存储。
- **fat_arch**
Describes the location within the binary of an object file targeted at a single architecture. Declared in /usr/include/mach-o/fat.h.
描述以单一架构为目标的目标文件二进制文件中的位置。
```c
struct fat_arch {
cpu_type_t cputype; /* cpu specifier (int) */
cpu_subtype_t cpusubtype; /* machine specifier (int) */
uint32_t offset; /* file offset to this object file */
uint32_t size; /* size of this object file */
uint32_t align; /* alignment as a power of 2 */
};
```
**Fields**
- `cputype`
An enumeration value of type cpu_type_t. Specifies the CPU family.
类型cpu_type_t的枚举值。指定CPU族
- `cpusubtype`
An enumeration value of type cpu_subtype_t. Specifies the specific member of the CPU family
on which this entry may be used or a constant specifying all members.
类型cpu_subtype_t的枚举值。指定可以使用此条目的CPU家族的特定成员,或指定所有成员的常量。
- `offset`
Offset to the beginning of the data for this CPU.
偏移到此CPU的数据开头。
- `size`
Size of the data for this CPU.
这个CPU的数据大小。
- `align`
The power of 2 alignment for the offset of the object file for the architecture specified in cputype
within the binary. This is required to ensure that, if this binary is changed, the contents it retains are correctly aligned for virtual memory paging and other uses.
对cputype中指定的体系结构的目标文件的偏移量进行2对齐的能力
在二进制。这是为了确保,如果这个二进制文件被更改,它保留的内容被正确对齐,以用于虚拟内存分页和其他用途。
**Discussion**
An array of fat_arch data structures appears directly after the fat_header (page 56) data structure of a binary that contains object files for multiple architectures.
Regardless of the content this data structure describes, all its fields are stored in big-endian byte order.
fat_arch数据结构数组直接出现在包含多个体系结构目标文件的二进制文件的fat_header(第56页)数据结构之后。
不管这个数据结构描述的内容是什么,它的所有字段都以大端字节顺序存储。 | 128,244 | Apache-2.0 |
Subsets and Splits